PythonLibrary-博客中文翻译-二-
PythonLibrary 博客中文翻译(二)
Disqus 取代 Convore 参加 PyCon 2012!
原文:https://www.blog.pythonlibrary.org/2012/03/09/disqus-replaces-convore-for-pycon-2012/
对于那些不知道的人来说,康沃不在了,看起来迪斯克斯在了:https://pycon.disqus.com/
我认为去年的 Convore 相当有趣,尽管有一些小问题。我很想听听人们对 disqus 系统和 convore 系统的看法。
如何分发 wxPython 应用程序
原文:https://www.blog.pythonlibrary.org/2019/03/19/distributing-a-wxpython-application/
假设您使用 wxPython 完成了一个精彩的 GUI 应用程序。如何与世界分享?当你完成一个惊人的程序时,这总是一个两难的选择。幸运的是,有几种方法可以共享您的代码。如果你想和其他开发者分享你的代码,那么 Github 或者类似的网站绝对是一个不错的选择。我不会在这里讨论使用 Git 或 Mercurial。相反,您将在这里学习如何将您的应用程序转换成可执行文件。
通过将您的代码转换为可执行文件,您可以允许用户只下载二进制文件并运行它,而不需要他们下载 Python、您的源代码和您的依赖项。所有这些都将被打包成可执行文件。
有许多工具可以用来生成可执行文件:
在本教程中,您将使用 PyInstaller 。使用 PyInstaller 的主要好处是它可以为 Windows、Mac 和 Linux 生成可执行文件。注意,它不不支持交叉编译。这意味着您不能在 Linux 上运行 PyInstaller 来创建 Windows 可执行文件。相反,PyInstaller 将只为运行它的操作系统创建一个可执行文件。换句话说,如果您在 Windows 上运行 PyInstaller,它将只创建一个 Windows 可执行文件。
安装 PyInstaller
安装 PyInstaller 包非常简单明了。你只需要匹普。
下面是将 PyInstaller 安装到 Python 系统的方法:
pip install pyinstaller
您还可以使用 Python 的 venv 模块或 virtualenv 包将 PyInstaller 安装到虚拟 Python 环境中。
生成可执行文件
PyInstaller 的优点是开箱即用非常容易。你所需要做的就是运行“pyinstaller”命令,后跟你要转换成可执行文件的应用程序主文件的路径。
下面是一个不起作用的例子:
pyinstaller path/to/main/script.py
如果没有找到 PyInstaller 应用程序,您可能需要指定它的完整路径。默认情况下,PyInstaller 安装到 Python 的Scripts子文件夹,该文件夹将位于您的系统 Python 文件夹或虚拟环境中。
让我们从我即将出版的书中选取一个简单的应用程序,并把它变成一个可执行程序。例如,您可以使用第 3 章中的image _ viewer _ slide show . py:
# image_viewer_slideshow.py
import glob
import os
import wx
class ImagePanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.max_size = 240
self.photos = []
self.current_photo = 0
self.total_photos = 0
self.layout()
self.slideshow_timer = wx.Timer(self)
self.Bind(wx.EVT_TIMER, self.on_next, self.slideshow_timer)
def layout(self):
"""
Layout the widgets on the panel
"""
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
btn_sizer = wx.BoxSizer(wx.HORIZONTAL)
img = wx.Image(self.max_size, self.max_size)
self.image_ctrl = wx.StaticBitmap(self, wx.ID_ANY,
wx.Bitmap(img))
self.main_sizer.Add(self.image_ctrl, 0, wx.ALL|wx.CENTER, 5)
self.image_label = wx.StaticText(self, label="")
self.main_sizer.Add(self.image_label, 0, wx.ALL|wx.CENTER, 5)
btn_data = [("Previous", btn_sizer, self.on_previous),
("Slide Show", btn_sizer, self.on_slideshow),
("Next", btn_sizer, self.on_next)]
for data in btn_data:
label, sizer, handler = data
self.btn_builder(label, sizer, handler)
self.main_sizer.Add(btn_sizer, 0, wx.CENTER)
self.SetSizer(self.main_sizer)
def btn_builder(self, label, sizer, handler):
"""
Builds a button, binds it to an event handler and adds it to a sizer
"""
btn = wx.Button(self, label=label)
btn.Bind(wx.EVT_BUTTON, handler)
sizer.Add(btn, 0, wx.ALL|wx.CENTER, 5)
def on_next(self, event):
"""
Loads the next picture in the directory
"""
if not self.photos:
return
if self.current_photo == self.total_photos - 1:
self.current_photo = 0
else:
self.current_photo += 1
self.update_photo(self.photos[self.current_photo])
def on_previous(self, event):
"""
Displays the previous picture in the directory
"""
if not self.photos:
return
if self.current_photo == 0:
self.current_photo = self.total_photos - 1
else:
self.current_photo -= 1
self.update_photo(self.photos[self.current_photo])
def on_slideshow(self, event):
"""
Starts and stops the slideshow
"""
btn = event.GetEventObject()
label = btn.GetLabel()
if label == "Slide Show":
self.slideshow_timer.Start(3000)
btn.SetLabel("Stop")
else:
self.slideshow_timer.Stop()
btn.SetLabel("Slide Show")
def update_photo(self, image):
"""
Update the currently shown photo
"""
img = wx.Image(image, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.max_size
NewH = self.max_size * H / W
else:
NewH = self.max_size
NewW = self.max_size * W / H
img = img.Scale(NewW, NewH)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
def reset(self):
img = wx.Image(self.max_size,
self.max_size)
bmp = wx.Bitmap(img)
self.image_ctrl.SetBitmap(bmp)
self.current_photo = 0
self.photos = []
class MainFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Image Viewer',
size=(400, 400))
self.panel = ImagePanel(self)
self.create_toolbar()
self.Show()
def create_toolbar(self):
"""
Create a toolbar
"""
self.toolbar = self.CreateToolBar()
self.toolbar.SetToolBitmapSize((16,16))
open_ico = wx.ArtProvider.GetBitmap(
wx.ART_FILE_OPEN, wx.ART_TOOLBAR, (16,16))
openTool = self.toolbar.AddTool(
wx.ID_ANY, "Open", open_ico, "Open an Image Directory")
self.Bind(wx.EVT_MENU, self.on_open_directory, openTool)
self.toolbar.Realize()
def on_open_directory(self, event):
"""
Open a directory dialog
"""
with wx.DirDialog(self, "Choose a directory",
style=wx.DD_DEFAULT_STYLE) as dlg:
if dlg.ShowModal() == wx.ID_OK:
self.folderPath = dlg.GetPath()
photos = glob.glob(os.path.join(self.folderPath, '*.jpg'))
self.panel.photos = photos
if photos:
self.panel.update_photo(photos[0])
self.panel.total_photos = len(photos)
else:
self.panel.reset()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MainFrame()
app.MainLoop()
如果您想将其转换为可执行文件,您可以运行以下命令:
pyinstaller image_viewer_slideshow.py
确保在运行该命令时,当前工作目录是包含要转换为可执行文件的脚本的目录。PyInstaller 将在当前工作目录下创建输出。
当您运行这个命令时,您应该在终端中看到类似这样的内容:

PyInstaller 将在与您正在转换的脚本相同的文件夹中创建两个文件夹,分别名为dist和build。如果 PyInstaller 成功完成,您将在dist文件夹中找到您的可执行文件。除了您的可执行文件,dist文件夹中还有许多其他文件。这些是运行可执行文件所必需的文件。
现在让我们尝试运行您新创建的可执行文件。当我运行我的副本时,我注意到一个终端/控制台出现在我的应用程序后面。

背景中带有控制台的图像查看器
这是正常的,因为 PyInstaller 的默认行为是将您的应用程序构建为命令行应用程序,而不是 GUI。
您需要添加 - noconsole 标志来移除控制台:
pyinstaller image_viewer_slideshow.py --noconsole
现在,当您运行结果时,您应该不会再看到一个控制台窗口出现在您的应用程序后面。
分发大量文件可能会很复杂,因此 PyInstaller 有另一个命令,您可以使用它将所有内容打包成一个可执行文件。该命令是- onefile。顺便说一下,您在 PyInstaller 中使用的许多命令都有较短的别名。例如,您也可以使用“- noconsole”的一个更短的别名: -w 。注意`-w '中的单破折号。
因此,让我们利用这些信息,让 PyInstaller 创建一个没有控制台的可执行文件:
dist folder.
规格文件
PyInstaller 有规范文件的概念。它们有点像是一个 setup.py 脚本,你可以在 Python 的 distutils 中使用它。这些规范文件告诉 PyInstaller 如何构建您的可执行文件。PyInstaller 将自动为您生成一个与脚本中传递的名称相同的文件,但是带有一个。规格扩展。所以如果你传入了image _ viewer _ slide show . py,那么在运行 PyInstaller 之后你应该会看到一个image _ viewer _ slide show . spec文件。该规格文件将创建在与应用程序文件相同的位置。
下面是上次运行 PyInstaller 时创建的规范文件的内容:
# -*- mode: python -*-
block_cipher = None
a = Analysis(['image_viewer.py'],
pathex=['C:\\Users\\mdriscoll\\Documents\\test'],
binaries=[],
datas=[],
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='image_viewer',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
runtime_tmpdir=None,
console=False )
虽然 PyInstaller 可以很好地处理图像查看器示例,但您可能会发现,如果您有其他依赖项,如 NumPy 或 Pandas,它就不能开箱即用了。如果您遇到 PyInstaller 的问题,它有非常详细的日志,您可以使用它来帮助您解决问题。一个很好的位置是“build/cli/warn-cli.txt”文件。您可能还想在不使用`-w '命令的情况下进行重建,以便可以在控制台窗口中看到输出到 stdout 的内容。
还有一些选项可以在构建过程中更改日志级别,这可能有助于发现问题。
如果这些都不起作用,试试谷歌或者去 PyInstaller 的支持页面获得帮助。
为 Mac 创建可执行文件
虽然相同的命令在 Mac OSX 上应该和在 Windows 上一样有效,但是我发现我需要运行以下命令来生成一个有效的可执行文件:
pyinstaller image_viewer_slideshow.py --windowed
PyInstaller 生成的输出会略有不同,结果是一个应用程序文件。
在 Mac 上生成应用程序的另一个流行选项是名为 py2app 的 Python 包。
为 Linux 创建可执行文件
对于 Linux,通常建议您用旧版本的 glibc 构建可执行文件,因为新版本的 glibc 是向后兼容的。通过使用旧版本的 Linux 进行构建,您通常可以针对更广泛的 Linux 版本。但是您的里程可能会有所不同。
文件生成后,您可以将它们打包成一个 gzipped tarball (.tax.gz)。如果您愿意,您甚至可以使用您在本书中创建的归档应用程序来完成这项工作。
另一种方法是学习如何创建一个大多数 Linux 版本都可以安装的. deb 或相关文件。
了解关于 PyInstaller 的更多信息
本文并不是 PyInstaller 的深入指南。它的变化可能比 wxPython 快得多,所以建议您阅读 PyInstaller 的文档。它将永远是您获取项目所需信息的最新位置。
安装工呢?
Windows 用户知道,大多数时候你都有一个安装程序,你可以运行它在你的计算机上安装你的应用程序,并在这里或那里放一些快捷方式。有几个有用的免费程序,你可以用来创建一个 Windows Installer 以及一些付费的
以下是我看到提及最多的两个免费软件应用:
我曾多次使用 Inno Setup 创建 Windows installer。它很容易使用,只需要阅读一点文档就可以工作。我以前没有用过 NSIS,但我想它也很容易使用。
让我们以 Inno Setup 为例,看看如何用它生成一个安装程序。
使用 Inno Setup 创建安装程序
Inno Setup 是一个很好的免费软件应用程序,可以用来创建专业外观的安装程序。它可以在大多数版本的 Windows 上运行。我个人用了好几年了。虽然 Inno Setup 不是开源的,但它仍然是一个非常好的程序。你需要从网站下载并安装它。
安装完成后,您可以使用该工具为您在本章前面创建的可执行文件创建一个安装程序。
要开始,只需运行 Inno Setup,您应该会看到以下内容:

Inno 安装程序的启动页面
虽然 Inno Setup 默认打开一个现有的文件,但你要做的是从顶部选择第二个选项:“使用脚本向导创建一个新的脚本文件”。然后按**确定* *。
您现在应该会看到 Inno 设置脚本向导的第一页。只需点击**下一个* *这里,因为你没有别的办法。
现在,您应该会看到类似这样的内容:

Inno 设置脚本向导应用程序信息页
您可以在此输入应用程序名称、版本信息、发行商名称和应用程序网站。我预先填写了一些例子,但你可以在这里输入你想输入的任何内容。
继续按下下一个,您应该会看到第 3 页:

Inno 设置脚本向导应用程序文件夹页
在向导的这一页,您可以设置应用程序的安装目录。在 Windows 上,大多数应用程序安装到**程序文件* *,这也是这里的默认设置。这也是您为应用程序设置文件夹名称的地方。这是将出现在程序文件中的文件夹的名称。或者,您可以选中底部的框,表示您的应用程序根本不需要文件夹。
让我们进入下一页:

Inno 设置脚本向导应用程序文件页
这里是您选择主可执行文件的地方。在这种情况下,您希望选择使用 PyInstaller 创建的可执行文件。如果您没有使用 - onefile 标志创建可执行文件,那么您可以使用添加文件来添加其他文件...按钮。如果您的应用程序需要任何其他特殊文件,如 SQLite 数据库文件或图像,这也是您想要添加它们的地方。
默认情况下,当安装程序完成时,此页面将允许用户运行您的应用程序。很多安装程序都这样做,所以实际上这是大多数用户所期望的。
让我们继续:

Inno 设置脚本向导应用程序快捷方式页
这是应用程序快捷方式页面,它允许您管理为您的应用程序创建了什么快捷方式以及它们应该去哪里。这些选项非常简单明了。我通常只使用默认值,但是你可以随意更改它们。
让我们看看文档页面上有什么:

Inno 设置脚本向导应用程序文档页
向导的文档页面是您添加应用程序许可文件的地方。例如,如果你要发布一个开源应用程序,你可以在那里添加 GPL 或者 MIT 或者任何你需要的许可文件。如果这是一个商业应用程序,您可以在这里添加您的最终用户许可协议(EULA)文件。
让我们看看接下来会发生什么:

Inno 设置脚本向导设置语言页
在这里您可以设置应该包括哪些安装语言。Inno Setup 支持相当多的语言,默认选择是英语。
现在让我们来看看什么是编译器设置:

Inno 设置脚本向导编译器设置页面
通过编译器设置页面,您可以命名输出设置文件,默认为setup。您可以在这里设置输出文件夹,添加自定义安装文件图标,甚至为安装文件添加密码保护。我通常只保留默认值,但是如果你手边有一个很好的图标文件,这是一个给设置添加一些品牌的机会。
下一页是为预处理器准备的:

Inno 设置脚本向导预处理程序页
预处理器主要用于捕捉 Inno 设置脚本文件中的错别字。它主要是在编译时向 Inno 设置脚本添加一些有用的选项。
查看文档了解全部细节。
点击下一步,您应该会看到向导的最后一页:

Inno 设置脚本向导结束页
点击完成,Inno Setup 将生成一个 Inno Setup 脚本(。iss)文件。完成后,它会问你是否愿意编译这个文件。
继续并接受该对话框,您应该看到以下内容:

Inno 安装脚本
这是 Inno 安装脚本编辑器,其中预加载了您新生成的脚本。上半部分是生成的脚本,下半部分显示编译器的输出。在这个屏幕截图中,它显示安装文件已成功生成,但也显示了一个警告,提示您可能需要重命名安装文件。
此时,您应该有一个工作的安装程序可执行文件,它会将您的程序和它所依赖的任何文件安装到正确的位置。它还会在 Windows“开始”菜单和您在向导中指定的任何其他位置创建快捷方式。
脚本文件本身可以编辑。它只是一个文本文件,语法在 Inno Setup 的网站上有很好的记录。
代码签名
Windows 和 Mac OSX 更喜欢应用程序由公司或开发者签名。否则你会看到一个警告,提示你正在使用一段未签名的代码或软件。这很重要的原因是它保护你的应用程序不被其他人修改。您可以将代码签名视为应用程序中的一种嵌入式 MD5 哈希。已签名的应用程序可以追溯到签名者,这使得它更值得信任。
如果你想在 Mac OSX 上签署代码,你可以使用 XCode
Windows 有几个签名代码的选项。这里有一个 URL,可以让您的应用程序获得 Windows 的认证
也可以从各种专门做代码签名的公司购买证书,比如 digicert 。
还有自签名证书的概念,但这不是针对生产或最终用户的。您将只为内部测试、概念验证等进行自签名。你可以自己查找如何做到这一点。
包扎
您现在已经学习了如何在 Windows、Mac 和 Linux 上使用 PyInstaller 生成可执行文件。生成可执行文件的命令在所有平台上都是相同的。虽然您不能通过在 Linux 上运行 PyInstaller 来创建 Windows 可执行文件,但它对于为目标操作系统创建可执行文件仍然非常有用。
您还了解了如何使用 Inno Setup 为 Windows 创建安装程序。现在,您可以使用这些技能为您自己的应用程序或本书中创建的一些其他应用程序创建可执行文件!
进一步阅读
- bbfreeze 教程-构建二进制序列!
- 包装 wxPyMail for Distribution
Python 101 -记录您的代码
原文:https://www.blog.pythonlibrary.org/2021/09/12/documenting-code/
在早期记录代码比大多数新开发人员意识到的要重要得多。软件开发中的文档是指给你的变量、函数和其他标识符起一个描述性的名字。也指添加好的评论。当你沉浸于开发你的最新作品时,用非描述性的名字创建变量和函数是很容易的。一个月或一年后,当你不可避免地回到你的代码时,你将花费大量的时间试图弄清楚你的代码做什么。
通过使您的代码自文档化(即,使用描述性名称)并在必要时添加注释,您将使您的代码对于您自己和任何可能使用您代码的人来说更具可读性。这也将使更新代码和重构代码变得更加容易!
在本章中,您将了解以下主题:
- 评论
- 文档字符串
- pep 8-Python 风格指南
- 用于记录代码的其他工具
让我们从了解评论开始。
什么是评论?
注释是为您编写的代码,不是为您的计算机编写的。我的意思是,注释基本上是给你自己的一个注解,解释在你的代码部分发生了什么。你使用注释来解释你为什么做某事或者一段代码是如何工作的。当你开始作为一个新的开发人员时,最好给自己留下大量的评论以供参考。但是一旦你学会了如何正确命名你的函数和变量,你会发现你不再需要注释了。
但是仍然建议使用注释,尤其是对于复杂的、乍一看不容易理解的代码。根据你工作的公司,你也可以使用注释来记录错误修复。例如,如果您正在修复一个 bug,您可以在注释中提到您正在修复的 bug,以帮助解释您为什么必须更改它。
您可以使用#符号后跟一些描述性文本来创建注释。
这里有一个例子:
# This is a bad comment
x = 10
在上面的代码中,第一行演示了如何创建一个简单的注释。当 Python 执行这段代码时,它会看到#符号,并忽略它后面的所有文本。实际上,Python 将跳过这一行,尝试执行第二行。
此评论被标记为“差评”。虽然它有利于演示,但它根本没有描述它后面的代码。这就是为什么它不是一个好的评论。好的注释描述了后面的代码。一个好的注释可以描述 Python 脚本的目的、代码行或其他内容。注释是代码的文档。如果他们不提供信息,那么他们应该被删除。
您还可以创建内嵌注释:
x = 10 # 10 is being assigned to x
这里您再次将 10 赋给变量x,但是您添加了两个空格和一个#符号,这允许您添加关于代码的注释。当您可能需要解释特定的代码行时,这很有用。如果你给你的变量起了一个描述性的名字,那么你很可能根本不需要注释。
注释掉
你会经常听到“注释掉代码”这个术语。这是将#符号添加到代码开头的做法。这将有效地禁用您的代码。
例如,您可能有这样一行代码:
number_of_people = 10
如果您想将其注释掉,可以执行以下操作:
# number_of_people = 10
当您尝试不同的解决方案或调试代码时,您可以注释掉代码,但您不想删除代码。Python 将忽略被注释掉的代码,允许您尝试其他东西。大多数 Python 代码编辑器(和文本编辑器)提供了一种方法来突出显示多行代码,并注释掉或取消注释掉整个代码块。
多行注释
一些编程语言,比如 C++,提供了创建多行注释的能力。Python 风格指南(PEP8)说英镑符号是首选。但是,您可以使用带三重引号的字符串作为多行注释。
这里有一个例子:
>>> '''This is a
multiline comment'''
>>> """This is also a
multiline comment"""
当您创建三重引号字符串时,您可能会创建一个文档字符串。
让我们看看什么是 docstrings 以及如何使用它们!
了解文档字符串
Python 有 PEP 或 Python 增强提案的概念。这些 pep 是 Python 指导委员会讨论并同意的 Python 语言的建议或新特性。
PEP 257 描述了文档字符串约定。如果你想知道完整的故事,你可以去看看。可以说,docstring 是一个字符串文字,应该作为模块、函数、类或方法定义中的第一条语句出现。你现在不需要理解所有这些术语。事实上,在本书的后面你会学到更多。
docstring 是使用三重双引号创建的。
这里有一个例子:
"""
This is a docstring
with multiple lines
"""
Python 会忽略文档字符串。他们不能被处决。但是,当您使用 docstring 作为模块、函数等的第一条语句时,docstring 将成为一个特殊的属性,可以通过__doc__访问。在关于类的章节中,你会学到更多关于属性和文档字符串的知识。
文档字符串可以用于单行或多行字符串。
下面是一个一行程序的示例:
"""This is a one-liner"""
单行 docstring 就是只有一行文本的 docstring。
以下是函数中使用的文档字符串的示例:
def my_function():
"""This is the function's docstring"""
pass
上面的代码展示了如何向函数中添加 docstring。你可以在第 14 章学到更多关于函数的知识。一个好的 docstring 描述了函数应该完成什么。
注意:虽然三个双引号是推荐标准,但是三个单引号、单个双引号和单个单引号都可以(但是单个双引号和单个单引号只能包含一行,不能包含多行)。
现在让我们根据 Python 的风格指南来学习编码。
Python 的风格指南:PEP8
风格指南是描述好的编程实践的文档,通常是关于单一语言的。一些公司有特定的公司风格指南,开发人员无论使用什么编程语言都必须遵循。
早在 2001 年,Python 风格指南被创建为 PEP8 。它记录了 Python 编程语言的编码约定,这些年来已经更新了几次。
如果你打算经常使用 Python,你真的应该看看这个指南。它会帮助你写出更好的 Python 代码。
此外,如果你想为 Python 语言本身做出贡献,你的所有代码必须符合风格指南,否则你的代码将被拒绝。
遵循风格指南将使你的代码更容易阅读和理解。这将有助于您和将来使用您代码的任何人。
不过,记住所有的规则可能很难。幸运的是,一些勇敢的开发人员已经创建了一些实用程序来提供帮助!
有帮助的工具
有很多优秀的工具可以帮助你写出优秀的代码。以下是几个例子:
- pycodestyle-https://pypi.org/project/pycodestyle/-检查你的代码是否遵循 PEP8
- 皮林特-https://www.pylint.org/-一个深入的静态代码测试工具,可以发现代码中的常见问题
- py flakes-https://pypi.org/project/pyflakes/-Python 的另一个静态代码测试工具
- flake 8-https://pypi.org/project/flake8/-一个包裹着 PyFlakes、pycodestyle 和 McCabe 脚本的包装
- 布莱克-https://black.readthedocs.io/en/stable/-一个主要遵循 PEP8 的代码格式化程序
您可以针对您的代码运行这些工具,以帮助您找到代码中的问题。我发现 Pylint 和 PyFlakes / flake8 是最有用的。如果您在团队中工作,并且希望每个人的代码都遵循相同的格式,黑色会很有帮助。可以将 Black 添加到您的工具链中,为您格式化代码。
更高级的 Python IDEs 提供了 Pylint 等的一些检查。实时提供。例如,PyCharm 会自动检查这些工具会发现的许多问题。WingIDE 和 VS 代码也提供了一些静态代码检查。您应该查看各种 ide,看看哪一个最适合您。
包扎
Python 提供了几种不同的方法来记录代码。你可以使用注释来解释一行或多行代码。这些应该在适当的时候适度使用。您还可以使用 docstrings 来记录您的模块、函数、方法和类。
您还应该查看一下 PEP8 中的 Python 风格指南。这将帮助您开发良好的 Python 编码实践。Python 还有其他几个风格指南。例如,你可能想要查找 Google 的风格指南或者 NumPy 的 Python 风格指南。有时看看不同的风格指南也会帮助你发展良好的实践。
最后,您了解了几个可以用来帮助您改进代码的工具。如果你有时间,我鼓励你去看看 PyFlakes 或 Flake8,特别是因为它们在指出你的代码中常见的编码问题时非常有帮助。
相关阅读
想了解更多关于 Python 的功能吗?查看这些教程:
-
matplotlib–用 Python 创建图表的介绍
-
Python 101: 使用 JSON 的介绍
-
Python 101 - 创建多个流程
-
python 101-用 pdb 调试你的代码
-
Python 101—使用 Python 启动子流程
用 wxPython 做淡入
原文:https://www.blog.pythonlibrary.org/2008/04/14/doing-a-fade-in-with-wxpython/
今天我们将讨论如何让你的应用程序做一个“淡入”。Windows 用户通常会在 Microsoft Outlook 的电子邮件通知中看到这一点。它淡入淡出。wxPython 提供了一种设置任何顶层窗口的 alpha 透明度的方法,这会影响放置在顶层小部件上的小部件。
在这个例子中,我将使用一个框架对象作为顶层对象,并使用一个计时器来改变 alpha 透明度,单位为每秒 5。计时器的事件处理程序将使帧淡入视图,然后再次退出。值的范围是 0 - 255,0 表示完全透明,255 表示完全不透明。
代码如下:
import wx
class Fader(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title='Test')
self.amount = 5
self.delta = 5
panel = wx.Panel(self, wx.ID_ANY)
self.SetTransparent(self.amount)
## ------- Fader Timer -------- ##
self.timer = wx.Timer(self, wx.ID_ANY)
self.timer.Start(60)
self.Bind(wx.EVT_TIMER, self.AlphaCycle)
## ---------------------------- ##
def AlphaCycle(self, evt):
self.amount += self.delta
if self.amount >= 255:
self.delta = -self.delta
self.amount = 255
if self.amount <= 0:
self.amount = 0
self.SetTransparent(self.amount)
if __name__ == '__main__':
app = wx.App(False)
frm = Fader()
frm.Show()
app.MainLoop()
如您所见,要更改顶级小部件的透明度,您只需调用该小部件的 SetTransparent()方法,并向其传递要设置的数量。实际上,我在自己的一个应用程序中使用了这种方法,它会在一个对话框中淡入提醒我 Zimbra 电子邮件帐户中有新邮件。
欲了解更多信息,请查看以下资源:
对以下代码进行了测试:
操作系统:Windows XP
Python:2 . 5 . 2
wxPython:2.8.8.1 和 2.8.9.1
用 Python 下载加密和压缩文件
今年早些时候,我负责创建一个应用程序,使用 Python 从我们组织的网站下载信息。棘手的部分是,它将被加密、压缩,有效载荷将是 JSON。Python 能做到这一切吗?这正是我想知道的。现在是时候让你知道我的发现了。
Python 和加密
当务之急是找出加密的东西。有效载荷应该是 AES 加密的。虽然 Python 似乎没有为这类事情内置的模块,但有一个用于 Python 2.x 的优秀的 PyCrypto 包,运行得很好。不幸的是,他们的主网站没有列出如何在 Windows 上安装它。你需要自己做一些编译工作(我想是用 Visual Studio),或者你可以在这里下载迈克尔·福德的版本。我选择了后者。
以下是我最终使用的基本代码:
from Crypto.Cipher import AES
cipher = AES.new(key, AES.MODE_ECB)
gzipData = cipher.decrypt(encData).strip('\000')
encData 变量就是使用 urllib2 下载的文件。我们很快就会看到如何做到这一点。耐心点。密钥是由我的一个开发伙伴提供的。无论如何,一旦你解密了它,你就得到 gzipped 数据了。
解压缩 Gzipped 文件
关于 gzipped 的文档相当混乱。你用 gzip 还是 zlib?我花了不少时间反复试验才弄明白,主要是因为我的同事给了我错误的文件格式。这一部分实际上也非常容易完成:
import zlib
jsonTxt = zlib.decompress(gzipData)
如果你这样做了,你将得到解压缩的数据。是的,就是这么简单。
JSON 和 Python
从 Python 2.6 开始,Python 中提供了一个 json 模块。你可以在这里阅读。如果你坚持使用旧版本,那么你可以从 PyPI 下载这个模块。或者你可以使用 simplejson 包,我用的就是这个包。
import simplejson
json = simplejson.loads(jsonTxt )
现在,您将拥有一个嵌套字典列表。基本上,你会想做这样的事情来使用它:
data = json['keyName']
这将返回另一个包含不同数据的字典。您需要稍微研究一下数据结构,以找出访问所需内容的最佳方式。
把所有的放在一起
现在,让我们将它们放在一起,并向您展示完整的脚本:
import simplejson
import urllib2
import zlib
from Crypto.Cipher import AES
from platform import node
from win32api import GetUserName
version = "1.0.4"
uid = GetUserName().upper()
machine = node()
#----------------------------------------------------------------------
def getData(url, key):
"""
Downloads and decrypts gzipped data and returns a JSON string
"""
try:
headers = {"X-ActiveCalls-Version":version,
"X-ActiveCalls-User-Windows-user-ID":uid,
"X-ActiveCalls-Client-Machine-Name":machine}
request = urllib2.Request(url, headers=headers)
f = urllib2.urlopen(request)
encData = f.read()
cipher = AES.new(key, AES.MODE_ECB)
gzipData = cipher.decrypt(encData).strip('\000')
jsonTxt = zlib.decompress(gzipData)
return jsonTxt
except:
msg = "Error: Program unable to contact update server. Please check configuration URL"
print msg
if __name__ == "__main__":
json = getData("some url", "some AES key")
在这个特定的例子中,我还需要让服务器知道哪个版本的应用程序正在请求数据,用户是谁,以及请求来自哪台机器。为此,我们使用 urllib2 的 Request 方法向服务器传递一个包含该信息的特殊头。代码的其余部分应该是不言自明的
包扎
我希望这些都有意义,并且对您的 Python 冒险有所帮助。如果没有,请查看我在各个部分提供的链接,并做一点研究。玩得开心!
用枕头和 Python 绘制圆角矩形
Pillow 是一个致力于用 Python 处理图像的包。从 Pillow 8.2 开始,有了一种新的绘图类型:圆角矩形。圆角矩形允许您对矩形的角进行圆角处理。所以你得到的不是尖角,而是圆角!您可以在枕头文档中阅读所有关于新绘图类型的信息。
入门指南
确保你有最新版本的枕头。如果你的 Pillow 版本早于 8.2,那么你将不能使用这种新的绘图类型。
以下是升级枕头的方法:
python3 -m pip install pillow --upgrade
现在您已经安装或升级了 Pillow,您可以使用新的绘图类型。
绘制圆角矩形
你现在可以画一个圆角矩形了。在您喜欢的 Python IDE 中打开一个新文件,并添加以下代码:
# draw_rounded_rectangle.py
from PIL import Image, ImageDraw
def rectangle(output_path):
image = Image.new("RGB", (400, 400), "green")
draw = ImageDraw.Draw(image)
# Draw a regular rectangle
draw.rectangle((200, 100, 300, 200), fill="red")
# Draw a rounded rectangle
draw.rounded_rectangle((50, 50, 150, 150), fill="blue", outline="yellow",
width=3, radius=7)
image.save(output_path)
if __name__ == "__main__":
rectangle("rounded_rectangle.jpg")
rounded_rectangle() 函数接受一个由四个整数组成的元组。这些整数定义了边界框的两点。半径定义了拐角的圆角程度。你可以用一种颜色填充矩形。您也可以使用轮廓参数添加边框。宽度是边框的像素宽度。
当您运行此代码时,它将创建一个包含一个常规矩形和一个圆角矩形的图像,如下所示:

左边的蓝色矩形显示了圆角矩形的样子。如果将半径设置为零,那么拐角根本不会被倒圆。半径值越大,弯道上的曲线越大。
包扎
虽然这种新的绘图类型并不令人惊讶,但它是添加到您的绘图工具包中的一个很好的新工具。如果你坚持使用 8.2 之前的 Pillow 版本,有一些替代的方法可以在 StackOverflow 上创建圆角矩形。玩得开心!
用 Python 和 Pillow 在图像上绘制形状
原文:https://www.blog.pythonlibrary.org/2021/02/23/drawing-shapes-on-images-with-python-and-pillow/
Pillow 提供了一个名为ImageDraw的绘图模块,你可以用它在你的Image对象上创建简单的 2D 图形。根据 Pillow 的文档,“你可以使用这个模块来创建新的图像,注释或修饰现有的图像,并动态生成图形供网络使用。”
如果你需要比 Pillow 更高级的绘图功能,你可以得到一个名为 aggdraw 的单独包。
在本文中,您将重点关注枕头附带的内容。具体来说,您将了解以下内容:
- 通用参数
- 画线
- 画弧线
- 绘制和弦
- 绘制椭圆
- 绘制饼图切片
- 绘制多边形
- 绘制矩形
当使用 Pillow 绘图时,它使用与 Pillow 其他部分相同的坐标系。比如左上角还是(0,0)。如果您在图像边界之外绘制,这些像素将被丢弃。
如果您想指定一种颜色,您可以像使用PIL.Image.new()一样使用一系列数字或元组。对于“1”、“L”和“I”图像,使用整数。对于“RGB”图像,使用包含整数值的三元组。您也可以使用在第 2 章中了解到的 Pillow 支持的颜色名称。
通用参数
当你去使用各种绘图方法时,你会发现它们有许多共同的参数。您将提前了解这些参数,而不是在每一节中解释相同的参数!
正常男性染色体组型
大多数绘图方法都有一个xy参数,用于设置要在其中绘制图形的矩形区域。这可以通过以下两种方式来定义:
- ((左上 x,左上 y),(右下 x,右下 y))或者干脆((x1,y1),(x2,y2))
- (x1,y1,x2,y2)的盒元组
在绘制直线、多边形或点时,可以通过以下任一方式指定多个坐标:
(x1, y1, x2, y2, x3, y3...)((x1, y1), (x2, y2), (x3, y3)...)
line()方法将画一条直线,连接每个点。polygon()将在每个点连接的地方画一个多边形。最后,point()会在每个点上画一个 1 像素的点。
充满
参数fill用于设置填充形状的颜色。设置fill的方式由图像模式决定:
RGB:使用(R,G,B)或颜色名称设置每个颜色值(0-255)L(灰度):设置一个整数值(0-255)
默认为None或不填充。
概述
outline设置绘图的边框颜色。其规格与您用于fill的规格相同。
默认为None,表示无边框。
现在你已经知道了常用的参数,你可以继续学习如何开始绘画了!
画线
你将学习的第一种绘画是如何在枕头上画线。所有的形状都是由线条组成的。在 Pillow 的例子中,通过告诉 Pillow 在开始和结束坐标之间画线来画线。或者,您可以传入一系列 XY 坐标,Pillow 将绘制连线来连接这些点。
下面是line()方法定义:
def line(self, xy, fill=None, width=0, joint=None):
"""Draw a line, or a connected sequence of line segments."""
您可以看到它接受几个不同的参数。在上一节中,您已经了解了其中一些参数的含义。width参数用于控制线条的宽度。
在你学会如何使用joint之前,你应该学会如何不用它画线。但是首先,你需要一张图片来画画。你将使用这张麦迪逊县大桥的图片:

麦迪逊县廊桥
现在打开您的 Python 编辑器,创建一个名为draw_line.py的新文件,并向其中添加以下代码:
# draw_line.py
import random
from PIL import Image, ImageDraw
def line(image_path, output_path):
image = Image.open(image_path)
draw = ImageDraw.Draw(image)
colors = ["red", "green", "blue", "yellow",
"purple", "orange"]
for i in range(0, 100, 20):
draw.line((i, 0) + image.size, width=5,
fill=random.choice(colors))
image.save(output_path)
if __name__ == "__main__":
line("madison_county_bridge_2.jpg", "lines.jpg")
这里你打开 Pillow 中的图像,然后将Image对象传递给ImageDraw.Draw(),后者返回一个ImageDraw对象。现在你可以在你的图像上画线了。在这种情况下,您使用一个for循环在图像上绘制五条线。在第一个循环中,起始图像从(0,0)开始。然后 X 位置在每次迭代中改变。端点是图像的大小。
您可以使用random模块从颜色列表中选择一种随机颜色。当您运行这段代码时,输出如下所示:

画在图像上的线条
现在你可以尝试创建一系列的点,并以这种方式画线。创建一个名为draw_jointed_line.py的新文件,并将以下代码放入您的文件中:
# draw_jointed_line.py
from PIL import Image, ImageDraw
def line(output_path):
image = Image.new("RGB", (400, 400), "red")
points = [(100, 100), (150, 200), (200, 50), (400, 400)]
draw = ImageDraw.Draw(image)
draw.line(points, width=15, fill="green", joint="curve")
image.save(output_path)
if __name__ == "__main__":
line("jointed_lines.jpg")
这一次,你使用枕头而不是在你自己的枕头上画画来创建一个图像。然后创建一个点列表。为了使线条连接看起来更好,您可以将joint参数设置为“曲线”。如果你看一下line()方法的源代码,你会发现除了None之外,“曲线”是赋予它的唯一有效值。这可能会在枕头的未来版本中改变。
当您运行这段代码时,您的图像将如下所示:

绘制接合线
现在试着从代码中删除joint参数,并重新运行这个例子。您的输出将如下所示:

没有接头的线条
将joint设置为“曲线”,输出会稍微顺眼一些。
现在你已经准备好学习用枕头画弧线了!
画弧线
弧是一条曲线。你也可以用枕头画弧线。下面是arc()方法规范:
def arc(self, xy, start, end, fill=None, width=1):
"""Draw an arc."""
也可以使用xy点生成一个arc()。start参数定义了起始角度,单位为度。end参数告诉 Pillow 结束角度是多少,也是以度为单位。另外两个参数已经介绍过了。
要查看如何绘制弧线,请创建一个名为draw_arc.py的新文件,并将以下代码添加到其中:
# draw_arc.py
from PIL import Image, ImageDraw
def arc(output_path):
image = Image.new("RGB", (400, 400), "white")
draw = ImageDraw.Draw(image)
draw.arc((25, 50, 175, 200), start=30, end=250, fill="green")
draw.arc((100, 150, 275, 300), start=20, end=100, width=5,
fill="yellow")
image.save(output_path)
if __name__ == "__main__":
arc("arc.jpg")
在这段代码中,您创建了一个白色背景的新图像。然后你创建你的Draw对象。接下来,创建两条不同的弧。第一条弧线将填充绿色。第二条弧线将被填充为黄色,但其线宽将为 5。绘制弧线时,填充是指弧线的线条颜色。你没有填充弧线本身。
当您运行此代码时,您的输出图像将如下所示:

画弧线
尝试更改一些参数并重新运行代码,看看如何自己更改弧线。
现在让我们继续学习如何画和弦!
绘制和弦
枕头还支持和弦的概念。弦与弧相同,只是端点用直线连接。
下面是chord()的方法定义:
def chord(self, xy, start, end, fill=None, outline=None, width=1):
"""Draw a chord."""
这里唯一的区别是你还可以添加一个outline颜色。可以用指定fill颜色的任何方式来指定该颜色。
创建一个新文件,命名为draw_chord.py。然后添加以下代码,这样您就可以看到自己是如何制作和弦的了:
# draw_chard.py
from PIL import Image, ImageDraw
def chord(output_path):
image = Image.new("RGB", (400, 400), "green")
draw = ImageDraw.Draw(image)
draw.chord((25, 50, 175, 200), start=30, end=250, fill="red")
draw.chord((100, 150, 275, 300), start=20, end=100, width=5, fill="yellow",
outline="blue")
image.save(output_path)
if __name__ == "__main__":
chord("chord.jpg")
此示例将在绿色图像上绘制两条弦。第一个和弦用红色填充。第二个和弦用黄色填充,但轮廓是蓝色的。蓝色轮廓的宽度为 5。
运行此代码时,您将创建以下图像:

绘制和弦
看起来不错。继续玩这个例子。稍加练习,你很快就会掌握用枕头制作和弦。
现在让我们继续学习画椭圆!
绘制椭圆
通过给 Pillow 一个边界框(xy ),在 Pillow 中绘制一个椭圆。在前面的章节中,您已经多次看到过这种情况。
下面是ellipse()方法的定义:
def ellipse(self, xy, fill=None, outline=None, width=1):
"""Draw an ellipse."""
ellipse()让你用一种颜色填充它,添加一个彩色边框(outline)并改变那个outline的width。
要了解如何创建ellipse(),创建一个名为draw_ellipse.py的新文件,并将该代码添加到其中:
# draw_ellipse.py
from PIL import Image, ImageDraw
def ellipse(output_path):
image = Image.new("RGB", (400, 400), "white")
draw = ImageDraw.Draw(image)
draw.ellipse((25, 50, 175, 200), fill="red")
draw.ellipse((100, 150, 275, 300), outline="black", width=5,
fill="yellow")
image.save(output_path)
if __name__ == "__main__":
ellipse("ellipse.jpg")
在这段代码中,您通过new()方法创建了一个漂亮的白色图像。然后你在它上面画一个红色的椭圆。最后,绘制第二个椭圆,用黄色填充并用黑色勾勒,轮廓宽度设置为 5。
当您运行此代码时,它创建的图像将如下所示:

绘制椭圆
您可以使用ellipse()创建椭圆形和圆形。试一试,看看你能用它做什么。
现在让我们来看看如何创建饼图切片!
绘制饼图切片
饼图切片与arc())相同,但也在边界框的端点和中心之间绘制直线。
下面是如何定义pieslice()方法的:
def pieslice(self, xy, start, end, fill=None, outline=None, width=1):
"""Draw a pieslice."""
您已经在其他图形中使用了所有这些参数。回顾一下,fill给pieslice()的内部添加颜色,而outline给图形添加彩色边框。
要开始练习这个形状,创建一个名为draw_pieslice.py的新文件,并将以下代码添加到您的文件中:
# draw_pieslice.py
from PIL import Image, ImageDraw
def pieslice(output_path):
image = Image.new("RGB", (400, 400), "grey")
draw = ImageDraw.Draw(image)
draw.pieslice((25, 50, 175, 200), start=30, end=250, fill="green")
draw.pieslice((100, 150, 275, 300), start=20, end=100, width=5,
outline="yellow")
image.save(output_path)
if __name__ == "__main__":
pieslice("pieslice.jpg")
在这段代码中,您生成了一个灰色的图像来绘制。然后创建两个饼图切片。第一个pieslice()用绿色填充。第二个没填,但是确实有黄色的outline。注意,每个pieslice()都有不同的开始和结束程度。
当您运行此代码时,您将获得以下图像:

绘制饼图切片
只需做一点工作,您就可以使用 Pillow 创建一个饼图!您应该稍微修改一下代码,并更改一些值。你将很快学会如何自己制作一些美味的馅饼。
现在让我们来看看如何用枕头画多边形!
绘制多边形
多边形是一种几何形状,它有许多点(顶点)和相等数量的线段或边。正方形、三角形和六边形都是多边形。枕头可以让你创建自己的多边形。Pillow 的文档是这样定义多边形的:多边形轮廓由给定坐标之间的直线,加上最后一个和第一个坐标之间的直线组成。
下面是polygon()方法的代码定义:
def polygon(self, xy, fill=None, outline=None):
"""Draw a polygon."""
现在,您应该对所有这些参数都很熟悉了。继续创建一个新的 Python 文件,并将其命名为draw_polygon.py。然后添加以下代码:
# draw_polygon.py
from PIL import Image, ImageDraw
def polygon(output_path):
image = Image.new("RGB", (400, 400), "grey")
draw = ImageDraw.Draw(image)
draw.polygon(((100, 100), (200, 50), (125, 25)), fill="green")
draw.polygon(((175, 100), (225, 50), (200, 25)),
outline="yellow")
image.save(output_path)
if __name__ == "__main__":
polygon("polygons.jpg")
这段代码将创建一个类似于上一节中最后一个例子的灰色图像。然后它将创建一个多边形,用绿色填充。然后它将创建第二个多边形,用黄色勾勒出它的轮廓,不填充它。
在这两幅图中,您提供了三个点。这将创建两个三角形。
当您运行这段代码时,您将得到以下输出:

绘制多边形
尝试通过向上述代码中的一个或多个多边形添加额外的点来更改代码。只要稍加练习,你就能使用 Pillow 快速创建复杂的多边形。
绘制矩形
rectangle()方法允许你用枕头画一个矩形或正方形。下面是rectangle()的定义:
def rectangle(self, xy, fill=None, outline=None, width=1):
"""Draw a rectangle."""
您可以传入定义开始和结束坐标的两个元组来绘制矩形。或者,您可以将四个坐标作为一个盒元组(4 项元组)来提供。然后你可以添加一个outline,fill给它加上颜色,并改变轮廓的width。
创建一个新文件,命名为draw_rectangle.py。然后用下面的代码填充它,这样你就可以开始画矩形了:
# draw_rectangle.py
from PIL import Image, ImageDraw
def rectangle(output_path):
image = Image.new("RGB", (400, 400), "blue")
draw = ImageDraw.Draw(image)
draw.rectangle((200, 100, 300, 200), fill="red")
draw.rectangle((50, 50, 150, 150), fill="green", outline="yellow",
width=3)
image.save(output_path)
if __name__ == "__main__":
rectangle("rectangle.jpg")
这段代码将创建一个 400x400 像素的蓝色图像。然后它会画两个矩形。第一个矩形将用红色填充。第二个将用绿色填充,用黄色勾勒。
当您运行此代码时,您将得到以下图像作为输出:

绘制矩形
那些可爱的长方形不是吗?您可以修改矩形的点来创建更薄或更宽的矩形。您还可以修改添加到矩形的轮廓宽度。
包扎
您可以使用 Pillow 为图像添加形状。这有助于为图像添加轮廓,突出显示图像的一个或多个部分,等等。
在本文中,您了解了以下主题:
- 通用参数
- 画线
- 画弧线
- 绘制和弦
- 绘制椭圆
- 绘制饼图切片
- 绘制多边形
- 绘制矩形
您可以利用 Pillow 提供的形状做很多事情。你应该拿这些例子,并修改它们,用你自己的照片来测试它们。试一试,看看你能想出什么!
相关阅读
- 用 Python 和 Pillow 在图像上绘制文本
- PySimpleGUI: 用 Python GUI 在图像上绘制文本
|  |
|
Pillow: image processing with Python
Buy
now on Lean Pub t3 |
使用 Pillow 和 Python 在图像上绘制文本
原文:https://www.blog.pythonlibrary.org/2021/02/02/drawing-text-on-images-with-pillow-and-python/
除了形状之外,Pillow 还支持在图像上绘制文本。Pillow 使用自己的字体文件格式存储位图字体,限制为 256 个字符。Pillow 还支持 TrueType 和 OpenType 字体,以及 FreeType 库支持的其他字体格式。
在本章中,您将了解以下内容:
- 绘图文本
- 加载 TrueType 字体
- 更改文本颜色
- 绘制多行文本
- 对齐文本
- 更改文本不透明度
- 了解文本锚点
虽然这篇文章并没有完全覆盖使用 Pillow 绘制文本,但是当您阅读完这篇文章后,您将会对文本绘制的工作原理有一个很好的理解,并且能够自己绘制文本。
让我们从学习如何绘制文本开始。
绘图文本
用枕头绘制文本类似于绘制形状。然而,绘制文本增加了复杂性,需要能够处理字体、间距、对齐等。您可以通过查看text()函数的签名来了解绘制文本的复杂性:
def text(xy, text, fill=None, font=None, anchor=None, spacing=4, align='left', direction=None,
features=None, language=None, stroke_width=0, stroke_fill=None, embedded_color=False)
这个函数接受的参数比你用 Pillow 绘制的任何形状都多!让我们依次检查一下这些参数:
xy-文本的锚点坐标(即开始绘制文本的位置)。text-您希望绘制的文本字符串。fill-文本的颜色(可以是一个元组,一个整数(0-255)或一个支持的颜色名称)。font-一个ImageFont实例。anchor-文本锚点对齐。确定锚点相对于文本的位置。默认对齐方式是左上方。spacing-如果文本被传递到multiline_text(),这将控制行间的像素数。align-如果文本被传递到multiline_text()、"left"、"center"或"right"。确定线条的相对对齐方式。使用锚定参数指定与xy的对齐。direction-文字的方向。可以是"rtl"(从右到左)"ltr"(从左到右)或"ttb"(从上到下)。需要 libraqm。features-文本布局期间使用的 OpenType 字体特性列表。需要 libraqm。language-文本的语言。不同的语言可能使用不同的字形或连字。此参数告诉字体文本使用哪种语言,并根据需要应用正确的替换(如果可用)。这应该是 BCP 47 语言代码。需要 libraqm。stroke_width-文本笔画的宽度stroke_fill-文字笔画的颜色。如果没有设置,它默认为fill参数的值。embedded_color-是否使用字体嵌入颜色字形(COLR 或 CBDT)。
除非您的工作需要使用外语或晦涩难懂的字体功能,否则您可能不会经常使用这些参数。
当谈到学习新事物时,从一个好的例子开始总是好的。打开 Python 编辑器,创建一个名为draw_text.py的新文件。然后向其中添加以下代码:
# draw_text.py
from PIL import Image, ImageDraw, ImageFont
def text(output_path):
image = Image.new("RGB", (200, 200), "green")
draw = ImageDraw.Draw(image)
draw.text((10, 10), "Hello from")
draw.text((10, 25), "Pillow",)
image.save(output_path)
if __name__ == "__main__":
text("text.jpg")
这里你使用 Pillow 的Image.new()方法创建一个小图像。它有一个漂亮的绿色背景。然后创建一个绘图对象。接下来,您告诉 Pillow 在哪里绘制文本。在这种情况下,您绘制两行文本。
当您运行此代码时,您将获得以下图像:

看起来不错。通常,当您在图像上绘制文本时,您会指定一种字体。如果手头没有字体,可以使用上面的方法,也可以使用 Pillow 的默认字体。
下面的示例更新了上一个示例,使用 Pillow 的默认字体:
# draw_text_default_font.py
from PIL import Image, ImageDraw, ImageFont
def text(output_path):
image = Image.new("RGB", (200, 200), "green")
draw = ImageDraw.Draw(image)
font = ImageFont.load_default()
draw.text((10, 10), "Hello from", font=font)
draw.text((10, 25), "Pillow", font=font)
image.save(output_path)
if __name__ == "__main__":
text("text.jpg")
在这个版本的代码中,您使用ImageFont.load_default()来加载 Pillow 的默认字体。然后将字体应用于文本,用font参数传递它。
这段代码的输出将与第一个示例相同。
现在让我们来看看如何使用枕头 TrueType 字体!
加载 TrueType 字体
Pillow 支持加载 TrueType 和 OpenType 字体。因此,如果你有一个最喜欢的字体或公司规定的字体,Pillow 可能会加载它。您可以下载许多开源 TrueType 字体。一个流行的选择是 Gidole ,你可以在这里得到:
Pillow 包的测试文件夹中也有几种字体。你可以在这里下载 Pillow 的源代码:
本书在 Github 上的代码库包括 Gidole 字体以及 Pillow tests 文件夹中的一些字体,您可以在本章的示例中使用这些字体:
要查看如何加载 TrueType 字体,创建一个新文件并命名为draw_truetype.py。然后输入以下内容:
# draw_truetype.py
from PIL import Image, ImageDraw, ImageFont
def text(input_image_path, output_path):
image = Image.open(input_image_path)
draw = ImageDraw.Draw(image)
y = 10
for font_size in range(12, 75, 10):
font = ImageFont.truetype("Gidole-Regular.ttf", size=font_size)
draw.text((10, y), f"Chihuly Exhibit ({font_size=}", font=font)
y += 35
image.save(output_path)
if __name__ == "__main__":
text("chihuly_exhibit.jpg", "truetype.jpg")
对于这个例子,您使用 Gidole 字体并加载一张在德克萨斯州达拉斯植物园拍摄的图像:

然后循环几种不同的字体大小,在图像的不同位置写出一个字符串。当您运行这段代码时,您将创建一个如下所示的图像:

这段代码演示了如何使用 TrueType 字体改变字体大小。现在,您已经准备好学习如何在不同的 TrueType 字体之间切换。
创建另一个新文件,并将其命名为draw_multiple_truetype.py。然后把这段代码放进去:
# draw_multiple_truetype.py
import glob
from PIL import Image, ImageDraw, ImageFont
def truetype(input_image_path, output_path):
image = Image.open(input_image_path)
draw = ImageDraw.Draw(image)
y = 10
ttf_files = glob.glob("*.ttf")
for ttf_file in ttf_files:
font = ImageFont.truetype(ttf_file, size=44)
draw.text((10, y), f"{ttf_file} (font_size=44)", font=font)
y += 55
image.save(output_path)
if __name__ == "__main__":
truetype("chihuly_exhibit.jpg", "truetype_fonts.jpg")
这里您使用 Python 的glob模块来搜索扩展名为.ttf的文件。然后你遍历这些文件,用glob找到的每种字体写出图片上的字体名称。
当您运行这段代码时,您的新图像将如下所示:

这演示了在一个代码示例中编写多种格式的文本。您始终需要提供要加载的 TrueType 或 OpenType 字体文件的相对或绝对路径。如果您不提供有效的路径,将会引发一个FileNotFoundError异常。
现在让我们继续学习如何改变你的文本颜色!
更改文本颜色
Pillow 允许您通过使用fill参数来改变文本的颜色。您可以使用 RGB 元组、整数或支持的颜色名称来设置此颜色。
继续创建一个新文件,命名为text_colors.py。然后在其中输入以下代码:
# text_colors.py
from PIL import Image, ImageDraw, ImageFont
def text_color(output_path):
image = Image.new("RGB", (200, 200), "white")
draw = ImageDraw.Draw(image)
colors = ["green", "blue", "red", "yellow", "purple"]
font = ImageFont.truetype("Gidole-Regular.ttf", size=12)
y = 10
for color in colors:
draw.text((10, y), f"Hello from Pillow", font=font, fill=color)
y += 35
image.save(output_path)
if __name__ == "__main__":
text_color("colored_text.jpg")
在本例中,您创建了一个新的白色图像。然后创建一个颜色列表。接下来,循环列表中的每种颜色,并使用fill参数应用颜色。
当您运行这段代码时,您将得到这个漂亮的输出:

这个输出演示了如何改变文本的颜色。
现在让我们学习如何一次绘制多行文本!
绘制多行文本
Pillow 还支持一次绘制多行文本。在本节中,您将学习绘制多条线的两种不同方法。第一种是通过使用 Python 的换行符:\n。
要了解其工作原理,创建一个文件并将其命名为draw_multiline_text.py。然后添加以下代码:
# draw_multiline_text.py
from PIL import Image, ImageDraw, ImageFont
def text(input_image_path, output_path):
image = Image.open(input_image_path)
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("Gidole-Regular.ttf", size=42)
text = "Chihuly Exhibit\nDallas, Texas"
draw.text((10, 25), text, font=font)
image.save(output_path)
if __name__ == "__main__":
text("chihuly_exhibit.jpg", "multiline_text.jpg")
对于本例,您创建一个中间插入换行符的字符串。当您运行此示例时,您的结果应该如下所示:

Pillow 也有一个用于绘制多行文本的内置方法。把你在上例中写的代码复制并粘贴到一个新文件中。保存新文件,并将其命名为draw_multiline_text_2.py。
现在修改代码,使其使用multiline_text()函数:
# draw_multiline_text_2.py
from PIL import Image, ImageDraw, ImageFont
def text(input_image_path, output_path):
image = Image.open(input_image_path)
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("Gidole-Regular.ttf", size=42)
text = """
Chihuly Exhibit
Dallas, Texas"""
draw.multiline_text((10, 25), text, font=font)
image.save(output_path)
if __name__ == "__main__":
text("chihuly_exhibit.jpg", "multiline_text_2.jpg")
在本例中,您使用 Python 的三重引号创建了一个多行字符串。然后通过调用multiline_text()将该字符串绘制到图像上。
当您运行这段代码时,您的图像会略有不同:

文本位于上一示例的右下方。原因是您使用了 Python 的三重引号来创建字符串。它保留了您给它的换行符和缩进。如果你把这个字符串放到前面的例子中,它看起来应该是一样的。
multiline_text()并不影响最终结果。
现在,让我们学习如何在绘制文本时对齐文本。
对齐文本
枕头让你对齐文本。但是,对齐是相对于锚点的,并且仅适用于多行文字。在本节中,您将看到一种不使用align参数来对齐文本的替代方法。
要开始使用align,创建一个新文件并将其命名为text_alignment.py。然后添加以下代码:
# text_alignment.py
from PIL import Image, ImageDraw, ImageFont
def alignment(output_path):
image = Image.new("RGB", (200, 200), "white")
draw = ImageDraw.Draw(image)
alignments = ["left", "center", "right"]
y = 10
font = ImageFont.truetype("Gidole-Regular.ttf", size=12)
for alignment in alignments:
draw.text((10, y), f"Hello from\n Pillow", font=font,
align=alignment, fill="black")
y += 35
image.save(output_path)
if __name__ == "__main__":
alignment("aligned_text.jpg")
这里你创建了一个小的,白色的图像。然后创建所有有效对齐选项的列表:“左”、“居中”和“右”。接下来,循环遍历这些对齐值,并将它们应用于同一个多行字符串。
运行此代码后,您将得到以下结果:

通过查看输出,您可以对 Pillow 中的对齐方式有所了解。这是否适合您的用例取决于您自己。除了设置参数align之外,您可能还需要调整开始绘图的位置,以获得您真正想要的结果。
你可以用 Pillow 来得到你的绳子的尺寸,然后做一些简单的数学运算来试着把它放在中间。为此,您可以使用绘图对象的textsize()方法或字体对象的getsize()方法。
要了解其工作原理,您可以创建一个名为center_text.py的新文件,并将以下代码放入其中:
# center_text.py
from PIL import Image, ImageDraw, ImageFont
def center(output_path):
width, height = (400, 400)
image = Image.new("RGB", (width, height), "grey")
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("Gidole-Regular.ttf", size=12)
text = "Pillow Rocks!"
font_width, font_height = font.getsize(text)
new_width = (width - font_width) / 2
new_height = (height - font_height) / 2
draw.text((new_width, new_height), text, fill="black")
image.save(output_path)
if __name__ == "__main__":
center("centered_text.jpg")
在这种情况下,您跟踪图像的大小以及字符串的大小。对于这个例子,您使用了getsize()来获得基于字体和字体大小的字符串的宽度和高度。
然后你把图像的宽度和高度减去字符串的宽度和高度,再除以 2。这将为您提供在图像中心书写文本所需的坐标。
当您运行这段代码时,您可以看到文本很好地居中:

然而,当你增加字体大小时,这个值开始下降。你增加得越多,它就离中心越远。在 StackOverflow 上有几个备选解决方案:
主要的收获是,你可能最终需要为你正在使用的字体计算你自己的偏移量。毕竟排版是一件复杂的事情。
现在让我们来看看如何改变你的文字的不透明度!
更改文本不透明度
Pillow 也支持改变文本的不透明度。这意味着你可以让文本透明、不透明或介于两者之间。这只适用于具有 alpha 通道的图像。
对于这个例子,您将使用这个花图像:

现在创建一个新文件,命名为text_opacity.py。然后将以下代码添加到新文件中:
# text_opacity.py
from PIL import Image, ImageDraw, ImageFont
def change_opacity(input_path, output_path):
base_image = Image.open(input_path).convert("RGBA")
txt_img = Image.new("RGBA", base_image.size, (255,255,255,0))
font = ImageFont.truetype("Gidole-Regular.ttf", 40)
draw = ImageDraw.Draw(txt_img)
# draw text at half opacity
draw.text((10,10), "Pillow", font=font, fill=(255,255,255,128))
# draw text at full opacity
draw.text((10,60), "Rocks!", font=font, fill=(255,255,255,255))
composite = Image.alpha_composite(base_image, txt_img)
composite.save(output_path)
if __name__ == "__main__":
change_opacity("flowers_dallas.png", "flowers_opacity.png")
在这个例子中,你打开花的形象,并将其转换为 RGBA。然后,创建一个与花图像大小相同的新图像。接下来,加载 Gidole 字体,并使用刚刚创建的自定义图像创建一个绘图上下文对象。
现在有趣的部分来了!你画一个字符串,设置 alpha 值为 128,这相当于大约一半的不透明度。然后你在下面的线上画第二条线,告诉 Pillow 使用完全不透明。请注意,在这两个实例中,您使用的是 RGBA 值,而不是颜色名称,就像您在前面的代码示例中所做的那样。这使您在设定 alpha 值时更加灵活。
最后一步是调用alpha_composite()并将txt_img合成到base_image上。
当您运行这段代码时,您的输出将如下所示:

这演示了如何用 Pillow 改变文本的不透明度。你应该为你的txt_img尝试一些不同的值,看看它如何改变文本的不透明度。
现在,让我们了解什么是文本锚点,以及它们如何影响文本位置。
了解文本锚点
您可以使用anchor参数来确定您的文本相对于您给定的xy坐标的对齐方式。默认是左上角,这是la(左上)锚。根据文档,la表示左上对齐的文本。
锚点中的第一个字母指定其水平对齐,而第二个字母指定其垂直对齐。在接下来的两个小节中,您将了解每个锚点名称的含义。
水平锚定对齐
有四个水平锚。以下内容改编自关于水平锚的文件:
l(左)-锚点位于文本的左侧。说到横文,这就是第一个字形的由来。m(中间)-锚点与文本水平居中。在垂直文本的情况下,你应该使用s(基线)对齐,因为它不会根据文本中使用的特定字形而改变。r(右)-锚点在文本的右边。对于横排文本,这是最后一个字形的高级原点。s-基线(仅垂直文本)。对于垂直文本这是推荐的对齐方式,因为它不会根据给定文本的特定字形而改变
垂直锚定对齐
有六个垂直锚。以下内容改编自关于垂直锚的文件:
a(上升/顶部)-(仅横向文本)。锚点位于文本第一行的上行(顶部),由字体定义。t(顶部)——(仅限单行文本)。锚点在文本的顶部。对于垂直文本,这是第一个字形的原点。对于水平文本,建议使用(上升)对齐,因为它不会基于给定文本的特定字形而改变。m(中间)-锚点与文本垂直居中。对于水平文本,这是第一个上行线和最后一个下行线的中点。s—基线(仅限水平文本)。锚点位于文本第一行的基线(底部),只有下行线延伸到锚点下方。b(底部)-(仅单行文本)。锚点在文本的底部。对于竖排文本这是最后一个字形的高级原点。对于水平文本,建议使用d(下行)对齐,因为它不会根据给定文本的特定字形而改变。d(下行/底部)-(仅横向文本)。锚点位于文本最后一行的下行线(底部),由字体定义。
锚点示例
如果你所做的只是谈论锚,锚是很难想象的。如果你能创造一些例子来看看到底发生了什么,那会很有帮助。Pillow 在他们关于 anchors 的文档中提供了一个例子,还有一些非常有用的图片:
你可以以他们为例,稍加修改,使之更有用。要了解如何操作,请创建一个新文件并将其命名为create_anchor.py。然后向其中添加以下代码:
# create_anchor.py
from PIL import Image, ImageDraw, ImageFont
def anchor(xy=(100, 100), anchor="la"):
font = ImageFont.truetype("Gidole-Regular.ttf", 32)
image = Image.new("RGB", (200, 200), "white")
draw = ImageDraw.Draw(image)
draw.line(((0, 100), (200, 100)), "gray")
draw.line(((100, 0), (100, 200)), "gray")
draw.text((100, 100), "Python", fill="black", anchor=anchor, font=font)
image.save(f"anchor_{anchor}.jpg")
if __name__ == "__main__":
anchor(anchor)
您可以按原样运行这段代码。默认锚点是“la ”,但是您在这里明确地调用了它。你也可以画一个十字线来标记xy的位置。如果你用其他设置运行它,你可以看到锚是如何影响它的。
下面是使用六个不同主播的六次不同跑步的截图:
您可以尝试使用这里没有显示的其他锚来运行这段代码。也可以调整位置元组,用不同的锚点重新运行一遍。如果你想的话,你甚至可以创建一个循环来遍历锚点并创建一组例子。
包扎
至此,您已经很好地理解了如何使用 Pillow 绘制文本。事实上,您已经学会了如何做以下所有事情:
- 绘图文本
- 加载 TrueType 字体
- 更改文本颜色
- 绘制多行文本
- 对齐文本
- 更改文本不透明度
- 了解文本锚点
- 创建文本绘图 GUI
你现在可以把你学到的东西付诸实践。本文中有很多例子,您可以用它们作为创建新应用程序的起点!
电子书竞赛:赢得免费的《掌握面向对象的 Python》副本
这场比赛结束了!

Packt Publishing 与我的博客合作,赠送了两本 Steven Lott 的电子书版本的《掌握面向对象的 Python》。你可以在这里阅读我的完整书评,但是坦率地说,我认为这是我很久以来读过的最好的高级 Python 书籍之一。它也是基于 Python 3 的,尽管大多数概念都适用于 Python 2。
你如何能赢
要赢得这本书,你需要做的就是在下面提出评论,强调“你为什么想赢得这本书”的原因。
竞赛持续时间和获胜者的选择
比赛有效期为两周,对所有人开放。获胜者将根据他们发表的评论选出。比赛将于 2014 年 5 月 26 日下午 1 点(美国中部时间)结束。
电子书赠品- Tkinter GUI 应用程序开发
原文:https://www.blog.pythonlibrary.org/2014/03/10/ebook-giveaway-tkinter-gui-application-development/
在小型 Python 技巧博客上正在进行一场 Python 书籍竞赛。你可以得到 3 本由巴斯卡尔·乔德里写的书 Tkinter GUI 应用程序开发中的一本。去年年底,我评论了这本书,发现它确实是一本有趣的书。我认为它会给你很多好的想法来尝试开发你自己的 GUI 应用程序。现在你有机会得到这本整洁的书了!
电子书评论:在 Kivy 中创建应用程序
原文:https://www.blog.pythonlibrary.org/2014/05/01/ebook-review-creating-apps-in-kivy/
Kivy 是一个简洁的包,允许 Python 开发者在移动设备上创建用户界面。您也可以将应用程序部署到桌面上。这是我看到的关于这个主题的第二本书。Roberto Ulloa 的第一本书《Python 中的 Kivy-Interactive Applications》于去年由 Packt 出版社出版。今年,我们有达斯丁·菲利普斯的作品,在奥莱利用基维语创作应用程序。我将评论这本书的 PDF 版本。
快速回顾
- 为什么拿起这本书:因为喜欢作者之前的作品 Python 3 面向对象编程所以拿起这本书
- 我为什么要读完它:这本书很短,而且很有趣
- 我会把它给:一个已经了解 Python 的人
图书格式
你可以得到这本书的平装本、epub、mobi 或 PDF。
书籍内容
这本书实际上只是关于创建一个应用程序。共 9 章,132 页。
全面审查
第一章是对基维语和基维语的介绍。KV 语言有点像 GUI 的强大 CSS 版本。在这一章中,你将学习如何创建基本的小部件,并对 KV 进行深入研究,同时开始这本书的总体项目。第二章介绍了 Kivy 的事件系统是如何工作的,以及如何在 KV 定义的小部件中访问属性。
第 3 章深入探讨了如何操作小部件。这意味着您将学习如何交换小部件和整个表单。第四章讨论了“迭代开发”的概念,并通过一个例子说明了作者是如何从不同的角度解决问题的。您还将学习如何使用 Kivy 从互联网上检索数据。在第五章中,我们学习了 Kivy 的图形(如绘画/动画)来使用户界面更有吸引力。它还讨论了向应用程序添加图标。
第六章是关于 Kivy 世界的坚持。你如何保存你的设置?你将在本章中找到答案。您还将了解所有 Kivy 应用程序的默认设置以及如何修改它们。在第七章,我们学习手势。如何记录手势、触摸事件、基于手势的击发事件等。
第八章是关于 Kivy 的高级部件。您将了解 Carousel 小部件(允许在多个小部件之间滑动)、ModalView 和 Popup 小部件(用于在其他小部件上显示小部件)以及 ActionBar。本章还有一个重构代码的例子。第九章讲述了如何使用定制部署工具 buildozer 将你的应用发布到 Android 和 iOS。
我发现这本书比我读的上一本 Kivy 的书好了一步。虽然标题有点误导,但您仍然会学到很多关于 Kivy 及其内部的知识。我在这里和那里看到一些错别字,但我也有这本书的早期版本,所以我猜我的版本还没有完全编辑好。我要说的是,我在图形章节中遇到了一点麻烦,最终只是阅读了示例,而没有尝试。我喜欢学习许多关于如何使用 Kivy 以及如何适当地将 KV 代码与 Python 混合的简洁的小提示。
虽然我很想在书中看到其他应用示例,但本文涵盖了开始使用 Kivy 所需了解的所有要点。我认为如果你将这本书与 Kivy 文档和示例片段结合起来,你将很快掌握 Kivy。
|  |
|
在 Kivy 中创建应用程序
达斯丁·菲利普斯[亚马逊](http://www.amazon.com/gp/product/B00JKZSYS6/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B00JKZSYS6&linkCode=as2&tag=thmovsthpy-20&linkId=KFVINA3S7TDFWMKF target=)奥莱利 |
其他书评
- Python 中的交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- Python 3 面向对象编程
关于 Kivy 的附加信息
电子书评论:烧瓶框架食谱
原文:https://www.blog.pythonlibrary.org/2014/12/19/ebook-review-flask-framework-cookbook/
Packt Publishing 最近发给我一本电子书版本的 Shalabh Aggarwal 的《Flask Framework Cookbook》。我没有读完整本书,因为烹饪书通常不是非常有趣的线性读物。我只是通过它和樱桃挑选了各种食谱。但是在我进入太多细节之前,让我们快速回顾一下!
快速回顾
- 拿起它的原因:出版社让我看这本书。
- 我完成它的原因:正如已经提到的,我实际上只是浏览了一下这本书,看了一些随意的食谱
- 我会把它给:一个初涉 Flask 或可能是中级 Flask 开发人员的人
图书格式
你可以得到这本书的平装本、epub、mobi 或 PDF。
书籍内容
这本书分为 12 章,258 页,80 多个食谱。
全面审查
Packt 总是推出小众 Python 书籍。Flask 是比较流行的 Python 微型 web 框架之一,所以它可能有相当多的受众。让我们花点时间看看这些章节涵盖了什么。在第一章中,我们找到了许多配置 Flask 的方法。它包含了关于使用基于类的设置,静态文件,蓝图和更多的信息。第二章用一组关于模板语言 Jinja 的食谱稍微改变了一些事情。在第三章中,我们使用 SQLAlchemy 进行数据建模。还有 Redis,Alembic,MongoDB 的配方。第四章是关于使用视图。它包含关于 XHR 请求、基于类的视图、自定义 404 处理程序和其他几个配方的信息。
在第五章中,作者重点讨论了带有 WTForms 的 webforms。在这里,我们将了解字段验证、上传文件和跨站伪造。对于第 6 章,我们将讨论认证方案。有 Flask-Login 扩展、OpenID、脸书、Google 和 Twitter 的配方。第 7 章讨论 RESTful API 构建。本章只有四种方法,其中两种是关于创建不同类型的 REST 接口的。最后一个方法是一个完整的 REST API 示例。第八章是关于 Flask 中的管理界面。在这里你将学习 Flask-Admin 扩展,自定义表单,用户角色等等!
第九章带我们进入国际化和本地化。它的食谱最少,只有 3 种。您将学习如何添加新语言、语言切换和 gettext/ngettext。继续第十章,我们将学习调试、错误处理和测试。在这里,我们涵盖了从发送错误邮件到使用 pdb 调试器到 nose、mock 和覆盖率测试的所有内容。第 11 章是关于部署的。它涵盖了关于 apach,Gunicornm 龙卷风,织物,Heroku,AWS 弹性豆茎,应用程序监控和其他一些项目的食谱。第 12 章用其他技巧和诀窍来充实这本书,比如全文搜索、使用信号、缓存、芹菜等等。
总的来说,我觉得这本书写得相当好。有一些地方有点起伏,因为我不相信作者是以英语为母语的人,但散文并没有因此受到很大影响。大多数食谱作为独立的片段运行良好。有时候代码片段看起来并不完全可以运行,但是您应该能够从 Packt 下载完整的代码。我并不总是发现食谱的分组是完全一致的,但在大多数情况下,它们在一起是有意义的。我推荐这本书给那些想把自己的技能提升到一个新水平的 Flask 初学者,以及那些需要更完整地理解你可以用 Flask 做的事情的人。
|  |
|
烧瓶框架食谱
作者:沙拉布·阿格沃尔[亚马逊](http://www.amazon.com/gp/product/178398340X/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=178398340X&linkCode=as2&tag=thmovsthpy-20&linkId=2QSNQXU6EGH5P7KH target=)打包发布 |
其他书评
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
电子书评论-指南:学习 Python 中的迭代和生成器
上个月大约在 2012 年美国 PyCon 的时候,Matt Harrison 给我发了一本他的新书,Guide to:Learning Iteration and Generators in Python。我一直想学习更多关于发电机的知识,所以我认为这是非常偶然的。可悲的是,我花了一个月才抽出时间来读它。mobi(即 Kindle)版本的电子书重量为 460 kb,epub 版本为 460 kb。在跳跃之后,我们将快速地看一下好的和坏的。
好人
这是一本技术性很强的书。我想如果它被印刷出来,它会有 50 页左右。所以是速读。另外,它在亚马逊上的零售价仅为 3.99 美元。我想说,这本书是为中高级 Python 程序员而写的,因为作者使用了许多高度技术性的术语,并深入挖掘了 Python 本身的本质,尤其是在最初几章。他也不会花太多时间来解释琐碎的事情,所以我认为这可以作为如今 PyCon 上自吹自擂的“极端”谈话的一个很好的模板。对我来说最重要的是,这本书向我展示了我可以在当天创建的代码中实现生成器的地方。我只是觉得那很酷!您还了解了迭代器和可迭代对象之间的区别,这有点令人难以置信。
坏事
作者并没有说他在给我发一个草稿,但我想这就是我收到的。我的意思是,有很多小句子问题,你会看到像“the”而不是“than”这样的东西,或者一个句子缺少“the”、“an”或“a”,这可能使句子读起来很别扭。我发现前几个例子有点令人困惑,因为作者使用了一个 while 循环来描述一个循环的。最令人困惑的一点是,他指的是一个而循环,因为它是前面的循环的例子。更有趣的错误之一是这句话:****
像 Stack Overfull 这样的网站充斥着声称 xrange 是一个生成器的答案。(Kindle 位置 403)
判决
我找不到这本书的勘误表,所以我不能说这些吹毛求疵的小问题已经解决了。因为这本书非常专业,所以这也不是初学者学习发电机的最佳方式。另一方面,有时先学习困难的方法是好的。如果你正在努力理解发电机,或者想知道它们为什么存在,那么我想这本书会帮助你。否则,您可以随时查看文档。
|  |
|
指南:学习 Python 中的迭代和生成器
电子书评论-指南:学习 Python 装饰者
原文:https://www.blog.pythonlibrary.org/2012/05/02/ebook-review-guide-to-learning-python-decorators/
本周,我买了马特·哈里森的书学习 Python 装饰者指南,想看看我是否能最终理解装饰者到底有什么了不起。我已经决定尝试用道格·海尔曼的方法来回顾这本书,先做一个快速回顾,然后再做一个更正式的深度回顾,给那些足够想多读点的人。
快速回顾
- 为什么我拿起它:因为我想了解装修工,我也想看看这本书与哈里森的其他书相比如何。
- 我为什么要读完它:简单地说,这本书很短,我可以在做其他事情的间隙读它。此外,哈里森关于函数的一些见解非常有趣。
- 我会把它给:一个需要做元编程或者必须理解函数和函数生成器的中级到高级 Python 开发人员
图书格式
我能找到的唯一购买这本书的地方是亚马逊的 Kindle,甚至是作者的 T2 网站。所以我猜 mobi 是目前唯一支持的格式,除非你能从作者那里骗到别的东西。
书籍内容
这本电子书没有真正的章节。对我来说,它们更像是命名的部分。
函数 -关于函数及其工作原理的各种信息
函数参数 -这一章讲述了如何args、**kwargs 以及它们的用处。它还讨论了使用“”操作符的“拼合”或展平。闭包, -快速而肮脏的一章,讲述了什么是闭包,以及它们如何引导装饰者。
装修工——这本书的最后一部分当然是关于装修工的。它涵盖了简单装饰器、装饰器模板、参数化装饰器、多个装饰器和一个类装饰器。
回顾
我觉得这本书相当直接有趣。大多数时候,作者以坦率、平易近人的方式写作。这听起来像一本初学者的书,但我认为它更适合有经验的初学者到中级程序员,因为 Harrison 先生在进入函数生成器、闭包和装饰器时会进入一些令人兴奋的主题。我在这里和那里看到了一个错别字,但总的来说,我认为这篇散文相当不错。偶尔会有一些重复的片段,有时音符部分会叠在一起。堆叠笔记的问题是它们有点像迷你的边角料,会打断文本的流动。
如果你不理解函数的具体细节,并且你想最终学习那些新的装饰者,我会推荐这本书作为一个处理这些主题的好方法。
电子书评论:即时烧瓶网络开发
原文:https://www.blog.pythonlibrary.org/2013/11/08/ebook-review-instant-flask-web-development/
Packt Publishing 最近联系我,讨论他们的新书《即时烧瓶网络开发》,作者是 Ron DuPlain。他们给了我一本电子书,我刚刚读完。我总是努力对我阅读的 Python 书籍给出诚实的意见,因为我希望我的读者知道一本书是否值得他们辛苦赚来的钱。如果你没有太多时间复习,那么你可以看看我下面的短文。如果你有几分钟的时间,你可以读完剩下的!
快速回顾
- 为什么选择它:我对学习 Flask(以及一般的 web 开发)感兴趣已经有一段时间了,这本书正好落在我的腿上。
- 为什么我看完了:它很短,有很多有趣的小食谱和小技巧。
- 我会把这本书送给:我会把这本书送给已经了解 Python 并且可能也对 web 编程略知一二的人。
Packt 出版公司最近开始发行其即时系列图书。这些书都很短。在Instant Flask Web Development的案例中,这本书长达 78 页,包括所有加在开头和结尾的样板文件。这不是给程序员初学者看的书。作者假设读者了解 Python,绝对不会花时间解释 Python 是如何工作的。这并不是一件坏事,因为许多书浪费了大约三分之一的内容来解释初学者的概念,而不是专注于他们的核心主题。它也是一种烹饪书,因为每一部分都是一个食谱,被标为简单,中级或高级。
另一方面,书中有些观点需要反复阅读才能理解作者在说什么。书中还有一些不完整的代码示例(如第 15 页),还有一些示例中有缺口,读者应该知道如何填补。我在第 46 页找到一个例子,其中两个 return 语句缩进到相同的级别,这样第二个语句就永远不会到达。我知道这些都是吹毛求疵的问题,但是如果一些读者试图直接使用书中的代码,他们会感到困惑。说到代码,Packt 提供的源代码只有代码的最终版本。事实上,我喜欢看到每一章或每一个食谱的代码,看看它是如何发展的,但这是个人的喜好。
我们来简单谈谈这本书的内容。本书的前提是在 Flask 中创建一个功能齐全的日程安排应用程序。DuPlain 先生谈到了处理请求/响应、静态文件、表单、使用数据库(通过 Flask-SQLAlchemy)、用 Jinja 制作模板、错误响应、认证用户、会话和部署。作者花了本书的大部分时间解释请求/响应处理和使用数据库(如何添加、编辑、删除和查询)。有很多有趣的插件,比如 Flask-WTForms,以及它们是如何工作的。你会发现自己想要点击作者提供的所有各种资源链接,这样你就可以学习到书以外的各种其他东西。我认为这是这本书最擅长的:激起你的食欲,让你越来越想学习。
结论
虽然这本书有些地方有些粗糙,但我觉得值得一读。当我读完它的时候,我发现自己想了解更多关于 Flask 和它的插件。因此,如果你有兴趣了解 Python 的一个微观网络框架,我认为这本书将帮助你入门。
注意:我正在为这本书举办一场竞赛,竞赛将于 2013 年 11 月 15 日结束。如果你想有机会赢得一份免费拷贝,就去看看那篇文章!
|  |
|
快速烧瓶网显影
其他书评
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 马特·哈里森著《踩 Python 第二卷:中级 Python》
- 约翰·罗兰的《快速学习 Python》
电子书评论:中级 Python
原文:https://www.blog.pythonlibrary.org/2015/09/02/ebook-review-intermediate-python/
最近,免费电子书《中级 Python》的作者 Muhammad Yasoob Ullah Khalid 找到我,评论他的作品。Yasoob 是 Python 技巧博客的幕后推手。这本书已经在 Github 上开源发布,但是可以从 ReadTheDocs 下载 PDF 格式。但是在我详细介绍这本书之前,我先简单回顾一下:
快速回顾
- 为什么拿起:作者让我看这本书。
- 为什么我读完了这本书:实际上,我通读了这本书的大部分内容,并浏览了剩下的部分
- 我想把它给:一个想要学习更多 Python 语言的初学者
图书格式
你可以得到这本书的 PDF,ePub,Mobi,HTML 或者它的源代码,在 RestructuredText 中。你可以在这里购买电子书。
书籍内容
在写这篇评论的时候,这本书被分成 24 章,共 75 页,但由于它是开源的,这可能会改变。
全面审查
这本书涵盖了很多材料,但没有深入任何主题。实际上,这让我想起了我自己的书。没有一堆介绍性的材料,每一章都给出了掌握主题所需的最少量的信息。有些话题确实比其他话题得到了更多的报道。每章长度在 2 至 8 页之间。我应该提一下,这本书相当粗糙,读起来像初稿。例如,目录是空的。英语似乎不是作者的第一语言,所以有些句子可能会有点尴尬。开源的好处之一是任何人都可以来解决这些小问题。
让我们花点时间讨论一下这本书涵盖的内容。
前几章介绍了args / **kwargs、调试、生成器和映射/过滤器。在这一点上,我相信我的一些读者会质疑这本书是否真的涵盖了中级水平的材料,因为有些人会认为args / **kwargs 或内置地图更适合初学者。坦率地说,在初级和中级之间有一条细微的界限,所以我真的不打算去那里。这本书是免费的,所以你可以自己做决定。此外,这里还有很多中级材料。
接下来的几章将介绍 decorators、mutation、slots 和 virtualenv 等。您还会发现关于集合模块、对象自省、协同程序、lambdas、函数缓存和上下文管理器的章节。还有一大堆其他的章节,涵盖了异常处理、全局、枚举、理解、虚拟、三元运算符等等。
我觉得这本书很有趣,它确实涵盖了各种各样的信息。不过,这些主题似乎没有按照逻辑顺序进行分组。总的来说,我认为普通的 Python 程序员会从这本书里发现一些有价值的信息,而且入门价格是免费的,我认为这本书值得一读。如果你确实喜欢这本书,你应该通过购买这本书来支持作者。
|  |
|
中级 Python
穆罕默德·亚索布·乌拉·哈立德橡胶路 T3 |
其他书评
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
电子书评论:IPython 笔记本必备
原文:https://www.blog.pythonlibrary.org/2014/12/04/ebook-review-ipython-notebook-essentials/
本周,Packt Publishing 让我评论 L. Felipe Martins 的《IPython 笔记本精要》。他们给我发了一本电子书来评论。我一直对学习 IPython 笔记本很感兴趣,但从来没有抽出时间来,所以这似乎是一个了解更多的好方法。
快速回顾
- 拿起它的原因:出版社让我看这本书。
- 为什么看完:我只看了书的笔记本部分。其余的我只是浏览了一下。
- 我会把它给:一个已经了解 Python 并且是数据科学家的人
图书格式
你可以得到这本书的平装本、epub、mobi 或 PDF。
书籍内容
这本书分为五章和三个附录。
全面审查
这本书首先在第一章向读者展示了 IPython 笔记本。作者建议您使用 Python 的 Anaconda 发行版,并注册 Wakari 以使共享笔记本更容易。然后,您将学习如何运行笔记本,作者将使用咖啡冷却算法进行示例。这听起来可能有点奇怪,但了解如何计算咖啡随着时间的推移冷却了多少确实很有趣。我还认为这是展示笔记本电脑功能的好方法。这一章以几个简短的练习结束。
在第二章中,我们学习了更多关于笔记本界面的知识。在这里,我们学习如何编辑和导航笔记本和 IPython magics。您还将学习如何运行脚本以及加载和保存数据。本章最后用几个例子展示了如何在你的笔记本中嵌入图片、Youtube 视频和 HTML。我很喜欢这一章。
对于第三章,我们戏剧性地改变齿轮。从这一点直到我们到达附录,这本书基本上是给科学家的。这一章是关于在笔记本里用 Matplotlib 创建情节和动画。笔记本本身很少讨论。
第四章是关于熊猫项目,这是一个强大的数据处理和分析库。这超出了我的专业范围,所以我不能评论它的准确性,更不用说理解作者在这一章中所写的一切。简单地说,我只浏览了第四章。
第五章是关于 SciPy,Numba 和 NumbaPro。再次强调,重点是科学计算(SciPy)和如何加速这些计算(Numba/NumbaPro)。我也跳过了这一章。
附录包括以下内容:
- IPython 笔记本参考卡
- Python 语言的简要概述
- NumPy 数组
进入这本书,我认为这将是一个 IPython 笔记本的指南。这个标题无疑给人一种这样的印象。然而,这本书的大部分内容根本不是关于 IPython 笔记本,而是专注于使用 Python 进行科学计算。有许多其他的书涉及这个主题,也许 IPython 笔记本主要是被科学家使用的。前言指出,这本书应该也在学习笔记本以及其他一些库。我只是觉得科学图书馆得到了大部分的散文,而笔记本受到了冷落。
如果你正在寻找一本 IPython 笔记本的指南,我不确定我能为你推荐这本书。它只有两章专门讨论这个主题,在附录中还有一张参考卡片。另一方面,如果您正在寻找一些可以在 Python 中使用的科学库的简要概述,并学习如何使用 IPython 笔记本,那么这本书可能适合您。
|  |
|
IPython 笔记本必备
菲利普·马丁斯[亚马逊](http://www.amazon.com/gp/product/B00Q2N0CL6/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B00Q2N0CL6&linkCode=as2&tag=thmovsthpy-20&linkId=H4S6DVUH5TTRXJA2 target=)打包发布 |
其他书评
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
电子书评论:Python 中的交互式应用
原文:https://www.blog.pythonlibrary.org/2013/12/17/ebook-review-kivy-interactive-applications-python/
我最近收到了一本 Roberto Ulloa 写的《Kivy:Python 中的交互式应用》。这是目前唯一一本关于 Kivy 的书。Kivy 是一个跨平台的 GUI 工具包,可以在 Linux、Windows 和 OS X 以及 Android 和 iOS 上运行。事实上,Kivy 背后的人强调这主要是针对移动编程的。Kivy 支持多点触控,有一群非常活跃的程序员。你可以在他们项目的主页上读到更多关于 Kivy 的信息。我将评论这本书的 PDF 版本。
这里是我给你们的快速回顾:
快速回顾
- 我买这本书的原因:我收到了这本书,作为帮助我复习另一本 Packt 书的报酬,但我自己也会买,因为我对学习 Android/iOS 版 Python 很感兴趣,而且我喜欢学习 Python GUI 工具包。
- 我为什么完成它:这本书很短,我乐观地认为它会变得更好。
- 我会把它给:一个已经了解 Python 和 Kivy 基础的人,尽管我不认为我会推荐它。
图书格式
你可以得到这本书的平装本、epub、mobi 或 PDF。
书籍内容
这本书分为五章。前四章涵盖了漫画创作者项目,这是关于创建形状和与 Kivy 绘图。读者应该学习 GUI 基础知识(第 1 章),布局(第 1 章),如何使用画布对象(第 2 章),小部件事件(第 3 章),改善用户体验(第 4 章),最后一章涵盖了第二个也是最后一个项目,这是一个太空入侵者的克隆。
全面审查
Kivy 工具包支持两种语言。你可以完全用 Python 写你的程序,也可以混合使用 Python 和 Kv 语言。Kv 语言看起来有点像 CSS+Python,它有类似于 Python 的缩进要求(即每个块必须缩进 4 个空格)。使用 Kv 语言的第一个例子在书中没有适当缩进。作者从来没有提到需要将 Kv 代码缩进四个空格,所以我花了一段时间才弄明白为什么代码不起作用。你会发现,书上几乎每一个 Kv 代码的例子,如果照搬都不行。一些 Python 代码也有缩进问题。Packt 雇佣了很多母语不是英语的作者。这本书有许多难以阅读或没有意义的句子的例子。让我们看看每一章。
第一章介绍了如何启动一个 Kivy 应用程序,如何添加一两个小部件,小部件的属性/变量,Kivy 和布局的各种坐标系。前几节非常简单。坐标部分很混乱,需要反复阅读才能理解。我只理解了版面部分的内容。Kivy 中的布局类似于 wxPython 中的 sizers。当用户改变窗口大小时,它们帮助控制部件如何动态定位。
第二章深入探讨了基维的画布物体。它涵盖了如何绘制形状,插入图像,如何使用颜色,缩放和翻译。本章中还有关于存储/检索当前坐标空间上下文的信息。图像和颜色部分是我的亮点。其余的,就没那么多了。
在第三章中,我们学习了 Kivy 中的事件绑定。您将学习如何覆盖、绑定、解除绑定和创建 Kivy 事件。您还将了解如何使用属性来保持 UI 最新。这一章旨在解释其他几个主题。我不确定我是否理解了作者不断绑定事件然后解除绑定的推理,但至少现在我知道怎么做了。有一节是关于小部件、小部件的父部件和窗口本身之间的相对和绝对坐标的转换。这一部分令人困惑,但也很有趣。
对于第四章,我们学习屏幕管理器。这个概念使得切换屏幕变得很容易,这有点像在 wxPython 中交换面板,只是它内置在 Kivy 中。它还谈到了一个颜色控制小部件,创建和保存手势,以及用于拖动、旋转和缩放的多点触摸。这一章的手势部分很吸引人,尽管我认为它解释得不够详细。Kivy 实际上内置了专门用于保存和检索自定义手势的类。我希望这一节提到 Kivy 在识别手势方面有多准确,但它没有。
第五章是关于太空入侵者的克隆。这一章只有 20 页,所以我认为它没有给出足够的细节来说明每件事情是如何工作的。我觉得太匆忙了。另一方面,我喜欢学习如何创建游戏,所以我会给作者一些支持。这一章有很多很酷的信息。不过,你只需要花大部分时间来破译密码。
最后,我想知道更多关于 Kivy 的事情。我发现 Kivy 的文档比这本书更有帮助,但这本书至少有一些有趣的想法。我认为这是它最有价值的地方。它让你想要学习 Kivy,这样你就可以改进书中的两个项目,并制作自己的项目。我认为非常缺少的一个关键话题是项目在一个或两个移动平台上的实际分配,以及如何在这些平台上进行测试。Kivy 在 Android 或 iOS 模拟器中工作吗?Kivy 有 7 个或 8 个以上的 widgets 吗?这些问题没有答案。如果你能便宜买到这本书,我会说去买吧。否则,坚持使用 Kivy 文档和演示程序。
|  |
|
kivy:Python 中的交互式应用
其他书评
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 马特·哈里森著《踩 Python 第二卷:中级 Python》
- 约翰·罗兰的《快速学习 Python》
关于 Kivy 的附加信息
电子书评论:快速学习 Python
原文:https://www.blog.pythonlibrary.org/2013/04/01/ebook-review-learn-python-quickly/
几个月前,约翰·罗兰联系了我。他是全新电子书快速学习 Python的作者,他联系我,想用我的一篇博客文章作为他书中一个例子的基础。这个确切的说是一个。无论如何,我告诉他当他的书出版的时候我会评论它。总之,这本书几周前出版了,这是我的评论。注:我设法在它免费的时候弄到了一本,我想那是它发售的第二天。
快速回顾
- 我选择它的原因:我选择这本书,首先是因为有人想在他们的书中使用我的一篇文章,这让我很感兴趣,其次,我偷偷看了几章,很喜欢作者的写作风格。此外,免费拿起它帮助!
- 为什么写完:因为想复习这本书。不过,我只阅读了正文,而且只浏览了相当广泛的术语表/附录。
- 我会把它给:新程序员,特别是如果他们已经有一点编程经验,比如 101 课程。
跳完可以看我的全评!
图书格式
在撰写本文时,这本书在亚马逊上仅作为 Kindle 图书出售。
全面审查
快速学习 Python教 Python 3。它涵盖了你能想到的所有话题和一些你想不到的话题。没想到只是涵盖了安装 Python,尤其是只在 Windows 上。我也很惊讶,像这本书这么短的一本书会在最后 3 章试图跳到用 Tkinter 进行 GUI 编程,但是它做到了。正常的东西当然也包括在内(不一定按这个顺序):数字、字符串、循环和 if 语句、列表和字典(尽管没有太多关于元组的内容)、函数和类、文件 I/O、异常处理、日期操作以及关于电子表格和数据库的一章。
电子表格和数据库章节(第 8 章)关注电子表格的 csv 模块,提到了 xlwt 包,但没有提到 xlrd 。我想这一章可能会谈到 PyWin32 以及如何使用 PyWin32 的 COM 模块访问 Microsoft Excel,但它没有。数据库部分是对 pyodbc 的快速展示和讲述。他不教 SQL,这没问题,但是要注意。
这本书在书的最后涵盖了几个应用程序的开发。Rowland 先生让读者在课程章节中创建一个简单的银行应用程序的几种变体。然后,他继续让读者创建一些小的 Tkinter 应用程序。
这本书最独特的地方在于它使用了大量的超链接。事实上,如果没有术语表和附录,这本书将只有一半长。作者链接到他的词汇表中的各种术语以及一些外部资源。写作风格吸引人,有时很有趣,尤其是当作者放弃一些英国术语时。我觉得这篇课文直截了当,易于理解。不过,我不得不指出几个缺点。代码示例并不多,他经常在书的配套网站上提到代码:http://www.learnpythonquickly.com。大多数情况下,这工作得很好,但是当我将 Tkinter 的代码复制到我的 Python IDE 中时,我的行号与作者的不太匹配。此外,如果你试图使用亚马逊云阅读器阅读这本书,那么代码大多数时候都不会正确缩进,尽管如果你在 Kindle 软件中打开这本书,它似乎会适当缩进代码。
除此之外,这本书非常好,我会推荐给那些刚接触这门语言,想快速入门的人。当然,如果你是新手,那么你会花很多时间阅读 Python 文档,而且这本书不可能涵盖整个 Python 语言的全部内容。无论如何,我认为这本书将让读者快速掌握 Python 的基础知识,并且当他们需要学习更多知识时,这些链接将帮助他们知道以后要搜索什么。
|  |
|
快速学习 Python
约翰·道兰德亚马逊 |
电子书评论:艰难地学习 Python
原文:https://www.blog.pythonlibrary.org/2014/01/28/ebook-review-learn-python-the-hard-way/
几年前,一个叫 Zed Shaw 的家伙创建了一个名为艰难地学 Python的网站,受到了很多人的称赞。该网站由许多简短的练习组成,帮助初级程序员学习 Python 的各种细微差别,但都是以小块的形式。他不时地更新这本书,最终艾迪森-韦斯利把它写成了同名的书。最近有人给了我一份该书的 PDF 版本供我审阅。下面是快速版本:
快速回顾
- 为什么选择这本书:我收到这本书是为了对它进行评论,尽管我对阅读这本书很感兴趣,只是因为我听说过这个网站
- 我完成它的原因:这本书的章节很短...严格来说,我浏览了很多
- 我会把它给:想学习 Python 并且以前没有任何其他语言经验的人
图书格式
平装本、EPUB、MOBI 和 PDF
书籍内容
如果你愿意,这本书被分成 52 个练习或章节。大多数章节的长度都不到四页。事实上,有很多章节在它和下一章之间有一个空白页,所以这里有一些填充符。每一章都有一些练习和一些常见的学生问题。正如在介绍性文本中所预期的,您将了解作为 Python 程序员所需的所有数据结构。从字符串、字典和列表等简单的东西,到条件、循环、函数和类。这里都有。这本书还介绍了布尔值、Is-a / has-a、继承、组合、测试和 lpthw.web 框架。
全面审查
在导言中,肖先生大谈如果你,读者,觉得他在侮辱你的智慧,那么你就不是这本书的预期读者。无论你是否是初学者,单单这一部分就相当具有侮辱性。当他说“程序员经常谎称自己是数学天才,而实际上他们并不是”时,我并不十分欣赏。我想他是想搞笑,但他给人的印象最多是刻薄。
这本书很好地涵盖了 Python 的基础知识。通常每个新题目都有几个练习。例如,像文件 I/O 一样,学习打印到标准输出在 3 个练习中涉及。我认为包括学习练习和问答部分绝对是一个好主意,因为它们增强了每章中涉及的材料。我确实认为最后几个练习不太合适。它们相互之间并不适合,看起来像是独立的主题(游戏、骨骼、测试、网站等)。另一方面,这最后几个练习也比前几个长得多,所以也许没关系。
不管你是否喜欢刻薄/傲慢的部分,核心内容还是很不错的。我喜欢每一部分是如何组合在一起的,以及章节是如何相互构建的,一步一步地提高读者的能力。我认为初学者会受益于这本书,但我建议在你购买这本书之前,先查看一下网站。
|  |
|
艰难地学习 Python
作者:泽德·肖亚马逊培生/ InformIT |
其他书评
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 马特·哈里森著《踩 Python 第二卷:中级 Python》
- 约翰·罗兰的《快速学习 Python》
电子书评论:学习 scikit-learn:Python 中的机器学习
Packt Publishing 的人最近给我发了一本 ral Garreta 和 Guillermo Moncecchi 的书《学习 sci kit-learn:Python 中的机器学习》,请我阅读。机器学习不是我非常熟悉的话题,但我尝试了这本书,因为它听起来很有趣。对于时间不多的人,我先快速回顾一下:
快速回顾
- 为什么我选择了它:这本书是一本回顾版,但实际上我对任何 Python 编程书籍都感兴趣
- 我为什么要读完它:这本书写得很好,虽然我不太懂其中的很多内容,但它的主旨很有趣...我浏览了很多。
- 我会把它给:出于科学目的或机器学习而使用 Python 的人
如果你觉得有趣,那么请随意阅读完整的评论!
图书格式
这本书可以买到平装本、PDF、epub 和 Kindle 格式
全面审查
Packt Publishing 有一个概念,他们称之为“即时”书籍。这些书往往有 100 页左右长。虽然这本书没有被贴上“即时”的标签,但我认为它符合这一类别,因为它只有 4 章 118 页。这本书是为高级用户准备的。事实上,我会说它是为拥有高等数学或其他科学学位的人准备的。坦率地说,虽然内容很有趣,但我几乎没有领会其中的概念。因此,这将是一个相当轻松的审查。
首先,你需要 scikit-learn 和 NumPy 。我不确定是否也需要 SciPy。第一章是关于安装 scikit-learn,也是对机器学习的“温和介绍”。第 2 章涵盖了一个名为的监督学习的主题。在这一章中,你将学习图像识别、朴素贝叶斯、泰坦尼克号假说、决策树、随机森林和向量机。我喜欢贝叶斯的解释,学习图像识别也很酷。
第三章进入了无监督学习的世界,这是一个我觉得相当困惑的话题。作者写了关于主成分分析、k 均值聚类和各种其他聚类方法。我没有真正理解这一章。第 4 章是关于 scikit-learn 的高级特性。它涵盖了诸如特征提取和选择、模型选择和网格搜索等项目。
作者似乎在他们的领域很有知识,这本书写得很好。我真的没有注意到他们的散文有什么大问题。代码示例看起来很干净,但是我没有测试它们。我当然会向需要学习如何使用 Python 进行机器学习的程序员推荐这本书。。
|  |
|
学习 scikit-learn:Python 中的机器学习
作者:ral Garreta 和 Guillermo Moncecchi亚马逊打包发布 |
其他书评
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 马特·哈里森著《踩 Python 第二卷:中级 Python》
- 约翰·罗兰的《快速学习 Python》
电子书评论:忙碌的 Python 开发者的现代 Tkinter
我最近从亚马逊购买了马克·罗斯曼为忙碌的 Python 开发者编写的 Modern Tkinter,昨天刚刚完成。我认为它很新,但我现在找不到它的发布日期。不管怎样,我们继续复习吧!
快速回顾
- 为什么我买了这本书:我买这本书是因为我一直打算深入研究其他 Python GUI 工具包,而且自从约翰·格雷森的 Python 和 Tkinter 编程之后,我就再也没有看过新的 Tkinter 书了
- 我完成它的原因:它有一个非常好的写作风格,尽管部件章节开始变得拖沓
- 我想把它给:任何想让他们的 Tkinter 应用程序看起来更本地或者想了解一点 Tkinter 新主题系统的人。
图书格式
据我所知,这是另一个亚马逊 Kindle 或其他任何接受 mobi 的 mobi 书。根据亚马逊的说法,它可以打印出大约 147 页,大小不到一兆。
书籍内容
第 1 章和第 2 章是介绍性的,给出了项目的一些背景信息。第 3 章只是关于安装 Tkinter,我不是很懂。然而,这本书对 Tkinter 的新 ttk 部分以及它如何只在 Python 2.7 和 3.x 中可用进行了大做文章,需要注意的是,在提到 2.7 一次后,作者的行为就像 ttk 只在 3.x 中可用一样,这是混乱和错误的。对于 2.7 之前的版本,你实际上可以下载它,但默认情况下它是 2.7 的(反正在 Windows 上)。
不管怎样,第 4 章和第 5 章介绍了 Tkinter 的概念。第 6 章和第 8 章是与第 7 章相关的小部件,讨论网格几何管理器。第 9 章介绍菜单;10 浏览窗口和对话框;11 是组织性的(笔记本、窗格式窗户等);12 是关于字体、颜色和图像。第 13-15 章涵盖了大部件:分别是画布、文本和树部件。最后一章,也就是第 16 章,讲述了应用程序的主题化。
回顾
正如我已经提到的,这本书是以一种引人入胜的方式写的。我听说你可以让 Tkinter 看起来更好,但是 Tk 8.5+中的新东西(包含在 Python 2.7+中)让让你的应用程序看起来更好变得容易了。ttk 小部件的主题化方式使它们看起来是本地的或接近本地的,由于新的主题化功能,听起来你实际上可以很容易地对其进行主题化。
我注意到的不好的地方是在文本中有几个 PYTHONTODO 语句的例子。我想作者是想在这些地方多写些东西,只是忘记删除了。第 6 章中有一部分是关于组合框的,听起来你可以将数据和列表中的项目联系起来。作者声明他将在后面的 Listbox 部分中讨论它,但结果是 Tkinter 根本没有提供这样做的方法。你必须想出自己的方法,尽管作者描述了一些想法,但他并没有展示它们。我认为它可能是类似 wxPython 内置的做这种事情的方式,我在这里写了和,但事实并非如此。哦好吧。
你应该设置 Tkinter 设置的一些方法不清楚,写得很奇怪,通常是这样的: "step?额?”。我不太确定问号是不是必须的,但我猜不是。通常当提到设置时,没有例子来说明它们是如何工作的。在阅读了所有这些内容并看到了一些配置 Tkinter 小部件或实例化它们的奇怪方式后,我仍然认为这非常不直观和不一致。
另一方面,我认为这本书在很短的时间内包含了很多有用的信息。我感到很受鼓舞,再次尝试 Tkinter,看看它能做什么,也因为我想写一些关于它的文章。我的裁决?如果你想学习关于 ttk 的新东西,这本书很有意义。据我所知,除了官方文档之外,市场上没有任何东西包含这方面的信息。请注意,很少有完整的例子,主题一章实际上从来没有展示如何创建自己的主题,它只是给你足够的信息来做这件事。因此,如果你是一名新的 Python GUI 开发人员,并且想使用 Tkinter,那么这本书可能适合你。
更新(2012 年 5 月 31 日):这篇文章被重新格式化并转载于I-Programmer
电子书评论:使用 Python 和 Ming 的 MongoDB
原文:https://www.blog.pythonlibrary.org/2012/08/08/ebook-review-mongodb-with-python-and-ming/
本周,我从亚马逊上买了里克·科普兰的《MongoDB with Python》和明的《T1》电子书。它刚刚在 2012 年 7 月发布,所以我想我应该检查一下,看看 MongoDB 和整个 NoSQL 时尚有什么大惊小怪的。
快速回顾
- 我选择它的原因:主要是因为我对 MongoDB 感兴趣有一段时间了,这本书价格合理,我还读过一点他的 SQLAlchemy 的书。我想我可能几年前也在 PyCon 见过这个人。
- 我为什么要读完一本书:我几乎总是试图读完一本书,尤其是如果我要复习的话。不过这个很难。
- 我会把它给:需要一个快速文本来让他们快速了解 MongoDB 和 Ming 的人
图书格式
据我所知,这本书只有 Lulu 的 epub 版本或 Kindle 版本。
书籍内容
这本书大约有 84 页长。它包含 6 个章节。第 1 章和第 2 章本质上是介绍性的。第一章是典型的一次性章节,简单描述了将会涉及的内容以及读者应该是谁。简单地说,如果你还不知道 Python,这本书不会帮助你。它也不会帮助您设置 MongoDB。实际上,我很惊讶第一章不是前言。第 2 章告诉你去设置 MongoDB 或者使用一个在线服务,比如 MongoLab 或者 MongoHQ。您还将学习如何安装 pyMongo 并使用它连接 MongoDB、插入数据、运行查询、创建索引、删除数据、更新数据,学习使用 GridFS,以及 MongoDB 中的聚合(mapreduce、分片、聚合框架)。是的,第二章很重。当你读完它的时候,这本书你差不多已经读了一半了。
第 3 章是关于如何获得 MongoDB 的最佳性能,并讨论了硬件升级和分片。第 4 章介绍 Ming(不要与 Windows 的 MingW 混淆)。Ming 基本上是 MongoDB 的一个 ORM(或 ODM - Object Document Mapper ),由 SourceForge 的人编写,并且是开源的。第 4 章非常全面地介绍了 Ming,包括强制性地和声明性地定义模式。它还涵盖了许多与第 2 章相同的内容(即 CRUD ),但都是从阿明/会议的角度出发。第五章建立在第四章的基础上,它谈到了明灿提供的另一个抽象层,它给了开发者自动持久化的能力,一个身份映射,一次刷新多个更新的方法和一些其他的东西。最后,第 6 章是一个零零碎碎的章节,包含了本书其他地方不适合的东西(这是作者的话,不是我的)。它讨论了在模式改变时支持数据库迁移的各种方法(比如使用 flyaway 模块)以及如何扩展 ODM 的 mapper。
回顾
这本书开头写得很好,作者写得很吸引人。然而,在第 2 章结束时,我发现自己陷入了一个又一个代码示例的泥潭。通常这不会困扰我,但有时感觉有点重复,我觉得没有足够的解释来解释来源。我自己只尝试了几个例子,但它们似乎在大多数时候都有效。就在 2.3 节之前,代码中有一个错别字,作者使用了一个不存在的 findOne()方法。而应该是 find_one()。我试图用谷歌查找 pyMongo 的 API 最近是否有变化,但什么也找不到。希望这是一个孤立的案例,但是正如我所说的,我没有测试很多代码。
这本书的另一个问题是有许多奇怪的小错别字。通常只是拼写错误,尽管偶尔会有一些语法问题。这是次要的东西,但是我用过的大多数拼写检查器都可以发现其中的大部分。有几处作者有点漫无边际,或者代码会话有点难以理解,但除此之外,我认为这本书相当不错。是的,到最后会变得很枯燥,但大多数编程教科书都是如此。如果你想加入 MongoDB 程序员的大军,并且想坚持使用 Python,那么这本书应该可以让你开始。如果你需要更多的信息,那么 Niall O'Higgins 的《MongoDB 和 Python:流行的面向文档的数据库的模式和过程 》可能会有所帮助(注意:我还没有读过那本书)。
|  |
|
使用 Python 和 Ming 的 MongoDB
里克·科普兰亚马逊 |
电子书评论:Python 高性能编程
原文:https://www.blog.pythonlibrary.org/2014/02/18/ebook-review-python-high-performance-programming/
去年,Packt Publishing 邀请我担任 Gabriele Lanaro 的《Python 高性能编程》一书的技术评审。它于 2013 年 12 月出版。对于那些注意力持续时间短的人,我给你们一个简短的回顾:
快速回顾
- 我拿起它的原因:我是免费得到它的,但我会拿起它,因为它的主题让我感兴趣
- 我为什么要读完它:这本书有很多有趣的提示,让我想继续读下去
- 我想把它给:想学习优化代码的人
如果这激起了你的兴趣,一定要点击查看完整的评论!
图书格式
这本书可以买到平装本,PDF,epub 和 Kindle 格式。
全面审查
这本书的编排方式让我想起了 Packt Publishing 的 Instant 系列,这是他们较短的书籍之一,只有 4 章 108 页。第一章是关于基准和剖析。它讲述了如何使用 Python 的 cProfile、dis 模块和 memory_profiler。我发现这一章非常有趣。虽然我知道这一章提到的几个项目,但它包含了足够多的新信息,让我的大脑充满了分析的想法。
在第二章中,我们学习了使用 NumPy 的快速数组。这有点奇怪,因为我通常不会想到通过向我的系统添加一个科学的 Python 包来提高性能。然而,如果您使用数组做大量工作,这是有意义的。它还讨论了一个粒子模拟器(整洁!)并使用 numexpr ,NumPy 的快速数值表达式求值器。我个人现在不怎么使用数组,但是对于那些使用数组的人来说,这一章可能会很有意思。
第三章深入研究了 Cython 的世界。这里的想法是通过使用静态类型、使用 C 数组/指针、内存视图等,使用 Cython 来加速常规 Python 代码。我认为仅仅通过几个调整就可以提高for循环的速度,从而将它变成 C for 循环,这真的很酷。它有大量的例子。就我个人而言,我想看一本以 Cython 为主题的书。
在第四章中,作者深入探讨了并行处理。本章的重点是使用 Python 自带的多重处理模块。还有一节是关于使用 IPython 并行的。你可以在这里阅读一些关于这个话题的内容。本章的最后一节将讨论如何使用 Cython 和 OpenMP 来实现 Cython 中的并行处理。
我觉得这本书唯一的问题是它有点太短了。我本想读一读关于这个主题的完整文本。无论如何,对于那些需要加速代码的人来说,我认为这本书可以帮助你开始。
|  |
|
Python 高性能编程
其他书评
- 学习 scikit-learn:Python 中的机器学习
- 艰难地学习 Python
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 马特·哈里森著《踩 Python 第二卷:中级 Python》
- 约翰·罗兰的《快速学习 Python》
http://www.packtpub.com/python-high-performance-programming
电子书评论:高质量的 Python 开发
原文:https://www.blog.pythonlibrary.org/2012/05/07/ebook-review-quality-python-development/
上周看了几本电子书后,我被要求为其他几位作者写评论。我甚至得到了为另一个网站写 Python 书评的机会!疯狂。无论如何,弗雷德里克·莱皮德今天联系我,评论他的电子书,这本书在亚马逊上有售。他以 mobi(即 Kindle)文件的形式发给我。我最终使用了 calibre 来阅读它,因为我使用的机器上没有 Kindle 软件。它非常短,大约有 42 页,所以我一口气读完了。不管怎样,我们继续复习吧!
快速回顾
- 我拿起它的原因:主要是因为这本书的作者要求我这么做。是的,作者给了我一本书来评论。
- 我为什么要读完它:这本书短小精悍,涉及的话题令人耳目一新
- 我想把它给:这本书是为想要扩展自己的技能并成长为中级 Python 编程的初学者而写的
图书格式
据我所知,这本书只在 Kindle 的亚马逊上有售,所以完全是 mobi。如果你有一台设备或者喜欢 PC/Mac 版的 Kindle 软件,那么这很好。它的重量约为。600 KB 或 42 页。
书籍内容
这本书有 7 章:
第 1 章 -编码风格(主要讨论 PEP8 和 pyLint)
第 2 章 -构建你的开发树(组织你的文件结构/目录层次结构)
第 3 章 -文档(讲述 reST 和 Sphinx)
第 4 章 -打包(如何用 distutils 创建一个包并放在 PyPI 上)
第 5 章 -单元测试
第 6 章 -打包 教一些 unittest 的东西,提到 Foord 的模拟库,并给出一小段关于 Nose 测试框架和覆盖率的内容。py)
第 7 章——持续集成(从第 5 章和第 6 章中提取内容,并与 Jenkins 结合)
回顾
让我们先解决这个问题。我怀疑这本书的作者不是以英语为母语的人。因此,作者太频繁地写“代码”而不是“代码”就有点粗糙了。另一方面,我没有发现很多拼写错误的单词。这本书没有深入探讨任何东西,这有点遗憾。不过,这确实会让你想学得更多。作者提到了许多不同的包和它们的用途,我觉得这很有趣。他没有花很多时间解释 Python 的基础知识。相反,他专注于让读者作为程序员开始提升自己。
我应该提一下,第 6 章与其说是一章,不如说只有一页长。第 7 章可能是最长和最详细的,因为它有很多关于让图形在 Jenkins 中工作的说明,所以你可以看到你的代码有多好。我发现这很有趣,因为我一直听到持续集成。我还发现文档和打包章节非常有趣。
你可以在亚马逊上花 4.99 美元购买这本书,如果你有真正的 Kindle 和亚马逊 Prime,也可以免费获得。我肯定会免费试用,或者在亚马逊上查看几个样本页面。如果你正在寻找构建你的程序、测试和文档的概述,那么这本书可能正合你的胃口。
电子书评论:真正的 Python
原文:https://www.blog.pythonlibrary.org/2013/04/19/ebook-review-real-python/
我最近收到了弗莱彻·海斯勒的《真正的 Python》,刚刚读完。我从最近的 KickStarter 活动中得到它作为这本书的续集Web 开发的真正 Python的奖金,这本书实际上是别人写的。你可以去这本书的网站购买这本书,并获得这本书谈到的文件。我将审查修订版 2.2,因为这是我几周前下载时得到的。似乎从那以后有了更新。这是我读过的第一本关于 Python 2.7.3 的书,尽管它提到了 Python 3 的一些不同之处。
快速回顾
- 我买这本书的原因:我买这本书是因为它的续集 Kickstarter 活动给了我额外的奖励。
- 我为什么要完成它:这本书有一种吸引人的写作风格
- 我想给:刚接触 Python 语言的程序员
如果你对那个介绍感兴趣,请在跳转之后和我一起阅读完整的评论!
图书格式
这本书有 PDF 版、MOBI 版(即 Kindles 版)和 EPUB 版。我不相信在这个审查的时候有一个死树版本。
全面审查
Heisler 先生很好地向我们介绍了 Python。起初,听起来好像你将通过编写大量代码来学习 Python(这让我想到了 Zed Shaw 的网站),但作者最终做了大多数 Python 作者做的事情,并经历了一堆基础知识。总之,这本书被分成 13 章(如果算上第 0 章的话是 14 章!)和一些“插曲”部分扔在这里和那里。以下是承保范围的细分:
第零章只是一个介绍。第一章介绍了下载 Python 和使用 IDLE 的基础知识。然后我们遇到了一个包含代码中注释的插曲。第二章和第三章涵盖了字符串和字符串方法(查找字符串、切片等)。第 4 章讨论函数和循环。然后是另一个插曲,这一次涵盖了 Python 调试器:pdb。第五章讨论条件句(如 if/elif/else ),并讨论如何在循环中中断和继续。第六章是关于列表和字典的。在第七节中,我们学习文件 I/O 以及如何读写 CSV 文件。然后我们进入了另一个插曲,作者谈到了如何安装第三方 Python 模块。出于某种原因,他推荐 easy_install,我认为它在 Python 社区中已经失宠了。但是没有提到替代品,比如 pip。总之,在第八章中,我们学习了如何用 pyPDF 来读、写和操作 PDF。有提到 reportlab 和 PDFMiner,但是没有例子。第 9 章讨论了使用 Python 的 SQL,主要集中在 SQLite 上,尽管它提到了 pyodbc、pyscopg 和 MySQLdb。
第 10 章介绍了使用 Python 正则表达式的 web 抓取,beautifulsoup 和 mechanize。第 11 章是关于 Python 和图形的科学编程。它涵盖了一点 NumPy 和一点 matplotlib。第 12 章用 EasyGUI 和 Tkinter 探讨 Python GUI 工作。我认为 EasyGUI 是一个奇怪的选择,因为它基本上只是一个对话框生成器,但无论如何。最后一章介绍了使用谷歌应用引擎的网络应用。
每一章都有多个部分,这些部分通常以一两个练习结束,供读者尝试。文本是以一种非常非正式的方式写的,有一些有趣的例子,比如写一个 L33T 的翻译脚本。因为这是 KickStarter 上的一本书,最后几页列出了所有帮助这本书出版的支持者。我认为这本书涵盖了足够多的语言,足以让一个新的程序员入门。这不是一本深入的 Python 书籍,但也不应该是。它是为了让读者开始他们的 Python 之旅,它在这方面做得很好!
|  |
|
真正的 Python
弗莱彻·海斯勒RealPython.com |
电子书评论:探索 Python 第 2 卷:中级 Python
上周, Matt Harrison 给我发了一本他最新的 Python 电子书,名为 踏上 Python Vol 2:中级 Python 。我很感兴趣,因为我很少阅读中级 Python 书籍。事实上,我想说作者谈到的一些东西进入了高级水平。无论如何,我认为这是一本非常好的小书,如果你有时间,我会告诉你为什么。
快速回顾
- 为什么选择它:正如我提到的,这是一本中级水平的书,这是我的必读书目。
- 为什么我读完了它:因为这本书被证明非常有趣。
- 我会把它给: Python 程序员,他们对基础知识有很好的理解,但希望提高他们的 Python 技能。
现在如果你有几分钟的时间,你可以在跳转后阅读我的完整评论!
图书格式
据我所知,这本书只有在我写作的时候才能在亚马逊上买到。我收到的副本是 epub 格式的,所以可能还有其他版本...
全面审查
马特·哈里森的新书是他迄今为止最好的作品。我发现写作几乎没有错误,只有一些错别字,大部分在书的后半部分。这本书分成三个部分(不包括导言)。哈里森没有花时间向我们介绍 Python 相反,他假设您已经知道了,并开始深入研究函数构造。第一部分就这样开始了,他涵盖了 lambda、map、reduce、filter、recursion、list、set 和 dict comprehensions,最后是操作符模块。他使用了 lambda 后面的许多主题来说明 lambda 结构的高级用法。我认为这很有趣,并最终学到了一些新的技巧,我希望很快在自己的代码中实现。
第二部分致力于迭代和生成器。在这本书里,你将学习 iterables 和 iterators 之间的区别,如何构造一个普通的生成器和一个对象生成器,作者也给出了关于什么时候使用生成器和列表的提示。他还展示了 Python 内核中生成器和迭代器的一些真实例子。他在第一部分也做了一点。
第三部分是关于函数、闭包和装饰器的,重点是后者。我认为这部分是他关于装饰者的书的更新版本,因为一些例子看起来有点熟悉。不管怎样,这很有启发性。我承认,在书的最后的“替代装饰器实现”部分是相当混乱的。
最后,我认为这本书非常值得拥有它的成本。你几乎肯定会在第一部分学到一些新东西。如果你不太了解 Python 中的生成器、迭代器或装饰器,那么这本书将帮助你搞清楚,并希望给你一些如何在你的代码中使用它们的想法。我知道我学到了一些东西(可能还重新学到了其他一些东西!).
|  |
|
行走在 Python 之上第二卷:中级 Python
马特·哈里森亚马逊 |
电子书评论:踩在 Python 上
原文:https://www.blog.pythonlibrary.org/2011/11/26/ebook-review-treading-on-python/

本周,我发现了一本关于 Python 的新书,书名是 《践踏 Python》第一卷 ,作者是马特·哈里森。这本书只有草稿形式,所以还很粗糙,但是作者好心地给了我一份 epub 和 mobi 格式的免费拷贝。我用 Firefox 的插件 EPUBReader 阅读了其中的一部分,这样我就可以在我的浏览器上阅读了。然后我就切换到 PC Kindle 软件来完成这本书。
这本书是典型的 Python 入门文本。我觉得它比我读过的一些介绍书要短一点,但这可能是因为它是一本电子书。他涵盖了你所期望的内容,但这里有一个简短的主题列表:
- Python 的安装
- 翻译
- 数字和字符串
- 指导和帮助(自省,尽管他从未使用过这个词)
- 评论
- 序列(列表、元组和字典)
- 函数、类和方法
- 文件输入输出
- 例外——非常简短,没有展示如何创建自己的例外
他使用了一些我从未听说过的奇怪术语,比如将 Python 的双下划线方法称为“dunder 方法”(比如 init 或 seq)。我只听说过“魔法方法”这个名字。他还说了下面的话:在 Python 中经常听到关于布尔和布尔类对象的“真”或“假” (Kindle 位置 700)。我读过很多关于 Python 的书,以前也从未遇到过。没什么大不了的,他们只是突然出现在我面前,让我挠头。
无论如何,我不能对它太苛刻,因为它仍然只是一个草稿。我确实注意到,这本书的前几节似乎在后来有所重复。我不确定那是不是故意的。也许这是强调材料的一种方式。不管怎样,书中的信息对于刚开始学习这门语言的人来说是相当不错的。我应该提到,这是一本概述性的书。每个主题平均只有 1-4 页的信息,所以这本书会给你足够的信息,但是如果你遇到困难,你仍然需要阅读文档。例如,他提到理解,但从来没有说它们是什么。当你编程的时候,你不需要这些,但是它们确实很好。另一方面,他确实说了很多“with”语句。
总的来说,我认为这是一本非常好的 Python 入门书。读者将会对这种语言有一个很好的了解,而不会对第三方包或者甚至是包含的模块感到困惑。他们对 Python 自省工具有一点了解,这很好。当这本书完成的时候,你可能会想把这本书记在心里,留给你的萌芽期的皮托尼斯塔。你现在可以从他的网站上以 4.99 美元的价格购买这本书,我想你会在完成后得到最终版本,有点像曼宁的早期访问计划(MEAP)。
出售教学 Python 101 / 201 课程
原文:https://www.blog.pythonlibrary.org/2017/10/30/educative-python-101-201-courses-on-sale/
又到了一年中的这个时候,假期就要来了,所以我正在出售我的一些作品。可以免费获得 Python 101 ,五折获得 Python 201:中级 Python 。以下是您可以使用的优惠券代码:
- 对于Python 101-au-py 101-free
- 对于python 201-au-py 201-50
注意 Python 101 是完全免费的,第二门课是 50%的折扣。你也可以在 Leanpub 上免费获得 Python 101 的电子书。你也可以用这个链接打五折买到 Python 201 的电子书:【http://leanpub.com/python201/c/py201free
所有这些优惠券在一周内有效。感谢您的支持!
PyCon 出售教育 Python 课程!
原文:https://www.blog.pythonlibrary.org/2017/05/17/educative-python-courses-on-sale-for-pycon/
本周,我将在 PyCon 上出售我的交互式教育 Python 课程。可以五折获得 Python 101 和 Python 201:中级 Python 。以下是您可以使用的优惠券代码:
- 对于python 101-au-pycon-py 101
- 对于python 201-au-pycon-py 201
Educative 也在半价出售他们的 Python 3:一门互动深度潜水课程,你可以用这张优惠券获得: au-pycon-deepdive 。
现在,为了完全不同的东西,Educative 正在提供 17%的折扣销售他们的 Coderust 2.0:使用交互式可视化更快地编写面试准备,所以如果你有兴趣学习一些稍微不同的东西,现在是你的机会!这是代码: au-pycon-coderust
使用 Python 启用屏幕锁定
原文:https://www.blog.pythonlibrary.org/2010/02/09/enabling-screen-locking-with-python/
几个月前,我的雇主需要锁定我们的一些工作站,以兼容我们从另一个政府机构安装的一些新软件。我们需要在这么多分钟过去后强制这些机器锁定,并且我们需要让用户无法更改这些设置。在本文中,您将了解如何做到这一点,另外,我还将向您展示如何使用 Python 按需锁定您的 Windows 机器。
黑进注册表锁定机器
首先,我们来看看我的原始脚本,然后我们将对它进行一点重构,以使代码更好:
from _winreg import CreateKey, SetValueEx
from _winreg import HKEY_CURRENT_USER, HKEY_USERS
from _winreg import REG_DWORD, REG_SZ
try:
i = 0
while True:
subkey = EnumKey(HKEY_USERS, i)
if len(subkey) > 30:
break
i += 1
except WindowsError:
# WindowsError: [Errno 259] No more data is available
# looped through all the subkeys without finding the right one
raise WindowsError("Could not apply workstation lock settings!")
keyOne = CreateKey(HKEY_USERS, r'%s\Control Panel\Desktop' % subkey)
keyTwo = CreateKey(HKEY_CURRENT_USER, r'Software\Microsoft\Windows\CurrentVersion\Policies\System')
# enable screen saver security
SetValueEx(keyOne, 'ScreenSaverIsSecure', 0, REG_DWORD, 1)
# set screen saver timeout
SetValueEx(keyOne, 'ScreenSaveTimeOut', 0, REG_SZ, '420')
# set screen saver
SetValueEx(keyOne, 'SCRNSAVE.EXE', 0, REG_SZ, 'logon.scr')
# disable screen saver tab
SetValueEx(keyTwo, 'NoDispScrSavPage', 0, REG_DWORD, 1)
CloseKey(keyOne)
CloseKey(keyTwo)
发现这一点花了一些时间,但是要设置正确的键,我们需要在 HKEY _ 用户配置单元下找到第一个长度大于 30 个字符的子键。我确信可能有更好的方法来做这件事,但是我还没有找到。无论如何,一旦我们找到了长键,我们就跳出循环,打开我们需要的键,或者创建它们,如果它们不存在的话。这就是我们使用 CreateKey 的原因,因为它将做到这一点。接下来,我们设置四个值,然后关闭按键以应用新的设置。您可以阅读注释来了解每个键的作用。现在,让我们稍微改进一下代码,使其成为一个函数:
from _winreg import *
def modifyRegistry(key, sub_key, valueName, valueType, value):
"""
A simple function used to change values in
the Windows Registry.
"""
try:
key_handle = OpenKey(key, sub_key, 0, KEY_ALL_ACCESS)
except WindowsError:
key_handle = CreateKey(key, sub_key)
SetValueEx(key_handle, valueName, 0, valueType, value)
CloseKey(key_handle)
try:
i = 0
while True:
subkey = EnumKey(HKEY_USERS, i)
if len(subkey) > 30:
break
i += 1
except WindowsError:
# WindowsError: [Errno 259] No more data is available
# looped through all the subkeys without finding the right one
raise WindowsError("Could not apply workstation lock settings!")
subkey = r'%s\Control Panel\Desktop' % subkey
data= [('ScreenSaverIsSecure', REG_DWORD, 1),
('ScreenSaveTimeOut', REG_SZ, '420'),
('SCRNSAVE.EXE', REG_SZ, 'logon.scr')]
for valueName, valueType, value in data:
modifyRegistry(HKEY_USERS, subkey, valueName,
valueType, value)
modifyRegistry(HKEY_CURRENT_USER,
r'Software\Microsoft\Windows\CurrentVersion\Policies\System',
'NoDispScrSavPage', REG_DWORD, 1)
如您所见,首先我们导入 _winreg 模块中的所有内容。不建议这样做,因为您可能会意外地覆盖您已经导入的函数,这就是为什么这有时被称为“毒害名称空间”。然而,我见过的几乎所有使用 _winreg 模块的例子都是这样做的。请参见第一个示例,了解从中导入的正确方法。
接下来,我们创建一个可以打开密钥的通用函数,或者创建密钥(如果它不存在的话)。该函数还将为我们设置值和关闭键。之后,我们基本上做了与上一个例子相同的事情:我们遍历 HKEY _ 用户配置单元并适当地中断。为了稍微混合一下,我们创建了一个保存元组列表的数据变量。我们对其进行循环,并使用适当的参数调用我们的函数,为了更好地测量,我们演示了如何在循环之外调用它。
以编程方式锁定机器
现在您可能会想,我们已经介绍了如何以编程方式锁定机器。从某种意义上来说,我们做到了。但我们真正做的是设置一个计时器,在将来机器空闲时锁定机器。如果我们现在想锁定机器呢?你们中的一些人可能会想,我们应该只按 Windows 键加“L ”,这是一个好主意。然而,我创建这个脚本的原因是因为我必须不时地用 VNC 远程连接到我的机器,当使用 VNC 时,我需要通过多个步骤来锁定机器,而如果你正确设置了 Python,你只需双击一个脚本文件,让它为你锁定。这就是这个小脚本的作用:
import os
winpath = os.environ["windir"]
os.system(winpath + r'\system32\rundll32 user32.dll, LockWorkStation')
这三行脚本导入 os 模块,使用其 environ 方法获取 Windows 目录,然后调用 os.system 来锁定机器。如果您在计算机上打开一个 DOS 窗口,并在其中键入以下内容,您会得到完全相同的效果:
C:\windows\system32\rundll32 user32.dll, LockWorkStation
包扎
现在你知道如何用 Python 锁定你的机器了。如果您将第一个示例放在登录脚本中,那么您可以使用它锁定网络上的一些或所有机器。如果您的用户喜欢闲逛或参加许多会议,但让他们的机器保持登录状态,这将非常方便。这可以防止他们窥探,也可以保护你的公司免受间谍活动的侵扰。
使用 Python 增强照片
原文:https://www.blog.pythonlibrary.org/2017/10/24/enhancing-photos-with-python/
有时当你拍照时,你会发现它并不是你想要的。这幅画看起来很棒,但就是有点太暗了。或者有点模糊,需要增加锐度。锐度问题现在已经不那么糟糕了,因为很多相机在拍照后会自动为你增加锐度。
无论如何,在这篇文章中,我们将学习如何做到以下几点:
- 如何调整照片的亮度
- 如何改变图像的对比度
- 如何锐化照片
您首先需要的是可以使用 pip 安装的枕头包:
pip install Pillow
现在我们已经安装了枕头,我们可以开始了!
改变亮度

我个人认为这张照片看起来很好,但出于演示的目的,让我们试着让这张照片变亮。增强照片的关键是使用 Pillow 的 ImageEnhance 模块。让我们来看看:
from PIL import Image
from PIL import ImageEnhance
def adjust_brightness(input_image, output_image, factor):
image = Image.open(input_image)
enhancer_object = ImageEnhance.Brightness(image)
out = enhancer_object.enhance(factor)
out.save(output_image)
if __name__ == '__main__':
adjust_brightness('lighthouse.jpg',
'output/lighthouse_darkened.jpg',
1.7)
这里我们从 Pillow 导入我们需要的图片,然后在函数中打开输入的图片。接下来我们需要创建一个“增强器”对象。在这种情况下,我们使用 ImageEnhance 的 Brightness 类,并将我们的 image 对象传递给它。接下来我们调用 enhance() 方法,并赋予它增强因子。根据枕头文档,你需要一个大于 1.0 的系数来增加照片的亮度。如果你只是给它一个 1.0 的因子,那么它将返回原始图像不变。
如果您运行这段代码,您将得到类似这样的结果:

您也可以将低于 1.0 的增强因子向下传递到 0.0。根据文档,如果一直降到 0.0,您将收到一个完全黑色的图像。只是为了好玩,试着将上面代码中的增强因子改为 0.7。如果你这样做了,那么你会得到以下结果:

现在让我们试着给图片增加一些对比度!
调整图像的对比度

我以前拍过一些非常暗的照片,并且能够通过给照片增加亮度和对比度来保存它们。在这个例子中,我们将只增加这张可爱的毛毛虫照片的对比。但是,您也可以通过将下面的代码与前面的示例相结合来轻松增加亮度:
from PIL import Image
from PIL import ImageEnhance
def adjust_contrast(input_image, output_image, factor):
image = Image.open(input_image)
enhancer_object = ImageEnhance.Contrast(image)
out = enhancer_object.enhance(factor)
out.save(output_image)
if __name__ == '__main__':
adjust_contrast('caterpillar.jpg',
'output/caterpillar_more_contrast.jpg',
1.7)
这段代码非常类似于增亮函数。唯一的区别是,这里我们使用的是 ImageEnhance 模块中的对比度类,而不是亮度类。当我运行这段代码时,我得到了以下增强:

ImageEnhance 模块中的所有类都以相同的方式运行。如果您碰巧尝试将增强值 1.0 传递给它,您只是得到原始图像,没有添加任何调整。但是如果你从 0.0 到 1.0,你会降低对比度。您可以自己尝试增强因子,看看可以对自己的图像进行什么样的更改。我试着把它改成 0.7,结果是这样的:

现在我们准备学习锐化照片!
更改照片的清晰度

我很少锐化模糊的照片,因为我很少发现它有帮助。然而,你可以锐化照片,使它看起来不同,在一个愉快的方式。让我们看看如何使用 Python 和 Pillow 来实现这一点:
from PIL import Image
from PIL import ImageEnhance
def adjust_sharpness(input_image, output_image, factor):
image = Image.open(input_image)
enhancer_object = ImageEnhance.Sharpness(image)
out = enhancer_object.enhance(factor)
out.save(output_image)
if __name__ == '__main__':
adjust_sharpness('mantis.png',
'output/mantis_sharpened.jpg',
1.7)
同样,唯一的变化是使用 ImageEnhance 的 Sharpness 类,而不是其他选择之一。同样像以前一样,我们需要使用一个大于 1.0 的增强因子来增加清晰度。结果如下:

实际上我有点喜欢这个的结局。你也可以通过使用小于 1.0 的增强因子来模糊图像,但我认为这只会使图像变得相当暗淡。尽管如此,你也可以随意摆弄这些值。
包扎
Pillow 包有这么多使用 Python 编程语言编辑和增强照片的简洁功能。试用起来也超级快。您应该给这些脚本一个旋转,并尝试增强因子,看看您自己能做些什么。还有一个颜色类,我没有在这里介绍,你也可以用它来增强你的照片。开心快乐编码!
相关阅读
- Kanoki - 为你的照片画铅笔素描
- 如何用 Python 给你的照片加水印
- 如何用 Python 调整照片大小
- 用 Python 将一张照片转换成黑白
- 如何用 Python 旋转/镜像照片
- 如何用 Python 裁剪照片
Python 101:异常处理(视频)
原文:https://www.blog.pythonlibrary.org/2021/06/25/exception_handling_video/
在本视频教程中,您将了解 Python 中异常处理的工作原理。
具体来说,您将学习以下内容:
- 常见例外
- 处理异常
- 引发异常
- 检查异常对象
- 使用
finally语句 - 使用
else语句
https://www.youtube.com/embed/uGIwpRF2T78?feature=oembed
如果您喜欢阅读教程,您可能会对以下内容感兴趣:
- Python 101 - 异常处理
想了解更多,买我的 Python 101 书:
- Gumroad(电子书)【https://gumroad.com/l/pypy101
- 亚马逊(平装/Kindle)-【https://amzn.to/2Zo1ARG
使用 Python 从 pdf 导出数据
原文:https://www.blog.pythonlibrary.org/2018/05/03/exporting-data-from-pdfs-with-python/
很多时候,您会希望从 PDF 中提取数据,并使用 Python 将其导出为不同的格式。不幸的是,没有很多 Python 包能很好地完成提取部分。在这一章中,我们将会看到各种不同的可以用来提取文本的包。我们还将学习如何从 pdf 中提取一些图像。虽然 Python 中没有针对这些任务的完整解决方案,但是您应该能够使用这里的信息来开始。一旦我们提取了我们想要的数据,我们还将研究如何获取这些数据并以不同的格式导出。
让我们从学习如何提取文本开始吧!
使用 PDFMiner 提取文本
可能最广为人知的是一个叫做 PDFMiner 的包。PDFMiner 包从 Python 2.4 开始就存在了。它的主要目的是从 PDF 中提取文本。事实上,PDFMiner 可以告诉您文本在页面上的确切位置以及关于字体的父信息。对于 Python 2.4 - 2.7,您可以参考以下网站以获得关于 PDFMiner 的更多信息:
- github-https://github.com/euske/pdfminer
- PyPI-https://pypi.python.org/pypi/pdfminer/
- 网页-https://euke . github . io/pdf miner/
PDFMiner 与 Python 3 不兼容。幸运的是,有一个名为 PDFMiner.six 的 PDFMiner 分支,其工作原理完全相同。你可以在这里找到:【https://github.com/pdfminer/pdfminer.sixT2
|  | 想了解更多关于使用 Python 处理 pdf 的信息吗?然后看看我的书:
| 想了解更多关于使用 Python 处理 pdf 的信息吗?然后看看我的书:
ReportLab:使用 Python 处理 PDF
在 Leanpub 上立即购买 |
安装 PDFMiner 的说明已经过时了。您实际上可以使用 pip 来安装它:
python -m pip install pdfminer
如果您想为 Python 3 安装 PDFMiner(这可能是您应该做的),那么您必须像这样进行安装:
python -m pip install pdfminer.six
关于 PDFMiner 的文档充其量只能算是相当差的。你很可能需要使用 Google 和 StackOverflow 来弄清楚如何有效地使用本章没有涉及的 PDFMiner。
提取所有文本
有时您会想要提取 PDF 中的所有文本。PDFMiner 包提供了几种不同的方法来实现这一点。我们将首先看一些编程方法。让我们试着读出国内税收服务 W9 表格中的所有文本。你可以从这里得到一份:https://www.irs.gov/pub/irs-pdf/fw9.pdf
一旦您正确保存了 PDF,我们就可以查看代码:
import io
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfpage import PDFPage
def extract_text_from_pdf(pdf_path):
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager, fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager, converter)
with open(pdf_path, 'rb') as fh:
for page in PDFPage.get_pages(fh,
caching=True,
check_extractable=True):
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
# close open handles
converter.close()
fake_file_handle.close()
if text:
return text
if __name__ == '__main__':
print(extract_text_from_pdf('w9.pdf'))
当您直接使用 PDFMiner 包时,它可能有点冗长。在这里,我们从 PDFMiner 的各个部分导入不同的片段。因为没有这些类的文档,也没有 docstrings,所以我不会深入解释它们是做什么的。如果你真的很好奇的话,可以自己钻研源代码。然而,我认为我们可以跟着代码走。
我们做的第一件事是创建一个资源管理器实例。然后我们通过 Python 的 io 模块创建一个类似文件的对象。如果你使用的是 Python 2,那么你会希望使用 StringIO 模块。我们的下一步是创建一个转换器。在本例中,我们选择了 TextConverter ,但是如果你愿意,你也可以使用 HTMLConverter 或者 XMLConverter 。最后,我们创建一个 PDF 解释器对象,它将接受我们的资源管理器和转换器对象并提取文本。
最后一步是打开 PDF 并循环浏览每一页。最后,我们获取所有文本,关闭各种处理程序,并将文本打印到 stdout。
逐页提取文本
坦白地说,从一个多页文档中抓取所有文本并不那么有用。通常,您会希望在文档的较小子集上工作。因此,让我们重写代码,以便它能够逐页提取文本。这将允许我们一页一页地检查文本:
# miner_text_generator.py
import io
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfpage import PDFPage
def extract_text_by_page(pdf_path):
with open(pdf_path, 'rb') as fh:
for page in PDFPage.get_pages(fh,
caching=True,
check_extractable=True):
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager, fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager, converter)
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
yield text
# close open handles
converter.close()
fake_file_handle.close()
def extract_text(pdf_path):
for page in extract_text_by_page(pdf_path):
print(page)
print()
if __name__ == '__main__':
print(extract_text('w9.pdf'))
在这个例子中,我们创建了一个生成器函数,生成每页的文本。 extract_text 函数打印出每一页的文本。在这里我们可以添加一些解析逻辑来解析出我们想要的东西。或者我们可以将文本(或 HTML 或 XML)保存为单独的文件,以便将来解析。
您会注意到文本可能没有按照您期望的顺序排列。所以你肯定需要找出解析出你感兴趣的文本的最佳方法。
PDFMiner 的好处在于,您已经可以将 PDF 导出为文本、HTML 或 XML。
如果您不想自己尝试找出 PDFMiner,也可以使用 PDFMiner 的命令行工具, pdf2txt.py 和 dumppdf.py 来为您完成导出。根据 pdf2txt.py 的源代码,可以用来将一个 pdf 导出为纯文本、html、xml 或者“标签”。
通过 pdf2txt.py 导出文本
默认情况下,pdfMiner 附带的 pdf2txt.py 命令行工具将从 PDF 文件中提取文本并将其打印到 stdout。它不能识别图像文本,因为 PDFMiner 不支持光学字符识别(OCR)。让我们试试使用它的最简单的方法,就是把路径传递给 PDF 文件。我们将使用 w9.pdf 的。打开终端并导航到您保存该 PDF 的位置,或者修改下面的命令以指向该文件:
pdf2txt.py w9.pdf
如果运行这个命令,它会将所有文本打印到 stdout。您也可以让 pdf2txt.py 将文本以文本、HTML、XML 或“标记 pdf”的形式写入文件。XML 格式将给出关于 PDF 的大部分信息,因为它包含文档中每个字母的位置以及字体信息。不推荐使用 HTML,因为 pdf2txt 生成的标记往往很难看。以下是获得不同格式输出的方法:
pdf2txt.py -o w9.html w9.pdf
pdf2txt.py -o w9.xml w9.pdf
第一个命令将创建一个 HTML 文档,而第二个命令将创建一个 XML 文档。以下是我在进行 HTML 转换时得到的一张照片:

正如你所看到的,最终的结果看起来有点差,但还不算太差。它输出的 XML 非常冗长,所以我不能在这里全部复制。不过,这里有一个片段可以让你了解它的样子:
<pages><page id="1" bbox="0.000,0.000,611.976,791.968" rotate="0"><textbox id="0" bbox="36.000,732.312,100.106,761.160"><textline bbox="36.000,732.312,100.106,761.160"><text font="JYMPLA+HelveticaNeueLTStd-Roman" bbox="36.000,736.334,40.018,744.496" size="8.162">F</text>
<text font="JYMPLA+HelveticaNeueLTStd-Roman" bbox="40.018,736.334,44.036,744.496" size="8.162">o</text>
<text font="JYMPLA+HelveticaNeueLTStd-Roman" bbox="44.036,736.334,46.367,744.496" size="8.162">r</text>
<text font="JYMPLA+HelveticaNeueLTStd-Roman" bbox="46.367,736.334,52.338,744.496" size="8.162">m</text>
<text font="ZWOHBU+HelveticaNeueLTStd-BlkCn" bbox="60.122,732.312,78.794,761.160" size="28.848">W</text>
<text font="ZWOHBU+HelveticaNeueLTStd-BlkCn" bbox="78.794,732.312,87.626,761.160" size="28.848">-</text>
<text font="ZWOHBU+HelveticaNeueLTStd-BlkCn" bbox="87.626,732.312,100.106,761.160" size="28.848">9</text></textline></textbox></page></pages>
使用 Slate 提取文本
Tim McNamara 不喜欢 PDFMiner 使用起来如此迟钝和困难,所以他写了一个名为 slate 的包装器,使得从 pdf 中提取文本更加容易。不幸的是,它似乎与 Python 3 不兼容。如果你想试一试,你可能需要有 easy_install 来安装 distribute 包,就像这样:
easy_install distribute
我无法让 pip 正确安装软件包。一旦安装完毕,您将能够使用 pip 来安装 slate:
python -m pip install slate
请注意,最新版本是 0.5.2,pip 可能会也可能不会获取该版本。如果没有,那么您可以直接从 Github 安装 slate:
python -m pip install git+https://github.com/timClicks/slate
现在我们准备编写一些代码来从 PDF 中提取文本:
# slate_text_extraction.py
import slate
def extract_text_from_pdf(pdf_path):
with open(pdf_path) as fh:
document = slate.PDF(fh, password='', just_text=1)
for page in document:
print(page)
if __name__ == '__main__':
extract_text_from_pdf('w9.pdf')
如您所见,要让 slate 解析 PDF,您只需导入 slate,然后创建其 PDF 类的一个实例。PDF 类实际上是 Python 的列表内置的一个子类,所以它只返回文本页面的列表/ iterable。您还会注意到,如果 PDF 设置了密码,我们可以传入一个密码参数。无论如何,一旦文档被解析,我们只需打印出每页上的文本。
我真的很喜欢 slate 的易用性。不幸的是,几乎没有与这个包相关的文档。查看源代码后,似乎这个包只支持文本提取。
导出您的数据
现在我们有了一些要处理的文本,我们将花一些时间学习如何以各种不同的格式导出数据。具体来说,我们将学习如何通过以下方式导出文本:
- 可扩展标记语言
- JSON
- 战斗支援车
我们开始吧!
导出到 XML
可扩展标记语言(XML)格式是最广为人知的输出和输入格式之一。它在互联网上被广泛用于许多不同的事情。正如我们在本章中已经看到的,PDFMiner 也支持 XML 作为其输出之一。
不过,让我们创建自己的 XML 创建工具。这里有一个简单的例子:
# xml_exporter.py
import os
import xml.etree.ElementTree as xml
from miner_text_generator import extract_text_by_page
from xml.dom import minidom
def export_as_xml(pdf_path, xml_path):
filename = os.path.splitext(os.path.basename(pdf_path))[0]
root = xml.Element('{filename}'.format(filename=filename))
pages = xml.Element('Pages')
root.append(pages)
counter = 1
for page in extract_text_by_page(pdf_path):
text = xml.SubElement(pages, 'Page_{}'.format(counter))
text.text = page[0:100]
counter += 1
tree = xml.ElementTree(root)
xml_string = xml.tostring(root, 'utf-8')
parsed_string = minidom.parseString(xml_string)
pretty_string = parsed_string.toprettyxml(indent=' ')
with open(xml_path, 'w') as fh:
fh.write(pretty_string)
#tree.write(xml_path)
if __name__ == '__main__':
pdf_path = 'w9.pdf'
xml_path = 'w9.xml'
export_as_xml(pdf_path, xml_path)
这个脚本将使用 Python 的内置 XML 库, minidom 和 ElementTree 。我们还导入了 PDFMiner 生成器脚本,用于一次抓取一页文本。在这个例子中,我们创建了顶层元素,它是 PDF 的文件名。然后我们在它下面添加一个页面元素。下一步是我们的 for 循环,我们从 PDF 中提取每一页并保存我们想要的信息。您可以在这里添加一个特殊的解析器,将页面分成句子或单词,解析出更多有趣的信息。例如,您可能只想要带有特定名称或日期/时间戳的句子。您可以使用 Python 的正则表达式来查找这些内容,或者只是检查句子中是否存在子字符串。
对于这个例子,我们只从每个页面中提取前 100 个字符,并将它们保存到一个 XML 子元素中。从技术上讲,下一段代码可以简化为只写出 XML。然而,ElementTree 并没有对 XML 做任何处理以使其易于阅读。它看起来有点像缩小的 javascript,因为它只是一个巨大的文本块。因此,我们没有将文本块写入磁盘,而是使用 minidom 在写出之前用空格“美化”XML。结果看起来像这样:
<w9><pages><page_1>Form W-9(Rev. November 2017)Department of the Treasury Internal Revenue Service Request for Taxp</page_1>
<page_2>Form W-9 (Rev. 11-2017)Page 2 By signing the filled-out form, you: 1\. Certify that the TIN you are g</page_2>
<page_3>Form W-9 (Rev. 11-2017)Page 3 Criminal penalty for falsifying information. Willfully falsifying cert</page_3>
<page_4>Form W-9 (Rev. 11-2017)Page 4 The following chart shows types of payments that may be exempt from ba</page_4>
<page_5>Form W-9 (Rev. 11-2017)Page 5 1\. Interest, dividend, and barter exchange accounts opened before 1984</page_5>
<page_6>Form W-9 (Rev. 11-2017)Page 6 The IRS does not initiate contacts with taxpayers via emails. Also, th</page_6></pages></w9>
这是非常干净的 XML,也很容易阅读。作为奖励,您可以利用在 PyPDF2 章节中学到的知识,从 PDF 中提取元数据并添加到 XML 中。
导出到 JSON
JavaScript Object Notation 或 JSON 是一种易于读写的轻量级数据交换格式。Python 在其标准库中包含了一个 json 模块,允许您以编程方式读写 json。让我们利用上一节学到的知识,创建一个输出 JSON 而不是 XML 的导出器脚本:
# json_exporter.py
import json
import os
from miner_text_generator import extract_text_by_page
def export_as_json(pdf_path, json_path):
filename = os.path.splitext(os.path.basename(pdf_path))[0]
data = {'Filename': filename}
data['Pages'] = []
counter = 1
for page in extract_text_by_page(pdf_path):
text = page[0:100]
page = {'Page_{}'.format(counter): text}
data['Pages'].append(page)
counter += 1
with open(json_path, 'w') as fh:
json.dump(data, fh)
if __name__ == '__main__':
pdf_path = 'w9.pdf'
json_path = 'w9.json'
export_as_json(pdf_path, json_path)
在这里,我们导入我们需要的各种库,包括我们的 PDFMiner 模块。然后我们创建一个接受 PDF 输入路径和 JSON 输出路径的函数。JSON 基本上是 Python 中的一个字典,所以我们创建了几个简单的顶级键:文件名和页面。第页的键映射到一个空列表。接下来,我们遍历 PDF 的每一页,提取每页的前 100 个字符。然后,我们创建一个以页码为键、以 100 个字符为值的字典,并将其添加到顶级页面的列表中。最后,我们使用 json 模块的 dump 命令来编写文件。
文件的内容最终看起来像这样:
{'Filename': 'w9',
'Pages': [{'Page_1': 'Form W-9(Rev. November 2017)Department of the Treasury Internal Revenue Service Request for Taxp'},
{'Page_2': 'Form W-9 (Rev. 11-2017)Page 2 By signing the filled-out form, you: 1\. Certify that the TIN you are g'},
{'Page_3': 'Form W-9 (Rev. 11-2017)Page 3 Criminal penalty for falsifying information. Willfully falsifying cert'},
{'Page_4': 'Form W-9 (Rev. 11-2017)Page 4 The following chart shows types of payments that may be exempt from ba'},
{'Page_5': 'Form W-9 (Rev. 11-2017)Page 5 1\. Interest, dividend, and barter exchange accounts opened before 1984'},
{'Page_6': 'Form W-9 (Rev. 11-2017)Page 6 The IRS does not initiate contacts with taxpayers via emails. Also, th'}]}
同样,我们有一些易读的输出。如果您愿意,也可以用 PDF 的元数据来增强这个例子。请注意,输出会根据您希望从每个页面或文档中解析出的内容而变化。
现在,让我们快速了解一下如何导出到 CSV。
导出到 CSV
CSV 代表**逗号分隔值* *。这是一种非常标准的格式,已经存在了很长时间。CSV 的好处在于 Microsoft Excel 和 LibreOffice 会自动在一个漂亮的电子表格中打开它们。如果您想查看原始值,也可以在文本编辑器中打开 CSV 文件。
Python 有一个内置的 csv 模块,可以用来读写 csv 文件。我们将在这里使用它从 PDF 中提取的文本创建一个 CSV。让我们来看看一些代码:
# csv_exporter.py
import csv
import os
from miner_text_generator import extract_text_by_page
def export_as_csv(pdf_path, csv_path):
filename = os.path.splitext(os.path.basename(pdf_path))[0]
counter = 1
with open(csv_path, 'w') as csv_file:
writer = csv.writer(csv_file)
for page in extract_text_by_page(pdf_path):
text = page[0:100]
words = text.split()
writer.writerow(words)
if __name__ == '__main__':
pdf_path = 'w9.pdf'
csv_path = 'w9.csv'
export_as_csv(pdf_path, csv_path)
对于这个例子,我们导入 Python 的 csv 库。否则,导入与前面的示例相同。在我们的函数中,我们使用 CSV 文件路径创建了一个 CSV 文件处理程序。然后,我们初始化一个 CSV writer 对象,将该文件处理程序作为唯一的参数。接下来,我们像以前一样遍历 PDF 的页面。这里唯一的不同是,我们将前 100 个字符拆分成单独的单词。这允许我们将一些实际数据添加到 CSV 中。如果我们不这样做,那么每一行中只有一个元素,这就不是一个真正的 CSV 文件。最后,我们将单词列表写入 CSV 文件。
这是我得到的结果:
Form,W-9(Rev.,November,2017)Department,of,the,Treasury,Internal,Revenue,Service,Request,for,Taxp
Form,W-9,(Rev.,11-2017)Page,2,By,signing,the,filled-out,"form,",you:,1.,Certify,that,the,TIN,you,are,g
Form,W-9,(Rev.,11-2017)Page,3,Criminal,penalty,for,falsifying,information.,Willfully,falsifying,cert
Form,W-9,(Rev.,11-2017)Page,4,The,following,chart,shows,types,of,payments,that,may,be,exempt,from,ba
Form,W-9,(Rev.,11-2017)Page,5,1.,"Interest,","dividend,",and,barter,exchange,accounts,opened,before,1984
Form,W-9,(Rev.,11-2017)Page,6,The,IRS,does,not,initiate,contacts,with,taxpayers,via,emails.,"Also,",th
我认为这个例子比 JSON 或 XML 例子更难理解,但也不算太差。现在让我们继续,看看我们如何从 PDF 中提取图像。
从 pdf 中提取图像
不幸的是,没有 Python 包真正从 pdf 中提取图像。我找到的最接近的是一个名为 minecart 的项目,它声称可以做到,但只在 Python 2.7 上工作。我无法让它与我拥有的样本 pdf 一起工作。内德·巴奇尔德的博客上有一篇文章讲述了他是如何从 pdf 中提取 jpg 的。他的代码如下:
# Extract jpg's from pdf's. Quick and dirty.
import sys
pdf = file(sys.argv[1], "rb").read()
startmark = "\xff\xd8"
startfix = 0
endmark = "\xff\xd9"
endfix = 2
i = 0
njpg = 0
while True:
istream = pdf.find("stream", i)
if istream < 0:
break
istart = pdf.find(startmark, istream, istream+20)
if istart < 0:
i = istream+20
continue
iend = pdf.find("endstream", istart)
if iend < 0:
raise Exception("Didn't find end of stream!")
iend = pdf.find(endmark, iend-20)
if iend < 0:
raise Exception("Didn't find end of JPG!")
istart += startfix
iend += endfix
print("JPG %d from %d to %d" % (njpg, istart, iend))
jpg = pdf[istart:iend]
jpgfile = file("jpg%d.jpg" % njpg, "wb")
jpgfile.write(jpg)
jpgfile.close()
njpg += 1
i = iend
这也不适用于我正在使用的 pdf。有些人在评论中声称它对他们的一些 pdf 文件有效,评论中也有一些更新代码的例子。StackOverflow 上有这段代码的变体,其中一些以某种方式使用了 PyPDF2。这些对我来说都不起作用。
我的建议是使用像 Poppler 这样的工具来提取图像。Poppler 有一个叫做 pdfimages 的工具,你可以和 Python 的子流程模块一起使用。以下是在没有 Python 的情况下如何使用它:
pdfimages -all reportlab-sample.pdf images/prefix-jpg
确保已经创建了图像文件夹(或您想要创建的任何输出文件夹),因为 pdfimages 不会为您创建它。
让我们编写一个 Python 脚本来执行这个命令,并确保输出文件夹也为您存在:
# image_exporter.py
import os
import subprocess
def image_exporter(pdf_path, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cmd = ['pdfimages', '-all', pdf_path,
'{}/prefix'.format(output_dir)]
subprocess.call(cmd)
print('Images extracted:')
print(os.listdir(output_dir))
if __name__ == '__main__':
pdf_path = 'reportlab-sample.pdf'
image_exporter(pdf_path, output_dir='images')
在这个例子中,我们导入了子进程和操作系统模块。如果输出目录不存在,我们尝试创建它。然后我们使用子进程的调用方法来执行 pdfimages。我们使用调用,因为它将等待 pdfimages 完成运行。你可以使用 Popen 来代替,但是那将基本上在后台运行这个过程。最后,我们打印出输出目录的列表,以确认图像被提取到其中。
互联网上还有其他一些文章引用了一个名为 Wand 的库,您可能也想试试。它是一个 ImageMagick 包装器。同样值得注意的是,有一个名为 pypoppler 的 Python 绑定到 Poppler,尽管我找不到该包进行图像提取的任何示例。
包扎
我们在这一章中讲述了许多不同的信息。您了解了几种不同的包,我们可以使用它们从 pdf(如 PDFMiner 或 Slate)中提取文本。我们还学习了如何使用 Python 的内置库将文本导出为 XML、JSON 和 CSV。最后,我们看了从 pdf 导出图像的难题。虽然 Python 目前没有任何好的库来完成这项任务,但是您可以通过使用其他工具来解决这个问题,比如 Poppler 的 pdfimage 实用程序。
相关阅读
- 使用 Wand 从 python 中的pdf 中提取图像
- Ned Batchelder - 从 pdf 中提取 JPGs】
- 用 Python 提取 PDF 元数据和文本
- StackOverflow: 在 python 中使用 PDFMiner 从 PDF 文件中提取文本?**
用 Python 提取 PDF 元数据和文本
原文:https://www.blog.pythonlibrary.org/2018/04/10/extracting-pdf-metadata-and-text-with-python/
有很多与 Python 相关的 PDF 包。我最喜欢的一个是 PyPDF2 。您可以使用它来提取元数据、旋转页面、分割或合并 pdf 等。这就像是现有 pdf 的瑞士军刀。在本文中,我们将学习如何使用 PyPDF2 提取 PDF 的基本信息
入门指南
PyPDF2 不是 Python 标准库的一部分,所以您需要自己安装它。这样做的首选方法是使用 pip 。
pip install pypdf2
现在我们已经安装了 PyPDF2,让我们学习如何从 PDF 中获取元数据!
提取元数据
您可以使用 PyPDF2 从任何 PDF 中提取大量有用的数据。例如,您可以了解文档的作者、标题和主题以及有多少页。让我们从位于 https://leanpub.com/reportlab 的 Leanpub 下载这本书的样本来了解一下。我下载的样本名为“reportlab-sample.pdf”。
代码如下:
# get_doc_info.py
from PyPDF2 import PdfFileReader
def get_info(path):
with open(path, 'rb') as f:
pdf = PdfFileReader(f)
info = pdf.getDocumentInfo()
number_of_pages = pdf.getNumPages()
print(info)
author = info.author
creator = info.creator
producer = info.producer
subject = info.subject
title = info.title
if __name__ == '__main__':
path = 'reportlab-sample.pdf'
get_info(path)
这里我们从 PyPDF2 导入 PdfFileReader 类。这个类让我们能够使用各种访问器方法读取 PDF 并从中提取数据。我们做的第一件事是创建我们自己的 get_info 函数,它接受 PDF 文件路径作为唯一的参数。然后,我们以只读二进制模式打开文件。接下来,我们将该文件处理程序传递给 PdfFileReader,并创建它的一个实例。
现在我们可以通过使用 getDocumentInfo 方法从 PDF 中提取一些信息。这将返回一个pypdf 2 . pdf . document information的实例,它具有以下有用的属性:
- 作者
- 创造者
- 生产者
- 科目
- 标题
如果您打印出 DocumentInformation 对象,您将会看到:
{'/Author': 'Michael Driscoll',
'/CreationDate': "D:20180331023901-00'00'",
'/Creator': 'LaTeX with hyperref package',
'/Producer': 'XeTeX 0.99998',
'/Title': 'ReportLab - PDF Processing with Python'}
我们还可以通过调用 getNumPages 方法来获得 PDF 中的页数。
从 pdf 中提取文本
PyPDF2 对从 PDF 中提取文本的支持有限。不幸的是,它没有提取图像的内置支持。我在 StackOverflow 上看到过一些使用 PyPDF2 提取图像的菜谱,但是代码示例似乎很随意。
让我们尝试从上一节下载的 PDF 的第一页中提取文本:
# extracting_text.py
from PyPDF2 import PdfFileReader
def text_extractor(path):
with open(path, 'rb') as f:
pdf = PdfFileReader(f)
# get the first page
page = pdf.getPage(1)
print(page)
print('Page type: {}'.format(str(type(page))))
text = page.extractText()
print(text)
if __name__ == '__main__':
path = 'reportlab-sample.pdf'
text_extractor(path)
您会注意到,这段代码的开始方式与我们之前的示例非常相似。我们仍然需要创建一个 PdfFileReader 的实例。但是这一次,我们使用 getPage 方法抓取页面。PyPDF2 是从零开始的,很像 Python 中的大多数东西,所以当你给它传递一个 1 时,它实际上抓取了第二页。在这种情况下,第一页只是一个图像,所以它不会有任何文本。
有趣的是,如果你运行这个例子,你会发现它没有返回任何文本。相反,我得到的是一系列换行符。不幸的是,PyPDF2 对提取文本的支持非常有限。即使它能够提取文本,它也可能不会按照您期望的顺序排列,并且间距也可能不同。
要让这个示例代码工作,您需要尝试在不同的 PDF 上运行它。我在美国国税局的网站上找到了一个:https://www.irs.gov/pub/irs-pdf/fw9.pdf
这是为个体经营者或合同工准备的 W9 表格。它也可以用在其他场合。无论如何,我以w9.pdf的名字下载了它,并把它添加到了 Github 库。如果您使用 PDF 文件而不是示例文件,它会很高兴地从第 2 页中提取一些文本。我不会在这里复制输出,因为它有点长。
您可能会发现 pdfminer 包比 PyPDF2 更适合提取文本。
包扎
PyPDF2 包非常有用。使用它,我们能够从 pdf 中获得一些有用的信息。我可以在 PDF 文件夹中使用 PyPDF,并使用元数据提取技术按照创建者名称、主题等对 pdf 进行分类。试试看,看你怎么想!
相关阅读
基于 Python 和 OpenCV 的人脸检测
原文:https://www.blog.pythonlibrary.org/2018/08/15/face-detection-using-python-and-opencv/
机器学习、人工智能和人脸识别是眼下的热门话题。所以我想看看用 Python 来检测照片中的人脸是多么容易,这会很有趣。本文将只关注检测人脸,而不是人脸识别,人脸识别实际上是给一张脸指定一个名字。使用 Python 检测人脸最流行也可能是最简单的方法是使用 OpenCV 包。OpenCV 是一个用 C++编写的计算机视觉库,有 Python 绑定。根据您使用的操作系统,安装可能有点复杂,但在大多数情况下,您可以使用 pip:
pip install opencv-python
我在旧版本的 Linux 上使用 OpenCV 时遇到了问题,我无法正确安装最新版本。但是这在 Windows 上工作得很好,并且现在似乎在最新版本的 Linux 上也工作得很好。对于本文,我使用的是 OpenCV 的 Python 绑定的 3.4.2 版本。
寻找面孔
使用 OpenCV 查找人脸主要有两种方法:
- 哈尔分类器
- LBP 级联分类器
大部分教程都用 Haar,因为它更准确,但也比 LBP 慢很多。在本教程中,我将继续使用 Haar。OpenCV 包实际上包含了有效使用 Harr 所需的所有数据。基本上,您只需要一个 XML 文件,其中包含正确的面部数据。如果你知道你在做什么,你可以创建你自己的,或者你可以使用 OpenCV 自带的。我不是数据科学家,所以我将使用内置的分类器。在这种情况下,您可以在您安装的 OpenCV 库中找到它。只需转到 Python 安装中的/Lib/site-packages/cv2/data文件夹,并查找Haar cascade _ frontal face _ alt . XML。我把那个文件复制出来,放在我写人脸检测代码的那个文件夹里。
哈尔通过观察一系列正面和负面的图像来工作。基本上,有人会将一堆照片中的特征标记为相关或不相关,然后通过机器学习算法或神经网络进行运行。哈尔着眼于边缘,线条和四矩形特征。OpenCV 网站上有一个很好的解释。一旦你有了数据,你就不需要做任何进一步的训练,除非你需要完善你的检测算法。
现在我们已经做好了准备,让我们写一些代码:
import cv2
import os
def find_faces(image_path):
image = cv2.imread(image_path)
# Make a copy to prevent us from modifying the original
color_img = image.copy()
filename = os.path.basename(image_path)
# OpenCV works best with gray images
gray_img = cv2.cvtColor(color_img, cv2.COLOR_BGR2GRAY)
# Use OpenCV's built-in Haar classifier
haar_classifier = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml')
faces = haar_classifier.detectMultiScale(gray_img, scaleFactor=1.1, minNeighbors=5)
print('Number of faces found: {faces}'.format(faces=len(faces)))
for (x, y, width, height) in faces:
cv2.rectangle(color_img, (x, y), (x+width, y+height), (0, 255, 0), 2)
# Show the faces found
cv2.imshow(filename, color_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
find_faces('headshot.jpg')
我们在这里做的第一件事是进口。OpenCV 绑定在 Python 中被称为 cv2 。然后,我们创建一个接受图像文件路径的函数。我们使用 OpenCV 的 imread 方法来读取图像文件,然后创建一个副本来防止我们意外修改原始图像。接下来,我们将图像转换为灰度。你会发现计算机视觉几乎总是用灰色比用彩色效果更好,至少 OpenCV 是这样。
下一步是使用 OpenCV 的 XML 文件加载 Haar 分类器。现在,我们可以尝试使用分类器对象的检测多尺度方法在我们的图像中找到人脸。我打印出我们找到的面孔的数量,如果有的话。分类器对象实际上返回元组的迭代器。每个元组包含它找到的面的 x/y 坐标以及面的宽度和高度。我们使用这些信息在使用 OpenCV 的矩形方法找到的脸部周围画一个矩形。最后我们展示了结果:

我直视镜头的照片效果很好。只是为了好玩,让我们试着运行我通过代码找到的这张免版税图片:

当我在代码中运行这个图像时,我得到了如下结果:

正如你所看到的,OpenCV 只找到了四个人脸中的两个,所以这个特定的层叠文件不足以找到照片中的所有人脸。
在照片中寻找眼睛
OpenCV 还有一个 Haar Cascade eye XML 文件,用于查找照片中的眼睛。如果你做过很多摄影,你可能知道当你做肖像的时候,你想试着聚焦在眼睛上。事实上,一些相机甚至有眼睛自动对焦功能。例如,我知道索尼已经吹嘘他们的眼睛对焦功能好几年了,在我对他们的一款相机的测试中,它实际上工作得很好。它很可能使用类似于 Haars 本身的东西来实时发现眼睛。
无论如何,我们需要稍微修改一下代码来创建一个眼睛探测器脚本:
import cv2
import os
def find_faces(image_path):
image = cv2.imread(image_path)
# Make a copy to prevent us from modifying the original
color_img = image.copy()
filename = os.path.basename(image_path)
# OpenCV works best with gray images
gray_img = cv2.cvtColor(color_img, cv2.COLOR_BGR2GRAY)
# Use OpenCV's built-in Haar classifier
haar_classifier = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
faces = haar_classifier.detectMultiScale(gray_img, scaleFactor=1.1, minNeighbors=5)
print('Number of faces found: {faces}'.format(faces=len(faces)))
for (x, y, width, height) in faces:
cv2.rectangle(color_img, (x, y), (x+width, y+height), (0, 255, 0), 2)
roi_gray = gray_img[y:y+height, x:x+width]
roi_color = color_img[y:y+height, x:x+width]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
# Show the faces / eyes found
cv2.imshow(filename, color_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
find_faces('headshot.jpg')
这里我们添加第二个级联分类器对象。这一次,我们使用 OpenCV 内置的 haarcascade_eye.xml 文件。另一个变化是在我们的循环中,我们对找到的人脸进行循环。在这里,我们也试图找到眼睛,并在眼睛周围画矩形。我试着在这个新例子中运行我的原始头像,得到了以下结果:

这做得相当好,虽然它没有在右边的眼睛周围画出那么好的矩形。
包扎
OpenCV 有很多强大的功能让你开始用 Python 做计算机视觉。你不需要写很多行代码来创建有用的东西。当然,您可能需要做比本教程中显示的更多的工作,训练您的数据并优化您的数据集,以使这种代码正常工作。我的理解是,培训部分是真正耗时的部分。无论如何,我强烈推荐去看看 OpenCV,试一试。这是一个非常整洁的图书馆,有很好的文档。
相关阅读
- OpenCV - 使用哈尔级联的人脸检测
- 用 Python 进行人脸识别
- DataScienceGo - OpenCV 人脸检测
用 Faker 软件包伪造数据
原文:https://www.blog.pythonlibrary.org/2021/09/09/faking-data/
如果您是一名软件开发人员或工程师,那么您知道拥有样本数据会非常有帮助。数据也不一定是真实的数据。相反,数据可能是假的。例如,如果您正在编写一个处理 HIPAA 数据的程序,那么您将不会使用实际数据进行测试,因为这将违反隐私法。
优秀的程序员知道他们应该测试他们的代码,但是当数据受到保护或不可用时,如何测试呢?这就是虚假数据的来源。你可以用假数据填充你的数据库,创建 XML 或 JSON,或者用它来匿名化真实数据。有一个叫做 Faker 的 Python 包,可以用来生成假数据。
Faker 的灵感主要来自于 PHP Faker 、 Perl Faker 和 Ruby Faker 。
使用 Faker 的第一步是安装它!
装置
如果你知道如何使用 pip ,Faker 很容易安装。以下是您可以运行的命令:
python3 -m pip install Faker
现在 Faker 已经安装好了,您可以开始创建假数据了!
用 Faker 创建假数据
Faker 让伪造数据变得异常容易。打开您的终端(或 cmd.exe/Powershell)并运行 Python。然后,您可以在您的 REPL 中尝试以下代码:
>>> from faker import Faker
>>> fake = Faker()
>>> fake.name()
'Paul Lynn'
>>> fake.name()
'Keith Soto'
>>> fake.address()
'Unit 6944 Box 5854\nDPO AA 14829'
>>> fake.address()
'44817 Wallace Way Apt. 376\nSouth Ashleymouth, GA 03737'
这里你从 faker 模块导入 Faker 类。接下来,调用几次名称()和地址()函数。每次调用这些函数时,都会返回一个新的假名字或假地址。
您可以通过创建一个循环并调用 name() 十次来看到这一点:
>>> for _ in range(10):
... print(fake.name())
...
Tiffany Mueller
Zachary Burgess
Clinton Castillo
Yvonne Scott
Randy Gilbert
Christina Frazier
Samantha Rodriguez
Billy May
Joel Ross
Lee Morales
这段代码演示了每次调用函数时,名字都是不同的!
创建假的国际数据
Faker 支持在实例化 Faker() 类时设置区域设置。这意味着你可以用其他语言伪造数据。
例如,尝试将地区设置为意大利语,然后打印出一些名字:
>>> fake_italian = Faker(locale="it_IT")
>>> for _ in range(10):
... print(fake_italian.name())
...
Virgilio Cignaroli
Annibale Tutino
Alessandra Iannucci
Flavio Bianchi
Pier Peruzzi
Marcello Mancini-Saragat
Marina Sismondi
Rolando Comolli
Dott. Benvenuto Luria
Giancarlo Folliero-Dallapé
这些名字现在都是意大利语。如果您想要更多的变化,您可以将一个地区列表传递给 Faker() 来代替:

注意:这个例子是一个图像而不是文本,因为语法荧光笔工具不能正确显示亚洲字符。
创建假的 Python 数据
Faker 包甚至可以伪造 Python 数据。如果你不想拿出你的 Python 列表、整数、字典等等,你可以让 Faker 帮你做。
这里有几个例子:
>>> fake.pylist()
['http://www.torres.com/category/', -956214947820.653, 'bPpdDhlEBEbhbQETwXOZ', Decimal('256.347612040523'), '
dPypmKDRlQqxpdkhOfmP', 5848, 'PGyduoxaLewOUdTEdeBs', Decimal('-43.8777257283172'), 'oxqvWiDyWaOErUBrkhIa',
'hkJbiRnTaPqZpEnuJoFF', 8471, 'scottjason@yahoo.com', 'rXQBeNIKEiGcQpLZKBvR']
>>> fake.pydict()
{'eight': 'http://nielsen.com/posts/about/', 'walk': Decimal('-2945142151233.25'), 'wide': 'mary80@yahoo.com',
'sell': 5165, 'information': 2947, 'fire': 'http://www.mitchell.com/author.html', 'sea': 4662,
'claim': 'xhogan@jackson.com'}
>>> fake.pyint()
493
>>> fake.pyint()
6280
这不是很好吗?
包扎
Faker 允许您设置自定义种子或创建自己的假数据提供者。要了解全部细节,请阅读 Faker 的文档。您应该今天就看看这个包,看看它对您自己的代码有多大用处。
其他简洁的 Python 包
想了解其他整洁的 Python 包吗?查看以下教程:
- arrow—Python 的新日期/时间包
- PySimpleGUI 简介
- OpenPyXL–使用 Python 使用 Microsoft Excel】
2018 年秋季电子书销售
原文:https://www.blog.pythonlibrary.org/2018/08/26/fall-ebook-sale-2018/
这是一个新学年的开始,所以今年秋天我要进行一次新的销售。请随意查看我目前的销售情况:
- ReportLab:Python 中的 PDF 处理
- Python 201: 中级 Python
- Python 101
- Jupyter notebook 101(预购/提前获取)-预计。2018 年 11 月交付
这些销售将持续到 9 月 1 日。我所有的电子书都有 PDF、mobi (Kindle)和 epub 格式。
2 月 5 日- 2009 年平壤会议总结
原文:https://www.blog.pythonlibrary.org/2009/02/06/feb-5th-2009-pyowa-meeting-wrap-up/
在我们昨晚的聚会上,除了我之外,我们还有 7 个新成员。考虑到过去几天有 5 个人退出,我认为这是一个很好的出席率。我们谈了一点关于我们自己的 Python 日,但是我们并没有提出太多。因此,我在征求意见,并希望为我们的下一次会议收集这些意见,这样我们就可以确定一个日期。
会议的其余时间都花在解决我遇到的前几个愚蠢的电脑问题上。我们有三个团队在研究它们,我们有相当多的种类。我用函数,另一个用类接口完全面向对象。我们只是把摄氏温度转换成华氏温度,反之亦然。第二个程序是将一系列数字转换成文本,例如:
如果用户输入:123,那么输出应该是“一二三”。为了让事情变得更困难,我们还需要一种处理负数的方法。有一种方法可以做到:
numberDict = {0:"zero", 1:"one", 2:"two", 3:"three", 4:"four",
5:"five", 6:"six", 7:"seven", 8:"eight", 9:"nine"}
value = raw_input("请输入要转换为文本的一个数字或一系列数字: ")
对于 val in value:
if is instance(val,str) and val == "-":
打印" minus ",
else:
try:
只打印可以转换为整数类型的字符
打印 numberDict[int(val)],
除:
pass
当然,这种实现方式存在很多问题。例如,异常处理的方式不多,如果不重新运行脚本,就没有办法再次运行它。作为一个函数或一个类会更好,但是我将把那些任务留给读者作为练习。
我们的下一次会议将于 2009 年 3 月 2 日在马歇尔郡治安官办公室举行。我希望在那里见到你!
用 Python 填充 PDF 表单
原文:https://www.blog.pythonlibrary.org/2018/05/22/filling-pdf-forms-with-python/
多年来,可填写表格一直是 Adobe PDF 格式的一部分。在美国,可填写表单最著名的例子之一是来自国内税收署的文档。有许多政府表格使用可填写的表格。以编程方式填写这些表单有许多不同的方法。我听说过的最耗时的方法是在 ReportLab 中手工重新创建表单,然后填写。坦白地说,我认为这可能是最糟糕的主意,除非你的公司自己负责创建 pdf。那么这可能是一个可行的选择,因为这样你就可以完全控制 PDF 的创建和输入。
创建简单的表单
我们需要一个简单的表单用于我们的第一个例子。ReportLab 内置了对创建交互式窗体的支持,所以让我们使用 ReportLab 来创建一个简单的窗体。下面是代码:
# simple_form.py
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfform
from reportlab.lib.colors import magenta, pink, blue, green
def create_simple_form():
c = canvas.Canvas('simple_form.pdf')
c.setFont("Courier", 20)
c.drawCentredString(300, 700, 'Employment Form')
c.setFont("Courier", 14)
form = c.acroForm
c.drawString(10, 650, 'First Name:')
form.textfield(name='fname', tooltip='First Name',
x=110, y=635, borderStyle='inset',
borderColor=magenta, fillColor=pink,
width=300,
textColor=blue, forceBorder=True)
c.drawString(10, 600, 'Last Name:')
form.textfield(name='lname', tooltip='Last Name',
x=110, y=585, borderStyle='inset',
borderColor=green, fillColor=magenta,
width=300,
textColor=blue, forceBorder=True)
c.drawString(10, 550, 'Address:')
form.textfield(name='address', tooltip='Address',
x=110, y=535, borderStyle='inset',
width=400, forceBorder=True)
c.drawString(10, 500, 'City:')
form.textfield(name='city', tooltip='City',
x=110, y=485, borderStyle='inset',
forceBorder=True)
c.drawString(250, 500, 'State:')
form.textfield(name='state', tooltip='State',
x=350, y=485, borderStyle='inset',
forceBorder=True)
c.drawString(10, 450, 'Zip Code:')
form.textfield(name='zip_code', tooltip='Zip Code',
x=110, y=435, borderStyle='inset',
forceBorder=True)
c.save()
if __name__ == '__main__':
create_simple_form()
运行此示例时,交互式 PDF 表单如下所示:

现在,我们准备学习填写此表格的方法之一!
合并覆盖
Jan Ch 撰写了一篇关于 Medium 的文章,其中包含了几种不同的方法来解决在 pdf 中填写表单的问题。提出的第一个解决方案是在 PDF 中获取一个未填充的表单,并使用 ReportLab 创建一个单独的 PDF,其中包含我们希望“填充”该表单的数据。然后作者使用 pdfrw 将两个 pdf 合并在一起。理论上,您也可以将 PyPDF2 用于合并过程。让我们来看看这个方法是如何使用 pdfrw 包工作的。
让我们从安装 pdfrw 开始:
python -m pip install pdfrw
现在我们已经安装了这些,让我们创建一个名为 fill_by_overlay.py 的文件。我们将向该文件添加两个函数。第一个函数将创建我们的覆盖。让我们来看看:
# fill_by_overlay.py
import pdfrw
from reportlab.pdfgen import canvas
def create_overlay():
"""
Create the data that will be overlayed on top
of the form that we want to fill
"""
c = canvas.Canvas('simple_form_overlay.pdf')
c.drawString(115, 650, 'Mike')
c.drawString(115, 600, 'Driscoll')
c.drawString(115, 550, '123 Greenway Road')
c.drawString(115, 500, 'Everytown')
c.drawString(355, 500, 'IA')
c.drawString(115, 450, '55555')
c.save()
在这里,我们导入了 pdfrw 包,还从 ReportLab 导入了画布子模块。然后我们创建一个名为 create_overlay 的函数,它使用 ReportLab 的 Canvas 类创建一个简单的 PDF。我们只是用拉带画布的方法。这需要反复试验。幸运的是,在 Linux 和 Mac 上,有不错的 PDF 预览应用程序,你可以用它来保持 PDF 打开,它们会随着每次更改自动刷新。这对于计算出绘制字符串所需的精确坐标非常有帮助。因为我们创建了原始表单,所以计算覆盖图的偏移量实际上非常容易。我们已经知道表单元素在页面上的位置,所以我们可以很好地猜测将字符串绘制到哪里。
这个难题的下一部分实际上是将我们在上面创建的覆盖图与我们在前一部分创建的表单合并。接下来让我们编写这个函数:
def merge_pdfs(form_pdf, overlay_pdf, output):
"""
Merge the specified fillable form PDF with the
overlay PDF and save the output
"""
form = pdfrw.PdfReader(form_pdf)
olay = pdfrw.PdfReader(overlay_pdf)
for form_page, overlay_page in zip(form.pages, olay.pages):
merge_obj = pdfrw.PageMerge()
overlay = merge_obj.add(overlay_page)[0]
pdfrw.PageMerge(form_page).add(overlay).render()
writer = pdfrw.PdfWriter()
writer.write(output, form)
if __name__ == '__main__':
create_overlay()
merge_pdfs('simple_form.pdf',
'simple_form_overlay.pdf',
'merged_form.pdf')
这里我们使用 pdfrw 的 PdfReader 类打开表单和覆盖 pdf。然后我们遍历两个 pdf 的页面,并使用页面合并将它们合并在一起。在代码的最后,我们创建了一个 PdfWriter 的实例,我们用它来写出新合并的 PDF。最终结果应该是这样的:

注意:当我运行这段代码时,我确实在 stdout 上收到了一些错误。这里有一个例子:
[ERROR] tokens.py:226 stream /Length attribute (171) appears to be too small (size 470) -- adjusting (line=192, col=1)
正如我提到的,这实际上并不妨碍合并 PDF 的创建。但是你可能要留意这些,因为如果你有任何问题,它们可能暗示着一个问题。
填写表单的其他方式
我读过一些其他的方法来“填充”这些类型的 pdf 中的字段。其中一个是获取一个 PDF 文件,并将页面保存为一系列图像。然后在您想要添加文本的位置绘制矩形,然后使用您的新图像作为配置文件来填写 PDF。似乎有点古怪,坦白说,我不想去做那些工作。
更好的方法是在 PDF 编辑器中打开 PDF,您可以在其中添加不可见的只读字段。您可以用唯一的名称标记字段,然后通过 PDF 的元数据访问它们。在元数据上循环,并使用 ReportLab 的 canvas 方法再次创建一个覆盖图,然后以与之前大致相同的方式将其合并。
我也看到很多人在谈论使用表单数据格式或 FDF。这是 PDF 应该用来保存要在 PDF 中填充的数据的格式。您可以使用 PyPDFtk 和 PdfJinja 来完成表单填写。有趣的是, PyPDFtk 不能处理图像字段,比如你可能想要粘贴签名图像的地方。为此,您可以使用 PdfJinja 。然而 PdfJinja 在使用复选框和单选按钮时似乎有一些限制。
您可以通过以下链接了解有关这些主题的更多信息:
- https://yoongkang.com/blog/pdf-forms-with-python/
- https://medium . com/@ zwin ny/filling-pdf-forms-in-python-the-right-way-EB 9592 e 03 DBA
使用 pdf 表单包
我认为在易用性方面最有希望的包是新的 pdfforms 包。不过它要求你安装一个名为 pdftk 的跨平台应用程序。幸运的是 pdftk 是免费的,所以这不是一个真正的问题。
您可以使用 pip 安装 pdfforms,如下所示:
python -m pip install pdfforms
要使用 pdfforms,您必须首先让它检查包含表单的 PDF,以便它知道如何填写。你可以这样做检查:
pdfforms inspect simple_form.pdf
如果 pdfforms 工作正常,它会在“test”子文件夹中创建一个“filled”PDF。该子文件夹出现在 pdfforms 本身所在位置的旁边,而不是您运行它的位置。它将按顺序用数字填充表单。这些是字段编号。
接下来您要做的是创建一个 CSV 文件,其中第一列和第一行包含 PDF 的名称。第一列中的其他行对应于字段编号。您在此输入要填写的字段的编号。然后,在 CSV 文件的第三列中输入要在表单中填写的数据。第二列被忽略,所以您可以在这里放置一个描述。第三列之后的所有列也将被忽略,因此这些列可以用于您想要的任何用途。
对于本例,您的 CSV 文件可能如下所示:
simple_form.pdf,,,
1,first name,Mike
2,last name,Driscoll
填写完 CSV 后,您可以运行以下命令,用您的自定义数据实际填写表单:
pdfforms fill data.csv
默认情况下,填充的 PDF 会出现在名为 filled 的子文件夹中。
现在说说坏消息。我无法让它在 Windows 或 Mac 上正常工作。我让 inspect 步骤在 Windows 上运行,但在 Mac 上它只是挂起。在 Windows 上,当我运行 fill 命令时,它失败了,并显示一个错误,说找不到要填充的 PDF。
我想当这个包变得不那么容易出错的时候,真的会很神奇。除了运行有问题之外,唯一主要的缺点是你需要安装一个根本不是用 Python 写的第三方工具。
包扎
在查看了 Python 开发人员可用于填充 PDF 表单的许多不同选项后,我认为最直接的方法是创建覆盖图,然后使用 pdfrw 之类的工具将其合并到可填充的表单 PDF 中。虽然这感觉有点像黑客,但我见过的其他方法看起来也一样的黑客和耗时。一旦您知道了表单中一个单元格的位置,您就可以合理地计算出页面上大多数其他单元格的位置。
附加阅读
使用 Python 查找已安装的软件
原文:https://www.blog.pythonlibrary.org/2010/03/03/finding-installed-software-using-python/
你有没有想过你的电脑上安装了什么软件?大多数使用 Windows 的人可能会通过添加/删除程序来找到这些信息,但他们不是程序员。不,程序员必须编写脚本,因为这样做是我们的天性。实际上,我这么做还有另一个原因:我的老板希望我记录用户电脑上安装了什么,这样我们就能知道用户是否安装了未经授权的软件。因此,尝试这样做还有一个实际的原因。
经过一些研究,我发现大多数行为良好的软件会在 Windows 注册表中存储关于它们自己的各种信息。具体来说,它们通常将这些信息存储在以下位置:HKEY _ LOCAL _ MACHINE \ Software \ Microsoft \ Windows \ current version \ Uninstall
应该注意的是,并非所有您安装的程序都会将该信息放入注册表中。例如,有些供应商根本不使用注册中心。此外,恶意软件之类的恶意程序可能也不会把任何东西放在那里。然而,超过 90%的人会这样做,这是获取信息的好方法。要获得更多信息,您可能需要使用 Python 的操作系统模块的“walk”方法进行一些目录遍历,并通过与注册表中的内容进行比较来查找不匹配的内容,或者从您从原始基础机器保存的一些存储映像中查找不匹配的内容。
总之,说够了。让我们来看看代码!注:如果你想跟着做,那么你需要下载并安装蒂姆·戈登的 WMI 模块。
import StringIO
import traceback
import wmi
from _winreg import (HKEY_LOCAL_MACHINE, KEY_ALL_ACCESS,
OpenKey, EnumValue, QueryValueEx)
softFile = open('softLog.log', 'w')
errorLog = open('errors.log', 'w')
r = wmi.Registry ()
result, names = r.EnumKey (hDefKey=HKEY_LOCAL_MACHINE, sSubKeyName=r"Software\Microsoft\Windows\CurrentVersion\Uninstall")
softFile.write('These subkeys are found under "HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Uninstall"\n\n')
errorLog.write("Errors\n\n")
separator = "*" * 80
keyPath = r"Software\Microsoft\Windows\CurrentVersion\Uninstall"
for subkey in names:
try:
softFile.write(separator + '\n\n')
path = keyPath + "\\" + subkey
key = OpenKey(HKEY_LOCAL_MACHINE, path, 0, KEY_ALL_ACCESS)
try:
temp = QueryValueEx(key, 'DisplayName')
display = str(temp[0])
softFile.write('Display Name: ' + display + '\nRegkey: ' + subkey + '\n')
except:
softFile.write('Regkey: ' + subkey + '\n')
except:
fp = StringIO.StringIO()
traceback.print_exc(file=fp)
errorMessage = fp.getvalue()
error = 'Error for ' + key + '. Message follows:\n' + errorMessage
errorLog.write(error)
errorLog.write("\n\n")
softFile.close()
errorLog.close()
这是一个很短的片段,但这里有很多东西。让我们打开它。首先,我们导入我们需要的模块,然后打开几个文件: softFile 将把我们的脚本找到的所有软件存储在“softLog.log”中,而我们的 errorLog 变量将把我们遇到的任何错误存储在“errors.log”中。接下来,我们使用 WMI 来枚举“Uninstall”键中的子项。之后,我们给每个日志文件写一些标题信息,使它们更容易阅读。
最后一个重要部分出现在循环结构中。在这里,我们循环从我们的 WMI 调用返回的结果。在我们的循环中,我们试图提取两条信息:软件的显示名称和与之相关的键。还有很多其他信息,但似乎没有任何标准可以遵循,所以我没有抓住任何一个。您将需要更复杂的错误处理来很好地提取它(或者使用生成器)。无论如何,如果我们试图取出的任何一部分失败了,我们会发现错误并继续下去。嵌套异常处理捕捉与获取显示名称相关的错误,而外部异常处理程序捕捉与访问注册表相关的错误。我们或许应该将这些异常显式化(比如,后者应该是 WindowsError,我认为),但这只是一个快速而肮脏的脚本。你认为有必要的话,可以随意延长。
如果我们在任一位置遇到错误,我们会记录一些内容。在嵌套的情况下,我们只是将 Regkey 的名称记录到“softLog.log”中,而在外部的情况下,我们只是将一个错误记录到“errors.log”中。最后,我们通过关闭文件进行清理。
下面是我在 Windows XP 机器上运行这个脚本时得到的部分示例:
These subkeys are found under "HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Uninstall"
显示名称:Windows 驱动程序包-Garmin(grmnusb)Garmin Devices(03/08/2007 2 . 2 . 1 . 0)
Regkey:45a 7283175 c 62 fac 673 f 913 C1 f 532 c 5361 f 97841
Regkey: AddressBook
显示名称:Adobe Flash Player 10 ActiveX
Regkey:Adobe Flash Player ActiveX
显示名称:Adobe Flash Player 10 插件
Regkey: Adobe Flash Player 插件
显示名称:Python 2.4 ado db-2.00
Regkey:ado db-py 2.4
显示名称:代理搜掠
Regkey:代理搜掠
显示名称:亚马逊游戏&软件下载器
Regkey:亚马逊游戏&软件下载器 _ is1
显示名称:亚马逊 MP3 下载器 1.0.3
Regkey:亚马逊 MP3 下载器
显示名称:ZoneAlarm Spy Blocker Toolbar
Regkey:Ask Toolbar _ is1
显示名称:Aspell 英语词典-0.50-2
Regkey: Aspell 英语词典 _ is1
现在你知道如何提取安装在你的 Windows 系统上的大部分软件了。我主要在使用 Python 2.5 的 Windows XP 上测试了这一点,但它应该也能在 Windows Vista 和 7 上运行。Windows 7 和 Vista 通常会强制默认用户以比 XP 更低的权限运行,因此您可能需要以管理员身份或模拟管理员身份运行此脚本。玩得开心!
烧瓶 101:添加数据库
原文:https://www.blog.pythonlibrary.org/2017/12/12/flask-101-adding-a-database/
上次我们学习了如何安装烧瓶。在这篇文章中,我们将学习如何添加一个数据库到我们的音乐数据网站。您可能还记得,Flask 是一个微型网络框架。这意味着它不像 Django 那样带有对象关系映射器(ORM)。如果您想要添加数据库交互性,那么您需要自己添加或者安装一个扩展。我个人喜欢 SQLAlchemy ,所以我认为有一个现成的扩展可以将 SQLAlchemy 添加到 Flask 中,这个扩展叫做 Flask-SQLAlchemy ,这很好。
要安装 Flask-SQLAlchemy,只需要使用 pip。在运行以下内容之前,请确保您处于我们在本系列第一部分中创建的激活的虚拟环境中,否则您将最终将扩展安装到您的基本 Python 而不是您的虚拟环境中:
pip install flask-sqlalchemy
现在我们已经安装了 Flask-SQLAlchemy 及其依赖项,我们可以开始创建数据库了!
创建数据库
用 SQLAlchemy 创建数据库实际上非常容易。SQLAlchemy 支持几种不同的数据库操作方式。我最喜欢的是使用它的声明性语法,允许您创建模拟数据库本身的类。所以在这个例子中我会用到它。我们也将使用 SQLite 作为我们的后端,但是如果我们想的话,我们可以很容易地将后端更改为其他东西,如 MySQL 或 Postgres。
首先,我们将看看如何使用普通的 SQLAlchemy 创建数据库文件。然后我们将创建一个单独的脚本,它使用稍微不同的 Flask-SQLAlchemy 语法。将以下代码放入名为 db_creator.py 的文件中
# db_creator.py
from sqlalchemy import create_engine, ForeignKey
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, backref
engine = create_engine('sqlite:///mymusic.db', echo=True)
Base = declarative_base()
class Artist(Base):
__tablename__ = "artists"
id = Column(Integer, primary_key=True)
name = Column(String)
def __repr__(self):
return "{}".format(self.name)
class Album(Base):
""""""
__tablename__ = "albums"
id = Column(Integer, primary_key=True)
title = Column(String)
release_date = Column(String)
publisher = Column(String)
media_type = Column(String)
artist_id = Column(Integer, ForeignKey("artists.id"))
artist = relationship("Artist", backref=backref(
"albums", order_by=id))
# create tables
Base.metadata.create_all(engine)
对于使用 Python 的人来说,这段代码的第一部分应该非常熟悉,因为我们在这里所做的只是从 SQLAlchemy 导入一些我们需要的片段,以使代码的其余部分工作。然后我们创建 SQLAlchemy 的引擎对象,它基本上将 Python 连接到选择的数据库。在本例中,我们连接到 SQLite 并创建一个文件,而不是在内存中创建数据库。我们还创建了一个“基类”,我们可以用它来创建实际定义数据库表的声明类定义。
接下来的两个类定义了我们关心的表,即艺术家和专辑。你会注意到我们通过 tablename 类属性来命名表格。我们还创建表的列,并根据需要设置它们的数据类型。Album 类有点复杂,因为我们设置了与 Artist 表的外键关系。你可以在我以前的 SQLAlchemy 教程中阅读更多关于这是如何工作的,或者如果你想要更深入的细节,那么查看写得很好的文档。
当您运行上面的代码时,您应该在终端中看到类似这样的内容:
2017-12-08 18:36:43,290 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2017-12-08 18:36:43,291 INFO sqlalchemy.engine.base.Engine ()
2017-12-08 18:36:43,292 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2017-12-08 18:36:43,292 INFO sqlalchemy.engine.base.Engine ()
2017-12-08 18:36:43,294 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("artists")
2017-12-08 18:36:43,294 INFO sqlalchemy.engine.base.Engine ()
2017-12-08 18:36:43,295 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("albums")
2017-12-08 18:36:43,295 INFO sqlalchemy.engine.base.Engine ()
2017-12-08 18:36:43,296 INFO sqlalchemy.engine.base.Engine
CREATE TABLE artists (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
2017-12-08 18:36:43,296 INFO sqlalchemy.engine.base.Engine ()
2017-12-08 18:36:43,315 INFO sqlalchemy.engine.base.Engine COMMIT
2017-12-08 18:36:43,316 INFO sqlalchemy.engine.base.Engine
CREATE TABLE albums (
id INTEGER NOT NULL,
title VARCHAR,
release_date DATE,
publisher VARCHAR,
media_type VARCHAR,
artist_id INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(artist_id) REFERENCES artists (id)
)
2017-12-08 18:36:43,316 INFO sqlalchemy.engine.base.Engine ()
2017-12-08 18:36:43,327 INFO sqlalchemy.engine.base.Engine COMMIT
现在让我们在烧瓶中完成所有这些工作!
使用烧瓶-SQLAlchemy
当我们使用 Flask-SQLAlchemy 时,我们需要做的第一件事是创建一个简单的应用程序脚本。我们就叫它 app.py 。将下面的代码放到这个文件中,并保存到 musicdb 文件夹中。
# app.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///mymusic.db'
app.secret_key = "flask rocks!"
db = SQLAlchemy(app)
在这里,我们创建 Flask 应用程序对象,并告诉它 SQLAlchemy 数据库文件应该放在哪里。我们还设置了一个简单的密钥,并创建了一个 db 对象,允许我们将 SQLAlchemy 集成到 Flask 中。接下来,我们需要创建一个 models.py 文件,并将其保存到 musicdb 文件夹中。完成后,向其中添加以下代码:
# models.py
from app import db
class Artist(db.Model):
__tablename__ = "artists"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String)
def __repr__(self):
return "".format(self.name)
class Album(db.Model):
""""""
__tablename__ = "albums"
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String)
release_date = db.Column(db.String)
publisher = db.Column(db.String)
media_type = db.Column(db.String)
artist_id = db.Column(db.Integer, db.ForeignKey("artists.id"))
artist = db.relationship("Artist", backref=db.backref(
"albums", order_by=id), lazy=True)
您会注意到 Flask-SQLAlchemy 并不需要所有的导入,就像普通的 SQLAlchemy 所需要的那样。我们所需要的是我们在应用程序脚本中创建的 db 对象。然后,我们只需在原始 SQLAlchemy 代码中使用的所有类前加上“db”。您还会注意到,它已经被预定义为 db,而不是创建一个基类。型号。
最后,我们需要创建一种初始化数据库的方法。您可以将它放在几个不同的地方,但我最终创建了一个名为 db_setup.py 的文件,并添加了以下内容:
# db_setup.py
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine('sqlite:///mymusic.db', convert_unicode=True)
db_session = scoped_session(sessionmaker(autocommit=False,
autoflush=False,
bind=engine))
Base = declarative_base()
Base.query = db_session.query_property()
def init_db():
import models
Base.metadata.create_all(bind=engine)
这段代码将用您在模型脚本中创建的表初始化数据库。为了进行初始化,让我们编辑掉上一篇文章中的 test.py 脚本:
# test.py
from app import app
from db_setup import init_db
init_db()
@app.route('/')
def test():
return "Welcome to Flask!"
if __name__ == '__main__':
app.run()
这里我们只是导入了我们的 app 对象和 init_db 函数。然后我们立即调用 init_db 函数。要运行这段代码,您只需在终端的 musicdb 文件夹中运行以下命令:
FLASK_APP=test.py flask run
当您运行这个命令时,您不会看到我们前面看到的 SQLAlchemy 输出。相反,您将只看到一些打印出来的信息,说明您的 Flask 应用程序正在运行。您还会发现在您的 musicdb 文件夹中已经创建了一个 mymusic.db 文件。
注意, init_db() 调用似乎并不总是有效,所以如果您的 SQLite 数据库文件没有正确生成,您可能需要运行我在上一篇文章中编写的 db_creator 脚本。
包扎
此时,您现在有了一个带有空数据库的 web 应用程序。您不能使用 web 应用程序向数据库添加任何内容,也不能查看数据库中的任何内容。是的,你刚刚创造了一些非常酷的东西,但它对你的用户来说也是完全无用的。在下一篇文章中,我们将学习如何添加一个搜索表单来搜索空数据库中的数据!是的,我的疯狂是有方法的,但是你必须继续阅读这个系列才能弄明白。
下载代码
从本文下载一个代码包:flask-music db-part _ ii . tar
本系列的其他文章
- 第一部分-101 号烧瓶:入门
相关阅读
- Flask-SQLAlchemy 网站
- SQLAlchemy 网站
- 一个简单的 SQLAlchemy 教程
烧瓶 101:添加、编辑和显示数据
原文:https://www.blog.pythonlibrary.org/2017/12/14/flask-101-adding-editing-and-displaying-data/
上次我们学习了如何在我们的音乐数据库应用程序中添加一个搜索表单。当然,我们还没有向数据库中添加任何数据,所以搜索表单实际上并没有做什么,只是告诉我们它没有找到任何东西。在本教程中,我们将学习如何实际添加数据,显示搜索结果和编辑数据库中的条目。
我们开始吧!
向数据库添加数据
让我们从编写新专辑开始吧。打开我们在上一个教程中创建的“forms.py”文件,并添加以下类:
class AlbumForm(Form):
media_types = [('Digital', 'Digital'),
('CD', 'CD'),
('Cassette Tape', 'Cassette Tape')
]
artist = StringField('Artist')
title = StringField('Title')
release_date = StringField('Release Date')
publisher = StringField('Publisher')
media_type = SelectField('Media', choices=media_types)
这定义了创建新相册所需的所有字段。现在我们需要打开“main.py”并添加一个函数来处理当我们想要创建新相册时发生的事情。
# main.py
from app import app
from db_setup import init_db, db_session
from forms import MusicSearchForm, AlbumForm
from flask import flash, render_template, request, redirect
from models import Album
init_db()
@app.route('/', methods=['GET', 'POST'])
def index():
search = MusicSearchForm(request.form)
if request.method == 'POST':
return search_results(search)
return render_template('index.html', form=search)
@app.route('/results')
def search_results(search):
results = []
search_string = search.data['search']
if search.data['search'] == '':
qry = db_session.query(Album)
results = qry.all()
if not results:
flash('No results found!')
return redirect('/')
else:
# display results
return render_template('results.html', table=table)
@app.route('/new_album', methods=['GET', 'POST'])
def new_album():
"""
Add a new album
"""
form = AlbumForm(request.form)
return render_template('new_album.html', form=form)
if __name__ == '__main__':
app.run()
在这里,我们添加了一个导入来导入顶部的新表单,然后我们创建了一个名为 new_album() 的新函数。然后,我们创建新表单的一个实例,并将其传递给我们的 render_template() 函数,该函数将呈现一个名为“new_album.html”的文件。当然,这个 HTML 文件还不存在,所以这将是我们需要创建的下一个东西。当您保存这个新的 HTML 文件时,请确保将其保存到“musicdb”文件夹内的“templates”文件夹中。
创建“new_album.html”后,向其中添加以下 html:
<title>New Album - Flask Music Database</title>
## 新相册
{% from "_formhelpers.html" import render_field %}
<form method="post">
{{ render_field(form.artist) }}
{{ render_field(form.title) }}
{{ render_field(form.release_date) }}
{{ render_field(form.publisher) }}
{{ render_field(form.media_type) }}
</form>
这段代码将呈现表单中的每个字段,它还创建了一个提交按钮,这样我们就可以保存我们的更改。我们需要做的最后一件事是更新我们的“index.html”代码,这样它就有一个链接可以加载我们的新相册页面。基本上,我们需要做的就是添加以下内容:
New Album
所以完整的变化看起来是这样的:
<title>Flask Music Database</title>
## 烧瓶音乐数据库
[新专辑]({{ url_for('.new_album') }})
{ % with messages = get _ flash _ messages()% }
{ % if messages % }
* {{消息}}
{% endif %}
{% endwith %}
{% from "_formhelpers.html" import render_field %}
<form method="post">
{{ render_field(form.select) }}
{{ render_field(form.search) }}
</form>
现在,如果您加载 web 应用程序的主页,它应该是这样的:

如果你点击“新相册”链接,你应该会在你的浏览器中看到这样的内容:
现在我们有了一个丑陋但功能强大的新相册表单,但我们实际上并没有让提交按钮工作。这是我们的下一个任务。
保存数据
当按下提交按钮时,我们需要新的相册表单来保存数据。但是当你按下提交按钮时会发生什么呢?如果您返回到“new_album.html”文件,您会注意到我们将表单方法设置为 POST。所以我们需要更新 main.py 中的代码,这样它就可以在 POST 上做一些事情。
为了进行保存,我们需要更新 main.py 中的 new_album() 函数,因此结果如下:
@app.route('/new_album', methods=['GET', 'POST'])
def new_album():
"""
Add a new album
"""
form = AlbumForm(request.form)
if request.method == 'POST' and form.validate():
# save the album
album = Album()
save_changes(album, form, new=True)
flash('Album created successfully!')
return redirect('/')
return render_template('new_album.html', form=form)
现在,当我们发布时,我们创建一个相册实例,并将其与表单对象一起传递给一个 save_changes() 函数。我们还传递一个标志,表明该项目是否是新的。我们将在文章的后面讨论我为什么添加最后一个。不过现在,我们需要创建 save_changes() 函数。将下面的代码保存在 main.py 脚本中。
def save_changes(album, form, new=False):
"""
Save the changes to the database
"""
# Get data from form and assign it to the correct attributes
# of the SQLAlchemy table object
artist = Artist()
artist.name = form.artist.data
album.artist = artist
album.title = form.title.data
album.release_date = form.release_date.data
album.publisher = form.publisher.data
album.media_type = form.media_type.data
if new:
# Add the new album to the database
db_session.add(album)
# commit the data to the database
db_session.commit()
这里,我们从表单中提取数据,并相应地将其分配给相册对象的属性。您还会注意到,我们需要创建一个艺术家实例来将艺术家正确地添加到相册中。如果不这样做,将会得到一个与 SQLAlchemy 相关的错误。这里使用新参数向数据库添加新记录。
下面是我做的一个测试:
一旦项目保存,它应该带你回到网站的主页。需要注意的一点是,我没有在数据库中做任何检查来防止用户多次保存一个条目。如果你想接受挑战,这是你可以自己添加的。无论如何,当我测试这个的时候,我提交了相同的条目几次,所以当我搜索的时候,我应该会得到相同条目的多个条目。如果您现在尝试进行搜索,您将会看到一个错误,因为我们还没有创建结果页面。
让我们接着做吧!
显示搜索结果
我更喜欢表格化的结果,这需要使用表格。您可以下载另一个名为烧瓶表的烧瓶扩展,而不是摆弄 HTML 表元素。要安装它,只需像这样使用 pip:
pip install flask_table
现在我们已经安装了 Flask 表,我们需要创建一个表定义。让我们创建一个名为“tables.py”的文件,并将其保存在 musicdb 文件夹中。在编辑器中打开它,并添加以下代码:
from flask_table import Table, Col
class Results(Table):
id = Col('Id', show=False)
artist = Col('Artist')
title = Col('Title')
release_date = Col('Release Date')
publisher = Col('Publisher')
media_type = Col('Media')
当您定义表类时,您会希望使类属性与将传递给它的对象中的属性具有相同的名称。在本例中,我使用了 Album 类中的属性。现在我们只需要创建一个results.html文件,并将其保存到模板文件夹中。该文件中应该包含以下内容:
<title>Search Results - Flask Music Database</title>
{{ table }}
正如您所看到的,我们需要做的只是添加一个 title 元素,这实际上是可选的,并在 Jinja 中添加一个 table 对象。
最后,我们需要更新我们的 main.py 中的搜索功能,以使用一个表:
@app.route('/results')
def search_results(search):
results = []
search_string = search.data['search']
if search.data['search'] == '':
qry = db_session.query(Album)
results = qry.all()
if not results:
flash('No results found!')
return redirect('/')
else:
# display results
table = Results(results)
table.border = True
return render_template('results.html', table=table)
现在,当您使用空字符串运行搜索时,您应该会看到类似这样的内容:

是的,它很简单,但是它很有效,你现在可以看到你数据库中的所有东西。
编辑数据库中的数据
我们需要涉及的最后一项是如何编辑数据库中的数据。最简单的方法之一是搜索一个条目,并为用户添加一种方法来编辑找到的条目。打开 tables.py 文件并添加一个 LinkCol :
from flask_table import Table, Col, LinkCol
class Results(Table):
id = Col('Id', show=False)
artist = Col('Artist')
title = Col('Title')
release_date = Col('Release Date')
publisher = Col('Publisher')
media_type = Col('Media')
edit = LinkCol('Edit', 'edit', url_kwargs=dict(id='id'))
LinkCol 将列名作为一个字符串以及端点应该是什么。端点是单击链接时将调用的函数。我们还传递条目的 id,以便在数据库中查找它(即 url_kwargs 参数)。现在我们需要用一个名为 edit() 的函数来更新我们的 main.py 文件:
@app.route('/item/', methods=['GET', 'POST'])
def edit(id):
qry = db_session.query(Album).filter(
Album.id==id)
album = qry.first()
if album:
form = AlbumForm(formdata=request.form, obj=album)
if request.method == 'POST' and form.validate():
# save edits
save_changes(album, form)
flash('Album updated successfully!')
return redirect('/')
return render_template('edit_album.html', form=form)
else:
return 'Error loading #{id}'.format(id=id)
这里要注意的第一点是,我们为 URL 设置了一个自定义路由,它使用我们传递给它的 id 来创建一个惟一的 URL。接下来,我们在数据库中搜索有问题的 id。如果我们找到了 id,那么我们就可以使用之前创建的表单来创建表单。但是这次我们传递给它的是相册对象,所以表单已经预先填充了数据,这样我们就有东西可以编辑了。如果用户按下这个页面上的 Submit 按钮,那么它会将条目保存到数据库中,并向用户显示一条消息。如果我们传入一个错误的 id,那么将向用户显示一条消息。
我们还需要在我们的模板文件夹中创建一个 edit_album.html 文件。下面是您需要放入该文件的 HTML:
<title>Edit Album - Flask Music Database</title>
## 编辑相册
{% from "_formhelpers.html" import render_field %}
<form method="post">
{{ render_field(form.artist) }}
{{ render_field(form.title) }}
{{ render_field(form.release_date) }}
{{ render_field(form.publisher) }}
{{ render_field(form.media_type) }}
</form>
现在,当我们运行之前的空搜索时,您应该会看到:
让我们点击第一行的编辑链接:
在这里,我编辑页面上的大多数字段。然后我点击提交,得到这个:

据推测,该条目已根据我的更改进行了更新。要进行验证,请尝试运行另一个空搜索:

看起来没错,所以现在我们已经完成了编辑功能!
包扎
此时,您应该能够向数据库添加条目,显示所有条目并编辑这些条目。缺少的主要项目是如何过滤搜索结果,以便它实际上寻找您想要的搜索词,而不是总是返回数据库中的所有内容。我们可能还应该添加从数据库中删除项目的功能。这些是我们将在下一篇文章中探讨的主题。现在,享受快乐的编码吧!
下载代码
从本文下载一个代码包:flask _ musicdb _ part _ iv . tar或者在 Github 上克隆它
本系列的其他文章
Flask 101:过滤搜索和删除数据
原文:https://www.blog.pythonlibrary.org/2017/12/15/flask-101-filtering-searches-and-deleting-data/
上次我们让基于 Flask 的音乐数据库应用程序部分运行。它现在可以向数据库中添加数据,编辑所述数据,还可以显示数据库中的所有内容。但是我们没有介绍如何使用用户的过滤器选择(艺术家、专辑名称或出版商名称)和搜索字符串来过滤数据。我们也没有讨论如何从数据库中删除条目。这是本文的双重目标。
过滤搜索结果
使用 SQLAlchemy(通过 Flask-SQLAlchemy)过滤搜索结果实际上非常容易。您需要做的就是创建一些非常简单的查询对象。打开我们上次编辑的 main.py 文件,用下面的代码版本替换 search_results() 函数:
@app.route('/results')
def search_results(search):
results = []
search_string = search.data['search']
if search_string:
if search.data['select'] == 'Artist':
qry = db_session.query(Album, Artist).filter(
Artist.id==Album.artist_id).filter(
Artist.name.contains(search_string))
results = [item[0] for item in qry.all()]
elif search.data['select'] == 'Album':
qry = db_session.query(Album).filter(
Album.title.contains(search_string))
results = qry.all()
elif search.data['select'] == 'Publisher':
qry = db_session.query(Album).filter(
Album.publisher.contains(search_string))
results = qry.all()
else:
qry = db_session.query(Album)
results = qry.all()
else:
qry = db_session.query(Album)
results = qry.all()
if not results:
flash('No results found!')
return redirect('/')
else:
# display results
table = Results(results)
table.border = True
return render_template('results.html', table=table)
这里我们添加了一个有点长的条件 if 语句。我们首先检查用户是否在搜索文本框中输入了搜索字符串。如果是,那么我们检查用户从组合框中选择了哪个过滤器:艺术家、专辑或出版商。根据用户的选择,我们创建一个定制的 SQLAlchemy 查询。如果用户没有输入搜索词,或者如果我们的 web 应用程序搞混了,不能识别用户的过滤器选择,那么我们对整个数据库进行查询。如果数据库变得非常大,那么在生产中可能不应该这样做,然后对数据库进行查询会导致您的 web 应用程序没有响应。您可以简单地向表单的输入添加一些验证来防止这种情况发生(即不要使用空的搜索字符串查询数据库)。然而,我们不会在这里涵盖这一点。
无论如何,继续尝试这段代码,看看它是如何工作的。我尝试了几个不同的搜索词,它似乎对我的用例很有效。您会注意到,我只是使用了 contains 方法,这对于在表的列中查找字符串非常有用。你可以随时索引你的数据库,并对其进行其他各种优化,包括让这些查询更加集中,如果你愿意的话。请随意使用这段代码,看看如何改进它。
现在我们将继续学习如何从数据库中删除项目!
删除数据
有时候,当你在数据库中输入一些东西,你只是想删除。从技术上讲,你可以使用我们的编辑功能来编辑条目,但有时你只需要永久清除数据。因此,我们需要做的第一件事是在结果表中添加一个 Delete 列。您将希望打开 tables.py 并将一个新的 LinkCol 实例添加到 Results 类中:
from flask_table import Table, Col, LinkCol
class Results(Table):
id = Col('Id', show=False)
artist = Col('Artist')
title = Col('Title')
release_date = Col('Release Date')
publisher = Col('Publisher')
media_type = Col('Media')
edit = LinkCol('Edit', 'edit', url_kwargs=dict(id='id'))
delete = LinkCol('Delete', 'delete', url_kwargs=dict(id='id'))
正如我们在创建用于编辑数据的链接时所做的那样,我们添加了一个用于删除数据的新链接。您会注意到第二个参数,也就是端点,指向一个删除函数。所以下一步是打开我们的 main.py 文件并添加所说的 delete() 函数:
@app.route('/delete/', methods=['GET', 'POST'])
def delete(id):
"""
Delete the item in the database that matches the specified
id in the URL
"""
qry = db_session.query(Album).filter(
Album.id==id)
album = qry.first()
if album:
form = AlbumForm(formdata=request.form, obj=album)
if request.method == 'POST' and form.validate():
# delete the item from the database
db_session.delete(album)
db_session.commit()
flash('Album deleted successfully!')
return redirect('/')
return render_template('delete_album.html', form=form)
else:
return 'Error deleting #{id}'.format(id=id)
这段代码实际上非常类似于上一篇文章中的 edit()函数。你会注意到我们更新了路线。所以没有指定'/item/<id>',而是做成'/delete/<id>'。这使得两个函数之间的 URL 不同,所以当链接被点击时,它们实际上执行正确的函数。另一个区别是,我们不需要在这里创建一个特殊的保存函数。我们只是直接引用 db_session 对象,并告诉它如果在数据库中找到相册就删除它,然后提交我们的更改。
如果您运行该代码,在执行空字符串搜索时,您应该会看到如下内容:

我们需要做的最后一件事是创建上面提到的 delete_album.html 。让我们创建该文件,并将其保存到我们的模板文件夹中。一旦创建了该文件,只需添加以下内容:
<title>Delete Album - Flask Music Database</title>
## 删除相册
{% from "_formhelpers.html" import render_field %}
<form method="post">
{{ render_field(form.artist) }}
{{ render_field(form.title) }}
{{ render_field(form.release_date) }}
{{ render_field(form.publisher) }}
{{ render_field(form.media_type) }}
</form>
这段代码将呈现我们的表单,向用户显示他们正在删除的内容。让我们尝试单击表中一个副本的删除链接。您应该会看到这样一个屏幕:

当您按下“删除”按钮时,它会将您重定向到主页,在那里您会看到一条消息,说明该项目已成功删除:
要验证删除是否有效,只需再进行一次空字符串搜索。您的结果应该在表格中少显示一项:
包扎
现在,您应该知道如何对数据库中的搜索结果进行一些基本的过滤。您还学习了如何在 Flask 应用程序中成功地从数据库中删除项目。代码中有几个地方可以使用重构和常规清理。您还可以在应用程序中添加一些 CSS 样式,使其看起来更漂亮。这些是我留给读者的练习。玩代码玩得开心点,试试 Flask 吧。这是一个简洁的 web 框架,非常值得一看!
下载代码
从本文下载一段代码: flask_musicdb_v.tar
本系列的其他文章
- 第一部分-101 号烧瓶:入门
- 第二部分 -烧瓶 101: 添加数据库
- 第三部分 -烧瓶 101: 如何添加搜索表单
- 第四部分 -烧瓶 101: 添加、编辑和显示数据
烧瓶 101:开始
原文:https://www.blog.pythonlibrary.org/2017/12/12/flask-101-getting-started/
Flask 101 系列是我学习 Python 的 Flask 微框架的尝试。对于那些没听说过的人来说,Flask 是用 Python 创建 web 应用程序的微型 web 框架。根据他们的网站, Flask 是基于 Werkzeug,Jinja 2 和 good intentions 。对于这一系列文章,我想创建一个 web 应用程序,它将做一些有用的事情,而不会太复杂。所以为了我的学习理智,我决定创建一个简单的 web 应用程序,我可以用它来存储我的音乐库的信息。
在多篇文章中,您将看到这一旅程是如何展开的。
获取设置
要开始使用 Flask,您需要安装它。我们将为这一系列教程创建一个虚拟环境,因为我们将需要添加许多其他 Flask 依赖项,而且大多数人可能不想用大量他们可能最终不会使用的 cruft 来污染他们的主 Python 安装。所以在我们安装 Flask 之前,让我们使用 virtualenv 创建一个虚拟环境。如果你想使用 virtualenv,那么我们需要安装 pip:
pip install virtualenv
现在我们已经安装了,我们可以创建我们的虚拟环境。在您的本地系统上找到一个您想要存储 web 应用程序的位置。然后打开终端并运行以下命令:
virtualenv musicdb
在 Windows 上,您可能必须给出 virtualenv 的完整路径,通常类似于C:\ python 36 \ Scripts \ virtualenv . exe。
注意,从 Python 3.3 开始,还可以使用 Python 内置的 venv 模块来创建虚拟环境,而不是使用 virtualenv。当然,virtualenv 包可以安装在 Python 3 中,所以要用哪个由你决定。它们的工作方式非常相似。
设置好虚拟环境后,您需要激活它。为此,您需要将终端中的目录更改为您刚刚使用“cd”命令创建的文件夹:
cd musicdb
如果您在 Linux 或 Mac OS 上,您应该运行以下程序:
source bin/activate
Windows 有点不同。您仍然需要“cd”到您的文件夹中,但是要运行的命令是这样的:
Scripts/activate
有关激活和停用虚拟环境的更多详细信息,请查看用户指南。
您可能已经注意到,当您创建您的虚拟环境时,它复制到您的 Python 可执行文件以及 pip 中。这意味着您现在可以使用 pip 将软件包安装到您的虚拟环境中,这也是许多人喜欢虚拟环境的原因。一旦虚拟环境被激活,您应该看到您的终端已经更改为将虚拟环境的名称添加到终端的提示符前面。下面是一个使用 Python 2.7 的截图示例:

现在我们准备安装 Flask!
开始使用 Flask
使用 pip 安装程序很容易安装 Flask。你可以这样做:
pip install flask
这个命令将安装 Flask 和它需要的任何依赖项。这是我收到的输出:
Collecting flask
Downloading Flask-0.12.2-py2.py3-none-any.whl (83kB)
100% |████████████████████████████████| 92kB 185kB/s
Collecting itsdangerous>=0.21 (from flask)
Downloading itsdangerous-0.24.tar.gz (46kB)
100% |████████████████████████████████| 51kB 638kB/s
Collecting Jinja2>=2.4 (from flask)
Downloading Jinja2-2.10-py2.py3-none-any.whl (126kB)
100% |████████████████████████████████| 133kB 277kB/s
Collecting Werkzeug>=0.7 (from flask)
Downloading Werkzeug-0.12.2-py2.py3-none-any.whl (312kB)
100% |████████████████████████████████| 317kB 307kB/s
Collecting click>=2.0 (from flask)
Downloading click-6.7-py2.py3-none-any.whl (71kB)
100% |████████████████████████████████| 71kB 414kB/s
Collecting MarkupSafe>=0.23 (from Jinja2>=2.4->flask)
Building wheels for collected packages: itsdangerous
Running setup.py bdist_wheel for itsdangerous ... done
Stored in directory: /home/mdriscoll/.cache/pip/wheels/fc/a8/66/24d655233c757e178d45dea2de22a04c6d92766abfb741129a
Successfully built itsdangerous
Installing collected packages: itsdangerous, MarkupSafe, Jinja2, Werkzeug, click, flask
Successfully installed Jinja2-2.10 MarkupSafe-1.0 Werkzeug-0.12.2 click-6.7 flask-0.12.2 itsdangerous-0.24
现在让我们写一些简单的东西来证明 Flask 工作正常。将下面的代码保存在我们之前创建的 musicdb 文件夹中。
# test.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def test():
return "Welcome to Flask!"
这些代码所做的就是导入 Flask 类并创建一个我们称之为 app 的实例。然后,我们为我们网站的主页(又名根或索引)设置默认路径。这是通过下面的装饰器完成的: @app.route('/') 。最后,我们创建一个函数,只返回一个字符串。
当这段代码在 Flask 中运行时,您将能够导航到您的新 web 应用程序的主页并看到该文本。这就引出了我们如何运行这段代码。在您的终端中,确保您在您的 musicdb 文件夹中。然后在终端中运行以下命令:
FLASK_APP=test.py flask run
当您运行这个命令时,您应该在终端中看到类似这样的内容:
* Serving Flask app "test"
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
现在你只需要打开一个浏览器,比如 Chrome 或者 Firefox,去上面提到的网址: http://127.0.0.1:5000/ 。以下是我在 Chrome 中访问该网址时得到的结果:

包扎
至此,您应该能够启动并运行 Flask 的工作版本。你可以用你现在拥有的东西做一些非常基本的网络应用。在本系列的下一篇文章中,我们将看看如何为我们的 web 应用程序添加数据库支持。
本系列的其他文章
- 第二部分:烧瓶 101 - 添加数据库
Flask 101:如何添加搜索表单
原文:https://www.blog.pythonlibrary.org/2017/12/13/flask-101-how-to-add-a-search-form/
在上一篇文章中,我们向 Flask web 应用程序添加了一个数据库,但是没有办法向数据库添加任何东西。我们也没有办法查看任何东西,所以基本上我们最终拥有了一个非常无用的 web 应用程序。本文将花时间教你如何做到以下几点:
- 创建一个表单来添加数据到我们的数据库
- 使用表单编辑我们数据库中的数据
- 创建数据库中内容的某种视图
一旦你弄清楚要安装什么扩展,向 Flask 添加表单也很容易。我听说过 WTForms 的优点,所以我将在本教程中使用它。要安装 WTForms,您需要安装 Flask-WTF 。安装 Flask-WTF 相当容易;只要打开你的终端,激活我们在第一教程中设置的虚拟环境。然后使用 pip 运行以下命令:
pip install Flask-WTF
这将把 WTForms 和 Flask-WTF(以及任何依赖项)安装到 web 应用程序的虚拟环境中。
提供 HTML 文件
最初当我开始这个系列时,我在 web 应用程序的索引页面上提供的只是一个字符串。我们可能应该稍微修饰一下,使用一个真正的 HTML 文件。在“musicdb”文件夹中创建一个名为“templates”的文件夹。现在,在“templates”文件夹中创建一个名为“index.html”的文件,并将以下内容放入其中:
<title>Flask Music Database</title>
## 烧瓶音乐数据库
现在,在我们更新 web 应用程序代码之前,让我们创建一个搜索表单来过滤音乐数据库的结果。
添加搜索表单
使用数据库时,您需要一种在其中搜索项目的方法。幸运的是,用 WTForms 创建搜索表单非常容易。创建一个名为“forms.py”的 Python 脚本,保存到“musicdb”文件夹,内容如下:
# forms.py
from wtforms import Form, StringField, SelectField
class MusicSearchForm(Form):
choices = [('Artist', 'Artist'),
('Album', 'Album'),
('Publisher', 'Publisher')]
select = SelectField('Search for music:', choices=choices)
search = StringField('')
这里我们只是从 wtforms 模块导入我们需要的项目,然后我们子类化forms类。在我们的子类中,我们创建了一个选择字段(一个组合框)和一个字符串字段。这使我们能够将搜索过滤到艺术家、专辑或出版商类别,并输入要搜索的字符串。
现在我们准备更新我们的主应用程序。
更新主应用程序
让我们将 web 应用程序的脚本从“test.py”重命名为“main.py ”,并对其进行更新,如下所示:
# main.py
from app import app
from db_setup import init_db, db_session
from forms import MusicSearchForm
from flask import flash, render_template, request, redirect
from models import Album
init_db()
@app.route('/', methods=['GET', 'POST'])
def index():
search = MusicSearchForm(request.form)
if request.method == 'POST':
return search_results(search)
return render_template('index.html', form=search)
@app.route('/results')
def search_results(search):
results = []
search_string = search.data['search']
if search.data['search'] == '':
qry = db_session.query(Album)
results = qry.all()
if not results:
flash('No results found!')
return redirect('/')
else:
# display results
return render_template('results.html', results=results)
if __name__ == '__main__':
app.run()
我们修改了 index() 函数,使其可以处理 POST 和 GET 请求,并告诉它加载我们的 MusicSearchForm。您会注意到,当您第一次加载 web 应用程序的索引页面时,它将执行 GET,index()函数将呈现我们刚刚创建的 index.html。当然,我们实际上还没有将表单添加到我们的 index.html 中,所以搜索表单还不会出现。
**我们还添加了一个 search_results() 来处理非常基本的搜索。然而,在我们真正实现显示结果的方法之前,这个函数不会被调用。因此,让我们继续让搜索表单对我们的用户可见。
在我学习如何用 wtforms 创建表单的时候, Flask-WTF 网站推荐用一个叫做“_formhelpers.html”的宏创建一个模板。继续创建一个同名文件,并将其保存到您的“模板”文件夹中。然后将以下内容添加到该文件中:
{% macro render_field(field) %}
{{ field.label }}
{{ field(**kwargs)|safe }} {% if field.errors %}
- {{错误}}
{% endmacro %}
这个语法可能看起来有点奇怪,因为它显然不仅仅是 HTML。这其实就是 Jinja2 语法,是 Flask 使用的模板语言。基本上,无论你在哪里看到弯弯曲曲的大括号(即{}),你都会看到 Jinja 语法。这里我们传入一个字段对象,并访问它的标签和错误属性。请随意查阅文档以获取更多信息。
现在打开您的“index.html”文件并更新它,使其包含以下内容:
<title>Flask Music Database</title>
## 烧瓶音乐数据库
{% from "_formhelpers.html" import render_field %}
<form method="post">
{{ render_field(form.select) }}
{{ render_field(form.search) }}
</form>
本例中的新代码展示了如何将创建的宏导入到另一个 HTML 文件中。接下来,我们将表单方法设置为 post ,并将选择小部件和搜索小部件传递给我们的 render_field 宏。我们还创建了一个带有以下标签的提交按钮:搜索。当您按下搜索按钮时,它会将表单的其他两个字段中的数据发布到它所在的页面,在本例中是我们的index.html或“/”。
当这种情况发生时,我们的 main.py 脚本中的 index()方法将执行:
@app.route('/', methods=['GET', 'POST'])
def index():
search = MusicSearchForm(request.form)
if request.method == 'POST':
return search_results(search)
return render_template('index.html', form=search)
你会注意到我们检查它是哪个请求方法,如果是 POST 方法,那么我们调用 search_results() 函数。如果你真的在这个阶段按下搜索按钮,你会收到一个内部服务器错误,因为我们还没有实现“results.html”。无论如何,现在您的 web 应用程序应该是这样的:
让我们花点时间让结果函数做些有用的事情。
更新结果功能
现在我们的数据库中实际上没有任何数据,所以当我们试图查询它时,我们不会得到任何结果。因此,我们需要让我们的 web 应用程序表明没有找到任何结果。为此,我们需要更新“index.html”页面:
<title>Flask Music Database</title>
## 烧瓶音乐数据库
{% with messages = get_flashed_messages() %}
{% if messages %}
* {{消息}}
{% endif %}
{% endwith %}
{% from "_formhelpers.html" import render_field %}
<form method="post">
{{ render_field(form.select) }}
{{ render_field(form.search) }}
</form>
你会注意到新代码是一个新的金贾块。在这里,我们抓取“闪现”的消息并显示它们。现在我们只需要运行 web 应用程序并尝试搜索一些东西。如果一切按计划进行,当您进行搜索时,应该会看到如下内容:

包扎
现在我们有了一个简洁的搜索表单,可以用来搜索我们的数据库,尽管坦白地说,由于我们的数据库目前是空的,它实际上并没有做太多事情。在我们的下一篇文章中,我们将关注最终创建一种向数据库添加数据、显示搜索结果以及编辑数据的方法!
下载代码
从本文下载一个代码包:flask _ music dv _ part _ iii . tar
本系列的其他文章
相关阅读
- Jinja2 网站
- Flask-WTForms 网站
- Flask-SQLAlchemy 网站
- SQLAlchemy 网站
- 一个简单的 SQLAlchemy 教程**
关于 Python 的免费书籍(和其他免费资源)
原文:https://www.blog.pythonlibrary.org/2013/07/11/free-books-and-other-free-resources-about-python/
有些人没有意识到这一点,但是有很多关于 Python 编程语言的免费书籍。是的,有些并不是很好,但是这里有很多非常好的免费资源。在这篇文章中,我们将看看一些免费的书籍和其他资源,你可以使用我最喜欢的编程语言。
免费 Python 书籍
我在网上找到的第一本免费的 Python 书籍是马克·皮尔格林的《深入研究 Python》。你可以在该书的网站上免费获得他的书,或者你可以在亚马逊上购买一本。事实上,他的书已经由出版社出版了一段时间。这些链接是这本书的 Python 2.x 版本。Pilgrim 还为 Python 3 写了一个版本,你可以在这里找到。当我学习 Python 的时候,我自己也使用过他的原版在线书籍,并且在必要的时候我仍然会参考它。
我听说过的另一本书叫做《思考 Python》,作者是艾伦·b·唐尼。你可以在绿茶出版社的网站上查看免费的 PDF 版本。这本书也是由奥赖利出版的,所以你也可以在亚马逊买到。这本书已经在我的阅读清单上了,但是我还没有开始读。然而,大多数以 O'Reilly 品牌推出的 Python 书籍往往都很好,所以我对这本书寄予厚望。在撰写本文时,PDF 版本最后一次更新是在 2013 年 5 月。
你也可以在作者的网站上找到由 Swaroop C H 编写的一个字节的 Python 。他有几个版本,包括一个死树版本,他似乎在推销自己。他的网站有点令人困惑,因为你需要向下滚动到底部才能找到这本书的链接。这是另一本书,我一直想读,但没有这样做。
WikiBooks 推出了 3 本涵盖 Python 的在线书籍:
我对这些不太了解,但是如果你已经读过了,请随意评论它们是否有用。
阿尔·斯威加特的三本书都是免费的。我读过他的一些书,它们很有趣。他的书是针对初学者的。这是他的书:
Zed Shaw 是一位著名的 Python 程序员,他编写了自己的在线书籍,名为艰难地学习 Python。我听说过很多关于它的好东西,但我自己没有试过。它看起来更像一个在线课程,而不是一本书,但多个网站称它为一本书,所以你去那里。
你也可以在http://pythonbooks.revolunet.com/找到这些书和一大堆其他免费的书,它们链接到这些书或它们的网站。
Python 的其他免费资源
以下是我最喜欢使用的一些 Python 资源:
- 官方 Python 文档
- 其他官方文档和链接
- 本周 Python 模块系列
- Raymond Hettinger 的博客——这个博客通常面向中高级程序员
以下是我最近发现或听到的一些好消息,或者两者兼而有之:
- Python 挑战赛
- 搭便车者的包装指南
- Python 在代码学院
- 学习 Python
- 谷歌的 Python 类
请随意在评论中列出你最喜欢的资源,不管它们是否在这个列表中。
Webucator 提供的免费 Python 入门课程
原文:https://www.blog.pythonlibrary.org/2016/02/02/free-intro-to-python-course-from-webucator/
Webucator 最近联系了我,告诉我他们已经完成了 Python 培训的介绍,他们允许人们在二月份免费参加。本课程由视频、练习、阅读和测验组成。您可以在注册时使用以下代码免费获得它:PYTHON
我认为他们基于我的上下文管理器文章制作的视频做得很好。
免费 Python 资源
原文:https://www.blog.pythonlibrary.org/2017/04/26/free-python-resources/
现在有很多学习 Python 的免费资源。早在 2013 年,我就写过关于他们中的一些人,但现在比那时更多!在这篇文章中,我想与你分享这些资源。如果我错过了任何对你有帮助的东西,请在评论中链接到它们。
博客和网站
当我学习 Python 时,我首先求助的地方之一是官方 Python 文档:
在 Python 网站上也可以找到很多其他的文档。
Dan Bader 和一组贡献者写了一些关于真正的 Python 的文章,上面有很多免费和付费的材料。
多年来,Doug Hellman 一直在制作一个名为 Python 每周模块(PyMOTW)的系列。他现在也有了 Python 3 的系列版本。以下是链接:
- PyMOTW-2 (Python 2)
- PyMOTW-3 (Python 3)
Python 上有两个有趣的“搭便车”网站,但我认为它们除了名字之外没有任何联系:
如果你喜欢阅读博客,那么 Planet Python 正适合你。Planet Python 基本上是几十个 Python 博客的 RSS 聚合器。你可以在页面左侧看到每个博客的链接。
如果你从事 web 开发,你应该查看一下 Marko Denic 的网站,获取不是专门针对 Python web 框架的技巧和教程。有关以 Python 为中心的 web 框架的更多信息,请参见以下内容:
免费 Python 书籍
马克·皮尔格林的书在网上已经有十多年了。他创建了两个版本的 Dive Into Python ,一个用于 Python 2,另一个用于 Python 3。我将在这里链接到 Python 3。
Al Sweigart 出版 Python 书籍也有一段时间了。他最新的 Python 书籍是用 Python 自动化枯燥的东西。这是一本有趣的书,非常值得一读。你可以在他的网站上看到他的其他书。它们都是免费的,但是你也可以购买。
WikiBooks 有一本 Python 3 的书叫做Python 3 的非程序员教程仍然推荐。
虽然没看过,但是听说过全栈 Python 不错。
如果你想学习测试驱动开发,有一本关于服从测试山羊的书。我会注意到这本书非常关注用 Python 进行 web 编程以及如何测试,所以请记住这一点。
有一本整洁的在线书籍叫做Program Arcade Games with Python 和 Pygame 可以免费获得多种语言版本,这是以前的书籍所不提供的。
最后,我想我应该提到我自己的书, Python 101 ,这本书可以免费获得,或者在 Leanpub 上付费,或者你可以在这里在线阅读。
包扎
还有大量其他关于 Python 的免费资源和书籍。这些只是一个概述。如果你碰巧陷入了这些书籍或资源中,那么你会很高兴地知道,在以下网站上有很多乐于助人的人会回答你的问题:
- 堆栈溢出
- reddit 的学习曲面的子 Reddit
- comp.lang.python 在谷歌群组上
享受学习 Python 的乐趣。这是一门伟大的语言!
曼宁出版社的免费 Python 视频
原文:https://www.blog.pythonlibrary.org/2020/11/24/free-python-videos-from-manning-publications/
Manning Publications 最近联系我,让我知道他们有一些新的 Python 视频要放在他们的 YouTube 频道上。
卡尔·奥西波夫云原生机器学习的作者。他创建了一个关于 py torch autogradated 用于深度学习的自动微分的会话:
https://www.youtube.com/embed/HOWm_C_P4NM?feature=oembed
Jonathan Rioux 是《使用 Python 和 PySpark 进行数据分析》一书的作者,他在 PySpark 上做了一个讲座,讲述了如何在编写代码之前进行推理,保持数据操作代码整洁,以及对代码性能进行推理。
https://www.youtube.com/embed/DPGN3CaHyYs?feature=oembed
注:曼宁出版公司不是这篇文章的赞助商。我只是觉得他们推出新的免费 Python 内容很棒!
更多 Python 视频,请查看 MouseVsPython YouTube 频道!
Python 函数重载(视频)
原文:https://www.blog.pythonlibrary.org/2022/05/31/function-overloading-with-python-video/
在本教程中,您将学习如何使用 Python 及其 functools 模块进行函数重载。
https://www.youtube.com/embed/2ldqYOfTwtw?feature=oembed
相关阅读
从文件生成对话框
原文:https://www.blog.pythonlibrary.org/2010/01/20/generating-a-dialog-from-a-file/
前几天写了一篇关于 wxPython 使用 ConfigObj 的文章。关于这篇文章,我被问到的第一个问题是关于使用配置文件来生成对话框。我认为这是一个有趣的想法,所以我尝试实现这个功能。我个人认为,使用 XRC 创建对话框并使用 ConfigObj 帮助管理以这种方式加载的对话框文件可能会更好。然而,这对我来说是一个有趣的练习,我想你也会发现它很有启发性。
免责声明:这是一个总的黑客,可能会或可能不会满足您的需求。我给出了各种扩展示例的建议,所以我希望这有所帮助!
既然已经解决了这个问题,让我们创建一个超级简单的配置文件。为了方便起见,我们称它为“config.ini ”:
config . ini
[Labels]
server = Update Server:
username = Username:
password = Password:
update interval = Update Interval:
agency = Agency Filter:
filters = ""
[Values]
server = http://www.someCoolWebsite/hackery.php
username = ""
password = ""
update interval = 2
agency_choices = Include all agencies except, Include all agencies except, Exclude all agencies except
filters = ""
这个配置文件有两个部分:标签和值。标签部分有我们将用来创建 wx 的标签。StaticText 控件。值部分有一些样本值,我们可以将它们用于相应的文本控件和一个组合框。请注意,机构选择字段是一个列表。列表中的第一项将是组合框中的默认选项,另外两项是小部件的实际内容。
现在,让我们来看看构建该对话框的代码:
偏好 sDlg.py
import configobj
import wx
########################################################################
class PreferencesDialog(wx.Dialog):
"""
Creates and displays a preferences dialog that allows the user to
change some settings.
"""
#----------------------------------------------------------------------
def __init__(self):
"""
Initialize the dialog
"""
wx.Dialog.__init__(self, None, wx.ID_ANY, 'Preferences', size=(550,300))
self.createWidgets()
#----------------------------------------------------------------------
def createWidgets(self):
"""
Create and layout the widgets in the dialog
"""
lblSizer = wx.BoxSizer(wx.VERTICAL)
valueSizer = wx.BoxSizer(wx.VERTICAL)
btnSizer = wx.StdDialogButtonSizer()
colSizer = wx.BoxSizer(wx.HORIZONTAL)
mainSizer = wx.BoxSizer(wx.VERTICAL)
iniFile = "config.ini"
self.config = configobj.ConfigObj(iniFile)
labels = self.config["Labels"]
values = self.config["Values"]
self.widgetNames = values
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD)
for key in labels:
value = labels[key]
lbl = wx.StaticText(self, label=value)
lbl.SetFont(font)
lblSizer.Add(lbl, 0, wx.ALL, 5)
for key in values:
print key
value = values[key]
if isinstance(value, list):
default = value[0]
choices = value[1:]
cbo = wx.ComboBox(self, value=value[0],
size=wx.DefaultSize, choices=choices,
style=wx.CB_DROPDOWN|wx.CB_READONLY,
name=key)
valueSizer.Add(cbo, 0, wx.ALL, 5)
else:
txt = wx.TextCtrl(self, value=value, name=key)
valueSizer.Add(txt, 0, wx.ALL|wx.EXPAND, 5)
saveBtn = wx.Button(self, wx.ID_OK, label="Save")
saveBtn.Bind(wx.EVT_BUTTON, self.onSave)
btnSizer.AddButton(saveBtn)
cancelBtn = wx.Button(self, wx.ID_CANCEL)
btnSizer.AddButton(cancelBtn)
btnSizer.Realize()
colSizer.Add(lblSizer)
colSizer.Add(valueSizer, 1, wx.EXPAND)
mainSizer.Add(colSizer, 0, wx.EXPAND)
mainSizer.Add(btnSizer, 0, wx.ALL | wx.ALIGN_RIGHT, 5)
self.SetSizer(mainSizer)
#----------------------------------------------------------------------
def onSave(self, event):
"""
Saves values to disk
"""
for name in self.widgetNames:
widget = wx.FindWindowByName(name)
if isinstance(widget, wx.ComboBox):
selection = widget.GetValue()
choices = widget.GetItems()
choices.insert(0, selection)
self.widgetNames[name] = choices
else:
value = widget.GetValue()
self.widgetNames[name] = value
self.config.write()
self.EndModal(0)
########################################################################
class MyApp(wx.App):
""""""
#----------------------------------------------------------------------
def OnInit(self):
"""Constructor"""
dlg = PreferencesDialog()
dlg.ShowModal()
dlg.Destroy()
return True
if __name__ == "__main__":
app = MyApp(False)
app.MainLoop()
首先,我们创建 wx 的子类。对话框及其所有的 createWidgets 方法。这个方法将读取我们的配置文件,并使用其中的数据来创建显示。一旦配置被读取,我们循环遍历标签部分中的键,并根据需要创建静态文本控件。接下来,我们遍历另一部分中的值,并使用一个条件来检查小部件的类型。在这种情况下,我们只关心 wx。这就是 ConfigObj 有帮助的地方,因为它实际上可以对我们的配置文件中的一些条目进行类型转换。如果您使用 configspec,您可以得到更细粒度的,这可能是您想要扩展本教程的方式。注意,对于文本控件和组合框,我设置了 name 字段。这对保存数据很重要,我们一会儿就会看到。
无论如何,在这两个循环中,我们使用垂直的 BoxSizers 来存放我们的小部件。对于您的专用接口,您可能希望将其替换为 GridBagSizer 或 FlexGridSizer。我个人真的很喜欢 BoxSizers。在 Steven Sproat ( Whyteboard )的建议下,我还为按钮使用了 StdDialogButtonSizer。如果您为按钮使用正确的标准 id,这个 sizer 会以跨平台的方式将它们按正确的顺序放置。它相当方便,虽然它不需要很多参数。还要注意,这个 sizer 的文档暗示您可以指定方向,但实际上您不能。我和 Robin Dunn(wxPython 的创建者)在 IRC 上讨论了这个问题,他说 epydoc 抓取了错误的文档字符串。
我们关心的下一个方法是 onSave 。这里是我们保存用户输入内容的地方。在程序的早些时候,我从配置中获取了小部件的名称,现在我们对它们进行循环。我们叫 wx。FindWindowByName 按名称查找小部件。然后我们再次使用 isinstance 来检查我们有哪种小部件。完成后,我们使用 GetValue 获取小部件保存的值,并将该值分配给配置中的正确字段。当循环结束时,我们将数据写入磁盘。立即改进警告:我在这里没有任何验证!这是你要做的事情来扩展这个例子。最后一步是调用 EndModal(0)关闭对话框,然后关闭应用程序。
现在您已经知道了从配置文件生成对话框的基本知识。我认为使用某种带有小部件类型名称(可能是字符串)的字典可能是让这个脚本与其他小部件一起工作的简单方法。发挥你的想象力,让我知道你想到了什么。
注意:所有代码都是在 Windows XP 上用 Python 2.5、ConfigObj 4.6.0 和 Validate 1.0.0 测试的。
延伸阅读
下载量
提前获取 Python 测验书籍和课程
原文:https://www.blog.pythonlibrary.org/2022/12/07/get-early-access-to-the-python-quiz-book-and-course/
Python 测验书和Python 测验课程现在可以提前获取。课程和书都将有 100 多个测验和答案。
以下是您将要了解的一些内容:
- (听力或阅读)理解测试
- f 弦
- 布尔数学
- 发电机
- 拆包概括
- 希腊字母的第 11 个
- 模数运算符
- 三元表达式
- 可召回商品
- 名称隐藏
- 限幅
- 赋值表达式(Walrus 运算符)
- 还有更多!

课程与书的主要区别在于,课程允许我包含更多的链接、媒体和互动,而这些是我在电子书上做不到的。
您可以从以下网址获得Python 问答书电子书:
可以在教我 Python 上获取 Python 小测验课程。
免费获取 Python 101 第二版 72 小时!
原文:https://www.blog.pythonlibrary.org/2021/01/11/get-python-101-2nd-edition-free-for-72-hours/
Python 101 第二版是 Python 101 的最新版本。这本书旨在帮助你学习 Python,然后超越基础。我一直觉得初学者的书不应该只教语法。如果你想尝试 Python 101,你可以在接下来的 72 小时内通过使用以下链接免费试用:https://leanpub.com/py101/c/mvp2021
**如果你有一个 Gumroad 帐户,你可以在这里(https://gumroad.com/l/pypy101)用这张优惠券免费得到这本书: mvp2021
上一次我让 Python 101 免费 3 天,就获得了 3-4 万的新读者。让我们看看我们是否能战胜它!
第二版 Python 101 完全从头重写。在本书中,您将学习 Python 编程语言以及更多内容。
这本书分为四个部分:
- Python 语言
- 中级主题
- 创建示例应用程序
- 分发您的代码
查看 Leanpub 或 Gumroad 了解书中所有内容的全部细节。**
使用 Python 获取 GPS EXIF 数据
原文:https://www.blog.pythonlibrary.org/2021/01/13/getting-gps-exif-data-with-python/
您知道可以使用 Python 编程语言从 JPG 图像文件中获取 EXIF 数据吗?您可以使用 Pillow 来实现这一点,Pillow 是 Python 图像库的友好分支。如果你想的话,你可以在这个网站上阅读一篇文章。
以下是从 JPG 文件中获取常规 EXIF 数据的示例代码:
# exif_getter.py
from PIL import Image
from PIL.ExifTags import TAGS
def get_exif(image_file_path):
exif_table = {}
image = Image.open(image_file_path)
info = image.getexif()
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
exif_table[decoded] = value
return exif_table
if __name__ == "__main__":
exif = get_exif("bridge.JPG")
print(exif)
该代码使用以下图像运行:

在本文中,您将关注如何从图像中提取 GPS 标签。这些是特殊的 EXIF 标签,只有在拍摄照片的相机打开了其位置信息时才会出现。你也可以事后在电脑上添加 GPS 标签。
例如,我在杰斯特公园的这张照片上添加了 GPS 标签,杰斯特公园位于伊利诺伊州的格兰杰:

要访问这些标记,您需要使用前面的代码示例并做一些小的调整:
# gps_exif_getter.py
from PIL import Image
from PIL.ExifTags import TAGS, GPSTAGS
def get_exif(image_file_path):
exif_table = {}
image = Image.open(image_file_path)
info = image.getexif()
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
exif_table[decoded] = value
gps_info = {}
for key in exif_table['GPSInfo'].keys():
decode = GPSTAGS.get(key,key)
gps_info[decode] = exif_table['GPSInfo'][key]
return gps_info
if __name__ == "__main__":
exif = get_exif("jester.jpg")
print(exif)
要访问 GPS 标签,您需要从 PIL.ExifTags 导入 GPS tags。如果存在,那么你就可以提取 GPS 标签。
运行此代码时,您应该会看到以下输出:
{'GPSLatitudeRef': 'N',
'GPSLatitude': (41.0, 47.0, 2.17),
'GPSLongitudeRef': 'W',
'GPSLongitude': (93.0, 46.0, 42.09)}
您可以获取这些信息,并使用 Python 加载 Google 地图,或者使用流行的 GIS 相关 Python 库。
相关阅读
使用 Python 通过构建状态获取 Jenkins 作业
原文:https://www.blog.pythonlibrary.org/2020/01/14/getting-jenkins-jobs-by-build-state-with-python/
我最近一直在与 Python 和 Jenkins 一起工作,最近需要找到一种方法在构建级别检查作业的状态。我发现了 jenkinsapi 包,并试用了一下,看看它是否能让我深入到 Jenkins 中的构建和结果集级别。
在我运行的构建中,有 X 数量的子作业。这些子作业中的每一个都可能通过或失败。如果其中一个失败了,整个构建就会被标上黄色,并被标记为“不稳定”,这在我的书中是失败的。我需要一种方法来跟踪这些子作业中哪个失败了,以及在一段时间内失败的频率。这些作业中的一些可能不稳定,因为它们访问网络资源,而另一些可能由于最近对代码库的提交而中断。
我最终想出了一些代码来帮助我理解这些信息。但是在深入研究代码之前,您需要安装一个包。
安装必备组件
jenkinsapi 包很容易安装,因为它是 pip 兼容的。您可以使用以下命令将其安装到您的主 Python 安装或 Python 虚拟环境中:
pip install jenkinsapi
您还需要安装请求,这也是 pip 兼容的:
pip install requests
这些是你唯一需要的包裹。现在你可以进入下一部分了!
询问詹金斯
您想要完成的第一步是按状态获取作业。Jenkins 中的标准状态包括成功、不稳定或中止。
让我们编写一些代码来查找不稳定的作业:
from jenkinsapi.jenkins import Jenkins
from jenkinsapi.custom_exceptions import NoBuildData
from requests import ConnectionError
def get_job_by_build_state(url, view_name, state='SUCCESS'):
server = Jenkins(url)
view_url = f'{url}/view/{view_name}/'
view = server.get_view_by_url(view_url)
jobs = view.get_job_dict()
jobs_by_state = []
for job in jobs:
job_url = f'{url}/{job}'
j = server.get_job(job)
try:
build = j.get_last_completed_build()
status = build.get_status()
if status == state:
jobs_by_state.append(job)
except NoBuildData:
continue
except ConnectionError:
pass
return jobs_by_state
if __name__ == '__main__':
jobs = get_job_by_build_state(url='http://myJenkins:8080', view_name='VIEW_NAME',
state='UNSTABLE')
在这里,您创建了一个 Jenkins 的实例,并将其分配给服务器。然后使用 get_view_by_url() 获取指定的视图名称。该视图基本上是您设置的一组相关联的职务。例如,您可以创建一组做开发/操作类事情的作业,并将它们放入 Utils 视图中。
一旦有了视图对象,就可以使用 get_job_dict() 来获取该视图中所有作业的字典。既然已经有了字典,就可以对它们进行循环,并在视图中获得各个作业。您可以通过调用 Jenkin 对象的 get_job() 方法来获得作业。既然有了 job 对象,您终于可以深入到构建本身了。
为了防止错误,我发现可以使用get _ last _ completed _ build()来获得最后一次完整的构建。这是最好的,如果你使用 get_build() 并且构建还没有完成,构建对象可能没有你期望的内容。现在您已经有了构建,您可以使用 get_status() 来获取它的状态,并将其与您传入的那个进行比较。如果它们匹配,那么将该作业添加到 jobs_by_state ,这是一个 Python 列表。
您还会发现一些可能发生的错误。你可能看不到 NoBuildData ,除非作业被中止或者你的服务器上发生了一些非常奇怪的事情。当你试图连接到一个不存在或离线的 URL 时,就会发生 ConnectionError 异常。
此时,您应该有一个筛选到您所要求的状态的作业列表。
如果您想进一步深入到作业中的子作业,那么您需要调用构建的 has_resultset() 方法来验证是否有要检查的结果。然后你可以这样做:
resultset = build.get_resultset()
for item in resultset.items():
# do something here
根据作业类型的不同,返回的 resultset 会有很大不同,所以您需要自己解析条目元组,看看它是否包含您需要的信息。
包扎
此时,您应该有足够的信息来开始挖掘 Jenkin 的内部信息,以获得您需要的信息。我使用了这个脚本的一个变体来帮助我提取构建失败的信息,帮助我更快地发现重复失败的作业。不幸的是, jenkinsapi 的文档不是很详细,所以你将会在调试器中花费大量的时间试图弄清楚它是如何工作的。然而,一旦你搞清楚了,它总体上工作得很好。
使用 Python 获取照片元数据(EXIF)
原文:https://www.blog.pythonlibrary.org/2010/03/28/getting-photo-metadata-exif-using-python/
上周,我试图找出如何获得我的照片的元数据。我注意到 Windows 可以在我的照片上显示相机型号、创建日期和许多其他数据,但我不记得这些数据叫什么了。我终于找到了我要找的东西。术语是 EXIF(可交换图像文件格式)。在本帖中,我们将看看各种第三方软件包,它们让您可以访问这些信息。
我的第一个想法是 Python 图像库会有这个功能,但是我还没有找到 EXIF 术语,如果没有它,在 PIL 的手册中也找不到这个信息。幸运的是,我最终通过一个 stackoverflow 线程找到了使用 PIL 的方法。这是它展示的方法:
from PIL import Image
from PIL.ExifTags import TAGS
def get_exif(fn):
ret = {}
i = Image.open(fn)
info = i._getexif()
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
ret[decoded] = value
return ret
这工作得很好,并返回一个很好的字典对象。我发现有几个字段没有用,比如“MakerNote”字段,它看起来像许多十六进制值,所以您可能只想使用某些数据。以下是我得到的一些信息的例子:
{'YResolution': (180, 1),
'ResolutionUnit': 2,
'Make': 'Canon',
'Flash': 16,
'DateTime': '2009:09:11 11:29:10',
'MeteringMode': 5,
'XResolution': (180, 1),
'ColorSpace': 1,
'ExifImageWidth': 3264,
'DateTimeDigitized': '2009:09:11 11:29:10',
'ApertureValue': (116, 32),
'FocalPlaneYResolution': (2448000, 169),
'CompressedBitsPerPixel': (3, 1),
'SensingMethod': 2,
'FNumber': (35, 10),
'DateTimeOriginal': '2009:09:11 11:29:10',
'FocalLength': (26000, 1000),
'FocalPlaneXResolution': (3264000, 225),
'ExifOffset': 196,
'ExifImageHeight': 2448,
'ISOSpeedRatings': 100,
'Model': 'Canon PowerShot S5 IS',
'Orientation': 1,
'ExposureTime': (1, 200),
'FileSource': '\x03',
'MaxApertureValue': (116, 32),
'ExifInteroperabilityOffset': 3346,
'FlashPixVersion': '0100',
'FocalPlaneResolutionUnit': 2,
'YCbCrPositioning': 1,
'ExifVersion': '0220'}
我真的不知道所有这些值意味着什么,但我知道我可以使用其中的一些。我想要这些数据的目的是扩展我的简单的图像浏览器,这样它可以向用户显示更多关于他们照片的信息。
以下是我发现的其他几个可以访问 EXIF 数据的图书馆:
我尝试了 Python Exif 解析器,它工作得相当好。当我在工作中试图在我的 Python 2.5 机器上安装 pyexiv2 时,我收到了一条关于 Python 2.6 未找到的错误消息,然后安装程序退出了。pyexiv2 网站上没有提到它需要特定版本的 Python 才能工作,所以这有点令人沮丧。这些模块中的大多数很少或者没有文档,这也非常令人沮丧。据我所知,EXIF.py 应该通过命令行使用,而不是作为一个可导入的模块。
总之,回到 Python Exif 解析器。它实际上比 PIL 更容易使用。将 exif.py 文件复制到 Python 路径后,您需要做的就是:
import exif
photo_path = "somePath\to\a\photo.jpg"
data = exif.parse(photo_path)
上面的代码返回的信息与 PIL 代码片段返回的信息基本相同,尽管它对“MakersNote”使用了整数而不是十六进制,并且它有几个“Tag0xa406”字段,而 PIL 数据有一些数字字段(我在上面排除了这些字段)。我假设他们以不同的方式引用相同的信息。
无论如何,当你试图发现这些信息时,如果你发现自己在网上游荡,希望你会偶然发现这篇文章,它会给你指出正确的方向。
获取 Windows 上的远程驱动器空间
原文:https://www.blog.pythonlibrary.org/2010/09/09/getting-remote-drive-space-on-windows/
在我目前的工作岗位上工作了大约一年后,当我们还在将最后几台 Windows 98 机器升级到 Windows XP 时,我们需要检查我们网络上哪些机器的磁盘空间越来越少。这个问题之所以会突然出现,是因为我们在几台有 10 GB 硬盘、几台有 20 GB 硬盘、一两台只有 4 GB 硬盘的机器上安装了 Windows XP。总之,在网上做了一些调查后,我发现 PyWin32 包可以完成我需要的功能。
以下是我使用的代码:
import win32com.client as com
def TotalSize(drive):
""" Return the TotalSize of a shared drive [GB]"""
try:
fso = com.Dispatch("Scripting.FileSystemObject")
drv = fso.GetDrive(drive)
return drv.TotalSize/2**30
except:
return 0
def FreeSpace(drive):
""" Return the FreeSpace of a shared drive [GB]"""
try:
fso = com.Dispatch("Scripting.FileSystemObject")
drv = fso.GetDrive(drive)
return drv.FreeSpace/2**30
except:
return 0
workstations = ['computeNameOne']
print 'Hard drive sizes:'
for compName in workstations:
drive = '\\\\' + compName + '\\c$'
print '*************************************************\n'
print compName
print 'TotalSize of %s = %f GB' % (drive, TotalSize(drive))
print 'FreeSpace on %s = %f GB' % (drive, FreeSpace(drive))
print '*************************************************\n'
注意在底部,我使用了一个列表。通常,我会列出我想检查的每台计算机的名称。然后,我将遍历这些名称,并从一台拥有完全域管理权限的机器上将我需要的正确路径放在一起。
为了让它工作,我们需要导入 win32com.client 并调用下面的代码: com。Dispatch("脚本。FileSystemObject") 。这将为我们提供一个 COM 对象,我们可以通过查询来获得一个 disk 对象。一旦我们有了这些,我们可以问磁盘它有多少总空间和多少空闲空间。今天来看看这段代码,我会将这两个函数合并成一个函数,并返回一个元组。如您所见,我对结果做了一点数学运算,让它返回以千兆字节为单位的大小。
这就是全部了。简单的东西。我怀疑我没有完全写好这段代码,因为变量名太烂了。它可能来自于一个活动状态的食谱或者一个论坛,但是我忘了注明它的属性。如果你认识这个代码,请在评论中告诉我!
JupyterLab 入门
原文:https://www.blog.pythonlibrary.org/2019/02/05/getting-started-with-jupyterlab/
JupyterLab 是来自 Project Jupyter 的最新包。在某些方面,它是 Jupyter 笔记本的替代品。然而,Jupyter 笔记本是 JupyterLab 的一个独立项目。我喜欢把 JupyterLab 想象成一种基于网络的集成开发环境,你可以用它来操作 Jupyter 笔记本,也可以使用终端、文本编辑器和代码控制台。你可能会说 JupyterLab 是 Jupyter Notebook 的更强大版本。
无论如何,这里有一些 JupyterLab 能够做到的事情:
- 代码控制台——这些是代码暂存区,你可以用它来交互式地运行代码,有点像 Python 的 IDLE
- 内核支持的文档——这些文档允许您启用任何文本文件(Markdown、Python、R 等)中的代码,然后这些代码可以在 Jupyter 内核中运行
- 镜像笔记本单元输出-这让您可以创建简单的仪表板
- 同一文档的多个视图-让您能够实时编辑文档并查看结果
JupyterLab 将允许您查看和处理多种类型的数据。您还可以使用各种可视化或降价来显示这些格式的丰富输出。
对于导航,您可以使用 vim、emacs 甚至 SublimeText 中的可定制键盘快捷键或键映射。
您可以通过扩展向 JupyterLab 实例添加新的行为。这包括主题支持、文件编辑器等等。

装置
可以使用 conda、pip 或 pipenv 来安装 JupyterLab。
康达
如果您是 Anaconda 用户,那么您可以使用以下命令将 conda 用于安装目的:
conda install -c conda-forge jupyterlab
点
如果您喜欢使用 Python 的本地安装程序 pip,那么这就是您想要的命令:
pip install jupyterlab
注意:如果您使用的是 pip install - user ,那么您需要将用户级的“bin”目录添加到 PATH 环境变量中,以便能够启动 jupyterlab。
pipenv
pipenv 工具是一个新的包,可用于创建 Python 虚拟环境并将包下载到其中。如果您碰巧安装了它,那么您可以使用以下两个命令来获取 JupyterLab:
pipenv install jupyterlab
pipenv shell
请注意,如果您想从安装 JupyterLab 的 virtualenv 中启动 JupyterLab,则需要调用 shell 命令。
运行 JupyterLab
现在我们已经安装了 JupyterLab,我们应该试着运行它。你可以使用 jupyter-lab 或者 jupyter lab 来运行它。当我运行这些命令时,我得到了下面的初始 web 应用程序:

新 JupyterLab 的初始登录页面
右边的标签叫做启动器。这是一个地方,你可以去开始一个新的笔记本,代码控制台,终端或文本文件。新文档作为新选项卡打开。你会注意到,当你创建一个新的笔记本或其他项目,启动消失。如果你想打开第二个文档,只需点击左边的“+”按钮,我在下面画了圈:

在 JupyterLab 中添加新项目
让我们打开笔记本,然后单击加号按钮。如果你这样做,你的屏幕应该是这样的:

JupyterLab 中的多个选项卡
您也可以使用屏幕顶部的菜单* *创建新项目。只需转到文件**-> * 新建 *,然后选择您要创建的项目类型。如果你用过 Jupyter Notebook,大部分菜单项你应该很熟悉。不过,这里有一些新条目是专门针对 JupyterLab 的。例如:
- 新启动器-启动一个新的启动器
- 从路径打开-从不同于开始路径的路径打开文档
- 将笔记本另存为...-让您用新文件名保存当前选定的笔记本
- 将笔记本导出为...-让您将笔记本导出为不同的格式,如 PDF、Markdown 等
浏览菜单,看看你还能找到什么。这是不言自明的。
文件浏览器
左边的树被称为文件浏览器。它显示了从您启动 JupyterLab 的位置可用的文件。只需单击文件夹图标使树折叠,以便选项卡可以充满浏览器:

文件浏览器最小化
您会注意到,您也可以通过单击文件夹+图标(下面画圈的)在文件浏览器中创建新文件夹:

创建新文件夹
如果您需要从计算机上的另一个位置向 JupyterLab 添加文件,您需要点击上传按钮:

将文件上传/保存到工作区
当你这样做时,它会弹出一个文件打开对话框:

上传对话框
就像在另一个程序中打开文件一样使用它。请记住,您不是打开一个文件,而是将它“上传”或“复制”到您的 JupyterLab 工作区。
最后,如果您碰巧通过使用上传按钮之外的方法将文件复制到工作区中,则可以使用刷新按钮来刷新工作区:

刷新文件浏览器按钮
特殊 URL
与 Jupyter Notebook 一样,JupyterLab 允许用户将 URL 复制到浏览器中,以打开特定的笔记本或文件。然而,JupyterLab 还增加了通过 URL 管理工作区和文件导航的能力。
例如,如果你想使用文件导航,你可以使用特殊的关键字树来实现。以下是使用无标题笔记本的 URL 示例:
http://localhost:8888/lab/tree/Untitled.ipynb
如果你尝试这样做,你会看到普通的 Jupyter 笔记本界面,而不是 JupyterLab 内部的笔记本。
工作区
默认的工作区没有名字,但是可以在 /lab 找到。如果您想要克隆您的工作区,您可以使用以下格式:
http://localhost:8888/lab/workspaces/test?clone
这将把您当前的工作区复制到一个名为 test 的工作区中。如果您想要将测试工作区复制到您的默认工作区中,URL 应该是这样的:
http://localhost:8888/lab?clone=test
您也可以使用重置 URL 参数重置工作区。重置工作区时,您正在清除其内容。以下是重置默认工作空间的示例:
http://localhost:8888/lab/workspaces/lab?reset
牢房检查员
让我们在 JupyterLab 实例中创建一个笔记本。转到启动器,选择一个内核。默认情况下,您将拥有 Python 2 或 Python 3。创建之后,您应该会看到一个名为“Untitled.ipynb”的新选项卡,如下所示:

JupyterLab 的一个空笔记本
如你所见,我们有一个只有一个电池的笔记本。让我们将以下代码添加到幻灯片中:
def adder(a, b):
return a + b
adder(2, 3)
现在,让我们单击左侧工具栏中的小扳手。下面是一个按钮被圈起来的屏幕截图:

牢房检查员
当您单击那个扳手时,您的屏幕应该看起来如上所示。这被称为细胞检查员。您可以在这里设置笔记本以用于演示目的。您可以设置哪些单元格是载玻片或子载玻片。我们在第 9 章中谈到的与笔记本本身相关的几乎任何事情都可以在这里完成。您还会注意到,单元格检查器将显示 JupyterLab / Notebook 添加到单元格中的任何元数据。
如果你想看实际操作,那么试着将你的第一个单元格设置为一个幻灯片。现在,您应该看到元数据字段是这样填充的:

单元格的元数据
使用文件
您可以使用 JupyterLab 的文件浏览器和文件菜单来处理系统中的文件和目录。这允许您打开、创建、删除、重命名、下载/上传、复制和共享文件和目录。您可以在左侧边栏中找到文件浏览器:

文件浏览器
如果您的浏览器中有文件,您只需双击该文件即可打开它,就像您通常在系统的文件浏览器中所做的那样。您也可以将文件从文件浏览器拖到工作区(右侧),这将打开该文件。
JupyterLab 支持的许多文件类型也有多个查看器和编辑器。例如,您可以在编辑器中打开 Markdown 文件,或者以 HTML 格式查看它。如果您想在非默认的查看器/编辑器中打开该文件,只需右键单击该文件并选择“打开方式...”即可从上下文菜单中:

文件的上下文菜单
请注意,您可以在多个查看器/编辑器中打开一个文件,它们将保持同步。
文本编辑器
JupyterLab 带有一个内置的文本编辑器,可以用来创建或打开文本文件。打开启动程序,不要创建笔记本,转到启动程序的底部,创建一个文本文件。

启动文本编辑器
它会默认创建一个 untitled.txt 文件。但是你可以进入文件菜单,使用“另存为……”把它存为别的东西。这允许你创建 Python 文件,Markdown 和几乎任何你想做的事情。它甚至为某些文件类型提供语法高亮,尽管不支持代码完成。您也可以通过文件菜单创建文件。
文本编辑器还支持可配置的缩进(制表符和空格)、键映射和基本主题。只需进入设置菜单查看或编辑即可:

文件设置
如果你想编辑一个现有的文本文件,你需要做的就是在文件浏览器中双击它。
交互式代码控制台
JupyterLab 的新特性之一是代码控制台,它基本上是浏览器中的 REPL。它将让你在当前选择的内核中交互式地运行代码。代码控制台的“单元”显示代码运行的顺序。要创建新的代码控制台,请单击文件浏览器中的“+”按钮,并选择您选择的内核:

代码控制台启动器
输入一些代码。如果你自己想不起来,这里有一个例子:
print('Hello Console!')
现在按下 Shift+Enter 运行代码。如果一切正常,您应该会看到以下输出:

代码控制台
代码完成通过选项卡键工作。你也可以通过按下 Shift+Tab 来调出工具提示。
如果需要在不重启内核的情况下清除代码控制台,可以右击控制台本身,选择“清除控制台单元格”。
终端
JupyterLab 项目继续支持浏览器中的系统外壳。对于 Mac / Linux,它支持 bash、tsch 等,而在 Windows 上,它支持 Powershell。这些终端可以运行您通常从系统终端运行的任何程序,包括其他程序,如 vim 或 emacs。请注意,JupyterLab 终端运行在您安装了 JupyterLab 的系统上,因此它也将使用您的用户权限。
无论如何,如果你想看到一个运行中的终端,只需按下文件浏览器中的“+”按钮启动启动器。然后选择终端:

终端发射器
如果您关闭终端标签,JupyterLab 将让它在后台运行。下面是一个运行的终端:

正在运行的终端
如果您想重新打开终端,只需转到运行选项卡:

运行应用程序
然后从运行的应用程序列表中选择终端。
命令选项板
JupyterLab 中的用户操作都要通过一个中央指挥系统。这包括菜单栏、上下文菜单、键盘快捷键等使用的命令。您可以通过命令面板访问可用的命令,您可以在命令选项卡下找到:

命令选项板
在这里,您可以搜索命令并直接执行它们,而不是在菜单系统中搜索它们。你也可以用下面的快捷键调出命令面板: Command/Ctrl Shift C
支持的文件类型
JupyterLab 支持相当多的文件类型,它可以显示或允许您编辑。这允许您在笔记本或代码控制台中布局丰富的单元格输出。对于文件,JupyterLab 将通过查看文件的扩展名或完整的文件名(如果扩展名不存在)来检测数据格式。请注意,多个编辑器/查看器可以与一个文件类型相关联。例如,您可以编辑降价文件并以 HTML 格式查看。只需右击一个文件,进入打开方式上下文菜单项,查看该文件类型可用的编辑器和查看器:

使用打开方式
您可以使用 Python 代码在笔记本或代码控制台中显示不同的数据格式。这里有一个例子:
from IPython.display import display, HTML
display(HTML('你好,来自 JupyterLab'))
当您在笔记本中运行这段代码时,它应该是这样的:

在笔记本中运行 HTML
关于 JupyterLab 支持的文件类型的完整列表,我建议查看文档。这应该总是最新的,而且比我自己列出这些项目更有用。
关于扩展的一句话
如您所料,JupyterLab 支持扩展,并且在设计时考虑了可扩展性。扩展可以定制用户体验或增强 JupyterLab 的一个或多个部分。例如,您可以向菜单或命令面板添加新项目,或者添加一些新的键盘快捷键。JupyterLab 本身其实就是一个扩展的集合。
如果你想为 JupyterLab 创建一个扩展,那么你需要熟悉 Javascript 或者愿意学习。扩展需要采用 npm 打包格式。要安装预制的扩展,您需要在您的机器上安装 Node.js 。一定要查看他们的网站,以获得你的操作系统的正确安装说明。
安装/卸载扩展
一旦安装了 Node.js,就可以通过运行以下命令来安装 JupyterLab 的扩展:
jupyter labextension install the-extension-name
如果您需要特定版本的扩展,那么该命令将如下所示:
jupyter labextension install the-extension-name@1.2
其中“1.2”是您需要的版本。您还可以扩展为 gzipped tarball 或 gzipped tarball 的 URL。
要获得当前安装的 JupyterLab 扩展的列表,只需运行
jupyter labextension list
如果您想卸载某个扩展,可以像这样轻松地完成:
jupyter labextension uninstall the-extension-name
您也可以通过在 install 或 uninstall 命令后列出软件包的名称来安装或卸载多个扩展。由于 JupyterLab 在每次安装后都会重新构建,这可能需要相当长的时间。为了在安装或卸载多个扩展时加快速度,可以包含** - no-build**标志。安装或卸载完成后,您需要自己运行构建命令,如下所示:
jupyter lab build
禁用扩展
如果你不想卸载一个扩展,但你想禁用它,这也很容易做到。只需运行禁用命令:
jupyter labextension disable the-extension-name
然后当你想重新启用它时,你可以运行 enable 命令:
jupyter labextension enable the-extension-name
包扎
JupyterLab 包真的很神奇。比起 Jupyter 笔记本,你可以用它做更多的事情。然而,用户界面也更复杂,所以学习曲线会更陡一些。然而,我认为值得学习如何使用它,因为编辑文档和实时查看文档的能力在创建演示文稿或做其他类型的工作时非常有用。至少,我会在虚拟环境中尝试一下,看看它是否适合您的工作流程。
相关阅读
- JupyterLab on Github
- 使用 Jupyter 笔记本小工具
- Jupyter 笔记本调试
pywebview 入门
原文:https://www.blog.pythonlibrary.org/2017/04/25/getting-started-with-pywebview/
几周前,我偶然发现了 pywebview 项目。pywebview 包“是一个轻量级的跨平台 webview 组件包装器,它允许在自己的本地 GUI 窗口中显示 HTML 内容它在 OSX 和 Linux 上使用 WebKit,在 Windows 上使用 Trident (MSHTML),这实际上也是 wxPython 的 webview 小工具所做的。pywebview 背后的想法是,它让你能够在桌面应用程序中加载网站,有点像电子。
虽然 pywebview 声称它“不依赖于外部 GUI 框架”,但在 Windows 上,它需要安装 pythonnet、PyWin32 和 comtypes。OSX 需要“pyobjc”,尽管它包含在 OSX 安装的默认 Python 中。对于 Linux 来说,这有点复杂。在基于 GTK3 的系统上,你需要 PyGObject,而在基于 Debian 的系统上,你需要安装 PyGObject + gir1.2-webkit-3.0。最后,你也可以使用 PyQt 4 或 5。
你可以通过 pywebview 使用 Python 微 web 框架,比如 Flask 或者 bottle,用 HTML5 代替 Python 来创建很酷的应用。
要安装 pywebview 本身,只需使用 pip:
pip install pywebview
安装完成后,假设您也具备了先决条件,您可以这样做:
import webview
webview.create_window('My Web App', 'http://www.mousevspython.com')
webview.start()
这将在具有指定标题(即第一个参数)的窗口中加载指定的 URL。您的新应用程序应该看起来像这样:

pywebview 的 API 非常简短,可以在以下位置找到:
你能使用的方法屈指可数,这使得它们很容易记住。但是因为您不能为 pywebview 应用程序创建任何其他控件,所以您需要在 web 应用程序中完成所有的用户界面逻辑。
pywebview 包支持使用 PyInstaller for Windows 和 py2app for OSX 进行冻结。它也适用于 virtualenv,尽管在使用 virtualenv 之前,您需要阅读一些已知的问题。
包扎
pywebview 包实际上非常简洁,我个人认为值得一看。如果您想要一些更好地集成到您的桌面的东西,那么您可能想要尝试 wxPython 或 PyQt。但是如果你需要做的只是发布一个基于 HTML5 的 web 应用程序,那么这个包可能就是你想要的。
Python 入门
原文:https://www.blog.pythonlibrary.org/2018/04/18/getting-started-with-qt-for-python/
Qt 团队最近发布了消息,Qt 现在将正式支持 PySide2 项目,他们称之为“Python 的 Qt”。它将是原 PySide 的完整端口,原 py side 只支持 Qt 4。PySide2 支持 Qt 5。Qt for Python 将拥有以下许可类型:GPL、LGPL 和商业许可。
PySide2 支持 Python 2.7 以及 Python 3.4 - 3.6。这里有可用的快照轮版本。假设我们下载了 Windows Python wheel。要安装它,您可以像这样使用 pip:
python -m pip install PySide2-5.11.0a1-5.11.0-cp36-cp36m-win_amd64.whl
一旦安装了 PySide2,我们就可以从一个非常简单的例子开始:
import sys
from PySide2.QtWidgets import QApplication, QLabel
if __name__ == '__main__':
app = QApplication([])
label = QLabel("Qt for Python!")
label.show()
sys.exit(app.exec_())
这段代码将创建我们的应用程序对象(QApplication)和一个 QLabel。当您运行 app.exec_() 时,您启动了 PySide2 的事件循环。因为我们没有指定标签或应用程序的大小,所以应用程序的大小默认为刚好足以容纳屏幕上的标签:

这是一个很无聊的例子,所以让我们看看如何把一个事件和一个按钮联系起来。
添加事件处理
PySide2 中的事件处理使用了信号和底层插槽的概念。你可以在他们的文档中了解这是如何工作的。让我们来看看如何设置按钮事件:
import sys
from PySide2.QtWidgets import QApplication, QLabel, QLineEdit
from PySide2.QtWidgets import QDialog, QPushButton, QVBoxLayout
class Form(QDialog):
""""""
def __init__(self, parent=None):
"""Constructor"""
super(Form, self).__init__(parent)
self.edit = QLineEdit("What's up?")
self.button = QPushButton("Print to stdout")
layout = QVBoxLayout()
layout.addWidget(self.edit)
layout.addWidget(self.button)
self.setLayout(layout)
self.button.clicked.connect(self.greetings)
def greetings(self):
""""""
text = self.edit.text()
print('Contents of QLineEdit widget: {}'.format(text))
if __name__ == "__main__":
app = QApplication([])
form = Form()
form.show()
sys.exit(app.exec_())
这里,我们通过 QLineEdit 小部件创建一个文本框,并通过 QPushButton 小部件创建一个按钮。然后,我们将这两个小部件放在 QVBoxLayout 中,这个容器允许您更改应用程序的大小,并让布局中包含的小部件相应地更改大小和位置。在这种情况下,我们使用垂直方向的布局,这意味着小部件垂直“堆叠”。
最后,我们将按钮的“clicked”信号与 greetings (slot)函数联系起来。每当我们点击按钮时,它都会调用我们指定的函数。这个函数将获取我们的文本框的内容,并将其打印到 stdout。下面是我运行代码时的样子:

我认为这看起来不错,但它仍然不是一个非常有趣的界面。
创建简单的表单

让我们通过用 PySide2 创建一个简单的表单来总结一下。在这个例子中,我们不会将表单与任何东西挂钩。这只是一段简单快速的示例代码,展示了如何创建一个简单的表单:
import sys
from PySide2.QtWidgets import QDialog, QApplication
from PySide2.QtWidgets import QHBoxLayout, QVBoxLayout
from PySide2.QtWidgets import QLineEdit, QLabel, QPushButton
class Form(QDialog):
""""""
def __init__(self, parent=None):
"""Constructor"""
super(Form, self).__init__(parent)
main_layout = QVBoxLayout()
name_layout = QHBoxLayout()
lbl = QLabel("Name:")
self.name = QLineEdit("")
name_layout.addWidget(lbl)
name_layout.addWidget(self.name)
name_layout.setSpacing(20)
add_layout = QHBoxLayout()
lbl = QLabel("Address:")
self.address = QLineEdit("")
add_layout.addWidget(lbl)
add_layout.addWidget(self.address)
phone_layout = QHBoxLayout()
self.phone = QLineEdit("")
phone_layout.addWidget(QLabel("Phone:"))
phone_layout.addWidget(self.phone)
phone_layout.setSpacing(18)
button = QPushButton('Submit')
main_layout.addLayout(name_layout, stretch=1)
main_layout.addLayout(add_layout, stretch=1)
main_layout.addLayout(phone_layout, stretch=1)
main_layout.addWidget(button)
self.setLayout(main_layout)
if __name__ == "__main__":
app = QApplication([])
form = Form()
form.show()
sys.exit(app.exec_())
在这段代码中,我们使用了几个盒子布局来排列屏幕上的小部件。也就是说,我们使用 QVBoxLayout 作为顶层布局,然后在其中嵌套 QHBoxLayouts。您还会注意到,当我们添加 QHBoxLayouts 时,我们告诉它们在我们调整主小部件大小时进行拉伸。代码的其余部分与您已经看到的几乎相同。
包扎
我已经很多年没有玩 PySide2(或者 PyQt)了,所以看到 Qt 再次拿起这个很令人兴奋。我认为 PySide2 和 PyQt 之间的一些竞争将是一件好事,它也可能推动其他 Python UI 框架的一些创新。虽然 PySide2 背后的开发人员目前没有支持移动平台的计划,但不幸的是,他们似乎很想知道开发人员是否会对此感兴趣。坦率地说,我希望很多人附和并告诉他们是的,因为我们在 Python 移动 UI 领域需要其他选择。
无论如何,我认为这个项目有很大的潜力,我期待看到它如何成长。
相关阅读
- PySide2 Wiki
- Python 的 Qt 是来到你身边的计算机
- 快照将 PySide2 的构建为 Python 轮子
ReportLab 画布入门
原文:https://www.blog.pythonlibrary.org/2021/09/15/getting-started-with-reportlabs-canvas/
ReportLab 是一个非常强大的库。只需一点点努力,你就可以做出任何你能想到的布局。这些年来,我用它复制了许多复杂的页面布局。在本教程中,您将学习如何使用 ReportLab 的 pdfgen 包。您将发现如何执行以下操作:
- 绘制文本
- 了解字体和文本颜色
- 创建文本对象
- 画线
- 画各种形状
pdfgen 包很低级。您将在画布上绘制或“绘画”来创建您的 PDF。画布从 pdfgen 包中导入。当您在画布上进行绘制时,您需要指定 X/Y 坐标来告诉 ReportLab 从哪里开始绘制。默认值为(0,0),其原点位于页面的左下角。许多桌面用户界面工具包,如 wxPython、Tkinter 等,也有这个概念。您也可以使用 X/Y 坐标在这些套件中放置按钮。这样可以非常精确地放置您添加到页面中的元素。
你需要知道的另一件事是,当你在 PDF 中定位一个项目时,你是根据你离原点的点数来定位的。是点,不是像素或毫米或英寸。积分!让我们来看看一张信纸大小的纸上有多少个点:
>>> from reportlab.lib.pagesizes import letter
>>> letter
(612.0, 792.0)
这里你了解到一个字母宽 612 点,高 792 点。让我们分别找出一英寸和一毫米中有多少个点:
>>> from reportlab.lib.units import inch
>>> inch
72.0
>>> from reportlab.lib.units import mm
>>> mm
2.834645669291339
这些信息将帮助您在绘画中定位您的绘图。至此,您已经准备好创建 PDF 了!
画布对象
画布对象位于 pdfgen 包中。让我们导入它并绘制一些文本:
# hello_reportlab.py
from reportlab.pdfgen import canvas
c = canvas.Canvas("hello.pdf")
c.drawString(100, 100, "Welcome to Reportlab!")
c.showPage()
c.save()
在本例中,您导入 canvas 对象,然后实例化一个 Canvas 对象。您会注意到唯一需要的参数是文件名或路径。接下来,调用 canvas 对象上的 drawString(),告诉它开始在原点右侧 100 点和上方 100 点处绘制字符串。之后,你调用 showPage() 方法。 showPage() 方法将保存画布的当前页面。其实不要求,但是推荐。
方法还会结束当前页面。如果您在调用 showPage()后绘制另一个字符串或其他元素,该对象将被绘制到一个新页面。最后,调用 canvas 对象的 save()方法,将文档保存到磁盘。现在你可以打开它,看看我们的 PDF 是什么样的:

您可能会注意到,您的文本位于文档底部附近。原因是原点(0,0)是文档的左下角。因此,当您告诉 ReportLab 绘制您的文本时,您是在告诉它从左侧开始绘制 100 个点,从底部开始绘制 100 个点。这与在像 Tkinter 或 wxPython 这样的 Python GUI 框架中创建用户界面形成对比,其中原点在左上方。
还要注意,因为您没有指定页面大小,所以它默认为 ReportLab 配置中的大小,通常是 A4。在 reportlab.lib.pagesizes 中可以找到一些常见的页面大小。
现在您已经准备好查看画布的构造函数,看看它需要什么参数:
def __init__(self,filename,
pagesize=None,
bottomup = 1,
pageCompression=None,
invariant = None,
verbosity=0,
encrypt=None,
cropMarks=None,
pdfVersion=None,
enforceColorSpace=None,
):
在这里你可以看到你可以把页面大小作为一个参数传入。页面大小实际上是以磅为单位的宽度和高度的元组。如果您想改变默认的左下角的原点,那么您可以将 bottomup 参数设置为 0,这会将原点改变到左上角。
pageCompression 参数默认为零或关闭。基本上,它会告诉 ReportLab 是否压缩每个页面。启用压缩后,文件生成过程会变慢。如果您的工作需要尽快生成 pdf,那么您会希望保持默认值零。
但是,如果速度不是问题,并且您希望使用更少的磁盘空间,那么您可以打开页面压缩。请注意,pdf 中的图像总是被压缩的,因此打开页面压缩的主要用例是当每页有大量文本或大量矢量图形时。
ReportLab 的用户指南没有提到不变参数的用途,所以我查看了源代码。根据消息来源,它用相同的时间戳信息产生可重复的、相同的 pdf。我从未见过任何人在他们的代码中使用这个参数,既然源代码说这是为了回归测试,我想你可以放心地忽略它。
下一个参数是 verbosity,用于记录级别。在零(0)时,ReportLab 将允许其他应用程序从标准输出中捕获 PDF。如果您将其设置为一(1),则每次创建 PDF 时都会打印出一条确认消息。可能会添加额外的级别,但在撰写本文时,只有这两个级别有文档记录。
encrypt 参数用于确定 PDF 是否应该加密,以及如何加密。缺省值显然是 None,这意味着根本没有加密。如果您传递一个要加密的字符串,该字符串将成为 PDF 的密码。如果您想要加密 PDF,那么您将需要创建一个report lab . lib . PDF encrypt . standard encryption的实例,并将其传递给 encrypt 参数。
可以将 cropMarks 参数设置为 True、False 或某个对象。印刷厂使用裁切标记来知道在哪里裁切页面。当您在 ReportLab 中将 cropMarks 设置为 True 时,页面将比您设置的页面大小大 3 mm,并在边角添加一些裁剪标记。可以传递给裁剪标记的对象包含以下参数:边框宽度、标记颜色、标记宽度和标记长度。对象允许您自定义裁剪标记。
pdfVersion 参数用于确保 PDF 版本大于或等于传入的版本。目前,ReportLab 支持版本 1-4。
最后, enforceColorSpace 参数用于在 PDF 中实施适当的颜色设置。您可以将其设置为以下选项之一:
- 用于印刷的四分色
- rgb
- 九月
- 性黑
- sep_cmyk
当其中一个被设置时,一个标准的 _PDFColorSetter 可调用函数将被用来执行颜色强制。您还可以传入一个用于颜色实施的可调用。
让我们回到你最初的例子,稍微更新一下。在 ReportLab 中,您可以使用点来定位元素(文本、图像等)。但是当你习惯使用毫米或英寸时,用点来思考就有点困难了。有一个巧妙的函数可以帮助你处理堆栈溢出:
def coord(x, y, height, unit=1):
x, y = x * unit, height - y * unit
return x, y
这个函数需要你的 x 和 y 坐标以及页面的高度。也可以传入单位大小。这将允许您执行以下操作:
# canvas_coords.py
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
from reportlab.lib.units import mm
def coord(x, y, height, unit=1):
x, y = x * unit, height - y * unit
return x, y
c = canvas.Canvas("hello.pdf", pagesize=letter)
width, height = letter
c.drawString(*coord(15, 20, height, mm), text="Welcome to Reportlab!")
c.showPage()
c.save()
在这个例子中,您向 coord 函数传递 x 和 y 坐标,但是您告诉它使用毫米作为您的单位。因此,不是以磅为单位,而是告诉 ReportLab,我们希望文本从页面左侧 15 毫米和顶部 20 毫米开始。
是的,你没看错。当您使用坐标功能时,它使用高度从底部到顶部交换原点的 y。如果你已经将画布的底向上参数设置为零,那么这个函数就不会像预期的那样工作。事实上,您可以将坐标函数简化为以下内容:
def coord(x, y, unit=1):
x, y = x * unit, y * unit
return x, y
现在,您可以像这样更新前面的示例:
# canvas_coords2.py
from reportlab.pdfgen import canvas
from reportlab.lib.units import mm
def coord(x, y, unit=1):
x, y = x * unit, y * unit
return x, y
c = canvas.Canvas("hello.pdf", bottomup=0)
c.drawString(*coord(15, 20, mm), text="Welcome to Reportlab!")
c.showPage()
c.save()
这似乎很简单。您应该花一两分钟的时间来试验这两个例子。尝试更改传入的 x 和 y 坐标。然后尝试改变文本,看看会发生什么!
画布方法
canvas 对象有许多方法。在本节中,您将学习如何使用这些方法使您的 PDF 文档更有趣。最容易使用的方法之一是 setFont ,它将允许您使用 PostScript 字体名称来指定您想要使用的字体。这里有一个简单的例子:
# font_demo.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def font_demo(my_canvas, fonts):
pos_y = 750
for font in fonts:
my_canvas.setFont(font, 12)
my_canvas.drawString(30, pos_y, font)
pos_y -= 10
if __name__ == '__main__':
my_canvas = canvas.Canvas("fonts.pdf",
pagesize=letter)
fonts = my_canvas.getAvailableFonts()
font_demo(my_canvas, fonts)
my_canvas.save()
为了让事情变得更有趣一点,您将使用getAvailableFonts()canvas 方法来获取您可以在运行代码的系统上使用的所有可用字体。然后你将把画布对象和字体名称列表传递给你的 font_demo ()函数。在这里,您循环遍历字体名称,设置字体,并调用 drawString ()方法将每个字体的名称绘制到页面上。
您还会注意到,您已经为起始 Y 位置设置了一个变量,然后每次循环时都将这个变量减 10。这是为了让每个文本字符串绘制在单独的一行上。如果你不这样做,字符串会写在对方的顶部,你会以一片混乱结束。
以下是运行字体演示的结果:

如果您想使用 canvas 方法来改变字体颜色,那么您会希望查看 setFillColor 或它的一个相关方法。只要在绘制字符串之前调用它,文本的颜色也会改变。
您可以使用画布的旋转方法从不同角度绘制文本。你还将学习如何使用翻译方法。让我们来看一个例子:
# rotating_demo.py
from reportlab.lib.pagesizes import letter
from reportlab.lib.units import inch
from reportlab.pdfgen import canvas
def rotate_demo():
my_canvas = canvas.Canvas("rotated.pdf",
pagesize=letter)
my_canvas.translate(inch, inch)
my_canvas.setFont('Helvetica', 14)
my_canvas.drawString(inch, inch, 'Normal')
my_canvas.line(inch, inch, inch+100, inch)
my_canvas.rotate(45)
my_canvas.drawString(inch, -inch, '45 degrees')
my_canvas.line(inch, inch, inch+100, inch)
my_canvas.rotate(45)
my_canvas.drawString(inch, -inch, '90 degrees')
my_canvas.line(inch, inch, inch+100, inch)
my_canvas.save()
if __name__ == '__main__':
rotate_demo()
在这里,您使用 translate 方法将您的原点从左下方设置为距左下方一英寸并向上一英寸。然后你设置字体和字体大小。接下来,正常写出一些文本,然后在你画一个字符串之前,你把坐标系本身旋转 45 度。
根据 ReportLab 用户指南,由于坐标系现在处于旋转状态,您可能希望以负数指定 y 坐标。如果你不这样做,你的字符串将被绘制在页面的边界之外,你将看不到它。最后,将坐标系再旋转 45 度,总共旋转 90 度,写出最后一个字符串并绘制最后一条线。
每次旋转坐标系时,观察线条如何移动是很有趣的。你可以看到最后一行的原点一直移动到了页面的最左边。
以下是运行代码时的结果:

现在是时候学习对齐了。
字符串对齐
画布支持更多的字符串方法,而不仅仅是普通的 drawString 方法。您也可以使用 drawRightString,它将绘制与 x 坐标右对齐的字符串。您也可以使用 drawAlignedString,它将绘制一个与第一个轴心字符对齐的字符串,默认为句点。
如果您想在页面上排列一系列浮点数,这很有用。最后,还有 drawCentredString 方法,它将绘制一个以 x 坐标为“中心”的字符串。让我们来看看:
# string_alignment.py
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
def string_alignment(my_canvas):
width, height = letter
my_canvas.drawString(80, 700, 'Standard String')
my_canvas.drawRightString(80, 680, 'Right String')
numbers = [987.15, 42, -1,234.56, (456.78)]
y = 650
for number in numbers:
my_canvas.drawAlignedString(80, y, str(number))
y -= 20
my_canvas.drawCentredString(width / 2, 550, 'Centered String')
my_canvas.showPage()
if __name__ == '__main__':
my_canvas = canvas.Canvas("string_alignment.pdf")
string_alignment(my_canvas)
my_canvas.save()
当您运行这段代码时,您将很快看到这些字符串是如何对齐的。
下面是运行代码的结果:

接下来你要学习的画布方法是如何绘制线条、矩形和网格!
在画布上画线
在 ReportLab 中画线其实挺容易的。一旦您习惯了它,您实际上可以在您的文档中创建非常复杂的绘图,尤其是当您将它与 ReportLab 的一些其他功能结合使用时。画直线的方法简单来说就是线。
以下是一些示例代码:
# drawing_lines.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def draw_lines(my_canvas):
my_canvas.setLineWidth(.3)
start_y = 710
my_canvas.line(30, start_y, 580, start_y)
for x in range(10):
start_y -= 10
my_canvas.line(30, start_y, 580, start_y)
if __name__ == '__main__':
my_canvas = canvas.Canvas("lines.pdf", pagesize=letter)
draw_lines(my_canvas)
my_canvas.save()
这里您创建了一个简单的 draw_lines 函数,它接受一个 canvas 对象作为它的唯一参数。然后通过设置线宽方法设置线条的宽度。最后,创建一条直线。line 方法接受四个参数: x1,y1,x2,y2 。这些是开始的 x 和 y 坐标以及结束的 x 和 y 坐标。通过使用一个用于循环的来添加另外 10 行。
如果您运行这段代码,您的输出将如下所示:

画布支持其他几种绘图操作。例如,你也可以画矩形、楔形和圆形。这里有一个简单的演示:
# drawing_polygons.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def draw_shapes():
c = canvas.Canvas("draw_other.pdf")
c.setStrokeColorRGB(0.2, 0.5, 0.3)
c.rect(10, 740, 100, 80, stroke=1, fill=0)
c.ellipse(10, 680, 100, 630, stroke=1, fill=1)
c.wedge(10, 600, 100, 550, 45, 90, stroke=1, fill=0)
c.circle(300, 600, 50)
c.save()
if __name__ == '__main__':
draw_shapes()
当您运行这段代码时,您应该会得到一个类似这样的文档:

让我们花点时间来看一下这些多边形方法接受的各种参数。rect 的代码签名如下所示:
def rect(self, x, y, width, height, stroke=1, fill=0):
这意味着您通过其 x/y 参数设置矩形位置的左下角。然后你设置它的宽度和高度。stroke 参数告诉 ReportLab 它是否应该画线,因此在演示代码中,我设置 stroke=1 或 True。fill 参数告诉 ReportLab 用一种颜色填充我绘制的多边形的内部。
现在让我们看看椭圆的定义:
def ellipse(self, x1, y1, x2, y2, stroke=1, fill=0):
这个和 rect 很像。根据方法的 docstring,x1、y1、x2、y2 参数是外接矩形的角点。stroke 和 fill 参数的操作方式与 rect 相同。只是为了好玩,你继续设置椭圆的填充为 1。
接下来,你有楔子:
def wedge(self, x1,y1, x2,y2, startAng, extent, stroke=1, fill=0):
楔形体的 x1、y1、x2、y2 参数实际上对应于围绕楔形体的完整 360 度圆形的不可见封闭矩形的坐标。所以你需要想象一个有矩形环绕的完整的圆来帮助你正确定位一个楔子。它也有一个起始角度参数( startAng )和范围参数,基本上是告诉楔形区要弧出多远。其他参数已经解释过了。
最后,你到达圆多边形。它的方法如下所示:
def circle(self, x_cen, y_cen, r, stroke=1, fill=0):
在你看过的所有多边形中,圆的论点可能是最不言自明的。x_cen 和 y_cen 参数是圆心的 x/y 坐标。r 参数是半径。描边和填充参数非常明显。
所有多边形都能够通过 setStrokeColorRGB 方法设置笔画(或线条)颜色。它接受红色、绿色、蓝色的参数值。您也可以使用 setStrokeColor 或 setStrokeColorCMYK 方法设置描边颜色。
也有相应的填充颜色设置器(即 setFillColor 、setfillcolorgb、 setFillColorCMYK ),虽然这些方法在这里没有演示。您可以通过将正确的名称或元组传递给适当的函数来使用这些函数。
现在,您已经准备好了解如何添加分页符了!
创建分页符
使用 ReportLab 创建 PDF 时,您首先需要知道的一件事是如何添加分页符,以便您可以拥有多页 PDF 文档。canvas 对象允许您通过 showPage 方法来实现这一点。
但是请注意,对于复杂的文档,您几乎肯定会使用 ReportLab 的 flowables,这是专门用于跨多个页面“流动”您的文档的特殊类。Flowables 本身就有点令人费解,但比起试图一直跟踪你在哪一页和你的光标位置,它们使用起来要好得多。
画布方向(纵向与横向)
ReportLab 将其页面方向默认为纵向,这也是所有文字处理程序所做的。但有时你会想用横向页面来代替。至少有两种方法可以告诉 Reportlab 使用风景:
from reportlab.lib.pagesizes import landscape, letter
from reportlab.pdfgen import canvas
c = canvas.Canvas('test.pdf', pagesize=letter)
c.setPageSize( landscape(letter) )
设置横向的另一种方法是直接设置页面大小:
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from reportlab.lib.units import inch
c = canvas.Canvas('test.pdf', pagesize=letter)
c.setPageSize( (11*inch, 8.5*inch) )
您可以通过这样做来使它更通用:
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
width, height = letter
c = canvas.Canvas('test.pdf', pagesize=letter)
c.setPageSize( (height, width) )
这可能更有意义,尤其是如果您想使用其他流行的页面大小,如 A4。
一个简单的示例应用程序
有时候,看看你如何运用你所学到的东西,看看是否能应用到实践中,这是一件好事。因此,让我们采用您在这里学到的一些方法,创建一个简单的应用程序来创建一个表单:
# sample_form_letter.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def create_form(filename, date, amount, receiver):
"""
@param date: The date to use
@param amount: The amount owed
@param receiver: The person who received the amount owed
"""
my_canvas = canvas.Canvas(filename, pagesize=letter)
my_canvas.setLineWidth(.3)
my_canvas.setFont('Helvetica', 12)
my_canvas.drawString(30, 750,'OFFICIAL COMMUNIQUE')
my_canvas.drawString(30, 735,'OF ACME INDUSTRIES')
my_canvas.drawString(500, 750, date)
my_canvas.line(480, 747, 580, 747)
my_canvas.drawString(275, 725,'AMOUNT OWED:')
my_canvas.drawString(500, 725, amount)
my_canvas.line(378,723, 580, 723)
my_canvas.drawString(30, 703,'RECEIVED BY:')
my_canvas.line(120, 700, 580, 700)
my_canvas.drawString(120, 703, receiver)
my_canvas.save()
if __name__ == '__main__':
create_form('form.pdf', '01/23/2018',
'$1,999', 'Mike')
这里创建一个名为 create_form 的简单函数,它接受文件名、表单日期、欠款金额和收款人。然后,在所需的位置绘制所有内容,并保存文件。运行该程序时,您将看到以下内容:

对于一小段代码来说,这看起来相当专业。
包扎
在本教程中,您了解了许多关于 ReportLab 画布及其许多方法的内容。虽然没有涵盖所有的 canvas 方法,但是您现在已经知道如何执行以下操作:
- 绘制文本
- 了解字体和文本颜色
- 创建文本对象
- 画线
- 画各种形状
试试 ReportLab。你会发现它非常有用,很快你就可以创建自己的令人惊叹的 PDF 报告了!
相关文章
想了解更多关于 ReportLab 和 Python 的信息吗?查看以下一些资源:
-
ReportLab - 关于字体的一切
-
reportlab—如何使用 Python 在 pdf 中创建条形码
-
Reportlab 表格–使用 Python 在 pdf 中创建表格
-
ReportLab: 使用 Python 向 PDF 添加图表
virtualenv 入门
原文:https://www.blog.pythonlibrary.org/2012/07/17/getting-started-with-virtualenv/
虚拟环境对于测试软件来说非常方便。在编程界也是如此。Ian Bicking 创建了 virtualenv 项目,这是一个用于创建隔离 Python 环境的工具。你可以使用这些环境来测试你的软件的新版本,你所依赖的软件包的新版本,或者只是作为一个沙箱来测试一些新的软件包。当您不能将文件复制到站点包中时,您也可以使用 virtualenv 作为工作空间,因为它位于共享主机上。当您使用 virtualenv 创建一个虚拟环境时,它会创建一个文件夹,并将 Python 与一个 site-packages 文件夹和几个其他文件夹一起复制到其中。它还安装 pip。一旦你的虚拟环境被激活,就像使用普通的 Python 一样。完成后,您可以删除要清理的文件夹。没有混乱,没有大惊小怪。或者,您可以继续使用它进行开发。
在本文中,我们将花一些时间来了解 virtualenv 以及如何使用它来制作我们自己的魔术。
装置
首先你大概需要安装 virtualenv。你可以使用 pip 或 easy_install 来安装它,或者你可以从他们的网站下载 virtualenv.py 文件,然后这样安装。此时,假设您的 Python 文件夹在系统路径上,您应该能够在命令行上调用 virtualenv
创建虚拟环境
用 virtualenv 包创建一个虚拟沙箱是相当容易的。你只需要做以下事情:
python virtualenv.py FOLDER_NAME
其中,FOLDER_NAME 是您希望沙盒所在的文件夹的名称。在我的 Windows 7 机器上,我将 C:\Python26\Scripts 添加到我的路径中,这样我就可以只调用 virtualenv.py FOLDER_NAME 而不用 Python 部分。如果你没有传递任何东西,那么你会在屏幕上看到一个选项列表。假设我们创建了一个名为沙盒的项目。我们如何使用它?我们需要激活它。方法如下:
在 Posix 上你可以做 source bin/activate 而在 Windows 上,你可以在命令行上做\ path \ to \ env \ Scripts \ activate。让我们实际经历这些步骤。我们将在桌面上创建 sandbox 文件夹,这样您就可以看到一个示例。这是它在我的机器上的样子:
C:\Users\mdriscoll\Desktop>virtualenv sandbox
New python executable in sandbox\Scripts\python.exe
Installing setuptools................done.
Installing pip...................done.
C:\Users\mdriscoll\Desktop>sandbox\Scripts\activate
(sandbox) C:\Users\mdriscoll\Desktop>
您将会注意到,一旦您的虚拟环境被激活,您将会看到您的提示更改为包含您创建的文件夹名称的前缀,在本例中是“sandbox”。这让你知道你正在使用你的沙箱。现在,您可以使用 pip 将其他包安装到您的虚拟环境中。完成后,您只需调用 deactivate 脚本来退出环境。
在创建虚拟游乐场时,有几个标志可以传递给 virtualenv,您应该知道。例如,您可以使用 - system-site-packages 来继承默认 Python 站点包中的包。如果你想使用 distribute 而不是 setuptools,你可以给 virtualenv 传递 - distribute 标志。
virtualenv 还为您提供了一种只安装库,但使用系统 Python 本身来运行它们的方法。根据文档,您只需创建一个特殊的脚本来完成它。你可以在这里阅读更多
还有一个简洁的(实验性的)标志叫做 -可重定位的,可以用来使文件夹可重定位。然而,在我写这篇文章的时候,它还不能在 Windows 上运行,所以我无法测试它。
最后,还有一个 - extra-search-dir 标志,您可以使用它来保持您的虚拟环境离线。基本上,它允许您在搜索路径中添加一个目录,以便安装 pip 或 easy_install。这样,您就不需要访问互联网来安装软件包。
包扎
至此,你应该可以自己使用 virtualenv 了。在这一点上,有几个其他项目值得一提。有道格·赫尔曼的 virtualenvwrapper 库,它使创建、删除和管理虚拟环境变得更加容易,还有 zc.buildout ,它可能是最接近 virtualenv 的东西,可以被称为竞争对手。我建议把它们都看看,因为它们可能对你的编程冒险有所帮助。
在 wxPython 中跨平台获取正确的笔记本选项卡
我最近在开发一个 GUI 应用程序,它有一个wx.Notebook in it. When the user changed tabs in the notebook, I wanted the application to do an update based on the newly shown (i.e. selected) tab. I quickly discovered that while it is easy to catch the tab change event, getting the right tab is not as obvious.
这篇文章将带你了解我的错误,并向你展示两个解决问题的方法。
下面是我最初做的一个例子:
# simple_note.py
import random
import wx
class TabPanel(wx.Panel):
def __init__(self, parent, name):
""""""
super().__init__(parent=parent)
self.name = name
colors = ["red", "blue", "gray", "yellow", "green"]
self.SetBackgroundColour(random.choice(colors))
btn = wx.Button(self, label="Press Me")
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(btn, 0, wx.ALL, 10)
self.SetSizer(sizer)
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
def __init__(self):
"""Constructor"""
super().__init__(None, wx.ID_ANY,
"Notebook Tutorial",
size=(600,400)
)
panel = wx.Panel(self)
self.notebook = wx.Notebook(panel)
self.notebook.Bind(wx.EVT_NOTEBOOK_PAGE_CHANGED, self.on_tab_change)
tabOne = TabPanel(self.notebook, name='Tab 1')
self.notebook.AddPage(tabOne, "Tab 1")
tabTwo = TabPanel(self.notebook, name='Tab 2')
self.notebook.AddPage(tabTwo, "Tab 2")
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(self.notebook, 1, wx.ALL|wx.EXPAND, 5)
panel.SetSizer(sizer)
self.Layout()
self.Show()
def on_tab_change(self, event):
# Works on Windows and Linux, but not Mac
current_page = self.notebook.GetCurrentPage()
print(current_page.name)
event.Skip()
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
这段代码可以在 Linux 和 Windows 上正常运行。然而,当你在 Mac OSX 上运行它时,报告的当前页面总是你在选择当前页面之前所在的标签。这有点像一个错误,但是是在 GUI 中。
在尝试了我自己的一些想法后,我决定向 wxPython Google group 寻求帮助。
他们有两种解决方法:
- 使用
GetSelection() along with the notebook'sGetPage() method`` - 使用平板笔记本小部件
使用 GetSelection()
使用事件对象的GetSelection() method will return the index of the currently selected tab. Then you can use the notebook's GetPage() method to get the actual page. This was the suggestion that Robin Dunn, the maintainer of wxPython, gave to me.``
下面是更新后使用该修复程序的代码:
# simple_note2.py
import random
import wx
class TabPanel(wx.Panel):
def __init__(self, parent, name):
""""""
super().__init__(parent=parent)
self.name = name
colors = ["red", "blue", "gray", "yellow", "green"]
self.SetBackgroundColour(random.choice(colors))
btn = wx.Button(self, label="Press Me")
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(btn, 0, wx.ALL, 10)
self.SetSizer(sizer)
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
def __init__(self):
"""Constructor"""
super().__init__(None, wx.ID_ANY,
"Notebook Tutorial",
size=(600,400)
)
panel = wx.Panel(self)
self.notebook = wx.Notebook(panel)
self.notebook.Bind(wx.EVT_NOTEBOOK_PAGE_CHANGED, self.on_tab_change)
tabOne = TabPanel(self.notebook, name='Tab 1')
self.notebook.AddPage(tabOne, "Tab 1")
tabTwo = TabPanel(self.notebook, name='Tab 2')
self.notebook.AddPage(tabTwo, "Tab 2")
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(self.notebook, 1, wx.ALL|wx.EXPAND, 5)
panel.SetSizer(sizer)
self.Layout()
self.Show()
def on_tab_change(self, event):
# Works on Windows, Linux and Mac
current_page = self.notebook.GetPage(event.GetSelection())
print(current_page.name)
event.Skip()
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
这是一个相当简单的修复,但有点烦人,因为不清楚为什么需要这么做。
使用平板笔记本
另一个选择是换掉wx.Notebook for the FlatNotebook. Let's see how that looks:
# simple_note.py
import random
import wx
import wx.lib.agw.flatnotebook as fnb
class TabPanel(wx.Panel):
def __init__(self, parent, name):
""""""
super().__init__(parent=parent)
self.name = name
colors = ["red", "blue", "gray", "yellow", "green"]
self.SetBackgroundColour(random.choice(colors))
btn = wx.Button(self, label="Press Me")
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(btn, 0, wx.ALL, 10)
self.SetSizer(sizer)
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
def __init__(self):
"""Constructor"""
super().__init__(None, wx.ID_ANY,
"Notebook Tutorial",
size=(600,400)
)
panel = wx.Panel(self)
self.notebook = fnb.FlatNotebook(panel)
self.notebook.Bind(wx.EVT_NOTEBOOK_PAGE_CHANGED, self.on_tab_change)
tabOne = TabPanel(self.notebook, name='Tab 1')
self.notebook.AddPage(tabOne, "Tab 1")
tabTwo = TabPanel(self.notebook, name='Tab 2')
self.notebook.AddPage(tabTwo, "Tab 2")
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(self.notebook, 1, wx.ALL|wx.EXPAND, 5)
panel.SetSizer(sizer)
self.Layout()
self.Show()
def on_tab_change(self, event):
# Works on Windows, Linux and Mac
current_page = self.notebook.GetCurrentPage()
print(current_page.name)
event.Skip()
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
现在你可以回到使用笔记本的GetCurrentPage() method. You can also use self.notebook.GetPage(event.GetSelection()) like you do in the other workaround, but I feel like `GetCurrentPage() is just more obvious what it is that you are doing.
包扎
这是我在 wxPython 中被一个奇怪的陷阱抓住的少数几次之一。当您编写旨在跨多个平台运行的代码时,您会不时地遇到这类事情。检查文档以确保您没有使用并非所有平台都支持的方法总是值得的。然后你会想自己做一些研究和测试。但是一旦你做了你的尽职调查,不要害怕寻求帮助。我会一直寻求帮助,避免浪费我自己的时间,尤其是当我的解决方案在三分之二的情况下都有效的时候。
使用 Python 获取 Windows 系统信息
原文:https://www.blog.pythonlibrary.org/2010/01/27/getting-windows-system-information-with-python/
我不得不为我的雇主想出的另一个脚本处理关于我们每个用户的物理机器的各种信息。我们希望跟踪他们的 CPU 速度、硬盘大小和 RAM 容量(以及其他信息),这样我们就能知道什么时候该升级他们的电脑了。从互联网上的各个地方收集所有的碎片是一件非常痛苦的事情,所以为了省去你的麻烦,我将把我发现的贴出来。请注意,这些代码中有很多是从 ActiveState 或邮件列表上的各种食谱中提取的。以下大部分内容几乎一字不差地出现在这份食谱中。
出于我不明白的原因,我们想知道用户在他们的机器上安装了哪个 Windows 操作系统。当我开始的时候,我们混合了 Windows 98 和 Windows XP Professional,后者超过了 90%。不管怎样,下面是我们用来判断用户正在运行什么的脚本:
def get_registry_value(key, subkey, value):
import _winreg
key = getattr(_winreg, key)
handle = _winreg.OpenKey(key, subkey)
(value, type) = _winreg.QueryValueEx(handle, value)
return value
def os_version():
def get(key):
return get_registry_value(
"HKEY_LOCAL_MACHINE",
"SOFTWARE\\Microsoft\\Windows NT\\CurrentVersion",
key)
os = get("ProductName")
sp = get("CSDVersion")
build = get("CurrentBuildNumber")
return "%s %s (build %s)" % (os, sp, build)
正确运行这段代码的方法是调用 os_version 函数。这将使用两个不同的键调用嵌套的 get 函数两次,以获取操作系统和服务包。从嵌套函数中调用了 get_registry_value 两次,我们也直接调用它来获取构建信息。最后,我们使用字符串替换来组合一个代表 PC 操作系统版本的字符串。
下面的代码片段用于找出客户端电脑中的处理器:
def cpu():
try:
cputype = get_registry_value(
"HKEY_LOCAL_MACHINE",
"HARDWARE\\DESCRIPTION\\System\\CentralProcessor\\0",
"ProcessorNameString")
except:
import wmi, pythoncom
pythoncom.CoInitialize()
c = wmi.WMI()
for i in c.Win32_Processor ():
cputype = i.Name
pythoncom.CoUninitialize()
if cputype == 'AMD Athlon(tm)':
c = wmi.WMI()
for i in c.Win32_Processor ():
cpuspeed = i.MaxClockSpeed
cputype = 'AMD Athlon(tm) %.2f Ghz' % (cpuspeed / 1000.0)
elif cputype == 'AMD Athlon(tm) Processor':
import wmi
c = wmi.WMI()
for i in c.Win32_Processor ():
cpuspeed = i.MaxClockSpeed
cputype = 'AMD Athlon(tm) %s' % cpuspeed
else:
pass
return cputype
注意,如果你想继续下去,你需要下载蒂姆·戈尔登的 WMI (Windows 管理规范)模块,我认为它依赖于 PyWin32 包(即使不是,在后面的例子中你也需要那个包)。请注意,我们首先尝试使用在前面的示例中定义的函数从 Windows 注册表中获取 cpu 类型。如果失败了,我们就用 WMI 模块来得到它。这样做的主要原因是在注册表中查找比拨打 WMI 电话要快。还要注意,我们将 WMI 代码包装在 pythoncom 方法中。我记得,之所以有这些,是因为我们在一个线程中运行这个脚本,你需要初始化的东西,让 WMI 高兴。否则,你会以一些愚蠢的错误或崩溃而告终。如果你不想用线,那么我想你可以去掉那些线。
这个片段中的下一部分是一个条件,它检查返回哪种 cpu 类型。如果它是一个 AMD 处理器,那么我们做另一个 WMI 调用来获得处理器的时钟速度,并将其添加到 CPU 字符串中。否则,我们只是按原样返回字符串(这通常意味着安装了 Intel 芯片)。
我们使用 VNC 连接到我们的大多数机器,所以我们想知道机器的名称。为此,我们运行以下命令:
from platform import node
def compname():
try:
return get_registry_value(
"HKEY_LOCAL_MACHINE",
'SYSTEM\\ControlSet001\\Control\\ComputerName\\ComputerName',
'ComputerName')
except:
compName = node
return compName
同样,我们首先检查 Windows 注册表,看看我们想要的东西是否存放在那里。如果失败,那么我们使用 Python 的平台模块。如您所见,我们使用了 bare except 语句,这是我们的糟糕设计。我必须解决这个问题。在我的辩护中,我在成为 Python 程序员的第一年就做了大部分这样的东西,我真的不知道还有什么更好的。无论如何,还有另一种方法可以得到这些信息,那就是 WMI:
c = wmi.WMI()
for i in c.Win32_ComputerSystem():
compname = i.Name
这不是很简单吗?我真的很喜欢这个东西,虽然我不知道为什么我们必须使用一个循环来获取 WMI 的信息。如果你知道,请在下面的评论中给我留言。
下一个话题是网络浏览器。在我工作的地方,除了 Internet Explorer,我们还在所有的机器上安装了 Mozilla Firefox。奇怪的是,我们有许多供应商没有升级他们的软件或网站,使其在 Internet Explorer 8 上正常运行,所以当微软推出更新时,我们有时会遇到问题。这为我们介绍了下一段代码:
def firefox_version():
try:
version = get_registry_value(
"HKEY_LOCAL_MACHINE",
"SOFTWARE\\Mozilla\\Mozilla Firefox",
"CurrentVersion")
version = (u"Mozilla Firefox", version)
except WindowsError:
version = None
return version
def iexplore_version():
try:
version = get_registry_value(
"HKEY_LOCAL_MACHINE",
"SOFTWARE\\Microsoft\\Internet Explorer",
"Version")
version = (u"Internet Explorer", version)
except WindowsError:
version = None
return version
def browsers():
browsers = []
firefox = firefox_version()
if firefox:
browsers.append(firefox)
iexplore = iexplore_version()
if iexplore:
browsers.append(iexplore)
return browsers
正确的运行方式是调用浏览器函数。它将调用另外两个函数,这两个函数继续重用我们从 Windows 注册表中获取所需信息的 get_registry_value 。这件作品有点无聊,但很容易使用。
我们的下一个脚本将获得大约安装的 RAM:
import ctypes
def ram():
kernel32 = ctypes.windll.kernel32
c_ulong = ctypes.c_ulong
class MEMORYSTATUS(ctypes.Structure):
_fields_ = [
('dwLength', c_ulong),
('dwMemoryLoad', c_ulong),
('dwTotalPhys', c_ulong),
('dwAvailPhys', c_ulong),
('dwTotalPageFile', c_ulong),
('dwAvailPageFile', c_ulong),
('dwTotalVirtual', c_ulong),
('dwAvailVirtual', c_ulong)
]
memoryStatus = MEMORYSTATUS()
memoryStatus.dwLength = ctypes.sizeof(MEMORYSTATUS)
kernel32.GlobalMemoryStatus(ctypes.byref(memoryStatus))
mem = memoryStatus.dwTotalPhys / (1024*1024)
availRam = memoryStatus.dwAvailPhys / (1024*1024)
if mem >= 1000:
mem = mem/1000
totalRam = str(mem) + ' GB'
else:
# mem = mem/1000000
totalRam = str(mem) + ' MB'
return (totalRam, availRam)
当我最初写这篇文章时,我使用了下面的 WMI 方法:
c = wmi.WMI()
for i in c.Win32_ComputerSystem():
mem = int(i.TotalPhysicalMemory)
它后面的条件是我的,但它们的主要用途是使返回的数字更有意义。我还没有完全理解 ctypes 是如何工作的,但是可以说上面的代码比 WMI 方法在更低的层次上获得信息。可能也会快一点。
最后一部分是获取硬盘空间,这是通过以下方式完成的:
def _disk_c(self):
drive = unicode(os.getenv("SystemDrive"))
freeuser = ctypes.c_int64()
total = ctypes.c_int64()
free = ctypes.c_int64()
ctypes.windll.kernel32.GetDiskFreeSpaceExW(drive,
ctypes.byref(freeuser),
ctypes.byref(total),
ctypes.byref(free))
return freeuser.value
这是原始配方作者使用 ctypes 的另一个例子。因为我不想听起来像个白痴,所以我不会假装理解得足够好来解释它。然而,Tim Golden 展示了一个类似的使用 WMI 查找硬盘剩余空闲空间的方法,您可能会感兴趣。去他的网站看看就知道了。
我希望这些都有意义。如果你有任何关于它的问题让我知道,我将尽力回答。
使用 Python 获得屏幕分辨率
原文:https://www.blog.pythonlibrary.org/2015/08/18/getting-your-screen-resolution-with-python/
我最近在寻找用 Python 获得我的屏幕分辨率的方法,以帮助诊断一个不能正常运行的应用程序的问题。在这篇文章中,我们将看看获得屏幕分辨率的一些方法。并非所有的解决方案都是跨平台的,但是在讨论这些方法时,我一定会提到这一点。我们开始吧!
使用 Linux 命令行
在 Linux 中有几种方法可以获得你的屏幕分辨率。如果你在谷歌上搜索,你会看到人们使用各种 Python GUI 工具包。我想找到一种不用安装第三方模块就能获得屏幕分辨率的方法。我最终找到了以下命令:
xrandr | grep '*'
然后我必须把这些信息翻译成 Python。这是我想到的:
import subprocess
cmd = ['xrandr']
cmd2 = ['grep', '*']
p = subprocess.Popen(cmd, stdout=subprocess.PIPE)
p2 = subprocess.Popen(cmd2, stdin=p.stdout, stdout=subprocess.PIPE)
p.stdout.close()
resolution_string, junk = p2.communicate()
resolution = resolution_string.split()[0]
width, height = resolution.split('x')
每当需要使用 Python 传输数据时,都需要创建两个不同的子流程实例。以上就是我做的。我通过 stdin 将来自 xrandr 的输出传送到我的第二个子流程。然后,我关闭了第一个进程的 stdout,基本上清除了它返回给第二个进程的所有内容。剩下的代码只是解析出监视器的宽度和高度。
使用 PyGTK
当然,上面的方法只适用于 Linux。如果你碰巧安装了 PyGTK ,那么你可以用它来获得你的屏幕分辨率。让我们来看看:
import gtk
width = gtk.gdk.screen_width()
height = gtk.gdk.screen_height()
这非常简单,因为 PyGTK 内置了这些方法。请注意,PyGTK 适用于 Windows 和 Linux。应该还有一个正在开发中的 Mac 版本。
使用 wxPython
正如您所料, wxPython 工具包也提供了一种获得屏幕分辨率的方法。它的用处不大,因为您实际上需要创建一个 App 对象,然后才能获得解决方案。
import wx
app = wx.App(False)
width, height = wx.GetDisplaySize()
这仍然是获得您想要的分辨率的简单方法。还应该注意的是,wxPython 运行在所有三个主要平台上。
使用 Tkinter
Tkinter 库通常包含在 Python 中,所以您应该将这个库作为默认库。它还提供屏幕分辨率,尽管它也要求您创建一个“app”对象:
import Tkinter
root = Tkinter.Tk()
width = root.winfo_screenwidth()
height = root.winfo_screenheight()
幸运的是,Tkinter 也可以在所有 3 个主要平台上使用,所以你几乎可以在任何地方使用这种方法。
使用 PySide / PyQt
正如你可能已经猜到的,你也可以使用 PySide 和 PyQt 来获得屏幕分辨率。以下是 PySide 版本:
from PySide import QtGui
app = QtGui.QApplication([])
screen_resolution = app.desktop().screenGeometry()
width, height = screen_resolution.width(), screen_resolution.height()
如果您使用 PyQt4,那么您需要将开头的导入更改为:
from PyQt4 import QtGui
其余都一样。你可能知道,这两个库都可以在 Windows、Linux 和 Mac 上使用。
包扎
此时,您应该能够在任何操作系统上获得屏幕分辨率。还有其他方法可以获得这些信息,这些方法依赖于平台。例如,在 Windows 上,您可以使用 PyWin32 的 win32api 或 ctypes。在 Mac 上,有 AppKit。但是这里列出的工具包方法可以在大多数平台上很好地工作,因为它们是跨平台的,所以您不需要使用特殊的情况来导入特定的包来使其工作。
附加阅读
- 在 Ubuntu 上用 Python 获取显示器分辨率
- 如何在 Python 中获得显示器分辨率?
圭多以 BDFL 的身份退休
原文:https://www.blog.pythonlibrary.org/2018/07/13/guido-retire-as-bdfl/
Python 的创造者,仁慈的终身独裁者(BDFL 饰)吉多·范·罗苏姆已经退休,成为 BDFL,截至 2018 年 7 月 12 日没有继任者。参见下面来自 Python 提交者列表的电子邮件,了解全部细节。
基本上有很多关于 PEP 572 赋值表达式的负面意见,这似乎促使 Python 的创造者提前退休。虽然他仍然会在周围提供帮助和指导,但他将不再以同样的方式参与社区活动。
我喜欢 Python 和它的社区,所以 Guido 以这种方式下台让我很难过。不过,我希望他一切顺利,并将继续在我们的社区中使用和推广 Python 和文明。
Python 书籍的假日销售
原文:https://www.blog.pythonlibrary.org/2016/12/05/holiday-sale-on-python-books/
现在是假期,所以我从今天开始把我所有的书都降价出售。拍卖将持续到 12 月 23 日。你可以在 Gumroad 或 Leanpub 上花 6.99 美元购买我的任何一本书。实际上,我现在推荐 Leanpub,因为我发现它的用户界面对我的读者来说更容易导航,但是如果你已经有一个 Gumroad 帐户,那么请随意使用它。
您将从 Leanpub 和 Gumroad 收到 PDF、mobi 和 epub 格式的书籍。
以下是链接:
Gumroad
- Python 101
- Python 201:中级 Python
- wxPython 食谱 (95%完成...您将收到早期版本+成品)
Leanpub
- Python 101
- Python 201:中级 Python
- wxPython 食谱 (95%完成...您将收到早期版本+成品)
软皮版本
我还有 10 份第一次运行的 Python 201:中级 Python 的拷贝,你现在可以购买。你还会收到这本书的电子版。请注意,第一次运行在 asyncio 章节中有一个错误,该错误已在数字副本中更正。平装本的未来版本将很快确定。
我如何写关于 Python 的书
原文:https://www.blog.pythonlibrary.org/2019/02/26/how-i-write-books-about-python/
我不时会被问到关于我写书过程的问题,我一直想写这个话题。我写第一本书 Python 101 的主要原因是因为我博客上的读者。他们鼓励我写一本关于 wxPython 的书已经有一段时间了,我决定我应该从写一本介绍性的书开始,这样我就不需要在我的中级书籍中包括一大堆介绍性的信息,如果我有时间去写它的话。
当我在写那本书的时候,我不得不寻找生成 PDF、mobi (Kindle)和 epub 格式的方法。我跳过了 Microsoft Word,因为我还没有找到将这种文档类型转换成其他文件类型的好方法,而且它在跨平台上也不太好用。
工具链
我最终选择了重组文本。我也尝试过 Sphinx,但是在我给自己的时间框架内,我无法让它按照我想要的方式工作。然而,RestructuredText 允许我用 rst2pdf 轻松地转换成 PDF。
然后我用 rst2html 创建了这本书的 html 版本。当你有了 HTML,你就可以使用图书转换工具 Calibre 来转换成 mobi 和 epub 格式。最后,我得到了一个 Python 脚本,它会调用 rst2pdf、rst2html 和 Calibre 将我的书转换成适当的格式。
这工作得很好,但是没有创建一个非常好的目录。
当我在开发 Python 101 的续集 Python 201:中级 Python 时,我发现了 Leanpub ,它对他们的书使用 Markdown,并将该格式转换为我想要的所有输出格式。输出看起来不错,最棒的是,它有一个合适的目录。
因此,我目前的工具链(截至 2019 年初)现在是用 RestructuredText 编写,并使用 Pandoc 将其转换为 Markdown。我这样做是为了在我出于某种原因决定放弃 Leanpub 的情况下,更容易切换回我自己创作的图书制作脚本。坦白地说,我想做的是使用 ReportLab 创建一个脚本,可以将 Markdown 或 RestructuredText 转换为 PDF。我怀疑我可以得到同样质量的东西,至少是 pdf。
2020 更新:我最终放弃了 RestructuredText,转而使用 Markdown,因为我发现 Pandoc 没有正确地转换代码示例和其他特殊结构。这导致语法突出显示无法正常工作。
研究与开发
当谈到为我的书选择主题时,我通常会使用我知道在我的博客上流行的主题。对于 Python 101 来说,有点不同,因为我已经阅读了许多关于 Python 的初学者书籍,并决定涵盖许多我在初学者书籍中不常看到的主题。其中一个例子是展示如何将代码发布到 PyPI 或者用 Python 创建可执行文件。
我密切关注我博客上的统计数据,以了解哪些文章做得很好,因为这也给了我关于书籍内容的想法。在 ReportLab 上创作我的书的两个原因是
- 没有这方面的书籍
- ReportLab 上的文章往往在我的前 10 名中
Kickstarter 在这里也发挥了一些作用,因为我会问我的支持者他们认为书里应该有什么,然后我会把这些想法排序,决定哪些会成功,哪些不会。
评论这本书
作为一名自行出版的作者,我的管理非常严格。我没有出版商付钱让人评论我的作品,所以我必须有创意。在某种程度上,我最终把我的博客当成了一个测试网站。我通常会在我的博客上发布我的书的新章节,以被动地获得读者的反馈。我也相信让我的书大部分是开源的,所以把章节放在那里对我的读者和我需要查找的时候都很好。
我也用 Kickstarter 做一些小的测试。通常会有支持者想要尽早阅读这本书,他们也给了我很多反馈。这很有帮助,这些书也因此变得更好。
在这一点上,我已经和两家出版商合作过,他们都没有给我读者给我的那种支持和反馈。我感谢你们所有人。
从读者那里获得反馈
说到反馈,我主要通过 Kickstarter 和我博客上的评论获得反馈。我所有的书都有电子邮件地址,读者也可以用它给我发邮件。我确实通过这种方法收到了不少读者的邮件,但我认为我从我提到的前两个来源得到了更多。
大多数反馈都是积极的,真的鼓励我继续写作。我偶尔会收到一些脾气暴躁的邮件,但即使是那些罕见的情况也有助于我看到我可以做得更好。
更新您的图书
当你选择写科技或计算机科学时,你知道你的书会随着时间的推移而过时。自助出版的最大好处之一是,我可以接受反馈,在几个小时或几天内修改一本书,并将这些更新直接推送给最终读者。在收到错误报告的几个小时内,我已经修复了错误并推出了新版本。
我更新书籍有几个不同的原因:
- 这本书现在已经过时了
- 这本书有一个印刷错误
- 这本书错了(该死!)
我尽量写一些暂时不会改变的话题。例如,wxPython 和 ReportLab 不会经常以中断的方式进行更改。所以我可以写它们,而不用担心我的例子在书出版时会被破坏。Python 本身在很大程度上也是如此。然而从 3.5 开始,Python 的变化超出了我的预期,所以我确实需要重写 Python 101 来解释这些差异。
卖你的书
谈到卖书,我最初的想法是把它贴在我的博客上,看看会发生什么。然后我意识到我可以用 Kickstarter 来衡量人们对我的想法的兴趣,所以我决定这么做。Kickstarter 在这方面很棒。这真的帮助我与我的读者建立了联系,并保持了早期采用者的反馈回路。
Kickstarter 在更新书籍和我未来的作品方面也很好。请注意,Kickstarter 确实收取总额的 8-10%,所以如果你决定使用它,你需要记住这一点。
我读到过,如果你做广告,你应该用不超过 5%的毛收入。我没怎么尝试过,因为我在网络广告方面的体验不是很好。
现在我有多本书,我可以把它们以不同的方式捆绑在一起。Leanpub 还支持将你的书与他们平台上其他作者的书捆绑在一起,如果你能找到一些想要这样做的人的话。
我最近开始在 Youtube 上做视频,我认为这有助于提高我的博客的知名度,但不是很多。Youtube 是一个非常不同的媒体,目前真的没有带来太多的流量,但我认为如果利用得当,它是可以的。
你也可以使用 gum road 来销售你的书。如果你能找到代销商,你可以使用他们的代销商计划。我已经尝试了一下,看起来效果不错。Leanpub 停止了分支机构,这很不幸。
与读者保持联系
与你的读者保持联系是困难的。根据您的销售平台,您可能无法做到。例如,亚马逊和 Leanpub 根本不共享买家信息。读者可以在 Leanpub 上选择接收更新,但我看不到他们的任何信息。Gumroad 确实给了卖家一个电子邮件地址,所以你可以用它来建立一个邮件列表。只要确保你除掉了所有不感兴趣的人。
正如我提到的,Kickstarter 对此很有用。我可以通过他们的网站向我所有的支持者发送更新。我还从他们那里得到了发送电子书的电子邮件地址。从技术上讲,你也可以用这种方式建立一个邮件列表。
我应该指出,我没有这样做。我只使用电子邮件地址来递送他们的货物,然后我不会再打扰任何人,除非我需要。
时间管理
在你为一本书设定最后期限之前,你应该尽可能多地勾勒出这本书的轮廓。我发现创建一个我想涵盖的章节列表有助于我缩小书的范围。我通常会把章节列表拿出来,用几种不同的方式重新排序。然后我把它们削减到必须拥有的章节和想要拥有的章节。
必读书籍是我所说的最少出货的书。这是我非常喜欢敏捷开发的一点,它确实很好地教授了范围界定。我想写的其他章节将在时间允许的情况下添加。这些是我通常在我的 Kickstarter 中作为延伸目标保留的章节,尽管除了这些延伸目标之外,我还有其他章节放在我的后兜里。
额外章节的好处是,你可能会发现你的主列表没有足够的内容。然后你可以添加一些想拥有的章节来弥补差异。
总之,所有这些都是说你需要写 4-10 章才能真正发现你的写作节奏是什么。一旦你知道了这一点,你就可以算出平均值,并预测你要花多长时间才能写出一本最少出货的书。这对我很有效。我知道我的速度是多少,然后我通常会在此基础上增加 1-3 个月,因为假期、旅行和不可避免的疾病似乎会在你最意想不到的时候突然出现。
代码示例
Github 已经成为事实上存储代码的地方。为了让我的读者简单起见,我已经开始把我的书的所有源代码放在与书相关的特定存储库中。然后,我可以在书的正文中添加一个链接,还可以从我的各种供应商网站上添加链接。
理论上,您可以将一个持续集成服务挂接到 Github 或类似的可以针对您的代码运行 linters 和测试的服务上。虽然我没有这样做,但我认为这可能是一个非常好的想法,我可能会在未来的书中尝试这样做。
外国观众
让外国读者看到你的书有点难。幸运的是,亚马逊、Gumroad 和 Leanpub 确实在国际上销售,所以从技术上来说,世界上任何地方的人都可以看到你的书。然而,如果你想让他们能够用自己的语言阅读,那就变得困难多了。
有几个人就翻译我的书找到我。你必须小心这类事情,因为你不知道他们是否有信誉。如果你想和某人一起工作并分享利润,Leanpub 提供了一种方法。然而,如果你把你的书的来源给了他们,他们就不会保护你,他们最终会把翻译贴在别的地方。
有类似于 Babelcube 的服务,你可以用它来翻译你的书。我还没有尝试过这些,所以我真的不能评论
电子书与印刷品
你会从电子书中赚到大部分的钱。因此,创建所有三种最流行的格式是绝对值得的:PDF、epub 和 mobi。据 Leanpub 称,PDF 是目前最流行的。
对于纸质书,我用的是 Lulu ,最近用的是亚马逊的 Createspace 。亚马逊的设置向导比 Lulu 的好。然而,他们每个人检查你的内容不同。如果你的截图分辨率太低,他们会告诉你。亚马逊会对你的作品进行拼写检查。
你需要一张 300 dpi 的封面图片,正面和背面都要。否则会显得模糊。你应该有 300 dpi 的截图,但我发现在那个分辨率下获取截图几乎是不可能的。尽你所能把它们弄高。
请注意,对于电子书封面,您不需要 300 dpi 的图像,因为这将使书籍的下载大小比它需要的大得多。这意味着你可以保留这本书的两个版本。
还要注意,亚马逊和 Lulu 都不希望封面成为 PDF 打印版本的一部分。封面需要分开。
书籍修订
作为一名技术作家,我喜欢对我的书进行修改。所以我用 Git 来做这个。我所有的源文件都进入 Git 存储库并保存在 Dropbox 和 Bitbucket 中。如果我开始使用技术评审员,我会考虑转而使用 Gitlab,因为他们对私有库有更好的政策。
包扎
我希望这篇有些脱节的文章对你有所帮助。我将在另一篇文章中写更多关于 indy 出版的利与弊。如果你有任何问题,欢迎在评论中提问。
如何用 Python 给你的照片添加边框
原文:https://www.blog.pythonlibrary.org/2017/10/26/how-to-add-a-border-to-your-photos-with-python/
有时给照片添加简单的边框很有趣。Pillow 软件包有一个非常简单的方法,通过它的 ImageOps 模块给你的图像添加这样的边框。像往常一样,您需要安装 Pillow 来完成本文中的任何示例。如果您还没有它,您可以使用 pip 安装它:
pip install Pillow
现在,我们已经处理好了那部分内务,让我们学习如何添加一个边框!
添加边框

本文的重点是使用 ImageOps 模块来添加我们的边框。对于这个例子,我们将使用我拍摄的这张整洁的蝴蝶照片。我们写点代码吧!
from PIL import Image, ImageOps
def add_border(input_image, output_image, border):
img = Image.open(input_image)
if isinstance(border, int) or isinstance(border, tuple):
bimg = ImageOps.expand(img, border=border)
else:
raise RuntimeError('Border is not an integer or tuple!')
bimg.save(output_image)
if __name__ == '__main__':
in_img = 'butterfly.jpg'
add_border(in_img, output_image='butterfly_border.jpg',
border=100)
在上面的代码中,我们创建了一个可以接受三个参数的函数:
- 输入图像路径
- 输出图像路径
- 边框,可以是一个整数或最多 4 个整数的元组,表示图像四个边中每一个边的像素
我们打开输入图像,然后检查边界的类型。是 int 还是 tuple 还是别的?如果是前两者之一,我们通过调用 expand() 函数来添加边框。否则我们会引发一个错误,因为我们传入了一个无效的类型。最后,我们保存图像。这是我得到的结果:

正如你所看到的,当你只是传入一个整数作为你的边界,它适用于图像的所有四边。如果我们希望顶部和底部的边界不同于右边和左边,我们需要指定。让我们更新代码,看看会发生什么!
from PIL import Image, ImageOps
def add_border(input_image, output_image, border):
img = Image.open(input_image)
if isinstance(border, int) or isinstance(border, tuple):
bimg = ImageOps.expand(img, border=border)
else:
raise RuntimeError('Border is not an integer or tuple!')
bimg.save(output_image)
if __name__ == '__main__':
in_img = 'butterfly.jpg'
add_border(in_img,
output_image='butterfly_border_top_bottom.jpg',
border=(10, 50))
在这里,我们想添加一个 10 像素的边界到左边和右边,一个 50 像素的边界到图片的顶部和底部。如果运行此代码,您应该会得到以下结果:

现在让我们尝试为所有四个边指定不同的值!
from PIL import Image, ImageOps
def add_border(input_image, output_image, border):
img = Image.open(input_image)
if isinstance(border, int) or isinstance(border, tuple):
bimg = ImageOps.expand(img, border=border)
else:
raise RuntimeError('Border is not an integer or tuple!')
bimg.save(output_image)
if __name__ == '__main__':
in_img = 'butterfly.jpg'
add_border(in_img,
output_image='butterfly_border_all_different.jpg',
border=(10, 30, 20, 50))
在这个例子中,我们告诉 Pillow 我们想要一个左边是 10 像素,上边是 30 像素,右边是 20 像素,下边是 50 像素宽的边框。当我运行这段代码时,我得到了这个:

坦白地说,我不知道为什么你希望所有的四个边都有不同大小的边框,但是如果你这样做了,就很容易应用了。
更改边框颜色
您还可以设置正在添加的边框的颜色。默认明显是黑色的。Pillow package 支持通过“rgb ”(即红色为“ff0000”)、“rgb(红、绿、蓝)”指定颜色,其中 RGB 值为 0 到 255 之间的整数、HSL 值或 HTML 颜色名称。让我们更新代码并给边框添加一些颜色:
from PIL import Image, ImageOps
def add_border(input_image, output_image, border, color=0):
img = Image.open(input_image)
if isinstance(border, int) or isinstance(border, tuple):
bimg = ImageOps.expand(img, border=border, fill=color)
else:
raise RuntimeError('Border is not an integer or tuple!')
bimg.save(output_image)
if __name__ == '__main__':
in_img = 'butterfly.jpg'
add_border(in_img,
output_image='butterfly_border_indianred.jpg',
border=100,
color='indianred')
你会注意到我们在这里添加了一个新的参数来指定我们想要的边框颜色。默认为黑色,即零(0)。在这个例子中,我们传入了 HTML 颜色‘Indian red’。结果如下:

通过将传入的值从' indianred '更改为' #CD5C5C ',可以获得相同的效果。
只是为了好玩,试着把你传入的值改成‘RGB(255,215,0)’,这是一种金色。如果你这样做,你可以让你的边界看起来像这样:

请注意,您也可以传入' gold '、' Gold '或' #FFD700 ',结果会是相同的颜色。
包扎
此时,你应该知道如何给你的照片添加简单的边框。如您所见,您可以单独或成对更改每条边的边框颜色像素数量,甚至可以同时更改所有四条边的边框颜色像素数量。你也可以把边框的颜色改成任何颜色。花点时间研究一下代码,看看你能想出什么来!
相关阅读
- Kanoki - 为你的照片画铅笔素描
- 如何用 Python 给你的照片加水印
- 如何用 Python 调整照片大小
- 用 Python 将一张照片转换成黑白
- 如何用 Python 旋转/镜像照片
- 如何用 Python 裁剪照片
- 使用 Python 增强照片
How to Override a List Attribute's Append() Method in Python
I had a use-case where I needed to create a class that had an attribute that was a Python list. Seems simple, right? The part that made it complicated is that I needed to do something special when anything was appended to that attribute. Watching for attribute changes don't work the same way for lists as it would for a string.
I tried a lot of different solutions, but most of them either didn't work or made the code really hard to understand.
Finally, someone on the Real Python Slack channel mentioned sub-classing collections.UserList and over-riding the append() method so that it executed a callback whenever that list object was appended to.
Here is a very simplified version of the code:
import datetime
from collections import UserList
from dataclasses import dataclass, field
from typing import Callable, Dict, List, Tuple
class ListWithCallback(UserList):
"""
Create a class that emulates a Python list and supports a callback
"""
def __init__(self, callback: Callable, *args: Tuple, **kwargs: Dict
) -> None:
super().__init__(*args, **kwargs)
self.callback = callback
def append(self, item) -> None:
super().append(item)
self.callback()
@dataclass
class Media:
channels: List = field(default_factory=list)
def update(self) -> None:
now = datetime.datetime.today()
print(f"{now:%B %d - %H:%m:%S}")
def __post_init__(self) -> None:
self.channels = ListWithCallback(self.update) # type: ignore
if __name__ == "__main__":
import time
impl = Media()
impl.channels.append("Blah")
time.sleep(2)
impl.channels.append("Blah")
The main class of interest here is Media, which is a data class. It has a single attribute, channels, which is a Python list. To make this work, you use post_init() to set channels to an instance of your custom class, ListWithCallback. This class takes in a function or method to call when an item is appended to your special list.
In this case, you call Media's update() method whenever an item is appended. To test that this functionality works, you import the time module at the bottom of the code and append two strings to the list with a sleep() between them.
Wrapping Up
If you ever find yourself needing to subclass a Python built-in, check out Python's collections module. It has several classes that are usually recommended over directly subclassing from the built-ins themselves. In this case, you used collections.UserList.
Subclassing from the collections module is straightforward. You will learn a lot and your code may even be better because you did that.
如何用 Python 检查文件是否是有效图像
原文:https://www.blog.pythonlibrary.org/2020/02/09/how-to-check-if-a-file-is-a-valid-image-with-python/
Python 的标准库中有许多模块。一个经常被忽视的是 imghdr ,它可以让你识别文件、字节流或类路径对象中包含的图像类型。
imghdr 可以识别以下图像类型:
- rgb
- 可交换的图像格式
- pbm
- precision-guided munition 精密制导武器
- 百万分率
- 一口
- 拉斯特
- xbm
- jpeg / jpg
- 位图文件的扩展名
- png
- webp
- 遗嘱执行人
下面是如何使用 imghdr 来检测文件的图像类型:
>>> import imghdr
>>> path = 'python.jpg'
>>> imghdr.what(path)
'jpeg'
>>> path = 'python.png'
>>> imghdr.what(path)
'png'
你所需要做的就是传递一个路径到 imghdr.what(path) 它会告诉你它认为图像类型是什么。
另一种方法是使用枕头包,如果你还没有 pip,你可以安装它。
以下是枕头的使用方法:
>>> from PIL import Image
>>> img = Image.open('/home/mdriscoll/Pictures/all_python.jpg')
>>> img.format
'JPEG'
这个方法几乎和使用 imghdr 一样简单。在这种情况下,您需要创建一个图像对象,然后调用它的格式属性。Pillow 支持的图像类型比 imghdr 多,但是文档并没有真正说明格式属性是否适用于所有这些图像类型。
无论如何,我希望这有助于您识别文件的图像类型。
如何用 Python 连接 Twitter
原文:https://www.blog.pythonlibrary.org/2014/09/26/how-to-connect-to-twitter-with-python/
有几个第三方包包装了 Twitter 的 API。我们将关注 tweepy 和 T2 的 twitter。tweepy 文档比 twitter 的更广泛一些,但是我觉得 twitter 包有更多具体的例子。让我们花一些时间来看看如何使用这些软件包!
入门指南
要开始使用 Twitter 的 API,您需要创建一个 Twitter 应用程序。为此,你必须去他们的开发者网站创建一个新的应用程序。创建应用程序后,您将需要获得您的 API 密钥(或者生成一些)。您还需要生成您的访问令牌。
因为 Python 中没有包含这两个包,所以您也需要安装它们。要安装 tweepy,只需执行以下操作:
pip install tweepy
要安装 twitter,你可以做同样的事情:
pip install twitter
现在你应该准备好出发了!
发布状态更新
你应该能够用这些包做的一个基本事情是在你的 Twitter 账户上发布一个更新。让我们看看这两个软件包在这方面是如何工作的。我们从十二层开始。
import tweepy
auth = tweepy.OAuthHandler(key, secret)
auth.set_access_token(token, token_secret)
client = tweepy.API(auth)
client.update_status("#Python Rocks!")
嗯,这是相当直截了当的。我们必须用我们的密钥创建一个 OAuth 处理程序,然后设置访问令牌。最后,我们创建了一个表示 Twitter API 的对象,并更新了状态。这个方法对我很有效。现在让我们看看我们是否能让 twitter 包工作。
import twitter
auth=twitter.OAuth(token, token_secret, key, secret)
client = twitter.Twitter(auth=auth)
client.statuses.update(status="#Python Rocks!")
这段代码也非常简单。事实上,我认为 twitter 包的 OAuth 实现比 tweepy 的更干净。
注意:我在使用 twitter 包时有时会得到以下错误:错误的认证数据,代码 215 。我不完全确定为什么当你查找这个错误时,它应该是因为你使用 Twitter 的旧 API 而引起的。如果是这样的话,那么它就永远不会起作用。
接下来,我们将看看如何获得我们的时间线。
获取时间线
在这两个包中获得你自己的 Twitter 时间表真的很容易。让我们来看看 tweepy 的实现:
import tweepy
auth = tweepy.OAuthHandler(key, secret)
auth.set_access_token(token, token_secret)
client = tweepy.API(auth)
timeline = client.home_timeline()
for item in timeline:
text = "%s says '%s'" % (item.user.screen_name, item.text)
print text
所以在这里我们得到认证,然后我们调用 home_timeline() 方法。这将返回一个对象的 iterable,我们可以循环遍历这些对象并从中提取各种数据。在这种情况下,我们只提取屏幕名称和 Tweet 的文本。让我们看看 twitter 包是如何做到这一点的:
import twitter
auth=twitter.OAuth(token, token_secret, key, secret)
client = twitter.Twitter(auth=auth)
timeline = client.statuses.home_timeline()
for item in timeline:
text = "%s says '%s'" % (item["user"]["screen_name"],
item["text"])
print text
twitter 包非常相似。主要区别在于它返回一个字典列表。
如果你想得到别人的时间线。在十二岁时,你会这样做:
import tweepy
auth = tweepy.OAuthHandler(key, secret)
auth.set_access_token(token, token_secret)
client = tweepy.API(auth)
user = client.get_user(screen_name='pydanny')
timeline = user.timeline()
twitter 包有点不同:
import twitter
auth=twitter.OAuth(token, token_secret, key, secret)
client = twitter.Twitter(auth=auth)
user_timeline = client.statuses.user_timeline(screen_name='pydanny')
在这种情况下,我认为 twitter 包更干净一些,尽管有人可能会说 tweepy 的实现更直观。
让你的朋友和追随者
几乎每个人在 Tritter 上都有朋友(他们追随的人)和追随者。在本节中,我们将了解如何访问这些项目。twitter 包并没有一个很好的例子来寻找你的 Twitter 朋友和追随者,所以在这一节我们将只关注 tweepy。
import tweepy
auth = tweepy.OAuthHandler(key, secret)
auth.set_access_token(token, token_secret)
client = tweepy.API(auth)
friends = client.friends()
for friend in friends:
print friend.name
如果您运行上面的代码,您会注意到它打印出来的最大朋友数是 20。如果你想打印出你所有的朋友,那么你需要使用光标。使用光标有两种方式。您可以使用它来返回页面或特定数量的项目。在我的例子中,我关注了 32 个人,所以我选择了 items 的工作方式:
for friend in tweepy.Cursor(client.friends).items(200):
print friend.name
这段代码将迭代多达 200 项。如果你有很多朋友或者你想迭代别人的朋友,但是不知道他们有多少,那么使用 pages 方法更有意义。让我们来看看这可能是如何工作的:
for page in tweepy.Cursor(client.friends).pages():
for friend in page:
print friend.name
这很简单。获取您的关注者列表完全相同:
followers = client.followers()
for follower in followers:
print follower.name
这也将只返回 20 个项目。我有很多追随者,所以如果我想获得他们的列表,我必须使用上面提到的光标方法之一。
包扎
这些包提供了比本文所涵盖的更多的功能。我特别推荐看 tweepy,因为使用 Python 的自省工具比 twitter 包更直观、更容易理解。如果你还没有一堆这样的应用程序,你可以很容易地使用 tweepy,并围绕它创建一个用户界面,让你与你的朋友保持同步。另一方面,对于初学者来说,这仍然是一个很好的程序。
附加阅读
如何用 Python 和熊猫把 CSV 转换成 Excel(视频)
了解如何使用 Python 和 pandas 包,使用 3 行代码将 CSV 文件转换为 Excel 文件!
还演示了当出现问题时如何修复问题!
https://www.youtube.com/embed/bXjoQuf9xMY?feature=oembed
如何用 Python 将十进制数转换成单词
原文:https://www.blog.pythonlibrary.org/2012/06/02/how-to-convert-decimal-numbers-to-words-with-python/
将这篇文章命名为“如何将浮点数转换成单词”可能是一个更好的主意,但是因为我谈论的是货币,所以我认为使用十进制更准确。总之,几年前,我写过关于如何将数字转换成 Python。我重提这个话题的主要原因是因为我最终需要再做一次,我发现我自己的例子相当缺乏。它没有展示如何实际使用它将类似“10.12”的东西转换为“十美元十二美分”。因此,我将在本文中向您展示如何做到这一点,然后我们还将看看我的读者给我的一些替代方案。
从头再来
首先,我们将获取原始代码,并在最后添加一些测试,以确保它按照我们想要的方式工作。然后我会告诉你一个稍微不同的方法。最后,我们将看看另外两个试图做这类事情的项目。
'''Convert number to English words
$./num2eng.py 1411893848129211
one quadrillion, four hundred and eleven trillion, eight hundred and ninety
three billion, eight hundred and forty eight million, one hundred and twenty
nine thousand, two hundred and eleven
$
Algorithm from http://mini.net/tcl/591
'''
# modified to exclude the "and" between hundreds and tens - mld
__author__ = 'Miki Tebeka '
__version__ = '$Revision: 7281 $'
# $Source$
import math
# Tokens from 1000 and up
_PRONOUNCE = [
'vigintillion',
'novemdecillion',
'octodecillion',
'septendecillion',
'sexdecillion',
'quindecillion',
'quattuordecillion',
'tredecillion',
'duodecillion',
'undecillion',
'decillion',
'nonillion',
'octillion',
'septillion',
'sextillion',
'quintillion',
'quadrillion',
'trillion',
'billion',
'million',
'thousand',
''
]
# Tokens up to 90
_SMALL = {
'0' : '',
'1' : 'one',
'2' : 'two',
'3' : 'three',
'4' : 'four',
'5' : 'five',
'6' : 'six',
'7' : 'seven',
'8' : 'eight',
'9' : 'nine',
'10' : 'ten',
'11' : 'eleven',
'12' : 'twelve',
'13' : 'thirteen',
'14' : 'fourteen',
'15' : 'fifteen',
'16' : 'sixteen',
'17' : 'seventeen',
'18' : 'eighteen',
'19' : 'nineteen',
'20' : 'twenty',
'30' : 'thirty',
'40' : 'forty',
'50' : 'fifty',
'60' : 'sixty',
'70' : 'seventy',
'80' : 'eighty',
'90' : 'ninety'
}
def get_num(num):
'''Get token <= 90, return '' if not matched'''
return _SMALL.get(num, '')
def triplets(l):
'''Split list to triplets. Pad last one with '' if needed'''
res = []
for i in range(int(math.ceil(len(l) / 3.0))):
sect = l[i * 3 : (i + 1) * 3]
if len(sect) < 3: # Pad last section
sect += [''] * (3 - len(sect))
res.append(sect)
return res
def norm_num(num):
"""Normelize number (remove 0's prefix). Return number and string"""
n = int(num)
return n, str(n)
def small2eng(num):
'''English representation of a number <= 999'''
n, num = norm_num(num)
hundred = ''
ten = ''
if len(num) == 3: # Got hundreds
hundred = get_num(num[0]) + ' hundred'
num = num[1:]
n, num = norm_num(num)
if (n > 20) and (n != (n / 10 * 10)): # Got ones
tens = get_num(num[0] + '0')
ones = get_num(num[1])
ten = tens + ' ' + ones
else:
ten = get_num(num)
if hundred and ten:
return hundred + ' ' + ten
#return hundred + ' and ' + ten
else: # One of the below is empty
return hundred + ten
def num2eng(num):
'''English representation of a number'''
num = str(long(num)) # Convert to string, throw if bad number
if (len(num) / 3 >= len(_PRONOUNCE)): # Sanity check
raise ValueError('Number too big')
if num == '0': # Zero is a special case
return 'zero '
# Create reversed list
x = list(num)
x.reverse()
pron = [] # Result accumolator
ct = len(_PRONOUNCE) - 1 # Current index
for a, b, c in triplets(x): # Work on triplets
p = small2eng(c + b + a)
if p:
pron.append(p + ' ' + _PRONOUNCE[ct])
ct -= 1
# Create result
pron.reverse()
return ', '.join(pron)
if __name__ == '__main__':
numbers = [1.37, 0.07, 123456.00, 987654.33]
for number in numbers:
dollars, cents = [int(num) for num in str(number).split(".")]
dollars = num2eng(dollars)
if dollars.strip() == "one":
dollars = dollars + "dollar and "
else:
dollars = dollars + "dollars and "
cents = num2eng(cents) + "cents"
print dollars + cents
我们只关注测试程序的最后一部分。这里我们有一个列表,列出了我们在程序中运行的各种值,并确保它输出了我们想要的。请注意,我们有不到一美元的金额。这是我见过的一个边缘案例,因为我的雇主想用真实金额测试我们的代码,但不希望转移巨额资金。以下是一种略有不同的数据输出方式:
temp_amount = 10.34
if '.' in temp_amount:
amount = temp_amount.split('.')
dollars = amount[0]
cents = amount[1]
else:
dollars = temp_amount
cents = '00'
amt = num2eng.num2eng(dollars)
total = amt + 'and %s/100 Dollars' % cents
print total
在这种情况下,我们不把美分部分写成单词,而只是把数字写在一百以上。是的,我知道这很微妙,但这篇文章对我来说也是一个大脑垃圾场,所以下次我必须这样做时,我会在我的指尖上有所有的信息。
试用 PyNum2Word
在我发布了我的原创文章后,有人过来告诉我关于 PyNum2Word 项目的事情,以及我应该如何使用它。PyNum2Word 项目当时还不存在,但我决定这次尝试一下。遗憾的是,这个项目没有我能找到的文档。连一个自述文件都没有!另一方面,它声称可以为美国、德国、英国、欧盟和法国做货币。我以为德国、英国和法国都在欧盟,所以我不知道在他们现在都使用欧元的情况下,使用法郎等货币有什么意义。
无论如何,在我们的例子中,我们将使用下面的文件, num2word_EN.py ,来自他们的测试包。文件底部实际上有一个测试,与我构建的测试相似。事实上我的测试是基于他们的。让我们试着编辑这个文件,在他们的第二个列表中添加一个小于 1 的数字,比如 0.45 ,看看这是否可行。下面是第二个列表的输出结果(为了简洁,我跳过了第一个列表的输出):
0.45 is zero point four five cents 0.45 is zero point four five 1 is one cent 1 is one 120 is one dollar and twenty cents 120 is one hundred and twenty 1000 is ten dollars 1000 is one thousand 1120 is eleven dollars and twenty cents 1120 is eleven hundred and twenty 1800 is eighteen dollars 1800 is eighteen hundred 1976 is nineteen dollars and seventy-six cents 1976 is nineteen hundred and seventy-six 2000 is twenty dollars 2000 is two thousand 2010 is twenty dollars and ten cents 2010 is two thousand and ten 2099 is twenty dollars and ninety-nine cents 2099 is two thousand and ninety-nine 2171 is twenty-one dollars and seventy-one cents 2171 is twenty-one hundred and seventy-one
它起作用了,但不是以我期望的方式。在美国,当我们谈论货币时,我们会称0.45“45 美分”而不是“0.45 美分”。当我研究这个的时候,我确实了解到其他一些国家的人们确实使用后一种术语。我觉得有趣的是,这个模块接受任何高于 100 的东西,并将其分为美元和美分。例如,注意 120 被翻译成“一美元二十美分”而不是“一百二十美元”。还要注意,上面写的是“二十美分”,不是“零点二零美分”。我不知道如何解释这种矛盾。如果你给它传递一个小于 100 的整数,它就能工作。因此,如果您让用户放入一个 float,您会希望像我前面所做的那样分解它:
if '.' in temp_amount:
amount = temp_amount.split('.')
dollars = amount[0]
cents = amount[1]
else:
dollars = temp_amount
cents = '00'
然后通过脚本传递每个部分以获得片段,然后将它们放在一起。
使用数字. py
我的另一个名叫埃里克·沃尔德的读者联系了我关于他的数字. py 脚本。让我们看看这是怎么回事!
看一下代码,你会很快发现它不能处理 float,所以我们必须分解我们的 float 并分别传递美元和美分。我用几个不同的数字试了一下,似乎可以正确地转换它们。该脚本甚至在千位标记处添加了逗号。它没有在任何地方添加“和”字,但我现在不关心这个。
结论
所有这三种方法都需要某种包装器来添加“美元”和“美分”(或数字/100)单词,并将浮点数分成两部分。我认为 Eric 的代码非常简单,也是最好的文档。PyNum2Word 项目的代码也非常简洁,并且运行良好,但是没有文档。我很久以前找到的解决方案也能工作,但是我发现代码非常难看,不太容易阅读。我真的没有推荐,但我想我最喜欢埃里克的。如果你需要做多币种的灵活性,那么 PyNum2Word 项目值得一看。
如何用 Python 和 Pillow 把图片转换成 pdf(视频)
在 Mike Driscoll 的最新视频教程中,学习如何使用 Python 编程语言和 Pillow 包将一张或多张照片转换为 PDF!
https://www.youtube.com/embed/KDs5YMo011I?feature=oembed
在 Mike 的书中了解更多关于使用 Python 处理 pdf 的信息:
- ReportLab - 用 Python 处理 PDF
想进一步了解 Python 和 Pillow 的图像处理吗?看看迈克的书:
如何使用 argparse 创建命令行应用程序
当你创建一个应用程序时,你通常会希望能够告诉你的应用程序如何去做一些事情。有两种流行的方法来完成这项任务。您可以让您的应用程序接受命令行参数,也可以创建一个图形用户界面。有些应用程序两者都支持。
当您需要在服务器上运行代码时,命令行界面非常有用。大多数服务器没有连接监视器,尤其是如果它们是 Linux 服务器。在这些情况下,即使您想运行图形用户界面,也可能无法运行。
Python 附带了一个名为argparse的内置库,可以用来创建命令行界面。在本文中,您将了解以下内容:
- Parsing Arguments
- Creating Helpful Messages
- Adding Aliases
- Using Mutually Exclusive Arguments
- Creating a Simple Search Utility
argparse模块的内容远不止本文将介绍的内容。如果你想了解更多,你可以查看一下文档。
现在是时候开始从命令行解析参数了!
解析参数
在学习如何使用argparse之前,最好知道还有另一种方法可以将参数传递给 Python 脚本。您可以向 Python 脚本传递任何参数,并通过使用sys模块来访问这些参数。
要查看它是如何工作的,创建一个名为sys_args.py的文件,并在其中输入以下代码:
# sys_args.py
import sys
def main():
print('You passed the following arguments:')
print(sys.argv)
if __name__ == '__main__':
main()
这段代码导入sys并打印出sys.argv中的内容。argv属性包含传递给脚本的所有内容的列表,第一项是脚本本身。
下面是一个示例,说明了在运行这段代码和几个示例参数时会发生什么:
$ python3 sys_args.py --s 45
You passed the following arguments:
['sys_args.py', '--s', '45']
使用sys.argv的问题是您无法控制可以传递给应用程序的参数:
- You can't ignore arguments
- You can't create default arguments
- You can't really tell what is a valid argument at all
这就是为什么在使用 Python 的标准库时使用argparse是正确的方法。argparse模块非常强大和有用。让我们考虑命令行应用程序遵循的一个常见过程:
- pass in a file
- do something to that file in your program
- output the result
这是一个如何工作的一般例子。继续创建file_parser.py并添加以下代码:
# file_parser.py
import argparse
def file_parser(input_file, output_file=''):
print(f'Processing {input_file}')
print('Finished processing')
if output_file:
print(f'Creating {output_file}')
def main():
parser = argparse.ArgumentParser('File parser')
parser.add_argument('--infile', help='Input file')
parser.add_argument('--out', help='Output file')
args = parser.parse_args()
if args.infile:
file_parser(args.infile, args.out)
if __name__ == '__main__':
main()
file_parser()函数是解析的逻辑所在。对于这个例子,它只接受一个文件名并打印出来。output_file参数默认为空字符串。
尽管如此,这个项目的核心仍在main()中。在这里,您创建了一个argparse.ArgumentParser()的实例,并为您的解析器命名。然后你添加两个参数,--infile和--out。要使用解析器,您需要调用parse_args(),它将返回传递给程序的任何有效参数。最后,检查用户是否使用了--infile标志。如果是,那么你运行file_parser()。
以下是您在终端中运行代码的方式:
$ python file_parser.py --infile something.txt
Processing something.txt
Finished processing
在这里,您使用带有文件名的--infile标志运行您的脚本。这将运行main(),而 T1 又调用file_parser()。
下一步是使用您在代码中声明的两个命令行参数来尝试您的应用程序:
$ python file_parser.py --infile something.txt --out output.txt
Processing something.txt
Finished processing
Creating output.txt
这一次,您会得到一行额外的输出,其中提到了输出文件名。这代表了代码逻辑中的一个分支。当指定输出文件时,可以使用新的代码块或函数让代码经历生成该文件的过程。如果不指定输出文件,那么该代码块将不会运行。
当你使用argparse创建你的命令行工具时,当你的用户不确定如何正确地与你的程序交互时,你可以很容易地添加信息来帮助他们。
现在是时候了解如何从您的应用程序中获得帮助了!
创建有用的信息
argparse库将使用您在创建每个参数时提供的信息,自动为您的应用程序创建一条有用的消息。下面是您的代码:
# file_parser.py
import argparse
def file_parser(input_file, output_file=''):
print(f'Processing {input_file}')
print('Finished processing')
if output_file:
print(f'Creating {output_file}')
def main():
parser = argparse.ArgumentParser('File parser')
parser.add_argument('--infile', help='Input file')
parser.add_argument('--out', help='Output file')
args = parser.parse_args()
if args.infile:
file_parser(args.infile, args.out)
if __name__ == '__main__':
main()
现在尝试运行带有-h标志的代码,您应该看到以下内容:
$ file_parser.py -h
usage: File parser [-h] [--infile INFILE] [--out OUT]
optional arguments:
-h, --help show this help message and exit
--infile INFILE Input file
--out OUT Output file
add_argument()的help参数用于创建上面的帮助消息。-h和--help选项由argparse自动添加。你可以通过给你的帮助加上一个description和一个epilog来增加它的信息量。
让我们使用它们来改进您的帮助信息。首先将上面的代码复制到一个名为file_parser_with_description.py的新文件中,然后将其修改为如下所示:
# file_parser_with_description.py
import argparse
def file_parser(input_file, output_file=''):
print(f'Processing {input_file}')
print('Finished processing')
if output_file:
print(f'Creating {output_file}')
def main():
parser = argparse.ArgumentParser(
'File parser',
description='PyParse - The File Processor',
epilog='Thank you for choosing PyParse!',
)
parser.add_argument('--infile', help='Input file for conversion')
parser.add_argument('--out', help='Converted output file')
args = parser.parse_args()
if args.infile:
file_parser(args.infile, args.out)
if __name__ == '__main__':
main()
在这里,您将description和epilog参数传递给ArgumentParser。您还可以将help参数更新为add_argument(),使其更具描述性。
在进行这些更改后,当您使用-h或--help运行这个脚本时,您将看到以下输出:
$ python file_parser_with_description.py -h
usage: File parser [-h] [--infile INFILE] [--out OUT]
PyParse - The File Processor
optional arguments:
-h, --help show this help message and exit
--infile INFILE Input file for conversion
--out OUT Converted output file
Thank you for choosing PyParse!
现在,您可以在帮助输出中看到新的描述和附录。这让您的命令行应用程序更加完美。
您也可以通过add_help到ArgumentParser的参数来完全禁用应用程序中的帮助。如果您认为您的帮助文本过于冗长,您可以像这样禁用它:
# file_parser_no_help.py
import argparse
def file_parser(input_file, output_file=''):
print(f'Processing {input_file}')
print('Finished processing')
if output_file:
print(f'Creating {output_file}')
def main():
parser = argparse.ArgumentParser(
'File parser',
description='PyParse - The File Processor',
epilog='Thank you for choosing PyParse!',
add_help=False,
)
parser.add_argument('--infile', help='Input file for conversion')
parser.add_argument('--out', help='Converted output file')
args = parser.parse_args()
if args.infile:
file_parser(args.infile, args.out)
if __name__ == '__main__':
main()
通过将add_help设置为False,可以禁用-h和--help标志。
You can see this demonstrated below:
$ python file_parser_no_help.py --help
usage: File parser [--infile INFILE] [--out OUT]
File parser: error: unrecognized arguments: --help
In the next section, you'll learn about adding aliases to your arguments!
Adding Aliases
An alias is a fancy word for using an alternate flag that does the same thing. For example, you learned that you can use both -h and --help to access your program's help message. -h is an alias for --help, and vice-versa
Look for the changes in the parser.add_argument() methods inside of main():
# file_parser_aliases.py
import argparse
def file_parser(input_file, output_file=''):
print(f'Processing {input_file}')
print('Finished processing')
if output_file:
print(f'Creating {output_file}')
def main():
parser = argparse.ArgumentParser(
'File parser',
description='PyParse - The File Processor',
epilog='Thank you for choosing PyParse!',
add_help=False,
)
parser.add_argument('-i', '--infile', help='Input file for conversion')
parser.add_argument('-o', '--out', help='Converted output file')
args = parser.parse_args()
if args.infile:
file_parser(args.infile, args.out)
if __name__ == '__main__':
main()
Here you change the first add_argument() to accept -i in addition to --infile and you also added -o to the second add_argument(). This allows you to run your code using two new shortcut flags.
Here's an example:
$ python3 file_parser_aliases.py -i something.txt -o output.txt
Processing something.txt
Finished processing
Creating output.txt
If you go looking through the argparse documentation, you will find that you can add aliases to subparsers too. A subparser is a way to create sub-commands in your application so that it can do other things. A good example is Docker, a virtualization or container application. It has a series of commands that you can run under docker as well as docker compose and more. Each of these commands has separate sub-commands that you can use.
Here is a typical docker command to run a container:
docker exec -it container_name bash
This will launch a container with docker. Whereas if you were to use docker compose, you would use a different set of commands. The exec and compose are examples of subparsers.
The topic of subparsers are outside the scope of this tutorial. If you are interested in more details dive right into the documentation.
Using Mutually Exclusive Arguments
Sometimes you need to have your application accept some arguments but not others. For example, you might want to limit your application so that it can only create or delete files, but not both at once.
The argparse module provides the add_mutually_exclusive_group() method that does just that!
Change your two arguments to be mutually exclusive by adding them to a group object like in the example below:
# file_parser_exclusive.py
import argparse
def file_parser(input_file, output_file=''):
print(f'Processing {input_file}')
print('Finished processing')
if output_file:
print(f'Creating {output_file}')
def main():
parser = argparse.ArgumentParser(
'File parser',
description='PyParse - The File Processor',
epilog='Thank you for choosing PyParse!',
add_help=False,
)
group = parser.add_mutually_exclusive_group()
group.add_argument('-i', '--infile', help='Input file for conversion')
group.add_argument('-o', '--out', help='Converted output file')
args = parser.parse_args()
if args.infile:
file_parser(args.infile, args.out)
if __name__ == '__main__':
main()
First, you created a mutually exclusive group. Then, you added the -i and -o arguments to the group instead of to the parser object. Now these two arguments are mutually exclusive.
Here is what happens when you try to run your code with both arguments:
$ python3 file_parser_exclusive.py -i something.txt -o output.txt
usage: File parser [-i INFILE | -o OUT]
File parser: error: argument -o/--out: not allowed with argument -i/--infile
Running your code with both arguments causes your parser to show the user an error message that explains what they did wrong.
After covering all this information related to using argparse, you are ready to apply your new skills to create a simple search tool!
Creating a Simple Search Utility
Before starting to create an application, it is always good to figure out what you are trying to accomplish. The application you want to build in this section should be able to search for files of a specific file type. To make it more interesting, you can add an additional argument that allows you to optionally search for specific file sizes as well.
You can use Python's glob module for searching for file types. You can read all about this module here:
There is also the fnmatch module, which glob itself uses. You should use glob for now as it is easier to use, but if you're interested in writing something more specialized, then fnmatch may be what you are looking for.
However, since you want to be able to optionally filter the files returned by the file size, you can use pathlib which includes a glob-like interface. The glob module itself does not provide file size information.
You can start by creating a file named pysearch.py and entering the following code:
# pysearch.py
import argparse
import pathlib
def search_folder(path, extension, file_size=None):
"""
Search folder for files
"""
folder = pathlib.Path(path)
files = list(folder.rglob(f'*.{extension}'))
if not files:
print(f'No files found with {extension=}')
return
if file_size is not None:
files = [
f
for f in files
if f.stat().st_size >= file_size
]
print(f'{len(files)} *.{extension} files found:')
for file_path in files:
print(file_path)
You start the code snippet above by importing argparse and pathlib. Next you create the search_folder() function which takes in three arguments:
path- The folder to search withinextension- The file extension to look forfile_size- What file size to filter on in bytes
You turn the path into a pathlib.Path object and then use its rglob() method to search in the folder for the extension that the user passed in. If no files are found, you print out a meaningful message to the user and exit.
If any files are found, you check to see whether file_size has been set. If it was set, you use a list comprehension to filter out the files that are smaller than the specified file_size.
Next, you print out the number of files that were found and finally loop over these files to print out their names.
To make this all work correctly, you need to create a command-line interface. You can do that by adding a main() function that contains your argparse code like this:
def main():
parser = argparse.ArgumentParser(
'PySearch',
description='PySearch - The Python Powered File Searcher',
)
parser.add_argument('-p', '--path',
help='The path to search for files',
required=True,
dest='path')
parser.add_argument('-e', '--ext',
help='The extension to search for',
required=True,
dest='extension')
parser.add_argument('-s', '--size',
help='The file size to filter on in bytes',
type=int,
dest='size',
default=None)
args = parser.parse_args()
search_folder(args.path, args.extension, args.size)
if __name__ == '__main__':
main()
This ArgumentParser() has three arguments added to it that correspond to the arguments that you pass to search_folder(). You make the --path and --ext arguments required while leaving the --size argument optional. Note that the --size argument is set to type=int, which means that you cannot pass it a string.
There is a new argument to the add_argument() function. It is the dest argument which you use to tell your argument parser where to save the arguments that are passed to them.
Here is an example run of the script:
$ python3 pysearch.py -p /Users/michael/Dropbox/python101code/chapter32_argparse -e py -s 650
6 *.py files found:
/Users/michael/Dropbox/python101code/chapter32_argparse/file_parser_aliases2.py
/Users/michael/Dropbox/python101code/chapter32_argparse/pysearch.py
/Users/michael/Dropbox/python101code/chapter32_argparse/file_parser_aliases.py
/Users/michael/Dropbox/python101code/chapter32_argparse/file_parser_with_description.py
/Users/michael/Dropbox/python101code/chapter32_argparse/file_parser_exclusive.py
/Users/michael/Dropbox/python101code/chapter32_argparse/file_parser_no_help.py
That worked quite well! Now try running it with -s and a string:
$ python3 pysearch.py -p /Users/michael/Dropbox/python101code/chapter32_argparse -e py -s python
usage: PySearch [-h] -p PATH -e EXTENSION [-s SIZE]
PySearch: error: argument -s/--size: invalid int value: 'python'
This time, you received an error because -s and --size only accept integers. Go try this code on your own machine and see if it works the way you want when you use -s with an integer.
Here are some ideas you can use to improve your version of the code:
- Handle the extensions better. Right now it will accept
*.pywhich won't work the way you might expect - Update the code so you can search for multiple extensions at once
- Update the code to filter on a range of file sizes (Ex. 1 MB - 5MB)
There are lots of other features and enhancements you can add to this code, such as adding error handling or unittests.
Wrapping Up
The argparse module is full featured and can be used to create great, flexible command-line applications. In this chapter, you learned about the following:
- Parsing Arguments
- Creating Helpful Messages
- Adding Aliases
- Using Mutually Exclusive Arguments
- Creating a Simple Search Utility
You can do a lot more with the argparse module than what was covered in this chapter. Be sure to check out the documentation for full details. Now go ahead and give it a try yourself. You will find that once you get the hang of using argparse, you can create some really neat applications!
如何在 Python 中创建图像的差异
原文:https://www.blog.pythonlibrary.org/2016/10/11/how-to-create-a-diff-of-an-image-in-python/
在过去的几年里,我一直在为我的雇主编写自动化测试。我做的许多测试类型之一是比较应用程序如何绘制。它每次都是以同样的方式画的吗?如果不是,那么我们就有一个严重的问题。检查它每次都绘制相同图形的一个简单方法是截取一个屏幕截图,然后在应用程序更新时将其与同一图形的未来版本进行比较。
枕头库为这种叫做图像印章的东西提供了一个方便的工具。如果你还没有枕头,你应该现在就去安装它,这样你就可以跟随这个简短的教程。
比较两幅图像
我们需要做的第一件事是找到两幅略有不同的图像。你可以使用相机的连拍模式,拍摄一组动物移动的照片,最好是使用三脚架。或者你可以在一张现有的照片上添加某种覆盖,比如文字。我打算采用后一种方法。这是我在俄勒冈州摩特诺玛瀑布的原始照片:

这是修改后的版本,我添加了一些文字来标识照片的位置:

现在让我们使用 ImageChops 来找出我们的不同之处!
import Image
import ImageChops
def compare_images(path_one, path_two, diff_save_location):
"""
Compares to images and saves a diff image, if there
is a difference
@param: path_one: The path to the first image
@param: path_two: The path to the second image
"""
image_one = Image.open(path_one)
image_two = Image.open(path_two)
diff = ImageChops.difference(image_one, image_two)
if diff.getbbox():
diff.save(diff_save_location)
if __name__ == '__main__':
compare_images('/path/to/multnomah_falls.jpg',
'/path/to/multnomah_falls_text.jpg',
'/path/to/diff.jpg')
这里我们有一个简单的函数,我们可以用它来寻找图像中的差异。你需要做的就是通过三条路径!前两条路径用于我们想要比较的图像。最后一个路径是保存 diff 图像的位置,如果我们找到一个 diff。对于这个例子,我们肯定应该找到一个差异,我们做到了。下面是我运行这段代码时得到的结果:

包扎
枕头包有许多惊人的功能来处理图像。我喜欢摄影,所以能够拍摄照片,然后使用我最喜欢的编程语言来帮助我处理结果,这很有趣。你也应该尝试一下,看看枕头文档,看看这个聪明的包还能做什么!
相关阅读
- 蟒蛇枕官网
- 枕头文档
- 介绍 Python 图像库/ Pillow
如何用 Python 创建“不可变”的类
原文:https://www.blog.pythonlibrary.org/2014/01/17/how-to-create-immutable-classes-in-python/
我最近读了很多关于 Python 的神奇方法,最近还读了一些创建不可变类的方法。不可变类不允许程序员向实例添加属性(即猴子补丁)。如果我们实际上先看一个正常的类,会更容易理解一点。我们将从一个猴子补丁的例子开始,然后看一种使类“不可变”的方法。
猴子修补 Python 类
首先,我们需要创建一个可以玩的类。这里有一个简单的类,它不做任何事情:
########################################################################
class Mutable(object):
"""
A mutable class
"""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
pass
现在让我们创建这个类的一个实例,看看是否可以添加一个属性:
>>> mut_obj = Mutable()
>>> mut_obj.monkey = "tamarin"
>>> mut_obj.monkey
'tamarin'
这个类允许我们在运行时向它添加属性。现在我们知道了如何做一些简单的猴子补丁,让我们尝试阻止这种行为。
创建不可变的类
我读到的一个关于不可变类的例子提到,你可以通过用_ _ 插槽 __ 替换一个类的 dict 来创建一个不可变类。让我们看看这是什么样子:
########################################################################
class Immutable(object):
"""
An immutable class
"""
__slots__ = ["one", "two", "three"]
#----------------------------------------------------------------------
def __init__(self, one, two, three):
"""Constructor"""
super(Immutable, self).__setattr__("one", one)
super(Immutable, self).__setattr__("two", two)
super(Immutable, self).__setattr__("three", three)
#----------------------------------------------------------------------
def __setattr__(self, name, value):
""""""
msg = "'%s' has no attribute %s" % (self.__class__,
name)
raise AttributeError(msg)
现在我们只需要创建这个类的一个实例,看看我们是否可以用猴子来修补它:
>>> i = Immutable(1, 2, 3)
>>> i.four = 4
Traceback (most recent call last):
File "", line 1, in <fragment>AttributeError: 'Immutable' object has no attribute 'four'
在这种情况下,该类不允许我们对实例进行猴子修补。相反,我们收到一个 AttibuteError。让我们尝试更改其中一个属性:
>>> i = Immutable(1, 2, 3)
>>> i.one = 2
Traceback (most recent call last):
File "c:\Users\mdriscoll\Desktop\rep-fonts\immutable\immute_slots.py", line 1, in ########################################################################
File "c:\Users\mdriscoll\Desktop\rep-fonts\immutable\immute_slots.py", line 33, in __setattr__
raise AttributeError(msg)
AttributeError: '<class>' has no attribute one
这是因为我们已经覆盖了 setattr 方法。如果你想的话,你可以重写这个方法,什么都不做。这将阻止追溯的发生,但也防止值被更改。如果您喜欢明确说明正在发生的事情,那么提出一个错误可能是一种方法。
如果你读了一些关于插槽的书,你会很快发现不鼓励以这种方式使用插槽。为什么?因为槽主要是作为内存优化而创建的(它减少了属性访问时间)。
您可以通过以下链接了解更多关于插槽的信息:
- 关于插槽的 Python 文档
- stack overflow:python _ _ slots _ _
- 什么是插槽?
https://stackoverflow.com/questions/472000/python-slots
如何用 Python 裁剪照片
原文:https://www.blog.pythonlibrary.org/2017/10/03/how-to-crop-a-photo-with-python/
如果你喜欢拍照,你可能会发现自己会时不时地裁剪照片。我会裁剪照片,以消除背景噪音,或者更专注于我试图捕捉的主题。我也喜欢拍摄昆虫或其他小生物的高分辨率照片,然后进行裁剪,让我看起来比实际情况更接近昆虫。
现在大多数人会使用照片编辑应用程序来裁剪他们的图像,例如 Photoshop Elements。我也使用这些工具,但是你也可以使用 Python 编程语言来为你进行裁剪。一个您可能想要使用 Python 的好例子是,如果您有数千个相同类型的扫描图像,那么只需编写一个脚本来为您进行裁剪就更有意义了。
Python 中最流行的图像操作包是 Pillow 包,它是“Python 图像库(PIL)的友好分支”。您可以使用 pip 安装枕头:
pip install Pillow
现在我们已经安装了枕头,我们只需要一张照片。这是我拍的一只蚱蜢:

让我们编写一些代码,尝试将图片裁剪到蚱蜢的头部:
from PIL import Image
def crop(image_path, coords, saved_location):
"""
@param image_path: The path to the image to edit
@param coords: A tuple of x/y coordinates (x1, y1, x2, y2)
@param saved_location: Path to save the cropped image
"""
image_obj = Image.open(image_path)
cropped_image = image_obj.crop(coords)
cropped_image.save(saved_location)
cropped_image.show()
if __name__ == '__main__':
image = 'grasshopper.jpg'
crop(image, (161, 166, 706, 1050), 'cropped.jpg')
在这段代码中,我们做的第一件事是从 PIL 导入图像子模块。然后我们创建一个 crop() 函数,它有 3 个参数:
- image_path -要裁剪的文件的文件路径
- coords——一个 4 元素元组,包含图像裁剪的开始和结束坐标
- saved_location -保存裁剪文件的文件路径
在我们打开初始图像后,我们得到一个可以调用 crop() on 的对象。crop 方法获取我们传入的坐标,并适当地裁剪图像,然后返回第二个图像对象。然后我们调用第二个图像对象的 save() 方法,并告诉它将它保存到指定的位置。
当您运行代码时,它将显示裁剪后的图像并保存它:

这非常接近我想要的。您可以在上面的代码中对 x/y 坐标进行一点试验,尝试以各种方式裁剪图像,看看效果如何。
包扎
这段代码应该有一个检查,防止用户覆盖原始图像。任何好的照片编辑器都不会覆盖原始照片,因为那真的很烦人,而且通常是件坏事。但是我将把它留给读者去解决。
无论如何,Pillow 项目对于用 Python 处理图像来说是一个非常强大和有用的包。试一试,看看你能完成什么有趣的事情!
相关阅读
如何用 Python 和 functools 做一个简单的缓存(视频)
了解如何使用 Python 惊人的标准库为函数添加缓存。在本视频教程中,您将学习如何使用 functools.cache 为函数添加缓存
https://www.youtube.com/embed/CtpSBau84xg?feature=oembed
如果你想了解更多关于 functools 模块的信息,你可以看看我的另一个视频:
https://www.youtube.com/embed/gIVRaAb-XzA?feature=oembed
如何用 Python 下载文件(视频)
原文:https://www.blog.pythonlibrary.org/2020/06/18/how-to-download-a-file-with-python-video/
在本视频教程中,您将学习如何使用 Python 的 urllib 从互联网下载文件:
https://www.youtube.com/embed/dkGRWJD0oQ4?feature=oembed
如果你喜欢阅读而不是观看,那么你可以看看这个相关的教程:
- Python 101: 如何下载文件
|  | 你想了解更多关于 Python 的知识吗?
| 你想了解更多关于 Python 的知识吗?
Python 101 -第二版
在 Leanpub 上立即购买 |
如何将 jupiter 笔记本导出为其他格式
原文:https://www.blog.pythonlibrary.org/2018/10/09/how-to-export-jupyter-notebooks-into-other-formats/
使用 Jupyter Notebook 时,您会发现自己需要分发笔记本,而不是笔记本文件。最有可能的原因是,您希望将笔记本的内容共享给非技术用户,这些用户不想安装 Python 或使用笔记本所需的其他依赖项。将笔记本导出为其他格式的最流行的解决方案是内置的 nbconvert 工具。您可以使用 nbconvert 导出到以下格式:
- HTML ( -到 HTML)
- 乳胶(至乳胶)
- PDF ( -至 PDF)
- 显示 JS ( -到幻灯片)
- 降价(md)
- 重新构造的文本(rst)
- 可执行脚本(- to 脚本)
nbconvert 工具使用 Jinja 模板来转换您的笔记本文件()。ipynb )转换为其他静态格式。Jinja 是 Python 的模板引擎。nbconvert 工具依赖于 Pandoc 和 TeX 进行一些转换。您可能需要在您的计算机上单独安装这些软件。这在 ReadTheDocs 上有记录。
|  | 想了解更多关于使用 Jupyter 笔记本的信息吗?然后看看我的书:
| 想了解更多关于使用 Jupyter 笔记本的信息吗?然后看看我的书:
Jupyter 笔记型电脑 101
在 Leanpub 上立即购买 |
使用 nbconvert
我们首先需要的是一台想要转换的笔记本。我用一个 Jupyter 笔记本做了一个关于 Python decorators 的演示。我们将使用那一个。可以在 Github 上获取。如果你想使用其他的东西,请随意下载你最喜欢的笔记本。我还发现了这个有趣的笔记本图库,你也可以用它。
我们将使用的笔记本名为 Decorators.ipynb 。使用 nbconvert 导出的典型命令如下:
jupyter nbconvert --to
默认的输出格式是 HTML。但是让我们从尝试将 Decorators 笔记本转换成 PDF 开始:
jupyter nbconvert Decorators.ipynb --to pdf
我不会在每次运行 nbconvert 时都提到这一点,但是当我运行这个命令时,我在终端中得到以下输出:
[NbConvertApp] Converting notebook Decorators.ipynb to pdf
[NbConvertApp] Writing 45119 bytes to notebook.tex
[NbConvertApp] Building PDF
[NbConvertApp] Running xelatex 3 times: [u'xelatex', u'notebook.tex']
[NbConvertApp] Running bibtex 1 time: [u'bibtex', u'notebook']
[NbConvertApp] WARNING | bibtex had problems, most likely because there were no citations
[NbConvertApp] PDF successfully created
[NbConvertApp] Writing 62334 bytes to Decorators.pdf
当您将笔记本转换为其他格式时,您会看到类似的内容,尽管输出会明显不同。这是输出的样子:

如果您将笔记本转换为 reStructuredText 或 latex,那么 nbconvert 将使用封面下的 pandoc 进行转换。这意味着 pandoc 是一个依赖项,在转换成这些格式之前,您可能需要安装它。
让我们尝试将我们的笔记本电脑转换为 Markdown,看看我们会得到什么:
jupyter nbconvert Decorators.ipynb --to markdown
当您运行此命令时,您将得到如下所示的输出:

让我们对笔记本进行一次转换。对于这种转换,我们将把我们的笔记本变成 HTML。HTML 转换实际上有两种模式:
- -模板完整(默认)
- -模板基本
完整版将使笔记本的 HTML 呈现看起来非常像普通笔记本在其“交互式视图”中的样子,而基本版使用 HTML 标题,主要针对那些希望将笔记本嵌入网页或博客的人。让我们试一试:
jupyter nbconvert Decorators.ipynb --to html
当我运行这个程序时,我得到了一个很好的 HTML 文件。如果在 web 浏览器中打开 HTML,您应该会看到以下内容:

转换多个笔记本
nbconvert 实用程序还支持一次转换多个笔记本。如果您有一组名称相似的笔记本,您可以使用以下命令:
jupyter nbconvert notebook*.ipynb --to FORMAT
这将把文件夹中的所有笔记本转换为您指定的格式,只要笔记本以“Notebook”开头。您也可以只向 nbconvert 提供一个以空格分隔的笔记本列表:
jupyter nbconvert Decorators.ipynb my_other_notebook.ipynb --to FORMAT
如果您有许多笔记本,另一种批量转换它们的方法是创建一个 Python 脚本作为配置文件。根据此文档,您可以创建一个包含以下内容的 Python 脚本:
c = get_config()
c.NbConvertApp.notebooks = ["notebook1.ipynb", "notebook2.ipynb"]
如果保存该文件,则可以使用以下命令运行它:
jupyter nbconvert --config mycfg.py
这将把列出的笔记本转换成您选择的格式。
执行笔记本
正如您所料,大多数情况下,Jupyter 笔记本是在输出单元格被清除的情况下保存的。这意味着,当您运行转换时,您不会自动在导出中获得输出。要做到这一点,您必须使用 - execute 标志。这里有一个例子:
jupyter nbconvert --execute my_notebook.ipynb --to pdf
请注意,笔记本中的代码不能有任何错误,否则转换将会失败。这就是为什么我在这个例子中没有使用 Decorators 笔记本的原因,因为我有一些故意创建的单元格,但它们不能用于演示目的。
使用 Python 执行笔记本
您还可以创建一个 Python 脚本,用于以编程方式执行笔记本。让我们写一些代码来运行我的 Decorators 笔记本中的所有单元,包括抛出异常的单元。让我们创建一个空的 Python 脚本,并将其命名为 notebook_runner.py 。在编辑器中输入以下代码:
# notebook_runner.py
import nbformat
import os
from nbconvert.preprocessors import ExecutePreprocessor
def run_notebook(notebook_path):
nb_name, _ = os.path.splitext(os.path.basename(notebook_path))
dirname = os.path.dirname(notebook_path)
with open(notebook_path) as f:
nb = nbformat.read(f, as_version=4)
proc = ExecutePreprocessor(timeout=600, kernel_name='python3')
proc.allow_errors = True
proc.preprocess(nb, {'metadata': {'path': '/'}})
output_path = os.path.join(dirname, '{}_all_output.ipynb'.format(nb_name))
with open(output_path, mode='wt') as f:
nbformat.write(nb, f)
if __name__ == '__main__':
run_notebook('Decorators.ipynb')
感兴趣的第一项位于代码的顶部。这里我们从 nbconvert.preprocessors 导入 nbformat 和一个预处理器,称为execute preprocessors。接下来,我们创建一个名为 run_notebook 的函数,它接受一个指向我们想要运行的笔记本的路径。在这个函数中,我们从传入的路径中提取文件名和目录名。
然后我们使用 nbformat.read 读取笔记本文件。您会注意到,您可以告诉 nbformat 将文件读取为哪个版本。请务必将此设置为与您正在使用的 Jupyter 笔记本的版本相匹配。下一步是实例化 ExecutePreprocessor 类。这里我们给它一个超时和内核名。如果您使用的是 Python 之外的东西,那么这里就是您想要指定该信息的地方。
因为我们想忽略错误,我们将 allow_errors 属性设置为 True 。默认为假。如果我们没有这样做,我们将需要在一个 try/except 块中包装下一步。无论如何,我们告诉 Python 通过预处理方法调用进行预处理。您会注意到,我们需要传入我们读取的笔记本数据,并通过元数据字典告诉它笔记本的位置。如果您的路径不同于本例中使用的路径,请务必更新此信息。
最后,我们创建输出路径,并将笔记本写到一个新位置。如果您打开它,您应该看到所有实际产生输出的代码单元格的输出。
配置
nbconvert 实用程序有许多配置选项,您可以使用它们来自定义其工作方式。要了解完整的细节,我推荐阅读这里的文档。
包扎
在本文中,我们学习了如何将 Jupyter 笔记本导出/转换为其他格式,如 HTML、Markdown 和 PDF。我们还了解到,我们可以用几种不同的方式一次转换多台笔记本电脑。最后,我们学习了在导出笔记本之前执行它的不同方法。
- Jupyter 笔记本扩展基础知识
- 使用 Jupyter 笔记本创建演示文稿
如何用 Python 从 Jenkins 提取构建信息
原文:https://www.blog.pythonlibrary.org/2019/05/14/how-to-extract-build-info-from-jenkins-with-python/
我工作的一部分是使用持续集成软件。我在我的角色中同时使用 Hudson 和 Jenkins,偶尔需要以编程方式与他们进行交互。有两个 Python 包可用于此任务:
- Python Jenkins 包
- 詹金斯皮
Python Jenkins 包可以与 Hudson 和 Jenkins 一起工作,而 JenkinsAPI 只能与 Jenkins 一起工作。因为这个原因,我通常使用 Python Jenkins,尽管我最近开始寻找哪一个更适合工件,并且我发现 JenkinsAPI 实际上更适合这种事情。所以你需要根据你需要做什么来评估这两个包。
安装 Python Jenkins
为了遵循本文中的代码示例,您需要安装 Python Jenkins。您可以使用画中画来做到这一点:
pip install python-jenkins
现在已经安装好了,让我们试一试 Python Jenkins 吧!
从詹金斯那里得到所有的工作
一个常见的任务是需要获得构建系统中配置的所有作业的列表。
要开始,您需要登录到您的 Jenkins 服务器:
import jenkins
server = jenkins.Jenkins('http://server:port/', username='user',
password='secret')
现在您有了一个 Jenkins 对象,您可以使用它对您的 Jenkins CI 服务器执行 REST 请求。返回的结果通常是 Python 字典或字典的字典。
以下是获取 CI 系统上配置的所有作业的示例:
import jenkins
server = jenkins.Jenkins('http://server:port/', username='user',
password='secret')
# Get all builds
jobs = server.get_all_jobs(folder_depth=None)
for job in jobs:
print(job['fullname'])
这将遍历 Jenkins 中配置的所有作业,并打印出它们的作业名。
获取工作信息
现在您已经知道了 Jenkins box 上的作业名称,您可以获得关于每个作业的更详细的信息。
方法如下:
import jenkins
server = jenkins.Jenkins('http://server:port/', username='user',
password='secret')
# Get information on specific build job
# This returns all the builds that are currently shown in
# hudson for this job
info = server.get_job_info('job-name')
# Passed
print(info['lastCompletedBuild'])
# Unstable
print(info['lastUnstableBuild'])
# Failed
print(info['lastFailedBuild'])
get_job_info() will give you a lot of information about the job, including all the currently saved builds. It is nice to be able to extract which builds have passed, failed or are unstable.
获取构建信息
如果您想知道一个作业运行需要多长时间,那么您需要深入到构建级别。
让我们来看看如何实现:
import jenkins
server = jenkins.Jenkins('http://server:port/', username='user',
password='secret')
info = server.get_job_info('job-name')
# Loop over builds
builds = info['builds']
for build in builds:
for build in builds:
print(server.get_build_info('job-name',
build['number']))
要获取构建元数据,您需要调用get_build_info(). This method takes in the job name and the build number and returns the metadata as a dictionary.
包扎
使用 Python Jenkins 包可以做更多的事情。例如,您可以使用它来启动一个构建作业、创建一个新作业或删除一个旧作业以及许多其他事情。不幸的是,文档是非常粗略的,所以您必须做一些试验来让它按照您想要的方式工作。
附加阅读
如何用 Python 找到并列出所有正在运行的进程
前几天,我的任务是找到一种方法来获取 Windows XP 虚拟机上所有正在运行的进程的列表。我还应该包括每个进程使用了多少 CPU 和内存的信息。幸运的是,这不必是一个远程脚本,而是一个可以在客户机上运行的脚本。在到处搜索了一番后,我终于找到了解决办法。在这篇文章中,我们将看看一些拒绝以及最终的解决方案,这恰好是跨平台的工作。
我发现的第一批脚本之一是 2006 年 3 月的这个脚本:
# http://mail.python.org/pipermail/python-win32/2006-March/004340.html
import win32com.client
wmi=win32com.client.GetObject('winmgmts:')
for p in wmi.InstancesOf('win32_process'):
print p.Name, p.Properties_('ProcessId'), \
int(p.Properties_('UserModeTime').Value)+int(p.Properties_('KernelModeTime').Value)
children=wmi.ExecQuery('Select * from win32_process where ParentProcessId=%s' %p.Properties_('ProcessId'))
for child in children:
print '\t',child.Name,child.Properties_('ProcessId'), \
int(child.Properties_('UserModeTime').Value)+int(child.Properties_('KernelModeTime').Value)
这个脚本需要 PyWin32 包才能工作。然而,虽然这是一个方便的小脚本,但除了 ProcessId 之外,它没有显示我想要的任何内容。我并不真正关心用户或内核模式时间(即用户或内核的总 CPU 时间)。此外,我真的不喜欢使用 COM 的黑魔法,所以我最终拒绝了这个。
接下来是一个活动状态配方。看起来很有希望:
# http://code.activestate.com/recipes/303339-getting-process-information-on-windows/
import win32pdh, string, win32api
def procids():
#each instance is a process, you can have multiple processes w/same name
junk, instances = win32pdh.EnumObjectItems(None,None,'process', win32pdh.PERF_DETAIL_WIZARD)
proc_ids=[]
proc_dict={}
for instance in instances:
if instance in proc_dict:
proc_dict[instance] = proc_dict[instance] + 1
else:
proc_dict[instance]=0
for instance, max_instances in proc_dict.items():
for inum in xrange(max_instances+1):
hq = win32pdh.OpenQuery() # initializes the query handle
path = win32pdh.MakeCounterPath( (None,'process',instance, None, inum,'ID Process') )
counter_handle=win32pdh.AddCounter(hq, path)
win32pdh.CollectQueryData(hq) #collects data for the counter
type, val = win32pdh.GetFormattedCounterValue(counter_handle, win32pdh.PDH_FMT_LONG)
proc_ids.append((instance,str(val)))
win32pdh.CloseQuery(hq)
proc_ids.sort()
return proc_ids
print procids()
唉,虽然这也从我的 Windows 系统中获得了一个进程列表(以及 PID),但它没有给我任何关于 CPU 和内存利用率的信息。我认为如果我使用不同的计数器名称,这个方法可能会有效。我猜如果你愿意,你可以通过 MSDN 找到这些信息。我不想搞砸,所以我继续挖。
这个配方让我想到了下面这个基于 ctypes 的配方:
# http://code.activestate.com/recipes/305279/
"""
Enumerates active processes as seen under windows Task Manager on Win NT/2k/XP using PSAPI.dll
(new api for processes) and using ctypes.Use it as you please.
Based on information from http://support.microsoft.com/default.aspx?scid=KB;EN-US;Q175030&ID=KB;EN-US;Q175030
By Eric Koome
email ekoome@yahoo.com
license GPL
"""
from ctypes import *
#PSAPI.DLL
psapi = windll.psapi
#Kernel32.DLL
kernel = windll.kernel32
def EnumProcesses():
arr = c_ulong * 256
lpidProcess= arr()
cb = sizeof(lpidProcess)
cbNeeded = c_ulong()
hModule = c_ulong()
count = c_ulong()
modname = c_buffer(30)
PROCESS_QUERY_INFORMATION = 0x0400
PROCESS_VM_READ = 0x0010
#Call Enumprocesses to get hold of process id's
psapi.EnumProcesses(byref(lpidProcess),
cb,
byref(cbNeeded))
#Number of processes returned
nReturned = cbNeeded.value/sizeof(c_ulong())
pidProcess = [i for i in lpidProcess][:nReturned]
for pid in pidProcess:
#Get handle to the process based on PID
hProcess = kernel.OpenProcess(PROCESS_QUERY_INFORMATION | PROCESS_VM_READ,
False, pid)
if hProcess:
psapi.EnumProcessModules(hProcess, byref(hModule), sizeof(hModule), byref(count))
psapi.GetModuleBaseNameA(hProcess, hModule.value, modname, sizeof(modname))
print "".join([ i for i in modname if i != '\x00'])
#-- Clean up
for i in range(modname._length_):
modname[i]='\x00'
kernel.CloseHandle(hProcess)
if __name__ == '__main__':
EnumProcesses()
这看起来很聪明,但是我很不擅长解析 ctypes。这是我想学的东西,但是我有一个截止日期,该死的!另外,这个程序只显示了正在运行的进程列表,但没有关于它们的信息。幸运的是,作者附上了参考文献,但我决定继续寻找。
接下来,我发现了一个关于使用蒂姆·戈登的便捷的 WMI 模块来做这类事情的帖子(下面是从该帖子直接复制的):
# http://mail.python.org/pipermail/python-win32/2003-December/001482.html
>>> processes = WMI.InstancesOf('Win32_Process')
>>> len(processes)
41
>>> [process.Properties_('Name').Value for process in processes] # get
the process names
[u'System Idle Process', u'System', u'SMSS.EXE', u'CSRSS.EXE',
u'WINLOGON.EXE', u'SERVICES.EXE', u'LSASS.EXE', u'SVCHOST.EXE',
u'SVCHOST.EXE', u'SVCHOST.EXE', u'SVCHOST.EXE', u'SPOOLSV.EXE',
u'ati2evxx.exe', u'BAsfIpM.exe', u'defwatch.exe', u'inetinfo.exe',
u'mdm.exe', u'rtvscan.exe', u'SCARDSVR.EXE', u'WLTRYSVC.EXE',
u'BCMWLTRY.EXE', u'EXPLORER.EXE', u'Apoint.exe', u'carpserv.exe',
u'atiptaxx.exe', u'quickset.exe', u'DSentry.exe', u'Directcd.exe',
u'vptray.exe', u'ApntEx.exe', u'FaxCtrl.exe', u'digstream.exe',
u'CTFMON.EXE', u'wuauclt.exe', u'IEXPLORE.EXE', u'Pythonwin.exe',
u'MMC.EXE', u'OUTLOOK.EXE', u'LineMgr.exe', u'SAPISVR.EXE',
u'WMIPRVSE.EXE']
Here is how to get a single process and get its PID.
>>> p = WMI.ExecQuery('select * from Win32_Process where
Name="Pythonwin.exe"')
>>> [prop.Name for prop in p[0].Properties_] # let's look at all the
process property names
[u'Caption', u'CommandLine', u'CreationClassName', u'CreationDate',
u'CSCreationClassName', u'CSName', u'Description', u'ExecutablePath',
u'ExecutionState', u'Handle', u'HandleCount', u'InstallDate',
u'KernelModeTime', u'MaximumWorkingSetSize', u'MinimumWorkingSetSize',
u'Name', u'OSCreationClassName', u'OSName', u'OtherOperationCount',
u'OtherTransferCount', u'PageFaults', u'PageFileUsage',
u'ParentProcessId', u'PeakPageFileUsage', u'PeakVirtualSize',
u'PeakWorkingSetSize', u'Priority', u'PrivatePageCount', u'ProcessId',
u'QuotaNonPagedPoolUsage', u'QuotaPagedPoolUsage',
u'QuotaPeakNonPagedPoolUsage', u'QuotaPeakPagedPoolUsage',
u'ReadOperationCount', u'ReadTransferCount', u'SessionId', u'Status',
u'TerminationDate', u'ThreadCount', u'UserModeTime', u'VirtualSize',
u'WindowsVersion', u'WorkingSetSize', u'WriteOperationCount',
u'WriteTransferCount']
>>> p[0].Properties_('ProcessId').Value # get our ProcessId
928
这是一些很酷的东西,我在其他代码中使用了 Golden 的模块。然而,我仍然不确定使用哪个柜台来获取我的信息。我以为这些东西大部分都是为我编码的。好吧,结果是有一个软件包完全满足了我的需求,它可以在所有三个主要平台上运行!太神奇了!
跨平台解决方案!
这个包的名字是 psutil ,这是我决定使用的。这是我最后得到的结果:
import os
import psutil
import time
logPath = r'some\path\proclogs'
if not os.path.exists(logPath):
os.mkdir(logPath)
separator = "-" * 80
format = "%7s %7s %12s %12s %30s, %s"
format2 = "%7.4f %7.2f %12s %12s %30s, %s"
while 1:
procs = psutil.get_process_list()
procs = sorted(procs, key=lambda proc: proc.name)
logPath = r'some\path\proclogs\procLog%i.log' % int(time.time())
f = open(logPath, 'w')
f.write(separator + "\n")
f.write(time.ctime() + "\n")
f.write(format % ("%CPU", "%MEM", "VMS", "RSS", "NAME", "PATH"))
f.write("\n")
for proc in procs:
cpu_percent = proc.get_cpu_percent()
mem_percent = proc.get_memory_percent()
rss, vms = proc.get_memory_info()
rss = str(rss)
vms = str(vms)
name = proc.name
path = proc.path
f.write(format2 % (cpu_percent, mem_percent, vms, rss, name, path))
f.write("\n\n")
f.close()
print "Finished log update!"
time.sleep(300)
print "writing new log data!"
是的,这是一个无限循环,是的,这通常是一件非常糟糕的事情(除了在 GUI 编程中)。然而,出于我的目的,我需要一种方法来每隔 5 分钟左右检查用户的进程,看看是什么导致机器行为如此怪异。因此,脚本需要永远运行,并将结果记录到唯一命名的文件中。这就是这个脚本所做的一切,还有一点格式化的魔力。你觉得合适就随意用或不用。
我希望这些资料对你有所帮助。希望它能让你省去我所有的挖掘工作!
注意:虽然最后一个脚本似乎在 Windows XP 上工作得很好,但在 Windows 7 32 和 64 位上,您将得到一个“拒绝访问”的回溯,我怀疑这是由 Windows 7 增强的安全性引起的,但我会尝试找到一个解决方法。
更新(10/09/2010)-psutil 的人不知道为什么它不能工作,但他们的一个开发者已经确认了这个问题。你可以关注他们的谷歌群列表。
如何在 Python 中获得类属性列表
原文:https://www.blog.pythonlibrary.org/2013/01/11/how-to-get-a-list-of-class-attributes/
前几天,我试图弄清楚是否有一种简单的方法来获取类的已定义属性(又名“实例变量”)。原因是我们使用我们创建的属性来匹配我们解析的文件中的字段。所以基本上我们一行一行地读取一个文件,每行可以分成 150 多个片段,这些片段需要映射到我们在类中创建的字段。问题是,我们最近向类中添加了更多的字段,并且在代码中有一个检查,该检查是用文件中应该有的字段的数量硬编码的。因此,当我添加更多的字段时,它打破了检查。我希望这些都有意义。现在你知道背景了,我们可以继续了。我发现了三种不同的方法来实现这一点,所以我们将从最复杂的到最简单的。
正如大多数 Python 程序员应该知道的,Python 提供了一个方便的小内置程序,叫做 dir 。我可以在一个类实例上使用它来获得该类的所有属性和方法的列表,以及一些继承的神奇方法,如' delattr '、' dict '、' doc '、' format '等。您可以通过执行以下操作自己尝试一下:
x = dir(myClassInstance)
然而,我不想要魔法方法,我也不想要方法。我只想要属性。为了让一切都清晰明了,让我们写一些代码吧!
########################################################################
class Test:
""""""
#----------------------------------------------------------------------
def __init__(self):
self.varOne = ""
self.varTwo = ""
self.varThree = ""
#----------------------------------------------------------------------
def methodOne(self):
""""""
print "You just called methodOne!"
#----------------------------------------------------------------------
if __name__ == "__main__":
t = Test()
我们想要得到的是一个只包含 self.varOne、self.varTwo 和 self.varThree 的列表。
import inspect
variables = [i for i in dir(t) if not inspect.ismethod(i)]
看起来不太复杂,是吗?但这需要进口,我不想这么做。另一方面,如果您需要进行自省,inspect 模块是一个不错的选择。它非常强大,可以告诉你很多关于你的班级或者你没有写过的班级的精彩内容。无论如何,我发现的下一个最简单的方法是使用 Python 的可调用内置:
variables = [i for i in dir(t) if not callable(i)]
你可以在 Python 文档中阅读更多关于 callable 的内容。基本上 callable 所做的就是根据你传递给它的对象是否可调用来返回一个 True 或 False。方法是可调用的,变量不是。因此,我们循环遍历类字典中的每一项,只有当它们是不可调用的(即不是方法)时,才把它们添加到列表中。相当光滑,它不需要任何进口!但是有一个更简单的方法!
我发现的最简单的方法是使用魔法方法, dict 。除非您覆盖它,否则它内置于您创建的每个类中。因为我们正在处理一个 Python 字典,我们可以直接调用它的键方法!
variables = t.__dict__.keys()
现在真正的问题是,你应该使用一种神奇的方法来做到这一点吗?大多数 Python 程序员可能会反对它。它们很神奇,所以除非你在做元编程,否则不应该使用它们。我个人认为对于这个用例来说完全可以接受。让我知道我错过的或者你认为更好的其他方法。
资源
- StackOverflow: 列出对象的属性
- StackOverflow: Python : 断言变量是实例方法?
如何用 Python 合并字典(视频)
原文:https://www.blog.pythonlibrary.org/2022/08/10/how-to-merge-dictionaries-with-python-video/
学习用 Mike Driscoll 合并 Python 字典的三种不同方法
您将学习三种不同的合并字典的方法:
- 使用字典的 update() 方法
- 使用**
- 使用 Union 运算符
https://www.youtube.com/embed/sak3PhNekaw?feature=oembed
如何用 Python 调整照片大小
原文:https://www.blog.pythonlibrary.org/2017/10/12/how-to-resize-a-photo-with-python/
有时你会发现自己想要调整照片的大小。我通常想这样做的照片,我想通过电子邮件或张贴在网站上,因为我的一些图像可以相当大。正常人用的是图像编辑器。我通常也这样做,但是为了好玩,我想我会研究如何用 Python 编程语言来做这件事。
最快的方法是使用 pip 可以安装的枕头包。一旦你有了它,打开你最喜欢的代码编辑器,尝试下面的代码:
from PIL import Image
def resize_image(input_image_path,
output_image_path,
size):
original_image = Image.open(input_image_path)
width, height = original_image.size
print('The original image size is {wide} wide x {height} '
'high'.format(wide=width, height=height))
resized_image = original_image.resize(size)
width, height = resized_image.size
print('The resized image size is {wide} wide x {height} '
'high'.format(wide=width, height=height))
resized_image.show()
resized_image.save(output_image_path)
if __name__ == '__main__':
resize_image(input_image_path='caterpillar.jpg',
output_image_path='caterpillar_small.jpg',
size=(800, 400))
这里我们从枕头包中导入图像类。接下来,我们有一个带 3 个参数的函数:我们要打开的文件的位置,我们要保存调整后的图像的位置,以及一个表示图像新大小的元组,其中元组分别是宽度和高度。接下来,我们打开我们的图像并打印出它的大小。然后我们用传入的 size 元组调用图像对象的 resize() 方法。最后,我们获取新的尺寸,将其打印出来,然后在保存调整后的照片之前显示图像。现在看起来是这样的:

如您所见,resize()方法不做任何缩放。接下来我们将看看如何去做!
缩放图像
大多数时候,除非你想写一个缩放方法,否则你不会想像我们在前面的例子中那样调整你的图像的大小。前一种方法的问题是,当调整大小时,它不能保持照片的纵横比。所以不用调整大小,你可以使用 thumbnail() 方法。让我们来看看:
from PIL import Image
def scale_image(input_image_path,
output_image_path,
width=None,
height=None
):
original_image = Image.open(input_image_path)
w, h = original_image.size
print('The original image size is {wide} wide x {height} '
'high'.format(wide=w, height=h))
if width and height:
max_size = (width, height)
elif width:
max_size = (width, h)
elif height:
max_size = (w, height)
else:
# No width or height specified
raise RuntimeError('Width or height required!')
original_image.thumbnail(max_size, Image.ANTIALIAS)
original_image.save(output_image_path)
scaled_image = Image.open(output_image_path)
width, height = scaled_image.size
print('The scaled image size is {wide} wide x {height} '
'high'.format(wide=width, height=height))
if __name__ == '__main__':
scale_image(input_image_path='caterpillar.jpg',
output_image_path='caterpillar_scaled.jpg',
width=800)
这里我们允许程序员传入输入和输出路径以及我们的最大宽度和高度。然后我们使用一个条件来决定我们的最大尺寸应该是多少,然后我们在打开的图像对象上调用 thumbnail() 方法。我们也传入了的图像。抗锯齿标志,该标志将应用高质量下采样滤波器,从而产生更好的图像。最后,我们打开新保存的缩放图像,并打印出它的大小,以便与原始大小进行比较。如果你打开缩放后的图像,你会看到照片的纵横比保持不变。
包扎
玩枕头包很有趣!在本文中,您了解了如何调整图像的大小,以及如何在保持照片纵横比的同时缩放照片。现在,您可以使用这些知识来创建一个函数,该函数可以迭代一个文件夹并创建该文件夹中所有照片的缩略图,或者您可以创建一个简单的照片查看应用程序,其中这种功能可能很方便。
相关阅读
- stack overflow:Python/Pillow:如何缩放图像
- 用 Python 将一张照片转换成黑白
- 如何用 Python 旋转/镜像照片
- 如何用 Python 裁剪照片
如何使用 Python 和 Pillow 旋转和镜像图像(视频)
在本视频教程中,您将学习如何使用 Python 和 Pillow 包旋转和镜像图像。这也称为移调图像。
https://www.youtube.com/embed/MwfBdEz1W8I?feature=oembed
想了解有关使用 Python 处理图像的更多信息吗?
看看我的书:枕头:用 Python 进行图像处理
如何用 Python 旋转/镜像照片
原文:https://www.blog.pythonlibrary.org/2017/10/05/how-to-rotate-mirror-photos-with-python/
在我们上一篇文章中,我们学习了如何用 Pillow 软件包裁剪图像。在这篇文章中,我们将学习如何旋转和镜像我们的图像。
旋转图像
使用 Python 和 Pillow 旋转图像非常简单。我们来看一些代码:
from PIL import Image
def rotate(image_path, degrees_to_rotate, saved_location):
"""
Rotate the given photo the amount of given degreesk, show it and save it
@param image_path: The path to the image to edit
@param degrees_to_rotate: The number of degrees to rotate the image
@param saved_location: Path to save the cropped image
"""
image_obj = Image.open(image_path)
rotated_image = image_obj.rotate(degrees_to_rotate)
rotated_image.save(saved_location)
rotated_image.show()
if __name__ == '__main__':
image = 'mantis.png'
rotate(image, 90, 'rotated_mantis.jpg')
这里我们只是从 PIL 导入图像模块,并创建一个 rotate() 函数。我们的自定义旋转函数采用以下参数:我们将要旋转的图像路径、我们想要旋转的角度以及我们想要保存结果的位置。实际代码非常简单。我们所做的就是打开图像,然后调用图像对象的 rotate() 方法,同时向它传递逆时针旋转的度数。然后我们保存结果并调用 image 对象的 show()方法来查看结果:

在上面的例子中,我们将螳螂逆时针旋转了 90 度。
镜像图像

现在让我们试着翻转或镜像我们的螳螂图像。下面是一个从左到右镜像图像的示例:
from PIL import Image
def flip_image(image_path, saved_location):
"""
Flip or mirror the image
@param image_path: The path to the image to edit
@param saved_location: Path to save the cropped image
"""
image_obj = Image.open(image_path)
rotated_image = image_obj.transpose(Image.FLIP_LEFT_RIGHT)
rotated_image.save(saved_location)
rotated_image.show()
if __name__ == '__main__':
image = 'mantis.png'
flip_image(image, 'flipped_mantis.jpg')
这段代码与前面的例子非常相似。这段代码的核心是我们使用图像对象的 transpose() 方法,该方法采用以下常量之一:
- PIL。图像。向左向右翻转
- PIL。图像.翻转 _ 顶部 _ 底部
- PIL。图像。转置
您也可以在这里使用 Pillow 的 ROTATE 常量之一,但是我们只关注 transpose()方法的镜像方面。试着将这些常量中的一个交换到上面的代码中,看看会发生什么。
包扎
现在你知道如何使用枕头包来旋转和翻转/镜像你的图像。Python 让这种事情变得很简单。你应该试一试,一定要查看 Pillow 的文档,看看你还能做些什么!
相关阅读
- 图像模块上的枕头文档
- 如何在 Python 中裁剪图像
- 介绍 Python 图像库/ Pillow
如何在编码时“连续”运行 Python 测试
原文:https://www.blog.pythonlibrary.org/2017/03/14/how-to-run-python-tests-continuously-while-coding/
上周,我做了一些测试驱动开发培训,无意中听到有人提到另一种编程语言,它有一个测试运行程序,你可以设置它来监视你的项目目录,并在文件改变时运行你的测试。我认为这是个好主意。我还认为我可以轻松地编写自己的 Python 脚本来做同样的事情。这是一个相当粗略的版本:
import argparse
import os
import subprocess
import time
def get_args():
parser = argparse.ArgumentParser(
description="A File Watcher that executes the specified tests"
)
parser.add_argument('--tests', action='store', required=True,
help='The path to the test file to run')
parser.add_argument('--project', action='store', required=False,
help='The folder where the project files are')
return parser.parse_args()
def watcher(test_path, project_path=None):
if not project_path:
project_path = os.path.dirname(test_path)
f_dict = {}
while True:
files = os.listdir(project_path)
for f in files:
full_path = os.path.join(project_path, f)
mod_time = os.stat(full_path).st_mtime
if full_path not in f_dict:
f_dict[full_path] = mod_time
elif mod_time != f_dict[full_path]:
# Run the tests
cmd = ['python', test_path]
subprocess.call(cmd)
print('-' * 70)
f_dict[full_path] = mod_time
time.sleep(1)
def main():
args = get_args()
w = watcher(args.tests, args.project)
if __name__ == '__main__':
main()
要运行这个脚本,您需要执行如下操作:
python watcher.py --test ~/path/to/tests.py --project ~/project/path
现在让我们花点时间来谈谈这个脚本。第一个函数使用 Python 的 argparse 模块让程序接受最多两个命令行参数:- test 和- project。第一个是 Python 测试脚本的路径,第二个是要测试的代码所在的文件夹。下一个函数, watcher ,将永远循环下去,从传入的文件夹中抓取所有文件,或者使用测试文件所在的文件夹。它将获取每个文件的修改时间,并将其保存到字典中。密钥设置为文件的完整路径,值为修改时间。接下来,我们检查修改时间是否已经更改。如果没有,我们睡一会儿,再检查一遍。如果它改变了,我们就运行测试。
此时,您应该能够在您最喜欢的 Python 编辑器中编辑您的代码和测试,并在终端中观察您的测试运行。
使用看门狗
我四处寻找其他跨平台的监视目录的方法,发现了 看门狗 项目。自 2015 年(撰写本文时)以来,它一直没有更新,但我测试了一下,似乎对我来说效果不错。您可以使用 pip 安装看门狗:
pip install watchdog
现在我们已经安装了 watchdog,让我们创建一些代码来执行类似于上一个示例的操作:
import argparse
import os
import subprocess
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
def get_args():
parser = argparse.ArgumentParser(
description="A File Watcher that executes the specified tests"
)
parser.add_argument('--tests', action="store", required=True,
help='The path to the test file to run')
parser.add_argument('--project', action='store', required=False,
help='The folder where the project files are')
return parser.parse_args()
class FW(FileSystemEventHandler):
def __init__(self, test_file_path):
self.test_file_path = test_file_path
def on_any_event(self, event):
if os.path.exists(self.test_file_path):
cmd = ['python', self.test_file_path]
subprocess.call(cmd)
print('-' * 70)
if __name__ =='__main__':
args = get_args()
observer = Observer()
path = args.tests
watcher = FW(path)
if not args.project:
project_path = os.path.dirname(args.tests)
else:
project_path = args.project
if os.path.exists(path) and os.path.isfile(path):
observer.schedule(watcher, project_path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
else:
print('There is something wrong with your test path')
在这段代码中,我们保留了我们的 get_args() 函数,并添加了一个类。class 子类的看门狗的 FileSystemEventHandler 类。我们最终将测试文件路径传递给该类,并覆盖了 on_any_event() 方法。此方法在文件系统事件发生时触发。当那发生时,我们运行我们的测试。最后一点在代码的末尾,我们创建了一个 Observer() 对象,告诉它监视指定的项目路径,并在文件发生任何变化时调用我们的事件处理程序。
包扎
此时,您应该能够在自己的代码中尝试这些想法了。也有一些特定于平台的方法来监视一个文件夹(比如 PyWin32 ),但是如果你像我一样在多个操作系统上运行,那么 watchdog 或者 rolling your own 可能是更好的选择。
相关阅读
- 如何使用 Python 来观察文件的变化?
- 观察目录的变化
如何用 Python 发邮件(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/28/how-to-send-an-email-with-python-video/
了解如何发送电子邮件(带附件!)使用 Python
https://www.youtube.com/embed/2qvOqzK135Y?feature=oembed
想了解更多?查看我的 Python 101 书籍:
- Leanpub (电子书)
- 亚马逊(平装)
或者查阅我的其他书籍,学习如何创建 Excel 电子表格、编辑图像、使用 Jupyter Notebook、创建 GUI 等等:
- Gumroad (电子书和视频)
如何用 Python 发送电子邮件
原文:https://www.blog.pythonlibrary.org/2010/05/14/how-to-send-email-with-python/
在我工作的地方,我们运行许多用 Python 编写的登录脚本。当其中一个脚本出现错误时,我们想知道。因此,我们编写了一个简单的 Python 脚本,通过电子邮件将错误发送给我们。从那时起,我就需要想办法用一些更高级的脚本来发送附件。如果你是这个博客的长期读者,那么你可能还记得 wxPyMail ,这是一个简单的 wxPython 程序,可以发送电子邮件。在本文中,您将发现如何仅使用 Python 的标准库来发送电子邮件。我们将重点讨论 smtplib 和电子邮件模块。
使用 smtplib 发送电子邮件
用 smtplib 发邮件超级简单。你想看看有多简单吗?你当然知道!让我们来看看:
import smtplib
import string
SUBJECT = "Test email from Python"
TO = "mike@mydomain.com"
FROM = "python@mydomain.com"
text = "blah blah blah"
BODY = string.join((
"From: %s" % FROM,
"To: %s" % TO,
"Subject: %s" % SUBJECT ,
"",
text
), "\r\n")
server = smtplib.SMTP(HOST)
server.sendmail(FROM, [TO], BODY)
server.quit()
请注意,电子邮件的实际连接和发送只有两行代码。剩下的代码只是设置要发送的消息。在工作中,我们将所有这些都包装在一个可调用的函数中,并向它传递一些信息,比如错误是什么以及将错误发送给谁。如果需要登录,请在创建服务器变量后添加一行,执行以下操作:server.login(username,password)
发送带有附件的电子邮件
现在让我们看看如何发送带有附件的电子邮件。对于这个脚本,我们还将使用电子邮件模块。这里有一个简单的例子,基于我最近写的一些代码:
import os
import smtplib
from email import Encoders
from email.MIMEBase import MIMEBase
from email.MIMEMultipart import MIMEMultipart
from email.Utils import formatdate
filePath = r'\\some\path\to\a\file'
def sendEmail(TO = "mike@mydomain.com",
FROM="support@mydomain.com"):
HOST = "mail.mydomain.com"
msg = MIMEMultipart()
msg["From"] = FROM
msg["To"] = TO
msg["Subject"] = "You've got mail!"
msg['Date'] = formatdate(localtime=True)
# attach a file
part = MIMEBase('application', "octet-stream")
part.set_payload( open(filePath,"rb").read() )
Encoders.encode_base64(part)
part.add_header('Content-Disposition', 'attachment; filename="%s"' % os.path.basename(filePath))
msg.attach(part)
server = smtplib.SMTP(HOST)
# server.login(username, password) # optional
try:
failed = server.sendmail(FROM, TO, msg.as_string())
server.close()
except Exception, e:
errorMsg = "Unable to send email. Error: %s" % str(e)
if __name__ == "__main__":
sendEmail()
这里发生了相当多的事情,所以让我们来看看新的内容。首先,我们从电子邮件模块导入所有我们需要的零碎信息。然后我们创建一个发送电子邮件的函数。接下来,我们创建一个 MIMEMultipart 对象。这个方便的东西可以保存我们的电子邮件。它使用一个类似 dict 的界面来添加字段,如收件人、发件人、主题等。您会注意到我们还有一个日期字段。这只是抓取你的电脑的当前日期,并将其转换为适当的 MIME 电子邮件格式。
我们最感兴趣的是如何附加文件。这里我们创建了一个 MIMEBase 对象,并将其有效负载设置为我们想要附加的文件。注意,我们需要告诉它将文件作为二进制文件读取,即使文件是纯文本的。接下来,我们用 64 进制对数据流进行编码。最后两步是添加一个头,然后将 MIMEBase 对象附加到我们的 MIMEMultipart 对象。如果您有多个文件要附加,那么您可能希望将这一部分放入某种循环中,并对这些文件进行循环。事实上,我在前面提到的 wxPyMail 示例中就是这么做的。
无论如何,一旦你完成了所有这些,你就可以做和上面的 smtplib 例子中一样的事情了。唯一的区别是我们更改了下面的行:
server.sendmail(FROM, TO, msg.as_string())
请注意 msg.as_string。我们需要将对象转换成字符串来完成这项工作。我们还将 sendmail 函数放在一个 try/except 语句中,以防发生不好的事情,我们的电子邮件无法发送。如果我们愿意,我们可以将 try/except 封装在一个 while 循环中,这样如果失败,我们可以重试发送 X 次电子邮件。
包扎
我们已经介绍了如何发送一封简单的电子邮件以及如何发送一封带有附件的电子邮件。电子邮件模块内置了更多的功能,这里没有介绍,所以请务必阅读文档。祝编码愉快!
附加阅读
- smtplib 模块
- Python 的邮件模块
如何用 Python 发送电子邮件
原文:https://www.blog.pythonlibrary.org/2021/09/21/how-to-send-emails-with-python/
Python 提供了几个非常好的模块,可以用来制作电子邮件。它们是电子邮件和 smtplib 模块。在这两个模块中,您将花一些时间学习如何实际使用这些模块,而不是复习各种方法。
具体来说,您将涉及以下内容:
- 电子邮件的基础
- 如何一次发送到多个地址
- 如何使用“收件人”、“抄送”和“密件抄送”行发送电子邮件
- 如何使用电子邮件模块添加附件和正文
我们开始吧!
电子邮件基础-如何用 smtplib 发送电子邮件
smtplib 模块使用起来非常直观。你将写一个简单的例子,展示如何发送电子邮件。
打开您最喜欢的 Python IDE 或文本编辑器,创建一个新的 Python 文件。将以下代码添加到该文件并保存:
import smtplib
HOST = "mySMTP.server.com"
SUBJECT = "Test email from Python"
TO = "mike@someAddress.org"
FROM = "python@mydomain.com"
text = "Python 3.4 rules them all!"
BODY = "\r\n".join((
"From: %s" % FROM,
"To: %s" % TO,
"Subject: %s" % SUBJECT ,
"",
text
))
server = smtplib.SMTP(HOST)
server.sendmail(FROM, [TO], BODY)
server.quit()
这里您只导入了 smtplib 模块。该代码的三分之二用于设置电子邮件。大多数变量都是显而易见的,所以您将只关注奇怪的一个,即 BODY。
在这里,您使用字符串的 join() 方法将前面的所有变量组合成一个字符串,其中每一行都以回车符("/r ")加新行("/n ")结束。如果你把正文打印出来,它会是这样的:
'From: python@mydomain.com\r\nTo: mike@mydomain.com\r\nSubject: Test email from Python\r\n\r\nblah blah blah'
之后,建立一个到主机的服务器连接,然后调用 smtplib 模块的 sendmail 方法发送电子邮件。然后断开与服务器的连接。您会注意到这段代码中没有用户名或密码。如果您的服务器需要身份验证,那么您需要添加以下代码:
server.login(username, password)
这应该在创建服务器对象后立即添加。通常,您会希望将这段代码放入一个函数中,并使用其中的一些参数来调用它。您甚至可能希望将这些信息放入配置文件中。
让我们将这段代码放入一个函数中。
import smtplib
def send_email(host, subject, to_addr, from_addr, body_text):
"""
Send an email
"""
BODY = "\r\n".join((
"From: %s" % from_addr,
"To: %s" % to_addr,
"Subject: %s" % subject ,
"",
body_text
))
server = smtplib.SMTP(host)
server.sendmail(from_addr, [to_addr], BODY)
server.quit()
if __name__ == "__main__":
host = "mySMTP.server.com"
subject = "Test email from Python"
to_addr = "mike@someAddress.org"
from_addr = "python@mydomain.com"
body_text = "Python rules them all!"
send_email(host, subject, to_addr, from_addr, body_text)
现在,您可以通过查看函数本身来了解实际代码有多小。那是 13 行!如果你不把正文中的每一项都放在自己的行上,你可以把它变得更短,但是它没有可读性。现在,您将添加一个配置文件来保存服务器信息和 from 地址。
你为什么要这么做?许多组织使用不同的电子邮件服务器来发送电子邮件,或者如果电子邮件服务器升级并且名称改变,那么你只需要改变配置文件而不是代码。如果你的公司被另一家公司收购并合并,同样的事情也适用于发件人地址。
让我们看看配置文件(保存为 email.ini ):
[smtp]
server = some.server.com
from_addr = python@mydomain.com
这是一个非常简单的配置文件。在其中,您有一个标记为 smtp 的部分,其中有两个项目:服务器和 from_addr 。您将使用 ConfigParser 来读取这个文件,并将它转换成一个 Python 字典。下面是代码的更新版本(保存为 smtp_config.py )
import os
import smtplib
import sys
from configparser import ConfigParser
def send_email(subject, to_addr, body_text):
"""
Send an email
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "email.ini")
if os.path.exists(config_path):
cfg = ConfigParser()
cfg.read(config_path)
else:
print("Config not found! Exiting!")
sys.exit(1)
host = cfg.get("smtp", "server")
from_addr = cfg.get("smtp", "from_addr")
BODY = "\r\n".join((
"From: %s" % from_addr,
"To: %s" % to_addr,
"Subject: %s" % subject ,
"",
body_text
))
server = smtplib.SMTP(host)
server.sendmail(from_addr, [to_addr], BODY)
server.quit()
if __name__ == "__main__":
subject = "Test email from Python"
to_addr = "mike@someAddress.org"
body_text = "Python rules them all!"
send_email(subject, to_addr, body_text)
您在这段代码中添加了一个小检查。你想首先获取脚本本身所在的路径,这就是 base_path 所代表的。接下来,将路径和文件名结合起来,得到配置文件的完全限定路径。然后检查该文件是否存在。
如果存在,您创建一个 ConfigParser ,如果不存在,您打印一条消息并退出脚本。为了安全起见,您应该在 ConfigParser.read() 调用周围添加一个异常处理程序,尽管该文件可能存在,但可能已损坏,或者您可能没有权限打开它,这将引发一个异常。
这将是一个你可以自己尝试的小项目。无论如何,假设一切顺利,并且成功创建了 ConfigParser 对象。现在,您可以使用常用的 ConfigParser 语法从 _addr 信息中提取主机和。
现在你已经准备好学习如何同时发送多封电子邮件了!
一次发送多封电子邮件
能够一次发送多封电子邮件是一个很好的功能。
继续修改你的最后一个例子,这样你就可以发送多封电子邮件了!
import os
import smtplib
import sys
from configparser import ConfigParser
def send_email(subject, body_text, emails):
"""
Send an email
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "email.ini")
if os.path.exists(config_path):
cfg = ConfigParser()
cfg.read(config_path)
else:
print("Config not found! Exiting!")
sys.exit(1)
host = cfg.get("smtp", "server")
from_addr = cfg.get("smtp", "from_addr")
BODY = "\r\n".join((
"From: %s" % from_addr,
"To: %s" % ', '.join(emails),
"Subject: %s" % subject ,
"",
body_text
))
server = smtplib.SMTP(host)
server.sendmail(from_addr, emails, BODY)
server.quit()
if __name__ == "__main__":
emails = ["mike@someAddress.org", "someone@gmail.com"]
subject = "Test email from Python"
body_text = "Python rules them all!"
send_email(subject, body_text, emails)
您会注意到,在这个例子中,您删除了 to_addr 参数,并添加了一个 emails 参数,这是一个电子邮件地址列表。为此,您需要在正文的 To:部分创建一个逗号分隔的字符串,并将电子邮件列表传递给 sendmail 方法。因此,您执行以下操作来创建一个简单的逗号分隔的字符串:','。加入(邮件)。很简单,是吧?
使用“收件人”、“抄送”和“密件抄送”行发送电子邮件
现在你只需要弄清楚如何使用“抄送”和“密件抄送”字段发送邮件。
让我们创建一个支持该功能的新版本的代码!
import os
import smtplib
import sys
from configparser import ConfigParser
def send_email(subject, body_text, to_emails, cc_emails, bcc_emails):
"""
Send an email
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "email.ini")
if os.path.exists(config_path):
cfg = ConfigParser()
cfg.read(config_path)
else:
print("Config not found! Exiting!")
sys.exit(1)
host = cfg.get("smtp", "server")
from_addr = cfg.get("smtp", "from_addr")
BODY = "\r\n".join((
"From: %s" % from_addr,
"To: %s" % ', '.join(to_emails),
"CC: %s" % ', '.join(cc_emails),
"BCC: %s" % ', '.join(bcc_emails),
"Subject: %s" % subject ,
"",
body_text
))
emails = to_emails + cc_emails + bcc_emails
server = smtplib.SMTP(host)
server.sendmail(from_addr, emails, BODY)
server.quit()
if __name__ == "__main__":
emails = ["mike@somewhere.org"]
cc_emails = ["someone@gmail.com"]
bcc_emails = ["schmuck@newtel.net"]
subject = "Test email from Python"
body_text = "Python rules them all!"
send_email(subject, body_text, emails, cc_emails, bcc_emails)
在这段代码中,你传入 3 个列表,每个列表有一个电子邮件地址。您创建的抄送和密件抄送字段与之前完全相同,但是您还需要将 3 个列表合并成一个,这样您就可以将合并后的列表传递给 sendmail() 方法。
在 StackOverflow 这样的论坛上有一些传言说,一些电子邮件客户端可能会以奇怪的方式处理密件抄送字段,从而允许收件人通过电子邮件标题看到密件抄送列表。我无法确认这种行为,但我知道 Gmail 成功地从邮件标题中删除了密件抄送信息。
现在您已经准备好使用 Python 的电子邮件模块了!
使用电子邮件模块添加附件/正文
现在,您将利用从上一节中学到的知识,将它与 Python 电子邮件模块结合起来,以便发送附件。
电子邮件模块使得添加附件变得极其容易。代码如下:
import os
import smtplib
import sys
from configparser import ConfigParser
from email import encoders
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email.mime.multipart import MIMEMultipart
from email.utils import formatdate
def send_email_with_attachment(subject, body_text, to_emails,
cc_emails, bcc_emails, file_to_attach):
"""
Send an email with an attachment
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "email.ini")
header = 'Content-Disposition', 'attachment; filename="%s"' % file_to_attach
# get the config
if os.path.exists(config_path):
cfg = ConfigParser()
cfg.read(config_path)
else:
print("Config not found! Exiting!")
sys.exit(1)
# extract server and from_addr from config
host = cfg.get("smtp", "server")
from_addr = cfg.get("smtp", "from_addr")
# create the message
msg = MIMEMultipart()
msg["From"] = from_addr
msg["Subject"] = subject
msg["Date"] = formatdate(localtime=True)
if body_text:
msg.attach( MIMEText(body_text) )
msg["To"] = ', '.join(to_emails)
msg["cc"] = ', '.join(cc_emails)
attachment = MIMEBase('application', "octet-stream")
try:
with open(file_to_attach, "rb") as fh:
data = fh.read()
attachment.set_payload( data )
encoders.encode_base64(attachment)
attachment.add_header(*header)
msg.attach(attachment)
except IOError:
msg = "Error opening attachment file %s" % file_to_attach
print(msg)
sys.exit(1)
emails = to_emails + cc_emails
server = smtplib.SMTP(host)
server.sendmail(from_addr, emails, msg.as_string())
server.quit()
if __name__ == "__main__":
emails = ["mike@someAddress.org", "nedry@jp.net"]
cc_emails = ["someone@gmail.com"]
bcc_emails = ["anonymous@circe.org"]
subject = "Test email with attachment from Python"
body_text = "This email contains an attachment!"
path = "/path/to/some/file"
send_email_with_attachment(subject, body_text, emails,
cc_emails, bcc_emails, path)
在这里,您重命名了您的函数并添加了一个新参数, file_to_attach 。您还需要添加一个头并创建一个 MIMEMultipart 对象。在添加附件之前,可以随时创建标题。
向 MIMEMultipart 对象( msg )添加元素,就像向字典中添加键一样。您会注意到,您必须使用 email 模块的 formatdate 方法来插入正确格式化的日期。
要添加消息体,您需要创建一个 MIMEText 的实例。如果您注意的话,您会发现您没有添加密件抄送信息,但是您可以通过遵循上面代码中的约定很容易地这样做。
接下来,添加附件。您将它包装在一个异常处理程序中,并使用带有语句的来提取文件,并将其放入您的 MIMEBase 对象中。最后,你把它添加到 msg 变量中,然后发送出去。注意,您必须在 sendmail ()方法中将 msg 转换成一个字符串。
包扎
现在你知道如何用 Python 发送电子邮件了。对于那些喜欢小型项目的人来说,您应该回去在服务器周围添加额外的错误处理。 sendmail 部分代码,以防在这个过程中发生一些奇怪的事情。
一个例子是 SMTPAuthenticationError 或 SMTPConnectError 。您还可以在附加文件的过程中加强错误处理,以捕捉其他错误。最后,您可能希望获得这些不同的电子邮件列表,并创建一个已删除重复项的规范化列表。如果您正在从文件中读取电子邮件地址列表,这一点尤其重要。
另外,请注意,您的发件人地址是假的。你可以使用 Python 和其他编程语言来欺骗电子邮件,但这是非常不礼貌的,而且可能是非法的,这取决于你住在哪里。你已经被警告了!
明智地使用你的知识,享受 Python 带来的乐趣和收益!
相关阅读
想学习更多 Python 基础知识?然后查看以下教程:
-
Python 101: 使用 JSON 的介绍
-
python 101-创建多个流程
-
python 101-用 pdb 调试你的代码
如何在 Windows 上为 Kivy 设置 Wing IDE
原文:https://www.blog.pythonlibrary.org/2013/11/18/how-to-set-up-wing-ide-for-kivy-on-windows/
我喜欢用 Wingware 的 IDE 用 Python 编码。我正在用 Kivy 开发一些示例应用程序,这是一个跨平台的 Python GUI 框架,也可以为移动设备创建 UI。无论如何,在 Wing 中设置 Kivy 有点令人困惑,所以这里有一个速成班:
- Download Kivy
- 拉开 Kivy 的拉链。在我的例子中,我在这里解压它:C:\kivy1.7.2\
- 运行解压到的目录中的 kivy.bat。您应该会看到如下所示的内容

现在我们准备打开机翼。一旦你打开了,开始一个新的项目。然后进入项目菜单,选择位于列表底部的项目属性选项。您应该会看到如下所示的内容:
将 Python 可执行文件选项设置为你的 Kivy 的 Python,在我的例子中是:c:\ Kivy 1 . 7 . 2 \ Python \ Python . exe
将 Python 路径设置为 C:\kivy1.7.2\kivy (或者修改以匹配提取 kivy 的位置)。
此时,您应该能够在您的环境中导入 kivy,但是您将无法实际执行您的 kivy 脚本。要解决这个问题,你需要进入项目属性对话框的底部,将环境设置下拉菜单更改为添加到继承的环境。最后,您需要将上面看到的 kivy.bat 屏幕中的路径信息复制到环境设置下的文本框中。在我的例子中,它看起来像这样:
PATH=C:\kivy1.7.2\;C:\kivy1.7.2\Python;C:\kivy1.7.2\Python\Scripts;C:\kivy1.7.2\gstreamer\bin;C:\kivy1.7.2\MinGW\bin;C:\Python26\Lib\site-packages\PyQt4;C:\Python27\Lib\site-packages\PyQt4;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;c:\Program Files (x86)\ATI Technologies\ATI.ACE\Core-Static;C:\Program Files (x86)\Intel\Services\IPT\;C:\Program Files (x86)\IBM\Client Access\Emulator;C:\Program Files (x86)\IBM\Client Access\Shared;C:\Program Files (x86)\IBM\Client Access\;C:\Python26;C:\Python26\Scripts;C:\Program Files\TortoiseSVN\bin;C:\Program Files\SlikSvn\bin;C:\Program Files (x86)\Calibre2\;C:\Program Files (x86)\QuickTime\QTSystem\;C:\Program Files (x86)\GNU\GnuPG\pub;C:\Windows\Microsoft.NET\Framework64\v4.0.30319;C:\PROGRA~1\IBM\SQLLIB\BIN;C:\PROGRA~1\IBM\SQLLIB\FUNCTION;C:\Program Files (x86)\Git\cmd;C:\Program Files (x86)\Mercurial;C:\MinGW\bin
除了它应该都在一行上。否则 Wing 会抱怨每个变量必须在 var=value 对中。一旦你完成了所有这些,你就可以在 Wing 中运行一个 kivy 脚本。这避免了将 Python 文件拖到 kivy.bat 上来运行 kivy 程序的需要。
如何截图并打印你的 wxPython 应用程序
你有没有想过让你的 wxPython 代码自己截图会很酷?嗯, Andrea Gavana 想出了一个很酷的方法来做到这一点,根据他在 wxPython 邮件列表上告诉我们的内容和我从其他来源了解到的内容,你很快就会知道如何不仅截取屏幕截图,而且如何将它发送到你的打印机!

我们先来看看如何截图:
import sys
import wx
import snapshotPrinter
class MyForm(wx.Frame):
#----------------------------------------------------------------------
def __init__(self):
wx.Frame.__init__(self, None, wx.ID_ANY, "Tutorial", size=(500,500))
# Add a panel so it looks the correct on all platforms
panel = wx.Panel(self, wx.ID_ANY)
screenshotBtn = wx.Button(panel, wx.ID_ANY, "Take Screenshot")
screenshotBtn.Bind(wx.EVT_BUTTON, self.onTakeScreenShot)
printBtn = wx.Button(panel, label="Print Screenshot")
printBtn.Bind(wx.EVT_BUTTON, self.onPrint)
sizer = wx.BoxSizer(wx.HORIZONTAL)
sizer.Add(screenshotBtn, 0, wx.ALL|wx.CENTER, 5)
sizer.Add(printBtn, 0, wx.ALL|wx.CENTER, 5)
panel.SetSizer(sizer)
def onTakeScreenShot(self, event):
""" Takes a screenshot of the screen at give pos & size (rect). """
print 'Taking screenshot...'
rect = self.GetRect()
# see http://aspn.activestate.com/ASPN/Mail/Message/wxpython-users/3575899
# created by Andrea Gavana
# adjust widths for Linux (figured out by John Torres
# http://article.gmane.org/gmane.comp.python.wxpython/67327)
if sys.platform == 'linux2':
client_x, client_y = self.ClientToScreen((0, 0))
border_width = client_x - rect.x
title_bar_height = client_y - rect.y
rect.width += (border_width * 2)
rect.height += title_bar_height + border_width
#Create a DC for the whole screen area
dcScreen = wx.ScreenDC()
#Create a Bitmap that will hold the screenshot image later on
#Note that the Bitmap must have a size big enough to hold the screenshot
#-1 means using the current default colour depth
bmp = wx.EmptyBitmap(rect.width, rect.height)
#Create a memory DC that will be used for actually taking the screenshot
memDC = wx.MemoryDC()
#Tell the memory DC to use our Bitmap
#all drawing action on the memory DC will go to the Bitmap now
memDC.SelectObject(bmp)
#Blit (in this case copy) the actual screen on the memory DC
#and thus the Bitmap
memDC.Blit( 0, #Copy to this X coordinate
0, #Copy to this Y coordinate
rect.width, #Copy this width
rect.height, #Copy this height
dcScreen, #From where do we copy?
rect.x, #What's the X offset in the original DC?
rect.y #What's the Y offset in the original DC?
)
#Select the Bitmap out of the memory DC by selecting a new
#uninitialized Bitmap
memDC.SelectObject(wx.NullBitmap)
img = bmp.ConvertToImage()
fileName = "myImage.png"
img.SaveFile(fileName, wx.BITMAP_TYPE_PNG)
print '...saving as png!'
#----------------------------------------------------------------------
def onPrint(self, event):
"""
Send screenshot to the printer
"""
printer = snapshotPrinter.SnapshotPrinter()
printer.sendToPrinter()
# Run the program
if __name__ == "__main__":
app = wx.App(False)
frame = MyForm()
frame.Show()
app.MainLoop()
这段代码创建了一个相当大框架,其中有两个按钮。是的,很无聊,但这是演示,不是艺术展。我们最关心的部分是 onTakeScreenShot 方法。如果你去第一个评论链接,你会找到安德里亚·加瓦那的这个剧本的原始版本。我们添加了一个来自 John Torres 的条件,使得这个脚本在 Linux 上表现得更好,因为它最初是为 Windows 编写的。注释讲述了代码的故事,所以请花点时间阅读它们,当您完成后,我们可以继续讨论如何将结果发送到打印机。
快照打印机脚本

#######################################################################
# snapshotPrinter.py
#
# Created: 12/26/2007 by mld
#
# Description: Displays screenshot image using html and then allows
# the user to print it.
#######################################################################
import os
import wx
from wx.html import HtmlEasyPrinting, HtmlWindow
class SnapshotPrinter(wx.Frame):
#----------------------------------------------------------------------
def __init__(self, title='Snapshot Printer'):
wx.Frame.__init__(self, None, wx.ID_ANY, title, size=(650,400))
self.panel = wx.Panel(self, wx.ID_ANY)
self.printer = HtmlEasyPrinting(name='Printing', parentWindow=None)
self.html = HtmlWindow(self.panel)
self.html.SetRelatedFrame(self, self.GetTitle())
if not os.path.exists('screenshot.htm'):
self.createHtml()
self.html.LoadPage('screenshot.htm')
pageSetupBtn = wx.Button(self.panel, wx.ID_ANY, 'Page Setup')
printBtn = wx.Button(self.panel, wx.ID_ANY, 'Print')
cancelBtn = wx.Button(self.panel, wx.ID_ANY, 'Cancel')
self.Bind(wx.EVT_BUTTON, self.onSetup, pageSetupBtn)
self.Bind(wx.EVT_BUTTON, self.onPrint, printBtn)
self.Bind(wx.EVT_BUTTON, self.onCancel, cancelBtn)
sizer = wx.BoxSizer(wx.VERTICAL)
btnSizer = wx.BoxSizer(wx.HORIZONTAL)
sizer.Add(self.html, 1, wx.GROW)
btnSizer.Add(pageSetupBtn, 0, wx.ALL, 5)
btnSizer.Add(printBtn, 0, wx.ALL, 5)
btnSizer.Add(cancelBtn, 0, wx.ALL, 5)
sizer.Add(btnSizer)
self.panel.SetSizer(sizer)
self.panel.SetAutoLayout(True)
#----------------------------------------------------------------------
def createHtml(self):
'''
Creates an html file in the home directory of the application
that contains the information to display the snapshot
'''
print 'creating html...'
html = '\n\n\n\n'
f = file('screenshot.htm', 'w')
f.write(html)
f.close()
#----------------------------------------------------------------------
def onSetup(self, event):
self.printer.PageSetup()
#----------------------------------------------------------------------
def onPrint(self, event):
self.sendToPrinter()
#----------------------------------------------------------------------
def sendToPrinter(self):
""""""
self.printer.GetPrintData().SetPaperId(wx.PAPER_LETTER)
self.printer.PrintFile(self.html.GetOpenedPage())
#----------------------------------------------------------------------
def onCancel(self, event):
self.Close()
class wxHTML(HtmlWindow):
#----------------------------------------------------------------------
def __init__(self, parent, id):
html.HtmlWindow.__init__(self, parent, id, style=wx.NO_FULL_REPAINT_ON_RESIZE)
if __name__ == '__main__':
app = wx.App(False)
frame = SnapshotPrinter()
frame.Show()
app.MainLoop()
这个小脚本使用 HtmlWindow 小部件和 HtmlEasyPrinting 方法向打印机发送内容。基本上,您可以创建一些非常简单的 HTML 代码(参见 createHtml 方法),然后使用 HtmlWindow 查看它。接下来,您使用 HtmlEasyPrinting 将其发送到打印机。它实际上会显示打印机对话框,让您选择要将文档发送到哪台打印机。
我希望这篇文章对您的编程有所帮助。希望能在评论里听到你的声音!
如何用 timeit 为小块 Python 代码计时
原文:https://www.blog.pythonlibrary.org/2014/01/30/how-to-time-small-pieces-of-python-code-with-timeit/
有时候当你在编码的时候,你想知道一个特定的函数运行需要多长时间。这个主题称为性能分析或性能调优。Python 的标准库中内置了几个分析器,但是对于小段代码,使用 Python 的 timeit 模块会更容易。因此, timeit 将是本教程的重点。 timeit 模块使用特定于平台的方法来获得最准确的运行时间。基本上, timeit 模块将进行一次设置,运行代码 n 次,并返回运行所用的时间。通常它会输出一个“3 分中最好”的分数。奇怪的是,默认运行代码的次数是 1,000,000 次循环。 timeit 在 Linux / Mac 上用 time.time()计时,在 Windows 上用 time.clock()计时,以获得最准确的读数,这是大多数人不会想到的。
您可以从命令行或通过导入来运行 timeit 模块。我们将查看这两个用例。
在控制台中计时
在命令行上使用 timeit 模块非常简单。这里有几个例子:
python -m timeit -s "[ord(x) for x in 'abcdfghi']"
100000000 loops, best of 3: 0.0115 usec per loop
python -m timeit -s "[chr(int(x)) for x in '123456789']"
100000000 loops, best of 3: 0.0119 usec per loop
这是怎么回事?当你在命令行上调用 Python 并给它传递“-m”选项时,你是在告诉它查找一个模块并把它作为主程序使用。“-s”告诉 timeit 模块运行一次设置。然后,它将代码运行 n 次循环,并返回 3 次运行的最佳平均值。对于这些愚蠢的例子,你不会看到太大的区别。让我们快速看一下 timeit's help,这样我们可以了解更多关于它是如何工作的:
C:\Users\mdriscoll>python -m timeit -h
Tool for measuring execution time of small code snippets.
This module avoids a number of common traps for measuring execution
times. See also Tim Peters' introduction to the Algorithms chapter in
the Python Cookbook, published by O'Reilly.
Library usage: see the Timer class.
Command line usage:
python timeit.py [-n N] [-r N] [-s S] [-t] [-c] [-h] [--] [statement]
Options:
-n/--number N: how many times to execute 'statement' (default: see below)
-r/--repeat N: how many times to repeat the timer (default 3)
-s/--setup S: statement to be executed once initially (default 'pass')
-t/--time: use time.time() (default on Unix)
-c/--clock: use time.clock() (default on Windows)
-v/--verbose: print raw timing results; repeat for more digits precision
-h/--help: print this usage message and exit
--: separate options from statement, use when statement starts with -
statement: statement to be timed (default 'pass')
A multi-line statement may be given by specifying each line as a
separate argument; indented lines are possible by enclosing an
argument in quotes and using leading spaces. Multiple -s options are
treated similarly.
If -n is not given, a suitable number of loops is calculated by trying
successive powers of 10 until the total time is at least 0.2 seconds.
The difference in default timer function is because on Windows,
clock() has microsecond granularity but time()'s granularity is 1/60th
of a second; on Unix, clock() has 1/100th of a second granularity and
time() is much more precise. On either platform, the default timer
functions measure wall clock time, not the CPU time. This means that
other processes running on the same computer may interfere with the
timing. The best thing to do when accurate timing is necessary is to
repeat the timing a few times and use the best time. The -r option is
good for this; the default of 3 repetitions is probably enough in most
cases. On Unix, you can use clock() to measure CPU time.
Note: there is a certain baseline overhead associated with executing a
pass statement. The code here doesn't try to hide it, but you should
be aware of it. The baseline overhead can be measured by invoking the
program without arguments.
The baseline overhead differs between Python versions! Also, to
fairly compare older Python versions to Python 2.3, you may want to
use python -O for the older versions to avoid timing SET_LINENO
instructions.
这告诉使用所有我们可以通过的奇妙的标志,以及它们做什么。它也告诉我们一些关于 timeit 如何在幕后运作的事情。让我们写一个简单的函数,看看我们能否从命令行计时:
# simple_func.py
def my_function():
try:
1 / 0
except ZeroDivisionError:
pass
这个函数所做的只是导致一个被忽略的错误。是的,这是一个愚蠢的例子。为了让 timeit 在命令行上运行这段代码,我们需要将代码导入到它的名称空间中,所以请确保您已经将当前的工作目录更改为该脚本所在的文件夹。然后运行以下命令:
python -m timeit "import simple_func; simple_func.my_function()"
1000000 loops, best of 3: 1.77 usec per loop
这里导入函数,然后调用它。注意,我们用分号分隔导入和函数调用,Python 代码用引号括起来。现在我们准备学习如何在实际的 Python 脚本中使用 timeit 。
导入 timeit 进行测试
在代码中使用 timeit 模块也很容易。我们将使用之前相同的愚蠢脚本,并在下面向您展示如何操作:
def my_function():
try:
1 / 0
except ZeroDivisionError:
pass
if __name__ == "__main__":
import timeit
setup = "from __main__ import my_function"
print timeit.timeit("my_function()", setup=setup)
在这里,我们检查脚本是否正在直接运行(即没有导入)。如果是,那么我们导入 timeit ,创建一个设置字符串将函数导入到 timeit 的名称空间,然后我们调用 timeit.timeit 。您会注意到,我们用引号将对函数的调用传递出去,然后是设置字符串。这真的就是全部了!
包扎
现在你知道如何使用 timeit 模块了。它非常擅长计时简单的代码片段。您通常会将它用于您怀疑运行时间过长的代码。如果您想要更详细地了解代码中正在发生的事情,那么您可能希望切换到分析器。开心快乐编码!
- 关于 timeit 的 Python 文档
- py motw-Time it "对小部分 Python 代码的执行进行计时。
- 在 timeit 上深入研究 Python 部分
- 关于 timeit 的梦想代码论坛教程
如何在演示之外使用 wxPython 演示代码
原文:https://www.blog.pythonlibrary.org/2018/01/23/how-to-use-wxpython-demo-code-outside-the-demo/
有时,有人会问他们如何在演示之外运行来自 wxPython 的演示代码。换句话说,他们想知道如何从演示中提取代码并在自己的程序中运行。我想我很久以前在 wxPython wiki 上写过这个主题,但是我想我也应该在这里写这个主题。
如何处理日志
我经常看到的第一个问题是,演示代码中充满了对某种日志的调用。它总是写入该日志,以帮助开发人员了解不同的事件是如何触发的,或者不同的方法是如何调用的。这一切都很好,但这使得从演示中复制代码变得很困难。让我们从 wx 中取出代码。ListBox 演示作为一个例子,看看我们是否可以让它在演示之外工作。下面是演示代码:
import wx
#----------------------------------------------------------------------
# BEGIN Demo Code
class FindPrefixListBox(wx.ListBox):
def __init__(self, parent, id, pos=wx.DefaultPosition, size=wx.DefaultSize,
choices=[], style=0, validator=wx.DefaultValidator):
wx.ListBox.__init__(self, parent, id, pos, size, choices, style, validator)
self.typedText = ''
self.log = parent.log
self.Bind(wx.EVT_KEY_DOWN, self.OnKey)
def FindPrefix(self, prefix):
self.log.WriteText('Looking for prefix: %s\n' % prefix)
if prefix:
prefix = prefix.lower()
length = len(prefix)
# Changed in 2.5 because ListBox.Number() is no longer supported.
# ListBox.GetCount() is now the appropriate way to go.
for x in range(self.GetCount()):
text = self.GetString(x)
text = text.lower()
if text[:length] == prefix:
self.log.WriteText('Prefix %s is found.\n' % prefix)
return x
self.log.WriteText('Prefix %s is not found.\n' % prefix)
return -1
def OnKey(self, evt):
key = evt.GetKeyCode()
if key >= 32 and key <= 127:
self.typedText = self.typedText + chr(key)
item = self.FindPrefix(self.typedText)
if item != -1:
self.SetSelection(item)
elif key == wx.WXK_BACK: # backspace removes one character and backs up
self.typedText = self.typedText[:-1]
if not self.typedText:
self.SetSelection(0)
else:
item = self.FindPrefix(self.typedText)
if item != -1:
self.SetSelection(item)
else:
self.typedText = ''
evt.Skip()
def OnKeyDown(self, evt):
pass
#---------------------------------------------------------------------------
class TestListBox(wx.Panel):
def __init__(self, parent, log):
self.log = log
wx.Panel.__init__(self, parent, -1)
sampleList = ['zero', 'one', 'two', 'three', 'four', 'five',
'six', 'seven', 'eight', 'nine', 'ten', 'eleven',
'twelve', 'thirteen', 'fourteen']
wx.StaticText(self, -1, "This example uses the wx.ListBox control.", (45, 10))
wx.StaticText(self, -1, "Select one:", (15, 50))
self.lb1 = wx.ListBox(self, 60, (100, 50), (90, 120), sampleList, wx.LB_SINGLE)
self.Bind(wx.EVT_LISTBOX, self.EvtListBox, self.lb1)
self.Bind(wx.EVT_LISTBOX_DCLICK, self.EvtListBoxDClick, self.lb1)
self.lb1.Bind(wx.EVT_RIGHT_UP, self.EvtRightButton)
self.lb1.SetSelection(3)
self.lb1.Append("with data", "This one has data");
self.lb1.SetClientData(2, "This one has data");
wx.StaticText(self, -1, "Select many:", (220, 50))
self.lb2 = wx.ListBox(self, 70, (320, 50), (90, 120), sampleList, wx.LB_EXTENDED)
self.Bind(wx.EVT_LISTBOX, self.EvtMultiListBox, self.lb2)
self.lb2.Bind(wx.EVT_RIGHT_UP, self.EvtRightButton)
self.lb2.SetSelection(0)
sampleList = sampleList + ['test a', 'test aa', 'test aab',
'test ab', 'test abc', 'test abcc',
'test abcd' ]
sampleList.sort()
wx.StaticText(self, -1, "Find Prefix:", (15, 250))
fp = FindPrefixListBox(self, -1, (100, 250), (90, 120), sampleList, wx.LB_SINGLE)
fp.SetSelection(0)
def EvtListBox(self, event):
self.log.WriteText('EvtListBox: %s, %s, %s\n' %
(event.GetString(),
event.IsSelection(),
event.GetSelection()
# event.GetClientData()
))
lb = event.GetEventObject()
# data = lb.GetClientData(lb.GetSelection())
# if data is not None:
# self.log.WriteText('\tdata: %s\n' % data)
def EvtListBoxDClick(self, event):
self.log.WriteText('EvtListBoxDClick: %s\n' % self.lb1.GetSelection())
self.lb1.Delete(self.lb1.GetSelection())
def EvtMultiListBox(self, event):
self.log.WriteText('EvtMultiListBox: %s\n' % str(self.lb2.GetSelections()))
def EvtRightButton(self, event):
self.log.WriteText('EvtRightButton: %s\n' % event.GetPosition())
if event.GetEventObject().GetId() == 70:
selections = list(self.lb2.GetSelections())
selections.reverse()
for index in selections:
self.lb2.Delete(index)
#----------------------------------------------------------------------
# END Demo Code
#----------------------------------------------------------------------
我不打算解释演示代码本身。相反,当我想尝试在演示之外运行它时,我将把重点放在这段代码出现的问题上。在演示的最后有一个 runTest 函数,我没有复制它,因为如果你在演示之外复制它,代码不会做任何事情。你看,演示代码有某种包装来使它工作。如果你想使用演示代码,你需要添加你自己的“包装器”。
这段代码呈现的主要问题是许多方法都调用了 self.log.WriteText 。您不能从代码中看出 log 对象是什么,但是您知道它有一个 WriteText 方法。在演示中,您会注意到,当其中一个方法触发时,WriteText 调用似乎会写入演示底部的文本控件。所以日志必须是一个文本控件!
有许多不同的方法可以解决日志问题。以下是我最喜欢的三个:
- 移除对 self.log.WriteText 的所有调用
- 创建我自己的文本控件并将其传入
- 用 WriteText 方法创建一个简单的类
我在很多场合都选择了第一种,因为这是一种简单的开始方式。但是对于教程来说,这有点无聊,所以我们将选择第三个选项,用 WriteText 方法创建一个类!将以下代码添加到包含上述代码的同一文件中:
#----------------------------------------------------------------------
# Start Your own code here
class FakeLog:
"""
The log in the demo is a text control, so just create a class
with an overridden WriteText function
"""
def WriteText(self, string):
print(string)
# Create a frame that can wrap your demo code (works in most cases)
class MyFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title='Listbox demo',
size=(800,600))
log = FakeLog()
panel = TestListBox(self, log=log)
self.Show()
if __name__ == '__main__':
app = wx.App(False)
frame = MyFrame()
app.MainLoop()
这里我们只是用 WriteText 方法创建了一个 FakeLog ,它接受一个字符串作为唯一的参数。该方法所做的就是将字符串打印到 stdout。然后我们创建 wx 的一个子类。框架,初始化我们的假日志和演示代码,并显示我们的框架。现在我们有了一个不在演示中的演示代码!如果你愿意,你可以在 Github 上获得完整的代码。
其他演示问题
还有一些其他的演示没有遵循与列表框演示完全相同的 API。例如,如果你尝试使用我在上面为 wx 创建的类。按钮演示,你会发现它的 log 对象调用的是 write()方法而不是 WriteText()方法。在这种情况下,解决方案是显而易见的,因为我们只需要向我们的假日志记录类添加第二个方法:
class FakeLog:
"""
The log in the demo is a text control, so just create a class
with an overridden WriteText function
"""
def WriteText(self, string):
print(string)
def write(self, string):
print(string)
现在我们的演示运行代码更加灵活了。然而,当我让我的一个读者测试这段代码时,他们注意到了一个关于 wx 的问题。ListCtrl 演示。问题是它导入了一个名为“images”的模块。实际上有几个演示引用了这个模块。你只需要从演示中复制 images.py ,并把它放在你正在编写的脚本所在的位置,这样你就可以导入它了。
注意:我收到一份报告,说 wxPython 4 最新测试版中包含的 images.py 文件对他们不适用,他们不得不从旧版本的演示中获取一份副本。我自己没有遇到过这个问题,但请记住这一点。
包扎
现在,您应该有了让 wxPython 演示中的大多数演示在您自己的代码中工作所需的工具。去抓些代码来试试吧!编码快乐!
如何用 Python 给你的照片加水印
原文:https://www.blog.pythonlibrary.org/2017/10/17/how-to-watermark-your-photos-with-python/
当你在网上查找照片时,你会注意到有些照片带有水印。水印通常是覆盖在照片上的一些文本或徽标,用于标识照片的拍摄者或照片的所有者。一些专业人士建议在社交媒体上分享照片之前给照片添加水印,以防止其他人将你的照片用作自己的照片,并从你的作品中获利。当然,水印可以很容易地被移除,所以这并不像过去作为数字版权工具那样有用。
反正枕头包提供了给照片添加水印所需的工具!如果你还没有安装枕头,你需要做的第一件事是:
pip install pillow
一旦安装完毕,我们就可以继续了!
添加文本水印
我们将从给照片添加一些文字开始。让我们用这张我在俄勒冈州拍摄的耶奎纳灯塔的照片:
现在我们将添加一些文字到图像中。在这种情况下,让我们添加我的域名:www.mousevspython.com
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
def watermark_text(input_image_path,
output_image_path,
text, pos):
photo = Image.open(input_image_path)
# make the image editable
drawing = ImageDraw.Draw(photo)
black = (3, 8, 12)
font = ImageFont.truetype("Pillow/Tests/fonts/FreeMono.ttf", 40)
drawing.text(pos, text, fill=black, font=font)
photo.show()
photo.save(output_image_path)
if __name__ == '__main__':
img = 'lighthouse.jpg'
watermark_text(img, 'lighthouse_watermarked.jpg',
text='www.mousevspython.com',
pos=(0, 0))
这里我们从 PIL 导入几个类: Image 、 ImageDraw 和 ImageFont 。然后我们创建一个函数, watermark_text ,它有四个参数:输入图像页面、输出图像路径、要添加到图像中的文本以及放置文本的位置坐标。
接下来,我们打开我们的形象。然后,我们基本上通过使用 ImageDraw 重新绘制图像来制作图像的副本。绘制方法。这使得我们可以更容易地向其中添加文本。然后我们使用 ImageFont.truetype 创建一个字体。该字体是 Pillow 库中包含的一种字体。我们也将字体大小设置为 40 磅。最后我们显示结果并保存到磁盘。结果如下:

现在让我们继续添加图像,而不仅仅是文本!
用图像加水印
大多数专业摄影师最终都会在他们的照片上打上商标。有时这包括他们网站的风格化“照片”版本。在 Pillow 中将一张照片添加到另一张照片也相当容易。让我们来看看怎么做吧!
在这个例子中,我们将使用我的一个标志作为水印图像。
from PIL import Image
def watermark_photo(input_image_path,
output_image_path,
watermark_image_path,
position):
base_image = Image.open(input_image_path)
watermark = Image.open(watermark_image_path)
# add watermark to your image
base_image.paste(watermark, position)
base_image.show()
base_image.save(output_image_path)
if __name__ == '__main__':
img = 'lighthouse.jpg'
watermark_with_photo(img, 'lighthouse_watermarked2.jpg',
'watermark.png', position=(0,0))
这里我们创建了一个与上一节中的函数非常相似的函数,但是我们没有传入文本,而是传入水印的文件路径。在该函数中,我们打开了我们想要水印的图像以及水印图像本身。然后,我们获取要添加水印的图像并调用它的 paste() 方法,同时传入我们想要粘贴的内容(即水印)和我们想要粘贴的位置。最后,我们显示图像并保存它。结果如下:

嗯,这并没有按照我预想的方式进行。正如你所看到的,有一个黑色的背景遮挡了很多照片,因为当我们粘贴它时,我们没有考虑到透明度。
用透明度给图像加水印
让我们创建一个新的函数,可以使用透明度,所以我们从水印中删除所有的黑色。我在 StackOverflow 上找到了这个问题的解决方案,所以我在这个例子中使用了它并稍微修改了一下
from PIL import Image
def watermark_with_transparency(input_image_path,
output_image_path,
watermark_image_path,
position):
base_image = Image.open(input_image_path)
watermark = Image.open(watermark_image_path)
width, height = base_image.size
transparent = Image.new('RGBA', (width, height), (0,0,0,0))
transparent.paste(base_image, (0,0))
transparent.paste(watermark, position, mask=watermark)
transparent.show()
transparent.save(output_image_path)
if __name__ == '__main__':
img = 'lighthouse.jpg'
watermark_with_transparency(img, 'lighthouse_watermarked3.jpg',
'watermark.png', position=(0,0))
在这段代码中,我们接受了与上一个例子中相同的所有参数。这一次,我们不仅打开了两幅图像,而且还获取了想要添加水印的图像的宽度和高度。然后,我们创建一个新的图像使用相同的宽度和高度的图像,我们是水印。你会注意到,我们创建的这个图像是 RGBA,这意味着它有红色,绿色和蓝色的阿尔法。接下来,我们粘贴在图像中,我们想水印从左上角开始,这是(0,0)。然后,我们使用传入的位置粘贴我们的水印,我们还用水印本身来屏蔽水印。最后我们显示并保存图像。
生成的图像如下所示:

很酷,是吧?
包扎
在这篇文章中,我们介绍了两种不同的给照片添加水印的方法。在第一个例子中,我们所做的只是将您选择的文本添加到图像中。第二个例子演示了一种添加图像水印的方法,但是它没有考虑 alpha(透明度)。我们用第三个例子纠正了这个问题。我希望这些例子对你有所帮助。编码快乐!
相关阅读
- StackOverflow: 如何将一张带有透明度的 PNG 图片粘贴到另一张没有白色像素的 PIL 图片上?
- 如何用 Python 调整照片大小
- 用 Python 将一张照片转换成黑白
- 如何用 Python 旋转/镜像照片
- 如何用 Python 裁剪照片
Python Kickstarter 的图像处理即将结束
原文:https://www.blog.pythonlibrary.org/2021/01/25/image-processing-with-python-kickstarter-ending-soon/
我的新书《枕头:用 Python 处理图像》的 Kickstarter 将在 8 天后结束。你应该去看看,学习如何用 Python 编辑照片!

你将在本书中了解到以下主题:
- 第 1 章-枕头基础知识
- 第 2 章-颜色
- 第 3 章-获取图像元数据(ExifTags / TiffTags)
- 第 4 章-图像过滤器
- 第 5 章-裁剪、旋转和调整图像大小
- 第 6 章-增强图像(ImageEnhance)
- 第 7 章-组合图像
- 第 8 章-用枕头画画(ImageDraw)
- 第 9 章-绘图文本
- 第 10 章-图像印章
- 还有更多!
上周末,我实现了我的第一个延伸目标,并将为这本书增加两个新的章节。查看 Kickstarter 了解详情!
改进 MediaLocker: wxPython、SQLAlchemy 和 MVC
原文:https://www.blog.pythonlibrary.org/2011/11/30/improving-medialocker-wxpython-sqlalchemy-and-mvc/
这个博客在本月早些时候发表了一篇关于 wxPython、SQLAlchemy、CRUD 和 MVC 的文章。我们在那篇文章中创建的程序被称为“MediaLocker”,不管它是否被明确地这样表述。无论如何,从那以后,我收到了一些关于改进程序的评论。一条来自 SQLAlchemy 本身的创意者之一 Michael Bayer,另一条来自 Werner Bruhin,一个经常出现在 wxPython 邮件列表中帮助新用户的好人。因此,我按照他们的建议着手创建代码的改进版本。沃纳随后对其进行了进一步的改进。所以在这篇文章中,我们将着眼于改进代码,首先是我的例子,然后是他的例子。尽管说得够多了;让我们进入故事的实质吧!
让 MediaLocker 变得更好
Michael Bayer 和 Werner Bruhin 都认为我应该只连接数据库一次,因为这是一个相当“昂贵”的操作。如果同时存在多个会话,这可能是一个问题,但即使在我的原始代码中,我也确保关闭会话,这样就不会发生这种情况。当我编写最初的版本时,我考虑过将会话创建分离出来,但最终采用了我认为更简单的方法。为了解决这个棘手的问题,我修改了代码,这样我就可以传递会话对象,而不是不断地调用控制器的 connectToDatabase 函数。你可以阅读更多关于会议在这里。请看来自 mediaLocker.py 的代码片段:
class BookPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent)
if not os.path.exists("devdata.db"):
controller.setupDatabase()
self.session = controller.connectToDatabase()
try:
self.bookResults = controller.getAllRecords(self.session)
except:
self.bookResults = []
注意,我们前面有一个小的条件,如果数据库还不存在,它将创建数据库。接下来,我在主 GUI 中创建会话对象,作为 panel 子类的属性。然后我把它传到我需要的地方。上面可以看到一个例子,我将会话对象传递给控制器的 getAllRecords 方法。
另一个大的变化是从 model.py 中删除了 ObjectListView 模型,而只使用 SQLAlchemy 表类:
########################################################################
class Book(DeclarativeBase):
""""""
__tablename__ = "book"
id = Column(Integer, primary_key=True)
author_id = Column(Integer, ForeignKey("person.id"))
title = Column(Unicode)
isbn = Column(Unicode)
publisher = Column(Unicode)
person = relation("Person", backref="books", cascade_backrefs=False)
@property
def author(self):
return "%s %s" % (self.person.first_name, self.person.last_name)
除了使用 SQLAlchemy 构造之外,这实际上与原始类基本相同。我还需要添加一个特殊的属性来返回作者的全名,以便在我们的小部件中显示,所以我们使用了 Python 的内置函数: property ,它返回一个 property 属性。如果只看代码的话更容易理解。如您所见,我们将属性作为装饰器应用于作者方法。
沃纳增补
沃纳的补充大多是在模型中增加更明确的进口。模型的最大变化如下:
import sys
if not hasattr(sys, 'frozen'):
# needed when having multiple versions of SA installed
import pkg_resources
pkg_resources.require("sqlalchemy") # get latest version
import sqlalchemy as sa
import sqlalchemy.orm as sao
import sqlalchemy.ext.declarative as sad
from sqlalchemy.ext.hybrid import hybrid_property
maker = sao.sessionmaker(autoflush=True, autocommit=False)
DBSession = sao.scoped_session(maker)
class Base(object):
"""Extend the base class
- Provides a nicer representation when a class instance is printed.
Found on the SA wiki, not included with TG
"""
def __repr__(self):
return "%s(%s)" % (
(self.__class__.__name__),
', '.join(["%s=%r" % (key, getattr(self, key))
for key in sorted(self.__dict__.keys())
if not key.startswith('_')]))
DeclarativeBase = sad.declarative_base(cls=Base)
metadata = DeclarativeBase.metadata
def init_model(engine):
"""Call me before using any of the tables or classes in the model."""
DBSession.configure(bind=engine)
前几行是为在机器上安装了 SetupTools / easy_install 的人准备的。如果用户安装了多个版本的 SQLALchemy,它将强制用户使用最新的版本。大多数其他导入都被缩短了,以使各种类和属性的来源变得非常明显。老实说,我对 hybrid_property 并不熟悉,所以下面是它的 docstring 所说的:
一个装饰器,允许用实例级和类级行为定义 Python 描述符。
你可以在这里阅读更多:http://www.sqlalchemy.org/docs/orm/extensions/hybrid.html
Werner 还在基类中添加了一个小的 repr 方法,使它在打印时返回一个更好的类实例表示,这对于调试来说很方便。最后,他添加了一个名为 init_model 的函数来初始化模型。
包扎
现在您应该知道,Werner 和我已经决定将 MediaLocker 做成一个支持 wxPython 数据库的应用程序的例子。自从我上面提到的简单编辑之后,他已经在这上面做了很多工作。我们将很快就此发布官方声明。与此同时,我希望这有助于打开你的眼界,找到一些有趣的方法来增强一个项目,并使它变得干净一点。我的计划是给这个程序增加很多新的特性,并且除了我所有的其他文章之外,在这个博客上记录这些特性。
源代码
Black 简介——不妥协的 Python 代码格式化程序
有几个 Python 代码检查器可用。例如,许多开发人员喜欢使用 Pylint 或 Flake8 来检查他们代码中的错误。这些工具使用静态代码分析来检查代码中的错误或命名问题。Flake8 还会检查你的代码,看看你是否遵守了 Python 的风格指南 PEP8 。
然而,有一个新的工具你可以使用,叫做黑色。Black 是一个 Python 代码格式化程序。它会根据黑色代码的风格重新格式化你的整个文件,非常接近 PEP8。
装置
安装黑色很容易。您可以使用 pip 来实现这一点:
pip install black
你也可以按照这些指令配置流行的文本编辑器和 ide 来使用黑色。
既然黑装了,那就试一试吧!
使用黑色
Black 要求你有一些代码来运行它。让我们创建一个有许多参数的简单函数,然后在该脚本上运行 Black。
这里有一个例子:
def long_func(x, param_one=None, param_two=[], param_three={}, param_four=None, param_five="", param_six=123456):
print("This function has several params")
现在,在您的终端中,尝试对您的代码文件运行black,如下所示:
black long_func.py
当您运行这个命令时,您应该看到下面的输出:
reformatted long_func.py All done! 1 file reformatted.
这意味着您的文件已被重新格式化,以遵循黑色标准。
让我们打开文件,看看它是什么样子的:
def long_func(
x,
param_one=None,
param_two=[],
param_three={},
param_four=None,
param_five="",
param_six=123456,
):
print("This function has several params")
如您所见,Black 已将每个参数放在各自的行上。
检查文件格式
如果您不希望 Black 更改您的文件,但您想知道 Black 是否认为某个文件应该更改,您可以使用以下命令标志之一:
--check-检查文件是否应该重新格式化,但不实际修改文件--diff-写出 Black 对文件的不同处理,但不修改文件
我喜欢用这些来测试我的文件,看看 Black 会如何重新格式化我的代码。我没有用黑色很长时间,所以这让我看看我是否喜欢黑色将要做的事情,而不实际做任何事情。
包扎
我喜欢黑色。我认为这真的很有用,尤其是在一个组织中实施某种 Python 风格的时候。请注意,黑色默认为 88 个字符,但您可以使用-l更改
或者--line-length
如果需要的话。在项目的页面上还列出了一些其他有用的选项。如果有机会,我觉得你应该给布莱克一个尝试!
相关阅读
- PyLint: 分析 Python 代码
- py flakes "Python 程序的被动检查器
- Python 101: 第 32 集—静态代码分析
使用 doctest 测试 Python 简介(视频)
原文:https://www.blog.pythonlibrary.org/2022/04/05/intro-to-testing-python-with-doctest-video/
这个视频教程教你使用 Python 的 doctest 模块测试代码的基本知识。
这个视频基于我的文章用 doctest 进行 Python 测试。
https://www.youtube.com/embed/JheIJurFvHs?feature=oembed
想学习更多 Python?在 Leanpub、T2、Gumroad 或 T4 亚马逊网站上查看我的一些 Python 书籍。
Python 社区正在变得有毒吗?
原文:https://www.blog.pythonlibrary.org/2020/08/04/is-the-python-community-becoming-toxic/
Python 社区太神奇了。我在 15 年前开始学习 Python,社区几乎总是非常支持我解决问题。然而,过去几年似乎发生了转变。我不确定这只是因为 Python 变得如此受欢迎,还是因为一些更基本的东西,比如人们对事物变得更加敏感。不管是什么,这个社区似乎正在远离它曾经的样子。
我第一次开始思考这个问题是在 Brett Cannon 的 PyCon 主题演讲中,他讲述了他在开源社区的经历,以及我们应该如何善待彼此。太多的人认为他们在请求功能或错误修复时会很粗鲁。但他也提到,维护者也需要有良好的态度,不要赶走潜在的新贡献者。
这个主题演讲之后的几个月,Python 语言的创始人 Guido Van Rossum 突然从 Python 负责人的位置上退了下来。当时给出的理由是围绕 PEP 572 有太多的恶语相向和争斗,以至于他提前下台了。
今年,我们看到 PyTest 团队的许多成员退出了这个项目。另外, Python 核心开发人员之一因不同意带有政治色彩的提交消息而被禁止。
虽然 Reddit 和 StackOverflow 仍然很受欢迎,但根据我的经验,我发现很难进入它们。Reddit Python 社区虽然非常庞大和多样化,但充满了巨魔,而且版主似乎不遵守 Reddit 自己的规则。就我个人而言,仅仅在上面发布文章就有问题,而我认识的其他人则因为他们的项目被认为不够“Pythonic 化”而受到骚扰。例如,PySimpleGUI 项目在那里被反复妖魔化。
我认为我们可以做得更好。Python 仍然是我最喜欢的语言,它的社区仍然很有趣。我认为我们应该注意我们社区发生的事情,并有意识地努力对彼此更友好。当你写错误报告或者请求一个特性的时候要小心。这些项目大多是志愿者在业余时间免费运营的。
不过,这些项目的核心开发人员也需要善良。我记得有一次我试图报告一个 bug,收到的回复是一条非常简洁的消息,说这是重复的,或者他们已经知道了这个问题。即使有经验的开发人员也不总是知道如何搜索合适的关键字,尤其是如果他们是该软件包或技术的新用户。
我只是想花一点时间来揭示这个话题,并鼓励我的读者在写作或说话之前思考。电话那头有一个真实的人可能今天过得很糟糕。不要让事情变得更糟。其实可以的话,做的更好!
2012 年 1 月 Pyowa 总结
原文:https://www.blog.pythonlibrary.org/2012/01/07/january-2012-pyowa-wrap-up/
上周四(5 日),我参加了几年前我创建的爱荷华 Python 用户团体 Pyowa。我们请来了信安金融集团的 Scott Peterson,他和我们聊了聊图书馆小工具,这是一个基于 Django 的很酷的网站,他创建这个网站是为了跟踪他的家人在图书馆借了什么书。现在他有很多用户使用他的网站。它不仅能跟踪你借的书,还能自动续借,并让你知道你的书是否过期了。
不过,他大部分时间都在谈论网站背后的后台内容。比如他为什么选择亚马逊网络服务,他如何使用木偶、流浪者和织物来管理他的服务器设置并备份它们。
第二个演讲是我自己做的,我谈到了我的 MediaLocker 项目,这是一个开源的 wxPython 应用程序,应该可以帮助你跟踪你的媒体库。我的大部分时间都花在讲述项目背后的故事和展示演示上。然后我回答了一些问题。
总的来说,我认为我们开了一个非常好的会议,有 10 个人出席。下个月,2 月 2 号,我们会带来大人物。我们已经安排了道格·海尔曼和 T2·史蒂夫·霍尔登通过 Skype 与我们交谈。
Doug Hellman 是 Python Standard Library By Example 的作者,是 Racemi,Inc .的高级开发人员,也是 Python 软件基金会的交流总监。他从 Python 版本开始编程,并在地图绘制、医学出版、银行和数据中心自动化的多个平台上工作过。Hellmann 以前是 Python 杂志的专栏作家和主编,自 2007 年以来,他一直在博客上发表流行的 Python 模块
史蒂夫·霍尔登是 Python 软件基金会主席,也是《Python Web 编程》一书的作者。他拥有 Python 咨询业务,从事 Python 培训。
jsonpickle:将 Python pickles 变成 JSON
原文:https://www.blog.pythonlibrary.org/2014/08/13/jsonpickle-turning-python-pickles-into-json/
前几天,我在 StackOverflow 上看到一个有趣的问题,作者问是否有办法将 Python 字典序列化为人类可读的格式。给出的答案是使用一个名为 jsonpickle 的包,它将复杂的 Python 对象序列化到 JSON 和从 JSON 序列化。本文将向您简要介绍如何使用这个项目。
入门指南
要正确开始,您需要下载并安装 jsonpickle。通常,您可以使用 pip 来完成这项任务:
pip install jsonpickle
Python 2.6 或更高版本没有依赖性。对于旧版本的 Python,您需要安装一个 JSON 包,比如 simplejson 或 demjson。
使用 jsonpickle
让我们从创建一个简单的基于汽车的类开始。然后我们将使用 jsonpickle 序列化该类的一个实例,并对其进行反序列化。
import jsonpickle
########################################################################
class Car(object):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self.wheels = 4
self.doors = 5
#----------------------------------------------------------------------
def drive(self):
""""""
print "Driving the speed limit"
if __name__ == "__main__":
my_car = Car()
serialized = jsonpickle.encode(my_car)
print serialized
my_car_obj = jsonpickle.decode(serialized)
print my_car_obj.drive()
如果您运行此代码,您应该会看到类似下面的输出:
{"py/object": "__main__.Car", "wheels": 4, "doors": 5}
Driving the speed limit
这非常有效。序列化的对象在打印出来时非常容易阅读。重构序列化对象也非常简单。
包扎
jsonpickle 包允许开发人员通过其 load_backend 和 set_preferred_backend 方法选择他们想要使用的 JSON 后端来编码和解码 JSON。如果愿意,您还可以自定义序列化处理程序。总的来说,我相信对于需要能够容易地阅读他们的序列化输出的开发人员来说,这可能是一个方便的项目。
相关阅读
- jsonpickle API 引用
2011 年 6 月 Pyowa 总结
原文:https://www.blog.pythonlibrary.org/2011/06/03/june-2011-pyowa-wrapup/
昨天,也就是 6 月 2 日星期四,我们在西得梅因的 IMT 集团大楼举行了每月一次的聚会。提供茶点。有汽水和小凯撒比萨。
我们进行了两次愉快的谈话。第一个演讲由 Scott 主讲,他谈到了使用 Python 在梁永能标签打印机上打印标签和使用 Python 在 IPP 打印的主题。梁永能打印是使用 PyWin32 库完成的。Scott 自己写了一个模块,包装了一些梁永能的 COM 对象。基本上,他可以将使用梁永能软件创建的预先创建的标签文件以及打印标签的字符串传递给他的模块。在他演讲的后半部分,他向我们讲述了他对 pkipplib 模块的使用,该模块允许他在任何使用 IPP 或 CUPS 的打印机上打印,CUPS 是 Linux 中常见的打印系统。你可以阅读模块的文档了解更多信息。从它的声音来看,你可以从任何地方通过 HTTPS 打印到打印机,假设你的防火墙和打印机配置正确。
最后一个演讲是关于 Pisa (又名 xhtml2pdf?)马特给的。这允许开发人员通过编写 HTML 然后通过 Pisa 运行它来创建 pdf。该模块可以使用 CSS 来帮助样式的报告,它支持页眉,页脚和分页符。总的来说,它看起来很酷。
我们的下一次 Pyowa 会议是在 2011 年 7 月 7 日。如果你想谈谈你最近用 Python 做的一些事情,只需给我发电子邮件:mike at pythonlibrary dot org 或者加入邮件列表或者留下评论。你也可以随时出来加入乐趣。我们也允许闪电对话!
2010 年 6 月 Pyowa 总结
原文:https://www.blog.pythonlibrary.org/2010/06/04/june-pyowa-2010-wrap-up/
我们昨晚在爱荷华州的艾姆斯开了六月派沃会议。有九个人出席,这对我们组来说是相当大的一个人数。我想我们只在另外一个场合管理过这么多人。感谢每一个传播消息并邀请他们朋友的人。
在会议上,我演示了一个我已经工作了大约一个月的 wxPython 音乐播放器。它使用跨平台的 mplayer 作为后端,wxPython 作为前端。现在,它允许用户将一个 MP3 文件夹加载到一个自定义列表控件(技术上是一个 ObjectListView 小部件实例)中,并通过选择一首曲目后按下播放按钮或双击曲目来逐个播放它们。该播放器还显示封面(如果有的话),有一个音量控制和播放滑块。
在我开始演示之前,有人问我如何使用 py2exe 创建可执行文件,所以我用 GUI2Exe 做了一个即兴演示。当我试图构建 exe 时,我重新发现 py2exe 不喜欢 egg 文件,所以我必须解压缩这些文件,以便它可以找到项目所需的模块。一旦完成,程序就可以很好地编译了。
下一次,我们将在西得梅因的 IMT 集团大楼见面。将提供比萨饼和汽水,所以饿着肚子来吧!会谈将是关于 Django,TurboGears 和(可能)SWIG。那将发生在 7 月 1 日。我希望你能成功!
Jupyter 笔记本 101 预购
原文:https://www.blog.pythonlibrary.org/2018/08/28/jupyter-notebook-101-pre-order/
我最新的书,Jupyter Notebook 101 T1,现在已经可以在 T2 Leanpub 上预订了。
这本书计划于 2018 年 11 月日前完成。如果你购买这本书,你会得到 PDF,ePub 和 mobi 格式。
以 5 美元的价格买下它,因为它是我 9 月 1 日结束的秋季销售的一部分!
以下是您可以使用的特殊链接:
朱庇特笔记本 101 预览章节
原文:https://www.blog.pythonlibrary.org/2018/07/25/jupyter-notebook-101-preview-chapters/
我目前正在写一本名为 Jupyter Notebook 101 的新书,计划在 2018 年 11 月发行。我整理了一份 PDF 文件,展示了这本书前几章的草稿以及一个附录。你可以在这里查看 PDF 文件:
如果你想预订这本书或者只是想了解更多,你可以在 Kickstarter 上预订。
Jupyter 笔记本 101 发布!
原文:https://www.blog.pythonlibrary.org/2018/11/13/jupyter-notebook-101-released/
我最新的一本书,Jupyter 笔记本 101 现在正式发行。

您可以在以下零售商处购买:
- 亚马逊 (Kindle 或平装)
- Leanpub (mobi、epub 和 PDF)在以 9.99 美元的价格出售,直到 11 月底
- Gumroad (mobi、epub 和 PDF)
你也可以从 Leanpub 下载这本书的样本。在 Leanpub 上只需花 9.99 美元就能在限定时间内买到!
Jupyter Notebook 101 将教你如何有效地创建和使用笔记本。您可以使用 Jupyter Notebook 来帮助您学习编码、创建演示文稿和制作精美的文档。
Jupyter 笔记本被科学界用来以一种易于复制的方式展示研究。
你将在 Jupyter 笔记本 101 中学到以下内容:
- 如何创建和编辑笔记本
- 如何添加样式、图像、图表等
- 如何配置笔记本
- 如何将您的笔记本导出为其他格式
- 笔记本扩展
- 使用笔记本进行演示
- 笔记本小工具
- 还有更多!
朱庇特笔记本 101:目录
原文:https://www.blog.pythonlibrary.org/2018/07/31/jupyter-notebook-101-table-of-contents/
我的新书 Jupyter Notebook 101 的 Kickstarter 活动已经进行了一半,我觉得分享我目前的暂定目录会很有趣:
- 介绍
- 第 1 章:创建笔记本
- 第 2 章:富文本(降价、图片等)
- 第 3 章:配置笔记本电脑
- 第 4 章:分发笔记本
- 第 5 章:笔记本扩展
- 第 6 章:笔记本部件
- 第 7 章:将笔记本转换成其他格式
- 第 8 章:用笔记本创建演示文稿
- 附录 A:魔法命令
目录的内容或顺序可能会改变。不过,我会尝试以某种形式涵盖所有这些主题。如果有时间的话,我还会研究一些其他的主题,比如对笔记本进行单元测试。我的一些支持者还要求提供跨 Python 版本管理 Jupyter、使用 Conda 和如果你可以将笔记本用作程序的章节。我也会研究这些,以确定它们是否在本书的范围内,以及我是否有时间添加它们。
朱庇特笔记本 101:写作更新
原文:https://www.blog.pythonlibrary.org/2018/09/18/jupyter-notebook-101-writing-update/
我通常不会在写书的过程中在我的博客上写我的书,但我知道一些读者可能会奇怪为什么我没有像往常一样定期写博客。原因通常是因为我很喜欢为一本书写章节,如果这本书的章节不能翻译成好的博客文章,那么博客本身就不会有很多新内容。
无论如何,正如你可能知道的,我目前正在写一本叫做 Jupyter Notebook 101 的书,我目前计划在 11 月发行。我已经完成了计划的 11 章中的 7 章,尽管我计划在完成后浏览整本书并检查错误。我希望能早点完成其他章节,这样我也可以写一些额外的章节,但是我们会看看写作进展如何。从好的方面来说,后面的章节将会成为很好的博客素材,所以你可以期待在不久的将来在这个博客上看到一些关于 Jupyter 笔记本的有趣文章。
如果你对这本书感兴趣,你可以从 Leanpub 下载一个样本。
Jupyter 笔记本调试
原文:https://www.blog.pythonlibrary.org/2018/10/17/jupyter-notebook-debugging/
调试是一个重要的概念。调试的概念是试图找出你的代码有什么问题,或者只是试图理解代码。有很多次我会遇到不熟悉的代码,我需要在调试器中一步一步地调试它,以掌握它是如何工作的。大多数 Python IDEs 都内置了很好的调试器。例如,我个人喜欢 Wing IDE。其他人喜欢 PyCharm 或 PyDev。但是如果你想调试 Jupyter 笔记本里的代码呢?这是怎么回事?
在这一章中,我们将看看调试笔记本的几种不同的方法。第一种是通过使用 Python 自己的 pdb 模块。
使用 pdb
pdb 模块是 Python 的调试器模块。就像 C++有 gdb 一样,Python 有 pdb。
让我们首先打开一个新的笔记本,添加一个包含以下代码的单元格:
def bad_function(var):
return var + 0
bad_function("Mike")
如果您运行这段代码,您应该会得到如下所示的输出:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in <module>()
2 return var + 0
3
----> 4 bad_function("Mike")
<ipython-input-1-2f23ed1cac1e>in bad_function(var)
1 def bad_function(var):
----> 2 return var + 0
3
4 bad_function("Mike")
TypeError: cannot concatenate 'str' and 'int' objects
这意味着你不能把一个字符串和一个整数连接起来。如果你不知道一个函数接受什么类型,这是一个很常见的问题。您会发现在处理复杂的函数和类时尤其如此,除非它们碰巧使用了类型提示。弄清楚发生了什么的一种方法是使用 pdb 的 set_trace() 函数添加一个断点:
def bad_function(var):
import pdb
pdb.set_trace()
return var + 0
bad_function("Mike")
现在,当您运行单元时,您将在输出中得到一个提示,您可以使用该提示来检查变量并实际运行代码。如果你碰巧有 Python 3.7 ,那么你可以通过使用新的内置断点来简化上面的例子,就像这样:
def bad_function(var):
breakpoint()
return var + 0
bad_function("Mike")
这段代码在功能上等同于前面的例子,但是使用了新的断点函数。当您运行这段代码时,它的行为应该与上一节中的代码相同。
你可以在这里阅读更多关于如何使用 pdb 的信息。
您可以在 Jupyter 笔记本中使用任何 pdb 命令。以下是一些例子:
- w(此处)-打印堆栈跟踪
- d(own) -将当前帧下移 X 层。默认为 1。
- u(p) -将当前帧上移 X 层。默认为 1。
- b(break)-使用lineno参数,在当前文件/上下文中行号处设置一个断点
- s(tep) -执行当前行并停在下一行
- c(继续)-继续执行
请注意,这些是单字母命令:w、d、u 和 b 是命令。您可以使用这些命令以及上面列出的文档中列出的其他命令在笔记本中交互式调试您的代码。
ipdb
IPython 还有一个名为 ipdb 的调试器。然而,它不能直接与 Jupyter 笔记本电脑一起使用。您需要使用类似 Jupyter 控制台的东西连接到内核,并从那里运行它来使用它。如果你想走这条路,你可以在这里阅读更多关于使用 Jupyter 控制台的信息。
然而,我们可以使用一个名为IPython . core . debugger . set _ trace的 IPython 调试器。让我们用下面的代码创建一个单元格:
from IPython.core.debugger import set_trace
def bad_function(var):
set_trace()
return var + 0
bad_function("Mike")
现在,您可以运行这个单元并获得 ipdb 调试器。下面是我的机器上的输出:

IPython 调试器使用与 Python 调试器相同的命令。主要区别在于它提供了语法高亮显示,并且最初是设计用于 IPython 控制台的。
还有另一种方法可以打开 ipdb 调试器,那就是使用 %pdb 魔法。以下是您可以在笔记本单元格中尝试的一些示例代码:
%pdb
def bad_function(var):
return var + 0
bad_function("Mike")
当您运行这段代码时,您应该会看到“typeerror”trace back,然后 ipdb 提示符会出现在输出中,您可以像以前一样使用它。
%%debug 呢?
还有另一种方法可以在笔记本中打开调试器。您可以使用`%%debug '来调试整个单元,如下所示:
%%debug
def bad_function(var):
return var + 0
bad_function("Mike")
这将在您运行单元时立即启动调试会话。这意味着您可能希望使用 pdb 支持的一些命令来单步执行代码,并根据需要检查函数或变量。
请注意,如果您想调试一行代码,也可以使用“%debug”。
包扎
在这一章中,我们学习了几种不同的方法,可以用来调试 Jupyter 笔记本中的代码。我个人更喜欢使用 Python 的 pdb 模块,但是您可以使用 IPython.core.debugger 来获得相同的功能,如果您喜欢语法突出显示,它可能会更好。
还有一个更新的“可视化调试器”包,名为 PixieDebugger,来自于pixedust包:
我自己没用过。一些评论家说这是惊人的,其他人说这是相当错误的。我将让您来决定是否要将它添加到您的工具集中。
就我而言,我认为使用 pdb 或 IPython 的调试器工作得很好,应该也适合你。
相关阅读
- StackOverflow: 在 IPython Noteobook 中调试的正确方法是什么?
- 你一直想要的 Jupyter 笔记本的可视化 Python 调试器
- 调试 Jupyter 笔记本- 大卫·哈曼
Jupyter 笔记本扩展基础
原文:https://www.blog.pythonlibrary.org/2018/10/02/jupyter-notebook-extension-basics/
有几种方法可以扩展 Jupyter 笔记本的功能。以下是其中的四个:
- 核心
- IPython 内核扩展
- 笔记本扩展
- 笔记本服务器扩展
出于本文的目的,我将重点关注第三项,笔记本扩展。但是,让我们花一点时间来谈谈其他三个,以便您了解它们会如何影响您的笔记本电脑。
核心
内核基本上是运行时使用的语言。默认是通过 IPython 内核的 Python。您可以扩展您的 Jupyter 笔记本以使用除 Python 之外的其他语言。有关更多信息,请访问以下 URL:
由于每个内核都有不同的安装说明,所以我不会在本文中介绍其他内核的安装。应该使用上面的 URL,因为它有关于这个主题的最新信息的超链接。
如果你愿意,你也可以实现你自己的内核。这里有一个关于这个话题的很好的入门:
IPython 内核扩展
IPython 内核扩展只是一个 Python 模块,可用于修改交互式 shell 环境。在 Jupyter 的例子中,这些扩展将修改代码单元的行为。您可以使用这种类型的扩展来注册新的 magics、定义变量和修改用户的名称空间。您可以使用以下三个魔法来管理 IPython 扩展:
- %加载 _ 扩展
- %重载 _ 扩展
- %卸载 _ 外部
参见 IPython 文档了解这些魔法的全部细节。
笔记本服务器扩展
Jupyter 笔记本也有“服务器扩展”的概念。服务器扩展是一个 Python 模块,在笔记本的 web 服务器应用程序启动时加载。当前加载这种类型的扩展的方法是通过 Jupyter 的配置系统,我们在第 3 章中讨论过。您需要在配置文件中或通过命令行界面指定要加载的扩展。
如果您在 Jupyter Notebook 运行时添加了新的扩展,您将需要重新启动笔记本进程来激活新的扩展。
笔记本扩展
本章我们最关心的扩展类型是笔记本扩展。笔记本扩展(或 nbextensions)是 JavaScript 模块,可以加载到笔记本前端的大多数视图中。他们可以访问页面的 DOM 和 Jupyter JavaScript API,后者允许扩展修改用户体验和界面。这种类型的扩展是笔记本前端独有的。
让我们了解一下如何安装笔记本扩展。假设您已经下载/ pip 安装了包含扩展的包,那么手动安装 Jupyter 笔记本扩展的方法看起来就像这样:
jupyter nbextension install EXTENSION
jupyter nbextension enable EXTENSION
请注意,您可以用您打算安装的扩展的名称替换扩展。
管理笔记本扩展的另一种方法是使用 Jupyter NbExtensions 配置器,这种方法似乎获得了很多支持。你可以在这里查看项目。
这个包不是 Jupyter 项目的一部分,但是它非常有帮助。您可以使用 pip 或 conda 来安装配置器。以下是使用 pip 的方法:
pip install jupyter_nbextensions_configurator
如果您使用 conda 作为您的 Python 包管理器,那么您将像这样安装配置器:
conda install -c conda-forge jupyter_nbextensions_configurator
配置器是 Jupyter 服务器扩展,必须启用。在启动 Jupyter Notebook 之前,您需要在终端中运行以下命令(或者您可以重新启动服务器):
jupyter nbextensions_configurator enable --user
当我运行这个命令时,我得到了以下输出:
Enabling: jupyter_nbextensions_configurator
- Writing config: /Users/michael/.jupyter
- Validating...
jupyter_nbextensions_configurator 0.4.0 OK
Enabling notebook nbextension nbextensions_configurator/config_menu/main...
Enabling tree nbextension nbextensions_configurator/tree_tab/main...
启动 Jupyter Notebook 后,只需点击 Nbextensions 选项卡,您应该会看到如下内容:

由于我们没有下载和安装任何扩展,配置器看起来有点贫瘠,现在真的不能为我们做那么多。让我们得到一些扩展来尝试!
如果您要搜索 Jupyter 笔记本扩展,您会很快找到* * Jupyter _ contrib _ nb extensions * *。它是由 Jupyter 社区提供的笔记本扩展的集合。您可以通过以下任一链接了解此软件包中包含的扩展的更多信息:
- https://github . com/ipython-contrib/jupyter _ contrib _ nb extensions
- https://jupyter-contrib-nb extensions . readthedocs . io/en/latest/index . html
要安装这套扩展,您可以再次使用 pip 或 conda。以下是您将需要的 pip 命令:
pip install jupyter_contrib_nbextensions
以下是 conda 命令:
conda install -c conda-forge jupyter_contrib_nbextensions
一旦你下载并安装了这个包,你将需要使用一个 Jupyter 来安装 javascript 和 css 文件到正确的位置,以便笔记本可以访问它们。下面是您应该运行的命令:
jupyter contrib nbextension install --user
现在您已经安装了新的扩展,您可以使用我们之前安装的配置器工具来轻松启用或禁用它们:

正如你在上面的截图中看到的,现在有很多扩展可以使用。配置器对于确定您已经安装并启用了哪些扩展非常方便。您也可以分别使用 jupyter nbextension 启用扩展或 jupyter nbextension 禁用扩展在终端中手动启用和禁用笔记本扩展,但我个人觉得配置器更容易使用。
包扎
在本文中,我们了解了 Jupyter 可以使用的不同类型的扩展。我们最关心的是 Jupyter 笔记本扩展。然后,我们继续学习安装扩展的基础知识。我们还学习了如何使用终端以及通过 Jupyter NbExtensions 配置器包来启用和禁用扩展。
相关阅读
- 使用 Jupyter 笔记本创建演示文稿
- Jupyter 贡献了扩展
Kivy 101:如何使用盒子布局
原文:https://www.blog.pythonlibrary.org/2013/11/25/kivy-101-how-to-use-boxlayouts/
最近我开始学习 Kivy,一个 Python 自然用户界面(NUI)工具包。据我所知,Kivy 是 pyMT 的精神继承者,你可以在这里阅读更多关于 T2 的内容。在这篇文章中,我们将学习 Kivy 如何处理布局管理。虽然您可以使用 x/y 坐标来定位小部件,但是在我使用过的每个 GUI 工具包中,使用工具包提供的某种布局管理几乎总是更好。这允许小部件在用户改变窗口大小时适当地调整大小和移动。在基维,这些东西布局。如果你用过 wxPython,它们类似于 wxPython 的 sizers。
我还应该注意到,Kivy 可以用两种不同的方式进行布局。第一种方法是只使用 Python 代码进行布局。第二种方式是混合使用 Python 和 Kv 语言。这是为了促进模型-视图-控制器的工作方式。它看起来有点像 CSS,让我想起了 wxPython 和 XRC。我们将在本文中研究如何使用这两种方法。虽然 Kivy 支持多种类型的布局,但本文将只关注 BoxLayout 。我们将展示如何嵌套 BoxLayouts。
Kivy, Python and BoxLayout
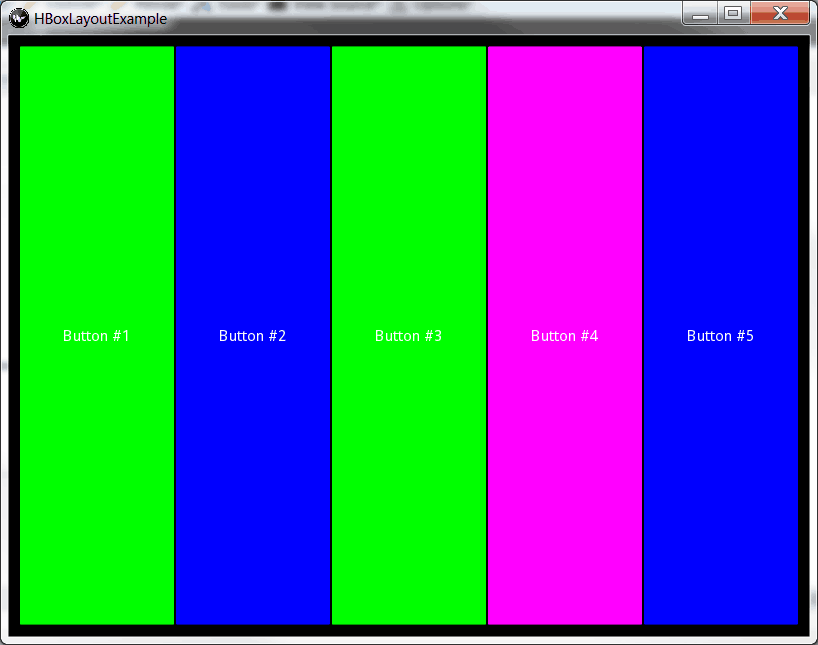
使用 Python 在 Kivy 中创建一个 BoxLayout 实际上非常简单和直观。我们将从一个代码示例开始,然后按照代码进行解释。我们开始吧!
import kivy
import random
from kivy.app import App
from kivy.uix.button import Button
from kivy.uix.boxlayout import BoxLayout
red = [1,0,0,1]
green = [0,1,0,1]
blue = [0,0,1,1]
purple = [1,0,1,1]
########################################################################
class HBoxLayoutExample(App):
"""
Horizontally oriented BoxLayout example class
"""
#----------------------------------------------------------------------
def build(self):
"""
Horizontal BoxLayout example
"""
layout = BoxLayout(padding=10)
colors = [red, green, blue, purple]
for i in range(5):
btn = Button(text="Button #%s" % (i+1),
background_color=random.choice(colors)
)
layout.add_widget(btn)
return layout
########################################################################
class VBoxLayoutExample(App):
"""
Vertical oriented BoxLayout example class
"""
#----------------------------------------------------------------------
def setOrientation(self, orient):
""""""
self.orient = orient
#----------------------------------------------------------------------
def build(self):
""""""
layout = BoxLayout(padding=10, orientation=self.orient)
for i in range(5):
btn = Button(text="Button #%s" % (i+1) )
layout.add_widget(btn)
return layout
#----------------------------------------------------------------------
if __name__ == "__main__":
app = HBoxLayoutExample()
#app = VBoxLayoutExample()
#app.setOrientation(orient="vertical")
app.run()
这里我们创建了一个垂直方向的 BoxLayout 类和一个水平方向的 BoxLayout 类。每个类包含 5 个随机背景颜色的按钮。颜色遵循 RGBA,但可以有介于 0 和 1 之间的单个值。奇怪的是,如果你使用大于 1 的数字,颜色会变得更亮。当我创建上面的截图时,我碰巧用了 255 而不是 1,所以如果你碰巧运行这段代码并看到一组更柔和的颜色,这就是原因。
为了使例子非常简单,我们只导入 Kivy 的 App、Button 和 BoxLayout 类。BoxLayout 类接受几个参数,但我们将重点关注以下 3 个参数:方向、填充和间距。因为 BoxLayout 是 Layout 和 Widget 的子类,所以它继承了这里没有涉及的许多其他方法和关键字参数。但是回到我们目前关心的论点。填充参数告诉 Kivy 在布局和它的孩子之间应该有多少间距,而间距参数告诉它在孩子之间应该有多少间距。
为了创建按钮,我们使用了一个简单的循环来遍历一个小范围的数字。每次迭代都会创建一个具有随机背景颜色的按钮,并将该按钮添加到布局实例中。然后我们在最后返回布局。
VBoxLayoutExample 类中的垂直 BoxLayout 示例略有不同,因为我认为能够以编程方式设置方向会很有趣。除了我添加了一个 setOrientation 方法之外,代码基本相同。注意,如果再次调用 setOrientation,将没有任何效果。正如我的一位评论者友好地指出的那样,你需要将 orientation 绑定到 App orient 属性,或者使用 Kv 语言来实现这一点。
如果您在脚本末尾注释掉对 HBoxLayoutExample 的调用,并取消注释掉其他两行,那么您应该会看到类似这样的结果:

请注意,当您不设置背景颜色时,Kivy 默认为深灰色。Kivy 并不试图看起来像一个本地应用程序。这对于你来说可能是也可能不是什么大不了的事情,这取决于你想要完成什么样的项目,但是这一点应该注意。现在我们准备学习嵌套!
嵌套框布局
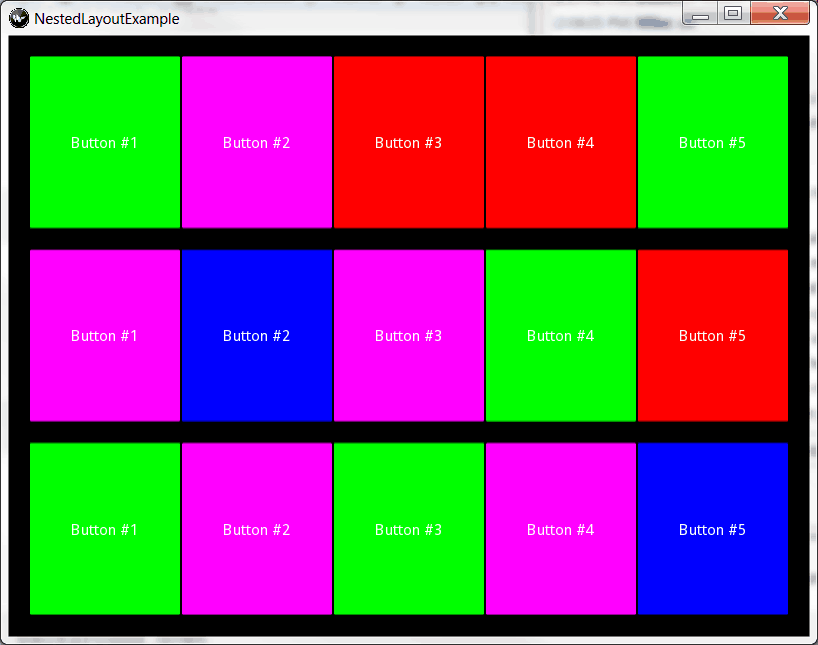
Kivy 也很容易将 BoxLayouts 嵌套在一起。每当你创建一个需要嵌套尺寸的复杂界面的应用程序时,你应该花些时间用铅笔和纸勾画出布局。然后,您可以用不同的方式在小部件周围画出方框,以帮助您可视化您需要的布局以及如何将它们嵌套在一起。我发现这对于 wxPython 很有帮助,并且我认为它适用于任何其他没有 WYSIWYG 编辑器的 GUI 工具包。顺便说一下,BoxLayouts 非常强大。如果你知道你在做什么,你就可以使用巧妙的嵌套来创建任何接口。
说够了,我们来看一些代码!
import kivy
import random
from kivy.app import App
from kivy.uix.button import Button
from kivy.uix.boxlayout import BoxLayout
red = [1,0,0,1]
green = [0,1,0,1]
blue = [0,0,1,1]
purple = [1,0,1,1]
########################################################################
class NestedLayoutExample(App):
"""
An example of nesting three horizontally oriented BoxLayouts inside
of one vertically oriented BoxLayout
"""
#----------------------------------------------------------------------
def build(self):
"""
Horizontal BoxLayout example
"""
main_layout = BoxLayout(padding=10, orientation="vertical")
colors = [red, green, blue, purple]
for i in range(3):
h_layout = BoxLayout(padding=10)
for i in range(5):
btn = Button(text="Button #%s" % (i+1),
background_color=random.choice(colors)
)
h_layout.add_widget(btn)
main_layout.add_widget(h_layout)
return main_layout
#----------------------------------------------------------------------
if __name__ == "__main__":
app = NestedLayoutExample()
app.run()
这个例子和上一个很像。不过,问题出在细节上。这里我们有一个嵌套的 for 循环,它创建了 3 个 BoxLayouts,每个 box layouts 包含 5 个按钮。然后,在外部循环的每次迭代结束时,将每个布局插入到顶级布局中。如果你错过了它,请向上滚动,看看结果如何。诀窍是创建一个顶层或主布局,并向其添加其他布局。现在让我们把注意力转向学习如何用 Kv 语言做这些事情。
Kv+Python 和 BoxLayout
学习一门新语言几乎总是有点痛苦。幸运的是,Kv 语言实际上非常接近 Python,包括 Python 使用缩进级别来表示一段代码何时开始和结束的要求。你可能想花几分钟在 Kivy 网站上阅读 Kv 语言。你准备好了,我们可以继续。首先,我们将从 Python 代码开始:
# kvboxlayout.py
from kivy.app import App
from kivy.uix.boxlayout import BoxLayout
########################################################################
class KVMyHBoxLayout(BoxLayout):
pass
########################################################################
class KVBoxLayoutApp(App):
""""""
#----------------------------------------------------------------------
def build(self):
""""""
return KVMyHBoxLayout()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = KVBoxLayoutApp()
app.run()
这段代码比我们前面的例子简单得多,但也相当神秘。首先,我们创建一个 BoxLayout 的空子类。然后我们创建我们的 App 类,它有一个 build 方法,该方法只返回空的 BoxLayout 类的一个实例。这是怎么回事?我们必须查看 Kv 文件才能找到答案!
:
color: .8,.9,0,1
font_size: 32
<boxlayout>:
orientation: 'horizontal'
MyButton:
text: "Btn1"
background_color: 1,0,0,1
MyButton:
text: "Btn2"
background_color: 0,1,0,1
MyButton:
text: "Btn3"
background_color: 0,0,1,1
MyButton:
text: "Btn4"
background_color: 1,0,1,1
MyButton:
text: "Btn5"
background_color: 1,0,0,1</boxlayout>
当您保存上面的代码时,您必须将其命名为与 App 类相同的名称,但是用. kv 代替. py,并且使用小写字母。这意味着这个 Kv 文件的名称需要是 kvboxlayout.kv 。您会注意到,您还需要去掉类名的 App 部分,这样 KVBoxLayoutApp 就变成了 kvboxlayout。是的,有点混乱。如果您没有正确遵循命名约定,文件将会运行,但是您将会看到一个空白的黑色窗口。
总之,首先在 Kv 文件中,我们有一个以<mybutton>:开头的部分。这告诉 Kivy,我们正在对 Button 类进行子类化,并将我们的子类叫做 MyButton 。然后我们缩进所需的四个空格,并设置按钮的标签颜色和字体大小。接下来,我们创建一个 BoxLayout 部分。注意,我们这次没有创建子类。然后我们告诉它应该是什么方向,并添加 5 个 MyButton 实例,每个实例都有自己的标签和颜色。
Kivy 的一位核心开发人员指出,通过以这种方式创建 BoxLayout,我正在为所有用途重新定义 BoxLayout。这是而不是一件好事,即使它确实使例子更简单。因此,在下一个例子中,我们将停止这样做,而是用正确的方法来做!
带 Kv 的嵌套盒布局
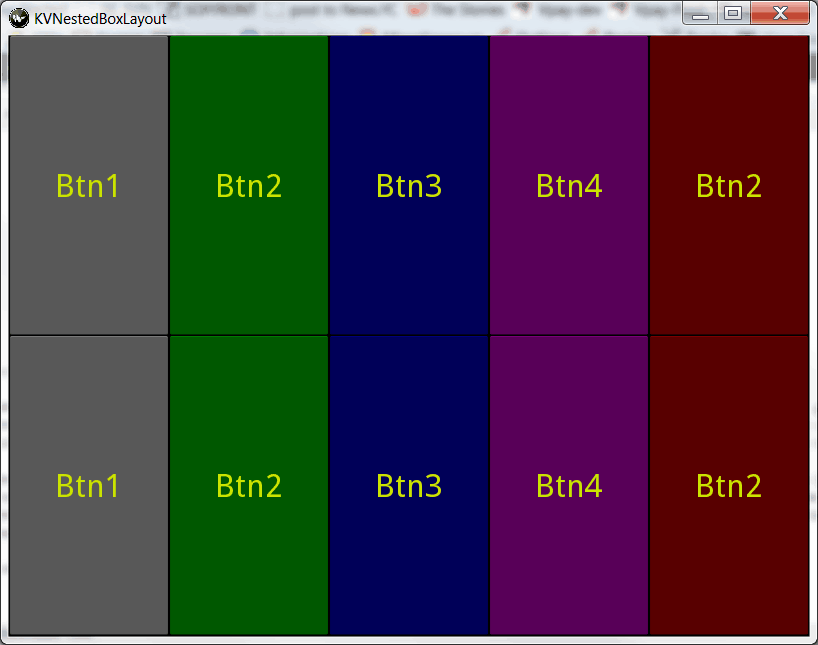
在 Kv 中嵌套 BoxLayouts 一开始有点混乱,但是一旦你掌握了它,你会发现它真的很容易。我们将从 Python 代码开始,看看它是如何工作的,然后看看 Kv 代码。
from kivy.app import App
from kivy.uix.boxlayout import BoxLayout
from kivy.uix.widget import Widget
########################################################################
class HBoxWidget(Widget):
pass
########################################################################
class VBoxWidget(Widget):
pass
########################################################################
class KVNestedBoxLayoutApp(App):
""""""
#----------------------------------------------------------------------
def build(self):
""""""
return VBoxWidget()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = KVNestedBoxLayoutApp()
app.run()
这一次,我们需要创建两个通用的小部件类:HBoxWidget 和 VBoxWidget。这些实际上是虚拟类,在 Kv 代码中变成了 BoxLayouts。说到这里,我们现在来看看。注意,您需要将 Kv 文件命名为 kvnestedboxlayout.kv ,您会注意到,它是 KVNestedBoxLayoutApp 的小写版本。
:
color: .8,.9,0,1
font_size: 32
<hboxwidget>:
BoxLayout:
size: root.size
pos: root.pos
orientation: 'horizontal'
MyButton:
text: "Btn1"
background_color: 1,1,1,1
MyButton:
text: "Btn2"
background_color: 0,1,0,1
MyButton:
text: "Btn3"
background_color: 0,0,1,1
MyButton:
text: "Btn4"
background_color: 1,0,1,1
MyButton:
text: "Btn2"
background_color: 1,0,0,1
<vboxwidget>:
BoxLayout:
size: root.size
pos: root.pos
id: foo_bar
orientation: 'vertical'
HBoxWidget:
HBoxWidget:
按钮代码和以前一样。接下来我们有了 HBoxWidget,我们将其定义为一个包含 5 个按钮的水平 BoxLayout。然后我们创建一个垂直 BoxLayout 的 VBoxWidget 的实例,但是这个布局包含 HBoxWidget 的两个实例。您会注意到,在 Python 代码的 build 方法中,我们返回 VBoxWidget,所以这就是操作所在。如果您删除这两个 HBoxWidget 调用,结果将是一个空的黑色窗口。
在 Kivy 中使用 Kv 文件还有另外一种方法。它是通过 kivy.lang.Builder.load_file(或 load_string) API 实现的,这使您能够加载 Kv 文件,而无需记住以某种特殊的方式命名 Kv 文件。你可以在他们的网站上读到这个 API,并在 github 上的 Kivy 示例中看到一个应用实例。使用这种方法的唯一警告是,您需要小心不要两次加载同一个文件,否则您的 UI 可能会出错。
包扎
这只是触及了 Kivy 布局系统的表面。还有 6 种其他布局类型可用。然而,我想你会发现本文中的例子会让你开始成功地创建你自己的酷 Kivy 应用程序。如果你需要帮助学习 Kivy,他们的网站上有一套很好的文档。他们在 freenode 上还有一个谷歌群和一个 T2 频道。
相关阅读
下载源代码
Kivy App Contest 2014
原文:https://www.blog.pythonlibrary.org/2014/03/17/kivy-app-contest-2014/

Kivy 是一个开源 Python 库,用于快速开发利用创新用户界面的应用程序,如多点触摸应用程序。Kivy 组织正在组织第二次应用程序开发竞赛。!这对新用户和有经验的用户来说是一个展示技能和争夺奖品的好机会。参赛作品将根据一系列标准进行评判,新的和有经验的程序员都可以使用,所以不要害怕投入进去!欲了解更多信息,请访问http://kivy.org/#contest
了解如何使用 Python 记录日志(视频)
原文:https://www.blog.pythonlibrary.org/2020/05/12/learn-how-to-log-with-python-video/
在此截屏中了解如何使用 Python 的日志模块:
https://www.youtube.com/embed/e4n8OLn_Yek?feature=oembed
您将了解以下内容:
- 创建日志
- 日志记录级别
- 日志处理程序
- 日志格式化程序
- 记录到多个位置
- 还有更多!
通过解决问题学习编码电子书竞赛
原文:https://www.blog.pythonlibrary.org/2021/07/13/learn-to-code-by-solving-problems-ebook-contest/
没有淀粉出版社与 Mouse vs Python 合作,为你带来一个电子书竞赛,题目是通过解决问题学习编码:丹尼尔·津加罗的 Python 编程初级读本。

将有 5 名获奖者。要想加入,你只需要在推特上发布这篇文章,并标记 @driscollis 和 @nostarch 。
从现在起到 2021 年 11 月 20 日午夜 CST 你将可以参加这场比赛。获胜者将在 Twitter 上宣布并贴上标签,这样他们就知道他们赢了。然后,您需要联系@driscollis 领取奖品。
wxPython Book Kickstarter 上线不到两天
原文:https://www.blog.pythonlibrary.org/2019/02/11/less-than-2-days-to-go-on-wxpython-book-kickstarter/
我的新书《用 wxPython 创建 GUI 应用程序》进展顺利。我只是想让我的读者知道, Kickstarter for it 在不到两天的时间里就要结束了。
如果你想以比今年 5 月晚些时候发布时更低的价格获得一份副本,Kickstarter 是一个不错的选择。你可以在上周的帖子中查看当前的目录。

感谢您的支持!
让用户更改 wx。wxPython 中 ComboBox 的内容
这个星期我遇到一个人,他想知道是否有一种方法允许用户编辑一个 wx 的内容。组合框。通过编辑内容,我的意思是更改 ComboBox 包含的预先存在的选项的名称,而不是向小部件添加新的项目。
当编辑组合框中所选项的内容时,小部件不会自动保存这些编辑。因此,如果您编辑了某个内容,然后在组合框中选择了不同的选项,被编辑的内容将恢复到之前的状态,您所做的更改将会丢失。
让我们看看如何创建一个允许这种功能的组合框!
|  |
|
用 wxPython 创建 GUI 应用程序
更改组合框

尝试新事物的第一步是写一些代码。您需要创建一个 wx 的实例。ComboBox 并向其传递一个选择列表,同时设置默认选择。当然,您不能孤立地创建一个小部件。小部件必须在父小部件内。在 wxPython 中,您几乎总是希望父对象是一个 wx。面板位于 wx 的内部。画面。
让我们编写一些代码,看看这一切是如何安排的:
import wx
class MainPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.cb_value = 'One'
self.combo_contents = ['One', 'Two', 'Three']
self.cb = wx.ComboBox(self, choices=self.combo_contents,
value=self.cb_value, size=(100, -1))
self.cb.Bind(wx.EVT_TEXT, self.on_text_change)
self.cb.Bind(wx.EVT_COMBOBOX, self.on_selection)
def on_text_change(self, event):
current_value = self.cb.GetValue()
if current_value != self.cb_value and current_value not in self.combo_contents:
# Value has been edited
index = self.combo_contents.index(self.cb_value)
self.combo_contents.pop(index)
self.combo_contents.insert(index, current_value)
self.cb.SetItems(self.combo_contents)
self.cb.SetValue(current_value)
self.cb_value = current_value
def on_selection(self, event):
self.cb_value = self.cb.GetValue()
class MainFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='ComboBox Changing Demo')
panel = MainPanel(self)
self.Show()
if __name__ == "__main__":
app = wx.App(False)
frame = MainFrame()
app.MainLoop()
您感兴趣的代码的主要部分在 MainPanel 类中。在这里创建小部件,设置它的选择列表和几个其他参数。接下来,您需要将 ComboBox 绑定到两个事件:
- wx。EVT _ 文本 -用于文本改变事件
- wx。EVT _ 组合框 -用于改变项目选择事件
第一个事件, wx。EVT _ 文本,当你通过输入改变小部件中的文本时触发,当你改变选择时也触发。另一个事件仅在您更改选择时触发。 wx。EVT_TEXT 事件首先触发,因此它优先于 wx。EVT _ 组合框。
当您更改文本时, on_text_change() 被调用。在这里,您将检查 ComboBox 的当前值是否与您期望的值相匹配。您还要检查当前值是否与当前设置的选择列表相匹配。这允许您查看用户是否更改了文本。如果有,那么您需要获取选择列表中当前所选项的索引。
然后使用列表的 pop() 方法删除旧字符串,并使用 insert() 方法添加新字符串。现在您需要调用小部件的 SetItems() 方法来更新它的选择列表。然后,将它的值设置为新的字符串,并更新 cb_value 实例变量,这样就可以检查它以后是否会再次改变。
on_selection() 法短而甜。它所做的只是将 cb_value 更新为当前的选择。
试试这段代码,看看它是如何工作的!
包扎
增加了允许用户更新 wx 的能力。ComboBox 的内容并不特别难。你甚至可以子类化 wx。ComboBox 并创建一个版本,让它一直为你做这件事。另一个有趣的增强是让小部件从配置文件或 JSON 文件中加载它的选择。然后你可以更新 on_text_change() 将你的更改保存到磁盘,然后你的应用程序可以保存这些选择,并在你下次启动应用程序时重新加载它们。
开心快乐编码!
提升您的 Python 销售水平
原文:https://www.blog.pythonlibrary.org/2021/12/23/level-up-your-python-sale/
我正在进行我的 Python 书籍的销售,在这里你可以从我在 gum road 上的任何一本书上减去 10 美元。你所需要做的就是在退房时使用这个优惠代码: tenoff 。本次销售将持续到2022 年 1 月 3 日!
这段代码适用于我所有的书,包括我最新的书!

为了让这变得更容易,下面是我已经申请了优惠券的书的链接:
- Python 101:第二版
- Python 201: Intermedia Python
- Jupyter Notebook 101
- ReportLab: PDF Processing with Python
- Creating GUI Applications with wxPython
- Pillow: Image Processing with Python
- Automating Excel with Python
节日快乐!
在 Qt for Python 中加载 UI 文件
原文:https://www.blog.pythonlibrary.org/2018/05/30/loading-ui-files-in-qt-for-python/
Qt for Python(即 PySide2)最近发布了,这让我有兴趣尝试用它来加载 UI 文件。如果你不知道,PyQt 和 PySide / PySide2 可以使用 Qt Creator 应用程序创建使用拖放界面的用户界面。这实际上与您使用 Visual Studio 创建界面的方式非常相似。Qt 创建者/设计者将生成一个带有*的 XML 文件。然后可以在 PySide2 应用程序(或 PyQt)中加载的 ui 扩展。
创建用户界面
对于这个例子,我打开 Qt Creator,进入“文件”->“新建文件或项目”。然后我选择了“Qt Widgets 应用”选项。见下面截图:

然后我打开了 Qt Creator 给我做的 mainwindow.ui 。你可以双击它或者点击程序左边的设计按钮。这里有一个截图可能会有所帮助:

我在我的 UI 中添加了三个小部件:
- QLabel
- QLineEdit
- q 按钮
当我保存文件时,我在我的 UI 文件中得到以下内容:
<class>MainWindow</class>
<widget class="QMainWindow" name="MainWindow"><property name="geometry"><rect><x>0</x>
<y>0</y>
<width>400</width>
<height>300</height></rect></property>
<property name="windowTitle"><string>MainWindow</string></property>
<widget class="QWidget" name="centralWidget"><widget class="QPushButton" name="pushButton"><property name="geometry"><rect><x>160</x>
<y>210</y>
<width>80</width>
<height>25</height></rect></property>
<property name="text"><string>OK</string></property></widget>
<widget class="QLineEdit" name="lineEdit"><property name="geometry"><rect><x>130</x>
<y>30</y>
<width>113</width>
<height>25</height></rect></property></widget>
<widget class="QLabel" name="label"><property name="geometry"><rect><x>20</x>
<y>30</y>
<width>111</width>
<height>17</height></rect></property>
<property name="text"><string>Favorite Language:</string></property></widget></widget>
<widget class="QMenuBar" name="menuBar"><property name="geometry"><rect><x>0</x>
<y>0</y>
<width>400</width>
<height>22</height></rect></property>
<widget class="QMenu" name="menuTest"><property name="title"><string>Test</string></property></widget></widget>
<widget class="QToolBar" name="mainToolBar"><attribute name="toolBarArea"><enum>TopToolBarArea</enum></attribute>
<attribute name="toolBarBreak"><bool>false</bool></attribute></widget>
<layoutdefault spacing="6" margin="11"></layoutdefault></widget>
现在我们只需要学习如何在 Qt for Python 中加载这个文件。
在 Qt for Python 中加载 UI 文件

我发现有几种不同的方法可以用来在 Qt for Python (PySide2)中加载 UI 文件。第一个是从 Qt 为 Python 的 wiki 大量引用的:
import sys
from PySide2.QtUiTools import QUiLoader
from PySide2.QtWidgets import QApplication
from PySide2.QtCore import QFile
if __name__ == "__main__":
app = QApplication(sys.argv)
file = QFile("mainwindow.ui")
file.open(QFile.ReadOnly)
loader = QUiLoader()
window = loader.load(file)
window.show()
sys.exit(app.exec_())
虽然这可以工作,但它并没有真正向您展示如何连接事件或从用户界面中获得任何有用的东西。坦白地说,我认为这是一个愚蠢的例子。因此,我在其他网站上查找了一些其他例子,并最终将以下内容整合在一起:
import sys
from PySide2.QtUiTools import QUiLoader
from PySide2.QtWidgets import QApplication, QPushButton, QLineEdit
from PySide2.QtCore import QFile, QObject
class Form(QObject):
def __init__(self, ui_file, parent=None):
super(Form, self).__init__(parent)
ui_file = QFile(ui_file)
ui_file.open(QFile.ReadOnly)
loader = QUiLoader()
self.window = loader.load(ui_file)
ui_file.close()
self.line = self.window.findChild(QLineEdit, 'lineEdit')
btn = self.window.findChild(QPushButton, 'pushButton')
btn.clicked.connect(self.ok_handler)
self.window.show()
def ok_handler(self):
language = 'None' if not self.line.text() else self.line.text()
print('Favorite language: {}'.format(language))
if __name__ == '__main__':
app = QApplication(sys.argv)
form = Form('mainwindow.ui')
sys.exit(app.exec_())
在这个例子中,我们创建一个表单对象,并使用 QUiLoader 和 QFile 加载 UI 文件。然后我们对从 QUiLoader 返回的对象使用 findChild 方法来提取我们感兴趣的小部件对象。对于这个例子,我提取了 QLineEdit 小部件,这样我就可以得到用户输入的内容,还提取了 QPushButton 小部件,这样我就可以捕捉按钮被点击的事件。最后,我将 click 事件连接到一个事件处理程序(或插槽)。
包扎
至此,您应该对如何使用 Qt 的 Creator / Designer 应用程序创建用户界面以及如何将它生成的 UI 文件加载到您的 Python 应用程序中有了大致的了解。这是相当直截了当的,但不是很好的记录。您也可以跳过创建 UI 文件,手动编写所有代码。不管您选择哪种方法,这似乎都是一个相当容易上手的工具包,尽管我希望文档/教程能尽快增加细节。
相关阅读
- Python Ui 文件的 Qtwiki 页面
- PySide 食谱
- StackOverflow - 加载 QtDesigner 的。PySide 中的 ui 文件
- PyQt4 在 Qt Designer 上的页面
用 Python 锁定窗口
原文:https://www.blog.pythonlibrary.org/2010/02/06/lock-down-windows-with-python/
大约四年前,我的任务是将一个 Kixtart 脚本转换成 Python。这个特殊的脚本被用来锁定 Windows XP 机器,以便它们可以被用作信息亭。显然,你不需要 Python 来做这些。任何可以访问 Windows 注册表的编程语言都可以做到这一点,或者您可以只使用组策略。但是这是一个 Python 博客,所以这就是你在这篇文章中将要得到的!
入门指南
本教程需要的只是标准的 Python 发行版和 PyWin32 包。我们将使用的模块是 _winreg 和子进程,它们内置在标准发行版和 PyWin32 的 win32api 和 win32con 中。
我们将把代码分成两半来看。前半部分将使用 _winreg 模块:
import subprocess, win32con
from win32api import SetFileAttributes
from _winreg import *
# Note: 1 locks the machine, 0 opens the machine.
UserPolicySetting = 1
# Connect to the correct Windows Registry key and path, then open the key
reg = ConnectRegistry(None, HKEY_CURRENT_USER)
regpath = r"Software\\Microsoft\\Windows\\CurrentVersion\\Policies\\Explorer"
key = OpenKey(reg, regpath, 0, KEY_WRITE)
# Edit registry key by adding new values (Lock-down the PC)
SetValueEx(key, "NoRecentDocsMenu", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoRun", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoFavoritesMenu", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoFind", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoSetFolders", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoSetTaskbar", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoSetActiveDesktop", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoWindowsUpdate", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoSMHelp", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoCloseDragDropBands", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoActiveDesktopChanges", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoMovingBands", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoViewContextMenu", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoChangeStartMenu", 0, REG_DWORD, UserPolicySetting)
SetValueEx(key, "NoTrayContextMenu", 0, REG_DWORD, UserPolicySetting)
CloseKey(key)
首先,我们导入我们需要的模块。然后,我们连接到 Windows 注册表,打开以下注册表项进行写入:
HKEY _ 当前用户\软件\微软\ Windows \当前版本\策略\资源管理器
警告:在继续之前,请注意,如果操作不当,篡改 Windows 注册表可能会对您的电脑造成损害。如果你不知道你在做什么,在做任何事情之前备份你的注册表或者使用一个你可以恢复的虚拟机(比如 VirtualBox 或者 VMWare)。上面的脚本将使你的电脑除了 kiosk 之外几乎不能用。
无论如何,打开密钥后,我们设置了十几个隐藏运行选项、收藏夹、最近和开始菜单中的查找的设置。我们还禁用了桌面上的右键点击、Windows Update 以及对各种菜单的所有更改(等等)。这都是由我们的用户策略设置变量控制的。如果它被设置为 1(即布尔真),它将锁定所有这些值;如果是零,那么它会再次启用所有设置。最后,我们调用关闭键来应用设置。
我们应该在这里停一会儿,并考虑这是一些真正丑陋的代码(正如在下面的评论中指出的)。我写这篇文章的时候,我只有一个月的编程经验,我是从一个 Kixtart 脚本移植过来的,这个脚本看起来和这篇一样差,甚至更差。让我们试着让它更干净:
from _winreg import *
UserPolicySetting = 1
# Connect to the correct Windows Registry key and path, then open the key
reg = ConnectRegistry(None, HKEY_CURRENT_USER)
regpath = r"Software\\Microsoft\\Windows\\CurrentVersion\\Policies\\Explorer"
key = OpenKey(reg, regpath, 0, KEY_WRITE)
sub_keys = ["NoRecentDocsMenu", "NoRun", "NoFavoritesMenu",
"NoFind", "NoSetFolders", "NoSetTaskbar",
"NoSetActiveDesktop", "NoWindowsUpdate",
"NoSMHelp", "NoCloseDragDropBands",
"NoActiveDesktopChanges", "NoMovingBands",
"NoViewContextMenu", "NoChangeStartMenu",
"NoTrayContextMenu"]
# Edit registry key by adding new values (Lock-down the PC)
for sub_key in sub_keys:
SetValueEx(key, sub_key, 0, REG_DWORD, UserPolicySetting)
CloseKey(key)
这里的主要区别是,我将所有的 sub_key 名称放入一个 Python 列表中,然后我们可以对其进行迭代,并将每个名称设置为正确的值。现在,如果我们在这些代码行中有多处不同,比如混合了 REG_DWORD 和 REG_SZ,那么我们需要做一些不同的事情。例如,我们需要迭代元组列表,或者创建一个函数来传递信息。如果你想要最大的灵活性,你可以创建一个类,除了错误处理和键的打开和关闭之外,还能为你做这些。不过,我将把它留给读者作为练习。
我们脚本的另一半将隐藏各种图标和文件夹:
# Sets the "Hidden" attribute for specified files/folders.
if UserPolicySetting == 1:
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Set Program Access and Defaults.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Windows Catalog.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Open Office Document.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\New Office Document.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
# NOTE: Two backslashes are required before the last directory only
subprocess.Popen('attrib +h "C:\Documents and Settings\All Users\Start Menu\Programs\\vnc"')
subprocess.Popen('attrib +h "C:\Documents and Settings\All Users\Start Menu\Programs\\Outlook Express"')
subprocess.Popen('attrib +h "C:\Documents and Settings\All Users\Start Menu\Programs\\Java Web Start"')
subprocess.Popen('attrib +h "C:\Documents and Settings\All Users\Start Menu\Programs\\Microsoft Office"')
subprocess.Popen('attrib +h "C:\Documents and Settings\All Users\Start Menu\Programs\\Microsoft SQL Server"')
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Programs\Adobe Reader 6.0.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Programs\Windows Media Player.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Programs\Windows Movie Maker.lnk", win32con.FILE_ATTRIBUTE_HIDDEN)
else:
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Set Program Access and Defaults.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Windows Catalog.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Open Office Document.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\New Office Document.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
subprocess.Popen('attrib -h "C:\Documents and Settings\All Users\Start Menu\Programs\\vnc"')
subprocess.Popen('attrib -h "C:\Documents and Settings\All Users\Start Menu\Programs\\Outlook Express"')
subprocess.Popen('attrib -h "C:\Documents and Settings\All Users\Start Menu\Programs\\Java Web Start"')
subprocess.Popen('attrib -h "C:\Documents and Settings\All Users\Start Menu\Programs\\Microsoft Office"')
subprocess.Popen('attrib -h "C:\Documents and Settings\All Users\Start Menu\Programs\\Microsoft SQL Server"')
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Programs\Adobe Reader 6.0.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Programs\Windows Media Player.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
SetFileAttributes("C:\Documents and Settings\All Users\Start Menu\Programs\Windows Movie Maker.lnk", win32con.FILE_ATTRIBUTE_NORMAL)
该代码片段隐藏了以下内容
- 通常出现在“开始”菜单中的指向 Microsoft Office 文档的各种链接
- Windows 目录和设置程序访问和默认值快捷方式
- “开始”菜单的“程序”子菜单中我们不希望用户访问的各种文件夹,如 VNC、Office、Microsoft SQL Connector 等。
- 程序子菜单中的其他链接
这是通过 win32api 的 SetFileAttributes 和 win32con 的快捷方式文件属性的组合来实现的。使用调用 Windows attrib 命令的子进程来切换文件夹的隐藏状态。
不幸的是,这是另一个重复代码的例子。让我们花点时间来尝试重构它。看起来我们设置的所有内容都在“开始”菜单或它的“程序”子文件夹中。我们可以像前面的例子一样,把这些路径放入一个循环中。我们还可以使用标志来告诉我们何时隐藏或显示文件夹。我们将把整个东西放入一个函数中,这样也更容易重用。让我们看看这是什么样子:
import os
import subprocess
import win32con
from win32api import SetFileAttributes
def toggleStartItems(flag=True):
items = ["Set Program Access and Defaults.lnk", "Windows Catalog.lnk",
"Open Office Document.lnk", "New Office Document.lnk",
"Programs\Adobe Reader 6.0.lnk", "Programs\Windows Media Player.lnk",
"Programs\Windows Movie Maker.lnk", "Programs\\vnc",
"Programs\\Outlook Express", "Programs\\Java Web Start",
"Programs\\Microsoft Office", "Programs\\Microsoft SQL Server"]
path = r'C:\Documents and Settings\All Users\Start Menu'
if flag:
toggle = "+h"
else:
toggle = "-h"
for item in items:
p = os.path.join(path, item)
if os.path.isdir(p):
subprocess.Popen('attrib %s "%s"' % (toggle, p))
elif flag:
SetFileAttributes(p, win32con.FILE_ATTRIBUTE_HIDDEN)
else:
SetFileAttributes(p, win32con.FILE_ATTRIBUTE_NORMAL)
现在,看起来是不是好多了?它还使添加和删除项目变得更加容易。这使得将来的维护更简单,麻烦也更少。
包扎
现在你知道如何用 Windows 和 Python 创建你自己的 kiosk 了。我希望这篇文章对你有所帮助。
注意:这些脚本是在 Windows XP 上使用 Python 2.4+测试的
延伸阅读
- 官方 _winreg 文档
- 【PyWin32 官方文档
使用 Python 记录当前运行的进程
原文:https://www.blog.pythonlibrary.org/2014/10/21/logging-currently-running-processes-with-python/
我查看了我的一些旧代码,注意到这个旧脚本,其中我每 5 分钟创建一个所有运行进程的日志。我相信我最初编写代码是为了帮助我诊断正在消耗内存或占用 CPU 的流氓进程。我正在使用 psutil 项目来获取我需要的信息,所以如果你想继续,你也需要下载并安装它。
代码如下:
import os
import psutil
import time
#----------------------------------------------------------------------
def create_process_logs(log_dir):
"""
Create a log of all the currently running processes
"""
if not os.path.exists(log_dir):
try:
os.mkdir(log_dir)
except:
pass
separator = "-" * 80
col_format = "%7s %7s %12s %12s %30s"
data_format = "%7.4f %7.2f %12s %12s %30s"
while 1:
procs = psutil.get_process_list()
procs = sorted(procs, key=lambda proc: proc.name)
log_path = os.path.join(log_dir, "procLog%i.log" % int(time.time()))
f = open(log_path, 'w')
f.write(separator + "\n")
f.write(time.ctime() + "\n")
f.write(col_format % ("%CPU", "%MEM", "VMS", "RSS", "NAME"))
f.write("\n")
for proc in procs:
cpu_percent = proc.get_cpu_percent()
mem_percent = proc.get_memory_percent()
rss, vms = proc.get_memory_info()
rss = str(rss)
vms = str(vms)
name = proc.name
f.write(data_format % (cpu_percent, mem_percent, vms, rss, name))
f.write("\n\n")
f.close()
print "Finished log update!"
time.sleep(300)
print "writing new log data!"
if __name__ == "__main__":
log_dir = r"c:\users\USERNAME\documents"
create_process_logs(log_dir)
让我们把它分解一下。这里我们传入一个日志目录,检查它是否存在,如果不存在就创建它。接下来,我们设置几个包含日志文件格式的变量。然后我们开始一个无限循环,使用 psutil 获取所有当前正在运行的进程。我们还按名称对流程进行分类。接下来,我们打开一个唯一命名的日志文件,写出每个进程的 CPU 和内存使用情况,以及它的虚拟机、RSS 和可执行文件的名称。然后,我们关闭文件,等待 5 分钟,然后再从头开始。
回想起来,将这些信息写入 SQLite 这样的数据库可能会更好,这样数据就可以被搜索和图形化。与此同时,希望你能在这里找到一些有用的信息,可以用于你自己的项目。
Lucid 编程播客——撰写关于 Python 的书籍
原文:https://www.blog.pythonlibrary.org/2019/09/04/lucid-programming-podcast-writing-books-about-python/
我最近在 Vincent Russo 的 Lucid Programming 播客上接受了关于撰写 Python 书籍的采访。
您可以在这里收听音频:
https://www.youtube.com/embed/AM-1Uz6O3OM?feature=oembed
如果你想知道更多关于我是如何写书的,你可能会喜欢我写的这篇关于这个话题的文章。我还写了一篇关于印第出版的利弊的文章。
上周,我很荣幸参加了盈利的 Python 播客。
相关播客
我参加过的其他播客:
- 上周,我很荣幸参加了盈利的 Python 播客。
- 谈论 Python 第 156 集: Python 的历史和观点
- 播客。init - Mike Driscoll 和他的 Python 生涯——第 169 集
使用 Python Kickstarter 的机器视觉
原文:https://www.blog.pythonlibrary.org/2015/01/28/machine-vision-with-python-kickstarter/
昨天我发布了关于 PyImageSearch 大师计算机视觉 Kickstarter,然后我遇到了另一个半相关的 Kickstarter 。这是一个机器视觉与 Python 使用 OpenMV 凸轮。它使用 MicroPython (微控制器的 Python)来控制电路板上的摄像头。该项目可通过 I2C、串行或 SPI 协议与 Arduino、mbed 或其它微控制器配合使用。我认为树莓派属于后一种或多种类型。
他们还没有达到目标,但是他们还有差不多一个月的时间来筹集资金。你可以在这里查看我们的项目。
在 Python 包索引(PyPI)上发现恶意库
在 Python 包索引(PyPI)上发现了恶意代码,这是共享 Python 包的最流行的位置。这是斯洛伐克国家安全办公室报告的,然后被其他地方的哔哔声计算机接收到(即 Reddit )。攻击载体使用了域名仿冒,这基本上是有人上传了一个流行包的名称拼写错误的包,例如 lmxl 而不是 lxml 。
你可以在这里看到斯洛伐克国家安全办公室的原始报告:http://www.nbu.gov.sk/skcsirt-sa-20170909-pypi/
去年八月,我在这篇博客文章中看到了关于这个向量的讨论,很多人似乎对此并不重视。有趣的是,现在人们对这个问题越来越感兴趣。
这也让我想起了关于一家名为 Kite 的初创公司的争议,该公司基本上将广告软件/间谍软件插入到插件中,如 Atom、autocomplete-python 等。
用 Python 打包需要一些帮助。我喜欢现在比 10 年前好得多,但仍有许多问题。
使用 Python 和 pyPdf 操作 Pdf
原文:https://www.blog.pythonlibrary.org/2010/05/15/manipulating-pdfs-with-python-and-pypdf/
有一个方便的第三方模块叫做 pyPdf ,你可以用它来合并 Pdf 文档,旋转页面,分割和裁剪页面,以及解密/加密 PDF 文档。在本文中,我们将看看其中的一些函数,然后用 wxPython 创建一个简单的 GUI,它将允许我们合并几个 pdf。
pyPdf 之旅
要充分利用 pyPdf,您需要了解它的两个主要功能:PdfFileReader 和 PdfFileWriter。它们是我用得最多的。让我们看看他们能做些什么:
# Merge two PDFs
from pyPdf import PdfFileReader, PdfFileWriter
output = PdfFileWriter()
pdfOne = PdfFileReader(file( "some\path\to\a\PDf", "rb"))
pdfTwo = PdfFileReader(file("some\other\path\to\a\PDf", "rb"))
output.addPage(pdfOne.getPage(0))
output.addPage(pdfTwo.getPage(0))
outputStream = file(r"output.pdf", "wb")
output.write(outputStream)
outputStream.close()
上面的代码将打开两个 PDF,从每一个中取出第一页,并通过合并这两页创建第三个 PDF。注意页面是从零开始的,所以零是第一页,一是第二页,以此类推。我使用这种脚本从 PDF 中提取一个或多个页面,或者将一系列 PDF 连接在一起。例如,有时我的用户会收到一堆扫描的文档,文档的每一页都以单独的 PDF 结束。他们需要将所有的单页合并成一个 PDF,pyPdf 允许我非常简单地做到这一点。
在我的日常体验中,pyPdf 提供给我的旋转功能的应用并不多,但也许你有很多横向而不是纵向扫描文档的用户,你最终需要做很多旋转。幸运的是,这是相当无痛的:
from pyPdf import PdfFileWriter, PdfFileReader
output = PdfFileWriter()
input1 = PdfFileReader(file("document1.pdf", "rb"))
output.addPage(input1.getPage(1).rotateClockwise(90))
# output.addPage(input1.getPage(2).rotateCounterClockwise(90))
outputStream = file("output.pdf", "wb")
output.write(outputStream)
outputStream.close()
上面的代码摘自 pyPdf 文档,在本例中被缩短了。如你所见,要调用的方法是 rotateClockwise 或 rotateCounterClockwise 。确保将翻页的度数传递给该方法。
现在,让我们来看看我们可以从 PDF 中获得什么信息:
>>> from pyPdf import PdfFileReader
>>> p = r'E:\My Documents\My Dropbox\ebooks\helloWorld book.pdf'
>>> pdf = PdfFileReader(file(p, 'rb'))
>>> pdf.documentInfo
{'/CreationDate': u'D:20090323080712Z', '/Author': u'Warren Sande', '/Producer': u'Acrobat Distiller 8.0.0 (Windows)', '/Creator': u'FrameMaker 8.0', '/ModDate': u"D:20090401124817-04'00'", '/Title': u'Hello World!'}
>>> pdf.getNumPages()
432
>>> info = pdf.getDocumentInfo()
>>> info.author
u'Warren Sande'
>>> info.creator
u'FrameMaker 8.0'
>>> info.producer
u'Acrobat Distiller 8.0.0 (Windows)'
>>> info.title
u'Hello World!'
如您所见,我们可以使用 pyPdf 收集相当多的有用数据。现在让我们创建一个简单的 GUI 来使合并两个 pdf 更加容易!
创建 wxPython PDF 合并应用程序

我昨天想出了这个剧本。它使用 Tim Golden 的 winshell 模块,让我在 Windows 上轻松访问用户的桌面。如果你在 Linux 或 Mac 上,那么你会想为你的平台改变这部分代码。我想使用 wxPython 的 StandardPaths 模块,但是它没有获取我可以看到的桌面的功能。总之,说够了。我们来看一些代码!
import os
import pyPdf
import winshell
import wx
class MyFileDropTarget(wx.FileDropTarget):
def __init__(self, window):
wx.FileDropTarget.__init__(self)
self.window = window
def OnDropFiles(self, x, y, filenames):
self.window.SetInsertionPointEnd()
for file in filenames:
self.window.WriteText(file)
########################################################################
class JoinerPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent=parent)
self.currentPath = winshell.desktop()
lblSize = (70,-1)
pdfLblOne = wx.StaticText(self, label="PDF One:", size=lblSize)
self.pdfOne = wx.TextCtrl(self)
dt = MyFileDropTarget(self.pdfOne)
self.pdfOne.SetDropTarget(dt)
pdfOneBtn = wx.Button(self, label="Browse", name="pdfOneBtn")
pdfOneBtn.Bind(wx.EVT_BUTTON, self.onBrowse)
pdfLblTwo = wx.StaticText(self, label="PDF Two:", size=lblSize)
self.pdfTwo = wx.TextCtrl(self)
dt = MyFileDropTarget(self.pdfTwo)
self.pdfTwo.SetDropTarget(dt)
pdfTwoBtn = wx.Button(self, label="Browse", name="pdfTwoBtn")
pdfTwoBtn.Bind(wx.EVT_BUTTON, self.onBrowse)
outputLbl = wx.StaticText(self, label="Output name:", size=lblSize)
self.outputPdf = wx.TextCtrl(self)
widgets = [(pdfLblOne, self.pdfOne, pdfOneBtn),
(pdfLblTwo, self.pdfTwo, pdfTwoBtn),
(outputLbl, self.outputPdf)]
joinBtn = wx.Button(self, label="Join PDFs")
joinBtn.Bind(wx.EVT_BUTTON, self.onJoinPdfs)
self.mainSizer = wx.BoxSizer(wx.VERTICAL)
for widget in widgets:
self.buildRows(widget)
self.mainSizer.Add(joinBtn, 0, wx.ALL|wx.CENTER, 5)
self.SetSizer(self.mainSizer)
#----------------------------------------------------------------------
def buildRows(self, widgets):
""""""
sizer = wx.BoxSizer(wx.HORIZONTAL)
for widget in widgets:
if isinstance(widget, wx.StaticText):
sizer.Add(widget, 0, wx.ALL|wx.CENTER, 5)
elif isinstance(widget, wx.TextCtrl):
sizer.Add(widget, 1, wx.ALL|wx.EXPAND, 5)
else:
sizer.Add(widget, 0, wx.ALL, 5)
self.mainSizer.Add(sizer, 0, wx.EXPAND)
#----------------------------------------------------------------------
def onBrowse(self, event):
"""
Browse for PDFs
"""
widget = event.GetEventObject()
name = widget.GetName()
wildcard = "PDF (*.pdf)|*.pdf"
dlg = wx.FileDialog(
self, message="Choose a file",
defaultDir=self.currentPath,
defaultFile="",
wildcard=wildcard,
style=wx.OPEN | wx.CHANGE_DIR
)
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
if name == "pdfOneBtn":
self.pdfOne.SetValue(path)
else:
self.pdfTwo.SetValue(path)
self.currentPath = os.path.dirname(path)
dlg.Destroy()
#----------------------------------------------------------------------
def onJoinPdfs(self, event):
"""
Join the two PDFs together and save the result to the desktop
"""
pdfOne = self.pdfOne.GetValue()
pdfTwo = self.pdfTwo.GetValue()
if not os.path.exists(pdfOne):
msg = "The PDF at %s does not exist!" % pdfOne
dlg = wx.MessageDialog(None, msg, 'Error', wx.OK|wx.ICON_EXCLAMATION)
dlg.ShowModal()
dlg.Destroy()
return
if not os.path.exists(pdfTwo):
msg = "The PDF at %s does not exist!" % pdfTwo
dlg = wx.MessageDialog(None, msg, 'Error', wx.OK|wx.ICON_EXCLAMATION)
dlg.ShowModal()
dlg.Destroy()
return
outputPath = os.path.join(winshell.desktop(), self.outputPdf.GetValue()) + ".pdf"
output = pyPdf.PdfFileWriter()
pdfOne = pyPdf.PdfFileReader(file(pdfOne, "rb"))
for page in range(pdfOne.getNumPages()):
output.addPage(pdfOne.getPage(page))
pdfTwo = pyPdf.PdfFileReader(file(pdfTwo, "rb"))
for page in range(pdfTwo.getNumPages()):
output.addPage(pdfTwo.getPage(page))
outputStream = file(outputPath, "wb")
output.write(outputStream)
outputStream.close()
msg = "PDF was save to " + outputPath
dlg = wx.MessageDialog(None, msg, 'PDF Created', wx.OK|wx.ICON_INFORMATION)
dlg.ShowModal()
dlg.Destroy()
self.pdfOne.SetValue("")
self.pdfTwo.SetValue("")
self.outputPdf.SetValue("")
########################################################################
class JoinerFrame(wx.Frame):
#----------------------------------------------------------------------
def __init__(self):
wx.Frame.__init__(self, None, wx.ID_ANY,
"PDF Joiner", size=(550, 200))
panel = JoinerPanel(self)
#----------------------------------------------------------------------
# Run the program
if __name__ == "__main__":
app = wx.App(False)
frame = JoinerFrame()
frame.Show()
app.MainLoop()
你会注意到框架和面板有愚蠢的名字。请随意更改它们。这毕竟是 Python 啊!MyFileDropTarget 类用于在前两个文本控件上启用拖放功能。如果用户愿意,他们可以将 PDF 拖到其中一个文本控件上,路径就会神奇地被插入。否则,他们可以使用浏览按钮来查找他们选择的 PDF。一旦他们选择了他们的 PDF,他们需要输入输出 PDF 的名称,这个名称在第三个文本控件中。你甚至不需要添加“.pdf”扩展名,因为这个应用程序将为您做这件事。
最后一步是按下“加入 pdf”按钮。这会将第二个 PDF 添加到第一个 PDF 的末尾,如果创建成功,会显示一个对话框。为了正确运行,我们需要循环每个 PDF 的所有页面,并按顺序将它们添加到输出中。
用某种拖放界面来增强这个应用程序会很有趣,用户可以看到 PDF 页面,并通过拖动它们来重新排列它们。或者只是能够从每个 PDF 文件中指定几页来添加,而不是将它们完整地连接起来。不过,我将把这些作为练习留给读者。
我希望你觉得这篇文章很有趣,它会激发你的创造力。如果你用这些想法写了一些很酷的东西,一定要发表评论让我能看到!
在 Windows 上映射驱动器
原文:https://www.blog.pythonlibrary.org/2008/05/12/mapping-drives-on-windows/
我必须帮助从 Kixtart 翻译到 Python 的第一批脚本之一是我们的地图驱动脚本。在其中,我们将根据用户所在的组和/或自定义注册表条目来映射驱动器。以下是 Kixtart 中每个类别的部分示例:
IF READVALUE("HKEY_LOCAL_MACHINE\SOFTWARE\MyOrg", "Office")= "officeName" $Drive="g:" $Path="\\serverName\" + @userid Call "@lserver\\folderName" ENDIF
IF in group(" Dept XYZ ")
$ Drive = " g:" $ Path = " \ \ serverName \ "+@ userid Call " @ lserver \ \ folderName "
ELSE
ENDIF
现在,您会注意到这个脚本正在调用另一个名为“ConnectDrive”的脚本来进行实际的映射。基本上它包含了错误处理和下面几行:
:ConnectDrive
使用\(Drive /DELETE 使用\)Drive $Path
现在让我们来看看我在 Python 中用什么来代替 Kixtart 代码。首先,我们需要获得用户所在的组。您会注意到下面有两种方法可以使用 PyWin32 包的不同部分来获得我们需要的组信息。
from win32com.client import GetObject as _GetObject
try:
user = _GetObject("WinNT://%s/%s,user" % (pdcName, userid))
fullName = user.FullName
myGroups = _GetGroups(user)
except:
try:
from win32net import NetUserGetGroups,NetUserGetInfo
myGroups = []
groups = NetUserGetGroups(pdcName,userid)
userInfo = NetUserGetInfo(pdcName,userid,2)
fullName = userInfo['full_name']
for g in groups:
myGroups.append(g[0])
except:
fullname = "Unknown"
myGroups = []
然后我们可以进行驱动器映射。请注意,我尝试取消任何已经映射到我想要映射到的驱动器号的映射。我这样做是因为我们有用户将插入 USB 驱动器,接管我的脚本映射的驱动器。有时这行得通,有时行不通。
import subprocess
import win32wnet
from win32netcon import RESOURCETYPE_DISK as DISK
drive_mappings = []
if "Dept XYZ" in myGroups:
drive_mappings.append(('V:', '\\\\ServerName\\folderName'))
for mapping in drive_mappings:
try:
# Try to disconnect anything that was previously mapped to that drive letter
win32wnet.WNetCancelConnection2(mapping[0],1,0)
except Exception, err:
print 'Error mapping drive!'
try:
win32wnet.WNetAddConnection2(DISK, mapping[0], mapping[1])
except Exception, err:
if 'already in use' in err[2]:
# change the drive letter since it's being mis-assigned
subprocess.call(r'diskpart /s \\%s\path\to\log\change_g.txt' % pdcName)
# try mapping again
win32wnet.WNetAddConnection2(DISK, mapping[0], mapping[1])
这就是全部了。它最终比 Kixtart 更复杂一点,但是我认为我的代码可读性更好,我不必搜索多个文件来理解它。
matplotlib——用 Python 创建图形的介绍
原文:https://www.blog.pythonlibrary.org/2021/09/07/matplotlib-an-intro-to-creating-graphs-with-python/
数据可视化是与他人共享数据的一种重要方法。有些人把可视化称为绘图、图表或图形。这些名字在本文中是同义的。
Python 有许多第三方包来实现数据可视化。事实上,有这么多,它可以有些不知所措。其中最古老也是最受欢迎的是 Matplotlib 。Matplotlib 以在 Python 中创建静态、动画和交互式可视化而闻名。
您可以使用 Matplotlib 创建许多不同类型的绘图和图表。它还可以与其他数据科学和数学库很好地集成,如 NumPy 和 pandas 。您还会发现 Matplotlib 可以与 Python 的大多数 GUI 工具包兼容,如 Tkinter、wxPython 和 PyQt。因为 Matplotlib 如此出名,所以它将是本文所涉及的图形包。
您将了解以下主题:
- 用 PyPlot 创建简单的折线图
- 创建条形图
- 创建饼图
- 添加标签
- 向地块添加标题
- 创造传奇
- 显示多个图形
让我们开始用 Matplotlib 绘图吧!
安装 Matplotlib
您需要安装 Matplotlib 才能使用它。幸运的是,使用pip很容易做到:
python -m pip install matplotlib
这将安装 Matplotlib 以及它需要的任何依赖项。现在你已经准备好开始绘图了!
用 PyPlot 创建简单的折线图
创建图表(或绘图)是使用绘图包的主要目的。Matplotlib 有一个名为pyplot的子模块,您将使用它来创建一个图表。首先,创建一个名为line_plot.py的新文件,并添加以下代码:
# line_plot.py
import matplotlib.pyplot as plt
def line_plot(numbers):
plt.plot(numbers)
plt.ylabel('Random numbers')
plt.show()
if __name__ == '__main__':
numbers = [2, 4, 1, 6]
line_plot(numbers)
在这里,您将matplotlib.pyplot作为plt导入。然后创建一个line_plot(),它接受一个 Python 数字列表。要绘制数字,您可以使用plot()功能。您还可以向 y 轴添加一个标签。最后,你调用show()来显示情节。
您现在应该会看到一个如下所示的窗口:

现在你知道如何使用 Matplotlib 创建一个简单的折线图了!现在,您将在下一节中了解如何制作条形图。
创建条形图
使用 Matplotlib 创建条形图与创建折线图非常相似。只需要一些额外的参数。继续创建一个名为bar_chart.py的新文件,并在其中输入以下代码:
# bar_chart.py
import matplotlib.pyplot as plt
def bar_chart(numbers, labels, pos):
plt.bar(pos, numbers, color='blue')
plt.xticks(ticks=pos, labels=labels)
plt.show()
if __name__ == '__main__':
numbers = [2, 1, 4, 6]
labels = ['Electric', 'Solar', 'Diesel', 'Unleaded']
pos = list(range(4))
bar_chart(numbers, labels, pos)
当您使用bar()创建一个条形图时,您会传入一个 x 轴的值列表。然后你传入一个酒吧的高度列表。您还可以选择设置条形的颜色。在这种情况下,您将它们设置为“蓝色”。接下来,设置xticks(),它是应该出现在 x 轴上的刻度线。您还可以传入对应于刻度的标签列表。
继续运行这段代码,您应该会看到下图:

也可以用 Matplotlib 做一个水平条形图。你需要做的就是把bar()改成barh()。创建一个名为bar_chartsh.py的新文件,并添加以下代码:
# bar_charth.py
import matplotlib.pyplot as plt
def bar_charth(numbers, labels, pos):
plt.barh(pos, numbers, color='blue')
plt.yticks(ticks=pos, labels=labels)
plt.show()
if __name__ == '__main__':
numbers = [2, 1, 4, 6]
labels = ['Electric', 'Solar', 'Diesel', 'Unleaded']
pos = list(range(4))
bar_charth(numbers, labels, pos)
这里还有一个偷偷摸摸的变化。你能发现它吗?变化在于,由于现在它是一个水平条形图,您将希望设置yticks()而不是xticks(),否则它看起来不会很正确。
一旦一切准备就绪,运行代码,您将看到以下内容:

这看起来很棒,而且根本不需要太多代码!现在让我们看看如何用 Matplotlib 创建一个饼图。
创建饼图
饼状图有点与众不同。要创建一个饼图,您将使用 Matplotlib 的subplots()函数,该函数返回一个Figure和一个Axes对象。要查看它是如何工作的,创建一个名为pie_chart_plain.py的新文件,并将以下代码放入其中:
# pie_chart_plain.py
import matplotlib.pyplot as plt
def pie_chart():
numbers = [40, 35, 15, 10]
labels = ['Python', 'Ruby', 'C++', 'PHP']
fig1, ax1 = plt.subplots()
ax1.pie(numbers, labels=labels)
plt.show()
if __name__ == '__main__':
pie_chart()
在这段代码中,您创建了subplots(),然后使用了Axes对象的pie()方法。您像以前一样传入一个数字列表,以及一个标签列表。然后当您运行代码时,您将看到您的饼图:

对于这么短的代码来说,这已经很不错了。但是你可以让你的饼图看起来更好。创建一个名为pie_chart_fancy.py的新文件,并添加以下代码,看看如何操作:
# pie_chart_fancy.py
import matplotlib.pyplot as plt
def pie_chart():
numbers = [40, 35, 15, 10]
labels = ['Python', 'Ruby', 'C++', 'PHP']
# Explode the first slice (Python)
explode = (0.1, 0, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(numbers, explode=explode, labels=labels,
shadow=True, startangle=90,
autopct='%1.1f%%')
ax1.axis('equal')
plt.show()
if __name__ == '__main__':
pie_chart()
对于本例,您使用explode参数来告诉饼图“爆炸”或从饼图中移除一个切片。在这种情况下,您删除第一个切片,它对应于“Python”。您还可以向饼图添加一个shadow。您可以通过设置startangle来告诉您的饼图逆时针旋转一定的角度。如果您想显示切片百分比,可以使用autopct,它将使用 Python 的字符串插值语法。
当您运行这段代码时,您的饼图将如下所示:

这不是很棒吗?你的饼图现在看起来更加完美了!现在是时候学习如何给其他图表添加标签了!
添加标签
当您绘制数据时,您通常会想要标注轴。您可以使用xlabel()功能标记 x 轴,使用相应的ylabel()功能标记 y 轴。要了解这是如何工作的,创建一个名为bar_chart_labels.py的文件,并向其中添加以下代码:
# bar_chart_labels.py
import matplotlib.pyplot as plt
def bar_chart(numbers, labels, pos):
plt.bar(pos, numbers, color='blue')
plt.xticks(ticks=pos, labels=labels)
plt.xlabel('Vehicle Types')
plt.ylabel('Number of Vehicles')
plt.show()
if __name__ == '__main__':
numbers = [2, 1, 4, 6]
labels = ['Electric', 'Solar', 'Diesel', 'Unleaded']
pos = list(range(4))
bar_chart(numbers, labels, pos)
这里你同时调用了xlabel()和ylabel()并将它们设置为不同的字符串。这将分别在图表的下方和左侧添加一些说明性文本。结果如下所示:

看起来很不错。你的图表更容易理解,但它缺少一个标题。您将在下一节学习如何做到这一点!
向地块添加标题
用 Matplotlib 给你的图表添加标题非常简单。事实上,你需要做的就是使用title()函数来添加一个。要了解如何操作,创建一个名为bar_chart_title.py的新文件,并向其中添加以下代码:
# bar_chart_title.py
import matplotlib.pyplot as plt
def bar_chart(numbers, labels, pos):
plt.bar(pos, [4, 5, 6, 3], color='green')
plt.bar(pos, numbers, color='blue')
plt.xticks(ticks=pos, labels=labels)
plt.title('Gas Used in Various Vehicles')
plt.xlabel('Vehicle Types')
plt.ylabel('Number of Vehicles')
plt.show()
if __name__ == '__main__':
numbers = [2, 1, 4, 6]
labels = ['Electric', 'Solar', 'Diesel', 'Unleaded']
pos = list(range(4))
bar_chart(numbers, labels, pos)
这里的主要变化在第 9 行,在那里调用title()并传入一个字符串。默认情况下,这会设置图形的标题,并使其沿顶部居中。您可以通过将loc参数设置为“left”或“right”来稍微更改位置,但是您不能指定标题位于顶部以外的任何位置。还有一个fontdict参数,可以用来控制标题字体的外观。
您还可以向图表中添加一个新的条形图。这有助于您了解堆积条形图的外观,并为下一节做好准备。
你的图表现在看起来是这样的:

这张图看起来更好,但它仍然缺少一些东西。哦!你需要一个传奇!让我们看看下一步该怎么做。
创造传奇
向 Matplotlib 图添加图例也很简单。您将使用legend()功能添加一个。创建一个名为bar_chart_legend.py的新文件。然后,向其中添加以下代码:
# bar_chart_legend.py
import matplotlib.pyplot as plt
def bar_chart(numbers, labels, pos):
plt.bar(pos, [4, 5, 6, 3], color='green')
plt.bar(pos, numbers, color='blue')
plt.xticks(ticks=pos, labels=labels)
plt.xlabel('Vehicle Types')
plt.ylabel('Number of Vehicles')
plt.legend(['First Label', 'Second Label'], loc='upper left')
plt.show()
if __name__ == '__main__':
numbers = [2, 1, 4, 6]
labels = ['Electric', 'Solar', 'Diesel', 'Unleaded']
pos = list(range(4))
bar_chart(numbers, labels, pos)
在这里,您在图表的show()前添加一个legend()。创建图例时,可以通过传入字符串列表来设置标签。列表应与图形中的地块数量相匹配。您也可以使用loc参数设置图例的位置。
当您运行这段代码时,您将看到您的图形更新成这样:
现在你的图拥有了你期望在图中拥有的所有正常组件。至此,您已经看到了许多使用 Matplotlib 可以完成的任务。最后一个要学习的主题是如何用 Matplotlib 将多个图形相加。
显示多个图形
Matplotlib 允许您在显示之前创建几个图。这使您可以同时处理多个数据集。有几种不同的方法可以做到这一点。您将看到一种最简单的方法。
创建一个名为multiple_figures.py的新文件,并添加以下代码:
# multiple_figures.py
import matplotlib.pyplot as plt
def line_plot(numbers, numbers2):
first_plot = plt.figure(1)
plt.plot(numbers)
second_plot = plt.figure(2)
plt.plot(numbers2)
plt.show()
if __name__ == '__main__':
numbers = [2, 4, 1, 6]
more_numbers = [5, 1, 10, 3]
line_plot(numbers, more_numbers)
这里您创建了两个线形图。在绘图之前,您调用figure(),这将为调用它之后的绘图创建一个顶级容器。因此,第一个图被添加到图 1,第二个图被添加到图 2。当您在最后调用show()时,Matplotlib 将打开两个窗口,分别显示每个图形。
运行代码,您将在机器上看到以下两个窗口:

Matplotlib 还支持在单个窗口中添加两个或多个图。要了解这是如何工作的,创建另一个新文件,并将其命名为multiple_plots.py。为了使事情更有趣,您将在本例中使用 NumPy 来创建这两个图。
注意:如果您还没有安装 NumPy,那么您需要安装它来运行这个例子。
此示例基于 Matplotlib 文档中的一个示例:
# multiple_plots.py
import matplotlib.pyplot as plt
import numpy as np
def multiple_plots():
# Some example data to display
x = np.linspace(0, 2 * np.pi, 400)
y = np.sin(x ** 2)
fig, axs = plt.subplots(2)
fig.suptitle('Vertically stacked subplots')
axs[0].plot(x, y)
axs[1].plot(x, -y)
plt.show()
if __name__ == '__main__':
multiple_plots()
这里你创建了两个独立的正弦波图。为了让它们都出现在同一个窗口中,您可以调用subplots(),这是一个方便的实用程序,可以在一次调用中创建多个图形。然后您可以使用它返回的Axes对象来绘制您用 NumPy 创建的数据。
结果看起来像这样:

如果您不想使用 NumPy,您可以绘制上一个示例中的两组数字。事实上,你应该试试。继续创建一个名为multiple_plots2.py的新文件,并添加以下代码:
# multiple_plots2.py
import matplotlib.pyplot as plt
def multiple_plots():
numbers = [2, 4, 1, 6]
more_numbers = [5, 1, 10, 3]
fig, axs = plt.subplots(2)
fig.suptitle('Vertically stacked subplots')
axs[0].plot(numbers)
axs[1].plot(more_numbers)
plt.show()
if __name__ == '__main__':
multiple_plots()
在这段代码中,您完全删除了 NumPy 代码,并添加了前面示例中的两个数字列表。然后使用Axes对象绘制它们。
这导致了以下堆积图:

至此,您应该已经很好地掌握了如何使用 Matplotlib 创建多个图形和堆叠图。
包扎
Matplotlib 是一个很棒的包,可以用来创建各种简洁的图形。令人惊讶的是,从数据中创建一个有用的绘图只需要编写几行代码。在本文中,您了解了以下主题:
- 用 PyPlot 创建简单的折线图
- 创建条形图
- 创建饼图
- 添加标签
- 向地块添加标题
- 创造传奇
- 显示多个图形
Matplotlib 非常强大,有很多这里没有涉及的特性。您可以使用 Matplotlib 创建许多其他类型的可视化。有一个更新的包叫做 Seaborn ,它构建在 Matplotlib 之上,使它的图形看起来更好。还有许多其他完全独立的 Python 绘图包。您会发现 Python 支持您能想到的几乎任何类型的图,可能还有许多您不知道的图。
相关阅读
想了解更多关于 Python 的功能吗?查看这些教程:
-
Python 101: 使用 JSON 的介绍
-
Python 101 - 创建多个流程
-
python 101-用 pdb 调试你的代码
-
Python 101—使用 Python 启动子流程
2010 年 5 月 Pyowa 总结
原文:https://www.blog.pythonlibrary.org/2010/05/07/may-2010-pyowa-wrap-up/
昨晚,我们举行了 2010 年 5 月的 Pyowa 会议。这是爱荷华州唯一的 Python 用户组,我们欢迎任何用 Python 编程的人(或对学习 Python 感兴趣的人)加入我们的组。在这次会议上,我们做了三个很好的报告。第一个是由吉姆,他的主题是网络抓取。他使用 Mechanize 和 lxml 的组合来抓取埃姆斯市的网站,以便在他自己的一个网站上存档。
Mechanize 允许 Jim 模拟浏览器并浏览网站。它可以填写表格,用你提供的凭证登录,等等。然后,他使用 lxml 解析他想要的页面,如果他需要下载什么,他只需结合 wget 使用 os.system 。也提到了美汤库,但是 Jim 没有使用它。我们的另一位成员说,他们的组织确实使用了一段时间美丽的汤,并对结果感到满意。
我们接下来的两个演示是由一个叫凯文的人做的。他谈到了 Mercurial 分布式版本控制系统和 Trac ,一个基于网络的问题跟踪器。Kevin 向我们展示了如何建立一个 Mercurial 存储库,添加文件,分支,更新,合并等等。他使用 virtualenv 完成了所有这些,这是一种分离项目的简便方法。完成 Mercurial 讲座后,Kevin 向我们展示了如何使用他的 Mercurial 存储库设置 Trac、添加票证、在 Mercurial 中提交票证修复程序,以及 Trac 中包含的各种管理工具。Kevin 还强调了一些他喜欢的 Trac 和 Mercurial 插件。
如果你愿意参加我们的下一次会议,它将在同一个地点举行,6 月 3 日,也就是星期四,在爱荷华州的埃姆斯公共图书馆。如果您想分享您使用 Python 或其众多项目中的一个的经验,那将非常好!请给我发电子邮件,地址是 python library . org 的 mike,这样我们可以给你安排时间。观看我们的网站获取最新信息。
用 Union 运算符合并字典
原文:https://www.blog.pythonlibrary.org/2021/09/18/merging-dictionaries-with-the-union-operator/
作为一名开发人员,有时您可能需要将两个或更多的字典合并成一个主字典。在 Python 编程语言中,有许多不同的方式来合并字典。
在本教程中,你将看到一些合并字典的老方法,然后再看看在 Python 3.9 中添加的最新方法。
以下是您将了解的方法:
- 使用 dict.update()
- 与**合并
- 用 Union 运算符合并
您将使用 update() 方法开始您的旅程!
使用 dict.update()
Python 的字典有很多不同的方法。这些方法中的一种可以用来将两个字典合并在一起。这个方法叫做 update() 。
这里有一个例子:
>>> first_dictionary = {"name": "Mike", "occupation": "Python Teacher"}
>>> second_dictionary = {"location": "Iowa", "hobby": "photography"}
>>> first_dictionary.update(second_dictionary)
>>> first_dictionary
{'name': 'Mike', 'occupation': 'Python Teacher', 'location': 'Iowa', 'hobby': 'photography'}
这工作完美!这个方法的唯一问题是它修改了其中一个字典。如果您想要创建第三个字典,而不修改其中一个输入字典,那么您将需要查看本文中的其他合并方法。
您现在已经准备好学习使用**!
与**合并
当你使用双星号时,它有时被称为“打开”、“展开”或“打开”字典。Python 中使用了 ****** ,函数中也使用了 kwargs 。
下面是如何使用**来合并两个字典:
>>> first_dictionary = {"name": "Mike", "occupation": "Python Teacher"}
>>> second_dictionary = {"location": "Iowa", "hobby": "photography"}
>>> merged_dictionary = {**first_dictionary, **second_dictionary}
>>> merged_dictionary
{'name': 'Mike', 'occupation': 'Python Teacher', 'location': 'Iowa', 'hobby': 'photography'}
这种语法看起来有点奇怪,但它非常有效!
现在,您已经准备好了解合并两个词典的最新方法了!
用 Union 运算符合并
从 Python 3.9 开始,可以使用 Python 的 union 操作符 | 来合并字典。你可以在 PEP 584 中了解所有的实质细节。
下面是如何使用 union 运算符合并两个字典:
>>> first_dictionary = {"name": "Mike", "occupation": "Python Teacher"}
>>> second_dictionary = {"location": "Iowa", "hobby": "photography"}
>>> merged_dictionary = first_dictionary | second_dictionary
>>> merged_dictionary
{'name': 'Mike', 'occupation': 'Python Teacher', 'location': 'Iowa', 'hobby': 'photography'}
这是将两本词典合二为一的最短方法。
包扎
您现在知道了三种不同的方法,可以用来将多个字典合并成一个。如果你有 Python 3.9 或更高版本的权限,你应该使用 union 操作符,因为这可能是看起来最干净的合并字典的方法。然而,如果你被困在一个旧版本的 Python 上,你不必绝望,因为你现在有另外两个方法可以工作!
Meta:新的鼠标 Vs Python 时事通讯
原文:https://www.blog.pythonlibrary.org/2017/06/28/meta-the-new-mouse-vs-python-newsletter/
我最近决定给我的读者一个选择,让他们注册每周一次的我在这个博客上发表的文章的综述。我把它添加到了我的关注博客页面,但是如果你有兴趣每周收到一封包含上周所有文章链接的电子邮件,你也可以在下面注册:
迷你书评:MySQL for Python
原文:https://www.blog.pythonlibrary.org/2010/12/09/mini-book-review-mysql-for-python/
|  |
|
Python 的 MySQL
上个月,Packt Publishing 的市场部找到我,让我对他们的新书 Albert Lukaszewski 的《MySQL for Python》进行评论。这本书有 440 页,我应该很快读完。不幸的是,现实生活挡住了我的去路,我将对这本书的内容做一个小小的回顾(即 161 页+略读)。为什么?因为他们市场部一直烦我。将来,我打算只买我自己的书,这样我就不会有这些愚蠢的时间限制。
另一个原因是,我花了这么长时间来阅读这篇文章,因为我只有一本电子书,这使得阅读起来不太方便。我承认我更喜欢真书。它们不会像显示器那样让我的眼睛很快变干。我发现我对 MySQL 并不感兴趣...但你来我的博客不是为了看我的牢骚吧?让我们来看看这本书是否值得你辛苦赚来的钱!
继续复习!
这本书背后有一些相当重要的凭据。作者在 About 上撰写“关于 Python”专栏,评论者涵盖了所有作者、MySQL for Python 背后的主要程序员以及 Sun/Oracle 的 MySQL 支持团队成员。这本书的写作(正如所料)相当不错。我承认我觉得它有点干。然而,我还没有读过一本激动人心的数据库书籍。
无论如何,这本书的第一章是关于在你的机器上设置 MySQL 和 MySQL for Python 的。你可以从各个项目的网站上获得这些信息。第二章和第三章介绍了基本的 SQL 语法,到处都有一些 Python 例子。这让我有点困惑,因为我以为这本书是给那些已经了解 SQL,并且正在学习如何使用 Python 编程语言与 MySQL 接口的人看的。这些章节没有什么特别的问题,但是我希望更多的 Python,而不是 SQL。你的品味可能会不同。
我读的最后一章是第四章,是关于异常处理的。作者花了很多时间讨论警告和异常之间的区别,以及应该如何处理它们。本文还介绍了 MySQL for Python 包可以捕获的各种自定义错误。
我读了第五章的一半。它涵盖了如何使用 fetchone()和 fetchmany()方法以及循环和迭代器来逐个记录地检索结果。在这一章的最后我没有讲到电影数据库项目。
我还没有读到的章节涵盖了以下主题:插入多个条目、创建和删除(我猜是表);创建用户和授予访问权限(我认为是权限或安全性);日期和时间值、聚合函数和子句;选择替代品;字符串函数;显示 MySQL 元数据;最后,灾难恢复。
判决结果?
据我所知,我认为这本书很好地涵盖了这些主题。虽然我发现有很多内容需要复习(因此有点无聊),但我认为作为一个学习 SQL 和 Python 程序员新手,这本书会对我很有帮助。不过,我现在倾向于使用 SqlAlchemy 来处理我所有的数据库工作。尽管如此,如果你需要了解这个主题或者想学习如何用 Python 连接 MySQL 而不使用 SqlAlchemy 这样的 ORM,那么这本书就是为你准备的!否则,尝试在亚马逊网站或书店预览,以确保它符合您的需求。
2014 年 PyCon 小姐?看回放!
原文:https://www.blog.pythonlibrary.org/2014/04/14/miss-pycon-2014-watch-the-replay/
如果你和我一样,你错过了今年的 PyCon 北美 2014。这事发生在上周末。虽然主要会议已经结束,但代码冲刺仍在进行。无论如何,对于那些错过 PyCon 的人,他们已经在 pyvideo 上发布了一堆视频!每年,他们似乎都比上一年更快地发布视频。我自己也觉得这很棒。我期待着看一些这样的视频,这样我就可以看到我错过了什么。
PyPI 上发现更多域名抢注恶意软件
原文:https://www.blog.pythonlibrary.org/2018/10/31/more-typo-squatting-malware-found-on-pypi/
最近在针对 Windows 用户的 Python 打包索引上发现了恶意软件。该软件包被称为 colourama ,如果它被安装,最终会在你的电脑上安装恶意软件。基本上是希望你会拼错流行的coloramapackage。
你可以在媒体上阅读关于该恶意软件的更多信息,该媒体将该恶意软件描述为“加密货币剪贴板劫持者”。
实际上,去年当斯洛伐克国家安全局在 Python 打包索引中发现了几个恶意库时,我也写过这个问题。
本周,我注意到 Python 软件基金会正在考虑在 2019 年给 PyPI 增加安全性,他们在他们的博客上宣布了这一消息,尽管现在似乎还没有说会增加什么样的安全性。
关于 Python 的更多 Windows 系统信息
原文:https://www.blog.pythonlibrary.org/2010/02/06/more-windows-system-information-with-python/
上个月我写了一篇关于获取 Windows 系统信息的文章,我在我的一条评论中提到有另一个脚本可以做这些事情,但是我找不到它。嗯,今天我去挖掘了一下,找到了我想要的剧本。因此,我们要回到兔子洞去寻找更多的技巧和窍门,以便使用 Python 获得关于 Windows 奇妙世界的信息。
以下脚本摘自我在职时使用和维护的登录脚本。我们通常需要几种方法来识别特定用户的机器。幸运的是,大多数工作站都有几个唯一的标识符,比如 IP、MAC 地址和工作站名称(尽管这些都不一定是唯一的...例如,我们实际上有一个工作站,它的网卡与我们的一台服务器的 MAC 相同。不管怎样,让我们来看看代码吧!
如何获得您工作站的名称
在本节中,我们将使用平台模块来获取我们计算机的名称。在我之前的文章中,我们实际上提到了这个技巧,但是因为我们在下一个片段中需要这个信息,所以我将在这里重复这个技巧:
from platform import node
computer_name = node()
一点也不痛苦,对吧?只有两行代码,我们得到了我们需要的。但是实际上至少还有一种方法可以得到它:
import socket
computer_name = socket.gethostname()
这个片段也非常简单,尽管第一个片段稍微短一些。我们所要做的就是导入内置的 socket 模块,并调用它的 gethostname 方法。现在我们已经准备好获取我们电脑的 IP 地址了。
如何用 Python 获取你的 PC 的 IP 地址
我们可以使用上面收集的信息来获取我们电脑的 IP 地址:
import socket
ip_address = socket.gethostbyname(computer_name)
# or we could do this:
ip_address2 = socket.gethostbyname(socket.gethostname())
在这个例子中,我们再次使用了 socket 模块,但是这次我们使用了它的 gethostbyname 方法并传入了 PC 的名称。然后插座模块将返回 IP 地址。
也可以用蒂姆·戈登的T2 的【WMI】模块。下面的例子来自他精彩的 WMI 烹饪书:
import wmi
c = wmi.WMI ()
for interface in c.Win32_NetworkAdapterConfiguration (IPEnabled=1):
print interface.Description
for ip_address in interface.IPAddress:
print ip_address
print
它所做的只是遍历已安装的网络适配器,并打印出它们各自的描述和 IP 地址。
如何用 Python 获取 MAC 地址
现在我们可以将注意力转向获取 MAC 地址。我们将研究两种不同的方法来获得它,从 ActiveState 方法开始:
def get_macaddress(host='localhost'):
""" Returns the MAC address of a network host, requires >= WIN2K. """
# http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/347812
import ctypes
import socket
import struct
# Check for api availability
try:
SendARP = ctypes.windll.Iphlpapi.SendARP
except:
raise NotImplementedError('Usage only on Windows 2000 and above')
# Doesn't work with loopbacks, but let's try and help.
if host == '127.0.0.1' or host.lower() == 'localhost':
host = socket.gethostname()
# gethostbyname blocks, so use it wisely.
try:
inetaddr = ctypes.windll.wsock32.inet_addr(host)
if inetaddr in (0, -1):
raise Exception
except:
hostip = socket.gethostbyname(host)
inetaddr = ctypes.windll.wsock32.inet_addr(hostip)
buffer = ctypes.c_buffer(6)
addlen = ctypes.c_ulong(ctypes.sizeof(buffer))
if SendARP(inetaddr, 0, ctypes.byref(buffer), ctypes.byref(addlen)) != 0:
raise WindowsError('Retreival of mac address(%s) - failed' % host)
# Convert binary data into a string.
macaddr = ''
for intval in struct.unpack('BBBBBB', buffer):
if intval > 15:
replacestr = '0x'
else:
replacestr = 'x'
if macaddr != '':
macaddr = ':'.join([macaddr, hex(intval).replace(replacestr, '')])
else:
macaddr = ''.join([macaddr, hex(intval).replace(replacestr, '')])
return macaddr.upper()
由于上面的代码不是我写的,所以就不深入了。然而,我的理解是,这个脚本首先检查它是否可以执行 ARP 请求,这仅在 Windows 2000 和更高版本上可用。一旦得到确认,它就会尝试使用 ctypes 模块来获取 inet 地址。完成之后,它会通过一些我不太理解的东西来建立 MAC 地址。
当我第一次开始维护这段代码时,我认为一定有更好的方法来获取 MAC 地址。我想也许 Tim Golden 的 WMI 模块或者 PyWin32 包会是答案。我很确定他给了我下面的片段,或者我是在 Python 邮件列表档案中找到的:
def getMAC_wmi():
"""uses wmi interface to find MAC address"""
interfaces = []
import wmi
c = wmi.WMI ()
for interface in c.Win32_NetworkAdapterConfiguration (IPEnabled=1):
if interface.DNSDomain == 'www.myDomain.com':
return interface.MACAddress
不幸的是,虽然这种方法有效,但它明显降低了登录脚本的速度,所以我最终还是使用了原来的方法。我想 Golden 先生已经发布了一个较新版本的 wmi 模块,所以现在可能更快了。
如何获得用户名
用 Python 获取当前用户的登录名很简单。你所需要的就是 PyWin32 包。
from win32api import GetUserName
userid = GetUserName()
一次快速导入,我们就有了两行代码的用户名。
如何找到用户所在的组
我们可以使用上面获得的 userid 来找出它属于哪个组。
import os
from win32api import GetUserName
from win32com.client import GetObject
def _GetGroups(user):
"""Returns a list of the groups that 'user' belongs to."""
groups = []
for group in user.Groups ():
groups.append (group.Name)
return groups
userid = GetUserName()
pdcName = os.getenv('dcName', 'primaryDomainController')
try:
user = GetObject("WinNT://%s/%s,user" % (pdcName, userid))
fullName = user.FullName
myGroups = _GetGroups(user)
except Exception, e:
try:
from win32net import NetUserGetGroups,NetUserGetInfo
myGroups = []
groups = NetUserGetGroups(pdcName,userid)
userInfo = NetUserGetInfo(pdcName,userid,2)
fullName = userInfo['full_name']
for g in groups:
myGroups.append(g[0])
except Exception, e:
fullname = "Unknown"
myGroups = []
这比我们之前看到的任何一个脚本都要吓人,但实际上非常容易理解。首先,我们导入我们需要的模块或方法。接下来我们有一个简单的函数,它将一个用户对象作为唯一的参数。该函数将遍历该用户的组,并将它们添加到一个列表中,然后返回给调用者。难题的下一部分是获得主域控制器,我们使用 os 模块来完成。
我们将 pdcName 和 userid 传递给 GetObject(它是 win32com 模块的一部分)来获取我们的用户对象。如果工作正常,那么我们可以获得用户的全名和组。如果它失败了,那么我们捕获错误,并尝试从 win32net 模块中获取一些函数信息。如果这也失败了,那么我们就设置一些默认值。
包扎
希望你已经学到了一些有价值的技巧,可以用在你自己的代码中。我已经在 Python 2.4+中使用这些脚本好几年了,它们工作得非常好!
CodeEval.com 最流行的语言是什么?Python!
原文:https://www.blog.pythonlibrary.org/2014/02/05/most-popular-language-on-codeeval-com-python/
2013 年最流行的语言是什么?按照CodeEval.com的说法,是 Python!如果你把它和 TIOBE 比较,Python 只排在第 8 位,但至少它还在前十!希望 Python 在 2014 年继续壮大,并在许多新的地方得到应用。
您可能还会发现最新的 PYPL 编程语言流行指数也很有帮助,Python 将第三名列为教程中搜索最多的编程语言。
鼠标 vs Python 有松弛通道
原文:https://www.blog.pythonlibrary.org/2021/06/25/mouse-vs-python-has-a-slack-channel/
这个网站现在有一个松弛频道。加入是免费的。不需要订阅!
如果您想加入,请使用以下链接,该链接在未来 30 天内有效:
https://join . slack . com/t/mousevspython/shared _ invite/ZT-s 4 r 3 rwt 2-ookhegzp 1 cqoxebwioecaa
您可以与该网站的作者 Mike Driscoll 以及该网站的其他读者聊天。Mouse vs Python 致力于提供关于 Python 编程语言的优秀教程。只要你尊重别人,欢迎你加入 Slack!
我希望在那里见到你!
鼠标 Vs Python 成为 Python 开发者的 11 个必读博客
Code Condo 最近将这个博客 Mouse Vs Python 命名为“Python 开发者必读的 11 个博客”之一。这篇文章值得一读,因为它列出了许多其他非常好的网站,如 pydanny 和 Doug Hellman 的网站。当我学习 Python 的时候,我真的很喜欢 Effbot,但是我不认为 Lundh 先生会继续更新它,所以我不确定我对它的感觉。无论如何,如果你需要一些关于其他 Python 博客的想法,一定要看看这篇文章。
Mozilla 在浏览器中宣布 Pyodide - Python
原文:https://www.blog.pythonlibrary.org/2019/04/18/mozilla-announces-pyodide-python-in-the-browser/
本周早些时候,Mozilla 宣布了一个名为的新项目。Pyodide 的目标是将 Python 的科学堆栈引入浏览器。
Pyodide 项目将为您提供一个完整的、标准的 Python 解释器,它可以在您的浏览器中运行,还可以让您访问浏览器的 Web APIs。目前,Pyodide 不支持线程或网络套接字。Python 在浏览器中运行的速度也相当慢,尽管它可用于交互式探索。
文章还提到了其他项目,比如布莱森和斯库尔普特。这些项目是用 Javascript 重写 Python 的解释器。与 Pyodide 相比,它们的缺点是不能使用用 C 编写的 Python 扩展,比如 Numpy 或 Pandas。Pyodide 克服了这个问题。
无论如何,这听起来是一个非常有趣的项目。我一直认为我以前在浏览器中看到的 Python 在 Silverlight 中运行的演示很酷。这个项目现在基本上已经死了,但是 Pyodide 听起来是一个非常有趣的让 Python 进入浏览器的新技术。希望它会去某个地方。
我的 Python 职业生涯。init 面试
我最近在播客上接受了托拜厄斯·小萌( @TobiasMacey )的采访。_ _ init _ _(@ Podcast _ _ init _ _)关于我在 Python 程序员生涯中做过的一些事情。
您可以在这里收听:
如果你今年早些时候错过了,我也参加了 Talk Python to Me 播客谈论 Python 的历史,以及其他话题。
我的上下文管理器文章变成了截屏
上个月,我写了一篇关于上下文管理器的文章,一家名为 Webucator 的公司请求我允许将这篇文章改编成视频。最后看起来还不错。请查看以下内容:
https://www.youtube.com/embed/HTDtmk__weM?feature=oembed
Webucator 也有其他 Python 相关的培训。我不太了解他们,但如果这个视频是任何迹象,我认为他们值得一试。
我用 wxPython 书创建 GUI 应用程序的封面故事
我认为为我的新书《用 wxPython 创建 GUI 应用程序》写一点封面设计会很有趣。我本打算在实际的 Kickstarter 活动中发布这个消息。
我最初的封面想法是让老鼠指挥一只凤凰去攻击一条蛇。Phoenix 是 wxPython 4 发布前的代码名,您仍然可以在 wxPython 项目的文档和一些页面上看到对 Phoenix 的引用。
事实上,是我委托做的封面。这是它的草图:

原创封面概念艺术
正如你所看到的,艺术家很难记住这条蛇应该是一条蟒蛇。他继续在成品中犯懒惰的错误,我最终取消了那个封面。我不确定我是否会在未来的书中使用这个封面。我个人很喜欢老鼠和凤凰的样子,但是蟒蛇会一直困扰我。
所以我最终再次雇佣了 Varya Kolesnikova 来做这本书的封面。她是为我创作 Python 201 封面艺术的艺术家。你可以在 Behance 或 Instagram 上查看更多她的艺术作品。
这是她对我的新概念的原始草图,我的新概念是让老鼠骑着凤凰,背着蟒蛇:

实际封面概念艺术素描
我更喜欢她的方法,尽管她对凤凰的想法与我最初的想象大相径庭。
这是概念艺术的彩色版本:

色彩概念艺术素描
我喜欢 Varya 的艺术方法,她最终完成了你今天所知道的艺术品:

最终封面艺术
我正在努力完成这本书的最后几章。如果你有兴趣提前得到这本书,你可以现在就在 Leanpub 上预订。该书的最终版本将于 2019 年 5 月在发布。
我的第一次面试
原文:https://www.blog.pythonlibrary.org/2014/06/26/my-first-interview/
上周,DZone 联系我,问我是否愿意出现在他们的“本周发展”系列中。换句话说,他们想对我做一个简短的采访。采访是昨天开始的。如果你喜欢,你可以在这里阅读:
我不知道为什么链接在他们的 java 子域上,但不用说,我几乎所有的回答都谈到了 Python。如果与 Python 无关,我不会在我的博客上发布我的采访链接。不管怎样,如果你想多了解我一点,我想你可能会感兴趣。
我的第一个补丁被接受了!
原文:https://www.blog.pythonlibrary.org/2012/05/23/my-first-patch-was-accepted/
今天我有点兴奋,因为我的第一个补丁(甚至是第一张票!)已被接受。而且真的也没花多长时间。在我提交了第一个补丁后不到 24 小时,我的贡献就被添加了。虽然我的第一个版本不太好,但我不得不提交更多的版本。我想对 Brian Curtin 和 Eli Bendersky 表示感谢,他们帮助我解决了所有这些问题,并使我首次涉足核心 Python 开发取得了成功。就我个人而言,我认为即使这个补丁没有被接受,这也是一个成功,因为我在这个过程中仍然学到了很多东西。
从这次经历中学到的东西:
- 尽量不要跑题!实际上,我在 devguide 中修复的段落中发现了第二个问题,这可能应该放在一个单独的错误报告中。
- 给你的补丁编号!我不知道为什么我没有想到这一点,但伊莱告诉我,我应该在未来这样做,以减少提交者的困惑。那是一个巴掌大的瞬间。
我一直在阅读一些所谓的“简单错误”,并试图找出我还能在哪些方面提供帮助。我已经在 Python 本身包含的文档中发现了另一个错别字,我可能会尝试修复它。当然,我想实际上为代码做贡献,而不仅仅是文档,但是我可能更有可能找到我可以帮助解决的文档错误。希望有了更多的经验,我能更有效地做出贡献。祝黑我的蟒蛇伙伴们愉快!
网飞发布 Polynote -一种多语种 Jupyter 笔记本变体
网飞宣布他们将发布一款新的开源软件,他们称之为 Polynote 。Polynote 是一个受 IDE 启发的多语言笔记本,包括一流的 Scala 支持、Python 和 SQL。从网站上看,它似乎是建立在 Jupyter 笔记本之上的。
他们该项目的最高目标是再现性和可见性。您可以在媒体上阅读带有示例的完整公告。
这看起来是一个有趣的项目,我很好奇它如何影响 Jupyter 项目。我个人希望网飞的工作能够对 Python 社区有所帮助,或许还能增强 Jupyter Notebook 和 JupyterLab。
我喜欢它,这款笔记本允许每个电池运行不同的语言。你可以用 Jupyter Notebook 来做,但是这样做有点笨拙,而且不像使用 Polynote 正在使用的下拉控件那样用户友好。
有趣的是,Polynote 将其配置和依赖关系存储在笔记本的代码中。
Polynote 还使用 [Vega](http://reproducibility and visibility) 和 Matplotlib 支持健壮的数据可视化。
点击查看 Polynote 。
新的有效的书籍创作课程由马特哈里森
马特·哈里森(Matt Harrison)邀请我参加他的最新课程有效的书籍创作。这门课程将帮助你学习如何写一本技术书籍。马特采访了我,问我是如何写书的。(注:实际上我去年在我的文章中提到过这个问题)。
这门课最有趣的一点是马特教你如何写书。他还采访了像我这样的独立出版商以及有出版公司支持的知名作者。这样你就可以从出版游戏的两个方面来看待它。
我很高兴能花些时间亲自完成这个课程,看看我如何能提高自己的写作水平。Matt 给了我一个六折优惠码,你可以限时使用: MD40 。
如果你自己有兴趣成为一名作者,就去看看吧!
Python 中的新特性:格式化字符串文字
原文:https://www.blog.pythonlibrary.org/2017/02/08/new-in-python-formatted-string-literals/
Python 3.6 增加了另一种进行字符串替换的方法,他们称之为“格式化字符串文字”。你可以在 PEP 498 中读到关于这个概念的所有内容。这里我有点不高兴,因为 Python 的禅宗说应该有一种——最好只有一种——显而易见的方法来做这件事。现在 Python 有三种方式。在谈论最新的弦乐演奏方式之前,让我们回顾一下过去。
旧字符串替换
Python 刚开始的时候,他们按照 C++的方式使用 %s、%i 等进行字符串替换。这里有几个例子:
>>> The %s fox jumps the %s' % ('quick', 'crevice')
'The quick fox jumps the crevice'
>>> foo = 'The total of your purchase is %.2f' % 10
>>> foo
'The total of your purchase is 10.00'
上面的第二个示例演示了如何将一个数字格式化为精度设置为两位小数的浮点数。这种字符串替换方法也支持关键字参数:
>>> 'Hi, my name is %(name)s' % {'name': 'Mike'}
Out[21]: 'Hi, my name is Mike'
语法有点奇怪,我总是要查找它才能正确工作。
虽然这些字符串替换方法仍然受支持,但人们发明了一种新的方法,这种方法应该更清晰、功能更强。让我们看看这是什么样子:
>>> bar = 'You need to pay {}'.format(10.00)
>>> bar
'You need to pay 10.0'
>>> swede = 'The Swedish chef is know for saying {0}, {1}, {2}'.format('bork', 'cork', 'spork')
>>> swede
'The Swedish chef is know for saying bork, cork, spork'
我认为这是一个非常聪明的新添加。不过,还有一个额外的增强,那就是您实际上可以使用关键字参数来指定字符串替换中的内容:
>>> swede = 'The Swedish chef is know for saying {something}, {something}, {something}'
>>> swede.format(something='bork')
'The Swedish chef is know for saying bork, bork, bork'
>>> test = 'This is a {word} of your {something}'.format(word='Test', something='reflexes')
>>> test
'This is a Test of your reflexes'
这很酷,实际上也很有用。你会看到一些程序员会争论哪种方法更好。我看到一些人甚至声称,如果你做大量的字符串替换,原来的方法实际上比新的方法更快。不管怎样,这让你对旧的做事方式有了一个简要的了解。让我们看看有什么新的!
使用格式化字符串文字
从 Python 3.6 开始,我们得到格式化的字符串或 f 字符串。格式化字符串的语法与我们之前看到的稍有不同:
>>> name = 'Mike'
>>> f'My name is {name}'
'My name is Mike'
让我们把它分解一下。我们要做的第一件事是定义一个要插入字符串的变量。接下来我们想告诉 Python 我们想创建一个格式化的字符串文字。为此,我们在字符串前面加上字母“f”。这意味着字符串将被格式化。最后一部分与上一节的最后一个例子非常相似,我们只需要将变量名插入到字符串中,并用一对花括号括起来。然后 Python 变了一些魔术,我们打印出了一个新的字符串。这实际上非常类似于一些 Python 模板语言,比如 mako。
f-string 也支持某些类型的转换,比如 str() via !!s '和 repr() via '!r '这里有一个更新的例子:
>>> f'My name is {name!r}'
Out[11]: "My name is 'Mike'"
您会注意到输出中的变化非常微妙,因为添加的只是插入变量周围的一些单引号。让我们来看看更复杂一点的东西,即浮点数!
>>> import decimal
>>> gas_total = decimal.Decimal('20.345')
>>> width = 10
>>> precision = 4
>>> f'Your gas total is: {gas_total:{width}.{precision}}'
'Your gas total is: 20.34'
这里,我们导入 Python 的十进制模块,并创建一个表示气体总量的实例。然后我们设置字符串的宽度为 10 个字符,精度为 4。最后,我们告诉 f 字符串为我们格式化它。正如您所看到的,插入的文本在前端有一些填充,使其宽度为 10 个字符,精度基本上设置为 4,这截断了 5,而不是向上舍入。
包扎
新的格式化字符串文字或 f-string 并没有给格式化字符串增加任何新的东西。然而声称比以前的方法更灵活,更不容易出错。我强烈推荐阅读文档和 PEP 498 来帮助您了解这个新特性,这样您就可以确定这是否是您将来进行字符串替换的方式。
相关阅读
- Python 3.6 的新特性
- PEP 498 - 文字字符串插值
- Python 中的新特性:变量注释的语法
- Python 中的新特性:数字文字中的下划线
Python 中的新特性:变量注释的语法
原文:https://www.blog.pythonlibrary.org/2017/01/12/new-in-python-syntax-for-variable-annotations/
Python 3.6 增加了另一个有趣的新特性,被称为变量注释的语法。这个新特性在 PEP 526 中有所概述。这个 PEP 的基本前提是将类型提示( PEP 484 )的思想带到它的下一个逻辑步骤,基本上是将选项类型定义添加到 Python 变量中,包括类变量和实例变量。请注意,添加这些注释或定义不会突然使 Python 成为静态类型语言。解释器仍然不关心变量是什么类型。但是,Python IDE 或其他实用程序(如 pylint)可以添加一个注释检查器,当您使用一个已经注释为一种类型的变量,然后通过在函数中间更改其类型而被错误使用时,该检查器会突出显示。
让我们看一个简单的例子,这样我们就可以知道这是如何工作的:
# annotate.py
name: str = 'Mike'
这里我们有一个 Python 文件,我们将其命名为 annotate.py 。在其中,我们创建了一个变量, name ,并对其进行了注释,表明它是一个字符串。这是通过在变量名后添加一个冒号,然后指定它应该是什么类型来实现的。如果你不想的话,你不必给变量赋值。以下内容同样有效:
# annotate.py
name: str
当您注释一个变量时,它将被添加到模块或类的 annotations 属性中。让我们尝试导入注释模块的第一个版本,并访问该属性:
>>> import annotate
>>> annotate.__annotations__
{'name': }
>>> annotate.name
'Mike'
如您所见, annotations 属性返回一个 Python dict,其中变量名作为键,类型作为值。让我们给我们的模块添加一些其他的注释,看看 annotations 属性是如何更新的。
# annotate2.py
name: str = 'Mike'
ages: list = [12, 20, 32]
class Car:
variable: dict
在这段代码中,我们添加了一个带注释的列表变量和一个带注释的类变量的类。现在让我们导入新版本的 annotate 模块,并检查它的 annotations 属性:
>>> import annotate
>>> annotate.__annotations__
{'name': , 'ages': <class>}
>>> annotate.Car.__annotations__
{'variable': <class>}
>>> car = annotate.Car()
>>> car.__annotations__
{'variable': <class>}
这一次,我们看到注释字典包含两个条目。您会注意到模块级别的 annotations 属性不包含带注释的类变量。要访问它,我们需要直接访问 Car 类,或者创建一个 Car 实例,并以这种方式访问属性。
正如我的一个读者指出的,你可以通过使用类型模块使这个例子更符合 PEP 484。看一下下面的例子:
# annotate3.py
from typing import Dict, List
name: str = 'Mike'
ages: List[int] = [12, 20, 32]
class Car:
variable: Dict
让我们在解释器中运行这段代码,看看输出是如何变化的:
import annotate
In [2]: annotate.__annotations__
Out[2]: {'ages': typing.List[int], 'name': str}
In [3]: annotate.Car.__annotations__
Out[3]: {'variable': typing.Dict}
您会注意到,现在大多数类型都来自于类型模块。
包扎
我发现这个新功能非常有趣。虽然我喜欢 Python 的动态特性,但在过去几年使用 C++后,我也看到了知道变量应该是什么类型的价值。当然,由于 Python 出色的内省支持,弄清楚一个对象的类型是微不足道的。但是这个新特性可以让静态检查器更好,也可以让你的代码更明显,特别是当你不得不回去更新一个几个月或几年都没用过的软件的时候。
附加阅读
Python 中的新特性:数字文本中的下划线
原文:https://www.blog.pythonlibrary.org/2017/01/11/new-in-python-underscores-in-numeric-literals/
Python 3.6 增加了一些有趣的新特性。我们将在本文中看到的一个来自于 PEP 515:数字文字中的下划线。正如 PEP 的名字所暗示的那样,这基本上给了你在逗号通常所在的地方写长数字加下划线的能力。换句话说, 1000000 现在可以写成 1_000_000 。让我们来看一些简单的例子:
>>> 1_234_567
1234567
>>>'{:_}'.format(123456789)
'123_456_789'
>>> '{:_}'.format(1234567)
'1_234_567'
第一个例子展示了 Python 如何解释包含下划线的大数。第二个例子演示了我们现在可以给 Python 一个字符串格式化程序,即“_”(下划线),来代替逗号。结果不言自明。
计算时,包含下划线的数字文字的行为与普通数字文字相同:
>>> 120_000 + 30_000
150000
>>> 120_000 - 30_000
90000
Python 文档和 PEP 还提到可以在任何基本说明符后使用下划线。以下是摘自 PEP 和文档的几个示例:
>>> flags = 0b_0011_1111_0100_1110
>>> flags
16206
>>> 0x_FF_FF_FF_FF
4294967295
>>> flags = int('0b_1111_0000', 2)
>>> flags
240
有一些关于下划线的注意事项需要提及:
- 您只能使用一个连续的下划线,并且必须在数字之间和任何基本说明符之后
- 不允许使用前导下划线和尾随下划线
这是 Python 中一个有趣的新特性。虽然我个人在我目前的工作中没有这方面的任何用例,但希望你在自己的工作中会有一个。
发现针对 Linux 的新恶意 Python 库
原文:https://www.blog.pythonlibrary.org/2019/07/18/new-malicious-python-libraries-found-targeting-linux/
ZDNet 最近发表了一篇文章关于 Python 包索引(PyPI)上新发现的一组恶意软件相关的 Python 包。这些软件包包含一个后门,只有安装在 Linux 上才会激活。
这些软件包被命名为:
- libpeshnx
- libmesh
- 天秤座
它们是由一个名叫 ruri12 的用户编写的。PyPI 团队在 2019 年 7 月 9 日移除了这些包。然而,它们自 2017 年 11 月以来一直可用,并被定期下载。
详见原文。
像往常一样,当使用一个你不熟悉的软件包时,一定要自己做彻底的检查,以确保你不是无意中安装了恶意软件。
相关阅读
- ZDNet - 从 PyPI 中删除了针对 Linux 服务器的恶意 Python 库
- PyPI 上发现更多域名抢注恶意软件
- 在 Python 包索引(PyPI) 上发现恶意库
一个新的 Python Kickstarter 项目:高级 Web 开发,以 Django 1.6 为特色
昨晚,我收到了一封关于一个新的 Python 相关的 Kickstarter 的邮件。真正的 Python 团队增加了一个新的作者来写一本完全关于 Django 1.6 的书。这是一个我一直想研究的课题,但一直没有机会。希望通过支持这个项目,我能最终了解 Django。
我对他们之前项目的质量印象深刻,所以我觉得我可以放心地为这些作者背书。我相信这个项目会是高质量的,非常值得你花时间和金钱。另外,支持这些想分享知识的人也很有趣。如果你有兴趣支持这个项目,你可以去以下地址:
注意:他们在这一点上已经得到了充分的资助,并且一些支持级别已经满了,所以如果你想早点加入,现在正是时候!
新年 Python Meme - #2012pythonmeme
原文:https://www.blog.pythonlibrary.org/2011/12/21/new-years-python-meme-2012pythonmeme/
昨天我正在阅读 Python 博客,无意中发现了 Tarek Ziade 的 Python Meme 文章。我觉得这听起来是个有趣的想法,所以以下是我对他的问题的回答。
1。2011 年你发现的最酷的 Python 应用、框架或库是什么?
我想不出今年真正用过的新东西。然而,就在这一年,我开始广泛使用 wxPython 中的 ObjectListView 小部件。这是一个伟大的 wx 包装。这使得它非常容易使用。也是在这一年,我开始着手一个大的涡轮 2 项目,但是我还没有决定这是不是我最喜欢的项目。
2。2011 年你学到了什么新的编程技巧?
最近,我开始让我的代码比过去更有组织性和结构化,将我的组件分成不同的模块,进行更多的重构,尝试更多地遵循模型-视图-控制器模式,等等。今年我也开始更多地使用 Mercurial 源码控制和 BitBucket 。我仍然不是使用它们的专家,但是我知道足够的信息来保证我的消息来源的安全。
3。2011 年你贡献最大的开源项目叫什么?你做了什么?
wxPython 。我在我的 wiki 上为它写了很多文档,并在 wxPython 邮件列表和 StackOverflow 上帮助很多人理解它。
4。2011 年你看得最多的 Python 博客或网站是什么?
嗯,这是个难题。我读了很多蒂姆·戈尔登的《T1》,还有一些《T2》中的杰西·诺勒和《T4》中的道格·赫尔曼。我也喜欢大卫·比兹利,但是他写的不多。
5。2012 年你最想学的三件事是什么?
我需要更好地处理 Mercurial 分支和合并。学习更多的 TurboGears 和另一个 Python web 框架。测试(我知道一些,但还不够,尤其是与 GUI 相关的)。
6。你希望有人在 2012 年编写的顶级软件、应用或库是什么?
我希望有更好的易贝包装纸。我想写我自己的狙击手剧本。另一个不错的例子是某种一体化脚本,它可以为我的博客文章创建我的 bit.ly 链接,然后提交给各种主要的技术网站。
想自己列清单吗?方法如下:
- 将问题和答案复制粘贴到您的博客中
- 用标签# 2012 pythonme发推文
2011 年 10 月 Pyowa 总结
原文:https://www.blog.pythonlibrary.org/2011/10/07/october-2011-pyowa-wrap-up/
昨晚(2011 年 10 月 7 日)我们在美国路易斯安那州西得梅因的 IMT 集团大楼举行了十月派欧瓦会议。他们的一个程序员做了一个关于 python 开放文档 (pod)库的演讲,该库包含在 Appy 框架中。演讲的要点是,你可以使用 LibreOffice 或 OpenOffice 的“跟踪修改”功能或“字段”功能创建模板文件,然后使用 Appy 的 pod 合并你的数据,就像微软 Word 中的邮件合并一样。他继续展示更高级的东西,比如使用 LibreOffice 的评论功能创建循环来制作表格或插入图片。
演示结束后,提到了托管您自己的本地 PyPI,并讨论了 Git 与 Mercurial 的优缺点。也有一些关于 Pyowa 与当地 Ruby 集团合并的讨论。我们还讨论了召开一次会议,在会上我们可能会讨论 Mercurial、Git 和其他未来的源代码管理系统。还要注意,在这次会议上有免费的比萨饼和汽水。我们希望你能参加我们的下一次会议。
Jupyter 笔记本 101 只剩 2 天了
原文:https://www.blog.pythonlibrary.org/2018/08/13/only-2-days-left-for-jupyter-notebook-101/
还有两天就要加入我的新书的 Kickstarter 了,Jupyter Notebook 101 。这也是你帮助塑造这本书的最佳时机之一。我在写书时总是会考虑读者的反馈,并根据他们的要求在书中添加了很多额外的信息。

OpenPyXL -使用 Python 处理 Microsoft Excel
原文:https://www.blog.pythonlibrary.org/2020/11/03/openpyxl-working-with-microsoft-excel-using-python/
商业世界使用微软 Office 。他们的电子表格软件解决方案微软 Excel 尤其受欢迎。Excel 用于存储表格数据、创建报告、绘制趋势图等等。在开始使用 Excel 和 Python 之前,让我们澄清一些特殊术语:
- 电子表格或工作簿-文件本身(。xls 或者。xlsx)。
- 工作表-工作簿中的一张内容表。电子表格可以包含多个工作表。
- 列-以字母标记的垂直数据行,以“A”开头。
- Row -用数字标记的水平数据行,从 1 开始。
- 单元格-列和行的组合,如“A1”。
在本文中,您将使用 Python 处理 Excel 电子表格。您将了解以下内容:
- Python Excel 包
- 从工作簿中获取工作表
- 读取单元格数据
- 遍历行和列
- 编写 Excel 电子表格
- 添加和移除工作表
- 添加和删除行和列
Excel 被大多数公司和大学使用。它可以以多种不同的方式使用,并使用 Visual Basic for Applications (VBA)进行增强。然而,VBA 有点笨拙——这就是为什么学习如何在 Python 中使用 Excel 是件好事。
现在让我们来看看如何使用 Python 编程语言处理 Microsoft Excel 电子表格!
Python Excel 包
您可以使用 Python 创建、读取和编写 Excel 电子表格。但是,Python 的标准库不支持使用 Excel 为此,您需要安装第三方软件包。最受欢迎的是 OpenPyXL 。您可以在此处阅读其文档:
OpenPyXL 不是你唯一的选择。还有其他几个支持 Microsoft Excel 的软件包:
- xlrd -用于读取旧的 Excel(。xls)文档
- xlwt -用于编写较老的 Excel(。xls)文档
- xlwings -可处理新的 Excel 格式,并具有宏功能
几年前,前两个库曾经是最流行的 Excel 文档库。然而,这些软件包的作者已经停止支持它们。xlwings 包很有前途,但是不能在所有平台上工作,并且需要安装 Microsoft Excel。
您将在本文中使用 OpenPyXL,因为它正在被积极开发和支持。OpenPyXL 不需要安装 Microsoft Excel,在所有平台上都可以使用。
您可以使用pip安装 OpenPyXL:
$ python -m pip install openpyxl
安装完成后,让我们看看如何使用 OpenPyXL 来读取 Excel 电子表格!
从工作簿中获取工作表
第一步是找到一个与 OpenPyXL 一起使用的 Excel 文件。这本书的 Github 资源库中有一个为您提供的books.xlsx文件。您可以通过以下网址下载:
请随意使用您自己的文件,尽管您自己的文件的输出不会与本书中的示例输出相匹配。
下一步是编写一些代码来打开电子表格。为此,创建一个名为open_workbook.py的新文件,并向其中添加以下代码:
# open_workbook.py
from openpyxl import load_workbook
def open_workbook(path):
workbook = load_workbook(filename=path)
print(f'Worksheet names: {workbook.sheetnames}')
sheet = workbook.active
print(sheet)
print(f'The title of the Worksheet is: {sheet.title}')
if __name__ == '__main__':
open_workbook('books.xlsx')
在这个例子中,您从openpyxl导入load_workbook(),然后创建open_workbook(),它接受 Excel 电子表格的路径。接下来,使用load_workbook()创建一个openpyxl.workbook.workbook.Workbook对象。该对象允许您访问电子表格中的工作表和单元格。是的,它的名字中确实有两个workbook。那不是错别字!
函数的其余部分演示了如何打印电子表格中所有当前定义的工作表,获取当前活动的工作表并打印出该工作表的标题。
当您运行此代码时,您将看到以下输出:
Worksheet names: ['Sheet 1 - Books']
<Worksheet "Sheet 1 - Books">
The title of the Worksheet is: Sheet 1 - Books
现在您已经知道了如何访问电子表格中的工作表,您已经准备好继续访问单元格数据了!
读取单元格数据
使用 Microsoft Excel 时,数据存储在单元格中。您需要一种从 Python 访问这些单元格的方法,以便能够提取这些数据。OpenPyXL 让这个过程变得简单明了。
创建一个名为workbook_cells.py的新文件,并将以下代码添加到其中:
# workbook_cells.py
from openpyxl import load_workbook
def get_cell_info(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
print(sheet)
print(f'The title of the Worksheet is: {sheet.title}')
print(f'The value of {sheet["A2"].value=}')
print(f'The value of {sheet["A3"].value=}')
cell = sheet['B3']
print(f'{cell.value=}')
if __name__ == '__main__':
get_cell_info('books.xlsx')
这段代码将在 OpenPyXL 工作簿中加载 Excel 文件。您将获取活动工作表,然后打印出它的title和几个不同的单元格值。您可以通过使用 sheet 对象后跟方括号(其中包含列名和行号)来访问单元格。例如,sheet["A2"]将获取“A”列第 2 行的单元格。要获得该单元格的值,可以使用value属性。
注意:这段代码使用了 Python 3.8 中添加到 f 字符串的新特性。如果您使用早期版本运行此程序,将会收到一个错误。
当您运行这段代码时,您将得到以下输出:
<Worksheet "Sheet 1 - Books">
The title of the Worksheet is: Sheet 1 - Books
The value of sheet["A2"].value='Title'
The value of sheet["A3"].value='Python 101'
cell.value='Mike Driscoll'
您可以使用单元格的一些其他属性来获取有关单元格的附加信息。将以下函数添加到文件中,并更新末尾的条件语句以运行它:
def get_info_by_coord(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
cell = sheet['A2']
print(f'Row {cell.row}, Col {cell.column} = {cell.value}')
print(f'{cell.value=} is at {cell.coordinate=}')
if __name__ == '__main__':
get_info_by_coord('books.xlsx')
在这个例子中,您使用cell对象的row和column属性来获取行和列信息。注意,列“A”映射到“1”,“B”映射到“2”,等等。如果要迭代 Excel 文档,可以使用coordinate属性获取单元格名称。
当您运行此代码时,输出将如下所示:
Row 2, Col 1 = Title
cell.value='Title' is at cell.coordinate='A2'
说到迭代,让我们看看下一步怎么做!
遍历行和列
有时,您需要迭代整个 Excel 电子表格或部分电子表格。OpenPyXL 允许您以几种不同的方式做到这一点。创建一个名为iterating_over_cells.py的新文件,并向其中添加以下代码:
# iterating_over_cells.py
from openpyxl import load_workbook
def iterating_range(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
for cell in sheet['A']:
print(cell)
if __name__ == '__main__':
iterating_range('books.xlsx')
在这里,您加载电子表格,然后循环遍历“A”列中的所有单元格。对于每个单元格,打印出cell对象。如果您想更精细地格式化输出,可以使用在上一节中学习的一些单元格属性。
运行这段代码的结果如下:
<Cell 'Sheet 1 - Books'.A1>
<Cell 'Sheet 1 - Books'.A2>
<Cell 'Sheet 1 - Books'.A3>
<Cell 'Sheet 1 - Books'.A4>
<Cell 'Sheet 1 - Books'.A5>
<Cell 'Sheet 1 - Books'.A6>
<Cell 'Sheet 1 - Books'.A7>
<Cell 'Sheet 1 - Books'.A8>
<Cell 'Sheet 1 - Books'.A9>
<Cell 'Sheet 1 - Books'.A10>
# output truncated for brevity
默认情况下,输出会被截断,因为它会打印出相当多的单元格。OpenPyXL 通过使用iter_rows()和iter_cols()函数提供了其他方法来迭代行和列。这些方法接受几个参数:
min_rowmax_rowmin_colmax_col
您还可以添加一个values_only参数,告诉 OpenPyXL 返回单元格的值,而不是单元格对象的值。继续创建一个名为iterating_over_cell_values.py的新文件,并将以下代码添加到其中:
# iterating_over_cell_values.py
from openpyxl import load_workbook
def iterating_over_values(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
for value in sheet.iter_rows(
min_row=1, max_row=3,
min_col=1, max_col=3,
values_only=True,
):
print(value)
if __name__ == '__main__':
iterating_over_values('books.xlsx')
这段代码演示了如何使用iter_rows()遍历 Excel 电子表格中的行,并打印出这些行的值。当您运行此代码时,您将获得以下输出:
('Books', None, None)
('Title', 'Author', 'Publisher')
('Python 101', 'Mike Driscoll', 'Mouse vs Python')
输出是一个 Python 元组,其中包含每一列中的数据。至此,您已经学会了如何打开电子表格和读取数据——既可以从特定的单元格读取,也可以通过迭代读取。现在您已经准备好学习如何使用 OpenPyXL 来创建 Excel 电子表格了!
编写 Excel 电子表格
使用 OpenPyXL 创建 Excel 电子表格并不需要很多代码。您可以使用Workbook()类创建一个电子表格。继续创建一个名为writing_hello.py的新文件,并将以下代码添加到其中:
# writing_hello.py
from openpyxl import Workbook
def create_workbook(path):
workbook = Workbook()
sheet = workbook.active
sheet['A1'] = 'Hello'
sheet['A2'] = 'from'
sheet['A3'] = 'OpenPyXL'
workbook.save(path)
if __name__ == '__main__':
create_workbook('hello.xlsx')
在这里实例化Workbook()并获得活动表。然后将“A”列的前三行设置为不同的字符串。最后,您调用save()并把保存新文档的path传递给它。恭喜你!您刚刚用 Python 创建了一个 Excel 电子表格。
接下来让我们看看如何在工作簿中添加和删除工作表!
添加和移除工作表
许多人喜欢在工作簿的多个工作表中组织他们的数据。OpenPyXL 支持通过其create_sheet()方法向Workbook()对象添加新工作表的能力。
创建一个名为creating_sheets.py的新文件,并将以下代码添加到其中:
# creating_sheets.py
import openpyxl
def create_worksheets(path):
workbook = openpyxl.Workbook()
print(workbook.sheetnames)
# Add a new worksheet
workbook.create_sheet()
print(workbook.sheetnames)
# Insert a worksheet
workbook.create_sheet(index=1,
title='Second sheet')
print(workbook.sheetnames)
workbook.save(path)
if __name__ == '__main__':
create_worksheets('sheets.xlsx')
这里您使用了两次create_sheet()来向工作簿添加两个新的工作表。第二个示例显示了如何设置工作表的标题以及在哪个索引处插入工作表。参数index=1意味着工作表将被添加到第一个现有工作表之后,因为它们的索引从0开始。
当您运行此代码时,您将看到以下输出:
['Sheet']
['Sheet', 'Sheet1']
['Sheet', 'Second sheet', 'Sheet1']
您可以看到新工作表已逐步添加到工作簿中。保存文件后,您可以通过打开 Excel 或其他与 Excel 兼容的应用程序来验证是否有多个工作表。
在这个自动创建工作表的过程之后,您突然得到了太多的工作表,所以让我们去掉一些。有两种方法可以移除板材。继续创建delete_sheets.py,看看如何使用 Python 的del关键字删除工作表:
# delete_sheets.py
import openpyxl
def create_worksheets(path):
workbook = openpyxl.Workbook()
workbook.create_sheet()
# Insert a worksheet
workbook.create_sheet(index=1,
title='Second sheet')
print(workbook.sheetnames)
del workbook['Second sheet']
print(workbook.sheetnames)
workbook.save(path)
if __name__ == '__main__':
create_worksheets('del_sheets.xlsx')
这段代码将创建一个新工作簿,然后向其中添加两个新工作表。然后它用 Python 的del关键字删除workbook['Second sheet']。您可以通过查看del命令前后的表单列表的打印结果来验证它是否按预期工作:
['Sheet', 'Second sheet', 'Sheet1']
['Sheet', 'Sheet1']
从工作簿中删除工作表的另一种方法是使用remove()方法。创建一个名为remove_sheets.py的新文件,并输入以下代码以了解其工作原理:
# remove_sheets.py
import openpyxl
def remove_worksheets(path):
workbook = openpyxl.Workbook()
sheet1 = workbook.create_sheet()
# Insert a worksheet
workbook.create_sheet(index=1,
title='Second sheet')
print(workbook.sheetnames)
workbook.remove(sheet1)
print(workbook.sheetnames)
workbook.save(path)
if __name__ == '__main__':
remove_worksheets('remove_sheets.xlsx')
这一次,通过将结果赋给sheet1,您保留了对您创建的第一个工作表的引用。然后在代码中删除它。或者,您也可以使用与前面相同的语法删除该工作表,如下所示:
workbook.remove(workbook['Sheet1'])
无论您选择哪种方法删除工作表,输出都是一样的:
['Sheet', 'Second sheet', 'Sheet1']
['Sheet', 'Second sheet']
现在让我们继续学习如何添加和删除行和列。
添加和删除行和列
OpenPyXL 有几个有用的方法,可以用来在电子表格中添加和删除行和列。以下是您将在本节中了解的四种方法的列表:
.insert_rows().delete_rows().insert_cols().delete_cols()
这些方法中的每一个都可以接受两个参数:
idx-插入行或列的索引amount-要添加的行数或列数
要了解这是如何工作的,创建一个名为insert_demo.py的文件,并向其中添加以下代码:
# insert_demo.py
from openpyxl import Workbook
def inserting_cols_rows(path):
workbook = Workbook()
sheet = workbook.active
sheet['A1'] = 'Hello'
sheet['A2'] = 'from'
sheet['A3'] = 'OpenPyXL'
# insert a column before A
sheet.insert_cols(idx=1)
# insert 2 rows starting on the second row
sheet.insert_rows(idx=2, amount=2)
workbook.save(path)
if __name__ == '__main__':
inserting_cols_rows('inserting.xlsx')
这里,您创建一个工作表,并在列“A”之前插入一个新列。列的索引从 1 开始,而相比之下,工作表从 0 开始。这实际上将 A 列中的所有单元格移动到 b 列,然后从第 2 行开始插入两个新行。
既然您已经知道了如何插入列和行,那么是时候了解如何删除它们了。
要了解如何删除列或行,创建一个名为delete_demo.py的新文件,并添加以下代码:
# delete_demo.py
from openpyxl import Workbook
def deleting_cols_rows(path):
workbook = Workbook()
sheet = workbook.active
sheet['A1'] = 'Hello'
sheet['B1'] = 'from'
sheet['C1'] = 'OpenPyXL'
sheet['A2'] = 'row 2'
sheet['A3'] = 'row 3'
sheet['A4'] = 'row 4'
# Delete column A
sheet.delete_cols(idx=1)
# delete 2 rows starting on the second row
sheet.delete_rows(idx=2, amount=2)
workbook.save(path)
if __name__ == '__main__':
deleting_cols_rows('deleting.xlsx')
这段代码在几个单元格中创建文本,然后使用delete_cols()删除 A 列。它还通过delete_rows()从第二行开始删除两行。在组织数据时,能够添加和删除列和行非常有用。
包扎
由于 Excel 在许多行业的广泛使用,能够使用 Python 与 Excel 文件进行交互是一项极其有用的技能。在本文中,您了解了以下内容:
- Python Excel 包
- 从工作簿中获取工作表
- 读取单元格数据
- 遍历行和列
- 编写 Excel 电子表格
- 添加和移除工作表
- 添加和删除行和列
OpenPyXL 可以做的甚至比这里介绍的更多。例如,您可以使用 OpenPyXL 向单元格添加公式、更改字体以及对单元格应用其他类型的样式。阅读文档并尝试在您自己的一些电子表格上使用 OpenPyXL,这样您就可以发现它的全部功能。
包装用于分发的 wxPyMail
原文:https://www.blog.pythonlibrary.org/2008/08/27/packaging-wxpymail-for-distribution/
在本文中,我将介绍打包我的程序 wxPyMail 所需的步骤,这样我就可以将它分发给其他 Windows 用户。我将使用 Andrea Gavana 的优秀的 GUI2Exe 实用程序来创建一个可执行文件,我将使用 Inno Setup 来创建一个安装程序。有人告诉我,Andrea 正在开发他的应用程序的新版本,所以当它发布时,我将针对该版本重新编写这篇文章并发布。
设置 GUI2Exe
用 GUI2Exe 创建可执行文件的过程非常简单。GUI2Exe 实际上是 py2exe 的一个 GUI 前端。我强烈推荐用 GUI2Exe 来创建你所有的可执行文件,因为它更容易使用。但是,如果您喜欢命令行,那么您可以单独使用 py2exe。它们甚至在 Samples 目录中包含 wxPython 应用程序的示例。反正下载完 GUI2Exe,安装好,加载程序。您现在应该会看到这样的内容:
现在进入文件 - > 新建项目,给你的项目起个名字。我要给我的起名叫 wxPyMail 。我准备加一个假的公司名,版权,给它一个节目名。一定要浏览您的主要 Python 脚本。这个项目是 wxPyMail.py,根据 Andrea 的网站,你应该把优化设置为 2,压缩设置为 2,捆绑文件设置为 1。这在大多数情况下似乎是可行的,但是我遇到过一些奇怪的错误,这些错误似乎是由于将最后一个设置为“1”而引起的。事实上,根据我在 py2exe 邮件列表上的一个联系人所说,“bundle”选项应该设置为 3,以尽量减少错误。将 bundle 设置为“1”的好处是,你最终只得到一个文件,但是因为我要用 Inno 把它卷起来,所以我要用选项“3”来确保我的程序运行良好。
还要注意,我已经包含了 XP 清单。这使得您的应用程序在 Windows 上看起来很“本地”,因此您的程序应该与当前有效的主题相匹配。
为了确保你能跟上,请看下面的截图:
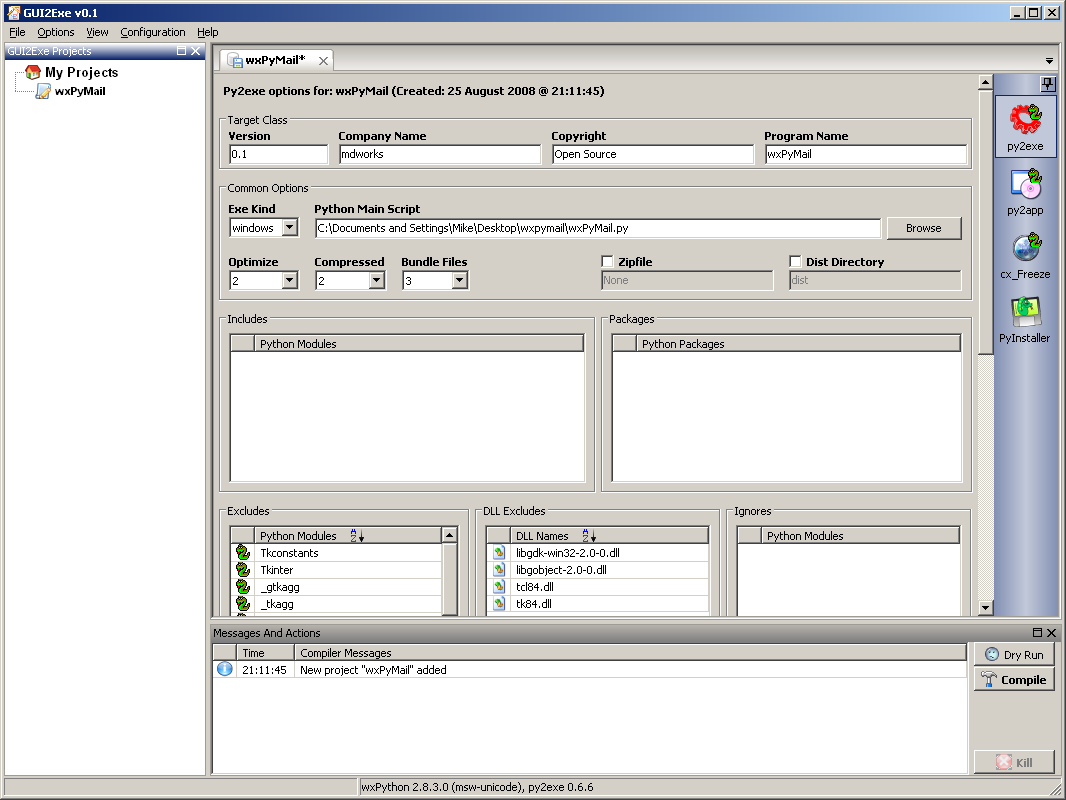
一旦你得到了你想要的一切,点击右下角的编译按钮。这将在区文件夹中创建您想要分发的所有文件,除非您通过选中区复选框并编辑随后的文本框更改了名称。编译完成后,GUI2Exe 会询问您是否要测试您的可执行文件。继续并点击是。我第一次这样做时遇到了一个错误,当我查看日志时,它说找不到 smtplib 模块。要修复这个特定的错误,我们需要包含它。
要包含此模块,请在标有包含的框内单击,然后按 CTRL+A。您应该会看到一个图标和文字编辑我。只需点击这些单词并输入 smtplib 。现在试着编译它。我得到另一个奇怪的错误:
Traceback (most recent call last):
File "wxPyMail.py", line 20, in
import smtplib
File "smtplib.pyo", line 46, in
ImportError: No module named email.Utils
看起来我需要电子邮件模块。嗯,如果你包括电子邮件模块,那么你需要把它从排除列表中删除。然而,在做了所有这些之后,您仍然会得到一个关于不能导入“multipart”的错误。这花了我一分钟才弄明白,不过看起来邮件模块其实是一个包。因此,我将电子邮件包添加到包列表控件中。像以前一样从 Excludes 列表中删除 email 模块,也从 Includes listctrl 中删除 smtplib 模块,因为它本来就不是问题。要从这些控件中删除项目,您需要右键单击项目并选择“删除所选项目”。现在,您的屏幕应该看起来像这样:

请注意,这是大量的试验和错误。最终,您可以大致猜出哪些模块将被包含,哪些不会。好像 wmi.py 或者 BeautifulSoup 这样的小模块会被 py2exe 抢,但是 lxml 包这样的东西不会。随着练习,这个过程变得越来越容易,所以不要放弃!此外,如果您有问题,py2exe 组和 Andrea 都是很好的资源。
我们来做一个安装程序吧!
现在我们有了一个可执行文件和一堆依赖项,我们如何创建一个安装程序呢?有各种各样的实用程序,但是我将使用 Inno Setup。下载并安装后,运行程序。选择标记为“使用脚本向导创建新脚本文件”的选项。单击下一个的,您应该会看到类似这样的内容:
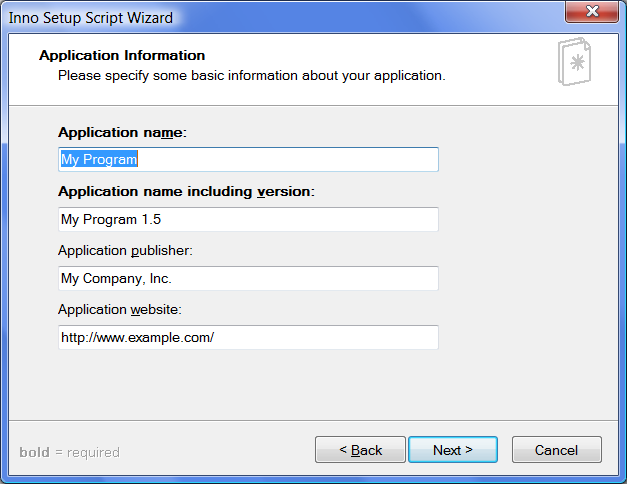
请随意填写,然后单击下一步。此屏幕允许您选择应用程序的默认安装位置。默认为程序文件即可。点击下一个。现在,您应该会看到以下屏幕:
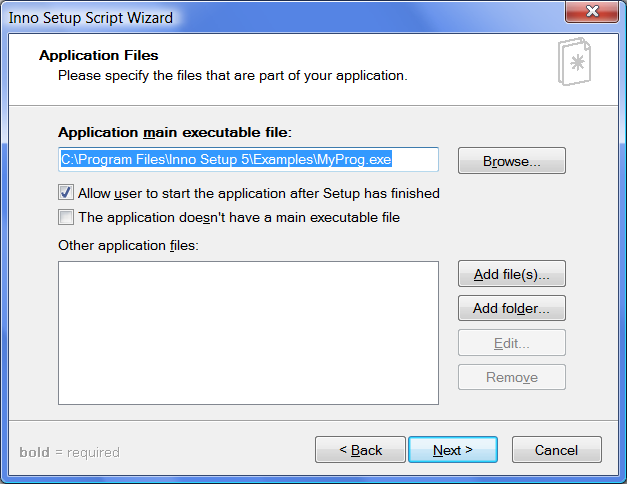
浏览到您创建的可执行文件以添加它。然后点击添加文件...按钮添加其余部分。你可以选择除 exe 文件之外的所有文件,然后点击 OK。然后点击下一个。确保开始菜单文件夹有正确的名称(在这种情况下,wxPyMail)并继续。如果您愿意,您可以忽略接下来的两个屏幕,或者尝试使用它们。不过,我没有使用许可证,也没有将信息文件显示给用户。完成前的最后一个屏幕允许您选择输出到的目录。我只是将它留空,因为它默认为可执行文件所在的位置,这对于本例来说很好。点击下一步和完成。
现在,您将拥有一个成熟的。iss 文件。请阅读 Inno 的文档,了解您能做些什么,因为这超出了本文的范围。相反,只需点击构建菜单并选择编译*。如果您没有收到任何错误消息,那么您已经成功地创建了一个安装程序!恭喜你!
然而,有一点需要注意。似乎有一些关于你是否能合法分发 MSVCR71.dll 文件的问题。有人说这个 dll 的发布需要 Visual Studio 2003 的许可,也有人说 python.org 团队以这样一种方式许可了 VS2003(即 VS7 ), Python 变成了“被许可软件”,而你变成了“发布者”。你可以在这个博客上读到所有血淋淋的细节,其中 Python 名人如 Phillip Eby(因 easy_install 而出名,是它的主要维护者)和 Fredrik Lundh 都参与其中。
我希望这有助于您成为一名优秀的 Python 应用程序开发人员。一如既往,如果您有任何问题或改进建议,请随时给我发电子邮件至 mike (at) pythonlibrary (dot) org。
Packt Publishing 支持 Pyowa
原文:https://www.blog.pythonlibrary.org/2009/04/18/packt-publishing-supports-pyowa/
Pycon 结束后,我联系了 python 组组织者邮件列表上的人,看看如何从出版商那里获得联系方式,希望为爱荷华 python 用户组(又名 Pyowa )会议收集联系方式并获得一些赠品。
我第一次接触是在 Packt Publishing 公司。他们给了我很大的帮助,甚至给了我一本关于姜戈的书让我复习。我希望能在接下来的几周内阅读和评论这本书。他们给了我一本贴在 Pyowa 主页上的书的样本。我也和奥莱利取得了联系,我希望这也能有好的结果。希望我能为未来的 Pyowa 会议带来一些像样的礼物。
下个月,Pyowa group 将接待一位来自 Mythbuntu 项目的核心开发人员,他将讲述他使用 Python 的经历。我们还计划了一个关于 SqlAlchemy 的演示,这是一个非常酷的 Python 对象关系映射器(ORM)。最后,我们将进行一次与 GIS 相关的代码审查。为此,我们将从我认为是 ArcGIS 的地方获取一些自动生成的代码,并尝试对其进行改进。所有这些活动将于 5 月 4 日(星期一)下午 7-9 点在马歇尔郡治安官办公室举行。还将提供小吃和饮料。方向在 Pyowa 网站上。
使用 Python 解析 MP3 中的 ID3 标签
原文:https://www.blog.pythonlibrary.org/2010/04/22/parsing-id3-tags-from-mp3s-using-python/
在开发我的 Python mp3 播放器时,我意识到我需要研究 Python 为解析 ID3 标签提供了什么。有大量的项目,但是大部分看起来不是死了,就是没有文档,或者两者都有。在这篇文章中,你将和我一起探索 Python 中 mp3 标签解析的广阔世界,我们将看看是否能找到一些我可以用来增强我的 MP3 播放器项目的东西。
在本练习中,我们将尝试从解析器中获取以下信息:
- 艺术家
- 相册标题
- 音轨标题
- 轨道长度
- 专辑发行日期
我们可能需要更多的元数据,但这是我在 mp3 播放体验中最关心的东西。我们将查看以下第三方库,看看它们的表现如何:
我们开始吧!
诱变剂能扭转乾坤吗?
在这次围捕中包括诱变剂的原因之一是因为除了 MP3 解析之外,它还支持 ASF,FLAC,M4A,Monkey's Audio,Musepack,Ogg FLAC,Ogg Speex,Ogg Theora,Ogg Vorbis,True Audio,WavPack 和 OptimFROG。因此,我们可以潜在地扩展我们的 MP3 播放器。当我发现这个包裹时,我非常兴奋。然而,虽然该软件包似乎正在积极开发,但文档几乎不存在。如果你是一个新的 Python 程序员,你会发现这个库很难直接使用。
要安装诱变剂,你需要打开它,并使用命令行导航到它的文件夹。然后执行以下命令:
python setup.py install
你也可以使用 easy_install 或 pip ,尽管他们的网站上并没有具体说明。现在有趣的部分来了:试图弄清楚如何在没有文档的情况下使用这个模块!幸运的是,我找到了一篇的博文,给了我一些线索。从我收集的信息来看,诱变剂非常接近 ID3 规范,所以你实际上是在阅读 ID3 文本框架并使用它们的术语,而不是将其抽象化,这样你就有了类似 GetArtist 的功能。因此,TPE1 =艺术家(或主唱),TIT2 =标题,等等。让我们看一个例子:
>>> path = r'D:\mp3\12 Stones\2002 - 12 Stones\01 - Crash.mp3'
>>> from mutagen.id3 import ID3
>>> audio = ID3(path)
>>> audio
>>> audio['TPE1']
TPE1(encoding=0, text=[u'12 Stones'])
>>> audio['TPE1'].text
[u'12 Stones']
这里有一个更恰当的例子:
from mutagen.id3 import ID3
#----------------------------------------------------------------------
def getMutagenTags(path):
""""""
audio = ID3(path)
print "Artist: %s" % audio['TPE1'].text[0]
print "Track: %s" % audio["TIT2"].text[0]
print "Release Year: %s" % audio["TDRC"].text[0]
我个人觉得这很难阅读和使用,所以我不会在我的 mp3 播放器上使用这个模块,除非我需要添加额外的数字文件格式。还要注意的是,我不知道如何获取音轨的播放长度或专辑名称。让我们继续下一个 ID3 解析器,看看它的表现如何。
眼睛 3
如果你去 eyeD3 的网站,你会发现它似乎不支持 Windows。这是许多用户的一个问题,几乎让我放弃了这个综述。幸运的是,我发现了一个论坛,其中提到了一种使它工作的方法。我们的想法是将主文件夹中的“setup.py.in”文件重命名为“setup.py”,将“init.py.in”文件重命名为“init”。py”,您可以在“src\eyeD3”中找到它。然后就可以用常用的“python setup.py install”来安装了。一旦你安装了它,它真的很容易使用。检查以下功能:
import eyeD3
#----------------------------------------------------------------------
def getEyeD3Tags(path):
""""""
trackInfo = eyeD3.Mp3AudioFile(path)
tag = trackInfo.getTag()
tag.link(path)
print "Artist: %s" % tag.getArtist()
print "Album: %s" % tag.getAlbum()
print "Track: %s" % tag.getTitle()
print "Track Length: %s" % trackInfo.getPlayTimeString()
print "Release Year: %s" % tag.getYear()
这个包确实满足我们任意的要求。该软件包唯一令人遗憾的方面是它缺乏官方的 Windows 支持。我们将保留判断,直到我们尝试了我们的第三种可能性。
Ned Batchelder 的 id3reader.py
这个模块可能是三个模块中最容易安装的,因为它只是一个文件。你需要做的就是下载它,然后把文件放到站点包或者 Python 路径上的其他地方。这个解析器的主要问题是 Batchelder 不再支持它。让我们看看是否有一种简单的方法来获得我们需要的信息。
import id3reader
#----------------------------------------------------------------------
def getTags(path):
""""""
id3r = id3reader.Reader(path)
print "Artist: %s" % id3r.getValue('performer')
print "Album: %s" % id3r.getValue('album')
print "Track: %s" % id3r.getValue('title')
print "Release Year: %s" % id3r.getValue('year')
在不了解 ID3 规格的情况下,我看不出有什么明显的方法可以用这个模块获得走线长度。唉!虽然我喜欢这个模块的简单和强大,但缺乏支持和超级简单的 API 使我拒绝了它,而支持 eyeD3。目前,这将是我的 mp3 播放器的选择库。如果你知道一个很棒的 ID3 解析脚本,请在评论中给我留言。我在谷歌上也看到了其他人的名单,但其中有相当一部分人和巴彻尔德一样已经死了。
用 Python 解析 XML 和创建 PDF 发票
原文:https://www.blog.pythonlibrary.org/2012/07/18/parsing-xml-and-creating-a-pdf-invoice-with-python/
注:以下帖子最初发表在 Dzone 上。我更改了标题,因为我已经写了几篇 XML 解析文章,不希望我的读者将这篇文章与其他文章混淆。
我日常工作中的一项常见任务是获取一些数据格式输入,并对其进行解析以创建报告或其他文档。今天,我们将查看一些 XML 输入,用 Python 编程语言对其进行解析,然后使用 report lab(Python 的第三方包)创建一封 PDF 格式的信件。比方说,我的公司收到了一份三件商品的订单,我需要履行订单。这样的 XML 可以看起来像下面的代码:
<order_number>456789</order_number>
<customer_id>789654</customer_id>
<address1>John Doe</address1>
<address2>123 Dickens Road</address2>
<address3>Johnston, IA 55555</address3>
<order_items><item><id>11123</id>
<name>Expo Dry Erase Pen</name>
<price>1.99</price>
<quantity>5</quantity></item>
<item><id>22245</id>
<name>Cisco IP Phone 7942</name>
<price>300</price>
<quantity>1</quantity></item>
<item><id>33378</id>
<name>Waste Basket</name>
<price>9.99</price>
<quantity>1</quantity></item></order_items>
将上面的代码保存为 order.xml,现在我只需要用 Python 写一个解析器和 PDF 生成器脚本。您可以使用 Python 内置的 XML 解析库,其中包括 SAX、minidom 或 ElementTree,或者您可以出去下载许多用于 XML 解析的外部包中的一个。我最喜欢的是 lxml,它包括 ElementTree 的一个版本以及一段非常好的代码,他们称之为“objectify”。后一部分主要是将 XML 转换成点符号 Python 对象。我将用它来做我们的解析,因为它非常简单,易于实现和理解。如前所述,我将使用 Reportlab 来创建 PDF 文件。
下面是一个简单的脚本,它将完成我们需要的一切:
from decimal import Decimal
from lxml import etree, objectify
from reportlab.lib import colors
from reportlab.lib.pagesizes import letter
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib.units import inch, mm
from reportlab.pdfgen import canvas
from reportlab.platypus import Paragraph, Table, TableStyle
########################################################################
class PDFOrder(object):
""""""
#----------------------------------------------------------------------
def __init__(self, xml_file, pdf_file):
"""Constructor"""
self.xml_file = xml_file
self.pdf_file = pdf_file
self.xml_obj = self.getXMLObject()
#----------------------------------------------------------------------
def coord(self, x, y, unit=1):
"""
# http://stackoverflow.com/questions/4726011/wrap-text-in-a-table-reportlab
Helper class to help position flowables in Canvas objects
"""
x, y = x * unit, self.height - y * unit
return x, y
#----------------------------------------------------------------------
def createPDF(self):
"""
Create a PDF based on the XML data
"""
self.canvas = canvas.Canvas(self.pdf_file, pagesize=letter)
width, self.height = letter
styles = getSampleStyleSheet()
xml = self.xml_obj
address = """ SHIP TO:
%s
%s
%s
%s
""" % (xml.address1, xml.address2, xml.address3, xml.address4)
p = Paragraph(address, styles["Normal"])
p.wrapOn(self.canvas, width, self.height)
p.drawOn(self.canvas, *self.coord(18, 40, mm))
order_number = '**Order #%s** ' % xml.order_number
p = Paragraph(order_number, styles["Normal"])
p.wrapOn(self.canvas, width, self.height)
p.drawOn(self.canvas, *self.coord(18, 50, mm))
data = []
data.append(["Item ID", "Name", "Price", "Quantity", "Total"])
grand_total = 0
for item in xml.order_items.iterchildren():
row = []
row.append(item.id)
row.append(item.name)
row.append(item.price)
row.append(item.quantity)
total = Decimal(str(item.price)) * Decimal(str(item.quantity))
row.append(str(total))
grand_total += total
data.append(row)
data.append(["", "", "", "Grand Total:", grand_total])
t = Table(data, 1.5 * inch)
t.setStyle(TableStyle([
('INNERGRID', (0,0), (-1,-1), 0.25, colors.black),
('BOX', (0,0), (-1,-1), 0.25, colors.black)
]))
t.wrapOn(self.canvas, width, self.height)
t.drawOn(self.canvas, *self.coord(18, 85, mm))
txt = "Thank you for your business!"
p = Paragraph(txt, styles["Normal"])
p.wrapOn(self.canvas, width, self.height)
p.drawOn(self.canvas, *self.coord(18, 95, mm))
#----------------------------------------------------------------------
def getXMLObject(self):
"""
Open the XML document and return an lxml XML document
"""
with open(self.xml_file) as f:
xml = f.read()
return objectify.fromstring(xml)
#----------------------------------------------------------------------
def savePDF(self):
"""
Save the PDF to disk
"""
self.canvas.save()
#----------------------------------------------------------------------
if __name__ == "__main__":
xml = "order.xml"
pdf = "letter.pdf"
doc = PDFOrder(xml, pdf)
doc.createPDF()
doc.savePDF()
下面是 PDF 输出:letter.pdf
让我们花几分钟来看一下这段代码。首先是一批进口货。这只是用来自 Reportlab 和 lxml 的所需内容设置了我们的环境。我还导入了十进制模块,因为我将添加数量,这对于浮点数学来说比仅仅使用普通的 Python 数学要精确得多。接下来,我们创建接受两个参数的 PDFOrder 类:一个 xml 文件和一个 pdf 文件路径。在我们的初始化方法中,我们创建两个类属性,读取 XML 文件并返回一个 XML 对象。coord 方法用于定位 Reportlab 流,这些流是动态对象,能够跨页面拆分并接受各种样式。
createPDF 方法是程序的核心。canvas 对象用于创建我们的 PDF 并在其上“绘图”。我将它设置为 letter 大小,还获取了一个默认样式表。接下来,我创建一个送货地址,并将其放置在页面顶部附近,距离左侧 18 毫米,距离顶部 40 毫米。之后,我创建并下订单编号。最后,我对订单中的项目进行迭代,并将它们放在一个嵌套列表中,然后将该列表放在 Reportlab 的表 flowable 中。最后,我定位表格并传递一些样式给它一个边框和内部网格。最后,我们将文件保存到磁盘。
文档已经创建好了,现在我已经有了一个很好的原型来展示给我的同事们。在这一点上,我需要做的就是通过为文本传递不同的样式(即粗体、斜体、字体大小)或稍微改变布局来调整文档的外观。这通常取决于管理层或客户,所以你必须等待,看看他们想要什么。
现在您知道了如何用 Python 解析 XML 文档并从解析的数据创建 PDF。
源代码
使用 lxml.objectify 用 Python 解析 XML
原文:https://www.blog.pythonlibrary.org/2012/06/06/parsing-xml-with-python-using-lxml-objectify/
几年前,我开始撰写一系列关于 XML 解析的文章。我介绍了 lxml 的 etree 和 Python 的 included minidom XML 解析库。不管出于什么原因,我没有注意到 lxml 的 objectify 子包,但我最近看到了它,并决定应该检查一下。在我看来,objectify 模块似乎比 etree 更“Pythonic 化”。让我们花点时间回顾一下我以前使用 objectify 的 XML 例子,看看它有什么不同!
让我们开始派对吧!
如果你还没有,出去下载 lxml ,否则你会跟不上。一旦你拿到了,我们可以继续。为了解析的方便,我们将使用下面这段 XML:
<appointment><begin>1181251680</begin>
<uid>040000008200E000</uid>
<alarmtime>1181572063</alarmtime>
<state><location><duration>1800</duration>
<subject>Bring pizza home</subject></location></state></appointment>
<appointment><begin>1234360800</begin>
<duration>1800</duration>
<subject>Check MS Office website for updates</subject>
<location><uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid>
<state>dismissed</state></location></appointment>
现在我们需要编写一些可以解析和修改 XML 的代码。让我们来看看这个小演示,它展示了 objectify 提供的一系列简洁的功能。
from lxml import etree, objectify
#----------------------------------------------------------------------
def parseXML(xmlFile):
""""""
with open(xmlFile) as f:
xml = f.read()
root = objectify.fromstring(xml)
# returns attributes in element node as dict
attrib = root.attrib
# how to extract element data
begin = root.appointment.begin
uid = root.appointment.uid
# loop over elements and print their tags and text
for appt in root.getchildren():
for e in appt.getchildren():
print "%s => %s" % (e.tag, e.text)
print
# how to change an element's text
root.appointment.begin = "something else"
print root.appointment.begin
# how to add a new element
root.appointment.new_element = "new data"
# print the xml
obj_xml = etree.tostring(root, pretty_print=True)
print obj_xml
# remove the py:pytype stuff
#objectify.deannotate(root)
etree.cleanup_namespaces(root)
obj_xml = etree.tostring(root, pretty_print=True)
print obj_xml
# save your xml
with open("new.xml", "w") as f:
f.write(obj_xml)
#----------------------------------------------------------------------
if __name__ == "__main__":
f = r'path\to\sample.xml'
parseXML(f)
代码被很好地注释了,但是我们还是会花一点时间来检查它。首先,我们将样本 XML 文件传递给它,将它对象化。如果你想访问一个标签的属性,使用 attrib 属性。它将返回标签属性的字典。要访问子标签元素,只需使用点符号。正如你所看到的,要得到 begin 标签的值,我们可以这样做:
begin = root.appointment.begin
如果需要迭代子元素,可以使用 iterchildren 。您可能必须使用嵌套的 for 循环结构来获取所有内容。改变一个元素的值就像给它分配一个新值一样简单。如果你需要创建一个新元素,只需添加一个句点和新元素的名称(如下所示):
root.appointment.new_element = "new data"
当我们使用 objectify 添加或更改项目时,它会给 XML 添加一些注释,比如xmlns:py = " http://code speak . net/lxml/objectify/pytype " py:py type = " str "。您可能不希望包含这些内容,所以您必须调用以下方法来删除这些内容:
etree.cleanup_namespaces(root)
您还可以使用“objectify.deannotate(root)”来做一些 deannotation 杂务,但是我无法让它在这个例子中工作。为了保存新的 XML,实际上似乎需要 lxml 的 etree 模块将它转换成一个字符串以便保存。
至此,您应该能够解析大多数 XML 文档,并使用 lxml 的 objectify 有效地编辑它们。我觉得很直观,很容易上手。希望你也会发现它对你的努力有用。
进一步阅读
抱枕:可预购 Python 图像处理
Pillow:用 Python 进行图像处理是我最新的一本关于 Python 的书。现在可以预订了。这意味着你可以购买这本书的早期版本,并在购买后免费获得所有更新,包括最终版本。最终版本将于 2021 年 4 月在完成。
你可以在 Leanpub 或 Gumroad 上预订这本书。

Python 图像库允许您使用 Python 编辑照片。Pillow 包是 Python 图像库的最新版本。您可以使用 Python 通过 Pillow 批量处理您的照片。
在本书中,您将了解以下内容:
- 打开和保存图像
- 提取图像元数据
- 使用颜色
- 应用图像滤镜
- 裁剪、旋转和调整大小
- 增强图像
- 组合图像
- 用枕头画画
- 图像印章
- 与 GUI 工具包集成
在这本书里,你会学到所有这些东西,甚至更多。很快你就能像专业人士一样使用 Python 编程语言编辑照片了!
Pillow:用 Python 进行图像处理的书籍示例
原文:https://www.blog.pythonlibrary.org/2021/01/05/pillow-image-processing-with-python-book-sample/
我的新书Pillow:Image Processing with Python的 Kickstarter 昨天获得了全额资助。我知道不看一本书很难决定是否要买,所以我免费发布这本书的前三章。你可以用这个 Dropbox 链接下载它们。这一小部分书还是 70 页的内容!
这本书进展顺利。如果你想在一本 Python 书中寻找一些新的和不同的东西,我希望你能抓住这个机会。
枕头:现在可以用 Python 进行图像处理了!
原文:https://www.blog.pythonlibrary.org/2021/04/06/pillow-image-processing-with-python-now-available/
Pillow:用 Python 进行图像处理是我最新的一本关于 Python 编程语言的书。平装本和 Kindle 版本现在可以在亚马逊上买到。
这本书的平装本是全彩色的。这就是为什么它比我买的其他书都贵的原因。我做了一个小视频,在这里我简单介绍了一下这本书:
https://www.youtube.com/embed/NwMPvmVtfxQ?feature=oembed
你可以在 Leanpub 或 Gumroad 上订购电子书版本。当您通过这些网站购买时,您将收到该书的 PDF、epub 和 mobi 版本。
Python 图像库允许您使用 Python 编辑照片。Pillow 包是 Python 图像库的最新版本。您可以使用 Python 通过 Pillow 批量处理您的照片。
在本书中,您将了解以下内容:
- 打开和保存图像
- 提取图像元数据
- 使用颜色
- 应用图像滤镜
- 裁剪、旋转和调整大小
- 增强图像
- 组合图像
- 用枕头画画
- 图像印章
- 与 GUI 工具包集成
在这本书里,你会学到所有这些东西,甚至更多。很快你就能像专业人士一样使用 Python 编程语言编辑照片了!
通过 Plotly 和 Python 在线绘制数据
原文:https://www.blog.pythonlibrary.org/2014/10/27/plotting-data-online-via-plotly-and-python/
我在工作中不怎么绘图,但我最近听说了一个名为plottly的网站,它为任何人的数据提供绘图服务。他们甚至有一个 Python 的 plotly 包(还有其他的)!因此,在这篇文章中,我们将学习如何与他们的包情节。让我们来做一些有趣的图表吧!
入门指南
您将需要 plotly 包来阅读本文。您可以使用 pip 获取软件包并安装它:
pip install plotly
现在你已经安装好了,你需要去 Plotly 网站创建一个免费账户。一旦完成,您将获得一个 API 密钥。为了使事情变得非常简单,您可以使用您的用户名和 API 密匙来创建一个凭证文件。下面是如何做到这一点:
import plotly.tools as tls
tls.set_credentials_file(
username="your_username",
api_key="your_api_key")
# to get your credentials
credentials = tls.get_credentials_file()
如果您不想保存凭据,也可以通过执行以下操作来登录他们的服务:
import plotly.plotly as py
py.sign_in('your_username','your_api_key')
出于本文的目的,我假设您已经创建了凭证文件。我发现这使得与他们的服务交互变得更容易使用。
创建图表
Plotly 似乎默认为散点图,所以我们就从这里开始。我决定从一个人口普查网站获取一些数据。您可以下载美国任何一个州的人口数据以及其他数据。在本例中,我下载了一个 CSV 文件,其中包含爱荷华州每个县的人口。让我们来看看:
import csv
import plotly.plotly as py
#----------------------------------------------------------------------
def plot_counties(csv_path):
"""
http://census.ire.org/data/bulkdata.html
"""
counties = {}
county = []
pop = []
counter = 0
with open(csv_path) as csv_handler:
reader = csv.reader(csv_handler)
for row in reader:
if counter == 0:
counter += 1
continue
county.append(row[8])
pop.append(row[9])
trace = dict(x=county, y=pop)
data = [trace]
py.plot(data, filename='ia_county_populations')
if __name__ == '__main__':
csv_path = 'ia_county_pop.csv'
plot_counties(csv_path)
如果您运行这段代码,您应该会看到如下所示的图形:
https://plot.ly/~driscollis/0.embed?width=640&height=480
转换为条形图
现在让我们看看能否将散点图转换成条形图。首先,我们将摆弄一下绘图数据。以下是通过 Python 解释器完成的:
>>> scatter = py.get_figure('driscollis', '0')
>>> print scatter.to_string()
Figure(
data=Data([
Scatter(
x=[u'Adair County', u'Adams County', u'Allamakee County', u'..', ],
y=[u'7682', u'4029', u'14330', u'12887', u'6119', u'26076', '..' ]
)
])
)
这显示了我们如何使用用户名和图的唯一编号来获取数字。然后我们打印出数据结构。您会注意到它没有打印出整个数据结构。现在,让我们进行条形图的实际转换:
from plotly.graph_objs import Data, Figure, Layout
scatter_data = scatter.get_data()
trace_bar = Bar(scatter_data[0])
data = Data([trace_bar])
layout = Layout(title="IA County Populations")
fig = Figure(data=data, layout=layout)
py.plot(fig, filename='bar_ia_county_pop')
这将在以下 URL 创建一个条形图:https://plot.ly/~driscollis/1。这是图表的图像:
https://plot.ly/~driscollis/1.embed?width=640&height=480
这段代码与我们最初使用的代码略有不同。在这种情况下,我们显式地创建了一个条对象,并将散点图的数据传递给它。然后我们将这些数据放入一个数据对象中。接下来,我们创建了一个布局对象,并给我们的图表加了一个标题。然后,我们使用数据和布局对象创建了一个图形对象。最后我们绘制了条形图。
将图形保存到磁盘
Plotly 还允许您将图形保存到硬盘上。您可以将其保存为以下格式:png、svg、jpeg 和 pdf。假设您手头还有上一个示例中的 Figure 对象,您可以执行以下操作:
py.image.save_as(fig, filename='graph.png')
如果您想使用其他格式保存,那么只需在文件名中使用该格式的扩展名。
包扎
至此,您应该能够很好地使用 plotly 包了。还有许多其他可用的图形类型,所以请务必通读 Plotly 的文档。它们还支持流式图形。据我了解,Plotly 允许你免费创建 10 个图表。在那之后,你要么删除一些图片,要么支付月费。
附加阅读
将 wxPyMail 移植到 Linux
原文:https://www.blog.pythonlibrary.org/2008/09/26/porting-wxpymail-to-linux/
将应用程序从一个操作系统移植到另一个操作系统是一个非常耗时的过程。幸运的是,wxPython 消除了这个过程中的痛苦。这只是我第二次把我的代码移植到 Linux 上。我平时上班都是在 Windows XP 上为 Windows XP 写。当我最初为工作编写 wxPyMail 时,我使用 Mark Hammond 的 PyWin32 库来获取用户的全名和用户名,以帮助构建他们的回信地址。以下是我当时使用的代码:
try:
userid = win32api.GetUserName()
info = win32net.NetUserGetInfo('server', userid, 2)
full_name = str(info['full_name'].lower())
name_parts = full_name.split(' ')
self.emailuser = name_parts[0][:1] + name_parts[-1]
email = self.emailuser + '@companyEmail'
except:
email = ''
如果我保留了那个代码,我将需要使用 wx。平台模块并测试“WXMSW”标志,如下所示:
if wx.Platform == '__WXMSW__':
try:
userid = win32api.GetUserName()
# rest of my win32 code
except:
# do something
pass
else:
# put some Linux or Mac specific stuff here
pass
这可能是移植代码最简单的方法,尤其是当您只有几个特定于操作系统的代码时。如果你有很多,那么你可能想把它们放入它们自己的模块中,并把它们导入到你的平台上。我相信还有其他方法可以实现这一点。
无论如何,我已经拿出了所有的 win32 的东西,因为它与我的组织。因此,wxPyMail 的新代码实际上在 Linux 上运行得很好。我在 Ubuntu Hardy Heron 上测试过。然而,我注意到一些美学问题。首先,这个框架似乎得到了关注,所以我不能在 wx 中输入电子邮件地址,甚至我的用户名。弹出的对话框。其次,我登录对话框中的标签和文本框在 Ubuntu 中太短了。它们在 Windows 上看起来很好,但在 Ubuntu 上标签被夹住了,当我完整输入用户名时,我看不到它。
因此,我更改了代码,使标签和文本框的大小更长。我还对主应用程序中的到字段和登录对话框中的用户名文本字段调用了 SetFocus()。除此之外,我做了一点重构,将 SMTP 服务器放在 init 中,这样更容易找到和设置。我还更改了我的各种控件实例,以便它们显式地反映它们的参数。
还要注意文件开头的“shebang”行:“#!/usr/bin/env python”。这告诉 Linux 这个文件可以使用 Python 执行,也告诉 Linux Python 安装文件夹在哪里。只要 python 在您的路径中的某个地方,您就应该能够使用这种方法。要检查路径上是否有 python,请打开命令提示符并键入“python”。如果您获得了 python shell,那么您就可以开始了。
你可能认为我们已经完成了,但是我们忘记了一个重要的部分。我们仍然需要告诉 Linux 使用 wxPyMail 作为 mailto 链接的默认电子邮件程序。我在 howtogeek 找到了一篇关于这个话题的操作文章。我们需要对它进行一些修改来使它工作,但是一旦你知道怎么做,它实际上是非常容易的。对于这个例子,我使用了 Ubuntu Hardy Heron (8.04)和 wxPython 2.8.9.1 以及 Python 2.5.2。
无论如何,首先你需要下载我的代码。当我第一次编写这个应用程序时,它是在 Windows 上。wxPython 邮件列表上的好心人向我指出我的代码有行尾问题,所以请确保您不会意外地将其转换回 Windows 格式。感谢罗宾·邓恩、克里斯托弗·巴克、科迪·普雷科德、弗兰克·米尔曼和一个叫基思的人。
其次,您需要告诉 Linux 在用户点击 mailto 链接时执行 python 脚本。在 Ubuntu 中,你可以通过进入系统,首选项,首选应用程序。将“邮件阅读器”更改为“自定义”,并在“命令”字段中添加以下内容:
/home/USERNAME/path/to/wxPyMail.py %s
用您的用户名替换 USERNAME,并根据需要调整路径。确保包含“%s ”,它表示传递给我们脚本的“mailto”字符串。现在,打开命令提示符,将目录更改为放置 python 脚本的位置。您将需要更改它的执行权限,所以应该这样做:
chmod +x wxPyMail.py
现在浏览到一个带有 mailto 链接的网站,并尝试一下吧!和往常一样,如果有任何问题或意见,欢迎发邮件给我,邮箱是 mike [at] pythonlibrary [dot] org。
下载源码
补充阅读
使用 Python 自动预订 Excel
原文:https://www.blog.pythonlibrary.org/2021/07/30/pre-order-automating-excel-with-python/
我的第十本 Python 书籍叫做用 Python 自动化 Excel:用 OpenPyXL 处理电子表格。还有 11 天就可以在 Kickstarter 上获得一件专属 t 恤了!
我也有电子书可以在 Gumroad 上预订。无论你是在 Kickstarter 还是 Gumroad 上购买,你都会得到这本书的早期版本,以及我对这本书的所有更新。
你可以在这里得到一些章节的样本,这样你就可以在决定购买之前试用这本书了!

在本书中,您将学习如何使用 Python 来完成以下任务:
- 创建 Excel 电子表格
- 阅读 Excel 电子表格
- 创建不同的细胞类型
- 添加和移除工作表
- 将 Excel 电子表格转换为其他文件类型
- 单元格样式(更改字体、插入图像、背景颜色等)
- 条件格式
- 添加图表
- 还有更多!
预购 Python 201 平装本
原文:https://www.blog.pythonlibrary.org/2016/04/11/pre-order-python-201-paperback/
我已经决定为我的下一本书提供平装本的预购。您将可以预订该书的签名版,该书将于 2016 年 9 月日发货。我将预购数量限制在 100 个。如果你有兴趣得到这本书,你可以这样做在这里

预购 Python 访谈
原文:https://www.blog.pythonlibrary.org/2018/02/07/pre-order-python-interviews/
我很高兴地宣布我正在写的另一本书,名为《Python 访谈》,由 Packt 出版社出版。这是他们网站的简介:

Python 访谈包含了 Mike Driscoll 和 Python 社区中各种领军人物之间的一系列一对一访谈。Mike 是 Python 社区的终身成员,多年来一直在他的博客 Mouse vs. Python 中对 Python 社区的精英进行“PyDev of the Week”采访。
在本书中,Mike 与 Python 社区的核心成员讨论了 Python,例如 Steve Holden(Python 软件基金会的前主席)、Mike Bayer(SQLAlchemy 的创建者)、Brett Cannon(Python 核心开发人员)、Glyph Lefkowitz(Twisted 的创建者)、Massimo DiPierro(web 2 py 的创建者)、Oliver schoen born(PyPubSub 的创建者)等等。采访中充满了对成功程序员的思想、Python 语言的内部运作、Python 的历史以及来自蓬勃发展的 Python 社区的幽默轶事的洞察。
Python 访谈目前可以预购,应该会在 2018 年 2 月下旬或者 2018 年 3 月出版。
注意:这些是全新的采访,并非摘自我的“本周 PyDev”系列。然而,这本书对这些采访有一些交叉,因为涉及了一些相同的主题。
产品评论:Python 闪存卡
原文:https://www.blog.pythonlibrary.org/2019/04/02/product-review-python-flash-cards/
没有哪家淀粉出版社以出版计算机编程书籍而闻名。然而,他们最近发布了一款名为 Python 闪存卡的新产品,作者是 Python 速成班的作者 Eric Matthes。我认为这是一个独特的产品,并决定要求审查副本。

这些卡片和它们的盒子是高质量的。我很喜欢他们用的卡片。卡本身针对 Python 3.7 。
每张卡的顶部都标有与其类别相匹配的颜色:

卡片也有编号。这在卡片引用其部分中的其他卡片或完全引用其他部分的时候很有用。这使得引用不同的卡片变得简单明了。
当然,抽认卡就其本质而言,短小精悍。所以卡片的测试和包装部分对我来说太简单了。另一方面,它们是闪存卡,所以介质不允许它们以我希望的方式被充实。如果你需要更多的细节,谷歌从未远离。
虽然我肯定不是这些卡片的目标市场,但我认为它们对想学习的高中生,甚至可能是大学新生很有用。它们对于刷新您的 Python 基础当然是有用的。如果你有学生,这一套可能会证明对他们很有用。

|  |
|
Python 闪存卡
书评
- 书评- 任务 Python:编写一个太空冒险游戏!肖恩·麦克马纳斯
- Julien Danjou 的《严肃的 Python:关于部署、可伸缩性、测试等的黑带建议》
- Brian Okken 的 pytestPython 测试
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
有利可图的 Python 插曲:把家庭放在第一位
原文:https://www.blog.pythonlibrary.org/2019/08/26/profitable-python-episode-put-your-family-first/
本周,我是盈利的 Python 播客的嘉宾。你可以在这里查看:
https://www.youtube.com/embed/qdPvZUzPNA0?feature=oembed
在面试中,有人问我希望 Python 在浏览器中运行,我想不起有哪个产品的名字能让这种事情成为可能。我想到的产品是 Anvil ,虽然浏览器中还没有 Python,但已经很接近了。
我想到的另一个产品是微软的 Silverlight 浏览器插件,你可以在其中使用 IronPython。或者至少你曾经可以。我有段时间没查这个了。
以下是本集提到的其他内容的一些链接:
- 谈谈 Python 和我在那里的一集:第 156 集:Python 的历史和观点
- Pyowa: 爱荷华 Python 用户组
- 我在 Leanpub 和亚马逊的书籍
- 一拳侠漫画
- Python 网站中的测试驱动开发
参加这个节目太棒了。我总是喜欢谈论 Python。关于播客中提到的任何事情或播客本身,请随时问我任何问题。
印地出版的利与弊
原文:https://www.blog.pythonlibrary.org/2019/02/27/pros-and-cons-of-indy-publishing/
我个人是真的爱自助出版还是印第出版,所以有点偏颇。在这篇文章中,我将回顾一下我认为印第出版公司与“真正的”出版商相比的优缺点。
赞成的意见
以下是我最喜欢印第出版公司的部分:
- 我控制发布日期
- 我控制内容
- 电子书可以在几分钟内更新
- 你的版税税率是 70-90%
- 价格可以在几秒钟内改变
- 闪购很容易
- 在简历上看起来不错
我将对其中的一些观点进行一些扩展。我曾作为作者与两家出版社合作过: Packt Publishing 和press。Packt 有非常积极的完成工作的时间表。章节必须根据时间表来完成。当你接近尾声时,出版商也会给你出难题。当你自助出版时,你控制了所有这些。
当我想修改书中的错误、修改例子或添加章节时,我只需这样做并发送更新即可。
如果我想把我的书免费送给学生或任何我想送给的人,我也可以这样做。我也给当地的 python 用户组捐过书。如果你想为你的小组要些礼物,请随时联系我。如果你住得很远,我可能会收取运费。
Leanpub、亚马逊和 Gumroad 都有报告,你可以看看你的书卖得怎么样。这些都很有用。
最后,我想指出的是,雇主似乎并不关心这本书是自己出版还是通过出版商出版。不管怎样,他们通常会感兴趣和/或留下深刻印象。
骗局
以下是我从印第出版社了解到的一些弊端:
- 你没有编辑
- 没有技术审查人员
- 没有市场部
- 没有艺术系
在与几家出版商合作后,我注意到我没有从编辑那里得到任何有用的反馈。作为一名技术评审,我曾与 No Starch Press 合作过,我认为他们给了作者更好的反馈,但我只看到了一点,所以我真的不知道他们实际收到了多少。
我的书《wxPython 食谱》确实有几个技术评论家。这很有帮助,尽管没有我想象的那么大。正如我在之前的帖子中提到的,我通常在发布我的书之前使用我的博客和 Kickstarter 来获得关于我的书的反馈,这很好,甚至更好。
让别人来做营销是很好的。帕克特甚至给我指派了一个公关。Apress 给了我一些关于章节风格更加一致的想法。
从某种意义上来说,最大的缺点是你必须为所有的东西付钱。艺术品很贵。广告也很贵。你必须关注所有这些,弄清楚你想花什么,以及你想怎么花。
谈判合同
当你自己出版或者只是写很多博客时,出版商可能会找上门来,让你为他们写作。或者他们可能会要求购买你的书的版权,并以他们的品牌重印。虽然我没有很多谈判合同的经验,但我还是要提几点。
如果你在任何你想销售的社区都不出名,那会在谈判桌上对你不利。在你决定最终要价之前,确保你有出版商的时间表。
写一本书是一个耗时且通常孤独的过程。除非你已经写了很多,否则它很可能会比你预期的花费更多的时间。如果出版商想让你做一个约定,一定要让你的报酬涨上去。他们可能不会支付所有费用,但通常会增加一些。
我想提到的另一件事是,你得到的预付款可能是你为这本书得到的全部报酬。事实上,最好只是认为这是将要发生的事情,这样你就不会失望。让我们处理一些数字。大多数出版商支付大约 10%的版税。现在假设你得到了 4000 美元的预付款。当版税达到 4000 美元时,你不会开始得到版税。相反,当你的版税金额超过 4000 美元时,你就会得到报酬。
如果这本书的售价是 25 美元,你的版税大概是 1.25 美元。你需要卖出 3000 多本书才能开始获得版税。遗憾的是,你可能永远也到不了那里。
你可以在这里阅读更多关于这个话题和写作的书籍。
我认为与出版商合作的最大好处是,我的一本书得到了一个小小的包裹。作为印第出版商,我不能进入这些。我能从中赚到钱吗?我不知道。捆绑包的版税很少,最多只能按季度了解你的书卖得有多好。
包扎
我真的很喜欢出版自己的书。我喜欢它给我的内容自由,以及以我认为合适的方式分享内容的能力。不过,我从与出版商的合作中学到了很多。他们当然有他们的位置。但是我认为如果你愿意投入工作,没有他们你也能做得一样好。
组装 wxPython 应用程序
原文:https://www.blog.pythonlibrary.org/2008/06/09/putting-together-a-wxpython-application/
大约一周前,我写道,我正在开发一个示例应用程序,我将在这里发布。当我在做的时候,我意识到我需要找到一种简单、有条理和通用的方法来分解它。因此,我决定就我的应用程序创建一系列“如何做”的文章,并将它们发布在这里。然后,我将发布另一篇文章,将所有的片段放在一起。
该应用程序包括以下部分:
- wx。箱式筛分机
- wx。对话类
- wx。菜单,wx。StatusBar 和 wx。工具栏
- wx。AboutBox
注意:我已经有一个 BoxSizer 教程完成。
我认为这涵盖了 wxPython 的主要部分。我还将使用标准 Python 2.5 库的 email、urllib 和 smtplib 模块以及一些特定于 win32 的模块。我想你会发现这套文章很有教育意义。请务必让我知道你的想法。
PyBites 播客:第 043 集——成为一个多产的 Python 内容提供商
本周,Mike Driscoll(本网站的作者)做客 PyBites 播客。标题是第 043 集——成为一个多产的 Python 内容提供商
你可以在 PyBites 上收听播客。
在播客中,主持人和我讨论了:
- Mike 是如何进入编程和 Python 的(以及社区的重要性),
- Mike 如何在自动化测试框架中使用 Python(测试 C++ GUI 应用程序),
- Mike 是如何通过写博客和后来写 9(!)书籍,
- 如何跟上新技术,
- 如何在制作内容时保持一致性和积极性,
- 如今作为 Python 开发人员的基本技能,
- 应对冒名顶替综合症(意识到你可能比你想象的要多得多!)
- 学习新的库,结对编程的好处(初级和高级工程师都适用),
- 更多...
PyChecker: Python 代码分析
原文:https://www.blog.pythonlibrary.org/2011/01/26/pychecker-python-code-analysis/
PyChecker 是一个很酷的工具,用于检查 Python 脚本中的错误。它适用于 Python 2.0 - 2.7。在本文中,我们将编写一些蹩脚的代码,看看 PyChecker 能从中发现什么。然后,我们将根据我们的发现改进代码,直到代码通过检查。根据 PyChecker 的网站,它可以检测到以下问题:
- 找不到全局(例如,使用模块而不导入它)
- 向函数/方法/构造函数传递了错误数量的参数
- 向内置函数和方法传递错误数量的参数
- 使用与参数不匹配的格式字符串
- 使用不存在的类方法和属性
- 重写方法时更改签名
- 在相同的范围内重新定义函数/类/方法
- 在设置变量之前使用它
- self 不是为方法定义的第一个参数
- 未使用的全局变量和局部变量(模块或变量)
- 未使用的函数/方法参数(可以忽略自身)
- 模块、类、函数和方法中没有文档字符串
入门指南
我们不会测试它能检测到的所有东西,但是我们可以编写一些非常混乱的代码供 PyChecker 检查。开始编码吧!
import sys
########################################################################
class CarClass:
""""""
#----------------------------------------------------------------------
def __init__(self, color, make, model, year):
"""Constructor"""
self.color = color
self.make = make
self.model = model
self.year = year
if "Windows" in platform.platform():
print "You're using Windows!"
self.weight = self.getWeight(1, 2, 3)
#----------------------------------------------------------------------
def getWeight(this):
""""""
return "2000 lbs"
这段代码实际上并没有做太多的事情,只是为了举例说明。根据 PyChecker 的说法,这段代码有四个问题。你能看到问题吗?如果没有,那么让我们来看看如何使用 PyChecker 来揭露它们!一旦您安装了 PyChecker 并将其放在您的路径中(参见 PyChecker 的文档),您应该能够执行以下命令:
C:\Users\Mike\Documents\My Dropbox\Scripts\code analysis>pychecker bad.py
注意:只有当你在 Windows 系统路径上有 pychecker 时,以上才有效。从技术上讲,在 Windows 上你将使用 pychecker.bat
如果您这样做,您将得到如下结果:

希望你能告诉我们这一切意味着什么,但我们会把它分解,以防你不知道。它发现了四个问题。它发现的第一个问题是我们导入了 sys 模块,但是我们没有使用它。第二个问题与第一个相反。我们指的是平台模块,但实际上不是进口的!第三,我们调用我们的 getWeight 方法,它报告我们给它传递了太多的参数。我认为 PyChecker 可能有一个错误,因为我们的方法应该接受一个方法,而不是零个。“this”参数肯定会让 PyChecker 感到困惑。幸运的是,它发现的最后一个问题是 getWeight 没有将 self 作为第一个参数。这就纠正了我提到的错误。虽然第一个方法不要求我们将其命名为“self ”,但这是类方法中第一个参数的常规命名约定。
其他提示
PyChecker 不只是在命令行上工作。也可以直接在代码中使用!您只需在模块顶部导入 PyChecker,如下所示:
import pychecker.checker
这将使 PyChecker 检查下面所有导入的模块,尽管它不会检查主模块。那是什么意思?这意味着,如果您在我们使用的示例中坚持这一行,您将不会看到任何与该代码相关的错误。PyChecker 文档说您还可以通过 os.environ 设置 PyChecker 的选项。
os.environ['PYCHECKER'] = 'command line options here'
说到这里,下面是常见的命令行选项:
[表 id=2 /]
如果您想要完整的命令列表,请键入以下命令:pychecker -h
注意:PyChecker 的文档字符串检查在默认情况下是关闭的,所以如果你想要的话,你需要传递"-m -f "命令。这只找到了类模块的空 docstring。“-f”似乎有一个小错误,它认为空文档字符串是可以的。我已经提醒过 PyChecker 小组了。
包扎
我认为 PyChecker 非常酷,看起来它可能是一个方便的工具。试试看,看你怎么想!
附加阅读
- PyChecker 官方网站
- PyLint -与 PyChecker 一脉相承的另一个项目
- 另一个类似的项目
- 来自 Python 杂志的 Doug Hellman 对 Python 静态代码分析器的评论
PyCon 2008(芝加哥)-第一天(第一部分)
原文:https://www.blog.pythonlibrary.org/2008/03/16/pycon-2008-chicago-day-1-part-one/
PyCon 的第一天(不包括辅导日)发生在 2008 年 3 月 14 日。我终于见到了 BDFL(仁慈的终身独裁者),吉多·范·罗苏姆。虽然我知道他来自荷兰,但我真的没有想到他有瑞士口音。太酷了!他最有趣的地方在于他描述了 Python 的下一次迭代;即同时发布 2.6 和 3.0。他希望他们能在 2008 年 8 月获释。
不过在 Guido 之前,有一个叫 Chris Hagner 的人在 White Oak Technologies 发表了“为什么 Python 很烂(但对我们有用)”之类的演讲。无论如何,他指出了 Python 的弱点,然后展示了如何利用它们的优势。哈格纳的缺点是:
- Python 开发人员数量少
- 很少有组织拥有 Python 解决方案(这使得他们在尝试新事物时有些紧张)
- Python“古怪”
- Python 很慢
他谈到了这些,但我的笔记不完整,所以我只谈重点。Python 开发人员相对较少的事实并没有阻止他的公司,因为与他交谈过的 Python 程序员通常比其他语言的程序员质量高得多。他用 Python 解决方案的“稀有性”作为卖点:“嘿!我们有一些不同的东西。”这在某种程度上也适用于“怪异”因素。最后,Python 的慢部分对他们大多数时间做的事情来说不是问题,这使他们更加注意测试和优化或为那些“慢”部分编写 C/C++扩展。
我下次再写我参加的讲座。
PyCon 2008(芝加哥)-第一天(第二部分)
原文:https://www.blog.pythonlibrary.org/2008/03/20/pycon-2008-chicago-day-1-part-two/
我参加的第一个讲座名为“用 Repoze 开发 2”。克里斯·P·麦克多诺的《佐普》。这是一个非常有趣的关于中间件的演示,它可以以允许 Zope2 在 Apache + mod_wsgi 中运行的方式重新实现 ZPublisher。Repoze 依赖于 Python 粘贴和 setuptools。如果我没记错的话,他给 Trac 演示了一个类似 Plone 的接口,但没有做任何修改。
在那之后,我去看了布雷特·坎农关于“进口是如何起作用的”的演讲。这是一个非常复杂的话题,我无法完全理解。它的要点是这样的:
- 有一个函数调用要导入
- 签发进口锁
- 名字是决心是坚决的
- 它检查 sys.modules 如果找到了,就停在这里。如果不是,那么
- 它检查 sys.meta _ path 如果找到了,就停在这里。如果不是,那么
- 它检查父 path 或 sys.path
你可以在这里下载他的幻灯片:http://us.pycon.org/2008/conference/schedule/
它有很多流程图,可能比我的总结更有意义。只需将鼠标放在上面,就会弹出一个窗口让你下载 PDF 文件。接下来,我看了杰夫·拉什关于创建一个本地 Python 用户组的演讲。他说话很快,但我得到了很多关于培养一只好哈巴狗的信息,希望我能为爱荷华州找到一只。他的幻灯片也可以在上面的链接中找到。
接下来我参加的两个讲座是针对系统管理员的。一篇是关于使用 Optparse 的,名为“使用 Optparse、子流程和 Doctest 来制作敏捷 Unix 实用程序”。这是诺亚·吉夫给的。我没有得到太多的好处,因为 PyCon 无线系统坏了,所以我不能使用代码。然而,它表现得很好,他的材料也可以在 PyCon schedule 网站上找到,所以我建议下载下来看看。
由于技术困难,Gift 之后的演示没有任何幻灯片,几乎与 Python 没有任何关系。它是由芝加哥用户组的一个成员 Sean Reifschneider 给出的,他称之为:“系统管理中的 Python:一个系统管理员如何、何时以及为什么使用 Python”。不幸的是,他大部分时间都在谈论他有多喜欢 Nagios 这个网络监控工具和 rsync 这个备份工具。他无法展示的幻灯片应该在这里:http://dev.tummy.com/~jafo/pycon2008/
“使用谷歌电子表格 API 在云中创建一个数据库”和杰弗里·斯卡德尔(谷歌)是下一个,它震撼了!他展示了如何使用 Python 实时修改谷歌电子表格。你可以在 http://rurl.com/kp7 的 观看幻灯片,但需要 Gmail 账户。无论如何,我认为把数据放在云端有很多好处,可以同时进行编辑,还可以把数据保存到硬盘上。他还展示了如何在 Atom 提要上进行 CRUD。python 绑定可以在 code.google.com的找到
斯卡德尔也是我在 PyCon 遇到的最好的人之一。
对我来说,这一天的最后一个话题是保罗·温克勒的《剩下的就容易了》。老实说,我也没从这本书里得到什么。主要原因是他在展示任何代码之前看了 23 张幻灯片。即便如此,代码也是乏味无趣的。也可以从 PyCon Schedule 网站上获得。希望温克勒会随着经验的增加而提高。主题很吸引人,但演讲的执行却不吸引人。
我会尽快把我在会议上的其他经历讲出来。抱歉耽搁了!
PyCon 2008(芝加哥)-第二天
原文:https://www.blog.pythonlibrary.org/2008/03/21/pycon-2008-chicago-day-2/
3 月 15 日,星期六,我终于找到了 PyCon 的窍门。我四处逛了逛,门一开,我就进了会议室。这是我住过的最大的房间之一。它让我想起了一个竞技场,只是没有高高的天花板。开场演讲是关于 Twisted,以及它如何获得某种支持,使他们成为一个真正的实体。有很多人在用麦克风玩烫手山芋,我很快就发现自己被弄糊涂了。话又说回来,我从一开始就对扭曲不感兴趣。
下一次全体会议由谷歌的 Brian Fitzpatick 主持。他的讲话是我见过的最圆滑、最有趣的。我也几乎什么都没学到。很奇怪这是怎么回事。
Van Lindberg 在最后一次全体会议上做了关于知识产权的发言。这是我第一次也是唯一一次真正有意识地走神的全体会议。我不反对知识产权。如果你想保护你的工作并获得报酬,这是非常重要的,但我发现这个谈话非常枯燥,坦率地说,很无聊。
接下来,有一个休息,然后是 6 个以上的会谈。列表如下:
使用 PyGame 和 PySight 创建一个交互式万圣节活动
Crunchy:Crunching on Python Documentation
不要给我们打电话,我们会给你打电话:Python 中的回调模式和习惯用法
使用 pyglet 的视觉和声音
Python 应用程序开发的案例研究——人性化的 Enso
Python 在您的浏览器中使用 IronPython & Silverlight
我真的很喜欢 PyGame 的万圣节演讲。约翰·哈里森是一个傻瓜,很高兴看到 Python 以一种有趣和创造性的方式被使用,吸引了社区的关注。观众也很喜欢。他有手工制作的激光枪、改装的《星球大战》激光枪、红外眼镜和一个运动跟踪装置。他的一些作品在 YouTube 上。我强烈建议你去看看。
嘎吱嘎吱是一个很好的想法,但是我仍然不知道如何将它应用到我正在做的或者可能会做的任何事情上。不过,你可以在这里仔细阅读:http://aroberge . blogspot . com/2007/01/crunchy-08-is-out . html
回拨习语的演讲者是亚历克斯·马尔泰利,我非常尊敬他。他是《果壳中的 Python》一书的作者,也是《Python 食谱》的编辑之一。不幸的是,亚历克斯浓重的口音加上深刻的主题让我很难理解。我认为你可以从这个家伙身上学到很多东西,所以如果你在下一次 PyCon 上看到他的名字,不要错过。请记住,你必须比平时更加注意。
皮格莱特吸引了很多人。那是一堂非常满的课。我之前喜欢 PyGame,但是这个也很有趣。幻灯片以 html 格式放在 PyCon 时间表网站上。去看看吧,因为我对此没什么可说的。
人性化的厄尔尼诺/南方涛动项目也没有为我做任何事情。不过,这里有一个获得更多信息的好地方:http://www.humanized.com/
迈克尔·福德谈到了 IronPython & Silverlight。他很酷,正在 Silverlight 上写一本关于 IronPython 的书。第二天还有一个关于 IronPython 的未来的演讲,也有一个令人印象深刻的 Silverlight 演示。但是我想得太多了。事实上,你可以在 Foord 的博客上看到他谈论的很多内容。
下次见。
PyCon 2008(芝加哥)-第三天
原文:https://www.blog.pythonlibrary.org/2008/03/22/pycon-2008-chicago-day-3/
我在 PyCon 的最后一天是 2008 年 3 月 16 日,星期天。我是第二天早上还要工作的不幸者之一。这一天对我来说似乎太匆忙了,这可能是我学到最少的原因。
第一次全体会议是用阿萨·拉斯金让客户端 Python 变得不那么糟糕。在某种程度上,这是关于 Mozilla 的,但拉斯金更关注于将 Python 变成一个易于更新的程序。这是一个让“冻结”你的 Python 应用程序变得更容易,让上述程序的整体更新和可插入性变得更容易的战斗号令。他的主要思想可以用这句名言“Python 需要成为一个平台”来概括。不过,他并没有给出如何实现这一目标的任何想法。你可以在这里了解更多:【http://www.toolness.com/wp/】T2
我非常期待哈蒙德关于 Python 和 Firefox 的演讲,他没有让我失望。我没意识到哈蒙德是澳大利亚人。他非常详细地介绍了自己多年来如何使用 Python、XPCOM 和 Mozilla,并讲述了 XPCOM / Mozilla 多年来的历史。
- XPCOM 绑定的问题:
- 文档不足
- 对麦克太苛刻了
- 没有二进制发行版(但这正在改变)
- 被认为是实验性的(但事实并非如此,只是缺乏社区)
- DOM 工作的性能问题
- 为什么没有社区(针对 XPCOM 绑定)?
- 高准入门槛
- 由非常大的项目使用
- Mozilla 社区认为它属于 Python,反之亦然
- 即使是 Mozilla 也在挣扎
最后,OLPC 代表伊万·克尔斯蒂奇站起来发言。他应该在哈蒙德之前,但伊万的笔记本电脑前一天晚上坏了,他疯狂地工作在他的幻灯片上,直到他的演讲。看到 OLPC 倡议的进展情况是令人感兴趣的。除了泛泛而谈之外,我对它了解得不多。我仍然对这个项目持“等等看”的态度,因为美国多年来一直在教育上砸钱,而且大部分都停滞不前。希望 OLPC 能真正帮助孩子们学习。伊万的谈话肯定是积极的。
休息之后,我参加了我的最后三场演讲:【Zope 做错了什么(以及它是如何被修复的),nose:对懒惰的程序员的测试,和 IronPython:前方的路。
Zope 讲座由 Lennart Regebro 主持。正如我参加的其他 Zope / Plone 讲座一样,Regebro 强调了迁移到 Zope3 和 Plone 3 以获得最新和最棒的产品的必要性。虽然利用新技术很好,但我的公司目前还做不到。所以我有点走神了。抱歉,伦纳特!欢迎你来看看他的博客:http://regebro.wordpress.com/
鼻子的演讲很受欢迎。事实上,这可能比前一天晚上的皮格莱特谈话更好。它是由《鼻子》的作者杰森·佩勒林给出的。然而,它与测试驱动开发(TDD)以及 nose 如何适应这种思维模式有更多的关系,而不仅仅是泛泛地谈论 nose。TDD 背后的想法非常好,也是我自己想要采纳的,所以这个演示是令人鼓舞的。希望我能在自己的作品中使用一些或全部 Pellerin 所说的内容。
最后,我们来到了 IronPython 展会。它由两名微软员工主持。主要发言人是吉姆·胡古宁和一个叫迪诺的程序员(我想)。我也看到迈克尔·福德在后面。他们展示了一个用 Python 和 Silverlight 设计的奇特的投票网站。它有小视频,每个问题都会在后台运行;当鼠标经过时,问题列表中的每一项都会稍微放大;在问题之间有一个简洁的过渡效果。还有一个很好的图表可以显示民意调查的进展情况。谈话非常圆滑,但我不得不在他们结束之前离开,以避免回家路上的交通堵塞。
他们还展示了如何在 IronPython 中运行 Django。这很酷,尽管我不确定这给了开发者什么额外的功能...除了能够将 Silverlight pizazz 添加到 Django 站点之外。
我本来希望他们会发布他们的代码,但我仍然没有在 PyCon 网站上看到任何东西。
这就是我在 PyCon 上的亮点——我会贴出更多关于我的观察和我所看到的其他东西的一般评论。
PyCon 2008(芝加哥)-在路上
原文:https://www.blog.pythonlibrary.org/2008/03/14/pycon-2008-chicago-on-the-road/
这是我的第一篇文章。我想我应该开始写我的 Python 经历,巧合的是, PyCon 正准备开始。所以我决定等等,这样我就可以写一些真正酷的东西了。这也将是我第一次参加 PyCon,也是我第一次来芝加哥。我的公司支付了这次旅行的费用,到目前为止,这是一次有趣的经历。
据谷歌地图显示,我住在爱荷华州的中部,所以这次旅行花了大约 5 个半小时或 299 英里。为了到达这里,我决定使用一个 Garmin Nuvi 350 GPS 装置。它完美地工作,除了它带我上了一些收费公路。我还没想出解决的办法。
到达目的地逸林酒店后,我很快办理了入住手续,晚餐后,我去看看能不能帮 ChiPy (芝加哥当地的用户群)打包行李。他们实际上似乎有太多的帮助,但我遇到了一些有趣的人。
我很快会写另一篇关于辅导日的文章。到时候见!
PyCon 2008(芝加哥)赞助利弊
原文:https://www.blog.pythonlibrary.org/2008/03/25/pycon-2008-chicago-sponsorship-pros-cons/
今年去 PyCon 的时候,我根本就没想过赞助商。然而,我在每样东西上都看到了他们的名字,直到会议的第一天,我才感到困扰。虽然我认为主持人 Goodger 先生是一个很好的人,但我认为赞助公告有时放错了地方。当圭多站起来做他的报告时,他不得不等到古德杰跑到房间的后面去找一些纸。每个人都在想“怎么回事!?"当古德杰回来读到“圭多的演讲是由……”我有点震惊。我是说,这是什么?
我也从未听说过“闪电谈话”。事实上,当我听说他们的时候,我认为他们听起来像一个蹩脚的主意。所以第一天就跳过了。第二天我决定去看看,因为我很无聊。在我看到的四个中,有两个是赞助的演讲,一个只是一些家伙咆哮着为什么他认为 Python 很烂。所有这些似乎都有点不合时宜。
在 c.l.py 上还可以听到更多:
我同意赞助商有助于降低会议成本,我完全支持这一点,支持免费赠品以及与他们交流的机会。但在某些情况下,它们可能有些过头,如果你读了上面的帖子,你会注意到闪电谈话是受损最严重的。我希望明年能参加,我希望组织者将来能学会如何更好地处理这个问题。
PyCon 2008(芝加哥)-辅导日
原文:https://www.blog.pythonlibrary.org/2008/03/15/pycon-2008-chicago-tutorial-day/
教程日,顾名思义,是 PyCon 参与者参加各种 Python 主题的教程的日子,包括 Django、Plone、wxPython、Python 101、SQLAlchemy、Python Eggs、Python 和 OLPC 等等。根据第二天的主题演讲,参加辅导日的人数超过了过去几年参加 PyCon 的人数。
我自己参加了 3 个:Python 中的 Eggs 和 Buildout 部署(Jeff Rush)、高级 SQLAlchemy (Michael Bayer、Jason Kirtland 和 Jonathan Ellis)和 Tail Wags Fangs:Python 开发人员应该了解的 Plone (Rob Lineberger)。
鸡蛋教程是我参加过的最好的一个。拉什先生知识渊博,善于交流这些知识。虽然它非常快,但我认为我在那一次学到了最多。
高级 SQLAlchemy 让模块的作者(Michael Bayer)做了演示。虽然显然非常聪明,但他有语速过快的倾向。无论如何我都不是 SQL 专家,所以我也不总是能理解。不过,我可能也会做同样的事情。他和杰森·科特兰搭档,听起来很酷,即使我不能总是跟上每件事。
最后一节课可能是最让我失望的。除了关于原型的部分,Plone 教程似乎更多的是针对用户和设计者,而不是开发者。我对 ZPT 的期望比什么都高。此外,尽管演示者看起来知识渊博,但他不断地犯小错误,或者告诉我们一件事,只是告诉我们不要理会他几分钟后说的话,从而改变了我的想法。这使得记笔记几乎不可能。
到那个教程结束的时候,是时候去酒店睡觉了。PyCon 的“真正”开始将在明天开始。不要换那个频道!我很快就会谈到这一点...
PyCon 2009 第 1 天-全体会议和早晨闪电
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-day-1-plenary-and-morning-lightning/
2009 年 3 月 27 日,芝加哥 PyCon 真正开始了。有些人可能会把前两天的教程称为 PyCon 前,但“真正的”会议直到今天才开始。今天早上,组织者已经安排了一个开幕全体会议和一些上午的闪电谈话。闪电过后,我们休息一会儿,然后开始更具体的讨论。 大卫·古德杰仍然是会议主席,并做了很好的介绍。巴里·哈肯斯接着就空地问题发表了讲话。闪电谈话涵盖了 DCVS (Brett Cannon),PyCon 本身(Doug Napoleone),Cassandra 数据库(Jonathan Ellis),Python 和 wiiMote (John Harris),ChiPy / PyCon Networking 的 Shawn 的某种数据库谈话,等等。在大多数情况下,他们相当不错,虽然肖恩让我的心思恍惚。他有一个艰难的工作来保持他的 PyCon 网络正常运行,所以我很欣赏他所做的。霍金斯和坎农似乎在人群中得到最多的回应,那不勒斯和哈里斯紧随其后。
目前就这些。回来拿我参加的会谈的报告,当我参加的时候(当 flakey 网络允许的时候)。

PyCon 2009-GUI 应用程序的功能测试(周五演讲)
上周五(3 月 27 日)去 PyCon 的最后一个讲座,我去了 Michael Foord 的、、桌面应用、的功能测试。他在演示中使用了他的书 中的 IronPython 示例。他的主要话题是关于测试图形用户界面及其固有的问题。Foord 给出了很多测试 GUI 的好理由,比如确保新代码不会破坏功能,它在重构时非常有用,单个测试充当应用程序的规范,它让你知道一个功能何时完成,测试可以推动开发。
使用 GUI 框架的一个大问题是,当你测试它们时,你不能阻塞主循环。这可能是一种痛苦。Foord 的解决方案是使用工具包的定时器对象来拉进并运行测试。他还提到在您的应用程序中创建钩子,允许您自己检测它。他的幻灯片列出了可以帮助 GUI 测试的各种包,比如 WATSUP 和 guitest,以及其他几个包。我不确定他的网站上是否有完整的列表,但是给他写封短信,他可能会给你。
最后,我发现这是我周五参加的内容更丰富的讲座之一。它给了我一些如何在我自己的应用程序中实现测试的想法。希望这些会有结果。

PyCon 2009-Python 是如何开发的(演讲)
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-how-python-is-developed-talk/
Python 核心开发人员 Brett Cannon 发表了关于如何开发 Pycon 的演讲。Brett 谈到了如何开始帮助编写 Python Core。首先,他建议学习错误跟踪系统以及如何使用它,然后开始修复错误。首先,请访问新闻-bugs-公告或 python-bugs-列表。在那里你可以提交 bug 并了解当前的 bug。随着你越来越出名(通过修复 bug),开发人员会给你额外的特权,最高的是提交特权。要修正一个 bug,一定要看 PEP 7 和 8。如果你遵守规则并正确提交你的补丁,它可能会被接受。提交 bug 时要有耐心,因为 Brett 提到过,目前只有 26 个开发人员真正在做核心的事情,并且要花很多时间来检查所有的 bug。
他还谈到了在内核中添加新特性或功能的过程。主要的想法是将你的想法提交到 python-ideas 列表。你也可以向 comp.lang.python 上的人反映。如果他们认为这是一个好主意,就写一个 PEP 并提交给 python-dev。准备好捍卫你的概念。还是那句话,做病人。这就是他真正谈论的一切。我认为这是一个非常好的演讲。

PyCon 2009 - IronPython:数据、方向和演示(演讲)
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-ironpython-data-directions-and-demos-talk/
Jim Hugunin 开始了他的演讲,他提到了他在微软的同事。他接着谈到了 IronPython 的最新版本,它是 2.6 Alpha,实际上尽可能地匹配 Python 2.6 版本。听起来最近版本的 IronPython 2.0 Final 也有很多很酷的东西,比如关闭了 500 个 bug,更多的内置功能和编译成 dll 的能力。
接下来,他介绍了 IronPython 在 Silverlight 中的使用。他展示了几个演示,其中一个看起来像 flash 游戏。他指出 Python 在 DLR 中运行时是沙箱化的,这很酷。说到这里,Huginin 快速浏览了一遍 DLR,然后继续深入讨论 C# 4.0。我想他说的是这个新版本允许在 C#程序中使用 Python 代码,但我不是很确定,因为这很令人困惑。如果你使用。NET 和 Python,您可能会发现这要有趣得多。等视频,看懂了再告诉我。

PyCon 2009 要来了,我要去!
原文:https://www.blog.pythonlibrary.org/2009/01/31/pycon-2009-is-coming-and-im-going/

PyCon 2009 将于 3 月 27 日星期五再次在伊利诺伊州芝加哥举行。去年有 1000 多人参加,我知道今年有希望再次打破去年的出席记录。今年是我第二次去。
我将参加两个辅导日(3 月 25 日和 26 日)。第一天我将参加马克·拉姆的涡轮齿轮教程。第二天,我打算去 Py。上午考,下午考 Chun 的互联网编程用 Python 课。希望春的课能像他的书一样好。
我希望在主会议期间也能看到 Christopher Barker 在 wxPython 和 web 上的演讲。除此之外,我没有任何其他具体的计划,所以我很乐意接受建议。如果你有任何建议,请告诉我。
PyCon 2009 -与 Jeff Rush 讨论名称空间
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-namespaces-talk-with-jeff-rush/
我参加的第一个 PyCon 演讲题为 关于 Python 名称空间(和代码对象) ,由杰夫·拉什主讲。这个演讲对我来说有点难懂。如果 PyCon 组织者发布了幻灯片和视频,一定要抓住它们并观看。快速浏览一下实例化如何创建各种对象,这些对象下面可能有代码对象。他还谈到了如何将变量和函数编译成代码对象。
Rush 还经历了代码对象/名称空间的执行前和执行后阶段。一个有趣的事实是,生成器保持名称空间的时间比普通的本地名称空间长。我不太清楚这在日常编码中意味着什么...但这可能很重要。
他的下一个话题是闭包。下面是他的简单例子:
def salary_above(amt):
def wages_test(person):
return person.salary
return wages_test
然后他继续讨论早期的绑定和名称空间。这是他的一个例子:
# Early binding
names = []
rollcall = names.append
rollcall("John")
他还谈到了授权和早期绑定,但正如我上面提到的,你最好只看视频和他的幻灯片。我不能像他那样解释清楚。

PyCon 2009 -开放空间和其他亮点
原文:https://www.blog.pythonlibrary.org/2009/03/31/pycon-2009-open-space-and-other-highlights/
既然我已经介绍了我在 2009 年 PyCon 上参加的主要内容,我想我应该写一篇关于我看到和做的其他内容的简短笔记。我已经提到了为作者和编辑以及 wxPython BoF 开放的空间,所以我在这里不再赘述。相反,让我们谈谈我参加的其他露天活动。我查看了当地用户组的网站,并获得了更多关于如何改进爱荷华网站的想法。在那次会议上,我还看到了更多的面孔,感觉还不错。凯瑟琳·戴弗林在那里,还有杰夫·拉什和其他一些我想不起名字的人。无论如何,我希望能够有效地利用他们的想法。
我也去了别的地方,但不管是什么,我现在都想不起来了。哦好吧。周六晚上,我和 Christopher Barker 共进晚餐,他是 wxPython 浮动画布部件的作者,也是 wxPython 邮件列表的定期撰稿人。能和一个我几乎每天都在使用的项目中如此博学的人聊天真是太好了。我觉得我是一个糟糕的谈话伙伴;他们决定在我们吃饭的时候“庆祝”地球一小时,这让我们很难看到。
我想现在就这样吧。如果你对 PyCon 有任何疑问,请给我写信。

PyCon 2009 - Reddit 主题演讲和早间会谈(周日)
原文:https://www.blog.pythonlibrary.org/2009/03/31/pycon-2009-reddit-keynote-and-morning-talks-sunday/
星期天,我去参加上午的闪电会谈有点晚了。没有一个真正引起我的注意,因为我被更新这个博客和试图更新自己的其他事情分散了注意力。不过,我肯定我错过了一些好东西。我没有错过的是 Reddit 的主题演讲。我仍然不知道 Reddit 到底是什么,但我现在知道它是用 Python 编写的,至少部分是。演示的人相当有趣,但他们诅咒了很多,似乎不知道如何对着麦克风说话。问答时间很长,但他们回答问题的方式让我觉得他们会成为优秀的政治家,因为他们一直在回避问题。偶尔他们会直接回答一个问题,这很酷,但大多数时候...没有那么多。
主题演讲后,我去了古斯塔沃·巴比耶里的 Python 启用移动媒体中心 。唉,这不是很有趣...更多的是因为我对这个问题缺乏理解。我知道他谈到了 EFL 和 openbossa ,但是不要问我那些是什么。
今天上午的第二个话题 Christopher Perkins 的 使用 Sphinx 和 DoctestsT3 创建健壮的文档。他做得很好,只有一个技术失误。他使用了一些他用 Sphinx 创建的截屏,并重组了他讨论过的文本(REST ),这是对技术的非常有效的利用。Chris 也是 TurboGears 项目的一部分,该项目在其文档和项目中使用了 Sphinx 和 REST。
奇怪的是,接下来的谈话也是在休息。它叫做 在你的项目中利用 REST,是由杰夫·拉什给出的。和拉什一样,他在很短的时间内讲了大量的信息,而且语速很快。只要你能跟上,他的讲座总是值得去听的。他似乎对他提出的任何主题都有百科全书般的知识,这让我相信他要么大量使用这个项目,要么研究得死去活来。
我建议拉什和珀金斯都去拿幻灯片,看视频。它将非常值得你花时间。

PyCon 2009 -周六下午会谈
原文:https://www.blog.pythonlibrary.org/2009/03/29/pycon-2009-saturday-afternoon-talks/
在 2009 年 PyCon 的第二个正式日下午,我开始了 Ed Leafe 的关于使用达波的 web 应用的达波T2 演讲。他使用了他们创造的一个叫做“跳板”的产品,这是一种类似谷歌齿轮的与网络互动的产品。它给你一个客户端,可以与远程服务器上的数据库连接,你可以在那里编辑数据,也可以从服务器上获取新数据。在我参加的演讲中,这是最好的一次。对我来说,第二好的可能是克里斯托弗·巴克在午餐前的讲话。我建议试试达波和跳板。即使不能直接使用,也很可能从源头学到很多东西。
我参加的第二个演讲是曼弗雷德·施文丁格的谷歌应用引擎,我觉得很无聊。他有一些很好的统计数据,关于你得到了多少处理能力等等,但那是我从它那里得到的全部。部分问题可能是由于他的母语不是英语,所以他并不总是容易理解。
我去的最后一个演讲是比尔·格里布的 数据分析应用的精确状态恢复和重启。我也没有从这次演讲中得到太多,原因和之前的演讲一样。我肯定这完全是我的错。可能是我的注意力持续时间缩短了什么的。我很确定我从没在这里做过到底如何恢复状态...至少不是一般意义上的。
我跳过了其他的演讲,这样我就可以去 Steve Holden 的教我 Web 测试开放空间,我会单独写一篇文章。我本来想看伊恩·比金的演讲,但是唉。有太多有趣的事情同时发生,你必须做出牺牲。敬请期待!

PyCon 2009 -周六上午
原文:https://www.blog.pythonlibrary.org/2009/03/29/pycon-2009-saturday-morning/
我没有机会写下周六在 PyCon 上发生的事情,所以这里有一个我早上所见所闻的快速摘要:我和一名来自比利时的研究员从皇冠假日酒店步行到凯悦酒店。然后我参加了上午的闪电讲座和圭多的主题演讲。
我总是希望 Guido 真的很有趣,但事实上,我发现今年和去年的谈话都相当乏味。他谈到了在未来 5-10 年的某个时候退休,Python 2.7 可能是 2.x 系列的最后一个,Twitter 如何改变了他,以及为什么他认为 Python(及其用户)太聪明了,不会失败。他偶尔会有一些有趣的见解,但我往往会过于频繁地走神。
最初的计划要求我上午去参加三个会谈。相反,我去了一个面向 Python 作者和编辑的开放空间聚会。史蒂夫·霍尔登、安德鲁·库奇林、道格·海尔曼、、布兰登·罗德斯以及其他各种作者/编辑(和想要成为作者的人)和奥莱利的代表,他们让我错过了前两次会议。我认为这是非常有益的和有趣的。这是一个建立关系网的好地方。接下来,我去听了 Christopher Barker 关于构建一个混合了 wxPython 和网站内容的浏览器界面的演讲。那是我参加的最后一次晨会,然后是午餐时间。

PyCon 2009 -教我网络测试(周六)
原文:https://www.blog.pythonlibrary.org/2009/03/29/pycon-2009-teach-me-web-testing-saturday/
从 4 点至 5 点 15 分,史蒂夫·霍尔登举行了一场教我 Web 测试的开放空间会议,他在会上设置了笔记本电脑和投影仪,加载了他的网站,在桌子上放了一些威士忌和伏特加,然后让人群教他如何使用用 Python 编写的工具来测试他的网站。开始时人群很小,但后来增长到 20-30 人左右。我认为增长的主要原因是人们在推特上谈论酒精。总之,人群中的各种开发人员让史蒂夫轻松安装twill 并使用 nose 运行他网站的各个部分。接下来,他们让他试着安装风车,但是他们无法在他的 Vista 笔记本电脑上安装。这似乎是一个问题,由于 UAC 和 Cygwin 的混合物对我来说,但它是相当恼人的。
他们针对史蒂夫网站运行的最后一个工具是 Selenium IDE Firefox 插件。我认为工具、知识和幽默的结合是一种很好的学习方式。唯一真正的缺点是,各种各样的开发人员一直在争论最好的方式,否则他们就会开始对话,很难听到霍尔登的声音。幸运的是,史蒂夫通常能让他们闭嘴。
最后,它给了我几个未来测试网站的想法,所以总的来说这是一次相当好的体验。我希望他继续做这些。如果它们也被记录下来就好了。如果你在那里或者因为错过了而有问题,给我写信。

PyCon 2009-Python 的现状(周五演讲)
原文:https://www.blog.pythonlibrary.org/2009/03/28/pycon-2009-the-state-of-python-friday-talk/
Steve Holden 在周五下午做了一个关于 Python 在哪里的演讲。对于那些不了解内情的人来说,Holden 是 Python 软件基金会(PSF)的现任主席。他的第一个话题是关于 PSF 和它有多少成员,以及他们如何计划在这次 PyCon 上增加额外的成员。Holden 谈到了谁是 Python 社区,新手们第一次使用 Python 时对它的看法,Python 会议,开发,PSF 资助,Python 网站等等。我认为他对网站改变的想法可能是好的,因为网站从 2006 年 4 月以来一直保持着它的外观。我也很欣赏他关于 Python 核心开发以及如何使其更容易做出贡献的想法。霍尔登给出了一些我以前不知道的关于 PSF 的好信息。因为他的演讲有 45 分钟,而且他涵盖了这么多不同的主题,所以我不想花时间重写他的演讲。我认为这是一个很好的演讲,当它被发布的时候你应该检查一下。

PyCon 2009 辅导日
原文:https://www.blog.pythonlibrary.org/2009/03/26/pycon-2009-tutorial-days/
今天 Pycon 2009 辅导日结束了。周三我参加了两个涡轮齿轮课程,然后我去了 Py。周四考试和网络编程课。涡轮 班大多由 TG 核心开发者之一的马克·拉姆带领。不幸的是,他的课堂笔记、幻灯片和代码样本错误百出,因此,这是一堂非常令人沮丧的课。他基于几个月前也有很多错误的 TG2.0 20 分钟 Wiki 。几个月前,我在 wiki 教程中指出了许多这样的问题,但是在被告知去学习 Sphinx 并提交补丁之后,我就不再关注他们的网站了。好的一面是,他们分发了一些印有 TG 2 标志的非常酷的 u 盘。另外,马克·拉姆是一个非常好的人,他的助手克里斯·帕金斯也是如此。
这个 Py。测试 类非常有用,但不是很有帮助。我从其他 Python 测试框架在线文档中读到了他们谈论的大部分内容。我仍然不明白如何将测试集成到我自己的应用程序中,这很可悲。我想我得用头撞墙一阵子,直到我“明白”为止。我要感谢多尔西和克雷克尔能够如此出色地展示,并能够以连贯的方式相互呼应。
我最后的教程是 Wesley Chun 的Python 中的互联网编程。他从 socket 编程开始,通过 TCP/IP、FTP、SMTP、POP3、IMAP,进入 Django。几年前,当我阅读他的书《核心 Python》时,我已经完成了他的大部分例子。然而,他非常有条理,我认为这是一个很好的复习。另外,我还认识了新朋友!
我期待着 2009 年 PyCon 剩下的时间。如果你在这里,给我写封短信,地址是 python library . org 的迈克。

PyCon 2009 -风车之谈
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-windmill-talk/
亚当·克里斯蒂安做了风车演讲。它是一个用于在各种浏览器中测试网站的 IDE。它允许开发人员构建、记录和编辑测试。回放和调试在 IDE 中完成。它可以在 Firefox 中启动 Firebug,或者在其他浏览器中使用 Firebug-Lite。它还有一个 DOM explorer。
风车使用 ipython 从命令行运行调试。它还有一个 Python 代理 API,可能会很酷。他播放了几个视频,演示了 Windmill 是如何工作的,但是文本太小,无法阅读。希望克里斯蒂安会把他的视频放到网上。首先,您可以将错误报告导出到与 JUnit 兼容的地方。虽然我没得到什么好处,但你可能会。至少浏览一下他们的网站。

PyCon 2009 - wxPython BoF 会议
原文:https://www.blog.pythonlibrary.org/2009/03/28/pycon-2009-wxpython-bof-meeting/
2009 年 3 月 27 日,我们在 PyCon 2009 上举行了一次物以类聚 (BoF)会议。我把它贴在开放空间板上,我们有大约 18 个人出现,其中一对会在房间里进进出出。我认为这对我来说是一个亮点,因为我去见其他使用 wx 框架的人。克里斯托弗·巴克也在那里,很高兴见到他。 我们讨论了我们在 wxPython 中正在做的各种事情以及我们遇到的问题。我们也给那些有问题或者考虑使用 wxPython 的人一些建议。了解其他人在做什么,接触一点社交网络,这很好。这就是我想说的。希望明年会有更多的人来,我们可以想出更多实质性的东西。

PyCon 2010 和志愿服务
原文:https://www.blog.pythonlibrary.org/2010/02/28/pycon-2010-and-volunteering/
今年,我决定在 PyCon 做志愿者。在我之前的两次 PyCons 上,我都打算帮忙,但不知道如何加入。2009 年教程开始的前一天晚上,我在酒店里四处游荡,寻找 PyCon 的工作人员,结果一个人也没找到。一旦教程开始了,我在晚上会感觉很累,因为我上了最大数量的教程,有很多信息要吸收。但是回到今年。我自愿当了一次会议的主席。这是一次有趣的经历。我见到了很多很酷的 Python 人,尽管在会议结束后我真正见到的只有 Stani 和 Nadia。
我在 PyCon 的第一个晚上,有个家伙找到我,想知道我是否愿意做一些数据录入工作。他有一堆辅导调查需要输入给优雅缝线(又名:WearPython)的创始人格雷格·林德斯特罗姆。所以当我找到 PyCon 无线网络工作的地方后,我就开始做这些事情。
我下一个善意的举动发生在星期五早上。我刚刚找到一个靠近接入点的位置,这时一个人走过来,问我是否可以帮忙把电源板放在桌子下面。这是在主礼堂。我最后做了大约一半的房间。在此期间,另一个人开始帮助我。目标是将它们从前到后全部插在一起,通常是两个系列。这种方法的最大缺点是,如果有人在后面碰了他们的电源板的开关,那么所有正在使用那个电源板的人都会断电。我从未听说这是否是一个问题。
我最后的志愿活动是担任会议主席。我实际上在另一篇文章的中谈到了这一点,所以我在这里不再重复。我只想说,除了一些小的音频问题和一些蝴蝶之外,这是一次很好的体验。
我有点希望得到一个很棒的员工球座,但是主要的员工球座很差劲。它们只是黑底白字和 PyCon 标志。如果你在会议上注意,那么你会知道工作人员和会议 t 恤之间的唯一区别是略有不同的措辞和一个是黑色和另一个是蓝色的事实。哦好吧。我确实喜欢 PyCon 的标志,但是如果他们在背面也有一个大的标志或者什么的,那会更酷。
明年,我鼓励大家走出去,成为志愿者,让 PyCon 2011 变得更好!
PyCon 2010:星期五(2010/02/19) -第一场会议
原文:https://www.blog.pythonlibrary.org/2010/02/19/pycon-2010-friday-20100219-session-one/
我上午参加了三个会议:建立 Leafy Chat,一个简短的 Pinax 教程和 Import This,that 和其他东西:自定义进口商。如果你感兴趣,你可以继续读下去,看看我是怎么想的。
Alex Gaynor 使用 AJAX 和 Comet 在“实时 web”上发言(尽管官方标题是“构建 Leafy Chat、DjangoDose 和 Hurricane,使用 Python 在实时 Web 上的经验教训”)。他谈到的第一个话题是 Leafy Chat ,这是一个在浏览器中使用 django 的聊天程序,他在一次 django 短跑比赛中用 48 小时组建了一个团队。Leafy Chat 使用 JSON 将数据包从客户端传递到服务器(反之亦然)。虽然它可以工作,但是不可扩展。下一个话题是djangode,使用了绕圈、扭转和跺脚。这个 web 应用程序运行得更好,但也不完全稳定,因为它依赖于 Twitter,如果 Twitter 宕机,DjangoDose 也会宕机。
下一个话题是飓风。它使用 jQuery、 Tornado 服务器和多处理队列来产生和消费数据。它可以提供 twitter feed 和聊天,但问题是应用程序状态完全在内存中。
最后一个题目是 Redis 。它建立在前面的例子之上,做了许多相同的事情,只是规模更大。幻灯片见 http://us.pycon.org/2010/conference/schedule/event/10/。我真的不明白这和他创造的其他东西有什么不同,但这可能是我的错,
第二个演讲人是丹尼尔·格林菲尔德(又名:皮丹尼)。我认为他要么是 Pinax 项目的创始人,要么是主要参与者之一。不幸的是,他有严重的技术问题,这使得他的演讲很难继续下去。他甚至没有机会展示任何代码,所以我有点失望。
第一场会议的最后一位演讲者是 Python 核心开发人员 Brett Cannon。它被评为先进,它是。我不太明白他在说什么,所以我很早就离开去吃午饭了。第二次治疗好多了,所以请尽快查看我的帖子。

PyCon 2010:周五全体会议
原文:https://www.blog.pythonlibrary.org/2010/02/19/pycon-2010-friday-plenaries/
这是 PyCon 的第一个正式日子:2010 年 2 月 19 日,星期五。根据我的经验,PyCon 全会要么非常有趣,要么非常无聊。我很少看到中间的。PyCon 的主席是 Van Lindberg(我想是 Python 软件基金会的律师)。史蒂夫·霍尔登是第一位全会发言人。他是 Python 软件基金会的主席,他的演讲题目是“构建 Python 社区”。他介绍了各种工作人员,并感谢志愿者。他谈到了 PSF 的用途(即“铲垃圾,这样我们就可以用 Python 编程”)。然后他把话题转到了多样性和他对 Python 社区将继续在世界范围内发展的希望上。他还告诉我们 Python 社区的人们是如何变得友好和热情的。他从他的演讲到 Guido van Rossums 的演讲有一个奇怪但有趣的转变,包括使用手机电话和一首愚蠢的歌曲。
Guido 是 Python 的创造者。他用PyCon djangode feed接收和回答问题,很有趣,很好玩。不幸的是,这使得谈话有点不集中。他确实宣布 Python 2.7 将是 2.x 系列的最后一个官方版本。有人问及字典理解的历史和未来。他还收到了姜戈小马的一个问题,问它要跑多少路才能变成一匹马。很奇怪,但是被忽略了。唉。不管怎样,他也收到了几个关于空载燕子和 GIL 的问题。如你所见,他收到了许多愚蠢的询问。
我认为这些全体会议非常好。这绝对是我迄今为止看到的最好的罗森演讲。霍尔登的有点干,但我的心思没有走神,所以总体来说还不错。敬请关注会谈。

PyCon 2010:周五-第二场会议
原文:https://www.blog.pythonlibrary.org/2010/02/19/pycon-2010-friday-session-2/
对于第二场会议,我决定自愿担任会议主席,这意味着我基本上会介绍发言者,并尽量让他们不要讲太长时间。我的第一位演讲者是塔里克·齐亚德,他谈到了 包装的状态 。在开始的 15 分钟里,他大部分时间都在谈论 distutils、setuptools (easy_install)和 pip。然后转投自己支持过、写过或者参与过的各种 PEP(比如 PEP 314、345、386、376)。这个想法是强迫开发者在使用 distutils 或类似的东西时,在他们的脚本的元数据中嵌入更多的信息。他还谈到了每种分配方法的各种问题。总的来说非常有趣。
第二个演讲是entthought 如何分发包? 伊兰·施内尔博士。他为entthought工作,看起来对自己的主题相当了解,但他也相当无趣。唉,我们都没有好的表达技巧。我知道我不是。
我的最后一次演讲是我最期待的一次,也是我决定主持这次会议的原因之一。这是由斯塔尼·米歇尔和纳迪亚·阿尔拉姆利完成的。演讲题目是 跨平台应用开发与分发 。他们是我在这次会议上见过的准备最充分的演讲者。对于那些不知道的人来说,Stani 是 Stani Python 编辑器 (SPE)和 Phatch 的创造者。他们在演示中使用了后者来展示如何将扩展与二进制文件相关联,将相关联的文件拖到快捷方式上以在其上运行 Phatch,以及其他各种很酷的技巧。
他们接着讲述了如何为 Windows、Mac 和 Linux 进行开发,他们使用的工具以及需要注意的陷阱。总的来说,它非常好,很受欢迎。
担任会议主席的其他注意事项。我认为这是学习新事物和结识新朋友的好方法。然而,弄清楚如何使用设备是很困难的,似乎也没有人知道如何去做。如果我明年去 PyCon,我希望他们使用同样的设备,这样如果我成为志愿者,我就能更有效地提供帮助。总的来说,这是一次积极的经历。

PyCon 2010:周五-第三场会议
原文:https://www.blog.pythonlibrary.org/2010/02/20/pycon-2010-friday-session-3/
第三次会议只有两次会谈。我决定去看看 Christopher Johnson 和 Chris Moffett 写的《Python 中的:Satchmo 和 GetPaid 简介(#144) 》。我参加这次演讲的主要原因是因为我认为开一家网上商店听起来很有趣,我可能会在工作中使用这些信息,因为我们已经为各种服务进行了大量的在线支付。
Satchmo 的诞生是因为一群家伙有想创业的女朋友或妻子。他提到玩具反斗城澳大利亚公司是使用 Satchmo 的最大公司之一,这很酷。Satchmo 是一个 Django“插件”。他说这只是普通的 Django 代码和一百多个模板。他展示的唯一例子是一个极其简单化的截图。
GetPaid 项目是从 BBQ Sprint 开始的。莫菲特不是程序员,但更像是项目背后的组织者,并为其募集支持。GetPaid 是针对 Plone / Zope3 的。两个项目都是“易用”、“灵活”、“易扩展”。奇怪的是,我没有和任何一个主持人订婚。诚然,我被#pycon IRC 频道上关于 Alex Martelli 讲话的抽象性的无聊讨论分散了注意力。
我很难选择第二个演讲,因为有几个我认为看起来很有趣。最后去了 大型应用是如何嵌入 Python 的? 出自彼得·辛纳斯。他似乎是在电影或游戏行业,所以他专注于在他们的程序中嵌入 Python 的软件。他提到的例子有 Maya,Nuke,Houdini 和 Blender。我对电脑动画和电影感兴趣已经很久了,但我只听说过这些节目的第一部和最后一部。Shinners 先生重点介绍了 Python 是如何嵌入到每一个组件中的,以及它们之间的差异和相似之处。虽然有趣,但对我来说,这些差异似乎相当微妙。
总的来说,这是一个体面的会议。我学到了一些新东西,这总是一个优势!

PyCon 2010 即将到来
原文:https://www.blog.pythonlibrary.org/2010/01/14/pycon-2010-is-coming/

PyCon USA 2010 将于今年 2 月 19 日至 21 日在佐治亚州亚特兰大举行。在会议前后还有辅导日和冲刺日。去年,我被告知,我的雇主下次不会支付我的费用。所以今年我必须决定我是否要独自去。
我不喜欢一次花费超过 1000 美元(300 美元的会议费用+800 美元的机票和酒店费用),但是 PyCon 是一个学习和与志同道合的程序员交流的好地方,所以它非常有吸引力。最后,我硬着头皮决定去。现在你也该走了!查看出席者的列表,看看是否有你想见的人。查看一下的时间表,看看如果你不去的话会错过什么!
我不喜欢这次会议的一点是,有太多的东西我想看,但不能。我需要想出一些方法来克隆我自己,让我可以和我的克隆人分享我的想法...与此同时,我想我只要复制范·林德伯格和杰西·诺勒 (Python 杂志作者和多处理模块的创造者维护者)并告诉你我想看的。
我期待着窃听供应商,并参加比去年更多的开放空间会议。我可能也会试着学习一种新的棋盘游戏!但我肯定你对我的谈话内容更感兴趣,所以我们开始吧:
- 布雷特·卡农的“进口这个、那个和其他东西:定制进口商”(Talk #9)
- 塔里克·齐亚当的“包装的现状”(Talk #63)或约瑟夫·李瑟娥的“一条水下巨蟒:巨蟒动力机器人托尔图加”(Talk #175)
- 杰夫·拉什的“一个物体的解构”(Talk #62)
- 克里斯托弗·约翰逊和
我听说过坎农的演讲,实际上我也去过杰夫·拉什的演讲和辅导课。我知道他真的很棒。其余的演讲者我真的一无所知,但这些演讲本身让我很感兴趣。我肯定我会检查其他的,甚至可能跳过其中的一些。
希望二月份能在那里见到你!
PyCon 2010 开放空间
原文:https://www.blog.pythonlibrary.org/2010/02/21/pycon-2010-open-spaces/
PyCon 2010 延续了开放空间的做法(如果你不知道那些是什么,点击这里)。我真的很喜欢去年的空地赛道,今年也非常期待。不幸的是,我只找到了一个,那就是我贴在板上的 wxPython BoF。我今年看到的主要缺陷是有两个矛盾的开放空间板。一个在通向开放空间走廊的门外,具有使用 24 小时时间格式(即 1300 小时)给出的块,然后另一个在门口内,具有相同的房间字母和大部分相同的时间,但是使用正常的美国格式(即下午 1 点、下午 2 点等)。因此,很难知道该遵循哪个委员会。
比如我想去 Python 作者 BoF (BoF =一丘之貉)。我下去的时候,外面的板子说在某某里面,里面的板子是空白的。我去寻找这个房间,但却发现了其他人(我想他们是姜戈人)。我不知道作者的东西在哪里,也不知道它是否发生过。
我的 wxPython BoF 也好不到哪里去。我在两块板上都写下了我的时间,希望能减轻困惑,但无论如何,我预订的房间里有很多人。他们在我的 BoF 应该开始后大约 5-10 分钟离开,我认为这导致我们失去了参与者。我们只有 6 个人出席,而去年这个数字接近三倍。
总而言之,我认为 wxPython BoF 还不错,因为我见到了达波背后的两位主要开发者,艾德·利夫和保罗·麦克内特。而且斯塔尼也出现了,所以我能够和 wxPython 利基市场的一些酷人接触。我们讨论了我们正在做的各种项目,并帮助了一个 wxPython 新手。
另一个烦恼是,似乎从来没有任何卡片可以方便地填写并张贴在公告板上!。如果我能参加明年的 PyCon,我希望会议的这个领域能得到更多的关注。
PyCon 2010:周六上午闪电会谈
原文:https://www.blog.pythonlibrary.org/2010/02/20/pycon-2010-saturday-morning-lightning-talks/
周六上午,PyCon 主持了约半小时的闪电会谈。以下是主题和作者(当我捕捉到他们的名字时):
Joseph Tate——一个 web 反模式
保护 Python 包管理 Justin Samuel
Python 中的加密技术——Geremy Condra
Django 的 Haystack,有自定义搜索,包括测试和文档。安装 Solr/Whoose/Xapian,然后安装 Haystack www.haystacksearch.org
为 Twisted 做贡献—呼吁人们参与 Twisted dev
还有一个人在没有幻灯片的情况下进行了演示,因为他或那个扭曲的人设法烧断了保险丝,导致投影仪出现故障之类的。我已经忘了他讲的是什么。我认为干草堆是最有趣的,因为它最吸引我。其他人以他们自己的方式很有趣,但是大部分的谈话需要超过 5-10 分钟来真正地引出他们的话题。

PyCon 2010:周六全体会议(迪诺·维兰、马切伊·菲哈尔科夫斯基和马克·舒托沃尔斯!)
在今天早上结束闪电会谈的技术困难之后,范·林德伯格站起来拖延时间,让他们把它修好,这样他就可以介绍第一次全体会议了。他做得非常好,让我们知道这个 PyCon 创下了两项纪录:首先,它有史以来最大的出席人数约为。1025 人。其次,大约 10-11%是妇女。非常酷!
第一次全体会议由 Dino Viehland 在“IronPython 的状态”上完成。他回顾了 IronPython 去年取得的成就,并谈了一点未来。在 IronPython 2.6 中,他们设法增加了对 ctypes,sys 的支持。_getframe 和 sys.settrace,后者允许 pdb 工作(我觉得)。他还说,IronPython 团队已经编写了一个新的解释器,速度要快得多。最后,他为 Visual Studio 2010 演示了一个简洁的 IronPython 插件。文字太小,看不清他在做什么,但听起来让人印象深刻。还要注意,他们终于有了真正的网站!
先生 Fijalkowski 是投稿人(可能是创始人?)的 PyPy ,不要和 PyPI 混淆。我不太了解这个项目,但听起来好像是某种新的、更快的 Python 实现。我必须密切关注这份报告,这样我才能弄清楚它到底是关于什么的,以及它是否是我应该关心的事情。
最后一次全体会议由 Ubuntu 项目的创始人马克·舒托沃尔斯主持。他演讲的题目是“节奏、质量和设计”。由于他应用的一些更新损坏了他的 VGA 端口,他结束了没有投影仪的演讲。无论如何,他提倡的主要话题是经常发布,让你的代码尽可能的高质量,和设计师一起工作。发布通常会导致更集中的发布,并帮助开发人员有目标。质量的原因很明显。设计方面有点微妙,因为大多数程序员通常不与 UI 设计师一起工作。我想这可能是我最喜欢的上午全体会议,它有很多好的建议。

PyCon 2010:周六第一场会议(上午)
原文:https://www.blog.pythonlibrary.org/2010/02/20/pycon-2010-saturday-session-1-morning/
对于上午的会议,我去了“装饰者从基础到类装饰者到装饰者库”和“接口、适配器和工厂”,这是在第一和第二部分。我跳过了所有中间的演讲,因为我没有看到任何我认为听起来有趣的东西。不幸的是,开放空间在上午和下午几乎完全没有得到利用,所以没有什么事情可做。无论如何,关于我将要看到的两个演讲的想法。
查尔斯·梅里亚姆做了《装饰者对话》。他报道得相当深入。我仍然不知道什么时候使用装饰者,什么时候不使用,所以我开始认为我在这个话题上很笨。无论如何,他讲述了混凝土装饰者和普通装饰者之间的区别(混凝土有支撑,而其他的没有)。他还写了一个叫做 dectools 的模块,据说可以让装饰者更容易使用。他还谈到了类装饰器和它们的一些用途,比如字典转换、回调注册、契约编程、非继承混合以及其他我不熟悉的奇怪东西。无论如何,这是一次很好的谈话,因为它有希望让我查阅所有这些新术语。
这个演讲是由德高望重的杰夫·拉什完成的。这个演讲对我来说也有点难懂,但是拉什先生总是深入地谈论他的话题,而且总是很好。他深入研究了接口、适配器和工厂。我强烈建议你下载他的幻灯片(见链接),并在视频发布后寻找视频版本。

PyCon 2010:周六第二场会议(下午早些时候)
原文:https://www.blog.pythonlibrary.org/2010/02/20/pycon-2010-saturday-session-2-early-afternoon/
我设法在中间阶段做了三次演讲。以下是清单:凯蒂·坎宁安的《508 和你:消除可及性的痛苦》、多诺万·普雷斯顿的《演员:什么、为什么和如何》和尼古拉斯·拉拉的《Python 元编程》。跳完之后再见!
我之所以去听坎宁安女士的演讲,主要是因为我为政府工作,我认为这个话题可能会有用。她重点讲述了 T2 和姜戈如何打破常规。如果你不知道 508 是什么,那么你应该看看她的谈话。一个简单的解释是,508 是美国网站的可访问性规则。基本上,他们告诉你如何使你的网站兼容,以便盲人、聋哑人可以使用它。这个演讲一点也不晦涩。相反,它更像是一个让你的网站正确设置的技巧和窍门的集合。这比我在这里解释的方式更有趣。参见 www.section508.gov的
普雷斯顿先生的演讲是关于一个我一无所知的话题。原来 Actors 是一种做线程或者多处理的方式。演讲者写了一个 actor 实现,因为没有内置 actors 模块,尽管他列出了一些第三方脚本。他们是帕利、戏剧家和糖果人。由于我对此了解不多,就交给你看他的笔记了。
最后一个主题是关于元编程,这是一个我一直想深入研究的主题,并且认为这是一个不错的选择。劳拉先生绝对知道他在说什么。你可以从这个演讲中学到很多好东西。有机会就去看看吧!

PyCon 2010:周六会议 3(下午晚些时候)-全球思考,本地黑客
我只参加了当天最后一节的两个讲座中的一个。它是由 Leigh Honeywell 女士提出的,名为:“放眼全球,在你的社区中教授 Python 语言”( T3)。
她在加拿大多伦多发起了“Python 新手之夜”。这是一个非正式的同辈教学的班级,经常用投影仪把代码挂在墙上。他们将通过 Python 书籍“如何像计算机科学家一样思考”来工作,这本书有章节练习(这本书在 http://thinkpython.com 上是免费的)。她在一个黑客空间(她在当地的名字是hacklab.co)并且似乎推荐他们。她列举了一系列教授编程的场所,如社区中心、教堂、养老院、学校、监狱等等。她还提到多伦多大学已经从 Java 转到教 Python 了(我觉得)。
她谈到了这些课程的成功之处和失败之处。在很大程度上,这个演讲只是讲授 Python 的通用技巧。我为 Pyowa(本地 python 用户组)做了她所说的大部分事情,并且完全同意独自做这件事很糟糕。我也同意教别人 Python 是非常有益的。我认为这是一次很好的非正式谈话,对以前从未做过这种事的人来说,会很有帮助。如果你打算建立一个用户群,看她讲话或读她的幻灯片将是朝着正确方向迈出的一步。

PyCon 2010:周日上午闪电会谈
原文:https://www.blog.pythonlibrary.org/2010/02/22/pycon-2010-sunday-morning-lightning-talks/
最后一次晨间闪电会谈是在周日。我没能留下来听下午的简短谈话。这里有一个快速的运行(注意,我不能在很多这样的幻灯片上看到演示者的名字,因为他们只会用几秒钟展示他们的第一张幻灯片):
-
请盗版——这是在闪电会谈预定前半个多小时给出的。我不知道为什么。他演讲的网站是 www.pleasepirate.com。他的前提是人们应该鼓励他人侵犯他们的知识产权。实际上,这很令人困惑。他认为知识共享也做得不够。
-
你可以用 postgres 编写存储过程——这就像一个 60 秒的广告。
-
PyAr 来自阿根廷 Python 用户组的 Natalia 讲述了他们的小组是如何成立的,以及他们的使命/愿景。它有 650 多个成员,每个月有 11000 多封邮件。她还谈到了他们作为一个群体所做的事情,比如 PyCamps 和 sprints (cocos2d,lalita,CDPedia)
-
python Spring clean up——回家,弄清楚如何为 Python 做贡献,在 Python 用户组演示你的东西,让其他人也这样做
-
你在我的 NumPy 中获得了你的Cython——作者 D. Huggins 经历了 k-means 代码的一系列迭代,展示了 cy thon 如何使 Python 代码变得更快。他在最后搞砸了,所以我们从来没有看到它到底有多快。
-
PiCloud 灵感来自 facebook 的照片标签助手,但它变成了某种云计算程序。我真的没有很好地理解这一点,但他们似乎已经创建了一个“云”模块/包,允许您利用亚马逊的资源(EC2?)来做计算。
-
MOX“Django 的移动网络”,由来自英国牛津的 Tim Fernando 介绍,Molly 是一个即将推出的开源项目,专注于为移动设备提供网络内容。例子(我认为)是 m.ox.ac.uk。它也做地图,它是 RESTful 的
-
CCP Gamesguy“customstackless或 socket api(重音很难理解),使用 cherrypy 的线程测试与他的程序进行比较,以显示他的版本超级快。我看不懂屏幕,所以我不知道他是否证明了什么。

PyCon 2010:周日全体会议
原文:https://www.blog.pythonlibrary.org/2010/02/22/pycon-2010-sunday-plenaries/
2010 年 PyCon】的最后一次全体会议是在周日。在这篇文章中,Van Lindberg 告诉我们,如果我们包括所有的供应商,我们的会议就有超过 1100 人参加。这意味着,对于 2011 年的 PyCon,他们可能不得不将出席人数限制在 1500 人,这样我们就不会在目前的场地上用完房间。这样好吗?我真的不知道。有时候感觉它已经太大了。时间会证明一切。
上午的第一次全体会议由酱实验室的 Frank Wierzbicki 主讲,他谈到了“Jython 的现状”,Python 的 Java 实现。事实证明,2.5.1 版本与普通的 Python 实现有很好的兼容性,因此 Jython 通过了几乎所有的 CPython 测试套件。Jython 还可以与大多数 Java 库和应用程序一起工作,因此您可以两全其美。
Wierzbicki 接着说,任何纯 Python 代码都应该在 Jython 中工作。他给出了 SqlAlchemy、Django、Pylons、pip、web2py 和 distribute 在 Jython 中工作的例子。Jython 目前的计划是争取在今年夏天发布 2.6 版本,让 Jython 达到 Python 2.6 的水平,然后,根据 Python 开发人员将他们的应用程序移植到 Python 3 的进度,他希望 Jython 也开始移植到 3.x。
他呼吁对 Jython 项目提供帮助,因为他们不再有赞助商。然后他用麻省理工学院的 Joseph Chang 用 Jython 玩 Bejeweled 的脚本做了一个演示。很奇怪,但是很酷!
第二次全体会议是关于“空载燕子的状态”,由谷歌工作人员科林·温特主讲。他没有使用幻灯片,因为他说如果我们需要视觉效果,我们可以参考他周六的一次演讲。温特告诉我们他们的解释器如何比 Jython 和 PyPy 更快,但它可以在 wazoo 上进行优化。他宣布 Guido 已经批准将 Unladen Swallow 合并到 Python 3.x 代码库,希望能赶上 3.3。温特说,他希望通过合并代码,他们将获得更多的开发人员,他们可以使优化过程达到最快速度,并做出真正快速的解释器。最后,Winter 指出,Unladen Swallow 与所有当前的 Python 代码 100%兼容,并举例说明 Unladen Swallow 使 Django 的运行速度提高了 20%。
最后一场全体会议由企业家安东尼奥·罗德里格斯(Antonio Rodriguez)主持,他是 tabblo 的创始人(后来他将该公司卖给了惠普)。以下是我在演讲中的一些笔记:
- success =[e . hack()for e in employees]
- 每台机器都可以运行完整的堆栈。任何人都可以检查完整的树并构建完整的产品。任何人都可以对源代码树的任何部分进行更改。每个人都有承诺位。任何人都可以推进生产。
- 98%的公司从 10 人左右开始
- 商业与技术是一个错误的二分法
- 精益创业应该是瘦弱的创业
他认为 Python 面临的挑战是让人们承诺移植到 3.x,这样分裂就不会继续,标准库中需要更多的电池以及打包问题。我强烈建议等待视频并观看,因为我没有很好地解释他的演讲,我认为他的演讲是我参加过的最好的演讲。
PyCon 2011:高级 Python 1 教程
原文:https://www.blog.pythonlibrary.org/2011/03/09/pycon-2011-advanced-python-1-tutorial/

我今天的第一个教程是 Raymond Hettinger 的高级 Python I 。他很博学,但我被堵在了教室的最后面,跟不上他的课。演讲者讲述了 Python 3.2 的一系列基础知识。他讲述了如何打开一个模块,并使用 IDLE 的内置类浏览器快速浏览代码。
然后他使用 itertools(他写的?)和 functools 进行矢量化处理。他会显示一些带有大量函数或方法调用的糟糕代码,然后使用 itertools、functools 或两者的一部分来修复代码。我想我知道更多关于最优化的知识,但是我没有准备好第二部分的课程。请注意,这被认为是一个“有经验”的水平教程。我想我还没有足够的经验,但我希望明年会有。
PyCon 2011:聚合器和创业故事
原文:https://www.blog.pythonlibrary.org/2011/02/10/pycon-2011-aggregator-and-startup-stories/
2011 年美国 PyCon 还有不到一个月的时间!今年,他们正在推广使用concure作为一种 PyCon 聚合器。我想这意味着去年那个很酷的 DjangoDose 现在已经死了。反正 Convore 和 Twitter 差不多,但是有主题的概念,所以更有条理一点。我想我会把它描述为 Twitter 和 IRC 的混合体。他们目前有三个话题:是否使用这项服务,为 PyCon 和苏格兰 BoF 做志愿者。
杰西·诺勒宣布了“创业故事”。创业是本次 PyCon 的主题,据我所知,它们将是全体会议的焦点。因此,除了与 Guido 的“炉边谈话”和 Hilary Mason 的谈话,我们还将了解 Dropbox、Disqus 和 Threadless。我用了三分之二,所以我很兴奋。
还有时间报名来 PyCon 吧。不要等到太晚了!
PyCon 2011:周五上午会谈(与 Bicking 和 Beazley)
我参加了迈克尔·福德的模拟演讲,开始了我的晨会,但是由于我的绿色房间志愿者职位,我不得不提前离开。我们有一些幕后问题需要处理。唉!总之,我最终跳过了大部分内容,但是我提到了另一个 Python 名人:
Ian Bicking 关于 Javascript 的演讲
Ian Bicking 在 Python 社区和 PyCon 都很受欢迎。今年他在 Pythonistas 的 Javascript 上发言。以下是我从中得到的收获:
- Javascript 到处都有对象,很像 Python
- Javascript 有一个类似于 Python 字典的对象,至少从语法上看是这样的
- 他谈到了可变范围,但我没有抓住那张幻灯片的要点
- undefined 是 falshish,不同于 null,不神奇,是一个对象!
- typeof 有点神奇
- 原型就像 Python 类?
- 这个就像是 Python 的自我。这个即使没用也总有价值
- Javascript 中的数组糟透了
- 如果你喜欢 Python,你可能会喜欢 CoffeeScript
大卫·比兹利的演讲
David Beazley 做了一个关于使用 Python 3 为我的 Superboard II 构建云计算服务的演讲。他也一直在他的博客上谈论这个项目,我觉得这听起来很有趣。他谈到 Superboard II 是他 12 岁时的第一台电脑。如果我的笔记是准确的,它有以下规格:1 兆赫中央处理器,8k 内存,300 波特磁带。
他发现他的父母仍然在他们的地下室里有这个东西,所以他把它拿出来,并试图找出如何处理它。他的主意?使用 Python 将它的程序存储在云中!或者类似的东西。它使用录音带来告诉它该做什么,所以他必须将 pyaudio 移植到 Python 3,然后使用他的 Mac 来模拟这些声音。最终,他出于测试目的编写了 Superboard II 的模拟器(我想)。他还谈到用 Python 3 用 500 行左右的代码编写 6502 汇编程序。
这里的要点是,他必须将大约 6 个库移植到 Python 3(包括 Redis 和 pyPng)。他使用 Redis 创建了他的云,并展示了许多录制的演示,展示了他如何与 Superboard 通信,并最终如何将程序存储在 Redis 云中,甚至将程序从云中恢复到 Superboard 中。总的来说,这个演讲棒极了!我绝对推荐试着找一下这个的视频。
PyCon 2011:周五全体会议(希拉里·梅森)
原文:https://www.blog.pythonlibrary.org/2011/03/11/pycon-2011-friday-plenaries-with-hilary-masen/
货车简介
官方 Python 会议日于今天,2011 年 3 月 11 日星期五开始。范·林德伯格以一个介绍性的演讲开始。他花了一些时间感谢捐赠者,并解释房间将如何分割。然后他给了一些门奖,似乎是 Python 编程书籍。
史蒂夫·霍尔登的全体会议
接下来是 PSF 主席史蒂夫·霍尔登,他发表了题为“PSF 年”的演讲。谈话似乎集中在 PSF 如何做 PyCon 背后的背景材料。他说今年的会议有超过 1300 人(或者 1400 人,这取决于你如何计算,不管这意味着什么)注册。他继续告诉听众 PSF 是如何支持其他会议和 Python 项目的。例如,他们资助了 Python 3 中的 OpenSSL 和 Python Miro 社区。霍尔登还提到了一个 PSF Python 宣传册。他也承认 PSF 董事会和成员。(会议也有一页是关于这个主题的)
杰西·诺勒全体会议
杰西也进行了一次“抽奖”,但只是为了 PyPy 项目。他给了他们一张一万美元的大支票。
希拉里·梅森
bit.ly 的首席科学家希拉里·梅森(Hilary Mason)谈到了她在工作中所做的事情,比如使用 Python 进行机器学习。她用 Python 展示了某种几乎无法读懂的奎因方程。她展示了一个有趣的图表,显示了 Python 在 StackOverflow 的问题数量中的位置。Python 在顶部附近。出于某种原因,她指出 BBC 的一篇文章显示伦敦出租车司机比其他人有更大的河马校园。她做了一个非正式的调查来寻找最流行的 Python 构造。获胜者?列出理解!
她谈到的其他话题包括 kinect 黑客、安全性、1700 方程、最喜欢的书籍等。然后,她开始谈论机器学习,以及我们需要如何构建工具来实现机器学习。她展示了一张有趣的地图,显示了点击 PyCon 相关链接的人来自哪里。然后她展示了接下来人们会去的两个网站。一个是“18 岁生日快乐 ro Ruby”,然后是某种赤裸裸的密码网站。
她在结束讲话时谈到了昨晚袭击日本的海啸。然后她和观众一起进入问答环节。另请参见 keynote 上的召集页面。
PyCon 2011:我成功了!
原文:https://www.blog.pythonlibrary.org/2011/03/09/pycon-2011-i-made-it/
几个月前,我告诉我的读者,我的组织不会支付我去 PyCon 的费用,我想知道他们是否会帮助我。我得到了不同的结果,并放弃了这个想法。然后我的老板说他会尽力让我去,他去了。所以我最终还是去了皮肯。我是昨天下午到达的,在与奇怪的亚特兰大班车服务发生了很多混乱之后,他们把我放在多辆货车里,最后把我带到了酒店。
到目前为止,我已经认识了几个人,也见过一些熟人。昨晚我还做了一些志愿者工作。今天我去上了今天的第一节课,但是我会在不同的帖子里写这两个活动。对于这个简短的问题,我想得到反馈和想法。让我知道你想看什么,如果我能把它放进我的时间表,我会去看看并写下来。查看 PyCon 日程获取一些想法。谢谢!
PyCon 2011:专访卫斯理·陈
原文:https://www.blog.pythonlibrary.org/2011/02/21/pycon-2011-interview-with-wesley-chun/
随着 PyCon 的临近,blogger 社区受邀采访即将参加活动的演讲者。我选择了 Wesley Chun,他是《核心 Python 编程》的作者,也是《与 Django 一起进行 Python Web 开发》的合著者。在这次采访中,我问了 Wesley 关于他的演讲,在 Google App Engine 上运行 Django Apps以及 PyCon 的总体情况。让我们看看他有什么要说的:
你希望与会者从这次演讲中学到什么?
我希望所有与会者带着更大的乐观情绪离开这个演讲,他们可以带着他们的 Django 应用程序,在 Google App Engine 上进行很少或没有修改的情况下运行它们,利用他们需要的可伸缩性,这是靠自己很难实现的。
这个演讲的一部分是伪营销,以提高 Django-nonrel 的知名度,这是如何让 Django 应用程序在 App Engine 上运行的基础。自从 App Engine 在 2008 年首次亮相以来的几年里,已经有几个工具,称为助手和补丁,来帮助你在 App Engine 上运行 Django 应用程序。不幸的是,这些旧系统要求你修改应用程序的数据模型,以便让它们在 App Engine 上运行。Django-nonrel 则不是这样,当用户希望在任何 NoSQL 或非关系数据库上运行 Django 应用程序时,它应该成为用户应该使用的主要工具。
除了 Django-nonrel,开发人员还需要相应的 NoSQL 适配器代码,djangoappengine(用于 Google App Engine 的数据存储),Django-mongodb-engine(用于 mongodb)。他们(和其他人)正在开发其他 NoSQL 数据库的适配器,但比这更令人兴奋的是 NoSQL 的加入!
是什么让你决定谈论这个话题的?
我想做这个演讲有很多原因...我之前已经提到了意识。另一件事是,人们如此习惯于助手和补丁,以至于他们没有意识到还有更好的工具。
另一个重要原因是供应商锁定的概念,这种现象是指您无法轻松地将应用程序和/或数据迁移到不同的平台,因为您被当前的供应商“锁定”了。人们抱怨你不能在其他地方运行 App Engine 应用程序,但这不是真的。除了谷歌的原始版本,你还可以选择不同的后端...其中两个后端是 AppScale 和 TyphoonAE。类似地,如果你创建了一个 Django 应用程序,并通过传统的主机运行它,Django-nonrel 可以帮助你把它移植到 App Engine,只需要很少的移植。类似地,如果你写了一个 Django 应用程序,并使用 Django-nonrel 在 App Engine 上运行它,把它转移到传统的主机上应该不需要太多的工作。
3)在 Google App Engine 上使用 Django 有什么利弊?
最明显的优点是可扩展性。这是一件既困难又昂贵的事情。为什么不利用谷歌的聪明人,他们在核心基础设施中构建了可伸缩性来帮助他们...,嗯,谷歌!有了 Django-nonrel,如果谷歌不适合你,你可以带着你的应用去别的地方运行!这里没有供应商锁定。
一个缺点是,如果你习惯于传统的关系数据库模型,App Engine 的数据存储仍然难以理解。您还不能完全执行原始 SQL 或连接。Google 确实给了你一个被称为 GQL 的简化的 SQL 语法,但是它并不是完整的图片。此外,为了换取它的好处,你必须放弃对你的应用程序的一些控制,让谷歌托管它。您不能使用任何 C/C++扩展,也不能访问您的日志或其他原始文件。
今年在 PyCon 上你最期待什么?
我期待着与我在过去十年参加 Python 和开源会议时遇到的那些熟悉而友好的面孔建立联系。因为我们都在不同的地理位置,这是你可以指望见到一年没见的人并叙叙旧的唯一时间,无论是在展厅还是在有趣的走廊谈话中。
我也很高兴学习 Python 世界中的新事物。它似乎每年都在增长,所以很难跟上社区的最新发展。我也期待着重复我去年的 Python 3 演讲,部分原因是它每年都变得越来越重要,作为我演讲研究的一部分,我将找出哪些项目已经转移到 Python 3。
5)往年 PyCon 你最喜欢的部分是什么?
Python 生态圈最棒的部分是有一个伟大的编程语言作为后盾,但是下一个最好的部分是人...Python 社区本身。PyCon 是与社区互动的最佳场所。会议是非凡的,因为会谈,能够达到所有技能水平(从初级到高级),持续两天的高超教程,引人注目的会议会谈,令人惊叹的闪电会谈和开放空间会议,当然,还有走廊对话,更不用说来自这种会议的疯狂迷因和黑客,如 oh war-http://pycon.ohwar.com。
想想看:你可能会在今年的 PyCon 上见到你最喜欢的 Python 作者,同时了解 Django 和 Google App Engine。如果这还不能让你满意,Wesley 也在做一个关于 Python 3 的演讲。你还在等什么?登陆 PyCon 网站并报名吧!
注:本文交叉发布到 PyCon 博客
PyCon 2011 需要你!
原文:https://www.blog.pythonlibrary.org/2011/01/22/pycon-2011-needs-you/
PyCon 是一个几乎完全由志愿者管理的会议。你知道这意味着什么吗?这意味着他们需要你!去年,我成为了志愿者,这是一次很好的经历。你可以查看一下的员工名单,看看有没有你想接手的职责。如果是这样,一定要加入pycon-组织者邮件列表。这里的是主要的志愿者页面,下面是他们目前需要帮助的内容的副本现场:
- 登记处志愿者
- 赃物袋填充物
- 会议人员(注意:我们需要为会议人员自愿参加特定会议设置一种方式;敬请期待!)
- 教程日帮助
- 电线锥形/非锥形
- 最后一分钟帮手暴徒
你可以在这里阅读这些职位。你可以在这里阅读我作为会议主席的经历。我做的时候有点紧张,但是我想一切都很顺利。
要记住的主要事情是:如果你看到有人明显需要帮助,不要像个傻瓜一样站在那里!去那边帮帮他们!
PyCon 2011: Panel - Python 在学校的演讲
原文:https://www.blog.pythonlibrary.org/2011/03/18/pycon-2011-panel-python-in-schools-talk/
在 PyCon 大会的第一天下午(2011 年 3 月 11 日,星期五),我参加了一个关于在学校教授 Python 的座谈会。它是由扎克·米勒领导的,他是首先提出建立专家组的人。他介绍了 Brian Brumley,Brian brum ley 讲述了他在学校使用 Python 的经历。
接下来是玛丽亚·利特温,一位数学和计算机科学老师。目前她在公立学校教 Python。她提到了她尝试过的教学生编程的各种想法。然后我们转到来自弗吉尼亚州阿灵顿的 Jeffrey Elkner,他在那里的高中教 Python。他还大力提倡 Python,以至于他所在地区的 5 所高中甚至中学都使用了 Python。他还提到有人在那里的小学用 Scratch 教学。
最后,他们介绍了印第安纳州坎特伯雷学校的技术总监 Vern Ceder。他用 Scribbler 机器人教 Python。他还提到一些人也用 turtle 来教编程。
介绍完每个人后,他们允许观众向小组提问。一个很好的问题是“对孩子来说最难学的是什么?”答案是循环、条件句和句法。
总的来说,我认为这是一个非常有趣的小组。我希望我在高中学过编程。观众认为学校也应该开设编程课程。你可以点击查看。
PyCon 2011:后 PyCon 文章
原文:https://www.blog.pythonlibrary.org/2011/04/01/pycon-2011-post-pycon-articles/
PyCon 2011(美国)结束了。但是很多人写了关于它的文章。因此,如果你错过了这次行动,你可以看看一些关于发生了什么的文章。如果你在这里没有看到你最喜欢的 PyCon 相关文章,请在评论中告诉我。
- 超级纸板拿下 Pycon!
- 参加 PyCon 的十大技巧
- PyCon 2011 CPython Sprint 新人
- 来自 PyCon 的两个圆周率日谜题
- PyCon 碎屑
- 【PyCon 2011 上的 Python IDEs 面板视频
- PyCon 2011 -快速回顾
- PyCon 发言
- PyCon 2011 想法
- PyCon 2011 视频
- PyCon 2011 年报告
- 道格·海尔曼的 PyCon 幻灯片在线
- 布雷特·卡农的【2011 年 PyCon 总结
- 诺亚礼物的 PyCon 2011:超出我的预期帖子
PyCon 2011 海报会议
原文:https://www.blog.pythonlibrary.org/2011/02/05/pycon-2011-poster-session/
去年我真的没有太多的时间来检查第一次 PyCon 海报会议,但今年我会有时间来真正检查一下。据我所知,今年的会议将会有 35 张海报,它们有一些非常令人惊讶的主题。这里有一个例子:
- 使用 Kinect 提高可访问性
- SPM 的技术剖析。Python,Python 的可扩展并行版本
- 用于水文地球化学建模的 Python
- 使用 Python 和 MySQL 捕获、存储、分析和比较超级计算机性能指标
- 协作制书
我甚至不知道那些东西是什么意思,但我想弄清楚。你呢?你不想看看这个吗?我很确定这次谈话不会被录下来,所以你需要亲自去看看。如果以上没有让你兴奋,那么试着阅读一下完整列表。
PyCon 2011: PyQt 教程第一期和第二期
原文:https://www.blog.pythonlibrary.org/2011/03/10/pycon-2011-pyqt-tutorial-sessions-i-and-ii/
今天早上,我参加了保罗·基普斯的使用 Qt I 在 Python 中创建 GUI 应用程序,然后今天下午,我参加了他的关于 PyQt 的第二个教程的一半。演讲者给了我们许多材料,包括相当广泛的例子。我认为我在上午的会议中学到了很多东西,因为我有相当多的实践代码编辑和使用 Qt 的设计器,这是一个用于创建 GUI 的所见即所得编辑器,有点像微软的 Visual Studio。
第二次会议只是一个讲座,没有任何形式的实际编码。我在这个教程中没有很好地参与,并决定我最好在休息时离开并做些其他事情。稍后我会研究演讲者的笔记和代码示例。期待以后有一些关于 PyQt,或许还有 PySide 的文章!
PyCon 2011:周六上午闪电会谈
原文:https://www.blog.pythonlibrary.org/2011/03/18/pycon-2011-saturday-morning-lightning-talks/
3 月 12 日周六,早上 8:30 以闪电会谈拉开帷幕!Alfredo Deza 在 chapa.vim 上发表讲话,开始了会议。接下来是迪安·霍尔谈论芯片上的 Python。他提到了 PyMite 项目和 Python 到 DryOS 的移植,这使得 Python 可以在佳能 DSLR 相机上运行。
Ned Batchelder 谈到了 Slippy 的幻灯片,以及他希望 Python 中也有类似的东西(我想)。他意识到他已经写了一个叫做 Cog 的东西,可以做他想做的事情,然后用剩下的时间谈论这个。
在 Ned 之后,有一个由 PSF 资助写文档的家伙的演讲。他重新编写了 Python 开发指南,Python 3 移植指南,并建立了网站py3ksupport.appspot.com。
最后,来自印度的 Baiju Muthukadan 谈到了 GetPython3.net。如果我理解正确的话,这个网站是为 Python 3 包提供反馈的。
你可以在这里观看演讲。
PyCon 2011:周六全体会议(有 Dropbox 和 Guido)
原文:https://www.blog.pythonlibrary.org/2011/03/18/pycon-2011-saturday-plenaries-with-dropbox-and-guido/
Dropbox 全会
2011 年 3 月 12 日的周六全体会议以 Dropbox 的一名工程师开始,他与 Rian Hunter 一起做了一个题为“Dropbox 是如何做到的以及 Python 是如何帮助的”的演讲。他首先向我们讲述了 Dropbox 必须克服的技术难题。他告诉我们,他们写的所有东西都是用 Python 写的,是他把 Dropbox 移植到 Linux 上的。不管怎样,他给了我们一些关于 Dropbox 的很酷的统计数据,比如下面这个:
- Dropbox 是自 Skype 以来下载量增长最快的应用
- Dropbox 上每天保存的文件比 Twitter 上的 tweets 还多——每 15 分钟就有 100 万个文件被保存!
- 所有这些都没有任何广告。都是口碑
老实说,这是一次有点无聊的谈话。视频现在上来了,就留给大家发表自己的看法吧。
与圭多·范·罗森的炉边谈话
与 Guido(Python 的创造者)的聊天由 Jesse Noller 主持。如果你愿意,可以在这里看视频。给 Guido 的问题由社区投票决定,但最终由 Jesse 选择。我认为对我来说最重要的是了解到 Guido 在某些编程范例上有困难,比如异步回调。Jesse 还提到 Python 3 对 Mark Pilgrim 来说是个问题。我想他说的话引起了一些争议,但不知何故我错过了。全体会议结束时,他们拿出一个蛋糕给 Guido,因为今年是 Python 的 20 岁生日。
PyCon 2011:需要会议人员
原文:https://www.blog.pythonlibrary.org/2011/03/04/pycon-2011-session-staff-needed/
PyCon USA 2011 网站终于在本周发布了日程安排,在过去的几天里,他们增加了注册成为会议主席或会议主持人的功能。这些都是相当重要的角色,需要填补,以使会议顺利进行。
基本上,一个会议主席将主持一系列的会谈。这意味着他或她将介绍发言人,并帮助保持准时。他们还可以帮助组织一个开放的空间,尽管我不认为这在今年的工作描述中有所提及。最后,他们帮助回答观众的问题。
会议主持人将帮助演讲者从绿色房间走到合适的舞台。他们以任何方式帮助会议顺利进行。换句话说,他们协助会议主席。
通过申请其中一个或两个职位,你可以认识有趣的人,结交新朋友。只需进入日程页面,点击演讲旁边的“S”符号即可报名。请记住,你报名参加的是一个房间里的 2 或 3 个讲座。一定要在第一次谈话前 15-30 分钟到休息室去拿你的装备。
更新 : 查看哪些会议有主席/跑步者的另一种方法已发布到 PyCon 网站
PyCon 2011:周日上午闪电会谈
原文:https://www.blog.pythonlibrary.org/2011/03/20/pycon-2011-sunday-morning-lightning-talks/
周日(3 月 13 日)开始时,日光节约时间让我们头脑混乱。从前一天晚上开始,我们失去了一个小时的睡眠。无论如何,会议日本身是从早上 8:30 的闪电谈话开始的。他们只有四个人,但是你看:
- 一位名叫 Fecundo Batista 的人谈到了 PyAr、阿根廷 Python 集团以及他们一直在做的事情。
- Ed Abrams 接着讲述了 Adobe 如何使用 Python。他也在 HP 和 Tabblo 上讲了一点。
- 接下来是关于今年十月即将到来的德国皮肯节的演讲。如果你在欧洲,你应该去看看!
- 最后一个演讲是关于 Gunicorn 项目,一个基于 Ruby unicorn 项目的 WSGI 服务器
即使只有四个人也有各种各样的演讲。当你去参加闪电会谈时,你永远不知道你会得到什么。即使一个很烂,也只会烂五分钟,所以一定要给他们一个机会!
PyCon 2011:周日全会,包括 Threadless、Disqus 和 OpenStack
3 月 13 日,星期天,最后一个正式的 PyCon 会议日(当然,接下来是冲刺日)。总之,他们有三个有趣的全体会议来引导我们进入那天的讨论。请继续阅读,找出它们的内容。
无聊的全体会议
芝加哥 Threadless 公司的技术副总裁克里斯·麦卡沃伊(Chris McAvoy)在全体会议上发表了他所谓的全面 Python 化。Threadless 是一家 t 恤公司,已经存在了至少 10 年,并且成为商界的宠儿已经有一段时间了。我猜这也是当地民主党人喜欢的竞选地点。
无论如何,他们在 PyCon 的原因是因为他们现在从 php 转向使用 django 作为他们的网站。他谈到了该公司的历史,以及他们现在如何支持各种事业,包括通过销售特殊衬衫来支持日本海啸灾难。他讲了许多蹩脚的笑话,我认为他的讲话是其中骂人最多的。你可以在大多数实时发生的召集线程上阅读关于它的评论。你也可以在这里看到的对话。总的来说,我认为这是一次有趣的谈话。
Disqus 全体会议
严雨松和大卫·克莱姆做了一个名为 disqus 的全体会议——世界上最大的 django 系统!他们有很多有趣的统计数据,比如:
- disqus 服务 5 亿用户
- 成立于 4 年前
- 只有 16 名员工,其中 8 名是工程师
- 流量每月增长 15-20%
- 6 个月内流量翻倍
他们创建了一个叫做石像鬼的程序,他们开源了这个程序,它是某种功能开关装饰器。虽然我并不真正理解它的用例。他们还提到使用以下项目:Hudson、Open Sentry、Monitor Graphite、pylint 和 pyflakes(我认为)。你可以在这里阅读与会者的发言,或者在这里观看全体会议。
OpenStack 全体会议
安迪·史密斯在 OpenStack 上做了一次全体会议,open stack 是一个起源于 NASA 和 Rackspace 的项目。以下是他提到的相关项目列表:
- 快速对象存储系统
- nova -计算规模,调配虚拟机
- 扫视-图像和注册表存储
- 嵌入 erlang 分布式消息
- 仪表板(dash) - django 管理界面
史密斯先生提到美国宇航局使用 OpenStack 来探测小行星,所以这很好。美国宇航局也用它来拍摄和管理 WYSE(某种卫星,我想)的照片。下面这些也都用 open stack:Citrix,SCALR,cloudkick,OPSCODE,NTT,piston。
PyCon 2011: TiP BoF
原文:https://www.blog.pythonlibrary.org/2011/03/19/pycon-2011-tip-bof/
备受尊崇的 TiP BoF(测试 Python“一丘之貉”)会议于周六(2011 年 3 月 12 日)晚上 7 点左右举行。迪士尼提供免费披萨和沙拉。有人(我认为)提供了一些流行音乐。这个房间只有后面有站立的地方。当人们在吃饭时,蛙跳乐队的特里·佩珀主持了会议。他告诉我们 TiP BoF 是如何工作的,然后让他的一名员工向我们展示如何做奇怪的手/手臂伸展动作。如果我没记错的话,他的名字是许飞鸿。
之后,测试相关的闪电会谈开始了。闪电谈话确实是这次活动的主要亮点,尽管在过去的几年里,酒精吸引了许多人前来。今年,酒店取缔了这种做法,几乎看不到任何酒,这对我来说还不错。我只呆了两个小时,所以我就简单介绍一下我的所见所闻:
- 甚至在我们吃任何东西之前,就有很多自慰和其他粗俗的笑话,它们持续了我在那里的大部分时间
- Peppers 以一个名为 Snakes on a domain 开始会谈,这是关于一个名为Nagios的插件
- 接下来,迪士尼授予杰西·诺勒一个迪士尼啤酒杯,以他们的动画电影《纠结》为主题。
- Alfredo Deza 做了一个叫做 Konira 的 DSL 测试框架的演讲
- 接下来是关于 Cram 的演讲——一个用于命令行测试的 mercurial 测试套件。我不知道是谁送的。我想是这个:https://bitbucket.org/brodie/cram/src
- 然后是关于实验室外套的演讲。他们让演讲者也穿上了实验服。这张不记得是谁做的了(可能是作者?)或者这个项目到底做了什么...
- Roman Lisagor 做了一个关于“清新”的演讲,这是 Ruby 黄瓜项目的一个克隆。这是一个鼻子的插件,应该类似于莴苣项目。
- 库马尔·麦克米兰做了一个名为用模拟物体捏造事实的演讲。是的,这是另一个模拟库,但是这个是基于一个叫做 Mocha 的项目(我想他说他也使用了 Michael Foord 的模拟库的东西)。你可以在这里查看:【http://farmdev.com/projects/fudge/
- 下一个演讲是 Python 中的科学测试。这一点我的笔记不好,但我认为它与光明项目有关(如果我错了请纠正我)。演讲者还提到了一个叫 goathub.com 的东西,但据我所知,那并不存在。
- 许飞鸿自己也发表了演讲。它有一个很长的标题:我对漫画的痴迷如何催生了一个新的功能工具。基本上这是一个网络抓取项目,用于下载用 Python 翻译成中文的日本漫画。他叉开了 spynner ,把它变得“更笨”,并把他的叉子叫做“Punky Browster”。我觉得这个项目还不可用。
为了报名参加闪电讲座,他们使用了一个 convore 线程。前排的人都是会向演讲者起哄的起哄者。他们似乎更喜欢用激烈的咒骂来对付诘问。它可能很有趣也很粗糙。我了解了许多我从未听说过的新项目。这绝对是我认为值得至少看一次的东西。
PyCon 2011:我想看的 5 场会谈
原文:https://www.blog.pythonlibrary.org/2011/01/22/pycon-2011-what-5-talks-i-want-to-see/
去年,博客写手们很流行写他们最想在 PyCon 上看到的五场演讲。我不知道今年我是否会去 PyCon,但如果我去了,这些是我的选择,没有特别的顺序。
- 你想知道但不敢问的关于腌制的一切!理查德·桑德斯。这不仅听起来很有趣,而且当我说我去参加了一个腌渍演讲时,看到人们的表情也会很有趣。
- 懂 Python 的人用的 Javascript】作者 Ian Bicking。这是 Python 杰出人物之一的一次极端演讲。我不喜欢 Javascript,但也许 Bicking 的谈话会改变我的想法。
- Python 和机器人:高中编程教学Vern Ceder 著。我在很多地方读到过 Ceder 的名字,我听说他教 Python,他也写了一本关于这个主题的书。此外,机器人很酷,让孩子们对编程感兴趣也很棒!
- 使用 Python 3 为我的 Superboard II 构建云计算服务。我最近断断续续地关注 Beazley 的博客,它总是很有趣,即使我并不总是明白他在做什么。他还时不时地教授 Python 课程,所以我希望这个演讲能够很好地组织起来。
- 藏在标准图书馆的宝藏作者道格·海尔曼。我不记得我是否听过赫尔曼的演讲,但我很喜欢他的博客。
当然,我想看的不止 5 部,而且我肯定会有很多部同时发生,所以我不会全部都去看。Alex Gaynor 有几个我想看的演讲,Martelli 正在做另一个大脑演示。卫斯理·陈也有几个讲座。我没有看到杰夫拉什的任何东西,这是一个耻辱。我过去很喜欢他。不管怎样,你想看什么样的会谈?请在评论中告诉我!
PyCon 2011:为什么你应该去!
原文:https://www.blog.pythonlibrary.org/2011/01/21/pycon-2011-why-you-should-go/
PyCon 一年只有一次,不管你是新的 Python 程序员还是过去 20 年的核心开发人员,我认为你都应该看看 PyCon。花点时间了解一些 PyCon 信息,这样你就可以告诉你的雇主为什么他们应该付钱让你去,或者为什么你应该把辛苦赚来的钱投资到一个只涉及一种编程语言的会议上!
辅导日
在会议开始之前,PyCon 非正式地开始了两天拥挤的辅导日。教程范围从简单的到高级的。你可以学习桌面 GUI 创建,谷歌应用引擎或者只是学习一些随机的食谱。它们甚至涵盖了文档!
会议本身
大会是大人物出场的地方。它们涵盖了一切: Django , Javascript ,模拟测试,甚至机器人!今年,他们有一个“极端”的轨道,这是一套把介绍性的材料扔出窗外,给与会者除了熏肉什么都没有的谈话。时间表中任何标有“E”的都是极端的。
会议也有供应商,一个海报会议和新的创业街,在那里你可以和 Python 创业公司的人面对面交流。如果你想找份新工作,那么这是个好去处!
短距离赛跑
发布会结束后,还有几天的冲刺。你可以加入其中的任何一个,帮助完成各种项目。他们需要文档、简单的 bug、增强,甚至从 2.x 移植到 3.x 的帮助。这意味着他们将接受经验丰富的专业人士,而不是刚刚开始 Python 生涯的人。
你要去吗?
那么,你去吗?我还没有发现我是不是,但是我希望你能试一试。受欢迎的 pydanny 写了为什么人们也应该去 PyCon,所以一定要读他的文章!
PyCon 2011:你错过了蠕虫或为什么你应该赞助
你知道吗,PyCon 的早鸟报名结束了,你错过了!好吧,现在你得付更多的钱!我建议在他们达到注册人数上限之前就开始,因为溜进会场是绝对错误的。此外,机票价格往往比海边的波浪波动更大,尽管与波浪不同,价格通常只会变得更大。如果你想要物有所值,看看 PyCon 博客页面,因为它列出了他们计划的一系列活动。
另一方面,PyCon 仍在寻找赞助商。你是否有现金藏在后院或床垫下,却不知道该怎么处理?您是否使用开源软件,并且总是想知道如何支持它们?嗯,PyCon 可以解决这两个问题!见鬼,你甚至不用花光你所有的战利品。找个朋友,让他也付出代价。
送钱时总会出现的一个大问题是:这能实现什么(也就是说,对我有什么好处)?好吧,看看这个方便的列表:
- 它保持会议便宜!
- 你会得到温暖的绒毛
- 你将支持 Python 软件基金会,该基金会反过来支持 sprints、Python 项目、其他 Python 会议和许多其他事情。
- 你会在程序中得到你的名字(我想)
如果你碰巧拥有一家公司,或者认识一个这样的人,这是一个很好的广告方式。尤其是如果你有适合极客的工作机会。有几个赞助级别可供选择。如有任何疑问,您可以直接联系 pycon-sponsors@python.org 或杰西·诺勒·(jnoller@python.org。
PyCon 2012:召集所有演讲者
原文:https://www.blog.pythonlibrary.org/2011/10/07/pycon-2012-calling-all-speakers/
PyCon USA 正在寻找人们来给讲座,教程和海报会议。所以,无论你是喜欢聊天的人,还是更喜欢视觉的人,这里都有你的位置。对于谈话者,我指的是严肃的谈话者,我会推荐教程或常规的谈话会议。如果你不是一个健谈的人,或者你想变得更好,那么你会选择 30 分钟的演讲,海报会议,或者只是用闪电式的演讲来试试,最后你必须报名参加现场演讲。
不知道聊什么?派康会支持你的。他们就话题写了一整篇文章。还有一篇关于教程主题的文章和一篇关于海报会议的全新文章。因此,如果你不知道该谈些什么,这些帖子应该会让你的创意源源不断。
不管你选择什么,你必须在 10 月 12 日之前提交你的作品。你还在等什么?圣诞节?那太晚了!马上去办这件事!
注:如果你只是讨厌说话,加入 PyCon 组织者邮件列表,以其他方式提供帮助。这不是免税的,但它可能会给你温暖的模糊。
PyCon 2012 视频发布了!
原文:https://www.blog.pythonlibrary.org/2012/03/11/pycon-2012-videos-are-up/
PyCon 美国演讲视频终于开始上线了。你可以在这里找到他们:http://pyvideo.org/category/17/pycon-us-2012。我想知道为什么他们选择这个网站而不是他们过去几年一直使用的 miro 网站。也许知道内情的人可以对此发表评论。
我注意到我链接的流看起来很不稳定,所以希望这对像我一样错过 PyCon 的人会有帮助。尽情享受吧!
PyCon 2012 网站启动
原文:https://www.blog.pythonlibrary.org/2011/08/03/pycon-2012-website-launched/
PyCon 2012 的网站今天刚刚上线。他们在网站上已经有了一堆赞助商和关于会议的信息。当然,他们还没有做一个演讲者的电话,所以不要指望找到几个月的演讲或教程列表。然而,网站本身看起来相当光滑。你可以在官方 PyCon 博客上阅读完整的新闻稿。他们真的在大肆宣传他们的多元化声明和行为准则。我认为这些是不言自明的,所以我不打算在这里讨论它们。你可以自己去看看。
现在是时候开始考虑你是否愿意在 PyCon 上做一次演讲或辅导,并开始整理你的建议了。我敢肯定今年会很大,所以可能会有很多提交。这意味着你需要付出额外的努力,让自己脱颖而出。抓住你的思维帽,开始思考!
你甚至可以开始和你的老板谈论 PyCon,希望他们派你去并赞助这个活动。我相信 PyCon 总能找到另一个赞助商。
仅供参考:我是 PyCon 的粉丝,不是营销人员。在过去的几年里,我很喜欢去那里,并且总是希望他们做得好。
PyCon 2017 -第一天印象
原文:https://www.blog.pythonlibrary.org/2017/05/19/pycon-2017-first-day-impressions/
这是我六年来第一次参加 PyCon。我在亚特兰大的最后时光。今年, PyCon 在俄勒冈州波特兰市举行。我参加会议的第一天,由于房间太满,我错过了上午的会议。所以我最终选择了走廊路线,并与 Python 社区的各种成员进行了交流。例如,我能够与《用 Python 自动化枯燥的东西》的作者 Al Sweigart 和《Python 速成班》的作者 Eric Matthes 交谈。认识其他作者很有趣。
稍微回顾一下,主题演讲是由 Jake Vanderplas 做的,他谈到了 Python 是如何在科学中使用的,特别是在天文学中。如此多的天文学项目使用 Python 进行数据分析,这非常有趣,也非常巧妙。
下午,我花了一些时间在“绿色房间”做志愿者。这些幕后人员确保会谈顺利进行。很有趣,也很忙..我见了很多人,我觉得一切都很顺利。
我第一个讲的是 Nicole zucker man(@ zucker punch)pdb 的 set_trace 的荣耀。她在 Clover Health 工作,发现人们仍然在使用 Python 的 print() 语句进行调试,而不是使用 pdb。她是使用 pdb 的 set_trace() 方法的巨大倡导者。此方法对于在代码中设置断点、遍历调用堆栈中的帧、检查变量等非常有用。你可以在 Python 的文档中读到更多关于 pdb 的内容。就我个人而言,我喜欢 Wingware 的 IDE 附带的调试器,但是当您在无法使用更强大的调试器的机器或远程服务器上时,pdb 会很有用。无论如何,这是一个有趣的演讲,可能对那些需要了解更多关于 pdb 模块以及如何建设性地使用它的人有用。
PyCon 2017 视频发布
原文:https://www.blog.pythonlibrary.org/2017/05/21/pycon-2017-videos-are-up/
PyCon 2017 视频已经在 Youtube 上发布。以下是一些亮点:
范德普拉斯主题演讲
https://www.youtube.com/watch?v=ZyjCqQEUa8o
Raymond Hettinger 的“现代 Python 词典——十几个伟大思想的汇集”
https://www.youtube.com/watch?v=npw4s1QTmPg
Brett Cannon 的“Python 3.6 有什么新特性?”
https://www.youtube.com/watch?v=c2rEbbGLPQc
这里还有更多:https://www . YouTube . com/channel/ucrjhliknq 8g 0 QoE _ zvl 8 evg/feed
PyCon 2018 -大会第 1 天(5 月 11 日)
原文:https://www.blog.pythonlibrary.org/2018/05/12/pycon-2018-conference-day-1-may-11/
俄亥俄州克利夫兰市的 PyCon 2018 以克利夫兰当地人欧内斯特·w·德宾三世的介绍拉开了他们第一个会议日的序幕。然后我们继续今天上午的主题演讲,由 Mozilla 的丹·卡拉汉主讲。他谈到了工具,以及 Python 目前在 web 上没有很大的影响力。这实际上很有趣,也有点令人失望,因为没有给出真正的解决方案。然而,他的讲话很好,很有见地。
我的第一个会议演讲是凯尔西·彼得森的《用数据科学增强人类决策》。凯尔西是一个很好的演讲者,但这个话题并没有真正吸引我。没有任何代码示例,只是一种关于凯尔西工作的公司如何使用数据科学的演示。如果你喜欢,你可以在这里看:
https://www.youtube.com/embed/hnSgIUA57hg?feature=oembed
我做的下一个演讲是丽莎·罗奇的揭开补丁功能。这是一个非常有趣的关于 Python 的模拟库的讨论,特别是关于模拟的补丁功能。她谈了很多,然后承认关于 patch 还有很多你可以了解的,只是她没有时间来谈论。迈克尔·福德(mock 的原作者)也在那里,他在演讲结束后帮助解释了关于 patch 的几个特质。
https://www.youtube.com/embed/ww1UsGZV8fQ?feature=oembed
下午,我去了几个空地。第一个是关于 Python 的 GUI 框架,我们讨论了 Python、wxPython、Tkinter 和 Kivy 的 PyQt 和 Qt。我们还谈了一点关于 Gooey 和 Sofi。这个开放空间的主要目标是回答关于各种 GUI 工具包的问题,并了解那里有什么。我已经知道了其中的大部分,但是我确实在这里或那里学到了一些关于 Python 的 Qt 的东西。
我参加的第二个开放空间是为 Python 书籍作者准备的。布鲁斯·埃凯尔和安德鲁·平克曼以及其他几位作家都在那里。不幸的是,我没有记住他们所有人的名字。无论如何,听到这些作者与出版商和书籍写作的不同观点和经历是很有趣的。
我试图去听 Stephanie Kim 的探索深度学习框架 PyTorch 演讲,但是我在数据科学领域的经验非常有限,所以这有点超出我的理解范围。然而,演讲者似乎知道她的东西,我认为这听起来像是在我熟悉了这个话题后查找会很有用。
https://www.youtube.com/embed/LEkyvEZoDZg?feature=oembed
我参加的最后一个讲座是 Brian Okken 用 PyCharm 和 pytest 做的视觉测试。我没有听完整个演讲,因为我需要去别的地方,但那看起来也不错。
https://www.youtube.com/embed/FjojZxDZscQ?feature=oembed
查看第一天的日程,我看到的主要趋势是很多关于测试和数据科学的讨论。我个人觉得当前的谈话趋势很有趣。我真的很想看一个名为的演讲,使用 Python 构建一个人工智能来玩并赢得 SNES 街头霸王 II ,然而它与前述的开放空间相冲突,因为我知道它会被记录下来,所以我去了开放空间。
这很有趣。当我第一次去 PyCon 时,我认为开放空间是一个奇怪的概念,它们似乎是浪费时间。现在我喜欢它们,甚至超过了会议上的演讲。另外,我也很喜欢 PyCon 的志愿者服务。我期待着第二天!
PyCon 2018 -大会第二天(5 月 12 日)
原文:https://www.blog.pythonlibrary.org/2018/05/13/pycon-2018-conference-day-2-may-12/
PyCon 2018 的第二天以几场闪电式的会谈拉开了序幕。接下来是主题演讲。来自 Docker 的李颖做了第一个主题发言。她在主题演讲中谈到了良好的网络安全实践,并用一本儿童书籍来阐述她的主题。这是一次有趣的谈话,表达得很好。
第二个主题演讲是我很久以来看到的最好的主题演讲。它是由专门研究技术的底特律公共图书馆的图书管理员 Qumisha Goss 给出的。她是一名认证的 Raspberry Pi 教师,向 6-17 岁的孩子教授 Python。这是一个鼓舞人心的主题演讲,谈论了很多关于我们如何需要跨越国界和年龄,互相教导打破障碍。如果您有几分钟的空闲时间,我强烈推荐您观看这个主题演讲!
https://www.youtube.com/embed/VJ0vibC_Hl0?feature=oembed
今天第一个真正的话题是拉里·哈斯丁的用邋遢的 Python 解决你的问题。房间里挤满了人,所以我很高兴我早到了。这是一次非常有趣的谈话,我相当喜欢。他的观点是,你应该试着找到解决问题的最简单的方法,如果足够好,继续前进。坦率地说,这有点令人耳目一新。
https://www.youtube.com/embed/Jd8ulMb6_ls?feature=oembed
接下来是卡罗尔·威林的演讲,实用的斯芬克斯。我认为她在解释 Sphinx 如何为文档工作方面做得很好,并且她提到了许多使用它来组合不同文档格式的不同方法,例如 RestructuredText、Markdown 和 Jupyter 笔记本。
https://www.youtube.com/embed/0ROZRNZkPS8?feature=oembed
上午的最后一个演讲是由 David Beazley 主持的,题目是重塑解析器生成器。我已经好几年没看过比兹利的演讲了,所以这是一次难得的享受。我可能应该看看我自己在做什么,尽管他基本上是从零开始创建一个编译器/词法分析器,这不是我所期望的。尽管如此,这仍然是一次很有启发性的谈话,尽管我并没有听懂他说的每一件事。
https://www.youtube.com/embed/zJ9z6Ge-vXs?feature=oembed
我没有在下午进行第一次谈话,因为我需要出去散步,寻找一些寄托。这个 PyCon 的食物选择有点参差不齐。有时食物是极好的,而其他时候我发现它缺少关键的配料。不管怎样,吃了点东西后,我又回到了节目中。
我对 PyBee 项目感兴趣已经有一段时间了,所以我很高兴看到它的创始人 Russell Keith-Mcgee 在他的演讲中所说的话,用 BeeWare 构建跨平台的原生应用程序。使用 Beeware 的托加 UI 工具包创建跨平台应用程序的代码很有趣。Russell 将其中一些描述为 CSS 风格,但老实说,这让我想起了一点 Tkinter。从好的方面来说,它是纯 Python 代码,所以它以一种很好的 Python 方式做事情,这很好看。
这次演讲的另一个积极方面是,他能够解释 Beeware 的公文包产品是如何工作的,它为包括移动设备在内的许多不同平台生成可执行文件。虽然还有很长的路要走,但我仍然相信 Beeware 有很多不错的概念,我很高兴看到这个开源项目走向何方。
https://www.youtube.com/embed/qaPzlIJ57dk?feature=oembed
我能参加的最后一个演讲是由著名的 Python 核心开发人员 Raymond Hettinger 做的。他的演讲主题是 Python 3.7 的新数据类。虽然这个演讲有很多人参加,也有很好的演示,但是我想知道什么时候应该使用数据类,什么时候不应该。我有兴趣尽快了解这个新工具。
https://www.youtube.com/embed/T-TwcmT6Rcw?feature=oembed
PyCon 2018 -大会第 3 天(5 月 13 日)
原文:https://www.blog.pythonlibrary.org/2018/05/14/pycon-2018-conference-day-3-may-13/
PyCon 2018 的第 3 天以 Python 的长期核心开发者之一 Brett Cannon 的主题演讲开始。他谈到了在开源中工作的困难,以及我们应该如何在整个过程中友好地对待彼此。我完全同意他的所有观点,因为我有时看到的消极情绪相当令人沮丧。例如,当我评论书籍时,我努力不要太消极。
主题演讲结束后,他们举行了海报发布会和招聘会。海报展示环节是留给那些没有被选中做演讲的人的,但是他们的提议对于海报来说已经足够好了。或者至少,这是第一次海报发布时我得到的解释。我确实注意到其中一个演讲者有一张海报和她前一天的演讲同名,所以也许规则已经改变了?我不知道。我想我最喜欢的是一个关于 Python 键盘的故事,其中的键被重新映射,以便更容易用 Python 编程。无论如何,她肯定已经做了调查。
我参加的第一个演讲是 Instagram 的 Carl Meyer 的真实世界中的类型检查 Python。他非常有说服力地讲述了打字模块是多么强大及其用途。
我原本计划去听 Ned Batchelder 的演讲,题目是 Big-O:代码如何随着数据的增长而变慢,但是我被另一个写开放空间和一个关于 Python 教育的演讲分散了注意力。后者是我可能应该跳过的,因为它是之前开放空间的延续。
那里有一个照相亭,供那些想为他们所爱的人拍摄母亲节照片的人使用,他们还留出了一个房间供人们打电话回家。
这次我遇到了很多人,真的很棒。我在 Kickstarter 上遇到了一些核心开发人员和一些支持我的项目的人。我甚至和圭多合影了!总的来说,我认为我学到了很多有趣的东西,并期待着在未来的许多年里与 Python 社区进行互动。
Python 101 的 PyCon US 折扣
原文:https://www.blog.pythonlibrary.org/2014/04/07/pycon-us-discount-for-python-101/
PyCon 美国/加拿大(北美?)将于本周开始,为了纪念我最喜欢的会议,我将为我的书 Python 101 举行预售。从现在起到 4 月 17 日,你可以获得 7 美元(几乎 50%)的 Python 101 折扣。结账时只需输入以下代码: pycon2014
PyCon USA 2012 来了
原文:https://www.blog.pythonlibrary.org/2012/03/09/pycon-usa-2012-is-here/
如果你还不知道的话, PyCon 今天在加州圣克拉拉正式开始了。遗憾的是,我的组织动作太慢,没能给我弄到一张票,所以我今年不会去那里报道了。相反,我会试着发布一些其他人博客的链接,这样你就可以了解那里的情况。你也可以在推特上关注:【https://twitter.com/#!/pycon。最后,PyCon 博客似乎在不断更新有趣的公告。希望明年,我将能够再次回到 PyCon,并再次给它一些现场报道。
PyCon 美国 2012 直播流会谈!
原文:https://www.blog.pythonlibrary.org/2012/03/09/pycon-usa-2012-livestreams/
我在推特上看到你可以在这里观看 PyCon 的直播:http://streamti.me/
这似乎很有效,甚至在网站底部还有一个 Twitter feed。如果你也没成功,那就去看看吧!
PyCon USA 2013 -公开征集提案
原文:https://www.blog.pythonlibrary.org/2012/07/12/pycon-usa-2013-call-for-proposals-are-open/
不知道我怎么会错过这个,但 PyCon 2013 已经开始接受提案,这意味着如果你喜欢谈论 Python,现在是你展示才华的机会了!你可以提议一个讲座、一个教程或者一张海报。前往他们的招股说明书了解更多信息。PyCon 非常有趣,是一个让您接触 Python 新事物的好地方。你可以在走廊上学到很多东西,更不用说实际的演讲了!戴上你的思考帽,因为他们只接受想法直到 9 月 28 日!
PyCon 美国注册是开放的,教程了
原文:https://www.blog.pythonlibrary.org/2011/12/12/pycon-usa-registration-is-open-and-tutorials-are-up/
2012 美国 Python 大会今天开放报名。官方声明没有提到它,但是我很确定这次会议的出席人数也和去年一样有 1500 人的上限。你应该早点报名,不仅因为人数有限,还因为有更便宜的“早鸟”价格!
完整的时间表还没有完成,但是你可以通过查看上周发布的教程列表来激起你的兴趣。
到目前为止,我很喜欢我参加的所有 PyCons。它们是学习新事物、向他人展示你的才华、与志同道合的人交往以及放松的好地方。今年,会议将在加州的圣克拉拉举行。如果你没钱去,他们甚至会提供经济援助。那你还等什么?
PyDev 和 Python profiler UI 众筹项目
原文:https://www.blog.pythonlibrary.org/2014/06/24/pydev-and-python-profiler-ui-crowdfunding-project/
去年有一个 Indiegogo 众筹活动支持 PyDev,Eclipse 的 Python IDE 插件。它是由 PyDev 的主要开发者 Fabio Zadrozny 开发的。作为该活动的一部分,法比奥还创建了 LiClipse 。
不管怎样,法比奥又开始了新的众筹活动。你可以在这里阅读。法比奥在这次竞选中有两个目标。首先是向 PyDev 添加以下特性:
- 允许为每个项目配置当前全局的首选项。
- 提供将 PyDev 设置导出/导入到新工作区的适当方法。
- 代码完成中对名称空间包的支持。
- 在进行测试运行时,提供自动记录类型以及检查文档字符串中现有类型的方法。
- 允许运行外部 pep8 linter(以支持 pep8.py 的新版本)。
- 显示缩进的垂直线。
- 将调试器附加到正在运行的进程(尽管有些警告适用,在某些情况下这可能是不可能的)。
- 在资金允许的情况下,根据机构群体意见确定其他请求。
在我看来,第二个更有趣。Fabio 正计划为 PyDev 编写一个分析器,它也可以使用 Python 和 Qt 在 PyDev 之外工作。他在竞选活动中列出了侧写器的一系列功能。听起来很有趣。还应该注意的是,PyDev 和提议的分析器将是开源的,因此您可以随时查看代码在幕后是如何工作的。
如果你认为这些项目听起来很有趣,那么你应该考虑支持法比奥的努力。
本月 PyDev:彼得·达莫克
原文:https://www.blog.pythonlibrary.org/2016/04/18/pydev-of-the-month-peter-damoc/
本周我们欢迎彼得·达莫克成为我们的本周 PyDev!我第一次在 wxPython 源代码中看到 Peter 的一些作品。让我们花些时间去更好地了解他吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我 39 岁,是五个孩子中最大的。我有三个姐妹和一个比我小 20 岁的兄弟。我完成了生物医学工程,获得了生物仪器的学位,我大部分的工作经历都是在一家整形外科诊所。我使用 Python 实现了一个供内部使用的分布式患者管理软件和一系列用于乳房植入物选择的软件,其中最著名的是由 Allergan 在国际上分发的 BioDynamic 乳房分析。在过去的 4 年里,我一直在休长假,探索教练和培训的职业生涯。在过去的三年里,我的主要爱好是阿根廷探戈。
你为什么开始使用 Python?
当我开始在整形外科诊所工作时,我继承了一个巨大的照片数据库,里面有一些文件夹中的文本文件。我很快厌倦了寻找病人的档案,并决定将这个过程自动化。一直听说 Python,决定试一试。我立刻被缺乏编译(这是我的第一个脚本语言)和即时反馈所吸引。
你还知道哪些编程语言,你最喜欢哪一种?
我在高中时学过 Basic、Pascal、xBase 和 C,我的大学论文是用 C++写的。2002-2003 年左右在 Java 工作过一段时间。十多年来,Python 一直是我的首选语言,但在最近几年,我对函数式编程变得非常好奇,在一次学习 Haskell 的失败尝试后,我最终学习了 Elm 。Elm 是一种非常年轻但可爱的函数式反应式编程语言,它可以编译成 JavaScript,我认为在未来的几年里它将成为一种非常著名的工具。Elm 是我现在最喜欢的语言。
你现在在做什么项目?
*My last Python project was a Dash docset generator for the Elm documentation. My current plans are to expand the Elm Challenges project that I did when I decided to learn Elm and to create a system that will help me teach programming to kids. *
—
哪些 Python 库是你最喜欢的(核心或第三方)?
我用 wxPython 来实现我所有 GUI 项目的 UI。我永远感谢 Robin Dunn(它的主要维护者)为这个社区付出的所有努力
sqlite3 是在本地存储程序信息的最佳方式。我是在经历了各种低效的选择后才明白这一点的。一旦我切换到它,我的生活变得非常,非常容易与本地数据。现在,如果我的程序需要记住执行之间的任何事情,sqlite 总是被使用的工具。
你还有什么想说的吗?
在任何年龄,学习都是有趣的。不管你是 6 岁还是 66 岁,你总能学到新技能,创造新事物,这很酷。人类所做的大部分工作都变得数字化了,因此,我认为在这一领域投资学习是有意义的,但请记住,如果不有趣,那就不可持续所以,让你的学习有趣。我想以一些资源来结束我的演讲,我希望当我开始学习编程时,有人能把这些资源还给我。
西蒙·派珀特的头脑风暴——我希望更多的人了解西摩。至少看看西蒙·派珀特——万物的发明者 TEDTalk。
2。Steven Petzold 的代码——它以一种非常容易理解的方式揭示了计算机的内部工作原理
3。计算机程序的结构和解释。在我职业生涯的后期,我已经看过这 20 个视频了。介意打开那里的东西吗?
4。简单变得容易作者里奇·希基。这是我最喜欢的技术演讲之一。
5。Bret Victor的作品,尤其是他的散文,还有一些有趣的东西,比如编程的未来。
非常感谢!
本周的 PyDev:a . Jesse Jiryu Davis
原文:https://www.blog.pythonlibrary.org/2015/02/09/pydev-of-the-week-a-jesse-jiryu-davis/
本周我们邀请了 a . Jesse Jiryu Davis(@ jessejiryudavis)加入我们,成为我们的本周 PyDev。我是通过 Jesse 在他的博客上发表的关于 Python 的文章来了解他的。他还受雇于 MongoDB 。Jesse 还是几个 Python 相关项目的贡献者,比如 pymongo 。让我们花些时间了解一下我们的蟒蛇同伴吧!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在奥柏林学院获得了计算机科学学士学位,这在当时并不是个好主意。我在网络泡沫时期上学。奥柏林的计算机科学教授被软件公司挖走了,或者被愿意支付足够的薪水让他们留在学术界的大大学挖走了。奥柏林是一个理想主义的地方,它不会给计算机科学教授比同等级别的人类学教授多两倍的薪水。这是一个很好的原则,它让我们系损失了很多教员。数学和物理的教授来了,本科生也互相教授。我教的是中级 C++。我没有教得很好。
所以我接受了不完整的教育,在网络泡沫破裂后我就毕业了,但我仍然设法在奥斯汀的一家小型飞行数据分析公司找到了一份好工作。几年后,我离开去南加州的横须贺禅山中心学习禅一年,然后来到纽约。
你为什么开始使用 Python?
当我来到纽约时,我有两年用 C++做 3D 图形的经验。不知何故,我在 Wireless Generation(现在是 Amplify Education)做了三年 Python 和 SQL。他们在 CGI 脚本中使用无栈 Python 2.3,所以这就是我第一次学习 Python 的方式。
无堆栈 Python 可以在生成器暂停时对其进行 pickle 处理,所以这就是我们如何处理多消息协议的:当 CGI 脚本等待客户端发送下一条消息时,它将其状态保存为 NFS 共享磁盘上的 pickle 生成器,并自行终止。当下一条消息到达时,无论哪个 web 前端接收到它,都会找到保存的文件,解开生成器,并恢复它,直到生成器生成回复消息。
这些天来,与我一起工作的大多数人都离开了 Amplify,去创建 Mortar Data 和 DataDog,而那些留在 Amplify 的人已经用现代 Python 和 MongoDB 更新了技术堆栈!
我离开后,在纽约的创业现场做自由职业者,MongoDB 是我在这里遇到的最令人兴奋的东西。所以我以 30 号员工的身份加入了。
你还知道哪些编程语言,你最喜欢哪一种?
我对任何东西的了解都不及 Python 的一半。我要改变这一切。明年我会专注于我的 C 技能。
你现在在做什么项目?
我和我的老板 Bernie Hackett 一起开发 PyMongo,Python 的 MongoDB 驱动程序。PyMongo 是顶级的 Python 包之一,它被用于所有平台上的所有 Python 版本。这是一项重大的责任,我们必须小心行事。
马达是我的一个有趣的副业。它类似于 PyMongo,但它是异步的。它与 Tornado、异步 Python 框架一起工作,我目前正在添加对 asyncio 的支持。最终它甚至会扭曲,所以这将是一个 Python 异步帽子戏法。
我还对另一个项目很感兴趣,Monary。这是一个专门为 NumPy 开发的 MongoDB 驱动程序,由 David Beach 编写。单线程每秒可以读取一两百万行。在 MongoDB,Inc .我们认为 Monary 真的很酷,所以我一直在领导我们对它的贡献。
MongoDB 有 C、C++、C#、Java、Node、Perl、PHP、Python、Ruby 和 Scala 的驱动程序。让所有这些司机行为一致是一项巨大的努力。我写了一些我们的规范,定义了所有的驱动程序应该如何运行。例如,我写了一个“服务器发现和监控规范”,它定义了我们的驱动程序用来与 MongoDB 服务器集群对话的分布式系统策略。我在 YAML 定义了单元测试,证明我们的驱动程序符合相同的规范,尽管有不同的实现。
哪些 Python 库是你最喜欢的(核心或第三方)?
龙卷风和阿辛西奥。上次我接近 Twisted 失败了,但我会再试一次。Yappi 是一个比 cProfile 好得多的分析器,但它鲜为人知。
你还有什么想说的吗?
对于那些以不使用 ide 为荣的人,我有一条信息要告诉他们:你需要使用 PyCharm,并且要善于使用它。当我看到你在 vim 中到处乱转,试图通过按名称搜索来找到函数,试图用“打印”语句来调试时,你看起来很可怜。你认为自己很有效率,但是不使用 PyCharm 浪费了太多时间。你就像一个不知道自己舞跳得有多差的人。学好 PyCharm,用它进行编辑、调试、版本控制。您将直接跳到函数定义,您将在几秒钟内解决合并冲突,您将立即诊断错误。你会感谢我的。
感谢您的宝贵时间!
一周的最后 10 个 PyDevs
- 伊夫林·德米罗夫
- Andrea Gavana
- 蒂姆·戈登
- 道格·赫尔曼
- 玛格丽塔·迪利奥博士
- 马里亚诺·莱因加特
- 巴斯卡尔·乔德里
- 蒂姆·罗伯茨
- 汤姆·克里斯蒂
- 史蒂夫·霍尔登
本周 PyDev:Aaron Maxwell
原文:https://www.blog.pythonlibrary.org/2015/07/27/pydev-of-the-week-aaron-maxwell/
本周,我们欢迎亚伦·马克斯韦尔成为我们本周的 PyDev!Aaron 是高级 Python 时事通讯的作者,也是一个非常热情的 Python 爱好者。你可以查看他的 github 简介来了解他最近在忙些什么。让我们花些时间更好地了解他。
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
当然可以。我喜欢去陌生的国家和地方旅行,我最喜欢的部分是学习一些当地语言。一个有趣的游戏:和一个当地人开始对话,看看在他们发现我不是本地人之前我们能聊多久!
在我的一生中,我做过俱乐部保镖、理论物理学家、屋顶工、作家、叉车司机、演说家和软件工程师。我的学位是物理学(有一堆额外的数学课),我真的很擅长开始研究生课程,然后退出。我很擅长这个。这个诀窍给了我一些生物物理学、神经科学和计算机科学方面的高等教育。
如果一个魔法精灵给了我一种超能力,我会选择立即传送到任何地方的能力——只要握住他们的手,就可以带走任何人。那太有趣了!
我在网上的昵称是“红色符号”——Github,黑客新闻,等等。有时候有人问我“红色象征”是什么意思。答案是:这是个秘密。
你为什么开始使用 Python?
它看起来设计得非常好。现在依然如此。
这很重要,因为语言赋予思想力量。代码不仅仅是控制机器的一种方式。它成为一种基本的媒介,在其中我们表达了我们工艺的精神创造力。一种语言可以阻碍或支持这种表达。这在很大程度上取决于对语言的细节做出正确的决定。
因此,真正迫使我以不可抗拒的方式使用 Python 的是,与我当时使用的其他语言相比,用代码表达我的想法要容易得多——而且是以一种健壮、可维护、可发展的方式。从那以后,我学习并掌握了其他语言,然而 Python 仍然是我在许多工程领域的最爱。
你还知道哪些编程语言,你最喜欢哪一种?
我最喜欢的是 Python 3.4。我当然喜欢 Python 2.x,但是我写了这么多,我都快厌倦了。它不会再改变了。
3.x 系列在每个版本中都不断推出令人兴奋的、功能丰富的工具。3.4 跨越了几个重要的门槛:许多 3 最初粗糙的边缘现在已经变得平滑,unittest 变得超级强大,asyncio 是标准库的一部分,pip 和 virtualenv 现在作为包含工具提供...没完没了。在 3.3 和 3.4 版本之间的某个时候,第三方库支持真正得到了巩固。现在我很少不能安装我需要的软件包。
(关于这一点 Py3k 真的有太多改进了...远远超出大多数人的想象。我曾经在一次演讲中描述了 Python 3 的新特性。我不停地尽可能快地讲了一个小时,但我仍然觉得我只提到了其中的一小部分。有些人似乎认为只有少数事情发生了变化;恕我直言,这是非常不准确的。)
在 Python 之后,我最熟悉的语言可能是 c。我一直发现它对某些事情很有用。我很惊讶 C 仍然如此重要,我开始认为它会比我们所有人都长寿。
最近,我很喜欢 Java。我不敢相信我刚刚写了那句话,但这是真的。我在开始用 Python 之前学过,忽略了很久,最近又开始需要用了。现在,作为工程团队的一员,我有了更多维护大型应用程序的经验,我可以看到它的一些设计决策(曾经让我抓狂)在这种情况下实际上是有价值的。
我知道一些 Lisp 和 Scheme,但是有一段时间没有练习了。我的思维天生就很函数化(函数式编程意义上的),所以它们很容易拿起和重新拿起。Javascript,出于同样的原因。(就我而言,JS 是用类似 C 的语法包装的 lisp。)
围棋是一门有趣的语言。我喜欢它语法上便宜的并发性,以及运行时对混合线程的可靠支持。这真的很难实现,特别是在用户空间,他们打了一个本垒打。缺乏泛型和(仍然!!)不过,没有内置类型真让我抓狂。有一段时间我想我可能会把我的主要语言从 Python 切换到 Go;但是随着 Python 3 令人兴奋的进步的无情冲击,现在这种情况不可能发生了。
不幸的是,我是 PHP 方面的专家。我一直试图摆脱它。这里有一段可以在推特上发布的原话:“用 PHP 编程就像开着一辆兰博基尼在满是坑坑洼洼的路上行驶。”
你现在在做什么项目?
今年我在做一些不同的事情:去一些公司,教他们的程序员 Python 如何真正增加他们工作的价值——让他们的项目更成功,更有趣。学生中有一部分是以创作小脚本为主的 IT 人;有些是有 CS 学位的经验丰富的工程师;以及两者之间的一切。多么神奇的冒险啊。我大部分时间都在美国境内飞行,但有时也在美国境外——最近是在波兰。(他们的食物很好吃。)
我是电子邮件时事通讯的作者,我称之为“高级 Python 时事通讯”——您应该订阅!我的一本书也已经完成了一半,书名暂定为“高级 Python:不适合初学者的提升 Python 代码指南”。对于已经了解 Python 基础的有经验的程序员来说,缺乏足够的材料,这正是我想要填补的。
沿着这些思路,我还设计了一些关于真正有影响力的主题的自定进度课程:通过 decorators 的表达性代码重用、掌握 Python 日志模块、构建 REST 服务器等。这就是现场教学很有帮助的地方——当我解释一些事情时,我可以看着他们的脸,并学习如何以一种灯泡熄灭的方式教授一些东西(而不是困惑他们)。然后,我可以将最佳方法整合到自定进度的版本中。
正如你可能想象的那样,有了这些,我今年编写的代码还远远不够。在去年年底离开 Lyft 去教书之后,这无疑是我有幸与之共事过的最好的工程团队!-我不再和真正优秀的工程师一起全职编码了。坦白说,我很怀念。
幸运的是,我经常能够偷偷摸摸地编写一些实际的代码。几周前,我翘了一天的课,开发了一个工具来管理我的媒体收藏的 ID3 标签(github.com/redsymbol/mtag)。减轻痛苦的是,我为课程编写了大量的代码——例如,实现了一个非常复杂的 REST 服务器,提供了丰富的“待办事项”API,这样我就可以教人们如何构建真实的 web/微服务。
哪些 Python 库是你最喜欢的(核心或第三方)?
我一直认为 Python 的日志模块是令人印象深刻的工程壮举。作为开发人员,我做得越好,我就越喜欢它。
我喜欢 asyncio 和 Python 3.5 的 async/await 扩展。这不仅仅是库的巨大变化,也是整个 Python 生态系统的巨大变化。像 Twisted,gevent 等优秀的库。启用异步编程已经有一段时间了;但是将如此坚实和设计良好的东西放入标准库中是完全不同的。最重要的是,Python 3 的异步支持真正开辟了新天地。
对于第三方,我对请求感到惊讶。这么多的编程是认知性的——取决于程序员脑子里在想什么。一个优秀的 API 可以让这个过程变得更加容易。Requests 在这方面做得比我见过的任何库都好。
我经常使用 Django 和 Flask,为了两个完全不同的东西。对于面向人的 web 应用程序,Django 是我的首选,从 0.96 版本开始就是如此。(回到 2007 年,哇!)对于通过 HTTPS 公开其 API 的构建服务,以我的经验来看,Flask 要好得多;在这种情况下,Django 的许多杀手级特性都成了多余的包袱,所以 Flask 没有太多麻烦。我非常高兴 Python 3 在这两个版本中已经得到了如此坚实的支持。
Jinja2 对我来说仍然非常有用。除了请求之外,它也是我认为是标准库的一部分的库之一。
作为一门编程语言,你认为 Python 将何去何从?
我有几个答案。首先,随着并发和分布式系统变得越来越重要,我认为人们会使用 Python 来增强和发展这些前沿技术。就在一年前,我还不相信这一点,因为 GIL。但是最近我终于明白了——我不敢相信花了这么长时间——对于许多工程领域来说,全局解释器锁不是一个重要的限制。
对于真正受 CPU 限制的令人尴尬的并行任务,我们可以通过多处理完全绕过 GIL(例如https://github.com/migrateup/thumper)——或者在极少数情况下,不做这项工作,C 扩展。对于受网络和 I/O 限制的任务,
线程可以让你走得更远...如果你达到了极限,asyncio 会带你走完剩下的路。实际上,我正在为我的一家客户公司设计一个为期两天的 Python 并发性课程,我可能会在某个时候将它变成一个自定进度的在线课程。
圭多用 3.4 和 3.5 所做的只是这一切的开始,我迫不及待地想看看他接下来会做什么。他是地球上最伟大的软件工程师之一!
总之,这是我的第一个预测。第二:我认为我们将在接下来的两年内看到大量向 Python 3 的迁移。我认为 2015 年不会发生,但不久之后。
原因是现在几个变化正在汇聚。首先,库支持是坚实的。许多库对 Python 3 都有经过充分测试的可靠支持;其他的没有也永远不会有(通常是因为它们已经变得不可维护了),但是有 Python 3 的替代物。这一切都是真实的,而不是“马上就要发生”的事情。
其次,开源领域的许多大人物都致力于 Python 3。特别是,Ubuntu 和 RedHat 都有近期的计划来切换到 Python 3 作为默认的发行版。至少在 Ubuntu 的情况下,Python 2 甚至不会被默认安装,除非其他一些包需要它。
Python 3 和 Python 2 安全地安装在同一个系统上也很有帮助,不会互相影响。
对我来说,最有希望的迹象是我在 github 上看到的事情。有很多活动涉及 Python 3 项目。以我的经验来看,最优秀的开发者天生好奇,想做新的东西,不会和 Python 2 这样的冷冻语言呆太久。
有趣的是:我的初级 Python 课程通常使用 2.7 版本,因为雇佣我来培训员工的公司在日常工作中大多使用这个 Python 版本。最近,当我开始上课,并告诉学生我们正在使用 2.7,他们真的很失望。当 3.5 即将推出时,他们感觉自己被迫学习一个过时的版本!我给他们编了些故事,让他们不再难过,但我觉得他们说对了。仅仅这个因素——也就是想要跟上技术的职业发展冲动——就开始推动事情向前发展。
谢谢!
一周的最后 10 个 PyDevs
- Yasoob Khalid
- 凯文·奥利维亚
- 亚历克斯·盖纳
- 大卫·比兹利
- 升降杆
- 塔里克·齐亚德
- 斯蒂芬·德贝尔
- 安娜·奥索斯基
- 加布里埃尔·佩蒂尔
- 瓦苏德夫拉姆
本周的 PyDev:Abdur-Rahmaan Janhangeer
原文:https://www.blog.pythonlibrary.org/2019/04/08/pydev-of-the-week-abdur-rahmaan-janhangeer/
本周,我们欢迎 Abdur-Rahmaan Janhangeer 成为我们本周的 PyDev!Abdur-Rahmaan 是 Think Python 的法语翻译。你可以在他的博客和 Github 上看到他在做什么。让我们花一些时间来更好地了解他!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是来自毛里求斯的 Abdur-Rahmaan Janhangeer,毛里求斯是印度洋上的一个天堂岛,也是目前最好的旅游目的地之一。我有一家 IT 公司,我害羞地成为了一名 Python 培训师。
编程方面我大多是自学的。关于 Python,我是 Python 文档的阿拉伯语协调员,将 Think Python 翻译成法语(即将出版),以及毛里求斯 py 用户组的组织成员。我也为 LinuxMint,Numpy 和 Odoo 做了一些很小的贡献。
作为“爱好”,我喜欢在业余时间钻研编译理论和编写一些玩具语言。作为一名画廊主持人,我使用 InkScape 为人们设计徽标和名片。摆弄图形!
你为什么开始使用 Python?
那时我是 Java 的狂热爱好者,真的迷上了它的 OOP 风格。如果你理解了事物是 Java 中的对象,许多奇怪的事情就会迎刃而解。有一天我发现自己在写一个 IRC 机器人。这个骨架对我来说太反直觉了,所以我寻找更简单的东西。我想起了一种叫做 Python 的语言,人们说它简单易用。我一直认为 Python 不是一门“严肃”的语言,但还是决定尝试一下。是的,我在谷歌搜索:“用 python 打印”...
你还知道哪些编程语言,你最喜欢哪一种?
因为想学编程,所以学了热门的。C++,Java,Html,CSS,Js,PHP+SQL,ruby。我学习 Haskell 只是为了体验一下。还学习了处理,尽管现在它更像是一个库,或者如果你愿意的话,是一个画布 API。除了 Python,我还根据需要使用其他语言,但 processing 是我的最爱,这是一个全新的世界。循环,OOP,以及任何你想要的都有插图。学习和教授编码更生动。你也有 python 风格的,但是运行在 Jython 上。
你现在在做什么项目?
- Think-Python-Fr:Think Python 的法语翻译
- py-docs-ar :文档的阿拉伯语翻译。更多的推力在我完成上述后不久。
- 与 Christopher Barker 一起,这个项目旨在收集 python-list 和 python-ideas 上常见的重复出现的问题(回答问题时易于参考)。还解释了为什么一些想法没有被接受,并涵盖了一些技术决策。如果你愿意的话,名单会被增加。
我也在私下维护和改进一些为企业开发的基于 Flask 的解决方案,我希望有一天能够开源。
哪些 Python 库是你最喜欢的(核心或第三方)?
烧瓶,离瓶金贾,要求和熊猫。
你是如何加入 pymug (Python Maurtius 用户群)的?
我正在考虑组织一个法语翻译工作室,这时我突然意识到,首先,必须在当地组织一些人。然后,你不能只是跳进去,你必须花时间去建立和编织一个社区。这为更大更大胆的项目奠定了基础。这就是我开始整理东西的方式,现在我们有了 4 个整理成员。如果你路过毛里求斯,给我留言,我们会在同一时间见面,或者安排一个特别的活动!
对于其他想创建本地 Python 用户组的人,你有什么建议吗?
不要害怕开始,即使开始时人很少。从你能得到的开始,在任何你能得到的地方。社区贡献其实就是投资自己。促使我个人创建 UG 的另一个原因是 python 的聚会总是内容丰富。即使你每周都被要求发言,Python 的容量也足以让你把一些东西拉进来。你正在建立的东西将首先使你受益,然后是其他人。社区一直在倾听。如果你不知道从哪里开始,如何进行,如何增强事物,请随时询问!
你还有什么想说的吗?
如果可以的话,用你的母语翻译这些文件,这是一项伟大的事业,需要很多时间。你很少有机会逐行阅读文档。这是一次丰富的经历。你的 Python 知识变得很深,真的很深。如果可以的话,参与到 PythonListsSummaries 项目中来,浏览线程并分享你所学到的东西是一个同时做两件有用事情的好方法。
我建议每个人都按照名单来,伟大的人在那里。另外,我要感谢 freenode 上的 python-fr 和在那里挂出的核心开发者@ vstinner(Victor Stinner)@ mdk(Julien Palard),希望还有@matrixise(夏羽 Wirtel)。朱利安做了很好的工作来支持我做一切与翻译相关的事情。
感谢您接受采访!
本周 PyDev-Abigail Mesrenyame dog be
原文:https://www.blog.pythonlibrary.org/2020/03/30/pydev-of-the-week-abigail-mesrenyame-dogbe/
本周,我们欢迎阿比盖尔·梅斯伦亚梅·多格贝(@梅斯伦亚梅多格贝 ) 成为我们本周的 PyDev!Abigail 活跃于非洲的 PyLadies 组织,也帮助组织了 PyCon Africa。Abigail 也是 Python 软件基金会的成员。

让我们花些时间来更好地了解阿比盖尔!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
在获得加纳塔克瓦矿业技术大学的计算机科学和工程学士学位后,我在加纳社区网络服务有限公司(GCNet)的内部审计部门工作。在成长过程中,我努力学习数学,并在业余爱好中画了很多画、画和唱歌。随着我越来越成熟,我的爱好变得越来越多,我不再画画了,但我在玩非洲珠子制作饰品的过程中找到了快乐,我仍然经常唱歌,尽管主要是唱给小团体或自己听。
我对体育很感兴趣,比如排球、足球和游泳。在大学的最后一年,我被选为女子排球队的队长。我们进行了大量的训练,赢了几场比赛。实际上,在我完成学业后,我对团队取得的进步印象深刻。
此外,我对技术社区建设有浓厚的兴趣,并且我在帮助他人的职业发展中找到了快乐。
你为什么开始使用 Python?
2017 年,一个朋友分享了阿克拉首届 Django 女孩活动的注册链接。它包括教女孩如何使用 Python 和 Django 建立网站。我冒险申请了,因为在我学习计算机科学和工程的四年里,我从未使用或学习过 Python。事件发生后,我意识到与我在学校学的其他语言相比,使用这种语言是多么简单。语法对我来说更容易理解,而且我对令人惊奇的 Python 社区特别感兴趣。我结交了这个社区的朋友,他们对我的生活产生了巨大的影响和作用。
你还知道哪些编程语言,你最喜欢哪一种?
我在大学学的编程语言有 Java,C++和 Visual Basic。对于 Web 开发,我们也做了一些 html 和 css。我自学了 C 语言,这是我在最后一年的项目工作中用到的,在这里发表。本项目是一个基于 GSM 通信的智能预付费电能表监控系统。
我知道对于每一个项目或一个想法的解决方案来说,使用一种适合于实现你的目标的编程语言是很重要的。去年,我用 Python 探索了自动化,并开始在数据分析和可视化方面进行更多的探索。所以是的,我认为 Python 是目前我最喜欢的语言。
你现在在做什么项目?
我目前正在使用 Django 构建我的个人网站,我也期待着学习和实践更多与自动化相结合的数据分析和可视化。
哪些 Python 库是你最喜欢的(核心或第三方)?
像 plotly 这样的库有助于制作交互式的、出版物质量的图形。
你是如何参与组织非洲皮拉迪斯的?
在我作为学员的第一次 Django Girls Accra 经历后,安德鲁·史密斯鼓励我在下一次活动中教其他女孩如何编程。我接受了这个挑战,并遇到了其他了不起的 Python 爱好者,他们也开始计划在加纳创建 Python 软件社区(Python 加纳)。我们走遍了全国,教更多的女孩,并鼓励她们帮助其他女孩。当时,我是众多向女孩介绍 Python 和 Django 的男性教练中唯一的女性教练,所以我对让更多的女士成为教练抱有浓厚的兴趣。后来,的曼尼·扬联系我,让我领导加纳的皮拉迪斯团队,到目前为止,这个团队一直很棒。
我和一个可爱的、非常支持我的团队一起工作。一起,我们已经能够开始六个不同的皮拉迪斯章节,他们自己运行。我们组织的辅导和会议大多是关于 Python 和其他软技能的,比如“如何在会议上发言”。在皮拉迪斯加纳公司,我们分享想法,并在工作机会方面相互关照。对我来说,一个最大的成就是,在 2019 年 Django Girls PyCon Africa 期间,所有教练都是女性,来自 PyLadies 社区,其中一些是以前在加纳举办的 Django Girls 活动的学员。
此外,我有机会帮助其他皮拉第人启动他们在加纳以外的社区,如埃塞俄比亚、利比里亚和赞比亚。我个人期待帮助更多的 Python 爱好者开始他们的 Python 社区,我相信当我们携手 时 我们会成长。
非洲从事科技行业的女性面临哪些挑战?
尽管科技领域的女性人数与日俱增,但仍有必要关注为科技领域的女性提供更多平台。挑战包括缺乏融资渠道、文化陈规定型观念以及在技术挑战中与其他女性建立联系。为了取得快速的进步,我们需要创造更多的榜样来引导下一代走向成功。
目前,我和我在 Future Bots 的团队正致力于培养 STEM 领域的下一代女性。到目前为止,我们的研究表明,很少有女孩在高等教育阶段追求 STEM 领域,我们发现,由于缺乏自信和难以接触榜样等因素,她们在毕业后的兴趣有所下降。我们希望通过解决目前学术培训和商业社会需求之间的差距,为小学、初中和高中的女孩创造一个空间。这将通过集中设计一门课程来实现,该课程侧重于让女孩学习基本的信息技术技能,利用插图和实践来帮助她们分别理解数学和科学。我们相信,这将有助于他们在发现和创新的同时,通过批判性思维发展自己的技能,并让他们接触 STEM 职业。
如果你想提供任何帮助或者为了将来的事情,请发电子邮件给 contact.futurebots@gmail.com。
你能分享一下你在非洲派康的经历吗?
作为 PyCon Africa 的联合组织者,我感到非常兴奋,我非常期待 2020 年的 PyCon Africa。2019 年,在第一届 PyCon Africa 举行之前,该团队举行了几次会议和任务。与伟大的头脑合作的经历简直太棒了。我们在不同的时区,但仍然一起有效地工作。
讲座、研讨会和短跑绝对有教育意义。我在多样性和关怀方面做了大量工作,我们看到大约三分之一的演讲者和与会者是女性。来自非洲的代表令人惊讶。我们在这里发布了 PyCon Africa 2019 的报道。
我期待着在 2020 年 PyCon Africa 期间与团队一起完成令人惊叹的工作。
你还有什么想说的吗?
我很欣赏 Python 加纳的团队。我们不知疲倦地为社区工作,我们希望做得更多。迈克,谢谢你给我这个机会。
阿比盖尔,谢谢你接受采访!
本周 PyDev:亚当·霍普金斯
原文:https://www.blog.pythonlibrary.org/2021/07/05/pydev-of-the-week-adam-hopkins/
本周我们欢迎 Adam Hopkins ( @AdmHpkns )成为我们的本周 PyDev!Adam 是 Python 服务器/ web 框架 Sanic 的核心开发人员。你可以在 GitHub 上看到亚当在做什么。
让我们花些时间来更好地了解亚当!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
最简洁的方法就是给你点我的简介。
我是 PacketFabric 的首席高级软件工程师。到目前为止,我已经构建 web 应用程序 20 多年了,但是软件工程是我的第二职业。我在转行之前做了几年律师。我认为自己很幸运,能够把我的爱好变成职业。我毕业于 DC 的乔治·华盛顿大学,然后在新英格兰法学院学习法律。我的计算机和开发背景是百分百自学的。
爱好?人们有时间吗?在我的工作、我所做的开源工作和我家里的五个孩子之间,我几乎没有时间去培养兴趣爱好。有一天,我想回到自制,我也在慢慢地尝试建立一个木工的家庭作坊。我确实试着每周花很多时间阅读,我也试着尽可能经常地写作。
你为什么开始使用 Python?
我第一次接触是在 21 世纪初的某个时候。当时我一直在使用 PHP,正如我提到的,我是自学的。我开始意识到 PHP 被严重破坏了。我记不清我第一次接触它是什么时候,但我记得当时觉得它对我来说太自然了。学习 PHP,由于语言完全不一致,我大部分时间都在看文档。要学习 Python,我只需要看代码,玩代码。我觉得语言教会了我。
你还知道哪些编程语言,你最喜欢哪一种?
花了这么多年做 web: Javascript。但是,我记得打字稿出现之前的那些日子,所以我仍然对它心怀怨恨和不屑。正如我提到的,我在将近 20 年前就放弃了 PHP。我做过一些 Java,C,C++的工作。然而 Python 是我的家。这是我最舒服和最有效率的地方。我也一直在玩锈周围的一些项目。这是一种很好的语言,我很喜欢和它一起工作。我通过编写一个 DB 引擎自学了如何使用它:https://github.com/ahopkins/merkava.我相信一个经验丰富的 Rust 开发者会对此有很多话要说,但是学习一些新的东西是很有趣的。
你现在在做什么项目?
我花了很多时间管理和研究 Sanic。在过去的三四年里,我一直在帮助它成为一个社区开发的框架。这非常有趣,也非常有意义。新的 6 月发行版(21.6)将很快发布,不久之后我计划发布一个新的包 sanic-ext,它将为 API 开发人员添加一些日期验证和其他有用的工具。
哪些 Python 库是你最喜欢的(核心或第三方)?
当然,我偏向于萨尼奇,所以我们将把它放在一边。然而,它真正突出了 asyncio 模块给 Python 带来的惊人增加。我认为这是我最喜欢的标准库模块,因为它给语言带来了什么。这是在一个非常好的时期的一个令人难以置信的补充,自推出以来已经非常成熟。很难说我“最喜欢”的第三方软件包是什么。因此,我将通过提出我自己的问题来回答这个问题:我无法想象没有哪个第三方包来构建东西?毒性测试。这是一个老黄牛,只是平原使我的生活更容易。
你还有什么想说的吗?
回顾我迄今为止的职业生涯,我最想强调的一点是:永远不要低估自己,但也不要高估自己。“冒名顶替综合症”对我来说确实是一个问题。参与 OSS 真的帮助我获得了一些自信。另一方面,不要建立你的自我。总会有人知道的比你多,所以尽你所能向他们学习。OSS 社区的核心充满了一些了不起的人。因为他们,我们的世界变得更加美好。从最新最年轻的开发人员到最有经验的专业人员,每个开发人员都有责任尽自己所能,尽自己最大的努力。我真诚地相信,每个人都有一个地方可以参与进来,一点一点地让互联网和世界的某个小角落变得更好。
亚当,谢谢你接受采访!
本周 PyDev:亚当·约翰逊
原文:https://www.blog.pythonlibrary.org/2021/05/03/pydev-of-the-week-adam-johnson/
本周我们欢迎亚当·约翰逊( @adamchainz )成为我们本周的 PyDev!亚当是 Django 项目技术委员会的成员。他还参与组织了伦敦 Django Meetup 。Adam 是加速 Django 测试的作者。你可以在亚当的网站上看到他还在做什么。

亚当·约翰逊
让我们花一些时间来更好地了解 Adam!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
嗨,我是亚当·约翰逊。我是英国人,和我的葡萄牙伴侣住在伦敦。她经常带我去里斯本,所以至少我可以在那里晒晒太阳。
当我爸爸在第一台家庭计算机上向我介绍 QuickBasic 时,我从 8 岁起就一直在编程。我哥哥和我自己编写电脑游戏,而不是购买任何游戏。这最终导致我们在十几岁的时候一起发布了游戏创作软件。
我目前是一名承包商,通过我的公司 Adam's Web Services Ltd 做 Django/Python 咨询。
我爱骑自行车,看书,喝茶(大部分是绿色的!).
你为什么开始使用 Python?
大学之前和大学期间,我都是用 PHP 做网站,没有任何框架。我认为这很棒,但是回想起来,一切都有点像牛仔——没有数据库迁移、测试和通过 FTP 的手动部署!
我大学毕业后的第一份工作是在一家初创公司 Memrise,在那里我转到了 Python 和 Django。从那以后我就喜欢上了它。我发现 Python 比 PHP 更容易理解,打字也更少。Django 给了我很多工具,帮助我更快地构建网页。这是一次很棒的学习经历,因为我加入的时候,这个网站正处于一个转折点,用户增加到了一百万。
你还知道哪些编程语言,你最喜欢哪一种?
我已经尝试了很多其他语言,尤其是在大学期间,第一门课程是 Haskell!我仍然尝试每年尝试一门新的语言,让自己接触新的想法。
最近的这种语言是 Rust,为此我在网上查阅了官方书籍。我认为它有很好的基础,Rust 社区也有很多很棒的东西。我很高兴看到更多的系统级工具转向它,以防止内存不安全。希望以后能直接用在一个项目上。
目前,我几乎每天都在使用 Python、JavaScript 和 c 语言。我在构建特定功能时会用到 JavaScript,但我会尽量避免使用。我最近写的 C 代码是针对 Python 扩展的,特别是 time-machine,这是我去年发布的一个日期时间模拟库。
你现在在做什么项目?
我有几个客户项目,我轮流。我在那里的主要职责是就 Django/Python 的最佳实践提供建议,并在基础设施方面提供帮助。
我的工作经常让我创建或更新开源项目,所以我可以在 PyPI 上创建或维护一些库。我为 Django、flake8 和 pytest 创建了扩展。
我也在努力更新我的书《加速你的 Django 测试》,以了解 Django 最近的变化。去年写这本书也促使我做了许多改变来改进 Python 测试生态系统(比如 time-machine ),其中一些现在需要回到书中!
最后,我已经开始开发一个数据库监控工具, DB Buddy 。我希望它能帮助用户采用 PostgreSQL 的一些最佳实践,尤其是在使用像 Django 这样的 ORM 时可能隐藏的东西。现在没什么可看的,但正在慢慢取得进展。
哪些 Python 库是你最喜欢的(核心或第三方)?
自然喜欢 Django,越来越强。每个新版本都带来了一些巨大的改进,这个社区真是太棒了。我真的很怀念和 Django 开发人员的聚会/会议。
我也非常喜欢使用 pytest。这是一个很棒的测试框架,我试图将所有的客户项目都移植到它上面。
对于网络开发,我最近很喜欢 htmx。这扩展了 HTML 在服务器上重新呈现部分页面的能力,使您可以避免编写 JavaScript。所以它不是一个 Python 库,但是它确实让你在你的 web 应用中使用更多的 Python。我构建了一个小库 django-htmx,来帮助 django 应用程序使用 htmx。
为什么是 Django 而不是另一个 Python web 框架?
很棒的问题!几年前,我写了一篇比较 Django 和 Flask 的博客文章,从它们在一个文件中工作得如何的角度进行了比较。当在单个文件中寻找一个最小的应用程序时,大多数开发人员会想到 Flask 或类似的东西,但是 Django 也可以在很少的代码中工作。
我的帖子着眼于相同应用程序的两个框架实现之间的差异,以及每个框架的代码意味着什么。它揭示了一些差异,也是我的偏好。
总而言之,我更喜欢 Django,因为它有一个稍微结构化的方法,更多的内置功能,更大的生态系统,并且由于它的捐赠,维护更加稳定。
直到最近,我一直在帮助维护一个 APM(应用程序性能监控)包,从那时起,我已经了解了大多数其他 Python web 框架。这让我与十几个框架建立了集成。有一些很棒的想法和一些很棒的特定于 API 的框架,但是我坚持让 Django 帮助复制我在那里看到的最好的想法。
你的书《加速 Django 测试》是怎么写的?
本质上,我被博客冲昏了头脑。有一天,我开始写一篇关于加速测试的最佳方法的文章,这些方法不断出现。24 小时后,我有了一个 4000 字的大纲,我意识到我需要更多的空间来涵盖一切。所以我决定勇往直前,把这些想法写成一本书。
我很幸运,在优化测试套件之前已经做了大量的工作,所以我已经将大部分我需要的信息埋藏在我的大脑中。把它拿出来,看到它帮助别人,这很好。
你还有什么想说的吗?
愿您的测试运行得又快又环保。
亚当,谢谢你接受采访!
本周 PyDev:Adina Howe
原文:https://www.blog.pythonlibrary.org/2015/04/27/pydev-of-the-week-adina-howe/
本周,我们欢迎 Adina Howe 成为本周的 PyDev。我第一次听说豪夫人是在一篇关于 Nature.com 的文章中,这篇文章讲述了 Python 如何在科学界取得成功并值得学习。目前她是爱荷华州立大学的生物系统工程教授。让我们花些时间去了解她吧!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是爱荷华州立大学农业和生物系统工程系的新教授。在那里,我和我的团队研究微生物对各种环境的影响,从土壤、水,甚至我们的内脏。除了研究,我真的很喜欢极限飞盘,并且正在参加轮滑队的选拔。
你为什么开始使用 Python?
我开始使用 Python,因为我处理的数据集太大,无法在 Excel 和 Word 中打开。在我的研究中,我也厌倦了一遍又一遍地做同样的事情。我对执行分析的可重复和自动化方法非常感兴趣。当我开始用 Python 写代码时,我发现我每天都有足够小的“胜利”,以至于我被说服继续使用它——这种情况一直持续到今天。
你还知道哪些编程语言,你最喜欢哪一种?
我的成绩单上说我应该懂 C++,但我一点都不记得了(那是 15 年前的事了)。我经常使用 R 和 shell 脚本。
你现在在做什么项目?
主要是我用编程做生物信息分析,主要是数据角力和 munging。我还将不同类型的数据集整合在一起,例如,为了研究水质,我整合了生物、化学和土地利用数据集。
哪些 Python 库是你最喜欢的(核心或第三方)?
我最喜欢的是 IPython(笔记本)。我也经常使用 NumPy 和 SciPy,还有 matplotlib 用于可视化。我最近一直在使用请求,因为我在处理大型数据库的自动化查询。有一天,有人向我介绍了 BeautifulSoup 它似乎很擅长解析 html。
你还有什么想说的吗?
我认为 Python 棒极了。用户和开发人员的社区非常棒——以我的经验来看,非常高效、乐于助人和无私。因此,我想感谢您和那些热情参与的人,并让您知道我正在使用您的工具来尝试对我的工作产生积极影响。
感谢您的宝贵时间!
一周的最后 10 个 PyDevs
- 诺亚礼物
- 道格拉斯·斯塔内斯
- 可降解的脊椎动物
- 迈克·弗莱彻
- 丹尼尔·格林菲尔德
- 伊莱·本德斯基
- Ned Batchelder
- 布莱恩·奥克利
- 足球妈妈
- 安东·诺沃西约洛夫
本周 PyDev:Adrian rose Brock
原文:https://www.blog.pythonlibrary.org/2017/11/20/pydev-of-the-week-adrian-rosebrock/
本周,我们欢迎 Adrian rose Brock(@ PyImageSearch)成为我们的本周 PyDev。Adrian 是几本关于 Python 和 OpenCV 的书籍的作者。他也是 PyImageSearch.com的作者,这是一个非常受欢迎的专注于计算机视觉的 Python 博客。让我们花些时间去更好地了解他吧!
你能给我们介绍一下你自己和 PyImageSearch 吗?

你好,迈克,感谢你给我机会在本周 PyDev 上接受采访。
我叫艾德里安·罗斯布鲁克。我在 UMBC 的马里兰大学获得了计算机科学博士学位,主要研究计算机视觉和机器学习。
我在 PyImageSearch.com 写了一篇关于 Python、计算机视觉和深度学习的博客。在过去几年运行 PyImageSearch 的过程中,我写了一些书/课程,包括:
- 实用 Python 和 OpenCV ,用 Python 温和地介绍了计算机视觉和 OpenCV 的世界。
- PyImageSearch 大师,深入研究计算机视觉,类似于你在大学水平的课程中可能会发现的,只是更多的实际操作和实践。
- 用 Python 进行计算机视觉的深度学习,我全新的 800 多页的书。这本书是我的“代表作”,是给那些想掌握神经网络和深度学习的读者的。
你的爱好是什么?
健身是我生活中很重要的一部分,所以当我不工作或编码时,我会花很多时间在健身房。
我一直对运动和身体活动感兴趣。从小到大,我踢过足球、棒球、篮球和一些其他运动。
到了大学三年级,我开始喜欢举重。我操作系统课上的一个朋友提出带我去举重房,教我几个举重动作。
从那以后,我不再那么关注团队运动,而是更多地关注举重。我结合了奥林匹克举重、交叉训练和个人训练。我喜欢不断的变化和挑战我的身体。
另外,我是一个超级 RPG 迷,尤其是 SNES 上的老式 RPG。我已经玩过最终幻想系列太多次了。
你是什么时候开始用 Python 的?
我第一次使用 Python 是在大约 13 年前,大约 15 年前,大约在 Python 2.1/Python 2.2 发布的时候。
我刚开始接触编程,说实话,我一开始并不喜欢 Python。我没有完全理解读取-评估-打印循环(REPL)的意义,我仍在努力适应命令行环境和 Unix 环境。
那时 Python 对于我(极其)新手的编程技能来说有点太复杂了。当我学习用其他语言编写代码时,我继续玩 Python,但是直到大学二年级,我才真正回到 Python。
从那以后,Python 一直是我选择的编程语言。
你还知道哪些编程语言,你最喜欢哪一种?
了解一门语言的语法和了解与这门语言相关的库和生态系统是有区别的。
在研究生院时,我做了大量大数据方面的工作,主要是 Hadoop 集群——这需要我用 Java 编写大量代码。在 UMBC,Java 也用于大多数 200 和 300 级的课程(尤其是数据结构,尽管现在 UMBC 使用 Python)。
我大学毕业后的第一份工作也要求我在 Hadoop 集群和 Accumulo 数据库上使用 Java。正因为如此,我变得非常熟悉 Java 库和构建可扩展的数据工作流和预测模型。
我也非常了解 PHP,尽管我不愿意承认。我学习这门语言是因为它有类似 C 的语法,但带有脚本语言的味道。这也为我早期的 web 开发生涯打开了大门。
在大学期间,我为 RateMyTeachers.com 工作,从初级开发人员做起,一路晋升到高级开发人员,最终成为首席技术官。
在这个过程中,我用 PHP 和 CodeIgniter 框架从头开始重写了这个站点(这远在 Laravel 或任何其他成熟的、体面的、可以轻松扩展的 PHP 框架出现之前)。这帮助我了解了很多关于可伸缩性和 web 应用程序的知识。
我对 C/C++也相当了解,但现在我主要只把它们用于优化各种 Python 例程。
在我人生的这个阶段,我可以说 Python 无疑是我最喜欢的编程语言。从生产代码到需要解析日志文件的一次性脚本,我都使用它。它确实是一种通用语言。
你现在在做什么项目?
除了我正在从事的少数咨询/承包工作,我的主要关注点是 PyImageSearch 以及围绕 Python 编程语言创建高质量的计算机视觉和深度学习教程。
我刚刚在本月早些时候发布了我的新书, 用 Python 进行计算机视觉的深度学习 。
在今年剩下的时间里,我将最终确定我将于 2018 年在加利福尼亚州旧金山举办的会议的细节。
我还为 2018 年准备了几本其他的书。
哪些 Python 库是你最喜欢的(核心或第三方)?
OpenCV 虽然不是一个纯 Python 库,但它提供了 Python 绑定。如果没有 OpenCV,计算机视觉就不会这么容易实现。我每天都用 OpenCV。
NumPy 和 SciPy 也是如此——这些库对转向 Python 编程语言的研究人员、从业人员和数据科学家负有重大责任。NumPy 和 SciPy 在我写的每一个计算机视觉+机器学习脚本中都扮演着举足轻重的角色。
Scikit-learn 和 scikit-image 是我每天使用的另一组库。如果没有 scikit-learn,我真的很难完成与我的论文相关的研究。
最后,我不能说太多关于 Keras 的积极的事情。正如 scikit-learn 使机器学习变得可访问一样,Keras 也为深度学习做了同样的事情。
你是如何成为一名作家的?
我成为一名作家的同时也成为了一名企业家。当我还是个孩子的时候,也许只有七八岁,我是一个狂热的读者。我阅读我能得到的一切。
在我童年早期的某个时候,我决定要写自己的书。
这正是我所做的。
我会拿 20 多张索引卡,在索引卡上写下我自己的故事(通常侧重于恐怖故事),然后用厚纸板设计我自己的封面。我会用蜡笔给封面上色。最后把它们钉在一起,形成一本书。
一旦这本书完成,我会以 25 美分的价格卖给我的父母。
当我还是个孩子的时候,我想成为(1)作家或者(2)建筑师。作为一个成年人,我在很多方面都将他们结合在了一起。
你能描述一下你写书时学到的一些东西吗?
我从 17 岁开始就以开发软件为职业,但直到 20 多岁,我才开始写计算机视觉书籍。
写作对我来说不是挑战——我有多年的写作经验,尤其是考虑到我的论文。
但是营销和销售一本书是一个全新的领域。一开始我不知道自己在做什么。有很多盲目的实验在进行。
我(愉快地)惊讶地发现,运输和销售一本书与运输一个软件没有太大的不同:最初的用户反馈很重要。
在我的情况下,我写了书的草稿,并在它们 100%定稿之前发布。这帮助我更快地获得最初的读者反馈,然后在书上重复;如果你要验证一个 SaaS 企业,你会采取的确切过程。
*事实证明,我在软件领域为小型初创公司工作时学到的技能可以直接用于写书。
你还有什么想说的吗?
我只想再次感谢你给我这次机会和面试。
如果你想更多地了解我,请前往 PyImageSearch.com。你也可以在 Twitter 上关注我。
如果你有兴趣了解更多关于我的新书《用 Python 进行计算机视觉的深度学习》,只需点击这里并获取免费的样本章节和目录。
感谢您接受采访!*
本周 PyDev:Adrienne Tacke
原文:https://www.blog.pythonlibrary.org/2019/05/20/pydev-of-the-week-adrienne-tacke/
本周我们欢迎艾德丽安·塔克(@艾德丽安·塔克)成为我们本周的 PyDev!阿德里安娜是《为孩子编写代码:Python:用 50 个令人敬畏的游戏和活动学习编码》一书的作者,她的书于今年早些时候出版。你可以在的 Instagram 上或者通过她的网站看到阿德里安娜在做什么。让我们花些时间去更好地了解她吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是拉斯维加斯的一名软件工程师,拥有拉斯维加斯大学的管理信息系统学位。我在教育和医疗行业工作过,现在专注于在金融科技领域打造令人敬畏的东西。我喜欢学习新的语言(口语和编程),喜欢吃任何能想到的甜点,喜欢和我的丈夫环游世界,喜欢想办法鼓励更多的年轻女孩和女人尝试软件工程师的职业。
你为什么开始使用 Python?
当我开始写我的书《为孩子编码:Python》时,我才真正开始使用这种语言。这是一种简单的语言,它让我能够专注于编程概念而不是语法,这对任何初学编码的人来说都很重要。
你还知道哪些编程语言,你最喜欢哪一种?
我的主要语言是 C#和 JavaScript。我每天都用这些来工作。我的第一语言是 VB.NET 语。我没有特别喜欢的语言,但是我坚信一些原则。这些包括关注点的分离、可重用性、人类可读的>机器可读的代码,以及干净的代码和设计。
你现在在做什么项目?
我有几个项目涉及到我教授一些与软件工程相关的东西。我迫不及待地想在接下来的几个月里分享更多!至于代码,我刚刚(终于)更新了我的网站,该网站急需更新。我最兴奋的项目是:我正在开始为我们公司的客户端架构进行迁移,以做出反应!
哪些 Python 库是你最喜欢的(核心或第三方)?
我还没有任何最喜欢的,因为我几乎没有触及可用的表面。也就是说,我已经尝试过 TensorFlow 和 T2 Luminoth,并且非常喜欢它们的潜力。我希望在未来的周末项目中与他们更多地合作!
你的书是怎么产生的?
一个出版商通过我的 Instagram 账户找到了我这个机会!我分享我的职业生涯,作为一个女性软件工程师的例子,更重要的是,分享教育帖子和迷你教程。我的系列文章之一叫做#DontBeAfraidOfTheTerminal,在这里我以一种平易近人的方式解释了常见的和广泛使用的命令。我想他们喜欢我教授技术主题的方式,所以他们让我写这本书!
你在写书的时候学到了哪些东西?
很难将话题简化成一种易于管理且对孩子友好的方式!为这种类型的读者(孩子或完全没有编程经验的人)写这本书是一个受欢迎的挑战,因为它要求我重新措辞并完善我如何解释编程中的事情。
你对其他有抱负的作者有什么建议吗?
如果你不得不重读你写的东西,重新开始或者想办法让句子更流畅。更重要的是,开始吧!你越早把你的想法写成草稿,你就能越快地提炼和润色它,使之成为一件有价值的作品。🙂
你还有什么想说的吗?
我只想提醒大家,没有开发者制服。知识就是力量,如果你知道你的东西,你看起来怎么样并不重要!
埃德里安娜,谢谢你接受采访!
本周 PyDev:Adrin Jalali
原文:https://www.blog.pythonlibrary.org/2020/06/22/pydev-of-the-week-adrin-jalali/
本周我们欢迎 Adrin Jalali(@ adrinjalali)成为我们本周的 PyDev!Adrin 致力于流行的 scikit-learn 包和 Fairlearn ,一个 Python 的 AI 包。你可以通过 Adrin 的网站或者查看他的 Github 简介来了解他还在做什么。
让我们花些时间更好地了解 Adrin!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我读的是计算机科学,然后是生物信息学硕士和博士(还有待答辩!).我在伊朗出生和长大,后来搬到加拿大,现在住在德国。我读的东西包括(左派)经济学、哲学、多样性和包容性、领导力和伦理/公平。我喜欢在城外骑自行车,周末和朋友一起通宵。
你为什么开始使用 Python?
我曾经用 R 作为生物信息学家,维护着两个包。然后我莫名其妙地花了一个周末学习 Python,开始用 Python 编程。感觉如此自然,我就和这种语言呆在一起了。那是 2012 年。
你还知道哪些编程语言,你最喜欢哪一种?
我从 QBASIC 开始,然后是 Pascal,Delphi,C,C++,C#,Matlab/Octave,r。
很长一段时间以来,C++是我最喜欢的语言。我猜现在是 Python 和 c 了。不过我对 Rust 很好奇。
你现在在做什么项目?
我一直在致力于 scikit-learn,一个机器学习库,和 fairlearn,一个 ML 库中的 fariness。我还参与了“选择退出工具”项目,该项目帮助女性识别出那些在推特上隐藏厌女症的人。
哪些 Python 库是你最喜欢的(核心或第三方)?
我会说 functools、numpy 和 scipy。
你是如何参与 scikit-learn 项目的?
两三年前,我们在 PyData 柏林会议上做了一个关于“我的第一个开源贡献”的演讲。那时,每当我遇到文档或代码的问题时,我都会参与一些不同的项目。那次谈话激励我做出更多贡献。我尝试了 tensorflow,但很快意识到这更像是一个商业产品,而不是一个基于社区的项目。然后搬到了 scikit-learn,马上就喜欢上了社区。我不得不说,我在 GitHub pull 请求上得到的指导,尤其是乔尔·诺思曼的指导非常出色,让我留在了那里。几个月后,我被邀请成为核心开发人员,现在我还在那里。
你最喜欢 scikit-learn 的什么功能?
我喜欢图书馆的模块化。我做不到没有管道,*GridSearchCV,ColumnTransformer,事实上编写一个
定制估算器真的很容易。一旦你熟悉了这些机制,你就可以用它来构建任何你需要的东西。
Adrin,谢谢你接受采访!
本周 PyDev:Agata grd al
原文:https://www.blog.pythonlibrary.org/2017/05/08/pydev-of-the-week-agata-grdal/
本周我们欢迎 Agata Grdal 成为我们的本周 PyDev!Agata 在欧洲和皮拉迪斯都积极参与当地的 Django Girls 团体。你可以在 DjangoGirls 博客上了解更多关于 Agata 的信息。Agata 在她的 Github 简介上也有一些有趣的项目,你可以去看看。让我们花一些时间来更好地了解 Agata!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我有数学学士学位,但我决定攻读计算机科学硕士学位。
我为我的社区工作感到骄傲。我是 Django Girls 的撰稿人、教练和当地组织者。我帮助将 DG 指南翻译成波兰语,在 Wroc aw 共同组织了两次研讨会,并在欧洲其他几个地方担任教练。我在阿姆斯特丹参与组织了 Django: Under the Hood 会议,并且是我的家乡 Wroc aw 当地 python meetup 组织团队的一员。
我最近搬到了华沙,加入了位于波兰的 Python 商店 Sunscrapers ,在那里我使用 Django 开发 web 应用程序。
我是睡觉、土豆和猫的超级粉丝。除了工作,我的第二个爱好是即兴戏剧。这完全是关于倾听、反应、接受、索取和给予。我鼓励每个人都尝试一下。
你为什么开始使用 Python?
我参加了 2014 年在柏林举办的首届 Django 女孩研讨会。这是 EuroPython 会议的一部分,研讨会结束后,与会者可以参加讲座并会见专业人士。我很惊讶每个人都如此友好和乐于助人。Python 非常优雅,容易上手,但正是它伟大的社区让我着迷。
你还知道哪些编程语言,你最喜欢哪一种?
当我学习数学的时候,我的第一门编程语言是 C++,现在我仍然喜欢它。我觉得它为我理解编程的核心概念打下了坚实的基础。
我知道的 JavaScript 刚好够用,因为在工作中确实无法逃避它。我 2017 年的计划是好好学学,也学着喜欢。😉
我对 SQL 情有独钟,因为我在大学上过非常有趣的数据库课程,其中包括现实生活中的练习和逻辑难题。直到今天,我仍然喜欢在工作中编写 SQL。
你现在在做什么项目?
正如我之前提到的,我最近搬到了华沙。那里有一个很棒的 Python 社区,每月聚会一次,名为 pyWaw。初学者可能会被那里进行的高级会谈吓倒,所以我们正在考虑为初学者举办一次会议,这将有助于弥合新手开发人员和专业人员之间的差距。
我会一直以这样或那样的方式参与 Django Girls。我仍然记得作为一个完全初学者的感觉,我计划继续使用这些知识来帮助其他人开始他们的编程生涯。
除此之外,我确实计划今年放松一下,专注于获得更多的经验和作为开发人员的成长。
哪些 Python 库是你最喜欢的(核心或第三方)?
姜戈,原因显而易见——它让人们有饭吃,也因为它,我结交了许多亲爱的朋友。
我不得不说两个 Python 经典:requests 和 pytest。使用它们是一种享受。
我也无法想象没有 ipdb 和 ipython 的工作生活。
你还有什么想说的吗?
对于初级开发人员:参加会议和聚会。成为社区的一部分比独自做事要容易得多,尤其是在开始的时候。别担心。小步前进。你会到达那里的。
感谢您接受采访!
本周 PyDev:艾琳·尼尔森
原文:https://www.blog.pythonlibrary.org/2017/06/19/pydev-of-the-week-aileen-nielsen/
本周,我们欢迎艾琳·尼尔森成为本周的 PyDev。Aileen 在数据科学领域使用 Python 已经有一段时间了。她最近在 PyCon 2017 上做了一个关于时间序列分析的辅导,她还在 PyData Amsterdam 2016 上做了一个关于 NoSQL Python 的演讲。让我们花点时间了解一下我们的开发伙伴吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是糖尿病管理平台 One Drop 的软件工程师。我们试图通过使用技术、数据分析和专家指导来帮助人们更好地了解和管理他们的慢性疾病。
我在学校呆了很长时间(法学院,在物理研究所),所以就学术兴趣而言,我认为自己是一个不拘一格的人,我喜欢阅读许多领域的非小说类作品。现在我最感兴趣的是关于间谍和有组织犯罪的非小说类书籍。我的爱好是旅游和徒步旅行。当我不工作的时候,我尽量不在屏幕前。
你为什么开始使用 Python?
我是在 R 和一些我在物理研究生院使用的专有数据分析软件包(Igor,Matlab)中“长大”的。然而,我对专有软件解决方案感到沮丧,因为它们不可移植,也没有在 Stack Overflow 这样的论坛上得到很好的讨论。
随着时间的推移,我对 Python 越来越感兴趣,因为它的文档对用户很友好,而且呈现得很好。此外,Python 社区非常活跃,在线和面对面都很受欢迎,很容易上手。我喜欢 Python 拥有如此广泛的行业、学术和业余爱好者用户基础。
你还知道哪些编程语言,你最喜欢哪一种?
我用 R、C++和 Objective-C 完成了大多数其他工作。除了 Python,我最喜欢的编程语言是 C++,因为它的语法非常精确,但也非常复杂。
你现在在做什么项目?
我喜欢谈论 Python 以及它与我工作的关系。目前,我正在用 Python 和 r 编写一个关于医疗机器学习的四部分教程
哪些 Python 库是你最喜欢的(核心或第三方)?
在我的工作中,必不可少的答案是熊猫、熊猫和松鼠。也就是说,我和 scrapy 一起度过了很多美好的私人时光。
否则,我倾向于寻找 scipy 和相关软件包中没有涉及的真正具体的算法。在这种情况下,我经常发现 github 是我最好的朋友,我寻找的大多数算法都有几个实现良好的 gists,我可以用它们来查看我想做的事情的示例。
你还有什么想说的吗?
我被 Python 社区所吸引,因为它是如此开放、友好和活跃。除了漂亮的语法之外,Python 还提供了很多机会,让你可以认识一些有趣的人,他们正在研究一些非常有趣的问题。我相信,只要这种情况持续下去,Python 将会继续发展。
感谢您接受采访!
本周 PyDev:艾莎·贝洛
原文:https://www.blog.pythonlibrary.org/2018/09/03/pydev-of-the-week-aisha-bello/
本周我们欢迎 Aisha Bello ( @AishaXBello )成为我们本周的 PyDev!Aisha 是 PyLadies Nigeria 的创始人,对发展中国家的 STEM 充满热情。她也是非洲 DjangoGirls 的组织者。Aisha 已经环游世界,在 EuroPython、DjangoCon、Python Brasil 和 PyData 会议上谈论 Python。让我们花一些时间来更好地了解她!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
目前,我在尼日利亚思科公司的数据中心和虚拟化实践部门担任虚拟系统工程师。我在加的夫大都会大学获得了信息技术硕士学位,在那里我参与了一个酒店行业的数据科学项目。我对发展中国家的女性赋权和科技教育充满热情。
当我不工作的时候,你会看到我在看电影,去上体育课或者探索新的地方。
你为什么开始使用 Python?
我在 2015 年参加欧洲 python 的 DjangoGirls 活动时开始使用 Python。那是我第一次接触 Python。我记得在研讨会期间我问自己,“我这辈子你去了哪里?”。“你”就是“蟒蛇”。这是来自一个完全放弃编程的女孩,因为她不能完全掌握她在学校学到的语言概念。那时候,我只想学习足够的 Java 或 C 语言来完成一个学校项目,或者只是通过考试。我完全相信编程是为第一课堂和天才学生准备的,绝对不是我。现在,当我回头看时,并不是这些概念太复杂而难以理解,而是其他语言解释这些概念的方式太复杂了,至少对我来说是这样。
你是如何和 DjangoGirls 和 PyLadies 开始的?
当我在毕尔巴鄂参加我的第一次 DjangoGirls 活动时,我呆了整个会议。我记得我回家的时候,我非常激动地想给尼日利亚的女性带去一个如此惊人的机会,向她们展示她们也可以编程。作为一名化妆师或时装设计师并不像我们中的一些人习惯性地认为的那样是我们所擅长的。从那里开始,Python 尼日利亚社区诞生了。DjangoGirls 活动之后,我在寻找一种方法来帮助参加活动的女士们继续学习,于是皮拉迪斯尼日利亚公司诞生了。
你还知道哪些编程语言,你最喜欢哪一种?
在学校的时候,我玩了 C、C++、Java 的“教科书风格”,过去我也做过一点 Javascript。当我刚刚完成本科学业时,我开始了化妆和美发业务,并使用“good ol”HTML & CSS 为我的业务建立了一个网站。我会说 Python 仍然是我的最爱。用 Python 开始构建东西是如此简单,也不那么复杂,但最重要的是呼应了智者 Brett Cannon 的话;我来是为了语言,但留下来是为了社区。我甚至无法开始解释这有多强大。
你现在在做什么项目?
我最引以为豪的一个项目是尼日利亚的 Python 社区,我们是如何开始的,在哪里开始的,以及我们已经走了多远。我们从 2016 年的一个 DjangoGirls 工作坊,发展到一个 1200 人的社区,在全国各地以其他活动的形式举办了 50 多场活动;DjangoGirls,Pyladies,PyData 和现在的 Python 尼日利亚 meetups。最让我兴奋的是 9 月份即将到来的 Python 大会,届时将有超过 250 名 Python 爱好者在同一屋檐下分享和讨论不同领域的 Python。
有趣的是,自从我买了一个个人域名,打算从零开始建立我的网站,并再次开始写作,打破开发者的网络概念,这是我去年 PyData 演讲的灵感。我想我们会看到🙂
你最喜欢哪个 Python 框架或库(核心或第三方)?
我不确定我会用最喜欢这个词。我通过学习 Django 开始学习 Python,然后用 Scikit-Learn 完成了我的第一个数据科学 ML 项目。现在我要处理大量的 API,我不能没有请求库。
你还有什么想说的吗?
如果我能对年轻时的自己说一句话,那就是“永远不要低估自己”。你足够聪明,足够优秀,你足够优秀。继续努力,继续攀登,永不放弃
Aisha,谢谢你接受采访!
本周 PyDev:Al Sweigart
原文:https://www.blog.pythonlibrary.org/2016/11/07/pydev-of-the-week-al-sweigart/
本周,我们欢迎阿尔·斯威加特成为我们的本周 PyDev。艾尔是 PyAutoGUI 和 Pyperclip 软件包的作者。他还是几本 Python 书籍的作者,例如:
- 用 Python 自动化枯燥的东西:完全初学者实用编程
- 用 Python 破解秘密密码
- 用 Python 制作游戏& Pygame
- 用 Python 发明自己的电脑游戏
他还在 Scratch 上发布了一本名为Scratch Programming Playground的书。Al 在 Python 世界非常有名,他的书获得了很好的评价。让我们花些时间去更好地了解他!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我很幸运很早就接触了编程,然后在 UT Austin 主修计算机科学(“hook 'em!”)但我讨厌告诉人们这些。很多人认为编程是你必须从蹒跚学步时就开始的东西,这样才能变得熟练。事实上,我在 3 年级到 12 年级期间学到的所有编程知识都可以在十几个空闲的周末学到。
除了编码,我喜欢写编码教程和录制编码截屏。我还在三藩市 SPCA 和奥克兰的电子游戏博物馆做志愿者。
你为什么开始使用 Python?
我想大约在大学四年级的时候。在那之前,我使用 Perl 和 PHP 编写快速的小脚本。Python 确实是一门优秀的语言,从那以后一直是我的最爱。不像 Perl,代码是可读的,它的文档水平和 PHP 一样好。
Python 社区是顶级的。参加 PyCon 是我这一年的亮点之一。
你还知道哪些编程语言,你最喜欢哪一种?
我做过一些 Java 和 JavaScript 的工作。最近我迷上了 Lua。在很久以前,我使用过 Perl、PHP、C++和 Visual Basic。我学了一点 Ruby。Python 仍然是我最喜欢的。
你现在在做什么项目?
我正试图了解问题,并为我的 PyAutoGUI 和 Pyperclip 模块拉取请求。刚完成一本书项目, Scratch 编程游乐场,2016 年 9 月出。我的下一个图书项目是通过使用一个叫做 ComputerCraft 的《我的世界》mod 来教孩子们编码。CC mod 允许你编程机器人在《我的世界》世界移动,所以你可以让机器人编程来做你的建筑,采矿和手工艺。不幸的是,国防部使用 Lua 而不是 Python。但是鉴于《我的世界》的流行,我认为它是进入编程的一个很好的入门药物。
哪些 Python 库是你最喜欢的(核心或第三方)?
硒的用处给我留下了深刻的印象。我也欣赏展示设计良好的 API 应该是什么样子的请求。对于 web 应用程序,我很难决定我更喜欢 Flask 还是 Django。OpenCV、计算机视觉库和 Kivy 是我期待了解更多的模块。
你为什么决定写关于 Python 的书?
几年前,我当时的女朋友是一个早熟的 10 岁女孩的保姆。他想学编程,就让她找我要一些资源。不过,我真的找不到。很多东西要么是为专业开发人员制作的,要么是被冲淡了的。我记得我进入编程的方式是复制一些游戏的源代码,然后随便玩玩。我自己的所有游戏都是衍生产品,但有一个项目来做比只是学习一堆没有应用的编程概念更好。我开始写一个教程,最终膨胀成了一本书的长度。在知识共享许可下,我可以在网上免费获得它,并决定自行出版它。人们似乎喜欢它,所以我又写了一个,然后又写了一个,这成了我的主要爱好。2014 年,我辞去了软件开发工作,开始全职写作。
你从关于 Python 的写作中学到了什么?
这很尴尬:我知道了表达和陈述之间的区别。多年来,我只是在某种程度上交替使用这些术语,而没有想太多。这是完全正确的,教别人照亮了你自己知识的所有缺口。就像写代码的大部分工作不是写代码而是调试代码一样,编辑我的书比写它们要花费更多的精力。总的来说,开发人员在解释编程方面非常糟糕:我们已经忘记了不熟悉这些概念是什么感觉。我经历了几轮“他们需要知道什么才能理解这些?我报道了吗?有没有更简单的解释方式?比这更简单怎么样?”这是一项艰苦的工作,通过细节来处理的诱惑是很大的。
你还有什么想说的吗?
我想对 PyCon 说一声,并鼓励任何技能水平的人都来参加。Python 社区是一流的:非常友好,他们努力降低对编程感兴趣的人的入门门槛。
非常感谢你接受采访!
本周 PyDev:Alan Vezina
原文:https://www.blog.pythonlibrary.org/2018/03/05/pydev-of-the-week-alan-vezina/
本周我们欢迎艾伦·维兹纳( @fancysandwiches )成为我们的本周 PyDev!他是 PuPPy(Puget Sound Programming Python)的联合创始人之一,这是一个位于华盛顿州西雅图的 Python 用户组。他也是不列颠哥伦比亚省温哥华 Python 会议 PyCascades 的组织者之一。虽然艾伦有一个博客,但它似乎不会定期更新,所以你可能想查看他的 Github 简介来了解他最近在做什么。现在,让我们花一些时间来更好地了解他!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
在中西部出生和长大,但过去 6 年一直住在西雅图。我拥有密歇根大学的计算机科学学士学位。我是一个狂热的自行车爱好者,我一年到头都骑自行车上班(西雅图让这变得很容易),我没有汽车。最近我尝试了很多自制的果酒和蜂蜜酒。
你为什么开始使用 Python?
几年来,我一直在专业地编写 Java 和 JavaScript,并在寻找一种新的语言,以便在空闲时间学习。我对一些语言(Ruby、Scala、Haskell 等等)做了一些简单的研究,但是最终选择了 Python,因为它看起来非常优雅和易于使用。事实证明它非常优雅且易于使用,所以我一直坚持使用它。
你还知道哪些编程语言,你最喜欢哪一种?
我有使用 JavaScript、Java、Go、Perl、PHP 和 Visual Basic 的经验。我可能会说 Go 或 JavaScript 是我的非 Python 爱好者。我从未使用过 Nim 或 OCaml,但一直打算使用它们。
你现在在做什么项目?
At work I have several projects, my most active one recently has been around setting up the required infrastructure so we can provide Single Sign On across several applications that we provide to our customers. Most of last year I spent my time working on various tools for the Mojaloop project. I am also working with a PuPPy member to make better tools for organizing a meetup, hopefully we'll make enough progress this year to release these tools to the wider meetup community.
哪些 Python 库是你最喜欢的(核心或第三方)?
对于标准库:我认为抽象基类模块被低估了,我也是类型模块的忠实粉丝。对于第三方:排名不分先后,Flask,Marshmallow,SQLAlchemy,Django,Requests。
What are the top 3 things you learned as an organizer/founder of a local Python Users Group?
- Python 社区真的很棒。我知道这听起来很老套,但这是真的。我参加过其他主题的会议,Python 社区确实是顶尖的。
- 我在接受批评方面已经进步了很多(仍然不完美)。听到别人批评你付出了巨大努力的东西是很难的。批评别人做的工作也很难,大多数人真的不想刻薄,他们真的想帮忙。在回应批评时,尽最大努力抑制自己的情绪,试着把它作为一个机会,让人们了解你参加活动的工作量,并作为一个获得新志愿者的机会。
- 人们比我想象的更乐于助人。现在人们有很多理由对人性缺乏信心,但是小狗和派喀斯喀特确实向我展示了人们想要帮助,并且将会帮助。皮卡斯卡德有如此多的志愿者,我们很难给他们所有人工作,事实上我们无法给他们中的一些人工作。
**Â **What advice do you have to others who want to start (or improve) their own group?
- 试着找另一个相关的团体,和他们一起举办活动,而不是成立自己的团体。PuPPy 成功的部分原因是,我们相当开放地允许其他人以 PuPPy 的“品牌”经营 meetup。你会有一群更愿意立即加入你的人,总的来说,你成功的几率会更高。如果你走这条路,参加一些会议,在你提出想法之前了解组织者,确保你的想法听起来不像“你们做得不够,请做得更多”,听起来更像“我真的很喜欢你们的团队为社区所做的事情,我想通过组织和与你们一起举办活动来提供帮助”。
- 制定行为准则,并在每次会议上宣传你有行为准则。如果你担心人们不会带着 CoC don't be 参加,你可能根本就不想要这些人。
- 保持一致。我怎么强调这一点都不为过。当你第一次开始的时候,你不会获得巨大的成功,最初的几次聚会最多只有 30-50 人。我相信,我们现在在 meetup.com T2 拥有 5000 多名会员,并且能够完成 150-250 人的月度活动的最大原因是,我们(几乎)总是在每月的 2 号 T3 T4 周三 T5 T6 见面。这让通勤困难、日程繁忙、有家庭等的人们。一切提前计划。如果你想参加 PuPPy,你可以推迟几乎任何一个月的第二个 星期三 并提前计划。人们也是习惯的动物,你最好接受它,而不是对抗它。
- 忘了网站吧,它真的没有必要。我们有一个域名,但我们没有一个网站,我们有一些网址,只是转发到谷歌的形式来注册一个讲座。其他一切都生活在Meetup.com
- 尽量不要做披萨。这很难,因为很多公司和场所默认披萨是他们的选择,因为它很受欢迎,人们认为它很便宜。披萨并不像你想象的那么便宜,我们曾经在一次活动中收到一张 5000 美元的披萨账单。试着找一家小公司,做一些像墨西哥卷饼,班米,甚至点心。它不仅比披萨便宜,更健康,而且你会被记住是一个不吃披萨的聚会。
- 谈论多样性是不够的。你可以日复一日地在山顶高喊你是多么支持多元化,但这不会让你的聚会更加多元化。解决方案是积极参与并招募更多不同的成员。您的扬声器系列没有任何多样性?求朋友同事推荐演讲者。发送一封通知邮件,邀请不同的演讲者。转到其他 meetup 并邀请成员加入您的 meetup。确保你的组织者群体也是多样化的。多样化的组织者导致多样化的聚会。
- 不要为小错误担心。错误无时无刻不在发生,我们的聚会几乎没有一次是没有问题的(食物晚了,很难找到场地,视听设备坏了,等等)。).大多数情况下,人们不会注意到这些错误,或者不会像你一样关心它们。
- 问&答很难,对许多演讲者来说压力很大。我建议将 Q &设为可选,询问每位演讲者是否想提问。
- 如果你决定做一个问答环节,确保你真的强调听众只应该提问,而不是陈述。我最近看到有人说“你的第一句话应该是一个问题,你的第二句话不应该存在”,我很喜欢这句话,我打算用它。粗鲁的问题会发生,我不止一次在所有人面前拿回麦克风,告诉演讲者“你不必回答这个问题”。
你还有什么想说的吗?
技术面试被打破了,我们作为一个社区需要做些什么。
非常感谢你接受采访!
本周 PyDev:阿莱西娅·马科利尼
原文:https://www.blog.pythonlibrary.org/2020/02/03/pydev-of-the-week-alessia-marcolini/
本周我们欢迎阿莱西娅·马科利尼( @viperale )成为我们本周的 PyDev!Alessia 是 Python 博客作者和演讲者。你可以在媒体上查看她的一些作品。你也可以在 Github 上看到她的一些编码技巧。让我们花一点时间来更好地了解她!

你能告诉我们一些关于你自己的情况吗(爱好、教育等):
大家好,我叫阿莱西娅,今年 21 岁。我来自意大利北部美丽的城市维罗纳附近的一个小镇。
我已经在意大利的特伦托住了两年半了。我搬到这里上大学:我现在是计算机科学学士学位的三年级学生。
2017 年,我也开始在布鲁诺·凯斯勒基金会兼职做初级研究助理。FBK 是一个位于特伦托的研究基金会,致力于科学、技术和社会科学。我是 MPBA 研究小组的一员,该小组专注于从复杂数据中进行深度学习的新应用:例如,工业过程中的精确医疗、成像和便携式光谱、时空数据的临近预报。我目前正在研究深度学习框架,以整合多种医学成像模式和不同的临床数据,从而获得更精确的预测/诊断功能。
不编码的时候,我喜欢跳舞和听音乐。直到 2017 年,我还是一个嘻哈团队的成员。
你为什么开始使用 Python?
嗯,这要追溯到我上技术高中的第一年。我们有一位老师,他违背了我们学校许多其他计算机科学老师的意见,决定教我班上的学生 Python 作为有史以来第一种编程语言。所以,这不是我的选择。然而,在这六年后,我意识到我有那个老师是多么幸运(开玩笑,我以前就意识到了,我仍然爱那个老师,我们关系最好,但也许我不明白他会对我的未来产生什么影响)。
你还知道哪些编程语言,你最喜欢哪一种?
很难说你“知道”还是“不知道”一种编程语言。我可以说 Python 是我练习得最多的语言,因为三年来我每天都在工作中使用它。除此之外,我在学校和大学也有机会练习 Java、C 和 C++。我还参加了几年的意大利信息学奥林匹克竞赛,我们被要求用 C++编写程序。
无论如何,Python 绝对是我最喜欢的编程语言:它简单易学,语法直观,使用 Python 可以用比其他语言少得多的代码完成任务。它对于编写脚本来说非常方便,但同时它也非常强大,让您有可能编写一个完整的端到端的面向对象的应用程序。它可以服务于多个应用领域,从 web 开发到桌面开发,再到数据科学。
他们说你“为语言而来,为社区而留”,这确实是我最欣赏 Python 环境的一个方面。我在 Python 社区的经历非常棒,这就是为什么我总是鼓励人们来到 Python 世界(稍后会有更多介绍)。
你现在在做什么项目?
我在工作中运行时间最长的项目之一是人工智能&开放创新实验室:我是 FBK 和艺术学院(意大利 TN)联合组织的一个技术实验室的联合主任,旨在向高中生介绍数据科学,并开发深度学习与艺术和设计相结合的新应用。三年前开始,教学生 Python 和深度学习;我们还将设计思维方法应用于项目管理。2019-2020 年的挑战是为葡萄酒业务开发智能包装解决方案,以确保生产和制造过程中的产品完整性和产品可追溯性。这很酷,因为我可以与来自不同背景(ITC 高中、中学、大学)和不同年龄(从 17 岁到 25 岁)的学生一起工作,团队可以与公司和客户建立直接联系(我们现在与一家包装公司和一家起泡酒公司合作)。
从研究角度来看,我目前正在研究数字病理学和放射学的深度学习算法。关于数字病理学,我正在优化一个可重复的深度学习框架,以预测病理组织的临床相关结果,并研究由数据泄露引起的过度拟合的效应。
考虑到放射学,我正在通过一个整合的深度学习框架评估放射组学和癌症生物成像的深度特征的预后能力,该框架应用于 PET-CT 扫描的组合数据集。
此外,我最近开始在机库工作。这是一个相当年轻的项目(诞生于 2019 年 4 月),但在我看来是非常有前途的。它基本上以一种智能的方式为数据版本化提供支持。它旨在解决传统版本控制系统面临的许多问题,只是适用于数字数据。我认为这是数据科学工具拼图中缺失的一块。
特别是,我开始为这个库开发新的教程和用例。
哪些 Python 库是你最喜欢的(核心或第三方)?
NumPy 和 Pandas,是 Python 中科学计算的核心库。Pandas 最强大的功能之一是将复杂的数据操作翻译成仅仅一两个命令。
你是如何开始组织 Python 会议的?
精彩提问。18 岁时,我有很好的机会被web valley 2016 International录取,这是一所关于数据科学的暑期学校,面向来自世界各地的 17-18 岁学生:15-20 名学生在特伦蒂诺的一个小村庄工作三周,从事由 FBK 研究人员辅导的研究项目。在那里,我遇到了后来成为我导师的人:瓦莱里奥·马吉奥和埃内斯托·阿比特里欧。皮托尼斯塔的同伴们,他们开始让我加入意大利皮肯组织。此外,还特别提到了意大利 PyCon 协会的创始人之一 Carlo Miron。我很感激他们对我的信任(现在仍然如此)。我们已经开始筹备明年的会议:2020 年 5 月 2 日至 5 日,佛罗伦萨,PyCon 11!会很有意思(一如既往!;))下面是上一期的简短回顾:https://www.youtube.com/watch?
组织一次会议最具挑战性的是什么?当你有一个支持、关心和友好的团队时,组织一次会议并不困难。关键词是团队合作。虽然,组织一次会议并时刻保持警惕是很费时间的。这种会议的幕后团队(通常)由志愿者组成,有时很难将会议和电话纳入每个人的议程(我们每两周组织一次公开电话会议——从 10 月到 5 月)。
无论如何,作为一名组织者(同时也是参与者)是我最有收获的经历之一,这要感谢我所建立的所有关系和对编程语言的热爱。
你还有什么想说的吗?
坏消息是:没有什么是永恒的。好消息是:没有什么是永恒的。-萝莉·达斯卡尔
Alessia,谢谢你接受采访!
本周 PyDev:亚历克斯·克拉克
原文:https://www.blog.pythonlibrary.org/2016/12/05/pydev-of-the-week-alex-clark/
本周我们欢迎亚历克斯·克拉克( @aclark4life )成为我们本周的 PyDev!Alex 是 fork 的作者和项目负责人 pillow ,这是 Python 图像库的一个“友好”的分支。亚历克斯在他自己的 Python 博客上写道,这当然值得一看。他也是 Plone 3.3 站点管理的作者。你可能还想看看我们的 Alex 的 Github 简介,看看有哪些项目值得他关注。让我们花些时间去了解他吧!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
最近 10 年左右,我一直称自己为专业的“Python Web 开发人员”,偶尔在末尾加上“&音乐家”;所以音乐是我在 Python 之外做的,或者至少是想做的很大一部分。我来自美国马里兰州的巴尔的摩,我在马里兰州的罗耀拉高中和大学(大学时就读)就读。花了大约 10 年时间,但我在 1998 年 5 月获得了计算机科学的理学学士学位。不是所有徘徊的人都会迷路,但就我而言,我不知道自己想做什么,直到我在 UNIX 实验室看到一屋子的数字检测站;在那一刻,我决定我想在那个房间里,我把我的专业从会计转到了计算机科学。
你为什么开始使用 Python?
简单的一个!21 世纪初,我开始在 NIH(美国马里兰州贝塞斯达的国家卫生研究院)工作,我的小组需要一个网站。一个邻近的小组正在使用 Plone 和“其余的是历史”。我使用 Plone(基于 Python 的 CMS)构建了他们的网站,并学习了完成这项任务所需的所有 Python 知识。我记得当时 Python 的美学给我留下了深刻的印象,我开始研究这种语言和社区。令我惊讶的是,第一次皮肯节刚刚在 DC 的华盛顿州附近举行。
你还知道哪些编程语言,你最喜欢哪一种?
我已经学习了(或者被迫学习)很多语言,从我上学的时候开始,我在那里上了一门编程语言课。在大多数课程中,C 是重点,但在编程语言课上,我们被迫(咳咳)去看看其他语言,如 Lisp、Smalltalk 等。我还必须参加 x86 汇编课程。放学后,我学习并使用了 Perl 和我的第一份工作。在这一点上,我可以肯定地说 Python 是我最喜欢的语言,无论是就语言本身还是周围的社区而言。这些天我在社区里不是很活跃,但我喜欢知道它在那里,我也关注事件。最重要的是,我仍然监督着 DC Python 的运行,这是我非常喜欢做的事情。最后,我将提到 JavaScript,因为作为 Python Web 开发人员,我不能忽视它。我被它迷住了,我也有涉猎,但这还不是我最喜欢的,我也不确定将来会不会是;同样,Python 的美学优于大多数(如果不是所有)语言,包括 JavaScript。哦,如果你可以称之为语言的话:我非常喜欢偶尔的 shell 编程(bash,zsh)。
你现在在做什么项目?
很高兴你这么问。几年前(2012 年),我忘乎所以,最终建立了我的第一个创业公司:“Python 包”;我被选中在 PyCon 2012 的 Startup Row 展出,这非常令人兴奋和有趣。不幸的是,创业失败了,但建立软件即服务(SaaS)创收业务的愿望并没有消失。2015 年底,我厌倦了使用和支付收获时间跟踪&开票服务。这是一个非常好的服务,但有一些小烦恼,逐渐开始消耗我脑海中的主要空间。所以我根据导出的数据,用 Django & Postgresql 运行了自己的T4。我在 2016 年 1 月开始“真正”使用它,它非常神奇。我可以用我(和其他人,通过开源)开发的软件给我的客户发送“类似收获”的发票,这个事实仍然让我感到震惊。本月早些时候,我开始更新软件,让我以外的人更容易使用。希望 2017 年 1 月 1 日开始销售。
我还会提到另外两个项目:
- 枕头(叉作者,投影组长)
- Python 项目 Makefile (我从 2016 年初开始做的一个新项目)
后者标有“请勿使用”,但我正准备打开开关,让它可供消费(我希望人们尝试、喜欢和贡献)。
哪些 Python 库是你最喜欢的(核心或第三方)?
很高兴你也问了这个问题。比起库,我更喜欢框架和实用程序,所以我将列出这些,并希望它们能回答这个问题:
- Django(最近我的大部分 web 编程都是在这个框架内进行的)
- Django Rest 框架(一个构建 web 服务的“just works”插件,有一个有趣的新融资机制
- (我喜欢这个工具,我每天都用它将代码从 GitHub 转移到我所有的开发站)
作为一门编程语言,你认为 Python 将何去何从?
我希望 Python 3 在 2020 年前“胜出”(如果不是更早的话)。我觉得与构建新的非向后兼容版本的 Python 相关的大部分戏剧性事件已经过去,我期待有一天所有供应商都默认包含 Python 3。
你对当前的 Python 程序员市场有什么看法?
我对此并没有太多的关注(除了不断尝试以我的标准工资被聘为 Python Web 开发人员!)但我希望 Python 数据科学家的市场继续增长。作为每年在 Mathworks 的 MATLAB 许可上花费大量美元的人,我希望看到 Python 继续在这一领域竞争;我希望能够轻松地将 Python 作为 MATLAB 的替代品。
你还有什么想说的吗?
感谢您邀请我参加 PyDev of the week 系列活动!
本周 PyDev:Alex Gaynor
原文:https://www.blog.pythonlibrary.org/2015/07/06/pydev-of-the-week-alex-gaynor/
本周,我们欢迎亚历克斯·盖纳(@亚历克斯 _ 盖纳)成为我们本周的 PyDev!Alex 写了一篇有趣的 Python 博客,并且是 Python 软件基金会的董事会成员。你可以通过 Alex 的 Github 页面感受一下他参与的项目。让我们花些时间去更好地了解他吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
【to】我是一名软件工程师,为美国政府工作。我已经编程大约 8 年了,使用 Python 的时间也差不多一样长。开源会消耗我很多时间,但当我不编程的时候,我是一个 NBA 篮球迷。我来自芝加哥,现在住在华盛顿特区。
你为什么开始使用 Python?
那时我只知道 PHP,在做了一个小的个人项目后,我和另一个开发人员聊起了一个类似的项目,我一时兴起问他们用的是什么技术,他们说“Python 和 Django”,我从未听说过 Django,当时对 Python 一无所知。我深深地爱上了她。
你还知道哪些编程语言,你最喜欢哪一种?
我可以自如地使用 Python、Ruby、Java、C、C++、Go、Javascript、SQL 以及其他一些我不记得的语言。我现在最常接触的两种语言是 Python 和 Go,但我更喜欢使用 Python。
你现在在做什么项目?
显然是一堆内部工作的东西。对于开源项目,占用我大部分时间的项目是 pyca/cryptography,我们正在努力为 Python 构建一个可靠而安全的加密库。
哪些 Python 库是你最喜欢的(核心或第三方)?
如果我说 pyca/cryptography,会不会是作弊;-).我非常喜欢 Raven、Werkzeug、SQLAlchemy 和 python-afl。
非常感谢!
一周的最后 10 个 PyDevs
- 大卫·比兹利
- 升降杆
- 塔里克·齐亚德
- 斯蒂芬·德贝尔
- 安娜·奥索斯基
- 加布里埃尔·佩蒂尔
- 瓦苏德夫拉姆
- Julien Danjou
- 马特·哈里森
- 阿迪娜·豪
PyDev of the Week: Alex Hall
原文:https://www.blog.pythonlibrary.org/2021/12/13/pydev-of-the-week-alex-hall/
This week we welcome Alex Hall as our PyDev of the Week! Alex is the creator of https://futurecoder.io/, a platform for learning Python. You can see what other projects Alex works on over at GitHub.
Let's spend some time getting to know Alex better!
Can you tell us a little about yourself (hobbies, education, etc):
I do a lot of coding in my spare time, mostly my own open source Python projects. That's my only regular hobby, when people ask what I do for fun I get a little stressed and think of https://xkcd.com/1423/. I'm interested in maths - I majored in Computer Science and Maths in university - but these days I do little more than watch maths YouTube videos and fiddle with random ideas.
Why did you start using Python?
I initially taught myself programming as a teenager in a very ad-hoc manner using GameMaker. At first I just used it to generate loads of pretty geometrical patterns by drawing lines and circles according to some mathematical rules. Probably the most significant thing I made with it was some games for practicing basic arithmetic. One of my teachers recommended that I enter a programming competition and suggested Python. It was my first 'real' programming language. I sped through the official tutorial and absolutely loved everything about it. I didn't get far in the competition because I still didn't really know what I was doing and hadn't had any formal training, but I had fun in the process. In particular when I looked up how to generate permutations and discovered recursion my mind was absolutely blown by the idea of a function calling itself, it was so exciting!
What other programming languages do you know and which is your favorite?
Python is by far my favourite language, no other language comes close. I think a big part of that is because I know it so well, again much better than any other language. I love metaprogramming, and that requires knowing intimately the details of how the language works, but it also seems like Python is much better suited to this than other languages. For example, decorators are perfectly natural in Python. In some statically typed languages like Java, I think no close equivalent is possible.
Apart from Python, most of the code I write these days (both in my job and my personal projects) is JavaScript and TypeScript. Some other languages that I've built significant projects in but are fading from memory are Kotlin, Java, Scala, and Ruby. Beyond that I've dabbled with more languages than I can count, there was a time when learning new languages seemed super fun and cool.
What projects are you working on now?
I'm mostly working on futurecoder, a 100% free and interactive Python course for beginners. Apart from the website, I've described the features and advantages in this reddit post which is also a good place to see what others think of it. futurecoder also uses several Python libraries that I've written and which are used in other places, particularly birdseye, snoop, executing, stack_data. I give an overview of these projects on my GitHub profile. They all involve the kind of metaprogramming that I love: analysing code and doing deep introspection to extract interesting information for debugging and understanding. So even when I'm not working directly on futurecoder, I'm often working on something related.
Which Python libraries are your favorite (core or 3rd party)?
A library that means a lot to me is asttokens. It makes it easy to retrieve the source code (and its location) associated with a node of the AST (Abstract Syntax Tree) which isn't something many people need, but I use it all the time. Recent versions of Python have a function for that but not for everything I need, so it's an essential dependency of my libraries. I made a bunch of contributions to the project, both because I was grateful for its existence and to make sure my own projects that depended on it kept working well. Some time later I shared futurecoder with the creator of asttokens so that they could see what it was being used for. They responded with a job offer for their company Grist, it looked interesting, and now I work there! Occasionally I even get to do some fun Python metaprogramming involving asttokens!
How did you futurecoder come about?
I've long daydreamed about making educational software, although originally it was for maths - remember that was one of my first projects. As my interests turned in general from maths to programming, so did my interest in education. At one point I got really into answering questions on StackOverflow, it was basically a hobby.
Somehow I came across Thonny, a Python IDE for beginners, and found the debugger really interesting, particularly its ability to step through one expression at a time. I looked at its source code to figure out how it worked, and that was when I first learned about the AST. I adapted the ideas to build birdseye.
At that time I already had something like futurecoder in mind, with the birdseye debugger being a primary feature, but I decided to build birdseye as a library that could be used on its own, not only as part of some learning resource. That turned out to be a much bigger project than I'd expected. Years later, after having built the other libraries I mentioned, I decided to actually start on futurecoder. It's a good thing I waited because I was now much more experienced in both Python and JavaScript, and could build a proper interface in React instead of some awkward spaghetti jQuery code like what birdseye still uses.
My motivation was and still is based on the observation that other similar resources (e.g. Codecademy) seem really lacking in features and could be improved in so many ways, and that's what futurecoder is doing. Plus, the best resources generally require payment, and I want good education to be freely available to all.
What are some challenges you faced working on futurecoder and how did you overcome them?
The biggest technical challenge was letting people run arbitrary Python code. Originally this meant running the code in a server, which was a concern for security, devops, architecture, scalability, and funding. I sort of hoped that I would figure it out (maybe with help) before futurecoder got too popular, and that people would donate enough to keep servers running. It wasn't a good plan.
Fortunately I found a much better solution: run Python in the browser using Pyodide. There's several older Python interpreters that run in the browser like Skulpt and Brython, but they wouldn't support the heavy metaprogramming like birdseye and snoop which rely on a lot of CPython-specific details. Pyodide is basically CPython running in the browser, so all that introspection still works perfectly, even down to disassembling bytecode instructions.
Pyodide is still pretty new and comes with challenges on its own, like reading from stdin (e.g. the input() function), but with a lot of work I managed to get it working. I did a massive overhaul of the futurecoder codebase, completely removing the Django backend servers and converting the whole thing to a 'static' website that costs very little in hosting and makes life much easier. It now uses a firebase database to store user data, which was also very helpful, there's some very cool technology there.
A challenge I'm struggling with is making the site look good. I hate CSS with a fiery passion and generally spend as little time on it as I can, which is why the course uses bootstrap a lot and looks generic and sad. I'm hugely grateful to a friend and coworker for making the awesome homepage, my own attempts looked hideous. But it still has issues, especially on mobile, and I dread the thought of trying to deal with them myself.
The other problem is marketing and promotion. I get lots of compliments from users who love learning on the site, but I don't know how to spread the word more widely. In particular I'm struggling to find people to help me build futurecoder further. I've been working on futurecoder for about 2 years now, mostly on my own, and it's getting exhausting. So I'm trying to figure out how other people advertise free stuff and attract open source contributors, and it's hard.
Thanks for doing the interview, Alex!
本周 PyDev:阿里·斯皮特尔
原文:https://www.blog.pythonlibrary.org/2019/02/04/pydev-of-the-week-ali-spittel/
本周,我们欢迎阿里·斯皮特尔( @ASpittel )成为我们本周的 PyDev!阿里是的博客作者和的演讲者,他喜欢教授科技知识。你可以看到她在 Github 上写了什么代码。让我们花一些时间来更好地了解 Ali!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
嘿!我是阿里。我是 DEV 的一名软件工程师,DEV 是一个很棒的程序员社区,在加入之前我曾是其中的一员。工作之余,我和我的小狗布莱尔一起攀岩和闲逛。我也真的参与了 DC 技术社区,这太不可思议了。
就编程而言,我基本上是自学的——我在汉密尔顿学院主修政府专业,但我参加了一些计算机科学课程,并爱上了它。我们到了!
你为什么开始使用 Python?
实际上,我在大学里学习 Python 作为我的第一门编程语言。那堂课棒极了——我们制作了一堆游戏,并且很好地学习了基础知识。
你还知道哪些编程语言,你最喜欢哪一种?
我曾经专业地做过很多前端开发,并且我从 JavaScript 中获得了很多乐趣。我在工作中也做过一些 Ruby。我在学校用过 Java 和 C++。然后,对于个人项目,我也用过 Elm 和 Go。我认为 JavaScript 是我最喜欢的——它对网络非常重要,你可以用它来创建非常酷的创意。
你现在在做什么项目?
现在,技术社区和写作占据了我很多时间,但我最大的副业项目是https://learncodefrom.us/,它突出了来自技术领域代表性不足的群体的内容创作者。
哪些 Python 库是你最喜欢的(核心或第三方)?
我职业生涯的很大一部分是编写 Django 代码(并为其创建课程),所以这绝对是一个大工程。绝对是我的 goto web 框架。我也认为熊猫是如此强大-超级酷你可以用它做很多事情。另一个(实用的)是集合——我做了很多代码挑战,这很有帮助。我认为 turtle 也是标准库的一部分真是太酷了——如此有趣的教育工具。
你是如何开始写博客的?
我有这样一个系列,我每周学习一项新技术,用它做一些东西,然后写下学习过程。这是一项繁重的工作,但也很有趣。一年多以前,我开始在 Medium 上写作——我并没有真正对它感兴趣,但是构建东西和写东西是很有趣的。然后,几个月后我加入了 dev.to ,我真的很喜欢这个社区,并且肯定有了一个更好的读者群。今年夏天,我把我的写作转移到了更普遍的编程主题上,我从中获得了更多的乐趣!
你从关于编程的写作中学到了什么?
我学到了很多!特别是从我让自己学习新技术的系列中——在公共场合学习真的会让你保持负责任!我也了解到了技术社区是多么的支持和鼓励——我通过写作交了这么多很棒的朋友!
阿里,谢谢你接受采访!
本周 PyDev:艾伦·唐尼
原文:https://www.blog.pythonlibrary.org/2022/06/13/pydev-of-the-week-allen-downey/
本周,我们欢迎艾伦·唐尼(@艾伦·唐尼)成为本周的 PyDev!艾伦是《T2 思考 Python 、Python 中的建模与仿真、思考 Java:如何像计算机科学家一样思考等几本书的作者。艾伦也是马萨诸塞州奥林学院的教授。
你可以通过访问艾伦的网站来了解他。现在让我们花些时间来更好地了解 Allen!
你为什么开始使用 Python?
我在 1999 年开始使用 Python,当时我在科尔比学院教授计算机科学。那时我写了这本书的第一个版本,后来成为 Think Java,我在免费许可下在网上发表了这本书。Jeff Elkner 利用许可权,把书翻译成了 Python,于是我通过看自己的书学会了 Python!
你还知道哪些编程语言,你最喜欢哪一种?
我学的第一门语言是 Commodore 64 上运行的 BASIC(我想是 1982 年),接着是 6502 汇编和 C,然后是 Java 和 C++,最后是 Python。我对其他一些语言略知一二,但 Python 是我最喜欢的。连同其他现代编程语言,我认为 Python 从根本上改变了编程的本质。第一代语言是用来编码的,也就是把想法翻译成代码。第二代语言是探索、学习、教学和思考的工具。
我在这篇文章中写了更多关于这个话题的内容:
你现在在做什么项目?
现在最大的项目可能是过度思考,一本基于我博客文章的新书。我现在正在写倒数第二章;如果一切按计划进行,它将于 2023 年初出版。同时,我会在 http://www.allendowney.com/blog/的博客上发布更新和摘录
哪些 Python 库是你最喜欢的(核心或第三方)?
我最喜欢的一个是 empiricaldist,它提供了表示经验分布的对象(基于数据而不是数学公式)。但那是我的库,我为了支持 Think Bayes 和 projects 而写的,所以可能那不算。我最喜欢的不是我写的库是 Pandas,我现在用它做几乎所有的事情,包括 empiricaldist 的实现。
你是如何决定成为一名作家的?
出于无奈!我正在教授一门使用 Java 的编程入门课,我对现有的书籍感到非常失望。除了别的以外,它们太长了。学生们没有办法阅读它们,因为他们没有时间。我想,如果我能把它压缩到 150 页,也就是每周 10 页,他们就能阅读并理解它们,我们就能在此基础上进行建设。我在学期开始前两周开始写作,一天一章,然后花一天时间编辑和印刷。这是简书的另一个好处——它们不用花很长时间来写。
你发现你的计算机科学学生最纠结的是什么概念?
功能,毫无疑问。对于许多学生来说,函数是学习编程的成败关键。如果你想一想,当你调用一个函数的时候,会发生很多事情:参数被赋值给参数,执行流程绕道而行,局部变量被创建和销毁,然后返回值被传回。这对初学者来说太难了。然后我们加上递归!不幸的是,这是许多学生无法逾越的障碍,至少在他们第一次尝试时是这样。
你还有什么想说的吗?
我有消息了!在这个学期结束时,我将从奥林学院退休,开始在 DrivenData 担任一个新的工作人员科学家。我仍然热爱教学,但自 1985 年以来,我一直在大学校园里担任这样或那样的角色,所以我准备改变一下。我很高兴有机会将数据科学应用于社会公益,特别是在发展和气候变化领域。
艾伦,谢谢你接受采访!
本周 PyDev:Aly SIV Ji
原文:https://www.blog.pythonlibrary.org/2021/02/15/pydev-of-the-week-aly-sivji/
本周我们欢迎 Aly SIV Ji(@ caussivjus)成为我们本周的 PyDev。Aly 是芝加哥 Python 用户组(ChiPy) 的组织者,这是最大的 Python 组之一。如果你想知道阿里在做什么,你可以访问他的博客或者查看他的 Github 简介。也可以在 LinkedIn 上和他联系。

现在让我们花些时间来更好地了解 Aly!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我住在芝加哥,在 Noteworth 公司做高级后端工程师。Noteworth 是一家种子期初创公司,致力于构建一个数字医疗平台,供提供商用来跟踪和监控患者。我喜欢在一个紧密团结的产品团队中工作,开发积极影响人们生活的创新解决方案。我们发展迅速,一直在寻找有才华的工程和产品人员-如果您看到您感兴趣的职位,请联系我们!我们与世界各地的员工完全保持距离。
我并不总是一名开发人员:我毕业于滑铁卢大学,获得了计算数学学位。虽然我确实上过一些(必修的)编程课,但我的兴趣主要在金融市场。在意识到衍生品和金融工程的世界不适合我之前,我在芝加哥的几家大银行和几家专业交易商店工作过。
这是 MOOCs 开始流行的时候,我花了很多工作之外的时间去思考下一步会发生什么。我参加了每一门听起来一点也不有趣的课程,并完成了我所关心的少数课程。一门课很突出:马克·布朗斯坦博士的医疗保健信息学(EdX上的最新版本);本课程概述了技术可用于改善美国医疗保健交付模式的不同方式。医疗保健影响着我们所有人,它似乎是一个令人满意的行业。课程结束后,我报名参加了西北大学的在线医疗保健信息学硕士项目,并开始了改变职业生涯的过程。
毕业前几个季度,我从 IBM Watson Health 的一个数据分析/数据工程职位转到了实验室测试领域的一个小型医疗保健初创公司的后端工程职位。这家初创公司没有成功,我花了几年时间在大型市场研究公司做后端工程师来支付账单。做一名企业程序员是一件苦差事,我差点就放弃了,去做一名开发人员关系或产品经理。幸运的是,我决定不这么做,加入了另一家医疗创业公司。
我觉得在疫情之前我有更多的爱好。我仍然试着每周出去跑一会儿步。我也喜欢看老的电视节目,比如《我爱露西》、《MAS*H》、《三人行》、《T5》和《T6》、《T7》。如果它在 MeTV 上,我的 TiVo 可能正在录制它。
你为什么开始使用 Python?
Python 和 R 都被用来在 Coursera 上教授数据科学课程。最初我对 R 更为适应,因为我在几门大学课程中使用了它,但我发现自己在 R 生态系统和 RStudio 中苦苦挣扎。
Python 感觉像是一种我可以在任何地方使用的编程语言。当我开始钻研 Python 的数据模型、方法和 T2 禅的时候...我被迷住了!
你还知道哪些编程语言,你最喜欢哪一种?
我懂 JavaScript。主要使用普通的 JS,但是我也喜欢使用 React 这样的框架。我 2021 年的目标之一是为我们在 Noteworth 的前端 React 应用程序完成一个复杂的功能。
我在金融行业工作时也有很多使用 Excel VBA 的经验。我成为 Excel 超级用户已经快十年了,但这些技能从未消失。
你现在在做什么项目?
我是芝加哥 Python 用户组(ChiPy)的组织者之一。ChiPy 是世界上最大的 Python 社区之一,拥有 6000 多名成员!在新冠肺炎之前,ChiPy 每个月在芝加哥地区我们慷慨的赞助商的办公室里举办 4-6 场活动。在疫情期间,我们已经过渡到一个虚拟的时间表:我们向芝加哥 Python YouTube 频道直播谈话活动,并每月举办项目之夜,人们可以在我们的聚会上合作。小镇空间。
疫情的一个好处是 Chicago Python 社区不仅仅是本地的,我们是全球性的!我们有来自津巴布韦、以色列、捷克共和国、克罗地亚、加拿大和美国各地的演讲者!与全球 Python 社区的联系令人惊叹!我们一直在寻找演讲者:如果你有兴趣发表演讲,请联系我们。
几年前,我开始创建一个名为 Busy Beaver 的社区参与 Slackbot。这个项目最初是一个周末黑客马拉松,为 ChiPy Slack workspace 构建 GitHub 活动机器人,后来发展成为一个相当复杂的 Flask 应用程序,部署到我在 DigitalOcean 上的 Kubernetes 集群中。我在 PyCon、PyCascades 和 PyOhio 的 Busy Beaver 上主持过开源冲刺会议,这个项目有来自世界各地的贡献者!我在 PyCon Africa 2020 上做了一个关于“忙碌的海狸”的的详细报告,供那些想深入了解的人参考。
我参与的另一个项目是有限状态机,它是 Python 中有限状态机(FSM)的一个轻量级、基于装饰器的实现。
在 Noteworth,我正在构建一个集成服务,它位于我们的客户和后端平台之间。该服务利用 AWS SAM 框架,并作为无服务器应用程序进行部署。这个项目完全是一片绿地,我有机会将我的许多观点插入到知识库中,这非常有趣!我将在 2021 年 3 月的 Python Web Conference 上讲述 Noteworth 如何使用 AWS SAM 和 LocalStack。
哪些 Python 库是你最喜欢的(核心或第三方)?
“显式比隐式好”是我最喜欢的 Python 禅宗中的一句话。当我编码的时候,我试着尽可能的清晰,像 django-fsm 和 jsonschema 这样的库帮助我设计出易于调试的健壮特性。我非常喜欢 django-fsm,所以我用类似的 API 构建了一个非 django 版本。
在标准库中,我总是使用“typing.NamedTuple”来创建数据传输对象。也是 itertools 的超级粉丝。
你是如何开始做科技演讲的?
不管你对软件工程或数据科学了解多少,得到你的第一份技术工作总是很难的。我知道我必须从人群中脱颖而出,以说服一个值得我冒险的团队,特别是作为一个没有任何正式训练的职业改变者。我知道 Python,但其他申请人也知道。
2017 年,我开了一个博客,记录小副业的搭建过程。我的方法非常有条理:我将问题分成小块,并引用我在哪里学到的东西(大喊到代码完成】!).我也开始在聚会和会议上发言,让招聘经理记住我的名字。幸运的是,我所有的努力工作都得到了回报:我能够指出我在 PyOhio 面试时的一次演讲,这导致了我的第一份开发工作。
从那以后,我一直把技术讲座作为学习新技术、新框架或新做事方式的一种方式。人们似乎很喜欢我的演讲风格,我喜欢这种帮助别人学习新东西或者从不同的角度看待他们已经知道的东西的感觉。
我所有演讲的视频和幻灯片链接可在https://github.com/alysivji/talks/获得
作为一名 Python 用户组组织者,你学到的前三件事是什么?
1.每个人至少知道一件他们可以谈论 5 分钟的事情。
芝加哥 Python 如此活跃的原因之一是我们有许多成员自愿通过演讲与我们的社区分享他们的知识。这可能需要一点哄骗和鼓励,但每个人都至少有一件事可以在一群人面前谈论 5 分钟。
2.制定招募赞助商的计划
ChiPy 的大多数赞助商都是当地公司,他们希望招聘有积极性的工程师,面对面的活动是招聘的好方法。我写了一个 scraper 来创建一个积极雇佣 Python 开发人员的公司列表。冷冰冰地给招聘经理发电子邮件并不好玩,但它很管用,能帮助我们找到面对面活动的场所。
3.虚拟活动将会持续下去
虚拟活动的轻松和便利意味着当地组织者不得不在面对面策略的基础上开始考虑虚拟策略。
不确定一旦在大群体中安全见面,新冠肺炎会有什么影响。赞助商会允许随机的人进入他们的办公室吗?直播活动会影响现场投票率吗?无论未来会发生什么,组织者都必须做出相应的调整。
你还有什么想说的吗?
疫情对每个人来说都很艰难,要恢复正常还需要一段时间。请一定要给自己留时间,充电。心理健康和幸福很重要。
Aly,谢谢你接受采访!
本周 PyDev:阿曼达·索普金
原文:https://www.blog.pythonlibrary.org/2020/12/28/pydev-of-the-week-amanda-sopkin/
本周,我们欢迎阿曼达·索普金(@阿曼达·索普金)成为我们本周的 PyDev!她喜欢写作、教学和黑客马拉松社区。Amanda 也在各种 Python 会议上做了几次演讲。你可以在她的网站上查看她最近在忙些什么。
让我们花点时间来了解更多关于 Amanda 的信息!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在科罗拉多州的丹佛长大,为了工作搬到了旧金山。我在伊利诺伊大学香槟分校获得了数学和计算机科学学位。在业余时间,我作为职业黑客联盟的教练参加黑客马拉松,帮助学生们在他们参加的活动中获得美好的体验。我喜欢写作、演讲和痴迷地阅读关于鲨鱼的文章。
你为什么开始使用 Python?
大约 10 年前,当我开始编程时,Python 是我最早的编程语言之一。我特别被热情的社区所吸引。每次参加 Python 活动,友好的文化都会给我留下深刻的印象!
你还知道哪些编程语言,你最喜欢哪一种?
Python 是迄今为止我最喜欢的,我这么说不仅仅是因为这是一个 Python 博客!当我忘记 Python 中某些东西的语法时,这几乎总是我首先想到的事情之一。
你现在在做什么项目?
最近我做了更多的教学工作。我刚刚用 Codepath 完成了一门关于 Python 技术面试的课程。我现在正在计划一个关于女孩面试准备的课程。
哪些 Python 库是你最喜欢的(核心或第三方)?
这听起来很简单,但是我可能从 requests 库中得到最多的东西。接下来我要说的是密码学库,这是我在为一个关于 python 中随机化的演讲做研究时学到的。
我看到你谈到了重构这个话题。您认为 Python 开发人员最容易陷入哪些需要重构的陷阱?
在我看来,有两大错误导致代码需要重构。第一个是过度优化,第二个是优化不足。当人们过早地将代码优化为更少的代码行,甚至过度抽象代码时,就会变得令人困惑。如果它变得足够混乱或者理解代码的人离开了团队,它可能需要重写。另一方面,如果你不维护代码,让它失去控制,也需要一些重构。这是在编写易于理解的良好的可维护代码和不根据您自己的个人偏好做过多事情之间的平衡行为。
Python 与加密有什么关系?
python 中的加密库为加密功能提供了许多预构建的功能。它有更抽象的“即插即用”界面以及更多可定制的底层内容。我做了一个关于随机数生成如何影响密码学的演讲,这是一个有趣的话题,包括产生随机性的方法,比如雷暴和熔岩灯。
阿曼达,谢谢你接受采访!
本周 PyDev:Amber Brown
原文:https://www.blog.pythonlibrary.org/2016/06/20/pydev-of-the-week-amber-brown/
本周,我们欢迎 Amber Brown ( @hawkieowl )成为我们本周的 PyDev。琥珀是扭曲包的核心开发者之一。她有一个有趣的小扭曲博客,你可能会喜欢看看。你也可以通过查看 Amber 的 Github 简介来了解她最近在做什么。她还接受了 DjangoGirls 的采访。让我们花一些时间来更好地了解她!
你能告诉我们一些关于你自己的情况吗(爱好、教育等):
我是澳大利亚人,出生在珀斯,但最终来自西部的几个小城镇。我自学了软件开发和 IT,在当地政府做了五年 IT,过去三年全职做软件开发。我的爱好是棋盘/纸牌游戏(主要是围棋和 MTG!)、视频游戏(Factorio、XCOM 2)以及偶尔的摄影。编程对我来说与其说是一种爱好,不如说是一种生活;对我来说,这无疑是健康的,我确定,但事实就是如此!最让我吃惊的是我的年龄,22 岁。我的中间名是 Hawkie(来自 HawkOwl,我的手柄),和大多数跨性别女性一样,我喜欢盐和双关语。
你为什么开始使用 Python?
当我全职转向软件开发时,我正在尝试 Node.js,这在 2012 年还是一个热门的新事物。我的朋友们,像他们一样聪明,扔了 Python,转而向我扭过来。几个月后,我承担了发布管理的职责,现在,三年后,我是核心开发人员之一,至少对 Twisted 在过去几年中取得的许多进展负有部分责任。
你还知道哪些编程语言,你最喜欢哪一种?
我的第一门编程语言是 VB6,第二门是 VB.NET。我也知道相当多的 HTML/CSS/JS 栈,和一些 c 语言。但是 Python 是我最喜欢的,到目前为止。。
你现在在做什么项目?
当然是扭!我目前正在推进 Python 3 的移植,以及一些新特性(作为 Cory Benfield 的 HTTP/2 工作的主要评审)。我今年的大致计划可以在我的博客上找到!(https://atleastfornow.net/blog/twisted-in-2017/)
除此之外,还有https://github.com/hawkowl/incremental,一个为你的 Python 版本化的库,和https://github.com/hawkowl/towncrier,一个小工具,从发布时拼凑的片段制作“新闻文件”。我还在开发 Crossbar.io 和 Autobahn,这是我在 Tavendo/Crossbar.io 工作的一部分。
我也在为 PyCon US、PyCon TW、EuroPython 和 PyCon AU 做一些演讲——一般来说,它们最终都是些小项目,因为写演讲通常能帮助我解决一些我正在谈论的问题!
哪些 Python 库是你最喜欢的(核心或第三方)?
最明显的选择是扭曲,因为这是我心中最珍视的东西!我也非常尊重 Django、Requests 和 Tornado 库(尽管在技术上有分歧)。Cory Benfield 的 hyper-h2 也是我最喜欢的一个例子——它展示了如何编写一个网络协议库,而不把它与特定的框架或同步/异步用法联系起来。
作为一门编程语言,你认为 Python 将何去何从?
我相信 asyncio 已经引领了一个疯狂的时代,向标准库中添加随机的东西——我不认为应该有很多东西放在那里,我认为还需要几年时间才能意识到电池在工作的 PyPI 中并不存在。也就是说,我认为 Python 3 的“生存能力”已经达到了极限,在未来的几年里,它只会更加流行。
你对当前的 Python 程序员市场有什么看法?
当我在 2014/15 年找工作时,“必须愿意搬到旧金山”对很多职位来说都是一个不幸的门槛——澳大利亚肯定没有太大的市场,这很不幸。
你还有什么想说的吗?
软件是硬的,但人也是!如果说在过去几年的 Twisted 工作中我意识到了一件事,那就是仅仅谈论代码、性能和完美是不够的——用户成果和用户学习曲线非常重要。Django 最好地证明了这一点;它几乎不是最快的,或者最好的图书馆,但是它正在变得更好,它变得更好是因为它有用户,并且它关心那些用户。这是我们需要学习去做更多的事情。
本周 PyDev:阿米尔·拉丘姆
原文:https://www.blog.pythonlibrary.org/2017/06/12/pydev-of-the-week-amir-rachum/
本周我们欢迎 Amir Rachum 成为我们本周的 PyDev。阿米尔是 pydocstyle 和 yieldfrom 的作者/维护者。阿米尔还写了一个有趣的关于 Python 的小博客。让我们花一些时间来更好地了解 Amir!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是一名来自特拉维夫地区的以色列软件开发人员。我有软件工程学士学位。我在大学四年中花了三年时间在学生岗位上工作,以获得一些现实世界的经验,我相信这一点直到今天都产生了巨大的影响(对我的技能来说是积极的,对我的成绩来说不是那么积极)。
在我的业余时间,我喜欢和朋友一起玩棋盘游戏——到目前为止,我的收藏中有超过 200 种棋盘游戏。
你为什么开始使用 Python?
我在学生时代玩过一点 Python,到处都是实用程序脚本,但大多数其他开发人员都使用 Tcl,所以我也跟着学。直到我的下一份工作,我才开始全职用 Python 开发——从 Python 2.4 开始,一直到 2.7。不幸的是,我们仍然没有迁移到 Python 3。
我花了大约 3 年的时间与 Django 合作开发 web 应用程序后端以及异步任务运行服务,该服务与定制的嵌入式板进行交互(并在其上运行)。
你还知道哪些编程语言,你最喜欢哪一种?
我也有在桌面和嵌入式系统中使用 C++的经验。我也涉猎了一些 Java 开发。到目前为止,Python 是我最喜欢的——在没有“官僚”障碍的情况下,我将想法付诸实施的速度是惊人的。
你现在在做什么项目?
我是 pydocstyle 的作者和维护者,这是 Python 的一个静态 docstring linter。大多数人都熟悉 PEP8,它是一个定义 Python 编码约定的 PEP。PEP257 是一个类似的 PEP,它定义了 docstring 约定——间距、内容等。我发现自己留下了很多关于 docstring 约定的评论,所以我寻找一个工具来自动执行它,就像 pep8 为 pep8 所做的那样。我偶然发现了 Vladimir Keleshev 的 pep257,并开始投稿,直到我成为维护者。
后来,吉多·范·罗苏姆要求这两个项目更改我们的名字,以便不暗示我们的实现是正式的。所以我们决定为“pep8”选择 pycodestyle ,为“pep257”选择“pydocstyle”。我们认为这一变化是“pep257”的分支。
随着名称的改变,我们也将项目转移到了 PyCQA 框架中。PyCQA 是 Python 代码质量(未授权)权威,它收集了几个代码质量工具,包括“pydocstyle”、“pycodestyle”、“pylint”、“flake8”等等。
我也刚刚发布了一个名为yields from的小库。这是从 Python 3 到 Python 2 的语义“屈服”的反向移植。它专注于一个非常具体的问题,所以我怀疑它会占用我更多的时间,但是我发现在 Python 2 中使用嵌套生成器时它非常有用。
当我有一个好主意和一些空闲时间时,我也写博客,在那里我写编程(主要是 Python)和相关主题。我特别自豪我在知识债上的帖子。
哪些 Python 库是你最喜欢的(核心或第三方)?
我是‘pathlib’的忠实粉丝,它突然让文件系统操作变得令人愉快。我个人的任务是将我们的遗留代码一点一点地转换成使用‘path lib’。
我也喜欢用‘mock’进行测试,用‘doc opt’进行命令行解析。
作为一门编程语言,你认为 Python 将何去何从?
向 Python 3 的转移正在发生。我记得当http://py3readiness.org/有几十个 Python 3 兼容库的时候,今天它显示 PyPI 中前 360 个包中有 343 个支持 Python 3。如果你仔细看看,大多数没有的包,只是它们的 Python 3 分支有不同的名字。
我在每个新项目中都使用 Python 3,并且我鼓励每个人都这样做。
非常感谢你接受采访!
本周 PyDev:Amit Saha
原文:https://www.blog.pythonlibrary.org/2015/11/16/pydev-of-the-week-amit-saha/
本周,我们欢迎 Amit Saha 成为我们本周的 PyDev!Amit 是《T2 用 Python 做数学运算》和《T4 写你的第一个程序》的作者。让我们花些时间来更好地了解 Amit!
你能告诉我们一些关于你自己的情况吗(爱好、教育等):
我是一名软件工程师(目前是澳大利亚悉尼 Freelancer.com API 团队的一员),主要从事后端服务的软件开发。我还对承载这些服务的基础设施非常感兴趣,并试图尽可能多地了解服务器配置和管理、监控以及所有相关的事情。我喜欢写各种编程和 Linux 主题的文章,我的文章已经发表在各种 Linux 杂志上,我的第二本书“用 Python 做数学”最近出版了。
你为什么开始使用 Python?
我开始学习 Python(大约在 2005-2006 年),因为我对这种“新”语言很好奇。有趣的是,直到 2012 年我参加了谷歌代码之夏,随后加入了布里斯班的红帽,从事烧杯项目,我才真正编写了严肃的 Python,并学到了很多我今天知道的东西。我喜欢它,这并不奇怪。
你还知道哪些编程语言,你最喜欢哪一种?
我懂 C,一点 C++,在过去的几个月里,除了 Python 之外,我还用 PHP 编程。我正在尝试学习 Golang,但我认为 Python 是我目前最喜欢的,因为如果我有一个想法,Python 允许我实现它,而不会妨碍我。我很想写更多的 Bash,但是语法和怪癖阻碍了我。
你现在在做什么项目?
我负责 Fedora Scientific ,在撰写文章的同时尝试探索和学习各种东西(Linux 容器、Web 应用等)。我也期待着“用 Python 做数学”的评论,并想出读者在阅读这本书后可能会发现有用的新文章/帖子。
哪些 Python 库是你最喜欢的(核心或第三方)?
由于 SymPy 形成了《用 Python 做数学》中几个章节的核心部分,我认为它已经成为我最喜欢的 Python 包。除此之外,当我想写一个 web 应用程序和/或与数据库和 Sphinx 交互时,Flask 和 SQLAlchemy 是两个必不可少的软件包。最近,假设和测试引起了我的注意,我想更多地玩它们。
在标准的库模块中,我发现“collections”模块很棒,所有的模块都在数字和数学模块部分。
你为什么决定写一本关于 Python 的书?
我写“用 Python 做数学”的主要目标是为初/高中的学生/教师提供一个将 Python 编程(已经开始向初次编程者介绍)和高中数学相结合的资源。这基本上是针对那些可能会感到疑惑的学生——“我为什么要学习编程?”告诉他们编程可以给他们实验室里的科学实验所能给的瞬间。我在这本书的介绍中写道,学生在书中写的一些程序只是高级计算器,但一些程序将允许探索否则不可能做的事情(如绘制分形)。
你还有什么想说的吗?
非常感谢参与 Python 生态系统的所有了不起的人。另外,谢谢迈克给我机会参加你的采访系列。
非常感谢!
一周的最后 10 个 PyDevs
本周 PyDev:Anand Balachandran Pillai
原文:https://www.blog.pythonlibrary.org/2017/05/15/pydev-of-the-week-anand-balachandran-pillai/
本周,我们欢迎 Anand Balachandran Pillai 成为我们的本周 PyDev!Anand 是 Packt Publishing 出版的新书《使用 Python 的软件架构》的作者。他是 Bangalore Python 用户组( BangPypers )的创始人,也是 Python 软件基金会的成员。让我们花一些时间来更好地了解 Anand!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我于 1998 年在钦奈的印度理工学院完成了我的工程——机械工程。然而,在我的一生中,我从未做过一天机械工程,因为毕业后我立即从事了我的第一份计算机软件工作。
爱好——过去我是一个狂热的徒步旅行者,现在有时我仍然喜欢这样做。尽管更有规律的爱好是平常的——听音乐、阅读和长途驾车。
从上学的时候起,我就是夏洛克·福尔摩斯的狂热粉丝。一个次要爱好是收集福尔摩斯故事和各种语言的书籍。我甚至在现实生活中对朋友和家人尝试他的理论,并取得了不同的成功!
你为什么开始使用 Python?
我第一次使用 Python 是在 2002 年 10 月左右,当时我是班加罗尔一家公司的软件工程师。
他们使用的是一种专有语言——比 C 多一些,但比 C++少一些。那时我已经进入职业生涯 5 年了,对仅仅知道 C 和 C++而没有机会使用后者感到沮丧。
我想学习 C/C++之外的东西。我尝试了一段时间 Perl,但是迷失在它晦涩的语法中,一个月后就放弃了。我当时不知怎么碰巧看到了 Python 网站。就像官方教程里说的(旧的那个——当时叫“一下午学会 Python”!)——我真的在一个下午第一次尝试了——并且当场就学会了。
在最初的几个月里,我只使用了官方教程和官方模块文档来学习 Python。
后来我买了一本 Alex Martelli 的《Python 简括》——这是我接下来 2-3 年的 Python 圣经。
请注意,在接下来的 3 年多时间里,我再也没有在任何官方工作中使用过 Python。我大部分时间都在用 Python 开发业余爱好项目——最有生产力的是 harvest man——我自己用 Python 写的网络爬虫。
你还知道哪些编程语言,你最喜欢哪一种?
我可以随时用 C 语言编程,我在大学和职业生涯中已经做了 10 多年,尽管我的 C++现在有点生疏了。
我非常了解 Perl 在雅虎工作期间,我注定会再次遇到它。(2010 - 2012 年)我在那里写了很多代码,已经失去了早期对其语法的厌恶。当时我确实发现它是一种非常有效的语言——尽管我离开了雅虎!,我没有在任何个人项目中使用过。
在雅虎!我也用 PHP 编程——没有别的办法——尽管现在如果可能的话,我不会用旗杆去碰它。
我试图学习 Ruby——但是坦白地说,我不喜欢这种语言,因为我知道 Python 和 Perl——我想我无法在我的脑海中找到 Ruby 的正确位置——所以我放弃了任何尝试去学习它。我最近的工作是在一家大部分工作都使用 Ruby 的公司——尽管我从未在那里编写过一行代码。我更喜欢使用 Python!😉
这些天来,我一直在花时间尝试学习 Rust,还在 Erlang 上做了一个在线课程。
我喜欢 Erlang 使用模式表达逻辑的方式——与我目前所学的任何东西相比,它感觉非常有象征性和表现力。然而,我从未在任何项目中使用过它。
你现在在做什么项目?
对于我现在的公司,我正致力于编写可扩展的爬虫——所以很多时间都花在 Scrapy 上,并用它编写定制的爬虫。
我确实为开源项目做了一点贡献。最近我花了一些时间在 Junction 上——我们在印度的 Python 社区中构建的会议软件——为 PyCon India 和类似的网站提供动力——帮助修复问题并指导一些学生贡献补丁。
我今年的另一个目标是为 CPython 贡献更多的补丁——自 2008 年以来,我已经做了大约 3 或 4 个——但我想在那里做更严肃的工作,并在未来几年内或多或少地将它作为一项常规活动——并希望指导年轻的大学毕业生为 CPython 贡献补丁。
哪些 Python 库是你最喜欢的(核心或第三方)?
核心——我认为是多重处理。这是我最近在工作中使用的东西——将数据并行计算分散到不同的内核上。我特别喜欢泳池对象!
第三方——许多库,尽管我印象最深的是 SQLAlchemy,考虑到它是多么强大,而且大部分是由一个人(Mike Bayer)开发的。我对它进行过专业的培训,但它的技巧和食谱总是让我惊叹不已。
是什么让你决定写一本关于 Python 的书?
在过去 10-15 年使用 Python 的过程中,作为一名架构师和一名 Python 程序员,我积累了丰富的(或许)独特的经验。
有一段时间,我想以书的形式分享我的经历。我想到将架构师处理问题的方式与 Python 解决问题的方式结合起来,并产生了用 Python 写一本关于软件架构的书的想法。
另一个方面是我使用 Python 以独特的方式编写设计模式的经历。
与 C++或 Java 等表达性较差的语言相比,Python 可以用来以非常不同的方式编写设计模式。在编写模式时,使用 Python 可以变得非常有创造性。
在我的书中,我试图在设计和架构模式章节的许多例子中说明这一点——没有必要拘泥于 Python 和模式,而是应该让他/她的创造力流动起来!
这种精神在亚历克斯·马尔泰利的博格(非模式?)模式,我已经在书中详细解释过了。关于如何获得创造性的例子,可以看看我在书中使用元类在一个模式中混合 Singleton 和 Prototype 的方式,以及我使用 Python 迭代器实现 State 模式的方式。
书的网址在这里:https://www . packtpub . com/application-development/software-architecture-python
谁是目标受众?
从事 Python 年多,已经习惯了它的表现力,但仍不确定自己下一步该何去何从的人。
那些一直在探索 Python 及其强大功能的人——在元类和生成器等方面——但在围绕模式构建代码和在产品中构建软件架构质量属性的正确 DNA 方面需要指导。
那些属于以上任何一类的人——渴望成为软件架构师——希望以更好、更结构化的方式使用 Python 来表达自己。
写这本书的时候你学到了什么?
我学到了很多如何正确构建思维的方法。我学会了如何以正确的方式接受反馈,并融入到我的工作中。我相信这份工作让我变得更加开放——和一个优秀的审稿人和编辑团队一起工作。
我认为我在书中给出的代码示例——它们中的许多都伴随着大量的艰苦工作和对问题的思考以及解决问题的创造性方法。我自己在写这本书的时候学到了很多关于并发性和可伸缩性的知识——并且在做研究的时候澄清了很多我自己的误解。
谢谢你评论我的书,迈克😉
你还有什么想说的吗?
我是在 2002 年遇到 Python 的,在它的陪伴下已经快 15 年了。Python 对我生活的影响是巨大的。因为 Python,我结交了一生的朋友,经历了一生的旅程,走过了一生的道路。
对于那些想使用开源语言并为之做出贡献的人,我想说试试 Python 吧!这个社区非常受欢迎,这种语言正在攀登新的高度——通过它在数据分析和机器学习中的应用。
总的来说,对我来说,这是一次丰富而有意义的旅程,也是一次愉快的旅程。
非常感谢你接受采访!
本周 PyDev:Andrea Gavana
原文:https://www.blog.pythonlibrary.org/2015/01/26/pydev-of-the-week-andrea-gavana/
安德里亚·加瓦娜是本周的 PyDev 周。他在 wxPython 项目中非常活跃,既是原创小部件的贡献者,也是许多在 wxPython 邮件列表上提问的人的巨大帮助。我认识他有一段时间了。让我们看看他有什么要说的!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我来自意大利米兰,学的是化学工程:我有幸参加了由我的第一个雇主(埃尼)和学校(意大利米兰理工大学)赞助的交流项目,所以我同时在意大利和加拿大完成了硕士学位。我目前在丹麦工作,是马士基石油公司的一名油藏工程师。
我最喜欢的爱好之一是 Python 编码,主要是针对开源框架,但我也喜欢骑自行车和游泳——尤其是如果我能和女儿一起去游泳池的话!
你为什么开始使用 Python?
我喜欢这个问题,当其他人看到我使用 Python 时,我总是会问这个问题,在我刚刚为马士基石油公司内部教授的油藏工程师 Python 课程中也是如此...早在 2003 年,我就在使用 Matlab 编写用户界面和前/后处理油藏模拟数据,但我对 Matlab 作为通用框架的局限性和相对匮乏的 GUI 功能越来越失望。所以我在各种论坛上四处打听,有人建议我看看 Boa Constructor(一个基于 wxPython 的 GUI 构建工具)。很快,我就迷上了 Python。在我开始学习和使用这门语言 10 年后的今天,它的美丽、简单和强大仍然让我惊叹。
我不得不说,我从学习曲线的错误一侧开始接触 Python,因为从一开始我就投身于 GUI 世界——在学习基础知识之前——这不是一个新用户应该做的事情。GUI 编程是任何语言中最复杂的任务之一,不是因为编码更复杂,而是因为您必须编写 GUI 来提供最无缝的“用户体验”,因为其他人(非程序员)是您产品的最终用户。
你还知道哪些编程语言,你最喜欢哪一种?
嗯,我最喜欢的仍然是 Python。但我也用 Fortran 编写代码,尤其是对于高度密集的数值模拟,然后我使用优秀的 f2py 和 voila 将我的 Fortran 例程连接到 Python,我将 Fortran 的速度与 Python 的美丽融为一体。我也知道 Matlab,但我接触它已经有一段时间了,在过去的几年里,我用 C#编写了一些程序。
你现在在做什么项目?
不幸的是,由于非常繁重的工作和个人承诺,这些天我在开源世界有点不活跃...然而,我仍然是 AGW 库的官方维护者,这是一个所有者绘制的、令人惊叹的 wxPython GUI 框架的通用部件的集合。我还为开源社区贡献了几个用户界面, GUI2Exe 和名称空间差异工具。由于我过去一直从事数值优化例程的工作,不久前我决定向开源世界发布我的一个算法 AMPGO 。它是一个非常强大的解算器,能够胜过 SciPy 优化堆栈中的所有数值算法。
哪些 Python 库是你最喜欢的(核心或第三方)?
我喜欢 wxPython,它使我能够创建漂亮、一致和独立于平台的用户界面,同时保持小部件的原始外观,无论我的 GUI 是在 Windows、Linux 还是 Mac 上运行。这是迄今为止我见过的最好的 GUI 框架。
我经常使用 NumPy 和 SciPy,因为我们的工作需要大量的数字处理,我总是对这两个库的能力和速度印象深刻。我也是 SQLAlchemy 的粉丝,因为它允许我以无缝的(并且独立于数据库的)方式在数据库中存储数据和结果。
你还有什么想说的吗?
谢谢你邀请我参加本周的 PyDev!
谢谢!
前一周的 PyDevs
- 蒂姆·戈登
- 道格·赫尔曼
- 玛格丽塔·迪利奥博士
- 马里亚诺·莱因加特
- 巴斯卡尔·乔德里
- 蒂姆·罗伯茨
- 汤姆·克里斯蒂
- 史蒂夫·霍尔登
- 卡尔查看
- 迈克尔·赫尔曼
- 布莱恩·柯廷
- 卢西亚诺·拉马拉
- 沃纳·布鲁欣
- 浸信会二次方阵
- 本·劳什
本周 PyDev:安德鲁·戈德温
原文:https://www.blog.pythonlibrary.org/2017/06/05/pydev-of-the-week-andrew-godwin/
本周我们欢迎安德鲁·戈德温( @ 安德鲁·戈德温 )成为我们本周的 PyDev!Andrew 是流行的 Python web 框架 Django 的核心开发人员。Andrew 维护着一个关于他冒险经历的博客,但是如果你对他的代码更感兴趣,那么你会想要查看他的 Github 简介。你也可以在这里查看他的一些项目。让我们花一些时间来更好地了解 Andrew!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
Well, I grew up in suburban South London, and initially started programming on my mum's Palm IIIx in BASIC when I was bored during holidays and longer trips, along with trying out my hand at HTML at the local library. Eventually this turned into me doing Computer Science at Oxford (I almost went for physics, but changed my mind as I wanted an easier life), where I learnt a decent amount of theory that I almost never use in practice, and instead draw on my time writing open source software since I was about 15 and what it's taught me about maintainability, software architecture and the importance of helping other people.Hobby-wise, I probably have too many; the one I spend most time on apart from programming (both open-source and noodling away on the occasional game) is probably flying (as in, piloting light aircraft) and then traveling (as in, flying on other people's aircraft). On the side, I also do electronics, 3D printing/making things, riding my motorbike, archery, photography, cinematography, baking, and when the season is right, snowsports. I'm also on a rough quest to visit every state and territory of the US as well as all 59 of the National Parks, so I have my work cut out.Why did you start using Python?I think it was about 2005 and I was looking for an alternative to PHP, having used it for a number of years and finding its organisational features and security features lacking (one of the open source projects I was working on back then, ByteHoard, had several security issues caused by some less-helpful features of the language not combining well with my own lack of experience). I searched around for what other web programming languages were around and stumbled upon a TurboGears tutorial, and liked the look of Python so I tried it out. I wrote in TurboGears for a year or two until I spent a summer working with Simon Willison, who taught me Django and then I've been working with Python pretty much ever since.What other programming languages do you know and which is your favorite?I only know a few other languages to what I call a "dangerous" level - Java, C#, Arduino C, JavaScript, PHP, and Go. Of the non-Python languages, I'd say C# is probably my favourite, because it's the other end of the spectrum; strongly typed, interfaces and generics everywhere, but it does it quite a bit better than Java and has some built-in features like LINQ that remind me of Python's best bits.I've dabbled in a few more, and of those, VHDL maybe has to be the most confusing. It's a Hardware Description Language - the language you use to program FPGAs, among other things - and because it translates into circuits, what looks like procedural code with if statements actually all executes perfectly in parallel, and assignments don't take effect until the next clock cycle. It's fun to make stuff in though, as the end result runs ridiculously fast.What projects are you working on now?My main project time goes into doing ongoing development and maintenance on Django Channels (http://channels.readthedocs.
你对当前的 Python 程序员市场有什么看法?
I can't really speak very well to this, as via a series of fortunate events I have not found myself on the open job market for many years now, but based on what I've seen of trying to hire, it still seems to very much be an employee's market for Python programmers, both on the smaller company side and increasingly on the big/corporate company side.Is there anything else you’d like to say?*Just because it's not said enough, if there's an open source project you like and use, take a moment to send a message to the maintainers and say how useful it's been. About 99% of all the communication open source maintainers basically is about bugs and issues, so the small amount of happy stories we hear are really the thing that keeps us going. And if a project is asking for donations, just think about how long it would have taken you to do the same thing yourself, and if you have the money to spare, consider giving them some. *
本周 PyDev:安德鲁·奈特
原文:https://www.blog.pythonlibrary.org/2018/04/16/pydev-of-the-week-andrew-knight/
本周我们欢迎安德鲁·奈特( @automationpanda )成为我们本周的 PyDev!Andrew 是一名企业家,他联合创立了改革男装,该网站是使用 Python 和 Django 创建的。如果你有时间,可以看看他的 Github 简介,看看 Andrew 都在做些什么。Andrew 也有编程博客,你可能想看看。让我们花一些时间来更好地了解他!

你能告诉我们一些关于你自己的事情吗(爱好、教育等)。)?
从专业上讲,我是一名软件工程师,专注于测试、自动化和 CI/CD。我的专业是构建测试自动化框架。我在北卡罗来纳州罗利附近的大型软件公司工作过,我在automationpanda.com经营一个软件博客,我也做独立咨询。
我来自美国马里兰州的巴尔的摩。我第一次接触软件是在 9 年级,当时我学会了如何将数学公式编程到我的 TI-83 Plus 图形计算器中。编码会上瘾!2010 年,我在罗切斯特理工学院获得了计算机科学的综合学士/硕士学位,从那以后,我一直在软件行业工作。
我是一个相当忙碌的人,但我喜欢烹饪、精酿啤酒和玩任天堂游戏。现在,我正在深入塞尔达传说:野性的呼吸。我在当地的教堂非常活跃:我曾经担任过引座员,现在正在教授一门系统神学的课程。我妻子和我也喜欢旅行。我们已经走遍了美国、中国,甚至泰国,并计划着更多有趣的旅行。
你为什么开始使用 Python?
为什么不是?Python 太牛了!
我第一次使用 Python 是在高中高年级的一堂计算机科学课上。那时,我还是一个年轻的程序员,主要是 Java 和 C++方面的经验。Python 简洁优雅的代码给我留下了深刻的印象。
快进到 2015 年,我开始在 MaxPoint 工作:我从高中开始第一次重新拿起 Python 进行测试自动化。MaxPoint 在 Python 自动化方面做了一点工作,但不多。他们的节俭服务框架也有 Python 绑定,这使得集成更加容易。我开始为定制的日志、服务、数据库、SSH、环境和输入开发自动化模块。这些模块可以被任何测试框架使用:unittest、nose、pytest、behavior 等等。我还开发了一些 Python 命令行工具来改进流程和辅助手工测试。Python 使得开发测试和工具变得快速而简单。
你还知道哪些编程语言,你最喜欢哪一种?
我主要的四门语言是 Python,Java,C#,JavaScript。现在,C#和 Java 是我的日常工作,Python 是独立项目,JavaScript 像打地鼠一样随处可见。我使用了带角度的类型脚本。在 NetApp,我只做 Perl。我也用过 C/C++、AspectJ、Scheme、Haskell、R,甚至 COBOL(那是一段可怕的过去)。
到目前为止,我最喜欢的语言是 Python。我坚信好的软件设计既是工程,也是艺术。语言应该帮助开发人员有效地表达设计,而不碍事。Pythonic 代码非常精确而简洁。
我也相信 Python 是测试自动化的最佳语言之一。测试必须是可读的,以便维护。Python 丰富的测试框架、包和工具生态系统使得构建像 LEGOs 这样的自动化解决方案变得容易。

你现在在做什么项目?
目前,我正在使用 Django 框架开发两个不同的网站。一个是为我共同创立的西装公司“改良男装”设计的。我为客户数据和订单处理建立了一个后端系统。唯一需要的页面是 Django 的自动生成的管理,因为它是一个私人后端网站!接受订单时,我们通过管理员输入尺寸、图片和风格点。由于我们的裁缝在中国,一个管理动作生成了英文和中文的 pdf 格式的订单规格。该网站位于 Heroku,图片存储在亚马逊 S3。我计划使用 Django REST 框架添加一个带有服务层的 Angular 前端,以便客户可以直接输入他们的订单。(新的前端将最终取代我们目前的 Wix 网站。)第二个 Django 站点是我妻子的一家公司的一个类似的订单处理系统。
哪些 Python 库是你最喜欢的(核心或第三方)?
除了 Django,我真的很喜欢测试自动化包。我最喜欢的 Python 测试框架是 pytest ,因为它如此强大却又如此简洁。像请求和 Selenium WebDriver 这样的包让测试变得轻而易举。标准日志模块负责测试日志。虚拟环境处理测试依赖性。几乎任何其他测试任务都可能在 PyPI 中有一个包。
你参加过会议或聚会吗?
是啊!今年 5 月,我将在俄亥俄州克利夫兰市举行的 2018 年 PyCon 大会上发表演讲。我将发表一篇题为“行为驱动的 Python”的演讲,在这篇演讲中,我将展示如何在 Python 测试自动化中使用行为驱动的开发。这将是我第一次参加 PyCon,我等不及了。
我还在 PyData Carolinas 2016 大会上发表了题为“Python 中的测试很有趣”的演讲。我概述了主要的 Python 测试框架。这个演讲被上传到了 YouTube 上。几个月后,我给皮拉迪斯·RDU 做了一次类似的演讲。
你还有什么想说的吗?
谢谢你花时间采访我。Python 很牛逼。查看自动化熊猫并在 PyCon 2018 上查找我!
感谢您接受采访!
本周 PyDev:安娜·马卡鲁泽
原文:https://www.blog.pythonlibrary.org/2022/03/07/pydev-of-the-week-anna-makarudze/
本周我们欢迎安娜·马卡鲁泽( @amakarudze) 成为我们本周的 PyDev!安娜是姜戈女孩基金会受托人&筹款协调员和 DSF 总统。你可以通过查看安娜的网站来了解她更多的信息。
让我们花些时间更好地了解安娜吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是一名自由软件工程师,住在津巴布韦的哈拉雷。我拥有津巴布韦米德兰兹州立大学的计算机科学学士学位(荣誉)和秦皇岛理工大学的战略管理硕士学位。在回到软件工程之前,我曾在 ICT 行业的不同部门工作过,包括系统管理、网络工程、电信计费和咨询。
我还积极参与 Django 社区的活动。2016 年起为 Django 软件基金会(DSF)个人会员;自 2018 年以来,他一直是 DSF 董事会成员,2019 年至 2020 年担任副总裁,2021 年担任总裁。在疫情大受欢迎之前,我组织了许多 Python 和 Django 活动,并在许多会议上出席和发言。我真的很怀念面对面的会议。
我过去喜欢读书,但现在我的阅读范围已经缩小到科技书籍,我最近读了很多。我喜欢看电影、喜剧、戏剧、听音乐、园艺和散步。我也喜欢去新的地方旅行,尤其是参加科技会议。我也喜欢与朋友和家人一起放松和闲逛。我喜欢开怀大笑。
你为什么开始使用 Python?
每次我被问到这个问题时,我都觉得很有趣,因为在开始使用 Python 年多之后,我还没有设法做任何与我为什么开始使用 Python 相关的项目。我最初学习的目的是用它进行数据分析。然而,在我学习 Python 的早期,我发现自己学习了更多关于 web 开发的知识,首先是 Flask,然后是 Django,我从未真正使用 Python 进行数据分析。
我的大部分项目都是用 Django 开发的,也有一些 Flask 项目,但是都没有数据分析。我发现 Python 很容易学,因为我在没有做过任何编程的情况下学了 5 年多,我想这就是 Python 成为我选择的语言的原因。我从事的最后一个编程项目是我大学最后一年的项目。
你还知道哪些编程语言,你最喜欢哪一种?
我很久以前就开始学习编程了,那时我还在高中,所以我接触过 Basic、Visual Basic 6.0、Pascal、C、C++和 Java,但那是很久以前的事了。最近,我一直在使用 JavaScript(我在这方面还是个初学者)和 Bash。Python 是我最喜欢的语言,这不仅仅是因为它易于学习并且有广泛的应用,还因为它有一个很棒、很棒、很受欢迎的社区。我喜欢这句话“我为语言而来,但为社区而留”。不知道是谁说的,但对我来说这是千真万确的。
你现在在做什么项目?
我有一个个人博客,我正在努力改进,并添加技术文章来充实我的简历。为了准备工作面试,我也读了很多书,主要是 SRE 系统工程师的角色,所以我在打磨我的数据结构和算法以及大型系统设计。我有很强的系统管理背景,所以我觉得这个角色更适合我的经历。
我还在为一个为注册会员提供咨询服务的客户开发 CMS,这将为他的出版物提供一个电子书店。我目前还在维护和支持 Django 女孩网站和其他 Django 女孩资源。时不时地,我也会做一些项目,作为 Udemy 课程的一部分,来建立我的技术堆栈,作为我持续学习的一部分。
哪些 Python 库是你最喜欢的(核心或第三方)?
我会说 Django 是我的最爱,还有 Pytest、Requests、Django Rest Framework 和 Pdfkit。Requests 和 Pdfkit 玩起来很有趣很酷,而 Django、DRF 和 Pytest 是 web 开发的强大工具。Pytest 以其强大而简单的方式提供测试夹具,简化了 Django 应用程序的测试。
你是如何结束与姜戈女孩的合作的?
我仍然是 Django 的初学者,但当牛人大使的职位空缺并在 Django 女孩社区公布时,我已经参与了 Django 女孩的活动。我喜欢 Django Girls 和我们所做的事情,所以我申请了,我完全知道我只能做一半的工作,筹款部分——我对财务管理很差,我甚至不知道 Django Girls 在英国注册的事情是如何运作的,但我还是申请了。
It turned out that their best candidate at the time could also only do the other half I couldn’t do so I had to be interviewed for the second time but for the role of Fundraising Coordinator, which I got. After the founders stepped down as trustees, I found myself being the only trustee who had experience managing the website so I was asked to be the lead maintainer of the project, which has been awesome.
What do you like most about Django Girls?
The Django Girls environment and community are very welcoming to newbies and beginner-friendly. It made it very easy for me to grow both my hard and soft skills in a welcoming environment, with patient coaching from Ola and Ola and after they stepped down, the new trustees, most of whom I already knew, were very supportive of me taking the technical lead.
We are very informal in our language but we do that to be friendly and the friendly environment is just what many people need when they are learning to code. I love what we do, providing free resources and empowering women to organize workshops that bring about diversity in tech. I love that we provide an environment for women and others who want to support us to develop and grow both in their coding and leadership skills.
Ola and Ola, and their first band of volunteers started an amazing project and fostered a friendly community of volunteers, and left a legacy of a warm, friendly, and welcoming environment in the Django Girls Foundation itself. I love the people I work with at Django Girls. I certainly hope that the Django community will continue to support our work so that we can keep Django Girls going and one day we will also be able to hand it over to a new group of trustees.
Is there anything else you’d like to say?
I knew I wanted to be a software engineer at 14 and chose my high school subjects around that idea and pursued a degree in Computer Science. I feel blessed to have managed to achieve what I set out to do many years ago. While the tech world is all about continuous learning and improvement and I continue to learn; I feel more blessed that I get to work and pursue my passion at the same time. I love to code and enjoy programming, though it’s stressful at times and I get stuck a lot of times but I am always happy when I find my way.
I have a hard time gauging my skills and I am hard on myself at times but I still love my work anyway. I love what I do and I hope I will be as happy as I am in my next role as I have been with Django Girls. I guess that’s why I took my time looking for a full-time role after my last full-time role ended. I wanted to be sure of my next steps and ensure I find a role that is a perfect fit for me. I hope that happens hopefully in the next couple of months.
Thanks for doing the interview, Anna!
本周 PyDev:安娜·奥索斯基
原文:https://www.blog.pythonlibrary.org/2015/06/01/pydev-of-the-week-anna-ossowski/
本周,我们欢迎安娜·奥索斯基( @OssAnna16 )成为我们本周的 PyDev。Anna 是一名来自德国的有抱负的开发人员。她拥有英语和神学学位,但不久前爱上了编程,现在正致力于在该领域建立职业生涯。她非常喜欢姜戈女孩。她共同组织了 Django Girls Budapest 和 PyCon 研讨会,并在 Django Girls 博客上运营“你的 Django 故事”采访系列。Anna 也是 Django 软件基金会资助委员会的成员,目前正在构建 PyLadies 远程分部。她非常热衷于多元化和社区拓展,并希望鼓励更多的女性学习编程,因为这太棒了!在空闲时间,她会写一篇博客。让我们花几分钟时间更好地了解安娜。

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我出生在德国的一个小镇,并在那里长大。高中期间,我作为交换生在密苏里州圣路易斯附近的一个更小的城镇呆了一年。这是我一生中最美好的一年,我深深地爱着美国和我在那里遇到的人们。我最大的梦想之一就是有一天能住在美国。我有英语和天主教神学学位,但我正在追求编程生涯,并努力成为一名优秀的开发人员。
我非常热衷于多样性,将更多的女性带入 Python/Django 社区,并帮助人们开始编程。我为姜戈女孩(http://djangogirls.org)工作,这是一个为女性组织为期一天的免费网络开发研讨会的组织。我共同组织了 Django 女孩布达佩斯和 Django 女孩@ PyCon 讲习班。我还在 Django Girls 博客(【http://blog.djangogirls.org】)上开设了“你的 Django Story”采访系列,采访了和 Django 一起工作的出色女士。我真的很喜欢旅行,探索新的地方,学习新的东西,参加编程会议,烘焙,观看 Youtube 视频,以及修补个人项目。
你为什么开始使用 Python / Django?
完成学位后,我有了一些空闲时间,但我真的不知道我的职业生涯将走向何方。我在考虑是否应该获得硕士学位,如果是,应该获得什么专业的学位。我喜欢学习英语和神学,但因为我不想成为一名教师,我从来不知道我的学位该做什么。我当时有个朋友是软件开发人员,对 Python 很有热情。一天晚上,我问他是否认为我可以学习编程,因为我很好奇他为什么这么喜欢编程。他说“是的,每个人都可以学习如何编程”,给了我 Codeacademy Python 教程的链接,这就是一切的开始。在学校里,我总是被告知我在数学或科学方面不是很有天赋,所以我从来没有想过我可以学习如何编程,如果没有我朋友的鼓励,我可能永远不会尝试。
解决 Codeacademy 练习题并发现我真的可以学习如何编码是世界上最棒的感觉。这并不总是容易的,事实上有时非常令人沮丧,但我喜欢解决问题的部分,我喜欢创造东西,我喜欢学习新的东西。我就是瞬间爱上了编程。我喜欢那一刻,当我终于明白了一些事情,或者终于得到了一些工作。过了一会儿,我决定把它作为我的职业。我去了蒙特利尔的 PyCon 2014,这是我第一次参加编程会议,度过了最美好的时光。人们很友好,很热情,我学到了很多新东西,我觉得我真正属于这里。
去年夏天,我申请了欧洲 Python 的第一个 Django 女孩工作坊,并被录取了,这是我经历过的最棒、最能改变生活的经历之一。我不仅学会了如何用 Python 和 Django 建立网站,还结交了很好的朋友,并成为了一个了不起的社区的一员,这个社区给了我信心,让我可以做很多我从未想过可以做的事情,比如今年在 PyTennessee 做我的第一次会议演讲。
你会如何帮助一个新的 Python 程序员入门?
我会建议他们挑选一本好的初学者教程,并通过它来理解 Python 的基础。我真的很喜欢 Zed Shaw 的《艰难地学习 Python 》,但是还有很多其他很棒的资源。如果一个教程对你不起作用,那并不意味着你愚蠢或者缺乏天赋,或者永远学不会编程。我们都有不同的学习方式。尝试不同的教程,不断尝试不同的东西,直到你找到适合你的东西。退出一个教程并不意味着你失败了或者缺乏野心,它只是意味着你正在向对你更好的方向前进。如果你陷入困境,开始感到沮丧,不要花几个小时试图自己解决问题,寻求帮助,使用谷歌。如果你还是不明白,休息一下,散散步,上床睡觉,第二天再试。不要把自己逼得太紧。我记得在 Codeacademy Python 教程中有一章是关于二进制数的,我根本不理解这个概念。一遍又一遍地读完这一章后,我终于向我的朋友求助。他很努力地向我解释,但我还是不明白。我非常沮丧,感觉很糟糕,因为我认为我浪费了他的时间。那天晚上,在我决定上床睡觉之前,我看了一个关于二进制数的 3 分钟的 Youtube 视频,它终于打开了。你会成功的,不要放弃!🙂有时候你理解事情很快,有时候需要一段时间。永远记住:做不好某件事是做好某件事的第一步。
一旦你掌握了基本知识,我会建议你选择一个项目,从头开始构建。挑一个你喜欢并且真的想做的事情。我知道这有多难。教程给你一些指导和保障。当你开始从零开始构建一个东西时,你必须自己解决很多问题。这就是为什么找一个导师很重要。不要害怕寻求帮助,人们通常非常友好并愿意提供帮助。你可以在当地的 PyLadies 或 Girl develop it 分会寻找导师,加入我们的 Django Girls 聊天室或在 Twitter 上寻求帮助,你可以发推特给我(@ossanna16),我会尽力帮助你或让你联系上有能力的人。拥有了不起的导师对我来说意义重大,他们不仅教我、给我解释,还帮助我保持动力。
我最后的建议是参与社区活动。参加编程会议、本地聚会、短跑和黑客马拉松。是的,即使你刚开始学习编程,我们也希望你能参加🙂你对社区很有价值。不要害怕!Python 和 Django 社区非常友好和热情。很多编程会议,比如 PyCon、EuroPython 和 DjangoCon EU,都有很棒的多样性和财政援助项目,你可以申请。参加会议在很多方面改变了我的生活。我学到了很多以前从未想到过的新东西,我遇到了很棒的人,找到了新朋友,这帮助我克服了很多恐惧。
你现在在做什么项目?
我目前正在向我的朋友 Ian 学习测试和 API。在 Ian 的指导下,我将构建我的第一个简单的 API,它也将实现 JSON Home。我们将编写一个库,从 JSON Home 文档构建客户机,并在此过程中测试一切。我们的最终目标是把所有的东西都放进一个关于初学者测试的教程里。我在我的博客(http://anna-oz.tumblr.com)上开始了一个名为“理解计算机词汇”的系列,在这个系列中,我解释了我在这个过程中学到的一些小事,例如“什么是室内装潢师?”?并从一个学习者到另一个学习者,用非常简单的术语解释它们。我认为这些帖子对刚开始编程的人以及努力用一种初学者容易理解的方式解释事情的老师会有帮助。
我还开始阅读特蕾西·奥斯本的书《你好,网络应用程序》,我非常喜欢这本书,它帮助我理解了姜戈的一些对我来说很难的部分。这是一个很好的学习资源,我强烈推荐它。
除此之外,我正在努力建立一个远程皮拉第斯分会,提供在线课程,让那些不住在皮拉第斯分会附近的皮拉第斯人有机会在家参加课程和研讨会。
我也在帮助组织 DjangoCon US。我对这个机会感到非常兴奋,也很高兴成为如此伟大的组织者团队的一员。
我还有很多其他的项目想法,我计划一步一步地实现它们🙂
你为什么开始“你的姜戈故事”采访系列?
我们开始“你的 Django 的故事”,因为我们想告诉大家,有很多了不起的女性在和 Django 一起工作,无论是工作还是业余时间。我们希望这些故事能激励其他女性开始编程,并向她们展示有很多途径可以让你走上编程生涯。你不需要有一个程序员男朋友,不需要有计算机科学学位,不需要数学很棒,也不需要在 10 岁时就开始编程。你可以现在就开始,你可以学着做得更好,你可以有一段美好的时光,做一些了不起的事情。如果你努力工作,你可以成为一名职业程序员。一些从事编程工作的女性不知道她们到底有多伟大,认为她们的故事没有意思或不值得讲述。我个人的目标是让每一位女性知道她的故事是有趣的、独特的和鼓舞人心的,并鼓励她与世界分享。
你还有什么想说的吗?
请友好地对待编程初学者,鼓励你遇到的每一个人。鼓励人们开始编程,向他们展示编程有多棒,提供你的帮助,做一个导师。我保证这是非常值得的,帮助别人是世界上最美好的感觉。想想你刚开始学新东西的时候有多难。表现出一些同情心。请记住,有时只需要一个人就能改变一个人的生活和/或职业道路。努力成为那个人!🙂
如果你有兴趣了解更多关于导师的知识,看看杰西·吉尤·戴维斯http://emptysqua.re/blog/mentoring/.的这篇博文吧
非常感谢!
一周的最后 10 个 PyDevs
本周 PyDev:安东尼·肖
原文:https://www.blog.pythonlibrary.org/2018/05/14/pydev-of-the-week-anthony-shaw/
本周我们欢迎安东尼·肖( @anthonypjshaw )成为我们本周的 PyDev!Anthony 参与了几个开源项目。你可以在他的网站上阅读所有这些内容。他在媒体上也有博客。让我们花一些时间来更好地了解安东尼!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我从小就开始编程,在学校接触了技术,在英国的大学学习了控制论,最后在一家云公司工作,这是我的第一份工作。我做过各种各样的角色,技术支持、开发、产品管理,我的最新角色是“技能转化”,这实际上是帮助人们学习新东西,鼓励人们发展他们的技术技能和指导。我不再为了工作而日复一日地编写代码,因为我管理着一个团队,经常出差,所以我通常在业余时间和飞行间隙为开源项目做贡献。
我喜欢用手建造东西来摆脱工作和 IT,所以我通常会在房子、墙壁、景观或其他大型 DIY 项目周围建造一些东西。我住在澳大利亚东海岸的海滩上,所以一年中有 9 个月我会找各种借口下水游泳。
你为什么开始使用 Python?
为了对 Apache Libcloud 做出贡献,我在一家公司(Dimension Data)工作,这家公司有自己的云平台,没有人贡献过稳定的驱动程序。我学习 Python 是为了对这个项目有所贡献,在这个过程中我爱上了这门语言,并且从那以后几乎在任何事情上都使用它!
你还知道哪些编程语言,你最喜欢哪一种?
JavaScript,C#。NET、C++和 Python 是我所熟知的可以用来编写大型应用程序的语言。我更喜欢 Python,它有 JavaScript 的动态特性,没有混乱的生态系统,它有 C++的灵活性,没有内存管理的挑战,它有 c# net 的 async/await 特性。
你现在在做什么项目?
作为即将到来的 Pluralsight 课程“Python 3.7 的新特性”的一部分,我一直致力于从上到下探索 Python 3.7。作为研究的一部分,我在博客上写了一些新特性,比如数据类、断点内置和新的速度提升。为了进行性能研究,我一直在测试 pyperformance 包,但是自动将它与多个运行时进行比较。 Python 3.7 快!
除此之外,我一直致力于为 PyTest 添加 Python 3.7 的断点内置支持,并对 Tox 库做了一些小的改进。一旦我完成了这个课程,我计划开始一个新版本的 Apache Libcloud,v3。
哪些 Python 库是你最喜欢的(核心或第三方)?
核心,Pathlib 很牛逼。您可以使用“斜杠”操作符来连接路径,因此您不必再使用 os.path.join。第三方,Tox 非常适合测试多个 Python 版本和运行时。不仅仅是 2 对 3,而是 3.6 和 3.7 中的所有变化,确保您的代码仍然适用于最新版本。
你还有什么想说的吗?
如果你需要任何职业建议,在 Twitter 上给我发消息,我会回答各种各样的问题,和难相处的人打交道,薪水,职业发展。
感谢您接受采访!
本周 PyDev:安东尼·索特瓦
原文:https://www.blog.pythonlibrary.org/2018/10/29/pydev-of-the-week-anthony-sottile/
本周,我们欢迎安东尼·索特瓦( @codewithanthony )成为我们本周的 PyDev!安东尼是 tox 和 pytest 软件包的维护者之一。他也是“死蛇”PPA 团队的成员,该团队为某些 EOL Linux 发行版反向移植 Python。虽然你可以在安东尼的网站上发现一些关于他的信息,但你可能会从他的 Github 简介中了解更多。
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
从小我就一直对电脑很着迷。我最早写的一些程序就是为了简化(阅读:作弊)作业。一个包含使用 visual basic 的基本二次公式求解 gui 界面的 word 文档被复制到了相当多的软盘上。我最终转向了 web 开发,因为这是一种更容易获得的发布机制。
我就读于密歇根大学。)原本是学生物化学的。我想通过医学和研究来改变世界,但两年后,我决定转向我更强烈的激情。经过激烈的竞争,我终于在两年内完成了四年的课程,并获得了计算机科学学位!
我的大部分个人时间都花在了骑自行车上(我在一个花哨的电子表格中仔细记录了这一点——今年记录了 4600 英里)。我的其他一些爱好是徒步旅行、烹饪、跑步、滑雪比赛、拉小提琴和写一点诗(这是一个约会网站吗?).当然,我花了很大一部分时间构建开源软件并为之做出贡献🙂
我最大的成就是成为一名口袋妖怪大师——不仅完成了一个活生生的口袋妖怪,还通过合法地捕捉每一个可能的闪亮的口袋妖怪,忍受了极度的乏味。从那以后一切都在走下坡路。
你为什么开始使用 Python?
我第一次接触 python 是通过在 Yelp 的就业。尽管我被聘为 JavaScript 前端开发人员,但由于好奇心的驱使,我很快就钻研了全栈开发。最终,我建立了一个 web 基础设施和开发工具团队。一路走来,我的补全主义天性将我带到了语言的许多角落,包括元编程、打包、python 3 移植、RPython (pypy)、C 扩展等等!作为我目前选择的毒药,我决定我最好知道它是如何工作的!
你还知道哪些编程语言,你最喜欢哪一种?
在某个时候,我会认为自己是 JavaScript、C#、Java、C++和 C(以及其他许多语言)的专家。我从编程语言中得到的一个价值是拥有静态保证的能力(通常以类型检查器的形式)。因此,我对 python 的渐进类型化方法在类型检查领域的改进感到兴奋!我用过的最喜欢的语言(就语法和特性而言)是 C#(尽管这可能只是因为 Visual Studio 有多好)。
这里的荣誉奖是 go。虽然我认为还有一些地方可以做得更好(标签、打包、泛型),但 go 有一个我希望每种语言都具备的杀手级特性:作为一等公民重写代码。“go fmt”不仅证明了这一原则的成功(格式化代码只有一种方式!)但是编写读取和操作代码的工具是很容易的,并且受到鼓励。
你现在在做什么项目?
我热衷的项目是pre-commit——一个用于管理 git 钩子(主要是 linters 和 fixers)的多语言框架。在维护框架的同时,我还构建了一些我的和自己的 修复程序。最近,我还花了一些时间帮助维护 tox 和 pytest 。我的一个较新的项目 all-repos ,是一个大规模管理微升的工具,使搜索和应用跨库的大规模变化变得容易。
哪些 Python 库是你最喜欢的(核心或第三方)?
对我来说,这实际上是一个非常有趣的问题——我不想把科学排除在外,于是求助于 all-repos 来尝试寻找答案!好的,所以结果并不完全是最有趣的(当然你导入了很多‘OS’!)但是让我们深入了解一些异常值和我的最爱。列表上的第一个是pytest——当然是第一个,我认为测试非常重要,还有什么比 pytest 更好的工具可以使用呢!在标准库中,我最喜欢的是“argparse ”,因为我倾向于编写大量的命令行实用程序,所以它被大量使用。在 favorites 部分的一些荣誉提名是“sqlite3 ”(非常适合原型设计和令人惊讶的性能)、“collections ”(适合“namedtuple ”)、“contextlib ”(适合“contextmanager ”)和“typing ”(这是我最近开始接触的)。我用得最多的是“ast”和“tokenize”——我真的很喜欢静态分析,并且倾向于为它编写一堆工具。
你是如何成为“死蛇”团队的一员的(顺便说一句,我真的很感激)?
也许我最喜欢开源的部分是,如果你提供帮助,人们通常会接受。我最初在 Yelp 工作时,在将各种包移植到生命周期结束的 ubuntu lucid 上时,开始从事 debian 打包工作。就在 python 3.5 发布之前,lucid 到达了其支持周期和 launchpad 的末尾(理应如此!)禁用 PPA 上传为 lucid(包括死蛇)。开发人员(包括我自己)想使用一些新特性,比如“subprocess.run”、“async ”/“await”以及解包泛化。当时,升级到尚未停产的发行版还需要 2 到 3 年的时间。我成功地移植了 3.5,并在这个过程中学到了很多东西(撤销多重架构、调整依赖关系、修补测试等等)。).当 3.6 发布时,deadsnakes ppa 主页上显示了一条消息,表示支持将停止。我主动提出帮助维护,稍加指导就有了 3.6 的工作资源,剩下的就是历史了!
作为团队的一员,你面临过哪些挑战?
老实说,一旦你学会了工具(或者说自动化工具), dead snakes 的大部分职责和维护都是非常简单明了的。大多数易维护性来自于三个相对高质量的上游:debian、ubuntu,当然还有 cpython。大部分的维护工作来自于新版本(一个新的 LTS 会导致所有包的重新构建和两年发行版变化的调整!).
安东尼,谢谢你接受采访!
本周 PyDev:安东尼·图伊宁加
原文:https://www.blog.pythonlibrary.org/2017/12/11/pydev-of-the-week-anthony-tuininga/
本周,我们欢迎安东尼·图宁加成为我们的本周 PyDev!Anthony 是 cx 套件中 cx_Freeze 库的创建者之一。你可以感受一下他目前在 Github 上的工作。让我们花些时间来更好地了解安东尼吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
I grew up in a small town in the central interior of British Columbia, Canada. In spite of it being a small town, my school managed to acquire a personal computer shortly after they were made available. I was fascinated and quickly became the school guru. That experience convinced me that computers and especially programming were in my future. I moved to Edmonton, Alberta, Canada in order to attend university and ended up staying there permanently. Instead of only taking computing science courses I ended up combining them with engineering and received a computer engineering degree. After university I first worked for a small consulting firm, then for a large consulting firm and am now working for the software company, Oracle, in the database group. Besides working with computers I enjoy reading and both cross-country and downhill skiing.Why did you start using Python?
在 20 世纪 90 年代末,我开发了一个 C++库和一套工具来管理 Oracle 数据库对象。这些工作得相当好,但它们需要相当多的时间来开发和维护。我发现了 Python 及其 C API,并对最终成为 cx_Oracle Python 模块的东西做了一些实验。几天之内,我已经用 Python 和 cx_Oracle 重写了 C++库和一些工具,向自己证明 Python 是一个很好的选择。尽管被解释并且理论上比 C++慢,但我用 Python 编写的工具实际上更快,主要是因为与 C++相比,我可以用 Python 使用更高级的数据操作技术。我用 Python 完成了重写,并继续扩展我对 Python 的使用,直到我工作的公司的旗舰产品广泛使用它。令人欣慰的是,我工作的公司看到了开源模式的好处,我能够将我在那里开发的库和工具开源。其中包括 cx_PyGenLib、cx_PyOracleLib、cx_Oracle、cx_OracleTools、cx_OracleDBATools、cx_bsdiff、cx_Logging、ceODBC 和 cx_Freeze。
你还知道哪些编程语言,你最喜欢哪一种?
由于我喜欢尝试语言,所以我对相当多的语言了解有限,但在我的职业生涯中,我经常使用的语言是 C、C++、SQL、PL/SQL、HTML、JavaScript 和 Python。其中,Python 是我的最爱。我最近开始尝试使用 Go,作为 C/C++的替代品,它给我带来了新鲜空气。时间会证明我是否能很好地利用它,特别是因为我目前的工作需要大量使用 C 语言,而且这种情况不太可能很快改变。
你现在在做什么项目?
During work hours I am working on a C wrapper for the Oracle Call Interface API called ODPI-C (https://github.com/oracle/
哪些 Python 库是你最喜欢的(核心或第三方)?
The modules I have found to be the most useful in my work have been reportlab (cross platform tool for creating PDFs programmatically), xlsxwriter (cross platform tool for creating Excel documents without requiring Excel itself) and wxPython (cross platform GUI toolkit). I have also recently been making use of the virtues of the venv module (earlier known as virtualenv) and have found it to be excellent for testing.What was your motivation for creating the cx_Freeze package?As mentioned earlier I had built a number of tools for managing Oracle database objects. I wanted to distribute these to others without requiring them to install Python itself. I first experimented with the freeze tool that comes with Python itself and found that it worked but wasn't easy to use or create executables. I discovered py2exe but it was only developed for Windows and we had Linux machines on which we wanted to run these tools. So I built cx_Freeze and it worked well enough that I was able to easily distribute my tools and later full applications on both Windows and Linux and (with some help from the community) macOS. My current job doesn't require this capability so I have not been able to spend as much time on it as I did before.
在维护这个项目的过程中,你学到的最重要的三件事是什么?
These lessons have been learned not just with cx_Freeze but also with cx_Oracle, the other well-used module I originally developed. First, code you write that works well for you will break when other people get their hands on it! Everyone thinks differently and makes mistakes differently and that becomes obvious very quickly. Second, although well-written code is the most important aspect of a project (keep in mind lesson #1), documentation, samples and test cases are nearly as important and take almost as much time to do well, and without them others will find your project considerably more difficult to use. Finally, even though additional people bring additional and possibly conflicting ideas, the project is considerably stronger and useful the more contributors there are.
你还有什么想说的吗?
I can't think of anything right now!Thanks for doing the interview!
本周 PyDev:安东·诺沃肖洛夫
原文:https://www.blog.pythonlibrary.org/2015/02/16/pydev-of-the-week-anton-novosyolov/
今天我们邀请了安东·诺沃西约洛夫(@ foreveryyoung _ ru)加入我们,成为我们本周的 PyDev!Anton 来自俄罗斯,已经使用 Python 很多年了。你可以通过他的 github 账户看到一些他最近在做什么。让我们花一些时间来更好地了解安东!
你能告诉我们一些关于你自己的事情吗(爱好、教育等)。):
我出生在俄罗斯的一个小镇,米什金(老鼠城😉 ).我在雅罗斯拉夫尔州立大学接受计算机科学教育。在我转向 Python 之前,我尝试过几种工作,主要使用 C++。有一段时间,我尝试了电信。现在远程工作,做 Python 程序员,住在老家。
我的爱好是家庭自动化。我在研究加热器恒温器和照明自动化。除了极客的东西,我喜欢骑自行车。
你为什么开始使用 Python?
我是从一个优秀的 IT 播客 Radio-T(http://radio-t.com,俄语)上听说 Python 的。我试了一下,我很喜欢!不考虑底层细节,只写有用而漂亮的代码要容易得多。那是我做电信工程师的时候,所以决定把专业换成 Python 和 web 开发。
你还知道哪些编程语言,你最喜欢哪一种?
我是在 90 年代开始接触计算机的,当时我使用的是 ZX 的 Basic,后来是 x86 的 C、C++和 Asm(试图编写自己的操作系统)🙂 ).现在想在 Ruby 和 Go 上一试身手,想了解一下 Erlang 和 Haskell 的一般知识。另外,我想学习应用于 Android 开发的 Java。
作为一名 web 开发人员,我对 JavaScript 有一些了解,我想提高它。我最喜欢的是 C,因为我实际上用它来为我的家庭自动化设备编写固件。对于像 AVR 这样的小型处理器,C 给了我全部的能力,并且(与 Asm 相比)隐藏了太低级的细节,同时也提高了可移植性。
你现在在做什么项目?
在工作中,现在我是汽车零配件搜索引擎项目的唯一程序员,用 Django(http://www . partarium . ru)编写。除了付费项目,我还有一些有用的宠物项目:
- SiliconValleyVoice MP3(http://svv . f-y . name)——某个特定 YouTube 频道的 MP3 提要。
- Youtube RSS proxy(http://Youtube-RSS . f-y . name)——有时候 Youtube 没有授权就不给这个 feed。
- Podcast proxy (WIP) -我正在做一项服务,用户可以添加播客提要,设置一些过滤器(例如标准化音量,或提高速度),并获得一个处理过的提要,将其添加到播客客户端。
哪些 Python 库是你最喜欢的(核心或第三方)?
Django 和 ReportLab(帮助创建漂亮的 PDF 文档的库)。我也使用非常方便的博客引擎——Blohg(http://blohg.org)
你还有什么想说的吗?
我希望一天有 48 小时。有那么多事情要做,要学!
感谢您的宝贵时间!
一周的最后 10 个 PyDevs
- 杰西·戴维斯
- 伊夫林·德米罗夫
- Andrea Gavana
- 蒂姆·戈登
- 道格·赫尔曼
- 玛格丽塔·迪利奥博士
- 马里亚诺·莱因加特
- 巴斯卡尔·乔德里
- 蒂姆·罗伯茨
- 汤姆·克里斯蒂
本周 PyDev:Aymeric Augustin
原文:https://www.blog.pythonlibrary.org/2019/09/09/pydev-of-the-week-aymeric-augustin/
本周,我们欢迎 Aymeric Augustin(@ aymericaugustin)成为我们本周的 PyDev。Aymeric 是一个 Python web 框架 Django 的核心开发者。他还是一名企业家,并在多个 Django 相关会议上发言。你可以在他的网站上找到 Aymeric,或者在 Github 上查看他的自由/开源软件贡献。让我们花一些时间来更好地了解他!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
你知道怎么认出法国人吗?那总是他们提到的第一件事!现在那已经不碍事了...
这些天来,我的爱好集中在做三个好女孩的父亲🙂我们一起做很多体育活动:游泳、骑自行车、园艺、演奏音乐等。
我在 CANAL+管理一个大约 200 人的软件工程部门,CANAL+是一家法国视听媒体集团,在几个国家经营电视服务。
我被培养成一名多面手工程师,最终专攻计算机科学和信息技术,但我在工作中学会了大部分知识。
你为什么开始使用 Python?
2006 年,一个朋友告诉我一种叫做 Python 的伟大而简单的语言。起初我拒绝了它:我说 PHP 对于我想做的任何事情来说都足够简单。这在我说过的一长串愚蠢的事情中排名很高🙂
一年后,我在(现已倒闭的)Zonbu 实习,在帕洛阿尔托过着创业的生活。那是我写第一个 Python 应用的时候。这是一个桌面图形用户界面,用于编码视频,以便在 iPods 或刚刚发布的 iPhone 上播放。我和 PyGTK 还有 glade 一起建的。在引擎盖下,它运行 mencoder 和 MP4box。
我从我的档案中找出了这次采访的源代码。它不仅使用制表符缩进和反斜杠换行,还拥有一个优雅的日志系统:
if __debug__:
print("INFO: Initializing BackgroundEncoder")
然后,在 2009 年,在我的第一份工作中,我写了两个重要的 Python 项目。我在做一个火车上的娱乐门户网站。第一个集中了门户网站和网络基础设施之间的板载通信。第二种方法根据可用的网络连接来管理内容同步。我发现了自动化测试的概念,并为我的测试覆盖率感到非常自豪。
你还知道哪些编程语言,你最喜欢哪一种?
我的第一语言是 Basic,1995 年第一次是 FutureBASIC,后来是 TI-BASIC。然后一个朋友在 1997 年给我介绍了 HTML 和万维网。我们一起为我们的高中做了一个网站。
我的计算机科学课程大部分是 Caml 一种面向数学的优秀语言,但在法国学术界、Java 和 c 之外鲜为人知。我还有机会尝试其他有趣的语言,如 Erlang、Factor、Haskell 和 Scheme。
我仍然喜欢写一些小的 C 语言,主要是 Python 扩展。我没有用过 Java,因为 1.5 是最新最棒的。我不能说我还知道它。我试过 C#。网大约在同一时间。我不喜欢它,因为文档总是告诉我我已经知道的,而不是我想知道的。
在课程之外,我写了很多 PHP。如果你正在阅读这篇文章,你可能已经意识到用 PHP 编写重要项目的挑战。然而,没有 PHP 我就不会在这里,所以我很感激它的存在。一步一步,我从静态 HTML 到小的动态比特,然后分解出重复的部分,然后编写自己的迷你框架,然后是 Python 和 Django。这是一个很好的学习途径。
专业上,除了 Python,我一直在写 JavaScript 和 CSS。当我联合创办或时,我自学了现代全栈开发——因为在初创公司担任首席技术官意味着一开始你是唯一的开发者。在我职业生涯的早期,我也写过一些 Ruby,但是我更喜欢 Django 而不是 Rails。
纯粹从语言角度,我还是很喜欢 Caml 的。我当然在美化我学习编程时的记忆🙂反正有时候感觉自己就是一个迷失在 Python 土地上的静态打字迷!
你现在在做什么项目?
这些天我主要在维护 websockets 。这是一个很好的挑战,因为在这两个领域我还有很多东西要学:并发编程和优秀的文档。
目前我正在考虑将协议从 I/O 中分离出来。我想基于 trio 和 curio 构建替代方案。然而,这将是对基于 asyncio 的当前实现的大规模重构。它的好处大多是理论上的。我仍然在想我是否真的想在那里度过时光。
我开始 websockets 的时候,吉多·范·罗苏姆正在建造一个叫郁金香的 asyncio。我在工作中有一个用例,WebSocket 协议似乎是一个很好的匹配。受请求营销的启发,我决定构建一个开源库,这将由于一个伟大的 API 而获得成功。我忽略了营销至少和 API 设计一样重要🙂尽管如此,websockets 还是适度地流行了起来。几个月后我离开了那份工作。在实践中,我从未使用过 websockets。这是我的一个爱好,给了我很大的自由去尝试。
不过,我正在努力应对一个意想不到的后果。从 GitHub 的问题来看,websockets 的主要用例似乎是连接到加密货币追踪器。我希望我不是这场环境灾难的罪魁祸首,哪怕是间接的。(比特币矿工燃烧了太多的煤,向大气中排放了太多的二氧化碳。我知道理论上的选择,但我对现实更感兴趣。比特币耗电量相当于奥地利,除了投机和购买非法商品之外没有主流用例。)
我理解为什么开源精神拒绝对软件使用方式的限制。尽管如此,把我的时间和精力无偿地给那些直接违背我的信念的人还是令人沮丧的。
哪些 Python 库是你最喜欢的(核心或第三方)?
对于 whitenoise 我只有好话要说。用 WSGI 服务器高效地提供静态文件,让 CDN 去做剩下的事情,这是一种解放。
我喜欢在我关心的一个方面比主流解决方案更好的挑战者。比起 gunicorn 我更喜欢 waste,因为它不太容易受到 slowloris 的攻击,所以不需要设置 nginx。我使用 django-s3-storage 而不是 django-storages,因为它的 listdir()实现具有不错的性能。我最近开始考虑将 trio 作为 asyncio 的替代方案,理论上我喜欢这种设计。希望我在实践中也会喜欢它。
我不能错过这个宣传我的一个图书馆的机会🙂检查日期增量。你会喜欢的!
你是如何成为 Django 的核心开发者的?
多亏了杰里米·莱恩,我在 2008 年发现了姜戈。2010 年 1 月,他就他遇到的一个 bug 征求我的意见,我们开了一张罚单。Jeremy 已经是一名经验丰富的开源贡献者——他是一名 Debian 开发人员。他让我意识到我可以为开源软件做贡献!
25 岁生日那天,我第一次尝试贡献。几天后,我设法提交了我的第一个补丁——一个 JavaScript 补丁🙂我不知道我为什么那样做;我没有再往前走。(顺便说一句,将所有的历史保存在公共工具中非常酷。)
2011 年 1 月,当我开始为巴黎的汽车共享服务 Autolib '构建软件时,我有机会选择堆栈。我决定用 Django 和 PostgreSQL。在接下来的三年里,我全职和姜戈一起工作,将它推向极限甚至超越极限。
2011 年 3 月,斯特凡尼和我结婚了,我开始更加积极地捐款——希望是巧合?那时候一个补丁很难得到评论。姜戈没有同伴。我对提交补丁的低成功率感到沮丧。
2011 年 4 月,Django 的 BDFL 雅各布·卡普兰-莫斯(Jacob Kaplan-Moss)提出了一个 5 对 1 的提议:分流 5 张票,核心开发人员将审核 1 张。正是我需要的!我抓住了这个机会,用了五次。我掌握了分类票的窍门,最终在三周内处理了 70 张票。
大约在那个时候,我挑战自己成为 Django 核心开发人员。我想我是在寻找与该职位的声望相关的自我提升,也许也是为了在没人关心的情况下,能够提交自己的补丁。(事后看来,我希望我没有那么自私的理由,但事情就是这样。2011 年是艰难的一年。)
所以,我照着手册做了。它说潜在的提交者应该贡献一个主要的特性。很好。我浏览了谷歌代码创意之夏的列表。我寻找一个能以最小风险完成的功能。我选择了“对日期时间表示的多时区支持”。
作为一个额外的收获,它对 Autolib '很有用。如果客户在夏令时变更期间租车,我们就无法计算出正确的时长和价格。这在 Django 1.3 中是不可能的,因为它不支持时区感知日期时间。
我彻底研究了这个问题。九月,我发了一份关于 django-developers 的提案。甚至在我写代码之前就已经成功了!两周后,卡尔·迈耶提议将我加入核心团队。我就是这样成为核心开发者的。
最后,当时区支持补丁准备好的时候,Luke Plant 好心地审核了它,我很高兴自己提交了它!
如你所见,如果没有足够的运气、同事们的好建议、同事们的帮助和 stphanie 的支持,我是不会成功的。
Django 让你兴奋的是什么?
Django 从一个框架到一个生态系统再到一个社区迅速成长。雅各布·卡普兰-莫斯就是这样塑造了这个项目。许多社区成员付出了惊人的努力,将这个机会转化为巨大的成功。
你知道很多技术社区吗...
而且我连 DjangoCon Europe 和 Django under the Hood 之类的优秀会议都没提。
从技术角度来说,Django 令人兴奋,因为它很无聊。谁愿意花时间考虑他们的框架而不是他们的应用程序?Django 及其生态系统涵盖了许多大大小小的 web 应用的需求。它是健壮的、有据可查的、经过充分测试的,并且不落伍。还有什么?
你还有什么想说的吗?
我发现从生态学的角度来看待开源是最有趣的。在过去的十年里,生态系统发生了巨大的变化。我们还在开始。
当看单个项目时,画面往往是暗淡的。大多数项目依赖于几个与倦怠作斗争的关键贡献者。我们还没有弄清楚可持续性。
从更广阔的角度来看,现在比以往任何时候都更有活力。新项目一直在开始。最佳实践日趋成熟。
Django 已经不像 2008 年那样炙手可热了,但 DSF 会支付全职人员来确保它得到良好的维护。自 2014 年以来,我一直在思考 Django 的下一个前沿领域是进军企业 IT。我不知道这是否真的会发生,但这似乎是可能的!
今天,志愿者时间是开源的货币。明天,金钱将发挥更大的作用。我们还不知道这将如何工作。企业与开源的交互经常令人失望,但是随着 IT 利益相关者对开源有了更好的理解,这种情况正在改善。
如果我们保持学习路径的开放,如果我们知道如何组织更大的努力,开源将会蓬勃发展。如果数百万有抱负的程序员编写他们自己的迷你框架,这没什么:他们正在为更大的项目培养技能。我们已经看到开源社区在社会规范及其编纂方面取得了很大进步。我希望我们将开发治理实践,使大型的、社区驱动的开源项目更容易扩展!
谢谢你接受采访,艾默瑞
本周 PyDev:巴里·华沙
原文:https://www.blog.pythonlibrary.org/2016/06/27/pydev-of-the-week-barry-warsaw/
本周,我们欢迎 Barry Warsaw ( @pumpichank )成为我们的本周 PyDev!Barry 为 Canonical 开发 Ubuntu 操作系统,他是 GNU Mailman 的项目负责人。他也曾经是 Jython 项目的主要维护者。如果你有时间,你应该去看看他的网站。巴里的 Github pag e 也值得一看,看看他觉得哪些项目有趣,或者你可以在 Gitlab 上查看他的个人项目。让我们花几分钟时间了解一下我们的同胞皮托尼斯塔吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在 Ubuntu 基金会团队的 Canonical 工作,所以我们负责 Ubuntu 的管道层。粗略地说,它是工具链(解释器、编译器、语言运行时等)之类的东西。)、映像构建、安装程序和一般归档良好性。我试着让 Python 栈开心,在过去的几个 Ubuntu 版本中,我真的集中精力将 Ubuntu 切换到 Python 3。我也是一名 Debian 开发人员,所以很多关于 Python 的更一般的工作首先在那里进行,然后自动导入 Ubuntu。当新的 Python 版本发布时,我们变得特别忙碌,以确保过渡顺利进行。在工作中,我还负责“系统映像更新客户端”,这是 Ubuntu Touch 风格的一部分,在 Ubuntu 手机和平板电脑上执行原子系统升级。
另一方面,我是一个半职业音乐家,在几个当地乐队演奏贝斯,为当地艺术家做工作室工作,并在自己的家庭工作室写作。我也是气从业者,在过去的 15 年左右,研究杨式短形式,剑,推手,以及最近的。
你为什么开始使用 Python?
1994 年,我刚开始在弗吉尼亚州莱斯顿的国家研究计划公司工作。我们正在与名为知识机器人的移动软件代理合作。我们开始在 NeXT 机器上使用 Objective-C。在我职业生涯的早期,我曾在美国国家标准与技术研究所工作,1994 年底,我在那里的一些前同事邀请我参加在 NIST 举办的一个小型研讨会。一位荷兰开发人员来访,研讨会的主题是他发明的相对较新的面向对象语言。
语言当然是 Python,开发者是吉多·范·罗苏姆。研讨会非常精彩,我们制定了一个计划来开发 Objective-C to Python bridge 来支持我们的项目。我们在 CNRI 的一位同事建议我们试着雇佣 Guido,事实证明,Guido 对来美国工作和生活很感兴趣。一到 CNRI,Guido 很快就让我们相信,我们可以用 Python 来完成整个项目,而不需要 Objective-C!在接下来的 8 年左右的时间里,我有幸通过三家公司与 Guido 密切合作,直到他搬到加州为谷歌工作。
我很早就爱上了 Python 语言,这些年来,我们的小团队将很多 Python 项目基础设施从荷兰转移到了美国。我们开发 Python,并在许多项目中使用 Python,我还担任过几次发布经理。回顾过去,Python 项目和社区在过去的 20 年里发展得令人难以置信,可能超过了我们任何人的想象,但没有超过我们的期望!
你还知道哪些编程语言,你最喜欢哪一种?
我一直很喜欢学习新的编程语言,并且(am?)相当精通许多传统的学校语言,如 C、C++、Lisp、FORTH、Perl 等等。但是我很快意识到 Python 是特殊的。对我来说,这是从我脑子里想的到工作代码的最直接的转换。我仍然喜欢偶尔深入 C 语言,调整我的 Emacs Lisp,摆弄 JavaScript,或者学习像 Go 这样的新技能。但是如果我开始一个新项目或者寻找一些有趣的工作,Python 将是我的首选。
你现在在做什么项目?
工作之外,我是 GNU Mailman 的项目负责人,这是一个邮件列表管理系统。这是一个有着悠久历史的项目,自 90 年代末以来,它一直在推动 Python 邮件列表的发展。虽然我最初没有发明它,但我已经领导这个项目很长时间了,这些天来一直专注于改进版本 3,它使一切都现代化,包括用于列表和订阅管理的非常好的新网络界面(Postorius)和基于网络的档案(HyperKitty)。Postorius 和 HyperKitty 是 Django 应用程序,由我们团队中其他出色的开发人员领导。他们是比我更好的 web 开发人员,我喜欢在核心管理引擎上工作,这当然是用 Python 3 编写的。
哪些 Python 库是你最喜欢的(核心或第三方)?
在 Mailman 中,我们使用 stdlib 中的电子邮件库,这是我在 Python 2 天前写的。最近,r .大卫·穆雷和其他人在 Python 3 中对它进行了很大的改进和扩展。我也是 stdlib contextlib 库的忠实粉丝,最近我有机会深入研究新的 asyncio 库。这很令人费解,但一旦你掌握了窍门,就真的很酷。
对于第三方库,我非常喜欢 Falcon,它是一个 REST API 库。Mailman 3 有一个分布式架构,像 Postorius 和 HyperKitty 这样的组件通过 REST 与内核通信,而 Falcon 是为我们提供动力的。这是一个非常酷的图书馆。
在 Mailman 中,我们还大量使用了 zope.interface 和 zope.component,这两个成熟的库用于提供复杂程序的基于组件的组合。ORM 层的 SQLAlchemy 和测试用的 nose2 也是我的最爱。我有自己的一套 flufl 库,也提供了一些不错的工具。
作为一门编程语言,你认为 Python 将何去何从?
我认为 Python 的未来是光明的。Pycon 的规模无疑证明了它持续的受欢迎程度,并且我认为有许多有趣的正在进行的开发。我们有很多 Python 的实现,像 PyPy 这样的实现在速度、兼容性和创新性方面都有持续的改进。我很高兴听到社区中正在进行的关于 JIT、可选静态类型以及其他性能和多核工作的一些工作。
我很高兴 Python 3 的采用变得越来越强。这不再是我们必须说服人们支持它的情况,但如果你不这样做,它更像是一个已知的错误。值得注意的例外正在减少,我们真的在移植到 Python 3 的长尾中。我现在几乎是独家使用了很多年,一点都不怀念 Python 2。
你还有什么想说的吗?
撰写本文时,距离 2016 年 Pycon 还有整整一个月,我和我的同事 Larry Hastings 再次主持语言峰会。每年的这个时候,我都兴奋不已,不仅仅是因为* Python 中发生的惊人的事情,也不仅仅是人们用* Python 做的不可思议的事情。最重要的是,我迫不及待地想再次与世界上最不可思议的开源社区亲密接触。早在 1994 年,我们有 20 个人参加了第一次 Python 研讨会,我听说今年的 Pycon 将接待大约 3000 名 Python 爱好者。在我的技术生涯中,没有什么能比得上在一个会议中心,与这么多了不起的人在一起,参加鼓舞人心的演讲,与朋友和合作开发人员一起冲刺 4 天。我等不及了!
PyDev of the Week: Bas Steins
原文:https://www.blog.pythonlibrary.org/2022/07/11/pydev-of-the-week-bas-steins/
This week we welcome Bas Steins (@bascodes) as our PyDev of the Week! Bas is active in the Python community and freely gives out advice on Twitter. You can see what else Bas is up to on his blog.

Let's take some time to get to know Bas better!
Can you tell us a little about yourself (hobbies, education, etc):
Hi, I'm Bas. I am a Software developer for more than a decade now. I started right after school working for a small web agency in the neighborhood and got my university degree in Scientific Programming while working for them.
When I'm not in front of a screen, I enjoy riding my road bike a lot (since I moved to the Netherlands, that's double the fun) and cooking.
Recently, I became a bee keeper and I expect to have my first self-made honey next year.
As a software developer, almost needles to say that I have a passion for great freshly grounded coffee. My hometown happens to be the domicile of Germany's oldest coffee roastery and their blends are still my favorites.
Why did you start using Python?
I started to have a look into Python in the early 2000s. I picked up a very weird book that was more about creating a Mayan calendar software than about Python. I enjoyed it a lot and started using it as part of my first job together with Django. That was before Django's 1.0 release and it was fun!
What other programming languages do you know and which is your favorite?
As a consultant, I have seen and touched many different technologies and programming languages, including Java, C#, C, C++, Rust, Go, PHP, and JavaScript.
Every now and then, I try something new – most of the time just out of curiosity. I spent a lot of time getting my head around LISP, for example.
I wouldn't say, I have a favorite programming language apart from Python. but I really like C# and JavaScript besides it.
What projects are you working on now?
At the moment, my main project is at a biotech company. They produce clinical devices, mostly for blood cell analysis. My job is to provide layers of abstraction to the biologists and physicists on the team and train them in software development.
As a freelancer, my projects change a lot over time, but all of them have in common that I help teams to make better software. It includes usually a lot of hands-on coding, training, and coaching, but most importantly a good understanding of the client's needs. I try to refrain from choosing development stacks based on popularity and hype. Maybe that's one reason why I like Python so much: It evolves, it is popular, but it has a stable ecosystem, too (let's not talk about 2to3).
Which Python libraries are your favorite (core or 3rd party)?
That depends a lot on the task I need to tackle. My all-time favorites for sure include Django, NumPy, and SciPy.
Do you have any advice for other people who would like to become trainers or go into consulting?
The worst part about being a consultant is the paperwork associated with working for larger corporations. I personally deal mostly with specialised recruiting agencies for these freelance roles to get around these hassles. I highly recommend doing the same. It might not be needed for contracts with smaller clients but when you want to work for larger corps, it really solves a lot of legal and accounting issues.
Is there anything else you’d like to say?
I started doing more of my work in public on Twitter and on my blog. I really made some great connections to awesome people.
Also, I started doing coffee chats to have a more personal connection to other people in tech. If you want to have such a chat over a (virtual) coffee, feel free to reach out!
Thanks for doing the interview, Bas!
本周 PyDev:batu Han task aya
原文:https://www.blog.pythonlibrary.org/2022/02/07/pydev-of-the-week-batuhan-taskaya/
本周我们欢迎巴图汉·塔斯卡娅( @isidentical )成为我们的本周 PyDev!Batuhan 是 Python 语言的核心开发人员。巴图汉也是多个 Python 包的维护者,包括帕索和黑。
你可以通过查看巴图汉的网站或 GitHub 简介来了解他还在做什么。
让我们花一点时间来更好地了解巴图汉!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
Hey there! My name is Batuhan, and I'm a software engineer who loves to work on developer tools to improve the overall productivity of the Python ecosystem.
I pretty much fill all my free time with open source maintenance and other programming related activities. If I am not programming at that time, I am probably reading a paper about PLT or watching some sci-fi show. I am a huge fan of the Stargate franchise.
Why did you start using Python?
I was always intrigued by computers but didn't do anything related to programming until I started using GNU/Linux on my personal computer (namely Ubuntu 12.04). Back then, I was searching for something to pass the time and found Python.
Initially, I was mind-blown by the responsiveness of the REPL. I typed 2 + 2, it replied 4 back to me. Such a joy! For someone with literally zero programming experience, it was a very friendly environment. Later, I started following some tutorials, writing more code and repeating that process until I got a good grasp of the Python language and programming in general.
What other programming languages do you know and which is your favourite?
After being exposed to the level of elegancy and the simplicity in Python, I set the bar too high for adopting a new language. C is a great example where the language (in its own terms) is very straightforward, and currently, it is the only language I actively use apart from Python. I also think it goes really well when paired with Python, which might not be surprised considering the CPython itself and the extension modules are written in C.
If we let the mainstream languages go, I love building one-off compilers for weird/esoteric languages.
What projects are you working on now?
Most of my work revolves around CPython, which is the reference implementation of the Python language. In terms of the core, I specialize in the parser and the compiler. But outside of it, I maintain the ast module, and a few others.
One of the recent changes I've collaborated (with Pablo Galindo Salgado an Ammar Askar) on CPython was the new fancy tracebacks which I hope will really increase the productivity of the Python developers:
Traceback (most recent call last):
File "query.py", line 37, in <module>
magic_arithmetic('foo')
^^^^^^^^^^^^^^^^^^^^^^^
File "query.py", line 18, in magic_arithmetic
return add_counts(x) / 25
^^^^^^^^^^^^^
File "query.py", line 24, in add_counts
return 25 + query_user(user1) + query_user(user2)
^^^^^^^^^^^^^^^^^
File "query.py", line 32, in query_user
return 1 + query_count(db, response['a']['b']['c']['user'], retry=True)
~~~~~~~~~~~~~~~~~~^^^^^
TypeError: 'NoneType' object is not subscriptable
Alongside that, I help maintain projects like
and I am a core member of the fsspec.
Which Python libraries are your favorite (core or 3rd party)?
It might be a bit obvious, but I love the ast module. Apart from that, I enjoy using dataclasses and pathlib.
I generally avoid using dependencies since nearly %99 of the time, I can simply use the stdlib. But there is one exception, rich. For the last three months, nearly every script I've written uses it. It is such a beauty (both in terms of the UI and the API). I also really love pytest and pre-commit.
Not as a library, though one of my favorite projects from the python ecosystem is PyPy. It brings an entirely new python runtime, which depending on your work can be 1000X faster (or just 4X in general).
Is there anything else you’d like to say?
I've recently started a GitHub Sponsors Page, and if any of my work directly touches you (or your company) please consider sponsoring me!
Thanks for the interview Mike, and I hope people reading the article enjoyed it as much as I enjoyed answering these questions!
Thanks for doing the interview, Batuhan!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号