PyImgSearch-博客中文翻译-一-
PyImgSearch 博客中文翻译(一)
图像中 1 个像素的偏移会如何影响您的 RBM 性能
原文:https://pyimagesearch.com/2014/06/16/1-pixel-shifts-images-can-kill-rbm-performance/

你能说出上面两幅图像的区别吗?
大概不会。
右边的那个已经向下移动了一个像素。
虽然对我们来说,它看起来仍然是同一个图像,对一台受限的玻尔兹曼机器来说,这种转换可能会带来麻烦。
作为特征向量的原始像素强度
你知道吗,当使用原始像素作为特征向量时,有一个微妙而又关键的问题,这通常是在基于图像的深度学习分类任务中完成的。
如果你不小心,没有采取适当的预防措施,输入图像中的小,1 像素偏移会显著损害你的分类器的性能。
我们只是在谈论一个像素的移动。如此小的位移几乎(如果有的话)不会被人眼察觉。
但是如果你已经在原始像素特征上训练了你的受限玻尔兹曼机器,你可能会大吃一惊。
当然,卷积神经网络有助于缓解这个翻译问题。其实,缓解这个词太强了。他们能够容忍在图像中的翻译。卷积网络(一般而言)仍然容易受到这种转换问题的影响。
正如谷歌最近的论文之一神经网络的有趣特性所表明的,输入图像的微小变化可以极大地改变网络的整体分类。
作者称这些类型的图像为“对立图像”,事实上,根据人眼的观察,它们实际上与原始图像完全相同。
注意:如果你有兴趣阅读更多关于谷歌的论文(以及我对机器学习时尚的批评),一定要看看我以前的帖子, 摆脱深度学习的狂热,获得一些观点 。
然而,这些对立的图像是用一种比输入图像的简单的一个像素平移复杂得多的方法构建的。事实上,这些图像是通过非常少量地操纵像素值来构造的,以便最大化深度学习网络的误差。
但它确实证明了当使用原始像素特征时,图像中人眼完全察觉不到的细微变化会导致错误分类。
图像中 1 个像素的偏移会如何影响您的 RBM 性能
为了证明(在相当小的规模上)与基于原始像素特征向量的深度学习网络相关的一些问题,我决定进行一个小实验: 如果我拿着我的测试图像集,将每张图像向上、向下、向左和向右移动一个像素,性能会下降吗?
再说一次,对于所有的意图和目的来说,这些一个像素的移动对于人类的眼睛来说是不明显的……但是受限玻尔兹曼机器呢?
所以我们接下来要做的是:
- 使用 MNIST 数据集的样本的原始像素特征构建训练和测试分割。
- 应用单个受限玻尔兹曼机器从 MNIST 样本学习无监督特征表示。
- 在学习的特征之上训练逻辑回归分类器。
- 使用测试集评估分类器以获得基线。
- 通过将图像上下左右移动一个像素来扰乱测试集。
- 重新评估我们的分类管道,看看准确性是否下降。同样,这些一个像素的偏移对人眼来说几乎是不可见的,但它们最终会损害系统的整体性能。
这是我们而不是要做的事情:
- 使用对立的图像复制谷歌的结果。
- 声称这些结果是所有基于原始像素的方法的罪证。他们不是。这里我只使用一个 RBM。所以不会有任何堆积——因此也不会有任何深度学习。
- 声称研究人员和开发人员应该放弃基于原始像素的方法。有很多方法可以解决我在这篇文章中提出的问题。最常见的方法是在训练时对图像应用变形(即通过人工转换图像来生成更多的训练数据),以使神经网络更加鲁棒。第二种方法是对输入图像的区域进行子采样。
但是我将要做的是向你展示如果不采取适当的预防措施,图像中一个像素的微小移动会极大地降低你的 RBM 的精确度。
**希望这一系列的博客文章,包括 Python 和 scikit-learn 代码,将帮助一些正在探索神经网络和将原始像素特征向量映射到输出的学生和研究人员。
初步结果
生成我的结果的代码还不太好看(将在下一篇文章中介绍),但是我想展示一些初步的结果:
RBM + LOGISTIC REGRESSION ON ORIGINAL DATASET
precision recall f1-score support
0 0.95 0.98 0.97 196
1 0.97 0.96 0.97 245
2 0.92 0.95 0.94 197
3 0.93 0.91 0.92 202
4 0.92 0.95 0.94 193
5 0.95 0.86 0.90 183
6 0.95 0.95 0.95 194
7 0.93 0.91 0.92 212
8 0.91 0.90 0.91 186
9 0.86 0.90 0.88 192
avg / total 0.93 0.93 0.93 2000
我做的第一件事是获取 MNIST 数据集的样本(2000 个数据点;大致均匀地分布在每个类别标签上)并构建了 60/40 的划分— 60%的数据用于训练,40%用于验证。
然后我使用伯努利限制的玻尔兹曼机器从训练数据中学习无监督的特征表示,然后将其输入到逻辑回归分类器中。
最后,使用测试数据评估该 RBM +逻辑回归管道,获得 93%的准确度。
所有相关参数都经过网格搜索和交叉验证,以帮助确保最佳值。
然后,我决定“微调”测试,将测试集中的每个图像向上、向下、向左和向右移动一个像素,产生一个比原始图像大四倍的测试集。
这些移位的图像虽然与人眼几乎相同,但对管道来说是一个挑战,精度下降了 5%。
RBM + LOGISTIC REGRESSION ON NUDGED DATASET
precision recall f1-score support
0 0.94 0.93 0.94 784
1 0.96 0.89 0.93 980
2 0.87 0.91 0.89 788
3 0.85 0.85 0.85 808
4 0.88 0.92 0.90 772
5 0.86 0.80 0.83 732
6 0.90 0.91 0.90 776
7 0.86 0.90 0.88 848
8 0.80 0.85 0.82 744
9 0.84 0.79 0.81 768
avg / total 0.88 0.88 0.88 8000
在小范围内,我们可以看到使用原始像素作为特征向量的问题。图像中轻微的平移、微小的旋转,甚至图像捕捉过程中的噪声,在输入网络时都会降低准确性。
虽然这些结果决不是结论性的,但它们至少证明了一般直觉,即使用原始像素特征向量在没有预先进行有效预处理的情况下容易出错。
摘要
在这篇博文中,我介绍了一个概念,即如果你不小心,图像中小的一个像素的移动会杀死你受限的玻尔兹曼机器的性能。
然后,我提供了一组“挑逗性”的结果,以证明图像中的一个像素平移虽然与人眼几乎相同,但会导致准确性下降。
接下来:
在我的下一篇博客文章中,我将向您展示我的 Python 代码,以将深度学习和受限玻尔兹曼机器应用于 MNIST 数据集。
请务必注册下面的时事通讯,以便在帖子发布时收到更新!你不会想错过它的…**
25 分钟后…PyimageSearch Gurus 完全资助!
原文:https://pyimagesearch.com/2015/01/14/25-minutes-later-pyimagesearch-gurus-fully-funded/

哇,我一时无语。你们真是不可思议——PyImageSearch 拥有地球上最优秀、最支持的读者。
PyImageSearch 大师 Kickstarter 活动于美国东部时间今天上午 10 点开始。
到美国东部时间上午 10:25,项目 资金 100%到位!
不到 25 分钟就 100%资助了这个项目!
展望未来,我很兴奋,因为我知道我可以花时间为你创造最好的计算机视觉课程。如果您对其他模块/主题有任何建议,请联系我或在 Kickstarter 页面上发表评论!
再次非常感谢你们——有你们的支持是一种奇妙的感觉!
如果你还没有支持 Kickstarter 的活动,一定要考虑这样做!
第二版+实用 Python 和 OpenCV 的硬拷贝现已上线!

实用 Python 与 OpenCV +案例分析第二版正式上线!**
*第二版是对该书的主要更新,包括:
纸质版本。

Figure 1: Hardcopy editions of Practical Python and OpenCV + Case Studies are now available!
自从一年前我写了这本书,我就想提供实用 Python 和 OpenCV 的印刷版,但我很难找到出版商——现在一切都变了,精装本已经准备好了和 现在可以购买了!
与 OpenCV 3 和 Python 3 完全兼容。
在过去的几个月里,我一直在努力更新实用 Python 和 OpenCV +案例研究中的所有源代码和解释,以确保与新发布的 OpenCV 3.0 库和 Python 3 编程语言完全兼容。现在你将能够了解 OpenCV 2.4 和 OpenCV 3 之间的区别——,并且也能够使用 Python 3!
树莓 Pi 支持。

Figure 2: All code examples in the 2nd edition of Practical Python and OpenCV + Case Studies run on the Raspberry Pi out-of-the-box.
拥有一台 Raspberry Pi 并想用它来检测视频流中的人脸?跟踪视频中的对象?或者识别笔迹?没问题!实用 Python 和 OpenCV +案例研究中所有章节的新源代码下载将在树莓 Pi 上开箱即用,无需修改。
视频教程。

Figure 3: Imagine having me at your side, helping you learn computer vision and OpenCV — that’s exactly what it’s like when you work through my 16 video tutorials covering 4+ hours of lessons.
和我一起编码吧——我已经录制了 16 个视频教程,涵盖了 4 个多小时的内容,来自实用 Python 和 OpenCV 。这些视频是帮助您学习 OpenCV 和计算机视觉的绝佳资产。
更新后的虚拟机。

Figure 4: The 2nd edition Ubuntu VirtualBox virtual machine has been re-engineered from the ground-up to support both Python 2.7 and Python 3+ with OpenCV bindings.
这本书的第二版中我最喜欢的一个特点是全新的,刚刚重建的 Ubuntu VirtualBox 虚拟机。这个虚拟机已经被从头开始重新设计,包括安装了Python 2.7和 Python 3 和 OpenCV 3!
拿起你的那份。
准备好拿起自己的副本第二版副本实用 Python 和 OpenCV +案例研究?
How-To:使用 OpenCV 和 Python 比较直方图的 3 种方法
原文:https://pyimagesearch.com/2014/07/14/3-ways-compare-histograms-using-opencv-python/
所以你已经从一组图像中提取了颜色直方图…
但是你如何比较它们的相似性呢?
你需要一个距离函数来处理这个问题。
但是哪一个呢?你如何选择?如何使用 Python 和 OpenCV 比较直方图?
别担心,我会掩护你的。
在这篇博文中,我将向您展示使用 Python 和 OpenCV 比较直方图的三种不同方法,包括cv2.compareHist函数。
在这篇文章的结尾,你将会像专家一样比较直方图。
我们的示例数据集

Figure 1: Our test dataset of four images — two images of Doge, another with Gaussian noise added, and velociraptors, for good measure.
我们的示例数据集由四幅图像组成:两幅 Doge memes,第三幅 Doge 图像,但这次添加了高斯噪声,从而扭曲了图像,然后是迅猛龙。因为老实说,我不能写一篇不包括《侏罗纪公园》的博文。
在这些示例中,我们将使用左上角的图像作为我们的“查询”图像。我们将获取此图像,然后根据直方图距离函数对最“相似”的图像的数据集进行排序。
理想情况下,Doge 图像将出现在前三个结果中,表明它们与查询更“相似”,猛禽的照片放在底部,因为它在语义上最不相关。
然而,正如我们将会发现的那样,在左下方的 Doge 图像中添加高斯噪声会打乱我们的直方图比较方法。选择使用哪种直方图比较函数通常取决于(1)数据集的大小(2)以及数据集中图像的质量-您肯定希望进行一些实验并探索不同的距离函数,以感受哪种度量最适合您的应用。
说了这么多,让 Doge 教我们比较直方图。
多直方图。哇哦。我 OpenCV。很多计算机视觉,真的。
使用 OpenCV 和 Python 比较直方图的 3 种方法
# import the necessary packages
from scipy.spatial import distance as dist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import glob
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory of images")
args = vars(ap.parse_args())
# initialize the index dictionary to store the image name
# and corresponding histograms and the images dictionary
# to store the images themselves
index = {}
images = {}
我们要做的第一件事是在2-7线导入我们需要的包。SciPy 的distance子包包含许多距离函数的实现,所以我们将用别名dist导入它,以使我们的代码更加简洁。
我们还将使用matplotlib来显示我们的结果,NumPy 用于一些数字处理,argparse用于解析命令行参数,glob用于获取图像数据集的路径,而cv2用于 OpenCV 绑定。
然后,第 10-13 行处理解析我们的命令行参数。我们只需要一个开关--dataset,它是包含我们的图像数据集的目录的路径。
最后,在第 18 行和第 19 行,我们初始化了两个字典。第一个是index,它存储从我们的数据集中提取的颜色直方图,文件名(假设是惟一的)作为键,直方图作为值。
第二个字典是images,它存储实际的图像本身。在展示我们的比较结果时,我们将使用这本词典。
现在,在我们开始比较直方图之前,我们首先需要从我们的数据集中提取直方图:
# loop over the image paths
for imagePath in glob.glob(args["dataset"] + "/*.png"):
# extract the image filename (assumed to be unique) and
# load the image, updating the images dictionary
filename = imagePath[imagePath.rfind("/") + 1:]
image = cv2.imread(imagePath)
images[filename] = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# extract a 3D RGB color histogram from the image,
# using 8 bins per channel, normalize, and update
# the index
hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8],
[0, 256, 0, 256, 0, 256])
hist = cv2.normalize(hist, hist).flatten()
index[filename] = hist
首先,我们利用glob抓取我们的图像路径,并开始在行 22 上循环。
然后,我们从路径中提取文件名,加载图像,然后将图像存储在第 25-27 行的images字典中。
记住,默认情况下,OpenCV 以 BGR 格式存储图像,而不是 RGB 格式。然而,我们将使用matplotlib来显示我们的结果,并且matplotlib假设图像是 RGB 格式的。为了解决这个问题,在第 27 行的上对cv2.cvtColor做了一个简单的调用,将图像从 BGR 转换成 RGB。
在行 32 上处理颜色直方图的计算。我们将提取一个每个通道有 8 个面元的 3D RGB 颜色直方图,在展平后产生一个 512 维的特征向量。直方图在第 34 行被归一化,并最终存储在第 35 行的索引字典中。
关于cv2.calcHist功能的更多细节,一定要看看我的关于利用计算机视觉和图像搜索引擎的颜色直方图的指南。
现在我们已经为每张图像计算了直方图,让我们试着比较它们。
方法 1:使用 OpenCV cv2.compareHist 函数
也许不足为奇的是,OpenCV 有一个内置的方法来简化直方图的比较:cv2.compareHist。查看下面的函数签名:
cv2.compareHist(H1, H2, method)
cv2.compareHist函数有三个参数:H1,它是要比较的第一个直方图,H2,它是要比较的第二个直方图,method,它是一个标志,表示应该执行哪种比较方法。
method标志可以是以下任何一种:
现在是时候应用cv2.compareHist函数来比较我们的颜色直方图了:
# METHOD #1: UTILIZING OPENCV
# initialize OpenCV methods for histogram comparison
OPENCV_METHODS = (
("Correlation", cv2.HISTCMP_CORREL),
("Chi-Squared", cv2.HISTCMP_CHISQR),
("Intersection", cv2.HISTCMP_INTERSECT),
("Hellinger", cv2.HISTCMP_BHATTACHARYYA))
# loop over the comparison methods
for (methodName, method) in OPENCV_METHODS:
# initialize the results dictionary and the sort
# direction
results = {}
reverse = False
# if we are using the correlation or intersection
# method, then sort the results in reverse order
if methodName in ("Correlation", "Intersection"):
reverse = True
第 39-43 行定义了我们的 OpenCV 直方图比较方法元组。我们将探索相关、卡方、交集和 Hellinger/Bhattacharyya 方法。
我们在第 46 行开始循环这些方法。
然后,我们在第 49 行的上定义我们的results字典,使用图像的文件名作为关键字,使用它的相似性得分作为值。
我想特别提请注意线 50-55 。我们首先将一个reverse变量初始化为False。该变量处理如何对results字典进行排序。对于一些相似性函数, 较大的 值表示较高的相似性(相关性和交集)。而对于其他人来说, 越小的 值表示相似性越高(卡方和海灵格)。
因此,我们需要对线 54 进行检查。如果我们的距离方法是相关或相交,我们的结果应该以相反的顺序排序。
现在,让我们比较一下直方图:
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the method and update the results dictionary
d = cv2.compareHist(index["doge.png"], hist, method)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()], reverse = reverse)
我们从第 58 行的开始循环我们的索引字典。
然后,我们将 Doge 查询图像的颜色直方图(见上面图 1 左上角的图像)与字典第 61 行的当前颜色直方图进行比较。然后用距离值更新results字典。
最后,我们在第 65 行的中将results排序。
现在,让我们继续展示我们的结果:
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: %s" % (methodName))
fig.suptitle(methodName, fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the OpenCV methods
plt.show()
我们首先在第 68-71 行创建我们的查询图。该图只是显示了我们的 Doge 查询图像,以供参考。
然后,我们在第 74-83 行为我们的每个 OpenCV 直方图比较方法创建一个图。这段代码相当简单明了。我们所做的就是循环第 78 行上的results,并将与当前结果相关的图像添加到第 82 行上的图形中。
最后,行 86 显示我们的数字。
执行时,您应该会看到以下结果:
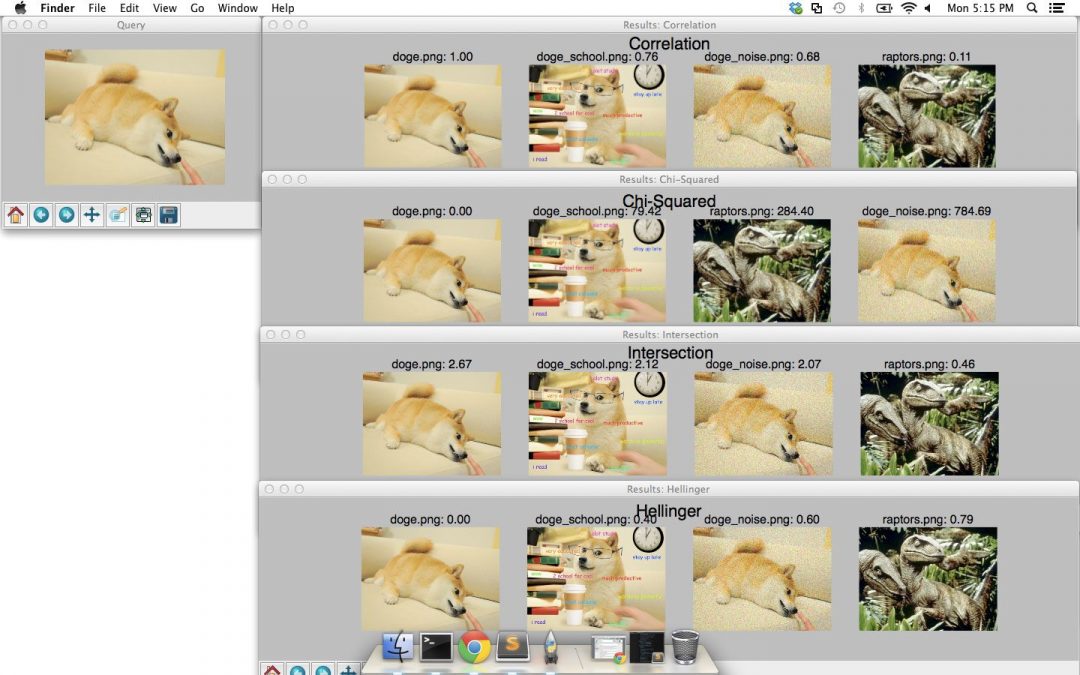
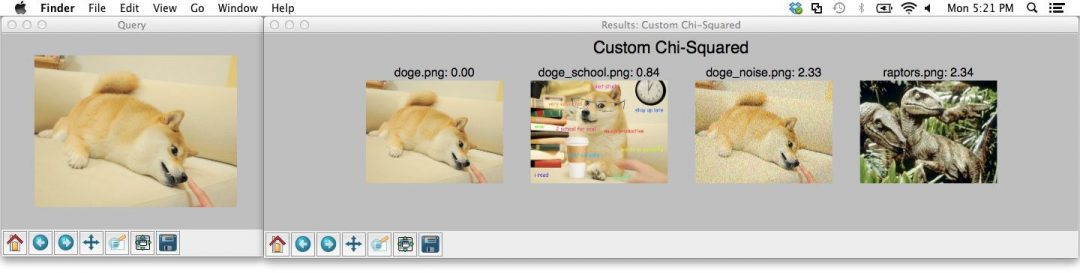
Figure 2: Comparing histograms using OpenCV, Python, and the cv2.compareHist function.
left 上的图像是我们最初的 Doge 查询。右边的数字包含我们的结果,分别使用相关、卡方、交集和海灵格距离进行排序。
对于每个距离度量,我们的原始 Doge 图像被放置在#1 结果位置-这是有意义的,因为我们正在使用我们的数据集中已经存在的图像作为查询。我们期望该图像位于#1 结果位置,因为该图像与其自身相同。如果这张图片不在结果的第一位,那么我们就会知道在我们的代码中可能有一个 bug!
然后我们看到 Doge school meme 在所有距离度量的结果中排名第二。
然而,将高斯噪声添加到原始 Doge 图像会损害性能。卡方距离似乎特别敏感。
这是否意味着不应使用卡方度量?
绝对不行!
实际上,您使用的相似性函数完全取决于您的数据集和应用程序的目标。 您将需要运行一些实验来确定最佳性能指标。
接下来,让我们探索一些科学的距离函数。
方法 2:使用科学距离度量
使用 SciPy 距离函数和 OpenCV 方法的主要区别在于 OpenCV 中的方法是特定于直方图的。SciPy 则不是这样,它实现了更一般的距离函数。但是,它们仍然值得注意,您可以在自己的应用程序中使用它们。
让我们来看看代码:
# METHOD #2: UTILIZING SCIPY
# initialize the scipy methods to compaute distances
SCIPY_METHODS = (
("Euclidean", dist.euclidean),
("Manhattan", dist.cityblock),
("Chebysev", dist.chebyshev))
# loop over the comparison methods
for (methodName, method) in SCIPY_METHODS:
# initialize the dictionary dictionary
results = {}
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the method and update the results dictionary
d = method(index["doge.png"], hist)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()])
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: %s" % (methodName))
fig.suptitle(methodName, fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the SciPy methods
plt.show()
在第行第 90-93 行,我们定义了包含我们将要探索的科学距离函数的元组。
具体来说,我们将使用 欧几里得 距离、 曼哈顿 (也称为城市街区)距离,以及 切比雪夫 距离。
从那以后,我们的代码与上面的 OpenCV 例子非常相似。
我们在行 96 上循环距离函数,在行 101-108 上执行排序,然后在行 111-129 上使用 matplotlib 呈现结果。
下图显示了我们的结果:
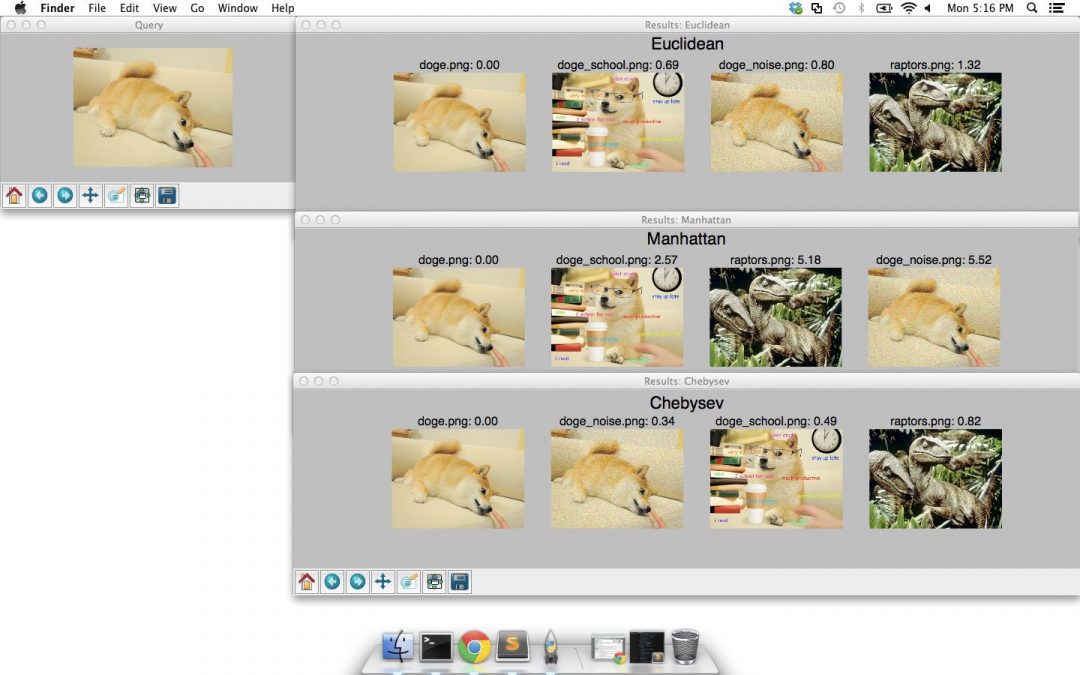
Figure 3: Comparing histograms using the built-in SciPy distance metrics.
方法 3:自己总结相似性度量
比较直方图的第三种方法是“滚动自己的”相似性度量。我将自己的卡方距离函数定义如下:
# METHOD #3: ROLL YOUR OWN
def chi2_distance(histA, histB, eps = 1e-10):
# compute the chi-squared distance
d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps)
for (a, b) in zip(histA, histB)])
# return the chi-squared distance
return d
你可能会想,嘿,卡方距离不是已经在 OpenCV 中实现了吗?
是的。确实是。
但是 OpenCV 实现只取每个独立仓的平方差,除以第一个直方图的仓计数。
在我的实现中,我取每个箱计数的平方差,除以箱计数值的总和,这意味着箱中的较大差异应该贡献较小的权重。
从这里,我们可以将我的自定义卡方函数应用于图像:
# initialize the results dictionary
results = {}
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the custom chi-squared method, then update
# the results dictionary
d = chi2_distance(index["doge.png"], hist)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()])
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: Custom Chi-Squared")
fig.suptitle("Custom Chi-Squared", fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the custom method
plt.show()
这段代码现在应该感觉很标准了。
我们对index进行循环,并在的第 144-152 行对结果进行排序。然后我们在第 155-173 行展示结果。
下面是使用我的自定义卡方函数的输出:
Figure 4: Applying my custom Chi-Squared function to compare histograms.
花点时间比较一下上面的图 4 和图 2。具体来说,检查 OpenCV 卡方结果与我的自定义卡方函数——添加了噪声的 Doge 图像现在位于第三个结果位置,而不是第四个。
这是否意味着你应该使用我的实现而不是 OpenCV?
不,不是真的。
实际上,我的实现会比 OpenCV 慢得多,因为 OpenCV 是编译的 C/C++代码,比 Python 快。
但如果你需要滚动自己的距离功能,这是最好的办法。
请务必花时间进行一些实验,看看哪个距离函数适合您的应用。
摘要
在这篇博文中,我展示了使用 Python 和 OpenCV 比较直方图的三种方法。
第一种方式是使用 OpenCV 内置的cv2.compareHist函数。这个功能的好处是它的极快。请记住,OpenCV 是编译的 C/C++代码,与标准的普通 Python 相比,您的性能会有很大提高。
第二个好处是这个函数实现了四种适合比较直方图的距离方法,包括相关、卡方、交集和 Bhattacharyya/Hellinger。
但是,你被这些函数限制了。如果你想定制距离函数,你必须实现你自己的。
使用 OpenCV 和 Python 比较直方图的第二种方法是利用 SciPy 的distance子包中包含的距离度量。
然而,如果以上两种方法不是你所寻找的,你将不得不采取第三种方法,手动实现“滚动”距离函数。
希望这有助于您使用 OpenCV 和 Python 进行直方图比较!
如果你想聊更多关于直方图比较方法的内容,欢迎在下面留下评论或给我发电子邮件。
一定要注册下面的时事通讯,以获得我没有在这个博客上发表的精彩的独家内容!
使用 TensorFlow 2.0 创建 Keras 模型的 3 种方法(顺序、函数和模型子类化)
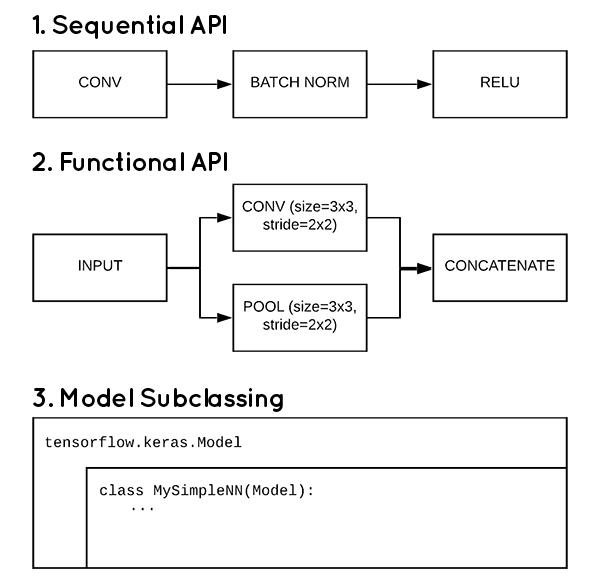
Keras 和 TensorFlow 2.0 为您提供了三种方法来实现您自己的神经网络架构:
- 顺序 API
- 功能 API
- 模型子类化
在本教程中,您将学习如何利用这些方法,包括如何为工作选择正确的 API。
要了解更多关于 Keras 和 TensorFlow 2.0 的顺序、函数和模型子类化的信息,请继续阅读!
使用 TensorFlow 2.0 创建 Keras 模型的 3 种方法(顺序、函数和模型子类化)
在本教程的前半部分,您将学习如何使用 Keras 和 TensorFlow 2.0 实现顺序、功能和模型子类化架构。然后,我将向您展示如何训练这些模型架构。
一旦我们的训练脚本被实现,我们将训练每个顺序的、功能的和子类化的模型,并检查结果。
此外,这里涵盖的所有代码示例都将与 Keras 和 TensorFlow 2.0 兼容。
项目结构
继续使用本教程的 “下载” 部分获取这篇文章的源代码。然后提取文件并使用tree命令检查目录内容:
$ tree --dirsfirst
.
├── output
│ ├── class.png
│ ├── functional.png
│ └── sequential.png
├── pyimagesearch
│ ├── __init__.py
│ └── models.py
└── train.py
2 directories, 6 files
我们的models.py包含三个函数,分别使用顺序、函数和模型子类 API 来构建 Keras/TensorFlow 2.0 模型。
训练脚本train.py将根据所提供的命令行参数加载一个模型。该模型将在 CIFAR-10 数据集上进行训练。精度/损耗曲线图将输出到output目录下的.png文件中。
使用 Keras 和 TensorFlow 2.0 实现序列模型

Figure 1: The “Sequential API” is one of the 3 ways to create a Keras model with TensorFlow 2.0.
顾名思义,顺序模型允许您一步一步地一层一层地创建模型。
Keras Sequential API 是迄今为止最容易启动并运行 Keras 的方法,但它也是最受限制的——您不能创建这样的模型:
- 共享图层
- 有分支(至少不容易)
- 有多个输入
- 有多个输出
您可能已经使用或实施的开创性顺序体系结构的示例包括:
- LeNet
- AlexNet
- VGGNet
让我们使用 TensorFlow 2.0 和 Keras 的顺序 API 实现一个基本的卷积神经网络。
打开项目结构中的models.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import concatenate
注意我们在2-13 行的所有 Keras 进口是如何来自tensorflow.keras(也称为tf.keras)。
为了实现我们的顺序模型,我们需要第 3 行的导入。现在让我们继续创建序列模型:
def shallownet_sequential(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" ordering
model = Sequential()
inputShape = (height, width, depth)
# define the first (and only) CONV => RELU layer
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
# softmax classifier
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
第 15 行定义了shallownet_sequential模型构建器方法。
注意在的第 18 行,我们将模型初始化为Sequential类的一个实例。然后我们将每一层添加到Sequential类中,一次一层。
ShallowNet 包含一个CONV => RELU层,后跟一个 softmax 分类器(第 22-29 行)。注意每一行代码,我们称之为model.add,用适当的构件组装 CNN。顺序很重要——你必须按照你想要插入层、标准化方法、softmax 分类器等的顺序调用model.add。
一旦你的模型拥有了你想要的所有组件,你就可以return这个对象,这样以后就可以编译它了。
第 32 行返回我们的顺序模型(我们将在我们的训练脚本中使用它)。
使用 Keras 和 TensorFlow 2.0 创建功能模型
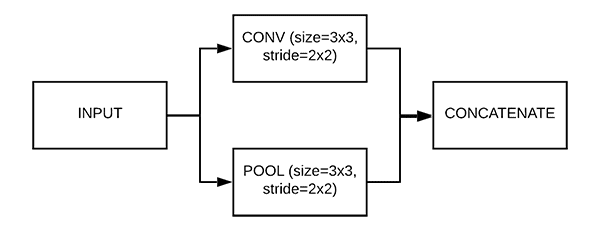
Figure 2: The “Functional API” is one of the 3 ways to create a Keras model with TensorFlow 2.0.
一旦你使用 Keras 的顺序 API 实现了一些基本的神经网络架构,你就会想要获得使用函数 API 的经验。
Keras 的函数式 API 易于使用,通常受到使用 Keras 深度学习库的大多数深度学习从业者的青睐。
使用功能 API,您可以:
- 创建更复杂的模型。
- 具有多个输入和多个输出。
- 轻松定义架构中的分支(例如初始块、ResNet 块等。).
- 设计有向无环图。
- 轻松共享架构内的层。
此外,任何顺序模型都可以使用 Keras 的 Functional API 实现。
具有功能特征(如层分支)的模型示例包括:
- ResNet
- 谷歌网/盗梦空间
- Xception
- 斯奎泽尼
为了获得使用 TensorFlow 2.0 和 Keras 的函数式 API 的经验,让我们实现一个 MiniGoogLeNet,它包括来自 Szegedy 等人的开创性的 用卷积 深入研究论文的初始模块的简化版本:

Figure 3: The “Functional API” is the best way to implement GoogLeNet to create a Keras model with TensorFlow 2.0. (image source)
如您所见,MiniGoogLeNet 架构中有三个模块:
conv_module:对输入体积执行卷积,利用批量标准化,然后应用 ReLU 激活。我们定义这个模块是出于简单性,并使其可重用,确保我们可以使用尽可能少的代码行在我们的架构内轻松应用“卷积块”,保持我们的实现整洁、有组织,并且更容易调试。inception_module:实例化两个conv_module对象。第一个 CONV 块应用 1×1 卷积,而第二个块使用“相同”填充执行 3×3 卷积,确保 1×1 和 3×3 卷积的输出音量大小相同。然后,输出音量沿着通道维度连接在一起。downsample_module:该模块负责缩小输入体积。与inception_module相似,这里使用了两个分支。第一分支执行 3×3 卷积,但是具有(1) 2×2 步距和(2)“有效”填充,从而减小了音量大小。第二个分支应用 3×3 最大池,步长为 2×2 。两个分支的输出音量大小相同,因此它们可以沿通道轴连接在一起。
将这些模块中的每一个都想象成乐高——我们实现每种类型的乐高,然后以特定的方式将它们堆叠起来,以定义我们的模型架构。
乐高可以以近乎无限的可能性组织和组合在一起;然而,既然形式定义功能,我们就需要小心翼翼,考虑这些乐高积木应该如何组合在一起。
注:如果你想详细回顾 MiniGoogLeNet 架构内的每个模块,请务必参考 用 Python 进行计算机视觉的深度学习 ,在那里我会详细介绍它们。
作为将我们的“乐高模块”拼凑在一起的一个例子,现在让我们开始实现 MiniGoogLeNet:
def minigooglenet_functional(width, height, depth, classes):
def conv_module(x, K, kX, kY, stride, chanDim, padding="same"):
# define a CONV => BN => RELU pattern
x = Conv2D(K, (kX, kY), strides=stride, padding=padding)(x)
x = BatchNormalization(axis=chanDim)(x)
x = Activation("relu")(x)
# return the block
return x
第 34 行定义了minigooglenet_functional模型构建器方法。
我们将定义三个可重用模块,它们是 GoogLeNet 架构的一部分:
conv_moduleinception_moduledownsample_module
请务必参考以上各项的详细说明。
像这样将模块定义为子功能允许我们重用结构并节省代码行,更不用说更容易阅读和修改了。
第 35 行定义了conv_module及其参数。最重要的参数是x —该模块的输入。其他参数传递给Conv2D和BatchNormalization。
第 37-39 行建立一组CONV => BN => RELU层。
请注意,每一行的开头以x =开始,结尾以(x)结束。这种风格是 Keras 函数式 API 的代表。层被附加到另一层,其中x作为后续层的输入。这种功能风格将贯穿整个minigooglenet_functional方法。
第 42 行将构建好的conv_module返回给调用者。
让我们创建由两个卷积模块组成的inception_module:
def inception_module(x, numK1x1, numK3x3, chanDim):
# define two CONV modules, then concatenate across the
# channel dimension
conv_1x1 = conv_module(x, numK1x1, 1, 1, (1, 1), chanDim)
conv_3x3 = conv_module(x, numK3x3, 3, 3, (1, 1), chanDim)
x = concatenate([conv_1x1, conv_3x3], axis=chanDim)
# return the block
return x
第 44 行定义了我们的inception_module和参数。
初始模块包含和conv_module的两个分支,这两个分支连接在一起:
- 在第一分支中,我们执行 1×1 卷积(第 47 行)。
- 在第二分支中,我们执行 3×3 卷积(第 48 行)。
对线 49 上concatenate的调用将模块分支跨通道维度集合在一起。因为填充是两个分支的“same”,所以输出音量大小相等。因此,它们可以沿着信道维度连接起来。
第 51 行将inception_module块返回给调用者。
最后,我们将实现我们的downsample_module:
def downsample_module(x, K, chanDim):
# define the CONV module and POOL, then concatenate
# across the channel dimensions
conv_3x3 = conv_module(x, K, 3, 3, (2, 2), chanDim,
padding="valid")
pool = MaxPooling2D((3, 3), strides=(2, 2))(x)
x = concatenate([conv_3x3, pool], axis=chanDim)
# return the block
return x
第 54 行定义了我们的downsample_module和参数。下采样模块负责减小输入体积大小,它还利用了两个分支:
- 第一分支执行 3×3 卷积与 2×2 步距(行 57 和 58 )。
- 第二分支以 2×2 步距(第 59 行)执行 3×3 最大拼版。
然后通过调用concatenate ( 第 60 行)将分支的输出沿着通道维度堆叠。
第 63 行将下采样块返回给调用者。
定义了我们的每个模块后,我们现在可以使用它们来构建使用功能 API 的整个 MiniGoogLeNet 架构:
# initialize the input shape to be "channels last" and the
# channels dimension itself
inputShape = (height, width, depth)
chanDim = -1
# define the model input and first CONV module
inputs = Input(shape=inputShape)
x = conv_module(inputs, 96, 3, 3, (1, 1), chanDim)
# two Inception modules followed by a downsample module
x = inception_module(x, 32, 32, chanDim)
x = inception_module(x, 32, 48, chanDim)
x = downsample_module(x, 80, chanDim)
# four Inception modules followed by a downsample module
x = inception_module(x, 112, 48, chanDim)
x = inception_module(x, 96, 64, chanDim)
x = inception_module(x, 80, 80, chanDim)
x = inception_module(x, 48, 96, chanDim)
x = downsample_module(x, 96, chanDim)
# two Inception modules followed by global POOL and dropout
x = inception_module(x, 176, 160, chanDim)
x = inception_module(x, 176, 160, chanDim)
x = AveragePooling2D((7, 7))(x)
x = Dropout(0.5)(x)
# softmax classifier
x = Flatten()(x)
x = Dense(classes)(x)
x = Activation("softmax")(x)
# create the model
model = Model(inputs, x, name="minigooglenet")
# return the constructed network architecture
return model
第 67-71 行设置我们的inputs到 CNN。
从那里,我们使用函数式 API 来组装我们的模型:
- 首先,我们应用一个单独的
conv_module( 第 72 行)。 - 然后,在使用
downsample_module减少体积大小之前,将两个inception_module模块堆叠在彼此的顶部。(第 75-77 行)。 - 然后,在通过
downsample_module( 第 80-84 行)减少卷大小之前,我们通过应用四个inception_module块来深化模块。 - 然后,在应用平均池和构建完全连接的层头之前,我们再堆叠两个
inception_module块(行 87-90 )。 - 然后应用 softmax 分类器(第 93-95 行)。
- 最后,完整构造的
Model被返回给调用函数(第 98-101 行)。
同样,请注意我们是如何使用函数式 API 与前一节中讨论的顺序式 API 进行比较的。
关于如何利用 Keras 的函数式 API 来实现您自己的定制模型架构的更详细的讨论,请务必参考我的书, 用 Python 进行计算机视觉的深度学习 ,在那里我更详细地讨论了函数式 API。
此外,我要感谢张等人,他们在论文 中以一种美丽的可视化方式首次提出了 MiniGoogLeNet 架构,理解深度学习需要重新思考泛化 。
使用 Keras 和 TensorFlow 2.0 创建模型子类

Figure 4: “Model Subclassing” is one of the 3 ways to create a Keras model with TensorFlow 2.0.
第三种也是最后一种使用 Keras 和 TensorFlow 2.0 实现模型架构的方法叫做模型子类化。
在 Keras 内部,Model类是用于定义模型架构的根类。由于 Keras 利用了面向对象编程,我们实际上可以子类化类,然后插入我们的架构定义。
模型子类化是完全可定制的,并且使你能够实现你自己定制的模型前向传递。
然而,这种灵活性和定制是有代价的——与顺序 API 或函数 API 相比,模型子类化更难利用。
那么,如果模型子类化方法如此难以使用,为什么还要费力去利用它呢?
奇特的架构或定制的层/模型实现,尤其是那些被研究人员利用的实现,如果不是不可能的话,使用标准的顺序或功能 API 来实现可能会非常具有挑战性(T2)。
相反,研究人员希望能够控制网络和训练过程的每一个细微差别——这正是模型子类化为他们提供的。
让我们看一个实现 MiniVGGNet 的简单例子,它是一个顺序模型,但是被转换成了一个模型子类:
class MiniVGGNetModel(Model):
def __init__(self, classes, chanDim=-1):
# call the parent constructor
super(MiniVGGNetModel, self).__init__()
# initialize the layers in the first (CONV => RELU) * 2 => POOL
# layer set
self.conv1A = Conv2D(32, (3, 3), padding="same")
self.act1A = Activation("relu")
self.bn1A = BatchNormalization(axis=chanDim)
self.conv1B = Conv2D(32, (3, 3), padding="same")
self.act1B = Activation("relu")
self.bn1B = BatchNormalization(axis=chanDim)
self.pool1 = MaxPooling2D(pool_size=(2, 2))
# initialize the layers in the second (CONV => RELU) * 2 => POOL
# layer set
self.conv2A = Conv2D(32, (3, 3), padding="same")
self.act2A = Activation("relu")
self.bn2A = BatchNormalization(axis=chanDim)
self.conv2B = Conv2D(32, (3, 3), padding="same")
self.act2B = Activation("relu")
self.bn2B = BatchNormalization(axis=chanDim)
self.pool2 = MaxPooling2D(pool_size=(2, 2))
# initialize the layers in our fully-connected layer set
self.flatten = Flatten()
self.dense3 = Dense(512)
self.act3 = Activation("relu")
self.bn3 = BatchNormalization()
self.do3 = Dropout(0.5)
# initialize the layers in the softmax classifier layer set
self.dense4 = Dense(classes)
self.softmax = Activation("softmax")
第 103 行定义了我们的MiniVGGNetModel类,后面是第 104 行定义了我们的构造函数。
第 106 行使用super关键字调用我们的父构造函数。
从那里,我们的层被定义为实例属性,每个都有自己的名字(第 110-137 行)。Python 中的属性使用self关键字,并且通常(但不总是)在构造函数中定义。现在让我们来回顾一下:
- 第
(CONV => RELU) * 2 => POOL层集合(第 110-116 行)。 - 第二
(CONV => RELU) * 2 => POOL层集合(第 120-126 行)。 - 我们的全连接网络头(
Dense)带有"softmax"分类器(线 129-138 )。
注意每一层是如何在构造函数中定义的——这是故意的!
假设我们有自己的自定义层实现,它执行一种特殊类型的卷积或池化。该层可以在MiniVGGNetModel中的其他地方定义,然后在构造函数中实例化。
一旦定义了我们的 Keras 层和自定义实现层,我们就可以在用于执行前向传递的call函数中定义网络拓扑/图形:
def call(self, inputs):
# build the first (CONV => RELU) * 2 => POOL layer set
x = self.conv1A(inputs)
x = self.act1A(x)
x = self.bn1A(x)
x = self.conv1B(x)
x = self.act1B(x)
x = self.bn1B(x)
x = self.pool1(x)
# build the second (CONV => RELU) * 2 => POOL layer set
x = self.conv2A(x)
x = self.act2A(x)
x = self.bn2A(x)
x = self.conv2B(x)
x = self.act2B(x)
x = self.bn2B(x)
x = self.pool2(x)
# build our FC layer set
x = self.flatten(x)
x = self.dense3(x)
x = self.act3(x)
x = self.bn3(x)
x = self.do3(x)
# build the softmax classifier
x = self.dense4(x)
x = self.softmax(x)
# return the constructed model
return x
注意这个模型本质上是一个序列模型;然而,我们可以很容易地定义一个具有多个输入/输出、分支等的模型。
大多数深度学习从业者不会必须使用模型子类化方法,但只要知道如果你需要它,它是可用的!
实施培训脚本
我们的三个模型架构都实现了,但是我们要如何训练它们呢?
答案就在train.py里面——我们来看看:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# there seems to be an issue with TensorFlow 2.0 throwing non-critical
# warnings regarding gradients when using the model sub-classing
# feature -- I found that by setting the logging level I can suppress
# the warnings from showing up (likely won't be required in future
# releases of TensorFlow)
import logging
logging.getLogger("tensorflow").setLevel(logging.CRITICAL)
# import the necessary packages
from pyimagesearch.models import MiniVGGNetModel
from pyimagesearch.models import minigooglenet_functional
from pyimagesearch.models import shallownet_sequential
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-24 行导入我们的包:
- 对于
matplotlib,我们将后端设置为"Agg",这样我们就可以将我们的绘图作为.png文件(第 2 行和第 3 行)导出到磁盘。 - 我们导入
logging并将日志级别设置为忽略除关键错误之外的任何内容(第 10 行和第 11 行)。TensorFlow 在使用 Keras 的模型子类化功能训练模型时报告了(不相关的)警告消息,因此我更新了日志记录,只报告关键消息。我认为警告本身是 TensorFlow 2.0 中的一个错误,在下一个版本中可能会被删除。 - 我们 CNN 的三款都是进口的:(1)
MiniVGGNetModel、(2)minigooglenet_functional、(3)shallownet_sequential(14-16 行)。 - 我们导入我们的 CIFAR-10 数据集(第 21 行)。
从这里开始,我们将继续解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="sequential",
choices=["sequential", "functional", "class"],
help="type of model architecture")
ap.add_argument("-p", "--plot", type=str, required=True,
help="path to output plot file")
args = vars(ap.parse_args())
我们的两个命令行参数包括:
--model:必须使用以下choices=["sequential", "functional", "class"]之一来使用 Keras 的 API 加载我们的模型。--plot:输出绘图图像文件的路径。你可以像我一样将你的图保存在output/目录中。
从这里,我们将(1)初始化一些超参数,(2)准备我们的数据,以及(3)构造我们的数据扩充对象:
# initialize the initial learning rate, batch size, and number of
# epochs to train for
INIT_LR = 1e-2
BATCH_SIZE = 128
NUM_EPOCHS = 60
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer", "dog",
"frog", "horse", "ship", "truck"]
# load the CIFAR-10 dataset
print("[INFO] loading CIFAR-10 dataset...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
# scale the data to the range [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=18, zoom_range=0.15,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
horizontal_flip=True, fill_mode="nearest")
在这个代码块中,我们:
- 初始化(1)学习率,(2)批量大小,以及(3)训练时期数(第 37-39 行)。
- 设置 CIFAR-10 数据集
labelNames,加载数据集,并对其进行预处理(第 42-51 行)。 - 将我们的标签二进制化(第 54-56 行)。
- 用随机旋转、缩放、移动、剪切和翻转的设置实例化我们的数据扩充对象(第 59-61 行)。
脚本的核心在下一个代码块中,我们在这里实例化我们的模型:
# check to see if we are using a Keras Sequential model
if args["model"] == "sequential":
# instantiate a Keras Sequential model
print("[INFO] using sequential model...")
model = shallownet_sequential(32, 32, 3, len(labelNames))
# check to see if we are using a Keras Functional model
elif args["model"] == "functional":
# instantiate a Keras Functional model
print("[INFO] using functional model...")
model = minigooglenet_functional(32, 32, 3, len(labelNames))
# check to see if we are using a Keras Model class
elif args["model"] == "class":
# instantiate a Keras Model sub-class model
print("[INFO] using model sub-classing...")
model = MiniVGGNetModel(len(labelNames))
在这里,我们检查我们的顺序、功能或模型子类化架构是否应该被实例化。在基于命令行参数的if/elif语句之后,我们初始化适当的model。
从那里,我们准备好编译模型并适合我们的数据:
# initialize the optimizer and compile the model
opt = SGD(lr=INIT_LR, momentum=0.9, decay=INIT_LR / NUM_EPOCHS)
print("[INFO] training network...")
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // BATCH_SIZE,
epochs=NUM_EPOCHS,
verbose=1)
我们所有的模型都是用随机梯度下降(SGD)和学习率衰减(第 82-85 行)编译的。
第 88-93 行开始使用 Keras 的.fit_generator方法处理数据扩充的培训。你可以在这篇文章中深入了解.fit_generator方法。
最后,我们将评估我们的模型并绘制培训历史:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# determine the number of epochs and then construct the plot title
N = np.arange(0, NUM_EPOCHS)
title = "Training Loss and Accuracy on CIFAR-10 ({})".format(
args["model"])
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title(title)
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
第 97-99 行对测试集进行预测并评估网络。分类报告被打印到终端。
第 102-117 行绘制了训练精度/损失曲线,并将该图输出到磁盘。
Keras 顺序模型结果
我们现在准备使用 Keras 和 TensorFlow 2.0 来训练我们的序列模型!
现在花点时间使用本教程的 【下载】 部分下载本指南的源代码。
从那里,打开一个终端并执行以下命令来训练和评估顺序模型:
$ python train.py --model sequential --plot output/sequential.png
[INFO] loading CIFAR-10 dataset...
[INFO] using sequential model...
[INFO] training network...
Epoch 1/60
390/390 [==============================] - 25s 63ms/step - loss: 1.9162 - accuracy: 0.3165 - val_loss: 1.6599 - val_accuracy: 0.4163
Epoch 2/60
390/390 [==============================] - 24s 61ms/step - loss: 1.7170 - accuracy: 0.3849 - val_loss: 1.5639 - val_accuracy: 0.4471
Epoch 3/60
390/390 [==============================] - 23s 59ms/step - loss: 1.6499 - accuracy: 0.4093 - val_loss: 1.5228 - val_accuracy: 0.4668
...
Epoch 58/60
390/390 [==============================] - 24s 61ms/step - loss: 1.3343 - accuracy: 0.5299 - val_loss: 1.2767 - val_accuracy: 0.5655
Epoch 59/60
390/390 [==============================] - 24s 61ms/step - loss: 1.3276 - accuracy: 0.5334 - val_loss: 1.2461 - val_accuracy: 0.5755
Epoch 60/60
390/390 [==============================] - 24s 61ms/step - loss: 1.3280 - accuracy: 0.5342 - val_loss: 1.2555 - val_accuracy: 0.5715
[INFO] evaluating network...
precision recall f1-score support
airplane 0.73 0.52 0.60 1000
automobile 0.62 0.80 0.70 1000
bird 0.58 0.30 0.40 1000
cat 0.51 0.24 0.32 1000
deer 0.69 0.32 0.43 1000
dog 0.53 0.51 0.52 1000
frog 0.47 0.84 0.60 1000
horse 0.55 0.73 0.62 1000
ship 0.69 0.69 0.69 1000
truck 0.52 0.77 0.62 1000
accuracy 0.57 10000
macro avg 0.59 0.57 0.55 10000
weighted avg 0.59 0.57 0.55 10000
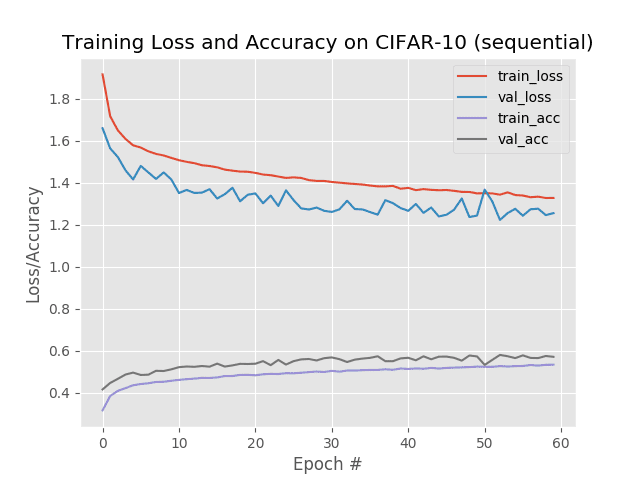
Figure 5: Using TensorFlow 2.0’s Keras Sequential API (one of the 3 ways to create a Keras model with TensorFlow 2.0), we have trained ShallowNet on CIFAR-10.
在这里,我们在 CIFAR-10 数据集上获得了 59%的准确率。
查看图 5 中的训练历史图,我们注意到,在几乎整个训练过程中,我们的验证损失小于我们的训练损失—我们可以通过增加模型复杂性来提高我们的准确性,这正是我们将在下一节中做的。
Keras 功能模型结果
我们的功能模型实现比我们的顺序示例更深入、更复杂。
同样,确保您已经使用本指南的 【下载】 部分下载了源代码。
有了源代码后,执行以下命令来训练我们的功能模型:
$ python train.py --model functional --plot output/functional.png
[INFO] loading CIFAR-10 dataset...
[INFO] using functional model...
[INFO] training network...
Epoch 1/60
390/390 [==============================] - 69s 178ms/step - loss: 1.6112 - accuracy: 0.4091 - val_loss: 2.2448 - val_accuracy: 0.2866
Epoch 2/60
390/390 [==============================] - 60s 153ms/step - loss: 1.2376 - accuracy: 0.5550 - val_loss: 1.3850 - val_accuracy: 0.5259
Epoch 3/60
390/390 [==============================] - 59s 151ms/step - loss: 1.0665 - accuracy: 0.6203 - val_loss: 1.4964 - val_accuracy: 0.5370
...
Epoch 58/60
390/390 [==============================] - 59s 151ms/step - loss: 0.2498 - accuracy: 0.9141 - val_loss: 0.4282 - val_accuracy: 0.8756
Epoch 59/60
390/390 [==============================] - 58s 149ms/step - loss: 0.2398 - accuracy: 0.9184 - val_loss: 0.4874 - val_accuracy: 0.8643
Epoch 60/60
390/390 [==============================] - 61s 156ms/step - loss: 0.2442 - accuracy: 0.9155 - val_loss: 0.4981 - val_accuracy: 0.8649
[INFO] evaluating network...
precision recall f1-score support
airplane 0.94 0.84 0.89 1000
automobile 0.95 0.94 0.94 1000
bird 0.70 0.92 0.80 1000
cat 0.85 0.64 0.73 1000
deer 0.77 0.92 0.84 1000
dog 0.91 0.70 0.79 1000
frog 0.88 0.94 0.91 1000
horse 0.95 0.85 0.90 1000
ship 0.89 0.96 0.92 1000
truck 0.89 0.95 0.92 1000
accuracy 0.86 10000
macro avg 0.87 0.86 0.86 10000
weighted avg 0.87 0.86 0.86 10000
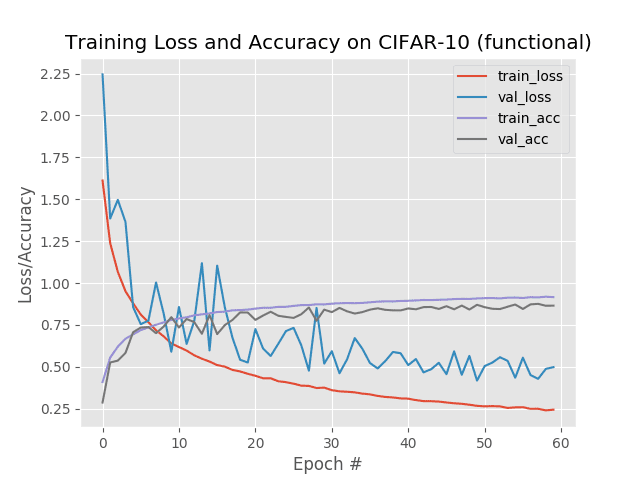
Figure 6: Using TensorFlow 2.0’s Keras Functional API (one of the 3 ways to create a Keras model with TensorFlow 2.0), we have trained MiniGoogLeNet on CIFAR-10.
这一次,我们已经能够将我们的准确率一路提高到 87%!
Keras 模型子类化结果
我们最后的实验评估了使用 Keras 的模型子类化的实现。
我们在这里使用的模型是 VGGNet 的一个变体,这是一个本质上连续的模型,由 3×3 CONVs 和 2×2 max-pooling 组成,用于减少卷维度。
我们在这里使用 Keras 模型子类化(而不是顺序 API)作为一个简单的例子,说明如何将现有的模型转换成子类化的架构。
注意:为模型子类化 API 实现你自己的定制层类型和训练程序超出了这篇文章的范围,但是我会在以后的指南中介绍它。
要查看 Keras 模型子类化的运行情况,请确保您已经使用了本指南的 “下载” 部分来获取代码——从那里您可以执行以下命令:
$ python train.py --model class --plot output/class.png
[INFO] loading CIFAR-10 dataset...
[INFO] using model sub-classing...
[INFO] training network...
Epoch 1/60
Epoch 58/60
390/390 [==============================] - 30s 77ms/step - loss: 0.9100 - accuracy: 0.6799 - val_loss: 0.8620 - val_accuracy: 0.7057
Epoch 59/60
390/390 [==============================] - 30s 77ms/step - loss: 0.9100 - accuracy: 0.6792 - val_loss: 0.8783 - val_accuracy: 0.6995
Epoch 60/60
390/390 [==============================] - 30s 77ms/step - loss: 0.9036 - accuracy: 0.6785 - val_loss: 0.8960 - val_accuracy: 0.6955
[INFO] evaluating network...
precision recall f1-score support
airplane 0.76 0.77 0.77 1000
automobile 0.80 0.90 0.85 1000
bird 0.81 0.46 0.59 1000
cat 0.63 0.36 0.46 1000
deer 0.68 0.57 0.62 1000
dog 0.78 0.45 0.57 1000
frog 0.45 0.96 0.62 1000
horse 0.74 0.81 0.77 1000
ship 0.90 0.79 0.84 1000
truck 0.73 0.89 0.80 1000
accuracy 0.70 10000
macro avg 0.73 0.70 0.69 10000
weighted avg 0.73 0.70 0.69 10000
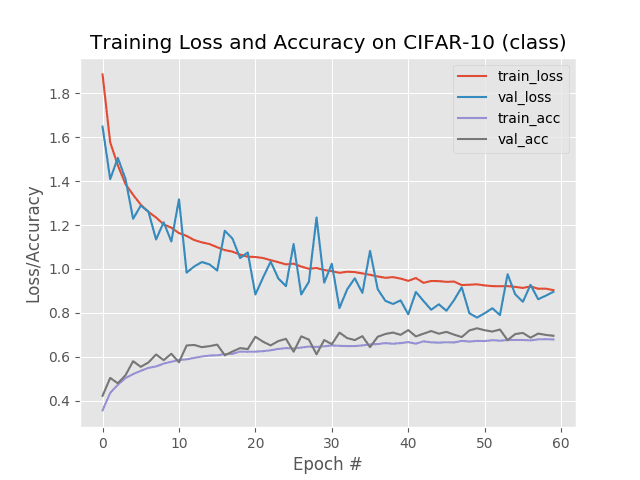
Figure 7: Using TensorFlow 2.0’s Keras Subclassing (one of the 3 ways to create a Keras model with TensorFlow 2.0), we have trained MiniVGGNet on CIFAR-10.
在这里,我们获得了 73%的准确率,没有我们的 MiniGoogLeNet 实现那么好,但是它仍然是一个如何使用 Keras 的模型子类化特性来实现架构的例子。
一般情况下,我不推荐使用 Keras 的模型子类:
- 比较难用。
- 它增加了代码的复杂性
- 更难调试。
…但是确实给了你对模型的完全控制权。
通常,我只推荐你使用 Keras 的模型子类化,如果你是:
- 深度学习研究员实现定制层、模型和训练程序。
- 深度学习实践者试图复制一个研究人员/论文的结果。
大多数深度学习实践者不需要 Keras 的模型子类化功能。
总结
在本教程中,您学习了使用 Keras 和 TensorFlow 2.0 实现神经网络架构的三种方法:
- 顺序:用于实现简单的逐层架构,没有多输入、多输出或层分支。通常是开始使用 Keras 时使用的第一个模型 API。
- 功能:最流行的 Keras 模型实现 API。允许顺序 API 中的一切,但也有助于实质上更复杂的架构,其中包括多个输入和输出、分支等。最棒的是,Keras 的功能 API 的语法是干净和易于使用。
- 模型子类化:当深度学习研究者/实践者需要完全控制模型、层和训练过程实现时使用。代码冗长,更难编写,更难调试。大多数深度学习实践者不需要使用 Keras 对模型进行子类化,但如果你在做研究或定制实现,如果你需要,模型子类化就在那里!
如果您有兴趣了解更多关于顺序、函数和模型子类化 API 的信息,请务必参考我的书, 使用 Python 的计算机视觉深度学习 ,在那里我会更详细地介绍它们。
我希望你喜欢今天的教程!
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!
4 点 OpenCV getPerspective 转换示例
原文:https://pyimagesearch.com/2014/08/25/4-point-opencv-getperspective-transform-example/
最后更新于 2021 年 7 月 4 日。

凌晨 4 点 18 分。警报响了。外面还是漆黑一片。床很暖和。我光着脚会觉得地板很冷。
但是我起床了。我勇敢地面对清晨,像冠军一样站在冰冷的地板上。
为什么?
因为我很兴奋。
很高兴今天能和大家分享一些非常特别的东西…
你看,在过去的几周里,我收到了一些来自 PyImageSearch 读者朋友的非常棒的电子邮件。这些邮件简短、甜蜜、切中要害。他们只是简单的“谢谢”而已,因为他们贴出了真实的、真正的 Python 和 OpenCV 代码,你可以拿来用它们来解决你自己的计算机视觉和图像处理问题。
经过昨晚的反思,我意识到我在分享我为自己开发的日常使用的库、包和代码方面做得不够好——所以这正是我今天要做的。
在这篇博文中,我将向你展示我的transform.py模块中的功能。每当我需要用 OpenCV 做 4 点cv2.getPerspectiveTransform的时候,我都会用到这些函数。
我想你会发现这里的代码非常有趣 … ,你甚至可以在自己的项目中使用它。
所以请继续阅读。并检查我的 4 点 OpenCV cv2.getPerspectiveTransform的例子。
- 【2021 年 7 月更新:新增两个章节。第一部分介绍了如何自动找到透视转换的左上、右上、右下和左下坐标。第二部分讨论如何通过考虑输入 ROI 的纵横比来改善透视变换结果。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
4 点 OpenCV getPerspectiveTransform 示例
你可能还记得我关于构建现实生活中的 Pokedex 的帖子,特别是我关于 OpenCV 和透视扭曲的帖子。
在那篇文章中,我提到了如何使用透视变换来获得图像的自上而下的“鸟瞰图”——当然,前提是你能找到参考点。
这篇文章将继续讨论自上而下的图像“鸟瞰图”。但是这次我要和你分享我每次使用的 个人代码我需要做一个 4 点透视变换。
所以我们不要再浪费时间了。打开一个新文件,命名为transform.py,我们开始吧。
# import the necessary packages
import numpy as np
import cv2
def order_points(pts):
# initialzie a list of coordinates that will be ordered
# such that the first entry in the list is the top-left,
# the second entry is the top-right, the third is the
# bottom-right, and the fourth is the bottom-left
rect = np.zeros((4, 2), dtype = "float32")
# the top-left point will have the smallest sum, whereas
# the bottom-right point will have the largest sum
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# now, compute the difference between the points, the
# top-right point will have the smallest difference,
# whereas the bottom-left will have the largest difference
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
# return the ordered coordinates
return rect
我们将从导入我们需要的包开始:NumPy 用于数值处理,而cv2用于 OpenCV 绑定。
接下来,让我们定义线 5 上的order_points函数。这个函数有一个参数pts,它是一个包含四个点的列表,指定了矩形中每个点的 (x,y) 坐标。
矩形中的点有一个一致的顺序是绝对重要的。实际的排序本身可以是任意的,只要在整个实现过程中保持一致。
就我个人而言,我喜欢按照左上、右上、右下和左下的顺序来说明我的观点。
我们将从为第 10 行上的四个有序点分配内存开始。
然后,我们将找到左上角的点,它将具有最小的 x + y 和,以及右下角的点,它将具有最大的 x + y 和。这在14-16 行处理。
当然,现在我们必须找到右上角和左下角的点。这里,我们将使用第 21 行上的np.diff函数来计算点之间的差值(即x–y)。
与最小差异相关的坐标将是右上角的点,而与最大差异相关的坐标将是左下角的点(行 22 和 23 )。
最后,我们将有序函数返回给第 26 行上的调用函数。
我再强调一次,保持点的一致排序是多么重要。
在下一个函数中你会明白为什么:
def four_point_transform(image, pts):
# obtain a consistent order of the points and unpack them
# individually
rect = order_points(pts)
(tl, tr, br, bl) = rect
# compute the width of the new image, which will be the
# maximum distance between bottom-right and bottom-left
# x-coordiates or the top-right and top-left x-coordinates
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
# compute the height of the new image, which will be the
# maximum distance between the top-right and bottom-right
# y-coordinates or the top-left and bottom-left y-coordinates
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# now that we have the dimensions of the new image, construct
# the set of destination points to obtain a "birds eye view",
# (i.e. top-down view) of the image, again specifying points
# in the top-left, top-right, bottom-right, and bottom-left
# order
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# compute the perspective transform matrix and then apply it
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# return the warped image
return warped
我们首先在第 28 行的上定义four_point_transform函数,它需要两个参数:image和pts。
image变量是我们想要应用透视变换的图像。而pts列表是包含我们想要变换的图像的 ROI 的四个点的列表。
我们在第 31 行的上调用了我们的order_points函数,这将我们的pts变量置于一个一致的顺序中。为了方便起见,我们将这些坐标放在第 32 行的上。
现在我们需要确定新的扭曲图像的尺寸。
我们在第 37-39 行上确定新图像的宽度,其中宽度是右下角和左下角的 x 坐标或右上角和左上角的 x 坐标之间的最大距离。
以类似的方式,我们在第 44-46 行上确定新图像的高度,其中高度是右上和右下 y 坐标或左上和左下 y 坐标之间的最大距离。
注:非常感谢汤姆·洛厄尔发来邮件,确保我修正了宽度和高度的计算!
所以这里是你真正需要注意的地方。
还记得我说过我们试图获得原始图像中 ROI 的自上而下的“鸟瞰图”吗?还记得我说过代表 ROI 的四个点的一致排序是至关重要的吗?
在的第 53-57 行你可以看到为什么。这里,我们定义了 4 个点来代表我们的“自上而下”的图像视图。列表中的第一个条目是指示左上角的(0, 0)。第二个条目是(maxWidth - 1, 0),对应右上角。然后我们有右下角的(maxWidth - 1, maxHeight - 1)。最后,我们有(0, maxHeight - 1),它是左下角。
这里的要点是,这些点是以一致的顺序表示定义的,这将允许我们获得图像的自上而下的视图。
为了实际获得自上而下的图像“鸟瞰图”,我们将利用第 60 行上的cv2.getPerspectiveTransform函数。这个函数需要两个参数,rect,它是原始图像中 4 个 ROI 点的列表,和dst,它是我们的变换点列表。cv2.getPerspectiveTransform函数返回M,这是实际的变换矩阵。
我们使用cv2.warpPerspective函数在行 61 上应用变换矩阵。我们传入image,我们的变换矩阵M,以及我们输出图像的宽度和高度。
cv2.warpPerspective的输出就是我们的warped图像,这是我们自顶向下的视图。
我们将第 64 行上的自顶向下视图返回给调用函数。
现在我们已经有了执行转换的代码,我们需要一些代码来驱动它并实际应用到图像上。
打开一个新文件,调用transform_example.py,让我们完成它:
# import the necessary packages
from pyimagesearch.transform import four_point_transform
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", help = "path to the image file")
ap.add_argument("-c", "--coords",
help = "comma seperated list of source points")
args = vars(ap.parse_args())
# load the image and grab the source coordinates (i.e. the list of
# of (x, y) points)
# NOTE: using the 'eval' function is bad form, but for this example
# let's just roll with it -- in future posts I'll show you how to
# automatically determine the coordinates without pre-supplying them
image = cv2.imread(args["image"])
pts = np.array(eval(args["coords"]), dtype = "float32")
# apply the four point tranform to obtain a "birds eye view" of
# the image
warped = four_point_transform(image, pts)
# show the original and warped images
cv2.imshow("Original", image)
cv2.imshow("Warped", warped)
cv2.waitKey(0)
我们要做的第一件事是在行 2 导入我们的four_point_transform函数。出于组织目的,我决定将它放在pyimagesearch子模块中。
然后,我们将使用 NumPy 实现数组功能,argparse用于解析命令行参数,而cv2用于 OpenCV 绑定。
我们在的第 8-12 行解析命令行参数。我们将使用两个开关,--image,它是我们想要应用变换的图像,和--coords,它是 4 个点的列表,代表我们想要获得自上而下的“鸟瞰图”的图像区域。
然后,我们将图像加载到第 19 行上,并将这些点转换成第 20 行上的 NumPy 数组。
现在,在你因为我使用了eval函数而生气之前,请记住,这只是一个例子。我不赞成以这种方式进行视角转换。
而且,正如你将在下周的帖子中看到的,我将向你展示如何自动确定透视变换所需的四个点——无需你手动操作!
接下来,我们可以在第 24 行应用我们的透视变换。
最后,让我们在第 27-29 行显示原始图像和扭曲的、自顶向下的图像视图。
获得图像的俯视图
好了,让我们看看这段代码的运行情况。
打开一个 shell 并执行以下命令:
$ python transform_example.py --image images/example_01.png --coords "[(73, 239), (356, 117), (475, 265), (187, 443)]"
您应该会看到便笺的自上而下视图,如下所示:

Figure 1: Applying an OpenCV perspective transform to obtain a “top-down” view of an image.
让我们尝试另一个图像:
$ python transform_example.py --image images/example_02.png --coords "[(101, 185), (393, 151), (479, 323), (187, 441)]"
第三个是好的措施:
$ python transform_example.py --image images/example_03.png --coords "[(63, 242), (291, 110), (361, 252), (78, 386)]"
正如你所看到的,我们已经成功地获得了自上而下的笔记卡的“鸟瞰图”!
在某些情况下,便笺看起来有点翘——这是因为照片拍摄的角度非常严重。我们越接近便笺上“向下看”的 90 度角,结果就越好。
自动寻找转换的角点
为了获得输入图像的自顶向下变换,我们必须手动提供/硬编码输入的左上、右上、右下和左下坐标。
这就提出了一个问题:
有没有办法让自动获取这些坐标?
*你打赌有。以下三个教程向您展示了如何做到这一点:
- 用 OpenCV 构建文档扫描仪
- 使用 OMR、Python 和 OpenCV 进行气泡表多项选择扫描和测试评分
- OpenCV 数独求解器和 OCR
通过计算纵横比改善自上而下的变换结果
图像的纵横比定义为宽度与高度的比率。调整图像大小或执行透视变换时,考虑图像的纵横比很重要。
例如,如果您曾经看到过看起来“压扁”或“嘎吱嘎吱”的图像,那是因为纵横比关闭了:
左边的是我们的原始图像。在右边的,我们有两张图像由于没有保持长宽比而被扭曲。它们已经通过忽略图像的宽高比而被调整了大小。**
*为了获得更好、更美观的透视变换,您应该考虑输入图像/ROI 的纵横比。StackOverflow 上的这个线程将告诉你如何去做。
摘要
在这篇博文中,我提供了一个使用 Python 的 OpenCV cv2.getPerspectiveTransform示例。
我甚至分享了我的个人库中关于如何做的代码!
但乐趣不止于此。
你知道那些 iPhone 和 Android 的“扫描仪”应用程序,可以让你给一份文件拍照,然后把它“扫描”到你的手机里吗?
没错——我将向您展示如何使用 4 点 OpenCV getPerspectiveTransform 示例代码来构建一个文档扫描仪应用程序!
我对此非常兴奋,希望你也是。
无论如何,一定要注册 PyImageSearch 时事通讯,以便在帖子发布时听到消息!**
你现在应该阅读的 7 本最佳深度学习书籍
原文:https://pyimagesearch.com/2018/03/05/7-best-deep-learning-books-reading-right-now/

在今天的帖子中,我将与你分享我遇到的 7 本最好的深度学习书籍(排名不分先后),并推荐你阅读。
这些深度学习书籍中的一些是理论性很强的,专注于神经网络和深度学习背后的数学和相关假设。
其他深度学习书籍是完全实用的,通过代码而不是理论来教授。
甚至其他深度学习书籍也跨越了这条线,给你一剂健康的理论,同时使你能够“弄脏你的手”,并通过实施来学习(这些往往是我最喜欢的深度学习书籍)。
对于每本深度学习书籍,我都会讨论其中涵盖的核心概念、目标读者,以及这本书是否适合你。
发现学习深度学习的 7 本最佳书籍,继续读!
你现在应该阅读的 7 本最佳深度学习书籍
在你选择一本深度学习书籍之前,最好评估一下你自己的个人学习风格,以确保你从书中获得最大的收益。
首先问自己以下问题:
我怎样才能最好地学习?我喜欢从理论文本中学习吗?还是我喜欢从代码片段和实现中学习?
每个人都有自己的个人学习风格,你在这里的答案将决定你应该阅读哪些深度学习书籍。
对我个人来说,我喜欢在两者之间取得平衡。
深度学习书籍完全是理论性的,过于抽象,让我的眼睛很容易忽略。
但另一方面,如果一本深度学习的书完全跳过理论,直接进入实施,我知道我错过了可能帮助我解决新的深度学习问题或项目的核心理论基础。
在我看来,一本好的深度学习书需要仔细平衡这两者。
我们需要理论来帮助我们理解深度学习的核心基础——同时我们需要实现和代码片段来帮助我们巩固我们刚刚学到的东西。
![]() 1。深度学习
1。深度学习

很难(如果不是不可能的话)写一篇关于最佳深度学习书籍的博文而不提到 Goodfellow、Bengio 和库维尔的 深度学习正文。
这本书旨在成为一本教科书,用于在大学级别的课堂上教授围绕深度学习的基础知识和理论。
Goodfellow 等人的深度学习是完全理论化的,是为学术受众写的。书中没有涉及代码。
该书从机器学习基础知识的讨论开始,包括有效研究深度学习所需的应用数学(线性代数、概率和信息论等。)从学术角度来说。
从那里,这本书进入现代深度学习算法和技术。
深度学习的最后一部分更加关注当前的研究趋势以及深度学习领域的发展方向。
我亲自通读了这本书两遍,从头到尾,并发现它非常有价值,前提是你具备这样一本教科书所需的数学/学术严谨性。
深度学习可从该书的首页免费在线观看。你可以从亚马逊购买文本的硬拷贝。
如果……你应该读读这本深度学习的书
- 你从学习理论而不是实现
- 你喜欢学术写作
- 你是从事深度学习的教授、本科生或研究生

2.神经网络和深度学习
我的第二本基于理论的深度学习(e)书籍推荐是迈克尔·尼尔森的 神经网络和深度学习 。
这本书确实包括一些代码,但强调一下“一些”是很重要的——这本书总共有七个 Python 脚本,都在讨论各种基本的机器学习、神经网络或 MNIST 数据集上的深度学习技术。这些实现并不是世界上最“激动人心”的,但是它们将有助于演示文本中的一些理论概念。
如果你是机器学习和深度学习的新手,但渴望潜入基于理论的学习方法,尼尔森的书应该是你的第一站。
这本书比 Goodfellow 的深度学习读起来要快得多,尼尔森的写作风格结合偶尔的代码片段使其更容易理解。
如果……你应该读读这本深度学习的书
- 你在找一本基于理论的深度学习教材
- 是机器学习/深度学习的新手,希望从更学术的角度来研究这个领域
![]() 3。使用 Python 进行深度学习
3。使用 Python 进行深度学习

Francois Chollet 是谷歌人工智能研究员,也是广受欢迎的 Keras 深度学习库的创建者,他在 2017 年 10 月出版了他的书 深度学习与 Python 。
弗朗索瓦的书采用了一种从业者的方法来进行深度学习。包括了一些理论和讨论,但是对于每几段理论,您会发现该技术的一个 Keras 实现。
这本书我最喜欢的一个方面是 Francois 如何将深度学习应用于计算机视觉、文本和序列的例子包括在内,这使得它成为了一本全面的书籍,适合那些希望在学习机器学习和深度学习基础知识的同时学习 Keras 库的读者。
我发现弗朗索瓦的作品清晰易懂。他对深度学习趋势和历史的额外评论是惊人的,有见地的。
值得注意的是,这本书并不是要深入学习。相反,它的主要用途是教你(1)深度学习的基础知识(2)通过 Keras 库(3)使用各种深度学习领域的实际例子。
如果……你应该读读这本深度学习的书
- 你对喀拉斯图书馆感兴趣
- 你“通过做/实施来学习”
- 你想快速了解深度学习是如何应用于各个领域的,比如计算机视觉、序列学习和文本

4.使用 Scikit-Learn 和 TensorFlow 进行机器实践学习
当我第一次用 Scikit-Learn 和 TensorFlow 购买 Aurélien Géron 的 手动机器学习的副本时,我不确定会期待什么——如果标题没有包含“TensorFlow”这个词,我可能会轻易错过它,以为它只是机器学习的基本介绍。
但与此同时,在一个似乎专注于基本机器学习的已经很长的标题上加上“TensorFlow”这个词,让我觉得这是一种廉价的营销策略,可以卖出更多的副本——每个人都对深度学习感兴趣,对吗?
幸运的是,我错了——这本书很值得一读,书名不应该阻止你通读。
Géron 的深度学习书分为两部分。
第一部分涵盖了基本的机器学习算法,如支持向量机(SVMs),决策,树,随机森林,集成方法和基本的无监督学习算法。每个算法的 Scikit-learn 示例都包括在内。
第二部分通过 TensorFlow 库介绍了基本的深度学习概念。
如果……你应该读读这本深度学习的书
- 你是机器学习的新手,想从核心原则和代码示例开始
- 您对流行的 scikit-learn 机器学习库感兴趣
- 您希望快速学习如何操作 TensorFlow 库来完成基本的深度学习任务

5.TensorFlow 深度学习食谱
如果你喜欢“食谱”式的教学(很少甚至没有理论和大量代码),我建议看看古利和卡普尔的 TensorFlow 深度学习食谱 。
这本深度学习书籍完全是动手操作,对 TensorFlow 用户来说是一个很好的参考。
同样,这本书并不意味着必然教授深度学习,而是向你展示如何在深度学习的背景下操作 TensorFlow 库。
不要误解我——你将绝对在这个过程中学习新的深度学习概念、技术和算法,但这本书采用了一种严厉的食谱方法:大量代码和对代码正在做什么的解释。
我对这本书唯一的批评是代码片段中有一些错别字。当写一本完全以代码为中心的书时,这是可以预料的。打字错误时有发生,我可以肯定地证明这一点。当你阅读课文的时候,要意识到这一点。
如果……你应该读读这本深度学习的书
- 你已经学习了深度学习的基础知识
- 您对 TensorFlow 库感兴趣
- 你喜欢“烹饪书”式的教学,提供代码来解决特定的问题,但不讨论基本的理论

6.深度学习:实践者的方法
虽然大多数包含代码样本的深度学习书籍都使用 Python,但亚当·吉布森和乔希·帕特森的 深度学习:从业者接近 而是使用 Java 和 DL4J 库。
为什么是 Java?
Java 是大公司最常用的编程语言,尤其是在企业层面。
Gibson 和 Patterson 书中的前几章讨论了基本的机器学习和深度学习基础知识。本书的其余部分包括使用 DL4J 的基于 Java 的深度学习代码示例。
如果……你应该读读这本深度学习的书
- 您有一个需要使用 Java 编程语言的特定用例
- 您在一家主要使用 Java 的大公司或企业机构工作
- 你想了解如何操作 DL4J 库

7.用 Python 实现计算机视觉的深度学习
我将完全诚实和坦率地承认我有偏见——我用 Python 编写了用于计算机视觉的 。
也就是说,我的书真的已经成为当今可用的最好的深度学习和计算机视觉资源之一(如果你需要诚实的第二意见,看看这篇评论和这篇)。
谷歌人工智能研究员、Keras 创始人 Francois Chollet 这样评价我的深度学习新书:
这本书是对计算机视觉的实用深度学习的一次伟大而深入的探索。我发现这是一本平易近人、令人愉快的读物:解释清晰且非常详细。你会发现许多实用的提示和建议,它们很少出现在其他书籍或大学课程中。无论是对练习者还是初学者,我都强烈推荐它。 —弗朗索瓦·乔莱
还有流行的 的作者 Adam Geitgey,机器学习很好玩! 博客系列,这样说:
我强烈推荐用 Python 抓一本计算机视觉深度学习。它涉及了很多细节,并有大量详细的例子。这是我迄今为止看到的唯一一本既涉及事物如何工作,又涉及如何在现实世界中实际使用它们来解决难题的书。看看吧!—亚当·盖特基
如果你有兴趣研究应用于计算机视觉的深度学习(图像分类、物体检测、图像理解等。这是一本最适合你的书。
在我的书中,你将:
- 以一种平衡理论和实现的可访问方式学习机器学习和深度学习的基础
- 研究高级深度学习技术,包括对象检测、多 GPU 训练、转移学习和生成对抗网络(GANs)
- 在 120 万 ImageNet 数据集上复制最先进论文的结果,包括 ResNet、SqueezeNet、VGGNet 和其他
此外,我提供了对理论和实践的最佳平衡。对于每一个理论上的深度学习概念,你都会找到一个相关的 Python 实现来帮助你巩固知识。
一定要看一看——当你借阅这本书的时候,别忘了带上你的(免费)目录+这本书的样本章节 PDF。
如果……你应该读读这本深度学习的书
- 你对应用于计算机视觉和图像理解的深度学习特别感兴趣
- 你需要理论和实现之间的完美平衡
- 你想要一本深度学习的书,让看似复杂的算法和技术容易掌握和理解
- 你想要一本清晰易懂的书来引导你走向深度学习的掌握
摘要
在这篇文章中,你发现了我最喜欢的七本研究深度学习的书。
你购买或通读过这些书吗?如果有,就留下评论,让我知道你对它的看法。
我错过了一本你认为应该在这份清单上的书吗?如果是这样,请务必联系我或留下评论。
更好、更快、更强的物体探测器(YOLOv2)
原文:https://pyimagesearch.com/2022/04/18/a-better-faster-and-stronger-object-detector-yolov2/
更好、更快、更强的物体探测器(YOLOv2)
检测框架已经变得越来越快速和准确,正如我们在 YOLOv1 上的上一篇文章中所看到的;然而,大多数检测方法仍然局限于一小组对象,如 PASCAL VOC 中的 20 个类和 Microsoft COCO 中的 80 个类。
图像分类数据集具有许多对象标签,并且注释起来比检测容易得多,也便宜得多。但是希望将检测扩展到物体分类的水平。
这也是雷德蒙和法尔哈迪(2017) 发表这篇论文的部分动机。
另一个主要动机是解决 YOLOv1 的问题:
- 成组检测小物体
- 本地化错误
- 锚箱的使用(先验)
- 介绍精确高效的新型 Darknet-19 架构
在本教程中,您将了解 YOLOv2 对象检测模型的所有内容,以及为什么它被称为更好、更快、更强。然后,我们将详细讨论论文中提到的所有基本概念。最后,在图像和视频上运行预训练的 YOLOv2 模型,看看它比它的前身 YOLOv1 表现得更好。
如果你还没有阅读我们之前在 YOLOv1 上的博文,我们强烈建议你先阅读这篇博文,因为理解这篇博文会变得更容易,并增强你的学习体验。
这一课是我们关于 YOLO 的七集系列的第三集:
- YOLO 家族简介
- 了解一个实时物体检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的天体探测器(YOLOv2) (今日教程)
- 使用 COCO 评估器 平均精度(mAP)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
- 【yolov 4】
- 在自定义数据集上训练 YOLOv5 物体检测器
今天的帖子将讨论 YOLO9000,更普遍的说法是 YOLOv2,它检测物体的速度比已经很快的 YOLOv1 快得多,并在 mAP 中实现了 13-16%的增益。
要学习 YOLOv2 物体探测器的理论概念,并观看实时探测物体的演示,继续阅读。
更好、更快、更强的物体探测器(YOLOv2)
在 YOLO 系列的第三部分中,我们将首先介绍 YOLOv2。
我们将讨论 YOLOv2 的更好的部分:
- 高分辨率分类器
- 批量标准化
- 锚箱的使用
- 维度群
- 直接位置预测
- 精细特征
- 多尺度分辨率训练
- 定量基准,将 YOLOv2 与 YOLOv1、更快的 R-CNN 和 SSD 进行比较
从那里,我们将讨论 YOLOv2 的更快的方面:
- Darknet-19 网络架构
- 侦查训练
- 分类培训
我们还将讨论构成 YOLO9000 基础的更强大的方面:
- 分层训练
- 将 imagenes 和 ms coco 与单词树相结合
- 分类和检测联合培训
最后,我们将通过在 Tesla V100 GPU 上安装 darknet 框架并使用 YOLOv2 预训练模型在图像和视频上运行推理来结束本教程。
配置您的开发环境
要遵循这个指南,您需要在您的系统上编译并安装 Darknet 框架。在本教程中,我们将使用 AlexeyAB 的 Darknet 库。
我们将逐步介绍如何在 Google Colab 上安装 darknet 框架。但是,如果您想现在配置您的开发环境,可以考虑前往配置 Darknet 框架并使用预训练的 YOLOv2 模型运行推理部分。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
约洛夫 2 简介
2017 年,约瑟夫·雷德蒙(华盛顿大学研究生)和阿里·法尔哈迪(艾伦人工智能研究所前团队负责人)在 CVPR 会议上发表了 YOLO9000:更好、更快、更强论文。作者在本文中提出了两种最先进的 YOLO 变种:YOLOv2 和 YOLO9000 两者完全相同,但训练策略不同。
YOLOv2 在标准检测数据集上接受训练,如 PASCAL VOC 和 MS COCO 。同时,YOLO9000 被设计成通过在 MS COCO 和 ImageNet 数据集上联合训练来预测 9000 多种不同的物体类别。
图 2 显示了 YOLO9000 模型的输出,该模型可以实时检测 9000 多个对象类。下面的输出显示模型已经学会检测不在 MS COCO 数据集中的对象。
YOLOv2 是 YOLO 家族的第二个版本,显著提高了精确度,速度更快。
改进的 YOLOv2 模型使用了各种新技术,在速度和准确性方面都优于 Faster-RCNN 和 SSD 等最先进的方法。一种这样的技术是多尺度训练,它允许网络在不同的输入规模下进行预测,从而允许在速度和准确性之间进行权衡。
在
input resolution, YOLOv2 achieved 76.8 mAP on VOC 2007 dataset and 67 FPS on Titan X GPU. On the same dataset with  input, YOLOv2 attained 78.6 mAP and 40 FPS.
input, YOLOv2 attained 78.6 mAP and 40 FPS.
他们还提出了在 COCO 检测数据集和 ImageNet 分类数据集上训练的 YOLO9000 模型。这种类型的训练背后的想法是检测不具有用于对象检测的基础真值的对象类,但是使用来自具有基础真值的对象类的监督。这种训练的领域被称为弱监督学习。这种方法帮助他们在 156 个没有探测地面真相的班级上实现了 16 个 mAP。是不是很棒!
更好的
在我们之前的文章中,我们了解到 YOLOv1 有一些限制。然而,与两阶段对象检测器相比,它主要受到定位误差的影响,导致低召回率。我们还在推理部分观察到,该模型检测到了置信度分数不是很高的对象。
YOLOv2 的目标是减少定位错误,从而提高召回率,同时保持并超越分类准确性。雷德蒙和法尔哈迪的想法是开发一种比其前辈更精确、更快速的物体探测器。因此,建立像 ResNet 这样更大、更深入的网络或者整合各种网络并不符合要求。相反,通过一种简化的网络架构方法,他们将注意力集中在将过去工作中的许多想法与他们的新技术结合起来。结果,他们提高了 YOLO 在速度和准确性方面的表现。
现在让我们来看看让 YOLO 表现更好的因素:
批量归一化
*** 在 YOLO 的所有卷积层中添加一个批量归一化层将 mAP 提高了 2% 。
- 它有助于改善网络训练的收敛性,并消除了对其他正则化技术的需要,如放弃,而不会使网络在训练数据上过度拟合。
高分辨率分类器
-
在 YOLOv1 中,在 ImageNet 数据集上以输入分辨率
 执行图像分类任务作为预训练步骤,之后升级到
执行图像分类任务作为预训练步骤,之后升级到 用于对象检测。因此,网络必须同时切换到学习对象检测并适应新的输入分辨率。对于网络权重来说,在学习检测任务时适应这个新的分辨率可能是一个问题。
用于对象检测。因此,网络必须同时切换到学习对象检测并适应新的输入分辨率。对于网络权重来说,在学习检测任务时适应这个新的分辨率可能是一个问题。 -
在 YOLOv2 中,雷德蒙和法尔哈迪用
 执行预训练分类步骤。尽管如此,他们在相同的 ImageNet 数据上以升级的
执行预训练分类步骤。尽管如此,他们在相同的 ImageNet 数据上以升级的 分辨率对分类网络进行了微调。通过这样做,网络获得了时间。由于在微调分类步骤中已经观察到该分辨率(图 3图 3 ),因此它调整了其滤波器,以更好地处理升级后的分辨率。
分辨率对分类网络进行了微调。通过这样做,网络获得了时间。由于在微调分类步骤中已经观察到该分辨率(图 3图 3 ),因此它调整了其滤波器,以更好地处理升级后的分辨率。 -
最后,我们针对检测任务对网络进行了微调,高分辨率分类器方法将 mAP 增加了接近 4% 。相信我,地图增加 4%是一个相当大的提升。
与锚框卷积
-
YOLOv1 是一个无锚模型,它直接使用每个网格单元中完全连接的层来预测 B 盒的坐标。
-
受 fast-RCNN 的启发,YOLOv2 也基于相同的原理工作,fast-RCNN 使用被称为锚盒的精选先验来预测 B 盒。
-
YOLOv2 移除完全连接的层,并使用锚定框来预测边界框。因此,使其完全卷积。
-
但是什么是锚盒呢?锚定框是一组具有特定高度和宽度的预定义框;它们充当数据集中对象的猜测或先验,有助于快速优化网络。它们是以每个像素为中心的具有不同纵横比和大小的多个边界框(先验)。目标检测网络的目标是预测包围盒及其类别标签。边界框通常以规范化的 xmin、ymin、xmax、ymax 格式表示。
例如,0.5 xmin 和 0.5 ymin 表示框的左上角在图像的中间。因此,直观地说,我们正在处理一个回归问题,以获得一个像 0.5 这样的数值。
我们可能有网络预测四个值,用均方差来比较地面真实情况。然而,由于盒子的比例和纵横比的显著差异,研究人员发现,如果我们使用这种“暴力”的方式来获得边界框,网络很难收敛。因此,在 fast-RCNN 论文中,提出了锚盒的概念。
-
在 YOLOv1 中,输出特征图的大小为
 ,并对图像进行 32 倍的下采样。在 YOLOv2 中, Redmon 和选择
,并对图像进行 32 倍的下采样。在 YOLOv2 中, Redmon 和选择 作为输出。这种输出大小主要有两个原因:
作为输出。这种输出大小主要有两个原因:- 允许每幅图像检测到更多的对象
- 奇数个位置将只有一个中心单元,这将有助于捕捉倾向于占据图像中心的大对象
-
为了实现
 的输出尺寸,将输入分辨率从
的输出尺寸,将输入分辨率从 改变为
改变为 ,并且消除一个最大池层以产生更高分辨率的输出特征图。
,并且消除一个最大池层以产生更高分辨率的输出特征图。 -
与 YOLOv1(其中每个网格单元)不同,该模型预测每个网格单元的一组类别概率,忽略框 B 的数量,YOLOv2 预测每个锚框的类别和对象。
-
锚框略微降低了 mAP,从 69.5mAP 降低到 69.2mAP,但是将召回率从 81%提高到 88%,这意味着该模型有更大的改进空间。
-
YOLOv1 对每幅图像预测了 98 个框,但是带有锚框的 YOLOv2 可以根据网格大小对每幅图像预测 845 个框(
 )甚至超过一千个。
)甚至超过一千个。
 ,并对图像进行 32 倍的下采样。在 YOLOv2 中,
,并对图像进行 32 倍的下采样。在 YOLOv2 中,  )甚至超过一千个。
)甚至超过一千个。维度星团
-
与使用手工挑选锚盒的 Faster-RCNN 不同,YOLOv2 使用一种智能技术来为 PASCAL VOC 和 MS COCO 数据集找到锚盒。
-
雷德蒙和法尔哈迪认为,我们不使用手工挑选的锚盒,而是挑选更好的先验知识来更好地反映数据。这将是网络的一个很好的起点,并且网络预测检测和更快地优化将变得容易得多。
-
使用
 -意味着在训练集边界框上聚类,以找到好的锚框或先验。
-意味着在训练集边界框上聚类,以找到好的锚框或先验。 -
一种标准的
 -均值聚类技术使用欧几里德距离作为距离度量来寻找聚类中心。然而,在对象检测中,与较小的盒子相比,较大的盒子可能会产生更多的错误(YOLOv1 loss 讨论过类似的问题),检测的最终目标是最大化 IOU 分数,而与盒子的大小无关。于是,作者将距离度量改为:
-均值聚类技术使用欧几里德距离作为距离度量来寻找聚类中心。然而,在对象检测中,与较小的盒子相比,较大的盒子可能会产生更多的错误(YOLOv1 loss 讨论过类似的问题),检测的最终目标是最大化 IOU 分数,而与盒子的大小无关。于是,作者将距离度量改为: = 1 - \text{IOU}(\text{box}, \text{centroid})") 。
。 -
图 4 显示
 被选为模型复杂度和高召回率之间的良好权衡。模型的复杂度会随着锚点数量的增加而增加。该图还显示了具有各种纵横比的锚定框(蓝色),并且该比例非常适合地面实况框。
被选为模型复杂度和高召回率之间的良好权衡。模型的复杂度会随着锚点数量的增加而增加。该图还显示了具有各种纵横比的锚定框(蓝色),并且该比例非常适合地面实况框。 -
作者观察到,与手工挑选的相比,簇质心或锚明显不同。这种新方法有更多又高又薄的盒子。
-
表 1 表示三种类型的前一代策略:聚类平方和、聚类 IOU、锚盒(手工挑选的先验)。我们可以看到,具有 5 个锚的集群 IOU 做得很好,平均 IOU 为 61.0,并且表现类似于手挑选的锚。此外,如果我们增加先验,我们会看到平均 IOU 的跳跃。这项研究的结论是,使用
 -手段来生成包围盒启动了具有更好表示的模型,并使网络的工作更容易。
-手段来生成包围盒启动了具有更好表示的模型,并使网络的工作更容易。
 = 1 - \text{IOU}(\text{box}, \text{centroid})") 。
。 被选为模型复杂度和高召回率之间的良好权衡。模型的复杂度会随着锚点数量的增加而增加。该图还显示了具有各种纵横比的锚定框(蓝色),并且该比例非常适合地面实况框。
被选为模型复杂度和高召回率之间的良好权衡。模型的复杂度会随着锚点数量的增加而增加。该图还显示了具有各种纵横比的锚定框(蓝色),并且该比例非常适合地面实况框。直接位置预测
在 YOLOv1 中,我们直接预测了中心")
locations for the bounding box, which caused model instability, especially during the early iterations. Furthermore, since in YOLOv1, there was no concept of priors, directly predicting box locations led to a more significant loss as the model had no idea about the objects in the dataset.
然而,在 YOLOv2 中,由于锚的概念,我们仍然遵循 YOLOv1 的方法,并预测相对于网格单元位置的位置坐标,但是模型输出偏移。这些偏移告诉我们先验距离真实边界框有多远。这个公式允许模型不偏离中心位置太多。因此,代替预测直接坐标![[\text{xmin}, \text{ymin}, \text{xmax}, \text{ymax}]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/c4e4a7cc3bf75019e4916fd9387fc974.png "[\text{xmin}, \text{ymin}, \text{xmax}, \text{ymax}]")
, we predict offsets to these bounding boxes during the training. This works because our ground-truth box should look like the anchor box we pick with  -means clustering, and only subtle adjustment is needed, which gives us a good head start in training.
-means clustering, and only subtle adjustment is needed, which gives us a good head start in training.
由于它们限制了相对于格网单元位置的预测坐标,这将地面实况限制在0和1之间。他们使用逻辑(sigmoid)激活函数来限制网络的预测落在[0, 1]中,以匹配地面真实范围。
图 5 显示了预测边界框(蓝色)和定位框(黑色虚线)。负责预测这个蓝框的单元/网格是第二行中的单元,因为边界框的中心落在这个特定的单元中。
该模型预测输出要素地图中每个像元处的五个边界框(每个像元五个锚点)。对于每个边界框,网络预测五个值(如图 6 中的所示):偏移量和比例")
and the confidence score  .
.
对应的预测包围盒
has center ") and width and height
and width and height ") . At each grid cell, the anchor/prior box has size
. At each grid cell, the anchor/prior box has size ") with its top-left corner at
with its top-left corner at ") . The confidence score is the sigmoid of the predicted output .
. The confidence score is the sigmoid of the predicted output .
更具体地说,
and  are the
are the  -coordinate and
-coordinate and  -coordinate of the centroid relative to the top-left corner of that cell. are the width and height of the anchor box,
-coordinate of the centroid relative to the top-left corner of that cell. are the width and height of the anchor box,  and
and  are the offsets for anchor adjustment predicted by the network.
are the offsets for anchor adjustment predicted by the network.
取的指数
and helps make them positive if the network predicts them as negative since width and height cannot be negative. To get the real width and height of the bounding box, we multiply the offsets with the anchor box width  and height
and height  .
.
像在 YOLOv1 中一样,这里,盒子置信度得分应该等于预测盒子和实际盒子之间的 IOU。
通过约束位置预测,网络的学习变得容易,使得网络更加稳定。
将维度聚类与直接预测边界框中心位置相结合,比带有锚框的版本提高了 yolov 2~5%。
细粒度特征
-
YOLOv2 预测在
 特征图上的检测,这对于大的物体很有效,但是检测较小的物体可以受益于细粒度的特征。细粒度特征指的是网络早期层的特征映射。
特征图上的检测,这对于大的物体很有效,但是检测较小的物体可以受益于细粒度的特征。细粒度特征指的是网络早期层的特征映射。 -
虽然速度更快的 R-CNN 和 SSD(单次检测器)都在网络中的不同层(特征地图)运行区域建议网络以实现多分辨率,但 YOLOv2 增加了一个直通层。
-
直通层的部分灵感来自于 U-Net 论文,其中跳过连接用于连接编码器和解码器层之间的特性。
-
类似地,YOLOv2 通过将相邻的特征堆叠到不同的通道来将高分辨率特征与低分辨率特征连接起来(图 7 )。这也可以被认为是 ResNet 架构中的身份映射。
-
由于高分辨率特征图的空间尺寸与低分辨率特征图不匹配,高分辨率图
 变成了
变成了 ,然后与原来的
,然后与原来的 特征串接在一起。
特征串接在一起。 -
这种串联将特征映射空间扩展到了
 ,提供了对细粒度特征的访问。
,提供了对细粒度特征的访问。 -
细粒度特性的使用帮助 YOLOv2 模型提高了 1%。
 变成了
变成了 ,然后与原来的
,然后与原来的 ,提供了对细粒度特征的访问。
,提供了对细粒度特征的访问。多尺度训练
-
YOLOv1 模型使用输入分辨率
 进行训练,并使用完全连接的层来预测边界框和类标签。但在 YOLOv2 中,增加了锚框,分辨率改为
进行训练,并使用完全连接的层来预测边界框和类标签。但在 YOLOv2 中,增加了锚框,分辨率改为 ;此外,网络没有完全连接的层。这是一个完全卷积的网络,只有卷积层和池层。因此,在训练模型时,网络的输入可以动态地调整大小。
;此外,网络没有完全连接的层。这是一个完全卷积的网络,只有卷积层和池层。因此,在训练模型时,网络的输入可以动态地调整大小。 -
网络输入每几次迭代都会发生变化。每十批之后,网络随机选择一个新的输入分辨率。回想一下,在与锚定框的卷积中,我们讨论了网络以因子 32 对图像进行下采样,因此它从以下分辨率中进行选择:
 。
。 -
这种类型的训练允许网络以不同的图像分辨率进行预测。该网络在较小尺寸的输入下预测更快,提供了速度和准确性之间的折衷。与最小的输入相比,较大的输入预测相对较慢,但达到最大的准确性。图 8 显示了当我们改变网络输入时,端到端工作流程的情况——输入越小,检测头的网格数越少。
-
多尺度训练也有助于避免过度拟合,因为我们强制用不同的模态来训练模型。
-
在测试时,我们可以在不修改训练好的权重的情况下,将图像调整到许多不同的大小。
-
在低分辨率
 下,YOLOv2 以 69.0 的地图运行速度超过 90 FPS,接近快速 R-CNN。当然,在 FPS 方面没有可比性。您可以在具有较少 CUDA 内核或较旧架构的 GPU 上使用低分辨率版本,甚至可以在嵌入式设备上部署优化版本,如 Jetson Nano、Xavier NX、英特尔神经计算棒。
下,YOLOv2 以 69.0 的地图运行速度超过 90 FPS,接近快速 R-CNN。当然,在 FPS 方面没有可比性。您可以在具有较少 CUDA 内核或较旧架构的 GPU 上使用低分辨率版本,甚至可以在嵌入式设备上部署优化版本,如 Jetson Nano、Xavier NX、英特尔神经计算棒。 -
高分辨率(即
 )优于所有其他检测框架,成为 78.6 mAP 的最先进检测器,同时仍实现超过实时的速度。
)优于所有其他检测框架,成为 78.6 mAP 的最先进检测器,同时仍实现超过实时的速度。 -
多尺度训练方法使平均动脉压提高了 1.5%。
-
表 2 显示了 YOLOv2 在 Titan X GPU 上不同分辨率下的综合性能指标评测,以及其他检测架构,如更快的 R-CNN、YOLOv1、SSD。我们可以观察到,几乎所有的 YOLOv2 变体在速度或准确性方面都比其他检测框架表现得更好。PASCAL VOC 上检测基准的图形表示如图图 9 所示。
 。
。 下,YOLOv2 以 69.0 的地图运行速度超过 90 FPS,接近快速 R-CNN。当然,在 FPS 方面没有可比性。您可以在具有较少 CUDA 内核或较旧架构的 GPU 上使用低分辨率版本,甚至可以在嵌入式设备上部署优化版本,如 Jetson Nano、Xavier NX、英特尔神经计算棒。
下,YOLOv2 以 69.0 的地图运行速度超过 90 FPS,接近快速 R-CNN。当然,在 FPS 方面没有可比性。您可以在具有较少 CUDA 内核或较旧架构的 GPU 上使用低分辨率版本,甚至可以在嵌入式设备上部署优化版本,如 Jetson Nano、Xavier NX、英特尔神经计算棒。更快
到目前为止,我们讨论了 YOLOv2 如何通过使用各种技术,如锚盒、批量标准化、高分辨率分类器、维度聚类等,使对象检测变得准确。但是速度呢?这就是我们将在文章的这一部分讨论的内容。
许多涉及物体检测的应用,如自动驾驶、机器人、视频监控,都需要实时性能,并依赖于低延迟预测。为了最大限度地提高速度,YOLOv2 被设计成从地面快速起飞。
雷德蒙和法尔哈迪在表 3 所示的速度、精度和 FLOPs(浮点运算)方面,对 Darknet-19(yolov 2 使用的)和其他分类架构进行了详细的比较研究,并展示了他们的架构在速度和精度方面做得最好。
VGG-16 是大多数检测框架的常用特征提取器;这是一个稳健而精确的图像分类网络,但在 处进行单次前向传递需要大量浮点运算(309.5 亿次浮点运算)
处进行单次前向传递需要大量浮点运算(309.5 亿次浮点运算)
image resolution. The YOLOv1 architecture used a custom architecture inspired by the GoogLeNet network. As we can see from Table 3, the YOLOv1 extraction module is much faster and more accurate than VGG-16 and only uses 8.52 billion operations for a single pass.
ResNet-50 是最慢的,但达到了最好的前 1 和前 5 精度;人们热爱雷斯内特一家。需要注意的重要一点是,与 VGG-16 相比,ResNet 使用的 FLOPs 不到三分之一,但仍然实现了更低的 FPS,这意味着 FLOPs 与 FPS 不成正比。此外,ResNet-50 的层数比 VGG-16 多得多,每层的过滤器更少,不会使 GPU 饱和,而且你最终要在层间传输数据,这增加了时间,使 ResNet 更慢。因此,速度不仅仅是一败涂地。
暗网-19
Darknet-19 是一种新的分类架构,被提出作为目标检测的基础,其概要如图图 10 所示。
- 它主要是受先前工作的启发;与 VGG-16 类似,它使用
 过滤器,并在每个汇集步骤后利用总共 5 个汇集层将通道数量加倍。
过滤器,并在每个汇集步骤后利用总共 5 个汇集层将通道数量加倍。 - 他们没有使用完全连接的层,而是使用全局平均池进行预测,并使用
 过滤器来压缩
过滤器来压缩 卷积之间的特征表示。
卷积之间的特征表示。 - 如前所述,我们使用批量标准化来稳定训练、调整模型并加快收敛速度。
- 设计了具有 19 个卷积层和 5 个最大池层的全卷积模型。
分类训练
如前所述,我们以高分辨率分类器的方式训练了 Darknet-19 网络。在时,网络最初在 ImageNet 1000 类数据集上被训练了 160 个时期
image resolution using stochastic gradient descent with a learning rate of 0.1. Then, various data augmentation techniques like random crops, exposure shifts, hue, and saturation were applied. As a result, the network achieved Top-1 accuracy of 72.9% and Top-5 accuracy of 91.2% with only 5.58 billion FLOPs.
同样的网络在更大的分辨率下被微调(
) with the same parameters for only ten epochs with a learning rate of 0.001. Again, the model performed better than the 224 resolution achieving Top-1 accuracy of 76.5% and Top-5 accuracy of 93.3%.
检测训练
雷德蒙和法尔哈迪为目标探测任务修改了 Darknet-19 网络。他们删除了最后一个卷积层以及平均池和 softmax,并用三个 替换了卷积层
替换了卷积层
convolutional layers with 1024 filters. Followed by a  convolutional layer to convert
convolutional layer to convert  (input resolution of downsampled to
(input resolution of downsampled to  ) with the number of outputs required for detection, that is,
) with the number of outputs required for detection, that is,  (five boxes predicted at each grid with each box having four box coordinates, one objectness score, and 20 conditional class probabilities per box so 125 filters).
(five boxes predicted at each grid with each box having four box coordinates, one objectness score, and 20 conditional class probabilities per box so 125 filters).
网络被训练了 160 个时期,学习率为 0.001。这使得学习率在 60 和 90 年代下降了 10 倍。相同的训练策略用于在 MS COCO 和 PASCAL VOC 数据集上的训练。
图 11 显示了目标检测架构,基础网络用虚线表示,用 imagenet 权重进行了预训练。如前所述,我们从 Darknet-19 的块 5 向倒数第二个卷积层添加了一个直通层,以便该模型学习细粒度的特征,并在较小的对象上表现良好。
祝贺你成功来到这里!您了解了本文对构建最先进的实时对象检测器 YOLOv2 的所有重要贡献。下一个也是最后一个理论部分是可选的,因为它本身没有讨论太多的对象检测,所以可以随意跳过它,直接进入推理部分。
变强
这个最后部分的动机来自于图像分类数据集中的标签比对象检测数据集中的标签多得多的事实,因为在图像上绘制用于对象检测的框比标记用于分类的图像要昂贵得多。
图 12 显示 MS COCO 对象检测数据集只有 100K 个图像和 80 个类别,而 ImageNet 数据集有 1400 万个图像和超过 22K 个类别。这是一个巨大的差异。这不仅仅是利用分类数据集来解决对象检测问题的原因。
COCO 数据集包含带有粗粒度标签的普通对象,如猫、狗、汽车、自行车等。另一方面,ImageNet 数据集是巨大的,并且具有像波斯猫、空中客车和美国双花这样的细粒度标签。
因此,该论文提出了一种方法来组合对象检测和分类数据集,并联合学习比仅仅 80 个类别大得多的类别(在 MS COCO 中)。雷德蒙和法尔哈迪称这个模型为 YOLO9000,因为它被训练成可以检测 9000 多种物体。想法是对象检测标签将学习特定于检测的特征,如边界框坐标、对象性分数和对常见对象的分类(在 MS COCO 中)。相比之下,只有类别标签的图像(来自 ImageNet)将有助于扩大它可以检测的类别数量。
图 13 以树形格式显示了 MS COCO 和 ImageNet 类表示,我们通常对所有这些类应用 softmax 函数来计算最终概率。softmax 函数假设数据集的类是互斥的;例如,不能将 softmax 应用于既有猫又有波斯猫的类的输出概率,因为波斯猫属于父类 cat。波斯猫图像也可以归类为猫。
最初,作者认为他们可以合并两个数据集(如图图 14 所示)并进行联合训练。当网络被馈送标记用于检测的图像时,它用完整的 YOLOv2 损失函数反向传播。当它被馈送标记用于分类的图像时,只有来自分类特定部分的损失被反向传播。
然而,雷德蒙和法尔哈迪认为上述方法带来了一些挑战:简单地合并两个数据集将违背使用 softmax 图层进行分类的目的,因为类将不再保持互斥。例如,给定一个熊的图像,网络将会混淆是给该图像分配“熊”的 COCO 标签还是“美国黑熊”的 ImageNet 标签
分级分类
为了解决 ImageNet 标签与 COCO 女士的合并问题, Redmon 和法尔哈迪参照形成 ImageNet 标签的WordNet(图 15 )利用层次树结构。例如,在 WordNet 中,“诺福克梗”和“约克夏梗”都是“梗”的下位词,“梗”是“猎狗”的一种,“狗”是“犬科动物”的一种,等等。
WordNet 是单词之间语义关系的数据库。它将单词链接成语义关系,包括同义词、下位词和部分词。名词、动词、形容词和副词被分组为同义词,称为同义词集(也称为一组同义词),每个同义词表达一个不同的概念。下位词是一个词或短语,它的语义场比它的上位词更具体。上位词的语义场比下位词的语义场更广。比如鸽子、乌鸦、老鹰、海鸥都是鸟的下位词,它们的上位词。
大多数分类方法假设标签是平面结构;然而,对于组合数据集,这种结构正是我们所需要的。但是 WordNet 的结构是一个有向图,而不是一棵树,而且图比树更容易连接和复杂。例如,“狗”既是“犬科动物”的一种,也是“家畜”的一种因此,不使用完整的图形结构,而是根据 ImageNet 中的概念构建一个简化的层次树。
通过考虑图像在数据集中出现的单词,WordNet 被清理并转换成树结构,这产生了描述物理对象的单词树。
更具体地说,执行以下步骤来构建树:
- 观察 ImageNet 中的视觉名词,我们沿着它们的路径通过 WordNet 图到达根节点。这里的根节点是“物理对象”
- 在图中只有一条路径的 Synsets 首先被添加到树中。
- 然后,我们迭代地观察我们留下的概念,并添加尽可能小的增长树的路径(如果一个概念有两条到根的路径,一条有五条边,另一条有三条边,我们将选择后者)。
这就产生了一个单词树,一个视觉概念的层次模型。分类是在单词树层次结构中进行的。我们预测给定同义词集的每个下位词的每个节点的条件概率。例如,在“梗”节点,我们预测:
Pr(诺福克梗|梗)
Pr(艾尔代尔梗|梗)
Pr(西利汉梗|梗)
Pr(莱克兰梗|梗)
…
在使用来自 ImageNet 的 1000 个类构建的单词树上训练 Darknet-19 模型。单词树具有 1000 个叶节点,对应于原始的 1K 标签加上 369 个节点用于它们的父类。
该模型预测 1369 个值的向量,并计算作为同一概念的下位词的所有同义词集的 softmax(参见图 16 )。大多数 ImageNet 模型使用一个大的 softmax 层来预测超过 1000 个类别的概率分布。但是,在 WordTree 中,对头、头发、静脉、嘴等共下位词执行多个 softmax 操作,因此 synset body 的所有下位词都是一个 softmax 计算。
使用具有相同参数但具有分级训练的相同 Darknet-19 模型,该模型实现了 71.9%的前 1 准确率和 90.4%的前 5 准确率。现在同样的想法被应用于对象检测。检测器预测包围盒和概率树,在每次分割时使用最高置信度的同义词集,直到我们达到一个阈值并预测该节点为对象类。
图 17 显示了一个使用 WordTree 来组合来自 ImageNet(具体概念:较低节点和叶子)和 COCO(一般概念:较高节点)的标签的例子。WordNet 是高度多样化的,所以我们可以对大多数数据集使用这种技术。蓝色节点是 COCO 标签,红色节点是 ImageNet 标签。
联合分类检测
现在我们已经组合了两个数据集(包含 9418 个类),我们可以在分类和检测上联合训练 YOLO9000 模型。
对于联合训练,只有 3 个先验而不是 5 个先验被考虑来限制输出大小。此外,还添加了 ImageNet 检测挑战数据集,用于评估 YOLO9000 型号。
YOLO9000 的培训以两种方式进行:
-
当网络看到检测图像时,完整的 YOLOv2 丢失被反向传播(即,包围盒坐标、对象性得分、分类误差)(图 18 )。
-
对于分类图像,网络反向传播分类和目标损失(图 19) 。通过假设预测的边界框与基本事实框重叠至少 0.3 IOU 来计算客观性损失。为了反向传播分类损失,找到对于该类具有最高概率的包围盒,并且仅在它的预测树上计算损失。
评测 YOLO9000
在 ImageNet 检测任务上对该模型进行了评估。评估数据集与 COCO 女士有 44 个共同的对象类别,这意味着它看到的用于检测的对象类别非常少,因为大多数测试图像都是用于图像分类的。尽管如此,YOLO9000 模型总体上实现了 19.7 的 mAP,在 156 个对象类别上实现了 16.0 的 mAP,该网络在训练期间从未见过这些对象类别的标记检测数据。
雷德蒙和法尔哈迪发现,联合 YOLO9000 模型在新物种动物上表现良好,但在服装和设备等学习类别上表现不佳。原因是相对于服装和装备,COCO 有很多动物的标签数据;事实上,它没有任何服装类别的边界框标签,因此性能下降是显而易见的。
现在,我们已经介绍了 YOLOv2 和 YOLO9000 的许多基础知识,让我们继续在 darknet 框架中运行 YOLOv2 模型的推理,该框架是在 PASCAL VOC 数据集上预先训练的。
配置暗网框架,用预先训练好的 YOLOv2 模型运行推理
在我们上一篇关于 YOLOv1 的文章中,我们已经学习了如何配置 darknet 框架,并使用预先训练的 YOLOv1 模型进行推理;我们将按照之前相同的步骤来配置 darknet 框架。然后,最后,用 YOLOv2 预训练模型运行推理,看它比 YOLOv1 执行得更好。
配置 darknet 框架并使用 YOLOv2 在图像和视频上运行推理分为七个易于遵循的步骤。所以,让我们开始吧!
注意 :请确保您的机器上安装了匹配的 CUDA、CUDNN 和 NVIDIA 驱动程序。对于这个实验,我们使用 CUDA-10.2,CUDNN-8.0.3。但是如果你计划在 Google Colab 上运行这个实验,不要担心,因为所有这些库都预装了它。
步骤#1: 我们将在本实验中使用 GPU,因此请确保 GPU 已启动并正在运行。
# Sanity check for GPU as runtime
$ nvidia-smi
图 20 显示了机器中可用的 GPU(即 V100)以及驱动程序和 CUDA 版本。
第二步:我们将安装一些库,比如 OpenCV,FFmpeg 等等。,这在编译和安装 Darknet 之前是必需的。
# Install OpenCV, ffmpeg modules
$ apt install libopencv-dev python-opencv ffmpeg
步骤#3: 接下来,我们从 AlexyAB 存储库中克隆 darknet 框架的修改版本。如前所述,Darknet 是由 Joseph Redmon 编写的开源神经网络。用 C 和 CUDA 编写,同时支持 CPU 和 GPU 计算。暗网的官方实现可在:【https://pjreddie.com/darknet/;我们会下载官网提供的 YOLOv2 砝码。
# Clone AlexeyAB darknet repository
$ git clone https://github.com/AlexeyAB/darknet/
$ cd darknet/
确保将目录更改为 darknet,因为在下一步,我们将配置Makefile并编译它。此外,使用!pwd进行健全性检查;我们应该在/content/darknet目录里。
步骤#4: 使用流编辑器(sed),我们将编辑 make 文件并启用标志:GPU、CUDNN、OPENCV和LIBSO。
图 21 显示了Makefile内容的一个片段,稍后将讨论:
- 我们让
GPU=1和CUDNN=1与CUDA一起构建暗网来执行和加速对GPU的推理。注意CUDA应该在/usr/local/cuda;否则,编译将导致错误,但如果您正在 Google Colab 上编译,请不要担心。 - 如果你的
GPU有张量核,使CUDNN_HALF=1获得最多3X推理和2X训练加速。由于我们使用带张量内核的 Tesla V100 GPU,因此我们将启用此标志。 - 我们使
OPENCV=1能够与OpenCV一起构建暗网。这将允许我们检测视频文件、IP 摄像头和其他 OpenCV 现成的功能,如读取、写入和在帧上绘制边界框。 - 最后,我们让
LIBSO=1构建darknet.so库和使用这个库的二进制可运行文件uselib。启用此标志将允许我们使用 Python 脚本对图像和视频进行推理,并且我们将能够在其中导入darknet。
现在让我们编辑Makefile并编译它。
# Enable the OpenCV, CUDA, CUDNN, CUDNN_HALF & LIBSO Flags and Compile Darknet
$ sed -i 's/OPENCV=0/OPENCV=1/g' Makefile
$ sed -i 's/GPU=0/GPU=1/g' Makefile
$ sed -i 's/CUDNN=0/CUDNN=1/g' Makefile
$ sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/g' Makefile
$ sed -i 's/LIBSO=0/LIBSO=1/g' Makefile
$ make
make命令将需要大约 90 秒来完成执行。既然编译已经完成,我们就可以下载 YOLOv2 权重并运行推理了。
你不兴奋吗?
步骤#4: 我们现在将从官方 YOLOv2 文档中下载 YOLOv2-VOC 砝码。
# Download YOLOv2 Weights
$ wget https://pjreddie.com/media/files/yolov2-voc.weights
步骤#5: 现在,我们将运行darknet_images.py脚本来推断图像。
# Run the darknet image inference script
$ python3 darknet_images.py --input data --weights \
yolov2-voc.weights --config_file cfg/yolov2-voc.cfg \
--data_file cfg/voc.data --dont_show
让我们来看看传递给darknet_images.py的命令行参数:
--input:图像目录或文本文件的路径,带有图像路径或单个图像名称。支持jpg、jpeg和png图像格式。在本例中,我们将路径传递给名为data的图像文件夹。--weights: YOLOv2 重量路径。--config_file:yolo v2 的配置文件路径。在抽象层次上,该文件存储神经网络模型架构和一些其他参数,如batch_size、classes、input_size等。我们建议您通过在文本编辑器中打开该文件来快速阅读它。- 这里,我们传递 PASCAL VOC 标签文件。
- 这将禁止 OpenCV 显示推理结果,我们使用它是因为我们正在与 Google Colab 合作。
在对下面的图像运行 YOLOv2 PASCAL VOC 预训练模型后,我们了解到,与 YOLOv1 相比,该模型检测物体的可信度更高,并且几乎接近零错误否定。但是,您会看到一些误报。
我们可以从图 22 中看到,该模型检测到一只狗、一辆自行车和一辆汽车,并且置信度非常高。
在图 23 中,模型正确检测到所有三个对象(即狗、人和马);然而,它将马检测为羊,但是具有低得多的置信度得分。回想一下在 YOLOv1 中,网络同样犯了把马预测为羊的错误,但至少 YOLOv2 也把它预测为马!由于绵羊的置信度得分较小,您可以通过增加--thresh参数来过滤检测结果!
在图 24 中,模型很好地检测了所有的马。然而,它也预测右边的一匹马是一头牛。但与 YOLOv1 不同,它不会错过检测对象。
图 25 是一只鹰的图像,类似于 YOLOv1 模型预测了 75%的鸟。然而,YOLOv2 也检测到了一只置信度高达 95%的鸟。
步骤#6: 现在,我们将在电影《天降》的视频上运行预训练的 YOLOv2 模型;这是作者在他们的一个实验中使用的同一段视频。
在运行darknet_video.py演示脚本之前,我们将首先使用 Pytube 库从 YouTube 下载视频,并使用 moviepy 库裁剪视频。所以让我们快速安装这些模块并下载视频。
# Install pytube and moviepy for downloading and cropping the video
$ pip install git+https://github.com/rishabh3354/pytube@master
$ pip install moviepy
# Import the necessary packages
$ from pytube import YouTube
$ from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
# Download the video in 720p and Extract a subclip
$ YouTube('https://www.youtube.com/watch?v=tHRLX8jRjq8'). \ streams.filter(res="720p").first().download()
$ ffmpeg_extract_subclip("/content/darknet/Skyfall.mp4", \
0, 30, targetname="/content/darknet/Skyfall-Sample.mp4")
步骤#7: 最后,我们将运行darknet_video.py脚本来为天崩地裂的视频生成预测。我们打印输出视频每一帧的 FPS 信息。
如果使用 mp4 视频文件,请务必在darknet_video.py的第 57 行将set_saved_video功能中的视频编解码器从MJPG更改为mp4v;否则,播放推理视频时会出现解码错误。
# Change the VideoWriter Codec
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
既然所有必要的安装和修改都已完成,我们将运行darknet_video.py脚本:
# Run the darknet video inference script
$ python darknet_video.py --input \
/content/darknet/Skyfall-Sample.mp4 \
--weights yolov2-voc.weights --config_file \
cfg/yolov2-voc.cfg --data_file ./cfg/voc.data \
--dont_show --out_filename pred-skyfall.mp4
让我们看看传递给darknet_video.py的命令行参数:
--input:视频文件的路径,如果使用网络摄像头,则为0--weights: YOLOv2 重量路径--config_file:配置文件路径- 在这里,我们传递 PASCAL VOC 标签文件
--dont_show:这将禁止 OpenCV 显示推理结果--out_filename:推理结果输出视频名称,如果为空则输出视频不保存
下面是天降行动场景视频上的推断结果,预测似乎比 YOLOv1 好了很多。YOLOv2 网络在混合精度的特斯拉 V100 GPU 上实现了平均 84 FPS 。
https://www.youtube.com/embed/p2dt4lljyLc***
阿德里安& # 183;罗斯布鲁克的一天:计算机视觉研究者、开发者和企业家。

有没有想过作为一名计算机视觉研究人员或开发人员是什么感觉?
你并不孤单
在过去几年运行 PyImageSearch 的过程中,我收到了传统计算机视觉和 OpenCV 问题之外的电子邮件和询问。
相反,他们关注的是更加个人化的东西——我的日常生活。
PyImageSearch 读者 Jared 问道:
“做计算机视觉研究者和开发者是什么感觉?你每天都在做些什么?”
另一位读者米格尔问道:
“你写了一本计算机视觉的书和一门课程。现在你开始写一本关于深度学习的新书?你是如何做到这一切的?你的秘诀是什么?”
Saanvi 的建议是我个人最喜欢的建议之一:
"阿德里安,你应该写下一本关于生产力的书."
现在,用 Python 进行计算机视觉深度学习的Kickstarter 活动已经上线,我收到的这些问题比以往任何时候都多。
正因为如此,我想我今天可以做一些稍微不同的事情——给你一个独家的幕后故事,请看的:
- 我如何度过我的一天。
- 在 PyImageSearch 上平衡我作为一名计算机视觉研究员/开发人员和一名 T2 作家的角色是什么感觉。
- 我花了几年时间完善的习惯和做法帮助我完成了任务。
想看看站在我的立场过一天是什么感觉,继续阅读。
上午(上午 5:15-中午 12:00)
下面这篇博文记录了我 1 月 23 日星期一的日常活动。
起床

Figure 1: I wake up around 5:15AM-5:20 every morning.
凌晨 5 点 20 分。
我的 iPhone 闹铃响了。
我伸手过去,几秒钟后关掉它,重新调整意识。
该起床了。
我对此毫不犹豫。
我没有查看脸书的通知。我看起来不像推特。我甚至没有想过要检查电子邮件。
我坐起来
拉伸。
立刻喝掉我床头柜上 12 盎司的 Nalgene 水。
水有助于启动我的新陈代谢,冲走前一天晚上积累的毒素,最重要的是,帮助我补充水分——此时我已经 8 个小时没有喝水了,我需要补充水分。毕竟你的脑组织 75%是水。
这 12 盎司的水是我今天剩余时间里要喝的第一杯~ 200 盎司。
新的一天已经开始,我只有一个目标:把事情做完。
咖啡因(战略上)

Figure 2: Every day starts off with a strong cup of coffee with a splash of heavy cream. This is my only caffeine intake for the entire day.
我的工作日马上开始。
我从卧室走到厨房,准备了一杯美味的热咖啡——这是我一整天唯一会喝的咖啡因。
不要误会我的意思:
我喜欢咖啡。
但我也坚信咖啡因的战略用途(无论是咖啡还是茶)。
回到研究生院,我会在早上喝一大杯咖啡,午饭后喝一大杯 Dunkin Donuts 的冰咖啡。到了下午,我感到筋疲力尽。我没有意识到我摄入的咖啡因实际上是在伤害我的生产力。
咖啡因可能会给你一个短期的能量冲击,但它也会在一天的晚些时候带来崩溃。因此,我们实际上可以把摄入咖啡因看作是在一天的晚些时候从 T2 那里借用能量。能量和注意力必须来自某个地方。不幸的是,这笔“贷款”必须在我们撞车的那个下午支付。
两年前,我停止摄入大量咖啡因。
现在我只吃了一份(非常)浓的黑烤肉,外加一点浓奶油。浓稠的奶油含有帮助大脑快速启动的脂肪。我尽可能避免吃糖。
神经网络训练检查
我目前正在 Kickstarter 上开展一项活动,为我的新书《用 Python 进行计算机视觉的深度学习的 T2》筹集资金。
为了这本书,我正在进行一系列的实验,在这些实验中我训练了各种网络架构(AlexNet、VGGNet、SqueezeNet、GoogLeNet、ResNet 等等)。)在海量 ImageNet 数据集上。
我目前正在为 VGGNet 和 SqueezeNet 运行实验。这些网络已经训练了一夜,所以我需要:
- 检查它们的精度/损耗曲线。
- 确定网络是否过度拟合(或有过度拟合的风险)。
- 调整任何相关的超参数(即学习率、体重衰减)并重新开始训练。
- 估计我应该什么时候再次检查网络。
首先是 VGGNet:

Figure 3: VGGNet is hitting 53.52% rank-1 accuracy after 20 epochs. Learning is starting to stagnate, but adjusting the learning rate now would be too early.
仅仅经过 20 个时期的训练,VGGNet 就达到了 53.52%的排名第一的准确率。
准确性(和损失,未图示)开始略微停滞——我可能不得不在接下来的 20 个时期内将学习率从 1e-2 降低到 1e-3。
然后是 SqueezeNet:

Figure 4: Learning has definitely stagnated for SqueezeNet. Time to update the learning rate.
用 1e-2 学习率训练 0-45 个时期。随着训练和验证精度/损失在第 45 个纪元开始出现分歧,我将学习率更新为 1e-3。
然而,我们现在可以看到学习相当停滞,无法超越 50.2%的 rank-1 驼峰。
我们也有一点过度拟合,但没有太可怕的担心。
我将把学习速率改为 1e-4,但我并不真的期望在这一点上从实验中获得更大的准确性。
未来的实验包括用一个泄漏的 ReLU 变体(如 eLU)替换默认激活函数(ReLU)。我还在考虑在架构中添加 BatchNorm 层,因为我不知道以前有任何 SqueezeNet 实验做到了这一点,但我以前见过它(成功地)与其他微架构一起工作,如 GoogLeNet 和 ResNet(毕竟,实验是一半的乐趣)。
我每天早上花前 10 分钟查看训练进度的原因是,我可以更新任何相关的超参数,并继续训练网络。
其中一些网络可能需要花费长的时间来训练(VGGNet 目前每个历元花费约 2.9 小时),因此花时间查看准确性/损失、然后继续你的一天(并尝试不要再去想它们,直到你有更多的数据来做出明智的决定)。
当我第一次开始研究深度学习时,我犯了一个严重的错误:过于频繁地查看我的损失/准确性图表。
当训练深度神经网络时,你通常需要 10-15 个时期的上下文来做出关于更新学习速率和在哪个时期重新开始训练的的明智决定。没有这个背景,你会发现自己在原地打转,过度思考训练过程。
让你的网络训练。
结果会出来的。
然后你就能做出如何继续的明智决定。
电子邮件呢?
你可能想知道为什么我不打开我的收件箱,阅读我的电子邮件?
答案是因为早晨是我一天中最有效率和创造力的时间,因此我会非常小心地守护这段时间。一天中的这几个小时相当于生物的黄金时间,我在这段时间精力最充沛,也最有可能高效工作。
简而言之,我每天这个时间的目标是尽快达到流畅状态尽可能长时间保持。****
我将电子邮件归类为程序性任务*——阅读电子邮件、回复、重复,直到收件箱清空。这不是需要创造性能量的任务。
另一方面,我承担的许多任务本质上都是创造性的。例子包括:
- 写一篇新的博客文章/教程。
- 在我即将出版的深度学习书籍中概述一个章节。
- 研究一段复杂的代码。
- 研究新的算法。
所有这些任务都需要来自创造性方面的额外脑力。我早上都在做这类工作。电子邮件有它的位置,只是直到一天的晚些时候。
规划我的“三件大事”
一两年前,在一次会议上,我第一次从罗布·沃林那里听到了“无情的执行”。这个想法的基础是我们都熟悉的东西:
- 将一个复杂的项目分解成更小的部分/子部分。
- 单独完成每件作品。
- 把这些碎片结合起来,形成问题的解决方案。
无情执行的概念集中在第 2 步。一旦我们确定了组成整体的各个部分,我们就需要坚持不懈地、持续不断地每天完成它们。
这也与增量改进— 齐头并进,小的、持续的每日变化在一段时间内累积起来会产生大的增长。
为了促进这个过程,我每个星期天早上都计划好下周要完成的任务。你可以把这个列表看作是开发人员使用的一个非正式的 sprint 任务列表,除了:
- 这个列表结合了业务和软件任务。
- 每周一次,而不是每 2-3 周一次。
每天早上,我从我的每周清单中选择三项任务,并把它们添加到我的 T2 3 件大事中,这三件事是我当天要完成的:

Figure 5: Setting my “3 Big Things” for the day. My goal will be to accomplish all three of these tasks before my day ends. (Note: Apparently I missed the “3” in “23” when writing in my notebook that day — I’m only human after all!)
今天我的三大任务是:
- 文档“我生命中的一天”(这让我写了这篇博文)。
- 为我的深度学习书籍(你可以在这里找到)规划 Kickstarter 的延伸目标。
- 开始研究年龄/性别分类(在我即将出版的深度学习书中,有一章将演示如何使用 CNN 从照片中对一个人的年龄和性别进行分类;在这篇文章的后面会有更多的介绍)。
再说一次,富有成效和解决挑战性的问题并不是一下子就能解决的。相反,把大而复杂的问题分解成小块,然后逐个解决。每天都这样做可以保证你获得越来越多的“胜利”,从长远来看。更不用说,在短期内瞄准较小的胜利可以让你创造动力,让你的大脑产生良好的内啡肽。
如果你还没有注意到,我是一个超级生产力极客,所以如果你有兴趣了解更多关于生产力黑客的知识,你可以把它应用到你自己的生活中,看看克里斯·贝利的 生产力项目:通过管理你的时间、注意力和精力 取得更大成就。
我通常不推荐生产力书籍(因为它们倾向于重复相同的材料),但克里斯的书是真的。
从项目#1 开始
在我计划好一天的“三件大事”后,我会立即开始第一件。
今天是一个特殊的案例,因为我已经记录了我的一天,并将持续一整天。
然后,我进入第二步,规划 Kickstarter 延伸目标。我会继续做这个任务直到早餐。
早餐
我妈妈总是告诉我,早餐是一天中最重要的一餐——我从来不相信她的话,但话说回来,那可能是因为我在大学时直到上午 10:30 才起床。
直到我开始每天早上 5 点左右起床,我的观点才转变,我意识到早餐(T2)是最重要的一餐(至少对我来说)。
吃一顿由蛋白质、脂肪和蔬菜组成的丰盛健康的早餐,可以确保我能够摆脱咖啡因的影响,继续保持高效,即使是在早上快结束的时候。此外,高蛋白、高脂肪的饮食可以确保脂肪在一天的剩余时间里提供更长时间、可持续的能量燃烧——当我下午去健身房时,这也是有益的。
对于那些健康爱好者(像我一样),我指的是一种古代风格的饮食,一种主要由蔬菜、水果、坚果、根茎和肉类组成的饮食。乳制品(重奶油中没有乳糖)、谷物和加工食品都要避免。
旧石器时代的饮食有许多不同的解释,我花了几年时间才找到适合我的。例如,我已经能够在我的饮食中添加少量的乳制品(如奶酪),而没有负面影响。关于这些类型的饮食,有趣的部分是找到适合你个人的。
就我而言,我很幸运有一个每天早上准备早餐的未婚夫(是的,每天早上*)。我非常幸运,也非常感激自己中了这样的大奖。
大约早上 7:45,在她去上班之前,我和她一起吃早餐。这样做可以确保我们每天早上都有美好的时光:

Figure 7: Between 7-7:30AM each morning I have a breakfast heavy in proteins and fats.
今天我有:
- 用香肠、洋葱、辣椒和菠菜炒的三个鸡蛋。
- 两片熏肉。
- 一把橘子片。
她和我一起吃早餐,然后大约 8:15 我回去工作。
关闭通知
早餐后,所有的通知都会消失,这样我就可以达到并保持心流状态。
我的 iPhone 静音了。
Slack 被关闭了。
我甚至没想过要去脸书、推特或 reddit 上看看。
接下来,我戴上贡纳眼睛眼镜(以减少眼睛疲劳;如果我在紧张的情况下眼睛疲劳太久,我会出现眼部偏头痛和取消噪音耳机以确保不受打扰的问题:

Figure 8: Noise canceling headphones and strain reducing glasses help me reach (and sustain) flow state.
最后,我甚至关闭了桌面上的实际时钟:

Figure 9: No distractions include turning off the clock on my desktop.
时间是持续的干扰。放下工作抬头想想“伙计,我已经干了 40 分钟了”然后让你的头脑去思考,这太容易了。简而言之,看钟打破心流状态。
相反,关掉你的时钟,停止关心——你会意识到时间是相对的,当你自然疲倦时,你就会脱离心流。
现在我已经“进入状态”,我的目标是完成 Kickstarter 延伸目标的规划,同时为谷歌网的初始模块和瑞思网的剩余模块创建可视化效果

Figure 10: Tackling the first task on my list for the day — planning the stretch goals and designing images for them.
到上午 10 点 54 分,我已经完成了 Kickstarter 延伸目标和网络模块可视化的计划。
从那里我脱离了心流,这样我就可以在社交媒体上分享最新的 PyImageSearch 博客帖子(因为今天是周一,新帖子会在周一发布):

Figure 11: Since it’s a Monday I need to compose a tweet for the latest blog post that was just published on PyImageSearch.com.
午饭前,我再次在 SqueezeNet 上登记,发现损失和准确性已经达到顶点。我也看到过度拟合的威胁变得令人烦恼(但同样,并不可怕):

Figure 12: Maxing out SqueezeNet accuracy for my current experiment. Time to record the results in my lab journal and try something new.
我将结果记录到我的实验室日志中,然后更新代码来试验 BatchNorm。我开始实验——然后该吃午饭了。
午餐
我吃午饭的理想时间是上午 11:00-11:30。
我通常吃前一天晚上的剩饭或者街边商店的沙拉。因为我没有昨晚的剩菜,所以我选择了沙拉:

Figure 13: A lighter lunch, but still packed with good fats.
我的沙拉里有烤火鸡、西红柿、鳄梨(健康脂肪!)是的,还有一点点奶酪。正如我上面提到的,这些年来我调整了自己的个人饮食,发现我可以食用少量的乳制品,而不会影响我的能量水平或整体健康。
在这一点上,我开始消耗我每天的配额椰子水(大约 300 毫升)以及我的常规水。椰子水有助于降低皮质醇水平,从而减少压力。它也是钾的良好来源。
冥想和正念
午饭后,我花 10-15 分钟沉思。我个人喜欢用冷静 app :

Figure 14: I like to use the Calm app for mindfulness and meditation.
一点点正念让我重新集中注意力,继续我的一天。
下午(中午 12 点至下午 5 点)
我从我的“三件大事”清单中挑出下一个未完成的任务,开始我的下午。我继续关闭通知,戴上我的降噪耳机。
如果我在概述一个教程或者写一篇博客,我倾向于器乐。这会毁了你、天空中的爆炸和上帝是一个 宇航员是这类任务的个人最爱。缺少歌词让我不会分心(如果有歌词,我倾向于跟着唱)。
另一方面,如果我在写代码,我通常会默认带歌词的音乐 ska、朋克和硬核音乐是我的最爱。我这辈子花了无数时间给乐队编码,比如小威胁、迪林杰四和强大的 Bosstones 。
今天我开始为我即将出版的深度学习书籍的年龄和性别分类章节做一些实验。给定一张人的照片,目标是:
- 检测图像中的人脸。
- 确定此人的年龄。
- 近似此人的性别。
深度学习算法在这一特定任务上非常成功,将成为本书中的一个精彩章节。
首先,我下载了 IMDB-WIKI 人脸图像数据集并开始探索。
我的第一个任务是理解数据集包含的.mat注释文件。经过大约 45 分钟的破解,我能够提取出数据集中每张脸的出生日期、年龄和边界框:

Figure 15: Exploring the IMBDB-WIKI dataset and unpacking the annotations file.
然后,我获取数据的一个子集,并尝试在数据上微调 VGG16,作为初始试运行:

Figure 16: A simple “proof of concept” experiment demonstrating that VGG16 can be fine-tuned for gender classification. This simple approach is obtaining 91%+ accuracy after only 5 epochs.
正如上面的截图所展示的,仅仅过了 5 个时期,我就获得了 91%的性别分类准确率+。这个初步实验是成功的,并保证了对微调 VGG16 的更多探索。
大约下午 2:30-3 点,我去健身房锻炼 1-1.5 个小时。
健身是我生活中很重要的一部分。
我从小就喜欢运动——足球、棒球、篮球,应有尽有。
在我读研的第一年,我开始举重。我花了大约一年时间和一个朋友一起举重,然后当他毕业时,我又花了一年时间独自锻炼。
从那以后,我发现自己厌倦了常规的健身房锻炼,开始做交叉训练。这最终让我参加了奥运会举重比赛。我现在混合了奥林匹克举重(为了力量)和交叉体能训练(为了耐力)。
这里重要的一点是,体育锻炼是健康生活的关键。不需要太多——只是离开你的椅子(或者更好的是,使用站立式办公桌),在街区周围散散步就可以极大地提高你的工作效率(并让你远离心脏问题)。找出对有效的方法,你和继续做下去。但也要注意,五年前对你有效的方法现在可能对你无效。
一旦我回到健身房,我淋浴,并登录到我的电脑。
晚上(下午 5 点至 8 点)
在一天中的这个时候,我大脑的创造性部分已经耗尽。我已经起床大约 12 个小时了,我正在进入一天中的自然循环,我的能量越来越少。
也就是说,我仍然可以毫无问题地处理程序性任务,因此我花了很多时间阅读和回复电子邮件。
如果我没有电子邮件要回复,我可能会写一点代码。
晚上(晚上 8 点至 10 点半)
一到晚上 8 点,我就尽可能地断开连接。
我的笔记本电脑进入睡眠状态,我试着远离我的手机。
我通常喜欢在晚上结束时放松一下,玩一会儿我最喜欢的 RPG 游戏:

Figure 17: Spending the night unwinding and playing a bit of old school Final Fantasy on the SNES.
我刚刚击败了《巫师 III:疯狂猎杀》(一款已经进入我的“史上最受欢迎游戏排行榜”的游戏),所以我目前正在 SNES 上玩《T2》最终幻想六(T3)(在北美被称为《T4》最终幻想三(T5))。
玩了一会儿游戏后,我可能会在收工前看一会儿电视。
然后,上床睡觉——准备第二天早上 【无情地执行】 。
如果您喜欢这篇博文,并且希望在以后的教程发布时得到通知,*请在下表中输入您的电子邮件地址。***
使用 TensorFlow 和 Keras 深入了解变形金刚:第 1 部分
原文:https://pyimagesearch.com/2022/09/05/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-1/
目录
用 TensorFlow 和 Keras 深入了解变形金刚:第 1 部分
当我们看着人工智能生成的华丽的未来景观或使用大规模模型写我们自己的推文时,记住这一切从哪里开始是很重要的。
数据,矩阵乘法,用非线性开关重复和缩放。也许这简化了很多事情,但即使在今天,大多数架构都可以归结为这些原则。即使是最复杂的系统、想法和论文也可以归结为:
数据,矩阵乘法,用非线性开关重复和缩放。
在过去的几个月里,我们已经通过教程介绍了自然语言处理(NLP) 。我们从 NLP 的历史和基础出发,用注意力讨论神经机器翻译。
以下是按时间顺序排列的所有教程。
- 自然语言处理入门
- 介绍词袋(BoW)模型
- Word2Vec:嵌入 NLP 的研究
- BagofWords 和 Word2Vec 的比较
- 带 Keras 和 TensorFlow 的递归神经网络简介
- 长短期记忆网络
- 神经机器翻译
- 神经机器翻译用 Bahdanau 的注意力使用 TensorFlow 和 Keras
- 神经机器翻译用 Luong 的注意力使用 TensorFlow 和 Keras
现在,正如所讨论的,NLP 的进展讲述了一个故事。我们从记号开始,然后构建这些记号的表示。我们使用这些表示来寻找记号之间的相似之处,并将它们嵌入到高维空间中。同样的嵌入也被传递到能够处理顺序数据的顺序模型**中。这些模型用于构建上下文,并通过一种巧妙的方式,关注输入句子中对翻译中的输出句子有用的部分。
唷!做了很多研究。我们自己也差不多是一名科学家。
但是前方是什么呢?一群真正的科学家聚集在一起回答这个问题,并制定了一个天才计划(如图图 1 所示),这将从根本上动摇深度学习领域。
在本教程中,你将了解导致变形金刚开创性架构的注意力机制的演变。
本课是关于 NLP 104 的三部分系列的第一部分:
- 用 TensorFlow 和 Keras 深度潜入变形金刚:第一部 (今日教程)
- 用 TensorFlow 和 Keras 深入了解变形金刚:第二部分
- 使用 TensorFlow 和 Keras 深入了解变形金刚:第 3 部分
要了解注意力机制是如何进化成变压器架构的, 就继续阅读吧。
用 TensorFlow 和 Keras 深入了解变形金刚:第 1 部分
简介
在我们的前一篇博文中,我们介绍了基于递归神经网络架构的神经机器翻译模型,其中包括一个编码器和一个解码器。另外,为了便于更好的学习,我们还引入了注意力模块。
Vaswani 等人对神经机器翻译模型提出了一个简单而有效的改变。这篇论文的摘录最好地描述了他们的建议。
我们提出了一种新的简单网络架构,即转换器,它完全基于注意力机制,完全不需要递归和卷积。
在今天的教程中,我们将讲述这个被称为变压器的神经网络架构背后的理论。在本教程中,我们将重点介绍以下内容:
- 变压器架构
- 编码器
- 解码器
- 注意力的进化
- 版本 0
- 版本 1
- 版本 2
- 版本 3
- 版本 4(交叉关注)
- 版本 5(自我关注)
- 版本 6(多头关注)
变压器架构
我们采用自顶向下的方法来构建 Transformer 架构背后的直觉。让我们先看看整个架构,然后再分解各个组件。
变压器由两个独立模块组成,分别是编码器和解码器,如图图 2 所示。
编码器
如图 3 所示,编码器是一堆
identical layers. Each layer is composed of two sub-layers.
第一个是多头自我关注机制,第二个是简单的位置式全连接前馈网络。
作者还在两个子层周围使用了剩余连接(红线)和标准化操作。
源令牌首先被嵌入到高维空间中。输入嵌入添加了位置编码(我们将在后面的系列教程中深入讨论位置编码)。求和后的嵌入值随后被送入编码器。
解码器
如图 4 所示,解码器是一堆
identical layers. Each layer is composed of three sub-layers.
除了每个编码器层中的两个子层之外,解码器还插入了第三个子层,该子层对编码器堆栈的输出执行多头关注。
解码器还具有围绕三个子层的残差连接和归一化操作。
注意,解码器的第一个子层是一个屏蔽的多头关注层,而不是多头关注层。
目标令牌偏移 1。像编码器一样,令牌首先被嵌入到一个高维空间中。然后嵌入被加上位置编码。求和后的嵌入值随后被送入解码器。
这个屏蔽,结合目标标记偏移一个位置的事实,确保了对位置
的预测
can depend only on the known outputs at positions less than
.
 的预测
的预测注意力的进化
编码器和解码器是围绕一个叫做多头注意力模块的核心部件构建的。架构的这一部分是将变形金刚置于深度学习食物链顶端的 formula X。但是多头注意力(MHA)并不总是以现在的形式存在。
我们在之前的博客文章中研究了一种非常基本的注意力形式,包括 Bahdanau 和 Luong 的注意力。然而,从早期的关注形式到变形金刚架构中实际使用的关注形式的旅程是漫长的,充满了可怕的符号。
但是不要害怕。我们的探索将是导航不同版本的注意力,并对抗我们可能面临的任何问题。在我们旅程的最后,我们将对注意力如何在变压器架构中工作有一个直观的理解。
版本 0
为了理解注意力的直觉,我们从一个输入和一个查询开始。然后,我们关注基于查询的部分输入。因此,如果你有一幅风景的图像,有人要求你解读那里的天气,你会首先注意天空。图像是输入,而查询是“那里的天气怎么样?”
在计算方面,关注于输入矩阵的部分,其类似于查询向量。我们计算输入矩阵和查询向量之间的相似度。在我们获得相似性得分之后,我们将输入矩阵转换成输出向量。输出向量是输入矩阵的加权求和(或平均)。
直观上,加权求和(或平均)在表示上应该比原始输入矩阵更丰富。它包括“去哪里和做什么”该基线版本(版本 0)的图表如图 5 所示。
输入:
相似度函数: 
, which is a feed-forward network. The feed-forward network takes the query and input, and projects both of them to dimension  .
.
输出:
版本 1
两个最常用的注意力函数是加法注意力和点积(乘法)注意力。附加注意使用前馈网络计算兼容性函数。
我们对该机制所做的第一个改变是用点积运算替换掉前馈网络。事实证明,这是非常高效的,结果相当好。当我们使用点积时,请注意输入向量的形状是如何变化的,以包含点积。版本 1 的示意图如图图 6 所示。
输入:
相似度函数:点积
输出:
第二版
在本节中,我们将讨论论文中实现的一个非常重要的概念。作者提出用“比例点积代替“正常点积作为相似度函数。缩放后的点积与点积完全相同,但缩放系数为
.
在这里,让我们提出一些问题,并自己设计解决方案。比例因子将隐藏在解决方案中。
问题
-
消失梯度问题:神经网络的权重与损失的梯度成比例地更新。问题是,在某些情况下,梯度会很小,有效地防止权重改变其值。这反过来又阻止了网络的进一步学习。这通常被称为消失梯度问题。
-
非正态化 softmax: 考虑正态分布。分布的 softmax 严重依赖于它的标准差。由于存在巨大的标准差,softmax 将导致峰值周围全是零。图 7-10 有助于将问题形象化。
-
非规格化 softmax 导致渐变消失:考虑如果你的 logits 经过 softmax 然后我们有损失(交叉熵)。反向传播的误差将取决于 softmax 输出。
现在假设你有一个非规格化的 softmax 函数,如上所述。对应于峰值的误差肯定会反向传播,而其他误差(对应于 softmax 中的零)则根本不会流动。这就产生了消失梯度问题。
解
为了解决由于非标准化 softmax 导致的渐变消失问题,我们需要找到一种方法来获得更好的 softmax 输出。
结果表明,分布的标准差在很大程度上影响 softmax 输出。让我们创建一个标准差为 100 的正态分布。我们还缩放分布,使标准偏差为 1。创建分布并对其进行缩放的代码可在图 11 的中找到。图 12** 显示了分布的直方图。**
两种分布的直方图看起来很相似。一个是另一个的缩小版(看x-轴)。
让我们计算两者的 softmax,并将其可视化,如图图 13 和图 14 所示。
缩放单位标准偏差的分布提供了一个分布的 softmax 输出。这个 softmax 允许渐变反向传播,保护我们的模型免于崩溃。
点积的缩放
我们遇到了消失梯度问题、非标准化的 softmax 输出,以及一种我们可以对抗它的方法。我们尚未理解上述问题与作者提出的缩放点积的解决方案之间的关系。
注意层由一个相似性函数组成,该函数采用两个向量并执行点积。这个点积然后通过 softmax 来创建注意力权重。这个食谱非常适合解决渐变消失的问题。解决问题的方法是将点积结果转换为单位标准差分布。
让我们假设我们有两个独立的随机分布的变量:
and , as shown in Figure 15. Both vectors have a mean of 0 and a standard deviation of 1.
有趣的是,无论随机变量的大小如何,这种点积的平均值仍然是 0,但是方差和标准差与随机变量的大小成正比。具体来说,方差与因子 成线性比例,而标准差与因子成比例
成线性比例,而标准差与因子成比例
.
为了防止点积出现渐变消失的问题,作者用来缩放点积
factor. This, in turn, is the scaled dot product that the authors have suggested in the paper. The visualization of Version 2 is shown in Figure 16.
输入:
相似度函数:点积
输出:
第三版
之前我们看了一个单个查询向量。让我们将这个实现扩展到多个查询向量。我们计算输入矩阵与所有查询向量(查询矩阵)的相似度。版本 3 的可视化如图图 17 所示。
输入:
相似度函数:点积
输出:
第四版【交叉关注】
为了建立交叉注意力,我们做了一些改变。这些更改特定于输入矩阵。我们已经知道,注意力需要一个输入矩阵和一个查询矩阵。假设我们将输入矩阵投影成一对矩阵,即键和值矩阵。
相对于查询矩阵关注关键矩阵。这导致了注意力权重。如前所述,与输入矩阵转换相反,这里用注意力权重来转换值矩阵。
这样做是为了解耦复杂性。输入矩阵现在可以有一个更好的投影来建立注意力权重和更好的输出矩阵。交叉注意的可视化如图图 18 所示。
输入:
相似度函数:点积
输出:
第五版【自我关注】
通过交叉注意,我们了解到在注意模块中有三个矩阵:键、值和查询。键和值矩阵是输入矩阵的投影版本。如果查询矩阵也是从输入中投影出来的呢?
这导致了我们所说的自我关注。这里的主要动机是在自我方面建立一个更丰富的自我实现。这听起来很有趣,但是它非常重要,并且构成了 Transformer 架构的基础。自我注意的可视化如图图 19 所示。
输入:
相似度函数:点积
输出:
第六版(多头关注)
这是进化的最后阶段。我们已经走了很长的路。我们从建立注意力的直觉开始,现在我们将讨论多头(自我)注意力。
作者希望通过引入多种注意力来进一步分离关系。这意味着键矩阵、值矩阵和查询矩阵现在被拆分成许多标题并进行投影。然后,个体分裂被传递到(自我)注意模块(如上所述)。
所有的分割然后被连接成一个单一的表现。多头注意力的可视化如图图 20 所示。
如果你已经走了这么远,停下来祝贺自己。这个旅程是漫长的,充满了可怕的符号和无数的矩阵乘法。但正如承诺的那样,我们现在对多头注意力是如何进化的有了直观的认识。概括一下:
- 版本 0 从基线开始,使用前馈网络在输入和查询之间计算相似性函数。
- 在版本 1 中,我们用一个简单点积代替了前馈网络。
- 由于消失梯度和非标准化概率分布等问题,我们在版本 2 中使用了缩放的点积。
- 在版本 3 中,我们使用多个查询向量,而不是一个。
- 在版本 4 中,我们通过将输入向量分解为键和值矩阵来构建交叉关注层。
- 在外面找到的东西在里面也能找到。因此,在版本 5 中,我们也从输入中获得查询向量,称之为自我关注层。
- 版本 6 是最后一种形式,其中我们看到查询、键和值之间的所有关系通过使用多个头被进一步解耦。
变形金刚可能有多个脑袋,但我们只有一个,如果它现在正在旋转,我们不会怪你。这是一个交互式演示,直观地总结了我们目前所学的内容。
使用 TensorFlow 和 Keras 深入了解变形金刚:第 2 部分
原文:https://pyimagesearch.com/2022/09/26/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-2/
目录
用 TensorFlow 和 Keras 深入了解变形金刚:第二部
在本教程中,您将了解将编码器和解码器连接在一起的变压器架构的连接部分。
本课是关于 NLP 104 的三部分系列的第二部分:
- 用 TensorFlow 和 Keras 深入了解变形金刚:第 1 部分
- 用 TensorFlow 和 Keras 深度潜入变形金刚:第二部 (今日教程)
- 使用 TensorFlow 和 Keras 深入了解变形金刚:第 3 部分
要了解变形金刚架构如何将多头注意力层与其他组件缝合在一起, 继续阅读。
用 TensorFlow 和 Keras 深入了解变形金刚:第二部
简述
在之前的教程中,我们研究了注意力从最简单的形式到我们今天看到的多头注意力的演变。在视频 1 中,我们展示了输入矩阵是如何投射到查询、键和值矩阵中的。
视频 1: 将输入矩阵投影到查询、键和值矩阵中。
这里输入矩阵通过初始灰度矩阵 表示
表示
. The matrix placed below matrix is our weight matrix (i.e.,  (red),
(red),  (green), and
(green), and  (blue), respectively). As the Input is multiplied by these three weight matrices, the Input is projected to produce the Query, Key, and Value matrices, shown with red, green, and blue colors, respectively.
(blue), respectively). As the Input is multiplied by these three weight matrices, the Input is projected to produce the Query, Key, and Value matrices, shown with red, green, and blue colors, respectively.
注意力之地
我们的三个朋友,查询、键、值,是让变形金刚活起来的核心演员。在视频 2 中,我们构建了一个动画,展示了如何从查询、键和值矩阵中计算关注分数。
视频二: 注意力模块的动画。
首先,将查询矩阵和键矩阵相乘,得到乘积项。让我们称这个术语为
Product. Next, we scale the product term with  ; this was done to prevent the vanishing gradient problem, as explained in our previous blog post. Finally, the scaled Product term is passed through a softmax layer. The resultant output is multiplied by the value matrix to arrive at the final attention layer.
; this was done to prevent the vanishing gradient problem, as explained in our previous blog post. Finally, the scaled Product term is passed through a softmax layer. The resultant output is multiplied by the value matrix to arrive at the final attention layer.
整个动画被巧妙地封装在注意力等式中,如等式 1 所示。
现在用上面的模块来说一个问题。正如我们之前看到的,注意力模块可以很容易地扩展到自我关注。在自关注块中,查询、键和值矩阵来自相同的源。
直观上,注意块将关注输入的每个标记。花点时间想想这里可能会出什么问题。
在 NMT(神经机器翻译)中,给定一组先前解码的目标标记和输入标记,我们预测解码器中的目标标记。
如果解码器已经可以访问所有目标令牌(之前的和未来的),它将不会学习解码。我们需要屏蔽掉尚未被解码器解码的目标令牌。这个过程对于拥有一个自回归解码器是必要的。
Vaswani 等人对这条注意力管道做了一个分钟的修改,完成屏蔽。在通过缩放后的之前
product through a softmax layer, they would mask certain parts of the product with a large number (e.g., negative infinity).
这种变化在视频 3 中被可视化,并被称为掩蔽多头注意力或 MMHA。
视频三:蒙版多头注意力模块动画。
连接线
至此,我们已经介绍了变压器架构中最重要的,注意。但是,尽管论文标题是这么说的(注意力是你所需要的全部),但是只有注意力并不能创造整个模型。我们需要连接线将每一块连接在一起,如图图 1** 所示。**
**将体系结构连接在一起的连接线有:
- 跳过连接
- 图层规范化
- 前馈网络
- 位置编码
跳过连接
直观上,跳过连接将前一阶段的表示引入后一阶段。这允许将子层之前的原始表示与子层的输出一起注入。在图 2 中,变压器架构中的跳过连接用红色箭头突出显示。
现在,这提出了一个问题,为什么它很重要?
你注意到了吗,在这个博客文章系列中,每次提到架构的一部分时,我们都会提到整个架构的原始图,就在开始的时候。这是因为当我们将信息与在更早的阶段接收到的信息进行参照时,我们能更好地处理信息。
原来变压器也是这样工作的。创建一种机制来将过去阶段的表示添加到体系结构的后面阶段,这允许模型更好地处理信息。
图层归一化
图层归一化的官方 TensorFlow 文档说:
请注意,使用层规范化时,规范化发生在每个示例内的轴上,而不是批处理中的不同示例上。
这里的输入是一个矩阵
with  rows where is the number of words in the input sentence. The normalization layer is a row-wise operation that normalizes each row with the same weights.
rows where is the number of words in the input sentence. The normalization layer is a row-wise operation that normalizes each row with the same weights.
在 NLP 任务中,以及在 transformer 架构中,要求能够独立地计算每个特征维度和实例的统计数据。因此,层标准化比批标准化更有直观意义。图 3 中突出显示的部分显示了图层归一化。
我们还想提出一个栈交换讨论线程,讨论为什么层规范化在 Transformer 架构中有效。
前馈网络
每个编码器和解码器层由一个完全连接的前馈网络组成。这一层的目的很简单,如等式 2 所示。
这个想法是将注意力层输出投射到一个更高维的空间。这实质上意味着制图表达被扩展到更高的维度,因此它们的细节在下一个图层中会被放大。这些层在变压器架构中的应用如图图 4 所示。
让我们在这里停下来,回头看看这个架构。
- 我们研究了编码器和解码器
- 注意力的进化,正如我们在中看到的瓦斯瓦尼等人
- 跳过上下文相关的连接
- 图层规范化
- 最后,前馈网络
但是仍然缺少整个架构的一部分。我们能从图 5 中猜出是什么吗?
位置编码
现在,在我们理解位置编码以及为什么在架构中引入它之前,让我们先看看我们的架构与 RNN 和 LSTM 等顺序模型相比实现了什么。
转换器可以处理部分输入令牌。编码器和解码器单元由这些关注块以及非线性层、层标准化和跳过连接构建而成。
但是 RNNs 和其他顺序模型有一些体系结构仍然缺乏的东西。就是了解数据的顺序。那么我们如何引入数据的顺序呢?
- 我们可以将注意力添加到顺序模型中,但这将类似于我们已经研究过的 Bahdanau 的或 Luong 的注意力。此外,增加一个顺序模型将打破使用只注意单元来完成手头任务的目的。
- 我们还可以将数据顺序与输入和目标标记一起注入到模型中。
瓦斯瓦尼等人选择了第二种方案。这意味着对每个标记的位置进行编码,并将其与输入一起注入。现在有几种方法可以实现位置编码。
第一种是简单地用二进制编码方案对所有东西进行编码,如图图 6 所示。考虑下面的代码片段,其中我们可视化了一系列数字的二进制编码。
n对应于0-n位置的范围dims对应于每个位置编码的维度
图 6 中代码片段的输出如图 7 中所示。
然而,Vaswani 等人引入了正弦和余弦函数,根据方程 3 和 4 对序列位置进行编码:
这里,pos是指位置,i是尺寸。图 8 是实现方程式的代码。
图 8 中的代码输出如图图 9 所示。
这两种编码看起来很相似,不是吗?位置编码是一种将每个位置编码成一个向量的系统。这里需要注意的一点是,每个向量都应该是唯一的。
二进制编码似乎是位置编码的完美候选。二进制系统的问题在于0 s。这意味着二进制在本质上是离散的。另一方面,深度学习模型喜欢处理连续数据。
因此,使用正弦编码的原因有三。
- 编码系统不仅密集,而且在 0 和 1 的范围内连续(正弦曲线被限制在这个范围内)。
- 它提供了一个几何级数,如图 10 所示。几何级数很容易学习,因为它在特定的间隔后会重复出现。学习间隔率和幅度将允许任何模型学习模式本身。
- Vaswani 等人假设这样做将允许模型更好地学习相对位置,因为任何位置偏移一个值

") 可以通过
可以通过 的线性函数来估计。
的线性函数来估计。
") 可以通过
可以通过 的线性函数来估计。
的线性函数来估计。汇总
至此,几乎所有关于变形金刚的事情我们都知道了。但是停下来思考这样一个架构的必要性也很重要。
2017 年,答案就在他们的论文里。 Vaswani 等人提到他们选择当时发表的其他转导模型的更简单版本的原因。但自 2017 年以来,我们已经走过了漫长的道路。
在过去的 5 年里,变形金刚绝对接管了深度学习。没有任何任务、角落或角落可以避开注意力应用程序。那么是什么让这个模型如此优秀呢?这在一个简单的机器翻译任务中是如何概念化的呢?
首先,深度学习研究人员不是预言家,所以没有办法知道变形金刚会在每项任务上都如此出色。但是架构直观上很简单。它通过关注与部分目标标记相关的部分输入标记来工作。这种方法为机器翻译创造了奇迹。但是它在其他任务上不会起作用吗?图像分类、视频分类、文本到图像生成、分割或体绘制?
任何可以表示为被映射到标记化输出集的标记化输入的东西都属于转换器的范畴。
这就结束了变形金刚的理论。在本系列的下一部分中,我们将重点介绍如何在 TensorFlow 和 Keras 中创建这种架构。
引用信息
A. R. Gosthipaty 和 R. Raha。“用 TensorFlow 和 Keras 深入研究变形金刚:第二部分”, PyImageSearch ,P. Chugh,S. Huot,K. Kidriavsteva,A. Thanki 编辑。,2022 年,【https://pyimg.co/pzu1j
@incollection{ARG-RR_2022_DDTFK2,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {A Deep Dive into Transformers with {TensorFlow} and {K}eras: Part 2},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/pzu1j},
}
使用 TensorFlow 和 Keras 深入了解变形金刚:第 3 部分
原文:https://pyimagesearch.com/2022/11/07/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-3/
目录
用 TensorFlow 和 Keras 深入了解变形金刚:第三部
在本教程中,您将学习如何在 TensorFlow 和 Keras 中从头开始编写转换器架构。
本课是关于 NLP 104 的 3 部分系列的最后一课:
- 用 TensorFlow 和 Keras 深入了解变形金刚:第 1 部分
- 用 TensorFlow 和 Keras 深入了解变形金刚:第二部
- 用 TensorFlow 和 Keras 深度潜入变形金刚:第三部 (今日教程)
要了解如何使用 TensorFlow 和 Keras 构建变压器架构, 继续阅读。
用 TensorFlow 和 Keras 深入了解变形金刚:第三部
我们现在是变形金刚系列的第三部分,也是最后一部分。在第一部分中,我们了解了注意力从简单的前馈网络到现在的多头自我注意的演变。接下来,在第二部分中,我们将重点放在连接线上,除了注意力之外的各种组件,它们将架构连接在一起。
教程的这一部分将主要关注使用 TensorFlow 和 Keras 从头构建一个转换器,并将其应用于神经机器翻译的任务。对于代码,我们受到了关于变形金刚的官方 TensorFlow 博客文章的极大启发。
正如所讨论的,我们将了解如何构建每个组件,并最终将它们缝合在一起,以训练我们自己的 Transformer 模型。
简介
在前面的教程中,我们介绍了构建 Transformer 架构所需的每个组件和模块。在这篇博文中,我们将重新审视这些组件,看看如何使用 TensorFlow 和 Keras 构建这些模块。
然后,我们将布置训练管道和推理脚本,这是训练和测试整个 Transformer 架构所需要的。
这是一个拥抱面部空间的演示,展示了只在 25 个时期训练的模型。 这个空间的目的不是挑战谷歌翻译,而是展示用我们的代码训练你的模型并将其投入生产 是多么容易。
配置您的开发环境
要遵循这个指南,您需要在系统上安装tensorflow和tensorflow-text。
幸运的是,TensorFlow 可以在 pip 上安装:
$ pip install tensorflow==2.8.0
$ pip install tensorflow-text==2.8.0
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
$ tree .
.
├── inference.py
├── pyimagesearch
│ ├── attention.py
│ ├── config.py
│ ├── dataset.py
│ ├── decoder.py
│ ├── encoder.py
│ ├── feed_forward.py
│ ├── __init__.py
│ ├── loss_accuracy.py
│ ├── positional_encoding.py
│ ├── rate_schedule.py
│ ├── transformer.py
│ └── translate.py
└── train.py
1 directory, 14 files
在pyimagesearch目录中,我们有以下内容:
attention.py:保存所有自定义注意模块config.py:任务的配置文件dataset.py:数据集管道的实用程序decoder.py:解码器模块encoder.py:编码器模块feed_forward.py:点式前馈网络loss_accuracy.py:保存训练模型所需的损失和准确性的代码片段positional_encoding.py:模型的位置编码方案rate_schedule.py:培训管道的学习率计划程序transformer.py:变压器模块- 训练和推理模型
在核心目录中,我们有两个脚本:
train.py:运行脚本来训练模型inference.py:推理脚本
配置
在我们开始实现之前,让我们检查一下项目的配置。为此,我们将转到位于pyimagesearch目录中的config.py脚本。
# define the dataset file
DATA_FNAME = "fra.txt"
在第 2 行的上,我们定义了数据集文本文件。在我们的例子中,我们使用下载的fra.txt。
# define the batch size
BATCH_SIZE = 512
在第 5 行的上,我们定义了数据集的批量大小。
# define the vocab size for the source and the target
# text vectorization layers
SOURCE_VOCAB_SIZE = 15_000
TARGET_VOCAB_SIZE = 15_000
在的第 9 行和第 10 行,我们定义了源和目标文本处理器的词汇量。这是让我们的文本矢量化层知道应该从所提供的数据集生成的词汇量所必需的。
# define the maximum positions in the source and target dataset
MAX_POS_ENCODING = 2048
在第 13 行,我们定义了我们编码的最大长度。
# define the number of layers for the encoder and the decoder
ENCODER_NUM_LAYERS = 6
DECODER_NUM_LAYERS = 6
在第 16 行和第 17 行,我们定义了变压器架构中编码器和解码器的层数。
# define the dimensions of the model
D_MODEL = 512
变压器是一种各向同性的架构。这实质上意味着中间输出的维度在整个模型中不会改变。这需要定义一个静态模型维度。在第 20 行,我们定义整个模型的尺寸。
# define the units of the point wise feed forward network
DFF = 2048
我们在线 23 上定义了点式前馈网络的中间尺寸。
# define the number of heads and dropout rate
NUM_HEADS = 8
DROP_RATE = 0.1
多头关注层中的头数在行 26 中定义。辍学率在第 27 行指定。
# define the number of epochs to train the transformer model
EPOCHS = 25
我们定义了在第 30 行的上训练的时期数。
# define the output directory
OUTPUT_DIR = "output"
输出目录在行 33 上定义。
数据集
如前所述,我们需要一个包含源语言-目标语言句子对的数据集。为了配置和预处理这样的数据集,我们在pyimagesearch目录中准备了dataset.py脚本。
# import the necessary packages
import random
import tensorflow as tf
import tensorflow_text as tf_text
# define a module level autotune
_AUTO = tf.data.AUTOTUNE
在第 8 行的上,我们定义了模块级别tf.data.AUTOTUNE。
def load_data(fname):
# open the file with utf-8 encoding
with open(fname, "r", encoding="utf-8") as textFile:
# the source and the target sentence is demarcated with tab,
# iterate over each line and split the sentences to get
# the individual source and target sentence pairs
lines = textFile.readlines()
pairs = [line.split("\t")[:-1] for line in lines]
# randomly shuffle the pairs
random.shuffle(pairs)
# collect the source sentences and target sentences into
# respective lists
source = [src for src, _ in pairs]
target = [trgt for _, trgt in pairs]
# return the list of source and target sentences
return (source, target)
在第 11 行上,我们定义了load_data函数,它从文本文件 fname 加载数据集。
接下来,在第 13 行,我们打开 utf-8 编码的文本文件,并使用textFile作为文件指针。
我们使用文件指针textFile从文件中读取行,如第 17 行所示。数据集中的源句子和目标句子用制表符分隔。在第 18 行的上,我们迭代所有的源和目标句子对,用 split 方法将它们分开。
在第 21 行的上,我们随机打乱源和目标对,以调整数据管道。
接下来,在第行的第 25 行和第 26 行,我们将源句子和目标句子收集到它们各自的列表中,稍后在第行的第 29 行返回。
def splitting_dataset(source, target):
# calculate the training and validation size
trainSize = int(len(source) * 0.8)
valSize = int(len(source) * 0.1)
# split the inputs into train, val, and test
(trainSource, trainTarget) = (source[:trainSize], target[:trainSize])
(valSource, valTarget) = (
source[trainSize : trainSize + valSize],
target[trainSize : trainSize + valSize],
)
(testSource, testTarget) = (
source[trainSize + valSize :],
target[trainSize + valSize :],
)
# return the splits
return (
(trainSource, trainTarget),
(valSource, valTarget),
(testSource, testTarget),
)
在的第 32 行,我们构建了splitting_dataset方法来将整个数据集分割成train、validation和test分割。
在第 34 行和第 35 行中,我们分别构建了 80%和 10%的列车大小和验证分割。
使用切片操作,我们将数据集分割成第 38-46 行上的各个分割。我们稍后返回第 49-53 行的数据集分割。
def make_dataset(
splits, batchSize, sourceTextProcessor, targetTextProcessor, train=False
):
# build a TensorFlow dataset from the input and target
(source, target) = splits
dataset = tf.data.Dataset.from_tensor_slices((source, target))
def prepare_batch(source, target):
source = sourceTextProcessor(source)
targetBuffer = targetTextProcessor(target)
targetInput = targetBuffer[:, :-1]
targetOutput = targetBuffer[:, 1:]
return (source, targetInput), targetOutput
# check if this is the training dataset, if so, shuffle, batch,
# and prefetch it
if train:
dataset = (
dataset.shuffle(dataset.cardinality().numpy())
.batch(batchSize)
.map(prepare_batch, _AUTO)
.prefetch(_AUTO)
)
# otherwise, just batch the dataset
else:
dataset = dataset.batch(batchSize).map(prepare_batch, _AUTO).prefetch(_AUTO)
# return the dataset
return dataset
在行 56 上,我们构建了make_dataset函数,该函数为我们的训练管道构建了一个tf.data.Dataset。
在第 60 行,从提供的数据集分割中抓取源句子和目标句子。然后使用tf.data.Dataset.from_tensor_slices()函数将源和目标句子转换成tf.data.Dataset,如行 61 所示。
在第 63-68 行,我们定义了prepare_batch函数,它将作为tf.data.Dataset的映射函数。在的第 64 行和第 65 行,我们将源句子和目标句子分别传递到sourceTextProcessor和targetTextProcessor。sourceTextProcessor和targetTextProcessor为适配tf.keras.layers.TextVectorization层。这些层对字符串句子应用矢量化,并将它们转换为令牌 id。
在行 66 上,我们从开始到倒数第二个标记分割目标标记,作为目标输入。在第 67 行,我们从第二个令牌到最后一个令牌对目标令牌进行切片。这作为目标输出。右移一是为了在培训过程中实施教师强制。
在第 68 行,我们分别返回输入和目标。这里的输入是source和targetInput,而目标是targetOuput。这种格式适用于在培训时使用model.fit() API。
在第 72-82 行,我们构建数据集。在第 85 行,我们返回数据集。
def tf_lower_and_split_punct(text):
# split accented characters
text = tf_text.normalize_utf8(text, "NFKD")
text = tf.strings.lower(text)
# keep space, a to z, and selected punctuations
text = tf.strings.regex_replace(text, "[^ a-z.?!,]", "")
# add spaces around punctuation
text = tf.strings.regex_replace(text, "[.?!,]", r" \0 ")
# strip whitespace and add [START] and [END] tokens
text = tf.strings.strip(text)
text = tf.strings.join(["[START]", text, "[END]"], separator=" ")
# return the processed text
return text
最后一个数据实用函数是tf_lower_and_split_punct,它接受任何一个句子作为参数(第 88 行)。我们从规范化句子开始,将它们转换成小写字母(分别是第 90 行和第 91 行)。
在第 94-97 行,我们去掉了句子中不必要的标点和字符。在第 100 行删除句子前的空格,然后在句子中添加开始和结束标记(第 101 行)。这些标记帮助模型理解何时开始或结束一个序列。
我们在第 104 行返回处理过的文本。
注意
在上一个教程中,我们学习了注意力的三种类型。总之,在构建变压器架构时,我们将注意以下三种类型:
我们在名为attention.py的pyimagesearch目录下的单个文件中构建这些不同类型的注意力。
# import the necessary packages
import tensorflow as tf
from tensorflow.keras.layers import Add, Layer, LayerNormalization, MultiHeadAttention
在第 2 行和第 3 行,我们导入构建注意模块所需的必要包。
class BaseAttention(Layer):
"""
The base attention module. All the other attention modules will
be subclassed from this module.
"""
def __init__(self, **kwargs):
# Note the use of kwargs here, it is used to initialize the
# MultiHeadAttention layer for all the subclassed modules
super().__init__()
# initialize a multihead attention layer, layer normalization layer, and
# an addition layer
self.mha = MultiHeadAttention(**kwargs)
self.layernorm = LayerNormalization()
self.add = Add()
在第 6 行的上,我们构建了父关注层,称为BaseAttention。所有其他具有特定任务的注意力模块都从该父层中被子类化。
在第 12 行上,我们构建了层的构造器。在第 15 行,我们调用超级对象来构建图层。
在第 19-21 行、、上,我们初始化了一个MultiHeadAttention层、一个LayerNormalization层和一个Add层。这些是本教程后面指定的任何注意模块的基本层。
class CrossAttention(BaseAttention):
def call(self, x, context):
# apply multihead attention to the query and the context inputs
(attentionOutputs, attentionScores) = self.mha(
query=x,
key=context,
value=context,
return_attention_scores=True,
)
# store the attention scores that will be later visualized
self.lastAttentionScores = attentionScores
# apply residual connection and layer norm
x = self.add([x, attentionOutputs])
x = self.layernorm(x)
# return the processed query
return x
在第 24 行的上,我们定义了CrossAttention层。该层是BaseAttention层的子类。这意味着该层已经有一个MultiHeadAttention、LayerNormalization和一个Add层。
在第 25 行的上,我们为该层构建call方法。该层接受x和context。在使用CrossAttention时,我们需要理解这里的x是查询,而context是稍后将构建键和值对的张量。
在第 27-32 行,我们对输入应用了多头关注层。注意query、key和value术语是如何在第 28-30 行中使用的。
我们将注意力分数存储在第 35 行的上。
第 38 行和第 39 行是我们应用剩余连接和层标准化的地方。
我们在线 42 上返回处理后的输出。
class GlobalSelfAttention(BaseAttention):
def call(self, x):
# apply self multihead attention
attentionOutputs = self.mha(
query=x,
key=x,
value=x,
)
# apply residual connection and layer norm
x = self.add([x, attentionOutputs])
x = self.layernorm(x)
# return the processed query
return x
我们在第 45 行的上定义GlobalSelfAttention。
第 46 行定义了该层的调用。这一层接受x。在第 48-52 行,我们将多头注意力应用于输入。请注意,query、key和value三个术语有相同的输入,x。这意味着我们在这一层使用多头自我关注。
在行 55 和 56 上,我们应用剩余连接和层标准化。处理后的输出在线 59 返回。
class CausalSelfAttention(BaseAttention):
def call(self, x):
# apply self multi head attention with causal masking (look-ahead-mask)
attentionOutputs = self.mha(
query=x,
key=x,
value=x,
use_causal_mask=True,
)
# apply residual connection and layer norm
x = self.add([x, attentionOutputs])
x = self.layernorm(x)
# return the processed query
return x
我们在第 62 行的上定义CausalSelfAttention。
这一层类似于GlobalSelfAttention层,不同之处在于使用了因果蒙版。在第 69 行显示了因果掩码的用法。其他一切都保持不变。
效用函数
仅仅建立注意力模块是不够的。我们确实需要一些实用功能和模块来将所有东西缝合在一起。
我们需要的模块如下:
- 位置编码:由于我们知道自我关注层是排列不变的,我们需要某种方式将顺序信息注入到这些层中。在本节中,我们构建了一个嵌入层,它不仅负责标记的嵌入,还将位置信息注入到输入中。
- 前馈网络:变压器架构使用的前馈网络模块。
- 速率调度器:学习速率调度器,使架构学习得更好。
- 损失准确性:为了训练模型,我们需要建立屏蔽损失和准确性。损失将是目标函数,而准确度将是训练的度量。
位置编码
如前一篇博文所示,为了构建位置编码,我们打开了pyimagesearch目录中的positional_encoding.py。
# import the necessary packages
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Embedding, Layer
从第 2-4 行,我们导入必要的包。
def positional_encoding(length, depth):
"""
Function to build the positional encoding as per the
"Attention is all you need" paper.
Args:
length: The length of each sentence (target or source)
depth: The depth of each token embedding
"""
# divide the depth of the positional encoding into two for
# sinusoidal and cosine embeddings
depth = depth / 2
# define the positions and depths as numpy arrays
positions = np.arange(length)[:, np.newaxis]
depths = np.arange(depth)[np.newaxis, :] / depth
# build the angle rates and radians
angleRates = 1 / (10000**depths)
angleRads = positions * angleRates
# build the positional encoding, cast it to float32 and return it
posEncoding = np.concatenate([np.sin(angleRads), np.cos(angleRads)], axis=-1)
return tf.cast(posEncoding, dtype=tf.float32)
在第 7 行的上,我们构建了positional_encoding函数。这个函数获取位置的长度和每次嵌入的深度。它计算由瓦斯瓦尼等人建议的位置编码。还可以看到编码的公式,如图图 1** 所示。**
在第 18 行,我们将深度分成相等的两半,一部分用于正弦频率,另一部分用于余弦频率。从第 21-26 行,我们构建公式所需的positions、depths、angleRates和angleRads。
在第 29 行上,我们将正弦和余弦输出连接在一起,构建了完整的位置编码;posEncoding然后在线 30 返回。
class PositionalEmbedding(Layer):
def __init__(self, vocabSize, dModel, maximumPositionEncoding, **kwargs):
"""
Args:
vocabSize: The vocabulary size of the target or source dataset
dModel: The dimension of the transformer model
maximumPositionEncoding: The maximum length of a sentence in the dataset
"""
super().__init__(**kwargs)
# initialize an embedding layer
self.embedding = Embedding(
input_dim=vocabSize, output_dim=dModel, mask_zero=True
)
# initialize the positional encoding function
self.posEncoding = positional_encoding(
length=maximumPositionEncoding, depth=dModel
)
# define the dimensions of the model
self.dModel = dModel
def compute_mask(self, *args, **kwargs):
# return the padding mask from the inputs
return self.embedding.compute_mask(*args, **kwargs)
def call(self, x):
# get the length of the input sequence
seqLen = tf.shape(x)[1]
# embed the input and scale the embeddings
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.dModel, tf.float32))
# add the positional encoding with the scaled embeddings
x += self.posEncoding[tf.newaxis, :seqLen, :]
# return the encoded input
return x
为我们模型中需要的定制层构建一个tf.keras.layers.Layer总是更好。PositionalEmbedding就是这样一层。我们在第 33 行定义自定义图层。
我们用一个Embedding和一个positional_encoding层初始化这个层,就像在第 44-51 行上所做的那样。我们还在线 54 上定义了模型的尺寸。
Keras 让我们为定制层公开一个compute_mask方法。我们在第 56 行定义了这个方法。有关填充和遮罩的更多信息,可以阅读官方 TensorFlow 指南。
call方法接受x作为它的输入(行 60 )。输入首先被嵌入(行 65 ),然后位置编码被添加到嵌入的输入(行 69 ),最后在行 72 返回。
前馈
为了构建前馈网络模块,如前一篇博文所示,我们打开了pyimagesearch目录中的feed_forward.py。
# import the necessary packages
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Add, Dense, Dropout, Layer, LayerNormalization
在行 2 和 3 上,我们导入必要的包。
class FeedForward(Layer):
def __init__(self, dff, dModel, dropoutRate=0.1, **kwargs):
"""
Args:
dff: Intermediate dimension for the feed forward network
dModel: The dimension of the transformer model
dropOutRate: Rate for dropout layer
"""
super().__init__(**kwargs)
# initialize the sequential model of dense layers
self.seq = Sequential(
[
Dense(units=dff, activation="relu"),
Dense(units=dModel),
Dropout(rate=dropoutRate),
]
)
# initialize the addition layer and layer normalization layer
self.add = Add()
self.layernorm = LayerNormalization()
def call(self, x):
# add the processed input and original input
x = self.add([x, self.seq(x)])
# apply layer norm on the residual and return it
x = self.layernorm(x)
return x
在第 6 行,我们定义了自定义图层FeedForward。该层由一个tf.keras.Sequential模块(行 17-23 )、一个Add层(行 26 )和一个LayerNormalization层(行 27 )初始化。顺序模型有一个密集层和漏失层的堆栈。这就是我们进入变压器子层的前馈网络。
call方法(第 29 行)接受x作为其输入。输入通过顺序模型并与原始输入相加,作为线 31 上的剩余连接。处理后的子层输出然后通过线 34 上的layernorm层。
然后输出在线 35 上返回。
费率明细表
为了构建学习率调度模块,我们打开了pyimagesearch目录中的rate_schedule.py文件。
# import the necessary packages
import tensorflow as tf
from tensorflow.keras.optimizers.schedules import LearningRateSchedule
在第 2 行和第 3 行,我们导入对费率表重要的必要包。
class CustomSchedule(LearningRateSchedule):
def __init__(self, dModel, warmupSteps=4000):
super().__init__()
# define the dmodel and warmup steps
self.dModel = dModel
self.dModel = tf.cast(self.dModel, tf.float32)
self.warmupSteps = warmupSteps
def __call__(self, step):
# build the custom schedule logic
step = tf.cast(step, dtype=tf.float32)
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmupSteps**-1.5)
return tf.math.rsqrt(self.dModel) * tf.math.minimum(arg1, arg2)
在第 6 行上,我们构建了本文中实现的自定义LearningRateSchedule。我们把它命名为CustomSchedule(很有创意)。
在第 7-13 行,我们用必要的参数初始化模块。我们分别在线 11 和 13 定义模型的尺寸和预热步骤的数量。
自定义时间表的逻辑如图图 2 所示。我们已经在 TensorFlow 的__call__方法中实现了相同的逻辑(来自第 15-21 行)。
损失准确度
我们构建了在pyimagesearch目录下的loss_accuracy.py中定义指标的模块。
# import the necessary packages
import tensorflow as tf
from tensorflow.keras.losses import SparseCategoricalCrossentropy
在行 2 和 3 上,我们导入必要的包。
def masked_loss(label, prediction):
# mask positions where the label is not equal to 0
mask = label != 0
# build the loss object and apply it to the labels
lossObject = SparseCategoricalCrossentropy(from_logits=True, reduction="none")
loss = lossObject(label, prediction)
# mask the loss
mask = tf.cast(mask, dtype=loss.dtype)
loss *= mask
# average the loss over the batch and return it
loss = tf.reduce_sum(loss) / tf.reduce_sum(mask)
return loss
在第 6 行的上,我们构建了我们的masked_loss函数。它接受真实标签和来自我们模型的预测作为输入。
我们首先在 8 号线的上制作掩模。标签不等于 0 时,掩码无处不在。以SparseCategoricalCrossentropy作为我们的损失对象,我们计算不包括线 11 和 12** 上的掩模的原始损失。**
然后将原始损耗与布尔掩码相乘,得到第 15 行和第 16 行的屏蔽损耗。在第 19 行上,我们对屏蔽损失进行平均,并在第 20 行上将其返还。
def masked_accuracy(label, prediction):
# mask positions where the label is not equal to 0
mask = label != 0
# get the argmax from the logits
prediction = tf.argmax(prediction, axis=2)
# cast the label into the prediction datatype
label = tf.cast(label, dtype=prediction.dtype)
# calculate the matches
match = label == prediction
match = match & mask
# cast the match and masks
match = tf.cast(match, dtype=tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
# average the match over the batch and return it
match = tf.reduce_sum(match) / tf.reduce_sum(mask)
return match
在第 23 行的上,我们定义了自定义的masked_accuracy函数。这将是我们训练 transformer 模型时的自定义指标。
在第 25 行的上,我们构建布尔掩码。然后掩码在第 31 行被转换为预测的数据类型。
第 34 行和第 35 行计算匹配(计算准确度所需的),然后应用掩码以获得被屏蔽的匹配。
第 38 行和第 39 行用打字机打出火柴和面具。在第 42 行上,我们对屏蔽的匹配进行平均,并在第 43 行上将其返回。
编码器
在图 3 中,我们可以看到变压器架构中突出显示的编码器。如图图 3 所示,编码器是 N 个相同层的堆叠。每层由两个子层组成。
第一个是多头自我关注机制,第二个是简单的位置式全连接前馈网络。
Vaswani 等人(2017) 也在两个子层周围使用剩余连接和归一化操作。
我们在pyimagesearch目录中构建编码器模块,并将其命名为encoder.py。
# import the necessary packages
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Layer
from .attention import GlobalSelfAttention
from .feed_forward import FeedForward
from .positional_encoding import PositionalEmbedding
在第 2 行和第 7 行,我们导入必要的包。
class EncoderLayer(Layer):
def __init__(self, dModel, numHeads, dff, dropOutRate=0.1, **kwargs):
"""
Args:
dModel: The dimension of the transformer module
numHeads: Number of heads of the multi head attention module in the encoder layer
dff: The intermediate dimension size in the feed forward network
dropOutRate: The rate of dropout layer
"""
super().__init__(**kwargs)
# define the Global Self Attention layer
self.globalSelfAttention = GlobalSelfAttention(
num_heads=numHeads,
key_dim=dModel // numHeads,
dropout=dropOutRate,
)
# initialize the pointwise feed forward sublayer
self.ffn = FeedForward(dff=dff, dModel=dModel, dropoutRate=dropOutRate)
def call(self, x):
# apply global self attention to the inputs
x = self.globalSelfAttention(x)
# apply feed forward network and return the outputs
x = self.ffn(x)
return x
编码器是编码器层的堆叠。在这里的第 10 行上,我们定义了保存两个子层的编码器层,即全局自关注(第 22-26 行)和前馈层(第 29 行)。
call的方法很简单。在第 33 行,我们将全局自我关注应用于编码器层的输入。在线 36 上,我们用逐点前馈网络处理相关输出。
编码器层的输出然后在线 37 上返回。
class Encoder(Layer):
def __init__(
self,
numLayers,
dModel,
numHeads,
sourceVocabSize,
maximumPositionEncoding,
dff,
dropOutRate=0.1,
**kwargs
):
"""
Args:
numLayers: The number of encoder layers in the encoder
dModel: The dimension of the transformer module
numHeads: Number of heads of multihead attention layer in each encoder layer
sourceVocabSize: The source vocabulary size
maximumPositionEncoding: The maximum number of tokens in a sentence in the source dataset
dff: The intermediate dimension of the feed forward network
dropOutRate: The rate of dropout layer
"""
super().__init__(**kwargs)
# define the dimension of the model and the number of encoder layers
self.dModel = dModel
self.numLayers = numLayers
# initialize the positional embedding layer
self.positionalEmbedding = PositionalEmbedding(
vocabSize=sourceVocabSize,
dModel=dModel,
maximumPositionEncoding=maximumPositionEncoding,
)
# define a stack of encoder layers
self.encoderLayers = [
EncoderLayer(
dModel=dModel, dff=dff, numHeads=numHeads, dropOutRate=dropOutRate
)
for _ in range(numLayers)
]
# initialize a dropout layer
self.dropout = Dropout(rate=dropOutRate)
def call(self, x):
# apply positional embedding to the source token ids
x = self.positionalEmbedding(x)
# apply dropout to the embedded inputs
x = self.dropout(x)
# iterate over the stacks of encoder layer
for encoderLayer in self.encoderLayers:
x = encoderLayer(x=x)
# return the output of the encoder
return x
在第 40-51 行上,我们定义了我们的Encoder层。如上所述,编码器由一堆编码器层组成。为了使编码器自给自足,我们还在编码器内部添加了位置编码层。
在行 65 和 66 上,我们定义了编码器的尺寸和构建编码器的编码器层数。
第 76-81 行构建编码器层堆栈。在第 84 行的处,我们初始化一个Dropout层来调整模型。
该层的call方法接受x作为输入。首先,我们在输入上应用位置编码层,如第 88 行所示。然后嵌入被发送到线 91 上的脱落层。然后,处理后的输入在行 94 和 95 上的编码器层上迭代。然后,编码器的输出通过线 98 返回。
解码器
接下来,在图 4 中,我们可以看到变压器架构中突出显示的解码器。
除了每个编码器层中的两个子层之外,解码器还插入了第三个子层,该子层对编码器堆栈的输出执行多头关注。
解码器还具有残差连接和围绕三个子层的归一化操作。注意,解码器的第一个子层是一个屏蔽的多头关注层,而不是多头关注层。
我们在pyimagesearch内部构建解码器模块,并将其命名为decoder.py。
# import the necessary packages
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Layer
from pyimagesearch.attention import CausalSelfAttention, CrossAttention
from .feed_forward import FeedForward
from .positional_encoding import PositionalEmbedding
在第 2-8 行上,我们导入必要的包。
class DecoderLayer(Layer):
def __init__(self, dModel, numHeads, dff, dropOutRate=0.1, **kwargs):
"""
Args:
dModel: The dimension of the transformer module
numHeads: Number of heads of the multi head attention module in the encoder layer
dff: The intermediate dimension size in the feed forward network
dropOutRate: The rate of dropout layer
"""
super().__init__(**kwargs)
# initialize the causal attention module
self.causalSelfAttention = CausalSelfAttention(
num_heads=numHeads,
key_dim=dModel // numHeads,
dropout=dropOutRate,
)
# initialize the cross attention module
self.crossAttention = CrossAttention(
num_heads=numHeads,
key_dim=dModel // numHeads,
dropout=dropOutRate,
)
# initialize a feed forward network
self.ffn = FeedForward(
dff=dff,
dModel=dModel,
dropoutRate=dropOutRate,
)
def call(self, x, context):
x = self.causalSelfAttention(x=x)
x = self.crossAttention(x=x, context=context)
# get the attention scores for plotting later
self.lastAttentionScores = self.crossAttention.lastAttentionScores
# apply feedforward network to the outputs and return it
x = self.ffn(x)
return x
解码器是单个解码器层的堆叠。在第 11 行,我们定义了自定义DecoderLayer。在的第 23-27 行,我们定义了CausalSelfAttention层。这一层是解码器层中的第一个子层。这为目标输入提供了因果掩蔽。
在第 30-34 行,我们定义了CrossAttention层。这将处理CausalAttention层的输出和Encoder输出。术语交叉来自解码器和编码器对此子层的输入。
在第 37-41 行上,我们定义了FeedForward层。
自定义层的call方法在行 43 定义。它接受x和context作为输入。在行 44 和 45 上,输入分别由因果层和交叉注意层处理。
注意力分数被缓存在行 48 上。之后,我们将前馈网络应用于线 51 上的处理输出。定制解码器层的输出然后在线 52 上返回。
class Decoder(Layer):
def __init__(
self,
numLayers,
dModel,
numHeads,
targetVocabSize,
maximumPositionEncoding,
dff,
dropOutRate=0.1,
**kwargs
):
"""
Args:
numLayers: The number of encoder layers in the encoder
dModel: The dimension of the transformer module
numHeads: Number of heads of multihead attention layer in each encoder layer
targetVocabSize: The target vocabulary size
maximumPositionEncoding: The maximum number of tokens in a sentence in the source dataset
dff: The intermediate dimension of the feed forward network
dropOutRate: The rate of dropout layer
"""
super().__init__(**kwargs)
# define the dimension of the model and the number of decoder layers
self.dModel = dModel
self.numLayers = numLayers
# initialize the positional embedding layer
self.positionalEmbedding = PositionalEmbedding(
vocabSize=targetVocabSize,
dModel=dModel,
maximumPositionEncoding=maximumPositionEncoding,
)
# define a stack of decoder layers
self.decoderLayers = [
DecoderLayer(
dModel=dModel, dff=dff, numHeads=numHeads, dropOutRate=dropOutRate
)
for _ in range(numLayers)
]
# initialize a dropout layer
self.dropout = Dropout(rate=dropOutRate)
def call(self, x, context):
# apply positional embedding to the target token ids
x = self.positionalEmbedding(x)
# apply dropout to the embedded targets
x = self.dropout(x)
# iterate over the stacks of decoder layer
for decoderLayer in self.decoderLayers:
x = decoderLayer(x=x, context=context)
# get the attention scores and cache it
self.lastAttentionScores = self.decoderLayers[-1].lastAttentionScores
# return the output of the decoder
return x
我们在第 55-66 行的上定义Decoder层。在第 80 行和第 81 行,我们定义了解码器模型的尺寸和解码器中使用的解码器层数。
第 84-88 行定义了位置编码层。在第 91-96 行,我们为解码器定义了解码器层的堆栈。我们还定义了一个Dropout层在线 99 上。
call方法定义在行 101 上。它接受x和context作为输入。在第 103 行,我们首先将x令牌通过positionalEmbedding层进行嵌入。在第 106 行,我们将 dropout 应用于嵌入以调整模型。
我们迭代解码器层的堆栈,并将其应用于嵌入和上下文输入,如第行 109 和 110 所示。我们还缓存了第 113 行的的最后关注分数。
解码器的输出在线 116 上返回。
变压器
最后,所有的模块和组件都准备好构建整个 transformer 架构了。让我们看看图 5 中的,我们可以看到整个架构。
我们在pyimagesearch目录下的transformer.py中构建整个模块。
# import the necessary packages
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras.layers import Dense
from tensorflow.keras.metrics import Mean
from pyimagesearch.decoder import Decoder
from pyimagesearch.encoder import Encoder
第 2-8 行导入必要的包。
class Transformer(Model):
def __init__(
self,
encNumLayers,
decNumLayers,
dModel,
numHeads,
dff,
sourceVocabSize,
targetVocabSize,
maximumPositionEncoding,
dropOutRate=0.1,
**kwargs
):
"""
Args:
encNumLayers: The number of encoder layers
decNumLayers: The number of decoder layers
dModel: The dimension of the transformer model
numHeads: The number of multi head attention module for the encoder and decoder layers
dff: The intermediate dimension of the feed forward network
sourceVocabSize: The source vocabulary size
targetVocabSize: The target vocabulary size
maximumPositionEncoding: The maximum token length in the dataset
dropOutRate: The rate of dropout layers
"""
super().__init__(**kwargs)
# initialize the encoder and the decoder layers
self.encoder = Encoder(
numLayers=encNumLayers,
dModel=dModel,
numHeads=numHeads,
sourceVocabSize=sourceVocabSize,
maximumPositionEncoding=maximumPositionEncoding,
dff=dff,
dropOutRate=dropOutRate,
)
self.decoder = Decoder(
numLayers=decNumLayers,
dModel=dModel,
numHeads=numHeads,
targetVocabSize=targetVocabSize,
maximumPositionEncoding=maximumPositionEncoding,
dff=dff,
dropOutRate=dropOutRate,
)
# define the final layer of the transformer
self.finalLayer = Dense(units=targetVocabSize)
def call(self, inputs):
# get the source and the target from the inputs
(source, target) = inputs
# get the encoded representation from the source inputs and the
# decoded representation from the encoder outputs and target inputs
encoderOutput = self.encoder(x=source)
decoderOutput = self.decoder(x=target, context=encoderOutput)
# apply a dense layer to the decoder output to formulate the logits
logits = self.finalLayer(decoderOutput)
# drop the keras mask, so it doesn't scale the losses/metrics.
try:
del logits._keras_mask
except AttributeError:
pass
# return the final logits
return logits
我们已经定义了Decoder和Encoder自定义层。是时候把所有东西放在一起,建立我们的变压器模型了。
注意我们是如何在第 11 行的上定义一个名为 Transformer 的自定义tf.keras.Model。在第 12-24 行中提到了建造变压器所需的论据。
从第 40-57 行,我们定义了编码器和解码器。在第 60 行,我们初始化计算逻辑的最终密集层。
模型的call方法在行 62 定义。输入是源令牌和目标令牌。我们先把 64 号线上的两个人分开。在第 68 行的上,我们对源令牌应用编码器以获得编码器表示。接下来,在行 69** 上,我们对目标令牌和编码器表示应用解码器。**
为了计算 logits,我们在解码器输出上应用最终的密集层,如第 72 行所示。然后我们移除第 75-78 行上附加的 keras 遮罩。然后我们返回第 81 行的逻辑。
译者
然而,我们还需要构建一些组件来训练和测试整个架构。第一个是翻译器模块,我们将需要它来执行神经机器翻译。
我们在pyimagesearch目录中构建翻译器模块,并将其命名为translate.py。
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import StringLookup
在行 1-3 上,我们导入必要的包。
class Translator(tf.Module):
def __init__(
self,
sourceTextProcessor,
targetTextProcessor,
transformer,
maxLength
):
# initialize the source text processor
self.sourceTextProcessor = sourceTextProcessor
# initialize the target text processor and a string from
# index string lookup layer for the target ids
self.targetTextProcessor = targetTextProcessor
self.targetStringFromIndex = StringLookup(
vocabulary=targetTextProcessor.get_vocabulary(),
mask_token="",
invert=True
)
# initialize the pre-trained transformer model
self.transformer = transformer
self.maxLength = maxLength
Transformer模型,经过训练后,需要一个 API 来进行推断。我们需要一个定制的翻译器,它使用经过训练的 transformer 模型,并以人类可读的字符串给出结果。
在第 5 行的上,我们定义了自定义的tf.Module names Translator,它将使用预先训练好的 Transformer 模型将源句子翻译成目标句子。在第 14 行,我们定义了源文本处理器。
在第 18-23 行上,我们定义了目标文本处理器和一个字符串查找层。字符串查找对于从令牌 id 中获取字符串非常重要。
第 26 行定义了预应变变压器模型。第 28 行定义了翻译句子的最大长度。
def tokens_to_text(self, resultTokens):
# decode the token from index to string
resultTextTokens = self.targetStringFromIndex(resultTokens)
# format the result text into a human readable format
resultText = tf.strings.reduce_join(
inputs=resultTextTokens, axis=1, separator=" "
)
resultText = tf.strings.strip(resultText)
# return the result text
return resultText
tokens_to_text方法是将令牌 id 转换成字符串所必需的。它接受resultTokens作为输入(行 30 )。
在第 32 行的上,我们将令牌从索引解码为字符串。这就是使用字符串查找层的地方。第 35-38 行负责连接字符串并去掉空格。这是将输出字符串转换成人类可读的句子所必需的。
处理后的文本然后在行 41 上返回。
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def __call__(self, sentence):
# the input sentence is a string of source language
# apply the source text processor on the list of source sentences
sentence = self.sourceTextProcessor(sentence[tf.newaxis])
encoderInput = sentence
# apply the target text processor on an empty sentence
# this will create the start and end tokens
startEnd = self.targetTextProcessor([""])[0] # 0 index is to index the only batch
# grab the start and end tokens individually
startToken = startEnd[0][tf.newaxis]
endToken = startEnd[1][tf.newaxis]
# build the output array
outputArray = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True)
outputArray = outputArray.write(index=0, value=startToken)
# iterate over the maximum length and get the output ids
for i in tf.range(self.maxLength):
# transpose the output array stack
output = tf.transpose(outputArray.stack())
# get the predictions from the transformer and
# grab the last predicted token
predictions = self.transformer([encoderInput, output], training=False)
predictions = predictions[:, -1:, :] # (bsz, 1, vocabSize)
# get the predicted id from the predictions using argmax and
# write the predicted id into the output array
predictedId = tf.argmax(predictions, axis=-1)
outputArray = outputArray.write(i+1, predictedId[0])
# if the predicted id is the end token stop iteration
if predictedId == endToken:
break
output = tf.transpose(outputArray.stack())
text = self.tokens_to_text(output)
return text
我们现在定义第 43 和 44 行的翻译器的__call__方法。输入句子是一串源语言。我们在第 47 行的源句子列表上应用源文本处理器。
编码器输入是符号化输入,如第 49 行所示。在的第 51-53 行,我们在一个空句子上应用目标文本处理器,创建开始和结束标记。开始和结束标记在线 56 和 57** 上被分开。**
我们在第 60 和 61 行的上构建输出数组tf.TensorArray。我们现在迭代生成的令牌的最大数量,并从预训练的 Transformer 模型生成输出令牌 id(第 64-80 行)。在行 66** 上,我们转置输出数组堆栈。在第 70 和 71 行**上,我们从转换器获得预测,并获取最后一个预测的令牌。
我们使用tf.argmax从预测中获得预测的 id,并将预测的 id 写入第 75 行和第 76 行的输出数组中。在行 79 和 80 上提供了停止迭代的条件。条件是预测标记应该与结束标记匹配。
然后,我们将tokens_to_text方法应用于输出数组,并在第行第 82 行和第 83 行获得字符串形式的结果文本。这个结果文本在第 85 行返回。
训练
我们组装所有部件来训练用于神经机器翻译任务的转换器架构。培训模块内置于train.py中。
# USAGE
# python train.py
# setting seed for reproducibility
import sys
import tensorflow as tf
from pyimagesearch.loss_accuracy import masked_accuracy, masked_loss
from pyimagesearch.translate import Translator
tf.keras.utils.set_random_seed(42)
from tensorflow.keras.layers import TextVectorization
from tensorflow.keras.optimizers import Adam
from pyimagesearch import config
from pyimagesearch.dataset import (
load_data,
make_dataset,
splitting_dataset,
tf_lower_and_split_punct,
)
from pyimagesearch.rate_schedule import CustomSchedule
from pyimagesearch.transformer import Transformer
在第行第 5-23 行,我们定义了导入并为可重复性设置了随机种子。
# load data from disk
print(f"[INFO] loading data from {config.DATA_FNAME}...")
(source, target) = load_data(fname=config.DATA_FNAME)
第 26 行和第 27 行使用load_data方法加载数据。
# split the data into training, validation, and test set
print("[INFO] splitting the dataset into train, val, and test...")
(train, val, test) = splitting_dataset(source=source, target=target
一个数据集需要拆分成train、val和test。第 30 行和第 31 行正好有助于此。数据集被发送到splitting_dataset函数,该函数将其分割成相应的数据片段。
# create source text processing layer and adapt on the training
# source sentences
print("[INFO] adapting the source text processor on the source dataset...")
sourceTextProcessor = TextVectorization(
standardize=tf_lower_and_split_punct, max_tokens=config.SOURCE_VOCAB_SIZE
)
sourceTextProcessor.adapt(train[0])
第 35-39 行创建源文本处理器,一个TextVectorization层,并在源训练数据集上修改它。
# create target text processing layer and adapt on the training
# target sentences
print("[INFO] adapting the target text processor on the target dataset...")
targetTextProcessor = TextVectorization(
standardize=tf_lower_and_split_punct, max_tokens=config.TARGET_VOCAB_SIZE
)
targetTextProcessor.adapt(train[1])
第 43-47 行创建目标文本处理器,一个TextVectorization层,并适应目标训练数据集。
# build the TensorFlow data datasets of the respective data splits
print("[INFO] building TensorFlow Data input pipeline...")
trainDs = make_dataset(
splits=train,
batchSize=config.BATCH_SIZE,
train=True,
sourceTextProcessor=sourceTextProcessor,
targetTextProcessor=targetTextProcessor,
)
valDs = make_dataset(
splits=val,
batchSize=config.BATCH_SIZE,
train=False,
sourceTextProcessor=sourceTextProcessor,
targetTextProcessor=targetTextProcessor,
)
testDs = make_dataset(
splits=test,
batchSize=config.BATCH_SIZE,
train=False,
sourceTextProcessor=sourceTextProcessor,
targetTextProcessor=targetTextProcessor,
)
第 50-71 行使用make_dataset函数构建tf.data.Dataset管道。
# build the transformer model
print("[INFO] building the transformer model...")
transformerModel = Transformer(
encNumLayers=config.ENCODER_NUM_LAYERS,
decNumLayers=config.DECODER_NUM_LAYERS,
dModel=config.D_MODEL,
numHeads=config.NUM_HEADS,
dff=config.DFF,
sourceVocabSize=config.SOURCE_VOCAB_SIZE,
targetVocabSize=config.TARGET_VOCAB_SIZE,
maximumPositionEncoding=config.MAX_POS_ENCODING,
dropOutRate=config.DROP_RATE,
)
我们在第 74-85 行上构建我们的变压器模型。
# compile the model
print("[INFO] compiling the transformer model...")
learningRate = CustomSchedule(dModel=config.D_MODEL)
optimizer = Adam(learning_rate=learningRate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
transformerModel.compile(
loss=masked_loss, optimizer=optimizer, metrics=[masked_accuracy]
)
我们用自定义优化器编译模型,在第 88-93 行的上有CustomSchedule和masked_loss以及masked_accuracy函数。
# fit the model on the training dataset
transformerModel.fit(
trainDs,
epochs=config.EPOCHS,
validation_data=valDs,
)
使用trainDs我们在行 96-100 上拟合模型。这里我们使用 Keras 提供的高效优雅的Model.fit API。我们还通过向 fit 方法提供valDs来验证培训渠道。
# infer on a sentence
translator = Translator(
sourceTextProcessor=sourceTextProcessor,
targetTextProcessor=targetTextProcessor,
transformer=transformerModel,
maxLength=50,
)
# serialize and save the translator
print("[INFO] serialize the inference translator to disk...")
tf.saved_model.save(
obj=translator,
export_dir="translator",
)
我们构建Translator进行推理,并在的第 103-115 行将其保存到磁盘。
以下是仅 25 个时期的训练脚本的输出。
$ python train.py
[INFO] loading data from fra.txt...
[INFO] splitting the dataset into train, val, and test...
[INFO] adapting the source text processor on the source dataset...
[INFO] adapting the target text processor on the target dataset...
[INFO] building TensorFlow Data input pipeline...
[INFO] building the transformer model...
[INFO] compiling the transformer model...
Epoch 1/25
309/309 [==============================] - 85s 207ms/step - loss: 7.1164 - masked_accuracy: 0.2238 - val_loss: 4.8327 - val_masked_accuracy: 0.3452
Epoch 2/25
309/309 [==============================] - 61s 197ms/step - loss: 3.9636 - masked_accuracy: 0.4155 - val_loss: 3.0660 - val_masked_accuracy: 0.5020
.
.
.
Epoch 24/25
309/309 [==============================] - 61s 195ms/step - loss: 0.2388 - masked_accuracy: 0.9185 - val_loss: 1.0194 - val_masked_accuracy: 0.8032
Epoch 25/25
309/309 [==============================] - 61s 195ms/step - loss: 0.2276 - masked_accuracy: 0.9217 - val_loss: 1.0323 - val_masked_accuracy: 0.8036
[INFO] serialize the inference translator to disk...
推论
现在是有趣的部分。我们将测试我们的转换器执行机器翻译任务的能力。我们在inference.py中构建推理脚本。
# USAGE
# python inference.py -s "input sentence"
我们在第 1 行和第 2 行定义推理脚本的用法。
# import the necessary packages
import tensorflow_text as tf_text # this is a no op import important for op registry
import tensorflow as tf
import argparse
我们在第 5-7 行导入必要的包。
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--sentence", required=True,
help="input english sentence")
args = vars(ap.parse_args())
我们构造参数 parse 并解析第 10-13 行的参数。
# convert the input english sentence to a constant tensor
sourceText = tf.constant(args["sentence"])
第 16 行将输入的源句子转换成tf.Tensor。这对翻译器来说很重要,因为它接受tf.Tensor而不是字符串。
# load the translator model from disk
print("[INFO] loading the translator model from disk...")
translator = tf.saved_model.load("translator")
我们现在从磁盘的第 19 行和第 20 行加载保存的翻译模块。
# perform inference and display the result
print("[INFO] translating english sentence to french...")
result = translator(sentence=sourceText)
translatedText = result.numpy()[0].decode()
print("[INFO] english sentence: {}".format(args["sentence"]))
print("[INFO] french translation: {}".format(translatedText))
在第 23-28 行,我们在翻译模块上执行推理,并在终端上显示结果。
以下输出显示了将英语句子翻译成法语的推理。
$ python inference.py -s "i am hungry, let's get some food"
[INFO] loading the translator model from disk...
[INFO] translating english sentence to french...
[INFO] english sentence: i am hungry, let's get some food
[INFO] french translation: [START] jai faim , allons chercher de la nourriture . [END]
你可以通过这里的拥抱界面直接看到模特并与之互动:
汇总
Transformer 博客帖子是 PyImageSearch 多个系列的高潮。我们从字母和单词(记号)开始,然后构建这些记号的表示。我们还使用这些表示来寻找记号之间的相似性,并将它们嵌入到高维空间中。
相同的嵌入还被传递到可以处理顺序数据的顺序模型(rnn)中。这些模型被用来构建语境,并巧妙地处理输入句子中对翻译输出句子有用的部分。这整个叙述跨越了多个博客帖子,我们非常感谢与我们一起踏上这一旅程的读者。
但是正如他们所说的,“每一个结束都是一个新的开始”,虽然 Transformer 架构和应用程序到 NLP 的旅程到此结束,但我们仍然有一些迫切的问题。
- 如何将此应用于图像?
- 我们如何扩展它?
- 我们能为各种形态制造变形金刚吗?
现在,这些问题需要自己的博文,有的需要自己的系列!那么,请告诉我们您希望我们接下来讨论的主题:
发推文 @pyimagesearch 或发电子邮件【ask.me@pyimagesearch.com
参考文献
我们在整个系列中使用了以下参考资料:
引用信息
A. R. Gosthipaty 和 R. Raha。“用 TensorFlow 和 Keras 深入研究变形金刚:第三部分”, PyImageSearch ,P. Chugh,S. Huot,K. Kidriavsteva,A. Thanki 编辑。,2022 年,【https://pyimg.co/9nozd
@incollection{ARG-RR_2022_DDTFK3,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {A Deep Dive into Transformers with {TensorFlow} and {K}eras: Part 3},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/9nozd},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
面向初学者、学生和业余爱好者的有趣的动手深度学习项目
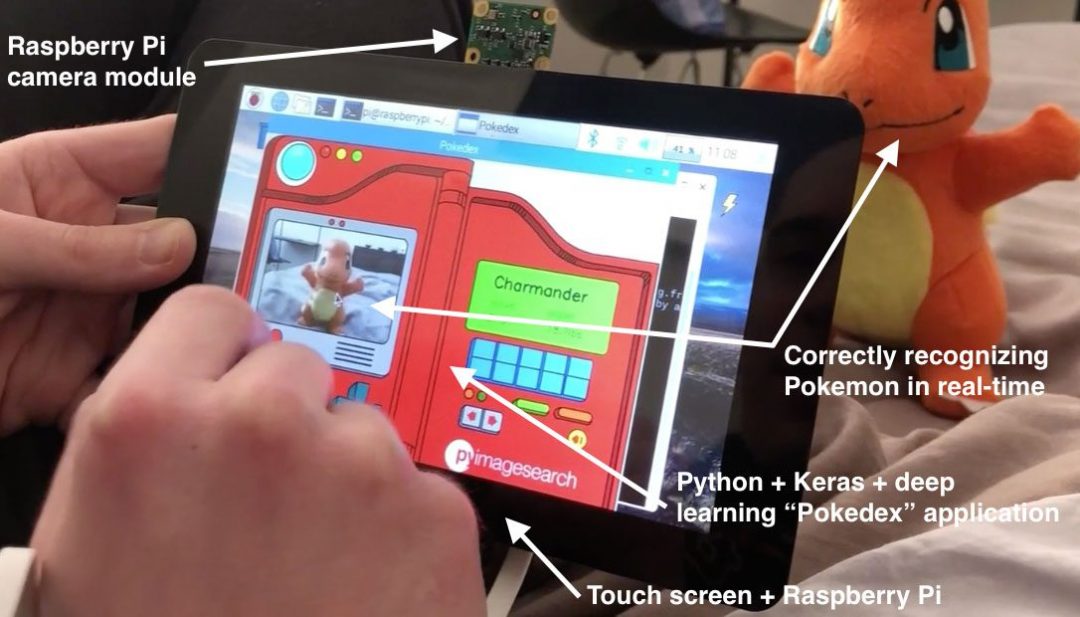
今天的博文是我们关于构建完整的端到端深度学习应用的最新系列中的“额外教程”:
- 第一部分: 如何(快速)建立深度学习图像数据集
- 第二部分 : Keras 和卷积神经网络
- 第三部分: 用 CoreML 在 iOS 上运行 Keras 模型
在这个系列中,我们一直在实现我儿时的梦想:建造一个 Pokedex。
Pokedex 是一个来自口袋妖怪世界的虚构设备(我过去是/现在仍然是一个超级口袋妖怪书呆子) 并允许最终用户:
- 把它对准一个口袋妖怪(类似动物的生物),大概是用某种相机
- 并且自动识别口袋妖怪,提供关于该生物的详细信息
因此,你可以把 Pokedex 想象成一个智能手机应用程序,它(1)访问你的相机,并且(2)实时识别动物/生物。
为了识别口袋妖怪,我们使用 Keras 训练了一个卷积神经网络——这个模型能够正确识别图像和视频流中的口袋妖怪。
然后使用 Keras、CoreML 和 iOS 将该模型部署到移动应用程序,以创建实际的“Pokedex 应用程序”。
但是为什么要止步于此呢?
PyImageSearch 博客的长期读者都知道我喜欢树莓派…
…我情不自禁地制作了一个实际的 Pokedex 设备,使用了:
- 树莓派
- 相机模块
- 7 英寸触摸屏
这个系列肯定是一个有趣的怀旧项目——谢谢你陪我走完这段旅程。
要了解这个有趣的深度学习项目的更多信息,并在树莓 Pi 上实时运行深度学习模型,请继续阅读!
面向初学者、学生和业余爱好者的有趣的动手深度学习项目
https://www.youtube.com/embed/em1oFZO-XW8?feature=oembed
深度学习对象检测的温和指南
原文:https://pyimagesearch.com/2018/05/14/a-gentle-guide-to-deep-learning-object-detection/

今天的博客帖子是受 PyImageSearch 读者 Ezekiel 的启发,他上周给我发了一封电子邮件,问我:
嘿阿德里安,
我浏览了你之前关于深度学习对象检测和
的博文,以及实时深度学习对象检测的后续教程。谢谢你。我一直在我的示例项目中使用您的源代码,但是我有两个问题:
- 如何过滤/忽略我不感兴趣的课程?
- 如何向我的对象检测器添加新的类?这可能吗?
如果你能在博客中对此进行报道,我将不胜感激。
谢了。
以西结不是唯一有这些问题的读者。事实上,如果你浏览我最近两篇关于深度学习对象检测的帖子的评论部分(链接如上),你会发现最常见的问题之一通常是(转述):
我如何修改你的源代码来包含我自己的对象类?
由于这似乎是一个如此常见的问题,最终是对神经网络/深度学习对象检测器实际工作方式的误解,我决定在今天的博客帖子中重新讨论深度学习对象检测的话题。
具体来说,在这篇文章中,你将学到:
- 图像分类和物体检测的区别
- 深度学习对象检测器的组成包括 n 对象检测框架和基础模型本身的区别
- 如何用预训练模型进行深度学习物体检测
- 如何从深度学习模型中过滤并忽略预测类
- 在深度神经网络中添加或删除类别时的常见误解和误会
要了解更多关于深度学习对象检测的信息,甚至可能揭穿你对基于深度学习的对象检测可能存在的一些误解或误会,请继续阅读。
深度学习对象检测的温和指南
今天的博客旨在温和地介绍基于深度学习的对象检测。
我已经尽了最大努力来提供深度学习对象检测器的组件的评论,包括使用预训练的对象检测器执行深度学习的 OpenCV + Python 源代码。
使用本指南来帮助你开始深度学习对象检测,但也要认识到对象检测是高度细致入微的——我不可能在一篇博客文章中包括深度学习对象检测的每个细节。
也就是说,我们将从讨论图像分类和对象检测之间的基本差异开始今天的博客文章,包括为图像分类训练的网络是否可以用于对象检测(以及在什么情况下)。
一旦我们理解了什么是对象检测,我们将回顾深度学习对象检测器的核心组件,包括对象检测框架以及基础模型,这两个关键组件是对象检测新手容易误解的。
从那里,我们将使用 OpenCV 实现实时深度学习对象检测。
我还将演示如何忽略和过滤你不感兴趣的对象类 而不必修改网络架构或重新训练模型。
最后,我们将通过讨论如何从深度学习对象检测器添加或删除类来结束今天的博客帖子,包括我推荐的帮助您入门的资源。
让我们继续深入学习对象检测!
图像分类和目标检测的区别

Figure 1: The difference between classification (left) and object detection (right) is intuitive and straightforward. For image classification, the entire image is classified with a single label. In the case of object detection, our neural network localizes (potentially multiple) objects within the image.
当执行标准的图像分类时,给定一个输入图像,我们将其呈现给我们的神经网络,并且我们获得一个单个类别标签,并且可能还获得与类别标签相关联的概率。
这个类标签用来描述整个图像的内容,或者至少是图像中最主要的可见内容。
例如,给定上面图 1(左)中的输入图像,我们的 CNN 将该图像标记为【小猎犬】。
因此我们可以把图像分类看作:
- 在中的一个图像
- 并且一个类标签出
物体检测,无论是通过深度学习还是其他计算机视觉技术执行,都建立在图像分类的基础上,并寻求准确定位每个物体在图像中出现的位置。
当执行对象检测时,给定输入图像,我们希望获得:
- 一个边界框列表,或 (x,y)-图像中每个对象的坐标
- 与每个边界框相关联的类标签
- 与每个边界框和类别标签相关联的概率/置信度得分
图 1 ( 右)演示了执行深度学习对象检测的示例。注意人和狗是如何被定位的,它们的边界框和类别标签是被预测的。
因此,物体检测使我们能够:
- 向网络展示一幅图像
- 并且获得多个包围盒和类别标签出
深度学习图像分类器可以用于物体检测吗?
Figure 2: A non-end-to-end deep learning object detector uses a sliding window (left) + image pyramid (right) approach combined with classification.
好了,至此你明白了图像分类和物体检测之间的根本区别:
- 当执行图像分类时,我们将一幅输入图像呈现给网络,并获得一个类别标签输出。
- 但是当执行对象检测时,我们可以呈现一个输入图像并获得多个包围盒和类别标签。
这引发了一个问题:
我们能不能用一个已经训练好的网络来进行分类,然后用它来进行物体检测呢?
这个答案有点棘手,因为从技术上来说它是“是”,但原因并不那么明显。
解决方案包括:
- 应用标准的基于计算机视觉的物体检测方法(即非深度学习方法),如滑动窗口和图像金字塔——这种方法通常用于您的 HOG +基于线性 SVM 的物体检测器。
- 取预先训练好的网络作为深度学习对象检测框架(即更快的 R-CNN、SSD、YOLO)中的基网络。
方法#1:传统的对象检测管道
第一种方法是而不是一个纯端到端的深度学习对象检测器。
相反,我们利用:
在滑动窗口+图像金字塔的每一站,我们提取 ROI,将其输入 CNN,并获得 ROI 的输出分类。
如果标签 L 的分类概率高于某个阈值 T ,我们将感兴趣区域的包围盒标记为标签( L )。对滑动窗口和图像金字塔的每次停止重复这个过程,我们获得输出对象检测器。最后,我们将非最大值抑制应用于边界框,产生我们的最终输出检测:

Figure 3: Applying non-maxima suppression will suppress overlapping, less confident bounding boxes.
这种方法可以在一些特定的用例中工作,但是一般来说它很慢,很乏味,并且有点容易出错。
然而,值得学习如何应用这种方法,因为它可以将任意图像分类网络变成对象检测器,避免了显式训练端到端深度学习对象检测器的需要。根据您的使用情况,这种方法可以节省您大量的时间和精力。
如果你对这种物体检测方法感兴趣,并想了解更多关于滑动窗口+图像金字塔+图像分类的物体检测方法,请参考我的书, 用 Python 进行计算机视觉的深度学习 。
方法#2:对象检测框架的基础网络
深度学习对象检测的第二种方法允许你将你预先训练的分类网络视为一个深度学习对象检测框架中的基础网络(例如更快的 R-CNN、SSD 或 YOLO)。
这里的好处是,你可以创建一个完整的端到端的基于深度学习的对象检测器。
缺点是,它需要一些关于深度学习对象检测器如何工作的深入知识——我们将在下一节中对此进行更多讨论。
深度学习对象检测器的组件
Figure 4: The VGG16 base network is a component of the SSD deep learning object detection framework.
深度学习对象检测器有许多组件、子组件和子子组件,但我们今天要关注的两个是大多数深度学习对象检测新手经常混淆的两个组件:
- 对象检测框架(例如。更快的 R-CNN,SSD,YOLO)。
- 适合目标检测框架的基础网络。
你可能已经熟悉的基础网络(你只是以前没有听说过它被称为“基础网络”)。
基本网络是您常见的(分类)CNN 架构,包括:
- VGGNet
- ResNet
- MobileNet
- DenseNet
通常,这些网络经过预先训练,可以在大型图像数据集(如 ImageNet)上执行分类,以学习一组丰富的辨别、鉴别过滤器。
对象检测框架由许多组件和子组件组成。
例如,更快的 R-CNN 框架包括:
- 区域提案网络
- 一套锚
- 感兴趣区域(ROI)汇集模块
- 最终基于区域的卷积神经网络
使用单触发探测器(SSD)时,您有组件和子组件,例如:
- 多框
- 传道者
- 固定前科
请记住,基础网络只是适合整体深度学习对象检测框架的众多组件之一——本节顶部的图 4 描绘了 SSD 框架内的 VGG16 基础网络。
通常,“网络手术”是在基础网络上进行的。这一修改:
- 形成完全卷积(即,接受任意输入维度)。
- 消除基础网络架构中更深层的 conv/池层,代之以一系列新层(SSD)、新模块(更快的 R-CNN)或两者的某种组合。
术语“网络手术”是一种通俗的说法,意思是我们移除基础网络架构中的一些原始层,并用新层取而代之。
你可能看过一些低成本的恐怖电影,在这些电影中,凶手可能拿着一把斧头或大刀,袭击受害者,并毫不客气地攻击他们。
网络手术比典型的 B 级恐怖片杀手更加精确和苛刻。
网络手术也是战术性的——我们移除网络中我们不需要的部分,并用一组新的组件替换它。
然后,当我们去训练我们的框架来执行对象检测时,修改(1)新的层/模块和(2)基础网络的权重。
同样,对各种深度学习对象检测框架如何工作(包括基础网络扮演的角色)的完整回顾不在这篇博文的范围之内。
如果你对深度学习对象检测的完整回顾感兴趣,包括理论和实现,请参考我的书, 用 Python 进行计算机视觉的深度学习 。
我如何衡量深度学习对象检测器的准确性?
在评估对象检测器性能时,我们使用一个名为平均精度 (mAP)的评估指标,该指标基于我们数据集中所有类的 交集与 (IoU)。
并集上的交集
Figure 5: In this visual example of Intersection over Union (IoU), the ground-truth bounding box (green) can be compared to the predicted bounding box (red). IoU is used with mean Average Precision (mAP) to evaluate the accuracy of a deep learning object detector. The simple equation to calculate IoU is shown on the right.
您通常会发现 IoU 和 mAP 用于评估 HOG +线性 SVM 检测器、Haar 级联和基于深度学习的方法的性能;但是,请记住,用于生成预测边界框的实际算法并不重要。
任何提供预测边界框(以及可选的类标签)作为输出的算法都可以使用 IoU 进行评估。更正式地说,为了应用 IoU 来评估任意对象检测器,我们需要:
- 真实边界框(即,我们的测试集中的手绘边界框,它指定了我们的对象在图像中的位置)。
- 我们模型中的预测边界框。
- 如果您想计算召回率和精确度,您还需要基本事实类标签和预测类标签。
在图 5 ( 左)中,我包含了一个真实边界框(绿色)与预测边界框(红色)的可视化示例。计算 IoU 可以通过图 5 ( 右)中的等式图示来确定。
检查这个等式,你会发现, IoU 仅仅是一个比率。
在分子中,我们计算预测边界框和真实边界框之间的重叠区域。
分母是并集的面积,或者更简单地说,是由预测边界框和实际边界框包围的面积。
将重叠面积除以并集面积得到最终分数,即并集上的交集。
平均精度
注:我决定编辑这一节的原貌。我想让对地图的讨论保持在更高的水平,避免一些更令人困惑的回忆计算,但正如一些评论者指出的,这一部分在技术上是不正确的。因此,我决定更新帖子。
因为这是对基于深度学习的对象检测的温和介绍,所以我将保持对 mAP 的简化解释,以便您理解基本原理。
不熟悉对象检测的读者和从业者可能会被地图计算弄糊涂。这部分是因为 mAP 是一个更复杂的评估指标。它也是 mAP 计算的定义,甚至可以从一个对象检测挑战变化到另一个(当我说“对象检测挑战”时,我指的是诸如 COCO、PASCAL VOC 等竞赛。).
计算特定对象检测流水线的平均精度(AP)基本上是一个三步过程:
- 计算精度,它是真阳性的比例。
- 计算召回,这是所有可能的阳性中真正阳性的比例。
- 以 s. 为步长,对所有召回级别的最大精度值进行平均
为了计算精度,我们首先将我们的对象检测算法应用于输入图像。然后,边界框分数按照置信度降序排列。
我们从先验知识中得知(即,这是一个验证/测试示例,因此我们知道图像中对象的总数)该图像中有 4 个对象。我们试图确定我们的网络进行了多少次“正确的”检测。这里的“正确”预测是指 IoU 最小值为 0.5(该值可根据挑战进行调整,但 0.5 是标准值)。
这就是计算开始变得有点复杂的地方。我们需要计算不同召回值(也称为“召回级别”或“召回步骤”)的精确度。
例如,假设我们正在计算前 3 个预测的精度和召回值。在深度学习对象检测器的前 3 个预测中,我们做出了 2 个正确的预测。那么我们的精度就是真阳性的比例:2/3 = 0.667。我们的回忆是图像中所有可能的阳性中真正的阳性的比例:2 / 4 = 0.5。我们对(通常)前 1 到前 10 个预测重复这个过程。这个过程产生一个精度值的列表。
下一步是计算所有 top- N 值的平均值,因此有术语平均精度(AP) 。我们循环所有的召回值 r ,找到我们可以用召回值r获得的最大精度 p ,然后计算平均值。我们现在有了单个评估图像的平均精度。
一旦我们计算了测试/验证集中所有图像的平均精度,我们将执行另外两个计算:
- 计算每个类别的平均 AP,为每个单独的类别提供一个地图(对于许多数据集/挑战,您将需要按类别检查地图,以便您可以发现您的深度学习对象检测器是否正在处理特定的类别)
- 获取每个单独类的地图,然后将它们平均在一起,得到数据集的最终地图
同样,地图比传统的准确性更复杂,所以如果你第一次看不懂也不要沮丧。这是一个评估指标,在你完全理解它之前,你需要多次研究。好消息是深度学习对象检测实现为你处理计算地图。
基于深度学习的 OpenCV 物体检测
在之前的帖子中,我们已经在这个博客上讨论了深度学习和对象检测;然而,为了完整起见,让我们回顾一下本帖中的实际源代码。
我们的示例包括带有 MobileNet 基本模型的单次检测器(框架)。该模型由 GitHub 用户 chuanqi305 在上下文通用对象(COCO)数据集上进行训练。
要了解更多细节,请查看我的 上一篇文章 ,在那里我介绍了传祺 305 的模型和相关的背景信息。
让我们从这篇文章的顶部回到以西结的第一个问题:
- How do I filter/ignore classes that I am not interested in?
我将在下面的示例脚本中回答这个问题。
但是首先你需要准备你的系统:
- 您需要在您的 Python 虚拟环境中安装最低的 OpenCV 3.3(假设您使用的是 Python 虚拟环境)。OpenCV 3.3+包括运行以下代码所需的 DNN 模块。确保使用下页的 OpenCV 安装教程,同时特别注意你下载并安装的是哪个版本的 OpenCV。
- 你也应该安装我的 imutils 包。要在 Python 虚拟环境中安装/更新 imutils,只需使用 pip:
pip install --upgrade imutils。
当你准备好了,继续创建一个名为filter_object_detection.py的新文件,让我们开始吧:
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import time
import cv2
在的第 2-8 行,我们导入我们需要的包和模块,特别是imutils和 OpenCV。我们将使用我的VideoStream类来处理从网络摄像头捕捉帧。
我们配备了必要的工具,所以让我们继续解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们的脚本在运行时需要两个命令行参数:
--prototxt:定义模型定义的 Caffe prototxt 文件的路径。--model:我们的 CNN 模型权重文件路径。
您可以选择指定一个阈值--confidence,用于过滤弱检测。
我们的模型可以预测 21 个对象类别:
# initialize the list of class labels MobileNet SSD was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
CLASSES列表包含网络被训练的所有类别标签(即 COCO 标签)。
对CLASSES列表的一个常见误解是,您可以:
- 向列表中添加一个新的类别标签
- 或者从列表中删除一个类别标签
…让网络自动“知道”您想要完成的任务。
事实并非如此。
你不能简单地修改一列文本标签,让网络自动修改自己,以学习、添加或删除它从未训练过的数据模式。这不是神经网络的工作方式。
也就是说,有一个快速技巧可以用来过滤和忽略你不感兴趣的预测。
解决方案是:
- 定义一组
IGNORE标签(即训练网络时要过滤和忽略的类别标签列表)。 - 对输入图像/视频帧进行预测。
- 忽略类别标签存在于
IGNORE集合中的任何预测。
用 Python 实现的IGNORE集合如下所示:
IGNORE = set(["person"])
这里我们将忽略所有带有类标签"person"的预测对象(用于过滤的if语句将在后面的代码审查中讨论)。
您可以轻松地向集合中添加要忽略的附加元素(来自CLASSES列表的类标签)。
接下来,我们将生成随机标签/盒子颜色,加载我们的模型,并开始视频流:
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# initialize the video stream, allow the cammera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
fps = FPS().start()
在线 27 上,生成随机数组COLORS以对应 21 个CLASSES中的每一个。我们稍后将使用这些颜色进行显示。
我们的 Caffe 模型通过使用cv2.dnn.readNetFromCaffe函数和作为参数传递的两个必需的命令行参数在行 31 上加载。
然后我们将VideoStream对象实例化为vs,并启动我们的fps计数器(第 36-38 行)。2 秒钟的sleep让我们的相机有足够的时间预热。
在这一点上,我们准备好循环从摄像机传入的帧,并通过我们的 CNN 对象检测器发送它们:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)),
0.007843, (300, 300), 127.5)
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
在第 44 行上,我们抓取一个frame然后resize,同时保留显示的纵横比(第 45 行)。
从那里,我们提取高度和宽度,因为我们稍后需要这些值( Line 48 )。
第 48 和 49 行从我们的帧生成一个blob。要了解更多关于一个blob以及如何使用cv2.dnn.blobFromImage函数构造它的信息,请参考上一篇文章了解所有细节。
接下来,我们通过我们的神经net发送那个blob来检测物体(线 54 和 55 )。
让我们循环一下检测结果:
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# `detections`
idx = int(detections[0, 0, i, 1])
# if the predicted class label is in the set of classes
# we want to ignore then skip the detection
if CLASSES[idx] in IGNORE:
continue
在第 58 条线上,我们开始了我们的detections循环。
对于每个检测,我们提取confidence ( 行 61 ),然后将其与我们的置信度阈值(行 65 )进行比较。
在我们的confidence超过最小值的情况下(默认值 0.2 可以通过可选的命令行参数来更改),我们将认为检测是积极的、有效的检测,并继续处理它。
首先,我们从detections ( 第 68 行)中提取类标签的索引。
然后,回到以西结的第一个问题,我们可以忽略第 72 行和第 73 行的IGNORE集合中的类。如果要忽略该类,我们只需continue返回到检测循环的顶部(并且我们不显示该类的标签或框)。这实现了我们的“快速破解”解决方案。
否则,我们在白名单中检测到一个对象,我们需要在框架上显示类别标签和矩形:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the prediction on the frame
label = "{}: {:.2f}%".format(CLASSES[idx],
confidence * 100)
cv2.rectangle(frame, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
在这个代码块中,我们提取边界框坐标(行 77 和 78 ),然后在框架上绘制一个标签和矩形(行 81-87 )。
对于每个唯一的类,标签+矩形的颜色将是相同的;相同类别的对象将具有相同的颜色(即视频中的所有"boats"将具有相同的颜色标签和框)。
最后,仍在我们的while循环中,我们将在屏幕上显示我们的辛勤工作:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
我们在第 90 和 91 行上显示frame并捕捉按键。
如果按下"q"键,我们通过中断循环退出(行 94 和 95 )。
否则,我们继续更新我们的fps计数器(行 98 )并继续抓取和处理帧。
在剩余的行中,当循环中断时,我们显示时间+每秒帧数指标和清理。
运行深度学习对象检测器
为了运行今天的脚本,您需要通过滚动到下面的 【下载】 部分来获取文件。
提取文件后,打开终端并导航到下载的代码+模型。在那里,执行以下命令:
$ python filter_object_detection.py --prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel
[INFO] loading model...
[INFO] starting video stream...
[INFO] elapsed time: 24.05
[INFO] approx. FPS: 13.18
Figure 6: A real-time deep learning object detection demonstration of using the same model — in the right video I’ve ignored certain object classes programmatically.
在上面的 GIF 中,你可以看到在的左边检测到了“人”类——这是因为我有一个空的IGNORE。在右边的中您可以看到我没有被检测到——这种行为是由于将“person”类添加到了IGNORE集合中。
当我们的深度学习对象检测器仍然在技术上检测“person”类时,我们的后处理代码能够将其过滤掉。
也许你在运行深度学习对象检测器时遇到了错误?
故障诊断的第一步是验证您是否连接了网络摄像头。如果这不是问题所在,您可能会在终端中看到以下错误消息:
$ python filter_object_detection.py
usage: filter_object_detection.py [-h] -p PROTOTXT -m MODEL [-c CONFIDENCE]
filter_object_detection.py: error: the following arguments are required: -p/--prototxt, -m/--model
如果你看到这个消息,那么你没有传递“命令行参数”给程序。如果 PyImageSearch 读者不熟悉 Python、argparse 和命令行参数 ,这是一个常见问题。如果你有问题,请查看链接。
以下是带评论的完整视频:
https://www.youtube.com/embed/5cwFBUQb6_w?feature=oembed
用 Keras 和 TensorFlow 训练你的第一个 CNN 的温和指南
在本教程中,您将使用 Python 和 Keras 实现一个 CNN。我们将从快速回顾 Keras 配置开始,在构建和训练您自己的 CNN 时,您应该记住这些配置。
然后我们将实现 ShallowNet,顾名思义,它是一个非常浅的 CNN,只有一个层。然而,不要让这个网络的简单性欺骗了你——正如我们的结果将证明的那样,与许多其他方法相比,ShallowNet 能够在 CIFAR-10 和 Animals 数据集上获得更高的分类精度。
注: 本教程要求你下载动物数据集。
Keras 配置和将图像转换为数组
在我们实现ShallowNet之前,我们首先需要回顾一下keras.json配置文件,以及这个文件中的设置将如何影响您实现自己的 CNN。我们还将实现第二个名为ImageToArrayPreprocessor的图像预处理器,它接受输入图像,然后将其转换为 Keras 可以处理的 NumPy 数组。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
图像到数组预处理器
正如我上面提到的,Keras 库提供了接受输入图像的img_to_array函数,然后根据我们的image_data_format设置对通道进行适当的排序。我们将把这个函数封装在一个名为ImageToArrayPreprocessor的新类中。创建一个具有特殊preprocess功能的类将允许我们创建预处理程序的“链”,以有效地准备用于训练和测试的图像。
为了创建我们的图像到数组预处理器,在pyimagesearch的preprocessing子模块中创建一个名为imagetoarraypreprocessor.py的新文件:
|--- pyimagesearch
| |--- __init__.py
| |--- datasets
| | |--- __init__.py
| | |--- simpledatasetloader.py
| |--- preprocessing
| | |--- __init__.py
| | |--- imagetoarraypreprocessor.py
| | |--- simplepreprocessor.py
从那里,打开文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
class ImageToArrayPreprocessor:
def __init__(self, dataFormat=None):
# store the image data format
self.dataFormat = dataFormat
def preprocess(self, image):
# apply the Keras utility function that correctly rearranges
# the dimensions of the image
return img_to_array(image, data_format=self.dataFormat)
第 2 行从 Keras 导入img_to_array函数。
然后,我们在第 5-7 行的中定义我们的ImageToArrayPreprocessor类的构造函数。构造函数接受一个名为dataFormat的可选参数。该值默认为None,表示应该使用keras.json内的设置。我们也可以显式地提供一个channels_first或channels_last字符串,但是最好让 Keras 根据配置文件选择使用哪个图像维度排序。
最后,我们在第 9-12 行的上有preprocess函数。这种方法:
- 接受一个
image作为输入。 - 在
image上调用img_to_array,根据我们的配置文件/T2 的值对通道进行排序。 - 返回一个通道正确排序的新 NumPy 数组。
定义一个类来处理这种类型的图像预处理,而不是简单地在每个图像上调用img_to_array的好处是,我们现在可以在从磁盘加载数据集时将预处理程序链接在一起。
例如,假设我们希望将所有输入图像的大小调整为 32×32像素的固定大小。为此,我们需要初始化一个SimplePreprocessor:
sp = SimplePreprocessor(32, 32)
调整图像大小后,我们需要应用适当的通道排序——这可以使用上面的ImageToArrayPreprocessor来完成:
iap = ImageToArrayPreprocessor()
现在,假设我们希望从磁盘加载一个图像数据集,并为训练准备数据集中的所有图像。使用SimpleDatasetLoader,我们的任务变得非常简单:
sdl = SimpleDatasetLoader(preprocessors=[sp, iap])
(data, labels) = sdl.load(imagePaths, verbose=500)
注意我们的图像预处理程序是如何链接在一起的,并将按照的顺序应用。对于数据集中的每个图像,我们将首先应用SimplePreprocessor将其调整为 32 × 32 像素。一旦调整了图像的大小,就应用ImageToArrayPreprocessor来处理图像通道的排序。该图像处理管道可以在图 2 中可视化。
以这种方式将简单的预处理器链接在一起,其中每个预处理器负责一个小任务,这是一种建立可扩展的深度学习库的简单方法,该库专用于分类图像。
浅水网
今天,我们将实现浅水网络架构。顾名思义,浅网架构只包含几层——整个网络架构可以概括为:INPUT => CONV => RELU => FC
这个简单的网络架构将允许我们使用 Keras 库实现卷积神经网络。在实现了 ShallowNet 之后,我将把它应用于动物和 CIFAR-10 数据集。正如我们的结果将展示的,CNN 能够显著地胜过许多其他的图像分类方法。
实施浅水网
为了保持我们的pyimagesearch包的整洁,让我们在nn中创建一个新的子模块,命名为conv,我们所有的 CNN 实现都将位于其中:
--- pyimagesearch
| |--- __init__.py
| |--- datasets
| |--- nn
| | |--- __init__.py
...
| | |--- conv
| | | |--- __init__.py
| | | |--- shallownet.py
| |--- preprocessing
在conv子模块中,创建一个名为shallownet.py的新文件来存储我们的 ShallowNet 架构实现。从那里,打开文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
第 2-7 行导入我们需要的 Python 包。Conv2D类是卷积层的 Keras 实现。然后我们有了Activation类,顾名思义,它处理对输入应用激活函数。在将输入输入到Dense(即完全连接的)层之前,Flatten类获取我们的多维体积,并将其“展平”成 1D 数组。
在实现网络架构时,我更喜欢将它们定义在一个类中,以保持代码有组织——我们在这里也将这样做:
class ShallowNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last"
model = Sequential()
inputShape = (height, width, depth)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
在第 9 行,我们定义了ShallowNet类,然后在第 11 行定义了一个build方法。我们在本书中实现的每个 CNN 都将有一个build方法——这个函数将接受许多参数,构建网络架构,然后将其返回给调用函数。在这种情况下,我们的build方法需要四个参数:
width:将用于训练网络的输入图像的宽度(即矩阵中的列数)。height:我们输入图像的高度(即矩阵中的行数)depth:输入图像中的通道数。classes:我们的网络要学习预测的总类数。对于动物,classes=3和对于 CIFAR-10,classes=10。
然后我们在线 15 上初始化inputShape到网络,假设“信道最后”排序。第 18 行和第 19 行检查 Keras 后端是否设置为“通道优先”,如果是,我们更新inputShape。通常的做法是为你建立的几乎每一个 CNN 都包含行 15-19 ,从而确保你的网络将会工作,不管用户如何订购他们的图像频道。
现在我们的inputShape已经定义好了,我们可以开始构建浅水网络架构了:
# define the first (and only) CONV => RELU layer
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
在第 22 行,我们定义了第一个(也是唯一的)卷积层。该层将有 32 个滤镜( K ),每个滤镜是 3 个 × 3(即方形 F×F 滤镜)。我们将应用same填充来确保卷积运算的输出大小与输入匹配(使用same填充对于这个例子来说不是绝对必要的,但是现在开始形成是一个好习惯)。卷积后,我们在线 24 上应用一个 ReLU 激活。
让我们完成浅水网的构建:
# softmax classifier
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
为了应用我们的全连接层,我们首先需要将多维表示展平为 1D 列表。展平操作由线 27 上的Flatten调用处理。然后,使用与输出类标签相同数量的节点创建一个Dense层(第 28 行)。第 29 行应用了一个 softmax 激活函数,它将给出每个类的类标签概率。浅网架构返回到线 32 上的调用函数。
现在已经定义了 ShallowNet,我们可以继续创建实际的“驱动程序脚本”来加载数据集,对其进行预处理,然后训练网络。我们将看两个利用浅水网的例子——动物和 CIFAR-10。
动物身上的浅网
为了在 Animals 数据集上训练 ShallowNet,我们需要创建一个单独的 Python 文件。打开您最喜欢的 IDE,创建一个名为shallownet_animals.py的新文件,确保它与我们的pyimagesearch模块在同一个目录级别(或者您已经将pyimagesearch添加到 Python 解释器/IDE 在运行脚本时将检查的路径列表中)。
从那里,我们可以开始工作:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.preprocessing import ImageToArrayPreprocessor
from pyimagesearch.preprocessing import SimplePreprocessor
from pyimagesearch.datasets import SimpleDatasetLoader
from pyimagesearch.nn.conv import ShallowNet
from tensorflow.keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-13 行导入我们需要的 Python 包。这些导入中的大部分你已经在前面的例子中见过了,但是我想提醒你注意第 5-7 行的,在这里我们导入了ImageToArrayPreprocessor、SimplePreprocessor和SimpleDatasetLoader——这些类将形成实际的管道,用于在图像通过我们的网络之前对它们进行处理。然后,我们将第 8 行的ShallowNet和第 9 行的SGD一起导入到行,我们将使用随机梯度下降来训练浅水网。****
**接下来,我们需要解析我们的命令行参数并获取我们的图像路径:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
# grab the list of images that we'll be describing
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
我们的脚本在这里只需要一个开关--dataset,它是包含我们的动物数据集的目录的路径。第 23 行然后抓取动物体内所有 3000 张图片的文件路径。
还记得我说过如何创建一个管道来加载和处理我们的数据集吗?现在让我们看看这是如何做到的:
# initialize the image preprocessors
sp = SimplePreprocessor(32, 32)
iap = ImageToArrayPreprocessor()
# load the dataset from disk then scale the raw pixel intensities
# to the range [0, 1]
sdl = SimpleDatasetLoader(preprocessors=[sp, iap])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.astype("float") / 255.0
第 26 行定义了用于将输入图像调整到 32×32像素的SimplePreprocessor。然后在线 27 上实例化ImageToArrayPreprocessor以处理信道排序。
我们在第 31 行将这些预处理器组合在一起,在那里我们初始化SimpleDatasetLoader。看一下构造函数的preprocessors参数——我们提供了一个列表,其中列出了将按照顺序应用的预处理程序。首先,给定的输入图像将被调整到 32×32像素。然后,调整大小后的图像将根据我们的keras.json配置文件按顺序排列其通道。第 32 行加载图像(应用预处理器)和分类标签。然后,我们将图像缩放到范围【0,1】。
既然已经加载了数据和标签,我们就可以执行我们的训练和测试分割,同时对标签进行一次性编码:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, random_state=42)
# convert the labels from integers to vectors
trainY = LabelBinarizer().fit_transform(trainY)
testY = LabelBinarizer().fit_transform(testY)
这里,我们将 75%的数据用于训练,25%用于测试。
下一步是实例化ShallowNet,然后训练网络本身:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.005)
model = ShallowNet.build(width=32, height=32, depth=3, classes=3)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=100, verbose=1)
我们使用学习率0.005初始化行 46 上的SGD优化器。ShallowNet架构在行 47 上被实例化,提供 32 像素的宽度和高度以及 3 的深度——这意味着我们的输入图像是 32×32 像素,具有三个通道。由于 Animals 数据集有三个类标签,我们设置了classes=3。
然后在的第 48 和 49 行编译model,在这里我们将使用交叉熵作为我们的损失函数,SGD 作为我们的优化器。为了训练网络,我们在第 53 和 54 行的上调用model的.fit方法。.fit方法要求我们传递训练和测试数据。我们还将提供我们的测试数据,以便我们可以在每个时期后评估 ShallowNet 的性能。将使用 32 的小批量大小对网络进行 100 个时期的训练(这意味着将一次向网络呈现 32 个图像,并且将进行完整的向前和向后传递以更新网络的参数)。
在训练我们的网络之后,我们可以评估它的性能:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=["cat", "dog", "panda"]))
为了获得测试数据的输出预测,我们调用了model的.predict。一份格式精美的分类报告显示在我们的屏幕上第 59-61 行。
我们的最终代码块处理和训练和测试数据的准确性和随时间的损失的绘图:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
要在 Animals 数据集上训练 ShallowNet,只需执行以下命令:
$ python shallownet_animals.py --dataset ../datasets/animals
训练应该非常快,因为网络非常浅,我们的图像数据集相对较小:
[INFO] loading images...
[INFO] processed 500/3000
[INFO] processed 1000/3000
[INFO] processed 1500/3000
[INFO] processed 2000/3000
[INFO] processed 2500/3000
[INFO] processed 3000/3000
[INFO] compiling model...
[INFO] training network...
Train on 2250 samples, validate on 750 samples
Epoch 1/100
0s - loss: 1.0290 - acc: 0.4560 - val_loss: 0.9602 - val_acc: 0.5160
Epoch 2/100
0s - loss: 0.9289 - acc: 0.5431 - val_loss: 1.0345 - val_acc: 0.4933
...
Epoch 100/100
0s - loss: 0.3442 - acc: 0.8707 - val_loss: 0.6890 - val_acc: 0.6947
[INFO] evaluating network...
precision recall f1-score support
cat 0.58 0.77 0.67 239
dog 0.75 0.40 0.52 249
panda 0.79 0.90 0.84 262
avg / total 0.71 0.69 0.68 750
由于训练数据量很小,epochs 非常快,在我的 CPU 和 GPU 上都不到一秒钟。
从上面的输出可以看出,在我们的测试数据上,ShallowNet 获得了 71%的分类准确率,比我们之前使用简单前馈神经网络的 59%有了很大的提高。使用更先进的训练网络,以及更强大的架构,我们将能够进一步提高分类精度。
**图 3 中显示了损耗和精度随时间的变化。在 x 轴上,我们有我们的纪元编号,在 y 轴上,我们有我们的损耗和精度。检查该图,我们可以看到学习有点不稳定,在第 20 个纪元和第 60 个纪元左右损失大,这一结果可能是由于我们的学习率太高。
还要注意,训练和测试损失在超过第 30 个时期后严重偏离,这意味着我们的网络对训练数据的建模过于接近并且过度拟合。我们可以通过获取更多数据或应用数据扩充等技术来解决这个问题。
在纪元 60 左右,我们的测试精度饱和——我们无法超过 ≈ 70%的分类精度,同时我们的训练精度继续攀升至 85%以上。同样,收集更多的训练数据,应用数据扩充,并更加注意调整我们的学习速度,将有助于我们在未来改善我们的结果。
这里的关键点是,一个极其简单的卷积神经网络能够在动物数据集上获得 71%的分类准确率,而我们以前的最好成绩仅为 59%——这是超过 12%的改进!
CIFAR-10 上的浅水网
让我们也将 ShallowNet 架构应用于 CIFAR-10 数据集,看看我们是否可以改进我们的结果。打开一个新文件,将其命名为shallownet_cifar10.py,并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from pyimagesearch.nn.conv import ShallowNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
第 2-8 行导入我们需要的 Python 包。然后,我们加载 CIFAR-10 数据集(预先分为训练集和测试集),然后将图像像素强度缩放到范围【0,1】。由于 CIFAR-10 图像经过预处理,并且通道排序是在cifar10.load_data内部自动处理的,我们不需要应用任何自定义预处理类。
*然后我们的标签被一次性编码成第 18-20 行上的向量。我们还在第 23 行和第 24 行的上初始化了 CIFAR-10 数据集的标签名称。
现在我们的数据准备好了,我们可以训练浅水网:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=40, verbose=1)
第 28 行用学习率0.01初始化 SGD 优化器。然后在线 29 上构建浅网,宽度为32,高度为32,深度为3(因为 CIFAR-10 图像有三个通道)。我们设置classes=10,因为顾名思义,在 CIFAR-10 数据集中有 10 个类。该模型在线 30 和 31 上编译,然后在 40 个时期内在线 35 和 36 上训练。
评估 ShallowNet 的方式与我们之前的动物数据集示例完全相同:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
我们还将绘制一段时间内的损耗和精度,以便了解我们的网络性能如何:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 40), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
要在 CIFAR-10 上训练 ShallowNet,只需执行以下命令:
$ python shallownet_cifar10.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/40
5s - loss: 1.8087 - acc: 0.3653 - val_loss: 1.6558 - val_acc: 0.4282
Epoch 2/40
5s - loss: 1.5669 - acc: 0.4583 - val_loss: 1.4903 - val_acc: 0.4724
...
Epoch 40/40
5s - loss: 0.6768 - acc: 0.7685 - val_loss: 1.2418 - val_acc: 0.5890
[INFO] evaluating network...
precision recall f1-score support
airplane 0.62 0.68 0.65 1000
automobile 0.79 0.64 0.71 1000
bird 0.43 0.46 0.44 1000
cat 0.42 0.38 0.40 1000
deer 0.52 0.51 0.52 1000
dog 0.44 0.57 0.50 1000
frog 0.74 0.61 0.67 1000
horse 0.71 0.61 0.66 1000
ship 0.65 0.77 0.70 1000
truck 0.67 0.66 0.66 1000
avg / total 0.60 0.59 0.59 10000
同样,由于浅网络架构和相对较小的数据集,历元非常快。使用我的 GPU,我获得了 5 秒的历元,而我的 CPU 为每个历元花费了 22 秒。
在 40 个时期之后,对 ShallowNet 进行评估,我们发现它在测试集上获得了 60%的准确度,比之前使用简单神经网络获得的 57%的准确度有所提高。
更重要的是,在图 4 中绘制我们的损失和准确性让我们对训练过程有了一些了解,这表明我们的验证损失并没有飙升。我们的训练和测试损失/准确性开始偏离超过纪元 10。同样,这可以归因于较大的学习率,以及我们没有使用方法来帮助克服过度拟合(正则化参数、丢失、数据扩充等)的事实。).
由于低分辨率训练样本的数量有限,也很容易在 CIFAR-10 数据集上过度拟合。随着我们越来越习惯于构建和训练我们自己的定制卷积神经网络,我们将发现在 CIFAR-10 上提高分类精度的方法,同时减少过拟合。
总结
在本教程中,我们实现了我们的第一个卷积神经网络架构 ShallowNet,并在 Animals 和 CIFAR-10 数据集上对其进行了训练。ShallowNet 获得了 71%的动物分类准确率,比我们以前使用简单前馈神经网络的最好成绩提高了 12%。
当应用于 CIFAR-10 时,ShallowNet 达到了 60%的准确率,比使用简单多层神经网络时的最高准确率提高了 57%(并且没有显著的过度拟合)。
ShallowNet 是一个极其简单的 CNN,仅使用一个 CONV层——通过多组CONV => RELU => POOL操作训练更深的网络,可以获得更高的精度。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!******
使用 TensorFlow 轻松介绍 tf.data
原文:https://pyimagesearch.com/2021/06/14/a-gentle-introduction-to-tf-data-with-tensorflow/
在本教程中,您将学习 TensorFlow 的tf.data模块的基础知识,该模块用于构建更快、更高效的深度学习数据管道。
这篇博文是我们关于tf.data的三部分系列的第一部分:
- TF . data 的温和介绍(本教程)
- 使用 tf.data 和 TensorFlow 的数据管道(下周博文)
- 用 tf.data 进行数据扩充(两周后的教程)
在我们开始之前,这里有一个你需要知道的快速分类:
tf.data模块允许我们在可重用的代码块中构建复杂的和高效的数据处理管道。- 它非常容易使用
- 与使用通常用于训练 Keras 和 TensorFlow 模型的
ImageDataGenerator对象相比,tf.data模块比≈快 38 倍。 - 我们可以很容易地用
tf.data代替ImageDataGenerator通话
只要有可能,你应该考虑交换掉ImageDataGenerator调用,转而使用tf.data——你的数据处理管道将快得多*(因此,你的模型将训练得更快)。
学习基本面tf.data进行深度学习, 保持阅读即可。
使用 TensorFlow 对 tf.data 的简单介绍
在本教程的第一部分,我们将讨论 TensorFlow 的tf.data模块是什么,包括它对于构建数据处理管道是否有效。
然后,我们将配置我们的开发环境,检查我们的项目目录结构,并讨论我们将用于基准测试tf.data和ImageDataGenerator的示例图像数据集。
为了比较tf.data和ImageDataGenerator的数据处理速度,我们今天将实现两个脚本:
- 第一个将在处理一个完全符合内存中的数据集时,比较
tf.data和ImageDataGenerator - 然后,当处理驻留在磁盘上图像时,我们将实现第二个东西来比较
tf.data和ImageDataGenerator
最后,我们将运行每个脚本并比较我们的结果。
什么是“tf.data”模块?
PyTorch 库的用户可能对Dataset和DatasetLoader类很熟悉——它们使得加载和预处理数据变得非常容易、高效和快速。
在 TensorFlow v2 之前,Keras 和 TensorFlow 用户必须:
- 手动定义自己的数据加载功能
- 利用 Keras 的
ImageDataGenerator功能处理太大而无法装入内存的图像数据集和/或需要应用数据扩充时
两种解决方案都不是最好的。
手动实现自己的数据加载功能是一项艰苦的工作,可能会导致错误。ImageDataGenerator函数虽然是一个非常好的选择,但也不是最快的方法。
TensorFlow v2 API 经历了许多变化,可以说最大/最重要的变化之一是引入了tf.data模块。
引用 TensorFlow 文档:
tf.data API 使您能够从简单的、可重用的部分构建复杂的输入管道。 例如,图像模型的流水线可以从分布式文件系统中的文件聚集数据,对每个图像应用随机扰动,并将随机选择的图像合并成一批用于训练。文本模型的管道可能涉及从原始文本数据中提取符号,用查找表将它们转换为嵌入的标识符,以及将不同长度的序列批处理在一起。tf.data API 使得处理大量数据、读取不同的数据格式以及执行复杂的转换成为可能。
使用tf.data处理数据现在明显更容易——正如我们将看到的,它也比依赖旧的ImageDataGenerator类更快更有效。
TF . data 构建数据管道效率更高吗?
简短的回答是 是的, 使用tf.data比使用ImageDataGenerator明显更快更高效——正如本教程的结果将向您展示的那样,当处理内存中的数据集时,我们能够获得大约 6.1 倍的加速,当处理驻留在磁盘上的图像数据时,我们能够获得大约 38 倍的效率提升。****
*tf.data的“秘方”在于 TensorFlow 的多线程/多处理实现,更具体地说,是“自动调整”的概念。
训练神经网络,尤其是在大型数据集上,无非是生产者/消费者关系。
神经网络需要消耗数据,以便它可以从中学习(即,当前的一批数据)。然而,数据处理实用程序本身负责向神经网络产生该数据。
一个非常天真的单线程数据生成实现将创建一个数据批,将其发送到神经网络,等待它请求更多数据,然后(只有到那时),创建一个新的数据批。这种实现的问题是数据处理器和神经网络都处于空闲状态,直到另一个完成其各自的工作。
相反,我们可以利用并行处理,这样任何组件都不会处于等待状态——数据处理器可以在内存中维护一个由 N 个批次组成的队列,同时网络在队列中训练下一个批次。
TensorFlow 的tf.data模块可以根据你的硬件/实验设计自动调整整个过程,从而使训练明显更快。
总的来说,我建议尽可能用tf.data代替ImageDataGenerator通话。
配置您的开发环境
对 tf.data 的介绍使用了 Keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都有助于在一个方便的 Python 虚拟环境中为您的系统配置这篇博客文章所需的所有软件。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
ka ggle 水果和蔬菜数据集
在本教程中,我们将实现两个 Python 脚本:一个在适合内存的数据集中使用tf.data(例如,CIFAR-100 ),另一个脚本在图像数据集太大而不适合 RAM 的情况下使用tf.data(因此我们需要从磁盘中批处理数据)。
对于后一种实现,我们将利用 Kaggle 水果和蔬菜数据集。
该数据集由 6,688 幅图像组成,属于七个大致平衡的类别:
- 苹果(955 张图片)
- 西兰花(946 张图片)
- 葡萄(965 张图片)
- 柠檬(944 张图片)
- 芒果(934 张图片)
- 橙色(970 张图片)
- 草莓(976 张图片)
目标是训练一个模型,以便我们可以正确地对输入图像中的水果/蔬菜进行分类。
为了方便起见,我在本教程的 【下载】 部分包含了 Kaggle 水果/蔬菜数据集。
项目结构
在我们继续之前,让我们首先回顾一下我们的项目目录结构。首先访问本指南的 “下载” 部分,检索源代码和 Python 脚本。
然后,您将看到以下目录结构:
$ tree . --Ddirsfirst --filelimit 10
.
├── fruits
│ ├── apple [955 entries exceeds filelimit, not opening dir]
│ ├── broccoli [946 entries exceeds filelimit, not opening dir]
│ ├── grape [965 entries exceeds filelimit, not opening dir]
│ ├── lemon [944 entries exceeds filelimit, not opening dir]
│ ├── mango [934 entries exceeds filelimit, not opening dir]
│ ├── orange [970 entries exceeds filelimit, not opening dir]
│ └── strawberry [976 entries exceeds filelimit, not opening dir]
├── pyimagesearch
│ ├── __init__.py
│ └── helpers.py
├── reading_from_disk.py
└── reading_from_memory.py
9 directories, 4 files
fruits目录包含我们的图像数据集。
在pyimagesearch模块中,我们有一个单独的文件helpers.py,它包含一个单独的函数benchmark——这个函数将用于基准测试我们的tf.data和ImageDataGenerator对象。
最后,我们有两个 Python 脚本:
reading_from_memory.py:对可以容纳内存的数据集进行数据处理速度基准测试reading_from_disk.py:针对太大而无法放入 RAM 的图像数据集,对我们的数据管道进行基准测试
现在让我们开始实现吧。
创建我们的基准计时函数
在我们对tf.data和ImageDataGenerator进行基准测试之前,我们首先需要创建一个函数,它将:
- 启动计时器
- 要求
tf.data或ImageDataGenerator生成总共 N 批数据 - 停止计时器
- 衡量这个过程需要多长时间
打开pyimagesearch模块中的helpers.py文件,现在我们将实现我们的benchmark功能:
# import the necessary packages
import time
def benchmark(datasetGen, numSteps):
# start our timer
start = time.time()
# loop over the provided number of steps
for i in range(0, numSteps):
# get the next batch of data (we don't do anything with the
# data since we are just benchmarking)
(images, labels) = next(datasetGen)
# stop the timer
end = time.time()
# return the difference between end and start times
return (end - start)
第 2 行导入了我们唯一需要的 Python 包time,它将允许我们在生成数据批次之前和之后抓取时间戳。
我们的benchmark功能定义在行 4 上。此方法需要两个参数:
datasetGen:我们的数据集生成器,我们假设它是tf.data.Dataset或ImageDataGenerator的一个实例numSteps:要生成的数据批次总数
线 6 抢start时间。
然后我们继续在线 9 上循环所提供的批次数量。对next函数的调用(第 12 行)告诉datasetGen迭代器产生下一批数据。
我们在第 15 行停止计时器,然后返回数据生成过程花费的时间。
使用 tf.data 在内存中构建数据集
随着我们的benchmark函数的实现,现在让我们创建一个脚本来比较tf.data和ImageDataGenerator的内存中的数据集(即,没有磁盘访问)。
根据定义,内存中的数据集可以放入系统的 RAM 中,这意味着不需要对磁盘进行昂贵的 I/O 操作。在这篇文章的后面,我们也将看看磁盘上的数据集,但是让我们先从更简单的方法开始。
打开项目目录中的reading_from_memory.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.helpers import benchmark
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.datasets import cifar100
from tensorflow.data import AUTOTUNE
import tensorflow as tf
第 2-6 行导入我们需要的 Python 包,包括:
benchmark:我们在上一节中刚刚实现的基准测试功能ImageDataGenerator: Keras 的数据生成迭代器cifar100:CIFAR-100 数据集(即我们将用于基准测试的数据集)AUTOTUNE:从基准测试的角度来看,这无疑是最重要的导入——使用 TensorFlow 的自动调优功能,我们可以在使用tf.data时获得大约 6.1 倍的加速tensorflow:我们的 TensorFlow 库
现在让我们来关注一些重要的初始化:
# initialize the batch size and number of steps
BS = 64
NUM_STEPS = 5000
# load the CIFAR-10 dataset from
print("[INFO] loading the cifar100 dataset...")
((trainX, trainY), (testX, testY)) = cifar100.load_data()
当对tf.data和ImageDataGenerator进行基准测试时,我们将使用64的批量。我们将要求每个方法生成5000批数据。然后我们将评估这两种方法,看看哪一种更快。
第 14 行从磁盘加载 CIFAR-100 数据集。我们将从这个数据集生成批量数据。
接下来,让我们实例化我们的ImageDataGenerator:
# create a standard image generator object
print("[INFO] creating a ImageDataGenerator object...")
imageGen = ImageDataGenerator()
dataGen = imageGen.flow(
x=trainX, y=trainY,
batch_size=BS, shuffle=True)
第 18 行初始化一个“空”ImageDataGenerator(即不应用数据增加,只产生数据)。
然后我们通过调用flow方法在的第 19-21 行创建数据迭代器。我们将训练数据作为我们各自的x和y参数,连同我们的batch_size一起传入。shuffle参数设置为True,表示数据将被混洗。
现在,我们期待已久的时刻到来了——使用tf.data创建数据管道:
# build a TensorFlow dataset from the training data
dataset = tf.data.Dataset.from_tensor_slices((trainX, trainY))
# build the data input pipeline
print("[INFO] creating a tf.data input pipeline..")
dataset = (dataset
.shuffle(1024)
.cache()
.repeat()
.batch(BS)
.prefetch(AUTOTUNE)
)
第 24 行创建了我们的dataset,它是从from_tensor_slices函数返回的。该函数创建 TensorFlow 的Dataset对象的实例,其数据集的元素是单个数据点(即,在本例中,图像和类标签)。
第 28-34 行通过链接大量 TensorFlow 方法来创建数据集管道本身。让我们逐一分析:
shuffle:用1024个数据点随机填充一个数据缓冲区,并随机打乱缓冲区中的数据。当数据被拉出缓冲区时(比如抓取下一批数据时),TensorFlow 会自动重新填充缓冲区。cache:高效地缓存数据集,以便更快地进行后续读取。repeat:告诉tf.data继续循环我们的数据集(否则,一旦我们用完数据/一个时期结束,TensorFlow 就会出错)。batch:返回一批BS数据点(在本例中,该批中共有 64 个图像和类别标签。prefetch: 从效率角度来看流水线中最重要的功能 —告诉tf.data在处理当前数据的同时,在后台准备更多的数据
调用prefetch可以确保神经网络需要的下一批数据始终可用,并且网络不必等待数据生成过程返回数据,从而提高吞吐量和延迟。
当然,调用prefetch会导致额外的 RAM 被消耗(来保存额外的数据点),但是额外的内存消耗是值得的,因为我们将有一个显著更高的吞吐率。
AUTOTUNE参数告诉 TensorFlow 构建我们的管道,然后进行优化,以便我们的 CPU 可以为管道中的每个参数预算时间。
完成初始化后,我们可以对我们的ImageDataGenerator进行基准测试:
# benchmark the image data generator and display the number of data
# points generated, along with the time taken to perform the
# operation
totalTime = benchmark(dataGen, NUM_STEPS)
print("[INFO] ImageDataGenerator generated {} images in " \
" {:.2f} seconds...".format(
BS * NUM_STEPS, totalTime))
第 39 行告诉ImageDataGenerator对象总共生成NUM_STEPS批数据。然后,我们在的第 40-42 行显示经过的时间。
类似地,我们对我们的tf.data对象做同样的事情:
# create a dataset iterator, benchmark the tf.data pipeline, and
# display the number of data points generator along with the time taken
datasetGen = iter(dataset)
totalTime = benchmark(datasetGen, NUM_STEPS)
print("[INFO] tf.data generated {} images in {:.2f} seconds...".format(
BS * NUM_STEPS, totalTime))
我们现在准备比较我们的tf.data管道和我们的ImageDataGenerator管道的性能。
比较内存数据集的 ImageDataGenerator 和 TF . data
我们现在准备比较 Keras 的ImageDataGenerator类和 TensorFlow v2 的tf.data模块。
请务必访问本指南的 “下载” 部分以检索源代码。
从那里,打开一个终端并执行以下命令:
$ python reading_from_memory.py
[INFO] loading the cifar100 dataset...
[INFO] creating a ImageDataGenerator object...
[INFO] creating a tf.data input pipeline..
[INFO] ImageDataGenerator generated 320000 images in 5.65 seconds...
[INFO] tf.data generated 320000 images in 0.92 seconds...
在这里,我们从磁盘加载 CIFAR-100 数据集。然后我们构造一个ImageDataGenerator对象和一个tf.data管道。
我们要求这两个类总共生成 5,000 个批处理。每批 64 幅图像导致生成总共 320,000 幅图像。
首先评估ImageDatanGenerator,在 5.65 秒内完成任务。然后tf.data模块运行,在 0.92 秒内完成同样的任务,T3 加速≈6.1x!
正如我们将看到的,当我们开始处理驻留在磁盘上的图像数据时,性能的提高甚至更加明显。
使用驻留在磁盘上的 tf.data 和数据集
在上一节中,我们学习了如何为驻留在内存中的数据集构建 TensorFlow 数据管道,但是驻留在磁盘上的数据集呢?
使用tf.data管道是否也能提高磁盘数据集的性能?
剧透警告:
答案是“是的,绝对是” —正如我们将看到的,性能改进甚至更加显著。
打开项目目录中的reading_from_disk.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.helpers import benchmark
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.data import AUTOTUNE
from imutils import paths
import tensorflow as tf
import numpy as np
import argparse
import os
第 2-9 行导入我们需要的 Python 包。这些导入或多或少与我们之前的例子相同,唯一显著的不同是来自imutils的paths子模块——使用paths将允许我们获取驻留在磁盘上的图像数据集的文件路径。
对驻留在磁盘上的图像使用tf.data管道要求我们定义一个函数,该函数可以:
- 接受输入图像路径
- 从磁盘加载图像
- 返回图像数据和类别标签(或者边界框坐标,例如,如果您正在进行对象检测)
此外,从磁盘加载图像和解析类标签 时,我们应该使用 TensorFlow 自带的函数 ,而不是使用 OpenCV、NumPy 或 Python 的内置函数 。
使用 TensorFlow 的方法将允许tf.data进一步优化自己的管道,从而使其运行得更快。
现在让我们定义我们的load_images函数:
def load_images(imagePath):
# read the image from disk, decode it, resize it, and scale the
# pixels intensities to the range [0, 1]
image = tf.io.read_file(imagePath)
image = tf.image.decode_png(image, channels=3)
image = tf.image.resize(image, (96, 96)) / 255.0
# grab the label and encode it
label = tf.strings.split(imagePath, os.path.sep)[-2]
oneHot = label == classNames
encodedLabel = tf.argmax(oneHot)
# return the image and the integer encoded label
return (image, encodedLabel)
load_images方法接受一个参数imagePath,它是我们想要从磁盘加载的图像的路径。
然后,我们继续:
- 从磁盘加载图像(第 14 行)
- 将图像解码为具有 3 个通道的无损 PNG(第 15 行)
- 将图像大小调整为 96 × 96 像素,将像素亮度从【0,255】缩放到【0,1】
此时,我们可以将image返回到tf.data管道;然而,我们仍然需要从imagePath中解析我们的类标签:
- 第 19 行根据我们操作系统的文件路径分隔符分割
imagePath字符串,并获取倒数第二个条目,在本例中,这是标签的子目录名称(参见本教程的“项目结构”部分,了解这是如何实现的) - 第 20 行使用我们的
classNames(我们将在后面的脚本中定义)对label进行单热编码 - 然后,我们在第 21 行的处获取标签“热”的整数索引
得到的 2 元组image和encodedLabel被返回到第 23 行上的调用函数。
现在已经定义了我们的load_images函数,让我们继续这个脚本的其余部分:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
第 27-30 行解析我们的命令行参数。这里我们只需要一个参数,--dataset,它是驻留在磁盘上的水果和蔬菜数据集的路径。
这里,我们关注一些重要的初始化:
# initialize batch size and number of steps
BS = 64
NUM_STEPS = 1000
# grab the list of images in our dataset directory and grab all
# unique class names
print("[INFO] loading image paths...")
imagePaths = list(paths.list_images(args["dataset"]))
classNames = np.array(sorted(os.listdir(args["dataset"])))
第 33 行和第 34 行定义了我们的批量大小(64)以及我们将在评估过程(1000)中生成的数据的批量。
第 39 行从我们的输入--dataset目录中抓取所有图像文件路径,而第 40 行从文件路径中提取类标签名。
现在,让我们创建我们的tf.data管道:
# build the dataset and data input pipeline
print("[INFO] creating a tf.data input pipeline..")
dataset = tf.data.Dataset.from_tensor_slices(imagePaths)
dataset = (dataset
.shuffle(1024)
.map(load_images, num_parallel_calls=AUTOTUNE)
.cache()
.repeat()
.batch(BS)
.prefetch(AUTOTUNE)
)
我们再次调用了from_tensor_slices函数,但是这次传入了我们的imagePaths。这样做将创建一个tf.data.Dataset实例,其中数据集的元素是单独的文件路径。
然后我们定义管道本身(第 45-52 行)
shuffle:从数据集中构建一个1024元素的缓冲区,并对其进行混洗。map:将load_images函数映射到批处理中的所有图像路径。这一行代码负责从磁盘实际加载我们的输入图像,并解析类标签。AUTOTUNE参数告诉 TensorFlow 自动优化这个函数调用,使其尽可能高效。cache:缓存结果,从而使后续的数据读取/访问更快。repeat:一旦到达数据集/时段的末尾,重复该过程。batch:返回一批数据。prefetch:在后台构建批量数据,从而提高吞吐率。
我们使用 Keras 的ImageDataGenerator对象创建一个类似的数据管道:
# create a standard image generator object
print("[INFO] creating a ImageDataGenerator object...")
imageGen = ImageDataGenerator(rescale=1.0/255)
dataGen = imageGen.flow_from_directory(
args["dataset"],
target_size=(96, 96),
batch_size=BS,
class_mode="categorical",
color_mode="rgb")
第 56 行创建ImageDataGenerator,告诉它从范围【0,255】到【0,1】重新调整所有输入图像的像素强度。
flow_from_directory函数告诉dataGen我们将从我们的输入--dataset目录中读取图像。从那里,每个图像被调整到 96×96 像素,并且返回BS大小的批次。
我们对下面的ImageDataGenerator进行了基准测试:
# benchmark the image data generator and display the number of data
# points generated, along with the time taken to perform the
# operation
totalTime = benchmark(dataGen, NUM_STEPS)
print("[INFO] ImageDataGenerator generated {} images in " \
" {:.2f} seconds...".format(
BS * NUM_STEPS, totalTime))
在这里,我们对我们的tf.data渠道进行了基准测试:
# create a dataset iterator, benchmark the tf.data pipeline, and
# display the number of data points generated, along with the time
# taken
datasetGen = iter(dataset)
totalTime = benchmark(datasetGen, NUM_STEPS)
print("[INFO] tf.data generated {} images in {:.2f} seconds...".format(
BS * NUM_STEPS, totalTime))
但是哪种方法更快呢?
我们将在下一节回答这个问题。
比较磁盘数据集的 ImageDataGenerator 和 TF . data
让我们比较一下使用磁盘数据集时的ImageDataGenerator和tf.data。
首先访问本教程的 “下载” 部分,检索源代码和示例数据。
从那里,您可以执行reading_from_disk.py脚本:
$ python reading_from_disk.py --dataset fruits
[INFO] loading image paths...
[INFO] creating a tf.data input pipeline..
[INFO] creating a ImageDataGenerator object...
Found 6688 images belonging to 7 classes.
[INFO] ImageDataGenerator generated 64000 images in 258.17 seconds...
[INFO] tf.data generated 64000 images in 6.81 seconds...
我们的ImageDataGenerator通过生成总共 1,000 个批次进行基准测试,每个批次中有 64 个图像,总共有 64,000 个图像。对于ImageDataGenerator来说,这个过程需要 258 秒多一点。
tf.data模块执行同样的任务 6.81 秒——大幅度提升≈38x!
只要有可能,我推荐使用tf.data而不是ImageDataGenerator。性能的提高简直是惊人的。
总结
在本教程中,我们介绍了tf.data,一个用于高效数据加载和预处理的 TensorFlow 模块。
然后,我们将tf.data的性能与 Keras 中的原始ImageDataGenerator类进行了基准测试:
- 当处理内存数据集时,我们使用
tf.data获得了 6.1 倍的吞吐率 - 当在磁盘上处理图像数据时,我们在使用
tf.data时达到了惊人的≈38 倍的吞吐率
数字说明了一切——如果您需要更快的数据加载和预处理,利用tf.data是值得的。
下周我将带着一些使用tf.data训练神经网络的更高级的例子回来。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
用 Python 和 Keras 实现的简单神经网络
原文:https://pyimagesearch.com/2016/09/26/a-simple-neural-network-with-python-and-keras/

如果你一直在关注这一系列的博客文章,那么你已经知道我是 Keras 的超级粉丝。
Keras 是一个超级强大、易于使用的 Python 库,用于构建神经网络和深度学习网络。
在这篇博文的剩余部分,我将演示如何使用 Python 和 Keras 构建一个简单的神经网络,然后将其应用于图像分类任务。
用 Python 和 Keras 实现的简单神经网络
为了开始这篇文章,我们将快速回顾一下最常见的神经网络架构——前馈网络。
然后,我们将讨论我们的项目结构,然后编写一些 Python 代码来定义我们的前馈神经网络,并将其具体应用于 Kaggle Dogs vs. Cats 分类挑战。这个挑战的目标是正确分类给定的图像是包含一只狗还是一只猫。
我们将回顾我们简单的神经网络结构的结果,并讨论改进它的方法。
我们的最后一步将是构建一个测试脚本,它将加载图像并用 OpenCV、Keras 和我们训练好的模型对它们进行分类。
前馈神经网络
虽然有许多许多不同的神经网络架构,但最常见的架构是 前馈网络:

Figure 1: An example of a feedforward neural network with 3 input nodes, a hidden layer with 2 nodes, a second hidden layer with 3 nodes, and a final output layer with 2 nodes.
在这种类型的架构中,两个节点之间的连接仅允许从层 i 中的节点到层 i + 1 中的节点(因此术语前馈;不允许向后或层间连接)。
此外,层 i 中的节点完全连接到层 i + 1 中的节点。这意味着层 i 中的每个节点都连接到层 i + 1 中的每个节点。例如,在上图中,第 0 层和第 1 层之间总共有 2 x 3 = 6 个连接,这就是术语“完全连接”或简称“FC”的来源。
我们通常使用一个整数序列来快速简洁地描述每一层中节点的数量。
例如,上面的网络是 3-2-3-2 前馈神经网络:
- 层 0 包含 3 个输入,我们的
 值。这些可以是原始像素亮度或来自特征向量的条目。
值。这些可以是原始像素亮度或来自特征向量的条目。 - 层 1 和 2 为 隐藏层 ,分别包含 2 和 3 个节点。
- 层 3 是 输出层 或 可见层——这是我们从我们的网络中获得整体输出分类的地方。输出层通常具有与类标签一样多的节点;每个潜在输出一个节点。在我们的 Kaggle Dogs vs. Cats 示例中,我们有两个输出节点——一个用于“dog ”,另一个用于“cat”。
 值。这些可以是原始像素亮度或来自特征向量的条目。
值。这些可以是原始像素亮度或来自特征向量的条目。项目目录结构
Figure 2: The Kaggle Dogs vs. Cats dataset is used in our simple neural network with Keras.
在我们开始之前,前往这篇博文的 【下载】 部分,下载文件和数据。从这里开始,你将能够跟随我们学习今天的例子。
一旦你的压缩文件被下载,解压文件。
在目录中,让我们运行带有两个命令行参数的tree命令来列出我们的项目结构:
$ tree --filelimit 10 --dirsfirst
.
├── kaggle_dogs_vs_cats
│ └── train [25000 entries exceeds filelimit, not opening dir]
├── test_images [50 entries exceeds filelimit, not opening dir]
├── output
│ └── simple_neural_network.hdf5
├── simple_neural_network.py
└── test_network.py
4 directories, 4 files
第一个命令行参数很重要,因为它可以防止tree显示所有的图像文件,使我们的终端变得混乱。
Kaggle Dogs vs. Cats 数据集在相关目录(kaggle_dogs_vs_cats)中。所有 25,000 张图像都包含在train子目录中。这些数据来自 Kaggle 上的train.zip 数据集。
我还在他们的网站上放了 50 个 Kaggle test1.zip的样品。
output目录包含我们的序列化模型,我们将在第一个脚本的底部用 Keras 生成该模型。
在接下来的章节中,我们将回顾两个 Python 脚本,simple_neural_network.py和test_network.py。
用 Python 和 Keras 实现我们自己的神经网络
既然我们已经了解了前馈神经网络的基础,让我们使用 Python 和 Keras 实现一个用于图像分类的前馈神经网络。
首先,您需要遵循适用于您的系统的教程来安装 TensorFlow 和 Keras:
注意:一个 GPU 是而不是今天的博文所需要的*——你的笔记本电脑可以轻松运行这个非常基本的网络。也就是说,一般来说,我不建议使用笔记本电脑进行深度学习。笔记本电脑是为了提高工作效率,而不是处理许多深度学习活动所需的 TB 级数据集。我推荐亚马逊 AWS 用我预配置的 AMI 或者微软的 DSVM 。这两个环境都在不到 5 分钟的时间内准备就绪。*
从那里,打开一个新文件,命名为simple_neural_network.py,我们将得到编码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Activation
from keras.optimizers import SGD
from keras.layers import Dense
from keras.utils import np_utils
from imutils import paths
import numpy as np
import argparse
import cv2
import os
我们从导入所需的 Python 包开始。我们将使用大量 scikit-learn 实现以及 Keras 层和激活函数。如果您还没有为 Keras 配置开发环境,请参见这篇博文。
我们还将使用 imutils ,这是我个人的 OpenCV 便利函数库。如果您的系统上尚未安装imutils,您可以通过pip进行安装:
$ pip install imutils
接下来,让我们定义一个方法来接受和成像并描述它。在之前的教程中,我们已经从图像中提取了颜色直方图,并使用这些分布来表征图像的内容。
这一次,让我们使用原始像素强度。为了实现这一点,我们定义了image_to_feature_vector函数,该函数接受一个输入image,并将其大小调整为一个固定的size,忽略纵横比:
def image_to_feature_vector(image, size=(32, 32)):
# resize the image to a fixed size, then flatten the image into
# a list of raw pixel intensities
return cv2.resize(image, size).flatten()
我们将image的大小调整为固定的空间维度,以确保输入数据集中的每个图像都具有相同的“特征向量”大小。这是利用我们的神经网络时的一个要求——每个图像必须用一个向量来表示。
在这种情况下,我们将图像的大小调整为 32 x 32 像素,然后将 32 x 32 x 3 像素的 T2 图像(其中我们有三个通道,分别用于红色、绿色和蓝色通道)展平成一个 3072-d 特征向量。
下一个代码块处理对命令行参数的解析,并负责一些初始化工作:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to output model file")
args = vars(ap.parse_args())
# grab the list of images that we'll be describing
print("[INFO] describing images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the data matrix and labels list
data = []
labels = []
这里我们只需要一个开关--dataset,它是包含 Kaggle Dogs vs. Cats 图片的输入目录的路径。这个数据集可以从官方的卡格狗对猫比赛页面下载。
第 30 行获取驻留在磁盘上的图像的路径。然后,我们分别在第 33 行和第 34 行初始化data和labels列表。
现在我们有了imagePaths,我们可以逐个循环它们,从磁盘加载它们,将图像转换成特征向量,并更新data和labels列表:
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# load the image and extract the class label (assuming that our
# path as the format: /path/to/dataset/{class}.{image_num}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-1].split(".")[0]
# construct a feature vector raw pixel intensities, then update
# the data matrix and labels list
features = image_to_feature_vector(image)
data.append(features)
labels.append(label)
# show an update every 1,000 images
if i > 0 and i % 1000 == 0:
print("[INFO] processed {}/{}".format(i, len(imagePaths)))
data列表现在包含我们数据集中每个图像的展平的 32 x 32 x 3 = 3,072-d 表示。然而,在我们可以训练我们的神经网络之前,我们首先需要执行一些预处理:
# encode the labels, converting them from strings to integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# scale the input image pixels to the range [0, 1], then transform
# the labels into vectors in the range [0, num_classes] -- this
# generates a vector for each label where the index of the label
# is set to `1` and all other entries to `0`
data = np.array(data) / 255.0
labels = np_utils.to_categorical(labels, 2)
# partition the data into training and testing splits, using 75%
# of the data for training and the remaining 25% for testing
print("[INFO] constructing training/testing split...")
(trainData, testData, trainLabels, testLabels) = train_test_split(
data, labels, test_size=0.25, random_state=42)
第 61 行和第 62 行处理将输入数据缩放到范围【0,1】,随后将labels从一组整数转换为一组向量(这是我们在训练神经网络时将应用的交叉熵损失函数的要求)。
然后,我们在第 67 行和第 68 行构建我们的训练和测试分割,使用 75%的数据进行训练,剩余的 25%用于测试。
关于数据预处理阶段更详细的回顾,请看这篇博文。
我们现在准备使用 Keras 定义我们的神经网络:
# define the architecture of the network
model = Sequential()
model.add(Dense(768, input_dim=3072, init="uniform",
activation="relu"))
model.add(Dense(384, activation="relu", kernel_initializer="uniform"))
model.add(Dense(2))
model.add(Activation("softmax"))
在第 71-76 行上,我们构建了我们的神经网络架构——3072-768-384-2 前馈神经网络。
我们的输入层有 3072 个节点,每个节点对应展平输入图像中的 32 x 32 x 3 = 3,072 个原始像素强度。
然后我们有两个隐藏层,分别有 768 和 384 个节点。这些节点数是通过交叉验证和离线执行的超参数调整实验确定的。
输出层有两个节点,分别对应“狗”和“猫”标签。
然后我们在网络上应用一个softmax激活函数——这将给出我们实际的输出类标签概率。
下一步是使用随机梯度下降 (SGD)来训练我们的模型:
# train the model using SGD
print("[INFO] compiling model...")
sgd = SGD(lr=0.01)
model.compile(loss="binary_crossentropy", optimizer=sgd,
metrics=["accuracy"])
model.fit(trainData, trainLabels, epochs=50, batch_size=128,
verbose=1)
为了训练我们的模型,我们将 SGD 的学习率参数设置为 0.01 。我们也将对网络使用binary_crossentropy损失函数。
在大多数情况下,你会希望只使用crossentropy,但是因为只有两个类标签,我们使用binary_crossentropy。对于 > 2 类标签,确保使用crossentropy。
然后,允许网络训练总共 50 个时期,这意味着模型“看到”每个单独的训练示例 50 次,以试图学习潜在的模式。
最后的代码块根据测试数据评估我们的 Keras 神经网络:
# show the accuracy on the testing set
print("[INFO] evaluating on testing set...")
(loss, accuracy) = model.evaluate(testData, testLabels,
batch_size=128, verbose=1)
print("[INFO] loss={:.4f}, accuracy: {:.4f}%".format(loss,
accuracy * 100))
# dump the network architecture and weights to file
print("[INFO] dumping architecture and weights to file...")
model.save(args["model"])
基于 Python 和 Keras 的神经网络图像分类
要执行我们的simple_neural_network.py脚本,请确保您已经使用本教程底部的 “下载” 部分下载了这篇文章的源代码和数据。
以下命令可用于使用 Python 和 Keras 训练我们的神经网络:
$ python simple_neural_network.py --dataset kaggle_dogs_vs_cats \
--model output/simple_neural_network.hdf5
我们脚本的输出可以在下面的截图中看到:

Figure 3: Training a simple neural network using the Keras deep learning library and the Python programming language.
在我的 Titan X GPU 上,特征提取、训练神经网络和评估的整个过程总共花费了 1m 15s 的时间,每个历元不到 0 秒就完成了。
在第 50 个纪元结束时,我们看到我们在训练数据上获得了 ~76%的准确度,在测试数据上获得了 67%的准确度。
这大约 9%的精度差异意味着我们的网络有点过度拟合;然而,在训练和测试的准确性之间有 10%的差距是很常见的,尤其是当你的训练数据有限的时候。
当你的训练准确率达到 90%以上,而你的测试准确率远低于这个数字时,你应该开始担心过度拟合。
无论是哪种情况,这个 67.376% 都是我们目前为止在这一系列教程中获得的最高精度。正如我们稍后将会发现的,通过利用卷积神经网络,我们可以很容易地获得 95%的准确性。
**### 使用我们的 Keras 模型对图像进行分类
我们将构建一个测试脚本来直观地验证我们的结果。
因此,让我们在您最喜欢的编辑器中创建一个名为test_network.py的新文件,并输入以下代码:
# import the necessary packages
from __future__ import print_function
from keras.models import load_model
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
def image_to_feature_vector(image, size=(32, 32)):
# resize the image to a fixed size, then flatten the image into
# a list of raw pixel intensities
return cv2.resize(image, size).flatten()
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to output model file")
ap.add_argument("-t", "--test-images", required=True,
help="path to the directory of testing images")
ap.add_argument("-b", "--batch-size", type=int, default=32,
help="size of mini-batches passed to network")
args = vars(ap.parse_args())
在2-8 线,我们装载必要的包裹。除了来自keras.models的load_model之外,我们在上面使用它们时应该很熟悉。load_model模块只是从磁盘加载序列化的 Keras 模型,这样我们就可以通过网络发送图像并获得预测。
image_to_feature_vector函数是相同的,我们将它包含在测试脚本中,因为我们希望以与训练相同的方式预处理我们的图像。
我们的脚本有三个命令行参数,可以在运行时提供(第 16-23 行):
--model:我们序列化模型文件的路径。--test-images:测试图像目录的路径。--batch-size:可选地,可以指定小批量的大小,默认值为32。
你不需要修改的第 16-23 行——如果你不熟悉argparse和命令行参数,只需给读一下这篇博文。
接下来,让我们定义我们的类并从磁盘加载我们的序列化模型:
# initialize the class labels for the Kaggle dogs vs cats dataset
CLASSES = ["cat", "dog"]
# load the network
print("[INFO] loading network architecture and weights...")
model = load_model(args["model"])
print("[INFO] testing on images in {}".format(args["test_images"]))
第 26 行创建了一个我们今天要学习的类的列表——一只猫和一只狗。
从那里,我们将模型加载到内存中,以便我们可以根据需要轻松地对图像进行分类。
让我们开始循环测试图像,并预测每个图像是猫科动物还是犬科动物:
# loop over our testing images
for imagePath in paths.list_images(args["test_images"]):
# load the image, resize it to a fixed 32 x 32 pixels (ignoring
# aspect ratio), and then extract features from it
print("[INFO] classifying {}".format(
imagePath[imagePath.rfind("/") + 1:]))
image = cv2.imread(imagePath)
features = image_to_feature_vector(image) / 255.0
features = np.array([features])
我们开始循环测试目录中第 34 行的所有图像。
首先,我们加载图像并对其进行预处理(第 39-41 行)。
从那里,让我们通过神经网络发送图像:
# classify the image using our extracted features and pre-trained
# neural network
probs = model.predict(features)[0]
prediction = probs.argmax(axis=0)
# draw the class and probability on the test image and display it
# to our screen
label = "{}: {:.2f}%".format(CLASSES[prediction],
probs[prediction] * 100)
cv2.putText(image, label, (10, 35), cv2.FONT_HERSHEY_SIMPLEX,
1.0, (0, 255, 0), 3)
cv2.imshow("Image", image)
cv2.waitKey(0)
在行 45 和 46 上进行预测。
剩余的行构建一个包含类名和概率分数的显示标签,并将其覆盖在图像上(行 50-54 )。在循环的每一次迭代中,我们等待一个按键,这样我们就可以一次检查一个图像(第 55 行)。
用 Keras 测试我们的神经网络
现在我们已经完成了测试脚本的实现,让我们运行它,看看我们的努力工作是如何进行的。要获取代码和图像,请务必向下滚动到这篇博文的 “下载” 部分。
当您提取文件后,要运行我们的test_network.py,我们只需在终端中执行它,并提供两个命令行参数:
$ python test_network.py --model output/simple_neural_network.hdf5 \
--test-images test_images
Using TensorFlow backend.
[INFO] loading network architecture and weights...
[INFO] testing on images in test_images
[INFO] classifying 48.jpg
[INFO] classifying 49.jpg
[INFO] classifying 8.jpg
[INFO] classifying 9.jpg
[INFO] classifying 14.jpg
[INFO] classifying 28.jpg
您是否看到了以下错误消息?
Using TensorFlow backend.
usage: test_network.py [-h] -m MODEL -t TEST_IMAGES [-b BATCH_SIZE]
test_network.py: error: the following arguments are required: -m/--model, -t/--test-images
此消息描述了如何使用带有命令行参数的脚本。
你对命令行参数和 argparse 不熟悉吗?不用担心——只需快速阅读一下这篇关于命令行参数的博客文章。
如果一切正常,在模型加载并运行第一个推理后,我们会看到一张狗的图片:
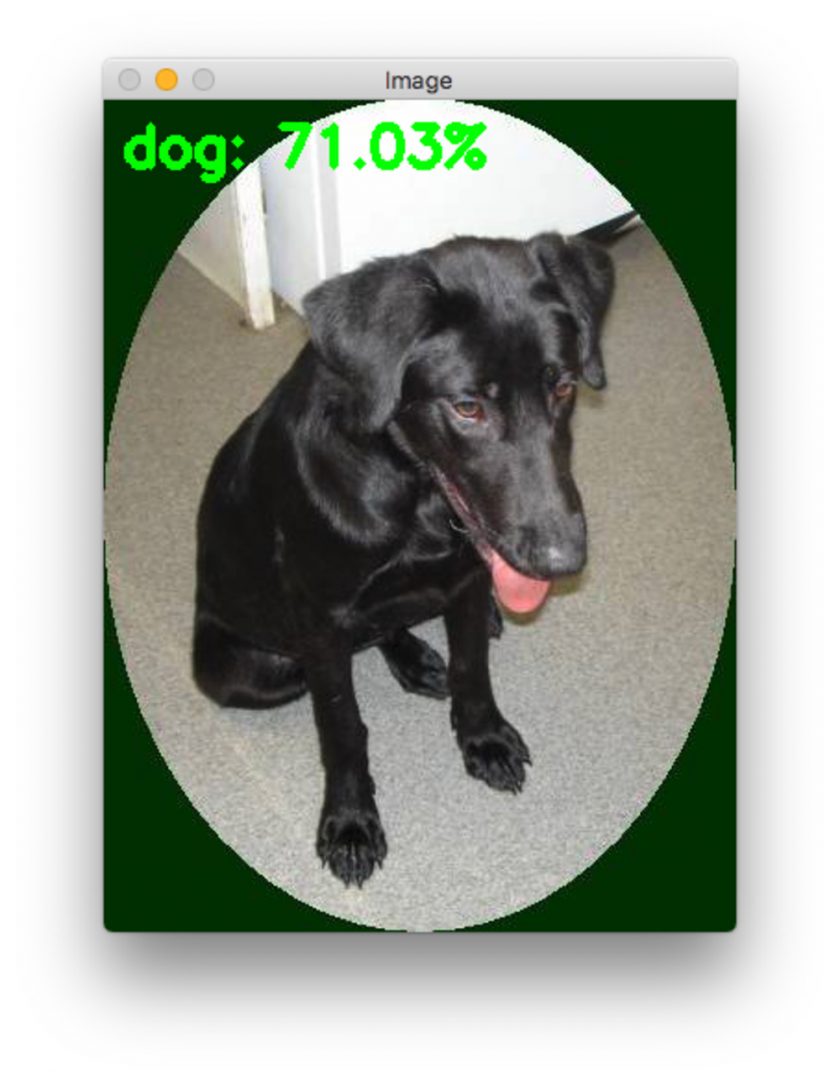
Figure 4: A dog from the Kaggle Dogs vs. Cats competition test dataset is correctly classified using our simple neural network with Keras script.
网络以 71%的预测准确率对狗进行了分类。到目前为止一切顺利!
准备好后,按一个键循环到下一个图像(窗口必须是活跃的)。

Figure 5: Even a simple neural network with Keras can achieve relatively good accuracy and distinguish between dogs and cats.
我们可爱的、令人想抱抱的白胸毛猫以 77%的准确率通过了测试!
露易丝,一只狗:

Figure 6: Lois likes the snow. He also likes when a simple deep learning neural network correctly classifies him as a dog!
露易丝绝对是一只狗——我们的模特对此有 97%的把握。
让我们试试另一只猫:

Figure 7: Deep learning classification allows us to do just that — to classify the image contents. Using the Kaggle Dogs vs. Cats dataset, we have built an elementary model to classify dog and cat images.
雅虎!这个毛球被正确地预测为一只猫。
让我们试试另一只狗:

Figure 8: This is an example of a misclassification. Our elementary neural network built with Keras has room for improvement as it is only 67% accurate. To learn how to improve the model, check out DL4CV.
多。我们网认为这只狗是猫有 61%的把握。显然这是一个错误分类。
怎么可能呢?嗯,我们的网络只有 67% 的准确性,就像我们上面演示的那样。经常会看到一些错误的分类。
我们的最后一张照片是 test_images 文件夹中最可爱的小猫之一。我给这只小猫取名为辛巴。但是根据我们的模型,辛巴是猫吗?
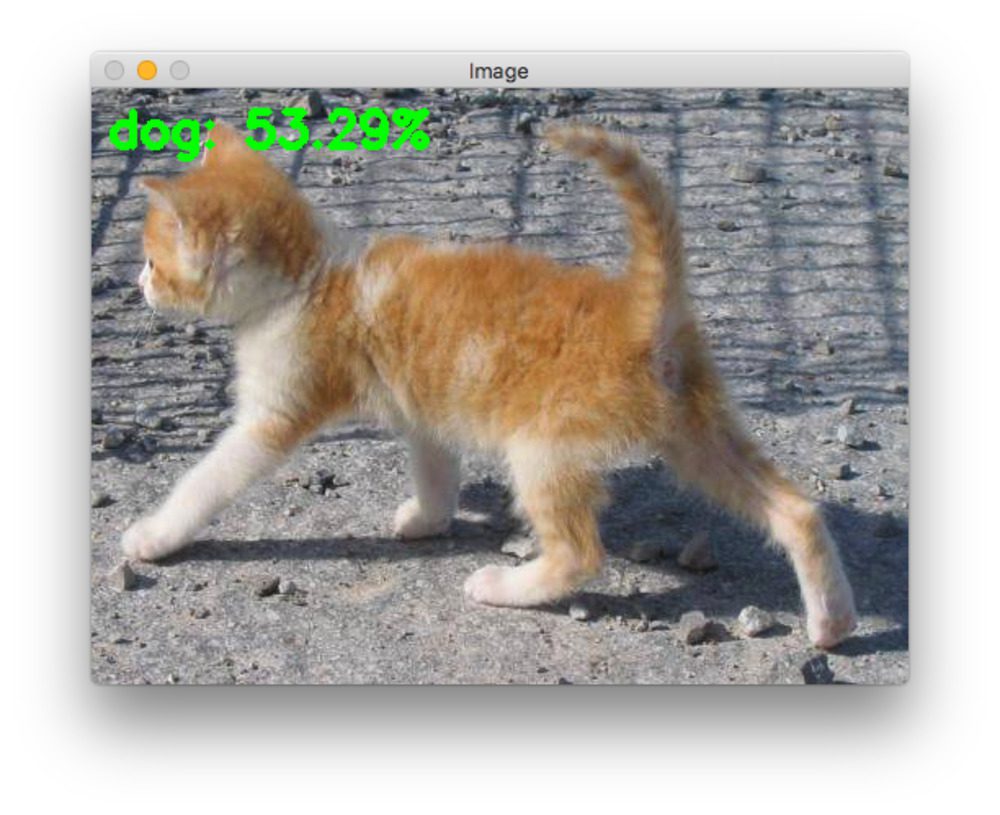
Figure 9: Our simple neural network built with Keras (TensorFlow backend), misclassifies a number of images such as of this cat (it predicted the image contains a dog). Deep learning requires experimentation and iterative development to improve accuracy.
唉,我们的网络辜负了我们,但仅仅是 3.29%。我几乎可以肯定我们的网络会把辛巴分类正确,但是我错了。
别担心——我们可以做出一些改进,在狗狗大战猫咪挑战赛的前 25 名排行榜上排名。
在我的新书《用 Python 进行计算机视觉的深度学习中,我演示了如何做到这一点。事实上,我甚至可以说,凭借你在书中学到的东西,你很可能会获得前 5 名的位置。
*要拿起你的文案,只需使用这个链接: 深度学习用 Python 进行计算机视觉 。
摘要
在今天的博文中,我演示了如何使用 Python 和 Keras 训练一个简单的神经网络。
然后,我们将我们的神经网络应用于 Kaggle Dogs vs. Cats 数据集,并仅利用图像的原始像素强度获得了 67.376%的准确度。
从下周开始,我将开始讨论优化方法,如梯度下降和随机梯度下降(SGD)。我还将包括一个关于反向传播的教程,来帮助你理解这个重要算法的内部工作原理。
在你离开之前,请务必在下面的表格中输入你的电子邮件地址,以便在未来的博客文章发表时得到通知——你不会想错过它们的!***
分段:使用 Python 的 SLIC 超像素教程
原文:https://pyimagesearch.com/2014/07/28/a-slic-superpixel-tutorial-using-python/

你有过眼皮抽搐的可怕经历吗?无论你做什么,你的眼皮都不会停止跳动?
这就是我目前的状况——已经持续了两个多星期了。你可以想象,我并不快乐。
然而,为了对抗这种持续的、经常分散注意力的麻烦,我开始更规律地睡觉,喝更少的咖啡因(开始时我每天只喝两杯咖啡),几乎不喝酒。当你像我一样喜欢泡沫啤酒时,这是一个真正的挑战。
更多的睡眠当然有所帮助。我也不怀念偶尔的啤酒。
但是男人,这些咖啡因头痛 是最糟糕的 。
幸运的是,我今天早上醒来时收到了一封邮件,这封邮件几乎治愈了我的无咖啡因烦恼和无休止的眼皮抽搐。
打开我的收件箱,我发现了一个非常好的问题,来自专门的 PyImageSearch 读者 Sriharsha Annamaneni,她写道:
嗨阿德里安,
在 Jitendra Malik 的一个 YouTube 视频中,他解释了超像素。我没有完全理解它。你能在你的网站上解释一下吗?
谢谢你,
斯里哈尔莎·安纳马涅尼
问得好 Sriharsha。我很乐意讨论超像素,我相信很多其他 PyImageSearch 的读者也会感兴趣。
但在我们深入研究一些代码之前,让我们讨论一下超像素到底是什么,以及为什么它在计算机视觉领域有着重要的应用。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
那么,什么是超像素呢?
花一点时间,理清你的思绪,想想我们是如何表现图像的。
在单通道或多通道中,图像被表示为像素网格。
我们采用这些 M x N 像素网格,然后对它们应用算法,例如人脸检测和识别、模板匹配,甚至直接应用于原始像素强度的深度学习。
问题是,我们的像素网格决不是图像的自然表示。
*例如,考虑下图:
![]()
Figure 1: If I were to take the single pixel pointed to by the red arrow (left) and show it to you on the right at an obviously zoomed-in scale, would you be able to tell me anything about the image based solely on that pixel? Anything descriptive? Or of semantic value?
如果我从左边的(用红色箭头突出显示)的图像中提取一个像素,然后在右边的展示给你看,你能合理地告诉我(1)那个像素来自迅猛龙,以及(2)那个像素实际上拥有某种语义意义吗?**
**除非你真的真的想玩“魔鬼代言人”游戏,否则答案是一个响亮的“不”——一个单独的像素本身并不是图像的自然表现。
总的来说,这种作为像素网格的像素分组只是图像的一个伪像,是捕捉和创建数字图像过程的一部分。
这让我们想到了超像素。
直觉上,探索由局部分组像素形成的图像的感知和语义意义更有意义。
当我们在我们的像素网格上执行这种类型的像素局部分组时,我们得到了 超像素 。
这些超像素比它们的简单像素网格对应物具有更多的感知和语义意义。
超级像素的优势
总结一下Xiaofeng Ren博士的工作,我们可以看到,从像素网格到超像素的映射(理想情况下)具有以下理想特性:
- 计算效率:虽然计算实际的超像素分组可能(在某种程度上)计算成本很高,但它允许我们将图像本身的复杂性从数十万像素减少到仅数百个超像素。这些超像素中的每一个都将包含某种感知的、理想的语义值。
- 感知意义:属于超像素组的像素共享某种共性,例如相似的颜色或纹理分布,而不是只检查像素网格中的单个像素,这几乎没有感知意义。
- 过度分割:大多数超像素算法过度分割图像。这意味着图像中的大多数重要边界被找到;然而,代价是产生许多无关紧要的边界。虽然这听起来像是使用超级像素的一个问题或障碍,但它实际上是一个积极因素——这种过度分割的最终产品是,从像素网格到超级像素映射中很少(或没有)像素丢失。
- 超像素上的图形:任博士把这个概念称为“表象效率”。为了更具体,想象在一个 50,000 x 50,000 像素网格上构建一个图形,其中每个像素代表图形中的一个节点——这导致了非常大的表示。然而,假设我们将超像素应用于像素网格空间,留给我们(任意)200 个超像素。在这种表示中,在 200 个超像素上构建图形要有效得多。
示例:简单线性迭代聚类(SLIC)
和往常一样,如果没有例子和一些代码,PyImageSearch 博客文章是不完整的。
准备好了吗?
打开您最喜欢的编辑器,创建slic.py,让我们开始编码:
# import the necessary packages
from skimage.segmentation import slic
from skimage.segmentation import mark_boundaries
from skimage.util import img_as_float
from skimage import io
import matplotlib.pyplot as plt
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
args = vars(ap.parse_args())
# load the image and convert it to a floating point data type
image = img_as_float(io.imread(args["image"]))
# loop over the number of segments
for numSegments in (100, 200, 300):
# apply SLIC and extract (approximately) the supplied number
# of segments
segments = slic(image, n_segments = numSegments, sigma = 5)
# show the output of SLIC
fig = plt.figure("Superpixels -- %d segments" % (numSegments))
ax = fig.add_subplot(1, 1, 1)
ax.imshow(mark_boundaries(image, segments))
plt.axis("off")
# show the plots
plt.show()
在的第 2-7 行,我们导入了将在这个例子中使用的包。为了执行 SLIC 超像素分割,我们将使用 sckit-image 实现,它是我们在行 2 导入的。为了绘制实际的超像素分割,scikit-image 为我们提供了一个mark_boundaries函数,我们在行 3 导入该函数。
从那里,我们导入一个实用函数,行 4 上的img_as_float,顾名思义,它将图像从无符号 8 位整数转换为浮点数据,所有像素值都被调用到范围【0,1】。
第 5 行导入 scikit-image 的io子包,用于加载和保存图像。
我们还将利用 matplotlib 来绘制我们的结果,并利用argparse来解析我们的命令行参数。
第 10-12 行处理解析我们的命令行参数。我们只需要一个开关--image,它是我们的映像驻留在磁盘上的路径。
然后,我们加载这个图像,并在第 15 行上将其从无符号 8 位整数转换为浮点数据类型。
有趣的事情发生了。
我们开始在第 18 行上循环我们的超像素段数量。在这种情况下,我们将分别检查三个逐渐增大的数据段:100、200 和 300。
我们在行 21 上执行 SLIC 超像素分割。slic函数只接受一个必需的参数,这是我们想要对其执行超像素分割的图像。
然而,slic函数也提供了许多可选参数,这里我只介绍一个例子。
第一个是n_segments参数,它定义了我们想要生成多少个超像素段。该值默认为 100 段。
然后我们提供sigma,它是在分割之前应用的平滑高斯核。
在该函数中可以利用其他可选参数,例如max_iter,其为 k-means 的最大迭代次数,compactness,其平衡色彩空间接近度与图像空间接近度,以及convert2lab,其确定在形成超像素之前是否应该将输入图像转换到 Lab色彩空间(在几乎所有情况下,将convert2lab设置为True是个好主意)。*
*现在我们有了我们的分段,我们使用 matplotlib 在第 24-27 行中显示它们。
为了绘制分段,我们使用了mark_boundaries函数,它简单地获取我们的原始图像并覆盖我们的超像素分段。
最后,我们的结果显示在第 30 行的上。
现在我们的代码完成了,让我们看看我们的结果是什么样的。
启动一个 shell 并执行以下命令:
$ python superpixel.py --image raptors.png
如果一切顺利,您应该会看到下图:
Figure 2: Applying SLIC superpixel segmentation to generate 100 superpixels using Python.
在这幅图像中,我们发现了(大约)100 个超像素分割。请注意图像中局部相似的区域,如迅猛龙和灌木的鳞片,是如何在相似的超像素中分组的。
现在,让我们增加到 200 个超像素段:
Figure 3: Applying SLIC superpixel segmentation to generate 200 superpixels using Python.
这里的情况相同——具有相似颜色和纹理分布的局部区域是同一个超像素组的一部分。
最后,让我们使用 300 个超级像素生成一个非常生动的图像过度分割:
Figure 4: Applying SLIC superpixel segmentation to generate 300 superpixels using Python.
请注意,随着分段数量的增加,分段也变得更像矩形和网格。这不是巧合,可以通过slic的可选compactness参数进一步控制。
摘要
在这篇博文中,我解释了什么是超像素分割,以及它如何在计算机视觉领域带来诸多好处。
例如,使用超像素而不是标准像素网格空间为我们带来了计算效率、感知意义、过度分割,以及跨图像区域的高效图形表示。
最后,我向您展示了如何利用简单的线性迭代聚类(SLIC)算法对您自己的图像应用超像素分割。
这当然不会是我们最后一次在这个博客上讨论超像素,所以期待未来更多的帖子!****
使用 Python 访问单个超像素分割
原文:https://pyimagesearch.com/2014/12/29/accessing-individual-superpixel-segmentations-python/
在我的生活中有三个巨大的影响使我想成为一名科学家。
第一位是大卫·a·约翰斯顿,美国地质勘探局的火山学家,于 1980 年 5 月 18 日,华盛顿州圣海伦斯火山灾难性爆发的那一天去世。他是第一个报道火山爆发的人,喊着“温哥华!温哥华!就是这个!”在他死于火山侧向喷发的前一刻。我被他的话所鼓舞。在那一刻,他知道自己就要死了——,但他为这项科学感到兴奋,因为他如此单调乏味地研究和预测的东西已经变成了现实。他死于研究他所热爱的东西。如果我们都这么幸运。
第二个灵感实际上是我童年爱好的融合。我喜欢用塑料和纸板做东西。我喜欢用卷起的纸和透明胶带制作建筑——起初,我以为我想成为一名建筑师。
但是几年后我发现了另一个爱好。写作。我把时间花在写虚构的短篇小说上,卖给我父母,卖 25 美分。估计也是发现创业基因挺年轻的。在之后的几年里,我确信我长大后会成为一名作家。
我最后的灵感是侏罗纪公园。是的。想笑就笑吧。但是爱伦·格兰特和伊恩·马尔科姆科学家之间的二分法在我年轻的时候给了我难以置信的启发。一方面,你有爱伦·格兰特脚踏实地、不修边幅的风度。另一方面,你有杰出的数学家(呃,不好意思,)摇滚明星。他们代表了两种科学家。我确信我会像他们一样死去。
从我的童年到现在。受戴维·约翰斯顿的启发,我的确是一名科学家。我也算是一名 T2 建筑师。我在虚拟世界中创建复杂的计算机系统,而不是用实物来构建。我也设法在作者方面工作。我已经写了两本书, 实用 Python 和 OpenCV +案例研究 (实际上是三本书,如果算上我的论文的话),许多论文和一堆技术报告。
但真正的问题是,我像哪个侏罗纪公园的科学家?脚踏实地的爱伦·格兰特?讽刺而现实的伊恩·马尔孔?或者两者都不是。我可能是丹尼斯·内德里,就等着看不见,恶心,被一头异特龙锋利的牙齿咬得浑身湿透。
无论如何,当我思考这个存在危机时,我将向你展示如何使用超像素算法访问scikit-image…中的个体分割,当然是用侏罗纪公园示例图像。
*OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
使用 Python、OpenCV 和 scikit-image 访问单个超像素分割
几个月前,我写了一篇关于分割和使用 scikit-image 库中实现的简单线性迭代聚类算法的文章。
虽然我不打算在这里重复整篇文章,但使用超像素分割算法的好处包括感知意义过分割* ,以及超像素 上的 图形。*
*要更详细地了解超像素算法及其优势,请务必阅读本文。
将 SLIC 应用于图像的典型结果如下所示:

Figure 1: Applying SLIC to find superpixel segmentations and then marking the segment boundaries.
请注意,具有相似颜色和纹理分布的局部区域是同一个超像素组的一部分。
这是一个很好的开始。
但是我们如何访问每个 个体 超像素分割呢?
很高兴你问了。
打开编辑器,创建一个名为superpixel_segments.py的文件,让我们开始吧:
# import the necessary packages
from skimage.segmentation import slic
from skimage.segmentation import mark_boundaries
from skimage.util import img_as_float
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
args = vars(ap.parse_args())
第 1-8 行处理导入我们需要的包。我们将在这里大量使用 scikit-image,特别是对于 SLIC 实现。我们还将使用mark_boundaries,这是一个方便的函数,可以让我们轻松地可视化分割的边界。
从那里,我们导入matplotlib进行绘图,导入 NumPy 进行数值处理,导入argparse解析命令行参数,导入cv2进行 OpenCV 绑定。
接下来,让我们继续解析第 10-13 行的命令行参数。我们只需要一个开关--image,它是我们的映像驻留在磁盘上的路径。
现在,让我们执行实际的分段:
# load the image and apply SLIC and extract (approximately)
# the supplied number of segments
image = cv2.imread(args["image"])
segments = slic(img_as_float(image), n_segments = 100, sigma = 5)
# show the output of SLIC
fig = plt.figure("Superpixels")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(mark_boundaries(img_as_float(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)), segments))
plt.axis("off")
plt.show()
我们首先在磁盘的第 17 行加载我们的映像。
通过调用slic函数,实际的超像素分割发生在行 18 上。该函数的第一个参数是我们的图像,表示为浮点数据类型,而不是 OpenCV 使用的默认 8 位无符号整数。第二个参数是我们希望从slic中得到的(大约)分段数。最后一个参数是sigma,它是分割之前应用的高斯核的大小。
现在我们有了我们的分割,我们使用matplotlib在行的 20-25 显示它们。
如果您按原样执行这段代码,您的结果将类似于上面的图 1 。
注意slic是如何在我们的图像中构建超像素的。而且我们可以清楚地看到这些超像素中每一个的“边界”。
但是真正的问题是“我们如何访问每个单独的细分?”
如果你知道面具是如何工作的,这其实很简单:
# loop over the unique segment values
for (i, segVal) in enumerate(np.unique(segments)):
# construct a mask for the segment
print "[x] inspecting segment %d" % (i)
mask = np.zeros(image.shape[:2], dtype = "uint8")
mask[segments == segVal] = 255
# show the masked region
cv2.imshow("Mask", mask)
cv2.imshow("Applied", cv2.bitwise_and(image, image, mask = mask))
cv2.waitKey(0)
你看,slic函数返回一个 2D NumPy 数组segments,其宽度和高度与原始图像相同。此外,每个分段由一个唯一的整数表示,这意味着属于特定分段的像素在segments数组中将具有相同的值。
为了演示这一点,让我们开始循环第 28 行上的 唯一值 segments。
从那里,我们在第 31 行和第 32 行上构造一个遮罩。这个遮罩与原始图像具有相同的宽度和高度,默认值为 0(黑色)。
然而, Line 32 为我们做了一些相当重要的工作。通过声明segments == segVal,我们在segments列表中找到具有当前段 ID 或segVal的所有索引,或 (x,y) 坐标。然后,我们将这个索引列表传递到掩码中,并将所有这些索引设置为值 255(白色)。
然后我们可以在第 35-37 行的中看到我们的工作结果,这里我们显示了应用于我们图像的mask和mask。
超像素分割正在发挥作用
要查看我们的工作结果,请打开一个 shell 并执行以下命令:
$ python superpixel_segments.py --image nedry.png
首先,你会看到超像素分割边界,就像上面一样:
但是当你关闭那个窗口时,我们将开始循环每个单独的片段。以下是我们访问每个细分市场的一些示例:
Figure 2: Exploring a “face” segment of Dennis Nedry using superpixel segmentation.
Figure 3: Jurassic Park trivia time. Do you know who the person is in that picture frame? Bonus points to the first correct answer in the comments!
Figure 4: Applying superpixel segmentation and exploring the shirt and ID badge segment.
没什么,对吧?现在您知道使用 Python、SLIC 和 scikit-image 访问单个超像素段是多么容易了。
摘要
在这篇博文中,我向您展示了如何利用简单的线性迭代聚类(SLIC)算法来执行超像素分割。
从那里,我提供了允许你访问每个 个体 分割算法产生的代码。
现在你有了这些细分,你会怎么做呢?
首先,您可以查看跨图像区域的图形表示。另一种选择是从每个分段中提取特征,您可以稍后利用这些特征来构建视觉单词包。这种视觉单词袋模型对于训练机器学习分类器或构建基于内容的图像检索系统是有用的。但稍后会有更多内容…
无论如何,我希望你喜欢这篇文章!这当然不会是我们最后一次讨论超像素分割。
如果你有兴趣下载这篇博文的代码,只需在下面的表格中输入你的电子邮件地址,我会把代码和示例图片通过电子邮件发给你。当新的精彩的 PyImageSearch 内容发布时,我一定会通知您!**
正在访问 RPi。GPIO 和 GPIO Zero 与 OpenCV + Python
原文:https://pyimagesearch.com/2016/05/02/accessing-rpi-gpio-and-gpio-zero-with-opencv-python/

我不敢相信这是我第一次在 GPIO 和树莓派上写博客。对我来说这是一个相当大的错误。我应该早点写这篇文章。
你看,平均来说,我每周会收到 1-3 封电子邮件,大致如下:
当我使用“cv”虚拟环境时,我可以访问我的 OpenCV 绑定。但是之后我就不能导入 RPi.GPIO 了,当我切换出虚拟环境(并且使用系统 Python)的时候,我就可以使用 RPi 了。GPIO,但是我不能导入 OpenCV。怎么回事?
这个问题的原因是 RPi.GPIO/GPIO Zero没有安装到你的 Python 虚拟环境中!要解决这个问题,您需要做的就是使用pip将它们安装到您的虚拟环境中——从那里,您就可以开始了。
但是说实话,我不认为这是真正的问题!
真正的问题是对什么是 Python 虚拟环境以及为什么我们使用它们没有足够的理解。利用 Python 虚拟环境是一种最佳实践,你需要去适应它。
在这篇博文的剩余部分,我将慢慢介绍 Python 虚拟环境的概念。从那里,我们将学习如何安装 RPi。GPIO 和 GPIO Zero 与我们的 OpenCV 绑定在同一个 Python 虚拟环境中,允许我们同时访问 OpenCV 和 RPi.GPIO/GPIO Zero!
继续阅读,了解如何……
正在访问 RPi。GPIO 和 GPIO Zero 与 OpenCV + Python
在我们学习如何(正确地)安装 RPi 之前。GPIO 和 GPIO Zero 在我们的 Raspberry Pi 上,我们首先需要回顾一下 Python 虚拟环境的概念。
如果你曾经关注过 PyImageSearch 博客上的 Raspberry Pi + OpenCV 安装教程,你会知道我是 Python 虚拟环境的超级粉丝,并且向几乎每个项目的推荐它们。
然而,我似乎没有很好地解释 什么是 Python 虚拟环境以及 我们为什么要使用 。以下部分应该有助于澄清任何问题。
什么是 Python 虚拟环境?
最核心的是,Python 虚拟环境允许我们为每个 Python 项目的创建隔离的、独立的环境。这意味着每个项目可以有自己的依赖关系集、而不管另一个项目有哪些依赖关系。**
那么,我们为什么要为我们的每个项目创建一个虚拟环境呢?
考虑一下这个:假设我们是软件承包商,受雇于一家公司开发项目 A 。但是在我们完成项目 A 之前,第二家公司雇佣我们开发项目 B 。我们注意到项目 A 和项目 B 都依赖于库 A … 但问题是 项目 A 需要 库 A 而 项目 B 需要
这对 Python 来说是一个真正的问题,因为我们不能将同一个库的两个不同版本安装到同一个site-packages目录中(即 Python 存储第三方库的地方,比如你从pip、GitHub 等下载并安装的库)。).
那么,我们该怎么办?
我们是不是应该跑到最近的苹果商店去买一台新的 MacBook Pro,这样我们就可以用一台笔记本电脑开发 ProjectA ,用另一台开发 ProjectB ?我真的希望不会。那会很快变得昂贵。
一定要使用 Linode、Digital Ocean 或 Amazon EC2 这样的网络主机,并为每个项目创建一个新实例。这是一个更好的解决方案,在某些情况下非常适用,但在我们的特定实例中,这有点矫枉过正。
或者我们使用 Python 虚拟环境?
你猜对了— 我们使用 Python 虚拟环境。
在这种情况下,我们需要做的就是为每个项目创建一个虚拟环境,这样所有项目都有一个单独、隔离和独立的环境:

Figure 1: Each Python environment we create is separate and independent from the others.
这允许我们为项目 A 和项目 B 安装完全不同的依赖项,确保我们可以在同一台计算机上完成两个项目的开发。
很漂亮,对吧?
当然,使用 Python 虚拟环境还有很多好处,但与其一一列举, 请参考 RealPython 博客 上这篇优秀的 Python 虚拟环境入门。
但是阿德里安,我已经在使用 Python 虚拟环境了!
如果你遵循了 PyImageSearch 博客上的任何 OpenCV 安装教程,那么你已经在使用 Python 虚拟环境了。
那么你怎么能确定呢?
如果你需要在执行你的 Python 脚本来导入 OpenCV 之前执行workon <virtual environment name> ,那么你猜怎么着,你正在使用 Python 虚拟环境。
但真正的问题来了……
你大概装了 RPi。GPIO 和 GPIO 零位不正确
“不正确”这个词用在这里是不恰当的,但我需要引起你的注意。你去装 RPi 的时候。GPIO 还是 GPIO Zero,我敢打赌你用的是apt-get。您的命令可能是这样的:
$ sudo apt-get install python-rpi.gpio python-gpiozero
此命令将下载 RPi。GPIO 和 GPIO Zero,并将它们安装到您的系统上。
问题是apt-get将安装包放入系统安装Python 和而不是你的 Python 虚拟环境。
这就是为什么会遇到这样的问题:
我可以在‘cv’虚拟环境中导入 OpenCV,但是不能导入 RPi.GPIO,另一方面,我可以导入 RPi。“cv”环境之外的 GPIO,但是我不能导入 cv2。
你如何解决这个问题?
你只需要将你的库安装到你的虚拟环境中,而不是 Python 的系统版本,这可以通过workon和pip轻松完成。
这就引出了我的下一个观点:
我不推荐用apt-get安装 Python 库。
你可能在想,“但是 Adrian,使用apt-get太简单了!只是一个命令,然后我就完事了!”
我要告诉你一个消息——使用pip也是一个命令。同样简单。
回到我的观点,不仅是apt-get将这些库安装到系统 Python(而不是你的虚拟环境)中,还有一个问题是apt-get包通常有点过时。
猜猜当你想安装给定库的最新版本时会发生什么?
提示:您遇到了上面详述的问题——您将试图将两个不同版本的同一个库安装到同一个site-packages 目录中,这根本不可能发生(由于 Python 的工作方式)。
相反,您应该使用 Python 包管理器, pip ,将您的 Python 包安装到虚拟环境中。关于pip,它是如何工作的,以及我们为什么使用它, 的更多信息,请参考这篇文章 。
正在安装 RPi。GPIO 和 GPIO 零点“正确”
我们去拿 RPi 吧。GPIO 和 GPIO zero 安装在我们的 Python 虚拟环境中。首先,使用workon命令进入 Python 虚拟环境:
$ workon <virtual environment name>
注意:您可能需要在运行workon命令之前执行source ~/.profile,以便加载虚拟环境启动脚本。
如果环境名称出现在提示符前的括号中,则可以判断您处于 Python 虚拟环境中:

Figure 2: I can tell I am in the “cv” virtual environment because I can see the text “(cv)” before my prompt.
在这种情况下,我已经进入了cv虚拟环境,我可以验证这一点,因为我在我的提示前看到了文本(cv)。
从那里,我们可以让pip安装 RPi。我们的 GPIO 和 GPIO Zero:
$ pip install RPi.GPIO
$ pip install gpiozero
最后,让我们测试安装并确保我们可以导入 RPi。GPIO、GPIO Zero 和 OpenCV 一起:
$ python
>>> import RPi.GPIO
>>> import gpiozero
>>> import cv2
>>>
注意:我假设你正在使用的虚拟环境已经安装了 OpenCV。我的cv虚拟环境已经安装了 OpenCV,所以通过使用pip安装RPi.GPIO和gpiozero安装各自的 GPIO 包,我能够从同一个环境中访问所有三个库。
一旦您可以在同一个环境中导入这些库,我们就可以继续了。
五金器具
在这篇博文中,我使用了我的 Raspberry Pi 3 和 TrafficHAT 板,这是一个非常酷的 Raspberry Pi 模块,可以让你快速轻松地开始 GPIO 编程:

Figure 3: The TrafficHAT module for the Raspberry Pi, which includes 3 LED lights, a buzzer, and push button, all of which are programmable via GPIO.
正如你所看到的,TrafficHAT 包括 3 个大 LED 灯、一个按钮和一个蜂鸣器。
注意:之所以称之为“帽子”,是因为我们只需要将它放在 GPIO 引脚的顶部——不需要分线板、额外的电缆或焊接。
一旦我们在 Raspberry Pi 上安装了 TrafficHAT,我们就可以使用几乎任何编程语言对其进行编程(只要该语言可以访问 GPIO 引脚),但是出于这篇博客文章的目的,我们将使用 Python + RPi。GPIO 和 GPIO 零。
使用 RPi。GPIO + OpenCV
让我们继续编写一些代码,使用 RPi 访问 TrafficHAT 板。GPIO 库。我们还将利用 OpenCV 从文件中加载一幅图像,并将其显示在屏幕上。
打开一个新文件,将其命名为gpio_demo.py,并插入以下代码:
# import the necessary packages
import RPi.GPIO as GPIO
import time
import cv2
# load the input image and display it to our screen
print("click on the image and press any key to continue...")
image = cv2.imread("hoover_dam.jpg")
cv2.imshow("Image", image)
cv2.waitKey(0)
print("moving on...")
# set the GPIO mode
GPIO.setmode(GPIO.BCM)
# loop over the LEDs on the TrafficHat and light each one
# individually
for i in (22, 23, 24):
GPIO.setup(i, GPIO.OUT)
GPIO.output(i, GPIO.HIGH)
time.sleep(3.0)
GPIO.output(i, GPIO.LOW)
# perform a bit of cleanup
GPIO.cleanup()
第 2-4 行处理导入我们需要的 Python 包。然后,我们从磁盘加载输入图像,并在的第 8-10 行将它显示到我们的屏幕上。我们的脚本将暂停执行,直到我们点击活动图像窗口并按下键盘上的任意键。
从那里,我们循环遍历 TrafficHAT 上的每个 led(行 18 )。对于每一盏灯,我们:
- 打开 LED 灯。
- 等待 3 秒钟。
- 关灯继续循环。
要执行gpio_demo.py,使用workon命令确保您在cv虚拟环境中(或者您用来存储 OpenCV 绑定+ GPIO 库的任何虚拟环境中):
$ workon cv
然后我们可以运行gpio_demo.py脚本:
$ python gpio_demo.py
如输出图像所示,我们可以看到我们的hoover_dam.jpg图像显示在屏幕上和交通上的绿色 LED 灯明亮地闪烁着:

Figure 4: Loading an image to my screen using OpenCV and then lighting up the green LED using GPIO.
root 呢?
但是如果我们想作为根用户执行gpio_demo.py呢?那我们该怎么办?
我们有两个选择。
第一种选择是在我们的 Python 虚拟环境中使用sudo命令,就像这样:
$ sudo python gpio_demo.py
注意:在用sudo执行你的脚本之前,确保你在你的 Python 虚拟环境;否则,您将无法访问虚拟环境中安装的库。
第二个选项是启动一个根 shell,访问我们的 Python 虚拟环境,然后执行脚本:
$ sudo /bin/bash
$ source /home/pi/.profile
$ workon cv
$ python gpio_demo.py
哪个最好?
说实话,这真的不重要。
有些情况下使用sudo更容易。还有一些地方,只需拔出根壳就很好。使用您更喜欢的选项— 以 root 用户身份执行命令时要小心!
使用 RPI Zero + OpenCV
既然我们已经研究了 RPi。GPIO,让我们重新创建同一个 Python 脚本,但是这次使用 GPIO Zero 库。打开一个不同的文件,将其命名为gpiozero_demo.py,并插入以下代码:
# import the necessary packages
from gpiozero import TrafficHat
import time
import cv2
# load the input image and display it to our screen
print("click on the image and press any key to continue...")
image = cv2.imread("hoover_dam.jpg")
cv2.imshow("Image", image)
cv2.waitKey(0)
print("moving on...")
# initialize the TrafficHAT, then create the list of lights
th = TrafficHat()
lights = (th.lights.green, th.lights.amber, th.lights.red)
# loop over the lights and turn them on one-by-one
for light in lights:
light.on()
time.sleep(3.0)
light.off()
2-4 线再次处理导入我们需要的包。这里真正有趣的是,gpiozero库有一个TrafficHat类,它使我们能够轻松地与 TrafficHAT 模块接口。
第 8-10 行处理将我们的输入图像加载并显示到 sour 屏幕。
然后我们可以初始化TrafficHat对象,并在的第 14 行和第 15 行上构建lights的列表。
最后,第 18-21 行处理每一个lights的循环,分别打开每一个,等待 3 秒,然后在移动到下一个之前关闭light。
就像 RPi 一样。GPIO 示例,我们首先需要访问我们的 Python 虚拟环境,然后执行我们的脚本:
$ workon cv
$ python gpiozero_demo.py
随着脚本的执行,我们可以看到屏幕上显示了一幅图像,led 灯亮起:

Figure 5: A second example of using OpenCV to display an image and then utilizing GPIO to illuminate an LED.
注意:要以 root 用户身份执行这个脚本,请按照上一节中的说明进行操作。
摘要
在这篇博文中,我首先回顾了什么是 Python 虚拟环境以及为什么我们使用 Python 虚拟环境的原因。简而言之,Python 虚拟环境允许我们为我们从事的每个项目创建独立、隔离的开发环境,确保我们不会遇到版本依赖问题。此外,虚拟环境允许我们保持 Python 系统安装的整洁。
一旦我们理解了 Python 虚拟环境的基础,我详细说明了如何(正确地)安装 RPi。GPIO 和 GPIO 清零,这样我们可以同时访问 GPIO 库和 OpenCV。
然后,我们开发了一个简单的 Python 脚本,它使用 OpenCV 从磁盘加载图像,将其显示在我们的屏幕上,然后点亮traffic that上的各种 led。
在下一篇博文中,我们将创建一个更高级的 GPIO + OpenCV 脚本,这一次,每当预定义的视觉动作发生时,就会点亮 led 并发出蜂鸣声。
请务必在下面的表格中输入您的电子邮件地址,以便在下一篇博文发布时得到通知,您不会想错过它的!【T2
使用 OpenCV 和 Python 访问 Raspberry Pi 摄像机
原文:https://pyimagesearch.com/2015/03/30/accessing-the-raspberry-pi-camera-with-opencv-and-python/

在过去的一年里,PyImageSearch 博客有很多受欢迎的博文。使用 k-means 聚类来寻找图像中的主色曾经(现在仍然)非常流行。我个人最喜欢的文章之一,构建一个超棒的移动文档扫描仪几个月来一直是最受欢迎的 PyImageSearch 文章。我写的第一个(大的)教程,霍比特人和直方图,一篇关于建立一个简单的图像搜索引擎的文章,今天仍然有很多点击。
但是 到目前为止 ,PyImageSearch 博客上最受欢迎的帖子是我的教程在你的 Raspberry Pi 2 和 B+ 上安装 OpenCV 和 Python。看到你和 PyImageSearch 的读者们对 Raspberry Pi 社区的喜爱真的是太棒了,我计划在未来继续写更多关于 OpenCV+Raspberry Pi 的文章。
无论如何,在我发布了 Raspberry Pi + OpenCV 安装教程之后,许多评论都要求我继续讨论如何使用 Python 和 OpenCV 访问 Raspberry Pi 相机。
在本教程中,我们将使用 picamera ,它为相机模块提供了一个纯 Python 接口。最棒的是,我将向您展示如何使用 picamera 来捕捉 OpenCV 格式的图像。
请继续阅读,了解如何…
重要:在遵循本教程中的步骤之前,请务必遵循我的 Raspberry Pi OpenCV 安装指南。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
第一步:我需要什么?
首先,你需要一个 Raspberry Pi 相机板模块。
我从亚马逊以不到 30 美元的价格买到了我的 5MP Raspberry Pi 相机板模块,含运费。很难相信相机板模块几乎和 Raspberry Pi 本身一样贵——但它只是显示了过去 5 年硬件的进步。我还拿起了一个相机外壳来保护相机的安全,因为为什么不呢?
假设你已经有了相机模块,你需要安装它。安装非常简单,我不会创建我自己的安装相机板的教程,我只会让你参考官方的 Raspberry Pi 相机安装指南:
https://www.youtube.com/embed/GImeVqHQzsE?feature=oembed
实现物体检测的最佳速度和精度(YOLOv4)
目录
【yolov 4】
在本教程中,您将从研究的角度了解 YOLOv4,因为我们将更深入地研究这一精确而快速的对象检测网络的工作原理。我们将通过将这个网络与之前的目标检测工作进行比较来建立直觉。
我们相信 YOLOv4 是许多实验和研究的结果,这些实验和研究结合了各种提高卷积神经网络准确性和速度的小的新技术。但最具挑战性的部分是将这些互补的不同特征结合起来,从而提供一个最佳和准确的对象检测模型。而这正是这篇论文做的最好的方式!
Bochkovskiy 等人(2020) 在不同的 GPU 架构上进行了广泛的实验,并表明 YOLOv4 在速度和准确性方面优于所有其他对象检测网络架构。这个实验的目的是激励人们利用 YOLOv4 模型的能力,而不要过多考虑 GPU 的类型,因为它即使在传统的 GPU 上也能发挥最佳性能,这使得本文更加令人兴奋和独特。
这节课是我们关于 YOLO 的 7 集系列的第 6 集:
- YOLO 家族简介
- 了解一个实时物体检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的物体探测器(YOLOv2)
- 使用 COCO 评估器 平均精度(mAP)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
- 【yolov 4】【今日教程】
- 在自定义数据集上训练 YOLOv5 物体检测器
*要了解使用的新技术和执行的各种实验,以构建一个快速准确的实用 YOLOv4 对象检测器,并使用 YOLOv4 运行推理以实时检测对象 ,请继续阅读。
【yolov 4】
在 YOLO 系列的第 6 部分中,我们将首先介绍 YOLOv4,并讨论 YOLOv4 的目标和贡献以及量化基准。然后,我们将讨论对象检测器中涉及的不同组件。
然后,我们将讨论“免费赠品包”,它有助于在不影响推理成本的情况下改进训练策略。我们还将讨论提高检测器精度所需的后处理方法和称为“特殊包”的插件模块,这些方法和模块只增加了少量的推理成本。最后,我们还将讨论 YOLOv4 架构的选择策略:主干、带有附加模块的瓶颈和头部。
接下来,我们将讨论 YOLOv4 模型为实现最先进的准确性和速度而利用的“一袋免费赠品”和“一袋特价商品”:
- 剪切混合和镶嵌数据扩充
- 类别标签平滑
- 自我对抗训练
- 丢弃块正则化
- 跨级部分连接
- 空间金字塔池
- 空间注意模块
- 路径聚合网络
我们还将讨论受各种实验相互作用影响的 YOLOv4 的定量基准:
- 主干上的 BoF 和 Mish 激活
- 探测器上的 BoF
- 探测器上的 BoS
- 探测器上的主干
最后,我们将通过在 Tesla V100 GPU 上运行两幅图像和一个预训练模型视频的推理来查看 YOLOv4 的运行情况。
配置您的开发环境
要遵循这个指南,您需要在您的系统上编译并安装 Darknet 框架。在本教程中,我们将使用 AlexeyAB 的 Darknet 库。
我们将逐步介绍如何在 Google Colab 上安装 darknet 框架。但是,如果您现在想配置您的开发环境,可以考虑前往配置 Darknet 框架并使用预训练的 YOLOv4 COCO 模型运行推理部分。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
约洛夫 4 简介
YOLOv3 发布后,《YOLO》的原作者(Joseph Redmon)因为伦理原因,停止了对 YOLO 的进一步开发,甚至退出了计算机视觉领域。
2020 年,Alexey Bochkovskiy 等人(著名 GitHub 知识库:Darknet 的作者)在 arXiv 上发表了 YOLOv4:物体检测的最佳速度和精度论文。如图图 2 所示,作者最大限度地利用了现有的新技术和新功能,通过这种方式将它们结合起来,产生了一种速度和精度都达到最佳水平的物体检测器,优于其他最先进的物体检测器。我们可以从下图中观察到,YOLOv4 的运行速度是 EfficientDet 的两倍,性能相当,并且在 MS COCO 数据集上,YOLOv3 的 mAP 和 FPS 分别提高了 10%和 12%。
在对象检测模型中,我们总是看到准确性和速度之间的权衡。例如,通过运行对象检测模型的摄像机来搜索商场中的空闲停车位是由慢速精确模型来执行的。相反,由快速不准确的模型来执行坑洞检测警告。因此,提高实时物体检测器的准确性对于准确的驾驶员警报、独立的过程管理和减少人工输入是至关重要的。
但通常,开发实时对象检测器的挑战是将它们部署在传统的 GPU 和边缘设备上。构建一个在这些低端传统 GPU 上运行的解决方案,可以让它们以可承受的价格得到广泛使用。
我们知道,最精确的神经网络模型不会实时运行,并且需要许多 GPU 来进行大批量的训练。不幸的是,这也意味着很难在边缘设备上部署它们。在 YOLOv4 中,作者试图通过创建一个在传统 GPU 上实时运行的 CNN 来解决这个问题,并且训练只需要一个传统 GPU。因此,任何拥有 1080 Ti 或 2080 Ti GPU 的人都可以训练这种超级快速准确的对象检测器。为了验证他们的模型,作者在各种 GPU 架构上测试了 YOLOv4。
卷积神经网络(CNN)的性能在很大程度上取决于我们使用和组合的功能。例如,某些功能仅适用于特定的模型、问题陈述和数据集。但是批量规范化和残差连接等功能适用于大多数模型、任务和数据集。因此,这些特征可以被称为普遍性的。
作者利用了这一思想,并假设了一些普遍特征,包括
- 加权剩余连接(WRC)
- 跨阶段部分连接
- 交叉小批量标准化(CmBN)
- 自我对抗训练
- 误激活
- 镶嵌数据增强
- 丢弃块正则化
- CIoU 损失
上述功能相结合,实现了最先进的结果:在特斯拉 V100 GPU 上以 65 FPS 的实时速度在 MS COCO 数据集上实现了 43.5%的 mAP (65.7% mAP50)。
YOLOv4 模型结合了上述和更多的特征,形成了用于改进模型训练的“免费赠品包”和用于改进物体检测器精度的“特殊包”。我们将在后面详细讨论这一点。
物体探测器中的组件
对象检测器的端到端架构通常由两部分组成:
- 毅力
- 头
正如我们在以前的 YOLO 帖子中了解到的,一个主干被用作特征提取器,在 ImageNet 数据集上进行分类任务的预训练。在 GPU 上训练和测试的对象检测器使用较重的主干(例如,VGG、ResNet、DenseNet 和 Darknet-19/53),而对于 CPU,使用较轻的主干(例如,SqueezeNet、MobileNet 等)。)被使用。在速度和准确性之间总是有一个折衷。较轻的脊椎比较重的脊椎更快,但准确性较低。
一个头用于预测对象的边界框坐标和类别标签。头部可以进一步分为两级(即一级和两级物体检测器)。RCNN 系列就是两级检波器的一个很好的例子。最能代表一级检测器的是 YOLO 系列、SSD 和 RetinaNet。
图 3 显示了一级和两级检测器的目标检测工作流程,由几个部分组成:输入、脊柱、颈部和头部。
近年来,物体探测器开始使用一个颈,即在脊柱和头部之间增加几层,用于收集脊柱不同阶段的特征图。例如,在 YOLOv3 中,主链由 53 层组成。有 53 个附加层(包括头部),其中来自后面层的特征被上采样并与来自前面层的特征连接。
通常,一个颈部由几个自底向上的路径组成,几个自顶向下的路径使用跳过连接进行连接。像特征金字塔网络(FPN)和路径聚合网络(PAN)这样的网络基于这种机制工作,并且经常被用作对象检测网络中的瓶颈(例如,YOLOv4 使用 PANet 作为瓶颈)。
【BoF】
在几乎所有情况下,对象检测器都是离线训练的,这使得研究人员可以自由地开发训练方法,使对象检测器更加准确,而不会影响推理成本。因此,这些仅改变培训策略或提高培训成本的方法被称为图 4 所示的“免费赠品包”。
我们最常用的训练策略是数据扩充,如图图 5 所示。数据扩充的目的是增加输入图像的可变性,使得设计的目标检测模型对从不同环境获得的图像具有更高的鲁棒性。
有各种数据扩充类别(例如,单图像、多图像等。).正如我们所看到的,在一幅图像中有两种失真:光度失真和几何失真。在光度失真中,您可以通过对图像应用亮度、噪波和色调来更改图像属性,而在几何失真中,我们可以旋转、裁剪或平移图像。
然后,一些研究人员提出使用多幅图像一起执行数据增强,如 Mixup 和 CutMix。Mixup 使用两幅图像以不同的系数比率相乘并叠加,然后用这些叠加的比率调整标签。至于 CutMix,它将裁剪后的图像覆盖到其他图像的矩形区域,并根据混合区域的大小调整标签。
YOLOv4 提出了一种新的多图像数据增强技术,称为马赛克,将四幅不同的图像缝合在一起。在后面的部分会有更多的介绍。
研究人员还提出了对象遮挡作为在图像分类和对象检测中成功的另一种数据增强。例如,“随机擦除”和“剪切”可以随机选择图像中的矩形区域,并填充零的随机 or 值。这有助于网络避免过度拟合;例如,给定一幅猫的图像,网络将被迫学习它身体的其他部分,并将它归类为猫,因为剪切器会随机移除它的头部或尾巴。
【BoS】
“特价包”是仅少量增加推理成本但能显著提高物体检测准确度的后处理方法和插件模块,称为“特价包”这些模块和方法有计算负荷,但有助于提高准确性。
这些插件模块用于增强模型中的特定属性,如使用空间金字塔池(SPP)扩大感受野,使用空间注意模块(SAM)引入注意机制,或使用 FPN 或 PAN 增强特征整合能力等。、以及用于筛选模型预测结果的类似非最大值抑制的后处理方法。
如图图 6 所示,我们可以对每个插件模块和后处理方法有无数的选择。当您设计对象检测网络或在数据集上从头开始训练时,下图应该是一个很好的参考。在 YOLOv4 中,作者使用改进的 PAN 进行特征整合,使用改进的空间注意模块(SAM)作为注意模块,使用 SPP 扩展感受野。在后处理方法上,检测器采用了欧弟-NMS 法。
在下一节中,我们将讨论使用哪些模块和方法来训练主干和检测器。我们还将详细讨论这些特定的方法。
YOLOv4 架构选择
主要目的是为生产系统建立一个快速运行的神经网络。要开发这样一个模型,目标是在
- 输入网络分辨率
- 卷积层数
- 网络中的参数数量
- 输出层数(过滤器)
以上四点很有道理,请记住,我们希望构建一个合理的低成本部署模型。例如,输入网络分辨率(图像尺寸)是必不可少的;图像尺寸越大,拥有的上下文信息就越多,有助于网络轻松检测更小的物体。但是更大的图像尺寸的缺点是,你将需要更多的内存带宽,尤其是在 GPU 上,更多的网络计算(FLOPs),并且可能设计更深的网络。因此,在这些参数之间取得平衡对于构建一个快速且最优的网络至关重要。
骨干
YOLOv4 使用 CSPDarknet53 模型作为主干。回想一下 YOLOv3 使用的是 Darknet53 型号,和 Darknet53 一样,CSPDarknet53 也是基于 DenseNet 的。现在,它前面的这个 CSP 前缀是什么?CSP 代表跨阶段部分连接。我们将在后面的部分研究 CSP。
根据之前的研究,CSPResNeXt50 模型在 ImageNet 数据集上的基准影像分类任务上明显优于 CSPDarknet53 模型。但是,在 MS COCO 数据集上检测对象方面,CSPDarknet53 模型比 CSPResNext50 要好。
表 1 显示了 CSPDarknet53 与其他骨干架构在图像分类任务上的网络信息比较,具有精确的输入网络分辨率。我们可以观察到 CSPDarknet53 是 RTX 2070 GPU 上最快的。
EfficientNet-B3 具有最大的感受野,但具有最低的 FPS,而 CSPDarknet53 是最快的,具有相当好的感受野。基于所进行的大量实验,CSPDarknet53 神经网络是作为检测器主干的两个模型中的最佳模型。
脖子上带附加挡
接下来,我们需要为不同的检测器水平(多尺度)从不同的主干水平选择用于增加感受野的附加块和参数聚集的最佳方法。我们可以选择、PAN、和 BiFPN 进行参数聚合。
随着感受野大小的增加,我们在物体周围和图像内获得了更多的上下文信息。作者在论文中很好地总结了感受野大小的作用,如下:
- 最大对象尺寸:允许查看整个对象
- 最大网络尺寸:允许查看对象周围的环境
- 超过网络大小:增加图像点和最终激活之间的连接数
要了解更多关于感受野的信息,我们推荐你参考 Adaloglou (2020) 的这篇文章。
因此,要构建声音检测器,您需要:
- 用于检测多个小型物体的更高输入网络分辨率
- 更多的层用于更大的感受野,以覆盖输入网络增加的尺寸
- 和更多的参数,以使模型具有更大的能力来在单个图像中检测不同尺寸的多个对象
最终架构
最终架构 YOLOv4 使用 CSPDarknet53 主干、SPP 附加模块、PANet 路径聚合颈部和 YOLOv3(基于锚点)头部,如图 7 中的高级概述所示。
选择 BoF 和 BoS
到目前为止,我们已经讨论了主干体系结构的选择以及带有颈部结构和头部的附加模块。在本节中,我们将讨论 YOLOv4 利用的 BoF 和 BoS 的选择。图 8 和图 9 显示了主干和探测器的 BoF 和 bo 列表。既然 YOLOv4 中使用了这么多模块和方法,我们就讨论几个。
【CutMix 数据增强(主干→ BoF)
CutMix 的工作方式类似于图像增强的“剪切”方法,而不是裁剪图像的一部分并用 0 值替换它。相反,CutMix 方法用不同图像的一部分替换它。
图像的剪切迫使模型基于大量特征进行预测。在没有剪切的情况下,该模型专门依靠狗的头部来进行预测。如果我们想准确地识别一只头藏起来的狗(可能藏在灌木丛后面),这是有问题的。表 2 显示了 ImageNet 分类、ImageNet 定位和 Pascal VOC 07 检测(SSD 微调迁移学习)任务的 Mixup、Cutout 和 CutMix 结果。
在 CutMix 中,剪切部分被替换为另一个图像的一部分以及第二个图像的基本事实标签。在图像生成过程中设置每个图像的比率(例如,0.4/0.6)。图 10 显示了剪切和剪切混合增强之间的差异。
【马赛克数据增强(主干→ BoF)
镶嵌数据增强的想法来自 Glenn Jocher 的 YOLOv3 PyTorch GitHub 知识库。马赛克增强以特定的比率将四个训练图像缝合成一个图像(而不是在 CutMix 中只有两个)。使用镶嵌数据增强的好处在于
- 网络在一个图像中看到更多的上下文信息,甚至在它们的正常上下文之外。
- 允许模型学习如何在比通常更小的尺度上识别对象。
- 批量标准化将减少 4 倍,因为它将在每层计算 4 个不同图像的激活统计数据。这将减少在训练期间对大的小批量的需求。
我们建议您观看该视频以深入了解镶嵌数据增强。
图 11 展示了几幅镶嵌数据增强的图像,我们可以看到,与单幅图像相比,每幅图像都有如此多的上下文。例如,在一张图片中,我们有一列火车,一辆自行车,一辆自行车,一艘船,等等。
【类标签平滑(骨干→ BoF)
类别标签平滑是一种正则化技术,用于修改类别标签的多类别分类问题。通常,对于涉及三个类别的问题陈述:猫、狗、大象,边界框的正确分类将表示类别[0,0,1]的独热向量,并且基于该表示计算损失函数。
然而,粗略的标注会迫使模型对最后一个元素 1 达到正无穷大,对 0 达到负无穷大。这将使模型过度拟合训练数据,因为它将学习变得超级好,并且对接近 1.0 的预测过于确定。然而,在现实中,它往往是错误的,过度拟合,并忽略了其他预测的复杂性。
根据这种直觉,对类标签表示进行编码以在某种程度上评估这种不确定性是更合理的。自然,作者选择 0.9,所以[0,0,0.9]代表正确的类。而现在,模型的目标并不是 100%准确地预测类猫。这同样适用于为零的类,并且可以修改为 0.05/0.1。
【探测器→BoF】
众所周知,即使在输入图像中存在最小扰动时,神经网络也往往表现不佳。例如,给定一幅干扰最小的猫图像作为输入,即使两幅图像在视觉上看起来相同,网络也可以将其分类为交通灯,如图图 12 所示。人类的视觉不会受到扰动的影响,但神经网络会受到这种攻击,你需要强制网络学习两幅图像是相同的。
自我对抗训练分向前和向后两个阶段进行。在第一阶段,它对训练样本执行正向传递。通常,我们在反向传播中调整模型权重,以改进该模型在该图像中检测对象。但是在这里,它是反方向的,就像梯度上升。因此,它会干扰图像,最大程度地降低检测机的性能。它创建了一个针对当前模型的对抗性攻击,即使新图像在视觉上可能看起来相似。在第二阶段,用具有原始边界框和类别标签的这个新的扰动图像来训练模型。这有助于创建一个健壮的模型,该模型能够很好地概括并减少过度拟合。
CSP:跨级部分连接(主干→ BoS)
Darknet53 主干采用跨级部分连接。在 2016 年,黄高等人提出了 DenseNet,如前所述,Darknet53 基于 DenseNet 架构,但进行了修改(即跨级部分连接)。
在我们了解主干网的 CSP 部分之前,让我们快速了解一下什么是 DenseNet?
致密网由许多致密嵌段组成。每个密集块(如图图十三所示)包含多个褶积层,每层
composed of batch normalization, ReLU, and followed by convolution. Instead of using the output of the last layer only, takes the output of all previous layers as well as the original as its input (i.e.,  ). Each below outputs four feature maps. Therefore, at each layer, the number of feature maps is increased by four (the growth rate ). As each layer is connected with every other layer in a dense block, the authors believed this improved the gradient flow.
). Each below outputs four feature maps. Therefore, at each layer, the number of feature maps is increased by four (the growth rate ). As each layer is connected with every other layer in a dense block, the authors believed this improved the gradient flow.
通过堆叠多个这样的致密块,可以形成致密网。正如我们在图 13 中看到的,在块的末端有一个过渡层。该过渡层有助于从一个密集块过渡到另一个密集块。它由卷积层和汇集层组成,如图图 14 所示。
回到 Darknet53 的 CSP 部分,原始 DenseNet 具有重复的梯度流信息,并且计算量也更大。YOLOv4 的作者受到了 CSPNet 论文的启发,该论文表明,向 ResNet、ResNext 和 DenseNet 添加跨阶段部分连接降低了这些网络的计算成本和内存使用,并有利于推理速度和准确性。
CSPNet 将输入要素地图或 DenseBlock 的基本图层分成两部分。第一部分绕过 DenseBlock,直接作为过渡层的输入。第二部分穿过密集块,如图图 15 所示。
图 16 显示了密集区块的更详细视图。卷积层应用于输入要素图,卷积输出与输入连接在一起,并按顺序贯穿整个密集块。然而,CSP 仅将输入特征图的一部分放入密集块,其余部分直接作为过渡层的输入。这种新设计通过将输入分成两部分来降低计算复杂度,其中只有一部分通过密集块。
修改的 SPP:空间金字塔池(探测器→ BoS)
何等(2015) 提出空间金字塔池;想法是进行多尺度输入图像训练。现有的卷积神经网络需要固定大小的输入图像,因为全连接层中需要指定固定的输入大小。
假设您的网络有许多卷积层和最大池层,一个完全连接的层。全连接层的输入将是展平的一维向量。如果网络的输入不断变化,则展平的一维向量大小也会变化,这将导致错误,因为完全连接的图层需要固定大小的输入。当感兴趣区域的尺寸可变时,在目标检测中也会出现同样的问题。这就是 SPP 层有帮助的地方。
SPP 层(见图 17 )有助于检测不同比例的物体。它将最后一个池图层替换为空间金字塔池图层。首先,将特征地图在空间上划分为
bins with  , say, equals 1, 2, and 4. Then a maximum pool is applied to each bin for each channel. This forms a fixed-length representation that can be further analyzed with fully connected layers. This solves the problem because now you can pass arbitrary size input to the SPP layer, and the output would always be a fixed-length representation.
, say, equals 1, 2, and 4. Then a maximum pool is applied to each bin for each channel. This forms a fixed-length representation that can be further analyzed with fully connected layers. This solves the problem because now you can pass arbitrary size input to the SPP layer, and the output would always be a fixed-length representation.
在 YOLO,SPP 被修改以保留输出空间维度。图 18 显示了一个具有三个最大汇集层的空间金字塔汇集块。SPP 层添加在 CSPDarknet53 的最后一个卷积层之后。特征地图以不同的比例汇集;最大池适用于大小可变的内核,比如说
,  ,
,  ,
,  . The spatial dimension is preserved, unlike traditional SPP, where the feature maps are resized into feature vectors with a fixed size.
. The spatial dimension is preserved, unlike traditional SPP, where the feature maps are resized into feature vectors with a fixed size.
然后,来自不同内核大小的特征映射与 SPP 块的输入特征映射连接在一起,以获得输出特征映射。这样我们就得到了
feature maps that extract and converge the multi-scale local region features as the output for object detection.
作者声称,修饰的 SPP 具有更大的感受野,这有利于检测器。
【路径聚合网络(检测器→ BoS)
PANet 用于模特的颈部。PAN 是对特征金字塔网络的改进。PAN 在 FPN 的顶部添加了一个自下而上的路径(如图图 19(b) 所示),用于确保使用每个特征级别的最有用信息。在 FPN 中,信息是在自下而上和自上而下的流中从相邻层组合而成的。
图 19 显示了用于物体检测的平移。增加了一条自下而上的路径 (b) ,使低层信息容易流向高层。在 FPN,局部空间信息向上传播,用红色箭头表示。虽然图中没有清楚地展示,但红色路径穿过大约 100+层。潘介绍了一条捷径(绿色路径),只需要 10 层左右就可以到达顶端
layer. These short-circuit concepts make fine-grain localized information available to top layers.
在 FPN,物体在不同的尺度水平上被分别和独立地探测。根据 PANet 作者的说法,这可能会产生重复的预测,并且不会利用来自其他比例特征地图的信息。相反,PAN 融合来自所有层的数据,如图图 19 (c) 所示。要了解这方面的更多信息,请查阅论文。
图 20 显示了 FPN 和帕内特的对比。
YOLOv4 作者稍微修改了 PAN 他们没有将相邻层加在一起,而是将快捷连接改为串联(图 21 )。
【空间注意模块(探测器→ BoS)
空间注意模块来自于 Woo et al. (2018) 发表的关于卷积块注意模块(CBAM)的工作,如图图 22 所示。这篇论文的思想是,给定一个中间特征图,该模块沿着两个独立的维度,通道和空间,顺序地推断注意力图。两个注意力图掩码都与输入特征图相乘,以输出细化的特征图。
但回到注意力模型的历史,甚至在 2017 年 CBAM 之前,挤压和激发(SE)网络就被引入了,这是一种通道式的注意力模型。SE 允许网络通过抑制不太有用的信息和强调信息特征来执行特征重新校准。压缩部分将在特征图上应用平均池,产生矢量输出,而激励部分是多层感知器。最后,将激励输出与输入特征图相乘,得到精确的特征。
YOLOv4 仅使用来自图 23 所示CBAM 的空间注意力模块(SAM ),因为 GPU 的通道式注意力模块效率低下。在 SAM 中,最大池和平均池分别应用于沿通道的输入特征地图,以创建两组特征地图。
然后,所有输入通道被压缩到一个通道中,最大池和平均池输出被连接起来。连接的结果被送入卷积层,然后是 sigmoid 函数,以创建空间注意力掩模。为了得到最终的输出,使用空间注意来执行逐元素乘法。
在 YOLOv4 中,SAM 从空间方式的注意修改为点方式的注意。此外,最大和平均池层替换为卷积层,如图图 24 所示。
【骨干→BoF】
丢弃块正则化技术类似于用于防止过拟合的丢弃正则化。然而,在丢弃块正则化中,丢弃的特征点不再随机分布,而是组合成块,并且丢弃整个块。如图图 25(b) 所示,随机退出激活对于去除语义信息是无效的,因为附近的激活包含密切相关的信息。相反,放下连续区域可以移除某些语义信息(例如,头或脚)(如图图 25(c) 所示),并因此强制剩余单元学习用于分类输入图像的特征。
量化基准
**作者在 ImageNet 数据集上对主干进行了分类任务的预处理,并在 MS COCO 2017 数据集上对对象检测任务的检测器进行了预处理。
BoF 和 Mish 激活对骨干网的影响
BoF 和激活功能对 CSPResNeXt-50 分级机的影响如表 3 所示。从表中可以明显看出,作者进行了消融研究。基于所进行的研究和实验,作者发现,使用剪切混合、镶嵌、标签平滑和 Mish 激活函数(在表 3 的最后一行),CSPResNeXt-50 分类器表现最佳。它实现了 79.8%的前 1 名准确率和 95.2%的前 5 名准确率。
作者对 CSPDarknet-53 主干进行了类似的实验。他们发现,使用相同的设置(即剪切混合、镶嵌、标签平滑和 Mish),他们实现了 78.7%的前 1 名准确性和 94.8%的前 5 名准确性(如表 4 所示)。
基于上述实验,作者得出结论,CSPResNeXt-50 在分类任务中的性能优于 CSPDarknet-53。
BoF 对探测器的影响
进一步的研究涉及不同的赠品袋对探测器训练精度的影响,如表 5 所示。从该表中可以明显看出,利用网格灵敏度、镶嵌增强、IoU 阈值、遗传算法和 GIoU/CIoU 损耗,CSPResNeXt50-PANet-SPP 检波器实现了最佳的平均精度。此外,将损耗从 GIoU 更改为 CIoU 对检测精度没有影响。
BoS 对探测器的影响
通过将空间注意力模块添加到 CSPResNeXt50-PANet-SPP,作为 PANet 和 SPP 的一个特殊包,我们可以在表 6 中看到检测器的平均精度有所提高。
骨干对探测器的影响
这是令人兴奋的,因为我们比较了两个带检测器的主干:CSPResNeXt-50 和 CSPDarknet-53。我们之前从表 3 和表 4 中了解到,CSPResNeXt-50 在图像分类任务上的表现优于 CSPDarknet-53。
然而,当我们将这两个主干与检测器一起使用时,我们可以从表 7 中看到,CSPDarknet53-PANet-SPP 在平均精度和 0.5 和 0.75 IoU 的平均精度方面明显胜出。因此,结论是 Darknet-53 适合于检测任务,所以作者选择 Darknet 作为检测器。
配置暗网框架,用预先训练好的 YOLOv4 COCO 模型运行推理
在我们之前关于约洛夫 1 、约洛夫 2 和约洛夫 3 的帖子中,我们学习了配置暗网框架,并用预先训练好的 YOLO 模型进行推理;我们将遵循与配置 darknet 框架之前相同的步骤。然后,最后,使用 YOLOv4 预训练模型运行推理,并将结果与以前的 YOLO 版本进行比较。
配置 darknet 框架并使用 YOLOv4 在图像和视频上运行推理分为七个易于遵循的步骤。所以,让我们开始吧!
注意: 请确保您的机器上安装了匹配的 CUDA、CUDNN 和 NVIDIA 驱动程序。对于这个实验,我们使用 CUDA-10.2 和 CUDNN-8.0.3。但是如果你计划在 Google Colab 上运行这个实验,不要担心,因为所有这些库都预装了它。
步骤#1: 我们将在本实验中使用 GPU,因此请确保使用以下命令启动并运行 GPU:
# Sanity check for GPU as runtime
$ nvidia-smi
图 26 显示了机器(即 V100)、驱动程序和 CUDA 版本中可用的 GPU。
第二步:我们将安装一些库,比如 OpenCV,FFmpeg 等等。,这在编译和安装 darknet 之前是必需的。
# Install OpenCV, ffmpeg modules
$ apt install libopencv-dev python-opencv ffmpeg
步骤#3: 接下来,我们从 AlexyAB 存储库中克隆 darknet 框架的修改版本。如前所述,Darknet 是由 Joseph Redmon 编写的开源神经网络。用 C 和 CUDA 编写,同时支持 CPU 和 GPU 计算。然而,与之前的 YOLO 版本不同,这一次,YOLOv4 的创造者是 AlexyAB 本身。
# Clone AlexeyAB darknet repository
$ git clone https://github.com/AlexeyAB/darknet/
$ cd darknet/
确保将目录更改为 darknet,因为在下一步中,我们将配置Makefile并编译它。此外,使用!pwd进行健全性检查;我们应该在/content/darknet目录里。
步骤#4: 使用流编辑器(sed),我们将编辑 make 文件并启用标志:GPU、CUDNN、OPENCV 和 LIBSO。
图 27 显示了Makefile的一个片段,其内容将在后面讨论:
- 我们让
GPU=1和CUDNN=1与CUDA一起构建暗网来执行和加速对GPU的推理。注意CUDA应该在/usr/local/cuda;否则,编译将导致错误,但如果您在 Google Colab 上编译,请不要担心。 - 如果你的
GPU有张量核,使CUDNN_HALF=1获得最多3X推理和2X训练加速。由于我们使用具有张量内核的 Tesla V100 GPU,因此我们将启用此标志。 - 我们使
OPENCV=1能够与OpenCV一起构建暗网。这将允许我们检测视频文件、IP 摄像头和其他 OpenCV 现成的功能,如读取、写入和在帧上绘制边界框。 - 最后,我们让
LIBSO=1构建darknet.so库和一个使用这个库的二进制可运行的uselib文件。启用此标志允许我们使用 Python 脚本对图像和视频进行推理,并且我们将能够在其中导入darknet。
现在,让我们编辑Makefile并编译它。
# Enable the OpenCV, CUDA, CUDNN, CUDNN_HALF & LIBSO Flags and Compile Darknet
$ sed -i 's/OPENCV=0/OPENCV=1/g' Makefile
$ sed -i 's/GPU=0/GPU=1/g' Makefile
$ sed -i 's/CUDNN=0/CUDNN=1/g' Makefile
$ sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/g' Makefile
$ sed -i 's/LIBSO=0/LIBSO=1/g' Makefile
$ make
make 命令将需要大约 90 秒来完成执行。既然编译已经完成,我们就可以下载 YOLOv4 权重并运行推理了。
步骤#4: 我们现在将下载 YOLOv4 COCO 砝码。由于 Alexey Bochkovskiy 是 YOLOv4 的第一作者,这个模型的权重可以在他的 Darknet GitHub 知识库中找到,也可以从这里下载。有各种配置和重量文件可用(例如,YOLOv4、YOLOv4-Leaky 和 YOLOv4-SAM-Leaky)。我们将下载输入分辨率为 的原始 YOLOv4 模型权重
的原始 YOLOv4 模型权重
.
# Download YOLOv4 Weights
$ wget https://github.com/AlexeyAB/darknet/releases/download/
darknet_yolo_v3_optimal/yolov4.weights
步骤#5: 现在,我们将运行darknet_images.py脚本来推断图像。
# Run the darknet image inference script
$ python3 darknet_images.py --input data --weights \
yolov4.weights --config_file cfg/yolov4.cfg \
--dont_show
让我们来看看传递给darknet_images.py的命令行参数:
--input:图像目录或文本文件的路径,带有图像路径或单个图像名称。支持jpg、jpeg和png图像格式。在本例中,我们将路径传递给名为data的图像文件夹。--weights: YOLOv4 重量路径。--config_file:yolov 4 的配置文件路径。在抽象层次上,该文件存储神经网络模型架构和一些其他参数(例如,batch_size、classes、input_size等)。).我们建议您通过在文本编辑器中打开该文件来快速阅读它。- 这将禁止 OpenCV 显示推理结果,我们使用它是因为我们正在与 Google Colab 合作。
在对下面的图像运行 YOLOv4 预训练 COCO 模型后,我们了解到该模型没有任何错误,并且可以完美地检测到所有图像中的对象。与漏掉一匹马的 YOLOv3 相比,YOLOv4 检测到了所有五匹马。此外,我们观察到 YOLOv3 中的置信度得分提高;我们在 YOLOv4 中看到了类似的趋势,因为它比 YOLOv3 更有信心检测对象。
我们可以从图 28 中看到,该模型正确地预测了一只狗、一辆自行车和一辆卡车,并且置信度非常高。
在图 29 中,该模型以几乎 100%的置信度正确检测到所有三个对象,与 YOLOv3 网络非常相似。
回想一下,YOLOv3 没有检测到一匹马,但 YOLOv4 模型没有留下任何出错的余地,并且通过正确地检测所有的马,表现得非常好,并且具有非常高的可信度(图 30 )。这是一个有点复杂的图像,因为它有一组重叠的马。尽管如此,我们都可以花点时间来欣赏 YOLO 版本是如何发展的,在准确性和速度上都变得更好。
最后,在图 31 中,一个所有变体都能检测到的简单得多的图,YOLOv4 模型也能正确地检测到它。
步骤#6: 现在,我们将在电影《天降》的一个小片段上运行预先训练好的 YOLOv4 模型。
在运行darknet_video.py演示脚本之前,我们将首先使用pytube库从 YouTube 下载视频,并使用moviepy库裁剪视频。所以让我们快速安装这些模块并下载视频。
# Install pytube and moviepy for downloading and cropping the video
$ pip install git+https://github.com/rishabh3354/pytube@master
$ pip install moviepy
# Import the necessary packages
$ from pytube import YouTube
$ from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
# Download the video in 720p and Extract a subclip
$ YouTube('https://www.youtube.com/watch?v=tHRLX8jRjq8'). \ streams.filter(res="720p").first().download()
$ ffmpeg_extract_subclip("/content/darknet/Skyfall.mp4", \
0, 30, targetname="/content/darknet/Skyfall-Sample.mp4")
步骤#7: 最后,我们将运行darknet_video.py脚本来为天崩地裂的视频生成预测。我们打印输出视频每一帧的 FPS 信息。
如果使用 mp4 视频文件,请务必在 darknet_video.py 的第 57 行将set_saved_video功能中的视频编解码器从MJPG更改为mp4v;否则,播放推理视频时会出现解码错误。
# Change the VideoWriter Codec
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
既然所有必要的安装和修改都已完成,我们将运行darknet_video.py脚本:
# Run the darknet video inference script
$ python darknet_video.py --input \
/content/darknet/Skyfall-Sample.mp4 \
--weights yolov4.weights --config_file \
cfg/yolov4.cfg --dont_show --out_filename \
pred-skyfall.mp4
让我们看看传递给darknet_video.py的命令行参数:
--input:视频文件的路径,如果使用网络摄像头,则为 0--weights: YOLOv4 重量路径--config_file:yolov 4 的配置文件路径--dont_show:这将禁止 OpenCV 显示推理结果--out_filename:推理结果输出视频名称,如果为空,则输出视频不保存。
下面是对天崩地裂动作场景视频的推断结果。检测是密集的,毫无疑问,是所有 YOLO 变种中最好的。YOLOv4 网络在混合精度的 Tesla V100 GPU 上实现了平均 81 FPS (作者报道的 83 FPS)。
https://www.youtube.com/embed/p2dt4lljyLc****
使用 OpenCV ( cv2.adaptiveThreshold)进行自适应阈值处理
原文:https://pyimagesearch.com/2021/05/12/adaptive-thresholding-with-opencv-cv2-adaptivethreshold/
在本教程中,您将了解自适应阈值以及如何使用 OpenCV 和cv2.adaptiveThreshold函数应用自适应阈值。
上周,我们学习了如何使用cv2.threshold函数应用基本阈值和 Otsu 阈值。
当应用基本阈值时,我们不得不手动提供阈值 T ,以分割我们的前景和背景。
假设我们的输入图像中的像素强度呈双峰分布,Otsu 的阈值方法可以自动确定 T 的最佳值。
然而,这两种方法都是全局阈值技术,这意味着使用相同的值 T 来测试输入图像中的所有像素,从而将它们分割成前景和背景。
这里的问题是只有一个值可能不够。由于光照条件、阴影等的变化。可能的情况是, T 的一个值将对输入图像的某一部分起作用,但在不同的部分将完全失效。
*我们可以利用自适应阈值处理,而不是立即抛出我们的手,声称传统的计算机视觉和图像处理不会解决这个问题(从而立即跳到训练像 Mask R-CNN 或 U-Net 这样的深度神经分割网络)。
顾名思义,自适应阈值处理一次考虑一小组相邻像素,为该特定局部区域计算 T ,然后执行分割。
根据您的项目,利用自适应阈值可以使您:
- 获得比使用全局阈值方法更好的分割,例如基本阈值和 Otsu 阈值
- 避免训练专用掩模 R-CNN 或 U-Net 分割网络的耗时且计算昂贵的过程
要了解如何使用 OpenCV 和cv2.adaptiveThreshold函数、 执行自适应阈值处理,请继续阅读。
使用 OpenCV ( cv2.adaptiveThreshold)的自适应阈值处理
在本教程的第一部分,我们将讨论什么是自适应阈值处理,包括自适应阈值处理与我们到目前为止讨论的“正常”全局阈值处理方法有何不同。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后我将向您展示如何使用 OpenCV 和cv2.adaptiveThreshold函数实现自适应阈值处理。
我们将讨论我们的自适应阈值结果来结束本教程。
什么是自适应阈值处理?自适应阈值与“正常”阈值有何不同?
正如我们在本教程前面所讨论的,使用简单阈值方法的一个缺点是我们需要手动提供我们的阈值, T 。此外,找到一个好的 T 值可能需要许多手动实验和参数调整,这在大多数情况下是不实际的。
为了帮助我们自动确定 T 的值,我们利用了 Otsu 的方法。虽然 Otsu 的方法可以节省我们玩“猜测和检查”游戏的大量时间,但我们只剩下一个单一的值 T 来对整个图像进行阈值处理。
对于光线条件受控的简单图像,这通常不是问题。但是对于图像中光照不均匀的情况,只有单一的值 T 会严重损害我们的阈值处理性能。
简单来说,只有一个值 T 可能不够。
为了克服这个问题,我们可以使用自适应阈值处理,它考虑像素的小邻居,然后为每个邻居找到一个最佳阈值 T 。这种方法允许我们处理像素强度可能存在巨大范围的情况,并且 T 的最佳值可能因图像的不同部分而变化。
在自适应阈值处理中,有时称为局部阈值处理,我们的目标是统计检查给定像素的邻域中的像素强度值, p 。
作为所有自适应和局部阈值方法基础的一般假设是,图像的较小区域更可能具有近似均匀的照明。这意味着图像的局部区域将具有相似的照明,与图像整体相反,图像整体的每个区域可能具有显著不同的照明。
然而,为局部阈值选择像素邻域的大小是绝对关键的。
邻域必须足够大以覆盖足够的背景和前景像素,否则 T 的值将或多或少无关紧要。
但是如果我们使我们的邻域值太大,那么我们完全违背了图像的局部区域将具有近似均匀照明的假设。同样,如果我们提供非常大的邻域,那么我们的结果将看起来非常类似于使用简单阈值或 Otsu 方法的全局阈值。
实际上,调整邻域大小(通常)并不是一个困难的问题。您通常会发现,有很大范围的邻域大小可以为您提供足够的结果-这不像找到一个最佳值 T ,它可能会影响或破坏您的阈值输出。
自适应阈值处理的数学基础
正如我上面提到的,我们在自适应阈值处理中的目标是统计地检查我们图像的局部区域,并为每个区域确定一个最佳值T——这就引出了一个问题:我们使用哪个统计量来计算每个区域的阈值 T?
通常的做法是使用每个区域中像素强度的算术平均值或高斯平均值(确实存在其他方法,但是算术平均值和高斯平均值是最流行的)。
在算术平均中,邻域中的每个像素对计算 T 的贡献相等。并且在高斯均值中,离区域的 (x,y)-坐标中心越远的像素值对 T 的整体计算贡献越小。
计算 T 的一般公式如下:
T =均值(I[L])–C
其中平均值是算术平均值或高斯平均值, I [L] 是图像的局部子区域, I ,并且 C 是我们可以用来微调阈值 T 的某个常数。
如果这一切听起来令人困惑,不要担心,我们将在本教程的后面获得使用自适应阈值的实践经验。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从回顾我们的项目目录结构开始。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像:
$ tree . --dirsfirst
.
├── adaptive_thresholding.py
└── steve_jobs.png
0 directories, 2 files
今天我们要回顾一个 Python 脚本,adaptive_thresholding.py。
我们将把这个脚本应用到我们的示例图像steve_jobs.png,它将显示比较和对比的结果:
- 基本全局阈值
- Otsu 全局阈值
- 自适应阈值
我们开始吧!
使用 OpenCV 实施自适应阈值处理
我们现在准备用 OpenCV 实现自适应阈值!
打开项目目录中的adaptive_thresholding.py文件,让我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包— argparse用于命令行参数,而cv2用于 OpenCV 绑定。
从那里我们解析我们的命令行参数。这里我们只需要一个参数,--image,它是我们想要阈值化的输入图像的路径。
现在让我们从磁盘加载我们的映像并对其进行预处理:
# load the image and display it
image = cv2.imread(args["image"])
cv2.imshow("Image", image)
# convert the image to grayscale and blur it slightly
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (7, 7), 0)
我们首先从磁盘加载我们的image,并在屏幕上显示原始图像。
在那里,我们对图像进行预处理,将它转换成灰度并用一个 7 × 7 内核进行模糊处理。应用高斯模糊有助于移除图像中我们不关心的一些高频边缘,并允许我们获得更“干净”的分割。
现在让我们应用带有硬编码阈值T=230的基本阈值:
# apply simple thresholding with a hardcoded threshold value
(T, threshInv) = cv2.threshold(blurred, 230, 255,
cv2.THRESH_BINARY_INV)
cv2.imshow("Simple Thresholding", threshInv)
cv2.waitKey(0)
在这里,我们应用基本的阈值处理并在屏幕上显示结果(如果你想了解简单阈值处理如何工作的更多细节,你可以阅读上周关于 OpenCV 阈值处理(cv2.threshold ) 的教程)。
接下来,让我们应用 Otsu 的阈值方法,该方法自动计算我们的阈值参数T的最佳值,假设像素强度的双峰分布:
# apply Otsu's automatic thresholding
(T, threshInv) = cv2.threshold(blurred, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
cv2.imshow("Otsu Thresholding", threshInv)
cv2.waitKey(0)
现在,让我们使用平均阈值方法应用自适应阈值:
# instead of manually specifying the threshold value, we can use
# adaptive thresholding to examine neighborhoods of pixels and
# adaptively threshold each neighborhood
thresh = cv2.adaptiveThreshold(blurred, 255,
cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 21, 10)
cv2.imshow("Mean Adaptive Thresholding", thresh)
cv2.waitKey(0)
第 34 行和第 35 行使用 OpenCV 的cv2.adaptiveThreshold函数应用自适应阈值。
我们从传入模糊的输入图像开始。
第二个参数是输出阈值,就像简单的阈值处理和 Otsu 方法一样。
第三个论点是自适应阈值方法。这里我们提供一个值cv2.ADAPTIVE_THRESH_MEAN_C来表示我们正在使用局部像素邻域的算术平均值来计算我们的阈值T。
我们还可以提供一个值cv2.ADAPTIVE_THRESH_GAUSSIAN_C(我们接下来会这样做)来表示我们想要使用高斯平均值——您选择哪种方法完全取决于您的应用和情况,所以您会想要尝试这两种方法。
cv2.adaptiveThreshold的第四个值是阈值法,也与简单阈值法和 Otsu 阈值法一样。这里我们传入一个值cv2.THRESH_BINARY_INV来表示任何通过阈值测试的像素值都将有一个输出值0。否则,它的值将为255。
第五个参数是我们的像素邻域大小。这里你可以看到,我们将计算图像中每个 21×21 子区域的平均灰度像素强度值,以计算我们的阈值T。
cv2.adaptiveThreshold的最后一个参数是我上面提到的常数C——这个值只是让我们微调我们的阈值。
可能存在平均值本身不足以区分背景和前景的情况——因此,通过增加或减少一些值C,我们可以改善阈值的结果。同样,您为C使用的值完全取决于您的应用和情况,但是这个值很容易调整。
在这里,我们设置C=10。
最后,平均自适应阈值的输出显示在我们的屏幕上。
现在让我们来看看高斯版本的自适应阈值处理:
# perform adaptive thresholding again, this time using a Gaussian
# weighting versus a simple mean to compute our local threshold
# value
thresh = cv2.adaptiveThreshold(blurred, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 21, 4)
cv2.imshow("Gaussian Adaptive Thresholding", thresh)
cv2.waitKey(0)
这一次,我们计算的是 21×21 T2 区域的加权高斯平均值,它赋予靠近窗口中心的像素更大的权重。然后我们设置C=4,这个值是我们在这个例子中根据经验调整的。
最后,高斯自适应阈值的输出显示在我们的屏幕上。
自适应阈值结果
让我们把自适应阈值工作!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,您可以执行adaptive_thresholding.py脚本:
$ python adaptive_thresholding.py --image steve_jobs.png
在这里,你可以看到我们的输入图像,steve_jobs.png,这是苹果电脑公司史蒂夫·乔布斯的名片:
我们的目标是从背景(名片的其余部分)中分割出前景(苹果标志和文字)。
使用具有预设值 T 的简单阈值能够在某种程度上执行这种分割:
是的,苹果的标志和文字是前景的一部分,但我们也有很多噪声(这是不可取的)。
让我们看看 Otsu 阈值处理能做什么:
不幸的是,Otsu 的方法在这里失败了。所有的文本都在分割中丢失了,还有苹果标志的一部分。
幸运的是,我们有自适应阈值来拯救:
图 6 显示了平均自适应阈值的输出。
通过应用自适应阈值处理,我们可以对输入图像的局部区域进行阈值处理(而不是使用我们的阈值参数 T 的全局值)。这样做极大地改善了我们的前景和分割结果。
现在让我们看看高斯自适应阈值处理的输出:
这种方法提供了最好的结果。文本和大部分苹果标志一样是分段的。然后我们可以应用形态学操作来清理最终的分割。
总结
在本教程中,我们学习了自适应阈值和 OpenCV 的cv2.adaptiveThresholding功能。
与作为全局阈值化方法的基本阈值化和 Otsu 阈值化不同,自适应阈值化代替了对像素的局部邻域进行阈值化。
本质上,自适应阈值处理假设图像的局部区域将比图像整体具有更均匀的照明和光照。因此,为了获得更好的阈值处理结果,我们应该研究图像的子区域,并分别对它们进行阈值处理,以获得我们的最终输出图像。
自适应阈值处理往往会产生良好的结果,但在计算上比 Otsu 方法或简单阈值处理更昂贵,但在照明条件不均匀的情况下,自适应阈值处理是一种非常有用的工具。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!**
用 Flask 为我们的图像搜索引擎添加一个 web 界面
原文:https://pyimagesearch.com/2014/12/08/adding-web-interface-image-search-engine-flask/
这是来自真实 Python 的 Michael Herman 的客座博文——通过实用有趣的实例来学习 Python 编程和 web 开发!
在本教程中,我们将从之前的教程中获取命令行图像搜索引擎,并使用 Python 和 Flask 将其转化为成熟的 web 应用程序。更具体地说,我们将创建一个单页面应用程序 (SPA),它通过 AJAX(在前端)从内部类似 REST 的 API 通过 Python/Flask(在后端)消费数据。
最终产品将如下所示:
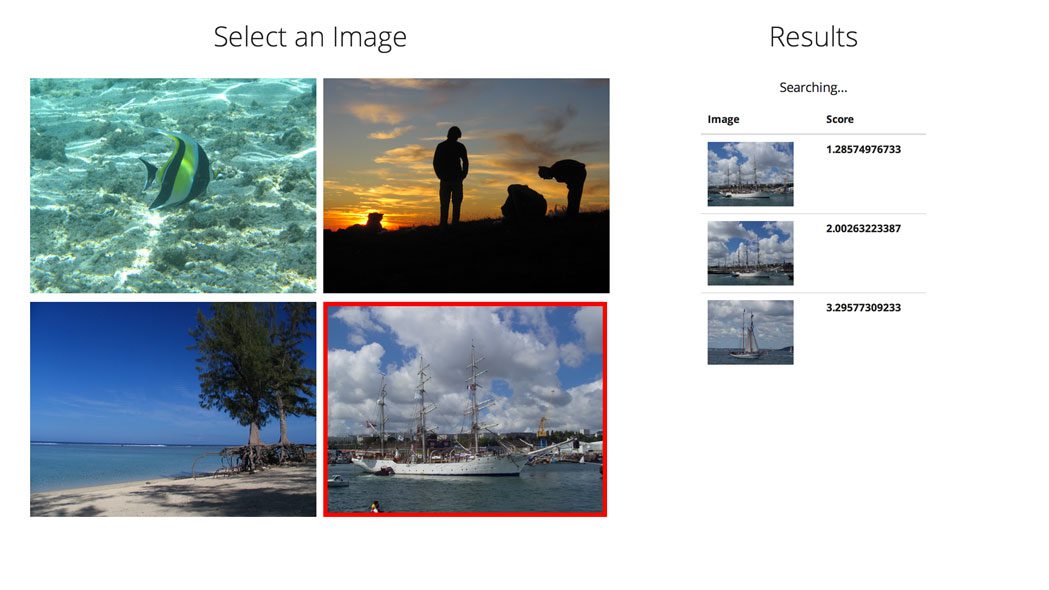
新来的烧瓶? 从官方快速入门指南或者第二期真正的 Python 课程中的“Flask: QuickStart”章节开始。
设置
你可以在有或没有 Docker 的情况下设置你的开发。
与 Docker:
如果你没有安装 Docker,按照官方 Docker 文档安装 Docker 和 boot2docker。然后启动并运行 boot2docker,运行docker version来测试 docker 安装。
创建一个目录来存放你的项目“flask-image-search”。
从库中抓取 _setup.zip ,解压缩文件,并将它们添加到您的项目目录中。
现在构建 Docker 映像:
$ docker build --rm -t opencv-docker .
构建完成后,运行 Docker 容器:
$ docker run -p 80:5000 opencv-docker
打开您的 web 浏览器,导航到与 DOCKER_HOST 变量相关联的 IP 地址——应该是http://192 . 168 . 59 . 103/;如果没有,运行boot2docker ip获得正确的地址——您应该看到文本“欢迎!”在您的浏览器中。
不带 Docker:
创建一个目录来存放你的项目“flask-image-search”。
从库中抓取 _setup.zip ,解压缩文件,并将它们添加到您的项目目录中。创建并激活一个 virtualenv,然后通过 Pip 安装需求:
$ pip install flask numpy scipy matplotlib scikit-image gunicorn
$ pip freeze > requirements.txt
基础
既然你已经构建了搜索引擎,我们只需要将相关的代码转移到 Flask。本质上,我们只是将图像搜索引擎包装在 Flask 中。
现在,您的项目目录应该如下所示:
├── Dockerfile
├── app
│ ├── app.py
│ ├── index.csv
│ ├── pyimagesearch
│ │ ├── __init__.py
│ │ ├── colordescriptor.py
│ │ └── searcher.py
│ ├── static
│ │ ├── main.css
│ │ └── main.js
│ └── templates
│ ├── _base.html
│ └── index.html
├── config
│ ├── app.ini
│ ├── nginx.conf
│ └── supervisor.conf
└── requirements.txt
Dockerfile 和带有“config”目录的文件专门用于让我们的应用程序在 Docker 容器中运行(当然,如果你使用 Docker 的话)。不要太担心这些是如何工作的,但是如果你好奇,你可以参考 Dockerfile 中的行内注释。在“app”目录中, index.csv 文件以及“pyimagesearch”目录中的文件是图像搜索引擎所特有的。更多信息请参考之前的教程。
现在,让我们仔细看看“app”目录中特定于 Flask 的文件和文件夹:
- app.py 文件是我们的 Flask 应用程序。一定要参考文件中的行内注释,以充分理解发生了什么。需要注意的是,在大多数情况下,你应该把你的应用分成更小的部分。然而,由于这个应用程序(以及我们完成的应用程序)很小,我们可以将所有功能存储在一个文件中。
- “静态”目录存放静态文件,如样式表、JavaScript 文件、图像等。
- “模板”目录存放了我们应用程序的模板。看看 _base.html 和【base.html】模板模板之间的关系。这叫做模板继承。想了解更多,请看的这篇博文。
这就是我们目前的项目结构。就这样,让我们开始建设吧!
工作流程
简而言之,我们将关注两个路由/端点:
- 主路由('/'):该路由处理主用户交互。用户可以选择一个图像(向搜索路径发送 POST 请求),然后显示相似的图像。
- 搜索路由('/search '):此路由处理 POST 请求。它将采取一个图像(名称),然后使用大多数搜索引擎代码返回类似的图像(网址)。
后端
干线
后端代码已经设置好了。没错——我们只需要在用户请求/时呈现一个模板。然而,我们确实需要更新模板,index.html,以及添加 HTML、CSS 和 Javascript/jQuery 代码。这将在前端部分处理。
搜索路线
同样,这条路线旨在:
- 处理发布请求,
- 拍摄一张图片并搜索相似的图片(使用已经完成的搜索引擎代码),以及
- 以 JSON 格式返回相似的图片(以 URL 的形式)
将下面的代码添加到 app.py 中,就在主路由的下面。
# search route
@app.route('/search', methods=['POST'])
def search():
if request.method == "POST":
RESULTS_ARRAY = []
# get url
image_url = request.form.get('img')
try:
# initialize the image descriptor
cd = ColorDescriptor((8, 12, 3))
# load the query image and describe it
from skimage import io
import cv2
query = io.imread(image_url)
query = (query * 255).astype("uint8")
(r, g, b) = cv2.split(query)
query = cv2.merge([b, g, r])
features = cd.describe(query)
# perform the search
searcher = Searcher(INDEX)
results = searcher.search(features)
# loop over the results, displaying the score and image name
for (score, resultID) in results:
RESULTS_ARRAY.append(
{"image": str(resultID), "score": str(score)})
# return success
return jsonify(results=(RESULTS_ARRAY[:3]))
except:
# return error
jsonify({"sorry": "Sorry, no results! Please try again."}), 500
发生了什么事?
- 我们定义端点
/search',以及允许的 HTTP 请求方法methods=['POST']。快速跳回/主端点。请注意,我们没有指定允许的请求方法。为什么?这是因为默认情况下,所有端点都响应 GET 请求。 - 我们抓取图像,然后使用 try/except 搜索相似的图像。
- 将上面代码中的循环与之前教程中的 search.py 中的循环进行比较。这里,我们不是输出结果,而是简单地获取它们并将其添加到一个列表中。然后,这个列表被传递到一个名为
jsonify的特殊 Flask 函数中,该函数返回一个 JSON 响应。
请务必更新导入-
import os
from flask import Flask, render_template, request, jsonify
from pyimagesearch.colordescriptor import ColorDescriptor
from pyimagesearch.searcher import Searcher
-并在创建 Flask 实例的下面添加以下变量,该变量指定图像搜索中使用的 index.csv 文件的路径-
INDEX = os.path.join(os.path.dirname(__file__), 'index.csv')
我们将在下一节中查看它的确切输出。
前端
因此,后端代码完成后,我们只需要更新结构和感觉(通过 HTML 和 CSS)以及添加用户交互(通过 JavaScript/jQuery)。为此,我们将使用 Bootstrap 前端框架。
打开 _base.html 模板。
我们已经包含了 Bootstrap 样式表(通过一个 CDN )以及 jQuery 和 Bootstrap JavaScript 库以及一个定制样式表和 JavaScript 文件(两者都位于“static”文件夹中):
<!-- stylesheets -->
<link href="//maxcdn.bootstrapcdn.com/bootswatch/3.2.0/yeti/bootstrap.min.css" rel="stylesheet" media="screen">
<link href="{{ url_for('static', filename='main.css') }}" rel="stylesheet">
... snip ...
<!-- Scripts -->
<script src="//code.jquery.com/jquery-2.1.1.min.js" type="text/javascript"></script>
<script src="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/js/bootstrap.min.js" type="text/javascript"></script>
<script src="{{ url_for('static', filename='main.js') }}" type="text/javascript"></script>
模板
首先,让我们更新一下index.html模板:
{% extends "_base.html" %}
{% block content %}
<div class="row">
<div class="col-md-7">
<h2>Select an Image</h2>
<br>
<div class="row">
<div class="col-md-6">
<p><img src="https://static.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/103100.png" style="height: 250px;" class="img"></p>
<p><img src="https://static.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/103300.png" style="height: 250px;" class="img"></p>
</div>
<div class="col-md-6">
<p><img src="https://static.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/127502.png" style="height: 250px;" class="img"></p>
<p><img src="https://static.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/123600.png" style="height: 250px;" class="img"></p>
</div>
</div>
</div>
<div class="col-md-3 col-md-offset-1">
<h2>Results</h2>
<br>
<table class="table" id="results-table">
<thead>b
<tr>
<th>Image</th>
<th>Score</th>
</tr>
</thead>
<tbody id="results">
</tbody>
</table>
</div>
</div>
<br>
{% endblock %}
现在我们来测试一下…
与 Docker:
重建 Docker 映像,然后运行新容器:
$ docker build --rm -t opencv-docker .
$ docker run -p 80:5000 opencv-docker
不带 Docker:
$ python app/app.py
在浏览器中导航至您的应用,您应该会看到:

正如您所看到的,我们在左侧添加了四个图像,在右侧添加了一个结果表。注意上面 HTML 代码中的 CSS 选择器 ( id s 和class es)。row和col-md-x类与引导网格系统相关联。剩下的id和class es 用于添加 CSS 样式和/或通过 JavaScript/jQuery 进行交互。
JavaScript/jQuery
注: 如果你不熟悉 JavaScript 和 jQuery 基础知识,请查阅 Madlibs 教程。
让我们将用户交互分解为每一个单独的交互。
图像点击
互动从图像点击开始。换句话说,最终用户单击页面左侧四个图像中的一个,最终目标是找到相似的图像。
更新 main.js 文件:
// ----- custom js ----- //
$(function() {
// sanity check
console.log( "ready!" );
// image click
$(".img").click(function() {
// add active class to clicked picture
$(this).addClass("active")
// grab image url
var image = $(this).attr("src")
console.log(image)
});
});
运行您的应用程序。要么:
- 重建 Docker 映像,并运行新容器。
- 运行
python app/app.py
然后在浏览器中导航至您的应用程序。打开您的 JavaScript 控制台,然后单击其中一个图像。您应该看到:
 所以,jQuery 代码通过抓取被点击的特定图片的 URL,并添加一个 CSS 类(这个类我们还需要添加到 CSS 文件中)来处理点击事件。jQuery 代码和 HTML 之间的链接分别是
所以,jQuery 代码通过抓取被点击的特定图片的 URL,并添加一个 CSS 类(这个类我们还需要添加到 CSS 文件中)来处理点击事件。jQuery 代码和 HTML 之间的链接分别是img类—$(".img").click(function()和class="img"。这一点应该是清楚的。
AJAX 请求
有了图像 URL,我们现在可以通过一个 AJAX 请求将它发送到后端,这是一种客户端技术,用于发出不会导致整个页面刷新的异步请求。大多数 spa 在请求数据时使用某种异步技术来防止页面刷新,因为这可以增强整体用户体验。
更新 main.js 这样:
// ----- custom js ----- //
$(function() {
// sanity check
console.log( "ready!" );
// image click
$(".img").click(function() {
// add active class to clicked picture
$(this).addClass("active")
// grab image url
var image = $(this).attr("src")
console.log(image)
// ajax request
$.ajax({
type: "POST",
url: "/search",
data : { img : image },
// handle success
success: function(result) {
console.log(result.results);
},
// handle error
error: function(error) {
console.log(error);
}
});
});
});
你知道该怎么做:运行应用程序,然后刷新浏览器。再次点按图像,几秒钟后您应该会看到:
 注意: 这个请求相当慢,因为我们搜索的是 CSV 而不是实际的数据库,即 SQLite、Postgres、MySQL。将数据转换成数据库是一件相当简单的工作。自己试试这个。如果您有问题和/或希望我们查看的解决方案,请随时在下面发表评论。干杯!
注意: 这个请求相当慢,因为我们搜索的是 CSV 而不是实际的数据库,即 SQLite、Postgres、MySQL。将数据转换成数据库是一件相当简单的工作。自己试试这个。如果您有问题和/或希望我们查看的解决方案,请随时在下面发表评论。干杯!
这一次,在用户点击之后,我们向/search端点发送一个 POST 请求,其中包括图像 URL。后端执行它的魔法(抓取图像,运行搜索代码),然后以 JSON 格式返回结果。AJAX 请求有两个处理程序——一个用于成功,一个用于失败。跳回到后端,/search路由或者返回 200 响应(成功)或者 500 响应(失败)以及数据或错误消息:
# return success
return jsonify(results=(RESULTS_ARRAY[::-1]))
except:
# return error
jsonify({"sorry": "Sorry, no results! Please try again."}), 500
回到前端…由于结果是成功的,您可以在 JavaScript 控制台中看到数据:
[Object, Object, Object, Object, Object, Object, Object, Object, Object, Object]
这只是一个 JSON 对象的数组。继续展开数组并打开单个对象:
 所以,每个对象都有一个图像和一个表示查询图像和结果图像之间“相似度”的分数。分数越小,查询与结果越“相似”。相似度为零表示“完全相似”。这就是我们想要呈现给最终用户的确切数据。
所以,每个对象都有一个图像和一个表示查询图像和结果图像之间“相似度”的分数。分数越小,查询与结果越“相似”。相似度为零表示“完全相似”。这就是我们想要呈现给最终用户的确切数据。
更新 DOM
我们在最后冲刺阶段!让我们更新成功和错误处理程序,以便一旦其中一个从后端接收到数据,我们就将该数据追加到 DOM:
<a href="'+url+data[i][" data-mce-href="'+url+data[i][">'+data[i]["image"]+'</a>'+data[i]['score']+'') }; }, // handle error error: function(error) { console.log(error); // show error $("#error").show(); }" >// handle success
success: function(result) {
console.log(result.results);
var data = result.results
// loop through results, append to dom
for (i = 0; i < data.length; i++) {
$("#results").append('<tr><th><a href="'+url+data[i]["image"]+'">'+data[i]["image"]+'</a></th><th>'+data[i]['score']+'</th></tr>')
};
},
// handle error
error: function(error) {
console.log(error);
// show error
$("#error").show();
}
在成功处理程序中,我们遍历结果,添加一些 HTML(用于表格),然后将数据附加到 idresults(它已经是 HTML 模板的一部分)。错误处理程序实际上并没有用返回的确切的错误来更新 DOM。相反,我们将确切的错误记录到控制台,供我们查看,然后“取消隐藏”一个 id 为error的 HTML 元素(同样,我们需要将其添加到 HTML 模板中)。
我们还需要在文件 JavaScript 文件的顶部添加一些全局变量:
// ----- custom js ----- //
// global
var url = 'http://static.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/dataset/';
var data = [];
... snip ...
浏览文件,看看能否找到这些变量的用法。
最后,在我们测试之前,让我们更新一下index.html模板…
添加:
<p id="error">Oh no! No results! Check your internet connection.</p>
正上方:
<table class="table" id="results-table">
好吧。想想我们测试的时候会发生什么。如果一切顺利,您应该会看到:

嘣!您甚至可以点击图像 URL 来查看实际的结果(例如,相似的图像)。请注意您是如何看到错误的。我们还有一些清理工作要做。
DOM 清理
主要功能完成后,我们只需要做一些日常工作。更新 main.js 这样:
// ----- custom js ----- //
// hide initial
$("#searching").hide();
$("#results-table").hide();
$("#error").hide();
// global
var url = 'http://static.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/dataset/';
var data = [];
$(function() {
// sanity check
console.log( "ready!" );
// image click
$(".img").click(function() {
// empty/hide results
$("#results").empty();
$("#results-table").hide();
$("#error").hide();
// add active class to clicked picture
$(this).addClass("active")
// grab image url
var image = $(this).attr("src")
console.log(image)
// show searching text
$("#searching").show();
console.log("searching...")
// ajax request
$.ajax({
type: "POST",
url: "/search",
data : { img : image },
// handle success
success: function(result) {
console.log(result.results);
var data = result.results
// loop through results, append to dom
for (i = 0; i < data.length; i++) {
$("#results").append('<tr><th><a href="'+url+data[i]["image"]+'">'+data[i]["image"]+'</a></th><th>'+data[i]['score']+'</th></tr>')
};
},
// handle error
error: function(error) {
console.log(error);
// append to dom
$("#error").append()
}
});
});
});
看一看添加的代码…
// hide initial
$("#searching").hide();
$("#results-table").hide();
$("#error").hide();
和
// empty/hide results
$("#results").empty();
$("#results-table").hide();
$("#error").hide();
和
// remove active class
$(".img").removeClass("active")
和
// show searching text
$("#searching").show();
console.log("searching...")
和
// show table
$("#results-table").show();
我们只是根据用户交互以及 AJAX 请求的结果是成功还是失败来隐藏和显示不同的 HTML 元素。如果你真的很注意,你可能会看到有一个你以前没有见过的新的 CSS 选择器—#searching。这是什么意思?首先,我们需要更新模板…
添加:
<p id="searching">Searching...</p>
正上方:
<p id="error">Oh no! No results! Check your internet connection.</p>
现在,我们来测试一下!有什么不同?当最终用户点击一个图像时,文本Searching...出现,当结果被添加时,文本消失。然后,如果用户单击另一个图像,以前的结果会消失,Searching...文本会重新出现,最后新的结果会添加到 DOM 中。
深呼吸。或者两个。我们现在已经完成了 JavaScript 部分。在继续之前,最好先回顾一下。
半铸钢ˌ钢性铸铁(Cast Semi-Steel)
在风格方面,我们可以做很多事情,但让我们保持简单。将以下代码添加到 main.css 中:
.center-container {
text-align: center;
padding-top: 20px;
padding-bottom: 20px;
}
.active {
border: 5px solid red;
}
运行应用程序,它现在应该看起来像这样:
 最大的变化是现在当用户点击一个图像时,它的周围会出现一个红色的边框,只是提醒最终用户她/他点击了哪个图像。请尝试单击另一个图像。红色边框现在应该出现在图像周围。返回 JavaScript 文件,查看代码,了解这是如何工作的。
最大的变化是现在当用户点击一个图像时,它的周围会出现一个红色的边框,只是提醒最终用户她/他点击了哪个图像。请尝试单击另一个图像。红色边框现在应该出现在图像周围。返回 JavaScript 文件,查看代码,了解这是如何工作的。
重构
我们可以在这里停下来,但是让我们稍微重构一下代码,以显示前三个结果的缩略图。毕竟,这是一个图片搜索引擎——我们应该展示一些真实的图片!
从后端开始,更新search()视图函数,以便它只返回前三个结果:
return jsonify(results=(RESULTS_ARRAY[::-1][:3]))
接下来更新成功处理程序 main.js 中的 for 循环:
// loop through results, append to dom
for (i = 0; i < data.length; i++) {
$("#results").append('<tr><th><a href="'+url+data[i]["image"]+'"><img src="'+url+data[i]["image"]+
'" class="result-img"></a></th><th>'+data[i]['score']+'</th></tr>')
};
最后,添加以下 CSS 样式:
.result-img {
max-width: 100px;
max-height: 100px;
}
您现在应该已经:
嘣!
结论和下一步措施
概括地说,我们从第一篇教程中提取了搜索引擎代码,并将其封装在 Flask 中,以创建一个全功能的 web 应用程序。如果您想继续从事 Flask 和 web 开发,请尝试:
- 用关系数据库替换静态 CSV 文件;
- 通过允许用户上传图像来更新整体用户体验,而不是限制用户仅通过四个图像进行搜索;
- 添加单元和集成测试;
- 部署到赫罗库。
请务必查看真正的 Python 课程,学习如何做所有这些以及更多。
干杯!
使用 FGSM(快速梯度符号法)的对抗性攻击
原文:https://pyimagesearch.com/2021/03/01/adversarial-attacks-with-fgsm-fast-gradient-sign-method/
在本教程中,您将学习如何使用快速梯度符号法(FGSM)进行对抗性攻击。我们将使用 Keras 和 TensorFlow 实现 FGSM。

之前,我们学习了如何实施两种形式的对抗性图像攻击:
- 无针对性对抗性攻击,我们无法控制对抗性图像的输出标签。
- 有针对性的对抗性攻击,这里我们可以控制图像的输出标签。
今天我们来看看另一种无针对性的对抗性图像生成方法,叫做快速梯度符号法(FGSM)。正如您将看到的,这个方法非常容易实现。
然后,在接下来的两周内,您将学习如何通过更新您的训练程序以利用 FGSM 来防御敌对攻击,从而提高您的模型的准确性和健壮性。
学习如何用快速梯度符号法进行对抗性攻击,继续阅读。
利用 FGSM(快速梯度符号法)的对抗性攻击
在本教程的第一部分,你将了解快速梯度符号方法及其在敌对图像生成中的应用。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们将实现三个 Python 脚本:
- 第一个将包含
SimpleCNN,我们将在 MNIST 数据集上训练的基本 CNN 的实现。 - 我们的第二个 Python 脚本将包含我们用于对抗性图像生成的 FGSM 实现。
- 最后,我们的第三个脚本将训练我们的 CNN 了解 MNIST,然后演示如何使用 FGSM 来欺骗我们训练过的 CNN 做出不正确的预测。
如果你还没有,我推荐你阅读我之前的两篇关于对抗性图像生成的教程:
这两个指南被认为是必读书目,因为我假设你已经知道了对抗性图像生成的基础知识。如果你还没有看过那些教程,我建议你现在就停下来,先看看。
快速梯度符号法
快速梯度符号法是一种简单而有效的生成对抗图像的方法。Goodfellow 等人在他们的论文 中首次介绍了解释和利用对立范例 ,FGSM 的工作原理是:
- 拍摄输入图像
- 使用经过训练的 CNN 对图像进行预测
- 基于真类标签计算预测的损失
- 计算损失相对于输入图像的梯度
- 计算梯度的符号
- 使用带符号的梯度来构造输出对抗图像
这个过程听起来可能很复杂,但是正如您将看到的,我们将能够用不到 30 行代码(包括注释)实现整个 FGSM 功能。
快速梯度符号法是如何工作的?
FGSM 利用神经网络的梯度来构建对抗图像,类似于我们在无目标对抗攻击和有目标对抗攻击教程中所做的。
本质上,FGSM 计算损失函数(例如,均方误差或分类交叉熵)相对于输入图像的梯度,然后使用梯度的符号来创建一个新图像(即,对手图像)最大化损失。
结果是输出图像,根据人眼,看起来与原始图像相同,但是使神经网络做出不正确的预测!***
引用 FGSM 上的 TensorFlow 文档,我们可以使用以下等式表达快速梯度符号法:
其中:
 : 我方输出对抗性图像
: 我方输出对抗性图像 : 原始输入图像
: 原始输入图像 :输入图像的地面实况标签
:输入图像的地面实况标签 :小值我们将带符号的梯度乘以,以确保扰动足够小以至于人眼无法检测到它们,但是足够大以至于它们愚弄了神经网络
:小值我们将带符号的梯度乘以,以确保扰动足够小以至于人眼无法检测到它们,但是足够大以至于它们愚弄了神经网络 :我们的神经网络模型
:我们的神经网络模型 :损失功能
:损失功能
 : 我方输出对抗性图像
: 我方输出对抗性图像 :小值我们将带符号的梯度乘以,以确保扰动足够小以至于人眼无法检测到它们,但是足够大以至于它们愚弄了神经网络
:小值我们将带符号的梯度乘以,以确保扰动足够小以至于人眼无法检测到它们,但是足够大以至于它们愚弄了神经网络 :我们的神经网络模型
:我们的神经网络模型 :损失功能
:损失功能如果你很难理解围绕 FGSM 的数学,不要担心,一旦我们在本指南后面开始看一些代码,理解起来会容易得多。
配置您的开发环境
这篇关于 FGSM 的对立图像的教程使用了 Keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都有助于在一个方便的 Python 虚拟环境中为您的系统配置这篇博客文章所需的所有软件。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从回顾我们的项目目录结构开始。请务必访问本教程的 【下载】 部分以检索源代码:
$ tree . --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── fgsm.py
│ └── simplecnn.py
└── fgsm_adversarial.py
1 directory, 4 files
在pyimagesearch模块中,我们有两个将要实现的 Python 脚本:
simplecnn.py:一个基本的 CNN 架构fgsm.py:我们实施的快速梯度标志法对抗性攻击
fgsm_adversarial.py文件是我们的驱动脚本。它将:
- 实例化
SimpleCNN的一个实例 - 在 MNIST 数据集上训练它
- 演示如何将 FGSM 对抗性攻击应用于训练好的模型
为对抗训练创建一个简单的 CNN 架构
在我们能够执行对抗性攻击之前,我们首先需要实现我们的 CNN 架构。
一旦我们的架构实现,我们将在 MNIST 数据集上训练它,评估它,使用 FGSM 生成一组对立图像,并重新评估它,从而证明对立图像对准确性的影响。
在下周和下一周的教程中,你将会学到一些训练技巧,你可以用这些技巧来抵御这些对抗性攻击。
但是这一切都是从实现 CNN 架构开始的——打开我们项目目录结构的pyimagesearch模块中的simplecnn.py,让我们开始工作:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
我们从第 2-8 行的开始,导入我们需要的 Keras/TensorFlow 类。当训练 CNN 时,这些都是相当标准的输入。
如果你是 Keras 和 TensorFlow 的新手,我建议你阅读我的入门 Keras 教程以及我的书 用 Python 进行计算机视觉的深度学习 ,其中详细介绍了深度学习。
考虑到我们的导入,我们可以定义我们的 CNN 架构:
class SimpleCNN:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# first CONV => RELU => BN layer set
model.add(Conv2D(32, (3, 3), strides=(2, 2), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
# second CONV => RELU => BN layer set
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
我们的SimpleCNN类的build方法接受四个参数:
width:数据集中输入图像的宽度height:数据集中输入图像的高度channels:图像中的通道数classes:数据集中唯一类的总数
在此基础上,我们定义了一个由以下部分组成的Sequential网络:
- 第一套
CONV => RELU => BN图层。CONV层学习总共 32 个 3×3 滤波器,用 2×2 步进卷积减少体积大小。 - 第二套
CONV => RELU => BN图层。同上,但这次CONV层学习 64 个滤镜。 - 一组密集/完全连接的层。其输出是我们的 softmax 分类器,用于返回每个类别标签的概率。
现在,我们的架构已经实现,我们可以继续快速梯度符号方法。
用 Keras 和 TensorFlow 实现快速梯度符号法
我们将实现的对抗性攻击方法称为快速梯度符号方法(FGSM)。之所以称之为这种方法是因为:
- 很快(名字里就有)
- 我们通过计算损失的梯度、计算梯度的符号来构建图像对手,然后使用该符号来构建图像对手
让我们现在实现 FGSM。打开项目目录结构中的fgsm.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.losses import MSE
import tensorflow as tf
def generate_image_adversary(model, image, label, eps=2 / 255.0):
# cast the image
image = tf.cast(image, tf.float32)
第 2 行和第 3 行导入我们需要的 Python 包。我们将使用均方误差(MSE)损失函数来计算我们的对抗性攻击,但您也可以使用任何其他合适的损失函数来完成任务,包括分类交叉熵、二元交叉熵等。
第 5 行开始定义我们的 FGSM 攻击,generate_image_adversary。该函数接受四个参数:
- 我们试图愚弄的人
- 我们想要错误分类的输入
image - 输入图像的地面实况类
label - 对梯度更新进行加权的小
eps值——这里应该使用一个小一点的值,使得梯度更新的足够大到导致输入图像被错误分类,但不会大到到人眼可以看出图像被操纵
让我们现在开始实施 FGSM 攻击:
# record our gradients
with tf.GradientTape() as tape:
# explicitly indicate that our image should be tacked for
# gradient updates
tape.watch(image)
# use our model to make predictions on the input image and
# then compute the loss
pred = model(image)
loss = MSE(label, pred)
第 10 行指示 TensorFlow 记录我们的梯度,而第 13 行明确告诉 TensorFlow 我们想要跟踪输入image上的梯度更新。
从那里,我们使用我们的model对图像进行预测,然后使用均方误差计算我们的损失(同样,你可以用另一个损失函数代替你的任务,但 MSE 是一个相当标准的选择)。
接下来,让我们实现 FGSM 攻击的“带符号梯度”部分:
# calculate the gradients of loss with respect to the image, then
# compute the sign of the gradient
gradient = tape.gradient(loss, image)
signedGrad = tf.sign(gradient)
# construct the image adversary
adversary = (image + (signedGrad * eps)).numpy()
# return the image adversary to the calling function
return adversary
第 22 行计算相对于图像的损失梯度。
然后我们在线 23 上取渐变的符号(因此有了这个术语,快速 渐变符号 方法)。这行代码的输出是一个填充了三个值的向量——或者是1(正值)、0或者是-1(负值)。
利用这些信息, Line 26 通过以下方式创建我们的形象对手:
- 取带符号的梯度并乘以一个小的ε因子。这里的目标是使我们的梯度更新大到足以对输入图像进行错误分类,但又不会大到人眼可以看出图像已经被篡改。
- 然后,我们将这个小增量值添加到我们的图像中,这稍微改变了图像中的像素亮度值。
这些像素更新后会被人眼察觉不到,但据我们 CNN 报道,图像会出现**的巨大差异,从而导致误分类。****
**### 创建我们的对抗性训练脚本
随着 CNN 架构和 FGSM 的实现,我们可以继续创建我们的训练脚本。
在我们的目录结构中打开fgsm_adversarial.py脚本,我们可以开始工作了:
# import the necessary packages
from pyimagesearch.simplecnn import SimpleCNN
from pyimagesearch.fgsm import generate_image_adversary
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import numpy as np
import cv2
第 2-8 行导入我们需要的 Python 包。我们值得注意的导入包括SimpleCNN(我们在本指南前面实现的基本 CNN 架构)和generate_image_adversary(我们执行 FGSM 攻击的辅助函数)。
我们将在mnist数据集上训练我们的SimpleCNN架构。该模型将通过分类交叉熵损失和Adam优化器进行训练。
导入工作完成后,我们现在可以从磁盘加载 MNIST 数据集了:
# load MNIST dataset and scale the pixel values to the range [0, 1]
print("[INFO] loading MNIST dataset...")
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX / 255.0
testX = testX / 255.0
# add a channel dimension to the images
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
# one-hot encode our labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
第 12 行从磁盘加载预分割的 MNIST 数据集。我们通过以下方式预处理 MNIST 数据集:
- 将像素强度从范围【0,255】缩放到【0,1】
- 向图像添加批次维度
- 一键编码标签
从那里,我们可以初始化我们的SimpleCNN模型:
# initialize our optimizer and model
print("[INFO] compiling model...")
opt = Adam(lr=1e-3)
model = SimpleCNN.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the simple CNN on MNIST
print("[INFO] training network...")
model.fit(trainX, trainY,
validation_data=(testX, testY),
batch_size=64,
epochs=10,
verbose=1)
# make predictions on the testing set for the model trained on
# non-adversarial images
(loss, acc) = model.evaluate(x=testX, y=testY, verbose=0)
print("[INFO] loss: {:.4f}, acc: {:.4f}".format(loss, acc))
第 26-29 行初始化我们的 CNN。然后我们在33-37 行训练它。
评估发生在第行的第 41 行和第 42 行的第行,显示我们在测试集上计算的损失和准确度。我们展示这些信息是为了证明我们的 CNN 在对测试集进行预测方面做得很好
*…直到产生敌对形象的时候。那时我们将会看到我们的准确性分崩离析。
说到这里,现在让我们使用 FGSM 生成一些敌对的图像:
# loop over a sample of our testing images
for i in np.random.choice(np.arange(0, len(testX)), size=(10,)):
# grab the current image and label
image = testX[i]
label = testY[i]
# generate an image adversary for the current image and make
# a prediction on the adversary
adversary = generate_image_adversary(model,
image.reshape(1, 28, 28, 1), label, eps=0.1)
pred = model.predict(adversary)
在的第 45 行,我们遍历了一个随机选择的 10 个测试图像的样本。第 47 和 48 行抓取当前图像的image和地面实况label。
从那里,我们可以使用我们的generate_image_adversary函数来创建图像adversary,使用快速梯度符号方法(行 52 和 53 )。
具体来说,注意image.reshape调用,其中我们确保图像的形状为(1, 28, 28, 1。这些值是:
1:批量维度;我们在这里使用的是一个单个图像,所以这个值被设置为 1。28:图像的高度28:图像的宽度1:图像中的通道数(MNIST 图像是灰度的,因此只有一个通道)
随着我们的图像adversary生成,我们要求我们的model通过线 54 对其进行预测。
现在让我们为可视化准备image和adversary:
# scale both the original image and adversary to the range
# [0, 255] and convert them to an unsigned 8-bit integers
adversary = adversary.reshape((28, 28)) * 255
adversary = np.clip(adversary, 0, 255).astype("uint8")
image = image.reshape((28, 28)) * 255
image = image.astype("uint8")
# convert the image and adversarial image from grayscale to three
# channel (so we can draw on them)
image = np.dstack([image] * 3)
adversary = np.dstack([adversary] * 3)
# resize the images so we can better visualize them
image = cv2.resize(image, (96, 96))
adversary = cv2.resize(adversary, (96, 96))
请记住,我们的预处理步骤包括将我们的训练/测试图像从范围【0,255】缩放到【0,1】—为了用 OpenCV 可视化我们的图像,我们现在需要撤销这些预处理操作。
第 58-61 行缩放我们的image和adversary,确保它们都是无符号的 8 位整数数据类型。
我们希望用绿色(正确)或红色(不正确)来绘制原始图像和敌对图像的预测。为此,我们必须将我们的图像从灰度转换为灰度图像的 RGB 表示(行 65 和 66 )。
MNIST 的图像只有 28×28 ,很难看清,尤其是在高分辨率的屏幕上,所以我们在的第 69 行和第 70 行将图像尺寸增加到 96×96 。
我们的最后一个代码块完成了可视化过程:
# determine the predicted label for both the original image and
# adversarial image
imagePred = label.argmax()
adversaryPred = pred[0].argmax()
color = (0, 255, 0)
# if the image prediction does not match the adversarial
# prediction then update the color
if imagePred != adversaryPred:
color = (0, 0, 255)
# draw the predictions on the respective output images
cv2.putText(image, str(imagePred), (2, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, (0, 255, 0), 2)
cv2.putText(adversary, str(adversaryPred), (2, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, color, 2)
# stack the two images horizontally and then show the original
# image and adversarial image
output = np.hstack([image, adversary])
cv2.imshow("FGSM Adversarial Images", output)
cv2.waitKey(0)
第 74 和 75 行抓取 MNIST 数字预测。
如果imagePred和adversaryPred相等,我们将标签的color初始化为“绿色”(第 76 行)。如果我们的模型能够正确标记敌对的图像,这将会发生。否则,我们将把预测颜色更新为红色(第 80 行和第 81 行)。
*然后我们在它们各自的图像上画出imagePred和adversaryPred(第 84-87 行)。
最后一步是将彼此相邻的image和adversary可视化,这样我们就可以看到我们的对抗性攻击是否成功。
FGSM 培训结果
我们现在可以看到快速梯度符号方法的实际应用了!
首先访问本教程的 【下载】 部分来检索源代码。从那里,打开一个终端并执行fgsm_adversarial.py脚本:
$ python fgsm_adversarial.py
[INFO] loading MNIST dataset...
[INFO] compiling model...
[INFO] training network...
Epoch 1/10
938/938 [==============================] - 12s 13ms/step - loss: 0.1945 - accuracy: 0.9407 - val_loss: 0.0574 - val_accuracy: 0.9810
Epoch 2/10
938/938 [==============================] - 12s 13ms/step - loss: 0.0782 - accuracy: 0.9761 - val_loss: 0.0584 - val_accuracy: 0.9814
Epoch 3/10
938/938 [==============================] - 13s 13ms/step - loss: 0.0594 - accuracy: 0.9817 - val_loss: 0.0624 - val_accuracy: 0.9808
Epoch 4/10
938/938 [==============================] - 13s 14ms/step - loss: 0.0479 - accuracy: 0.9852 - val_loss: 0.0411 - val_accuracy: 0.9867
Epoch 5/10
938/938 [==============================] - 12s 13ms/step - loss: 0.0403 - accuracy: 0.9870 - val_loss: 0.0357 - val_accuracy: 0.9875
Epoch 6/10
938/938 [==============================] - 12s 13ms/step - loss: 0.0365 - accuracy: 0.9884 - val_loss: 0.0405 - val_accuracy: 0.9863
Epoch 7/10
938/938 [==============================] - 12s 13ms/step - loss: 0.0310 - accuracy: 0.9898 - val_loss: 0.0341 - val_accuracy: 0.9889
Epoch 8/10
938/938 [==============================] - 12s 13ms/step - loss: 0.0289 - accuracy: 0.9905 - val_loss: 0.0388 - val_accuracy: 0.9873
Epoch 9/10
938/938 [==============================] - 12s 13ms/step - loss: 0.0217 - accuracy: 0.9928 - val_loss: 0.0652 - val_accuracy: 0.9811
Epoch 10/10
938/938 [==============================] - 11s 12ms/step - loss: 0.0216 - accuracy: 0.9925 - val_loss: 0.0396 - val_accuracy: 0.9877
[INFO] loss: 0.0396, acc: 0.9877
正如你所看到的,我们的脚本在我们的训练集上获得了 99.25% 的准确性,在测试集上获得了 98.77% 的准确性,这意味着我们的模型在进行数字预测方面做得很好。
然而,让我们看看当我们使用 FGSM 生成敌对图像时会发生什么:
图 4 显示了十幅图像的蒙太奇,包括来自测试集(左)的原始 MNIST 图像和输出 FGSM 图像 (右)。
视觉上,对立的 FGSM 图像与原始数字图像相同;然而,我们的 CNN完全被愚弄了,对每张图片都做出了错误的预测。
有什么大不了的?
用敌对的图像愚弄 CNN,让它在 MNIST 数据集上做出不正确的预测,看起来后果很轻。
但是,如果这种模型被训练成能够检测过马路的行人,并被部署到自动驾驶汽车上,会发生什么呢?将会有巨大的后果,因为现在人们的生命危在旦夕。
这就提出了一个问题:
如果愚弄 CNN 这么容易,我们能做些什么来抵御对抗性攻击呢?
在接下来的两篇博文中,我将向你展示如何通过更新我们的训练程序来加入对抗性图片,从而抵御对抗性攻击。
演职员表和参考资料
FGSM 的实现受到了塞巴斯蒂安·蒂勒关于对抗性攻击和防御的精彩文章的启发。非常感谢 Sebastian 分享他的知识。
总结
在本教程中,您学习了如何实现快速梯度符号方法(FGSM)来生成对抗性图像。我们使用 Keras 和 TensorFlow 实现了 FGSM,但是您当然可以将代码翻译成您选择的深度学习库。
FGSM 通过以下方式开展工作:
- 拍摄输入图像
- 使用经过训练的 CNN 对图像进行预测
- 基于真实类别标签计算预测的损失
- 计算损失相对于输入图像的梯度
- 计算梯度的符号
- 使用带符号的梯度来构造输出对抗图像
这听起来可能很复杂,但正如我们所见,我们能够用不到 30 行代码实现 FGSM,这要感谢 TensorFlow 神奇的GradientTape函数,它使梯度计算变得轻而易举。
既然你已经学会了如何使用 FGSM构建 对抗性图像,你将在下周的训练过程中学习如何通过将对抗性图像融入 来防御这些攻击 。
敬请关注。你不会想错过这个教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
使用 Keras 和 TensorFlow 的敌对图像和攻击
原文:https://pyimagesearch.com/2020/10/19/adversarial-images-and-attacks-with-keras-and-tensorflow/
在本教程中,您将学习如何使用基于图像的对抗性攻击来打破深度学习模型。我们将使用 Keras 和 TensorFlow 深度学习库来实施我们的对抗性攻击。
想象一下二十年后。路上几乎所有的汽车和卡车都被自动驾驶汽车取代,由人工智能、深度学习和计算机视觉提供动力——每一次转弯、车道切换、加速和刹车都由深度神经网络提供动力。
现在,想象你在高速公路上。你正坐在“驾驶座”上(如果汽车在驾驶,这真的是“驾驶座”吗?)而你的配偶坐在副驾驶座上,你的孩子坐在后排。
向前看,你看到你的车正在行驶的车道上贴着一张大贴纸。看起来够无辜的。这只是涂鸦艺术家班克斯广受欢迎的 拿着气球的女孩 作品的大幅印刷。一些高中生可能只是把它放在那里作为一个奇怪的挑战/恶作剧的一部分。
一瞬间之后,你的汽车做出反应,猛地刹车,然后变换车道,就好像贴在路上的大型艺术印刷品是一个人、一只动物或另一辆车。你被猛地拉了一下,感觉到了鞭打。你的配偶尖叫着,而后座上你孩子的麦片向前飞去,撞在挡风玻璃上,在中控台上弹来弹去。
你和你的家人都很安全… 但是情况可能会更糟。
发生了什么事?为什么你的自动驾驶汽车会有这种反应?是你的汽车运行的代码/软件中的某种奇怪的“错误”吗?
答案是,驱动车辆“视觉”组件的深度神经网络刚刚看到了一幅敌对图像。
对立的图像有:
- 有像素的图像被故意扰乱以迷惑和欺骗模型…
- …但同时,看起来对人类无害和无辜。
这些图像导致深度神经网络故意做出不正确的预测。对立的图像受到干扰,以至于模型无法正确地对它们进行分类。
事实上,对于人类来说,从一个因敌对攻击而受到视觉干扰的图像中识别出一个正常的图像可能是不可能的,从本质上来说,这两个图像在人眼看来是完全相同的。
虽然不是精确(或正确)的比较,但我喜欢在图像隐写术的背景下解释对抗性攻击。使用隐写术算法,我们可以在图像中嵌入数据(例如明文消息),而不会扭曲图像本身的外观。该图像可以被无害地传输给接收者,然后接收者可以从图像中提取隐藏的信息。
类似地,对抗性攻击在输入图像中嵌入一条消息——但是,对抗性攻击在输入图像中嵌入一个噪声向量,而不是用于人类消费的明文消息。这个噪声向量是特意构建的用来愚弄和混淆深度学习模型。
但是对抗性攻击是如何工作的呢?我们如何抵御它们?
这篇教程,以及本系列的其他文章,将会涉及到同样的问题。
要学习如何使用 Keras/TensorFlow 用对抗性攻击和图像打破深度学习模型,继续阅读。
使用 Keras 和 TensorFlow 的敌对图像和攻击
在本教程的第一部分,我们将讨论什么是对抗性攻击,以及它们如何影响深度学习模型。
从这里开始,我们将实现三个独立的 Python 脚本:
- 第一个将是一个助手工具,用于从 ImageNet 数据集加载和解析类标签。
- 我们的下一个 Python 脚本将使用 ResNet 执行基本的影像分类,在 ImageNet 数据集上进行预训练(从而演示“标准”影像分类)。
- 最终的 Python 脚本将执行对抗性攻击,并构建一个对抗性图像,故意混淆我们的 ResNet 模型,即使这两个图像在人眼看来是相同的。
我们开始吧!
什么是对抗性图像和对抗性攻击?它们如何影响深度学习模型?
2014 年,Goodfellow 等人发表了一篇题为 的论文,解释并利用了对立的例子 ,该论文显示了深度神经网络的一个有趣的属性——有可能故意扰动一个输入图像,以至于神经网络将其错误分类。这种类型的干扰被称为对抗性攻击。
对抗性攻击的经典例子可以在上面的图 2 中看到。在左边的,是我们的输入图像,我们的神经网络以 57.7%的置信度将其正确分类为“熊猫”。
在中间的,我们有一个噪声向量,对于人眼来说,它看起来是随机的。然而,它离随机的很远。
相反,噪声向量中的像素等于相对于输入图像的成本函数的梯度元素的符号 (Goodfellow 等人)。
然后,我们将这个噪声向量添加到输入图像中,这产生了图 2 中的输出(右)。对我们来说,这个图像看起来与输入相同;然而,我们的神经网络现在以 99.7%的置信度将图像分类为“长臂猿”(一种小猿,类似于猴子)。
令人毛骨悚然,对吧?
对抗性攻击和图像的简史
对抗性机器学习不是一个新领域,这些攻击也不是针对深度神经网络的。2006 年,Barreno 等人发表了一篇名为 的论文,机器学习能安全吗? 本文讨论了对抗性攻击,包括针对它们提出的防御措施。
早在 2006 年,最先进的机器学习模型包括支持向量机(SVMs)和随机森林(RFs)——已经证明这两种类型的模型都容易受到敌对攻击。
随着深度神经网络从 2012 年开始流行起来,人们希望这些高度非线性的模型不那么容易受到攻击;然而,古德费勒等人(以及其他人)粉碎了这些希望。
事实证明,深度神经网络容易受到对抗性攻击,就像它们的前辈一样。
关于对抗性攻击历史的更多信息,我推荐阅读比格吉奥和花小蕾 2017 年的优秀论文, 狂野模式:对抗性机器学习兴起后的十年。
为什么对抗性攻击和图像是一个问题?
本教程顶部的例子概述了为什么敌对攻击会对健康、生命和财产造成巨大损失。
后果不太严重的例子可能是一群黑客发现谷歌在 Gmail 中使用特定模型过滤垃圾邮件,或者脸书在 NSFW 过滤器中使用给定模型自动检测色情内容。
如果这些黑客想向 Gmail 用户发送大量绕过 Gmail 垃圾邮件过滤器的电子邮件,或者绕过 NSFW 过滤器向脸书上传大量色情内容,理论上他们可以这么做。
这些都是后果较小的对抗性攻击的例子。
在后果更高的场景中,对抗性攻击可能包括黑客-恐怖分子识别出一个特定的深度神经网络正被用于世界上几乎所有的自动驾驶汽车(想象一下,如果特斯拉垄断了市场,并且是唯一的自动驾驶汽车制造商)。
敌对的图像可能会被战略性地放置在道路和高速公路上,造成大规模的连环相撞、财产损失,甚至车内乘客的伤亡。
对抗性攻击的限制只受您的想象力、您对给定模型的了解以及您对模型本身的访问权限的限制。
我们能抵御敌对攻击吗?
好消息是我们可以帮助减少对抗性攻击的影响(但不一定完全消除它们)。
这个主题不会在今天的教程中讨论,但是会在以后的 PyImageSearch 教程中讨论。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
这样说来,你是:
- 时间紧迫?
- 在你雇主被行政锁定的笔记本电脑上学习?
- 想要跳过与包管理器、bash/ZSH 概要文件和虚拟环境的争论吗?
- 准备好运行代码了吗(并尽情体验它)?
那今天就加入 PyImageSearch 加吧!在您的浏览器中访问运行在谷歌的 Colab 生态系统上的 PyImageSearch 教程 Jupyter 笔记本——无需安装!
项目结构
首先使用本教程的 【下载】 部分下载源代码和示例图像。从那里,让我们检查我们的项目目录结构。
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── imagenet_class_index.json
│ └── utils.py
├── adversarial.png
├── generate_basic_adversary.py
├── pig.jpg
└── predict_normal.py
1 directory, 7 files
准备好用 Keras 和 TensorFlow 实施你的第一次对抗性攻击了吗?
让我们开始吧。
我们的 ImageNet 类标签/索引辅助工具
在我们可以执行正常的图像分类或对受到恶意攻击的图像进行分类之前,我们首先需要创建一个 Python 辅助函数,用于加载和解析 ImageNet 数据集的类标签。
我们已经在项目目录结构的pyimagesearch模块的imagenet_class_index.json文件中提供了一个 JSON 文件,其中包含 ImageNet 类标签索引、标识符和人类可读的字符串。
我在下面包含了这个 JSON 文件的前几行:
{
"0": [
"n01440764",
"tench"
],
"1": [
"n01443537",
"goldfish"
],
"2": [
"n01484850",
"great_white_shark"
],
"3": [
"n01491361",
"tiger_shark"
],
...
"106": [
"n01883070",
"wombat"
],
...
这里你可以看到这个文件是一个字典。字典的关键字是整数类标签索引,而值是由以下内容组成的二元组:
- 标签的 ImageNet 唯一标识符
- 人类可读的类标签
我们的目标是实现一个 Python 函数,它将通过以下方式解析 JSON 文件:
- 接受输入类标签
- 返回相应标签的整数类标签索引
# import necessary packages
import json
import os
def get_class_idx(label):
# build the path to the ImageNet class label mappings file
labelPath = os.path.join(os.path.dirname(__file__),
"imagenet_class_index.json")
现在让我们加载 JSON 文件的内容:
# open the ImageNet class mappings file and load the mappings as
# a dictionary with the human-readable class label as the key and
# the integer index as the value
with open(labelPath) as f:
imageNetClasses = {labels[1]: int(idx) for (idx, labels) in
json.load(f).items()}
# check to see if the input class label has a corresponding
# integer index value, and if so return it; otherwise return
# a None-type value
return imageNetClasses.get(label, None)
- 标签的整数索引(如果它存在于字典中)
- 如果
label在imageNetClasses中不存在,则返回None
正常图像分类无使用 Keras 和 TensorFlow 的对抗性攻击
实现了我们的 ImageNet 类标签/索引助手函数之后,让我们首先创建一个图像分类脚本,该脚本执行基本分类,并且没有恶意攻击。
该脚本将证明我们的 ResNet 模型正在按照我们的预期运行(即做出正确的预测)。在本教程的后面,你会发现如何构建一个敌对的形象,使其混淆 ResNet。
让我们从基本的图像分类脚本开始——打开项目目录结构中的predict_normal.py文件,并插入以下代码:
# import necessary packages
from pyimagesearch.utils import get_class_idx
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.resnet50 import preprocess_input
import numpy as np
import argparse
import imutils
import cv2
我们在第 2-9 行的中导入我们需要的 Python 包。如果你以前使用过 Keras、TensorFlow 和 OpenCV,这些对你来说都是相当标准的。
也就是说,如果你是 Keras 和 TensorFlow 的新手,我强烈建议你阅读我的 Keras 教程:如何入门 Keras、深度学习和 Python 指南。此外,你可能想阅读我的书 用 Python 进行计算机视觉的深度学习 ,以更深入地了解如何训练你自己的定制神经网络。
def preprocess_image(image):
# swap color channels, preprocess the image, and add in a batch
# dimension
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = preprocess_input(image)
image = cv2.resize(image, (224, 224))
image = np.expand_dims(image, axis=0)
# return the preprocessed image
return image
接下来,让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load image from disk and make a clone for annotation
print("[INFO] loading image...")
image = cv2.imread(args["image"])
output = image.copy()
# preprocess the input image
output = imutils.resize(output, width=400)
preprocessedImage = preprocess_image(image)
# load the pre-trained ResNet50 model
print("[INFO] loading pre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# make predictions on the input image and parse the top-3 predictions
print("[INFO] making predictions...")
predictions = model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
# loop over the top three predictions
for (i, (imagenetID, label, prob)) in enumerate(predictions):
# print the ImageNet class label ID of the top prediction to our
# terminal (we'll need this label for our next script which will
# perform the actual adversarial attack)
if i == 0:
print("[INFO] {} => {}".format(label, get_class_idx(label)))
# display the prediction to our screen
print("[INFO] {}. {}: {:.2f}%".format(i + 1, label, prob * 100))
# draw the top-most predicted label on the image along with the
# confidence score
text = "{}: {:.2f}%".format(predictions[0][1],
predictions[0][2] * 100)
cv2.putText(output, text, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
在点击 OpenCV 打开的窗口并按下一个键之前,output图像一直显示在我们的终端上。
非对抗性图像分类结果
我们现在准备好使用 ResNet 执行基本的图像分类(即,没有恶意攻击)。
首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python predict_normal.py --image pig.jpg
[INFO] loading image...
[INFO] loading pre-trained ResNet50 model...
[INFO] making predictions...
[INFO] hog => 341
[INFO] 1\. hog: 99.97%
[INFO] 2\. wild_boar: 0.03%
[INFO] 3\. piggy_bank: 0.00%
用 Keras 和 TensorFlow 实现对抗性图像和攻击
我们现在将学习如何用 Keras 和 TensorFlow 实现对抗性攻击。
在我们的项目目录结构中打开generate_basic_adversary.py文件,并插入以下代码:
# import necessary packages
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.resnet50 import preprocess_input
import tensorflow as tf
import numpy as np
import argparse
import cv2
我们从在第 2-10 行导入我们需要的 Python 包开始。你会注意到我们再次使用ResNet50架构及其相应的preprocess_input函数(用于预处理/缩放输入图像)和decode_predictions实用程序来解码输出预测并显示人类可读的 ImageNet 标签。
SparseCategoricalCrossentropy计算标签和预测之间的分类交叉熵损失。通过使用分类交叉熵的稀疏版本实现,我们不需要像使用 scikit-learn 的LabelBinarizer或 Keras/TensorFlow 的to_categorical实用程序那样显式地一次性编码我们的类标签。
就像我们的predict_normal.py脚本中有一个preprocess_image实用程序一样,我们也需要一个用于这个脚本的实用程序:
def preprocess_image(image):
# swap color channels, resize the input image, and add a batch
# dimension
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
image = np.expand_dims(image, axis=0)
# return the preprocessed image
return image
def clip_eps(tensor, eps):
# clip the values of the tensor to a given range and return it
return tf.clip_by_value(tensor, clip_value_min=-eps,
clip_value_max=eps)
def generate_adversaries(model, baseImage, delta, classIdx, steps=50):
# iterate over the number of steps
for step in range(0, steps):
# record our gradients
with tf.GradientTape() as tape:
# explicitly indicate that our perturbation vector should
# be tracked for gradient updates
tape.watch(delta)
# add our perturbation vector to the base image and
# preprocess the resulting image
adversary = preprocess_input(baseImage + delta)
# run this newly constructed image tensor through our
# model and calculate the loss with respect to the
# *original* class index
predictions = model(adversary, training=False)
loss = -sccLoss(tf.convert_to_tensor([classIdx]),
predictions)
# check to see if we are logging the loss value, and if
# so, display it to our terminal
if step % 5 == 0:
print("step: {}, loss: {}...".format(step,
loss.numpy()))
# calculate the gradients of loss with respect to the
# perturbation vector
gradients = tape.gradient(loss, delta)
# update the weights, clip the perturbation vector, and
# update its value
optimizer.apply_gradients([(gradients, delta)])
delta.assign_add(clip_eps(delta, eps=EPS))
# return the perturbation vector
return delta
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to original input image")
ap.add_argument("-o", "--output", required=True,
help="path to output adversarial image")
ap.add_argument("-c", "--class-idx", type=int, required=True,
help="ImageNet class ID of the predicted label")
args = vars(ap.parse_args())
# define the epsilon and learning rate constants
EPS = 2 / 255.0
LR = 0.1
# load the input image from disk and preprocess it
print("[INFO] loading image...")
image = cv2.imread(args["input"])
image = preprocess_image(image)
第 76 行定义了我们的ε(EPS)值,用于在构建对抗图像时裁剪张量。2 / 255.0的EPS值是敌对出版物和教程中使用的标准值(如果您有兴趣了解关于这个“默认”值的更多信息,下面指南中的也很有帮助)。
然后我们在第 77 行定义我们的学习率。通过经验调整获得了一个值LR = 0.1—在构建您自己的对立图像时,您可能需要更新这个值。
# load the pre-trained ResNet50 model for running inference
print("[INFO] loading pre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# initialize optimizer and loss function
optimizer = Adam(learning_rate=LR)
sccLoss = SparseCategoricalCrossentropy()
# create a tensor based off the input image and initialize the
# perturbation vector (we will update this vector via training)
baseImage = tf.constant(image, dtype=tf.float32)
delta = tf.Variable(tf.zeros_like(baseImage), trainable=True)
# generate the perturbation vector to create an adversarial example
print("[INFO] generating perturbation...")
deltaUpdated = generate_adversaries(model, baseImage, delta,
args["class_idx"])
# create the adversarial example, swap color channels, and save the
# output image to disk
print("[INFO] creating adversarial example...")
adverImage = (baseImage + deltaUpdated).numpy().squeeze()
adverImage = np.clip(adverImage, 0, 255).astype("uint8")
adverImage = cv2.cvtColor(adverImage, cv2.COLOR_RGB2BGR)
cv2.imwrite(args["output"], adverImage)
之后,我们通过以下方式对最终的对抗图像进行后处理:
- 剪裁超出范围【0,255】的任何值
- 将图像转换为无符号的 8 位整数(以便 OpenCV 现在可以对图像进行操作)
- 交换从 RGB 到 BGR 的颜色通道排序
经过上述预处理步骤后,我们将输出的对抗图像写入磁盘。
真正的问题是,我们新构建的对抗性图像能骗过我们的 ResNet 模型吗?
下一个代码块将解决这个问题:
# run inference with this adversarial example, parse the results,
# and display the top-1 predicted result
print("[INFO] running inference on the adversarial example...")
preprocessedImage = preprocess_input(baseImage + deltaUpdated)
predictions = model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
label = predictions[0][1]
confidence = predictions[0][2] * 100
print("[INFO] label: {} confidence: {:.2f}%".format(label,
confidence))
# draw the top-most predicted label on the adversarial image along
# with the confidence score
text = "{}: {:.2f}%".format(label, confidence)
cv2.putText(adverImage, text, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", adverImage)
cv2.waitKey(0)
我们再次在第 113 行上构建我们的对抗图像,方法是将 delta 噪声向量添加到我们的原始输入图像中,但这次我们调用 ResNet 的preprocess_input实用程序。
产生的预处理图像通过 ResNet,之后我们获取前 3 个预测并解码它们(行 114 和 115 )。
然后,我们用 top-1 预测获取标签和相应的概率/置信度,并将这些值显示到我们的终端(行 116-119 )。
最后一步是在我们输出的敌对图像上绘制顶部预测,并将其显示到我们的屏幕上。
对抗性图像和攻击的结果
准备好观看对抗性攻击了吗?
确保您使用了本教程的 “下载” 部分来下载源代码和示例图像。
从那里,您可以打开一个终端并执行以下命令:
$ python generate_basic_adversary.py --input pig.jpg --output adversarial.png --class-idx 341
[INFO] loading image...
[INFO] loading pre-trained ResNet50 model...
[INFO] generating perturbation...
step: 0, loss: -0.0004124982515349984...
step: 5, loss: -0.0010656398953869939...
step: 10, loss: -0.005332294851541519...
step: 15, loss: -0.06327803432941437...
step: 20, loss: -0.7707189321517944...
step: 25, loss: -3.4659299850463867...
step: 30, loss: -7.515471935272217...
step: 35, loss: -13.503922462463379...
step: 40, loss: -16.118188858032227...
step: 45, loss: -16.118192672729492...
[INFO] creating adversarial example...
[INFO] running inference on the adversarial example...
[INFO] label: wombat confidence: 100.00%
在左边是原始的猪图像,而在右边我们有输出的对抗图像,它被错误地分类为“袋熊”。
正如你所看到的,这两幅图像之间没有明显的差异,我们的人眼可以看到这两幅图像之间的差异,但对雷斯内特来说,它们是完全不同的 T2。
这很好,但是我们显然无法控制对抗性图像中的最终类标签。这就提出了一个问题:
可以控制输入图像的最终输出类标签是什么吗?答案是是的——我将在下周的教程中讨论这个问题。
我最后要说的是,如果你让你的想象力占了上风,你很容易被对抗性的图像和对抗性的攻击吓到。但是正如我们将在后面的 PyImageSearch 教程中看到的,我们实际上可以防御这些类型的攻击。稍后会详细介绍。
学分
如果没有 Goodfellow、Szegedy 和许多其他深度学习研究人员的研究,本教程是不可能的。
此外,我想指出,今天教程中使用的实现是受 TensorFlow 的快速梯度符号方法的官方实现的启发。我强烈建议你看一下他们的例子,这个例子很好地解释了本教程更多的理论和数学方面。
总结
在本教程中,您学习了对抗性攻击,它们如何工作,以及它们对越来越依赖人工智能和深度神经网络的世界构成的威胁。
然后,我们使用 Keras 和 TensorFlow 深度学习库实现了一个基本的对抗性攻击算法。
使用对抗性攻击,我们可以故意干扰输入图像,使得:
- 输入图像被错误分类
- 然而,对于人眼来说,被打乱的图像看起来与原始图像完全相同
然而,使用今天在这里应用的方法,我们绝对无法控制图像的最终类别标签是什么——我们所做的只是创建和嵌入一个噪声向量,这导致深度神经网络对图像进行错误分类。
但是如果我们能够控制最终的目标类标签是什么呢?例如,是否有可能拍摄一张“狗”的图像,并构建一个对抗性攻击,使卷积神经网络认为该图像是一只“猫”?
答案是肯定的——我们将在下周的教程中讨论完全相同的主题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
计算机视觉和深度学习的伦理应用——通过自动年龄和军事疲劳检测识别儿童兵
在本教程中,我们将学习如何应用计算机视觉、深度学习和 OpenCV,通过自动年龄检测和军事疲劳识别来识别潜在的儿童兵。
服兵役对我个人来说很重要,我认为这是值得尊敬和钦佩的。这正是为什么这个项目,利用技术来识别儿童兵,是我强烈感受到的东西——任何人都不应该被强迫服役,尤其是年幼的儿童。
你知道,在我的成长过程中,军队一直是我家庭的一个重要组成部分,尽管我没有亲自服役。
- 我的曾祖父在一战期间是一名步兵
- 我的祖父在军队里当了 25 年的厨师/面包师
- 我的父亲在美国军队服役了八年,在越南战争结束后研究传染病
- 我的堂兄高中一毕业就加入了海军陆战队,在光荣退伍前在阿富汗服役了两次
即使在我的直系亲属之外,军队仍然是我生活和社区的一部分。我在马里兰州的一个农村地区上的高中。高中毕业后没有多少机会,只有三条真正的道路:
- 成为一名农民——许多人都这样做了,在各自的家庭农场工作,直到他们最终继承了它
- 试着在大学里坚持下去——相当一部分人选择了这条路,但在这个过程中,他们或他们的家庭都背负了巨额债务
- 参军——获得报酬,学习可以转移到现实工作中的实用技能,通过《退伍军人法案》支付高达 5 万美元的大学费用(也可以部分转移到你的配偶或孩子身上),如果被部署,还可以获得额外的福利(当然,要冒着失去生命的风险)
如果你不想成为农民或从事农业,那就只剩下两个选择——上大学或参军。对一些人来说,大学没有任何意义。它不值得花费。
如果我没记错的话,在我高中毕业之前,我们班至少有 10 个孩子参了军,其中一些我认识,也和他们一起上过课。
像我这样长大的人,我对军人、尤其是那些为国效力的人、无论他们来自哪个国家,都怀有无比的敬意。你是否曾在美国、芬兰、日本等国服役。为你的国家服务是一件大事,我尊重所有这样做的人。
我这辈子没有多少遗憾,但是真的,回头看看,没有服役就是其中之一。我真希望我在军队里呆了四年,每次回想起来,我仍然会感到后悔和内疚。
也就是说,选择不服役是我的选择。
我们中的大多数人都可以选择我们的服务——尽管当然有复杂的社会问题,如贫困或道德问题,超出了这篇博文的范围。然而,底线是小孩子永远不应该被强迫参军。
世界上有些地方,孩子们没有选择的权利。由于极端贫困、恐怖主义、政府宣传和/或操纵,儿童被迫参战。
这场战斗也不总是使用武器。在战争中,儿童可以被用作间谍/告密者、信使、人盾,甚至作为谈判的筹码。
无论是发射武器还是在大型游戏中充当棋子,儿童兵都会产生持久的健康影响,包括但不限于( source ):
- 精神疾病(慢性压力、焦虑、PTSD 等。)
- 读写能力差
- 更高的贫困风险
- 成年人失业
- 酒精和药物滥用
- 自杀风险更高
儿童服兵役也不是一个新现象。这是一个古老的故事:
- 1212 年的儿童十字军因招募儿童而臭名昭著。一些人死了,但还有许多人被卖为奴隶
- 拿破仑征募儿童入伍
- 在第一次和第二次世界大战期间,儿童被利用
- 1973 年出版的非小说类书籍和 2001 年的电影《兵临城下》讲述了斯大林格勒战役的故事,更具体地说,是虚构的瓦西里·扎依采夫,一位著名的苏联狙击手。在那本书/电影中,还是个孩子的萨沙·菲利波夫被用作间谍和线人。萨沙通常会和纳粹交朋友,然后把信息反馈给苏联。萨沙后来被纳粹抓住并杀害
- 在现代,我们都太熟悉恐怖组织,如基地组织和 ISIS 招募弱势儿童加入他们的努力
虽然我们许多人都同意在战争中使用儿童是不可接受的,但儿童最终仍然参与战争的事实是一个更复杂的问题。当你的生命危在旦夕,当你的家人饥肠辘辘,当你周围的人奄奄一息,这就成了生死攸关的事情。
战斗或死亡。
这是一个令人悲伤的现实,但这是我们可以通过适当的教育来改善(并理想地解决)的事情,并慢慢地,逐渐地,让世界变得更安全,更美好。
与此同时,我们可以使用一点计算机视觉和深度学习来帮助识别潜在的儿童兵,无论是在战场上还是在他们接受教育/灌输的不太好的国家或组织中。
在我被介绍给来自 GDI.Foundation 的 Victor Gevers(一位受人尊敬的道德黑客)之后,今天的帖子是我过去几个月工作的高潮。
维克多和他的团队发现了教室面部识别软件的漏洞,该软件用于验证儿童是否出席。在检查这些照片时,似乎这些孩子中的一些正在接受军事教育和训练(也就是说,孩子们穿着军装和其他证据,这让我感到不舒服)。
我不打算讨论所涉及的政治、国家或组织的细节,这不是我的位置,这完全取决于 Victor 和他的团队如何处理这种特殊情况。
相反,我是来报告科学和算法的。
计算机视觉和深度学习领域理所当然地受到了一些应得的批评,因为它们允许强大的政府和组织创建“老大哥”般的警察国家,在那里一只警惕的眼睛总是存在。
也就是说,CV/DL 可以用来“观察观察者”总会有和组织和国家试图监视我们。我们可以反过来使用 CV/DL 作为一种问责形式,让他们对自己的行为负责。是的,如果应用得当,它可以用来拯救生命。
要了解计算机视觉和深度学习的道德应用,特别是通过自动年龄和军事疲劳检测识别儿童兵,继续阅读!
计算机视觉和深度学习的道德应用——通过自动年龄和军事疲劳检测识别儿童兵
在本教程的第一部分,我们将讨论我是如何参与这个项目的。
从这里,我们将看看在图像和视频流中识别潜在儿童兵的四个步骤。
一旦我们理解了我们的基本算法,我们将使用 Python、OpenCV 和 Keras/TensorFlow 实现我们的儿童士兵检测方法。
我们将通过检查我们的工作结果来结束本教程。
军队中的儿童、儿童兵和人权——我对这一事业的尝试
我第一次参与这个项目是在一月中旬,当时我和来自 GDI.Foundation 的 Victor Gevers 联系
维克多和他的团队发现了用于课堂面部识别(即基于面部识别自动考勤的“智能考勤系统”)的软件中的数据泄露。
这次数据泄露暴露了数百万儿童的记录,包括身份证号码,GPS 定位,是的,甚至是他们的面部照片。
任何类型的数据泄露都令人担忧,但至少可以说,暴露儿童的泄露是非常严重的。
不幸的是,事情变得更糟了。
在检查泄漏的照片时,发现一群穿着军装的儿童。
这立刻引起了一些人的惊讶。
Victor 和我联系并简短地交换了电子邮件,讨论如何利用我的知识和专业技能来提供帮助。
Victor 和他的团队需要一种方法来自动检测人脸,确定他们的年龄,并确定此人是否穿着军装。
我同意了,条件是我可以在伦理上分享科学成果(而不是政治、国家或相关组织),作为一种教育形式,帮助其他人从现实世界的问题中学习。
有一些组织、联盟和个人比我更适合处理人道主义方面的问题——虽然我是 CV/DL 方面的专家,但我不是政治或人道主义方面的专家(尽管我尽最大努力教育自己并尽可能做出最好的决定)。
我希望你把这篇文章当作一种教育。这绝不是公开所涉及的国家或组织,我已经确保在本教程中不提供任何原始训练数据或示例图像。所有原始数据已被删除或适当匿名化。
我们如何利用计算机视觉和深度学习来检测和识别潜在的儿童兵?
发现和识别潜在的儿童兵是一个分四步走的过程:
- 步骤# 1–人脸检测:应用人脸检测在输入图像/视频流中定位人脸
- 步骤# 2——年龄检测:利用基于深度学习的年龄检测器确定通过步骤#1 检测到的人的年龄
- 步骤# 3——军事疲劳检测:将深度学习应用于自动检测军装的伪装或其他迹象
- 步骤# 4–组合结果:从步骤#2 和步骤#3 中获取结果,以确定儿童是否可能穿着军装,根据原始图像的来源和上下文,哪个可能是儿童兵的指示
如果你已经注意到,在过去的 1-1.5 个月里,我已经有目的地在 PyImageSearch 博客上报道了这些话题,为这篇博客做准备。
我们将快速回顾下面四个步骤中的每一个,但是我建议您使用上面的链接来获得每个步骤的更多细节。
步骤#1:检测图像或视频流中的人脸
在我们能够确定一个孩子是否在图像或视频流中之前,我们首先需要检测人脸。
人脸检测是自动定位人脸在图像中的位置的过程。
在本教程中,我们将使用 OpenCV 的基于深度学习的人脸检测器,但你也可以轻松地使用哈尔级联、HOG +线性 SVM 或任何其他人脸检测方法。
步骤#2:获取面部 ROI 并执行年龄检测
一旦我们定位了图像/视频流中的每个人脸,我们就可以确定他们的年龄。
我们将使用 Levi 和 Hassner 在他们 2015 年的出版物 中训练的年龄检测器,使用卷积神经网络进行年龄和性别分类。
步骤#3:训练一个迷彩/军用疲劳检测器,并将其应用于图像
潜在儿童兵的标志可能是穿着军装,这通常包括某种类似迷彩的图案。
训练伪装探测器在之前的教程中有所介绍——我们今天将在这里使用训练过的模型。
步骤#4:综合模型结果,寻找 18 岁以下穿军装的儿童
最后一步是将我们的年龄探测器和我们的军用疲劳/伪装探测器的结果结合起来。
如果我们(1)在照片中检测到一个 18 岁以下的人,并且(2)图像中似乎还有伪装,我们会将该图像记录到磁盘中以供进一步查看。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助你为你的系统配置这篇博文所需的所有软件,只有一个例外。您还需要通过以下方式将progressbar2 软件包安装到您的虚拟环境中:
$ workon dl4cv
$ pip install progressbar2
配置好系统后,您就可以继续学习本教程的其余部分了。
项目结构
请务必从 “下载” 部分获取今天教程的文件。我们的项目组织如下:
$ tree --dirsfirst
.
├── models
│ ├── age_detector
│ │ ├── age_deploy.prototxt
│ │ └── age_net.caffemodel
│ ├── camo_detector
│ │ └── camo_detector.model
│ └── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── output
│ ├── ages.csv
│ └── camo.csv
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── helpers.py
├── parse_results.py
└── process_dataset.py
6 directories, 12 files
models/目录包含我们每个预先训练的深度学习模型:
- 人脸检测器
- 年龄分类器
- 伪装分类器
注意:我不能像往常一样在本指南的“下载”*部分提供本教程中使用的原始数据集。该数据集是敏感的,不能以任何方式分发。*
我们的配置文件
在深入研究我们的实现之前,让我们首先定义一个简单的配置文件,分别存储我们的人脸检测器、年龄检测器和伪装检测器模型的文件路径。
打开项目目录结构中的config.py文件,并插入以下代码:
# import the necessary packages
import os
# define the path to our face detector model
FACE_PROTOTXT = os.path.sep.join(["models", "face_detector",
"deploy.prototxt"])
FACE_WEIGHTS = os.path.sep.join(["models", "face_detector",
"res10_300x300_ssd_iter_140000.caffemodel"])
# define the path to our age detector model
AGE_PROTOTXT = os.path.sep.join(["models", "age_detector",
"age_deploy.prototxt"])
AGE_WEIGHTS = os.path.sep.join(["models", "age_detector",
"age_net.caffemodel"])
# define the path to our camo detector model
CAMO_MODEL = os.path.sep.join(["models", "camo_detector",
"camo_detector.model"])
通过使我们的配置成为 Python 文件并使用os 模块,我们能够直接构建与操作系统无关的路径。
我们的配置包含:
- 人脸检测器模型路径(行 5-8);一定要看我的深度学习人脸检测器教程
- 老化检测器路径(第 11-14 行);花点时间阅读我的深度学习年龄检测教程,其中介绍了这个模型
- 伪装探测器模型路径(行 17 和 18);用深度学习阅读全部关于迷彩服分类
定义了每一条路径后,我们就可以在下一节中在一个单独的 Python 文件中定义便利函数了。
人脸检测、年龄预测、伪装检测和人脸匿名化的便利功能
为了完成这个项目,我们将使用以前教程中涉及的许多计算机视觉/深度学习技术,包括:
现在让我们在儿童兵检测项目的中心位置为每种技术定义便利函数。
注:关于人脸检测、人脸匿名化、年龄检测、迷彩服检测的更详细回顾,请务必点击上面相应的链接。
打开pyimagesearch模块中的helpers.py文件,在输入图像中插入以下用于检测人脸和预测年龄的代码:
# import the necessary packages
import numpy as np
import cv2
def detect_and_predict_age(image, faceNet, ageNet, minConf=0.5):
# define the list of age buckets our age detector will predict
# and then initialize our results list
AGE_BUCKETS = ["(0-2)", "(4-6)", "(8-12)", "(15-20)", "(25-32)",
"(38-43)", "(48-53)", "(60-100)"]
results = []
我们的助手工具只需要 OpenCV 和 NumPy ( 第 2 行和第 3 行)。
让我们继续执行面部检测:
# grab the dimensions of the image and then construct a blob
# from it
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
faceNet.setInput(blob)
detections = faceNet.forward()
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > minConf:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the ROI of the face
face = image[startY:endY, startX:endX]
# ensure the face ROI is sufficiently large
if face.shape[0] < 20 or face.shape[1] < 20:
continue
第 23-37 行在detections上循环,确保高confidence,并提取一个face ROI,同时确保它足够大,原因有二:
- 首先,我们想过滤掉图像中的假阳性人脸检测
- 第二,年龄分类结果对于远离相机的面部(即,可察觉的小)将是不准确的
为了完成我们的人脸检测和年龄预测辅助工具,我们将执行人脸预测:
# construct a blob from *just* the face ROI
faceBlob = cv2.dnn.blobFromImage(face, 1.0, (227, 227),
(78.4263377603, 87.7689143744, 114.895847746),
swapRB=False)
# make predictions on the age and find the age bucket with
# the largest corresponding probability
ageNet.setInput(faceBlob)
preds = ageNet.forward()
i = preds[0].argmax()
age = AGE_BUCKETS[i]
ageConfidence = preds[0][i]
# construct a dictionary consisting of both the face
# bounding box location along with the age prediction,
# then update our results list
d = {
"loc": (startX, startY, endX, endY),
"age": (age, ageConfidence)
}
results.append(d)
# return our results to the calling function
return results
def detect_camo(image, camoNet):
# initialize (1) the class labels the camo detector can predict
# and (2) the ImageNet means (in RGB order)
CLASS_LABELS = ["camouflage_clothes", "normal_clothes"]
MEANS = np.array([123.68, 116.779, 103.939], dtype="float32")
# resize the image to 224x224 (ignoring aspect ratio), convert
# the image from BGR to RGB ordering, and then add a batch
# dimension to the volume
image = cv2.resize(image, (224, 224))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = np.expand_dims(image, axis=0).astype("float32")
# perform mean subtraction
image -= MEANS
# make predictions on the input image and find the class label
# with the largest corresponding probability
preds = camoNet.predict(image)[0]
i = np.argmax(preds)
# return the class label and corresponding probability
return (CLASS_LABELS[i], preds[i])
def anonymize_face_pixelate(image, blocks=3):
# divide the input image into NxN blocks
(h, w) = image.shape[:2]
xSteps = np.linspace(0, w, blocks + 1, dtype="int")
ySteps = np.linspace(0, h, blocks + 1, dtype="int")
# loop over the blocks in both the x and y direction
for i in range(1, len(ySteps)):
for j in range(1, len(xSteps)):
# compute the starting and ending (x, y)-coordinates
# for the current block
startX = xSteps[j - 1]
startY = ySteps[i - 1]
endX = xSteps[j]
endY = ySteps[i]
# extract the ROI using NumPy array slicing, compute the
# mean of the ROI, and then draw a rectangle with the
# mean RGB values over the ROI in the original image
roi = image[startY:endY, startX:endX]
(B, G, R) = [int(x) for x in cv2.mean(roi)[:3]]
cv2.rectangle(image, (startX, startY), (endX, endY),
(B, G, R), -1)
# return the pixelated blurred image
return image
对于面部匿名化,我们将使用像素化类型的面部模糊。这种方法通常是大多数人听到“面部模糊”时想到的——这与你在晚间新闻中看到的面部模糊类型相同,主要是因为它比更简单的高斯模糊(这确实有点“不和谐”)更“美观”。
使用 OpenCV 和 Keras/TensorFlow 实现我们的潜在儿童兵探测器
配置文件和助手函数就绪后,让我们继续将它们应用于可能包含儿童兵的图像数据集。
打开process_dataset.py脚本,插入以下代码:
# import the necessary packages
from pyimagesearch.helpers import detect_and_predict_age
from pyimagesearch.helpers import detect_camo
from pyimagesearch import config
from tensorflow.keras.models import load_model
from imutils import paths
import progressbar
import argparse
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input directory of images to process")
ap.add_argument("-o", "--output", required=True,
help="path to output directory where CSV files will be stored")
args = vars(ap.parse_args())
# initialize a dictionary that will store output file pointers for
# our age and camo predictions, respectively
FILES = {}
# loop over our two types of output predictions
for k in ("ages", "camo"):
# construct the output file path for the CSV file, open a path to
# the file pointer, and then store it in our files dictionary
p = os.path.sep.join([args["output"], "{}.csv".format(k)])
f = open(p, "w")
FILES[k] = f
这两个文件指针都是打开的,以便在进程中写入。
此时,我们将初始化三个深度学习模型:
# load our serialized face detector, age detector, and camo detector
# from disk
print("[INFO] loading trained models...")
faceNet = cv2.dnn.readNet(config.FACE_PROTOTXT, config.FACE_WEIGHTS)
ageNet = cv2.dnn.readNet(config.AGE_PROTOTXT, config.AGE_WEIGHTS)
camoNet = load_model(config.CAMO_MODEL)
# grab the paths to all images in our dataset
imagePaths = sorted(list(paths.list_images(args["dataset"])))
print("[INFO] processing {} images".format(len(imagePaths)))
# initialize the progress bar
widgets = ["Processing Images: ", progressbar.Percentage(), " ",
progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(imagePaths),
widgets=widgets).start()
我们现在进入数据集处理脚本的核心。我们将开始循环所有图像以检测面部,预测年龄,并确定是否存在伪装:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the image from disk
image = cv2.imread(imagePath)
# if the image is 'None', then it could not be properly read from
# disk (so we should just skip it)
if image is None:
continue
# detect all faces in the input image and then predict their
# perceived age based on the face ROI
ageResults = detect_and_predict_age(image, faceNet, ageNet)
# use our camo detection model to detect whether camouflage exists in
# the image or not
camoResults = detect_camo(image, camoNet)
# loop over the age detection results
for r in ageResults:
# the output row for the ages CSV consists of (1) the image
# file path, (2) bounding box coordinates of the face, (3)
# the predicted age, and (4) the corresponding probability
# of the age prediction
row = [imagePath, *r["loc"], r["age"][0], r["age"][1]]
row = ",".join([str(x) for x in row])
# write the row to the age prediction CSV file
FILES["ages"].write("{}\n".format(row))
FILES["ages"].flush()
# check to see if our camouflage predictor was triggered
if camoResults[0] == "camouflage_clothes":
# the output row for the camo CSV consists of (1) the image
# file path and (2) the probability of the camo prediction
row = [imagePath, camoResults[1]]
row = ",".join([str(x) for x in row])
# write the row to the camo prediction CSV file
FILES["camo"].write("{}\n".format(row))
FILES["camo"].flush()
# update the progress bar
pbar.update(i)
# stop the progress bar
pbar.finish()
print("[INFO] cleaning up...")
# loop over the open file pointers and close them
for f in FILES.values():
f.close()
第 92 行更新了我们的进度条,此时,我们将从循环的顶部开始处理数据集中的下一幅图像。
第 95-100 行停止进度条并关闭 CSV 文件指针。
很好地实现了数据集处理脚本。在下一节中,我们将让它发挥作用!
处理我们的潜在儿童兵数据集
$ time python process_dataset.py --dataset VictorGevers_Dataset --output output
[INFO] loading trained models...
[INFO] processing 56037 images
Processing Images: 100% |############################| Time: 1:49:48
[INFO] cleaning up...
real 109m53.034s
user 428m1.900s
sys 306m23.741s
该数据集由 Victor Gevers 提供(即在数据泄露期间获得的数据集)。
在我的 3 GHz 英特尔至强 W 处理器上,处理整个数据集花费了将近两个小时,—,如果有 GPU,速度会更快。
**当然,我 不能像往常一样在指南的部分提供本教程中使用的原始数据集**。该数据集是私有的、敏感的,并且不能以任何方式分发。
*脚本执行完毕后,我的output目录中有两个 CSV 文件:
$ ls output/
ages.csv camo.csv
以下是ages.csv的输出示例:
$ tail output/ages.csv
rBIABl3RztuAVy6gAAMSpLwFcC0051.png,661,1079,1081,1873,(48-53),0.6324904
rBIABl3RzuuAbzmlAAUsBPfvHNA217.png,546,122,1081,1014,(8-12),0.59567857
rBIABl3RzxKAaJEoAAdr1POcxbI556.png,4,189,105,349,(48-53),0.49577188
rBIABl3RzxmAM6nvAABRgKCu0g4069.png,104,76,317,346,(8-12),0.31842607
rBIABl3RzxmAM6nvAABRgKCu0g4069.png,236,246,449,523,(60-100),0.9929517
rBIABl3RzxqAbJZVAAA7VN0gGzg369.png,41,79,258,360,(38-43),0.63570714
rBIABl3RzxyABhCxAAav3PMc9eo739.png,632,512,1074,1419,(48-53),0.5355053
rBIABl3RzzOAZ-HuAAZQoGUjaiw399.png,354,56,1089,970,(60-100),0.48260492
rBIABl3RzzOAZ-HuAAZQoGUjaiw399.png,820,475,1540,1434,(4-6),0.6595153
rBIABl3RzzeAb1lkAAdmVBqVDho181.png,258,994,826,2542,(15-20),0.3086191
如您所见,每行包含:
- 图像文件路径
- 特定面的边界框坐标
- 面部年龄范围预测和相关概率
下面是来自camo.csv的输出示例:
$ tail output/camo.csv
rBIABl3RY-2AYS0RAAaPGGXk-_A001.png,0.9579516
rBIABl3Ra4GAScPBAABEYEkNOcQ818.png,0.995684
rBIABl3Rb36AMT9WAABN7PoYIew817.png,0.99894327
rBIABl3Rby-AQv5MAAB8CPkzp58351.png,0.9577539
rBIABl3Re6OALgO5AABY5AH5hJc735.png,0.7973979
rBIABl3RvkuAXeryAABlfL8vLL4072.png,0.7121747
rBIABl3RwaOAFX21AABy6JNWkVY010.png,0.97816855
rBIABl3Rz-2AUOD0AAQ3eMMg8gg856.png,0.8256913
rBIABl3RztOAeFb1AABG-K96F_c092.png,0.50594944
rBIABl3RzxeAGI5XAAfg5J_Svmc027.png,0.98626024
该 CSV 文件包含的信息较少,仅包含:
- 图像文件路径
- 指示图像是否包含伪装的概率
我们现在有了年龄和伪装预测。
但是我们如何结合这些预测来确定一个特定的图像是否有潜在的儿童兵呢?
我将在下一节回答这个问题。
实现 Python 脚本来解析我们的检测结果
您可以轻松地将儿童兵数据输出到另一个 CSV 文件,并将其提供给报告机构(如果您正在做这种工作的话)。
相反,我们要开发的脚本只是在可疑的儿童兵图像中匿名化人脸(即应用我们的像素化模糊方法)并在屏幕上显示结果。
现在让我们来看看parse_results.py:
# import the necessary packages
from pyimagesearch.helpers import anonymize_face_pixelate
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-a", "--ages", required=True,
help="path to input ages CSV file")
ap.add_argument("-c", "--camo", required=True,
help="path to input camo CSV file")
args = vars(ap.parse_args())
# load the contents of the ages and camo CSV files
ageRows = open(args["ages"]).read().strip().split("\n")
camoRows = open(args["camo"]).read().strip().split("\n")
# initialize two dictionaries, one to store the age results and the
# other to store the camo results, respectively
ages = {}
camo = {}
# loop over the age rows
for row in ageRows:
# parse the row
row = row.split(",")
imagePath = row[0]
bbox = [int(x) for x in row[1:5]]
age = row[5]
ageProb = float(row[6])
# construct a tuple that consists of the bounding box coordinates,
# age, and age probability
t = (bbox, age, ageProb)
# update our ages dictionary to use the image path as the key and
# the detection information as a tuple
l = ages.get(imagePath, [])
l.append(t)
ages[imagePath] = l
# loop over the camo rows
for row in camoRows:
# parse the row
row = row.split(",")
imagePath = row[0]
camoProb = float(row[1])
# update our camo dictionary to use the image path as the key and
# the camouflage probability as the value
camo[imagePath] = camoProb
# find all image paths that exist in *BOTH* the age dictionary and
# camo dictionary
inter = sorted(set(ages.keys()).intersection(camo.keys()))
# loop over all image paths in the intersection
for imagePath in inter:
# load the input image and grab its dimensions
image = cv2.imread(imagePath)
(h, w) = image.shape[:2]
# if the width is greater than the height, resize along the width
# dimension
if w > h:
image = imutils.resize(image, width=600)
# otherwise, resize the image along the height
else:
image = imutils.resize(image, height=600)
# compute the resize ratio, which is the ratio between the *new*
# image dimensions to the *old* image dimensions
ratio = image.shape[1] / float(w)
计算新的图像尺寸和旧的图像尺寸(第 76 行)之间的比率允许我们在下一个代码块中缩放我们的面部边界框。
让我们循环一下这张图片的年龄预测:
# loop over the age predictions for this particular image
for (bbox, age, ageProb) in ages[imagePath]:
# extract the bounding box coordinates of the face detection
bbox = [int(x) for x in np.array(bbox) * ratio]
(startX, startY, endX, endY) = bbox
# anonymize the face
face = image[startY:endY, startX:endX]
face = anonymize_face_pixelate(face, blocks=5)
image[startY:endY, startX:endX] = face
# set the color for the annotation to *green*
color = (0, 255, 0)
# override the color to *red* they are potential child soldier
if age in ["(0-2)", "(4-6)", "(8-12)", "(15-20)"]:
color = (0, 0, 255)
# draw the bounding box of the face along with the associated
# predicted age
text = "{}: {:.2f}%".format(age, ageProb * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY), color, 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)
让我们更进一步,在图像的左上角标注伪装的概率:
# draw the camouflage prediction probability on the image
label = "camo: {:.2f}%".format(camo[imagePath] * 100)
cv2.rectangle(image, (0, 0), (300, 40), (0, 0, 0), -1)
cv2.putText(image, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.8, (255, 255, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
结果:利用计算机视觉和深度学习带来好处
我们现在准备结合年龄预测和伪装输出的结果来确定特定图像是否包含潜在的儿童兵。
为了执行这个脚本,我使用了以下命令:
$ python parse_results.py --ages output/ages.csv --camo output/camo.csv
注:出于隐私考虑,即使使用了面部匿名技术,我也不愿意分享 Victor Gevers 提供给我的数据集中的原始图片。我在网上放了其他图片的样本来证明这个脚本运行正常。我希望你能理解和欣赏我为什么做这个决定。
下面是一个包含潜在儿童兵的图像示例:
这是我们检测潜在儿童兵的方法的第二个图像:
这里的年龄预测有点偏差。
我估计这位年轻女士(参见图 1 中的原图)大约在 12-16 岁之间;然而,我们的年龄预测模型预测 4-6-年龄预测模型的局限性在下面的【概要】部分中讨论。
总结
在本教程中,您学习了计算机视觉和深度学习的道德应用——识别潜在的儿童兵。
为了完成这项任务,我们应用了:
- 年龄检测 —用于检测图像中人的年龄
- 迷彩/疲劳检测 —用于检测图像中是否有迷彩,表明此人可能穿着军装
我们的系统相当准确,但正如我在我的年龄检测帖子以及伪装检测教程中所讨论的,结果可以通过以下方式得到改善:
- 用平衡数据集训练更准确的年龄检测器
- 收集额外的儿童图像,以便更好地识别儿童的年龄段
- 通过应用更积极的数据扩充和正则化技术来训练更精确的伪装检测器
- 通过服装分割构建更好的军用疲劳/制服检测器
我希望你喜欢这篇教程——我也希望你不会觉得这篇文章的主题太令人沮丧。
计算机视觉和深度学习,就像几乎任何产品或科学一样,可以用于善或恶。尽你所能保持好的一面。世界是一个可怕的地方——让我们一起努力,创造一个更美好的世界。
要下载这篇文章的源代码(包括预先训练的人脸检测器、年龄检测器和伪装检测器模型),只需在下面的表格中输入您的电子邮件地址!***
Darknet-53 和多尺度预测的增量改进(YOLOv3)
用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
在本教程中,您将了解 YOLOv2 中所做的改进;更具体地说,我们将看看设计的变化,大大提高了 YOLO 的性能,产生了一个新版本的 YOLO 称为 YOLOv3。YOLOv3 和它的前辈之间的显著区别在于称为 Darknet-53 的网络架构,我们将在本教程的下一节详细探讨这一点。我们还将演示如何使用 YOLOv3 模型在 80 类 MS COCO 数据集上进行预训练。
YOLOv3 是 2019 年实时物体检测方面最好的模型之一。
如果你按照之前关于 YOLO 的教程学习,那么理解这并不是一个挑战,因为没有太多的修改,而且大多数概念都是从 YOLOv1 和 YOLOv2 中获得的。
这一课是我们关于 YOLO 的 7 集系列的第 5 集:
- YOLO 家族简介
- 了解一个实时物体检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的物体探测器(YOLOv2)
- 使用 COCO 评估器 平均精度(mAP)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3) (今日教程)
- 【yolov 4】
- 在自定义数据集上训练 YOLOv5 物体检测器
要了解 YOLOv3 对象检测器的网络架构修改,并观看实时检测对象的演示,请继续阅读。
增量改进与 Darknet-53 和多尺度预测(yolov 3)
在 YOLO 系列的第 5 部分中,我们将从介绍 YOLOv3 开始。然后,我们将简要回顾 YOLO 物体检测的一般概念。
从那里,我们将详细讨论 YOLOv3 的新 Darknet-53 架构,包括:
- 预训练阶段
- 检测阶段
- 跨三个尺度的预测
- 网络输出预测张量
- 特征抽出
- 锚箱的使用
- 损失函数的修正:用 sigmoid 进行分类预测
我们将讨论 YOLOv3 与 fast-RCNN、YOLOv2、SSD 和 RetinaNet 的定量基准比较。
最后,我们将通过安装 Darknet 框架并在 Tesla V100 GPU 上使用 MS COCO pretrained 模型对图像和视频运行推理,将 YOLOv3 投入实际使用。
配置您的开发环境
要遵循这个指南,您需要在您的系统上编译并安装 Darknet 框架。在本教程中,我们将使用 AlexeyAB 的 Darknet 库。
我们涵盖了在 Google Colab 上安装 Darknet 框架的逐步说明。但是,如果您现在想配置您的开发环境,可以考虑前往配置 Darknet 框架并使用预训练的 YOLOv3 COCO 模型运行推理部分。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
约洛夫 3 简介
继 YOLOv2 论文之后,2018 年,约瑟夫·雷德蒙(华盛顿大学研究生)和阿里·法尔哈迪(华盛顿大学副教授)发表了关于 arXiv 的 YOLOv3:增量改进论文。作者对网络体系结构进行了许多设计上的修改,采用了以前 YOLO 版本中的大多数其他技术。
YOLOv3 论文介绍了一种新的网络架构,称为 Darknet-53,与 YOLOv2 中的 Darknet-19 架构相对。Darknet-53 是一个比以前更广泛的网络,但更准确和更快。它以不同的图像分辨率进行训练,如 YOLOv2 所示;在
resolution, YOLOv3 achieves 28.2 mAP runs at 45 FPS and is as accurate as Single-Shot Detector (SSD321) but 3x faster (Figure 2). The authors performed the quantitative benchmarks on the Titan X GPU.
与之前不同的是,在 YOLOv3 中,作者在不同的借据上比较地图;在 0.5 IOU 时,它达到 57.9 
in 51ms compared to 57.5 in 198 ms by RetinaNet-101-800. Thus, though both achieve almost the same mAP, YOLOv3 is 3.8x faster than RetinaNet.
什么是 YOLO?
YOLO 代表“你只看一次”它是一个单级对象检测器,利用卷积神经网络的能力来检测给定图像中的多个对象。它将图像划分为一个网格,并为图像的每个网格单元预测分类概率和盒子坐标。
YOLO 在整个图像上应用单个神经网络,并且在单个网络通道中检测对象。这种体系结构在精神上类似于图像分类网络,在该网络中,对象在单次正向传递中被分类。因此,YOLO 比其他最先进的检测器更快,是许多工业应用的理想选择。
Darknet-53 网络架构
**表 1 显示了由 53 个卷积层组成的 Darknet-53 架构,用作对象检测网络或特征提取器的基础。使用 ImageNet 数据集对 53 个图层进行影像分类任务的预训练。对于对象检测任务,在基础/主干网络之上又堆叠了 53 层,使其总共为 106 层,并且我们得到了被称为 YOLOv3 的最终模型。
在 YOLOv2 中,作者使用了一个由 19 层组成的小得多的网络;然而,随着深度学习领域的发展,我们被引入了更广泛、更深入的网络,如 ResNet、DenseNet 等。受新分类网络的启发,YOLOv3 比其前身更深入,并借鉴了残余块(跳过加法连接)和跳过串联连接等概念,以避免消失梯度问题,并帮助传播有助于预测不同比例对象的信息。
YOLOv3 网络架构中需要注意的重要部分是残差块、跳过连接和上采样层。
Darknet-53 网络架构比 Darknet-19 更强大,比 ResNet-101 和 ResNet-152 更高效。如表 2 所示,Darknet-53 每秒执行的浮点运算比其他主干架构多十亿次,效率很高。这也意味着网络结构更好地利用了 GPU,使其评估更有效,从而更快。此外,在 Top-1 和 Top-5 图像分类精度方面,Darknet-53 的性能优于 Darknet-19,性能与 ResNet 相似。以下结果是在 ImageNet 数据集上进行的基准测试,推理是在 Titan X GPU 上计算的。
预训练阶段
在预处理步骤中,使用 ImageNet 数据集在图像分类任务上训练 Darknet-53 架构。该架构简单明了,但是让我们看看一些主要的组件。在每个卷积层之后,残差组(用矩形示出)具有不同的残差块,例如 1x、2x、4x 和 8x。为了对特征图的空间维度进行下采样,在每个残差组之前使用步长为 2 的步长卷积。这有助于防止低级特征的丢失,并对用于物体检测的位置信息进行编码;此外,由于步长卷积有参数,下采样不会像最大池那样完全没有参数。它提高了探测更小物体的能力。
滤波器的数量从 32 开始,并且在每个卷积层和残差组加倍。每个剩余块都有一个瓶颈结构
filter followed by a filter followed by a residual skip connection. Finally, for image classification in the last layers, we have a fully connected layer and a softmax function for outputting a 1000 class probability score.
检测阶段
在检测步骤中,移除最后一个剩余组之后的层(即,分类头),为我们的检测器提供主干。由于 YOLOv3 应该在最后三个残差组的每个残差组中检测多个尺度的对象,因此附加了一个检测层来进行对象检测预测,如图图 3 所示。下图显示了三个残差组的输出被提取为三个不同比例的特征向量,并输入检测机。假设网络的输入是
, the three feature vectors we obtain are  ,
,  , and , responsible for detecting small, medium, and large objects, respectively.
, and , responsible for detecting small, medium, and large objects, respectively.
预测跨越三个尺度
在以前的 YOLO 体系结构中,检测只发生在最后一层;然而,在 YOLOv3 中,在网络的三个不同阶段/层检测对象,即 82、94 和 106 ( 图 4) 。
该网络使用类似于要素金字塔网络或 FPN 的概念从三个等级中提取要素。金字塔网络是什么特征我们就不细说了,简而言之,FPN 的结构有自下而上的通路,自上而下的通路,横向连接(图 5) 。使用 FPN 的想法是改进具有不同级别语义的 ConvNet 金字塔特征层次,并构建具有高级语义的特征金字塔。目标是将信息丰富的低分辨率特征(在网络的较后层)与高分辨率特征(在网络的初始层)相结合。因此,FPN 有助于改善识别尺度差异极大的物体的问题。
从图 6 中,我们可以看到在基本特征提取器之上增加了几个卷积层。每个尺度的最后一层预测 3D 张量编码:边界框坐标、客观分数和类别预测。对于 COCO 数据集,在每个尺度上预测三个边界框(每个尺度三个框先验/锚)。所以输出预测张量是![N \times N \times [3 \times (4+1+80)]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/3620296943f289ae0630f50a1b204260.png "N \times N \times [3 \times (4+1+80)]")
for the four bounding box offsets, one objectness score prediction, and 80 class predictions. For detecting medium-scale objects, large-scale features are upsampled and concatenated. Similarly, for detecting small-scale objects, medium-scale features are upsampled and concatenated. This setting allowed small-scale detection to benefit from both medium and large detections.
通过对不同比例的要素进行上采样和连接,网络可以从早期要素地图中获取更精细的信息,并从上采样后的图层要素地图中获取更有意义的语义信息。
与 YOLOv2 类似,为了选择精确的先验/锚,作者使用
-means clustering in YOLOv3. But instead of five, in YOLOv3, nine clusters are selected, dividing them evenly across the three scales, which means three anchors for each scale per grid cell.
类预测
YOLOv1 和 YOLOv2 都使用平方和误差进行边界框类预测,而不是通常使用的 softmax(用于多标签分类)。然而,在 YOLOv3 中,类别预测被视为多标签分类问题,这意味着类别标签被视为相互不排斥的。作者发现,使用 sigmoid 或 logistic 分类器来预测每个边界框的类别标签比 softmax 更有益。
在训练期间,二元交叉熵损失用于类别预测。当我们移动到更复杂的数据集,如开放图像数据集时,该设置很有帮助。此数据集包含许多相互不排斥(或重叠)的标签,如女人和人;因此,使用 softmax 会强加一个假设,即每个盒子恰好有一个类,但事实往往并非如此。多标记方法可以更好地模拟数据。
定量结果
本节比较 YOLOv3(用 训练
训练
input resolution) with state-of-the-art two-stage and single-stage object detectors benchmarked on the COCO dataset. As shown in Table 3, YOLOv3 does a decent job in mAP though it’s not the best. The table shows various AP columns; however, in previous YOLO versions, the performance was benchmarked on just AP50 (i.e., at 0.5 IOU). These different AP columns measure the performance of the models in a more fine-grained way; here, AP{50,75} is average precision at 0.5 and 0.75 IOU, AP{s,m,l} means average precision for small, medium, and large objects.
我们从图 2 中了解到,YOLOv3 的性能与 SSD 版本相当,但速度快了 3 倍。和 RetinaNet 等其他机型还是有相当距离的。当我们查看 AP50 结果时,YOLOv3 做得相当好,表现与几乎所有检测器相当。但是,当我们将 IOU 阈值增加到 0.75 时,性能会显著下降,这表明 YOLOv3 很难让盒子与对象完全对齐。早期的 YOLO 版本很难检测到小物体,但 YOLOv3 凭借其多尺度训练方法,表现相对较好,达到 18.3 APs。但是,它在中型和大型对象上的性能相对较差。
从这些结果中,我们可以得出结论,YOLOv3 在 AP50 时表现更好,当然是所有其他物体探测器中最快的。
用预先训练好的 YOLOv3 COCO 模型 配置暗网框架并运行推理
在我们之前关于 YOLOv1 和 YOLOv2 的两篇文章中,我们学习了如何配置 Darknet 框架,并使用预训练的 YOLO 模型进行推理;我们将遵循与配置 Darknet 框架之前相同的步骤。然后,最后,用 YOLOv3 预训练模型运行推理,看它比以前的版本执行得更好。
配置 Darknet 框架并使用 YOLOv3 在图像和视频上运行推理分为八个易于遵循的步骤。所以,让我们开始吧!
注意: 请确保您的机器上安装了匹配的 CUDA、CUDNN 和 NVIDIA 驱动程序。对于这个实验,我们使用 CUDA-10.2 和 CUDNN-8.0.3。但是如果你计划在 Google Colab 上运行这个实验,不要担心,因为所有这些库都预装了它。
步骤#1: 我们将在本实验中使用 GPU,以确保 GPU 正常运行。
# Sanity check for GPU as runtime
$ nvidia-smi
图 7 显示了机器(即 V100)、驱动程序和 CUDA 版本中可用的 GPU。
第二步:我们将安装一些库,比如 OpenCV,FFmpeg 等等。,这在编译和安装 Darknet 之前是必需的。
# Install OpenCV, ffmpeg modules
$ apt install libopencv-dev python-opencv ffmpeg
步骤#3: 接下来,我们从 AlexyAB 存储库中克隆 Darknet 框架的修改版本。如前所述,Darknet 是由 Joseph Redmon 编写的开源神经网络。用 C 和 CUDA 编写,同时支持 CPU 和 GPU 计算。暗网的官方实现可在:【https://pjreddie.com/darknet/;我们会下载官网提供的 YOLOv3 砝码。
# Clone AlexeyAB darknet repository
$ git clone https://github.com/AlexeyAB/darknet/
$ cd darknet/
确保将目录更改为 darknet,因为在下一步中,我们将配置Makefile并编译它。此外,使用!pwd进行健全性检查;我们应该在/content/darknet目录里。
步骤#4: 使用流编辑器(sed),我们将编辑 make 文件并启用标志:GPU、CUDNN、OPENCV 和 LIBSO。
图 8 显示了Makefile内容的一个片段,稍后会讨论:
- 我们让
GPU=1和CUDNN=1与CUDA一起构建暗网来执行和加速对GPU的推理。注意CUDA应该在/usr/local/cuda;否则,编译将导致错误,但如果您正在 Google Colab 上编译,请不要担心。 - 如果你的
GPU有张量核,使CUDNN_HALF=1获得高达 3 倍的推理和 2 倍的训练加速。由于我们使用具有张量内核的 Tesla V100 GPU,因此我们将启用此标志。 - 我们使
OPENCV=1能够用 OpenCV 构建 darknet。这将允许我们检测视频文件、IP 摄像头和其他 OpenCV 现成的功能,如读取、写入和在帧上绘制边界框。 - 最后,我们让
LIBSO=1构建darknet.so库和使用这个库的二进制可运行文件uselib。启用此标志将允许我们使用 Python 脚本对图像和视频进行推理,并且我们将能够在其中导入darknet。
现在让我们编辑Makefile并编译它。
# Enable the OpenCV, CUDA, CUDNN, CUDNN_HALF & LIBSO Flags and Compile Darknet
$ sed -i 's/OPENCV=0/OPENCV=1/g' Makefile
$ sed -i 's/GPU=0/GPU=1/g' Makefile
$ sed -i 's/CUDNN=0/CUDNN=1/g' Makefile
$ sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/g' Makefile
$ sed -i 's/LIBSO=0/LIBSO=1/g' Makefile
$ make
make命令将需要大约 90 秒来完成执行。既然编译已经完成,我们就可以下载 YOLOv3 权重并运行推理了。
步骤#5: 我们现在将从官方 YOLOv3 文档中下载 YOLOv3 COCO 砝码。
# Download YOLOv3 Weights
$ wget https://pjreddie.com/media/files/yolov3.weights
步骤#6: 现在,我们将运行darknet_images.py脚本来推断图像。
# Run the darknet image inference script
$ python3 darknet_images.py --input data --weights \
yolov3.weights --config_file cfg/yolov3.cfg \
--dont_show
让我们来看看传递给darknet_images.py的命令行参数:
--input:图像目录或文本文件的路径,带有图像路径或单个图像名称。支持jpg、jpeg和png图像格式。在本例中,我们将路径传递给名为data的图像文件夹。--weights: YOLOv3 加权路径。--config_file:yolo v3 的配置文件路径。在抽象层次上,该文件存储神经网络模型架构和一些其他参数,如batch_size、classes、input_size等。我们建议您通过在文本编辑器中打开该文件来快速阅读它。- 这将禁止 OpenCV 显示推理结果,我们使用它是因为我们正在与 Google Colab 合作。
在对下面的图像运行 YOLOv3 预训练的 MS COCO 模型后,我们了解到该模型几乎不会出错,并且可以完美地检测到所有图像中的对象。此外,与 YOLOv1 和 YOLOv2 相比,yolo v2 很少出现假阳性和假阴性,YOLOv3 的表现优于两者,事实上,它检测到的对象具有非常高的置信度。
我们可以从图 9 中看到,该模型以几乎 100%的高置信度正确预测了狗、自行车和卡车。
在图 10 中,模型再次以 100%的置信度正确检测到所有三个对象。如果你还记得, YOLOv1 检测出一匹马是一只羊,而 YOLOv2 两次预测出一匹马是马和羊。
在图 11 中,该模型检测出了五匹马中的四匹,并且具有非常高的置信度得分。然而,回想一下 YOLOv1 和 YOLOv2 都在这个图像中挣扎,要么预测一匹像牛一样的马,要么没有检测到四匹马中的一匹,并且两个模型都以非常低的置信度预测它们。
最后,在图 12 中,YOLOv3 模型预测一只鹰是一只类似于 YOLOv1 和 YOLOv2 的鸟。
步骤#7: 现在,我们将在电影《天降》的视频上运行预训练的 YOLOv3 模型;这是作者在他们的一个实验中使用的同一段视频。
在运行darknet_video.py演示脚本之前,我们将首先使用pytube库从 YouTube 下载视频,并使用moviepy库裁剪视频。所以让我们快速安装这些模块并下载视频。
# Install pytube and moviepy for downloading and cropping the video
$ pip install git+https://github.com/rishabh3354/pytube@master
$ pip install moviepy
在2 号线和 3 号线上,我们安装了pytube和moviepy库。
# Import the necessary packages
$ from pytube import YouTube
$ from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
# Download the video in 720p and Extract a subclip
$ YouTube('https://www.youtube.com/watch?v=tHRLX8jRjq8'). \ streams.filter(res="720p").first().download()
$ ffmpeg_extract_subclip("/content/darknet/Skyfall.mp4", \
0, 30, targetname="/content/darknet/Skyfall-Sample.mp4")
在2 号线和 3 号线,我们导入pytube和ffmpeg_extract_subclip模块。在第 6-8 行,在导入模块的帮助下,我们从 YouTube 上下载了 720p 分辨率的 Skyfall 视频。然后,我们使用moviepy的ffmpeg_extract_subclip模块从下载的视频中提取子片段(前 30 秒)。
第 8 步:最后,我们将运行darknet_video.py脚本来为天崩地裂的视频生成预测。我们打印输出视频每一帧的 FPS 信息。
如果使用 mp4 视频文件,请务必在darknet_video.py的第 57 行将set_saved_video功能中的视频编解码器从MJPG更改为mp4v;否则,播放推理视频时会出现解码错误。
# Change the VideoWriter Codec
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
既然所有必要的安装和修改都已完成,我们将运行darknet_video.py脚本:
# Run the darknet video inference script
$ python darknet_video.py --input \
/content/darknet/Skyfall-Sample.mp4 \
--weights yolov3.weights --config_file \
cfg/yolov3.cfg --dont_show --out_filename \
pred-skyfall.mp4
让我们看看传递给darknet_video.py的命令行参数:
--input:视频文件的路径,如果使用网络摄像头,则为 0--weights: YOLOv3 重量路径--config_file:yolo v3 的配置文件路径--dont_show:这将禁止 OpenCV 显示推理结果--out_filename:推理结果输出视频名称,如果为空则输出视频不保存。
下面是对天崩地裂动作场景视频的推断结果。预测必须比 YOLOv1 和 YOLOv2 更好,因为网络学会了在多个尺度上预测,从而减少了假阴性的机会。此外,YOLOv3 在 COCO 数据集上接受了 80 个类的训练(相比之下,VOC 中有 20 个类),因此您会看到更多的对象类别被检测到,如 VOC 数据集中不存在的瓶子或领带。YOLOv3 网络在混合精度的特斯拉 V100 GPU 上实现了平均 100 FPS 。
https://www.youtube.com/embed/p2dt4lljyLc***
采访 Adam Geitgey,人脸识别 Python 库的创造者

你可能已经注意到,在过去的几周里,我们在 PyImageSearch 博客上经常使用一个叫做face_recognition的特殊 Python 包:
- 我们首先用它来建立一个人脸识别系统
- 然后我们将人脸识别应用于树莓派
- 最近我们对人脸进行聚类,以在数据集中找到独特的个体
没有(1)face_recognition模块和(dlib 库,就不可能创建这些人脸识别应用程序。
今天,我很高兴与大家分享对亚当·盖特基的采访,他是face_recognition图书馆的创建者。
在采访中,亚当讨论了:
- 他如何以及为什么创建了
face_recognitionPython 模块 - 使用 RNNs 生成新的超级马里奥兄弟视频游戏水平
- 他最喜欢的工具和选择的库
- 作为 PyImageSearch 的读者,他对你的建议是,如何开始研究计算机视觉和深度学习
- 他在基于深度学习的细分、自动驾驶汽车和卫星/航空摄影方面的工作
要查看 Adam 的完整邮件,请继续阅读!
采访 Adam Geitgey,人脸识别 Python 库的创造者
阿德里安:嘿,亚当!谢谢你今天来到这里。很高兴你能来到 PyImageSearch 博客。对于不认识你的人,你是谁,你是做什么的?
亚当:嗨,阿德里安!谢谢你邀请我!
我从小就开始编程。当我七岁的时候,我开始从我能找到的任何书籍中自学 Basic 和 Pascal。所以从我记事起,我就对编程很感兴趣。
这让我最终从事各行各业的软件工作——从中国的 3D CAD 软件到硅谷的初创企业。在过去的一年半时间里,我一直在为 LinkedIn Learning 创建机器学习教育课程,并做咨询项目。最近,我一直在与比尔和梅林达盖茨基金会的一个人工智能项目团队合作。
这是在说我不是在大学里专门研究机器学习的人。我有更传统的计算机科学和软件工程背景,我在职业生涯的后期进入了机器学习领域。
Adrian: 你最初是如何对机器学习和计算机视觉产生兴趣的?
当我在大学的时候,我对当时所谓的“人工智能”并不感兴趣。这发生在 2000 年左右,比 GPU 使大型神经网络实用化早了几年。在那一点上,整个人工智能领域对我来说就像一个科幻幻想,我对如何使用计算机解决更直接的问题更感兴趣。
但是几年后,我读了彼得·诺维格的“如何写拼写纠正器”的文章。它解释了用概率来解决一个本来很难解决的问题的想法。这完全让我大吃一惊!我觉得我已经错过了一个完全平行的编程世界,我开始学习我能学的一切。这导致了机器学习,计算机视觉,自然语言处理和其他一切。

Figure 1: One of Adam’s most popular Machine Learning is Fun! articles is on face recognition.
阿德里安:你的 机器学习很有趣!你博客上的 系列很棒——是什么激发了你创作它的灵感?
每当我学习新东西时,无论是摄影、音乐理论还是机器学习,当我觉得学习材料可以更简单、更直接时,我就会感到沮丧。
某个领域的专家倾向于为其他未来的专家写作。但对我来说,更具挑战性和更有趣的是,尝试将一个话题简化为最基本的内容,并以任何人都能理解的方式呈现出来。我痴迷于试图将复杂的话题分解成最简单的形式。这可能与我的学习方式有很大关系——我喜欢在挖掘细节之前先了解全局。
对于任何一个程序员来说,这里有一些免费的职业建议——如果你能写非常清晰简单的电子邮件,解释你的团队正在解决的问题,这将会让你在大型科技公司的职业生涯中走得更远。

Figure 2: Adam used RNNs to generate new levels of the Super Mario Bros video game.
阿德里安:你在写的最喜欢的文章是什么?机器学习很有趣!为什么?
Adam: 我喜欢使用计算机作为创意工具的想法,并探索人类生成的艺术和计算机生成的艺术之间的界限。我写了一篇关于使用 RNNs 生成新的超级马里奥兄弟视频游戏关卡的文章。
Adrian: 你的人脸识别库是 GitHub 上最受欢迎的人脸识别库之一。我甚至在过去的三篇博文中都用过!你能告诉我们更多创建它的过程吗?
几乎每周都有令人兴奋的新研究论文问世,其中很多都包含工作代码。这是一个令人惊叹的程序员时代!问题是大多数研究代码都是作为一次性实验编写的。在您可以在生产应用程序中使用它之前,通常必须重写它。
我在用 Python 寻找一个好的人脸识别解决方案,但是我找到的所有东西都是用几种不同的编程语言拼凑起来的,并且需要下载额外的文件。我写了一篇关于人脸识别如何工作的文章,但是我收到的大多数问题都来自那些不能正确安装库的读者。我想要像“pip install face_recognition”一样简单的部署。
大约在那个时候, Davis King 更新了他优秀的 dlib 库,加入了一个新的人脸识别模型。这看起来非常适合我想做的事情。因为 Davis 已经完成了大部分艰苦的工作,所以我所要做的就是用我喜欢的 API 把它打包,写一堆文档和例子,然后让它托管在 pip 上。老实说,整个过程中最困难的部分是说服运行 pip 的人托管它,因为它比他们通常允许的最大文件大小要大。
阿德里安:你见过的最酷/最整洁的项目是什么?
人们已经用它来构建各种各样的东西,比如在教室里使用人脸识别来自动点名的工具。但对我来说最酷的是一个用户,他使用人脸识别模型生成的编码作为输入来训练情绪检测模型。迁移学习真的很酷,我喜欢利用现有模型建立新模型的想法。

Figure 3: Some of Adam’s favorite libraries include Keras, spaCy, fastText, NumPy, and Pandas.
阿德里安:你有哪些工具和库可供选择?
我断断续续用 Python 编码大约有 20 年了,我在所有的机器学习项目中都使用它。最好的部分是所有令人惊叹的图书馆!
我最喜欢的一些库是用于训练新神经网络的 Keras ,用于自然语言处理的 spaCy ,以及用于快速建立文本分类模型的 fastText 。知道如何很好地使用 numpy 和 Pandas 将会为你节省很多清理数据的时间。
还有,我真的很喜欢 Python 3.6 和 3.7 最近的变化。如果你还在用 Python 2,那绝对是时候升级了!
阿德里安:接下来是什么?你正在进行什么类型的项目?
我正在撰写一系列关于自然语言处理的新文章。如果你想学习如何用电脑理解书面文字,请关注我的网站上的新帖子!
Adrian: 对于刚开始学习计算机视觉和深度学习的读者,你有什么建议吗?
如果你是 Python 编程语言的新手,花点时间好好学习语法和语言结构。从长远来看,这会节省你很多时间。我得到的许多问题实际上只是 Python 语法问题或误解。这是一种与 C++或 Java 非常不同的语言。
除此之外,学习训练模型的基本概念,然后直接投入到你感兴趣的项目中进行尝试!通过实践,你会学到比阅读更多的东西。

Figure 4: PyImageConf 2018 will be head in San Francisco, CA on August 26-28th.
Adrian: 你将在 PyImageConf 2018 发表演讲,这是 PyImageSearch 自己的计算机视觉和深度学习会议——我们很高兴邀请到你!你能告诉我们更多关于你演讲的内容吗?
亚当:我将谈论如何进行图像分割。图像分割是指拍摄一张照片,不仅要识别照片中的物体,还要在每个物体周围画出线条。
图像分割有很多潜在的用途。例如,自动驾驶汽车需要能够将摄像头对准道路,并以高精度识别每个行人,图像分割是实现这一目标的一种方法。你也可以想象 Photoshop 的未来版本真的很擅长从图像中提取对象,能够自动跟踪每个对象。
但对我来说,图像分割最令人兴奋的用途是处理卫星和航空摄影。通过图像分割,我们实际上可以输入原始的卫星照片,然后让计算机自动描绘出每座建筑的轮廓和每条道路。这项工作过去由成千上万的人手工完成,耗资数百万美元。
这项技术有可能改变整个测绘行业。例如, OpenStreetMap 是一个令人惊叹的项目,志愿者们试图通过使用他们的本地知识来追踪卫星图像和注释 GPS 轨迹,从而绘制整个世界的地图。但随着图像分割技术变得更加容易,计算机将能够完成 80%的追踪地图的繁重工作,然后人类只需清理和注释结果。图像分割技术有潜力最终大大加快这一进程,我们的目标将不再只是绘制整个世界的地图,而是看看我们能以多快的速度根据最新的卫星图像绘制整个世界的地图。
获取偏远地区的高质量地图数据对于人道主义和医疗团队至关重要。更好地提供偏远地区人口居住的地图有可能拯救生命。
Adrian: 如果一个 PyImageSearch 的读者想和你联系,最好去哪里联系?
亚当:你可以在 https://www.machinelearningisfun.com/的阅读我所有的文章,也可以在推特上给我打电话 @ageitgey 。谢谢!
摘要
在今天的博客文章中,我们采访了计算机视觉和深度学习从业者亚当·盖特基(Adam Geitgey),他是流行的机器学习很有趣的作者!博客系列,以及广受欢迎的face_recognition图书馆的创建者。
请花点时间感谢 Adam 抽出时间接受采访。
在 PyImageSearch 上发布未来的博客文章和采访时,我们会通知您,请务必在下面的表格中输入您的电子邮件地址,,我会让您随时了解情况。
Adithya Gaurav Singh 访谈:用计算机视觉和人脸识别寻找爱情
知道我这件事的人不多,但我和我老婆是在网上认识的,当时她 18 岁,我 20 岁。
它不是 Match、eHarmony、Tinder 等交友网站/应用。
…取而代之的是 Last.fm ,一个与约会毫无关系的网站。
相反,Last.fm 是一个音乐网站,它分析你在笔记本电脑、台式机和 iPod 上听的音乐,然后向你推荐你喜欢的其他音乐。
Last.fm 计算出你的音乐品味和网站上其他用户之间的“匹配分数”,以鼓励用户之间的社交互动。
总的想法是,你可以找到有相似音乐偏好的用户,一起讨论乐队和歌曲,甚至一起去看演出和音乐会。
我是 Last.fm 的付费用户,pro 帐户的好处之一是你可以看到其他用户在查看你的个人资料。
一天晚上,我在查看我的 Last.fm 账户时,注意到一个非常可爱的女孩浏览了我的个人资料。
所以,很自然地,我点击了她的个人资料,看看她对什么音乐感兴趣。
令我惊讶的是,我们在音乐品味上完全一致。
在我使用 Last.fm 的 5 年多时间里,我从未见过 100%匹配的情况。
我评论了她的个人资料,然后我们开始聊天。
这些对话被转移到 Last.fm 网站的 DMs 上。
然后去脸书。
最终到短信/电话。
Trisha 和我已经在一起 13 年了,结婚也才 3 年多。
最疯狂的是,当时我住在马里兰州,而 Trisha 住在纽约。
我们不可能仅仅通过去听音乐会就找到彼此。演出不会有太多的地理重叠,即使有和,也不能保证我们会在一个有 500 多人的地方神奇地相遇。
但是……由于这个默默无闻的音乐网站,我们找到了彼此。
在一个越来越基于“左右滑动”的约会世界里,当我听说原本不用于约会的技术最终被用于两个人寻找爱情时,我感到非常惊讶。
现在,PyImageSearch 也加入了这个俱乐部。
在这篇博文中,我采访了马里兰大学帕克分校的硕士学生 Adithya Gaurav Singh,他使用计算机视觉和面部识别来帮助打动他感兴趣的女孩——现在他们已经在一起超过 3 年了。
我喜欢这个故事,因为它是如此的甜蜜和真实。
和我一起听听 Adithya 的故事,以及他是如何利用计算机视觉和 PyImageSearch 博客找到爱情的。
aditya gaur av Singh 访谈:用计算机视觉和人脸识别寻找爱情
阿德里安:嗨,阿迪蒂亚!感谢您抽出时间接受采访。很高兴您能来到 PyImageSearch 博客。
非常感谢你,阿德里安。我读了你的博客有一段时间了。在工作和学习的许多场合,它们都是我的救命稻草。
阿德里安:在我们开始之前,你能简单介绍一下你自己吗?你在哪里工作,你是做什么的?
我来自印度北部的一个小镇。技术和设计智能系统让我着迷了很长一段时间。我于 2018 年完成了工程学士学位,毕业后直接进入了计算机视觉行业。我从小做起,在新德里的初创公司 BaseApp Systems 实习,在此期间,我在深度学习及其与计算机视觉的交叉方面获得了大部分技能。
在那之后,我有机会在班加罗尔的另一家初创公司 Flux Auto 工作。我被聘为深度学习工程师,为公司的旗舰产品 Flux 自动驾驶系统开发感知堆栈。在研究了像自动驾驶这样具有挑战性的问题两年后,我深深着迷于进一步探索计算机视觉及其为开发真正智能的系统提供的杠杆作用。
我想深入这个领域的愿望使我来到了马里兰大学帕克分校,目前我正在攻读机器人硕士学位。我到达美国已经一个多月了,到现在为止,这是一次令人兴奋又充满挑战的经历。
阿德里安:是什么让你对研究计算机视觉感兴趣?我听说是因为一个女孩,对吗?
像几乎每一个计算机视觉从业者一样,我从图像处理开始,仅仅通过研究图像的像素,我就立刻对它所能做的事情感到惊讶。那是在我大学二年级的时候。到我毕业的时候,我已经可以用计算机视觉实现视觉跟踪系统了。
毕业后,由于我在这一领域的普通技能,我可以得到一份实习工作。在开始实习后,我遇到了我现在的女朋友,Ananya。我们是在网上认识的,就像你和特里莎一样。虽然我们在许多激烈的话题上很快就联系上了,但我很害羞,所以不容易约她出去。那就是你进来救了我的地方艾利安。
在一个非常普通的工作日,我看到了你关于使用 OpenCV 进行人脸识别的教程。你准备了这个教程作为给 Trisha 的特别礼物,它是一个面部识别应用程序,用来检测你们两个。我发现这很可爱,这时候我突然想到设计一个类似的应用程序来专门检测 Ananya,并把它作为礼物送给她。
你的教程和非常直观的说明使得编写代码变得更加容易。我要了 8-10 张她的照片,为每张照片生成了一个 128D 的嵌入向量,并训练了一个小模型来轻松地识别她面部的嵌入向量。瞧,我有了一个功能应用程序,可以在看不见的图像和视频中识别她的脸。她深受感动,这也是我们在一起的原因之一。
阿德里安:你和安娜亚约会多久了?
aditya:我们现在交往 3 年了,在一起很开心。
阿德里安:这个项目最难的部分是什么:处理代码还是鼓起勇气约她出去?
嗯,阿德里安,在编写代码的时候,我得到了你的帮助和指导,但是要起来约她出去,我基本上只能靠自己了。玩笑归玩笑,我可以非常自信地说,一个基于 OpenCV-Numpy-PyTorch 的 python 脚本从未让我像约她出去那样紧张。
Adrian: 自从你“得到了那个女孩”,你在计算机视觉/深度学习方面的任务完成了吗?还是继续研究这个领域?
哦,我一点也没做完。计算机视觉是我渴望建立长期职业生涯的地方。我真的相信计算机视觉是将在实现真正先进的人工智能中发挥先锋作用的领域。毕竟,如果没有计算机视觉,人类自己会是什么样子呢?
在过去的 4-5 年里,我走过了一段相当长的路。然而,还有很远很深的路要走。现在,我的重点是在 UMD 大学的研究生课程中表现出色,然后回到行业,为解决我们的计算机视觉社区面临的大量问题做出贡献。
阿德里安:如果有人想学习计算机视觉并建立自信以在日常生活中取得成功,你会给他们什么建议?
adityya:自信,在我看来,只有一把钥匙,知识。一个人对尽可能多的事情了解得越多,他就越自信。我不相信这和一个人有多内向或外向有什么关系。我个人见过那么多内向的人,对自己那么有信心,却比谁都爱自己的公司。
当然,这不仅仅包括计算机视觉或者任何一个人所从事的其他专业领域。它可以是任何事情,历史,天文,音乐,美食,电影,体育,你能想到的。一个人对事物了解得越多,信心就越高。这是我的看法。
Adrian: 感谢您成为图片搜索大学的一员!你会向其他想学习计算机视觉、深度学习和 OpenCV 的读者推荐这个程序吗?
aditya:我全心全意推荐 PyImageSearch 大学,无论你在计算机视觉/深度学习方面的技能水平如何。即使作为一名经验丰富的从业者,许多人也容易对该领域的基础知识感到生疏。
这一计划涵盖了你的差距,并帮助选择正确的工具来解决一个给定的问题。对于初学者来说,我要说找到一个教授计算机视觉的学位课程并不容易,从基础到高级,每月 24 美元。PyImageSearch 大学是获得计算机视觉和深度学习技能的首选途径。
Adrian: 如果一个 PyImageSearch 的读者想和你联系,他们该怎么做?
我将很高兴通过我的 LinkedIn 个人资料或通过电子邮件 agsingh[at]ter mail[dot]UMD[dot]edu 连接到任何 PyImageSearch 阅读器
总结
今天,我们采访了马里兰大学帕克分校的硕士学生阿迪蒂亚·高拉夫·辛格。
Adithya 使用计算机视觉和 PyImageSearch 博客上的人脸识别教程来打动他感兴趣的女孩。
他们已经约会 3 年了。
它只是向你展示了一点创造力,你不需要向左/向右滑动。
技术,甚至是 OpenCV 和 Python 的人脸识别教程可以被有机地用来培养一种关系…我认为这是一件美好的事情。
在 PyImageSearch, 在下面的表格中输入您的电子邮件地址!
对 Anthony Lowhur 的采访——用计算机视觉和深度学习识别 10,000 张 Yugioh 卡
在这篇博文中,我采访了计算机视觉和深度学习工程师 Anthony Lowhur。Anthony 分享了他用来构建能够识别 10,000+ Yugioh 交易卡的计算机视觉和深度学习系统的算法和技术。
我喜欢安东尼的项目——我希望几年前就有了它。
当我还是个孩子的时候,我喜欢收集交易卡。我有很多活页夹,里面装满了棒球卡、篮球卡、足球卡、口袋妖怪卡等等。我甚至有侏罗纪公园的交易卡!
我甚至无法开始估算我花了多少时间整理我的卡片,先按团队,再按职位,最后按字母顺序。
然后,当我完成后,我会想出一个“新的更好的方法”来整理卡片,并重新开始。在我年轻的时候,我在探索一个八岁孩子能给卡片分类的算法复杂性。充其量,我可能只有 O(N² ,所以我还有相当大的提升空间。
安东尼将卡片识别提升到了一个全新的水平。用你的智能手机,你可以拍一张 Yugioh 交易卡的照片,然后立刻认出它。这种应用程序对于以下方面非常有用:
- 想要快速确定其收藏中是否已有交易卡的收藏者
- 想要建立游戏卡数据库的档案管理员,游戏卡的属性,生命值,伤害等。(即,在识别后对卡进行 OCR)
- Yugioh 玩家不仅希望识别一张卡片,还希望翻译它(如果你不能阅读日语,但希望同时玩英语和日语卡片,或者反之亦然,这非常有用)。
Anthony 使用几种计算机视觉和深度学习算法构建了他的 Yugioh 卡识别系统,包括:
- 暹罗网络
- 三重损失
- 最终重新排序的关键点匹配(这是一个特别是聪明的技巧,你会想了解更多)
请和我一起坐下来和安东尼讨论他的项目。
学习如何用计算机视觉和深度学习识别 Yugioh 牌, 继续看就好。
对 Anthony Lowhur 的采访——用计算机视觉和深度学习识别 10,000 张 Yugioh 卡
阿德里安:欢迎你,安东尼!非常感谢你能来。很高兴您能来到 PyImageSearch 博客。
安东尼:谢谢你邀请我。很荣幸来到这里。
阿德里安:介绍一下你自己,你在哪里工作,你的工作是什么?
Anthony: 我目前是一名全职的计算机视觉(CV)和机器学习(ML)工程师,离华盛顿 DC 不远,我设计和构建供客户使用的人工智能(AI)系统。我实际上是不久前从大学毕业并获得学士学位的,所以我对这个行业还比较陌生。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
安东尼:当我开始了解被称为 DARPA 大挑战的自动驾驶汽车比赛时,我还是一名高中生。这本质上是不同大学和研究实验室之间建造自动驾驶汽车在沙漠中相互比赛的竞争。赢得比赛的汽车来自斯坦福大学,由巴斯蒂安·特龙领导。
随后,巴斯蒂安·特龙继续领导谷歌 X 项目,研发无人驾驶汽车。以前被认为是科幻小说一部分的东西现在正在成为现实,这一事实真的激励了我,从那以后我开始学习计算机视觉和深度学习。我开始在 CV 和 ML 中做个人项目,并开始在 REUs(本科生的研究经历)进行 CV/ML 研究,一切都从那里开始。
Adrian: 你刚刚开发完一个可以自动识别 10,000+ Yugioh 卡的计算机视觉系统。出色的工作!是什么激发了你创建这样一个系统?这样的系统如何帮助 Yugioh 玩家和卡片收藏者?
Anthony: 所以就有了我小时候看的一个叫 Yugioh 的纸牌游戏和电视剧。直到今天,它一直占据着我的心灵,它让我想起了每天放学后坐在电视机前的时光。
我添加 AI 是因为制造它实际上是一个更大项目的先决条件,是一个 Yugioh duel disk 。
你可以在这里阅读更多关于它的信息:我做了一个功能性的双盘(由 AI 提供动力)。
这是一个演示视频:
简而言之,这是一个让你在几英尺之外决斗的浮华设备,它在电视剧中出现过。我认为这是一个有趣的项目,可以制作并展示给其他 Yugioh 粉丝,这足以激励我继续这个项目,直到原型完成。
除了创建 duel disk 之外,还有人来找我,说他们有兴趣让它组织他们的 Yugioh 卡收藏,或者为他们的一个应用程序创意提供动力。虽然有一些不完善的地方,但它目前在 GitHub 上是开源的,所以人们有机会试用它。
阿德里安:你是如何建立 Yugioh 卡的数据集的?最后你每张卡片上有多少示例图片?
安东尼:首先,我必须提取我们的数据集。卡数据集是从 API 中检索的。卡片的全尺寸版本被使用:游戏王!API 指南–ygo prodeck。
该 API 用于将所有 Yugioh 卡(10,856 张卡)下载到我们的机器上,以将它们转换为数据集。
但是,主要问题是,大多数卡片只包含一种卡牌艺术(而其他包含多种卡牌艺术的卡片,其卡牌艺术彼此之间有显著差异)。在机器学习的意义上,本质上,有超过 10,000 个类,其中每个类只包含一个图像。
这是一个问题,因为传统的深度学习方法在少于 100 幅图像的数据集上表现不佳,更不用说每类一幅图像了。我做了一万节课。
因此,我不得不使用一次性学习来解决这个问题。一次性学习是一种比较两个图像之间的相似性而不是预测一个类别的方法。
阿德里安:基本上每张卡片只有一张样本图像,你没有多少东西可以从神经网络中学到。你应用了任何类型的数据增强吗?如果是,您使用了什么类型的数据增强?
Anthony: 虽然我们每个类只处理一个图像,但我们想看看我们是否能从这个模型中获得尽可能多的鲁棒性。因此,我们执行图像增强来创建每个卡片艺术的多个版本,但有细微的差异(亮度变化、对比度变化、偏移等)。).这将为我们的网络提供更多的数据,让我们的模型更好地泛化。
阿德里安:现在你的磁盘上有一个 Yugioh 卡的数据集。你是如何选择深度学习模型架构的?
安东尼:最初,我为暹罗网络做了一个简单的浅层网络实验,作为衡量的基准。
不足为奇的是,该网络表现不佳。网络不适合我给它的训练数据,所以我想解决这个问题。向网络添加更多层是解决方案的补救措施之一,因此我尝试了 Resnet101 ,这是一个以其巨大的层深度而闻名的网络。这最终成为我需要的架构,因为它的性能明显更好,并且达到了我的精度目标。因此,这就是最终的主要架构。
当然,如果我以后想让单个图像预测的推断时间更快,我总是可以求助于使用像 VGG16 这样的层数更少的网络。
Adrian: 您显然做了充分的准备,知道暹罗网络是这个项目的最佳架构选择。你使用标准的“香草”暹罗网络图像对吗?还是用了三胞胎和三胞胎损失来训练你的网络?
安东尼:最初,我尝试了主要使用一对图像进行比较的香草暹罗网络,尽管它的局限性开始显现。
结果,我研究了其他架构,最终发现了三元组网络。它主要不同于暹罗网络,因为它使用三个图像而不是两个,并使用不同的损失函数,称为三重损失。它主要能够在训练过程中使用正负锚来操纵图像之间的距离。因此,它实现起来相对较快,并且恰好是最终的解决方案。
Adrian: 在这一点上,你有了一个深度学习模型,它可以识别输入的 Yugioh 卡,或者非常接近返回前 10 名结果中的正确 Yugioh 卡。你是如何进一步提高准确性的?你使用了某种图像重新排序算法吗?
Anthony: 因此,尽管由 resnet101 制成的三联体网络显示出显著的改进,但似乎存在一些边界情况,在这些情况下,它不能预测正确的秩 1 类,但相对接近。为了克服这一点,ORB(面向快速和旋转简短)算法被用作支持。ORB 是一种在图像内搜索特征点的算法,因此,如果两幅图像完全相同,则这两幅图像应该具有相同数量的特征点。
该算法为我们的一次性学习方法提供了支持。一旦我们的神经网络在所有 10,000 张卡片上生成分数并对它们进行排名,我们的 ORB 就会获得 top- N 卡片排名(例如,前 50 张卡片)并计算图像上的 ORB 点数。然后,将原始相似性得分和 ORB 点数输入公式,以获得最终加权相似性得分。比较前- N 张牌的加权分数,并将分数重新排列到它们的最终排名。
图 3 显示了一个先前具有挑战性的边缘案例,在该案例中,我们在不同的对比度设置下比较了顶牌(黑暗魔术师)的两幅图像。本来没有 ORB 匹配支持就失败了,但是考虑到头脑中特征点的数量,可以得到更准确的排名。
经过一些实验和对某些值的调整,我显著提高了正确预测的数量。
Adrian: 在您的实验中,您发现即使输入图像中很小的偏移/平移也会导致准确性显著下降,这意味着您的卷积神经网络(CNN)没有很好地处理平移。你是如何克服这个问题的?
安东尼:处理这个问题的确很有趣,也很棘手。现代 CNN 在本质上不是平移不变的,即使很小的翻译也会使其混淆。我们正在处理的数据非常少,并且该算法依赖于将特征图放在一起进行比较来进行预测,这一事实进一步强调了这一点。
- 在左侧,原始图像与相同但向右平移的图像进行比较(我们跳了 0.71 点)。
- 在中间的图像中,原始图像与向右上方平移的同一图像进行比较。
- 在右侧图像中,原始图像与向右上方平移的同一图像进行比较。
这个问题表明,我们的模型对轻微的错位非常敏感,并阻止我们的模型实现其全部潜力。
我的第一种方法是通过在数据扩充过程中添加更多的翻译来简单地扩充数据。然而,这还不够,我必须寻找其他方法。
结果,我发现一些研究创造了用于解决类似问题的模糊池算法。模糊池是一种用于解决 CNN 不是 sift 不变的问题的方法,并且应用于每个卷积层的末端。
阿德里安:你的算法本质上是为你数据集中的所有卡片生成一个相似性得分。在比较 10,000 多张输入 Yugioh 卡时,您是否遇到过任何速度或效率问题?
安东尼:因此,在这一点上,我有一个模型能够以合理的准确度生成每张卡片的相似性得分。现在我所要做的就是为我们的输入图像和所有我想要比较的卡片生成相似性分数。
如果我测量我的模型的推理时间,我们可以看到,通过我们的三元 Resnet 架构传递一幅图像需要大约 0.12 秒,以及 0.08 秒的图像预处理步骤。从表面上看,这听起来不错,但是请记住,我们必须对数据集中的所有卡片都这样做。问题是,我们需要将超过 10,000 张卡片与输入进行比较,并生成分数。
因此,如果我们计算生成相似性得分所需的秒数以及数据集中卡片的总数(10,856),我们会得到:
(0.12+0.08) * 10,856 = 2171.2 秒
2171.2/60 = 36.2 分钟
为了预测单个输入图像是什么,我们必须等待 30 分钟以上。结果,这并没有使我们的模型实用。
为了解决这个问题,我最终提前预计算了所有 10,000 张卡的输出卷积特征图,并将其存储在一个字典中。字典的伟大之处在于,从字典中检索预先计算的特征图将是恒定的时间( O(1) time)。因此,随着数据集中卡片数量的增加,这将是一项不错的工作。
因此,在训练之后,我们迭代超过 10,000 张卡片,将它们输入我们的三元组网络,以获得输出卷积特征图,并将其存储在我们的字典中。我们只是在预测阶段迭代我们的新字典,而不是让我们的模型执行 10,000 次正向传播。
因此,之前 36 分钟的单幅图像预测时间已经显著减少了近 5 秒。这导致了更易于管理的模型。
Adrian: 你是如何测试和评估你的 Yugioh 卡识别系统的准确性的?
安东尼:总的来说,我主要处理两种类型的数据集。
我使用了一个数据集进行训练,其中官方卡片艺术图像来自 ygoprodeck(数据集 A)以及野外卡片的真实照片(数据集 B),这些照片是由相机拍摄的卡片照片。数据集 B 本质上是我用来取得长期成功的最终测试数据集。
人工智能/机器学习模型在卡片的真实照片上进行测试(有袖子和没有袖子的卡片)。这是数据集 b 的一个例子。
这些类型的图像是我最终希望我的人工智能分类器能够成功地让相机指向你的卡,并能够识别它。
然而,由于购买超过 10,000 张卡片并给它们拍照并不现实,我尝试了退而求其次的方法:在 Yugioh 卡片的在线数据集上进行测试,并人工添加具有挑战性的修改。修改包括改变亮度、对比度和剪切,以模拟现实生活中不同照明/照片质量场景下的 Yugioh 卡(数据集 A)。
以下是数据集中的一些输入图像和卡片艺术:
这是最终的结果:
以下是卡片识别器的几个应用示例:
在 Yugioh 的游戏中,人工智能分类器对所有卡片的准确率达到了 99%。
这本来是一个快速的项目,所以我很高兴的进展。我可能会尝试看看我是否可以收集更多的 Yugioh 卡,并尝试改善系统。
阿德里安:你项目的下一步是什么?
Anthony: 肯定有一些不完美的地方会阻碍我的模型发挥出它的全部潜力。
用于训练的数据集是来自 ygoprodeck 的官方卡片艺术图像(数据集 A),而不是野外卡片的真实照片(数据集 B),后者是由相机拍摄的卡片照片。
99%的准确性结果来自数据集 A 上的训练和测试,而训练的模型也在数据集 B 上的一些卡片上进行测试。然而,我们没有数据集 B 的大量数据来对其执行实际训练或甚至大规模评估。这个报告证明了我们的模型可以通过数据集 A 学习 Yugioh 卡,并有可能在数据集 B 上取得成功,数据集 B 是我们模型的更真实和自然的图像集目标。建立一个数据收集基础设施来大规模收集数据集 B 的图像样本将极大地推进该项目,并有助于确认模型的强度。
这个程序也没有合适的对象检测器,只是使用简单的图像处理方法( 4 点变换)来获得卡片的边界框并对齐它。使用像 YOLO(你只看一次)这样合适的物体检测器将是理想的,这也将有助于检测多个演示卡。
更精确和更真实的图像增强方法将有助于添加眩光、更自然的光照和扭曲,这可能有助于我的模型从数据集 A 适应甚至更真实的图像。
Adrian: 你从 2017 年开始就是 PyImageSearch 的读者和客户了!谢谢你支持 PyImageSearch 和我。你有哪些 PyImageSearch 的书籍和课程?他们是如何帮助你为这个项目的完成做准备的?
Anthony: 我目前拥有用于计算机视觉的深度学习 for Python bundle 以及用于计算机视觉的Raspberry Pi本书。
从读你的书到我尝试这个项目的时间间隔是 3 年左右,所以一路上我经历了很多事情,从各种渠道获得了很多东西。
PyImageSearch 博客和使用 Python 捆绑包的计算机视觉深度学习已经成为我巨大旅程的一部分,教会了我并加强了我的计算机视觉和深度学习基础。多亏了这个包,我知道了更多像 Resnet 这样的架构和像迁移学习这样的方法。它们帮助我形成了基础知识,使我能够深入到更高级的概念中,而这些概念是我通常不会经历的。
当我开始着手 Yugioh 项目时,我在项目中应用的大多数概念对我来说已经是第二天性了。他们给了我信心去计划和试验模型,直到我得到满意的结果。
Adrian: 你会向其他尝试学习计算机视觉、深度学习和 OpenCV 的初露头角的开发者、学生和研究人员推荐这些书籍和课程吗?
Anthony: 当然,像用 Python 进行计算机视觉深度学习这样的书有丰富的知识,可以用来启动或加强任何人的计算机视觉和机器学习之旅。它对每个主题的解释,以及代码示例,使其易于理解,并提供了广泛的信息。这无疑加强了我在该领域的基础知识,并帮助我过渡到能够学习更高级的主题,否则我将无法学习。
Adrian: 如果一个 PyImageSearch 的读者想聊聊你的项目,那么和你联系的最佳地点是哪里?
安东尼:与我联系的最好方式是通过我在雅虎网站的电子邮件
你也可以通过 LinkedIn 、 Medium 联系我,如果你想看更多我的项目,可以查看我的 GitHub 页面。
总结
今天我们采访了计算机视觉和深度学习工程师 Anthony Lowhur。
安东尼创造了一个能够识别超过 10,000 张 Yugioh 交易卡的计算机视觉项目。
他的算法工作原理是:
- 使用数据扩充为每个 Yugioh 卡生成额外的数据样本
- 根据数据训练一个连体网络
- 预先计算卡之间的特征图和距离(有助于实现更快的卡识别)
- 利用关键点匹配来重新排列来自暹罗网络模型的顶部输出
总的来说,他的系统有将近 99%的准确率!
在 PyImageSearch 上发布以后的教程和采访时,我们会通知您,只需在下面的表格中输入您的电子邮件地址!
对计算机视觉和深度学习研究员阿斯卡特·库兹德约夫的采访
在这篇博客文章中,我采访了智能系统和人工智能研究所(ISSAI)的计算机视觉和深度学习研究员 Askat Kuzdeuov。
Askat 不仅是一名出色的研究人员,也是一名狂热的 PyImageSearch 读者。
几周前我第一次被介绍给 Askat。我们刚刚宣布向第一个完成该计划所有课程的 PyImageSearch 大学成员奖励 500 美元。不到 24 小时后,阿斯卡特完成了所有课程并赢得了奖品。
我们从那里开始了电子邮件对话,他分享了他的一些最新研究。退一步说,我被深深打动了。
Askat 和他的同事们的最新作品, SpeakingFaces:一个带有视觉和热视频流的大规模多模态语音命令数据集 ,介绍了一个新的数据集,计算机视觉和深度学习的研究人员/从业者可以使用它来:
- 人机交互
- 生物认证
- 识别系统
- 域名转移
- 语音识别
我真正喜欢 SpeakingFaces 的是传感器融合组件,包括:
- 高分辨率热图像
- 可见光谱图像流(即人眼所能看到的)
- 同步录音
从 142 名受试者中收集了数据,产生了超过 13,000 个同步数据实例(∼3.8 TB)……但是收集数据只是 容易 的一部分!
接下来是困难的部分——预处理所有数据,确保数据同步,并以计算机视觉/深度学习研究人员可以在自己的工作中使用的方式打包。
从那里,Askat 和他的同事训练了一个 GAN 来获取输入的热图像,然后从它们生成一个 RGB 图像,正如 Askat 可以证明的那样,这不是一件容易的事情!
在本次采访的其余部分,您将了解 Askat 和他的同事如何构建 SpeakingFaces 数据集,包括他们用于清理和准备数据集以进行分发的预处理技术。
您还将了解他们如何训练 GAN 从热感相机输入中生成 RGB 图像。
如果你有兴趣了解如何在计算机视觉社区进行值得发表的工作, 那么一定要阅读这篇访谈!
采访计算机视觉和深度学习研究员阿斯卡特·库兹德乌夫
阿德里安:你好,阿斯特!感谢您抽出时间接受采访。很高兴您能来到 PyImageSearch 博客。
阿斯特:嗨,阿德里安!谢谢你邀请我。很荣幸成为 PyImageSearch 的嘉宾。
阿德里安:在我们开始之前,你能简单介绍一下你自己吗?你在哪里工作,你的角色是什么?
Askat: 我是智能系统和人工智能研究院 (ISSAI)的一名数据科学家。我的主要职责是进行与计算机视觉、深度学习和数学建模相关的研究。
阿德里安:我真的很喜欢阅读你的谷歌学术个人资料和你的一些出版物。是什么让你对研究计算机视觉和深度学习感兴趣?
Askat: 谢谢!我很高兴听到你喜欢它们!在研究生学习期间,在导师 Varol 博士的推荐下,我学习了一门图像处理课程,从而发现了计算机视觉。它很快成为我最喜欢的科目。我在游戏格式中操作图像时获得了很多乐趣,在课程结束时,我意识到这正是我想要追求的。
Adrian: 你最近的出版物, SpeakingFaces:一个带有视觉和热视频流 的大规模多模态语音命令数据集,介绍了一个数据集,计算机视觉从业者可以使用它来更好地理解和解释通过视觉线索发出的语音命令。你能告诉我们更多关于这个数据集和相关论文的信息吗?是什么让你和你的团队想要创建这个数据集?
我们研究所的两个主要研究方向是多感官数据和语音数据。热感相机是我们实验的传感器之一,我们有兴趣研究它如何用于录音。当我们开始研究时,我们意识到没有适合这项任务的现有数据集,所以我们决定设计一个。由于大多数作品主要将音频与视觉数据联系在一起,我们选择将所有三种形式结合起来,以扩大潜在的应用范围。
Adrian: 你能描述一下数据集的获取过程吗?我相信这是一项艰巨的任务。你是如何如此高效地完成它的?
阿斯特:这的确是一项任务。一旦我们设计了采集方案,我们必须通过一个伦理委员会来证明我们的研究对我们的潜在参与者的风险很小或没有风险。只有在他们同意后,我们才能继续进行。由于参与人数众多且日程繁忙,安排录制会议相当棘手。我们要求每个参与者贡献 30 分钟的时间,并在另一天回来重复整个拍摄过程。参与者的数量是另一个挑战,尤其是在疫情的条件下。我们的目标是多元化和性别平衡的代表,所以我们在寻找潜在的参与者时必须牢记这一点。
与全球许多人一样,我们意外地受到了疫情的袭击,不得不调整我们的计划,转向可以远程执行的数据处理任务,优化在线协作。
我感谢我的合著者和其他 ISSAI 成员对数据集的帮助。最后,就像他们说的,需要一个村庄来获取和处理数据!
阿德里安:收集原始数据后,你需要对其进行预处理,然后将其组织成其他研究人员可以利用的逻辑结构。处理多模态数据使这个过程变得非常重要。你是怎么解决这个问题的?
是的,预处理步骤有它自己的挑战,因为它揭示了在数据收集过程中发生的一些问题。事实上,我们发现您的教程有助于解决这些问题,并在我们的论文中引用了它们。
例如,在某些情况下,由于网络摄像头的自动对焦模式,视觉图像变得模糊。考虑到我们记录了数百万帧,手动搜索模糊帧将是一项极其困难的任务。幸运的是,我们已经阅读了你的博客文章“用 OpenCV 进行模糊检测”,这帮助我们实现了这个过程的自动化。
此外,我们注意到热感相机在某些情况下冻结,因此受影响的帧没有正确更新。我们通过比较连续的帧并利用结构相似性指数方法来检测这些情况,这在您的“How-To:Python Compare Two Images”帖子中有很好的解释。
Adrian: 我注意到你使用 GANs 将热图像转换为面部的“正常”RGB 表示——你能告诉我们更多关于这个过程的信息吗?为什么你需要在这里使用 GANs?
Askat: 人脸识别和面部标志预测模型的技术水平仅使用视觉图像进行训练。因此,我们不能将它们直接应用于热图像。有几种可能的选择来解决这个问题。
第一种是收集大量带注释的热图像,从零开始训练模型。这个过程需要大量的时间和人力。
第二种选择是结合视觉和热图像,使用迁移学习方法。然而,这种方法也需要注释热图像。
我们在论文中选择的方案是使用深度生成模型将图像从热域转换到可见光域。我们选择 GANs 是因为目前的技术水平表明,GANs 在生成真实图像方面优于自动编码器。然而,缺点是 GANs 极难训练。
Adrian: 你设想使用说话脸数据集有哪些更实际的应用?
总的来说,我们认为该数据集可以用于广泛的人机交互目的。我们希望我们的工作将鼓励其他人将多模态数据集成到不同的识别系统中,并使它们更加健壮。
Adrian: 你在研究中利用了哪些计算机视觉和深度学习工具、库和包?
第一步是数据收集。我们使用了罗技 C920 Pro 相机,带有双麦克风和 FLIR T540 热感相机。
热感相机的官方 API 是用 MATLAB 编写的。因此,我不得不使用 MATLAB 的计算机视觉和 ROS 工具箱从两台相机同时获取帧。
下一步是清理和预处理数据。我们主要利用了 Python 和 OpenCV,并且大量使用了你的 imutils 包。它非常有用!
在最后一步,我们使用 PyTorch 为热视觉面部图像翻译和多模态性别分类建立基线模型。
Adrian: 如果您必须选择在构建 SpeakingFaces 数据集时面临的最具挑战性的问题,会是什么?
Askat: 锁定期间肯定在操作。当我们转到预处理阶段时,我们意识到一些收集到的图像帧被破坏了。不幸的是,由于隔离措施,我们不能重拍,所以我们安全地删除了我们能做的,并记录了其余的。
阿德里安:作为一名研究人员,你下一步有什么打算?你会继续在 SpeakingFaces 上工作还是会转向其他项目?
目前我参与了几个项目。其中一些与说话的表情有关。例如,我正致力于建立一个基于暹罗神经网络的热视觉姿态不变人脸验证系统。在另一个项目中,我们在野外使用相同的热感相机收集了额外的数据。我们的目标是建立稳健的热人脸检测和地标预测模型。
阿德里安:如果有人想追随你的脚步,成为一名成功的出版研究者,但不知道如何开始,你会给他们什么建议?
我建议你找一个可以和有相似兴趣和热情的人一起工作的环境。如果你对工作充满热情,而且你和有趣的人一起工作,那么这真的不像是一份工作!
阿德里安:几周前,我们向完成所有课程的图片搜索大学的第一名成员提供了 500 美元的奖金,你就是获胜者!恭喜你!你能告诉我们那次经历吗?你在 PyImageSearch 大学学到了什么,你是如何如此快速地完成所有课程的?
再次感谢您的奖励!这是对伟大课程的一个很好的奖励。
我关注这个博客已经有一段时间了:在我开始进入计算机视觉领域的旅程时,我浏览了 PyImageSearch 上的大多数免费课程。我一行一行地重写了每一段代码。我强烈推荐这种方法,尤其是对初学者来说,因为它不仅能让你理解内容,还能教会你正确编程。
当你提供一周免费进入 PyImageSearch 大学的机会时,我加入观看视频,因为更新你的知识总是好的。这是一个伟大的决定,因为我从阅读博客和观看视频中获得的体验是完全不同的。我在一周内看完了几乎所有的题目,只剩下一两个了。然而,我决定购买年度会员资格,因为我喜欢这种形式,也想支持你的努力工作。
对于研究人员和从业人员,我绝对推荐 PyImageSearch 大学,尤其是在计算机视觉、深度学习和 OpenCV 领域。这些课程提供了一个坚实的基础,如果你想理解高级概念,这是必不可少的。
Adrian: 如果一个 PyImageSearch 的读者想和你联系,他们该怎么做?
如果你想和我讨论一些有趣的想法,你可以通过 Linkedin 联系我。
如果您有兴趣了解有关 SpeakingFaces 数据集的更多信息,这里有一个很好的概述视频:
https://www.youtube.com/embed/A0D_WS2L558?feature=oembed
采访 OpenCV 人工智能套件(OAK)的创造者布兰登·吉勒

在这篇文章中,我采访了 Brandon Gilles,他是 PyImageSearch 的长期读者,也是 OpenCV AI Kit (OAK)的创造者,OpenCV AI Kit 正在彻底改变我们执行嵌入式计算机视觉和深度学习的方式。
为了庆祝 OpenCV 图书馆成立 20 周年,Brandon 与官方的OpenCV.org组织合作创建了 OpenCV AI Kit、一个麻省理工学院许可的开源软件 API 和无数基于 X 的嵌入式板/相机。
橡木有两种口味:
- OAK-1: 标准的 OpenCV AI 板,可以执行神经网络推理、对象跟踪、April 标签识别、特征检测和基本的图像处理操作。
- OAK-D:OAK-1 中的一切,但带有立体深度相机,3D 对象定位,并在 3D 空间中跟踪对象。
上周,布兰登和 OpenCV 组织发起了一项 Kickstarter 活动来资助这些令人惊叹的嵌入式人工智能板的创建。在撰写本文时,OpenCV AI Kit 目前从其 Kickstarter 支持者那里获得了 419,833 美元的资金,这有可能使其成为众筹历史上最成功的嵌入式主板之一!
Brandon 和 OpenCV 团队非常慷慨地让 PyImageSearch 团队提前获得了 OpenCV AI 工具包,所以请期待将来在 PyImageSearch 博客上的 OAK 教程。
此外,我已经决定 OAK 将包含在我们的嵌入式计算机视觉和深度学习书籍的下一个版本中, 计算机视觉的树莓派书籍 (特别是完整捆绑包)。
- 如果你已经有了一份完整套装的副本,你将会在 OAK 章节发布时通过电子邮件更新免费收到。
- 如果你还没有已经拿到 RPi4CV 的副本,确保你拿到了,等它们准备好了你就会收到 OAK 章节。
OpenCV 人工智能套件将彻底改变嵌入式计算机视觉和深度学习的执行方式。我们迫不及待地想与董事会合作(并帮助您开始使用它)。
让我们热烈欢迎 Brandon Gilles 分享他的作品。
采访 OpenCV 人工智能套件(OAK)的创造者布兰登·吉勒
阿德里安:嗨,布兰登!很高兴你能来到 PyImageSearch 博客。我肯定你正忙于运行 OpenCV AI Kit (OAK) Kickstarter 活动——我们都很感谢你花时间做这次采访。
布兰登:非常感谢邀请我。如你所知,我和整个团队都是 PyImageSearch 的超级粉丝。你们所做的对计算机视觉和深度学习知识的民主化非常重要,是一个非常好的资源。以及源源不断的教程、新内容等。对于在这个快速发展的领域保持速度是无价的。因此,我谨代表我自己和整个 OAK 团队,感谢您和您的团队所做的一切!我想我还没遇到一个 CV/AI 的人没用过你的教程或者书。
阿德里安:布兰登,非常感谢你的美言!我们真的很感激。你能给我们介绍一下你自己吗?你在哪里工作,你的工作是什么?
布兰登:我是一名电气工程师。我是 Luxonis 的创始人兼首席执行官。
我一直想自己创业。我一直在寻找能够对世界产生积极影响的东西。
有趣的是,我也一直厌恶风险……所以我花了十多年时间梦想创业,但从未真正全力以赴去做。因此,这是我第一次尝试全力以赴,从零开始打造一个重要的产品和一家公司。
Adrian: 你在计算机视觉和深度学习方面有什么背景?还有你最初是怎么对计算机视觉和深度学习产生兴趣的?
Brandon: 所以,和大多数 EEs 一样,我在大学课堂上做过基本的计算机视觉(现在是 16 年前了!),在像线性系统这样的类中实现传统的计算机功能,但我的职业轨迹根本没有涉及计算机视觉或深度学习,直到我的一位导师离开了我们都为之工作的公司。
*我喜欢那里,他也喜欢那里(实际上,他是那里的一名天线设计师),所以这很令人困惑。
在采访他为什么要离开时,他告诉我:“人工智能和深度学习将会提升每个行业的地位;这是我职业生涯中最大的机会,我必须去尝试。
当时我对深度学习知之甚少,我上一次想到“人工智能”这个词是在 2004 年,当时我的一位大学室友在 Lisp 中尝试一些人工智能技术,他向我描述了它是多么无用。所以我从 2004 年到 2016 年年中对 AI 的心智模型是‘没用’。
然后这位导师(我非常尊敬他)离开了,全职从事人工智能/机器学习/深度学习,离开了一份我们都喜欢做的工作。这是一个震惊,让我大开眼界。
那天回家,开始谷歌深度学习、机器学习、AI 等。在接下来的大约 12 个月里,我沉迷于此,利用我所有的空闲时间(比如在马桶上阅读),阅读/潜伏在 PyImageSearch 上(主要是),跟随教程 PyImageSearch,关注《数据科学》、《麻省理工技术评论》等。
Adrian: 跟我说说这个 OpenCV AI Kit Kickstarter 活动。我记得 2018 年你第一次向我提到这个项目时,但当时它被称为“DepthAI”。你能告诉我们你是如何想到 DepthAI,验证这个想法,然后把它变成 OpenCV AI Kit 的吗?
布兰登:所以这有点迂回,而且已经改了很多次名字——对此我很抱歉——但这实际上是从我试图解决一个问题开始的,这个问题是由我的亲密和扩展的朋友和家人圈子中的几个人的悲剧引起的。
所以我实际上想做一个非 80 年代技术版本的激光标签(想象一下完全增强的播放器、墙壁、建筑等等。)当我离职全职追求 CV/ML 时,我认为这些技术的突破可以让这样一个多人 AR 系统成为可能,作为对现有激光标签设施的廉价改造。这是 2017 年。
但在我记忆中的一个星期里,似乎我认识的每个人都在告诉我他们的朋友、家人或同事是如何在骑自行车上下班时被分心的司机撞了。对我来说幸运的是,这些人没有一个是我的直接圈子……但这对我有巨大的影响。
我爸爸最好的朋友从后面被击中,背部多处骨折,股骨骨折,臀部骨折,严重到他不得不卧床 9 个月,然后才能做手术消肿。我好朋友的商业伙伴有着几乎相同的经历。我的大学滑雪伙伴(我通过一个共同的朋友发现的)也有同样的问题,但是额外遭受了创伤性脑损伤。我有时参加的 hackerspace 的创始人,他的商业伙伴也死于同样的撞击(汽车的镜子击中了他的颈部,导致他死亡)。
所以突然之间,我正在原型制作的这个增强现实激光标签系统感觉不像是正确的事情。在这一点上,我已经花了数年时间研究计算机视觉、机器学习、深度学习和其他新兴技术背后的所有艺术状态,我想知道你是否可以建立一个嵌入式系统来防止这些事故。
在所有的情况下,如果汽车只是再向左偏 12 英寸,这一切都不会发生。几年前,我看过乔纳森·兰西(Jonathan Lansey)的自行车 Kickstarter,并对它的有效性产生了潜在的兴趣,我想知道是否有可能建立一个系统来警告骑自行车的人和司机,以防止这种悲剧的发生。
在我看来,如果计算机视觉和深度学习能够在分析 CT 扫描图像方面胜过医生,在图像分类、物体检测、3D 感知等方面胜过人类。必须有一种方法来制造这种生命安全装置。
我想象的是一个相当于一个朋友倒着骑在你的自行车上,当事情看起来不对劲时,他可以拍拍你的肩膀,当司机要撞上你时,他会开始向汽车闪烁超高亮度的发光二极管,然后实际上按一下汽车喇叭(这是非常小的!)如果汽车肯定要撞上你……有足够的时间转弯。因此,利用我从 PyImageSearch 中学到的东西,以及从胜矢兵库(PINTO0309)的 Github 上的一大步,我制作了一个原型,可以做到这一点:
这是一个巨大的,非常丑陋的原型,但它完全有效!整个原型和测试过程教会了我一件非常重要的事情:
- 深度+现代化的对象检测使解决这个问题变得容易处理…而且它用很少的代码/努力就能工作得非常好。
现在这个概念已经被证实,包括实际上用反馈警告骑车人,闪烁的 led 和汽车,甚至按喇叭真正的汽车喇叭(声音超级大),我去看看如何建造一个实际的产品。这教会了我第二件重要的事:
- 尽管为此存在单独的组件(深度相机、AI 处理器、嵌入式 CPU 等。)没有办法围绕这些解决方案构建一个小型的嵌入式产品(它们太大太笨重,实际上不适合放在自行车座位下,或者成本不合理)。
有趣的是,Myriad X 在这个时候刚刚开始出货,它具有解决这个问题的所有 CV/AI 功能,但它只在 USB 棒或 PCIE 卡中可用……这两者都不允许嵌入式使用,也不允许使用深度引擎及其其他 CV 加速功能(运动估计、边缘检测、对象跟踪、特征跟踪、视频编码等)。).因此,USB 棒/PCIE 卡在这种(1)嵌入式和(2)不仅仅需要神经推理的应用中是不可用的。
所以在这一点上,现在有一个团队在我身后,我们要么放弃任务,要么建立平台。
我们选择建立这个平台。当时我们称它为 DepthAI……但实际上,在一些初步销售之后,你在推特上谈论了我们的平台(现在是永远的过去了),这导致来自 OpenCV 的 Mallick 博士提出了这个想法,接受我们的使命,这个平台,并使其成为 OpenCV 的核心部分,以解决这种嵌入式 CV &人工智能问题。
Adrian: 告诉我们 OpenCV AI Kit 背后的硬件。这款嵌入式设备的驱动力是什么?更重要的是,作为深度学习/计算机视觉的从业者,我们为什么要关心OpenCV AI KIt?
Brandon: 所以让我们找到 Myriad X 的原因是,它将我们试图解决的问题的所有功能都集成在一个低功耗芯片中:
- 实时神经推理(覆盖几乎所有类型的网络)
- 立体深度
- 包括运动估计和平台运动估计的特征跟踪
- 目标跟踪
- H.265/H.264 编码(用于记录事件和/或通常只是记录)
- JPEG 编码
- 16 倍高效矢量处理器,用于将这些功能结合在一起并运行加速的 CV 功能(可以将这些视为链接嵌入式视觉专用 GPU)
作为一个 EE,我说‘好吧,那太好了,我只需要芯片,SDK,我就可以走了’。我发现,该芯片唯一的 SDK 是用于神经推理的……所有其他功能都不能被市场上的任何产品使用(计算棒、PCIE 卡等)。).他们只能做推断。
所以它的独特之处(以及我们选择它的原因)是所有这些特征的结合。当用于 u 盘或 PCIE 时,你得到的只是芯片功能的 1/7(还有一些我忘记了…所以它可能更像是芯片功能的 1/10)。
所以有了 OAK,我们获得了芯片并展示了我们需要的能力,我们认为其他人也一定需要。简而言之,我们展示了 Myriad X 的真正力量……它是所有这些功能的组合,用于解决空间 AI 问题。
在这方面——空间人工智能是使用人工智能来获得物理坐标结果的能力——以米为单位的物体或特征的位置。这正是我们实时监控和跟踪车辆(及其边缘/镜子)的 3D 轨迹所需要的。
Adrian: 澄清一下,OpenCV 人工智能套件不仅仅是一个嵌入式人工智能板。也是 API 吧?用户如何与 API 交互?Python 和 OpenCV 兼容吗?
布兰登:很棒的问题。关于该平台的头号困惑是“它只是另一个板”。虽然硬件是有价值的,因为它提供了 Myriad X 应该使用的功能,但关键是 API 和我们以新颖的方式配置 Myriad X 的硬件块的方式,以便以简单的方式提供所有这些功能。我们花了大量时间优化高速缓存、芯片内通信系统和 DDR 通信,包括大量的重写,以允许 Myriad X 完成所有这些事情。
我们通过一个简单的 API 来展示这一点,这个 API 是 Python 和 OpenCV 兼容的。实际上是用 C++编写的(也是开源的,所以可以在任何可以编译 OpenCV 的东西上编译), pybind11 提供 Python 中的 API 功能。所以简而言之,C++接口和直接编程也可以。
Kickstarter 专注于 OAK 的 USB 接口版本,但我们正在后台开发 SPI 接口版本……因此这种电源可以连接到其他系统,如甚至没有操作系统的微控制器。这可能会在 Kickstarter 活动结束时开源。
Adrian: 很明显,你在嵌入式系统、电路板设计和制造方面有丰富的经验。制造 OpenCV AI 套件板最具挑战性的部分是什么?您预计如何满足需求?
布兰登:谢谢你的美言!因此,最具挑战性的部分是零部件的采购,特别是相机模块。在过去的几十年里,我们已经看到了信息透明和购买各种组件的趋势…这一浪潮尚未冲击相机模块市场。它仍然非常不透明和僵硬。顺便说一句,在我看来,这是一个颠覆性的成熟市场。
所以我们花了大量的时间与供应商沟通,做订单和谈判。除此之外,制造和供应链一直无忧无虑。我们在 Kickstarter 之前进行了相当数量的控制运行,获得了 99.7%的收益率,这让我们非常兴奋。
Adrian: 你是 PyImageSearch 的长期读者和客户,阅读了《T2》《计算机视觉的树莓派》 和《用 Python 进行计算机视觉的深度学习》——这些书对你开发 OpenCV AI 工具包有什么帮助?
*是的,我们的团队实际上集体购买了你的每一本书(其中大部分是在我们开始合作之前独立购买的)。
因此,PyImageSearch 帮助加速完成原型的第一种方式。我们利用你的教程和书籍,并在 20 秒内完成工作,而不是花 10 个小时来弄清楚如何让事情进展顺利,因为你和你的团队已经打了一场漂亮的仗来弄清楚如何让 codebase-x 或机器学习技术-x 实际运行,并正确运行。
因此,PyImageSearch 让我们能够快速构建原型,发现应用计算机视觉解决此类问题的能力和可行性。这导致人们发现硬件生态系统中有一个漏洞,Myriad X 的功能实际上并不是每个人都可以获得和使用的。因此,PyImageSearch 是发现我们使命的核心部分,并继续帮助我们顺利运行,没有不必要的麻烦。
Adrian: 您会向其他正在尝试学习计算机视觉和深度学习的开发者、学生和研究人员推荐用于计算机视觉的 树莓派 和用于计算机视觉的 深度学习用 Python 吗?
布兰登:绝对是。所以我根本不知道技术上什么是可行的,PyImageSearch 有助于向我展示什么是可行的,并允许我让工作系统(如上面的机箱)立即运行。
对任何感兴趣的人来说,这些书可以让你变得熟练,并马上解决现实世界的问题。
Adrian: 对于想跟随你的脚步,学习计算机视觉和深度学习,然后在 CV/DL 领域推出产品的人,你有什么建议吗?
Brandon: 从一个 PyImageSearch 教程开始。我花了太多时间阅读关于理论等的文章。当我真正开始运行 PyImageSearch 代码,并修改它来解决我的实际问题和满足我的好奇心时,事情才真正开始发生。
Adrian: 如果一个 PyImageSearch 的读者想聊天,最好在哪里联系你?
Brandon: 我非常相信工程师能够与任何感兴趣的人直接交流,所以我们有几种方式可以实现这一点——我们的社区 slack 频道(【https://luxonis-community.slack.com/】)当我醒着的时候,我可以在那里有效地找到我,还有我们的论坛(【https://discuss.luxonis.com/】)。人们也可以随时给我发电子邮件,地址是 brandon [at] luxonis [dot] com!
摘要
在这篇博客文章中,我们采访了企业家 Brandon Gilles,PyImageSearch 的读者/客户,OpenCV AI 工具包的创造者。
Brandon 和 OpenCV 团队最近发起了一项针对OpenCV AI Kit(OAK)的众筹活动,这是一款嵌入式硬件,它使计算机视觉和深度学习从业者将 CV/DL 应用于嵌入式设备的比以往任何时候都更容易。
OpenCV 人工智能套件的 Kickstarter 活动将持续三周。Brandon 和 OpenCV 在 OpenCV AI 套件上提供折扣,直到活动结束,所以如果你有兴趣在特别众筹交易中购买这款硬件,现在将是一个好时机。
如果你有兴趣跟随布兰登的脚步,学习如何将计算机视觉/深度学习应用到自己的项目和研究中,一定要拿一份包含 Python 和 树莓派的计算机视觉 的 深度学习——这些都是布兰登使用的完全相同的资源。
为了在 PyImageSearch 上发布未来的博客文章和采访时得到通知,只要在下面的表格中输入您的电子邮件地址,,我一定会让您了解最新情况。**
计算机视觉和野火探测专家大卫·波恩访谈
想象一下:
你在乡下建了一个全新的家,远离大城市。你需要远离喧嚣,想让自己回归自然。
你建的房子很漂亮。晚上很安静,你可以看到星座在天空跳舞,你睡得很好,知道你会醒来休息和恢复活力。
然后,你在半夜醒来。抽烟?有火吗?!
你跑下楼梯,来到门廊上。在地平线上,你会看到橙色的光芒,仿佛整个天空都着火了。浓烟滚滚,就像一个愤怒的风暴云准备窒息你。
果然,是野火。根据风向判断,它正朝你吹来。
你美丽宁静的家现在变成了一场易燃的噩梦。
你不得不怀疑……计算机视觉是否可以在早期被用来探测这场野火,从而向该地区的消防队员发出警报?
不过现在没时间想这些了,只要拿起你能拿的贵重物品,扔到卡车后面,然后离开那里。
当熊熊大火逼近你的房子时,你最后看了一眼后视镜,发誓总有一天你会发现如何及早发现野火…然后你开着车在一条土路上寻找文明。
恐怖故事,对吧?
虽然我为了戏剧效果对它做了一些修饰,但这和大卫·波恩在华盛顿州的家中多次经历的事情没有什么不同!
大卫在过去几年的职业生涯中致力于开发一种早期预警计算机视觉系统来检测野火。
该系统运行在 Raspberry Pi 上,并通过 WiFi 或蜂窝调制解调器连接到互联网。如果检测到火灾,RPi 会 pings David,之后他可以向消防部门报警。
此外,美国专利局刚刚授予大卫多项专利!
今天很高兴大卫来到了 PyImageSearch 博客。他是社区论坛的长期读者、客户和版主。
最重要的是,他的工作有助于防止伤害和生命损失,这可以说是最臭名昭著的难以早期发现的自然灾害之一。
要了解大卫·波恩是如何创造出一种计算机视觉系统来探测野火的,请继续阅读完整篇访谈!
采访计算机视觉和野火探测专家 David Bonn
阿德里安:嗨,大卫!感谢您抽出时间接受采访。很高兴您能来到 PyImageSearch 博客。
大卫:谢谢你,阿德里安。和你聊天总是很愉快。
阿德里安:在我们开始之前,你能简单介绍一下你自己吗?你在哪里工作,你是做什么的?
大卫:从大学开始,我就断断续续地从事开发和工程师的工作。在这些工作之间,我做过各种“有趣”的工作,比如公园管理员、河道向导、滑雪教练和火灾了望员。
1996 年,我和其他几个人一起创建了 WatchGuard Technologies ,它取得了巨大的成功,事实上,今天它仍然存在并保持独立。那次冒险之后,我处于半退休状态,四处旅行。在同一时期,我花了很多时间从事环境教育项目和其他自然历史项目。
这些天来,我一直在努力创办一家新公司——Deepseek Labs。
Adrian: 是什么让你对研究计算机视觉和深度学习产生了兴趣?
大卫:大约十年前,对我来说很明显,神经网络及其工作方式发生了巨大的变化。他们终于走上了拥有可以解决实际问题的工具包的道路。对我来说更有趣的是,有一大类真正的问题,你可能无法用更好的方法来解决。
几年后,我开始涉猎 OpenCV,主要是通过下载书籍和浏览它们的例子,然后我在 2015 年偶然发现了你的博客。
2014 年和 2015 年,我家附近发生了一系列大规模野火。虽然我的家毫发无损,但近 500 所房屋在大火中被毁,几名消防员牺牲。我想到这里有一个巨大的未解决的问题,我想知道我能做些什么来解决它。
2017 年末,我发现自己处于这样一种情况,人们需要评估他们的生活以及他们在做什么。与此同时,我与朋友和邻居就野火问题以及我们需要什么工具来适应这种新情况进行了多次交谈。
在这些对话中,我脑海中闪现的一件事是(大约),“天哪,难道我不能制造一些能够探测火灾并在几分钟内警告人们逃命的东西吗?”因此,我决心学习足够多的计算机视觉和深度学习知识,以弄清楚这样的事情是否可能实现。
通常,我发现如果你希望掌握一项新技能,如果你头脑中有一个项目(或一系列目标)需要这项新技能来推动你前进,会有很大帮助。所以我掌握计算机视觉和深度学习的项目是建立一个简单但实用的火灾探测系统。
Adrian: 我与你互动的最初记忆之一是在 PyImageSearch 社区论坛上,你在那里讨论火灾/烟雾探测,以及在你居住的地方这是一个多么大的问题。这些野火是如何开始的,为什么早期发现如此重要?
大卫:每场火都不一样。现在,在我家 30 英里范围内有 4 处大火。三起是由闪电引起的,一起是由一个在灌溉泵上工作的人引起的。通常情况下,美国的大多数“野火”都发生在由人类活动引起的相当发达的地区。这可能是任何事情,从树枝上短路的电线,到在干草中空转的车辆,到某人在篝火上不小心煮热狗。
从成本和公共安全的角度来看,早期检测非常重要。扑灭一场小火可能要花费几千美元。一场大火很容易造成数千万美元的损失。我家附近的 Cub Creek 2 火灾,高峰期有 800 多人救火。一辆刷车里的一个小团队每天可能要花费 1000 美元,而一架大型直升机通常每小时要花费 8000 美元。这些费用迅速增加。
此外,虽然大多数人都可以用铲子和水桶安全地扑灭营火,但扑灭大火更像是抗击天气现象。你也许可以让它慢下来或者稍微控制一下,但是你不可能停止它或者完全压制它。
可能在我附近燃烧的火还会在某个地方燃烧,直到 11 月开始下雪。但是,随着大量的灌木丛被大火清除,今年冬天滑雪可能会很棒!
强调早期发现的另一个重要原因是,许多“野火”始于人们居住的地区。如果给人们几分钟时间安全疏散,早期检测可以挽救生命。在美国西部和加拿大,大约有 450 万个家庭处于野火的高风险或极端风险中。
阿德里安:几周前,你自己的家受到了野火的影响。你能告诉我们发生了什么吗?
大卫:我可以从我的角度告诉你发生了什么。
一个重要的背景:我住在华盛顿州的中北部,尽管华盛顿的名声在外,但这是一个非常干燥的地方,夏天经常非常温暖。这是一个极其干燥的春天(该州东部的大部分地区正处于严重的干旱之中),而且我们在六月下旬经历了一场令人难以置信的热浪。所以植被非常干燥。有多干?嗯,火灾研究人员从树上提取核心样本来评估燃料的干燥度。火灾前两周在我所在的地区采集的岩芯样本发现,活树比窑干木材干燥,含水量约为 2%。典型的纸张含水量为 3%。
7 月 16 日星期五,白天最热的时候,我在家,也在屋里。大约下午 1 点 45 分,我向外望去,注意到南边有一股不祥的烟柱。就在那时,我出去了,从烟的方向吹来了一股相当强劲的风。
那时,大量的练习和计划开始了。我迅速关闭了所有的窗户(大多数已经关闭)。入口里有一包衣服、一箱文件和硬盘,我很快就把它们装进了卡车。然后我把四只狗都带上了卡车。最后看了一眼房子,我向山下走去,与此同时,我开始给我的邻居发短信,告诉他们火灾的情况,并鼓励他们离开那里。
在这一点上,我和我所有的邻居都非常幸运。在区域有另一场大火,他们立即将消防队和飞机转移到这场新的火灾中。因此,在一个小时内,有几架飞机和大约 100 名消防队员到达现场(当消防队员到达现场时,火灾已经估计有 1000 英亩大小)。
附近还有一名重型设备操作员,甚至在所有消防员到场之前,他就在用推土机到处切割火线。
我的邻居和消防队员们的快速行动产生了一个近乎奇迹的结果:只有几栋建筑受损,其他几栋也有轻微损坏。没有人受伤或死亡。
尽管有一个全县范围的紧急警报系统,我们没有一个人得到任何警告——来自县系统的警告在下午 2:30 左右到达我的手机。如果这一系列事件发生在凌晨 1 点 45 分,而不是下午 1 点 45 分,事情会更加悲惨,肯定会造成房屋和财产的损失,也可能会造成生命损失。
有趣的是,当这一切发生时,我有一个原型火灾探测系统在外面运行。当然,当它探测到火的时候,我已经在相当远的地方了。不幸的是,当它检测到火灾时,WiFi 已经关闭(当我撤离时,我家停电了,第二天很晚才恢复)。因此,我无法保存任何检测图像。此外,探测器本身是靠零目标电池组运行的。
阿德里安:你和你的公司开发了一种可用于农村地区的火灾探测系统。你能告诉我们解决方案吗?它是如何工作的?
大卫:30 秒的答案是,我使用热感相机( FLIR 轻子 3 )和基本的 OpenCV 图像处理功能来寻找好的候选区域。我传递给另一个程序,该程序用光学相机检查这些区域,然后将光学图像的切片传递给二元分类器。
更长的答案是,热感相机寻找两个靠近的东西:热点(热感图像中非常明亮的部分)和湍流运动区域。因此,如果我可以在一个非常热的点附近找到湍流运动,并且湍流运动主要在该热点上方(记住热空气上升),热点和湍流运动重叠的区域(或者如果适当扩大它们重叠的区域)是找到火焰的可能位置。
然后,光学算法获取该候选区域,并将它们的坐标转换到光学相机的坐标系。因此,通过仔细观察候选区域,我可以选择光学图像中适合传递给训练有素的二进制分类器的良好切片。
我的一个重大发现(嗯,对我来说,这是一个重大发现)是,虽然有一个很好的数据集和一个良好的网络,但如果你的分类器正在查看一幅图像的精心选择的切片,你可以获得 96-97%的准确率,准确率高达 99%以上。我怀疑通过精心构建的集合,你可以达到更高的精确度。
如果热算法和分类器都同意有火灾,则系统进入报警状态。
该系统本身的准确率超过 99.99%,这意味着在样品(户外)中运行时,每 3-5 天就会出现一次“错误”。样本外(例如,在我的厨房里用煤气灶)每天会出现 4 到 5 次错误。使用帧平均或系综可能会有更高的精度。由于热图像的分辨率(160×120)和帧速率(9 fps)在大多数情况下都非常低,因此该系统不必非常努力就可以获得这些令人印象深刻的结果。
我使用的方法远非完美,在某些情况下仍然很困难。内燃机,尤其是重型设备或农用设备的热废气经常会扰乱热算法。分类器与明亮的主题斗争,甚至更明亮的背光主题。靠近传感器的色彩鲜艳的鸟有时会产生令人困惑的结果。随着时间的推移,通常通过收集更具代表性的训练数据,这些问题正在得到缓解。
我已经为这个系统的许多部分申请了专利,8 月 11 日,我被告知那些专利是允许的。在更多的费用和文书工作之后,这些专利将被正式发布和出版,然后我可以分享更多关于该系统如何工作的细节。
阿德里安:你们的火灾探测系统运行在什么硬件上?你需要一台笔记本电脑/台式机,或者你正在使用类似树莓派,杰特森纳米等。?
大卫:核心火灾探测器运行在树莓派上。现在的参考实现是 Pi 3B+,检测时间大约为 1-2 秒。目前,该系统要么通过 WiFi 连接到互联网,要么使用蜂窝调制解调器。我的首选是使用蜂窝调制解调器,因为我们可以自行配置系统,并在没有任何最终用户设置的情况下启动和运行它。
我正在引导只读的 Pi。这使得该系统在面对断电和其他故障时更加稳健,但不可能将检测图像直接保存在 SD 卡上。
这个系统的其他部分将在云上运行,也将有一个客户端(网页或应用程序),可以向您显示部署的检测器,它们部署在哪里,以及它们的状态如何。
Adrian: 将红外摄像头与“标准”图像处理和 OpenCV 代码结合起来,最难的是什么?你遇到了哪些拦路虎?
大卫:对我来说,最大的障碍是让硬件工作起来。GitHub 上有许多硬件障碍(包括不支持和不推荐的部分)和许多过时的代码,我必须努力克服。我终于找到了一些还算过得去的代码,至少让我可以开始了。例如,普通的轻子分线板使用 I2C,所以你有一堆电线连接到你的 Raspberry Pi 上的 GPIO 总线。我让所有这些工作,但它不是探索更好的火焰检测算法的最佳环境。
当我切换到使用一个 Purethermal 2 USB 模块时,我的进度大大提高了。这是一个巨大的进步,因为只需很少的努力,我就可以在笔记本电脑上试验热感相机的图像处理算法。因此,与其将代码上传到 Pi 并重新启动 Pi,然后在另一个显示器上查看输出,我可以只在我的笔记本电脑上进行代码-测试-调试循环,然后在我的办公桌上、厨房的桌子上或面包店工作。因此,我很快就在这个系统上花了更多的时间,并且在一个月内学到了比过去六个月还多的东西。
一旦你与硬件对话,真正的工作就开始了。轻子是一种非常敏感的仪器,它只有 160×120 的空间分辨率,但每个像素都是 16 位深——像素值的 1 位变化代表大约 0.05C 的温度变化。这足够敏感,如果你赤脚走在寒冷的地板上,你的脚印将在热成像中“发光”几分钟。另一方面,许多 opencv 函数并不真正喜欢 16 位灰度图像,所以您需要小心您调用的函数,并且您可能需要使用 numpy 进行一些操作。
你需要注意的最后一点是热图像的对比度非常低。因此,除非您以某种方式增强它们(通常归一化直方图就足够了),否则当您显示图像时,您将看不到任何有趣的东西。
阿德里安:你认为你从建立火灾探测系统中学到了什么?
大卫:简答:很多!
我认为(到目前为止)最大的收获是,你应该期待花很多时间来构建伟大的数据集。你不应该期望它是容易的,你应该期望一路上会有很多试错和学习的经历。然而,一旦你开始构建一个伟大的数据集,并有一个框架让你不断改进它,你就处在一个奇妙的地方。
在你的文章中,你大谈高质量数据集的价值。那是百分之百正确的。然而,我会更进一步说,如果您构建了一个框架和流程,让您可以轻松地增长和扩展数据集,那么您正在创造更有价值的东西。
Adrian: 您在构建火灾探测系统时使用了哪些计算机视觉和深度学习工具、库和软件包?
David: 我使用了 OpenCV、Tensorflow、Keras、picamera 模块和您的 imutils 库。
阿德里安:你在这个项目中的下一步是什么?
大卫:我们现在正在做两件事:第一件是我们有一些原型,我们正在花时间研究它们,了解我们正在使用的方法的局限性以及如何使它变得更好。与此同时,我们正在与潜在客户交谈,向他们展示我们所拥有的,并谈论我们的想法,并试图找出如何解决他们的问题。
我们学到的一件大事是,如果你能在一个社区周围部署许多(至少几十个,可能几百个)火灾探测器,整个想法会更好。然后,你可以给人们一个网站或一个应用程序,让他们回答他们关心的问题:火在哪里?
阿德里安:你是 PyImageSearch 的长期读者和顾客。谢谢你支持我们!(还有更感谢成为社区论坛中非常有用的版主。)PyImageSearch 对你的工作和公司有什么帮助?
David: 我可以接触到更明智、更有经验的人(你和 Sayak Paull 都非常有帮助),他们可以在我陷入困境时帮我解决问题(当我切换到 Tensorflow 2.x 和 tf-data 时,我有几次都搞砸了,你和 Sayak 都在帮我找出问题所在方面发挥了巨大作用)。
我喜欢参与 PyImageSearch 的另一点是,帮助他人是提高自己技能和学习新事物的好方法。所以对我来说,这是一次很棒的经历。
Adrian: 如果一个 PyImageSearch 的读者想和你联系,他们该怎么做?
David: 与我联系的最佳方式是在我的 LinkedIn 上,地址是 David Bonn 。
总结
今天我们采访了大卫·波恩,他是利用计算机视觉探测野火的专家。
大卫已经建立了一个专利的计算机视觉系统,可以成功地检测野火,使用:
- 树莓派
- 前视轻子热感相机
- 蜂窝调制解调器
- 专有 OpenCV 和深度学习代码
该系统已经被用于探测野火和向消防队员发出警报,防止人员伤亡。
早期野火检测是计算机视觉和深度学习如何彻底改变我们生活几乎每个方面的又一个例子。作为计算机视觉从业者,大卫的工作展示了我们的工作可以对世界产生多大的影响。
我祝 David 好运,因为他将继续开发这个系统——它确实有潜力拯救生命,保护环境,并防止巨大的财产损失。
在 PyImageSearch、 上发布未来教程和采访时,您只需在下面的表格中输入您的电子邮件地址即可获得通知!
采访 dlib 工具包的创建者戴维斯·金
原文:https://pyimagesearch.com/2017/03/13/an-interview-with-davis-king-creator-of-the-dlib-toolkit/

在今天的博客文章中,我采访了 Davis King ,他是 dlib 的创建者和主要维护者,dlib 是一个用 C++编写的用于现实世界机器学习、计算机视觉和数据分析的工具包(在适当的时候包括 Python 绑定)。
我个人在许多项目中使用过 dlib(特别是用于物体检测),所以很荣幸能在 PyImageSearch 博客上采访 Davis。
在这篇博文的剩余部分,戴维斯:
- 讨论他在计算机视觉和机器学习领域工作背后的灵感。
- 解释了 dlib 的由来,为什么存在,以及这个库主要用来做什么。
- 谈论维护一个流行的开源库(如 dlib)最困难的方面。
- 描述了他的小说 Max-Margin 对象检测 论文背后的细节,dlib 库中对象检测的基石。
- 反映了 dlib 的最新版本,其中包括深度度量学习,适用于最先进的人脸识别和人脸验证。
- 为刚刚开始计算机视觉和深度学习生涯的读者提供有用的建议和意见。
这些问题大部分来自才华横溢的凯尔·麦克唐纳,我第一次见到他是在 Twitter 上,当时我正和戴维斯谈论他最新的 dlib 版本。Kyle 很友好,让我使用并修改了他最初的问题(同时添加了一些我和 David McDuffee(PyImageSearch 的通信协调员)的其他问题),从而使这次采访成为可能。一定要给凯尔和大卫大声喊出来,并告诉他们谢谢!
要了解更多关于 Davis King、dlib 工具包以及该库如何用于计算机视觉、机器学习和深度学习的信息,请继续阅读。
dlib 创始人戴维斯·金访谈
阿德里安:嘿,戴维斯!我知道您很忙,感谢您抽出时间接受采访。很荣幸您能来到 PyImageSearch 博客。对于不认识你的人,你是谁,你是做什么的?
戴维斯 :谢谢邀请我。我是一名软件开发人员,研究应用机器学习问题。我的大部分工作是为美国国防应用研究机器视觉和自然语言处理。很多都是用不同种类的传感器,如声纳、激光雷达、雷达、光学相机等,来做计算机视觉的事情。我还致力于工业自动化和自主水下航行器的传感,以及自动化金融交易的机器学习系统。
但是在公开场合,大多数人都知道我是开源项目 dlib(dlib.net)和 MITIE(github.com/mit-nlp/MITIE)的作者。
Adrian: 是什么激励你开始从事计算机视觉、机器学习和深度学习领域的工作?
戴维斯 :我想在一些有趣且重要的领域工作。长久以来,我一直相信自动化非常重要。此外,当我还是个孩子的时候,我就知道我想做一些计算机科学的事情,事实证明我非常擅长编程,而且我热爱数学。机器学习是自动化的前沿所在,涉及大量数学和编程,所以我来了。我也是科幻作家的粉丝,比如艾萨克·阿西莫夫和维诺·文奇。机器学习及其相关领域似乎是通向有趣的科幻人工智能的最明显的途径。所以这也很酷,即使现在还很遥远🙂

Figure 1: dlib — A toolkit for real-world computer vision and machine learning (higher resolution).
阿德里安 :什么是 dlib?图书馆主要用来做什么?
戴维斯 : Dlib 是一个通用的开源 C++软件库。我在 15 年前开始写它,最初它与机器学习无关。无论如何,我那时是,现在仍然是合同编程的狂热爱好者。所以 dlib 最初的动机是使用“契约式设计”的方法来制作一堆当时还没有的跨平台工具。例如,15 年前,C++还没有令人沮丧的可移植线程、网络或线性代数工具。
dlib 就是这样开始的,作为一个包含一堆随机系统工具的跨平台 C++库。例如,dlib 中最流行的东西之一是 dlib::pipe,这是一种在线程之间传递消息的类型安全工具,它被用于大量不进行任何类型的机器学习的嵌入式/实时处理应用程序。实际上,这仍然是今天的 dlib,一个以契约式设计风格编写的 C++工具集合。只是我花了 10 年时间来制作机器学习工具。因此,截至 2017 年,dlib 由机器学习材料主导,这在过去几年中真正推动了它的流行。特别是,人脸检测、地标和识别示例程序现在可能是 dlib 中最受欢迎的部分。
阿德里安 :你认为 dlib 在新的研究方面开创了先例吗,或者你渴望让已发表的作品更容易被人理解?
戴维斯 :不尽然。dlib 中有些东西很新颖,比如 MMOD 探测器。但总的来说,我对 dlib 的目标一直是制造真正干净和易于使用的工具。这是一个不同于做新颖研究的目标,而且有点不一致,因为全新的想法通常不会以干净和易于使用的形式出现。大多数时候,当我向 dlib 添加一些东西时,它是来自已出版的文献中的一些已经被认为非常棒的东西,这意味着它已经存在了一段时间。
因此,对于 dlib 来说,我的目标无疑是让已发表的作品更容易被人获取。这也是我选择 dlib 许可证的原因。我希望尽可能多的人能够利用最先进的机器学习工具,并将其用于他们想要的任何事情。我觉得这很好。
我也是在工作中完成大部分原创研究,这意味着我通常不能发表。原创研究也很辛苦。我在 dlib 上工作的部分原因是,我可以在工作之余做一些相对容易和放松的事情。还有一个问题是,原创研究,至少是我在日常工作中倾向于做的那种,是非常具体的应用,而不是非常普遍的兴趣。所以它通常不适合 dlib。
阿德里安 :你认为 dlib 最终会“功能完善”吗,还是一个正在进行的项目?
戴维斯 :不,它永远不会完整。Dlib 只是一个有用工具的集合,显然你总是可以制造更多的工具,除非有一天人类不再对新的更好的东西有想法。但这似乎不太可能。我也很喜欢写软件,并把它免费放到网上。我已经这样做了 15 年,我看不出有任何理由在短期内改变。
阿德里安 :维护像 dlib 这样的开源库,最困难的方面是什么?
戴维斯 :让该死的构建系统在任何地方都能工作。dlib 的核心很容易构建。但是 Python 绑定呢?没那么简单。这是因为,正如我从运行 dlib 中学到的,有大量的 Python 版本都是不兼容的,因为为一个 Python 构建的扩展模块不能与另一个兼容。由于 dlib 使用 boost.python 来构建扩展模块,这变得更加糟糕。所以你会遇到这样的问题,有人会为 python 版本 A 安装 boost.python,然后他们会尝试将它用于 Python 版本 B,结果,Python 崩溃了。这里的问题是 python 版本有 3 个地方必须匹配(运行时使用的 Python 解释器、编译 boost.python 时使用的 Python 和编译 dlib 时使用的 Python),这对用户来说是很大的混淆机会。我从用户那里得到很多关于这个的问题,我不清楚如何避免这种用户困惑。
使这个问题变得特别糟糕的是,在一个用户的系统上安装多个版本的 Python 是很常见的,尤其是在 Mac 上。还有多个包管理器(例如 conda、pip、brew)。所以安装 Python,boost.python,dlib 的方法都有,没有标准什么的。所以超级容易搞混,版本不兼容。
有人正致力于将 dlib 的 Python 绑定从 boost.python 迁移到 pybind11,这将改善这一点。这是因为只有 2 个东西需要匹配(编译后的 dlib 和 Python 解释器),而不是 3 个(dlib/python/boost)。所以这应该会让事情简单很多。但我确信我仍然会从安装了多个版本 Python 的用户那里获得大量论坛流量。因此,如果有人有任何关于如何使 Python 绑定安装过程更加简单的想法,请联系 github🙂
阿德里安 :开源最令人兴奋的一个方面是看到你的工作是如何被其他人使用的。你见过 dlib 更令人惊讶的用法有哪些?
戴维斯 :看到艺术家使用 dlib,我真的很惊讶。这是我从未预料到的。我想到的通常应用都是工业的。所以看到像凯尔·麦克唐纳这样的人使用它是令人惊讶和酷的。

Figure 2: An example of dlib’s face detector.
艾德里安 :我记得两年前看过你关于 Max-Margin 物体检测 的论文。本文主要研究基于 HOG 的检测器。你最近更新了 dlib,也将这种方法用于深度学习的对象检测。你是如何将之前的物体检测研究与 dlib 中新的深度学习检测模块融合在一起的?
戴维斯 :那篇论文有两个主要部分。第一个也是最重要的一个论点是,在训练对象检测器时应该使用某个损失函数(MMOD 损失),因为它可以更好地利用可用的训练数据。第二部分描述了当检测器是固定特征提取器(例如,HOG、BoW 等)的一些线性函数时,用于优化该损失的算法。).论文接着做了一些实验来证明 MMOD 损失是一个好主意,并使用了 HOG 和其他一些方法作为例子。但是猪的选择并没有什么根本性的东西。我用它只是因为它在我最初写这篇论文的时候很流行,那是在 2012 年。
然后出现了 CNN,它超级擅长物体探测。我仍然认为 MMOD 损失是学习物体探测器时要走的路,并想用 CNN 试试。所有这些都需要将纸上的 MMOD 损失函数编码成 CNN 损失层。然后你就像每个人用随机梯度下降法一样优化 CNN,结果发现 MMOD 损失对 CNN 也很有效。事实上, dlib 的一个示例程序显示它训练一个 CNN 只用 4 张训练图像找到人脸。这比训练 CNN 通常所需的训练数据少得多,支持了 MMOD 更有效利用训练数据的说法。

Figure 3: A screenshot of my Papers2 database. Think of it as iTunes, only for PDF files. Davis recommends keeping up with recent publications in the computer vision and deep learning space.
阿德里安:dlib 最近的很多工作都围绕着深度学习。你如何跟上当前深度学习的趋势(以及一般的研究趋势)?)
戴维斯 :我花很多时间阅读。这是唯一的办法。你得看报纸。有做这些事情的朋友也会有帮助,因为他们会告诉你他们发现的你可能错过的好论文。但这没有你自己阅读论文重要。所以读这篇文章的人不应该认为仅仅靠自己会让事情变得更加困难,因为事实并非如此。你不需要成为某个大实验室的一员来参与这些事情。
对于感兴趣的人来说,有一些学术会议会定期发表很棒的论文,你可以在网上免费找到。对谷歌来说,一些好的会议是 CVPR 、 ICML 、 NIPS 和 ICLR 。例如,用谷歌搜索“CVPR 论文”,你会发现各种各样的好东西。另一个很好的资源是谷歌学术。在那里你可以搜索到几乎所有的世界学术文献。结果或多或少按引用次数排序,所以你可以很容易地找到真正受欢迎的论文,因为它们被引用了很多。如果你对某个话题感兴趣,但不知道从何入手,这些通常是最好的阅读材料。你也可以点击 google scholar 中的“被 XX 引用”链接,找到你喜欢的任何论文的最重要的后续研究。这将显示所有引用你喜欢的论文的论文,同样,你可以看到引用它的最受欢迎的论文。允许您快速找到研究路径。谷歌学术是如此重要的资源,我怎么推荐都不为过。
阿德里安注: 为了补充戴维斯的建议,我还建议谷歌搜索“{ { topic } }调查论文”以查找总结一段时间内特定主题研究趋势的文献调查(通常很长)。查找调查论文是一种极好的方式,可以快速跟上您感兴趣的研究领域中以前的开创性方法。
阿德里安 :在你和 MMOD 在 HOG 和深度学习方面的合作中,你的图书馆已经取得了最先进的成果。除了你关于 MMOD 的 arXiv 论文,还有什么原因让你不经常发表文章?
戴维斯 :我发表过一些其他的论文,但是我一般不发表。这没有什么深层原因,除了要花很多时间来完成一篇高质量的论文,然后让它被接受,然后在会议上发表。我的确有一份白天的工作,而且大多数时候,我不能在那里发表我的作品。而且,大多数雇主并不真的在乎你是否发表。我没有那种发表论文对职业成功很重要的工作,如果我纯粹在学术界工作的话,这种工作会很重要。
所以我没有太多动力去埋头写论文。同样值得记住的是,发表论文的根本目的是传播思想。如果我有一些有用的算法,我想让人们使用它,最有效的方法是什么?如果我把它放入 dlib,成千上万的人会使用它,这比一般的学术出版物要多得多。就公共利益最大化而言,我不认为写论文是对我时间的最好利用。
围绕出版也有很多废话。事实上,我在 2012 年写了那篇 MMOD 论文,那是很久以前的事了。我向 CVPR 和其他几个地方提交了两次,每次都得到了好评,除了每次都会有一个评论者发表一些无意义的评论,大意是“我认为实验是错误的,不相信这是可行的”。他们中的一些人显然没有看报纸。这类评论尤其令人恼火,因为与此同时,成千上万的人正在使用这种方法,并取得了巨大的成功。但是你不能说“去运行 dlib,看看它是如何工作的”,因为提交是双盲的,并且在大多数情况下只基于论文。反正发表的人都抱怨这种事。这真是件苦差事,发表论文要花很多时间。我可以通过把想法放在 dlib 中,并附带解释它的文档来更容易地传播它们。所以我通常都是这么做的。
阿德里安 :我看到 ODNI 和 IARPA 被列为 dlib 的赞助商。你能告诉我们更多关于这次赞助的情况吗?这种联系是怎么产生的?又是如何推动 dlib 的发展?
戴维斯 :我职业生涯的大部分时间都在国防部工作,我的大多数朋友都是我在那个世界认识的人。IARPA 赞助的发生是因为人们渴望一个易于使用的 C++深度学习库。也就是说,从 C++程序中容易使用的东西。Python 或其他语言中有许多可用的深度学习工具,但 C++中没有,这有点令人惊讶,因为所有的深度学习工具最终都是用 C++或 C 编写的。所以我在国防部认识的一个人说服我编写一个易于使用的 C++深度学习 API,并将其放入 dlib。我维护的另一个开源项目 MITIE 也是由 DARPA 国防部机构赞助的,是 DARPA XDATA 项目的一部分。
然而,dlib 中的大多数东西都不是由任何人赞助的。通常我做 dlib 只是为了好玩。但是,当有人想赞助对 dlib 进行一些添加或更改时,我只接受我认为它实际上是一个有用的工具,有意义放入 dlib 的情况。

Figure 4: Applying deep metric learning in the latest release of dlib to the task of face recognition and face verification.
阿德里安 :最新版本的 dlib 搭载了深度度量学习,可与其他最先进的人脸识别技术相媲美。是什么促使你从事人脸识别的工作?当你开始做这个项目的时候,你的意图是“解决”人脸识别吗?(注:我已经看过几次你的公告博文,我实际上有点搞不清楚你是在做人脸识别(给定一张 1 张脸的图像,在 N 张脸的数据库中识别)还是人脸验证(给定两张图像,确定两张照片中的人是否是同一个人)。如果你能详细说明这一点,那将非常有帮助。
戴维斯 :哦,我不在乎人脸识别。对我来说,有趣的是学习算法,在上一个版本中,它主要是一些深度度量学习工具的添加。度量学习对于很多和人脸没有任何关系的事情都是有用的。这正是我喜欢添加到 dlib 中的那种广泛有用且有趣的工具。我在上一个 dlib 版本中包含人脸识别模型的主要原因是为了展示新工具可以正常工作。它也是有用的教学工具。当我向 dlib 添加新东西时,我会尝试编写示例程序来解释如何使用这些工具以及它们为什么有用和有趣。在深度度量学习的情况下,要写的明显的例子是展示如何进行某种面部识别的例子。所以我添加了人脸识别的东西,因为这是最引人注目的文档,而不是因为我关心人脸识别。
至于你的另一个关于识别和验证的问题,示例程序没有做这两件事。相反,它显示了如何将人脸嵌入到 128D 向量空间中,在该空间中同一个人的图像彼此靠近。它本身没有任何作用。但它是大多数用人脸做有趣事情的系统所使用的基本构件。例如,如果你想进行人脸验证,你需要两张人脸,并检查它们在 128D 空间中是否相距一定距离。如果他们足够接近,你说他们是同一个人。为了进行识别,你可以说“这是我的新面孔,在我的数据库中,它最接近哪张面孔?”?还是离数据库里的一切都很远?”。或者做人脸聚类,dlib 的一个例子,你可以在人脸的矢量嵌入上运行聚类算法,弹出人脸的聚类。
在我的博文中,我提到新的 dlib 模型在 LFW 基准测试中获得了 99.38%的分数。 该基准是人脸验证基准。 但是你可以很容易地使用工具来做人脸识别或聚类。
艾德里安 :为 dlib 开发一个新特性时,一般的时间表是什么样子的?拥有一个“基本完成”的特性,对它进行润色,然后发布它,这中间有很长的差距吗?或者你在特写“完成”后马上发表?
戴维斯 :这要看特点。大多数事情不需要那么长时间。例如,我想我用一个周末的时间在 dlib 中编写了 face landmarking 工具。虽然有时需要更长时间。真的要看是什么了。然而,我通常会马上把它放到网上。你通常可以立即看到代码出现在 github 上。但是我会等到我觉得一切都稳定了再发布官方编号的 dlib。
这也取决于你在时间表中包含了什么。我花很多时间阅读。有时我会对一些事情感到兴奋,这可能涉及到买一本关于某个主题的教科书并从头到尾阅读。然后最终会有一些具体的东西我想添加到 dlib。花在阅读上的时间可能是几个月也可能是几年,取决于你如何看待它。
我有时也会跑题。例如,当我为某些东西编写代码时,我经常会意识到我需要一些其他工具来制作我想要制作的机器学习算法。那我去做另一个工具。在编写另一个工具时,我可能意识到我还需要另一个工具来实现它。有时会失去控制,dlib 全新的主要部分随之而来,比如优化工具或线性代数库。
阿德里安 :虽然值得,但作为一个开源项目的主要维护者需要你投入时间、创造力和耐心。你觉得管理用户的期望很有挑战性吗?
戴维斯 :不尽然。我在 dlib 上工作是因为我喜欢。我还发现大多数人都很理智。我从用户那里得到的唯一持续不断的令人讨厌的问题来自那些明显不知道如何编程并且明显不想学习的人。像“我不知道怎么编程,你能告诉我打什么吗?”。无一例外,回答这类问题会导致无休止的进一步的问题“…好吧…那么我之后该键入什么?”。我肯定没时间在网上给大家做免费的代码编写服务。
但是我会尽力帮忙。我还有一个“推荐书籍”页面,供刚刚起步的人使用。
阿德里安 :作为你所在领域的专家,当你被一个难题困住时,你会找谁?
戴维斯 :通常没有人。不是因为我不想,而是因为通常当你被困在某件事情上时,你不知道有谁知道如何解决它。例如,通常当我试图从一篇论文中实现一些东西时,它起初并不工作。为什么不管用?是因为我的代码有 bug 吗?大概吧。还是因为我忽略了一些微妙但重要的细节?也许吧。是因为论文错了,永远不会成功吗?有时候。
在每一种情况下,你都会发现,在你花了很多时间解决这个问题并陷入困境之后,你会比你可能询问的任何人都更熟悉相关的细节。一部分是因为你写了你的代码,只有你见过它,一部分是因为你试图实现的文件在你的头脑中是新鲜的,而不是在你可能会问的其他人的头脑中。所以问别人可能一点帮助都没有。这并不是说你不应该这样做,有时它帮助很大。但通常你在解决这类问题时都是靠自己。
阿德里安 :你对那些刚刚开始计算机视觉和深度学习事业的读者有什么建议吗?
戴维斯 :多读书,不要跳过基本面。这无疑是人们开始面临的最大问题。每个人都想直接跳到结尾最酷的部分。但你不能这么做。如果你跳过重要的事情,那么理解计算机视觉似乎是不可能的,你会很快变得沮丧。在你希望在计算机视觉或机器学习方面取得任何进展之前,你必须理解一堆核心领域。然而,如果你按照正确的顺序学习,一切都会变得容易得多。
具体来说,我会说你需要很好地了解这六件事:如何编程、微积分、线性代数、概率、统计和数值优化。如果你不知道这六个领域,那么你就无法理解机器学习和计算机视觉论文。
你也不能用电脑做事,因为你不会编程。但没什么大不了的,你可以通过阅读来解决这个问题:)。特别是,你应该阅读每一个主题的教科书。我意识到很多人不想读教科书。但是如果你不读书,你就不会学习。事情就是这样。
所以你必须找到一些方法来激发自己阅读线性代数等主题的教科书。获得动力的一个好方法是选择一些你感兴趣的话题。也许你在 CVPR 找到了一些你真正想要理解和实现的文件。所以你读了,但有些部分你不明白。可能他们用了很多线性代数,而你线性代数很弱。现在你知道你需要学习线性代数,更重要的是,你有一个具体的目标,你很兴奋推动你去做。你可以从我的列表中挑选一本书:http://dlib.net/books.html。或者你可以去大学网站,看看他们用什么书来上同等的课。
此外,许多机器学习算法最终涉及复杂的循环计算,中间有逻辑语句。当用 Python 执行时,这类事情真的真的很慢,所以尽管这是一个 Python 博客,而且 Python 很棒,我还是要插上学习 C++的插头:)。所以也学 C++。很多时候,你会想做一些在 Python 中不容易矢量化的计算,或者你想写一些定制的 CUDA 代码,或者使用 SIMD 指令,或者其他什么。所有这些在 C++中非常简单,但在函数调用开销高、循环结构慢、无法访问硬件的语言中却非常困难或不可能(例如 Python、MATLAB、Lua)。但是如果你懂 C++的话,只要你愿意,你可以写一个 Python 扩展模块来处理这些事情,这很简单。
摘要
在今天的博文中,我们采访了 Davis King,他是用于现实世界计算机视觉和机器学习应用的工具包 dlib 的创建者和维护者。
虽然 dlib 主要用在 C++应用程序中,但是某些功能也有 Python 绑定——尽管 Davis 建议使用 C++来利用 dlib 的全部功能。
我可以亲自证明 dlib 的易用性——我已经在许多计算机视觉项目中使用过它,我甚至在 PyImageSearch 大师课程 中的对象检测背景下讨论过它。
我想再次感谢戴维斯·金抽出时间来做这次采访(并对凯尔·麦克唐纳和大卫·麦克杜菲帮忙收集这次采访的问题表示感谢)。
为了跟上 Davis,一定要在 Twitter 上关注他,同时关注他在 T2 的 GitHub 项目。
为了在以后的博客文章(包括采访)发布时得到通知,请务必在下面的表格中输入您的电子邮件地址!
弗朗索瓦·乔莱访谈
原文:https://pyimagesearch.com/2018/07/02/an-interview-with-francois-chollet/

在今天的博文中,我采访了现代深度学习领域最重要的研究人员和实践者之一,Fran ois Chollet。
弗朗索瓦不仅是 Keras 深度学习库的创建者,他还是谷歌人工智能研究员。他还将在今年 8 月的 PyImageConf 2018 上发表演讲。
在这次采访中,弗朗索瓦讨论了:
- 他对人工智能研究的启示
- 他创造 Keras 的原因
- 深度学习最终将如何在每个行业、每个企业和每个非营利组织中普及
- 人工智能行业的问题和挑战(以及我们如何帮助解决它们)
- 他会改变深度学习领域的什么,以及研究社区可能如何陷入困境
- 作为一名图片搜索者,他给你的建议是研究深度学习的最佳方式
请和我一起欢迎弗朗索瓦加入 PyImageSearch——他能来到这里真的是我的荣幸。
弗朗索瓦·乔莱访谈

Figure 1: Creator of Keras and Google researcher, François Chollet (Image credit: RedHat).
阿德里安:嗨,弗朗索瓦!我知道你在谷歌人工智能和 Keras 图书馆的工作非常繁忙,我真的很感谢你花时间接受采访。非常荣幸您能来到 PyImageSearch 博客!对于不认识你的人,你是谁,你是做什么的?
我在加州山景城的谷歌公司担任软件工程师。我开发深度学习库 Keras。我在 2015 年开始它,作为一个兼职项目,随着时间的推移,它变得比预期的更大——现在超过 25 万用户,是深度学习世界的一大部分。我也做一些主题的人工智能研究,包括计算机视觉和程序合成。
Adrian: 是什么激励你开始从事机器学习、深度学习和计算机视觉领域的工作?
弗朗索瓦:我迷上 AI 很久了。我最初是从哲学的角度来研究它的——我想了解智力是如何工作的,意识的本质是什么,诸如此类的事情。我从阅读神经心理学开始,从远处看,这个领域应该能够回答这些问题。能学的都学了,结果发现神经心理学并没有什么真正的答案。这太令人失望了。
所以我转向了人工智能——这个想法是试图通过从第一原则开始,自下而上地创造思维来理解思维,这与神经心理学的方法非常相反。当然,那时的大多数人工智能根本不关心大脑以及它们可能如何工作,所以我最终进入了人工智能中似乎与我的兴趣最相关的一个领域:发展认知机器人学,这是关于使用机器人和人工智能来测试人类认知发展模型的。然后,因为我不太擅长长时间做同一件事,我最终分支到了更应用的子领域,比如计算机视觉和自然语言处理。

Figure 2: The Keras deep learning library.
Adrian: 给我们介绍一下 Keras 深度学习库。你为什么要创建它,它填补了现有 ML/DL 库和包中的什么空白?
弗朗索瓦:我在 2015 年 2 月/3 月左右创作了 Keras。深度学习在当时是一个非常不同的领域。首先,它比较小。当时可能有 1 万人在做深度学习。现在已经接近一百万了。
就工具而言,你没有太多选择。您可以使用 Caffe,它在计算机视觉中很流行,但是只适用于相当狭窄的用例(convnets ),并且不太具有可扩展性。您可以使用 Torch 7,这是一个不错的选择,但这意味着您必须用 Lua 编码,而 Lua 没有 Python 数据科学生态系统的任何好处。任何你想加载的数据格式——你必须在 Lua 中从头开始构建你自己的解析器,因为你在 GitHub 上找不到这样的解析器。然后是 Theano,一个 Python 库,它是 TensorFlow 的精神祖先。我很喜欢这个 ano,它感觉像是未来,但它非常低级,很难使用。你必须从头开始写所有的东西。
当时我正在研究将深度学习应用于自然语言处理,重点是问答。现有工具生态系统中对 RNNs 的支持几乎不存在。所以我决定在 Theano 的基础上制作自己的 Python 库,从我喜欢的 Scikit-Learn API 和 Torch API 的部分借鉴一些想法。当我推出时,主要的价值主张是 Keras 是第一个同时支持 RNNs 和 convnets 的 Python 深度学习库。据我所知,它还有第一个可重用的 LSTM 开源实现(以前可用的实现本质上是研究代码)。而且很容易使用。
Keras 从第一天起就开始获得用户,从那以后就一直是一场不间断的开发马拉松。

Figure 3: Why might we use Keras over other deep learning libraries?
Adrian: 为什么深度学习研究人员、从业者或开发人员会选择 Keras,而不是 PyTorch、Caffe 甚至 strict TensorFlow 等其他库/框架?
Fran ois:我认为让 Keras 在今天的深度学习框架格局中脱颖而出的是它对用户体验的关注。Keras API 中的一切都是为了遵循减少认知负荷、更易访问、更高效的最佳实践。我认为这是 Keras 达到这一水平的主要原因,尽管 Torch 和 Caffe 已经领先一步。无论对于从业者还是研究人员,你都不能夸大易用性和生产力的重要性。在一个紧密的迭代循环中,尽可能快地从想法到结果,是做伟大研究或开发伟大产品的关键。
还有,关于 Keras 和 TensorFlow 还有一点。没有“Keras 或 TensorFlow”的选择。Keras 是 TensorFlow 的官方高级接口。它与 TensorFlow 一起打包为 tf.keras 模块。你可以将 Keras 视为深度学习的前端,它针对易用性和生产力进行了调整,可以在不同的后端引擎上运行,TensorFlow 是主要的一个。
Adrian: 开源最令人兴奋的一个方面是看到你的作品如何被其他人使用。你见过的 Keras 有哪些更有趣甚至令人惊讶的用法?
我们这个领域真正吸引人的一点是,你可以用我们的技术和工具解决各种各样的问题。我已经看到 Keras 被用来解决许多我甚至不知道存在的问题。比如优化鲑鱼养殖场的运营。在发展中国家分配小额贷款。为实体店建立自动结账系统。总的来说,在硅谷的人们意识到的一系列问题和人们在那里面临的、可以用这些技术解决的所有问题之间,似乎存在着差距。
这就是关注可访问性如此重要的一个重要原因:硅谷本身永远不会解决所有可以解决的问题。不会有一个硅谷的“深度学习行业”垄断深度学习专业知识,并向其他所有人出售咨询服务和软件。相反,深度学习将出现在每个行业、每个企业和非营利组织中,成为每个人手中的工具。让 Keras 和 TensorFlow 这样的框架免费使用并尽可能容易获得是一种发起大规模分布式问题解决浪潮的方式:理解目标领域的人将使用我们的工具自己构建解决方案,其影响力是我们单独一个人的 100 倍。
我认为 Keras 在让每个人都可以访问方面做得很好,相比之下,其他框架的目标只是让专家研究人员和其他内部人士使用。当我与从事深度学习的人交谈时,他们通常在研究和行业圈子之外,他们通常使用 Keras。

Figure 4: Important open source libraries, including Scikit-learn, Requests, Flask, and Theano.
Adrian: 除了 Keras 和/或 TensorFlow,你最喜欢的开源库有哪些?
Fran ois:我非常喜欢 Scikit-Learn,它在科学 Python 生态系统中产生了巨大的影响。这是一个非常以用户为中心、设计良好的库。我通常是以用户为中心的设计的忠实粉丝。像 Requests 和 Flask 这样的库也是很好的例子。
此外,谈到深度学习框架,我不能夸大 Theano 对深度学习世界的重要性。它有它的问题,但它在许多方面真的很有远见。
阿德里安:有时候,即使是出于好意的人最好的意图也会带来灾难性的后果——这种逻辑也适用于机器学习和人工智能。你同意这种说法吗?如果是这样,作为 ML/DL 社区,我们能做些什么来帮助确保我们没有造成比我们解决的更多的问题?
弗朗索瓦:是的,肯定的。不适当地应用机器学习可能会导致简单、不准确、不负责任、不可审计的决策系统在严重的情况下部署,并对人们的生活产生负面影响。如果你看看公司和政府今天使用机器学习的一些方式,这不是一个假设的风险,而是一个紧迫的问题。
谢天谢地,我认为最近机器学习社区出现了积极的趋势。人们越来越意识到这些问题。一个例子是算法偏差,这是机器学习系统在其决策中反映其训练数据固有的偏差的事实,无论是由于有偏差的数据采样、有偏差的注释,还是现实世界在各方面都有偏差的事实。一年前,这个重要的问题几乎不为人所知。现在,大多数从事机器学习的大公司都在研究这个问题。因此,至少在对其中一些问题的认识方面,我们正在取得进展。但这只是第一步。
Adrian: 如果你能改变深度学习行业的一件事,会是什么?
Fran ois:我认为应用深度学习在行业中总体表现良好,除了普遍倾向于过度销售当前技术的能力,并对不久的将来过于乐观(放射科医生在五年内肯定仍会有工作)。在我看来,有麻烦的是研究界。在这方面,我会改变很多事情。
首先,我们应该尝试修复研究界破碎的激励机制。目前,我们有许多违背科学方法和科学严谨性的激励措施。当你过度宣称而调查不足时,在深度学习会议上发表更容易,同时模糊了你的方法论。人们被增量架构技巧所吸引,如果你不进行对抗性的测试,这些技巧看起来似乎是有效的。他们使用弱基线,他们过度适应他们的基准的验证集。很少有人进行消融研究(试图验证你的经验结果实际上与你提出的想法有关),对他们的模型进行严格验证(而不是使用验证集作为超参数的训练集),或者进行显著性测试。
然后,我们有了公关驱动研究的问题。科幻叙事和神经科学术语赋予了人工智能领域一种特殊的光环。当它真的是数学和计算机科学的交叉领域时。一些知名实验室专门为公关挑选他们的研究项目,而不考虑 T2 能从项目中学到什么,能获得什么有用的知识。我们应该记住,研究的目的是创造知识。不是为了得到媒体的报道,也不是为了升职而发表论文。
另外,我对我们破碎的复习过程感到难过。深度学习领域在不到 5 年的时间里,从几百人到上万人。他们中的大多数都很年轻,没有经验,经常对这个领域有不切实际的想法,对科学方法没有真正的经验。他们不只是写论文,还会审核论文,这就是为什么你最终会遇到我提到的第一个问题——缺乏严谨性。
Adrian: 你在 2017 年出版了一本书, 用 Python 进行深度学习——恭喜你出版了!你的书涵盖了哪些内容,目标读者是谁?
Fran ois:这是为开发者编写的深度学习课程。它带你从基础(理解什么是张量,什么是机器学习等等)到能够自己处理相对高级的问题,比如图像分类、时间序列预测、文本分类等等。它的写作重点是易于理解和切中要点。我尝试做的一件事是用代码而不是数学符号来表达所有的数学概念。数学符号可能是一个巨大的可及性障碍,它根本不是理解深度学习的必要条件。在许多情况下,代码是处理数学思想的一种非常直观的媒介。
Adrian: 你会给有兴趣研究深度学习的 PyImageSearch 读者什么建议?你会建议一个“理论第一”的方法,一个“实践”的方法,或者两者之间的某种平衡?
弗朗索瓦: 我绝对推荐亲自动手的方法。理论是一个更高层次的框架,可以帮助你理解迄今为止所积累的经验。在缺乏经验的情况下,理论是没有意义的,过早地关注它可能会导致你对自己以后要做的事情建立误导性的心理模型。
Adrian:Fran ois,你是一名成功的人工智能研究人员,你在开源 DL/ML 社区中备受推崇,你是一名作家,也是一名艺术家。很明显,你是一个喜欢创造新的想法、概念和创造性作品的人。我完全能够欣赏和理解这种创造的动力。然而,当我们创作时,无论是在创意还是艺术作品方面,我们都必然会遇到“讨厌的人”。你会建议某人如何处理这些对我们的作品过分挑剔/完全不尊重的人?
弗朗索瓦:我认为不同的人会因为不同的原因表现得像巨魔。但是巨魔似乎在每个领域都遵循同样的剧本,无论是艺术、软件工程还是科学。你可以看到所有人都有相同的模式。知名度更高的人似乎在玩地位游戏,攻击某人以吸引注意力并提升自己在任何观众眼中的地位。匿名者往往是缺乏安全感的人,他们通过扮演看门人的角色来应对自己,憎恨“无足轻重的人”和局外人,并通过对最能提醒他们自己个人失败的人或团体表现出残忍来发泄他们的沮丧。
我的建议是忽略巨魔。不要和他们交往。不要和他们说话,也不要谈论他们——不要给他们平台。与不守信用、以伤害为目的的人交往不会有什么收获(只是压力大)。它剥夺了巨魔们寻求的注意力。

阿德里安:你将在今年的 PyImageConf 大会上发表演讲——你的到来让我们非常兴奋和幸运。你能告诉我们更多关于你将要谈论的内容吗?
Fran ois:我将谈谈我以前在计算机视觉方面的一些研究,特别是在 convnet 架构中使用深度方向可分卷积。在我看来,这是一个真正被低估的模式。它基本上是一组关于视觉空间结构的先验知识,使你能够同时建立更小的模型,运行更快,概括得更好。同样,与全连接网络相比,convnet 利用的平移不变性先验是一个相当大的改进,我认为 con vnet 特征中的深度方向可分性先验在处理 2D 图像或连续 3D 空间时严格优于常规卷积。
摘要
在今天的博文中,我们采访了谷歌人工智能研究员、广受欢迎的 Keras 深度学习库的创建者 Franç ois Chollet。
请花点时间在这个帖子上留下评论,并感谢 Franç ois 从百忙之中抽出时间来参加我们的 PyImageSearch 采访。我们真的很荣幸也很幸运有他在这里。
谢谢你,弗朗索瓦!
Unity Technologies 深度学习实践者 Gary Song 访谈
在这篇博文中,我采访了 Unity Technologies 的深度学习实践者 Gary Song。
我们现在处于新冠肺炎一周年纪念日。对我们所有人来说,这是特别艰难的一年。对加里来说,这真的很糟糕。
但是正如他的故事所展示的,总有办法把柠檬变成柠檬水… 如果你愿意付出努力的话。
2020 年,加里正在处理一个家庭紧急事件,就在他回家的时候,新冠肺炎突然袭击了他。经济陷入混乱。疫情对他的雇主特别苛刻,导致了大幅度的减薪。
出于对未来的担忧,无论是在经济上还是在职业上,Gary 都努力学习计算机视觉和深度学习。他创建的项目展示了他在该领域的知识。他把自己的简历放在那里,尽管招聘条件很苛刻。
简而言之,加里投资了自己和 尽管 一场全球范围的疫情正在进行, 他在世界上最著名的视频游戏公司之一获得了一个深度学习实践者的职位 。
我喜欢分享像加里一样的故事。我坚信地球上的每个人都是自己命运的主人…但是为了实现你的全部潜力,你需要努力工作。
一点点运气也没用,但正如我最喜欢的一句谚语所说:
命运偏爱努力工作的人。
看到世界在一年内下降了这么多令人惊讶——但看到我们恢复得如此之快同样令人难以置信。谁也说不准什么时候一切会恢复“正常”(或者不管新版本的“正常”是什么),但鉴于我们现在正处于新冠肺炎一周年纪念日,我想不出更好、更鼓舞人心的故事来分享了。
和我一起了解 Gary Song 如何在全球最著名的视频游戏公司之一 获得深度学习工作,尽管 正在进行全球疫情。
采访 Unity Technologies 深度学习实践者 Gary Song
阿德里安:嗨,加里!感谢您抽出时间接受采访。我知道你忙于新工作。很高兴您能来到 PyImageSearch 博客。
加里:嗨,阿德里安!这是我的荣幸。
Adrian: 过去的一年,COVID 对个人和企业都造成了很大的影响。COVID 对你和你的工作有什么影响?
今年年初,我确实经历了一段艰难时期。我刚从海外的一个家庭紧急事件中回来,COVID 在我回来后就受到了很大的打击。我当时的雇主马上受到了影响,工资很快就降了。我很感激还能被雇用,但是前方只有不确定性,压力和焦虑很快就变得无法控制。
阿德里安:降薪后,你最终离开了原来的工作,在全球疫情期间,你在视频游戏软件开发公司 Unity Technologies 找到了一份深度学习从业者的新工作。太神奇了。恭喜你!你能给我们介绍一下这个过程吗?你是如何有勇气在 COVID 期间离职,然后获得这个令人惊叹的职位的?
加里:谢谢!绝对的。所以我记得的第一件事是到处的招聘门槛突然提高了。许多地方停止招聘初级和中级职位,现有的工作机会也被取消。即使在那种环境下,我知道仅仅为了被雇佣而满足于一份工作很可能是我职业生涯的死刑判决,所以我必须有所选择。
我试图让我的简历脱颖而出的方式是强调这样一个事实,即我已经利用计算机视觉和深度学习快速构建了一个原型,来解决一个现有的商业问题。这可能对获得面试机会很有帮助。
我知道我已经为这些面试做好了充分的准备,因为我通过学习 PyImageSearch 课程和阅读博客,获得了关于使用深度学习模型的细微差别的实践经验和知识。我认为,这是与众不同之处。
我是说,任何学了一学期多元微积分的人都可以回答一些关于深度学习的一般性问题,你知道吗?但是需要准备数据,训练模型,调试,改善不好的结果等经验。,所有这些你的资料都涵盖了,才能真正了解它。
现在,我确实总是不得不明确表示,我到那时为止的经验仅仅是深度学习的计算机视觉应用,但这些知识肯定是可以转移的,甚至适用于我目前的日常工作。
阿德里安:你在 Unity 的日常职责是什么?你在用什么类型的深度学习模型?
Gary: 这本质上是一个与利益相关者会面、围绕业务需求构建项目、然后理解数据并迭代模型的循环。
例如,我目前正在做一个客户流失预测项目。虽然众所周知,梯度推进算法往往会在表格数据上击败简单的深度学习模型,但我仍然可以使用深度学习来理解数据,并补充梯度推进模型的结果。
作为一个例子,来自一个非常深的多任务模型的潜在空间特征可以用来寻找目标感知集群,以帮助我们更好地了解我们的客户,这一点很重要,超出了本项目的范围。
因为我的角色是在业务方面,我不经常遇到像图像这样的非结构化数据,所以除非有业务案例,否则我不会在这个特定的角色中做太多计算机视觉。然而,我知道我们已经非常成功地使用我们的 感知工具包 来生成用于对象检测和图像分割的合成数据。非常酷,推荐大家去看看!
Adrian: 在加入 Unity 之前,你在计算机视觉和深度学习方面的背景如何?
我在计算机视觉方面的知识仅仅是我在 PyImageSearch 大师班中学到的一切,再加上我自己在做项目时学到的一些东西。
另一方面,我非常了解深度学习的基本原理和主要发展,能够从零开始实现论文中的模型,知道如何定制现有的模型架构,并对给定业务用例的模型有效性有很好的感觉。
深度学习的基础来自于参加一些在线课程、阅读书籍、观看讲座视频和阅读论文。然而,大多数实现经验来自于使用 Python ImageNet 捆绑包对计算机视觉进行 深度学习。
一旦我理解了每个模型的组件,我就开始阅读书中引用的论文来理解实现细节。我喜欢 PyImageSearch 书籍的另一点是,它们引用了原始的研究论文,而许多在线课程不会这样做。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Gary: 我想我第一次在细节层面上遇到计算机视觉和深度学习是在 2018 年,当时我的好朋友兼同事王静用它做了实验。
由于深度学习在过去几年中一直是最具颠覆性的技术之一,我自然想学习它,但对于新技术,如果你只是听说过,就永远不清楚是否值得花时间学习。因此,看到有人在工作中使用它,我清楚地意识到,将它添加到我的工具包中是我应该优先考虑的事情。
我选择计算机视觉作为深度学习的切入点,因为计算机视觉似乎非常直观,所以更容易提出假设和应用该技术。
阿德里安:对于想追随你脚步的读者,你有什么推荐吗?
加里:我可以肯定地说。当我在学校的时候,没有任何课程提供深度学习,所以我在深度学习方面没有很深的学术背景。因此,大多数建议都是给业内有抱负的从业者的,也就是说,这是关于最终获得一个深度学习是你工作主要部分的角色。排名不分先后:
-
关注硬件领域的发展。由于计算限制,某些事情现在可能已经完成,但一旦硬件足够强大,这些事情可能就变得不那么重要了。某些型号对于只能使用消费级硬件的普通从业者来说也是遥不可及的。由于实践中深度学习的实验性质,这可能会严重限制你能够负担得起的研究,即使你使用云资源。这是我选择计算机视觉而不是 NLP 的一个原因,因为前沿的 NLP 模型已经变得难以置信的大,因此,实验成本高昂。
-
不要犹豫投入计算能力,无论是硬件还是云。计算能力会让你实验得更快,让你学得更快。
-
不要犹豫,投资那些能让你经历端到端深度学习过程的课程。带你走过端到端深度学习管道的好课程会节省你的时间,让你可以专注于你想学的部分。此外,最好将课程和所有信息都放在一个地方,而不是在网上搜索各种资源。
-
建立一个东西,然后考虑如何扩展它。建模过程通常只是工作的一部分。关键是你要展示出处理一个项目所有方面的能力。这不一定是深度学习特有的东西,而是雇主会关心的东西。
-
读取源代码。从好的实施中可以学到很多东西,包括如何思考问题及其解决方案。
-
阅读至少一篇论文,并从头开始实现模型。细节决定成败。您将对模型架构背后的原则有更深的理解。
-
一般来说,试着花时间深入你感兴趣的话题。现成的解决方案只能带你走这么远,可以作为快速和肮脏的基线,但只有通过这些深入的探索,你才能了解如何改善你的结果。
最后,以下是 Andrej Karpathy 给我的一些关于成为专家的建议:
Adrian: 从 2019 年 6 月开始,你就是 PyImageSearch 的读者和客户了!谢谢你支持 PyImageSearch 和我。你有哪些 PyImageSearch 的书籍和课程?他们是如何帮助你准备在 Unity 的新工作的?
Gary: 实际上,我拥有所有的,除了 OCR,这是我的一个兼职项目。这些书籍和课程充当了指导实验室,在那里我可以获得实践经验,并熟悉深度学习管道的所有部分,这在业内很重要。
这些材料实际上是我对深度学习的“真实”世界的介绍,而不仅仅是一门理论和推导课。因此,它们不仅涵盖了模型,还涵盖了用于进行基准测试的数据集,从而成为对深度学习前景的调查。
你们中的一些人可能听说过这样一个概念,当学习一门新的学科时,建立一个“动物园”是很重要的,就像,意识到并理解有趣的和说明性的案例。这基本上就是 PyImageSearch 书籍和课程为你做的事情。
Adrian: 你会向其他尝试学习计算机视觉、深度学习和 OpenCV 的初露头角的开发者、学生和研究人员推荐这些书籍和课程吗?
加里:百分之百!我认为这些书和课程非常有价值,尤其是对我所在的人群而言。
当我在学校的时候,没有任何关于深度学习的课程,所以我从来没有机会建立一个心智模型来解释一切是如何结合在一起的。有了这些书和课程,我能够做到这一点。
我推荐使用 Python ImageNet 捆绑包开始使用用于计算机视觉的 深度学习。它可以用作指导深度学习实验室或作为参考。该代码也非常有用,因为官方文档可能不完整,或者更糟的是,其范围可能超出您的需求,使您陷入信息过载的境地。
最后,但也许是最重要的,它富含其他地方不常提及的实用知识。
Adrian: 如果一个 PyImageSearch 的读者想和你联系,和你联系的最佳地点是哪里?
Gary: 我总是可以在 LinkedIn 上或者通过 PyImageSearch direct messaging 找到我。期待和大家的联系!
总结
在这篇博文中,我们采访了著名视频游戏开发公司 Unity Technologies 的深度学习实践者 Gary Song。
Gary 在新冠肺炎疫情中部的 Unity 获得了他的深度学习职位。他用前一份工作的降薪作为学习、提升自己的动力,并获得了一份他不仅引以为豪,而且更为 T2 稳定的工作。
我为加里感到无比骄傲。他付出了艰苦的努力,现在正在享受他的劳动成果。
记住,财富偏爱努力工作的人——你在努力工作吗?还是几乎不工作?
谷歌视频人工智能研究员胡格恩斯·让访谈
原文:https://pyimagesearch.com/2020/09/02/an-interview-with-huguens-jean-video-ai-researcher-at-google/

在这篇文章中,我采访了我以前的 UMBC 实验室伙伴胡格恩斯·吉恩博士,他刚刚被谷歌视频人工智能小组聘为人工智能研究员。
胡格恩斯分享了他的励志故事,从他出生和长大的海地太子港开始,到他在 UMBC 的学校教育,以及现在他在谷歌的最新职位。
他还分享了他的人道主义努力的细节,他成功地将计算机视觉和深度学习应用到卢旺达农村,以帮助计算客流量。
他和他的团队通过客流量分析收集的数据被用于帮助一个非营利组织建设桥梁和道路等基础设施,以更好地连接撒哈拉以南非洲的村庄。
让我们热烈欢迎胡格恩斯·让博士分享他的故事。
谷歌视频人工智能研究员胡格恩斯·让博士访谈
阿德里安:你好,胡格人!谢谢你接受这次采访。非常高兴您能来到 PyImageSearch 博客。
胡格恩斯:很高兴和你在一起。
阿德里安:你能介绍一下你自己吗?你在哪里上学,是如何对计算机视觉产生兴趣的?
胡格恩派教徒:我来自海地的太子港。我去了圣路易学院,冈萨格。
2010 年海地地震后,我和 UMBC 大学的校友 Philip Knowlton 一起拍摄了一部非常亲密的纪录片。这部电影讲述了两兄弟信守对祖父的承诺的故事。在这本书里,我更多地谈论了我的家人和在海地的生活。
当我 1997 年来到美国时,我去了霍华德高中。蔻驰·大卫·格伦向我介绍了跳高。我被 UMBC 的蔻驰·吉姆·弗洛格纳和蔻驰·大卫·鲍勃招募了。这让我在 UMBC 大学学习了计算机工程和电子工程。
我读研期间在 NASA 工作。2010 年海地地震后,我进入了私营部门,开始做软件工程师。我想这场悲剧让我不再相信我的导师们想获得博士学位的愿景。
一天,UMBC 研究生院院长珍妮特·拉特利奇博士带我出去吃午饭。她说:“你让我看起来很糟糕。”我辞掉了工作,去看蒂姆·奥茨医生。我们赢得了一些研究资金,我最终在 2015 年获得了博士学位。
我不相信我能做到,直到我去了坦桑尼亚。我在伯克利大学读过匡辰的研究。他的作品激励了我。在 Captricity,我和他一起写了一份关于分析数字图像内容的专利,毕业后我在加州奥克兰住了大约 3 年。
阿德里安:你最近在谷歌的视频人工智能部门获得了一个职位,祝贺你!你是怎么得到这么好的机会的?
胡格恩斯:我重新联系了两年前的招聘人员。在谷歌第一次失败后,人们需要等待一年才能再次尝试。两年前我尝试过,但没有成功。我在纽约办公室面试,我的表现不是很好。我知道它会进去。
但 6 周前,我是另一个工程师。我对计算机科学有不同的感受。面试前,我拼命学习了大约两个星期。
我按照他们的指导,专注于真正了解数据结构,比如列表、堆栈、队列、树、堆、图和 trie。我练习了像 DFS、BFS、A*和排序这样的算法。我想做好一切准备。对于计算机视觉和数据科学部分,我从你那里学到了很多。
阿德里安:我们都知道谷歌因挑战性面试而在臭名昭著。计算机视觉/深度学习工作的面试过程是怎样的?
如你所说,这是出了名的困难。一周内,我做了 7 次技术面试。一天 5 次视频采访和两次技术展示,一次在谷歌,另一次在脸书。
在谷歌,我同时面试两个职位:机器学习通才和数据科学职位。对于机器学习通才的角色,前两次面试是关于数据结构的。用数据结构解决问题需要练习。你必须快速思考,避免过度思考解决方案。我不是最好的应试者,在没有运行代码的情况下,在谷歌文档中解决这些问题是很伤脑筋的。
第三次面试是在谷歌上。第四次和第五次面试是关于计算机视觉的。这是因为我的招聘人员提出了一个特殊的要求,以确保我有公平的机会展示我在机器学习方面的优势。领域广阔。
有太多的东西需要了解,谷歌已经准备好询问 NLP 和强化学习。我在这些领域不是很强。
对于数据科学的角色,经过技术筛选,Google 觉得我会更适合他们的视频 AI 组。
Adrian: 在谷歌工作之前,你参与了一些令人难以置信的人道主义工作,这些工作在撒哈拉以南非洲的农村地区使用了计算机视觉和深度学习技术。你能告诉我们关于这个项目,以及你是如何提交一篇关于这个主题的论文发表的吗?
一名研究人员雇佣了 Synaptiq 来进行这个项目。 Synaptiq.ai 归蒂姆·奥茨博士所有。作为 UMBC 大学的博士生,他给你和我都提了建议。
我需要离女儿近一点,而在马里兰州当地工作提供了合适的机会。奥茨博士需要一个 OCR 项目的人,我开始在那里做顾问。蒂姆和我过去做过类似的研究。
我在那里的工作最终引导我做了这个项目。他在撒哈拉以南的非洲农村架设了摄像机来观察行人过桥。

Figure 4: An example pedestrian footbridge in Subsaharan Africa.
起初,研究人员试图使用你的代码对人计数,但在该教程中,预先训练的 MobileNet SSD 用于检测物体的性能很差。在 Synaptiq 的帮助下,我们能够在 GPU 上将探测器升级到 YOLOv3,并使用 DeepSort 加强质心跟踪器。
注: 最初我曾收录了一张展示胡格恩派和研究团队工作的图;然而,该团队要求我在他们的论文正式发表之前记下这个数字。
在我们的论文中引用这两个教程确实是一种荣誉。在 GPU 上使用这些新模型,我们能够及时地从数小时的视频中提取有意义的信息。
Adrian: 在你的农村人流计数器项目中,最困难的方面是什么,为什么?
即使在 GPU 机器上,为了收集数据而处理数小时的视频也需要很长时间。我的合同快到期了,我们需要一个 NVIDIA docker 容器,它可以在 RTX2080 计算机(也就是 UMBC 的 Synaptiq 机器)上自动运行几个小时剩余镜头的代码。就在那时,蒂姆和我们的另一个共同朋友祖贝尔·艾哈迈德冲过了终点线。
阿德里安:如果你必须选择你在研究过程中应用的最重要的技术,那会是什么?
胡格恩斯:如果你在谈论计算机科学技术,递归胜出。但如果你在谈论计算机视觉和机器学习,聚类运动向量是一个很好的方法。
Adrian: 你平时用什么深度学习/计算机视觉工具和库?哪些是你的最爱?
胡格恩斯:我用了很多 OpenCV。这是迄今为止我最喜欢的计算机视觉 Python 库。通过深度学习,我又一次从你们身上学到了很多。我是 Keras 和 Tensorflow 的超级粉丝。
Adrian: 你会给想进行计算机视觉/深度学习研究但不知道如何入门的人什么建议?
胡格恩斯:读完研究生后,我自己也不确定从哪里开始,直到从 PyImageSearch 购买了大量资料,并开始关注你的博客。我们边做边学。你在你的书里说过。那不是谎言。
如果你想真正擅长某件事,你必须练习。我像运动员一样思考。关于学习新的东西,我试着比前一天做得更多。我的心灵不像我的身体那样疼痛。我一天都不用翘课。我上 LinkedIn 或脸书,搜索一个引人注目的知识库,或者一些令人惊叹的技术/书籍,然后阅读。
Adrian: 你是 PyImageSearch 的长期读者和客户,已经阅读了用 Python 编写的 用于计算机视觉的深度学习 、 用于计算机视觉的树莓派 ,并参加了 PyImageSearch 大师课程。这些书籍和课程对你的职业生涯有什么帮助?
胡格恩派教徒:他们给了我很大的帮助。就像我的朋友,Jezette 工作室的首席执行官 Salette Thimot-Campos 在脸书上写道:
消除疑虑的唯一方法是通过教育。我学得越多,就越觉得自己强大,越觉得自己与这个世界联系紧密。4 年前,我在探索一些我从未想过自己有任何业务需要探究的话题。但是现在,随着我对每一个技术术语和功能的理解和掌握,我感到越来越强大和勇敢。
我对你的书和博客的体验与她的话相呼应。博士学位只会提醒我,我一直都很优秀,足以学习任何东西。
我不知道你是否记得蔡福森教授。他和蒂姆一起给我出主意。他会说【广度和深度】。对我来说,这通常意味着对一件事知道很多,对每件事都知道一点。他鼓励我永远保持好奇心。
除了为你的读者提供评论良好的代码之外,你还有一种创造性的方式来解释事情,很多时候是通过图片和视频。我等待你的下一个博客,就像等待下一部 iPhone,因为我不知道会发生什么。有时候我很忙,但每周一早上,我至少会努力去回忆你做了什么。你永远不知道在哪里会再次看到类似的想法。
Adrian: 您会向其他试图学习计算机视觉和深度学习的开发人员、学生和研究人员推荐使用 PythonT5、Raspberry Pi for Computer Vision和 PyImageSearch Gurus 课程的?
胡格恩派:绝对。像电影《T4 空手道小子》中的上蜡,下蜡一样学习基本原理。我不得不在 Linux 上多次安装 OpenCV。为 GPU 机器做,需要耐心。训练深度学习模型需要耐心,但体验其中的魔力是值得的。
阿德里安:如果有人想追随你的脚步,学习计算机视觉和深度学习,然后在谷歌找到一份令人惊叹的工作,你有什么建议吗?
胡格恩斯:我鼓励人们把他们的教育当成一种运动,一种精神上的运动,就像国际象棋一样,并且永远向比你年长和年轻的人学习。练习。练习。为月亮练习和射击。
Adrian: 如果一个 PyImageSearch 的读者想聊天,最好在哪里联系你?
胡格恩派:他们可以在 LinkedIn 上关注我,在me@huguensjean.com给我发电子邮件,或者在 huguensjean.ai 查看我的网站。
摘要
在这篇博文中,我们采访了谷歌视频 AI 小组的人工智能研究员胡格恩斯·让博士。
我和胡格恩斯在 UMBC 大学读研时是实验室的同事。从那以后我们就成了朋友(他甚至参加了我的婚礼)。
分享胡格恩斯的作品真的是一种荣誉——他真的改变了世界。
如果你想成功地将计算机视觉和深度学习应用到现实世界的项目中(就像胡格恩斯所做的那样),一定要拿起一本用 Python 编写的 用于计算机视觉的深度学习。
使用本书,您可以:
- 成功地将深度学习和计算机视觉应用到您自己的工作项目中
- 转换职业,在一家受人尊敬的公司/组织获得一个简历/DL 职位
- 获得完成理学硕士或博士学位所需的知识
- 进行值得在著名期刊和会议上发表的研究
- 周末完成你的业余爱好 CV/DL 项目
我希望你能加入我,Huguens Jean 博士,以及成千上万的其他 PyImageSearch 的读者,他们不仅掌握了计算机视觉和深度学习,而且利用这些知识改变了他们的生活。
我们在另一边见。
在 PyImageSearch 上发布未来的博客文章和采访时,我们会通知您,只需在下面的表格中输入您的电子邮件地址,,我会确保让您随时了解情况。
OpenCV 空间人工智能竞赛冠军 Jagadish Mahendran 访谈
在这篇文章中,我采访了高级计算机视觉/人工智能(AI)工程师 Jagadish Mahendran,他最近使用新的 OpenCV AI 套件(OAK)在 OpenCV 空间 AI 比赛中获得了第一名。
Jagadish 的获奖项目是一个为视障人士设计的计算机视觉系统,让用户能够成功地在 T2 和 T4 导航。他的项目包括:
- 人行横道自动检测
- 人行横道和停车标志检测
- 悬垂障碍物检测
- …还有更多!
最重要的是,整个项目是围绕新的 OpenCV 人工智能套件(OAK)构建的,这是一种专为计算机视觉设计的嵌入式设备。
和我一起了解 Jagadish 的项目,以及他如何使用计算机视觉来帮助视障人士。
采访 OpenCV 空间人工智能竞赛冠军 Jagadish Mahendran
阿德里安:欢迎你,贾加迪什!非常感谢你能来。很高兴您能来到 PyImageSearch 博客。
阿德里安,很高兴接受你的采访。谢谢你邀请我。
阿德里安:在我们开始之前,你能简单介绍一下你自己吗?你在哪里工作,你在那里的角色是什么?
Jagadish: 我是一名高级计算机视觉/人工智能(AI)工程师。我曾为多家创业公司工作,在那里我为库存管理机器人和烹饪机器人构建了 AI 和感知解决方案。
阿德里安:你最初是如何对计算机视觉和机器人感兴趣的?
Jagadish: 我从本科开始就对 AI 感兴趣,在那里我有机会和朋友一起制作了一个微型鼠标机器人。我在硕士期间被计算机视觉和机器学习吸引住了。从那以后,与这些令人惊奇的技术一起工作变得非常有趣。
Adrian: 您最近在 OpenCV 空间人工智能竞赛中获得了第一名,祝贺您!你能给我们更多关于比赛的细节吗?有多少支队伍参加了比赛,比赛的最终目标是什么?
Jagadish: 谢谢。由英特尔赞助的 OpenCV Spatial AI 2020 竞赛分为两个阶段。包括大学实验室和公司在内的约 235 个具有各种背景的团队参与了第一阶段,其中涉及提出一个使用带有深度(OAK-D)传感器的 OpenCV AI 套件解决现实世界问题的想法。31 个团队被选入第二阶段,我们必须用 3 个月的时间来实现我们的想法。最终目标是开发一个使用 OAK-D 传感器的全功能人工智能系统。
Adrian: 你的获奖解决方案是一个为视障人士设计的视觉系统。你能告诉我们更多关于你的项目吗?
Jagadish: 文献上甚至市场上都有各种视觉辅助系统。由于硬件限制、成本和其他挑战,他们中的大多数人不使用深度学习方法。但最近,在 edge AI 和传感器空间方面有了显著的改善,我认为这可以为硬件有限的视觉辅助系统提供深度学习支持。
我开发了一个可穿戴视觉辅助系统,使用 OAK-D 传感器进行感知,使用外部神经计算棒(NCS2)和我 5 岁的笔记本电脑进行计算。该系统可以执行各种计算机视觉任务,帮助视障人士理解场景。
这些任务包括:探测障碍物;海拔变化;了解道路、人行道和交通状况。
该系统可以检测交通标志以及许多其他类别,如人、汽车、自行车等。该系统还可以使用点云检测障碍物,并使用语音界面更新个人关于其存在的信息。个人也可以使用语音识别系统与系统交互。
以下是一些输出示例:
阿德里安:请告诉我们用于开发项目提交材料的硬件。个人是否需要佩戴大量笨重的硬件和设备?
Jagadish: 我采访了一些视障人士,了解到走在街上受到太多关注是视障人士面临的主要问题之一。因此,物理系统作为辅助设备不引人注目是一个主要目标。开发的系统很简单——物理设置包括我 5 岁的笔记本电脑、2 个神经计算棒、藏在棉背心内的摄像头、GPS,如果需要,还可以在腰包/腰包内放置一个额外的摄像头。大多数这些设备都很好地包装在背包里。总的来说,它看起来像一个穿着背心到处走的大学生。我在我的商业区走来走去,完全没有引起特别的注意。
Adrian: 你为什么选择 OpenCV AI Kit (OAK),更确切的说是可以计算深度信息的 OAK-D 模块?
Jagadish: 主办方提供 OAK-D 作为比赛的一部分,它有很多好处。它很小。除了 RGB 图像,它还可以提供深度图像。这些深度图像对于探测障碍物非常有用,即使不知道障碍物是什么。此外,它还有一个片上人工智能处理器,这意味着计算机视觉任务在帧到达主机之前就已经执行了。这使得系统超快。
阿德里安:你有针对视觉障碍的视觉系统的演示吗?
Jagadish: 演示可以在这里找到:
https://www.youtube.com/embed/ui_p5x8n2tA?feature=oembed
采访 ImageZMQ 的创造者杰夫·巴斯
原文:https://pyimagesearch.com/2019/04/17/an-interview-with-jeff-bass-creator-of-imagezmq/

本周早些时候,我分享了一个关于使用 OpenCV 通过 ImageZMQ — 在网络上传输实时视频的教程,今天我很高兴分享对 ImageZMQ 的创始人杰夫·巴斯的采访!
Jeff 拥有超过 40 年的电脑和电子产品黑客经验,现在他将计算机视觉+ Raspberry Pis 应用于他的永久农场:
- 数据收集
- 野生动物监测
- 水表和温度读数
杰夫是我有幸遇到的最喜欢的人之一。在他 40 年的职业生涯中,他积累了大量计算机科学、电子学、统计学等方面的知识。
他还在一家大型生物技术公司做了 20 年的统计和数据分析。他给的建议实用、中肯,而且总是说得很好。很荣幸他今天能来到这里。
就个人而言,Jeff 也是 PyImageSearch Gurus course course 的最初成员之一。他是一个长期的读者和支持者——他是真正的帮助这个博客成为可能。
很高兴今天有 Jeff 在这里,无论您是在寻找计算机视觉和 OpenCV 的独特、实用的应用,还是只是在寻找如何为计算机科学职业生涯建立投资组合的建议, 看看这个采访就知道了!
采访 ImageZMQ 的创造者杰夫·巴斯
阿德里安:嘿,杰夫!谢谢你今天来到这里。很高兴你能来到 PyImageSearch 博客。对于不认识你的人,你是谁,你是做什么的?
杰夫:我是一个终生学习者,已经玩了 40 多年的电子产品和电脑。我在研究生院学习计量经济学、统计学和计算机科学。当个人电脑还是新事物的时候,我为个人电脑开发了一个统计软件包。我在一家大型生物技术公司做了 20 年的统计和数据分析。
现在,我已经从创收事业中退休,并在南加州建立了一个小型永久性农场。我正在使用计算机视觉、传感器和树莓 Pis 作为工具来观察和管理农场。我偶尔在花园俱乐部和会议上发言。我真的很喜欢成为 2018 年 PyImageConf 的演讲者。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Jeff:2013 年,当它们首次上市时,我得到了一个树莓 Pi 和一个 Pi 相机模块。当我开始经营农场时,我想用它们来观察和记录野生动物的活动。我已经非常熟悉 Linux 和 C,但是最好的 Pi 相机接口是 Python 中的“Picamera”模块。我开始了“web 漫游”来学习更多关于 Python 编程和计算机视觉的知识。我浏览了你的教程博客,买了你的 实用 Python 和 OpenCV 的书。一旦我看完你书中的例子,我就被吸引住了。

Figure 1: Jeff Bass runs Ying Yang Ranch, a permaculture farm designed to grow food with long term sustainability.
阿德里安:你能告诉我们更多关于你农场的事吗?什么是永久农业?为什么它很重要,它与“传统”农业有什么不同?
杰夫:我把这个农场叫做阴阳农场。这是一个位于郊区的 2 英亩的小型“科学项目”。我开始了解永久栽培的同时,我开始了解树莓。
永久农业是以长期可持续性为主要目标的种植食物的实践和设计原则的集合。它从创造具有不同微生物的深层土壤开始,模仿古老的森林。永久性的设计选择将可持续性置于效率之上。它以科学为基础,强调仔细观察、可重复实验和开放共享最佳实践的循环。
永久性农场通常很小,包括许多不同种类的植物在一起生长,而不是一排排相似的作物。食用植物与本地植物生长在同一空间。我种植无花果、梨、石榴、李子、葡萄、鳄梨、橙子、桑葚、黑莓和其他食物。但是它们与加州海岸的橡树和悬铃木套种在一起。它看起来不太像传统的农场。传统农业效率很高,但会破坏土壤和水资源。永久文化正试图改变这种状况。

Figure 2: Jeff uses Raspberry Pis + computer vision around his farm. An example of such is automatic water meter reading using OpenCV.
阿德里安:树莓汁和计算机视觉对你的农场有什么帮助?
杰夫:我们在南加州,距离马里布海岸约 10 英里。干旱和降雨量有限是最严峻的气候问题。监控和观察很重要,所以我建了一个覆盆子 Pi 摄像系统来读取水表和监控温度,以优化灌溉。
这引出了更多的问题和许多收集和分析数据的有趣方法:
- 今天浇桑葚花了多少加仑?
- 郊狼最后一次跑到谷仓后面是什么时候?
- 鳄梨树下的温度和土壤湿度是多少?
- 5 个堆肥堆的温度和含水量是多少?
- 它是如何随时间变化的?
- 我们今天生产了多少太阳能电力?
- 雨水桶有多满?
- 鸟儿、蝴蝶和其他生物的活动是如何随着季节和开花结果的变化而变化的?
树莓派还记录了车库和谷仓门的开关。他们可以让我知道包裹什么时候送到。
阿德里安:你创建了一个名为 imagezmq 的库。它是什么,有什么作用?
Jeff:imagezmq 库实现了一个简单快速的 Raspberry Pis(客户端)和服务器网络。
早期,我决定采用分布式设计,使用 Raspberry Pis 来捕获图像,使用 MAC 来分析图像。目标是让 Raspberry Pis 进行图像捕捉和运动检测(水表在旋转吗?)并以编程方式决定将一小部分图像传递给 Mac。
我花了一年时间尝试不同的方法将图像从多个树莓电脑发送到 Mac 电脑。我选择了开源的 ZMQ 库和它的 PyZMQ python 包装器。我的 imagezmq 库使用 zmq 将图像和事件消息从十几个 Raspberry Pis 发送到 Mac hub。ZMQ 快速、小巧、易于使用,并且不需要消息代理。
下面是一对代码片段,展示了如何使用 imagezmq 从 Raspberry Pi 向 Mac 连续发送图像。首先,在每个 Raspberry Pi 上运行的代码:
# run this program on each RPi to send a labelled image stream
import socket
import time
from imutils.video import VideoStream
import imagezmq
sender = imagezmq.ImageSender(connect_to='tcp://jeff-macbook:5555')
rpi_name = socket.gethostname() # send RPi hostname with each image
picam = VideoStream(usePiCamera=True).start()
time.sleep(2.0) # allow camera sensor to warm up
while True: # send images as stream until Ctrl-C
image = picam.read()
sender.send_image(rpi_name, image)
然后是运行在 Mac(服务器)上的代码:
# run this program on the Mac to display image streams from multiple RPis
import cv2
import imagezmq
image_hub = imagezmq.ImageHub()
while True: # show streamed images until Ctrl-C
rpi_name, image = image_hub.recv_image()
cv2.imshow(rpi_name, image) # 1 window for each RPi
cv2.waitKey(1)
image_hub.send_reply(b'OK')
每个 Raspberry Pi 的主机名允许 Mac 将来自该 Raspberry Pi 的图像流放在一个单独的、标记为cv2.imshow()的窗口中。我在我的 imagezmq github 存储库中有一张照片,显示 8 个 Raspberry Pi 摄像头同时显示在一台 Mac 上:

Figure 3: Live streaming video from 8 Raspberry Pis to a central hub using Python, OpenCV, and ImageZMQ.
它在每个 Raspberry Pi 上使用了 12 行 Python 代码,在 Mac 上使用了 8 行 Python 代码。一台 Mac 可以以 10 FPS 的速度跟上 8 到 10 个树莓 pi。 ZMQ 快。
imagezmq 使计算机视觉管道能够轻松地分布在多个 Raspberry Pis 和 MAC 上。Raspberry Pi 以每秒 16 帧的速度捕捉图像。它可以检测水表指针旋转引起的运动。它只发送指针开始移动或停止移动的图像,这只是它捕获的图像的一小部分。然后,Mac 使用更先进的计算机视觉技术读取水表图像的“数字”部分,并确定使用了多少水。每台计算机都能够完成它最适合的计算机视觉管道部分。imagezmq 实现了这一点。
Adrian: 你在阴阳牧场部署过的最喜欢的计算机视觉+树莓 Pi 项目是什么?
杰夫:我用红外线泛光灯在谷仓的后墙上安装了一个树莓派。当运动“像动物一样”时,它跟踪运动并发送图像。我捕捉到了郊狼、浣熊、负鼠、蝙蝠、鹰、松鼠和兔子的图像。我还在研究深度学习模型,以便正确分类。对我和我的邻居来说,更多地了解我们周围的野生动物非常有趣。

Figure 4: A selection of Raspberry Pi components and cameras, including (left to right) Waveshare Combo IR lens and dual IR floodlights, PiNoir IR Camera with IR “Ring Light” floodlight, RPi Zero with PiCamera in white light “Ring Light” with DS18B20 temperature probe, RPi Zero with “Spy Cam” and longer range WiFi, and RPi Zero with older model (and half price) PiCamera.
阿德里安:树莓派虽然便宜,但功能远不及标准笔记本电脑/台式机。在农场使用树莓 Pis 的过程中有哪些经验教训?
杰夫:树莓馅饼很擅长捕捉图像。Pi 相机模块在 Python 中是非常可控的,可以改变曝光模式之类的东西。USB 或笔记本电脑网络摄像头通常根本无法控制。控制曝光和其他相机设置对追踪野生动物甚至读取水表非常有帮助。
Raspberry Pi GPIO 引脚可以收集温度传感器、湿度传感器和其他传感器的读数。GPIO 引脚可以用来控制灯,比如照亮我的水表和谷仓区域的灯。笔记本电脑和台式机不容易做到这些。
另一方面,Raspberry Pis 缺乏高速磁盘驱动器——sd 卡不适合写入大量二进制图像文件。在我的系统中,Raspberry Pis 通过网络发送图像文件,而不是将它们存储在本地。笔记本电脑和台式机有快速的磁盘存储和大量的 RAM 内存,允许更精细的图像处理。我试图让我的树莓派做他们擅长的事情,让苹果做他们擅长的事情。
我的大多数 Raspberry Pi 是 Raspberry Pi 3,但我也使用更便宜、更小的 Raspberry Pi Zero,用于只需要进行简单运动检测的 Pi 相机,如我的车道摄像头。当不需要额外的图像处理时,即使 Pi Zero 的内存更小、处理器功能更弱也足够了。
阿德里安:你在农场使用什么类型的硬件、相机和树莓派配件?你如何保护你的 Pis 不被淋湿和毁坏?
Jeff: 我在农场的很多地方使用带有 Pi 摄像头的树莓 Pi。它们通常有温度、湿度和其他传感器。我建造了多种围栏来保护树莓。
我最喜欢的一个方法是将现有的户外灯具改造成防水的树莓派容器。你卸下灯泡,拧上一个简单的交流插座适配器,你就有了一个简单的防雨外壳,可以容纳树莓 Pi 和 Pi 相机模块。GPIO 温度探头也很合适。添加 Raspberry Pi 控制的 led 灯很容易,因此灯具仍能像以前一样提供照明:

Figure 5: Converting an outdoor light fixture into a waterproof Raspberry Pi container.
另一个外壳是一个简单的带塑料盖的玻璃缸。它适合一个树莓皮和防水。电源和摄像头电缆可以穿过塑料盖中的孔。这就是我的水表 Pi 相机的构造,它已经在各种天气下工作了两年多:

Figure 6: A simple Raspberry Pi enclosure using a simple mason jar.
对于红外应用,比如我的谷仓后面的夜间生物摄像机,我把树莓派放在谷仓里面。摄像头和温度传感器电缆穿过谷仓墙壁上的小孔。Pi NoIR 相机模块被保护在一个简单的旧木瓦下。红外光不能穿过玻璃,因此 Pi NoIR 相机模块不能在玻璃外壳中。在其他未受保护的引脚模块上的木瓦悬垂非常有效:

Figure 7: A simple wooden overhang to protect the Raspberry Pi.
下面可以看到更近的视图:

Figure 8: A closer up view of the overhang (you can see the red light from the Raspberry Pi camera if you look closely).
我还发现便宜(大约 5 美元)的“假安全摄像头”外壳和防水的 Raspberry Pi 和 Pi 摄像头外壳一样好用。他们可以轻松地拿着一个树莓派,他们有一个三脚架一样的角度调节器:

Figure 9: The shell of a fake security security camera can easily house a Raspberry Pi + camera module.
一旦将“假”安全摄像机组合在一起,就变成了真正的安全摄像机:

Figure 10: Adding the Raspberry Pi + camera components to the security camera shell.
对于电源,我倾向于在 12 伏下运行更长的电源线(超过 20 英尺长),然后在树莓码头转换为 5 伏。我使用 12 伏的电源适配器,就像汽车上用来给手机充电的那种。便宜又有效。我的大多数树莓 Pis 都与 WiFi 联网,但我在我的谷仓和房子周围的各个地方都有以太网,所以我的一些树莓 Pis 正在使用以太网发送图像。
Adrian: 在你的 PyImageConf 2018 演讲中,你讨论了像这样的项目如何实际上帮助人们建立他们的计算机视觉和深度学习简历。你能详细说明你在那里的意思吗?
Jeff: 在我管理编程和数据分析团队的 30 年中,我发现当求职者带着展示他们优势的特定项目来面试时,会非常有帮助。一个计算机视觉项目——甚至是像我的树莓派水表摄像头这样的爱好项目——真的可以帮助展示实际技能和能力。
一个记录良好的项目展示了实践经验和解决问题的能力。它展示了完全完成大型项目的能力(80%的解决方案是好的,但 100%的解决方案展示了完成的能力)。一个 portfolio 项目可以展示其他特定的技能,比如使用多个计算机视觉库、编写有效文档的能力、使用 Git / GitHub 作为协作工具的能力以及技术交流技能。能够讲述一个简短的、引人注目的项目故事——关于你的投资组合项目的“电梯演讲”——是很重要的。
Adrian:PyImageSearch 博客、PyImageSearch 大师课程和书籍/课程是如何帮助你使这个项目成功的?
Jeff: 当我开始学习计算机视觉时,我发现网上的许多材料要么过于理论化,要么给出简单的代码片段,没有任何具体的例子或完整的代码。
当我发现你的 PyImageSearch 博客时,我发现你的教程项目非常完整和有用。你为每个正在解决的问题提供了一个可以理解的故事线。你的解释清晰完整,代码功能齐全。运行你博客中的一些程序让我买了你的 实用 Python 和 OpenCV 的书。
我参加了你的 PyImageSearch 大师课程,学习了许多特定的计算机视觉技术的编码。我以前读过许多这类技术,但是您的具体代码示例提供了我为自己的项目编写计算机视觉代码所需的“如何做”。
你的大师课程中的车牌号码读取部分是我的水表数字读取程序初稿的基础。你的深度学习书籍正在帮助我编写下一版本的物体识别软件,用于标记农场周围的动物(浣熊或负鼠?).
Adrian: 你会向其他开发者、研究人员和试图学习计算机视觉+深度学习的学生推荐 PyImageSearch 和书籍/课程吗?
杰夫:我肯定会向那些试图了解这个快速发展领域的人推荐你的 PyImageSearch 博客、书籍和课程。你非常擅长用代码和叙述性讨论的有益组合来解释复杂的技术。你的书和课程为我理解现代计算机视觉算法的理论和实践提供了一个跳跃的起点。
我以前没有用 Python 编程过,它的一些习惯用法对我的 C 语言大脑来说有点奇怪。您的实际例子帮助我以“Python 化”的方式使用 Python 的最佳特性。你的大师课程结构良好,有一个很好的流程,建立在简单的例子上,一课一课地扩展成解决复杂问题的完全开发的程序。您对许多不同的计算机视觉和深度学习技术的报道广泛而全面。你的书和课程物有所值。强烈推荐。
Adrian: 你对阴阳牧场和你目前的计算机视觉/深度学习项目的下一步计划是什么?
杰夫:我想做更多的野生动物鉴定和计数工作。农场紧挨着一片空地,那是一条穿过郊区的野生动物走廊。我要用更先进的深度学习技术来按物种识别不同的动物。特定的动物什么时候来来去去?什么鸟和蝴蝶在季节的哪个部分出现?它们的数量与季节性降雨有什么关系?我想使用深度学习来识别狼群中的特定个体。一只特定的土狼会在我们的区域待多久?当我看拍摄的图像时,我能认出特定的个人。我想用深度学习的软件来做这件事。
阿德里安:你还有什么想分享的吗?
Jeff: 用软件和硬件构建东西会很有趣。如果有人正在读这篇文章,不知道如何开始,我建议他们从自己热爱的事情开始。计算机视觉和深度学习可能会以某种方式帮助他们感兴趣领域的项目。我想做一些永久性农业科学,我的计算机视觉项目正在帮助我做到这一点。我学到了很多东西,做了一些讲座和农场参观来帮助其他人学习…我玩得很开心。
Adrian: 如果一个 PyImageSearch 的读者想聊天,和你联系的最佳地点是哪里?
Jeff: 人们可以在我在 GitHub 上的阴阳农场仓库阅读和查看更多项目图片:
https://github.com/jeffbass/yin-yang-ranch
或者他们可以给我发电子邮件,地址是杰夫·yin-yang-ranch.com。
摘要
在这篇博文中,我们采访了 ImageZMQ 库的创建者 Jeff Bass(我们在上周的教程中使用了该库),该库用于使用 Python + OpenCV 促进从 Raspberry Pi 到中央服务器/中心的实时视频流。
Jeff 的动机是创建 ImageZMQ 库来帮助他的永久农场。使用 ImageZMQ 和一套 Raspberry Pis,Jeff 可以应用计算机视觉和数据科学技术来收集和分析温度读数、水表流量、用电量、等等!
请花点时间感谢 Jeff 抽出时间接受采访。
在 PyImageSearch 上发布未来的博客文章和采访时,我们会通知您,请务必在下面的表格中输入您的电子邮件地址,,我会让您随时了解情况。
R&D Esri 数据科学家 Kapil Varshney 访谈
原文:https://pyimagesearch.com/2019/08/12/an-interview-with-kapil-varshney-data-scientist-at-esri-rd/

在今天的博客文章中,我采访了一位 PyImageSearch 读者 Kapil Varshney,他最近被 Esri 研发中心聘为数据科学家,专注于计算机视觉和深度学习。
Kapil 的故事非常重要,因为它表明,无论你的背景如何,你都可以在计算机视觉和深度学习方面取得成功——你只需要首先接受正确的教育!
你看,Kapil 是 PyImageSearch 的长期读者,去年用 Python (DL4CV)阅读了 用于计算机视觉的深度学习。
在阅读 DL4CV 后不久,Kapil 参加了由 Esri 赞助的一项挑战,即检测和定位卫星图像中的物体(包括汽车、游泳池等。).
他在 53 名参赛者中名列第三。
Esri 对 Kapil 的工作印象深刻,以至于比赛结束后他们叫他去面试。
Kapil 通过了面试,并被 Esri 研究院& D. 全职聘用
他在 Esri 的卫星图像分析工作现在每天影响着全球数百万人,这是他辛勤工作的真实证明。
我非常喜欢 Kapil(更不用说,作为一名 PyImageSearch 读者,我为他感到非常自豪)。
让我们热烈欢迎 Kapil 分享他的故事。在面试过程中,你将了解到你如何跟随他的脚步。
R&D Esri 数据科学家 Kapil Varshney 访谈
阿德里安:嗨,卡皮尔!谢谢你接受这次采访。很高兴您能来到 PyImageSearch 博客。
你好,阿德里安!谢谢你邀请我上 PyImageSearch 博客。很荣幸。我关注这个博客已经有一段时间了,并从中学到了很多。

Figure 1: Kapil works as a Data Scientist at Esri R&D in New Delhi. He applies Computer Vision and Deep Learning to satellite image analysis.
阿德里安:介绍一下你自己,你在哪里工作,你的工作是什么?
目前,我作为一名数据科学家在 Esri 研发中心(T2)工作。我的大部分工作都集中在应用于卫星和航空图像的计算机视觉和深度学习上。但是,我有过不同的职业生涯。
我喜欢称自己为从火箭科学家转变为数据科学家。我在伊利诺伊大学香槟分校学习航空航天工程。在过去的几年里,我做过航天设计工程师、营销经理、教师,也尝试过创业。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Kapil: 它首先从分析开始。当我意识到基本分析的力量时,我开始在我的初创公司应用它。后来,随着我在这个领域的深入研究,我发现了机器学习,然后是深度学习,这最终将我引向了计算机视觉应用。我是一个视觉型的人。当我看到和想象事物时,我记得更清楚,而且我有更好的视觉回忆。你能让计算机像人类一样“看”和推断的想法天生就让我兴奋。

Figure 2: Satellite image analysis with deep learning (image source).
Adrian: 让我们投入到你参加的 Esri 航拍影像竞赛中。比赛的目标是什么,是什么让比赛如此具有挑战性?
Esri 最近举办了一场比赛,目标是在美国城市居民区的航空影像中识别汽车和游泳池。可用的数据集包括 3748 个 224×224 像素的图像芯片。主要挑战是:
- 可用的有限数据集
- 低分辨率图像
- 被探测的物体(尤其是汽车)的尺寸非常小

Figure 3: Left: Input image captured from satellite. Right: Output of applying the RetinaNet object detector to detect and localize vehicles in the image.
Adrian: 告诉我们你获得第三名的解决方案。你用了什么算法和技术?
Kapil: 我用 RetinaNet 解决了这个问题。RetinaNet 是一个最先进的对象检测模型,非常适合小对象。它采用特征金字塔网络和焦点损失来提供很好的结果。
我使用了 RetinaNet 的 TensorFlow/Keras 实现,这是你在简历书的深度学习中使用过的。
我对锚箱的比例和比率做了一点试验,以改善结果,最终得到了 77.99 的地图,这使我在比赛中获得了第三名。本部分的顶部显示了一个应用于其中一个芯片的检测示例。原始图像在左侧的处,右侧的处的图像带有用绿色方框标记的车辆检测。
Adrian: 在你获得第三名后,Esri 叫你去面试。你能告诉我们这个过程吗?它是什么样的?
比赛结束后,我收到一封来自 Esri 的电子邮件,要求下周在新德里安排一次面对面的面试。有两轮面试——一轮是采访新德里研发中心的总经理罗希特·辛格,另一轮是采访 ArcGIS Enterprise 的首席技术官杰伊·西奥多。
面试包括围绕我对挑战的解决方案、我的非传统背景以及许多关于计算机视觉和深度学习的技术问题的讨论。几天后,人力资源部又进行了一次简短的电话面试,几周后,我得到了肯定的答复。
阿德里安:你现在在 Esri 的研发团队&工作,恭喜你!从参加计算机视觉挑战赛到被公司录用,你有什么感受?那一定很棒!
Kapil: 谢谢。的确,这是一种奇妙的感觉。
我参加 Esri 挑战赛更多的是作为一个项目而不是竞赛,几个月后,我在新德里的 Esri R&D 中心全职工作。
我开始研究卫星/航空图像和空间数据,这结合了我对地理、GIS、航空航天技术、视觉和深度学习的兴趣。成千上万的 Esri 用户将使用我正在研究的问题解决方案,这将直接或间接影响全球数百万人和我们的星球。

Figure 4: Kapil used the knowledge inside Deep Learning for Computer Vision with Python to help prepare himself for the Esri competition and interview.
Adrian:用 Python 进行计算机视觉的深度学习 (DL4CV)是如何为你准备/帮助你参加航拍影像比赛的?
Kapil:DL4CV 这本书是一个巨大的资源,它不仅帮助我为 Esri 挑战赛和面试做好准备,还帮助我过渡到计算机视觉专业人员的角色。
我从你的书中了解了 RetinaNet(我在 Esri 比赛中使用的物体探测器)以及如何使用它。
此外,我在其他项目中也使用了很多从 DL4CV 中学到的东西。
Adrian: 你会向其他试图学习计算机视觉和深度学习的开发者、学生和研究人员推荐用 Python 进行计算机视觉的深度学习吗?
Kapil: 绝对!对于任何试图学习计算机视觉和深度学习的人来说,这是必不可少的。有很多资源,但你在书中和教程中采用的实用方法是惊人的。仅仅谈论概念和理论是一回事,但在数据集上实际应用模型并用结构良好的代码实现它是学习者需要练习的。DL4CV 正好有助于这一点。
我还想补充一下,用 Python 进行计算机视觉深度学习的是 SenseHawk 的 CTOSaideep Talari向我推荐的。他是一个好朋友,在我的转变过程中一直引导着我。现在我已经成功过渡了,我可以毫无疑问地提出同样的建议。
Adrian: 如果一个 PyImageSearch 的读者想聊天,联系你的最佳地点是哪里?
与我联系的最佳地点是 LinkedIn。以下是我个人资料的链接:
https://www.linkedin.com/in/kapilvarshney14/
读者也可以关注我的博客:
https://medium.com/@kapilvarshney
再次感谢阿德里安,感谢你为你的书和教程所做的一切。你的作品帮助并激励了我,就像它激励了成千上万的其他读者一样。保持下去。
摘要
在这篇博文中,我们采访了计算机视觉和深度学习从业者 Kapil Varshney,他刚刚被聘为 Esri 在新德里的研发团队的一部分。
Kapil 是一个长期的 PyImageSearch 读者,他最近读完了我的书, 用 Python 进行计算机视觉的深度学习。
读完这本书后不久,他参加了由 Esri 赞助的物体探测比赛。
挑战?
检测和定位卫星图像中的对象,包括汽车、游泳池和其他对象。
Kapil 在 53 名参赛选手中名列第三,比赛结束后不久, Esri 为 Kapil 提供了一个全职职位。
他的故事表明,你可以在计算机视觉和深度学习方面取得成功。你只需要:
- 适当的教育
- 自我激励和奉献
Kapil 两者都有,但你呢?
如果你想追随他的脚步,一定要拿起一本用 Python (DL4CV)编写的 计算机视觉深度学习。
使用 DL4CV 图书您可以:
- 获得完成理学硕士或博士学位所需的知识
- 进行值得在期刊上发表的研究
- 转换职业,在一家公司或机构获得一个简历或 DL 职位
- 将深度学习和计算机视觉应用到您自己的工作项目中
- 周末完成你的业余爱好 CV/DL 项目
我希望你能加入我、Kapil 和其他成千上万的 PyImageSearch 读者的行列,他们不仅掌握了计算机视觉和深度学习,还利用这些知识改变了他们的生活。
我们在另一边见。
在 PyImageSearch 上发布未来的博客文章和采访时,我们会通知您,请务必在下面的表格中输入您的电子邮件地址,,我会让您随时了解情况。*
采访 OpenMV 的创始人之一、微控制器专家夸贝纳·阿杰曼

在上周发表了关于用 Python 和 OpenMV 读取条形码的博文后,我收到了很多来自读者的电子邮件,询问关于嵌入式计算机视觉以及微控制器如何用于计算机视觉的问题。
与其试图自己解决这些问题,我认为最好请一位真正的专家来——夸贝纳·阿杰曼,他是 OpenMV 的联合创始人,OpenMV 是一种小型、廉价、可扩展的嵌入式计算机视觉设备。
Kwabena 在这次采访中很谦虚,否认自己是专家(这是他善良性格和风度的真实证明),但相信我,与他见面和聊天是一次令人谦卑的经历。他在嵌入式编程和微控制器设计方面的知识令人难以置信。我可以整天听他谈论嵌入式计算机视觉。
我不经常在 PyImageSearch 上讨论嵌入式设备,所以今天有 Kwabena 在这里真是一种享受。
和我一起欢迎夸贝纳·阿杰曼来到图片搜索博客。要了解更多关于嵌入式计算机视觉的知识,请继续阅读。
采访 OpenMV 的创始人之一、微控制器专家夸贝纳·阿杰曼

Figure 1: The OpenMV camera is a powerful embedded camera board that runs MicroPython.
阿德里安:嘿,夸贝纳,谢谢你接受采访!很高兴有你在 PyImageSearch 博客上。对于不了解你和 OpenMV 的人来说,你是谁,你是做什么的?
Kwabena: 嗨,Adrian,谢谢你今天邀请我。我和我的联合创始人 Ibrahim 创建了 OpenMV Cam 并运行 OpenMV 项目。
OpenMV 致力于使嵌入式计算机/机器视觉更容易实现。该项目的最终目标是在比现在更多的嵌入式设备中实现机器视觉。
例如,假设您想在烤面包机上安装一个面部检测传感器。对于任何应用程序来说,这可能都是多余的,但是,请原谅我。
首先,你不能今天就出去买一个 50 美元的面部检测传感器。相反,您至少需要设置一个运行 OpenCV 的单板计算机(SBC) Linux 系统。这意味着给你的烤面包机添加人脸检测功能现在已经成为一个全新的项目。
如果你的目标只是检测视野中是否有人脸,然后在你看着烤面包机的时候拨动一根线来释放面包片,你就不一定想走 SBC 这条路了。
相反,你真正想要的是一个微控制器,它可以通过最少的设置来实现开箱检测人脸和切换电线的目标。
因此,OpenMV 项目基本上是为那些希望在项目中添加强大功能而不必关注所有细节的开发人员提供开箱即用的高级机器视觉功能,以完成各种任务。

Figure 2: The CMUcam4 is a fully programmable embedded computer vision sensor developed by Kwabena Agyeman while at Carnegie Mellon University.
Adrian: 对于必须设置一个 SBC Linux 系统、安装 OpenCV 并编写代码来实现一点点功能来说,这是一个很好的观点。我在嵌入式设备方面做的不多,所以从不同的角度来看很有见地。是什么激励你开始从事计算机视觉、机器学习和嵌入式领域的工作?
Kwabena: 感谢 Adrian 的提问,我回到卡耐基梅隆大学开始研究机器视觉,在 Anthony Rowe 手下工作,他创造了 CMUcam 1、2 和 3 。当我在那里上学的时候,我为简单的颜色跟踪应用程序开发了 CMUcam 4 。
虽然受到限制,但 CMUcams 能够很好地完成跟踪颜色的工作(如果部署在恒定的照明环境中)。我真的很喜欢在 CMUcam4 上工作,因为它在一个项目中融合了电路板设计、微控制器编程、GUI 开发和数据可视化。

Figure 3: A small, affordable, and expandable embedded computer vision device.
Adrian: 让我们更详细地了解 OpenMV 和 OpenMV Cam。OpenMV Cam 到底是什么,是用来做什么的?
Kwabena: 所以,OpenMV Cam 是一个低功率的机器视觉相机。我们当前的型号是 OpenMV Cam M7,它由 216 MHz Cortex-M7 处理器提供支持,每时钟可以执行两条指令,计算速度大约是 Raspberry Pi zero 的一半(单线程无 SIMD)。
OpenMV Cam 也是一个 MicroPython 板。这意味着你用 Python 3 编程。注意,这并不意味着桌面 python 库是可用的。但是,如果你会用 Python 编程,你就可以对 OpenMV Cam 编程,你会觉得用起来很舒服。
不过最酷的是,我们在 OpenMV Cam 的固件中内置了许多高级机器视觉算法(它是用 C 语言编写的——python 只是为了让你像使用 OpenCV 的 python 库绑定一样将视觉逻辑粘在一起)。
特别是,我们有:
- 多色斑点跟踪
- 人脸检测
- AprilTag 跟踪
- QR 码、条形码、数据矩阵检测和解码
- 模板匹配
- 相位相关
- 光流
- 帧差分
- 更内置。
基本上,它就像低功耗微控制器上的 OpenCV(通过 USB 端口运行)和 Python 绑定
无论如何,我们的目标是将尽可能多的功能包装到一个易于使用的函数调用中。例如,我们有一个“find_blobs()”方法,它返回图像中颜色 blobs 对象的列表。每个斑点对象都有一个质心、边界框、像素数、旋转角度等。因此,该函数调用通过颜色阈值列表自动分割图像(RGB 或灰度),找到所有斑点(连接的组件),基于它们的边界框合并重叠的斑点,并另外计算每个斑点的质心、旋转角度等。主观上,如果你是初学者,使用我们的“find_blobs()”比用 OpenCV 寻找彩色斑点要简单得多。也就是说,如果你需要做一些我们没有想到的事情,我们的算法也不太灵活。所以,有一个权衡。
继续,感知只是问题的一部分。一旦你察觉到什么,你就需要采取行动。因为 OpenMV Cam 是一个微控制器,所以您可以切换 I/O 引脚、控制 SPI/I2C 总线、发送 UART 数据、控制伺服系统等,所有这些都可以从您的视觉逻辑所在的同一个脚本中完成。使用 OpenMV Cam,您可以从一个简短的 python 脚本中感知、计划和行动。
阿德里安:伟大的解释。你能详细说明 OpenMV 的目标市场吗?如果你必须描述你理想的最终用户,他们必须有一个 OpenMV,他们会是谁?
Kwabena: 现在,我们的目标市场是业余爱好者。到目前为止,业余爱好者是我们最大的买家,去年帮助我们卖出了 5000 多台 OpenMV Cam M7s。我们也有一些公司购买相机。
无论如何,随着我们的固件变得越来越成熟,我们希望向更多生产产品的公司出售更多的相机。
目前,我们仍在快速构建我们的固件功能,以或多或少地补充 OpenCV 的基本图像处理功能。我们已经有了很多东西,但我们试图确保你有任何你需要的工具,如阴影去除和修复,以创建一个无阴影的背景帧差分应用程序。

Figure 4: An example of AprilTags.
阿德里安:阴影去除,真好玩。那么,在组装 OpenMV 时,你不得不争论的最困难的特性或方面是什么?
Kwabena: 将 AprilTags 移植到 OpenMV Cam 是在船上运行的最具挑战性的算法。
我从针对 PC 的 AprilTag 2 源代码开始。让它在 OpenMV Cam M7 上运行,与台式机相比,OpenMV Cam M7 只有 512 KB 的内存。我已经检查了所有 15K+行代码,并重做了内存分配如何更有效地工作。
有时这就像将大型数组分配从 malloc 转移到专用堆栈一样简单。有时我不得不改变一些算法的工作方式,以提高效率。
例如,AprilTags 用 0、1、2 等计算每个可能的汉明码字的查找表。尝试将检测到的标签位模式与标签字典匹配时出现位错误。这个查找表(LUT)对于一些标签字典可以超过 30 MBs!当然,索引 LUT 很快,但是,在标签字典中线性搜索匹配的标签也可以。
无论如何,在将算法移植到 OpenMV Cam M7 之后,它可以以 12 FPS 的速度运行 160×120 的 AprilTags。这让你可以用一个可以从你的 USB 端口运行的微控制器,从大约 8 英寸远的地方检测打印在 8 英寸 x11 英寸纸上的标签。
阿德里安:哇!不得不手动检查所有 15K 行代码和重新实现某些功能肯定是一项艰巨的任务。我听说在下一个版本中会有一些非常棒的 OpenMV 新特性。你能给我们讲讲他们吗?
是的,我们的下一款产品,由 STM32H7 处理器驱动的 OpenMV Cam H7 将使我们的性能翻倍。事实上,它的 coremark 得分与 1 GHz 的 Raspberry Pi zero 相当(2020.55 对 2060.98)。也就是说,Cortex-M7 内核没有 NEON 或 GPU。但是,我们应该能够跟上 CPU 有限的算法。
然而,最大的特点是增加了可移动的摄像头模块支持。这使得我们能够像现在一样为 OpenMV Cam H7 提供廉价的卷帘快门相机模块。但是,对于更专业的用户,我们将为那些试图在高速应用中进行机器视觉的人提供全局快门选项,如拍摄传送带上移动的产品。更好的是,我们还计划为机器视觉支持 FLIR 轻子热传感器。最重要的是,每个相机模块将使用相同的“sensor.snapshot()”构造,我们现在使用它来拍照,允许您在不更改代码的情况下将一个模块切换到另一个模块。
最后,多亏了 ARM,你现在可以在 Cortex-M7 上构建神经网络。以下是 OpenMV Cam 在船上运行 CIFAR-10 网络的视频:
https://www.youtube.com/embed/PdWi_fvY9Og?feature=oembed
对学习机器人学和计算机视觉的高中生玛丽亚·罗斯沃尔德和什利亚·纳马的采访
https://www.youtube.com/embed/3q6gOlVzGDo?feature=oembed
采访保罗·李——医生、心脏病专家和深度学习研究员

在今天的博文中,我采访了 Paul Lee 博士,他是 PyImageSearch 的读者和纽约西奈山医学院附属的介入心脏病专家。
李博士最近在宾夕法尼亚州费城著名的美国心脏协会科学会议上展示了他的研究,他在会上演示了卷积神经网络如何能够:
- 自动分析和解释冠状动脉造影照片
- 检测患者动脉中的堵塞
- 并最终帮助减少和预防心脏病
此外,李博士已经证明了自动血管造影分析可以部署到智能手机上,使医生和技术人员比以往任何时候都更容易分析、解释和理解心脏病发作的风险因素。
李博士的工作确实非常出色,为计算机视觉和深度学习算法铺平了道路,以帮助减少和预防心脏病发作。
让我们热烈欢迎李博士分享他的研究。
采访保罗·李——医生、心脏病专家和深度学习研究员
阿德里安:嗨,保罗!谢谢你接受这次采访。很高兴您能来到 PyImageSearch 博客。
保罗:谢谢你邀请我。

Figure 1: Dr. Paul Lee, an interventional cardiologist affiliated with NY Mount Sinai School of Medicine, along with his family.
阿德里安:介绍一下你自己,你在哪里工作,你的工作是什么?
Paul: 我是纽约西奈山医学院的介入心脏病专家。我在布鲁克林有一家私人诊所。

Figure 2: Radiologists may one day be replaced by Computer Vision, Deep Learning, and Artificial Intelligence.
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Paul: 在《纽约客》杂志 2017 年一篇题为 人工智能对医学博士的文章中,当诊断自动化时会发生什么? ,乔治·辛顿评论说“他们现在应该停止培训放射科医生”。我意识到总有一天人工智能会取代我。我想成为控制人工智能的人,而不是被取代的人。
阿德里安:你最近在美国心脏协会上展示了你的作品《自动心脏冠状动脉造影分析》。你能给我们讲讲吗?
保罗:两年前开始上你的课程后,我开始熟悉计算机视觉技术。我决定把你教的东西应用到心脏病学上。
作为一名心脏病专家,我进行冠状动脉造影,以诊断我的病人是否有可能导致心脏病发作的心脏动脉堵塞。我想知道我是否可以应用人工智能来解释冠状动脉造影照片。
尽管困难重重,但由于你的持续支持,神经网络学会了可靠地解释这些图像。
我被邀请在今年费城的美国心脏协会科学会议上展示我的研究。这是心脏病专家最重要的研究会议。我的海报题为卷积神经网络用于冠状动脉造影的解释(CathNet) 。
(流通。2019;140:a 12950;https://ahajournals.org/doi/10.1161/circ.140.suppl_1.12950);海报如下:【https://github.com/AICardiologist/Poster-for-AHA-2019

Figure 3: Normal coronary angiogram (left) and stenotic coronary artery (right). Interpretation of angiograms can be subjectives and difficult. Computer vision algorithms can be used to make analyzations more accurate.
阿德里安:你能告诉我们更多关于心脏冠状动脉造影的信息吗?这些图像是如何捕捉的,计算机视觉/深度学习算法如何更好/更有效地分析这些图像(与人类相比)?
Paul: 为了明确诊断和治疗冠状动脉疾病(例如,在心脏病发作期间),心脏病专家进行冠状动脉血管造影,以确定解剖结构和狭窄程度。在手术过程中,心脏病专家从手腕或腿部插入一根狭窄的导管。通过导管,我们将造影剂注入冠状动脉,图像由 x 光捕捉。然而,血管造影照片的解释有时很困难:计算机视觉有可能使这些决定更加客观和准确。
图 3 (左)显示正常的冠状动脉造影照片,而图 3 (右)显示狭窄的冠状动脉。
阿德里安:你的研究中最困难的方面是什么,为什么?
保罗:我只有大约 5000 张照片。
起初,我们不知道为什么在获得高精度方面会有这么多困难。我们认为我们的图像没有经过适当的预处理,或者有些图像很模糊。
后来,我们意识到我们的图像没有问题:问题是 ConvNets 需要大量数据来学习一些对我们人类来说简单的东西。
确定图像中的冠状动脉树中是否有狭窄在计算上是复杂的。因为样本大小取决于分类的复杂性,所以我们很努力。我们必须找到一种用非常有限的样本训练神经网络的方法。
阿德里安:你花了多长时间来训练你的模型和进行你的研究?
保罗:花了一年多的时间。一半时间用于收集和预处理数据,一半时间用于训练和调整模型。我会收集数据,训练和调整我的模型,收集更多的数据或以不同的方式处理数据,并改进我以前的模型,并不断重复这个循环。

Figure 4: Utilizing curriculum learning to improve model accuracy.
阿德里安:如果你必须选择你在研究过程中应用的最重要的技术,那会是什么?
Paul: 我搜遍了 PyImageSearch,寻找用小样本数训练 ConvNets 的技术技巧:迁移学习,图像增强,用 SGD 代替 Adam,学习率计划表,提前停止。
每项技术都有助于 F1 分数的小幅提高,但我只达到了大约 65%的准确率。
我查看了 Kaggle 竞赛解决方案,寻找技术技巧。最大的突破来自一种叫做“课程学习”的技术我首先训练 DenseNet 解释一些非常简单的事情:“在那一小段直的动脉中有狭窄吗?”那只需要大约一百个样本。
然后我用有更多分支的更长的动脉段来训练这个预先训练好的网络。课程逐渐建立复杂性,直到学会在复杂图形的背景下解释狭窄。这种方法极大地提高了我们的测试准确率,达到 82%。也许预训练步骤通过将信息输入神经网络降低了计算复杂性。
文献中的“课程学习”其实有所不同:它一般是指根据错误率拆分他们的训练样本,然后根据错误率递增对训练数据批次进行排序。相比之下,我实际上创建了学习材料供 ConvNet 学习,而不仅仅是根据错误率重新安排批次。我是从我学习外语的经历中得到这个想法的,而不是从计算机文献中。一开始,我很难理解用日语写的报纸文章。随着我从初级,然后到中级,最后到高级日语课程,我终于可以理解这些文章了。

Figure 5: Example screenshots from the CathNet iPhone app.
Adrian: 你的计算机视觉和深度学习工具、库和软件包的选择是什么?
Paul: 我用的是标准包:Keras,Tensorflow,OpenCV 4。
我用 Photoshop 清理图像并创建课程。
最初我使用云实例[用于培训],但我发现我的 RTX 2080 Ti x 4 工作站更具成本效益。来自 GPU 的“全球变暖”杀死了我妻子的植物,但它大大加快了模型迭代的速度。
我们使用 Core ML 将 Tensorflow 模型转换为 iPhone 应用程序,就像您为您的口袋妖怪识别应用程序所做的一样。
我们的应用演示视频在这里:
https://www.youtube.com/embed/CaHPezrpAY8?feature=oembed
首席数据科学家彼得·叶访谈
原文:https://pyimagesearch.com/2022/08/03/an-interview-with-peter-ip-chief-data-scientist/
https://www.youtube.com/embed/TUvySJ2CWB8?feature=oembed
博士研究生、计算机视觉企业家劳尔·加西亚·马丁访谈
在这篇博文中,我采访了劳尔·加西亚·马丁,他是卡洛斯三世大学生物识别专业的博士生。
劳尔的工作重点是通过生物特征识别个人。您可能已经熟悉最流行的生物识别方法:
- 人脸识别
- 指纹识别
- 视网膜扫描
…但是你知道吗,你身体里的 静脉 也可以用来进行人体识别?
这种生物识别被称为静脉或血管生物识别(VBR)。
它没有其他生物识别系统研究得那么深入,但研究表明,它可以与其他方法一样准确,如果不是更准确的话。
劳尔在他的研究生生涯中一直在研究 VBR。正如他的谷歌学术简介显示的,他已经在计算机视觉的这个子领域发表了许多文章。
我不得不承认,劳尔让我想起了我读研究生时的自己。
劳尔不仅在进行研究并完成他的博士学位,而且他还是一名企业家。他的公司开发了可用于红外和热成像的专用相机(以及相关软件)。
这些摄像机可用于:
- 火灾探测
- 行业检查
- 安全性
- 军事应用
- 新冠肺炎体温检测
- 更不用说静脉识别了!
要了解更多关于 Raul 在静脉/血管生物识别方面的工作,包括他的工作如何帮助他建立自己的公司, 请务必阅读完整的采访内容!
博士候选人、计算机视觉企业家劳尔·加西亚·马丁的访谈
阿德里安:嗨,劳尔!感谢您抽出时间接受采访。很高兴您能来到 PyImageSearch 博客。
劳尔:嗨,阿德里安!非常感谢你给我这个绝佳的机会:你无法想象来到这里对我意味着什么,能够为 PyImageSearch 博客做贡献是一种荣誉和快乐。我真诚地希望 PyImageSearchers 可以在这次采访中找到一些有趣的东西,激励他们,就像你和我一样,追随他们的梦想和成为计算机视觉和深度学习专家的道路。
阿德里安:在我们开始之前,你能简单介绍一下你自己吗?你是马德里卡洛斯三世大学的博士生,除此之外还从事其他项目,对吗?
劳尔:我是马德里卡洛斯三世大学生物识别专业的博士生,今年是我的第三年,这是我四年来的第三年。正如你提到的,与此同时,我正试图继续进行一个创业计算机视觉项目。
阿德里安:是什么让你对研究计算机视觉感兴趣?
劳尔:从小我就记得我想成为一名发明家。2002 年左右,计算机视觉和深度学习还没有现在这么先进。我对他们一无所知,但我的梦想很明确:设计和开发技术解决方案来改善人们的生活。
因此,带着这个明确但尚未定义的目标,并感谢技术为我们提供的无限知识领域,我攻读了工业电子和自动化工程学士学位。从这个意义上说,我感到非常幸运,因为我有机会上大学,而且我一直得到家人的支持。
在还没有找到方向的情况下,我开始攻读电子系统和应用的硕士学位。我将大学学习与我的第一份工作结合起来,在一家工业领域的小公司担任电子硬件和固件开发员,在一家铁路领域的跨国公司担任软件测试员。
但是直到我开始硕士论文的时候,我才爱上了计算机视觉。这发生在我第一次使用 Python 和 OpenCV 从网络摄像头获得实时视频流的时候。
Adrian: 根据你在谷歌学术的简介,你的大部分工作都涉及到使用计算机视觉进行静脉识别和血管生物特征分析。你能告诉我们更多关于这项研究的信息吗?
Raul: 我的博士学位主要研究静脉或血管生物识别(VBR)。这是一种不太为人所知的生物识别模式,它使用独特人类模式的提取和分类来验证或识别人,就像面部或指纹识别一样。
有四种主要的 VBR 变体:手指、手掌、手背和手腕。我正在研究手腕 VBR,因为已经有了手指和手掌静脉模式的专利和一些商业系统。此外,我认为手腕静脉模式更容易可视化和捕捉。
Adrian: 你最近在 IEEE Access 上发表了一篇论文, 智能手机上静脉生物识别的深度学习 ( 图 1 )。你能告诉我们更多关于这篇论文的信息吗?在柯维德/疫情的世界里,我们为什么要用智能手机来识别静脉呢?
Raul: 首先我要提一下,我非常感谢你,因为这篇文章中呈现的大部分深度学习知识都是基于你的优秀的 用 Python 进行计算机视觉的深度学习 这本书中提炼出来的教导。我之前对深度学习(卷积神经网络,这里是 CNN)没有任何概念,在创纪录的时间内,我获得了具有良好组织和结构化信息的坚实知识。
这项工作的主要目标是使静脉生物识别更接近我们的日常生活,将这种生物识别变体嵌入到小型但功能强大的计算机中,该计算机已经成为我们身体的延伸:智能手机。为此,深度学习模型已集成到智能手机中,用于实时视频流认证和识别。
PyImageSearch 的读者可以在这里找到一个很好的视频摘要和演示:
https://www.youtube.com/embed/_DvuN3-LTKc?feature=oembed
对 SenseHawk 首席技术官 Saideep Talari 的采访(他刚刚筹集了 510 万美元资金)

回到 2017 年,我请当时是 PyImageSearch 大师课程毕业生的 Saideep Talari 来到博客上,分享他如何从安全分析师转变为机器学习工程师和计算机视觉从业者的故事。
今天,他是同一家公司 SenseHawk 的首席技术官,该公司刚刚筹集了 510 万美元的资金。
Saideep 的故事一直是我最感兴趣的。他来自印度低收入地区的一个非常卑微的地方,努力工作,找到了他的第一份工作,成为一名 CV/ML 工程师,现在他是首席技术官,管理着一个分布在两个大陆的人工智能团队。
这是一个令人难以置信的故事,老实说,这不是我/PyImageSearch 可以邀功的。我真的相信不管 Saideep 在哪里学习计算机视觉和深度学习,他都会成功-他是一股不可阻挡的力量,他有勇气和决心不仅要构建世界级的人工智能应用程序,还要为他和他的家人提供令人惊叹的生活。
Saideep 是一个不可思议的人,一个我有幸称之为朋友的人,我们都很幸运他今天回到了 PyImageSearch 博客。
如果你还没有阅读 2017 年 Saideep 的采访,我建议你现在就阅读。然后回到这里看故事的第二部分。
对 SenseHawk 首席技术官 Saideep Talari 的采访(他刚刚筹集了 510 万美元资金)
阿德里安:嗨,赛德普!上次我们在 PyImageSearch 博客上看到你是在 2017 年。感谢您回来告诉我们您职业生涯的最新进展!为了让读者跟上进度,你能告诉我们一些关于你自己的情况吗?
嘿,阿德里安!在我开始之前,我想感谢你,因为这是一个很荣幸的采访的一部分。
尽管我出生并成长在互联网出现之前的文化中,但从 15 岁起,我就对技术产生了兴趣。不久之后,我开始为小型企业构建网络基础设施解决方案。
早在我读大学的时候,我就在信息安全领域为几家公司提供咨询,构建数据中心安全软件、防火墙管理、渗透测试和恶意软件分析。我对编程的热爱让我开发了分布式和去中心化的 web 应用程序,并帮助了几家初创公司开发他们的产品。
我个人主张用新技术和升级现有技术来扩展我的知识和技能基础。在我的旅程中,我亲身体会到技术本身并不重要。重要的是技术如何赋予人们权力并使其受益。
我于 2017 年加入 SenseHawk,担任 ML 工程师,迅速成长为 CTO,领导开发团队。
Adrian: 在 2017 年,你是一名网络安全分析师。然后你在印度找到了一份计算机视觉工程师的工作。你能告诉我们更多关于那份工作的情况吗?你在那家公司是如何使用计算机视觉的?
说实话,我从没想过自己会在那里呆很长一段时间。虽然一开始我很想知道为一家公司工作是什么感觉,但我从不相信我会喜欢它。
当我面试这份工作时,他们向我介绍了他们正在努力解决的一个问题。他们有来自一个拥有 250 万个光伏组件的太阳能站点的热图像,他们的目标是使用计算机视觉来识别和分类这些组件中的缺陷。
虽然他们相信人工智能可以解决他们的问题,但我并不确定,因此,我反驳了他们,让他们想知道为什么传统的算法 CV 做不到这一点。
我的第一个项目如此巨大,同时满足了我的好奇心和自尊心。尽管这个项目很简单,但它让我在最初的几个月里忙得不可开交。
过了一会儿,我又遇到了第二个需要解决的挑战,那就是利用图像推断基于跟踪器的太阳能站点的等级和自动索引。随着一系列项目的到来,我决定在这里多花些时间。我在这里——还有很多事情要做,还有很长的路要走。我必须说,兴奋和好奇仍然处于顶峰。
阿德里安:看着你的职业生涯令人难以置信,迪普说。你从安全分析师一路走到计算机视觉工程师,现在你是 SenseHawk 的首席技术官,这是一家为太阳能发电厂开发人工智能软件的公司!你能告诉我们更多关于 SenseHawk 的工作和你的角色吗?
SenseHawk 一直致力于让太阳能的每一步都尽可能简单无缝。
太阳能行业一直在解决设计、财务建模、建设、运营优化等诸多问题。
这使得他们依赖 20 种不同的工具和大型复杂的企业软件。由于这些系统大多没有集成,因此大量的数据、知识和流程都是手工完成的也就不足为奇了。
SenseHawk 试图通过构建一个系统来解决这个问题,该系统可以将 Solar 中的所有数据和流程集成到一个具有多个应用模块的平台中。
我们的目标是创建一个每一个太阳系的数字双胞胎,它集成了从预先规划到生命终结的所有数据和过程信息。该系统可以进一步使用这些信息来帮助自动化和优化下一代。我们最终想让太阳能的生命周期成为一个流水线过程。
我的职责是定义架构并构建一个系统,该系统可以利用基于 GIS 的物理站点模型无缝集成来自技术和业务流程的各种数据类型,同时开发业务和技术应用模块,并确保系统高度安全和企业就绪!
阿德里安:这听起来比计算机视觉和深度学习要多得多?SenseHawk 依靠无人机收集太阳能信息,对吗?使用无人机的背后动机是什么?为什么不让“脚踏实地”的人来设计这些太阳能电站,并验证电池板是否优化并正常工作?
实际上,要走下数千公顷的太阳能发电厂去检测和解决持续存在的问题是不可能的。有鉴于此,我们早些时候认为无人机可以成为现场检查和维护的重要工具,收集数据的速度比人工方法快 50 倍以上,并通过避免危险的工时来提高安全性。
然而,我们很快意识到,虽然依靠无人机收集高质量的数据是合法的,但它不是绝对必要的。在下文中,我们将重点转移到构建生产力工具和其他业务工具,以对太阳能资产进行尽职调查。
在确保没有其他工具可以提高现场人员的工作效率,同时又不影响使用的简单性的情况下,我们继续在移动中升级我们的软件。有了我们,太阳能公司可以重新想象他们的所有业务,并大大提高生产力。
阿德里安:你的客户如何使用 SenseHawk?SenseHawk 如何帮助这些公司赚钱和/或省钱?
Saideep: 我们的客户以多种方式使用 SenseHawk。太阳能产业是建立在公司的分层模型上的,这些公司专门从事生命周期的一部分。有:
- 为项目寻找资源并进行初始阶段工作的开发人员
- 一旦项目可行,投资并拥有项目的资产所有者
- 建造工地的 EPC 公司
- 试运行后管理场地 20 年的 O&M 公司
- 承担资产财务管理的资产经理
- 认证资产的独立工程师
- 和提供资本的金融机构
我们有这些公司都可以使用并合作的产品。
开发人员使用我们的系统进行场地评估和初始地形。然后,他们将这些数据传递给购买项目的资产经理和建设网站的 EPC。然后,EPC 使用这些数据完成初始设计并开始施工。
在施工期间,EPC 可以使用我们的系统来管理地形、监控施工进度、向现场操作人员分配和完成任务、进行质量控制检查、与其他参与公司共享信息,并建立整个现场的数字存储库,包括组件序列号、性能数据、质量控制清单、协议等。
这个“数字双胞胎”可以交给资产所有者,他现在可以访问管理网站所需的所有信息。
此时,O&M 公司和资产管理公司可以“接管”网站,并使用数据和附带的工具来简化管理。特别是 O&M 公司,仅通过采用我们的票务系统和应用程序来分配和完成现场工作,就可以节省成本,这总是一个昂贵的提议,因为需要进行卡车滚动并派人到现场。
我们的解决方案提供了必要的工具,以最大限度地减少现场操作人员需要在现场花费的时间。这在现有的解决方案中是不可能的。
就交付的价值而言,由于我们平台上的业务流程工具与现场应用程序相结合所推动的自动化和工作简化,我们的系统可显著节省成本和时间。
阿德里安:你的日常工作是什么样的?你是在管理其他开发人员还是仍然自己写代码?
当然,我仍然写代码,但不一定每天都写了。每当公司着手处理一个复杂而又令人兴奋的问题时,我都会亲自动手,在委派给团队之前努力找到解决方案。
我的一天很早就开始了,因为早晨是我工作效率最高的时候。从审查代码和设计新的解决方案到提高现有应用程序的性能和安全性,每件事都在我一天的前半天完成。
我通常在下午与我的团队一起安排电话会议,帮助他们解决问题并清除存在的障碍(如果有的话)。我还与其他利益相关者建立了联系,但这些联系并不频繁。
我通常会提前下班,给自己的私人生活留出空间。
虽然工作很重要,但我们对事业成功的渴望永远不应该驱使我们放弃自己的幸福。我把个人生活看得和职业一样重要,甚至更重要。我认为,创造和谐的工作生活平衡不仅对改善我们的身心健康至关重要,而且对我们的职业生涯也很重要。
阿德里安: SenseHawk 在印度和美国都有分支机构。你能告诉我们更多关于这些地点的信息吗?为什么要跨洲拆分团队?
Saideep: 在美国是至关重要的,因为我们的大多数客户都在这里,尤其是早期采用者和测试版客户,他们愿意快速采用新的解决方案并进行尝试。因此,对于 SenseHawk 来说,美国是产品定义过程中的一个关键输入源。美国也贡献了我们 60%以上的收入。
印度的角度很简单。所有的核心团队都有印度血统,印度提供了大量的工程人才,而不会耗尽国库!印度也是一个巨大的太阳能市场。
我们现在也在向中东扩张,在阿布扎比设立了办事处!这又是一次接近该地区客户的努力,该地区的定位是推动可再生能源领域的重大投资。阿布扎比还提供了与世界大部分地区的单一航班连接,因此是经营全球业务的理想地点。
阿德里安: SenseHawk 刚刚结束了一轮融资, 筹集了令人难以置信的 510 万美元! 你能告诉我们更多关于资金的情况吗?你是如何抚养它的,体验如何?
最初的外联活动由 Swarup 和 Rahul(创始人)领导。他们在去年 12 月底和今年 1 月进行了几次谈话——在世界与新冠肺炎陷入混乱之前。
有趣的是,与 Falcon Edge 的对话发生在 SF 的 Swarup,孟买的 Rahul 和伦敦的 FE 团队!仿佛这是未来几个月世界走向的一个信号。
所有的谈判都是远程进行的,在情人节那天,我们达成了协议!
在此之后,我们需要完成所有的尽职调查活动,包括财务、法律和技术方面的。事实上,这不是我第一次参与技术尽职调查。我知道这是一个漫长的过程,并认为这将需要几个星期。然而,这很简单,我们可以毫不费力地快速完成。它所做的只是让我认真记录我们正在做的事情,所以如果我们再次这样做,我们将来需要的所有信息都可以很容易地获得。
财务 DD 和法律 DD 花费了更长时间,因为每个人都在不同的地理位置,而且我们在美国和印度都有运营。由于所有的 COVID 不确定性,这真是一个奇怪的时间-有时,我从来不相信它会到来。但最终,资金确实到位了,对此我非常高兴。
阿德里安:现在资金有了保障,SenseHawk 的下一步是什么?你和你的团队在开发什么?
Saideep: 对我来说,下一步是扩大我的团队,在管道中建立新的模块,同时改进我们现有的产品,包括计算机视觉模块。所有这些都需要改进,以便更好地处理我们正在处理的各种网站和数据集。
此外,我还想应用深度学习来解决太阳能电站布局设计优化挑战,这些挑战需要大量的努力和迭代才能实现。
阿德里安:你这么年轻就拥有令人难以置信的辉煌事业。对于想追随你脚步的 PyImageSearch 读者,你有什么建议?
阿德里安,谢谢你的美言。
我给所有有志于技术的人的建议是,除了追随你的激情之外,还要在自己身上投资时间/金钱。
其次,练习,练习,再练习。如果你想学点什么,练习不仅会有帮助,还会让你在这方面变得完美。制造例子并让它们发挥作用,因为仅仅阅读一些东西是不够的。
不要停止学习,但比起新的语言或框架,更要关注你现有的资产。永远不要放弃你已经获得的东西,无论是技能还是经验。
最后,要明白不是每个复杂的问题都需要复杂的解决方案。它可以被分解成一堆简单的问题,因此,我们会有简单的解决方案。毕竟,简单问题的组合可能会变得复杂,但简单解决方案的总和总是简单的。
阿德里安:谢谢你加入我们,赛德普!如果一个 PyImageSearch 的读者想聊天,在哪里和你联系最好?
我愿意通过我的 LinkedIn 与的人联系。
摘要
在今天的博文中,我们采访了 SenseHawk 的首席技术官 Saideep Talari,他刚刚筹集了 510 万美元的资金。
我最初在 2017 年的 PyImageSearch 博客上说过 deep。当时,他刚刚从 PyImageSearch Gurus 课程毕业,并利用课程中的知识,成功地从安全分析师转向了计算机视觉和机器学习工程师。
如今,他是 SenseHawk 的首席技术官,也是他作为 CV/ML 工程师加入的那家公司,并管理着一个横跨两大洲的团队。
如果你想追随塞迪普的脚步,我建议你看看我的书和课程。他们为 Saideep 工作,我毫不怀疑他们也会为你工作。
专访 123 所机器学习工程师 Yi Shern
在今天的博文中,我采访了知名图片网站 123RF.com 的图片搜索阅读器和机器学习工程师 Yi Shern。
如果你不熟悉这个术语,“库存照片”是由专业摄影师拍摄的照片,然后授权给其他个人或公司用于营销、广告、产品开发等。
123RF 从知名摄影师那里收集高质量的库存照片,使它们易于搜索和发现,然后允许用户以合理的价格购买/许可这些照片。
最近,Yi Shern 和 123RF R & D 团队的其他成员在网站上发布了一个视觉搜索功能,使用户能够通过以下方式搜索和发现图片:
- 精确定位/选择图像的特定部分
- 自动表征和量化这些区域
- 然后返回与原始查询图像在视觉上相似的股票照片
他们的工作使得【123RF 的用户更容易快速找到适合他们项目的完美库存照片,让他们的用户更开心,更有效率,最重要的是,回头客。
让我们热烈欢迎 Yi Shern 分享他的作品。
专访 123 所机器学习工程师 Yi Shern
阿德里安:嗨伊!谢谢你接受这次采访。很高兴您能来到 PyImageSearch 博客。
易:不客气!谢谢你邀请我。
阿德里安:你能介绍一下你自己吗?你在哪里工作,你的工作是什么?
易:我在 123RF 做机器学习工程师。作为一个研发团队,我们主要致力于解决与计算机视觉和自然语言处理相关的问题,以改善用户在搜索和发现内容方面的体验。
Adrian: 你能告诉我们你在 123RF 参与的新的计算机视觉和深度学习项目吗?
易:最近,在 123RF 的网站上发布了一个名为视觉搜索的新功能,它使我们的用户能够通过精确定位图像的各个部分来搜索和发现图像,并获得视觉上相似的结果。视觉搜索有两个主要计算机视觉/深度学习组件:
- 第一部分是从 123RF 的整个图像集合中导出关于输入图像的视觉特征并执行最近邻检索。
- 第二个组件是我们的对象检测组件,使视觉搜索更容易使用。我主要参与了这个组件从研究到生产的开发。
阿德里安:你通常使用什么工具和库?哪些是你的最爱?
易: Arxiv Sanity 和 Twitter 一直是我了解最新人工智能新闻和发展的非常有用的工具。
我真的很喜欢 Keras 作为 Tensorflow 的接口,因为它简单易用,可以用于研究和生产机器学习模型。
我也很高兴 Keras 现在是 Tensorflow 2.0 的核心 API,我相信这是让机器学习更容易被从业者或研究人员使用的一个伟大进步。
Adrian: 在加入 123RF 团队之前,你在计算机视觉和深度学习方面的背景如何?
易:我在马来西亚莫纳什大学攻读计算机科学本科学位时,对计算机视觉和深度学习的知识和接触是零。
当我在那里学习时,教学大纲没有随着当前的趋势和进步而更新,所以深度学习没有包括在教学大纲中。我确实报名参加了一个图像处理班,在深度学习时代之前,该班教授那些历史悠久的传统图像处理技术。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Yi: 我最初是在本科最后一年的项目中开始深度学习的,该项目是建立一个心电图(ECG)节律分类系统。
当时,有很多关于神经网络的讨论,所以对我来说这是一个很好的机会来了解神经网络及其对我的项目和医疗保健的贡献。
我第一次接触深度学习是通过 Hugo Larochelle 的 MOOC 以及 TensorFlow 网站上的编码教程。从那以后,它成了我的主要爱好。
我通过各种免费的 MOOCs 继续学习更多关于计算机视觉和深度学习的知识,并获得了一个研究实习机会,在马来西亚国家应用研发中心 MIMOS 从事应用研究并开发计算机视觉应用。
当我接近完成本科学位时,我确定我想追求一个能让我进一步学习和理解深度学习和计算机视觉的职业,这就是我如何在 123RF 结束的。
Adrian:用 Python 进行计算机视觉的深度学习 (DL4CV)在 123RF 中是如何准备/帮助你的工作的?
易:我非常欣赏 DL4CV 对不同计算机视觉任务的广泛覆盖,如图像识别、物体检测、风格转换、超分辨率等。
该材料呈现了一个非常系统的流程,以非常清晰和直观的方式介绍概念,并以连贯的方式构建更高级的概念。
除此之外,DL4CV 超越了理论,传授了非常实用的技能和建议,例如使用大型数据集,以高效和科学的方式反复创建和评估实验。这份材料对我在 123RF 解决问题和进行实验的方式产生了强烈的影响。
Adrian: 您会向其他正在尝试学习计算机视觉和深度学习的开发者、学生和研究人员推荐使用 Python 的 计算机视觉深度学习吗?
易:肯定是的。我会向任何对计算机视觉和深度学习感兴趣的人推荐这本书,不管他们的经验水平如何。
这本书已经做了一个伟大的工作,带来了清晰和详细的解释与实际演练。
除此之外,这份材料充满了阿德里安在该领域的经验和智慧,这本身就是无价的。
Adrian: 对于想跟随你的脚步,学习计算机视觉,并在计算机视觉/深度学习领域获得一份工作的人,你还有什么其他的建议吗?
易:我认为在编码和研究计算机视觉/深度学习文献之间取得良好的平衡,对于在该领域工作的人来说,都是很有价值的技能。
令人欣慰的是,arXiv 上有许多开源实现和文献,让我们能够跟上快速发展的步伐。
首先,我建议挑选一个你感兴趣的想法,围绕它开发一个项目,这可以提高你对类似问题的现有解决方案的理解,并随着项目的进展提高你的开发技能。
Adrian: 如果一个 PyImageSearch 的读者想聊天,联系你的最佳地点是哪里?
易:在推特上给我发 DM!我的句柄是 @yishern 。
摘要
在这篇博文中,我们采访了 123 RF R&D 部门的机器学习工程师 Yi Shern。
最近,谢恩和 123RF R&D 团队的其他成员发布了一个视觉搜索功能,允许用户使用图像查询而不是文本查询来查找股票照片。
这个功能不仅让 123RF 用户更容易找到照片,还让他们更有效率——最终带来回头客。
如果你想追随 Yi Shern 的脚步,一定要拿起一本用 Python 编写的 计算机视觉深度学习。
使用本书,您可以:
- 成功地将深度学习和计算机视觉应用到您自己的工作项目中
- 转换职业,在一家受人尊敬的公司/组织获得一个简历/DL 职位
- 获得完成理学硕士或博士学位所需的知识
- 进行值得在著名期刊和会议上发表的研究
- 周末完成你的业余爱好 CV/DL 项目
我希望你能加入我、Yi Shern 以及成千上万的 PyImageSearch 读者的行列,他们不仅掌握了计算机视觉和深度学习,还利用这些知识改变了他们的生活。
我们在另一边见。
为了在 PyImageSearch 上发布未来的博客文章和采访时得到通知,只要在下面的表格中输入您的电子邮件地址,,我一定会让您了解最新情况。
Python 线性分类简介
原文:https://pyimagesearch.com/2016/08/22/an-intro-to-linear-classification-with-python/
我们之前学习了 k-NN 分类器——一个简单到根本不做任何实际“学习”的机器学习模型。我们只需将训练数据存储在模型中,然后在测试时通过将测试数据点与我们的训练数据进行比较来进行预测。
我们已经讨论了 k-NN 的许多利弊,但在大规模数据集和深度学习的背景下,k-NN 最令人望而却步的方面是数据本身。虽然训练可能很简单,但测试非常慢,瓶颈是向量之间的距离计算。计算训练点和测试点之间的距离与数据集中的点数成线性比例,当数据集变得非常大时,这种方法就不切实际了。虽然我们可以应用近似最近邻方法,如 ANN 、 FLANN 或airy,来加速搜索,但这仍然不能缓解 k-NN 在实例化中没有维护数据副本的情况下无法工作的问题(或者至少在磁盘上有一个指向训练集的指针,等等)。).
要了解为什么在模型中存储训练数据的精确副本是一个问题,请考虑训练一个 k-NN 模型,然后将其部署到拥有 100、1,000 甚至 1,000,000 个用户的客户群。如果你的训练集只有几兆字节,这可能不是问题——但如果你的训练集是以千兆字节到兆兆字节来衡量的(正如我们应用深度学习的许多数据集的情况一样),你就有一个真正的问题了。
考虑一下 ImageNet 数据集的训练集,它包括超过 120 万张图像。如果我们在这个数据集上训练一个 k-NN 模型,然后试图将其部署到一组用户,我们将需要这些用户下载 k-NN 模型,它在内部表示 120 万张图像的副本。根据您压缩和存储数据的方式,该模型的存储成本和网络开销可能高达数百千兆字节到数千兆字节。这不仅浪费资源,而且对于构建机器学习模型来说也不是最优的。
相反,更理想的方法是定义一个机器学习模型,该模型可以在训练期间从我们的输入数据中学习 模式(要求我们在训练过程中花费更多时间),但具有由少量参数定义的好处,这些参数可以容易地用于表示模型,而不管训练规模。这种类型的机器学习称为参数化学习,定义为:
用一组固定大小的参数(与训练样本的数量无关)来概括数据的学习模型称为参数模型。无论您向参数模型扔多少数据,它都不会改变它需要多少参数的想法。
我们将回顾参数化学习的概念,并讨论如何实现简单的线性分类器。正如我们稍后将看到的,参数化学习是现代机器学习和深度学习算法的基石。
备注: 这份材料的大部分灵感来自安德烈·卡帕西在斯坦福的 cs231n 班里面的优秀线性分类笔记。非常感谢 Karpathy 和 cs231n 的其他助教整理了这么容易理解的笔记。
Python 线性分类简介
我已经使用过“参数化”这个词几次了,但是它到底是什么意思呢?
简单来说: 参数化 就是定义给定模型必要参数的过程。在机器学习的任务中,参数化涉及根据四个关键部分定义问题:数据,一个评分函数,一个损失函数,以及权重和偏差。我们将在下面逐一回顾。
数据
这个组件是我们将要学习的输入数据。该数据包括和数据点(即图像的原始像素强度、提取的特征等。)及其相关的类标签。通常我们用多维 设计矩阵 来表示我们的数据。
设计矩阵中的每一行代表一个数据点,而矩阵的每一列(其本身可以是多维数组)对应于一个不同的特征。例如,考虑 RGB 颜色空间中 100 个图像的数据集,每个图像的大小为 32×32 像素。该数据集的设计矩阵将是 X ⊆ R ^(100×(32×32×3)) ,其中 X [i] 定义了 R 中的第 i 幅图像。使用此符号, X [1] 是第一个图像,X2 是第二个图像,依此类推。
除了设计矩阵,我们还定义了一个向量 y ,其中y**I为数据集中的第 i 个示例提供了类标签。
计分功能
评分函数接受我们的数据作为输入,并将数据映射到类标签。例如,给定我们的输入图像集,评分函数获取这些数据点,应用某个函数 f (我们的评分函数),然后返回预测的类别标签,类似于下面的伪代码:
INPUT_IMAGES => F(INPUT_IMAGES) => OUTPUT_CLASS_LABELS
损失函数
损失函数量化了我们的预测类别标签与我们的真实类别标签的吻合程度。这两组标签之间的一致程度越高,就会降低我们的损失(并且提高我们的分类精度,至少在训练集上是如此)。
我们在训练机器学习模型时的目标是最小化损失函数,从而提高我们的分类精度。
权重和偏差
通常表示为 W 的权重矩阵和偏置向量 b 被称为我们将实际优化的分类器的权重或参数。基于我们的得分函数和损失函数的输出,我们将调整和摆弄权重和偏差的值,以提高分类的准确性。
根据您的模型类型,可能存在更多的参数,但在最基本的层面上,这些是您通常会遇到的参数化学习的四个构件。一旦我们定义了这四个关键部分,我们就可以应用优化方法,这些方法允许我们找到一组参数和 b ,这些参数使我们的损失函数相对于我们的得分函数最小化(同时增加我们的数据的分类精度)。
**接下来,让我们看看这些组件如何一起工作来构建一个线性分类器,将输入数据转换为实际的预测。
线性分类:从图像到标签
在这一节中,我们将探讨机器学习的参数化模型方法的更多数学动机。
开始,我们需要我们的 数据 。让我们假设我们的训练数据集被表示为x[I],其中每个图像具有相关联的类别标签y[I]。我们将假设 i = 1,…,N 和 y [i] = 1,…,K ,这意味着我们有 N 个维度为 D 的数据点,被分成 K 个唯一的类别。**
为了使这个想法更加具体,考虑一下来自图像分类器课程的“动物”数据集。在这样的数据集中,我们可能有 N = 3,000 个图像。每幅图像都是 32×32 像素,在 RGB 颜色空间中表示(即每幅图像三个通道)。我们可以将每幅图像表示为 D = 32×32×3 = 3,072 个不同的值。最后,我们知道总共有 K = 3 类标签:一个分别用于狗、猫和熊猫类。
给定这些变量,我们现在必须定义一个评分函数 f ,它将图像映射到类标签分数。完成该评分的一种方法是通过简单的线性映射:
【①
让我们假设每个 x [i] 被表示为具有形状[ D×1 ]的单个列向量(在这个示例中,我们将把 32×32×3 图像展平为 3072 个整数的列表)。我们的权重矩阵 W 将具有[ K×D ]的形状(类别标签的数量取决于输入图像的维度)。最后 b ,偏置向量**的大小为[ K×1 ]。偏差向量允许我们在一个或另一个方向上移动和平移我们的得分函数,而不会实际影响我们的权重矩阵 W 。偏差参数通常对成功学习至关重要。
回到动物数据集示例,每个 x [i] 由 3072 个像素值的列表表示,因此 x [i] 具有形状3072×1。权重矩阵 W 将具有[3×3072]的形状,并且最终偏置向量 b 将具有[ 3×1 ]的大小。
图 1 跟随线性分类评分函数 f 的图示。在左侧,我们有我们的原始输入图像,表示为 32×32×3 图像。然后我们将这个图像展平成一个 3072 像素亮度的列表,方法是获取 3D 阵列并将其重新成形为 1D 列表。
我们的权重矩阵 W 包含三行(每个类别标签一行)和 3072 列(图像中的每个像素一列)。取 W 和 x [i] 之间的点积后,我们在偏差向量中加入——结果就是我们实际的得分函数。我们的评分函数在右边的产生三个值:分别与狗、猫和熊猫标签相关的分数。
**备注: 不熟悉取点积的读者,不妨看看这篇快速简洁的教程。对于有兴趣深入学习线性代数的读者,我强烈推荐通过 Philip N. Klein (2013) 的《应用于计算机科学的矩阵线性代数的编码。
看着图 1 和方程(1) ,你可以说服自己,输入x[I]和y[I]是固定的和不是我们可以修改的东西。当然,我们可以通过对输入图像应用各种变换来获得不同的x[I]——但是一旦我们将图像传递到评分函数中,这些值不会改变。事实上,我们唯一可以控制的参数(就参数化学习而言)是我们的权重矩阵 W 和我们的偏差向量 b 。因此,我们的目标是利用我们的得分函数和损失函数来优化(即,以系统的方式修改)权重和偏差向量,使得我们的分类准确度增加。**
确切地说,我们如何优化权重矩阵取决于我们的损失函数,但通常涉及某种形式的梯度下降。
参数化学习和线性分类的优势
利用参数化学习有两个主要优势:
- 一旦我们完成了对模型的训练,我们可以丢弃输入数据,只保留权重矩阵 W 和偏差向量b。这个大大地减少了我们模型的大小,因为我们需要存储两组向量(相对于整个训练集)。
- 分类新的测试数据是快。为了执行分类,我们需要做的就是取 W 和 x [i] 的点积,然后加上 biasb(即应用我们的评分函数)。这样做比需要将每个测试点与 k-NN 算法中的每个训练样本进行比较要快得多(T20)。
*### 用 Python 实现的简单线性分类器
现在我们已经回顾了参数化学习和线性分类的概念,让我们使用 Python 实现一个非常简单的线性分类器。
这个例子的目的是而不是展示我们如何从头到尾训练一个模型。这个例子的目的是展示我们如何初始化一个权重矩阵 W ,偏置向量 b ,然后使用这些参数通过一个简单的点积对图像进行分类。
让我们开始这个例子。我们在这里的目标是编写一个 Python 脚本,将图 2 正确分类为的“狗”
要了解我们如何完成这种分类,请打开一个新文件,将其命名为linear_example.py,并插入以下代码:
# import the necessary packages
import numpy as np
import cv2
# initialize the class labels and set the seed of the pseudorandom
# number generator so we can reproduce our results
labels = ["dog", "cat", "panda"]
np.random.seed(1)
第 2 行和第 3 行导入我们需要的 Python 包。我们将使用 NumPy 进行数值处理,并使用 OpenCV 从磁盘加载示例图像。
第 7 行初始化“Animals”数据集的目标类别标签列表,而第 8 行为 NumPy 设置伪随机数发生器,确保我们可以重现该实验的结果。
接下来,让我们初始化权重矩阵和偏差向量:
# randomly initialize our weight matrix and bias vector -- in a
# *real* training and classification task, these parameters would
# be *learned* by our model, but for the sake of this example,
# let's use random values
W = np.random.randn(3, 3072)
b = np.random.randn(3)
第 14 行用正态分布的随机值初始化权重矩阵W,均值和单位方差为零。神经网络内部的权重可以取负值、正值和零值。这个权重矩阵有3行(每个类别标签一行)和3072列(我们的 32×32×3 图像中的每个像素一行)。
然后我们初始化行 15 上的偏差向量——这个向量也随机填充了在标准正态分布上采样的值。我们的偏差向量有3行(对应于类别标签的数量)和一列。
如果我们从零开始训练这个线性分类器,我们将需要通过优化过程学习W和b的值。然而,由于我们还没有达到训练模型的优化阶段,我已经用值1初始化了伪随机数发生器,以确保随机值给我们“正确”的分类(我提前测试了随机初始化值,以确定哪个值给我们正确的分类)。目前,简单地将权重矩阵W和偏置向量b视为以神奇的方式优化的“黑盒数组”——我们将拉开帷幕,揭示这些参数是如何在未来的课程中学习的。
*既然我们的权重矩阵和偏差向量已经初始化,让我们从磁盘加载我们的示例图像:
# load our example image, resize it, and then flatten it into our
# "feature vector" representation
orig = cv2.imread("beagle.png")
image = cv2.resize(orig, (32, 32)).flatten()
第 19 行通过cv2.imread从磁盘加载我们的图像。然后,我们在第 20 行的上将图像调整为 32×32 像素(忽略纵横比)——我们的图像现在表示为一个(32, 32, 3) NumPy 数组,我们将其展平为一个 3072 维的向量。
下一步是通过应用我们的评分函数来计算输出类标签分数:
# compute the output scores by taking the dot product between the
# weight matrix and image pixels, followed by adding in the bias
scores = W.dot(image) + b
第 24 行是评分函数本身——它只是权重矩阵W和输入图像像素强度之间的点积,然后加上偏差b。
最后,我们的最后一个代码块处理将每个类标签的评分函数值写入我们的终端,然后将结果显示在我们的屏幕上:
# loop over the scores + labels and display them
for (label, score) in zip(labels, scores):
print("[INFO] {}: {:.2f}".format(label, score))
# draw the label with the highest score on the image as our
# prediction
cv2.putText(orig, "Label: {}".format(labels[np.argmax(scores)]),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# display our input image
cv2.imshow("Image", orig)
cv2.waitKey(0)
要执行我们的示例,只需发出以下命令:
$ python linear_example.py
[INFO] dog: 7963.93
[INFO] cat: -2930.99
[INFO] panda: 3362.47
请注意狗类如何具有最大得分函数值,这意味着“狗”类将被我们的分类器选为预测。事实上,我们可以在图 3 中的图 2 上看到正确绘制的文本dog。
再次提醒,请记住这是一个的工作示例。我 特意 设置我们的 Python 脚本的随机状态,以生成将导致正确分类的W和b值(您可以更改行 8 上的伪随机种子值,亲自查看不同的随机初始化将如何产生不同的输出预测)。
实际上,你永远不会初始化你的W和b值,并且认为会在没有某种学习过程的情况下给你正确的分类。相反,当从头开始训练我们自己的机器学习模型时,我们需要优化和通过优化算法(如梯度下降)学习 W和b。
我们将在未来的课程中介绍优化和梯度下降,但同时,请花时间确保您理解了第 24 行的以及线性分类器如何通过获取权重矩阵和输入数据点之间的点积,然后添加偏差来进行分类。因此,我们的整个模型可以通过两个值来定义:权重矩阵和偏差向量。当我们从零开始训练机器学习模型时,这种表示不仅简洁,而且强大。
损失函数的作用
在上一节中,我们讨论了参数化学习的概念。这种类型的学习允许我们获取多组输入数据和类别标签,并通过定义一组参数并对其进行优化,实际学习一个将输入映射到输出预测的函数。
但是为了通过我们的评分函数实际“学习”从输入数据到类标签的映射,我们需要讨论两个重要的概念:
- 损失函数
- 优化方法
让我们探讨一下在构建神经网络和深度学习网络时会遇到的常见损失函数。
我们的探索是对损失函数及其在参数化学习中的作用的简要回顾。如果你希望用更严格的数学推导来补充这一课,我强烈推荐吴恩达的 Coursera 课程、威滕等人(2011) 、哈林顿(2012) 和马斯兰德(2009) 。
什么是损失函数?
在最基本的层面上,损失函数量化了给定预测器在对数据集中的输入数据点进行分类时的好坏程度。图 4 显示了在 CIFAR-10 数据集上训练的两个独立模型的损失函数随时间的变化情况。损失越小,分类器在对输入数据和输出类别标签之间的关系建模方面就越好(尽管有一点我们可以过度拟合我们的模型——通过对训练数据过于接近建模,我们的模型失去了概括的能力)。相反,我们的损失越大,就需要做更多的工作来提高分类精度。
为了提高我们的分类精度,我们需要调整我们的权重矩阵 W 或偏差向量 b 的参数。确切地说我们如何着手更新这些参数是一个优化 问题,我们将在以后的课程中讨论这个问题。目前,简单地理解一个损失函数可以用来量化我们的评分函数在分类输入数据点方面做得有多好。
理想情况下,随着我们调整模型参数,我们的损失应该会随着时间的推移而减少。如图 4 所示,模型#1 的损失开始略高于模型#2 ,但随后迅速下降,并在 CIFAR-10 数据集上训练时继续保持较低水平。相反,型号#2 的损失最初会降低,但很快会停滞。在此特定示例中,模型#1 实现了更低的总体损失,并且可能是用于对来自 CIFAR-10 数据集的其他图像进行分类的更理想的模型。我说“可能”是因为模型#1 有可能过度拟合训练数据。我们将在以后的课程中讨论过度拟合的概念以及如何发现它。
多级 SVM 损耗
多类 SVM 损失(顾名思义)的灵感来自于(线性)支持向量机(SVMs) ,它使用一个评分函数 f 将我们的数据点映射到每个类标签的数值分数。这个函数 f 是一个简单的学习映射:
② = W x_i +b")
现在我们有了评分函数,我们需要确定这个函数在进行预测时有多“好”或“坏”(给定权重矩阵【W】和偏差向量 b )。为了做出这个决定,我们需要一个损失函数。
回想一下,当创建机器学习模型时,我们有一个设计矩阵* X ,其中 X 中的每一行都包含一个我们希望分类的数据点。在图像分类的上下文中, X 中的每一行都是一个图像,我们寻求正确地标记这个图像。我们可以通过语法 x [i] 来访问 X 里面的第 i 个图像。
同样,我们也有一个向量【y】,其中包含了我们对每个【X】的类标签。这些 y 值是我们的基础事实标签并且我们希望我们的评分函数能够正确预测。就像我们可以通过x[I]来访问给定的图像一样,我们可以通过y[I]来访问相关的类标签。**
*为了简单起见,让我们将我们的评分函数缩写为 s :
( 3 ) ")
这意味着我们可以通过第 i 个数据点获得第 j 类的预测得分:
( 4 ) _{j}")
使用这种语法,我们可以把所有这些放在一起,得到 铰链损失函数 :
( 5 ) ")
备注: 几乎所有的损失函数都包含一个正则项。我现在跳过这个想法,因为当我们更好地理解损失函数时,我们将在未来的课程中回顾正则化。
看着上面的铰链损耗公式,你可能会对它的实际作用感到困惑。本质上,铰链损失函数是对所有个不正确的类(I≦**j)求和,并比较我们为第 j 个类标签(不正确的类)和第 y [i] 个类(正确的类)返回的评分函数 s 的输出。我们应用max 操作将值箝位在零,这对于确保我们不累加负值很重要。
**当损失 L [i] = 0 时,给定的x[I]被正确分类(我将在下一节提供一个数值例子)。为了得到整个训练集的损失,我们简单地取每个个体的平均值:
(6) 
你可能遇到的另一个相关损失函数是 平方铰链损失 :
^{2}") (7)
(7)
**平方项通过对输出进行平方来更严重地惩罚我们的损失,这导致预测不正确时损失的二次增长(相对于线性增长)。
至于您应该使用哪个损失函数,这完全取决于您的数据集。标准铰链损失函数通常被更多地使用,但在某些数据集上,平方变化可能会获得更好的精度。总的来说,这是一个您应该考虑调整的超参数。
多级 SVM 损失示例
现在我们已经了解了铰链损耗背后的数学原理,让我们来看一个实际例子。我们将再次使用“动物”数据集,该数据集旨在将给定图像分类为包含一只猫、狗或熊猫。首先,请看图 5 中的,这里我已经包含了来自“动物”数据集的三个类的三个训练示例。
给定一些任意的权重矩阵 W 和偏置向量 b , f ( x,W)=W x+b的输出分数显示在矩阵体中。分数越大,越有信心我们的评分函数是关于预测的。
让我们从计算“狗”类的损失L[I]开始:
>>> max(0, 1.33 - 4.26 + 1) + max(0, -1.01 - 4.26 + 1)
0
请注意我们的等式是如何包含两项的——狗的预测得分与猫和熊猫的得分之差。此外,观察“狗”的损失如何为零——这意味着狗被正确预测。对来自图 5 的图片#1 的快速调查证明了这一结果是正确的:“狗”的得分高于“猫”和“熊猫”的得分。
类似地,我们可以计算出图像#2 的铰链损耗,其中包含一只猫:
>>> max(0, 3.76 - (-1.20) + 1) + max(0, -3.81 - (-1.20) + 1)
5.96
在这种情况下,我们的损失函数大于零,说明我们的预测不正确。查看我们的评分函数,我们看到我们的模型预测狗为建议的标签,评分为 3 。 76(因为这是得分最高的标签)。我们知道这个标签是不正确的,在未来的课程中,我们将学习如何自动调整我们的权重来纠正这些预测。
最后,让我们以熊猫为例计算铰链损耗:
>>> max(0, -2.37 - (-2.27) + 1) + max(0, 1.03 - (-2.27) + 1)
5.199999999999999
同样,我们的损失是非零的,所以我们知道我们有一个不正确的预测。查看我们的评分函数,我们的模型错误地将这张图像标记为“猫”,而它应该是“熊猫”
然后,我们可以通过取平均值来获得三个示例的总损失:
>>> (0.0 + 5.96 + 5.2) / 3.0
3.72
因此,给定我们的三个训练示例,我们的总铰链损耗为 3 。 72 为参数 W 和 b 。
还要注意,我们的损失只有三幅输入图像中的幅幅为零,这意味着我们预测的幅幅是不正确的。在未来的课程中,我们将学习如何优化 W 和 b 以使用损失函数做出更好的预测,帮助我们朝着正确的方向前进。
交叉熵损失和 Softmax 分类器
虽然铰链损失非常普遍,但在深度学习和卷积神经网络的背景下,你更有可能遇到交叉熵损失和 Softmax 分类器。
这是为什么呢?简单来说:
Softmax 分类器给你每个类标签的 概率 ,而铰链损耗给你 余量 。
对我们人类来说,解释概率比解释分数要容易得多。此外,对于像 ImageNet 这样的数据集,我们经常查看卷积神经网络的 5 级精度(其中我们检查地面实况标签是否在网络为给定输入图像返回的前 5 个预测标签中)。查看(1)真正的类别标签是否存在于前 5 个预测中,以及(2)与每个标签相关联的概率是否是一个很好的属性。
了解交叉熵损失
Softmax 分类器是二进制形式的逻辑回归的推广。就像在铰链损失或平方铰链损失中一样,我们的映射函数 f 被定义为,它获取一组输入数据x**I并通过数据 x [i] 和权重矩阵 W 的点积将它们映射到输出类别标签(为简洁起见省略了偏差项):
(8)  = W x_i")
然而,与铰链损失不同,我们可以将这些分数解释为每个类别标签的非标准化对数概率,这相当于用交叉熵损失替换铰链损失函数:
(9) ")
那么,我是怎么来到这里的呢?让我们把功能拆开来看看。首先,我们的损失函数应该最小化正确类别的负对数可能性:
") (10)
(10)
**概率陈述可以解释为:
 = e^{s_{y_{i}}} / \sum\limits_{j} e^{s_{j}}") (11)
(11)
**我们使用标准的评分函数形式:
(12)
**总的来说,这产生了一个单个数据点的最终损失函数,如上所示:
") (13)
(13)
**请注意,这里的对数实际上是以 e 为底的(自然对数),因为我们之前对 e 取了幂的倒数。通过指数之和的实际取幂和归一化是我们的 Softmax 函数。负对数产生我们实际的交叉熵损失。
正如铰链损失和平方铰链损失一样,计算整个数据集的交叉熵损失是通过取平均值来完成的:
 (14)
(14)
**再次,我故意从损失函数中省略正则项。我们将在未来的课程中回到正则化,解释它是什么,如何使用它,以及为什么它对神经网络和深度学习至关重要。如果上面的等式看起来很可怕,不要担心——我们将在下一节通过数字示例来确保您理解交叉熵损失是如何工作的。
一个工作过的 Softmax 例子
为了演示实际的交叉熵损失,考虑图 6 。我们的目标是分类上面的图像是否包含一只狗、猫或熊猫。很明显,我们可以看到图像是一只“熊猫”— 但是我们的 Softmax 分类器是怎么想的呢?为了找到答案,我们需要逐一查看图中的四个表格。
第一个表包括我们的评分函数 f 的输出,分别用于三个类中的每一个。这些值是我们的三个类别的非标准化对数概率。让我们对评分函数的输出( e ^(s) ,其中 s 是我们的评分函数值),产生我们的非规范化概率 ( 第二个表)。
下一步是取等式(11) 的分母,对指数求和,并除以和,从而产生与每个类标签 ( 第三表)相关联的实际概率。注意概率总和是多少。
最后,我们可以取负的自然对数,-ln(p),其中 p 是归一化的概率,产生我们的最终损失(第四个和最后一个表)。
在这种情况下,我们的 Softmax 分类器将以 93.93%的置信度正确地将图像报告为熊猫。然后,我们可以对训练集中的所有图像重复这一过程,取平均值,并获得训练集的总体交叉熵损失。这个过程允许我们量化一组参数在我们的训练集上表现的好坏。
备注: 我使用了一个随机数生成器来获得这个特定示例的得分函数值。这些值仅用于演示如何执行 Softmax 分类器/交叉熵损失函数的计算。实际上,这些值不是随机生成的,而是基于参数 W 和 b 的评分函数 f 的输出。
总结
在本课中,我们回顾了参数化学习的四个组成部分:
- 数据
- 评分功能
- 损失函数
- 权重和偏差
在图像分类的上下文中,我们的输入数据是我们的图像数据集。评分函数为给定的输入图像产生预测。然后损失函数量化一组预测对数据集的好坏程度。最后,权重矩阵和偏置向量使我们能够从输入数据中实际“学习”——这些参数将通过优化方法进行调整和调谐,以获得更高的分类精度。
然后我们回顾了两个流行的损失函数:铰链损失和交叉熵损失。虽然铰链损失在许多机器学习应用程序(例如,支持向量机)中使用,但我几乎可以绝对肯定地保证,你会看到更多频率的交叉熵损失,主要是因为 Softmax 分类器输出的是概率而不是余量。概率对于我们人类来说更容易解释,所以这个事实是交叉熵损失和 Softmax 分类器的一个特别好的特性。更多关于铰链损耗和交叉熵损耗的信息,请参考斯坦福大学的 CS231n 课程(http://cs231n.stanford.edu、https://cs231n.github.io/linear-classify)。
在未来的课程中,我们将回顾用于调整权重矩阵和偏差向量的优化方法。优化方法允许我们的算法通过基于我们的得分和损失函数的输出更新权重矩阵和偏差向量,实际上从我们的输入数据中学习。使用这些技术,我们可以对获得更低损耗和更高精度的参数值采取增量步骤。优化方法是现代神经网络和深度学习的基石,没有它们,我们将无法从输入数据中学习模式。**************************
带有 ZBar 的 OpenCV 条形码和 QR 码扫描仪
原文:https://pyimagesearch.com/2018/05/21/an-opencv-barcode-and-qr-code-scanner-with-zbar/

今天这篇关于用 OpenCV 读取条形码和二维码的博文是受到了我从 PyImageSearch 阅读器 Hewitt 那里收到的一个问题的启发:
嘿,阿德里安,我真的很喜欢图片搜索博客。我每周都期待你的邮件。继续做你正在做的事情。
我有个问题要问你:
OpenCV 有没有可以用来读取条形码或者二维码的模块?或者我需要使用一个完全独立的库吗?
谢谢艾利安。
好问题,休伊特。
简单的回答是没有,OpenCV 没有任何可以用来读取和解码条形码和二维码的专用模块。
然而,OpenCV 能做的是方便读取条形码和二维码的过程,包括从磁盘加载图像,从视频流中抓取新的一帧,并对其进行处理。
一旦我们有了图像或帧,我们就可以将它传递给专用的 Python 条形码解码库,比如 Zbar。
然后,ZBar 库将解码条形码或 QR 码。OpenCV 可以返回来执行任何进一步的处理并显示结果。
如果这听起来像一个复杂的过程,它实际上非常简单。ZBar 库及其各种分支和变体已经走过了漫长的道路。其中一套 ZBar 绑定,pyzbar,是我个人最喜欢的。
在今天的教程中,我将向您展示如何使用 OpenCV 和 ZBar 读取条形码和二维码。
另外,我还将演示如何将我们的条形码扫描仪部署到 Raspberry Pi 上!
要了解更多关于使用 OpenCV 和 ZBar 读取条形码和二维码的信息,请继续阅读。
带有 ZBar 的 OpenCV 条形码和 QR 码扫描仪
今天的博文分为四个部分。
在第一部分,我将向您展示如何安装 ZBar 库(使用 Python 绑定)。
ZBar 库将与 OpenCV 一起用于扫描和解码条形码和 QR 码。
一旦 ZBar 和 OpenCV 被正确配置,我将演示如何在单幅图像中扫描条形码和 QR 码。
从单幅图像开始会给我们提供为下一步做准备所需的练习:用 OpenCV 和 ZBar 实时读取条形码和二维码,
最后,我将演示如何将我们的实时条形码扫描器部署到 Raspberry Pi。
为条形码解码安装 ZBar(使用 Python 绑定)
几周前,来自 LearnOpenCV 博客的 Satya Mallick 发布了一篇关于使用 ZBar 库扫描条形码的非常棒的教程。
在今天的帖子中安装 ZBar 的说明主要是基于他的说明,但是有一些更新,最大的一个是关于我们如何安装 Python zbar绑定本身,确保我们可以:
- 使用 Python 3 (官方
zbarPython 绑定只支持 Python 2.7) - 检测并准确定位条形码在图像中的位置。
安装必要的软件是一个简单的三步过程。
第一步:从apt或brew库安装zbar
为 Ubuntu 或 Raspbian 安装 ZBar】
安装 ZBar for Ubuntu 可以通过以下命令完成:
$ sudo apt-get install libzbar0
为 macOS 安装 ZBar】
使用 brew 安装 ZBar for macOS 同样简单(假设您安装了 Homebrew):
$ brew install zbar
步骤 2(可选):创建一个虚拟环境并安装 OpenCV
您有两种选择:
- 使用一个已经准备好 OpenCV 的现有虚拟环境(跳过这一步,直接进入步骤 3 )。
- 或者创建一个新的、隔离的虚拟环境,包括安装 OpenCV。
虚拟环境是 Python 开发的最佳实践,我强烈建议您利用它们。
我选择创建一个新的、隔离的 Python 3 虚拟环境,并遵循链接在本页的 Ubuntu(或 macOS,取决于我使用的机器)OpenCV 安装说明。在遵循这些说明时,我所做的唯一改变是将我的环境命名为barcode:
$ mkvirtualenv barcode -p python3
注意:如果您的系统上已经安装了 OpenCV,您可以跳过 OpenCV 编译过程,只需将您的cv2.so绑定符号链接到新 Python 虚拟环境的site-packages目录中。
第三步:安装pyzbar
现在我的机器上有了一个名为barcode的 Python 3 虚拟环境,我激活了barcode环境(您的可能有不同的名称)并安装了pyzbar:
$ workon barcode
$ pip install pyzbar
如果您没有使用 Python 虚拟环境,您可以:
$ pip install pyzbar
如果你试图将pyzbar安装到 Python 的系统版本中,确保你也使用了sudo命令。
用 OpenCV 解码单幅图像中的条形码和 QR 码

Figure 1: Both QR and 1D barcodes can be read with our Python app using ZBar + OpenCV.
在我们实现实时条形码和二维码读取之前,让我们先从一台单图像扫描仪开始,先试一试。
打开一个新文件,将其命名为barcode_scanner_image.py,并插入以下代码:
# import the necessary packages
from pyzbar import pyzbar
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
在第 2-4 行上,我们导入我们需要的包。
pyzbar和cv2 (OpenCV)都需要按照上一节中的说明进行安装。
相比之下,argparse包含在 Python 安装中,它负责解析命令行参数。
这个脚本(--image)有一个必需的命令行参数,它在第 7-10 行被解析。
在本节的最后,您将看到如何在传递包含输入图像路径的命令行参数的同时运行脚本。
现在,让我们使用输入图像并让pyzbar工作:
# load the input image
image = cv2.imread(args["image"])
# find the barcodes in the image and decode each of the barcodes
barcodes = pyzbar.decode(image)
在的第 13 行,我们通过路径加载输入image(包含在我们方便的args字典中)。
从那里,我们调用pyzbar.decode找到并解码image ( 行 16 )中的barcodes。这就是泽巴所有神奇的地方。
我们还没有完成——现在我们需要解析包含在barcodes变量中的信息:
# loop over the detected barcodes
for barcode in barcodes:
# extract the bounding box location of the barcode and draw the
# bounding box surrounding the barcode on the image
(x, y, w, h) = barcode.rect
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
# the barcode data is a bytes object so if we want to draw it on
# our output image we need to convert it to a string first
barcodeData = barcode.data.decode("utf-8")
barcodeType = barcode.type
# draw the barcode data and barcode type on the image
text = "{} ({})".format(barcodeData, barcodeType)
cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 0, 255), 2)
# print the barcode type and data to the terminal
print("[INFO] Found {} barcode: {}".format(barcodeType, barcodeData))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
从第 19 行的开始,我们循环检测到的barcodes。
在这个循环中,我们继续:
- 从
barcode.rect对象(第 22 行)中提取包围盒【T1(x,y)- 坐标,使我们能够定位并确定当前条码在输入图像中的位置。 - 在检测到的
barcode( 线 23 )周围的image上绘制一个包围盒矩形。 - 将
barcode解码成"utf-8"字符串,并提取条形码的类型(第 27 行和第 28 行)。在对象上调用.decode("utf-8")函数将字节数组转换成字符串是很关键的。您可以通过删除/注释它来进行试验,看看会发生什么——我将把这作为一个试验留给您来尝试。 - 格式化并在图像上绘制
barcodeData和barcodeType(第 31-33 行)。 - 最后,输出相同的数据和类型信息到终端用于调试目的(行 36 )。
让我们测试我们的 OpenCV 条形码扫描仪。你应该使用这篇博文底部的 【下载】 部分下载代码和示例图片。
从那里,打开您的终端并执行以下命令:
$ python barcode_scanner_image.py --image barcode_example.png
[INFO] Found QRCODE barcode: {"author": "Adrian", "site": "PyImageSearch"}
[INFO] Found QRCODE barcode: https://pyimagesearch.com/
[INFO] Found QRCODE barcode: PyImageSearch
[INFO] Found CODE128 barcode: AdrianRosebrock
正如您在终端中看到的,所有四个条形码都被找到并被正确解码!
参考图 1 获取处理后的图像,该图像覆盖了我们的软件找到的每个条形码的红色矩形和文本。
利用 OpenCV 实时读取条形码和二维码
在上一节中,我们学习了如何为单幅图像创建一个 Python + OpenCV 条形码扫描仪。
我们的条形码和二维码扫描仪工作得很好,但它提出了一个问题,我们能实时检测和解码条形码+二维码吗?
要找到答案,打开一个新文件,将其命名为barcode_scanner_video.py,并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from pyzbar import pyzbar
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", type=str, default="barcodes.csv",
help="path to output CSV file containing barcodes")
args = vars(ap.parse_args())
在第 2-8 行上,我们导入我们需要的包。
此时,回想上面的解释,你应该认得出pyzbar、argparse、cv2。
我们还将使用VideoStream以高效、线程化的方式处理视频帧的捕获。你可以在这里了解更多关于视频流课程的信息。如果您的系统上没有安装imutils,只需使用以下命令:
$ pip install imutils
我们将解析一个可选的命令行参数--output,它包含输出逗号分隔值(CSV)文件的路径。该文件将包含从我们的视频流中检测和解码的每个条形码的时间戳和有效载荷。如果没有指定这个参数,CSV 文件将被放在我们当前的工作目录中,文件名为"barcodes.csv" ( 第 11-14 行)。
从那里,让我们初始化我们的视频流,并打开我们的 CSV 文件:
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
# vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# open the output CSV file for writing and initialize the set of
# barcodes found thus far
csv = open(args["output"], "w")
found = set()
在第 18 和 19 行上,我们初始化并开始我们的VideoStream。您可以:
- 使用你的 USB 摄像头(取消注释第 18 行和注释第 19 行
- 或者,如果你正在使用树莓 Pi(像我一样),你可以使用 PiCamera(取消注释行 19 和注释行 18 )。
我选择使用我的 Raspberry Pi PiCamera,如下一节所示。
然后我们暂停两秒钟,让摄像机预热( Line 20 )。
我们会将找到的所有条形码写入磁盘的 CSV 文件中(但要确保不会写入重复的条形码)。这是一个(微不足道的)记录条形码的例子。当然,一旦条形码被检测和读取,您可以做任何您想做的事情,例如:
- 将其保存在 SQL 数据库中
- 将其发送到服务器
- 上传到云端
- 发送电子邮件或短信
实际操作是任意的 —我们只是用 CSV 文件作为例子。
请随意更新代码,以包含您希望的任何通知。
我们打开csv文件在行 24 上写。如果您正在修改代码以追加到文件中,您可以简单地将第二个参数从"w"更改为"a"(但是您必须以不同的方式搜索文件中的重复项)。
我们还为found条形码初始化了一个set。该集合将包含唯一的条形码,同时防止重复。
让我们开始捕捉+处理帧:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it to
# have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# find the barcodes in the frame and decode each of the barcodes
barcodes = pyzbar.decode(frame)
在第 28 行的上,我们开始循环,从我们的视频流中抓取并调整一个frame(第 31 行和第 32 行)的大小。
从那里,我们调用pyzbar.decode来检测和解码frame中的任何 QR +条形码。
让我们继续循环检测到的barcodes:
# loop over the detected barcodes
for barcode in barcodes:
# extract the bounding box location of the barcode and draw
# the bounding box surrounding the barcode on the image
(x, y, w, h) = barcode.rect
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2)
# the barcode data is a bytes object so if we want to draw it
# on our output image we need to convert it to a string first
barcodeData = barcode.data.decode("utf-8")
barcodeType = barcode.type
# draw the barcode data and barcode type on the image
text = "{} ({})".format(barcodeData, barcodeType)
cv2.putText(frame, text, (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# if the barcode text is currently not in our CSV file, write
# the timestamp + barcode to disk and update the set
if barcodeData not in found:
csv.write("{},{}\n".format(datetime.datetime.now(),
barcodeData))
csv.flush()
found.add(barcodeData)
如果您阅读了前面的部分,这个循环应该看起来非常熟悉。
事实上,第 38-52 行与那些单一形象剧本的相同。有关该代码块的详细介绍,请参考“单图像条形码检测和扫描”部分。
第 56-60 行是新的。在这些行中,我们检查是否发现了一个唯一的(以前没有发现的)条形码(行 56 )。
如果是这种情况,我们将时间戳和数据写入csv文件(第 57-59 行)。我们还将barcodeData添加到found集合中,作为处理重复的简单方法。
在实时条形码扫描器脚本的其余行中,我们显示帧,检查是否按下了退出键,并执行清理:
# show the output frame
cv2.imshow("Barcode Scanner", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# close the output CSV file do a bit of cleanup
print("[INFO] cleaning up...")
csv.close()
cv2.destroyAllWindows()
vs.stop()
在行 63 上,我们显示输出frame。
然后在第 64-68 行,我们检查按键,如果"q"被按下,我们break退出主执行循环。
最后,我们在第 72-74 行上执行清理。
在 Raspberry Pi 上构建条形码和 QR 码扫描仪

Figure 2: My Raspberry Pi barcode scanner project consists of a Raspberry Pi, PiCamera, 7-inch touchscreen, and battery pack.
如果我被限制在办公桌前,条形码扫描仪还有什么意思?
我决定带上我的条形码扫描仪,使用我的 Pi、触摸屏和电池组。
图 2 中显示的是我的设置——正是我最近用于我的移动 Pokedex 深度学习项目的设置。如果您想用所示的外围设备构建自己的产品,我列出了产品和链接:
构建这个系统真的很容易,我已经在这篇博文中做了一步一步的说明。
一旦你的移动 ZBar 条形码扫描仪准备好了,使用这篇博文的 【下载】 部分下载这篇博文的相关代码。
从那里,在您的 Pi 上打开一个终端,使用以下命令启动应用程序(这一步您需要一个键盘/鼠标,但之后您可以断开连接并让应用程序运行):
$ python barcode_scanner_video.py
[INFO] starting video stream...
现在,您可以向摄像机展示条形码,完成后,您可以打开barcodes.csv文件(或者,如果您愿意,您可以在单独的终端中执行tail -f barcodes.csv,以便在数据进入 CSV 文件时实时查看数据)。
我尝试的第一个二维码显示在黑色背景上,ZBar 很容易发现:
Figure 3: A QR code with the code “PyImageSearch” is recognized with our Python + ZBar application
然后我走向我的厨房,手里拿着 Pi、屏幕和电池组,找到了另一个二维码:
Figure 4: My website, “https://pyimagesearch.com/” is encoded in a QR code and recognized with ZBar and Python on my Raspberry Pi.
成功!它甚至可以在多个角度工作。
现在让我们尝试一个包含 JSON-blob 数据的二维码:
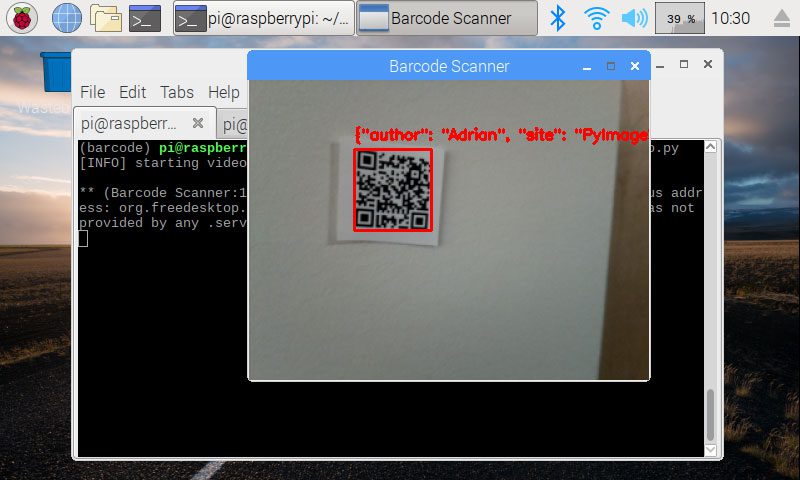
Figure 5: An OpenCV barcode and QR scanner with ZBar decodes an image of a QR with ease. I deployed the project to my Raspberry Pi so I can take it on the go.
不是我 OpenCV + ZBar + Python 条码扫描器项目的对手!
最后,我尝试了传统的一维条形码:
Figure 6: ZBar coupled with OpenCV and Python makes for a great Raspberry Pi barcode project. My name, “AdrianRosebrock” is encoded in this CODE128 barcode.
一维条形码对系统来说更具挑战性,尤其是在 PiCamera 不支持自动对焦的情况下。也就是说,我也成功地检测和解码了这个条形码。
你可能有最好的运气与 USB 网络摄像头,如罗技 C920 有很大的自动对焦。或者,你可以使用 Jeff Geerling 在他的博客中描述的方法来改变你的 PiCamera 的工厂焦点。
这是一个总结!
如果你有兴趣在我的网站上阅读额外的条形码博客帖子,请查看带有“条形码”标签的帖子。
摘要
在今天的博文中,您学习了如何构建 OpenCV 条形码和 QR 码扫描仪。
为此,我们使用了 ZBar 库。
一旦 ZBar 库安装到我们的系统上,我们就创建了两个 Python 脚本:
- 第一个在单一图像中扫描条形码和 QR 码的
- 以及实时读取条形码和 QR 码的第二脚本
在这两种情况下,我们都使用 OpenCV 来简化构建条形码/QR 码扫描仪的过程。
最后,我们通过将条形码阅读器部署到 Raspberry Pi 来结束今天的博文。
条形码扫描仪足够快,可以在 Raspberry Pi 上实时运行,没有任何问题。
您可以在自己的项目中随意使用这种条形码和 QR 码扫描仪功能!
如果你用它做了一些有趣的事情,一定要在评论中分享你的项目。
我希望你喜欢今天的帖子。下周见。
为了在 PyImageSearch 上发布博客文章时得到通知,请务必在下表中输入您的电子邮件地址!
分析 91 年《时代》杂志封面的视觉趋势
原文:https://pyimagesearch.com/2015/10/19/analyzing-91-years-of-time-magazine-covers-for-visual-trends/

今天的博文将建立在我们上周所学的内容之上:如何使用 Python + Scrapy 构建一个图像刮刀来刮取~ 4000 张时代杂志封面图像。
现在我们有了这个数据集,我们要用它做什么呢?
问得好。
当检查这些类型的同质数据集时,我最喜欢应用的视觉分析技术之一是简单地在给定的时间窗口 (即时间帧)内对图像进行平均 。这个平均是一个简单的操作。我们所需要做的就是循环遍历我们的数据集(或子集)中的每一幅图像,并为每个 (x,y) 【坐标】保持 的平均像素亮度值。**
通过计算这个平均值,我们可以获得图像数据(即时间杂志封面)在给定时间范围内的外观的单一表示。在探索数据集中的可视化趋势时,这是一种简单而高效的方法。
在这篇博文的剩余部分,我们将把我们的时代杂志封面数据集分成 10 组——每一组代表已经出版的 10 十年 时代杂志。然后,对于这些组中的每一组,我们将计算该组中所有图像的平均值,给我们一个关于时间封面图像看起来如何的单个 视觉表示。该平均图像将允许我们识别封面图像中的视觉趋势;具体来说,在给定的十年中时间所使用的营销和广告技术。
分析 91 年《时代》杂志封面的视觉趋势
在我们深入这篇文章之前,通读一下我们之前关于刮时间杂志封面图片的课程可能会有所帮助——阅读之前的文章当然不是必须的,但确实有助于给出一些背景。
也就是说,让我们开始吧。打开一个新文件,命名为analyze_covers.py,让我们开始编码:
# import the necessary packages
from __future__ import print_function
import numpy as np
import argparse
import json
import cv2
def filter_by_decade(decade, data):
# initialize the list of filtered rows
filtered = []
# loop over the rows in the data list
for row in data:
# grab the publication date of the magazine
pub = int(row["pubDate"].split("-")[0])
# if the publication date falls within the current decade,
# then update the filtered list of data
if pub >= decade and pub < decade + 10:
filtered.append(row)
# return the filtered list of data
return filtered
第 2-6 行简单地导入我们必需的包——这里没有什么太令人兴奋的。
然后我们在第 8 行的上定义一个效用函数filter_by_decade。顾名思义,这种方法将遍历我们收集的封面图像,并找出所有在指定十年内的封面。我们的filter_by_decade函数需要两个参数:我们想要获取封面图片的decade,以及data,T3 只是来自我们前一篇文章的output.json数据。
现在我们的方法已经定义好了,让我们继续看函数体。我们将初始化filtered,这是data中符合十年标准的行列表(第 10 行)。
然后我们循环遍历data ( 第 13 行)中的每个row,提取发布日期(第 15 行),然后更新我们的filtered列表,前提是发布日期在我们指定的decade ( 第 19 行和第 20 行)内。
最后,过滤后的行列表在第 23 行上返回给调用者。
既然我们的助手函数已经定义好了,让我们继续解析命令行参数并加载我们的output.json文件:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output visualizations directory")
args = vars(ap.parse_args())
# load the JSON data file
data = json.loads(open("output.json").read())
同样,这里的代码非常简单。第 26-29 行处理解析命令行参数。这里我们只需要一个开关,--visualizations,它是到目录的路径,我们将在这个目录中存储 1920 年到 2010 年之间每十年的平均封面图像。
然后我们在第 32 行的处加载output.json文件(同样,这是从我们之前关于用 Python + Scrapy 抓取图像的文章中生成的)。
我们现在准备对时间杂志封面数据集进行实际分析:
# loop over each individual decade Time magazine has been published
for decade in np.arange(1920, 2020, 10):
# initialize the magazine covers list
print("[INFO] processing years: {}-{}".format(decade, decade + 9))
covers = []
# loop over the magazine issues belonging to the current decade
for row in filter_by_decade(decade, data):
# load the image
cover = cv2.imread("output/{}".format(row["files"][0]["path"]))
# if the image is None, then there was an issue loading it
# (this happens for ~3 images in the dataset, likely due to
# a download problem during the scraping process)
if cover is not None:
# resize the magazine cover, flatten it into a single
# list, and update the list of covers
cover = cv2.resize(cover, (400, 527)).flatten()
covers.append(cover)
# compute the average image of the covers then write the average
# image to disk
avg = np.average(covers, axis=0).reshape((527, 400, 3)).astype("uint8")
p = "{}/{}.png".format(args["output"], decade)
cv2.imwrite(p, avg)
我们首先在第 35 行的上循环 1920 年和 2010 年之间的每个decade,并初始化一个列表covers,以存储当前decade的实际封面图像。
对于每一个十年,我们需要从output.json中取出属于十年范围内的所有行。幸运的是,这很容易,因为我们有上面定义的filter_by_decade方法。
下一步是在线 43 上从磁盘加载当前封面图像。如果图像是None,那么我们知道从磁盘加载封面时出现了问题——数据集中大约有 3 张图像会出现这种情况,这可能是由于下载问题或抓取过程中的网络问题。
假设cover不是None,我们需要将它调整到一个规范的已知大小,这样我们就可以计算每个像素位置 ( 第 51 行)的 的平均值。这里我们将图像的大小调整为固定的 400 x 527 像素,忽略长宽比——调整后的图像随后被展平为一系列 400 x 527 x 3= 632,400 像素(其中 3 来自图像的红色、绿色和蓝色通道)。如果我们不将封面大小调整为固定大小,那么我们的行将不会对齐,我们将无法计算十年范围内的平均图像。
展平后的cover然后被累积到行 52 上的covers列表中。
使用np.average功能在第 56 行对十年的封面图片进行真正的“分析”。每个时间的杂志封面图像都由covers列表中一个展平的行表示。因此,要计算十年间所有封面的平均值,我们需要做的就是取每个列的平均像素值。这将给我们留下一个单个列表(同样是 632,400 -dim ),表示每个(x,y)坐标处的每个红色、绿色和蓝色像素的平均值。
然而,由于avg图像被表示为浮点值的 1D 列表,我们无法将其可视化。首先,我们需要对avg图像进行整形,使其宽度为 400 像素,高度为 527 像素,深度为 3(分别用于红色、绿色和蓝色通道)。最后,由于 OpenCV 期望 8 位无符号整数,我们将从np.average返回的float数据类型转换为uint8。
最后,行 57 和 58 获取我们的avg封面图像并将其写入磁盘。
要运行我们的脚本,只需执行以下命令:
$ python analyze_covers.py --output visualizations
几秒钟后,您应该会在您的visualizations目录中看到以下图像:
Figure 1: The output of our analyze_covers.py script for image averaging.
结果
Figure 2: Visualizing ten decades’ worth of Time magazine covers.
我们现在在我们的visualizations目录中有 10 张图片,平均每张对应于已经出版的**时间杂志的 10 个十年。
*但是这些可视化实际上意味着什么呢?通过研究它们,我们能获得什么样的洞见?
事实证明, 相当多——尤其是关于时代如何在过去 90 多年里用他们的封面进行营销和广告:

Figure 3: Average of Time magazine covers from 1920-1929.
- 原来时代杂志的封面是 全 黑白。但在 20 世纪 20 年代末,我们可以看到他们开始转移到现在标志性的红色边界。然而,封面的其他部分(包括肖像)仍然是黑白的。
- 时间标志总是出现在封面的顶部。
- 华丽的设计将封面肖像框在左边和右边。

Figure 4: Average of Time magazine covers from 1930-1939.
- Time 现在完全投入到他们的红色边框中,实际上边框的厚度已经略有增加。
- 总的来说,从 20 世纪 20 年代到 30 年代的设计变化不大。

Figure 5: Average of Time magazine covers from 1940-1949.
- 我们注意到的第一个变化是红色边框不是唯一的颜色!封面人物的肖像开始彩色打印。鉴于肖像区域似乎有相当多的颜色,这种变化可能发生在 20 世纪 40 年代早期的
** 另一个微妙的变化是“每周新闻杂志”版式的变化,直接在“时代”文本的下面。* 同样值得注意的是,“TIME”文本本身与前几十年相比更加固定(即位置变化非常小)。*
*
Figure 6: Average of Time magazine covers from 1950-1959.
- 20 世纪 50 年代的封面图片展示了时代杂志的巨变,无论是从 封面版式 还是 营销和广告 。
** 首先,曾经被白色边框/华丽设计框住的肖像现在被扩展到覆盖整个封面——这一趋势一直延续到现代。* 元信息(如期刊名称和出版日期)总是刊登在杂志封面上;然而,我们现在开始在杂志的四个角落里看到这个元信息的一个非常固定和高度格式化的版本。* 最值得注意的是营销和广告方面的变化,用斜黄条来突出这期杂志的封面故事。*
*
Figure 7: Average of Time magazine covers from 1960-1969.
- 关于 20 世纪 60 年代的时代封面,你首先会注意到的是“时代”文字的变化。虽然文本看起来是紫色的,但它实际上是从黑色到红色的过渡(平均起来是紫色)。之前的几十年时间都使用黑色文字作为他们的标志,但是在 20 世纪 60 年代我们可以看到他们转换成了现在现代的红色。
- 其次,您会看到“TIME”文本以白色边框突出显示,用于在徽标和中心部分之间形成对比。
- 《时代周刊》仍在使用对角线条进行营销,让他们能够突出封面故事——但这些条现在更多的是“白色”而不是黄色。酒吧的宽度也减少了 1/3。

Figure 8: Average of Time magazine covers from 1970-1979.
- 在这里,我们看到营销和广告策略的另一个重大变化————开始使用的人工折页(右上角),让我们可以“先睹为快”这期杂志的内容。
- 还要注意问题左下角开始出现的条形码。
- “时间”文本周围的白色边框已被移除。

Figure 9: Average of Time magazine covers from 1980-1989.
- 20 世纪 80 年代的《时间》杂志似乎延续了 20 世纪 70 年代的人工折页营销策略。
- 他们还重新插入了包围“TIME”文本的白色边框。
- 条形码现在主要用在左下角。
- 还要注意,条形码也开始出现在右下角。

Figure 10: Average of Time magazine covers from 1990-1999.
- 围绕【TIME】的白色边框又一次消失了——这让我很好奇这些年他们在进行什么类型的对比测试,以确定白色边框是否有助于杂志的更多销售。
- 条形码现在始终出现在杂志的左下角和右下角,条形码位置的选择高度依赖于美学。
- 还要注意,存在了近 20 年的人工折页现在已经不存在了。
- 最后,请注意“TIME”徽标的大小变化很大。

Figure 11: Average of Time magazine covers from 2000-2009.
- 可变标志尺寸在 2000 年代变得更加明显。
- 我们还可以看到条形码完全消失了。

Figure 12: Average of Time magazine covers from 2010-Present.
- 我们现在来到现代时间杂志封面。
- 总的来说,2010 年和 2000 年没有太大区别。
- 然而,时间标志本身的大小似乎实质上变化不大,只沿 y 轴波动。
摘要
在这篇博文中,我们探索了在上一课中收集的时间杂志封面数据集。
为了对数据集进行可视化分析,并确定杂志封面的趋势和变化,我们对几十年来的封面进行了平均。鉴于《T2 时间》已经出版了十年,这给我们留下了十种不同的视觉表现。
总的来说,封面的变化可能看起来很微妙,但它们实际上对杂志的发展很有洞察力,特别是在营销和广告方面。
以下方面的变化:
- 标志颜色和白色镶边
- 突出封面故事的横幅
- 和人工折页
清楚地表明 Time 杂志正试图确定哪些策略足够“吸引眼球”,让读者从当地的报摊上买一份。
此外,他们在白边和无白边之间的转换向我表明,他们正在进行一系列的对比测试,积累了几十年的数据,最终形成了他们现在的现代标志。***
有 WGAN 和 WGAN-GP 的动漫脸
原文:https://pyimagesearch.com/2022/02/07/anime-faces-with-wgan-and-wgan-gp/
在这篇文章中,我们实现了两种 GAN 变体:Wasserstein GAN (WGAN)和 wasser stein GAN with Gradient Penalty(WGAN-GP),以解决我在上一篇文章 GAN 训练挑战:彩色图像的 DCGAN】中讨论的训练不稳定性。我们将训练 WGAN 和 WGAN-GP 模型,生成丰富多彩的64×64动漫脸。
这是我们 GAN 教程系列的第四篇文章:
- 生成对抗网络简介
- 入门:DCGAN for Fashion-MNIST
- GAN 训练挑战:DCGAN 换彩色图像
- 有 WGAN 和 WGAN-GP 的动漫脸(本教程)
我们将首先一步一步地浏览 WGAN 教程,重点介绍 WGAN 论文中介绍的新概念。然后我们讨论如何通过一些改变来改进 WGAN,使之成为 WGAN-GP。
瓦瑟斯坦甘
论文中介绍了 Wasserstein GAN 。其主要贡献是利用 Wasserstein 损失解决 GAN 训练不稳定性问题,这是 GAN 训练的一个重大突破。
回想一下在 DCGAN 中,当鉴别器太弱或太强时,它不会给生成器提供有用的反馈来进行改进。训练时间更长并不一定让 DCGAN 模型更好。
有了 WGAN,这些训练问题可以用新的 Wasserstein loss 来解决:我们不再需要在鉴别器和生成器的训练中进行仔细的平衡,也不再需要仔细设计网络架构。WGAN 具有几乎在任何地方都连续且可微的线性梯度(图 1 )。这解决了常规 GAN 训练的消失梯度问题,
以下是 WGAN 白皮书中介绍的一些新概念或主要变化:
- Wasserstein distance (或推土机的距离):测量将一种分布转换成另一种分布所需的努力。
- 瓦瑟斯坦损失:一个新的损失函数,衡量瓦瑟斯坦距离。
- 在 WGAN 中,这个鉴别器现在被称为评论家。我们训练一个输出数字的评论家,而不是训练一个鉴别器(二进制分类器)来辨别一个图像是真是假(生成的)。
- 批评家必须满足 李普希兹约束 才能对瓦瑟斯坦的损失起作用。
- WGAN 使用权重剪辑来执行 1-Lipschitz 约束。
在我们实施每个新的 GAN 架构时,我将重点介绍与以前的 GAN 版本相比的变化,以帮助您了解新概念。以下是 WGAN 与 DCGAN 相比的主要变化:
表 1 总结了将 DCGAN 更新为 WGAN 所需的更改:
现在让我们浏览代码,用 TensorFlow 2 / Keras 在 WGAN 中实现这些更改。在遵循下面的教程时,请参考 WGAN Colab 笔记本这里的完整代码。
设置
首先,我们确保将 Colab 硬件加速器的运行时设置为 GPU。然后我们导入所有需要的库(例如 TensorFlow 2、Keras 和 Matplotlib 等。).
准备数据
我们将使用来自 Kaggle 的一个名为动漫人脸数据集的数据集来训练 DCGAN,该数据集是从www.getchu.com刮来的动漫人脸集合。有 63,565 个小彩色图像要调整大小到64×64进行训练。
要从 Kaggle 下载数据,您需要提供您的 Kaggle 凭据。你可以上传卡格尔。或者把你的 Kaggle 用户名和密钥放在笔记本里。我们选择了后者。
os.environ['KAGGLE_USERNAME']="enter-your-own-user-name"
os.environ['KAGGLE_KEY']="enter-your-own-user-name"
将数据下载并解压缩到名为dataset的目录中。
!kaggle datasets download -d splcher/animefacedataset -p dataset
!unzip datasets/animefacedataset.zip -d datasets/
下载并解压缩数据后,我们设置图像所在的目录。
anime_data_dir = "/content/datasets/images"
然后,我们使用image_dataset_from_directory的 Keras utils 函数从目录中的图像创建一个tf.data.Dataset,它将用于稍后训练模型。我们指定了64×64的图像大小和256的批量大小。
train_images = tf.keras.utils.image_dataset_from_directory(
anime_data_dir, label_mode=None, image_size=(64, 64), batch_size=256)
让我们想象一个随机的训练图像。
image_batch = next(iter(train_images))
random_index = np.random.choice(image_batch.shape[0])
random_image = image_batch[random_index].numpy().astype("int32")
plt.axis("off")
plt.imshow(random_image)
plt.show()
下面是这个随机训练图像在图 2 中的样子:
和以前一样,我们将图像归一化到[-1, 1]的范围,因为生成器的最终层激活使用了tanh。最后,我们通过使用带有lambda函数的tf.dataset的map函数来应用规范化。
train_images = train_images.map(lambda x: (x - 127.5) / 127.5)
发电机
WGAN 发生器架构没有变化,与 DCGAN 相同。我们在build_generator函数中使用 Keras Sequential API 创建生成器架构。参考我之前两篇 DCGAN 帖子中关于如何创建生成器架构的细节: DCGAN 用于时尚-MNIST 和 DCGAN 用于彩色图像。
在build_generator()函数中定义了生成器架构之后,我们用generator = build_generator()构建生成器模型,并调用generator.summary()来可视化模型架构。
评论家
在 WGAN 中,我们有一个批评家指定一个衡量 Wasserstein 距离的分数,而不是真假图像二进制分类的鉴别器。请注意,评论家的输出现在是一个分数,而不是一个概率。批评家被 1-Lipschitz 连续性条件所约束。
这里有相当多的变化:
- 将
discriminator重命名为critic - 使用权重剪裁在批评家上实施 1-Lipschitz 连续性
- 将评论家的激活功能从
sigmoid更改为linear
将discriminator更名为critic
如果您从 DCGAN 代码开始,您需要将discriminator重命名为critic。您可以使用 Colab 中的“查找和替换”功能进行所有更新。
所以现在我们有一个函数叫做build_critic而不是build_discriminator。
重量削减
WGAN 通过使用权重裁剪来实施 1-Lipschitz 约束,我们通过子类化keras.constraints.Constraint来实现权重裁剪。详细文件参考 Keras 层重量约束。下面是我们如何创建WeightClipping类:
class WeightClipping(tf.keras.constraints.Constraint):
def __init__(self, clip_value):
self.clip_value = clip_value
def __call__(self, weights):
return tf.clip_by_value(weights, -self.clip_value, self.clip_value)
def get_config(self):
return {'clip_value': self.clip_value}
然后在build_critic函数中,我们用WeightClipping类创建了一个[-0.01, 0.01]的constraint。
constraint = WeightClipping(0.01)
现在我们将kernel_constraint = constraint添加到评论家的所有CONV2D层中。例如:
model.add(layers.Conv2D(64, (4, 4),
padding="same", strides=(2, 2),
kernel_constraint = constraint,
input_shape=input_shape))
线性激活
在 critic 的最后一层,我们将激活从sigmoid更新为linear。
model.add(layers.Dense(1, activation="linear"))
请注意,在 Keras 中,Dense层默认有linear激活,所以我们可以省略activation="linear"部分,编写如下代码:
model.add(layers.Dense(1))
我把activation = "linear"留在这里是为了说明,在将 DCGAN 更新为 WGAN 时,我们将从sigmoid变为linear激活。
现在我们已经在build_critic函数中定义了模型架构,让我们用critic = build_critic(64, 64, 3)构建 critic 模型,并调用critic.summary()来可视化 critic 模型架构。
WGAN 模型
我们通过子类keras.Model定义 WGAN 模型架构,并覆盖train_step来定义定制的训练循环。
WGAN 的这一部分有一些变化:
- 更新批评家比更新生成器更频繁
- 评论家不再有形象标签
- 使用 Wasserstein 损失代替二元交叉熵(BCE)损失
更新评论家比更新生成器更频繁
根据论文建议,我们更新评论家的频率是生成器的 5 倍。为了实现这一点,我们向WGAN类的critic_extra_steps到__init__传递了一个额外的参数。
def __init__(self, critic, generator, latent_dim, critic_extra_steps):
...
self.c_extra_steps = critic_extra_steps
...
然后在train_step()中,我们使用一个for循环来应用额外的训练步骤。
for i in range(self.c_extra_steps):
# Step 1\. Train the critic
...
# Step 2\. Train the generator
图像标签
根据我们如何编写 Wasserstein 损失函数,我们可以 1)将 1 作为真实图像的标签,将负的作为伪图像的标签,或者 2)不分配任何标签。
下面是对这两个选项的简要说明。使用标签时,Wasserstein 损失计算为tf.reduce mean(y_true * y_pred)。如果我们有真实图像上的损耗+虚假图像上的损耗和仅虚假图像上的发生器损耗的评论家损耗,那么它导致评论家损耗的tf.reduce_mean (1 * pred_real - 1 * pred_fake)和发生器损耗的-tf.reduce_mean(pred_fake)。
请注意,评论家的目标并不是试图给自己贴上1或-1的标签;相反,它试图最大化其对真实图像的预测和对虚假图像的预测之间的差异。因此,在沃瑟斯坦损失的案例中,标签并不重要。
所以我们选择后一种不分配标签的选择,你会看到所有真假标签的代码都被去掉了。
瓦瑟斯坦损失
批评家和创造者的损失通过model.compile传递:
def compile(self, d_optimizer, g_optimizer, d_loss_fn, g_loss_fn):
super(WGAN, self).compile()
...
self.d_loss_fn = d_loss_fn
self.g_loss_fn = g_loss_fn
然后在train_step中,我们使用这些函数分别计算训练期间的临界损耗和发电机损耗。
def train_step(self, real_images):
for i in range(self.c_extra_steps):
# Step 1\. Train the critic
...
d_loss = self.d_loss_fn(pred_real, pred_fake) # critic loss
# Step 2\. Train the generator
...
g_loss = self.g_loss_fn(pred_fake) # generator loss
用于训练监控的KerasCallback
与 DCGAN 相同的代码,没有变化—覆盖 Keras Callback以在训练期间监控和可视化生成的图像。
class GANMonitor(keras.callbacks.Callback):
def __init__():
...
def on_epoch_end():
...
def on_train_end():
...
编译并训练 WGAN
组装 WGAN 模型
我们将wgan模型与上面定义的 WGAN 类放在一起。请注意,根据 WGAN 文件,我们需要将评论家的额外培训步骤设置为5。
wgan = WGAN(critic=critic,
generator=generator,
latent_dim=LATENT_DIM,
critic_extra_steps=5) # UPDATE for WGAN
瓦瑟斯坦损失函数
如前所述,WGAN 的主要变化是 Wasserstein loss 的用法。以下是如何计算评论家和发电机的 Wasserstein 损失——通过在 Keras 中定义自定义损失函数。
# Wasserstein loss for the critic
def d_wasserstein_loss(pred_real, pred_fake):
real_loss = tf.reduce_mean(pred_real)
fake_loss = tf.reduce_mean(pred_fake)
return fake_loss - real_loss
# Wasserstein loss for the generator
def g_wasserstein_loss(pred_fake):
return -tf.reduce_mean(pred_fake)
编译 WGAN
现在我们用 RMSProp 优化器编译wgan模型,按照 WGAN 论文,学习率为 0.00005。
LR = 0.00005 # UPDATE for WGAN: learning rate per WGAN paper
wgan.compile(
d_optimizer = keras.optimizers.RMSprop(learning_rate=LR, clipvalue=1.0, decay=1e-8), # UPDATE for WGAN: use RMSProp instead of Adam
g_optimizer = keras.optimizers.RMSprop(learning_rate=LR, clipvalue=1.0, decay=1e-8), # UPDATE for WGAN: use RMSProp instead of Adam
d_loss_fn = d_wasserstein_loss,
g_loss_fn = g_wasserstein_loss
)
注意在 DCGAN 中,我们使用keras.losses.BinaryCrossentropy()而对于 WGAN,我们使用上面定义的自定义wasserstein_loss函数。这两个wasserstein_loss函数通过model.compile()传入。它们将用于自定义训练循环,如上面的覆盖_step部分所述。
训练 WGAN 模型
现在我们干脆调用model.fit()来训练wgan模型!
NUM_EPOCHS = 50 # number of epochs
wgan.fit(train_images, epochs=NUM_EPOCHS, callbacks=[GANMonitor(num_img=16, latent_dim=LATENT_DIM)])
Wasserstein GAN 用梯度罚
虽然 WGAN 通过 Wasserstein 的损失提高了训练的稳定性,但即使是论文本身也承认“重量削减显然是一种实施 Lipschitz 约束的可怕方式。”大的削波参数会导致训练缓慢,并阻止评论家达到最佳状态。与此同时,过小的剪裁很容易导致渐变消失,这正是 WGAN 提出要解决的问题。
本文介绍了 Wasserstein 梯度罚函数(WGAN-GP),改进了 Wasserstein GANs 的训练。它进一步改进了 WGAN,通过使用梯度惩罚而不是权重剪裁来加强评论家的 1-Lipschitz 约束。
我们只需要做一些更改就可以将 WGAN 更新为 WGAN-WP:
- 从评论家的建筑中删除批量规范。
- 使用梯度惩罚而不是权重剪裁来加强 Lipschitz 约束。
- 用亚当优化器 (α = 0.0002,β [1] = 0.5,β [2] = 0.9)代替 RMSProp。
请参考 WGAN-GP Colab 笔记本此处获取完整的代码示例。在本教程中,我们只讨论将 WGAN 更新为 WGAN-WP 的增量更改。
添加梯度惩罚
梯度惩罚意味着惩罚具有大范数值的梯度,下面是我们在 Keras 中如何计算它:
def gradient_penalty(self, batch_size, real_images, fake_images):
""" Calculates the gradient penalty.
Gradient penalty is calculated on an interpolated image
and added to the discriminator loss.
"""
alpha = tf.random.normal([batch_size, 1, 1, 1], 0.0, 1.0)
diff = fake_images - real_images
# 1\. Create the interpolated image
interpolated = real_images + alpha * diff
with tf.GradientTape() as gp_tape:
gp_tape.watch(interpolated)
# 2\. Get the Critic's output for the interpolated image
pred = self.critic(interpolated, training=True)
# 3\. Calculate the gradients w.r.t to the interpolated image
grads = gp_tape.gradient(pred, [interpolated])[0]
# 4\. Calculate the norm of the gradients.
norm = tf.sqrt(tf.reduce_sum(tf.square(grads), axis=[1, 2, 3]))
# 5\. Calculate gradient penalty
gradient_penalty = tf.reduce_mean((norm - 1.0) ** 2)
return gradient_penalty
然后在train_step中,我们计算梯度惩罚,并将其添加到原始评论家损失中。注意惩罚权重(或系数λƛ)控制惩罚的大小,它被设置为每张 WGAN 纸 10。
gp = self.gradient_penalty(batch_size, real_images, fake_images)
d_loss = self.d_loss_fn(pred_real, pred_fake) + gp * self.gp_weight
移除批次号
虽然批归一化有助于稳定 GAN 训练中的训练,但它对梯度惩罚不起作用,因为使用梯度惩罚,我们会单独惩罚每个输入的 critic 梯度的范数,而不是整个批。所以我们需要从批评家的模型架构中移除批量规范代码。
Adam Optimizer 而不是 RMSProp
DCGAN 使用 Adam 优化器,对于 WGAN,我们切换到 RMSProp 优化器。现在对于 WGAN-GP,我们切换回 Adam 优化器,按照 WGAN-GP 论文建议,学习率为 0.0002。
LR = 0.0002 # WGAN-GP paper recommends lr of 0.0002
d_optimizer = keras.optimizers.Adam(learning_rate=LR, beta_1=0.5, beta_2=0.9) g_optimizer = keras.optimizers.Adam(learning_rate=LR, beta_1=0.5, beta_2=0.9)
我们编译和训练 WGAN-GP 模型 50 个时期,并且我们观察到由该模型生成的更稳定的训练和更好的图像质量。
图 3 分别比较了真实(训练)图像和 WGAN 和 WGAN-GP 生成的图像。
WGAN 和 WGAN-GP 都提高了训练稳定性。权衡就是他们的训练收敛速度比 DCGAN 慢,图像质量可能会稍差;然而,随着训练稳定性的提高,我们可以使用更复杂的生成器网络架构,从而提高图像质量。许多后来的 GAN 变体采用 Wasserstein 损失和梯度惩罚作为缺省值,例如 ProGAN 和 StyleGAN。甚至 TF-GAN 库默认使用 Wasserstein 损失。
总结
在这篇文章中,你学习了如何使用 WGAN 和 WGAN-GP 来提高 GAN 训练的稳定性。您了解了使用 TensorFlow 2 / Keras 从 DCGAN 迁移到 WGAN,然后从 WGAN 迁移到 WGAN-GP 的增量变化。你学会了如何用 WGAN 和 WGAN-GP 生成动漫脸。
引用信息
梅纳德-里德,M. 《有 WGAN 和 WGAN-GP 的动漫脸》, PyImageSearch ,2022,【https://pyimg.co/9avys】T4
@article{Maynard-Reid_2022_Anime_Faces,
author = {Margaret Maynard-Reid},
title = {Anime Faces with {WGAN} and {WGAN-GP}},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimg.co/9avys},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
宣布“案例研究:用计算机视觉解决现实世界的问题”

今天我有一些重大消息要宣布…
除了写一大堆关于计算机视觉、图像处理和图像搜索引擎的博客帖子,我一直在幕后, 在写第二本书 。
而且你可能在想,哎,你不是刚做完 实用 Python 和 OpenCV 吗?
没错。我做到了。
别误会我的意思。实用 Python 和 OpenCV 的反馈令人惊讶。它完成了我所想的——在一个周末 教授开发者、程序员和像你一样的学生计算机视觉的基础知识 。
但是现在你已经知道了计算机视觉的基础,并且有了一个坚实的起点,是时候继续学习一些更有趣的东西了…
让我们用你的计算机视觉知识来解决一些 实际的、真实世界的问题 。
什么类型的问题?
我很高兴你问了。继续读下去,我会告诉你的。
这本书包括什么?
这本书涵盖了现实世界中与计算机视觉相关的五个主要主题。看看下面的每一个,以及每一个的截图。
#1.照片和视频中的人脸检测
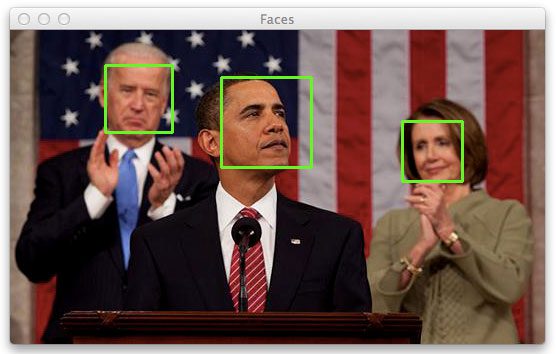
Figure 1: Learn how to use OpenCV and Python to detect faces in images.
到目前为止,这个博客上最受欢迎的教程一直是 “我如何在图像中找到人脸?” 如果你对人脸检测以及在图像和视频中寻找人脸感兴趣,那么这本书正适合你。
#2.视频中的目标跟踪
![]()
Figure 2: My Case Studies book will show you how to track objects in video as they move along the screen.
另一个我经常被问到的问题是 “我如何在视频中追踪物体?” 在这一章中,我将讨论如何使用一个物体的颜色来跟踪它在视频中移动时的轨迹。
#3.基于梯度方向直方图的手写识别

Figure 3: Learn how to use HOG and a Linear Support Vector Machine to recognize handwritten text.
这可能是整本案例研究书中我最喜欢的一章,因为它是如此实用和有用。
想象一下,你和一群朋友在酒吧或酒馆,突然一个漂亮的陌生人向你走来,递给你写在餐巾上的电话号码。
你会把餐巾塞在口袋里,希望不要弄丢吗?你会拿出手机手动创建一个新的联系人吗?
你可以。或者。你可以拍下电话号码的照片,让它被自动识别并安全存储。
在我的案例研究一书中的这一章,你将学习如何使用梯度方向直方图(HOG)描述符和线性支持向量机到对图像中的数字进行分类。
#4.基于颜色直方图和机器学习的植物分类
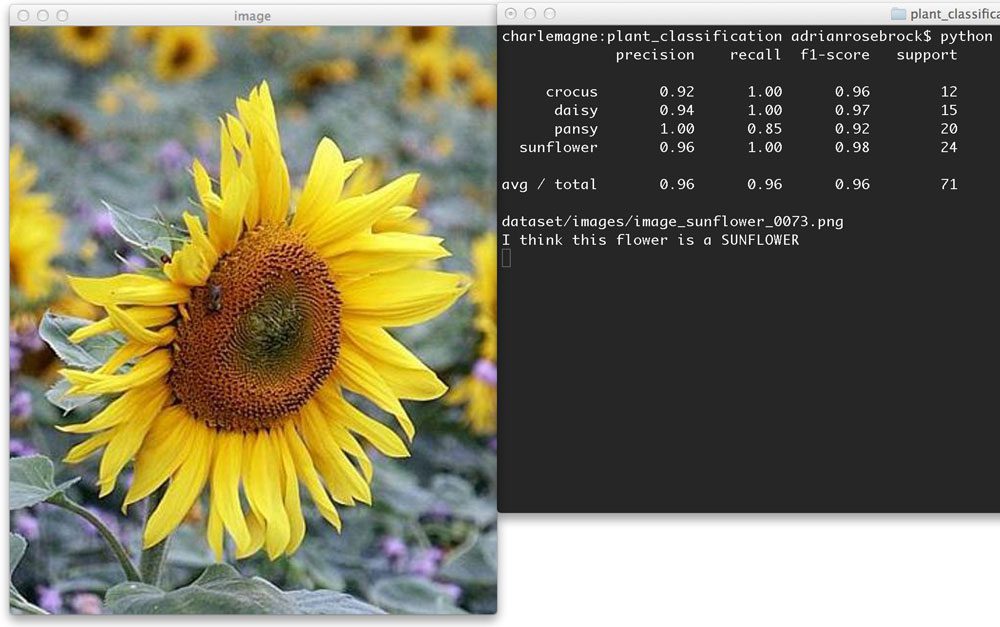
Figure 4: Learn how to apply machine learning techniques to classify the species of flowers.
计算机视觉的一个常见用途是对图像内容进行分类。为了做到这一点,你需要利用机器学习。这一章探索了如何使用 OpenCV 提取颜色直方图,然后使用 scikit-learn 训练一个随机森林分类器对一种花进行分类。
#5.构建 Amazon.com 图书封面搜索
Figure 5: Applying keypoint detection and SIFT descriptors to recognize and identify book covers.
三周前,我和我的朋友格雷戈里出去喝了几杯啤酒,格雷戈里是旧金山一位炙手可热的企业家,他一直在开发一款软件,只使用一张图像就能立即识别和识别图书封面。使用这款软件,用户可以拍下他们感兴趣的书籍的照片,然后将它们自动添加到他们的购物车并运送到他们的家门口——比你的标准Barnes&Noble 便宜得多!
总之,我猜格雷戈里喝了太多啤酒,因为你猜怎么着?
他向我透露了他的秘密。
格雷戈里求我不要说出来…但我无法抗拒。
在本章中,你将学习如何利用关键点提取和 SIFT 描述符来执行关键点匹配。
最终的结果是一个系统,可以识别和识别一本书的封面在一瞬间…你的智能手机!
所有这些例子都有详细的介绍,从前面到后面,有很多代码。
当你读完我的案例研究书后,你将成为解决现实世界计算机视觉问题的专家。
那么这本书是给谁看的呢?
这本书是为像你一样有扎实的计算机视觉和图像处理基础的人准备的。理想情况下,你已经通读了实用 Python 和 OpenCV 并且对基础知识有了很强的掌握(如果你还没有机会阅读实用 Python 和 OpenCV ,绝对拿起一本)。
我认为我的新案例研究书是你学习计算机视觉旅程的下一步。
你看,这本书侧重于计算机视觉的基础知识,然后将它们应用于 解决实际现实世界的问题 。
因此,如果你对应用计算机视觉解决现实世界的问题感兴趣,你肯定会想买一本。
请排队预留您的位置,以便提前入场
如果你注册了我的时事通讯,我会发送每一章的预览,这样你就可以直接看到如何使用计算机视觉技术来解决现实世界的问题。
但是,如果你只是等不及并且想要锁定你的位置来排队接收 提前访问 到我的新案例研究电子书,只需点击这里。
听起来不错吧?
宣布 PyImageJobs:计算机视觉和深度学习工作委员会

今天,我很高兴地宣布 PyImageJobs 已经 正式推出 。
无论你是(1)期待 在计算机视觉、OpenCV 或深度学习领域找到一份工作 ,还是(2)试图 为你的公司、组织或项目填补一个计算机视觉职位——我都有你。
尽管 PyImageJobs 刚刚推出,庞大的 PyImageSearch 网络和社区已经使其成为 最大的计算机视觉就业在线平台 ,将数千名有才华的计算机视觉、图像处理和深度学习开发人员与渴望聘用他们的公司联系起来。
在 PyImageJobs 中,您可以找到以下职位:
- 全职工作
- 兼职职位
- 承包和咨询
- 博士后职位
- 实习
- 小型项目
- …还有更多!
不管你是在找工作还是准备好下一次雇佣,PyImageJobs 都是适合你的工具。
为什么选择 PyImageJobs?
PyImageJobs 是出于需要而发展起来的。为了使 PyImageSearch 社区能够:
- 查找计算机视觉开发人员和工程师的工作职位、承包工作或项目。
- 将潜在的计算机视觉员工与渴望雇用他们的公司、组织和个人联系起来。
你看,每个月我都会收到近 100 份合同/咨询邀请,对我来说太多了,即使我围绕计算机视觉咨询建立了一个完整的公司。
我没有简单地拒绝这些提议,而是决定创建 PyImageJobs,帮助有才华的计算机视觉、图像处理和深度学习开发人员与准备招聘的公司和个人联系。
PyImageJobs 不仅仅是一个工作平台。无论你是在寻找全职员工、兼职员工,还是只是一个小项目的承包商/顾问——请放心,这就是 正是我创建 PyImageJobs 的原因。
由于 PyImageJobs 是由 PyImageSearch.com 社区提供支持的,你可以放心,因为有成千上万的读者准备申请你的职位。
如何在 PyImageJobs 上发布工作或项目?

Figure 1: You can post part-time positions, freelance/contract work, internships, post-doc positions, remote work, and simple projects on PyImageJobs.
我之前提到过,PyImageJobs 并不局限于全职工作。您还可以发布:
- 兼职职位
- 自由职业者/合同工
- 实习
- 博士后职位
- 远程工作
- 简单的项目
无论你是需要在你的公司雇用一名全职计算机视觉工程师,还是仅仅需要一名计算机视觉开发人员来帮助你当前的项目,试试 PyImageJobs 吧——我非常有信心你能找到一名符合你需求的开发人员。
要在 PyImageJobs 上发布您的下一份工作/项目:
- 前往 PyImageJobs 网站。
- 点击定价链接并选择一个计划。
- 填写职位描述。
一旦提交,您的工作将在 24 小时内发布,使您能够接触到成千上万活跃的计算机视觉、深度学习和 OpenCV 求职者。
**## 礼宾职位描述撰写服务(仅限限时)
在过去的一周里,我非常愉快地和一些雇主一起测试了 PyImageJobs 网站。
在几乎所有情况下我都注意到在雇主发布工作和他们找到下一个计算机视觉雇员之间的主要障碍是起草工作描述本身。
*招聘费用不是问题。这也不是信任问题——他们知道 PyImageJobs 和相关的 PyImageSearch 社区可以提供合格的应用程序。
相反,最主要的问题是,写一份工作描述可能是一个耗时且乏味的过程,尤其是如果你几乎没有写工作清单的经验。
毫无疑问——写一份完美的工作描述具有挑战性。幸运的是,我有多年的经验,不仅是与计算机视觉工程师一起工作,也有雇佣他们的经验。
对于一个 限时 ,我提供一个 礼宾职位说明书撰写服务 。在未来,我将为这项服务向收费,所以如果你想让我为你写你的工作/项目描述,确保你现在利用这个机会。
简单地告诉我你的工作,我会帮你起草一份工作描述,保证得到申请人。
很难达成这样的交易。
要注册礼宾写作服务,只需使用以下链接并给我发消息:
https://pyimagesearch.com/contact/
我如何获得 PyImageJobs 上的工作或项目?
为了得到一份工作或一个项目,我建议你做两件事。
首先,前往 PyImageJobs 网站并注册即时电子邮件通知:

Figure 2: Sign up for instant notifications to receive an email whenever a new job is posted on PyImageJobs. Don’t miss out on a great opportunity because you found out too late!
这将确保您在发布新职位的第一时间收到电子邮件通知。你不想因为发现得太晚而错过一个绝佳的工作机会吧!注册即时职位发布通知还将确保您每周收到 PyImageJobs 上发布的热门/新职位的精选摘要。
其次,准备好你的简历或者履历。确保它是最新的,并且包含您最近的项目。
当您准备申请工作时,点击工作列表,然后滚动到“申请该工作”按钮:

Figure 3: Applying for a job/position on PyImageJobs is as simple as filling out four quick fields.
点击此按钮将打开一个表格,您可以用它来申请该职位。您的信息将直接发送给雇主。
在未来的 PyImageSearch 博客帖子中,我将分享更多关于如何在申请 PyImageJobs 职位时让自己从人群中脱颖而出的信息。
摘要
今天,我很高兴地宣布 PyImageJobs 正式上线 。
无论你是(1)期待 在计算机视觉、OpenCV 或深度学习领域找到一份工作 ,还是(2)试图 为你的公司、组织或项目填补一个计算机视觉职位——我都有你。
如果你有兴趣提交你的工作或项目,请联系我,我会帮你发布你的工作。在有限的时间里,我甚至提供礼宾写作服务来帮你起草完美的工作/项目描述。
如果你想开始申请计算机视觉的工作,去 PyImageJobs 网站注册即时电子邮件通知列表(这样你就不会错过一个很好的工作机会)。
享受就业委员会,如果你有任何问题,请让我知道!***
宣布 PyImageSearch Web API
原文:https://pyimagesearch.com/2015/05/18/announcing-the-pyimagesearch-web-api/

今天我超级兴奋地正式宣布PyImageSearch web API。
我已经计划构建这个 API 有一段时间了,最后,上周关于构建一个人脸检测 Web API 的博客帖子正是我完成这个项目并将其发布到网上所需要的动力。
PyImageSearch Web API 是一个教学工具,用于进一步促进 PyImageSearch 博客上的高质量计算机视觉教程。
目前唯一的终点是图像中的人脸检测,但随着我在 PyImageSearch 博客上发布更多文章,终点的列表将继续增长。
例如,想象一下能够与我们构建的图像搜索引擎进行交互,以通过度假照片 进行 搜索。
一个 API 端点来处理 移动文档扫描 怎么样?
或者也许我们可以包装一个 深度学习分类器来识别手写数字 ?
正如你所看到的,有相当多的可能性——我认为我们会从这个 API 中获得很多乐趣。
因此,请留意新的 PyImageSearch 博客帖子的发布。在适当的时候,我会加入新的 API 端点。
在哪里可以访问 PyImageSearch Web API?
PyImageSearch Web API 可以在 http://api.pyimagesearch.com 的找到,其中也包括每个端点的文档。
PyImageSearch Web API 是免费的吗?
你打赌!PyImageSearch Web API100%免费。健康地使用它来帮助你的计算机视觉教育。
我可以在自己的应用程序中使用 PyImageSearch Web API 吗?
我会建议反对这样做。PyImageSearch web API 本来是一个教学工具,所以如果你滥用 API,我将不得不开始发布 API 密钥——这是我、真的不想做的事情。
PyImageSearch Web API 有商业版吗?
也许将来会有 PyImageSearch Web API 的商业版本,您可以在自己的应用程序中使用它,但不是现在。如果随着 API 的发展,人们对它有足够的兴趣,我当然可以想象创建一个商业的、生产级别的 API 版本,并授权给开发者。
我可以贡献 PyImageSearch Web API 吗?
如果你已经开发了一个你认为会成为一个伟大的端点的计算机视觉应用,请给我发消息。我还会建议你使用我的样板 Django 视图模板(可以在页面中间找到)来包装你的应用程序,以构建基于计算机视觉的 web APIs。
如何支持 PyImageSearch Web API?
我个人为运行 PyImageSearch Web API 的服务器和主机支付现金。如果你喜欢它,觉得它有用,或者从中学习到什么,你可以拿起我的书 实用 Python 和 OpenCV 的副本来支持我自己和 PyImageSearch 博客。否则,请欣赏 API!
请求一个 API 端点?
你认为之前在 PyImageSearch 博客上的一篇文章会成为一个好的 API 端点吗?或者对包含 API 端点的计算机视觉教程有什么建议?在下面评论这篇文章让我知道或者给我发消息。
使用 Keras、TensorFlow 和深度学习进行异常检测
原文:https://pyimagesearch.com/2020/03/02/anomaly-detection-with-keras-tensorflow-and-deep-learning/
在本教程中,您将学习如何使用自动编码器、Keras 和 TensorFlow 执行异常和异常值检测。
早在一月份,我就向您展示了如何使用标准的机器学习模型来执行图像数据集中的异常检测和异常值检测。
我们的方法非常有效,但它回避了一个问题:
深度学习可以用来提高我们异常检测器的准确性吗?
要回答这样一个问题,我们需要深入兔子洞,回答如下问题:
- 我们应该使用什么模型架构?
- 对于异常/异常值检测,某些深度神经网络架构是否优于其他架构?
- 我们如何处理阶级不平衡的问题?
- 如果我们想训练一个无人监管的异常检测器会怎么样?
本教程解决了所有这些问题,在它结束时,您将能够使用深度学习在自己的图像数据集中执行异常检测。
要了解如何使用 Keras、TensorFlow 和深度学习执行异常检测,继续阅读!
使用 Keras、TensorFlow 和深度学习进行异常检测
在本教程的第一部分,我们将讨论异常检测,包括:
- 是什么让异常检测如此具有挑战性
- 为什么传统的深度学习方法不足以检测异常/异常值
- 自动编码器如何用于异常检测
在此基础上,我们将实现一个自动编码器架构,该架构可用于使用 Keras 和 TensorFlow 进行异常检测。然后,我们将以一种无人监管的方式训练我们的自动编码器模型。
一旦训练了自动编码器,我将向您展示如何使用自动编码器来识别您的训练/测试集和不属于数据集分割的新图像中的异常值/异常。
什么是异常检测?
引用我的介绍异常检测教程:
异常被定义为偏离标准、很少发生、不遵循“模式”其余部分的事件
异常情况的例子包括:
- 由世界事件引起的股票市场的大幅下跌和上涨
- 工厂里/传送带上的次品
- 实验室中被污染的样本
根据您的具体使用案例和应用,异常通常只发生 0.001-1%的时间——这是一个令人难以置信的小部分时间。
这个问题只是因为我们的阶级标签中存在巨大的不平衡而变得更加复杂。
根据定义,异常将很少发生,所以我们的大多数数据点将是有效事件。
为了检测异常,机器学习研究人员创建了隔离森林、一类支持向量机、椭圆包络和局部离群因子等算法来帮助检测此类事件;然而,所有这些方法都植根于传统的机器学习。
深度学习呢?
深度学习是否也可以用于异常检测?
答案是肯定的——但是你需要正确地描述这个问题。
深度学习和自动编码器如何用于异常检测?
正如我在我的自动编码器简介教程中所讨论的,自动编码器是一种无监督的神经网络,它可以:
- 接受一组输入数据
- 在内部将数据压缩成潜在空间表示
- 从潜在表示中重建输入数据
为了完成这项任务,自动编码器使用两个组件:一个编码器和一个解码器。
编码器接受输入数据并将其压缩成潜在空间表示。解码器然后试图从潜在空间重建输入数据。
当以端到端的方式训练时,网络的隐藏层学习鲁棒的滤波器,甚至能够对输入数据进行去噪。
然而,从异常检测的角度来看,使自动编码器如此特殊的是重建损失。当我们训练自动编码器时,我们通常测量以下各项之间的均方误差 (MSE):
- 输入图像
- 来自自动编码器的重建图像
损失越低,自动编码器在重建图像方面做得越好。
现在让我们假设我们在整个 MNIST 数据集上训练了一个自动编码器:
然后,我们向自动编码器提供一个数字,并告诉它重建它:
我们希望自动编码器在重建数字方面做得非常好,因为这正是自动编码器被训练做的事情,如果我们观察输入图像和重建图像之间的 MSE,我们会发现它非常低。
现在让我们假设我们向自动编码器展示了一张大象的照片,并要求它重建它:
由于自动编码器在之前从未见过大象,更重要的是,从未被训练来重建大象,* 我们的 MSE 将非常高。*
如果重建的 MSE 很高,那么我们可能有一个异常值。
Alon Agmon 在这篇文章中更详细地解释了这个概念。
配置您的开发环境
为了跟随今天的异常检测教程,我推荐您使用 TensorFlow 2.0。
要配置您的系统并安装 TensorFlow 2.0,您可以遵循 my Ubuntu 或 macOS 指南:
- 如何在 UbuntuT3 上安装 tensor flow 2.0【Ubuntu 18.04 OS;CPU 和可选的 NVIDIA GPU)
- 如何在 macOS 上安装 tensor flow 2.0(Catalina 和 Mojave OSes)
请注意: PyImageSearch 不支持 Windows — 参考我们的 FAQ 。
项目结构
继续从这篇文章的 “下载” 部分抓取代码。一旦你解压了这个项目,你会看到下面的结构:
$ tree --dirsfirst
.
├── output
│ ├── autoencoder.model
│ └── images.pickle
├── pyimagesearch
│ ├── __init__.py
│ └── convautoencoder.py
├── find_anomalies.py
├── plot.png
├── recon_vis.png
└── train_unsupervised_autoencoder.py
2 directories, 8 files
我们的convautoencoder.py文件包含负责构建 Keras/TensorFlow 自动编码器实现的ConvAutoencoder类。
我们将使用train_unsupervised_autoencoder.py中未标记的数据训练一个自动编码器,产生以下输出:
autoencoder.model:序列化、训练好的 autoencoder 模型。- 一系列未标记的图像,我们可以从中发现异常。
- 由我们的训练损失曲线组成的图。
recon_vis.png:将地面实况数字图像的样本与每个重建图像进行比较的可视化图形。
从那里,我们将在find_anomalies.py内部开发一个异常检测器,并应用我们的自动编码器来重建数据并发现异常。
使用 Keras 和 TensorFlow 实现我们的异常检测自动编码器
深度学习异常检测的第一步是实现我们的 autoencoder 脚本。
我们的卷积自动编码器实现与我们的自动编码器介绍文章以及我们的去噪自动编码器教程中的实现完全相同;然而,为了完整起见,我们将在这里回顾一下——如果你想了解关于自动编码器的更多细节,请务必参考那些帖子。
打开convautoencoder.py并检查:
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
import numpy as np
class ConvAutoencoder:
@staticmethod
def build(width, height, depth, filters=(32, 64), latentDim=16):
# initialize the input shape to be "channels last" along with
# the channels dimension itself
# channels dimension itself
inputShape = (height, width, depth)
chanDim = -1
# define the input to the encoder
inputs = Input(shape=inputShape)
x = inputs
# loop over the number of filters
for f in filters:
# apply a CONV => RELU => BN operation
x = Conv2D(f, (3, 3), strides=2, padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# flatten the network and then construct our latent vector
volumeSize = K.int_shape(x)
x = Flatten()(x)
latent = Dense(latentDim)(x)
# build the encoder model
encoder = Model(inputs, latent, name="encoder")
进口包括tf.keras和 NumPy。
我们的ConvAutoencoder类包含一个静态方法build,它接受五个参数:
width:输入图像的宽度。height:输入图像的高度。depth:图像中的通道数。filters:编码器和解码器将分别学习的滤波器数量latentDim:潜在空间表示的维度。
然后为编码器定义了Input,此时我们使用 Keras 的函数 API 循环遍历我们的filters,并添加我们的CONV => LeakyReLU => BN层集合。
然后我们拉平网络,构建我们的潜在向量。潜在空间表示是我们数据的压缩形式。
在上面的代码块中,我们使用自动编码器的encoder部分来构建我们的潜在空间表示——这个相同的表示现在将用于重建原始输入图像:
# start building the decoder model which will accept the
# output of the encoder as its inputs
latentInputs = Input(shape=(latentDim,))
x = Dense(np.prod(volumeSize[1:]))(latentInputs)
x = Reshape((volumeSize[1], volumeSize[2], volumeSize[3]))(x)
# loop over our number of filters again, but this time in
# reverse order
for f in filters[::-1]:
# apply a CONV_TRANSPOSE => RELU => BN operation
x = Conv2DTranspose(f, (3, 3), strides=2,
padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# apply a single CONV_TRANSPOSE layer used to recover the
# original depth of the image
x = Conv2DTranspose(depth, (3, 3), padding="same")(x)
outputs = Activation("sigmoid")(x)
# build the decoder model
decoder = Model(latentInputs, outputs, name="decoder")
# our autoencoder is the encoder + decoder
autoencoder = Model(inputs, decoder(encoder(inputs)),
name="autoencoder")
# return a 3-tuple of the encoder, decoder, and autoencoder
return (encoder, decoder, autoencoder)
这里,我们采用潜在的输入,并使用完全连接的层将其重塑为 3D 体积(即,图像数据)。
我们再次循环我们的过滤器,但是以相反的顺序,应用一系列的CONV_TRANSPOSE => RELU => BN层。CONV_TRANSPOSE层的目的是将体积大小增加回原始图像的空间尺寸。
最后,我们建立了解码器模型并构建了自动编码器。回想一下,自动编码器由编码器和解码器组件组成。然后,我们返回编码器、解码器和自动编码器的三元组。
同样,如果您需要关于我们的 autoencoder 实现的更多细节,请务必查看前面提到的教程。
实施异常检测培训脚本
随着我们的 autoencoder 的实现,我们现在准备继续我们的训练脚本。
打开项目目录中的train_unsupervised_autoencoder.py文件,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.convautoencoder import ConvAutoencoder
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
导入包括我们的ConvAutoencoder、数据集mnist的实现,以及一些来自 TensorFlow、scikit-learn 和 OpenCV 的导入。
假设我们正在执行无监督学习,接下来我们将定义一个函数来构建一个无监督数据集:
def build_unsupervised_dataset(data, labels, validLabel=1,
anomalyLabel=3, contam=0.01, seed=42):
# grab all indexes of the supplied class label that are *truly*
# that particular label, then grab the indexes of the image
# labels that will serve as our "anomalies"
validIdxs = np.where(labels == validLabel)[0]
anomalyIdxs = np.where(labels == anomalyLabel)[0]
# randomly shuffle both sets of indexes
random.shuffle(validIdxs)
random.shuffle(anomalyIdxs)
# compute the total number of anomaly data points to select
i = int(len(validIdxs) * contam)
anomalyIdxs = anomalyIdxs[:i]
# use NumPy array indexing to extract both the valid images and
# "anomlay" images
validImages = data[validIdxs]
anomalyImages = data[anomalyIdxs]
# stack the valid images and anomaly images together to form a
# single data matrix and then shuffle the rows
images = np.vstack([validImages, anomalyImages])
np.random.seed(seed)
np.random.shuffle(images)
# return the set of images
return images
我们的build_supervised_dataset函数接受一个带标签的数据集(即用于监督学习)并把它变成一个无标签的数据集(即用于非监督学习)。
该函数接受一组输入data和labels,包括有效标签和异常标签。
鉴于我们的validLabel=1默认只有 MNIST 数字的被选中;然而,我们也会用一组数字三个图像(validLabel=3)污染我们的数据集。
contam百分比用于帮助我们采样和选择异常数据点。
从我们的一组labels(并使用有效标签),我们生成一个列表validIdxs ( 第 22 行)。完全相同的过程适用于抓取anomalyIdxs ( 线 23 )。然后,我们继续随机shuffle索引(第 26 行和第 27 行)。
考虑到我们的异常污染百分比,我们减少了我们的anomalyIdxs ( 行 30 和 31 )。
第 35 行和第 36 行然后构建两组图像:(1)有效图像和(2)异常图像。
这些列表中的每一个被堆叠以形成单个数据矩阵,然后被混洗并返回(行 40-45 )。注意到标签被有意丢弃,有效地使我们的数据集为无监督学习做好准备。
我们的下一个功能将帮助我们可视化无监督自动编码器做出的预测:
def visualize_predictions(decoded, gt, samples=10):
# initialize our list of output images
outputs = None
# loop over our number of output samples
for i in range(0, samples):
# grab the original image and reconstructed image
original = (gt[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# return the output images
return outputs
visualize_predictions函数是一个助手方法,用于可视化自动编码器的输入图像及其相应的输出重建。original和重建(recon)图像将根据samples参数的数量并排排列并垂直堆叠。如果你读过我的自动编码器简介指南或者去噪自动编码器教程,这段代码应该看起来很熟悉。
既然我们已经定义了导入和必要的函数,我们将继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to output dataset file")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to output trained autoencoder")
ap.add_argument("-v", "--vis", type=str, default="recon_vis.png",
help="path to output reconstruction visualization file")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
我们的函数接受四个命令行参数,它们都是输出文件路径:
--dataset:定义输出数据集文件的路径--model:指定输出训练自动编码器的路径--vis:指定输出可视化文件路径的可选参数。默认情况下,我将这个文件命名为recon_vis.png;但是,欢迎您用不同的路径和文件名覆盖它--plot: 可选的表示输出训练历史图的路径。默认情况下,该图将在当前工作目录中被命名为plot.png
现在,我们准备好了用于训练的数据:
# initialize the number of epochs to train for, initial learning rate,
# and batch size
EPOCHS = 20
INIT_LR = 1e-3
BS = 32
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, trainY), (testX, testY)) = mnist.load_data()
# build our unsupervised dataset of images with a small amount of
# contamination (i.e., anomalies) added into it
print("[INFO] creating unsupervised dataset...")
images = build_unsupervised_dataset(trainX, trainY, validLabel=1,
anomalyLabel=3, contam=0.01)
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
images = np.expand_dims(images, axis=-1)
images = images.astype("float32") / 255.0
# construct the training and testing split
(trainX, testX) = train_test_split(images, test_size=0.2,
random_state=42)
首先,我们初始化三个超参数:(1)训练时期的数量,(2)初始学习率,以及(3)我们的批量大小(第 86-88 行)。
行 92 加载 MNIST,而行 97 和 98 构建我们的无监督数据集,其中添加了 1%的污染(即异常)。
从这里开始,我们的数据集没有标签,我们的自动编码器将尝试学习模式,而无需事先了解数据是什么。
现在我们已经建立了无监督数据集,它由 99%的数字 1 和 1%的数字 3(即异常/异常值)组成。
从那里,我们通过添加通道维度和缩放像素强度到范围【0,1】(行 102 和 103 )来预处理我们的数据集。
使用 scikit-learn 的便利功能,我们将数据分成 80%的训练集和 20%的测试集(行 106 和 107 )。
我们的数据已经准备好了,所以让我们构建我们的自动编码器并训练它:
# construct our convolutional autoencoder
print("[INFO] building autoencoder...")
(encoder, decoder, autoencoder) = ConvAutoencoder.build(28, 28, 1)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
autoencoder.compile(loss="mse", optimizer=opt)
# train the convolutional autoencoder
H = autoencoder.fit(
trainX, trainX,
validation_data=(testX, testX),
epochs=EPOCHS,
batch_size=BS)
# use the convolutional autoencoder to make predictions on the
# testing images, construct the visualization, and then save it
# to disk
print("[INFO] making predictions...")
decoded = autoencoder.predict(testX)
vis = visualize_predictions(decoded, testX)
cv2.imwrite(args["vis"], vis)
我们用Adam优化器构建我们的autoencoder,用均方差loss ( 第 111-113 行)构建compile。
第 116-120 行使用 TensorFlow/Keras 启动培训程序。我们的自动编码器将尝试学习如何重建原始输入图像。不容易重建的图像将具有大的损失值。
一旦训练完成,我们将需要一种方法来评估和直观检查我们的结果。幸运的是,我们的后口袋里有我们的visualize_predictions便利功能。第 126-128 行对测试集进行预测,根据结果构建可视化图像,并将输出图像写入磁盘。
从这里开始,我们将总结:
# construct a plot that plots and saves the training history
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# serialize the image data to disk
print("[INFO] saving image data...")
f = open(args["dataset"], "wb")
f.write(pickle.dumps(images))
f.close()
# serialize the autoencoder model to disk
print("[INFO] saving autoencoder...")
autoencoder.save(args["model"], save_format="h5")
最后,我们:
- 绘制我们的训练历史损失曲线,并将结果图导出到磁盘(行 131-140 )
- 将我们无监督的采样 MNIST 数据集序列化为 Python pickle 文件存储到磁盘,这样我们就可以用它来发现
find_anomalies.py脚本中的异常(第 144-146 行 - 救救我们训练有素的
autoencoder( 第 150 行)
开发无监督的自动编码器训练脚本的精彩工作。
使用 Keras 和 TensorFlow 训练我们的异常探测器
为了训练我们的异常检测器,请确保使用本教程的 “下载” 部分下载源代码。
从那里,启动一个终端并执行以下命令:
$ python train_unsupervised_autoencoder.py \
--dataset output/images.pickle \
--model output/autoencoder.model
[INFO] loading MNIST dataset...
[INFO] creating unsupervised dataset...
[INFO] building autoencoder...
Train on 5447 samples, validate on 1362 samples
Epoch 1/20
5447/5447 [==============================] - 7s 1ms/sample - loss: 0.0421 - val_loss: 0.0405
Epoch 2/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0129 - val_loss: 0.0306
Epoch 3/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0045 - val_loss: 0.0088
Epoch 4/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0033 - val_loss: 0.0037
Epoch 5/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0029 - val_loss: 0.0027
...
Epoch 16/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0018 - val_loss: 0.0020
Epoch 17/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0018 - val_loss: 0.0020
Epoch 18/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0017 - val_loss: 0.0021
Epoch 19/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0018 - val_loss: 0.0021
Epoch 20/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0016 - val_loss: 0.0019
[INFO] making predictions...
[INFO] saving image data...
[INFO] saving autoencoder...
Figure 5: In this plot we have our loss curves from training an autoencoder with Keras, TensorFlow, and deep learning.
在我的 3Ghz 英特尔至强处理器上训练整个模型花费了 ~2 分钟,正如我们在图 5 中的训练历史图所示,我们的训练相当稳定。
此外,我们可以查看我们的输出recon_vis.png可视化文件,以了解我们的自动编码器已经学会从 MNIST 数据集正确地重建1数字:

Figure 6: Reconstructing a handwritten digit using a deep learning autoencoder trained with Keras and TensorFlow.
在继续下一部分之前,您应该确认autoencoder.model和images.pickle文件已经正确保存到您的output目录中:
$ ls output/
autoencoder.model images.pickle
在下一节中,您将需要这些文件。
使用 autoencoder 实现我们的脚本来发现异常/异常值
我们现在的目标是:
- 以我们预先训练的自动编码器为例
- 使用它进行预测(即,重建数据集中的数字)
- 测量原始输入图像和重建图像之间的 MSE
- 计算 MSE 的分位数,并使用这些分位数来识别异常值和异常值
打开find_anomalies.py文件,让我们开始吧:
# import the necessary packages
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import pickle
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input image dataset file")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained autoencoder")
ap.add_argument("-q", "--quantile", type=float, default=0.999,
help="q-th quantile used to identify outliers")
args = vars(ap.parse_args())
我们将从导入和命令行参数开始。从tf.keras导入的load_model使我们能够从磁盘加载序列化的 autoencoder 模型。命令行参数包括:
--dataset:我们的输入数据集 pickle 文件的路径,该文件作为我们的无监督训练脚本的结果被导出到磁盘--model:我们训练有素的自动编码器路径--quantile:识别异常值的第 q 个分位数
从这里,我们将(1)加载我们的自动编码器和数据,以及(2)进行预测:
# load the model and image data from disk
print("[INFO] loading autoencoder and image data...")
autoencoder = load_model(args["model"])
images = pickle.loads(open(args["dataset"], "rb").read())
# make predictions on our image data and initialize our list of
# reconstruction errors
decoded = autoencoder.predict(images)
errors = []
# loop over all original images and their corresponding
# reconstructions
for (image, recon) in zip(images, decoded):
# compute the mean squared error between the ground-truth image
# and the reconstructed image, then add it to our list of errors
mse = np.mean((image - recon) ** 2)
errors.append(mse)
第 20 行和第 21 行从磁盘加载autoencoder和images数据。
然后,我们通过我们的autoencoder传递images的集合,以进行预测并尝试重建输入(第 25 行)。
在原始和重建图像上循环,行 30-34 计算地面实况和重建图像之间的均方误差,建立errors的列表。
从这里,我们会发现异常:
# compute the q-th quantile of the errors which serves as our
# threshold to identify anomalies -- any data point that our model
# reconstructed with > threshold error will be marked as an outlier
thresh = np.quantile(errors, args["quantile"])
idxs = np.where(np.array(errors) >= thresh)[0]
print("[INFO] mse threshold: {}".format(thresh))
print("[INFO] {} outliers found".format(len(idxs)))
第 39 行计算误差的 q 分位数——这个值将作为我们检测异常值的阈值。
对照thresh、线 40 测量每个误差,确定数据中所有异常的指数。因此,任何具有值>= thresh的 MSE 都被认为是异常值。
接下来,我们将遍历数据集中的异常指数:
# initialize the outputs array
outputs = None
# loop over the indexes of images with a high mean squared error term
for i in idxs:
# grab the original image and reconstructed image
original = (images[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# show the output visualization
cv2.imshow("Output", outputs)
cv2.waitKey(0)
在循环内部,我们并排排列每个original和recon图像,将所有结果垂直堆叠为一个outputs图像。第 66 和 67 行显示结果图像。
具有深度学习结果的异常检测
我们现在准备使用深度学习和我们训练的 Keras/TensorFlow 模型来检测我们数据集中的异常。
首先,确保您已经使用本教程的 “下载” 部分下载了源代码——从这里,您可以执行以下命令来检测我们数据集中的异常:
$ python find_anomalies.py --dataset output/images.pickle \
--model output/autoencoder.model
[INFO] loading autoencoder and image data...
[INFO] mse threshold: 0.02863757349550724
[INFO] 7 outliers found
MSE 阈值约为 0.0286,对应于 99.9%的分位数,我们的自动编码器能够找到七个异常值,其中五个被正确标记为:
Figure 7: Shown are anomalies that have been detected from reconstructing data with a Keras-based autoencoder.
尽管自动编码器仅在 MNIST 数据集(总共 67 个样本)的所有3数字中的 1%上被训练,但在给定有限数据的情况下,自动编码器在重建它们方面做得非常好— ,但我们可以看到这些重建的 MSE 高于其他重建。
此外,被错误标记为异常值的1数字也可能被认为是可疑的。
深度学习实践者可以使用自动编码器来发现他们数据集中的异常值,即使图像被正确标记为!
正确标记但表明深度神经网络架构存在问题的图像应该表示值得进一步探索的图像子类——自动编码器可以帮助您发现这些异常子类。
我的自动编码器异常检测精度不够好。我该怎么办?
Figure 8: Anomaly detection with unsupervised deep learning models is an active area of research and is far from solved. (image source: Figure 4 of Deep Learning for Anomaly Detection: A Survey by Chalapathy and Chawla)
无监督学习,特别是异常/异常值检测,距离机器学习、深度学习和计算机视觉的解决领域很远—没有现成的异常检测解决方案是 100%正确的。
我建议你阅读 2019 年的调查论文, 深度学习异常检测:一项调查 ,由 Chalapathy 和 Chawla 撰写,以了解更多关于当前基于深度学习的异常检测的最新信息。
虽然很有希望,但请记住,该领域正在快速发展,但异常/异常值检测距离解决问题还很远。
摘要
在本教程中,您学习了如何使用 Keras、TensorFlow 和深度学习来执行异常和异常值检测。
传统的分类架构不足以进行异常检测,因为:
- 它们不能在无人监督的情况下使用
- 他们努力处理严重的阶级不平衡
- 因此,他们很难正确地回忆起异常值
另一方面,自动编码器:
- 自然适用于无人监督的问题
- 学会对输入图像进行编码和重构
- 可以通过测量编码图像和重建图像之间的误差来检测异常值
我们以一种无监督的方式在 MNIST 数据集上训练我们的自动编码器,通过移除类别标签,抓取所有具有值1的标签,然后使用 1%的3标签。
正如我们的结果所显示的,我们的自动编码器能够挑出许多用来“污染”我们的1的3数字。
如果你喜欢这个基于深度学习的异常检测教程,请在评论中告诉我!你的反馈有助于指导我将来写什么教程。
要下载这篇博文的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
使用 Python 将深度学习和 RBM 应用于 MNIST
原文:https://pyimagesearch.com/2014/06/23/applying-deep-learning-rbm-mnist-using-python/

在我的上一篇文章中,我提到过,当利用原始像素作为特征向量时,图像中微小的一个像素偏移会破坏受限的玻尔兹曼机器+分类器流水线的性能。
今天我将继续这一讨论。
更重要的是,我将提供一些 Python 和 scikit-learn 代码,你可以使用这些代码来将受限的波尔兹曼机器应用到你自己的图像分类问题中。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
但是在我们进入代码之前,让我们花点时间来讨论一下 MNIST 数据集。
MNIST 数据集

Figure 1: MNIST digit recognition sample
MNIST 数据集是计算机视觉和机器学习文献中研究得最多的数据集之一。在许多情况下,它是一个基准,一些机器学习算法的排名标准。
这个数据集的目标是正确分类手写数字 0-9。我们不打算利用整个数据集(由 60,000 幅训练图像和 10,000 幅测试图像组成),而是利用一个小样本(3,000 幅用于训练,2,000 幅用于测试)。每个数字的数据点大致均匀分布,因此不存在明显的类别标签不平衡。
每个特征向量是 784-dim,对应于图像的28×28灰度像素强度。这些灰度像素强度是无符号整数,范围在[0,255]内。
所有数字都放在黑色背景上,前景是白色和灰色阴影。
给定这些原始像素强度,我们将首先根据我们的训练数据训练一个受限的玻尔兹曼机器,以学习数字的无监督特征表示。
然后,我们将采用这些“学习”的特征,并在它们的基础上训练一个逻辑回归分类器。
为了评估我们的管道,我们将获取测试数据,并通过我们的分类器运行它,并报告准确性。
然而,我在之前的帖子中提到,测试集图像简单的一个像素平移会导致精度下降,即使这些平移小到人眼几乎察觉不到(如果有的话)。
为了测试这种说法,我们将通过将每幅图像向上、向下、向左和向右平移一个像素来生成一个比原始图像大四倍的测试集。
最后,我们将通过管道传递这个“轻推”数据集,并报告我们的结果。
听起来不错吧?
让我们检查一些代码。

使用 Python 将 RBM 应用于 MNIST 数据集
我们要做的第一件事是创建一个文件rbm.py,并开始导入我们需要的包:
# import the necessary packages
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import BernoulliRBM
from sklearn.grid_search import GridSearchCV
from sklearn.pipeline import Pipeline
import numpy as np
import argparse
import time
import cv2
我们将从导入 scikit-learn 的cross_validation子包中的train_test_split函数开始。train_test_split函数将使我们创建 MNIST 数据集的训练和测试分割变得非常简单。
接下来,我们将从metrics子包中导入classification_report函数,我们将使用它来生成一个关于(1)整个系统和(2)每个单独类标签的精度的格式良好的精度报告。
在第 4 行的上,我们将导入我们将在整个例子中使用的分类器——一个LogisticRegression分类器。
我提到过,我们将使用受限玻尔兹曼机器来学习原始像素值的无监督表示。这将由 scikit-learn 的neural_network子包中的BernoulliRBM类来处理。
BernoulliRBM实现(顾名思义),由二进制可见单元和二进制隐藏节点组成。算法本身是 O(d² ) ,其中 d 是需要学习的元件个数。
为了找到逻辑回归系数C的最佳值,以及我们的 RBM 的最佳学习速率、迭代次数和组件数量,我们需要在特征空间上执行交叉验证网格搜索。GridSearchCV类(我们在6 号线上导入的)将为我们处理这个搜索。
接下来,我们需要在行 7 导入的Pipeline类。这个类允许我们使用 scikit-learn 估计器的拟合和转换方法来定义一系列步骤。
我们的分类管道将包括首先训练一个BernoulliRBM来学习特征空间的无监督表示,然后在学习的特征上训练一个LogisticRegression分类器。
最后,我们导入 NumPy 进行数值处理,argparse解析命令行参数,time跟踪给定模型训练所需的时间,而cv2用于 OpenCV 绑定。
但是在我们开始之前,我们首先需要设置一些函数来加载和操作我们的 MNIST 数据集:
def load_digits(datasetPath):
# build the dataset and then split it into data
# and labels
X = np.genfromtxt(datasetPath, delimiter = ",", dtype = "uint8")
y = X[:, 0]
X = X[:, 1:]
# return a tuple of the data and targets
return (X, y)
load_digits函数,顾名思义,从磁盘上加载我们的 MNIST 数字数据集。该函数采用一个参数datasetPath,它是数据集 CSV 文件所在的路径。
我们使用np.genfromtxt函数从磁盘上加载 CSV 文件,在行 17 上抓取类标签(这是 CSV 文件的第一列),然后在行 18 上抓取实际的原始像素特征向量。这些特征向量是 784 维的,对应于灰度数字图像的28×28展平表示。
最后,我们在第 21 行的上返回我们的特征向量矩阵和类标签的元组。
接下来,我们需要一个函数对我们的数据进行一些预处理。
BernoulliRBM假设我们的特征向量的列落在范围[0,1]内。但是,MNIST 数据集表示为无符号的 8 位整数,范围在[0,255]内。
为了将列缩放到范围[0,1],我们需要做的就是定义一个scale函数:
def scale(X, eps = 0.001):
# scale the data points s.t the columns of the feature space
# (i.e the predictors) are within the range [0, 1]
return (X - np.min(X, axis = 0)) / (np.max(X, axis = 0) + eps)
scale函数有两个参数,我们的数据矩阵X和一个用于防止被零除错误的 epsilon 值。
这个函数是不言自明的。对于矩阵中 784 列中的每一列,我们从该列的最小值中减去该值,然后除以该列的最大值。通过这样做,我们确保了每一列的值都在范围[0,1]内。
现在我们需要最后一个函数:一个生成比原始数据集大四倍的“轻推”数据集的方法,将每张图像向上、向下、向左和向右平移一个像素。
为了处理数据集的这种微调,我们将创建nudge函数:
def nudge(X, y):
# initialize the translations to shift the image one pixel
# up, down, left, and right, then initialize the new data
# matrix and targets
translations = [(0, -1), (0, 1), (-1, 0), (1, 0)]
data = []
target = []
# loop over each of the digits
for (image, label) in zip(X, y):
# reshape the image from a feature vector of 784 raw
# pixel intensities to a 28x28 'image'
image = image.reshape(28, 28)
# loop over the translations
for (tX, tY) in translations:
# translate the image
M = np.float32([[1, 0, tX], [0, 1, tY]])
trans = cv2.warpAffine(image, M, (28, 28))
# update the list of data and target
data.append(trans.flatten())
target.append(label)
# return a tuple of the data matrix and targets
return (np.array(data), np.array(target))
nudge函数有两个参数:我们的数据矩阵X和我们的类标签y。
我们首先初始化一个(x,y) translations列表,然后是新的data矩阵和第 32-34 行的标签。
然后,我们开始遍历Line 37上的每个图像和类标签。
正如我提到的,每个图像都被表示为一个 784 维的特征向量,对应于 28 x 28 数字图像。
然而,为了利用cv2.warpAffine函数来翻译我们的图像,我们首先需要将 784 特征向量重新整形为一个形状为(28, 28)的二维数组——这是在行 40 上处理的。
接下来,我们开始在第 43 条线上的translations上循环。
我们在行 45 上构建我们实际的翻译矩阵M,然后通过调用行 46 上的cv2.warpAffine函数来应用翻译。
然后,我们能够通过将 28 x 28 图像展平回 784-dim 特征向量来更新行 48 上的新的微推data矩阵。
我们的类标签target列表随后在行的第 50 处被更新。
最后,我们在第 53 行的返回新数据矩阵和类标签的元组。
这三个辅助函数虽然本质上很简单,但对于设置我们的实验却至关重要。
现在我们终于可以开始把这些碎片拼在一起了:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "path to the dataset file")
ap.add_argument("-t", "--test", required = True, type = float,
help = "size of test split")
ap.add_argument("-s", "--search", type = int, default = 0,
help = "whether or not a grid search should be performed")
args = vars(ap.parse_args())
第 56-63 行处理解析我们的命令行参数。我们的rbm.py脚本需要三个参数:--dataset,这是我们的 MNIST 所在的路径。csv 文件驻留在磁盘上,--test,用于我们的测试分割的数据百分比(其余用于训练),以及--search,一个用于确定是否应该执行网格搜索来调整超参数的整数。
--search的值1表示应该执行网格搜索;值0表示已经进行了网格搜索,并且已经手动设置了BernoulliRBM和LogisticRegression模型的模型参数。
# load the digits dataset, convert the data points from integers
# to floats, and then scale the data s.t. the predictors (columns)
# are within the range [0, 1] -- this is a requirement of the
# Bernoulli RBM
(X, y) = load_digits(args["dataset"])
X = X.astype("float32")
X = scale(X)
# construct the training/testing split
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size = args["test"], random_state = 42)
现在我们的命令行参数已经被解析了,我们可以在第 69 行的上从磁盘上加载我们的数据集。然后我们在行 70** 上将其转换为浮点数据类型,并使用行 71 上的scale函数将特征向量列缩放到范围[0,1]内。**
为了评估我们的系统,我们需要两组数据:训练集和测试集。我们的管道将使用训练数据进行训练,然后使用测试集进行评估,以确保我们的准确性报告不会有偏差。
为了生成我们的训练和测试分割,我们将调用第 74 行上的train_test_split函数。这个函数会自动为我们生成拆分。
# check to see if a grid search should be done
if args["search"] == 1:
# perform a grid search on the 'C' parameter of Logistic
# Regression
print "SEARCHING LOGISTIC REGRESSION"
params = {"C": [1.0, 10.0, 100.0]}
start = time.time()
gs = GridSearchCV(LogisticRegression(), params, n_jobs = -1, verbose = 1)
gs.fit(trainX, trainY)
# print diagnostic information to the user and grab the
# best model
print "done in %0.3fs" % (time.time() - start)
print "best score: %0.3f" % (gs.best_score_)
print "LOGISTIC REGRESSION PARAMETERS"
bestParams = gs.best_estimator_.get_params()
# loop over the parameters and print each of them out
# so they can be manually set
for p in sorted(params.keys()):
print "\t %s: %f" % (p, bestParams[p])
在行 78 上进行检查,以查看是否应该执行网格搜索来调整我们管道的超参数。
如果要执行网格搜索,我们首先在第 81-85 行上搜索逻辑回归分类器的系数C。我们将对原始像素数据 和 仅使用逻辑回归分类器来评估我们的方法,受限的波尔兹曼机器+逻辑回归分类器,因此我们需要独立地搜索系数C空间。
第 89-97 行然后打印出标准逻辑回归分类器的最佳参数值。
现在我们可以继续我们的管道:一个BernoulliRBM和一个LogisticRegression分类器一起使用。
# initialize the RBM + Logistic Regression pipeline
rbm = BernoulliRBM()
logistic = LogisticRegression()
classifier = Pipeline([("rbm", rbm), ("logistic", logistic)])
# perform a grid search on the learning rate, number of
# iterations, and number of components on the RBM and
# C for Logistic Regression
print "SEARCHING RBM + LOGISTIC REGRESSION"
params = {
"rbm__learning_rate": [0.1, 0.01, 0.001],
"rbm__n_iter": [20, 40, 80],
"rbm__n_components": [50, 100, 200],
"logistic__C": [1.0, 10.0, 100.0]}
# perform a grid search over the parameter
start = time.time()
gs = GridSearchCV(classifier, params, n_jobs = -1, verbose = 1)
gs.fit(trainX, trainY)
# print diagnostic information to the user and grab the
# best model
print "\ndone in %0.3fs" % (time.time() - start)
print "best score: %0.3f" % (gs.best_score_)
print "RBM + LOGISTIC REGRESSION PARAMETERS"
bestParams = gs.best_estimator_.get_params()
# loop over the parameters and print each of them out
# so they can be manually set
for p in sorted(params.keys()):
print "\t %s: %f" % (p, bestParams[p])
# show a reminder message
print "\nIMPORTANT"
print "Now that your parameters have been searched, manually set"
print "them and re-run this script with --search 0"
我们在行 100-102 上定义我们的流水线,由我们的受限波尔兹曼机器和逻辑回归分类器组成。
然而,现在我们有更多的参数可以搜索,而不仅仅是逻辑回归分类器的系数C。现在,我们还必须搜索迭代次数、组件数量(即所得特征空间的大小),以及 RBM 的学习速率。我们在第 108-112 行中定义了这个搜索空间。
我们从第 115-117 行的开始网格搜索。
然后在行 121-129 显示管道的最佳参数。
要确定管道的最佳值,请执行以下命令:
$ python rbm.py --dataset data/digits.csv --test 0.4 --search 1
在搜索网格空间时,您可能想泡一杯咖啡或者出去散散步。对于我们选择的每一个参数,都需要对模型进行训练和交叉验证。肯定不是快速操作。但这是你为最佳参数所付出的代价,当使用受限玻尔兹曼机时,这是至关重要的。
走了很长一段路后,您应该看到已经选择了以下最佳值:
rbm__learning_rate: 0.01
rbm__n_iter: 40
rbm__n_components: 200
logistic__C: 1.0
太棒了。我们的超参数已经调整好了。
让我们设置这些参数并评估我们的分类管道:
# otherwise, use the manually specified parameters
else:
# evaluate using Logistic Regression and only the raw pixel
# features (these parameters were cross-validated)
logistic = LogisticRegression(C = 1.0)
logistic.fit(trainX, trainY)
print "LOGISTIC REGRESSION ON ORIGINAL DATASET"
print classification_report(testY, logistic.predict(testX))
# initialize the RBM + Logistic Regression classifier with
# the cross-validated parameters
rbm = BernoulliRBM(n_components = 200, n_iter = 40,
learning_rate = 0.01, verbose = True)
logistic = LogisticRegression(C = 1.0)
# train the classifier and show an evaluation report
classifier = Pipeline([("rbm", rbm), ("logistic", logistic)])
classifier.fit(trainX, trainY)
print "RBM + LOGISTIC REGRESSION ON ORIGINAL DATASET"
print classification_report(testY, classifier.predict(testX))
# nudge the dataset and then re-evaluate
print "RBM + LOGISTIC REGRESSION ON NUDGED DATASET"
(testX, testY) = nudge(testX, testY)
print classification_report(testY, classifier.predict(testX))
为了获得基线精度,我们将在第行第 140 和 141 的原始像素特征向量上训练一个标准的逻辑回归分类器(无监督学习)。然后使用classification_report功能在行 143 上打印出基线的精度。
然后,我们构建我们的BernoulliRBM + LogisticRegression分类器流水线,并在行 147-155 的测试数据上对其进行评估。
但是,当我们通过将每张图片向上、向下、向左和向右平移一个像素来微调测试集时,会发生什么呢?
为了找到答案,我们在第 162 行的处挪动数据集,然后在第 163 行的处重新评估它。
要评估我们的系统,发出以下命令:
$ python rbm.py --dataset data/digits.csv --test 0.4
几分钟后,我们应该会看到一些结果。
结果
第一组结果是我们在原始像素特征向量上严格训练的逻辑回归分类器:
LOGISTIC REGRESSION ON ORIGINAL DATASET
precision recall f1-score support
0 0.94 0.96 0.95 196
1 0.94 0.97 0.95 245
2 0.89 0.90 0.90 197
3 0.88 0.84 0.86 202
4 0.90 0.93 0.91 193
5 0.85 0.75 0.80 183
6 0.91 0.93 0.92 194
7 0.90 0.90 0.90 212
8 0.85 0.83 0.84 186
9 0.81 0.84 0.83 192
avg / total 0.89 0.89 0.89 2000
使用这种方法,我们能够达到 89%的准确率。使用像素亮度作为我们的特征向量并不坏。
但是看看当我们训练我们的受限玻尔兹曼机+逻辑回归流水线时会发生什么:
RBM + LOGISTIC REGRESSION ON ORIGINAL DATASET
precision recall f1-score support
0 0.95 0.98 0.97 196
1 0.97 0.96 0.97 245
2 0.92 0.95 0.94 197
3 0.93 0.91 0.92 202
4 0.92 0.95 0.94 193
5 0.95 0.86 0.90 183
6 0.95 0.95 0.95 194
7 0.93 0.91 0.92 212
8 0.91 0.90 0.91 186
9 0.86 0.90 0.88 192
avg / total 0.93 0.93 0.93 2000
我们的准确率能够从 89%提高到 93%!这绝对是一个重大的飞跃!
但是现在问题开始了…
当我们轻推数据集,将每幅图像向上、向下、向左和向右平移一个像素时,会发生什么?
我的意思是,这些变化是如此之小,以至于肉眼几乎无法识别。
这当然不成问题,是吗?
事实证明,是这样的:
RBM + LOGISTIC REGRESSION ON NUDGED DATASET
precision recall f1-score support
0 0.94 0.93 0.94 784
1 0.96 0.89 0.93 980
2 0.87 0.91 0.89 788
3 0.85 0.85 0.85 808
4 0.88 0.92 0.90 772
5 0.86 0.80 0.83 732
6 0.90 0.91 0.90 776
7 0.86 0.90 0.88 848
8 0.80 0.85 0.82 744
9 0.84 0.79 0.81 768
avg / total 0.88 0.88 0.88 8000
在轻推我们的数据集后,RBM +逻辑回归管道下降到 88%的准确率。比原始测试集低 5%,比基线逻辑回归分类器低 1%。
所以现在你可以看到使用原始像素亮度作为特征向量的问题。即使是图像中微小的偏移也会导致精确度下降。
但别担心,有办法解决这个问题。
我们如何解决翻译问题?
神经网络、深度网络和卷积网络中的研究人员有两种方法来解决移位和翻译问题。
第一种方法是在训练时生成额外的数据。
在这篇文章中,我们在训练后轻推了一下我们的数据集,看看它对分类准确度的影响。然而,我们也可以在训练之前微调我们的数据集,试图让我们的模型更加健壮。
第二种方法是从我们的训练图像中随机选择区域,而不是完整地使用它们。
例如,我们可以从图像中随机抽取一个 24 x 24 区域,而不是使用整个 28 x 28 图像。做足够多的次数,足够多的训练图像,我们可以减轻翻译问题。
摘要
在这篇博文中,我们已经证明了,即使是人眼几乎无法分辨的图像中微小的一个像素的平移也会损害我们的分类管道的性能。
我们看到精确度下降的原因是因为我们利用原始像素强度作为特征向量。
此外,当利用原始像素强度作为特征时,平移不是唯一会导致精度损失的变形。捕获图像时的旋转、变换甚至噪声都会对模型性能产生负面影响。
为了处理这些情况,我们可以(1)生成额外的训练数据,以尝试使我们的模型更加健壮,和/或(2)从图像中随机采样,而不是完整地使用它。
在实践中,神经网络和深度学习方法比这个实验要稳健得多。通过堆叠层和学习一组卷积核,深度网络能够处理许多这些问题。
不过,如果你刚开始使用原始像素亮度作为特征向量,这个实验还是很重要的。
要么准备好花大量时间预处理您的数据,要么确保您知道如何利用分类模型来处理数据可能不像您希望的那样“干净”和预处理良好的情况。
Python 的 AprilTag
原文:https://pyimagesearch.com/2020/11/02/apriltag-with-python/
在本教程中,您将学习如何使用 Python 和 OpenCV 库执行 AprilTag 检测。
AprilTags 是一种基准标记。基准点,或更简单的“标记”,是参照物,当图像或视频帧被捕获时,这些参照物被放置在摄像机的视野中。
然后,在后台运行的计算机视觉软件获取输入图像,检测基准标记,并基于标记的类型和标记在输入图像中所处的的执行一些操作。
AprilTags 是一种特定的类型的基准标记,由一个以特定图案生成的黑色正方形和白色前景组成(如本教程顶部的图所示)。
标记周围的黑色边框使计算机视觉和图像处理算法更容易在各种情况下检测 AprilTags,包括旋转、缩放、光照条件等的变化。
你可以从概念上认为 AprilTag 类似于 QR 码,这是一种可以使用计算机视觉算法检测的 2D 二进制模式。然而,AprilTag 只能存储 4-12 位数据,比 QR 码少几个数量级(典型的 QR 码最多可存储 3KB 数据)。
那么,为什么还要使用 AprilTags 呢?如果 AprilTags 保存的数据如此之少,为什么不直接使用二维码呢?
AprilTags 存储更少数据的事实实际上是一个特性,而不是一个缺陷/限制。套用官方 AprilTag 文档,由于 AprilTag 有效载荷如此之小,它们可以更容易检测到,更稳健识别到,并且在更长的范围内不太难检测到。
基本上,如果你想在 2D 条形码中存储数据,使用二维码。但是,如果您需要使用更容易在计算机视觉管道中检测到的标记,请使用 AprilTags。
诸如 AprilTags 的基准标记是许多计算机视觉系统的组成部分,包括但不限于:
- 摄像机标定
- 物体尺寸估计
- 测量相机和物体之间的距离
- 3D 定位
- 面向对象
- 机器人技术(即自主导航至特定标记)
- 等。
AprilTags 的主要优点之一是可以使用基本软件和打印机创建。只需在您的系统上生成 AprilTag,将其打印出来,并将其包含在您的图像处理管道中— Python 库的存在是为了自动为您检测 April tag!
在本教程的剩余部分,我将向您展示如何使用 Python 和 OpenCV 检测 AprilTags。
要学习如何用 OpenCV 和 Python 检测 AprilTags,继续阅读。
Python 的 AprilTag
在本教程的第一部分,我们将讨论什么是 AprilTags 和基准标记。然后我们将安装 apriltag ,我们将使用 Python 包来检测输入图像中的 apriltag。
接下来,我们将回顾我们的项目目录结构,然后实现用于检测和识别 AprilTags 的 Python 脚本。
我们将通过回顾我们的结果来结束本教程,包括讨论与 AprilTags 具体相关的一些限制(和挫折)。
什么是 AprilTags 和基准标记?
AprilTags 是一种基准标记。基准点是我们放置在摄像机视野中的特殊标记,这样它们很容易被识别。
例如,以下所有教程都使用基准标记来测量图像中某个对象的大小或特定对象之间的距离:
- 使用 Python 和 OpenCV 找到相机到物体/标记的距离
- 用 OpenCV 测量图像中物体的尺寸
- 用 OpenCV 测量图像中物体间的距离
成功实施这些项目的唯一可能是因为在摄像机的视野中放置了一个标记/参考对象。一旦我检测到物体,我就可以推导出其他物体的宽度和高度,因为我已经知道参考物体的尺寸。
AprilTags 是一种特殊的类型的基准标记。这些标记具有以下特性:
- 它们是具有二进制值的正方形。
- 背景是“黑色”
- 前景是以“白色”显示的生成的图案
- 图案周围有黑边,因此更容易被发现。
- 它们几乎可以以任何尺寸生成。
- 一旦生成,就可以打印出来并添加到您的应用程序中。
一旦在计算机视觉管道中检测到,AprilTags 可用于:
- 摄像机标定
- 3D 应用
- 猛击
- 机器人学
- 自主导航
- 物体尺寸测量
- 距离测量
- 面向对象
- …还有更多!
使用基准的一个很好的例子是在一个大型的履行仓库(如亚马逊),在那里你使用自动叉车。
你可以在地板上放置一个标签来定义叉车行驶的“车道”。可以在大货架上放置特定的标记,这样叉车就知道要拉下哪个板条箱。
标记甚至可以用于“紧急停机”,如果检测到“911”标记,叉车会自动停止、暂停操作并停机。
AprilTags 和密切相关的 ArUco tags 的用例数量惊人。在本教程中,我将讲述如何检测 AprilTags 的基础知识。PyImageSearch 博客上的后续教程将在此基础上构建,并向您展示如何使用它们实现真实世界的应用程序。
在系统上安装“April tag”Python 包
为了检测图像中的 AprilTag,我们首先需要安装一个 Python 包来促进 April tag 检测。
我们将使用的库是 apriltag ,幸运的是,它可以通过 pip 安装。
首先,确保你按照我的 pip 安装 opencv 指南在你的系统上安装 opencv。
如果您正在使用 Python 虚拟环境(这是我推荐的,因为这是 Python 的最佳实践),请确保使用workon命令访问您的 Python 环境,然后将apriltag安装到该环境中:
$ workon your_env_name
$ pip install apriltag
从那里,验证您可以将cv2(您的 OpenCV 绑定)和apriltag(您的 AprilTag 检测器库)导入到您的 Python shell 中:
$ python
>>> import cv2
>>> import apriltag
>>>
祝贺您在系统上安装了 OpenCV 和 AprilTag!
配置您的开发环境有问题吗?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!在你的浏览器中获得运行在 Google Colab 生态系统上的 PyImageSearch 教程 Jupyter 笔记本!无需安装。
最棒的是,这些笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们实现 Python 脚本来检测图像中的 AprilTags 之前,让我们先回顾一下我们的项目目录结构:
$ tree . --dirsfirst
.
├── images
│ ├── example_01.png
│ └── example_02.png
└── detect_apriltag.py
1 directory, 3 files
用 Python 实现 AprilTag 检测
# import the necessary packages
import apriltag
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image containing AprilTag")
args = vars(ap.parse_args())
接下来,让我们加载输入图像并对其进行预处理:
# load the input image and convert it to grayscale
print("[INFO] loading image...")
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
第 14 行使用提供的--image路径从磁盘加载我们的输入图像。然后,我们将图像转换为灰度,这是 AprilTag 检测所需的唯一预处理步骤。
说到 AprilTag 检测,现在让我们继续执行检测步骤:
# define the AprilTags detector options and then detect the AprilTags
# in the input image
print("[INFO] detecting AprilTags...")
options = apriltag.DetectorOptions(families="tag36h11")
detector = apriltag.Detector(options)
results = detector.detect(gray)
print("[INFO] {} total AprilTags detected".format(len(results)))
为了检测图像中的 AprilTag,我们首先需要指定options,更具体地说,是 AprilTag 家族:
AprilTags 中的族定义了 AprilTag 检测器将在输入图像中采用的标签集。标准/默认 AprilTag 系列为“tag 36h 11”;然而,AprilTags 总共有六个家庭:
- Tag36h11
- 工作日标准 41h12
- 工作日标准 52 小时 13 分
- TagCircle21h7
- TagCircle49h12
- TagCustom48h12
你可以在官方 AprilTag 网站上阅读更多关于 AprilTag 家族的信息,但在大多数情况下,你通常会使用“Tag36h11”。
第 20 行用默认的 AprilTag 家族tag36h11初始化我们的options。
这里的最后一步是遍历 AprilTags 并显示结果:
# loop over the AprilTag detection results
for r in results:
# extract the bounding box (x, y)-coordinates for the AprilTag
# and convert each of the (x, y)-coordinate pairs to integers
(ptA, ptB, ptC, ptD) = r.corners
ptB = (int(ptB[0]), int(ptB[1]))
ptC = (int(ptC[0]), int(ptC[1]))
ptD = (int(ptD[0]), int(ptD[1]))
ptA = (int(ptA[0]), int(ptA[1]))
# draw the bounding box of the AprilTag detection
cv2.line(image, ptA, ptB, (0, 255, 0), 2)
cv2.line(image, ptB, ptC, (0, 255, 0), 2)
cv2.line(image, ptC, ptD, (0, 255, 0), 2)
cv2.line(image, ptD, ptA, (0, 255, 0), 2)
# draw the center (x, y)-coordinates of the AprilTag
(cX, cY) = (int(r.center[0]), int(r.center[1]))
cv2.circle(image, (cX, cY), 5, (0, 0, 255), -1)
# draw the tag family on the image
tagFamily = r.tag_family.decode("utf-8")
cv2.putText(image, tagFamily, (ptA[0], ptA[1] - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
print("[INFO] tag family: {}".format(tagFamily))
# show the output image after AprilTag detection
cv2.imshow("Image", image)
cv2.waitKey(0)
我们开始在第 26 行的上循环我们的 AprilTag 检测。
每个 AprilTag 由一组corners指定。第 29-33 行提取 AprilTag 正方形的四个角,第 36-39 行在image上绘制 AprilTag 包围盒。
我们还计算 AprilTag 边界框的中心 (x,y)-坐标,然后画一个代表 AprilTag 中心的圆(第 42 行和第 43 行)。
我们将执行的最后一个注释是从结果对象中抓取检测到的tagFamily,然后将其绘制在输出图像上。
最后,我们通过显示 AprilTag 检测的结果来结束我们的 Python。
AprilTag Python 检测结果
让我们来测试一下 Python AprilTag 检测器吧!确保使用本教程的 “下载” 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python detect_apriltag.py --image images/example_01.png
[INFO] loading image...
[INFO] detecting AprilTags...
[INFO] 1 total AprilTags detected
[INFO] tag family: tag36h11
尽管 AprilTag 已经被旋转,我们仍然能够在输入图像中检测到它,从而证明 April tag 具有一定程度的鲁棒性,使它们更容易被检测到。
让我们试试另一张图片,这张图片有多个 AprilTags:
$ python detect_apriltag.py --image images/example_02.png
[INFO] loading image...
[INFO] detecting AprilTags...
[INFO] 5 total AprilTags detected
[INFO] tag family: tag36h11
[INFO] tag family: tag36h11
[INFO] tag family: tag36h11
[INFO] tag family: tag36h11
[INFO] tag family: tag36h11
这里我们有一个无人驾驶的车队,每辆车上都有一个标签。我们能够检测输入图像中的所有 AprilTag,除了被其他机器人部分遮挡的(这是有意义的——整个April tag 必须在我们的视野中才能检测到它;遮挡给许多基准标记带来了一个大问题。
*当您需要在自己的输入图像中检测 AprilTags 时,请确保使用此代码作为起点!
局限和挫折
您可能已经注意到,我没有介绍如何手动生成您自己的 AprilTag 图像。这有两个原因:
- 所有 AprilTag 家族中所有可能的 April tag 都可以从官方 AprilRobotics repo 下载。
- 此外, AprilTags repo 包含 Java 源代码,您可以用它来生成自己的标记。
- 如果你真的想深入兔子洞, TagSLAM 库包含一个特殊的 Python 脚本,可以用来生成标签——你可以在这里阅读关于这个脚本的更多信息。
综上所述,我发现生成 AprilTags 是一件痛苦的事情。相反,我更喜欢使用 ArUco 标签,OpenCV 既可以使用它的cv2.aruco子模块 检测 和 生成 。
我将在 2020 年末/2021 年初的一个教程中向你展示如何使用cv2.aruco模块来检测T2 的 AprilTags 和 ArUco 标签。一定要继续关注那个教程!
信用
在本教程中,我们使用了来自其他网站的 AprilTags 的示例图像。我想花一点时间感谢官方 AprilTag 网站以及来自 TagSLAM 文档的 Bernd Pfrommer 提供的 April tag 示例。
摘要
在本教程中,您学习了 AprilTags,这是一组常用于机器人、校准和 3D 计算机视觉项目的基准标记。
我们在这些情况下使用 AprilTags(以及密切相关的 ArUco tags ),因为它们易于实时检测。存在库来检测几乎任何用于执行计算机视觉的编程语言中的 AprilTags 和 ArUco 标记,包括 Python、Java、C++等。
在我们的例子中,我们使用了四月标签 Python 包。这个包是 pip 可安装的,允许我们传递 OpenCV 加载的图像,使它在许多基于 Python 的计算机视觉管道中非常有效。
今年晚些时候/2021 年初,我将向您展示使用 AprilTags 和 ArUco 标记的真实项目,但我想现在介绍它们,以便您有机会熟悉它们。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
CNN 对于平移、旋转和缩放是不变的吗?
原文:https://pyimagesearch.com/2021/05/14/are-cnns-invariant-to-translation-rotation-and-scaling/
我被问到的一个常见问题是:
卷积神经网络对于平移、旋转和缩放的变化是不变的吗?这就是为什么它们是如此强大的图像分类器吗?
为了回答这个问题,我们首先需要区分网络中的个单独的过滤器和个最终训练好的网络。CNN 中的单个滤镜对于图像旋转的变化不是不变的。
CNN 对于平移、旋转和缩放是不变的吗?
然而,一个 CNN 作为一个整体可以学习过滤器,当一个模式出现在一个特定的方向时,过滤器就会启动。比如考虑图 1 ,改编自 Goodfellow 等人的 深度学习(2016)。
在这里,我们看到数字“9”(底部)呈现给 CNN,以及 CNN 已经学习的一组过滤器(中间)。由于 CNN 内部有一个过滤器,它已经“学习”了一个【9】的样子,旋转 10 度,它就发射出强烈的激活。这种大量激活在汇集阶段被捕获,并最终报告为最终分类。
第二个例子也是如此(图一、右)。这里我们看到“9”旋转了-45 度,由于 CNN 中有一个滤波器已经知道了“9”旋转了-45 度时的样子,神经元激活并触发。同样,这些过滤器本身是而不是旋转不变的——这只是 CNN 已经了解了在训练集中存在的小旋转下“9”是什么样子。
除非你的训练数据包括在整个 360 度范围内旋转的数字,否则你的 CNN 不是真正的旋转不变的。
缩放也是一样——滤镜本身不是缩放不变,但是很有可能你的 CNN 已经学习了一套滤镜,当模式以不同的缩放比例存在时就会触发。
我们还可以“帮助”我们的 CNN 在不同的尺度和作物下在测试时间向它们呈现我们的示例图像,然后将结果平均在一起。
平移不变性;然而,这是 CNN 擅长的事情。请记住,滤镜在输入中从从左到右和从上到下滑动,当它遇到特定的边缘状区域、角落或颜色斑点时就会激活。在池操作期间,发现了这个大的响应,并因此通过具有更大的激活来“击败”它的所有邻居。因此,CNN 可以被视为“不关心”激活的确切位置,简单地说,它确实激活了——这样,我们自然地在 CNN 内部处理翻译。
总结
在本教程中,我们回答了这个问题,“ccn 对于平移、旋转和缩放是不变的吗?”我们探索了 CNN 如何通过缩放和旋转训练数据来识别缩放和旋转的对象,以及当它们滑过输入时,CNN 如何对平移具有鲁棒性。
使用 Keras 和 TensorFlow 关注渠道
原文:https://pyimagesearch.com/2022/05/30/attending-to-channels-using-keras-and-tensorflow/
目录
利用 Keras 和 TensorFlow 参加渠道
使用卷积神经网络(CNN),我们可以让我们的模型从图像中找出空间和通道特征。然而,空间特征侧重于如何计算等级模式。
在本教程中,您将了解如何使用 Keras 和 TensorFlow 关注渠道,这是一种新颖的研究理念,其中您的模型侧重于信息的渠道表示,以更好地处理和理解数据。
要学习如何实施渠道关注, 只要保持阅读。
利用 Keras 和 TensorFlow 参加渠道
2017 年,胡等人发表了题为压缩-激发网络的论文。他们的方法基于这样一个概念,即以某种方式关注通道方式的特征表示和空间特征将产生更好的结果。
这个想法是一种新颖的架构,它自适应地为通道特性分配一个加权值,本质上是模拟通道之间的相互依赖关系。
这种被提议的结构被称为挤压激励(SE)网络。作者成功地实现了利用频道功能重新校准的附加功能来帮助网络更多地关注基本功能,同时抑制不太重要的功能的目标。
SE 网络块可以是任何标准卷积神经网络的附加模块。网络的完整架构见图 1** 。
在进入代码之前,让我们先看一下完整的架构。
首先,我们有一个输入数据
, of dimensions  . is passed through a transformation (consider it to be a convolution operation)
. is passed through a transformation (consider it to be a convolution operation)  .
.
现在我们有
feature map of dimensions  . We know that another normal convolution operation will give us channels that will have some spatial information or the other.
. We know that another normal convolution operation will give us channels that will have some spatial information or the other.
但是如果我们走不同的路线呢?我们使用操作
to squeeze out our input feature map . Now we have a representation of the shape  . This is considered a global representation of the channels.
. This is considered a global representation of the channels.
现在我们将应用“激发”操作。我们将简单地创建一个具有 sigmoid 激活函数的小型密集网络。这确保了我们没有对这种表示使用简单的一次性编码。
一键编码违背了在多个通道而不仅仅是一个通道上实现强调的目的。我们可以从图 2 中大致了解一下密集网络。
通过该模块的激励部分,我们旨在创建一个没有线性的小网络。当我们在网络中前进时,你可以看到层的形状是如何变化的。
第一密集层使用比率 减少过滤器
减少过滤器
. This reduces the computational complexity while the network’s intention of a non-linear, sigmoidal nature is maintained.
SE 块的最后一个 sigmoid 层输出一个通道式关系,应用到你的特征图
. Now you have achieved a convolution block output where the importance of channels is also specified! (Check Figure 1 for the colored output at the end. The color scheme represents channel-wise importance.)
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install tensorflow
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── output.txt
├── pyimagesearch
│ ├── config.py
│ ├── data.py
│ ├── __init__.py
│ └── model.py
├── README.md
└── train.py
1 directory, 7 files
首先,让我们检查一下pyimagesearch目录:
config.py:包含完整项目的端到端配置管道。data.py:包含处理数据的实用函数。- 包含了我们项目要使用的模型架构。
__init__.py:在 python 目录中创建目录,以便于包调用和使用。
在核心目录中,我们有:
output.txt:包含我们项目输出的文本文件。train.py:包含我们项目的培训程序。
配置先决条件
首先,我们将回顾位于我们代码的pyimagesearch目录中的config.py脚本。该脚本包含几个定义的参数和超参数,将在整个项目流程中使用。
# define the number of convolution layer filters and dense layer units
CONV_FILTER = 64
DENSE_UNITS = 4096
# define the input shape of the dataset
INPUT_SHAPE = (32, 32, 3)
# define the block hyperparameters for the VGG models
BLOCKS = [
(1, 64),
(2, 128),
(2, 256)
]
# number of classes in the CIFAR-10 dataset
NUMBER_CLASSES = 10
# the ratio for the squeeze-and-excitation layer
RATIO = 16
# define the model compilation hyperparameters
OPTIMIZER = "adam"
LOSS = "sparse_categorical_crossentropy"
METRICS = ["acc"]
# define the number of training epochs and the batch size
EPOCHS = 100
BATCH_SIZE = 32
在第 2 行和第 3 行上,我们已经定义了卷积滤波器和密集节点的数量,稍后在定义我们的模型时将会用到它们。
在第 6 行的上,定义了我们的图像数据集的输入形状。
VGG 模型的块超参数在第 9-13 行的中定义。它采用元组格式,包含层的数量和层的过滤器数量。接下来指定数据集中类的数量(第 16 行)。
励磁块所需的比率已在行 19 中定义。然后,在的第 22-24 行,指定了优化器、损失和度量等模型规范。
我们最终的配置变量是时期和批量大小(第 27 行和第 28 行)。
预处理 CIFAR-10 数据集
对于我们今天的项目,我们将使用 CIFAR-10 数据集来训练我们的模型。数据集将为我们提供 60000 个 32×32×3 图像的实例,每个实例属于 10 个类别中的一个。
在将其插入我们的项目之前,我们将执行一些预处理,以使数据更适合于训练。为此,让我们转到pyimagesearch目录中的data.py脚本。
# import the necessary packages
from tensorflow.keras.datasets import cifar10
import numpy as np
def standardization(xTrain, xVal, xTest):
# extract the mean and standard deviation from the train dataset
mean = np.mean(xTrain)
std = np.std(xTrain)
# standardize the training, validation, and the testing dataset
xTrain = ((xTrain - mean) / std).astype(np.float32)
xVal = ((xVal - mean) / std).astype(np.float32)
xTest = ((xTest - mean) / std).astype(np.float32)
# return the standardized training, validation and the testing
# dataset
return (xTrain, xVal, xTest)
我们已经使用 tensorflow 将cifar10数据集直接加载到我们的项目中( Line 2 )。
我们将使用的第一个预处理函数是standardization ( 第 5 行)。它使用训练图像、验证图像和测试图像作为其参数。
我们在第 7 行和第 8 行获取训练集的平均值和标准偏差。我们将使用这些值来改变我们所有的分割。在的第 11-13 行,我们根据训练集的平均值和标准偏差值对训练集、验证集和测试集进行标准化。
你可能会想,为什么我们要故意改变图像的像素值呢?这是为了让我们可以将完整数据集的分布调整为更精确的曲线。这有助于我们的模型更好地理解数据,并更准确地做出预测。
这样做的唯一缺点是,在将推断图像输入到我们的模型之前,我们还必须以这种方式改变它们,否则我们很可能会得到错误的预测。
def get_cifar10_data():
# get the CIFAR-10 data
(xTrain, yTrain), (xTest, yTest) = cifar10.load_data()
# split the training data into train and val sets
trainSize = int(0.9 * len(xTrain))
((xTrain, yTrain), (xVal, yVal)) = (
(xTrain[:trainSize], yTrain[:trainSize]),
(xTrain[trainSize:], yTrain[trainSize:]))
(xTrain, xVal, xTest) = standardization(xTrain, xVal, xTest)
# return the train, val, and test datasets
return ((xTrain, yTrain), (xVal, yVal), (xTest, yTest))
我们的下一个功能是 19 号线的上的get_cifar10_data。我们使用 tensorflow 加载 cifar10 数据集,并将其解包到训练集和测试集中。
接下来,在第 24-27 行,我们使用索引将训练集分成两部分:训练集和验证集。在返回 3 个分割之前,我们使用之前创建的standardization函数来预处理数据集(第 28-31 行)。
定义我们的培训模式架构
随着我们的数据管道都开始工作,我们清单上的下一件事是模型架构。为此,我们将转移到位于pyimagesearch目录中的model.py脚本。
模型架构受到惯用程序员模型动物园的大量启发。
# import the necessary packages
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Multiply
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import ReLU
from tensorflow.keras import Input
from tensorflow.keras import Model
from tensorflow import keras
class VGG:
def __init__(self, inputShape, ratio, blocks, numClasses,
denseUnits, convFilters, isSqueezeExcite, optimizer, loss,
metrics):
# initialize the input shape, the squeeze excitation ratio,
# the blocks for the VGG architecture, and the number of
# classes for the classifier
self.inputShape = inputShape
self.ratio = ratio
self.blocks = blocks
self.numClasses = numClasses
# initialize the dense layer units and conv filters
self.denseUnits = denseUnits
self.convFilters = convFilters
# flag that decides whether to add the squeeze excitation
# layer to the network
self.isSqueezeExcite = isSqueezeExcite
# initialize the compilation parameters
self.optimizer = optimizer
self.loss = loss
self.metrics = metrics
为了使事情更简单,我们在第 13 行的上为我们的模型架构创建了一个类模板,命名为VGG。
我们的第一个函数是 __init__,它接受以下参数(第 14-36 行)。
inputShape:确定输入数据的形状,以馈入我们的模型。ratio:确定excitation模块降维时的比率。blocks:指定我们想要的图层块的数量。numClasses:指定我们需要的输出类的数量。denseUnits:指定密集节点的数量。convFilters:指定一个conv层的卷积滤波器的数量。isSqueezeExcite:检查一个块是否是阿瑟块。optimizer:定义用于模型的优化器。loss:定义用于模型的损耗。metrics:定义模型训练要考虑的指标。
def stem(self, inputs):
# pass the input through a CONV => ReLU layer block
x = Conv2D(filters=self.convFilters, kernel_size=(3, 3),
strides=(1, 1), padding="same", activation="relu")(inputs)
# return the processed inputs
return x
def learner(self, x):
# build the learner by stacking blocks of convolutional layers
for numLayers, numFilters in self.blocks:
x = self.group(x, numLayers, numFilters)
# return the processed inputs
return x
接下来,我们有基本功能。第一个是stem ( 第 38 行),它接受一个层输入作为它的参数。然后,在函数内部,它通过卷积层传递层输入并返回输出(第 40-44 行)。
线 46 上的以下功能为learner。它将图层输入作为其参数。此功能的目的是堆叠层块。
我们之前已经将blocks定义为包含层和针对层的过滤器的元组的集合。我们迭代那些在第 48 行的。在第 49 行引用了一个名为group的函数,在此之后定义。
def group(self, x, numLayers, numFilters):
# iterate over the number of layers and build a block with
# convolutional layers
for _ in range(numLayers):
x = Conv2D(filters=numFilters, kernel_size=(3, 3),
strides=(1, 1), padding="same", activation="relu")(x)
# max pool the output of the convolutional block, this is done
# to reduce the spatial dimension of the output
x = MaxPooling2D(2, strides=(2, 2))(x)
# check if we are going to add the squeeze excitation block
if self.isSqueezeExcite:
# add the squeeze excitation block followed by passing the
# output through a ReLU layer
x = self.squeeze_excite_block(x)
x = ReLU()(x)
# return the processed outputs
return x
之前引用的函数group在行 54 中定义。它接受层输入、层数和过滤器数作为参数。
在第 57 行上,我们迭代层数并添加卷积层。一旦循环结束,我们添加一个最大池层(第 63 行)。
在线路 66 上,我们检查该模型是否为 SE 网络,并相应地在线路 69 上添加一个 SE 块。接下来是一个ReLU层。
def squeeze_excite_block(self, x):
# store the input
shortcut = x
# calculate the number of filters the input has
filters = x.shape[-1]
# the squeeze operation reduces the input dimensionality
# here we do a global average pooling across the filters, which
# reduces the input to a 1D vector
x = GlobalAveragePooling2D(keepdims=True)(x)
# reduce the number of filters (1 x 1 x C/r)
x = Dense(filters // self.ratio, activation="relu",
kernel_initializer="he_normal", use_bias=False)(x)
# the excitation operation restores the input dimensionality
x = Dense(filters, activation="sigmoid",
kernel_initializer="he_normal", use_bias=False)(x)
# multiply the attention weights with the original input
x = Multiply()([shortcut, x])
# return the output of the SE block
return x
最后,我们到达 SE 块(第 75 行)。但是,首先,我们将输入存储在线 77 上以备后用。
在第 80 行上,我们计算挤压操作的过滤器数量。
在85行,我们有squeeze操作。接下来是excitation操作。我们首先将过滤器的数量减少到
for purposes explained in the introduction section by adding a dense layer with nodes. (For a quick reminder, it is for complexity reduction.)
随后是维度恢复,因为我们有另一个密度函数,其滤波器等于
.
恢复维度后,sigmoid 函数为我们提供了每个通道的权重。因此,我们需要做的就是将它乘以我们之前存储的输入,现在我们有了加权的通道输出(第 96 行)。这也是论文作者所说的规模经营。
def classifier(self, x):
# flatten the input
x = Flatten()(x)
# apply Fully Connected Dense layers with ReLU activation
x = Dense(self.denseUnits, activation="relu")(x)
x = Dense(self.denseUnits, activation="relu")(x)
x = Dense(self.numClasses, activation="softmax")(x)
# return the predictions
return x
def build_model(self):
# initialize the input layer
inputs = Input(self.inputShape)
# pass the input through the stem => learner => classifier
x = self.stem(inputs)
x = self.learner(x)
outputs = self.classifier(x)
# build the keras model with the inputs and outputs
model = Model(inputs, outputs)
# return the model
return model
在第 101 行,我们为架构的剩余层定义了classifier函数。我们添加一个展平层,然后是 3 个密集层,最后一个是我们的输出层,其过滤器的数量等于cifar10数据集中的类的数量(第 106-111 行)。
有了我们的架构,我们接下来的函数就是build_model ( 第 113 行)。这个函数只是用来使用我们到目前为止定义的函数,并按照正确的顺序设置它。在第 118-120 行上,我们首先使用stem函数,然后使用learner函数,最后用classifier函数将其加满。
在第 124-126 行上,我们初始化并返回模型。这就完成了我们的模型架构。
def train_model(self, model, xTrain, yTrain, xVal, yVal, epochs,
batchSize):
# compile the model
model.compile(
optimizer=self.optimizer, loss=self.loss,
metrics=self.metrics)
# initialize a list containing our callback functions
callbacks = [
keras.callbacks.EarlyStopping(monitor="val_loss",
patience=5, restore_best_weights=True),
keras.callbacks.ReduceLROnPlateau(monitor="val_loss",
patience=3)
]
# train the model
model.fit(xTrain, yTrain, validation_data=(xVal, yVal),
epochs=epochs, batch_size=batchSize, callbacks=callbacks)
# return the trained model
return model
在第 128 行的上,我们有函数train_model,它接受以下参数:
model:将用于训练的模型。xTrain:训练图像输入数据集。yTrain:训练数据集标签。xVal:验证图像数据集。yVal:验证标签。epochs:指定运行训练的次数。batchSize:指定抓取数据的批量大小。
我们首先用优化器、损失和指标来编译我们的模型(第 131-133 行)。
在第 136-141 行上,我们设置了一些回调函数来帮助我们的训练。最后,我们将数据放入我们的模型,并开始训练(第 144 和 145 行)。
训练压缩激励网络
我们最后的任务是训练 SE 网络并记录其结果。然而,首先,为了理解它如何优于常规的 CNN,我们将一起训练一个普通的 CNN 和阿瑟区块供电的 CNN 来记录它们的结果。
为此,让我们转到位于我们项目根目录中的train.py脚本。
# USAGE
# python train.py
# setting the random seed for reproducibility
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.model import VGG
from pyimagesearch.data import get_cifar10_data
# get the dataset
print("[INFO] downloading the dataset...")
((xTrain, yTrain), (xVal, yVal), (xTest, yTest)) = get_cifar10_data()
# build a vanilla VGG model
print("[INFO] building a vanilla VGG model...")
vggObject = VGG(inputShape=config.INPUT_SHAPE, ratio=config.RATIO,
blocks=config.BLOCKS, numClasses=config.NUMBER_CLASSES,
denseUnits=config.DENSE_UNITS, convFilters=config.CONV_FILTER,
isSqueezeExcite=False, optimizer=config.OPTIMIZER, loss=config.LOSS,
metrics=config.METRICS)
vggModel = vggObject.build_model()
# build a VGG model with SE layer
print("[INFO] building VGG model with SE layer...")
vggSEObject = VGG(inputShape=config.INPUT_SHAPE, ratio=config.RATIO,
blocks=config.BLOCKS, numClasses=config.NUMBER_CLASSES,
denseUnits=config.DENSE_UNITS, convFilters=config.CONV_FILTER,
isSqueezeExcite=True, optimizer=config.OPTIMIZER, loss=config.LOSS,
metrics=config.METRICS)
vggSEModel = vggSEObject.build_model()
在第 6 行的上,和其他导入一起,我们定义了一个特定的随机种子,使得我们的项目在每次有人运行时都是可重复的。
在的第 14 和 15 行,我们使用之前在data.py脚本中创建的get_cifar10_data函数下载cifar10数据集。数据被分成三部分:训练、验证和测试。
然后,我们使用我们的模型架构脚本model.py ( 第 19-24 行)初始化普通 CNN。如果你没记错的话,我们的类中有一个isSqueezeExcite bool 变量,它告诉函数要初始化的模型是否有阿瑟块。对于普通的 CNN,我们只需将该变量设置为False ( 第 22 行)。
现在,我们将使用 SE 块初始化 CNN。我们遵循与之前创建的普通 CNN 相同的步骤,保持所有参数不变,除了isSqueezeExcite bool 变量,在本例中我们将它设置为True。
注意: 所有你看到正在使用的参数都已经在我们的config.py脚本中定义好了。
# train the vanilla VGG model
print("[INFO] training the vanilla VGG model...")
vggModel = vggObject.train_model(model=vggModel, xTrain=xTrain,
yTrain=yTrain, xVal=xVal, yVal=yVal, epochs=config.EPOCHS,
batchSize=config.BATCH_SIZE)
# evaluate the vanilla VGG model on the testing dataset
print("[INFO] evaluating performance of vanilla VGG model...")
(loss, acc) = vggModel.evaluate(xTest, yTest,
batch_size=config.BATCH_SIZE)
# print the testing loss and the testing accuracy of the vanilla VGG
# model
print(f"[INFO] VANILLA VGG TEST Loss: {loss:0.4f}")
print(f"[INFO] VANILLA VGG TEST Accuracy: {acc:0.4f}")
首先,使用来自VGG类模板的train_model函数训练普通的 CNN(第 37-39 行)。然后,使用测试数据集测试的普通 CNN 的损失和准确性被存储在行 43 和 44 上。
# train the VGG model with the SE layer
print("[INFO] training the VGG model with SE layer...")
vggSEModel = vggSEObject.train_model(model=vggSEModel, xTrain=xTrain,
yTrain=yTrain, xVal=xVal, yVal=yVal, epochs=config.EPOCHS,
batchSize=config.BATCH_SIZE)
# evaluate the VGG model with the SE layer on the testing dataset
print("[INFO] evaluating performance of VGG model with SE layer...")
(loss, acc) = vggSEModel.evaluate(xTest, yTest,
batch_size=config.BATCH_SIZE)
# print the testing loss and the testing accuracy of the SE VGG
# model
print(f"[INFO] SE VGG TEST Loss: {loss:0.4f}")
print(f"[INFO] SE VGG TEST Accuracy: {acc:0.4f}")
现在是用 SE 块(线 53-55 )训练VGG模型的时候了。我们类似地存储在测试数据集上测试的VGG SE 模型的损失和准确性(行 59 和 60 )。
我们打印这些值,以便与普通的 CNN 结果进行比较。
让我们来看看这些模特们的表现如何!
[INFO] building a vanilla VGG model...
[INFO] training the vanilla VGG model...
Epoch 1/100
1407/1407 [==============================] - 22s 10ms/step - loss: 1.5038 - acc: 0.4396 - val_loss: 1.1800 - val_acc: 0.5690 - lr: 0.0010
Epoch 2/100
1407/1407 [==============================] - 13s 9ms/step - loss: 1.0136 - acc: 0.6387 - val_loss: 0.8751 - val_acc: 0.6922 - lr: 0.0010
Epoch 3/100
1407/1407 [==============================] - 13s 9ms/step - loss: 0.8177 - acc: 0.7109 - val_loss: 0.8017 - val_acc: 0.7200 - lr: 0.0010
...
Epoch 8/100
1407/1407 [==============================] - 13s 9ms/step - loss: 0.3874 - acc: 0.8660 - val_loss: 0.7762 - val_acc: 0.7616 - lr: 0.0010
Epoch 9/100
1407/1407 [==============================] - 13s 9ms/step - loss: 0.1571 - acc: 0.9441 - val_loss: 0.9518 - val_acc: 0.7880 - lr: 1.0000e-04
Epoch 10/100
1407/1407 [==============================] - 13s 9ms/step - loss: 0.0673 - acc: 0.9774 - val_loss: 1.1386 - val_acc: 0.7902 - lr: 1.0000e-04
[INFO] evaluating performance of vanilla VGG model...
313/313 [==============================] - 1s 4ms/step - loss: 0.7785 - acc: 0.7430
[INFO] VANILLA VGG TEST Loss: 0.7785
[INFO] VANILLA VGG TEST Accuracy: 0.7430
首先,我们有香草 VGG,它已经训练了10个时代,达到了97%的训练精度。验证精度在79%达到峰值。我们已经可以看到,香草 VGG 没有推广好。
在评估测试数据集时,精确度达到74%。
[INFO] building VGG model with SE layer...
[INFO] training the VGG model with SE layer...
Epoch 1/100
1407/1407 [==============================] - 18s 12ms/step - loss: 1.5177 - acc: 0.4352 - val_loss: 1.1684 - val_acc: 0.5710 - lr: 0.0010
Epoch 2/100
1407/1407 [==============================] - 17s 12ms/step - loss: 1.0092 - acc: 0.6423 - val_loss: 0.8803 - val_acc: 0.6892 - lr: 0.0010
Epoch 3/100
1407/1407 [==============================] - 17s 12ms/step - loss: 0.7834 - acc: 0.7222 - val_loss: 0.7986 - val_acc: 0.7272 - lr: 0.0010
...
Epoch 8/100
1407/1407 [==============================] - 17s 12ms/step - loss: 0.2723 - acc: 0.9029 - val_loss: 0.8258 - val_acc: 0.7754 - lr: 0.0010
Epoch 9/100
1407/1407 [==============================] - 17s 12ms/step - loss: 0.0939 - acc: 0.9695 - val_loss: 0.8940 - val_acc: 0.8058 - lr: 1.0000e-04
Epoch 10/100
1407/1407 [==============================] - 17s 12ms/step - loss: 0.0332 - acc: 0.9901 - val_loss: 1.1226 - val_acc: 0.8116 - lr: 1.0000e-04
[INFO] evaluating performance of VGG model with SE layer...
313/313 [==============================] - 2s 5ms/step - loss: 0.7395 - acc: 0.7572
[INFO] SE VGG TEST Loss: 0.7395
[INFO] SE VGG TEST Accuracy: 0.7572
SE VGG 达到了99%的训练精度。验证精度在81%达到峰值。概括仍然不好,但可以称为比香草 VGG 更好。
经过相同次数的训练后,测试精度达到了75%,超过了普通的 VGG。
汇总
这篇文章结束了我们关于修正卷积神经网络(CNN)的连续博客。在我们的上一篇文章中,我们看到了如何教会 CNN 自己校正图像的方向。本周,我们知道了当频道特性也包含在特性池中时会发生什么。
结果一清二楚;我们可以推动 CNN 采取额外的措施,并通过正确的方法获得更好的结果。
今天,我们使用了经常被忽略的通道来支持空间信息。虽然空间信息对肉眼来说更有意义,但算法提取信息的方式不应受到破坏。
我们比较了附加挤压激励(SE)模块的普通架构。结果显示,当 SE 模块连接到网络上时,网络评估模式的能力有所提高。SE 块简单地添加到全局特征池中,允许模型从更多特征中进行选择。
引用信息
Chakraborty,D. “使用 Keras 和 TensorFlow 关注频道”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/jq94n
@incollection{Chakraborty_2022_Attending_Channels,
author = {Devjyoti Chakraborty},
title = {Attending to Channels Using {Keras} and {TensorFlow}},
booktitle = {PyImageSearch}, editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/jq94n},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
Auto-Keras 和 AutoML:入门指南
原文:https://pyimagesearch.com/2019/01/07/auto-keras-and-automl-a-getting-started-guide/

在本教程中,您将学习如何使用 Auto-Keras,这是谷歌 AutoML 的开源替代产品,用于自动化机器学习和深度学习。
当在数据集上训练神经网络时,深度学习实践者试图优化和平衡两个主要目标:
- 定义适合数据集特性的神经网络架构
- 通过多次实验调整一组超参数,这将产生一个具有高精度的模型,并且能够推广到训练和测试集之外的数据。需要调整的典型超参数包括优化器算法(SGD、Adam 等。),学习率和学习率调度,以及正则化,等等
根据数据集和问题的不同,深度学习专家可能需要进行多达十到数百次实验,才能在神经网络架构和超参数之间找到平衡。
这些实验在 GPU 计算时间上总计可达数百到数千小时。
而且这还只是针对专家——非深度学习专家呢?
输入自动角和自动:
Auto-Keras 和 AutoML 的最终目标都是通过使用自动化神经架构搜索(NAS)算法来降低执行机器学习和深度学习的门槛。
Auto-Keras 和 AutoML 使非深度学习专家能够利用深度学习或其实际数据的最少领域知识来训练自己的模型。
使用 AutoML 和 Auto-Keras,具有最少机器学习专业知识的程序员可以应用这些算法,不费吹灰之力实现最先进的性能。
听起来好得难以置信?
嗯,也许吧——但你需要先阅读这篇文章的其余部分,找出原因。
要了解更多关于 AutoML(以及如何自动用 Auto-Keras 训练和调整神经网络),继续阅读!
Auto-Keras 和 AutoML:入门指南
在这篇博文的第一部分,我们将讨论自动机器学习(AutoML) 和神经架构搜索(NAS) ,这种算法使 AutoML 在应用于神经网络和深度学习时成为可能。
我们还将简要讨论谷歌的 AutoML ,这是一套工具和库,允许具有有限机器学习专业知识的程序员根据自己的数据训练高精度模型。
当然,Google 的 AutoML 是一个专有算法(它也有点贵)。
AutoML 的替代方案是围绕 Keras 和 PyTorch 构建的开源 Auto-Keras。
然后,我将向您展示如何使用 Auto-Keras 自动训练一个网络,并对其进行评估。
*### 什么是自动机器学习(AutoML)?

Figure 1: Auto-Keras is an alternative to Google’s AutoML. These software projects can help you train models automatically with little intervention. They are great options for novice deep learning practitioners or to obtain a baseline to beat later on.
在无监督学习(从未标记数据中自动学习模式)之外,面向非专家的自动化机器学习被认为是机器学习的“圣杯”。
想象一下通过以下方式自动创建机器学习模型的能力:
- 安装库/使用 web 界面
- 将库/接口指向您的数据
- 根据数据自动训练模型,而不必调整参数/需要深入了解驱动它的算法
一些公司正试图创造这样的解决方案——一个大的例子是谷歌的 AutoML。
Google AutoML 使机器学习经验非常有限的开发人员和工程师能够在自己的数据集上自动训练神经网络。
在引擎盖下,谷歌的 AutoML 算法是迭代的:
- 在训练集上训练网络
- 在测试集上评估网络
- 修改神经网络架构
- 调谐超参数
- 重复这个过程
使用 AutoML 的程序员或工程师不需要定义他们自己的神经网络架构或调整超参数——AutoML 会自动为他们完成这些工作。
神经结构搜索(NAS)使 AutoML 成为可能

Figure 2: Neural Architecture Search (NAS) produced a model summarized by these graphs when searching for the best CNN architecture for CIFAR-10 (source: Figure 4 of Zoph et al.)
谷歌的 AutoML 和 Auto-Keras 都是由一种叫做神经架构搜索(NAS)的算法驱动的。
给定你的输入数据集,一个神经结构搜索算法将自动搜索最佳的结构和相应的参数。
神经架构搜索本质上是用一套自动调优模型的算法来代替深度学习工程师/从业者!
在计算机视觉和图像识别的背景下,神经架构搜索算法将:
- 接受输入训练数据集
- 优化并找到称为“单元”的架构构建块——这些单元是自动学习的,可能看起来类似于初始、剩余或挤压/发射微架构
- 不断训练和搜索“NAS 搜索空间”以获得更优化的单元
如果 AutoML 系统的用户是经验丰富的深度学习实践者,那么他们可以决定:
- 在训练数据集的一个非常小的子集上运行 NAS
- 找到一组最佳的架构构建块/单元
- 获取这些单元,并手动定义在架构搜索期间发现的网络的更深版本
- 使用他们自己的专业知识和最佳实践对网络进行全面培训
这样的方法是完全自动化的机器学习解决方案和需要专业深度学习实践者的解决方案之间的混合——通常这种方法会比 NAS 自己发现的方法更准确。
我建议阅读 带强化学习的神经架构搜索 (Zoph 和 Le,2016)以及 学习可扩展图像识别的可转移架构 (Zoph 等人,2017),以了解这些算法如何工作的更多详细信息。
auto-Keras:Google AutoML 的开源替代方案
![]()
Figure 3: The Auto-Keras package was developed by the DATA Lab team at Texas A&M University. Auto-Keras is an open source alternative to Google’s AutoML.
由德克萨斯 A & M 大学的数据实验室团队开发的 Auto-Keras 软件包是谷歌 AutoML 的替代产品。
Auto-Keras 还利用神经架构搜索,但应用“网络态射”(在改变架构时保持网络功能)以及贝叶斯优化来指导网络态射,以实现更高效的神经网络搜索。
你可以在金等人的 2018 年出版物中找到 Auto-Keras 框架的完整细节, Auto-Keras:使用网络态射的高效神经架构搜索 。
项目结构
继续从今天博客文章的 【下载】 部分抓取压缩文件。
从那里你应该解压文件并使用你的终端导航到它。
让我们用tree命令来检查今天的项目:
$ tree --dirsfirst
.
├── output
│ ├── 14400.txt
│ ├── 28800.txt
│ ├── 3600.txt
│ ├── 43200.txt
│ ├── 7200.txt
│ └── 86400.txt
└── train_auto_keras.py
1 directory, 7 files
今天我们将回顾一个 Python 脚本:train_auto_keras.py。
由于会有大量输出打印到屏幕上,我选择将我们的分类报告(在 scikit-learn 的classification_report工具的帮助下生成)作为文本文件保存到磁盘上。检查上面的output/文件夹,您可以看到一些已经生成的报告。继续在您的终端(cat output/14400.txt)上打印一个,看看它是什么样子。
安装 Auto-Keras

Figure 4: The Auto-Keras package depends upon Python 3.6, TensorFlow, and Keras.
正如 Auto-Keras GitHub 库声明的,Auto-Keras 处于“预发布”状态——这是而不是正式发布。
其次,Auto-Keras 需要 Python 3.6,并且只有兼容 Python 3.6。
如果你使用的是除了 3.6 之外的任何其他版本的 Python,你将能够使用 Auto-Keras 包而不是。
要检查您的 Python 版本,只需使用以下命令:
$ python --version
如果您有 Python 3.6,您可以使用 pip 安装 Auto-Keras:
$ pip install tensorflow # or tensorflow-gpu
$ pip install keras
$ pip install autokeras
如果您在安装或使用 Auto-Keras 时有任何问题,请确保您在官方的 Auto-Keras GitHub 问题页面上发帖,作者将能够帮助您。
用 Auto-Keras 实现我们的培训脚本
让我们继续使用 Auto-Keras 实现我们的培训脚本。打开train_auto_keras.py文件并插入以下代码:
# import the necessary packages
from sklearn.metrics import classification_report
from keras.datasets import cifar10
import autokeras as ak
import os
def main():
# initialize the output directory
OUTPUT_PATH = "output"
首先,我们在第 2-5 行导入必要的包:
- 如前所述,我们将使用 scikit-learn 的
classification_report来计算统计数据,并将其保存在输出文件中。 - 我们将使用 CIFAR-10 数据集,它方便地内置在
keras.datasets中。 - 接下来是我们最显著的导入,
autokeras,为了简化,我将其导入为ak。 - 需要
os模块,因为我们将在构建输出文件路径时在各种操作系统上容纳路径分隔符。
让我们在第 7 行为我们的脚本定义main函数。由于 Auto-Keras 和 TensorFlow 处理线程的方式,我们需要将代码包装在一个main函数中。详见本 GitHub 发布线程。
我们的基地OUTPUT_PATH定义在线 9 上。
现在,让我们初始化自动 Keras 的训练时间列表:
# initialize the list of training times that we'll allow
# Auto-Keras to train for
TRAINING_TIMES = [
60 * 60, # 1 hour
60 * 60 * 2, # 2 hours
60 * 60 * 4, # 4 hours
60 * 60 * 8, # 8 hours
60 * 60 * 12, # 12 hours
60 * 60 * 24, # 24 hours
]
第 13-20 行定义了一组TRAINING_TIMES ,包括[1, 2, 4, 8, 12, 24]小时。今天,我们将使用 Auto-Keras 探索更长的训练时间对准确性的影响。
让我们加载 CIFAR-10 数据集并初始化类名:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
我们的 CIFAR-10 数据被加载并存储到线 25 上的训练/测试分割中。
随后,我们将把这个数据缩放到范围【0,1】(第 26 行和第 27 行)。
我们的类labelNames在行的第 30 行和第 31 行被初始化。这 10 个类包含在 CIFAR-10 中。请注意,顺序在这里很重要。
现在让我们开始循环我们的TRAINING_TIMES,每次都使用 Auto-Keras:
# loop over the number of seconds to allow the current Auto-Keras
# model to train for
for seconds in TRAINING_TIMES:
# train our Auto-Keras model
print("[INFO] training model for {} seconds max...".format(
seconds))
model = ak.ImageClassifier(verbose=True)
model.fit(trainX, trainY, time_limit=seconds)
model.final_fit(trainX, trainY, testX, testY, retrain=True)
# evaluate the Auto-Keras model
score = model.evaluate(testX, testY)
predictions = model.predict(testX)
report = classification_report(testY, predictions,
target_names=labelNames)
# write the report to disk
p = os.path.sep.join(OUTPUT_PATH, "{}.txt".format(seconds))
f = open(p, "w")
f.write(report)
f.write("\nscore: {}".format(score))
f.close()
上面的代码块是今天脚本的核心。在第 35 行的上,我们定义了一个循环,其中我们:
- 初始化我们的
model(ak.ImageClassifier)并允许训练开始(第 39 和 40 行)。请注意,我们没有像在之前的教程中一样为特定的 CNN 类实例化一个对象,比如这个。我们也不需要像通常那样调整超参数。Auto-Keras 为我们处理所有这些问题,并提供其调查结果报告。 - 一旦达到时间限制,采用 Auto-Keras 找到的最佳
model和参数+重新训练模型(第 41 行)。 - 评估并构建分类
report( 第 44-47 行)。 - 将分类
report和精度score写入磁盘,这样我们可以评估更长训练时间的影响(第 50-54 行)。
我们将对每个TRAINING_TIMES重复这个过程。
最后,我们将检查并启动执行的main线程:
# if this is the main thread of execution then start the process (our
# code must be wrapped like this to avoid threading issues with
# TensorFlow)
if __name__ == "__main__":
main()
这里我们已经检查过,确保这是执行的main线程,然后是main函数。
仅仅 60 行代码之后,我们就完成了使用 CIFAR-10 示例脚本编写 Auto-Keras 的工作。但是我们还没有完成…
用 Auto-kers 训练神经网络
让我们继续使用 Auto-Keras 训练我们的神经网络。
确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端,导航到您下载源代码的位置,并执行以下命令:
$ python train_auto_keras.py
[INFO] training model for 3600 seconds max...
Preprocessing the images.
Preprocessing finished.
Initializing search.
Initialization finished.
+----------------------------------------------+
| Training model 0 |
+----------------------------------------------+
Using TensorFlow backend.
No loss decrease after 5 epochs.
Saving model.
+--------------------------------------------------------------------------+
| Model ID | Loss | Metric Value |
+--------------------------------------------------------------------------+
| 0 | 4.816269397735596 | 0.5852 |
+--------------------------------------------------------------------------+
+----------------------------------------------+
| Training model 1 |
+----------------------------------------------+
Using TensorFlow backend.
Epoch-14, Current Metric - 0.83: 28%|██████▊ | 110/387 [01:02<02:46, 1.67 batch/s]Time is out.
[INFO] training model for 86400 seconds max...
Preprocessing the images.
Preprocessing finished.
Initializing search.
Initialization finished.
+----------------------------------------------+
| Training model 0 |
+----------------------------------------------+
Using TensorFlow backend.
No loss decrease after 5 epochs.
...
+----------------------------------------------+
| Training model 21 |
+----------------------------------------------+
Using TensorFlow backend.
No loss decrease after 5 epochs.
+--------------------------------------------------------------------------+
| Father Model ID | Added Operation |
+--------------------------------------------------------------------------+
| | to_deeper_model 16 ReLU |
| 16 | to_wider_model 16 64 |
+--------------------------------------------------------------------------+
Saving model.
+--------------------------------------------------------------------------+
| Model ID | Loss | Metric Value |
+--------------------------------------------------------------------------+
| 21 | 0.8843476831912994 | 0.9316000000000001 |
+--------------------------------------------------------------------------+
+----------------------------------------------+
| Training model 22 |
+----------------------------------------------+
Using TensorFlow backend.
Epoch-3, Current Metric - 0.9: 80%|████████████████████▊ | 310/387 [03:50<00:58, 1.31 batch/s]Time is out.
No loss decrease after 30 epochs.
在这里,您可以看到我们的脚本指示 Auto-Keras 执行六组实验。
在 NVIDIA K80 GPU 上,包括时间限制+重新适应模型的时间在内的总训练时间为 3 天多一点。
自动 Keras 结果
Figure 5: Using Auto-Keras usually is a very time-consuming process. Training with Auto-Keras produces the best models for CIFAR-10 in the 8-12 hour range. Past that, Auto-Keras is not able to optimize further.
在上面的图 5 中,您可以看到使用 Auto-Keras 的训练时间(x-轴)对整体精度(y-轴)的影响。
较低的训练时间,即 1 和 2 小时,导致约 73%的准确率。一旦我们训练了 4 个小时,我们就能达到 93%的准确率。
我们获得的最佳精度在 8-12 范围内,在此范围内我们达到了 95%的精度。
超过 8-12 小时的训练不会增加我们的准确性,这意味着我们已经达到了饱和点,Auto-Keras 不能进一步优化。
Auto-Keras 和 AutoML 值得吗?

Figure 6: Is Auto-Keras (or AutoML) worth it? It is certainly a great step forward in the industry and is especially helpful for those without deep learning domain knowledge. That said, seasoned deep learning experts can craft architectures + train them in significantly less time + achieve equal or greater accuracy.
在无监督学习(从未标记数据中自动学习模式)之外,面向非专家的自动化机器学习被认为是机器学习的“圣杯”。
谷歌的 AutoML 和开源的 Auto-Keras 包都试图将机器学习带给大众,即使没有丰富的技术经验。
虽然 Auto-Keras 在 CIFAR-10 上工作得相当好,但我使用我之前关于深度学习、医学成像和疟疾检测的帖子运行了第二组实验。
在之前的那篇文章中,我使用一个简化的 ResNet 架构获得了 97.1%的准确率,训练时间不到一个小时。
然后,我让 Auto-Keras 在同一个数据集上运行 24 小时——结果只有 96%的准确率,低于我手动定义的架构。
谷歌的 AutoML 和 Auto-Keras 都是巨大的进步;然而,自动化机器学习还远未解决。
自动机器学习(目前)无法击败深度学习方面的专业知识——领域专业知识,特别是你正在处理的数据,对于获得更高精度的模型来说是绝对关键的。
我的建议是投资你自己的知识,不要依赖自动化算法。
要成为一名成功的深度学习实践者和工程师,你需要为工作带来正确的工具。使用 AutoML 和 Auto-Keras,它们是什么,工具,然后继续用额外的知识填充你自己的工具箱。
摘要
在今天的博文中,我们讨论了 Auto-Keras 和 AutoML,这是一组用于执行自动化机器学习和深度学习的工具和库。
Auto-Keras 和 AutoML 的最终目标都是通过使用神经架构搜索(NAS)算法来降低执行机器学习和深度学习的门槛。
NAS 算法,Auto-Keras 和 AutoML 的主干,将自动 :
- 定义和优化神经网络架构
- 根据模型调整超参数
主要优势包括:
- 能够在几乎没有专业知识的情况下执行机器学习和深度学习
- 获得高精度模型,该模型能够推广到训练和测试集之外的数据
- 使用 GUI 界面或简单的 API 快速启动和运行
- 不费吹灰之力就有可能达到艺术水平的表演
当然,这是要付出代价的——事实上是两种代价。
首先,谷歌的 AutoML 很贵,大约 20 美元/小时。
为了节省资金,你可以使用 Auto-Keras,这是谷歌 AutoML 的一个开源替代品,但你仍然需要为 GPU 计算时间付费。
用 NAS 算法替换实际的深度学习专家将需要许多小时的计算来搜索最佳参数。
虽然我们实现了 CIFAR-10 的高精度模型(约 96%的精度),但当我将 Auto-Keras 应用于我之前关于医学深度学习和疟疾预测的帖子时, Auto-Keras 仅实现了 96.1%的精度,比我的 97%的精度低了整整一个百分点(Auto-Keras 要求多 2300%的计算时间! )
虽然 Auto-Keras 和 AutoML 在自动化机器学习和深度学习方面可能是朝着正确方向迈出的一步,但在这一领域仍有相当多的工作要做。
没有现成算法解决机器学习/深度学习的灵丹妙药。相反,我建议你投资自己成为一名深度学习实践者和工程师。
你今天和明天学到的技能将在未来获得巨大的回报。
我希望你喜欢今天的教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 Keras 和 TensorFlow 进行基于内容的图像检索的自动编码器
在本教程中,您将学习如何使用卷积自动编码器,通过 Keras 和 TensorFlow 创建一个基于内容的图像检索系统(即图像搜索引擎)。
几周前,我撰写了一系列关于自动编码器的教程:
- 第一部分: 自动编码器简介
- 第二部分: 去噪自动编码器
- 第三部分: 用自动编码器进行异常检测
这些教程大受欢迎;然而,我没有触及的一个话题是基于内容的图像检索(CBIR) ,这实际上只是一个用于图像搜索引擎的花哨的学术词汇。
图像搜索引擎类似于文本搜索引擎,只是没有向搜索引擎提供文本查询,而是提供了图像查询 — 。然后,图像搜索引擎在其数据库中找到所有视觉上相似/相关的图像,并将其返回给您(就像文本搜索引擎返回文章、博客帖子等的链接一样。).
基于深度学习的 CBIR 和图像检索可以被框定为一种形式的无监督学习:
- 当训练自动编码器时,我们不使用任何类别标签
- 然后,自动编码器用于计算我们数据集中每个图像的潜在空间向量表示(即,给定图像的“特征向量”)
- 然后,在搜索时,我们计算潜在空间向量之间的距离——距离更小,更相关/视觉上相似两幅图像是**
因此,我们可以将 CBIR 项目分为三个不同的阶段:
- 阶段#1: 训练自动编码器
- 阶段#2: 通过使用自动编码器计算图像的潜在空间表示,从数据集中的所有图像中提取特征
- 阶段#3: 比较潜在空间向量以找到数据集中的所有相关图像
在本教程中,我将向您展示如何实现这些阶段,给您留下一个功能齐全的自动编码器和图像检索系统。
要了解如何使用自动编码器通过 Keras 和 TensorFlow 进行图像检索,请继续阅读!
使用 Keras 和 TensorFlow 进行基于内容的图像检索的自动编码器
在本教程的第一部分,我们将讨论如何自动编码器可以用于图像检索和建立图像搜索引擎。
从那里,我们将实现一个卷积自动编码器,然后在我们的图像数据集上进行训练。
一旦自动编码器被训练,我们将为数据集中的每幅图像计算特征向量。计算给定图像的特征向量只需要图像通过网络向前传递——编码器的输出(即潜在空间表示)将作为我们的特征向量。
所有图像编码后,我们可以通过计算矢量之间的距离来比较矢量。距离较小的图像将比距离较大的图像更相似。
最后,我们将回顾应用我们的自动编码器进行图像检索的结果。
如何将自动编码器用于图像检索和图像搜索引擎?
正如在我的自动编码器简介教程中所讨论的,自动编码器:
- 接受一组输入数据(即输入)
- 在内部将输入数据压缩成一个潜在空间表示(即压缩和量化输入的单个向量)
- 从这个潜在表示(即输出)中重建输入数据
为了用自动编码器建立一个图像检索系统,我们真正关心的是潜在空间表示向量。
一旦自动编码器被训练编码图像,我们就可以:
- 使用网络的编码器部分来计算我们的数据集中每个图像的潜在空间表示— 该表示用作我们的特征向量,其量化图像的内容
- 将查询图像的特征向量与数据集中的所有特征向量进行比较(通常使用欧几里德距离或余弦距离)
具有较小距离的特征向量将被认为更相似,而具有较大距离的图像将被认为不太相似。
然后,我们可以根据距离(从最小到最大)对结果进行排序,并最终向最终用户显示图像检索结果。
项目结构
继续从 “下载” 部分获取本教程的文件。从那里,提取。zip,并打开文件夹进行检查:
$ tree --dirsfirst
.
├── output
│ ├── autoencoder.h5
│ ├── index.pickle
│ ├── plot.png
│ └── recon_vis.png
├── pyimagesearch
│ ├── __init__.py
│ └── convautoencoder.py
├── index_images.py
├── search.py
└── train_autoencoder.py
2 directories, 9 files
本教程由三个 Python 驱动程序脚本组成:
train_autoencoder.py:使用ConvAutoencoderCNN/class 在 MNIST 手写数字数据集上训练一个自动编码器index_images.py:使用我们训练过的自动编码器的编码器部分,我们将计算数据集中每个图像的特征向量,并将这些特征添加到可搜索的索引中search.py:使用相似性度量查询相似图像的索引
我们的output/目录包含我们训练过的自动编码器和索引。训练还会产生一个训练历史图和可视化图像,可以导出到output/文件夹。
为图像检索实现我们的卷积自动编码器架构
在训练我们的自动编码器之前,我们必须首先实现架构本身。为此,我们将使用 Keras 和 TensorFlow。
我们之前已经在 PyImageSearch 博客上实现过几次卷积自动编码器,所以当我今天在这里报道完整的实现时,你会想要参考我的自动编码器简介教程以获得更多细节。
在pyimagesearch模块中打开convautoencoder.py文件,让我们开始工作:
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
import numpy as np
导入包括来自tf.keras和 NumPy 的选择。接下来我们将继续定义我们的 autoencoder 类:
class ConvAutoencoder:
@staticmethod
def build(width, height, depth, filters=(32, 64), latentDim=16):
# initialize the input shape to be "channels last" along with
# the channels dimension itself
# channels dimension itself
inputShape = (height, width, depth)
chanDim = -1
# define the input to the encoder
inputs = Input(shape=inputShape)
x = inputs
# loop over the number of filters
for f in filters:
# apply a CONV => RELU => BN operation
x = Conv2D(f, (3, 3), strides=2, padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# flatten the network and then construct our latent vector
volumeSize = K.int_shape(x)
x = Flatten()(x)
latent = Dense(latentDim, name="encoded")(x)
我们的ConvAutoencoder类包含一个静态方法build,它接受五个参数:(1) width、(2) height、(3) depth、(4) filters和(5) latentDim。
然后为编码器定义了Input,此时我们使用 Keras 的功能 API 循环遍历我们的filters并添加我们的CONV => LeakyReLU => BN层集合(第 21-33 行)。
然后我们拉平网络,构建我们的潜在向量 ( 第 36-38 行)。
潜在空间表示是我们数据的压缩形式— 一旦经过训练,这一层的输出将是我们用于量化和表示输入图像内容的特征向量。
从这里开始,我们将构建网络解码器部分的输入:
# start building the decoder model which will accept the
# output of the encoder as its inputs
x = Dense(np.prod(volumeSize[1:]))(latent)
x = Reshape((volumeSize[1], volumeSize[2], volumeSize[3]))(x)
# loop over our number of filters again, but this time in
# reverse order
for f in filters[::-1]:
# apply a CONV_TRANSPOSE => RELU => BN operation
x = Conv2DTranspose(f, (3, 3), strides=2,
padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# apply a single CONV_TRANSPOSE layer used to recover the
# original depth of the image
x = Conv2DTranspose(depth, (3, 3), padding="same")(x)
outputs = Activation("sigmoid", name="decoded")(x)
# construct our autoencoder model
autoencoder = Model(inputs, outputs, name="autoencoder")
# return the autoencoder model
return autoencoder
解码器模型接受编码器的输出作为其输入(行 42 和 43 )。
以相反的顺序循环通过filters,我们构造CONV_TRANSPOSE => LeakyReLU => BN层块(第 47-52 行)。
第 56-63 行恢复图像的原始depth。
最后,我们构造并返回我们的autoencoder模型(第 60-63 行)。
有关我们实现的更多细节,请务必参考我们的【Keras 和 TensorFlow 自动编码器简介教程。
使用 Keras 和 TensorFlow 创建自动编码器训练脚本
随着我们的自动编码器的实现,让我们继续训练脚本(阶段#1 )。
打开train_autoencoder.py脚本,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.convautoencoder import ConvAutoencoder
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
在2-12 号线,我们处理我们的进口。我们将使用matplotlib的"Agg"后端,这样我们可以将我们的训练图导出到磁盘。我们需要前一节中的自定义ConvAutoencoder架构类。当我们在 MNIST 基准数据集上训练时,我们将利用Adam优化器。
为了可视化,我们将在visualize_predictions助手函数中使用 OpenCV:
def visualize_predictions(decoded, gt, samples=10):
# initialize our list of output images
outputs = None
# loop over our number of output samples
for i in range(0, samples):
# grab the original image and reconstructed image
original = (gt[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# return the output images
return outputs
在visualize_predictions助手中,我们将我们的原始地面实况输入图像(gt)与来自自动编码器(decoded)的输出重建图像进行比较,并生成并排比较蒙太奇。
第 16 行初始化我们的输出图像列表。
然后我们循环遍历samples:
- 抓取原始和重建图像(第 21 和 22 行)
- 并排堆叠一对图像(第 25 行)
** 垂直堆叠线对*(第 29-34 行)**
**最后,我们将可视化图像返回给调用者( Line 37 )。
我们需要一些命令行参数来让我们的脚本从我们的终端/命令行运行:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to output trained autoencoder")
ap.add_argument("-v", "--vis", type=str, default="recon_vis.png",
help="path to output reconstruction visualization file")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
这里我们解析三个命令行参数:
--model:指向我们训练过的输出 autoencoder 的路径——执行这个脚本的结果--vis:输出可视化图像的路径。默认情况下,我们将我们的可视化命名为recon_vis.png--plot:matplotlib 输出图的路径。如果终端中未提供该参数,则分配默认值plot.png
既然我们的导入、助手函数和命令行参数已经准备好了,我们将准备训练我们的自动编码器:
# initialize the number of epochs to train for, initial learning rate,
# and batch size
EPOCHS = 20
INIT_LR = 1e-3
BS = 32
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, _), (testX, _)) = mnist.load_data()
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# construct our convolutional autoencoder
print("[INFO] building autoencoder...")
autoencoder = ConvAutoencoder.build(28, 28, 1)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
autoencoder.compile(loss="mse", optimizer=opt)
# train the convolutional autoencoder
H = autoencoder.fit(
trainX, trainX,
validation_data=(testX, testX),
epochs=EPOCHS,
batch_size=BS)
在行 51-53 中定义了超参数常数,包括训练时期数、学习率和批量大小。
我们的自动编码器(因此我们的 CBIR 系统)将在 MNIST 手写数字数据集上被训练,我们从磁盘的第 57 行加载该数据集。
为了预处理 MNIST 图像,我们向训练/测试集添加通道维度(行 61 和 62 )并将像素强度缩放到范围【0,1】(行 63 和 64 )。
随着我们的数据准备就绪,第 68-70 行 compile我们的autoencoder与Adam优化器和均方差loss。
第 73-77 行然后将我们的模型与数据拟合(即训练我们的autoencoder)。
一旦模型被训练好,我们就可以用它来做预测:
# use the convolutional autoencoder to make predictions on the
# testing images, construct the visualization, and then save it
# to disk
print("[INFO] making predictions...")
decoded = autoencoder.predict(testX)
vis = visualize_predictions(decoded, testX)
cv2.imwrite(args["vis"], vis)
# construct a plot that plots and saves the training history
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# serialize the autoencoder model to disk
print("[INFO] saving autoencoder...")
autoencoder.save(args["model"], save_format="h5")
第 83 行和第 84 行对测试集进行预测,并使用我们的助手函数生成我们的自动编码器可视化。第 85 行使用 OpenCV 将可视化写入磁盘。
最后,我们绘制培训历史(第 88-97 行)并将我们的autoencoder序列化到磁盘(第 101 行)。
在下一部分中,我们将使用培训脚本。
训练自动编码器
我们现在准备训练我们的卷积自动编码器进行图像检索。
确保使用本教程的 【下载】 部分下载源代码,并从那里执行以下命令开始训练过程:
$ python train_autoencoder.py --model output/autoencoder.h5 \
--vis output/recon_vis.png --plot output/plot.png
[INFO] loading MNIST dataset...
[INFO] building autoencoder...
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 73s 1ms/sample - loss: 0.0182 - val_loss: 0.0124
Epoch 2/20
60000/60000 [==============================] - 73s 1ms/sample - loss: 0.0101 - val_loss: 0.0092
Epoch 3/20
60000/60000 [==============================] - 73s 1ms/sample - loss: 0.0090 - val_loss: 0.0084
...
Epoch 18/20
60000/60000 [==============================] - 72s 1ms/sample - loss: 0.0065 - val_loss: 0.0067
Epoch 19/20
60000/60000 [==============================] - 73s 1ms/sample - loss: 0.0065 - val_loss: 0.0067
Epoch 20/20
60000/60000 [==============================] - 73s 1ms/sample - loss: 0.0064 - val_loss: 0.0067
[INFO] making predictions...
[INFO] saving autoencoder...
在我的 3Ghz 英特尔至强 W 处理器上,整个培训过程花费了大约 24 分钟。
查看图 2、中的曲线,我们可以看到训练过程是稳定的,没有过度拟合的迹象:

Figure 2: Training an autoencoder with Keras and TensorFlow for Content-based Image Retrieval (CBIR).
此外,下面的重构图表明,我们的自动编码器在重构输入数字方面做得非常好。

Figure 3: Visualizing reconstructed data from an autoencoder trained on MNIST using TensorFlow and Keras for image search engine purposes.
我们的自动编码器做得如此之好的事实也意味着我们的潜在空间表示向量在压缩、量化和表示输入图像方面做得很好——当构建图像检索系统时,拥有这样的表示是要求。
如果特征向量不能捕捉和量化图像的内容,那么CBIR 系统将无法返回相关图像。
如果您发现您的自动编码器无法正确重建图像,那么您的自动编码器不太可能在图像检索方面表现良好。
小心训练一个精确的自动编码器——这样做将有助于确保你的图像检索系统返回相似的图像。
使用经过训练的自动编码器实现图像索引器
随着我们的自动编码器成功训练(阶段#1 ,我们可以继续进行图像检索管道的特征提取/索引阶段(阶段#2 )。
这个阶段至少要求我们使用经过训练的自动编码器(特别是“编码器”部分)来接受输入图像,执行前向传递,然后获取网络编码器部分的输出,以生成我们的特征向量的索引。这些特征向量意味着量化每个图像的内容。
可选地,我们也可以使用专门的数据结构,例如 VP-Trees 和随机投影树来提高我们的图像检索系统的查询速度。
打开目录结构中的index_images.py文件,我们将开始:
# import the necessary packages
from tensorflow.keras.models import Model
from tensorflow.keras.models import load_model
from tensorflow.keras.datasets import mnist
import numpy as np
import argparse
import pickle
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained autoencoder")
ap.add_argument("-i", "--index", type=str, required=True,
help="path to output features index file")
args = vars(ap.parse_args())
我们从进口开始。我们的tf.keras导入包括(1) Model以便我们可以构建编码器,(2) load_model以便我们可以加载我们在上一步中训练的自动编码器模型,以及(3)我们的mnist数据集。我们的特征向量索引将被序列化为一个 Python pickle文件。
我们有两个必需的命令行参数:
--model:上一步训练好的自动编码器输入路径--index:输出特征索引文件的路径,格式为.pickle
从这里,我们将加载并预处理我们的 MNIST 数字数据:
# load the MNIST dataset
print("[INFO] loading MNIST training split...")
((trainX, _), (testX, _)) = mnist.load_data()
# add a channel dimension to every image in the training split, then
# scale the pixel intensities to the range [0, 1]
trainX = np.expand_dims(trainX, axis=-1)
trainX = trainX.astype("float32") / 255.0
请注意,预处理步骤与我们训练过程的步骤相同。
然后我们将加载我们的自动编码器:
# load our autoencoder from disk
print("[INFO] loading autoencoder model...")
autoencoder = load_model(args["model"])
# create the encoder model which consists of *just* the encoder
# portion of the autoencoder
encoder = Model(inputs=autoencoder.input,
outputs=autoencoder.get_layer("encoded").output)
# quantify the contents of our input images using the encoder
print("[INFO] encoding images...")
features = encoder.predict(trainX)
第 28 行从磁盘加载我们的autoencoder(在上一步中训练的)。
然后,使用自动编码器的input,我们创建一个Model,同时只访问网络的encoder部分(即潜在空间特征向量)作为output ( 行 32 和 33 )。
然后,我们将 MNIST 数字图像数据通过encoder来计算第 37 行上的特征向量features。
最后,我们构建了特征数据的字典映射:
# construct a dictionary that maps the index of the MNIST training
# image to its corresponding latent-space representation
indexes = list(range(0, trainX.shape[0]))
data = {"indexes": indexes, "features": features}
# write the data dictionary to disk
print("[INFO] saving index...")
f = open(args["index"], "wb")
f.write(pickle.dumps(data))
f.close()
第 42 行构建了一个由两部分组成的data字典:
indexes:数据集中每个 MNIST 数字图像的整数索引features:数据集中每幅图像对应的特征向量
最后,第 46-48 行以 Python 的pickle格式将data序列化到磁盘。
为图像检索索引我们的图像数据集
我们现在准备使用自动编码器量化我们的图像数据集,特别是使用网络编码器部分的潜在空间输出。
要使用经过训练的 autoencoder 量化我们的图像数据集,请确保使用本教程的 “下载” 部分下载源代码和预训练模型。
从那里,打开一个终端并执行以下命令:
$ python index_images.py --model output/autoencoder.h5 \
--index output/index.pickle
[INFO] loading MNIST training split...
[INFO] loading autoencoder model...
[INFO] encoding images...
[INFO] saving index...
如果您检查您的output目录的内容,您现在应该看到您的index.pickle文件:
$ ls output/*.pickle
output/index.pickle
使用 Keras 和 TensorFlow 实现图像搜索和检索脚本
我们的最终脚本,我们的图像搜索器,将所有的片段放在一起,并允许我们完成我们的 autoencoder 图像检索项目(阶段#3 )。同样,我们将在这个实现中使用 Keras 和 TensorFlow。
打开search.py脚本,插入以下内容:
# import the necessary packages
from tensorflow.keras.models import Model
from tensorflow.keras.models import load_model
from tensorflow.keras.datasets import mnist
from imutils import build_montages
import numpy as np
import argparse
import pickle
import cv2
如您所见,这个脚本需要与我们的索引器相同的tf.keras导入。此外,我们将使用我的 imutils 包中的build_montages便利脚本来显示我们的 autoencoder CBIR 结果。
让我们定义一个函数来计算两个特征向量之间的相似性:
def euclidean(a, b):
# compute and return the euclidean distance between two vectors
return np.linalg.norm(a - b)
这里我们用欧几里德距离来计算两个特征向量a和b之间的相似度。
有多种方法可以计算距离-对于许多 CBIR 应用程序来说,余弦距离是一种很好的替代方法。我还会在 PyImageSearch 大师课程中介绍其他距离算法。
接下来,我们将定义我们的搜索函数:
def perform_search(queryFeatures, index, maxResults=64):
# initialize our list of results
results = []
# loop over our index
for i in range(0, len(index["features"])):
# compute the euclidean distance between our query features
# and the features for the current image in our index, then
# update our results list with a 2-tuple consisting of the
# computed distance and the index of the image
d = euclidean(queryFeatures, index["features"][i])
results.append((d, i))
# sort the results and grab the top ones
results = sorted(results)[:maxResults]
# return the list of results
return results
我们的perform_search函数负责比较所有特征向量的相似性,并返回results。
该函数接受查询图像的特征向量queryFeatures和要搜索的所有特征的index。
我们的results将包含顶部的maxResults(在我们的例子中,64是默认的,但我们很快会将其覆盖为225)。
第 17 行初始化我们的列表results,然后第 20-20 行填充它。这里,我们循环遍历index中的所有条目,计算queryFeatures和index中当前特征向量之间的欧几里德距离。
说到距离:
- 距离越小,两幅图像越相似
- 距离越大,越不相似
我们排序并抓取顶部的results,这样通过第 29 行与查询更相似的图像就在列表的最前面。
最后,我们return将搜索结果传递给调用函数(第 32 行)。
定义了距离度量和搜索工具后,我们现在准备好解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained autoencoder")
ap.add_argument("-i", "--index", type=str, required=True,
help="path to features index file")
ap.add_argument("-s", "--sample", type=int, default=10,
help="# of testing queries to perform")
args = vars(ap.parse_args())
我们的脚本接受三个命令行参数:
--model:从“训练自动编码器”部分到被训练自动编码器的路径--index:我们要搜索的特征索引(即来自“为图像检索而索引我们的图像数据集”部分的序列化索引)--sample:要执行的测试查询的数量,默认值为10
现在,让我们加载并预处理我们的数字数据:
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, _), (testX, _)) = mnist.load_data()
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
然后我们将加载我们的自动编码器和索引:
# load the autoencoder model and index from disk
print("[INFO] loading autoencoder and index...")
autoencoder = load_model(args["model"])
index = pickle.loads(open(args["index"], "rb").read())
# create the encoder model which consists of *just* the encoder
# portion of the autoencoder
encoder = Model(inputs=autoencoder.input,
outputs=autoencoder.get_layer("encoded").output)
# quantify the contents of our input testing images using the encoder
print("[INFO] encoding testing images...")
features = encoder.predict(testX)
这里,线 57 从磁盘加载我们训练好的autoencoder,而线 58 从磁盘加载我们腌制好的index。
然后我们构建一个Model,它将接受我们的图像作为一个input和我们的encoder层的output(即特征向量)作为我们模型的输出(第 62 和 63 行)。
给定我们的encoder , 行 67 通过网络向前传递我们的测试图像集,生成一个features列表来量化它们。
我们现在将随机抽取一些图像样本,将它们标记为查询:
# randomly sample a set of testing query image indexes
queryIdxs = list(range(0, testX.shape[0]))
queryIdxs = np.random.choice(queryIdxs, size=args["sample"],
replace=False)
# loop over the testing indexes
for i in queryIdxs:
# take the features for the current image, find all similar
# images in our dataset, and then initialize our list of result
# images
queryFeatures = features[i]
results = perform_search(queryFeatures, index, maxResults=225)
images = []
# loop over the results
for (d, j) in results:
# grab the result image, convert it back to the range
# [0, 255], and then update the images list
image = (trainX[j] * 255).astype("uint8")
image = np.dstack([image] * 3)
images.append(image)
# display the query image
query = (testX[i] * 255).astype("uint8")
cv2.imshow("Query", query)
# build a montage from the results and display it
montage = build_montages(images, (28, 28), (15, 15))[0]
cv2.imshow("Results", montage)
cv2.waitKey(0)
第 70-72 行采样一组测试图像索引,将它们标记为我们的搜索引擎查询。
然后我们从第 75 行的开始循环查询。在内部,我们:
- 抓住
queryFeatures,执行搜索(79 行和 80 行) - 初始化一个列表来保存我们的结果
images( 第 81 行) - 对结果进行循环,将图像缩放回范围【0,255】,从灰度图像创建 RGB 表示用于显示,然后将其添加到我们的
images结果中(第 84-89 行) - 在自己的 OpenCV 窗口中显示查询图像(第 92 行和第 93 行)
- 显示搜索引擎结果中的
montage(第 96 行和第 97 行) - 当用户按下一个键时,我们用一个不同的查询图像重复这个过程(行 98);您应该在检查结果时继续按键,直到搜索完所有的查询样本
回顾一下我们的搜索脚本,首先我们加载了自动编码器和索引。
然后,我们抓住自动编码器的编码器部分,用它来量化我们的图像(即,创建特征向量)。
从那里,我们创建了一个随机查询图像的样本来测试我们的基于欧氏距离计算的搜索方法。较小的距离表示相似的图像——相似的图像将首先显示,因为我们的results是sorted ( 第 29 行)。
我们搜索了每个查询的索引,在每个剪辑中最多只显示了maxResults。
在下一节中,我们将有机会直观地验证我们基于 autoencoder 的搜索引擎是如何工作的。
使用自动编码器、Keras 和 TensorFlow 的图像检索结果
我们现在可以看到我们的 autoencoder 图像检索系统的运行了!
首先确保你有:
- 使用本教程的 【下载】 部分下载源代码
- 执行
train_autoencoder.py文件来训练卷积自动编码器 - 运行
index_images.py来量化我们数据集中的每幅图像
从那里,您可以执行search.py脚本来执行搜索:
$ python search.py --model output/autoencoder.h5 \
--index output/index.pickle
[INFO] loading MNIST dataset...
[INFO] loading autoencoder and index...
[INFO] encoding testing images...
下面的例子提供了一个包含数字9 ( 顶部)的查询图像,以及来自我们的 autoencoder 图像检索系统(底部)的搜索结果:

Figure 4: Top: MNIST query image. Bottom: Autoencoder-based image search engine results. We learn how to use Keras, TensorFlow, and OpenCV to build a Content-based Image Retrieval (CBIR) system.
在这里,您可以看到我们的系统返回的搜索结果也包含 9。
现在让我们使用一个2作为我们的查询图像:

Figure 5: Content-based Image Retrieval (CBIR) is used with an autoencoder to find images of handwritten 2s in our dataset.
果然,我们的 CBIR 系统返回包含二的数字,这意味着潜在空间表示已经正确量化了2的样子。
下面是一个使用4作为查询图像的例子:

Figure 6: Content-based Image Retrieval (CBIR) is used with an autoencoder to find images of handwritten 4s in our dataset.
同样,我们的 autoencoder 图像检索系统返回所有四个作为搜索结果。
让我们看最后一个例子,这次使用一个0作为查询图像:

Figure 7: No image search engine is perfect. Here, there are mistakes in our results from searching MNIST for handwritten 0s using an autoencoder-based image search engine built with TensorFlow, Keras, and OpenCV.
这个结果更有趣—注意截图中突出显示的两个结果。
第一个高亮显示的结果可能是一个5,但是五的尾部似乎连接到中间部分,创建了一个数字,看起来像是一个0和一个8之间的交叉。
然后,我们在搜索结果的底部看到我认为是一个8(也用红色突出显示)。同样,我们可以理解我们的图像检索系统是如何将8视为与0在视觉上相似的。
提高 autoencoder 图像检索准确性和速度的技巧
在本教程中,我们在 MNIST 数据集上执行图像检索,以演示如何使用自动编码器来构建图像搜索引擎。
但是,您很可能希望使用自己的影像数据集,而不是 MNIST 数据集。
换入您自己的数据集就像用您自己的数据集加载器替换 MNIST 数据集加载器辅助函数一样简单-然后您可以在您的数据集上训练自动编码器。
然而,确保你的自动编码器足够精确。
如果您的自动编码器无法合理地重建您的输入数据,则:
- 自动编码器无法捕获数据集中的模式
- 潜在空间向量不会正确量化你的图像
- 没有适当的量化,您的图像检索系统将返回不相关的结果
因此,几乎您的 CBIR 系统的整体精度取决于您的自动编码器——请花时间确保它经过适当的培训。
一旦你的自动编码器运行良好,你就可以继续优化搜索过程的速度。
其次,您还应该考虑 CBIR 系统的可扩展性。
我们在这里的实现是一个线性搜索的例子,复杂度为 O(N) ,这意味着它不能很好地扩展。
为了提高检索系统的速度,您应该使用近似最近邻算法和专门的数据结构,如 VP 树、随机投影树等。,可以将计算复杂度降低到 O(log N)。
要了解更多关于这些技术的内容,请参考我的文章用 VP-Trees 和 OpenCV 构建一个图像哈希搜索引擎。
摘要
在本教程中,您学习了如何使用 TensorFlow 和 Keras 将卷积自动编码器用于图像检索。
为了创建我们的图像检索系统,我们:
- 在我们的图像数据集上训练卷积自动编码器
- 使用经过训练的自动编码器来计算我们的数据集中每个图像的潜在空间表示——该表示作为我们的特征向量来量化图像的内容
- 使用距离函数将查询图像的特征向量与数据集中的所有特征向量进行比较(在这种情况下,使用欧几里德距离,但余弦距离也适用)。向量之间的距离越小,我们的图像就越相似。
然后,我们根据计算出的距离对结果进行排序,并向用户显示结果。
自动编码器对于 CBIR 应用来说非常有用— 缺点是它们需要大量的训练数据,这些数据你可能有也可能没有。
更高级的深度学习图像检索系统依赖于连体网络和三重损失来嵌入图像的向量,以便更相似的图像在欧几里得空间中靠得更近,而不太相似的图像离得更远——我将在未来的某个日期讨论这些类型的网络架构和技术。
要下载这篇文章的源代码(包括预先训练的 autoencoder),*只需在下面的表格中输入您的电子邮件地址!***
具有 Keras、TensorFlow 和深度学习的自动编码器
原文:https://pyimagesearch.com/2020/02/17/autoencoders-with-keras-tensorflow-and-deep-learning/
在本教程中,您将学习如何使用 Keras、TensorFlow 和深度学习来实现和训练自动编码器。
今天的教程开始了自动编码器应用的三部分系列:
- 具有 Keras、TensorFlow 和深度学习的自动编码器(今天的教程)
- 用 Keras 和 TensorFlow 去噪自动编码器(下周教程)
- 使用 Keras、TensorFlow 和深度学习进行异常检测(两周后的教程)
几周前,我发表了一篇关于使用标准机器学习算法进行异常/异常检测的介绍性指南。
我的意图是立即跟进那个帖子,提供一个关于基于深度学习的异常检测的指南;然而,当我开始写教程的代码时,我意识到我从来没有在 PyImageSearch 博客上讨论过自动编码器!
试图在没有关于什么是自动编码器和它们如何工作的的先验背景的情况下讨论基于深度学习的异常检测,将很难理解、理解和消化。
因此,我们将在接下来的几周时间里研究自动编码器算法,包括它们的实际应用。
要了解使用 Keras 和 TensorFlow 的自动编码器的基础知识,请继续阅读!
具有 Keras、TensorFlow 和深度学习的自动编码器
在本教程的第一部分,我们将讨论什么是自动编码器,包括卷积自动编码器如何应用于图像数据。我们还将讨论自动编码器和其他生成模型之间的差异,例如生成对抗网络(GANs)。
从那以后,我将向您展示如何使用 Keras 和 TensorFlow 实现和训练卷积自动编码器。
然后我们将回顾训练脚本的结果,包括可视化 autoencoder 如何重构输入数据。
最后,如果您有兴趣了解更多关于应用于图像数据集的深度学习的信息,我将向您推荐接下来的步骤。
什么是自动编码器?
自动编码器是一种类型的无监督神经网络(即,没有类别标签或标记数据),它寻求:
- 接受一组输入数据(即输入)。
- 在内部将输入数据压缩到一个潜在空间表示(也就是说,压缩和量化输入的单个向量)。
- 从该潜在表示(即输出)中重建输入数据。
通常,我们认为自动编码器有两个组件/子网:
- 编码器:接受输入数据并将其压缩到潜在空间。如果我们把我们的输入数据表示为
 ,把编码器表示为
,把编码器表示为 ,那么输出的潜在空间表示,
,那么输出的潜在空间表示, ,就会是
,就会是") 。
。 - 解码器:解码器负责接受潜在空间表示
 ,然后重构原始输入。如果我们将解码器功能表示为
,然后重构原始输入。如果我们将解码器功能表示为 ,检测器的输出表示为
,检测器的输出表示为 ,那么我们可以将解码器表示为
,那么我们可以将解码器表示为") 。
。
 ,就会是
,就会是 ,检测器的输出表示为
,检测器的输出表示为 ,那么我们可以将解码器表示为
,那么我们可以将解码器表示为使用我们的数学符号,自动编码器的整个训练过程可以写成:
)")
下面的图 1 展示了自动编码器的基本架构:
在这里你可以看到:
- 我们向自动编码器输入一个数字。
- 编码器子网创建数字的潜在表示。这种潜在的表现形式(就维度而言)远小于输入。
- 解码器子网络然后从潜在表示中重建原始数字。
你可以把自动编码器想象成一个网络,重构它的输入!*
为了训练自动编码器,我们输入数据,尝试重建数据,然后最小化均方误差(或类似的损失函数)。
理想情况下,自动编码器的输出与输入的几乎相同。
自动编码器重构它的输入,这有什么大不了的?
在这一点上,你们中的一些人可能会想:
艾德里安,这有什么大不了的?
如果自动编码器的目标仅仅是重建输入,为什么一开始还要使用网络呢?
如果我想要我的输入数据的一个副本,我可以用一个函数调用来复制它。
我究竟为什么要应用深度学习,还要经历训练一个网络的麻烦?
这个问题,虽然是一个合理的问题,但确实包含了一个关于自动编码器的误解。
是的,在训练过程中,我们的目标是训练一个网络,它可以学习如何重建我们的输入数据— 但自动编码器的真正价值存在于潜在空间表示中。
请记住,自动编码器压缩我们的输入数据,更重要的是,当我们训练自动编码器时,我们真正关心的是编码器
, and the latent-space representation, ") .
.
") 解码器
解码器
, is used to train the autoencoder end-to-end, but in practical applications, we often (but not always) care more about the encoder and the latent-space.
在本教程的后面,我们将在 MNIST 数据集上训练一个自动编码器。MNIST 数据集由单通道的 28×28 像素的数字组成,这意味着每个数字由28×28 = 784个值表示。我们将在这里训练的自动编码器将能够把这些数字压缩成一个只有 16 个值的向量——这减少了近 98%!
那么如果一个输入数据点被压缩成这么小的向量,我们能做什么呢?
这就是事情变得非常有趣的地方。
自动编码器有哪些应用?
自动编码器通常用于:
- 降维(即认为 PCA 但更强大/智能)。
- 去噪(例如。去除噪声并预处理图像以提高 OCR 准确度)。
- 异常/异常值检测(例如。检测数据集中标注错误的数据点,或者检测输入数据点何时超出我们的典型数据分布)。
在计算机视觉领域之外,您将看到自动编码器应用于自然语言处理(NLP)和文本理解问题,包括理解单词的语义,构建单词嵌入,甚至文本摘要。
自动编码器和 GANs 有什么不同?
如果你以前做过生成对抗网络(GANs)的工作,你可能想知道自动编码器和 GANs 有什么不同。
GANs 和自动编码器都是生成模型;然而,自动编码器本质上是通过压缩来学习身份函数。
自动编码器将接受我们的输入数据,将其压缩到潜在空间表示,然后尝试仅使用潜在空间向量来重建输入。
典型地,潜在空间表示将具有比原始输入数据少得多的维度。
*甘斯另一方面:
- 接受低维输入。
- 从中构建一个高维空间。
- 生成最终输出,该输出是原始训练数据的而非部分,但理想情况下同样通过。
此外,gan 具有自动编码器所没有的进化损失景观。
*在训练 GAN 时,生成模型生成“假”图像,然后将这些图像与真实的“真实”图像混合在一起,然后鉴别器模型必须确定哪些图像是“真实”的,哪些是“假的/生成的”。
随着生成模型越来越好地生成可以骗过鉴别者的假图像,损失格局也在演变和变化(这也是为什么训练 GANs 如此之难的原因之一)。
虽然 GANs 和 autoencoders 都是生成模型,但它们的大多数相似之处也就到此为止了。
自动编码器无法生成新的、真实的数据点,而这些数据点可能被人类认为是“可以通过的”。相反,自动编码器主要用作将输入数据点压缩成潜在空间表示的方法。然后,该潜在空间表示可以用于压缩、去噪、异常检测等。
关于 GANs 和自动编码器之间的差异的更多细节,我建议读一读 Quora 上的这个帖子。
配置您的开发环境
为了跟随今天关于自动编码器的教程,你应该使用 TensorFlow 2.0。我有两个 TF 2.0 的安装教程和相关的包,可以帮助您的开发系统跟上速度:
- 如何在 UbuntuT3 上安装 tensor flow 2.0【Ubuntu 18.04 OS;CPU 和可选的 NVIDIA GPU)
- 如何在 macOS 上安装 tensor flow 2.0(Catalina 和 Mojave OSes)
请注意: PyImageSearch 不支持 Windows — 参考我们的 FAQ 。
项目结构
一定要抓取与博文相关的 【下载】 。从那里,提取。压缩并检查文件/文件夹布局:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── convautoencoder.py
├── output.png
├── plot.png
└── train_conv_autoencoder.py
1 directory, 5 files
今天我们将回顾两个 Python 脚本:
convautoencoder.py:包含用tf.keras组装我们的神经网络所需的ConvAutoencoder类和build方法。train_conv_autoencoder.py:在 MNIST 数据集上训练一个数字自动编码器。一旦 autoencoder 被训练好,我们将遍历大量的输出示例,并将它们写入磁盘供以后检查。
我们的训练脚本会生成plot.png图和output.png图。输出图像包含原始图像和重建图像的并排样本。
在下一节中,我们将使用 TensorFlow 内置的高级 Keras API 实现我们的自动编码器。
用 Keras 和 TensorFlow 实现卷积自动编码器
在训练自动编码器之前,我们首先需要实现自动编码器架构本身。
为此,我们将使用 Keras 和 TensorFlow。
我的实现大致遵循了 Francois Chollet 在官方 Keras 博客上自己的自动编码器实现。我在这里的主要贡献是更详细地介绍实现本身。
打开项目结构中的convautoencoder.py文件,并插入以下代码:
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
import numpy as np
class ConvAutoencoder:
@staticmethod
def build(width, height, depth, filters=(32, 64), latentDim=16):
# initialize the input shape to be "channels last" along with
# the channels dimension itself
# channels dimension itself
inputShape = (height, width, depth)
chanDim = -1
我们从选择从tf.keras和 NumPy 的进口开始。如果您的系统上没有安装 TensorFlow 2.0,请参考上面的“配置您的开发环境”一节。
我们的ConvAutoencoder类包含一个静态方法build,它接受五个参数:
width:输入图像的宽度,单位为像素。height:输入图像的高度,单位为像素。depth:输入体积的通道数(即深度)。filters:包含用于卷积运算的过滤器集合的元组。默认情况下,该参数包括32和64滤镜。latentDim:我们的全连通(Dense)潜在向量中的神经元数量。默认情况下,如果该参数未被传递,则该值被设置为16。
从那里,我们初始化inputShape和通道维度(我们假设“通道最后”排序)。
我们现在准备初始化输入,并开始向网络添加图层:
# define the input to the encoder
inputs = Input(shape=inputShape)
x = inputs
# loop over the number of filters
for f in filters:
# apply a CONV => RELU => BN operation
x = Conv2D(f, (3, 3), strides=2, padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# flatten the network and then construct our latent vector
volumeSize = K.int_shape(x)
x = Flatten()(x)
latent = Dense(latentDim)(x)
# build the encoder model
encoder = Model(inputs, latent, name="encoder")
第 25 和 26 行定义了编码器的输入。
准备好我们的输入,我们开始循环filters的数目,并添加我们的CONV=>LeakyReLU=>BN层集合(第 29-33 行)。
接下来,我们拉平网络并构建我们的潜在向量(第 36-38 行)——这是我们实际的潜在空间表示(即“压缩”的数据表示)。
然后我们建立我们的encoder模型(线 41 )。
如果我们要对encoder做一个print(encoder.summary()),假设 28×28 单通道图像(depth=1)和filters=(32, 64)和latentDim=16,我们会得到如下结果:
Model: "encoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 14, 14, 32) 320
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 14, 14, 32) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 14, 14, 32) 128
_________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 64) 18496
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 7, 7, 64) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 7, 7, 64) 256
_________________________________________________________________
flatten (Flatten) (None, 3136) 0
_________________________________________________________________
dense (Dense) (None, 16) 50192
=================================================================
Total params: 69,392
Trainable params: 69,200
Non-trainable params: 192
_________________________________________________________________
在这里我们可以观察到:
- 我们的编码器首先接受一个 28x28x1 输入音量。
- 我们接着应用两轮
CONV=>RELU=>BN,每轮用 3×3 跨步卷积。步长卷积允许我们减少体积的空间维度。 - 在应用最后一批规范化后,我们最终得到一个 7x7x64 卷,它被展平成一个 3136 -dim 向量。
- 我们的全连通层(即
Dense层)充当我们的 潜在空间表征。
接下来,让我们了解解码器模型如何获取这种潜在空间表示并重建原始输入图像:
# start building the decoder model which will accept the
# output of the encoder as its inputs
latentInputs = Input(shape=(latentDim,))
x = Dense(np.prod(volumeSize[1:]))(latentInputs)
x = Reshape((volumeSize[1], volumeSize[2], volumeSize[3]))(x)
# loop over our number of filters again, but this time in
# reverse order
for f in filters[::-1]:
# apply a CONV_TRANSPOSE => RELU => BN operation
x = Conv2DTranspose(f, (3, 3), strides=2,
padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
为了开始构建解码器模型,我们:
- 基于
latentDim构建解码器模型的输入。(第 45 行和第 46 行)。 - 接受 1D
latentDim矢量,把它变成 2D 体,这样我们就可以开始应用卷积了( 第 47 行 )。 - 循环多个过滤器,这次以相反的顺序应用一个
CONV_TRANSPOSE => RELU => BN操作( 第 51-56 行 )。
转置卷积用于增加体积的空间尺寸(即宽度和高度)。
让我们完成自动编码器的创建:
# apply a single CONV_TRANSPOSE layer used to recover the
# original depth of the image
x = Conv2DTranspose(depth, (3, 3), padding="same")(x)
outputs = Activation("sigmoid")(x)
# build the decoder model
decoder = Model(latentInputs, outputs, name="decoder")
# our autoencoder is the encoder + decoder
autoencoder = Model(inputs, decoder(encoder(inputs)),
name="autoencoder")
# return a 3-tuple of the encoder, decoder, and autoencoder
return (encoder, decoder, autoencoder)
总结一下,我们:
- 在第 60 行的处应用一个最终的
CONV_TRANSPOSE图层,用于恢复图像的原始通道深度(单通道/灰度图像为 1 个通道,RGB 图像为 3 个通道)。 - 应用一个 sigmoid 激活功能(第 61 行 )。
- 建立
decoder模型,用encoder添加到autoencoder( 第 64-68 行 )。 自动编码器变成了编码器+解码器。 - 返回编码器、解码器和自动编码器的三元组。
如果我们要在这里完成一个print(decoder.summary())操作,我们会得到如下结果:
Model: "decoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 16)] 0
_________________________________________________________________
dense_1 (Dense) (None, 3136) 53312
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 14, 14, 64) 36928
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 28, 28, 32) 18464
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 28, 28, 32) 128
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 1) 289
_________________________________________________________________
activation (Activation) (None, 28, 28, 1) 0
=================================================================
Total params: 109,377
Trainable params: 109,185
Non-trainable params: 192
_________________________________________________________________
decoder从encoder接受我们的 16 维潜在表示,然后建立一个新的3136 维全连通层,它是7×7×64 = 3136 的乘积。
使用我们新的 3136-dim FC 层,我们将其重塑为一个 7 x 7 x 64 的 3D 体积。从那里我们可以开始应用我们的CONV_TRANSPOSE=>RELU=>BN操作。与用于减少音量大小的标准步进卷积不同,我们的转置卷积用于增加音量大小。
最后,应用转置卷积层来恢复图像的原始通道深度。由于我们的图像是灰度的,我们学习一个单滤波器,其输出是一个28×28×1的体积(即原始 MNIST 数字图像的尺寸)。
print(autoencoder.summary())操作显示了编码器和解码器的组合特性:
Model: "autoencoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
encoder (Model) (None, 16) 69392
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 109377
=================================================================
Total params: 178,769
Trainable params: 178,385
Non-trainable params: 384
_________________________________________________________________
我们encoder的输入是来自 MNIST 数据集的原始 28 x 28 x 1 图像。我们的encoder然后学习数据的 16 维潜在空间表示,之后decoder 重建原始 28 x 28 x 1 图像。
在下一节中,我们将开发脚本来训练我们的自动编码器。
创建卷积自动编码器训练脚本
实现了我们的 autoencoder 架构后,让我们继续学习训练脚本。
打开项目目录结构中的train_conv_autoencoder.py,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.convautoencoder import ConvAutoencoder
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--samples", type=int, default=8,
help="# number of samples to visualize when decoding")
ap.add_argument("-o", "--output", type=str, default="output.png",
help="path to output visualization file")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
在2-12 号线,我们处理我们的进口。我们将使用matplotlib的"Agg"后端,这样我们可以将我们的训练图导出到磁盘。
我们需要我们的定制ConvAutoencoder架构类,它是我们在上一节中实现的。
我们将在 MNIST 基准数据集上训练时使用Adam优化器。为了可视化,我们将使用 OpenCV。
接下来,我们将解析三个命令行参数,它们都是可选的:
--samples:可视化输出样本数。默认情况下,该值设置为8。--output:输出可视化图像的路径。默认情况下,我们将我们的可视化命名为 output.png--plot:matplotlib 输出图的路径。如果终端中未提供此参数,则默认为 plot.png。
现在,我们将设置几个超参数并预处理我们的 MNIST 数据集:
# initialize the number of epochs to train for and batch size
EPOCHS = 25
BS = 32
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, _), (testX, _)) = mnist.load_data()
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
第 25 行和第 26 行初始化批量大小和训练时期的数量。
从那里,我们将使用我们的 MNIST 数据集。TensorFlow/Keras 有一个方便的load_data方法,我们可以调用mnist来获取数据(第 30 行)。从那里,第 34-37 行 (1)为数据集中的每个图像添加一个通道维度,以及(2)将像素强度缩放到范围【0,1】。
我们现在准备好构建和训练我们的自动编码器:
# construct our convolutional autoencoder
print("[INFO] building autoencoder...")
(encoder, decoder, autoencoder) = ConvAutoencoder.build(28, 28, 1)
opt = Adam(lr=1e-3)
autoencoder.compile(loss="mse", optimizer=opt)
# train the convolutional autoencoder
H = autoencoder.fit(
trainX, trainX,
validation_data=(testX, testX),
epochs=EPOCHS,
batch_size=BS)
为了构建卷积自动编码器,我们在我们的ConvAutoencoder类上调用build方法,并传递必要的参数(第 41 行)。回想一下,这产生了(encoder, decoder, autoencoder)元组——在这个脚本中,我们只需要autoencoder进行训练和预测。
我们用初始学习率1e-3初始化我们的Adam优化器,然后用均方误差损失对其进行编译(第 42 行和第 43 行)。
从那里,我们在 MNIST 数据(线 46-50 )上fit(训练)我们的autoencoder。
让我们继续绘制我们的培训历史:
# construct a plot that plots and saves the training history
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
从那里,我们将对我们的测试集进行预测:
# use the convolutional autoencoder to make predictions on the
# testing images, then initialize our list of output images
print("[INFO] making predictions...")
decoded = autoencoder.predict(testX)
outputs = None
# loop over our number of output samples
for i in range(0, args["samples"]):
# grab the original image and reconstructed image
original = (testX[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# save the outputs image to disk
cv2.imwrite(args["output"], outputs)
第 67 行对测试集进行预测。然后我们循环遍历作为命令行参数传递的--samples的编号(第 71 行),这样我们就可以构建我们的可视化。在循环内部,我们:
- 抓取原始图像和重建图像(第 73 行和第 74 行)。
- 并排堆叠一对图像(第 77 行 )。
** 将对垂直堆叠 ( 第 81-86 行 )。* 最后,我们将可视化图像输出到磁盘( Line 89 )。*
*在下一部分,我们将看到我们努力工作的成果。
用 Keras 和 TensorFlow 训练卷积自动编码器
我们现在可以看到我们的自动编码器在工作了!
确保你使用了这篇文章的 “下载” 部分来下载源代码——从那里你可以执行下面的命令:
$ python train_conv_autoencoder.py
[INFO] loading MNIST dataset...
[INFO] building autoencoder...
Train on 60000 samples, validate on 10000 samples
Epoch 1/25
60000/60000 [==============================] - 68s 1ms/sample - loss: 0.0188 - val_loss: 0.0108
Epoch 2/25
60000/60000 [==============================] - 68s 1ms/sample - loss: 0.0104 - val_loss: 0.0096
Epoch 3/25
60000/60000 [==============================] - 68s 1ms/sample - loss: 0.0094 - val_loss: 0.0086
Epoch 4/25
60000/60000 [==============================] - 68s 1ms/sample - loss: 0.0088 - val_loss: 0.0086
Epoch 5/25
60000/60000 [==============================] - 68s 1ms/sample - loss: 0.0084 - val_loss: 0.0080
...
Epoch 20/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0067 - val_loss: 0.0069
Epoch 21/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0066 - val_loss: 0.0069
Epoch 22/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0066 - val_loss: 0.0068
Epoch 23/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0066 - val_loss: 0.0068
Epoch 24/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0065 - val_loss: 0.0067
Epoch 25/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0065 - val_loss: 0.0068
[INFO] making predictions...

Figure 4: Our deep learning autoencoder training history plot was generated with matplotlib. Our autoencoder was trained with Keras, TensorFlow, and Deep Learning.
如图 4 和终端输出所示,我们的训练过程能够最小化自动编码器的重建损失。
但是自动编码器在重建训练数据方面做得如何呢?
答案是 很好:
Figure 5: A sample of of Keras/TensorFlow deep learning autoencoder inputs (left) and outputs (right).
在图 5 中,左边的是我们的原始图像,而右边的是自动编码器预测的重建数字。如你所见,这些数字几乎无法区分!
此时,你可能会想:
太好了…所以我可以训练一个网络来重建我的原始图像。
但是你说过真正重要的是内部潜在空间的表示。
我如何访问该表示,以及如何使用它进行去噪和异常/异常值检测?
这些都是很好的问题— 我将在 PyImageSearch 的下两个教程中回答这两个问题,敬请关注!
摘要
在本教程中,您学习了自动编码器的基础知识。
自动编码器是生成型模型,由一个编码器和一个解码器模型组成。训练时,编码器获取输入数据点,并学习数据的潜在空间表示。这种潜在空间表示是数据的压缩表示,允许模型用比原始数据少得多的参数来表示它。
然后,解码器模型采用潜在空间表示,并试图从中重建原始数据点。当端到端训练时,编码器和解码器以组合的方式工作。
在实践中,我们使用自动编码器进行降维、压缩、去噪和异常检测。
理解了基本原理之后,我们使用 Keras 和 TensorFlow 实现了一个卷积自动编码器。
在下周的教程中,我们将学习如何使用卷积自动编码器去噪。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****


 浙公网安备 33010602011771号
浙公网安备 33010602011771号