
PyImgSearch-博客中文翻译-五-
PyImgSearch 博客中文翻译(五)
如何安装 dlib
原文:https://pyimagesearch.com/2017/03/27/how-to-install-dlib/

两周前,我采访了 Davis King,他是 T2 dlib 库 T3 的创建者和主要维护者。
今天我将演示如何在 macOS 和 Ubuntu 上安装带有 Python 绑定的 dlib。
我 强烈建议 在接下来的几天里花点时间在你的系统上安装 dlib。
从下周开始,我们将一头扎进 dlib 的核心计算机视觉实现之一——面部标志检测 。
我将演示如何使用面部标志:
- 面部部分(即眼睛、鼻子、嘴巴等。)提取
- 面部对齐
- 眨眼检测
- …以及更多。
但这一切都要从安装 dlib 开始!
要了解如何在您的系统上安装带有 Python 绑定的 dlib,请继续阅读。
如何安装 dlib
dlib C++库由 Davis King 开发,是一个用于线程、网络、数值运算、机器学习、计算机视觉和压缩的跨平台包,重点强调了极高质量的和可移植代码。dlib 的文档也很棒。
从计算机视觉的角度来看,dlib 有许多最先进的实现,包括:
- 面部标志检测
- 相关跟踪
- 深度度量学习
在接下来的几周里,我们将探索其中的一些技术(尤其是面部标志检测),所以现在一定要花时间在您的系统上配置和安装 dlib。
步骤 1:安装 dlib 先决条件
dlib 库只有四个主要的先决条件:
- Boost : Boost 是一个经过同行评审的(也就是非常高质量的)C++库的集合,帮助程序员不要陷入重复发明轮子的困境。Boost 提供了线性代数、多线程、基本图像处理和单元测试等实现。
- 助推。Python : 顾名思义,Boost。Python 提供了 C++和 Python 编程语言之间的互操作性。
- CMake : CMake 是一套开源的跨平台工具,用于构建、测试和打包软件。如果您曾经在系统上使用 CMake 编译过 OpenCV,那么您可能已经对它很熟悉了。
- X11/XQuartx:简称【X Window System】,X11 提供了 GUI 开发的基本框架,常见于类 Unix 操作系统上。X11 的 macOS/OSX 版本被称为 XQuartz 。
下面我将向您展示如何在您的 Ubuntu 或 macOS 机器上安装这些先决条件。
人的本质
安装 CMake,Boost,Boost。Python 和 X11 可以通过apt-get轻松实现:
$ sudo apt-get install build-essential cmake
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libboost-all-dev
我假设您的机器上已经安装了pip(用于管理、安装和升级 Python 包),但是如果没有,您可以通过以下方式安装pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
完成这些步骤后,继续第 2 步。
马科斯
为了安装 Boost,Boost。Python 和 macOS 上的 CMake,你将使用自制软件包管理器。把 Homebrew 想象成一个类似的 Ubuntu 的apt-get版本,只适用于 macOS。
如果您尚未安装 Homebrew,可以通过执行以下命令来安装:
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew update
提示:你可以通过在终端执行brew命令来检查你的机器上是否已经安装了家酿软件。如果你得到一个brew: command not found错误,那么你的机器上没有安装 Homebrew。
既然已经安装了 Homebrew,打开您的~/.bash_profile文件(如果它不存在,创建它):
$ nano ~/.bash_profile
在检查你系统的其他部分之前,更新你的PATH变量来检查自制软件安装的软件包:
# Homebrew
export PATH=/usr/local/bin:$PATH
更新您的~/.bash_profile文件后,它看起来应该类似于我的:

Figure 1: After updating your ~/.bash_profile file, yours should look similar to mine.
我们现在需要通过source命令重新加载~/.bash_profile文件的内容:
$ source ~/.bash_profile
该命令只需要执行一次。或者,你可以打开一个新的终端窗口,它会自动为你source``~/.bash_profile。
*接下来,让我们安装 Python 2.7 和 Python 3:
$ brew install python
$ brew install python3
然后,我们可以安装 CMake、Boost 和 Boost。Python:
$ brew install cmake
$ brew install boost
$ brew install boost-python --with-python3
--with-python3标志确保 Python 3 绑定 Boost。Python 也会被编译-默认情况下会编译 Python 2.7 绑定。
一旦你开始boost-python安装,考虑去散散步,因为构建可能需要一点时间(10-15 分钟)。
作为健全性检查,我建议在继续之前验证您已经安装了boost和boost-python:
$ brew list | grep 'boost'
boost
boost-python
从我的终端输出可以看到,Boost 和 Boost 都有。Python 已成功安装。
最后一步是安装 XQuartz 窗口管理器,这样我们就可以访问 X11 了。XQuartz 易于安装——只需下载.dmg并运行安装向导。 安装后,请务必注销并重新登录!
趣闻 : XQuartz 曾经在 OSX 10.5-10.7 上被默认安装。我们现在需要手动安装它。
现在我们已经安装了我们的先决条件,让我们继续下一步(可选)的步骤。
步骤 2:访问您的 Python 虚拟环境(可选)
如果你遵循了我的任何关于安装 OpenCV 的 PyImageSearch 教程,那么你可能正在使用 Python 虚拟环境。
使用 Python 的 virtualenv 和 virtualenvwrapper 库,我们可以为我们正在进行的每个项目创建单独、独立的 Python 环境——这被认为是用 Python 编程语言开发软件时的最佳实践。
注意:我之前已经在 PyImageSearch 博客上多次讨论过 Python 虚拟环境,所以今天我不会在这里花更多时间讨论它们——如果你想了解更多,请查看我的安装 OpenCV 教程。
如果您想将 dlib 安装到一个预先存在的 Python 虚拟环境中,请使用workon命令:
$ workon <your virtualenv name>
例如,如果我想访问一个名为cv的 Python 虚拟环境,我会使用以下命令:
$ workon cv
注意我的终端窗口发生了怎样的变化——文本(cv)现在出现在我的提示符之前,表明我在cv Python 虚拟环境中:

Figure 2: I can tell that I am in the “cv” Python virtual environment by validating that the text “(cv)” appears before my prompt.
否则,我可以使用mkvirtualenv命令创建一个完全独立的虚拟环境——下面的命令创建一个名为py2_dlib的 Python 2.7 虚拟环境:
$ mkvirtualenv py2_dlib
虽然这个命令将创建一个名为py3_dlib的 Python 3 虚拟环境:
$ mkvirtualenv py3_dlib -p python3
再次请记住,使用 Python 虚拟环境是可选的,但是如果你正在进行任何类型的 Python 开发,强烈推荐使用。
对于在 PyImageSearch 博客上关注过我之前的 OpenCV 安装教程的读者,请确保在继续第 3 步之前访问您的 Python 虚拟环境(因为您需要将 Python 先决条件+ dlib 安装到您的虚拟环境中)。
步骤 3:用 Python 绑定安装 dlib
dlib 库没有任何真正的 Python 先决条件,但是如果您计划将 dlib 用于任何类型的计算机视觉或图像处理,我建议安装:
这些软件包可以通过pip安装:
$ pip install numpy
$ pip install scipy
$ pip install scikit-image
几年前,我们必须从源代码手动编译 dlib(类似于我们如何安装 OpenCV)。然而,我们现在也可以使用pip来安装 dlib:
$ pip install dlib
这个命令将从 PyPI 下载 dlib 包,通过 CMake 自动配置它,然后编译并安装在您的系统上。
只要你有动力,动力,动力。Python,并且 X11/XQuartz 安装在您的系统上,该命令应该没有错误地退出(留给您一个成功的 dlib 安装)。
我建议出去喝杯咖啡,因为这个步骤可能需要 5-10 分钟来完成编译。
回来后,您应该看到 dlib 已经成功安装:

Figure 3: The dlib library with Python bindings on macOS have been successfully installed.
我的 Ubuntu 安装也是如此:

Figure 4: Installing dlib with Python bindings on Ubuntu.
步骤 4:测试您的 dlib 安装
要测试您的 dlib 安装,只需打开一个 Python shell(确保访问您的虚拟环境,如果您使用它们的话),并尝试导入dlib库:
$ python
Python 3.6.0 (default, Mar 4 2017, 12:32:34)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.42.1)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>>

Figure 5: Testing out my dlib + Python install on macOS and Python 3.6.
如果您已经在安装 OpenCV 的同一个 Python 虚拟环境中安装了 dlib,那么您也可以通过您的cv2绑定来访问 OpenCV。下面是我的 Ubuntu 机器上的一个例子:
$ python
Python 2.7.12 (default, Jul 1 2016, 15:12:24)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>> import cv2
>>> cv2.__version__
'3.1.0'
>>>

Figure 6: Validating that I can import both dlib and OpenCV into the same Python shell.
恭喜,您现在已经在系统上安装了 dlib!
摘要
在今天的博文中,我演示了如何在 Ubuntu 和 macOS 上安装带有 Python 绑定的 dlib 库。
下周我们将开始探索如何使用 dlib 具体来说,面部标志检测。
你不想错过这个教程,所以为了在下一篇文章发表时得到通知,请务必在下面的表格中输入你的电子邮件地址!
下周见!*
深度学习如何安装 mxnet
原文:https://pyimagesearch.com/2017/11/13/how-to-install-mxnet-for-deep-learning/

说到深度学习, Keras 是我最喜欢的 Python 库…
但是紧随其后的是 mxnet 。
我喜欢 mxnet 的一点是,它在性能和易用性方面结合了两者的优点。在 mxnet 中,您会发现:
- Caffe-like binary帮助您构建高效打包的图像数据集/记录文件。
- 一个类似 Keras 的语法让 Python 编程语言轻松构建深度学习模型。
- 在多个 GPU 上训练深度神经网络并跨多台机器进行扩展的方法。
每当我实现卷积神经网络时,我倾向于首先使用 Keras。Keras 没有 mxnet 那么冗长,并且通常更容易实现给定的神经网络架构+训练过程。
但是,当我需要从最初的实验扩大到 ImageNet 大小的数据集(或更大)时,我经常使用 mxnet 来(1)构建高效打包的数据集,然后(2)在多个 GPU 和/或多台机器上训练我的网络。
由于 mxnet 的 Python 绑定是编译的 C/C++二进制文件,所以我能够充分利用我的机器的性能。
事实上,当在 ImageNet 和上训练卷积神经网络以复制开创性论文(如 VGGNet、ResNet、SqueezeNet 等)的最先进结果时,我们使用 mxnet 内的 深度学习和 Python (特别是 ImageNet 包)进行计算机视觉..
在这篇博文的剩余部分,你将学习如何在你的 Ubuntu 机器上安装和配置用于深度学习的 mxnet。
深度学习如何安装 mxnet
在今天的博客文章中,我将向你展示如何在你的系统上安装 mxnet 进行深度学习,只需要 5 个(相对)简单的步骤。
mxnet 深度学习包是一个 Apache 项目,并有强大的 T2 社区支持。要开始使用 mxnet,我推荐这里的教程和解释。鉴于 Apache 社区对 mxnet 深度学习的贡献(就更不用说了,亚马逊的)我认为在可预见的未来,它会一直存在下去。
在我们继续安装 mxnet 之前,我想指出的是,第 4 步分为:
- 针对纯 CPU 用户的步骤# 4a
- 以及针对 GPU 用户的步骤#4b。
GPU 的安装要复杂得多,有可能出错。这些说明已经过测试,我相信它们将成为您安装过程中的良好指南。
让我们开始吧。
步骤 1:安装必备组件
首先,你要确保你的 Ubuntu 16.04 或 14.04 系统是最新的。您可以执行以下命令从 Ubuntu 存储库中更新软件包:
$ sudo apt-get update
$ sudo apt-get upgrade
接下来,让我们安装一些开发工具、图像/视频 I/O、GUI 操作和其他包(并非所有这些都是 100%必要的,但如果你在深度学习或机器学习领域工作,你会希望安装它们):
$ sudo apt-get install build-essential cmake git unzip pkg-config
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng12-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libhdf5-serial-dev graphviz
$ sudo apt-get install libopenblas-dev libatlas-base-dev gfortran
$ sudo apt-get install python-tk python3-tk python-imaging-tk
第三,让我们安装 Python 头文件:
$ sudo apt-get install python2.7-dev python3-dev
现在我们已经安装了适当的系统先决条件,让我们继续。
步骤 2:建立虚拟环境
虚拟环境对于 Python 开发至关重要,并且是一种标准实践。Python 虚拟环境允许开发人员在一台机器上创建多个独立的开发环境。您甚至可以使用 Python 虚拟环境来安装来自 Python 包索引或其他来源的包的两个不同版本。
我非常鼓励你使用虚拟环境进行深度学习。如果你不相信,那么看看这篇关于为什么 Python 虚拟环境是最佳实践的文章。
出于本安装指南其余部分的目的,我们将创建一个名为dl4cv的 Python 虚拟环境——这是我的书《用 Python 进行计算机视觉深度学习的中使用的虚拟环境的名称。我选择了dl4cv这个名字,以保持我的书/博客帖子的命名一致。如果您愿意,可以使用不同的名称。
首先我们将安装 PIP,一个 Python 包管理器。然后我们将安装 Python 虚拟环境和一个方便的包装工具。随后,我们将创建一个虚拟环境,然后上路。
让我们安装pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo python3 get-pip.py
然后,我们需要 pip-安装我们将使用的两个 Python 虚拟环境库:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip get-pip.py
现在让我们更新我们的~/.bashrc文件,在文件的底部包含以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
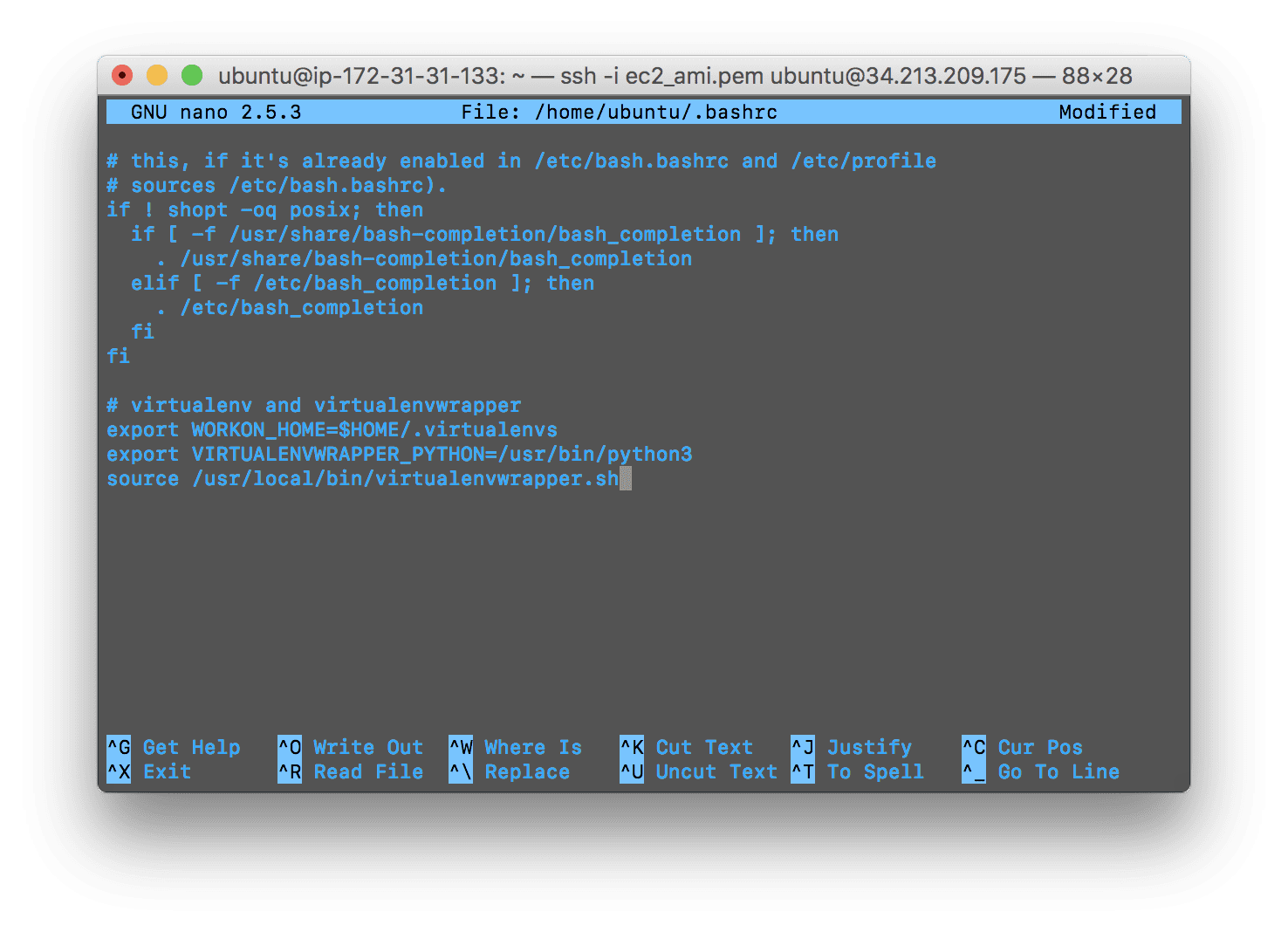
Figure 1: Editing your ~/.bashrc file with virtualenvwrapper settings using nano terminal text editor.
既然~/.bashrc已经更改,我们需要重新加载它:
$ source ~/.bashrc
您将看到几条消息,表明virtualenvwrapper已经在您的系统上进行了自我配置。
创建 dl4cv 虚拟环境
出于我的深度学习书籍的目的,我们使用 Python 3,所以让我们在我们的系统上创建一个名为dl4cv的 Python 3 环境。这个环境将容纳深度学习和计算机视觉的相关包,特别是 mxnet。
$ mkvirtualenv dl4cv -p python3
每当您想要创建一个新的虚拟环境时,只需提供一个名称和您想要使用的 Python 版本。就这么简单。今天我们只需要一个环境,所以让我们继续。
我怎么知道我在一个正确的环境中或者根本不在一个环境中?
如果您曾经停用虚拟环境或重启机器,您将需要在恢复工作之前访问 Python 虚拟环境。
为此,只需使用workon命令:
$ workon dl4cv
在本例中,我已经提供了我的环境的名称,dl4cv,但是您可能想要指定您想要使用的环境的名称。
为了验证您是否在环境中,您将在 bash 提示符前看到(dl4cv),如下图所示:
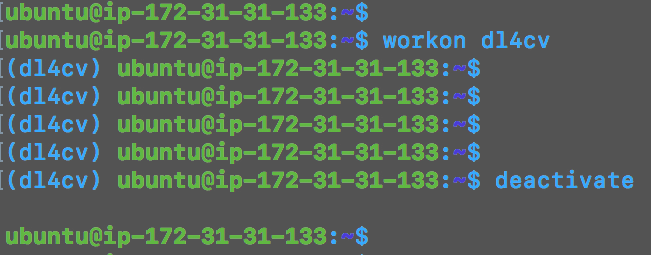
Figure 2: Using the workon dl4cv command we can activate the dl4cv virtual environment. Similarly we can use the deactivate command to exit the environment.
要退出您的环境,只需停用它:
$ deactivate
然后您会看到(dl4cv)已经从 bash 提示符的开头删除,如图 2 中的所示。
步骤 3:将 OpenCV 安装到 dl4cv 虚拟环境中
在本节中,我们将把 OpenCV 安装到 dl4cv 虚拟环境中。首先,我们将下载并解压缩 OpenCV 3.3。然后我们将从源代码构建和编译 OpenCV。最后,我们将测试 OpenCV 是否已经安装。
安装 NumPy
首先,我们将把 NumPy 安装到虚拟环境中:
$ workon dl4cv
$ pip install numpy
下载 OpenCV
接下来,让我们将 opencv 和 opencv_contrib 下载到您的主目录中:
$ cd ~
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.3.1.zip
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.3.1.zip
您需要扩展上面的命令(使用 " < = > " 按钮)来复制并粘贴完整路径到opencv_contrib URL。
然后,让我们解压缩这两个文件:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
运行 CMake
让我们创建一个build目录并运行 CMake:
$ cd ~/opencv-3.3.1/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D WITH_CUDA=OFF \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.3.1/modules \
-D BUILD_EXAMPLES=ON ..
对于 CMake,为了兼容性,您的标志与我的标志匹配是很重要的。此外,确保你的opencv_contrib版本与你下载的 OpenCV 版本3.3.1相同。如果版本不匹配,那么你的编译将会失败。
在我们进入实际的编译步骤之前,请确保您检查了 CMake 的输出!
首先滚动到标题为Python 3的部分。
确保您的 Python 3 部分如下图所示:
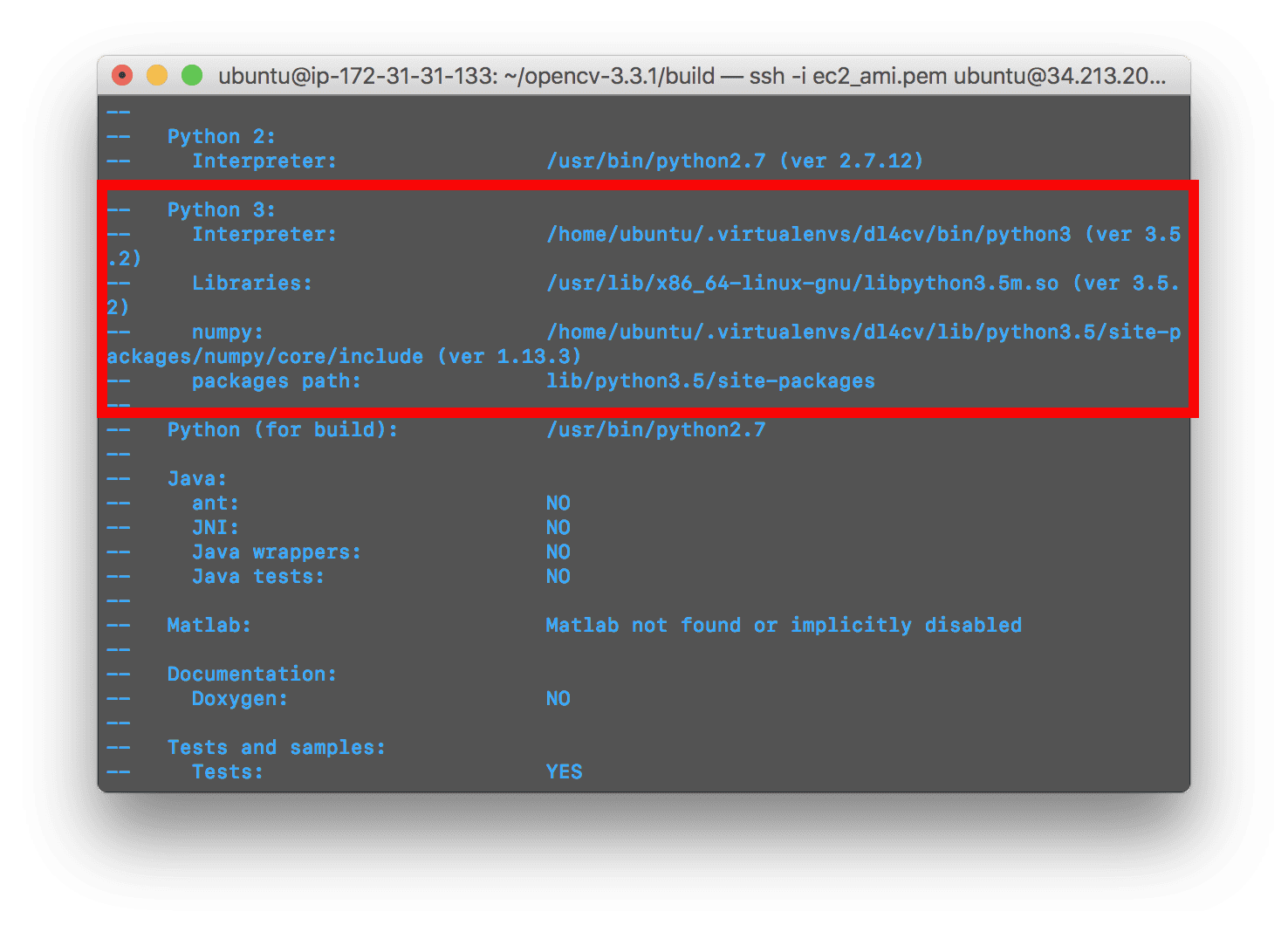
Figure 3: OpenCV 3.3.1 CMake command results show that the dl4cv virtual environment will be used.
你需要确保解释器指向位于虚拟环境中的二进制文件,而 T2 指向我们的 NumPy 安装。
在任何一种情况下,如果您 没有 看到这些变量路径中的dl4cv虚拟环境,那么 几乎肯定是因为您在运行 CMake 之前不在dl4cv虚拟环境中!
如果是这种情况,使用workon dl4cv访问dl4cv虚拟环境,并重新运行上面概述的命令(我还建议删除build目录,重新创建它,并再次运行 CMake)。
编译 OpenCV
现在我们已经准备好编译 OpenCV 了。假设您的cmake命令已正确退出,确保您在build目录中并执行以下命令:
$ make -j4
注:-j标志指定编译时使用的处理器内核数量。在这种情况下,我使用了-j4,因为我的机器有四个内核。如果遇到编译错误,您可以运行命令make clean,然后在没有并行标志make的情况下编译。
从那里,你需要做的就是安装 OpenCV 3.3,然后如果你愿意的话,释放一些磁盘空间:
$ sudo make install
$ sudo ldconfig
$ cd ~
$ rm -rf opencv-3.3.0 opencv.zip
$ rm -rf opencv_contrib-3.3.1 opencv_contrib.zip
将 OpenCV 符号链接到您的虚拟环境
要将 OpenCV 绑定符号链接到dl4cv虚拟环境中,发出以下命令:
$ cd ~/.virtualenvs/dl4cv/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
$ cd ~
注意:同样,确保使用上面工具栏中的“< = >”按钮展开代码块以抓取完整的ln命令(你不想忘记cv2.so文件吧!)
注意,在这个例子中,我使用的是 Python 3.5 。如果您使用的是 Python 3.6 (或更新版本),您将需要更新上面的路径以使用您的特定 Python 版本。
其次,您的.so文件(也就是实际的 OpenCV 绑定)可能是上面显示的一些变体,所以一定要通过仔细检查路径来使用合适的文件。
测试您的 OpenCV 3.3 安装
现在我们已经安装并链接了 OpenCV 3.3,让我们做一个快速的健全性测试来看看事情是否正常:
$ workon dl4cv
$ python
>>> import cv2
>>> cv2.__version__
'3.3.1'
在启动 Python ( workon dl4cv)之前,确保您处于dl4cv虚拟环境中。当您打印出版本时,它应该与您安装的 OpenCV 版本相匹配(在我们的例子中,OpenCV 3.3.1)。
就这样——假设您没有遇到导入错误,您准备好继续步骤#4 了,我们将在那里安装 mxnet。
第四步
遵循适用于您的系统的说明:
- 步骤#4.a :纯 CPU 模式
- 步骤#4.b : GPU 模式
步骤#4.a:为纯 CPU 模式安装 mxnet
如果你有一台 GPU 机器,并希望利用你的 GPU 通过 mxnet 进行深度学习,那么你应该跳过这一步,继续进行步骤# 4 . b——这一部分是针对 CPU 专用的。
让我们克隆 mxnet 存储库和检验分支0.11.0 —一个与我的书 一起使用的分支,用 Python 进行计算机视觉的深度学习 :
$ cd ~
$ git clone --recursive https://github.com/apache/incubator-mxnet.git mxnet --branch 0.11.0
然后我们可以编译 mxnet:
$ cd mxnet
$ make -j4 \
USE_OPENCV=1 \
USE_BLAS=openblas
最后,我们需要将 mxnet 符号链接到我们的 dl4cv 环境:
$ cd ~/.virtualenvs/dl4cv/lib/python3.5/site-packages/
$ ln -s ~/mxnet/python/mxnet mxnet
$ cd ~
注意:务必不要*删除你 home 文件夹里的 mxnet 目录。我们的 Python 绑定在那里,我们还需要~/mxnet/bin中的文件来创建序列化的图像数据集。*
步骤#4.b:为 GPU 模式安装 mxnet
这一步只针对 GPU 用户。如果您的计算机上没有 GPU,请参考上面的纯 CPU 说明。
首先,我们需要准备我们的系统,用 NVIDIA CUDA 驱动程序替换默认驱动程序:
$ sudo apt-get install linux-image-generic linux-image-extra-virtual
$ sudo apt-get install linux-source linux-headers-generic
我们现在将安装 CUDA 工具包。安装的这一部分要求您注意所有说明,并注意系统警告和错误。
首先,通过创建一个新文件来禁用新内核驱动程序:
$ sudo nano /etc/modprobe.d/blacklist-nouveau.conf
然后将以下几行添加到文件中,然后保存+退出:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
如果您使用的是nano,您的屏幕应该是这样的,但是您可以随意使用其他终端文本编辑器:
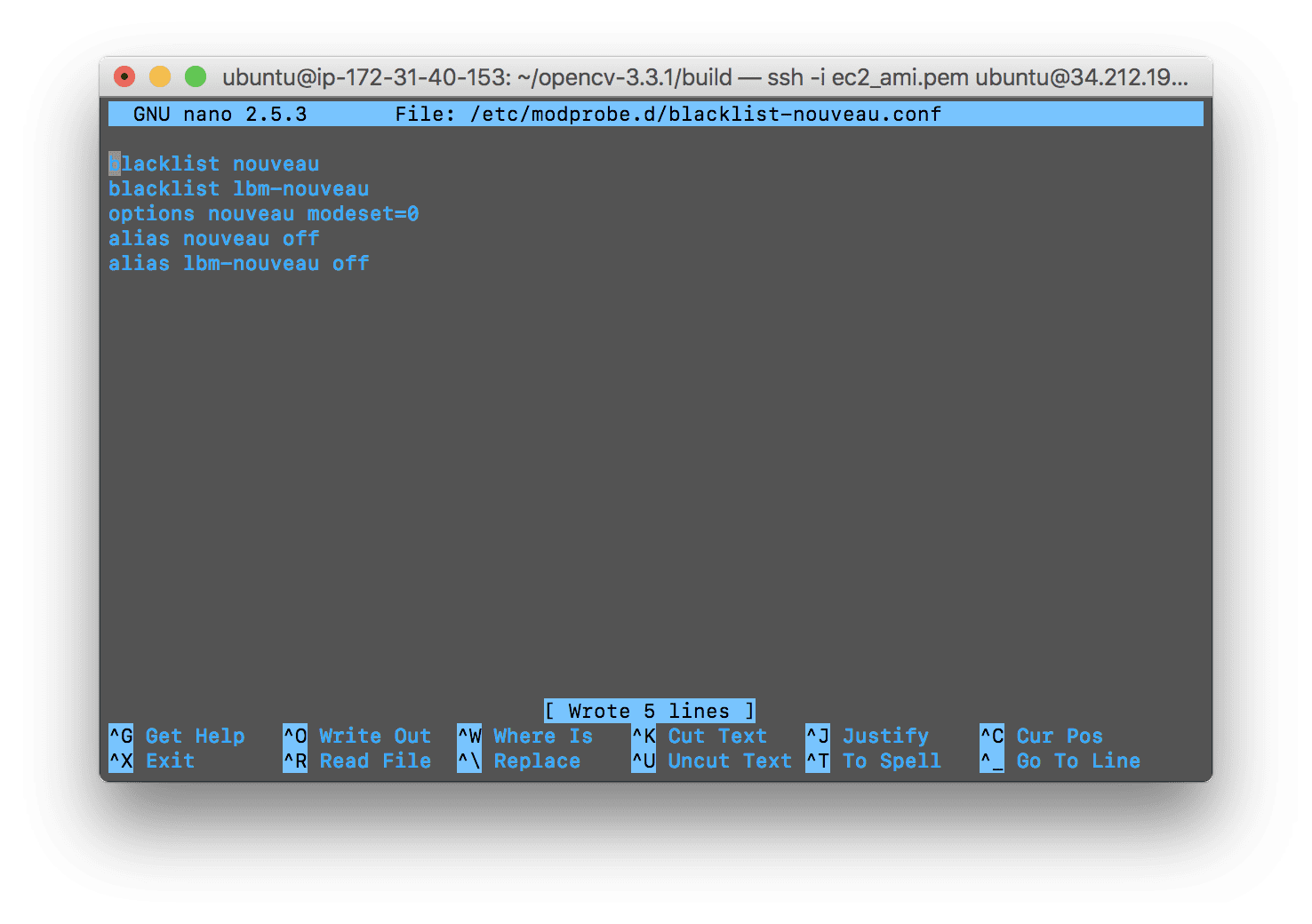
Figure 4: The blacklist_noveau.conf file has been created prior to installing mxnet for deep learning with GPU capability.
不要忘记我们更新初始 RAM 文件系统并重启机器的关键步骤:
$ echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
$ sudo update-initramfs -u
$ sudo reboot
如果您通过 SSH 连接,您的会话将会结束,您需要等待一段时间才能重新连接。
安装 CUDA
现在让我们从 NVIDIA CUDA Toolkit 网站获取 CUDA Toolkit v8.0 版:
https://developer.nvidia.com/cuda-80-ga2-download-archive
然后,您应该为您的系统选择合适的下载。我假设你用的是 Ubuntu 16.04,所以你的浏览器应该是这样的:

Figure 5: Selecting the CUDA 8.0 download for a GPU machine running Ubuntu 16.04.
注意我是如何选择Linux => x86_64 => Ubuntu => 16.04 runfile (local)的。
从该屏幕下载文件名为cuda_8.0.61_375.26_linux-run或类似名称的-run文件。
为此,只需右击复制下载链接,并使用wget回到您的终端下载文件:
wget https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda_8.0.61_375.26_linux-run
重要提示:在撰写本文时,NVIDIA 网站上有一个小的出入。如图 5* 所示,在“基础安装程序”下载下,文件名(如所写)以.run结尾。实际可下载的文件以-run结尾。你现在应该可以复制我的wget + URL 命令了,除非 NVIDIA 再次更改文件名。*
注意:您需要点击上面代码块工具栏中的< = >按钮来展开代码块。这将使您能够将的完整 URL* 复制到-run文件中。*
从这里开始,您需要做的就是解压-run文件:
$ chmod +x cuda_8.0.61_375.26_linux-run
$ mkdir installers
$ sudo ./cuda_8.0.61_375.26_linux-run -extract=`pwd`/installers
执行-run脚本大约需要一分钟。
现在让我们安装 NVIDIA 内核驱动程序:
$ cd installers
$ sudo ./NVIDIA-Linux-x86_64-375.26.run
在此步骤中,您需要遵循屏幕上的提示,其中之一是接受 EULA。
然后,我们可以将 NVIDIA 可加载内核模块添加到 Linux 内核中:
$ modprobe nvidia
最后,安装 CUDA 工具包和示例:
$ sudo ./cuda-linux64-rel-8.0.61-21551265.run
$ sudo ./cuda-samples-linux-8.0.61-21551265.run
您需要接受许可并再次按照提示进行操作。当它要求您指定安装路径时,您可以按下<enter>接受默认值。
既然已经安装了 NVIDIA CUDA 驱动程序和工具,让我们更新~/.bashrc以包含使用 nano 的 CUDA 工具包:
$ nano ~/.bashrc
将这些行附加到文件的末尾:
# NVIDIA CUDA Toolkit
export PATH=/usr/local/cuda-8.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64/
接下来,重新加载~/.bashrc并通过编译+运行deviceQuery示例程序来测试 CUDA 工具包的安装:
$ source ~/.bashrc
$ cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
$ sudo make
$ ./deviceQuery
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0,
NumDevs = 1, Device0 = Tesla K80
Result = PASS
从这里开始,如果你有一个Result = PASS,那么我们准备安装 cuDNN。
安装 cuDNN
对于这一步,你需要在 NVIDIA 创建一个免费账户,并下载 cuDNN 。
对于本教程,请务必下载用于 Linux 的 cud nn v 6.0,这是 TensorFlow 所需要的(假设你想在你的深度学习机器上安装 TensorFlow 和 mxnet) 。
**NVIDIA 需要认证才能访问下载,因此你将无法使用wget下载文件。
如果你在本地机器上,你可以通过浏览器下载 cuDNN 文档。
然而,如果您在一台远程机器上(即,SSH'ing 到一台机器上),您将希望首先将文件下载到您的本地机器和,然后使用scp来传输文件(当然,同时用您适当的值替换username和your_ip_address):
$ scp -i EC2KeyPair.pem ~/Downloads/cudnn-8.0-linux-x64-v6.0.tgz \
username@your_ip_address:~
现在文件已经在你的远程 GPU 机器上了(在我的例子中是 EC2),解压文件,然后将结果文件分别复制到lib64和include中,使用-P开关保留符号链接:
$ cd ~
$ tar -zxf cudnn-8.0-linux-x64-v6.0.tgz
$ cd cuda
$ sudo cp -P lib64/* /usr/local/cuda/lib64/
$ sudo cp -P include/* /usr/local/cuda/include/
$ cd ~
这就是安装 cuDNN 的方法——这一步相当简单,只要你保存了符号链接,你就可以开始了。
用 CUDA 安装 mxnet
让我们用 Python 克隆已经过 计算机视觉深度学习测试的 mxnet 库和检出分支0.11.0:
$ cd ~
$ git clone --recursive https://github.com/apache/incubator-mxnet.git mxnet --branch 0.11.0
然后我们可以编译 mxnet:
$ cd mxnet
$ make -j4 \
USE_OPENCV=1 \
USE_BLAS=openblas \
USE_CUDA=1 \
USE_CUDA_PATH=/usr/local/cuda \
USE_CUDNN=1
最后,我们需要将 mxnet 符号链接到我们的dl4cv环境:
$ cd ~/.virtualenvs/dl4cv/lib/python3.5/site-packages/
$ ln -s ~/mxnet/python/mxnet mxnet
$ cd ~
注意:务必不要*删除你 home 文件夹里的 mxnet 目录。我们的 Python 绑定在那里,我们还需要~/mxnet/bin中的文件来创建序列化的图像数据集。*
步骤#5:验证安装
最后一步是测试 mxnet 是否已经正确安装:
$ workon dl4cv
$ python
>>> import mxnet
>>>
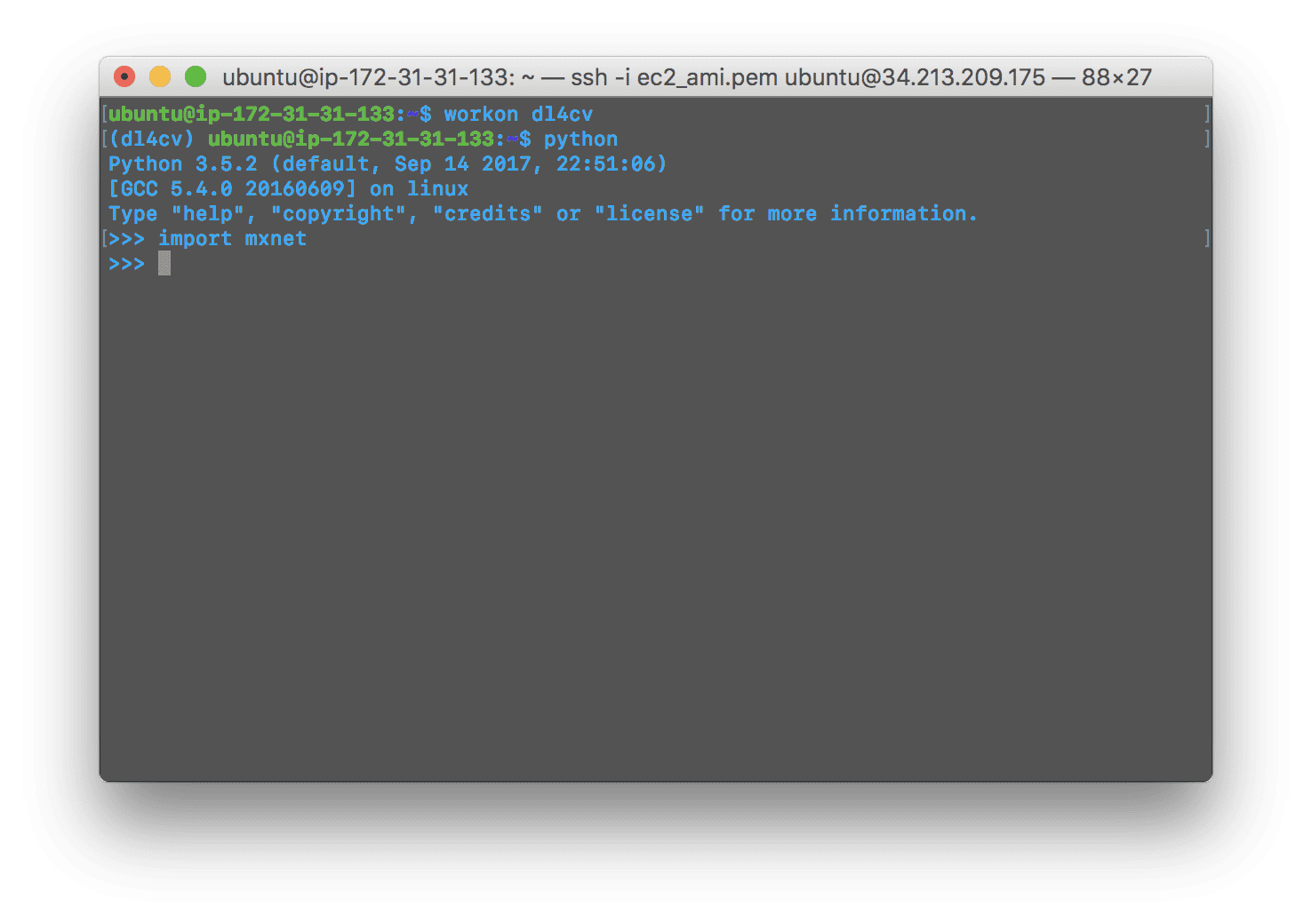
Figure 6: Validating our mxnet for deep learning install completed successfully.
如果 mxnet 导入没有错误,那么恭喜你——你已经成功安装了用于深度学习的 mxnet。
接下来是什么?我推荐 PyImageSearch 大学。
 课程信息:
课程信息:
60+总课时 64+学时点播代码演练视频最后更新:2022 年 12 月
★★★4.84(128 评分)15800+学员报名人数
我强烈
你是否认为学习计算机视觉和深度学习必须是耗时的、势不可挡的、复杂的?还是必须涉及复杂的数学和方程?还是需要计算机科学的学位?
那是而不是的情况。
要掌握计算机视觉和深度学习,你需要的只是有人用简单、直观的术语向你解释事情。而这正是我做的。我的使命是改变教育和复杂的人工智能主题的教学方式。
如果你是认真学习计算机视觉的,你的下一站应该是 PyImageSearch 大学,最全面的计算机视觉,深度学习,以及今天在线的 OpenCV 课程。在这里,你将学习如何成功地将计算机视觉应用到你的工作、研究和项目中。和我一起掌握计算机视觉。
PyImageSearch 大学里面你会发现:
- & check; 60+Course About basic computer vision, deep learning, and OpenCV topics
- & check; 60+completion certificate
- & check; 64+hours of video on demand
- & check; The new course will be published regularly to ensure that you can keep up with the latest technology.
- Check of&; The pre-configured Jupyter notebook is in Google Colab 【T1]
- & check; Run all code examples in your web browser—for Windows, macOS and Linux (no development environment configuration required! )
- &检查;访问 PyImageSearch
- & check in the centralized code warehouse of all 500+tutorials on ; Easily click to download code, data set, pre-training model, etc.
- & check; Access on mobile phones, notebooks, desktops and other devices.
摘要
在今天的博客文章中,你学习了如何在你的 Ubuntu 机器上安装 mxnet 进行深度学习,包括纯 CPU和基于 GPU 的培训。
一旦你开始使用 mxnet,你会发现它:
- 包括 Caffe-like 二进制文件来帮助你构建高效的备份图像记录文件(这将为你节省大量磁盘空间)。
- 提供了一个类似 Keras 的 API 来构建深度神经网络(尽管 mxnet 肯定比 Keras 更冗长)。
现在,你已经配置好了你的深度学习环境,我建议你采取下一步,看看我的新书,《用 Python 进行计算机视觉的深度学习》。
在书中,你将从学习深度学习的基础开始,然后逐步学习更高级的内容,包括从零开始在具有挑战性的 ImageNet 数据集上训练网络的。
你还会发现我的个人蓝图/最佳实践**,我用它来决定在面临新问题时应用哪种深度学习技术。
要了解更多关于用 Python 进行计算机视觉深度学习的、、、只需点击这里、、。
否则,请务必在下面的表格*中输入您的电子邮件地址,以便在 PyImageSearch 上发布新的博客文章时得到通知。*****
如何在 Raspbian Jessie 上安装 OpenCV 3
原文:https://pyimagesearch.com/2015/10/26/how-to-install-opencv-3-on-raspbian-jessie/
几周前,Raspbian Jessie 发布了,带来了大量新的、伟大的功能。
然而,对 Jessie 的更新也打破了之前 Raspbian Wheezy 的 OpenCV + Python 安装说明:
- 在 Raspbian Wheezy 上安装 OpenCV 2.4 与 Python 2.7 绑定。
- 在 Raspbian Wheezy 上安装带有 Python 2.7/Python 3+绑定的 OpenCV 3.0。
由于 PyImageSearch 已经成为在 Raspberry Pi 上学习计算机视觉+ OpenCV 的在线目的地,我决定写一个关于在 Raspbian Jessie 上安装 OpenCV 3 和 Python 绑定的新教程。
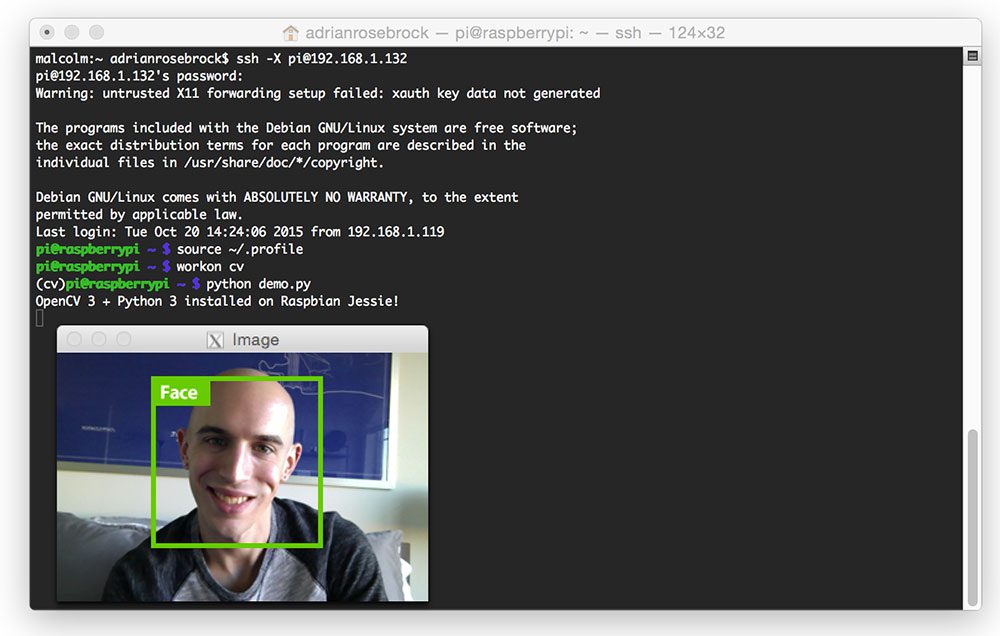
作为额外的奖励,我还包含了一个视频教程 ,当我在我自己的运行 Raspbian Jessie 的 Raspberry Pi 2 上安装 OpenCV 3 时,你可以使用它来跟随我。
这个视频教程应该有助于解决第一次在 Raspberry Pi 上安装 OpenCV + Python 绑定时出现的最常见的问题、疑虑和陷阱。
假设
在本教程中,我假设你已经拥有一台 Raspberry Pi 2 并安装了Raspbian Jessie。除此之外,你应该有(1) 物理访问到你的 Pi 2 并且可以打开一个终端,或者(2) 远程访问在那里你可以 SSH 进入。我将通过 SSH 来完成本教程,但是只要您可以访问终端,这真的没有关系。
快速入门视频教程
在我们开始本教程之前,让我问你两个简单的问题:
- 这是你第一次安装 OpenCV 吗?
- 你是刚刚开始学习 Linux 和如何使用命令行吗?
如果你对这些问题中的任何一个回答了 是 ,我强烈建议你观看下面的视频,并跟随我一步一步地指导你如何在运行 Raspbian Jessie 的 Raspberry Pi 2 上安装 OpenCV 3 和 Python 绑定:
https://www.youtube.com/embed/YStdNJwcovY?feature=oembed
如何在 Ubuntu 上安装 OpenCV 4
原文:https://pyimagesearch.com/2018/08/15/how-to-install-opencv-4-on-ubuntu/

在本教程中,你将学习如何在你的 Ubuntu 系统上安装 OpenCV 4。
OpenCV 4 已于 2018 年 11 月 20 日正式发布!
那么,为什么要费心安装 OpenCV 4 呢?
你可能想考虑安装 OpenCV 4 以获得进一步的优化,C++11 支持,更紧凑的模块,以及对深度神经网络(DNN)模块的许多改进。
不要觉得需要立即升级——但是当你准备好切换到 OpenCV 4 时,一定要记住这些说明。
如何在 Ubuntu 上安装 OpenCV 4
在这篇博文中,我将带你完成在你的 Ubuntu 系统上安装 OpenCV 4 的六个步骤。
我还将介绍一些常见问题(FAQ ),如果遇到错误消息,这些问题将有助于您进行故障排除。我强烈建议你在提交评论之前阅读常见问题。
在我们开始之前,你可能有两个迫切的问题:
1。OpenCV 4 应该用哪个版本的 Ubuntu OS?
今天我将在 Ubuntu 18.04 上安装 OpenCV 4。我也用 Ubuntu 16.04 测试了这些指令。
如果你打算使用这台机器进行深度学习,我可能会建议你使用 Ubuntu 16.04,因为 GPU 驱动程序更成熟。如果你打算使用这台机器只是为了 OpenCV 和其他计算机视觉任务,Ubuntu 18.04 是非常好的。
2。OpenCV 4 应该用 Python 2.7 还是 Python 3?
Python 3 已经成为标准,我强烈推荐你在 OpenCV 4 中安装 Python 3。
也就是说,如果您有意识地选择使用 Python 2.7,您当然可以遵循这些说明,只是要确保您注意安装 Python 2.7 开发头文件和库,以及在创建虚拟环境时指定 Python 2.7。其他的都一样。如果你需要 Python 2.7 的指针,请参考下面的常见问题。
我们开始吧。
步骤 1:在 Ubuntu 上安装 OpenCV 4 依赖项
我将使用 Ubuntu 18.04 在我的机器上安装 OpenCV 4 和 Python 3 绑定。
要启动 OpenCV 4 安装程序,启动你的 Ubuntu 机器并打开一个终端。或者,您可以 SSH 到安装部分的框中。
从那里,让我们更新我们的系统:
$ sudo apt-get update
$ sudo apt-get upgrade
然后安装开发人员工具:
$ sudo apt-get install build-essential cmake unzip pkg-config
接下来,让我们安装一些图像和视频 I/O 库。
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
这些库使我们能够从磁盘加载图像以及读取视频文件。
从那里,让我们为我们的 GUI 后端安装 GTK:
$ sudo apt-get install libgtk-3-dev
然后安装两个包含 OpenCV 数学优化的包:
$ sudo apt-get install libatlas-base-dev gfortran
最后,让我们安装 Python 3 开发头:
$ sudo apt-get install python3-dev
一旦安装了所有这些先决条件,您就可以进入下一步。
步骤 2:下载 OpenCV 4
我们的下一步是下载 OpenCV。
让我们导航到我们的主文件夹,下载 opencv 和 T2 的 opencv_contrib。contrib repo 包含我们在 PyImageSearch 博客上经常使用的额外模块和函数。你应该也在安装 OpenCV 库和附加的 contrib 模块。
当你准备好了,就跟着下载opencv和opencv_contrib代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.0.0.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.0.0.zip
更新 2018-11-26:OpenCV 4 . 0 . 0发布了,我更新了各自的wget网址。
**从那里,让我们解压缩档案:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
我也喜欢重命名目录:
$ mv opencv-4.0.0 opencv
$ mv opencv_contrib-4.0.0 opencv_contrib
如果您跳过重命名目录,不要忘记更新 CMake 路径。
既然opencv和opencv_contrib已经下载并准备好了,让我们设置我们的环境。
步骤 3:为 OpenCV 4 配置 Python 3 虚拟环境
让我们安装 pip,一个 Python 包管理器。
要安装 pip,只需在终端中输入以下内容:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
利用虚拟环境进行 Python 开发
Python 虚拟环境允许您单独处理 Python 项目。它们是 Python 开发的最佳实践。
例如,您可能有一个 Python + OpenCV 项目,它需要一个旧版本的 scikit-learn (v0.14),但是您希望在所有新项目中继续使用最新版本的 scikit-learn (0.19)。
使用虚拟环境,您可以分别处理这两个软件版本的依赖关系,这是使用 Python 的系统安装不可能做到的。
如果你想了解更多关于 Python 虚拟环境的信息,看看这篇关于 RealPython 的文章,或者阅读这篇关于 PyImageSearch 的博客文章的前半部分。
注意:我更喜欢通过virtualenv和virtualenvwrapper包来使用 Python 虚拟环境;但是,如果您更熟悉 conda 或 PyEnv,请随意使用它们并跳过这一部分。
让我们继续安装virtualenv和virtualenvwrapper —这些包允许我们创建和管理 Python 虚拟环境:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
为了完成这些工具的安装,我们需要更新我们的~/.bashrc文件。
使用终端文本编辑器,如vi / vim或nano,将下列行添加到您的~/.bashrc中:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
或者,您可以通过 bash 命令直接附加这些行:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.bashrc
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bashrc
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.bashrc
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
接下来,获取~/.bashrc文件:
$ source ~/.bashrc
创建一个虚拟环境来存放 OpenCV 4 和其他包
现在我们可以创建 OpenCV 4 + Python 3 虚拟环境了:
$ mkvirtualenv cv -p python3
这个命令简单地创建了一个名为cv的 Python 3 虚拟环境。
你可以(也应该)随心所欲地命名你的环境——我喜欢让它们简洁明了,同时提供足够的信息,以便我记住它们的用途。例如,我喜欢这样命名我的环境:
py3cv4py3cv3py2cv2- 等等。
这里我的py3cv4虚拟环境可以用 Python 3 + OpenCV 4。我的py3cv3虚拟环境用的是 Python 3 和 OpenCV 3。我的py2cv2环境可以用来测试遗留的 Python 2.7 + OpenCV 2.4 代码。这些虚拟环境的名字很容易记住,并且允许我在 OpenCV + Python 版本之间无缝切换。
让我们通过使用workon命令来验证我们是否处于cv环境中:
$ workon cv
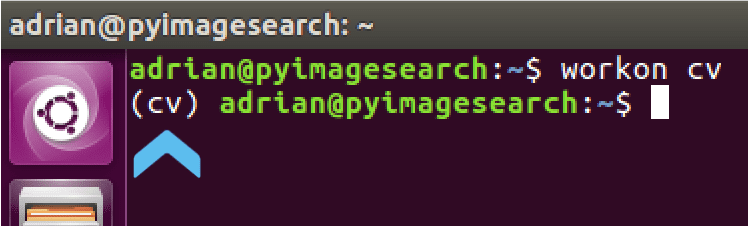
Figure 1: We use the workon command to activate our cv virtual environment on Ubuntu prior to installing NumPy and OpenCV 4.
安装 NumPy
我们将安装的第一个包和唯一的 Python 先决条件是 NumPy:
$ pip install numpy
我们现在可以准备 OpenCV 4 在我们的 Ubuntu 机器上进行编译。
步骤 4:为 Ubuntu 创建并编译 OpenCV 4
对于这一步,我们将使用 CMake 设置我们的编译,然后运行make来实际编译 OpenCV。这是今天博文最耗时的一步。
导航回 OpenCV repo 并创建+输入一个build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
为 OpenCV 4 运行 CMake
现在让我们运行 CMake 来配置 OpenCV 4 版本:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON_EXECUTABLE=~/.virtualenvs/cv/bin/python \
-D BUILD_EXAMPLES=ON ..
更新 2018-11-26: 注意-D OPENCV_ENABLE_NONFREE=ON旗。用 OpenCV 4 设置这个标志可以确保你可以访问 SIFT/SURF 和其他专利算法。
确保更新上面的命令,以便在您工作的虚拟环境中使用正确的OPENCV_EXTRA_MODULES_PATH和PYTHON_EXECUTABLE。如果你使用的是相同的目录结构 Python 虚拟环境名称这些路径应该而不是需要更新。
一旦 CMake 完成,检查输出是很重要的。您的输出应该类似于下面的内容:
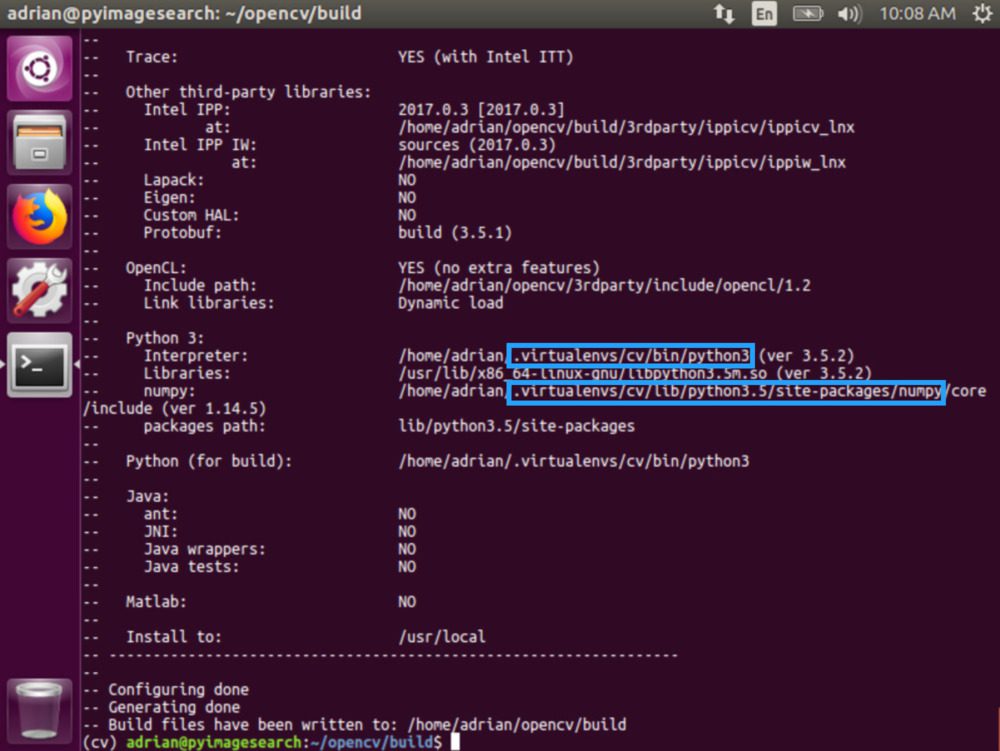
Figure 2: It is critical to inspect your CMake output when installing OpenCV 4 on Ubuntu prior to kicking off the compile process.
现在花一点时间来确保Interpreter指向正确的 Python 3 二进制文件。还要检查numpy是否指向我们的 NumPy 包,该包安装在虚拟环境的中。
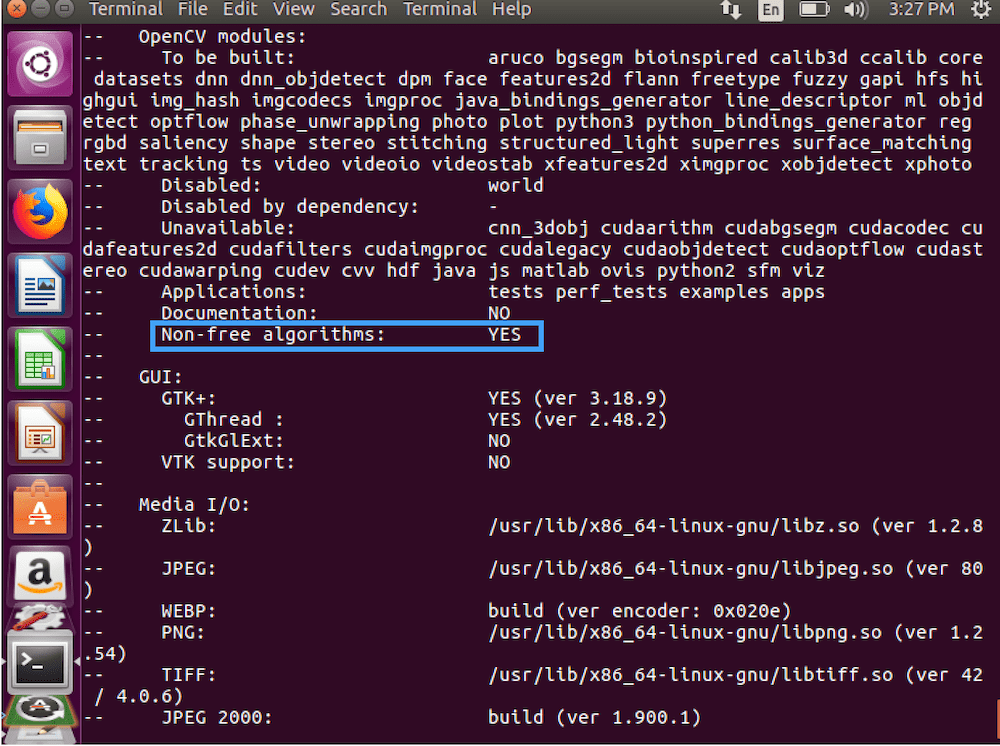
Figure 3: Be sure to check the CMake output to ensure that the “Non-free algorithms” will be installed.
编译 OpenCV 4
现在我们准备编译 OpenCV 4:
$ make -j4
注意:在上面的make命令中,-j4参数指定我有 4 个内核进行编译。大多数系统都有 2、4 或 8 个内核。您应该更新该命令,以使用处理器上的内核数量来加快编译速度。如果您遇到编译失败,您可以通过跳过可选参数来尝试使用 1 个内核进行编译,以消除竞争情况。
在这里,您可以看到 OpenCV 4 编译时没有任何错误:
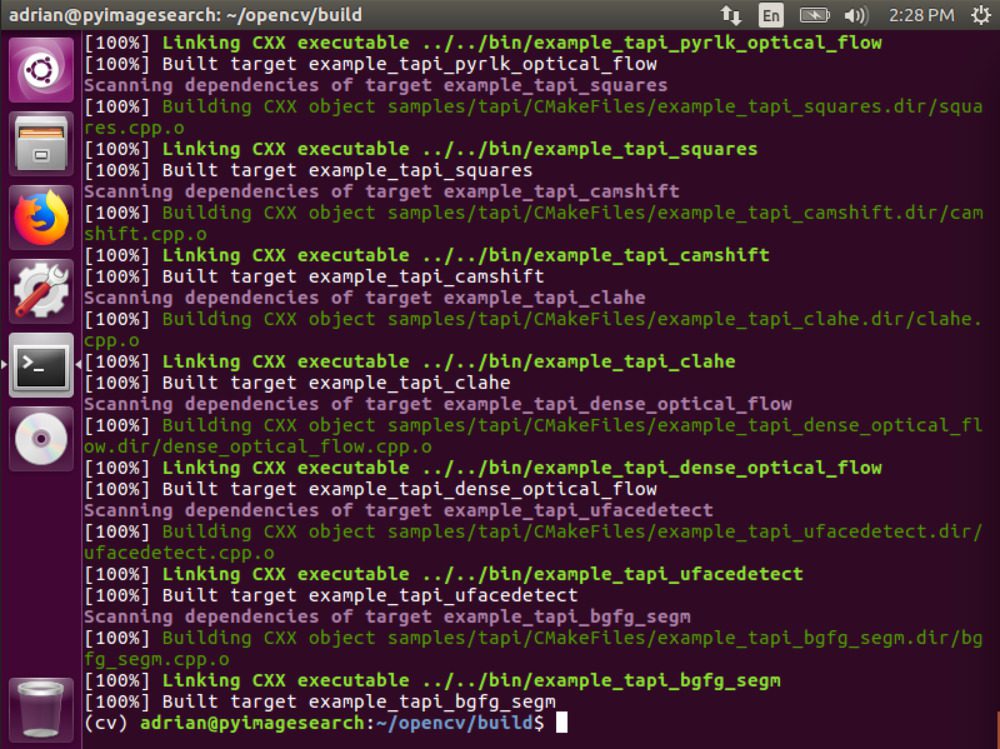
Figure 4: When compiling OpenCV 4 for Ubuntu, once the make output reaches 100% we can move on.
接下来,让我们用另外两个命令安装 OpenCV 4:
$ sudo make install
$ sudo ldconfig
步骤 5:将 OpenCV 4 链接到 Python 3 虚拟环境中
在我们创建一个符号链接将 OpenCV 4 链接到我们的 Python 虚拟环境之前,让我们确定一下我们的 Python 版本:
$ workon cv
$ python --version
Python 3.5
使用 Python 版本,接下来我们可以很容易地导航到正确的site-packages目录(尽管我建议在终端中使用制表符补全)。
更新 2018-12-20: 以下路径已更新。以前版本的 OpenCV 在不同的位置(/usr/local/lib/python3.5/site-packages)安装了绑定,所以一定要仔细看看下面的路径。
此时,OpenCV 的 Python 3 绑定应该位于以下文件夹中:
$ ls /usr/local/python/cv2/python-3.5
cv2.cpython-35m-x86_64-linux-gnu.so
让我们简单地将它们重命名为cv2.so:
$ cd /usr/local/python/cv2/python-3.5
$ sudo mv cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
Pro-tip: 如果您同时安装 OpenCV 3 和 OpenCV 4,而不是将文件重命名为cv2.so,您可以考虑将其命名为cv2.opencv4.0.0.so,然后在下一个子步骤中,将该文件适当地 sym-link 到cv2.so。
我们的最后一个子步骤是将 OpenCV cv2.so绑定符号链接到我们的cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python3.5/site-packages/
$ ln -s /usr/local/python/cv2/python-3.5/cv2.so cv2.so
步骤 6:在 Ubuntu 上测试 OpenCV 4 的安装
让我们做一个快速的健全性测试,看看 OpenCV 是否准备好了。
打开终端并执行以下操作:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'4.0.0'
>>> quit()
第一个命令激活我们的虚拟环境。然后我们运行与环境相关的 Python 解释器。
注意:没有必要指定python3,因为 Python 3 是环境中唯一的 Python 可执行文件。
如果你看到你已经安装了 4.0.0 版本,那么一个“祝贺你!”妥当。喝一大口你最喜欢的啤酒或波旁威士忌,让我们做一些比安装库和包更有趣的事情。
让我们用 OpenCV 4 执行视频中的对象跟踪
![]()
我知道您渴望用一个实际的例子来测试您的安装。追踪视频中的运动是一个有趣的小项目,可以让你在 Ubuntu 机器上使用 OpenCV 4。
要开始,滚动到这篇博文的 【下载】 部分下载源代码和示例视频。
从那里,在您的新虚拟环境中安装imutils库:
$ workon cv
$ pip install imutils
然后导航到您存储 zip 文件的位置并将其解压缩。例如,您可以将其保存在~/Downloads中,然后执行以下步骤:
$ cd ~/Downloads
$ unzip ball-tracking.zip
$ cd ball-tracking
现在我们准备开始我们的 OpenCV + Python 脚本。
您可以使用以下命令执行该脚本:
$ python ball_tracking.py --video ball_tracking_example.mp4
准备好用你自己的球和网络摄像头试试了吗?命令如下:
$ python ball_tracking.py
此时,你应该看清自己。将球放入框架中,并移动它以查看红色的跟踪轨迹!
要了解这个对象跟踪示例是如何工作的,请务必 参考这篇博文 。
故障排除和常见问题
在 Ubuntu 上安装 OpenCV 4 遇到错误了吗?
先不要跳槽。您第一次安装 OpenCV 时,可能会非常沮丧,我最不希望您做的事情就是在此结束学习过程。
我列出了一些常见问题(FAQ ),建议您熟悉这些问题。
Q. 我能用 Python 2.7 吗?
A. Python 3 是我最近建议开发的,但我确实理解 Python 2.7 需要处理遗留代码。
从 Ubuntu 18.04 开始,Python 2.7 甚至不包括在内。如果你使用的是 Ubuntu 18.04(或更高版本),你仍然可以在第一步的最后手动安装
$ sudo apt-get install python2.7 python2.7-dev
从那里,当您在步骤#3 中创建您的虚拟环境时,首先安装 Python 2.7 的 pip:
$ sudo python2.7 get-pip.py
然后(也是在步骤#3 中)当您创建虚拟环境时,只需使用相关的 Python 版本标志:
$ mkvirtualenv cv -p python2.7
从那以后,一切都应该是一样的。
Q. 为什么我不能直接 pip 安装 OpenCV 4?
A. 根据您的操作系统和架构,OpenCV 有许多可安装 pip 的版本。您可能会遇到的问题是,它们可能是在没有各种优化和图像/视频 I/O 支持的情况下编译的。使用它们——但是使用它们要自担风险。本教程旨在让你在 Ubuntu 上完全安装 OpenCV 4,同时让你完全控制编译。
Q. 为什么我不能直接 apt-get 安装 OpenCV?
我会不惜一切代价避免这个的“解决方案”,即使它可能有效。在您的系统上,您最终会得到一个旧的、过时的 OpenCV 版本。其次,apt-get 不适合虚拟环境,而且您无法控制编译和构建。
***Q. 执行mkvirtualenv或workon时,遇到“命令未找到错误”。我该怎么办?
A. 你会看到这个错误消息的原因有很多,都来自于步骤#3:
- 首先,确保你已经使用
pip软件包管理器正确安装了virtualenv和virtualenvwrapper。通过运行pip freeze进行验证,确保在已安装包列表中看到virtualenv和virtualenvwrapper。 - 您的
~/.bashrc文件可能有错误。查看您的~/.bashrc文件的内容,查看正确的export和source命令是否存在(检查步骤#3 中应该附加到~/.bashrc的命令)。 - 你可能忘记了你的 T1。确保编辑完
source ~/.bashrc后运行它,以确保你可以访问mkvirtualenv和workon命令。
问 当我打开一个新的终端,注销或者重启我的 Ubuntu 系统时,我无法执行mkvirtualenv或者workon命令。
A. 参考上一题的 #2 。
问:我正在尝试使用一个专利算法,比如 SURF,但我看到了一个关于非免费选项的异常。如何使用专利算法?
A. 请务必参考第 4 步** (CMake 命令)和图 4 这篇博文已经更新,以适应 OpenCV 开发人员所做的这一更改。
Q. 当我尝试导入 OpenCV 时,遇到了这个消息:Import Error: No module named cv2。
发生这种情况有几个原因,不幸的是,很难诊断。我推荐以下建议来帮助诊断和解决错误:
**1. 使用workon cv命令确保您的cv虚拟环境处于活动状态。如果这个命令给你一个错误,然后验证virtualenv和virtualenvwrapper是否正确安装。
2. 尝试在您的cv虚拟环境中研究site-packages目录的内容。根据您的 Python 版本,您可以在~/.virtualenvs/cv/lib/python3.5/site-packages/中找到site-packages目录。确保(1)在site-packages目录中有一个cv2目录,并且(2)它正确地用符号链接到一个有效的目录。
3. 务必分别检查位于/usr/local/python/的 Python 的系统安装的site-packages(甚至dist-packages)目录。理想情况下,您应该在那里有一个cv2目录。
4. 作为最后一招,检查 OpenCV 构建的build/lib目录。那里的应该是那里的cv2目录(如果cmake和make都执行无误)。如果cv2.so文件不存在,手动将它复制到系统site-packages目录以及cv虚拟环境的site-packages目录中。
摘要
今天我们学习了如何在 Ubuntu 上安装 OpenCV 4。
从源代码编译允许您完全控制安装过程,包括添加您可能希望使用的任何附加优化。
然后,我们用一个简单的球跟踪演示来测试这个装置。
你运行 macOS 吗?我将在周五带着 macOS + OpenCV 4 安装指南回来,敬请期待!
如果你喜欢今天的安装教程和球跟踪演示,请务必填写下面的表格,这样当新的博客帖子发布时,你就会收到更新!*********
如何在 macOS 上安装 TensorFlow 2.0
原文:https://pyimagesearch.com/2019/12/09/how-to-install-tensorflow-2-0-on-macos/

在本教程中,您将学习在运行 Catalina 或 Mojave 的 macOS 系统上安装 TensorFlow 2.0
TensorFlow 2.0 中有许多重要的更新,包括急切执行、自动微分和更好的多 GPU/分布式训练支持,但最重要的更新是 Keras 现在是 TensorFlow 的官方高级深度学习 API。
此外,如果你有我的书《用 Python 进行计算机视觉的深度学习的副本,你应该使用这个指南在你的 macOS 系统上正确安装 TensorFlow 2.0。
*在本教程中,您将学习如何在 macOS 上安装 TensorFlow 2.0(使用 Catalina 或 Mojave)。
或者,点击这里获取我的 Ubuntu + TensorFlow 2.0 安装说明。
要了解如何在 macOS 上安装 TensorFlow 2.0,继续阅读。
如何在 macOS 上安装 TensorFlow 2.0
在本教程的第一部分,我们将简要讨论预配置的深度学习开发环境,这是我的书 用 Python 进行计算机视觉的深度学习的一部分。
然后,我们将在 macOS 系统上配置和安装 TensorFlow 2.0。
我们开始吧。
预先配置的深度学习环境

Figure 1: My deep learning Virtual Machine with TensorFlow, Keras, OpenCV, and all other Deep Learning and Computer Vision libraries you need, pre-configured and pre-installed.
当谈到使用深度学习和 Python 时,我强烈推荐使用基于 Unix 的环境。
深度学习工具可以更容易地配置和安装在 Unix 系统上,允许您快速开发和运行神经网络。
当然,配置自己的深度学习+ Python + Linux 开发环境可能是一项非常繁琐的任务,尤其是如果您是 Unix 新手,是命令行/终端的初学者,或者是手动编译和安装包的新手。
为了帮助您快速启动深度学习+ Python 教育,我创建了两个预配置的环境:
- 预配置 VirtualBox Ubuntu 虚拟机(VM) 拥有成功所需的所有必要深度学习库(包括 Keras 、 TensorFlow 、 scikit-learn 、 scikit-image 、 OpenCV 等) 预配置 和 预安装【
- 预先配置的深度学习亚马逊机器映像(AMI) ,它运行在亚马逊网络服务(AWS)的弹性计算(EC2)基础设施上。互联网上的任何人都可以免费使用这个环境,不管你是否是我的 DL4CV 客户(需要支付云/GPU 费用)。深度学习库是 预装的 除了 TFOD API 、 Mask R-CNN 、 RetinaNet 、 mxnet 之外还包括#1 中列出的两个。
我 强烈敦促 如果您正在阅读我的书籍,请考虑使用我预先配置的环境。使用预先配置好的环境不是欺骗— 他们只是让你专注于学习,而不是系统管理员的工作。
如果你更熟悉微软 Azure 的基础设施,一定要看看他们的 Ubuntu 数据科学虚拟机(DSVM),包括我对环境的评测。Azure 团队为你维护了一个很好的环境,我不能说他们提供了足够高的支持,同时我确保我所有的深度学习章节都在他们的系统上成功运行。
也就是说,预配置环境并不适合所有人。
在本教程的剩余部分,我们将作为“深度学习系统管理员”在我们的裸机 macOS 上安装 TensorFlow 2.0。
配置您的 macOS TensorFlow 2.0 深度学习系统
在计算机上安装 TensorFlow 2.0 的以下说明假设:
- 您拥有系统的管理权限
- 您可以打开一个终端,或者您有一个到目标机器的活动 SSH 连接
- 你知道如何操作命令行。
我们开始吧!
第一步:选择你的 macOS 深度学习平台 Catalina 或 Mojave
Figure 3: This tutorial supports installing TensorFlow 2.0 on macOS Mojave or macOS Catalina.
本指南中的这些 TensorFlow 2.0 安装说明与以下操作系统兼容:
- macOS: 10.15“卡特琳娜”
- macOS: 10.14“莫哈韦”
或者,你可以遵循我的 Ubuntu + TensorFlow 2.0 安装说明。
注:你可能会疑惑“Windows 呢?”请记住,我不支持 PyImageSearch 博客上的窗口。你可以在我的常见问题中了解更多关于我的“无窗口政策”。
第二步(仅限卡特琳娜):选择巴什或 ZSH 作为你的 shell
这一步只针对 macOS 卡特琳娜的T3。如果您使用 Mojave,请忽略此步骤并跳到步骤#3** 。**
在 macOS Catalina 上,您可以选择使用 Bash shell 或 ZSH shell。
你可能已经习惯了 Bash。先前版本的 macOS 使用 Bash,默认情况下,Ubuntu 也使用 Bash。苹果公司现已做出决定,今后他们的操作系统将使用 ZSH。
有什么大不了的,我应该换吗?
描述 Bash 和 ZSH 之间的区别超出了本文的范围——这完全由您决定。我会推荐你阅读这个 ZSH vs. Bash 教程来开始,但是同样的,选择权在你。
一方面,您可能会发现这些变化对您没有太大影响,并且使用 ZSH 将非常类似于 Bash。另一方面,高级用户可能会注意到一些附加功能。
如果您将从 High Sierra 或 Mojave 升级到 Catalina,默认情况下,您的系统可能会使用 Bash,除非您通过进入终端配置文件设置来明确更改它。
如果你的电脑安装了 Catalina,或者你从头开始安装 Catalina,那么你的系统可能会默认使用 ZSH。
无论哪种方式,如果你决定需要在卡特琳娜上切换,你可以按照这些指示设置你的个人资料使用 ZSH 。
通过“终端首选项”>“配置文件”>“外壳”菜单更改外壳相对简单,如图图 4 所示:
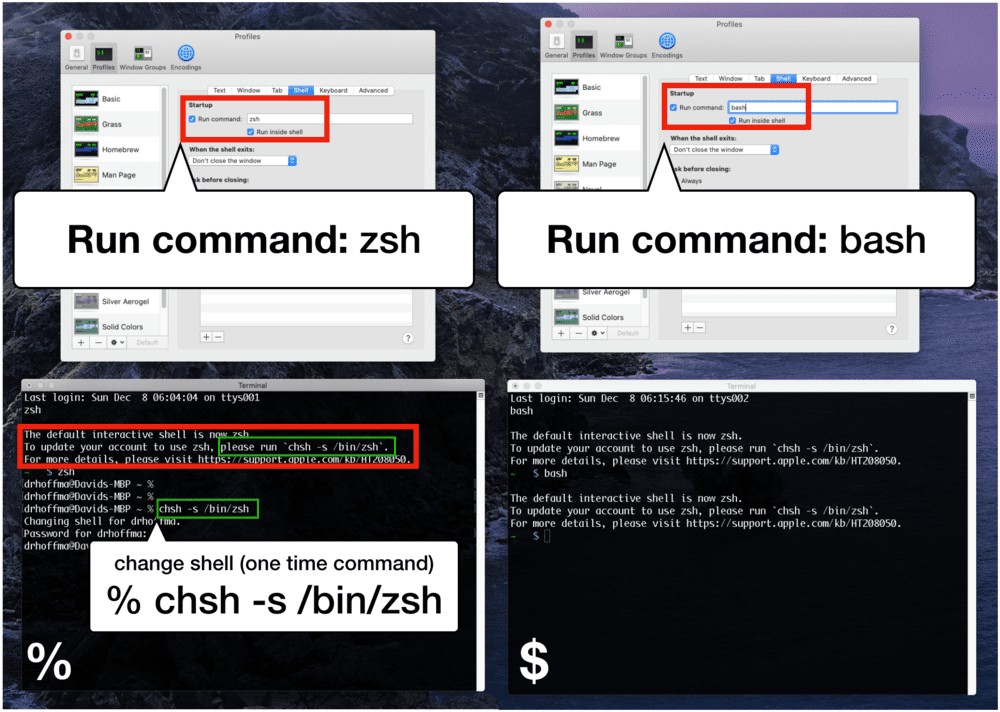
Figure 4: Changing your macOS Catalina shell to ZSH (left), a step you may wish to do before installing TensorFlow 2.0 on macOS (click for high-res).
您使用的 shell 决定了您稍后在本安装指南中编辑哪个终端配置文件:
- ZSH:
~/.zshrc - 迎头痛击:
~/.bash_profile
如果你从~/.zshrc内部采购,ZSH 将会满足~/.bash_profile。请记住,不是所有的设置都有效。例如,在我的~/.bash_profile中,我有一个定制的 bash 提示符,它只显示当前最低级别的工作目录(更短)以及我正在工作的 Git 库的哪个分支(对软件开发有用)。问题是 ZSH 不喜欢我定制的 Bash 提示符,所以我必须删除它。我将不得不建立一个自定义的 ZSH 提示在未来。
实际上,如果将所需的 Bash 配置文件中的设置复制到 ZSH 配置文件中,并确保它们能够工作,效果可能会更好。或者,您可以在您的 ZSH 概要文件中获得 Bash 概要文件(例如,将source ~/.bash_profile作为一行插入到您的~/.zshrc文件中——然后打开一个新的 shell 或者用source ~/.zshrc命令重新加载它)。
如果您以前在 Bash 中工作(例如,您升级到了 Catalina),您可能会在终端中遇到以下消息:
The default interactive shell is now zsh.
To update your account to use zsh, please run chsh -s /bin/zsh
For more details, please visit https://support.apple.com/kb/HT208050.
这意味着要切换 shells,您应该在提示符下输入命令:
$ chsh -s /bin/zsh
注意 ZSH 提示是%。本教程的剩余部分将在提示符的开头显示$,但是如果你使用的是 ZSH,你可以把它想象成%。
步骤 3:安装 macOS 深度学习依赖项
Figure 5: Prior to installing TensorFlow 2.0 on macOS Mojave or macOS Catalina, you must install Xcode from the App Store.
在任一版本的 macOS 中,打开你的 macOS 应用商店,找到并下载/安装 Xcode ( 图 5 )。
从那里,在终端中接受 Xcode 许可证:
$ sudo xcodebuild -license
阅读协议时按下space键。然后在提示符下键入agree。
然后安装 Xcode select:
$ sudo xcode-select --install
注意: 如果你遇到这个错误信息xcode-select: error: tool 'xcodebuild' requires Xcode, but active developer directory '/Library/Developer/CommandLineTools' is a command line tools instance 你可能需要遵循这些 SOF 指令。
Figure 6: To install TensorFlow 2.0 on macOS Mojave/Catalina, be sure to install the Xcode-select tools.
非官方的、社区驱动的 macOS 软件包管理器被称为 Homebrew (简称 brew)。许多你可以用 Aptitude (apt)在 Ubuntu 上安装的软件包都可以通过 macOS 上的 HomeBrew 获得。
我们将使用自制软件安装一些依赖项。它没有预装在 macOS 上,所以让我们现在安装它(只有在你还没有自制软件的情况下才这样做):
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
从那里,更新家酿:
$ brew update
现在继续编辑您的 ZSH 个人资料或 Bash 个人资料。确保根据您在 macOS 上使用的是 ZSH 还是 Bash 来更新正确的文件:
~/.zshrc~/.bash_profile(猛击)
$ nano ~/.zshrc # ZSH
$ nano ~/.bash_profile # Bash
同样,你应该只根据你的 macOS 系统使用的 shell 来编辑上述文件中的一个。
从这里开始,在您的概要文件的末尾插入以下行:
# Homebrew
export PATH=/usr/local/bin:$PATH
保存文件(ctrl + x、y、enter),并退出到您的终端。
现在,开始创建概要文件(即重新加载):
$ source ~/.zshrc # ZSH
$ source ~/.bash_profile # Bash
同样,根据您使用的 macOS shell,应该只执行上述命令中的一个。
我们现在准备好安装 Python 3:
$ brew install python3
让我们检查一下 Python 3 在这一点上是否正确链接:
$ which python3
/usr/local/bin/python3
警告:根据我们的经验,Python 3.8 与 TensorFlow 2.0 不兼容。如果您的系统安装了 Python 3.8,我们建议在步骤#5* 中安装 TensorFlow 2.2+。否则,坚持使用 Python 3.6 或 3.7 是一个稳妥的选择。确保通过执行python3 --version来检查您的 Python 版本。*
您应该验证输出路径以/usr/local开始。如果没有,那么仔细检查是否安装了 Homebrew 的 Python。我们不想使用系统 Python,因为我们的虚拟环境将基于家酿的 Python。
此时,Homebrew 和 Python 已经准备好让我们安装依赖项:
$ brew install cmake pkg-config wget
$ brew install jpeg libpng libtiff openexr
$ brew install eigen tbb hdf5
我们的依赖项包括编译器工具、图像 I/O、优化工具和用于处理大型数据集/序列化文件的 HDF5。
在 macOS 上安装依赖项做得很好——您现在可以继续进行步骤#4 。
警告: 在这一节我们与家酿一起工作。当您处于步骤#4 描述的虚拟环境中时,千万不要执行brew命令,因为从那里恢复您系统的包和依赖树可能很困难。如果您看到 bash/ZSH 提示符以({env_name})开头,那么您处于 Python 虚拟环境 中,您应该在运行brew命令之前执行 deactivate。
步骤 4:安装 pip 和虚拟环境
在这一步中,我们将设置 pip 和 Python 虚拟环境。
我们将使用事实上的 Python 包管理器 pip。
注意:虽然欢迎您选择 Anaconda(或替代产品),但我仍然发现 pip 在社区中更普遍。如果您愿意的话,可以随意使用 Anaconda,但请理解我不能为它提供支持。
让我们下载并安装 pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
为了补充 pip,我推荐同时使用 virtualenv 和 virtualenvwrapper 来管理虚拟环境。
就 Python 开发而言,虚拟环境是最佳实践。它们允许您在隔离的开发和生产环境中测试不同版本的 Python 库。我每天都在使用它们,对于所有 Python 开发,你也应该使用它们。
换句话说,不要将 TensorFlow 2.0 和相关的 Python 包直接安装到您的系统环境中。以后只会出问题。
现在让我们安装我喜欢的虚拟环境工具:
$ pip3 install virtualenv virtualenvwrapper
注意:您的系统可能需要您使用sudo命令来安装上述虚拟环境工具。这将只需要一次—从现在开始,不要使用sudo。
从这里开始,我们需要更新 bash 概要文件:
$ nano ~/.zshrc # ZSH
$ nano ~/.bash_profile # Bash
根据您的 macOS 系统使用的 shell,只编辑上述文件中的一个。
接下来,在文件底部输入以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
保存文件(ctrl + x、y、enter),并退出到您的终端。
Figure 7: How to install TensorFlow 2.0 on macOS. This figure shows the Bash or ZSH profile in macOS configured with Homebrew and virtualenvwrapper.
不要忘记在您的个人资料中查找变更:
$ source ~/.zshrc # ZSH
$ source ~/.bash_profile # Bash
您只需要执行上述命令中的一个——验证您首先使用的是哪个 shell(ZSH 或 Bash)。
输出将显示在您的终端上,表明virtualenvwrapper已安装。
注意:如果您在这里遇到错误,您需要在继续之前解决它们。通常,这一点上的错误是由于您的 Bash/ZSH 配置文件中的打字错误。
现在我们准备创建你的 Python 3 深度学习虚拟环境命名为dl4cv:
$ mkvirtualenv dl4cv -p python3
您可以根据需要使用不同的名称(以及其中的包)创建类似的虚拟环境。在我的个人系统上,我有许多虚拟环境。为了给我的书 开发和测试软件,用 Python 进行计算机视觉的深度学习,我喜欢用dl4cv来命名(或在名称前)环境。也就是说,请随意使用对您来说最有意义的术语。
在您的系统上设置虚拟环境非常棒!
第五步:在 macOS 上安装 TensorFlow 2.0 到你的虚拟环境中
在这一步,我们将安装 TensorFlow 2.0。
张量流的先决条件是数值处理的 NumPy。继续使用 pip 安装 NumPy 和 TensorFlow 2.0:
$ pip install numpy
$ pip install tensorflow==2.0.0
安装 TensorFlow 2.0 非常棒!
第 6 步:将相关的包安装到你的dl4cv 虚拟环境

Figure 8: A fully-fledged TensorFlow 2.0 deep learning environment requires a handful of other Python libraries as well.
在这一步,我们将安装通用深度学习开发所需的附加包。
我们从标准图像处理库开始,包括 OpenCV:
$ pip install opencv-contrib-python
$ pip install scikit-image
$ pip install pillow
$ pip install imutils
这些图像处理库将允许我们执行图像 I/O、各种预处理技术以及图形显示。
从那里,让我们安装机器学习库和支持库,包括 scikit-learn 和 matplotlib:
$ pip install scikit-learn
$ pip install matplotlib
$ pip install progressbar2
$ pip install beautifulsoup4
$ pip install pandas
伟大的工作安装相关的图像处理和机器学习库。
步骤 7:测试您的安装
在这一步,作为一个快速的健全测试,我们将测试我们的安装。
在您的dl4cv环境中启动一个 Python shell(或者您命名的任何 Python 虚拟环境),并确保您可以导入以下包:
$ workon dl4cv
$ python
>>> import tensorflow as tf
>>> tf.__version__
2.0.0
>>> import tensorflow.keras
>>> import cv2
>>> cv2.__version__
4.1.2
注意:如果你在 Python 3.7.3 ( 卡特琳娜)和 Clang 11.0 上你可能会遇到这个错误。这是一个已知问题,有可用的解决方案此处。
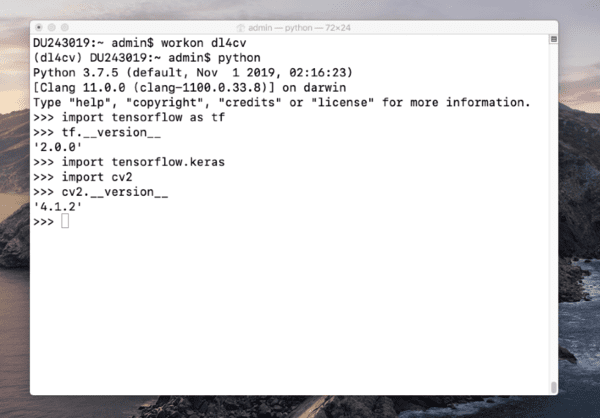
Figure 8: Testing TensorFlow 2.0 installation on macOS inside a Python interpreter.
访问您的 TensorFlow 2.0 虚拟环境
至此,你的 TensorFlow 2.0 dl4cv环境已经整装待发。无论何时你想执行 TensorFlow 2.0 代码(比如来自我的深度学习书籍,一定要使用workon命令进入安装了 TensorFlow 2.0 的 Python 虚拟环境:
$ workon dl4cv
您的 ZSH 或 Bash 提示符前面会有(dl4cv),表明您“在”TensorFlow 2.0 虚拟环境中。
如果您需要回到系统级环境,可以停用当前的虚拟环境:
$ deactivate
常见问题(FAQ)
问:这些说明看起来真的很复杂。您有预配置的环境吗?
答:是的,说明可能会让人望而生畏。我建议在遵循这些说明之前,先复习一下您的 Unix 命令行技能。
也就是说,我确实为我的书提供了两个预配置环境:
- 预配置深度学习虚拟机 : 我的 VirtualBox VM 包含在您购买的我的深度学习本中。只需下载 VirtualBox 并将虚拟机导入 VirtualBox。从那里,启动它,你将在几分钟内运行示例代码。
- 【亚马逊机器映像(EC2 AMI) : 在网上免费提供给大家。即使你没有我的深度学习书,你也可以无条件地使用这个环境(当然,AWS 收费)。同样,AWS 上的计算资源不是免费的——你需要支付云/GPU 费用,而不是 AMI 本身。可以说,在云中的深度学习平台上工作比在现场保持深度学习箱更便宜,更省时。免费的硬件升级,没有系统管理员的麻烦,没有打电话给硬件供应商询问保修政策,没有电费,只需按使用量付费。如果您有几个一次性项目,并且不想投资硬件,这是最佳选择。
问:为什么我们没有安装 Keras?
答:从 TensorFlow v1.10.0 开始,Keras 正式成为 TensorFlow 的一部分。通过安装 TensorFlow 2.0,Keras API 被固有地安装。
Keras 已经深深嵌入到 TensorFlow 中,tf.keras是 TensorFlow 2.0 中主要的高级 API。TensorFlow 附带的传统函数现在与tf.keras配合得很好。
为了更详细地理解 Keras 和tf.keras之间的区别,看看我最近的博客文章。
现在,您可以在 Python 程序中使用以下语句导入 Keras:
$ workon dl4cv
$ python
>>> import tensorflow.keras
>>>
问:这些指令支持 macOS Mojave 和 macOS Catalina 吗?
答:是的,这些说明已经在 Mojave 和 Catalina 上进行了全面测试。也就是说,自制软件经常变化,可能是问题的根源。如果您有任何问题,请联系我或在下面留言。请尊重这个网页和我的电子邮件收件箱,不要倾倒大量的终端输出。请记住这个关于调试开发环境的 PyImageSearch 策略。
问:我真的卡住了。有东西坏了。你能帮我吗?
答:我真的很喜欢帮助读者,我也很乐意帮助你配置你的深度学习开发环境。
也就是说,我每天会收到 100 多封电子邮件和博客帖子评论——我根本没有时间一一回复
由于我自己和我的团队收到的请求数量,我的客户比非客户得到的支持优先。请通过浏览 我的图书和课程库 考虑成为客户。
我个人推荐你去拿一本《用 Python 进行计算机视觉的深度学习——那本书包括访问我预先配置的深度学习开发环境,有 TensorFlow,Keras,OpenCV 等。预装。您将在几分钟内启动并运行。
*## 摘要
在本教程中,您学习了如何在 MAC OS(Catalina 或 Mojave)上安装 TensorFlow 2.0。
现在你的深度学习装备已经配置好了,我建议你拿一份用 Python 编写的 计算机视觉深度学习。你将获得很好的教育,你将学会如何成功地将深度学习应用到你自己的项目中。
要在 PyImageSearch 上发布未来教程时得到通知,*只需在下表中输入您的电子邮件地址!***
如何在 Ubuntu 上安装 TensorFlow 2.0
原文:https://pyimagesearch.com/2019/12/09/how-to-install-tensorflow-2-0-on-ubuntu/

在本教程中,您将学习在 Ubuntu 系统上安装 TensorFlow 2.0,无论有无 GPU。
TensorFlow 2.0 中有许多重要的更新,包括急切执行、自动微分和更好的多 GPU/分布式训练支持,但最重要的更新是 Keras 现在是 TensorFlow 的官方高级深度学习 API。
简而言之——在训练自己的深度神经网络时,你应该使用 TensorFlow 2.0(即tf.keras)内的 Keras 实现。官方的 Keras 包仍然会收到错误修复,但是所有的新特性和实现都将在tf.keras中。
Francois Chollet(Keras 的创建者)以及 TensorFlow 的开发者和维护者都建议您使用tf.keras继续前进。
此外,如果你有我的书《用 Python 进行计算机视觉的深度学习》的副本,你应该使用这个指南在你的 Ubuntu 系统上安装 TensorFlow 2.0。
*在本教程中,您将学习如何在 Ubuntu 上安装 TensorFlow 2.0。
或者,点击此处获取我的 macOS + TensorFlow 2.0 安装说明。
要了解如何在 Ubuntu 上安装 TensorFlow 2.0,继续阅读。
如何在 Ubuntu 上安装 TensorFlow 2.0
在本教程的第一部分,我们将讨论预配置的深度学习开发环境,这是我的书 用 Python 进行计算机视觉的深度学习的一部分。
从那里,您将了解为什么应该使用 TensorFlow 2.0,包括 TensorFlow 2.0 的中的 Keras 实现。
然后我们将在我们的 Ubuntu 系统上配置和安装 TensorFlow 2.0。
我们开始吧。
预先配置的深度学习环境

Figure 1: My deep learning Virtual Machine with TensorFlow, Keras, OpenCV, and all other Deep Learning and Computer Vision libraries you need, pre-configured and pre-installed.
当谈到使用深度学习和 Python 时,我强烈推荐使用基于 Unix 的环境。
深度学习工具可以更容易地配置和安装在 Linux 上,允许您快速开发和运行神经网络。
当然,配置自己的深度学习+ Python + Linux 开发环境可能是一项非常繁琐的任务,尤其是如果您是 Linux 新手,是命令行/终端的初学者,或者是手动编译和安装包的新手。
为了帮助您快速启动深度学习+ Python 教育,我创建了两个预配置的环境:
- 预配置 VirtualBox Ubuntu 虚拟机(VM) 拥有成功所需的所有必要深度学习库(包括 Keras 、 TensorFlow 、 scikit-learn 、 scikit-image 、 OpenCV 等) 预配置 和 预安装【
- 预先配置的深度学习亚马逊机器映像(AMI) ,它运行在亚马逊网络服务(AWS)的弹性计算(EC2)基础设施上。互联网上的任何人都可以免费使用这个环境,不管你是否是我的 DL4CV 客户(需要支付云/GPU 费用)。深度学习库是 预装的 除了 TFOD API 、 Mask R-CNN 、 RetinaNet 、 mxnet 之外还包括#1 中列出的两个。
我 强烈敦促 如果您正在阅读我的书籍,请考虑使用我预先配置的环境。使用预先配置好的环境不是欺骗— 他们只是让你专注于学习,而不是系统管理员的工作。
如果你更熟悉微软 Azure 的基础设施,一定要看看他们的数据科学虚拟机(DSVM),包括我对环境的评论。Azure 团队为你维护了一个很好的环境,我不能说他们提供了足够高的支持,同时我确保我所有的深度学习章节都在他们的系统上成功运行。
也就是说,预配置环境并不适合所有人。
在本教程的剩余部分,我们将作为“深度学习系统管理员”在我们的裸机 Ubuntu 上安装 TensorFlow 2.0。
为什么是 TensorFlow 2.0,Keras 在哪里?
Figure 2: Keras and TensorFlow have a complicated history together. When installing TensorFlow 2.0 on Ubuntu, keep in mind that Keras is the official high-level API built into TensorFlow.
Twitter 上似乎每天都在进行一场关于最佳深度学习框架的战争。问题是这些讨论对每个人的时间都是适得其反的。
我们应该谈论的是你的新模型架构,以及你如何应用它来解决问题。
也就是说,我使用 Keras 作为我的日常深度学习库和这个博客的主要教学工具。
如果你能学会 Keras,你将在 TensorFlow、PyTorch、mxnet 或任何其他类似的框架中得心应手。它们只是你工具箱中不同的棘轮扳手,可以完成相同的目标。
Francois Chollet(Keras 的主要维护者/开发者)在 2015 年 3 月 27 日将他的第一个 Keras 版本提交到了他的 GitHub 上。此后,该软件经历了多次更改和迭代。
2019 年早些时候,TensorFlow v1.10.0 中引入了tf.keras子模块。
现在有了 TensorFlow 2.0,Keras 是 TensorFlow 的官方高级 API。
从现在开始,keras包将只接收错误修复。如果现在想用 Keras,需要用 TensorFlow 2.0。
要了解更多关于 Keras 和 TensorFlow 的婚姻,一定要阅读我之前的文章。
TensorFlow 2.0 具有一系列新功能,包括:
- 通过
tf.keras将 Keras 集成到 TensorFlow 中 - 会话和急切执行
- 自动微分
- 模型和层子类化
- 更好的多 GPU/分布式培训支持
- 面向移动/嵌入式设备的 TensorFlow Lite
- TensorFlow 扩展用于部署生产模型
长话短说——如果你想使用 Keras 进行深度学习,那么你需要安装 TensorFlow 2.0。
配置您的 TensorFlow 2.0 + Ubuntu 深度学习系统
在计算机上安装 TensorFlow 2.0 的以下说明假设:
- 您拥有系统的管理权限
- 您可以打开一个终端,或者您有一个到目标机器的活动 SSH 连接
- 你知道如何操作命令行。
我们开始吧!
第一步:安装 Ubuntu + TensorFlow 2.0 深度学习依赖项
此步骤针对GPU 用户和非 GPU 用户。
**我们的 Ubuntu 安装说明假设你使用的是 Ubuntu 18.04 LTS 版。这些说明将于 2003 年 4 月 18 日进行测试。
我们将首先打开一个终端并更新我们的系统:
$ sudo apt-get update
$ sudo apt-get upgrade
从那里我们将安装编译器工具:
$ sudo apt-get install build-essential cmake unzip pkg-config
$ sudo apt-get install gcc-6 g++-6
然后我们将安装screen,这是一个用于同一个窗口中多个终端的工具——我经常用它进行远程 SSH 连接:
$ sudo apt-get install screen
从那里我们将安装 X windows 库和 OpenGL 库:
$ sudo apt-get install libxmu-dev libxi-dev libglu1-mesa libglu1-mesa-dev
以及图像和视频 I/O 库:
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
接下来,我们将安装优化库:
$ sudo apt-get install libopenblas-dev libatlas-base-dev liblapack-dev gfortran
和用于处理大型数据集的 HDF5:
$ sudo apt-get install libhdf5-serial-dev
我们还需要我们的 Python 3 开发库,包括 TK 和 GTK GUI 支持:
$ sudo apt-get install python3-dev python3-tk python-imaging-tk
$ sudo apt-get install libgtk-3-dev
如果你有 GPU ,继续步骤#2 。
否则,如果你没有 GPU ,跳到步骤#3 。
第 2 步(仅限 GPU):安装 NVIDIA 驱动程序、CUDA 和 cuDNN

Figure 3: How to install TensorFlow 2.0 for a GPU machine.
此步骤 仅针对 GPU 用户。
在这一步中,我们将在 Ubuntu 上为 TensorFlow 2.0 安装 NVIDIA GPU 驱动程序、CUDA 和 cuDNN。
我们需要添加一个 apt-get 存储库,以便我们可以安装 NVIDIA GPU 驱动程序。这可以在您的终端中完成:
$ sudo add-apt-repository ppa:graphics-drivers/ppa
$ sudo apt-get update
继续安装您的 NVIDIA 显卡驱动程序:
$ sudo apt-get install nvidia-driver-418
然后发出 reboot 命令,等待系统重新启动:
$ sudo reboot now
回到终端/SSH 连接后,运行nvidia-smi命令查询 GPU 并检查其状态:
$ nvidia-smi
Fri Nov 22 03:14:45 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 430.50 Driver Version: 430.50 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:1E.0 Off | 0 |
| N/A 41C P0 39W / 300W | 0MiB / 16160MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
nvidia-smi命令输出有助于查看您的 GPU 的健康状况和使用情况。
让我们继续下载 CUDA 10.0 。从现在开始,我推荐 CUDA 10.0,因为它现在非常可靠和成熟。
以下命令将从你的终端下载和安装 CUDA 10.0
$ cd ~
$ mkdir installers
$ cd installers/
$ wget https://developer.nvidia.com/compute/cuda/10.0/Prod/local_installers/cuda_10.0.130_410.48_linux
$ mv cuda_10.0.130_410.48_linux cuda_10.0.130_410.48_linux.run
$ chmod +x cuda_10.0.130_410.48_linux.run
$ sudo ./cuda_10.0.130_410.48_linux.run --override
注意:当你执行这些命令时,注意长 URLs 文件名引起的换行。
系统将提示您接受最终用户许可协议(EULA)。在此过程中,您可能会遇到以下错误:
Please make sure that
PATH includes /usr/local/cuda-10.0/bin
LD_LIBRARY_PATH includes /usr/local/cuda-10.0/lib64, or, add /usr/local/cuda-10.0/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-10.0/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-10.0/doc/pdf for detailed information on setting up CUDA.
*WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 384.00 is required for CUDA 10.0 functionality to work.
To install the driver using this installer, run the following command, replacing with the name of this run file:
sudo .run -silent -driver
Logfile is /tmp/cuda_install_25774.log
您可以放心地忽略这条错误消息。
现在让我们使用nano更新我们的 bash 配置文件(如果你更习惯使用vim或emacs,你可以使用它们):
$ nano ~/.bashrc
在配置文件的底部插入以下几行:
# NVIDIA CUDA Toolkit
export PATH=/usr/local/cuda-10.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64
保存文件(ctrl + x、y、enter),并退出到您的终端。
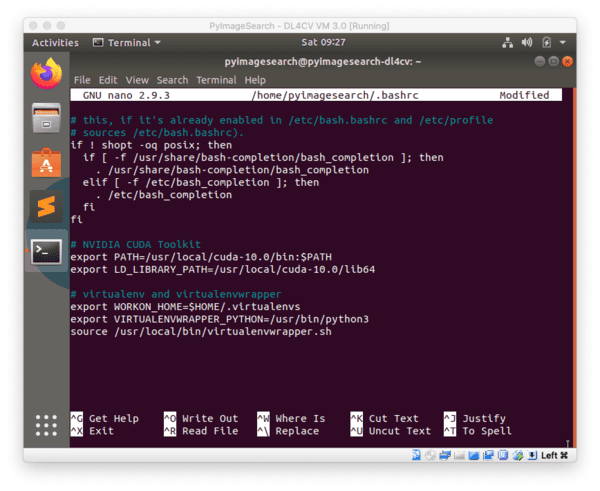
Figure 4: How to install TensorFlow 2.0 on Ubuntu with an NVIDIA CUDA GPU.
然后,获取配置文件:
$ source ~/.bashrc
在这里,我们将查询 CUDA 以确保它已成功安装:
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
如果您的输出显示 CUDA 已经构建,那么您现在就可以安装 cud nn——CUDA 兼容的深度神经网络库。
请从以下链接下载适用于 CUDA 10.0 的 cuDNN v7.6.4 版本:
https://developer.nvidia.com/rdp/cudnn-archive
确保您选择了:
- 为 CUDA 10.0 下载 cud nn v 7 . 6 . 4(2019 年 9 月 27 日)
- 用于 Linux 的 cuDNN 库
- 然后允许。zip 文件下载(您可能需要在 NVIDIA 的网站上创建一个帐户来下载 cuDNN 文件)
然后,您可能需要将其从您的家用机器 SCP(安全复制)到您的远程深度学习箱:
$ scp ~/Downloads/cudnn-10.0-linux-x64-v7.6.4.24.tgz \
username@your_ip_address:~/installers
回到你的 GPU 开发系统,让我们安装 cuDNN:
$ cd ~/installers
$ tar -zxf cudnn-10.0-linux-x64-v7.6.4.38.tgz
$ cd cuda
$ sudo cp -P lib64/* /usr/local/cuda/lib64/
$ sudo cp -P include/* /usr/local/cuda/include/
$ cd ~
至此,我们已经安装了:
- NVIDIA GPU v418 驱动程序
- CUDA 10.0
- cuDNN 7.6.4 for CUDA 10.0
困难的部分现在已经过去了——GPU 安装可能会很有挑战性。伟大的工作设置你的 GPU!
继续执行步骤#3 。
步骤 3:安装 pip 和虚拟环境
此步骤针对GPU 用户和非 GPU 用户。
**在这一步中,我们将设置 pip 和 Python 虚拟环境。
我们将使用事实上的 Python 包管理器 pip。
注意:虽然欢迎您选择 Anaconda(或替代产品),但我仍然发现 pip 在社区中更普遍。如果您愿意的话,可以随意使用 Anaconda,但请理解我不能为它提供支持。
让我们下载并安装 pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
为了补充 pip,我推荐同时使用 virtualenv 和 virtualenvwrapper 来管理虚拟环境。
就 Python 开发而言,虚拟环境是最佳实践。它们允许您在隔离的开发和生产环境中测试不同版本的 Python 库。我每天都在使用它们,对于所有 Python 开发,你也应该使用它们。
换句话说,不要将 TensorFlow 2.0 和相关的 Python 包直接安装到您的系统环境中。以后只会出问题。
现在让我们安装我喜欢的虚拟环境工具:
$ pip3 install virtualenv virtualenvwrapper
注意:您的系统可能需要您使用sudo命令来安装上述虚拟环境工具。这将只需要一次—从现在开始,不要使用sudo。
从这里开始,我们需要更新 bash 概要文件以适应virtualenvwrapper。用 Nano 或其他文本编辑器打开~/.bashrc文件:
$ nano ~/.bashrc
并在文件末尾插入以下行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.local/bin/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export VIRTUALENVWRAPPER_VIRTUALENV=$HOME/.local/bin/virtualenv
source $HOME/.local/bin/virtualenvwrapper.sh
保存文件(ctrl + x、y、enter),并退出到您的终端。
继续将更改来源/加载到您的个人资料中:
$ source ~/.bashrc
输出将显示在您的终端上,表明virtualenvwrapper已安装。如果您在这里遇到错误,您需要在继续之前解决它们。通常,这一点上的错误是由于您的~/.bashrc文件中的打字错误。
现在我们准备创建你的 Python 3 深度学习虚拟环境命名为dl4cv:
$ mkvirtualenv dl4cv -p python3
您可以根据需要使用不同的名称(以及其中的包)创建类似的虚拟环境。在我的个人系统上,我有许多虚拟环境。为了给我的书 开发和测试软件,用 Python 进行计算机视觉的深度学习,我喜欢用dl4cv来命名(或在名称前)环境。也就是说,请随意使用对您来说最有意义的术语。
在您的系统上设置虚拟环境非常棒!
步骤 3:将 TensorFlow 2.0 安装到您的dl4cv虚拟环境中
此步骤针对GPU 用户和非 GPU 用户。
**在这一步中,我们将使用 pip 安装 TensorFlow 2.0。
确保您仍然在您的dl4cv虚拟环境中(通常虚拟环境名称在您的 bash 提示符之前)。如果没有,不用担心。只需使用以下命令激活环境:
$ workon dl4cv
TensorFlow 2.0 的先决条件是 NumPy 用于数值处理。继续使用 pip 安装 NumPy 和 TensorFlow 2.0:
$ pip install numpy
$ pip install tensorflow==2.0.0 # or tensorflow-gpu==2.0.0
要为 GPU 安装 TensorFlow 2.0,请确保将 替换为tensorflow-gputensorflow。
你不应该两个都安装了——使用 或者 tensorflow安装 CPU或者 tensorflow-gpu安装 GPU,不要两个都安装!
安装 TensorFlow 2.0 非常棒!
步骤#4:将 TensorFlow 2.0 相关包安装到您的dl4cv 虚拟环境
Figure 5: A fully-fledged TensorFlow 2.0 + Ubuntu deep learning environment requires additional Python libraries as well.
此步骤针对GPU 用户和非 GPU 用户。
**在这一步中,我们将使用 TensorFlow 2.0 安装通用深度学习开发所需的附加包。
确保您仍然在您的dl4cv虚拟环境中(通常虚拟环境名称在您的 bash 提示符之前)。如果没有,不用担心。只需使用以下命令激活环境:
$ workon dl4cv
我们首先安装标准图像处理库,包括 OpenCV:
$ pip install opencv-contrib-python
$ pip install scikit-image
$ pip install pillow
$ pip install imutils
这些图像处理库将允许我们执行图像 I/O、各种预处理技术以及图形显示。
从那里,让我们安装机器学习库和支持库,最著名的两个是 scikit-learn 和 matplotlib:
$ pip install scikit-learn
$ pip install matplotlib
$ pip install progressbar2
$ pip install beautifulsoup4
$ pip install pandas
就机器学习而言,Scikit-learn 是一个特别重要的库。我们将使用该库中的许多功能,包括分类报告、标签编码器和机器学习模型。
伟大的工作安装相关的图像处理和机器学习库。
步骤#5:测试您的 TensorFlow 2.0 安装
此步骤针对GPU 用户和非 GPU 用户。
**作为快速健全测试,我们将测试我们的 TensorFlow 2.0 安装。
在您的dl4cv环境中启动一个 Python shell,并确保您可以导入以下包:
$ workon dl4cv
$ python
>>> import tensorflow as tf
>>> tf.__version__
2.0.0
>>> import tensorflow.keras
>>> import cv2
>>> cv2.__version__
4.1.2
如果您的系统配置了 NVIDIA GPU,请务必检查 TensorFlow 2.0 的安装是否能够利用您的 GPU:
$ workon dl4cv
$ python
>>> import tensorflow as tf
>>> tf.test.is_gpu_available()
True
在 Ubuntu 上测试 TensorFlow 2.0 安装非常棒。
访问您的 TensorFlow 2.0 虚拟环境
至此,你的 TensorFlow 2.0 dl4cv环境已经整装待发。无论何时你想执行 TensorFlow 2.0 代码(比如来自我的深度学习书籍,一定要使用workon命令:
$ workon dl4cv
您的 bash 提示符前面会有一个(dl4cv),表示您在 TensorFlow 2.0 虚拟环境的“内部”。
如果您需要回到系统级环境,可以停用当前的虚拟环境:
$ deactivate
常见问题(FAQ)
问:这些说明看起来真的很复杂。您有预配置的环境吗?
答:是的,说明可能会让人望而生畏。我建议在遵循这些说明之前,先复习一下您的 Linux 命令行技能。我为我的书提供了两个预配置的环境:
- 预配置深度学习虚拟机 : 我的 VirtualBox VM 包含在您购买的我的深度学习本中。只需下载 VirtualBox 并将虚拟机导入 VirtualBox。从那里,启动它,你将在几分钟内运行示例代码。
- 预先配置好的亚马逊机器镜像(EC2 AMI) : 在网上免费提供给大家。即使你没有我的深度学习书,你也可以无条件地使用这个环境(当然,AWS 收费)。同样,AWS 上的计算资源不是免费的——你需要支付云/GPU 费用,而不是 AMI 本身。可以说,在云中的深度学习平台上工作比在现场保持深度学习箱更便宜,更省时。免费的硬件升级,没有系统管理员的麻烦,没有打电话给硬件供应商询问保修政策,没有电费,只需按使用量付费。如果您有几个一次性项目,并且不想用硬件费用耗尽您的银行帐户,这是最佳选择。
问:为什么我们没有安装 Keras?
答:自 TensorFlow v1.10.0 起,Keras 正式成为 TensorFlow 的一部分。通过安装 TensorFlow 2.0,Keras API 被固有地安装。
Keras 已经深深嵌入到 TensorFlow 中,tf.keras是 TensorFlow 2.0 中主要的高级 API。TensorFlow 附带的传统函数现在与tf.keras配合得很好。
为了更详细地理解 Keras 和tf.keras之间的区别,看看我最近的博客文章。
现在,您可以在 Python 程序中使用以下语句导入 Keras:
$ workon dl4cv
$ python
>>> import tensorflow.keras
>>>
问:我应该使用哪个版本的 Ubuntu?
答:Ubuntu 18.04.3 是“长期支持”(LTS),非常合适。也有很多传统系统使用 Ubuntu 16.04,但如果你正在构建一个新系统,我会推荐 Ubuntu 18.04.3。目前,我不建议使用 Ubuntu 19.04,因为通常当一个新的 Ubuntu 操作系统发布时,会有 Aptitude 包冲突。
问:我真的卡住了。有东西坏了。你能帮我吗?
答:我真的很喜欢帮助读者,我也很乐意帮助你配置你的深度学习开发环境。
也就是说,我每天会收到 100 多封电子邮件和博客帖子评论——我根本没有时间一一回复
由于我自己和我的团队收到的请求数量,我的客户比非客户得到的支持优先。请通过浏览 我的图书和课程库 考虑成为客户。
我个人推荐你去拿一本《用 Python 进行计算机视觉的深度学习——那本书包括访问我预先配置的深度学习开发环境,有 TensorFlow,Keras,OpenCV 等。预装。您将在几分钟内启动并运行。
*## 摘要
在本教程中,您学习了如何在 Ubuntu 上安装 TensorFlow 2.0(无论是否有 GPU 支持)。
现在你的 TensorFlow 2.0 + Ubuntu 深度学习钻机配置好了,我建议你拿一份 用 Python 进行计算机视觉的深度学习。你将获得很好的教育,你将学会如何成功地将深度学习应用到你自己的项目中。
要在 PyImageSearch 上发布未来教程时得到通知,只需在下表中输入您的电子邮件地址!************
操作方法:使用 Keras、Python 和深度学习进行多 GPU 培训
原文:https://pyimagesearch.com/2017/10/30/how-to-multi-gpu-training-with-keras-python-and-deep-learning/

Using Keras to train deep neural networks with multiple GPUs (Photo credit: Nor-Tech.com).
Keras 无疑是我最喜欢的深度学习+ Python 框架,尤其是用于图像分类的。
*我在生产应用程序、个人深度学习项目和 PyImageSearch 博客中使用 Keras。
我甚至在 Keras 上用 Python 编写了超过三分之二的新书 《计算机视觉深度学习》。
然而,我对 Keras 最大的障碍之一是执行多 GPU 训练是一件痛苦的事情。在样板代码和配置 TensorFlow 之间,这可能有点像一个过程…
……但再也不是了。
随着 Keras (v2.0.9)的最新提交和发布,现在使用 多个 GPU 训练深度神经网络变得极其容易。**
其实就像一个 单函数调用那么简单!
要了解更多关于使用 Keras、Python 和多个 GPU 训练深度神经网络的信息,继续阅读。
操作方法:使用 Keras、Python 和深度学习进行多 GPU 培训
2020-06-16 更新:此博文现已兼容 TensorFlow 2+!Keras 现在内置在 TensorFlow 2 中,作为 TensorFlow 的高级 API。鉴于 TensorFlow/Keras 的更新,本简介部分中的句子可能会产生误导;出于历史目的,它们“按原样”保留。
当我第一次开始使用 Keras 时,我爱上了这个 API。简单优雅,类似 scikit-learn。然而,它非常强大,能够实现和训练最先进的深度神经网络。
然而,我对 Keras 最大的不满之一是,在多 GPU 环境中使用它可能有点不简单。
如果你用的是 Theano,那就别想了——多 GPU 训练是不会发生的。
TensorFlow 是一种可能性,但它可能需要大量的样板代码和调整,才能让您的网络使用多个 GPU 进行训练。
当执行多 GPU 训练时,我更喜欢使用 mxnet 后端(或者甚至直接使用 mxnet 库)而不是 Keras,但是这引入了更多要处理的配置。
随着Fran ois Chollet 宣布使用 TensorFlow 后端的多 GPU 支持现已纳入到 Keras v2.0.9 中,这一切都改变了。大部分功劳归于 @kuza55 和他们的 keras-extras 回购。
我已经使用和测试这个多 GPU 功能将近一年了,我非常兴奋地看到它成为官方 Keras 发行版的一部分。
在今天博客的剩余部分,我将展示如何使用 Keras、Python 和深度学习来训练卷积神经网络进行图像分类。
MiniGoogLeNet 深度学习架构
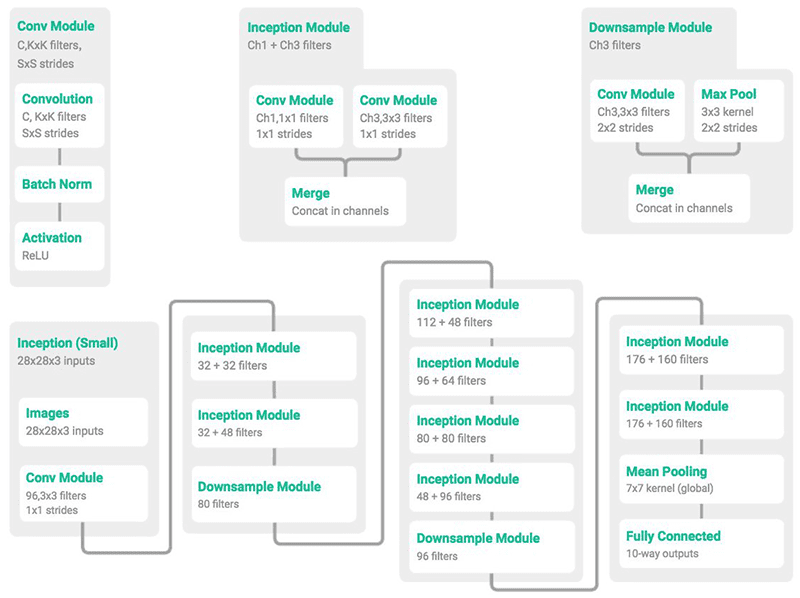
Figure 1: The MiniGoogLeNet architecture is a small version of it’s bigger brother, GoogLeNet/Inception. Image credit to @ericjang11 and @pluskid.
在上面的图 1 中,我们可以看到单独的卷积(左)、初始(中)和下采样(右)模块,随后是由这些构建块构建的整体 MiniGoogLeNet 架构(底)。我们将在本文后面的多 GPU 实验中使用 MiniGoogLeNet 架构。
MiniGoogLenet 中的 Inception 模块是由 Szegedy 等人设计的原始 Inception 模块的变体。
我第一次知道这个“Miniception”模块是在 @ericjang11 和 @pluskid 的一条推文中,他们在那里漂亮地可视化了模块和相关的 MiniGoogLeNet 架构。
我做了一点研究,发现这个图形来自张等人 2017 年的发表, 理解深度学习需要重新思考概括 。
然后我开始用 Keras + Python 实现 MiniGoogLeNet 架构——我甚至用 Python 把它作为计算机视觉的 深度学习的一部分。
对 MiniGoogLeNet Keras 实现的全面回顾超出了这篇博文的范围,所以如果你对网络如何工作(以及如何编码)感兴趣,请参考我的书。
否则,您可以使用本帖底部的 【下载】 部分下载源代码。
配置您的开发环境
要为本教程配置您的系统,我建议遵循我的 如何在 Ubuntu 上安装 TensorFlow 2.0 指南,其中有关于如何使用您的 GPU 驱动程序、CUDA 和 cuDNN 设置您的系统的说明。
此外,您将学习设置一个方便的 Python 虚拟环境来存放您的 Python 包,包括 TensorFlow 2+。
我不建议用 macOS 来配合 GPU 工作;如果需要非 -GPU macOS TensorFlow 安装指南(今天的教程是非)请点击此链接。
此外,请注意 PyImageSearch 不推荐或支持 CV/DL 项目的窗口。
用 Keras 和多个 GPU 训练深度神经网络
让我们开始使用 Keras 和多个 GPU 来训练深度学习网络。
打开一个新文件,将其命名为train.py,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
# (uncomment the lines below if you are using a headless server)
# import matplotlib
# matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minigooglenet import MiniGoogLeNet
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.compat.v2.keras.utils import multi_gpu_model
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import argparse
如果您使用的是 headless 服务器,那么您需要通过取消注释来在第 3 行和第 4 行配置 matplotlib 后端。这将使您的 matplotlib 图保存到磁盘。如果你是而不是使用一个无头服务器(也就是说,你的键盘+鼠标+显示器被插入到你的系统中,你可以把这些行注释掉)。
从那里,我们导入这个脚本所需的包。
第 7 行从我的pyimagesearch模块导入 MiniGoogLeNet(包含在 “下载” 部分的下载中)。
另一个值得注意的导入是在第行的第 13 处,我们导入了 CIFAR10 数据集。这个帮助器函数将使我们只需一行代码就能从磁盘加载 CIFAR-10 数据集。
现在让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output plot")
ap.add_argument("-g", "--gpus", type=int, default=1,
help="# of GPUs to use for training")
args = vars(ap.parse_args())
# grab the number of GPUs and store it in a conveience variable
G = args["gpus"]
我们使用argparse解析第 20-25 行上的一个必需和一个可选参数:
--output:训练完成后输出图的路径。--gpus:用于训练的 GPU 数量。
在加载了命令行参数之后,为了方便起见,我们将 GPU 的数量存储为G(第 28 行)。
从那里,我们初始化两个用于配置我们的训练过程的重要变量,然后定义一个基于多项式的学习率时间表函数:
# definine the total number of epochs to train for along with the
# initial learning rate
NUM_EPOCHS = 70
INIT_LR = 5e-3
def poly_decay(epoch):
# initialize the maximum number of epochs, base learning rate,
# and power of the polynomial
maxEpochs = NUM_EPOCHS
baseLR = INIT_LR
power = 1.0
# compute the new learning rate based on polynomial decay
alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power
# return the new learning rate
return alpha
我们设置NUM_EPOCHS = 70 —这是我们的训练数据将通过网络的次数(时期)(行 32 )。
我们还初始化了学习速率INIT_LR = 5e-3,这是在之前的试验中通过实验发现的值(第 33 行)。
从那里,我们定义了poly_decay函数,它相当于 Caffe 的多项式学习率衰减(第 35-46 行)。本质上,这个函数在训练期间更新学习率,在每个时期之后有效地降低它。设置power = 1.0将衰减从 多项式 变为 线性 。
接下来,我们将加载我们的训练+测试数据,并将图像数据从整数转换为浮点:
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
从那里,我们将均值减法应用于数据:
# apply mean subtraction to the data
mean = np.mean(trainX, axis=0)
trainX -= mean
testX -= mean
在第行第 56 处,我们计算所有训练图像的平均值,然后是第行第 57 和 58 处,我们从训练和测试集中的每幅图像中减去平均值。
然后,我们执行“一键编码”,这是一种我在书中详细讨论的编码方案:
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
一键编码将分类标签从单个整数转换为向量,因此我们可以应用分类交叉熵损失函数。我们已经在第 61-63 行中解决了这个问题。
接下来,我们创建一个数据增强器和一组回调函数:
# construct the image generator for data augmentation and construct
# the set of callbacks
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
callbacks = [LearningRateScheduler(poly_decay)]
在第行第 67-69 行,我们构建了用于数据扩充的图像生成器。
数据增强在 的从业者捆绑包中有详细介绍,使用 Python 进行计算机视觉深度学习;然而,暂时理解它是在训练过程中使用的一种方法,其中我们通过对训练图像应用随机变换来随机改变它们。
由于这些变化,网络会不断看到增加的示例-这使网络能够更好地概括验证数据,而在训练集上的表现可能会更差。在大多数情况下,这种权衡是值得的。
我们在第 70 行的上创建了一个回调函数,它将允许我们的学习率在每个时期后衰减——注意我们的函数名,poly_decay。
接下来让我们检查 GPU 变量:
# check to see if we are compiling using just a single GPU
if G <= 1:
print("[INFO] training with 1 GPU...")
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=10)
如果 GPU 计数小于或等于 1,我们通过.build函数(第 73-76 行)初始化model,否则我们将在训练期间并行化模型:
# otherwise, we are compiling using multiple GPUs
else:
# disable eager execution
tf.compat.v1.disable_eager_execution()
print("[INFO] training with {} GPUs...".format(G))
# we'll store a copy of the model on *every* GPU and then combine
# the results from the gradient updates on the CPU
with tf.device("/cpu:0"):
# initialize the model
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=10)
# make the model parallel
model = multi_gpu_model(model, gpus=G)
在 Keras 中创建一个多 GPU 模型需要一些额外的代码,但并不多!
首先,你会注意到在第 86 行的处,我们已经指定使用 CPU (而不是 GPU )作为网络上下文。
为什么我们需要中央处理器?
嗯,CPU 负责处理任何开销(例如将训练图像移入和移出 GPU 内存),而 GPU 本身则负责繁重的工作。
在这种情况下,CPU 实例化基础模型。
然后我们可以调用 92 号线上的的multi_gpu_model。这个函数将模型从 CPU 复制到我们所有的 GPU,从而获得单机、多 GPU 的数据并行性。
训练时,我们的网络图像将被批量分配给每个 GPU。CPU 将从每个 GPU 获取梯度,然后执行梯度更新步骤。
然后,我们可以编译我们的模型,并开始培训过程:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=64 * G),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // (64 * G),
epochs=NUM_EPOCHS,
callbacks=callbacks, verbose=2)
2020-06-16 更新: 以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
在第 96 行上,我们用我们的初始学习率构建了一个随机梯度下降(SGD)优化器。
随后,我们用 SGD 优化器和分类交叉熵损失函数编译该模型。
我们现在准备好训练网络了!
为了启动训练过程,我们调用model.fit并提供必要的参数。
我们希望每个 GPU 的批量大小为64,以便由batch_size=64 * G指定。
我们的训练将持续 70 个纪元(这是我们之前指定的)。
梯度更新的结果将在 CPU 上合并,然后在整个训练过程中应用到每个 GPU。
现在,培训和测试已经完成,让我们绘制损失/准确性,以便我们可以可视化培训过程:
# grab the history object dictionary
H = H.history
# plot the training loss and accuracy
N = np.arange(0, len(H["loss"]))
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H["loss"], label="train_loss")
plt.plot(N, H["val_loss"], label="test_loss")
plt.plot(N, H["accuracy"], label="train_acc")
plt.plot(N, H["val_accuracy"], label="test_acc")
plt.title("MiniGoogLeNet on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
# save the figure
plt.savefig(args["output"])
plt.close()
2020-06-16 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H["val_accuracy"]和H["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
这最后一个块简单地使用 matplotlib 来绘制训练/测试损失和准确性(行 110-123 ),然后将数字保存到磁盘(行 126 )。
如果你想更多地了解训练过程(及其内部工作方式),请参考 用 Python 进行计算机视觉的深度学习。
Keras 多 GPU 结果
让我们检查一下我们努力工作的结果。
首先,使用本文底部的 “下载” 部分获取本课的代码。然后你就可以跟踪结果了
让我们在一个单 GPU 上训练以获得基线:
$ python train.py --output single_gpu.png
[INFO] loading CIFAR-10 data...
[INFO] training with 1 GPU...
[INFO] compiling model...
[INFO] training network...
Epoch 1/70
- 64s - loss: 1.4323 - accuracy: 0.4787 - val_loss: 1.1319 - val_ accuracy: 0.5983
Epoch 2/70
- 63s - loss: 1.0279 - accuracy: 0.6361 - val_loss: 0.9844 - accuracy: 0.6472
Epoch 3/70
- 63s - loss: 0.8554 - accuracy: 0.6997 - val_loss: 1.5473 - accuracy: 0.5592
...
Epoch 68/70
- 63s - loss: 0.0343 - accuracy: 0.9898 - val_loss: 0.3637 - accuracy: 0.9069
Epoch 69/70
- 63s - loss: 0.0348 - accuracy: 0.9898 - val_loss: 0.3593 - accuracy: 0.9080
Epoch 70/70
- 63s - loss: 0.0340 - accuracy: 0.9900 - val_loss: 0.3583 - accuracy: 0.9065
Using TensorFlow backend.
real 74m10.603s
user 131m24.035s
sys 11m52.143s
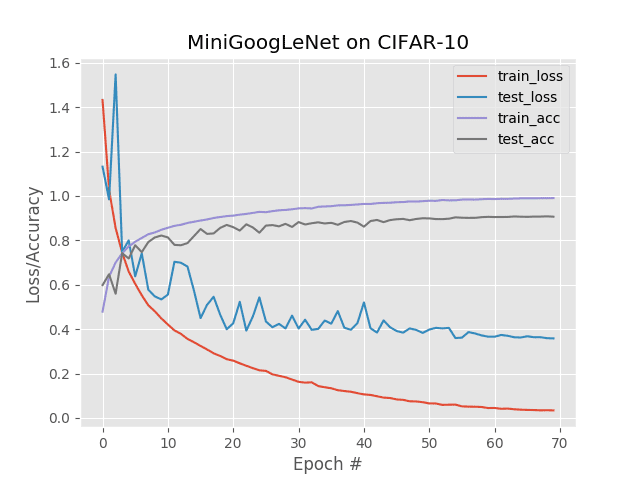
Figure 2: Experimental results from training and testing MiniGoogLeNet network architecture on CIFAR-10 using Keras on a single GPU.
对于这个实验,我在我的 NVIDIA DevBox 上的一个 Titan X GPU 上进行训练。每个历元花费 ~63 秒,总训练时间 74m10s 。
然后,我执行以下命令,用我的四个 Titan X GPU:
$ python train.py --output multi_gpu.png --gpus 4
[INFO] loading CIFAR-10 data...
[INFO] training with 4 GPUs...
[INFO] compiling model...
[INFO] training network...
Epoch 1/70
- 21s - loss: 1.6793 - accuracy: 0.3793 - val_loss: 1.3692 - accuracy: 0.5026
Epoch 2/70
- 16s - loss: 1.2814 - accuracy: 0.5356 - val_loss: 1.1252 - accuracy: 0.5998
Epoch 3/70
- 16s - loss: 1.1109 - accuracy: 0.6019 - val_loss: 1.0074 - accuracy: 0.6465
...
Epoch 68/70
- 16s - loss: 0.1615 - accuracy: 0.9469 - val_loss: 0.3654 - accuracy: 0.8852
Epoch 69/70
- 16s - loss: 0.1605 - accuracy: 0.9466 - val_loss: 0.3604 - accuracy: 0.8863
Epoch 70/70
- 16s - loss: 0.1569 - accuracy: 0.9487 - val_loss: 0.3603 - accuracy: 0.8877
Using TensorFlow backend.
real 19m3.318s
user 104m3.270s
sys 7m48.890s
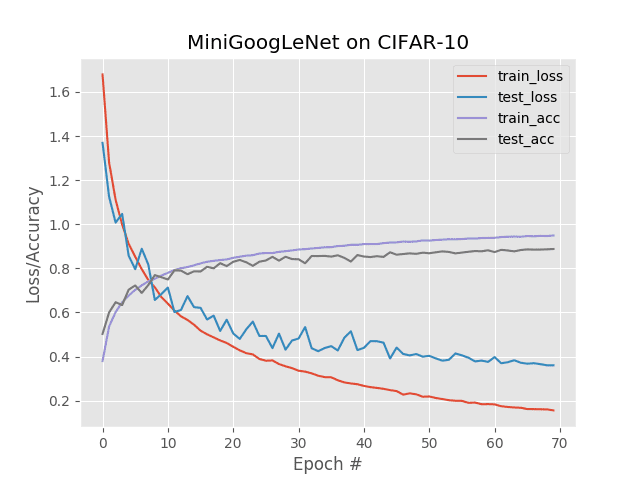
Figure 3: Multi-GPU training results (4 Titan X GPUs) using Keras and MiniGoogLeNet on the CIFAR10 dataset. Training results are similar to the single GPU experiment while training time was cut by ~75%.
在这里你可以看到训练中的准线性加速:使用四个 GPU,我能够将每个纪元减少到只有 16 秒。全网在 19m3s 完成训练。
正如你所看到的,用 Keras 和多个 GPU 训练深度神经网络不仅简单,而且效率也很高!
注:在这种情况下,单 GPU 实验获得的精度略高于多 GPU 实验。在训练任何一个随机机器学习模型的时候,都会有一些方差。如果你在数百次运行中平均这些结果,它们将是(大致)相同的。
摘要
在今天的博客文章中,我们学习了如何使用多个 GPU 来训练基于 Keras 的深度神经网络。
使用多个 GPU 使我们能够获得准线性加速。
为了验证这一点,我们在 CIFAR-10 数据集上训练了 MiniGoogLeNet。
使用单个 GPU,我们能够获得 63 秒的时间,总训练时间 74m10s 。
然而,通过使用 Keras 和 Python 进行多 GPU 训练,我们将训练时间减少到了 16 秒,总训练时间为 19m3s 。
使用 Keras 启用多 GPU 训练就像一个函数调用一样简单——我建议您尽可能利用多 GPU 训练。在未来,我认为multi_gpu_model将会发展,并允许我们进一步定制,特别是应该使用哪些 GPU 进行训练,最终也可以实现多系统训练。
准备好深入学习了吗?跟着我。
如果你有兴趣了解更多关于深度学习的知识(以及在多个 GPU 上训练最先进的神经网络),一定要看看我的新书, 用 Python 进行计算机视觉的深度学习 。
无论你是刚刚开始深度学习,还是已经是经验丰富的深度学习实践者,我的新书都保证能帮助你达到专家的地位。
要了解更多关于使用 Python 进行计算机视觉深度学习的(并获取您的副本) 请点击此处。*
如何(快速)构建深度学习图像数据集
原文:https://pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/

An example of a Pokedex (thank you to Game Trader USA for the Pokedex template!)
当我还是个孩子的时候,我是一个超级口袋妖怪迷。我收集了交易卡,玩了游戏机,看了电视节目。如果它涉及口袋妖怪,我可能会对它感兴趣。
口袋妖怪给我留下了持久的印象——回想起来,口袋妖怪甚至启发了我学习计算机视觉。
你看,在该剧的第一集(以及游戏的前几分钟),主角小智得到了一种叫做 Pokedex 的特殊电子设备。
一个口袋妖怪索引被用来记录和提供关于口袋妖怪在旅行中遇到灰烬的种类的信息。你可以把 Pokedex 看作是某种“口袋妖怪百科全书”。
当偶然发现一种以前从未见过的新物种口袋妖怪 Ash 时,他会把 Pokedex 举到口袋妖怪面前,然后 Pokedex 会自动为他识别它,大概是通过某种相机传感器(类似于本文顶部的图像)。
从本质上来说,Pokedex 就像一个利用计算机视觉的智能手机应用程序!
我们可以想象今天在我们的 iPhone 或 Android 上有一个类似的应用程序,其中:
- 我们打开手机上的“Pokedex”应用程序
- 该应用程序访问我们的摄像头
- 我们拍了一张口袋妖怪的照片
- 然后应用程序会自动识别口袋妖怪
小时候,我一直觉得 Pokedex 很酷…
……现在我要造一个。
在这个由三部分组成的博客文章系列中,我们将建立我们自己的 Pokedex:
- 我们今天将开始使用 Bing 图像搜索 API 来(轻松地)构建我们的口袋妖怪图像数据集。
- 下周,我将演示如何使用 Keras 实现和训练 CNN 来识别每个口袋妖怪。
- 最后,我们将使用我们训练过的 Keras 模型,并将其部署到一个 iPhone 应用程序中(或者至少是一个 Raspberry Pi——我仍在解决 iPhone 部署中的问题)。
到这个系列的最后,我们将会有一个功能齐全的 Pokedex!
要开始使用 Bing 图像搜索 API 建立用于深度学习的图像数据集,继续阅读。
如何(快速)构建深度学习图像数据集
为了建立我们的深度学习图像数据集,我们将利用微软的 Bing 图像搜索 API ,它是微软认知服务的一部分,用于将人工智能引入视觉、语音、文本以及更多应用和软件。
在之前的一篇博文中,你会记得我演示了如何抓取谷歌图片来构建你自己的数据集——这里的问题是这是一个繁琐的手动过程。
相反,我在寻找一种解决方案,它能让我通过查询以编程方式下载图片。
我不想打开我的浏览器或利用浏览器扩展从我的搜索中下载图像文件。
许多年前,谷歌弃用了自己的图片搜索 API(这也是我们首先需要抓取谷歌图片的原因)。
几个月前,我决定试试微软的 Bing 图像搜索 API。我非常高兴。
结果是相关的,API 是易于使用的。
它还包括一个 30 天的免费试用期,之后这个 API 的价格似乎还算合理(我还没有变成付费用户,但如果有愉快的体验,我可能会的)。
在今天博客的剩余部分,我将展示我们如何利用 Bing 图像搜索 API 来快速构建适合深度学习的图像数据集。
创建您的认知服务帐户
在这一节中,我将提供一个简短的演示,介绍如何获得你的(免费)Bing 图片搜索 API 帐户。
实际的注册过程很简单;然而,找到启动注册过程的实际页面有点令人困惑——这是我对该服务的主要评论。
首先,请访问 Bing 图片搜索 API 页面:

Figure 1: We can use the Microsoft Bing Search API to download images for a deep learning dataset.
正如我们从截图中看到的那样,该试验包括 Bing 的所有搜索 API,每月共有 3,000 次交易——这将足够用于构建我们的第一个基于图像的深度学习数据集。
要注册 Bing 图像搜索 API,请点击“获取 API 密钥”按钮。
在那里,你可以用你的微软、脸书、LinkedIn 或 GitHub 账户注册(为了简单起见,我用了 GitHub)。
完成注册过程后,您将进入您的 API 页面,该页面应类似于下面的我的浏览器:
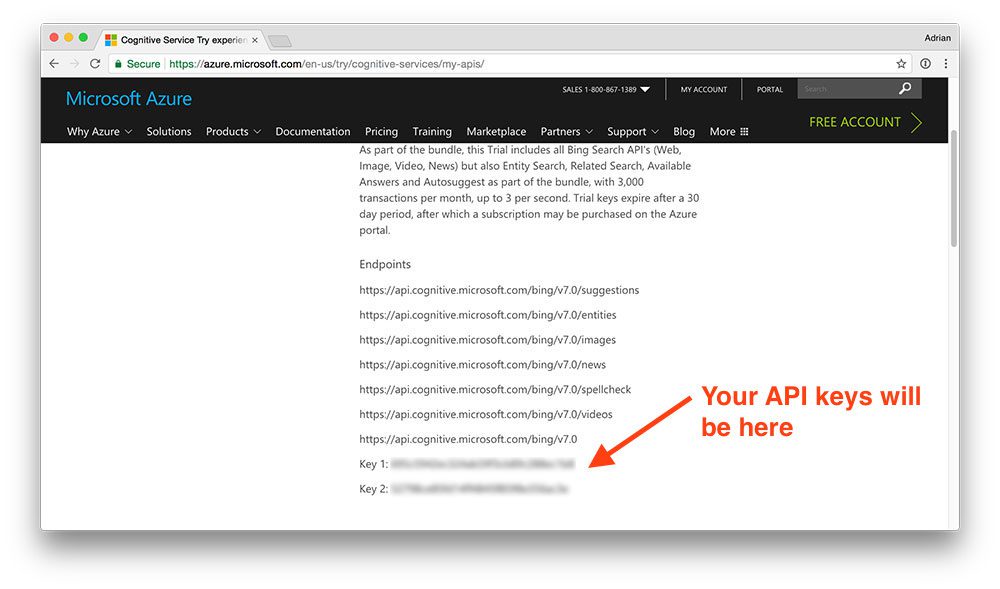
Figure 2: The Microsoft Bing API endpoints along with my API keys which I need in order to use the API.
在这里你可以看到我的 Bing 搜索端点列表,包括我的两个 API 键(由于明显的原因被模糊了)。
记下您的 API 密钥,因为您将在下一节用到它。
用 Python 构建深度学习数据集
现在我们已经注册了 Bing 图像搜索 API,我们已经准备好建立我们的深度学习数据集。
阅读文件
在继续之前,我建议您在浏览器中打开以下两个 Bing 图像搜索 API 文档页面:
如果你对(1)API 如何工作或者(2)我们在发出搜索请求后如何使用 API 有任何疑问,你应该参考这两个页面。
安装requests包
如果您的系统上尚未安装requests,您可以通过以下方式安装:
$ pip install requests
requests包让我们可以非常轻松地发出 HTTP 请求,而不会陷入与 Python 的斗争中,无法优雅地处理请求。
此外,如果您正在使用 Python 虚拟环境,请确保在安装requests之前使用workon命令访问环境:
$ workon your_env_name
$ pip install requests
创建 Python 脚本来下载图像
让我们开始编码吧。
打开一个新文件,将其命名为search_bing_api.py,并插入以下代码:
# import the necessary packages
from requests import exceptions
import argparse
import requests
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-q", "--query", required=True,
help="search query to search Bing Image API for")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
args = vars(ap.parse_args())
第 2-6 行处理导入该脚本所需的包。您需要在虚拟环境中安装 OpenCV 和 requests。要在您的系统上设置 OpenCV,只需在这里遵循您系统的相关指南。
接下来,我们解析两个命令行参数:
--query:您正在使用的图片搜索查询,可以是任何内容,如【皮卡丘】**【圣诞老人】或【侏罗纪公园】。--output:图像的输出目录。我个人的偏好(为了组织和理智)是将你的图像分离到个单独的子目录,所以一定要指定你想要你的图像进入的正确文件夹(在下面的“下载用于训练深度神经网络的图像”部分显示)。
您不需要修改这个脚本的命令行参数部分(第 9-14 行)。这些是你在运行时给脚本的输入。要学习如何正确使用命令行参数,请参见我最近的博客文章。
接下来,让我们配置一些全局变量:
# set your Microsoft Cognitive Services API key along with (1) the
# maximum number of results for a given search and (2) the group size
# for results (maximum of 50 per request)
API_KEY = "YOUR_API_KEY_GOES_HERE"
MAX_RESULTS = 250
GROUP_SIZE = 50
# set the endpoint API URL
URL = "https://api.cognitive.microsoft.com/bing/v7img/search"
这个脚本中你必须修改的部分是API_KEY。您可以通过登录微软认知服务并选择您想要使用的服务来获取 API 密钥(如上图所示,您需要点击“获取 API 密钥”按钮)。在这里,只需将 API 键粘贴到这个变量的引号中。
您也可以为您的搜索修改MAX_RESULTS和GROUP_SIZE。这里,我将我的结果限制在第一个250图片,并返回 Bing API 每个请求的最大图片数(50总图片数)。
你可以把GROUP_SIZE参数想象成“每页”返回的搜索结果的数量。因此,如果我们想要总共 250 个图像,我们将需要遍历 5 个“页面”,每页 50 个图像。
当训练一个卷积神经网络时,我真的希望每个类有大约 1000 个图像,但这只是一个例子。您可以随意下载任意数量的图片,但请注意:
- 你下载的所有图片都应该与查询相关。
- 你不会碰到 Bing 免费 API 层的限制(否则你将需要开始为这项服务付费)。
从那里,让我们确保我们准备好处理所有(编辑:大多数)可能的异常,这些异常在尝试获取图像时可能会出现,首先列出我们可能会遇到的异常:
# when attempting to download images from the web both the Python
# programming language and the requests library have a number of
# exceptions that can be thrown so let's build a list of them now
# so we can filter on them
EXCEPTIONS = set([IOError, FileNotFoundError,
exceptions.RequestException, exceptions.HTTPError,
exceptions.ConnectionError, exceptions.Timeout])
当处理网络请求时,会抛出许多异常,所以我们将它们列在第 30-32 行的中。我们会尽力抓住他们,稍后优雅地处理他们。
从这里,让我们初始化我们的搜索参数并进行搜索:
# store the search term in a convenience variable then set the
# headers and search parameters
term = args["query"]
headers = {"Ocp-Apim-Subscription-Key" : API_KEY}
params = {"q": term, "offset": 0, "count": GROUP_SIZE}
# make the search
print("[INFO] searching Bing API for '{}'".format(term))
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
# grab the results from the search, including the total number of
# estimated results returned by the Bing API
results = search.json()
estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS)
print("[INFO] {} total results for '{}'".format(estNumResults,
term))
# initialize the total number of images downloaded thus far
total = 0
在第 36-38 行上,我们初始化搜索参数。请务必根据需要查看 API 文档。
从那里,我们执行搜索(第 42-43 行)并获取 JSON 格式的结果(第 47 行)。
接下来,我们计算并向终端打印估计的结果数(第 48-50 行)。
我们会保存一个下载图像的计数器,所以我在第 53 行初始化total。
现在是时候在GROUP_SIZE块中循环结果了:
# loop over the estimated number of results in `GROUP_SIZE` groups
for offset in range(0, estNumResults, GROUP_SIZE):
# update the search parameters using the current offset, then
# make the request to fetch the results
print("[INFO] making request for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
params["offset"] = offset
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
print("[INFO] saving images for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
这里,我们在GROUP_SIZE批中循环估计的结果数,因为这是 API 允许的(第 56 行)。
当我们调用requests.get来抓取 JSON blob ( 行 62 )时,当前的offset被作为参数传递。
从那里,让我们尝试保存当前批次中的图像:
# loop over the results
for v in results["value"]:
# try to download the image
try:
# make a request to download the image
print("[INFO] fetching: {}".format(v["contentUrl"]))
r = requests.get(v["contentUrl"], timeout=30)
# build the path to the output image
ext = v["contentUrl"][v["contentUrl"].rfind("."):]
p = os.path.sep.join([args["output"], "{}{}".format(
str(total).zfill(8), ext)])
# write the image to disk
f = open(p, "wb")
f.write(r.content)
f.close()
# catch any errors that would not unable us to download the
# image
except Exception as e:
# check to see if our exception is in our list of
# exceptions to check for
if type(e) in EXCEPTIONS:
print("[INFO] skipping: {}".format(v["contentUrl"]))
continue
在这里,我们将遍历当前的一批图像,并尝试将每个图像下载到我们的输出文件夹中。
我们建立了一个 try-catch 块,这样我们就可以捕获我们在脚本前面定义的可能的EXCEPTIONS。如果我们遇到异常,我们将跳过该特定图像并继续前进(第 71 行和第 88-93 行)。
在try块内部,我们试图通过 URL 获取图像(第 74 行),并为其构建一个路径+文件名(第 77-79 行)。
然后,我们尝试打开文件并将其写入磁盘(第 82-84 行)。这里值得注意的是,我们正在创建一个由"wb"中的b表示的二进制文件对象。我们通过r.content访问二进制数据。
接下来,让我们看看 OpenCV 是否真的可以加载图像,这意味着(1)图像文件下载成功,( 2)图像路径有效:
# try to load the image from disk
image = cv2.imread(p)
# if the image is `None` then we could not properly load the
# image from disk (so it should be ignored)
if image is None:
print("[INFO] deleting: {}".format(p))
os.remove(p)
continue
# update the counter
total += 1
在这个块中,我们在第 96 行加载图像文件。
只要image数据不是None,我们就更新我们的total计数器并循环回到顶部。
否则,我们调用os.remove来删除无效图像,并且我们继续返回到循环的顶部,而不更新我们的计数器。行 100 上的 if 语句可能由于下载文件时的网络错误、没有安装正确的镜像 I/O 库等而触发。如果你有兴趣了解更多关于 OpenCV 和 Python 中的NoneType错误,可以参考这篇博文。
下载用于训练深度神经网络的图像

Figure 3: The Bing Image Search API is so easy to use that I love it as much as I love Pikachu!
现在我们已经编写好了脚本,让我们使用 Bing 的图像搜索 API 为我们的深度学习数据集下载图像。
确保使用本指南的 “下载” 部分下载代码和示例目录结构。
在我的例子中,我正在创建一个dataset目录:
$ mkdir dataset
所有下载的图像都将存储在dataset中。从那里,执行以下命令创建一个子目录,并运行对“charmander”的搜索:
$ mkdir dataset/charmander
$ python search_bing_api.py --query "charmander" --output dataset/charmander
[INFO] searching Bing API for 'charmander'
[INFO] 250 total results for 'charmander'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://fc06.deviantart.net/fs70/i/2012/355/8/2/0004_c___charmander_by_gaghiel1987-d5oqbts.png
[INFO] fetching: http://th03.deviantart.net/fs71/PRE/f/2010/067/5/d/Charmander_by_Woodsman819.jpg
[INFO] fetching: http://fc05.deviantart.net/fs70/f/2011/120/8/6/pokemon___charmander_by_lilnutta10-d2vr4ov.jpg
...
[INFO] making request for group 50-100 of 250...
[INFO] saving images for group 50-100 of 250...
...
[INFO] fetching: http://38.media.tumblr.com/f0fdd67a86bc3eee31a5fd16a44c07af/tumblr_nbhf2vTtSH1qc9mvbo1_500.gif
[INFO] deleting: dataset/charmander/00000174.gif
...
正如我在这篇文章的介绍中提到的,我们正在下载口袋妖怪的图像,以便在构建 Pokedex (一种实时识别口袋妖怪的特殊设备)时使用。
在上面的命令中,我正在下载流行的口袋妖怪小火龙的图像。这 250 张图片中的大部分都可以成功下载,但是如上面的输出所示,有一些无法用 OpenCV 打开,将会被删除。
我为皮卡丘做同样的事情:
$ mkdir dataset/pikachu
$ python search_bing_api.py --query "pikachu" --output dataset/pikachu
[INFO] searching Bing API for 'pikachu'
[INFO] 250 total results for 'pikachu'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://www.mcmbuzz.com/wp-content/uploads/2014/07/025Pikachu_OS_anime_4.png
[INFO] fetching: http://images4.fanpop.com/image/photos/23300000/Pikachu-pikachu-23385603-814-982.jpg
[INFO] fetching: http://images6.fanpop.com/image/photos/33000000/pikachu-pikachu-33005706-895-1000.png
...
连同杰尼龟:
$ mkdir dataset/squirtle
$ python search_bing_api.py --query "squirtle" --output dataset/squirtle
[INFO] searching Bing API for 'squirtle'
[INFO] 250 total results for 'squirtle'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://fc03.deviantart.net/fs71/i/2013/082/1/3/007_squirtle_by_pklucario-d5z1gj5.png
[INFO] fetching: http://fc03.deviantart.net/fs70/i/2012/035/b/2/squirtle_by_maii1234-d4oo1aq.jpg
[INFO] fetching: http://3.bp.blogspot.com/-yeK-y_dHCCQ/TWBkDZKi6vI/AAAAAAAAABU/_TVDXBrxrkg/s1600/Leo%2527s+Squirtle.jpg
...
然后妙蛙种子:
$ mkdir dataset/bulbasaur
$ python search_bing_api.py --query "bulbasaur" --output dataset/bulbasaur
[INFO] searching Bing API for 'bulbasaur'
[INFO] 250 total results for 'bulbasaur'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://fc06.deviantart.net/fs51/f/2009/261/3/e/Bulbasaur_by_elfaceitoso.png
[INFO] skipping: http://fc06.deviantart.net/fs51/f/2009/261/3/e/Bulbasaur_by_elfaceitoso.png
[INFO] fetching: http://4.bp.blogspot.com/-b-dLFLsHtm4/Tq9265UAmjI/AAAAAAAAHls/CrkUUFrj6_c/s1600/001Bulbasaur+pokemon+firered+leafgreen.png
[INFO] skipping: http://4.bp.blogspot.com/-b-dLFLsHtm4/Tq9265UAmjI/AAAAAAAAHls/CrkUUFrj6_c/s1600/001Bulbasaur+pokemon+firered+leafgreen.png
[INFO] fetching: http://fc09.deviantart.net/fs71/i/2012/088/9/6/bulbasaur_by_songokukai-d4gecpp.png
...
最后是 Mewtwo :
$ mkdir dataset/mewtwo
$ python search_bing_api.py --query "mewtwo" --output dataset/mewtwo
[INFO] searching Bing API for 'mewtwo'
[INFO] 250 total results for 'mewtwo'
[INFO] making request for group 0-50 of 250...
[INFO] saving images for group 0-50 of 250...
[INFO] fetching: http://sickr.files.wordpress.com/2011/09/mewtwo.jpg
[INFO] fetching: http://4.bp.blogspot.com/-_7XMdCIyKDs/T3f-0h2X4zI/AAAAAAAABmQ/S2904beJlOw/s1600/Mewtwo+Pokemon+Wallpapers+3.jpg
[INFO] fetching: http://2.bp.blogspot.com/-3jDdQdPl1yQ/T3f-61gJXEI/AAAAAAAABmg/AUmKm65ckv8/s1600/Mewtwo+Pokemon+Wallpapers.jpg
...
我们可以通过使用一点find魔法来计算每次查询下载的图片总数(感谢格伦·杰克曼在 StackOverflow 上的精彩演讲):
$ find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*)
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir"
> done
2 files in directory .
5 files in directory ./dataset
235 files in directory ./dataset/bulbasaur
245 files in directory ./dataset/charmander
245 files in directory ./dataset/mewtwo
238 files in directory ./dataset/pikachu
230 files in directory ./dataset/squirtle
这里我们可以看到每个类大约有 230-245 张图片。理想情况下,我希望每个类有大约 1,000 张图片,但是为了这个例子的简单性和网络开销(对于没有快速/稳定互联网连接的用户),我只下载了 250 张。
注:如果你经常使用那个难看的find命令,那就值得在你的~/.bashrc里做个别名!
修剪我们的深度学习图像数据集
然而,并不是我们下载的每一张图片都与查询相关——大多数是相关的,但不是全部。
不幸的是,这是一个手动干预的步骤,你需要检查你的目录,删除不相关的图片。
在 macOS 上,这实际上是一个相当快的过程。
我的工作流程包括打开 Finder,然后在“Cover Flow”视图中浏览所有图像:
Figure 4: I’m using the macOS “Cover Flow” view in order to quickly flip through images and filter out those that I don’t want in my deep learning dataset.
如果一个图像不相关,我可以通过键盘上的cmd + delete把它移到垃圾箱。其他操作系统上也有类似的快捷方式和工具。
修剪完不相关的图像后,让我们再做一次图像计数:
$ find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*);
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir";
> done
3 files in directory .
5 files in directory ./dataset
234 files in directory ./dataset/bulbasaur
238 files in directory ./dataset/charmander
239 files in directory ./dataset/mewtwo
234 files in directory ./dataset/pikachu
223 files in directory ./dataset/squirtle
正如你所看到的,我只需要在每个类中删除一些图片 Bing 图片搜索 API 工作得非常好!
注意:你也应该考虑删除重复的图像。我没有采取这一步,因为没有太多的重复(除了“squirtle”类;我不知道为什么那里会有这么多重复的东西),但是如果你有兴趣了解更多关于如何找到重复的东西,请看这篇关于图像哈希的博文。
摘要
在今天的博客文章中,你学习了如何使用微软的 Bing 图像搜索 API 快速构建深度学习图像数据集。
使用 API,我们能够以编程方式下载图像来训练深度神经网络,这比不得不使用 Google Images 手动抓取图像迈出了一大步。
Bing 图片搜索 API 可以免费使用 30 天,如果你想跟进这一系列的帖子,这是一个完美的选择。
我仍处于试用阶段,但鉴于迄今为止的积极体验,我可能会在未来为该 API 付费(特别是因为它将帮助我快速创建有趣的数据集,实践深度学习 PyImageSearch 教程)。
在下周的博客文章中,我将展示如何在我们今天下载的深度学习图像的基础上,用 Keras 训练一个卷积神经网络。在该系列的最后一篇文章中(将在两周内发布),我将向您展示如何将 Keras 模型部署到您的智能手机上(如果可能,我仍在解决 Keras + iOS 集成中的问题)。
这是一个不能错过的系列帖子,所以不要错过!要在下一篇文章发布时得到通知,只需在下面的表格中输入您的电子邮件地址。
如何用 Python 和 scikit 调优超参数-学习
原文:https://pyimagesearch.com/2016/08/15/how-to-tune-hyperparameters-with-python-and-scikit-learn/

在上周的帖子中,我介绍了 k-NN 机器学习算法,然后我们将其应用于图像分类任务。
使用 k-NN 算法,我们在 Kaggle Dogs vs. Cats 数据集挑战上获得了 57.58%的分类准确率:

Figure 1: Classifying an image as whether it contains a dog or a cat.
问题是:“我们能做得更好吗?”
我们当然可以!几乎任何机器学习算法要获得更高的精度,都要归结为调整各种旋钮和级别。
在 k-NN 的情况下,我们可以调一下 k ,最近邻的个数。我们也可以调整我们的距离度量/相似性函数。
当然,超参数调整也有 k-NN 算法之外的含义。在深度学习和卷积神经网络的背景下,我们可以很容易地拥有数百个各种各样的超参数来调整和玩(尽管在实践中我们试图将变量的数量限制在少数几个),每个都在某种程度上影响我们的整体分类(潜在未知)。
因此,理解超参数调整的概念以及您在超参数中的选择如何能够显著影响您的分类准确性是非常重要的。
如何用 Python 和 scikit 调优超参数-学习
在今天教程的剩余部分,我将演示如何为狗与猫数据集调整 k-NN 超参数。我们将首先讨论什么是超参数,然后查看一个关于调整 k-NN 超参数的具体示例。
然后,我们将探索如何使用两种搜索方法来调整 k-NN 超参数:网格搜索和随机搜索。
正如我们的结果所示,我们可以将分类准确率从 57.58%提高到 64%以上!
什么是超参数?
超参数只是在构建机器学习分类器时你拉动和转动的旋钮和级别。调整超参数的过程更正式地称为 超参数优化 。
那么正常的“模型参数”和“超参数”有什么区别呢?
嗯,一个标准的“模型参数”通常是一个以某种方式优化的内部变量。在线性回归、逻辑回归和支持向量机的上下文中,我们会将参数视为学习算法找到的权重向量系数。
另一方面,“超参数”通常由人类设计者设定或通过算法方法调整。超参数的例子包括 k-最近邻算法中的邻居数量 k ,神经网络的学习速率α,或者 CNN 中给定卷积层中学习的滤波器数量。
一般而言,模型参数根据某个损失函数进行优化,而超参数则通过探索各种设置来寻找的,以查看哪些值提供了最高水平的精确度。
因此,调整模型参数往往更容易(因为我们正在根据训练数据优化一些目标函数),而超参数可能需要近乎盲目的搜索才能找到最佳参数。
k-NN 超参数
作为调整超参数的具体例子,让我们考虑一下k-最近邻分类算法。对于您的标准 k-NN 实现,有两个主要的超参数您将想要调整:
- 邻居数量 k 。
- 距离度量/相似性函数。
这两个值都会显著影响 k-NN 分类器的准确性。为了在图像分类的背景下演示这一点,让我们对上周的 Kaggle Dogs vs. Cats 数据集应用超参数调整。
打开一个新文件,将其命名为knn_tune.py,并插入以下代码:
# import the necessary packages
from sklearn.neighbors import KNeighborsClassifier
from sklearn.grid_search import RandomizedSearchCV
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import train_test_split
from imutils import paths
import numpy as np
import argparse
import imutils
import time
import cv2
import os
第 2-12 行从导入我们需要的 Python 包开始。我们将会大量使用 scikit-learn 库,所以如果你还没有安装它,请确保你遵循这些说明。
我们还将使用我的个人 imutils 库,所以请确保您也安装了它:
$ pip install imutils
接下来,我们将定义我们的extract_color_histogram函数:
def extract_color_histogram(image, bins=(8, 8, 8)):
# extract a 3D color histogram from the HSV color space using
# the supplied number of `bins` per channel
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
hist = cv2.calcHist([hsv], [0, 1, 2], None, bins,
[0, 180, 0, 256, 0, 256])
# handle normalizing the histogram if we are using OpenCV 2.4.X
if imutils.is_cv2():
hist = cv2.normalize(hist)
# otherwise, perform "in place" normalization in OpenCV 3 (I
# personally hate the way this is done
else:
cv2.normalize(hist, hist)
# return the flattened histogram as the feature vector
return hist.flatten()
该函数为图像的每个通道接受一个输入image和多个bins。
我们将图像转换到 HSV 颜色空间,并计算 3D 颜色直方图来表征图像的颜色分布(行 17-19 )。
这个直方图然后被展平成一个单一的8×8×8 = 512-d特征向量,该向量被返回给调用函数。
关于这个方法更详细的回顾,请参考上周的博文。
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-j", "--jobs", type=int, default=-1,
help="# of jobs for k-NN distance (-1 uses all available cores)")
args = vars(ap.parse_args())
# grab the list of images that we'll be describing
print("[INFO] describing images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the data matrix and labels list
data = []
labels = []
第 34-39 行处理解析我们的命令行参数。这里我们只需要两个开关:
- 从 Kaggle challenge 到我们的输入狗与猫数据集的路径。
--jobs:计算特定数据点的最近邻居时要使用的处理器/内核数量。将该值设置为-1表示应该使用所有可用的处理器/内核。再一次,对于这些论点的更详细的回顾,请参考上周的教程。
第 43 行获取我们的 25,000 幅输入图像的路径,而第 46 和 47 行分别初始化data列表(我们将存储从每幅图像提取的颜色直方图)和labels列表(每幅输入图像的“狗”或“猫”)。
接下来,我们可以循环我们的imagePaths并描述它们:
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# load the image and extract the class label (assuming that our
# path as the format: /path/to/dataset/{class}.{image_num}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-1].split(".")[0]
# extract a color histogram from the image, then update the
# data matrix and labels list
hist = extract_color_histogram(image)
data.append(hist)
labels.append(label)
# show an update every 1,000 images
if i > 0 and i % 1000 == 0:
print("[INFO] processed {}/{}".format(i, len(imagePaths)))
线 50 开始在每个imagePaths上循环。对于每个imagePath,我们从磁盘加载它并提取label ( 行 53 和 54 )。
现在我们有了image,我们计算一个颜色直方图(第 58 行,然后更新data和labels列表(第 59 和 60 行)。
最后,行 63 和 64 向我们的屏幕显示特征提取进度。
为了训练和评估我们的 k-NN 分类器,我们需要将我们的data分成两部分:一个训练部分和一个测试部分:
# partition the data into training and testing splits, using 75%
# of the data for training and the remaining 25% for testing
print("[INFO] constructing training/testing split...")
(trainData, testData, trainLabels, testLabels) = train_test_split(
data, labels, test_size=0.25, random_state=42)
在这里,我们将使用 75%的数据进行训练,剩下的 25%用于评估。
最后,让我们定义一组要优化的超参数:
# construct the set of hyperparameters to tune
params = {"n_neighbors": np.arange(1, 31, 2),
"metric": ["euclidean", "cityblock"]}
上面的代码块定义了一个包含两个键的params字典:
n_neighbors:k-NN 算法中最近邻 k 的个数。这里我们将在【0,29】范围内搜索奇数(记住np.arange函数是独占)。metric:这是 k-NN 的距离函数/相似性度量。通常这默认为欧几里德距离,但是我们也可以使用任何返回单个浮点值的函数,该浮点值表示两幅图像有多“相似”。在这种情况下,我们将搜索欧几里德距离和曼哈顿/城市街区距离。
既然我们已经定义了想要搜索的超参数,我们需要一个方法来实际地应用搜索。幸运的是,scikit-learn 库已经有两种方法可以为我们执行超参数搜索:网格搜索和随机搜索。
我们会发现,在几乎所有情况下,随机搜索通常比网格搜索更好。
网格搜索超参数
网格搜索调整算法将系统地(并且详尽地)训练和评估机器学习分类器,用于超参数值的 的每个和每个组合 。
在这种情况下,给定 16 个唯一值的 k 和 2 个唯一值的距离度量,网格搜索将应用30 个不同的实验来确定最佳值。
您可以在下面的代码段中看到网格搜索是如何执行的:
# tune the hyperparameters via a cross-validated grid search
print("[INFO] tuning hyperparameters via grid search")
model = KNeighborsClassifier(n_jobs=args["jobs"])
grid = GridSearchCV(model, params)
start = time.time()
grid.fit(trainData, trainLabels)
# evaluate the best grid searched model on the testing data
print("[INFO] grid search took {:.2f} seconds".format(
time.time() - start))
acc = grid.score(testData, testLabels)
print("[INFO] grid search accuracy: {:.2f}%".format(acc * 100))
print("[INFO] grid search best parameters: {}".format(
grid.best_params_))
网格搜索算法的主要好处也是它的主要缺点:作为一个穷举搜索,随着超参数和超参数值的数量增加,你的可能参数值的数量会激增。
当然,你可以评估超参数的每一个组合,但是你要付出成本,这是一个非常耗时的 T2 成本。而且在大多数情况下,这几乎不值得。
正如我在下面的“使用随机搜索进行超参数调整(在大多数情况下)”部分中所解释的,很少有只有一组超参数获得最高精度。
*相反,存在超参数的“热区”,它们都获得几乎相同的精度。目标是尽可能快地探索超参数 a 的这些“区域”,并定位这些“热区”中的一个。事实证明,随机搜索是一种很好的方法。
随机搜索超参数
超参数调整的随机搜索方法将通过随机、均匀分布从我们的params字典中采样超参数。给定一组随机采样的参数,然后对模型进行训练和评估。
我们将这组随机超参数采样和模型构建/评估执行预设次数。只要你愿意等待,你就可以将评估次数设置为。如果你不耐烦并且很匆忙,把这个值设得低一点。如果你有时间花在更长的实验上,增加迭代次数。
无论哪种情况,随机搜索的目标都是快速探索一大组可能的超参数空间——实现这一目标的最佳方式是通过简单的随机采样。在实践中,它运行得相当好!
您可以在下面找到对 k-NN 算法的超参数进行随机搜索的代码:
# tune the hyperparameters via a randomized search
grid = RandomizedSearchCV(model, params)
start = time.time()
grid.fit(trainData, trainLabels)
# evaluate the best randomized searched model on the testing
# data
print("[INFO] randomized search took {:.2f} seconds".format(
time.time() - start))
acc = grid.score(testData, testLabels)
print("[INFO] grid search accuracy: {:.2f}%".format(acc * 100))
print("[INFO] randomized search best parameters: {}".format(
grid.best_params_))
使用 Python 和 scikit 进行超参数调整-学习结果
要调整 k-NN 算法的超参数,请确保您:
- 使用本文底部的 “下载” 表单下载源代码。
- 前往 Kaggle Dogs vs. Cats 竞赛页面并下载数据集。
从那里,您可以执行以下命令来优化超参数:
$ python knn_tune.py --dataset kaggle_dogs_vs_cats
当knn_tune.py脚本执行时,你可能想去散散步,伸伸腿。
在我的机器上,花了 19m 26s 完成,其中 86%以上的时间花在网格搜索上:

Figure 2: Applying a Grid Search and Randomized to tune machine learning hyperparameters using Python and scikit-learn.
从输出截图可以看出,网格搜索法发现 k=25 和 metric='cityblock' 获得的准确率最高,为 64.03%。然而,这次网格搜索花了 13 分钟。
另一方面,随机搜索获得了 64.03% — 的相同准确率,并且在不到 5 分钟的内完成。
这两种超参数调整方法都提高了我们的分类精度(64.03%的精度,高于上周文章的 57.58%)——但是随机搜索更高效。
使用随机搜索进行超参数调整(在大多数情况下)
除非你的搜索空间很小,很容易被列举出来,否则随机搜索会更有效率,更快地产生更好的结果。
正如我们的实验所展示的,随机搜索能够在< 5 分钟内获得 64.03%的准确率,而彻底的网格搜索需要更长的时间 13 分钟才能获得相同的 64.03%的准确率——对于相同的准确率,评估时间增加了 202%!
一般来说,不仅仅有一组超参数获得最佳结果,相反,通常有一组超参数存在于凹碗的底部(即优化表面)。**
只要你朝着碗的底部点击这些参数中的一个,你仍然会获得和你沿着碗列举所有可能性一样的准确度。此外,通过应用随机搜索,你可以更快地探索这个碗的各个区域。
总的来说,在大多数情况下,这将导致更快、更有效的超参数调整。
摘要
在今天的博客文章中,我演示了如何使用 Python 编程语言和 scikit-learn 库将超参数调优到机器学习算法。
首先,我定义了标准“模型参数”和需要调整的“超参数”之间的区别。
在此基础上,我们应用了两种方法来调整超参数:
- 彻底的网格搜索
- 随机搜索
然后将这两个超参数调整例程应用于 k-NN 算法和 Kaggle Dogs vs. Cats 数据集。
每个相应的调优算法都获得了相同的准确度— ,但是随机搜索能够在很短的时间内获得这种准确度的提高!
总的来说,我强烈建议您在调整超参数时使用随机搜索。您经常会发现,很少有一组超参数能够获得最佳精度。相反,存在超参数的“热区”,它们将获得几乎相同的精度——目标是探索尽可能多的区域,并尽可能快地在这些区域中的一个着陆。
在没有好的超参数选择的先验知识的情况下,随机搜索超参数调整是在短时间内找到合理的超参数值的最佳方式,因为它允许您探索优化表面的许多区域。
无论如何,我希望你喜欢这篇博文!下周我会回来讨论线性分类的基础知识(以及它在神经网络和图像分类中的作用)。
但在你离开之前,请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在未来的博客文章发表时得到通知!*
如何使用 Keras fit 和 fit_generator(动手教程)
原文:https://pyimagesearch.com/2018/12/24/how-to-use-keras-fit-and-fit_generator-a-hands-on-tutorial/
最后更新于 2021 年 7 月 4 日。
在本教程中,您将了解 Keras .fit和.fit_generator函数是如何工作的,包括它们之间的区别。为了帮助您获得实践经验,我包含了一个完整的示例,向您展示如何从头实现一个 Keras 数据生成器。
今天的博文是受 PyImageSearch 阅读器 Shey 的启发。
谢伊问道:
嗨,阿德里安,感谢你的教程。我有条不紊地检查了每一个。他们真的帮助我学会了深度学习。
我有一个关于 Keras 的问题。fit_generator”功能。
我注意到你在博客中经常使用它,但我不确定这个功能与 Keras 的标准有何不同。适合”功能。
有什么不同?我如何知道何时使用每一个?以及如何为“创建数据生成器”。fit_generator”功能?
谢伊问了一个很好的问题。
Keras 深度学习库包括三个独立的函数,可用于训练您自己的模型:
.fit.fit_generator.train_on_batch
如果你是 Keras 和深度学习的新手,你可能会觉得有点不知所措,试图确定你应该使用哪个函数——如果你需要使用自己的定制数据,这种困惑只会变得更加复杂。
为了帮助消除关于 Keras fit 和 fit_generator 函数的困惑,我将在本教程中讨论:
- Keras'
.fit、.fit_generator、.train_on_batch功能之间的 差异 - 什么时候用每个 训练自己的深度学习模型
- 如何 实现自己的 Keras 数据生成器 并在 使用
.fit_generator训练模型 时利用它 - 在培训后评估你的网络 时如何使用
.predict_generator功能
要了解关于 Keras 的.fit和.fit_generator函数的更多信息,包括如何在你自己的定制数据集上训练深度学习模型,请继续阅读!
- 【2021 年 7 月更新:对于 TensorFlow 2.2+的用户,只需对自己的项目使用
.fit方法即可。在 TensorFlow 的未来版本中,.fit_generator方法将被弃用,因为.fit方法可以自动检测输入数据是数组还是生成器。
如何使用 Keras fit 和 fit_generator(动手教程)
2020-05-13 更新:此博文现已兼容 TensorFlow 2+!TensorFlow 正在对支持数据扩充的.fit_generator方法进行弃用。如果您使用的是tensorflow==2.2.0或tensorflow-gpu==2.2.0(或更高版本),那么必须使用和.fit方法(现在支持数据扩充)。请记住这一点,而阅读这个遗产教程。当然,数据扩充的概念保持不变。请注意,本教程中的代码已针对 TensorFlow 2.2+兼容性进行了更新,但是您可能仍会看到对传统* .fit_generator方法的文本引用。*
在今天教程的第一部分,我们将讨论 Keras 的.fit、.fit_generator和.train_on_batch函数之间的区别。
接下来,我将向您展示一个“非标准”图像数据集的示例,它不包含任何实际的 PNG、JPEG 等。一点图像都没有!相反,整个图像数据集由两个 CSV 文件表示,一个用于训练,另一个用于评估。
我们的目标是实现一个 Keras 生成器,能够根据这个 CSV 图像数据训练一个网络(不要担心,我将向您展示如何从头开始实现这样一个生成器功能)。
最后,我们将训练和评估我们的网络。
什么时候使用 Keras 的 fit、fit_generator、train_on_batch 函数?
Keras 提供了三个函数,可以用来训练你自己的深度学习模型:
.fit.fit_generator.train_on_batch
所有这三个功能本质上可以完成相同的任务——但是它们如何去做是非常不同的。
让我们一个接一个地研究这些函数,看一个函数调用的例子,然后讨论它们之间的区别。
喀拉山脉。拟合函数
让我们先给.fit打个电话:
model.fit(trainX, trainY, batch_size=32, epochs=50)
这里你可以看到我们正在提供我们的训练数据(trainX)和训练标签(trainY)。
然后,我们指示 Keras 允许我们的模型以32的批量为50个时期进行训练。
对.fit的调用在这里做了两个主要假设:
- 我们的整个训练集可以放入 RAM
- 没有正在进行的数据扩充(即,不需要 Keras 生成器)
相反,我们的网络将根据原始数据进行训练。
原始数据本身将放入内存中——我们不需要将旧的数据批次移出 RAM,并将新的数据批次移入 RAM。
此外,我们将不会使用数据扩充来即时操纵训练数据。
Keras fit_generator 函数
Figure 2: The Keras .fit_generator function allows for data augmentation and data generators.
对于小而简单的数据集,使用 Keras 的.fit函数是完全可以接受的。
这些数据集通常不太具有挑战性,也不需要任何数据扩充。
然而,真实世界的数据集很少如此简单:
- 真实世界的数据集通常太大,无法放入内存。
- 它们也趋向于挑战,要求我们执行数据扩充以避免过度拟合并增加我们模型的泛化能力。
在这些情况下,我们需要利用 Keras 的.fit_generator功能:
# initialize the number of epochs and batch size
EPOCHS = 100
BS = 32
# construct the training image generator for data augmentation
aug = ImageDataGenerator(rotation_range=20, zoom_range=0.15,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
horizontal_flip=True, fill_mode="nearest")
# train the network
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
2020-05-13 更新:在 TensorFlow 2.2+中,我们现在使用.fit而不是.fit_generator,如果提供的第一个参数是 Python 生成器对象,那么其工作方式完全相同,以适应数据扩充。
在这里,我们首先初始化我们要训练网络的时期数以及批量大小。
然后我们初始化aug,一个 Keras ImageDataGenerator对象,用于应用数据扩充、随机平移、旋转、调整大小等。动态图像。
执行数据扩充是正则化的一种形式,使我们的模型能够更好地泛化。
然而,应用数据扩充意味着我们的训练数据不再是“静态的”——数据是不断变化的。
根据提供给ImageDataGenerator的参数,随机调整每一批新数据。
因此,我们现在需要利用 Keras 的.fit_generator函数来训练我们的模型。
顾名思义,.fit_generator函数假设有一个底层函数为它生成数据。
函数本身是一个 Python 生成器。
在内部,Keras 在使用.fit_generator训练模型时使用以下流程:
- Keras 调用提供给
.fit_generator(本例中为aug.flow)的生成器函数。 - 生成器函数向
.fit_generator函数生成一批大小为BS的数据。 .fit_generator函数接受批量数据,执行反向传播,并更新我们模型中的权重。- 重复这个过程,直到我们达到期望的历元数。
你会注意到我们现在需要在调用.fit_generator时提供一个steps_per_epoch参数(.fit方法没有这样的参数)。
我们为什么需要steps_per_epoch?
请记住,Keras 数据生成器意味着无限循环——它应该永远不会返回或退出。
由于该函数旨在无限循环,Keras 没有能力确定何时一个时期开始和一个新时期开始*。
因此,我们将steps_per_epoch值计算为训练数据点的总数除以批量大小。一旦 Keras 达到这个步数,它就知道这是一个新时代。
Keras 批量训练函数
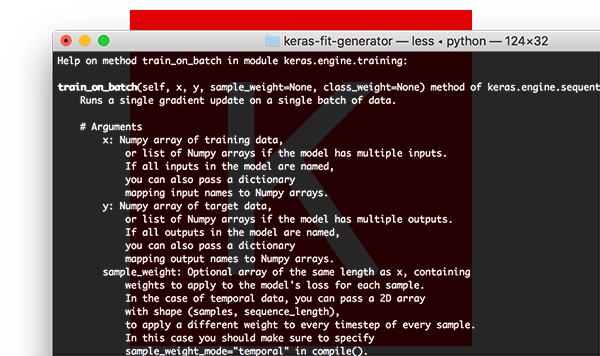
Figure 3: The .train_on_batch function in Keras offers expert-level control over training Keras models.
对于深度学习实践者来说,如果他们正在寻找对训练 Keras 模型的最细粒度控制,你可能希望使用.train_on_batch函数:
model.train_on_batch(batchX, batchY)
train_on_batch函数接受单批数据,进行反向传播,然后更新模型参数。
该批数据可以是任意大小的(即,它不需要提供明确的批量大小)。
数据本身也可以按照您喜欢的方式生成。这些数据可以是磁盘上的原始图像,也可以是经过某种方式修改或扩充的数据。
当你有个非常明确的理由想要维护你自己的训练数据迭代器时,比如数据迭代过程非常复杂并且需要定制代码,你通常会使用.train_on_batch函数。
如果你发现自己在问是否需要.train_on_batch函数,那么很可能你并不需要。
在 99%的情况下,你不需要这样细粒度的控制来训练你的深度学习模型。相反,自定义的 Keras .fit_generator函数可能就是您所需要的。
也就是说,如果你需要这个函数,知道它的存在是件好事。
如果你是高级深度学习实践者/工程师,并且你确切地知道你在做什么和为什么,我通常只推荐使用.train_on_batch函数。
图像数据集…作为 CSV 文件?
Figure 4: The Flowers-17 dataset has been serialized into two CSV files (training and evaluation). In this blog post we’ll write a custom Keras generator to parse the CSV data and yield batches of images to the .fit_generator function. (credits: image & icon)
我们今天将在这里使用的数据集是 Flowers-17 数据集,它是 17 种不同花卉的集合,每类有 80 张图像。
我们的目标是训练一个 Keras 卷积神经网络来正确分类每一种花。
然而,这个项目有点曲折:
- 不是处理驻留在磁盘上的原始图像文件…
- …我已经将整个图像数据集序列化为两个 CSV 文件(一个用于训练,一个用于评估)。
要构建每个 CSV 文件,我:
- 循环遍历输入数据集中的所有图像
- 将它们调整为 64×64 像素
- 将 64x64x3=12,288 个 RGB 像素亮度合并到一个列表中
- 将 12,288 像素值+类别标签写入 CSV 文件(每行一个)
我们的目标是现在编写一个定制的 Keras 生成器来解析 CSV 文件,并为.fit_generator函数生成成批的图像和标签。
等等,如果你已经有图像了,为什么还要麻烦一个 CSV 文件呢?
今天的教程旨在举例说明如何为.fit_generator函数实现自己的 Keras 生成器。
在现实世界中,数据集并不适合你:
- 您可能有非结构化的图像目录。
- 你可以同时处理图像和文本。
- 您的图像可以以特定格式序列化,无论是 CSV 文件、Caffe 或 TensorFlow 记录文件等。
在这些情况下,你需要知道如何编写你自己的 Keras 生成器函数。
请记住,这里重要的是而不是特定的数据格式——您需要学习的是编写自己的 Keras 生成器的实际过程(这正是本教程剩余部分所涵盖的内容)。
项目结构
让我们检查一下今天示例的项目树:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── minivggnet.py
├── flowers17_testing.csv
├── flowers17_training.csv
├── plot.png
└── train.py
1 directory, 6 files
今天我们将使用迷你 CNN。我们今天不会在这里讨论实现,因为我假设您已经知道如何实现 CNN。如果没有,不用担心——参考我的 Keras 教程 就行了。
我们的序列化图像数据集包含在flowers17_training.csv和flowers17_testing.csv中(包含在与今天的帖子相关的 【下载】 )。
在接下来的两节中,我们将回顾我们的培训脚本train.py。
实现自定义的 Keras fit_generator 函数
Figure 5: What’s our fuel source for our ImageDataGenerator? Two CSV files with serialized image text strings. The generator engine is the ImageDataGenerator from Keras coupled with our custom csv_image_generator. The generator will burn the CSV fuel to create batches of images for training.
让我们开始吧。
我假设您的系统上安装了以下库:
- NumPy
- TensorFlow + Keras
- Scikit-learn
- Matplotlib
这些包中的每一个都可以通过 pip 安装在您的虚拟环境中。如果您安装了 virtualenvwrapper,您可以使用mkvirtualenv创建一个环境,并使用workon命令激活您的环境。在那里,您可以使用 pip 来设置您的环境:
$ mkvirtualenv cv -p python3
$ workon cv
$ pip install numpy
$ pip install tensorflow # or tensorflow-gpu
$ pip install keras
$ pip install scikit-learn
$ pip install matplotlib
一旦建立了虚拟环境,您就可以继续编写培训脚本了。确保您使用今天帖子的 【下载】 部分获取源代码和 Flowers-17 CSV 图像数据集。
打开train.py文件并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from pyimagesearch.minivggnet import MiniVGGNet
import matplotlib.pyplot as plt
import numpy as np
2-12 行导入我们需要的包和模块。因为我们将把我们的训练图保存到磁盘上,第 3 行适当地设置了matplotlib的后端。
值得注意的进口包括ImageDataGenerator,它包含数据增强和图像生成器功能,以及MiniVGGNet,我们的 CNN,我们将培训。
让我们定义一下csv_image_generator函数:
def csv_image_generator(inputPath, bs, lb, mode="train", aug=None):
# open the CSV file for reading
f = open(inputPath, "r")
在第 14 行我们定义了csv_image_generator。这个函数负责读取我们的 CSV 数据文件并将图像加载到内存中。它向我们的 Keras .fit_generator函数生成批量数据。
因此,该函数接受以下参数:
inputPath:CSV 数据集文件的路径。bs:批量大小。我们将使用 32。lb:一个包含我们的类标签的标签二进制化器对象。mode:(缺省值为"train")当且仅当mode=="eval"时,则做出特殊调整,不通过aug对象(如果提供的话)应用数据扩充。aug:(默认为None)如果指定了增强对象,那么我们将在生成图像和标签之前应用它。
在第 16 行,我们将打开 CSV 数据文件进行读取。
让我们开始遍历数据行:
# loop indefinitely
while True:
# initialize our batches of images and labels
images = []
labels = []
CSV 文件中的每一行数据都包含一个序列化为文本字符串的图像。同样,我从 Flowers-17 数据集生成了文本字符串。此外,我知道这不是存储图像的最有效的方式,但是对于这个例子来说非常好。
我们的 Keras 发生器必须按照第 19 行的定义无限循环。每当需要新的一批数据时,.fit_generator函数将调用我们的csv_image_generator函数。
此外,Keras 维护着一个数据缓存/队列,确保我们正在训练的模型始终有数据可以训练。Keras 一直保持这个队列满,所以即使你已经达到了训练的总次数,记住 Keras 仍然在给数据生成器提供数据,保持数据在队列中。
一定要确保你的函数返回数据,否则,Keras 会报错说它不能从你的生成器获得更多的训练数据。
在循环的每次迭代中,我们将把我们的images和labels重新初始化为空列表(第 21 行和第 22 行)。
从这里开始,我们将开始向这些列表添加图像和标签,直到达到我们的批量大小:
# keep looping until we reach our batch size
while len(images) < bs:
# attempt to read the next line of the CSV file
line = f.readline()
# check to see if the line is empty, indicating we have
# reached the end of the file
if line == "":
# reset the file pointer to the beginning of the file
# and re-read the line
f.seek(0)
line = f.readline()
# if we are evaluating we should now break from our
# loop to ensure we don't continue to fill up the
# batch from samples at the beginning of the file
if mode == "eval":
break
# extract the label and construct the image
line = line.strip().split(",")
label = line[0]
image = np.array([int(x) for x in line[1:]], dtype="float32")
image = image.reshape((64, 64, 3))
# update our corresponding batches lists
images.append(image)
labels.append(label)
让我们来看看这个循环:
- 首先,我们从文本文件对象
f( 第 27 行)中读取一个line。 - 如果
line为空:- …我们重置我们的文件指针并尝试读取一个
line( 第 34 行和第 35 行)。 - 如果我们在评估
mode,我们继续从循环break(第 40 行和第 41 行)。
- …我们重置我们的文件指针并尝试读取一个
- 此时,我们将从 CSV 文件中解析我们的
image和label(第 44-46 行)。 - 我们继续调用
.reshape将我们的 1D 数组整形为我们的图像,它是 64×64 像素,有 3 个颜色通道(第 47 行)。 - 最后,我们将
image和label添加到它们各自的列表中,重复这个过程,直到我们的图像批次满了 ( 第 50 行和第 51 行)。
注:这里做评价工作的关键是我们提供steps到model.predict_generator的数量,保证测试集中的每张图像只被预测一次。我将在教程的后面介绍如何完成这个过程。
准备好我们的图像批次和相应的标签后,我们现在可以在生成批次之前采取两个步骤:
# one-hot encode the labels
labels = lb.transform(np.array(labels))
# if the data augmentation object is not None, apply it
if aug is not None:
(images, labels) = next(aug.flow(np.array(images),
labels, batch_size=bs))
# yield the batch to the calling function
yield (np.array(images), labels)
我们的最后步骤包括:
- 一键编码
labels( 第 54 行) - 必要时应用数据扩充(第 57-59 行)
最后,我们的生成器根据请求将我们的图像数组和标签列表“产出”给调用函数( Line 62 )。如果您不熟悉yield关键字,它被用于 Python 生成器函数,作为一种方便的快捷方式来代替构建一个消耗较少内存的迭代器类。你可以在这里阅读更多关于 Python 生成器的内容。
让我们初始化我们的训练参数:
# initialize the paths to our training and testing CSV files
TRAIN_CSV = "flowers17_training.csv"
TEST_CSV = "flowers17_testing.csv"
# initialize the number of epochs to train for and batch size
NUM_EPOCHS = 75
BS = 32
# initialize the total number of training and testing image
NUM_TRAIN_IMAGES = 0
NUM_TEST_IMAGES = 0
在本示例培训脚本中,许多初始化都是硬编码的:
- 我们的培训和测试 CSV 文件路径(第 65 行和第 66 行)。
- 用于训练的时期数和批量大小(行 69 和 70 )。
- 保存训练和测试图像数量的两个变量(行 73 和 74 )。
让我们看看下一段代码:
# open the training CSV file, then initialize the unique set of class
# labels in the dataset along with the testing labels
f = open(TRAIN_CSV, "r")
labels = set()
testLabels = []
# loop over all rows of the CSV file
for line in f:
# extract the class label, update the labels list, and increment
# the total number of training images
label = line.strip().split(",")[0]
labels.add(label)
NUM_TRAIN_IMAGES += 1
# close the training CSV file and open the testing CSV file
f.close()
f = open(TEST_CSV, "r")
# loop over the lines in the testing file
for line in f:
# extract the class label, update the test labels list, and
# increment the total number of testing images
label = line.strip().split(",")[0]
testLabels.append(label)
NUM_TEST_IMAGES += 1
# close the testing CSV file
f.close()
这段代码很长,但它有三个用途:
- 从我们的训练数据集中提取所有标签,以便我们可以随后确定唯一的标签。注意
labels是一个set,它只允许唯一的条目。 - 汇总一份
testLabels清单。 - 数一数
NUM_TRAIN_IMAGES和NUM_TEST_IMAGES。
让我们构建我们的LabelBinarizer对象,并构建数据扩充对象:
# create the label binarizer for one-hot encoding labels, then encode
# the testing labels
lb = LabelBinarizer()
lb.fit(list(labels))
testLabels = lb.transform(testLabels)
# construct the training image generator for data augmentation
aug = ImageDataGenerator(rotation_range=20, zoom_range=0.15,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
horizontal_flip=True, fill_mode="nearest")
使用唯一的标签,我们将.fit我们的LabelBinarizer对象(第 107 行和第 108 行)。
我们还将继续把我们的testLabels转换成二进制的单热码testLabels ( 第 109 行)。
从那里,我们将构造aug,一个ImageDataGenerator ( 行 112-114 )。我们的图像数据增强对象将随机旋转、翻转、剪切等。我们的训练图像。
现在让我们初始化我们的训练和测试图像生成器:
# initialize both the training and testing image generators
trainGen = csv_image_generator(TRAIN_CSV, BS, lb,
mode="train", aug=aug)
testGen = csv_image_generator(TEST_CSV, BS, lb,
mode="train", aug=None)
我们的trainGen和testGen生成器对象使用csv_image_generator ( 第 117-120 行)从各自的 CSV 文件生成图像数据。
注意细微的相似和不同之处:
- 我们对两个生成器都使用了
mode="train" - 只有
trainGen会执行数据扩充
让我们用 Keras 初始化+编译我们的 MiniVGGNet 模型,并开始训练:
# initialize our Keras model and compile it
model = MiniVGGNet.build(64, 64, 3, len(lb.classes_))
opt = SGD(lr=1e-2, momentum=0.9, decay=1e-2 / NUM_EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training w/ generator...")
H = model.fit(
x=trainGen,
steps_per_epoch=NUM_TRAIN_IMAGES // BS,
validation_data=testGen,
validation_steps=NUM_TEST_IMAGES // BS,
epochs=NUM_EPOCHS)
2020-05-13 更新:本帖现已兼容 TensorFlow 2+!我们不再使用.fit_generator函数;相反,我们使用.fit方法。
第 123-126 行编译我们的模型。我们正在使用一个随机梯度下降优化器,它的初始学习速率为1e-2。学习率衰减应用于每个时期。使用分类交叉熵是因为我们有两个以上的类(否则会使用二进制交叉熵)。请务必参考我的 Keras 教程进行额外阅读。
在行 130-135 我们调用.fit开始训练。
trainGen生成器对象负责向.fit函数生成批量数据和标签。
请注意我们如何根据图像数量和批次大小计算每个时期的步骤和验证步骤。我们提供steps_per_epoch值是非常重要的,否则 Keras 将不知道一个纪元何时开始,另一个纪元何时开始。
现在让我们来评估培训的结果:
# re-initialize our testing data generator, this time for evaluating
testGen = csv_image_generator(TEST_CSV, BS, lb,
mode="eval", aug=None)
# make predictions on the testing images, finding the index of the
# label with the corresponding largest predicted probability
predIdxs = model.predict(x=testGen, steps=(NUM_TEST_IMAGES // BS) + 1)
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print("[INFO] evaluating network...")
print(classification_report(testLabels.argmax(axis=1), predIdxs,
target_names=lb.classes_))
我们继续并重新初始化我们的testGen,这一次为了评估的目的将mode改为"eval"。
重新初始化后,我们使用我们的.predict函数和testGen ( 第 143 和 144 行)进行预测。在这个过程的最后,我们将继续获取最大预测指数(第 145 行)。
使用testLabels和predIdxs,我们将通过 scikit-learn 生成一个classification_report(第 149 和 150 行)。在培训和评估结束时,分类报告被很好地打印到我们的终端以供检查。
最后一步,我们将使用我们的训练历史字典H,用 matplotlib 生成一个图:
# plot the training loss and accuracy
N = NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig("plot.png")
生成精度/损失图,并作为plot.png保存到磁盘,以备脚本退出时检查。
使用 fit_generator 训练 Keras 模型并使用 predict_generator 进行评估
2020-06-03 更新:尽管这一节的标题,我们现在用.fit(无 .fit_generator)和.predict(无.predict_generator)。
要使用我们的定制数据生成器训练我们的 Keras 模型,请确保使用 “下载” 部分下载源代码和示例 CSV 图像数据集。
从那里,打开一个终端,导航到您下载源代码+数据集的位置,并执行以下命令:
$ python train.py
Using TensorFlow backend.
[INFO] training w/ generator...
Train for 31 steps, validate for 10 steps
Epoch 1/75
31/31 [==============================] - 10s 317ms/step - loss: 3.6791 - accuracy: 0.1401 - val_loss: 1828.6441 - val_accuracy: 0.0625
Epoch 2/75
31/31 [==============================] - 9s 287ms/step - loss: 3.0351 - accuracy: 0.2077 - val_loss: 246.5172 - val_accuracy: 0.0938
Epoch 3/75
31/31 [==============================] - 9s 288ms/step - loss: 2.8571 - accuracy: 0.2621 - val_loss: 92.0763 - val_accuracy: 0.0750
...
31/31 [==============================] - 9s 287ms/step - loss: 0.4484 - accuracy: 0.8548 - val_loss: 1.3388 - val_accuracy: 0.6531
Epoch 73/75
31/31 [==============================] - 9s 287ms/step - loss: 0.4025 - accuracy: 0.8619 - val_loss: 1.1642 - val_accuracy: 0.7125
Epoch 74/75
31/31 [==============================] - 9s 287ms/step - loss: 0.3401 - accuracy: 0.8720 - val_loss: 1.2229 - val_accuracy: 0.7188
Epoch 75/75
31/31 [==============================] - 9s 287ms/step - loss: 0.3605 - accuracy: 0.8780 - val_loss: 1.2207 - val_accuracy: 0.7063
[INFO] evaluating network...
precision recall f1-score support
bluebell 0.63 0.81 0.71 21
buttercup 0.69 0.73 0.71 15
coltsfoot 0.55 0.76 0.64 21
cowslip 0.73 0.40 0.52 20
crocus 0.53 0.88 0.66 24
daffodil 0.82 0.33 0.47 27
daisy 0.77 0.94 0.85 18
dandelion 0.71 0.83 0.77 18
fritillary 1.00 0.77 0.87 22
iris 0.95 0.75 0.84 24
lilyvalley 0.92 0.55 0.69 22
pansy 0.89 0.89 0.89 18
snowdrop 0.69 0.50 0.58 22
sunflower 0.90 1.00 0.95 18
tigerlily 0.87 0.93 0.90 14
tulip 0.33 0.50 0.40 16
windflower 0.81 0.85 0.83 20
accuracy 0.72 340
macro avg 0.75 0.73 0.72 340
weighted avg 0.76 0.72 0.71 340
在这里你可以看到我们的网络在评估集上获得了 76%的准确率,这对于使用的相对较浅的 CNN 来说是相当可观的。
最重要的是,您学会了如何利用:
- 数据生成器
.fit(原.fit_generator).predict(原.predict_generator)
`…这一切都是为了训练和评估您自己的定制 Keras 模型!
同样,这里重要的是而不是数据本身的实际格式。除了 CSV 文件,我们还可以使用 Caffe 或 TensorFlow 记录文件,即数字/分类数据与图像的组合,或者您在现实世界中可能遇到的任何其他数据合成。
相反,实现自己的 Keras 数据生成器的实际过程才是最重要的。
按照本教程中的步骤,您将有一个蓝图,可以用来实现自己的 Keras 数据生成器。
如果你用的是 TensorFlow 2.2+,就用”。适合”,没理由用”。fit_generator"
您可以使用pip freeze检查您的 TensorFlow 版本,然后查找您的 TensorFlow 版本:
$ pip freeze | grep 'tensorflow'
tensorflow==2.4.1
tensorflow-estimator==2.4.0
如果你使用 TensorFlow 2.2 或更高版本,你应该只使用.fit方法。
TensorFlow 将在未来的版本中取消.fit_generator方法,因为.fit方法可以自动检测输入数据是数组还是生成器。
摘要
在本教程中,您学习了 Keras 用于训练深度神经网络的三个主要功能之间的差异:
.fit:当整个训练数据集可以放入内存并且没有应用数据扩充时使用。从 TensorFlow 2 开始,该方法现在支持数据扩充。.fit_generator: 针对使用 tensor flow/Keras 2.2 之前版本的遗留代码。应在以下情况下使用:( 1)数据集太大,内存容纳不下,(2)需要应用数据扩充,或(3)更方便批量生成训练数据的任何情况(即使用flow_from_directory函数)。.train_on_batch:可用于在单次批量数据上训练 Keras 模型。应该只在需要对网络进行最细粒度的控制训练时使用,比如在数据迭代器非常复杂的情况下。
从那里,我们发现了如何:
- 实现我们自己定制的 Keras 生成器函数
- 使用我们的定制生成器和 Keras ' T0 '来训练我们的深度神经网络
在自己的项目中实现自己的 Keras 生成器时,可以使用今天的示例代码作为模板。
我希望你喜欢今天的博文!
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!`*
如何在 NVIDIA GPUs、CUDA 和 cuDNN 上使用 OpenCV 的“dnn”模块
原文:https://pyimagesearch.com/2020/02/03/how-to-use-opencvs-dnn-module-with-nvidia-gpus-cuda-and-cudnn/
在本教程中,您将学习如何使用 OpenCV 的“深度神经网络”(DNN)模块与 NVIDIA GPUs、CUDA 和 cuDNN 进行 211-1549% 更快的推理。
回到 2017 年 8 月,我发表了我的第一篇关于使用 OpenCV 的“深度神经网络”(DNN)模块进行图像分类的教程。
PyImageSearch 的读者非常喜欢 OpenCV 的dnn模块的便利性和易用性,因此我继续发布了关于dnn模块的附加教程,包括:
这些指南中的每一个都使用 OpenCV 的dnn模块来(1)从磁盘加载预训练的网络,(2)对输入图像进行预测,然后(3)显示结果,允许您为您的特定项目构建自己的定制计算机视觉/深度学习管道。
然而,OpenCV 的dnn模块的最大问题是缺乏 NVIDIA GPU/CUDA 支持——使用这些模型,你无法轻松使用 GPU 来提高你的流水线的每秒帧数(FPS)处理速率。
对于单镜头探测器(SSD)教程来说,这不是什么大问题,它可以在 CPU 上轻松地以 25-30+ FPS 运行,但对于 YOLO 和马斯克 R-CNN 来说,这是一个巨大的问题,他们很难在 CPU 上达到 1-3 FPS 以上。
这一切都在 2019 年的谷歌代码之夏(GSoC)中改变了。
由 dlib 的 Davis King 领衔, Yashas Samaga , OpenCV 4.2 现在支持 NVIDIA GPUs 使用 OpenCV 的dnn模块进行推理,推理速度提升高达 1549%!
在今天的教程中,我将向您展示如何编译和安装 OpenCV,以利用您的 NVIDIA GPU 进行深度神经网络推理。
然后,在下周的教程中,我将为您提供单次检测器、YOLO 和屏蔽 R-CNN 代码,这些代码可用于利用 OpenCV 来利用您的 GPU。然后,我们将对结果进行基准测试,并将它们与纯 CPU 推理进行比较,这样您就知道哪些模型可以从使用 GPU 中受益最多。
要了解如何在 NVIDIA GPU、CUDA 和 cuDNN 支持下编译和安装 OpenCV 的“dnn”模块,继续阅读!
如何在 NVIDIA GPUs、CUDA 和 cuDNN 上使用 OpenCV 的“dnn”模块
在本教程的剩余部分,我将向您展示如何从源代码编译 OpenCV,以便您可以利用 NVIDIA GPU 加速的预训练深度神经网络推理。
为 NVIDIA GPU 支持编译 OpenCV 时的假设
为了在 NVIDIA GPU 支持下编译和安装 OpenCV 的“深度神经网络”模块,我将做出以下假设:
- 你有一个 NVIDIA GPU。这应该是显而易见的假设。如果您没有 NVIDIA GPU,则无法在 NVIDIA GPU 支持下编译 OpenCV 的“dnn”模块。
- 你正在使用 Ubuntu 18.04(或另一个基于 Debian 的发行版)。说到深度学习,我强烈推荐基于 Unix 的机器而不是 Windows 系统(事实上,我在 PyImageSearch 博客上不支持 Windows)。如果你打算使用 GPU 进行深度学习,那么使用 Ubuntu 而不是 macOS 或 Windows——配置起来要容易得多。
- 你知道如何使用命令行。我们将在本教程中使用命令行。如果你对命令行不熟悉,我建议先阅读这篇命令行简介,然后花几个小时(甚至几天)练习。同样,本教程是而不是给那些命令行新手的。
- 您能够阅读终端输出并诊断问题。如果你以前从未做过,从源代码编译 OpenCV 可能是一个挑战——有许多事情可能会让你出错,包括丢失的包、不正确的库路径等。即使有我详细的指导,你也可能会一路犯错。不要气馁!花时间理解你正在执行的命令,它们做什么,最重要的是, 阅读命令的输出! 不要去盲目的复制粘贴;你只会遇到错误。
说了这么多,让我们开始为 NVIDIA GPU 推断配置 OpenCV 的“dnn”模块。
步骤 1:安装 NVIDIA CUDA 驱动程序、CUDA 工具包和 cuDNN
本教程假设你已经已经:
- 一个 NVIDIA GPU
- 安装的特定 GPU 的 CUDA 驱动程序
- 配置和安装了 CUDA 工具包和 cuDNN
如果您的系统上有 NVIDIA GPU,但尚未安装 CUDA 驱动程序、CUDA Toolkit 和 cuDNN,您将需要首先配置您的机器— 我不会在本指南中介绍 CUDA 配置和安装。
要了解如何安装 NVIDIA CUDA 驱动程序、CUDA 工具包和 cuDNN,我建议你阅读我的 Ubuntu 18.04 和 TensorFlow/Keras GPU 安装指南——一旦你安装了正确的 NVIDIA 驱动程序和工具包,你就可以回到本教程。
步骤 2:安装 OpenCV 和“dnn”GPU 依赖项
为 NVIDIA GPU 推断配置 OpenCV 的“dnn”模块的第一步是安装适当的依赖项:
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get install build-essential cmake unzip pkg-config
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev
$ sudo apt-get install libv4l-dev libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libatlas-base-dev gfortran
$ sudo apt-get install python3-dev
如果你遵循了我的 Ubuntu 18.04 深度学习配置指南,这些包中的大部分应该已经安装了,但是为了安全起见,我会推荐你运行上面的命令。
步骤 3:下载 OpenCV 源代码
没有“pip-installable”版本的 OpenCV 附带 NVIDIA GPU 支持——相反,我们需要使用适当的 NVIDIA GPU 配置集从头开始编译 OpenCV 。
这样做的第一步是下载 OpenCV v4.2 的源代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.2.0.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.2.0.zip
$ unzip opencv.zip
$ unzip opencv_contrib.zip
$ mv opencv-4.2.0 opencv
$ mv opencv_contrib-4.2.0 opencv_contrib
我们现在可以继续配置我们的构建了。
步骤 4:配置 Python 虚拟环境
Figure 2: Python virtual environments are a best practice for both Python development and Python deployment. We will create an OpenCV CUDA virtual environment in this blog post so that we can run OpenCV with its new CUDA backend for conducting deep learning and other image processing on your CUDA-capable NVIDIA GPU (image source).
如果你遵循了我的 Ubuntu 18.04、TensorFlow 和 Keras 深度学习配置指南,那么你应该已经安装了 virtualenv 和 virtualenvwrapper :
- 如果您的机器已经配置了,请跳到本节中的
mkvirtualenv命令。 - 否则,按照这些步骤来配置您的机器。
Python 虚拟环境是 Python 开发的最佳实践。它们允许您在隔离的、独立的开发和生产环境中测试不同版本的 Python 库。Python 虚拟环境被认为是 Python 世界中的最佳实践——我每天都在使用它们,你也应该如此。
如果您还没有安装 Python 的包管理器pip,您可以使用下面的命令来安装:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
一旦pip安装完毕,您就可以同时安装virtualenv和virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
然后,你需要打开你的~/.bashrc文件,并将其更新为每当你打开一个终端时,自动加载 virtualenv/virtualenvwrapper。
我更喜欢使用nano文本编辑器,但是你可以使用你最喜欢的编辑器:
$ nano ~/.bashrc
打开~/.bashrc文件后,滚动到文件底部,插入以下内容:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
从那里,保存并退出您的终端(ctrl + x、y、enter)。
然后,您可以在终端会话中重新加载您的~/.bashrc文件:
$ source ~/.bashrc
您只需要运行上面的命令一次 —因为您更新了您的~/.bashrc文件,每当您打开一个新的终端窗口时,virtualenv/virtualenvwrapper 环境变量将自动设置为。
最后一步是创建 Python 虚拟环境:
$ mkvirtualenv opencv_cuda -p python3
mkvirtualenv命令使用 Python 3 创建一个名为opencv_cuda的新 Python 虚拟环境。
然后您应该将 NumPy 安装到opencv_cuda环境中:
$ pip install numpy
如果您关闭了您的终端或者停用了您的 Python 虚拟环境,您可以通过workon命令再次访问它:
$ workon opencv_cuda
如果你是 Python 虚拟环境的新手,我建议你花点时间阅读一下它们是如何工作的——它们是 Python 世界中的最佳实践。
如果您选择不使用它们,那完全没问题,但是请记住,您的选择并不能免除您学习适当的 Python 最佳实践的责任。现在就花时间投资你的知识。
步骤 5:确定您的 CUDA 架构版本
当在 NVIDIA GPU 支持下编译 OpenCV 的“dnn”模块时,我们需要确定我们的 NVIDIA GPU 架构版本:
- 当我们在下一节的
cmake命令中设置CUDA_ARCH_BIN变量时,这个版本号是一个需求。 - NVIDIA GPU 架构版本取决于您使用的 GPU 型号,因此请确保您提前了解您的 GPU 型号 T2。
- 未能正确设置您的
CUDA_ARCH_BIN变量会导致 OpenCV 仍在编译,但无法使用您的 GPU 进行推理(使诊断和调试变得很麻烦)。
确定你的 NVIDIA GPU 架构版本最简单的方法之一就是简单地使用nvidia-smi命令:
$ nvidia-smi
Mon Jan 27 14:11:32 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:04.0 Off | 0 |
| N/A 35C P0 38W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
检查输出,你可以看到我正在使用一个 NVIDIA Tesla V100 GPU 。在继续之前,确保你自己运行nvidia-smi命令来验证你的 GPU 型号。
现在我有了我的 NVIDIA GPU 模型,我可以继续确定架构版本。
您可以使用此页面找到您的特定 GPU 的 NVIDIA GPU 架构版本:
https://developer.nvidia.com/cuda-gpus
向下滚动到支持 CUDA 的 Tesla、Quadro、NVS、GeForce/Titan 和 Jetson 产品列表:
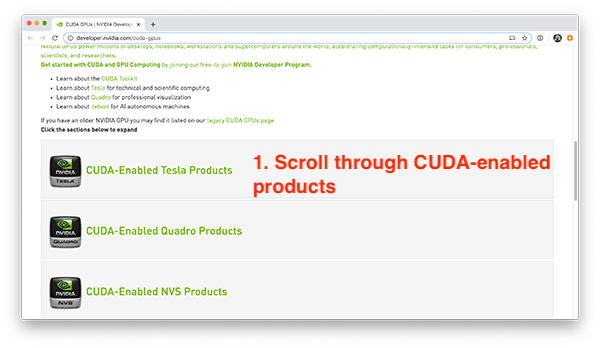
Figure 3: How to enable CUDA in your OpenCV installation for NVIDIA GPUs.
由于我使用的是 V100,我将点击“支持 CUDA 的特斯拉产品”部分:
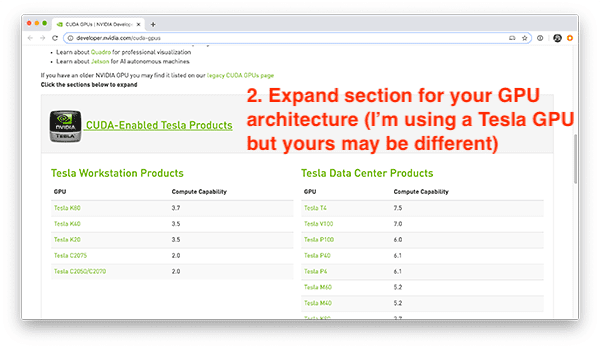
Figure 4: Click on the “CUDA-Enabled Tesla Products” section as the next step to install CUDA into your OpenCV installation for your NVIDIA GPU.
向下滚动,我可以看到我的 V100 GPU:

Figure 5: Select your NVIDIA GPU architecture for installing CUDA with OpenCV.
如你所见,我的 NVIDIA GPU 架构版本是7.0 —你应该对你自己的 GPU 型号执行同样的过程。
一旦您确定了您的 NVIDIA GPU 架构版本,记下它,然后继续下一部分。
第 6 步:用 NVIDIA GPU 支持配置 OpenCV
此时,我们已经准备好使用cmake命令来配置我们的构建。
cmake命令扫描依赖项,配置构建,并生成make实际编译 OpenCV 所需的文件。
要配置构建,首先要确保您在使用 NVIDIA GPU 支持编译 OpenCV 的 Python 虚拟环境中:
$ workon opencv_cuda
接下来,将目录切换到您下载 OpenCV 源代码的位置,然后创建一个build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
然后,您可以运行下面的cmake命令,确保您根据您在上一节中找到的 NVIDIA GPU 架构版本设置了CUDA_ARCH_BIN变量:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D WITH_CUDA=ON \
-D WITH_CUDNN=ON \
-D OPENCV_DNN_CUDA=ON \
-D ENABLE_FAST_MATH=1 \
-D CUDA_FAST_MATH=1 \
-D CUDA_ARCH_BIN=7.0 \
-D WITH_CUBLAS=1 \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D HAVE_opencv_python3=ON \
-D PYTHON_EXECUTABLE=~/.virtualenvs/opencv_cuda/bin/python \
-D BUILD_EXAMPLES=ON ..
这里你可以看到我们正在编译 OpenCV,同时启用了 CUDA 和 cuDNN 支持(分别是WITH_CUDA和WITH_CUDNN)。
我们还指示 OpenCV 构建支持 CUDA 的“dnn”模块(OPENCV_DNN_CUDA)。
出于优化目的,我们还使用了ENABLE_FAST_MATH、CUDA_FAST_MATH和WITH_CUBLAS。
最重要也是最容易出错的配置是你的CUDA_ARCH_BIN——确保你设置正确!
CUDA_ARCH_BIN变量必须映射到您在上一节中找到的 NVIDIA GPU 架构版本。
如果您没有正确设置这个值,OpenCV 仍然可以编译,但是当您试图使用dnn模块执行推理时,您会收到以下错误消息:
File "ssd_object_detection.py", line 74, in
detections = net.forward()
cv2.error: OpenCV(4.2.0) /home/a_rosebrock/opencv/modules/dnn/src/cuda/execution.hpp:52: error: (-217:Gpu API call) invalid device function in function 'make_policy'
如果您遇到这个错误,那么您应该知道您的CUDA_ARCH_BIN设置不正确。
您可以通过查看输出来验证您的cmake命令是否正确执行:
...
-- NVIDIA CUDA: YES (ver 10.0, CUFFT CUBLAS FAST_MATH)
-- NVIDIA GPU arch: 70
-- NVIDIA PTX archs:
--
-- cuDNN: YES (ver 7.6.0)
...
这里可以看到 OpenCV 和cmake已经正确识别了我的支持 CUDA 的 GPU,NVIDIA GPU 架构版本,以及 cuDNN 版本。
我还喜欢看OpenCV modules部分,尤其是To be built部分:
-- OpenCV modules:
-- To be built: aruco bgsegm bioinspired calib3d ccalib core cudaarithm cudabgsegm cudacodec cudafeatures2d cudafilters cudaimgproc cudalegacy cudaobjdetect cudaoptflow cudastereo cudawarping cudev datasets dnn dnn_objdetect dnn_superres dpm face features2d flann fuzzy gapi hdf hfs highgui img_hash imgcodecs imgproc line_descriptor ml objdetect optflow phase_unwrapping photo plot python3 quality reg rgbd saliency shape stereo stitching structured_light superres surface_matching text tracking ts video videoio videostab xfeatures2d ximgproc xobjdetect xphoto
-- Disabled: world
-- Disabled by dependency: -
-- Unavailable: cnn_3dobj cvv freetype java js matlab ovis python2 sfm viz
-- Applications: tests perf_tests examples apps
-- Documentation: NO
-- Non-free algorithms: YES
这里你可以看到有许多cuda*模块,表明cmake正在指示 OpenCV 构建我们的支持 CUDA 的模块(包括 OpenCV 的“dnn”模块)。
您还可以查看Python 3部分来验证您的Interpreter和numpy都指向您的 Python 虚拟环境:
-- Python 3:
-- Interpreter: /home/a_rosebrock/.virtualenvs/opencv_cuda/bin/python3 (ver 3.5.3)
-- Libraries: /usr/lib/x86_64-linux-gnu/libpython3.5m.so (ver 3.5.3)
-- numpy: /home/a_rosebrock/.virtualenvs/opencv_cuda/lib/python3.5/site-packages/numpy/core/include (ver 1.18.1)
-- install path: lib/python3.5/site-packages/cv2/python-3.5
确保你也记下了install path!
当我们完成 OpenCV 安装时,您将需要该路径。
步骤 7:用“dnn”GPU 支持编译 OpenCV
假设cmake没有错误地退出,那么您可以使用以下命令在 NVIDIA GPU 支持下编译 OpenCV:
$ make -j8
您可以用处理器上可用的内核数量替换8。
因为我的处理器有八个内核,所以我提供了一个8。如果你的处理器只有四个内核,用一个4代替8。
如您所见,我的编译没有错误地完成了:
Figure 6: CUDA GPU capable OpenCV has compiled without error. Learn how to install OpenCV with CUDA and cuDNN for your your NVIDIA GPU in this tutorial.
您可能会看到以下常见错误:
$ make
make: * No targets specified and no makefile found. Stop.
如果发生这种情况,您应该返回到步骤#6 并检查您的cmake输出——cmake命令可能因出错而退出。如果cmake出错退出,那么make的构建文件就无法生成,因此make命令报告没有可以编译的构建文件。如果发生这种情况,返回到您的cmake输出并寻找错误。
第 8 步:安装支持“dnn”GPU 的 OpenCV
假设您从步骤#7 发出的make命令成功完成,您现在可以通过以下方式安装 OpenCV:
$ sudo make install
$ sudo ldconfig
最后一步是将 OpenCV 库符号链接到 Python 虚拟环境中。
为此,您需要知道 OpenCV 绑定的安装位置——您可以通过第 6 步中的install path配置来确定路径。
在我的例子中,install path是lib/python3.5/site-packages/cv2/python-3.5。
这意味着我的 OpenCV 绑定应该在/usr/local/lib/python3.5/site-packages/cv2/python-3.5中。
我可以使用ls命令来确认位置:
$ ls -l /usr/local/lib/python3.5/site-packages/cv2/python-3.5
total 7168
-rw-r--r-
1 root staff 7339240 Jan 17 18:59 cv2.cpython-35m-x86_64-linux-gnu.so
在这里你可以看到我的 OpenCV 绑定被命名为cv2.cpython-35m-x86_64-linux-gnu.so — 你的应该有一个相似的名字,基于你的 Python 版本和 CPU 架构。
现在我知道了 OpenCV 绑定的位置,我需要使用ln命令将它们符号链接到我的 Python 虚拟环境中:
$ cd ~/.virtualenvs/opencv_cuda/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2/python-3.5/cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
花一秒到一秒的时间验证你的文件路径——如果 OpenCV 的绑定路径不正确的话,ln命令将会“无声失败”。
,还是那句话,不要盲目复制粘贴上面的命令! 再三检查你的文件路径!
步骤 9:验证 OpenCV 使用你的 GPU 和“dnn”模块
最后一步是验证:
- OpenCV 可以导入到您的终端
- OpenCV 可以通过
dnn模块访问你的 NVIDIA GPU 进行推理
让我们从验证我们可以导入cv2库开始:
$ workon opencv_cuda
$ python
Python 3.5.3 (default, Sep 27 2018, 17:25:39)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'4.2.0'
>>>
请注意,我使用了workon命令来首先访问我的 Python 虚拟环境——如果您正在使用虚拟环境,也应该这样做。
从那里我导入cv2库并显示版本。
果然,报道的 OpenCV 版本是 v4.2,这确实是我们编译的 OpenCV 版本。
接下来,让我们验证 OpenCV 的“dnn”模块可以访问我们的 GPU。确保 OpenCV 的“dnn”模块使用 GPU 的关键可以通过在模型加载后和推理执行前立即添加下面两行代码:
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
上面两行指令 OpenCV,推断要用我们的 NVIDIA GPU。
要查看 OpenCV + GPU 模型的运行示例,首先使用本教程的 【下载】 部分下载我们的示例源代码和预训练的 SSD 对象检测器。
从那里,打开一个终端并执行以下命令:
$ python ssd_object_detection.py --prototxt MobileNetSSD_deploy.prototxt \
--model MobileNetSSD_deploy.caffemodel \
--input guitar.mp4 --output output.avi \
--display 0 --use-gpu 1
[INFO] setting preferable backend and target to CUDA...
[INFO] accessing video stream...
[INFO] elasped time: 3.75
[INFO] approx. FPS: 65.90
--use-gpu 1标志指示 OpenCV 通过 OpenCV 的“dnn”模块使用我们的 NVIDIA GPU 进行推理。
正如你所看到的,我正在使用我的 NVIDIA Tesla V100 GPU 获得 ~65.90 FPS 。
然后,我可以将我的输出与只使用 CPU(即没有 GPU)的输出进行比较:
$ python ssd_object_detection.py --prototxt MobileNetSSD_deploy.prototxt \
--model MobileNetSSD_deploy.caffemodel --input guitar.mp4 \
--output output.avi --display 0
[INFO] accessing video stream...
[INFO] elasped time: 11.69
[INFO] approx. FPS: 21.13
这里我只获得了 ~21.13 FPS ,这意味着通过使用 GPU,我获得了3 倍的性能提升!
在下周的博客文章中,我将为你提供详细的代码演示。
救命啊!我遇到了“make_policy”错误
超级,超级对CUDA_ARCH_BIN变量的检查、复核、三次复核很重要。
如果设置不正确,在运行上一节中的ssd_object_detection.py脚本时,您可能会遇到以下错误:
File "real_time_object_detection.py", line 74, in
detections = net.forward()
cv2.error: OpenCV(4.2.0) /home/a_rosebrock/opencv/modules/dnn/src/cuda/execution.hpp:52: error: (-217:Gpu API call) invalid device function in function 'make_policy'
该错误表明您的CUDA_ARCH_BIN值在运行cmake时设置不正确。
你需要返回到步骤#5 (在这里你识别你的 NVIDIA CUDA 架构版本),然后重新运行cmake和make。
我也建议你删除你的build目录,在运行cmake和make之前重新创建:
$ cd ~/opencv
$ rm -rf build
$ mkdir build
$ cd build
从那里你可以重新运行cmake和make——在一个新的build目录中这样做将确保你有一个干净的构建,并且任何以前的(不正确的)配置都被删除。
摘要
在本教程中,您学习了如何在 NVIDIA GPU、CUDA 和 cuDNN 支持下编译和安装 OpenCV 的“深度神经网络”(DNN)模块,使您获得 211-1549%的推理和预测速度。
使用 OpenCV 的“dnn”模块需要您从源代码编译— 您不能在 GPU 支持下“pip 安装”OpenCV。
在下周的教程中,我将对流行的深度学习模型进行 CPU 和 GPU 推理速度的基准测试,包括:
- 单触发探测器(SSD)
- 你只看一次(YOLO)
- 屏蔽 R-CNN
使用这些信息,您将知道哪些模型使用 GPU 受益最大,从而确保您可以做出明智的决定,确定 GPU 是否是您特定项目的好选择。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
如何在 Keras 和 TensorFlow 中使用 ModelCheckpoint 回调
之前,我们讨论了如何在训练完成后将您的模型保存并序列化到磁盘上。我们还学习了如何发现正在发生的欠拟合和过拟合,使您能够取消表现不佳的实验,同时保留在训练中表现出希望的模型。
然而,你可能想知道是否有可能将这两种策略结合起来。每当我们的损失/准确性提高时,我们可以序列化模型吗?还是在训练过程中可以只连载最好的*型号(即损耗最低或精度最高的型号)?你打赌。幸运的是,我们也不需要构建一个定制的回调函数——这个功能已经内置到 Keras 中了。
要学习如何用 Keras 和 TensorFlow 使用 ModelCheckpoint 回调,继续阅读。**
如何通过 Keras 和 TensorFlow 使用 ModelCheckpoint 回调
检查点的一个很好的应用是,每当在训练期间有改进时,将您的网络序列化到磁盘。我们将“改进”定义为损失的减少或准确度的增加——我们将在实际的 Keras 回调中设置该参数。
在本例中,我们将在 CIFAR-10 数据集上训练 MiniVGGNet 架构,然后在每次模型性能提高时将我们的网络权重序列化到磁盘。首先,打开一个新文件,将其命名为cifar10_checkpoint_improvements.py,并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from pyimagesearch.nn.conv import MiniVGGNet
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import argparse
import os
第 2-8 行导入我们需要的 Python 包。请注意在行 4 上导入的ModelCheckpoint类——这个类将使我们能够在发现模型性能有所提高时检查点并序列化我们的网络到磁盘。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-w", "--weights", required=True,
help="path to weights directory")
args = vars(ap.parse_args())
我们需要的唯一命令行参数是--weights,它是输出目录的路径,该目录将在训练过程中存储我们的序列化模型。然后,我们执行从磁盘加载 CIFAR-10 数据集的标准例程,将像素强度缩放到范围[0, 1],然后对标签进行一次性编码:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
给定我们的数据,我们现在准备初始化我们的 SGD 优化器以及 MiniVGGNet 架构:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
我们将使用初始学习率为 α = 0 的 SGD 优化器。然后在 40 个时期的过程中缓慢衰减。我们也将应用一个动量 γ = 0 。 9,表示也应使用内斯特罗夫加速度。
MiniVGGNet 架构被实例化为接受宽度为 32 像素、高度为 32 像素、深度为 3(通道数)的输入图像。我们设置classes=10,因为 CIFAR-10 数据集有十个可能的类标签。
对我们的网络进行检查点操作的关键步骤可以在下面的代码块中找到:
# construct the callback to save only the *best* model to disk
# based on the validation loss
fname = os.path.sep.join([args["weights"],
"weights-{epoch:03d}-{val_loss:.4f}.hdf5"])
checkpoint = ModelCheckpoint(fname, monitor="val_loss", mode="min",
save_best_only=True, verbose=1)
callbacks = [checkpoint]
在的第 37 行和第 38 行,我们构造了一个特殊的文件名(fname)模板字符串,Keras 在将我们的模型写到磁盘时使用它。模板中的第一个变量{epoch:03d}是我们的纪元编号,写成三位数。
第二个变量是我们想要监控改进的度量,{val_loss:.4f},即在当前时期设置的验证损失本身。当然,如果我们想监控验证的准确性,我们可以用val_acc代替val_loss。相反,如果我们想要监控训练损失和准确性,变量将分别变成train_loss和train_acc(尽管我会建议监控您的验证度量,因为它们会让您更好地了解您的模型将如何概括)。
一旦定义了输出文件名模板,我们就在第 39 行和第 40 行的上实例化ModelCheckpoint类。ModelCheckpoint的第一个参数是代表文件名模板的字符串。然后我们把我们想要的传递给monitor。在这种情况下,我们希望监控验证损失(val_loss)。
mode参数控制ModelCheckpoint是否应该寻找使最小化我们的度量或者最大化的值。既然我们正在处理损失,越低越好,所以我们设置mode="min"。如果我们改为使用val_acc,我们将设置mode="max"(因为精度越高越好)。
设置save_best_only=True确保最新的最佳模型(根据监控的指标)不会被覆盖。最后,当一个模型在训练期间被序列化到磁盘时,verbose=1设置简单地记录一个通知到我们的终端。
第 41 行然后构造一个callbacks列表——我们唯一需要的回调是我们的checkpoint。
最后一步是简单地训练网络,让我们的checkpoint去处理剩下的事情:
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=64, epochs=40, callbacks=callbacks, verbose=2)
要执行我们的脚本,只需打开一个终端并执行以下命令:
$ python cifar10_checkpoint_improvements.py --weights weights/improvements
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/40
171s - loss: 1.6700 - acc: 0.4375 - val_loss: 1.2697 - val_acc: 0.5425
Epoch 2/40
Epoch 00001: val_loss improved from 1.26973 to 0.98481, saving model to test/
weights-001-0.9848.hdf5
...
Epoch 40/40
Epoch 00039: val_loss did not improve
315s - loss: 0.2594 - acc: 0.9075 - val_loss: 0.5707 - val_acc: 0.8190
正如我们可以从我的终端输出和图 1 中看到的,每次验证损失减少时,我们都会将新的序列化模型保存到磁盘上。
在培训过程结束时,我们有 18 个单独的文件,每个文件代表一个增量改进:
$ find ./ -printf "%f\n" | sort
./
weights-000-1.2697.hdf5
weights-001-0.9848.hdf5
weights-003-0.8176.hdf5
weights-004-0.7987.hdf5
weights-005-0.7722.hdf5
weights-006-0.6925.hdf5
weights-007-0.6846.hdf5
weights-008-0.6771.hdf5
weights-009-0.6212.hdf5
weights-012-0.6121.hdf5
weights-013-0.6101.hdf5
weights-014-0.5899.hdf5
weights-015-0.5811.hdf5
weights-017-0.5774.hdf5
weights-019-0.5740.hdf5
weights-022-0.5724.hdf5
weights-024-0.5628.hdf5
weights-033-0.5546.hdf5
如您所见,每个文件名都有三个组成部分。第一个是静态字符串, weights 。然后我们有了纪元编号。文件名的最后一部分是我们衡量改进的指标,在本例中是验证损失。
我们最好的验证损失是在第 33 个时段获得的,值为 0 。 5546。然后我们可以把这个模型从磁盘上载入。
请记住,你的结果将不会匹配我的,因为网络是随机的,并用随机变量初始化。根据初始值的不同,您可能会有显著不同的模型检查点,但在训练过程结束时,我们的网络应该会获得类似的准确性(几个百分点)。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
只检查最佳神经网络
也许检查点增量改进的最大缺点是,我们最终会得到一堆我们(不太可能)感兴趣的额外文件,如果我们的验证损失在训练时期上下波动,这种情况尤其如此——这些增量改进中的每一个都将被捕获并序列化到磁盘上。在这种情况下,最好只保存一个模型,并在训练期间每次我们的指标提高时,简单地覆盖它。
幸运的是,完成这个动作很简单,只需更新ModelCheckpoint类来接受一个简单字符串(即,一个没有任何模板变量的文件路径)。然后,每当我们的指标提高时,该文件就会被简单地覆盖。为了理解这个过程,让我们创建第二个名为cifar10_checkpoint_best.py的 Python 文件,并回顾一下其中的区别。
首先,我们需要导入所需的 Python 包:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from pyimagesearch.nn.conv import MiniVGGNet
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import argparse
然后解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-w", "--weights", required=True,
help="path to best model weights file")
args = vars(ap.parse_args())
命令行参数本身的名称是相同的(--weights),但是开关的描述现在是不同的:“路径到最佳模型权重文件”因此,这个命令行参数将是一个输出路径的简单字符串——没有模板应用于这个字符串。
从那里,我们可以加载我们的 CIFAR-10 数据集,并为训练做准备:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
以及初始化我们的 SGD 优化器和 MiniVGGNet 架构:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
我们现在准备更新ModelCheckpoint代码:
# construct the callback to save only the *best* model to disk
# based on the validation loss
checkpoint = ModelCheckpoint(args["weights"], monitor="val_loss",
save_best_only=True, verbose=1)
callbacks = [checkpoint]
注意fname模板字符串是如何消失的——我们所做的就是将--weights的值提供给ModelCheckpoint。由于没有需要填写的模板值,每当我们的监控指标提高时(在这种情况下,验证损失),Keras 将简单地覆盖现有的序列化权重文件。
最后,我们在网络上训练下面的代码块:
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=64, epochs=40, callbacks=callbacks, verbose=2)
要执行我们的脚本,发出以下命令:
$ python cifar10_checkpoint_best.py \
--weights weights/best/cifar10_best_weights.hdf5
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/40
Epoch 00000: val_loss improved from inf to 1.26677, saving model to
test_best/cifar10_best_weights.hdf5
305s - loss: 1.6657 - acc: 0.4441 - val_loss: 1.2668 - val_acc: 0.5584
Epoch 2/40
Epoch 00001: val_loss improved from 1.26677 to 1.21923, saving model to
test_best/cifar10_best_weights.hdf5
309s - loss: 1.1996 - acc: 0.5828 - val_loss: 1.2192 - val_acc: 0.5798
...
Epoch 40/40
Epoch 00039: val_loss did not improve
173s - loss: 0.2615 - acc: 0.9079 - val_loss: 0.5511 - val_acc: 0.8250
在这里,您可以看到,如果我们的验证损失减少,我们仅使用更新的网络覆盖我们的cifar10_best_weights.hdf5文件。这有两个主要好处:
- 训练过程的最后只有一个序列化文件——获得最低损失的模型历元。
- 我们没有捕捉到亏损上下波动的“增量改善”。相反,如果我们的度量获得的损失低于所有之前的时期,我们只保存和覆盖现有的最佳模型。
为了证实这一点,请看一下我的weights/best目录,在那里您可以看到只有一个输出文件:
$ ls -l weights/best/
total 17024
-rw-rw-r-- 1 adrian adrian 17431968 Apr 28 09:47 cifar10_best_weights.hdf5
然后,您可以获取这个序列化的 MiniVGGNet,并根据测试数据对其进行进一步评估,或者将其应用到您自己的映像中。
总结
在本教程中,我们回顾了如何监控给定的指标(例如,验证损失、验证准确性等。)然后将高性能网络保存到磁盘。在 Keras 中有两种方法可以实现这一点:
- 检查点增量改进。
- 检查点仅流程中找到的最佳模型。
就个人而言,我更喜欢后者而不是前者,因为它产生更少的文件和一个表示在训练过程中找到的最佳时期的输出文件。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
基于 OpenCV 和深度学习的人体行为识别
原文:https://pyimagesearch.com/2019/11/25/human-activity-recognition-with-opencv-and-deep-learning/
在本教程中,您将学习如何使用 OpenCV 和深度学习来执行人体活动识别。
我们的人体活动识别模型可以识别超过 400 个活动的, 78.4-94.5%的准确率(取决于任务)。
**活动示例如下:
人类活动识别的实际应用包括:
- 对磁盘上的视频数据集进行自动分类。
- 培训和监督新员工正确执行任务(例如制作比萨饼时的正确步骤和程序,包括擀面团、加热烤箱、放上调味汁、奶酪、浇头等。).
- 验证餐饮服务人员在去洗手间或处理可能导致交叉污染的食物后是否洗手(即鸡肉和沙门氏菌)。
- 监控酒吧/餐厅顾客,确保他们不会被过度服务。
要学习如何用 OpenCV 和深度学习进行人体活动识别,继续阅读!
基于 OpenCV 和深度学习的人体行为识别
在本教程的第一部分,我们将讨论动力学数据集,该数据集用于训练我们的人类活动识别模型。
在那里,我们将讨论如何扩展 ResNet,它通常使用 2D 内核,而不是利用 3D 内核,使我们能够包括用于活动识别的时空组件。
然后,我们将使用 OpenCV 库和 Python 编程语言实现两个版本的人类活动识别。
最后,我们将通过查看将人类活动识别应用于几个示例视频的结果来结束本教程。
动力学数据集

Figure 1: The pre-trained human activity recognition deep learning model used in today’s tutorial was trained on the Kinetics 400 dataset.
我们的人类活动识别模型被训练的数据集是 Kinetics 400 数据集。
该数据集包括:
- 400 个人类活动识别类
- 每堂课至少 400 个视频剪辑(通过 YouTube 下载)
- 总共 30 万个视频
你可以在这里查看模型可以识别的类的完整列表。
要了解更多关于数据集的信息,包括它是如何策划的,请务必参考凯等人 2017 年的论文, 《动力学人体动作视频数据集 》。
用于人体活动识别的 3D ResNet
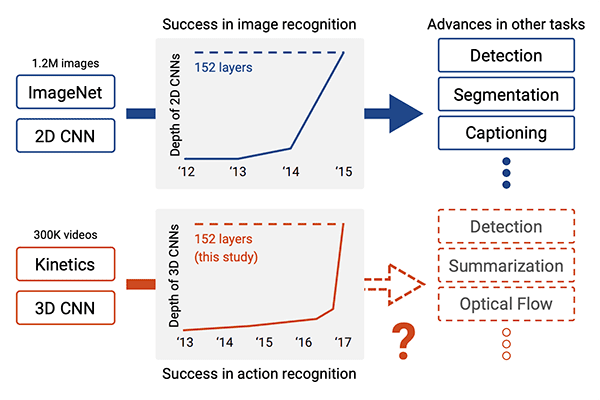
Figure 2: Deep neural network advances on image classification with ImageNet have also led to success in deep learning activity recognition (i.e. on videos). In this tutorial, we perform deep learning activity recognition with OpenCV. (image source: Figure 1 from Hara et al.)
我们正在使用的人体活动识别模型来自 Hara 等人 2018 年的 CVPR 论文, 时空 3D CNNs 能否追溯 3D CNNs 和 ImageNet 的历史?
在这项工作中,作者探索了现有的最先进的 2D 架构(如 ResNet,ResNeXt,DenseNet 等)。)可以通过 3D 内核扩展到视频分类。
作者认为:
- 这些体系结构已经成功地应用于图像分类。
- 大规模 ImageNet 数据集允许这样的模型被训练到如此高的精度。
- 动力学数据集也足够大。
…因此,这些架构应该能够通过(1)改变输入体积形状以包括时空信息和(2)利用架构内部的 3D 内核来执行视频分类。
作者事实上是正确的!
通过修改输入体积形状和内核形状,作者获得:
- 动力学测试集的准确率为 78.4%
- 在 UCF-101 测试集上的准确率为 94.5%
- 在 HMDB-51 测试集上的准确率为 70.2%
这些结果类似于在 ImageNet 上训练的最先进模型上报告的等级 1 精度,从而证明这些模型架构可以用于视频分类,只需包括时空信息并将 2D 核替换为 3D 核。
有关我们改进的 ResNet 架构、实验设计和最终精度的更多信息,请务必参考该论文。
为 OpenCV 下载人体活动识别模型
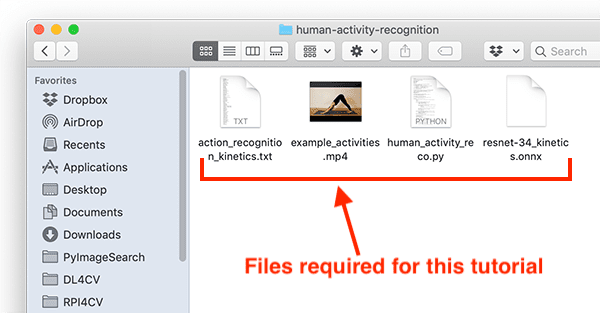
Figure 3: Files required for human activity recognition with OpenCV and deep learning.
要完成本教程的其余部分,您需要下载:
- 人类活动模型
- Python + OpenCV 源代码
- 用于分类的示例视频
你可以使用本教程的 【下载】 部分下载包含这三个文件的. zip 文件。
下载完成后,继续本教程的剩余部分。
项目结构
让我们检查我们的项目文件:
$ tree
.
├── action_recognition_kinetics.txt
├── resnet-34_kinetics.onnx
├── example_activities.mp4
├── human_activity_reco.py
└── human_activity_reco_deque.py
0 directories, 5 files
我们的项目由三个辅助文件组成:
action_recognition_kinetics.txt:动力学数据集的类别标签。resnet-34_kinetics.onx: Hara 等人在 Kinetics 数据集上训练的预训练和序列化的人体活动识别卷积神经网络。example_activities.mp4:测试人体活动识别的剪辑汇编。
我们将回顾两个 Python 脚本,每个脚本都接受上述三个文件作为输入:
human_activity_reco.py:我们的人体活动识别脚本,它一次采样 N 帧,以进行活动分类预测。human_activity_reco_deque.py:一个类似的人类活动识别脚本,实现了一个滚动平均队列。此脚本运行速度较慢;但是,我提供了实现,以便您可以从中学习和体验。
用 OpenCV 实现人体行为识别
让我们继续用 OpenCV 实现人类活动识别。我们的实现是基于 OpenCV 的官方例子;然而,我已经提供了额外的修改(在这个例子和下一个例子中),以及关于代码正在做什么的额外注释/详细解释。
打开项目结构中的human_activity_reco.py文件,插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import sys
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained human activity recognition model")
ap.add_argument("-c", "--classes", required=True,
help="path to class labels file")
ap.add_argument("-i", "--input", type=str, default="",
help="optional path to video file")
args = vars(ap.parse_args())
我们从第 2-6 行的导入开始。对于今天的教程,你需要安装 OpenCV 4 和 imutils。如果您还没有安装 opencv,请访问我的 pip install opencv 说明在您的系统上安装 OpenCV。
第 10-16 行 解析我们的命令行参数:
--model:训练好的人类活动识别模型的路径。--classes:活动识别类标签文件的路径。--input:输入视频文件的可选路径。如果命令行中不包含此参数,将调用您的网络摄像机。
从这里开始,我们将执行初始化:
# load the contents of the class labels file, then define the sample
# duration (i.e., # of frames for classification) and sample size
# (i.e., the spatial dimensions of the frame)
CLASSES = open(args["classes"]).read().strip().split("\n")
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
第 21 行从文本文件中加载我们的类标签。
第 22 行和第 23 行定义了样本持续时间(即用于分类的帧数)和样本大小(即帧的空间尺寸)。
接下来,我们将加载并初始化我们的人类活动识别模型:
# load the human activity recognition model
print("[INFO] loading human activity recognition model...")
net = cv2.dnn.readNet(args["model"])
# grab a pointer to the input video stream
print("[INFO] accessing video stream...")
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
第 27 行使用 OpenCV 的 DNN 模块读取 PyTorch 预训练的人体活动识别模型。
然后使用视频文件或网络摄像头实例化我们的视频流。
我们现在准备开始循环帧并执行人体活动识别:
# loop until we explicitly break from it
while True:
# initialize the batch of frames that will be passed through the
# model
frames = []
# loop over the number of required sample frames
for i in range(0, SAMPLE_DURATION):
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we've reached the end of
# the video stream so exit the script
if not grabbed:
print("[INFO] no frame read from stream - exiting")
sys.exit(0)
# otherwise, the frame was read so resize it and add it to
# our frames list
frame = imutils.resize(frame, width=400)
frames.append(frame)
第 34 行开始在我们的帧上循环,首先我们初始化将通过神经网络传递的那批frames(第 37 行)。
从那里,行 40-53 直接从我们的视频流中填充一批frames。线 52 在保持纵横比的同时,将每一帧的大小调整为一个400像素的width。
让我们构建我们的blob输入帧,我们将很快通过人类活动识别 CNN:
# now that our frames array is filled we can construct our blob
blob = cv2.dnn.blobFromImages(frames, 1.0,
(SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750),
swapRB=True, crop=True)
blob = np.transpose(blob, (1, 0, 2, 3))
blob = np.expand_dims(blob, axis=0)
第 56-60 行从我们的输入frames列表中构造一个blob。
请注意,我们使用的是blobFromImages(即复数)而不是blobFromImage(即单数)函数——这里的原因是我们正在构建一批多幅图像以通过人类活动识别网络,使其能够利用时空信息。
如果您要在代码中插入一个print(blob.shape)语句,您会注意到blob具有以下维度:
(1, 3, 16, 112, 112)
让我们更深入地分析一下这个维度:
1:批量维度。这里我们只有一个正在通过网络传递的单个数据点(本文中的“数据点”是指将通过网络传递以获得单个分类的 N 个帧)。3:我们输入帧中的通道数。16:blob中frames的总数。112(第一次出现):帧的高度。112(第二次出现):帧的宽度。
此时,我们准备好执行人类活动识别推理,然后用预测标签注释帧,并在屏幕上显示预测:
# pass the blob through the network to obtain our human activity
# recognition predictions
net.setInput(blob)
outputs = net.forward()
label = CLASSES[np.argmax(outputs)]
# loop over our frames
for frame in frames:
# draw the predicted activity on the frame
cv2.rectangle(frame, (0, 0), (300, 40), (0, 0, 0), -1)
cv2.putText(frame, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.8, (255, 255, 255), 2)
# display the frame to our screen
cv2.imshow("Activity Recognition", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
行 64 和 65 通过网络传递blob,获得一个outputs列表,即预测。
然后我们为blob ( 第 66 行)抓取最高预测的label。
使用label,我们可以对frames列表中的每一帧进行预测(第 69-73 行),显示输出帧,直到按下q键,此时我们break退出。
使用 Deque 数据结构的替代人工活动实现
在上一节的人类活动识别中,您会注意到下面几行:
# loop until we explicitly break from it
while True:
# initialize the batch of frames that will be passed through the
# model
frames = []
# loop over the number of required sample frames
for i in range(0, SAMPLE_DURATION):
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we've reached the end of
# the video stream so exit the script
if not grabbed:
print("[INFO] no frame read from stream - exiting")
sys.exit(0)
# otherwise, the frame was read so resize it and add it to
# our frames list
frame = imutils.resize(frame, width=400)
frames.append(frame)
这种实现意味着:
- 我们从输入视频中读取总共
SAMPLE_DURATION帧。 - 我们将这些帧通过我们的人类活动识别模型来获得输出。
- 然后我们读取另一个
SAMPLE_DURATION帧并重复这个过程。
因此,我们的实现是而不是一个滚动预测。
相反,它只是抓取一个帧样本,对它们进行分类,然后进入下一批——前一批中的任何帧都被丢弃。
我们这样做的原因是为了 速度 。
如果我们对每个单独的帧进行分类,那么脚本运行的时间会更长。
也就是说,通过队列数据结构 使用滚动帧预测可以产生更好的结果,因为它不会丢弃所有先前的帧——滚动帧预测仅丢弃列表中最老的帧,为最新的帧腾出空间。
为了了解这如何导致与推断速度相关的问题,让我们假设一个视频文件中有N个总帧数:
- 如果我们使用滚动帧预测,我们执行
N分类,每个帧一个分类(当然,一旦deque数据结构被填充) - 如果我们不使用滚动帧预测,我们只需执行
N / SAMPLE_DURATION分类,从而显著减少处理视频流所需的时间。
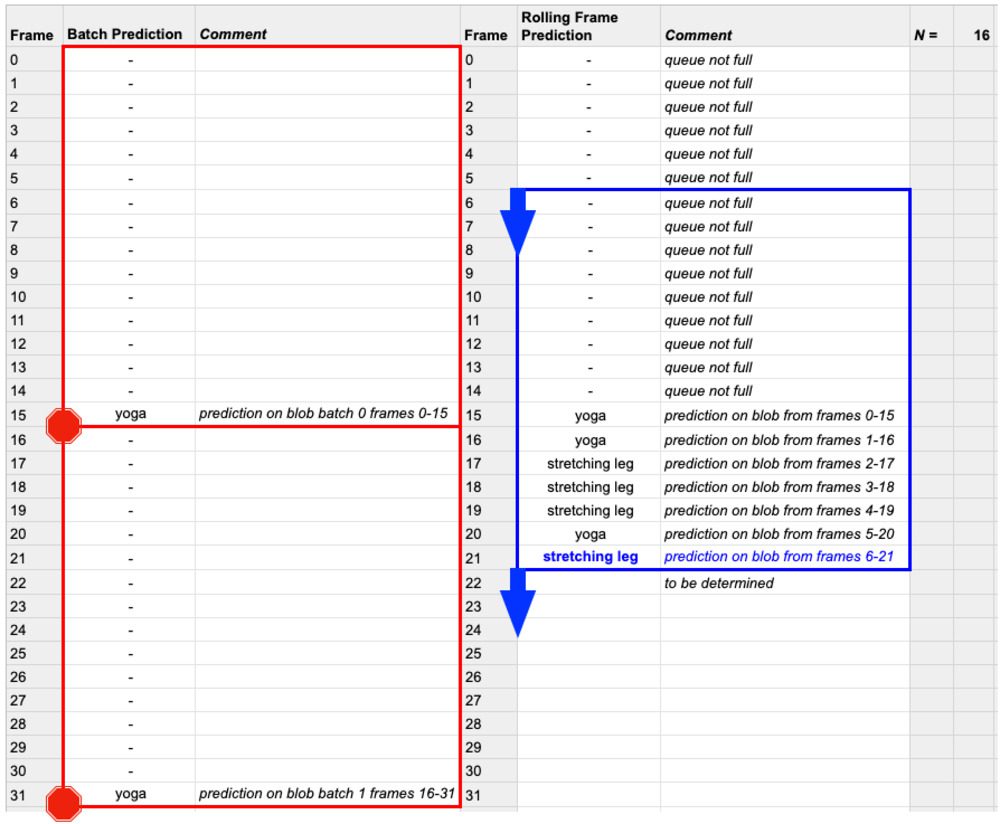
Figure 4: Rolling prediction (blue) uses a fully populated FIFO queue window to make predictions. Batch prediction (red) does not “roll” from frame to frame. Rolling prediction requires more computational horsepower but leads to better results for human activity recognition with OpenCV and deep learning.
鉴于 OpenCV 的dnn模块不支持大多数 GPU(包括 NVIDIA GPUs),我会建议你不要对大多数应用使用滚动帧预测。
也就是说在。今天教程的 zip 文件(可以在帖子的 “下载” 部分找到)你会发现一个名为human_activity_reco_deque.py的文件——这个文件包含了一个人体活动识别的实现,这个识别是执行滚动帧预测的。
该脚本与上一个脚本非常相似,但是我在这里包含它是为了让您进行试验:
# import the necessary packages
from collections import deque
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained human activity recognition model")
ap.add_argument("-c", "--classes", required=True,
help="path to class labels file")
ap.add_argument("-i", "--input", type=str, default="",
help="optional path to video file")
args = vars(ap.parse_args())
# load the contents of the class labels file, then define the sample
# duration (i.e., # of frames for classification) and sample size
# (i.e., the spatial dimensions of the frame)
CLASSES = open(args["classes"]).read().strip().split("\n")
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
# initialize the frames queue used to store a rolling sample duration
# of frames -- this queue will automatically pop out old frames and
# accept new ones
frames = deque(maxlen=SAMPLE_DURATION)
# load the human activity recognition model
print("[INFO] loading human activity recognition model...")
net = cv2.dnn.readNet(args["model"])
# grab a pointer to the input video stream
print("[INFO] accessing video stream...")
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
除了 Python 内置的来自collections模块的deque实现(行 2 )之外,导入是相同的。
在第 28 行上,我们初始化 FIFO frames队列,其最大长度等于我们的样本持续时间。我们的“先进先出”(FIFO)队列将自动弹出旧帧并接受新帧。我们将对帧队列执行滚动推理。
上面的所有其他行都是一样的,所以现在让我们检查一下我们的帧处理循环:
# loop over frames from the video stream
while True:
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we've reached the end of
# the video stream so break from the loop
if not grabbed:
print("[INFO] no frame read from stream - exiting")
break
# resize the frame (to ensure faster processing) and add the
# frame to our queue
frame = imutils.resize(frame, width=400)
frames.append(frame)
# if our queue is not filled to the sample size, continue back to
# the top of the loop and continue polling/processing frames
if len(frames) < SAMPLE_DURATION:
continue
第 41-57 行与我们之前的脚本不同。
之前,我们对一批SAMPLE_DURATION帧进行了采样,稍后将对该批帧进行推断。
在这个脚本中,我们仍然批量执行推理;不过,现在是滚批。不同之处在于,我们将帧添加到第 52 行的【FIFO 队列中。同样,这个队列有一个我们的采样持续时间的maxlen,队列的头将总是我们视频流的当前frame。一旦队列填满,旧帧会自动弹出,并执行队列 FIFO。
这种滚动实现的结果是,一旦队列满了,任何给定的帧(除了第一帧之外)都将被“触摸”(即包括在滚动批次中)不止一次。这种方法效率较低;然而,它导致更准确的活动识别,尤其是当视频/场景的活动周期性变化时。
行 56 和 57 允许我们的frames队列在执行任何推断之前填满(即图 4、蓝色所示的 16 帧)。
一旦队列满了,我们将执行滚动的人类活动识别预测:
# now that our frames array is filled we can construct our blob
blob = cv2.dnn.blobFromImages(frames, 1.0,
(SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750),
swapRB=True, crop=True)
blob = np.transpose(blob, (1, 0, 2, 3))
blob = np.expand_dims(blob, axis=0)
# pass the blob through the network to obtain our human activity
# recognition predictions
net.setInput(blob)
outputs = net.forward()
label = CLASSES[np.argmax(outputs)]
# draw the predicted activity on the frame
cv2.rectangle(frame, (0, 0), (300, 40), (0, 0, 0), -1)
cv2.putText(frame, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.8, (255, 255, 255), 2)
# display the frame to our screen
cv2.imshow("Activity Recognition", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
该代码块包含与我们之前的脚本相同的代码行。在这里我们:
- 从我们的
frames队列中构造一个blob。 - 执行推理并抓取
blob的最高概率预测。 - 用滚动平均人体活动识别的结果
label注释并显示当前frame。 - 按下
q键后退出。
人类活动识别结果
让我们看看我们的人类活动识别代码的实际效果!
使用本教程的 “下载” 部分下载预先训练好的人体活动识别模型、Python + OpenCV 源代码和示例演示视频。
从那里,打开一个终端并执行以下命令:
$ python human_activity_reco_deque.py --model resnet-34_kinetics.onnx \
--classes action_recognition_kinetics.txt \
--input example_activities.mp4
[INFO] loading human activity recognition model...
[INFO] accessing video stream...
请注意,我们的人体活动识别模型要求至少是 OpenCV 4.1.2。
如果您运行的是旧版本的 OpenCV,您将收到以下错误:
net = cv2.dnn.readNet(args["model"])
cv2.error: OpenCV(4.1.0) /Users/adrian/build/skvark/opencv-python/opencv/modules/dnn/src/onnx/onnx_importer.cpp:245: error: (-215:Assertion failed) attribute_proto.ints_size() == 2 in function 'getLayerParams'
如果您收到该错误,您需要将 OpenCV 安装程序至少升级到 OpenCV 4.1.2。
下面是一个例子,我们的模型正确地将一个输入视频剪辑标记为“yoga”
注意模型如何在【瑜伽】和【伸展腿】之间来回摆动——这两种姿势在技术上都是正确的,因为按照定义,你在做瑜伽,但同时也在伸展你的腿。
在下一个示例中,我们的人类活动识别模型正确地将该视频预测为“滑板”:
你可以看到为什么这个模型也预测了“跑酷”——溜冰者正在跳过栏杆,这类似于公园游客可能会做的动作。
有人饿了吗?
如果是这样,你可能会对“做披萨”感兴趣:
但是在你吃饭之前,在你坐下来吃饭之前,确保你已经“洗手”了:
如果你选择沉迷于【喝啤酒】你最好注意你喝了多少——酒保可能会打断你:**
使用 scikit-learn、Keras 和 TensorFlow 进行深度学习的超参数调整
在本教程中,您将学习如何使用 scikit-learn、Keras 和 TensorFlow 来调整深度神经网络的超参数。
本教程是我们关于超参数调优的四部分系列的第三部分:
- 使用 scikit-learn 和 Python 进行超参数调优的介绍(本系列的第一篇教程)
- 【网格搜索超参数调优用 scikit-learn(GridSearchCV)(上周教程)
- 使用 scikit-learn、Keras 和 TensorFlow 进行深度学习的超参数调优(今天的帖子)
- 使用 Keras 调谐器和 TensorFlow 进行简单的超参数调谐(下周发布)
当训练一个深度神经网络时,优化你的超参数是非常关键的。一个网络有许多旋钮、转盘和参数——更糟糕的是,网络本身不仅对训练构成挑战,而且对训练也很慢(即使有 GPU 加速)。
未能正确优化深度神经网络的超参数可能会导致性能不佳。幸运的是,有一种方法可以让我们搜索超参数搜索空间,并自动找到最优值—我们今天将介绍这些方法。
*要了解如何用 scikit-learn、Keras、TensorFlow、 将超参数调至深度学习模型,只需继续阅读。
使用 scikit-learn、Keras 和 TensorFlow 进行深度学习的超参数调整
在本教程的第一部分,我们将讨论深度学习和超参数调整的重要性。我还将向您展示 scikit-learn 的超参数调节功能如何与 Keras 和 TensorFlow 接口。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
从这里,我们将实现两个 Python 脚本:
- 一种是通过用 no 超参数调谐来训练基本多层感知器(MLP)来建立基线
- 另一个搜索超参数空间,导致更精确的模型
我们将讨论我们的结果来结束本教程。
如何用 scikit-learn 调优深度学习超参数模型?
这篇关于神经网络超参数调整的教程是从 PyImageSearch 读者 Abigail 给我的一个问题中得到启发的:
嗨,阿德里安,
感谢所有关于神经网络的教程。我有一些关于选择/构建架构的问题:
- 您如何“知道”给定层中要使用的节点数量?
- 如何选择学习率?
- 最佳批量是多少?
- 你怎么知道网络要训练多少个纪元?
If you could shed some light on that, I would really appreciate it.”
通常,有三种方法可以设置这些值:
- 什么都不做(只是猜测):这是很多初学机器学习的从业者都会做的事情。他们阅读书籍、教程或指南,了解其他架构使用的内容,然后简单地复制并粘贴到自己的代码中。有时这行得通,有时行不通— 但是在几乎所有的情况下,不调整超参数会留下一些误差。
- 依靠你的经验:训练一个深度神经网络,一部分是艺术,一部分是科学。一旦你训练了 100 或 1000 个神经网络,你就开始发展一种第六感,知道什么可行,什么不可行。问题是,达到这一水平需要很长时间(当然,会有你的直觉不正确的情况)。
- 用算法调整你的超参数:这是你找到最佳超参数的简单方法。是的,由于需要运行 100 次甚至 1000 次的试验,这有点耗时,但您肯定会得到一些改进。
*今天,我们将学习如何调整神经网络的以下超参数:
- 层中的节点数
- 学习率
- 辍学率
- 批量
- 为之训练的时代
我们将通过以下方式完成这项任务:
- 实现基本的神经网络架构
- 定义要搜索的超参数空间
- 从
tensorflow.keras.wrappers.scikit_learn子模块实例化KerasClassifier的实例 - 通过 scikit-learn 的
RandomizedSearchCV类在超参数和模型架构上运行随机搜索
到本指南结束时,我们将把精确度从 78.59% (无超参数调整)提高到 98.28% (有超参数调整的)。
配置您的开发环境
这个超参数调优教程需要 Keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都有助于在一个方便的 Python 虚拟环境中为您的系统配置这篇博客文章所需的所有软件。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们实现任何代码之前,让我们首先确保理解我们的项目目录结构。
请务必访问本指南的 “下载” 部分以检索源代码。
然后,您将看到以下目录结构:
$ tree . --dirsfirst
.
├── pyimagesearch
│ └── mlp.py
├── random_search_mlp.py
└── train.py
1 directory, 3 files
在pyimagesearch模块中,我们有一个单独的文件mlp.py。这个脚本包含get_mlp_model,它接受几个参数,然后构建一个多层感知器(MLP)架构。它接受的参数将由我们的超参数调整算法设置,从而允许我们以编程方式调整网络的内部参数。
为了建立一个没有超参数调整的基线,我们将使用train.py脚本创建我们的 MLP 的一个实例,然后在 MNIST 数字数据集上训练它。
一旦我们的基线建立,我们将通过random_search_mlp.py执行随机超参数搜索。
如本教程的结果部分所示,超参数搜索会导致大规模的准确性—** 增加 20%!****
增加 20%!****
*### 实现我们的基本前馈神经网络
为了调整神经网络的超参数,我们首先需要定义模型架构。在模型架构中,我们将包含给定层中节点数量和辍学率的变量。
我们还将包括优化器本身的学习率。
该模型一旦构建,将被返回到超参数调谐器。然后,调谐器将根据我们的训练数据拟合神经网络,对其进行评估,并返回分数。
所有试验完成后,超参数调谐器将告诉我们哪些超参数提供了最佳精度。
但是这一切都是从实现模型架构本身开始的。在pyimagesearch模块中打开mlp.py文件,让我们开始工作:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
第 2-6 行导入我们需要的 Python 包。这些都是构建基本前馈神经网络的相当标准的输入。如果你需要学习用 Keras/TensorFlow 构建神经网络的基础知识,我推荐阅读这个教程。
现在让我们定义我们的get_mlp_model函数,它负责接受我们想要测试的超参数,构建神经网络,并返回它:
def get_mlp_model(hiddenLayerOne=784, hiddenLayerTwo=256,
dropout=0.2, learnRate=0.01):
# initialize a sequential model and add layer to flatten the
# input data
model = Sequential()
model.add(Flatten())
我们的get_mlp_model接受四个参数,包括:
hiddenLayerOne:第个全连通层的节点数hiddenLayerTwo:第第二全连通层的节点数dropout:全连接层之间的脱落率(有助于减少过度拟合)learnRate:Adam 优化器的学习率
12-13 线开始建造model建筑。
让我们继续在下面的代码块中构建架构:
# add two stacks of FC => RELU => DROPOUT
model.add(Dense(hiddenLayerOne, activation="relu",
input_shape=(784,)))
model.add(Dropout(dropout))
model.add(Dense(hiddenLayerTwo, activation="relu"))
model.add(Dropout(dropout))
# add a softmax layer on top
model.add(Dense(10, activation="softmax"))
# compile the model
model.compile(
optimizer=Adam(learning_rate=learnRate),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
# return compiled model
return model
第 16-20 行定义了两堆FC => RELU => DROPOUT层。
注意,我们在构建架构时使用了hiddenLayerOne、hiddenLayerTwo和dropout层。将这些值中的每一个编码为变量允许我们在执行超参数搜索时向get_mlp_model提供不同的值。这样做是 scikit-learn 如何将超参数调整到 Keras/TensorFlow 模型的“魔法”。
第 23 行在我们最终的 FC 层上添加了一个 softmax 分类器。
然后,我们使用 Adam 优化器和指定的learnRate(将通过我们的超参数搜索进行调整)来编译模型。
得到的模型返回到第 32 行上的调用函数。
创建我们的基本训练脚本( 否 超参数调优)
在我们执行超参数搜索之前,让我们首先获得一个没有超参数调整的基线。这样做将会给我们一个基线准确度分数,让我们去超越。
打开项目目录结构中的train.py文件,让我们开始工作:
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch.mlp import get_mlp_model
from tensorflow.keras.datasets import mnist
第 2 行和第 3 行导入 TensorFlow 库并修复随机种子。固定随机种子有助于(但不一定保证)更好的再现性。
请记住,神经网络是随机算法,这意味着有一点随机性,特别是在:
- 层初始化(从随机分布初始化神经网络中的节点)
- 训练和测试集拆分
- 数据批处理过程中注入的任何随机性
使用固定种子有助于通过确保至少层初始化随机性是一致的(理想情况下)来提高可再现性。
从那里,我们加载 MNIST 数据集:
# load the MNIST dataset
print("[INFO] downloading MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
如果这是您第一次使用 Keras/TensorFlow,那么 MNIST 数据集将被下载并缓存到您的磁盘中。
然后,我们将训练和测试图像中的像素强度从范围【0,255】缩放到【0,1】,这是使用神经网络时常见的预处理技术。
现在让我们训练我们的基本前馈网络:
# initialize our model with the default hyperparameter values
print("[INFO] initializing model...")
model = get_mlp_model()
# train the network (i.e., no hyperparameter tuning)
print("[INFO] training model...")
H = model.fit(x=trainData, y=trainLabels,
validation_data=(testData, testLabels),
batch_size=8,
epochs=20)
# make predictions on the test set and evaluate it
print("[INFO] evaluating network...")
accuracy = model.evaluate(testData, testLabels)[1]
print("accuracy: {:.2f}%".format(accuracy * 100))
第 19 行调用get_mlp_model函数,用默认选项构建我们的神经网络(我们稍后将通过超参数搜索调整学习率、辍学率和隐藏层节点数)。
第 23-26 行训练我们的神经网络。
然后,我们通过第 30 和 31 行在我们的测试集上评估模型的准确性。
在执行超参数搜索时,这一准确度将作为我们需要超越的基线。
获得基线精度
在我们为我们的网络调整超参数之前,让我们先用我们的“默认”配置获得一个基线(即,根据我们的经验,我们认为会产生良好精度的超参数)。
通过访问本教程的 【下载】 部分来检索源代码。
从那里,打开一个 shell 并执行以下命令:
$ time python train.py
Epoch 1/20
7500/7500 [==============================] - 18s 2ms/step - loss: 0.8881 - accuracy: 0.7778 - val_loss: 0.4856 - val_accuracy: 0.9023
Epoch 2/20
7500/7500 [==============================] - 17s 2ms/step - loss: 0.6887 - accuracy: 0.8426 - val_loss: 0.4591 - val_accuracy: 0.8658
Epoch 3/20
7500/7500 [==============================] - 17s 2ms/step - loss: 0.6455 - accuracy: 0.8466 - val_loss: 0.4536 - val_accuracy: 0.8960
...
Epoch 18/20
7500/7500 [==============================] - 19s 2ms/step - loss: 0.8592 - accuracy: 0.7931 - val_loss: 0.6860 - val_accuracy: 0.8776
Epoch 19/20
7500/7500 [==============================] - 17s 2ms/step - loss: 0.9226 - accuracy: 0.7876 - val_loss: 0.9510 - val_accuracy: 0.8452
Epoch 20/20
7500/7500 [==============================] - 17s 2ms/step - loss: 0.9810 - accuracy: 0.7825 - val_loss: 0.8294 - val_accuracy: 0.7859
[INFO] evaluating network...
313/313 [==============================] - 1s 2ms/step - loss: 0.8294 - accuracy: 0.7859
accuracy: 78.59%
real 5m48.320s
user 19m53.908s
sys 2m25.608s
使用我们实现中的默认超参数,没有超参数调整,我们可以达到 78.59%的准确度。
现在我们有了基线,我们可以战胜它了——正如您将看到的,应用超参数调整会彻底击败这个结果!
实施我们的 Keras/TensorFlow 超参数调整脚本
让我们学习如何使用 scikit-learn 将超参数调整到 Keras/TensorFlow 模型。
我们从进口开始:
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch.mlp import get_mlp_model
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import RandomizedSearchCV
from tensorflow.keras.datasets import mnist
同样,第 2-3 行导入 TensorFlow 并修复我们的随机种子以获得更好的可重复性。
第 6-9 行导入我们需要的 Python 包,包括:
get_mlp_model:接受几个超参数,并基于它们构建一个神经网络KerasClassifier:获取一个 Keras/TensorFlow 模型,并以一种与 scikit-learn 函数兼容的方式包装它(例如 scikit-learn 的超参数调整函数)RandomizedSearchCV: scikit-learn 的随机超参数搜索的实现(如果您不熟悉随机超参数调整算法,请参见本教程mnist:MNIST 数据集
然后,我们可以继续从磁盘加载 MNIST 数据集并对其进行预处理:
# load the MNIST dataset
print("[INFO] downloading MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
现在是时候构建我们的KerasClassifier对象了,这样我们可以用get_mlp_model构建一个模型,然后用RandomizedSearchCV调整超参数:
# wrap our model into a scikit-learn compatible classifier
print("[INFO] initializing model...")
model = KerasClassifier(build_fn=get_mlp_model, verbose=0)
# define a grid of the hyperparameter search space
hiddenLayerOne = [256, 512, 784]
hiddenLayerTwo = [128, 256, 512]
learnRate = [1e-2, 1e-3, 1e-4]
dropout = [0.3, 0.4, 0.5]
batchSize = [4, 8, 16, 32]
epochs = [10, 20, 30, 40]
# create a dictionary from the hyperparameter grid
grid = dict(
hiddenLayerOne=hiddenLayerOne,
learnRate=learnRate,
hiddenLayerTwo=hiddenLayerTwo,
dropout=dropout,
batch_size=batchSize,
epochs=epochs
)
第 21 行实例化我们的KerasClassifier对象。我们传入我们的get_mlp_model函数,告诉 Keras/tensor flow,get_mlp_model函数负责构建模型架构。
接下来,行 24-39 定义了我们的超参数搜索空间。我们将调谐:
- 第一个全连接层中的节点数
- 第二个全连接层中的节点数
- 我们的学习速度
- 辍学率
- 批量
- 要训练的时代数
然后将超参数添加到名为grid的 Python 字典中。
注意,字典的关键字是get_mlp_model中变量的同名。此外,batch_size和epochs变量与您在使用 Keras/TensorFlow 调用model.fit时提供的变量相同。
该命名约定是设计的,并且是当您构建 Keras/TensorFlow 模型并试图用 scikit-learn 调整超参数时所必需的**。****
**定义好grid超参数后,我们可以开始超参数调整过程:
# initialize a random search with a 3-fold cross-validation and then
# start the hyperparameter search process
print("[INFO] performing random search...")
searcher = RandomizedSearchCV(estimator=model, n_jobs=-1, cv=3,
param_distributions=grid, scoring="accuracy")
searchResults = searcher.fit(trainData, trainLabels)
# summarize grid search information
bestScore = searchResults.best_score_
bestParams = searchResults.best_params_
print("[INFO] best score is {:.2f} using {}".format(bestScore,
bestParams))
第 44 和 45 行初始化我们的searcher。我们传入model,运行-1值的并行作业的数量告诉 scikit——学习使用您机器上的所有内核/处理器、交叉验证折叠的数量、超参数网格以及我们想要监控的指标。
从那里,调用searcher的fit开始超参数调整过程。
一旦搜索完成,我们获得在搜索过程中找到的bestScore和bestParams,在我们的终端上显示它们(第 49-52 行)。
最后一步是获取bestModel并对其进行评估:
# extract the best model, make predictions on our data, and show a
# classification report
print("[INFO] evaluating the best model...")
bestModel = searchResults.best_estimator_
accuracy = bestModel.score(testData, testLabels)
print("accuracy: {:.2f}%".format(accuracy * 100))
第 57 行从随机搜索中抓取best_estimator_。
然后,我们根据测试数据评估最佳模型,并在屏幕上显示精确度(第 58 行和第 59 行)。
使用 scikit-learn 结果调整 Keras/TensorFlow 超参数
让我们看看我们的 Keras/TensorFlow 超参数调优脚本是如何执行的。
访问本教程的 “下载” 部分来检索源代码。
从那里,您可以执行以下命令:
$ time python random_search_mlp.py
[INFO] downloading MNIST...
[INFO] initializing model...
[INFO] performing random search...
[INFO] best score is 0.98 using {'learnRate': 0.001, 'hiddenLayerTwo': 256, 'hiddenLayerOne': 256, 'epochs': 40, 'dropout': 0.4, 'batch_size': 32}
[INFO] evaluating the best model...
accuracy: 98.28%
real 22m52.748s
user 151m26.056s
sys 12m21.016s
random_search_mlp.py脚本占用了
4x longer to run than our basic no hyperparameter tuning script (23m versus 6m, respectively) — but that extra time is well worth it as the difference in accuracy is tremendous.
在没有任何超参数调整的情况下,我们仅获得了 78.59%的准确度。但是通过使用 scikit-learn 进行随机超参数搜索,我们能够将准确率提高到 98.28%!
这是一个巨大的准确性提升,如果没有专门的超参数搜索,这是不可能的。
总结
在本教程中,您学习了如何使用 scikit-learn、Keras 和 TensorFlow 将超参数调整到深度神经网络。
通过使用 Keras/TensorFlow 的KerasClassifier实现,我们能够包装我们的模型架构,使其与 scikit-learn 的RandomizedSearchCV类兼容。
从那里,我们:
- 从我们的超参数空间随机抽样
- 在当前的超参数集上训练我们的神经网络(交叉验证)
- 评估模型的性能
在试验结束时,我们从随机搜索中获得最佳超参数,训练最终模型,并评估准确性:
- 没有超参数调整,我们只能获得 78.59%的准确度
- 但是通过超参数调整,我们达到了 98.28%的准确度
正如你所看到的,调整神经网络的超参数可以在准确性上产生巨大的差异…这只是在简单的 MNIST 数据集上。想象一下它能为您更复杂的真实数据集做些什么!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!******
我想在新冠肺炎期间尽我所能帮助你
原文:https://pyimagesearch.com/2020/03/17/i-want-to-help-you-the-best-i-can-during-covid-19/
由于新冠肺炎病毒,许多 PyImageSearch 的读者(包括我自己)被隔离或离开他们的工作、学校或研究实验室。
我知道这对每个人来说都是一个可怕的时刻,我想尽我所能帮助他们。
正如我昨天承诺的那样:
- 我为 PyImageSearch 的读者整理了免费和付费的学习资源,供他们在新冠肺炎隔离期间学习 CV/DL。
- 我在这篇文章的后面附上了我推荐的免费教程,包括一个基本的学习计划。
- 至于我的付费材料,我在 PyImageSearch 博客上向每个人提供我的《用 Python 进行计算机视觉的深度学习》的书的“紧急折扣 30%”。
- 如果对折扣有足够的兴趣,我也会对我的其他书籍和课程开放折扣。
- 更新 : 基于读者的兴趣,我现在对我所有的书籍和课程提供相同的 30%折扣。
我们将一起度过这个难关,我将尽我的最大努力帮助你和 PyImageSearch 社区的其他人在你流离失所或被隔离期间获得尽可能好的计算机视觉和深度学习教育。
这是一篇较长的博客文章,所以我在顶部列出了更高层次的要点,以便您可以快速查看,但请请完整阅读这篇文章以了解上下文——这些是非常敏感的话题,由于冠状病毒的微妙性质(包括它如何以不同方式影响不同的人和家庭),我试图机智而谨慎地处理这些话题。
平衡这些细微差别很有挑战性,我正在尽我最大的努力,所以如果我说的话让你不舒服,请放心,那是我的本意,不是我的本意。我们都是这里的朋友和家人,最重要的是,我们心里都有彼此最好的打算。
我的优先事项。
我现在脑子里有 4 件事:
- 我的家人。我的妻子、我的狗和我自己在我们的房子里自我隔离,一切正常。
- 我的队友。我们是一支偏远的球队,并且如此幸运如此。他们的健康,以及他们家人的健康,被放在高于一切的位置。
- 我队友的家人。昨天,我向团队的每个成员发放了 500 美元的新冠肺炎津贴。如果他们需要支付冠状病毒、个人、商业或其他方面的任何自付费用,请向 PyImageSearch 支付,我会支付。
- 我的 PyImageSearch 社区。我希望你平安,无论是身体上还是精神上。这是一个可怕的时代。不管我们身体上是否有病,COVID 仍然对你的精神健康有很大影响。我尊重这一点,并愿意提供帮助。
简短的版本。
你们中的许多人目前已经离开了工作、学校和研究实验室。
我尊重并理解这对你来说是多么的有压力、令人心烦意乱和精神上的负担(尤其是如果你是一个家长,带着孩子试图管理一个强制性的在家工作的要求)。
我也相信在这个艰难的时刻尽我所能帮助你是我的道义责任。
我能帮助你的最好方法是通过“教育转移注意力”来创造一个安全的空间。
对于寻求免费教育的读者,我有:
- PyImageSearch 博客上的 350 多个免费教程——你可以随时访问它们并从中学习(它们永远不会躲在付费墙后面)
- 我在我的 【入门】 页面上对这些教程进行了分类、交叉引用和编辑,共涵盖了 13 个热门的简历/简历主题
- 如果你正在寻找更多的学习“结构”,我也有一个关于计算机视觉、深度学习和 OpenCV 的免费 17 天电子邮件速成班
- 另外,不要忘记在博客中搜索与你想学习的主题相关的关键词——我已经写了关于最流行的简历/简历主题的教程
对于希望获得我的付费书籍和课程的读者:
- 许多读者要求我出售我的书和课程,这样他们就可以在休息/隔离期间学习
- 起初,我对此有点犹豫——我最不希望的事情就是让人们认为我在利用冠状病毒来“赚钱”
- 然而,我尊重并理解一些读者想利用这段时间来学习——在这段艰难的时间里,他们需要分散注意力
- 因此,我对我的计算机视觉深度学习与 Python 书 提供 30%的折扣(这是我公开提供的最大折扣之一,所以请理解,我已经尽力了)
如果有足够多的人对这个折扣感兴趣,我会对我的其他书籍和课程也开放这个折扣。
更新 : 基于读者的兴趣,我现在对我所有的书籍和课程提供相同的 30%折扣。
我想再次强调,这个折扣不是为了盈利,它当然不是计划中的(正如我昨天提到的,我整个周末都在生病,试图把所有这些放在一起)——我相信这是我需要为那些想利用这段休息时间学习和/或从世界其他地方转移注意力的人做的事情。
更长更好的版本。
我们现在正处于人生中一个非常可怕的时期。
像所有季节一样,它会过去,但我们需要蹲下身子,为寒冷的冬天做准备——最糟糕的情况可能还没有到来。
坦率地说,我感到难以置信的沮丧和孤立。我明白了:
- 股票市场暴跌。
- 封锁边境的国家。
- 大型体育赛事被取消。
- 一些世界上最受欢迎的乐队推迟了他们的巡演。
- 在当地,我最喜欢的餐馆和咖啡店都关门了。
以上都是宏观层面的— 但是微观层面的呢?
作为个体的我们又如何呢?
太容易陷入全球统计数据中。
我们看到的数字是 6000 人死亡,160000 例确诊病例(由于缺乏新冠肺炎检测试剂盒,一些人选择自我隔离,因此可能会多几个数量级)。
当我们用这些术语思考时,我们就看不到自己和我们所爱的人。我们需要日复一日地对待事情。我们需要在个人层面上考虑我们自己的心理健康和理智。我们需要可以撤退的安全空间。
当我 5 年前开始 PyImageSearch 时,我知道这将是一个安全的空间。我为 PyImageSearch 后来的发展树立了榜样,直到今天我依然如此。为此,我不允许任何形式的骚扰,包括但不限于种族主义、性别歧视、仇外心理、精英主义、欺凌等。
PyImageSearch 社区很特别。这里的人尊重他人——如果他们不尊重,我就把他们赶走。
也许我最喜欢的善良、接受和利他的人类性格表现之一是在我运行 PyImageConf 2018(关于计算机视觉、深度学习和 OpenCV 的 PyImageSearch 会议)时出现的。
与会者对的友好和的欢迎会议感到不知所措。
软件工程师 Dave Snowdon 和 PyImageConf 与会者说:
毫无疑问,PyImageConf 是我参加过的最友好、最受欢迎的会议。技术含量也很高!很荣幸见到一些人,并向他们学习,他们贡献了自己的时间来构建我们工作(和娱乐)所依赖的工具。
工程学博士、弗吉尼亚联邦大学教授大卫斯通分享了以下内容:
感谢您整理 PyImageConf。我也同意这是我参加过的最友好的会议。
我为什么要说这些?
因为我知道你现在可能很害怕。
我知道你可能已经穷途末路了(相信我,我也是)。
最重要的是,因为我想让 PyImageSearch 成为你的安全空间。
- 你可能是一个学期提前结束后从学校回家的学生,对你的教育被搁置感到失望。
- 你可能是一名开发人员,在你的工作场所在可预见的未来关上大门后,你完全迷失了。
- 你可能是一名研究人员,因为无法继续你的实验和撰写那篇小说论文而感到沮丧。
- 你可能是一位家长,试图兼顾两个孩子和一个强制性的“在家工作”的要求,但没有成功。
或者,你可能像我一样——只是试图通过学习一项新技能、算法或技术来度过一天。
我收到了许多来自 PyImageSearch 读者的电子邮件,他们想利用这段时间研究计算机视觉和深度学习,而不是在家里发疯。
我尊重这一点,也想提供帮助,在某种程度上,我认为尽我所能提供帮助是我的道德义务:
- 首先,你可以在 PyImageSearch 博客上学习超过 350 个免费教程。美国东部时间每周一上午 10 点,我会发布一个新的教程。在隔离期间我会继续这样做。
- 我已经在我的 【开始】 页面上对这些教程进行了分类、交叉引用和编译。
- 在【入门】页面上最受欢迎的话题包括 【深度学习】 和 【人脸应用】 。
- 我还建议你看看我的关于计算机视觉、深度学习和 OpenCV 的 17 天免费电子邮件速成课程
所有这些指南都是 100%免费的,而且从不收费。用它们来学习和借鉴。
也就是说,许多读者也要求我出售我的书籍和课程:
嗨,阿德里安和他的团队,
我有用于计算机视觉的树莓派(黑客捆绑包),我正在考虑升级到完整的捆绑包。我知道你们有时会有升级折扣,但是我希望你们现在能给我一个优惠。
由于新冠肺炎的原因,我有一些停机时间,想继续我在 CV 的旅程。
多谢,祝平安,
鲍勃
起初,我对打折有点犹豫——我最不想做的事情是让人们认为我在以某种方式利用冠状病毒来“赚钱”。
但事实是,作为一个小企业主,不仅要对我自己和我的家庭负责,还要对我队友的生活和家庭负责,有时会令人恐惧和不知所措。
为此,就像:
- 乐队和表演者正在提供打折的“仅在线”表演
- 餐馆提供送货上门服务
- 健身教练在网上提供培训课程
…我也在做同样的事情。
目前,我正在为我的深度学习书籍提供 30%的折扣,用 Python 进行计算机视觉的深度学习。
这是我公开提供的最大的折扣之一,所以,请理解,我已经尽力了。
如果有足够的兴趣,我会开放我图书馆的剩余书籍/课程,并提供同样的折扣。
我想再次强调,这个折扣不是为了盈利,它肯定没有计划(我花了整个周末,生病,试图把所有这些放在一起)。
相反,帮助像我这样的人(也许就像你自己一样)是打折扣的,他们正在这场混乱中努力寻找自己的安全空间。让我自己和 PyImageSearch 成为你的退路。
谢谢,注意安全。
阿德里安·罗斯布鲁克
我通常每年只进行一次大减价(黑色星期五),但考虑到有多少人要求这样做,我相信对于那些想利用这段时间学习和/或从世界其他地方转移注意力的人来说,这是我需要做的事情。
随意加入或不加入。完全没问题。我们都以自己的方式处理这些艰难的时刻。
但是,如果你需要休息,如果你需要一个避风港,如果你需要通过教育撤退,无论是通过我的免费教程还是付费书籍/课程,我都会在这里等你。
我刚刚在“Python 对我说”播客上接受了采访。
原文:https://pyimagesearch.com/2015/06/09/i-was-just-interviewed-on-the-talk-python-to-me-podcast/

炎炎夏日、车牌自动识别和 跟我聊 Python 播客 有什么共同点?
好吧。这是一个有趣的故事——也是一个让我被警察处以巨额罚款的故事。
但是完整的故事,你必须听听最新的跟我说 Python播客来找到答案!
如果你从来没有听过跟我说 Python,我必须说,这太棒了。每周,主持人 Michael Kennedy 都会采访一位 Python 开发伙伴,并深入研究某个特定的专业领域,包括测试驱动开发和 DevOps、Python 和 MongoDB,甚至机器人操作系统 ROS。
几周前,迈克尔和我联系上了,我非常荣幸地被邀请参加这个节目。
这是一次奇妙的经历——非常感谢迈克尔!
在最新一集的跟我说说 Python中,Michael 和我使用 Python 编程语言讨论了计算机视觉和 OpenCV。一定要 点击这里,听一听 。
构思解决方案和计划实验
原文:https://pyimagesearch.com/2022/03/30/ideating-the-solution-and-planning-experiments/
构思解决方案和计划实验
在本系列的上一课中,我们学习了缩小研究主题搜索范围并有效更新相关文献的策略。“方法”和“实验”部分可能是任何研究论文中最重要的部分。当方法新颖且实验全面时,销售研究变得容易。当他们中的任何一个妥协时,评论者往往会变得挑剔。
除了是研究论文中最重要的部分,构思和实验阶段也需要最多的时间。当提交截止日期临近时,这会使事情变得很有挑战性。因此,正如我们将在本课中学到的,在这些阶段进行规划和实施变得至关重要。
在这个系列中,你将学习如何发表小说研究。
本课是关于如何发表小说研究的五部分系列的第二部分:
- 选择研究课题并阅读其文献
- (本教程)
- 计划并撰写研究论文
- 计划事情不顺利时的后续步骤
- 确保你的研究保持可见性和一般提示
学习如何构思解决方案和计划实验,继续阅读。*
构思解决方案
既然我们已经意识到构思阶段是多么的重要,那么让我们来看看计划和进行的一些最好的方法。
读了足够多的论文后,你会开始形成直觉。你需要做的就是继续做下去。直觉比智力更强大,有更好的机会解决(图 1 )。它可以是一个想法,就像尝试一个特定的损失函数一样简单,或者是一个突破,就像在视觉中尝试变形金刚(现在普遍称为视觉变形金刚)。不管是什么,都值得追求。既然你在阅读了大量论文后有了这种直觉,那么它很有可能是新颖的。
逐渐接近
开始逐渐增加新颖性或复杂性,而不是一开始就寻求一个完整的解决方案(包含几个组件和模块)。最初寻找一个完整的解决方案会耗费你大量的时间,而且不能保证一定有效。即使有效,也很难分析或理解哪个组件或模块的贡献更大。另一方面,渐进式思维将帮助你理解哪些组件工作得更好,为什么——从而让你专注于相关的部分。
从根本上接近
从一个现有的数学方程来看待这个问题,可以帮助我们找到强有力的解决方案。观察并思考如何解决这个问题,从这个等式开始。能分解成更小的成分吗?可以用上界或下界来近似吗?举个例子,
- 张等(2019) 将对立实例的预测误差(稳健误差)分解为自然(分类)误差和边界误差之和,并给出可微上界。受这一分析的启发,他们提出了一种新的防御方法——交易——来交易对抗性鲁棒性和准确性。
- 在生成对抗网络(GANs)中馈送条件信息的传统方式是通过将(嵌入的)条件向量连接到特征向量。 Miyato 和 Koyama (2018) 通过观察标准对抗性损失函数的最优解形式( Goodfellow 等人,2014 ),提出了一种投影损失,这是一种传统方法的替代方法。
- Singh 等人(2020) 通过从属性脆弱性的基本方程出发,并根据输入图像及其解释图之间的空间相关性,推导出属性脆弱性的上界,来研究属性鲁棒性问题(即,具有鲁棒解释的模型)。此外,他们提出了一种方法,ART,通过使用软裕度三重损失最小化该上限来学习鲁棒特征。
结合已有的思想
一种相对简单的思考解决方案的方法是将现有的想法或想法合并成一个。由于这些现有的方法已被经验证明是有效的,因此将它们结合起来带来进一步改进的可能性很大。举个例子,
- 受生成建模方法在零触发学习中的成功以及在领域泛化中利用领域特定信息的有用性的激励, Mangla 等人(2021) ( 图 2 ,左上 ) 提出了一个统一的特征生成框架,该框架集成了上下文条件自适应(COCOA)批量规范化层,以无缝集成类级语义和领域特定信息。
- 混合和风格化是流行的增强策略,以增强模型的泛化能力。受此启发, Hong et al. (2021) ( 图 2 、 ) 提出 StyleMix 和 StyleCutMix 作为第一种分别处理输入图像对的内容和样式信息的混合方法。通过仔细混合图像的内容和风格,他们创建了更加丰富和健壮的样本,最终增强了模型训练的泛化能力。
- Larsen et al. (2016) ( 图 2 、下 ) 通过将 VAE 解码器和 GAN 生成器折叠为一个,将变分自动编码器(VAE)与生成对抗网络(GAN)结合起来。这允许他们利用 GAN 鉴别器中的学习特征表示作为 VAE 重建目标的基础。
简单却有效
有时,一个简单的想法可以大大胜过最先进的方法(图 3) 。这些想法很直观,更容易理解和实现。
这里有一些例子
- S2M2 ( 图 4 , top ) 通过向迁移学习基线添加自我监督损失和流形混合正则化来工作,在少镜头分类中显著击败最先进的元学习方法。
- AugMix ( 图 4 ,左下角 ) 是一个简单的增强策略,混合一组不同的已知增强(如随机翻转、颜色抖动、旋转等)。)随机。
- 插值对抗训练(IAT) ( 图 4 ,右下 ) 简单地将最近提出的基于插值的训练方法如混合和流形混合集成在对抗训练的框架中,以减少标准和鲁棒精度之间的折衷。
够了吗?
开发一个新的解决方案的另一个重要步骤是在两者之间进行短暂的停顿,并评估当前状态下的解决方案是否足够强大。您需要在某个时候收敛到一个解决方案,这样的习惯可以帮助您确定该方法在当前状态下是否合适,或者是否需要进一步的思考。但是如何评价呢?这里有一些参数,你可以据此评估你的方法的强度。
- 性能: 该方法是否优于最先进的技术?如果是,相差多少?它在所有基准和架构中的表现都更好吗?是否稳健?
- 效率:该方法是否需要更少的参数?收敛快吗?它很容易适应新奇的任务吗?它能同时解决多项任务吗?它需要更少的样本进行训练吗?
- 洞察力: 方法或分析是否提供了新的洞察力?有什么耐人寻味或者有趣的现象吗?是否提供了很多问题的一站式解决方案?
- 新奇: 这个想法看起来是递增的吗?这个想法与相关作品有区别吗,或者有相似的作品吗?
- 复杂性: 方法是否简洁明了,或者管道中是否有太多移动部件?很难理解哪个组件更好用吗?超参数太多了吗?
充当审核人
从评审者的角度批评和质疑你的方法是很重要的。做你的评审员,问问你的方法的优缺点是什么?主要关注点是什么?在实验方面还有什么?你如何评价这个想法?这样做有助于您解决实际评审者可以提前指出的问题,从而减少评审者吹毛求疵的机会。
然而,自我检讨只在一定程度上起作用。由于我们在心理上偏向于支持自己的想法,我们往往会错过或忽略在第三人看来可能很重要的事情。为此,你可以请你的顾问、导师或朋友回顾这个想法,并与你分享他们的想法和担忧。这让你有机会注意到你错过的事情,并盘点出进展顺利的事情。
我总是喜欢向更多、更多样化的观众介绍这个想法(例如,在我们的研究实验室会议上),在那里每个人都可以分享他们的想法和建议,不管他们的专业知识或经验如何。参与这种互动的最大好处是,你经常会获得新的想法和方向来解决你的问题和解决你的顾虑。如果你能接触到这样的观众(可能是你的同龄人、实验室成员、以前的合作者等等)。),这可能是你的工作获得反馈的最好方式(图 5) 。
计划实验
接下来,让我们看看运行实验时要遵循的一些最佳实践。因为您将尝试几种想法,所以最好遵循标准协议来公平地评估它们并与现有方法进行比较。
选择你的基准线
定义和复制基线是应该开始的第一步。与一组全面的基线进行比较让评审者很高兴。这减少了他们突然要求你与另一个基线进行比较的机会。
尝试建立一套全面的基线,可以是最新的技术,也可以是任何看起来微不足道的东西。你可以避免与未发表的论文进行比较,但如果可以的话,那将是蛋糕上的樱桃。确保使用其论文中描述的相同架构和评估协议来复制基准。如果基线是不可重复的(可能是因为代码库有一些问题或者不可用),使用实际的数字(论文中提到的那些)进行比较。
先执行标准实验
在定义和复制基线之后,从文献中的标准实验开始。为了进行公平的比较,请确保您正在使用的架构或者与现有技术相同,或者具有相同的复杂性(例如,可训练的参数)。基准和评估协议也应该与现有技术相同。表 1 提到了一些热门领域的标准基准、架构和评估协议。
花费时间进行消融和分析
通过做一系列彻底的分析,你可以通过帮助他们对你的作品有一个完整的理解来取悦评论者。您可以选择一个小数据集来更快地获得结果,因为没有人希望您在标准实验中使用的每个数据集上都显示消融。以下是对初学者的一些建议:
- 组件分析是指当某些组件被删除或修改时,分析您的方法的性能。这有助于更好地理解您的方法的每个组件的贡献。
- 显示性能如何随着超参数的选择而变化的图有助于理解该方法是否需要仔细调整。理想情况下,性能不应随着超参数的选择而显著变化。但如果是这样的话,超参数图可以帮助确定超参数选择的理想范围。
- 视觉结果可以由 T-SNE 图组成,以显示通过您的方法实现的表示比基线方法更有组织性:显著图或注意力图,以解释模型在进行预测时是否专注于正确的输入区域。
良好的实施做法
遵循良好的实践有助于您组织您的实验,并避免以后复杂的代码库。这里有几个在进行实验时应该遵循的做法。
- 永远做多次运行:不要通过一次运行来判断一个实验的表现。在几次运行中,性能可能会有很大差异,这通常是不好的。根据我的经验,这通常是因为小数据集规模的训练、不稳定的训练算法或者代码中的任何显式随机化。在多次运行中(最好是 5 次、7 次、10 次)计算出结果的平均值,并记下标准偏差。较大的标准差反映出需要解决不稳定的运行。
- 利用验证集:如果您有一个验证集,您可以利用它来自动调整您的超参数,为最终测试选择好的检查点,安排您的学习速度,并决定您的实验的停止标准。
- 构建现有的代码库:无论何时实现一个想法,最好从现有的开源代码库(例如,现有技术作者的官方实现)开始并构建,它已经为您提供了加载数据集、训练、评估和可视化的脚本。这样现在节省了很多时间;您只需要在几个地方进行修改,就可以集成和运行您的方法。示例:
- 组织你的代码库:在最开始的时候,由于文件更少,代码通常更容易管理,但是当它增长到需要尝试几个实验和想法的程度时,它通常会变得复杂和难以管理。因此,为了保持高效,最好从一开始就组织好你的代码。以下是我学会实现的一些事情:
- 让你的项目目录有适当的结构。解释了如何创建一个合适的 python 项目。
- 使用 git 进行版本控制。提交小的更改,以确保所有内容都已备份,并且可以随时恢复。
- 不要硬编码,使用命令行参数来指定细节,如架构、超参数和功能(例如,培训、测试或恢复)。
- 正确记录你的损失和结果。你可以使用在线工具如权重&偏差来达到同样的效果。
提交截止日期及计划说明
如果你的目标是即将到来的会议,你可能需要仔细计划你的实验。你很大一部分时间将花在论文写作上。不要把任何重大实验拖到最后。如果你没有时间做任何特定的实验,把它留到第二周。其截止日期通常是主要提交截止日期之后的 7-14 天。
汇总
构思和实验是任何研究项目中最重要的两个阶段,需要适当的计划和执行。当构思解决方案时,尝试那些对你的直觉有意义的事情,因为它们最有可能成功。总是增加新奇和复杂性,而不是一次想出一个完整的解决方案。试着像一个基本的数学方程一样处理这个问题,用更简单和可解的部分分解或限制它。
以新颖的方式结合现有的想法是另一个相对简单的方向。不要认为方法需要复杂。有时,甚至一个简单的想法也能胜过复杂的最先进的方法。定期评估和批评你在绩效、洞察力、新颖性、复杂性和效率方面的方法。这将帮助您了解当前状态的解决方案是否足够,或者是否需要进一步改进。最后,把你的想法呈现给你的顾问、导师、同事或更广泛的受众,以获得第三人称视角和反馈。
当开始实验时,优先运行和复制基线。然后继续运行文献中的标准实验。根据文献中之前的工作选择您的数据集、架构和评估协议。花时间做一套彻底的消融术,以提供对你工作的整体理解。遵循正确组织代码的良好实践,使用版本控制、命令行参数和日志记录。最后,计划你的实验,牢记你的工作目标。如果你时间不够,把一些实验留到第二周。
我希望这一课能帮助你有效地计划和执行你的想法和实验。请继续关注下一课关于计划和撰写研究论文的内容。
引用信息
Mangla,P. “构思解决方案和规划实验”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/h3joc
@incollection{Mangla_2022_Ideating,
author = {Puneet Mangla},
title = {Ideating the Solution and Planning Experiments},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/h3joc},
}
我正在写一本关于计算机视觉和树莓派的书(我需要你的意见)。
https://www.youtube.com/embed/bQhp7Y6KM7o?feature=oembed
我正在写一本关于深度学习和卷积神经网络的书(我需要你的建议)。

你可能听过我在 PyImageSearch 博客上的评论中提到它…
也许我甚至在一对一的邮件中暗示过…
或者也许你只是因为最近博客上深度学习/神经网络教程的上升而看到了墙上的文字…
但是我今天在这里告诉你,谣言是真的:
我正在写一本关于深度学习的新书,重点是:
*** 神经网络和机器学习。
- 卷积神经网络(CNN)。
- 深度学习的物体检测/定位。
- 训练大规模(ImageNet 级)网络。
- 使用 Python 编程语言和 Keras + mxnet 库进行实际操作。
如你所见,这本书将主要关注在图像分类和理解背景下的深度学习。虽然深度学习有许多方面,但我觉得更有资格(也最有能力)写一本深度学习的书专门针对卷积神经网络和图像分类的(因此也是与计算机视觉的一般关系)。
但在我出版这本书之前,我需要你的帮助……
首先,我还没有确定这本书的名字。我将在下周发送一封电子邮件,附上一份调查来确定书名,所以如果你有兴趣帮助命名这本书,请继续关注这封电子邮件。
在这本书被命名后,我将在 2017 年 1 月中旬发起 Kickstarter 活动,以完成对深度学习书的资助。
一旦资金到位,我完全打算在 2017 年夏秋完成**出版这本书。**
**要了解更多即将出版的《深度学习+卷积神经网络+图像分类》一书,更重要的是 借你的观点帮助塑造《T2》一书的未来,继续阅读。
我需要你对我即将出版的深度学习书籍的建议
每年我都会进行三天的“静修”。
我冒险去了美国西部的一个国家公园(通常在犹他州、亚利桑那州或内华达州的某个地方)。
我一个人坐在天使降落、地铁,甚至观测点的山峰上,完全断开连接:

Figure 1: Sitting on top of Observation Point, contemplating life, existence…and what to put in the upcoming Deep Learning book.
除了我背上的衣服、我的徒步装备以及食物和水的供应,我基本上是“裸体的”——我没有带我的笔记本电脑、iPad 或任何电子产品(除了一部手机,关机,安全防水并埋在包里以备不时之需)。
我坐在那里俯瞰壮丽的景色,只有两种“自然”资源:我的笔和笔记本。
大约 6 个月前,我参加了一次为期 3 天的静修,花了个小时沉浸在思考中,思考我应该在这本即将出版的深度学习+图像分类书中涵盖哪些主题。
这些日子是我一生中最有收获、最有成效的时期。
仅仅徒步旅行了 3 天,我的笔记本上就有了 60 多页的笔记。
我旅行一回到家,就立刻开始写这本书。
我开始写代码。
收集结果。
我现在很高兴地说,我已经编写了超过 70%的项目代码,并收集了超过 60%的结果,这些结果是将这本深度学习+卷积神经网络的书放在一起所需要的…**
**但是我需要你的帮助来走完剩下的路。
任何成功的作家、企业家或企业主(尤其是在高度技术化的领域)都会告诉你,与你的观众分享你正在做的事情/创造的东西的重要性,这样他们就可以为你提供反馈、意见和见解。
你最不想做的事情就是写一本没人想要的书(或者开发一个产品)。
我没什么不同。
为了让这本深度学习的书成功,我需要你们的帮助。
在接下来的部分,我已经包括了我计划在这本深度学习书中涵盖的内容的草图。
这个草图绝不是最终定稿,但它确实反映了我认为在一本专注于深度学习、卷积神经网络和图像分类的书中需要回顾的重要内容。
看看这个话题列表,然后一定要给我发电子邮件,给我发消息,或者在这篇文章底部的评论中回复你的反馈/建议。
这本深度学习+卷积神经网络的书打算涵盖哪些内容?
我对这本即将出版的深度学习书籍的总体计划是主要关注卷积神经网络(CNN)和使用 Python 编程语言的图像分类/理解。
这本书将非常详细,包括学术引文和对当前最先进工作的参考,同时也是超级实用和动手(有大量代码),风格与 PyImageSearch 博客的其余部分相同。所有代码示例都将使用 Python 中的 Keras 或 mxnet 库来完成。
虽然深度学习有许多方面,但我的主要专业领域是计算机视觉和图像分类——因此我认为我写下我所知道的东西很重要。
说到结构化深度学习的书,我会把书分成“层”,就像我对 实用 Python 和 OpenCV 所做的那样。
通过将书分成不同的层次,我可以让你(读者)选择最适合你的需求和预算的层次。
这意味着,如果你刚刚开始深度学习,你将能够负担得起一个更便宜的软件包来帮助你跟上速度。
如果你已经在深度学习领域有了经验(或者如果你只是想要完整的包,并且想要学习更高级、可扩展的技术,那么你也可以选择更高层的包。
我还没有完全充实每一层/包之间的分界线(虽然我有一个很好的想法),但是下面你可以找到我计划在书中涉及的主题列表。
如果您对将要涉及的其他主题有任何建议, 请给我发电子邮件,在这篇博客上发表评论,或者给我发消息。
深度学习+卷积神经网络书籍主题
正如我所承诺的,这里是我计划在这本深度学习+卷积神经网络书中涵盖的主题的大致轮廓。
如果你有一个主题的建议,只需在这个帖子上留下评论或给我发消息,我会看看我们是否能做到!
机器学习基础知识
- 了解如何设置和配置您的开发环境来研究深度学习。
- 了解图像基础知识,包括坐标系;宽度、高度、深度;和长宽比。
- 回顾用于测试机器学习、深度学习和卷积神经网络算法的流行图像数据集。
- 形成对机器学习基础知识的坚实理解,包括:
- 简单的 k-NN 分类器。
- 参数化学习(即“从数据中学习”):
- 数据和特征向量。
- 了解评分功能。
- 损失函数的工作原理。
- 定义权重矩阵和偏差向量(以及它们如何促进学习)。
- 基本优化方法(即“学习”实际上是如何完成的),通过:
- 梯度下降。
- 随机梯度下降(SGD)。
神经网络基础
- 探索前馈神经网络架构。
- 手工实现经典感知器算法。
- 使用感知器算法学习实际的函数(并理解感知器算法的局限性)。
- 取一个 深入潜 进入 反向传播算法 。
- 用 Python + NumPy 手工实现反向传播。
- 利用工作表来帮助你练习这个重要的算法。
- 掌握多层网络(并从头开始训练)。
- 手动实现神经网络和用 Keras 库 。
*#### 卷积神经网络简介
- 理解卷积(以及为什么它们比看起来容易理解)。
- 研究卷积神经网络(它们是用来做什么的,我们为什么要用它们等等。).
- 回顾卷积神经网络的构建模块,包括:
- 卷积层
- 激活层
- 池层
- 批量标准化
- 拒绝传统社会的人
- …等等。
- 发现通用的网络体系结构模式,您可以使用这些模式来设计自己的体系结构,从而最大限度地减少挫折和麻烦。
- 利用现成的 CNN 进行分类,这些 CNN 已经过预训练并准备好应用于您自己的图像/图像数据集(VGG16、VGG19、ResNet50 等)。).
- 从头开始训练你的第一个卷积神经网络。
- 从磁盘保存和加载您自己的网络模型。
- 检查您的模型以发现高性能的时代/重新开始训练。
- 了解如何发现欠拟合和过拟合,从而允许您纠正它们并提高分类精度。
- 利用衰减和学习率调度程序。
- 从零开始训练经典的 LeNet 架构来识别手写数字。
使用您自己的数据集
- 了解如何收集您自己的培训图像。
- 了解如何注释和标注数据集。
- 在你的数据集上训练一个卷积神经网络。
- 评估你的模型的准确性。
- 所有这些都通过演示如何收集、注释和训练 CNN 破解图像验证码来解释。
高级卷积神经网络
- 了解如何使用转移学习来:
- 将预先训练的网络视为特征提取器,以不费吹灰之力获得高分类精度。
- 利用微调来提高预训练网络的准确性。
- 应用数据扩充来提高网络分类准确性而不需要收集更多的训练数据。
- 了解等级 1 和等级 5 的准确性(以及我们如何使用它们来衡量给定网络的分类能力)。
- 探索如何简单地通过训练多个网络使用网络集成来提高分类精度。
- 发现我应用深度学习技术来最大化分类准确性的最佳途径(以及以何种顺序应用这些技术来实现最大的有效性)。
缩放至大型图像数据集
- 了解如何将图像数据集从磁盘上的原始图像转换为 HDF5 格式,从而使网络训练更容易(更快)。
- 实现 VGGNet 架构(以及的变体)。
- 对 AlexNet 架构进行手工编码,并将其用于:
- 在Kaggle Dogs vs . Cats challenge上训练一个网络。
- 不费吹灰之力就能跻身前 25 名排行榜。
- 利用图像裁剪这种简单的方法来提高测试集的准确性。
- 探索更高级的优化算法,包括:
- RMSprop
- 阿达格拉德
- 阿达德尔塔
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
- 阿达马斯
- 那达慕
- …以及如何微调 SGD 参数。
使用深度学习的物体检测和定位
- 利用朴素的图像金字塔和滑动窗口进行对象检测。
- 训练你自己的 YOLO 探测器实时识别图像/视频流中的物体。
ImageNet:大规模视觉识别挑战
- 了解什么是海量ImageNet(1000 个类别)数据集以及为什么它被认为是事实上的图像分类对基准算法的挑战。
- 获取 ImageNet 数据集并将其转换为适合培训的格式。
- 了解如何利用多个 GPU 并行训练您的网络,从而大大减少训练时间。
- 了解如何在 ImageNet 上训练 AlexNet 和 VGGNet 架构。
- 将 SqueezeNet 架构应用到 ImageNet 以获得(高精度)模型,完全可部署到较小的设备,如 Raspberry Pi。
ImageNet:提示和技巧
- 通过发现实际有效的学习率计划表,节省数周(甚至数月)的培训时间。
- 在 ImageNet 上发现过度拟合并在之前发现它,你会浪费几个小时(甚至几天)看着你的验证准确性停滞不前。
- 了解如何从保存的纪元重新开始训练,降低学习率,并提高准确性。
- 解锁深度学习专家用于调整超参数到其网络的相同技术。
个案研究
- 使用深度学习技术训练网络,从图像中预测人的性别和年龄。
- 使用卷积神经网络对汽车的品牌和型号进行自动分类。
- 使用预先训练的 CNN 确定(并校正)图像方向。
你觉得怎么样?
正如你所看到的,这是一本相当于深度学习+卷积神经网络+图像分类的书。
如果您对应该(甚至不应该)涉及的话题有任何反馈或建议,请随时联系我或在这篇博文的底部留下评论。
为什么是 Kickstarter 活动?
在接下来的几周内,我会有更多关于即将到来的深度学习新书 Kickstarter 活动的细节,但因为我知道我现在会被问到这个问题,所以我想就此说几句。
首先,我喜欢 Kickstarter 活动。
这是一种向你的观众以外的人传播项目信息的极好方式(如果项目成功获得资助,这在 T2 尤其如此)。
其次,我已经有了在 Kickstarter 上开展活动的经验。
也许没有多少读者知道这一点,但是 PyImageSearch 大师课程最初是由 2015 年的 Kickstarter 活动资助的。
如果没有这个 Kickstarter 活动,我就没有必要的资金来投入写作、课程软件许可和整合整个课程体验。
在这本深度学习书籍的背景下,我将在 Kickstarter 上开展一项活动,为亚马逊 EC2 生态系统中的(额外)GPU 实例筹集资金。
我已经有了我的 NVIDIA DIGITS DevBox ,它已经昼夜不停地运行了近 6 个月,进行实验并收集结果——,但最终,它仍然只是一台机器。
我运行更快的更多 GPU 实例我可以收集结果,因此允许我更快地发布深度学习书籍。
这些 GPU 实例也不便宜。
亚马逊 EC2 上的 px.8xlarge (8 个 GPU)和 p2.16xlarge (16 个 GPU)分别为每小时 7.20 美元和 14.40 美元。
我想强调的一点是,作为这本书的读者,你不会必须使用高端 GPU或预计将访问它们。
这本书的基本章节将很容易在您的 CPU 上运行,而更高级的章节可以利用更多基于商品的 GPU。
相反,我在 EC2 生态系统中使用更高层 GPU 实例的目的是,我将能够更快地发布深度学习书籍(更重要的是,更快地将它拿在手中)。
有兴趣了解更多信息吗?
要了解即将出版的《深度学习+卷积神经网络》一书,请点击以下按钮并输入您的电子邮件地址:
随着书籍的更新,我还会发送一份简短的调查,帮助 在下周内给书 命名,所以请务必留意你的收件箱——我真的需要你的意见!
请记住:我写这本书是为了你。
我想通过说我正在为你写这本深度学习的书来结束这篇文章。
如果你看到任何你想写进书里的话题,请给我发电子邮件,给我发信息,或者在下面的评论区发帖。
我不能保证我能够满足所有(甚至大部分)的请求/建议,但是我会尽我最大的努力考虑所有的意见和建议,以帮助使这本书成为今天最好的深度学习书籍。
请留意您的收件箱中的书名调查,否则我会在一月初带着 Kickstarter 活动和书籍主题列表的最终细节回来。*********
我正在写一本书:“实用 Python 和 OpenCV:图像处理和计算机视觉的介绍性、示例驱动指南”
在过去的几个月里,我一直在思考写一本书的想法,但我不确定具体的重点是什么。我对它进行了大量的思考,制定了具体细节,并与许多像你们一样的开发人员、程序员和研究人员进行了交谈。
所有这些工作导致了今天——我的书的出版。
实用 Python 和 OpenCV:图像处理和计算机视觉的介绍性示例驱动指南 涵盖了计算机视觉的基础知识,从回答“什么是像素”这个问题开始并逐步完成更具挑战性的任务,如边缘检测、阈值处理、在图像中找到对象并计数。注册即可在该书发布时获得一笔可观的预发行交易。
你能从这本书里期待什么?
- 计算机视觉和图像处理的实践介绍。
- 大量的可视化例子,大量的代码让你快速而轻松地开始。
- 一个可下载的 VirtualBox 虚拟机,预装了您需要的所有计算机视觉和图像处理库。
- 一本为希望学习计算机视觉和图像处理基础知识的开发人员、程序员和学生编写的通俗易懂的书。
- 我还在考虑创建一系列截屏,在这些截屏中,我会分解书中的每个示例,并逐行解释代码在做什么。如果你对此感兴趣,请给我发消息。
这本书是非常典型的例子驱动的。当我第一次开始写这本书的时候,我希望它尽可能的实用。我想要大量的可视化代码的例子。我想写一些你可以很容易从中学到的东西,而不需要大学水平的计算机视觉和图像处理课程相关的数学的严格性和细节。你不需要计算机科学或数学学位来理解这本书里的例子。
那么这本书是给谁看的呢?
这本书面向对计算机视觉和图像处理感兴趣,但仍然需要学习基础知识的开发人员、程序员和学生。它涵盖了基础知识,提供了大量的代码示例,让您快速、轻松地上手。无论你是一名经验丰富的开发人员,希望了解更多关于计算机视觉的知识,还是一名大学学生,准备在计算机视觉领域进行研究,这本书都适合你。
这本书包括什么?
这本书使用 Python 编程语言和 OpenCV(世界上最常用的计算机视觉库)涵盖了计算机视觉和图像处理的基础知识。在这本书里,你会学到所有关于图像基础知识,绘画,图像变换,如平移,旋转,调整大小,图像运算,蒙版,直方图,平滑和模糊,阈值,边缘检测和轮廓。
同样,所有这些主题都包含了大量的示例代码,唯一的目标就是让您尽快上手。
这是真正的快速启动方法!
我认识到设置开发环境(甚至编译和安装 OpenCV)并不是世界上最有趣的事情。更别说还挺费时间的。为了让你尽快学会,我创建了一个可下载的 VirtualBox 虚拟机,它预装了你需要的所有计算机视觉和图像处理库。
你没有工作!启动虚拟机,开始学习吧!
听起来不错吧?
使用 OpenCV 进行图像对齐和配准
原文:https://pyimagesearch.com/2020/08/31/image-alignment-and-registration-with-opencv/
在本教程中,您将学习如何使用 OpenCV 执行图像对齐和图像配准。

图像对齐和配准有许多实际的真实使用案例,包括:
- 医学: MRI 扫描、SPECT 扫描和其他医学扫描产生多个图像。为了帮助医生和内科医生更好地解释这些扫描,图像配准可以用于将多个图像对齐在一起,并将它们叠加在彼此之上。从那里,医生可以读取结果,并提供更准确的诊断。
- 军用:自动目标识别(ATR)算法接受目标的多个输入图像,将它们对齐,并细化其内部参数,以提高目标识别能力。
- 光学字符识别(OCR): 图像对齐(在 OCR 环境中通常称为文档对齐)可用于构建自动表单、发票或收据扫描仪。我们首先将输入图像与我们要扫描的文档的模板对齐。OCR 算法可以从每个单独的字段中读取文本。
在本教程的上下文中,我们将从文档对齐/配准的角度来看图像对齐,这通常用于光学字符识别(OCR)应用。
今天,我们将讨论图像配准和对齐的基础知识。下周,我们将把图像对齐与光学字符识别(OCR)结合起来,使我们能够创建一个文档、表格和发票扫描仪,它将输入图像与模板文档对齐,然后从文档中的每个字段提取文本。
注:本教程的部分内容将出现在我即将出版的新书 OCR with OpenCV、Tesseract 和 Python 中。
要了解如何使用 OpenCV 执行图像对齐和配准,请继续阅读。
使用 OpenCV 进行图像对齐和配准
在本教程的第一部分,我们将简要讨论什么是图像对齐和注册。我们将了解 OpenCV 如何使用关键点检测器、局部不变描述符和关键点匹配来帮助我们对齐和注册图像。
准备好开始了吗?
那我们开始吧!
什么是图像对齐和配准?
图像对齐和配准的过程是:
- 接受两幅输入图像,这两幅图像包含相同的物体,但视角略有不同
- 自动计算用于对齐图像的单应矩阵(无论是基于特征的关键点对应、相似性度量,还是自动学习变换的深度神经网络)
- 采用该单应矩阵并应用透视变形来将图像对准在一起
例如,让我们考虑下图:
在图 1 ( 左)中,我们有一个 W-4 表格的模板,这是一个美国国税局(IRS)的税务表格,员工填写该表格,以便雇主知道从他们的薪水中扣缴多少税(取决于扣除额、申报状态等)。).
我用虚假数据填写了部分 W-4 表格,然后用手机拍了一张照片(中间)。
最后,您可以在右侧的 — 看到输出图像的对齐和配准。请注意输入图像现在是如何与模板对齐的。
在下周的教程中,您将学习如何从输入文档中 OCR 每个单独的字段,并将它们与模板中的字段相关联。不过现在,我们将只学习如何将表单与其模板对齐,这是应用 OCR 之前的一个重要预处理步骤。
当我们从 OCR 的角度检查图像对齐和注册时,请注意同样的原则也适用于其他领域。
OpenCV 如何帮助图像对齐和配准?
有许多图像对齐和配准算法:
- 最流行的图像对齐算法是基于特征的,包括关键点检测器(DoG、Harris、GFFT 等。)、局部不变描述符(SIFT、SURF、ORB 等。),以及关键点匹配(RANSAC 及其变体)。
- 医学应用通常使用相似性度量进行图像配准,通常是互相关、强度差平方和以及互信息。
- 随着神经网络的重新兴起,深度学习甚至可以通过自动学习单应变换来用于图像对齐。
我们将使用基于特征的方法实现图像对齐和配准。
基于特征的方法从检测两个输入图像中的关键点开始:
关键点意味着识别输入图像的显著区域。
对于每个关键点,我们提取局部不变描述符,这些描述符量化输入图像中每个关键点周围的区域。
例如,SIFT 特征是 128 维的,所以如果我们在给定的输入图像中检测到 528 个关键点,那么我们将总共有 528 个向量,每个向量都是 128 维的。
给定我们的特征,我们应用诸如 RANSAC 的算法来匹配我们的关键点并确定它们的对应关系:
假设我们有足够的关键点匹配和对应,我们可以计算一个单应矩阵,它允许我们应用透视变形来对齐图像:
在本教程的剩余部分,您将学习如何构建一个 OpenCV 项目,通过单应矩阵完成图像对齐和配准。
有关单应矩阵构建及其在计算机视觉中的作用的更多详细信息,请务必参考该 OpenCV 参考资料。
配置您的 OCR 开发环境
如果您尚未配置 TensorFlow 和上周教程中的相关库,我首先建议您遵循下面链接的相关教程:
上面的教程将帮助您在一个方便的 Python 虚拟环境中,用这篇博客文章所需的所有软件来配置您的系统。
项目结构
花点时间找到本教程的 【下载】 部分,并获取我们今天将在这里使用的代码和示例税表。在里面,您会发现以下内容:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── alignment
│ │ ├── __init__.py
│ │ └── align_images.py
│ └── __init__.py
├── scans
│ ├── scan_01.jpg
│ └── scan_02.jpg
├── align_document.py
└── form_w4.png
3 directories, 7 files
对于本教程,我们有一个简单的项目结构,由以下图像组成:
scans/:包含两张税单的 JPG 测试照片form_w4.png:2020 年美国国税局 W-4 表格的模板图像
此外,我们将回顾两个 Python 文件:
- 持有我们的助手函数,它通过 OpenCV 管道将扫描与模板对齐
align_document.py:主目录中的驱动文件,它将所有的部分放在一起,用 OpenCV 执行图像对齐和注册
在下一节中,我们将实现对齐图像的辅助工具。
使用 OpenCV 和关键点匹配对齐图像
我们现在准备使用 OpenCV 实现图像对齐和注册。出于本节的目的,我们将尝试对齐以下图像:
在左侧我们有我们的 W-4 表格模板,而在右侧我们有一份我已经填写好并用手机拍摄的 W-4 表格样本。
最终目标是对齐这些图像,使它们的字段匹配(允许我们在下周的教程中对每个字段进行 OCR)。
我们开始吧!
打开align_images.py,让我们一起编写脚本:
# import the necessary packages
import numpy as np
import imutils
import cv2
def align_images(image, template, maxFeatures=500, keepPercent=0.2,
debug=False):
# convert both the input image and template to grayscale
imageGray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
templateGray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
我们的助手脚本需要 OpenCV 和imutils;您可以按照上面的“配置您的 OCR 开发环境”小节在您的系统上安装这两个软件包。NumPy 是 OpenCV 的必备组件,也将被安装。
假设我们已经定义了我们的函数,让我们实现我们的图像处理管道。开始时,我们采取的第一个动作是将我们的image和template都转换成灰度(第 9 行和第 10 行)。
接下来,我们将检测关键点,提取局部二进制特征,并在输入图像和模板之间关联这些特征:
# use ORB to detect keypoints and extract (binary) local
# invariant features
orb = cv2.ORB_create(maxFeatures)
(kpsA, descsA) = orb.detectAndCompute(imageGray, None)
(kpsB, descsB) = orb.detectAndCompute(templateGray, None)
# match the features
method = cv2.DESCRIPTOR_MATCHER_BRUTEFORCE_HAMMING
matcher = cv2.DescriptorMatcher_create(method)
matches = matcher.match(descsA, descsB, None)
我们使用 ORB 算法来检测关键点并提取二元局部不变特征(第 14-16 行)。汉明方法计算这些二元特征之间的距离,以找到最佳匹配(第 19-21 行)。你可以在我的 本地二进制模式与 Python & OpenCV 教程或者我的 PyImageSearch 大师课程 中了解更多关于关键点检测和本地二进制模式的知识。
现在我们已经有了关键点matches,接下来的步骤包括排序、过滤和显示:
# sort the matches by their distance (the smaller the distance,
# the "more similar" the features are)
matches = sorted(matches, key=lambda x:x.distance)
# keep only the top matches
keep = int(len(matches) * keepPercent)
matches = matches[:keep]
# check to see if we should visualize the matched keypoints
if debug:
matchedVis = cv2.drawMatches(image, kpsA, template, kpsB,
matches, None)
matchedVis = imutils.resize(matchedVis, width=1000)
cv2.imshow("Matched Keypoints", matchedVis)
cv2.waitKey(0)
接下来,在计算我们的单应矩阵之前,我们将执行几个步骤:
# allocate memory for the keypoints (x, y)-coordinates from the
# top matches -- we'll use these coordinates to compute our
# homography matrix
ptsA = np.zeros((len(matches), 2), dtype="float")
ptsB = np.zeros((len(matches), 2), dtype="float")
# loop over the top matches
for (i, m) in enumerate(matches):
# indicate that the two keypoints in the respective images
# map to each other
ptsA[i] = kpsA[m.queryIdx].pt
ptsB[i] = kpsB[m.trainIdx].pt
给定我们有组织的关键点匹配对,现在我们准备对齐我们的图像:
# compute the homography matrix between the two sets of matched
# points
(H, mask) = cv2.findHomography(ptsA, ptsB, method=cv2.RANSAC)
# use the homography matrix to align the images
(h, w) = template.shape[:2]
aligned = cv2.warpPerspective(image, H, (w, h))
# return the aligned image
return aligned
恭喜你!您已经完成了教程中最技术性的部分。
注:非常感谢 LearnOpenCV 的 Satya 为 提供的关键点匹配 的简洁实现,我们的正是基于此。
实现我们的 OpenCV 图像对齐脚本
现在我们已经有了align_images函数,我们需要开发一个驱动程序脚本:
- 从磁盘加载图像和模板
- 执行图像对齐和配准
- 将对齐的图像显示到我们的屏幕上,以验证我们的图像注册过程是否正常工作
打开align_document.py,让我们回顾一下,看看我们如何才能做到这一点:
# import the necessary packages
from pyimagesearch.alignment import align_images
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image that we'll align to template")
ap.add_argument("-t", "--template", required=True,
help="path to input template image")
args = vars(ap.parse_args())
--image:输入图像扫描或照片的路径--template:我们的模板图像路径;这可能是一个正式的公司表格或在我们的情况下,2020 年国税局 W-4 模板图像
我们的下一步是对齐我们的两个输入图像:
# load the input image and template from disk
print("[INFO] loading images...")
image = cv2.imread(args["image"])
template = cv2.imread(args["template"])
# align the images
print("[INFO] aligning images...")
aligned = align_images(image, template, debug=True)
就我们本周的目的而言,我们将以两种方式展示我们的结果:
- 并排堆叠
- 一个在另一个的顶部重叠
我们结果的这些可视化表示将允许我们确定比对是否成功。
让我们准备好我们的aligned图像,用于堆叠与其template的比较:
# resize both the aligned and template images so we can easily
# visualize them on our screen
aligned = imutils.resize(aligned, width=700)
template = imutils.resize(template, width=700)
# our first output visualization of the image alignment will be a
# side-by-side comparison of the output aligned image and the
# template
stacked = np.hstack([aligned, template])
# our second image alignment visualization will be *overlaying* the
# aligned image on the template, that way we can obtain an idea of
# how good our image alignment is
overlay = template.copy()
output = aligned.copy()
cv2.addWeighted(overlay, 0.5, output, 0.5, 0, output)
# show the two output image alignment visualizations
cv2.imshow("Image Alignment Stacked", stacked)
cv2.imshow("Image Alignment Overlay", output)
cv2.waitKey(0)
除了上面的并排堆叠可视化,另一个可视化是覆盖模板上的输入图像,这样我们就可以很容易地看到错位量。第 38-40 行使用 OpenCV 的cv2.addWeighted将两幅图像透明地混合成一幅output图像,每幅图像的像素具有相同的权重。
最后,我们在屏幕上显示我们的两个可视化(行 43-45 )。
干得好!现在是检验我们成果的时候了。
OpenCV 图像对齐和配准结果
我们现在准备使用 OpenCV 应用图像对齐和注册!
使用本教程的 “下载” 部分下载源代码和示例图像。从那里,打开一个终端,并执行以下命令:
$ python align_document.py --template form_w4.png --image scans/scan_01.jpg
[INFO] loading images...
[INFO] aligning images...
上面的图像显示了我们的输入图像,scan_01.jpg —请注意这张图像是如何用我的智能手机以非 90 度视角拍摄的(即,不是输入图像的俯视鸟瞰图)。
然后,我们应用图像对齐和配准,结果如下:
在左侧您可以看到输入图像(校准后),而右侧显示原始 W-4 模板图像。
注意这两幅图像是如何使用关键点匹配自动对齐的!
下面可以看到另一种可视化效果:
这里,我们将输出的对齐图像覆盖在模板的顶部。
我们的对齐不是完美的(获得像素完美的对齐是非常具有挑战性的,并且在某些情况下是不现实的),但是表单的字段是充分对齐的,因此我们将能够 OCR 文本并将字段关联在一起(我们将在下周的教程中介绍)。
注意: 我推荐你看一下这里的全分辨率输出图像,这样你就可以看到对齐叠加的差异。
让我们尝试另一个示例图像:
$ python align_document.py --template form_w4.png --image scans/scan_02.jpg
[INFO] loading images...
[INFO] aligning images...
scan_02.jpg图像包含相同的形式,但以不同的视角拍摄
通过应用图像对齐和配准,我们能够将输入图像与form_w4.png模板对齐:
这里你可以看到叠加的可视化效果:
下周,您将学习如何将 OCR 应用于我们的对齐文档,允许我们对每个字段进行 OCR,然后将输入图像中的字段与原始模板相关联。
这将是一个非常棒的教程,你绝对不想错过!
总结
在本教程中,您学习了如何使用 OpenCV 执行图像对齐和配准。
图像对齐有许多用例,包括医学扫描、基于军事的自动目标获取和卫星图像分析。
我们选择从一个最重要的(也是最常用的)目的——光学字符识别(OCR)来研究图像对齐。
对输入图像应用图像对齐允许我们将其与模板文档对齐。一旦输入图像与模板对齐,我们就可以应用 OCR 来识别每个单独字段中的文本。因为我们知道文档中每个字段的位置,所以很容易将 OCR 文本与每个字段相关联。
下周,我将向您展示如何使用我们的图像对齐脚本,并将其扩展到 OCR 输入文档中的每个字段。
敬请关注下期帖子;你不会想错过的!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
图像算法 OpenCV
原文:https://pyimagesearch.com/2021/01/19/image-arithmetic-opencv/
在本教程中,您将学习如何使用 OpenCV 执行图像运算(加法和减法)。
还记得你在小学学习加减法的时候吗?
事实证明,用图像进行算术运算是非常相似的——当然,只有一些注意事项。
在这篇博文中,您将学习如何添加和减去图像,以及您需要了解的关于 OpenCV 和 Python 中算术运算的两个重要区别。
要学习如何用 OpenCV 执行图像运算,继续阅读。
图像运算 OpenCV
在本指南的第一部分,我们将讨论什么是图像算法,包括您在现实世界应用中看到的图像算法。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我将向您展示两种执行图像运算的方法:
- 第一种方式是使用 OpenCV 的
cv2.add和cv2.subtract - 第二种方法是使用 NumPy 的基本加减运算符
在这两者之间有非常重要的警告你需要理解,所以当你回顾这个教程的时候一定要注意!
什么是图像算术?
图像算法就是简单的矩阵加法(关于数据类型有一个附加的警告,我们将在后面解释)。
让我们花点时间复习一些非常基础的线性代数。假设我们要添加以下两个矩阵:

矩阵加法的输出是什么?
答案就是矩阵元素的元素和:

很简单,对吧?
所以在这一点上很明显,我们都知道像加法和减法这样的基本算术运算。但是当处理图像时,我们需要记住我们的颜色空间和数据类型的数值限制。
例如,RGB 图像具有落在范围【0,255】内的像素。如果我们检查一个亮度为 250 的像素,并尝试给它加上 10 会发生什么?
在正常的算术规则下,我们最终得到的值是 260 。然而,由于我们将 RGB 图像表示为 8 位无符号整数,它们只能取范围【0,255】, 260 是而不是有效值。
那么应该发生什么呢?我们是否应该执行某种检查,以确保没有像素落在【0,255】的范围之外,从而将所有像素裁剪为最小值 0 和最大值 255?
或者我们应用一个模数运算并“回绕”(NumPy 就是这么做的)?在模数规则下,将 10 加到 255 会简单地绕回一个值 9 。
哪种方式是处理超出【0,255】范围的图像加减的“正确”方式?
答案是没有“正确的方法”——这完全取决于你如何处理你的像素,以及你想要什么样的结果。
然而,一定要记住 OpenCV 和 NumPy 加法是有区别的。NumPy 将执行模数运算和“回绕”另一方面,OpenCV 将执行裁剪,并确保像素值不会超出范围【0,255】。
但是不用担心!随着我们探索下面的一些代码,这些细微差别将变得更加清晰。
图像算术是用来做什么的?
现在我们了解了图像算法的基础,你可能想知道在现实世界中我们会在哪里使用图像算法。
基本示例包括:
- 通过增加或减少设定的量来调整亮度和对比度(例如,将 50 加到所有像素值上以增加图像的亮度)
- 使用阿尔法混合和透明度,正如我们在本教程中所做的
- 创建类似 Instagram 的滤镜 —这些滤镜是应用于像素亮度的简单数学函数
虽然你可能会很快忽略这个图像算法指南,转到更高级的主题,但我强烈建议你详细阅读这个教程。虽然过于简单,但图像算法在许多计算机视觉和图像处理应用中使用(无论你是否意识到)。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
准备好用 OpenCV 学习图像算法的基础知识了吗?
太好了,我们走吧。
首先使用本教程的 【下载】 部分访问源代码和示例图像:
$ tree . --dirsfirst
.
├── grand_canyon.png
└── image_arithmetic.py
0 directories, 2 files
我们的image_arithmetic.py文件将展示 OpenCV 和 NumPy 中加法和减法运算的区别/注意事项。
然后,您将学习如何使用 OpenCV 的图像算法来手动调整图像的亮度。
用 OpenCV 实现图像运算
我们现在准备用 OpenCV 和 NumPy 探索图像算法。
打开项目文件夹中的image_arithmetic.py文件,让我们开始吧:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="grand_canyon.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包。注意我们是如何为数值数组处理导入 NumPy 的。
第 7-10 行然后解析我们的命令行参数。这里我们只需要一个开关,--image,它指向我们将要应用图像算术运算的磁盘上的图像。我们将默认镜像路径为磁盘上的grand_canyon.png镜像,但是如果您想使用自己的镜像,您可以很容易地更新这个开关。
还记得我上面怎么提到 OpenCV 和 NumPy 算术的区别吗?现在,我们将进一步探索它,并提供一个具体的示例来确保我们完全理解它:
# images are NumPy arrays stored as unsigned 8-bit integers (unit8)
# with values in the range [0, 255]; when using the add/subtract
# functions in OpenCV, these values will be *clipped* to this range,
# even if they fall outside the range [0, 255] after applying the
# operation
added = cv2.add(np.uint8([200]), np.uint8([100]))
subtracted = cv2.subtract(np.uint8([50]), np.uint8([100]))
print("max of 255: {}".format(added))
print("min of 0: {}".format(subtracted))
在第 17 行,我们定义了两个 8 位无符号整数的 NumPy 数组。第一个数组有一个元素:一个值200。第二个数组只有一个元素,但值为100。然后我们使用 OpenCV 的cv2.add方法将这些值相加。
你认为产量会是多少?
根据标准的算术规则,我们会认为结果应该是300,但是请记住,我们使用的是范围在【0,255】之间的 8 位无符号整数。
由于我们使用的是cv2.add方法,OpenCV 会为我们处理裁剪,并确保加法产生最大值255。
当我们执行这段代码时,我们可以在下面清单的第一行看到结果:
max of 255: [[255]]
果然,加法返回值255。
第 20 行然后使用cv2.subtract执行减法。同样,我们定义了两个 NumPy 数组,每个数组都有一个元素,并且是 8 位无符号整数数据类型。第一个数组的值为50,第二个数组的值为100。
按照我们的算术规则,减法应该返回值-50;然而 OpenCV 又一次为我们进行了裁剪。我们发现该值被削波为值0。我们下面的输出证实了这一点:
min of 0: [[0]]
使用cv2.subtract从50中减去100得到一个值0。
但是如果我们使用 NumPy 而不是 OpenCV 来执行运算会发生什么呢?
现在让我们来探索一下:
# using NumPy arithmetic operations (rather than OpenCV operations)
# will result in a modulo ("wrap around") instead of being clipped
# to the range [0, 255]
added = np.uint8([200]) + np.uint8([100])
subtracted = np.uint8([50]) - np.uint8([100])
print("wrap around: {}".format(added))
print("wrap around: {}".format(subtracted))
首先,我们定义两个 NumPy 数组,每个数组都有一个元素,并且是 8 位无符号整数数据类型。第一个数组的值为200,第二个数组的值为100。
如果我们使用cv2.add函数,我们的加法将被剪切,并且返回一个值255;然而,NumPy 并不执行裁剪,而是执行模运算和“回绕”
一旦达到255的值,NumPy 返回到零,然后再次开始向上计数,直到达到100步。您可以通过下面的第一行输出看到这一点:
wrap around: [44]
第 26 行定义了另外两个 NumPy 数组:一个的值是50,另一个是100。
当使用cv2.subtract方法时,这个减法将被裁剪以返回一个值0;但是,我们知道 NumPy 执行的是模运算,而不是裁剪。相反,一旦在减法过程中达到了0,取模运算就会绕回并从255开始倒数——我们可以从下面的输出中验证这一点:
wrap around: [206]
在执行整数运算时,记住您想要的输出非常重要:
- 如果所有值超出范围 [0,255] ,您是否希望对其进行裁剪?然后使用 OpenCV 内置的方法进行图像运算。
- 如果值超出了【0,255】的范围,您是否希望进行模数算术运算并使其换行?然后像平常一样简单地加减 NumPy 数组。
既然我们已经探讨了 OpenCV 和 NumPy 中图像算法的注意事项,让我们在实际图像上执行算法并查看结果:
# load the original input image and display it to our screen
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
我们从第行第 31 和 32 行开始,从磁盘加载我们的原始输入图像,然后将其显示到我们的屏幕上:
随着我们的图像从磁盘加载,让我们继续增加亮度:
# increasing the pixel intensities in our input image by 100 is
# accomplished by constructing a NumPy array that has the *same
# dimensions* as our input image, filling it with ones, multiplying
# it by 100, and then adding the input image and matrix together
M = np.ones(image.shape, dtype="uint8") * 100
added = cv2.add(image, M)
cv2.imshow("Lighter", added)
第 38 行定义了一个 1 的 NumPy 数组,与我们的image具有相同的维数。同样,我们肯定会使用 8 位无符号整数作为我们的数据类型。
为了用 100 的值而不是 1 来填充我们的矩阵,我们简单地将 1 的矩阵乘以100。
最后,我们使用cv2.add函数将我们的 100 的矩阵添加到原始图像,从而将图像中的每个像素强度增加100,但确保所有值都被限制在范围【0,255】,如果它们试图超过255。
我们的操作结果如下所示:
请注意,图像看起来比原始图像更“褪色”且更亮。这是因为我们通过添加100来增加像素强度,并将它们推向更亮的颜色。
现在让我们使用cv2.subtract来加深我们的图像:
# similarly, we can subtract 50 from all pixels in our image and make it
# darker
M = np.ones(image.shape, dtype="uint8") * 50
subtracted = cv2.subtract(image, M)
cv2.imshow("Darker", subtracted)
cv2.waitKey(0)
第 44 行创建另一个填充了 50 的 NumPy 数组,然后使用cv2.subtract从图像中的每个像素减去50。
图 5 显示了该减法的结果:
我们的图像现在看起来比大峡谷的原始照片暗得多。曾经是白色的像素现在看起来是灰色的。这是因为我们从像素中减去50并将它们推向 RGB 颜色空间的较暗区域。
OpenCV 图像运算结果
要使用 OpenCV 和 NumPy 执行图像运算,请确保您已经进入本教程的 “下载” 部分,以访问源代码和示例图像。
从那里,打开一个 shell 并执行以下命令:
$ python image_arithmetic.py
max of 255: [[255]]
min of 0: [[0]]
wrap around: [44]
wrap around: [206]
您的裁剪输出应该与我在上一节中的输出相匹配。
总结
在本教程中,我们学习了如何使用 OpenCV 应用图像加法和减法,这是两个基本(但很重要)的图像算术运算。
正如我们所见,图像算术运算只不过是基本的矩阵加法和减法。
我们还探索了使用 OpenCV 和 NumPy 的图像算法的特性。请记住:
- OpenCV 加法和减法将超出范围
[0, 255]的值剪辑到无符号 8 位整数范围内… - …而 NumPy 执行模数运算并“回绕”
记住这些警告很重要。否则,在对图像执行算术运算时,您可能会得到不想要的结果。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
影像分类基础
原文:https://pyimagesearch.com/2021/04/17/image-classification-basics/
一图抵千言。
— English idiom
我们在生活中无数次听到这句格言。它只是意味着一个复杂的想法可以在一个单一的图像中传达。无论是检查我们的股票投资组合的折线图,还是查看即将到来的足球比赛的分布,或者仅仅是欣赏绘画大师的艺术和笔触,我们都在不断地吸收视觉内容,解释意义,并将知识存储起来以备后用。
然而,对于计算机来说,解释图像的内容就不那么简单了——我们的计算机看到的只是一个大的数字矩阵。它对图像试图传达的思想、知识或意义毫无概念。
为了理解一幅图像的内容,我们必须应用 图像分类 ,这是使用计算机视觉和机器学习算法从一幅图像中提取意义的任务。这个操作可以简单到给图像所包含的内容分配一个标签,也可以高级到解释图像的内容并返回一个人类可读的句子。
图像分类是一个非常大的研究领域,包括各种各样的技术——随着深度学习的流行,它还在继续增长。
现在是驾驭深度学习和图像分类浪潮的时候了——那些成功做到这一点的人将获得丰厚的回报。
图像分类和图像理解目前是(并将继续是)未来十年计算机视觉最热门的子领域。在未来,我们会看到像谷歌、微软、百度和其他公司迅速获得成功的图像理解创业公司。我们将在智能手机上看到越来越多的消费应用程序,它们可以理解和解释图像的内容。甚至战争也可能使用由计算机视觉算法自动导航的无人驾驶飞机。
在这一章中,我将提供什么是图像分类的高层次概述,以及图像分类算法必须克服的许多挑战。我们还将回顾与图像分类和机器学习相关的三种不同类型的学习。
最后,我们将通过讨论训练用于图像分类的深度学习网络的四个步骤以及这四个步骤的管道与传统、 手工设计的特征提取管道相比如何来结束这一章。
什么是图像分类?
图像分类,就其核心而言,是从预定义的 类别集中给图像分配标签的任务。
实际上,这意味着我们的任务是分析输入图像并返回一个对图像进行分类的标签。标签总是来自一组预定义的可能类别。
例如,让我们假设我们的可能类别集包括:
categories = {cat, dog, panda}
然后,我们将下面的图像(图 1 )呈现给我们的分类系统:
我们在这里的目标是获取这个输入图像,并从我们的类别集合中给它分配一个标签——在本例中,是狗。
我们的分类系统还可以通过概率给图像分配多个标签,例如dog:95%;猫:4%;熊猫:1% 。
更正式的说法是,给定我们的输入图像为具有三个通道的 W×H 像素,分别为红色、绿色和蓝色,我们的目标是获取 W×H×3 = N 像素图像,并找出如何正确地对图像内容进行分类。
术语注释
当执行机器学习和深度学习时,我们有一个 数据集 我们试图从中提取知识。数据集中的每个例子/项目(无论是图像数据、文本数据、音频数据等等。)是一个 数据点 。因此,数据集是数据点的集合(图 2 )。
我们的目标是应用机器学习和深度学习算法来发现数据集中的潜在模式,使我们能够正确分类我们的算法尚未遇到的数据点。现在请花时间熟悉这些术语:
- 在图像分类的背景下,我们的数据集是图像的集合。
- 因此,每个图像是一个数据点。
在本书的其余部分,我将交替使用术语图像和数据点,所以请记住这一点。
语义鸿沟
看看图 3 中的两张照片(上)。对我们来说,分辨两张照片之间的差异应该是相当微不足道的——左边明显是一只猫,右边是一只狗。但是计算机看到的只是两个大的像素矩阵(底部)。
假设计算机看到的只是一个大的像素矩阵,我们就有了语义差距的问题。语义鸿沟是人类如何感知图像内容与图像如何以计算机能够理解的方式表示之间的差异。
再一次,对上面两张照片的快速视觉检查可以揭示两种动物之间的差异。但事实上,计算机一开始就不知道图像中有动物。为了说明这一点,请看一下图 4 ,其中有一张宁静海滩的照片。
我们可以这样描述这幅图像:
- 空间:天空在图像的顶部,沙子/海洋在底部。
- 颜色:天空是深蓝色,海水是比天空更淡的蓝色,而沙子是黄褐色。
- 纹理:天空有比较均匀的花纹,而沙子很粗糙。
我们如何以计算机能够理解的方式对所有这些信息进行编码?答案是应用特征提取来量化图像的内容。特征提取是获取输入图像、应用算法并获得量化我们的图像的特征向量(即,数字列表)的过程。
为了完成这个过程,我们可以考虑应用手工设计的特征,如 HOG、LBPs 或其他“传统的”方法来量化图像。另一种方法,也是这本书采用的方法,是应用深度学习来自动学习一组特征,这些特征可以用来量化并最终标记图像本身的内容。
然而,事情没那么简单。。。因为一旦我们开始检查现实世界中的图像,我们就会面临许多挑战。
挑战
如果语义差距还不足以成为问题,我们还必须处理图像或物体如何出现的的变异因素。图 5 显示了这些变化因素的可视化。
首先,我们有 视点变化 ,其中对象可以根据对象的拍摄和捕捉方式在多个维度上定向/旋转。无论我们从哪个角度捕捉这个树莓皮,它仍然是一个树莓皮。
我们还必须考虑到的尺度变化。你曾经在星巴克点过一杯大杯或超大杯的咖啡吗?从技术上讲,它们都是一样的东西——一杯咖啡。但是它们都是一杯不同大小的咖啡。此外,同样的大杯咖啡,近距离拍摄和远距离拍摄看起来会有很大的不同。我们的图像分类方法必须能够容忍这些类型的尺度变化。
最难解释的变化之一是。对于那些熟悉电视连续剧的人来说,我们可以在上图中看到主角。正如电视节目的名字所暗示的,这个角色富有弹性,可拉伸,能够以许多不同的姿势扭曲他的身体。我们可以将 Gumby 的这些图像视为一种对象变形——所有图像都包含 Gumby 角色;然而,它们彼此之间都有很大的不同。
我们的图像分类还应该能够处理,其中我们想要分类的对象的大部分在图像中隐藏起来(图 5 )。在左边的,我们必须有一张狗的照片。在右边的,我们有一张同一只狗的照片,但是请注意这只狗是如何在被子下休息的,从我们的视角来看被遮挡。狗在两幅图像中都清晰可见——只是在一幅图像中她比另一幅更明显。图像分类算法应该仍然能够在两幅图像中检测和标记狗的存在。*
正如上面提到的变形和遮挡一样具有挑战性,我们还需要处理 光照 的变化。看看在标准和弱光下拍摄的咖啡杯(图 5 )。左侧的图像是在标准顶灯照明下拍摄的,而右侧*的图像是在非常微弱的照明下拍摄的。我们仍然在检查同一个杯子——但根据照明条件,杯子看起来有很大的不同(杯子的垂直纸板接缝在低照明条件下清晰可见,但不是标准照明条件下)。**
继续下去,我们还必须考虑 背景杂波 。玩过游戏吗,沃尔多在哪里?沃利在哪里?为了我们的国际读者。)如果是这样,那么你知道游戏的目标是找到我们最喜欢的红白条纹衬衫朋友。然而,这些谜题不仅仅是一个有趣的儿童游戏——它们也是背景混乱的完美代表。这些图像非常“嘈杂”,里面有很多东西。我们只对图像中的一个特定对象感兴趣;然而,由于所有的“噪音”,不容易挑出瓦尔多/沃利。如果对我们来说都不容易做到,想象一下对图像没有语义理解的计算机有多难!
最后,我们有 类内变异 。计算机视觉中类内变异的典型例子是展示椅子的多样化。从我们用来蜷缩着看书的舒适椅子,到家庭聚会餐桌上摆放的椅子,再到知名家庭中的超现代艺术装饰风格的椅子,椅子仍然是椅子——我们的图像分类算法必须能够正确地对所有这些变化进行分类。
您是否开始对构建图像分类器的复杂性感到有点不知所措?不幸的是,情况只会变得更糟——对于我们的图像分类系统来说,独立地对这些变化鲁棒是不够的,但是我们的系统还必须处理多个变化组合 在一起!
那么,我们如何解释物体/图像中如此惊人数量的变化呢?总的来说,我们尽可能把问题框住。我们对图像的内容以及我们想要容忍的变化做出假设。我们还考虑项目的范围——最终目标是什么?我们想要建立什么?
在编写一行代码之前,部署到现实世界中的成功的计算机视觉、图像分类和深度学习系统会做出仔细的假设和考虑。
如果你采取的方法过于宽泛,比如“我想分类并检测我厨房里的每一个物体**”(可能有数百个可能的物体),那么你的分类系统不太可能表现良好,除非你有多年构建图像分类器的经验——即使如此,也不能保证项目成功。
但是如果你把你的问题框起来,缩小范围,比如“我只想识别炉子和冰箱”,那么你的系统更有可能准确并正常工作,尤其是如果这是你第一次使用图像分类和深度学习。
这里的关键要点是 始终考虑你的图像分类器 的范围。虽然深度学习和卷积神经网络在各种挑战下表现出了显著的鲁棒性和分类能力,但你仍然应该尽可能保持你的项目范围紧凑和定义明确。
请记住,ImageNet,事实上的图像分类算法标准基准数据集,由我们日常生活中遇到的 1000 个对象组成——并且这个数据集仍然被试图推动深度学习发展的研究人员积极使用。
深度学习是而不是魔法。相反,深度学习就像你车库里的一把锯子——正确使用时强大而有用,但如果使用不当则很危险。在本书的其余部分,我将指导您进行深度学习,并帮助您指出何时应该使用这些强大的工具,何时应该参考更简单的方法(或者提及图像分类无法解决的问题)。
学习类型
在你的机器学习和深度学习生涯中,你很可能会遇到三种类型的学习:监督学习、非监督学习和半监督学习。这本书主要关注深度学习背景下的监督学习。尽管如此,下面还是介绍了所有三种类型的学习。
监督学习
想象一下:你刚刚大学毕业,获得了计算机科学的学士学位。你还年轻。破产了。在这个领域找工作——也许你甚至会在找工作的过程中感到迷茫。
但在你意识到之前,一位谷歌招聘人员在 LinkedIn 上找到了你,并给你提供了一个在他们的 Gmail 软件上工作的职位。你会接受吗?很有可能。
几个星期后,你来到谷歌位于加州山景城的壮观园区,被令人惊叹的景观、停车场的特斯拉车队和自助餐厅几乎永无止境的美食所淹没。
你终于在自己的办公桌前坐下来,置身于数百名员工之间的一个敞开的工作空间。。。然后你会发现你在公司中的角色。你受雇开发一款软件,让自动将电子邮件分类为垃圾邮件或非垃圾邮件。
你将如何完成这个目标?基于规则的方法可行吗?您能否编写一系列if/else语句来查找特定的单词,然后根据这些规则确定一封电子邮件是否是垃圾邮件?那可能有用。。。在某种程度上。但这种方法也很容易被击败,而且几乎不可能维持下去。
相反,你真正需要的是机器学习。你需要一个训练集,由电子邮件本身以及它们的标签组成,在本例中,是垃圾邮件或非垃圾邮件。有了这些数据,您可以分析电子邮件中的文本(即单词的分布),并利用垃圾邮件/非垃圾邮件标签来教导机器学习分类器哪些单词出现在垃圾邮件中,哪些没有出现,而无需手动创建一系列复杂的if/else语句。
这个创建垃圾邮件过滤系统的例子是监督学习的例子。监督学习可以说是最知名和最受研究的机器学习类型。给定我们的训练数据,通过训练过程创建模型(或“分类器”),其中对输入数据进行预测,然后在预测错误时进行纠正。这个训练过程一直持续到模型达到某个期望的停止标准,例如低错误率或训练迭代的最大次数。
常见的监督学习算法包括逻辑回归、支持向量机(SVMs) ( Cortes 和 Vapnik,1995 、 Boser 等人,1992 )、随机森林和人工神经网络。
在图像分类的背景下,我们假设我们的图像数据集由图像本身以及它们对应的类别标签组成,我们可以使用它们来教导我们的机器学习分类器每个类别“看起来像什么”如果我们的分类器做出了不正确的预测,我们可以应用方法来纠正它的错误。
通过查看表 1 中的示例,可以更好地理解监督学习、非监督学习和半监督学习之间的区别。表格的第一列是与特定图像相关联的标签。其余六列对应于每个数据点的特征向量,这里,我们选择通过计算每个 RGB 颜色通道的平均值和标准偏差来量化图像内容。
| 标签 | B | R[σ] | G[σ] | B[σ] | ||
|---|---|---|---|---|---|---|
| 猫 | Fifty-seven point six one | Forty-one point three six | One hundred and twenty-three point four four | One hundred and fifty-eight point three three | One hundred and forty-nine point eight six | Ninety-three point three three |
| 猫 | One hundred and twenty point two three | One hundred and twenty-one point five nine | One hundred and eighty-one point four three | One hundred and forty-five point five eight | Sixty-nine point one three | One hundred and sixteen point nine one |
| 猫 | One hundred and twenty-four point one five | One hundred and ninety-three point three five | Sixty-five point seven seven | Twenty-three point six three | One hundred and ninety-three point seven four | One hundred and sixty-two point seven |
| 狗 | One hundred point two eight | One hundred and sixty-three point eight two | One hundred and four point eight one | Nineteen point six two | One hundred and seventeen point zero seven | Twenty-one point one one |
| 狗 | One hundred and seventy-seven point four three | Twenty-two point three one | One hundred and forty-nine point four nine | One hundred and ninety-seven point four one | Eighteen point nine nine | One hundred and eighty-seven point seven eight |
| 狗 | One hundred and forty-nine point seven three | Eighty-seven point one seven | One hundred and eighty-seven point nine seven | Fifty point two seven | Eighty-seven point one five | Thirty-six point six five |
Table 1: A table of data containing both the class labels (either dog or cat) and feature vectors for each data point (the mean and standard deviation of each Red, Green, and Blue color channel, respectively). This is an example of a supervised classificationtask.
我们的监督学习算法将对这些特征向量中的每一个进行预测,如果它做出不正确的预测,我们将试图通过告诉它正确的标签实际上是什么来纠正它。然后,该过程将继续,直到满足期望的停止标准,例如精度、学习过程的迭代次数或者仅仅是任意数量的墙壁时间。
备注: 为了解释监督、非监督和半监督学习之间的差异,我选择了使用基于特征的方法(即 RGB 颜色通道的均值和标准差)来量化图像的内容。当我们开始使用卷积神经网络时,我们实际上会跳过特征提取步骤,使用原始像素亮度本身。由于图像可能是很大的矩阵(因此不能很好地适应这个电子表格/表格示例),我使用了特征提取过程来帮助可视化不同类型的学习之间的差异。
无监督学习
与监督学习相反,无监督学习(有时称为自学学习)没有与输入数据相关联的标签,因此如果它做出不正确的预测,我们就无法纠正我们的模型。
回到电子表格的例子,将监督学习问题转换为非监督学习问题就像删除“标签”列一样简单(表 2 )。
无监督学习有时被认为是机器学习和图像分类的“圣杯”。当我们考虑 Flickr 上的图片数量或 YouTube 上的视频数量时,我们很快意识到互联网上有大量未标记的数据。如果我们可以让我们的算法从未标记数据中学习模式,那么我们就不必花费大量的时间(和金钱)费力地为监督任务标记图像。
| B | R[σ] | G[σ] | B[σ] | ||
|---|---|---|---|---|---|
| Fifty-seven point six one | Forty-one point three six | One hundred and twenty-three point four four | One hundred and fifty-eight point three three | One hundred and forty-nine point eight six | Ninety-three point three three |
| One hundred and twenty point two three | One hundred and twenty-one point five nine | One hundred and eighty-one point four three | One hundred and forty-five point five eight | Sixty-nine point one three | One hundred and sixteen point nine one |
| One hundred and twenty-four point one five | One hundred and ninety-three point three five | Sixty-five point seven seven | Twenty-three point six three | One hundred and ninety-three point seven four | One hundred and sixty-two point seven |
| One hundred point two eight | One hundred and sixty-three point eight two | One hundred and four point eight one | Nineteen point six two | One hundred and seventeen point zero seven | Twenty-one point one one |
| One hundred and seventy-seven point four three | Twenty-two point three one | One hundred and forty-nine point four nine | One hundred and ninety-seven point four one | Eighteen point nine nine | One hundred and eighty-seven point seven eight |
| One hundred and forty-nine point seven three | Eighty-seven point one seven | One hundred and eighty-seven point nine seven | Fifty point two seven | Eighty-seven point one five | Thirty-six point six five |
Table 2: Unsupervised learning algorithms attempt to learn underlying patterns in a dataset without class labels. In this example we have removed the class label column, thus turning this task into an unsupervised learning problem.
当我们可以学习数据集的底层结构,然后反过来将我们学习到的特征应用于一个监督学习问题时,大多数无监督学习算法都是最成功的,在这种情况下,只有很少的标记数据可供使用。
用于无监督学习的经典机器学习算法包括主成分分析(PCA)和 k-means 聚类。具体到神经网络,我们看到自动编码器,自组织映射(SOMs),以及应用于无监督学习的自适应共振理论。无监督学习是一个非常活跃的研究领域,也是一个尚未解决的问题。在本书中,我们不关注无监督学习。
半监督学习
那么,如果我们只有一些与我们的数据相关联的标签,而没有标签与其他的相关联,会发生什么呢?有没有一种方法可以应用监督和非监督学习的混合,并且仍然能够对每个数据点进行分类?结果答案是是的——我们只需要应用半监督学习。
回到我们的电子表格示例,假设我们只有一小部分输入数据的标签(表 3 )。我们的半监督学习算法将获取已知的数据,分析它们,并尝试标记每个未标记的数据点,以用作额外的训练数据。随着半监督算法学习数据的“结构”以做出更准确的预测并生成更可靠的训练数据,该过程可以重复多次。
| 标签 | B | R[σ] | G[σ] | B[σ] | ||
|---|---|---|---|---|---|---|
| 猫 | Fifty-seven point six one | Forty-one point three six | One hundred and twenty-three point four four | One hundred and fifty-eight point three three | One hundred and forty-nine point eight six | Ninety-three point three three |
| ? | One hundred and twenty point two three | One hundred and twenty-one point five nine | One hundred and eighty-one point four three | One hundred and forty-five point five eight | Sixty-nine point one three | One hundred and sixteen point nine one |
| ? | One hundred and twenty-four point one five | One hundred and ninety-three point three five | Sixty-five point seven seven | Twenty-three point six three | One hundred and ninety-three point seven four | One hundred and sixty-two point seven |
| 狗 | One hundred point two eight | One hundred and sixty-three point eight two | One hundred and four point eight one | Nineteen point six two | One hundred and seventeen point zero seven | Twenty-one point one one |
| ? | One hundred and seventy-seven point four three | Twenty-two point three one | One hundred and forty-nine point four nine | One hundred and ninety-seven point four one | Eighteen point nine nine | One hundred and eighty-seven point seven eight |
| 狗 | One hundred and forty-nine point seven three | Eighty-seven point one seven | One hundred and eighty-seven point nine seven | Fifty point two seven | Eighty-seven point one five | Thirty-six point six five |
Table 3: When performing semi-supervised learning we only have the labels for a subset of the images/feature vectors and must try to label the other data points to utilize them as extra training data.
半监督学习在计算机视觉中特别有用,在计算机视觉中,标记我们训练集中的每一幅图像通常是耗时、乏味和昂贵的(至少在工时方面)。在我们根本没有时间或资源来标记每张图像的情况下,我们可以只标记一小部分数据,并利用半监督学习来标记和分类其余的图像。
半监督学习算法通常用较小的标记输入数据集来换取分类精度的某种可容忍的降低。通常情况下,监督学习算法的标签训练越准确,它可以做出的预测就越准确(对于深度学习算法来说,尤其是是这样)。
随着训练数据量的减少,准确性不可避免地受到影响。半监督学习将准确性和数据量之间的这种关系考虑在内,并试图将分类准确性保持在可容忍的范围内,同时大幅减少构建模型所需的训练数据量-最终结果是一个准确的分类器(但通常不如监督分类器准确),只需较少的工作和训练数据。半监督学习的流行选择包括标签传播、标签传播、梯形网络和共同学习/共同训练。
同样,我们将主要关注本书中的监督学习,因为在计算机视觉深度学习的背景下,无监督和半监督学习仍然是非常活跃的研究主题,没有关于使用哪种方法的明确指南。****
基于 Keras 和深度学习的图像分类
原文:https://pyimagesearch.com/2017/12/11/image-classification-with-keras-and-deep-learning/
圣诞节在我心中占有特殊的位置。
不是因为我特别信仰宗教或精神。不是因为我喜欢寒冷的天气。当然也不是因为我喜欢蛋奶酒的味道(单是这种稠度就让我反胃)。
相反,因为我的父亲,圣诞节对我来说意义重大。
正如我在几周前的一篇帖子中提到的,我有一个特别艰难的童年。我家有很多精神疾病。我不得不在那样的环境中快速成长,有时我会错过作为一个孩子的纯真以及活在当下的时光。
但不知何故,在所有的挣扎中,我父亲让圣诞节成为幸福的灯塔。
也许我小时候最美好的回忆之一是在幼儿园的时候(5-6 岁)。我刚下公共汽车,手里拿着书包。
我正走在我们长长的、弯曲的车道上,在山脚下,我看到爸爸正在布置圣诞灯,这些圣诞灯后来装饰了我们的房子、灌木丛和树木,把我们的家变成了一个圣诞仙境。
我像火箭一样起飞,漫不经心地跑在车道上(只有孩子才能做到),拉开拉链的冬衣在我身后翻滚,我一边跑一边喊着:
“等等我,爸爸!”
我不想错过装饰庆典。
在接下来的几个小时里,我父亲耐心地帮我解开打结的圣诞彩灯,把它们摆好,然后看着我随意地把彩灯扔向灌木丛和树木(比我的体型大很多倍),毁掉了他孜孜不倦地设计的任何有条不紊、计划周密的装饰蓝图。
我说完后,他骄傲地笑了。他不需要任何言语。他的微笑表明我的装修是他见过的最好的。
这只是我爸爸为我准备的无数次特别圣诞节中的一个例子(不管家里可能还发生了什么)。
他可能甚至不知道他正在我的脑海中打造一个终身记忆——他只是想让我开心。
每年,当圣诞节来临的时候,我都会试着放慢脚步,减轻压力,享受一年中的时光。
没有我的父亲,我就不会有今天——我也肯定不会度过我的童年。
为了庆祝圣诞节,我想把这篇博客献给我的父亲。
即使你很忙,没有时间,或者根本不关心深度学习(今天教程的主题),也要放慢脚步,读一读这篇博文,不为别的,只为我爸。
我希望你喜欢它。
基于 Keras 和深度学习的图像分类
2020-05-13 更新:此博文现已兼容 TensorFlow 2+!
这篇博客是我们构建非圣诞老人深度学习分类器(即,可以识别圣诞老人是否在图像中的深度学习模型)的三部分系列中的第二部分:
- 第一部分: 深度学习+谷歌图片获取训练数据
- 第二部分:使用深度学习训练圣诞老人/非圣诞老人检测器(本文)
- 第三部分:将圣诞老人/非圣诞老人深度学习检测器部署到树莓派(下周帖子)
在本教程的第一部分,我们将检查我们的“圣诞老人”和“不是圣诞老人”数据集。
总之,这些图像将使我们能够使用 Python 和 Keras 训练一个卷积神经网络,以检测图像中是否有圣诞老人。
一旦我们探索了我们的训练图像,我们将继续训练开创性的 LeNet 架构。我们将使用一个较小的网络架构,以确保没有昂贵的 GPU 的读者仍然可以跟随本教程。这也将确保初学者可以通过 Keras 和 Python 理解卷积神经网络的深度学习的基本原理。
最后,我们将在一系列图像上评估我们的不是圣诞老人模型,然后讨论我们方法的一些限制(以及如何进一步扩展它)。
我们的“圣诞老人”和“非圣诞老人”数据集
为了训练我们的非圣诞老人深度学习模型,我们需要两组图像:
- 图片包含圣诞老人(“Santa”)。
- 不包含圣诞老人(“非圣诞老人”)的图像。
上周,我们使用我们的 Google Images hack 快速获取深度学习网络的训练图像。
在这种情况下,我们可以看到使用该技术收集的包含圣诞老人的 461 幅图像的样本(图 1 ,左)。
然后,我从 UKBench 数据集中随机抽取了 461 张不包含圣诞老人的图片(图 1 ,右),这是一组用于构建和评估基于内容的图像检索(CBIR)系统(即图像搜索引擎)的~10,000图片。
这两个图像集一起使用,将使我们能够训练我们的而不是圣诞老人深度学习模型。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
你的第一个带有卷积神经网络和 Keras 的图像分类器
LetNet 架构是卷积神经网络的优秀“第一图像分类器”。最初设计用于分类手写数字,我们可以很容易地将其扩展到其他类型的图像。
本教程旨在介绍使用深度学习、Keras 和 Python 进行图像分类,因此我不会讨论每一层的内部工作原理。如果你有兴趣深入研究深度学习,请看看我的书, 用 Python 进行计算机视觉的深度学习 ,我在书中详细讨论了深度学习(并且有大量代码+实践,以及动手实现)。
让我们继续定义网络架构。打开一个新文件,将其命名为lenet.py,并插入以下代码:
注意:在运行代码之前,您需要使用本文的“下载”*部分下载源代码+示例图片。出于完整性考虑,我在下面添加了代码,但是您需要确保您的目录结构与我的相匹配。*
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
class LeNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model
model = Sequential()
inputShape = (height, width, depth)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
第 2-8 行处理导入我们需要的 Python 包。Conv2D类负责执行卷积。我们可以使用MaxPooling2D类进行最大池操作。顾名思义,Activation类应用了一个特定的激活函数。当我们准备好将Flatten我们的网络拓扑变成完全连通的时候,Dense层我们可以使用各自的类名。
在行 10 上定义了LeNet类,然后在行 12 上定义了build方法。每当我定义一个新的卷积神经网络架构时,我喜欢:
- 将它放在自己的类中(出于命名空间和组织的目的)
- 创建一个静态的
build函数来构建架构本身
顾名思义,build方法有许多参数,下面我将逐一讨论:
width:我们输入图像的宽度height:输入图像的高度depth:我们输入图像中的通道数(1用于灰度单通道图像,3用于我们将在本教程中使用的标准 RGB 图像)classes:我们想要识别的类的总数(在本例中是两个)
我们在第 14 行的上定义我们的model。我们使用Sequential类,因为我们将依次添加层到model。
第 15 行使用通道最后一次排序初始化我们的inputShape(tensor flow 的默认)。如果您正在使用 Theano(或任何其他假定通道优先排序的 Keras 后端),行 18 和 19 正确更新inputShape。
现在我们已经初始化了我们的模型,我们可以开始向它添加层:
# first set of CONV => RELU => POOL layers
model.add(Conv2D(20, (5, 5), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
第 21-25 行创建了我们的第一组CONV => RELU => POOL图层。
CONV层会学习 20 个卷积滤波器,每个 5×5 。
然后,我们应用一个 ReLU 激活函数,接着是在 x 和 y 方向上的 2×2 max-pooling,步幅为 2。为了可视化这个操作,考虑一个滑动窗口,它在激活体积上“滑动”,在每个区域上取最大值操作,同时在水平和垂直方向上取两个像素的步长。
让我们定义第二组CONV => RELU => POOL层:
# second set of CONV => RELU => POOL layers
model.add(Conv2D(50, (5, 5), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
这次我们学习的是 50 个卷积滤波器,而不是之前层集中的 20 个卷积滤波器。我们在网络架构中经常会看到学习到的CONV过滤器数量 增加更深 。
我们的最后一个代码块处理将卷展平为一组完全连接的层:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation("relu"))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
在第 33 行的上,我们将前面MaxPooling2D层的输出展平成一个矢量。该操作允许我们应用我们的密集/全连接层。
我们的全连接层包含 500 个节点(行 34 ),然后我们通过另一个非线性 ReLU 激活。
第 38 行定义了另一个全连接层,但这一层比较特殊——节点的数量等于classes的数量(即我们要识别的类)。
这个Dense层然后被输入到我们的 softmax 分类器中,该分类器将为每个类别产生概率。
最后, Line 42 将我们完全构建的深度学习+ Keras 图像分类器返回给调用函数。
用 Keras 训练我们的卷积神经网络图像分类器
让我们开始使用深度学习、Keras 和 Python 来训练我们的图像分类器。
注:务必向下滚动到“下载”*部分,抓取代码+训练图像。这将使您能够跟随帖子,然后使用我们为您整理的数据集来训练您的图像分类器。*
打开一个新文件,将其命名为train_network.py,并插入以下代码(或者简单地跟随代码下载):
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.utils import to_categorical
from pyimagesearch.lenet import LeNet
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import cv2
import os
在第 2-18 行,我们导入所需的包。这些软件包使我们能够:
- 从磁盘加载我们的图像数据集
- 预处理图像
- 实例化我们的卷积神经网络
- 训练我们的图像分类器
注意,在的第 3 行上,我们将matplotlib后端设置为"Agg",这样我们就可以在后台将绘图保存到磁盘上。如果您正在使用一个无头服务器来训练您的网络(例如 Azure、AWS 或其他云实例),这一点很重要。
从那里,我们解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
这里我们有两个必需的命令行参数,--dataset和--model,以及一个到我们的准确度/损失图表的可选路径,--plot。
--dataset开关应该指向包含我们将在其上训练我们的图像分类器的图像的目录(即,“圣诞老人”和“非圣诞老人”图像),而--model开关控制我们将在训练后保存我们的序列化图像分类器的位置。如果不指定--plot,则默认为该目录中的plot.png。
接下来,我们将设置一些训练变量,初始化列表,并收集图像路径:
# initialize the number of epochs to train for, initia learning rate,
# and batch size
EPOCHS = 25
INIT_LR = 1e-3
BS = 32
# initialize the data and labels
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
在第 32-34 行上,我们定义了训练时期的数量、初始学习率和批量大小。
然后我们初始化数据和标签列表(第 38 行和第 39 行)。这些列表将负责存储我们从磁盘加载的图像以及它们各自的类标签。
从那里我们获取输入图像的路径,然后对它们进行洗牌(第 42-44 行)。
现在让我们对图像进行预处理:
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (28, 28))
image = img_to_array(image)
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
label = 1 if label == "santa" else 0
labels.append(label)
这个循环简单地将每个图像加载并调整大小为固定的 28×28 像素(LeNet 所需的空间尺寸),并将图像数组附加到data列表中(第 49-52 行),然后从第 56-58 行的imagePath中提取类label。
我们能够执行此类标签提取,因为我们的数据集目录结构是按以下方式组织的:
|--- images
| |--- not_santa
| | |--- 00000000.jpg
| | |--- 00000001.jpg
...
| | |--- 00000460.jpg
| |--- santa
| | |--- 00000000.jpg
| | |--- 00000001.jpg
...
| | |--- 00000460.jpg
|--- pyimagesearch
| |--- __init__.py
| |--- lenet.py
| | |--- __init__.py
| | |--- networks
| | | |--- __init__.py
| | | |--- lenet.py
|--- test_network.py
|--- train_network.py
因此,imagePath的一个例子是:
images/santa/00000384.jpg
从imagePath中提取label后,结果是:
santa
我更喜欢以这种方式组织深度学习图像数据集,因为它允许我们有效地组织我们的数据集并解析出类别标签,而不必使用单独的索引/查找文件。
接下来,我们将缩放图像并创建训练和测试分割:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
# convert the labels from integers to vectors
trainY = to_categorical(trainY, num_classes=2)
testY = to_categorical(testY, num_classes=2)
在行 61 上,我们通过将数据点从【0,255】(图像的最小和最大 RGB 值)缩放到范围【0,1】来进一步预处理我们的输入数据。
然后,我们使用 75%的图像进行训练,25%的图像进行测试,对数据进行训练/测试分割(行 66 和 67 )。这是这种数据量的典型拆分。
我们还使用一键编码将标签转换成矢量——这是在第 70 行和第 71 行处理的。
随后,我们将执行一些数据扩充,使我们能够通过使用以下参数随机变换输入图像来生成“附加”训练数据:
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
数据增强在我的新书《用 Python 进行计算机视觉的深度学习的实践者包中有深入的介绍。
*实际上,第 74-76 行创建了一个图像生成器对象,它对我们的图像数据集执行随机旋转、移动、翻转、裁剪和剪切。这使得我们可以使用更小的数据集,但仍然可以获得高质量的结果。
让我们继续使用深度学习和 Keras 来训练我们的图像分类器。
# initialize the model
print("[INFO] compiling model...")
model = LeNet.build(width=28, height=28, depth=3, classes=2)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
我们选择在这个项目中使用 LeNet 有两个原因:
- LeNet 是一个小型的卷积神经网络,初学者很容易理解
- 我们可以很容易地在我们的圣诞老人/非圣诞老人数据集上训练 LeNet,而不必使用 GPU
- 如果你想更深入地研究深度学习(包括 ResNet、GoogLeNet、SqueezeNet 等)请看看我的书, 用 Python 进行计算机视觉的深度学习。
我们在第 80-83 行的上构建 LeNet 模型和Adam优化器。由于这是一个两类分类问题,我们将使用二进制交叉熵作为我们的损失函数。如果您使用 > 2 类进行分类,请确保将loss替换为categorical_crossentropy。
训练我们的网络在行 87-89 开始,在那里我们调用model.fit,提供我们的数据增强对象、训练/测试数据以及我们希望训练的时期数。
2020-05-13 更新:以前,TensorFlow/Keras 需要使用一种叫做fit_generator的方法来完成数据扩充。现在,fit方法也可以处理数据扩充,使代码更加一致。请务必查看我关于 fit 和 fit 生成器以及数据扩充的文章。
第 93 行处理将模型序列化到磁盘,这样我们稍后就可以使用我们的图像分类而不需要重新训练它。
最后,让我们绘制结果,看看我们的深度学习图像分类器的表现如何:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
N = EPOCHS
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Santa/Not Santa")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-05-13 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
使用 matplotlib,我们构建我们的绘图,并使用包含路径+文件名的--plot命令行参数将绘图保存到磁盘。
为了训练非圣诞老人网络(在使用本博文的 【下载】 部分下载代码+图片之后),打开一个终端并执行以下命令:
$ python train_network.py --dataset images --model santa_not_santa.model
Using TensorFlow backend.
[INFO] loading images...
[INFO] compiling model...
[INFO] training network...
Train for 21 steps, validate on 231 samples
Epoch 1/25
1/21 [>.............................] - ETA: 11s - loss: 0.6757 - accuracy: 0.7368
21/21 [==============================] - 1s 43ms/step - loss: 0.7833 - accuracy: 0.4947 - val_loss: 0.5988 - val_accuracy: 0.5022
Epoch 2/25
21/21 [==============================] - 0s 21ms/step - loss: 0.5619 - accuracy: 0.6783 - val_loss: 0.4819 - val_accuracy: 0.7143
Epoch 3/25
21/21 [==============================] - 0s 21ms/step - loss: 0.4472 - accuracy: 0.8194 - val_loss: 0.4558 - val_accuracy: 0.7879
...
Epoch 23/25
21/21 [==============================] - 0s 23ms/step - loss: 0.1123 - accuracy: 0.9575 - val_loss: 0.2152 - val_accuracy: 0.9394
Epoch 24/25
21/21 [==============================] - 0s 23ms/step - loss: 0.1206 - accuracy: 0.9484 - val_loss: 0.4427 - val_accuracy: 0.8615
Epoch 25/25
21/21 [==============================] - 1s 25ms/step - loss: 0.1448 - accuracy: 0.9469 - val_loss: 0.1682 - val_accuracy: 0.9524
[INFO] serializing network...
如您所见,网络训练了 25 个时期,我们实现了高精度( 95.24% 测试精度)和跟随训练损耗的低损耗,如下面的图中所示:
评估我们的卷积神经网络图像分类器
下一步是在示例图像上评估我们的非圣诞老人模型非部分的训练/测试分割。
打开一个新文件,命名为test_network.py,让我们开始吧:
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import imutils
import cv2
在2-7 行,我们导入我们需要的包。请特别注意load_model方法——该函数将使我们能够从磁盘加载我们的序列化卷积神经网络(即,我们刚刚在上一节中训练的网络)。
接下来,我们将解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
我们需要两个命令行参数:我们的--model和一个输入--image(即我们要分类的图像)。
从那里,我们将加载图像并对其进行预处理:
# load the image
image = cv2.imread(args["image"])
orig = image.copy()
# pre-process the image for classification
image = cv2.resize(image, (28, 28))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
我们加载image并在的第 18 行和第 19 行上复制它。该副本允许我们稍后回忆原始图像,并在其上贴上我们的标签。
第 22-25 行处理将我们的图像缩放到范围【0,1】,将其转换为一个数组,并添加一个额外的维度(第 22-25 行)。
正如我在我的书《用 Python 进行计算机视觉的 深度学习 中解释的那样,我们用 CNN 分批训练/分类图像。假设通道最后排序,通过np.expand_dims向数组添加额外的维度允许我们的图像具有形状(1, width, height, 3)。
*如果我们忘记添加维度,当我们调用下面的model.predict时会导致错误。
从那里,我们将加载而非圣诞老人图像分类器模型,并进行预测:
# load the trained convolutional neural network
print("[INFO] loading network...")
model = load_model(args["model"])
# classify the input image
(notSanta, santa) = model.predict(image)[0]
这个代码块非常简单明了,但是因为这是执行这个脚本的地方,所以让我们花一点时间来理解一下在这个引擎盖下发生了什么。
我们在第 29 行加载非圣诞老人模型,然后在第 32 行进行预测。
最后,我们将使用我们的预测在orig图像副本上绘图,并将其显示到屏幕上:
# build the label
label = "Santa" if santa > notSanta else "Not Santa"
proba = santa if santa > notSanta else notSanta
label = "{}: {:.2f}%".format(label, proba * 100)
# draw the label on the image
output = imutils.resize(orig, width=400)
cv2.putText(output, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
我们在第 35 行的处建立标签(要么是“圣诞老人”,要么不是圣诞老人),然后在第 36 行的处选择相应的概率值。
在第 37行上使用了label和proba来构建标签文本以显示在图像上,如下图左上角所示。
我们将图像调整到标准宽度,以确保它们适合我们的屏幕,然后将标签文本放在图像上(第 40-42 行)。
最后,在行 45 上,我们显示输出图像,直到一个键被按下(行 46 )。
让我们试试我们的不是圣诞老人深度学习网络:
$ python test_network.py --model santa_not_santa.model \
--image examples/santa_01.png
天哪!我们的软件认为这是好的老圣尼克,所以它真的必须是他!
让我们尝试另一个图像:
$ python test_network.py --model santa_not_santa.model \
--image examples/santa_02.png
圣诞老人被“不是圣诞老人”检测器正确地检测出来,看起来他很高兴能送来一些玩具!
现在,让我们对不包含圣诞老人的图像执行图像分类:
$ python test_network.py --model santa_not_santa.model \
--image examples/manhattan.png
2020-06-03 更新:曼哈顿地平线的图片不再包含在“下载”中*更新这篇博文以支持 TensorFlow 2+导致了这张图片的错误分类。这个图保留在帖子中是为了遗留的演示目的,要知道你不会在* “下载”中找到它
看起来外面太亮了,圣诞老人不可能飞过天空,在世界的这个地方(纽约市)送礼物——此时夜幕已经降临,他一定还在欧洲。
说到夜晚和平安夜,这里有一张寒冷夜空的图片:
$ python test_network.py --model santa_not_santa.model \
--image examples/night_sky.png
但对圣尼古拉斯来说肯定太早了。他也不在上面的图像中。
但是不要担心!
正如我下周将展示的,我们将能够发现他偷偷从烟囱下来,用树莓皮送礼物。
我们深度学习图像分类模型的局限性
我们的图像分类器有许多限制。
第一个是 28×28 像素图像相当小(LeNet 架构最初是为了识别手写数字,而不是照片中的物体)。
对于一些示例图像(其中圣诞老人已经很小了),将输入图像的尺寸缩小到 28×28 像素有效地将圣诞老人缩小到只有 2-3 像素大小的微小红/白斑点。
在这些类型的情况下,我们的 LeNet 模型可能只是预测何时在我们的输入图像中有大量的红色和白色集中在一起(也可能是绿色,因为红色、绿色和白色是圣诞节的颜色)。
最先进的卷积神经网络通常接受最大维度为 200-300 像素的图像——这些更大的图像将帮助我们建立一个更强大的 Not Santa 分类器。然而,使用更大分辨率的图像还需要我们利用更深层次的网络架构,这反过来意味着我们需要收集额外的训练数据,并利用计算成本更高的训练过程。
这当然是可能的,但也超出了这篇博文的范围。
因此,如果你想改进我们的而不是圣诞老人应用程序,我建议你:
- 收集额外的培训数据(理想情况下,5,000 多个“圣诞老人”图像示例)。
- 在训练中使用更高分辨率的图像。我想象 64×64 像素会产生更高的精度。 128×128 像素可能是理想的(尽管我没有试过)。
- 在培训中使用更深层次的网络架构。
- 通读我的书, 用 Python 进行计算机视觉的深度学习 ,我在其中更详细地讨论了在你自己的定制数据集上训练卷积神经网络。
尽管有这些限制,我还是对而不是圣诞老人应用的表现感到非常惊讶(我将在下周讨论)。我原以为会有相当数量的误报,但考虑到网络如此之小,它却异常强大。
摘要
在今天的博客文章中,你学习了如何在一系列包含“圣诞老人”和“非圣诞老人”的图像上训练开创性的 LeNet 架构,我们的最终目标是构建一个类似于 HBO 的硅谷 非热狗应用的应用。
通过跟随我们之前关于通过谷歌图像收集深度学习图像的的帖子,我们能够收集我们的“圣诞老人”数据集(~460图像)。
“非圣诞老人”数据集是通过对 UKBench 数据集(其中没有包含圣诞老人的图像)进行采样而创建的。
然后,我们在一系列测试图像上评估了我们的网络——在每种情况下,我们的 Not Santa 模型都正确地对输入图像进行了分类。
在我们的下一篇博客文章中,我们将把我们训练好的卷积神经网络部署到 Raspberry Pi,以完成我们的 Not Santa 应用程序的构建。
现在怎么办?
现在,您已经学会了如何训练您的第一个卷积神经网络,我敢打赌,您对以下内容感兴趣:
- 掌握机器学习和神经网络的基础知识
- 更详细地研究深度学习
- 从头开始训练你自己的卷积神经网络
如果是这样,你会想看看我的新书, 用 Python 进行计算机视觉的深度学习 。
在这本书里,你会发现:
- 超级实用的演练
- 实践教程(有大量代码)
- 详细、全面的指南帮助您从开创性的深度学习出版物中复制最先进的结果。
要了解更多关于我的新书(并开始你的深度学习掌握之旅), 只需点击这里 。
否则,请务必在下表中输入您的电子邮件地址,以便在 PyImageSearch 上发布新的深度学习帖子时得到通知。**
PyTorch 中的图像数据加载器
原文:https://pyimagesearch.com/2021/10/04/image-data-loaders-in-pytorch/
任何基于深度学习的系统的一个重要部分是构建数据加载管道,以便它可以与您的深度学习模型无缝集成。在本教程中,我们将了解 PyTorch 提供的数据加载功能的工作原理,并学习在我们自己的深度学习项目中有效地使用它们。
要学习如何使用 PyTorch 数据集和数据加载器, 只需继续阅读。
py torch 中的图像数据加载器
我们将详细讨论以下内容:
- 如何将数据集重新构造为定型集和验证集
- 如何在 PyTorch 中加载数据集并利用内置的 PyTorch 数据扩充
- 如何设置 PyTorch 数据加载器以有效访问数据样本
我们的示例花卉数据集
我们的目标是在 PyTorch Dataset和DataLoader类的帮助下创建一个基本的数据加载管道,使我们能够轻松高效地访问我们的数据样本,并将它们传递给我们的深度学习模型。
在本教程中,我们将使用由 5 种花卉组成的花卉数据集(见图 1 ):
- 郁金香
- 雏菊
- 蒲公英
- 玫瑰
- 向日葵
配置您的开发环境
为了遵循这个指南,您需要在您的系统上安装 PyTorch 深度学习库、matplotlib、OpenCV 和 imutils 包。
幸运的是,使用 pip 安装这些包非常容易:
$ pip install torch torchvision
$ pip install matplotlib
$ pip install opencv-contrib-python
$ pip install imutils
如果你在为 PyTorch 配置开发环境时需要帮助,我强烈推荐阅读 PyTorch 文档 — PyTorch 的文档很全面,可以让你快速上手。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们继续之前,我们需要首先下载我们将在本教程中使用的 flowers 数据集。
从本教程的 “下载” 部分开始,访问源代码和示例 flowers 数据集。
从那里,解压缩档案文件,您应该会找到下面的项目目录:
├── build_dataset.py
├── builtin_dataset.py
├── flower_photos
│ ├── daisy
│ ├── dandelion
│ ├── roses
│ ├── sunflowers
│ └── tulips
├── load_and_visualize.py
├── pyimagesearch
│ ├── config.py
│ ├── __init__.py
build_dataset.py脚本负责将数据集划分和组织成一个训练和验证集。
此外,builtin_dataset.py脚本显示了如何使用 PyTorch API 直接下载和加载一些常用的计算机视觉数据集,如 MNIST。
flower_photos文件夹包含我们将使用的数据集。它由 5 个子目录(即雏菊、蒲公英、玫瑰、向日葵、郁金香)组成,每个子目录包含相应花卉类别的图像。
另一方面,load_and_visualize.py脚本负责在 PyTorch Dataset和DataLoader类的帮助下加载和访问数据样本。
pyimagesearch文件夹中的config.py 文件存储我们代码的参数、初始设置、配置等信息。
请注意,在下载数据集之后,每个图像都将具有以下格式的路径,folder_name/class_name/image_id.jpg。例如,下面显示的是花卉数据集中一些图像的路径。
flower_photos/dandelion/8981828144_4b66b4edb6_n.jpg
flower_photos/sunflowers/14244410747_22691ece4a_n.jpg
flower_photos/roses/1666341535_99c6f7509f_n.jpg
flower_photos/sunflowers/19519101829_46af0b4547_m.jpg
flower_photos/dandelion/2479491210_98e41c4e7d_m.jpg
flower_photos/sunflowers/3950020811_dab89bebc0_n.jpg
创建我们的配置文件
首先,我们讨论存储教程中使用的配置和参数设置的config.py文件。
# specify path to the flowers and mnist dataset
FLOWERS_DATASET_PATH = "flower_photos"
MNIST_DATASET_PATH = "mnist"
# specify the paths to our training and validation set
TRAIN = "train"
VAL = "val"
# set the input height and width
INPUT_HEIGHT = 128
INPUT_WIDTH = 128
# set the batch size and validation data split
BATCH_SIZE = 8
VAL_SPLIT = 0.1
我们在第 2 行的上定义了 flowers 数据集文件夹的路径,在第 3 行上定义了 MNIST 数据集的路径。除此之外,我们在的第 6 行和第 7 行指定了训练和验证集文件夹的路径名。****
在第 10 行和第 11 行,我们定义了输入图像所需的高度和宽度,这将使我们能够在以后将输入调整到我们的模型可以接受的尺寸。
此外,我们在第 14 行和第 15 行定义了批量大小和作为验证集的数据集部分。
将数据集分割成训练和验证集
在这里,我们讨论如何将 flowers 数据集重组为一个训练和验证集。
打开项目目录结构中的build_dataset.py文件,让我们开始吧。
# USAGE
# python build_dataset.py
# import necessary packages
from pyimagesearch import config
from imutils import paths
import numpy as np
import shutil
import os
我们从在第 5-9 行导入所需的包开始。
def copy_images(imagePaths, folder):
# check if the destination folder exists and if not create it
if not os.path.exists(folder):
os.makedirs(folder)
# loop over the image paths
for path in imagePaths:
# grab image name and its label from the path and create
# a placeholder corresponding to the separate label folder
imageName = path.split(os.path.sep)[-1]
label = path.split(os.path.sep)[-2]
labelFolder = os.path.join(folder, label)
# check to see if the label folder exists and if not create it
if not os.path.exists(labelFolder):
os.makedirs(labelFolder)
# construct the destination image path and copy the current
# image to it
destination = os.path.join(labelFolder, imageName)
shutil.copy(path, destination)
从第 11 行的开始,我们定义了copy_images函数。该方法接受一个列表— imagePaths(即一组图像的路径)和一个目的地folder,并将输入的图像路径复制到目的地。
当我们想要将一组图像路径复制到 training 或 validation 文件夹中时,这个函数会很方便。接下来,我们详细理解这个函数的每一行。
我们首先检查目标文件夹是否已经存在,如果不存在,我们在第 13 行和第 14 行创建它。
在第 17 行,上,我们循环输入imagePaths列表中的每条路径。
对于列表中的每个path (其形式为root/class_label/image_id.jpg ) :
- 我们将
image_id和class_label分别存储在的 20 行和 21 行上。 - 在第 22 行的上,我们在输入目的地定义了一个文件夹
labelFolder来存储来自特定class_label的所有图像。我们在第 25 行和第 26 行上创建labelFolder,如果它还不存在的话。 - 然后,我们为给定的
image_id( 行 30 )的图像构建目的地路径(在labelFolder内),并将当前图像复制到其中(行 31 )。
一旦我们定义了copy_images函数,我们就可以理解将数据集分成训练集和验证集所需的主要代码了。
# load all the image paths and randomly shuffle them
print("[INFO] loading image paths...")
imagePaths = list(paths.list_images(config.FLOWERS_DATASET_PATH))
np.random.shuffle(imagePaths)
# generate training and validation paths
valPathsLen = int(len(imagePaths) * config.VAL_SPLIT)
trainPathsLen = len(imagePaths) - valPathsLen
trainPaths = imagePaths[:trainPathsLen]
valPaths = imagePaths[trainPathsLen:]
# copy the training and validation images to their respective
# directories
print("[INFO] copying training and validation images...")
copy_images(trainPaths, config.TRAIN)
copy_images(valPaths, config.VAL)
第 35 行将花卉数据集中所有图像的路径加载到一个名为imagePaths的列表中。我们借助第 36 行上的numpy随机打乱图像路径,以确保训练集和验证集中的图像统一来自所有类别。
现在,我们定义了总图像的一部分,我们希望将其保留下来作为验证数据。
这由config.VAL_SPLIT定义。
一个常见的选择是留出 10-20%的数据进行验证。在第 39 行,我们将总图像路径的confg.VAL_SPLIT部分作为验证集长度(即valPathsLen)。
这是四舍五入到最接近的整数,因为我们希望图像的数量是一个整数。剩余的分数作为线 40 的车组长度(即trainPathsLen)。
在第 41 行和第 42 行,我们从imagePaths列表中获取训练路径和验证路径。
然后,我们将其传递给copy_images函数(如前所述),该函数接收列车路径和验证路径的列表,并将它们复制到由目标文件夹定义的train和val文件夹,即分别为config.TRAIN和config.VAL,如第行第 47 和 48 行所示。
这构建了我们的文件系统,如下所示。在这里,我们有单独的train和val文件夹,其中包括来自不同类的训练和验证图像,在它们各自的类文件夹中。
├── train
│ ├── daisy
│ ├── dandelion
│ ├── roses
│ ├── sunflowers
│ └── tulips
└── val
├── daisy
├── dandelion
├── roses
├── sunflowers
└── tulips
PyTorch 数据集和数据加载器
既然我们已经将数据集划分为训练集和验证集,我们就可以使用 PyTorch 数据集和数据加载器来设置数据加载管道了。
PyTorch 数据集提供了加载和存储带有相应标签的数据样本的功能。除此之外,PyTorch 还有一个内置的DataLoader类,它在数据集周围包装了一个 iterable,使我们能够轻松地访问和迭代数据集中的数据样本。
让我们更深入一点,借助代码来理解数据加载器。基本上,我们的目标是在 PyTorch Dataset类的帮助下加载我们的训练集和 val 集,并在DataLoader类的帮助下访问样本。
打开项目目录中的load_and_visualize.py文件。
我们从导入所需的包开始。
# USAGE
# python load_and_visualize.
# import necessary packages
from pyimagesearch import config
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
import matplotlib.pyplot as plt
import torch
我们著名的进口产品(第 6-9 行)包括:
ImageFolder类:负责将图像从train和val文件夹加载到 PyTorch 数据集中- 类:使我们能够在数据集周围包装一个 iterable,以便我们的深度学习模型可以有效地访问数据样本
- 一个内置的 PyTorch 类,提供了常见的图像转换
matplotlib.pyplot:用于绘制和可视化图像
现在,我们定义visualize_batch函数,稍后它将使我们能够绘制和可视化来自训练和验证批次的样本图像。
def visualize_batch(batch, classes, dataset_type):
# initialize a figure
fig = plt.figure("{} batch".format(dataset_type),
figsize=(config.BATCH_SIZE, config.BATCH_SIZE))
# loop over the batch size
for i in range(0, config.BATCH_SIZE):
# create a subplot
ax = plt.subplot(2, 4, i + 1)
# grab the image, convert it from channels first ordering to
# channels last ordering, and scale the raw pixel intensities
# to the range [0, 255]
image = batch[0][i].cpu().numpy()
image = image.transpose((1, 2, 0))
image = (image * 255.0).astype("uint8")
# grab the label id and get the label from the classes list
idx = batch[1][i]
label = classes[idx]
# show the image along with the label
plt.imshow(image)
plt.title(label)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
从第 12 行开始,visualize_batch函数将一批数据样本(即batch)、类别标签列表(即classes)和该批所属的dataset_type(即训练或验证)作为输入。
函数循环给定批次中的索引:
- 在第 i 个索引(第 25 行)处抓取图像
- 将其转换为通道最后格式,并将其缩放至常规图像像素范围
[0-255]( 第 26 行和第 27 行) - 获取第 i 个样本的整数标签,并借助列表
classes( 第 30 行和第 31 行)将其映射到 flower 数据集的原始类标签 - 显示带有标签的图像(行 34 和 35 )
在训练深度模型时,我们通常希望在训练集的图像上使用数据增强技术来提高模型的泛化能力。PyTorch 提供了常见的图像转换,可以在 transform 类的帮助下开箱即用。
我们现在将看看这是如何工作的,以及如何整合到我们的数据加载管道中。
# initialize our data augmentation functions
resize = transforms.Resize(size=(config.INPUT_HEIGHT,
config.INPUT_WIDTH))
hFlip = transforms.RandomHorizontalFlip(p=0.25)
vFlip = transforms.RandomVerticalFlip(p=0.25)
rotate = transforms.RandomRotation(degrees=15)
在第行第 43-47 行,我们定义了四种我们想要应用到图像的图像变换:
resize:这种变换使我们能够将图像调整到我们的深度模型可以接受的特定输入维度(即config.INPUT_HEIGHT、config.INPUT_WIDTH)hFlip、vFlip:允许我们水平/垂直翻转图像。注意,它使用了一个参数p,该参数定义了将该变换应用于输入图像的概率。rotate: 使我们能够将图像旋转给定的角度
请注意,PyTorch 除了上面提到的以外,还提供了许多其他的图像转换。
# initialize our training and validation set data augmentation
# pipeline
trainTransforms = transforms.Compose([resize, hFlip, vFlip, rotate,
transforms.ToTensor()])
valTransforms = transforms.Compose([resize, transforms.ToTensor()])
我们在Compose方法的帮助下合并变换,这样所有的变换都可以一个接一个地应用于我们的输入图像。注意,这里我们有另一个To.Tensor()转换,它简单地将所有输入图像转换成 PyTorch 张量。此外,该变换还将原来在[0, 255]范围内的输入 PIL 图像或numpy.ndarray转换为[0, 1]。
这里,我们为我们的训练和验证集定义了单独的转换,如第 51-53 行所示。这是因为我们通常不在验证或测试集上使用数据扩充,除了像resize和ToTensor()这样的转换,它们是将输入数据转换成我们的深度模型可以接受的格式所必需的。
既然我们已经设置了要应用的转换,我们就可以将图像加载到数据集中了。
PyTorch 提供了一个内置的ImageFolder功能,它接受一个根文件夹,并自动从给定的根目录获取数据样本来创建数据集。注意ImageFolder期望图像以如下格式排列:
root/class_name_1/img_id.png
root/class_name_2/img_id.png
root/class_name_3/img_id.png
root/class_name_4/img_id.png
这允许它识别所有唯一的类名,并将它们映射到整数类标签。此外,ImageFolder还接受我们在加载图像时想要应用到输入图像的变换(如前所述)。
# initialize the training and validation dataset
print("[INFO] loading the training and validation dataset...")
trainDataset = ImageFolder(root=config.TRAIN,
transform=trainTransforms)
valDataset = ImageFolder(root=config.VAL,
transform=valTransforms)
print("[INFO] training dataset contains {} samples...".format(
len(trainDataset)))
print("[INFO] validation dataset contains {} samples...".format(
len(valDataset)))
在的第 57-60 行,我们使用ImageFolder分别为训练集和验证集创建 PyTorch 数据集。注意,每个 PyTorch 数据集都有一个__len__方法,使我们能够获得数据集中的样本数,如第 61-64 行的所示。
此外,每个数据集都有一个__getitem__方法,使我们能够直接索引样本并获取特定的数据点。
假设我们想检查数据集中第 i 个数据样本的类型。我们可以简单地将数据集索引为trainDataset[i]并访问数据点,它是一个元组。这是因为我们数据集中的每个数据样本都是一个格式为(image, label)的元组。
现在,我们准备为数据集创建一个数据加载器。
# create training and validation set dataloaders
print("[INFO] creating training and validation set dataloaders...")
trainDataLoader = DataLoader(trainDataset,
batch_size=config.BATCH_SIZE, shuffle=True)
valDataLoader = DataLoader(valDataset, batch_size=config.BATCH_SIZE)
DataLoader 接受 PyTorch 数据集并输出 iterable,这样就可以轻松访问数据集中的数据样本。
在第 68-70 行,我们将训练和验证数据集传递给DataLoader类。
PyTorch 数据加载器接受一个batch_size,这样它就可以将数据集分成样本块。
然后,我们的深度模型可以并行处理每个块或批次中的样本。此外,我们还可以决定是否要在将样本传递到深度模型之前对其进行洗牌,这通常是基于批量梯度的优化方法的最佳学习和收敛所需要的。
第 68-70 行返回两个 iterables(即trainDataLoader和valDataLoader)。
# grab a batch from both training and validation dataloader
trainBatch = next(iter(trainDataLoader))
valBatch = next(iter(valDataLoader))
# visualize the training and validation set batches
print("[INFO] visualizing training and validation batch...")
visualize_batch(trainBatch, trainDataset.classes, "train")
visualize_batch(valBatch, valDataset.classes, "val")
我们使用第 73 和 74 行的所示的iter()方法将trainDataLoader和valDataLoader iterable 转换为 python 迭代器。这允许我们在next()方法的帮助下简单地迭代通过一批批的训练或验证。
最后,我们在visualize_batch函数的帮助下可视化训练和验证批次。
第 78 行和第 79 行借助visualize_batch方法可视化trainBatch和valBatch,给出以下输出。图 3 和图 4 分别显示了来自训练和验证批次的样本图像。
内置数据集
在 PyTorch 数据加载器教程的前几节中,我们学习了如何下载自定义数据集、构建数据集、将其作为 PyTorch 数据集加载,以及在数据加载器的帮助下访问其示例。
除此之外,PyTorch 还提供了一个简单的 API,可以用来直接从计算机视觉中一些常用的数据集下载和加载图像。这些数据集包括 MNIST、CIFAR-10、CIFAR-100、CelebA 等。
现在,我们将了解如何轻松访问这些数据集,并将其用于我们自己的项目。出于本教程的目的,我们使用 MNIST 数据集。
让我们首先打开项目目录中的builtin_dataset.py文件。
# USAGE
# python builtin_dataset.py
# import necessary packages
from pyimagesearch import config
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
import matplotlib.pyplot as plt
我们从在第 5-9 行导入必要的包开始。torchvision.datasets模块为我们提供了直接加载常用的、广泛使用的数据集的功能。
在第 6 行的上,我们从这个模块导入了MNIST数据集。
我们其他值得注意的导入包括 PyTorch DataLoader类(第 7 行)、torchvision 的 transforms 模块(第 8 行)和用于可视化的 matplotlib 库(第 9 行)。
def visualize_batch(batch, classes, dataset_type):
# initialize a figure
fig = plt.figure("{} batch".format(dataset_type),
figsize=(config.BATCH_SIZE, config.BATCH_SIZE))
# loop over the batch size
for i in range(0, config.BATCH_SIZE):
# create a subplot
ax = plt.subplot(2, 4, i + 1)
# grab the image, convert it from channels first ordering to
# channels last ordering, and scale the raw pixel intensities
# to the range [0, 255]
image = batch[0][i].cpu().numpy()
image = image.transpose((1, 2, 0))
image = (image * 255.0).astype("uint8")
# grab the label id and get the label from the classes list
idx = batch[1][i]
label = classes[idx]
# show the image along with the label
plt.imshow(image[..., 0], cmap="gray")
plt.title(label)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
接下来,我们定义了visualize_batch函数,帮助我们可视化一批样品。
这个函数类似于我们之前在load_and_visualize.py文件中定义的visualize_batch函数。这里唯一的不同是在第 33 行,这里我们以cmap="gray"模式绘制图像,因为 MNIST 由单通道灰度图像组成,这与花卉数据集中的 3 通道 RGB 图像形成对比。
# define the transform
transform = transforms.Compose([transforms.ToTensor()])
# initialzie the training and validation dataset
print("[INFO] loading the training and validation dataset...")
trainDataset = MNIST(root=config.MNIST_DATASET_PATH, train=True,
download=True, transform=transform)
valDataset = MNIST(root=config.MNIST_DATASET_PATH, train=False,
download=True, transform=transform)
我们在第 42 行定义我们的变换。在第 46-49 行上,我们使用torchvision.datasets模块直接下载 MNIST 训练和验证集,并将其加载为 PyTorch 数据集trainDataset和valDataset。这里,我们需要提供以下论据:
root:我们要保存数据集的根目录train:表示是要加载训练集(如果train=True)还是测试集(如果train=False)download:负责自动下载数据集transforms:应用于输入图像的图像变换
# create training and validation set dataloaders
print("[INFO] creating training and validation set dataloaders...")
trainDataLoader = DataLoader(trainDataset,
batch_size=config.BATCH_SIZE, shuffle=True)
valDataLoader = DataLoader(valDataset, batch_size=config.BATCH_SIZE)
# grab a batch from both training and validation dataloader
trainBatch = next(iter(trainDataLoader))
valBatch = next(iter(valDataLoader))
# visualize the training set batch
print("[INFO] visualizing training batch...")
visualize_batch(trainBatch, trainDataset.classes, "train")
# visualize the validation set batch
print("[INFO] visualizing validation batch...")
visualize_batch(valBatch, valDataset.classes, "val")
我们为训练和验证数据集创建数据加载器,即第 53-55 行的trainDataLoader和valDataLoader。接下来,我们从训练和验证数据加载器中获取批次,并在第 58-67 行上可视化样本图像,如前所述。
现在您已经了解了如何将 PyTorch 数据加载器与内置的 PyTorch 数据集一起使用。
总结
在本教程中,我们学习了如何在内置 PyTorch 功能的帮助下构建数据加载管道。具体来说,我们了解了 PyTorch 数据集和数据加载器如何高效地从我们的数据集中加载和访问数据样本。
我们的目标是通过将 flowers 数据集分为训练集和测试集来构建数据集,并在 PyTorch 数据集的帮助下加载数据样本。
我们讨论了在应用各种数据扩充时,如何使用 PyTorch 数据加载器有效地访问数据样本。
最后,我们还了解了一些常见的内置 PyTorch 数据集,这些数据集可以直接加载并用于我们的深度学习项目。
遵循教程后,我们建立了一个数据加载管道,可以无缝集成并用于训练手头的任何深度学习模型。恭喜你!
引用信息
Chandhok,s .“py torch 中的图像数据加载器”, PyImageSearch ,2021 年,https://PyImageSearch . com/2021/10/04/Image-Data-Loaders-in-py torch/
@article{Chandhok_2021, author = {Shivam Chandhok}, title = {Image Data Loaders in {PyTorch}}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/10/04/image-data-loaders-in-pytorch/} }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
OpenCV 和 Python 的图像差异
原文:https://pyimagesearch.com/2017/06/19/image-difference-with-opencv-and-python/
最后更新于 2021 年 7 月 7 日。
在之前的 PyImageSearch 博客文章中,我详细介绍了如何使用结构相似性指数(SSIM)用 Python 比较两幅图像。
使用这种方法,我们能够很容易地确定两幅图像是相同的,还是由于轻微的图像处理、压缩伪影或故意篡改而存在差异。
今天,我们将扩展 SSIM 方法,以便我们可以使用 OpenCV 和 Python 可视化图像之间的差异。具体来说,我们将围绕两幅输入图像中不同的区域绘制边界框。
要了解更多关于用 Python 和 OpenCV 计算和可视化图像差异的信息,继续阅读。
- 【2021 年 7 月更新:增加了一节,介绍比较图像差异的方法以及如何使用 siamese 网络的补充阅读资源。
OpenCV 和 Python 的图像差异
为了计算两幅图像之间的差异,我们将利用结构相似性指数,该指数由王等人在其 2004 年的论文 图像质量评估:从错误可见性到结构相似性 中首次提出。该方法已经在用于图像处理的 scikit-image 库中实现。
诀窍是学习我们如何确定在的确切位置,根据 (x,y)-坐标位置,图像差异是。
为了实现这一点,我们首先需要确保我们的系统有 Python、OpenCV、scikit-image 和 imutils。
你可以使用我的 OpenCV 安装教程中的来学习如何在你的系统上配置和安装 Python 和 OpenCV。
如果您尚未安装/升级scikit-image,请通过以下方式升级:
$ pip install --upgrade scikit-image
同时,继续安装/升级imutils:
$ pip install --upgrade imutils
现在我们的系统已经具备了先决条件,让我们继续。
计算图像差异
你能看出这两幅图像的不同之处吗?
如果你花点时间研究这两张信用卡,你会注意到万事达卡的标志出现在左边的图片上,但是已经从右边的图片上被 PS 掉了。
你可能马上就注意到了这种不同,也可能花了你几秒钟的时间。无论如何,这展示了比较图像差异的一个重要方面— 有时图像差异是微妙的— 如此微妙,以至于肉眼难以立即理解差异(我们将在本文后面看到这样一个图像的例子)。
那么,为什么计算图像差异如此重要呢?
一个例子是网络钓鱼。攻击者可以非常轻微地操纵图像,欺骗没有验证 URL 的不知情用户,让他们认为他们正在登录他们的银行网站,但后来发现这是一个骗局。
将网页上的徽标和已知的用户界面(UI)元素与现有的数据集进行比较,可以帮助减少网络钓鱼攻击(非常感谢查尔斯·克利夫兰传递了 PhishZoo:通过查看来检测网络钓鱼网站 作为应用计算机视觉来防止网络钓鱼的一个例子)。
开发一个网络钓鱼检测系统显然比简单的图像差异要复杂得多,但是我们仍然可以应用这些技术来确定给定的图像是否被篡改过。
现在,让我们计算两幅图像之间的差异,并使用 OpenCV、scikit-image 和 Python 并排查看这些差异。
打开一个新文件,将其命名为image_diff.py,并插入以下代码:
# import the necessary packages
from skimage.metrics import structural_similarity as compare_ssim
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--first", required=True,
help="first input image")
ap.add_argument("-s", "--second", required=True,
help="second")
args = vars(ap.parse_args())
第 2-5 行显示我们的进口。我们将使用compare_ssim(来自 scikit-image)、argparse、imutils和cv2 (OpenCV)。
我们建立两个命令行参数,--first和--second,它们是我们希望比较的两个相应输入图像的路径(第 8-13 行)。
接下来,我们将从磁盘加载每个图像,并将其转换为灰度:
# load the two input images
imageA = cv2.imread(args["first"])
imageB = cv2.imread(args["second"])
# convert the images to grayscale
grayA = cv2.cvtColor(imageA, cv2.COLOR_BGR2GRAY)
grayB = cv2.cvtColor(imageB, cv2.COLOR_BGR2GRAY)
我们将第一个和第二个图像--first和--second加载到的第 16 行和第 17 行,分别存储为imageA和imageB。

Figure 2: Our two input images that we are going to apply image difference to.
然后,我们在第 20 行和第 21 行将它们转换成灰度。

Figure 3: Converting the two input images to grayscale.
接下来,让我们计算两幅灰度图像之间的结构相似性指数(SSIM)。
# compute the Structural Similarity Index (SSIM) between the two
# images, ensuring that the difference image is returned
(score, diff) = compare_ssim(grayA, grayB, full=True)
diff = (diff * 255).astype("uint8")
print("SSIM: {}".format(score))
使用 scikit-image 中的compare_ssim函数,我们计算出一个score和差值图像diff ( 第 25 行)。
score表示两个输入图像之间的结构相似性指数。该值可以落在范围 [-1,1] 内,值 1 表示“完全匹配”。
diff图像包含我们希望可视化的两个输入图像之间的实际图像差异。差异图像目前被表示为范围 [0,1] 中的浮点数据类型,因此我们首先将数组转换为范围 [0,255] ( 第 26 行)中的 8 位无符号整数,然后才能使用 OpenCV 对其进行进一步处理。
现在,让我们找到轮廓,以便我们可以在被标识为“不同”的区域周围放置矩形:
# threshold the difference image, followed by finding contours to
# obtain the regions of the two input images that differ
thresh = cv2.threshold(diff, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
在的第 31 行和第 32 行,我们使用cv2.THRESH_BINARY_INV和cv2.THRESH_OTSU为我们的diff图像设定阈值——使用竖线‘或’符号|同时应用这两个设置。有关 Otsu 双峰阈值设置的详细信息,请参见 OpenCV 文档。
随后我们在第 33-35 条线上找到了thresh的轮廓。第 35 行的上的三进制操作符简单地适应了 OpenCV 不同版本中 cv2.findContours 返回签名之间的差异。
下面的图 4 中的图像清楚地显示了经过处理的图像的感兴趣区域:

Figure 4: Using thresholding to highlight the image differences using OpenCV and Python.
现在我们已经将轮廓存储在列表中,让我们在每个图像的不同区域周围绘制矩形:
# loop over the contours
for c in cnts:
# compute the bounding box of the contour and then draw the
# bounding box on both input images to represent where the two
# images differ
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(imageA, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.rectangle(imageB, (x, y), (x + w, y + h), (0, 0, 255), 2)
# show the output images
cv2.imshow("Original", imageA)
cv2.imshow("Modified", imageB)
cv2.imshow("Diff", diff)
cv2.imshow("Thresh", thresh)
cv2.waitKey(0)
从第 38 行开始,我们循环遍历我们的轮廓cnts。首先,我们使用cv2.boundingRect函数计算轮廓周围的边界框。我们将相关的 *(x,y)*-坐标存储为x和y,矩形的宽度/高度存储为w和h。**
然后我们用这些值在每张图片上画一个红色的矩形,用cv2.rectangle ( 第 43 和 44 行)。
最后,我们用方框围绕差异显示比较图像、差异图像和阈值图像(第 47-50 行)。
我们调用第 50 行的上的cv2.waitKey,这使得程序等待直到一个键被按下(此时脚本将退出)。

Figure 5: Visualizing image differences using Python and OpenCV.
接下来,让我们运行脚本,并可视化一些更多的图像差异。
可视化图像差异
使用这个脚本和下面的命令,我们可以快速轻松地突出显示两幅图像之间的差异:
$ python image_diff.py --first images/original_02.png
--second images/modified_02.png
如图 6 中的所示,安全芯片和账户持有人的姓名都被移除了:

Figure 6: Comparing and visualizing image differences using computer vision (source).
让我们尝试另一个计算图像差异的例子,这一次是杰拉尔德·福特总统写的一张支票。
通过运行下面的命令并提供相关图像,我们可以看到这里的差异更加微妙:
$ python image_diff.py --first images/original_03.png
--second images/modified_03.png
注意图 7 中的以下变化:
- 贝蒂·福特的名字被删除了。
- 支票号码被删除。
- 日期旁边的符号被删除。
- 姓氏被删除。
在像支票这样的复杂图像上,通常很难用肉眼发现所有的差异。幸运的是,我们现在可以轻松地计算差异,并使用 Python、OpenCV 和 scikit-image 制作的这个方便的脚本可视化结果。
比较图像差异的其他方法
本教程讲述了如何使用结构相似性指数(SSIM)来比较两幅图像并找出两者之间的差异。
SSIM 是图像比较的传统计算机视觉方法;然而,还有其他图像差异算法可以利用,特别是深度学习算法。
首先,可以通过以下方式应用迁移学习:
- 选择预先训练的 CNN (ResNet、VGGNet 等)。)在大型、多样化的图像数据集(例如,ImageNet)上
- 从网络中移除完全连接的层头
- 通过 CNN 传递数据集中的所有影像,并从最终图层中提取要素
- 计算特征之间的k-最近邻比较,然后找到与输入查询最相似的图像
但是,请记住,k-NN 方法实际上并不“学习”数据集中图像的任何潜在模式/相似性得分。
为了真正了解图像差异并在它们之间进行稳健的比较,你应该利用暹罗网络。
以下教程将向您介绍暹罗网络:
- 用 Python 为连体网络构建图像对
- 与 Keras、TensorFlow、深度学习的连体网络
- 使用暹罗网络、Keras 和 TensorFlow 比较图像的相似性
- 与 Keras 和 TensorFlow 的暹罗网络损耗对比
此外,暹罗网络在 PyImageSearch 大学中有详细介绍。
摘要
在今天的博文中,我们学习了如何使用 OpenCV、Python 和 scikit-image 的结构相似性指数(SSIM)计算图像差异。基于图像差异,我们还学习了如何标记和可视化两幅图像中的不同区域。
要了解更多关于 SSIM 的信息,请务必参考这篇文章和 scikit-image 文档。
我希望你喜欢今天的博文!
在您离开之前,请务必在下面的表格中输入您的电子邮件地址,以便在未来发布 PyImageSearch 博客帖子时得到通知!
使用 OpenCV 的图像渐变(Sobel 和 Scharr)
原文:https://pyimagesearch.com/2021/05/12/image-gradients-with-opencv-sobel-and-scharr/
在本教程中,您将了解图像渐变以及如何使用 OpenCV 的cv2.Sobel函数计算 Sobel 渐变和 Scharr 渐变。
图像梯度是许多计算机视觉和图像处理例程的基本构件。
- 我们使用梯度来检测图像中的边缘,这允许我们找到图像中对象的轮廓和外形
- 我们使用它们作为输入,通过特征提取来量化图像——事实上,非常成功和众所周知的图像描述符,如梯度方向直方图和 SIFT,都是建立在图像梯度表示上的
- 梯度图像甚至被用于构建显著图,其突出了图像的主题
虽然图像渐变不经常详细讨论,因为其他更强大和有趣的方法建立在它们之上,但我们将花时间详细讨论它们。
要学习如何用 OpenCV 计算 Sobel 和 Scharr 梯度,请继续阅读。
使用 OpenCV 的图像渐变(Sobel 和 Scharr)
在本教程的第一部分,我们将讨论什么是图像渐变,它们的用途,以及我们如何手动计算它们(这样我们就有一个直观的理解)。
从这里我们将了解 Sobel 和 Scharr 内核,它们是卷积运算符,允许我们使用 OpenCV 和cv2.Sobel函数自动计算图像梯度(我们只需将特定于 Scharr 的参数传递给cv2.Sobel来计算 Scharr 梯度)。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构,其中您将实现两个 Python 脚本:
- 一个用于计算梯度幅度
- 另一个用于计算梯度方向
这些计算共同推动了传统的计算机视觉技术,如 SIFT 和梯度方向直方图。
我们将讨论我们的结果来结束本教程。
什么是图像渐变?
正如我在引言中提到的,图像梯度在许多计算机视觉和图像处理应用中被用作基本的构建模块。
然而,图像梯度的主要应用在于边缘检测。
顾名思义,边缘检测是在图像中寻找边缘的过程,它揭示了关于图像中对象的结构信息。因此,边可以对应于:
- 图像中对象的边界
- 图像中阴影或光照条件的边界
- 对象内“部分”的边界
下图是在图像中检测到的边缘:
在左边的,是我们的原始输入图像。在右边的,我们有检测到边缘的图像——通常称为边缘图。
右图清楚地显示了图像中物体的结构和轮廓。请注意笔记卡的轮廓,以及写在笔记卡上的文字是如何清晰地显现出来的。
使用这个轮廓,我们可以应用轮廓从区域中提取实际的对象,或者量化形状,以便我们可以在以后识别它们。正如图像梯度是边缘检测等方法的构建模块一样,边缘检测也是开发完整计算机视觉应用的构建模块。
手动计算图像梯度
那么我们如何在图像中找到这些边缘呢?
第一步是计算图像的梯度。形式上,图像梯度被定义为图像强度的方向变化。
或者更简单地说,在输入(灰度)图像的每个像素处,梯度测量给定方向上像素强度的变化。通过估计方向或方位以及大小(即方向的变化有多强),我们能够检测出图像中看起来像边缘的区域。
在实践中,使用内核来估计图像梯度,就像我们使用平滑和模糊一样——但这次我们试图找到图像的结构成分。我们的目标是在 x 和 y 方向上找到红色标记的中心像素的方向变化:
然而,在我们深入到梯度估计的内核之前,让我们实际上经历一下手动计算梯度的过程。第一步是简单地找到并标记围绕中心像素的北、南、东和西像素:
在上图中,我们检查了中心像素周围的 3×3 邻域。我们的 x 值从左到右,我们的 y 值从上到下。为了计算方向上的任何变化,我们需要北、南、东、西像素,在图 3中标出。
如果我们将输入图像表示为 I ,那么我们使用以下符号定义北、南、东和西像素:
- 北:
")
- 南:
")
- 东:
")
- 西:
")
")
")
")
")
同样,在计算图像强度在 x 和 y 方向的变化时,这四个值是关键的。
为了演示这一点,让我们通过获取南方和北方像素之间的差异来计算垂直变化或y-变化:
G**y=I(x,y+1)–**I(x,y—1)
类似地,我们可以通过取东西像素之间的差来计算水平变化或x-变化:
G**x=I(x+1,y)【T12—**I(x—1, y )
太棒了——现在我们有了 G [x] 和 G [y] ,它们代表了中心像素在 x 和 y 方向上的图像强度变化。
所以现在最大的问题变成了:我们如何利用这些价值?
为了回答这个问题,我们需要定义两个新术语——梯度幅度和梯度方向。
梯度幅度用于衡量图像强度的变化有多强。梯度幅度是量化强度变化的“强度”的实数值。
梯度方向用于确定强度变化所指向的方向。顾名思义,渐变取向会给我们一个角度或者?我们可以用它来量化变化的方向。
例如,看看下面的梯度方向的可视化:
在左边,我们有一个图像的 3 × 3 区域,其中图像的上半部分是白色,图像的下半部分是黑色。因此,梯度方向等于
.
而在右边,我们又有了一个图像的 3 个 × 3 邻域,上面的三角形区域是白色,下面的三角形区域是黑色。这里我们可以看到方向的变化等于
.
所以我实话实说——当我第一次接触计算机视觉和图像渐变时,图 4 把我搞得晕头转向。我的意思是,我们究竟是如何得出这些计算结果的??!直觉上,方向的改变是有意义的,因为我们可以实际看到和想象结果。
但是我们究竟如何着手计算渐变的方向和幅度呢?
*很高兴你问了。让我们看看是否可以解开梯度方向和幅度计算的谜团。
让我们继续,从我们信任的 3 × 3 邻域图像开始:
在这里,我们可以看到中心像素用红色标记。确定梯度方向和大小的下一步实际上是计算在 x 和 y 方向上的梯度变化。幸运的是,我们已经知道如何做到这一点——它们只是我们之前计算的 G [x] 和 G [y] 值!
使用G[x]和G[y],我们可以应用一些基本的三角学来计算梯度大小 G 和方向?:**
看到这个例子,才是真正固化了我对梯度方向和大小的理解。检查这个三角形你可以看到梯度大小 G 是三角形的斜边。因此,我们需要做的就是应用毕达哥拉斯定理,我们将得到梯度幅度:

然后,梯度方向可以被给定为G[y]与G[x]的比值。技术上我们会使用 **
**
to compute the gradient orientation, but this could lead to undefined values — since we are computer scientists, we’ll use the  function to account for the different quadrants instead (if you’re unfamiliar with the arc-tangent, you can read more about it here):
function to account for the different quadrants instead (if you’re unfamiliar with the arc-tangent, you can read more about it here):
 \times \left(\displaystyle\frac{180}{\pi}\right)")
function gives us the orientation in radians, which we then convert to degrees by multiplying by the ratio of 180/?.
让我们继续手动计算 G 和?所以我们可以看到这个过程是如何完成的:
在上面的图像中,我们有一个上面三分之一是白色,下面三分之二是黑色的图像。使用等式 G [x] 和 G [y] ,我们得出:
G**x= 0 0 = 0
并且:
**G[y]= 0 255 = 255
将这些值代入梯度幅度方程,我们得到:
^{2}} = 255")
至于我们的梯度方向:
 \times \left(\displaystyle\frac{180}{\pi}\right) = -90^{\circ}")
看,计算梯度大小和方向并不太糟糕!
为了好玩,我们再举一个例子:
在这张特殊的图像中,我们可以看到下三角区域是白色的,而上三角区域是黑色的。计算 GxT3 和 G[y]T7,我们得到:
G[x]= 0 255 = 255 并且G[y]= 255 0 = 255**
留给我们的梯度值是:
^{2} + 255^{2}} = 360.62")
和梯度方向:
 \times \left(\displaystyle\frac{180}{\pi}\right) = 135^{\circ}")
果然,我们的坡度指向下和左,角度为
.
当然,我们只计算了两个唯一像素值的梯度方向和大小:0 和 255。通常情况下,您会在一张灰度图像上计算方向和幅度,其中有效的值范围是【0,255】。
索贝尔和沙尔内核
既然我们已经学会了如何手动计算梯度,让我们看看如何使用内核来近似它们,这将极大地提高我们的速度。就像我们使用核来平滑和模糊图像一样,我们也可以使用核来计算我们的梯度。
我们将从 Sobel 方法开始,该方法实际上使用了两个内核:一个用于检测方向的水平变化,另一个用于检测方向的垂直变化:

给定下面的输入图像邻域,让我们计算梯度的 Sobel 近似:

因此:

并且:


给定这些值G[x]和G[y],那么计算梯度幅度 G 和方向就变得很简单了?:**
 \times \displaystyle\frac{180}{\pi} = 31.4^{\circ}")
我们也可以使用 Scharr 核代替 Sobel 核,这可以给我们更好的梯度近似值:

关于为什么 Scharr 核可以导致更好的近似的确切原因深深植根于数学细节,并且远远超出了我们对图像梯度的讨论。
如果你有兴趣阅读更多关于 Scharr 与 Sobel 核的内容,并构建一个最佳的图像梯度近似(并能阅读德语),我建议看一看 Scharr 关于主题的论文。
总的来说,当量化和抽象地表示图像时,梯度幅度和方向有助于优秀的特征和图像描述符。
但是对于边缘检测,梯度表示对局部噪声极其敏感。我们还需要增加几个步骤来创建一个真正鲁棒的边缘检测器——我们将在下一篇教程中详细讨论这些步骤,届时我们将回顾 Canny 边缘检测器。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们用 OpenCV 实现图像渐变之前,让我们先回顾一下我们的项目目录结构。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像:
$ tree . --dirsfirst
.
├── images
│ ├── bricks.png
│ ├── clonazepam_1mg.png
│ ├── coins01.png
│ └── coins02.png
├── opencv_magnitude_orientation.py
└── opencv_sobel_scharr.py
1 directory, 6 files
我们今天将实现两个 Python 脚本:
opencv_sobel_scharr.py:利用 Sobel 和 Scharr 算子计算输入图像的梯度信息。opencv_magnitude_orientation.py:获取 Sobel/Scharr 内核的输出,然后计算梯度幅度和方向信息。
images目录包含了我们将对其应用这两个脚本的各种示例图像。
用 OpenCV 实现 Sobel 和 Scharr 内核
到目前为止,我们已经讨论了很多关于图像核的理论和数学细节。但是我们实际上如何应用我们在 OpenCV 中学到的东西呢?
我很高兴你问了。
打开一个新文件,命名为opencv_sobel_scharr.py,开始编码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
ap.add_argument("-s", "--scharr", type=int, default=0,
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包——我们所需要的只是用于命令行参数的argparse和用于 OpenCV 绑定的cv2。
我们有两个命令行参数:
--image:我们想要计算 Sobel/Scharr 梯度的驻留在磁盘上的输入图像的路径。- 我们是否在计算沙尔梯度。默认情况下,我们将计算 Soble 梯度。如果我们为这个标志传入一个值 > 0 ,那么我们将计算 Scharr 梯度
现在让我们加载并处理我们的图像:
# load the image, convert it to grayscale, and display the original
# grayscale image
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Gray", gray)
第 15-17 行从磁盘加载我们的图像,将其转换为灰度(因为我们在图像的灰度版本上计算渐变表示),并将其显示在我们的屏幕上。
# set the kernel size, depending on whether we are using the Sobel
# operator of the Scharr operator, then compute the gradients along
# the x and y axis, respectively
ksize = -1 if args["scharr"] > 0 else 3
gX = cv2.Sobel(gray, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=ksize)
gY = cv2.Sobel(gray, ddepth=cv2.CV_32F, dx=0, dy=1, ksize=ksize)
# the gradient magnitude images are now of the floating point data
# type, so we need to take care to convert them back a to unsigned
# 8-bit integer representation so other OpenCV functions can operate
# on them and visualize them
gX = cv2.convertScaleAbs(gX)
gY = cv2.convertScaleAbs(gY)
# combine the gradient representations into a single image
combined = cv2.addWeighted(gX, 0.5, gY, 0.5, 0)
# show our output images
cv2.imshow("Sobel/Scharr X", gX)
cv2.imshow("Sobel/Scharr Y", gY)
cv2.imshow("Sobel/Scharr Combined", combined)
cv2.waitKey(0)
计算G[x]和G[y]值是通过调用cv2.Sobel在第 23 行和第24 行处理的。指定值dx=1和dy=0表示我们想要计算穿过 x 方向的梯度。并且提供值dx=0和dy=1表明我们想要计算跨越 y 方向的梯度。**
注意: 如果我们想要使用 Scharr 内核而不是 Sobel 内核,我们只需简单地指定我们的--scharr命令行参数为> 0 — ,从那里设置合适的ksize(Line 22)。
然而,此时,gX和gY都是浮点数据类型。如果我们想在屏幕上显示它们,我们需要将它们转换回 8 位无符号整数。第 30 行和第 31 行获取渐变图像的绝对值,然后将这些值压缩回范围【0,255】。
最后,我们使用cv2.addWeighted函数将gX和gY组合成一幅图像,对每个梯度表示进行平均加权。
第 37-40 行然后在屏幕上显示我们的输出图像。
Sobel 和 Scharr 内核结果
让我们来学习如何用 OpenCV 应用 Sobel 和 Scharr 内核。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,打开一个终端窗口并执行以下命令:
$ python opencv_sobel_scharr.py --image images/bricks.png
在顶部,我们有我们的原始图像,这是一个砖墙的图像。
然后左下方的沿 x 方向显示 Sobel 梯度图像。注意计算沿 x 方向的索贝尔梯度如何揭示砖块的垂直砂浆区域。
类似地,底部中心显示沿 y 方向计算的索贝尔梯度——现在我们可以看到砖块的水平砂浆区域。
最后,我们可以将gX和gY相加,并在右下角的上接收我们的最终输出图像。
让我们看另一个图像:
$ python opencv_sobel_scharr.py --image images/coins01.png
这次我们正在研究一套硬币。沿着硬币的边界/轮廓可以找到许多 Sobel 梯度信息。
现在,让我们计算同一图像的沙尔梯度信息:
$ python opencv_sobel_scharr.py --image images/coins01.png \
--scharr 1
请注意 Scharr 操作符是如何比前一个例子包含更多信息的。
让我们看另一个 Sobel 例子:
$ python opencv_sobel_scharr.py --image images/clonazepam_1mg.png
这里,我们已经计算了药丸的 Sobel 梯度表示。药丸的轮廓清晰可见,药丸上的数字也清晰可见。
现在让我们看看沙尔表示法:
$ python opencv_sobel_scharr.py --image images/clonazepam_1mg.png \
--scharr 1
药丸的边界就像定义的一样,而且,Scharr 渐变表示提取了药丸本身的更多纹理。
您是否为您的应用程序使用 Sobel 或 Scharr 渐变取决于您的项目,但一般来说,请记住,Scharr 版本会显得更“视觉嘈杂”,但同时会捕捉纹理中更细微的细节。
用 OpenCV 计算梯度大小和方向
到目前为止,我们已经学习了如何计算 Sobel 和 Scharr 算子,但是对于这些梯度实际上代表什么,我们没有太多的直觉。
在本节中,我们将计算输入灰度图像的渐变幅度和渐变方向,并可视化结果。然后,在下一节中,我们将回顾这些结果,让您更深入地了解梯度幅度和方向实际代表什么。
如上所述,打开一个新文件,将其命名为opencv_magnitude_orienation.py,并插入以下代码:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
args = vars(ap.parse_args())
第 2-5 行导入我们需要的 Python 包,包括用于绘图的matplotlib,用于数值数组处理的 NumPy,argparse用于命令行参数,cv2用于 OpenCV 绑定。
然后我们在第 8-11 行解析我们的命令行参数。这里我们只需要一个开关--image,它是我们驻留在磁盘上的输入图像的路径。
让我们现在加载我们的图像,并计算梯度大小和方向:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# compute gradients along the x and y axis, respectively
gX = cv2.Sobel(gray, cv2.CV_64F, 1, 0)
gY = cv2.Sobel(gray, cv2.CV_64F, 0, 1)
# compute the gradient magnitude and orientation
magnitude = np.sqrt((gX ** 2) + (gY ** 2))
orientation = np.arctan2(gY, gX) * (180 / np.pi) % 180
第 14 行和第 15 行从磁盘加载我们的image并转换成灰度。
然后,我们计算沿着 x 和 y 轴的索贝尔梯度,就像我们在上一节所做的一样。
然而,与上一节不同,我们不打算在屏幕上显示渐变图像(至少不通过cv2.imshow函数),因此我们不必将它们转换回范围【0,255】或使用cv2.addWeighted函数将它们组合在一起。
相反,我们继续在第 22 行和第 23 行进行梯度大小和方向的计算。注意这两条线是如何与我们上面的方程精确匹配的。
梯度幅度简单地说就是在 x 和 y 方向上的平方梯度的平方根相加。
梯度方向是 x 和 y 方向梯度的反正切。
现在让我们来看一下梯度幅度和梯度方向:
# initialize a figure to display the input grayscale image along with
# the gradient magnitude and orientation representations, respectively
(fig, axs) = plt.subplots(nrows=1, ncols=3, figsize=(8, 4))
# plot each of the images
axs[0].imshow(gray, cmap="gray")
axs[1].imshow(magnitude, cmap="jet")
axs[2].imshow(orientation, cmap="jet")
# set the titles of each axes
axs[0].set_title("Grayscale")
axs[1].set_title("Gradient Magnitude")
axs[2].set_title("Gradient Orientation [0, 180]")
# loop over each of the axes and turn off the x and y ticks
for i in range(0, 3):
axs[i].get_xaxis().set_ticks([])
axs[i].get_yaxis().set_ticks([])
# show the plots
plt.tight_layout()
plt.show()
第 27 行创建一个一行三列的图形(一个用于原始图像,一个用于梯度幅度表示,一个用于梯度方向表示)。
然后,我们将每个灰度、梯度幅度和梯度方向图像添加到绘图中(行 30-32 ),同时设置每个轴的标题(行 35-37 )。
最后,我们关闭轴记号(第 40-42 行)并在屏幕上显示结果。
梯度大小和方向结果
我们现在准备计算我们的梯度大小!
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从那里,执行以下命令:
$ python opencv_magnitude_orientation.py --image images/coins02.png
在左边的,我们有硬币的原始输入图像。
中间的使用喷射色图显示渐变幅度。
接近蓝色范围的值非常小。例如,图像的背景具有0的渐变,因为那里没有渐变。
更接近黄色/红色范围的值相当大(相对于其余值)。看一看硬币的轮廓/边界,你可以看到这些像素具有很大的梯度幅度,因为它们包含边缘信息。
最后,右侧的图像显示渐变方向信息,同样使用 Jet 色彩映射表。
这里的值在范围 [0,180],内,接近 0 的值显示为蓝色,接近 180 的值显示为红色。注意,许多方向信息包含在硬币本身中。
让我们试试另一个例子:
$ python opencv_magnitude_orientation.py \
--image images/clonazepam_1mg.png
左边的图像包含我们输入的处方药丸冥想的图像。然后我们计算中间的渐变幅度,并在右边显示渐变方向。
与我们的硬币示例类似,大部分梯度幅度信息位于药丸的边界/边界上,而梯度方向由于药丸本身的纹理而更加明显。
在我们的下一个教程中,您将学习如何使用这个渐变信息来检测输入图像中的边缘。
总结
在本课中,我们定义了什么是图像渐变:图像强度的方向变化。
我们还学习了如何仅使用像素亮度值的邻域来手动计算中心像素周围的方向变化。
然后,我们使用这些方向变化来计算我们的梯度方向——强度变化所指向的方向——以及梯度幅度,这是强度变化的强度。
当然,使用我们的简单方法计算梯度方向和大小并不是最快的方法。相反,我们可以依靠 Sobel 和 Scharr 内核,它们允许我们获得图像导数的近似。类似于平滑和模糊,我们的图像核将我们的输入图像与设计用于近似我们的梯度的核进行卷积。
最后,我们学习了如何使用cv2.Sobel OpenCV 函数来计算 Sobel 和 Scharr 梯度表示。使用这些梯度表示,我们能够确定图像中哪些像素的方向在范围 内
内
.
图像渐变是您将要学习的最重要的图像处理和计算机视觉构建模块之一。在幕后,它们用于强大的图像描述符方法,如梯度方向直方图和 SIFT。
它们被用来构建显著图以揭示图像中最“有趣”的区域。
正如我们将在下一个教程中看到的,我们将看到图像梯度是如何检测图像边缘的 Canny 边缘检测器的基石。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!**
用 OpenCV 和 Python 实现图像哈希
原文:https://pyimagesearch.com/2017/11/27/image-hashing-opencv-python/

今天的博文是关于图像哈希的— ,这是我写过的最难的博文。
图像哈希并不是一项特别难的技术(事实上,这是我在 PyImageSearch 博客上教过的最简单的算法之一)。
但是 为什么 的主题和潜在原因,我今天在所有的日子里几乎撕心裂肺地讨论。
这篇博文剩下的介绍是非常个人化的,涵盖了五年前发生在我生活中的事件,几乎直到今天。
**如果你想跳过个人讨论,直接跳到图像哈希内容,我就不做评判了 PyImageSearch 的重点毕竟是做计算机视觉博客。
要跳到计算机视觉内容,只需滚动到“使用 OpenCV 和 Python 的图像哈希”部分,在那里我将深入研究算法和实现。
虽然 PyImageSearch 是一个计算机视觉和深度学习博客,但我是一个非常真实的人。
有时候我内心的人性需要一个分享的地方。
一个分享童年的地方。
精神疾病。
以及爱和失去的感觉。
我很感激你是 PyImageSearch 的读者,我希望你能让我写这篇介绍,倾诉,并继续我寻找平静的旅程。
五年前,就在今天,我最好的朋友死在了我的怀里。
她的名字叫乔西。
你们中的一些人可能认识这个名字——它出现在我所有书籍和出版物的献词中。
乔西是一只狗,一只完美、可爱、体贴的小猎犬,是我 11 岁时爸爸送给我的。
也许你已经理解失去童年宠物的感受。
或者也许你没看到这有什么大不了的——“这只是一只狗,对吗?”
但对我来说,乔西不仅仅是一只狗。
她是把我的童年和成年联系在一起的最后一根线。任何纯真的童年情感都与那根线联系在一起。
当那根线断了的时候,我也几乎断了。
至少可以说,我的童年有点混乱。
我在一个破碎的家庭中长大。我的母亲患有(现在仍然患有)双相精神分裂症、抑郁症、严重焦虑和许多其他精神疾病,不胜枚举。
不用说太多细节,我母亲的病肯定不是她的错——但她经常拒绝她如此迫切需要的照顾和帮助。当她接受帮助,如果经常不顺利。
我的童年包括(看起来没完没了的)去精神病院的参观,然后是和我母亲近乎紧张的互动。当她从紧张症中走出来时,我的家庭生活经常陷入混乱和混乱。
你在那种环境下成长得很快。
你很容易失去童年的纯真。
我的父亲一定意识到了我早年潜在的灾难性轨迹(以及它如何对我成年后的幸福产生重大影响),他在我 11 岁的时候给我带了一只小猎犬回家,很可能帮助我保留童年的一部分。
他是对的。而且成功了。
作为一个孩子,没有比抱着一只小狗更好的感觉了,感觉它的心跳贴着你的心跳,顽皮地在你的怀里扭动,五分钟后在你的腿上睡着了。
乔西还给我一些童年的纯真。
每当我放学回家,她都在。
每当我独自坐着,深夜玩电子游戏(这是我经常用来帮助我“逃离”和应对的一种仪式),她都在那里。
每当我的家庭生活变成尖叫、叫喊和精神疾病折磨的完全无法理解的尖叫时,乔西总是在我身边。
随着我进入尴尬的中后期青少年时期,我自己也开始受到焦虑问题的困扰,我后来知道,这种情况对于在这种环境下长大的孩子来说太常见了。
在高中一年级和二年级期间,由于我患有急性焦虑症,我爸爸不得不从学校护士办公室接我回家不下 20 次。
尽管我十几岁时也有问题,试图长大并以某种方式理解我和我的家庭发生了什么,但乔西总是躺在我身边,陪着我,提醒我小时候是什么样的。
但是当乔西五年前死在我怀里时,那根线断了——那根唯一的线将“成年的我”和“童年的我”联系在一起。
接下来的一年是残酷的。我正在完成我博士的最后一个学期的课程,准备开始我的论文。我在全职工作。我甚至有一些兼职项目正在进行中…
一直以来,我不仅要面对失去最好的朋友,还要面对失去童年的痛苦。
那不是一个好年景,我挣扎了很久。
然而,乔西去世后不久,我在收集和整理我家人所有的她的照片中找到了一点安慰。
这项治疗性的怀旧任务包括扫描实物照片,翻旧的数码相机 SD 卡,甚至在打包好的盒子里寻找早已被遗忘的存储卡上有照片的手机。
当我不工作或不在学校的时候,我花了很多时间将所有这些照片导入 Mac 上的 iPhoto。这是单调乏味的体力劳动,但这正是我需要的工作。
然而,当我完成了 80%的照片导入时,重量变得让我无法承受。为了自己的精神健康,我需要休息一下。
现在已经过去五年了。
我还有剩下的 20%要完成,这正是我现在正在做的。
我现在在一个更好的地方,在个人、精神和身体上。该是我完成我开始的事情的时候了,不为别的,只为我欠自己和乔西的。
问题是我看这些 JPEGs 的目录已经五年了。
有些目录已经导入 iPhoto(我平时看照片的地方)。
其他人没有。
我不知道哪些照片已经存在 iPhoto 中。
那么,我该如何决定我还需要对哪些目录的照片进行排序,然后导入/组织呢?
答案是图像哈希。
我发现它非常有说服力,以至于我可以应用计算机视觉,我的激情,来完成一项对我来说意义重大的任务。
感谢你阅读这篇文章,并和我一起踏上这段旅程。
用 OpenCV 和 Python 实现图像哈希

Figure 1: Image hashing (also called perceptual hashing) is the process of constructing a hash value based on the visual contents of an image. We use image hashing for CBIR, near-duplicate detection, and reverse image search engines.
图像哈希或知觉哈希或的过程是:
- 检查图像的内容
- 基于图像的内容构建唯一标识输入图像的哈希值
*也许最著名的图像哈希实现/服务是 TinEye ,一个反向图像搜索引擎。
使用 TinEye,用户能够:
- 上传图像
- 然后 TinEye 会告诉用户图片出现在网络的哪个位置
在这一部分的顶部可以看到感知散列/图像散列算法的视觉示例。
给定一个输入图像,我们的算法根据图像的视觉外观计算图像散列。
感觉上相似的图像应该具有相似的散列(其中“相似”通常被定义为散列之间的汉明距离)。
通过利用图像散列算法,我们可以在常数时间内,或者在最坏的情况下,当利用适当的数据结构时,在 O(lg n) 时间内找到几乎相同的图像。
在这篇博文的剩余部分,我们将:
- 讨论图像哈希/感知哈希(以及为什么传统哈希不起作用)
- 实现图像散列,特别是差异散列 (dHash)
- 将图像哈希应用于现实世界的问题和数据集
为什么不能用 md5,sha-1 等。?

Figure 2: In this example I take an input image and compute the md5 hash. I then resize the image to have a width of 250 pixels rather than 500 pixels, followed by computing the md5 hash again. Even though the contents of the image did not change, the hash did.
以前有密码学或文件验证(即校验和)背景的读者可能会奇怪,为什么我们不能使用 md5 、 sha-1 等。
这里的问题在于加密散列算法的本质:改变文件中的一个比特将导致不同的散列。
这意味着,如果我们仅仅改变输入图像中一个单像素的颜色,我们最终会得到一个不同的校验和,而事实上我们(很可能)无法判断这个单像素是否发生了变化——对我们来说,两幅图像在感知上看起来是一样的。
这方面的一个例子见上面的图 2 。这里,我取一个输入图像并计算 md5 散列。然后,我将图像的宽度调整为 250 像素,而不是 500 像素——没有对图像做任何修改。然后,我重新计算 md5 散列。注意哈希值是如何变化的,即使图像的视觉内容没有变化!
在图像哈希和感知哈希的情况下,我们实际上希望相似的图像也有相似的哈希。因此,如果图像相似,我们实际上会寻求一些哈希冲突。
我们项目的图像散列数据集
这个项目的目标是帮助我开发一个计算机视觉应用程序,它可以(使用针和干草堆类比):
- 取两个图像输入目录,分别是草堆和针。
- 确定哪些针已经在干草堆里,哪些针没有在干草堆里。
完成这项任务(对于这个特定的项目)最有效的方法是使用图像散列,这个概念我们将在本文后面讨论。
在这里,我的干草堆是我在 iPhotos 中收集的照片——这个目录的名称是Masters:

Figure 3: The “Masters” directory contains all images in my iPhotos album.
从截图中我们可以看到,我的Masters目录包含了 11944 张照片,总共 38.81GB。
然后我有了我的针,一组图像(和相关的子目录):

Figure 4: Inside the “Josie_Backup” directory I have a number of images, some of which have been imported into iPhoto and others which have not. My goal is to determine which subdirectories of photos inside “Josie_Backup” need to be added to “Masters”.
目录包含了许多我的狗(乔西)的照片以及许多不相关的家庭照片。
我的目标是确定哪些目录和图像已经被导入 iPhoto,哪些目录我还需要导入并整理。
使用图像哈希,我们可以快速完成这个项目。
理解感知图像哈希和差异哈希
我们将为这篇博文实现的图像哈希算法被称为差分哈希或者简称为哈希。
我第一次记得是在我本科/研究生生涯的末期,在 HackerFactor 博客上读到关于 dHash 的文章。
我今天的目标是:
- 为 dHash 感知哈希算法提供额外的见解。
- 给你配备一个手工编码的 dHash 实现。
- 提供一个应用于实际数据集的图像哈希的真实示例。
dHash 算法只有四个步骤,非常简单易懂。
第一步:转换成灰度

Figure 5: The first step in image hashing via the difference hashing algorithm is to convert the input image (left) to grayscale (right).
我们的图像哈希算法的第一步是将输入图像转换为灰度,并丢弃任何颜色信息。
丢弃颜色使我们能够:
- 更快地散列图像因为我们只需要检查一个通道
- 匹配完全相同但颜色空间略有变化的图像(因为颜色信息已被移除)
无论出于什么原因,如果您对颜色特别感兴趣,您可以在每个通道上独立运行哈希算法,然后在最后合并(尽管这将导致 3 倍大的哈希)。
第二步:调整大小

Figure 6: The next step in perceptual hashing is to resize the image to a fixed size, ignoring aspect ratio. For many hashing algorithms, resizing is the slowest step. Note: Instead of resizing to 9×8 pixels I resized to 257×256 so we could more easily visualize the hashing algorithm.
既然我们的输入图像已经被转换为灰度,我们需要将其压缩到 9×8 像素,忽略纵横比。对于大多数图像+数据集,调整大小/插值步骤是算法中最慢的部分。
然而,现在你可能有两个问题:
- 为什么我们在调整大小时忽略了图像的长宽比?
- 为什么9×8——这似乎是一个“奇怪”的尺寸?
要回答第一个问题:
我们将图像压缩到 9×8,T2 忽略长宽比,以确保生成的图像散列将匹配相似的照片,而不管它们的初始空间尺寸。
第二个问题需要更多的解释,我们将在下一步中给出完整的答案。
第三步:计算差异
我们的最终目标是计算 64 位哈希——因为 8×8 = 64 我们已经非常接近这个目标了。
那么,我们究竟为什么要把尺寸调整到 9×8 呢?
好吧,记住我们正在实现的算法的名字:差分哈希。
差异哈希算法通过计算个相邻像素之间的差异(即相对梯度)来工作。
如果我们取每行有 9 个像素的输入图像,并计算相邻列像素之间的差异,我们最终得到 8 个差异。八行八个差(即 8×8 )是 64,这将成为我们的 64 位哈希。
在实践中,我们实际上不需要计算差异——我们可以应用“大于”测试(或“小于”测试,只要始终使用相同的操作,这并不重要,我们将在下面的步骤 4 中看到)。
如果这一点令人困惑,不要担心,一旦我们开始实际查看一些代码,一切都会变得清晰。
步骤#4:构建散列

Figure 6: Here I have included the binary difference map used to construct the image hash. Again, I am using a 256×256 image so we can more easily visualize the image hashing algorithm.
最后一步是分配位并构建结果散列。为了做到这一点,我们使用一个简单的二进制测试。
给定一个差分图像 D 和相应的一组像素 P ,我们应用下面的测试:P【x】>P【x+1】= 1 否则 0。
在这种情况下,我们测试左像素是否比右像素更亮。如果左边的像素更亮,我们将输出值设置为 1。否则,如果左边的像素更暗,我们将输出值设置为零。
这个操作的输出可以在上面的图 6 中看到(这里我已经将可视化的大小调整为 256×256 像素,以便更容易看到)。如果我们假设这个差异图是 8×8 像素,这个测试的输出产生一组 64 个二进制值,然后将它们组合成单个 64 位整数(即,实际的图像散列)。
dHash 的优势
使用差异散列(dHash)有许多好处,但主要的好处包括:
- 如果输入图像的纵横比发生变化,我们的图像哈希不会发生变化(因为我们忽略了纵横比)。
- 调整亮度或对比度将(1)不改变我们的哈希值,或者(2)仅稍微改变它,确保哈希值紧密结合。
** 差异散列法非常快。*
*#### 比较不同的哈希
通常我们使用汉明距离来比较哈希值。汉明距离测量两个不同散列中的位数。
汉明距离为零的两个散列意味着这两个散列是相同的(因为没有不同的比特),并且这两个图像也是相同的/感觉上相似的。
HackerFactor 的 Neal Krawetz 博士认为,具有差异 > 10 位的散列最有可能是不同的,而 1 和 10 之间的汉明距离可能是同一图像的变体。实际上,您可能需要为自己的应用程序和相应的数据集调整这些阈值。
为了这篇博文的目的,我们将只检查哈希是否相同。我将把优化搜索以计算汉明差异留在 PyImageSearch 的未来教程中。
用 OpenCV 和 Python 实现图像哈希
我对图像哈希和差异哈希的实现受到了 GitHub 上的 imagehash 库的启发,但做了调整,以(1)使用 OpenCV 而不是 PIL,以及(2)正确地(在我看来)利用完整的 64 位哈希而不是压缩它。
我们将使用图像哈希而不是加密哈希(如 md5、sha-1 等。)由于我的针或干草堆中的一些图像可能被轻微修改过,包括潜在的 JPEG 伪像。
因此,我们需要依靠我们的感知哈希算法来处理输入图像的这些微小变化。
首先,确保您已经安装了我的 imutils 包,这是一系列方便的函数,可以使 OpenCV 的使用更加容易(并且确保您可以访问您的 Python 虚拟环境,假设您正在使用它):
$ workon cv
$ pip install imutils
从那里,打开一个新文件,命名为hash_and_search.py,我们将得到编码:
# import the necessary packages
from imutils import paths
import argparse
import time
import sys
import cv2
import os
第 2-7 行处理导入我们需要的 Python 包。确保您已经安装了imutils来访问paths子模块。
从这里开始,让我们定义dhash函数,它将包含我们的差分散列实现:
def dhash(image, hashSize=8):
# resize the input image, adding a single column (width) so we
# can compute the horizontal gradient
resized = cv2.resize(image, (hashSize + 1, hashSize))
# compute the (relative) horizontal gradient between adjacent
# column pixels
diff = resized[:, 1:] > resized[:, :-1]
# convert the difference image to a hash
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
我们的dhash函数需要一个输入image和一个可选的hashSize。我们设置hashSize=8来表示我们的输出散列将是8×8 = 64位。
第 12 行将我们的输入image调整为(hashSize + 1, hashSize)——这完成了我们算法的步骤#2 。
给定resized图像,我们可以计算线 16 上的二进制diff,它测试相邻像素是更亮还是更暗 ( 步骤#3 )。
最后,第 19 行通过将布尔值转换成 64 位整数来构建散列(步骤#4 )。
然后将得到的整数返回给调用函数。
既然已经定义了我们的dhash函数,让我们继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-a", "--haystack", required=True,
help="dataset of images to search through (i.e., the haytack)")
ap.add_argument("-n", "--needles", required=True,
help="set of images we are searching for (i.e., needles)")
args = vars(ap.parse_args())
我们的脚本需要两个命令行参数:
--haystack:图像输入目录的路径,我们将检查--needles路径。- 我们正在搜索的一组图像。
我们的目标是确定--needles中的每个图像是否存在于--haystack中。
现在让我们开始加载--haystack和--needles图像路径:
# grab the paths to both the haystack and needle images
print("[INFO] computing hashes for haystack...")
haystackPaths = list(paths.list_images(args["haystack"]))
needlePaths = list(paths.list_images(args["needles"]))
# remove the `\` character from any filenames containing a space
# (assuming you're executing the code on a Unix machine)
if sys.platform != "win32":
haystackPaths = [p.replace("\\", "") for p in haystackPaths]
needlePaths = [p.replace("\\", "") for p in needlePaths]
第 31 行和第 32 行获取每个目录中相应图像的路径。
当实现这个脚本时,我的数据集中的许多图像在它们的文件名中有个空格。在普通的 Unix 系统中,我们对文件名中带有\的空格进行转义,从而将文件名Photo 001.jpg转换为Photo\ 001.jpg。
然而,Python 假设路径是未转义的,所以我们必须删除路径中任何出现的\(行 37 和 38 )。
注意:Windows 操作系统使用\来分隔路径,而 Unix 系统使用/。Windows 系统在路径中自然会有一个\,因此我在行 36* 上做了这个检查。我还没有在 Windows 上测试过这段代码——这只是我对它在 Windows 中应该如何处理的“最佳猜测”。用户小心。*
# grab the base subdirectories for the needle paths, initialize the
# dictionary that will map the image hash to corresponding image,
# hashes, then start the timer
BASE_PATHS = set([p.split(os.path.sep)[-2] for p in needlePaths])
haystack = {}
start = time.time()
第 43 行抓取needlePaths里面的子目录名——我需要这些子目录名来确定哪些文件夹已经添加到草堆里了,哪些子目录我还需要检查。
然后第 44 行初始化haystack,这是一个将图像散列映射到各自文件名的字典。
我们现在准备为我们的haystackPaths提取图像散列:
# loop over the haystack paths
for p in haystackPaths:
# load the image from disk
image = cv2.imread(p)
# if the image is None then we could not load it from disk (so
# skip it)
if image is None:
continue
# convert the image to grayscale and compute the hash
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
imageHash = dhash(image)
# update the haystack dictionary
l = haystack.get(imageHash, [])
l.append(p)
haystack[imageHash] = l
在第 48 行的上,我们在haystackPaths的所有图像路径上循环。
对于每个图像,我们从磁盘中加载它(第 50 行),并检查图像是否是None ( 第 54 和 55 行)。如果image是None,那么图像无法从磁盘正确读取,可能是由于图像编码的问题(这种现象你可以在这里了解更多关于的信息),所以我们跳过图像。
行 58 和 59 计算imageHash,而行 62-64 维护一个文件路径列表,这些路径映射到相同的散列值。
下一个代码块显示了散列过程的一些诊断信息:
# show timing for hashing haystack images, then start computing the
# hashes for needle images
print("[INFO] processed {} images in {:.2f} seconds".format(
len(haystack), time.time() - start))
print("[INFO] computing hashes for needles...")
然后我们可以继续从我们的needlePaths中提取哈希值:
# loop over the needle paths
for p in needlePaths:
# load the image from disk
image = cv2.imread(p)
# if the image is None then we could not load it from disk (so
# skip it)
if image is None:
continue
# convert the image to grayscale and compute the hash
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
imageHash = dhash(image)
# grab all image paths that match the hash
matchedPaths = haystack.get(imageHash, [])
# loop over all matched paths
for matchedPath in matchedPaths:
# extract the subdirectory from the image path
b = p.split(os.path.sep)[-2]
# if the subdirectory exists in the base path for the needle
# images, remove it
if b in BASE_PATHS:
BASE_PATHS.remove(b)
这个代码块的一般流程与上面的几乎相同:
- 我们从磁盘加载图像(同时确保它不是
None) - 将图像转换为灰度
- 并计算图像散列
与的区别在于,我们不再将哈希值存储在haystack中。
相反,我们现在检查的haystack字典,看看是否有任何图像路径 具有相同的散列值 ( 行 87 )。
如果有图像具有相同的哈希值,那么我知道我已经手动检查了这个特定的图像子目录,并将它们添加到 iPhoto 中。既然我已经手动检查过了,那我就没有必要再检查一遍了;因此,我可以循环所有的matchedPaths并将它们从BASE_PATHS ( 第 89-97 行)中移除。
简单来说:所有图片+相关子目录matchedPaths都已经在我的 iPhotos 相册里了。
我们的最终代码块遍历了BASE_PATHS中所有剩余的子目录,并让我知道哪些仍然需要手动调查并添加到 iPhoto 中:
# display directories to check
print("[INFO] check the following directories...")
# loop over each subdirectory and display it
for b in BASE_PATHS:
print("[INFO] {}".format(b))
我们的图像哈希实现现在已经完成了!
让我们继续应用我们的图像哈希算法来解决我一直试图解决的针/干草堆问题。
使用 OpenCV 和 Python 结果的图像哈希
要查看我们的图像哈希算法,请向下滚动到本教程的 “下载” 部分,然后下载源代码+示例图像数据集。
我没有在这里包括我的个人 iPhotos 数据集,因为:
- 整个数据集大约为 39GB
- 有许多我不想分享的个人照片
相反,我包含了来自 UKBench 数据集的样本图像,您可以使用它们。
为了确定我还需要检查哪些目录(即“needles”)并在以后添加到“haystack”中,我打开了一个终端并执行了以下命令:
$ python hash_and_search.py --haystack haystack --needles needles
[INFO] computing hashes for haystack...
[INFO] processed 7466 images in 1111.63 seconds
[INFO] computing hashes for needles...
[INFO] check the following directories...
[INFO] MY_PIX
[INFO] 12-25-2006 part 1
正如您从输出中看到的,整个散列和搜索过程花费了大约 18 分钟。
然后,我有了一个清晰的输出,显示了我仍然需要检查的目录:在 14 个可能的子目录中,我仍然需要对其中的两个进行排序,分别是MY_PIX和12-25-2006 part 1。
通过浏览这些子目录,我可以完成我的照片整理项目。
正如我上面提到的,我是而不是,包括我在本帖【下载】中的个人照片档案。如果您对我在下载中提供的示例执行hash_and_search.py脚本,您的结果将如下所示:
$ python hash_and_search.py --haystack haystack --needles needles
[INFO] computing hashes for haystack...
[INFO] processed 1000 images in 7.43 seconds
[INFO] computing hashes for needles...
[INFO] check the following directories...
[INFO] PIX
[INFO] December2014
它有效地演示了完成相同任务的脚本。
在哪里可以了解更多关于图像哈希的信息?
如果你有兴趣了解更多关于图像哈希的知识,我建议你先看看 imagehashing GitHub repo ,这是一个流行的(基于 PIL 的)Python 库,用于感知图像哈希。这个库包括许多图像哈希实现,包括差异哈希、平均哈希等。
从那里,看一看Tham Ngap Wei(PyImageSearch 大师成员)的博客,他写了大量关于图像散列的文章,甚至为 OpenCV-contrib 库贡献了一个 C++图像散列模块。
摘要
在今天的博文中,我们讨论了图像哈希、感知哈希,以及如何使用这些算法来(快速)确定图像的视觉内容是否相同或相似。
从那里,我们实现了差异哈希,一种常见的感知哈希算法,它(1)非常快,同时(2)非常准确。
在 Python 中实现了差异哈希之后,我们将它应用于现实世界的数据集,以解决我正在处理的一个实际问题。
我希望你喜欢今天的帖子!
为了在 PyImageSearch 上发布未来的计算机视觉教程时得到通知,请务必在下表中输入您的电子邮件地址!****
基于 OpenCV 和 Python 的图像修复
原文:https://pyimagesearch.com/2020/05/18/image-inpainting-with-opencv-and-python/
在本教程中,你将学习如何使用 OpenCV 和 Python 进行图像修复。
图像修复是图像保护和图像修复的一种形式,可以追溯到 18 世纪,当时意大利威尼斯公共图片修复主管皮埃特罗·爱德华兹应用这种科学方法修复和保护著名作品(来源)。
技术极大地促进了图像绘画,使我们能够:
- 恢复旧的、退化的照片
- 修复因损坏和老化而缺失区域的照片
- 从图像中遮罩并移除特定的对象(以一种美学上令人愉悦的方式)
今天,我们将看看 OpenCV“开箱即用”的两种图像修复算法
学习如何使用 OpenCV 和 Python 进行图像修复,继续阅读!
利用 OpenCV 和 Python 进行图像修复
在本教程的第一部分,你将学习 OpenCV 的修复算法。
从那里,我们将使用 OpenCV 的内置算法实现一个修复演示,然后将修复应用于一组图像。
最后,我们将查看结果并讨论后续步骤。
我也将坦率地说,这个教程是一个介绍修复包括它的基础知识,它是如何工作的,以及我们可以期待什么样的结果。
虽然本教程不一定在修复结果方面“开辟新天地”,但它是未来教程的必要先决条件,因为:
- 它向您展示了如何使用 OpenCV 进行修复
- 它为您提供了一个我们可以改进的基线
- 它显示了传统修复算法所需的一些手动输入,深度学习方法现在可以自动化
OpenCV 的修复算法
引用 OpenCV 文档,Telea 方法:
…基于快速行进法。考虑图像中要修补的区域。算法从该区域的边界开始,进入该区域,首先逐渐填充边界中的所有内容。需要在要修复的邻域的像素周围有一个小的邻域。该像素被邻域中所有已知像素的归一化加权和所代替。砝码的选择是一件重要的事情。对那些靠近该点、靠近边界法线的像素和那些位于边界轮廓上的像素给予更大的权重。一旦像素被修复,它就使用快速行进方法移动到下一个最近的像素。FMM 确保已知像素附近的像素首先被修复,因此它就像一个手动启发式操作。
第二种方法,纳维尔-斯托克斯方法,是基于流体动力学。
再次引用 OpenCV 文档:
该算法基于流体动力学并利用偏微分方程。基本原理是启发式的。它首先沿着边缘从已知区域行进到未知区域(因为边缘应该是连续的)。它继续等照度线(连接具有相同强度的点的线,就像轮廓连接具有相同海拔的点),同时在修复区域的边界匹配梯度向量。为此,使用了流体动力学的一些方法。一旦它们被获得,颜色被填充以减少该区域的最小变化。
在本教程的剩余部分,您将学习如何使用 OpenCV 应用cv2.INPAINT_TELEA和cv2.INPAINT_NS方法。
如何使用 OpenCV 进行修复?
当用 OpenCV 应用修补时,我们需要提供两幅图像:
- 我们希望修复和恢复的输入图像。推测起来,这个图像以某种方式被“损坏”,我们需要应用修复算法来修复它
- 掩模图像,指示图像中损伤的位置。该图像应具有与输入图像相同的空间尺寸(宽度和高度)。非零像素对应于应该修补(即,修复)的区域,而零像素被认为是“正常的”并且不需要修补
这些图像的示例可以在上面的图 2 中看到。
左边的上的图像是我们的原始输入图像。请注意这张图片是如何陈旧、褪色、破损/撕裂的。
右边的图像是我们的蒙版图像。注意蒙版中的白色像素是如何标记输入图像中的损坏位置(左图)。**
最后,在底部的,我们得到了用 OpenCV 修补后的输出图像。我们陈旧、褪色、受损的形象现在已经部分恢复了。
我们如何用 OpenCV 创建用于修补的蒙版?
此时,最大的问题是:
“阿德里安,你是怎么创造出面具的?这是通过编程创建的吗?还是手动创建的?”
对于上面的图 2 (上一节),我不得不手动创建蒙版。为此,我打开了 Photoshop ( GIMP 或其他照片编辑/处理工具也可以),然后使用魔棒工具和手动选择工具来选择图像的受损区域。
然后我用白色的填充选区,将背景设为黑色,并将蒙版保存到磁盘。
这样做是一个手动的、繁琐的过程——你也许能够使用图像处理技术,如阈值处理、边缘检测和轮廓来标记损坏的原因,以编程方式为你自己的图像定义蒙版,但实际上,可能会有某种人工干预。
手动干预是使用 OpenCV 内置修复算法的主要限制之一。
我在“我们如何改进 OpenCV 修复结果?”中讨论了我们如何改进 OpenCV 的修复算法,包括基于深度学习的方法一节。
项目结构
滚动到本教程的 “下载” 部分,获取包含我们的代码和图像的.zip。这些文件组织如下:
$ tree --dirsfirst
.
├── examples
│ ├── example01.png
│ ├── example02.png
│ ├── example03.png
│ ├── mask01.png
│ ├── mask02.png
│ └── mask03.png
└── opencv_inpainting.py
1 directory, 7 files
用 OpenCV 和 Python 实现修复
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path input image on which we'll perform inpainting")
ap.add_argument("-m", "--mask", type=str, required=True,
help="path input mask which corresponds to damaged areas")
ap.add_argument("-a", "--method", type=str, default="telea",
choices=["telea", "ns"],
help="inpainting algorithm to use")
ap.add_argument("-r", "--radius", type=int, default=3,
help="inpainting radius")
args = vars(ap.parse_args())
# initialize the inpainting algorithm to be the Telea et al. method
flags = cv2.INPAINT_TELEA
# check to see if we should be using the Navier-Stokes (i.e., Bertalmio
# et al.) method for inpainting
if args["method"] == "ns":
flags = cv2.INPAINT_NS
# load the (1) input image (i.e., the image we're going to perform
# inpainting on) and (2) the mask which should have the same input
# dimensions as the input image -- zero pixels correspond to areas
# that *will not* be inpainted while non-zero pixels correspond to
# "damaged" areas that inpainting will try to correct
image = cv2.imread(args["image"])
mask = cv2.imread(args["mask"])
mask = cv2.cvtColor(mask, cv2.COLOR_BGR2GRAY)
# perform inpainting using OpenCV
output = cv2.inpaint(image, mask, args["radius"], flags=flags)
# show the original input image, mask, and output image after
# applying inpainting
cv2.imshow("Image", image)
cv2.imshow("Mask", mask)
cv2.imshow("Output", output)
cv2.waitKey(0)
我们在屏幕上显示三幅图像:(1)我们的原始受损照片,(2)我们的mask突出显示受损区域,以及(3)修复(即修复)output照片。这些图像中的每一个都将保留在您的屏幕上,直到当其中一个 GUI 窗口成为焦点时按下任何键。
OpenCV 修复结果
我们现在准备使用 OpenCV 应用修复。
确保您已经使用本教程的 【下载】 部分下载了源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python opencv_inpainting.py --image examples/example01.png \
--mask examples/mask01.png
在左边的,你可以看到我的狗 Janie 的原始输入图像,穿着一件超级朋克/ska 牛仔夹克。
我特意给图片添加了文字【阿德里安·乌兹在此】,图片的蒙版显示在中间的。**
$ python opencv_inpainting.py --image examples/example02.png \
--mask examples/mask02.png --method ns
在顶部,你可以看到一张旧照片,已经损坏。然后我手动为右边的受损区域创建了一个蒙版(使用 Photoshop,如“我们如何使用 OpenCV 创建修复蒙版?”节)。
底部显示了纳维尔-斯托克斯修复方法的输出。通过应用这种 OpenCV 修复方法,我们已经能够部分修复旧的、损坏的照片。
让我们尝试最后一张图片:
$ python opencv_inpainting.py --image examples/example03.png \
--mask examples/mask03.png
在左边的,我们有原始图像,而在右边的,我们有相应的遮罩。
请注意,该遮罩有两个我们将尝试“修复”的区域:
- 右下角的水印
- 圆形区域对应于其中一棵树
在这个例子中,我们将 OpenCV 修复视为一种从图像中移除对象的方法,其结果可以在 T2 底部看到。
不幸的是,结果没有我们希望的那么好。我们希望移除的树显示为圆形模糊,而水印也是模糊的。
这就引出了一个问题— 我们能做些什么来改善我们的结果呢?
如何提高 OpenCV 修复效果?
OpenCV 内置修复算法的最大问题之一是它们需要手动干预,这意味着我们必须手动提供我们希望修复和恢复的被遮罩区域。
手动供应面膜繁琐— 没有更好的方法吗?
其实是有的。
使用基于深度学习的方法,包括完全卷积神经网络和生成对抗网络(GANs),我们可以“学习修复”。
这些网络:
- 要求零手动干预
- 可以生成自己的训练数据
- 生成比传统计算机视觉修复算法更美观的结果
基于深度学习的修复算法超出了本教程的范围,但将在未来的博客文章中介绍。
总结
这些方法是传统的计算机视觉算法,不依赖于深度学习,使它们易于高效利用。
然而,尽管这些算法很容易使用(因为它们是内置在 OpenCV 中的),但它们在准确性方面还有很多不足之处。
更不用说,必须手动提供蒙版图像,标记原始照片的损坏区域,这相当繁琐。
在未来的教程中,我们将研究基于深度学习的修复算法——这些方法需要更多的计算,编码有点困难,但最终会产生更好的结果(另外,没有遮罩图像要求)。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
使用 OpenCV 进行图像遮罩
原文:https://pyimagesearch.com/2021/01/19/image-masking-with-opencv/
在本教程中,您将学习如何使用 OpenCV 遮罩图像。
我之前的指南讨论了位运算,这是一组在图像处理中大量使用的非常常见的技术。
正如我之前暗示的,我们可以使用位运算和掩码来构建非矩形的感兴趣区域。这使得我们能够从图像中提取出完全任意形状的区域。
简单地说;蒙版让我们只关注图像中我们感兴趣的部分。
例如,假设我们正在构建一个计算机视觉系统来识别人脸。我们感兴趣寻找和描述的唯一图像部分是图像中包含人脸的部分——我们根本不关心图像的其余内容。假如我们可以找到图像中的人脸,我们可以构造一个遮罩来只显示图像中的人脸。
你会遇到的另一个图像蒙版应用是阿尔法混合和透明(例如,在本指南中的 用 OpenCV 创建 gif)。当使用 OpenCV 对图像应用透明时,我们需要告诉 OpenCV 图像的哪些部分应该应用透明,哪些部分不应该应用— 遮罩允许我们进行区分。
要了解如何使用 OpenCV 执行图像遮罩,请继续阅读。
使用 OpenCV 进行图像遮蔽
在本教程的第一部分,我们将配置我们的开发环境并回顾我们的项目结构。
然后,我们将使用 OpenCV 实现一个 Python 脚本来屏蔽图像。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
使用 OpenCV 执行图像遮罩比您想象的要容易。但是在我们写任何代码之前,让我们先回顾一下我们的项目目录结构。
首先使用本指南的 “下载” 部分访问源代码和示例图像。
您的项目文件夹应该如下所示:
$ tree . --dirsfirst
.
├── adrian.png
└── opencv_masking.py
0 directories, 2 files
我们的opencv_masking.py脚本将从磁盘加载输入的adrian.png图像。然后,我们将使用矩形和圆形遮罩分别从图像中提取身体和面部。
用 OpenCV 实现图像遮罩
让我们来学习如何使用 OpenCV 应用图像遮罩!
打开项目目录结构中的opencv_masking.py文件,让我们开始工作:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包。然后我们在的第 7-10 行解析我们的命令行参数。
这里我们只需要一个开关,--image,它是我们想要遮罩的图像的路径。我们继续将--image参数默认为项目目录中的adrian.png文件。
现在,让我们从磁盘加载这个映像并执行屏蔽:
# load the original input image and display it to our screen
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# a mask is the same size as our image, but has only two pixel
# values, 0 and 255 -- pixels with a value of 0 (background) are
# ignored in the original image while mask pixels with a value of
# 255 (foreground) are allowed to be kept
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.rectangle(mask, (0, 90), (290, 450), 255, -1)
cv2.imshow("Rectangular Mask", mask)
# apply our mask -- notice how only the person in the image is
# cropped out
masked = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Mask Applied to Image", masked)
cv2.waitKey(0)
第 13 行和第 14 行从磁盘加载原始的image并显示在我们的屏幕上:
然后,我们构造一个 NumPy 数组,用零填充,其宽度和高度与第 20 行的原始图像相同。
正如我在之前关于 OpenCV 裁剪 图像的教程中提到的,我们可以使用物体检测方法自动检测图像中的物体/人物。不过,我们将暂时使用我们对示例图像的先验知识。
我们知道我们想要提取的区域在图像的左下角。第 21 行在我们的蒙版上画了一个白色的矩形,对应着我们要从原始图像中提取的区域。
记得在我们的位运算教程中复习过cv2.bitwise_and函数吗?事实证明,这个函数在对图像应用蒙版时被广泛使用。
我们使用cv2.bitwise_and函数在第 26 行应用我们的蒙版。
前两个参数是image本身(即我们想要应用位运算的图像)。
然而,这个函数的重要部分是mask关键字。当提供时,当输入图像的像素值相等时,bitwise_and函数为True,并且掩码在每个 (x,y)-坐标处为非零(在这种情况下,仅是白色矩形的像素部分)。
应用我们的掩码后,我们在第 27 和 28 行显示输出,你可以在图 3 中看到:
使用我们的矩形遮罩,我们可以只提取图像中包含人的区域,而忽略其余部分。
让我们来看另一个例子,但是这次使用的是一个非矩形遮罩:
# now, let's make a circular mask with a radius of 100 pixels and
# apply the mask again
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.circle(mask, (145, 200), 100, 255, -1)
masked = cv2.bitwise_and(image, image, mask=mask)
# show the output images
cv2.imshow("Circular Mask", mask)
cv2.imshow("Mask Applied to Image", masked)
cv2.waitKey(0)
在第 32 行的,上,我们重新初始化我们的mask,用零和与我们原始图像相同的尺寸填充。
然后,我们在我们的蒙版图像上画一个白色的圆圈,从我的脸的中心开始,半径为100像素。
然后再次使用cv2.bitwise_and功能,在线 34 上应用圆形掩模。
我们的圆形遮罩的结果可以在图 4 中看到:
在这里,我们可以看到我们的圆形遮罩显示在左边的和右边的上。与图 3 的输出不同,当我们提取一个矩形区域时,这一次,我们提取了一个圆形区域,它只对应于图像中我的脸。**
此外,我们可以使用这种方法从任意形状(矩形、圆形、直线、多边形等)的图像中提取区域。).
OpenCV 图像屏蔽结果
要使用 OpenCV 执行图像遮罩,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,打开一个 shell 并执行以下命令:
$ python opencv_masking.py
您的屏蔽输出应该与我在上一节中的输出相匹配。
OpenCV 图像遮罩是处理图像的强大工具。它允许您将效果应用到单个图像,并创建一个全新的外观。
使用 OpenCV 图像遮罩,您可以选择性地修改颜色、对比度、变亮或变暗、添加或移除噪点,甚至从图像中擦除部分或对象。还可以添加文本和特殊效果,甚至将图像转换成不同的文件格式。
OpenCV 图像遮罩是一种轻松创建令人惊叹的视觉效果的好方法,可以帮助您:
- 装帧设计艺术
- 应用开发
- 机器人学
- 自治
- 计算机视觉研究主题
总结
你来学计算机视觉和基础蒙版,超!在本教程中,您学习了使用 OpenCV 进行遮罩的基础知识。
遮罩的关键点在于,它们允许我们将计算集中在感兴趣的图像区域。当我们探索机器学习、图像分类和对象检测等主题时,将我们的计算集中在我们感兴趣的区域会产生巨大的影响。
例如,让我们假设我们想要建立一个系统来对花的种类进行分类。
实际上,我们可能只对花瓣的颜色和纹理感兴趣来进行分类。但是,由于我们是在自然环境中拍摄的照片,我们的图像中也会有许多其他区域,包括地面上的灰尘、昆虫和其他花卉。我们如何量化和分类我们感兴趣的花?正如我们将看到的,答案是面具。
更新时间:2022 年 12 月 30 日,更新链接和内容。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
使用 Python 和 OpenCV 制作影像金字塔
原文:https://pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/

康涅狄格州实在太冷了——冷得我不得不认输,逃离一会儿。
上周,我去佛罗里达州奥兰多度周末,只是为了逃避现实。虽然天气并不完美(华氏 60 度左右,多云,下着小雨,正如你在上面的照片中看到的),但 比康涅狄格州 整整暖和了 60 度——这对我来说才是最重要的。
虽然我没有去动物王国,也没有参加任何迪斯尼冒险游乐项目,但我确实很喜欢在迪斯尼市区散步,在 Epcot 的每个国家喝饮料。
侧边栏:也许我有偏见,因为我是德国人,但德国红酒可能是最不受重视的葡萄酒之一。想象一下,拥有基安蒂酒浓郁的味道,但酸度稍低。完美。如果你曾经在 Epcot,一定要去看看德国葡萄酒品尝会。
无论如何,当我登上从温暖的佛罗里达天堂飞回康涅狄格州苔原的飞机时,我开始思考 PyImageSearch 的下一篇博文会是什么。
真的,这不应该是那么长时间(或艰苦)的锻炼,但这是早上 5 点 27 分的航班,我仍然半睡半醒,我非常确定我的身体里还有一点德国红酒。
喝了一杯(糟糕的)飞机咖啡后,我决定写一篇由两部分组成的博客:
-
第一部分:用 Python 和 OpenCV 制作图像金字塔。
-
第二部分:用 Python 和 OpenCV 实现图像分类的滑动窗口。
你看,几个月前我写了一篇关于利用 梯度方向直方图 图像描述符和线性 SVM 来检测图像中的物体的博文。这个 6 步框架可以用来轻松训练物体分类模型。
这个 6 步框架的一个关键方面包括 图像金字塔 和 滑动窗口 。
今天我们将回顾使用 Python、OpenCV 和 sickit-image 创建图像金字塔的两种方法。下周我们将发现创建高效滑动窗口的简单技巧。
利用这两篇文章,我们可以开始将 HOG +线性 SVM 框架的各个部分粘在一起,这样你就可以构建自己的对象分类器了!
请继续阅读,了解更多信息…
什么是形象金字塔?
Figure 1: An example of an image pyramid. At each layer of the pyramid the image is downsized and (optionally) smoothed (image source).
“图像金字塔”是图像的多尺度表示。
*利用图像金字塔可以让我们在图像的不同尺度下找到图像中的物体。当与滑动窗口结合使用时,我们可以在不同的位置找到图像中的物体。
在金字塔的底部,我们有原始大小的原始图像(就宽度和高度而言)。并且在每个后续层,图像被调整大小(二次采样)并且可选地被平滑(通常通过高斯模糊)。
图像被渐进地二次采样,直到满足某个停止标准,这通常是已经达到最小尺寸,并且不需要进行进一步的二次采样。
方法 1:用 Python 和 OpenCV 制作影像金字塔
我们将探索的构建影像金字塔的第一种方法将利用 Python + OpenCV。
事实上,这是我在自己的项目中使用的 完全相同的 图像金字塔实现!
让我们开始这个例子。创建一个新文件,将其命名为helpers.py,并插入以下代码:
# import the necessary packages
import imutils
def pyramid(image, scale=1.5, minSize=(30, 30)):
# yield the original image
yield image
# keep looping over the pyramid
while True:
# compute the new dimensions of the image and resize it
w = int(image.shape[1] / scale)
image = imutils.resize(image, width=w)
# if the resized image does not meet the supplied minimum
# size, then stop constructing the pyramid
if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]:
break
# yield the next image in the pyramid
yield image
我们从导入imutils包开始,它包含了一些常用的图像处理功能,如调整大小、旋转、平移等。你可以在这里 了解更多imutils套餐 。也可以从我的 GitHub 上抢下来。该软件包也可通过 pip 安装:
$ pip install imutils
接下来,我们在第 4 行定义我们的pyramid函数。这个函数有两个参数。第一个参数是scale,它控制图像在每一层的大小。较小的scale会在金字塔中产生更多的层。并且更大的scale产生更少的层。
其次,我们定义了minSize,它是图层所需的最小宽度和高度。如果金字塔中的图像低于这个minSize,我们停止构建图像金字塔。
第 6 行产生金字塔(底层)中的原始图像。
从那里,我们开始在第 9 行的图像金字塔上循环。
第 11 行和第 12 行处理金字塔下一层图像的尺寸计算(同时保持纵横比)。该比例由scale因子控制。
在行的第 16 行和第 17 行,我们进行检查以确保图像符合minSize要求。如果没有,我们就脱离循环。
最后,行 20 产生了我们调整后的图像。
但是在我们开始使用图像金字塔的例子之前,让我们快速回顾一下第二种方法。
方法 2:使用 Python + scikit-image 构建影像金字塔
构建影像金字塔的第二种方法是利用 Python 和 scikit-image。 scikit-image 库已经有一个内置的构建图像金字塔的方法叫做pyramid_gaussian ,你可以在这里阅读更多关于的内容。
以下是如何使用 scikit-image 中的pyramid_gaussian功能的示例:
# METHOD #2: Resizing + Gaussian smoothing.
for (i, resized) in enumerate(pyramid_gaussian(image, downscale=2)):
# if the image is too small, break from the loop
if resized.shape[0] < 30 or resized.shape[1] < 30:
break
# show the resized image
cv2.imshow("Layer {}".format(i + 1), resized)
cv2.waitKey(0)
与上面的例子类似,我们简单地遍历图像金字塔,并进行检查以确保图像有足够的最小尺寸。这里我们指定downscale=2来表示我们是 在金字塔的每一层将图像的尺寸 减半。
运行中的图像金字塔
现在我们已经定义了两个方法,让我们创建一个驱动脚本来执行我们的代码。创建一个新文件,命名为pyramid.py,让我们开始工作:
# import the necessary packages
from pyimagesearch.helpers import pyramid
from skimage.transform import pyramid_gaussian
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
ap.add_argument("-s", "--scale", type=float, default=1.5, help="scale factor size")
args = vars(ap.parse_args())
# load the image
image = cv2.imread(args["image"])
# METHOD #1: No smooth, just scaling.
# loop over the image pyramid
for (i, resized) in enumerate(pyramid(image, scale=args["scale"])):
# show the resized image
cv2.imshow("Layer {}".format(i + 1), resized)
cv2.waitKey(0)
# close all windows
cv2.destroyAllWindows()
# METHOD #2: Resizing + Gaussian smoothing.
for (i, resized) in enumerate(pyramid_gaussian(image, downscale=2)):
# if the image is too small, break from the loop
if resized.shape[0] < 30 or resized.shape[1] < 30:
break
# show the resized image
cv2.imshow("Layer {}".format(i + 1), resized)
cv2.waitKey(0)
我们将从导入我们需要的包开始。出于组织目的,我将我个人的pyramid功能放在了pyimagesearch的helpers子模块中。
你可以在这篇博文的底部下载我的项目文件和目录结构的代码。
然后我们导入 scikit-image pyramid_gaussian函数、argparse用于解析命令行参数,以及cv2用于 OpenCV 绑定。
接下来,我们需要解析第 9-11 行上的一些命令行参数。我们的脚本只需要两个开关,--image,它是我们将要构建图像金字塔的图像的路径,和--scale,它是控制图像在金字塔中如何调整大小的比例因子。
第 14 行从磁盘加载我们的图像。
我们可以在第行第 18-21 行开始使用我们的图像金字塔方法#1(我个人的方法),我们简单地循环金字塔的每一层,并在屏幕上显示出来。
然后从第 27-34 行开始,我们利用 scikit-image 方法(方法#2)构建图像金字塔。
要查看我们的脚本运行情况,请打开一个终端,将目录切换到您的代码所在的位置,然后执行以下命令:
$ python pyramid.py --image images/adrian_florida.jpg --scale 1.5
如果一切顺利,您应该会看到类似如下的结果:
Figure 2: Constructing an image pyramid with 7 layers and no smoothing (Method #1).
在这里,我们可以看到 7 层已经生成的图像。
与 scikit-image 方法类似:
Figure 3: Generating 4 layers of the image pyramid with scikit-image (Method #2).
scikit-image 金字塔生成了 4 层,因为它在每层将图像缩小了 50%。
现在,让我们将比例因子改为3.0,看看结果如何变化:
$ python pyramid.py --image images/adrian_florida.jpg --scale 1.5
最终的金字塔看起来像这样:
Figure 4: Increase the scale factor from 1.5 to 3.0 has reduced the number of layers generated.
使用比例因子3.0,仅生成了 3 层。
通常,在性能和生成的图层数量之间会有一个折衷。比例因子越小,需要创建和处理的图层就越多,但这也给了图像分类器更好的机会来定位图像中要检测的对象。
较大的比例因子将产生较少的层,并且可能损害您的对象分类性能;然而,您将获得更高的性能增益,因为您将处理更少的层。
摘要
在这篇博文中,我们发现了如何使用两种方法构建图像金字塔。
构建图像金字塔的第一个方法使用了 Python 和 OpenCV,这是我在自己的个人项目中使用的方法。与传统的图像金字塔不同,这种方法不在金字塔的每一层用高斯平滑图像,从而使它更适合与 HOG 描述符一起使用。
构建金字塔的第二种方法利用了 Python + scikit-image,而在金字塔的每一层应用了高斯平滑。
那么应该用哪种方法呢?
实际上,这取决于你的应用。如果您使用 HOG 描述符进行对象分类,您会希望使用第一种方法,因为平滑会损害分类性能。
如果你正在尝试实现像 SIFT 或者高斯关键点检测器之类的东西,那么你可能想要利用第二种方法(或者至少将平滑合并到第一种方法中)。*
使用掩模 R-CNN、GrabCut 和 OpenCV 的图像分割
原文:https://pyimagesearch.com/2020/09/28/image-segmentation-with-mask-r-cnn-grabcut-and-opencv/
在本教程中,您将学习如何使用 Mask R-CNN、GrabCut 和 OpenCV 执行图像分割。
几个月前,你学习了如何使用 GrabCut 算法从背景 中分割出前景物体。 GrabCut 工作得相当好,但是需要我们手动提供,在输入图像中的处,对象是,这样 GrabCut 可以应用它的分割魔法。
另一方面,掩模 R-CNN 可以自动预测输入图像中每个对象的边界框和逐像素分割掩模。缺点是 Mask R-CNN 生成的遮罩并不总是“干净的”——通常会有一点背景“渗入”前景分割。
这提出了以下问题:
有没有可能把 Mask R-CNN 和 GrabCut 结合在一起?
我们是否可以使用 Mask R-CNN 计算初始分割,然后使用 GrabCut 进行细化?
我们当然可以——本教程的其余部分将告诉你如何做。
要了解如何使用 Mask R-CNN、GrabCut 和 OpenCV 执行图像分割,继续阅读。
使用掩膜 R-CNN、GrabCut 和 OpenCV 进行图像分割
在本教程的第一部分,我们将讨论为什么我们可能要结合 GrabCut 与掩模 R-CNN 的图像分割。
在此基础上,我们将实现一个 Python 脚本:
- 从磁盘加载输入图像
- 为输入图像中的每个对象计算逐像素分割遮罩
- 通过遮罩对对象应用 GrabCut 以改进图像分割
然后,我们将回顾一起应用 Mask R-CNN 和 GrabCut 的结果。
教程的【概要】涵盖了这种方法的一些局限性。
为什么要一起使用 GrabCut 和 Mask R-CNN 进行图像分割?
Mask R-CNN 是一种最先进的深度神经网络架构,用于图像分割。使用 Mask R-CNN,我们可以自动计算图像中物体的像素级遮罩,允许我们从背景中分割出前景。
通过屏蔽 R-CNN 计算的屏蔽示例可以在本节顶部的图 1 的中看到。
- 在左上角的,我们有一个谷仓场景的输入图像。
- 屏蔽 R-CNN 检测到一匹马,然后自动计算其对应的分割屏蔽(右上)。
- 在底部,我们可以看到将计算出的遮罩应用到输入图像的结果——注意马是如何被自动分割的。
然而,掩模 R-CNN 的输出与完美的掩模相差远。我们可以看到背景(例如。马站立的场地上的泥土)正在“渗透”到前景中。
我们在这里的目标是使用 GrabCut 改进这个遮罩,以获得更好的分割:
在上图中,您可以看到使用 mask R-CNN 预测的 Mask 作为 GrabCut 种子应用 GrabCut 的输出。
注意分割有多紧,特别是在马的腿部周围。 不幸的是,我们现在已经失去了马的头顶以及它的蹄子。
同时使用 GrabCut 和 Mask R-CNN 可能会有所取舍。在某些情况下,它会工作得很好,而在其他情况下,它会让你的结果更糟。这完全取决于您的应用和您要分割的图像类型。
在今天的剩余教程中,我们将探索一起应用 Mask R-CNN 和 GrabCut 的结果。
配置您的开发环境
本教程只要求您在 Python 虚拟环境中安装 OpenCV。
对于大多数读者来说,最好的入门方式是遵循我的 pip install opencv 教程,该教程指导如何设置环境以及在 macOS、Ubuntu 或 Raspbian 上需要哪些 Python 包。
或者,如果你手头有一个支持 CUDA 的 GPU,你可以遵循我的 OpenCV with CUDA 安装指南。
项目结构
继续从这篇博文的 【下载】 部分抓取代码并屏蔽 R-CNN 深度学习模型。一旦你提取了。zip,您将看到以下文件:
$ tree --dirsfirst
.
├── mask-rcnn-coco
│ ├── colors.txt
│ ├── frozen_inference_graph.pb
│ ├── mask_rcnn_inception_v2_coco_2018_01_28.pbtxt
│ └── object_detection_classes_coco.txt
├── example.jpg
└── mask_rcnn_grabcut.py
1 directory, 6 files
用掩模 R-CNN 和 GrabCut 实现图像分割
让我们一起开始使用 OpenCV 实现 Mask R-CNN 和 GrabCut 进行图像分割。
打开一个新文件,将其命名为mask_rcnn_grabcut.py,并插入以下代码:
# import the necessary packages
import numpy as rnp
import argparse
import imutils
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--mask-rcnn", required=True,
help="base path to mask-rcnn directory")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="minimum threshold for pixel-wise mask segmentation")
ap.add_argument("-u", "--use-gpu", type=bool, default=0,
help="boolean indicating if CUDA GPU should be used")
ap.add_argument("-e", "--iter", type=int, default=10,
help="# of GrabCut iterations (larger value => slower runtime)")
args = vars(ap.parse_args())
在导入必要的包(第 2-6 行)之后,我们定义我们的命令行参数 ( 第 9-22 行):
# load the COCO class labels our Mask R-CNN was trained on
labelsPath = os.path.sep.join([args["mask_rcnn"],
"object_detection_classes_coco.txt"])
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the Mask R-CNN weights and model configuration
weightsPath = os.path.sep.join([args["mask_rcnn"],
"frozen_inference_graph.pb"])
configPath = os.path.sep.join([args["mask_rcnn"],
"mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"])
# load our Mask R-CNN trained on the COCO dataset (90 classes)
# from disk
print("[INFO] loading Mask R-CNN from disk...")
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)
# check if we are going to use GPU
if args["use_gpu"]:
# set CUDA as the preferable backend and target
print("[INFO] setting preferable backend and target to CUDA...")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
第 35-38 行给出了模型配置和预训练权重的路径。我们的模型是基于张量流的。然而,如果需要的话,OpenCV 的 DNN 模块能够加载模型,并使用支持 CUDA 的 NVIDIA GPU 为推理做准备(第 43-50 行)。
既然我们的模型已经加载,我们也准备加载我们的图像并执行推理:
# load our input image from disk and display it to our screen
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
cv2.imshow("Input", image)
# construct a blob from the input image and then perform a
# forward pass of the Mask R-CNN, giving us (1) the bounding box
# coordinates of the objects in the image along with (2) the
# pixel-wise segmentation for each specific object
blob = cv2.dnn.blobFromImage(image, swapRB=True, crop=False)
net.setInput(blob)
(boxes, masks) = net.forward(["detection_out_final",
"detection_masks"])
rcnnMask: R-CNN 屏蔽rcnnOutput: R-CNN 屏蔽输出outputMask:基于来自我们的 mask R-CNN 的 Mask 近似值的 GrabCut mask(参考我们的以前的 GrabCut 教程的“用 OpenCV 进行 GrabCut:用 masks 初始化”部分)output: GrabCut + Mask R-CNN 屏蔽输出
请务必参考这个列表,这样您就可以跟踪剩余代码块的每个输出图像。
让我们开始循环检测:
# loop over the number of detected objects
for i in range(0, boxes.shape[2]):
# extract the class ID of the detection along with the
# confidence (i.e., probability) associated with the
# prediction
classID = int(boxes[0, 0, i, 1])
confidence = boxes[0, 0, i, 2]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > args["confidence"]:
# show the class label
print("[INFO] showing output for '{}'...".format(
LABELS[classID]))
# scale the bounding box coordinates back relative to the
# size of the image and then compute the width and the
# height of the bounding box
(H, W) = image.shape[:2]
box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
boxW = endX - startX
boxH = endY - startY
第 67 行开始我们的检测循环,此时我们继续:
- 抽出
classID和confidence( 线 71 和 72 ) - 基于我们的
--confidence阈值(第 76 行),过滤掉弱预测 - 根据图像的原始尺寸缩放边界框坐标(行 84 和 85 )
- 提取边界框坐标,并确定该框的宽度和高度(行 86-88 )
从这里开始,我们准备开始制作我们的 R-CNN 蒙版和蒙版图像:
# extract the pixel-wise segmentation for the object, resize
# the mask such that it's the same dimensions as the bounding
# box, and then finally threshold to create a *binary* mask
mask = masks[i, classID]
mask = cv2.resize(mask, (boxW, boxH),
interpolation=cv2.INTER_CUBIC)
mask = (mask > args["threshold"]).astype("uint8") * 255
# allocate a memory for our output Mask R-CNN mask and store
# the predicted Mask R-CNN mask in the GrabCut mask
rcnnMask = np.zeros(image.shape[:2], dtype="uint8")
rcnnMask[startY:endY, startX:endX] = mask
# apply a bitwise AND to the input image to show the output
# of applying the Mask R-CNN mask to the image
rcnnOutput = cv2.bitwise_and(image, image, mask=rcnnMask)
# show the output of the Mask R-CNN and bitwise AND operation
cv2.imshow("R-CNN Mask", rcnnMask)
cv2.imshow("R-CNN Output", rcnnOutput)
cv2.waitKey(0)
# clone the Mask R-CNN mask (so we can use it when applying
# GrabCut) and set any mask values greater than zero to be
# "probable foreground" (otherwise they are "definite
# background")
gcMask = rcnnMask.copy()
gcMask[gcMask > 0] = cv2.GC_PR_FGD
gcMask[gcMask == 0] = cv2.GC_BGD
# allocate memory for two arrays that the GrabCut algorithm
# internally uses when segmenting the foreground from the
# background and then apply GrabCut using the mask
# segmentation method
print("[INFO] applying GrabCut to '{}' ROI...".format(
LABELS[classID]))
fgModel = np.zeros((1, 65), dtype="float")
bgModel = np.zeros((1, 65), dtype="float")
(gcMask, bgModel, fgModel) = cv2.grabCut(image, gcMask,
None, bgModel, fgModel, iterCount=args["iter"],
mode=cv2.GC_INIT_WITH_MASK)
回想一下我之前的 GrabCut 教程,有两种使用 GrabCut 进行分割的方法:
- 基于包围盒的
- 基于遮罩的(我们将要执行的方法)
第 116 行克隆了rcnnMask,这样我们就可以在应用 GrabCut 时使用它。
然后我们设置“可能的前景”和“确定的背景”值(第 117 和 118 行)。我们还为 OpenCV 的 GrabCut 算法内部需要的前景和背景模型分配数组(第 126 行和第 127 行)。
从那里,我们用必要的参数(第 128-130 行)调用cv2.grabCut,包括我们初始化的掩码(我们掩码 R-CNN 的结果)。如果你需要重温 OpenCV 的 GrabCut 输入参数和 3 元组返回签名,我强烈推荐参考我的第一篇 GrabCut 博文中的“OpenCV grab cut”部分。
关于返回,我们只关心gcMask,我们将在接下来看到。
让我们继续并生成我们的最后两个输出图像:
# set all definite background and probable background pixels
# to 0 while definite foreground and probable foreground
# pixels are set to 1, then scale the mask from the range
# [0, 1] to [0, 255]
outputMask = np.where(
(gcMask == cv2.GC_BGD) | (gcMask == cv2.GC_PR_BGD), 0, 1)
outputMask = (outputMask * 255).astype("uint8")
# apply a bitwise AND to the image using our mask generated
# by GrabCut to generate our final output image
output = cv2.bitwise_and(image, image, mask=outputMask)
# show the output GrabCut mask as well as the output of
# applying the GrabCut mask to the original input image
cv2.imshow("GrabCut Mask", outputMask)
cv2.imshow("Output", output)
cv2.waitKey(0)
我们的最后两个图像可视化然后通过剩余的行显示。
在下一部分,我们将检查我们的结果。
屏蔽 R-CNN 和 GrabCut 图像分割结果
我们现在准备应用掩模 R-CNN 和 GrabCut 进行图像分割。
确保您使用了本教程的 “下载” 部分来下载源代码、示例图像和预训练的屏蔽 R-CNN 权重。
作为参考,下面是我们将应用 GrabCut 和 Mask R-CNN 的输入图像:
打开终端,执行以下命令:
$ python mask_rcnn_grabcut.py --mask-rcnn mask-rcnn-coco --image example.jpg
[INFO] loading Mask R-CNN from disk...
[INFO] showing output for 'horse'...
[INFO] applying GrabCut to 'horse' ROI...
[INFO] showing output for 'person'...
[INFO] applying GrabCut to 'person' ROI...
[INFO] showing output for 'dog'...
[INFO] applying GrabCut to 'dog' ROI...
[INFO] showing output for 'truck'...
[INFO] applying GrabCut to 'truck' ROI...
[INFO] showing output for 'person'...
[INFO] applying GrabCut to 'person' ROI...
现在让我们来看看每个单独的图像分割:
在这里,您可以看到 Mask R-CNN 在输入图像中检测到了一匹马。
然后,我们通过 GrabCut 传递该蒙版以改进蒙版,希望获得更好的图像分割。
虽然我们能够通过马的腿来移除背景,但不幸的是,它会切断马蹄和马的头顶。
现在让我们来看看如何分割坐在马背上的骑手:
这种分割比前一种好得多;但是,使用 GrabCut 后,人的头发会脱落。
以下是从输入图像中分割卡车的输出:
Mask R-CNN 在分割卡车方面做得非常好;然而,GrabCut 认为只有格栅,引擎盖和挡风玻璃在前景中,去除了其他部分。
下一个图像包含分割第二个人的可视化效果(远处栅栏旁边的那个人):
这是如何将 Mask R-CNN 和 GrabCut 成功结合用于图像分割的最佳范例之一。
注意我们有一个明显更紧密的分割——在应用 GrabCut 后,任何渗入前景的背景(如田野中的草)都被移除了。
最后,这是对狗应用 Mask R-CNN 和 GrabCut 的输出:
掩模 R-CNN 产生的掩模中仍然有大量的背景。
通过应用 GrabCut,可以删除该背景,但不幸的是,狗的头顶也随之丢失。
喜忧参半的结果、局限性和缺点
在查看了本教程的混合结果后,您可能会奇怪为什么我还要写一篇关于一起使用 GrabCut 和 Mask R-CNN 的教程— 在许多情况下,似乎将 GrabCut 应用于 Mask R-CNN mask 实际上会使结果更糟!
虽然这是真的,但是仍然有种情况(例如图 7 中的第二个人物分割),其中将 GrabCut 应用到遮罩 R-CNN 遮罩实际上改进了分割。
我使用了一个具有复杂前景/背景的图像来向您展示这种方法的局限性,但是复杂性较低的图像将获得更好的结果。
一个很好的例子是从输入图像中分割出服装来构建一个时尚搜索引擎。
实例分割网络如 Mask R-CNN,U-Net 等。可以预测每件衣服的位置和面具,从那里 GrabCut 可以提炼面具。
虽然将 Mask R-CNN 和 GrabCut 一起应用于图像分割时肯定会有混合的结果,但仍然值得进行一次实验,看看您的结果是否有所改善。
总结
在本教程中,您学习了如何使用 Mask R-CNN、GrabCut 和 OpenCV 执行图像分割。
我们使用掩模 R-CNN 深度神经网络来计算图像中给定对象的初始前景分割掩模。
来自掩模 R-CNN 的掩模可以自动计算,但是通常具有“渗入”前景分割掩模的背景。为了解决这个问题,我们使用 GrabCut 来改进由 mask R-CNN 生成的 Mask。
在某些情况下,GrabCut 产生的图像分割比 Mask R-CNN 产生的原始掩模更好。在其他情况下,产生的图像分割是 更差——如果我们坚持使用由掩模 R-CNN 制作的掩模,情况会更好。
*最大的限制是,即使使用 Mask R-CNN 自动生成的 Mask/bounding box,GrabCut 仍然是一种迭代地需要手动注释来提供最佳结果的算法。由于我们没有手动向 GrabCut 提供提示和建议,因此不能进一步改进这些掩码。
我们是否使用过 Photoshop、GIMP 等图片编辑软件包?,那么我们将有一个漂亮的,易于使用的图形用户界面,这将允许我们提供提示,以 GrabCut 什么是前景,什么是背景。
你当然应该尝试使用 GrabCut 来改进你的屏蔽 R-CNN 屏蔽。在某些情况下,你会发现它工作完美,你会获得更高质量的图像分割。在其他情况下,你最好使用 R-CNN 面具。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
用 OpenCV 和 Python 实现图像拼接
原文:https://pyimagesearch.com/2018/12/17/image-stitching-with-opencv-and-python/

在本教程中,您将学习如何使用 Python、OpenCV 以及cv2.createStitcher和cv2.Stitcher_create函数来执行图像拼接。使用今天的代码,你将能够将多张图像拼接在一起,创建拼接图像的全景。
就在两年前,我发表了两本关于图像拼接和全景图构建的指南:
这两个教程都涵盖了典型图像拼接算法的基础知识,至少需要四个关键步骤:
- 检测关键点(狗、哈里斯等。)并提取局部不变描述符(SIFT、SURF 等)。)来自两个输入图像
- 匹配图像之间的描述符
- 使用 RANSAC 算法来估计使用我们的匹配特征向量的单应矩阵
- 使用从步骤#3 获得的单应矩阵应用扭曲变换
然而,我最初实现的最大问题是它们不能处理两个以上的输入图像。
在今天的教程中,我们将再次讨论使用 OpenCV 进行图像拼接,包括如何将两幅以上的图像拼接成一幅全景图像。
要学习如何用 OpenCV 和 Python 拼接图像,继续阅读!
用 OpenCV 和 Python 实现图像拼接
在今天教程的第一部分,我们将简要回顾 OpenCV 的图像拼接算法,该算法是通过cv2.createStitcher和cv2.Stitcher_create函数嵌入 OpenCV 库的。
从这里,我们将回顾我们的项目结构,并实现一个可用于图像拼接的 Python 脚本。
我们将回顾第一个脚本的结果,注意它的局限性,然后实现第二个 Python 脚本,该脚本可用于获得更美观的图像拼接结果。
最后,我们将回顾第二个脚本的结果,并再次注意任何限制或缺点。
OpenCV 的图像拼接算法

Figure 1: The stitching module pipeline implemented in the Stitcher class (source).
我们今天在这里使用的算法类似于 Brown 和 Lowe 在他们 2007 年的论文 中提出的具有不变特征的自动全景图像拼接 的方法。
与之前对输入图像排序敏感的图像拼接算法不同,Brown and Lowe 方法更加鲁棒,使其对以下各项不敏感:
- 图像排序
- 图像的方向
- 照明变化
- 实际上不是全景的一部分的噪声图像
此外,他们的图像拼接方法能够通过使用增益补偿和图像混合来产生更美观的输出全景图像。
完整、详细的算法回顾超出了本文的范围,所以如果你有兴趣了解更多,请参考原始出版物。
项目结构
让我们看看这个项目是如何用tree命令组织的:
$ tree --dirsfirst
.
├── images
│ └── scottsdale
│ ├── IMG_1786-2.jpg
│ ├── IMG_1787-2.jpg
│ └── IMG_1788-2.jpg
├── image_stitching.py
├── image_stitching_simple.py
└── output.png
2 directories, 6 files
输入图像放在images/文件夹中。我选择为我的scottsdale/图片集创建一个子文件夹,以防以后我想在这里添加更多的子文件夹。
今天我们将回顾两个 Python 脚本:
image_stitching_simple.py:我们的简单版图像拼接,不到 50 行 Python 代码就可以完成!- 这个脚本包含了我提取拼接图像的 ROI 以获得美观效果的技巧。
最后一个文件output.png,是最终拼接图像的名称。使用命令行参数,您可以很容易地改变输出图像的文件名+路径。
cv2.createStitcher 和 cv2。Stitcher_create 函数
Figure 2: The constructor signature for creating a Stitcher class object with OpenCV.
OpenCV 已经通过cv2.createStitcher (OpenCV 3.x)和cv2.Stitcher_create (OpenCV 4)函数实现了一个类似于 Brown 和 Lowe 论文的方法。
假设您已经正确配置并安装了的 OpenCV,您将能够研究 OpenCV 3.x 的cv2.createStitcher的函数签名:
createStitcher(...)
createStitcher([, try_use_gpu]) -> retval
请注意,这个函数只有一个参数try_gpu,它可以用来提高图像拼接流水线的吞吐量。OpenCV 的 GPU 支持是有限的,我从来没有能够让这个参数工作,所以我建议总是让它作为False。
OpenCV 4 的cv2.Stitcher_create函数也有类似的特征:
Stitcher_create(...)
Stitcher_create([, mode]) -> retval
. @brief Creates a Stitcher configured in one of the stitching
. modes.
.
. @param mode Scenario for stitcher operation. This is usually
. determined by source of images to stitch and their transformation.
. Default parameters will be chosen for operation in given scenario.
. @return Stitcher class instance.
为了执行实际的图像拼接,我们需要调用.stitch方法:
OpenCV 3.x:
stitch(...) method of cv2.Stitcher instance
stitch(images[, pano]) -> retval, pano
OpenCV 4.x:
stitch(...) method of cv2.Stitcher instance
stitch(images, masks[, pano]) -> retval, pano
. @brief These functions try to stitch the given images.
.
. @param images Input images.
. @param masks Masks for each input image specifying where to
. look for keypoints (optional).
. @param pano Final pano.
. @return Status code.
该方法接受一系列输入images,然后尝试将它们拼接成一幅全景图,将输出的全景图像返回给调用函数。
status变量表示图像拼接是否成功,可以是以下四个变量之一:
- 图像拼接成功了。
- 如果您收到此状态代码,您将需要更多的输入图像来构建您的全景。通常,如果在输入图像中没有检测到足够的关键点,就会出现此错误。
ERR_HOMOGRAPHY_EST_FAIL = 2:当 RANSAC 单应性估计失败时,出现此错误。同样,您可能需要更多的图像,或者您的图像没有足够的独特纹理/对象来精确匹配关键点。- 我以前从未遇到过这个错误,所以我对它了解不多,但要点是它与未能从输入图像中正确估计相机的内在/外在特性有关。如果您遇到这个错误,您可能需要参考 OpenCV 文档,甚至钻研 OpenCV C++代码。
既然我们已经回顾了cv2.createStitcher、cv2.Stitcher_create和.stitch方法,让我们继续用 OpenCV 和 Python 实际实现图像拼接。
用 Python 实现图像拼接
让我们开始实施我们的图像拼接算法吧!
打开image_stitching_simple.py文件并插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", type=str, required=True,
help="path to input directory of images to stitch")
ap.add_argument("-o", "--output", type=str, required=True,
help="path to the output image")
args = vars(ap.parse_args())
我们需要的包在线 2-6 导入。值得注意的是,我们将使用 OpenCV 和 imutils 。如果您还没有,请继续安装它们:
- 要安装 OpenCV,只需遵循我的 OpenCV 安装指南。
- imutils 包可以用 pip:
pip install --upgrade imutils安装/更新。一定要升级它,因为经常会添加新功能。
从这里我们将解析第 9-14 行的两个命令行参数:
--images:要拼接的输入图像的目录路径。--output:保存结果的输出图像的路径。
如果你不熟悉argparse和命令行参数的概念,那么阅读这篇博文。
让我们加载输入图像:
# grab the paths to the input images and initialize our images list
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["images"])))
images = []
# loop over the image paths, load each one, and add them to our
# images to stitch list
for imagePath in imagePaths:
image = cv2.imread(imagePath)
images.append(image)
这里我们抓住我们的imagePaths ( 第 18 行)。
然后对于每个imagePath,我们将加载image并将其添加到images列表中(第 19-25 行)。
现在images已经在内存中,让我们继续使用 OpenCV 的内置功能将它们拼接成一个全景图:
# initialize OpenCV's image stitcher object and then perform the image
# stitching
print("[INFO] stitching images...")
stitcher = cv2.createStitcher() if imutils.is_cv3() else cv2.Stitcher_create()
(status, stitched) = stitcher.stitch(images)
在线 30 上创建stitcher对象。注意,根据您使用的是 OpenCV 3 还是 4,调用了不同的构造函数。
随后,我们可以将我们的images传递给.stitch方法(行 31 )。对.stitch的调用返回一个status和我们的stitched图像(假设拼接成功)。
最后,我们将(1)将拼接的图像写入磁盘,并(2)将其显示在屏幕上:
# if the status is '0', then OpenCV successfully performed image
# stitching
if status == 0:
# write the output stitched image to disk
cv2.imwrite(args["output"], stitched)
# display the output stitched image to our screen
cv2.imshow("Stitched", stitched)
cv2.waitKey(0)
# otherwise the stitching failed, likely due to not enough keypoints)
# being detected
else:
print("[INFO] image stitching failed ({})".format(status))
假设我们的status标志指示成功(行 35 ),我们将stitched图像写入磁盘(行 37 )并显示它,直到按下一个键(行 40 和 41 )。
否则,我们将简单地打印一条失败消息(行 45 和 46 )。
基本图像拼接结果
为了尝试我们的图像拼接脚本,请确保使用教程的 “下载” 部分下载源代码和示例图像。
在目录里,你会找到三张我在参观弗兰克·劳埃德·赖特位于亚利桑那州斯科茨代尔的著名的塔利辛西屋时拍摄的照片:

Figure 3: Three photos to test OpenCV image stitching with. These images were taken by me in Scottsdale, AZ at Frank Lloyd Wright’s famous Taliesin West house.
我们的目标是将这三幅图像拼接成一幅全景图像。要执行拼接,请打开一个终端,导航到下载代码+图像的位置,并执行以下命令:
$ python image_stitching_simple.py --images images/scottsdale --output output.png
[INFO] loading images...
[INFO] stitching images...

Figure 4: Image stitching performed with OpenCV. This image has undergone stitching but has yet to be cropped.
请注意我们是如何成功执行图像拼接的!
但是全景图周围的那些黑色区域呢?那些是什么?
这些区域来自执行构建全景所需的透视扭曲。
有一种方法可以消除它们…但是我们需要在下一节实现一些额外的逻辑。
用 OpenCV 和 Python 实现更好的图像拼接

Figure 5: In this section, we’ll learn how to improve image stitching with OpenCV by cropping out the region of the panorama inside the red-dash border shown in the figure.
我们的第一个图像拼接脚本是一个良好的开端,但全景图周围的黑色区域并不是我们所说的“审美愉悦”。
更重要的是,你不会从 iOS、Android 等内置的流行图像拼接应用程序中看到这样的输出图像。
因此,我们将对我们的脚本进行一些修改,并加入一些额外的逻辑来创建更加美观的全景图。
我要再次重申,这种方法是一种黑客行为。
我们将回顾基本的图像处理操作,包括阈值、轮廓提取、形态学操作等。以获得我们想要的结果。
据我所知,OpenCV 的 Python 绑定没有为我们提供手动提取全景图的最大内部矩形区域所需的信息。如果 OpenCV 有,请在评论中告诉我,我很想知道。
让我们开始吧——打开image_stitching.py脚本并插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", type=str, required=True,
help="path to input directory of images to stitch")
ap.add_argument("-o", "--output", type=str, required=True,
help="path to the output image")
ap.add_argument("-c", "--crop", type=int, default=0,
help="whether to crop out largest rectangular region")
args = vars(ap.parse_args())
# grab the paths to the input images and initialize our images list
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["images"])))
images = []
# loop over the image paths, load each one, and add them to our
# images to stich list
for imagePath in imagePaths:
image = cv2.imread(imagePath)
images.append(image)
# initialize OpenCV's image sticher object and then perform the image
# stitching
print("[INFO] stitching images...")
stitcher = cv2.createStitcher() if imutils.is_cv3() else cv2.Stitcher_create()
(status, stitched) = stitcher.stitch(images)
所有这些代码都与我们之前的脚本相同,只有一个例外。
添加了--crop命令行参数。当在终端中为这个参数提供了一个1时,我们将继续执行我们的裁剪操作。
下一步是我们开始实施额外的功能:
# if the status is '0', then OpenCV successfully performed image
# stitching
if status == 0:
# check to see if we supposed to crop out the largest rectangular
# region from the stitched image
if args["crop"] > 0:
# create a 10 pixel border surrounding the stitched image
print("[INFO] cropping...")
stitched = cv2.copyMakeBorder(stitched, 10, 10, 10, 10,
cv2.BORDER_CONSTANT, (0, 0, 0))
# convert the stitched image to grayscale and threshold it
# such that all pixels greater than zero are set to 255
# (foreground) while all others remain 0 (background)
gray = cv2.cvtColor(stitched, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)[1]
请注意我是如何在第 40 行的上设置了--crop标志时创建一个新块的。让我们开始穿过这个街区:
- 首先,我们将为我们的
stitched图像的所有边添加一个10像素边界(第 43 行和第 44 行),确保我们能够在这一部分的后面找到完整的全景轮廓。 - 然后我们将为我们的
stitched图像创建一个gray版本(第 49 行)。 - 从那里我们开始处理
gray图像(线 50 )。
以下是这三个步骤的结果(thresh):

Figure 6: After thresholding, we’re presented with this threshold mask highlighting where the OpenCV stitched + warped image resides.
我们现在有了全景的二进制图像,其中白色像素(255)是前景,黑色像素(0)是背景。
给定阈值图像,我们可以应用轮廓提取,计算最大轮廓的边界框(即全景本身的轮廓),并绘制边界框:
# find all external contours in the threshold image then find
# the *largest* contour which will be the contour/outline of
# the stitched image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
# allocate memory for the mask which will contain the
# rectangular bounding box of the stitched image region
mask = np.zeros(thresh.shape, dtype="uint8")
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(mask, (x, y), (x + w, y + h), 255, -1)
在行 55-57 提取并解析轮廓。线 58 然后抓取面积最大的轮廓(即拼接图像本身的轮廓)。
注:imutils.grab_contours函数是imutils==0.5.2中新增的,以适应 OpenCV 2.4、OpenCV 3、OpenCV 4 及其对cv2.findContours不同的返回签名。
第 62 行为我们新的矩形遮罩分配内存。第 63 行然后计算我们最大轮廓的包围盒。使用包围矩形信息,在第 64 行,我们在蒙版上画一个白色的实心矩形。
上述代码块的输出如下所示:

Figure 7: The smallest rectangular region that the entire OpenCV panorama can fit in.
这个边界框是整个全景图能够容纳的最小矩形区域。
现在,这里是我为博客帖子整理的最大的黑客之一:
# create two copies of the mask: one to serve as our actual
# minimum rectangular region and another to serve as a counter
# for how many pixels need to be removed to form the minimum
# rectangular region
minRect = mask.copy()
sub = mask.copy()
# keep looping until there are no non-zero pixels left in the
# subtracted image
while cv2.countNonZero(sub) > 0:
# erode the minimum rectangular mask and then subtract
# the thresholded image from the minimum rectangular mask
# so we can count if there are any non-zero pixels left
minRect = cv2.erode(minRect, None)
sub = cv2.subtract(minRect, thresh)
在第 70 行和第 71 行,我们创建了我们的mask图像的两个副本:
- 第一个蒙版
minMask,将慢慢缩小尺寸,直到它可以放入全景图的内部(见图 5 )。 - 第二个遮罩
sub,将用于确定我们是否需要继续减小minMask的大小。
第 75 行开始一个while循环,该循环将继续循环,直到sub中不再有前景像素。
第 79 行执行腐蚀形态学操作以减小minRect的尺寸。
第 80 行然后从minRect中减去thresh——一旦minRect中没有更多的前景像素,我们就可以脱离循环。
我在下面放了一个黑客的动画:

Figure 8: An animation of the hack I came up with to extract the minRect region of the OpenCV panorama image, making for an aesthetically pleasing stitched image
在顶部,我们有我们的sub图像,在底部我们有minRect图像。
请注意minRect的大小是如何逐渐减小的,直到sub中不再有前景像素——此时,我们知道我们已经找到了能够适合全景图最大矩形区域的最小矩形遮罩。
给定最小的内部矩形,我们可以再次找到轮廓并计算边界框,但这次我们将简单地从stitched图像中提取 ROI:
# find contours in the minimum rectangular mask and then
# extract the bounding box (x, y)-coordinates
cnts = cv2.findContours(minRect.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
(x, y, w, h) = cv2.boundingRect(c)
# use the bounding box coordinates to extract the our final
# stitched image
stitched = stitched[y:y + h, x:x + w]
这里我们有:
- 在
minRect( 行 84 和 85 )中找到轮廓。 - 处理多个 OpenCV 版本的轮廓解析(第 86 行)。您需要
imutils>=0.5.2来使用此功能。 - 抓取最大轮廓(线 87 )。
- 计算最大轮廓的包围盒(线 88 )。
- 使用边界框信息从我们的
stitched中提取 ROI(第 92 行)。
最终的stitched图像可以显示在我们的屏幕上,然后保存到磁盘上:
# write the output stitched image to disk
cv2.imwrite(args["output"], stitched)
# display the output stitched image to our screen
cv2.imshow("Stitched", stitched)
cv2.waitKey(0)
# otherwise the stitching failed, likely due to not enough keypoints)
# being detected
else:
print("[INFO] image stitching failed ({})".format(status))
第 95-99 行处理保存和显示图像,不管我们的裁剪是否被执行。
和以前一样,如果status标志没有成功返回,我们将打印一条错误消息(第 103 行和第 104 行)。
让我们继续检查我们改进的图像拼接+ OpenCV 管道的结果。
改进的图像拼接结果
同样,确保您已经使用今天教程的 【下载】 部分下载了源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python image_stitching.py --images images/scottsdale --output output.png \
--crop 1
[INFO] loading images...
[INFO] stitching images...
[INFO] cropping...

Figure 8: The result of our multiple image stitching with OpenCV and Python.
请注意,这次我们通过应用上一节中详细介绍的方法,从输出的拼接图像中移除了黑色区域(由扭曲变形引起)。
局限性和缺点
在之前的教程中,我演示了如何构建一个实时全景图和图像拼接算法 —本教程依赖于这样一个事实,即我们手动执行关键点检测、特征提取和关键点匹配,使我们能够访问用于将两幅输入图像变形为全景图的单应矩阵。
虽然 OpenCV 的内置cv2.createStitcher和cv2.Stitcher_create函数肯定能够构建精确、美观的全景图,但该方法的一个主要缺点是它抽象了对单应矩阵的任何访问。
实时全景图构建的一个假设是场景本身在内容上变化不大。
一旦我们计算了初始单应性估计,我们应该只需要偶尔重新计算矩阵。
不必执行全面的关键点匹配和 RANSAC 估计,这极大地提高了我们构建全景图的速度,因此,如果无法访问原始单应矩阵,采用 OpenCV 的内置图像拼接算法并将其转换为实时算法将是一个挑战。
使用 OpenCV 执行图像拼接时遇到错误?
尝试使用cv2.createStitcher功能或cv2.Stitcher_create功能时,您可能会遇到错误。
我看到人们遇到的两个“容易解决”的错误是忘记他们正在使用的 OpenCV 版本。
例如,如果您正在使用 OpenCV 4,但试图调用cv2.createSticher,您将会遇到以下错误消息:
>>> cv2.createStitcher
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'cv2' has no attribute 'createStitcher'
你应该使用cv2.Stitcher_create函数。
类似地,如果您使用 OpenCV 3 并试图调用cv2.Sticher_create,您将收到以下错误:
>>> cv2.Stitcher_create
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'cv2' has no attribute 'Stitcher_create'
而是使用cv2.createSticher功能。
如果您不确定您正在使用哪个 OpenCV 版本,您可以使用cv2.__version__进行检查:
>>> cv2.__version__
'4.0.0'
这里可以看到我用的是 OpenCV 4.0.0。
您可以在您的系统上执行相同的检查。
您可能遇到的最后一个错误,也可能是最常见的错误,与 OpenCV 有关(1)没有 contrib 支持,以及(2)在没有启用OPENCV_ENABLE_NONFREE=ON选项的情况下被编译。
要解决此错误,您必须安装opencv_contrib模块,并将OPENCV_ENABLE_NONFREE选项设置为ON。
如果你遇到一个与 OpenCV 的非自由和贡献模块相关的错误,确保你参考我的 OpenCV 安装指南以确保你有 OpenCV 的完整安装。
注意:请注意,如果你没有遵循我的安装指南,我无法帮助你调试你自己的 OpenCV 安装,所以请确保你在配置你的系统时使用我的 OpenCV 安装指南。
摘要
在今天的教程中,您学习了如何使用 OpenCV 和 Python 执行多幅图像拼接。
使用 OpenCV 和 Python,我们能够将多幅图像拼接在一起,并创建全景图像。
我们输出的全景图像不仅在拼接位置上精确,而且在审美上令人愉悦。
然而,使用 OpenCV 内置图像拼接类的最大缺点之一是它抽象掉了大量的内部计算,包括产生的单应矩阵本身。
如果您试图执行实时图像拼接,正如我们在上一篇文章中所做的,您可能会发现缓存单应矩阵并偶尔执行关键点检测、特征提取和特征匹配是有益的。
跳过这些步骤并使用缓存的矩阵来执行透视扭曲可以减少管道的计算负担,并最终加快实时图像拼接算法,但不幸的是,OpenCV 的cv2.createStitcher Python 绑定不为我们提供对原始矩阵的访问。
如果你有兴趣了解更多关于实时全景构建的知识,可以参考我之前的帖子。
我希望你喜欢今天的图像拼接教程!
要下载今天帖子的源代码,请注意 PyImageSearch 上发布的教程,只需在下面的表格中输入您的电子邮件地址!
图像超分辨率
原文:https://pyimagesearch.com/2022/02/14/image-super-resolution/
在本教程中,您将学习使用图像超分辨率。
本课是关于超分辨率的 3 部分系列的一部分:
- OpenCV 超分辨率与深度学习
- 图像超分辨率(本教程)
- 用 TensorFlow、Keras、深度学习实现像素洗牌超分辨率
要了解如何使用图像超分辨率,继续阅读。
图像超分辨率
正如深度学习和卷积神经网络已经完全改变了通过深度学习方法产生的艺术景观,超分辨率算法也是如此。然而,值得注意的是,计算机视觉的超分辨率子领域已经得到了更严格的研究。以前的方法主要是基于示例的,并且倾向于:
- 利用输入图像的内部相似性建立超分辨率输出(崔,2014);弗里德曼和法塔,2011;格拉斯纳等人,2009 年
- 学习低分辨率到高分辨率的补丁(常等,2004;弗里曼等人,2000 年;【贾等著】2013 年
- 使用稀疏编码的一些变体(杨等人,2010 )
在本教程中,我们将实现董等人(2016) 的工作。这种方法证明了以前的稀疏编码方法实际上等同于应用深度卷积神经网络——主要区别在于我们实现的方法更快,产生更好的结果,并且完全是端到端的。
虽然自 Dong 等人在 2016 的工作(包括 Johnson 等人(2016) 关于将超分辨率框架化为风格转移的精彩论文)以来,已经有了许多超分辨率论文,但 Dong 等人的工作形成了许多其他超分辨率卷积神经网络(SRCNNs)建立的基础。
了解 SRCNNs
SRCNNs 有许多重要的特征。下面列出了最重要的属性:
- src nn 是全卷积(不要和全连接混淆)。我们可以输入任何图像大小(假设宽度和高度可以平铺),并在其上运行 SRCNN。这使得 SRCNNs 非常快。
- 我们是为了过滤器而训练,而不是为了准确性。在其他课程中,我们主要关注训练我们的 CNN,以在给定数据集上实现尽可能高的准确性。在这种情况下,我们关心的是 SRCNN 学习的实际滤波器,这将使我们能够放大图像——在训练数据集上获得的学习这些滤波器的实际精度是无关紧要的。
- 它们不需要解决使用优化问题。在 SRCNN 已经学习了一组滤波器之后,它可以应用简单的正向传递来获得输出超分辨率图像。我们不必在每个图像的基础上优化损失函数来获得输出。
- 它们完全是端到端的。同样,SRCNNs 完全是端到端的:向网络输入图像并获得更高分辨率的输出。没有中间步骤。一旦训练完成,我们就可以应用超分辨率了。
如上所述,我们的 SRCNN 的目标是学习一组过滤器,允许我们将低分辨率输入映射到高分辨率输出。因此,我们将构建两组图像补片,而不是实际的全分辨率图像:
- 将作为网络输入的低分辨率面片
- 将作为网络预测/重建的目标的高分辨率补丁
通过这种方式,我们的 SRCNN 将学习如何从低分辨率输入面片重建高分辨率面片。
实际上,这意味着我们:
- 首先,需要构建低分辨率和高分辨率输入面片的数据集
- 训练网络以学习将低分辨率补丁映射到它们的高分辨率对应物
- 创建一个脚本,该脚本利用低分辨率图像的输入面片上的循环,通过网络传递它们,然后根据预测的面片创建输出高分辨率图像。
正如我们将在本教程后面看到的,构建 SRCNN 可以说比我们在其他课程中遇到的其他分类挑战更容易。
实施 src nn
首先,我们将回顾这个项目的目录结构,包括任何需要的配置文件。接下来,我们将回顾一个用于构建低分辨率和高分辨率面片数据集的 Python 脚本。然后,我们将实现我们的 SRCNN 架构本身,并对其进行训练。最后,我们将利用训练好的模型将 SRCNNs 应用于输入图像。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
开始项目
让我们从回顾这个项目的目录结构开始。第一步是在pyimagesearch的conv子模块中创建一个名为srcnn.py的新文件——这就是我们的超分辨率卷积神经网络将要存在的地方:
--- pyimagesearch
| |--- __init__.py
...
| |--- nn
| | |--- __init__.py
| | |--- conv
| | | |--- __init__.py
| | | |--- alexnet.py
| | | |--- dcgan.py
...
| | | |--- srcnn.py
...
从那里,我们有了项目本身的以下目录结构:
--- super_resolution
| |--- build_dataset.py
| |--- config
| | |--- sr_config.py
| |--- output/
| |--- resize.py
| |--- train.py
| |--- uk_bench/
sr_config.py文件存储了我们需要的任何配置。然后我们将使用build_dataset.py来创建我们的低分辨率和高分辨率补丁用于训练。
备注: 董等人将面片改为子图。这种澄清的尝试是为了避免关于面片的任何歧义(在一些计算机视觉文献中,这可能意味着重叠的 ROI)。我将交替使用这两个术语,因为我相信工作的上下文将定义一个补丁是否重叠——这两个术语都完全有效。**
从那里,我们有了实际训练我们网络的train.py脚本。最后,我们将实现resize.py来接受低分辨率输入图像并创建高分辨率输出。
output目录将存储
- 我们的 HDF5 训练图像集
- 输出模型本身
最后,uk_bench目录将包含我们正在学习模式的示例图像。
现在让我们来看看sr_config.py文件:
# import the necessary packages
import os
# define the path to the input images we will be using to build the
# training crops
INPUT_IMAGES = "ukbench100"
# define the path to the temporary output directories
BASE_OUTPUT = "output"
IMAGES = os.path.sep.join([BASE_OUTPUT, "images"])
LABELS = os.path.sep.join([BASE_OUTPUT, "labels"])
# define the path to the HDF5 files
INPUTS_DB = os.path.sep.join([BASE_OUTPUT, "inputs.hdf5"])
OUTPUTS_DB = os.path.sep.join([BASE_OUTPUT, "outputs.hdf5"])
# define the path to the output model file and the plot file
MODEL_PATH = os.path.sep.join([BASE_OUTPUT, "srcnn.model"])
PLOT_PATH = os.path.sep.join([BASE_OUTPUT, "plot.png"])
第 6 行定义了ukbench100数据集的路径,它是更大的 UKBench 数据集的子集。 Dong 等人对 91 幅图像数据集和 120 万幅 ImageNet 数据集进行了实验。复制在 ImageNet 上训练的 SRCNN 的工作超出了本课的范围,因此我们将坚持使用更接近 Dong 等人的第一个实验大小的图像数据集。
第 9-11 行构建了到临时输出目录的路径,我们将在那里存储我们的低分辨率和高分辨率子图像。给定低分辨率和高分辨率子图像,我们将从它们生成输出 HDF5 数据集(第 14 行和第 15 行)。第 18 行和第 19 行定义了输出模型文件的路径以及一个训练图。
让我们继续定义我们的配置:
# initialize the batch size and number of epochs for training
BATCH_SIZE = 128
NUM_EPOCHS = 10
# initialize the scale (the factor in which we want to learn how to
# enlarge images by) along with the input width and height dimensions
# to our SRCNN
SCALE = 2.0
INPUT_DIM = 33
# the label size should be the output spatial dimensions of the SRCNN
# while our padding ensures we properly crop the label ROI
LABEL_SIZE = 21
PAD = int((INPUT_DIM - LABEL_SIZE) / 2.0)
# the stride controls the step size of our sliding window
STRIDE = 14
按照NUM_EPOCHS的定义,我们将只训练十个纪元。董等人发现,长时间的训练实际上会损害的性能(这里的“性能”定义为输出超分辨率图像的质量)。十个历元应该足以让我们的 SRCNN 学习一组过滤器,以将我们的低分辨率补丁映射到它们的更高分辨率对应物。
SCALE ( 第 28 行)定义了我们放大图像的因子——这里我们放大了2x,但你也可以放大3x或4x。
INPUT_DIM是我们的子窗口的空间宽度和高度(33×33像素)。我们的LABEL_SIZE是 SRCNN 的输出空间维度,而我们的PAD确保我们在构建数据集和对输入图像应用超分辨率时正确地裁剪标签 ROI。
最后,STRIDE在创建子图像时控制滑动窗口的步长。董等人建议对于较小的图像数据集采用14像素的步距,对于较大的数据集采用33像素的步距。
在我们走得太远之前,你可能会困惑为什么INPUT_DIM比LABEL_SIZE大——这里的整个想法不就是构建更高分辨率的输出图像吗?当我们的神经网络的输出比输入的小时,这怎么可能呢?答案是双重的。
- 在本课的前面,我们的 SRCNN 不包含零填充。使用零填充会引入边界伪影,这会降低输出图像的质量。由于我们没有使用零填充,我们的空间维度将在每一层之后自然减少。
- 当将超分辨率应用于输入图像时(在训练之后),我们实际上将通过因子
SCALE增加输入低分辨率图像的——网络然后将较高比例的低分辨率图像转换为高分辨率输出图像。如果这个过程看起来很混乱,不要担心,本教程的剩余部分将有助于使它变得清晰。
构建数据集
让我们继续为 SRCNN 构建我们的训练数据集。打开build_dataset.py并插入以下代码:
# import the necessary packages
from pyimagesearch.io import HDF5DatasetWriter
from conf import sr_config as config
from imutils import paths
from PIL import Image
import numpy as np
import shutil
import random
import PIL
import cv2
import os
# if the output directories do not exist, create them
for p in [config.IMAGES, config.LABELS]:
if not os.path.exists(p):
os.makedirs(p)
# grab the image paths and initialize the total number of crops
# processed
print("[INFO] creating temporary images...")
imagePaths = list(paths.list_images(config.INPUT_IMAGES))
random.shuffle(imagePaths)
total = 0
2-11 号线办理我们的进口业务。注意我们是如何再次使用HDF5DatasetWriter类以 HDF5 格式将数据集写入磁盘的。我们的sr_config脚本被导入到的第 3 行,,这样我们就可以访问我们指定的值。
第 14-16 行创建临时输出目录来存储我们的子窗口。生成所有子窗口后,我们将它们添加到 HDF5 数据集,并删除临时目录。第 21-23 行然后获取输入图像的路径,并初始化一个计数器来计算生成的子窗口的数量total。
让我们遍历每一个图像路径:
# loop over the image paths
for imagePath in imagePaths:
# load the input image
image = cv2.imread(imagePath)
# grab the dimensions of the input image and crop the image such
# that it tiles nicely when we generate the training data +
# labels
(h, w) = image.shape[:2]
w -= int(w % config.SCALE)
h -= int(h % config.SCALE)
image = image[0:h, 0:w]
# to generate our training images we first need to downscale the
# image by the scale factor...and then upscale it back to the
# original size -- this will process allows us to generate low
# resolution inputs that we'll then learn to reconstruct the high
# resolution versions from
lowW = int(w * (1.0 / config.SCALE))
lowH = int(h * (1.0 / config.SCALE))
highW = int(lowW * (config.SCALE / 1.0))
highH = int(lowH * (config.SCALE / 1.0))
# perform the actual scaling
scaled = np.array(Image.fromarray(image).resize((lowW, lowH),
resample=PIL.Image.BICUBIC))
scaled = np.array(Image.fromarray(scaled).resize((highW, highH),
resample=PIL.Image.BICUBIC))
对于每个输入图像,我们首先从磁盘中加载它(第 28 行),然后裁剪图像,使其在生成子窗口(第 33-36 行)时能很好地平铺。如果我们不采取这一步,我们的步幅大小将会不合适,我们将会在图像的空间维度之外裁剪出小块。
要为我们的 SRCNN 生成训练数据,我们需要:
- 将原始输入图像缩小
SCALE(对于SCALE = 2.0,我们将输入图像的尺寸减半) - 然后重新调整到原来的大小
该过程生成具有相同原始空间维度的低分辨率图像。我们将学习如何从这个低分辨率输入中重建一个高分辨率图像。
备注: 我发现使用 OpenCV 的双线性插值(由董等人推荐)产生的结果较差(它也引入了更多的代码来执行缩放)。我选择了 PIL/枕头的.resize功能,因为它更容易使用,效果也更好。
我们现在可以为输入和目标生成子窗口:
# slide a window from left-to-right and top-to-bottom
for y in range(0, h - config.INPUT_DIM + 1, config.STRIDE):
for x in range(0, w - config.INPUT_DIM + 1, config.STRIDE):
# crop output the 'INPUT_DIM x INPUT_DIM' ROI from our
# scaled image -- this ROI will serve as the input to our
# network
crop = scaled[y:y + config.INPUT_DIM,
x:x + config.INPUT_DIM]
# crop out the 'LABEL_SIZE x LABEL_SIZE' ROI from our
# original image -- this ROI will be the target output
# from our network
target = image[
y + config.PAD:y + config.PAD + config.LABEL_SIZE,
x + config.PAD:x + config.PAD + config.LABEL_SIZE]
# construct the crop and target output image paths
cropPath = os.path.sep.join([config.IMAGES,
"{}.png".format(total)])
targetPath = os.path.sep.join([config.LABELS,
"{}.png".format(total)])
# write the images to disk
cv2.imwrite(cropPath, crop)
cv2.imwrite(targetPath, target)
# increment the crop total
total += 1
第 55 行和第 56 行在我们的图像上从左到右和从上到下滑动一个窗口。我们在第 60 行和第 61 行上裁剪INPUT_DIM × INPUT_DIM子窗口。这个crop就是从我们的scaled(即低分辨率图像)输入到我们神经网络的33×33。
我们还需要一个target供 SRCNN 预测(第 66-68 行)—target是 SRCNN 将试图重建的LABEL_SIZE x LABEL_SIZE ( 21×21)输出。我们将target和crop写入磁盘的第 77 行和第 78 行。
最后一步是构建两个 HDF5 数据集,一个用于输入,另一个用于输出(即目标):
# grab the paths to the images
print("[INFO] building HDF5 datasets...")
inputPaths = sorted(list(paths.list_images(config.IMAGES)))
outputPaths = sorted(list(paths.list_images(config.LABELS)))
# initialize the HDF5 datasets
inputWriter = HDF5DatasetWriter((len(inputPaths), config.INPUT_DIM,
config.INPUT_DIM, 3), config.INPUTS_DB)
outputWriter = HDF5DatasetWriter((len(outputPaths),
config.LABEL_SIZE, config.LABEL_SIZE, 3), config.OUTPUTS_DB)
# loop over the images
for (inputPath, outputPath) in zip(inputPaths, outputPaths):
# load the two images and add them to their respective datasets
inputImage = cv2.imread(inputPath)
outputImage = cv2.imread(outputPath)
inputWriter.add([inputImage], [-1])
outputWriter.add([outputImage], [-1])
# close the HDF5 datasets
inputWriter.close()
outputWriter.close()
# delete the temporary output directories
print("[INFO] cleaning up...")
shutil.rmtree(config.IMAGES)
shutil.rmtree(config.LABELS)
重要的是要注意,类标签是不相关的(因此我指定了一个值-1)。“类标签”在技术上是输出子窗口,我们将尝试训练我们的 SRCNN 来重建它。我们将在train.py中编写一个定制的生成器来产生一个输入子窗口和目标输出子窗口的元组。
在我们的 HDF5 数据集生成之后,行 108 和 109 删除临时输出目录。
要生成数据集,请执行以下命令:
$ python build_dataset.py
[INFO] creating temporary images...
[INFO] building HDF5 datasets...
[INFO] cleaning up...
之后,您可以检查您的BASE_OUTPUT目录,找到inputs.hdf5和outputs.hdf5文件:
$ ls ../datasets/ukbench/output/*.hdf5
inputs.hdf5 outputs.hdf5
Sr CNN 架构
我们正在实现的 SRCNN 架构完全遵循董等人的思路,使其易于实现。打开srcnn.py并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras import backend as K
class SRCNN:
@staticmethod
def build(width, height, depth):
# initialize the model
model = Sequential()
inputShape = (height, width, depth)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
# the entire SRCNN architecture consists of three CONV =>
# RELU layers with *no* zero-padding
model.add(Conv2D(64, (9, 9), kernel_initializer="he_normal",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(Conv2D(32, (1, 1), kernel_initializer="he_normal"))
model.add(Activation("relu"))
model.add(Conv2D(depth, (5, 5),
kernel_initializer="he_normal"))
model.add(Activation("relu"))
# return the constructed network architecture
return model
与其他架构相比,我们的 SRCNN 再简单不过了。整个架构仅由三层CONV => RELU组成,没有零填充(我们避免使用零填充,以确保我们不会在输出图像中引入任何边界伪影)。
我们的第一个CONV层学习64个滤镜,每个滤镜都是9×9。这个体积被送入第二个CONV层,在这里我们学习用于减少维度和学习局部特征的32 1×1过滤器。最后的CONV层一共学习了depth个通道(对于 RGB 图像会是3,对于灰度会是1,每个通道都是5×5。
此网络体系结构有两个重要组成部分:
- 它小而紧凑,这意味着它将快速训练(记住,我们的目标不是在分类意义上获得更高的准确性——我们更感兴趣的是从网络中学习的过滤器,这将使我们能够执行超分辨率)。
- 它是完全卷积的,这使得它(1)再次更快,并且(2)我们可以接受任何输入图像大小,只要它能很好地平铺。
训练 SRCNN
训练我们的 SRCNN 是一个相当简单的过程。打开train.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from conf import sr_config as config
from pyimagesearch.io import HDF5DatasetGenerator
from pyimagesearch.nn.conv import SRCNN
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
2-11 号线办理我们的进口业务。我们将需要HDF5DatasetGenerator来访问我们的序列化 HDF5 数据集以及我们的SRCNN实施。然而,需要稍加修改才能使用我们的 HDF5 数据集。
请记住,我们有两个 HDF5 数据集:输入子窗口和目标输出子窗口。我们的HDF5DatasetGenerator类旨在只处理一个 HDF5 文件,而不是两个。幸运的是,这很容易用我们的super_res_generator函数解决:
def super_res_generator(inputDataGen, targetDataGen):
# start an infinite loop for the training data
while True:
# grab the next input images and target outputs, discarding
# the class labels (which are irrelevant)
inputData = next(inputDataGen)[0]
targetData = next(targetDataGen)[0]
# yield a tuple of the input data and target data
yield (inputData, targetData)
这个函数需要两个参数,inputDataGen和targetDataGen,它们都被假定为HDF5DatasetGenerator对象。
我们开始一个无限循环,它将继续循环我们在行 15 上的训练数据。对每个对象调用next(一个内置的 Python 函数,用于返回生成器中的下一项)会产生下一批集合。我们丢弃类标签(因为我们不需要它们)并返回一个由inputData和targetData组成的元组。
我们现在可以初始化我们的HDF5DatasetGenerator对象以及我们的模型和优化器:
# initialize the input images and target output images generators
inputs = HDF5DatasetGenerator(config.INPUTS_DB, config.BATCH_SIZE)
targets = HDF5DatasetGenerator(config.OUTPUTS_DB, config.BATCH_SIZE)
# initialize the model and optimizer
print("[INFO] compiling model...")
opt = Adam(lr=0.001, decay=0.001 / config.NUM_EPOCHS)
model = SRCNN.build(width=config.INPUT_DIM, height=config.INPUT_DIM,
depth=3)
model.compile(loss="mse", optimizer=opt)
当董等人使用 RMSprop 时,我发现:
- 使用
Adam以较少的超参数调谐获得更好的结果 - 一点点的学习速度衰减会产生更好、更稳定的训练
最后,注意我们将使用均方损失(MSE)而不是二元/分类交叉熵。
我们现在准备训练我们的模型:
# train the model using our generators
H = model.fit_generator(
super_res_generator(inputs.generator(), targets.generator()),
steps_per_epoch=inputs.numImages // config.BATCH_SIZE,
epochs=config.NUM_EPOCHS, verbose=1)
我们的模型将被训练总共NUM_EPOCHS (10 个时期,根据我们的配置文件)。注意我们如何使用我们的super_res_generator分别从inputs和targets生成器联合产生训练批次。
我们的最后一个代码块处理将训练好的模型保存到磁盘、绘制损失以及关闭 HDF5 数据集:
# save the model to file
print("[INFO] serializing model...")
model.save(config.MODEL_PATH, overwrite=True)
# plot the training loss
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, config.NUM_EPOCHS), H.history["loss"],
label="loss")
plt.title("Loss on super resolution training")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend()
plt.savefig(config.PLOT_PATH)
# close the HDF5 datasets
inputs.close()
targets.close()
训练 SRCNN 架构就像执行以下命令一样简单:
$ python train.py
[INFO] compiling model...
Epoch 1/10
1100/1100 [==============================] - 14s - loss: 243.1207
Epoch 2/10
1100/1100 [==============================] - 13s - loss: 59.0475
...
Epoch 9/10
1100/1100 [==============================] - 13s - loss: 47.1672
Epoch 10/10
1100/1100 [==============================] - 13s - loss: 44.7597
[INFO] serializing model...
我们的模型现在已经训练好了,可以增加新输入图像的分辨率了!
使用 SRCNNs 提高图像分辨率
我们现在准备实现resize.py,这个脚本负责从低分辨率输入图像构建高分辨率输出图像。打开resize.py并插入以下代码:
# import the necessary packages
from conf import sr_config as config
from tensorflow.keras.models import load_model
from PIL import Image
import numpy as np
import argparse
import PIL
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-b", "--baseline", required=True,
help="path to baseline image")
ap.add_argument("-o", "--output", required=True,
help="path to output image")
args = vars(ap.parse_args())
# load the pre-trained model
print("[INFO] loading model...")
model = load_model(config.MODEL_PATH)
第 11-18 行解析我们的命令行参数——这个脚本需要三个开关:
- 我们输入的路径,一个我们想要放大的低分辨率图像。
--baseline:标准双线性插值后的输出基线图像——该图像将为我们提供一个基线,我们可以将其与我们的 SRCNN 结果进行比较。--output:应用超分辨率后输出图像的路径。
第 22 行然后装盘后我们序列化的 SRCNN。
接下来,让我们准备一下要放大的图像:
# load the input image, then grab the dimensions of the input image
# and crop the image such that it tiles nicely
print("[INFO] generating image...")
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
w -= int(w % config.SCALE)
h -= int(h % config.SCALE)
image = image[0:h, 0:w]
# resize the input image using bicubic interpolation then write the
# baseline image to disk
lowW = int(w * (1.0 / config.SCALE))
lowH = int(h * (1.0 / config.SCALE))
highW = int(lowW * (config.SCALE / 1.0))
highH = int(lowH * (config.SCALE / 1.0))
scaled = np.array(Image.fromarray(image).resize((lowW, lowH),
resample=PIL.Image.BICUBIC))
scaled = np.array(Image.fromarray(scaled).resize((highW, highH),
resample=PIL.Image.BICUBIC))
cv2.imwrite(args["baseline"], scaled)
# allocate memory for the output image
output = np.zeros(scaled.shape)
(h, w) = output.shape[:2]
我们首先从磁盘的行 27 载入图像。第 28-31 行裁剪我们的图像,当应用我们的滑动窗口并通过我们的 SRCNN 传递子图像时,它可以很好地平铺。第 35-42 行使用 PIL/皮鲁的resize函数对我们的输入--image应用标准双线性插值。
将我们的图像放大SCALE倍有两个目的:
- 它为我们提供了使用传统图像处理进行标准升迁的基线。
- 我们的 SRCNN 需要原始低分辨率图像的高分辨率输入——这张
scaled图像就是为了这个目的。
最后,行 46 为我们的output图像分配内存。
我们现在可以应用我们的滑动窗口:
# slide a window from left-to-right and top-to-bottom
for y in range(0, h - config.INPUT_DIM + 1, config.LABEL_SIZE):
for x in range(0, w - config.INPUT_DIM + 1, config.LABEL_SIZE):
# crop ROI from our scaled image
crop = scaled[y:y + config.INPUT_DIM,
x:x + config.INPUT_DIM].astype("float32")
# make a prediction on the crop and store it in our output
# image
P = model.predict(np.expand_dims(crop, axis=0))
P = P.reshape((config.LABEL_SIZE, config.LABEL_SIZE, 3))
output[y + config.PAD:y + config.PAD + config.LABEL_SIZE,
x + config.PAD:x + config.PAD + config.LABEL_SIZE] = P
对于沿途的每一站,在LABEL_SIZE步骤中,我们从scaled(53 和 54 线)中crop出子图像。crop的空间维度与我们 SRCNN 要求的输入维度相匹配。
然后我们获取crop子图像,并通过我们的 SRCNN 进行推理。SRCNN、P的输出具有空间维度LABEL_SIZE x LABEL_SIZE x CHANNELS,也就是21×21×3——然后我们将来自网络的高分辨率预测存储在output图像中。
备注: 为了简单起见,我通过.predict方法一次处理一个子图像。为了实现更快的吞吐率,尤其是在 GPU 上,您将需要批处理crop子图像。这个动作可以通过维护一个批次的(x,y)-坐标列表来完成,该列表将批次中的每个样本映射到它们相应的output位置。
我们的最后一步是删除输出图像上由填充引起的任何黑色边框,然后将图像保存到磁盘:
# remove any of the black borders in the output image caused by the
# padding, then clip any values that fall outside the range [0, 255]
output = output[config.PAD:h - ((h % config.INPUT_DIM) + config.PAD),
config.PAD:w - ((w % config.INPUT_DIM) + config.PAD)]
output = np.clip(output, 0, 255).astype("uint8")
# write the output image to disk
cv2.imwrite(args["output"], output)
至此,我们完成了 SRCNN 管道的实现!在下一节中,我们将把resize.py应用到几个示例输入低分辨率图像,并将我们的 SRCNN 结果与传统图像处理进行比较。
超分辨率结果
现在我们已经(1)训练了我们的 SRCNN 并且(2)实现了resize.py,我们准备好对输入图像应用超分辨率。打开一个 shell 并执行以下命令:
$ python resize.py --image jemma.png --baseline baseline.png \
--output output.png
[INFO] loading model...
[INFO] generating image...
图 2 包含了我们的输出图像。在左侧是我们希望提高分辨率的输入图像(125×166)。
然后,在中间的,我们通过标准双线性插值将输入图像分辨率增加2x到250×332。这张图片是我们的基线。请注意图像是如何低分辨率,模糊,并且一般来说,视觉上没有吸引力。
最后,在右边的,我们有来自 SRCNN 的输出图像。在这里,我们可以看到我们再次将分辨率提高了2x,但这次图像明显不那么模糊,而且更加美观。
*我们还可以通过更高的倍数来提高我们的图像分辨率,前提是我们已经训练了我们的 SRCNN 这样做。
概要****
在本教程中,我们回顾了“超分辨率”的概念,然后实现了超分辨率卷积神经网络(SRCNN)。在训练我们的 SRCNN 之后,我们对输入图像应用了超分辨率。
我们的实现遵循了董等人(2016) 的工作。尽管此后出现了许多超分辨率论文(并将继续出现), Dong et al. 的论文仍然是最容易理解和实现的论文之一,对于任何有兴趣研究超分辨率的人来说,这是一个极好的起点。
引用信息
罗斯布鲁克,A. “图像超分辨率”, PyImageSearch ,2022,【https://pyimg.co/jia4g】T4
@article{Rosebrock_2022_ISR,
author = {Adrian Rosebrock},
title = {Image Super Resolution},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimg.co/jia4g},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
使用 Pix2Pix 进行图像翻译
原文:https://pyimagesearch.com/2022/07/27/image-translation-with-pix2pix/
目录
图像翻译用 Pix2Pix
我们之前遇到的生成对抗网络(GAN)将我们带到了超分辨率领域,在那里我们训练了一个 GAN 来将低分辨率图像提升到更高的分辨率。该教程有效地展示了如何强大的甘可以。
这就把我们带到了今天的研究领域:图像到图像的翻译。我们本质上是将属于输入数据分布的图像转换为属于输出数据分布的图像。在当今的技术世界中,与计算机视觉相关的翻译问题非常普遍,这放大了今天主题的重要性。
在本教程中,您将学习使用 Pix2Pix GAN 进行图像翻译。
本课是关于 GANs 201 的 4 部分系列的一部分:
- 图片翻译用 Pix2Pix (本教程)
- CycleGAN
要学习如何用 Pix2Pix ,进行图像翻译,继续阅读。
图像翻译用 Pix2Pix
简介
图像翻译适用于各种任务,从简单的照片增强和编辑到更细微的任务,如灰度到 RGB。例如,假设您的任务是图像增强,而您的数据集是一组成对的正常图像及其增强的对应物。这里的目标是学习输入图像到输出图像的有效映射。
Pix2Pix 的作者建立在找出输入-输出映射的基础方法上,并训练了一个额外的损失函数来加强这种映射。根据 Pix2Pix 论文,他们的方法在各种任务中都很有效,包括(但不限于)从分割蒙版合成照片。
今天,我们将应用构建 Pix2Pix GAN 来学习如何使用加州大学伯克利分校托管的 cityscapes 数据集从分割图构建真实图像。该数据集包含成对的分割蒙版集及其对应的城市景观实景图像。
需要注意的是,意象翻译可以分为两类:成对翻译和不成对翻译。我们今天的任务属于成对翻译,因为特定的分段掩码将对应于特定的真实对象。
Pix2Pix 甘解构
在我们深入架构细节之前,让我们理解标准 GAN 和条件 GAN 之间的区别。标准 GAN 发生器描述为 \rightarrow y)")
, where  is the generator,
is the generator,  is some random noise, and
is some random noise, and  is our output.
is our output.
问题是,由于随机噪声被映射到我们的输出,我们将无法控制产生什么输出。在条件 GAN 中,我们是将标签(不同于真假标签,这里的标签是指不同类型的输出数据)的思想插入到 GAN 方程中(图 1 )。
鉴别器现在考虑输入数据
as well as the output . The generator size of the equation now shows that instead of noise, we feed the input data + noise to the generator. At the same time, the discriminator observes the input data and the generator output.
这有助于我们创建输入和我们想要的输出类型之间的映射。
在条件 GANs 的基础上,Pix2Pix 还混合了真实图像和生成图像之间的 L1 距离(两点之间的距离)。
对于发生器,Pix2Pix 利用了 U 形网(图 2 ),因为它采用了跳跃连接。U-Net 通常由其第一组下采样层(瓶颈层)以及随后的上采样层来表征。这里要记住的关键点是下采样层连接到相应的上采样层,在图 2 中用虚线表示。
鉴别器是贴片 GAN 鉴别器。我们来看看图 3 。
正常的 GAN 鉴别器将图像作为输入,并输出单个值 0(假)或 1(真)。补丁 GAN 鉴别器将输入作为本地图像补丁进行分析。它将评估图像中的每个补丁是真是假。
在 Pix2Pix 中,补丁 GAN 将接受一对图像:输入遮罩和生成的图像,以及输入遮罩和目标图像。这是因为输出取决于输入。因此,将输入图像保留在混音中很重要(如图图 1 所示,其中鉴频器接收两个输入)。
让我们回顾一下发电机培训程序(图 4 )。
输入屏蔽被送到发生器,给我们假输出。然后,我们将把(输入掩码,生成的输出)对提供给鉴别器,但标签为 1。这是“愚弄鉴别器”的部分,它将告诉生成器离生成真实图像还有多远。
接下来我们来了解一下鉴别器的流程(图 5 )。
鉴别器训练相当简单,唯一的区别是有条件的补丁 GAN 训练。将(输入掩码,目标图像)对与 1 的标签补丁进行比较,将(输入掩码,生成的输出)对与 0 的标签补丁进行比较。
让我们使用 tensorflow 来实现它,看看它是如何工作的。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── inference.py
├── outputs
│ ├── images
│ └── models
├── pyimagesearch
│ ├── config.py
│ ├── data_preprocess.py
│ ├── __init__.py
│ ├── Pix2PixGAN.py
│ ├── Pix2PixTraining.py
│ └── train_monitor.py
└── train_pix2pix.py
2 directories, 10 files
在pyimagesearch目录中,我们有:
config.py:包含我们项目的完整配置管道。data_preprocess.py:包含帮助我们准备 GAN 培训数据的脚本。__init__.py:使pyimagesearch目录像 python 库一样工作。Pix2PixGAN.py:包含 Pix2Pix GAN 架构。Pix2PIxTraining.py:包含打包成类的完整 GAN 训练管道。train_monitor.py:包含帮助监控模型训练的回调。
在核心目录中,我们有:
outputs:包含我们项目的输出(即推理图像和模型权重)。inference.py:包含使用我们训练的模型权重进行推理的脚本。train_pix2pix.py:包含训练 Pix2Pix GAN 模型的脚本。
配置先决条件
pyimagesearch目录中的config.py脚本包含了这个项目的整个配置管道。
# import the necessary packages
import os
# name of the dataset we will be using
DATASET = "cityscapes"
# build the dataset URL
DATASET_URL = f"http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{DATASET}.tar.gz"
# define the batch size
TRAIN_BATCH_SIZE = 32
INFER_BATCH_SIZE = 8
# dataset specs
IMAGE_WIDTH = 256
IMAGE_HEIGHT = 256
IMAGE_CHANNELS = 3
# training specs
LEARNING_RATE = 2e-4
EPOCHS = 150
STEPS_PER_EPOCH = 100
# path to our base output directory
BASE_OUTPUT_PATH = "outputs"
# GPU training pix2pix model paths
GENERATOR_MODEL = os.path.join(BASE_OUTPUT_PATH, "models",
"generator")
# define the path to the inferred images and to the grid image
BASE_IMAGES_PATH = os.path.join(BASE_OUTPUT_PATH, "images")
GRID_IMAGE_PATH = os.path.join(BASE_IMAGE_PATH, "grid.png")
在第 5 行,我们指定了将用于我们项目的加州大学伯克利分校数据集。数据集的相应 URL 在第 8 行的中指定。
随后在行 11 和 12 上定义训练和推理批量。
接下来,定义图像规范(第 15-17 行)。最后,定义 GAN 训练规范,即学习速率、时期和每个时期的步数(第 20-22 行)。
在第 25 行上,我们定义了outputs文件夹,接着是保存发电机重量的路径(第 28 和 29 行)。最后,定义images文件夹和推理图像网格路径(第 32 行和第 33 行),结束config.py脚本。
创建数据处理管道
gan 严重依赖于数据。因此,拥有强大的数据管道非常重要。让我们看看data_preprocess.py脚本中的数据管道。
# import the necessary packages
import tensorflow as tf
# define the module level autotune
AUTO = tf.data.AUTOTUNE
def load_image(imageFile):
# read and decode an image file from the path
image = tf.io.read_file(imageFile)
image = tf.io.decode_jpeg(image, channels=3)
# calculate the midpoint of the width and split the
# combined image into input mask and real image
width = tf.shape(image)[1]
splitPoint = width // 2
inputMask = image[:, splitPoint:, :]
realImage = image[:, :splitPoint, :]
# convert both images to float32 tensors and
# convert pixels to the range of -1 and 1
inputMask = tf.cast(inputMask, tf.float32)/127.5 - 1
realImage = tf.cast(realImage, tf.float32)/127.5 - 1
# return the input mask and real label image
return (inputMask, realImage)
在第 7 行的上,我们有load_image函数,它将图像路径作为它的参数。
首先,我们从图像的路径中读取并解码图像(行 9 和 10 )。我们数据集的图像采用图 7 的格式。
图像的形状为(256, 512, 3)。为了创建输入掩模和实像对,我们计算中点(行 14 和 15 )并相应地将基础图像分割成输入掩模和实像对(行 16 和 17 )。
有了创建的对,我们将张量转换成float32格式,并将像素带到从0到255``-1到1的范围内(第 21 行和第 22 行)。
def random_jitter(inputMask, realImage, height, width):
# upscale the images for cropping purposes
inputMask = tf.image.resize(inputMask, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
realImage = tf.image.resize(realImage, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# return the input mask and real label image
return (inputMask, realImage)
Pix2Pix 的作者谈到了发电机输入中随机噪声的重要性。注意在图 1 中,随着输入x,发生器也接收随机噪声z。这是因为如果我们不提供噪声,我们会使 GAN 非常特定于数据集。
为了确保泛化,我们需要在输入中加入一些随机噪声。我们通过简单地将输入图像调整到更高的分辨率(第 29-32 行)然后使用random_jitter函数将它们缩小(在我们加载数据之前)来实现。
class ReadTrainExample(object):
def __init__(self, imageHeight, imageWidth):
self.imageHeight = imageHeight
self.imageWidth = imageWidth
def __call__(self, imageFile):
# read the file path and unpack the image pair
inputMask, realImage = load_image(imageFile)
# perform data augmentation
(inputMask, realImage) = random_jitter(inputMask, realImage,
self.imageHeight+30, self.imageWidth+30)
# reshape the input mask and real label image
inputMask = tf.image.resize(inputMask,
[self.imageHeight, self.imageWidth])
realImage = tf.image.resize(realImage,
[self.imageHeight, self.imageWidth])
# return the input mask and real label image
return (inputMask, realImage)
现在我们将使用read_train_example类对所有创建的函数进行分组。__init__函数初始化图像高度和宽度的类变量(第 38-40 行),而__call__函数将图像路径作为其参数(第 42 行)。
在第 44 行,我们使用之前定义的load_image函数得到图像对。然后我们使用random_jitter函数来放大图像,并给我们的图像添加随机的伪像(第 47 行)。
然后,我们将图像调整为(256, 256, 3),以适应我们的项目管道(第 51-54 行)。
class ReadTestExample(object):
def __init__(self, imageHeight, imageWidth):
self.imageHeight = imageHeight
self.imageWidth = imageWidth
def __call__(self, imageFile):
# read the file path and unpack the image pair
(inputMask, realImage) = load_image(imageFile)
# reshape the input mask and real label image
inputMask = tf.image.resize(inputMask,
[self.imageHeight, self.imageWidth])
realImage = tf.image.resize(realImage,
[self.imageHeight, self.imageWidth])
# return the input mask and real label image
return (inputMask, realImage)
像read_train_example一样,我们专门为测试数据集创建了ReadTestExample类(第 59 行)。类的内容保持不变,除了我们没有应用任何增加和调整图像大小以适应项目管道(第 59-75 行)。
def load_dataset(path, batchSize, height, width, train=False):
# check if this is the training dataset
if train:
# read the training examples
dataset = tf.data.Dataset.list_files(str(path/"train/*.jpg"))
dataset = dataset.map(ReadTrainExample(height, width),
num_parallel_calls=AUTO)
# otherwise, we are working with the test dataset
else:
# read the test examples
dataset = tf.data.Dataset.list_files(str(path/"val/*.jpg"))
dataset = dataset.map(ReadTestExample(height, width),
num_parallel_calls=AUTO)
# shuffle, batch, repeat and prefetch the dataset
dataset = (dataset
.shuffle(batchSize * 2)
.batch(batchSize)
.repeat()
.prefetch(AUTO)
)
# return the dataset
return dataset
在的第 77 行,我们创建了load_dataset函数,它接受数据集路径、批量大小和一个 bool 变量train,该变量将确定函数是返回训练数据集还是测试数据集。
在第 79-83 行上,我们定义了train布尔值被设置为True的条件。数据集被初始化,并且ReadTrainExample函数被映射到所有条目。对于被设置为False的train布尔值,我们初始化数据集并将read_test_example函数映射到所有条目。
接下来是批处理和预取数据(第 92-97 行)。这就结束了load_dataset功能。
创建 Pix2Pix 架构
对于 Pix2Pix 架构,我们需要定义一个 U-Net 生成器和一个补丁 GAN 鉴别器。让我们进入Pix2PixGAN.py脚本。
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import concatenate
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras import Model
from tensorflow.keras import Input
class Pix2Pix(object):
def __init__(self, imageHeight, imageWidth):
# initialize the image height and width
self.imageHeight = imageHeight
self.imageWidth = imageWidth
def generator(self):
# initialize the input layer
inputs = Input([self.imageHeight, self.imageWidth, 3])
# down Layer 1 (d1) => final layer 1 (f1)
d1 = Conv2D(32, (3, 3), activation="relu", padding="same")(
inputs)
d1 = Dropout(0.1)(d1)
f1 = MaxPool2D((2, 2))(d1)
# down Layer 2 (l2) => final layer 2 (f2)
d2 = Conv2D(64, (3, 3), activation="relu", padding="same")(f1)
f2 = MaxPool2D((2, 2))(d2)
# down Layer 3 (l3) => final layer 3 (f3)
d3 = Conv2D(96, (3, 3), activation="relu", padding="same")(f2)
f3 = MaxPool2D((2, 2))(d3)
# down Layer 4 (l3) => final layer 4 (f4)
d4 = Conv2D(96, (3, 3), activation="relu", padding="same")(f3)
f4 = MaxPool2D((2, 2))(d4)
# u-bend of the u-bet
b5 = Conv2D(96, (3, 3), activation="relu", padding="same")(f4)
b5 = Dropout(0.3)(b5)
b5 = Conv2D(256, (3, 3), activation="relu", padding="same")(b5)
# upsample Layer 6 (u6)
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2),
padding="same")(b5)
u6 = concatenate([u6, d4])
u6 = Conv2D(128, (3, 3), activation="relu", padding="same")(
u6)
# upsample Layer 7 (u7)
u7 = Conv2DTranspose(96, (2, 2), strides=(2, 2),
padding="same")(u6)
u7 = concatenate([u7, d3])
u7 = Conv2D(128, (3, 3), activation="relu", padding="same")(
u7)
# upsample Layer 8 (u8)
u8 = Conv2DTranspose(64, (2, 2), strides=(2, 2),
padding="same")(u7)
u8 = concatenate([u8, d2])
u8 = Conv2D(128, (3, 3), activation="relu", padding="same")(u8)
# upsample Layer 9 (u9)
u9 = Conv2DTranspose(32, (2, 2), strides=(2, 2),
padding="same")(u8)
u9 = concatenate([u9, d1])
u9 = Dropout(0.1)(u9)
u9 = Conv2D(128, (3, 3), activation="relu", padding="same")(u9)
# final conv2D layer
outputLayer = Conv2D(3, (1, 1), activation="tanh")(u9)
# create the generator model
generator = Model(inputs, outputLayer)
# return the generator
return generator
我们将生成器和鉴别器打包成一个类,以便于访问( Line 12 )。
在图 2 中,我们已经展示了 U 型网应该是什么样子。在第 20 行,我们开始定义发电机模型的输入。接下来是一个Conv2D、Dropout和一个MaxPool2D层。该层稍后将与一个上采样层连接,因此我们存储Conv2D层输出(行 23-26 )。
接下来是 3 组Conv2D和MaxPool2D层(线 29-38 )。这些图层表示缩减像素采样图层。第 41-43 行表示 U 形网的瓶颈层。
后续层是上采样层。第一组上采样层与最后一个下采样层连接。第二组上采样层与倒数第二个下采样层连接。最后一组上采样层与第一个下采样层Conv2D输出连接在一起(第 46-70 行)。
最后的输出层是一个Conv2D层,将输出带到256, 256, 3 ( 线 73 )。
def discriminator(self):
# initialize input layer according to PatchGAN
inputMask = Input(shape=[self.imageHeight, self.imageWidth, 3],
name="input_image"
)
targetImage = Input(
shape=[self.imageHeight, self.imageWidth, 3],
name="target_image"
)
# concatenate the inputs
x = concatenate([inputMask, targetImage])
# add four conv2D convolution layers
x = Conv2D(64, 4, strides=2, padding="same")(x)
x = LeakyReLU()(x)
x = Conv2D(128, 4, strides=2, padding="same")(x)
x = LeakyReLU()(x)
x = Conv2D(256, 4, strides=2, padding="same")(x)
x = LeakyReLU()(x)
x = Conv2D(512, 4, strides=1, padding="same")(x)
# add a batch-normalization layer => LeakyReLU => zeropad
x = BatchNormalization()(x)
x = LeakyReLU()(x)
# final conv layer
last = Conv2D(1, 3, strides=1)(x)
# create the discriminator model
discriminator = Model(inputs=[inputMask, targetImage],
outputs=last)
# return the discriminator
return discriminator
在第 81 行,我们定义了鉴别器。如前所述,条件鉴别器将接受两幅图像作为其输入(第 83-89 行)。我们在第 92 行的处连接两个图像,接着是标准的Conv2D和LeakyReLU层(行 95-101** )。**
在线 104 上添加一个批次归一化层,之后是另一个LeakyReLU层。最后的Conv2D层被添加为具有30x30x1面片输出(线 108 )。鉴频器在线 111 上创建,包括鉴频器和 Pix2Pix GAN 架构。
搭建 Pix2Pix GAN 训练流水线
Pix2Pix GAN 训练过程与普通 GAN 略有不同。所以让我们进入Pix2PixTraining.py脚本。
# import the necessary packages
from tensorflow.keras import Model
import tensorflow as tf
class Pix2PixTraining(Model):
def __init__(self, generator, discriminator):
super().__init__()
# initialize the generator, discriminator
self.generator = generator
self.discriminator = discriminator
def compile(self, gOptimizer, dOptimizer, bceLoss, maeLoss):
super().compile()
# initialize the optimizers for the generator
# and discriminator
self.gOptimizer = gOptimizer
self.dOptimizer = dOptimizer
# initialize the loss functions
self.bceLoss = bceLoss
self.maeLoss = maeLoss
为了便于理解,我们将整个过程打包成一个类( Line 5 )。
在第 6 行上,我们定义了__init__函数,它将生成器和鉴别器作为参数,并创建这些参数的特定于类的变量副本(第 9 行和第 10 行)。
下一个函数是compile,它包含生成器优化器、鉴别器优化器和损失函数(第 12 行)。该函数创建参数的对应类变量(第 16-21 行)。
def train_step(self, inputs):
# grab the input mask and corresponding real images
(inputMask, realImages) = inputs
# initialize gradient tapes for both generator and discriminator
with tf.GradientTape() as genTape, tf.GradientTape() as discTape:
# generate fake images
fakeImages = self.generator(inputMask, training=True)
# discriminator output for real images and fake images
discRealOutput = self.discriminator(
[inputMask, realImages], training=True)
discFakeOutput = self.discriminator(
[inputMask, fakeImages], training=True)
第 23 行上的train_step函数将图像对作为其参数。首先,我们解开图像对(第 25 行)。然后我们初始化两个梯度带,一个用于鉴别器,一个用于发生器(行 28** )。**
我们首先将输入遮罩图像通过生成器,并获得假输出(第 30 行)。
接下来,我们将输入遮罩和真实目标图像通过补丁 GAN 鉴别器,并将其存储为discRealOutput ( 第 33 行和第 34 行)。类似地,我们将输入掩码和假图像一起通过补丁 GAN,并将输出存储为discFakeOutput ( 行 35 和 36 )。
# compute the adversarial loss for the generator
misleadingImageLabels = tf.ones_like(discFakeOutput)
ganLoss = self.bceLoss(misleadingImageLabels, discFakeOutput)
# compute the mean absolute error between the fake and the
# real images
l1Loss = self.maeLoss(realImages, fakeImages)
# compute the total generator loss
totalGenLoss = ganLoss + (10 * l1Loss)
# discriminator loss for real and fake images
realImageLabels = tf.ones_like(discRealOutput)
realDiscLoss = self.bceLoss(realImageLabels, discRealOutput)
fakeImageLabels = tf.zeros_like(discFakeOutput)
generatedLoss = self.bceLoss(fakeImageLabels, discFakeOutput)
# compute the total discriminator loss
totalDiscLoss = realDiscLoss + generatedLoss
# calculate the generator and discriminator gradients
generatorGradients = genTape.gradient(totalGenLoss,
self.generator.trainable_variables
)
discriminatorGradients = discTape.gradient(totalDiscLoss,
self.discriminator.trainable_variables
)
# apply the gradients to optimize the generator and discriminator
self.gOptimizer.apply_gradients(zip(generatorGradients,
self.generator.trainable_variables)
)
self.dOptimizer.apply_gradients(zip(discriminatorGradients,
self.discriminator.trainable_variables)
)
# return the generator and discriminator losses
return {"dLoss": totalDiscLoss, "gLoss": totalGenLoss}
首先,我们将计算发电机损耗。为此,我们简单地将伪标签(1s) ( 第 39 行)关联到伪鉴别器输出补丁,并计算目标真实图像和预测伪图像(第 40-44 行)之间的l1距离。l1距离将通过直接将信息从真实图像转换到生成器来帮助捕捉更精细的细节。
我们将两个损耗相加,得出发电机损耗(行 47 )。对于我们的项目,L1损失的lambda系数设置为10。但是,论文要求放成 1000。
接下来,我们进入鉴别训练。输入掩模-真实图像补丁 GAN 输出与 1 的补丁进行比较,而输入掩模-伪图像补丁 GAN 输出与 0 的补丁进行比较。这是正常的 GAN 训练,但增加了对补丁 GAN 和条件 GAN 的要求(第 50-53 行)。
然后计算梯度并应用于可训练重量(第 59-75 行)。
训练 Pix2Pix 甘
有了我们的架构和培训管道,我们只需要正确地执行这两个脚本。让我们进入train_pix2pix.py脚本。
# USAGE
# python train_pix2pix.py
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.Pix2PixTraining import Pix2PixTraining
from pyimagesearch.Pix2PixGAN import Pix2Pix
from pyimagesearch.data_preprocess import load_dataset
from pyimagesearch.train_monitor import get_train_monitor
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.losses import MeanAbsoluteError
from tensorflow.keras.utils import get_file
import pathlib
import os
# download the cityscape training dataset
print("[INFO] downloading the dataset...")
pathToZip = get_file(
fname=f"{config.DATASET}.tar.gz",
origin=config.DATASET_URL,
extract=True
)
pathToZip = pathlib.Path(pathToZip)
path = pathToZip.parent/config.DATASET
# build the training dataset
print("[INFO] building the train dataset...")
trainDs = load_dataset(path=path, train=True,
batchSize=config.TRAIN_BATCH_SIZE, height=config.IMAGE_HEIGHT,
width=config.IMAGE_WIDTH)
# build the test dataset
print("[INFO] building the test dataset...")
testDs = load_dataset(path=path, train=False,
batchSize=config.INFER_BATCH_SIZE, height=config.IMAGE_HEIGHT,
width=config.IMAGE_WIDTH)
使用tensorflow的get_file函数下载cityscapes数据集(第 23-27 行,我们使用pathlib高效地存储指向文件路径的指针(第 28 和 29 行)。
在的第 33-35 行,我们使用之前在data_processing.py脚本中创建的load_dataset函数构建训练数据集。
在的第 39-41 行,我们使用之前在data_processing.py脚本中创建的load_dataset函数构建测试数据集。
# initialize the generator and discriminator network
print("[INFO] initializing the generator and discriminator...")
pix2pixObject = Pix2Pix(imageHeight=config.IMAGE_HEIGHT,
imageWidth=config.IMAGE_WIDTH)
generator = pix2pixObject.generator()
discriminator = pix2pixObject.discriminator()
# build the pix2pix training model and compile it
pix2pixModel = Pix2PixTraining(
generator=generator,
discriminator=discriminator)
pix2pixModel.compile(
dOptimizer=Adam(learning_rate=config.LEARNING_RATE),
gOptimizer=Adam(learning_rate=config.LEARNING_RATE),
bceLoss=BinaryCrossentropy(from_logits=True),
maeLoss=MeanAbsoluteError(),
)
# check whether output model directory exists
# if it doesn't, then create it
if not os.path.exists(config.BASE_OUTPUT_PATH):
os.makedirs(config.BASE_OUTPUT_PATH)
# check whether output image directory exists, if it doesn't, then
# create it
if not os.path.exists(config.BASE_IMAGES_PATH):
os.makedirs(config.BASE_IMAGES_PATH)
# train the pix2pix model
print("[INFO] training the pix2pix model...")
callbacks = [get_train_monitor(testDs, epochInterval=10,
imagePath=config.BASE_IMAGES_PATH,
batchSize=config.INFER_BATCH_SIZE)]
pix2pixModel.fit(trainDs, epochs=config.EPOCHS, callbacks=callbacks,
steps_per_epoch=config.STEPS_PER_EPOCH)
# set the path for the generator
genPath = config.GENERATOR_MODEL
# save the pix2pix generator
print(f"[INFO] saving pix2pix generator to {genPath}...")
pix2pixModel.generator.save(genPath)
在行 45 上,我们构建Pix2Pix网络对象,接着是生成器和鉴别器(行 47 和 48 )。然后构建一个Pix2PixTraining管道对象,将之前创建的生成器和鉴别器作为参数传递。然后使用Adam优化器和二进制交叉熵以及平均绝对误差损失来编译流水线(第 51-59 行)。
如果输出目录还没有被创建的话,就创建输出目录(第 63-69 行)。我们定义callbacks并使用我们的定制回调函数来跟踪训练(第 73-75 行)。
倒数第二步是将数据拟合到我们的 Pix2Pix 模型中,参数包括时期和每个时期的步数(行 76 和 77 )。
最后,我们将训练生成器保存在配置管道中设置的路径中(行 80 和 84 )。
构建推理脚本
为了评估生成器的预测,我们将构建一个推理脚本。让我们进入inference.py脚本。
# USAGE
# python inference.py
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.data_preprocess import load_dataset
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import get_file
from matplotlib.pyplot import subplots
import pathlib
import os
# download the cityscape training dataset
print("[INFO] downloading the dataset...")
pathToZip = get_file(
fname=f"{config.DATASET}.tar.gz",
origin=config.DATASET_URL,
extract=True
)
pathToZip = pathlib.Path(pathToZip)
path = pathToZip.parent/config.DATASET
# build the test dataset
print("[INFO] building the test dataset...")
testDs = load_dataset(path=path, train=False,
batchSize=config.INFER_BATCH_SIZE, height=config.IMAGE_HEIGHT,
width=config.IMAGE_WIDTH)
回显训练脚本,我们使用 tensorflow 和 pathlib ( 第 20-32 行)中的get_file函数,以与构建训练数据集相同的方式构建测试数据集。
# get the first batch of testing images
(inputMask, realImage) = next(iter(testDs))
# set the path for the generator
genPath = config.GENERATOR_MODEL
# load the trained pix2pix generator
print("[INFO] loading the trained pix2pix generator...")
pix2pixGen = load_model(genPath, compile=False)
# predict using pix2pix generator
print("[INFO] making predictions with the generator...")
pix2pixGenPred = pix2pixGen.predict(inputMask)
# plot the respective predictions
print("[INFO] saving the predictions...")
(fig, axes) = subplots(nrows=config.INFER_BATCH_SIZE, ncols=3,
figsize=(50, 50))
在第 35 行,我们抓取第一批测试图像。然后使用发电机路径将训练好的发电机重量加载到线 42 上。
输入的测试图像然后被用于进行预测(行 46 )。为了绘制这些图像,我们定义了一个支线剧情(第 50 行和第 51 行)。
# plot the predicted images
for (ax, inp, pred, tar) in zip(axes, inputMask,
p2pGenPred, realImage):
# plot the input mask image
ax[0].imshow(array_to_img(inp))
ax[0].set_title("Input Image")
# plot the predicted Pix2Pix image
ax[1].imshow(array_to_img(pred))
ax[1].set_title("pix2pix prediction")
# plot the ground truth
ax[2].imshow(array_to_img(tar))
ax[2].set_title("Target label")
# check whether output image directory exists, if it doesn't, then
# create it
if not os.path.exists(config.BASE_IMAGEs_PATH):
os.makedirs(config.BASE_IMAGES_PATH)
# serialize the results to disk
print("[INFO] saving the pix2pix predictions to disk...")
fig.savefig(config.GRID_IMAGE_PATH)
我们循环输入图像、预测和真实图像,为我们的最终网格图像绘制每个图像(第 54-66 行)。可视化然后被保存在配置文件中设置的输出图像路径中(第 70-75 行)。
大楼训练班长
在我们看到训练结果之前,让我们快速浏览一下train_monitor.py脚本。
# import the necessary packages
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.keras.callbacks import Callback
from matplotlib.pyplot import subplots
import matplotlib.pyplot as plt
import tensorflow as tf
def get_train_monitor(testDs, imagePath, batchSize, epochInterval):
# grab the input mask and the real image from the testing dataset
(tInputMask, tRealImage) = next(iter(testDs))
class TrainMonitor(Callback):
def __init__(self, epochInterval=None):
self.epochInterval = epochInterval
def on_epoch_end(self, epoch, logs=None):
if self.epochInterval and epoch % self.epochInterval == 0:
# get the pix2pix prediction
tPix2pixGenPred = self.model.generator.predict(tInputMask)
(fig, axes) = subplots(nrows=batchSize, ncols=3,
figsize=(50, 50))
在行 8 上定义了get_train_monitor函数,该函数将测试数据集、图像路径、批量大小和时期间隔作为其参数。我们用iter抓取一批数据来预测(第 10 行)。
我们创建一个名为TrainMonitior的类,继承自 keras Callback类(第 12 行)。这里要注意的主要函数是on_epoch_end,它接受历元作为参数(第 16 行)。
当历元达到可以被epochInterval值整除的某些点时,我们将显示来自生成器的预测(第 19 行)。为了绘制这些结果,我们将在第 21 行和第 22 行创建一个支线剧情。
# plot the predicted images
for (ax, inp, pred, tgt) in zip(axes, tInputMask,
tPix2pixGenPred, tRealImage):
# plot the input mask image
ax[0].imshow(array_to_img(inp))
ax[0].set_title("Input Image")
# plot the predicted Pix2Pix image
ax[1].imshow(array_to_img(pred))
ax[1].set_title("Pix2Pix Prediction")
# plot the ground truth
ax[2].imshow(array_to_img(tgt))
ax[2].set_title("Target Label")
plt.savefig(f"{imagePath}/{epoch:03d}.png")
plt.close()
# instantiate a train monitor callback
trainMonitor = TrainMonitor(epochInterval=epochInterval)
# return the train monitor
return trainMonitor
该功能的下一部分是绘制输入掩码、预测和基本事实(第 25-40 行)。最后,我们实例化一个trainMonitor对象并结束函数。
分析训练程序
我们来分析一下培训损失。
[INFO] training pix2pix...
Epoch 1/150
100/100 [==============================] - 62s 493ms/step - dLoss: 0.7812 - gLoss: 4.8063
Epoch 2/150
100/100 [==============================] - 46s 460ms/step - dLoss: 1.2357 - gLoss: 3.3020
Epoch 3/150
100/100 [==============================] - 46s 460ms/step - dLoss: 0.9255 - gLoss: 4.4217
...
Epoch 147/150
100/100 [==============================] - 46s 457ms/step - dLoss: 1.3285 - gLoss: 2.8975
Epoch 148/150
100/100 [==============================] - 46s 458ms/step - dLoss: 1.3033 - gLoss: 2.8646
Epoch 149/150
100/100 [==============================] - 46s 457ms/step - dLoss: 1.3058 - gLoss: 2.8853
Epoch 150/150
100/100 [==============================] - 46s 458ms/step - dLoss: 1.2994 - gLoss: 2.8826
我们看到损耗值有些波动,但最终,发电机损耗会下降。波动可归因于L1损失,其中我们比较像素值。
由于许多图像,我们分别比较像素的距离,以复制图像的更好的细节,损失将试图抵抗,最终下降到一个值得尊敬的值。
Pix2Pix 可视化
让我们分析我们的 Pix2Pix 模型的可视化(图 8 和 9 )。
正如我们从输入分段掩码中看到的,Pix2Pix 预测几乎捕获了由输入图像掩码表示的信息的全部本质。
请注意,输入掩码没有更好的细节,如白色道路油漆、标志文字等。因此,这些没有反映在预测中。然而,一般的观察,像灰色的道路、绿色的树木和黑色的汽车,已经成功地出现在预测中。
汇总
今天,我们学习了 Pix2Pix,这是一种生成性对抗网络,可以创建输入到输出的映射。它利用了对抗损失的概念和生成图像与输出图像之间的像素距离。不利的损失使我们的发电机按预期工作。像素损失有助于开发更精细的细节。
可视化结果表明,我们的模型已经非常健壮地学习了输入-输出映射。输出非常接近实际的真实图像,表明我们的损失函数也工作正常。
损失的停滞有时可归因于难以使像素方向的损失达到较低值。
引用信息
Chakraborty,D. “使用 Pix2Pix 的图像翻译”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/ma1qi
@incollection{Chakraborty_2022_ImageTransPix2Pix,
author = {Devjyoti Chakraborty},
title = {Image Translation with Pix2Pix},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/ma1qi},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 python 和 keras 进行图像分类
原文:https://pyimagesearch.com/2016/08/10/imagenet-classification-with-python-and-keras/
通常,我只在周一 发表博文,但我对这一篇如此兴奋,以至于迫不及待,我决定提前按下发布键。
你看,就在几天前,Fran ois Chollet在网上推了三个 Keras 模型(VGG16、VGG19 和 resnet 50)——这些网络是在 ImageNet 数据集上预先训练好的,也就是说它们可以开箱即可识别1000 个常见对象类。******
**要在您自己的应用中利用这些模型,您需要做的就是:
- Install Keras.
- 下载预训练网络的权重文件(当您导入和实例化相应的网络架构时,我们会自动为您完成)。
- 将预先训练的 ImageNet 网络应用到您自己的映像中。
真的就这么简单。
那么,为什么这如此令人兴奋呢?我的意思是,我们已经有了流行的预训练 ImageNet 分类网络的权重,对吗?
问题是这些权重文件是 Caffe 格式的——虽然 Caffe 库可能是许多研究人员用来构建新的网络架构、训练和评估它们的当前标准,但 Caffe 也不是世界上对 Python 最友好的库,至少在构建网络架构本身方面是如此。
注意:你可以用 Caffe-Python 绑定做一些很酷的东西,但是我主要关注 Caffe 架构和训练过程本身是如何通过.prototxt配置文件定义的,而不是可以插入逻辑的代码。
还有一个事实是,没有一个简单的方法可以将 Caffe 权重转换成 Keras 兼容的模型。
现在一切都开始改变了 —我们现在可以使用 Keras 和 Python 轻松地将 VGG16、VGG19 和 ResNet50 应用到我们自己的应用程序中,而不必担心 Caffe = > Keras 重量转换过程。
事实上,现在用 Python 和 Keras 在 ImageNet 数据集上预先训练的卷积神经网络对图像进行分类就像这三行代码一样简单:
model = VGG16(weights="imagenet")
preds = model.predict(preprocess_input(image))
print(decode_predictions(preds))
当然,还有一些其他需要使用的导入和帮助函数— 但是我想你已经明白了:
现在使用 Python 和 Keras 应用 ImageNet 级别的预训练网络非常简单。
想知道怎么做,请继续阅读。
使用 python 和 keras 进行图像分类
在本教程的剩余部分,我将解释什么是 ImageNet 数据集,然后提供 Python 和 Keras 代码,使用最先进的网络架构将图像分类到 1,000 个不同的类别。
什么是 ImageNet?
在计算机视觉和深度学习社区中,围绕 ImageNet 是什么和不是什么,您可能会遇到一点上下文混淆。
你看, ImageNet 实际上是一个项目,旨在根据一组定义好的单词和短语将图像标记和分类成近 22,000 个类别。在撰写本文时,ImageNet 项目中有超过 1400 万张图片。
那么,ImageNet 是如何组织的呢?
为了订购如此大量的数据,ImageNet 实际上遵循了 WordNet 层次结构。WordNet 中的每个有意义的单词/短语被称为“同义词集”或简称“同义词集”。在 ImageNet 项目中,根据这些 synset 组织图像,目标是每个 synset 有 1,000 多个图像。
ImageNet 大规模识别挑战(ILSVRC)
在计算机视觉和深度学习的背景下,每当你听到人们谈论 ImageNet 时,他们很可能指的是 ImageNet 大规模识别挑战 ,或者简称为 ILSVRC。
这项挑战中图像分类跟踪的目标是训练一个模型,该模型可以使用超过 100,000 张测试图像将图像分类为 1,000 个单独的类别-训练数据集本身包含大约 120 万张图像。
当您阅读这篇博文的剩余部分或其他与 ImageNet 相关的教程和论文时,请务必牢记 ImageNet 的背景。虽然在图像分类、对象检测和场景理解的上下文中,我们经常将 ImageNet 称为分类挑战以及与挑战相关联的数据集,但请记住,还有一个更广泛的项目称为 ImageNet,在该项目中,这些图像被收集、注释和组织。
为 keras 和 imagenes 配置您的系统
要配置您的系统使用最先进的 VGG16、VGG19 和 ResNet50 网络,请确保您遵循我的最新教程在 Ubuntu 上安装 Keras或在 macOS 上安装。GPU Ubuntu 用户要看这个教程。
Keras 库将使用 PIL/Pillow 来完成一些辅助功能(比如从磁盘加载图像)。您可以使用以下命令安装 Pillow ,这是 PIL 的一个更加 Python 友好的分支:
$ pip install pillow
要使用 Python 在 ImageNet 数据集上运行预训练的网络,您需要确保安装了最新版本的 Keras。在撰写本文时,Keras 的最新版本是1.0.6,这是使用预训练模型的最低要求。
您可以通过执行以下命令来检查您的 Keras 版本:
$ python
Python 3.6.3 (default, Oct 4 2017, 06:09:15)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.37)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import keras
Using TensorFlow backend.
>>> keras.__version__
'2.2.0'
>>>
或者,您可以使用pip freeze列出您的环境中安装的软件包:
Figure 1: Listing the set of Python packages installed in your environment.
如果你使用的是在2.0.0之前的 Keras 的早期版本,卸载它,然后使用我的以前的教程来安装最新版本。
用于 ImageNet CNNs 的 Keras 和 Python 代码
我们现在准备编写一些 Python 代码,利用在 ImageNet 数据集上预先训练的卷积神经网络(CNN)对图像内容进行分类。
首先,打开一个新文件,将其命名为test_imagenet.py,并插入以下代码:
# import the necessary packages
from keras.preprocessing import image as image_utils
from keras.applications.imagenet_utils import decode_predictions
from keras.applications.imagenet_utils import preprocess_input
from keras.applications import VGG16
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
# load the original image via OpenCV so we can draw on it and display
# it to our screen later
orig = cv2.imread(args["image"])
我们从第 2-8 行的开始,导入我们需要的 Python 包。第 2 行直接从 Keras 库中导入image预处理模块。
*第 11-14 行解析我们的命令行参数。这里我们只需要一个开关--image,它是我们输入图像的路径。
然后,我们在第 18 行的中加载 OpenCV 格式的图像。这一步并不是严格要求的,因为 Keras 提供了加载图像的辅助函数(我将在下一个代码块中演示),但是这两个函数的工作方式有所不同,所以如果您打算对图像应用任何类型的 OpenCV 函数,我建议通过cv2.imread加载图像,然后再通过 Keras 辅助函数加载。一旦您在操作 NumPy 数组和交换通道方面有了更多的经验,您就可以避免额外的 I/O 开销,但是目前,让我们保持简单。
# load the input image using the Keras helper utility while ensuring
# that the image is resized to 224x224 pxiels, the required input
# dimensions for the network -- then convert the PIL image to a
# NumPy array
print("[INFO] loading and preprocessing image...")
image = image_utils.load_img(args["image"], target_size=(224, 224))
image = image_utils.img_to_array(image)
第 25 行应用.load_img Keras 辅助函数从磁盘加载我们的映像。我们提供了 224 x 224 像素的target_size,这是 VGG16、VGG19 和 ResNet50 网络架构所需的空间输入图像尺寸。
在调用.load_img之后,我们的image实际上是 PIL/枕头格式,所以我们需要应用.img_to_array函数将image转换成 NumPy 格式。
接下来,让我们预处理我们的图像:
# our image is now represented by a NumPy array of shape (224, 224, 3),
# assuming TensorFlow "channels last" ordering of course, but we need
# to expand the dimensions to be (1, 3, 224, 224) so we can pass it
# through the network -- we'll also preprocess the image by subtracting
# the mean RGB pixel intensity from the ImageNet dataset
image = np.expand_dims(image, axis=0)
image = preprocess_input(image)
如果在这个阶段我们检查我们的image的.shape,你会注意到 NumPy 数组的形状是 (3,224,224)——每个图像是 224 像素宽,224 像素高,有 3 个通道(分别用于红色、绿色和蓝色通道)。
但是,在我们可以通过 CNN 将我们的image进行分类之前,我们需要将维度扩展为 (1,3,224,224) 。
我们为什么要这样做?
当使用深度学习和卷积神经网络对图像进行分类时,为了提高效率,我们经常通过网络“批量”发送图像。因此,通过网络一次只传递一张图像实际上是非常罕见的——当然,除非你只有一张图像要分类(就像我们一样)。
然后,我们通过减去从 ImageNet 数据集计算出的平均 RGB 像素强度来预处理第 34 行上的image。
最后,我们可以加载我们的 Keras 网络并对图像进行分类:
# load the VGG16 network pre-trained on the ImageNet dataset
print("[INFO] loading network...")
model = VGG16(weights="imagenet")
# classify the image
print("[INFO] classifying image...")
preds = model.predict(image)
P = decode_predictions(preds)
# loop over the predictions and display the rank-5 predictions +
# probabilities to our terminal
for (i, (imagenetID, label, prob)) in enumerate(P[0]):
print("{}. {}: {:.2f}%".format(i + 1, label, prob * 100))
# load the image via OpenCV, draw the top prediction on the image,
# and display the image to our screen
orig = cv2.imread(args["image"])
(imagenetID, label, prob) = P[0][0]
cv2.putText(orig, "Label: {}, {:.2f}%".format(label, prob * 100),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.imshow("Classification", orig)
cv2.waitKey(0)
在的第 38 行,我们初始化了我们的VGG16类。我们也可以在这里用VGG19或ResNet50来代替,但是为了这个教程,我们将使用VGG16。
提供weights="imagenet"表示我们想要为相应的模型使用预训练的 ImageNet 权重。
一旦网络被加载和初始化,我们可以通过调用model的.predict方法来预测类标签。这些预测实际上是一个包含 1000 个条目的 NumPy 数组,即与 ImageNet 数据集中每个类相关联的预测概率。
在这些预测上调用decode_predictions给我们标签的 ImageNet 惟一 ID,以及标签的可读文本版本。
最后,第 47-57 行将预测的label打印到我们的终端,并将输出图像显示到我们的屏幕上。
ImageNet + Keras 影像分类结果
要将 ImageNet 数据集上预先训练的 Keras 模型应用于您自己的图像,请确保使用本文底部的 【下载】 表单下载源代码和示例图像。这将确保您的代码格式正确(没有错误)并且您的目录结构是正确的。
但是在我们可以将预先训练的 Keras 模型应用到我们自己的图像之前,让我们首先讨论模型权重是如何(自动)下载的。
下载模型重量
第一次执行test_imagenet.py脚本时,Keras 会自动下载架构权重并缓存到磁盘的~/.keras/models目录中。
test_imagenet.py的后续运行将会快得多(因为网络权重已经被下载了)——但是由于下载过程的原因,第一次运行将会非常慢(相对而言)。
也就是说,请记住,这些权重是相当大的 HDF5 文件,如果您没有快速的互联网连接,下载可能需要一段时间。为了方便起见,我列出了每个网络架构的权重文件的大小:
- ResNet50: 102MB
- VGG16: 553MB
- VGG19: 574MB
imagenes 和 keras 结果
我们现在准备使用预先训练好的 Keras 模型对图像进行分类!为了测试这些模型,我从维基百科下载了几张图片(“棕熊”和“航天飞机”)——其余的来自我的个人图书馆。
要开始,请执行以下命令:
$ python test_imagenet.py --image images/dog_beagle.png
注意,由于这是我第一次运行test_imagenet.py,需要下载与 VGG16 ImageNet 模型相关的权重:
Figure 2: Downloading the pre-trained ImageNet weights for VGG16.
一旦我们的权重被下载,VGG16 网络被初始化,ImageNet 权重被加载,并且最终的分类被获得:
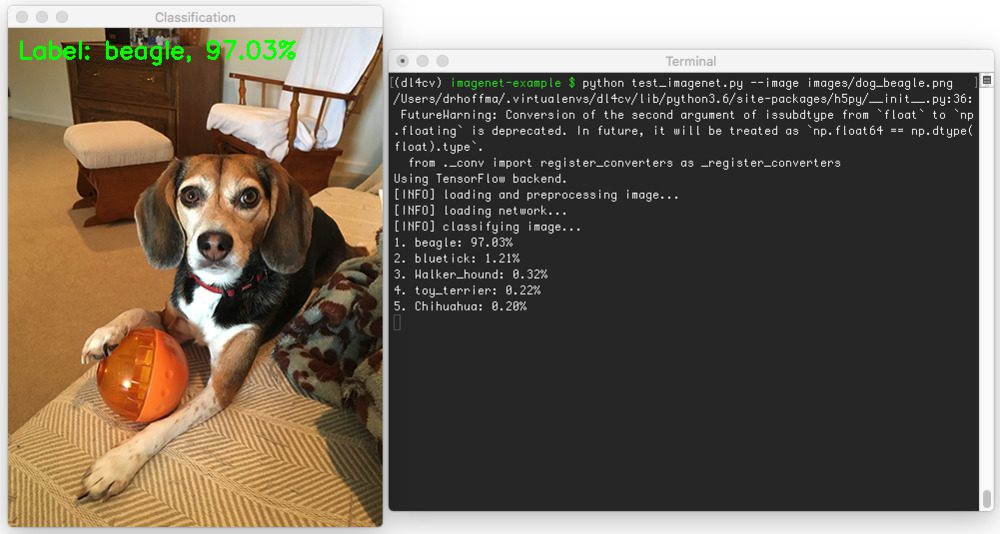
Figure 3: Utilizing the VGG16 network trained on ImageNet to recognize a beagle in an image.
让我们尝试另一个图像,这是一个啤酒杯:
$ python test_imagenet.py --image images/beer.png
Figure 4: Recognizing a beer glass using a Convolutional Neural Network trained on ImageNet.
下图是一只棕熊:
$ python test_imagenet.py --image images/brown_bear.png
Figure 5: Utilizing VGG16, Keras, and Python to recognize the brown bear in an image.
我拍了下面这张键盘的照片,用 Python 和 Keras 测试了 ImageNet 网络:
$ python test_imagenet.py --image images/keyboard.png
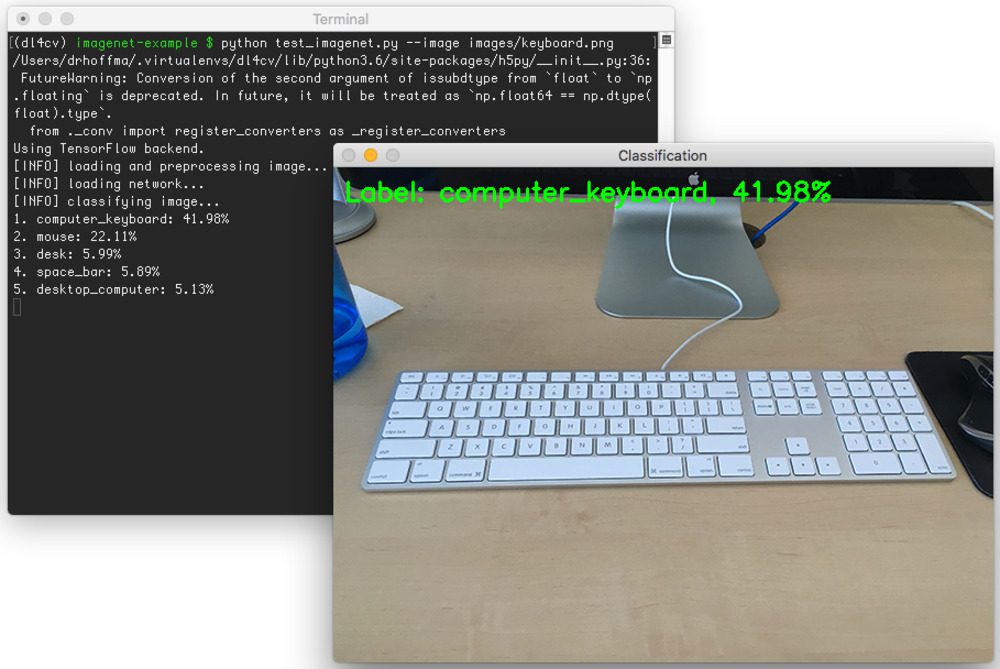
Figure 6: Utilizing Python, Keras, and a Convolutional Neural Network trained on ImageNet to recognize image contents.
然后,当我为这篇博客写代码时,我拍了一张显示器的照片。有趣的是,网络将这张图片归类为“台式电脑”,这是有道理的,因为显示器是图片的主要主题:
$ python test_imagenet.py --image images/monitor.png
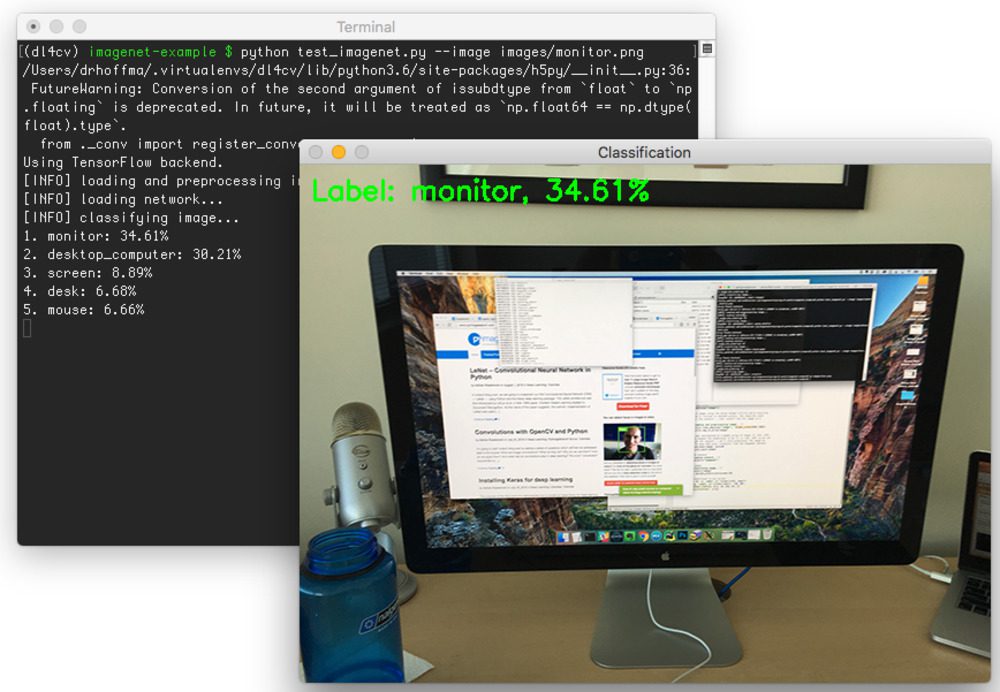
Figure 7: Image classification via Python, Keras, and CNNs.
下一张照片是一架航天飞机:
$ python test_imagenet.py --image images/space_shuttle.png

Figure 8: Recognizing image contents using a Convolutional Neural Network trained on ImageNet via Keras + Python.
最后一张照片是一只蒸螃蟹,具体来说是一只蓝色螃蟹。
$ python test_imagenet.py --image images/steamed_crab.png
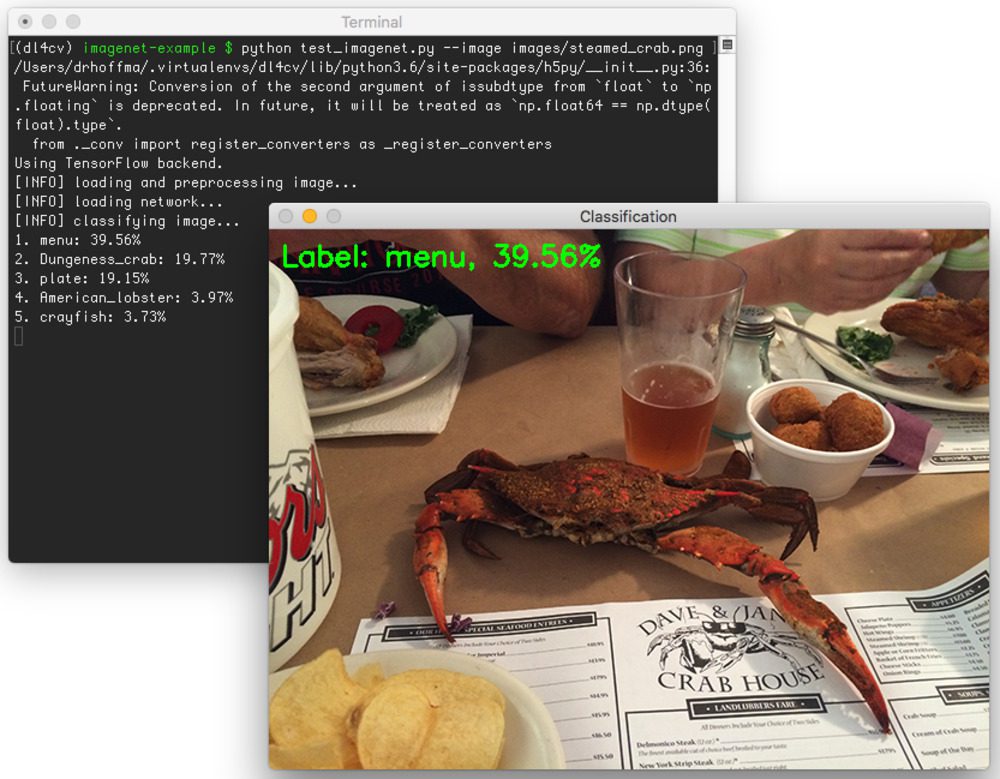
Figure 9: Convolutional Neural Networks and ImageNet for image classification with Python and Keras.
我发现这个特殊例子的有趣之处在于,VGG16 将这张图片归类为【菜单】,而【邓杰内斯蟹】在图片中同样突出。
此外,这实际上是而不是图像中的邓杰内斯蟹——它实际上是一只蓝蟹被蒸过,所以它的壳变红了。邓杰内斯蟹天生红色。一只青蟹只有在食用前蒸过之后才会变红。
关于模型计时的一个注记
从开始到结束(不包括下载网络权重文件),在我的 Titan X GPU 上使用 VGG16 对一张图像进行分类大约需要 11 秒 。这包括从磁盘实际加载映像和网络、执行任何初始化、通过网络传递映像以及获得最终预测的过程。
然而,一旦网络被实际加载到内存中,分类只需要 1.8 秒 ,这就向您显示了实际加载和初始化一个大型卷积神经网络需要多少开销。此外,由于图像可以在批次中呈现给网络,因此用于分类的相同时间将适用于多个图像。
如果你在你的 CPU 上对图像进行分类,那么你应该获得相似的分类时间。这主要是因为将图像从内存复制到 GPU 的开销很大。当您通过批处理传递多个图像时,使用 GPU 的 I/O 开销更容易被接受。
摘要
在这篇博客文章中,我演示了如何使用新发布的深度学习模型库使用在 ImageNet 数据集上训练的最先进的卷积神经网络对图像内容进行分类。
为了实现这一目标,我们利用了由弗朗索瓦·乔莱维护的喀拉斯图书馆——一定要联系他,感谢他维护了这么一个令人难以置信的图书馆。如果没有 Keras,使用 Python 进行深度学习就没有一半容易(或有趣)。
当然,您可能想知道如何使用 ImageNet 从头开始训练自己的卷积神经网络。别担心,我们正在实现这一目标——我们只需要首先了解神经网络、机器学习和深度学习的基础知识。可以说,先走后跑。
下周我会带着超参数调整的教程回来,这是最大化模型准确性的关键步骤。
为了在 PyImageSearch 博客上发布新的博文时得到通知,请务必在下表中输入您的电子邮件地址——下周见!***
ImageNet: VGGNet、ResNet、Inception 和 Xception with Keras
原文:https://pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception-xception-keras/
几个月前,我写了一篇教程,讲述如何使用在 ImageNet 数据集上用 Python 和 Keras 深度学习库预训练的卷积神经网络(具体来说就是 VGG16)对图像进行分类。
Keras 内部预先训练的网络能够识别 1,000 种不同的物体类别,与我们日常生活中遇到的物体相似,具有很高的准确性。
当时,预先训练的 ImageNet 模型是从核心 Keras 库中 分离 ,要求我们克隆一个独立的 GitHub repo ,然后手动将代码复制到我们的项目中。
这个解决方案足够好;然而,自从我最初的博客文章发表以来,预训练的网络(VGG16、VGG19、ResNet50、Inception V3 和 Xception)已经 完全集成到 Keras 核心 (不再需要克隆一个单独的回购)——这些实现可以在应用程序子模块中找到。
因此,我决定创建一个新的、更新的教程,演示如何在你自己的分类项目中利用这些最先进的网络。
具体来说,我们将创建一个特殊的 Python 脚本,它可以使用tensor flow 或 Theano 后端加载这些网络中的任何,然后对您自己的自定义输入图像进行分类。
要了解更多关于使用 VGGNet、ResNet、Inception 和 Xception 对图像进行分类的信息,请继续阅读。*
VGGNet、ResNet、Inception 和带有 Keras 的 Xception
2020-06-15 更新:此博文现已兼容 TensorFlow 2+!
在这篇博文的前半部分,我将简要讨论 Keras 库中包含的 VGG、ResNet、Inception 和 Xception 网络架构。
然后,我们将使用 Keras 创建一个定制的 Python 脚本,它可以从磁盘加载这些预先训练好的网络架构,并对您自己的输入图像进行分类。
最后,我们将在一些示例图像上查看这些分类的结果。
Keras 中最先进的深度学习图像分类器
Keras 提供了五个现成的卷积神经网络,它们已经在 ImageNet 数据集上进行了预训练:
- VGG16
- VGG19
- ResNet50
- 盗梦空间 V3
- Xception
让我们从 ImageNet 数据集的概述开始,然后简要讨论每个网络架构。
什么是 ImageNet?
ImageNet 是一个正式的项目,旨在为计算机视觉研究的目的(手动)将图像标记和分类成近 22,000 个独立的对象类别。
然而,当我们在深度学习和卷积神经网络的上下文中听到术语“ImageNet”时,我们很可能指的是 ImageNet 大规模视觉识别挑战 ,或简称为 ILSVRC。
这个图像分类挑战的目标是训练一个模型,该模型可以将输入图像正确地分类成 1,000 个单独的对象类别。
模型在大约 120 万张训练图像上进行训练,另外 50,000 张图像用于验证,100,000 张图像用于测试。
这 1,000 个图像类别代表了我们在日常生活中遇到的对象类别,如狗、猫、各种家用物品、车辆类型等。你可以在这里找到 ILSVRC 挑战赛中物体类别的完整列表。
当谈到图像分类时,ImageNet 挑战赛是计算机视觉分类算法事实上的基准测试——自 2012 年以来,这项挑战的排行榜一直由卷积神经网络和深度学习技术的 主导 。
Keras 核心库中包含的最先进的预训练网络代表了过去几年 ImageNet 挑战赛中一些最高性能的卷积神经网络。这些网络还展示了强大的能力,能够通过转移学习将推广到 ImageNet 数据集之外的图像,例如特征提取和微调。
VGG16 和 VGG19
Simonyan 和 Zisserman 在他们 2014 年的论文 中介绍了 VGG 网络架构,用于大规模图像识别的超深度卷积网络 。
这种网络的特点是简单,仅使用 3×3 个卷积层,这些卷积层以递增的深度堆叠在一起。减少卷大小是由最大池处理的。两个完全连接的层,每个层有 4,096 个节点,然后是 softmax 分类器(上图)。
“16”和“19”代表网络中重量层的数量(下面图 2 中的栏 D 和 E):
在 2014 年,16 层和 19 层网络被认为是非常深的(尽管我们现在有 ResNet 架构,它可以在 ImageNet 的 50-200 深度和 CIFAR-10 的 1000 深度以上成功训练)。
Simonyan 和 Zisserman 发现训练 VGG16 和 VGG19 具有挑战性(特别是关于在更深的网络上的收敛),因此为了使训练更容易,他们首先训练了具有更轻权重层(A 列和 C 列)的更小版本的 VGG。
较小的网络融合在一起,然后被用作更大、更深的网络的初始化——这个过程被称为 预训练 。
虽然从逻辑上讲,预训练是一项非常耗时、乏味的任务,需要在之前对整个网络进行训练,它可以作为更深层次网络的初始化。
我们不再使用预训练(在大多数情况下),而是更喜欢 Xaiver/Glorot 初始化或初始化(有时称为何等人的论文初始化, 深入研究整流器:在 ImageNet 分类上超越人类水平的性能 )。你可以在 内部阅读更多关于权重初始化和深度神经网络收敛的重要性你需要的只是一个好的 init 、Mishkin 和 Matas (2015)。
不幸的是,VGGNet 有两个主要缺点:
- 训练慢得令人痛苦。
- 网络架构权重本身相当大(就磁盘/带宽而言)。
由于其深度和全连接节点的数量,VGG16 的 VGG 超过 533MB,VGG19 超过 574MB。这使得部署 VGG 成为一项令人厌倦的任务。
我们在很多深度学习的图像分类问题中仍然使用 VGG;然而,更小的网络架构往往更可取(如 SqueezeNet、GoogLeNet 等。).
ResNet
与 AlexNet、OverFeat 和 VGG 等传统的顺序网络架构不同,ResNet 是一种依赖于微架构模块的“奇异架构”(也称为“网络中的网络架构”)。
术语微架构指的是用于构建网络的一组“构建模块”。一组微架构构建块(以及您的标准 CONV、池等)。层)导致了宏观架构(即终端网络本身)。
由何等人在其 2015 年的论文 中首次介绍的用于图像识别的深度残差学习 ,ResNet 架构已经成为一项开创性的工作,证明了通过使用残差模块,可以使用标准 SGD(和合理的初始化函数)来训练极深度网络:
通过更新残差模块以使用身份映射,可以获得进一步的准确性,如他们 2016 年的后续出版物 深度残差网络 中的身份映射所示:
也就是说,请记住,Keras 核心中的 ResNet50(如 50 个权重层)实施基于之前的 2015 年论文。
尽管 ResNet 比 VGG16 和 vgg 19深得多,但由于使用了全局平均池而不是完全连接的层,模型大小实际上要小得多—这将 ResNet50 的模型大小降低到了 102MB。
盗梦空间 V3
“盗梦空间”微架构首先由 Szegedy 等人在他们 2014 年的论文 中提出,用卷积 深化:
初始模块的目标是通过计算网络的同一个模块内的 1×1 、 3×3 和 5×5 卷积来充当“多级特征提取器”——这些滤波器的输出随后沿着信道维度堆叠,然后馈入网络的下一层。
这种架构的最初化身被称为 GoogLeNet ,但随后的表现形式被简单地称为 Inception vN ,其中 N 指的是谷歌发布的版本号。
Keras 核心中包含的 Inception V3 架构来自 Szegedy 等人的后续出版物, 重新思考计算机视觉的 Inception 架构 (2015),该出版物提出了对 Inception 模块的更新,以进一步提高 ImageNet 分类的准确性。
Inception V3 的重量比 VGG 和 ResNet 都小,只有 96MB。
Xception
提出这一概念的不是别人,正是 Keras 图书馆的创建者和主要维护者 Franç ois Chollet 自己。
Xception 是 Inception 架构的扩展,它用深度方向可分离的卷积代替了标准的 Inception 模块。
原始出版物,例外:深度可分卷积深度学习可在这里找到。
Xception 是重量最小的系列,只有 91MB。
SqueezeNet 怎么样?
值得一提的是, SqueezeNet 架构通过使用“挤压”和“扩展”的“发射”模块,可以在仅 4.9MB 的情况下获得 AlexNet 级别的精度(大约 57% rank-1 和大约 80% rank-5)。
虽然留下一个小脚印,但 SqueezeNet 训练起来也非常棘手。
也就是说,在我即将出版的书《用 Python 进行计算机视觉的深度学习 】中,我演示了如何在 ImageNet 数据集上从头开始训练 SqueezeNet。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
使用 VGGNet、ResNet、Inception 和 Xception 对图像进行分类,使用 Python 和 Keras
让我们学习如何使用 Keras 库用预训练的卷积神经网络对图像进行分类。
打开一个新文件,将其命名为classify_image.py,并插入以下代码:
# import the necessary packages
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications import InceptionV3
from tensorflow.keras.applications import Xception # TensorFlow ONLY
from tensorflow.keras.applications import VGG16
from tensorflow.keras.applications import VGG19
from tensorflow.keras.applications import imagenet_utils
from tensorflow.keras.applications.inception_v3 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
import numpy as np
import argparse
import cv2
第 2-13 行导入我们需要的 Python 包。如您所见,大多数包都是 Keras 库的一部分。
具体来说,第 2-6 行分别处理导入 ResNet50、Inception V3、Xception、VGG16 和 VGG19 的 Keras 实现。
请注意,Xception network 仅与 TensorFlow 后端兼容(如果您试图用 Theano 后端实例化它,该类将抛出一个错误)。
第 7 行为我们提供了进入imagenet_utils子模块的途径,这是一组方便的功能,将使我们的输入图像预处理和解码输出分类更加容易。
其余的导入是其他辅助函数,接下来是用于数字处理的 NumPy 和用于 OpenCV 绑定的cv2。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-model", "--model", type=str, default="vgg16",
help="name of pre-trained network to use")
args = vars(ap.parse_args())
我们只需要一个命令行参数,--image,它是我们想要分类的输入图像的路径。
我们还将接受一个可选的命令行参数,--model,一个指定我们想要使用哪个预训练的卷积神经网络的字符串——对于 VGG16 网络架构,该值默认为vgg16。
假设我们通过命令行参数接受预训练网络的名称,我们需要定义一个 Python 字典,将模型名称(字符串)映射到它们实际的 Keras 类:
# define a dictionary that maps model names to their classes
# inside Keras
MODELS = {
"vgg16": VGG16,
"vgg19": VGG19,
"inception": InceptionV3,
"xception": Xception, # TensorFlow ONLY
"resnet": ResNet50
}
# esnure a valid model name was supplied via command line argument
if args["model"] not in MODELS.keys():
raise AssertionError("The --model command line argument should "
"be a key in the `MODELS` dictionary")
第 25-31 行定义了我们的MODELS字典,它将模型名称字符串映射到相应的类。
如果在MODELS中找不到--model名称,我们将引发一个AssertionError ( 第 34-36 行)。
卷积神经网络将图像作为输入,然后返回对应于类别标签的一组概率作为输出。
在 ImageNet 上训练的卷积神经网络的典型输入图像大小是 224×224 、 227×227 、 256×256 和299×299;然而,你也可以看到其他维度。
VGG16、VGG19 和 ResNet 都接受 224×224 输入图像,而 Inception V3 和 Xception 需要 299×299 像素输入,如以下代码块所示:
# initialize the input image shape (224x224 pixels) along with
# the pre-processing function (this might need to be changed
# based on which model we use to classify our image)
inputShape = (224, 224)
preprocess = imagenet_utils.preprocess_input
# if we are using the InceptionV3 or Xception networks, then we
# need to set the input shape to (299x299) [rather than (224x224)]
# and use a different image pre-processing function
if args["model"] in ("inception", "xception"):
inputShape = (299, 299)
preprocess = preprocess_input
这里我们初始化我们的inputShape为 224×224 像素。我们还将我们的preprocess函数初始化为来自 Keras 的标准preprocess_input(执行均值减法)。
然而,如果我们正在使用 Inception 或 Xception,我们需要将inputShape设置为 299×299 像素,然后更新preprocess以使用 单独的预处理函数 ,该函数执行不同类型的缩放。
下一步是从磁盘加载我们预先训练的网络架构权重,并实例化我们的模型:
# load our the network weights from disk (NOTE: if this is the
# first time you are running this script for a given network, the
# weights will need to be downloaded first -- depending on which
# network you are using, the weights can be 90-575MB, so be
# patient; the weights will be cached and subsequent runs of this
# script will be *much* faster)
print("[INFO] loading {}...".format(args["model"]))
Network = MODELS[args["model"]]
model = Network(weights="imagenet")
第 58 行使用MODELS字典和--model命令行参数来获取正确的Network类。
然后使用预先训练的 ImageNet 权重在行 59 上实例化卷积神经网络;
注:【VGG16 和 VGG19 的权重为> 500MB。ResNet 权重约为 100MB,而 Inception 和 Xception 权重在 90-100MB 之间。如果这是您第一次运行给定网络的脚本,这些权重将(自动)下载并缓存到您的本地磁盘。根据您的网速,这可能需要一段时间。然而,一旦下载了权重,它们将而不是需要再次下载,允许classify_image.py的后续运行快得多。
*我们的网络现在已经加载完毕,可以对图像进行分类了——我们只需准备好该图像进行分类:
# load the input image using the Keras helper utility while ensuring
# the image is resized to `inputShape`, the required input dimensions
# for the ImageNet pre-trained network
print("[INFO] loading and pre-processing image...")
image = load_img(args["image"], target_size=inputShape)
image = img_to_array(image)
# our input image is now represented as a NumPy array of shape
# (inputShape[0], inputShape[1], 3) however we need to expand the
# dimension by making the shape (1, inputShape[0], inputShape[1], 3)
# so we can pass it through the network
image = np.expand_dims(image, axis=0)
# pre-process the image using the appropriate function based on the
# model that has been loaded (i.e., mean subtraction, scaling, etc.)
image = preprocess(image)
第 65 行使用提供的inputShape从磁盘加载我们的输入图像,以调整图像的宽度和高度。
第 66 行将图像从 PIL/枕头实例转换成 NumPy 数组。
我们的输入图像现在被表示为一个形状为(inputShape[0], inputShape[1], 3)的 NumPy 数组。
然而,我们通常用卷积神经网络对批中的图像进行训练/分类,因此我们需要通过行 72 上的np.expand_dims向数组添加额外的维度。
调用np.expand_dims后,image的形状为(1, inputShape[0], inputShape[1], 3)。当您调用model的.predict时,忘记添加这个额外的维度将会导致错误。
最后,行 76 调用适当的预处理函数来执行均值减法/缩放。
我们现在准备通过网络传递我们的图像,并获得输出分类:
# classify the image
print("[INFO] classifying image with '{}'...".format(args["model"]))
preds = model.predict(image)
P = imagenet_utils.decode_predictions(preds)
# loop over the predictions and display the rank-5 predictions +
# probabilities to our terminal
for (i, (imagenetID, label, prob)) in enumerate(P[0]):
print("{}. {}: {:.2f}%".format(i + 1, label, prob * 100))
对第 80 行上的.predict的调用返回来自卷积神经网络的预测。
给定这些预测,我们将它们传递到 ImageNet 实用函数.decode_predictions中,以给出 ImageNet 类标签 id、“人类可读”标签以及与标签相关联的概率的列表。
然后,前 5 个预测(即概率最大的标签)被打印到我们终端的第 85 行和第 86 行。
在结束示例之前,我们要做的最后一件事是通过 OpenCV 从磁盘加载输入图像,在图像上绘制#1 预测,最后将图像显示在屏幕上:
# load the image via OpenCV, draw the top prediction on the image,
# and display the image to our screen
orig = cv2.imread(args["image"])
(imagenetID, label, prob) = P[0][0]
cv2.putText(orig, "Label: {}, {:.2f}%".format(label, prob * 100),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
cv2.imshow("Classification", orig)
cv2.waitKey(0)
要查看我们预先培训的 ImageNet 网络的运行情况,请查看下一部分。
VGGNet、ResNet、Inception 和 Xception 分类结果
本博文中所有 更新的 例子均为 TensorFlow 2.2 所收集。之前这篇博文使用了 Keras > = 2.0 和 TensorFlow 后端(当它们是单独的包时),并且也用 Theano 后端进行了测试,并确认了实现也可以用 Theano 工作。
一旦安装了 TensorFlow/Theano 和 Keras,确保使用教程底部的 “下载” 部分将源代码+示例图片下载到这篇博文中。
从这里开始,让我们尝试用 VGG16 对图像进行分类:
$ python classify_image.py --image images/soccer_ball.jpg --model vgg16

Figure 8: Classifying a soccer ball using VGG16 pre-trained on the ImageNet database using Keras (source).
看看输出,我们可以看到 VGG16 以 93.43%的准确率正确地将图像分类为“足球”。
要使用 VGG19,我们只需更改--model命令行参数:
$ python classify_image.py --image images/bmw.png --model vgg19

Figure 9: Classifying a vehicle as “convertible” using VGG19 and Keras (source).
VGG19 能够以 91.76%的概率将输入图像正确分类为“可转换”。然而,看看其他前 5 的预测:跑车4.98%的概率(车就是这样)豪华轿车1.06%(不正确,但仍合理)“车轮”0.75%(由于图中有车轮,技术上也是正确的)。
在使用预训练 ResNet 架构的下例中,我们可以看到类似的前 5 级精度:
$ python classify_image.py --image images/clint_eastwood.jpg --model resnet

Figure 10: Using ResNet pre-trained on ImageNet with Keras + Python (source).
ResNet 以 69.79%的准确率将这张克林特·伊斯特伍德持枪的图像正确分类为“左轮手枪”。有趣的是,《来福枪》以 7.74%的比率和《突击步枪》以 5.63%的比率也位列前五。考虑到左轮手枪的视角和枪管的长度(对于手枪来说),很容易看出卷积神经网络对于步枪也将返回更高的概率。
下一个示例尝试使用 ResNet 对狗的种类进行分类:
$ python classify_image.py --image images/jemma.png --model resnet

Figure 11: Classifying dog species using ResNet, Keras, and Python.
狗的种类以 94.48%的置信度被正确识别为【比格犬】。
然后我试着给下面这张来自《加勒比海盗》系列的约翰尼·德普的照片分类:
$ python classify_image.py --image images/boat.png --model inception

Figure 12: Classifying a ship wreck with ResNet pre-trained on ImageNet with Keras (source).
虽然 ImageNet 中确实有一个“船”类,但有趣的是,盗梦空间网络能够以 96.29%的概率正确识别场景为(船)残骸。所有其他预测标签,包括、【海滨】、【独木舟】、【船桨】、和、【防波堤】、都是相关的,在某些情况下也是绝对正确的。
关于盗梦空间网络的另一个例子,我拍了一张坐在我办公室沙发上的照片:
$ python classify_image.py --image images/office.png --model inception

Figure 13: Recognizing various objects in an image with Inception V3, Python, and Keras.
Inception 以 69.68%的置信度正确预测图像中有一个【台灯】。其他前五名的预测也完全正确,包括一个、【工作室沙发】、、【窗帘】、(在图像的最右边,几乎看不到)、、【灯罩】、、、【枕头】、。
在上面的上下文中,Inception 甚至没有被用作对象检测器,但它仍然能够将图像的所有部分分类到它的前 5 个预测中。难怪卷积神经网络是优秀的物体探测器!
继续讨论例外情况:
$ python classify_image.py --image images/scotch.png --model xception

Figure 14: Using the Xception network architecture to classify an image (source).
这里我们有一个苏格兰桶的图像,特别是我最喜欢的苏格兰酒,Lagavulin。异常正确地将该图像分类为“桶”。
最后一个例子使用 VGG16 分类:
$ python classify_image.py --image images/tv.png --model vgg16

Figure 15: VGG16 pre-trained on ImageNet with Keras.
这张照片是几个月前我完成《巫师 III:疯狂狩猎》时拍摄的(很容易就进入了我最喜欢的前三名游戏)。VGG16 的第一个预测是【家庭影院】——这是一个合理的预测,因为在前 5 个预测中还有一个【电视/显示器】。
从这篇博文中的例子可以看出,在 ImageNet 数据集上预先训练的网络能够识别各种常见的日常物体。我希望您可以在自己的项目中使用这些代码!
摘要
在今天的博文中,我们回顾了在 Keras 库中的 ImageNet 数据集上预先训练的五个卷积神经网络:
- VGG16
- VGG19
- ResNet50
- 盗梦空间 V3
- Xception
然后,我演示了如何使用 Keras 库和 Python 编程语言,使用这些架构对您自己的输入图像进行分类。
如果你有兴趣了解更多关于深度学习和卷积神经网络的知识(以及如何从零开始训练自己的网络),一定要看看我的书, 用 Python 进行计算机视觉的深度学习 ,现在可以订购。**
用 Keras 和 TensorFlow 实现前馈神经网络
既然我们已经在 pure Python 中实现了神经网络,那么让我们转到首选的实现方法——使用一个专用的(高度优化的)神经网络库,比如 Keras。
今天,我将讨论如何实现前馈多层网络,并将其应用于 MNIST 和 CIFAR-10 数据集。这些结果很难说是“最先进”,但有两个用途:
- 演示如何使用 Keras 库实现简单的神经网络。
- 使用标准神经网络获得基线,我们稍后将与卷积神经网络进行比较(注意 CNN 将显著优于我们之前的方法)。
赔偿
今天,我们将使用由 70,000 个数据点组成的完整 MNIST 数据集(每位数 7,000 个示例)。每个数据点由一个 784 维向量表示,对应于 MNIST 数据集中的(展平的) 28×28 图像。我们的目标是训练一个神经网络(使用 Keras)在这个数据集上获得 > 90% 的准确率。
我们将会发现,使用 Keras 来构建我们的网络架构比我们的纯 Python 版本要简单得多。事实上,实际的网络架构将只占用四行代码——本例中剩余的代码只涉及从磁盘加载数据、转换类标签,然后显示结果。
首先,打开一个新文件,将其命名为keras_mnist.py,并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import mnist
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-11 行导入我们需要的 Python 包。LabelBinarizer将用于将我们的整数标签一次性编码为向量标签。一键编码将分类标签从单个整数转换为向量。许多机器学习算法(包括神经网络)受益于这种类型的标签表示。我将在本节的后面更详细地讨论一键编码,并提供多个例子(包括使用LabelBinarizer)。
classification_report函数将给我们一个格式良好的报告,显示我们模型的总精度,以及每个数字的分类精度。
第 4-6 行导入必要的包,用 Keras 创建一个简单的前馈神经网络。Sequential类表示我们的网络将是前馈的,各层将按顺序添加到类中,一层在另一层之上。行 5 上的Dense类是我们全连接层的实现。为了让我们的网络真正学习,我们需要应用SGD ( 行 6 )来优化网络的参数。最后,为了访问完整的 MNIST 数据集,我们需要在第 7 行的上导入mnist辅助函数。
让我们继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
这里我们只需要一个开关--output,它是我们绘制的损耗和精度图保存到磁盘的路径。
接下来,让我们加载完整的 MNIST 数据集:
# grab the MNIST dataset (if this is your first time using this
# dataset then the 11MB download may take a minute)
print("[INFO] accessing MNIST...")
((trainX, trainY), (testX, testY)) = mnist.load_data()
# each image in the MNIST dataset is represented as a 28x28x1
# image, but in order to apply a standard neural network we must
# first "flatten" the image to be simple list of 28x28=784 pixels
trainX = trainX.reshape((trainX.shape[0], 28 * 28 * 1))
testX = testX.reshape((testX.shape[0], 28 * 28 * 1))
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
第 22 行从磁盘加载 MNIST 数据集。如果以前从未运行过这个功能,那么 MNIST 数据集将被下载并存储到你的本地机器上。一旦数据集被下载,它将被缓存到您的计算机中,并且不必再次下载。
MNIST 数据集中的每幅图像都表示为 28×28×1 像素图像。为了在图像数据上训练我们的神经网络,我们首先需要将 2D 图像展平成一个由 28×28 = 784 个值组成的平面列表(第 27 行和第 28 行)。
然后,我们通过将像素强度缩放到范围 [0,1] ,对第 31 行和第 32 行执行数据归一化。
给定训练和测试分割,我们现在可以编码我们的标签:
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
MNIST 数据集中的每个数据点都有一个范围为【0,9】的整数标签,MNIST 数据集中可能的十位数字中的每一位都有一个标签。值为0的标签表示对应的图像包含一个零数字。同样,值为8的标签表示相应的图像包含数字 8。
但是,我们首先需要将这些整数标签转换成向量标签,其中标签向量中的索引设置为1,否则设置为0(这个过程称为一键编码)。
例如,考虑标签3,我们希望对其进行二进制化/一键编码——标签3现在变成:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
请注意,只有数字 3 的索引被设置为 1,向量中的所有其他条目都被设置为零。精明的读者可能会奇怪为什么向量中的第四个条目而不是第三个条目被更新?回想一下,标签中的第一个条目实际上是数字 0。因此,数字 3 的条目实际上是列表中的第四个索引。
下面是第二个例子,这次标签1被二进制化:
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
向量中的第二个条目被设置为 1(因为第一个条目对应于标签0),而所有其他条目被设置为零。
我在下面的清单中包含了每个数字的独热编码表示,0-9:
0: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
1: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
2: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
3: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
4: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
5: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
6: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
7: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
8: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
9: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
这种编码可能看起来很乏味,但许多机器学习算法(包括神经网络)都受益于这种标签表示。幸运的是,大多数机器学习软件包提供了一种方法/功能来执行一键编码,消除了许多繁琐。
第 35-37 行简单地执行对训练集和测试集的输入整数标签进行一次性编码为向量 标签的过程。
接下来,让我们定义我们的网络架构:
# define the 784-256-128-10 architecture using Keras
model = Sequential()
model.add(Dense(256, input_shape=(784,), activation="sigmoid"))
model.add(Dense(128, activation="sigmoid"))
model.add(Dense(10, activation="softmax"))
正如你所看到的,我们的网络是一个前馈架构,由第 40 行的类实例化——这种架构意味着各层将堆叠在彼此之上,前一层的输出馈入下一层。
第 41 行定义了网络中第一个完全连接的层。将input_shape设置为784,每个 MNIST 数据点的维数。然后,我们在这一层学习 256 个权重,并应用 sigmoid 激活函数。下一层(第 42 行)学习 128 个重量。最后,行 43 应用另一个全连接层,这次只学习 10 个权重,对应于十个(0-9)输出类。代替 sigmoid 激活,我们将使用 softmax 激活来获得每个预测的归一化类别概率。
让我们继续训练我们的网络:
# train the model using SGD
print("[INFO] training network...")
sgd = SGD(0.01)
model.compile(loss="categorical_crossentropy", optimizer=sgd,
metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=100, batch_size=128)
在第 47 行,我们用学习率0.01(我们通常可以写成1e-2)初始化 SGD 优化器。我们将使用类别交叉熵损失函数作为我们的损失度量(第 48 和 49 行)。使用交叉熵损失函数也是我们必须将整数标签转换为向量标签的原因。
对线 50 和 51 上的model的.fit的调用启动了我们神经网络的训练。我们将提供训练数据和训练标签作为该方法的前两个参数。
然后可以提供validation_data,这是我们的测试分割。在大多数情况下,比如当你调整超参数或者决定一个模型架构时,你会希望你的验证集是一个真的验证集,而不是你的测试数据。在这种情况下,我们只是演示如何使用 Keras 从头开始训练神经网络,所以我们对我们的指导方针有点宽容。
我们将允许我们的网络一次使用 128 个数据点的批量来训练总共 100 个纪元。该方法返回一个字典H,我们将使用它在几个代码块中绘制网络随时间的损失/准确性。
一旦网络完成训练,我们将需要根据测试数据对其进行评估,以获得我们的最终分类:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))
对model的.predict方法的调用将返回testX ( 第 55 行)中每个数据点的的类标签概率。因此,如果您要检查predictions NumPy 数组,它将具有形状(X, 10),因为在测试集中有 17500 个数据点和 10 个可能的类别标签(数字 0-9)。
因此,给定行中的每个条目都是一个概率。为了确定具有最大概率的的类,我们可以像在行 56 上一样简单地调用.argmax(axis=1),这将给出具有最大概率的类标签的索引,并因此给出我们最终的输出分类。网络的最终输出分类被制成表格,然后最终分类报告在行 56-58 上显示给我们的控制台。
我们的最终代码块处理随时间绘制训练损失、训练精度、验证损失和验证精度:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
然后根据--output命令行参数将该图保存到磁盘。要在 MNIST 上训练我们的全连接层网络,只需执行以下命令:
$ python keras_mnist.py --output output/keras_mnist.png
[INFO] loading MNIST (full) dataset...
[INFO] training network...
Train on 52500 samples, validate on 17500 samples
Epoch 1/100
1s - loss: 2.2997 - acc: 0.1088 - val_loss: 2.2918 - val_acc: 0.1145
Epoch 2/100
1s - loss: 2.2866 - acc: 0.1133 - val_loss: 2.2796 - val_acc: 0.1233
Epoch 3/100
1s - loss: 2.2721 - acc: 0.1437 - val_loss: 2.2620 - val_acc: 0.1962
...
Epoch 98/100
1s - loss: 0.2811 - acc: 0.9199 - val_loss: 0.2857 - val_acc: 0.9153
Epoch 99/100
1s - loss: 0.2802 - acc: 0.9201 - val_loss: 0.2862 - val_acc: 0.9148
Epoch 100/100
1s - loss: 0.2792 - acc: 0.9204 - val_loss: 0.2844 - val_acc: 0.9160
[INFO] evaluating network...
precision recall f1-score support
0.0 0.94 0.96 0.95 1726
1.0 0.95 0.97 0.96 2004
2.0 0.91 0.89 0.90 1747
3.0 0.91 0.88 0.89 1828
4.0 0.91 0.93 0.92 1686
5.0 0.89 0.86 0.88 1581
6.0 0.92 0.96 0.94 1700
7.0 0.92 0.94 0.93 1814
8.0 0.88 0.88 0.88 1679
9.0 0.90 0.88 0.89 1735
avg / total 0.92 0.92 0.92 17500
如结果所示,我们获得了 ≈92% 的准确度。此外,训练和验证曲线彼此匹配几乎相同 ( 图 1 ),表明训练过程没有过度拟合或问题。
事实上,如果你不熟悉 MNIST 数据集,你可能会认为 92%的准确率是非常好的——这可能是在 20 年前。利用卷积神经网络,我们可以很容易地获得 > 98% 的准确率。目前最先进的方法甚至可以突破 99%的准确率。
虽然表面上看起来我们的(严格)全连接网络运行良好,但实际上我们可以做得更好。正如我们将在下一节中看到的,应用于更具挑战性的数据集的严格全连接网络在某些情况下比随机猜测好不了多少。
CIFAR-10
当谈到计算机视觉和机器学习时,MNIST 数据集是“基准”数据集的经典定义,这种数据集太容易获得高精度的结果,并且不代表我们在现实世界中看到的图像。
对于一个更具挑战性的基准数据集,我们通常使用 CIFAR-10,这是一个由 60,000 张 32×32 RGB 图像组成的集合,这意味着数据集中的每张图像都由 32×32×3 = 3,072 个整数表示。顾名思义,CIFAR-10 由 10 类组成,包括飞机、汽车、鸟、猫、鹿、狗、蛙、马、船、卡车。在图 2 的中可以看到每个类别的 CIFAR-10 数据集样本。
每类平均表示为每类 6,000 个图像。在 CIFAR-10 上训练和评估机器学习模型时,通常使用作者预定义的数据分割,并使用 50,000 张图像进行训练,10,000 张图像进行测试。
CIFAR-10 比 MNIST 数据集要硬得多。挑战来自于物体呈现方式的巨大差异。例如,我们不能再假设在给定的 (x,y)-坐标包含绿色像素的图像是一只青蛙。这个像素可以是包含鹿的森林的背景。或者它可以是绿色汽车或卡车的颜色。
这些假设与 MNIST 数据集形成鲜明对比,在后者中,网络可以学习关于像素强度空间分布的假设。例如, 1 的前景像素的空间分布与 0 或 5 的前景像素的空间分布有很大不同。对象外观的这种变化使得应用一系列完全连接的层变得更加困难。正如我们将在本节的其余部分发现的,标准FC(全连接)层网络不适合这种类型的图像分类。
让我们开始吧。打开一个新文件,将其命名为keras_cifar10.py,并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-10 行导入我们需要的 Python 包来构建我们完全连接的网络,与上一节的 MNIST 相同。例外情况是第 7 行上的特殊实用函数——由于 CIFAR-10 是一个如此常见的数据集,研究人员在其上对机器学习和深度学习算法进行基准测试,因此经常看到深度学习库提供简单的助手函数来自动从磁盘加载该数据集。
接下来,我们可以分析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
我们需要的唯一命令行参数是--output,这是输出损耗/精度图的路径。
让我们继续加载 CIFAR-10 数据集:
# load the training and testing data, scale it into the range [0, 1],
# then reshape the design matrix
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
trainX = trainX.reshape((trainX.shape[0], 3072))
testX = testX.reshape((testX.shape[0], 3072))
对行 21 上的cifar10.load_data的调用自动从磁盘加载 CIFAR-10 数据集,预先分割成训练和测试分割。如果这是您在第一次调用cifar10.load_data,那么该函数将为您获取并下载数据集。这个文件是 ≈170MB ,所以在下载和解压的时候要有耐心。一旦文件被下载一次,它将被缓存在您的本地机器上,而不必再次下载。
第 22 行和第 23 行将 CIFAR-10 的数据类型从无符号 8 位整数转换为浮点,然后将数据缩放到范围 [0,1] 。线 24 和 25 负责重塑训练和测试数据的设计矩阵。回想一下,CIFAR-10 数据集中的每个图像都由一个 32×32×3 图像表示。
例如,trainX具有形状(50000, 32, 32, 3),而testX具有形状(10000, 32, 32, 3)。如果我们要将这个图像展平成一个浮点值列表,那么列表中总共会有32×32×3 = 3072个条目。
为了展平训练和测试集中的每个图像,我们只需使用 NumPy 的.reshape函数。这个函数执行后,trainX现在有了(50000, 3072)的形状,而testX有了(10000, 3072)的形状。
既然已经从磁盘加载了 CIFAR-10 数据集,让我们再次将类标签整数二进制化为向量,然后初始化类标签的实际名称的列表:
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
现在是时候定义网络架构了:
# define the 3072-1024-512-10 architecture using Keras
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="relu"))
model.add(Dense(512, activation="relu"))
model.add(Dense(10, activation="softmax"))
第 37 行实例化了Sequential类。然后,我们添加第一个Dense层,它的input_shape为3072,是设计矩阵中 3072 个展平像素值中每一个的节点——该层负责学习 1024 个权重。我们还将把过时的 sigmoid 换成 ReLU activation,希望能提高网络性能。
下一个完全连接的层(行 39 )学习 512 个权重,而最后一层(行 40 )学习对应于十个可能的输出分类的权重,以及 softmax 分类器,以获得每个分类的最终输出概率。
既然已经定义了网络的架构,我们就可以训练它了:
# train the model using SGD
print("[INFO] training network...")
sgd = SGD(0.01)
model.compile(loss="categorical_crossentropy", optimizer=sgd,
metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=100, batch_size=32)
我们将使用 SGD 优化器以0.01的学习速率训练网络,这是一个相当标准的初始选择。该网络将使用每批 32 个来训练总共 100 个时期。
一旦训练好网络,我们可以使用classification_report对其进行评估,以获得对模型性能的更详细的回顾:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
最后,我们还将绘制一段时间内的损耗/精度图:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
要在 CIFAR-10 上训练我们的网络,请打开一个终端并执行以下命令:
$ python keras_cifar10.py --output output/keras_cifar10.png
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/100
7s - loss: 1.8409 - acc: 0.3428 - val_loss: 1.6965 - val_acc: 0.4070
Epoch 2/100
7s - loss: 1.6537 - acc: 0.4160 - val_loss: 1.6561 - val_acc: 0.4163
Epoch 3/100
7s - loss: 1.5701 - acc: 0.4449 - val_loss: 1.6049 - val_acc: 0.4376
...
Epoch 98/100
7s - loss: 0.0292 - acc: 0.9969 - val_loss: 2.2477 - val_acc: 0.5712
Epoch 99/100
7s - loss: 0.0272 - acc: 0.9972 - val_loss: 2.2514 - val_acc: 0.5717
Epoch 100/100
7s - loss: 0.0252 - acc: 0.9976 - val_loss: 2.2492 - val_acc: 0.5739
[INFO] evaluating network...
precision recall f1-score support
airplane 0.63 0.66 0.64 1000
automobile 0.69 0.65 0.67 1000
bird 0.48 0.43 0.45 1000
cat 0.40 0.38 0.39 1000
deer 0.52 0.51 0.51 1000
dog 0.48 0.47 0.48 1000
frog 0.64 0.63 0.64 1000
horse 0.63 0.62 0.63 1000
ship 0.64 0.74 0.69 1000
truck 0.59 0.65 0.62 1000
avg / total 0.57 0.57 0.57 10000
查看输出,您可以看到我们的网络获得了 57%的准确率。检查我们的损失和准确性随时间的变化图(图 3 ),我们可以看到我们的网络与过去的纪元 10 的过度拟合作斗争。亏损最初开始减少,稍微持平,然后飙升,再也没有下降。与此同时,培训损失也在不断下降。这种减少训练损失而增加的行为表明极度过拟合。
我们当然可以考虑进一步优化我们的超参数,特别是,尝试不同的学习速率,增加网络节点的深度和数量,但我们将为微薄的收益而战。
事实是,具有严格全连接层的基本前馈网络不适合挑战性的图像数据集。为此,我们需要一种更先进的方法:卷积神经网络。
在 Python 和 OpenCV 中实现 RootSIFT
原文:https://pyimagesearch.com/2015/04/13/implementing-rootsift-in-python-and-opencv/

还在使用大卫·劳的原始、简单的 ole 实现吗?
好吧,根据 Arandjelovic 和 Zisserman 在他们 2012 年的论文 中所说的,每个人都应该知道的三件事来改善对象检索 ,你正在通过使用最初的实现来低估你自己(和你的准确性)。
相反,您应该利用 SIFT 的一个简单扩展,称为 RootSIFT,它可以用来显著提高对象识别的准确性、量化和检索的准确性。
无论是匹配关键点周围区域的描述符,使用 k-means 对 SIFT 描述符进行聚类,还是构建一个视觉单词包模型,RootSIFT 扩展都可以用来改善结果。
最棒的是,RootSIFT 扩展 位于原始 SIFT 实现之上,不需要修改原始 SIFT 源代码。
*您不必重新编译或修改您最喜欢的 SIFT 实现来利用 RootSIFT 的优势。
因此,如果你经常在你的计算机视觉应用中使用 SIFT,但还没有升级到 RootSIFT,请继续阅读。
这篇博文将向您展示如何在 Python 和 OpenCV 中实现 RootSIFT 而无需(1)更改 OpenCV SIFT 原始实现中的一行代码,( 2)无需编译整个库。
听起来有趣吗?查看这篇博文的其余部分,了解如何在 Python 和 OpenCV 中实现 RootSIFT。
OpenCV 和 Python 版本:
为了运行这个例子,你需要 Python 2.7 和 OpenCV 2.4.X 。
Why RootSIFT?
众所周知,在比较直方图时,欧几里德距离通常比使用卡方距离或 Hellinger 核产生的性能差[Arandjelovic 等人,2012]。
如果是这样的话,为什么我们在匹配关键点时经常使用欧几里德距离来比较 SIFT 描述符呢?或者聚类 SIFT 描述符形成码本?或者量化 SIFT 描述符形成视觉单词包?
请记住,虽然最初的 SIFT 论文讨论了使用欧几里德距离比较描述符,但 SIFT 本身仍然是一个直方图——难道其他距离度量标准不会提供更高的准确性吗?
原来,答案是是。代替使用不同的度量来比较 SIFT 描述符,我们可以代之以直接修改从 SIFT 返回的 128-dim 描述符。
你看,Arandjelovic 等人建议对 SIFT 描述符本身进行简单的代数扩展,称为 RootSIFT,它允许使用 Hellinger 核来“比较”SIFT 描述符,但仍然利用欧几里德距离。
下面是将 SIFT 扩展到 RootSIFT 的简单算法:
- 步骤 1: 使用你最喜欢的 SIFT 库计算 SIFT 描述符。
- 步骤 2: 对每个 SIFT 向量进行 L1 归一化。
- 第三步:取 SIFT 向量中每个元素的平方根。那么向量是 L2 归一化的。
就是这样!
这是一个简单的扩展。但这个小小的修改可以极大地改善结果,无论你是匹配关键点,聚集 SIFT 描述符,还是量化以形成一袋视觉单词,Arandjelovic 等人已经表明,RootSIFT 可以很容易地用于 SIFT 的所有场景,同时改善结果。
在这篇博文的剩余部分,我将展示如何使用 Python 和 OpenCV 实现 RootSIFT。使用这个实现,您将能够将 RootSIFT 整合到您自己的应用程序中——并改进您的结果!
在 Python 和 OpenCV 中实现 RootSIFT
打开您最喜欢的编辑器,创建一个新文件并命名为rootsift.py,让我们开始吧:
# import the necessary packages
import numpy as np
import cv2
class RootSIFT:
def __init__(self):
# initialize the SIFT feature extractor
self.extractor = cv2.DescriptorExtractor_create("SIFT")
def compute(self, image, kps, eps=1e-7):
# compute SIFT descriptors
(kps, descs) = self.extractor.compute(image, kps)
# if there are no keypoints or descriptors, return an empty tuple
if len(kps) == 0:
return ([], None)
# apply the Hellinger kernel by first L1-normalizing and taking the
# square-root
descs /= (descs.sum(axis=1, keepdims=True) + eps)
descs = np.sqrt(descs)
#descs /= (np.linalg.norm(descs, axis=1, ord=2) + eps)
# return a tuple of the keypoints and descriptors
return (kps, descs)
我们要做的第一件事是导入我们需要的包。我们将使用 NumPy 进行数值处理,使用cv2进行 OpenCV 绑定。
然后我们在第 5 行的上定义我们的RootSIFT类,在第 6-8 行的上定义构造器。构造函数简单地初始化 OpenCV SIFT 描述符提取器。
第 10 行上的compute函数处理 RootSIFT 描述符的计算。该函数需要两个参数和一个可选的第三个参数。
compute函数的第一个参数是我们想要从中提取 RootSIFT 描述符的image。第二个参数是关键点或局部区域的列表,将从这些区域中提取 RootSIFT 描述符。最后,提供一个ε变量eps,以防止任何被零除的错误。
从那里,我们提取第 12 行上的原始 SIFT 描述符。
我们检查第 15 行和第 16 行——如果没有关键点或描述符,我们简单地返回一个空元组。
将原始 SIFT 描述符转换成 RootSIFT 描述符发生在第 20-22 行的处。
我们首先对descs数组中的每个向量进行 L1 归一化(第 20 行)。
从那里,我们得到 SIFT 向量中每个元素的平方根(第 21 行)。
最后,我们要做的就是将关键点元组和 RootSIFT 描述符返回给第 25 行的调用函数。
运行 RootSIFT
要真正看到 RootSIFT 的运行,打开一个新文件,命名为driver.py,我们将探索如何从图像中提取 SIFT 和 RootSIFT 描述符:
# import the necessary packages
from rootsift import RootSIFT
import cv2
# load the image we are going to extract descriptors from and convert
# it to grayscale
image = cv2.imread("example.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect Difference of Gaussian keypoints in the image
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
# extract normal SIFT descriptors
extractor = cv2.DescriptorExtractor_create("SIFT")
(kps, descs) = extractor.compute(gray, kps)
print "SIFT: kps=%d, descriptors=%s " % (len(kps), descs.shape)
# extract RootSIFT descriptors
rs = RootSIFT()
(kps, descs) = rs.compute(gray, kps)
print "RootSIFT: kps=%d, descriptors=%s " % (len(kps), descs.shape)
在的第 1 行和第 2 行,我们导入了我们的RootSIFT描述符和 OpenCV 绑定。
然后,我们加载我们的示例图像,将其转换为灰度,并检测第 7-12 行上的高斯关键点的差异。
从那里,我们提取第 15-17 行上的原始 SIFT 描述符。
我们在第 20-22 行提取 RootSIFT 描述符。
要执行我们的脚本,只需发出以下命令:
$ python driver.py
您的输出应该如下所示:
SIFT: kps=1006, descriptors=(1006, 128)
RootSIFT: kps=1006, descriptors=(1006, 128)
如你所见,我们已经提取了 1006 个狗关键点。对于每个关键点,我们提取了 128 维 SIFT 和 RootSIFT 描述符。
从这里开始,您可以将这个 RootSIFT 实现应用到您自己的应用程序中,包括关键点和描述符匹配、对描述符进行聚类以形成质心,以及量化以创建一个视觉单词包模型——所有这些我们将在以后的帖子中介绍。
摘要
在这篇博文中,我向您展示了如何扩展 David Lowe 最初的 OpenCV SIFT 实现来创建 RootSIFT 描述符,这是 Arandjelovic 和 Zisserman 在他们 2012 年的论文 中建议的一个简单扩展,这是每个人都应该知道的改进对象检索的三件事。
RootSIFT 扩展不需要修改您最喜欢的 SIFT 实现的源代码——它只是位于原始实现之上。
计算 RootSIFT 的简单的 4 步 3 步流程是:
- 步骤 1: 使用你最喜欢的 SIFT 库计算 SIFT 描述符。
- 步骤 2: 对每个 SIFT 向量进行 L1 归一化。
- 第三步:取 SIFT 向量中每个元素的平方根。然后向量被 L2 归一化
无论您是使用 SIFT 来匹配关键点,使用 k-means 形成聚类中心,还是量化 SIFT 描述符来形成一个视觉单词包,您都应该明确考虑使用 RootSIFT 而不是原始 SIFT 来提高对象检索的准确性。*
在 OpenCV 中实现最大 RGB 滤镜
原文:https://pyimagesearch.com/2015/09/28/implementing-the-max-rgb-filter-in-opencv/

今天的博客文章直接来自于 PyImageSearch 大师课程。在 PyImageSearch Gurus 内部,我们有一个社区页面(很像论坛+ Q & A + StackOverflow 的组合),在这里我们讨论各种计算机视觉主题,提出问题,并让彼此对学习计算机视觉和图像处理负责。
这篇文章的灵感来自 PyImageSearch 大师成员克里斯蒂安·史密斯,他问是否有可能使用 OpenCV 和 Python 实现 GIMP 的最大 RGB 过滤器:
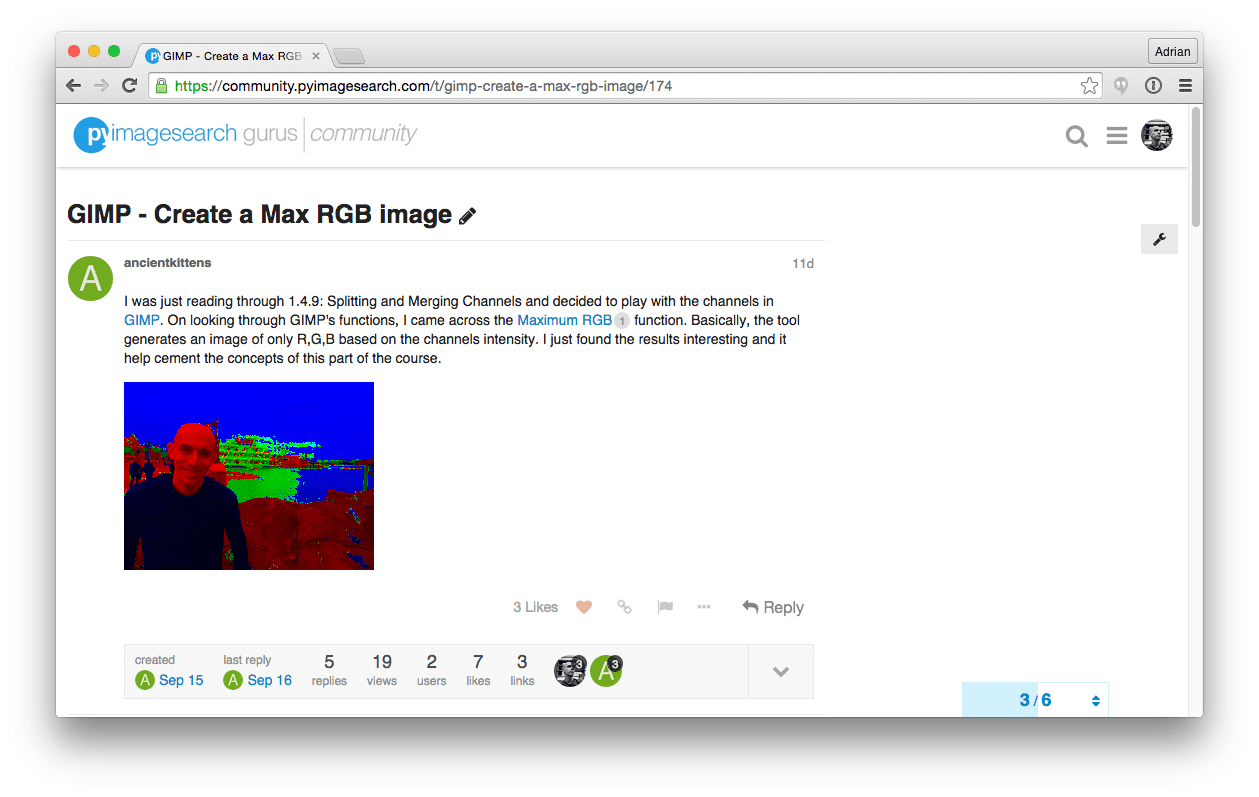
Figure 1: Christian, a member of PyImageSearch Gurus, asked if it was possible to replicate GIMP’s Max RGB filter using Python and OpenCV.
这个帖子引发了关于这个话题的大讨论,甚至导致了一个实现(今天我将与你分享)。
最大 RGB 过滤器不用于许多图像处理管道;然而,当可视化图像的红色、绿色和蓝色通道,以及哪个通道对图像的给定区域贡献最大时,这是一个非常有用的工具。对于简单的基于颜色的分割,这也是一个很好的过滤器。
在这篇文章的剩余部分,我将演示如何用几行 Python 和 OpenCV 代码实现 Max RGB 滤镜。
什么是 Max RGB 滤镜?
Max RGB 滤镜是一款极其简单直接的图像处理滤镜。算法是这样的。
- 对于图像中的每个像素 I :
- 抓取位于I【x,y】的 r 、 g 和 b 像素亮度
- 确定 r 、 g 、 b : m = max(r,g,b) 的最大值
- 如果 r < m: r = 0
- 如果 g < m: g = 0
- 如果 b < m: b = 0
- 将 r 、 g 和 b 值存储回图像: I[x,y] = (r,g,b)
唯一需要说明的是,如果两个通道强度相同,比如: (155,98,155) 。在这种情况下,的两个 值保持不变,最小的减小为零: (155,0,155) 。
输出图像应该如下所示:

Figure 2: An example of applying the Max RGB filter.
我们可以在左边的看到原始图像,在右边的看到过滤后的输出图像。**
在 OpenCV 中实现 GIMP 的 Max RGB 滤镜
现在我们已经很好地掌握了 Max RGB 滤镜算法(以及预期的输出应该是什么样子),让我们继续用 Python 和 OpenCV 实现它。打开一个新文件,将其命名为max_filter.py,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
def max_rgb_filter(image):
# split the image into its BGR components
(B, G, R) = cv2.split(image)
# find the maximum pixel intensity values for each
# (x, y)-coordinate,, then set all pixel values less
# than M to zero
M = np.maximum(np.maximum(R, G), B)
R[R < M] = 0
G[G < M] = 0
B[B < M] = 0
# merge the channels back together and return the image
return cv2.merge([B, G, R])
第 2-4 行简单导入我们需要的包。
第 6 行定义了我们的max_rgb_filter功能。这个方法只需要一个参数,即我们想要过滤的image。
给定我们的输入image,然后我们使用cv2.split函数将image分割成相应的蓝色、绿色和红色成分(第 8 行
注意: 需要记住的是,OpenCV 是以 BGR 顺序存储图像,而不是 RGB。如果你刚刚开始使用 OpenCV ,这可能会造成一点混乱和一些难以追踪的错误。
给定我们的R、G和B通道,然后我们使用 NumPy 的maximum方法(第 13 行)来找到在 每个、、 (x,y)-、所有三个、、G和B通道的最大强度值
使用 np.maximum 而不是 np.max 是 非常重要的 !与在每个(x,y)坐标 找到最大值 的np.maximum相反,np.max方法将只找到跨越 整个数组 的最大值。
从那里,行 14-16 抑制低于最大值 M 的红色、绿色和蓝色像素强度。
最后,第 19 行将通道合并在一起(再次按照 BGR 顺序,因为这是 OpenCV 所期望的)并将最大 RGB 过滤图像返回给调用函数。
既然已经定义了max_rgb_filter方法,我们需要做的就是编写一些代码来从磁盘上加载我们的图像,应用最大 RGB 滤镜,并将结果显示到我们的屏幕上:
# import the necessary packages
import numpy as np
import argparse
import cv2
def max_rgb_filter(image):
# split the image into its BGR components
(B, G, R) = cv2.split(image)
# find the maximum pixel intensity values for each
# (x, y)-coordinate,, then set all pixel values less
# than M to zero
M = np.maximum(np.maximum(R, G), B)
R[R < M] = 0
G[G < M] = 0
B[B < M] = 0
# merge the channels back together and return the image
return cv2.merge([B, G, R])
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the image, apply the max RGB filter, and show the
# output images
image = cv2.imread(args["image"])
filtered = max_rgb_filter(image)
cv2.imshow("Images", np.hstack([image, filtered]))
cv2.waitKey(0)
这段代码应该是不言自明的。第 22-25 行处理解析我们的命令行参数。我们需要的唯一开关是--image,它是我们想要处理的图像在磁盘上驻留的路径。
从那里,第 29-32 行处理加载我们的image,应用最大 RGB 过滤器,最后在我们的屏幕上显示原始和过滤后的图像。
要查看我们的脚本,只需打开您的终端并执行以下命令:
$ python max_filter.py --image images/horseshoe_bend_02.jpg
Figure 3: Our original image (left) and the Max RGB filtered image (right).
左边的是原始图像——我自己在亚利桑那州马蹄弯附近的沙漠中的照片。然后,在右边的中,我们得到了应用最大 RGB 滤镜后的图像。在图像的顶部,我们可以看到天空是浓郁的蓝色,这表明蓝色通道在该区域具有较大的像素强度值。在蓝天的对面,图像的底部更红(他们不会无缘无故地称之为红石’)—这里红色通道具有较大的像素强度值,绿色和蓝色通道被抑制。
让我们试试另一个图像:
$ python max_filter.py --image images/max_filter_horseshoe_bend_01.png

Figure 4: Another example of applying the Max RGB filter using Python and OpenCV.
我特别喜欢这张图片,因为它突出了水并不总是像我们想象的那样是“清澈的蓝色”。毫不奇怪,红石突出显示为红色,天空非常蓝。然而,水本身是蓝色和绿色的混合物。此外,这两个水域彼此明显分开。
让我们做最后一个例子:
$ python max_filter.py --image images/max_filter_antelope_canyon.png

Figure 5: Applying the Max RGB filter to a photo taken in Antelope Canyon. Are you surprised by the results?
这张图片来自亚利桑那州佩奇的羚羊峡谷(可能是世界上最美丽的地区之一)。在插槽峡谷的底部,光线很弱,所以我们根本看不到太多的颜色(虽然如果你仔细看,你可以看到深蓝/紫色的斑块,这些洞穴是众所周知的)。然后,当我们沿着峡谷壁向上移动时,更多的光线进入,呈现出奇妙的红光。最后,在洞穴的顶部是天空,在这张照片中,天空是如此明亮,以至于被洗去了。
就像我说的,我们很少在图像处理管道中使用 Max RGB 滤镜;但是,由于过滤器允许您调查图像的哪些通道对给定区域的贡献最大,因此在执行基本分割和调试时,它是一个很有价值的工具。
摘要
今天的博客帖子是受克里斯蒂安·史密斯的一个问题的启发,他是 PyImageSearch 大师的成员(感谢基督徒!).Christian 问是否有可能只用 Python 和 OpenCV 来实现 GIMP 的 Max RGB 滤镜——显然,答案是肯定的。但是令人惊讶的是它只需要几行代码就可以完成!
继续下载这篇文章的代码,将最大 RGB 滤镜应用到你自己的图片上。看看你是否能猜出哪个红色、绿色或蓝色通道对图像的特定区域贡献最大——你可能会惊讶于在某些情况下你对颜色的直觉和感知是多么的错误!
最后,如果你有兴趣加入 PyImageSearch 大师课程,请务必点击此处,排队领取你的位置。课程内的位置是有限的(一次只允许一小批读者进入),所以非常重要如果你对课程感兴趣,就申请你的位置!
用 Python 实现感知器神经网络
原文:https://pyimagesearch.com/2021/05/06/implementing-the-perceptron-neural-network-with-python/
由 Rosenblatt 在 1958 年首次介绍的感知器:大脑中信息存储和组织的概率模型 可以说是最古老和最简单的人工神经网络算法。这篇文章发表后,基于感知器的技术在神经网络社区风靡一时。单单这篇论文就对今天神经网络的流行和实用性负有巨大的责任。
但后来,在 1969 年,一场“人工智能冬天”降临到机器学习社区,几乎永远冻结了神经网络。明斯基和帕佩特出版了感知器:计算几何 导论,这本书实际上使神经网络的研究停滞了近十年——关于这本书有很多争议(奥拉扎兰,1996 ),但作者确实成功证明了单层感知器无法分离非线性数据点。
鉴于大多数真实世界的数据集自然是非线性可分的,这似乎是感知器,以及神经网络研究的其余部分,可能会达到一个不合时宜的结束。
在 Minsky 和 Papert 的出版物和神经网络使工业发生革命性变化的承诺之间,对神经网络的兴趣大大减少了。直到我们开始探索更深层次的网络(有时称为多层感知器)以及反向传播算法(沃博斯和鲁梅尔哈特等人),20 世纪 70 年代的“人工智能冬天”才结束,神经网络研究又开始升温。
尽管如此,感知器仍然是一个需要理解的非常重要的算法,因为它为更高级的多层网络奠定了基础。我们将从感知机架构的回顾开始这一部分,并解释用于训练感知机的训练程序(称为德尔塔规则)。我们还将看看网络的终止标准(即,感知机何时应该停止训练)。最后,我们将在纯 Python 中实现感知器算法,并使用它来研究和检查网络如何无法学习非线性可分离数据集。
与、或和异或数据集
在研究感知机本身之前,我们先来讨论一下“按位运算”,包括 AND、OR 和 XOR(异或)。如果你以前学过计算机科学的入门课程,你可能已经熟悉了位函数。
按位运算符和关联的按位数据集接受两个输入位,并在应用运算后生成一个最终输出位。给定两个输入位,每个可能取值为0或1,这两个位有四种可能的组合— 表 1 提供了 and、or 和 XOR 的可能输入和输出值:
| x[0] | x[1] | x[0]&x[1] | x[0] | x[1] | x[0]x[1] | x[0] | x[1] | x[0]∧x[1] |
|---|---|---|---|---|---|---|---|---|
| Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero |
| Zero | one | Zero | Zero | one | one | Zero | one | one |
| one | Zero | Zero | one | Zero | one | one | Zero | one |
| one | one | one | one | one | one | one | one | Zero |
Table 1: Left: The bitwise AND dataset. Given two inputs, the output is only 1 if both inputs are 1. Middle: The bitwise OR dataset. Given two inputs, the output is 1 if either of the two inputs is 1. Right: The XOR (e(X)clusive OR) dataset. Given two inputs, the output is 1 if and only if one of the inputs is 1, but not both.
正如我们在左边的上看到的,当且仅当两个输入值都是1时,逻辑与为真。如果输入值的或为0,则 AND 返回0。因此,当 and 的输出为真时,只有一个组合,x0= 1 和 x [1] = 1。
在中间的中,我们有 OR 运算,当输入值中至少有一个为1时,OR 运算为真。因此,产生值 y = 1 的两位x0 和xT11 有三种可能的组合。
最后,右显示异或运算,当且仅当一个输入为1 但不是两个都为时,该运算为真。OR 有三种可能的情况,其中 y = 1,而 XOR 只有两种。
我们经常使用这些简单的“按位数据集”来测试和调试机器学习算法。如果我们在图 1 中绘制并可视化 and、OR 和 XOR 值(红色圆圈表示零输出,蓝色星号表示一输出),您会注意到一个有趣的模式:
AND 和 OR 都是线性可分的——我们可以清楚地画出一条线来区分0和1类 XOR 则不是这样。现在花点时间说服自己不可能在异或问题中划出一条清晰的分界线来区分这两个类。因此,XOR 是一个非线性可分离数据集的例子。
理想情况下,我们希望我们的机器学习算法能够分离非线性类,因为现实世界中遇到的大多数数据集都是非线性的。因此,当构造、调试和评估给定的机器学习算法时,我们可以使用按位值 x 、T2【0】T3 和 x 、 1 作为我们的设计矩阵,然后尝试预测相应的 y 值。
与我们将数据分割成训练和测试分割的标准程序不同,当使用逐位数据集时,我们只是在同一组数据上训练和评估我们的网络。我们在这里的目标仅仅是确定我们的学习算法是否有可能学习数据中的模式。我们将会发现,感知器算法可以正确分类 AND 和 OR 函数,但无法分类 XOR 数据。
感知器架构
Rosenblatt (1958) 将感知器定义为使用特征向量(或原始像素强度)的标记示例(即监督学习)进行学习的系统,将这些输入映射到其相应的输出类别标签。
在其最简单的形式中,感知器包含 N 个输入节点,一个用于设计矩阵的输入行中的每个条目,随后是网络中的仅一层,在该层中仅有一个单节点(图 2 )。
从输入端 x [i] 到网络中的单个输出节点存在连接和它们相应的权重 w [1] ,w [2] ,…,w [i] 。该节点获取输入的加权和,并应用阶跃函数来确定输出类别标签。感知器为类#1 输出0或1 — 0,为类#2 输出1;因此,在其原始形式中,感知器只是一个二元、两类分类器。
| 1.用小的随机值
2 初始化我们的权重向量 w 。直到感知器收敛:
(a)循环遍历我们训练集 D 中的每个特征向量 x [j] 和真实类标签D[I](b)取 x 通过网络, 计算输出值:y[j]j=f(w(t)x[j])
(c)更新权重w:w[I]( +α(d[j]y[j])x[j,i] 对于所有特性 0<=I<=n |
Figure 3: The Perceptron algorithm training procedure.
感知器训练程序和德尔塔法则
训练一个感知机是一个相当简单的操作。我们的目标是获得一组权重 w ,这些权重能够准确地对我们训练集中的每个实例进行分类。为了训练我们的感知机,我们多次用我们的训练数据迭代地输入网络。每当网络已经看到训练数据的全套,我们就说一个时期已经过去。通常需要许多代才能学习到权重向量 w 来线性分离我们的两类数据。
感知器训练算法的伪代码可以在下面找到:
实际的“学习”发生在步骤 2b 和 2c 中。首先,我们通过网络传递特征向量x[j],取与权重w的点积,得到输出y[j]。然后,该值通过 step 函数传递,如果x>0,该函数将返回 1,否则返回 0。****
现在我们需要更新我们的权重向量 w 以朝着“更接近”正确分类的方向前进。权重向量的更新由步骤 2c 中的德尔塔规则处理。
表达式(d[j]——y**[j])决定输出分类是否正确。如果分类是正确的,那么这个差值将为零。否则,差异将是正的或负的,给我们权重更新的方向(最终使我们更接近正确的分类)。然后我们将(d[j]——y**[j])乘以 x [j] ,让我们更接近正确的分类。
值 α 是我们的学习速率,它控制着我们迈出的一步的大小。该值设置正确是的关键。更大的值 α 会使我们朝着正确的方向迈出一步;然而,这一步可能太大,我们很容易超越局部/全局最优。
相反,一个小的值 α 允许我们在正确的方向上迈出小步,确保我们不会超越局部/全局最小值;然而,这些小小的步骤可能需要很长时间才能让我们的学习趋于一致。
最后,我们在时间 t 、wjT7(t)添加先前的权重向量,这完成了朝向正确分类的“步进”过程。如果你觉得这个训练过程有点混乱,不要担心。
感知器训练终止
感知器训练过程被允许继续进行,直到所有训练样本被正确分类或达到预设数量的时期。如果 α 足够小并且训练数据是线性可分的,则确保终止。
那么,如果我们的数据不是线性可分的,或者我们在 α 中做了一个糟糕的选择,会发生什么?训练会无限延续下去吗?在这种情况下,否-我们通常在达到设定数量的历元后停止,或者如果在大量历元中错误分类的数量没有变化(表明数据不是线性可分的)。关于感知机算法的更多细节,请参考吴恩达的斯坦福讲座或梅罗塔等人(1997) 的介绍章节。
在 Python 中实现感知器
现在我们已经学习了感知器算法,让我们用 Python 实现实际的算法。在您的pyimagesearch.nn包中创建一个名为perceptron.py的文件——这个文件将存储我们实际的Perceptron实现:
|--- pyimagesearch
| |--- __init__.py
| |--- nn
| | |--- __init__.py
| | |--- perceptron.py
创建文件后,打开它,并插入以下代码:
# import the necessary packages
import numpy as np
class Perceptron:
def __init__(self, N, alpha=0.1):
# initialize the weight matrix and store the learning rate
self.W = np.random.randn(N + 1) / np.sqrt(N)
self.alpha = alpha
第 5 行定义了我们的Perceptron类的构造函数,它接受一个必需的参数,后跟第二个可选的参数:
N:我们输入特征向量中的列数。在我们的按位数据集的上下文中,我们将设置N等于 2,因为有两个输入。- 感知器算法的学习率。默认情况下,我们将这个值设置为
0.1。学习率的常见选择通常在 α = 0 的范围内。 1 , 0 。 01 , 0 。 001。
第 7 行用从均值和单位方差为零的“正态”(高斯)分布中采样的随机值填充我们的权重矩阵W。权重矩阵将具有 N +1 个条目,一个用于特征向量中的每个N输入,另一个用于偏差。我们将W除以输入数量的平方根,这是一种用于调整权重矩阵的常用技术,可以加快收敛速度。我们将在本章后面讨论权重初始化技术。
接下来,让我们定义step函数:
def step(self, x):
# apply the step function
return 1 if x > 0 else 0
这个函数模拟了步进方程的行为——如果x为正,我们返回1,否则,我们返回0。
为了实际训练感知器,我们将定义一个名为fit的函数。如果你以前有过机器学习、Python 和 scikit-learn 库的经验,那么你会知道将你的训练过程函数命名为fit是很常见的,比如“根据数据拟合模型”:
def fit(self, X, y, epochs=10):
# insert a column of 1's as the last entry in the feature
# matrix -- this little trick allows us to treat the bias
# as a trainable parameter within the weight matrix
X = np.c_[X, np.ones((X.shape[0]))]
fit方法需要两个参数,后跟一个可选参数:
X值是我们实际的训练数据。 y 变量是我们的目标输出类标签(即,我们的网络应该预测什么)。最后,我们提供epochs,我们的感知机将训练的纪元数量。
第 18 行通过在训练数据中插入一列 1 来应用偏差技巧,这允许我们将偏差作为权重矩阵中的可训练参数直接来处理。
接下来,让我们回顾一下实际的培训程序:
# loop over the desired number of epochs
for epoch in np.arange(0, epochs):
# loop over each individual data point
for (x, target) in zip(X, y):
# take the dot product between the input features
# and the weight matrix, then pass this value
# through the step function to obtain the prediction
p = self.step(np.dot(x, self.W))
# only perform a weight update if our prediction
# does not match the target
if p != target:
# determine the error
error = p - target
# update the weight matrix
self.W += -self.alpha * error * x
在第 21 行的上,我们开始循环所需数量的epochs。对于每个时期,我们还循环每个单独的数据点x并输出target类标签(行 23** )。**
第 27 行获取输入特征x和权重矩阵W之间的点积,然后通过step函数传递输出,以获得感知器的预测。
应用图 3 中详述的相同训练程序,我们仅在我们的预测与目标不匹配的情况下执行权重更新(第 31 行)。如果是这种情况,我们通过差分运算计算符号(正或负)来确定error ( 行 33 )。
在第 36 行处理权重矩阵的更新,在这里我们向正确的分类迈出一步,通过我们的学习速率alpha缩放这一步。经过一系列时期,我们的感知机能够学习底层数据中的模式,并移动权重矩阵的值,以便我们正确地对输入样本进行分类x。
我们需要定义的最后一个函数是predict,顾名思义,它用于预测给定输入数据集的类别标签:
def predict(self, X, addBias=True):
# ensure our input is a matrix
X = np.atleast_2d(X)
# check to see if the bias column should be added
if addBias:
# insert a column of 1's as the last entry in the feature
# matrix (bias)
X = np.c_[X, np.ones((X.shape[0]))]
# take the dot product between the input features and the
# weight matrix, then pass the value through the step
# function
return self.step(np.dot(X, self.W))
我们的predict方法需要一组需要分类的输入数据X。对线 43 进行检查,查看是否需要添加偏置柱。
获取X的输出预测与训练过程相同——只需获取输入特征X和我们的权重矩阵W之间的点积,然后通过我们的阶跃函数传递该值。阶跃函数的输出返回给调用函数。
现在我们已经实现了我们的Perceptron类,让我们试着将它应用到我们的按位数据集,看看神经网络如何执行。
评估感知器逐位数据集
首先,让我们创建一个名为perceptron_or.py的文件,该文件试图将感知器模型与按位 OR 数据集相匹配:
# import the necessary packages
from pyimagesearch.nn import Perceptron
import numpy as np
# construct the OR dataset
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [1]])
# define our perceptron and train it
print("[INFO] training perceptron...")
p = Perceptron(X.shape[1], alpha=0.1)
p.fit(X, y, epochs=20)
第 2 行和第 3 行导入我们需要的 Python 包。我们将使用我们的Perceptron实现。第 6 行和第 7 行根据表 1 定义 OR 数据集。
第 11 行和第 12 行以 α = 0 的学习率训练我们的感知机。 1 共 20 个历元。
然后,我们可以根据数据评估我们的感知器,以验证它确实学习了 OR 函数:
# now that our perceptron is trained we can evaluate it
print("[INFO] testing perceptron...")
# now that our network is trained, loop over the data points
for (x, target) in zip(X, y):
# make a prediction on the data point and display the result
# to our console
pred = p.predict(x)
print("[INFO] data={}, ground-truth={}, pred={}".format(
x, target[0], pred))
在第 18 行,我们循环 OR 数据集中的每个数据点。对于这些数据点中的每一个,我们通过网络传递它并获得预测(第 21 行)。
最后,行 22 和 23 向我们的控制台显示输入数据点、地面实况标签以及我们的预测标签。
要查看我们的感知器算法是否能够学习 OR 函数,只需执行以下命令:
$ python perceptron_or.py
[INFO] training perceptron...
[INFO] testing perceptron...
[INFO] data=[0 0], ground-truth=0, pred=0
[INFO] data=[0 1], ground-truth=1, pred=1
[INFO] data=[1 0], ground-truth=1, pred=1
[INFO] data=[1 1], ground-truth=1, pred=1
果然,我们的神经网络能够正确地预测出 x [0] = 0 和 x [1] = 0 的 OR 运算是零——所有其他组合都是一。
现在,让我们继续讨论 AND 函数——创建一个名为perceptron_and.py的新文件,并插入以下代码:
# import the necessary packages
from pyimagesearch.nn import Perceptron
import numpy as np
# construct the AND dataset
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [0], [0], [1]])
# define our perceptron and train it
print("[INFO] training perceptron...")
p = Perceptron(X.shape[1], alpha=0.1)
p.fit(X, y, epochs=20)
# now that our perceptron is trained we can evaluate it
print("[INFO] testing perceptron...")
# now that our network is trained, loop over the data points
for (x, target) in zip(X, y):
# make a prediction on the data point and display the result
# to our console
pred = p.predict(x)
print("[INFO] data={}, ground-truth={}, pred={}".format(
x, target[0], pred))
注意,这里只有行代码发生了变化,这是的第 6 行和第 7 行,在这里我们定义了 and 数据集,而不是 OR 数据集。
执行以下命令,我们可以评估 and 函数上的感知器:
$ python perceptron_and.py
[INFO] training perceptron...
[INFO] testing perceptron...
[INFO] data=[0 0], ground-truth=0, pred=0
[INFO] data=[0 1], ground-truth=0, pred=0
[INFO] data=[1 0], ground-truth=0, pred=0
[INFO] data=[1 1], ground-truth=1, pred=1
同样,我们的感知器能够正确地模拟这个函数。只有当x[0]= 1 且 x [1] = 1 时,and 函数才成立——对于所有其他组合,按位 AND 为零。
最后,我们来看看perceptron_xor.py内部的非线性可分 XOR 函数:
# import the necessary packages
from pyimagesearch.nn import Perceptron
import numpy as np
# construct the XOR dataset
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
# define our perceptron and train it
print("[INFO] training perceptron...")
p = Perceptron(X.shape[1], alpha=0.1)
p.fit(X, y, epochs=20)
# now that our perceptron is trained we can evaluate it
print("[INFO] testing perceptron...")
# now that our network is trained, loop over the data points
for (x, target) in zip(X, y):
# make a prediction on the data point and display the result
# to our console
pred = p.predict(x)
print("[INFO] data={}, ground-truth={}, pred={}".format(
x, target[0], pred))
同样,唯一被修改的代码行是第 6 行和第 7 行,在那里我们定义了 XOR 数据。异或运算符为真当且仅当一(但不是两个) x 为一。
执行以下命令,我们可以看到感知器无法学习这种非线性关系:
$ python perceptron_xor.py
[INFO] training perceptron...
[INFO] testing perceptron...
[INFO] data=[0 0], ground-truth=0, pred=1
[INFO] data=[0 1], ground-truth=1, pred=1
[INFO] data=[1 0], ground-truth=1, pred=0
[INFO] data=[1 1], ground-truth=0, pred=0
无论你用不同的学习速率或不同的权重初始化方案运行这个实验多少次,你都永远不能用单层感知器正确地模拟异或函数。相反,我们需要的是更多层和非线性激活函数,随之而来的是深度学习的开始。
使用基本图像处理改进 OCR 结果
原文:https://pyimagesearch.com/2021/11/22/improving-ocr-results-with-basic-image-processing/
在我们的之前的教程中,您学习了如何通过提供适当的页面分割模式(PSM)来提高 Tesseract OCR 的准确性。PSM 允许您根据特定图像及其拍摄环境选择分割方法。
然而,有时改变 PSM 是不够的,相反,您需要使用一点计算机视觉和图像处理来清理图像,然后再将图像通过 Tesseract OCR 引擎。
要了解如何使用基本的图像处理来改善 OCR 结果, 继续阅读。
通过基本图像处理改善 OCR 结果
确切地说您使用哪种图像处理算法或技术在很大程度上取决于您的具体情况、项目要求和输入图像;然而,尽管如此,在进行光学字符识别之前,获得应用图像处理来清理图像的经验仍然很重要。
本教程将为您提供这样一个例子。然后,您可以使用此示例作为起点,通过 OCR 的基本图像处理来清理图像。
学习目标
在本教程中,您将:
- 了解基本图像处理如何显著提高 Tesseract OCR 的准确性
- 了解如何应用阈值、距离变换和形态学操作来清理图像
- 比较应用我们的图像处理程序之前的 OCR 准确度和之后的 T2
- 了解如何为您的特定应用构建图像处理管道
图像处理和镶嵌光学字符识别
我们将从回顾我们的项目目录结构开始本教程。从这里,我们将看到一个示例图像,其中无论 PSM 如何,Tesseract OCR 都无法正确地对输入图像进行 OCR。然后,我们将应用一些图像处理和 OpenCV 来预处理和清理输入,让 Tesseract 成功地对图像进行 OCR。最后,我们将学习在哪里可以提高你的计算机视觉技能,这样你就可以制作有效的图像处理管道,就像本教程中的一样。让我们开始吧!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本电脑将在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从回顾我们的项目目录结构开始:
|-- challenging_example.png
|-- process_image.py
这个项目涉及一个具有挑战性的例子图像,我收集的堆栈溢出(图 2 )。challenging_example.png全力以赴不能与宇宙魔方一起工作(即使有宇宙魔方 v4 的深度学习能力)。为了解决这个问题,我们将开发一个图像处理脚本process_image.py,为使用 Tesseract 的成功 OCR 准备图像。
当魔方本身无法对图像进行光学字符识别时
在本教程中,我们将对来自图 2 的图像进行光学字符识别。作为人类,我们可以很容易地看到这张图像包含文本“12-14,”,但对于计算机来说,它提出了几个挑战,包括:
- 复杂的纹理背景
- 背景不一致——左侧的明显比右侧的亮而右侧则更暗
- 背景中的文本有一点倾斜,这可能会使前景文本与背景难以分割
- 图像顶部有许多黑色斑点,这也增加了文本分割的难度
为了演示在当前状态下分割该图像有多困难,让我们将 Tesseract 应用于原始图像:
$ tesseract challenging_example.png stdout
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 169
使用默认的 PSM(--psm 3);全自动页面分割,但没有 OSD), Tesseract 完全无法对图像进行 OCR,返回空输出。
如果你要试验来自先前教程的各种 PSM 设置,你会看到返回任何输出的唯一 PSM 之一是--psm 8(将图像视为一个单词):
$ tesseract challenging_example.png stdout --psm 8
Warning: Invalid resolution 0 dpi. Using 70 instead.
T2eti@ce
不幸的是,不管 PSM 如何,Tesseract 完全无法按原样 OCR 这个图像,要么什么都不返回,要么完全是乱码。那么,在这种情况下我们该怎么办呢?我们是否将该图像标记为“无法进行 OCR ”,然后继续下一个项目?
没那么快——我们需要的只是一点图像处理。
实现用于 OCR 的图像处理流水线
在这一节中,我将向您展示一个使用 OpenCV 库的巧妙设计的图像处理管道如何帮助我们预处理和清理输入图像。结果将是更清晰的图像,Tesseract 可以正确地进行 OCR。
我通常不包括图像子步骤结果。我将在这里包括图像子步骤结果,因为我们将执行图像处理操作,改变图像在每个步骤中的外观。您将看到阈值处理、形态学操作等的子步骤图像结果。,所以你可以很容易地跟随。
如上所述,打开一个新文件,将其命名为process_image.py,并插入以下代码:
# import the necessary packages
import numpy as np
import pytesseract
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
args = vars(ap.parse_args())
导入我们的包之后,包括用于管道的 OpenCV 和用于 OCR 的 PyTesseract,我们解析输入的--image命令行参数。
现在让我们深入研究图像处理管道:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# threshold the image using Otsu's thresholding method
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
cv2.imshow("Otsu", thresh)
这里,我们加载输入--image并将其转换为灰度(第 15 行和第 16 行)。使用我们的gray图像,然后我们应用 Otsu 的自动阈值算法,如图图 3 ( 第 19 行和第 20 行)。假设我们已经通过cv2.THRESH_BINARY_INV标志反转了二进制阈值,我们希望进行 OCR 的文本现在是白色的(前景),我们开始看到部分背景被移除。
在我们的图像准备好进行 OCR 之前,我们还有许多路要走,所以让我们看看接下来会发生什么:
# apply a distance transform which calculates the distance to the
# closest zero pixel for each pixel in the input image
dist = cv2.distanceTransform(thresh, cv2.DIST_L2, 5)
# normalize the distance transform such that the distances lie in
# the range [0, 1] and then convert the distance transform back to
# an unsigned 8-bit integer in the range [0, 255]
dist = cv2.normalize(dist, dist, 0, 1.0, cv2.NORM_MINMAX)
dist = (dist * 255).astype("uint8")
cv2.imshow("Dist", dist)
# threshold the distance transform using Otsu's method
dist = cv2.threshold(dist, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv2.imshow("Dist Otsu", dist)
第 25 行使用 5 x 5 的maskSize对我们的thresh图像进行距离变换——这种计算确定了输入图像中每个像素到最近的 0 像素(黑色)的距离。随后,我们将dist归一化并缩放到范围[0, 255] ( 行 30 和 31 )。距离变换开始显示数字本身,因为从前景像素到背景有一个更大的距离。距离变换还有一个好处,就是可以清除图像背景中的大部分噪声。有关此转换的更多详细信息,请参考 OpenCV 文档。
从那里,我们再次应用 Otsu 的阈值方法,但是这次是应用到dist图(第 35 和 36 行)的结果显示在图 4 中。请注意,我们没有使用反向二进制阈值(我们已经丢弃了标志的_INV部分),因为我们希望文本保留在前景中(白色)。
*让我们继续清理我们的前景:
# apply an "opening" morphological operation to disconnect components
# in the image
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7, 7))
opening = cv2.morphologyEx(dist, cv2.MORPH_OPEN, kernel)
cv2.imshow("Opening", opening)
应用开放形态学操作(即,膨胀后腐蚀)断开连接的斑点并去除噪声(行 41 和 42 )。图 5 展示了我们的打开操作有效地将【1】字符从图像顶部(洋红色圆圈)的斑点中断开。
此时,我们可以从图像中提取轮廓,并对其进行过滤,以仅显示和数字:
# find contours in the opening image, then initialize the list of
# contours which belong to actual characters that we will be OCR'ing
cnts = cv2.findContours(opening.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
chars = []
# loop over the contours
for c in cnts:
# compute the bounding box of the contour
(x, y, w, h) = cv2.boundingRect(c)
# check if contour is at least 35px wide and 100px tall, and if
# so, consider the contour a digit
if w >= 35 and h >= 100:
chars.append(c)
在二值图像中提取轮廓意味着我们要找到所有孤立的前景斑点。第 47 行和第 48 行找到所有轮廓(包括字符和噪声)。
在我们找到轮廓(cnts)的所有后,我们需要确定哪些要丢弃哪些要添加到我们的角色列表中。第 53–60 行在cnts上循环,过滤掉至少 35 像素宽和 100 像素高的轮廓。通过测试的人将被添加到chars列表中。
现在我们已经隔离了我们的角色轮廓,让我们清理一下周围的区域:
# compute the convex hull of the characters
chars = np.vstack([chars[i] for i in range(0, len(chars))])
hull = cv2.convexHull(chars)
# allocate memory for the convex hull mask, draw the convex hull on
# the image, and then enlarge it via a dilation
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.drawContours(mask, [hull], -1, 255, -1)
mask = cv2.dilate(mask, None, iterations=2)
cv2.imshow("Mask", mask)
# take the bitwise of the opening image and the mask to reveal *just*
# the characters in the image
final = cv2.bitwise_and(opening, opening, mask=mask)
为了消除字符周围的所有斑点,我们:
- 计算将包围数字的所有(行 63 和 64 )的凸面
hull - 为一个
mask( 行 68 )分配内存 - 画出数字的凸起
hull(行 69 - 放大
mask( 线 70
这些凸包遮蔽操作的效果在图 6 ( 上)中描绘。通过线 75 计算opening和mask之间的按位 AND 清理我们的opening图像,并产生我们的final图像,该图像仅由数字组成,没有背景噪声图 6 (底部)。
这就是我们的图像处理流程——我们现在有了一个清晰的图像,可以很好地处理宇宙魔方。让我们执行 OCR 并显示结果:
# OCR the input image using Tesseract
options = "--psm 8 -c tessedit_char_whitelist=0123456789"
text = pytesseract.image_to_string(final, config=options)
print(text)
# show the final output image
cv2.imshow("Final", final)
cv2.waitKey(0)
使用我们从早期教程、中获得的关于宇宙魔方选项的知识,我们构建我们的options设置(第 78 行):
用我们的设置对图像进行 OCR 后(第 79 行,我们在终端上显示text,并在屏幕上保持所有管道步骤图像(包括final图像),直到按下一个键(第 83 和 84 行)。
基本图像处理和镶嵌 OCR 结果
让我们测试一下我们的图像处理程序。打开终端并启动process_image.py脚本:
$ python process_image.py --image challenging_example.png
1214
成功!通过使用一些基本的图像处理和 OpenCV 库,我们能够清理我们的输入图像,然后使用宇宙魔方正确地 OCR 它,即使宇宙魔方不能 OCR 原始输入图像!
总结
在本教程中,您了解到基本的图像处理可能是使用 Tesseract OCR 引擎获得足够 OCR 准确度的一个要求。
虽然在之前的教程中介绍的页面分割模式(PSM)在应用 Tesseract 时极其重要,但有时 PSM 本身不足以对图像进行 OCR。通常,当输入图像的背景复杂,并且 Tesseract 的基本分割方法无法正确地将前景文本从背景中分割出来时,就会出现这种情况。当这种情况发生时,你需要开始应用计算机视觉和图像处理来清理输入图像。
并非所有用于 OCR 的图像处理管道都是相同的。对于这个特殊的例子,我们可以结合使用阈值、距离变换和形态学操作。但是,您的示例图像可能需要针对这些操作或不同的图像处理操作进行额外的参数调整!
在我们的下一个教程中,您将学习如何使用拼写检查算法进一步改善 OCR 结果。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
利用 OpenCV 和 GPU 提高文本检测速度
原文:https://pyimagesearch.com/2022/03/14/improving-text-detection-speed-with-opencv-and-gpus/
在本教程中,您将学习使用 OpenCV 和 GPU 来提高文本检测速度。
本教程是关于使用 Python 进行 OCR 的 4 部分系列的最后一部分:
- 多栏表格 OCR
- OpenCV 快速傅立叶变换(FFT)用于图像和视频流中的模糊检测
- OCR 识别视频流
- 使用 OpenCV 和 GPU 提高文本检测速度(本教程)
学习如何用 OpenCV 和 GPU 提高文本检测速度, 继续阅读。
使用 OpenCV 和 GPU 提高文本检测速度
到目前为止,除了 EasyOCR 之外的所有内容都集中在我们的 CPU 上执行 OCR。但是如果我们可以在我们的 GPU 上应用 OCR 呢?由于许多最先进的文本检测和 OCR 模型都是基于深度学习的,难道这些模型不能在 GPU 上运行得更快更有效吗?
答案是是;他们绝对可以。
本教程将向您展示如何使用 NVIDIA GPU 在 OpenCV 的dnn(深度神经网络)模块上运行高效准确的场景文本检测器(EAST)模型。正如我们将看到的,我们的文本检测吞吐率接近三倍,从每秒~23帧(FPS)提高到惊人的~97 FPS!
在本教程中,您将:
- 了解如何使用 OpenCV 的
dnn模块在基于 NVIDIA CUDA 的 GPU 上运行深度神经网络 - 实现一个 Python 脚本来测试 CPU 和 GPU 上的文本检测速度
- 实现第二个 Python 脚本,这个脚本在实时视频流中执行文本检测
- 比较在 CPU 和 GPU 上运行文本检测的结果
通过 OpenCV 使用 GPU 进行 OCR
本教程的第一部分包括回顾我们的项目目录结构。
然后,我们将实现一个 Python 脚本,在 CPU 和 GPU 上对运行的文本检测进行基准测试。我们将运行这个脚本,并测量在 GPU 上运行文本检测对我们的 FPS 吞吐率有多大影响。
一旦我们测量了我们的 FPS 增加,我们将实现第二个 Python 脚本,这一个,在实时视频流中执行文本检测。
我们将讨论我们的结果来结束本教程。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们可以用 GPU 应用文本检测之前,我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
|-- pyimagesearch
| |-- __init__.py
| |-- east
| | |-- __init__.py
| | |-- east.py
|-- ../models
| |-- east
| | |-- frozen_east_text_detection.pb
-- images
| |-- car_wash.png
|-- text_detection_speed.py
|-- text_detection_video.py
在本教程中,我们将回顾两个 Python 脚本:
text_detection_speed.py:使用我们的images目录中的car_wash.png图像,在 CPU 和 GPU 上测试文本检测速度。text_detection_video.py:演示如何在你的 GPU 上执行实时文本检测。
实施我们的 OCR GPU 基准测试脚本
在使用我们的 GPU 实现实时视频流中的文本检测之前,让我们首先测试在我们的 CPU 上运行 EAST 检测模型与我们的 GPU 相比,我们获得了多少加速。
要找到答案,请打开我们项目目录中的text_detection_speed.py文件,让我们开始吧:
# import the necessary packages
from pyimagesearch.east import EAST_OUTPUT_LAYERS
import numpy as np
import argparse
import time
import cv2
第 2-6 行处理导入我们需要的 Python 包。我们需要 EAST 模型的输出层(行 2 )来获取文本检测输出。如果您需要复习这些输出值,请务必参考《使用 OpenCV、Tesseract 和 Python 的OCR:OCR 简介 一书。
接下来,我们有命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-e", "--east", required=True,
help="path to input EAST text detector")
ap.add_argument("-w", "--width", type=int, default=320,
help="resized image width (should be multiple of 32)")
ap.add_argument("-t", "--height", type=int, default=320,
help="resized image height (should be multiple of 32)")
ap.add_argument("-c", "--min-conf", type=float, default=0.5,
help="minimum probability required to inspect a text region")
ap.add_argument("-n", "--nms-thresh", type=float, default=0.4,
help="non-maximum suppression threshold")
ap.add_argument("-g", "--use-gpu", type=bool, default=False,
help="boolean indicating if CUDA GPU should be used")
args = vars(ap.parse_args())
--image命令行参数指定了我们将执行文本检测的输入图像的路径。
第 12-21 行然后指定东文本检测模型的命令行参数。
最后,我们有我们的--use-gpu命令行参数。默认情况下,我们将使用我们的 CPU。但是通过指定这个参数(并且假设我们有一个支持 CUDA 的 GPU 和 OpenCV 的dnn模块在 NVIDIA GPU 支持下编译),我们可以使用我们的 GPU 进行文本检测推断。
考虑到我们的命令行参数,我们现在可以加载 EAST text 检测模型,并设置我们是使用 CPU 还是 GPU:
# load the pre-trained EAST text detector
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
# check if we are going to use GPU
if args["use_gpu"]:
# set CUDA as the preferable backend and target
print("[INFO] setting preferable backend and target to CUDA...")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
# otherwise we are using our CPU
else:
print("[INFO] using CPU for inference...")
第 28 行从磁盘加载我们的 EAST 文本检测模型。
第 31-35 行检查是否提供了--use-gpu命令行参数,如果提供了,则表明我们想要使用我们的支持 NVIDIA CUDA 的 GPU。
注: 要使用你的 GPU 进行神经网络推理,你需要有 OpenCV 的dnn模块在 NVIDIA CUDA 支持下编译。OpenCV 的dnn模块没有通过 pip 安装的 NVIDIA 支持。相反,你需要用 GPU 支持显式编译 OpenCV。我们在 PyImageSearch 的 教程中介绍了如何做到这一点。
接下来,让我们从磁盘加载示例图像:
# load the input image and then set the new width and height values
# based on our command line arguments
image = cv2.imread(args["image"])
(newW, newH) = (args["width"], args["height"])
# construct a blob from the image, set the blob as input to the
# network, and initialize a list that records the amount of time
# each forward pass takes
print("[INFO] running timing trials...")
blob = cv2.dnn.blobFromImage(image, 1.0, (newW, newH),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
timings = []
第 43 行从磁盘加载我们的输入--image,而第 50 行和第 51 行构造一个blob对象,这样我们就可以将它传递给东方文本检测模型。
第 52 行将我们的blob设置为东方网络的输入,而第 53 行初始化一个timings列表以测量推断需要多长时间。
当使用 GPU 进行推理时,与其余预测相比,您的第一个预测往往非常慢,原因是您的 GPU 尚未“预热”。因此,在您的 GPU 上进行测量时,您通常希望获得几次预测的平均值。
在下面的代码块中,我们对500试验执行文本检测,记录每个预测需要多长时间:
# loop over 500 trials to obtain a good approximation to how long
# each forward pass will take
for i in range(0, 500):
# time the forward pass
start = time.time()
(scores, geometry) = net.forward(EAST_OUTPUT_LAYERS)
end = time.time()
timings.append(end - start)
# show average timing information on text prediction
avg = np.mean(timings)
print("[INFO] avg. text detection took {:.6f} seconds".format(avg))
在所有试验完成后,我们计算timings的平均值,然后在终端上显示我们的平均文本检测时间。
速度测试:有无 GPU 的 OCR
现在让我们在没有 GPU(即运行在 CPU 上)的情况下测量我们的 EAST text detection FPS 吞吐率:
$ python text_detection_speed.py --image images/car_wash.png --east ../models/east/frozen_east_text_detection.pb
[INFO] loading EAST text detector...
[INFO] using CPU for inference...
[INFO] running timing trials...
[INFO] avg. text detection took 0.108568 seconds
我们的平均文本检测速度是~0.1秒,相当于~9-10 FPS。在 CPU 上运行的深度学习模型对于许多应用来说是快速且足够的。
然而,就像 20 世纪 90 年代电视剧《T2 家装》中的蒂姆·泰勒(由《玩具总动员》中的蒂姆·艾伦饰演),说的那样,“更强大!”
现在让我们来看看 GPU:
$ python text_detection_speed.py --image images/car_wash.png --east ../models/east/frozen_east_text_detection.pb --use-gpu 1
[INFO] loading EAST text detector...
[INFO] setting preferable backend and target to CUDA...
[INFO] running timing trials...
[INFO] avg. text detection took 0.004763 seconds
使用 NVIDIA V100 GPU,我们的平均帧处理速率降至~0.004秒,这意味着我们现在可以处理~250 FPS!如你所见,使用你的 GPU 带来了实质性的差异!
在 GPU 上对实时视频流进行 OCR
准备好使用您的 GPU 实现我们的脚本来执行实时视频流中的文本检测了吗?
打开项目目录中的text_detection_video.py文件,让我们开始吧:
# import the necessary packages
from pyimagesearch.east import EAST_OUTPUT_LAYERS
from pyimagesearch.east import decode_predictions
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import time
import cv2
第 2-10 行导入我们需要的 Python 包。EAST_OUTPUT_LAYERS和decode_predictions函数来自我们在教程 OpenCV 文本检测中实现的东方文本检测器。如果您需要复习 EAST 检测模型,请务必复习该课程。
第 4 行导入我们的VideoStream来访问我们的网络摄像头,而第 5 行提供我们的FPS类来测量我们流水线的 FPS 吞吐率。
现在让我们继续我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str,
help="path to optional input video file")
ap.add_argument("-e", "--east", required=True,
help="path to input EAST text detector")
ap.add_argument("-w", "--width", type=int, default=320,
help="resized image width (should be multiple of 32)")
ap.add_argument("-t", "--height", type=int, default=320,
help="resized image height (should be multiple of 32)")
ap.add_argument("-c", "--min-conf", type=float, default=0.5,
help="minimum probability required to inspect a text region")
ap.add_argument("-n", "--nms-thresh", type=float, default=0.4,
help="non-maximum suppression threshold")
ap.add_argument("-g", "--use-gpu", type=bool, default=False,
help="boolean indicating if CUDA GPU should be used")
args = vars(ap.parse_args())
这些命令行参数与前面的命令行参数几乎相同。唯一的例外是我们用一个--input参数替换了--image命令行参数,该参数指定了磁盘上可选视频文件的路径(以防万一我们想要使用视频文件而不是我们的网络摄像头)。
接下来,我们进行一些初始化:
# initialize the original frame dimensions, new frame dimensions,
# and ratio between the dimensions
(W, H) = (None, None)
(newW, newH) = (args["width"], args["height"])
(rW, rH) = (None, None)
在这里,我们初始化我们的原始框架的宽度和高度,东方模型的新框架尺寸,随后是原始和新尺寸之间的比率。
下一个代码块处理从磁盘加载 EAST text 检测模型,然后设置我们是使用 CPU 还是 GPU 进行推理:
# load the pre-trained EAST text detector
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
# check if we are going to use GPU
if args["use_gpu"]:
# set CUDA as the preferable backend and target
print("[INFO] setting preferable backend and target to CUDA...")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
# otherwise we are using our CPU
else:
print("[INFO] using CPU for inference...")
我们的文本检测模型需要帧来操作,所以下一个代码块访问我们的网络摄像头或驻留在磁盘上的视频文件,这取决于是否提供了--input命令行参数:
# if a video path was not supplied, grab the reference to the webcam
if not args.get("input", False):
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(1.0)
# otherwise, grab a reference to the video file
else:
vs = cv2.VideoCapture(args["input"])
# start the FPS throughput estimator
fps = FPS().start()
Line 62 开始测量我们的 FPS 吞吐率,以了解我们的文本检测管道在一秒钟内可以处理的帧数。
现在让我们开始循环视频流中的帧:
# loop over frames from the video stream
while True:
# grab the current frame, then handle if we are using a
# VideoStream or VideoCapture object
frame = vs.read()
frame = frame[1] if args.get("input", False) else frame
# check to see if we have reached the end of the stream
if frame is None:
break
# resize the frame, maintaining the aspect ratio
frame = imutils.resize(frame, width=1000)
orig = frame.copy()
# if our frame dimensions are None, we still need to compute the
# ratio of old frame dimensions to new frame dimensions
if W is None or H is None:
(H, W) = frame.shape[:2]
rW = W / float(newW)
rH = H / float(newH)
第 68 和 69 行从我们的网络摄像头或视频文件中读取下一个frame。
如果我们确实在处理一个视频文件,行 72 检查我们是否在视频的末尾,如果是,我们break退出循环。
第 81-84 行获取输入frame的空间尺寸,然后计算原始帧尺寸与 EAST 模型所需尺寸的比率。
现在我们已经有了这些维度,我们可以构造我们对东方文本检测器的输入:
# construct a blob from the image and then perform a forward pass
# of the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(frame, 1.0, (newW, newH),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
(scores, geometry) = net.forward(EAST_OUTPUT_LAYERS)
# decode the predictions from OpenCV's EAST text detector and
# then apply non-maximum suppression (NMS) to the rotated
# bounding boxes
(rects, confidences) = decode_predictions(scores, geometry,
minConf=args["min_conf"])
idxs = cv2.dnn.NMSBoxesRotated(rects, confidences,
args["min_conf"], args["nms_thresh"])
第 88-91 行从输入frame构建blob。然后,我们将这个blob设置为我们的东文本检测net的输入。执行网络的前向传递,产生我们的原始文本检测。
然而,我们的原始文本检测在我们的当前状态下是不可用的,所以我们对它们调用decode_predictions,产生文本检测的边界框坐标以及相关概率的二元组(行 96 和 97 )。
然后,我们应用非最大值抑制来抑制弱的、重叠的边界框(否则,每个检测将有多个边界框)。
如果您需要关于这个代码块的更多细节,包括如何实现decode_predictions函数,请务必查看 OpenCV 文本检测,在那里我将更详细地介绍东方文本检测器。
在非最大值抑制(NMS)之后,我们现在可以在每个边界框上循环:
# ensure that at least one text bounding box was found
if len(idxs) > 0:
# loop over the valid bounding box indexes after applying NMS
for i in idxs.flatten():
# compute the four corners of the bounding box, scale the
# coordinates based on the respective ratios, and then
# convert the box to an integer NumPy array
box = cv2.boxPoints(rects[i])
box[:, 0] *= rW
box[:, 1] *= rH
box = np.int0(box)
# draw a rotated bounding box around the text
cv2.polylines(orig, [box], True, (0, 255, 0), 2)
# update the FPS counter
fps.update()
# show the output frame
cv2.imshow("Text Detection", orig)
key = cv2.waitKey(1) & 0xFF
# if the 'q' key was pressed, break from the loop
if key == ord("q"):
break
第 102 行验证至少找到了一个文本边界框,如果是,我们在应用 NMS 后循环遍历保留的边界框的索引。
对于每个结果索引,我们计算文本 ROI 的边界框,将边界框 (x,y)-坐标缩放回orig输入帧尺寸,然后在orig帧上绘制边界框(第 108-114 行)。
第 117 行更新我们的 FPS 吞吐量估算器,而第 120-125 行在我们的屏幕上显示输出文本检测。
这里的最后一步是停止我们的 FPS 时间,估算吞吐率,并释放任何视频文件指针:
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# if we are using a webcam, release the pointer
if not args.get("input", False):
vs.stop()
# otherwise, release the file pointer
else:
vs.release()
# close all windows
cv2.destroyAllWindows()
第 128-130 行停止我们的 FPS 定时器并逼近我们的文本检测流水线的 FPS。然后,我们释放所有视频文件指针,关闭 OpenCV 打开的所有窗口。
GPU 和 OCR 结果
这一部分需要在配有 GPU 的机器上本地执行。在 NVIDIA RTX 2070 超级 GPU(配有 i9 9900K 处理器)上运行text_detection_video.py脚本后,我获得了~97 FPS:
$ python text_detection_video.py --east ../models/east/frozen_east_text_detection.pb --use-gpu 1
[INFO] loading EAST text detector...
[INFO] setting preferable backend and target to CUDA...
[INFO] starting video stream...
[INFO] elapsed time: 74.71
[INFO] approx. FPS: 96.80
当我在不使用任何 GPU 的情况下运行同样的脚本时,我达到了~23的 FPS,比上面的结果慢了~77%。**
$ python text_detection_video.py --east ../models/east/frozen_east_text_detection.pb
[INFO] loading EAST text detector...
[INFO] using CPU for inference...
[INFO] starting video stream...
[INFO] elapsed time: 68.59
[INFO] approx. FPS: 22.70
如你所见,使用你的 GPU 可以显著提高你的文本检测管道的吞吐速度!
总结
在本教程中,您学习了如何使用 GPU 在实时视频流中执行文本检测。由于许多文本检测和 OCR 模型都是基于深度学习的,因此使用 GPU(而不是 CPU)可以极大地提高帧处理吞吐率。
使用我们的 CPU,我们能够处理~22-23 FPS。然而,通过在 OpenCV 的dnn模块上运行 EAST 模型,我们可以达到~97 FPS!
如果你有可用的 GPU,一定要考虑利用它——你将能够实时运行文本检测模型!
引用信息
Rosebrock,A. “使用 OpenCV 和 GPU 提高文本检测速度”, PyImageSearch ,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki,eds .,2022 年,【https://pyimg.co/9wde6
@incollection{Rosebrock_2022_Improving_Text,
author = {Adrian Rosebrock},
title = {Improving Text Detection Speed with {OpenCV} and {GPUs}},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/9wde6},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
使用 Python 和 OpenCV 增加 Raspberry Pi FPS
原文:https://pyimagesearch.com/2015/12/28/increasing-raspberry-pi-fps-with-python-and-opencv/
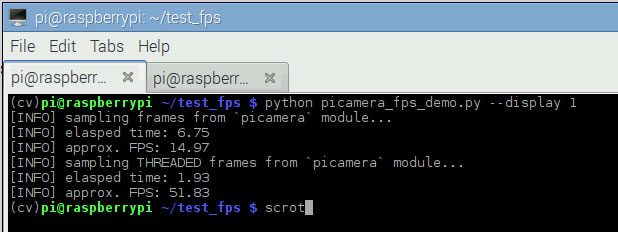
今天是我们关于从你的网络摄像头或树莓派相机中榨取最后一点性能的系列文章的第二篇。
上周我们讨论了如何:
- 提高我们视频处理管道的 FPS 速率。
- 使用线程减少 I/O 延迟对标准 USB 和内置网络摄像头的影响。
本周我们将继续利用线程来提高 Raspberry Pi 的 FPS/延迟,使用T2 模块和 USB 网络摄像头。
我们将会发现,线程化可以显著降低我们的 I/O 延迟,从而大幅提高我们流水线的 FPS 处理速率。
https://www.youtube.com/embed/-VXMgvabKG8?feature=oembed
使用 Python 和 OpenCV 提高网络摄像头的 FPS
原文:https://pyimagesearch.com/2015/12/21/increasing-webcam-fps-with-python-and-opencv/
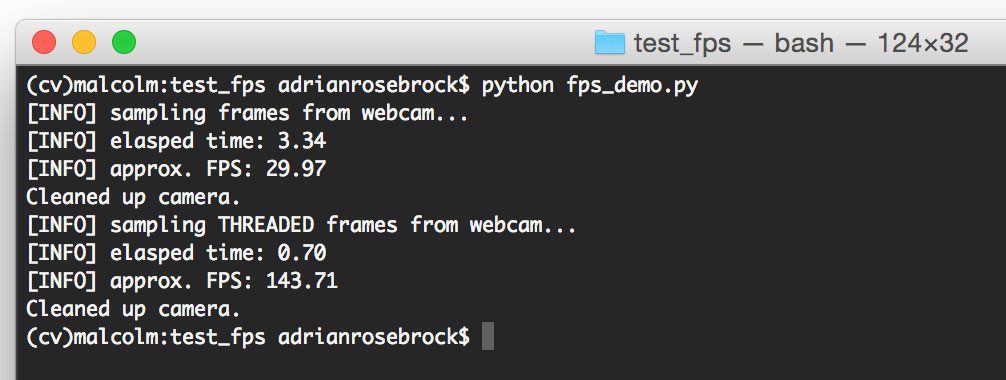
在接下来的几周里,我会写一系列博客文章,讲述如何使用 Python、OpenCV 和线程技术 提高你的网络摄像头 的每秒帧数(FPS)。
使用线程处理 I/O 繁重的任务(例如从相机传感器读取帧)是一种已经存在了几十年的编程模型。
例如,如果我们要构建一个网络爬虫来抓取一系列网页(根据定义,这是一个任务, I/O 绑定),我们的主程序将产生多个线程来处理并行下载一组页面,而不是仅仅依靠单线程(我们的“主线程”)来按照顺序下载页面。这样做可以让我们更快地抓取网页。
同样的概念也适用于计算机视觉和从相机读取帧— 我们可以简单地通过创建一个新线程来提高我们的 FPS,这个新线程除了轮询相机以获取新帧之外什么也不做,而我们的主线程则处理当前帧。
这是一个简单的概念,但在 OpenCV 示例中很少见到,因为它确实给项目增加了几行额外的代码(或者有时是许多行,这取决于您的线程库)。多线程也可能使你的程序更难调试,但是一旦你做对了,你就可以极大地提高你的 FPS。
我们将通过编写一个线程化的 Python 类来使用 OpenCV 访问您的网络摄像头或 USB 摄像头,从而开始这一系列的帖子。
下周我们将使用线程来提高你的 Raspberry Pi 和 picamera 模块的 FPS。
最后,我们将通过创建一个类来结束这一系列帖子,该类将线程化网络摄像头/USB 摄像头代码和线程化代码picamera统一到一个 单个类 ,使得 PyImageSearch 上的所有网络摄像头/视频处理示例不仅运行更快、,而且可以在您的笔记本电脑/台式机或 Raspberry Pi 上运行,而无需更改一行代码!
使用线程来获得更高的 FPS
使用 OpenCV 处理视频流时获得更高 FPS 的“秘密”是将 I/O(即从相机传感器读取帧)移动到一个单独的线程。
你看,使用cv2.VideoCapture功能和.read()方法访问你的网络摄像头/USB 摄像头是一个 阻塞操作 。我们的 Python 脚本的主线程被完全阻塞(即“停止”),直到从相机设备读取帧并将其返回给我们的脚本。
与 CPU 限制的操作相反,I/O 任务往往非常慢。虽然计算机视觉和视频处理应用程序肯定会占用大量 CPU 资源(特别是如果它们打算实时运行的话),但事实证明相机 I/O 也可能是一个巨大的瓶颈。
正如我们将在本文后面看到的,仅仅通过调整相机 I/O 过程, 我们就可以将我们的 FPS 提高 379%!
当然,这不是 FPS 的真正增加,因为它是延迟的显著减少(即,一帧总是可用于处理;我们不需要轮询相机设备并等待 I/O 完成)。在这篇文章的其余部分,为了简洁起见,我将我们的指标称为“FPS 增加”,但也要记住,这是延迟减少和 FPS 增加的组合。
为了实现这种 FPS 增加/延迟减少,我们的目标是将从网络摄像头或 USB 设备读取帧转移到一个完全不同的线程,与我们的主 Python 脚本完全分离。
这将允许从 I/O 线程连续不断地读取帧,同时我们的根线程处理当前帧。一旦根线程处理完它的帧,它只需要从 I/O 线程获取当前帧。这是在无需等待阻塞 I/O 操作的情况下完成的。
实现我们的线程视频流功能的第一步是定义一个FPS类,我们可以用它来测量我们的每秒帧数。这个课程将帮助我们获得线程化确实增加 FPS 的定量证据。
然后我们将定义一个WebcamVideoStream类,它将以线程方式访问我们的网络摄像头或 USB 摄像头。
最后,我们将定义我们的驱动程序脚本fps_demo.py,它将比较单线程 FPS 和多线程 FPS。
注:感谢罗斯·米利根和他的博客启发了我写这篇博文。
使用 Python 和 OpenCV 提高网络摄像头的 FPS
我实际上已经在 imutils 库中实现了网络摄像头/USB 摄像头和picamera线程。然而,我认为对实现的讨论可以极大地提高我们对如何和为什么线程化增加 FPS 的认识。
首先,如果您还没有安装imutils,您可以使用pip来安装它:
$ pip install imutils
否则,您可以通过以下方式升级到最新版本:
$ pip install --upgrade imutils
正如我上面提到的,第一步是定义一个FPS类,我们可以用它来估算给定相机+计算机视觉处理流水线的每秒帧数:
# import the necessary packages
import datetime
class FPS:
def __init__(self):
# store the start time, end time, and total number of frames
# that were examined between the start and end intervals
self._start = None
self._end = None
self._numFrames = 0
def start(self):
# start the timer
self._start = datetime.datetime.now()
return self
def stop(self):
# stop the timer
self._end = datetime.datetime.now()
def update(self):
# increment the total number of frames examined during the
# start and end intervals
self._numFrames += 1
def elapsed(self):
# return the total number of seconds between the start and
# end interval
return (self._end - self._start).total_seconds()
def fps(self):
# compute the (approximate) frames per second
return self._numFrames / self.elapsed()
在第 5-10 行我们定义了FPS类的构造函数。我们不需要任何参数,但是我们初始化了三个重要的变量:
_start:我们开始测量帧读取的起始时间戳。_end:我们停止测量帧读取的结束时间戳。_numFrames:在_start和_end间隔内读取的总帧数。
第 12-15 行定义了start方法,顾名思义,它启动计时器。
类似地,第 17-19 行定义了获取结束时间戳的stop方法。
行 21-24 上的update方法只是增加在开始和结束间隔期间已经读取的帧数。
我们可以通过使用elapsed方法来获取第 26-29 行上的开始和结束间隔之间经过的总秒数。
最后,我们可以通过在第 31-33 行的上使用fps方法来近似我们的摄像机+计算机视觉流水线的 FPS。通过获取间隔期间读取的总帧数并除以经过的秒数,我们可以获得估计的 FPS。
现在我们已经定义了我们的FPS类(这样我们可以根据经验比较结果),让我们定义包含实际线程摄像机读取的WebcamVideoStream类:
# import the necessary packages
from threading import Thread
import cv2
class WebcamVideoStream:
def __init__(self, src=0):
# initialize the video camera stream and read the first frame
# from the stream
self.stream = cv2.VideoCapture(src)
(self.grabbed, self.frame) = self.stream.read()
# initialize the variable used to indicate if the thread should
# be stopped
self.stopped = False
我们在第 6 行的上为我们的WebcamVideoStream类定义构造函数,传入一个(可选的)参数:流的src。
如果src是一个整数,那么它被假定为您系统上网络摄像头/USB 摄像头的索引。例如,src=0的值表示第个摄像头,src=1的值表示连接到您系统的第个摄像头(当然,前提是您有第二个)。
如果src是一个字符串,那么它被假定为一个视频文件的路径(比如. mp4 或者。avi)驻留在磁盘上。
第 9 行获取我们的src值并调用cv2.VideoCapture,后者返回一个指向摄像机/视频文件的指针。
现在我们有了我们的stream指针,我们可以调用.read()方法来轮询流并获取下一个可用的帧(第 10 行)。这样做完全是为了初始化的目的,所以我们在类中存储了一个初始帧。
我们还将初始化stopped,这是一个布尔值,表示线程化的帧读取是否应该停止。
现在,让我们继续使用 OpenCV,利用线程从视频流中读取帧:
def start(self):
# start the thread to read frames from the video stream
Thread(target=self.update, args=()).start()
return self
def update(self):
# keep looping infinitely until the thread is stopped
while True:
# if the thread indicator variable is set, stop the thread
if self.stopped:
return
# otherwise, read the next frame from the stream
(self.grabbed, self.frame) = self.stream.read()
def read(self):
# return the frame most recently read
return self.frame
def stop(self):
# indicate that the thread should be stopped
self.stopped = True
第 16-19 行定义了我们的start方法,顾名思义,它启动线程从我们的视频流中读取帧。我们通过使用线程的run()方法调用的update方法作为可调用对象来构建一个Thread对象来实现这一点。
一旦我们的驱动脚本调用了WebcamVideoStream类的start方法,就会调用update方法(第 21-29 行)。
从上面的代码中可以看出,我们在第 23 行的上开始了一个无限循环,它通过.read()方法(第 29 行)从视频stream中连续读取下一个可用帧。如果stopped指示器变量被设置,我们就从无限循环中脱离出来(第 25 行和第 26 行)。
再次请记住,一旦调用了start方法,update方法就被放置在一个与我们的主 Python 脚本——分开的线程中,这个分开的线程就是我们如何获得增加的 FPS 性能的。
为了从stream访问最近轮询的frame,我们将在的第 31-33 行上使用read方法。
最后,stop方法(第 35-37 行)简单地设置了stopped指示器变量,并表示线程应该被终止。
现在我们已经定义了我们的FPS和WebcamVideoStream类,我们可以把所有的部分放在fps_demo.py中:
# import the necessary packages
from __future__ import print_function
from imutils.video import WebcamVideoStream
from imutils.video import FPS
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--num-frames", type=int, default=100,
help="# of frames to loop over for FPS test")
ap.add_argument("-d", "--display", type=int, default=-1,
help="Whether or not frames should be displayed")
args = vars(ap.parse_args())
我们从在2-7 号线进口必要的包装开始。注意我们是如何从 imutils 库中导入FPS和WebcamVideoStream类的。如果您没有安装imutils或者您需要升级到最新版本,请参见本节顶部的注释。
第 10-15 行处理解析我们的命令行参数。这里我们需要两个开关:--num-frames,它是循环获得我们的 FPS 估计的帧数,和--display,一个指示变量,用来指定我们是否应该使用cv2.imshow函数在我们的监视器上显示帧。
在估算视频处理管道的 FPS 时,--display参数实际上非常重要。就像从视频流中读取帧是 I/O 的一种形式一样,将帧显示到您的显示器上也是如此!我们将在本帖的线程结果部分详细讨论这个问题。
让我们继续下一个代码块,它不执行线程并在从摄像机流中读取帧时使用阻塞 I/O 。这段代码将帮助我们获得 FPS 的基线:
# grab a pointer to the video stream and initialize the FPS counter
print("[INFO] sampling frames from webcam...")
stream = cv2.VideoCapture(0)
fps = FPS().start()
# loop over some frames
while fps._numFrames < args["num_frames"]:
# grab the frame from the stream and resize it to have a maximum
# width of 400 pixels
(grabbed, frame) = stream.read()
frame = imutils.resize(frame, width=400)
# check to see if the frame should be displayed to our screen
if args["display"] > 0:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
stream.release()
cv2.destroyAllWindows()
第 19 和 20 行抓取一个指向我们视频流的指针,然后启动 FPS 计数器。
然后我们在行 23 上循环所需的帧数,从摄像机中读取帧(行 26 ),更新我们的 FPS 计数器(行 35 ),并可选地在我们的监视器上显示帧(行 30-32 )。
在我们从流中读取了--num-frames之后,我们停止 FPS 计数器,并在的第 38-40 行显示经过的时间和大概的 FPS。
现在,让我们看看从视频流中读取帧的线程化代码:
# created a *threaded* video stream, allow the camera sensor to warmup,
# and start the FPS counter
print("[INFO] sampling THREADED frames from webcam...")
vs = WebcamVideoStream(src=0).start()
fps = FPS().start()
# loop over some frames...this time using the threaded stream
while fps._numFrames < args["num_frames"]:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# check to see if the frame should be displayed to our screen
if args["display"] > 0:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
总的来说,这段代码看起来与上面的代码块几乎相同,只是这次我们利用了WebcamVideoStream类。
我们在行 49 上启动线程流,在行 53-65 上循环所需数量的帧(再次记录读取的总帧数),然后在行 69 和 70 上显示我们的输出。
线程结果
要查看网络摄像头 I/O 线程的效果,只需执行以下命令:
$ python fps_demo.py
Figure 1: By using threading with Python and OpenCV, we are able to increase our FPS by over 379%!
正如我们所见,通过在 Python 脚本的主线程中不使用线程并顺序读取视频流中的帧,我们能够获得可观的 29.97 FPS。
然而,一旦我们切换到使用线程摄像机 I/O ,我们就达到了 143.71 FPS — ,增加了超过 379%!
这显然是我们延迟的巨大减少和 FPS 的巨大增加,这仅仅是通过使用线程实现的。
然而,正如我们即将发现的,使用cv2.imshow可以大幅降低我们的 FPS。仔细想想,这种行为是有意义的——cv2.show函数只是另一种形式的 I/O,只是这次我们不是从视频流中读取帧,而是将帧发送到显示器上输出。
注意: 我们在这里也使用了cv2.waitKey(1)函数,它给我们的主循环增加了 1 毫秒的延迟。也就是说,这个函数对于键盘交互和在屏幕上显示帧是必要的(尤其是在我们学习 Raspberry Pi 线程课程之后)。
要演示cv2.imshow I/O 如何降低 FPS,只需发出以下命令:
$ python fps_demo.py --display 1
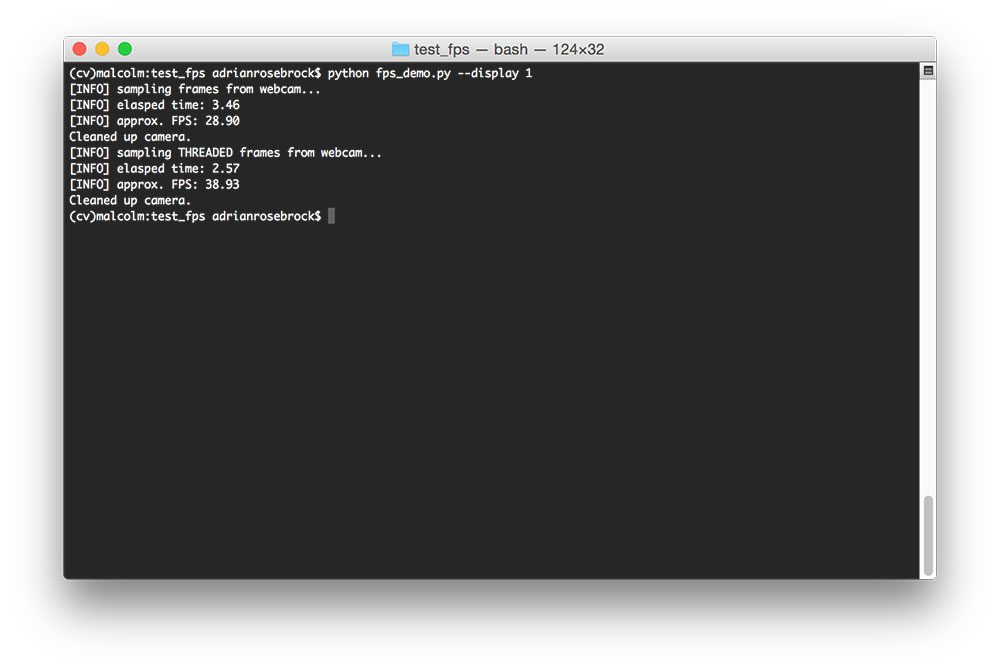
Figure 2: Using the cv2.imshow function can reduce our FPS — it is another form of I/O, after all!
使用无线程,我们达到 28.90 FPS。而用线程我们达到了 39.93 FPS。这仍然是 FPS 的 38%的增长,但是与我们之前例子中的 379%的增长相差甚远。
总的来说,我推荐使用cv2.imshow函数来帮助调试你的程序——但是如果你的最终产品代码不需要它,就没有理由包含它,因为你会损害你的 FPS。
这种程序的一个很好的例子是开发一个家庭监控运动探测器,它向你发送一条包含刚走进你家前门的人的照片的 txt 消息。实际上,你不需要cv2.imshow函数来完成这个任务。通过移除它,您可以提高运动检测器的性能,并允许它更快地处理更多帧。
摘要
在这篇博文中,我们了解了如何使用 Python 和 OpenCV,利用线程来提高网络摄像头和 USB 摄像头的 FPS。
正如这篇文章中的例子所展示的,我们能够简单地通过使用线程来获得 379%的 FPS 提升。虽然这不一定是一个公平的比较(因为我们可能会多次处理同一个帧),但它确实证明了减少延迟并始终为处理准备好一个帧的重要性。
在几乎所有情况下,使用线程访问您的网络摄像头可以显著改善您的视频处理流程。
下周我们将学习如何使用 picamera 模块增加我们的树莓 Pi 的 FPS。
请务必在下表中输入您的电子邮件地址,以便在下一篇帖子发布时收到通知!【T2
安装 dlib(简单完整的指南)
原文:https://pyimagesearch.com/2018/01/22/install-dlib-easy-complete-guide/

dlib 的最新版本很特别。
它完全消除了对 boost.python 的依赖,使其更容易在 macOS、Ubuntu 和 Raspbian 上全面安装。
**多亏了Davis King(dlib 库的创建者和维护者)和 Mischan Toos-Haus (负责移除 boost.python 依赖)的工作,我们现在可以:
- 轻松利用所有 Python + dlib 功能(面部检测、面部标志、相关性跟踪等。)…
- …依赖性更低,安装过程更简单。
在今天的博文中,我将提供安装 dlib 的说明:
- 马科斯
- 人的本质
- Raspbian (Raspberry Pi 的操作系统)
这些安装说明是完整的、简单的、易于遵循的,并且将在几分钟内让您开始使用 dlib + Python 绑定。
要了解如何在您的系统上安装 dlib,继续阅读!
安装 dlib(简单完整的指南)
在本指南中,您将学习如何在 macOS、Ubuntu 和 Raspbian 上安装 dlib。请随意跳到与您的操作系统对应的部分。
一旦您在各自的操作系统上安装了 dlib,我们将使用 Python、dlib 和 OpenCV ( 假设您也安装了 OpenCV)来验证安装,以检测面部标志。
从那时起,我提供了额外的教程和指南,以帮助将 dlib 应用于计算机视觉和机器学习项目,包括检测和计数眨眼以及建立一个系统来识别车辆驾驶员何时变得困倦/疲劳(并提醒他们醒来)。
在 macOS 上安装 dlib
我假设您已经在 macOS 机器上安装了 XCode。如果没有,请花时间打开 App Store,安装 XCode。
从那里,你需要安装 Homebrew,一个 macOS 的软件包管理器,类似于 Debian/Ubuntu 的apt-get:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew update
注意:确保使用上面代码块中的< >按钮来展开部分——这将确保您复制并粘贴整个自制软件安装命令。**
**一旦安装了自制软件,你需要更新你的PATH来寻找自制软件的二进制文件、包和库。这可以通过使用编辑器(如 nano、vi 等)手动编辑文件来完成。或者简单地使用echo和重定向:
$ echo -e "\n# Homebrew" >> ~/.bash_profile
$ echo "export PATH=/usr/local/bin:$PATH" >> ~/.bash_profile
然后,您需要source这个~/.bash_profile文件来重新加载更改:
$ source ~/.bash_profile
然后我们将安装cmake(一个用于构建、测试和打包软件的工具)以及 Python 2.7 和 Python 3:
$ brew install cmake
$ brew install python python3
您可以使用which来验证 Python 2.7 和 Python 3 是否已经成功安装:
$ which python2
/usr/local/bin/python2
$ which python3
/usr/local/bin/python3
这里有两个关键点你需要注意。
首先,您希望确保两个 Python 二进制文件的根路径都在/usr/local/bin中——这是 Homebrew 存储 Python 二进制文件的地方。
如果您的根路径改为/usr/bin,那么您正在利用系统 Python 安装。我们想避免使用系统 Python 安装,所以如果你看到的是/usr/bin而不是/usr/local/bin,那么很可能是由于更新你的~/.bash_profile时出错(确保你返回并确保文件已被正确更新;这可能需要手动打开和编辑文件)。
要考察的第二个关键点是 Python 二进制本身:python2和python3。注意我们是如何而不是执行只是 python — 而不是明确提供版本。
这是因为 Homebrew 现在处理 Python 安装的方式。在旧版本的 Homebrew 中,Homebrew 会自动将python命令别名为 Python 2.7 或 Python 3 — 这种情况不再存在。相反,我们需要明确地提供 Python 版本号。
这个名字对于pip来说也是真实的:我们现在使用pip2和pip3。
接下来,让我们准备我们的 Python 环境。
如果您正在使用 Python 虚拟环境(如果您遵循了我的任何 OpenCV 安装教程,您可能正在使用它们),您可以为 dlib 安装创建一个新的 Python 虚拟环境:
$ mkvirtualenv dlib_test -p python3
或者访问一个现有的:
$ workon cv
使用 Python 虚拟环境完全是可选的,但是 强烈推荐 ,因为 Python 虚拟环境是 Python 开发的最佳实践。要了解更多关于 Python 虚拟环境的知识(以及如何使用它们)请参考我的 OpenCV 安装教程,在那里它们有广泛的介绍。
从那里,我们可以安装 NumPy (dlib 唯一的 Python 依赖项),然后安装 dlib 库本身:
$ pip install numpy
$ pip install dlib
如果你是使用 Python 虚拟环境的而不是,你需要将pip命令更新为pip2或pip3。如果你用的是 Python 2.7,用pip2代替pip。类似地,如果你正在使用 Python 3,用pip3代替pip。
从那里,启动 Python shell 并验证 dlib 的安装:
(dlib_test) DU481:~ admin$ python
Python 3.6.4 (default, Jan 6 2018, 11:51:15)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>> dlib.__version__
'19.8.2'
>>>

Figure 1: Successfully installing dlib on macOS.
在 Ubuntu 上安装 dlib
以下说明是在 Ubuntu 16.04 上收集的,但应该也适用于较新版本的 Ubuntu。
首先,让我们安装所需的依赖项:
$ sudo apt-get update
$ sudo apt-get install build-essential cmake
$ sudo apt-get install libopenblas-dev liblapack-dev
$ sudo apt-get install libx11-dev libgtk-3-dev
$ sudo apt-get install python python-dev python-pip
$ sudo apt-get install python3 python3-dev python3-pip
我提供了一些关于您应该考虑的依赖项的注释:
- 我们正在 dlib 中安装 GTK 和 X11 的 GUI 功能。如果你不关心 GUI 功能,这些库可以跳过,节省 100-200MB 的空间。
- 我们为线性代数优化安装了 OpenBLAS,这允许 dlib 功能执行得更快。从技术上来说,你也可以跳过这一步,但是我强烈建议你安装 OpenBLAS,因为它的优化非常重要。
接下来,让我们为 dlib 安装准备 Python 环境。
如果您正在使用 Python 虚拟环境(如果您遵循了我的任何 OpenCV 安装教程,您可能正在使用它们),您可以为 dlib 安装创建一个新的 Python 虚拟环境:
$ mkvirtualenv dlib_test -p python3
或者访问一个现有的:
$ workon cv
使用 Python 虚拟环境完全是可选的,但是 强烈推荐 ,因为 Python 虚拟环境是 Python 开发的最佳实践。要了解更多关于 Python 虚拟环境的知识(以及如何使用它们)请参考我的 OpenCV 安装教程,在那里它们有广泛的介绍。
然后,您可以在 Ubuntu 系统上安装 dlib:
$ pip install numpy
$ pip install dlib
如果使用 Python 虚拟环境的是而不是,请确保将sudo添加到pip install命令的开头(否则pip install命令将由于权限错误而失败)。此外,记住pip用于安装 Python 2.7 的包,而pip3用于 Python 3。根据您想要安装 dlib 的 Python 版本,您可能需要更新上面的pip命令。
最后,打开 Python shell,通过导入dlib库来验证您在 Ubuntu 上的 dlib 安装:
(dlib_test) ubuntu@ip-172-31-12-187:~$ python
Python 3.5.2 (default, Nov 23 2017, 16:37:01)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>> dlib.__version__
'19.8.2'
>>>

Figure 2: Installing dlib on Ubuntu (Note: I was SSH’d into an Ubuntu machine in the Amazon EC2 cloud from my macOS machine when taking this screenshot, hence why the screenshot looks like the macOS GUI).
在 Raspberry Pi/Raspbian 上安装 dlib
本节介绍如何在 Raspberry Pi 和 Raspbian Stretch 操作系统上安装 dlib 库。这些说明应该也适用于较新版本的 Rasbpian。
我们的 Raspbian dlib 安装和我们的 Ubuntu dlib 安装是一样的,但是有一些小的调整:
- Python 2.7 和 Python 3 都是预装在 Raspbian 上的,所以我们不需要自己安装。
- 我们需要安装
libatlas-base-dev。 - 我们可以通过
USE_NEON_INSTRUCTIONS开关优化我们在 Raspberry Pi 架构上的 dlib 安装(这将要求您从源代码而不是pip安装 dlib)。
让我们开始在我们的 Raspberry Pi 上安装 dlib,确保我们已经满足了库/包的依赖性:
$ sudo apt-get update
$ sudo apt-get install build-essential cmake
$ sudo apt-get install libopenblas-dev liblapack-dev libatlas-base-dev
$ sudo apt-get install libx11-dev libgtk-3-dev
关于 X11/GTK 和 OpenBLAS 的一些快速说明:
- 我们正在 dlib 中安装 GTK 和 X11 的 GUI 功能。如果你不关心 GUI 功能,这些库可以跳过,节省 100-200MB 的空间。空间可能是树莓 Pi 的一个溢价,但同样,如果你需要 GUI 功能确保你安装它们。
- 我们为线性代数优化安装了 OpenBLAS,这允许 dlib 功能执行得更快。从技术上来说,你也可以跳过这一步,但是我强烈建议你安装 OpenBLAS,因为它的优化非常重要——你可以在 Raspberry Pi 上实现的任何优化都是值得的!
接下来,让我们为在 Raspberry Pi 上安装 dlib 准备 Python 环境。
如果您正在使用 Python 虚拟环境(如果您遵循了我的任何 OpenCV 安装教程,您可能正在使用它们),您可以为 dlib 安装创建一个新的 Python 虚拟环境:
$ mkvirtualenv dlib_test -p python3
或者访问一个现有的:
$ workon cv
使用 Python 虚拟环境完全是可选的,但是 强烈推荐 ,因为 Python 虚拟环境是 Python 开发的最佳实践。要了解更多关于 Python 虚拟环境的知识(以及如何使用它们)请参考我的 OpenCV 安装教程,在那里它们有广泛的介绍。
然后我们可以在 Raspberry Pi 上安装 dlib:
$ pip install numpy
$ pip install dlib
如果使用 Python 虚拟环境的是而不是,请确保将sudo添加到pip install命令的开头(否则pip install命令将由于权限错误而失败)。此外,记住pip用于安装 Python 2.7 的包,而pip3用于 Python 3。根据您想要安装 dlib 的 Python 版本,您可能需要更新上面的pip命令。
如果您决定使用 NEON 指令来优化 dlib 安装,请跳过通过pip安装 dlib,而是通过 source:
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ python setup.py install --yes USE_NEON_INSTRUCTIONS
从源代码编译将比通过pip安装花费更长的时间,所以要有耐心。
最后,打开一个 Python shell,通过导入dlib库来验证您在 Raspbian 上的 dlib 安装:
(dlib_test) pi@raspberrypi:~ $ python
Python 3.5.3 (default, Jan 19 2017, 14:11:04)
[GCC 6.3.0 20170124] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>> dlib.__version__
'19.8.99'
注意:树莓 Pi 的 dlib 安装版本与我的 macOS 和 Ubuntu 输出不同,因为我从 源安装的利用了 NEON 优化,而不是通过 pip 安装的。****

Figure 3: Successfully installing dlib on the Raspberry Pi and Raspbian operating system.
测试您的 dlib 安装
作为在 Raspberry Pi 上使用 dlib 的最后一个例子,这里是我整理的一个简短的例子,我们在输入图像中检测面部标志:
# import the necessary packages
from imutils import face_utils
import dlib
import cv2
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
p = "shape_predictor_68_face_landmarks.dat"
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(p)
# load the input image and convert it to grayscale
image = cv2.imread("example.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale image
rects = detector(gray, 0)
# loop over the face detections
for (i, rect) in enumerate(rects):
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(image, (x, y), 2, (0, 255, 0), -1)
# show the output image with the face detections + facial landmarks
cv2.imshow("Output", image)
cv2.waitKey(0)
注意:这个例子假设您的系统上已经安装了 OpenCV 和 dlib。如果你没有安装 OpenCV,请参考我的 OpenCV 安装教程。
对于上面用于面部标志预测的代码的详细回顾,请参考我以前的关于面部标志的基础教程。
要执行上述脚本:
- 确保已经安装了 OpenCV、dlib 和 imutils (
pip install --upgrade imutils)。 - 使用下面的 “下载” 部分下载源代码+示例图像+预训练的 dlib 面部标志预测器。
从那里,您可以发出以下命令来执行我们的示例脚本:
$ python facial_landmarks.py
然后,您应该会看到以下输出,其中面部标志显示在图像上:

Figure 4: Detecting facial landmarks using the dlib library and Python.
趣闻:上图是我~8 年前本科大学时期的我。那时候我真的有头发!
现在怎么办?
既然您已经开始使用 dlib,我建议您:
- 也在您的系统上安装 OpenCV(如果您还没有安装的话)。我这里有很多适用于 macOS、Ubuntu 和 Raspbian 的 OpenCV 安装教程。
- 使用 OpenCV + dlib 安装程序来构建实际的、真实的项目。
我建议从本教程开始,你将学习如何应用实时面部标志检测:

Figure 5: Using dlib to apply real-time facial landmark detector.
从那里,你可以利用面部标志来建立一个眨眼检测器:

Figure 6: Building an eye blink detector with dlib, OpenCV, and Python.
最后,我们将前两个教程中的所有内容放在一起制作一个睡意探测器:

Figure 7: Creating a drowsiness detector with dlib, OpenCV, and Python.
一定要看看教程!它们很有趣,可以亲自动手,会给你很多用 dlib 和 OpenCV 构建真实世界的计算机视觉应用程序的经验。
摘要
在今天的博文中,你学习了如何在 macOS、Ubuntu 和 Raspbian 上安装 dlib。
多亏了 Davis King 和 Mischan Toos-Haus 的工作,现在安装 dlib 比以往任何时候都容易,需要更少的依赖和更快的过程。
现在请花一点时间感谢 Davis 和 Mischan 的辛勤工作以及他们对开源社区的贡献。
我希望你喜欢这篇博文!为了在未来的 PyImageSearch 教程发布时得到通知,*请务必在下表中输入您的电子邮件地址。*****
在树莓 Pi 上安装 dlib
原文:https://pyimagesearch.com/2017/05/01/install-dlib-raspberry-pi/

几周前,我写了一篇关于如何在 Ubuntu 和 macOS 上安装 dlib 库的博文。
由于 Raspbian ,(大多数)Raspberry Pi 用户运行的操作系统是基于 Debian 的(Ubuntu 也是如此),相同的安装指令可以用于 Raspbian,就像 Ubuntu 一样…
……不过,这里面有蹊跷。
Raspberry Pi 3 的内存只有 1GB。这 1GB 的 RAM 负责所有的系统操作,显示 GUI/桌面,并处理我们的编译。
事实上,如果你试图在 Raspberry Pi 上编译 dlib,你的编译可能会出错。
为了让带有 Python 绑定的 dlib 成功安装在你的 Raspberry Pi 上,你需要更新你的系统来回收尽可能多的内存以及更新你的交换文件大小。
幸运的是,这并不像听起来那样具有挑战性,如果您遵循本指南中详细介绍的步骤,您将在接下来的 45 分钟内将 dlib 安装到您的 Raspbian 系统上。
要了解如何在你的树莓 Pi 上安装 dlib,继续阅读。
在树莓 Pi 上安装 dlib
本教程的第一部分讨论了在 Raspberry Pi 上使用 Python 绑定编译 dlib 时会遇到的常见内存错误。
然后我们进入我的在 Raspberry Pi 上安装 dlib 的六步指南。
最后,我们将通过一个示例来展示如何使用 dlib、Python 和 Raspberry Pi 来检测面部标志。
遇到内存错误?系统崩溃?
如果你使用我之前的 dlib 安装教程中的 Ubuntu 指令在你的 Raspberry Pi 上安装 dlib,你的编译可能会失败,并显示如下错误信息:

Figure 1: The dlib compile failing on the Raspberry Pi due to the C++ compiler being killed.
此错误的原因可以在突出显示的框中找到:
c++: internal compiler error: Killed (program cc1plus)
这个错误消息归结为 dlib 编译程序使用了太多的内存,Raspbian 操作系统杀死了这个进程,阻止了 Raspberry Pi 的抓取。
然而,预防措施是不够的——我尝试在我的 Raspberry Pi 上编译 dlib,而没有更新我的交换文件大小、引导选项和内存分割(详细如下),我的 Pi 只是被锁定,我不得不硬重置它。
为了在 Raspbian 上安装带有 Python 绑定的 dlib,我们需要回收尽可能多的可用内存。我们将在下一节深入探讨如何做到这一点。
步骤 1:更新交换文件大小、引导选项和内存分割
为 dlib 编译准备 Raspberry Pi 分为三个步骤,每个步骤都有一个相同的目标——增加编译可用的内存量:
- 增加交换文件的大小。
- 切换您的启动选项。
- 更新你的 GPU/RAM 分割。
注意:对于本教程中的几乎所有截图,我都是通过 SSH 从我的主机 macOS 系统进入我的 Raspberry Pi 的(这就是为什么截图来自 macOS 终端而不是 Raspbian 终端)。
增加交换文件大小
交换文件或交换空间是硬盘/内存卡上的空间,用作系统真实内存(RAM)的扩展虚拟内存。
启用交换文件允许您的操作系统“假装”拥有比实际更多的板载内存。使用交换文件体系结构,RAM 中的页面被“换出”到磁盘,直到再次需要它们时才被“换入”。
几乎所有主流操作系统都在某种程度上支持交换。
在 Raspbian 中,使用了 dphys-swapfile 解决方案,默认 100MB 专用于我们卡上的交换。
为了更新我们的交换空间的大小,我们需要编辑 dphys-swapfile 配置文件,它位于/etc/dphys-swapfile中。您可以使用您喜欢的文本编辑器来编辑配置:
$ sudo nano /etc/dphys-swapfile
向下滚动到如下配置:
CONF_SWAPSIZE=100
然后将其更新为使用 1024MB 而不是 100MB:

Figure 2: Updating the Raspbian swap size to be 1024MB rather than 100MB.
注意这里的CONF_SWAPSIZE=1024——这对于我们在 Raspberry Pi 上编译 dlib 来说已经足够了。
注:增加交换容量是烧掉你的树莓 Pi 卡的好方法。基于闪存的存储可以执行的写入次数有限,直到卡基本上无法再容纳 1 和 0。我们只会在短时间内启用大规模互换,所以这没什么大不了的。不管怎样,一定要在安装 dlib 后备份你的.img文件,以防你的卡意外提前死亡。你可以在本页的阅读更多关于大容量交换损坏存储卡的信息。
更新完/etc/dphys-swapfile文件后,运行以下两个命令来重新启动交换服务:
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
start命令可能需要几分钟才能执行完,因为交换空间正在增加和重新分配。
然后,您可以运行:
$ free -m
以确认您的交换大小已经增加。
在这里,您可以看到我的交换空间从之前的 100MB 增加到了 1024MB:

Figure 3: Running free -m confirms that the new swap size of 1024MB is being used.
更改您的启动选项
默认情况下,你的 Raspberry Pi 会引导到 PIXEL 桌面(假设你用的是最新版本的 Raspbian)。这很好;除了 PIXEL 桌面需要内存 dlib 编译急需的 RAM。
我们应该将直接引导到终端,而不是引导到 PIXEL GUI。这将为我们节省大量内存。
为此,请执行:
$ sudo raspi-config
然后选择Boot Options => Desktop / CLI => Console Autologin:

Figure 4: How to set your Raspberry Pi to boot to a terminal rather than a desktop.
这将确保你的 Raspberry Pi 直接引导到终端,跳过 PIXEL 桌面。
然而,在退出raspi-config之前,一定要更新内存分割,如下所述。
更新您的内存分割
默认情况下,Raspberry Pi 为板载 GPU 分配 64MB 内存。我们应该将这个数字减少到 16MB,以便为编译回收内存。
使用raspi-config就足够简单了。回到主屏幕,选择Advanced Options => Memory Split,在这里你会看到 64MB 的提示:

Figure 5: Update your GPU/RAM split to be 16MB rather than 64MB.
将该值更新为 16MB,然后退出。
重启你的树莓派
退出时,raspi-config会询问您是否要重新启动系统。
继续并重新启动,然后我们可以继续安装教程的其余部分。
步骤 2:安装 dlib 先决条件
dlib 库需要四个先决条件:
- 促进
- 助推。计算机编程语言
- CMake
- X11
这些都可以通过以下命令安装:
$ sudo apt-get update
$ sudo apt-get install build-essential cmake
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libboost-all-dev
pip命令应该已经安装在您的 Raspberry Pi 上(您可以通过执行pip命令并确保它确实存在来验证这一点)——否则,您可以通过以下方式安装pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
一旦你确认pip已经安装,我们就可以继续了。
步骤 3:访问您的 Python 虚拟环境(如果您正在使用它们)
我在 PyImageSearch 博客上的所有 OpenCV 安装教程都使用了 Python 虚拟环境。
使用 Python 的 virtualenv 和 virtualenvwrapper 库,我们可以为我们正在进行的每个项目创建单独的 Python 环境——这被认为是用 Python 编程语言开发软件时的最佳实践。
我以前在 PyImageSearch 博客上多次讨论过 Python 虚拟环境,所以我在这里就不再讨论了。如果你想了解更多关于 Python 虚拟环境的内容,请参考我的任何安装 OpenCV 教程以及这本优秀的 Python 虚拟环境初级读本。
如果您想将 dlib 安装到一个预先存在的 Python 虚拟环境中,请使用workon命令:
$ workon <your virtualenv name>
例如,PyImageSearch 上的大多数教程都创建了一个名为cv的虚拟环境。我们可以通过以下方式访问cv虚拟环境:
$ workon cv
否则,我建议使用mkvirtualenv命令创建一个完全独立的虚拟环境。
下面的命令将使用 Python 2.7 解释器创建一个名为py2_dlib的 Python 虚拟环境:
$ mkvirtualenv py2_dlib
虽然这个命令将创建一个名为py3_dlib的 Python 3 虚拟环境:
$ mkvirtualenv py3_dlib -p python3
请记住,这一步是可选,但是T3 强烈推荐 T5。
对于在 PyImageSearch 上关注过我之前的 OpenCV 安装教程的读者,请确保在进行第 4 步之前访问了您的 Python 虚拟环境。
步骤 4:使用 pip 安装带有 Python 绑定的 dlib
我们将从基本的 NumPy + SciPy 栈开始,然后是 scikit-image ,一个通常与 dlib 一起使用的库:
$ pip install numpy
$ pip install scipy
$ pip install scikit-image
然后我们也可以通过pip安装 dlib:
$ pip install dlib
在我的 Raspberry Pi 3 上,这一编译花费了大约 40 分钟,但是正如您所看到的,库被成功编译,没有出现错误:

Figure 6: Successfully compiling dlib with Python bindings on your Raspberry Pi.
步骤 5:测试您的 dlib 安装
为了测试您的 dlib 安装,打开一个 Python shell(如果您使用了 Python 虚拟环境,请确保访问您的 Python 虚拟环境),然后尝试导入dlib:
$ python
Python 3.4.2 (default, Oct 19 2014, 13:31:11)
[GCC 4.9.1] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>>
如果您想从同一个虚拟环境中访问 OpenCV 绑定和 dlib 绑定,请确保您的cv2.so绑定正确地符号链接到 Python 虚拟环境的site-packages目录中。
第 6 步:重置你的交换文件大小,引导选项和内存分割
重要提示—在离开机器之前,请务必将您的交换文件大小重置为 100MB (使用上述“步骤 1:增加交换文件大小”部分中详述的过程)。
然后,您可以将 GPU/RAM 分割重置为 64MB,并更新引导选项以引导到桌面界面,而不是命令行。
完成这些更改后,重启您的 Raspberry Pi 以确保它们生效。
额外收获:使用 dlib 和 Raspberry Pi 进行面部标志检测
作为在 Raspberry Pi 上使用 dlib 的最后一个例子,这里是我编写的一个简短的例子,我们将在输入图像中检测面部标志:
# import the necessary packages
from imutils import face_utils
import dlib
import cv2
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
p = "shape_predictor_68_face_landmarks.dat"
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(p)
# load the input image and convert it to grayscale
image = cv2.imread("example.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale image
rects = detector(gray, 0)
# loop over the face detections
for (i, rect) in enumerate(rects):
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(image, (x, y), 2, (0, 255, 0), -1)
# show the output image with the face detections + facial landmarks
cv2.imshow("Output", image)
cv2.waitKey(0)
对于上面用于面部标志预测的代码的详细回顾,请参考我以前关于面部标志的基础的帖子。
要执行脚本:
- 确保你已经通过
pip install --upgrade imutils安装/升级了 imutils 库。 - 使用下面的 “下载” 部分下载代码+示例图像+预训练的 dlib 面部标志预测器)。
从那里,您可以发出以下命令:
$ python pi_facial_landmarks.py
然后,您应该会看到以下输出,其中面部标志正确显示在输入图像上:

Figure 7: Detecting facial landmarks on an image using dlib on the Raspberry Pi.
趣闻:上图是我在大学期间的照片——那时我还留着头发呢!
不幸的是,从我的测试来看,Raspberry Pi 3 的速度不够快,无法实时执行面部标志检测。在我的实验中,在轮询视频流的下一帧,然后应用面部标志预测之间有一个显著滞后,即使在使用线程视频流以获得最佳性能时也是如此。其原因是因为面部检测过程极其缓慢。
请记住,Raspberry Pi 3 处理器的运行频率仅为 1.2Ghz,而我的 Mac(很可能是你的机器)上的处理器运行频率为 3.1GHz(或类似)。这是一个巨大的速度提升。
加速 dlib 的面部标志预测器的方法可以在这里找到—我将在未来的博客文章中回顾它们,并附带 Python 实现,以帮助我们在 Raspberry Pi 上获得实时面部标志预测性能。
摘要
在今天的博文中,我们学习了如何在 Raspberry Pi 上编译和安装带有 Python 绑定的 dlib。
为了在 Raspberry Pi 上正确安装 dlib,我们必须采取一些与内存使用相关的预防措施,包括:
- 增加我们系统可用的交换容量。
- 将我们的 Raspberry Pi 引导到终端而不是桌面。
- 减少分配给 GPU 的内存,并将其分配给主内存。
通过执行这三个步骤,我们能够回收足够的内存来在我们的 Raspberry Pi 上安装 dlib。然而,现在我们遇到了一个问题,Pi 对于实时面部标志预测来说不够快。我们将在以后的教程中讨论如何加速面部标志预测。
最后,我想提一下,下周的教程是关于驾驶机动车 时的 睡意检测,这是 PyImageSearch 上一篇被大量引用的博文:
Figure 8: A preview of next week’s tutorial on drowsiness detection while driving a motor vehicle.
我非常兴奋能够演示如何从头开始构建一个睡意检测器,所以为了确保当不能错过的博文发布时,你会得到通知,请务必在下面的表格中输入你的电子邮件地址!
安装指南:Raspberry Pi 3+Raspbian Jessie+OpenCV 3
原文:https://pyimagesearch.com/2016/04/18/install-guide-raspberry-pi-3-raspbian-jessie-opencv-3/

你能相信距离原版树莓派 B 型发布已经过去 四年 了吗?当时,Pi Model B 只配备了 256MB 内存和 700MHz 单核处理器。
刚过 一年前树莓派 2 向全世界发布。而人类,为了一个叫做“Pi”的东西,这个野兽像小行星一样对计算机世界造成了冲击。这款主板配有 1GB 内存和 900MHz 四核 处理器——与最初的单核 700MHz 系统相比是相当大的升级!
在我看来, 树莓 Pi 2 是让计算机视觉在 Pi 平台 上成为可能的东西(至少从 Python + OpenCV 的角度来看)。最初的 model B 根本没有足够强大的处理能力(或 RAM)来处理图像和视频流,除了琐碎的操作之外没有任何其他功能——Pi 2 改变了这一切。
事实上,Raspberry Pi 2 对计算机视觉领域产生了如此有意义的影响,以至于我甚至花时间制作了一个与 Pi 兼容的实用 Python 和 OpenCV 的所有代码示例。
现在我们有了树莓派 3 :
- 1.2Ghz 64 位四核处理器。
- 1GB 内存。
- 集成 802.11n 无线和蓝牙。
就个人而言,我希望有更多的内存(可能在 1.5-2GB 的范围内)。但是升级到 64 位处理器和 33%的性能提升对来说是非常值得的。
正如我在以前的博客文章中所做的,我将展示如何在 Raspbian Jessie 上使用 Python 绑定安装 OpenCV 3。
如果您正在寻找不同平台的先前安装说明,请参考以下列表:
- 如何在 Raspbian Jessie 上安装 OpenCV 3.0?
- 在你的Raspberry Pi ZerorunningRaspbian Jessie 上安装 OpenCV。
- 在 拉斯边喘息上同时安装 Python 2.7 和 Python 3+的 OpenCV 3.0。
- 在 拉斯边喘息 上为 Python 2.7 安装 OpenCV 2.4。
否则,让我们继续将 OpenCV 3 安装到您全新的 Raspberry Pi 3 上吧!
假设
在本教程中,我将假设您已经拥有一台 树莓 Pi 3 并安装了Raspbian Jessie。
你还应该有或者:
- 物理访问您的 Raspberry Pi 3,以便您可以打开终端并执行命令。
- 通过 SSH 远程访问。
我将通过 SSH 完成本教程的大部分内容,但是只要您可以访问终端,您就可以轻松地跟着做。
在运行 Raspbian Jessie 的 Raspberry Pi 3 上安装 OpenCV 3
如果您曾经在 Raspberry Pi(或任何其他平台)上安装过 OpenCV,您会知道这个过程非常耗时,因为必须安装许多依赖项和先决条件。本教程的目标是逐步引导你完成编译和安装过程。
为了使安装过程更加顺利,我已经包括了每个步骤的时间,这样当 Pi 编译 OpenCV 时,您就知道什么时候该休息一下,喝杯咖啡,检查一下电子邮件。也就是说, Pi 3 比 Pi 2 快得多,所以编译 OpenCV 所花的时间已经大大减少了。
*无论如何,让我们开始在您全新的运行 Raspbian Jessie 的 Raspberry Pi 3 上安装 OpenCV 3。
步骤#1:扩展文件系统
你用的是全新的 Raspbian Jessie 吗?
如果是这样的话,你应该做的第一件事就是扩展你的文件系统,在你的 micro-SD 卡上包含所有可用空间:
$ sudo raspi-config

Figure 1: Expanding the filesystem on your Raspberry Pi 3.
一旦出现提示,你应该选择第一个选项, "1。展开文件系统 , 点击键盘上的 Enter ,向下箭头到<【完成】>按钮,然后重新启动你的 Pi:
$ sudo reboot
重新启动后,您的文件系统应该已经扩展到包括 micro-SD 卡上的所有可用空间。您可以通过执行df -h并检查输出来验证磁盘是否已经扩展:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 7.2G 3.3G 3.6G 48% /
devtmpfs 459M 0 459M 0% /dev
tmpfs 463M 0 463M 0% /dev/shm
tmpfs 463M 6.4M 457M 2% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 463M 0 463M 0% /sys/fs/cgroup
/dev/mmcblk0p1 60M 20M 41M 34% /boot
tmpfs 93M 0 93M 0% /run/user/1000
如您所见,我的 Raspbian 文件系统已经扩展到包括所有 8GB 的 micro-SD 卡。
然而,即使我的文件系统扩展了,我已经使用了 48%的 8GB 卡!
OpenCV 及其所有依赖项在编译过程中需要几千兆字节,因此您应该删除 Wolfram 引擎以释放 Pi 上的一些空间:
$ sudo apt-get purge wolfram-engine
移除 Wolfram 引擎后,您可以回收差不多 700mb!
步骤 2:安装依赖项
这不是我第一次讨论如何在 Raspberry Pi 上安装 OpenCV,所以我将把这些说明保持在更简短的一面,让您能够完成安装过程:我还包括了执行每个命令 所需的 时间,这样您就可以相应地计划 OpenCV + Raspberry Pi 3 的安装(OpenCV 本身需要 1h 12m 来编译)。
第一步是更新和升级任何现有的软件包:
$ sudo apt-get update
$ sudo apt-get upgrade
计时:1 米 26 秒
然后我们需要安装一些开发工具,包括 CMake ,它帮助我们配置 OpenCV 构建过程:
$ sudo apt-get install build-essential cmake pkg-config
计时:40 秒
接下来,我们需要安装一些图像 I/O 包,允许我们从磁盘加载各种图像文件格式。这种文件格式的例子包括 JPEG、PNG、TIFF 等。:
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng12-dev
计时:32s
就像我们需要图像 I/O 包一样,我们也需要视频 I/O 包。这些库允许我们从磁盘读取各种视频文件格式,并直接处理视频流:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
计时:34 秒
OpenCV 库附带了一个名为highgui的子模块,用于在屏幕上显示图像和构建基本的 GUI。为了编译highgui模块,我们需要安装 GTK 开发库:
$ sudo apt-get install libgtk2.0-dev
计时:3m 6s
OpenCV 内部的许多操作(即矩阵操作)可以通过安装一些额外的依赖项来进一步优化:
$ sudo apt-get install libatlas-base-dev gfortran
计时:46s
这些优化库对于资源受限的设备(如 Raspberry Pi)尤为重要。
最后,让我们安装 Python 2.7 和 Python 3 头文件,这样我们就可以使用 Python 绑定来编译 OpenCV:
$ sudo apt-get install python2.7-dev python3-dev
计时:45s
如果您跳过这一步,您可能会注意到在运行make来编译 OpenCV 时,没有找到与Python.h头文件相关的错误。
步骤 3:下载 OpenCV 源代码
现在我们已经安装了依赖项,让我们从官方 OpenCV 库获取 OpenCV 的3.1.0档案。(注:随着 openCV 未来版本的发布,可以用最新的版本号替换3.1.0):
$ cd ~
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.1.0.zip
$ unzip opencv.zip
计时:1 米 26 秒
我们希望 OpenCV 3 的完整安装(例如,可以访问 SIFT 和 SURF 等特性),所以我们还需要获取 opencv_contrib 库:
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.1.0.zip
$ unzip opencv_contrib.zip
计时:43s
在复制和粘贴过程中,您可能需要使用“<=>”按钮来扩展上面的命令。在某些浏览器中,3.1.0.zip中的.zip可能会被截断。OpenCV 3.1.0 档案的完整 URL 是:
https://github.com/Itseez/opencv_contrib/archive/3.1.0.zip
注意:确保你的opencv和opencv_contrib版本相同(这里是3.1.0)。如果版本号不匹配,那么您可能会遇到编译时或运行时问题。
第四步:Python 2.7 还是 Python 3?
在我们开始在我们的 Raspberry Pi 3 上编译 OpenCV 之前,我们首先需要安装pip,一个 Python 包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
计时:20 秒
如果你是一个长期的 PyImageSearch 读者,那么你会知道我是 virtualenv 和 virtualenvwrapper 的超级粉丝。安装这些包并不是必需的,你完全可以安装 OpenCV 而不安装它们,但是我强烈建议你安装它们 ,因为将来的其他 PyImageSearch 教程也将利用 Python 虚拟环境。在本指南的剩余部分,我还假设您已经安装了virtualenv和virtualenvwrapper。
*那么,既然如此,使用virtualenv和virtualenvwrapper又有什么意义呢?
首先,重要的是要理解虚拟环境是一种特殊工具,用于通过为每个项目创建隔离的、独立的 Python 环境,将不同项目所需的依赖关系保存在不同的地方。
简而言之,它解决了“项目 X 依赖版本 1.x,但项目 Y 需要 4 . X”的困境。它还能保持你的全球site-packages整洁、干净、没有杂乱。
如果你想知道为什么 Python 虚拟环境是好的实践的完整解释,绝对读一读 RealPython 上这篇出色的博客文章。
使用某种虚拟环境是 Python 社区的标准做法,所以我强烈建议你也这么做:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip
计时:9s
既然已经安装了virtualenv和virtualenvwrapper,我们需要更新我们的~/.profile文件,在文件的底部包含以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
在之前的教程中,我已经推荐使用您最喜欢的基于终端的文本编辑器,如vim、emacs或nano来更新~/.profile文件。如果您对这些编辑器感到满意,请继续更新文件以反映上面提到的更改。
否则,您应该简单地使用cat和输出重定向来处理更新~/.profile:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.profile
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.profile
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.profile
现在我们已经更新了我们的~/.profile,我们需要重新加载它以确保更改生效。您可以通过以下方式强制重新加载您的~/.profile文件:
- 注销然后重新登录。
- 关闭终端实例并打开一个新实例
- 还是我个人最喜欢的, 就用
source命令:
$ source ~/.profile
注意:我建议每次打开一个新的终端 时运行source ~/.profile文件 ,以确保系统变量设置正确。
创建您的 Python 虚拟环境
接下来,让我们创建将用于计算机视觉开发的 Python 虚拟环境:
$ mkvirtualenv cv -p python2
该命令将使用 Python 2.7 创建一个名为cv的新 Python 虚拟环境。
如果你想使用 Python 3 ,你可以使用这个命令:
$ mkvirtualenv cv -p python3
再次, 这一点我怎么强调都不为过:cvPython 虚拟环境是 完全独立于 Raspbian Jessie 下载中包含的默认 Python 版本 。任何在全局 site-packages目录中的 Python 包将对cv虚拟环境不可用。类似的,任何安装在cv 的site-packages中的 Python 包都不会对 Python 的全局安装可用。当您在 Python 虚拟环境中工作时,请记住这一点,这将有助于避免许多困惑和头痛。
如何检查你是否在虚拟环境中
如果你重启你的树莓派;注销并重新登录;或者打开一个新的终端,您需要使用workon命令来重新访问cv虚拟环境。在以前的博文中,我看到读者使用mkvirtualenv命令—T5,这完全没有必要!mkvirtualenv命令只被执行一次:实际上创建虚拟环境。
之后,您可以使用workon进入您的虚拟环境:
$ source ~/.profile
$ workon cv
为了验证并确保您处于cv虚拟环境中,请检查您的命令行— 如果您在提示前看到文本(cv),那么您处于cv虚拟环境中的:

Figure 2: Make sure you see the “(cv)” text on your prompt, indicating that you are in the cv virtual environment.
否则,如果你 没有 看到(cv)文本,那么你 在cv虚拟环境中就不是 :

Figure 3: If you do not see the “(cv)” text on your prompt, then you are not in the cv virtual environment and need to run “source” and “workon” to resolve this issue.
要解决这个问题,只需执行上面提到的source和workon命令。
在您的树莓 Pi 上安装 NumPy
假设你已经走了这么远,你现在应该在cv虚拟环境中(在本教程的剩余部分你应该呆在这个环境中)。我们唯一的 Python 依赖项是 NumPy ,一个用于数值处理的 Python 包:
$ pip install numpy
计时:9 分 39 秒
一定要喝杯咖啡或散散步,NumPy 安装可能需要一点时间。
注:另一个我经常看到的问题是“救命,我的 NumPy 安装挂了,不安装了!”*实际上,它正在安装,只是需要时间来下载源代码并编译。耐心点。树莓派没有你的笔记本电脑/台式机快。*
步骤 5:编译并安装 OpenCV
我们现在准备编译和安装 OpenCV!通过检查您的提示(您应该看到它前面的(cv)文本),再次检查您是否在cv虚拟环境中,如果不是,简单地执行workon:
$ workon cv
一旦您确保您处于cv虚拟环境中,我们就可以使用 CMake 设置我们的构建:
$ cd ~/opencv-3.1.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.1.0/modules \
-D BUILD_EXAMPLES=ON ..
计时:1 米 57 秒
现在,在我们进入实际的编译步骤之前, 确保您检查了 CMake 的输出!
首先向下滚动标题为Python 2和Python 3的部分。
如果你正在为 Python 2.7 编译 OpenCV 3,那么请确保你的Python 2部分包含到Interpreter、Libraries、numpy和packages path的有效路径,类似于我下面的截图:

Figure 4: Ensuring that Python 2.7 will be used when compiling OpenCV 3 for Raspbian Jessie on the Raspberry Pi 3.
注意Interpreter是如何指向位于cv虚拟环境中的python2.7二进制文件的。numpy变量也指向cv环境中的 NumPy 安装。
类似地, 如果你正在为 Python 3 编译 OpenCV,确保Python 3部分如下图所示:

Figure 5: Checking that Python 3 will be used when compiling OpenCV 3 for Raspbian Jessie on the Raspberry Pi 3.
同样,Interpreter指向位于cv虚拟环境中的python3.4二进制文件,而numpy指向我们的 NumPy 安装。
在这两种情况下,如果您 没有 看到这些变量路径中的cv虚拟环境, 几乎可以肯定是因为您在运行 CMake 之前不在cv虚拟环境中!
如果是这种情况,使用workon cv访问cv虚拟环境,并重新运行上述cmake命令。
最后,我们现在准备编译 OpenCV:
$ make -j4
计时:1 小时 12 分钟
注:在树莓 Pi 3 上用 72 分钟编译 OpenCV,比之前树莓 Pi 2 的 95 分钟提升了 24% 。额外的 300MHz 带来了很大的不同!
-j4命令控制编译 OpenCV 3 时要利用的内核数量。Raspberry Pi 3 有四个内核,因此我们提供了一个值4来允许 OpenCV 更快地编译。
然而,由于竞争条件,当使用多个内核时,有时会出现make错误。如果这种情况发生在你身上,我建议重新开始编译,并且只使用一个内核:
$ make clean
$ make
一旦 OpenCV 3 完成编译,您的输出应该类似于下面的输出:

Figure 5: Our OpenCV 3 compile on Raspbian Jessie has completed successfully.
从那里,你需要做的就是在你的 Raspberry Pi 3 上安装 OpenCV 3:
$ sudo make install
$ sudo ldconfig
计时:52s
步骤 6:在您的 Pi 上完成 OpenCV 的安装
我们几乎完成了——只需再走几步,您就可以将您的 Raspberry Pi 3 与 OpenCV 3 一起使用了。
对于 Python 2.7:
如果您的步骤#5 没有错误地完成,OpenCV 现在应该安装在/usr/local/lib/python2.7/site-pacakges中。您可以使用ls命令来验证这一点:
$ ls -l /usr/local/lib/python2.7/site-packages/
total 1852
-rw-r--r-- 1 root staff 1895772 Mar 20 20:00 cv2.so
注意:某些情况下,OpenCV 可以安装在/usr/local/lib/python2.7/dist-packages(注意是dist-packages而不是site-packages)。如果您在site-packages中没有找到cv2.so绑定,我们一定要检查dist-packages。
我们的最后一步是将 OpenCV 绑定符号链接到 Python 2.7 的虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
对于 Python 3:
运行make install后,您的 OpenCV + Python 绑定应该安装在/usr/local/lib/python3.4/site-packages中。同样,您可以使用ls命令来验证这一点:
$ ls -l /usr/local/lib/python3.4/site-packages/
total 1852
-rw-r--r-- 1 root staff 1895932 Mar 20 21:51 cv2.cpython-34m.so
老实说,我不知道为什么,也许这是 CMake 脚本中的一个错误,但在为 Python 3+编译 OpenCV 3 绑定时,输出的.so文件被命名为cv2.cpython-34m.so(或的某种变体),而不是简单的cv2.so(就像在 Python 2.7 绑定中一样)。
再说一次,我不确定为什么会发生这种情况,但这很容易解决。我们需要做的就是重命名文件:
$ cd /usr/local/lib/python3.4/site-packages/
$ sudo mv cv2.cpython-34m.so cv2.so
重命名为cv2.so后,我们可以将 OpenCV 绑定符号链接到 Python 3.4 的cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python3.4/site-packages/
$ ln -s /usr/local/lib/python3.4/site-packages/cv2.so cv2.so
步骤 7:测试 OpenCV 3 的安装
祝贺你,你现在已经在运行 Raspbian Jessie 的 Raspberry Pi 3 上安装了 OpenCV 3!
但是在我们开香槟庆祝我们的胜利之前,让我们先验证一下您的 OpenCV 安装是否工作正常。
打开一个新的终端,执行source和workon命令,最后尝试导入 Python + OpenCV 绑定:
$ source ~/.profile
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.1.0'
>>>
从我自己的终端截图可以看到, OpenCV 3 已经成功安装在我的树莓 Pi 3 + Python 2.7 环境:

Figure 5: Confirming OpenCV 3 has been successfully installed on my Raspberry Pi 3 running Raspbian Jessie.
一旦安装了 OpenCV,您可以删除opencv-3.1.0和opencv_contrib-3.1.0目录来释放磁盘上的大量空间:
$ rm -rf opencv-3.1.0 opencv_contrib-3.1.0
但是,使用该命令时要小心!在清空这些目录之前,请确保 OpenCV 已经正确安装在您的系统上。这里的一个错误可能会让你在编译时损失 小时 。
故障排除和常见问题
Q. 当我尝试执行mkvirtualenv和workon时,得到一个“命令未找到错误”。
A. 发生这种情况有三个原因,都与步骤#4 有关:
- 确保您已经通过
pip安装了virtualenv和virtualenvwrapper。您可以通过运行pip freeze然后检查输出来检查这一点,确保您看到了virtualenv和virtualenvwrapper的出现。 - 您可能没有正确更新您的
~/.profile。使用文本编辑器如nano查看您的~/.profile文件,并确保正确的export和source命令存在(再次检查步骤#4 中应该追加到~/.profile的内容)。 - 在编辑、重启、打开新终端等操作后,您没有
source您的~/.profile。任何时候你打开一个新的终端并想要使用一个虚拟环境,确保你执行source ~/.profile来加载内容——这将让你访问mkvirtualenv和workon命令。
问 当我打开一个新的终端,注销或者重启我的 Pi 后,我无法执行mkvirtualenv或者workon。
A. 见原因#3 来自上一题。
Q. 当我(1)打开一个导入 OpenCV 的 Python shell 或者(2)执行一个调用 OpenCV 的 Python 脚本时,我得到一个错误:ImportError: No module named cv2。
答: 不幸的是,这个错误极难诊断,主要是因为有多个问题可能导致这个问题。首先,使用workon cv确保您处于cv虚拟环境中。如果workon命令失败,那么请看这个 FAQ 中的第一个问题。如果您仍然得到一个错误,请调查您的cv虚拟环境的site-packages目录的内容。您可以在~/.virtualenvs/cv/lib/python2.7/site-packages/或~/.virtualenvs/cv/lib/python3.4/site-packages/中找到site-packages目录(取决于您用于安装的 Python 版本)。确保指向cv2.so文件的符号链接是有效的,并且指向一个现有的文件。
摘要
在这篇博文中,我们学习了如何在你的 Raspberry Pi 3 运行 Raspbian Jessie 上安装带有 Python 2.7 或 Python 3 绑定的 OpenCV 3 。
如果你运行的是不同版本的 Raspbian(比如 Raspbian Wheezy )或者想安装不同版本的 OpenCV(比如 OpenCV 2.4),请查阅以下教程:
- 如何在 Raspbian Jessie 上安装 OpenCV 3.0?
- 在你的Raspberry Pi ZerorunningRaspbian Jessie 上安装 OpenCV。
- 在 拉斯边喘息上同时安装 Python 2.7 和 Python 3+的 OpenCV 3.0。
- 在 拉斯边喘息 上为 Python 2.7 安装 OpenCV 2.4。
但是在你走之前……
我倾向于在这个博客上使用 Raspberry Pi,所以如果你有兴趣了解更多关于 Raspberry Pi +计算机视觉的信息,请在下面的表格中输入你的电子邮件地址,以便在这些帖子发布时得到通知!****
在 OSX 上安装 OpenCV 3.0 和 Python 2.7+
原文:https://pyimagesearch.com/2015/06/15/install-opencv-3-0-and-python-2-7-on-osx/
正如我上周提到的, OpenCV 3.0 终于来了 !
如果你一直在关注我的 Twitter 流,你可能已经注意到了一堆关于在 OSX 和 Ubuntu 上安装 T4【OpenCV 的推文(是的,我最近一直在发推文,但那只是因为我对 3.0 版本太兴奋了!)
为了庆祝 OpenCV 3.0,我决定发表一系列博客文章,详细介绍如何在 Python 2.7+ 和 Python 3+ 上安装 OpenCV 3.0。
我们还将在各种平台上执行这些 Python 2.7 和 Python 3+安装,包括【OSX】Ubuntu以及 树莓派 。
我相信你已经知道,OpenCV 从来就不是一个容易安装的库。这不像你能让pip或easy_install为你负重前行。在大多数情况下,你会拉下回购,安装先决条件,手工编译,并希望你的安装顺利进行。
有了 OpenCV 3.0,它并没有变得更容易——而且肯定有一些警告和陷阱需要你留意(例如 opencv_contrib 库——没有它,你将会错过一些重要的功能,例如 SIFT、SURF 等。)
但是别担心,我会掩护你的!只要继续关注 PyImageSearch 博客,我保证这些教程会让你很快开始使用 OpenCV 3.0。
我们将通过在平台上安装带有 Python 2.7+ 绑定 的 3.0 版来开始我们的 OpenCV 3.0 安装节。
*如果你是 Ubuntu 或 Raspberry Pi 用户,请务必关注 PyImageSearch,因为我将发布 OpenCV 3.0 安装 Ubuntu 和 Raspberry Pi 的说明。
在我们开始之前,有一个小注意:虽然 OpenCV 3.0 确实兼容 Python 3+,但大多数计算机视觉开发人员仍在使用 Python 2.7(因为 OpenCV 2.4.X 只兼容 Python 2.7)。如果你是 Python 3 的用户,并且很想尝试一下绑定——不要担心!我将在以后的教程中介绍 OpenCV 3.0 和 Python 3+的安装。但是现在,让我们坚持我们所知道的,使用 Python 2.7。
更新:您现在正在阅读的教程涵盖了如何在 OSX 优山美地、 以下安装带有 Python 2.7 绑定的 OpenCV 3.0。如果你使用的是 OSX 优胜美地或者更早的版本,这个教程 仍然可以很好地工作 ,但是如果你想在更新的 El Capitan 和 macOS Sierra 上安装 OpenCV,请使用这个最新更新的教程。
如何在 OSX 上安装 OpenCV 3.0 和 Python 2.7+
这是我们 OpenCV 3.0 安装系列的第一个教程。在本教程中,我将详细介绍如何在 OSX 操作系统上安装 OpenCV 3.0 和 Python 2.7+—我将在以后的帖子中介绍 Python 3+。
让我们继续深入研究 OpenCV 3.0 和 Python 2.7+安装说明。
第一步:
我们需要做的第一步是安装 Xcode ,这是一个 IDE 和软件开发工具的组合,用于在 OSX 和 iOS 平台上开发应用程序——我们大多数人已经安装了 Xcode。
但是如果你没有,你会想打开 App Store 应用程序并搜索 Xcode 。在那里,只需点击获取和安装应用(当出现提示时,你需要输入你的 Apple ID 用户名和密码):
Figure 1: Installing Xcode on your OSX system.
第二步:
既然 Xcode 已经安装好了,我们需要安装 Homebrew ,它的标签是【OSX 缺失的软件包管理器】(他们真的没有拿这个开玩笑)。可以把 Homebrew 看作(几乎)Ubuntu 的 apt-get 的等价物。
要安装家酿软件,只需进入家酿软件网站,将“安装家酿软件”部分下的命令复制并粘贴到您的终端:
$ cd ~
$ $ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
既然已经安装了 Homebrew,您需要更新它并获取最新的包(即“formula”)定义。这些公式只是关于如何安装给定软件包或库的简单说明。
要更新 Homebrew,只需执行:
$ brew update
第三步:
用系统 Python 作为你的主要解释器是不好的形式。如果您打算使用virtualenv和virtualenvwrapper(我们将会这样做),这一点尤其正确。
让我们继续使用 Homebrew 来安装我们特定于用户的 Python 2.7 版本:
$ brew install python
注: 本教程将涵盖如何用 Python 2.7 安装和设置 OpenCV 3.0 。我将在本月晚些时候介绍如何用 Python 3+ 安装 OpenCV 3.0 。
然而,在我们继续之前,我们需要更新我们的~/.bash_profile文件中的PATH,以表明我们想要在任何系统库或包之前使用自制包。这是绝对关键的一步,所以一定不要跳过!**
在您最喜欢的编辑器中打开您的 ~/.bash_profile文件(如果它不存在,创建它,并将下面几行添加到文件中:
# Homebrew
export PATH=/usr/local/bin:$PATH
从那里,重新加载您的~./bash_profile文件以确保已经进行了更改:
$ source ~/.bash_profile
作为健全性检查,让我们确认我们使用的是 Python 的自制版本,而不是系统版本:
$ which python
/usr/local/bin/python
如果你的which python的输出是/usr/local/bin/python,那么你确实在使用 Python 的自制版本。如果您的输出是/usr/bin/python,那么您仍然在使用 Python 的系统版本——您需要返回并确保您的~/.bash_profile文件被正确更新和重新加载。
还是那句话,这是非常重要的一步,一定不要跳过!
第四步:
好了,是时候正确安装和配置 virtualenv 和 virtualenvwrapper 了。这些包允许我们为我们正在进行的每个项目创建单独的 Python 环境。如果您的项目需要给定库的不同(或冲突)版本,这尤其有用。
需要注意的是在 OSX 上安装 OpenCV 3.0 和 Python 2.7+绝不需要virtualenv和virtualenvwrapper是和。然而, 在做 Python 开发的时候,你真的应该使用这些包 。更干净。更容易维护。而 完全值得 前期的努力。
无论如何,要安装virtualenv和virtualenvwrapper,只需执行以下命令:
$ pip install virtualenv virtualenvwrapper
同样,我们需要通过追加以下两行来更新我们的~/.bash_profile文件:
# Virtualenv/VirtualenvWrapper
source /usr/local/bin/virtualenvwrapper.sh
更新完~/.bash_profile文件后,我们需要重新加载它:
$ source ~/.bash_profile
此时,virtualenv和virtualenvwrapper都已正确安装,因此我们可以创建我们的cv虚拟环境:
$ mkvirtualenv cv
这个命令将创建一个新的 Python 环境,这个环境与我们的系统和自制 Python 安装完全隔离。虚拟环境是我们进行所有计算机视觉开发的地方(更不用说编译支持 Python 2.7+的 OpenCV 3.0)。
第五步:
现在我们可以开始安装一些 Python 包了。我们需要安装 NumPy ,因为 OpenCV Python 绑定将图像表示为多维 NumPy 数组:
$ pip install numpy
第六步:
到目前为止,我们主要关注于实际的设置和配置我们的开发环境来编译和安装 OpenCV — 这里是真正工作开始的地方。
首先,我们将使用 brew 安装所需的开发人员工具,例如出色的 CMake 实用程序:
$ brew install cmake pkg-config
在这里,我们将安装必要的映像 I/O 包。这些软件包允许您加载各种图像文件格式,如 JPEG、PNG、TIFF 等。
$ brew install jpeg libpng libtiff openexr
最后,让我们安装用于优化 OpenCV 中各种操作的库(如果我们愿意的话):
$ brew install eigen tbb
第七步:
好了,我们的系统已经准备好了——现在是编译和安装 OpenCV 3.0 并支持 Python 2.7+的时候了。
我们要做的第一件事是将目录切换到我们的主目录,然后从 GitHub 下拉 OpenCV,并检查3.0.0版本:
$ cd ~
$ git clone https://github.com/Itseez/opencv.git
$ cd opencv
$ git checkout 3.0.0
更新(2016 年 1 月 3 日):你可以用任何当前版本替换3.0.0版本(目前是3.1.0)。请务必查看OpenCV.org了解最新发布的信息。
不像以前版本的 OpenCV(本质上)是自包含的,我们还需要从 GitHub 下载额外的 opencv_contrib repo 。包含 OpenCV 额外模块的opencv_contrib repo,例如特征检测、局部不变描述符(SIFT、SURF 等。)、自然图像中的文本检测、行描述符等等。
$ cd ~
$ git clone https://github.com/Itseez/opencv_contrib
$ cd opencv_contrib
$ git checkout 3.0.0
同样,确保你为opencv_contrib检查的 版本与你为上面的opencv检查的 版本相同,否则你可能会遇到编译错误。
注意:如果我们不想的话,我们没有有来取消opencv_contrib回购。OpenCV 没有它也可以编译和安装。但是如果你编译 OpenCV 而没有 opencv_contrib,要注意你将会错过一些非常重要的特性,这将变得非常明显,非常快,特别是如果你习惯于使用 OpenCV 的 2.4.X 版本。
第八步:
让我们通过创建build目录来设置 OpenCV 构建:
$ cd ~/opencv
$ mkdir build
$ cd build
我们将使用 CMake 来配置我们的构建:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local \
-D PYTHON2_PACKAGES_PATH=~/.virtualenvs/cv/lib/python2.7/site-packages \
-D PYTHON2_LIBRARY=/usr/local/Cellar/python/2.7.10/Frameworks/Python.framework/Versions/2.7/bin \
-D PYTHON2_INCLUDE_DIR=/usr/local/Frameworks/Python.framework/Headers \
-D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON \
-D BUILD_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules ..
这里有一些非常重要的选项我们提供给 CMake,所以让我们把它们分解一下:
***** 这个选项表明我们正在构建 OpenCV 的发布二进制文件。
CMAKE_INSTALL_PREFIX:OpenCV 将要安装的基础目录。PYTHON2_PACKAGES_PATH:显式 路径,指向我们的site-packages目录在我们的cv虚拟环境中的位置。PYTHON2_LIBRARY:Python 的 Hombrew 安装路径。PYTHON2_INCLUDE_DIR:我们用于编译的 Python 头文件的路径。INSTALL_C_EXAMPLES:表示我们要在编译后安装 C/C++示例。INSTALL_PYTHON_EXAMPLES:表示我们要安装复杂后的 Python 例子。BUILD_EXAMPLES:一个标志,决定是否编译包含的 OpenCV 例子。OPENCV_EXTRA_MODULES_PATH: 这个选项极其重要——这里我们提供了之前拉下的opencv_contribrepo 的路径,表明 OpenCV 也应该编译额外的模块。
更新(2016 年 1 月 3 日):为了构建 OpenCV 3.1.0,需要在cmake命令中设置-D INSTALL_C_EXAMPLES=OFF(而不是ON)。OpenCV v3.1.0 CMake 构建脚本中有一个错误,如果您打开此开关,可能会导致错误。一旦您将此开关设置为 off,CMake 应该会顺利运行。
咻,有很多选择。
相信我,在 Ubuntu 上安装 OpenCV 3.0 要容易得多,因为这些选项是通过 CMake 自动确定的。
但是当使用 OSX 时,你需要明确地定义、PYTHON2_PACKAGES_PATH、PYTHON2_LIBRARY和PYTHON2_INCLUDE_DIR。这确实很痛苦,但是如果不这样做,编译就会失败。
下面是我的 CMake 输出的一个例子:
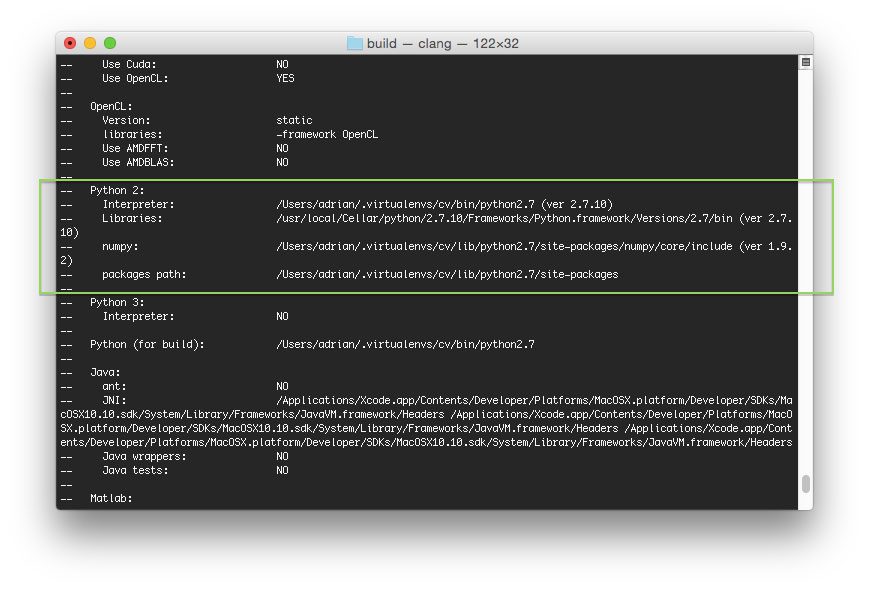
Figure 2: Before compiling OpenCV 3.0 on your OSX system, make sure that cmake has picked up the correct Python interpreter, library, numpy version, and packages path.
注意 Python 2 解释器、库、numpy 版本和包路径是如何被正确选择的。
您还需要确保python2在要构建的模块列表中,就像这样:
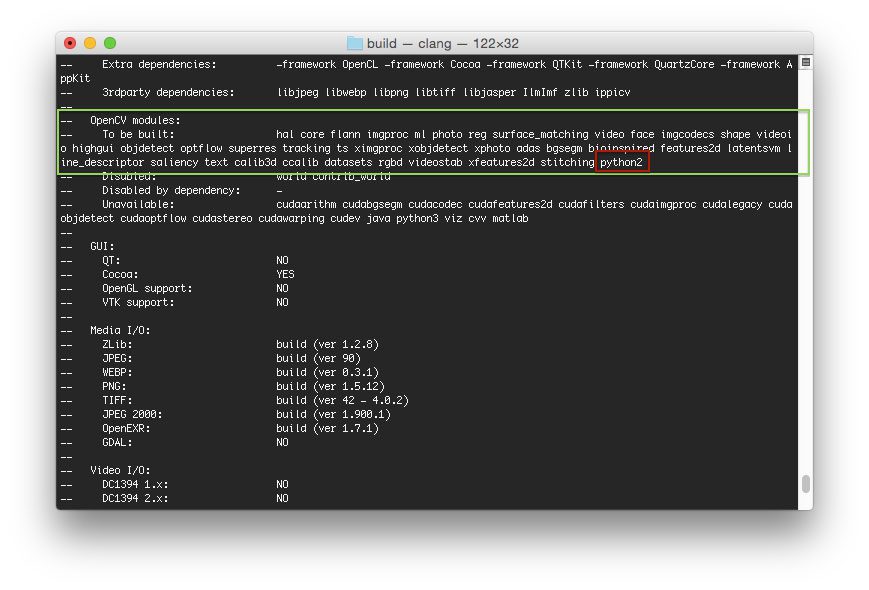
Figure 2: Ensuring the “python2” module is in our list of modules “To be built”.
如果它python2不在这个列表中,并且在不可用列表中,那么您需要返回到 CMake 步骤并确保您已经正确地提供了您的PYTHON2_PACKAGES_PATH、PYTHON2_LIBRARY和PYTHON2_INCLUDE_DIR。
现在 CMake 已经正确配置了构建,我们可以编译 OpenCV:
$ make -j4
其中 4 可以用您处理器上的任意数量的内核来替换。下面是一个在我的系统上编译 OpenCV 的例子:
Figure 3: OpenCV 3.0 with Python 2.7+ support compiling on my system.
假设 OpenCV 编译无误,现在您可以将它安装在您的 OSX 系统上:
$ make install
如果您得到一个与权限相关的错误消息(尽管这真的不应该发生),您将需要以sudo的身份运行 install 命令:
$ sudo make install
第九步:
假设您已经做到了这一步,让我们执行一个健全性检查并确保安装了 OpenCV:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ls -l cv2.so
-rwxr-xr-x 1 adrian staff 2013052 Jun 5 15:20 cv2.so
果然,我们可以看到 OpenCV 已经安装在我们的cv虚拟环境的site-packages目录下了!
简单地说,您也可以在您的build/lib目录中找到cv2.so文件(这是您的 OpenCV 绑定)。
让我们通过启动 shell 并导入 OpenCV 来验证我们的安装:
(cv)annalee:~ adrianrosebrock$ python
Python 2.7.8 (default, Jul 31 2014, 15:41:09)
[GCC 4.2.1 Compatible Apple LLVM 5.1 (clang-503.0.40)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.0.0'
那不是看起来很好吗?
恭喜你,你已经在你的 OSX 系统上安装了 OpenCV 3.0 和 Python 2.7+!
第十步:
做完这些工作后,让我们给我们的 OpenCV 3.0 安装一个测试驱动程序吧!
我在计算机视觉方面的大部分工作涉及图像搜索引擎,或者更正式地说,基于内容的图像检索。CBIR 的一个关键步骤是提取特征来量化和抽象地表示图像的内容。
OpenCV 3.0 有许多更新和更改,但我个人最喜欢的可能是 Alcantarilla 等人的 AKAZE 特性的实现— 非线性尺度空间中加速特性的快速显式扩散 。
由于侏罗纪世界刚刚上映(而侏罗纪公园是我一直以来最喜欢的电影),让我们来探索如何从下图中计算和提取赤泽特征:

Figure 4: Our Jurassic World test image that we are going to detect keypoints and extract features in using AKAZE.
打开一个新文件,将其命名为test_akaze.py,并插入以下代码:
# import the necessary packages
from __future__ import print_function
import cv2
# load the image and convert it to grayscale
image = cv2.imread("jurassic_world.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Original", image)
# initialize the AKAZE descriptor, then detect keypoints and extract
# local invariant descriptors from the image
detector = cv2.AKAZE_create()
(kps, descs) = detector.detectAndCompute(gray, None)
print("keypoints: {}, descriptors: {}".format(len(kps), descs.shape))
# draw the keypoints and show the output image
cv2.drawKeypoints(image, kps, image, (0, 255, 0))
cv2.imshow("Output", image)
cv2.waitKey(0)
然后通过以下方式执行它:
$ python test_akaze.py
keypoints: 762, descriptors: (762, 61)
假设您已经下载了jurassic_world.jpg图像并将其放在与test_akaze.py脚本相同的目录中,您应该会看到以下输出:
Figure 5: We have successfully been able to detect keypoints, extract AKAZE features, and then draw the keypoints on our image using OpenCV 3.0 and Python 2.7+!
请注意我们是如何检测关键点并提取图像中的 AKAZE 特征的!
显然,我们需要做更多的工作来使用 AKAZE 特性构建一个有用的项目——但是这个例子证明了(1)我们的 OpenCV 3.0 安装正在工作,以及(2)我们能够使用 Python 2.7 来使用独特的 OpenCV 3.0 特性。
摘要
OpenCV 3.0 终于来了!为了庆祝 OpenCV 3.0 的发布,我们将在各种操作系统上为 Python 2.7+ 和 Python 3+ 执行一次 OpenCV 3.0 安装仪式 ,这些操作系统包括Ubuntu和 树莓派!
*本文通过详细介绍如何在 OSX 操作系统上设置和安装 OpenCV 3.0 和 Python 2.7+拉开了安装节的序幕。
下周,我们将转移到 Ubuntu,并详细说明如何在 Ubuntu 14.04+上安装 OpenCV 3.0 和 Python 2.7(提示:这比 OSX 要容易得多)。
无论如何,我希望你喜欢这篇文章,并发现它很有用!
请考虑通过在下表中输入您的电子邮件地址来订阅 PyImageSearch 时事通讯——随着新的 OpenCV 3.0 + Python 安装说明的发布,我将发送更新!******
在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7+
原文:https://pyimagesearch.com/2015/06/22/install-opencv-3-0-and-python-2-7-on-ubuntu/

上周,我们通过详细介绍如何在 OSX 平台上安装 OpenCV 3.0 和 Python 2.7+开始了 OpenCV 3.0 安装节。
今天我们将继续 OpenCV 3.0 安装说明系列,转到 Ubuntu 操作系统。
在这篇文章的剩余部分,我将提供如何在 Ubuntu 上配置和安装 OpenCV 3.0 和 Python 2.7+的说明。我已经在 Ubuntu 14.04 上亲自测试了这些指令,但是它们应该可以在任何基于 Debian 的操作系统上运行。
在我们开始之前有一个小提示:是的,OpenCV 3.0 确实兼容 Python 3+。然而,Python 2.7+和 Python 3+之间的安装说明略有不同。为了让每篇文章保持独立且易于理解,我为 Python 2.7 和 Python 3+创建了单独的 OpenCV 3.0 安装教程。如果你想在你的 Ubuntu 系统上使用 OpenCV 3.0 和 Python 3+,请关注这个博客——我将在本月晚些时候发布 OpenCV 3.0 和 Python 3+的安装说明。但是目前,让我们继续使用 Python 2.7。
如何在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7+
更新:您现在正在阅读的教程涵盖了如何在 Ubuntu 14.04 上安装带有 Python 2.7+绑定的 OpenCV 3.0。本教程 仍然可以完美运行 ,但是如果你想用 OpenCV 3.1 和 Python 2.7(或 Python 3.5)绑定在更新的 Ubuntu 16.04 上安装 OpenCV,请使用本最新更新的教程:
https://pyimagesearch . com/2016/10/24/Ubuntu-16-04-how-to-install-opencv/
这是 OpenCV 3.0 install-fest 系列的第二篇文章。上周我们报道了如何在 OSX 上安装 OpenCV 3.0 和 Python 2.7+。今天我们将执行相同的 OpenCV 3.0 和 Python 2.7 安装,只是在 Ubuntu 操作系统上。一般来说,你会发现在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7+比在 OSX 上安装容易得多。
第一步:
打开一个终端,更新apt-get包管理器,然后升级任何预安装的包:
$ sudo apt-get update
$ sudo apt-get upgrade
第二步:
现在我们需要安装我们的开发工具:
$ sudo apt-get install build-essential cmake git pkg-config
pkg-config可能已经安装了,但是为了以防万一,一定要包括它。我们将使用git从 GitHub 下载 OpenCV 库。cmake包用于配置我们的构建。
第三步:
OpenCV 需要能够从磁盘加载各种图像文件格式,包括 JPEG、PNG、TIFF 等。为了从磁盘加载这些图像格式,我们需要我们的图像 I/O 包:
$ sudo apt-get install libjpeg8-dev libtiff4-dev libjasper-dev libpng12-dev
第四步:
此时,我们能够从磁盘上加载给定的图像。但是我们如何在屏幕上显示实际的图像呢?答案是 GTK 开发库,OpenCV 的highgui模块依赖它来引导图形用户界面(GUI):
$ sudo apt-get install libgtk2.0-dev
第五步:
我们可以使用 OpenCV 加载图像,但是处理视频流和访问单个帧怎么办?我们在这里已经讨论过了:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
第六步:
安装用于优化 OpenCV 内部各种例程的库:
$ sudo apt-get install libatlas-base-dev gfortran
第七步:
安装pip,一个 Python 包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
第八步:
安装虚拟器和虚拟器包装器。这两个包允许我们为我们正在进行的每个项目创建 单独的 Python 环境 。虽然安装virtualenv和virtualenvwrapper是 而不是 要求 让 OpenCV 3.0 和 Python 2.7+在你的 Ubuntu 系统上运行, 我强烈推荐它 并且本教程的其余部分 将假设你已经安装了它们!
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip
现在我们已经安装了virtualenv和virtualenvwrapper,我们需要更新我们的~/.bashrc文件:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
这种快速更新将确保每次登录时都加载virtualenv和virtualenvwrapper。
要使对我们的~/.bashrc文件的更改生效,您可以(1)注销并重新登录,(2)关闭您当前的终端窗口并打开一个新窗口,或者最好是(3)重新加载您的~/.bashrc文件的内容:
$ source ~/.bashrc
最后,我们可以创建我们的cv虚拟环境,在那里我们将进行计算机视觉开发和 OpenCV 3.0 + Python 2.7+安装:
$ mkvirtualenv cv
第九步:
正如我上面提到的,本教程涵盖了如何安装 OpenCV 3.0 和 Python 2.7+(我将在本月晚些时候推出 OpenCV 3.0 + Python 3 教程),因此我们需要安装我们的 Python 2.7 开发工具:
$ sudo apt-get install python2.7-dev
由于 OpenCV 将图像表示为多维 NumPy 数组,我们最好将 NumPy 安装到我们的cv虚拟环境中。我们还安装了imutils——我的便利功能包:
$ pip install numpy
$ pip install imutils
第十步:
我们的环境现在已经设置好了——我们可以转到我们的主目录,从 GitHub 中下载 OpenCV,并检查3.0.0版本:
$ cd ~
$ git clone https://github.com/Itseez/opencv.git
$ cd opencv
$ git checkout 3.0.0
更新(2016 年 1 月 3 日):你可以用任何当前版本替换3.0.0版本(目前是3.1.0)。请务必查看OpenCV.org了解最新发布的信息。
正如我上周提到的,我们也需要 opencv_contrib 回购。没有这个库,我们将无法访问标准的关键点检测器和局部不变描述符(如 SIFT、SURF 等)。)在 OpenCV 2.4.X 版本中可用。我们还将错过一些新的 OpenCV 3.0 特性,如自然图像中的文本检测:
$ cd ~
$ git clone https://github.com/Itseez/opencv_contrib.git
$ cd opencv_contrib
$ git checkout 3.0.0
同样,确保你为opencv_contrib检查的 版本与你为上面的opencv检查的 版本相同,否则你可能会遇到编译错误。
设置构建的时间:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D BUILD_EXAMPLES=ON ..
更新(2016 年 1 月 3 日):为了构建 OpenCV 3.1.0,需要在cmake命令中设置-D INSTALL_C_EXAMPLES=OFF(而不是ON)。OpenCV v3.1.0 CMake 构建脚本中有一个错误,如果您打开此开关,可能会导致错误。一旦您将此开关设置为 off,CMake 应该会顺利运行。
请注意,与上周的相比,我们的 CMake 命令更加简洁,需要的手动调整也更少——这是因为 CMake 能够更好地自动调整我们的安装参数(至少与 OSX 相比)。
现在我们终于可以编译 OpenCV 了:
$ make -j4
在这里,您可以用处理器上的可用内核数替换 4 ,以加快编译速度。
这里有一个 OpenCV 3.0 在我的系统上编译的例子:
Figure 1: OpenCV 3.0 with Python 2.7+ support compiling on my Ubuntu 14.04 system.
假设 OpenCV 编译无误,您现在可以将它安装到您的 Ubuntu 系统上:
$ sudo make install
$ sudo ldconfig
第十一步:
如果您已经顺利完成这一步,OpenCV 现在应该安装在/usr/local/lib/python2.7/site-packages中
然而,我们的cv虚拟环境位于我们的主目录中——因此,要在我们的cv环境中使用 OpenCV,我们首先需要将 OpenCV 符号链接到cv虚拟环境的site-packages目录中:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
第十二步:
恭喜你!您已经在您的 Ubuntu 系统 上成功安装了 OpenCV 3.0 与 Python 2.7+绑定!
要确认您的安装,只需确保您在cv虚拟环境中,然后导入cv2:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.0.0'
这里有一个在我自己的 Ubuntu 机器上演示 OpenCV 3.0 和 Python 2.7+安装的例子:
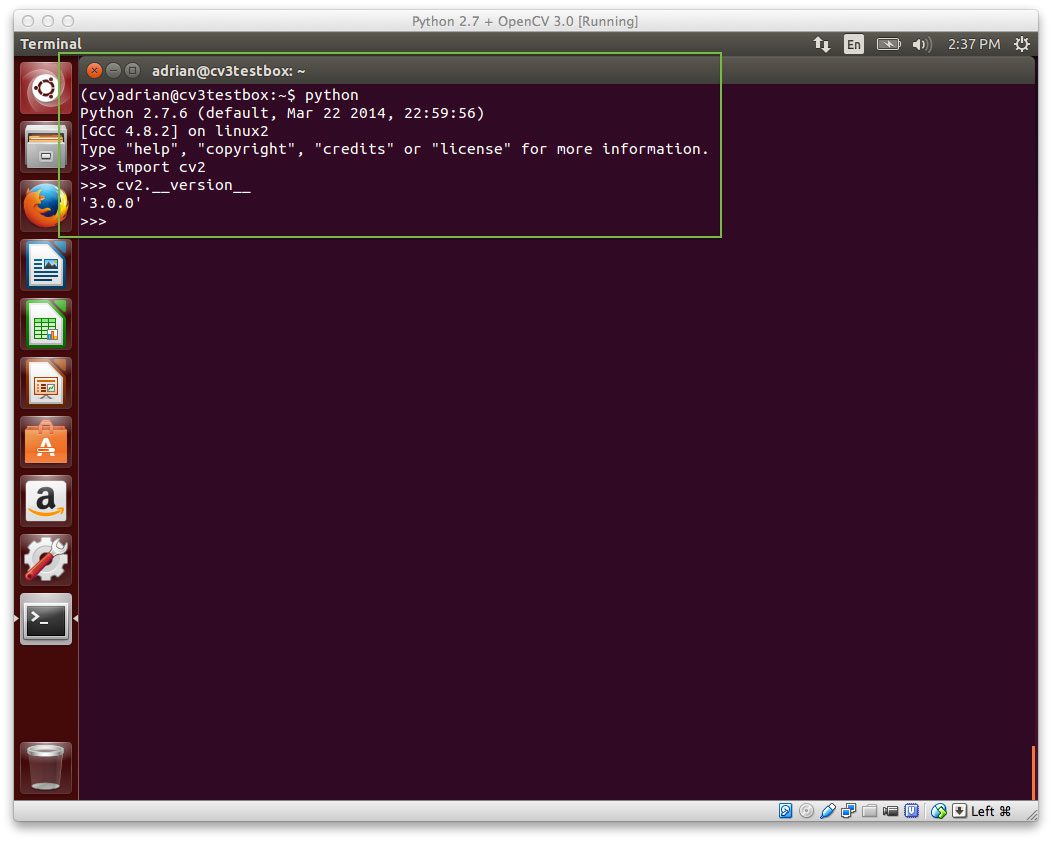
Figure 2: OpenCV 3.0 with Python 2.7+ bindings has been successfully installed on Ubuntu!
第十三步:
现在 OpenCV 已经配置并安装好了,让我们构建一个快速的 Python 脚本来检测下面名为games.jpg的图片中的 红色 游戏卡带:

Figure 3: Our goal is to detect the red game cartridge (on the right) in this image.
打开您最喜欢的编辑器,创建一个新文件,将其命名为find_game.py,并插入以下代码:
# import the necessary packages
import numpy as np
import imutils
import cv2
# load the games image
image = cv2.imread("games.jpg")
# find the red color game in the image
upper = np.array([65, 65, 255])
lower = np.array([0, 0, 200])
mask = cv2.inRange(image, lower, upper)
# find contours in the masked image and keep the largest one
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.05 * peri, True)
# draw a green bounding box surrounding the red game
cv2.drawContours(image, [approx], -1, (0, 255, 0), 4)
cv2.imshow("Image", image)
cv2.waitKey(0)
你还需要 下载 games.jpg 图像 ,并将其放在与你的find_game.py文件相同的目录下。下载完games.jpg文件后,您可以通过以下方式执行脚本:
$ python find_game.py
假设您已经下载了games.jpg图像并将其放在与我们的find_game.py脚本相同的目录中,您应该会看到以下输出:
Figure 4: We have successfully detected the red game cartridge in the image!
请注意,我们的脚本是如何成功地检测到图像右侧的红色游戏盒,然后在它周围绘制一个绿色的边界框。
显然,这不是世界上最令人兴奋的例子——但它证明了我们已经在 Ubuntu 系统上运行了 OpenCV 3.0 和 Python 2.7+绑定!
那么,下一步是什么?
恭喜你。你的 Ubuntu 系统上有一个全新的 OpenCV 安装——我敢肯定你只是渴望利用你的新安装来构建一些很棒的计算机视觉应用程序。
但是我也愿意打赌你才刚刚开始学习计算机视觉和 OpenCV ,你可能会对到底从哪里开始感到有点困惑和不知所措。
就我个人而言,我是通过实例学习的忠实粉丝,所以好的第一步是阅读这篇关于使用 OpenCV 访问网络摄像头的博文。本教程详细介绍了你需要采取的准确步骤(1)从你的网络摄像头捕捉照片和(2)访问原始视频流。
如果你真的对提升你的计算机视觉技能感兴趣,你绝对应该看看我的书,《实用 Python 和 OpenCV +案例研究》 。我的书不仅涵盖了计算机视觉和图像处理的基础知识,还教你如何解决现实世界的计算机视觉问题包括 图像和视频流中的人脸检测视频中的物体跟踪手写识别。

所以,让我们好好利用你在 Ubuntu 系统上新安装的 OpenCV—只需点击这里 了解更多关于你可以使用新的 OpenCV 安装+实用 Python 和 OpenCV 解决的真实项目。
摘要
为了庆祝 OpenCV 3.0 的发布,我正在研究 OpenCV 3.0 和 Python 2.7/Python 3.4 在【OSX】【Ubuntu】和 树莓派 上的安装说明。
上周我报道了如何在 OSX 上安装 OpenCV 3.0 和 Python 2.7+。
今天我们介绍了如何在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7 绑定。我已经亲自在我自己的 Ubuntu 14.04 机器上测试了这些指令,但是它们应该可以在任何基于 Debian 的系统上运行。
下周我们将继续安装活动,并返回 OSX——这次安装 OpenCV 3.0 和 Python 3!
这将是我们第一次在 PyImageSearch 博客上使用 Python 3,所以你不会想错过它的!
请考虑通过在下表中输入您的电子邮件地址来订阅 PyImageSearch 时事通讯。当我们在 OpenCV 安装节上工作时,我会在每个新的 OpenCV 3.0 + Python 安装教程发布时发送更新!
在 OSX 上安装 OpenCV 3.0 和 Python 3.4+
原文:https://pyimagesearch.com/2015/06/29/install-opencv-3-0-and-python-3-4-on-osx/

两周前,我们以一个关于如何在 OSXT3 上安装 OpenCV 3.0 和 Python 2.7 的教程开始了 OpenCV 3.0 安装节。
今天我又带着另一个 OSX 教程回来了——只是这次我们要用 Python 3.4+绑定来编译 OpenCV 3.0!
没错!随着 OpenCV 3.0 黄金版的发布,我们正式拥有了 Python 3 支持。这是一个漫长的过程——在 Python 2.7 领域停滞不前多年后,启动 Python 3 shell 并成为 Python 编程语言未来的一部分是一种很棒的感觉。
在本文的剩余部分,我将向您展示如何使用 Python 3.4+绑定编译和安装 OpenCV 3.0。
更新:您现在正在阅读的教程涵盖了如何在 OSX 优山美地、 以下安装带有 Python 3.4+绑定的 OpenCV 3.0。如果你使用的是 OSX 优胜美地或者更早的版本,这个教程 仍然可以很好地工作 ,但是如果你想在更新的 El Capitan 和 macOS Sierra 上安装 OpenCV,请使用这个最新更新的教程。
如何在 OSX 上安装 OpenCV 3.0 和 Python 3.4+
正如我在本文开头提到的,我已经在之前的文章中介绍了如何在 OSX 上安装 OpenCV 3.0 和 Python 2.7 绑定。您会注意到,大多数步骤非常相似(在某些情况下,完全相同),所以我删减了每个步骤的解释以减少冗余。如果你在寻找每个步骤和命令的更多细节,请查看之前的帖子,我会在那里做更详细的介绍。
也就是说,让我们开始在 OSX 上安装带有 Python 3.4 绑定的 OpenCV 3.0。
步骤 1:安装 Xcode
在你的系统上编译 OpenCV 之前,你首先需要安装 Xcode ,这是苹果公司为 OSX 和 iOS 开发提供的一套开发工具。安装 Xcode 非常简单,可以通过使用 App Store 应用程序来完成。只需搜索 Xcode ,点击获取,然后是安装 App ,你的下载就开始了:
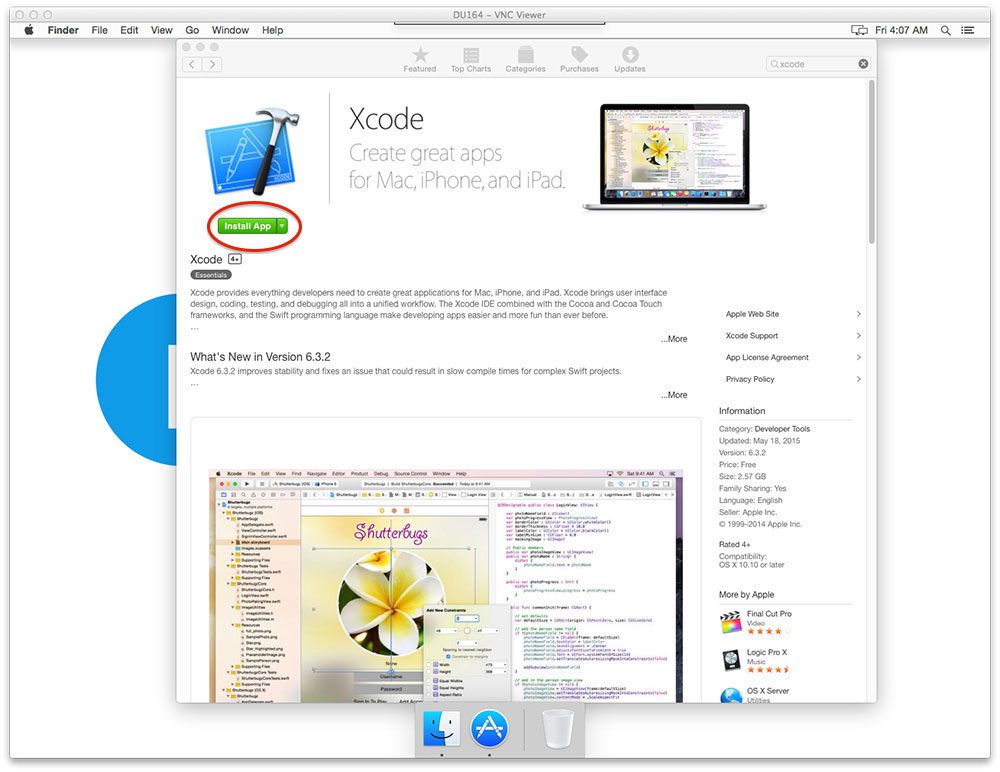
Figure 1: Installing Xcode on OSX.
下载本身相当大(> 2gb),而且苹果的内容交付服务器也不是世界上最快的,所以在 Xcode 安装期间,你可能会想出去走走,呼吸点新鲜空气。
步骤 2:安装自制软件
家酿是 OSX 的软件包管理器,类似于 Ubuntu 的 apt-get。我们将使用 Homebrew 来帮助我们安装和管理 OpenCV 的一些先决条件和依赖项。要安装 Homebrew,只需启动终端,复制并粘贴以下命令:
$ cd ~
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew update
步骤 3:安装 Python 3
OSX 没有附带 Python 3 的副本,所以我们需要通过自制软件安装它:
$ brew install python3
$ brew linkapps
我们还需要更新~/.bash_profile中的PATH(如果文件不存在,创建它)以表明自制软件包应该在任何系统软件包之前使用:
# Homebrew
export PATH=/usr/local/bin:$PATH
让我们重新加载我们的~/.bash_profile以确保更改已经生效:
$ source ~/.bash_profile
最后,让我们确认 Python 3.4 已经安装:
$ which python3
/usr/local/bin/python
$ python3 --version
Python 3.4.3
步骤 4:设置我们的 Python 3.4 环境
现在我们可以专注于为 OpenCV 编译设置 Python 3.4 环境了。
使用 virtualenv 和 virtualenvwrapper 绝对是而不是在你的 OSX 机器上安装 OpenCV 的一个要求, 但是我强烈推荐使用 这些包! 能够为每个项目创建单独的 Python 环境非常有用,所以一定要考虑使用它们!
无论如何,让我们安装virtualenv和virtualenvwrapper:
$ pip3 install virtualenv virtualenvwrapper
记下pip3命令。我使用pip3来表示virtualenv和virtualenvwrapper包应该为 Python 3.4、而不是 Python 2.7 安装(尽管这些包可以用于这两个 Python 版本)。
我们还需要再次更新我们的~/.bash_profile文件,在文件底部添加以下几行:
# Virtualenv/VirtualenvWrapper
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
接着是重装我们的.bash_profile:
$ source ~/.bash_profile
现在我们有进展了。让我们创建我们的cv3虚拟环境,OpenCV 将使用它来编译我们的 Python 3.4 绑定。这个虚拟环境还将包含我们想要存储的用于计算机视觉和图像处理开发的任何额外的包:
$ mkvirtualenv cv3 -p python3
注意我是如何明确地指定-p python3到的表明我们想要使用 Python 3.4 二进制文件创建一个虚拟环境。
在执行完mkvirtualenv命令后,我们进入了我们的cv3虚拟环境。如果你想再次访问这个虚拟环境(正如我将在本文底部演示的),只需使用workon命令:
$ workon cv3
你将被放回我们的cv3虚拟环境。
就 Python 的先决条件而言,我们需要的只是 NumPy:
$ pip install numpy
注意我在这里是如何使用pip而不是pip3的——因为我们是在cv3虚拟环境中,所以virtualenv和virtualenvwrapper脚本足够聪明,知道应该使用与cv3环境相关联的pip,所以没有必要显式使用pip3。
步骤 5:安装 OpenCV 先决条件
为了从源代码编译 OpenCV,我们需要一些开发工具:
$ brew install cmake pkg-config
以及一些处理从磁盘读取各种图像格式的包:
$ brew install jpeg libpng libtiff openexr
和另一对优化 OpenCV 内部各种例程的包:
$ brew install eigen tbb
步骤 6:编译 OpenCV
编译 OpenCV 的第一步是从 GitHub 中抓取源代码,并检查 3.0.0 版本:
$ cd ~
$ git clone https://github.com/Itseez/opencv.git
$ cd opencv
$ git checkout 3.0.0
更新(2016 年 1 月 3 日):你可以用任何当前版本替换3.0.0版本(目前是3.1.0)。请务必查看OpenCV.org了解最新发布的信息。
我们还将获取包含 opencv 额外模块的 opencv_contrib 包,例如特征检测和局部不变描述符(SIFT、SURF 等)。)、文本检测等等:
$ cd ~
$ git clone https://github.com/Itseez/opencv_contrib
$ cd opencv_contrib
$ git checkout 3.0.0
同样,确保你为opencv_contrib检查的 版本与你为上面的opencv检查的 版本相同,否则你可能会遇到编译错误。
既然存储库已经被删除,我们可以创建build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
并使用 CMake 来配置构建本身:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D PYTHON3_PACKAGES_PATH=~/.virtualenvs/cv3/lib/python3.4/site-packages \
-D PYTHON3_LIBRARY=/usr/local/Cellar/python3/3.4.3/Frameworks/Python.framework/Versions/3.4/lib/libpython3.4m.dylib \
-D PYTHON3_INCLUDE_DIR=/usr/local/Cellar/python3/3.4.3/Frameworks/Python.framework/Versions/3.4/include/python3.4m \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D BUILD_EXAMPLES=ON \
-D BUILD_opencv_python3=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules ..
更新(2016 年 1 月 3 日):为了构建 OpenCV 3.1.0,需要在cmake命令中设置-D INSTALL_C_EXAMPLES=OFF(而不是ON)。OpenCV v3.1.0 CMake 构建脚本中有一个错误,如果您打开此开关,可能会导致错误。一旦您将此开关设置为 off,CMake 应该会顺利运行。
在我之前关于在 OSX 上安装带有 Python 2.7 绑定的 OpenCV 3.0 的帖子中,我已经解释了这些选项中的每一个,所以如果你想要每个参数的详细解释,请参考那个帖子。
这里的要点是,您希望检查 CMake 的输出,以确保您的 Python 3 绑定将针对通过 Homebrew 和我们的cv3虚拟环境安装的 Python 3.4 解释器进行编译:
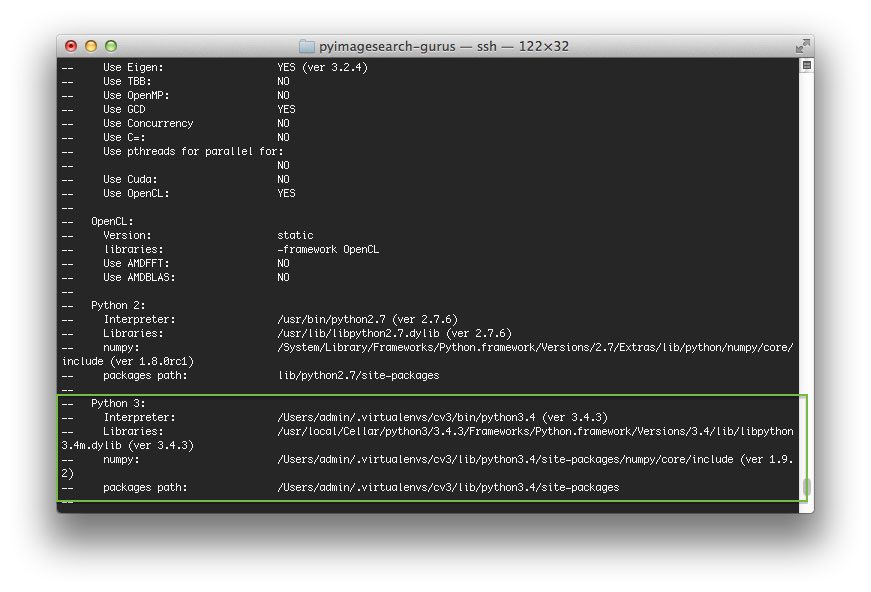
Figure 2: CMake has picked up the correct Python 3 interpreter, libraries, and site-packages path.
注意我们的 Python 3 解释器、库、numpy 版本和包路径是如何被 CMake 选中的。
另一个要做的检查是python3在要构建的模块列表中:
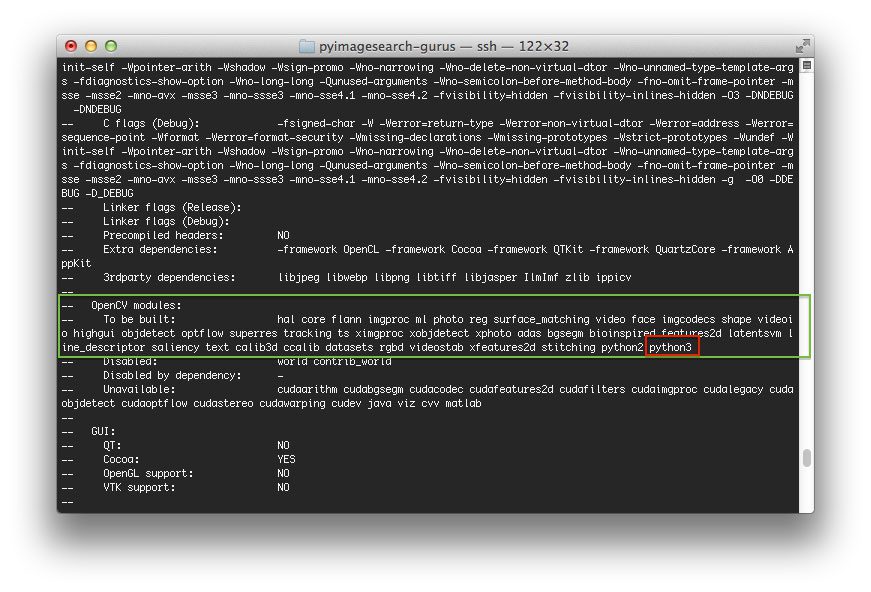
Figure 3: A good sanity check to perform prior to kicking off the compile process is to ensure that
“python3” is in the list of modules to be compiled.
如果您在要构建的模块列表中没有看到python3,并且在不可用列表中,那么您需要返回到 CMake 步骤并确保到您的PYTHON3_PACKAGES_PATH、PYTHON3_LIBRARY和PYTHON3_INCLUDE_DIR的路径是正确的。同样,我已经在我之前关于在 OSX 上安装 OpenCV 3.0 的帖子中提供了每个选项的详细解释,所以请参考那里的更多信息。
假设 CMake 已经返回,没有任何错误,我们现在可以编译 OpenCV:
$ make -j4
为了更快地编译,用系统上可用的内核数量替换 4 。
编译时间本身不应该超过 5-10 分钟,所以在 OpenCV 安装时喝杯咖啡,当你回来时(当然,假设 OpenCV 编译没有错误),你可以安装它:
$ make install
如果出于某种原因,您得到一个与安装 OpenCV 的权限无效相关的错误,只需在命令前面加上sudo:
$ sudo make install
步骤 7:验证安装
此时,您的系统上应该安装了 OpenCV 3.0 和 Python 3.4+绑定。您可以通过将目录更改为我们的cv3虚拟环境所在的位置并检查cv2.so文件来验证这一点:
$ cd ~/.virtualenvs/cv3/lib/python3.4/site-packages/
$ ls -l cv2.so
-rwxr-xr-x 1 admin _developer 2013028 Jun 19 06:11 cv2.so
毫无疑问,我们的 OpenCV 绑定位于虚拟环境的目录中。
注意:您也可以在您的build/lib目录中找到cv2.so文件(同样是您的 OpenCV 绑定)。make install脚本获取我们的cv2.so文件,并将其复制到我们的目标site-packages目录。
最后,让我们打开一个 shell 并导入 OpenCV 来验证我们的安装:
(cv3)74-80-245-164:~ admin$ python3
Python 3.4.3 (default, Jun 19 2015, 05:23:16)
[GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.0.0'
祝贺你,你现在已经在你的 OSX 系统上安装了 OpenCV 3.0 和 Python 3.4+绑定!
摘要
在本教程中,我们学习了如何使用 CMake 实用程序手动编译和安装 OpenCV 3.0 和 Python 3.4+绑定(如果您正在寻找安装 OpenCV 3.0 和 Python 2.7+绑定的教程,请参见我之前的帖子)。当然,手工编译并不是最有趣的体验——但是它确实给了我们对安装的完全控制权。
幸运的是,就在一周前,一个 OpenCV 3.0 安装脚本在科学论坛中为自制软件创建。在以后的文章中,我将展示如何利用自制软件来大大简化编译和安装过程,让我们的生活变得更加轻松。
尽管如此,我仍然建议你尝试手动安装 OpenCV 3.0 自制软件很好,但你永远不会像使用 CMake 那样获得完全的控制。
为了在 Homebrew + OpenCV 3.0 安装帖子发布时得到通知,请在下面的表格中输入您的电子邮件地址,我会在教程发布时通知您。
在 Ubuntu 上安装 OpenCV 3.0 和 Python 3.4+
原文:https://pyimagesearch.com/2015/07/20/install-opencv-3-0-and-python-3-4-on-ubuntu/

几周前,我提供了一步一步的安装说明,让在你的 Ubuntu 机器上安装 OpenCV 3.0 和 Python 2.7+。
然而,迁移到 OpenCV 3.0 的巨大好处之一是新的 Python 3.4+支持。在 OpenCV 之前的 2.4.X 版本中,只支持 Python 2.7+版本。但是现在,我们终于可以在我们的新项目中利用 Python 3.4+了。
在这篇博文的剩余部分,我将详细介绍如何在你的 Ubuntu 14.04+系统上安装 OpenCV 3.0 和 Python 3.4+绑定。如果您遵循了上一篇教程,您会注意到许多步骤是相同的(或者至少非常相似),所以我对这篇文章进行了压缩。也就是说,当我们在本教程后面开始使用 CMake 时,一定要特别注意,以确保您正在编译支持 Python 3.4+的 OpenCV 3.0!
如何在 Ubuntu 上安装 OpenCV 3.0 和 Python 3.4+
更新:您现在正在阅读的教程涵盖了如何在 Ubuntu 14.04 上安装带有 Python 3.4+绑定的 OpenCV 3.0。本教程 仍然可以完美运行 ,但是如果你想在 OpenCV 3.1 和 Python 3.5+的较新 Ubuntu 16.04 上安装 OpenCV,请使用本最新更新的教程:
https://pyimagesearch . com/2016/10/24/Ubuntu-16-04-how-to-install-opencv/
几周前我报道了如何在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7+,虽然这是一个很棒的教程(因为我们中的许多人仍在使用 Python 2.7),但我认为它确实错过了 OpenCV 3.0 的一个主要方面——Python 3.4+支持!
没错,直到 3.0 版本,OpenCV 只提供了到 Python 2.7 编程语言的绑定。
对我们大多数人来说,这没什么。作为科学开发人员和研究人员,一个非常标准的假设是,我们将被隔离到 Python 2.7。
然而,这种情况正在开始改变。重要的科学库,如 NumPy、SciPy 和 scikit-learn,现在都提供 Python 3 支持。而现在 OpenCV 3.0 也加入了这个行列!
总的来说,你会发现本教程与上一篇关于在 Ubuntu 上安装 OpenCV 3.0 和 Python2.7 的教程非常相似,所以我将根据需要浓缩我对每个步骤的解释。如果你想完整解释每一步,请参考以前的 OpenCV 3.0 文章。否则,只需跟随本教程,不到 10 分钟,你就可以在你的 Ubuntu 系统上安装 OpenCV 3.0 和 Python 3.4+。
步骤 1:安装必备组件
升级任何预安装的软件包:
$ sudo apt-get update
$ sudo apt-get upgrade
安装用于编译 OpenCV 3.0 的开发工具:
$ sudo apt-get install build-essential cmake git pkg-config
安装用于从磁盘读取各种图像格式的库和包;
$ sudo apt-get install libjpeg8-dev libtiff4-dev libjasper-dev libpng12-dev
安装几个用来从磁盘读取视频格式的库:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
安装 GTK,这样我们就可以使用 OpenCV 的 GUI 特性:
$ sudo apt-get install libgtk2.0-dev
安装用于优化 OpenCV 内部各种功能的软件包,例如矩阵运算:
$ sudo apt-get install libatlas-base-dev gfortran
步骤 2:设置 Python(第 1 部分)
让我们来看看为 Python 3 安装的 Python 包管理器pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
注意我在安装pip的时候特意注明了python3。如果你不提供python3,那么 Ubuntu 将试图在你的 Python 2.7 发行版上安装pip,这不是我们想要的。
好吧,我之前在 PyImageSearch 博客上说过,我会再看一遍。您应该真正使用虚拟环境进行 Python 开发!
在本教程中,我们将使用 virtualenv 和 virtualenvwrapper 。这些包允许我们创建 完全分离和独立的 Python 环境 ,,确保我们不会破坏我们的系统 Python 安装(更重要的是,这样我们可以为我们的每个项目拥有一个单独的 Python 环境)。
让我们使用新的pip3安装来设置virtualenv和virtualenvwrapper:
$ sudo pip3 install virtualenv virtualenvwrapper
同样,注意我是如何指定pip3而不仅仅是pip的——我只是清楚地表明这些包应该为 Python 3.4 安装。
现在我们可以更新我们的~/.bashrc文件(放在文件的底部):
# virtualenv and virtualenvwrapper
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
注意我是如何将VIRTUALENVWRAPPER_PYTHON指向我们的 Python 3 二进制文件在 Ubuntu 系统上的位置的。
要使这些更改生效,您可以打开一个新的终端或重新加载您的~/.bashrc文件:
$ source ~/.bashrc
最后,让我们创建我们的cv虚拟环境,在这里我们将使用 OpenCV 3.0 和 Python 3.4 进行计算机视觉开发:
$ mkvirtualenv cv
步骤 2:设置 Python(第 2 部分)
我们已经完成了一半的 Python 设置。但是为了用 Python 3.4+绑定编译 OpenCV 3.0,我们需要安装 Python 3.4+头文件和开发文件:
$ sudo apt-get install python3.4-dev
OpenCV 将图像表示为 NumPy 数组,因此我们需要将 NumPy 安装到我们的cv虚拟环境中:
$ pip install numpy
如果你最终得到一个与 pip 的.cache目录相关的权限被拒绝错误,就像这样:
Figure 1: If you get a “Permission Denied” error, no worries — that’s an easy fix!
然后只需删除缓存目录并重新运行 NumPy install 命令:
$ sudo rm -rf ~/.cache/pip/
$ pip install numpy
现在您应该有一个很好的 NumPy 的干净安装了:
Figure 2: Deleting the .cache/pip directory and re-running pip install numpy will take care of the problem.
步骤 3:使用 Python 3.4+绑定构建并安装 OpenCV 3.0
好了,我们的系统已经设置好了!让我们从 GitHub 下载 OpenCV 并检查3.0.0版本:
$ cd ~
$ git clone https://github.com/Itseez/opencv.git
$ cd opencv
$ git checkout 3.0.0
更新(2016 年 1 月 3 日):你可以用任何当前版本替换3.0.0版本(目前是3.1.0)。请务必查看OpenCV.org了解最新发布的信息。
我们还需要获取 opencv_contrib 回购(关于我们为什么需要opencv_contrib的更多信息,请看我之前的OpenCV 3.0 Ubuntu 安装帖子):
$ cd ~
$ git clone https://github.com/Itseez/opencv_contrib.git
$ cd opencv_contrib
$ git checkout 3.0.0
同样,确保你为opencv_contrib检查的 版本与你为上面的opencv检查的 版本相同,否则你可能会遇到编译错误。
设置构件的时间:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D BUILD_EXAMPLES=ON ..
更新(2016 年 1 月 3 日):为了构建 OpenCV 3.1.0,需要在cmake命令中设置-D INSTALL_C_EXAMPLES=OFF(而不是ON)。OpenCV v3.1.0 CMake 构建脚本中有一个错误,如果您打开此开关,可能会导致错误。一旦您将此开关设置为 off,CMake 应该会顺利运行。
让我们花点时间来看看我的 CMake 输出:
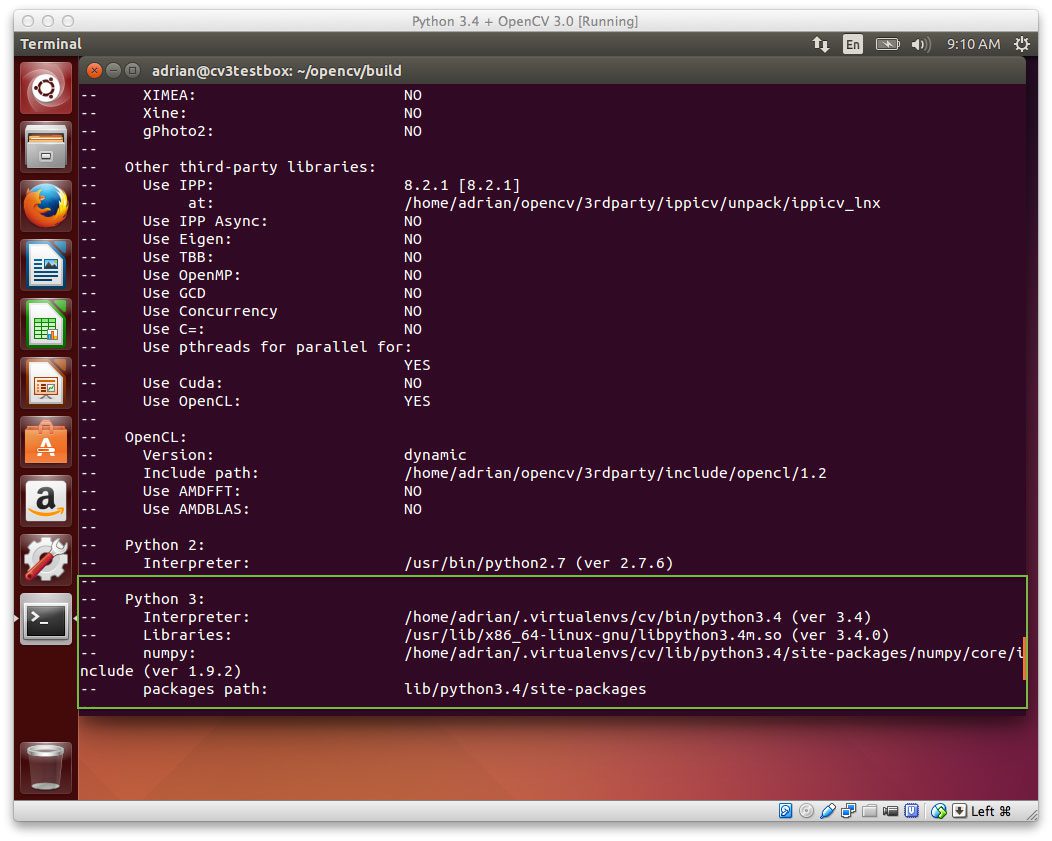
Figure 3: It’s a good idea to inspect the output of CMake to ensure the proper Python 3 interpreter, libraries, etc. have been picked up.
请注意 CMake 是如何获得我们的 Python 3 解释器的!这表明 OpenCV 3.0 将使用我们的 Python 3.4+绑定进行编译。
说到编译,让我们开始 OpenCV 编译过程:
$ make -j4
其中 4 可以替换为处理器上可用内核的数量,以加快编译时间。
假设 OpenCV 3.0 编译无误,您现在可以将它安装到您的系统上:
$ sudo make install
$ sudo ldconfig
第四步:Sym-link OpenCV 3.0
如果你已经到了这一步,OpenCV 3.0 现在应该已经安装在/usr/local/lib/python3.4/site-packages/了
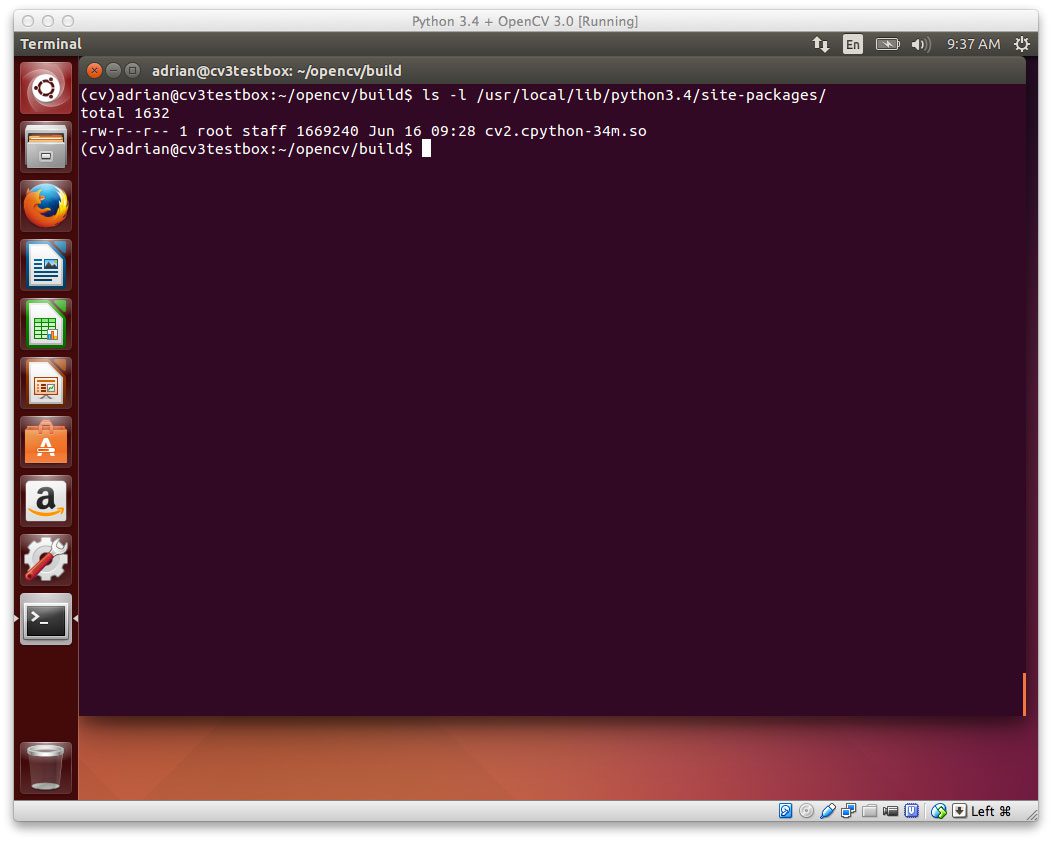
Figure 4: The Python 3.4+ OpenCV 3.0 bindings are now installed in /usr/local/lib/python3.4/site-packages/
这里,我们的 OpenCV 绑定存储在名称cv2.cpython-34m.so下
务必记下这个文件名,几秒钟后你就会用到它!
然而,为了在我们的cv虚拟环境中使用 OpenCV 3.0,我们首先需要将 OpenCV 符号链接到cv环境的site-packages目录中,如下所示:
$ cd ~/.virtualenvs/cv/lib/python3.4/site-packages/
$ ln -s /usr/local/lib/python3.4/site-packages/cv2.cpython-34m.so cv2.so
注意我是如何将名称从cv2.cpython-34m.so改为cv2.so的——这样 Python 可以使用名称cv2导入我们的 OpenCV 绑定。
所以现在当你列出cv虚拟环境的site-packages目录的内容时,你会看到我们的 OpenCV 3.0 绑定(cv2.so文件):

Figure 5: In order to access the OpenCV 3.0 bindings from our Python 3.4+ interpreter, we need to sym-link the cv2.so file into our site-packages directory.
再次强调,t his 是非常重要的一步,所以一定要确保你的虚拟环境中有cv2.so文件,否则你将无法在你的 Python 脚本中导入 OpenCV!
步骤 5:测试 OpenCV 3.0 和 Python 3.4+安装
做得好!您已经在您的 Ubuntu 系统上成功安装了 OpenCV 3.0 和 Python 3.4+绑定(以及虚拟环境支持)!
但是在我们打开香槟和啤酒之前,让我们确认一下这个装置已经工作了。首先,确保您处于cv虚拟环境中,然后启动 Python 3 并尝试导入cv2:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.0.0'
下面是我在自己的 Ubuntu 系统上用 Python 3.4+导入 OpenCV 3.0 的例子:
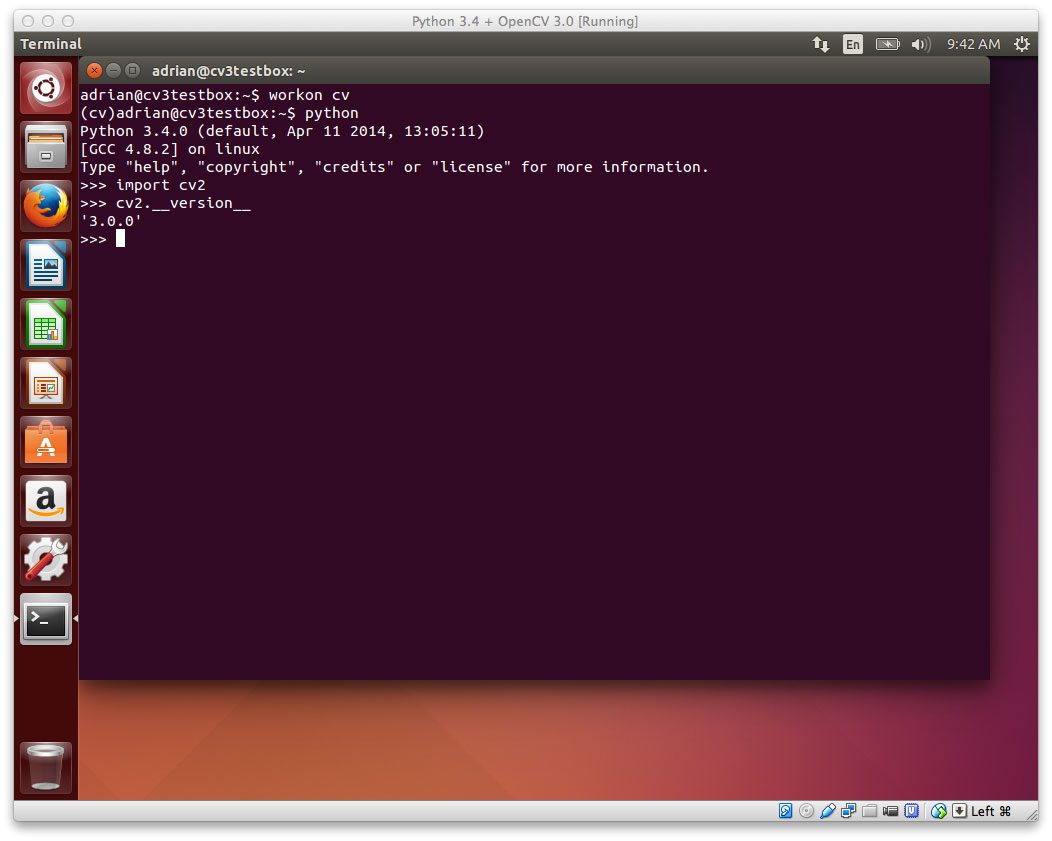
Figure 6: OpenCV 3.0 with Python 3.4+ bindings has been successfully installed on the Ubuntu system!
如你所见,OpenCV 3.0 与 Python 3.4+绑定已经成功安装在我的 Ubuntu 系统上!
摘要
在本教程中,我演示了如何在你的 Ubuntu 系统上安装 OpenCV 3.0 和 Python 3.4+绑定。这篇文章与我们之前关于在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7 的教程非常相似,但是利用了 OpenCV 3.0 新的 Python 3+支持,确保我们可以在工作中使用 Python 3 解释器。
虽然拥有 Python 3.4+支持真的很棒,而且肯定是 Python 编程语言的未来,但我也建议您在考虑从 Python 2.7 迁移到 Python 3.4 时要特别小心。对于许多科学开发人员来说,从 Python 2.7 迁移到 3.4 是一个缓慢而艰难的过程。虽然像 NumPy、SciPy 和 scikit-learn 这样的大型 Python 包已经做出了改变,但是仍然有其他较小的库依赖于 Python 2.7。也就是说,如果你是一名从事计算机视觉、机器学习或数据科学的科学开发人员,当你迁移到 Python 3.4 时,你会想要小心,因为你可以很容易地将你的研究归类。
在接下来的几周内,OpenCV 3.0 安装节将会继续,所以如果你想在新的安装教程发布时收到电子邮件更新(例如用家酿安装 OpenCV 3.0,在 Raspberry Pi 上安装 OpenCV 3.0,等等),请在下面的表格中输入你的电子邮件地址。
用自制软件在 macOS 上安装 OpenCV 3(简单的方法)
原文:https://pyimagesearch.com/2016/12/19/install-opencv-3-on-macos-with-homebrew-the-easy-way/

在过去的几周里,我演示了如何在 macOS 上使用 Python ( 2.7 , 3.5 )绑定从源代码编译 OpenCV 3。
通过源代码编译 OpenCV 给你 完全和完全的控制权 在你想要构建哪些模块,它们是如何构建的,以及它们被安装在哪里。
然而,所有这些控制都是有代价的。
不利的一面是,确定 Python 解释器、库和包含目录的正确 CMake 路径可能不简单,尤其是对于不熟悉 OpenCV/Unix 系统的用户。
这引出了一个问题……
“在 macOS 上安装 OpenCV 有没有更简单的方法?避免复杂的 CMake 配置的方法?”
事实证明,有——就用 Homebrew 吧,许多人认为它是“Mac 缺失的软件包管理器”。
那么,真的有那么容易吗?仅仅几个简单的键击和命令就可以避免麻烦并安装 OpenCV 3 吗?
嗯,还不止这些… 但是这个过程被大大简化了。你失去了一点控制权(与从源代码编译相比),但是你得到的是在你的 Mac 系统上安装 OpenCV 的一个更容易遵循的路径。
要发现通过自制软件在 macOS 上安装 OpenCV 3 的简单方法,继续阅读。
用自制软件在 macOS 上安装 OpenCV 3(简单的方法)
这篇博客文章的剩余部分演示了如何通过自制程序在 macOS 上安装 OpenCV 3 与 Python 2.7 和 Python 3 绑定。使用自制软件的好处是它 极大地简化了安装过程 (尽管如果你不小心的话,它可能会带来自己的问题)只需要运行几组命令。
如果您喜欢在 macOS 上使用 Python 绑定从源代码编译 OpenCV,请参考这些教程:
步骤 1:安装 XCode
在我们可以通过家酿在 macOS 上安装 OpenCV 3 之前,我们首先需要安装 Xcode,这是一套用于 Mac 操作系统的软件开发工具。
Download Xcode
下载和安装 Xcode 最简单的方法是在 macOS 系统上使用附带的 App Store 应用程序。只需打开应用商店,在搜索栏搜索【Xcode】,然后点击【获取】按钮:

Figure 1: Downloading and installing Xcode on macOS.
根据您的互联网连接和系统速度,下载和安装过程可能需要 30 到 60 分钟。我建议您在完成其他工作或者出去散步的时候,在后台安装 Xocde。
接受苹果开发者许可
我假设您正在使用全新安装的 macOS 和 Xcode。如果是这样,你需要接受开发者许可才能继续。我个人认为,通过终端更容易做到这一点。只需打开一个终端并执行以下命令:
$ sudo xcodebuild -license
滚动到许可证的底部并接受它。
如果您已经安装了 Xcode 并且之前接受了 Apple developer license,您可以跳过这一步。
安装 Apple 命令行工具
既然 Xcode 已经安装好了,我们也接受了 Apple developer license,我们就可以安装 Apple 命令行工具了。这些工具包括 make、GCC、clang 等包。 这是一个必需的步骤 ,所以让你通过:
$ sudo xcode-select --install
执行上述命令时,您将看到一个弹出的确认窗口,询问您是否批准安装:

Figure 2: Installing Apple Command Line Tools on macOS.
只需点击“安装”按钮继续。苹果命令行工具的实际安装过程应该不到 5 分钟。
如果您还没有接受 Xcode 许可,请使用以下命令确定您已经接受了 Xcode 许可:
$ sudo xcodebuild -license
第二步:安装自制软件
我们现在准备安装家酿,一个 macOS 的包管理器。你可以把家酿看作是 macOS 上基于 Ubuntu/Debian 的 apt-get 。
安装家酿非常简单——只需将命令复制并粘贴到家酿网站的“安装家酿”部分下面(确保将整个命令复制并粘贴到您的终端中)。我包含了下面的命令作为参考:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
在 Homebrew 安装之后,您应该通过执行以下命令来确保包定义(即,用于安装给定库/包的指令)是最新的:
$ brew update
既然家酿已经成功安装和更新,我们需要更新我们的~/.bash_profile文件,以便它在搜索系统路径之前搜索家酿路径中的包/库。当试图利用 Python 和 OpenCV,时,不完成这一步可能会导致混乱的错误、导入问题和 segfaults,所以请确保正确更新您的~/.bash_profile 文件!
文件的~/.bash_profile可能或者可能已经不在你的系统上了。在这两种情况下,用您最喜欢的文本编辑器打开它(在这个例子中我将使用nano):
$ nano ~/.bash_profile
然后在文件底部插入以下几行(如果~/.bash_profile不存在,文件将是空的——这没关系,只需将以下几行添加到文件中):
# Homebrew
export PATH=/usr/local/bin:$PATH
这个代码片段所做的就是在搜索系统路径之前,更新你的PATH变量,沿着自制程序路径寻找库/二进制文件。
更新完~/.bash_profile文件后,保存并退出文本编辑器。
为了确保你是在正确的道路上,我在下面附上了我的~/.bash_profile的截图,这样你就可以和你的进行比较了:

Figure 3: Updating my .bash_profile file to include Homebrew.
记住,你的~/.bash_profile可能和我的 看起来很不一样——没关系! 只要确保你已经在你的文件中包含了上面的家酿代码片段,然后成功保存并编辑编辑器。
最后,我们需要手动source这个~/.bash_profile文件,以确保修改已经被重新加载:
$ source ~/.bash_profile
上述命令只需要执行一次。每当你打开一个新的终端,登录等。,您的.bash_profile文件将自动为您加载和获取。
步骤 3:使用自制软件安装 Python 2.7 和 Python 3
下一步是安装 Python 2.7 和 Python 3 的自制版本。将 Python 系统作为您的主要解释器来开发被认为是不好的形式。Python 的系统版本应该正好服务于那个——系统例程。
相反,你应该安装你自己的 Python 版本,该版本独立于系统安装。使用自制软件,我们可以使用以下命令安装Python 2.7 和Python 3:
$ brew install python python3
在撰写本文时,自制软件安装的最新 Python 版本是 Python 2.7.12 和 Python 3.5.2 。
作为健全性检查,让我们确认你使用的是 Python 的自制版本,而不是 Python 的系统版本。您可以通过which命令来完成:
$ which python
/usr/local/bin/python
$ which python3
/usr/local/bin/python3
仔细检查which的输出。如果你看到每条路径的/usr/local/bin/python和/usr/local/bin/python3,那么你使用 Python 的自制版本就是正确的。然而,如果输出是/usr/bin/python和/usr/bin/python3,那么你就不正确地使用了 Python 的系统版本。
如果你发现自己处于这种情况,你应该:
- 返回到步骤#2 并确保自制软件安装无误。
- 检查
brew install python python3是否成功完成。 - 您已经正确更新了您的
~/.bash_profile文件,并通过source重新加载了更改。你的~/.bash_profile看起来应该和上面图 3 中我的相似。
检查您的 Python 版本
安装 Python 2.7 和 Python 3 之后,您将需要使用以下命令检查您的 Python 版本号:
$ python --version
Python 2.7.10
$ python3 --version
Python 3.5.0
特别是既要注意 大调 又要注意 小调 版本号。对于第一个命令,我的主要 Python 版本是 2 ,次要版本是 7 。类似地,对于第二个命令,我的主要 Python 版本是 3 ,次要版本是 5 。
我提出这个问题的原因是因为文件路径可以并且将会根据您特定的 Python 版本号而改变。本教程中的详细说明将成功地在你的 macOS 机器上安装 OpenCV,前提是你注意你的 Python 版本号。
例如,如果我告诉您检查 Python 3 安装的site-packages目录,并提供一个示例命令:
$ ls /usr/local/opt/opencv3/lib/python3.5/site-packages/
你应该首先检查你的 Python 3 版本。如果上面的python3 --version命令报告了 3.6 ,那么您需要将您的路径更新为:
$ ls /usr/local/opt/opencv3/lib/python3.6/site-packages/
注意python3.5是如何变成python3.6的。
忘记检查和验证文件路径是我看到的读者第一次试图在 macOS 机器上安装 OpenCV 时犯的一个常见错误。不要盲目复制粘贴命令和文件路径。相反,应该花时间根据 Python 版本号来验证文件路径。这样做将确保您的命令被正确地构造,并且在您第一次安装 OpenCV 时会对您有很大的帮助。
步骤 4:使用自制软件在 macOS 上安装 OpenCV 3 和 Python 绑定
既然我们已经安装了 Python 2.7 和 Python 3 的自制版本,我们现在准备安装 OpenCV 3。
点击“自制/科学”回购
第一步是将homebrew/science存储库添加到我们正在跟踪的包集合中。这允许我们访问安装 OpenCV 的公式。为此,只需使用以下命令:
$ brew tap homebrew/science
了解“brew install”命令
为了通过自制软件在我们的 macOS 系统上安装 OpenCV,我们将使用brew install命令。该命令接受要安装的软件包的名称(如 Debian/Ubuntu 的 apt-get ),后跟一组可选参数。
我们的指挥基础是:brew install opencv3;但是,我们需要添加一些额外的参数。
最重要的组参数如下:
--with-contrib:这确保安装了 opencv_contrib 库,让我们能够访问额外的、关键的 opencv 特性,如 SIFT、SURF 等。--with-python3: OpenCV 3 + Python 2.7 绑定会被自动编译;然而,为了编译 OpenCV 3 + Python 3 绑定,我们需要显式地提供--with-python3开关。--HEAD:而不是编译一个带标签的 OpenCV 版本(即 v3.0、v3.1 等)。)相反,--HEAD交换机从 GitHub 克隆了 OpenCV 的最新版本。我们为什么要这么做呢?简单。我们需要避免困扰 macOS Sierra 系统的 QTKit 错误与当前标记的 OpenCV 3 版本(请参见“避免 QTKit/QTKit.h 文件未找到错误”的部分了解更多信息)
您可以通过运行brew info opencv3来查看选项/开关的完整列表,我在下面列出了它的输出:
$ brew info opencv3
...
--32-bit
Build 32-bit only
--c++11
Build using C++11 mode
--with-contrib
Build "extra" contributed modules
--with-cuda
Build with CUDA v7.0+ support
--with-examples
Install C and python examples (sources)
--with-ffmpeg
Build with ffmpeg support
--with-gphoto2
Build with gphoto2 support
--with-gstreamer
Build with gstreamer support
--with-jasper
Build with jasper support
--with-java
Build with Java support
--with-libdc1394
Build with libdc1394 support
--with-opengl
Build with OpenGL support (must use --with-qt5)
--with-openni
Build with openni support
--with-openni2
Build with openni2 support
--with-python3
Build with python3 support
--with-qt5
Build the Qt5 backend to HighGUI
--with-quicktime
Use QuickTime for Video I/O instead of QTKit
--with-static
Build static libraries
--with-tbb
Enable parallel code in OpenCV using Intel TBB
--with-vtk
Build with vtk support
--without-eigen
Build without eigen support
--without-numpy
Use a numpy you've installed yourself instead of a Homebrew-packaged numpy
--without-opencl
Disable GPU code in OpenCV using OpenCL
--without-openexr
Build without openexr support
--without-python
Build without Python support
--without-test
Build without accuracy & performance tests
--HEAD
Install HEAD version
对于那些好奇的人来说,自制公式(即用于安装 OpenCV 3 的实际命令)可以在这里找到。如果您想要添加任何附加的 OpenCV 3 特性,请使用上面的参数和安装脚本作为参考。
我们现在已经准备好通过自制程序在你的 macOS 系统上安装 OpenCV 3 和 Python 绑定。根据您已经安装或尚未安装的依赖项,以及您的系统速度,这种编译可能需要几个小时,所以您可能想在开始安装过程后出去走走。
通过自制程序安装带有 Python 3 绑定的 OpenCV 3
要启动 OpenCV 3 安装过程,只需执行以下命令:
$ brew install opencv3 --with-contrib --with-python3 --HEAD
这个命令将通过 Homebew 在您的 macOS 系统上安装 OpenCV 3,同时使用Python 2.7 和 Python 3 绑定。我们还将编译 OpenCV 3 的最新、最前沿版本(以避免任何 QTKit 错误)以及启用的opencv_contrib支持。
更新—2017 年 5 月 15 日:
最近有一个用于在 macOS 机器上安装 OpenCV 的家酿公式的更新,可能会导致两种类型的错误。
理想情况下,家酿公式将在未来更新,以防止这些错误,但在此期间,如果您遇到下面的或错误:
opencv3: Does not support building both Python 2 and 3 wrappersNo such file or directory 3rdparty/ippicv/downloader.cmake
那么一定要参考 这篇更新的博文 ,我在那里提供了两个错误的解决方案。
正如我提到的,这个安装过程需要一些时间,所以考虑在 OpenCV 安装的时候出去走走。然而,当你离开时,确保你的电脑不会进入睡眠/关机状态!如果是这样,安装过程将会中断,您必须重新启动它。
假设 OpenCV 3 安装没有问题,您的终端输出应该与下面的类似:

Figure 4: Compiling and installing OpenCV 3 with Python bindings on macOS with Homebrew.
然而,我们还没有完全完成。
您会在安装输出的底部注意到一个小注释:
If you need Python to find bindings for this keg-only formula, run:
echo /usr/local/opt/opencv3/lib/python2.7/site-packages >> /usr/local/lib/python2.7/site-packages/opencv3.pth
这意味着我们的 Python 2.7 + OpenCV 3 绑定现在安装在/usr/local/opt/opencv3/lib/python2.7/site-packages中,这是 OpenCV 编译的自制路径。我们可以通过ls命令验证这一点:
$ ls -l /usr/local/opt/opencv3/lib/python2.7/site-packages
total 6944
-r--r--r-- 1 admin admin 3552288 Dec 15 09:28 cv2.so
然而,我们需要将这些绑定放入/usr/local/lib/python2.7/site-packages/,这是 Python 2.7 的site-packages目录。我们可以通过执行以下命令来实现这一点:
$ echo /usr/local/opt/opencv3/lib/python2.7/site-packages >> /usr/local/lib/python2.7/site-packages/opencv3.pth
上面的命令创建了一个.pth文件,它告诉 Homebrew 的 Python 2.7 install 在/usr/local/opt/opencv3/lib/python2.7/site-packages中寻找附加包——本质上,.pth文件可以被认为是一个“美化的符号链接”。
至此,您已经安装了 OpenCV 3 + Python 2.7 绑定!
然而,我们还没有完全完成…对于 Python 3,我们还需要采取一些额外的步骤。
处理 Python 3 问题
还记得我们提供给brew install opencv3的--with-python3选项吗?
嗯,这个选项确实起作用了(虽然看起来不像)——我们确实在我们的系统上安装了 Python 3 + OpenCV 3 绑定。
注:非常感谢 Brandon Hurr 指出这一点。很长一段时间,我认为这个开关根本不起作用。
然而,有一个小问题。如果你检查一下/usr/local/opt/opencv3/lib/python3.5/site-packages/的内容,你会发现我们的cv2.so文件有一个有趣的名字:
$ ls -l /usr/local/opt/opencv3/lib/python3.5/site-packages/
total 6952
-r--r--r-- 1 admin admin 3556384 Dec 15 09:28 cv2.cpython-35m-darwin.so
我不知道为什么 Python 3 + OpenCV 3 绑定没有像它们应该的那样被命名为cv2.so,但是跨操作系统也是如此。你会在 macOS、Ubuntu 和 Raspbian 上看到同样的问题。
幸运的是,修复很容易——您需要做的只是将cv2.cpython-35m-darwin.so重命名为cv2.so:
$ cd /usr/local/opt/opencv3/lib/python3.5/site-packages/
$ mv cv2.cpython-35m-darwin.so cv2.so
$ cd ~
从那里,我们可以创建另一个.pth文件,这次是为了 Python 3 + OpenCV 3 安装:
$ echo /usr/local/opt/opencv3/lib/python3.5/site-packages >> /usr/local/lib/python3.5/site-packages/opencv3.pth
至此,你已经通过自制软件在 macOS 系统上安装了Python 2.7+OpenCV 3 和 Python 3 + OpenCV 3。
*#### 验证 OpenCV 3 是否已安装
下面是我用来验证 OpenCV 3 和 Python 2.7 绑定在我的系统上工作的命令:
$ python
Python 2.7.12 (default, Oct 11 2016, 05:20:59)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.38)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.1.0-dev'
>>>
下面的屏幕截图显示了如何将 OpenCV 3 绑定导入到 Python 3 shell 中:

Figure 5: Confirming that OpenCV 3 with Python 3 bindings have been successfully installed on my macOS system via Homebrew.
恭喜你,你已经通过 Homebrew 在 macOS 系统上安装了带 Python 绑定的 OpenCV 3!
但是如果你是这个博客的长期读者,你应该知道我广泛使用 Python 虚拟环境— ,你也应该这样做。
步骤 5:设置 Python 虚拟环境(可选)
你会注意到,与我之前的许多 OpenCV 3 安装教程不同,自制软件(T2)没有利用 Python 虚拟环境,这是 Python 开发的最佳实践。
虽然步骤#5-#7 是可选的,但是 我强烈建议您执行这些步骤 ,以确保您的系统配置与我之前的教程相同。你会在 PyImageSearch 博客上看到许多教程利用了 Python 虚拟环境。虽然它们确实是可选的,但从长远来看,你会发现它们让你的生活更轻松。
安装 virtualenv 和 virtualenvwrapper
virtualenv 和 virtualenvwrapper 包允许我们为我们正在进行的每个项目创建单独、独立的 Python 虚拟环境。我在这个博客上已经多次提到 Python 虚拟环境,所以我不会重复已经说过的话。相反,如果你不熟悉 Python 虚拟环境、它们如何工作,以及我们为什么使用它们,请参考这篇博文的前半部分。我还推荐 RealPython.com 博客上的这篇优秀教程,它对 Python 虚拟环境进行了更深入的探究。
要安装virtualenv和virtualenvwrapper,只需使用pip:
$ pip install virtualenv virtualenvwrapper
两个包成功安装后,您需要再次更新您的~/.bash_profile文件:
$ nano ~/.bash_profile
将下列行追加到文件中:
# Virtualenv/VirtualenvWrapper
source /usr/local/bin/virtualenvwrapper.sh
更新后,您的~/.bash_profile应该与我的类似:

Figure 6: Update your .bash_profile file to include virtualenv/virtualenvwrapper.
一旦您确认您的~/.bash_profile已经创建,您需要使用source命令刷新您的 shell:
$ source ~/.bash_profile
该命令只需要执行一次。假设您的~/.bash_profile已经被正确更新,它将在您每次打开新的 shell、登录等时自动加载并sourced。
创建您的 Python 虚拟环境
我们现在准备使用mkvirtualenv命令创建一个名为cv(用于“计算机视觉”)的 Python 虚拟环境。
对于 Python 2.7,使用以下命令:
$ mkvirtualenv cv -p python
对于 Python 3,使用这个命令:
$ mkvirtualenv cv -p python3
-p开关控制使用哪个 Python 版本来创建您的虚拟环境。请注意,每个虚拟环境都需要用唯一的名字命名,所以如果你想创建两个独立的虚拟环境,一个用于 Python 2.7,另一个用于 Python 3,你需要确保每个环境都有一个独立的名字——两个都不能命名为“cv”。
mkvirtualenv命令只需要执行一次。要在创建完cv Python 虚拟环境后访问它,只需使用workon命令:
$ workon cv
为了直观地验证您是否在cv虚拟环境中,只需检查您的命令行。如果你在提示前看到文本(cv),那么你 在cv虚拟环境中是 :

Figure 7: Make sure you see the “(cv)” text on your prompt, indicating that you are in the cv virtual environment.
否则,如果你 没有 看到cv文本,那么你 在cv虚拟环境中就不是 :

Figure 8: If you do not see the “(cv)” text on your prompt, then you are not in the cv virtual environment and you need to run the “workon” command to resolve this issue before continuing.
安装 NumPy
OpenCV 的唯一 Python 先决条件是一个科学计算包 NumPy 。
要安装 NumPy,首先确保您在cv虚拟环境中,然后让pip处理实际安装:
$ pip install numpy
步骤 6:Sym-link OpenCV 3 绑定(可选)
我们现在准备将cv2.so绑定符号链接到我们的cv虚拟环境中。我已经包含了用于 Python 2.7 和 Python 3 的命令,尽管过程与非常相似。**
对于 Python 2.7
要将cv2.so绑定符号链接到名为cv的 Python 2.7 虚拟环境中,请使用以下命令:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/opt/opencv3/lib/python2.7/site-packages/cv2.so cv2.so
$ cd ~
对于 Python 3:
要将通过 Homebrew 安装的cv2.so绑定符号链接到您的 Python 3 虚拟环境(名为cv),请执行以下命令:
$ cd ~/.virtualenvs/cv/lib/python3.5/site-packages/
$ ln -s /usr/local/opt/opencv3/lib/python3.5/site-packages/cv2.so cv2.so
$ cd ~
必要时重复
如果你想为 Python 2.7 和 Python 3 安装 OpenCV 3 绑定,那么你需要为两个 Python 版本重复步骤#5 和步骤#6 。这包括创建一个唯一命名的 Python 虚拟环境,安装 NumPy,以及在cv2.so绑定中进行符号链接。
步骤 7:测试 OpenCV 3 的安装(可选)
为了验证您的 OpenCV 3+Python+virtual environment 在 macOS 上的安装是否正常工作,您应该:
- 打开一个新的终端窗口。
- 执行
workon命令来访问cvPython 虚拟环境。 - 尝试在 macOS 上导入您的 Python + OpenCV 3 绑定。
以下是我用来验证我的 Python 虚拟环境+ OpenCV 安装是否正常工作的确切命令:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.1.0-dev'
>>>
注意,上面的输出演示了如何在虚拟环境中使用 OpenCV 3 + Python 2.7。
我还创建了一个 OpenCV 3 + Python 3 虚拟环境(名为py3cv3),安装了 NumPy,并对 OpenCV 3 绑定进行了符号链接。我访问py3cv3虚拟环境并导入 OpenCV 的输出如下图所示:

Figure 10: Utilizing virtual environments with Python 3 + OpenCV 3 on macOS.
那么,下一步是什么?
恭喜你。你现在在 macOS 系统上有了一个全新的 OpenCV 安装——我敢肯定你只是渴望利用你的安装来构建一些很棒的计算机视觉应用程序…
…但我也愿意打赌你刚刚开始学习计算机视觉和 OpenCV ,可能会对到底从哪里开始感到有点困惑和不知所措。
就我个人而言,我是通过实例学习的忠实粉丝,所以好的第一步是找点乐子,阅读这篇关于在图像/视频中检测猫的博文。本教程旨在非常实用,演示如何(快速)构建一个 Python + OpenCV 应用程序来检测图像中猫的存在。
如果你真的对提升你的计算机视觉技能感兴趣,你绝对应该看看我的书《实用 Python 和 OpenCV +案例研究》。我的书不仅涵盖了计算机视觉和图像处理的基础知识,还教你如何解决现实世界的计算机视觉问题包括 图像和视频流中的人脸检测视频中的物体跟踪手写识别 。

因此,让我们在 macOS 系统上充分利用 OpenCV 3 新安装程序
摘要
在今天的博文中,我演示了如何通过自制程序在 macOS 系统上安装 OpenCV 3 与 Python 2.7 和 Python 3 的绑定。
正如你所看到的,利用家酿是一个很好的方法,可以避免手动配置 CMake 命令来通过源代码编译 OpenCV 的繁琐过程(我的 OpenCV 安装教程的完整列表可以在本页的中找到)。
缺点是您失去了 CMake 提供给您的大部分控制。
此外,虽然家酿方法当然需要执行更少的命令,并避免潜在的令人沮丧的配置,但仍然值得一提的是,你仍然需要自己做一些工作,尤其是当涉及到 Python 3 绑定时。
如果您决定使用虚拟环境,这些步骤也很复杂,这是进行 Python 开发时的最佳实践。
说到在你自己的 macOS 系统上安装 OpenCV 3,我建议你:
- 首先尝试通过源码安装 OpenCV 3。如果你遇到了相当大的麻烦,并且很难编译 OpenCV 3,利用这个机会自学更多关于 Unix 环境的知识。OpenCV 3 编译失败通常是由于不正确的 CMake 参数造成的,只要稍微了解一下 Unix 系统、路径和库,就可以正确地确定这个参数。
- 使用自制软件作为退路。我会推荐使用自制方法安装 OpenCV 3 作为你的后备选择。当你通过自制软件安装 OpenCV 3 时,你会失去一些控制,更糟糕的是,如果在一个主要的操作系统升级期间任何符号链接中断,你将很难解决它们。不要误会我的意思:我喜欢家酿啤酒,并且认为它是一个伟大的工具——但是要确保你明智地使用它。
无论如何,我希望你喜欢这篇博文!我希望它能帮助你在他们的 macOS 系统上安装 OpenCV 3。
如果您有兴趣了解关于 OpenCV、计算机视觉和图像处理的更多信息,请务必在下面的表格中输入您的电子邮件地址,以便在新的博客帖子和教程发布时收到通知!**
在 macOS 上安装 OpenCV 4
原文:https://pyimagesearch.com/2018/08/17/install-opencv-4-on-macos/

本教程提供了在 macOS 机器上安装 OpenCV 4(带有 Python 绑定)的分步说明。
OpenCV 4 于 2018 年 11 月 20 日发布。
我最初是在 alpha 版本发布的时候写的这篇博文,现在已经 更新于 2018 年 11 月 30 日支持正式发布。
OpenCV 4 带有新功能,特别是在深度学习的 DNN 模块中。
要了解如何在 macOS 上安装 OpenCV 4,继续阅读。
在 macOS 上安装 OpenCV 4
在这篇博文中,我们将在 macOS 上安装 OpenCV 4。OpenCV 4 充满了新功能,其中许多都是深度学习。
注:如果你登陆了错误的安装教程(也许你想在 Ubuntu 或你的树莓 Pi 上安装 OpenCV),那么你应该访问我的 OpenCV 安装指南页面。我在那里发布了所有 OpenCV 安装教程的链接。
首先,我们将安装 Xcode 并设置 Homebrew。
从那里,我们将建立 Python 虚拟环境。
然后我们将从源代码编译 OpenCV 4。从源代码编译允许我们完全控制编译和构建,以及安装完整的 OpenCV 4 构建。我将在未来的安装指南中介绍替代方法(pip 和 Homebrew)(在 OpenCV 4 正式发布之前,这两种方法都不会介绍)。
最后,我们将测试我们的 OpenCV 4 安装,并尝试一个真正的 OpenCV 项目。
我们开始吧!
步骤 1:安装 Xcode
首先我们需要安装 Xcode 。
要安装 Xcode,打开苹果应用商店,找到 Xcode 应用,然后安装。如图所示,您需要耐心等待:
Figure 1: Xcode is a dependency for Homebrew and therefore OpenCV 4 on macOS. To install Xcode, launch the App Store, find Xcode, and run the installation.
Xcode 安装后,我们需要接受许可协议。启动终端并输入以下命令:
$ sudo xcodebuild -license
要接受许可证,只需向下滚动并接受它。
一旦你接受了许可协议,让我们安装苹果命令行工具。这需要****这样你就有了make``gcc``clang等等。您可以通过以下方式安装工具:
$ sudo xcode-select --install
Figure 2: Installing Apple Command Line Tools on macOS.
点击“安装”按钮,等待大约 5 分钟,安装完成。
第二步:安装自制软件
在这一步,我们将安装 Mac 社区包管理器, Homebrew 。
家酿运行在 Ruby 上,这是一种流行的编程语言。准备好之后,复制下面的整个命令来安装 Homebrew:
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
自制命令被缩短为brew。
让我们更新自制软件的定义:
$ brew update
现在让我们编辑 Mac 的 bash 配置文件。每次启动终端时都会运行这个脚本。为简单起见,我建议使用 nano 文本编辑器。如果你更喜欢 vim 或 emacs,那就去用吧。
使用以下命令用 nano 编辑 bash 概要文件:
$ nano ~/.bash_profile
一旦您正在编辑文件,在末尾添加以下几行来更新您的PATH:
# Homebrew
export PATH=/usr/local/bin:$PATH
从那里,保存配置文件。如果你使用的是 nano,你会在窗口底部看到快捷键,演示如何保存(写)和退出。
回到 bash 后,获取 bash 概要文件:
$ source ~/.bash_profile
步骤 3:使用自制软件安装 OpenCV 先决条件
在本节中,我们将确保安装了 Python 3.6。我们还将安装从源代码构建 OpenCV 的先决条件。
安装 Python 3.6
使用 Python 3.6 非常重要。默认情况下,High Sierra 和 Mojave 现在随 Python 3.7 一起发布。听起来不错, 但是 Python 3.7 不被 Keras/TensorFlow(这两者在这个博客上经常使用)支持,因此对于 OpenCV 也不是一个好的选择。
*这些命令将安装 Python 3.6.5_1:
$ brew install https://raw.githubusercontent.com/Homebrew/homebrew-core/f2a764ef944b1080be64bd88dca9a1d80130c558/Formula/python.rb
$ brew switch python 3.6.5_1
确保复制整个命令+ URL。
让我们验证一下:
$ python3
Python 3.6.5 (default, Jun 17 2018, 12:13:06)
[GCC 4.2.1 Compatible Apple LLVM 9.1.0 (clang-902.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
太好了!我可以看到我们现在安装了 Python 3.6.5。
让我们再验证一件事:
$ which python3
/usr/local/bin/python3
如果你看到/usr/local/bin/python3你正在使用自制 Python(这正是我们想要的)。如果您看到了/usr/bin/python3,那么您正在使用系统 Python,您可能需要修改您的 bash 概要文件和/或对其进行开源。
现在花点时间验证你使用的是 Python 的自制版本和而不是系统版本。
安装其他必备组件
OpenCV 要求在我们编译它之前安装一些先决条件。这些软件包与(1)用于构建和编译的工具,(2)用于图像 I/O 操作的库(即,从磁盘加载各种图像文件格式,如 JPEG、PNG、TIFF 等)相关。)或(3)优化库。
要在 macOS 上安装 OpenCV 的这些必备组件,请执行以下命令:
$ brew install cmake pkg-config
$ brew install jpeg libpng libtiff openexr
$ brew install eigen tbb
你将学会爱上的一个工具是wget。所有的wget都是从命令行下载文件。我们可以用自制软件安装 wget:
$ brew install wget
步骤 4:为 OpenCV 4 安装 Python 依赖项
在这一步,我们将为 OpenCV 4 安装 Python 依赖项。
利用我们刚刚安装的wget工具,让我们下载并安装 pip(一个 Python 包管理器):
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
现在我们已经安装了 pip,我们可以安装 virtualenv 和 virtualenvwrapper ,这是两个用于管理虚拟环境的工具。Python 虚拟环境是 Python 开发的最佳实践,我 强烈建议 你充分利用它们。
每周,我都会收到数不清的电子邮件和博客评论,内容是关于使用虚拟环境可以避免的问题。尽管名称相似,但虚拟环境不同于虚拟机。
要了解虚拟环境,我建议你阅读一下这篇文章。
让我们安装virtualenv和virtualenvwrapper,然后做一些清理:
$ sudo pip3 install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
从那里,我们需要再次编辑 bash 概要文件,以便这两个工具能够正常工作。
启动 nano(或您喜欢的文本编辑器):
$ nano ~/.bash_profile
然后将这几行添加到文件的末尾:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /usr/local/bin/virtualenvwrapper.sh

Figure 3: Using the nano text editor to edit the ~/.bash_profile prior to installing OpenCV 4 for macOS.
提示:您可以使用 bash 命令在不打开编辑器的情况下向文件追加内容:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.bash_profile
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bash_profile
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3" >> ~/.bash_profile
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bash_profile
然后对文件进行源文件处理:
$ source ~/.bash_profile
您将看到在您的终端中打印了几行,表明 virtualenvwrapper 已经设置好了。
virtualenvwrapper工具为我们提供了许多终端命令:
mkvirtualenv <env_name> <options>:用于“制作虚拟环境”rmvirtualenv <env_name>:破坏虚拟环境workon <env_name>:激活虚拟环境deactivate:停用当前虚拟环境- 你会想阅读文档了解更多信息。
让我们利用第一个命令为 OpenCV 创建一个 Python 虚拟环境:
$ mkvirtualenv cv -p python3
Running virtualenv with interpreter /usr/local/bin/python3
Using base prefix '/usr/local/Cellar/python/3.6.5_1/Frameworks/Python.framework/Versions/3.6'
New python executable in /Users/admin/.virtualenvs/cv/bin/python3.6
Also creating executable in /Users/admin/.virtualenvs/cv/bin/python
Installing setuptools, pip, wheel...
done.
virtualenvwrapper.user_scripts creating /Users/admin/.virtualenvs/cv/bin/predeactivate
virtualenvwrapper.user_scripts creating /Users/admin/.virtualenvs/cv/bin/postdeactivate
virtualenvwrapper.user_scripts creating /Users/admin/.virtualenvs/cv/bin/preactivate
virtualenvwrapper.user_scripts creating /Users/admin/.virtualenvs/cv/bin/postactivate
virtualenvwrapper.user_scripts creating /Users/admin/.virtualenvs/cv/bin/get_env_details
请注意,cv是我们环境的名称,我正在创建一个 Python 3(由-p python3开关控制)环境。
重要提示:注意输出中 Python 3.6 也用于环境中(突出显示)。
如果您愿意,可以用不同的名称命名您的环境。实际上,我喜欢这样命名我的环境:
py3cv4py3cv3py2cv2- 等等。
这里我的py3cv4虚拟环境可以用 Python 3 + OpenCV 4。我的py3cv3虚拟环境用的是 Python 3 和 OpenCV 3。我的py2cv2环境可以用来测试遗留的 Python 2.7 + OpenCV 2.4 代码。这些虚拟环境的名字很容易记住,并且允许我在 OpenCV + Python 版本之间无缝切换。
接下来,让我们在环境中安装 NumPy。
很可能,环境已经是活动的了(由 bash 提示符前的(cv)表示)。为了以防万一,让我们workon(激活)环境:
$ workon cv

Figure 4: We are “in” the cv virtual environment as is denoted by (cv) before the bash prompt. This is necessary prior to installing packages and compiling OpenCV 4.
每次你想使用这个环境或者在其中安装软件包的时候,你应该使用workon命令。
现在我们的环境已经激活,我们可以安装 NumPy:
$ pip install numpy
第 5 步:为 macOS 编译 OpenCV 4
与 pip、Homebrew 和 Anaconda 等包管理器相比,从源代码进行编译可以让您更好地控制您的构建。
包管理器肯定很方便,我将在未来的安装教程中介绍它们,我只是想给你一个合理的警告——虽然它们表面上看起来很容易,但你无法获得 OpenCV 的最新版本,在某些情况下,它在虚拟环境中不能很好地工作。您也可能会遗漏一些功能。
我仍然一直在编译源代码,如果你真的想使用 OpenCV 的话,你一定要学会如何编译。
下载 OpenCV 4
让我们下载 OpenCV。
首先,导航到我们的主文件夹,下载 opencv 和 T2 的 opencv_contrib。contrib repo 包含我们在 PyImageSearch 博客上经常使用的额外模块和函数。你应该也在安装 OpenCV 库和附加的 contrib 模块。
当你准备好了,就跟着下载opencv和opencv_contrib代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.0.0.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.0.0.zip
更新 2018-11-30:OpenCV 4 . 0 . 0 正式发布我已经更新了上面的下载网址。
从那里,让我们解压缩档案:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
我也喜欢重命名目录:
$ mv opencv-4.0.0 opencv
$ mv opencv_contrib-4.0.0 opencv_contrib
如果您跳过了重命名目录,接下来不要忘记更新 CMake 路径。
既然opencv和opencv_contrib已经下载并准备好了,让我们设置我们的环境。
从源代码编译 OpenCV4
既然opencv和opencv_contrib已经下载并准备好了,让我们使用 CMake 来设置我们的编译并让 Make 来执行编译。
导航回 OpenCV repo 并创建+输入一个build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
现在我们准备好了。在执行cmake命令之前,一定要使用workon 命令,如图:
$ workon cv
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON3_LIBRARY=`python -c 'import subprocess ; import sys ; s = subprocess.check_output("python-config --configdir", shell=True).decode("utf-8").strip() ; (M, m) = sys.version_info[:2] ; print("{}/libpython{}.{}.dylib".format(s, M, m))'` \
-D PYTHON3_INCLUDE_DIR=`python -c 'import distutils.sysconfig as s; print(s.get_python_inc())'` \
-D PYTHON3_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_python3=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D BUILD_EXAMPLES=ON ..
更新 2018-11-30: 我增加了一个 CMake 编译标志来启用非自由算法(OPENCV_ENABLE_NONFREE=ON)。如果您想出于教育目的访问专利算法,这对于 OpenCV 4 是必需的。
注意:对于上面的 CMake 命令,我花了相当多的时间来创建、测试和重构它。这是一种有效的自我配置,您无需做任何工作。*我相信,如果你完全按照它显示的那样使用它,它会为你节省时间,减少挫折。*
CMake 完成后,向上滚动(稍微向上)直到您在终端中看到以下信息:
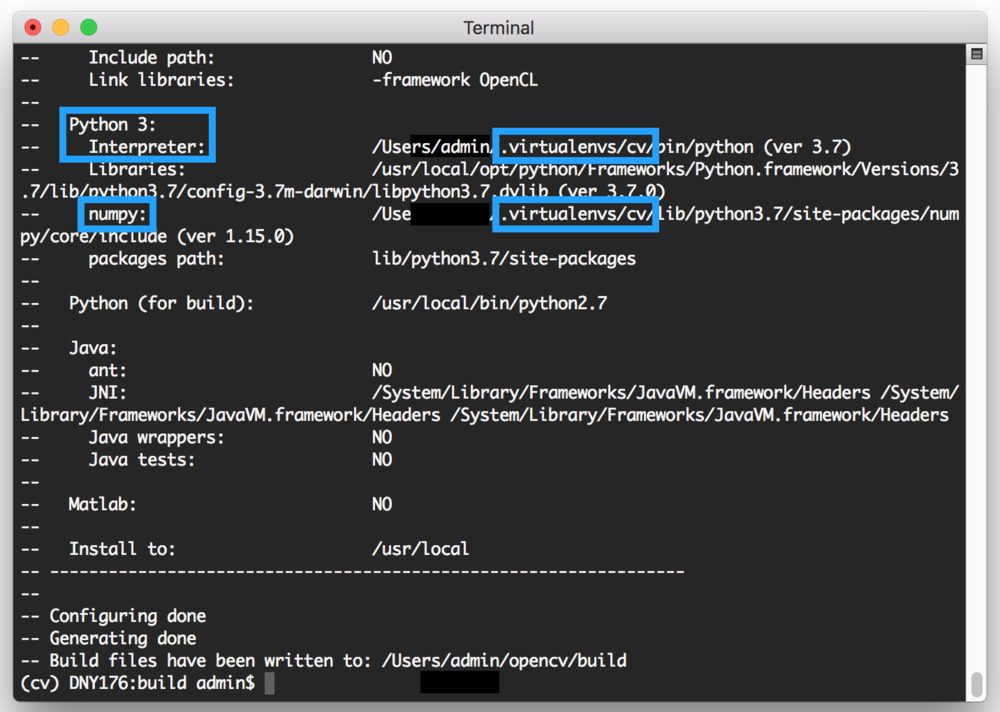
Figure 5: Inspecting CMake output while installing OpenCV 4 on macOS is important. Be sure that your cv virtual environment is being used for Python and NumPy.
您的输出应该与我的非常相似。你所寻求的是确保你的 Python 3 解释器和虚拟环境中的 NumPy 都能被使用。如果您看不到这一点,那么您可能在没有“在”虚拟环境(或者您命名的 Python 虚拟环境)中的情况下执行了 CMake。如果是这种情况,不用担心——只需删除build目录,用workon命令激活虚拟环境,然后重新运行 CMake。
接下来,再向上滚动一点,检查您的输出是否与我突出显示的内容相匹配:
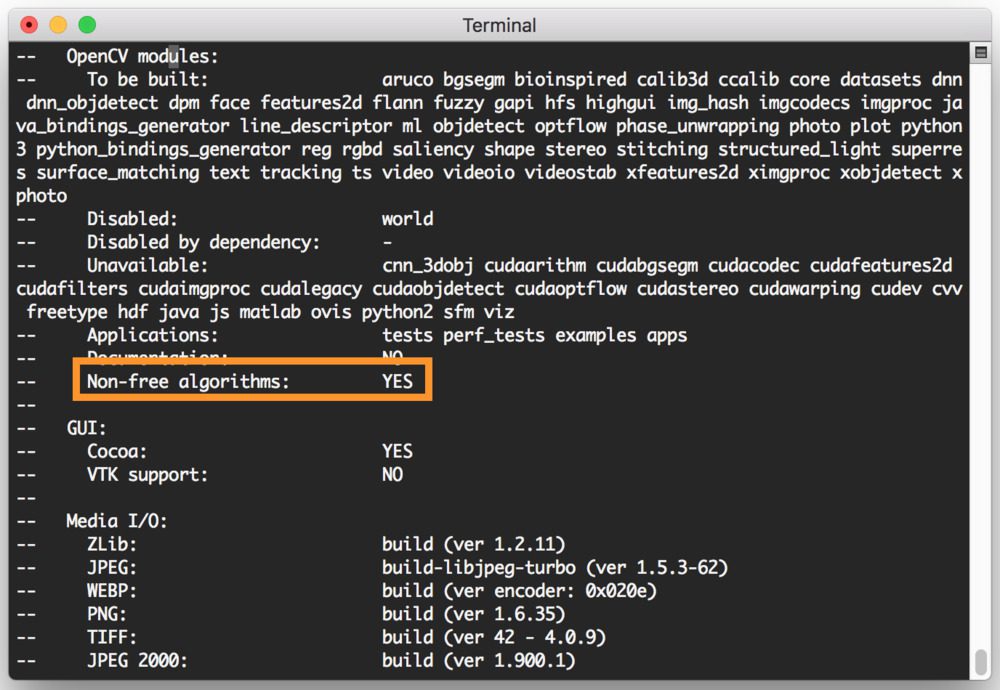
Figure 6: Verify that the “Non-free algorithms” will be installed in OpenCV 4.
如果您的 CMake 输出可以运行,您可以通过以下方式开始编译:
$ make -j4
注意:-j4 参数是可选的,它将指示make利用 4 个 CPU 内核。您可以调整数值或完全不使用该参数。这种情况并不经常发生,但有时竞争条件可能会阻止编译完成——此时您应该在没有标志的情况下执行make。
在编译继续的时候休息一下,但是不要忘记回来创建符号链接。
当make完成时,您应该会看到:
Figure 6: Compiling OpenCV 4 on macOS has reached 100%. We’re now ready to link OpenCV 4 into our cv environment.
如果您已经达到 100%,那么在步骤#6 之前还有一个额外的命令来安装 OpenCV 4:
$ sudo make install
步骤 6:将 macOS 上的 OpenCV 4 符号链接到您的虚拟环境site-packages
现在让我们创建一个所谓的“符号链接”。我们需要一个从我们的cv虚拟环境site-packages 到我们的安装了 OpenCV 的系统site-packages的链接。实际上,OpenCV 将被“链接”到虚拟环境中,允许您将其导入 Python 脚本和命令行解释器。
在我们创建一个符号链接将 OpenCV 4 链接到我们的 Python 虚拟环境之前,让我们确定一下我们的 Python 版本:
$ workon cv
$ python --version
Python 3.6
使用 Python 版本,接下来我们可以很容易地导航到正确的site-packages目录(尽管我建议在终端中使用制表符补全)。
更新 2018-12-20: 以下路径已更新。以前版本的 OpenCV 在不同的位置(/usr/local/lib/python3.6/site-packages)安装了绑定,所以一定要仔细看看下面的路径。
此时,OpenCV 的 Python 3 绑定应该位于以下文件夹中:
$ ls /usr/local/python/cv2/python-3.6
cv2.cpython-36m-darwin.so
让我们简单地将它们重命名为cv2.so:
$ cd /usr/local/python/cv2/python-3.6
$ sudo mv cv2.cpython-36m-darwin.so cv2.so
Pro-tip: 如果您同时安装 OpenCV 3 和 OpenCV 4,而不是将文件重命名为cv2.so,您可以考虑将其命名为cv2.opencv4.0.0.so,然后在下一个子步骤中,将该文件适当地 sym-link 到cv2.so。
我们的最后一个子步骤是将 OpenCV cv2.so绑定符号链接到我们的cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python3.6/site-packages/
$ ln -s /usr/local/python/cv2/python-3.6/cv2.so cv2.so
重要注意事项:
- 花点时间去理解符号链接是如何工作的——你可能会阅读这篇文章。
- 确保你的道路是正确的。我建议使用制表符补全,而不是复制/粘贴。
我怎么强调这一点都不为过:cvPython 虚拟环境是 完全独立于系统上的默认 Python 版本 。全局目录 中的任何 Python 包将对cv虚拟环境不可用。同样,任何安装在cv 的site-packages中的 Python 包都不会对 Python 的全局安装可用。当您在 Python 虚拟环境中工作时,请记住这一点,这将有助于避免许多困惑和头痛。
安装imutils
如果你经常访问我的博客,我也建议你安装我自己的 imutils 包,因为我们经常使用它:
$ workon cv
$ pip install imutils
步骤 7:测试你的 macOS + OpenCV 3 安装
测试你的 OpenCV 安装以确保正确的链接总是很重要的。
我喜欢在虚拟环境中启动 Python shell,并检查它是否正确导入,以及版本是否符合我的意图:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'4.0.0'
>>> exit()
Figure 7: To test that OpenCV 4 is installed on macOS, fire up Python in your virtual environment and execute cv2.__version__ after importing cv2.
如果您没有看到错误并且 OpenCV 4 已经安装,那么您就可以开始了!
运行您的第一个 OpenCV 4 新安装的例子!
如果你想用 OpenCV 进入计算机视觉领域,我猜你想用 OpenCV 运行一些很酷的东西。
让我们从用 OpenCV 构建一个简单的“文档扫描仪”开始。
我不会在这里回顾所有的代码——如果你有兴趣或者有更多的时间,你应该看看最初的帖子。
要开始,只需滚动到 【下载】 ,抓取源代码+图片。
在那里,只需输入以下命令进行准备:
$ workon cv
$ unzip document-scanner.zip
$ cd document-scanner
$ tree
.
├── images
│ ├── page.jpg
│ └── receipt.jpg
├── pyimagesearch
│ ├── __init__.py
│ └── transform.py
└── scan.py
2 directories, 5 files
如您所见,有两个示例映像,一个pyimagesearch模块(需要通过“下载”部分下载——它是而不是 pip-installable),以及扫描脚本。
我们需要在我们的环境中添加一个额外的库:Scikit-image。要安装它,只需使用画中画。如果您之前没有安装 imutils,那么现在也安装它:
$ pip install scikit-image imutils
在那里,您可以执行以下命令来对 OpenCV 4 进行测试:
$ python scan.py --image images/receipt.jpg
STEP 1: Edge Detection
STEP 2: Find contours of paper
STEP 3: Apply perspective transform
在每一步结束时,您需要按一个键,此时窗口在您的桌面上处于焦点位置。
有时 OpenCV 会将窗口隐藏在另一个之下,所以一定要拖动 OpenCV 图像窗口,看看有什么可用的。
下面是文档扫描最后一步的截图:

Figure 8: Applying step 3 of our document scanner, perspective transform. The original image is on the left and the scanned image on the right.
那很有趣!
通过阅读原始博客文章了解代码是如何工作的。
如果你想用 OpenCV 4 构建更多的项目,请继续关注我的博客!
故障排除和常见问题
在这一节中,我将解决读者在 macOS 上安装 OpenCV 4 时遇到的一些常见问题。
Q. 能在 macOS 上用 Python 2.7 运行 OpenCV 4 吗?
我建议你坚持使用 Python 3,但是如果你正在从事遗留项目,我知道你可能想要使用 Python 2.7。你需要做的是:
- 使用
brew install python2通过自制软件安装 Python 2.7 - 你应该在第三步 :
sudo python get-pip.py和sudo pip install virtualenv virtualenvwrapper中用 2.7 画幅 - 在步骤#3 中,简单地创建一个 Python 2.7 环境:
mkvirtualenv cv -p python2.7 - 在图 5 的步骤#4、 中,验证 CMake 输出使用的是您的 Python 2.7 虚拟环境解释器。
问 我需要运行 brew 安装 Python 吗?Python 好像已经安装在我的 Mac 上了!
A. 是的。Python 已安装,但您可能需要 Brew 的更新 Python,而且 Brew 会将 Python 放在与您的系统 Python 分开的/usr/local/bin中。
Q. 执行mkvirtualenv或workon时,遇到“命令未找到错误”。
A. 你会看到这个错误消息的原因有很多,都来自于步骤#3:
- 首先,确保你已经使用
pip软件包管理器正确安装了virtualenv和virtualenvwrapper。通过运行pip freeze进行验证,确保在已安装包列表中看到virtualenv和virtualenvwrapper。 - 您的
~/.bash_profile文件可能有错误。查看您的~/.bash_profile文件的内容,查看正确的export和source命令是否存在(检查步骤#3 中应该附加到~/.bash_profile的命令)。 - 你可能忘记了你的
~/.bash_profile。确保编辑完source ~/.bash_profile后运行它,以确保你可以访问mkvirtualenv和workon命令。
问: 当我打开一个新的终端、注销或重启我的 macOS 系统时,我无法执行mkvirtualenv或workon命令。
A. 见上一题的 #2 。
Q. 我到达了终点,然而当我在我的终端中运行 Python 并尝试import cv2时,我遇到了一个错误。接下来呢?
A. 不幸的是,如果不在你的系统上,这种情况很难诊断。很多事情都可能出错。最可能的失败点是符号链接步骤。我建议您执行以下操作来检查符号链接:
$ cd ~/.virtualenvs/cv/lib/python3.6/site-packages
$ ls -al cv2*
lrwxr-xr-x 1 admin _developer 21 Nov 30 11:31 cv2.so -> /usr/local/python/cv2/python-3.6/cv2.so
您正在寻找的是->箭头,它指向您系统上的一个有效路径。如果路径无效,那么您需要解决符号链接问题。您可以通过删除符号链接并再次尝试步骤#5 来纠正它。
Q. 为什么我在尝试使用 SURF 等专利算法时会出现“非自由”错误?
A. 随着 OpenCV 4 对编译有了新的要求。请参考第 5 步,这是用 CMake 参数为 OpenCV 4 解决的。
Q. 可以用 Brew 安装 OpenCV 而不用从源码编译吗?
A. 当心!答案是肯定的,但是如果你计划使用虚拟环境,你仍然需要符号链接。以后我会再写一篇关于自制方法的文章。
问: 我可以把 OpenCV 4 和 pip 一起安装到我的虚拟环境中吗?
A. 目前不能用 pip 安装 OpenCV 4。但是可以安装 OpenCV 3.4.3。参见如何pip 安装 opencv 。
摘要
今天我们在你的 macOS 机器上安装了带有 Python 绑定的 OpenCV4。
我会带着 OpenCV 4 的未来安装教程回来(包括一个关于 Raspberry Pi 的)。如果你正在寻找我的另一个已经出版的 OpenCV 安装教程,一定要参考这个页面。
敬请期待!
要下载今天教程的源代码,只需在下表中输入您的电子邮件地址。***


 浙公网安备 33010602011771号
浙公网安备 33010602011771号