PyImgSearch-博客中文翻译-四-
PyImgSearch 博客中文翻译(四)
确保您的研究保持可见和一般提示
原文:https://pyimagesearch.com/2022/06/01/ensuring-your-research-stays-visible-and-general-tips/
目录
**在本系列的前一课中,我们学习了当事情不顺利时如何计划下一步。在多次应对挫折、拒绝和批评后,当你的论文最终被接受时,喜悦和成就感是无与伦比的。通常这种成就感意味着你漫长研究旅程的结束。
然而,随着如此多的论文不时发表,集中精力提高你的研究的知名度是很重要的。可见的研究最终会为其作者带来更多的引用和更好的机会(会谈、合作、就业、高等研究)。
通过这节课,我将分享我们在 Lab1055 中遵循的任务清单,以确保我们研究的可见性。
在本教程中,您将学习如何确保您的研究保持可见。
本课是关于如何发表小说研究的 5 集系列的最后一集:
- 选择研究课题并阅读其文献
- 构思解决方案并规划实验
- 策划并撰写研究论文
- 计划下一步****
- 【确保你的研究保持可见】通用提示 (本教程)
**学习如何确保你的研究保持可见, 继续阅读。
**以下是你可以遵循的任务清单,以确保你的研究保持可见。并不是所有的事情都需要立即完成,但是有组织地完成它们可以极大地提高工作的可见性。
摄像机准备就绪并鸣谢
论文被接受后,你要做的第一件事就是准备好可以拍摄的版本。确保作者的顺序、隶属关系和电子邮件地址是正确的和最新的。接下来,在事情新鲜的时候,整合评审者和元评审者的反馈。可直接拍摄的版本不应与已审核和接受的版本有显著差异。提供代码库的链接是个好主意。如果您需要时间来组织和验证代码,请提供指向空的 GitHub 存储库的链接,它将在以后被上传到这个存储库。
确保你和你的导师谈过,得到认可,并在主要论文中提到它们。这可以是结尾的一个单独的部分(在结论之后,参考文献之前)或者是最后一页的最后几行。利用这个机会感谢资助来源、奖学金来源和帮助完成论文的实验室同事,他们不能被列为共同作者。您可以在致谢部分使用以下模板。
"这项工作得到了 ______________ 的资金支持。我们感谢匿名审稿人的宝贵反馈,他们的反馈改进了本文的陈述。我们也感谢 XYZ 就这项工作进行了富有洞察力的讨论。
图 1 提供了更多关于如何写感谢信的模板。
【开源(arXiv,GitHub,和项目页面)
一旦你完成了可拍照的版本,就把它上传到 arXiv 上。提及作品被接受的地点(增加作品的可信度)以及项目页面或代码库的链接。
代码库应该是干净的,并且应该遵循适当的文件结构。自述文件应该以作品的标题、作者、会议、摘要和主要人物开始。然后,它应该描述硬件(GPU、RAM、处理器等的数量。)和在论文中复制结果所需的库。好主意是提供一个“requirements.txt”文件,它可以与“pip install”一起使用,以安装代码中使用的库的精确版本。
接下来,它应该提供脚本和链接来下载和设置数据集,并运行训练和推理代码。使用配置文件(。yml 或者。json 或者。py)来运行论文中描述的精确实验。最后,用 BibTeX 参考书目结束自述文件。
你可以做的另一件事是增加引用的机会,发布你的网络的预训练检查点(通过 Torch Hub,Google Drive 或 Dropbox ),并提供一个 Google Colab 教程,介绍如何加载它们并做出推断。这对于那些希望使用现成模型的人来说特别有用。
此外,创建一个项目页面(图 2) ,用示例结果和 arXiv 页面和代码的链接总结工作的主要思想。再一次,这增加了人们在工作基础上继续努力的机会。
社交媒体
使用社交媒体,你可以将你的作品的影响范围扩大几倍。在你觉得合适的社交媒体平台(如网站、Twitter、LinkedIn 等)上公布这项研究是个不错的主意。).如果你不倾向于任何特定的平台,我更喜欢 Twitter,因为它有一个更活跃的研究社区。
您可以使用 Twitter 线程(图 3) 和趋势标签(如#CVPR2022、#ICLR2022 等)简要描述想法、方法和关键结果。)来增加触及面。你可以指向 arXiv/Github/project 页面链接,交叉引用文章中的任何作者/实验室句柄。
博客是宣传你的研究的另一种方式。对于那些不需要阅读整篇论文就能轻松理解核心思想的人来说,它们是有益的。如果你感兴趣,你可以使用免费的平台,如 Medium、WordPress 和个人网站来发布和分享你的研究。为了锁定合适的受众,你也可以尝试其他流行的平台(如 PyImageSearch 、Weights&bias、 Paperspace 、 Neptune AI 等)。).
专利
如果你是一个研究产品或用例的研究员,你的工作可能有潜在的商业价值和现实生活中的应用。在这种情况下,申请发明专利来保护知识产权(图 4) 不失为一个好主意。但是,你应该避免以任何形式(像 arXiv、codebase 等)向公众(社交媒体)披露这项发明。)可以用来模仿发明,除非已经为其申请了专利。
许多公司鼓励并激励员工申请专利。而如果你是这样一个组织的成员,你应该借此机会提高你工作的可信度。
提交给车间和期刊
这些天来,每个会议都会组织一些研讨会,这些研讨会关注并针对人工智能的一个特定研究领域。因此,通过在研讨会上发表你的论文,你可以锁定一个集中的读者群。这些研讨会中的大多数允许提交非存档的论文(即,不包括在任何研讨会记录中)。它们通常由海报会议、密切关注特定研究主题的研究人员的谈话、小组讨论和辅导会议组成。
由于这些研讨会是在会议决定发布后不久宣布的,您可能需要迅速采取行动。一旦你确定了一个与你工作相关的研讨会,你只需要根据研讨会的要求缩短并调整你的论文。
期刊提供了一个很好的方法来扩展你的工作,并给你的工作带来更多的可信度。如果你认为你可以为你的研究(分析、实验)添加更多的材料,你可以向期刊提交一个扩展版本。他们一年到头都接受论文,因此你可以花时间延长研究。
准备海报和视频
除了可以拍摄的版本,会议还要求作者准备一张海报和作品的视频。这个的截止日期比相机准备好的截止日期晚很多,通常更接近发布会的日期。仔细遵循海报要求:尺寸、纸张质量(现场会议)、方向等。添加您的研究所/实验室徽标、所有作者的电子邮件 id 以及一个引用您的 Github 代码/项目页面/arXiv 登录页面的 QR 代码(图 5) 。很多与会者拍下海报和二维码,以备日后参考。
避免过多的文字。相反,要包括尽可能多的图表、表格和视觉效果。您可以浏览背页的寻找海报模板。
如果准备视频,请确保遵循相同的分辨率、格式、编码等。如会议网站所述。在规定的时间内编写视频脚本,以获得流畅的视频。海报和视频完成后,上传到你的项目页面和 YouTube 频道。
参加会议的
在会议上出席并展示你的作品可能是让你的论文被接受的最好的部分和优势(图 6) 。利用这个机会认识新朋友,和他们讨论。停下来参加海报会议,讨论并听取作者自己的意见。腾出时间逛逛行业展台,在那里你可以找到大量的工作机会、实习机会、合作机会和好东西。
如果计划参加会议,需要考虑的一件重要事情是申请和寻找旅行资助。如果你有一篇论文在 A*会议上被接受,你很可能会得到一笔旅行资助。以下是一些旅行资助机会。
- 会议差旅补助:每个会议都有自己的差旅补助。请积极侦察大会网站并申请。一般来说,学生第一作者最常获得这种资助。
- 谷歌旅行资助
- 微软印度研究院旅行资助 : 如果链接中断,请发送电子邮件给萨迪什桑加姆斯瓦兰<satishsa@microsoft.com>,询问如何申请。
- 会议志愿者:每个会议都为自愿参加会议的一两个会议的作者提供免费注册。这是建立关系网和结识其他同龄人的好方法。请积极侦察大会网站并申请。
- 【ACM India-IARC 差旅补助
- 塔塔信任
- 如果你没有被上述任何一个项目选中,问问你的大学或公司是否能为你的旅行费用提供部分资助。
阅读以下博客文章,了解其他资金来源。
通用提示
我想分享一些我过去用来收集研究经验和技巧的技巧。
为会议复习
为会议审阅论文是培养自我批评能力的最快方法之一(图 7) 。从评论者的角度评论论文也有助于你为你的论文做同样的事情。这可以让你提前发现潜在的问题,写出更好的论文。
复习的其他好处是:
- 比任何人都先阅读最新的研究和了解新的方向。
- 在研究界获得可见性,因为一些会议在其会议记录或网站上突出了杰出评审者的名字。
- 将这一点添加到你的简历中会非常有用,尤其是对于那些打算在学术界工作或申请高等教育的人。
有几种方法可以让一个人成为会议评审员。
- 如果你的导师曾经担任过任何会议的评审员或区域主席,你可以通过充当分评审员或外部评审员来代表他评审论文。
- 一些会议要求作者担任审稿人。如果你已经向任何会议提交了你的作品,你应该寻找这样的机会。
- 有时会议会在 Twitter 或他们的网站上发布广告,说他们需要审稿人。你也可以在 Twitter 或电子邮件上明确地联系区域和项目主席,告诉他们你可以作为评审员。
暑期学校
暑期学校是由大学或公司组织的为期 3-14 天的活动。它们为初学者和年轻的研究人员提供了深入他们感兴趣的领域并向有经验的研究人员学习的绝佳机会。它们包括海报会议(在这里你可以展示你已经发表或正在进行的项目)、分组会议、小组会议、讲座、实践会议等活动。这些活动旨在将年轻和有经验的研究人员聚集在一起,进行互动、学习和分享他们的经验。
最棒的是,这些暑期学校大多不要求你具备任何机器学习或深度学习的先决知识(一些数学和编程经验就足够了)。他们也有奖学金项目,部分或全部资助注册费和差旅费。要想获得奖学金,你需要有很强的知名度。
以下是一些每年都会组织的热门机器学习暑期学校。
- 东欧机器学习(EEML)暑期学校是一个为期一周的学校,围绕关于机器学习和人工智能的核心主题,包括讲座和实践环节。学校由 DeepMind(人工智能研究的先驱)组织。
- Skoltech (SMILES)的机器学习暑期学校(T1)是一个为期一周的关于现代统计机器学习方法的在线强化课程。它旨在汇集来自独联体、中亚和高加索地区的机器学习社区(图 8) 。
- IIIT·海德拉巴举办的计算机视觉和机器学习暑期学校讲述了机器学习的基础知识或经典机器学习在计算机视觉、图像处理、生物识别和机器学习最新进展方面的应用。
- CIFAR 与加拿大三个国家人工智能研究所合作举办了深度学习+强化学习(DLRL)暑期学校:埃德蒙顿 Amii ,蒙特娄 Mila ,多伦多 Vector Institute 。它涵盖了深度学习和强化学习的基础研究、新发展和现实世界的应用。
可以参考下面 GitHub 编译中的暑期学校完整列表。
研究项目
像实习、奖学金、住院实习和博士预科这样的研究项目提供了与有经验的研究人员一起工作和积累经验的最佳方式之一,同时还能获得可观的薪水。在申请高等教育(硕士或博士)或全职研究职位时,参加这些项目会为你提供优势。
实习是 3 至 6 个月的项目,可以是工业和学术。科技巨头(如谷歌、微软、亚马逊、Adobe、优步和苹果)在全球范围内招聘本科生、研究生和博士,开展他们久负盛名的暑期实习项目。学术机构(如加州大学伯克利分校、印度理工学院、斯坦福大学和 CMU 大学)也有类似的研究项目,你可以和他们的教授一起工作。
奖学金和人工智能居住计划是 1 至 2 年的研究培训计划,在那里你可以从事前沿研究,发表论文和申请专利。像谷歌、微软(图 9) 、优步和苹果这样的公司每年都会为他们的研究奖学金或人工智能常驻项目招聘员工。这些项目的完整列表可以在 https://github.com/dangkhoasdc/awesome-ai-residency 的找到。
在 Linkedin、Twitter 和职业页面等平台上保持更新,以了解更多关于这些程序的应用程序。
汇总
可见的研究得到更多的引用,并为其作者提供更好的机会。因此,在你的研究被接受后,集中时间和精力来提高它的可见性是很重要的。
一旦你的论文被接受,你要做的第一件事就是准备一个可供拍摄的版本。由于反馈在你的脑海中是新鲜的,它可以很容易地被吸收。一定要在论文的结尾加上致谢,并利用这个机会感谢资助来源、奖学金来源和帮助论文的实验室同事,他们不能被列为共同作者。
将准备好的版本上传到 arXiv ,将代码库上传到 GitHub 。确保 ReadME.md 提到了设置环境和数据集以及运行训练和推理脚本的说明。此外,您可以拥有一个项目页面,该页面通过示例结果和到 arXiv 页面和代码的链接总结了作品的主要思想。
在 Twitter 和 LinkedIn 等社交媒体平台上公布你的研究。使用趋势会议标签,标记你的合著者,以扩大影响范围。写并分享博客文章,因为它们有益于那些不需要花时间阅读整篇文章就能轻松理解核心思想的人。
申请专利,提交给工作室,将你的工作扩展到期刊。这将进一步提高你的研究的可信度。在准备海报和视频的同时,确保满足会议要求。拥有一个链接到您的 arXiv、GitHub 或项目页面的二维码。如果打算参加会议,可以考虑申请 conference、微软、Google、ACM 等。、差旅补助。
收集研究经验和技能,审查会议论文,参加暑期学校,申请研究实习和奖学金计划。
希望这一课能帮助你提高自己的研究在被接受后的知名度。关于如何发表小说研究的系列到此结束。感谢你坚持到最后,请继续关注另一个新系列。
引用信息
Mangla,P. “确保你的研究保持可见性和一般提示”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/kfguv
@incollection{Mangla_2022_Ensuring_Research,
author = {Puneet Mangla},
title = {Ensuring Your Research Stays Visible and General Tips},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/kfguv},
}
我在 CUDAMat、深度信仰网络和 Python 方面的经验
原文:https://pyimagesearch.com/2014/10/06/experience-cudamat-deep-belief-networks-python/
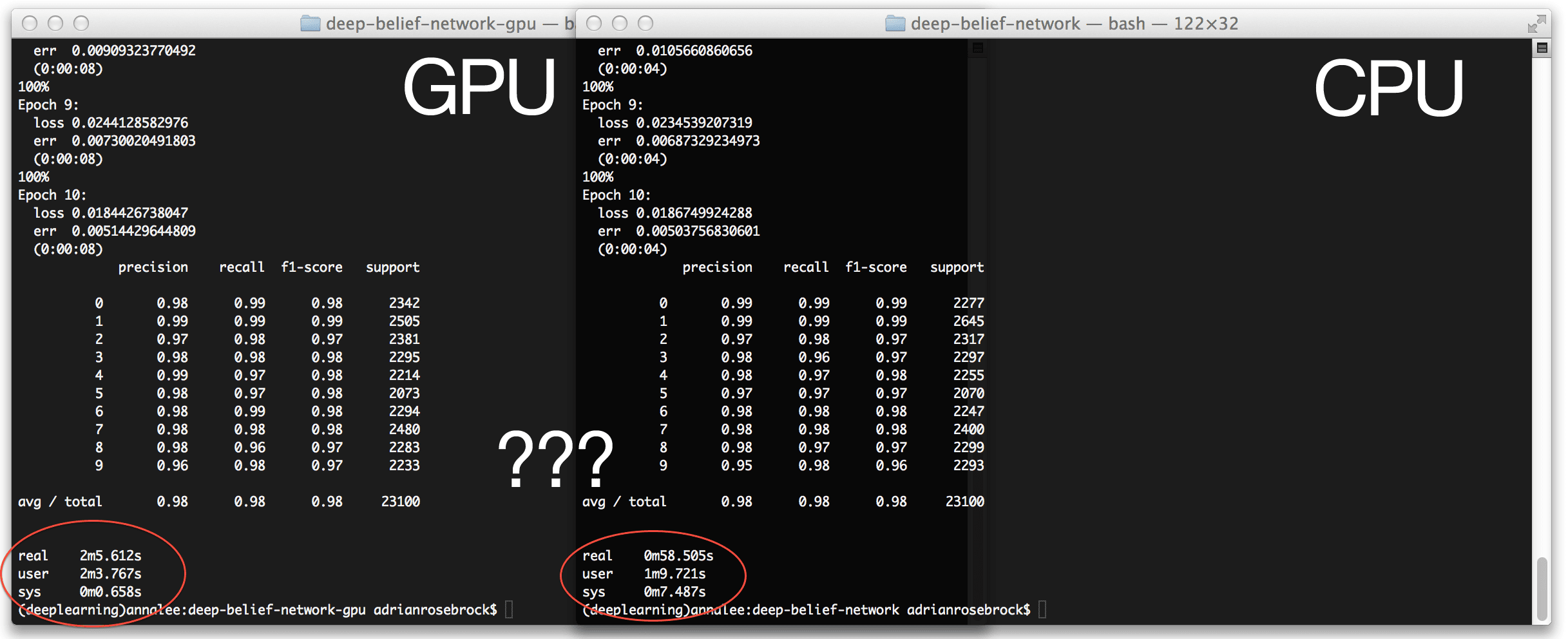
拿纸巾。
这是我的 MacBook Pro、GPU 和 CUDAMat 库的一个尾巴——它没有一个美好的结局。
两周前,我发布了一篇关于深度学习和 Python 的入门指南。指南很棒,很受欢迎。我写得很开心。很多 PyImageSearch 的读者真的很喜欢它。
因此,作为本指南的自然后续,我想演示如何使用 GPU 来加速深度信念网络的训练(以前,只使用了 CPU)。
然而,我从来没有设置我的 MacBook Pro 来利用 GPU 进行计算处理。我认为这很好。这将成为一个很好的教程,我通过试错进行实验——并记录下我一路上的步骤,希望其他人会发现这个教程很有用。
简而言之就是:我成功地安装了 CUDA 工具包、驱动程序和 CUDAMat。
然而。
出于我无法理解的原因,在我的 GPU 上用 nolearn 训练我的深度信念网络比在 CPU 上多花了 整整一分多钟 。说实话。我已经尝试了所有我能想到的方法。没有骰子。
仅仅因为我用的是 MacBook Pro,我的 GeForce GT 750m 的性能就不够好吗?我的配置有问题吗?我是不是漏了一个开关?
老实说,我不确定。
因此,如果有人能对这个问题有所了解,那就太好了!
但与此同时,我将继续写下我安装 CUDA 工具包、驱动程序和 CUDAMat 的步骤。
我在 OSX 使用 CUDAMat、深度信仰网络和 Python 的经历
因此,在您考虑使用显卡来加快训练时间之前,您需要确保满足 CUDA 工具包最新版本的所有先决条件(在撰写本文时,版本 6.5.18 是最新版本),包括:
- Mac OSX 10.8 或更高版本
- gcc 或 Clang 编译器(如果您的系统上有 Xcode,这些应该已经安装好了)
- 支持 CUDA 的 GPU
- NVIDIA CUDA 工具包
这个清单上的前两项检查起来很简单。最后一项,NVIDIA Cuda 工具包是一个简单的下载和安装,前提是你有一个支持 Cuda 的 GPU。
要检查你在 OSX 上是否有支持 CUDA 的 GPU,只需点击屏幕左上方的苹果图标,选择“关于这台 Mac”,然后是“更多信息”,然后是“系统报告”,最后是“图形/显示”标签。
它应该是这样的:
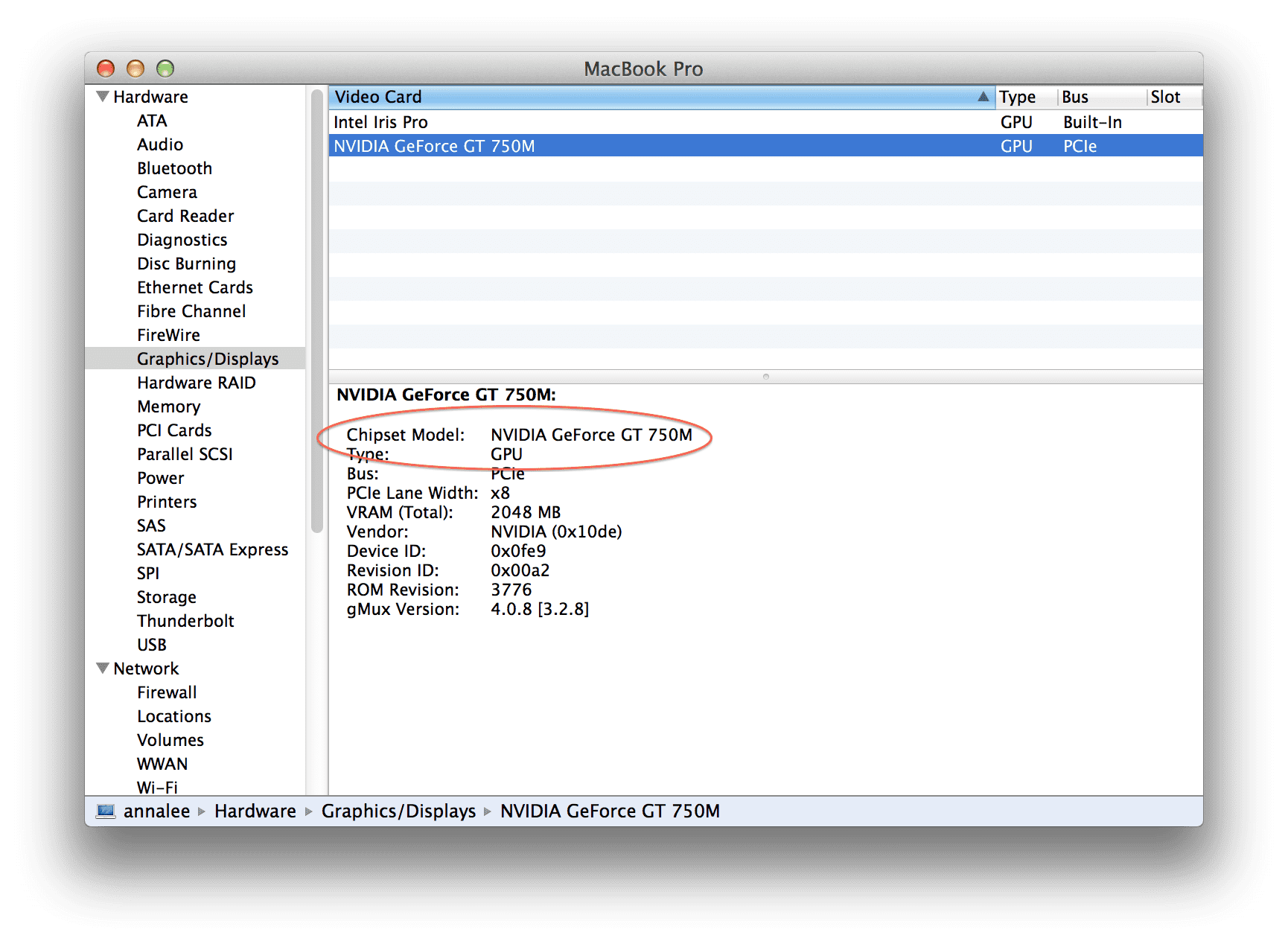
在我的“芯片组型号”下,我看到我使用的是 NVIDIA GeForce GT 750m 显卡。
我们去看看 CUDA 工具包是否支持这个模型。
要执行检查,只需点击此处查看支持的 GPU 列表,并查看您的 GPU 是否在列表中。
果然,我的 750m 被列为受支持:
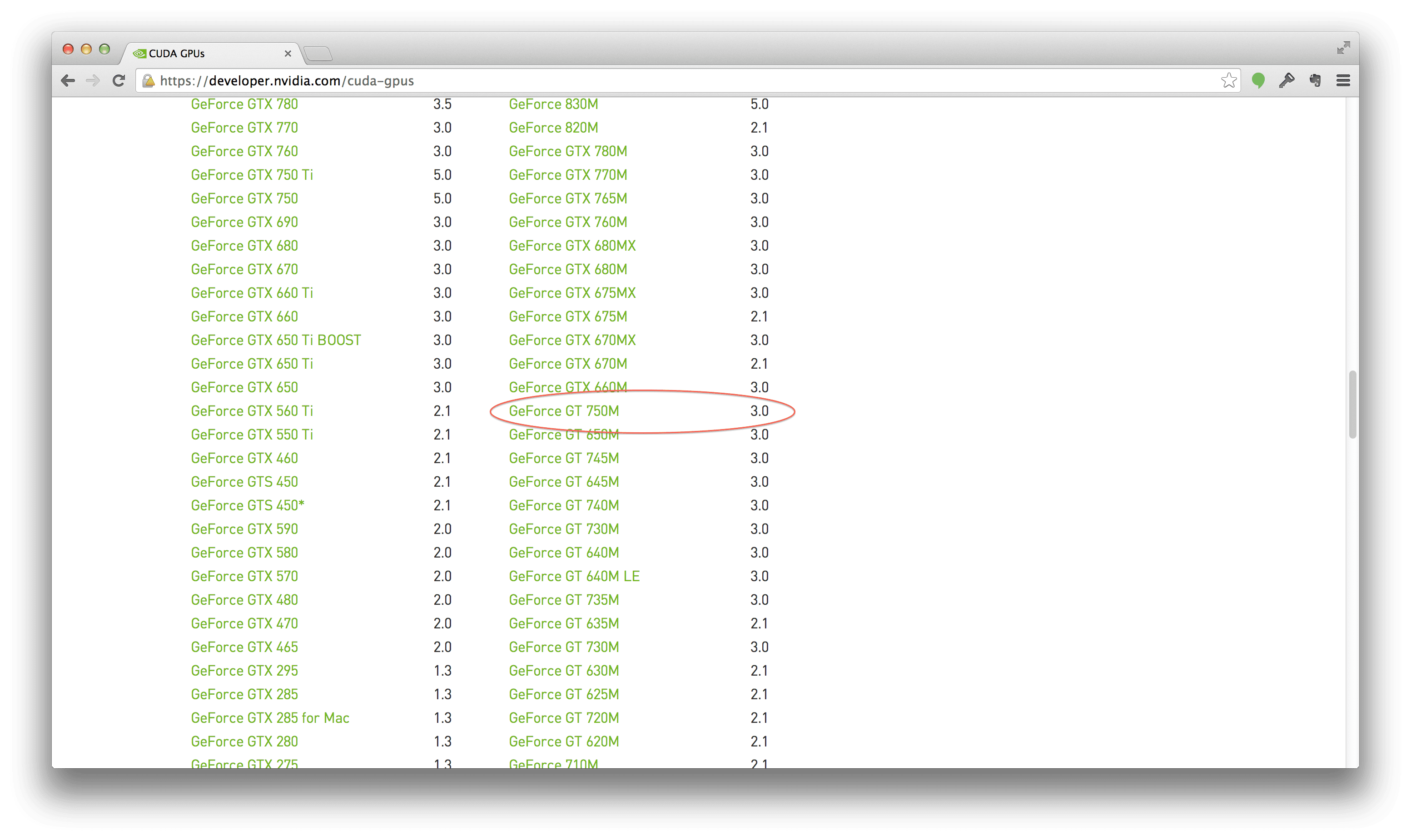
太棒了。那是一种解脱。至少我知道我的 MacBook Pro 是支持 CUDA 的。
下一步是下载并安装 CUDA 驱动程序、工具包和示例。
为此,只需进入 CUDA 下载页面,选择您的操作系统(在我的例子中是 OSX),并下载安装程序:

在撰写本文时,CUDA 工具包的最新版本是 v6.5.18。这也是一个相当大的 800mb 的下载量,所以请确保您有一些带宽。
PKG 下载完成后,开始安装过程:
 对我来说,安装过程非常快捷,从打开安装程序到安装完成不到 30 秒。
对我来说,安装过程非常快捷,从打开安装程序到安装完成不到 30 秒。
现在 CUDA 工具包已经安装好了,您需要设置一些环境变量:
export PATH=/Developer/NVIDIA/CUDA-6.5/bin:$PATH
export DYLD_LIBRARY_PATH=/Developer/NVIDIA/CUDA-6.5/lib:$DYLD_LIBRARY_PATH
我喜欢把这些放在我的.bash_profile文件中,这样我每次打开一个新的终端时都会设置我的路径:
 编辑完
编辑完.bash_profile文件后,关闭终端并打开一个新的终端,这样您的更改就会被读取。或者。您可以执行source ~/.bash_profile来重新加载您的设置。
为了验证 CUDA 驱动程序确实安装正确,我执行了以下命令:
$ kextstat | grep -i cuda
并收到以下输出:
果然,CUDA 司机如获至宝!
根据 OSX 的 CUDA 入门指南,你现在应该打开你的系统偏好,进入节能器设置。
你会想要 取消自动图形开关(这确保你的 GPU 将一直被利用)并且也将你的系统睡眠时间拖到从不。
注意:老实说,我尝试过这两种设置。他们都没有提高我的表现。
现在,让我们继续安装 CUDA 示例,这样我们就可以确保 CUDA 工具包正常工作,驱动程序正常工作。安装示例只是一个简单的 shell 脚本,如果您已经重新加载了您的.bash_profile,那么您的PATH上应该有这个脚本。
$ cuda-install-samples-6.5.sh
这个脚本在我的主目录中安装了 CUDA 示例。以下脚本的输出并不令人兴奋,只是证明它成功了:
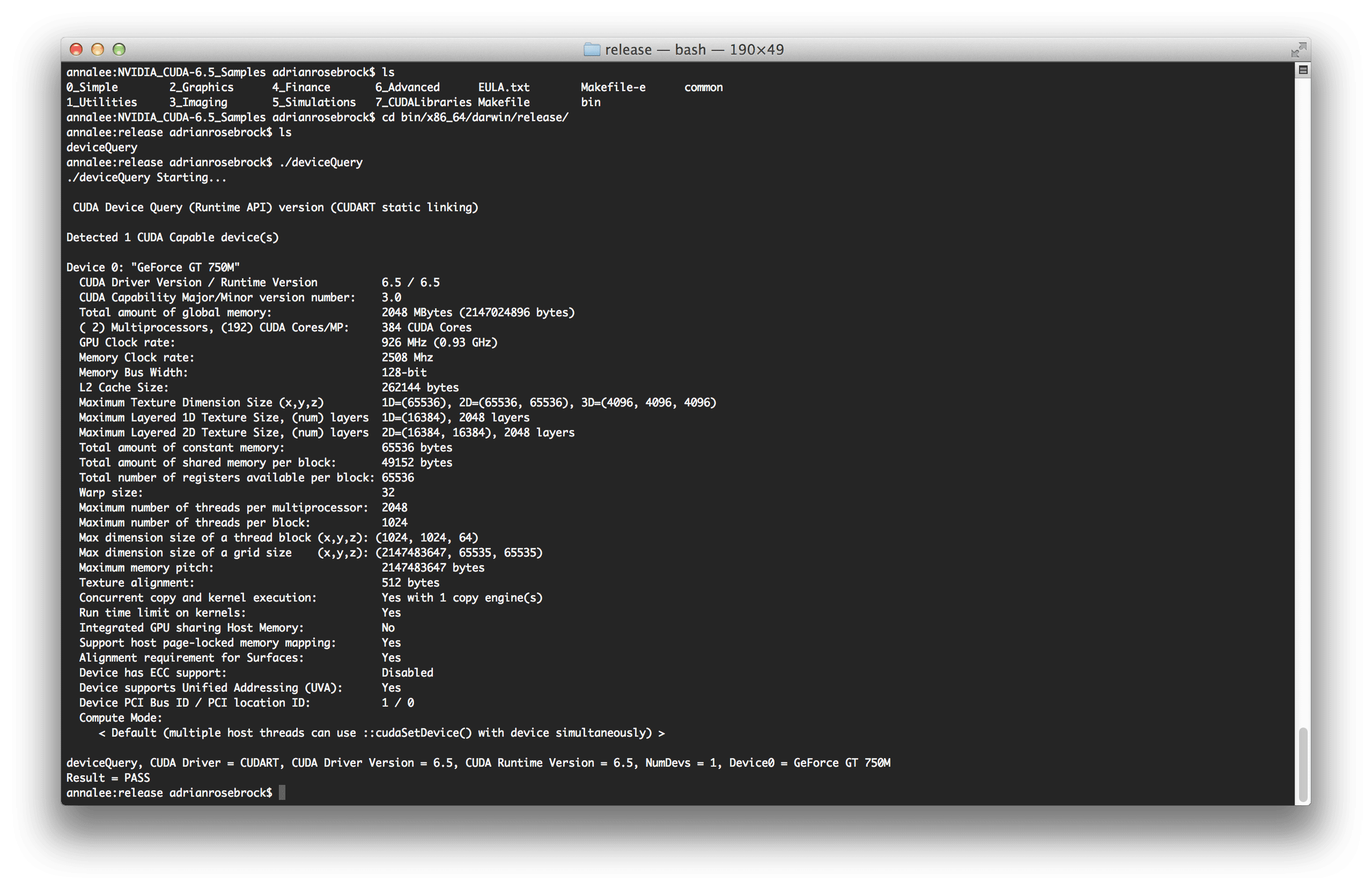
在那里,我用以下命令编译了deviceQuery和deviceBandwith示例:
$ make -C 1_Utilities/deviceQuery
$ make -C 1_Utilities/bandwidthTest
这两个例子编译时都没有任何错误。
运行编译过的deviceQuery程序,我能够确认 GPU 正在被拾取:
 类似地,
类似地,deviceBandwith的输出表明 GPU 是可访问的并且行为正确:
 此时我已经开始觉得不错了。
此时我已经开始觉得不错了。
CUDA 工具包、驱动程序和示例安装没有问题。我能够毫无问题地编译和执行这些示例。
因此,现在是时候继续前进到 CUDAMat 了,它允许通过 Python 在 GPU 上进行矩阵计算,从而(有望)大幅加快神经网络的训练时间。
我将 CUDAMat 克隆到我的系统中,并使用提供的Makefile顺利编译它:
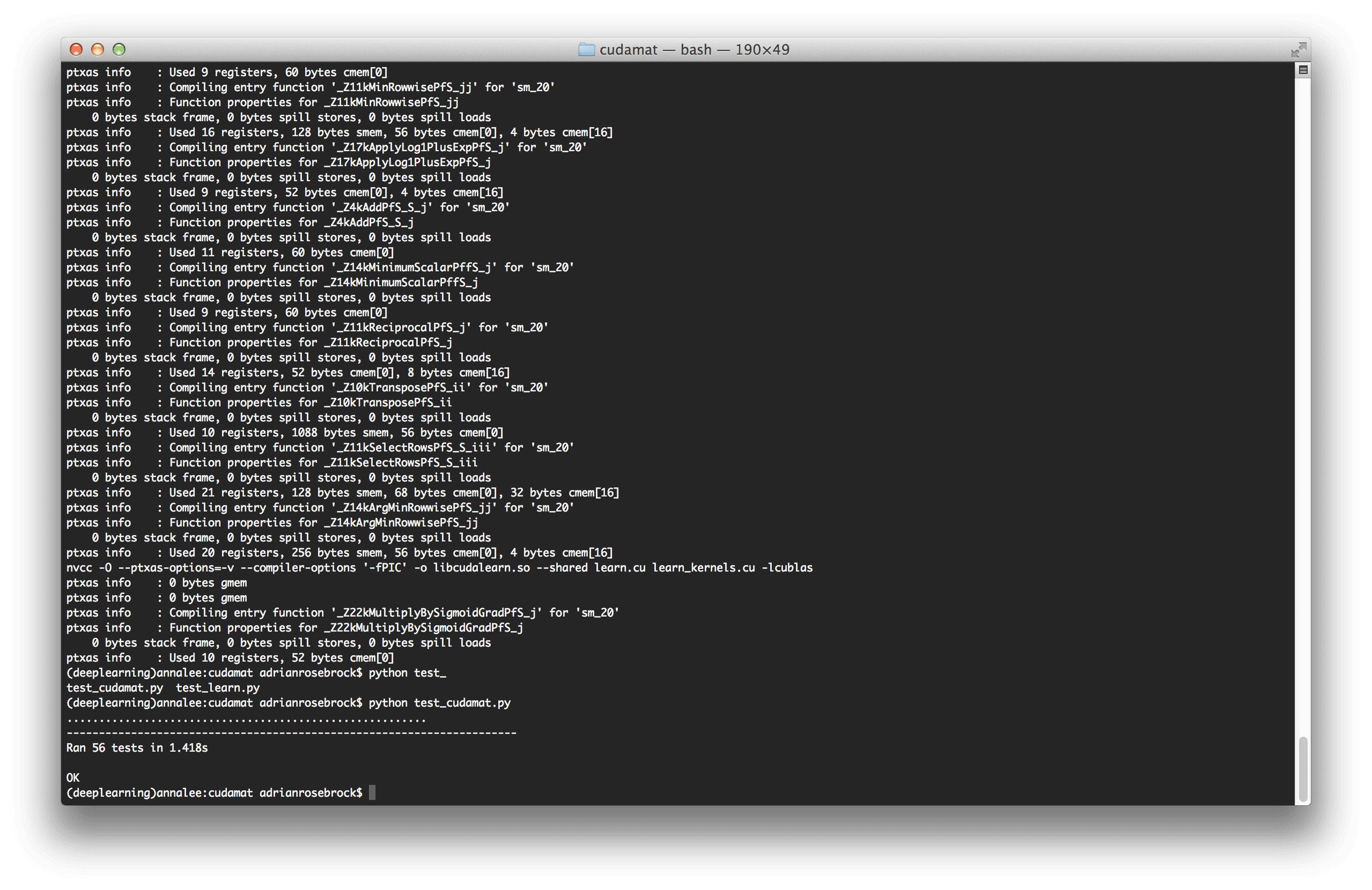 然后我运行
然后我运行test_cudamat.py以确保一切都运行顺利——确实看起来一切都运行良好。
现在我真的很兴奋!
CUDA 工具包安装完毕,CUDAMat 编译顺利,所有的 CUDAMat 测试都通过了。我将很快获得 GPU 加速!
至少我是这样认为的…
丑陋的结果
所以我们在这里。结果部分。
在 GPU 上训练我的深度信念网络应该产生显著的加速。
然而,在我的例子中,使用 GPU 比使用 CPU慢一分钟。
在下面报告的基准测试中,我使用了在 MNIST 数据集上训练的深度信念网络(DBN)的 nolearn 实现。我的网络包括一个 784 个节点的输入层(每个节点对应一个 28 x 28 像素图像的输入像素),一个 300 个节点的隐藏层,以及一个 10 个节点的输出层,每个节点对应一个可能的数字。我允许网络训练 10 个纪元。
我首先使用 CPU 获得了一个基线:
(deeplearning)annalee:deep-belief-network adrianrosebrock$ time python dbn.py
gnumpy: failed to import cudamat. Using npmat instead. No GPU will be used.
[X] downloading data...
[DBN] fitting X.shape=(46900, 784)
[DBN] layers [784, 300, 10]
[DBN] Fine-tune...
100%
Epoch 1:
loss 0.2840207848
err 0.0822020150273
(0:00:04)
100%
Epoch 2:
loss 0.171618364679
err 0.0484332308743
(0:00:04)
100%
Epoch 3:
loss 0.123517068572
err 0.0357112363388
(0:00:04)
100%
Epoch 4:
loss 0.0954012227419
err 0.0278133538251
(0:00:04)
100%
Epoch 5:
loss 0.0675616915956
err 0.0207906420765
(0:00:04)
100%
Epoch 6:
loss 0.0503800100696
err 0.0156463456284
(0:00:04)
100%
Epoch 7:
loss 0.0398645849321
err 0.0122096994536
(0:00:04)
100%
Epoch 8:
loss 0.0268006172097
err 0.0083674863388
(0:00:04)
100%
Epoch 9:
loss 0.0210037707263
err 0.00587004781421
(0:00:04)
100%
Epoch 10:
loss 0.0183086322316
err 0.00497353142077
(0:00:04)
precision recall f1-score support
0 0.99 0.99 0.99 2281
1 0.99 0.99 0.99 2611
2 0.97 0.98 0.98 2333
3 0.98 0.97 0.97 2343
4 0.98 0.99 0.98 2297
5 0.96 0.97 0.97 2061
6 0.99 0.99 0.99 2282
7 0.99 0.97 0.98 2344
8 0.97 0.97 0.97 2236
9 0.97 0.97 0.97 2312
avg / total 0.98 0.98 0.98 23100
real 1m1.586s
user 1m13.888s
sys 0m7.856s
如你所见,我收到了来自gnumpy(NumPy 的 GPU 优化版本)的警告,表明无法找到 CUDAMat,CPU 将用于训练:
gnumpy: failed to import cudamat. Using npmat instead. No GPU will be used.
10 个时期的训练和评估时间刚刚超过 1 分钟,感觉非常好。
但是 GPU 呢?它能做得更好吗?
我当然满怀希望。
但是结果让我很困惑:
(deeplearning)annalee:deep-belief-network adrianrosebrock$ time python dbn.py
[X] downloading data...
[DBN] fitting X.shape=(46900, 784)
[DBN] layers [784, 300, 10]
gnumpy: failed to use gpu_lock. Using board #0 without knowing whether it is in use or not.
[DBN] Fine-tune...
100%
Epoch 1:
loss 0.285464493333
err 0.083674863388
(0:00:08)
100%
Epoch 2:
loss 0.173001268822
err 0.0487107240437
(0:00:08)
100%
Epoch 3:
loss 0.125673221345
err 0.0372054303279
(0:00:08)
100%
Epoch 4:
loss 0.0976806794358
err 0.0285604508197
(0:00:08)
100%
Epoch 5:
loss 0.0694847570084
err 0.0209400614754
(0:00:08)
100%
Epoch 6:
loss 0.0507848879893
err 0.015881147541
(0:00:09)
100%
Epoch 7:
loss 0.0385255556989
err 0.0123804644809
(0:00:08)
100%
Epoch 8:
loss 0.0291288460832
err 0.00849556010929
(0:00:08)
100%
Epoch 9:
loss 0.0240176528952
err 0.00766308060109
(0:00:08)
100%
Epoch 10:
loss 0.0197711178206
err 0.00561390027322
(0:00:08)
precision recall f1-score support
0 0.99 0.99 0.99 2290
1 0.99 0.99 0.99 2610
2 0.98 0.98 0.98 2305
3 0.98 0.97 0.97 2337
4 0.97 0.98 0.98 2302
5 0.98 0.97 0.97 2069
6 0.98 0.99 0.98 2229
7 0.98 0.99 0.98 2345
8 0.97 0.97 0.97 2299
9 0.97 0.97 0.97 2314
avg / total 0.98 0.98 0.98 23100
real 2m8.462s
user 2m7.977s
sys 0m0.505s
在 GPU 上训练网络超过两分钟?
这不可能是正确的——这是 两倍于 的 CPU 训练所花费的时间!
但是果然。结果是这样说的。
我对这场奇怪表演的唯一了解是这条gnumpy消息:
gnumpy: failed to use gpu_lock. Using board #0 without knowing whether it is in use or not.
我做了一些谷歌搜索,但我不知道这条消息是否是一个关键的警告。
更重要的是,我不知道这条消息是否表明我的性能因为无法获得gpu_lock而严重受损。
悲伤和失败,我收集了我的截图和结果,并打印了这篇博文。
虽然我经常去健身房,但我的收获显然没有转化为 GPU。
希望有人在使用 CUDA 工具包,OSX 和 GPU 更多的专业知识可以指导我在正确的方向。
摘要
在这篇博文中,我试图展示如何利用 OSX 上的 GPU 来加速深度信念网络的训练时间。
不幸的是,我的结果表明,GPU 产生的训练时间比 CPU 慢——这对我来说完全没有意义,完全违背直觉。
**我的配置有问题吗?
我错过了一步吗?
肯定是我弄错了,或者是我的直觉出了问题。
如果你正在读这篇文章,并且在想“嗨,阿德里安,你是个白痴。你忘了做步骤 X、Y 和 Z" 然后请给我发一封电子邮件主题为你是个白痴并纠正我。非常感谢。
至少我希望这篇文章是我经历的一个可靠的编年史,并且有人在某处发现它是有帮助的。
更新:
我找到了我的救赎!要了解我是如何抛弃 MacBook Pro,转而使用亚马逊 EC2 GPU 的,只需点击这里**
使用 OpenCV、Python 和 dlib 进行眨眼检测
原文:https://pyimagesearch.com/2017/04/24/eye-blink-detection-opencv-python-dlib/

在上周的博客文章中,我演示了如何在视频流中实时检测面部标志。
今天,我们将在这一知识的基础上开发一个计算机视觉应用程序,它能够使用面部标志和 OpenCV 在视频流中 检测和计数眨眼 。
为了构建我们的眨眼检测器,我们将计算一种称为眼睛纵横比(耳朵)的度量,这是由 Soukupová和 ech 在他们 2016 年的论文 中介绍的,使用面部标志 进行实时眨眼检测。
与用于计算眨眼的传统图像处理方法不同,传统图像处理方法通常包括以下的一些组合:
- 眼睛定位。
- 阈值化以找到眼白。
- 确定眼睛的“白色”区域是否消失一段时间(表示眨眼)。
相反,眼睛的长宽比是一个更加优雅的解决方案,它包括一个非常简单的基于眼睛面部标志之间距离比的 T2 计算。
这种检测眨眼的方法快速、高效且易于实现。
要了解更多关于使用 OpenCV、Python 和 dlib 构建计算机视觉系统来检测视频流中眨眼的信息,请继续阅读。
使用 OpenCV、Python 和 dlib 进行眨眼检测
我们的眨眼检测博文分为四个部分。
在第一部分中,我们将讨论眼睛纵横比以及如何用它来确定一个人在给定的视频帧中是否在眨眼。
从那里,我们将编写 Python、OpenCV 和 dlib 代码来(1)执行面部标志检测和(2)检测视频流中的眨眼。
基于这种实现,我们将应用我们的方法来检测示例网络摄像机流以及视频文件中的眨眼。
最后,我将通过讨论改进我们的眨眼检测器的方法来结束今天的博文。
了解“眼睛纵横比”(耳朵)
正如我们从之前的教程中了解到的,我们可以应用面部标志检测来定位面部的重要区域,包括眼睛、眉毛、鼻子、耳朵和嘴巴:

Figure 1: Detecting facial landmarks in an video stream in real-time.
这也意味着我们可以通过知道特定面部部分的索引来提取特定面部结构:

Figure 2: Applying facial landmarks to localize various regions of the face, including eyes, eyebrows, nose, mouth, and jawline.
在眨眼检测方面,我们只对两组面部结构感兴趣——眼睛。
每只眼睛由 6 个 (x,y)-坐标表示,从眼睛的左上角开始(就好像你正在看着这个人),然后围绕该区域的其余部分顺时针工作:

Figure 3: The 6 facial landmarks associated with the eye.
基于这一形象,我们应该抓住关键点:
这些坐标的宽度和高度有关系。
基于 Soukupová和 ech 在他们 2016 年的论文 中的工作,使用面部标志 进行实时眨眼检测,然后我们可以推导出一个反映这种关系的方程,称为眼睛纵横比(耳朵):

Figure 4: The eye aspect ratio equation.
其中 p1,…,p6 为 2D 面部标志点位置。
该等式的分子计算垂直眼界标之间的距离,而分母计算水平眼界标之间的距离,适当地加权分母,因为只有一组水平点,但是有两组垂直点。
为什么这个方程这么有趣?
嗯,我们会发现,当眼睛睁开时,眼睛的长宽比几乎是恒定的,但是当眨眼时,眼睛的长宽比会迅速下降到零。
使用这个简单的等式,我们可以避免图像处理技术,而简单地依靠眼睛标志距离的比率来确定一个人是否在眨眼。
为了更清楚地说明这一点,请看 Soukupová和 ech 的下图:

Figure 5: Top-left: A visualization of eye landmarks when then the eye is open. Top-right: Eye landmarks when the eye is closed. Bottom: Plotting the eye aspect ratio over time. The dip in the eye aspect ratio indicates a blink (Figure 1 of Soukupová and Čech).
在左上角的上,我们有一只完全睁开的眼睛——这里的眼睛纵横比很大(r ),并且随着时间的推移相对恒定。
然而,一旦这个人眨眼(右上方),眼睛的纵横比就会急剧下降,接近于零。
底部的图绘制了一个视频剪辑的眼睛纵横比随时间变化的图表。正如我们所看到的,眼睛的纵横比是恒定的,然后迅速下降到接近零,然后再次增加,这表明发生了一次眨眼。
在下一节中,我们将学习如何使用面部标志、OpenCV、Python 和 dlib 实现眨眼检测的眼睛纵横比。
使用面部标志和 OpenCV 检测眨眼
首先,打开一个新文件,命名为detect_blinks.py。从那里,插入以下代码:
# import the necessary packages
from scipy.spatial import distance as dist
from imutils.video import FileVideoStream
from imutils.video import VideoStream
from imutils import face_utils
import numpy as np
import argparse
import imutils
import time
import dlib
import cv2
要访问我们磁盘上的视频文件(FileVideoStream)或内置的网络摄像头/USB 摄像头/Raspberry Pi 摄像头模块(VideoStream),我们需要使用我的 imutils 库,这是一组方便的函数,使 OpenCV 的工作更容易。
如果您的系统上没有安装imutils(或者如果您使用的是旧版本),请确保使用以下命令安装/升级:
$ pip install --upgrade imutils
注意:如果你正在使用 Python 虚拟环境(正如我所有的 OpenCV 安装教程所做的),确保你首先使用workon命令访问你的虚拟环境,然后安装/升级imutils。
除此之外,我们大部分的导入都是相当标准的——例外是 dlib ,它包含了我们面部标志检测的实现。
如果你的系统上没有安装 dlib,请按照我的 dlib 安装教程来配置你的机器。
接下来,我们将定义我们的eye_aspect_ratio函数:
def eye_aspect_ratio(eye):
# compute the euclidean distances between the two sets of
# vertical eye landmarks (x, y)-coordinates
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# compute the euclidean distance between the horizontal
# eye landmark (x, y)-coordinates
C = dist.euclidean(eye[0], eye[3])
# compute the eye aspect ratio
ear = (A + B) / (2.0 * C)
# return the eye aspect ratio
return ear
该函数接受一个必需的参数,即给定eye的面部标志的 (x,y) 坐标。
行 16 和 17 计算两组垂直眼标之间的距离,而行 21 计算水平眼标之间的距离。
最后,第 24 行结合分子和分母得到最终的眼睛纵横比,如上面的图 4 所述。
第 27 行然后将眼睛纵横比返回给调用函数。
让我们继续分析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-v", "--video", type=str, default="",
help="path to input video file")
args = vars(ap.parse_args())
我们的detect_blinks.py脚本需要一个命令行参数,后跟第二个可选参数:
--shape-predictor:这是通往 dlib 预先训练好的面部标志检测器的路径。你可以使用这篇博文底部的 【下载】 部分下载这个探测器以及源代码和示例视频。--video:此可选开关控制驻留在磁盘上的输入视频文件的路径。如果你想使用一个实时视频流,只需在执行脚本时省略这个开关。
我们现在需要设置两个重要的常量,您可能需要为自己的实现进行调优,同时初始化另外两个重要的变量, ,所以一定要注意这个解释:
# define two constants, one for the eye aspect ratio to indicate
# blink and then a second constant for the number of consecutive
# frames the eye must be below the threshold
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 3
# initialize the frame counters and the total number of blinks
COUNTER = 0
TOTAL = 0
当确定视频流中是否发生眨眼时,我们需要计算眼睛的纵横比。
如果眼睛长宽比低于某个阈值,然后又高于该阈值,那么我们将记录一次“眨眼”——EYE_AR_THRESH就是这个阈值。我们将它默认为值0.3,因为这是最适合我的应用程序的值,但是您可能需要针对自己的应用程序进行调整。
然后,我们有一个重要的常数,EYE_AR_CONSEC_FRAME——该值被设置为3以指示眼睛纵横比小于EYE_AR_THRESH的三个连续帧必须发生,以便记录眨眼。
同样,根据管道的帧处理吞吐率,您可能需要根据自己的实现提高或降低这个数字。
第 44 和 45 行初始化两个计数器。COUNTER是眼睛长宽比小于EYE_AR_THRESH的连续帧的总数,而TOTAL是脚本运行时眨眼的总数。
现在我们的导入、命令行参数和常量都已经处理好了,我们可以初始化 dlib 的面部检测器和面部标志检测器了:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
dlib 库使用预训练的人脸检测器,该检测器基于对用于对象检测的方向梯度直方图+线性 SVM 方法的修改。
然后,我们初始化第 51 行上的实际面部标志预测器。
你可以了解更多关于 dlib 的面部标志检测器的信息(例如,它是如何工作的,它是在什么数据集上训练的,等等。,在这篇博文中。
dlib 生成的面部标志遵循一个可索引列表,正如我在本教程中描述的:

Figure 6: The full set of facial landmarks that can be detected via dlib (higher resolution).
因此,我们可以确定用于提取左眼和右眼的 (x,y)-坐标的开始和结束阵列切片索引值,如下:
# grab the indexes of the facial landmarks for the left and
# right eye, respectively
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
使用这些索引,我们将能够毫不费力地提取眼睛区域。
接下来,我们需要决定我们是使用基于文件的视频流还是使用 USB/网络摄像头/Raspberry Pi 摄像头直播的视频流:
# start the video stream thread
print("[INFO] starting video stream thread...")
vs = FileVideoStream(args["video"]).start()
fileStream = True
# vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
# fileStream = False
time.sleep(1.0)
如果你使用的是一个文件视频流,那么让代码保持原样。
否则,如果你想使用内置网络摄像头或 USB 摄像头,取消注释行 62 。
对于 Raspberry Pi 摄像机模块,取消第 63 行的注释。
如果您取消了第 62 行 或第 63 行的注释,那么也取消第 64 行的**注释,以表明您是而不是从磁盘读取视频文件。**
最后,我们到达了脚本的主循环:
# loop over frames from the video stream
while True:
# if this is a file video stream, then we need to check if
# there any more frames left in the buffer to process
if fileStream and not vs.more():
break
# grab the frame from the threaded video file stream, resize
# it, and convert it to grayscale
# channels)
frame = vs.read()
frame = imutils.resize(frame, width=450)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
在第 68 行,我们开始循环视频流中的帧。
如果我们正在访问一个视频文件流,并且视频中没有剩余的帧,我们从循环中断开(行 71 和 72 )。
第 77 行从我们的视频流中读取下一帧,然后调整其大小并将其转换为灰度(第 78 和 79 行)。
然后,我们通过 dlib 的内置人脸检测器在第 82 行的灰度帧中检测人脸。
我们现在需要遍历帧中的每张脸,然后对每张脸应用面部标志检测:
# loop over the face detections
for rect in rects:
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# extract the left and right eye coordinates, then use the
# coordinates to compute the eye aspect ratio for both eyes
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# average the eye aspect ratio together for both eyes
ear = (leftEAR + rightEAR) / 2.0
行 89 确定面部区域的面部标志,而行 90 将这些 (x,y) 坐标转换成一个 NumPy 数组。
使用脚本前面的数组切片技术,我们可以分别提取左眼和右眼的 (x,y)-坐标(第 94 行和第 95 行)。
从那里,我们在第 96 行和第 97 行上计算每只眼睛的眼睛纵横比。
根据 Soukupová和 ech 的建议,我们将两只眼睛的长宽比一起平均,以获得更好的眨眼估计值(当然,假设一个人同时眨两只眼睛)。
我们的下一个代码块只是处理眼睛区域本身的面部标志的可视化:
# compute the convex hull for the left and right eye, then
# visualize each of the eyes
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
你可以在这篇文章中阅读更多关于提取和可视化个人面部标志区域的信息。
在这一点上,我们已经计算了我们的(平均)眼睛纵横比,但我们还没有实际确定是否发生了眨眼——这将在下一节中讨论:
# check to see if the eye aspect ratio is below the blink
# threshold, and if so, increment the blink frame counter
if ear < EYE_AR_THRESH:
COUNTER += 1
# otherwise, the eye aspect ratio is not below the blink
# threshold
else:
# if the eyes were closed for a sufficient number of
# then increment the total number of blinks
if COUNTER >= EYE_AR_CONSEC_FRAMES:
TOTAL += 1
# reset the eye frame counter
COUNTER = 0
行 111 进行检查以查看眼睛纵横比是否低于我们的眨眼阈值——如果是,我们增加指示眨眼正在发生的连续帧的数量(行 112 )。
否则,线 116 处理眼睛纵横比不低于眨眼阈值的情况。
在这种情况下,我们在行 119 上进行另一次检查,以查看是否有足够数量的连续帧包含低于我们预定义阈值的眨眼比率。
如果检查通过,我们增加眨眼次数TOTAL(第 120 行)。
然后我们重置连续眨眼的次数COUNTER ( 第 123 行)。
我们的最终代码块只是处理在输出帧上绘制眨眼次数,以及显示当前眼睛的纵横比:
# draw the total number of blinks on the frame along with
# the computed eye aspect ratio for the frame
cv2.putText(frame, "Blinks: {}".format(TOTAL), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
要查看我们的眨眼检测器,请进入下一部分。
眨眼检测结果
在执行任何这些示例之前,请确保使用本指南的 “下载” 部分下载源代码+示例视频+预训练的 dlib 面部标志预测器。从那里,您可以打开归档文件并开始使用代码。
在过去的这个周末,我去拉斯维加斯参加一个会议。在等待登机的时候,我坐在登机口,整理了这篇博文的代码——这包括录制一段简单的视频,我可以用它来评估眨眼检测软件。
要将我们的眨眼检测器应用于示例视频,只需执行以下命令:
$ python detect_blinks.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--video blink_detection_demo.mp4
正如你将看到的,我们可以使用 OpenCV 和面部标志成功计算视频中眨眼的次数:
https://www.youtube.com/embed/72_7ByIfvEI?feature=oembed
基于 OpenCV 和 Python 的人脸对齐
原文:https://pyimagesearch.com/2017/05/22/face-alignment-with-opencv-and-python/

继续我们关于面部标志的系列博文,今天我们要讨论面部对齐的过程:
**1. 识别数字图像中人脸的几何结构。
2. 尝试基于平移、缩放和旋转获得面部的规范对齐。
面部对齐有多种形式。
一些方法试图强加(预定义的)3D 模型,然后对输入图像应用变换,使得输入面上的界标匹配 3D 模型上的界标。
其他更简单的方法(如这篇博客中讨论的方法),仅依靠面部标志本身(特别是眼睛区域)来获得面部的标准化旋转、平移和比例表示(T2)。
我们执行这种标准化的原因是因为许多面部识别算法,包括用于面部识别的特征脸、LBPs、鱼脸和深度学习/度量方法都可以从在尝试识别面部之前应用面部对齐中受益。
因此,人脸对齐可以被视为“数据规范化”的一种形式。正如您可以在训练机器学习模型之前通过零中心化或缩放到单位范数来归一化一组特征向量一样,在训练人脸识别器之前对齐数据集中的人脸是非常常见的。
通过执行此过程,您将享受到面部识别模型的更高准确性。
注意:如果你有兴趣了解更多关于创建你自己的定制人脸识别器的知识,请务必参考 PyImageSearch 大师课程,在那里我提供了关于人脸识别的详细教程*。*
要了解更多关于面部对齐和标准化的信息,继续阅读。
基于 OpenCV 和 Python 的人脸对齐
这篇博文的目的是演示如何使用 OpenCV、Python 和面部标志来对齐面部。
给定一组面部标志(输入坐标),我们的目标是扭曲和转换图像到输出坐标空间。
在这个输出坐标空间中,整个数据集的所有面应该:
- 在图像中居中。
- 旋转,使眼睛位于一条水平线上(即,旋转面部,使眼睛位于相同的 y 坐标)。
- 被缩放以使面的大小大致相同。
为了实现这一点,我们将首先实现一个专用的 Python 类来使用仿射变换对齐面部。我已经在 imutils 中实现了这个 FaceAligner 类。
注:仿射变换用于旋转、缩放、平移等。我们可以将上述三个需求打包成一个单独的 cv2.warpAffine 调用;诀窍是创建旋转矩阵, M 。
然后,我们将创建一个示例驱动程序 Python 脚本来接受输入图像、检测人脸并对齐它们。
最后,我们将回顾使用 OpenCV 过程进行人脸对齐的结果。
实现我们的面部对准器
人脸对齐算法本身是基于 用实用的计算机视觉项目 (巴乔,2012)掌握 OpenCV 的第八章,如果你有 C++背景或者兴趣的话我强烈推荐。这本书在 GitHub 上提供了开放代码样本。
让我们从检查我们的FaceAligner实现和理解幕后发生的事情开始。
# import the necessary packages
from .helpers import FACIAL_LANDMARKS_IDXS
from .helpers import shape_to_np
import numpy as np
import cv2
class FaceAligner:
def __init__(self, predictor, desiredLeftEye=(0.35, 0.35),
desiredFaceWidth=256, desiredFaceHeight=None):
# store the facial landmark predictor, desired output left
# eye position, and desired output face width + height
self.predictor = predictor
self.desiredLeftEye = desiredLeftEye
self.desiredFaceWidth = desiredFaceWidth
self.desiredFaceHeight = desiredFaceHeight
# if the desired face height is None, set it to be the
# desired face width (normal behavior)
if self.desiredFaceHeight is None:
self.desiredFaceHeight = self.desiredFaceWidth
2-5 号线处理我们的进口。要阅读面部标志和我们相关的辅助功能,请务必查看之前的帖子。
在第 7 行,我们开始我们的FaceAligner类,我们的构造函数在第 8-20 行被定义。
我们的构造函数有 4 个参数:
predictor:面部标志预测模型。desiredLeftEye:可选的 (x,y) 元组,默认显示,指定期望的输出左眼位置。对于这一变量,常见的百分比在 20-40%之间。这些百分比控制对齐后有多少面是可见的。所用的确切百分比因应用而异。20%的话,你基本上会得到一个“放大”的脸部视图,而更大的值会让脸部看起来更“缩小”desiredFaceWidth:另一个可选参数,以像素为单位定义我们想要的脸。我们将这个值默认为 256 像素。desiredFaceHeight:最后一个可选参数,以像素为单位指定我们想要的面部高度值。
这些参数中的每一个都被设置为第 12-15 行上的相应实例变量。
接下来,让我们决定我们是想要一个正方形的人脸图像,还是矩形的。第 19 行和第 20 行检查desiredFaceHeight是否为None,如果是,我们将其设置为desiredFaceWidth,表示脸是方的。正方形图像是典型的例子。或者,我们可以为desiredFaceWidth和desiredFaceHeight指定不同的值,以获得感兴趣的矩形区域。
现在我们已经构建了我们的FaceAligner对象,接下来我们将定义一个对齐面部的函数。
这个函数有点长,所以我把它分成了 5 个代码块,使它更容易理解:
def align(self, image, gray, rect):
# convert the landmark (x, y)-coordinates to a NumPy array
shape = self.predictor(gray, rect)
shape = shape_to_np(shape)
# extract the left and right eye (x, y)-coordinates
(lStart, lEnd) = FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = FACIAL_LANDMARKS_IDXS["right_eye"]
leftEyePts = shape[lStart:lEnd]
rightEyePts = shape[rStart:rEnd]
从第 22 行的开始,我们定义了接受三个参数的 align 函数:
image:RGB 输入图像。gray:灰度输入图像。rect:dlib 的猪脸检测器产生的包围盒矩形。
在第 24 行和第 25 行,我们应用 dlib 的面部标志预测器,并将标志转换为 NumPy 格式的 (x,y)-坐标。
接下来,在的第 28 行和第 29 行,我们从FACIAL_LANDMARK_IDXS字典中读取left_eye和right_eye区域,该字典是在helpers.py脚本中找到的。这些二元组值存储在左/右眼起始和结束索引中。
使用第 30 和 31 行上的起始和结束索引从形状列表中提取leftEyePts和rightEyePts。
接下来,让我们来计算每只眼睛的中心以及眼睛质心之间的角度。
这个角度是调整我们形象的关键部分。
下图图 1 所示的两眼之间绿线的角度,就是我们所关心的角度。

Figure 1: Computing the angle between two eyes for face alignment.
要查看角度是如何计算的,请参考下面的代码块:
# compute the center of mass for each eye
leftEyeCenter = leftEyePts.mean(axis=0).astype("int")
rightEyeCenter = rightEyePts.mean(axis=0).astype("int")
# compute the angle between the eye centroids
dY = rightEyeCenter[1] - leftEyeCenter[1]
dX = rightEyeCenter[0] - leftEyeCenter[0]
angle = np.degrees(np.arctan2(dY, dX)) - 180
在第行第 34 和 35 行,我们分别通过平均每只眼睛的所有 (x,y) 点来计算每只眼睛的质心,也称为质心。
给定眼睛中心,我们可以计算 (x,y)-坐标中的差异,并取反正切来获得眼睛之间的旋转角度。
这个角度将允许我们对旋转进行校正。
为了确定角度,我们首先计算在 y 方向dY的增量。这是通过找出线 38 上的rightEyeCenter和leftEyeCenter之间的差异来完成的。
类似地,我们计算第 39 条线上 x 方向的增量dX。
接下来,在第 40 行,我们计算脸部旋转的角度。我们使用带有参数dY和dX的 NumPy 的arctan2函数,然后转换成度数,同时减去 180°以获得角度。
在下面的代码块中,我们计算所需的右眼坐标(作为左眼位置的函数),并计算新生成图像的比例。
# compute the desired right eye x-coordinate based on the
# desired x-coordinate of the left eye
desiredRightEyeX = 1.0 - self.desiredLeftEye[0]
# determine the scale of the new resulting image by taking
# the ratio of the distance between eyes in the *current*
# image to the ratio of distance between eyes in the
# *desired* image
dist = np.sqrt((dX ** 2) + (dY ** 2))
desiredDist = (desiredRightEyeX - self.desiredLeftEye[0])
desiredDist *= self.desiredFaceWidth
scale = desiredDist / dist
在第 44 行上,我们根据期望的左眼 x 坐标计算期望的右眼。我们从1.0中减去self.desiredLeftEye[0],因为desiredRightEyeX值应该与图像的右边缘等距,因为相应的左眼 x 坐标距离图像的左边缘。
然后,我们可以通过获取当前图像中双眼之间的距离与期望图像中双眼之间的距离的比值来确定面部的scale
首先,我们计算第 50 行上的欧几里德距离比dist。
接下来,在线 51 上,使用右眼和左眼之间的差值x-值,我们计算期望的距离desiredDist。
我们通过将desiredDist乘以行 52 上的desiredFaceWidth来更新desiredDist。这实际上是根据想要的宽度来调整我们的眼距。
最后,我们的规模是通过将desiredDist除以我们之前计算的dist来计算的。
现在我们有了旋转angle和scale,在计算仿射变换之前,我们需要采取一些步骤。这包括找到两眼之间的中点以及计算旋转矩阵并更新其平移分量:
# compute center (x, y)-coordinates (i.e., the median point)
# between the two eyes in the input image
eyesCenter = ((leftEyeCenter[0] + rightEyeCenter[0]) // 2,
(leftEyeCenter[1] + rightEyeCenter[1]) // 2)
# grab the rotation matrix for rotating and scaling the face
M = cv2.getRotationMatrix2D(eyesCenter, angle, scale)
# update the translation component of the matrix
tX = self.desiredFaceWidth * 0.5
tY = self.desiredFaceHeight * self.desiredLeftEye[1]
M[0, 2] += (tX - eyesCenter[0])
M[1, 2] += (tY - eyesCenter[1])
在第 57 行和第 58 行上,我们计算左右眼的中点eyesCenter。这将用于我们的旋转矩阵计算。本质上,这个中点位于鼻子的顶部,也是我们旋转面部的点:

Figure 2: Computing the midpoint (blue) between two eyes. This will serve as the (x, y)-coordinate in which we rotate the face around.
为了计算我们的旋转矩阵,M,我们利用cv2.getRotationMatrix2D指定eyesCenter、angle和scale ( 行 61 )。这三个值中的每一个都已经预先计算过了,所以根据需要参考第行 40 、行 53 和行 57 。
cv2.getRotationMatrix2D的参数描述如下:
- 两眼之间的中点是我们旋转脸部的点。
- 我们将脸部旋转到的角度,以确保眼睛位于同一水平线。
scale:我们将放大或缩小图像的百分比,确保图像缩放到所需的大小。
现在,我们必须更新矩阵的平移分量,以便在仿射变换后人脸仍然在图像中。
在第 64 行上,我们取desiredFaceWidth的一半,并将值存储为tX,即在 x 方向的平移。
为了计算在 y 方向上的平移tY,我们将desiredFaceHeight乘以期望的左眼 y 值desiredLeftEye[1]。
使用tX和tY,我们通过从它们对应的眼睛中点值eyesCenter ( 行 66 和 67 )中减去每个值来更新矩阵的平移分量。
我们现在可以应用仿射变换来对齐面部:
# apply the affine transformation
(w, h) = (self.desiredFaceWidth, self.desiredFaceHeight)
output = cv2.warpAffine(image, M, (w, h),
flags=cv2.INTER_CUBIC)
# return the aligned face
return output
为了方便起见,我们将desiredFaceWidth和desiredFaceHeight分别存储到w和h(线 70 )。
然后我们通过调用cv2.warpAffine在行 70 和 71 上执行最后一步。该函数调用需要 3 个参数和 1 个可选参数:
image:人脸图像。M:平移、旋转和缩放矩阵。(w, h):输出面所需的宽度和高度。flags:用于扭曲的插值算法,在本例中为INTER_CUBIC。要阅读其他可能的标志和图像转换,请参考OpenCV 文档。
最后,我们返回第 75 条线上对齐的面。
使用 OpenCV 和 Python 对齐人脸
现在让我们用一个简单的驱动程序脚本来处理这个对齐类。打开一个新文件,命名为align_faces.py,让我们开始编码。
# import the necessary packages
from imutils.face_utils import FaceAligner
from imutils.face_utils import rect_to_bb
import argparse
import imutils
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
在第 2-7 行上,我们导入所需的包。
如果您的系统上没有安装imutils和/或dlib ,请确保通过pip安装/升级它们:
$ pip install --upgrade imutils
$ pip install --upgrade dlib
注意:如果你正在使用 Python 虚拟环境(正如我所有的 OpenCV 安装教程所做的),确保你首先使用 workon 命令访问你的虚拟环境,然后安装/升级 imutils 和 dlib 。
在第 10-15 行的上使用argparse,我们指定了两个必需的命令行参数:
--shape-predictor:dlib 面部标志预测器。--image:包含人脸的图像。
在下一个代码块中,我们初始化基于 HOG 的检测器(方向梯度直方图)、面部标志预测器和面部对准器:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor and the face aligner
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
fa = FaceAligner(predictor, desiredFaceWidth=256)
第 19 行使用 dlib 的get_frontal_face_detector初始化我们的探测器对象。
在第 20 行上,我们使用--shape-predictor,dlib 的预训练预测器的路径,实例化我们的面部标志预测器。
我们通过在第 21 行的上初始化一个对象fa来利用我们在上一节刚刚构建的FaceAligner类。我们指定 256 像素的面宽。
接下来,让我们加载我们的图像,并为人脸检测做准备:
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=800)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# show the original input image and detect faces in the grayscale
# image
cv2.imshow("Input", image)
rects = detector(gray, 2)
在第 24 行的上,我们加载由命令行参数–-image指定的图像。我们调整图像的大小,保持第 25 行的宽高比为 800 像素。然后我们在第 26 行将图像转换成灰度。
检测输入图像中的人脸是在行 31 处理的,这里我们应用了 dlib 的人脸检测器。这个函数返回rects,这是我们的检测器已经找到的面部周围的边界框列表。
在下一个块中,我们迭代rects,对齐每个面,并显示原始和对齐的图像。
# loop over the face detections
for rect in rects:
# extract the ROI of the *original* face, then align the face
# using facial landmarks
(x, y, w, h) = rect_to_bb(rect)
faceOrig = imutils.resize(image[y:y + h, x:x + w], width=256)
faceAligned = fa.align(image, gray, rect)
# display the output images
cv2.imshow("Original", faceOrig)
cv2.imshow("Aligned", faceAligned)
cv2.waitKey(0)
我们从第 34 行的开始循环。
对于 dlib 预测的每个边界框rect,我们将其转换为格式(x, y, w, h) ( 第 37 行)。
随后,我们将框的宽度调整为 256 像素,保持第行第 38 的纵横比。我们将这个原始的、但是调整了大小的图像存储为faceOrig。
在第 39 行上,我们对齐图像,指定我们的图像、灰度图像和矩形。
最后,行 42 和 43 在各自的窗口中向屏幕显示原始的和相应的对准的面部图像。
在第行第 44 处,我们等待用户在显示下一个原始/校准图像对之前,在任一窗口处于焦点时按下一个键。
对所有检测到的面部重复第 35-44 行的过程,然后脚本退出。
要查看我们的面部矫正器,请进入下一部分。
面部对齐结果
让我们继续将我们的面部对齐器应用于一些示例图像。确保你使用这篇博文的 【下载】 部分下载源代码+示例图片。
解压缩归档文件后,执行以下命令:
$ python align_faces.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_01.jpg
从这里你会看到下面的输入图像,一张我和我的未婚妻 Trisha 的照片:

Figure 3: An input image to our OpenCV face aligner.
该图像包含两张脸,因此我们将执行两张面部对齐。
第一个如下所示:

Figure 4: Aligning faces with OpenCV.
在左边的上,我们有原始的检测到的人脸。然后对齐的面显示在右侧。
现在是特丽莎的脸:

Figure 5: Facial alignment with OpenCV and Python.
注意在面部对齐之后,我们两张脸的比例相同和,眼睛出现在相同的输出 (x,y) 坐标中。
让我们试试第二个例子:
$ python align_faces.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_02.jpg
在感恩节的早晨,我正在享用一杯葡萄酒:

Figure 6: An input image to our face aligner.
检测到我的面部后,它会被对齐,如下图所示:

Figure 7: Using facial landmarks to align faces in images.
这里是第三个例子,这是我和我父亲去年春天烹饪了一批软壳蟹后的一个例子:
$ python align_faces.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_03.jpg

Figure 8: Another example input to our face aligner.
我父亲的脸首先对齐:

Figure 9: Applying facial alignment using OpenCV and Python.
其次是我自己的:

Figure 10: Using face alignment to obtain canonical representations of faces.
第四个例子是我祖父母最后一次去北卡罗来纳时的照片:
$ python align_faces.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_04.jpg

Figure 11: Inputting an image to our face alignment algorithm.
我奶奶的脸先对齐了:

Figure 12: Performing face alignment using computer vision.
然后是我祖父的:

Figure 13: Face alignment in unaffected by the person in the photo wearing glasses.
尽管两个人都戴着眼镜,但他们的脸还是被正确地对齐了。
让我们做最后一个例子:
$ python align_faces.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_05.jpg

Figure 14: The final example input image to our face aligner.
应用面部检测后,首先对齐 Trisha 的面部:

Figure 15: Facial alignment using facial landmarks.
然后是我自己的:

Figure 16: Face alignment still works even if the input face is rotated.
我的脸的旋转角度被检测和纠正,然后被缩放到适当的大小。
为了证明这种面部对齐方法确实可以(1)使面部居中,(2)旋转面部,使眼睛沿着水平线,以及(3)缩放面部,使它们的大小大致相同,我制作了一个 GIF 动画,如下所示:
Figure 17: An animation demonstrating face alignment across multiple images.
正如你所看到的,每张输入图像的眼睛位置和面部尺寸几乎相同。
摘要
在今天的帖子中,我们学习了如何使用 OpenCV 和 Python 应用面部对齐。面部对齐是一种标准化技术,通常用于提高面部识别算法的准确性,包括深度学习模型。
面部对齐的目标是将输入坐标空间转换为输出坐标空间,使得整个数据集上的所有面部应该:
- 在图像中居中。
- 旋转,使眼睛位于一条水平线上(即,旋转面部,使眼睛位于相同的 y 坐标)。
- 被缩放以使面的大小大致相同。
使用仿射变换可以实现这三个目标。诀窍是确定变换矩阵的分量M。
我们的面部对齐算法依赖于知道眼睛的 (x,y)-坐标。在这篇博文中,我们使用了 dlib,但是你也可以使用其他面部标志库——同样的技术也适用。
对于面部对齐,面部标志往往比 Haar cascades 或 HOG 检测器工作得更好,因为我们获得了对眼睛位置的更精确的估计(而不仅仅是边界框)。
如果你有兴趣学习更多关于人脸识别和物体检测的知识,一定要看看 PyImageSearch 大师课程 ,在那里我有超过 25 节以上关于这些主题的课程。**
用 Python 进行人脸聚类
原文:https://pyimagesearch.com/2018/07/09/face-clustering-with-python/
今天这篇博文的灵感来自于 PyImageSearch 读者 Leonard Bogdonoff 的一个问题。
在我发表了我之前关于使用 OpenCV 的 人脸识别和深度学习 的帖子之后,Leonard 写道:
嘿,阿德里安,你能进入身份聚类吗?我有一个由照片和 组成的数据集,但我似乎无法确定如何处理它们来识别独特的人。
这种“面部聚类”或“身份聚类”的应用可以用于帮助执法。
考虑一个场景,两个罪犯在一个繁忙的城市如波士顿或纽约抢劫一家银行。银行的安全摄像头工作正常,捕捉到了抢劫过程——但是罪犯戴着滑雪面罩,所以你看不到他们的脸。
行凶者将现金藏在衣服下面逃离银行,摘下他们的面具,并将其扔进附近的垃圾桶,以免在公共场合显得“可疑”。
他们会逍遥法外吗?
也许吧。
但是安装在附近加油站、餐馆和红灯/主要十字路口的安全摄像头捕捉到了附近所有的行人活动。
在警察到达后,他们的侦探可以利用人脸聚类来查找该地区所有视频源中的所有独特人脸 —给定这些独特的人脸,侦探可以:(1)手动调查它们并将其与银行出纳员的描述进行比较,(2)运行自动搜索来将人脸与已知的罪犯数据库进行比较,或者(3)应用良好的 ole’侦探工作来查找可疑的个人。
这当然是一个虚构的例子,但我希望你能看到人脸聚类在现实世界中的应用价值。
要了解更多关于人脸聚类的知识,以及如何使用 Python 实现它,以及深度学习,请继续阅读。
用 Python 进行人脸聚类
人脸识别和人脸聚类是不同的,但高度相关的概念。当执行人脸识别时,我们应用监督学习,其中我们有(1)我们想要识别的人脸的示例图像,以及(2)对应于每个人脸的名称(即“类别标签”)。
但是在人脸聚类中,我们需要执行无监督学习——我们只有人脸本身,没有名字/标签。从那里我们需要识别和计算数据集中唯一的人的数量。
在这篇博文的第一部分,我们将讨论我们的面聚类数据集和我们将用于构建项目的项目结构。
接下来,我将帮助您编写两个 Python 脚本:
- 一个是提取和量化数据集中的人脸
- 另一个是聚类面部,其中每个结果聚类(理想地)代表一个独特的个体
从那里,我们将在一个样本数据集上运行我们的面部聚类管道,并检查结果。
配置您的开发环境
在我们之前的人脸识别帖子中,我在标题为“安装你的人脸识别库”的部分解释了如何配置你的开发环境——请确保在配置你的环境时参考它。
作为快速分解,这里是您在 Python 环境中需要的一切:
如果你有一个 GPU,你会想要安装带有 CUDA 绑定的 dlib,这也在之前的文章中描述过。
我们的人脸聚类数据集
随着 2018 年 FIFA 世界杯半决赛明天开始,我认为将面部聚类应用于著名足球运动员的面部会很有趣。
正如你从上面的图 1 中看到的,我收集了五名足球运动员的数据集,包括:
- 穆罕默德·萨拉赫
- 小内马尔
- 克里斯蒂亚诺·罗纳尔多
- 莱昂内尔·梅西
- 路易斯·苏亚雷斯
数据集中总共有 129 幅图像。
我们的目标是提取量化图像中每张脸的特征,并对得到的“面部特征向量”进行聚类。理想情况下,每个足球运动员都有自己的仅包含他们面部的聚类。
面聚类项目结构
在我们开始之前,请务必从这篇博文的 “下载” 部分获取可下载的 zip 文件。
我们的项目结构如下:
$ tree --dirsfirst
.
├── dataset [129 entries]
│ ├── 00000000.jpg
│ ├── 00000001.jpg
│ ├── 00000002.jpg
│ ├── ...
│ ├── 00000126.jpg
│ ├── 00000127.jpg
│ └── 00000128.jpg
├── encode_faces.py
├── encodings.pickle
└── cluster_faces.py
1 directory, 132 files
我们的项目有一个目录和三个文件:
- 包含了我们五个足球运动员的 129 张照片。请注意,在上面的输出中,文件名或另一个文件中没有标识每个图像中的人的标识信息。仅仅根据文件名,不可能知道哪个足球运动员在哪个图像中。我们将设计一个人脸聚类算法来识别数据集中相似和唯一的人脸。
- 这是我们的第一个脚本——它为数据集中的所有人脸计算人脸嵌入,并输出一个序列化的编码文件。
encodings.pickle:我们的脸嵌入序列化泡菜文件。- 神奇的事情发生在这个脚本中,我们将相似的脸聚集在一起,并理想地找出离群值。
通过深度学习对人脸进行编码
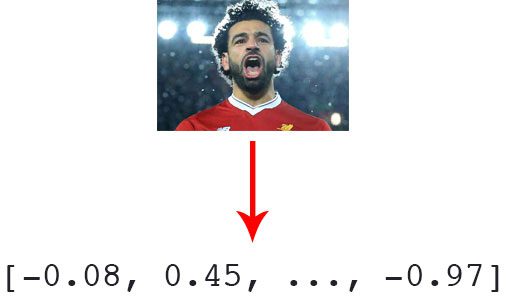
Figure 2: In order to represent faces numerically, we quantify all faces in the dataset with a 128-d feature vector generated by a neural network. We’ll use these feature vectors later in our face clustering Python script.
在对一组人脸进行聚类之前,我们首先需要对它们进行量化。这个量化面部的过程将使用深度神经网络来完成,该深度神经网络负责:
- 接受输入图像
- 以及输出量化面部的 128 维特征向量
我讨论了这个深度神经网络是如何工作的,以及它是如何在我的之前的人脸识别帖子中被训练的,所以如果你对网络本身有任何问题,请务必参考它。我们的encode_faces.py脚本将包含用于提取每张人脸的 128 维特征向量表示的所有代码。
要查看这个过程是如何执行的,创建一个名为encode_faces.py的文件,并插入以下代码:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
我们需要的包在线 2-7 导入。注意到:
- 从我的 imutils 包里
face_recognition由亚当·盖特基,一位 PyImageConf2018 主讲
从那里,我们将解析第 10-17 行****:上的命令行参数
*** --dataset:人脸和图像输入目录的路径。
--encodings:包含面部编码的输出序列化 pickle 文件的路径。--detection-method:在量化人脸之前,您可以使用卷积神经网络(CNN)或梯度方向直方图(HOG)方法来检测输入图像中的人脸。CNN 方法更准确(但较慢),而 HOG 方法更快(但不太准确)。
如果你不熟悉命令行参数以及如何使用它们,请参考我的上一篇文章。
我还会提到,如果你认为这个脚本运行缓慢,或者你想在没有 GPU 的情况下实时运行面部聚类帖子,你绝对应该将--detection-method设置为hog而不是cnn。虽然 CNN 人脸检测器更准确,但如果没有 GPU,它的速度太慢,无法实时运行。
*让我们获取输入数据集中所有图像的路径:
# grab the paths to the input images in our dataset, then initialize
# out data list (which we'll soon populate)
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
在第 22 行的上,我们使用命令行参数中提供的数据集路径创建了数据集中所有imagePaths的列表。
从那里,我们初始化我们的data列表,稍后我们将用图像路径、边界框和面部编码来填充它。
让我们开始循环所有的imagePaths:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the input image and convert it from RGB (OpenCV ordering)
# to dlib ordering (RGB)
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
print(imagePath)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
在线 26 上,我们开始在imagePaths上循环,并继续装载image ( 线 32 )。然后我们在image中交换颜色通道,因为 dlib 采用rgb排序,而不是 OpenCV 的默认 BGR。(第 33 行)。
现在图像已经被处理了,让我们检测所有的脸并且抓取它们的边界框坐标:
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input image
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
我们必须检测一张脸在图像中的实际位置,然后才能量化它。该检测发生在线 37 和 38 上。你会注意到face_recognition API 非常容易使用。
注意:我们使用 CNN 面部检测器以获得更高的准确性,但如果你使用 CPU 而不是 GPU,运行时间会明显更长。如果您希望编码脚本或您的系统运行得更快,并且您的系统没有足够的 RAM 或 CPU 来运行 CNN 人脸检测器,请使用 HOG +线性 SVM 方法。
让我们来看看这个剧本的“精髓”。在下一个模块中,我们将计算面部编码:
# compute the facial embedding for the face
encodings = face_recognition.face_encodings(rgb, boxes)
# build a dictionary of the image path, bounding box location,
# and facial encodings for the current image
d = [{"imagePath": imagePath, "loc": box, "encoding": enc}
for (box, enc) in zip(boxes, encodings)]
data.extend(d)
这里,我们为在rgb图像中检测到的每个人脸计算 128 维人脸encodings(线 41 )。
对于每个检测到的人脸+编码,我们构建一个字典(第 45 行和第 46 行),包括:
- 输入图像的路径
- 图像中人脸的位置(即边界框)
- 128-d 编码本身
然后我们将词典添加到我们的data列表中(第 47 行)。稍后当我们想要可视化哪些人脸属于哪个聚类时,我们将使用这些信息。
为了结束这个脚本,我们只需将数据列表写入一个序列化的 pickle 文件:
# dump the facial encodings data to disk
print("[INFO] serializing encodings...")
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
使用我们的命令行参数args["encodings"]作为路径+文件名,我们将数据列表作为序列化的 pickle 文件写入磁盘(第 51-53 行)。
运行人脸编码脚本
继续之前,滚动到 【下载】 部分下载代码+图像。您可以选择使用您自己的图像数据集——这也完全没问题,只是要确保在命令行参数中提供适当的路径。
然后,打开一个终端并激活 Python 虚拟环境(如果您正在使用的话),其中包含您在本文前面安装的库和包。
从那里,使用两个命令行参数,执行脚本来编码著名足球运动员的脸,如下所示:
$ python encode_faces.py --dataset dataset --encodings encodings.pickle
[INFO] quantifying faces...
[INFO] processing image 1/129
dataset/00000038.jpg
[INFO] processing image 2/129
dataset/00000010.jpg
[INFO] processing image 3/129
dataset/00000004.jpg
...
[INFO] processing image 127/129
dataset/00000009.jpg
[INFO] processing image 128/129
dataset/00000021.jpg
[INFO] processing image 129/129
dataset/00000035.jpg
[INFO] serializing encodings...
这个过程可能需要一段时间,您可以使用终端输出来跟踪进度。
如果你使用的是 GPU,它会很快执行——大约 1-2 分钟。只要确保你安装了带有 CUDA 绑定的 dlib 来利用你的 GPU(正如我上面提到的和在这篇文章中描述的)。
但是,如果您只是在带 CPU 的笔记本电脑上执行脚本,脚本可能需要 20-30 分钟才能运行。
聚类人脸
既然我们已经将数据集中的所有人脸量化和编码为 128 维向量,下一步就是用将它们聚类成组。
我们希望每个独特的个体都有自己独立的集群。
问题是,很多聚类算法如 k-means 和层次凝聚聚类,都要求我们提前指定要寻找的聚类数。
对于这个例子,我们知道只有五名足球运动员——但是在现实世界的应用程序中,您可能不知道一个数据集中有多少不同的个体。
因此,我们需要使用一个基于密度或基于图的聚类算法,它不仅可以聚类数据点,还可以根据数据的密度确定聚类的数量。
对于人脸聚类,我推荐两种算法:
我们将在本教程中使用 DBSCAN,因为我们的数据集相对较小。对于真正的大规模数据集,你应该考虑使用中文耳语算法,因为它在时间上是线性的。
DBSCAN 算法的工作原理是将紧密封装在一个 N 维空间中的点组合在一起。距离较近的点将被分组到一个聚类中。
DBSCAN 还自然地处理异常值,如果它们落在“最近的邻居”距离很远的低密度区域,就标记它们。
让我们继续使用 DBSCAN 实现面部聚类。
打开一个新文件,将其命名为cluster_faces.py,并插入以下代码:
# import the necessary packages
from sklearn.cluster import DBSCAN
from imutils import build_montages
import numpy as np
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-j", "--jobs", type=int, default=-1,
help="# of parallel jobs to run (-1 will use all CPUs)")
args = vars(ap.parse_args())
DBSCAN 内置于 scikit-learn 中。我们在第 2 行的上导入 DBSCAN 实现。
我们也从线 3 上的imutils导入build_montages模块。我们将使用这个函数为每个集群建立一个“人脸蒙太奇”。如果你对图像剪辑感兴趣,一定要看看我之前关于 OpenCV 的 图像剪辑的帖子。
我们的其他进口产品应该对第 4-7 行相当熟悉。
让我们解析两个命令行参数:
--encodings:我们在前面的脚本中生成的编码 pickle 文件的路径。--jobs: DBSCAN 是多线程的,可以将一个参数传递给包含要运行的并行作业数量的构造函数。值-1将使用所有可用的 CPU(也是这个命令行参数的默认值)。
让我们加载面部嵌入数据:
# load the serialized face encodings + bounding box locations from
# disk, then extract the set of encodings to so we can cluster on
# them
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
data = np.array(data)
encodings = [d["encoding"] for d in data]
在这个街区,我们已经:
- 从磁盘加载面部编码
data(第 21 行)。 - 将
data组织成一个 NumPy 数组(第 22 行)。 - 从
data中提取 128-dencodings,将它们放入一个列表中(第 23 行)。
现在我们可以在下一个代码块中聚集encodings:
# cluster the embeddings
print("[INFO] clustering...")
clt = DBSCAN(metric="euclidean", n_jobs=args["jobs"])
clt.fit(encodings)
# determine the total number of unique faces found in the dataset
labelIDs = np.unique(clt.labels_)
numUniqueFaces = len(np.where(labelIDs > -1)[0])
print("[INFO] # unique faces: {}".format(numUniqueFaces))
为了让 对编码 进行聚类,我们只需创建一个DBSCAN对象,然后在encodings本身上fit模型(第 27 行和第 28 行)。
没有比这更简单的了!
现在让我们来确定在数据集中找到的独特面孔!
参考第 31 行,clt.labels_包含我们数据集中所有人脸的标签 ID(即每个人脸属于哪个聚类)。要找到唯一的面孔/唯一的标签 id,我们只需使用 NumPy 的unique函数。结果是一个独特的labelIDs列表。
在第 32 行的上,我们数着numUniqueFaces。在labelIDs中可能存在值-1——该值对应于“离群值”类,其中 128-d 嵌入离任何其他聚类太远而不能添加到它。这种点被称为“异常值”,并且可能值得检查或者基于面部聚类的应用而简单地丢弃。
在我们的例子中,我们在这个计数中排除了负数labelIDs,因为我们知道我们的数据集只包含 5 个人的图像。你是否做出这样的假设在很大程度上取决于你的项目。
我们的接下来的三个代码块的目标是在我们的数据集中生成独特的足球/五人制足球运动员的面部蒙太奇。
我们通过循环所有独特的labelIDs来开始这个过程:
# loop over the unique face integers
for labelID in labelIDs:
# find all indexes into the `data` array that belong to the
# current label ID, then randomly sample a maximum of 25 indexes
# from the set
print("[INFO] faces for face ID: {}".format(labelID))
idxs = np.where(clt.labels_ == labelID)[0]
idxs = np.random.choice(idxs, size=min(25, len(idxs)),
replace=False)
# initialize the list of faces to include in the montage
faces = []
在第 41-43 行中,我们找到当前labelID的所有索引,然后随机抽取最多 25 张图像包含在蒙太奇中。
faces列表将包括面部图像本身(第 46 行)。我们需要另一个循环来填充这个列表:
# loop over the sampled indexes
for i in idxs:
# load the input image and extract the face ROI
image = cv2.imread(data[i]["imagePath"])
(top, right, bottom, left) = data[i]["loc"]
face = image[top:bottom, left:right]
# force resize the face ROI to 96x96 and then add it to the
# faces montage list
face = cv2.resize(face, (96, 96))
faces.append(face)
我们在第 49 行的开始循环我们随机样本中的所有idxs。
在循环的第一部分,我们:
- 从磁盘中加载
image并使用在我们的面部嵌入步骤中找到的边界框坐标提取faceROI ( 第 51-53 行)。 - 将脸部大小调整为固定的 96×96 ( 第 57 行),这样我们就可以将它添加到用于可视化每个集群的
faces蒙太奇(第 58 行)中。
为了完成我们的顶级循环,让我们构建蒙太奇并将其显示到屏幕上:
# create a montage using 96x96 "tiles" with 5 rows and 5 columns
montage = build_montages(faces, (96, 96), (5, 5))[0]
# show the output montage
title = "Face ID #{}".format(labelID)
title = "Unknown Faces" if labelID == -1 else title
cv2.imshow(title, montage)
cv2.waitKey(0)
我们使用 imutils 的build_montages函数生成包含faces ( 行 61 )的 5×5 网格的单幅图像montage。
从那里,我们title窗口(第 64 行和第 65 行),然后在我们的屏幕上显示窗口中的montage。
只要 OpenCV 打开的窗口是打开的,你就可以按一个键来显示下一个人脸聚类蒙太奇。
人脸聚类结果
请务必使用这篇博文的 【下载】 部分来下载运行这个脚本所需的代码和数据。
这个脚本只需要一个命令行参数——编码文件的路径。要为足球运动员执行面部聚类,只需在终端中输入以下命令:
$ python cluster_faces.py --encodings encodings.pickle
[INFO] loading encodings...
[INFO] clustering...
[INFO] # unique faces: 5
[INFO] faces for face ID: -1
[INFO] faces for face ID: 0
[INFO] faces for face ID: 1
[INFO] faces for face ID: 2
[INFO] faces for face ID: 3
[INFO] faces for face ID: 4
识别五个面部聚类类别。-1 的面 ID 包含找到的任何离群值。你会在屏幕上看到集群蒙太奇。要生成下一个面部聚类蒙太奇,只需按一个键(窗口处于焦点状态,以便 OpenCV 的 highgui 模块可以捕获您的按键)。
以下是从我们的 128 维面部嵌入和数据库扫描聚类算法中生成的面部聚类:

图 3: 用 Python 进行人脸聚类对世界杯球员小内马尔的相似人脸进行分组

图 4: 在用 Python 脚本运行我们的人脸聚类后,梅西的人脸图像由于相似而被分组在一起。

图 5: 人脸聚类通过 Python 和 face_recognition 库识别出 2018 世界杯球员穆罕默德·萨拉赫的聚类。

图 6: 我们的 Python 人脸聚类脚本可以让我们找到相似的人脸图片,识别离群点。在这种情况下,我们发现了 2018 世界杯球员路易斯·苏亚雷斯的类似图片。

图 7:c 罗是 2018 世界杯足球运动员。克里斯蒂亚诺的所有 25 张照片被我们的 Python 人脸聚类脚本分组在一起。
最后,未知的面孔出现了(它实际上是首先显示的,但我最后在这里提供评论):

Figure 8: This picture of Lionel Messi didn’t get clustered together and is presented as an “Unknown face” as it does not belong to any other cluster. Our Python face clustering algorithm did a reasonably good job clustering images and only mis-clustered this face picture.
在我们的数据集中的 5 个人的 129 个图像中,只有一个单个人脸没有被分组到现有的聚类中(图 8;莱昂内尔·梅西)。
我们的无监督学习 DBSCAN 方法生成了五组数据。不幸的是,莱昂内尔·梅西的一张照片没有与他的其他照片聚集在一起,但总的来说,这种方法非常有效。
我们今天使用的这种方法可以用于在您自己的应用程序中对人脸进行聚类。
摘要
在今天的博文中,你学习了如何使用 Python 和深度学习来执行人脸聚类。
与人脸识别不同,人脸识别是一个监督学习任务,人脸聚类是一个非监督学习任务。
有了人脸识别,我们同时拥有了:
- 人们的面孔
- 以及它们的名(即类别标签)
但是在人脸聚类中,我们只有人脸,也没有相应的名字。缺乏名称/类别标签,我们只能利用无监督的学习算法,在这种情况下,聚类技术。
为了将真实的人脸分组,我们选择使用 DBSCAN 算法。也可以使用其他聚类算法——Davis King(dlib 的创建者)建议使用中文耳语算法。
要了解更多关于人脸识别和计算机视觉+人脸应用的信息,请务必参考本系列的前两篇博文:
我希望你喜欢今天的帖子!
在 PyImageSearch 博客上发布新的博文时,我们会通知您,请在下面的表格中输入您的电子邮件地址!***
人脸检测提示、建议和最佳实践
原文:https://pyimagesearch.com/2021/04/26/face-detection-tips-suggestions-and-best-practices/
在本教程中,您将学习我的技巧、建议和最佳实践,以使用 OpenCV 和 dlib 实现高人脸检测准确性。
我们已经在 PyImageSearch 博客上四次讨论了人脸检测:
- 利用 OpenCV 和 Haar 级联进行人脸检测
- 利用 OpenCV 和深度神经网络(DNNs)进行人脸检测
- 使用 dlib 和 HOG +线性 SVM 算法进行人脸检测
- 使用 dlib 和最大余量对象检测器(MMOD)进行人脸检测
注: #3、#4 链接到同一个教程作为指南封面HOG+线性 SVM 和 MMOD CNN 人脸检测器。
*今天,我们将比较和对比这些方法,让你知道什么时候应该使用每种方法,让你平衡速度、准确性和效率。
要了解我的面部检测技巧、建议和最佳实践,请继续阅读。
人脸检测技巧、建议和最佳实践
在本教程的第一部分,我们将回顾您在构建自己的计算机视觉管道时会遇到的四种主要人脸检测器,包括:
- OpenCV 和哈尔级联
- OpenCV 基于深度学习的人脸检测器
- Dlib 的 HOG +线性 SVM 实现
- Dlib 的 CNN 人脸检测器
然后我们将比较和对比这些方法。此外,我会给你每一个优点和缺点,以及我个人的建议,当你应该使用一个特定的人脸检测器。
在本教程的最后,我将推荐一种“默认的、通用的”人脸检测器,当你构建自己的需要人脸检测的计算机视觉项目时,这应该是你的“第一次尝试”。
您将在计算机视觉项目中经常使用的 4 种流行的人脸检测方法
我们在 PyImageSearch 博客中介绍了四种主要的人脸检测方法:
注: #3、#4 链接到同一个教程作为指南封面HOG+线性 SVM 和 MMOD CNN 人脸检测器。
*在继续之前,我建议你逐个查看这些帖子,以便更好地欣赏我们将要进行的比较/对比。
OpenCV 的 Haar cascade 人脸检测器的优缺点
OpenCV 的 Haar cascade 人脸检测器是库自带的原装人脸检测器。它也是大多数人都熟悉的面部检测器。
优点:
- 非常快,能够超实时运行
- 低计算要求——可以轻松地在嵌入式、资源受限的设备上运行,如 Raspberry Pi (RPi)、NVIDIA Jetson Nano 和 Google Coral
- 小型号(400KB 多一点;作为参考,大多数深度神经网络将在 20-200MB 之间。
缺点:
- 非常容易出现假阳性检测
- 通常需要手动调谐到
detectMultiScale功能 - 远不如其 HOG +线性 SVM 和基于深度学习的人脸检测技术准确
我的建议:当速度是您的主要关注点,并且您愿意牺牲一些准确性来获得实时性能时,请使用 Haar cascades。
如果您正在使用 RPi、Jetson Nano 或 Google Coral 等嵌入式设备,请考虑:
- 在 RPi 上使用 Movidius 神经计算棒(NCS)——这将允许您实时运行基于深度学习的面部检测器
- 阅读与您的设备相关的文档 Nano 和 Coral 有专门的推理引擎,可以实时运行深度神经网络
OpenCV 深度学习人脸检测器的利弊
OpenCV 的深度学习人脸检测器是基于单镜头检测器(SSD)的小型 ResNet 主干,使其既有 的准确性 又有 的快速性。
优点:
- 精确人脸检测器
- 利用现代深度学习算法
- 不需要调整参数
- 可以在现代笔记本电脑和台式机上实时运行
- 模型大小合理(刚刚超过 10MB)
- 依赖于 OpenCV 的
cv2.dnn模块 - 通过使用 OpenVINO 和 Movidius NCS,可以在嵌入式设备上运行得更快
缺点:
- 比哈尔瀑布和 HOG +线性 SVM 更准确,但不如 dlib 的 CNN MMOD 人脸检测器准确
- 可能在训练集中存在无意识的偏见——可能无法像检测浅色皮肤的人那样准确地检测深色皮肤的人
我的推荐: OpenCV 的深度学习人脸检测器是你最好的“全能”检测器。使用起来非常简单,不需要额外的库,依靠 OpenCV 的cv2.dnn模块,这个模块被烘焙到 OpenCV 库中。
此外,如果您使用的是嵌入式设备,如 Raspberry Pi,您可以插入 Movidius NCS,并利用 OpenVINO 轻松获得实时性能。
也许这个模型最大的缺点是,我发现肤色较深的人的面部检测不如肤色较浅的人准确。这不一定是模型本身的问题,而是训练数据的问题——为了解决这个问题,我建议在更多样化的种族集上训练/微调面部检测器。
dlib 的 HOG +线性 SVM 人脸检测器的优劣
HOG +线性 SVM 算法是由 Dalal 和 Triggs 在他们 2005 年的开创性工作 中首次提出的,用于人体检测的梯度方向直方图 。
与哈尔级联类似,HOG +线性 SVM 依靠图像金字塔和滑动窗口来检测图像中的对象/人脸。
该算法是计算机视觉文献中的经典,至今仍在使用。
优点:
- 比哈尔瀑布更准确
- 比哈尔级联更稳定的检测(即需要调节的参数更少)
- 由 dlib 创建者和维护者 Davis King 专业实现
- 非常有据可查,包括计算机视觉文献中的 dlib 实现和 HOG +线性 SVM 框架
缺点:
- 仅适用于正面视图——轮廓面将而非被检测到,因为 HOG 描述符不能很好地容忍旋转或视角的变化
- 需要安装一个额外的库(dlib)——本质上不一定是问题,但是如果你使用的是 OpenCV,那么你会发现添加另一个库很麻烦
- 不如基于深度学习的人脸检测器准确
- 对于准确性,由于图像金字塔结构、滑动窗口和在窗口的每一站计算 HOG 特征,它实际上在计算上相当昂贵
我的推荐: HOG +线性 SVM 是每个计算机视觉从业者都应该了解的经典物体检测算法。也就是说,对于 HOG +线性 SVM 给你的精度来说,算法本身相当慢,尤其是当你把它与 OpenCV 的 SSD 人脸检测器进行比较时。
我倾向于在哈尔级联不够准确的地方使用 HOG +线性 SVM,但我不能承诺使用 OpenCV 的深度学习人脸检测器。
dlib 的 CNN 人脸检测器的利弊
dlib 的创造者戴维斯·金(Davis King)根据他在 max-margin 对象检测方面的工作训练了一个 CNN 人脸检测器。这种方法非常精确,这要归功于算法本身的设计,以及 Davis 在管理训练集和训练模型时的细心。
也就是说,如果没有 GPU 加速,这个模型就无法实时运行。
优点:
- y精确* 人脸检测器*
- 小型模型(小于 1MB)
- 专业实施和记录
*缺点:
- 需要安装额外的库(dlib)
- 代码更加冗长——如果使用 OpenCV,最终用户必须小心转换和修剪边界框坐标
- 没有 GPU 加速,无法实时运行
- 并非开箱即用,兼容 OpenVINO、Movidius NCS、NVIDIA Jetson Nano 或 Google Coral 的加速功能
我的推荐:离线批量处理人脸检测时,我倾向于使用 dlib 的 MMOD CNN 人脸检测器,意思是我可以设置好我的脚本,让它以批处理模式运行,而不用担心实时性能。
我唯一倾向于而不是使用 dlib 的 CNN 人脸检测器的地方是在我使用嵌入式设备的时候。这种模型不会在嵌入式设备上实时运行,它与嵌入式设备加速器(如 Movidius NCS)开箱即用。
也就是说, 你就是打不过 dlib 的 MMOD CNN 的 ,所以如果你需要准确的人脸检测, 就用这个模式吧。
我个人对人脸检测的建议
说到一个好的,万能的人脸检测器,我建议用 OpenCV 的 DNN 人脸检测器 :
- 它实现了速度和精度的良好平衡
- 作为一个基于深度学习的检测器,它比它的 Haar cascade 和 HOG +线性 SVM 同行更准确
- 它足够快,可以在 CPU 上实时运行
- 使用诸如 Movidius NCS 等 USB 设备可以进一步加速
- 不需要额外的库/包——对人脸检测器的支持通过
cv2.dnn模块嵌入 OpenCV
也就是说,有时候你会想要使用上面提到的每一个面部检测器,所以一定要仔细阅读每一个章节。
总结
在本教程中,您了解了我关于人脸检测的技巧、建议和最佳实践。
简而言之,它们是:
- 当速度是您的主要关注点时(例如,当您使用 Raspberry Pi 等嵌入式设备时),请使用 OpenCV 的 Haar cascades。 Haar cascades 不像它们的 HOG +线性 SVM 和基于深度学习的同行那样准确,但它们在原始速度上弥补了这一点。请注意肯定会有,调用
detectMultiScale时需要一些误报检测和参数调整。 - 当哈尔级联不够准确时,使用 dlib 的 HOG +线性 SVM 检测器,但你不能承诺基于深度学习的人脸检测器的计算要求。HOG+线性 SVM 物体检测器是计算机视觉文献中的经典算法,至今仍然适用。dlib 库在实现它方面做了一件了不起的工作。请注意,在 CPU 上运行 HOG +线性 SVM 对于您的嵌入式设备来说可能太慢了。
- 当你需要超精确的人脸检测时,使用 dlib 的 CNN 人脸检测。说到人脸检测的准确性,dlib 的 MMOD CNN 人脸检测器是难以置信的准确。也就是说,这是一种折衷——精度越高,运行时间越长。这种方法不能在笔记本电脑/台式机 CPU 上实时运行,即使有 GPU 加速,你也很难达到实时性能。我通常在离线批处理中使用这个人脸检测器,我不太关心人脸检测需要多长时间(相反,我想要的只是高精度)。
- 使用 OpenCV 的 DNN 人脸检测器作为一个很好的平衡。作为一种基于深度学习的人脸检测器,这种方法是准确的——而且由于这是一个以 SSD 为骨干的浅层网络,它很容易在 CPU 上实时运行。此外,由于您可以将该模型与 OpenCV 的
cv2.dnn模块一起使用,因此也就是意味着(1)您可以通过使用 GPU 来进一步提高速度,或者(2)在您的嵌入式设备上利用 Movidius NCS。
总的来说,OpenCV 的 DNN 人脸检测器应该是你应用人脸检测的“第一站”。根据 OpenCV DNN 人脸检测器的精确度,您可以尝试其他方法。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!***
基于 dlib (HOG 和 CNN)的人脸检测
原文:https://pyimagesearch.com/2021/04/19/face-detection-with-dlib-hog-and-cnn/
在本教程中,您将学习如何使用 HOG +线性 SVM 和 CNN 通过 dlib 库执行人脸检测。
dlib 库可以说是人脸识别最常用的软件包之一。一个名为face_recognition的 Python 包将 dlib 的人脸识别功能封装到一个简单易用的 API 中。
注: 如果你对使用 dlib 和face_recognition库进行人脸识别感兴趣, 参考本教程 ,在这里我会详细介绍这个话题。
然而,我经常惊讶地听到读者不知道 dlib 包括两个内置在库中的人脸检测方法:
- 精确且计算高效的 HOG +线性 SVM 人脸检测器。
- 一个 Max-Margin (MMOD) CNN 人脸检测器,它既是高度精确的又是非常健壮的,能够从不同的视角、光照条件和遮挡情况下检测人脸。
最重要的是,MMOD 人脸检测器可以在 NVIDIA GPU 上运行,速度超快!
要了解如何使用 dlib 的 HOG +线性 SVM 和 MMOD 人脸检测器,继续阅读。
用 dlib (HOG 和 CNN)进行人脸检测
在本教程的第一部分,你会发现 dlib 的两个人脸检测功能,一个用于 HOG +线性 SVM 人脸检测器,另一个用于 MMOD CNN 人脸检测器。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们将实现两个 Python 脚本:
hog_face_detection.py:应用 dlib 的 HOG +线性 SVM 人脸检测器。cnn_face_detection.py:利用 dlib 的 MMOD CNN 人脸检测器。
然后,我们将在一组图像上运行这些面部检测器,并检查结果,注意在给定的情况下何时使用每个面部检测器。
我们开始吧!
Dlib 的人脸检测方法
dlib 库提供了两个可用于人脸检测的函数:
- 猪+线性 SVM:
dlib.get_frontal_face_detector() - MMOD CNN:
dlib.cnn_face_detection_model_v1(modelPath)
get_frontal_face_detector函数不接受任何参数。对它的调用返回包含在 dlib 库中的预训练的 HOG +线性 SVM 人脸检测器。
Dlib 的 HOG +线性 SVM 人脸检测器快速高效。根据梯度方向直方图(HOG)描述符的工作原理,它对于旋转和视角的变化不是不变的。
对于更强大的面部检测,您可以使用 MMOD CNN 面部检测器,可通过cnn_face_detection_model_v1功能获得。这个方法接受一个参数modelPath,它是驻留在磁盘上的预先训练好的mmod_human_face_detector.dat文件的路径。
注意: 我已经将mmod_human_face_detector.dat文件包含在本指南的 【下载】 部分,所以你不必去寻找它。
在本教程的剩余部分,您将学习如何使用这两种 dlib 人脸检测方法。
配置您的开发环境
为了遵循这个指南,您需要在您的系统上安装 OpenCV 库和 dlib。
幸运的是,您可以通过 pip 安装 OpenCV 和 dlib:
$ pip install opencv-contrib-python
$ pip install dlib
如果你需要帮助配置 OpenCV 和 dlib 的开发环境,我强烈推荐阅读以下两个教程:
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在使用 dlib 执行人脸检测之前,我们首先需要回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
$ tree . --dirsfirst
.
├── images
│ ├── avengers.jpg
│ ├── concert.jpg
│ └── family.jpg
├── pyimagesearch
│ ├── __init__.py
│ └── helpers.py
├── cnn_face_detection.py
├── hog_face_detection.py
└── mmod_human_face_detector.dat
我们首先回顾两个 Python 脚本:
hog_face_detection.py:使用 dlib 应用 HOG +线性 SVM 人脸检测。cnn_face_detection.py:通过从磁盘加载训练好的mmod_human_face_detector.dat模型,使用 dlib 进行基于深度学习的人脸检测。
我们的helpers.py文件包含一个 Python 函数convert_and_trim_bb,它将帮助我们:
- 将 dlib 边界框转换为 OpenCV 边界框
- 修剪超出输入图像边界的任何边界框坐标
images目录包含三张图像,我们将使用 dlib 对其进行人脸检测。我们可以将 HOG +线性 SVM 人脸检测方法与 MMOD CNN 人脸检测器进行比较。
创建我们的包围盒转换和裁剪函数
OpenCV 和 dlib 以不同的方式表示边界框:
- 在 OpenCV 中,我们认为边界框是一个四元组:起始坐标 x ,起始坐标 y ,坐标,宽度和高度
- Dlib 通过具有左、上、右和下属性的
rectangle对象表示边界框
此外,dlib 返回的边界框可能会落在输入图像尺寸的边界之外(负值或图像宽度和高度之外的值)。
为了使使用 dlib 进行人脸检测更容易,让我们创建一个辅助函数来(1)将边界框坐标转换为标准 OpenCV 排序,以及(2)修剪图像范围之外的任何边界框坐标。
打开pyimagesearch模块中的helpers.py文件,让我们开始工作:
def convert_and_trim_bb(image, rect):
# extract the starting and ending (x, y)-coordinates of the
# bounding box
startX = rect.left()
startY = rect.top()
endX = rect.right()
endY = rect.bottom()
# ensure the bounding box coordinates fall within the spatial
# dimensions of the image
startX = max(0, startX)
startY = max(0, startY)
endX = min(endX, image.shape[1])
endY = min(endY, image.shape[0])
# compute the width and height of the bounding box
w = endX - startX
h = endY - startY
# return our bounding box coordinates
return (startX, startY, w, h)
我们的convert_and_trim_bb函数需要两个参数:我们应用人脸检测的输入image和 dlib 返回的rect对象。
第 4-7 行提取边界框的起点和终点 (x,y)-坐标。
然后,我们确保边界框坐标落在第 11-14 行的输入image的宽度和高度内。
最后一步是计算边界框的宽度和高度(第 17 行和第 18 行),然后以startX、startY、w和h的顺序返回边界框坐标的 4 元组。
用 dlib 实现 HOG +线性 SVM 人脸检测
随着我们的convert_and_trim_bb助手工具的实现,我们可以继续使用 dlib 来执行 HOG +线性 SVM 人脸检测。
打开项目目录结构中的hog_face_detection.py文件,插入以下代码:
# import the necessary packages
from pyimagesearch.helpers import convert_and_trim_bb
import argparse
import imutils
import time
import dlib
import cv2
第 2-7 行导入我们需要的 Python 包。注意,我们刚刚实现的convert_and_trim_bb函数被导入了。
当我们为 OpenCV 绑定导入cv2时,我们也导入了dlib,因此我们可以访问它的人脸检测功能。
接下来是我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
ap.add_argument("-u", "--upsample", type=int, default=1,
help="# of times to upsample")
args = vars(ap.parse_args())
我们有两个命令行参数要解析:
--image:应用 HOG +线性 SVM 人脸检测的输入图像路径。--upsample:在应用面部检测之前对图像进行上采样的次数。
为了检测大输入图像中的小人脸,我们可能希望提高输入图像的分辨率,从而使较小的人脸看起来更大。这样做允许我们的滑动窗口检测脸部。
向上采样的缺点是,它会在我们的图像金字塔中创建更多层,使检测过程更慢。
对于更快的面部检测,将--upsample值设置为0,这意味着不执行上采样(但是您有丢失面部检测的风险)。
接下来我们从磁盘加载 dlib 的 HOG +线性 SVM 人脸检测器:
# load dlib's HOG + Linear SVM face detector
print("[INFO] loading HOG + Linear SVM face detector...")
detector = dlib.get_frontal_face_detector()
# load the input image from disk, resize it, and convert it from
# BGR to RGB channel ordering (which is what dlib expects)
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# perform face detection using dlib's face detector
start = time.time()
print("[INFO[ performing face detection with dlib...")
rects = detector(rgb, args["upsample"])
end = time.time()
print("[INFO] face detection took {:.4f} seconds".format(end - start))
对dlib.get_frontal_face_detector()的调用返回 dlib 的 HOG +线性 SVM 人脸检测器(第 19 行)。
然后,我们继续:
- 从磁盘加载输入
image - 调整图像大小(图像越小,HOG +线性 SVM 运行越快)
- 将图像从 BGR 转换为 RGB 通道排序(dlib 需要 RGB 图像)
从那里,我们将我们的 HOG +线性 SVM 人脸检测器应用于线 30 ,计时人脸检测过程需要多长时间。
现在让我们分析我们的边界框:
# convert the resulting dlib rectangle objects to bounding boxes,
# then ensure the bounding boxes are all within the bounds of the
# input image
boxes = [convert_and_trim_bb(image, r) for r in rects]
# loop over the bounding boxes
for (x, y, w, h) in boxes:
# draw the bounding box on our image
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
请记住,返回的rects列表需要一些工作——我们需要将 dlib rectangle对象解析成一个四元组,起始 x 坐标,起始 y 坐标,宽度和高度——这正是第行第 37 所完成的。
对于每个rect,我们调用我们的convert_and_trim_bb函数,确保(1)所有的边界框坐标都落在image的空间维度内,以及(2)我们返回的边界框是正确的 4 元组格式。
Dlib HOG +线性 SVM 人脸检测结果
让我们来看看将我们的 dlib HOG +线性 SVM 人脸检测器应用于一组图像的结果。
请务必访问本教程的 “下载” 部分,以检索源代码、示例图像和预训练模型。
从那里,打开一个终端窗口并执行以下命令:
$ python hog_face_detection.py --image images/family.jpg
[INFO] loading HOG + Linear SVM face detector...
[INFO[ performing face detection with dlib...
[INFO] face detection took 0.1062 seconds
图 3 显示了将 dlib 的 HOG +线性 SVM 人脸检测器应用于包含多张人脸的输入图像的结果。
面部检测过程花费了
0.1 seconds, implying that we could process 10 frames per second in a video stream scenario.
最重要的是,注意这四张脸都被正确地检测到了。
让我们尝试一个不同的图像:
$ python hog_face_detection.py --image images/avengers.jpg
[INFO] loading HOG + Linear SVM face detector...
[INFO[ performing face detection with dlib...
[INFO] face detection took 0.1425 seconds
几年前,当《复仇者联盟 4:终局之战》上映时,我和妻子决定装扮成电影《复仇者联盟》中的角色(抱歉,如果你没看过这部电影,但是拜托,已经两年了!)
注意我妻子的脸(呃,黑寡妇?)被检测到了,但显然,dlib 的 HOG +线性 SVM 人脸检测器不知道钢铁侠长什么样。
十有八九,我的脸没有被检测到,因为我的头稍微旋转了一下,不是相机的“正视图”。同样,HOG +线性 SVM 系列物体检测器在旋转或视角变化的情况下表现不佳。
让我们来看最后一张照片,这张照片上的人脸更加密集:
$ python hog_face_detection.py --image images/concert.jpg
[INFO] loading HOG + Linear SVM face detector...
[INFO[ performing face detection with dlib...
[INFO] face detection took 0.1069 seconds
早在 COVID 之前,就有这些叫做“音乐会”的东西乐队过去常常聚在一起,为人们演奏现场音乐以换取金钱。很难相信,我知道。
几年前,我的一群朋友聚在一起开音乐会。虽然这张照片上有八张脸,但只有六张被检测到。
正如我们将在本教程的后面看到的,我们可以使用 dlib 的 MMOD CNN 人脸检测器来提高人脸检测的准确性,并检测这张图像中的所有人脸。
用 dlib 实现 CNN 人脸检测
到目前为止,我们已经了解了如何使用 dlib 的 HOG +线性 SVM 模型进行人脸检测。这种方法效果很好,但是使用 dlib 的 MMOD CNN 面部检测器要获得更高的准确度。
现在让我们来学习如何使用 dlib 的深度学习人脸检测器:
# import the necessary packages
from pyimagesearch.helpers import convert_and_trim_bb
import argparse
import imutils
import time
import dlib
import cv2
我们这里的导入与我们之前的 HOG +线性 SVM 人脸检测脚本完全相同。
命令行参数类似,但是增加了一个参数(--model):
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
ap.add_argument("-m", "--model", type=str,
default="mmod_human_face_detector.dat",
help="path to dlib's CNN face detector model")
ap.add_argument("-u", "--upsample", type=int, default=1,
help="# of times to upsample")
args = vars(ap.parse_args())
这里有三个命令行参数:
--image:驻留在磁盘上的输入图像的路径。--model:我们预先训练的 dlib MMOD CNN 人脸检测器。--upsample:在应用面部检测之前对图像进行上采样的次数。
考虑到我们的命令行参数,我们现在可以从磁盘加载 dlib 的深度学习人脸检测器:
# load dlib's CNN face detector
print("[INFO] loading CNN face detector...")
detector = dlib.cnn_face_detection_model_v1(args["model"])
# load the input image from disk, resize it, and convert it from
# BGR to RGB channel ordering (which is what dlib expects)
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# perform face detection using dlib's face detector
start = time.time()
print("[INFO[ performing face detection with dlib...")
results = detector(rgb, args["upsample"])
end = time.time()
print("[INFO] face detection took {:.4f} seconds".format(end - start))
第 22 行通过调用dlib.cnn_face_detection_model_v1从磁盘加载detector。在这里,我们通过--model,这是经过训练的 dlib 人脸检测器所在的路径。
从那里,我们预处理我们的图像(行 26-28 ),然后应用面部检测器(行 33 )。
正如我们解析 HOG +线性 SVM 结果一样,我们在这里也需要这样做,但有一点需要注意:
# convert the resulting dlib rectangle objects to bounding boxes,
# then ensure the bounding boxes are all within the bounds of the
# input image
boxes = [convert_and_trim_bb(image, r.rect) for r in results]
# loop over the bounding boxes
for (x, y, w, h) in boxes:
# draw the bounding box on our image
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
Dlib 的 HOG +线性 SVM 探测器返回一个rectangle物体列表;然而,MMOD CNN 对象检测器返回一个结果对象列表,每个对象都有自己的矩形(因此我们在列表理解中使用r.rect)。否则,实现是相同的。
最后,我们在边界框上循环,并把它们画在我们的输出上image。
Dlib 的 CNN 人脸检测器结果
让我们看看 dlib 的 MMOD CNN 人脸检测器如何与 HOG +线性 SVM 人脸检测器相媲美。
要跟进,请务必访问本指南的 “下载” 部分,以检索源代码、示例图像和预训练的 dlib 人脸检测器。
从那里,您可以打开一个终端并执行以下命令:
$ python cnn_face_detection.py --image images/family.jpg
[INFO] loading CNN face detector...
[INFO[ performing face detection with dlib...
[INFO] face detection took 2.3075 seconds
就像 HOG +线性 SVM 实现一样,dlib 的 MMOD CNN 人脸检测器可以正确检测输入图像中的所有四张人脸。
让我们尝试另一个图像:
$ python cnn_face_detection.py --image images/avengers.jpg
[INFO] loading CNN face detector...
[INFO[ performing face detection with dlib...
[INFO] face detection took 3.0468 seconds
此前,猪+线性 SVM 未能检测到我的脸在左边。但是通过使用 dlib 的深度学习人脸检测器,我们可以正确地检测出两张人脸。
让我们看最后一张图片:
$ python cnn_face_detection.py --image images/concert.jpg
[INFO] loading CNN face detector...
[INFO[ performing face detection with dlib...
[INFO] face detection took 2.2520 seconds
之前,使用 HOG +线性 SVM,我们只能检测到这张图像中八个人脸中的六个。但正如我们的输出所示,切换到 dlib 的深度学习人脸检测器会检测到所有八张人脸。
我应该使用哪种 dlib 人脸检测器?
如果你使用的是 CPU 并且速度不是问题,使用 dlib 的 MMOD CNN 人脸检测器。它的比 HOG +线性 SVM 人脸检测器的更加准确和稳健。
此外,如果你有 GPU,那么毫无疑问你应该使用 MMOD CNN 面部检测器——你将享受到精确面部检测的所有好处,以及能够实时运行的速度。
假设你仅限于一个 CPU。在这种情况下,速度是的一个问题,你愿意容忍稍微低一点的准确性,那么就用 HOG +线性 SVM 吧——它仍然是一个准确的人脸检测器,而且比 OpenCV 的 Haar cascade 人脸检测器更准确。
总结
在本教程中,您学习了如何使用 dlib 库执行人脸检测。
Dlib 提供了两种执行人脸检测的方法:
- 猪+线性 SVM:
dlib.get_frontal_face_detector() - MMOD CNN:
dlib.cnn_face_detection_model_v1(modelPath)
HOG +线性 SVM 人脸检测器将比 MMOD CNN 人脸检测器快,但也将不太准确,因为 HOG +线性 SVM 不容忍视角旋转的变化。
为了更鲁棒的人脸检测,使用 dlib 的 MMOD CNN 人脸检测器。这个模型需要更多的计算(因此更慢),但是对脸部旋转和视角的变化更加精确和稳定。
此外,如果你有一个 GPU,你可以在上面运行 dlib 的 MMOD CNN 人脸检测器,从而提高实时人脸检测速度。MMOD CNN 面部检测器结合 GPU 是天作之合——你既有深度神经网络的准确性,又有计算成本较低的模型的速度。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
基于 OpenCV 和深度学习的人脸检测
原文:https://pyimagesearch.com/2018/02/26/face-detection-with-opencv-and-deep-learning/
最后更新于 2021 年 7 月 4 日。
今天,我将与您分享一个关于 OpenCV 库的鲜为人知的秘密:
您可以使用库附带的预训练深度学习人脸检测器模型,通过 OpenCV 执行快速、准确的人脸检测。
您可能已经知道 OpenCV 出厂时就带有预先训练好的 Haar 级联,可用于面部检测…
…但我敢打赌,你不知道从 OpenCV 3.3 开始就成为 OpenCV 一部分的“隐藏”的基于深度学习的人脸检测器。
在今天博文的剩余部分,我将讨论:
- 这个“隐藏的”深度学习人脸检测器在 OpenCV 库中的位置
- 如何使用 OpenCV 和深度学习在图像 中执行人脸检测
- 如何使用 OpenCV 和深度学习在视频 中执行人脸检测
正如我们将看到的,很容易将哈尔级联替换为更准确的深度学习人脸检测器。
要了解更多关于 OpenCV 和深度学习的人脸检测,继续阅读!
- 【2021 年 7 月更新:包括了一个新的部分,关于您可能希望在您的项目中考虑的替代人脸检测方法。
将 OpenCV 的深度神经网络模块与 Caffe 模型一起使用时,您将需要两组文件:
- 。定义模型架构的 prototxt 文件(即层本身)
- 。包含实际层的权重的 caffemodel 文件
当使用使用 Caffe 训练的模型进行深度学习时,这两个文件都是必需的。
然而,您只能在 GitHub repo 中找到 prototxt 文件。
权重文件不包含在 OpenCV samples目录中,需要更多的挖掘才能找到它们…
我在哪里可以得到更准确的 OpenCV 人脸检测器?
为了您的方便,我把和都包括在内了:
- Caffe prototxt 文件
- 和咖啡模型重量文件
…在这篇博文的“下载”部分。
要跳到下载部分,只需点击这里。
OpenCV 深度学习人脸检测器是如何工作的?
OpenCV 的深度学习人脸检测器基于具有 ResNet 基础网络的单镜头检测器(SSD)框架(与您可能已经看到的通常使用 MobileNet 作为基础网络的其他 OpenCV SSDs 不同)。
对 SSD 和 ResNet 的全面回顾超出了这篇博客的范围,所以如果你有兴趣了解更多关于单次检测器的信息(包括如何训练你自己的定制深度学习对象检测器),从 PyImageSearch 博客上的这篇文章开始,然后看看我的书,用 Python 进行计算机视觉的深度学习,其中包括深入的讨论和代码,使你能够训练你自己的对象检测器。
基于 OpenCV 和深度学习的图像人脸检测
在第一个例子中,我们将学习如何使用 OpenCV 对单个输入图像进行人脸检测。
在下一节中,我们将学习如何修改这段代码,并使用 OpenCV 将人脸检测应用于视频、视频流和网络摄像头。
打开一个新文件,将其命名为detect_faces.py,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
这里我们导入我们需要的包(第 2-4 行)并解析命令行参数(第 7-16 行)。
我们有三个必需的参数:
--image:输入图像的路径。- 【the Caffe prototxt 文件的路径。
--model:通往预训练的 Caffe 模型的道路。
可选参数--confidence可以覆盖默认阈值 0.5,如果您愿意的话。
从那里,让我们加载我们的模型,并从我们的图像创建一个斑点:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# load the input image and construct an input blob for the image
# by resizing to a fixed 300x300 pixels and then normalizing it
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
首先,我们使用我们的--prototxt和--model文件路径加载我们的模型。我们把型号存为net(20 线)。
然后我们加载image ( 第 24 行),提取维度(第 25 行),创建一个blob ( 第 26 行和第 27 行)。
dnn.blobFromImage负责预处理,包括设置blob尺寸和标准化。如果你有兴趣了解更多关于dnn.blobFromImage功能的信息,我会在这篇博文中详细回顾。
接下来,我们将应用面部检测:
# pass the blob through the network and obtain the detections and
# predictions
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
为了检测人脸,我们将第 32 和 33 行上的blob通过net。
从这里开始,我们将在detections上循环,并在检测到的人脸周围绘制方框:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box of the face along with the associated
# probability
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
我们开始在第 36 行上循环检测。
从那里,我们提取confidence ( 第 39 行)并将其与置信度阈值(第 43 行)进行比较。我们执行此检查以过滤掉弱检测。
如果置信度满足最小阈值,我们继续画一个矩形,并沿着行 46-56 上检测的概率。
为此,我们首先计算边界框的 (x,y)——坐标(第 46 行和第 47 行)。
然后,我们建立我们的信心text字符串(行 51 ),它包含检测的概率。
万一我们的text会偏离图像(例如当面部检测出现在图像的最顶端时),我们将其下移 10 个像素(第 52 行)。
我们的脸矩形和信心text画在线 53-56 的image上。
从那里,我们再次循环进行后续的额外检测。如果没有剩余的detections,我们准备在屏幕上显示我们的输出image(行 59 和 60 )。
基于 OpenCV 结果的图像人脸检测
我们来试试 OpenCV 深度学习人脸检测器。
确保你使用了这篇博文的“下载”部分来下载:
- 这篇博文中使用的源代码
- 用于深度学习人脸检测的 Caffe prototxt 文件
- 用于深度学习人脸检测的 Caffe 权重文件
- 本帖中使用的示例图片
从那里,打开一个终端并执行以下命令:
$ python detect_faces.py --image rooster.jpg --prototxt deploy.prototxt.txt \
--model res10_300x300_ssd_iter_140000.caffemodel
上面的照片是我第一次去佛罗里达州的 Ybor 市时的照片,在那里,鸡可以在整个城市自由漫步。甚至有保护鸡的法律,我认为这很酷。即使我是在农村的农田里长大的,我仍然对看到一只公鸡过马路感到十分惊讶——这当然引发了许多“小鸡为什么要过马路?”笑话。
这里你可以看到我的脸以 74.30%的置信度被检测到,尽管我的脸有一个角度。OpenCV 的 Haar cascades 因丢失不在“直上”角度的面部而臭名昭著,但通过使用 OpenCV 的深度学习面部检测器,我们能够检测到我的面部。
现在我们来看看另一个例子是如何工作的,这次有三张脸:
$ python detect_faces.py --image iron_chic.jpg --prototxt deploy.prototxt.txt \
--model res10_300x300_ssd_iter_140000.caffemodel
这张照片是在佛罗里达州盖恩斯维尔拍摄的,当时我最喜欢的乐队之一在该地区一个很受欢迎的酒吧和音乐场所 Loosey's 结束了一场演出。在这里你可以看到我的未婚妻(左)、我(中)和乐队成员杰森(右)。
令我难以置信的是,OpenCV 可以检测到 Trisha 的脸,尽管在黑暗的场地中灯光条件和阴影投射在她的脸上(并且有 86.81%的概率!)
同样,这只是表明深度学习 OpenCV 人脸检测器比库附带的标准 Haar cascade 检测器好多少(在准确性方面)。
# import the necessary packages
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
与上面相比,我们将需要导入三个额外的包:VideoStream、imutils和time。
如果您的虚拟环境中没有imutils,您可以通过以下方式安装:
$ pip install imutils
我们的命令行参数大部分是相同的,除了这次我们没有一个--image路径参数。我们将使用网络摄像头的视频。
从那里,我们将加载我们的模型并初始化视频流:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
加载模型同上。
我们初始化一个VideoStream对象,指定索引为零的相机作为源(一般来说,这将是您的笔记本电脑的内置相机或您的台式机的第一个检测到的相机)。
这里有一些简短的注释:
- Raspberry Pi + picamera 用户如果希望使用 Raspberry Pi 相机模块,可以将第 25 行替换为
vs = VideoStream(usePiCamera=True).start()。 - 如果你要解析一个视频文件(而不是一个视频流),用
VideoStream类替换FileVideoStream。你可以在这篇博文中了解更多关于filevodestream 类的信息。
然后,我们让摄像机传感器预热 2 秒钟(第 26 行)。
从那里,我们循环遍历帧,并使用 OpenCV 计算人脸检测:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
这个块应该与上一节中的静态图像版本非常相似。
在这个模块中,我们从视频流中读取一个frame(第 32 行),创建一个blob ( 第 37 行和第 38 行),并让blob通过深度神经net来获得人脸检测(第 42 行和第 43 行)。
我们现在可以循环检测,与置信度阈值进行比较,并在屏幕上绘制面部框+置信度值:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence < args["confidence"]:
continue
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box of the face along with the associated
# probability
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
要详细查看此代码块,请查看上一节,其中我们对静止的静态图像执行人脸检测。这里的代码几乎相同。
既然我们的 OpenCV 人脸检测已经完成,让我们在屏幕上显示该帧并等待按键:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
我们在屏幕上显示frame,直到按下“q”键,这时我们break退出循环并执行清除。
使用 OpenCV 结果在视频和网络摄像头中进行人脸检测
要试用 OpenCV 深度学习人脸检测器,请确保您使用这篇博客文章的 【下载】 部分来获取:
- 这篇博文中使用的源代码
- 用于深度学习人脸检测的 Caffe prototxt 文件
- 用于深度学习人脸检测的 Caffe 权重文件
下载完文件后,使用这个简单的命令就可以轻松运行带有网络摄像头的深度学习 OpenCV 人脸检测器:
$ python detect_faces_video.py --prototxt deploy.prototxt.txt \
--model res10_300x300_ssd_iter_140000.caffemodel
你可以在下面的视频中看到完整的视频演示,包括我的评论:
https://www.youtube.com/embed/v_rZcmLVma8?feature=oembed
基于局部二值模式和 OpenCV 的人脸识别
原文:https://pyimagesearch.com/2021/05/03/face-recognition-with-local-binary-patterns-lbps-and-opencv/
在本教程中,您将学习如何使用本地二进制模式(LBPs)、OpenCV 和cv2.face.LBPHFaceRecognizer_create函数来执行人脸识别。
在我们之前的教程中,我们讨论了人脸识别的基础,包括:
- 人脸检测和人脸识别的区别
- 人脸识别算法如何工作
- 经典人脸识别方法和基于深度学习的人脸识别器的区别
今天我们将首次尝试通过局部二进制模式算法实现人脸识别。本教程结束时,你将能够实现你的第一个人脸识别系统。
要了解如何使用 LBPs 和 OpenCV 进行人脸识别, 继续阅读。
采用局部二值模式(LBPs)和 OpenCV 的人脸识别
在本教程的第一部分,我们将讨论人脸识别算法的 LBPs,包括它是如何工作的。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
然后,我将向您展示如何使用 OpenCV 实现 LBPs 进行人脸识别。
局部二进制模式(LBPs)用于人脸识别算法
我们今天在这里讨论的人脸识别算法首先是由 Ahonen 等人在他们 2004 年的出版物上提出的, 用本地二进制模式进行人脸识别 。
在这一节中,我们将对算法进行概述。正如你将看到的,这其实很简单。
给定数据集中的人脸,算法的第一步是将人脸分成 7×7 个大小相等的单元:
然后,对于这些细胞中的每一个,我们计算一个局部二进制模式直方图。
根据定义,直方图丢弃了关于模式如何彼此相邻的所有空间信息。然而,通过计算每个细胞的直方图,我们实际上能够对空间信息的级别进行编码,例如眼睛、鼻子、嘴等。否则我们就不会有。
这种空间编码还允许我们对来自每个单元的结果直方图进行不同的加权,从而为面部的更多区别特征提供更强的辨别能力:
在这里,我们可以看到原始人脸图像被分成 7×7 个细胞(左)。然后,在右边的,我们可以看到每个单元格的加权方案:
** 白色细胞(如眼睛)的 LBP 直方图的权重是其他细胞的 4 倍。这仅仅意味着我们从白细胞区域提取 LBP 直方图,并将它们乘以 4(考虑直方图的任何缩放/归一化)。
- 浅灰色细胞(嘴和耳朵)多贡献 2 倍。
- 深灰色细胞(内颊和前额)仅贡献 1 倍。
- 最后,黑色细胞,如鼻子和外颊,完全被忽略,并被加权为 0x。
这些加权值是 Ahonen 等人通过在他们的训练、验证和测试数据分割之上运行超参数调整算法而实验发现的。
最后,加权的 7×7 LBP 直方图连接在一起形成最终的特征向量。
使用 完成面部识别
完成面部识别
distance and a nearest neighbor classifier:
- 一张脸被呈现给系统
- LBP 以与训练数据相同的方式被提取、加权和连接
- 用
 距离进行 k-NN(用 k=1 )在训练数据中寻找最近的人脸。
距离进行 k-NN(用 k=1 )在训练数据中寻找最近的人脸。 - 与脸部关联的人的名字以最小的
 距离被选为最终分类
距离被选为最终分类
如你所见,LBPs 人脸识别算法非常简单!提取局部二进制模式并不是一项具有挑战性的任务——扩展提取方法来计算 7×7 = 49 个单元的直方图是足够简单的。
在我们结束这一部分之前,重要的是要注意,LBPs 人脸识别算法还有一个额外的好处,即当新的人脸被引入到数据集中时,它可以更新。
其他流行的算法,如特征脸,要求所有要识别的人脸在训练时出现。这意味着如果一个新的人脸被添加到数据集中,整个特征脸分类器必须被重新训练,这在计算上是相当密集的。
相反,LBPs for face recognition 算法可以简单地插入新的人脸样本,而根本不需要重新训练——这在处理人脸数据集时是一个明显的优势,因为在人脸数据集上,人们经常被添加或删除。
配置您的开发环境
要了解如何使用本地二进制模式进行人脸识别,您需要在计算机上安装 OpenCV:
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install scikit-image
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
加州理工学院人脸数据集
加州理工学院人脸挑战赛是人脸识别算法的基准数据集。总的来说,该数据集由大约 27 个不同的人的 450 幅图像组成。每个对象都是在各种照明条件、背景场景和面部表情下拍摄的,如图 4 中的所示。
本教程的总体目标是应用 Eigenfaces 人脸识别算法来识别加州理工学院人脸数据集中的每个主题。
注意:我已经在与本教程相关的“下载”中包含了加州理工学院人脸数据集的一个稍微修改的版本。 稍加修改的版本包括一个更容易解析的目录结构,每个主题都有假名,这使得更容易评估我们的人脸识别系统的准确性。同样,您 不需要 从加州理工学院的服务器上下载加州理工学院人脸数据集——只需使用与本指南相关的“下载”即可
项目结构
在我们可以用本地二进制模式实现人脸识别之前,让我们先回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,以检索源代码、预训练的人脸检测器和示例加州理工学院人脸数据集:
$ tree --dirsfirst --filelimit 20
.
├── caltech_faces [26 entries exceeds filelimit, not opening dir]
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── pyimagesearch
│ ├── __init__.py
│ └── faces.py
└── lbp_face_reco.py
4 directories, 7 files
face_detector目录包含我们的基于 OpenCV 深度学习的人脸检测器。该检测器既快速又准确,能够在没有 GPU 的情况下实时运行。
我们将对caltech_faces数据集中的每张图像应用人脸检测器模型。该目录中有一个子目录,包含我们想要识别的每个人的图像:
$ ls -l caltech_faces/
abraham
alberta
allen
carmen
conrad
cynthia
darrell
flyod
frank
glen
gloria
jacques
judy
julie
kathleen
kenneth
lewis
mae
phil
raymond
rick
ronald
sherry
tiffany
willie
winston
$ ls -l caltech_faces/abraham/*.jpg
caltech_faces/abraham/image_0022.jpg
caltech_faces/abraham/image_0023.jpg
caltech_faces/abraham/image_0024.jpg
...
caltech_faces/abraham/image_0041.jpg
如你所见,我们为每个想要识别的人准备了多张图片。这些图像将作为我们的训练数据,以便我们的 LBP 人脸识别器可以了解每个人的长相。
从那里,我们今天要回顾两个 Python 脚本。
第一个是faces.py,位于pyimagesearch模块中。该文件包含两个函数:
- 将我们的人脸检测器应用于给定的图像,返回人脸的边界框坐标
load_face_dataset:循环浏览caltech_faces中的所有图像,并对每个图像应用detect_faces功能
最后,lbp_face_reco.py将所有的片段粘在一起,形成我们最终的局部二值模式人脸识别实现。
创建我们的人脸检测器
正如我们在人脸识别简介指南中了解到的,在执行人脸识别之前,我们需要:
- 检测图像/视频流中人脸的存在
- 提取感兴趣区域(ROI),即人脸本身
一旦我们有了面部 ROI,我们就可以应用我们的面部识别算法来从个人的面部学习辨别模式。一旦训练完成,我们实际上就可以在图像和视频中识别人了。
让我们学习如何应用 OpenCV 人脸检测器来检测图像中的人脸。打开pyimagesearch模块中的faces.py文件,让我们开始工作:
# import the necessary packages
from imutils import paths
import numpy as np
import cv2
import os
我们从第 2-5 行的开始,开始我们需要的 Python 包。我们将需要imutils的paths子模块来获取驻留在磁盘上的所有加州理工学院人脸图像的路径。cv2导入提供了我们的 OpenCV 绑定。
现在让我们定义detect_faces函数:
def detect_faces(net, image, minConfidence=0.5):
# grab the dimensions of the image and then construct a blob
# from it
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),
(104.0, 177.0, 123.0))
该方法接受三个参数:
net:我们用于人脸检测的深度神经网络image:我们要对其应用人脸检测的图像minConfidence:正面人脸检测的最小置信度——概率小于该值的检测将作为假阳性结果被丢弃
从那里,我们获取输入image的空间维度,并构建一个blob,以便它可以通过我们的深度神经网络传递。
随着blob的创建,我们将其设置为面部检测器的输入并执行推断:
# pass the blob through the network to obtain the face detections,
# then initialize a list to store the predicted bounding boxes
net.setInput(blob)
detections = net.forward()
boxes = []
我们还初始化了一个列表boxes来存储应用人脸检测后的边界框坐标。
说到这里,现在让我们循环我们的detections并填充boxes列表:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > minConfidence:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# update our bounding box results list
boxes.append((startX, startY, endX, endY))
# return the face detection bounding boxes
return boxes
21 线循环所有detections,而24 线提取当前检测的confidence。
第 28 行通过丢弃任何具有小于minConfidence的confidence的面部检测来过滤弱/假阳性检测。
从那里,我们提取人脸检测的边界框坐标,缩放它们,并更新我们的边界boxes列表(第 31-35 行)。
最终的边界框返回到第 38 行的调用函数。
注: 如果需要更详细的复习 OpenCV 的深度学习人脸检测器,一定要参考我的关于 用 OpenCV 进行人脸检测和深度学习 的指南。那篇文章更详细地介绍了人脸检测器的工作原理,会让你对它有更深的理解。
加载加州理工学院人脸数据集
实现了人脸检测辅助函数之后,我们可以开始实现第二个辅助实用程序load_face_dataset。
该职能部门负责:
- 遍历加州理工学院人脸数据集中的所有图像
- 计算每个人的示例图像数量
- 对于训练数据,排除任何少于 N 张面孔的个体(否则我们会遇到类别不平衡的问题)
- 应用我们的
detect_faces函数 - 提取每个单独的人脸 ROI
- 将面部 ROI 和类别标签(即人名)返回给调用函数
让我们现在就开始实现load_face_dataset。再次打开pyimagesearch模块中的faces.py文件,并在文件底部添加以下代码:
def load_face_dataset(inputPath, net, minConfidence=0.5,
minSamples=15):
# grab the paths to all images in our input directory, extract
# the name of the person (i.e., class label) from the directory
# structure, and count the number of example images we have per
# face
imagePaths = list(paths.list_images(inputPath))
names = [p.split(os.path.sep)[-2] for p in imagePaths]
(names, counts) = np.unique(names, return_counts=True)
names = names.tolist()
我们的load_face_dataset函数接受四个参数:
inputPath:我们想要在其上训练 LBP 人脸识别器的输入数据集的人脸(在这种情况下,是caltech_faces目录)net:我们的 OpenCV 深度学习人脸检测器网络minConfidence:用于过滤弱/假阳性检测的人脸检测的最小概率/置信度minSamples:每个人所需的最少图像数量
第 46 行获取了inputPath中所有图像的路径。然后我们从第 47 行的中提取这些imagePaths的名字。
线 48 执行两个操作:
- 首先,它从
names(即我们想要识别的人的名字)中确定一组唯一的类标签 - 第二,它统计每个人的名字出现的次数
我们执行这个计数操作,因为我们想要丢弃任何少于minSamples的个体。如果我们试图在具有少量训练样本的个体上训练我们的 LBP 人脸识别器,我们会遇到类别不平衡的问题,并且准确性会受到影响(这个概念超出了本教程的范围)。
让我们现在处理我们的每一个图像:
# initialize lists to store our extracted faces and associated
# labels
faces = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# load the image from disk and extract the name of the person
# from the subdirectory structure
image = cv2.imread(imagePath)
name = imagePath.split(os.path.sep)[-2]
# only process images that have a sufficient number of
# examples belonging to the class
if counts[names.index(name)] < minSamples:
continue
第 53 和 54 行初始化两个列表——一个存储提取的人脸 ROI,另一个存储每个人脸 ROI 包含的个人姓名。
然后我们循环第 57 行上的所有imagePaths。对于每张脸,我们:
- 从磁盘加载它
- 从子目录结构中提取个人的姓名
- 查看
name是否少于与其相关联的minSamples
如果最小测试失败(行 65 和 66 ),意味着没有足够的训练图像用于该个体,我们丢弃该图像并且不考虑将其用于训练。
否则,我们假设通过了最小测试,然后继续处理图像:
# perform face detection
boxes = detect_faces(net, image, minConfidence)
# loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
# extract the face ROI, resize it, and convert it to
# grayscale
faceROI = image[startY:endY, startX:endX]
faceROI = cv2.resize(faceROI, (47, 62))
faceROI = cv2.cvtColor(faceROI, cv2.COLOR_BGR2GRAY)
# update our faces and labels lists
faces.append(faceROI)
labels.append(name)
# convert our faces and labels lists to NumPy arrays
faces = np.array(faces)
labels = np.array(labels)
# return a 2-tuple of the faces and labels
return (faces, labels)
对行 69 上的detect_faces的调用执行面部检测,产生一组边界框,我们在行 72 上循环。
对于每个包围盒,我们:
- 使用 NumPy 数组切片提取人脸感兴趣区域
- 将脸部 ROI 调整为固定大小
- 将面部 ROI 转换为灰度
- 更新我们的
faces和labels列表
然后将结果faces和labels返回给调用函数。
实现用于人脸识别的局部二进制模式
实现了助手工具后,我们可以继续创建驱动程序脚本,负责从人脸 ROI 中提取 LBP,训练模型,然后最终执行人脸识别。
打开项目目录结构中的lbp_face_reco.py文件,让我们开始工作:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.faces import load_face_dataset
import numpy as np
import argparse
import imutils
import time
import cv2
import os
第 2-11 行导入我们需要的 Python 包。值得注意的进口包括:
LabelEncoder:用于将类别标签(即个人姓名)编码为整数而不是字符串(这是利用 OpenCV 的 LBP 人脸识别器的要求train_test_split:从我们的加州理工学院人脸数据集构建一个训练和测试分割load_face_dataset:从磁盘加载我们的加州理工学院人脸数据集
现在让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, required=True,
help="path to input directory of images")
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们需要解析一个必需的和两个可选的命令行参数:
--input:我们的输入数据集的路径,该数据集包含我们想要训练 LBP 人脸识别器的个人的图像--face:OpenCV 深度学习人脸检测器之路--confidence:用于过滤弱检测的最小概率
考虑到我们的命令行参数,我们可以从磁盘加载面部检测器:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNet(prototxtPath, weightsPath)
从那里,我们应用load_face_dataset函数来加载我们的面部数据:
# load the CALTECH faces dataset
print("[INFO] loading dataset...")
(faces, labels) = load_face_dataset(args["input"], net,
minConfidence=0.5, minSamples=20)
print("[INFO] {} images in dataset".format(len(faces)))
# encode the string labels as integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# construct our training and testing split
(trainX, testX, trainY, testY) = train_test_split(faces,
labels, test_size=0.25, stratify=labels, random_state=42)
第 33 和 34 行加载加州理工学院人脸数据集。这里我们提供包含数据集的--input目录的路径。我们还提供人脸检测器(net))和一个人参与训练过程所需的最少人脸数量(20)。
然后,我们使用我们的LabelEncoder ( 第 38 和 39 行)对labels进行编码,然后构建我们的训练和测试分割,使用 75%的数据进行训练,25%的数据进行评估(第 42 和 43 行)。
我们现在准备使用 LBPs 和 OpenCV 来训练我们人脸识别器:
# train our LBP face recognizer
print("[INFO] training face recognizer...")
recognizer = cv2.face.LBPHFaceRecognizer_create(
radius=2, neighbors=16, grid_x=8, grid_y=8)
start = time.time()
recognizer.train(trainX, trainY)
end = time.time()
print("[INFO] training took {:.4f} seconds".format(end - start))
cv2.face.LBPHFaceRecognizer_create函数接受几个(可选的)参数,我显式定义这些参数是为了让这个例子更清楚。
radius=2和neighbors=16参数是局部二进制模式图像描述符的一部分。这些值控制直方图计算中包含的像素数,以及这些像素所在的半径。如果你需要复习这些参数,请参阅本地二进制模式教程。
grid_x和grid_y控制人脸识别算法中 MxN 细胞的数量。
虽然 Ahonen 等人的原始论文建议使用 7×7 网格,但我更喜欢使用 8×8 网格,它允许更大的粒度,从而导致更高的精度。
然而,这种增加的精度是以(1)更长的特征提取/比较时间(由于要计算的 LBP 直方图的数量从 49 跳到 64)为代价的,并且可能更重要的是,(2)存储特征向量的相当多的存储器消耗。
在实践中,您应该在自己的数据集上调整grid_x和grid_y超参数,看看哪个值产生的精度最高。
为了训练我们的 LBP 人脸识别器,我们简单地调用train方法,传入我们的加州理工学院人脸训练数据以及每个主题的(整数)标签。
现在让我们使用 LBP 面部识别器来收集预测:
# initialize the list of predictions and confidence scores
print("[INFO] gathering predictions...")
predictions = []
confidence = []
start = time.time()
# loop over the test data
for i in range(0, len(testX)):
# classify the face and update the list of predictions and
# confidence scores
(prediction, conf) = recognizer.predict(testX[i])
predictions.append(prediction)
confidence.append(conf)
# measure how long making predictions took
end = time.time()
print("[INFO] inference took {:.4f} seconds".format(end - start))
# show the classification report
print(classification_report(testY, predictions,
target_names=le.classes_))
我们初始化两个列表predictions和confidences,以存储预测的类标签和预测的置信度/概率。
从那里,我们循环测试集中的所有图像(行 61 )。
对于这些面孔中的每一个,我们调用recognizer的predict方法,该方法返回一个二元组(1)prediction(即主题的整数标签)和(2)conf(信心的简称),它只是
distance between the current testing vector and the closest data point in the training data. The lower the distance, more likely the two faces are of the same subject.
最后,分类报告显示在行 73 和 74 上。
我们的最后一步是可视化人脸识别结果的子集:
# generate a sample of testing data
idxs = np.random.choice(range(0, len(testY)), size=10, replace=False)
# loop over a sample of the testing data
for i in idxs:
# grab the predicted name and actual name
predName = le.inverse_transform([predictions[i]])[0]
actualName = le.classes_[testY[i]]
# grab the face image and resize it such that we can easily see
# it on our screen
face = np.dstack([testX[i]] * 3)
face = imutils.resize(face, width=250)
# draw the predicted name and actual name on the image
cv2.putText(face, "pred: {}".format(predName), (5, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.putText(face, "actual: {}".format(actualName), (5, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
# display the predicted name, actual name, and confidence of the
# prediction (i.e., chi-squared distance; the *lower* the distance
# is the *more confident* the prediction is)
print("[INFO] prediction: {}, actual: {}, confidence: {:.2f}".format(
predName, actualName, confidence[i]))
# display the current face to our screen
cv2.imshow("Face", face)
cv2.waitKey(0)
第 77 行随机抽取所有测试数据指标。
然后我们在第 80 行的上循环这些索引。对于每个指数,我们:
- 从我们的标签编码器中提取预测的人的名字(行 82
- 抢地面实况人名(线 83
- 调整
face的大小,以便我们可以在屏幕上轻松看到它(第 87 行和第 88 行) - 在脸上画出预测名和实际名(第 91-94 行)
- 将最终输出显示到我们的屏幕上(第 99-104 行)
这就是全部了!恭喜用局部二值模式和 LBPs 实现人脸识别!
局部二值模式人脸识别结果
我们现在准备用局部二进制模式和 OpenCV 进行人脸识别!
请务必访问本教程的 “下载” 部分,以检索源代码和示例 CALTECH Faces 数据集。
从那里,打开一个终端并执行以下命令:
$ python lbp_face_reco.py --input caltech_faces
[INFO] loading face detector model...
[INFO] loading dataset...
[INFO] 397 images in dataset
[INFO] training face recognizer...
[INFO] training took 3.0534 seconds
[INFO] gathering predictions...
[INFO] inference took 127.8610 seconds
precision recall f1-score support
abraham 1.00 1.00 1.00 5
allen 1.00 1.00 1.00 8
carmen 1.00 0.80 0.89 5
conrad 0.86 1.00 0.92 6
cynthia 1.00 1.00 1.00 5
darrell 1.00 1.00 1.00 5
frank 1.00 1.00 1.00 5
gloria 1.00 1.00 1.00 5
jacques 1.00 1.00 1.00 6
judy 1.00 1.00 1.00 5
julie 1.00 1.00 1.00 5
kenneth 1.00 1.00 1.00 6
mae 1.00 1.00 1.00 5
raymond 1.00 1.00 1.00 6
rick 1.00 1.00 1.00 6
sherry 1.00 0.83 0.91 6
tiffany 0.83 1.00 0.91 5
willie 1.00 1.00 1.00 6
accuracy 0.98 100
macro avg 0.98 0.98 0.98 100
weighted avg 0.98 0.98 0.98 100
正如我们的输出所示,我们首先遍历数据集中的所有输入图像,检测人脸,然后使用人脸识别算法提取 LBP。由于需要为每个单元计算 LBP,因此该过程需要一些时间。
从那里我们执行推理,获得 98%的准确性。
这种方法的缺点是,识别我们数据集中的所有人脸只需要 2 分多钟。推理如此缓慢的原因是因为我们必须在整个训练集中执行最近邻搜索。
为了提高我们算法的速度,我们应该考虑使用专门的近似最近邻算法,这可以大大减少执行最近邻搜索所需的时间。
现在,让我们将我们的 LBP 人脸识别器应用于单独的图像:
[INFO] prediction: jacques, actual: jacques, confidence: 163.11
[INFO] prediction: jacques, actual: jacques, confidence: 164.36
[INFO] prediction: allen, actual: allen, confidence: 192.58
[INFO] prediction: abraham, actual: abraham, confidence: 167.72
[INFO] prediction: mae, actual: mae, confidence: 154.34
[INFO] prediction: rick, actual: rick, confidence: 170.42
[INFO] prediction: rick, actual: rick, confidence: 171.12
[INFO] prediction: tiffany, actual: carmen, confidence: 204.12
[INFO] prediction: allen, actual: allen, confidence: 192.51
[INFO] prediction: mae, actual: mae, confidence: 167.03
图 5 显示了我们的 LBP 人脸识别算法的合成结果。我们能够使用 LBP 方法正确地识别每个个体。
总结
本课详细介绍了局部二进制模式人脸识别算法的工作原理。我们首先回顾了加州理工学院人脸数据集,这是一个用于评估人脸识别算法的流行基准。
从那里,我们回顾了 Ahonen 等人在他们 2004 年的论文用局部二进制模式进行人脸识别中介绍的 LBPs 人脸识别算法。这个方法很简单,但很有效。整个算法基本上由三个步骤组成:
- 将每个输入图像分成 7×7 个大小相等的单元
- 从每个单元中提取局部二进制模式;根据每个细胞对人脸识别的区分程度对它们进行加权;最后将 7×7 = 49 个直方图串联起来,形成最终的特征向量
- 通过使用具有 k=1 和
 距离度量的 k-NN 分类器来执行人脸识别
距离度量的 k-NN 分类器来执行人脸识别
虽然算法本身实现起来非常简单,但 OpenCV 预构建了一个类,专门用于使用 LBP 执行人脸识别。我们使用cv2.face.LBPHFaceRecognizer_create在加州理工学院人脸数据集上训练我们的人脸识别器,并获得了 98%的准确率,这是我们人脸识别之旅的良好开端。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
基于 OpenCV、Python 和深度学习的人脸识别
原文:https://pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/
最后更新于 2022 年 12 月 30 日,内容更新。
在今天的博文中,你将学习如何使用以下工具在图像和视频流中执行人脸识别:
- OpenCV
- 计算机编程语言
- 深度学习
正如我们将看到的,我们今天在这里使用的基于深度学习的面部嵌入既(1) 高度准确又(2)能够在实时执行。
要用 OpenCV 、 Python 、深度学习、了解更多关于人脸识别的知识,就继续阅读吧!
- 【2021 年 7 月更新:增加了备选人脸识别方法部分,包括基于深度学习和非基于深度学习的方法。
基于 OpenCV、Python 和深度学习的人脸识别
在本教程中,您将学习如何使用 OpenCV、Python 和深度学习来执行面部识别。
我们将从简单讨论基于深度学习的面部识别如何工作开始,包括“深度度量学习”的概念
在那里,我将帮助您安装实际执行人脸识别所需的库。
最后,我们将实现静态图像和视频流的人脸识别。
我们将会发现,我们的人脸识别实现将能够实时运行。
理解深度学习人脸识别嵌入
那么,深度学习+人脸识别是如何工作的呢?
秘密是一种叫做深度度量学习的技术。
如果你以前有深度学习的经验,你会知道我们通常训练一个网络来:
- 接受单个输入图像
- 并输出图像分类/标签
然而,深度度量学习是不同的。
我们不是试图输出单个标签(或者甚至是图像中对象的坐标/边界框),而是输出一个实值特征向量。
对于 dlib 人脸识别网络,输出的特征向量是 128-d (即 128 个实数值的列表),用于量化人脸。使用三元组来训练网络:
这里我们向网络提供三个图像:
- 这些图像中的两个是同一个人的示例面部。
- 第三张照片是从我们的数据集中随机选择的一张脸,与另外两张照片中的不是同一个人。
作为一个例子,让我们再次考虑图 1,其中我们提供了三张图片:一张查德·史密斯的图片和两张威尔·法瑞尔的图片。
我们的网络对人脸进行量化,为每个人脸构建 128 维嵌入(量化)。
从那里,总的想法是,我们将调整我们的神经网络的权重,这样两个威尔·费雷尔的 128-d 测量值将更接近彼此的 T2,而远离查德·史密斯的测量值。
我们用于人脸识别的网络架构是基于来自何等人的论文 【用于图像识别的深度残差学习】中的 ResNet-34,但是具有更少的层并且滤波器的数量减少了一半。
网络本身由 戴维斯·金 在大约 300 万张图像的数据集上训练。在标记的野外人脸(LFW) 数据集上,该网络与其他最先进的方法进行了比较,达到了 99.38%的准确率。
戴维斯·金( dlib 的创造者)和 亚当·盖特吉(面部识别模块的作者,我们很快就会用到)都写了关于基于深度学习的面部识别如何工作的详细文章:
- (Davis)深度度量学习的高质量人脸识别
- 深度学习的现代人脸识别(亚当)
*我强烈建议你阅读上面的文章,了解更多关于深度学习面部嵌入如何工作的细节。
安装您的人脸识别库
为了使用 Python 和 OpenCV 执行人脸识别,我们需要安装两个额外的库:
dlib 库由 Davis King 维护,包含我们的“深度度量学习”实现,该实现用于构建我们的人脸嵌入,用于实际的识别过程。
由亚当·盖特基创建的face_recognition库将包裹在 dlib 的面部识别功能周围,使其更容易使用。
Learn from Adam Geitgey and Davis King at PyImageConf 2018
我假设您的系统上已经安装了 OpenCV。如果没有,不用担心——只需访问我的 OpenCV 安装教程页面,并遵循适合您系统的指南。
从那里,让我们安装dlib和face_recognition包。
注意: 对于以下安装,如果您正在使用 Python 虚拟环境,请确保您处于其中。我强烈推荐使用虚拟环境来隔离您的项目——这是 Python 的最佳实践。如果你遵循了我的 OpenCV 安装指南(并安装了virtualenv + virtualenvwrapper,那么你可以在安装dlib和face_recognition之前使用workon命令。
安装dlib 没有 GPU 支持
如果你没有 GPU,你可以按照本指南使用 pip 通过安装dlib:
$ workon # optional
$ pip install dlib
或者您可以从源代码编译:
$ workon <your env name here> # optional
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS
使用 GPU 支持安装dlib (可选)
如果你有兼容 CUDA 的 GPU,你可以安装有 GPU 支持的dlib,让面部识别更快更有效。
为此,我建议从源代码安装dlib,因为您将对构建有更多的控制权:
$ workon <your env name here> # optional
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDA
安装face_recognition包
人脸识别模块可通过简单的 pip 命令安装:
$ workon <your env name here> # optional
$ pip install face_recognition
安装imutils
你还需要我的便利功能包。您可以通过 pip 将它安装在您的 Python 虚拟环境中:
$ workon <your env name here> # optional
$ pip install imutils
我们的人脸识别数据集
由于 《侏罗纪公园》 (1993)是我一直以来最喜欢的电影,为了纪念 《侏罗纪世界:堕落王国》 (2018)于本周五在美国上映,我们将对电影中的角色样本应用人脸识别:
- 爱伦·格兰特,古生物学家 (22 张图片)
- 克莱尔·迪林,公园运营经理 (53 张图片)
- 爱丽·萨特勒,古植物学家 (31 张图片)
- 伊恩·马尔科姆,数学家 (41 张图片)
- 约翰·哈蒙德,商人/侏罗纪公园主人 (36 张图片)
- 欧文·格雷迪,恐龙研究员 (35 张图片)
这个数据集是在< 30 minutes using the method discussed in my 如何(快速)构建深度学习图像数据集 教程中构建的。给定这个图像数据集,我们将:
- 为数据集中的每个面创建 128 维嵌入
- 使用这些嵌入来识别图像和视频流中的人物面部
人脸识别项目结构
通过检查tree命令的输出可以看到我们的项目结构:
$ tree --filelimit 10 --dirsfirst
.
├── dataset
│ ├── alan_grant [22 entries]
│ ├── claire_dearing [53 entries]
│ ├── ellie_sattler [31 entries]
│ ├── ian_malcolm [41 entries]
│ ├── john_hammond [36 entries]
│ └── owen_grady [35 entries]
├── examples
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
├── output
│ └── lunch_scene_output.avi
├── videos
│ └── lunch_scene.mp4
├── search_bing_api.py
├── encode_faces.py
├── recognize_faces_image.py
├── recognize_faces_video.py
├── recognize_faces_video_file.py
└── encodings.pickle
10 directories, 11 files
我们的项目有 4 个顶级目录:
dataset/:包含六个角色的面部图像,根据他们各自的名字组织到子目录中。examples/:在数据集中有三张不是的人脸图像进行测试。output/:这是你可以存储处理过的人脸识别视频的地方。我会把我的一个留在文件夹里——原侏罗纪公园电影中的经典“午餐场景”。videos/:输入的视频应该保存在这个文件夹中。这个文件夹还包含“午餐场景”视频,但它还没有经过我们的人脸识别系统。
我们在根目录下还有 6 个文件:
- 第一步是建立一个数据集(我已经为你完成了)。要了解如何使用 Bing API 用我的脚本构建数据集,只需查看这篇博文。
encode_faces.py:脸部的编码(128 维向量)是用这个脚本构建的。recognize_faces_image.py:识别单幅图像中的人脸(基于数据集中的编码)。recognize_faces_video.py:通过网络摄像头识别实时视频流中的人脸,并输出视频。recognize_faces_video_file.py:识别驻留在磁盘上的视频文件中的人脸,并将处理后的视频输出到磁盘。我今天不会讨论这个文件,因为骨骼和视频流文件来自同一个骨骼。encodings.pickle:面部识别编码通过encode_faces.py从你的数据集生成,然后序列化到磁盘。
在创建了一个图像数据集(用search_bing_api.py)之后,我们将运行encode_faces.py来构建嵌入。
在那里,我们将运行识别脚本来实际识别人脸。
使用 OpenCV 和深度学习对人脸进行编码
在我们能够识别图像和视频中的人脸之前,我们首先需要量化训练集中的人脸。请记住,我们在这里实际上不是在训练网络— 网络已经被训练过在~3百万张图像的数据集上创建 128 维嵌入。
我们当然可以从零开始训练一个网络,甚至微调现有模型的权重,但这对许多项目来说很可能是矫枉过正。此外,你还需要大量图片来从头开始训练网络。
相反,使用预训练的网络,然后使用它为我们数据集中的 218 个人脸中的每一个构建 128-d 嵌入会更容易。
然后在分类的时候,我们可以用一个简单的 k-NN 模型+投票来做最终的人脸分类。这里也可以使用其他传统的机器学习模型。
为了构建我们的人脸嵌入,打开与这篇博文相关的 【下载】encode_faces.py:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
首先,我们需要导入所需的包。再次注意,这个脚本需要安装imutils、face_recognition和 OpenCV。向上滚动到“安装您的面部识别库”以确保您已经准备好在您的系统上运行这些库。
让我们用argparse来处理运行时处理的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
如果你是 PyImageSearch 的新手,让我把你的注意力引向上面的代码块,随着你阅读我的博客文章越来越多,你会越来越熟悉它。我们使用argparse来解析命令行参数。当您在命令行中运行 Python 程序时,您可以在不离开终端的情况下向脚本提供附加信息。第 10-17 行不需要修改,因为它们解析来自终端的输入。如果这些命令行看起来不熟悉,可以看看我关于命令行参数的博文。
让我们列出参数标志并进行讨论:
--dataset:我们数据集的路径(我们用上周博文的方法#2 中描述的search_bing_api.py创建了一个数据集)。- 我们的面部编码被写到这个参数指向的文件中。
--detection-method:在我们能够编码图像中的张脸之前,我们首先需要检测张脸。或者两种人脸检测方法包括hog或cnn。这两个标志是唯一适用于--detection-method的标志。
现在我们已经定义了参数,让我们获取数据集中文件的路径(并执行两次初始化):
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the list of known encodings and known names
knownEncodings = []
knownNames = []
第 21 行使用我们的输入数据集目录的路径来构建其中包含的所有imagePaths的列表。
我们还需要在循环之前初始化两个列表,分别是knownEncodings和knownNames。这两个列表将包含数据集中每个人的面部编码和相应的姓名(第 24 行和第 25 行)。
是时候开始循环我们的侏罗纪公园角色脸了!
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the input image and convert it from BGR (OpenCV ordering)
# to dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
该循环将循环 218 次,对应于数据集中的 218 张人脸图像。我们将遍历第 28 行上每个图像的路径。
从那里,我们将从第 32 行的imagePath(我们的子目录被恰当地命名)中提取这个人的name。
然后让我们装载image,同时将imagePath传递到cv2.imread ( 线 36 )。
OpenCV 在 BGR 订购颜色通道,但是dlib实际上需要 RGB。face_recognition模块使用dlib,所以在我们继续之前,让我们交换一下第 37 行的颜色空间,命名新图像为rgb。
接下来,让我们本地化面部和计算机编码:
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input image
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
# compute the facial embedding for the face
encodings = face_recognition.face_encodings(rgb, boxes)
# loop over the encodings
for encoding in encodings:
# add each encoding + name to our set of known names and
# encodings
knownEncodings.append(encoding)
knownNames.append(name)
这是剧本有趣的地方!
对于循环的每一次迭代,我们将检测一张脸(或者可能是多张脸,并假设在图像的多个位置都是同一个人——这一假设在您自己的图像中可能成立,也可能不成立,因此在这里要小心)。
例如,假设rgb包含一张(或多张)爱丽·萨特勒的脸。
第 41 行和第 42 行实际上找到/定位了她的脸部,从而得到一个脸部列表boxes。我们向face_recognition.face_locations方法传递两个参数:
rgb:我们的 RGB 图像。model:或者是cnn或者是hog(这个值包含在与"detection_method"键相关的命令行参数字典中)。CNN 方法更准确,但速度较慢。HOG 更快,但不太准确。
然后,我们将把爱丽·萨特勒脸部的边界boxes转换成在第 45 行的 128 个数字的列表。这就是所谓的将面部编码成一个矢量,然后face_recognition.face_encodings方法为我们处理它。
从那里我们只需要将爱丽·萨特勒encoding和name添加到适当的列表中(knownEncodings和knownNames)。
我们将对数据集中的所有 218 幅图像继续这样做。
除非我们可以在另一个处理识别的脚本中使用encodings,否则编码图像的意义何在?
现在让我们来解决这个问题:
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = {"encodings": knownEncodings, "names": knownNames}
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
第 56 行用两个键"encodings"和"names"构造一个字典。
从那里开始第 57-59 行将名称和编码转储到磁盘,以备将来调用。
我应该如何在终端中运行encode_faces.py脚本?
要创建我们的面部嵌入,打开一个终端并执行以下命令:
$ python encode_faces.py --dataset dataset --encodings encodings.pickle
[INFO] quantifying faces...
[INFO] processing image 1/218
[INFO] processing image 2/218
[INFO] processing image 3/218
...
[INFO] processing image 216/218
[INFO] processing image 217/218
[INFO] processing image 218/218
[INFO] serializing encodings...
$ ls -lh encodings*
-rw-r--r--@ 1 adrian staff 234K May 29 13:03 encodings.pickle
正如您从我们的输出中看到的,我们现在有一个名为encodings.pickle的文件—该文件包含我们数据集中每个人脸的 128-d 人脸嵌入。
在我的 Titan X GPU 上,处理整个数据集需要一分多钟,但如果你使用 CPU, 请准备好等待脚本完成!
在我的 Macbook Pro(无 GPU)上,编码 218 张图像需要21 分 20 秒。
如果你有一个 GPU 和有 GPU 支持的编译 dlib,你应该期待更快的速度。
识别图像中的人脸
现在,我们已经为数据集中的每张图像创建了 128 维人脸嵌入,我们现在可以使用 OpenCV、Python 和深度学习来识别图像中的人脸。
打开recognize_faces_image.py并插入以下代码(或者更好的是,从这篇文章底部的的“下载”部分获取与这篇博客文章相关的文件和图像数据,并跟随其后):
# import the necessary packages
import face_recognition
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
这个脚本在第 2-5 行只需要四次导入。模块将完成繁重的工作,OpenCV 将帮助我们加载、转换和显示处理后的图像。
我们将解析第 8-15 行的三个命令行参数:
--encodings:包含我们面部编码的 pickle 文件的路径。- 这是正在接受面部识别的图像。
--detection-method:现在你应该对这个方法很熟悉了——根据你的系统的能力,我们将使用hog或cnn方法。对于速度,选择hog,对于精度,选择cnn。
重要!如果你是:
- 在CPUT3 上运行人脸识别代码
- 或者你用的是
*** …你会想要将--detection-method设置为hog,因为 CNN 人脸检测器(1)在没有 GPU 的情况下速度很慢,并且(Raspberry Pi 也没有足够的内存来运行 CNN。**
**从这里,让我们加载预先计算的编码+人脸名称,然后为输入图像构造 128-d 人脸编码:
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# load the input image and convert it from BGR to RGB
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# detect the (x, y)-coordinates of the bounding boxes corresponding
# to each face in the input image, then compute the facial embeddings
# for each face
print("[INFO] recognizing faces...")
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
encodings = face_recognition.face_encodings(rgb, boxes)
# initialize the list of names for each face detected
names = []
第 19 行从磁盘加载我们的酸洗编码和面孔名称。在实际的人脸识别步骤中,我们将需要这些数据。
然后,在第 22 和 23 行的上,我们加载并转换输入image到rgb颜色通道排序(就像我们在encode_faces.py脚本中所做的)。
然后,我们继续检测输入图像中的所有人脸,并在第 29-31 行的上计算它们的 128-d encodings(这些行看起来也应该很熟悉)。
现在是为每个检测到的人脸初始化一个names列表的好时机——这个列表将在下一步中填充。
接下来,让我们循环面部表情encodings:
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
在第 37 行的上,我们开始遍历从输入图像中计算出的人脸编码。
然后面部识别魔法就发生了!
我们尝试使用face_recognition.compare_faces ( 第 40 行和第 41 行)将输入图像(encoding)中的每个人脸与我们已知的编码数据集(保存在data["encodings"])进行匹配。
这个函数返回一个由True / False值组成的列表,数据集中的每张图片对应一个值。对于我们的侏罗纪公园的例子,数据集中有 218 张图像,因此返回的列表将有 218 个布尔值。
在内部,compare_faces函数计算候选嵌入和数据集中所有人脸之间的欧几里德距离:
- 如果距离低于某个容差(容差越小,我们的面部识别系统将越严格),那么我们返回
True,指示面部匹配。 - 否则,如果距离高于公差阈值,我们返回
False作为面不匹配。
本质上,我们正在利用一个“更奇特”的 k-NN 模型进行分类。更多细节请参考 compare_faces 实现。
name变量将最终保存这个人的姓名字符串——现在,我们把它保留为"Unknown",以防没有“投票”(第 42 行)。
给定我们的matches列表,我们可以计算每个名字的“投票”数量(与每个名字相关联的True值的数量),合计投票,并选择具有最多相应投票的人的名字:
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number of
# votes (note: in the event of an unlikely tie Python will
# select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
如果matches ( 行 45 )中有True票,我们需要确定matches中这些True值所在的索引。我们在第 49 行上做了同样的事情,在那里我们构造了一个简单的matchedIdxs列表,对于example_01.png可能是这样的:
(Pdb) matchedIdxs
[35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 71, 72, 73, 74, 75]
然后我们初始化一个名为counts的字典,它将保存角色名作为键票数作为值 ( 第 50 行)。
从这里开始,让我们遍历matchedIdxs并设置与每个名字相关联的值,同时根据需要在counts中递增该值。对于伊恩·马尔科姆的高票,T2 字典可能是这样的:
(Pdb) counts
{'ian_malcolm': 40}
回想一下,我们在数据集中只有 41 张 Ian 的照片,所以没有其他人投票的 40 分是非常高的。
第 61 行从counts中抽取票数最多的名字,在这种情况下,应该是'ian_malcolm'。
主面部编码循环的第二次迭代(因为在我们的示例图像中有两个人脸)为counts产生如下结果:
(Pdb) counts
{'alan_grant': 5}
这绝对是一个较小的投票分数,但字典中只有一个名字,所以我们很可能找到了爱伦·格兰特。
注:PDB Python 调试器用于验证counts字典的值。PDB 的用法超出了这篇博客的范围;然而,你可以在 Python 文档页面上找到如何使用它。
如下面的图 5 所示,伊恩·马尔科姆和爱伦·格兰特都已被正确识别,因此脚本的这一部分运行良好。
让我们继续,循环每个人的边界框和标签名称,并出于可视化目的将它们绘制在输出图像上:
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# draw the predicted face name on the image
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
在第 67 行的上,我们开始循环检测到的脸部边界boxes和预测的names。为了创建一个 iterable 对象,这样我们就可以很容易地遍历这些值,我们调用zip(boxes, names)产生元组,我们可以从中提取盒子坐标和名称。
我们使用框坐标在第 69 行的上画一个绿色矩形。
我们还使用坐标来计算应该在哪里绘制人名文本(行 70 ),然后实际将姓名文本放置在图像上(行 71 和 72 )。如果人脸包围盒在图像的最顶端,我们需要将文本移动到包围盒顶端的下方(在第 70 行处理),否则,文本会被截掉。
然后我们继续显示图像,直到按下一个键(行 75 和 76 )。
您应该如何运行面部识别 Python 脚本?
使用您的终端,首先使用workon命令确保您处于各自的 Python 正确的虚拟环境中(当然,如果您使用的是虚拟环境)。
然后运行脚本,同时至少提供两个命令行参数。如果选择使用 HoG 方法,也一定要通过--detection-method hog(否则会默认为深度学习检测器)。
让我们去吧!
要使用 OpenCV 和 Python 识别人脸,请打开您的终端并执行我们的脚本:
$ python recognize_faces_image.py --encodings encodings.pickle \
--image examples/example_01.png
[INFO] loading encodings...
[INFO] recognizing faces...
第二个人脸识别示例如下:
$ python recognize_faces_image.py --encodings encodings.pickle \
--image examples/example_03.png
[INFO] loading encodings...
[INFO] recognizing faces...
视频中的人脸识别
既然我们已经对图像应用了人脸识别,那么让我们也对视频(实时)应用人脸识别。
重要性能提示:CNN 人脸识别器只应在使用 GPU 的情况下实时使用(可以与 CPU 一起使用,但预计低于 0.5 FPS,这会导致视频断断续续)。或者(您正在使用 CPU),您应该使用 HoG 方法(或者甚至 OpenCV Haar cascades,将在以后的博客文章中介绍)并期望足够的速度。
下面的脚本与前面的recognize_faces_image.py脚本有许多相似之处。因此,我将轻松跳过我们已经介绍过的内容,只回顾视频组件,以便您了解正在发生的事情。
一旦你抓取了 【下载】 ,打开recognize_faces_video.py并跟随:
# import the necessary packages
from imutils.video import VideoStream
import face_recognition
import argparse
import imutils
import pickle
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-o", "--output", type=str,
help="path to output video")
ap.add_argument("-y", "--display", type=int, default=1,
help="whether or not to display output frame to screen")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
我们在第 2-8 行导入包,然后在第 11-20 行解析我们的命令行参数。
我们有四个命令行参数,其中两个您应该从上面就知道了(--encodings和--detection-method)。另外两个论点是:
--output:输出视频的路径。--display:指示脚本将帧显示到屏幕上的标志。值为1的显示器和值为0的显示器不会将输出帧显示到我们的屏幕上。
从那里我们将加载我们的编码并开始我们的VideoStream:
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# initialize the video stream and pointer to output video file, then
# allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
writer = None
time.sleep(2.0)
为了访问我们的相机,我们使用了来自 imutils 的VideoStream类。第 29 行开始播放。如果您的系统上有多个摄像头(如内置网络摄像头和外部 USB 摄像头),您可以将src=0更改为src=1,以此类推。
稍后我们将可选地将处理过的视频帧写入磁盘,所以我们初始化writer到None ( 第 30 行)。整整两秒钟的睡眠让我们的相机预热(第 31 行)。
从那里我们将开始一个while循环,并开始抓取和处理帧:
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
frame = vs.read()
# convert the input frame from BGR to RGB then resize it to have
# a width of 750px (to speedup processing)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
rgb = imutils.resize(frame, width=750)
r = frame.shape[1] / float(rgb.shape[1])
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input frame, then compute
# the facial embeddings for each face
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
encodings = face_recognition.face_encodings(rgb, boxes)
names = []
我们的循环从第 34 行的开始,我们采取的第一步是从视频流中抓取一个frame(第 36 行)。
以上代码块中剩余的行 40-50 与之前脚本中的行几乎相同,只是这是一个视频帧而不是静态图像。本质上,我们读取frame,进行预处理,然后检测人脸边界boxes +计算每个边界框的encodings。
接下来,让我们循环一下与我们刚刚找到的面部相关联的面部encodings:
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number
# of votes (note: in the event of an unlikely tie Python
# will select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
在这个代码块中,我们循环遍历每个encodings并尝试匹配人脸。如果找到匹配,我们计算数据集中每个名字的投票数。然后,我们提取最高票数,这就是与该脸相关联的名字。这些台词和我们之前看过的剧本一模一样,所以让我们继续。
在下一个块中,我们循环遍历已识别的人脸,并继续在人脸周围绘制一个框,并在人脸上方显示该人的姓名:
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# rescale the face coordinates
top = int(top * r)
right = int(right * r)
bottom = int(bottom * r)
left = int(left * r)
# draw the predicted face name on the image
cv2.rectangle(frame, (left, top), (right, bottom),
(0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
这些行也是相同的,所以让我们把重点放在与视频相关的代码上。
可选地,我们将把帧写入磁盘,所以让我们看看 如何使用 OpenCV 将视频写入磁盘:
# if the video writer is None *AND* we are supposed to write
# the output video to disk initialize the writer
if writer is None and args["output"] is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 20,
(frame.shape[1], frame.shape[0]), True)
# if the writer is not None, write the frame with recognized
# faces to disk
if writer is not None:
writer.write(frame)
假设我们在命令行参数中提供了一个输出文件路径,并且我们还没有初始化一个视频writer ( 第 99 行),让我们继续初始化它。
在行 100 ,我们初始化VideoWriter_fourcc。 FourCC 是一个 4 字符代码,在我们的例子中,我们将使用“MJPG”4 字符代码。
从那里,我们将把该对象连同我们的输出文件路径、每秒帧数目标和帧尺寸一起传递到VideoWriter(第 101 行和第 102 行)。
最后,如果writer存在,我们可以继续向磁盘写入一个帧(第 106-107 行)。
让我们来决定是否应该在屏幕上显示人脸识别视频帧:
# check to see if we are supposed to display the output frame to
# the screen
if args["display"] > 0:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
如果设置了显示命令行参数,我们将继续显示该帧(第 112 行)并检查退出键("q")是否已被按下(第 113-116 行),此时我们将break从循环中退出(第 117 行)。
最后,让我们履行家务职责:
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
# check to see if the video writer point needs to be released
if writer is not None:
writer.release()
在第 120-125 行中,我们清理并释放显示器、视频流和视频写入器。
你准备好看剧本了吗?
要使用 OpenCV 和 Python 演示实时人脸识别,打开一个终端并执行以下命令:
$ python recognize_faces_video.py --encodings encodings.pickle \
--output output/webcam_face_recognition_output.avi --display 1
[INFO] loading encodings...
[INFO] starting video stream...
下面您可以找到我录制的演示面部识别系统运行的输出示例视频:
https://www.youtube.com/embed/dCKl4oGP69s?feature=oembed*****
使用 dlib、OpenCV 和 Python 的面部标志
原文:https://pyimagesearch.com/2017/04/03/facial-landmarks-dlib-opencv-python/
最后更新于 2021 年 7 月 3 日。
上周我们学习了如何用 Python 绑定在我们的系统上安装和配置 dlib。
今天我们将使用 dlib 和 OpenCV 来检测图像中的面部标志。
*面部标志用于定位和表示面部的显著区域,例如:
- 眼睛
- 眉毛
- 鼻子
- 口
- 下颌的轮廓
面部标志已经成功地应用于面部对齐、头部姿势估计、面部交换、眨眼检测等等。
在今天的博文中,我们将关注面部标志的基础,包括:
- 到底什么是面部标志以及它们是如何工作的。
- 如何使用 dlib、OpenCV 和 Python 从图像中检测和提取面部标志。
在本系列的下一篇博文中,我们将更深入地探究面部标志,并学习如何基于这些面部标志提取特定的面部区域。
要了解更多关于面部标志的信息,继续阅读。
- 【2021 年 7 月更新: 增加了替代面部标志检测器的部分,包括 dlib 的 5 点面部标志检测器、OpenCV 的内置面部标志检测器和 MediaPipe 的面部网格检测器。
使用 dlib、OpenCV 和 Python 的面部标志
这篇博客文章的第一部分将讨论面部标志以及为什么它们被用于计算机视觉应用。
从那以后,我将演示如何使用 dlib、OpenCV 和 Python 来检测和提取面部标志。
最后,我们将查看将面部标志检测应用于图像的一些结果。
什么是面部标志?
检测面部标志是形状预测问题的子集。给定输入图像(通常是指定感兴趣对象的 ROI ),形状预测器试图沿着形状定位感兴趣的关键点。
在面部标志的背景下,我们的目标是使用形状预测方法检测面部的重要面部结构。
因此,检测面部标志是一个两步过程:
- 步骤#1: 定位图像中的人脸。
- 步骤#2: 检测人脸 ROI 上的关键人脸结构。
面部检测(步骤#1)可以以多种方式实现。
我们可以使用 OpenCV 的内置哈尔级联。
我们可以应用预训练的 HOG +线性 SVM 对象检测器专门用于面部检测的任务。
或者我们甚至可以使用基于深度学习的算法进行人脸定位。
在这两种情况下,用于检测图像中人脸的实际算法并不重要。相反,重要的是通过某种方法我们获得人脸包围盒(即 (x,y)——图像中人脸的坐标)。
给定面部区域后,我们可以应用步骤#2:检测面部区域中的关键面部结构。
有多种面部标志检测器,但是所有方法本质上都试图定位和标记以下面部区域:
- 口
- 右眉
- 左眉毛
- 右眼
- 左眼
- 鼻子
- 颌
dlib 库中包含的面部标志检测器是卡泽米和沙利文(2014)的论文 一毫秒面部对齐与回归树 集合的实现。
该方法首先使用:
- 图像上标记的面部标志的训练集。这些图像被手动标记为,指定特定的 (x,y)-每个面部结构周围区域的坐标。
- 先验,更具体地说,输入像素对之间距离的概率。
给定该训练数据,回归树的集合被训练来直接从像素强度本身估计面部标志位置(即,没有“特征提取”发生)。
最终结果是一个面部标志检测器,它可以用于在具有高质量预测的实时 中检测面部标志。
关于这种特定技术的更多信息和细节,请务必阅读上面链接的卡泽米和沙利文的论文,以及官方 dlib 公告。
了解 dlib 的面部标志检测器
dlib 库中预先训练的面部标志检测器用于估计映射到面部上面部结构的 68 (x,y)坐标的位置。
下图显示了 68 个坐标的索引:
这些注释是 dlib 面部标志预测器被训练的 68 点 iBUG 300-W 数据集的一部分。
值得注意的是,还存在其他风格的面部标志检测器,包括可以在海伦数据集上训练的 194 点模型。
无论使用哪种数据集,都可以利用相同的 dlib 框架根据输入训练数据训练形状预测器,如果您想要训练面部标志检测器或自己的自定义形状预测器,这将非常有用。
在这篇博文的剩余部分,我将演示如何在图像中检测这些面部标志。
本系列未来的博客文章将使用这些面部标志来提取面部的特定区域,应用面部对齐,甚至建立眨眼检测系统。
用 dlib、OpenCV 和 Python 检测面部标志
为了准备这一系列关于面部标志的博文,我在我的 imutils 库中添加了一些便利的函数,具体来说就是在 face_utils.py 中添加了。
现在我们将在face_utils.py中回顾其中的两个函数,下周我们将回顾其余的函数。
第一个效用函数是rect_to_bb,是“矩形到边界框”的简称:
def rect_to_bb(rect):
# take a bounding predicted by dlib and convert it
# to the format (x, y, w, h) as we would normally do
# with OpenCV
x = rect.left()
y = rect.top()
w = rect.right() - x
h = rect.bottom() - y
# return a tuple of (x, y, w, h)
return (x, y, w, h)
该函数接受单个参数rect,该参数被假定为由 dlib 检测器(即面部检测器)产生的边界框矩形。
rect对象包括检测的 (x,y) 坐标。
然而,在 OpenCV 中,我们通常根据(x,y,宽度,高度)来考虑边界框,因此为了方便起见,rect_to_bb函数将这个rect对象转换成一个 4 元组坐标。
同样,这仅仅是一个便利和品味的问题。
其次,我们有shape_to_np函数:
def shape_to_np(shape, dtype="int"):
# initialize the list of (x, y)-coordinates
coords = np.zeros((68, 2), dtype=dtype)
# loop over the 68 facial landmarks and convert them
# to a 2-tuple of (x, y)-coordinates
for i in range(0, 68):
coords[i] = (shape.part(i).x, shape.part(i).y)
# return the list of (x, y)-coordinates
return coords
dlib 面部标志检测器将返回一个包含面部标志区域的 68 个 (x,y) 坐标的shape对象。
使用shape_to_np函数,我们可以将这个对象转换成一个 NumPy 数组,允许它“更好地”使用我们的 Python 代码。
给定这两个辅助函数,我们现在准备好检测图像中的面部标志。
打开一个新文件,将其命名为facial_landmarks.py,并插入以下代码:
# import the necessary packages
from imutils import face_utils
import numpy as np
import argparse
import imutils
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
第 2-7 行导入我们需要的 Python 包。
我们将使用imutils的face_utils子模块来访问上面详述的助手函数。
然后我们将导入dlib。如果你的系统上还没有安装 dlib,请按照我之前的博客文章中的说明来正确配置你的系统。
第 10-15 行解析我们的命令行参数:
--shape-predictor:这是通往 dlib 预先训练好的面部标志检测器的路径。你可以在这里下载探测器型号,或者你也可以使用这篇文章的 “下载” 部分来获取代码+示例图像+预训练的探测器。--image:我们要检测面部标志的输入图像的路径。
既然我们的导入和命令行参数已经处理好了,让我们初始化 dlib 的面部检测器和面部标志预测器:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
第 19 行基于对用于对象检测的标准梯度方向直方图+线性 SVM 方法的修改,初始化 dlib 的预训练人脸检测器。
第 20 行然后使用提供的路径--shape-predictor加载面部标志预测器。
但是在我们实际检测面部标志之前,我们首先需要检测输入图像中的面部:
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale image
rects = detector(gray, 1)
第 23 行通过 OpenCV 从磁盘加载我们的输入图像,然后预处理图像,调整宽度为 500 像素,并将其转换为灰度(第 24 行和第 25 行)。
第 28 行处理检测我们图像中人脸的边界框。
detector的第一个参数是我们的灰度图像(尽管这个方法也可以用于彩色图像)。
第二个参数是在应用检测器之前放大图像时要应用的图像金字塔层数(这相当于在图像上计算cv2 . pyrapN次)。
在人脸检测之前提高输入图像的分辨率的好处是,它可以让我们在图像中检测到更多的张张人脸——坏处是,输入图像越大,检测过程的计算成本就越高。
给定图像中面部的 (x,y)-坐标,我们现在可以将面部标志检测应用于每个面部区域:
# loop over the face detections
for (i, rect) in enumerate(rects):
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# convert dlib's rectangle to a OpenCV-style bounding box
# [i.e., (x, y, w, h)], then draw the face bounding box
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the face number
cv2.putText(image, "Face #{}".format(i + 1), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(image, (x, y), 1, (0, 0, 255), -1)
# show the output image with the face detections + facial landmarks
cv2.imshow("Output", image)
cv2.waitKey(0)
我们开始在第 31 行的上循环每个面部检测。
对于每个面部检测,我们在第 35 行上应用面部标志检测,给我们 68 (x,y)-坐标映射到图像中的特定面部特征。
第 36 行然后将 dlib shape对象转换成形状为 (68,2) 的 NumPy 数组。
第 40 和 41 行在image上画出包围被检测人脸的边界框,而第 44 和 45 行画出人脸的索引。
最后,行 49 和 50 在检测到的面部标志上循环,并单独绘制它们中的每一个。
第 53 行和第 54 行简单地将输出image显示到我们的屏幕上。
面部标志可视化
在我们测试我们的面部标志检测器之前,请确保您已经升级到包含face_utils.py文件的最新版本imutils:
$ pip install --upgrade imutils
注意:如果您正在使用 Python 虚拟环境,请确保在虚拟环境中升级imutils。
从那里,使用本指南的 “下载” 部分下载源代码、示例图像和预训练的 dlib 面部标志检测器。
一旦你下载了。压缩归档文件,将其解压缩,将目录更改为facial-landmarks,并执行以下命令:
$ python facial_landmarks.py --shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_01.jpg

Figure 3: Applying facial landmark detection using dlib, OpenCV, and Python.
注意我的脸的边界框是如何用绿色绘制的,而每个单独的面部标志是用红色绘制的。
第二个示例图像也是如此:
$ python facial_landmarks.py --shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_02.jpg

Figure 4: Facial landmarks with dlib.
在这里,我们可以清楚地看到红色圆圈映射到特定的面部特征,包括我的下颌线、嘴、鼻子、眼睛和眉毛。
让我们来看最后一个例子,这次图像中有多个人:
$ python facial_landmarks.py --shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_03.jpg
对于图像中的两个人(我自己和我的未婚妻特里莎),我们的脸不仅被检测到,还被通过面部标志标注到。
替代面部标志检测器
由于 Dlib 库的速度和可靠性,dlib 的 68 点面部标志检测器往往是计算机视觉领域最受欢迎的面部标志检测器。
然而,存在其他面部标志检测模型。
首先,dlib 提供了一个替代的 5 点面部标志检测器,它比 68 点检测器更快。如果你只需要眼睛和鼻子的位置,这个模型会很好用。
最受欢迎的新面部标志检测器之一来自 MediaPipe 库,它能够计算 3D 面部网格:
在不久的将来,我会在 PyImageSearch 博客上用 MediaPipe 和 face mesh 做教程。
如果你想完全避免使用 OpenCV 之外的库(例如,没有 dlib、MediaPipe 等。),那么值得注意的是OpenCV是否支持内置面部标志检测器;然而,我以前没有使用过它,我不能评论它的准确性,易用性等。
*## 摘要
在今天的博文中,我们学习了什么是面部标志,以及如何使用 dlib、OpenCV 和 Python 来检测它们。
检测图像中的面部标志是一个两步过程:
- 首先,我们必须定位图像中的人脸。这可以使用多种不同的技术来实现,但通常涉及 Haar 级联或 HOG +线性 SVM 检测器(但任何在面部周围产生边界框的方法都可以)。
- 应用形状预测器,特别是面部标志检测器,以获得面部 ROI 中面部区域的 (x,y)-坐标。
给定这些面部标志,我们可以应用许多计算机视觉技术,包括:
- 面部部分提取(即,鼻子、眼睛、嘴、下颌线等。)
- 面部对齐
- 头部姿态估计
- 扇耳光
- 眨眼检测
- …还有更多!
在下周的博客文章中,我将展示如何通过使用一点 NumPy 数组切片魔法,单独访问每个面部部分和提取眼睛、眉毛、鼻子、嘴和下颌线特征。
为了在下一篇博文发布时得到通知,*请务必在下表中输入您的电子邮件地址!***
用 Keras 和深度学习时尚 MNIST
原文:https://pyimagesearch.com/2019/02/11/fashion-mnist-with-keras-and-deep-learning/
在本教程中,您将学习如何在时尚 MNIST 数据集上使用 Keras 训练一个简单的卷积神经网络(CNN ),使您能够对时尚图像和类别进行分类。

时尚 MNIST 数据集旨在替代(挑战性较小的)MNIST 数据集(挑战性稍大)。
类似于 MNIST 数字数据集,时尚 MNIST 数据集包括:
- 60,000 个培训示例
- 10,000 个测试示例
- 10 节课
- 28×28 灰度/单通道图像
十大时尚类标签包括:
- t 恤/上衣
- 裤子
- 套头衬衫
- 连衣裙
- 外套
- 凉鞋
- 衬衫
- 运动鞋
- 包
- 踝靴
在整个教程中,您将学习如何在时尚 MNIST 数据集上使用 Keras 训练一个简单的卷积神经网络(CNN ),这不仅会让您获得使用 Keras 库的实践经验,还会让您初次体验服装/时尚分类。
要了解如何在时尚 MNIST 数据集上训练一个 Keras CNN,继续阅读!
用 Keras 和深度学习时尚 MNIST
2020-06-11 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将回顾时尚 MNIST 数据集,包括如何将其下载到您的系统。
从那里,我们将使用 Keras 深度学习库定义一个简单的 CNN 网络。
最后,我们将在时尚 MNIST 数据集上训练我们的 CNN 模型,评估它,并检查结果。
让我们开始吧!
时尚 MNIST 数据集

Figure 1: The Fashion MNIST dataset was created by e-commerce company, Zalando, as a drop-in replacement for MNIST Digits. It is a great dataset to practice with when using Keras for deep learning. (image source)
时尚 MNIST 数据集是由电子商务公司 Zalando 创建的。
正如他们在时尚 MNIST 数据集、的官方 GitHub repo 上指出的,标准的 MNIST 数字识别数据集存在一些问题:
- 对于标准的机器学习算法来说,获得 97%以上的准确率太容易了。
- 深度学习模型要达到 99%+的准确率甚至更容易。
- 数据集被过度使用。
- MNIST 不能代表现代计算机视觉任务。
因此,Zalando 创建了时尚 MNIST 数据集,作为 MNIST 的替代物。
时尚 MNIST 数据集在训练集大小、测试集大小、类别标签数量和图像尺寸方面与 MNIST 数据集相同:
- 60,000 个培训示例
- 10,000 个测试示例
- 10 节课
- 28×28 灰度图像
如果你曾经在 MNIST 数字数据集上训练过一个网络,那么你基本上可以改变一两行代码,然后在时尚 MNIST 数据集上训练同样的网络!
How to install TensorFlow/Keras
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
获取时尚 MNIST 数据集

Figure 2: The Fashion MNIST dataset is built right into Keras. Alternatively, you can download it from GitHub. ([image source](https://medium.com/tensorflow/hello-deep-learning-fashion- mnist-with-keras-50fcff8cd74a))
有两种方法可以获得时尚 MNIST 数据集。
如果你使用 TensorFlow/Keras 深度学习库,时尚 MNIST 数据集实际上是直接内置在datasets模块中的:
from tensorflow.keras.datasets import fashion_mnist
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
否则,如果你正在使用另一个深度学习库,你可以从 MNIST 官方时尚 GitHub repo 下载它的目录。
非常感谢 Margaret Maynard-Reid 将的精彩插图放在图 2 中。
项目结构
要跟进,一定要抓住今天博文的 【下载】 。
解压缩文件后,目录结构将如下所示:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── minivggnet.py
├── fashion_mnist.py
└── plot.png
1 directory, 4 files
我们今天的项目相当简单——我们正在查看两个 Python 文件:
pyimagesearch/minivggnet.py:包含一个简单的基于 VGGNet 的 CNN。fashion_mnist.py:我们用 Keras 和深度学习进行时尚 MNIST 分类的训练脚本。这个脚本将加载数据(记住,它内置在 Keras 中),并训练我们的 MiniVGGNet 模型。培训完成后,将生成分类报告和剪辑。
定义简单的卷积神经网络(CNN)
今天,我们将定义一个非常简单的卷积神经网络,在时尚 MNIST 数据集上进行训练。
我们称这个 CNN 为“MiniVGGNet ”,因为:
- 这个模型的灵感来自于它的哥哥 VGGNet
- 该模型具有 VGGNet 特性,包括:
- 仅使用 3×3 CONV 滤波器
- 在应用最大池操作之前堆叠多个 CONV 图层
我们之前在 PyImageSearch 博客上使用过几次 MiniVGGNet 模型,但是为了完整起见,我们今天在这里简单回顾一下。
打开一个新文件,将其命名为minivggnet.py,并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
class MiniVGGNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们的 Keras 进口产品列在第 2-10 行中。我们的卷积神经网络模型相对简单,但我们将利用批量归一化和丢弃,这是我几乎总是推荐的两种方法。如需进一步阅读,请查看使用 Python 进行计算机视觉深度学习的。
我们的MiniVGGNet类及其build方法在行的第 12-14 行中定义。build函数接受四个参数:
width:以像素为单位的图像宽度。height:图像高度,单位为像素。depth:通道数。通常,对于彩色,该值为3,对于灰度,该值为1(时尚 MNIST 数据集为灰度)。classes:我们能识别的时尚物品的种类数量。类的数量会影响最终完全连接的输出图层。对于时尚 MNIST 数据集,总共有10个类。
我们的model在第 17 行使用Sequential API 初始化。
从那里,我们的inputShape被定义(线 18 )。我们将使用"channels_last"排序,因为我们的后端是 TensorFlow,但是如果您使用不同的后端,第 23-25 行将会提供。
现在让我们将我们的图层添加到 CNN:
# first CONV => RELU => CONV => RELU => POOL layer set
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# second CONV => RELU => CONV => RELU => POOL layer set
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
我们的model有两套(CONV => RELU => BN) * 2 => POOL层(线 28-46 )。这些图层集还包括批量归一化和丢弃。
卷积层,包括它们的参数,在之前的文章中有详细描述。
汇集图层有助于逐步减少输入体积的空间维度。
顾名思义,批量标准化寻求在将输入传递到下一层之前,对给定输入量的激活进行标准化。已经证明,以增加每历元时间为代价,减少训练 CNN 所需的历元数量是有效的。
辍学是一种旨在防止过度适应的正规化形式。随机连接被丢弃,以确保网络中没有单个节点在面对给定模式时负责激活。
接下来是全连接层和 softmax 分类器(第 49-57 行)。softmax 分类器用于获取输出分类概率。
然后在线 60 上返回model。
关于用 Keras 构建模型的进一步阅读,请参考我的 Keras 教程和 用 Python 进行计算机视觉的深度学习。
用 Keras 实现时尚 MNIST 培训脚本
现在 MiniVGGNet 已经实现,我们可以继续看驱动程序脚本,它:
- 加载时尚 MNIST 数据集。
- 在时尚 MNIST 上训练 MiniVGGNet 生成训练历史情节。
- 评估结果模型并输出分类报告。
- 创建一个蒙太奇可视化,让我们可以直观地看到我们的结果。
创建一个名为fashion_mnist.py的新文件,打开它,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minivggnet import MiniVGGNet
from sklearn.metrics import classification_report
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import backend as K
from imutils import build_montages
import matplotlib.pyplot as plt
import numpy as np
import cv2
# initialize the number of epochs to train for, base learning rate,
# and batch size
NUM_EPOCHS = 25
INIT_LR = 1e-2
BS = 32
我们从在第 2-15 行导入必要的包、模块和函数开始
- 后端用于 Matplotlib,这样我们可以将我们的训练图保存到磁盘上(第 3 行)。
- 我们的
MiniVGGNetCNN(在上一节的minivggnet.py中定义)在6 号线导入。 - 我们将使用 scikit-learn 的
classification_report来打印最终的分类统计数据/精确度(第 7 行)。 - 我们的 TensorFlow/Keras 导入,包括我们的
fashion_mnist数据集,是在第 8-11 行上获取的。 - 来自 imutils 的
build_montages功能将用于可视化(第 12 行)。 - 最后还导入了
matplotlib、numpy和 OpenCV(cv2)(第 13-15 行)。
在第 19-21 行上设置了三个超参数,包括:
- 学习率
- 批量
- 我们要训练的时代数
让我们继续加载时尚 MNIST 数据集,并在必要时对其进行整形:
# grab the Fashion MNIST dataset (if this is your first time running
# this the dataset will be automatically downloaded)
print("[INFO] loading Fashion MNIST...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# if we are using "channels first" ordering, then reshape the design
# matrix such that the matrix is:
# num_samples x depth x rows x columns
if K.image_data_format() == "channels_first":
trainX = trainX.reshape((trainX.shape[0], 1, 28, 28))
testX = testX.reshape((testX.shape[0], 1, 28, 28))
# otherwise, we are using "channels last" ordering, so the design
# matrix shape should be: num_samples x rows x columns x depth
else:
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
我们正在使用的时尚 MNIST 数据集是从磁盘的第 26 行上加载的。如果这是您第一次使用时尚 MNIST 数据集,那么 Keras 会自动为您下载并缓存时尚 MNIST。
此外,时尚 MNIST 已经组织成培训/测试部门,所以今天我们不使用 scikit-learn 的train_test_split功能,你通常会在这里看到。
从那里我们继续前进,并根据"channels_first"或"channels_last"图像数据格式(第 31-39 行)对我们的数据进行重新排序。订单很大程度上取决于你的后端。我用的是 TensorFlow/Keras,我想你也在用 ( 2020-06-11 更新:以前 Keras 和 TensorFlow 是分开的,我用 TensorFlow 作为我的 Keras 后端)。
让我们继续预处理+准备我们的数据:
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# one-hot encode the training and testing labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
# initialize the label names
labelNames = ["top", "trouser", "pullover", "dress", "coat",
"sandal", "shirt", "sneaker", "bag", "ankle boot"]
这里,我们的像素强度被缩放到范围【0,1】(线 42 和 43 )。然后我们对标签进行一次性编码(第 46 行和第 47 行)。
下面是一个基于第 50 和 51 行上的labelNames的一键编码的例子:
- "t 恤/上衣":
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0] - “袋”
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
让我们继续安装我们的model:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9, decay=INIT_LR / NUM_EPOCHS)
model = MiniVGGNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training model...")
H = model.fit(x=trainX, y=trainY,
validation_data=(testX, testY),
batch_size=BS, epochs=NUM_EPOCHS)
在的第 55-58 行上,我们的model被初始化,并用随机梯度下降(SGD)优化器和学习率衰减进行编译。
从那里,model通过在线路 62-64 上对model.fit的调用而被训练。
完成NUM_EPOCHS的培训后,我们将继续评估我们的网络+生成一个培训图:
# make predictions on the test set
preds = model.predict(testX)
# show a nicely formatted classification report
print("[INFO] evaluating network...")
print(classification_report(testY.argmax(axis=1), preds.argmax(axis=1),
target_names=labelNames))
# plot the training loss and accuracy
N = NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig("plot.png")
2020-06-11 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
为了评估我们的网络,我们在测试集上做了预测(行 67 ),然后在我们的终端上打印了一个classification_report(行 71 和 72 )。
绘制训练历史并输出到磁盘(第 75-86 行)。
好像我们到目前为止所做的还不够有趣,我们现在要可视化我们的结果!
# initialize our list of output images
images = []
# randomly select a few testing fashion items
for i in np.random.choice(np.arange(0, len(testY)), size=(16,)):
# classify the clothing
probs = model.predict(testX[np.newaxis, i])
prediction = probs.argmax(axis=1)
label = labelNames[prediction[0]]
# extract the image from the testData if using "channels_first"
# ordering
if K.image_data_format() == "channels_first":
image = (testX[i][0] * 255).astype("uint8")
# otherwise we are using "channels_last" ordering
else:
image = (testX[i] * 255).astype("uint8")
为此,我们:
- 通过
random采样对一组测试图像进行采样,逐个循环(行 92 )。 - 对每张
random测试图像进行预测,确定label名称(第 94-96 行)。 - 基于频道排序,抓取
image本身(行 100-105 )。
现在,让我们为每张图片添加一个彩色标签,并将它们排列成一个蒙太奇:
# initialize the text label color as green (correct)
color = (0, 255, 0)
# otherwise, the class label prediction is incorrect
if prediction[0] != np.argmax(testY[i]):
color = (0, 0, 255)
# merge the channels into one image and resize the image from
# 28x28 to 96x96 so we can better see it and then draw the
# predicted label on the image
image = cv2.merge([image] * 3)
image = cv2.resize(image, (96, 96), interpolation=cv2.INTER_LINEAR)
cv2.putText(image, label, (5, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.75,
color, 2)
# add the image to our list of output images
images.append(image)
# construct the montage for the images
montage = build_montages(images, (96, 96), (4, 4))[0]
# show the output montage
cv2.imshow("Fashion MNIST", montage)
cv2.waitKey(0)
在这里我们:
- 将我们的标签
color初始化为代表“正确”的green和代表“不正确”分类的红色(第 108-112 行)。 - 通过将灰度图像合并三次(线 117 ,创建一个三通道图像。
- 放大
image( 线 118 )并在上面画一个label(线 119-120 )。 - 将每个
image添加到images列表中(行 123
一旦images都通过for循环中的步骤被注释,我们的 OpenCV 蒙太奇就通过第 126 行被构建。
最后,显示可视化直到检测到按键(行 129 和 130 )。
时尚 MNIST 结果
我们现在准备在时尚 MNIST 数据集上训练我们的 Keras CNN!
确保你已经使用了这篇博文的 【下载】 部分来下载源代码和项目结构。
从那里,打开一个终端,导航到您下载代码的位置,并执行以下命令:
$ python fashion_mnist.py
Using TensorFlow backend.
[INFO] loading Fashion MNIST...
[INFO] compiling model...
[INFO] training model...
Epoch 1/25
1875/1875 [==============================] - 7s 4ms/step - loss: 0.5265 - accuracy: 0.8241 - val_loss: 0.3284 - val_accuracy: 0.8847
Epoch 2/25
1875/1875 [==============================] - 7s 4ms/step - loss: 0.3347 - accuracy: 0.8819 - val_loss: 0.2646 - val_accuracy: 0.9046
Epoch 3/25
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2897 - accuracy: 0.8957 - val_loss: 0.2620 - val_accuracy: 0.9056
...
Epoch 23/25
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1728 - accuracy: 0.9366 - val_loss: 0.1905 - val_accuracy: 0.9289
Epoch 24/25
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1713 - accuracy: 0.9372 - val_loss: 0.1933 - val_accuracy: 0.9274
Epoch 25/25
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1705 - accuracy: 0.9376 - val_loss: 0.1852 - val_accuracy: 0.9324
[INFO] evaluating network...
precision recall f1-score support
top 0.89 0.88 0.89 1000
trouser 1.00 0.99 0.99 1000
pullover 0.89 0.92 0.90 1000
dress 0.92 0.94 0.93 1000
coat 0.90 0.90 0.90 1000
sandal 0.99 0.98 0.99 1000
shirt 0.81 0.77 0.79 1000
sneaker 0.96 0.98 0.97 1000
bag 0.99 0.99 0.99 1000
ankle boot 0.98 0.96 0.97 1000
accuracy 0.93 10000
macro avg 0.93 0.93 0.93 10000
weighted avg 0.93 0.93 0.93 10000

Figure 3: Our Keras + deep learning Fashion MNIST training plot contains the accuracy/loss curves for training and validation.
这里你可以看到我们的网络在测试集上获得了 93%的准确率。
该模型对“裤子”类的分类 100%正确,但对“衬衫”类的分类似乎有点困难(准确率约为 81%)。
根据我们在图 3 中的绘图,似乎很少有过度拟合。
具有数据增强的更深层次架构可能会带来更高的准确性。
下面我列举了一些时尚分类的例子:

Figure 4: The results of training a Keras deep learning model (based on VGGNet, but smaller in size/complexity) using the Fashion MNIST dataset.
正如你所看到的,我们的网络在时尚识别方面表现很好。
该模型适用于时尚 MNIST 数据集之外的时尚图片吗?

Figure 5: In a previous tutorial I’ve shared a separate fashion-related tutorial about using Keras for multi-output deep learning classification — be sure to give it a look if you want to build a more robust fashion recognition model.
在这一点上,你很想知道我们刚刚在时尚 MNIST 数据集上训练的模型是否会直接适用于时尚 MNIST 数据集之外的图像?
简短的回答是“不,不幸的是没有。”
更长的答案需要一点解释。
首先,请记住,时尚 MNIST 数据集旨在替代 MNIST 数据集,这意味着我们的图像已经过处理。
每张图片都被:
- 转换成灰度。
- 分段,使所有背景像素为黑色,所有前景像素为某种灰色,非黑色像素强度。
- 调整尺寸为 28×28 像素。
对于真实世界的时装和服装图像,您必须以与时装 MNIST 数据集相同的方式对数据进行预处理。
此外,即使您可以以完全相同的方式预处理您的数据集,该模型仍然可能无法转移到真实世界的图像。
相反,您应该在示例图像上训练 CNN,这些示例图像将模仿 CNN 在部署到真实世界情况时“看到”的图像。
为此,您可能需要利用多标签分类和多输出网络。
有关这两种技术的更多详细信息,请务必参考以下教程:
摘要
在本教程中,您学习了如何使用 Keras 在时尚 MNIST 数据集上训练一个简单的 CNN。
时尚 MNIST 数据集旨在替代标准 MNIST 数字识别数据集,包括:
- 60,000 个培训示例
- 10,000 个测试示例
- 10 节课
- 28×28 灰度图像
虽然时尚 MNIST 数据集比 MNIST 数字识别数据集稍具挑战性,但不幸的是,它不能直接用于现实世界的时尚分类任务,除非您以与时尚 MNIST 完全相同的方式预处理您的图像(分割、阈值、灰度转换、调整大小等)。).
在大多数真实世界的时尚应用中,模仿时尚 MNIST 预处理步骤几乎是不可能的。
您可以而且应该使用时尚 MNIST 作为 MNIST 数字数据集的直接替代品;然而,如果你对实际识别现实世界图像中的时尚物品感兴趣,你应该参考以下两个教程:
上面链接的两个教程将指导你建立一个更强大的时尚分类系统。
我希望你喜欢今天的帖子!
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!
使用分布式训练和 Google TPUs 的快速神经网络训练
我的日常生活包括训练很多深度学习模型。有时候我很幸运拥有一个小小的架构,却能够提供非凡的结果。其他时候,我不得不踏上训练大型架构的艰难道路,以获得好的结果。
随着数据饥渴的深度学习模型的规模不断增加,我们很少谈论训练一个少于1000 万个参数的模型。因此,硬件访问受限的人没有机会训练这些模型,即使他们有机会,训练时间也是如此之长,他们不能以他们想要的速度迭代该过程。
利用分布式训练和 Google TPUs 进行快速神经网络训练
在这篇文章中,我将提供一些我发现对加快我的培训过程特别有用的商业秘密。我们将讨论用于深度学习的不同硬件,以及不会使正在使用的硬件挨饿的高效数据管道。这篇文章将会让你和你的培训渠道更有效率。
在文章中,我们将讨论:
- 用于深度学习的不同硬件
- 高效的数据管道
- 分发培训流程
要了解如何使用 Google TPUs、 执行分布式训练,请继续阅读。
配置您的开发环境
为了遵循这个指南,你需要在你的系统上安装 TensorFlow 和 TensorFlow 数据集库。
幸运的是,这些包是 pip 可安装的:
$ pip install tensorflow
$ pip install tensorflow-datasets
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们继续之前,让我们首先回顾一下我们的项目目录结构。首先访问本指南的 “下载” 部分,检索源代码和 Python 脚本。
然后,您将看到以下目录结构:
$ tree . --dirsfirst
.
├── outputs
│ ├── cpu.png
│ ├── gpu.png
│ └── tpu.png
├── pyimagesearch
│ ├── autoencoder.py
│ ├── config.py
│ ├── data.py
│ └── loss.py
├── train_cpu.py
├── train_gpu.py
└── train_tpu.py
2 directories, 10 files
在pyimagesearch模块中,我们有以下文件:
autoencoder.py:定义需要训练的自动编码器模型config.py:定义培训所需的配置文件data.py:定义模型训练步骤的数据管道loss.py:定义将用于培训的损失
最后,我们有三个 Python 脚本:
train_cpu.py:在 CPU 上训练模型train_gpu.py:在 GPU 上训练模型- 在 TPU 上训练模型
outputs目录包含在不同硬件上训练的自动编码器的推理图像。
硬件
在深度学习中,最基本的运算是矩阵乘法的运算。我们乘得越快,我们在训练中达到的速度就越快。密歇根大学有一个关于深度学习中的硬件的精彩讲座,我建议观看,以了解硬件多年来如何演变以适应深度学习。在这一节中,我们将反复讨论硬件的类型,并试图找出哪一种更适合我们的目的。
CPU
中央处理器(CPU)是一个基于冯·诺伊曼T2【nn】架构的处理器。该架构提出了一种具有以下组件的电子计算机:
- 处理单元:处理输入的数据
- 一个控制单元:它保存指令和一个程序计数器来控制整个工作流程
- 内存:用于存储
在冯诺依曼体系结构中,指令和数据存在于存储器中。处理器访问指令并相应地处理数据。它还使用内存来存储中间计算,并在以后访问它来完成任何计算。
这种架构非常灵活。我们基本上可以提供任何指令和数据,处理器将完成剩下的工作。然而,这种灵活性是有代价的——速度。
该架构依赖于存储器访问,也依赖于下一步的控制指令。内存访问变成了所谓的冯诺依曼瓶颈。即使我们整天都在做矩阵乘法,CPU 也没有办法去猜测未来的运算;因此,它需要不断访问数据和指令。
谷歌关于 TPUs 的指南中的一个片段揭示了上述问题。
每个 CPU 的算术逻辑单元(alu)是保存和控制乘法器和加法器的组件,一次只能执行一个计算。每次,CPU 都必须访问内存,这限制了总吞吐量并消耗大量能量。
图 2 显示了 CPU 中矩阵乘法的简化版本。操作按顺序进行,每一步都有存储器访问。
让我们用 TensorFlow 测试一下我们的 CPU 执行矩阵乘法的速度。打开 Google Colab 笔记本,粘贴以下代码,亲自查看结果。
# import the necessary packages
import tensorflow as tf
import time
# initialize the operands
w = tf.random.normal((1024, 512, 16))
x = tf.random.normal((1024, 16, 512))
b = tf.random.normal((1024, 512, 512))
# start timer
start = time.time()
# perform matrix multiplication
output = tf.matmul(w, x) + b
# end timer
end = time.time()
# print the time taken to perform the operation
print(f"time taken: {(end-start):.2f} sec")
>>> time taken: 0.79 sec
让我们用上面的代码对我们的 CPU 做一点时间测试。在这里,我们模拟了乘法和加法运算,这是深度学习中最常见的运算。我们看到操作需要0.79 sec来完成。
图形处理器
图形处理单元(GPU)试图通过在单个处理器上集成数千个算术逻辑单元(alu)来提高 CPU 的吞吐量。通过这种方式,GPU 实现了操作的并行性。
矩阵乘法是让深度学习计算适合 GPU 的并行运算。GPU 不是专门为矩阵乘法而构建的,这意味着它们仍然需要从下一步开始访问内存和控制指令——这就是冯诺依曼瓶颈。即使遇到瓶颈,由于并行操作,GPU 在训练过程中也提供了一个重要的进步。
图 3 展示了 GPU 上矩阵乘法的简化版本。请注意 alu 的增加如何帮助实现并行和更快的计算。
下面的代码和用 CPU 做的一样。这里的变化与所使用的硬件有关。我们在这里使用 GPU 来运行代码。结果,代码比 CPU 少花了大约~99%时间。这表明了我们的 GPU 有多么强大,以及并行性如何产生巨大的差异。我强烈推荐在带有 GPU 运行时的 Google Colab 笔记本中运行以下代码。
# import the necessary packages
import tensorflow as tf
import time
# initialize the operands
w = tf.random.normal((1024, 512, 16))
x = tf.random.normal((1024, 16, 512))
b = tf.random.normal((1024, 512, 512))
# start timer
start = time.time()
# perform matrix multiplication
output = tf.matmul(w, x) + b
# end timer
end = time.time()
# print the time taken to perform the operation
print(f"time taken: {(end-start):.6f} sec")
>>> time taken: 0.000436 sec
TPUs
我们已经可以破译张量处理单元(TPU)在深度学习中的优势。
以下是该指南的一个片段:
云 TPU 是定制设计的机器学习 ASIC(专用集成芯片),为翻译、照片、搜索、助手和 Gmail 等谷歌产品提供支持。TPU 优于其他设备的一个好处是大大减少了冯诺依曼瓶颈。因为这种处理器的主要任务是矩阵处理,TPU 的硬件设计人员知道执行该操作的每个计算步骤。因此,他们能够放置数千个乘法器和加法器,并将它们直接连接起来,形成一个由这些运算符组成的大型物理矩阵。这被称为脉动阵列架构。
在脉动阵列架构的帮助下,TPU 首先加载参数,然后动态处理数据。该架构使得数据可以被系统地相乘和相加,而不需要存储器访问来获取指令或存储中间结果。
图 4 显示了 TPU 处理步骤的可视化资源:
https://www.youtube.com/embed/JC84GCU7zqA?feature=oembed*
利用 OpenCV 和 Python 快速优化像素循环
原文:https://pyimagesearch.com/2017/08/28/fast-optimized-for-pixel-loops-with-opencv-and-python/

你是否曾经不得不使用 Python 和 OpenCV 逐个像素地遍历图像?
如果是这样的话,你就知道这是一个非常慢的操作,尽管图像在内部是由 NumPy 数组表示的。
那么这是为什么呢?为什么 NumPy 中的单个像素访问这么慢?
你看,NumPy 操作是用 c 实现的,这让我们避免了 Python 循环的昂贵开销。当使用 NumPy 时,性能提高几个数量级并不少见(与标准 Python 列表相比)。一般来说,如果你能使用 NumPy 数组把你的问题框定为一个向量运算,你将能从速度提升中获益。
这里的问题是访问单个像素是而不是一个向量操作。因此,尽管 NumPy 可以说是几乎任何编程语言都可用的最好的数值处理库,但当与 Python 的for循环+单个元素访问结合使用时,我们会损失很多性能增益。
在您的计算机视觉之旅中,您可能需要实现一些算法,这些算法需要您执行这些手动for循环。无论您是需要从头开始实现本地二进制模式,创建自定义的卷积算法,还是仅仅不能依赖矢量化运算,您都需要了解如何使用 OpenCV 和 Python 来优化for循环。
在这篇博文的剩余部分,我将讨论我们如何使用 Python 和 OpenCV 创建超快速的“for”像素循环——要了解更多,请继续阅读。
利用 OpenCV 和 Python 实现超快速像素循环
几周前,我读了 Satya Mallick 精彩的 LearnOpenCV 博客。他的最新文章讨论了一个名为forEach的特殊函数。forEach函数允许您在对图像中的每个像素应用函数时利用机器上的所有内核。
将计算分布在多个内核上可以实现大约 5 倍的加速。
但是 Python 呢?
有没有一个forEach OpenCV 函数暴露给 Python 绑定?
不幸的是,没有——相反,我们需要创建自己的类似forEach的方法。幸运的是,这并不像听起来那么难。
我已经使用这种精确方法来加速for使用 OpenCV 和 Python 的像素循环年了——今天我很高兴与你分享实现。
在这篇博文的第一部分,我们将讨论 Cython 以及如何使用它来加速 Python 内部的操作。
从那里,我将提供一个 Jupyter 笔记本详细说明如何用 OpenCV 和 Python 实现我们更快的像素循环。
Cython 是什么?它将如何加速我们的像素循环?
我们都知道,作为一种高级语言,Python 提供了很多抽象和便利,这就是它对图像处理如此重要的主要原因。随之而来的通常是比更接近汇编语言如 c 语言更慢的速度。
你可以把 Cython 看作是 Python 和 C 语言的结合,它提供了类似 C 语言的性能。
Cython 与 Python 的不同之处在于,使用 CPython 解释器将代码翻译成 C。这使得脚本大部分可以用 Python 编写,还有一些装饰器和类型声明。
那么什么时候应该在图像处理中利用 Cython 呢?
使用 Cython 的最佳时机可能是当你发现自己在图像中逐个像素地循环时。你看,OpenCV 和 scikit-image 已经被优化了——对模板匹配等函数的调用,就像我们对银行支票和 T2 信用卡进行 OCR 时所做的那样,已经在底层 c 中被优化了。函数调用中有一点点开销,但仅此而已。你永远不会用 Python 写你自己的模板匹配算法——它不够快。
如果你发现自己在用 Python 编写任何定制的图像处理函数来逐像素地分析或修改图像(也许用一个内核),那么极有可能你的函数不会尽可能快地运行。
其实会跑的很慢。
然而,如果您利用 Cython,它可以与主要的 C/C++编译器一起编译,您可以实现显著的性能提升,正如我们今天将演示的。
用 OpenCV 和 Python 实现更快的像素循环
几年前,我在努力寻找一种方法来帮助提高使用 Python 和 OpenCV 访问 NumPy 数组中各个像素的速度。
我尝试的一切都不起作用——我求助于将我的问题框架化为复杂的、难以在 NumPy 数组上进行向量运算来实现我期望的速度提升。但是有时候,遍历图像中的每个像素是不可避免的。
直到我发现了马修·派瑞关于用 Cython 并行化 NumPy 数组循环的精彩博文,我才找到了一个解决方案,并将其应用于图像处理。
在这一节中,我们将回顾我整理的一个 Jupyter 笔记本,以帮助您
了解如何用 OpenCV 和 Python 实现更快的逐像素循环。
但是在我们开始之前,请确保您安装了 NumPy、Cython、matplotlib 和 Jupyter:
$ workon cv
$ pip install numpy
$ pip install cython
$ pip install matplotlib
$ pip install jupyter
注 : 我建议你把这些安装到你用 Python 进行计算机视觉开发的虚拟环境中。如果你遵循了这个网站上的安装教程,你可能有一个名为cv的虚拟环境。在发出上述命令(第 2-5 行*)之前,只需在您的 shell 中输入workon cv(如果 PyImageSearch Gurus 成员愿意,他们可以将安装到他们的gurus环境中)。如果您还没有虚拟环境,请创建一个,然后按照此处的说明符号链接您的cv2.so绑定。*
从那里,您可以在您的环境中启动 Jupyter 笔记本,并开始输入本文中的代码:
$ jupyter notebook
或者,使用这篇博文的 【下载】 部分,跟随我为你创建的 Jupyter 笔记本 (强烈推荐) 。如果您使用下载部分中的笔记本,请确保将您的工作目录更改为笔记本在磁盘上的位置。
无论您是选择使用预烤笔记本还是从头开始,本节的剩余部分都将讨论如何使用 OpenCV 和 Python 将逐像素循环提升两个数量级以上 。
在这个例子中,我们将实现一个简单的阈值函数。对于图像中的每个像素,我们将检查输入像素是否大于或等于某个阈值T。
如果像素通过了阈值测试,我们将输出值设置为 255 。否则,输出像素将被设置为 0 。
使用这个函数,我们将能够二值化我们的输入图像,非常类似于 OpenCV 和 scikit-image 的内置阈值方法的工作方式。
我们将使用一个简单的阈值函数作为示例,因为它使我们能够(1)不关注实际的图像处理代码,而是(2)学习如何在手动循环图像中的每个像素时获得速度提升。
要将“幼稚”的像素循环与我们更快的 Cython 循环进行比较,请看下面的笔记本:
# import the necessary packages
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
注意:当你的笔记本启动时,我建议你点击菜单栏中的【查看】>【切换行号】——在 Jupyter 中,每个In [ ]和Out [ ]块都从 1 开始重新编号,所以你会在这里的代码块中看到那些相同的编号。如果你使用的是本帖下载部分的笔记本,可以随意点击“Cell”>“Run All”来执行所有的块。
在上面的In [1]中,在的 2-3 行中,我们导入我们需要的包。第 5 行简单地指定我们希望 matplotlib 图在笔记本中显示。
接下来,我们将加载并预处理一个示例图像:
# load the original image, convert it to grayscale, and display
# it inline
image = cv2.imread("example.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
plt.imshow(image, cmap="gray")
在In [2]的第 3 行,我们加载example.png,然后在第 4 行将其转换为灰度。
然后我们使用 matplotlib ( Line 5 )显示图形。
该命令的内联输出如下所示:

Figure 1: Our input image (400×400 pixels) that we will be thresholding.
接下来,我们将加载 Cython:
%load_ext cython
在上面的In [3]中,我们加载 Cython。
现在我们已经将 Cython 存储在内存中,我们将指示 Cython 显示哪些行可以在我们的自定义阈值函数中进行优化:
%%cython -a
def threshold_slow(T, image):
# grab the image dimensions
h = image.shape[0]
w = image.shape[1]
# loop over the image, pixel by pixel
for y in range(0, h):
for x in range(0, w):
# threshold the pixel
image[y, x] = 255 if image[y, x] >= T else 0
# return the thresholded image
return image
上面In [3]中的第 1 行告诉解释器,我们希望 Cython 确定哪些行可以优化。
然后,我们定义我们的函数,threshold_slow。我们的函数需要两个参数:
T:门槛image:输入图像
在第 5 行和第 6 行,我们从图像的.shape对象中提取高度和宽度。我们需要w和h,这样我们就可以逐个像素地循环图像。
第 9 行和第 10 行开始一个嵌套的 for 循环,我们从上到下从左到右循环,直到我们的高度和宽度。后面我们会看到这个循环还有优化的空间。
在第 12 行上,我们使用三元运算符对每个像素执行原位二进制阈值——如果像素是>= T,我们将像素设置为白色( 255 ),否则,我们将像素设置为黑色( 0 )。
最后,我们返回结果image。
在 Jupyter 中(假设您执行了上面的In [ ]块),您将看到以下输出:
01:
+02: def threshold_slow(T, image):
03: # grab the image dimensions
+04: h = image.shape[0]
+05: w = image.shape[1]
06:
07: # loop over the image, pixel by pixel
+08: for y in range(0, h):
+09: for x in range(0, w):
10: # threshold the pixel
+11: image[y, x] = 255 if image[y, x] >= T else 0
12:
13: # return the thresholded image
+14: return image
Out [4]中的黄色高亮线展示了 Cython 可用于优化的区域——我们稍后将看到如何使用 Cython 执行优化。请注意逐像素循环动作是如何突出显示的。
提示:你可以点击行首的“+”来查看底层的 C 代码——这是我觉得非常有趣的事情。
接下来,让我们计时函数的操作:
%timeit threshold_slow(5, image)
使用%timeit语法,我们可以执行函数并计时——我们指定一个阈值 5 和我们已经加载的图像。结果输出如下所示:
1 loop, best of 3: 244 ms per loop
输出显示该函数在我的系统上运行的最快时间是 244 ms。这是我们的基准时间——我们将在本文后面大幅减少这个数字。
让我们看看阈值操作的结果,从视觉上验证我们的函数是否正常工作:
# threshold our image to validate that it's working
image = threshold_slow(5, image)
plt.imshow(image, cmap="gray")
In [6]中显示的两行运行该功能,并在笔记本上显示输出。产生的阈值图像如下所示:

Figure 2: Thresholding our input image using the threshod_slow method.
现在我们到了有趣的部分。让我们利用 Cython 创建一个高度优化的逐像素环路:
%%cython -a
import cython
@cython.boundscheck(False)
cpdef unsigned char[:, :] threshold_fast(int T, unsigned char [:, :] image):
# set the variable extension types
cdef int x, y, w, h
# grab the image dimensions
h = image.shape[0]
w = image.shape[1]
# loop over the image
for y in range(0, h):
for x in range(0, w):
# threshold the pixel
image[y, x] = 255 if image[y, x] >= T else 0
# return the thresholded image
return image
In [7]的行 1 再次指定我们希望 Cython 突出显示可以优化的行。
然后,我们在第 2 行的处导入 Cython。
Cython 的美妙之处在于,我们的 Python 代码只需要很少的修改——你会的;但是,看到一些 C 语法的痕迹。第 4 行是一个 Cython decorator 声明我们不会检查数组索引界限,提供了一个轻微的加速。
以下段落强调了一些 Cython 语法,所以要特别注意。
然后我们使用cpdef关键字而不是 Python 的def来定义函数(第 5 行)——这为 C 类型创建了一个cdef类型,为 Python 类型创建了一个def类型(源)。
threshold_fast函数将返回一个unsigned char [:,:],这将是我们的输出 NumPy 数组。我们使用unsigned char,因为 OpenCV 将图像表示为无符号的 8 位整数,而unsigned char(有效地)为我们提供了相同的数据类型。[:, :]暗示我们正在使用 2D 阵列。
从那里,我们向我们的函数提供实际的数据类型,包括int T(阈值),和另一个unsigned char数组,我们的输入image。
在第 7 行,使用cdef我们可以将 Python 变量声明为 C 变量——这允许 Cython 理解我们的数据类型。
In [7]中的其他一切都是 与threshold_slow中的 相同,这 展示了 Cython 的便利性。
我们的输出如下所示:
+01: import cython
02:
03: @cython.boundscheck(False)
+04: cpdef unsigned char[:, :] threshold_fast(int T, unsigned char [:, :] image):
05: # set the variable extension types
06: cdef int x, y, w, h
07:
08: # grab the image dimensions
+09: h = image.shape[0]
+10: w = image.shape[1]
11:
12: # loop over the image
+13: for y in range(0, h):
+14: for x in range(0, w):
15: # threshold the pixel
+16: image[y, x] = 255 if image[y, x] >= T else 0
17:
18: # return the thresholded image
+19: return image
这次注意到在Out [7]中,Cython 突出显示的行更少了。事实上,只有 Cython 导入和函数声明被突出显示——这是典型的。
接下来,我们将重新加载并重新预处理我们的原始图像(有效地重置它):
# reload the original image and convert it to grayscale
image = cv2.imread("example.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
重新加载图像的目的是因为我们的第一个threshold_slow操作就地修改了图像。我们需要将其重新初始化为已知状态。
让我们继续,根据 Python 中最初的threshold_slow函数对我们的threshold_fast函数进行基准测试:
%timeit threshold_fast(5, image)
结果是:
10000 loops, best of 3: 41.2 µs per loop
这次我们实现了每次调用41.2 微秒,对使用严格 Python 的 244 毫秒 进行了大规模改进。这意味着通过使用 Cython,我们可以将逐像素循环 的速度提高 2 个数量级以上!
**### OpenMP 呢?
通读本教程后,您可能会想知道我们是否可以获得更多的性能提升。虽然我们通过使用 Cython 而不是 Python 获得了巨大的性能提升,但我们实际上仍然只使用了我们 CPU 的一个核心。
但是,如果我们想要在多个 CPUs 内核之间分配计算,那该怎么办呢?这可能吗?
绝对是——我们只需要使用 OpenMP (开放式多处理)。
在后续的博客文章中,我将演示如何使用 OpenMP 来进一步增强使用 OpenCV 和 Python 的“for”像素循环。
摘要
受到萨蒂亚·马里克(Satya Mallick)的原始博客文章的启发,我决定写一篇教程,试图用 Python 完成同样的事情——。
不幸的是,Python 只有一小部分函数调用可以作为绑定使用(与 C++相比)。正因为如此,我们需要使用 Cython“推出我们自己的”更快的“for”循环方法。
结果相当惊人——通过使用 Cython,我们能够将阈值函数从每个函数调用 244 ms(纯 Python)提升到不到 40.8 μs (Cython)。
有意思的是,还有待优化。
到目前为止,我们的简单方法只使用了 CPU 的一个内核。通过启用 OpenMP 支持,我们实际上可以将for循环计算分布在多个CPU/内核上——这样做只会进一步提高我们函数的速度。
我将在以后的博文中介绍如何使用 OpenMP 来提升 OpenCV 和 Python 的像素循环。
目前,请务必在下面的表格中输入您的电子邮件地址,以便在发布新的博客帖子时得到通知!**
(更快)带 dlib 的面部标志检测器
原文:https://pyimagesearch.com/2018/04/02/faster-facial-landmark-detector-with-dlib/
早在 2017 年 9 月,戴维斯·金发布了 dlib 的 v19.7 版本——在发行说明中,你会在 dlib 的新 5 点面部标志检测器上找到一个简短、不显眼的圆点:
增加了一个 5 点人脸标记模型,比 68 点模型小 10 倍以上,运行速度更快,并且可以处理 HOG 和 CNN 生成的人脸检测。
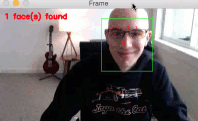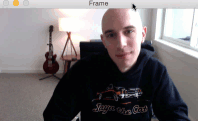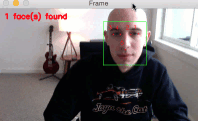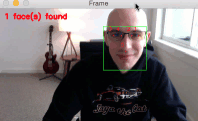
我今天的目标是向大家介绍新的 dlib 面部标志检测器,它比原来的版本更快(快 8-10%),更有效,和(小 10 倍)。
在今天博客的剩余部分,我们将讨论 dlib 的新面部标志探测器,包括:
- 五点面部标志检测器的工作原理
- 为您自己的应用选择新的 5 点版本或原始的 68 点面部标志检测器时的注意事项
- 如何在自己的脚本中实现 5 点面部标志检测器
- 5 点面部标志检测器的运行演示
要了解更多关于 dlib 面部标志检测的信息,请继续阅读。
(更快)带 dlib 的面部标志检测器
在这篇博文的第一部分,我们将讨论 dlib 的新的、更快、更小的 5 点面部标志检测器,并将其与随库发布的原始 68 点面部标志检测器进行比较。
在那里,我们将使用 Python、dlib 和 OpenCV 实现面部标志检测,然后运行它并查看结果。
最后,我们将讨论使用 5 点面部标志检测器的一些限制,并强调您应该使用 5 点版本的 68 点面部标志检测器的一些场景。
Dlib 的 5 点面部标志检测器

Figure 1: A comparison of the dlib 68-point facial landmarks (top) and the 5-point facial landmarks (bottom).
上面的图 1 可视化了 dlib 新的 5 点面部标志检测器与原始的 68 点检测器之间的差异。
68 点检测器定位沿着眼睛、眉毛、鼻子、嘴和下颌线的区域,而 5 点面部标志检测器将这些信息简化为:
- 左眼扣 2 分
- 右眼扣 2 分
- 鼻子得 1 分
5 点面部标志检测器最合适的用例是面部对齐。
在加速方面,我发现新的 5 点探测器比原来的版本快 8-10%,但这里真正的胜利是模型大小: 9.2MB 对 99.7MB ,分别(比小 10 倍以上)。
同样重要的是要注意,面部标志检测器开始时往往非常快(特别是如果它们被正确实现,就像在 dlib 中一样)。
就加速而言,真正的胜利将是决定你应该使用哪种人脸检测器。一些面部检测器比其他检测器更快(但可能不太准确)。如果你还记得我们的睡意检测系列:
您应该记得,我们在笔记本电脑/台式机实施中使用了更准确的 HOG +线性 SVM 人脸检测器,但需要一个不太准确但更快的 Haar cascade 来实现 Raspberry Pi 上的实时速度。
一般来说,在选择人脸检测模型时,您会发现以下准则是一个很好的起点:
- 哈尔喀:速度快,但不太准确。调整参数可能会很痛苦。
- HOG +线性 SVM: 通常(显著)比 Haar 级联更准确,假阳性更少。通常在测试时需要调整的参数较少。与哈尔瀑布相比可能很慢。
- 基于深度学习的检测器:当被正确训练时,比哈尔级联和 HOG +线性 SVM 显著更准确和鲁棒。可能会非常慢,这取决于模型的深度和复杂性。可以通过在 GPU 上执行推理来加速(你可以在这篇文章中看到一个 OpenCV 深度学习人脸检测器)。
当您构建自己的应用程序来利用人脸检测和面部标志时,请记住这些准则。
用 dlib、OpenCV 和 Python 实现面部标志
现在我们已经讨论了 dlib 的 5 点面部标志检测器,让我们编写一些代码来演示并查看它的运行情况。
打开一个新文件,将其命名为faster_facial_landmarks.py,并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from imutils import face_utils
import argparse
import imutils
import time
import dlib
import cv2
在线 2-8 我们导入必要的包,特别是dlib和来自imutils的两个模块。
imutils 包已经更新,可以处理68 点和 5 点面部标志模型。确保在您的环境中通过进行升级
$ pip install --upgrade imutils
同样,更新 imutils 将允许您使用68 点和 5 点面部标志。
接下来,让我们解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
args = vars(ap.parse_args())
我们有一个命令行参数:--shape-predictor。该参数允许我们更改将在运行时加载的面部标志预测器的路径。
注:对命令行参数一头雾水?请务必查看我最近的帖子,其中深入讨论了命令行参数。
接下来,让我们加载形状预测器并初始化我们的视频流:
# initialize dlib's face detector (HOG-based) and then create the
# facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# initialize the video stream and sleep for a bit, allowing the
# camera sensor to warm up
print("[INFO] camera sensor warming up...")
vs = VideoStream(src=1).start()
# vs = VideoStream(usePiCamera=True).start() # Raspberry Pi
time.sleep(2.0)
在第 19 行和第 20 行,我们初始化 dlib 预训练的 HOG +线性 SVM 人脸detector并加载shape_predictor文件。
为了访问相机,我们将使用 imutils 的VideoStream类。
您可以选择(通过注释/取消注释第 25 行和第 26 行)是否使用:
- 内置/USB 网络摄像头
- 或者你是否会在你的树莓派上使用 PiCamera
从那里,让我们循环帧,做一些工作:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream, resize it to
# have a maximum width of 400 pixels, and convert it to
# grayscale
frame = vs.read()
frame = imutils.resize(frame, width=400)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
# check to see if a face was detected, and if so, draw the total
# number of faces on the frame
if len(rects) > 0:
text = "{} face(s) found".format(len(rects))
cv2.putText(frame, text, (10, 20), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 0, 255), 2)
首先,我们从视频流中读取一个frame,调整它的大小,并转换成灰度(第 34-36 行)。
然后让我们使用 HOG +线性 SVM detector来检测灰度图像中的人脸(第 39 行)。
从那里,我们首先确定至少有一张脸被检测到,从而在原始图像上画出人脸的总数(第 43-46 行)。
接下来,让我们循环面部检测并绘制界标:
# loop over the face detections
for rect in rects:
# compute the bounding box of the face and draw it on the
# frame
(bX, bY, bW, bH) = face_utils.rect_to_bb(rect)
cv2.rectangle(frame, (bX, bY), (bX + bW, bY + bH),
(0, 255, 0), 1)
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw each of them
for (i, (x, y)) in enumerate(shape):
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
cv2.putText(frame, str(i + 1), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)
从第 49 行开始,我们循环播放rects中的人脸。
我们通过使用来自imutils的face_utils模块,在原始帧上绘制人脸边界框(第 52-54 行)(你可以在这里阅读更多关于的内容)。
然后,我们将面部传递给predictor以确定面部标志(第 59 行),随后我们将面部标志坐标转换为一个 NumPy 数组。
现在有趣的部分来了。为了可视化地标,我们将使用cv2.circle绘制小点,并对每个坐标进行编号。
在第 64 行的上,我们在地标坐标上循环。然后我们在原始的frame上画一个小的填充圆以及地标号。
让我们完成面部标志性的脚本:
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
在这个块中,我们显示帧(行 70 ) 、如果按下“q”则退出循环(行 71-75 ) 、,并执行清除(行 78 和 79 )。
运行我们的面部标志探测器
现在我们已经实现了面部标志检测器,让我们来测试一下。
请务必向下滚动到这篇博客文章的 “下载” 部分,下载源代码和 5 点面部标志检测器。
从那里,打开一个 shell 并执行以下命令:
$ python faster_facial_landmarks.py \
--shape-predictor shape_predictor_5_face_landmarks.dat
Figure 2: The dlib 5-point facial landmark detector in action.
从上面的 GIF 可以看出,我们已经成功定位了 5 个面部标志,包括:
- 左眼扣 2 分
- 右眼扣 2 分
- 鼻子底部得 1 分
我在下面的视频中加入了面部标志检测器的较长演示:
https://www.youtube.com/embed/6sN9Oo1CBWY?feature=oembed
(更快)Python 中的非最大抑制
原文:https://pyimagesearch.com/2015/02/16/faster-non-maximum-suppression-python/

我有问题— 我无法停止思考物体探测。
你看,昨晚我在看《行尸走肉》,而不是欣赏僵尸的残暴、被迫的同类相食或者迷人的故事情节,《T3 》,我只想做的是建立一个物体检测系统来识别僵尸。
会很有用吗?大概不会。
我是说,很明显如果有僵尸在追你。光是那股恶臭就应该是一个(嘿,看那双关语)死人了,更别说咬牙切齿和伸出手臂了。我们还可以加上喉音【大脑神经】呻吟。
*就像我说的,如果有僵尸在追你,这是非常明显的——你当然不需要计算机视觉系统来告诉你。但这只是我每天脑海中浮现的一个例子。
为了给你一些背景,两周前我发布了关于使用方向梯度直方图和线性支持向量机来构建一个物体检测系统。厌倦了使用 OpenCV Haar cascades 并获得糟糕的性能,更不用说极长的训练时间,我决定自己编写自己的 Python 对象检测框架。
到目前为止,它进行得非常顺利,并且实现起来非常有趣。
但是在构建一个物体检测系统时,有一个不可避免的问题你必须处理,那就是重叠包围盒。这是要发生的,没有办法。事实上,这实际上是一个好的迹象,表明你的物体检测器正在正常工作,所以我甚至不会称之为一个“问题”。
为了处理重叠边界框(指同一对象)的移除,我们可以对均值偏移算法使用非最大抑制。虽然 Dalal 和 Triggs 更喜欢均值漂移,但我发现均值漂移给出的结果并不理想。
在收到我的朋友(也是物体检测专家)Tomasz Malisiewicz 博士的建议后,我决定将他的非最大抑制 MATLAB 实现移植到 Python 上。
上周我向你展示了如何实现 Felzenszwalb 等人的方法。本周我将向你们展示比 T4 快 100 倍的马利西维茨等人的方法。
注:早在 11 月我就打算发表这篇博文了,但是由于我计划不周,这篇博文花了我一段时间才发表。反正现在已经上线了!
那么这种加速来自哪里呢?我们如何获得更快的抑制时间?
请继续阅读,寻找答案。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
(更快)Python 中的非最大抑制
在我们开始之前,如果你还没有阅读上周关于非最大抑制的帖子,我肯定会从那里开始。
否则,在您喜欢的编辑器中打开一个新文件,将其命名为nms.py,让我们开始创建一个更快的非最大抑制实现:
# import the necessary packages
import numpy as np
# Malisiewicz et al.
def non_max_suppression_fast(boxes, overlapThresh):
# if there are no boxes, return an empty list
if len(boxes) == 0:
return []
# if the bounding boxes integers, convert them to floats --
# this is important since we'll be doing a bunch of divisions
if boxes.dtype.kind == "i":
boxes = boxes.astype("float")
# initialize the list of picked indexes
pick = []
# grab the coordinates of the bounding boxes
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
# compute the area of the bounding boxes and sort the bounding
# boxes by the bottom-right y-coordinate of the bounding box
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(y2)
# keep looping while some indexes still remain in the indexes
# list
while len(idxs) > 0:
# grab the last index in the indexes list and add the
# index value to the list of picked indexes
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
# find the largest (x, y) coordinates for the start of
# the bounding box and the smallest (x, y) coordinates
# for the end of the bounding box
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
# compute the ratio of overlap
overlap = (w * h) / area[idxs[:last]]
# delete all indexes from the index list that have
idxs = np.delete(idxs, np.concatenate(([last],
np.where(overlap > overlapThresh)[0])))
# return only the bounding boxes that were picked using the
# integer data type
return boxes[pick].astype("int")
花点时间仔细检查一下这段代码,并将其与上周 Felzenszwalb 等人的实现进行比较。
代码看起来 几乎一模一样 对吧?
所以你可能会问自己“这 100 倍的速度提升来自哪里?”
答案是去除一个内部for循环。
上周的实现需要一个额外的内部for循环来计算边界区域的大小和重叠区域的比例。
相反,Malisiewicz 博士用矢量化代码— 取代了这个内部for循环,这就是我们在应用非最大抑制时能够实现更快速度的方法。
不要像我上周那样重复自己的话,一行一行地检查代码,让我们只检查重要的部分。
我们的快速非最大值抑制函数的第 6-22 行与上周的基本相同。我们首先获取边界框的 (x,y) 坐标,计算它们的面积,并根据每个框右下角的 y 坐标将索引排序到boxes列表中。
31-55 线包含我们的提速,其中41-55 线尤为重要。
我们没有使用内部的for循环来遍历每个单独的框,而是使用np.maximum和np.minimum函数对代码进行矢量化——这允许我们找到跨越轴的最大值和最小值,而不仅仅是单独的标量。
注意:你 有 在这里使用np.maximum和np.minimum函数——它们允许你混合标量和向量。而np.max和np.min功能则不然,如果你使用它们,你会发现自己有一些非常严重的错误需要查找和修复。当我将算法从 MATLAB 移植到 Python 时,我花了很长时间来调试这个问题。
第 47 行和第 48 行也被矢量化——这里我们计算每个矩形的宽度和高度来检查。类似地,计算线 51 上的overlap比率也被矢量化。从那里,我们只需从我们的idx列表中删除所有大于我们提供的重叠阈值的条目。重叠阈值的典型值通常在 0.3-0.5 的范围内。
Malisiewicz 等人的方法本质上与 Felzenszwalb 等人的方法相同,但通过使用矢量化代码,我们能够在非最大抑制方面达到报告的 100 倍加速!
更快的非最大抑制
让我们继续探索几个例子。我们将从我们在这张图片顶部看到的令人毛骨悚然的小女孩僵尸开始:
Figure 1: Detecting three bounding boxes in the image, but non-maximum suppression suppresses two of the overlapping boxes.
事实上,非常有趣的是,我们的人脸检测器在真实、健康的人脸上训练得如此之好,也同样适用于僵尸脸。诚然,他们仍然是“人类”的脸,但所有的血和毁容,我不会惊讶地看到一些奇怪的结果。

Figure 2: It looks like our face detector didn’t generalize as well — the teeth of this zombie looks like a face to the detector.
说到奇怪的结果,看起来我们的面部检测器检测到了右边僵尸的嘴/牙齿区域。也许如果我在僵尸图像上明确训练 HOG +线性 SVM 人脸检测器,结果会更好。

Figure 3: Six bounding boxes are detected around the face, but by applying fast non-maximum suppression we are correctly able to reduce the number of bounding boxes to one.
在这个最后的例子中,我们可以再次看到我们的非最大值抑制算法正在正确地工作——即使 HOG +线性 SVM 检测器检测到了六个原始边界框,应用非最大值抑制已经正确地抑制了五个框,留给我们最后的检测。
摘要
在这篇博文中,我们回顾了 Malisiewicz 等人的非最大抑制方法。
这种方法与 Felzenszwalb 等人的方法几乎相同,但是通过移除内部for循环并使用矢量化代码,我们能够获得显著的加速。
如果你有空的话,一定要感谢托马斯·马利西维茨医生!*
cv2 提供更快的视频文件 FPS。视频捕捉和 OpenCV
原文:https://pyimagesearch.com/2017/02/06/faster-video-file-fps-with-cv2-videocapture-and-opencv/

你有没有通过 OpenCV 的cv2.VideoCapture功能处理过一个视频文件,发现读帧 就是感觉很慢很呆滞?
我经历过,我完全了解那种感觉。
您的整个视频处理管道缓慢移动,每秒钟无法处理一两帧以上的图像,即使您没有执行任何类型的计算开销很大的图像处理操作。
这是为什么呢?
为什么有时候cv2.VideoCapture和相关的.read方法从你的视频文件中轮询另一帧看起来像是一个永恒?
答案几乎都是 视频压缩和帧解码。
根据您的视频文件类型、您安装的编解码器,更不用说您的机器的物理硬件,您的大部分视频处理管道实际上都可能被读取视频文件中的下一帧的解码 所消耗。
*这只是计算上的浪费——还有更好的方法。
在今天博文的剩余部分,我将演示如何使用线程和队列数据结构来 提高您的视频文件 FPS 率超过 52%!
cv2 提供更快的视频文件 FPS。视频捕捉和 OpenCV
当处理视频文件和 OpenCV 时,您可能会使用cv2.VideoCapture功能。
首先,通过传入输入视频文件的路径来实例化cv2.VideoCapture对象。
然后您开始一个循环,调用cv2.VideoCapture的.read方法来轮询视频文件的下一帧,以便您可以在管道中处理它。
问题(以及为什么这种方法会感觉缓慢的原因)是你在 在你的主处理线程中读取和解码帧!
正如我在以前的文章中提到的,.read方法是一个 阻塞操作——你的 Python + OpenCV 应用程序的主线程被完全阻塞(即停滞),直到从视频文件中读取帧,解码,并返回到调用函数。
通过将这些阻塞 I/O 操作转移到一个单独的线程,并维护一个解码帧队列 ,我们实际上可以将 FPS 处理速率提高 52%以上!
这种帧处理速率的提高(因此我们的整体视频处理流水线)来自于大幅降低延迟——我们不必等待.read方法完成读取和解码一帧;取而代之的是,总有一个预解码的帧等待我们去处理。
为了减少延迟,我们的目标是将视频文件帧的读取和解码转移到程序的一个完全独立的线程中,释放我们的主线程来处理实际的图像处理。
但是,在我们欣赏更快的线程化的视频帧处理方法之前,我们首先需要用更慢的非线程版本设置一个基准/基线。
用 OpenCV 读取视频帧的缓慢而简单的方法
本节的目标是使用 OpenCV 和 Python 获得视频帧处理吞吐率的基线。
首先,打开一个新文件,将其命名为read_frames_slow.py,并插入以下代码:
# import the necessary packages
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
args = vars(ap.parse_args())
# open a pointer to the video stream and start the FPS timer
stream = cv2.VideoCapture(args["video"])
fps = FPS().start()
第 2-6 行导入我们需要的 Python 包。我们将使用我的 imutils 库,这是一系列方便的函数,使 OpenCV 和 Python 的图像和视频处理操作更加容易。
如果您还没有安装imutils或 如果您使用的是以前的版本,您可以使用以下命令安装/升级imutils:
$ pip install --upgrade imutils
第 9-12 行然后解析我们的命令行参数。对于这个脚本,我们只需要一个开关--video,它是我们输入视频文件的路径。
第 15 行使用cv2.VideoCapture类打开一个指向--video文件的指针,而第 16 行启动一个计时器,我们可以用它来测量 FPS,或者更具体地说,我们的视频处理流水线的吞吐率。
随着cv2.VideoCapture的实例化,我们可以开始从视频文件中读取帧并逐个处理它们:
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video file stream
(grabbed, frame) = stream.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# resize the frame and convert it to grayscale (while still
# retaining 3 channels)
frame = imutils.resize(frame, width=450)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame = np.dstack([frame, frame, frame])
# display a piece of text to the frame (so we can benchmark
# fairly against the fast method)
cv2.putText(frame, "Slow Method", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# show the frame and update the FPS counter
cv2.imshow("Frame", frame)
cv2.waitKey(1)
fps.update()
在第 19 行我们开始循环视频文件的帧。
对第 21 行上的.read方法的调用返回一个包含以下内容的二元组:
grabbed:布尔值,表示帧是否被成功读取。frame:实际的视频帧本身。
如果grabbed是False,那么我们知道我们已经到达了视频文件的末尾,可以从循环中断开(第 25 和 26 行)。
否则,我们执行一些基本的图像处理任务,包括:
- 将框架的宽度调整为 450 像素。
- 将框架转换为灰度。
- 通过
cv2.putText方法在框架上绘制文本。我们这样做是因为我们将使用cv2.putText函数在下面的快速线程示例中显示我们的队列大小,并且希望有一个公平的、可比较的管道。
第 40-42 行将帧显示到我们的屏幕上,并更新我们的 FPS 计数器。
最后一个代码块处理计算管道的近似 FPS/帧速率吞吐量,释放视频流指针,并关闭任何打开的窗口:
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
stream.release()
cv2.destroyAllWindows()
要执行这个脚本,一定要使用教程底部的 “下载” 部分将源代码+示例视频下载到这篇博文中。
对于这个例子,我们将使用侏罗纪公园预告片的 前 31 秒 (代码下载中包含. mp4 文件):
https://www.youtube.com/embed/lc0UehYemQA?feature=oembed*
我参加了 Hanselminutes 播客:计算机视觉及其对我们日常生活的影响。

高中的时候,我并不是一个出色的演说家。
压力。焦虑。害怕犯一个愚蠢的错误,害怕在满是人的礼堂前说错话,这种恐惧令人麻痹——这种压力压在我身上,严重打击了我公开演讲的信心。
但是在研究生院的四年里,我在渴望战斗的学者面前提交论文,等着一有闪失就扑向你,在我的委员会面前为我的论文辩护,知道我随时会被盘问,我能够克服我对公开演讲的恐惧。
然而,我必须承认:几天前我有点紧张。
你看,我最近在 Hanselminutes 播客 上讲了计算机视觉****监视跟踪,【银行】支票检测识别背后的算法。
《Hanselminutes》的主持人斯科特·汉塞尔曼(Scott Hanselman)是一个很棒的人,也是播客界的传奇人物。能够和他在播客上聊天是一种荣誉!
无论如何,这次采访是相当高层次的(即没有那么技术性),面向的是第一次听到计算机视觉的观众。但它仍然是一个很棒的听力,我肯定会鼓励你去看看。
使用 Python 和 OpenCV 查找相机到对象/标记的距离
原文:https://pyimagesearch.com/2015/01/19/find-distance-camera-objectmarker-using-python-opencv/
最后更新于 2021 年 7 月 8 日。
几天前,一位 PyImageSearch 的读者 Cameron 发来电子邮件,询问如何找到从相机到图像中的物体/标记的距离。他花了一些时间研究,但还没有找到一个实现。
我完全了解卡梅伦的感受。几年前,我在做一个小项目,分析棒球离开投手的手向本垒板移动的过程。
使用运动分析和基于轨迹的跟踪,我能够在视频帧中找到/估计球的位置。因为棒球有已知的大小,我也能估计到本垒板的距离。
这是一个有趣的工作项目,尽管该系统并不像我希望的那样准确——球快速移动的“运动模糊”使得很难获得高度准确的估计。
我的项目绝对是一个“异常”的情况,但总的来说,确定从相机到标记的距离实际上是计算机视觉/图像处理领域中一个非常好的研究问题。你可以找到非常简单明了的技术,比如三角形相似度。您可以使用相机模型的内在参数找到复杂(尽管更精确)的方法。
在这篇博文中,我将向你展示卡梅伦和我是如何想出一个解决方案来计算我们的相机到一个已知物体或标记的距离的。
一定要读一读这篇文章——你不会想错过的!
- 更新 2021 年 7 月:新增三个章节。第一部分介绍如何通过相机校准改进距离测量。第二部分讨论立体视觉和深度相机来测量距离。最后一节简要介绍了激光雷达如何与相机数据配合使用,以提供高度精确的距离测量。
物体/标记到摄像机距离的三角形相似性
为了确定我们的相机到一个已知物体或标记的距离,我们将利用三角形相似度。
三角形的相似性是这样的:假设我们有一个已知宽度的标记或物体。然后我们把这个标记放在离我们相机有一段距离 D 的地方。我们用相机给物体拍照,然后测量像素的表观宽度 P 。这使我们能够推导出我们相机的感知焦距 F :
F =(P×D)/W
例如,假设我将一张标准的8.5×11 英寸的纸放在一张纸上(水平放置; W = 11 ) D = 24 寸在我的相机前,拍一张照片。当我测量图像中纸张的宽度时,我注意到纸张的感知宽度是 P = 248 像素。
我的焦距 F 是:
F =(248 px x24in)/11in = 543.45
随着我继续将相机移近和移离对象/标记,我可以应用三角形相似性来确定对象到相机的距离:
D' = (W x F) / P
同样,为了更具体,让我们假设我把我的相机移动到离我的记号笔 3 英尺(或 36 英寸)远的地方,拍下同一张纸的照片。通过自动图像处理,我能够确定这张纸的感知宽度现在是 170 像素。把这个代入我们现在得到的等式:
D’=(11 英寸 x 543.45)/170 = 35 英寸
或者大约 36 英寸,也就是 3 英尺。
注意:当我为这个例子拍摄照片时,我的卷尺有点松,因此结果会有大约 1 英寸的误差。此外,我还匆忙地拍摄了照片,而不是 100%地在卷尺的尺标上,这增加了 1 英寸的误差。尽管如此,三角形相似性仍然成立,你可以使用这种方法来计算从一个物体或标记到你的相机的距离非常容易。
现在有意义了吗?
太棒了。让我们来看一些代码,看看如何使用 Python、OpenCV、图像处理和计算机视觉技术来找到从您的相机到一个对象或标记的距离。
使用 Python 和 OpenCV 查找相机到物体/标记的距离
让我们着手开始这个项目吧。打开一个新文件,命名为distance_to_camera.py,然后我们开始工作:
# import the necessary packages
from imutils import paths
import numpy as np
import imutils
import cv2
def find_marker(image):
# convert the image to grayscale, blur it, and detect edges
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(gray, 35, 125)
# find the contours in the edged image and keep the largest one;
# we'll assume that this is our piece of paper in the image
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key = cv2.contourArea)
# compute the bounding box of the of the paper region and return it
return cv2.minAreaRect(c)
我们要做的第一件事是导入我们必需的包(第 2-5 行)。我们将使用imutils中的paths将可用图像加载到一个目录中。我们将使用 NumPy 进行数值处理,使用cv2进行 OpenCV 绑定。
从那里我们定义了我们的find_marker函数。这个函数接受一个参数,image,用来查找我们想要计算距离的对象。
在这种情况下,我们使用一张 8.5 x 11 英寸的标准纸作为标记。
我们的第一个任务是在图像中找到这张纸。
为此,我们将把图像转换成灰度,稍微模糊以去除高频噪声,并对第 9-11 行应用边缘检测。
应用这些步骤后,我们的图像应该看起来像这样:

Figure 1: Applying edge detection to find our marker, which in this case is a piece of paper.
如你所见,我们的记号笔(这张纸)的边缘显然已经被损坏了。现在我们需要做的就是找到代表这张纸的轮廓(即轮廓)。
我们通过使用cv2.findContours函数(注意处理不同的 OpenCV 版本)在行 15 和 16 上找到我们的标记,然后在行 17 上确定面积最大的轮廓。
我们假设面积最大的轮廓是我们的一张纸。这个假设适用于这个特殊的例子,但实际上在图像中寻找标记是高度特定的应用。
在我们的例子中,简单的边缘检测和寻找最大的轮廓效果很好。我们还可以通过应用轮廓近似,丢弃没有 4 个点的任何轮廓(因为一张纸是矩形的,因此有 4 个点),然后找到最大的 4 点轮廓,来使这个例子更加健壮。
注意:关于这种方法的更多信息可以在这篇文章中找到关于构建一个超级移动文档扫描仪的文章。
在图像中寻找标记的其他替代方法是利用颜色,使得标记的颜色与图像中场景的其余部分明显不同。您还可以应用关键点检测、局部不变描述符和关键点匹配等方法来查找标记;然而,这些方法超出了本文的范围,而且是高度特定于应用程序的。
无论如何,现在我们有了对应于我们的标记的轮廓,我们将包含 (x,y)-坐标和框的宽度和高度(以像素为单位)的边界框返回给第 20 行的调用函数。
让我们快速定义一个函数,使用上面详述的三角形相似性计算到一个对象的距离:
def distance_to_camera(knownWidth, focalLength, perWidth):
# compute and return the distance from the maker to the camera
return (knownWidth * focalLength) / perWidth
该函数采用标记的knownWidth、计算的focalLength和图像中对象的感知宽度(以像素为单位测量),并应用上面详述的三角形相似度来计算到对象的实际距离。
要了解我们如何利用这些功能,请继续阅读:
# initialize the known distance from the camera to the object, which
# in this case is 24 inches
KNOWN_DISTANCE = 24.0
# initialize the known object width, which in this case, the piece of
# paper is 12 inches wide
KNOWN_WIDTH = 11.0
# load the furst image that contains an object that is KNOWN TO BE 2 feet
# from our camera, then find the paper marker in the image, and initialize
# the focal length
image = cv2.imread("images/2ft.png")
marker = find_marker(image)
focalLength = (marker[1][0] * KNOWN_DISTANCE) / KNOWN_WIDTH
找到图像中物体或标记的距离的第一步是校准和计算焦距。为此,我们需要知道:
- 相机与物体的距离。
- 宽度(单位为英寸、米等。)的这个对象。注意:也可以使用高度,但是这个例子只使用宽度。
让我们也花点时间,提一下我们正在做的并不是真正的摄像机校准。真正的相机校准涉及相机的内在参数,你可以在这里阅读更多。
在第 28 行我们初始化我们已知的KNOWN_DISTANCE从相机到我们的对象是 24 英寸。在的第 32 行,我们将对象的KNOWN_WIDTH初始化为 11 英寸(即一张水平放置的标准 8.5×11 英寸的纸)。
下一步很重要: 这是我们简单的校准步骤。
我们在第 37 行处从磁盘上加载第一张图像—我们将使用这张图像作为我们的校准图像。
一旦图像被加载,我们在图像的第 38 行的处找到这张纸,然后使用三角形相似度计算第 39 行的处的focalLength。
现在我们已经“校准”了我们的系统,并且有了focalLength,我们可以很容易地计算从我们的相机到后续图像中的标记的距离。
让我们看看这是如何做到的:
# loop over the images
for imagePath in sorted(paths.list_images("images")):
# load the image, find the marker in the image, then compute the
# distance to the marker from the camera
image = cv2.imread(imagePath)
marker = find_marker(image)
inches = distance_to_camera(KNOWN_WIDTH, focalLength, marker[1][0])
# draw a bounding box around the image and display it
box = cv2.cv.BoxPoints(marker) if imutils.is_cv2() else cv2.boxPoints(marker)
box = np.int0(box)
cv2.drawContours(image, [box], -1, (0, 255, 0), 2)
cv2.putText(image, "%.2fft" % (inches / 12),
(image.shape[1] - 200, image.shape[0] - 20), cv2.FONT_HERSHEY_SIMPLEX,
2.0, (0, 255, 0), 3)
cv2.imshow("image", image)
cv2.waitKey(0)
我们开始在第 42 行的图像路径上循环。
然后,对于列表中的每一幅图像,我们在行 45 处从磁盘上加载图像,在行 46、处找到图像中的标记,然后在行 47 处计算物体到摄像机的距离。
从那里,我们简单地在我们的标记周围画出边界框,并在第 50-57 行的上显示距离(在第 50 行的上计算boxPoints,注意处理不同的 OpenCV 版本)。
结果
要查看我们的脚本,请打开终端,导航到您的代码目录,并执行以下命令:
$ python distance_to_camera.py
如果一切顺利,您应该首先看到2ft.png的结果,这是我们用来“校准”系统和计算初始focalLength的图像:
从上面的图像中我们可以看到,我们的焦距是正确确定的,根据代码中的KNOWN_DISTANCE和KNOWN_WIDTH变量,到纸张的距离是 2 英尺。
现在我们有了焦距,我们可以计算到后续图像中标记的距离:
在上面的例子中,我们的相机现在距离标记大约 3 英尺。
让我们试着再向后移动一英尺:
同样,重要的是要注意,当我捕捉这个例子的照片时,我做得太匆忙,在卷尺中留下了太多的松弛。此外,我也没有确保我的相机是 100%对齐的脚标记,所以再次,在这些例子中大约有 1 英寸的误差。
尽管如此,本文中详细介绍的三角形相似性方法仍然有效,并允许您找到从图像中的对象或标记到您的相机的距离。
通过摄像机校准改进距离测量
为了进行距离测量,我们首先需要校准我们的系统。在这篇文章中,我们使用了一个简单的“像素/度量”技术。
然而,通过计算外部和内部参数来执行适当的摄像机校准,可以获得更好的精度:
- 外部参数是用于将物体从世界坐标系转换到摄像机坐标系的旋转和平移矩阵
- 内在参数是内部相机参数,如焦距,将信息转换成像素
最常见的方法是使用 OpenCV 执行棋盘式摄像机校准。这样做将会消除影响输出图像的径向失真和切向失真,从而影响图像中对象的输出测量。
这里有一些资源可以帮助您开始进行相机校准:
用于距离测量的立体视觉和深度相机
作为人类,我们认为拥有两只眼睛是理所当然的。即使我们在事故中失去了一只眼睛,我们仍然可以看到和感知我们周围的世界。
然而,只用一只眼睛我们就失去了重要的信息——。
*深度知觉给我们从我们站的地方到我们面前的物体的感知距离。为了感知深度,我们需要两只眼睛。
另一方面,大多数相机只有一只眼睛,这就是为什么使用标准 2D 相机获得深度信息如此具有挑战性(尽管你可以使用深度学习模型来尝试从 2D 图像中“学习深度”)。
您可以使用两个摄像头(如 USB 网络摄像头)创建能够计算深度信息的立体视觉系统:
或者,你可以使用内置深度相机的特定硬件,如 OpenCV 的 AI Kit (OAK-D) 。
深度信息激光雷达
为了获得更精确的深度信息,你应该考虑使用激光雷达。激光雷达使用光传感器来测量传感器与其前方任何物体之间的距离。
激光雷达在无人驾驶汽车中尤其受欢迎,因为在无人驾驶汽车中,摄像头根本不够用。
我们将在 PyImageSearch 大学内部介绍如何将激光雷达用于自动驾驶汽车应用。
摘要
在这篇博文中,我们学习了如何确定图像中的一个已知物体到我们相机的距离。
为了完成这项任务,我们利用了三角形相似度,这要求我们在应用我们的算法之前知道两个重要参数:
- 我们用作标记的对象的宽度(或高度),以某种距离度量,如英寸或米。
- 步骤 1 中摄像机到标记的距离(英寸或米)。
然后,可以使用计算机视觉和图像处理算法来自动确定以像素为单位的物体的感知宽度/高度,并完成三角形相似性,给出我们的焦距。
然后,在随后的图像中,我们只需要找到我们的标记/对象,并利用计算的焦距来确定从相机到对象的距离。*
使用 Python 和 OpenCV 寻找图像中的亮点
原文:https://pyimagesearch.com/2014/09/29/finding-brightest-spot-image-using-python-opencv/
最初我打算写一篇关于我的开始使用深度学习指南的后续文章,但是由于一些不幸的个人事件,我没能完成这篇博文。但是不要担心…我今天仍然有一个非常棒的教程给你!
烂教程比温啤酒还烂。
你想知道为什么吗?
因为你总能在几秒钟内一口气喝下一杯温啤酒…
但是你可以花 小时 在阅读误导性的教程时误入歧途。
这是我写这篇文章的灵感——我真的很讨厌我看过的所有详细说明如何使用 OpenCV 找到图像最亮点的博客文章。
你看,他们省略了一行代码,这对于提高抗噪能力至关重要。
如果你和我一样,那就不太好了。
所以请坐好。放松点。并且知道你将会读到一本好的教程。你不会在这里浪费时间。
在这篇博文中,我将向你展示如何使用 Python 和 OpenCV 找到图像中最亮的地方……我还将向你展示一行预处理代码,你将需要这些代码来改善你的结果。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
你需要的不仅仅是cv2.minMaxLoc
几周前,一位 PyImageSearch 的读者来信询问寻找图像中最亮点的最佳方法。
你看,他们正在处理视网膜图像(见本文顶部的例子)。这些图像通常为橙色或黄色,圆形,包含眼睛的重要物理结构,包括视神经和黄斑。
这位读者想知道找到视神经中心的最佳方法,视神经中心通常是视网膜图像中最亮的地方。
要使用 Python 和 OpenCV 找到图像的最亮点,可以使用cv2.minMaxLoc函数。
然而,这里的术语“斑点”有点误导。
根据cv2.minMaxLoc图像的“最亮点”实际上不是一个区域——它只是整个图像中最亮的单个像素。
这意味着如果不采取必要的预防措施,cv2.minMaxLoc功能极易受到噪音的影响。在正常情况下不会有亮点的区域(在这种情况下,除了视神经中心以外的区域)中的单个亮点可能会极大地影响您的结果。
相反,你最好检查图像的区域,而不是单个像素。当你检查区域时,你让平均值平衡了一切——并且你不容易受噪音影响。
那么,在不明确检查图像的每个区域的情况下,如何模仿这种“区域”效果呢?
我带你去看。
这篇博客文章的其余部分致力于向你展示如何使用 Python 和 OpenCV 找到图像的亮点
使用 Python 和 OpenCV 寻找图像中的亮点
让我们开始吧。
打开你喜欢的编辑器,创建一个名为bright.py的新文件,让我们开始吧。
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", help = "path to the image file")
ap.add_argument("-r", "--radius", type = int,
help = "radius of Gaussian blur; must be odd")
args = vars(ap.parse_args())
# load the image and convert it to grayscale
image = cv2.imread(args["image"])
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
在2-4 行我们将导入我们需要的包。如果你是一个普通的 PyImageSearch 读者,这些包现在对你来说应该感觉像旧帽子。我们将使用 NumPy 进行数值处理,argparse解析命令行参数,而cv2用于 OpenCV 绑定。
从那里,我们将在的第 7-11 行解析我们的命令行参数。这里没什么特别的。
第一个开关,--image,是我们要寻找的最亮点的图像路径。第二个开关--radius,是一个整数,表示我们将要应用于图像的高斯模糊的半径。
需要注意的是,这个半径值必须是奇数和而不是 偶数。
接下来,让我们继续在行 14 加载图像,在行 15 复制它,并在行 15 将其转换为灰度。
易感方法:
现在,让我们继续应用“可能方法”来检测图像中最亮的点:
# perform a naive attempt to find the (x, y) coordinates of
# the area of the image with the largest intensity value
(minVal, maxVal, minLoc, maxLoc) = cv2.minMaxLoc(gray)
cv2.circle(image, maxLoc, 5, (255, 0, 0), 2)
# display the results of the naive attempt
cv2.imshow("Naive", image)
找到图像中最亮点的简单方法是使用cv2.minMaxLoc函数 ,无需任何预处理 。这个函数需要一个参数,也就是我们的灰度图像。然后,该函数获取我们的灰度图像,并分别找到具有最小和最大亮度值的像素的值和 (x,y) 位置。
分解一下:minVal包含最小像素亮度值,maxVal包含最大像素亮度值,minLoc指定 minVal 的 (x,y) 坐标,maxLoc指定maxLoc的 (x,y) 坐标。
在这个应用程序中,我们只关心具有最大值的像素,所以我们将抓住它,在第 20 行的区域周围画一个圆,并在第 24 行的上显示它。
这种方法的最大问题,也是为什么我称之为寻找图像中最亮点的敏感方法,是它的极易受噪声影响。
*一个像素可能会严重影响您的结果…
那么我们如何解决这个问题呢?
简单。
我们将通过预处理步骤应用高斯模糊。
稍微稳健一点的方法:
让我们来看看如何做到这一点:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", help = "path to the image file")
ap.add_argument("-r", "--radius", type = int,
help = "radius of Gaussian blur; must be odd")
args = vars(ap.parse_args())
# load the image and convert it to grayscale
image = cv2.imread(args["image"])
orig = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# perform a naive attempt to find the (x, y) coordinates of
# the area of the image with the largest intensity value
(minVal, maxVal, minLoc, maxLoc) = cv2.minMaxLoc(gray)
cv2.circle(image, maxLoc, 5, (255, 0, 0), 2)
# display the results of the naive attempt
cv2.imshow("Naive", image)
# apply a Gaussian blur to the image then find the brightest
# region
gray = cv2.GaussianBlur(gray, (args["radius"], args["radius"]), 0)
(minVal, maxVal, minLoc, maxLoc) = cv2.minMaxLoc(gray)
image = orig.copy()
cv2.circle(image, maxLoc, args["radius"], (255, 0, 0), 2)
# display the results of our newly improved method
cv2.imshow("Robust", image)
cv2.waitKey(0)
就像我上面提到的,使用没有任何预处理的cv2.minMaxLoc会让你非常容易受到噪声的影响。
相反,最好先对图像应用高斯模糊以消除高频噪声。这样,即使像素值非常大(还是因为噪声),也会被其邻居平均掉。
在第 28 行上,我们使用命令行参数提供的半径来应用高斯模糊。
然后我们再次调用cv2.minMaxLoc来寻找图像中最亮的像素。
然而,由于我们已经应用了模糊预处理步骤,我们已经将所有像素与彼此提供的radius一起平均。这样做可以消除高频噪声,使cv2.minMaxLoc更不容易受到影响。
通过使用更大的半径,我们将在更大的像素邻域内进行平均——从而模仿图像的更大区域。
通过使用更小的半径,我们可以在更小的区域内进行平均。
确定正确的半径在很大程度上取决于您正在开发的应用程序和您试图解决的任务。
结果
启动终端并执行以下命令:
$ python bright.py --image retina.png --radius 41
如果一切顺利,您应该会看到下图:
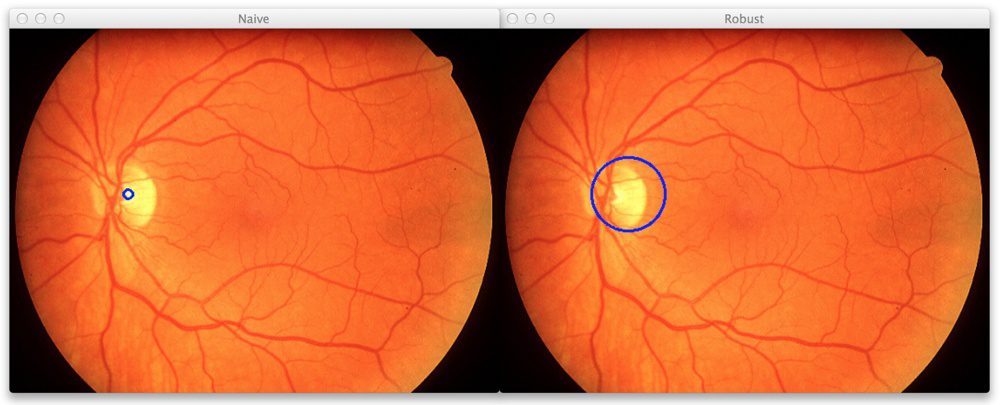
Figure 1: Detecting the brightest area of a retinal image using our naive and robust methods. The results are good and look quite similar.
在左边的*上,我们有使用没有任何预处理的cv2.minMaxLoc 的易受影响的方法,在右边的上,我们有健壮的方法。***
**但是你可能会看着这些图像说,“嗨,阿德里安,他们都探测到了图像的同一个区域!”
你说得对。他们做到了。
但是,请注意,当您发出以下命令时,如果我将一个亮点添加到该图像的顶部中间部分,会发生什么情况:
$ python bright.py --image images/retina-noise.png --radius 41
您的结果应该类似于:
Figure 2: Adding a single bright pixel to the image has thrown off the results of cv2.minMaxLoc without any pre-processing (left), but the robust method is still able to easily find the optic center (right).
现在,朴素的cv2.minMaxLoc方法找到这个白色像素。先说清楚。该功能工作正常。它实际上是在整个图像中找到一个最亮的像素。
然而,这真的不是我们想要的。
我们感兴趣的是图像中最亮的 区域 ,也就是视神经中心。
幸运的是,通过利用高斯模糊,我们能够对给定半径内的像素邻域进行平均,从而丢弃单个亮像素,并缩小光学中心区域,这没有问题。
显然,让健壮方法正确工作的一个重要方面是正确设置您的radius大小。如果您的radius尺寸太小,您将无法找到图像中更大、更亮的区域。
但是如果你将radius的大小设置得太大,那么你将会检测到太大的区域,错过较小的区域,导致低于标准的结果。
一定要花些时间玩玩radius尺寸,看看结果。
摘要
在这篇博文中,我向你展示了为什么在找到图像中最亮的点之前应用高斯模糊是至关重要的。
通过应用高斯模糊,可以将给定半径内的像素平均在一起。取平均值可以消除高频噪声,否则这些噪声会干扰cv2.minMaxLoc函数的结果。
确保探索高斯模糊半径的适当值。如果你取的值太小,你会减轻平均值的影响,错过更大更亮的区域。但是如果你的半径太大,你就探测不到小的明亮区域。***
用 OpenCV 寻找轮廓中的极值点
原文:https://pyimagesearch.com/2016/04/11/finding-extreme-points-in-contours-with-opencv/

几周前,我演示了如何以顺时针方式对旋转的边界框的 (x,y) 坐标进行排序——这是一项非常有用的技能,在许多计算机视觉应用程序中至关重要,包括(但不限于)透视变换和计算图像中对象的尺寸。
一位 PyImageSearch 读者发来电子邮件,对这种顺时针顺序感到好奇,并提出了类似的问题:
有可能从原始轮廓中找到最北、最南、最东、最西的坐标吗?
“当然是!”,我回答。
今天,我将分享我的解决方案,用 OpenCV 和 Python 沿着轮廓寻找极值点。
用 OpenCV 寻找轮廓中的极值点
在这篇博文的剩余部分,我将演示如何找到最北、最南、最东和最西 (x,y)-沿着等高线的坐标,就像这篇博文顶部的图像一样。
虽然这项技能本身并不十分有用,但它通常被用作更高级的计算机视觉应用的预处理步骤。这种应用的一个很好的例子是 手势识别:

Figure 1: Computing the extreme coordinates along a hand contour
在上图中,我们已经从图像中分割出皮肤/手,计算出手轮廓的凸包(用蓝色勾勒),然后沿着凸包红色圆圈找到极值点。
通过计算手部的极值点,我们可以更好地逼近手掌区域(突出显示为蓝色圆圈):

Figure 2: Using extreme points along the hand allows us to approximate the center of the palm.
这反过来让我们能够识别手势,比如我们举起的手指数量:

Figure 3: Finding extreme points along a contour with OpenCV plays a pivotal role in hand gesture recognition.
注:我在 PyImageSearch 大师课程中讲述了如何识别手势,所以如果你有兴趣了解更多,一定要在下一次开放注册中申请你的位置!**
实现这样一个手势识别系统超出了这篇博文的范围,所以我们将利用下面的图片:

Figure 4: Our example image containing a hand. We are going to compute the extreme north, south, east, and west (x, y)-coordinates along the hand contour.
我们的目标是计算图像中沿着手的轮廓的极值点。
让我们开始吧。打开一个新文件,命名为extreme_points.py,让我们开始编码:
# import the necessary packages
import imutils
import cv2
# load the image, convert it to grayscale, and blur it slightly
image = cv2.imread("hand_01.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# threshold the image, then perform a series of erosions +
# dilations to remove any small regions of noise
thresh = cv2.threshold(gray, 45, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.erode(thresh, None, iterations=2)
thresh = cv2.dilate(thresh, None, iterations=2)
# find contours in thresholded image, then grab the largest
# one
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
2 号线和 3 号线导入我们需要的包。然后,我们从磁盘加载示例图像,将其转换为灰度,并稍微模糊。
第 12 行执行阈值处理,允许我们从图像的其余部分中分割出手部区域。阈值处理后,我们的二值图像如下所示:

Figure 5: Our image after thresholding. The outlines of the hand are now revealed.
为了检测手的轮廓,我们调用cv2.findContours,然后对轮廓进行排序以找到最大的轮廓,我们假设它就是手本身(第 18-21 行)。
在我们能够沿着一个轮廓找到极值点之前,重要的是理解一个轮廓仅仅是一个由 (x,y) 坐标组成的 NumPy 数组。因此,我们可以利用 NumPy 函数来帮助我们找到极值坐标。
# determine the most extreme points along the contour
extLeft = tuple(c[c[:, :, 0].argmin()][0])
extRight = tuple(c[c[:, :, 0].argmax()][0])
extTop = tuple(c[c[:, :, 1].argmin()][0])
extBot = tuple(c[c[:, :, 1].argmax()][0])
例如,行 24 通过对 x- 值调用argmin()并抓取与argmin()返回的索引关联的整个 (x,y)-坐标,找到整个轮廓数组c中最小的**x-坐标(即“西”值)。
类似地,行 25 使用argmax()函数找到轮廓数组中最大的x-坐标(即“东”值)。*
****第 26 行和第 27 行**执行相同的操作,只是对于 y 坐标,分别给出“北”和“南”坐标。
现在我们有了最北、最南、最东和最西的坐标,我们可以把它们画在我们的image上:
# draw the outline of the object, then draw each of the
# extreme points, where the left-most is red, right-most
# is green, top-most is blue, and bottom-most is teal
cv2.drawContours(image, [c], -1, (0, 255, 255), 2)
cv2.circle(image, extLeft, 8, (0, 0, 255), -1)
cv2.circle(image, extRight, 8, (0, 255, 0), -1)
cv2.circle(image, extTop, 8, (255, 0, 0), -1)
cv2.circle(image, extBot, 8, (255, 255, 0), -1)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
线 32 在黄色处画出手的轮廓,而线 33-36 为每个极值点画出圆圈,详细如下:
- 西:红色
- 东方:绿色
- 北:蓝色
- 南方:蓝绿色
最后,第 39 行和第 40 行将结果显示到我们的屏幕上。
要执行我们的脚本,请确保下载与本文相关的代码和图像(使用本教程底部的“下载”表单),导航到您的代码目录,然后执行以下命令:
$ python extreme_points.py
然后,您应该会看到下面的输出图像:

Figure 6: Detecting extreme points in contours with OpenCV and Python.
正如你所看到的,我们已经成功地标记了手上的每个极值点。最西边的点用红色标注,最北边的点用蓝色,最东边的点用绿色,最后最南边的点用青色标注。
下面我们可以看到第二个标记 a 手的极值点的例子:

Figure 7: Labeling extreme points along a hand contour using OpenCV and Python.
让我们检查最后一个实例:

Figure 8: Again, were are able to accurately compute the extreme points along the contour.
这就是全部了!
请记住,cv2.findContours返回的轮廓列表只是一个由 (x,y) 坐标组成的 NumPy 数组。通过调用这个数组上的argmin()和argmax(),我们可以提取出极值 (x,y)-坐标。
摘要
在这篇博文中,我详细介绍了如何沿着给定的等高线找到最北、最南、最东、最西的坐标 (x,y) 。该方法可用于原始轮廓和旋转边界框。
虽然沿着轮廓寻找极值点本身似乎并不有趣,但它实际上是一项非常有用的技能,尤其是作为更高级的计算机视觉和图像处理算法的预处理步骤,例如手势识别的 T4。
要了解更多关于手势识别的信息,以及如何沿着轮廓寻找极值点对识别手势有用, 请务必注册 PyImageSearch Gurus 课程的下一次公开注册!
里面见!***
使用 Python 和 OpenCV 在图像中查找形状
原文:https://pyimagesearch.com/2014/10/20/finding-shapes-images-using-python-opencv/

在我们开始这篇文章之前,让我们先来谈谈 Oscar,一个专门的 PyImageSearch 阅读器。
他在计算机视觉方面刚刚起步——他已经采取了掌握这门学科的最佳途径: 创建自己的项目并解决它们。
Oscar 拿起一本我的书, 实用 Python 和 OpenCV ,单个周末通读一遍,然后决定给自己创建一个项目,解决它。
他绝对、100%证明你可以从非常有限(或者没有)的计算机视觉知识开始,在 单周末 学习构建和解决计算机视觉项目所必需的技能。
今天我们将讨论奥斯卡的第一个项目。他给我发来了这篇文章顶部的图片,并向我寻求一些指导,告诉我如何:
- 仅识别黑色背景的图形
- 如果两个或更多的图形重叠,它们都应该被当作一个对象
- 检测并绘制每个黑色形状周围的轮廓
- 计算黑色形状的数量
老实说,这是一个伟大的第一个项目。
我回复了奥斯卡,并就如何解决这个问题给了他一些建议。我告诉他实用 Python 和 OpenCV 中哪些章节该读,我建议了一个解决问题的高级方法。
一天后,我发现我的收件箱里有了回复——奥斯卡解决了这个问题!
我们继续调整他的代码,并改善结果。
今天我将展示最终产品。
所以让我们为奥斯卡鼓掌。他做得很好。而他的证明是,使用 实用 Python 和 OpenCV 只需要一个的单周末就可以学会计算机视觉。
*# 使用 Python 和 OpenCV 在图像中查找形状
让我们开始吧。
打开一个新文件,命名为find_shapes.py,然后我们开始工作。
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", help = "path to the image file")
args = vars(ap.parse_args())
# load the image
image = cv2.imread(args["image"])
我们要做的第一件事是导入我们需要的 Python 包。我们将使用 NumPy 进行数值处理,argparse解析我们的命令行参数,而cv2用于 OpenCV 绑定。我的 imutils 套装有一个我们会用到的便利功能。
第 8-10 行处理命令行参数的解析。我们只需要一个开关--image,它是我们在磁盘上的映像的路径。
最后,我们将在第 13 行加载我们的映像。
现在我们已经从磁盘上加载了我们的图像,我们可以继续检测图像中的黑色形状。
我们的目标:检测图像中的黑色形状。
使用cv2.inRange功能检测这些黑色形状实际上非常容易:
# find all the 'black' shapes in the image
lower = np.array([0, 0, 0])
upper = np.array([15, 15, 15])
shapeMask = cv2.inRange(image, lower, upper)
在第 16 行和第 17 行上,我们在 BGR 颜色空间中定义了一个lower和一个upper边界点。记住,OpenCV 以 BGR 顺序存储图像,而不是 RGB。
我们的lower边界由纯黑色组成,分别为蓝色、绿色和红色通道指定零。
我们的upper边界由非常暗的灰色阴影组成,这次为每个通道指定 15。
然后我们在第 18 行的上找到上下范围内的所有像素。
我们的shapeMask现在看起来像这样:

Figure 1: Finding all the black shapes in the image.
正如你所看到的,原始图像中的所有黑色形状现在都是在黑色背景上的白色。
下一步是检测shapeMask中的轮廓。这也很简单:
# find the contours in the mask
cnts = cv2.findContours(shapeMask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
print("I found {} black shapes".format(len(cnts)))
cv2.imshow("Mask", shapeMask)
# loop over the contours
for c in cnts:
# draw the contour and show it
cv2.drawContours(image, [c], -1, (0, 255, 0), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
我们调用行 21 和 22 上的cv2.findContours,指示它找到形状的所有外部轮廓(即边界)。
由于不同版本的 OpenCV 处理轮廓的方式不同,我们解析第 23 行的轮廓。
从那里,我们将找到的轮廓数打印到控制台上。
然后,我们开始在第 28 行的每个单独的轮廓上循环,并在第 30 行的原始图像上绘制形状的轮廓。
这就是全部了!
要执行该脚本,启动一个 shell,并发出以下命令:
$ python find_shapes.py --image shapes.png
I found 6 black shapes
如果一切顺利,您现在可以在黑色形状之间循环,在每个形状周围绘制绿色轮廓:

Figure 2: We have successfully found the black shapes in the image.
正如你所看到的,我们已经清楚地发现了图像中的黑色形状!
所有这些都在 30 行代码之内,其中大部分是导入、注释和解析命令行参数。
摘要
在这篇文章中,我们讨论了如何使用cv2.inRange和cv2.findContours函数在图像中找到形状。
这篇文章很大程度上是受 Oscar 的启发,他是一位专门的 PyImageSearch 读者,他来信询问如何解决这个问题。
你看,Oscar 拿起一本 实用 Python 和 OpenCV ,通读一遍,然后决定自己开发项目来磨砺和磨练自己的技能。
这是目前为止最好的学习方法——我强烈推荐给任何对计算机视觉感兴趣的人。
无论如何,如果你想像 Oscar 一样学习计算机视觉的秘密(在一个单周末), 只需点击这里 ,拿起一份实用 Python 和 OpenCV。奥斯卡成功了,我知道你也会成功的!
再次感谢奥斯卡!祝贺您的第一个 OpenCV 项目成功!*
使用 Keras、TensorFlow 和深度学习微调 ResNet
原文:https://pyimagesearch.com/2020/04/27/fine-tuning-resnet-with-keras-tensorflow-and-deep-learning/

在本教程中,您将学习如何使用 Keras、TensorFlow 和深度学习来微调 ResNet。
几个月前,我在 Twitter 上发帖请求我的粉丝们帮助创建一个数据集,里面有迷彩服和非迷彩服:
这个数据集将被用于一个特别的项目,这个项目由 Victor Gevers 负责,他是 GDI 一个受人尊敬的道德黑客。基础,我正在努力(两个星期后会有更多的内容,届时我将公布我们所构建的内容的细节)。
两个 PyImageSearch 的读者,Julia Riede 和 Nitin Rai,不仅站出来帮忙 还打了一个本垒打!
他们俩花了几天时间为每门课下载图片,整理文件,然后上传,这样我和 Victor 就可以用它们来训练一个模型了——非常感谢你们,Julia 和 Nitin 没有你我们不可能成功!
在我开始使用伪装与非伪装数据集的几天后,我收到了一封来自 PyImageSearch 读者 Lucas 的电子邮件:
嗨,阿德里安,我是图片搜索博客的忠实粉丝。这对我的本科项目帮助很大。
我有个问题要问你:
有没有关于如何微调 ResNet 的教程?
我看了你的档案,看起来你已经涉及了其他架构的微调(例如。VGGNet)但是我在 ResNet 上什么都找不到。过去几天,我一直试图用 Keras/TensorFlow 对 ResNet 进行微调,但总是出错。
如果你能帮我,我将不胜感激。
我已经计划在迷彩与非迷彩服装数据集的基础上微调一个模型,所以帮助卢卡斯似乎是一个自然的选择。
在本教程的剩余部分,您将:
- 探索创新的 ResNet 架构
- 了解如何使用 Keras 和 TensorFlow 对其进行微调
- 用于伪装与非伪装服装检测的微调 ResNet
两周后,我将向您展示我和 Victor 应用伪装检测的实际、真实的使用案例——这是一个很棒的故事,您不会想错过它的!
要了解如何使用 Keras 和 TensorFlow 微调 ResNet,继续阅读!
使用 Keras、TensorFlow 和深度学习微调 ResNet
在本教程的第一部分,您将了解 ResNet 架构,包括我们如何使用 Keras 和 TensorFlow 微调 ResNet。
从那里,我们将详细讨论我们的迷彩服与普通服装图像数据集。
然后,我们将查看我们的项目目录结构,并继续:
- 实现我们的配置文件
- 创建一个 Python 脚本来构建/组织我们的图像数据集
- 使用 Keras 和 TensorFlow 实现用于微调 ResNet 的第二个 Python 脚本
- 执行训练脚本并在我们的数据集上微调 ResNet
我们开始吧!
什么是 ResNet?
ResNet 是由何等人在他们 2015 年的开创性论文 深度残差学习用于图像识别 中首次介绍的——该论文被引用了惊人的 43064 次!
2016 年的一篇后续论文, 深度剩余网络 中的身份映射,进行了一系列的消融实验,玩弄了剩余模块中各种成分的包含、移除和排序,最终产生了 ResNet 的一个变种,即:
- 更容易训练
- 更能容忍超参数,包括正则化和初始学习率
- 广义更好
ResNet 可以说是最重要的网络架构,因为:
- Alex net——这在 2012 年重新点燃了研究人员对深度神经网络的兴趣
- VGGNet——演示了如何仅使用 3×3 卷积成功训练更深层次的神经网络(2014 年)
- Google net——介绍了初始模块/微架构(2014 年)
事实上,ResNet 采用的技术已经成功应用于非计算机视觉任务,包括音频分类和自然语言处理(NLP)!
ResNet 是如何工作的?
注:以下部分改编自我的书第十二章用 Python 进行计算机视觉的深度学习(从业者捆绑)。
何等人介绍的原始残差模块依靠的是标识映射的概念,即取模块的原始输入并将其加到一系列运算的输出的过程:
在模块的顶端,我们接受一个输入到模块(即网络中的前一层)。右分支是一个“线性捷径”——它将输入连接到模型底部的加法运算。然后,在剩余模块的左分支上,我们应用一系列卷积(两者都是 3×3 )、激活和批量规格化。这是构造卷积神经网络时要遵循的标准模式。
但令 ResNet 有趣的是,他等人建议将 CONV、RELU 和 BN 层的输出加上原始输入。
我们称这种加法为身份映射,因为输入(身份)被添加到一系列操作的输出中。
这也是术语残差的使用方式——“残差”输入被添加到一系列层操作的输出中。输入和加法节点之间的连接称为快捷方式。
虽然传统的神经网络可以被视为学习函数 y = f(x) ,但残差层试图通过 f(x) + id(x) = f(x) + x 来逼近 y ,其中 id(x) 是恒等函数。
这些剩余层从身份函数开始,随着网络的学习而进化变得更加复杂。这种类型的剩余学习框架允许我们训练比以前提出的架构更深的网络。
此外,由于输入包含在每个剩余模块中,结果是网络可以更快地学习和更大的学习速率。**
*在 2015 年的原始论文中,何等人还包括了对原始残差模块的扩展,称为瓶颈:
在这里,我们可以看到相同的身份映射正在发生,只是现在剩余模块的左分支中的 CONV 层已被更新:
- 我们使用了三个 CONV 层,而不是两个
- 第一个和最后一个 CONV 层是 1×1 卷积
- 在前两个 CONV 层中学习的过滤器数量是在最终 CONV 中学习的过滤器数量的 1/4
残差模块的这种变化充当了一种形式的维度缩减,从而减少了网络中的参数总数(并且这样做不会牺牲准确性)。这种形式的降维被称为瓶颈。
何等人 2016 年发表的关于深度剩余网络中身份映射的论文进行了一系列的消融研究,玩转了剩余模块中各种组件的包含、移除和排序,最终产生了预激活:的概念
在不涉及太多细节的情况下,预激活残差模块重新排列了卷积、批量归一化和激活的执行顺序。
原始剩余模块(具有瓶颈)接受一个输入(即 RELU 激活图),然后在将该输出添加到原始输入并应用最终 RELU 激活之前应用一系列(CONV => BN => RELU) * 2 => CONV => BN。
他们 2016 年的研究表明,相反,应用一系列(BN => RELU => CONV) * 3会导致更高精度的模型,更容易训练。
我们称这种层排序方法为预激活,因为我们的 RELUs 和批处理规格化被放置在卷积之前,这与在卷积之后应用 RELUs 和批处理规格化的典型方法形成对比。
关于 ResNet 更完整的回顾,包括如何使用 Keras/TensorFlow 从头实现,一定要参考我的书, 用 Python 进行计算机视觉的深度学习 。
如何用 Keras 和 TensorFlow 进行微调?
为了用 Keras 和 TensorFlow 微调 ResNet,我们需要使用预训练的 ImageNet 权重从磁盘加载 ResNet,但忽略了全连接层头。
我们可以使用以下代码来实现这一点:
>>> baseModel = ResNet50(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
检查baseModel.summary() ,你会看到以下内容:
...
conv5_block3_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 conv5_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_add (Add) (None, 7, 7, 2048) 0 conv5_block2_out[0][0]
conv5_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 conv5_block3_add[0][0]
==================================================================================================
在这里,我们可以看到 ResNet 架构中的最后一层(同样,没有全连接的层头)是一个激活层,即 7 x 7 x 2048。
我们可以通过接受baseModel.output然后应用 7×7 平均池来构造一个新的、刚刚初始化的层头,然后是我们的全连接层:
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(256, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(len(config.CLASSES), activation="softmax")(headModel)
在构造了headModel之后,我们只需要将它附加到 ResNet 模型的主体:
model = Model(inputs=baseModel.input, outputs=headModel)
现在,如果我们看一下model.summary(),我们可以得出结论,我们已经成功地向 ResNet 添加了一个新的全连接层头,使架构适合微调:
conv5_block3_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 conv5_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_add (Add) (None, 7, 7, 2048) 0 conv5_block2_out[0][0]
conv5_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 conv5_block3_add[0][0]
__________________________________________________________________________________________________
average_pooling2d (AveragePooli (None, 1, 1, 2048) 0 conv5_block3_out[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 2048) 0 average_pooling2d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 256) 524544 flatten[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 256) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 2) 514 dropout[0][0]
==================================================================================================
在本教程的剩余部分,我将为您提供一个使用 Keras 和 TensorFlow 微调 ResNet 的完整工作示例。
我们的迷彩服和普通服装数据集
在本教程中,我们将训练一个迷彩服对普通服装探测器。
我将在两周内讨论为什么我们要建立一个迷彩服检测器,但目前,让它作为一个如何用 Keras 和 TensorFlow 微调 ResNet 的独立示例。
我们在这里使用的数据集是由 PyImageSearch 的读者朱莉娅·里德和尼廷·拉伊策划的。
数据集由两个类组成,每个类包含相同数量的图像:
camouflage_clothes:7949 张图片normal_clothes:7949 张图片
在图 6 中可以看到每类图像的样本。
在本教程的剩余部分,您将学习如何微调 ResNet 来预测这两个类,您获得的知识将使您能够在自己的数据集上微调 ResNet。
下载我们的迷彩服和普通服装数据集
迷彩服与普通服装数据集可直接从 Kaggle 下载:
https://www . ka ggle . com/imneonizer/normal-vs-迷彩服
只需点击“下载”按钮(图 7 )即可下载数据集的.zip档案。
项目结构
一定要从这篇博文的 “下载” 部分抓取并解压代码。让我们花点时间检查一下我们项目的组织结构:
$ tree --dirsfirst --filelimit 10
.
├── 8k_normal_vs_camouflage_clothes_images
│ ├── camouflage_clothes [7949 entries]
│ └── normal_clothes [7949 entries]
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── build_dataset.py
├── camo_detector.model
├── normal-vs-camouflage-clothes.zip
├── plot.png
└── train_camo_detector.py
4 directories, 7 files
如您所见,我已经将数据集(normal-vs-camouflage-clothes.zip)放在我们项目的根目录中,并提取了文件。其中的图像现在位于8k_normal_vs_camouflage_clothes_images目录中。
今天的pyimagesearch模块带有一个单独的 Python 配置文件(config.py),其中包含了我们重要的路径和变量。我们将在下一节回顾这个文件。
我们的 Python 驱动程序脚本包括:
- 将我们的数据分成训练、测试和验证子目录
train_camo_detector.py:用 Python,TensorFlow/Keras,微调训练一个伪装分类器
我们的配置文件
在我们能够(1)构建我们的伪装与非伪装图像数据集和(2)在我们的图像数据集上微调 ResNet 之前,让我们首先创建一个简单的配置文件来存储我们所有重要的图像路径和变量。
打开项目中的config.py文件,并插入以下代码:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = "8k_normal_vs_camouflage_clothes_images"
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = "camo_not_camo"
# derive the training, validation, and testing directories
TRAIN_PATH = os.path.sep.join([BASE_PATH, "training"])
VAL_PATH = os.path.sep.join([BASE_PATH, "validation"])
TEST_PATH = os.path.sep.join([BASE_PATH, "testing"])
模块导入允许我们直接在配置文件中构建动态路径。
我们现有的输入数据集路径应该放在第 5 行(此时您应该已经下载了 Kaggle 数据集)。
我们的新数据集目录的路径显示在第 9 行的上,该目录将包含我们的训练、测试和验证分割。这条路径将由build_dataset.py脚本创建。
每个类的三个子目录(我们有两个类)也将被创建(第 12-14 行)——到我们的训练、验证和测试数据集分割的路径。每个都将由我们数据集中的图像子集填充。
接下来,我们将定义分割百分比和分类:
# define the amount of data that will be used training
TRAIN_SPLIT = 0.75
# the amount of validation data will be a percentage of the
# *training* data
VAL_SPLIT = 0.1
# define the names of the classes
CLASSES = ["camouflage_clothes", "normal_clothes"]
训练数据将由所有可用数据的 75%表示(行 17 ),其中 10%将被标记为验证(行 21 )。
我们的迷彩服和常服类别在线 24 处定义。
我们将总结一些超参数和我们的输出模型路径:
# initialize the initial learning rate, batch size, and number of
# epochs to train for
INIT_LR = 1e-4
BS = 32
NUM_EPOCHS = 20
# define the path to the serialized output model after training
MODEL_PATH = "camo_detector.model"
在第 28-30 行中设置初始学习率、批量和训练的时期数。
微调后输出序列化的基于 ResNet 的伪装分类模型的路径将存储在行 33 定义的路径中。
实现我们的伪装数据集构建器脚本
实现了配置文件后,让我们继续创建数据集构建器,它将:
- 将我们的数据集分别分成训练集、验证集和测试集
- 在磁盘上组织我们的图像,这样我们就可以使用 Keras 的
ImageDataGenerator类和相关的flow_from_directory函数来轻松地微调 ResNet
打开build_dataset.py,让我们开始吧:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import random
import shutil
import os
我们从导入前一节中的config和paths模块开始,这将帮助我们找到磁盘上的图像文件。Python 中内置的三个模块将用于混合路径和创建目录/子目录。
让我们继续获取数据集中所有原始图像的路径:
# grab the paths to all input images in the original input directory
# and shuffle them
imagePaths = list(paths.list_images(config.ORIG_INPUT_DATASET))
random.seed(42)
random.shuffle(imagePaths)
# compute the training and testing split
i = int(len(imagePaths) * config.TRAIN_SPLIT)
trainPaths = imagePaths[:i]
testPaths = imagePaths[i:]
# we'll be using part of the training data for validation
i = int(len(trainPaths) * config.VAL_SPLIT)
valPaths = trainPaths[:i]
trainPaths = trainPaths[i:]
# define the datasets that we'll be building
datasets = [
("training", trainPaths, config.TRAIN_PATH),
("validation", valPaths, config.VAL_PATH),
("testing", testPaths, config.TEST_PATH)
]
第 25-29 行定义了我们将在这个脚本的剩余部分构建的数据集分割。让我们继续:
# loop over the datasets
for (dType, imagePaths, baseOutput) in datasets:
# show which data split we are creating
print("[INFO] building '{}' split".format(dType))
# if the output base output directory does not exist, create it
if not os.path.exists(baseOutput):
print("[INFO] 'creating {}' directory".format(baseOutput))
os.makedirs(baseOutput)
# loop over the input image paths
for inputPath in imagePaths:
# extract the filename of the input image along with its
# corresponding class label
filename = inputPath.split(os.path.sep)[-1]
label = inputPath.split(os.path.sep)[-2]
# build the path to the label directory
labelPath = os.path.sep.join([baseOutput, label])
# if the label output directory does not exist, create it
if not os.path.exists(labelPath):
print("[INFO] 'creating {}' directory".format(labelPath))
os.makedirs(labelPath)
# construct the path to the destination image and then copy
# the image itself
p = os.path.sep.join([labelPath, filename])
shutil.copy2(inputPath, p)
最后一个代码块处理将图像从原始位置复制到目标路径;在此过程中会创建目录和子目录。让我们更详细地回顾一下:
- 我们循环遍历每个
datasets,如果它不存在就创建目录(第 32-39 行) - 对于我们的每个
imagePaths,我们继续:- 提取
filename和label类(行 45 和 46 - 构建标签目录的路径(行 49 )并创建子目录,如果需要的话(行 52-54 )
- 将图像从源目录复制到目的地(第 58 行和第 59 行)
- 提取
在下一节中,我们将相应地构建数据集。
构建伪装图像数据集
让我们现在建立和组织我们的图像伪装数据集。
确保你有:
- 使用本教程的 【下载】 部分下载源代码
- 按照上面的“下载我们的迷彩服与普通服装数据集”部分下载数据集
从那里,打开一个终端,并执行以下命令:
$ python build_dataset.py
[INFO] building 'training' split
[INFO] 'creating camo_not_camo/training' directory
[INFO] 'creating camo_not_camo/training/normal_clothes' directory
[INFO] 'creating camo_not_camo/training/camouflage_clothes' directory
[INFO] building 'validation' split
[INFO] 'creating camo_not_camo/validation' directory
[INFO] 'creating camo_not_camo/validation/camouflage_clothes' directory
[INFO] 'creating camo_not_camo/validation/normal_clothes' directory
[INFO] building 'testing' split
[INFO] 'creating camo_not_camo/testing' directory
[INFO] 'creating camo_not_camo/testing/normal_clothes' directory
[INFO] 'creating camo_not_camo/testing/camouflage_clothes' directory
然后,您可以使用tree命令来检查camo_not_camo目录,以验证每个训练、测试和验证分割都已创建:
$ tree camo_not_camo --filelimit 20
camo_not_camo
├── testing
│ ├── camouflage_clothes [2007 entries]
│ └── normal_clothes [1968 entries]
├── training
│ ├── camouflage_clothes [5339 entries]
│ └── normal_clothes [5392 entries]
└── validation
├── camouflage_clothes [603 entries]
└── normal_clothes [589 entries]
9 directories, 0 files
使用 Keras 和 TensorFlow 实现我们的 ResNet 微调脚本
在磁盘上创建并正确组织数据集后,让我们学习如何使用 Keras 和 TensorFlow 微调 ResNet。
打开train_camo_detector.py文件,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch import config
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import ResNet50
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
# determine the total number of image paths in training, validation,
# and testing directories
totalTrain = len(list(paths.list_images(config.TRAIN_PATH)))
totalVal = len(list(paths.list_images(config.VAL_PATH)))
totalTest = len(list(paths.list_images(config.TEST_PATH)))
我们有一个单独的命令行参数--plot,它是一个图像文件的路径,该文件将包含我们的精度/损失训练曲线。我们的其他配置在我们之前查看的 Python 配置文件中。
第 30-32 行分别确定训练、验证和测试图像的总数。
接下来,我们将准备数据扩充:
# initialize the training training data augmentation object
trainAug = ImageDataGenerator(
rotation_range=25,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.2,
horizontal_flip=True,
fill_mode="nearest")
# initialize the validation/testing data augmentation object (which
# we'll be adding mean subtraction to)
valAug = ImageDataGenerator()
# define the ImageNet mean subtraction (in RGB order) and set the
# the mean subtraction value for each of the data augmentation
# objects
mean = np.array([123.68, 116.779, 103.939], dtype="float32")
trainAug.mean = mean
valAug.mean = mean
数据扩充允许训练我们图像的时间突变,包括随机旋转、缩放、移位、剪切、翻转和均值减法。第 35-42 行用这些参数的选择初始化我们的训练数据扩充对象。类似地,第 46 行初始化确认/测试数据增加对象(它将仅用于均值减法)。
我们的两个数据扩充对象都被设置为实时执行均值减法(第 51-53 行)。
我们现在将从我们的数据扩充对象实例化三个 Python 生成器:
# initialize the training generator
trainGen = trainAug.flow_from_directory(
config.TRAIN_PATH,
class_mode="categorical",
target_size=(224, 224),
color_mode="rgb",
shuffle=True,
batch_size=config.BS)
# initialize the validation generator
valGen = valAug.flow_from_directory(
config.VAL_PATH,
class_mode="categorical",
target_size=(224, 224),
color_mode="rgb",
shuffle=False,
batch_size=config.BS)
# initialize the testing generator
testGen = valAug.flow_from_directory(
config.TEST_PATH,
class_mode="categorical",
target_size=(224, 224),
color_mode="rgb",
shuffle=False,
batch_size=config.BS)
让我们加载我们的 ResNet50 分类模型,并为微调做准备:
# load the ResNet-50 network, ensuring the head FC layer sets are left
# off
print("[INFO] preparing model...")
baseModel = ResNet50(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(256, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(len(config.CLASSES), activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the training process
for layer in baseModel.layers:
layer.trainable = False
微调的最后一步是确保我们 CNN 的基础权重被冻结(行 103 和 104)——我们只想训练(即微调)网络的负责人。
如果你需要温习微调的概念,请参考我的微调文章,特别是 用 Keras 和深度学习进行微调。
我们现在已经准备好使用 TensorFlow、Keras 和深度学习来微调我们基于 ResNet 的伪装检测器:
# compile the model
opt = Adam(lr=config.INIT_LR, decay=config.INIT_LR / config.NUM_EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the model
print("[INFO] training model...")
H = model.fit_generator(
trainGen,
steps_per_epoch=totalTrain // config.BS,
validation_data=valGen,
validation_steps=totalVal // config.BS,
epochs=config.NUM_EPOCHS)
首先,我们用学习率衰减和 Adam 优化器使用"binary_crossentropy"损失来编译我们的模型,因为这是两类问题(第 107-109 行)。如果您使用两类以上的数据进行训练,请确保将您的loss设置为"categorical_crossentropy"。
第 113-118 行然后使用我们的训练和验证数据生成器训练我们的模型。
培训完成后,我们将在测试集上评估我们的模型:
# reset the testing generator and then use our trained model to
# make predictions on the data
print("[INFO] evaluating network...")
testGen.reset()
predIdxs = model.predict_generator(testGen,
steps=(totalTest // config.BS) + 1)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testGen.classes, predIdxs,
target_names=testGen.class_indices.keys()))
# serialize the model to disk
print("[INFO] saving model...")
model.save(config.MODEL_PATH, save_format="h5")
# plot the training loss and accuracy
N = config.NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
一旦绘图生成, Line 151 将它保存到磁盘上由我们的--plot命令行参数指定的位置。
使用 Keras 和 TensorFlow 结果微调 ResNet
我们现在准备用 Keras 和 TensorFlow 对 ResNet 进行微调。
确保你有:
- 使用本教程的 【下载】 部分下载源代码
- 按照上面的“下载我们的迷彩服与普通服装数据集”部分下载数据集
- 执行
build_dataset.py脚本,将数据集组织到项目目录结构中进行训练
从那里,打开一个终端,运行train_camo_detector.py脚本:
$ python train_camo_detector.py
Found 10731 images belonging to 2 classes.
Found 1192 images belonging to 2 classes.
Found 3975 images belonging to 2 classes.
[INFO] preparing model...
[INFO] training model...
Epoch 1/20
335/335 [==============================] - 311s 929ms/step - loss: 0.1736 - accuracy: 0.9326 - val_loss: 0.1050 - val_accuracy: 0.9671
Epoch 2/20
335/335 [==============================] - 305s 912ms/step - loss: 0.0997 - accuracy: 0.9632 - val_loss: 0.1028 - val_accuracy: 0.9586
Epoch 3/20
335/335 [==============================] - 305s 910ms/step - loss: 0.0729 - accuracy: 0.9753 - val_loss: 0.0951 - val_accuracy: 0.9730
...
Epoch 18/20
335/335 [==============================] - 298s 890ms/step - loss: 0.0336 - accuracy: 0.9878 - val_loss: 0.0854 - val_accuracy: 0.9696
Epoch 19/20
335/335 [==============================] - 298s 891ms/step - loss: 0.0296 - accuracy: 0.9896 - val_loss: 0.0850 - val_accuracy: 0.9679
Epoch 20/20
335/335 [==============================] - 299s 894ms/step - loss: 0.0275 - accuracy: 0.9905 - val_loss: 0.0955 - val_accuracy: 0.9679
[INFO] evaluating network...
precision recall f1-score support
normal_clothes 0.95 0.99 0.97 2007
camouflage_clothes 0.99 0.95 0.97 1968
accuracy 0.97 3975
macro avg 0.97 0.97 0.97 3975
weighted avg 0.97 0.97 0.97 3975
[INFO] saving model...
在这里,你可以看到我们在普通服装与迷彩服检测器上获得了 ~97%的准确率。
我们的训练图如下所示:
我们的培训损失比我们的验证损失减少得更快;此外,在训练接近尾声时,验证损失可能上升,这表明模型可能过度拟合。
未来的实验应该考虑对模型应用额外的正则化,以及收集额外的训练数据。
两周后,我将向您展示如何将这个经过微调的 ResNet 模型用于实际的应用程序中!
敬请关注帖子;你不会想错过的!
信用
没有以下条件,本教程是不可能完成的:
- GDI 的维克多·格弗斯。基金会,他让我注意到了这个项目
- Nitin Rai 负责策划普通服装与迷彩服的对比,并将数据集发布在 Kaggle 上
- Julia Riede 策划了一个数据集的变体
此外,我要感谢韩等人在此图片标题中使用的 ResNet-152 可视化。
摘要
在本教程中,您学习了如何使用 Keras 和 TensorFlow 微调 ResNet。
微调是以下过程:
- 采用预先训练的深度神经网络(在这种情况下,ResNet)
- 从网络中移除全连接的层头
- 在网络主体的顶部放置新的、刚刚初始化的层头
- 可选地冻结身体中各层的重量
- 训练模型,使用预先训练的权重作为起点来帮助模型更快地学习
使用微调,我们可以获得更高精度的模型,通常需要更少的工作、数据和训练时间。
作为一个实际应用,我们在迷彩服和非迷彩服的数据集上对 ResNet 进行了微调。
这个数据集是由 PyImageSearch 的读者 Julia Riede 和 T2 Nitin Rai 为我们策划和整理的——没有他们,这个教程以及我和 Victor Gevers 正在进行的项目就不可能完成!如果你在网上看到朱莉娅和尼廷,请向他们致谢。
在两周内,我将详细介绍我和 Victor Gevers 正在进行的项目,其中包括我们最近在 PyImageSearch 上涉及的以下主题:
- 人脸检测
- 年龄检测
- 从深度学习数据集中移除重复项
- 迷彩服与非迷彩服检测的模型微调
这是一个很棒的帖子,有非常真实的应用程序,用计算机视觉和深度学习让世界变得更美好——你不会想错过它的!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 Keras 和深度学习进行微调
原文:https://pyimagesearch.com/2019/06/03/fine-tuning-with-keras-and-deep-learning/

在本教程中,您将学习如何使用 Keras 和深度学习进行微调。
我们将在 ImageNet 数据集上对 CNN 进行预训练,并对其进行微调,以执行图像分类并识别从未训练过的类别。
今天是我们关于微调的三部分系列的最后一篇文章:
- Part #1: 用 Keras 迁移学习和深度学习
- 第二部分: 利用 Keras 和深度学习对大数据集进行特征提取
- 第三部分:用 Keras 和深度学习进行微调(今天的帖子)
如果你还没有阅读过本系列的前两个教程,我强烈建议你阅读本系列的前两个教程——理解迁移学习的概念,包括通过预先训练的 CNN 执行特征提取,将使你更好地理解(并欣赏)微调。
当执行特征提取时,我们没有重新训练原始 CNN。相反,我们将 CNN 视为一个任意的特征提取器,然后在提取的特征之上训练一个简单的机器学习模型。
另一方面,微调要求我们不仅更新CNN 架构,而且重新训练它学习新的对象类。
微调是一个多步骤的过程:
- 移除网络末端(即进行实际分类标签预测的位置)的全连接节点。
- 用新初始化的节点替换完全连接的节点。
- 在网络中较早地冻结较早的 CONV 层(确保 CNN 学习到的任何先前的健壮特征不被破坏)。
- 开始训练,但是只训练 FC 层头。
- 可选地解冻网络中的部分/全部 CONV 层,并执行第二遍训练。
如果你是深度学习和 CNN 的新手,我会建议你在这里停下来,学习如何训练你的第一个 CNN 。
使用 Keras 进行微调是一种更高级的技术,其中有许多陷阱和隐患,会让您一路出错(例如,如果您不小心,在执行微调时,很容易使网络过载)。
要了解如何使用 Keras 和深度学习进行微调,继续阅读。
使用 Keras 和深度学习进行微调
2020-06-04 更新:此博文现已兼容 TensorFlow 2+!
注意:我将在这篇文章中涉及的许多微调概念也出现在我的书《用 Python 进行计算机视觉的深度学习》中。在这本书里,我进行了更详细的讨论(包括更多我的技巧、建议和最佳实践)。*如果你想在阅读完本指南后了解更多关于 Keras 微调的细节,请务必看看我的书。*
在本教程的第一部分,我们将讨论微调的概念,以及我们如何重新训练神经网络来识别它最初没有训练识别的类。
在那里,我们将查看我们用于微调的数据集。
然后我将讨论我们的项目目录结构。
一旦我们很好地处理了数据集,我们将切换到使用 Keras 实现微调。
完成本教程后,您将能够:
- 使用 Keras 微调网络。
- 使用微调网络进行预测。
我们开始吧!
什么是微调?
Figure 1: Fine-tuning with Keras and deep learning using Python involves retraining the head of a network to recognize classes it was not originally intended for.
注:以下章节改编自我的书,用 Python 进行计算机视觉的深度学习。关于迁移学习和微调的全套章节,请参考正文。
在这一系列关于迁移学习的帖子中,我们学习了如何将预训练的卷积神经网络作为特征提取器。
使用这个特征提取器,我们通过网络向前传播我们的图像数据集,提取给定层的激活(将激活视为特征向量),然后将值保存到磁盘。
一个标准的机器学习分类器(在我们的情况下,逻辑回归)在 CNN 特征之上被训练,就像我们对手工设计的特征如 SIFT、HOG、LBPs 等所做的一样。
这种转移学习的方法叫做 特征提取 。
但是还有另一种类型的迁移学习,这种学习实际上比特征提取法更好。这种方法叫做 微调 ,需要我们进行“网络手术”。
首先,我们拿起手术刀,从一个预先训练好的 CNN(通常是 VGG、雷斯网或盗梦空间)上切下最后一组完全连接的层(即返回分类标签预测的网络“头”)。
然后我们用一组新的随机初始化的完全连接的层来代替头部。
从那里,头下面的所有层被冻结,因此它们的权重不能被更新(即,反向传播中的反向传递不能到达它们)。
然后,我们使用非常小的学习速率来训练网络,以便新的一组完全连接的层可以从网络中先前学习的conv 层学习模式— 。这个过程被称为允许 FC 层“预热”。
可选地,我们可以解冻网络的其余部分并继续培训。应用微调允许我们利用预先训练的网络来识别最初没有在上训练过的类。
此外,该方法比通过特征提取的迁移学习具有更高的准确率。
微调和网络手术
注:以下章节改编自我的书,用 Python 进行计算机视觉的深度学习。关于迁移学习和微调的全套章节,请参考正文。
正如我们在本系列早些时候讨论的通过特征提取进行迁移学习一样,预训练网络(如在 ImageNet 数据集上训练的网络)包含丰富的鉴别过滤器。过滤器可用于数据集,以预测网络已经训练过的类别标签之外的类别标签。
然而,我们不是简单地应用特征提取,而是要执行网络手术并修改实际架构,以便我们可以重新训练网络的部分。
如果这听起来像一部糟糕的恐怖电影;别担心,不会有任何流血和流血——但我们会从中获得一些乐趣,并通过我们的 Frankenstien 博士式的网络实验学到很多关于迁移学习的知识。
要了解微调的工作原理,请考虑下图:
Figure 2: Left: The original VGG16 network architecture. Middle: Removing the FC layers from VGG16 and treating the final POOL layer as a feature extractor. Right: Removing the original FC Layers and replacing them with a brand new FC head. These FC layers can then be fine-tuned to a specific dataset (the old FC Layers are no longer used).
左边的是 VGG16 网络的各层。
正如我们所知,最后一组层(即“头部”)是我们与 softmax 分类器完全连接的层。
在进行微调时,我们实际上是切断网络的头部,就像在特征提取中一样(图二、中)。
然而,与特征提取不同,当我们执行微调时,我们实际上构建了一个新的全连接头部并且将它放置在原始架构的顶部(图 2 、右)。
新的 FC 层报头被随机初始化(就像新网络中的任何其他层一样)并连接到原始网络的主体。
但是,有一个问题:
我们的 CONV 层已经学会了丰富的,有区别的过滤器,而我们的 FC 层是全新的,完全随机的。
如果我们允许梯度从这些随机值一直通过网络反向传播,我们就有破坏这些强大特征的风险。
为了避免这个问题,我们反而让我们的 FC 头通过(讽刺的是)“冻结”网络体中的所有层来“热身”(我告诉过你恐怖/尸体的类比在这里很有效),如图图 2 ( 左)所示。
Figure 3: Left: When we start the fine-tuning process, we freeze all CONV layers in the network and only allow the gradient to backpropagate through the FC layers. Doing this allows our network to “warm up”. Right: After the FC layers have had a chance to warm up, we may choose to unfreeze all or some of the layers earlier in the network and allow each of them to be fine-tuned as well.
训练数据像我们通常所做的那样通过网络向前传播;然而,反向传播在 FC 层之后停止,这允许这些层开始从高区分度的 CONV 层学习模式。
在某些情况下,我们可能会决定永远不解冻网络体,因为我们的新 FC 头可能会获得足够的准确性。
然而,对于某些数据集,在微调过程中允许修改原始 CONV 图层通常也是有利的(图 3 、右)。
在 FC 头部已经开始学习我们数据集中的模式之后,我们可以暂停训练,解冻身体,并继续训练,但是学习速率非常小——我们不想大幅改变我们的 CONV 滤波器。
然后允许继续训练,直到获得足够的准确度。
微调是一种超级强大的方法,用于从预训练的 CNN 中获得您自己的定制数据集上的图像分类器(甚至比通过特征提取的迁移学习更强大)。
如果您想通过深度学习了解更多关于迁移学习的信息,包括:
- 基于深度学习的特征提取
- 在提取的特征之上训练模型
- 在您自己的自定义数据集上微调网络
- 我个人关于迁移学习的技巧、建议和最佳实践
…然后你会想看一看我的书, 用 Python 进行计算机视觉的深度学习 ,在那里我详细介绍了这些算法和技术。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
2020-06-03 更新:本次 TensorFlow 2.0 bug 影响本博文:Filling up shuffle buffer (this may take a while) 。根据本次 GitHub 问题tensor flow 2.1 中已经修复了 bug。请使用 TensorFlow > = 2.1,这样才不会遇到这个 bug!
Food-11 数据集

Figure 4: The Food-11 dataset is curated by the Multimedia Signal Processing Group (MSPG) of the Swiss Federal Institute of Technology. (image source)
我们将用于微调的数据集是瑞士联邦理工学院多媒体信号处理小组(MSPG) 的 Food-11 数据集 。
该数据集由 16,643 张图像组成,属于 11 个主要食物类别:
- 面包 (1724 张图片)
- 乳制品 (721 张图片)
- 甜点(2500 张图片)
- 彩蛋(1648 张图片)
- 油炸食品(1461 张图片)
- 肉(2206 张图片)
- 面条/意大利面 (734 张图片)
- 大米 (472 张图片)
- 海鲜(1505 张图片)
- 汤(2500 张图片)
- 蔬菜/水果(1172 张图片)
使用 Food-11 数据集,我们可以训练一个能够识别每个主要食物组的深度学习模型——例如,这种模型可以用于移动健身应用程序,自动跟踪估计的食物组和热量摄入。
为了训练这样一个模型,我们将利用 Keras 深度学习库进行微调。
下载 Food-11 数据集
继续从这篇博文的 【下载】 部分抓取压缩文件。
下载完源代码后,将目录更改为fine-tuning-keras:
$ unzip fine-tuning-keras.zip
$ cd fine-tuning-keras
2020-06-04 更新:根据我的经验,我发现从原始来源下载 Food-11 数据集是不可靠的。*因此,我提供了 Food-11 数据集的直接下载链接。使用 wget 或 FTP 的选项现在从本文中删除了。*
现在,请使用以下链接下载 Food-11:
下载数据集后,可以将其提取到项目目录(fine-tuning-keras):
$ unzip Food-11.zip
项目结构
现在我们已经下载了项目和数据集,接下来导航回项目根目录。让我们从这里开始分析项目结构:
$ cd ..
$ tree --dirsfirst --filelimit 10
.
├── Food-11
│ ├── evaluation [3347 entries]
│ ├── training [9866 entries]
│ └── validation [3430 entries]
├── dataset
├── output
│ ├── unfrozen.png
│ └── warmup.png
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── build_dataset.py
├── predict.py
├── Food-11.zip
└── train.py
7 directories, 8 files
我们的项目结构类似于上周的。
我们的原始数据集在Food-11/目录中。参见上面的直接链接下载数据集。
执行build_dataset.py使我们能够将 Food-11 图像组织到dataset/目录中。
从那里,我们将使用train.py到进行微调。
最后,我们将使用predict.py通过我们的微调网络对样本图像进行预测。
前面提到的每个脚本都利用了一个名为config.py的配置文件。现在让我们继续学习关于配置脚本的更多内容。
了解我们的配置文件
在我们实际微调我们的网络之前,我们首先需要创建我们的配置文件来存储重要的变量,包括:
- 输入数据集的路径
- 类别标签
- 批量大小/训练参数
- 输出路径,包括模型文件、标签编码器、绘图历史等。
由于我们需要如此多的参数,我选择使用一个配置文件来保持我们的代码整洁有序(而不是必须使用许多命令行参数)。
我们的配置文件config.py位于一个名为pyimagesearch的 Python 模块中。
我们在那里保存config.py文件有两个原因:
- 为了确保我们可以将配置导入到我们自己的 Python 脚本中
- 保持我们的代码整洁有序
现在让我们填充我们的config.py文件——在您最喜欢的代码编辑器中打开它,并插入下面几行:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = "Food-11"
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = "dataset"
首先,我们导入os,使我们能够在这个配置中直接构建文件/目录路径。
我们提取 Food-11 数据集的原始数据集路径包含在ORIG_INPUT_DATASET ( 第 5 行)中。
然后,我们指定组织好的数据集将很快驻留的BASE_PATH。
在这里,我们将定义我们的TRAIN、TEST和VAL目录的名称:
# define the names of the training, testing, and validation
# directories
TRAIN = "training"
TEST = "evaluation"
VAL = "validation"
接着列出了我们的 Food-11 数据集的 11 个CLASSES:
# initialize the list of class label names
CLASSES = ["Bread", "Dairy product", "Dessert", "Egg", "Fried food",
"Meat", "Noodles/Pasta", "Rice", "Seafood", "Soup",
"Vegetable/Fruit"]
最后,我们将指定批量大小和模型+绘图路径:
# set the batch size when fine-tuning
BATCH_SIZE = 32
# initialize the label encoder file path and the output directory to
# where the extracted features (in CSV file format) will be stored
LE_PATH = os.path.sep.join(["output", "le.cpickle"])
BASE_CSV_PATH = "output"
# set the path to the serialized model after training
MODEL_PATH = os.path.sep.join(["output", "food11.model"])
# define the path to the output training history plots
UNFROZEN_PLOT_PATH = os.path.sep.join(["output", "unfrozen.png"])
WARMUP_PLOT_PATH = os.path.sep.join(["output", "warmup.png"])
我们的32中的BATCH_SIZE表示将流经 CNN 的数据块的大小。
我们最终会将序列化的标签编码器存储为 pickle 文件(第 27 行)。
我们微调后的系列化 Keras 车型将出口到MODEL_PATH(31 线)。
类似地,我们指定存储预热和解冻绘图图像的路径(行 34 和 35 )。
构建我们的图像数据集进行微调
如果我们将整个 Food-11 数据集存储在内存中,它将占用 ~10GB 的 RAM 。
大多数深度学习设备应该能够处理如此大量的数据,但尽管如此,我将向您展示如何使用 Keras 的.flow_from_directory函数,一次只从磁盘加载少量数据。
然而,在我们真正开始微调和重新训练网络之前,我们首先必须(正确地)组织我们在磁盘上的图像数据集。
为了使用.flow_from_directory函数,Keras 要求我们使用以下模板组织数据集:
dataset_name/class_label/example_of_class_label.jpg
由于 Food-11 数据集也提供预先提供的数据分割,我们最终的目录结构将具有以下形式:
dataset_name/split_name/class_label/example_of_class_label.jpg
拥有上述目录结构可确保:
.flow_from_directory功能将正常工作。- 我们的数据集被组织成一个整洁、易于遵循的目录结构。
为了获取原始的 Food-11 图像,然后将它们复制到我们想要的目录结构中,我们需要build_dataset.py脚本。
现在让我们回顾一下这个脚本:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import shutil
import os
# loop over the data splits
for split in (config.TRAIN, config.TEST, config.VAL):
# grab all image paths in the current split
print("[INFO] processing '{} split'...".format(split))
p = os.path.sep.join([config.ORIG_INPUT_DATASET, split])
imagePaths = list(paths.list_images(p))
# loop over the image paths
for imagePath in imagePaths:
# extract class label from the filename
filename = imagePath.split(os.path.sep)[-1]
label = config.CLASSES[int(filename.split("_")[0])]
# construct the path to the output directory
dirPath = os.path.sep.join([config.BASE_PATH, split, label])
# if the output directory does not exist, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
# construct the path to the output image file and copy it
p = os.path.sep.join([dirPath, filename])
shutil.copy2(imagePath, p)
2-5 线进口我们必要的包装,特别是我们的config。
从那里,我们循环从第 8 行的开始的数据分割。在内部,我们:
- 提取
imagePaths和每个类label( 第 11-18 行)。 - 为我们组织好的图像文件创建一个目录结构(第 21-25 行)。
- 将图像文件复制到适当的目的地(第 28 行和第 29 行)。
这个脚本已经在 Keras 的 转移学习和深度学习 帖子中进行了更详细的回顾。如果你想知道更多关于build_dataset.py内部工作的细节,请参考之前的教程。
在继续之前,确保您已经使用教程的 【下载】 部分下载了与这篇博文相关的源代码。
从那里,打开一个终端并执行以下命令:
$ python build_dataset.py
[INFO] processing 'training split'...
[INFO] processing 'evaluation split'...
[INFO] processing 'validation split'...
如果您研究一下dataset/目录,您会看到三个目录,分别对应于我们各自的数据分割:
$ ls dataset/
evaluation training validation
在每个数据分割目录中,您还可以找到类别标签子目录:
$ ls -l dataset/training/
Bread
Dairy product
Dessert
Egg
Fried food
Meat
Noodles
Rice
Seafood
Soup
Vegetable
在每个类别标签子目录中,您会找到与该标签相关的图像:
$ ls -l dataset/training/Bread/*.jpg | head -n 5
dataset/training/Bread/0_0.jpg
dataset/training/Bread/0_1.jpg
dataset/training/Bread/0_10.jpg
dataset/training/Bread/0_100.jpg
dataset/training/Bread/0_101.jpg
使用 Keras 实现微调
现在我们的图像已经在适当的目录结构中,我们可以使用 Keras 进行微调。
让我们实现train.py中的微调脚本:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from sklearn.metrics import classification_report
from pyimagesearch import config
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import os
第 2-19 行导入所需的包。让我们简要回顾一下对今天帖子中的微调概念最重要的那些:
- 我们将计划我们冻结和解冻的训练努力。第 3 行设置后端,确保我们可以将绘图作为图像文件保存到磁盘。
ImageDataGenerator:允许数据扩充。请务必参考 DL4CV 和这篇博文以获得更多关于这个类的信息。- 在 ImageNet 上训练的开创性网络,我们将用我们的手术刀对其进行切割,以达到微调的目的。
classification_report:在评估我们的模型时计算基本的统计信息。config:我们在“了解我们的配置文件”一节中查看过的自定义配置文件。
一定要熟悉其余的导入。
包裹唾手可得,我们现在准备继续前进。让我们首先定义一个绘制培训历史的函数:
def plot_training(H, N, plotPath):
# construct a plot that plots and saves the training history
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(plotPath)
2020-06-03 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
plot_training功能在行 21-33 中定义。这个辅助函数将用于构建和保存我们的训练历史图。
让我们确定每个分割中的图像总数:
# derive the paths to the training, validation, and testing
# directories
trainPath = os.path.sep.join([config.BASE_PATH, config.TRAIN])
valPath = os.path.sep.join([config.BASE_PATH, config.VAL])
testPath = os.path.sep.join([config.BASE_PATH, config.TEST])
# determine the total number of image paths in training, validation,
# and testing directories
totalTrain = len(list(paths.list_images(trainPath)))
totalVal = len(list(paths.list_images(valPath)))
totalTest = len(list(paths.list_images(testPath)))
第 37-39 行分别定义了训练、验证和测试目录的路径。
然后,我们通过行 43-45 确定每次分割的图像总数——这些值将使我们能够计算每个时期的步数。
让我们初始化我们的数据扩充对象,并建立我们的平均减法值:
# initialize the training data augmentation object
trainAug = ImageDataGenerator(
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# initialize the validation/testing data augmentation object (which
# we'll be adding mean subtraction to)
valAug = ImageDataGenerator()
# define the ImageNet mean subtraction (in RGB order) and set the
# the mean subtraction value for each of the data augmentation
# objects
mean = np.array([123.68, 116.779, 103.939], dtype="float32")
trainAug.mean = mean
valAug.mean = mean
数据扩充的过程对于小数据集是很重要的。事实上,它几乎总是被推荐。第 48-55 行定义了我们的训练数据增强对象。这些参数指定了在我们训练时对训练数据的随机旋转、缩放、平移、剪切和翻转。
注:我看到的一个关于数据扩充的常见误解是,图像的随机变换然后被添加到原始训练数据中事实并非如此。由数据扩充执行的随机变换在就地执行,这意味着数据集大小不会增加。这些转换在培训期间就地、动态执行。
尽管我们的验证数据扩充对象( Line 59 )使用了相同的类,但是我们不提供任何参数(我们不对验证或测试数据应用数据扩充)。验证ImageDataGenerator将仅用于均值减法,这就是不需要参数的原因。
接下来,我们在行 64 上设置 ImageNet 平均减数值。在这种预处理技术中,我们对所有图像执行逐像素减法。均值减法是我在 的实践者捆绑包中解释的几种缩放技术之一,用于使用 Python 进行计算机视觉的深度学习。在本文中,我们甚至将构建一个定制的预处理器来更有效地完成均值减法。
给定逐像素的减法值,我们为每个数据扩充对象准备均值减法(行 65 和 66 )。
我们的数据扩充生成器将直接从各自的目录中生成数据:
# initialize the training generator
trainGen = trainAug.flow_from_directory(
trainPath,
class_mode="categorical",
target_size=(224, 224),
color_mode="rgb",
shuffle=True,
batch_size=config.BATCH_SIZE)
# initialize the validation generator
valGen = valAug.flow_from_directory(
valPath,
class_mode="categorical",
target_size=(224, 224),
color_mode="rgb",
shuffle=False,
batch_size=config.BATCH_SIZE)
# initialize the testing generator
testGen = valAug.flow_from_directory(
testPath,
class_mode="categorical",
target_size=(224, 224),
color_mode="rgb",
shuffle=False,
batch_size=config.BATCH_SIZE)
第 69-93 行定义了生成器,它将从它们各自的训练、验证和测试分割中加载批量图像。
使用这些生成器可以确保我们的机器不会因为试图一次加载所有数据而耗尽 RAM。
让我们继续进行执行网络手术:
# load the VGG16 network, ensuring the head FC layer sets are left
# off
baseModel = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(512, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(len(config.CLASSES), activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
首先,我们将从磁盘加载 VGG16 架构(带有预训练的 ImageNet 权重),留下完全连接的层(行 97 和 98 )。通过省略完全连接的层,我们已经有效地将网络放入了断头台,将我们的网络斩首,如图图 2 。
从那里,我们定义一个新的完全连接的层头(行 102-106 )。
注:如果你不熟悉第 102-106 行*上的内容,我推荐你看我的 Keras 教程或者 CNN 教程。如果你想完全沉浸在深度学习的世界中,一定要看看我的高度评价的深度学习书籍。*
在行 110 上,我们将新的 FC 层头放在 VGG16 基础网络的顶部。你可以认为这是在手术后增加缝线将头部重新缝合到网络体上。
花点时间仔细查看上面的代码块,因为它是使用 Keras 进行微调的核心。
继续微调,让我们冻结 VGG16 的所有 CONV 层:
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers:
layer.trainable = False
第 114 和 115 行冻结 VGG16 基本模型中的所有 CONV 图层。
鉴于基地现在被冻结,我们将继续训练我们的网络(只有头部权重会被更新):
# compile our model (this needs to be done after our setting our
# layers to being non-trainable
print("[INFO] compiling model...")
opt = SGD(lr=1e-4, momentum=0.9)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network for a few epochs (all other layers
# are frozen) -- this will allow the new FC layers to start to become
# initialized with actual "learned" values versus pure random
print("[INFO] training head...")
H = model.fit(
x=trainGen,
steps_per_epoch=totalTrain // config.BATCH_SIZE,
validation_data=valGen,
validation_steps=totalVal // config.BATCH_SIZE,
epochs=50)
# reset the testing generator and evaluate the network after
# fine-tuning just the network head
print("[INFO] evaluating after fine-tuning network head...")
testGen.reset()
predIdxs = model.predict(x=testGen,
steps=(totalTest // config.BATCH_SIZE) + 1)
predIdxs = np.argmax(predIdxs, axis=1)
print(classification_report(testGen.classes, predIdxs,
target_names=testGen.class_indices.keys()))
plot_training(H, 50, config.WARMUP_PLOT_PATH)
2020-06-03 更新:根据 TensorFlow 2.0+,我们不再使用.fit_generator方法;它被替换为.fit,并具有相同的函数签名(即,第一个参数可以是 Python 生成器对象)。同样,.predict_generator换成了.predict。
在这一环节中,我们训练我们的model,记住在基础阶段不会发生体重更新。此时只有网络的头头会被调整。
在这个代码块中,我们:
- 编译
model( 第 120-122 行)。我们将"categorical_crossentropy"用于我们的loss函数。如果只对两个类别进行分类,请务必使用"binary_crossentropy"。 - 在应用数据扩充的同时训练我们的网络,仅更新网络头部的权重(行 128-133
- 重置我们的测试发生器(线 138 )。
- 根据我们的测试数据评估我们的网络(第 139-141 行)。我们将通过线 142 和 143 在终端打印分类统计。
- 通过我们的
plot_training功能(第 144 行)绘制训练历史。
现在让我们继续 解冻基础模型图层中的最后一组 CONV 图层:
# reset our data generators
trainGen.reset()
valGen.reset()
# now that the head FC layers have been trained/initialized, lets
# unfreeze the final set of CONV layers and make them trainable
for layer in baseModel.layers[15:]:
layer.trainable = True
# loop over the layers in the model and show which ones are trainable
# or not
for layer in baseModel.layers:
print("{}: {}".format(layer, layer.trainable))
我们首先重置我们的训练和验证生成器(行 147 和 148 )。
我们然后 解冻 最后的 CONV 图层块在 VGG16 ( 第 152 行和第 153 行)。同样,只有 VGG16 的最终 CONV 块被解冻(不是网络的其余部分)。
为了不混淆我们网络中正在发生的事情,行 157 和 158 将向我们显示哪些层是冻结的/未冻结的(即可训练的)。信息会在我们的终端打印出来。
继续,让我们微调两个最后一组 CONV 图层和我们的一组 FC 图层:
# for the changes to the model to take affect we need to recompile
# the model, this time using SGD with a *very* small learning rate
print("[INFO] re-compiling model...")
opt = SGD(lr=1e-4, momentum=0.9)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the model again, this time fine-tuning *both* the final set
# of CONV layers along with our set of FC layers
H = model.fit(
x=trainGen,
steps_per_epoch=totalTrain // config.BATCH_SIZE,
validation_data=valGen,
validation_steps=totalVal // config.BATCH_SIZE,
epochs=20)
2020-06-03 更新:每 TensorFlow 2.0+,我们不再使用.fit_generator方法;它被替换为.fit,并具有相同的函数签名(即,第一个参数可以是 Python 生成器对象)。
因为我们已经解冻了额外的层,我们必须重新编译模型(第 163-165 行)。
然后我们再次训练模型,这次微调两个FC 层头和最后的 CONV 块(第 169-174 行)。
总结一下,让我们再次评估一下网络:
# reset the testing generator and then use our trained model to
# make predictions on the data
print("[INFO] evaluating after fine-tuning network...")
testGen.reset()
predIdxs = model.predict(x=testGen,
steps=(totalTest // config.BATCH_SIZE) + 1)
predIdxs = np.argmax(predIdxs, axis=1)
print(classification_report(testGen.classes, predIdxs,
target_names=testGen.class_indices.keys()))
plot_training(H, 20, config.UNFROZEN_PLOT_PATH)
# serialize the model to disk
print("[INFO] serializing network...")
model.save(config.MODEL_PATH, save_format="h5")
2020-06-03 更新:根据 TensorFlow 2.0+,我们不再使用.predict_generator;换成了.predict。并且具有相同的函数签名(即,第一个参数可以是 Python 生成器对象)。
在这里我们:
- 对测试数据进行预测(第 179-182 行)。
- 打印新的分类报告(第 183 行和第 184 行)。
- 生成解冻的训练并保存到磁盘( Line 185 )。
- 并将模型序列化到磁盘,允许我们在我们的
predict.py脚本中调用模型(第 189 行)。
在我们的微调之旅中坚持与我一起做得很好。接下来我们将让我们的脚本发挥作用!
通过使用 Keras 进行微调来训练网络
现在我们已经实现了 Python 脚本来执行微调,让我们试一试,看看会发生什么。
确保您已经使用了本教程的 “下载” 部分来下载这篇文章的源代码,并从那里执行以下命令:
$ python train.py
Using TensorFlow backend.
Found 9866 images belonging to 11 classes.
Found 3430 images belonging to 11 classes.
Found 3347 images belonging to 11 classes.
[INFO] compiling model...
[INFO] training head...
Epoch 1/50
308/308 [==============================] - 91s 294ms/step - loss: 4.5022 - accuracy: 0.2844 - val_loss: 1.7583 - val_accuracy: 0.4238
Epoch 2/50
308/308 [==============================] - 89s 289ms/step - loss: 1.9905 - accuracy: 0.3551 - val_loss: 1.4969 - val_accuracy: 0.4909
Epoch 3/50
308/308 [==============================] - 90s 294ms/step - loss: 1.8038 - accuracy: 0.3991 - val_loss: 1.4215 - val_accuracy: 0.5301
...
Epoch 48/50
308/308 [==============================] - 88s 285ms/step - loss: 0.9199 - accuracy: 0.6909 - val_loss: 0.7735 - val_accuracy: 0.7614
Epoch 49/50
308/308 [==============================] - 87s 284ms/step - loss: 0.8974 - accuracy: 0.6977 - val_loss: 0.7749 - val_accuracy: 0.7602
Epoch 50/50
308/308 [==============================] - 88s 287ms/step - loss: 0.8930 - accuracy: 0.7004 - val_loss: 0.7764 - val_accuracy: 0.7646
[INFO] evaluating after fine-tuning network head...
precision recall f1-score support
Bread 0.72 0.58 0.64 368
Dairy product 0.75 0.56 0.64 148
Dessert 0.72 0.68 0.70 500
Egg 0.66 0.72 0.69 335
Fried food 0.72 0.70 0.71 287
Meat 0.75 0.84 0.79 432
Noodles 0.97 0.95 0.96 147
Rice 0.85 0.88 0.86 96
Seafood 0.79 0.81 0.80 303
Soup 0.89 0.95 0.92 500
Vegetable 0.86 0.91 0.88 231
accuracy 0.78 3347
macro avg 0.79 0.78 0.78 3347
weighted avg 0.78 0.78 0.77 3347
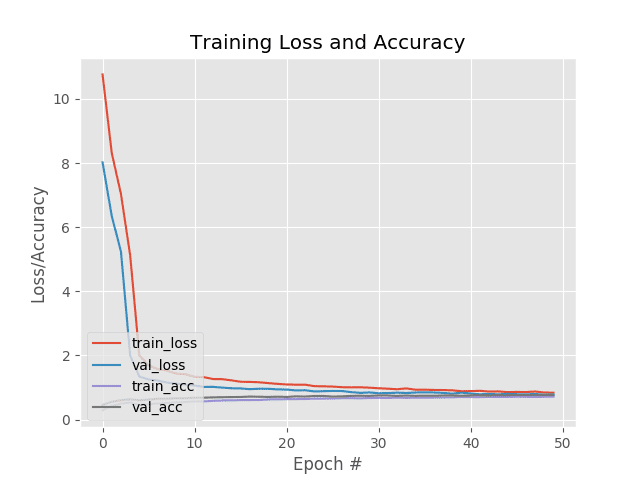
Figure 6: Our Keras fine-tuning network is allowed to “warm up” prior to unfreezing only the final block of CONV layers in VGG16.
在微调我们新初始化的 FC 层头并让 FC 层预热后,我们获得了相当可观的 ~76%的准确度。
接下来,我们看到我们已经解冻了 VGG16 中的最后一块 CONV 层,同时保持其余网络权重冻结:
<tensorflow.python.keras.engine.input_layer.InputLayer object at 0x7f2baa5f6eb8>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c21583198>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c8075ffd0>: False
<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f2c80725630>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c807254a8>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c8072f828>: False
<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f2c807399b0>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c80739828>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804c0b70>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804c52b0>: False
<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f2c804cd0f0>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804cdac8>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804d4dd8>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804d94a8>: False
<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f2c804de3c8>: False
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804e2cf8>: True
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804e2e10>: True
<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f2c804ed828>: True
<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f2c804f2550>: True
一旦我们解冻了最后一个 CONV 块,我们就继续微调:
[INFO] re-compiling model...
Epoch 1/20
308/308 [==============================] - 88s 285ms/step - loss: 0.9120 - accuracy: 0.6978 - val_loss: 0.7333 - val_accuracy: 0.7818
Epoch 2/20
308/308 [==============================] - 88s 285ms/step - loss: 0.8302 - accuracy: 0.7252 - val_loss: 0.6916 - val_accuracy: 0.7941
Epoch 3/20
308/308 [==============================] - 88s 285ms/step - loss: 0.7882 - accuracy: 0.7401 - val_loss: 0.6982 - val_accuracy: 0.7953
Epoch 4/20
308/308 [==============================] - 88s 285ms/step - loss: 0.7418 - accuracy: 0.7557 - val_loss: 0.6813 - val_accuracy: 0.8110
Epoch 5/20
308/308 [==============================] - 88s 285ms/step - loss: 0.6744 - accuracy: 0.7808 - val_loss: 0.6259 - val_accuracy: 0.8195
...
Epoch 16/20
308/308 [==============================] - 89s 289ms/step - loss: 0.4534 - accuracy: 0.8537 - val_loss: 0.5958 - val_accuracy: 0.8516
Epoch 17/20
308/308 [==============================] - 88s 285ms/step - loss: 0.4332 - accuracy: 0.8608 - val_loss: 0.5809 - val_accuracy: 0.8537
Epoch 18/20
308/308 [==============================] - 88s 285ms/step - loss: 0.4188 - accuracy: 0.8646 - val_loss: 0.6200 - val_accuracy: 0.8490
Epoch 19/20
308/308 [==============================] - 88s 285ms/step - loss: 0.4115 - accuracy: 0.8641 - val_loss: 0.5874 - val_accuracy: 0.8493
Epoch 20/20
308/308 [==============================] - 88s 285ms/step - loss: 0.3807 - accuracy: 0.8721 - val_loss: 0.5939 - val_accuracy: 0.8581
[INFO] evaluating after fine-tuning network...
precision recall f1-score support
Bread 0.84 0.79 0.81 368
Dairy product 0.85 0.70 0.77 148
Dessert 0.82 0.82 0.82 500
Egg 0.84 0.84 0.84 335
Fried food 0.82 0.86 0.84 287
Meat 0.87 0.92 0.89 432
Noodles 1.00 0.97 0.98 147
Rice 0.91 0.97 0.94 96
Seafood 0.91 0.90 0.91 303
Soup 0.96 0.96 0.96 500
Vegetable 0.92 0.95 0.94 231
accuracy 0.88 3347
macro avg 0.89 0.88 0.88 3347
weighted avg 0.88 0.88 0.88 3347
[INFO] serializing network...
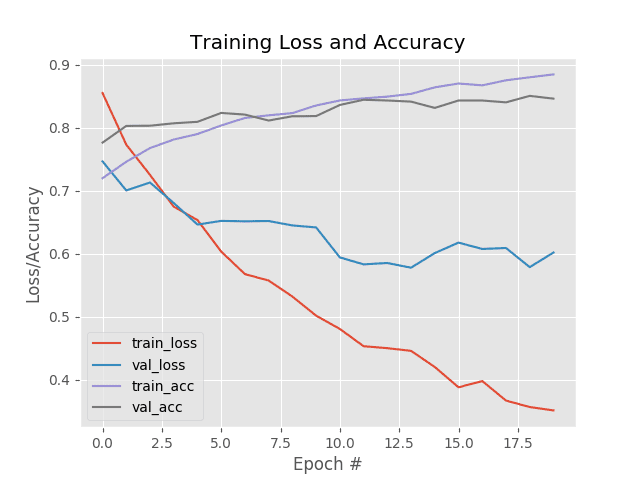
Figure 7: We have unfrozen the final CONV block and resumed fine-tuning with Keras and deep learning. Training and validation loss are starting to divide indicating the start of overfitting, so fine-tuning stops at epoch 20.
因为害怕过度适应,我决定不训练超过 20 岁。如果你看一下图 7 ,你会发现我们的培训和验证损失开始迅速分化。当你看到培训损失快速下降,而验证损失停滞不前甚至增加时,你知道你过度拟合了。
也就是说,在我们的微调过程结束时,我们现在获得了 88%的准确度,比仅微调 FC 层磁头有了显著提高!
通过微调和 Keras 进行预测
现在我们已经微调了我们的 Keras 模型,让我们看看如何使用它来预测训练/测试集之外的图像(即我们自己的自定义图像)。
打开predict.py并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import load_model
from pyimagesearch import config
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to our input image")
args = vars(ap.parse_args())
2-7 线导入我们需要的包。我们将使用load_model从磁盘中调用我们的 Keras 微调模型并进行预测。这也是我们今天第一次使用 OpenCV ( cv2)。
在第 10-13 行我们解析我们的命令行参数。--image参数允许我们在运行时从我们的终端提供任何图像,而无需修改代码。利用命令行参数比在这里或我们的配置中硬编码值更有意义。
让我们继续从磁盘加载图像并对其进行预处理:
# load the input image and then clone it so we can draw on it later
image = cv2.imread(args["image"])
output = image.copy()
output = imutils.resize(output, width=400)
# our model was trained on RGB ordered images but OpenCV represents
# images in BGR order, so swap the channels, and then resize to
# 224x224 (the input dimensions for VGG16)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
# convert the image to a floating point data type and perform mean
# subtraction
image = image.astype("float32")
mean = np.array([123.68, 116.779, 103.939][::-1], dtype="float32")
image -= mean
第 16-30 行加载并预处理我们的image。预处理步骤与训练相同,包括:
- 制作图像的
copy并为output的目的调整大小(第 17 行和第 18 行)。 - 交换颜色通道,因为我们用 RGB 图像进行了训练,OpenCV 按照 BGR 顺序加载了这个
image(第 23 行)。 - 调整
image到 224×224 像素大小进行推断(第 24 行)。 - 将
image转换成浮点(第 28 行)。 - 执行均值减法(第 29 行和第 30 行)。
注:当我们使用定制的预测脚本进行推理时,如果结果十有八九不令人满意,那是由于预处理不当。通常,颜色通道顺序错误或忘记执行均值减法将导致不利的结果。在编写自己的脚本时,请记住这一点。
现在我们的图像已经准备好了,让我们预测它的类标签:
# load the trained model from disk
print("[INFO] loading model...")
model = load_model(config.MODEL_PATH)
# pass the image through the network to obtain our predictions
preds = model.predict(np.expand_dims(image, axis=0))[0]
i = np.argmax(preds)
label = config.CLASSES[i]
# draw the prediction on the output image
text = "{}: {:.2f}%".format(label, preds[i] * 100)
cv2.putText(output, text, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
我们通过行 34 加载我们微调过的model,然后执行推理。在第 37-39 行的上提取顶部预测类label。
最后,我们对output图像进行注释,并将其显示在屏幕上(第 42-48 行)。text注释包含最高的预测及其相关的置信度。
接下来是有趣的部分——测试我们的食物脚本!光是想想我就饿了,我打赌你可能也饿了。
Keras 微调结果
要查看我们微调过的 Keras 模型,请确保使用本教程的 “下载” 部分下载源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python predict.py --image dataset/evaluation/Seafood/8_186.jpg

Figure 8: Our fine-tuned Keras deep learning network correctly recognizes oysters as “seafood”.
从图 7 可以看出,我们已经正确地将输入图像分类为“海鲜”。
让我们试试另一个例子:
$ python predict.py --image dataset/evaluation/Meat/5_293.jpg

Figure 9: With 64% accuracy this image of chicken wings is classified as “fried food”. We have applied the process fine-tuning to a pre-trained model to recognize new classes with Keras and deep learning.
尽管它在我们的数据集 中属于“肉”类,但我们的微调网络已经将该图像标记为“油炸食品” 。
鸡翅通常是油炸的,这些显然是油炸的。它们既是“肉”又是“油炸食品”,这就是为什么我们被拉向两个方向。因此,我仍然声明它是一个“正确的”分类。一个有趣的实验是使用多标签分类进行微调。我将把它作为一个练习留给你去实现。
以下是我在微调实验中获得的一些额外结果:
Figure 10: Fine-tuning with Keras and deep learning on the Food-11 dataset.
摘要
在本教程中,您学习了如何使用 Keras 和深度学习进行微调。
为了执行微调,我们:
- 已从磁盘加载 VGG16 网络架构,权重已在 ImageNet 上预先训练。
- 确保移除原始完全连接的图层头(即,从网络进行输出预测的位置)。
- 用全新的、刚初始化的层替换了原来完全连接的层。
- 冻结了 VGG16 中的所有 CONV 图层。
- 仅训练完全连接的层头。
- 在 VGG16 中解冻最后一组 CONV 图层块。
- 继续训练。
总的来说,我们能够在 Food-11 数据集上获得 88%的准确率。
通过应用额外的数据扩充并调整我们的优化器和 FC 层节点数量的参数,可以获得更高的准确性。
如果你有兴趣学习更多关于 Keras 的微调,包括我的技巧、建议和最佳实践,一定要看看 用 Python 进行计算机视觉的深度学习 ,我在那里更详细地介绍了微调。
我希望你喜欢今天的微调教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
使用 Keras 和深度学习进行火灾和烟雾检测
原文:https://pyimagesearch.com/2019/11/18/fire-and-smoke-detection-with-keras-and-deep-learning/

在本教程中,您将学习如何使用计算机视觉、OpenCV 和 Keras 深度学习库来检测火灾和烟雾。
今天的教程是受上周我收到的一封来自 PyImageSearch 阅读器丹尼尔的电子邮件的启发。
丹尼尔写道:
嗨,阿德里安,我不知道你有没有看到新闻,但我的家乡加利福尼亚州在过去几周已经被野火彻底摧毁了。
我家住在洛杉矶地区,离盖蒂大火不太远。很难不担心我们的家和我们的安全。
这是一个可怕的情况,它让我思考:
你认为计算机视觉可以用来探测野火吗?从人们家中开始的火灾呢?
如果你能写一篇关于这个话题的教程,我将不胜感激。我很乐意从中学习,并尽自己的一份力量去帮助别人。
简短的回答是, 是的,计算机视觉和深度学习能用来探测野火吗:**
** 配备摄像头的物联网/边缘设备可以战略性地部署在山坡、山脊和高海拔地区,自动监控烟雾或火灾迹象。
- 无人机和四轴飞行器可以在容易发生野火的地区上空飞行,战略性地扫描烟雾。
- 卫星可以用来拍摄大面积区域的照片,而计算机视觉和深度学习算法可以处理这些图像,寻找烟雾的迹象。
对于野火来说,这一切都很好,但如果你想监控自己家的烟雾或火灾呢?
答案是增加现有的传感器来帮助火灾/烟雾探测:
- 现有的烟雾探测器利用光电传感器和一个光源来检测光源粒子是否被散射(意味着烟雾存在)。
- 然后你可以在房子周围分布温度传感器来监控每个房间的温度。
- 摄像机也可以放在可能起火的地方(厨房、车库等)。).
- 每个单独的传感器可以用来触发警报,或者您可以将传感器信息中继到一个中央集线器,该集线器聚合并分析传感器数据,计算家庭火灾的概率。
不幸的是,说起来容易做起来难。
虽然世界各地有 100 多名计算机视觉/深度学习从业者积极致力于火灾和烟雾探测(包括 PyImageSearch 大师成员、大卫·波恩),但这仍然是一个开放式的问题。
也就是说,今天我将帮助你开始烟雾和火灾检测-在本教程结束时,你将拥有一个能够检测图像中火灾的深度学习模型(我甚至包括了我预先训练的模型,以使你立即启动并运行)。
要了解如何利用计算机视觉、深度学习和 Keras 创建自己的火灾和烟雾探测器,请继续阅读!
使用 Keras 和深度学习进行火灾和烟雾检测

Figure 1: Wildfires can quickly become out of control and endanger lives in many parts of the world. In this article, we will learn to conduct fire and smoke detection with Keras and deep learning.
在本教程的第一部分,我们将讨论用于火灾和烟雾探测的两个数据集。
从那里,我们将审查该项目的目录结构,然后实施FireDetectionNet,我们将使用 CNN 架构来检测图像/视频中的火灾和烟雾。
接下来,我们将训练我们的火灾探测模型,并分析分类准确性和结果。
我们将通过讨论该方法的一些限制和缺点来结束本教程,包括如何改进和扩展该方法。
我们的火灾和烟雾数据集

Figure 2: Today’s fire detection dataset is curated by Gautam Kumar and pruned by David Bonn (both of whom are PyImageSearch readers). We will put the dataset to work with Keras and deep learning to create a fire/smoke detector.
我们将用于火灾和烟雾示例的数据集是由 PyImageSearch 阅读器 Gautam Kumar 策划的。
瓜塔姆通过在谷歌图片中搜索与术语【火】**【烟】等相关的查询,总共收集了1315 张图片。
然而,原始数据集还没有清除无关的、不相关的图像,这些图像与火灾和烟雾不相关(例如,在火灾发生之前的著名建筑的例子)。
同是 PyImageSearch 的读者,大卫·波恩,花时间手动浏览火灾/烟雾图像,并识别出那些不应该包括在内的图像。
注意: 我获取了大卫识别出的无关图像列表,然后创建了一个 shell 脚本将它们从数据集中删除。shell 脚本可以在本教程的 【下载】 部分找到。
8 场景数据集

Figure 3: We will combine Gautam’s fire dataset with the 8-scenes natural image dataset so that we can classify Fire vs. Non-fire using Keras and deep learning.
我们将用于非火灾示例的数据集被称为 8 场景 ,因为它包含属于八个自然场景类别(全部没有火灾)的2688 个图像示例:
- 海岸
- 山
- 森林
- 空旷地区
- 街道
- 市内
- 高层建筑
- 公路
该数据集最初是由 Oliva 和 Torralba 在他们 2001 年的论文中策划的, 模拟场景的形状:空间包络的整体表示。
8 场景数据集是对我们的火/烟数据集的自然补充,因为它描绘了自然场景,因为它们应该看起来没有火或烟存在。
虽然这个数据集有 8 个独特的类别,当我们将它与高塔姆的火灾数据集组合时,我们将把它视为一个单一的非火灾类别。
项目结构
Figure 4: The project structure for today’s tutorial on fire and smoke detection with deep learning using the Keras/TensorFlow framework.
去拿今天的。使用这篇博文的 “下载” 部分从源代码和预训练模型中解压。
从那里你可以在你的机器上解压它,你的项目将看起来像图 4 。还有 一个例外 :都不是数据集。zip ( 白色箭头)将会出现。我们将在下一节的中下载、提取和删减数据集。
我们的output/目录包含:
- 我们的系列化火灾探测模型。我们今天用 Keras 和深度学习来训练模型。
- 将生成学习率探测器图,并在培训前检查最佳学习率。
- 培训过程完成后,将生成一个培训历史图。
examples/子目录将由predict_fire.py填充样本图像,这些样本图像将被注释以用于演示和验证目的。
我们的pyimagesearch模块包含:
- 我们可定制的配置。
FireDetectionNet:我们的 Keras 卷积神经网络类,专为探测火灾和烟雾而设计。LearningRateFinder:Keras 类,用于协助寻找深度学习训练的最优学习速率的过程。
项目的根目录包含三个脚本:
prune.sh:一个简单的 bash 脚本,从 Gautam 的 fire 数据集中删除不相关的图像。train.py:我们的 Keras 深度学习训练脚本。该脚本有两种操作模式:(1) 学习率查找器模式,和(2)训练模式。predict_fire.py:一个快速而肮脏的脚本,从我们的数据集中采样图像,生成带注释的火灾/非火灾图像用于验证。
让我们在下一部分继续准备我们的火灾/非火灾数据集。
准备我们的火灾和非火灾组合数据集
准备我们的火灾和非火灾数据集包括四个步骤:
- 步骤#1: 确保您遵循了上一节中的说明,从 “下载” 部分抓取并解压缩今天的文件。
- 步骤#2 :下载并提取火灾/烟雾数据集到项目中。
- 步骤#3: 删除火灾/烟雾数据集中无关的无关文件。
- 步骤#4: 下载并提取 8 场景数据集到项目中。
步骤#2-4 的结果将是包含两个类的数据集:
- 火
- 非火灾
组合数据集是我经常使用的一种策略。它节省了宝贵的时间,并经常导致一个伟大的模型。
让我们开始将合并的数据集放在一起。
步骤#2 :下载并提取火灾/烟雾数据集到项目中。
使用此链接下载火灾/烟雾数据集。商店。压缩在上一节中提取的keras-fire-detection/项目目录。
下载后,解压缩数据集:
$ unzip Robbery_Accident_Fire_Database2.zip
第三步:删除数据集中无关的文件。
执行prune.sh脚本,从 fire 数据集中删除无关的文件:
$ sh prune.sh
至此,我们有了火的数据。现在我们需要非火灾数据来解决我们的两类问题。
步骤#4: 下载并提取 8 场景数据集到项目中。
使用此链接 下载 8 场景数据集。存储。在 Fire 数据集旁边的keras-fire-detection/项目目录中压缩。
下载完成后,导航到项目文件夹并取消归档数据集:
$ unzip spatial_envelope_256x256_static_8outdoorcategories.zip
审查项目+数据集结构
此时,是时候再次检查我们的目录结构了。你的应该和我的一样:
$ tree --dirsfirst --filelimit 10
.
├── Robbery_Accident_Fire_Database2
│ ├── Accident [887 entries]
│ ├── Fire [1315 entries]
│ ├── Robbery [2073 entries]
│ └── readme.txt
├── spatial_envelope_256x256_static_8outdoorcategories [2689 entries]
├── output
│ ├── examples [48 entries]
│ ├── fire_detection.model
│ │ ├── assets
│ │ ├── variables
│ │ │ ├── variables.data-00000-of-00002
│ │ │ ├── variables.data-00001-of-00002
│ │ │ └── variables.index
│ │ └── saved_model.pb
│ ├── lrfind_plot.png
│ └── training_plot.png
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ ├── firedetectionnet.py
│ └── learningratefinder.py
├── Robbery_Accident_Fire_Database.zip
├── spatial_envelope_256x256_static_8outdoorcategories.zip
├── prune.sh
├── train.py
└── predict_fire.py
11 directories, 16 files
确保您的数据集被修剪过(即Fire/目录应该正好有1315 个条目和而不是之前的 1405 个条目)。
我们的配置文件
这个项目将跨越需要执行的多个 Python 文件,所以让我们将所有重要的变量存储在一个单独的config.py文件中。
现在打开config.py并插入以下代码:
# import the necessary packages
import os
# initialize the path to the fire and non-fire dataset directories
FIRE_PATH = os.path.sep.join(["Robbery_Accident_Fire_Database2",
"Fire"])
NON_FIRE_PATH = "spatial_envelope_256x256_static_8outdoorcategories"
# initialize the class labels in the dataset
CLASSES = ["Non-Fire", "Fire"]
我们将使用os模块来合并路径(行 2 )。
第 5-7 行包含到我们的(1) 火灾图像和(2) 非火灾图像的路径。
第 10 行是我们两个类名的列表。
让我们设置一些培训参数:
# define the size of the training and testing split
TRAIN_SPLIT = 0.75
TEST_SPLIT = 0.25
# define the initial learning rate, batch size, and number of epochs
INIT_LR = 1e-2
BATCH_SIZE = 64
NUM_EPOCHS = 50
第 13 行和第 14 行定义了我们的训练和测试数据集分割的大小。
第 17-19 行包含三个超参数——初始学习率、批量大小和训练的时期数。
从这里开始,我们将定义几条路径:
# set the path to the serialized model after training
MODEL_PATH = os.path.sep.join(["output", "fire_detection.model"])
# define the path to the output learning rate finder plot and
# training history plot
LRFIND_PLOT_PATH = os.path.sep.join(["output", "lrfind_plot.png"])
TRAINING_PLOT_PATH = os.path.sep.join(["output", "training_plot.png"])
第 22-27 行包括以下路径:
- 我们尚待训练的系列火灾探测模型。
- 学习率探测器图,我们将对其进行分析,以设置我们的初始学习率。
- 训练精度/损失历史图。
为了总结我们的配置,我们将定义预测抽查的设置:
# define the path to the output directory that will store our final
# output with labels/annotations along with the number of images to
# sample
OUTPUT_IMAGE_PATH = os.path.sep.join(["output", "examples"])
SAMPLE_SIZE = 50
我们的预测脚本将使用我们的模型对图像进行采样和注释。
第 32 行和第 33 行包括输出目录的路径,我们将在那里存储输出分类结果和要采样的图像数量。
实现我们的火灾探测卷积神经网络

Figure 5: FireDetectionNet is a deep learning fire/smoke classification network built with the Keras deep learning framework.
在这一节中,我们将实现FireDetectionNet,这是一个卷积神经网络,用于检测图像中的烟雾和火灾。
该网络利用深度方向可分离卷积而不是标准卷积作为深度方向可分离卷积:
- 更高效,因为边缘/物联网设备的 CPU 和功耗有限。
- 需要更少的内存,同样,Edge/IoT 设备的 RAM 有限。
- 需要更少的计算,因为我们的 CPU 能力有限。
- 在某些情况下,可以比标准卷积执行得更好,可以产生更好的火灾/烟雾探测器。
现在让我们开始实现FireDetectioNet——现在打开firedetectionnet.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import SeparableConv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
class FireDetectionNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
我们的 TensorFlow 2.0 Keras 进口横跨2-9 线。我们将使用 Keras 的顺序 API 来构建我们的火灾探测 CNN。
第 11 行定义了我们的FireDetectionNet类。我们从定义第 13 行的方法开始。
build方法接受的参数包括我们图像的尺寸(width、height、depth)以及我们将训练模型识别的classes的数量(即该参数影响 softmax 分类器的头部形状)。
然后我们初始化model和inputShape ( 第 16-18 行)。
从这里开始,我们将定义第一组CONV => RELU => POOL层:
# CONV => RELU => POOL
model.add(SeparableConv2D(16, (7, 7), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
这些层使用较大的内核大小,以便(1)更快地减少输入体积空间维度,以及(2)检测包含火焰的较大颜色斑点。
然后我们将定义更多的CONV => RELU => POOL层集合:
# CONV => RELU => POOL
model.add(SeparableConv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
# (CONV => RELU) * 2 => POOL
model.add(SeparableConv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(SeparableConv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
第 34-40 行允许我们的模型在应用一个POOL之前通过堆叠两个组CONV => RELU来学习更丰富的特性。
从这里开始,我们将创建全连接的网络负责人:
# first set of FC => RELU layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# second set of FC => RELU layers
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
第 43-53 行增加两组FC => RELU图层。
行 56 和 57 在行 60 返回model之前添加我们的 Softmax 分类器。
创建我们的培训脚本
我们的培训脚本将负责:
- 从磁盘加载我们的火灾和非火灾组合数据集。
- 实例化我们的
FireDetectionNet架构。 - 通过使用我们的
LearningRateFinder类找到我们的最佳学习率。 - 采用最佳的学习速率,并为所有的时代训练我们的网络。
我们开始吧!
打开目录结构中的train.py文件,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.learningratefinder import LearningRateFinder
from pyimagesearch.firedetectionnet import FireDetectionNet
from pyimagesearch import config
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import sys
第 1-19 行处理我们的进口:
matplotlib:用 Python 生成图。第 3 行设置后端,这样我们可以将我们的绘图保存为图像文件。tensorflow.keras:我们的 TensorFlow 2.0 导入了,包括数据增强、随机梯度下降优化器和一键标签编码器。sklearn:数据集拆分和分类报告的两次导入。LearningRateFinder:在培训之前,我们将使用该类来寻找最佳学习率。当我们在这种模式下运行我们的脚本时,它将为我们生成一个图,以便(1)手动检查和(2)将最佳学习率插入到我们的配置文件中。FireDetectionNet:我们在上一节构建的火/烟卷积神经网络(CNN)。config:我们对该训练脚本的设置的配置文件(它也包含我们对预测脚本的设置)。paths:包含我的 imutils 包中的函数,用于在目录树中列出图像。argparse:用于解析命令行参数标志。cv2: OpenCV 用于加载和预处理图像。
现在我们已经导入了包,让我们定义一个可重用的函数来加载我们的数据集:
def load_dataset(datasetPath):
# grab the paths to all images in our dataset directory, then
# initialize our lists of images
imagePaths = list(paths.list_images(datasetPath))
data = []
# loop over the image paths
for imagePath in imagePaths:
# load the image and resize it to be a fixed 128x128 pixels,
# ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.resize(image, (128, 128))
# add the image to the data lists
data.append(image)
# return the data list as a NumPy array
return np.array(data, dtype="float32")
我们的load_dataset助手功能协助加载、预处理和准备火灾和非火灾数据集。
第 21 行定义了接受数据集路径的函数。
第 24 行抓取数据集中的所有图像路径。
第 28-35 行在imagePaths上循环。图像被加载,调整到 128×128 的尺寸,并添加到data列表中。
第 38 行返回 NumPy 数组格式的data。
我们现在将解析一个命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--lr-find", type=int, default=0,
help="whether or not to find optimal learning rate")
args = vars(ap.parse_args())
--lr-find标志为我们的脚本设置模式。如果标志设置为1,那么我们将进入学习率查找模式,生成学习率图供我们检查。否则,我们的脚本将在训练模式下运行,并为整个历元集训练网络(即当--lr-find标志不存在时)。
现在让我们开始加载我们的data:
# load the fire and non-fire images
print("[INFO] loading data...")
fireData = load_dataset(config.FIRE_PATH)
nonFireData = load_dataset(config.NON_FIRE_PATH)
# construct the class labels for the data
fireLabels = np.ones((fireData.shape[0],))
nonFireLabels = np.zeros((nonFireData.shape[0],))
# stack the fire data with the non-fire data, then scale the data
# to the range [0, 1]
data = np.vstack([fireData, nonFireData])
labels = np.hstack([fireLabels, nonFireLabels])
data /= 255
第 48 和 49 行加载并调整火灾和非火灾图像。
第 52 行和第 53 行为两个类别构造标签(1表示火灾, 0表示非火灾)。
随后,我们通过行 57 和 58 将data和labels堆叠成单个 NumPy 数组(即组合数据集)。
第 59 行将像素强度缩放到范围【0,1】。
我们还有三个步骤来准备数据:
# perform one-hot encoding on the labels and account for skew in the
# labeled data
labels = to_categorical(labels, num_classes=2)
classTotals = labels.sum(axis=0)
classWeight = classTotals.max() / classTotals
# construct the training and testing split
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=config.TEST_SPLIT, random_state=42)
首先,我们在我们的labels ( 行 63 )上执行一次热编码。
然后,我们 在我们的数据集 ( 行 64 和 65 )中说明了偏斜。为此,在梯度更新期间,我们计算classWeight来加权火图像多于非火图像(因为我们拥有比非火图像多两倍的火 图像)。
第 68 行和第 69 行基于我们的配置构建训练和测试分割(在我的配置中,我将分割设置为 75%训练/25%测试)。
接下来,我们将初始化数据扩充并编译我们的FireDetectionNet模型:
# initialize the training data augmentation object
aug = ImageDataGenerator(
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=config.INIT_LR, momentum=0.9,
decay=config.INIT_LR / config.NUM_EPOCHS)
model = FireDetectionNet.build(width=128, height=128, depth=3,
classes=2)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
第 74-79 行实例化我们的数据扩充对象。
我们然后build和compile我们的FireDetectionNet模型(第 83-88 行)。注意,我们的初始学习率和衰减是在初始化我们的SGD优化器时设置的。
让我们来处理我们的 学习率探测器模式:
# check to see if we are attempting to find an optimal learning rate
# before training for the full number of epochs
if args["lr_find"] > 0:
# initialize the learning rate finder and then train with learning
# rates ranging from 1e-10 to 1e+1
print("[INFO] finding learning rate...")
lrf = LearningRateFinder(model)
lrf.find(
aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
1e-10, 1e+1,
stepsPerEpoch=np.ceil((trainX.shape[0] / float(config.BATCH_SIZE))),
epochs=20,
batchSize=config.BATCH_SIZE,
classWeight=classWeight)
# plot the loss for the various learning rates and save the
# resulting plot to disk
lrf.plot_loss()
plt.savefig(config.LRFIND_PLOT_PATH)
# gracefully exit the script so we can adjust our learning rates
# in the config and then train the network for our full set of
# epochs
print("[INFO] learning rate finder complete")
print("[INFO] examine plot and adjust learning rates before training")
sys.exit(0)
第 92 行检查我们是否应该尝试找到最佳学习率。假设如此,我们:
- 初始化
LearningRateFinder( 第 96 行)。 - 以
1e-10的学习率开始训练,并以指数方式增加,直到我们达到1e+1( 第 97-103 行)。 - 绘制损失与学习率的关系图,并保存结果数字(第 107 行和第 108 行)。
- 优雅地向用户打印几条消息后的脚本(第 115 行)。
在这段代码执行之后,我们现在需要:
- 步骤#1: 手动检查生成的学习率图。
- 步骤#2: 用我们的
INIT_LR(即我们通过分析情节确定的最优学习率)更新config.py。 - 步骤#3: 在我们的完整数据集上训练网络。
假设我们已经完成了步骤#1 和步骤#2 ,现在让我们处理步骤#3 ,其中我们的初始学习率已经在配置中确定并更新。在这种情况下,是时候在我们的脚本中处理训练模式了:
# train the network
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
class_weight=classWeight,
verbose=1)
第 119-125 行使用数据扩充和我们的倾斜数据集类别加权来训练我们的火灾探测model。一定要复习我的.fit_generator教程。
最后,我们将评估模型,将其序列化到磁盘,并绘制培训历史:
# evaluate the network and show a classification report
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=config.BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=config.CLASSES))
# serialize the model to disk
print("[INFO] serializing network to '{}'...".format(config.MODEL_PATH))
model.save(config.MODEL_PATH)
# construct a plot that plots and saves the training history
N = np.arange(0, config.NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.TRAINING_PLOT_PATH)
129-131 行对测试数据进行预测,并在我终端打印分类报告。
第 135 行序列化model并保存到磁盘。我们将在预测脚本中回忆这个模型。
第 138-149 行生成了训练期间准确度/损失曲线的历史图。我们将检查这块地是否过度拟合或拟合不足。
用 Keras 训练火灾探测模型
培训我们的火灾探测模型分为三个步骤:
- 步骤#1: 运行带有
--lr-find命令行参数的train.py脚本,找到我们的最佳学习率。 - 步骤#2: 更新我们配置文件(
config.py)的第 17 行,将我们的INIT_LR值设置为最优学习率。 - 步骤#3: 再次执行
train.py脚本,但是这次让它为全套纪元进行训练。
首先使用本教程的 【下载】 部分将源代码下载到本教程中。
在那里,您可以通过执行以下命令来执行步骤#1 :
$ python train.py --lr-find 1
[INFO] loading data...
[INFO] finding learning rate...
Epoch 1/20
47/47 [==============================] - 10s 221ms/step - loss: 1.2949 - accuracy: 0.4923
Epoch 2/20
47/47 [==============================] - 11s 228ms/step - loss: 1.3315 - accuracy: 0.4897
Epoch 3/20
47/47 [==============================] - 10s 218ms/step - loss: 1.3409 - accuracy: 0.4860
Epoch 4/20
47/47 [==============================] - 10s 215ms/step - loss: 1.3973 - accuracy: 0.4770
Epoch 5/20
47/47 [==============================] - 10s 219ms/step - loss: 1.3170 - accuracy: 0.4957
...
Epoch 15/20
47/47 [==============================] - 10s 216ms/step - loss: 0.5097 - accuracy: 0.7728
Epoch 16/20
47/47 [==============================] - 10s 217ms/step - loss: 0.5507 - accuracy: 0.7345
Epoch 17/20
47/47 [==============================] - 10s 220ms/step - loss: 0.7554 - accuracy: 0.7089
Epoch 18/20
47/47 [==============================] - 10s 220ms/step - loss: 1.1833 - accuracy: 0.6606
Epoch 19/20
37/47 [======================>.......] - ETA: 2s - loss: 3.1446 - accuracy: 0.6338
[INFO] learning rate finder complete
[INFO] examine plot and adjust learning rates before training

Figure 6: Analyzing our optimal deep learning rate finder plot. We will use the optimal learning rate to train a fire/smoke detector using Keras and Python.
检查上面的图 6 ,你可以看到我们的网络能够获得牵引力,并在1e-5左右开始学习。
在1e-2和1e-1之间可以找到最低损耗;然而,在1e-1我们可以看到损耗开始急剧增加,这意味着学习速率太大和网络过度拟合。
为了安全起见,我们应该使用初始学习率1e-2。
现在让我们继续进行第二步。
打开config.py并滚动到第 16-19 行,在这里我们设置我们的训练超参数:
# define the initial learning rate, batch size, and number of epochs
INIT_LR = 1e-2
BATCH_SIZE = 64
NUM_EPOCHS = 50
这里我们看到我们的初始学习率(INIT_LR)值——我们需要将这个值设置为1e-2(如我们的代码所示)。
最后一步(步骤#3 )是为全套NUM_EPOCHS训练FireDetectionNet:
$ python train.py
[INFO] loading data...
[INFO] compiling model...
[INFO] training network...
Epoch 1/50
46/46 [==============================] - 11s 233ms/step - loss: 0.6813 - accuracy: 0.6974 - val_loss: 0.6583 - val_accuracy: 0.6464
Epoch 2/50
46/46 [==============================] - 11s 232ms/step - loss: 0.4886 - accuracy: 0.7631 - val_loss: 0.7774 - val_accuracy: 0.6464
Epoch 3/50
46/46 [==============================] - 10s 224ms/step - loss: 0.4414 - accuracy: 0.7845 - val_loss: 0.9470 - val_accuracy: 0.6464
Epoch 4/50
46/46 [==============================] - 10s 222ms/step - loss: 0.4193 - accuracy: 0.7917 - val_loss: 1.0790 - val_accuracy: 0.6464
Epoch 5/50
46/46 [==============================] - 10s 224ms/step - loss: 0.4015 - accuracy: 0.8070 - val_loss: 1.2034 - val_accuracy: 0.6464
...
Epoch 46/50
46/46 [==============================] - 10s 222ms/step - loss: 0.1935 - accuracy: 0.9275 - val_loss: 0.2985 - val_accuracy: 0.8781
Epoch 47/50
46/46 [==============================] - 10s 221ms/step - loss: 0.1812 - accuracy: 0.9244 - val_loss: 0.2325 - val_accuracy: 0.9031
Epoch 48/50
46/46 [==============================] - 10s 226ms/step - loss: 0.1857 - accuracy: 0.9241 - val_loss: 0.2788 - val_accuracy: 0.8911
Epoch 49/50
46/46 [==============================] - 11s 229ms/step - loss: 0.2065 - accuracy: 0.9129 - val_loss: 0.2177 - val_accuracy: 0.9121
Epoch 50/50
46/46 [==============================] - 63s 1s/step - loss: 0.1842 - accuracy: 0.9316 - val_loss: 0.2376 - val_accuracy: 0.9111
[INFO] evaluating network...
precision recall f1-score support
Non-Fire 0.96 0.90 0.93 647
Fire 0.83 0.94 0.88 354
accuracy 0.91 1001
macro avg 0.90 0.92 0.91 1001
weighted avg 0.92 0.91 0.91 1001
[INFO] serializing network to 'output/fire_detection.model'...
Figure 7: Accuracy/loss curves for training a fire and smoke detection deep learning model with Keras and Python.
这里的学习有点不稳定,但是你可以看到我们获得了 92%的准确率。
对火灾/非火灾图像进行预测
给定我们训练有素的火灾探测模型,现在让我们学习如何:
- 从磁盘加载训练好的模型。
- 从我们的数据集中随机抽取图像样本。
- 使用我们的模型对每个输入图像进行分类。
打开predict_fire.py并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import load_model
from pyimagesearch import config
from imutils import paths
import numpy as np
import imutils
import random
import cv2
import os
# load the trained model from disk
print("[INFO] loading model...")
model = load_model(config.MODEL_PATH)
第 2-9 行处理我们的导入,即load_model,这样我们可以从磁盘加载我们序列化的 TensorFlow/Keras 模型。
让我们从合并的数据集中抓取 25 张随机图像:
# grab the paths to the fire and non-fire images, respectively
print("[INFO] predicting...")
firePaths = list(paths.list_images(config.FIRE_PATH))
nonFirePaths = list(paths.list_images(config.NON_FIRE_PATH))
# combine the two image path lists, randomly shuffle them, and sample
# them
imagePaths = firePaths + nonFirePaths
random.shuffle(imagePaths)
imagePaths = imagePaths[:config.SAMPLE_SIZE]
第 17 行和第 18 行从我们的组合数据集中抓取图像路径,而第 22-24 行对 25 个随机图像路径进行采样。
从这里开始,我们将遍历每个单独的图像路径,并执行火灾探测推断:
# loop over the sampled image paths
for (i, imagePath) in enumerate(imagePaths):
# load the image and clone it
image = cv2.imread(imagePath)
output = image.copy()
# resize the input image to be a fixed 128x128 pixels, ignoring
# aspect ratio
image = cv2.resize(image, (128, 128))
image = image.astype("float32") / 255.0
# make predictions on the image
preds = model.predict(np.expand_dims(image, axis=0))[0]
j = np.argmax(preds)
label = config.CLASSES[j]
# draw the activity on the output frame
text = label if label == "Non-Fire" else "WARNING! Fire!"
output = imutils.resize(output, width=500)
cv2.putText(output, text, (35, 50), cv2.FONT_HERSHEY_SIMPLEX,
1.25, (0, 255, 0), 5)
# write the output image to disk
filename = "{}.png".format(i)
p = os.path.sep.join([config.OUTPUT_IMAGE_PATH, filename])
cv2.imwrite(p, output)
第 27 行开始在我们采样的图像路径上循环:
- 我们加载并预处理图像,就像在训练中一样(第 29-35 行)。
- 做预测,抓住概率最高的标签(第 38-40 行)。
- 在图像的顶角标注标签(第 43-46 行)。
- 将输出图像保存到磁盘(第 49-51 行)。
火灾探测结果
要查看我们的火灾探测器,请确保使用本教程的 “下载” 部分下载源代码和预训练模型。
从那里,您可以执行以下命令:
$ python predict_fire.py
[INFO] loading model...
[INFO] predicting...
Figure 8: Fire and smoke detection with Keras, deep learning, and Python.
我在图 8 中包含了一组结果样本——请注意我们的模型如何能够正确预测其中的【着火】和【非着火】。
局限性和缺点
然而,我们的结果并不完美。以下是一些不正确分类的例子:

Figure 9: Examples of incorrect fire/smoke detection.
左边的图像尤其令人不安——夕阳将红色和橙色的阴影投射在天空,创造出“地狱”般的效果。似乎在这些情况下,我们的火灾探测模型将会非常困难。
那么,为什么会有这些不正确的分类呢?
答案就在数据集本身。
首先,我们只处理原始图像数据。
随着火灾以闷烧的形式开始,慢慢发展到临界点,然后爆发成巨大的火焰,烟和火可以用视频更好地探测。这种模式在视频流中比在图像中更容易检测到。
其次,我们的数据集非常小。
结合这两个数据集,我们总共只有 4003 张图像。火灾和烟雾数据集很难获得,这使得创建高精度模型极具挑战性。
最后,我们的数据集不一定能代表问题。
我们的火灾/烟雾数据集中的许多示例图像包含由新闻报道捕获的专业照片的示例。野外的火看起来不像这样。
为了改进我们的火灾和烟雾探测模型,我们需要更好的数据。
火灾/烟雾探测研究的未来努力应该少关注实际的深度学习架构/训练方法,多关注实际的数据集收集和管理过程,**确保数据集更好地代表火灾如何在自然场景图像中开始、阴燃和蔓延。****
摘要
在本教程中,您学习了如何使用计算机视觉、深度学习和 Keras 库来创建烟雾和火灾探测器。
为了构建我们的烟雾和火灾探测器,我们利用了两个数据集:
- 由 PyImageSearch 阅读器 Gautam Kumar 管理的火/烟实例数据集(1315 张图片)。
- 无火/无烟示例数据集 (2,688 张图像),包含 8 个自然户外场景的示例(森林、海岸线、山脉、野外等)。).这个数据集最初是由 Oliva 和 Torralba 在他们 2001 年的论文 中收集的,该论文对场景的形状进行建模:空间包络 的整体表示。
然后我们设计了一个FireDetectionNet——一个用于烟雾和火灾探测的卷积神经网络。这个网络是在我们的两个数据集上训练的。一旦我们的网络被训练,我们在我们的测试集上评估它,发现它获得了 92%的准确率。
然而,这种方法有许多限制和缺点:
- 首先,我们只处理图像数据。通过视频可以更好地检测烟雾和火灾,因为火灾开始时是闷烧,慢慢发展到临界点,然后爆发成巨大的火焰。
- 其次,我们的数据集很小。结合这两个数据集,我们总共只有 4,003 张图像。火灾和烟雾数据集很难获得,这使得创建高精度模型极具挑战性。
基于上一点,我们的数据集不一定代表这个问题。我们的火灾/烟雾数据集中的许多示例图像都是由新闻报道捕获的专业照片。野外的火看起来不像这样。
重点是:
火灾和烟雾探测是一个可解决的问题……但是我们需要更好的数据集。
幸运的是, PyImageSearch Gurus 成员大卫·波恩正在积极解决这个问题,并在 PyImageSearch Gurus 社区论坛上讨论这个问题。如果你有兴趣了解他的项目,一定要联系他。
我希望你喜欢这个教程!
要下载这篇文章的源代码(并在 PyImageSearch 上发布以后的教程时得到通知),只需在下面的表格中输入您的电子邮件地址。*
GAN 培训挑战:用于彩色图像的 DCGAN
原文:https://pyimagesearch.com/2021/12/13/gan-training-challenges-dcgan-for-color-images/
在本教程中,您将学习如何训练 DCGAN 生成彩色时尚图像。在培训过程中,您将了解常见挑战、应对这些挑战的技术以及 GAN 评估指标。
本课是 GAN 系列教程的第三篇:
- 生成对抗网络简介
- 入门:DCGAN for Fashion-MNIST
- GAN 训练 挑战:彩色图像的 DCGAN】(本帖)
要了解如何训练 DCGAN 生成彩色时尚图像,以及常见的 GAN 训练挑战和最佳实践, 继续阅读。
在我之前的文章中,开始:时尚 MNIST 的 DCGAN,你学习了如何训练一个 DCGAN 来生成灰度时尚 MNIST 图像。在这篇文章中,让我们用彩色图像训练一个 DCGAN,以展示 GAN 训练的常见挑战。我们还将简要讨论一些改进技术和 GAN 评估指标。请跟随 Colab 笔记本的教程,这里是完整的代码示例。
用于彩色图像的 DCGAN
我们将从我之前的帖子中获取 DCGAN 代码作为基线,然后对训练彩色图像进行调整。由于我们已经在我的上一篇文章中详细介绍了 DCGAN 的端到端培训,现在我们将只关注为彩色图像培训 DCGAN 所需的关键变化:
- 数据:从 Kaggle 下载彩色图像,预处理到
[-1, 1]范围。 - 生成器:调整如何对模型架构进行上采样,以生成彩色图像。
- 鉴别器:将输入图像形状从
28×28×1调整到64×64×3。
有了这些改变,你就可以开始在彩色图像上训练 DCGAN 了;然而,当处理彩色图像或除 MNIST 或时尚-MNIST 之外的任何数据时,您会意识到 GAN 培训是多么具有挑战性。甚至用时尚 MNIST 的灰度图像进行训练也可能很棘手。
1.准备数据
我们将使用 Kaggle 的一个名为服装&模特的数据集来训练 DCGAN,这个数据集是从Zalando.com那里收集的服装碎片。有六个类别,超过 16k 的彩色图像,大小为606×875,将调整到64×64进行训练。
要从 Kaggle 下载数据,您需要提供您的 Kaggle 凭据。您可以将 Kaggle json 文件上传到 Colab,或者将您的 Kaggle 用户名和密钥放在笔记本中。我们选择了后者。
os.environ['KAGGLE_USERNAME']="enter-your-own-user-name"
os.environ['KAGGLE_KEY']="enter-your-own-user-name"
下载并解压到一个名为dataset的目录。
!kaggle datasets download -d dqmonn/zalando-store-crawl -p datasets
!unzip datasets/zalando-store-crawl.zip -d datasets/
下载并解压缩数据后,我们设置数据所在的目录。
zalando_data_dir = "/content/datasets/zalando/zalando/zalando"
然后,我们使用 Keras' image_dataset_from_directory从目录中的图像创建一个tf.data.Dataset,它将在稍后用于训练模型。最后,我们指定了64×64的图像大小和32的批量大小。
train_images = tf.keras.utils.image_dataset_from_directory(
zalando_data_dir, label_mode=None, image_size=(64, 64), batch_size=32)
让我们在图 1 中想象一个训练图像作为例子:
和以前一样,我们将图像归一化到[-1, 1]的范围,因为生成器的最终层激活使用了tanh。最后,我们通过使用tf.dataset的map函数和lambda函数来应用规范化。
train_images = train_images.map(lambda x: (x - 127.5) / 127.5)
2.发电机
我们在build_generator函数中使用 keras Sequential API 创建生成器架构。在我之前的【DCGAN 帖子中,我们已经讨论了如何创建生成器架构的细节。下面我们来看看如何调整上采样来生成期望的64×64×3彩色图像尺寸:
- 我们为彩色图像更新
CHANNELS = 3,而不是为灰度图像更新 1。 - 2 的步幅是宽度和高度的一半,所以你可以向后算出最初的图像尺寸:对于时尚 MNIST,我们向上采样为
7 -> 14 -> 28。现在,我们正在使用大小为64×64的训练图像,因此我们会像8 -> 16 -> 32 -> 64一样向上采样几次。这意味着我们多加了一套Conv2DTranspose -> BatchNormalization -> ReLU。
生成器的另一个变化是将内核大小从 5 更新为 4,以避免减少生成图像中的棋盘状伪像(参见图 2 )。
这是因为根据后解卷积和棋盘伪影,内核大小 5 不能被步幅 2 整除。所以解决方案是使用内核大小 4 而不是 5。
我们可以在图 3 中看到 DCGAN 发生器的架构:
通过调用图 4 中的generator.summary(),用代码可视化生成器架构:
3.鉴别器
鉴别器架构的主要变化是图像输入形状:我们使用的是形状[64, 64, 3]而不是[28, 28, 1]。我们还增加了一组Conv2D -> BatchNormalization -> LeakyReLU来平衡上面提到的生成器中增加的架构复杂性。其他一切都保持不变。
我们可以在图 5 中看到 DCGAN 鉴频器架构:
通过调用图 6 中的discriminator.summary(),用代码可视化鉴别器架构:
DCGAN 模型
我们再次通过子类keras.Model定义 DCGAN 模型架构,并覆盖train_step来定义定制的训练循环。代码中唯一的细微变化是对真正的标签应用单侧标签平滑。
real_labels = tf.ones((batch_size, 1))
real_labels += 0.05 * tf.random.uniform(tf.shape(real_labels))
这种技术降低了鉴频器的过度自信,因此有助于稳定 GAN 训练。参考 Adrian Rosebrock 的帖子使用 Keras、TensorFlow 和深度学习进行标签平滑了解标签平滑的一般详细信息。在训练 GANs 的改进技术一文中提出了用于正则化 GAN 训练的“单侧标签平滑”技术,在这里你也可以找到其他的改进技术。
为培训监控定义 Kera Callback
没有变化的相同代码—覆盖 Keras 回调以在训练期间监视和可视化生成的图像。
class GANMonitor(keras.callbacks.Callback):
def __init__():
...
def on_epoch_end():
...
def on_train_end():
...
训练 DCGAN 模型
这里我们将 dcgan 模型和 DCGAN 类放在一起:
dcgan = DCGAN(discriminator=discriminator, generator=generator, latent_dim=LATENT_DIM)
编译 dcgan 模型,主要变化是学习率。在这里,我将鉴别器学习率设置为0.0001,将发电机学习率设置为0.0003。这是为了确保鉴别器不会超过发生器的功率。
D_LR = 0.0001 # discriminator learning rate
G_LR = 0.0003 # generator learning rate
dcgan.compile(
d_optimizer=keras.optimizers.Adam(learning_rate=D_LR, beta_1 = 0.5),
g_optimizer=keras.optimizers.Adam(learning_rate=G_LR, beta_1 = 0.5),
loss_fn=keras.losses.BinaryCrossentropy(),
)
现在我们干脆调用model.fit()来训练dcgan模型!
NUM_EPOCHS = 50 # number of epochs
dcgan.fit(train_images, epochs=NUM_EPOCHS,
callbacks=[GANMonitor(num_img=16, latent_dim=LATENT_DIM)])
以下是生成器在整个 DCGAN 训练过程中创建的图像截图(图 7 ):
GAN 培训挑战
现在我们已经完成了用彩色图像训练 DCGAN。让我们来讨论一下 GAN 训练的一些常见挑战。
gan 很难训练,以下是一些众所周知的挑战:
- 不收敛:不稳定,消失梯度,或缓慢训练
- 模式崩溃
- 难以评估
不收敛
与训练其他模型(如图像分类器)不同,训练期间 D 和 G 的损失或准确性仅单独测量 D 和 G,而不测量 GAN 的整体性能以及生成器创建图像的能力。当发生器和鉴频器之间达到平衡时,GAN 模型是“好”的,通常鉴频器的损耗约为 0.5。
甘练不稳:很难让 D 和 G 保持平衡达到一个均衡。看看训练中的损失,你会发现它们可能会剧烈波动。D 和 G 都可能停滞不前,永远无法改善。长时间的训练并不总是让发电机变得更好。发生器的图像质量可能会随着时间而恶化。
消失梯度:在定制训练循环中,我们讨论了如何计算鉴频器和发电机损耗,计算梯度,然后使用梯度进行更新。发生器依靠鉴别器的反馈进行改进。如果鉴别器如此强大,以至于它压倒了生成器:它可以分辨出每次都有假图像,那么生成器就停止了训练。
您可能会注意到,有时生成的图像即使经过一段时间的训练,质量仍然很差。这意味着模型无法在鉴别器和发生器之间找到平衡。
实验:让 D 架构强很多(模型架构中的参数更多)或者比 G 训练得更快(比如把 D 的学习率提高到比 G 的学习率高很多)。
模式崩溃
当生成器重复生成相同的图像或训练图像的小子集时,会发生模式崩溃。一个好的生成器应该生成各种各样的图像,这些图像在所有类别上都类似于训练图像。当鉴别器不能辨别出生成的图像是假的时,就会发生模式崩溃,因此生成器会不断生成相同的图像来欺骗鉴别器。
实验:为了模拟代码中的模式崩溃问题,尝试将噪声向量维数从 100 减少到 10;或者将噪声向量维数从 100 增加到 128 以增加图像多样性。
难以评估
评估 GAN 模型具有挑战性,因为没有简单的方法来确定生成的图像是否“好”。与图像分类器不同,根据基本事实标签,预测是正确的还是不正确的。这就引出了下面关于我们如何评估 GAN 模型的讨论。
GAN 评估指标
成功的生成器有两个标准——它应该生成具有以下特征的图像:
- 良好的品质:高保真逼真,
- 多样性(或多样性):训练图像不同类型(或类别)的良好表示。
我们可以用一些度量标准定性地(视觉检查图像)或定量地评估模型。
通过目视检查进行定性评估。正如我们在 DCGAN 训练中所做的那样,我们查看在同一种子上生成的一组图像,并在视觉上检查随着训练的进行图像是否看起来更好。这对于一个玩具例子来说是可行的,但是对于大规模训练来说太耗费人力了。
初始得分(IS)和弗雷歇初始距离(FID)是定量比较 GAN 模型的两个流行指标。
本文介绍了初始评分:训练 GANs 的改进技术。它测量生成图像的质量和多样性。这个想法是使用 inception 模型对生成的图像进行分类,并使用预测来评估生成器。分数越高,表示模型越好。
弗雷歇初始距离 (FID)也使用初始网络进行特征提取并计算数据分布。FID 通过查看生成的图像和训练图像而不是孤立地只查看生成的图像来改进 IS。较低的 FID 意味着生成的图像更接近真实图像,因此是更好的 GAN 模型。
总结
在这篇文章中,你已经学会了如何训练 DCGAN 生成彩色时尚图片。您还了解了 GAN 培训的常见挑战、一些改进技巧以及 GAN 评估指标。在我的下一篇文章中,我们将学习如何进一步提高瓦瑟斯坦甘(WGAN)和瓦瑟斯坦甘梯度惩罚(WGAN-GP)的训练稳定性。
引用信息
Maynard-Reid,m .“GAN 训练挑战:用于彩色图像的 DCGAN”, PyImageSearch ,2021,https://PyImageSearch . com/2021/12/13/GAN-Training-Challenges-DCGAN-for-Color-Images/
@article{Maynard-Reid_2021_GAN_Training,
author = {Margaret Maynard-Reid},
title = {{GAN} Training Challenges: {DCGAN} for Color Images},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/12/13/gan-training-challenges-dcgan-for-color-images/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
带 Keras 和 TensorFlow 的 GANs
原文:https://pyimagesearch.com/2020/11/16/gans-with-keras-and-tensorflow/
在本教程中,你将学习如何使用 Keras 和 TensorFlow 实现生成式对抗网络(GANs)。
Goodfellow 等人在其 2014 年的论文 中首次引入了生成对抗网络。这些网络可用于生成合成(即伪造)图像,这些图像在感知上与真实可信的原始图像几乎相同。
为了生成合成图像,我们在训练期间使用了两个神经网络:
- 一个发生器,它接受随机产生的噪声的输入向量,并产生一个输出“模仿”图像,该图像看起来与真实图像相似,如果不是完全相同的话
- 一个鉴别器或对手,试图确定给定图像是“真实的”还是“伪造的”
通过同时训练这些网络,一个给另一个反馈,我们可以学习生成合成图像。
在本教程中,我们将实现拉德福德等人论文的一个变体, 使用深度卷积生成对抗网络 的无监督表示学习——或者更简单地说, DCGANs。
我们会发现,训练 GANs 可能是一项众所周知的艰巨任务,因此我们将实施拉德福德等人和弗朗索瓦·乔莱(Keras 的创始人和谷歌深度学习科学家)推荐的一些最佳实践。
在本教程结束时,您将拥有一个功能完整的 GAN 实现。
要学习如何用 Keras 和 TensorFlow 实现生成式对抗网络(GANs),继续阅读。
具有 Keras 和 TensorFlow 的 GANs】
注:本教程是我的书用 Python 进行计算机视觉的深度学习中的一章。如果你喜欢这篇文章,并想了解更多关于深度学习在计算机视觉中的应用,请务必阅读我的书 — 我毫不怀疑它将带你从深度学习初学者一路成为专家。
在本教程的第一部分,我们将讨论什么是生成对立网络,包括它们与你以前见过的用于分类和回归的更“普通”的网络架构有何不同。
在此基础上,我们将讨论一般的 GAN 培训流程,包括您在培训自己的 GAN 时应该遵循的一些指南和最佳实践。
接下来,我们将回顾项目的目录结构,然后使用 Keras 和 TensorFlow 实现我们的 GAN 架构。
一旦我们的 GAN 被实现,我们将在时尚 MNIST 数据集上训练它,从而允许我们生成假的/合成的时尚服装图像。
最后,我们将讨论我们的结果来结束这个关于生成性敌对网络的教程。
什么是生成敌对网络?
对 GANs 的典型解释通常涉及两个人合谋伪造一套文件、复制一件艺术品或印刷假币的某种变体——假币印刷机是我个人最喜欢的,也是 Chollet 在工作中使用的。
在这个例子中,我们有两个人:
- 杰克,假冒的打印机(发生器
- 杰森(Jason),美国财政部(负责美国印钞)的雇员,专门检测假币(即鉴别器)
杰克和杰森是青梅竹马,都是在波士顿的贫民区长大的,没有多少钱。经过艰苦的努力,杰森获得了大学奖学金,而杰克没有,随着时间的推移,他开始转向非法企业赚钱(在这种情况下,制造假币)。
杰克知道他不太擅长制造假币,但他觉得经过适当的训练,他可以复制出流通中还过得去的钞票。
一天,在感恩节假期里,杰森在当地一家酒吧喝了几杯后,无意中向杰克透露了他对自己的工作不满意。他报酬过低。他的老板既讨厌又恶毒,经常在其他员工面前大喊大叫,让杰森尴尬。杰森甚至想辞职。
杰克发现了一个机会,可以利用杰森在美国财政部的权限来设计一个复杂的伪造印刷计划。他们的阴谋是这样运作的:
- 假钞印刷商杰克会印刷假钞,然后把假钞和真钱混在一起,然后给专家杰森看。
- 杰森会对钞票进行分类,将每张钞票分为“假钞”或“真钞”,一路上向杰克提供反馈,告诉他如何改进伪造的印刷技术。
起初,杰克在印制伪钞方面做得很差。但随着时间的推移,在杰森的指导下,杰克最终提高到杰森不再能够分辨钞票之间的差异。在这个过程结束时,杰克和杰森都有了一叠叠可以骗过大多数人的假币。
甘的一般训练程序
我们已经从类比的角度讨论了什么是甘,但是训练他们的实际程序是什么?大多数 GANs 都是通过六个步骤来训练的。
首先(步骤 1),我们随机生成一个矢量(即噪声)。我们让这个噪声通过我们的生成器,它生成一个实际的图像(步骤 2)。然后,我们从我们的训练集中采样真实图像,并将它们与我们的合成图像混合(步骤 3)。
下一步(步骤 4)是使用这个混合集训练我们的鉴别器。鉴别器的目标是正确地将每个图像标记为“真”或“假”
接下来,我们将再次生成随机噪声,但这一次我们将有目的地将每个噪声向量标记为“真实图像”(步骤 5)。然后,我们将使用噪声向量和“真实图像”标签来训练 GAN,即使它们不是实际的真实图像(步骤 6)。
这一过程之所以有效是由于以下原因:
- 我们在这个阶段冻结了鉴别器的权重,这意味着当我们更新生成器的权重时,鉴别器没有学习。
- 我们试图“愚弄”鉴别者,使其无法判断哪些图像是真实的,哪些是合成的。来自鉴别器的反馈将允许生成器学习如何产生更真实的图像。
如果您对这个过程感到困惑,我会继续阅读本教程后面的实现——看到用 Python 实现的 GAN,然后进行解释,会更容易理解这个过程。
培训 GANs 时的指南和最佳实践
众所周知,由于不断演变的亏损格局,gan 们很难训练。在我们算法的每次迭代中,我们:
- 生成随机图像,然后训练鉴别器来正确区分这两者
- 生成额外的合成图像,但这一次故意试图欺骗鉴别者
- 基于鉴别器的反馈更新生成器的权重,从而允许我们生成更真实的图像
从这个过程中,你会注意到我们需要观察两个损耗:一个是鉴频器的损耗,另一个是发电机的损耗。由于发电机的损耗状况可以根据鉴频器的反馈而改变,我们最终得到了一个动态系统。
在训练 gan 时,我们的目标不是寻求最小损失值,而是在两者之间找到某种平衡(Chollet 2017)。
这种寻找平衡的概念在理论上可能是有意义的,但是一旦你尝试实现和训练你自己的 GANs,你会发现这是一个不简单的过程。
在他们的论文中,拉德福德等人为更稳定的 GANs 推荐了以下架构指南:
- 用交错卷积替换任何池层(参见本教程了解更多关于卷积和交错卷积的信息)。
- 在生成器和鉴别器中使用批处理规范化。
- 移除深层网络中的全连接层。
- 在发生器中使用 ReLU,除了最后一层,它将使用 tanh。
- 在鉴别器中使用泄漏 ReLU。
在他的书中,Francois Chollet 提供了更多关于训练 GANs 的建议:
- 从正态分布(即高斯分布)而非均匀分布中抽取随机向量。
- 将 dropout 添加到鉴别器中。
- 训练鉴别器时,将噪声添加到类别标签中。
- 要减少输出图像中的棋盘格像素伪像,在发生器和鉴别器中使用卷积或转置卷积时,请使用可被步幅整除的核大小。
- 如果你的对抗性损失急剧上升,而你的鉴别器损失下降到零,尝试降低鉴别器的学习率,增加鉴别器的漏失。
请记住,这些都只是在许多情况下有效的试探法——我们将使用拉德福德等人和乔莱建议的一些技术,而不是所有的。
很可能,甚至很有可能,这里列出的技巧对你的 GANs 不起作用。现在花时间设定你的期望,当调整你的 GANs 的超参数时,与更基本的分类或回归任务相比,你可能会运行数量级更多的实验。
配置您的开发环境,使用 Keras 和 TensorFlow 训练 GANs】
我们将使用 Keras 和 TensorFlow 来实现和培训我们的 gan。
我建议您按照这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
现在我们已经了解了生成性对抗网络的基础,让我们回顾一下这个项目的目录结构。
确保您使用本教程的 【下载】 部分将源代码下载到我们的 GAN 项目:
$ tree . --dirsfirst
.
├── output
│ ├── epoch_0001_output.png
│ ├── epoch_0001_step_00000.png
│ ├── epoch_0001_step_00025.png
...
│ ├── epoch_0050_step_00300.png
│ ├── epoch_0050_step_00400.png
│ └── epoch_0050_step_00500.png
├── pyimagesearch
│ ├── __init__.py
│ └── dcgan.py
└── dcgan_fashion_mnist.py
3 directories, 516 files
用 Keras 和 TensorFlow 实现我们的“生成器”
现在我们已经回顾了我们的项目目录结构,让我们开始使用 Keras 和 TensorFlow 实现我们的生成式对抗网络。
在我们的项目目录结构中打开dcgan.py文件,让我们开始吧:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
第 2-10 行导入我们需要的 Python 包。所有这些类对你来说应该看起来相当熟悉,尤其是如果你已经读过我的 Keras 和 TensorFlow 教程或者我的书 用 Python 进行计算机视觉的深度学习。
唯一的例外可能是Conv2DTranspose类。转置卷积层,有时被称为分数步长卷积或(不正确的)反卷积,当我们需要在常规卷积的相反方向进行变换时使用。
我们的 GAN 的生成器将接受一个 N 维输入向量(即一个列表的数字,但是一个体积像一个图像),然后将 N 维向量转换成一个输出图像。
这个过程意味着我们需要重塑,然后在这个向量通过网络时将其放大成一个体积——为了完成这种重塑和放大,我们需要转置卷积。
因此,我们可以将转置卷积视为实现以下目的的方法:
- 接受来自网络中前一层的输入量
- 产生比输入量大的输出量
- 维护输入和输出之间的连接模式
本质上,我们的转置卷积层将重建我们的目标空间分辨率,并执行正常的卷积操作,利用花哨的零填充技术来确保满足我们的输出空间维度。
要了解转置卷积的更多信息,请查看 Theano 文档中的 卷积运算教程以及 Paul-Louis prve 的 深度学习中不同类型卷积的介绍 。
现在让我们开始实现我们的DCGAN类:
class DCGAN:
@staticmethod
def build_generator(dim, depth, channels=1, inputDim=100,
outputDim=512):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (dim, dim, depth)
chanDim = -1
当我们在下一个代码块中定义网络主体时,这些参数的用法将变得更加清楚。
下面我们可以找到我们的发电机网络的主体:
# first set of FC => RELU => BN layers
model.add(Dense(input_dim=inputDim, units=outputDim))
model.add(Activation("relu"))
model.add(BatchNormalization())
# second set of FC => RELU => BN layers, this time preparing
# the number of FC nodes to be reshaped into a volume
model.add(Dense(dim * dim * depth))
model.add(Activation("relu"))
model.add(BatchNormalization())
第 23-25 行定义了我们的第一组FC => RELU => BN层——应用批量标准化来稳定 GAN 训练是拉德福德等人的指导方针(参见上面的“训练 GAN 时的指导方针和最佳实践”部分)。
注意我们的FC层将如何拥有一个输入维度inputDim(随机生成的输入向量),然后输出维度outputDim。通常outputDim会比inputDim大。
*第 29-31 行应用第二组FC => RELU => BN层,但是这次我们准备FC层中的节点数等于inputShape ( 第 29 行)中的单元数。尽管我们仍在使用扁平化的表示,但我们需要确保这个FC层的输出可以被整形为我们的目标卷 sze(即inputShape)。
实际的整形发生在下一个代码块中:
# reshape the output of the previous layer set, upsample +
# apply a transposed convolution, RELU, and BN
model.add(Reshape(inputShape))
model.add(Conv2DTranspose(32, (5, 5), strides=(2, 2),
padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
在提供inputShape的同时调用Reshape允许我们从行 29 上的全连接层创建一个 3D 体积。同样,这种整形仅在FC层中输出节点的数量与目标inputShape匹配的情况下才有可能。
在训练你自己的 GANs 时,我们现在达成了一个重要的指导方针:
- 为了增加空间分辨率,使用步长为 > 1 的转置卷积。
- 要创建更深的 GAN 而不增加空间分辨率,您可以使用标准卷积或转置卷积(但保持跨距等于 1)。
在这里,我们的转置卷积层正在学习32滤波器,每个滤波器都是 5×5 ,同时应用一个 2×2 步幅——由于我们的步幅是 > 1 ,我们可以增加我们的空间分辨率。
让我们应用另一个转置卷积:
# apply another upsample and transposed convolution, but
# this time output the TANH activation
model.add(Conv2DTranspose(channels, (5, 5), strides=(2, 2),
padding="same"))
model.add(Activation("tanh"))
# return the generator model
return model
第 43 行和第 44 行应用另一个转置卷积,再次增加空间分辨率,但是注意确保学习的滤波器数量等于channels的目标数量(灰度的1和 RGB 的3)。
然后,我们按照拉德福德等人的建议应用一个 tanh 激活函数。然后,模型返回到第行 48 上的调用函数。
了解我们 GAN 中的“发电机”
假设dim=7、depth=64、channels=1、inputDim=100和outputDim=512(我们将在本教程稍后对我们的 GAN 进行时尚培训时使用),我已经包括了以下模型摘要:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 51712
_________________________________________________________________
activation (Activation) (None, 512) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 512) 2048
_________________________________________________________________
dense_1 (Dense) (None, 3136) 1608768
_________________________________________________________________
activation_1 (Activation) (None, 3136) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 3136) 12544
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 14, 14, 32) 51232
_________________________________________________________________
activation_2 (Activation) (None, 14, 14, 32) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 32) 128
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 28, 28, 1) 801
_________________________________________________________________
activation_3 (Activation) (None, 28, 28, 1) 0
=================================================================
我们来分析一下这是怎么回事。
应用步长为 2×2 的转置卷积将我们的空间维度从 7×7 增加到 14×14。
第二个转置卷积(同样,步长为 2×2 )使用单个通道将我们的空间维度分辨率从 14×14 增加到 28×18 ,这是我们在时尚 MNIST 数据集中输入图像的精确维度。
在实现自己的 GANs 时,确保输出体积的空间尺寸与输入图像的空间尺寸相匹配。使用转置卷积增加生成器中体积的空间维度。我也推荐经常使用model.summary()来帮助你调试空间维度。
用 Keras 和 TensorFlow 实现我们的“鉴别器”
鉴别器模型实质上更简单,类似于你可能在我的书或 PyImageSearch 博客的其他地方读过的基本 CNN 分类架构。
请记住,虽然生成器旨在创建合成图像,但鉴别器用于对进行分类,以确定任何给定的输入图像是真实的还是虚假的。
继续我们在dcgan.py中对DCGAN类的实现,现在让我们看看鉴别器:
@staticmethod
def build_discriminator(width, height, depth, alpha=0.2):
# initialize the model along with the input shape to be
# "channels last"
model = Sequential()
inputShape = (height, width, depth)
# first set of CONV => RELU layers
model.add(Conv2D(32, (5, 5), padding="same", strides=(2, 2),
input_shape=inputShape))
model.add(LeakyReLU(alpha=alpha))
# second set of CONV => RELU layers
model.add(Conv2D(64, (5, 5), padding="same", strides=(2, 2)))
model.add(LeakyReLU(alpha=alpha))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512))
model.add(LeakyReLU(alpha=alpha))
# sigmoid layer outputting a single value
model.add(Dense(1))
model.add(Activation("sigmoid"))
# return the discriminator model
return model
正如我们所见,这个网络简单明了。我们先学习 32 个, 5×5 滤镜,接着是第二个CONV层,这一层总共学习 64 个, 5×5 滤镜。我们这里只有一个单独的FC层,这一层有512节点。
所有激活层都利用漏 ReLU 激活来稳定训练,除了最后的激活函数为 sigmoid 的。我们在这里使用一个 sigmoid 来捕捉输入图像是真实的还是合成的概率。
实施我们的 GAN 培训脚本
现在,我们已经实现了我们的 DCGAN 架构,让我们在时尚 MNIST 数据集上训练它,以生成虚假的服装项目。训练过程结束时,我们将无法从合成图像中识别出真实图像。
在我们的项目目录结构中打开dcgan_fashion_mnist.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.dcgan import DCGAN
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import fashion_mnist
from sklearn.utils import shuffle
from imutils import build_montages
import numpy as np
import argparse
import cv2
import os
我们从导入所需的 Python 包开始。
让我们开始解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-e", "--epochs", type=int, default=50,
help="# epochs to train for")
ap.add_argument("-b", "--batch-size", type=int, default=128,
help="batch size for training")
args = vars(ap.parse_args())
对于这个脚本,我们只需要一个命令行参数--output,它是输出目录的路径,我们将在该目录中存储生成的图像的剪辑(从而允许我们可视化 GAN 训练过程)。
我们还可以(可选地)提供--epochs,训练的总时期数,以及--batch-size,用于在训练时控制批量大小。
现在让我们来关注一些重要的初始化:
# store the epochs and batch size in convenience variables, then
# initialize our learning rate
NUM_EPOCHS = args["epochs"]
BATCH_SIZE = args["batch_size"]
INIT_LR = 2e-4
我们在第 26 和 27 行的方便变量中存储了时期数和批量大小。
我们还在第 28 行上初始化我们的初始学习速率(INIT_LR)。这个值是通过大量实验和反复试验根据经验调整的。如果您选择将这个 GAN 实现应用到您自己的数据集,您可能需要调整这个学习率。
我们现在可以从磁盘加载时尚 MNIST 数据集:
# load the Fashion MNIST dataset and stack the training and testing
# data points so we have additional training data
print("[INFO] loading MNIST dataset...")
((trainX, _), (testX, _)) = fashion_mnist.load_data()
trainImages = np.concatenate([trainX, testX])
# add in an extra dimension for the channel and scale the images
# into the range [-1, 1] (which is the range of the tanh
# function)
trainImages = np.expand_dims(trainImages, axis=-1)
trainImages = (trainImages.astype("float") - 127.5) / 127.5
第 33 行从磁盘加载时尚 MNIST 数据集。这里我们忽略类标签,因为我们不需要它们——我们只对实际的像素数据感兴趣。
此外,不存在 gan 的“测试集”概念。训练 GAN 时,我们的目标不是最小损失或高精度。相反,我们寻求生成器和鉴别器之间的平衡。
为了帮助我们获得这种平衡,我们结合训练和测试图像(第 34 行)来为我们提供额外的训练数据。
第 39 行和第 40 行通过将像素强度缩放到范围【0,1】, tanh 激活函数的输出范围,来准备我们的训练数据。
现在让我们初始化我们的生成器和鉴别器:
# build the generator
print("[INFO] building generator...")
gen = DCGAN.build_generator(7, 64, channels=1)
# build the discriminator
print("[INFO] building discriminator...")
disc = DCGAN.build_discriminator(28, 28, 1)
discOpt = Adam(lr=INIT_LR, beta_1=0.5, decay=INIT_LR / NUM_EPOCHS)
disc.compile(loss="binary_crossentropy", optimizer=discOpt)
第 44 行初始化发生器,该发生器将把输入随机向量转换成形状为 7x7x64- 通道图的体积。
第 48-50 行构建鉴别器,然后使用带有二进制交叉熵损失的 Adam 优化器编译它。
请记住,我们在这里使用的是二元交叉熵,因为我们的鉴别器有一个 sigmoid 激活函数,它将返回一个概率,指示输入图像是真实的还是伪造的。由于只有两个“类别标签”(真实与合成),我们使用二进制交叉熵。
Adam 优化器的学习率和 beta 值是通过实验调整的。我发现 Adam 优化器的较低学习速率和 beta 值改善了时尚 MNIST 数据集上的 GAN 训练。应用学习率衰减也有助于稳定训练。
给定生成器和鉴别器,我们可以构建 GAN:
# build the adversarial model by first setting the discriminator to
# *not* be trainable, then combine the generator and discriminator
# together
print("[INFO] building GAN...")
disc.trainable = False
ganInput = Input(shape=(100,))
ganOutput = disc(gen(ganInput))
gan = Model(ganInput, ganOutput)
# compile the GAN
ganOpt = Adam(lr=INIT_LR, beta_1=0.5, decay=INIT_LR / NUM_EPOCHS)
gan.compile(loss="binary_crossentropy", optimizer=discOpt)
实际的 GAN 由发生器和鉴别器组成;然而,我们首先需要冻结鉴别器权重(第 56 行),然后我们才组合模型以形成我们的生成性对抗网络(第 57-59 行)。
这里我们可以看到,gan的输入将采用一个 100-d 的随机向量。该值将首先通过生成器,其输出将进入鉴别器——我们称之为“模型合成”,类似于我们在代数课上学到的“函数合成”。
鉴别器权重在这一点上被冻结,因此来自鉴别器的反馈将使生成器能够学习如何生成更好的合成图像。
第 62 行和第 63 行编译了gan。我再次使用 Adam 优化器,其超参数与鉴别器的优化器相同——这个过程适用于这些实验,但是您可能需要在自己的数据集和模型上调整这些值。
此外,我经常发现将 GAN 的学习速率设置为鉴频器的一半通常是一个好的起点。
在整个训练过程中,我们希望看到我们的 GAN 如何从随机噪声中进化出合成图像。为了完成这项任务,我们需要生成一些基准随机噪声来可视化训练过程:
# randomly generate some benchmark noise so we can consistently
# visualize how the generative modeling is learning
print("[INFO] starting training...")
benchmarkNoise = np.random.uniform(-1, 1, size=(256, 100))
# loop over the epochs
for epoch in range(0, NUM_EPOCHS):
# show epoch information and compute the number of batches per
# epoch
print("[INFO] starting epoch {} of {}...".format(epoch + 1,
NUM_EPOCHS))
batchesPerEpoch = int(trainImages.shape[0] / BATCH_SIZE)
# loop over the batches
for i in range(0, batchesPerEpoch):
# initialize an (empty) output path
p = None
# select the next batch of images, then randomly generate
# noise for the generator to predict on
imageBatch = trainImages[i * BATCH_SIZE:(i + 1) * BATCH_SIZE]
noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
第 68 行生成我们的benchmarkNoise。请注意,benchmarkNoise是从范围 [-1,1] 中的均匀分布生成的,这个范围与我们的 tanh 激活函数相同。第 68 行表示我们将生成 256 个合成图像,其中每个输入都以一个 100 维向量开始。
从第 71 行开始,我们循环我们想要的历元数。第 76 行通过将训练图像的数量除以提供的批次大小来计算每个时期的批次数量。
然后我们在第 79 行上循环每一批。
# generate images using the noise + generator model
genImages = gen.predict(noise, verbose=0)
# concatenate the *actual* images and the *generated* images,
# construct class labels for the discriminator, and shuffle
# the data
X = np.concatenate((imageBatch, genImages))
y = ([1] * BATCH_SIZE) + ([0] * BATCH_SIZE)
y = np.reshape(y, (-1,))
(X, y) = shuffle(X, y)
# train the discriminator on the data
discLoss = disc.train_on_batch(X, y)
第 89 行接受我们的输入noise,然后生成合成服装图像(genImages)。
给定我们生成的图像,我们需要训练鉴别器来识别真实图像和合成图像之间的差异。
为了完成这个任务,线 94 将当前的imageBatch和合成的genImages连接在一起。
然后我们需要在行 95 上建立我们的类别标签——每个真实图像将有一个类别标签1,而每个虚假图像将被标记为0。
然后在第 97 行上联合混洗连接的训练数据,因此我们的真实和虚假图像不会一个接一个地相继出现(这将在我们的梯度更新阶段造成问题)。
此外,我发现这种洗牌过程提高了鉴别器训练的稳定性。
第 100 行训练当前(混洗)批次的鉴别器。
我们训练过程的最后一步是训练gan本身:
# let's now train our generator via the adversarial model by
# (1) generating random noise and (2) training the generator
# with the discriminator weights frozen
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
fakeLabels = [1] * BATCH_SIZE
fakeLabels = np.reshape(fakeLabels, (-1,))
ganLoss = gan.train_on_batch(noise, fakeLabels)
我们首先生成总共BATCH_SIZE个随机向量。然而,不像在我们之前的代码块中,我们很好地告诉我们的鉴别器什么是真的什么是假的,我们现在将试图通过将随机的noise标记为真实的图像来欺骗鉴别器。
来自鉴别器的反馈使我们能够实际训练发生器(记住,鉴别器权重对于该操作是冻结的)。
在训练 GAN 时,不仅看损失值很重要,而且你也需要检查你benchmarkNoise上gan的输出:
# check to see if this is the end of an epoch, and if so,
# initialize the output path
if i == batchesPerEpoch - 1:
p = [args["output"], "epoch_{}_output.png".format(
str(epoch + 1).zfill(4))]
# otherwise, check to see if we should visualize the current
# batch for the epoch
else:
# create more visualizations early in the training
# process
if epoch < 10 and i % 25 == 0:
p = [args["output"], "epoch_{}_step_{}.png".format(
str(epoch + 1).zfill(4), str(i).zfill(5))]
# visualizations later in the training process are less
# interesting
elif epoch >= 10 and i % 100 == 0:
p = [args["output"], "epoch_{}_step_{}.png".format(
str(epoch + 1).zfill(4), str(i).zfill(5))]
如果我们已经到达了纪元的末尾,我们将构建路径p,到我们的输出可视化(第 112-114 行)。
否则,我发现在之前的步骤中比在之后的步骤(第 118-129 行)中更频繁地目视检查我们 GAN 的输出会有所帮助。
输出可视化将是完全随机的盐和胡椒噪声在开始,但应该很快开始开发输入数据的特征。这些特征可能看起来不真实,但不断演变的属性将向您展示网络实际上正在学习。
如果在 5-10 个时期之后,您的输出可视化仍然是盐和胡椒噪声,这可能是您需要调整您的超参数的信号,可能包括模型架构定义本身。
我们的最后一个代码块处理将合成图像可视化写入磁盘:
# check to see if we should visualize the output of the
# generator model on our benchmark data
if p is not None:
# show loss information
print("[INFO] Step {}_{}: discriminator_loss={:.6f}, "
"adversarial_loss={:.6f}".format(epoch + 1, i,
discLoss, ganLoss))
# make predictions on the benchmark noise, scale it back
# to the range [0, 255], and generate the montage
images = gen.predict(benchmarkNoise)
images = ((images * 127.5) + 127.5).astype("uint8")
images = np.repeat(images, 3, axis=-1)
vis = build_montages(images, (28, 28), (16, 16))[0]
# write the visualization to disk
p = os.path.sep.join(p)
cv2.imwrite(p, vis)
141 线用我们的发电机从我们的benchmarkNoise产生images。然后,我们将图像数据从范围 [-1,1](tanh激活函数的边界)缩放回范围【0,255】(行 142 )。
因为我们正在生成单通道图像,所以我们将图像的灰度表示重复三次,以构建一个 3 通道 RGB 图像(行 143 )。
build_montages函数生成一个 16×16 的网格,每个矢量中有一个 28×28 的图像。然后在线 148 上将剪辑写入磁盘。
用 Keras 和 TensorFlow 训练我们的 GAN
为了在时尚 MNIST 数据集上训练我们的 GAN,请确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端,并执行以下命令:
$ python dcgan_fashion_mnist.py --output output
[INFO] loading MNIST dataset...
[INFO] building generator...
[INFO] building discriminator...
[INFO] building GAN...
[INFO] starting training...
[INFO] starting epoch 1 of 50...
[INFO] Step 1_0: discriminator_loss=0.683195, adversarial_loss=0.577937
[INFO] Step 1_25: discriminator_loss=0.091885, adversarial_loss=0.007404
[INFO] Step 1_50: discriminator_loss=0.000986, adversarial_loss=0.000562
...
[INFO] starting epoch 50 of 50...
[INFO] Step 50_0: discriminator_loss=0.472731, adversarial_loss=1.194858
[INFO] Step 50_100: discriminator_loss=0.526521, adversarial_loss=1.816754
[INFO] Step 50_200: discriminator_loss=0.500521, adversarial_loss=1.561429
[INFO] Step 50_300: discriminator_loss=0.495300, adversarial_loss=0.963850
[INFO] Step 50_400: discriminator_loss=0.512699, adversarial_loss=0.858868
[INFO] Step 50_500: discriminator_loss=0.493293, adversarial_loss=0.963694
[INFO] Step 50_545: discriminator_loss=0.455144, adversarial_loss=1.128864
图 5 显示了我们的随机噪声向量(即benchmarkNoise在训练的不同时刻):
- 在开始训练 GAN 之前,左上角的包含 256 个(在一个 8×8 网格中)初始随机噪声向量。我们可以清楚地看到这种噪音中没有规律。甘还没学会什么时尚单品。
- 然而,在第二个纪元(右上)结束时,类似服装的结构开始出现。
- 到了第五纪元结束(左下方),时尚物品的明显更加清晰。
- 当我们到达第 50 个纪元结束时(右下),我们的时尚产品看起来是真实的。
再次强调,重要的是要理解这些时尚单品是由随机噪声输入向量生成的——它们完全是合成图像!
总结
在本教程中,我们讨论了生成敌对网络(GANs)。我们了解到 GANs 实际上由两个网络组成:
- 负责生成假图像的生成器
- 一个鉴别器,它试图从真实图像中识别出合成图像
通过同时训练这两个网络,我们可以学习生成非常逼真的输出图像。
然后我们实现了深度卷积对抗网络(DC GAN),这是 Goodfellow 等人最初的 GAN 实现的变体。
使用我们的 DCGAN 实现,我们在时尚 MNIST 数据集上训练了生成器和鉴别器,产生了时尚物品的输出图像:
- 不是训练集的一部分,是完全合成的
- 看起来与时尚 MNIST 数据集中的任何图像几乎相同且无法区分
问题是训练 GANs 可能非常具有挑战性,比我们在 PyImageSearch 博客上讨论的任何其他架构或方法都更具挑战性。
众所周知,gan 很难训练的原因是由于不断变化的亏损格局——随着每一步,我们的亏损格局都会略有变化,因此一直在变化。
不断变化的损失状况与其他分类或回归任务形成鲜明对比,在这些任务中,损失状况是“固定的”且不变的。
当训练你自己的 GAN 时,你无疑必须仔细调整你的模型架构和相关的超参数——确保参考本教程顶部的“训练 GAN 时的指导方针和最佳实践”部分,以帮助你调整你的超参数并运行你自己的 GAN 实验。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
引导深度做梦产生艺术。
原文:https://pyimagesearch.com/2015/07/13/generating-art-with-guided-deep-dreaming/

用于深度做梦和可视化的 bat-country Python 包的主要好处之一是它的易用性、可扩展性和可定制性。
让我告诉你,定制 在上周五 真的派上了用场,当时谷歌研究团队发布了他们深度梦想作品的更新,展示了一种“引导”你的输入图像可视化目标图像特征的方法。
结果相当令人印象深刻,所以我决定将这个功能移植到 bat-country。
说实话,从开始到结束只花了大约 20 分钟就把代码编好了。老实说,与更新代码库相比,我花了更多的时间运行 Python 脚本来收集示例图像和更新文档。
这种快速转变的秘密在于BatCountry类的可扩展性,其中几乎每个函数和每个方法都可以被覆盖和扩展。
想要更改每个图像的预处理或后处理方式?没问题。定义您自己的自定义处理器并将其传入。想改变目标函数?再说一遍,只要确定你自己的目标,你就可以开始了。
事实上,定义你自己的定制目标函数是我在扩展bat-country时所走的精确路线。我简单地定义了一个新的目标函数,允许进一步定制阶跃函数,我们就完成了!
在这篇博客文章的剩余部分,我们将玩新的蝙蝠国更新来执行引导做梦——,甚至使用它来生成我们自己的艺术使用引导深度做梦!
引导深度做梦
上周五,谷歌研究团队发布了他们深度做梦工作的更新,展示了通过提供种子图像来指导你的做梦过程是可能的。这种方法以类似的方式通过网络传递您的输入图像,但这次使用您的种子图像来引导和影响输出。
使用bat-country,进行引导做梦和深度做梦一样简单。下面是一些快速示例代码:
# import the necessary packages
from batcountry import BatCountry
from PIL import Image
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-b", "--base-model", required=True, help="base model path")
ap.add_argument("-l", "--layer", type=str, default="inception_4c/output",
help="layer of CNN to use")
ap.add_argument("-i", "--image", required=True, help="path to base image")
ap.add_argument("-g", "--guide-image", required=True, help="path to guide image")
ap.add_argument("-o", "--output", required=True, help="path to output image")
args = ap.parse_args()
# we can't stop here...
bc = BatCountry(args.base_model)
features = bc.prepare_guide(Image.open(args.guide_image), end=args.layer)
image = bc.dream(np.float32(Image.open(args.image)), end=args.layer,
iter_n=20, objective_fn=BatCountry.guided_objective,
objective_features=features)
bc.cleanup()
# write the output image to file
result = Image.fromarray(np.uint8(image))
result.save(args.output)
如果你还没有安装bat-country,要么从 GitHub repo 中下载代码,要么使用 pip 在你的系统上安装:pip install bat-country或pip install --upgrade bat-country。你还需要一个可以工作的咖啡馆。
这种方法的好处是我们可以“引导”输出图像的样子。在这里,我使用文森特·梵高的星夜的种子图像,并应用到云的图像:

Figure 1: An example of applying guided dreaming using Starry Night and a cloud image.
正如你所看到的,应用引导做梦后的输出云图像似乎模仿了梵高绘画中的许多笔触。
这让我想到——如果我从极其著名的艺术家那里拿一些著名的画,比如安迪·沃霍尔、麦克·埃舍尔、巴勃罗·毕加索、杰森·布拉克和文森特·梵高并把它们作为彼此的输入和指导,会发生什么?
结果会是什么样的?每幅画的艺术风格会转移到另一幅上吗?
为了验证这一点,我收集了以下作品的图片:
然后我通过上面详述的demo_guided.py脚本传递它们。
用深度做梦产生艺术
总的来说,结果看起来真的很棒。我特别满意的是麦田与柏树和格尔尼卡作为输入图像和其他绘画作为引导图像的结果。
下面你可以找到一些我最喜欢的图片:
文森特·梵高——有柏树的麦田

Figure 2: Vincent van Gogh’s Wheat Field with Cypresses guided using Warhol’s Marilyn Monroe. Notice how eyes are now present in the sky.

Figure 3: Vincent van Gogh’s Wheat Field with Cypresses guided using Jackson Pollock’s Energy Made Visible.

Figure 4: Vincent van Gogh’s Wheat Field with Cypresses guided using Picasso’s Guernica.
巴勃罗·毕加索——格尔尼卡

Figure 5: Pablo Picasso’s Guernica guided with MC Escher’s Mosaic II.

Figure 6: Pablo Picasso’s Guernica guided with Jackson Pollock’s Energy Made Visible.

Figure 7: Pablo Picasso’s Guernica guided with Andy Warhol’s Marilyn Monroe.
MC 埃舍尔–马赛克 II

Figure 8: MC Esher’s Mosaic II guided by Jackson Pollock’s Energy Made Visible.

Figure 9: MC Esher’s Mosaic II guided by Vincent van Gogh’s Wheat Field with Cypresses.
安迪·沃霍尔–玛丽莲·梦露

Figure 10: Andy Warhol’s Marilyn Monroe guided using MC Escher’s Sky and Water I.

Figure 11: Andy Warhol’s Marilyn Monroe guided using Picasso’s Guernica.
摘要
在这篇博文中,我回顾了对 bat-country 包的更新,它将通过提供两个图像来允许引导深度做梦:一个将通过网络传递的输入图像,以及一个网络将用来“引导”输出的种子图像。
**然后,我将更新后的代码用于从著名作品中生成艺术,如杰森·布拉克的能量可见,巴勃罗·毕加索的格尔尼卡,以及文森特·梵高的翠柏麦田。
一定要考虑在你的系统上安装bat-country包,试试深度做梦吧!玩一玩并生成自己的图像会令人奇怪地上瘾(更不用说,很有趣)。
最后,如果你对深度学习、深度做梦和计算机视觉感兴趣,可以考虑通过在下表中输入你的电子邮件地址来注册 PyImageSearch 时事通讯。我在 PyImageSearch 博客上定期更新,每次更新都充满了可操作的、真实世界的计算机视觉项目。
下次见!**
用 OpenCV 和 Python 生成 ArUco 标记
原文:https://pyimagesearch.com/2020/12/14/generating-aruco-markers-with-opencv-and-python/
在本教程中,您将学习如何使用 OpenCV 和 Python 生成 ArUco 标记。
今天的博文是我们关于 ArUCo 标记和基准的三部分系列的第一部分:
- 用 OpenCV 和 Python 生成 ArUco 标记(今天的帖子)
- 用 OpenCV 检测图像和视频中的 ArUco 标记(下周教程)
- 使用 OpenCV 自动确定 ArUco 标记类型(两周后的博客文章)
与 AprilTags 类似,ArUco 标记是计算机视觉算法可以轻松检测到的 2D 二进制模式。
通常,我们将 AprilTags 和 ArUco 标记用于:
- 摄像机标定
- 物体尺寸估计
- 测量相机和物体之间的距离
- 3D 位置
- 面向对象
- 机器人和自主导航
- 等。
与 AprilTags 相比,使用 ArUco 标记的主要优势包括:
在这个 ArUco 标记的介绍系列中,您将学习如何生成它们,在图像和实时视频流中检测它们,甚至如何自动检测图像中 ArUco 标记的类型(即使您不知道正在使用哪种类型的标记)。
然后,在未来的 PyImageSearch 教程中,我们将利用这些知识,在我们自己的计算机视觉和图像处理管道中使用 ArUco 标记。
更新于 2021 年 11 月 25 日,附有在白色背景上使用 ArUco 标记的说明。
要学习如何用 OpenCV 和 Python 生成 ArUco 标记,继续阅读。
用 OpenCV 和 Python 生成 ArUco 标记
在本教程的第一部分,我们将讨论 ArUco 标记,包括它们是什么,以及为什么我们可能要在我们的计算机视觉和图像处理管道中使用它们。
然后我们将讨论如何使用 OpenCV 和 Python 生成 ArUco 标记。如果您不想编写代码来生成 ArUco 标记,我还会提供几个示例网站,它们会为您生成 ArUco 标记(尽管代码实现本身非常简单)。
从这里,我们将回顾我们的项目目录结构,然后实现一个名为opencv_generate_aruco.py的 Python 脚本,它将生成一个特定的 ArUco 映像,然后将其保存到磁盘。
我们将讨论我们的结果来结束本教程。
什么是 ArUco 标记?
在之前的教程中,我已经介绍了基准标记、AprilTags 和 ArUco 标记的基础知识,所以我不打算在这里重复这些基础知识。
如果你是基准标记的新手,需要了解它们为什么重要,它们是如何工作的,或者我们什么时候想在计算机视觉/图像处理管道中使用它们,我建议你读一下我的 AprilTag 教程。
从那里你应该回到这里,用 OpenCV 完成 ArUco 标记的教程。
如何用 OpenCV 和 Python 生成 ArUco 标记?
OpenCV 库通过其 cv2.aruco.drawMarker 函数内置了 ArUco 标记生成器。
该函数的参数包括:
dictionary:ArUco 字典,指定我们正在使用的标记类型id:我们将要绘制的标记的 id(必须是 ArUcodictionary中的有效 ID)sidePixels:我们将在其上绘制 ArUco 标记的(正方形)图像的像素大小borderBits:边框的宽度和高度(像素)
然后,drawMarker 函数返回绘制了 ArUco 标记的输出图像。
正如您将在本教程后面看到的,使用该函数在实践中相当简单。所需的步骤包括:
- 选择您想要使用的 ArUco 词典
- 指定您要抽取的 ArUco ID
- 为输出 ArUco 图像分配内存(以像素为单位)
- 使用
drawMarker功能绘制 ArUco 标签 - 画阿鲁科标记本身
也就是说,如果你不想写任何代码,你可以利用在线 ArUco 生成器。
有在线 ArUco 标记生成器吗?
如果你不想写一些代码,或者只是赶时间,你可以使用在线 ArUco 标记生成器。
我最喜欢的是奥列格·卡拉切夫的这张。
你要做的就是:
- 选择您想要使用的 ArUco 词典
- 输入标记 ID
- 指定标记大小(以毫米为单位)
在那里,您可以将 ArUco 标记保存为 SVG 文件或 PDF,打印它,然后在您自己的 OpenCV 和计算机视觉应用程序中使用它。
什么是 ArUco 字典?
到目前为止,在本教程中,我已经提到了“阿鲁科字典”的概念,但是到底什么是阿鲁科字典呢?以及在 ArUco 生成和检测中起到什么作用?
简单的回答是,ArUco 字典指定了我们正在生成和检测的 ArUco 标记的类型。如果没有字典,我们将无法生成和检测这些标记。
想象你被绑架,蒙上眼睛,被带上飞机,然后被丢在世界上一个随机的国家。然后你得到一个笔记本,里面有你释放的秘密,但它是用你一生中从未见过的语言写的。
一个俘获者同情你,给你一本字典来帮助你翻译你在书中看到的内容。
使用字典,你能够翻译文件,揭示秘密,并完好无损地逃离你的生活。
但是如果没有那本字典,你将永远无法逃脱。正如你需要那本字典来解释你逃跑的秘密一样,我们必须知道我们正在使用哪种 ArUco 标记来生成和检测它们。
*### OpenCV 中 ArUco 字典的类型
OpenCV 库中内置了 21 种不同的 ArUco 词典。我在下面的 Python 字典中列出了它们:
ARUCO_DICT = {
"DICT_4X4_50": cv2.aruco.DICT_4X4_50,
"DICT_4X4_100": cv2.aruco.DICT_4X4_100,
"DICT_4X4_250": cv2.aruco.DICT_4X4_250,
"DICT_4X4_1000": cv2.aruco.DICT_4X4_1000,
"DICT_5X5_50": cv2.aruco.DICT_5X5_50,
"DICT_5X5_100": cv2.aruco.DICT_5X5_100,
"DICT_5X5_250": cv2.aruco.DICT_5X5_250,
"DICT_5X5_1000": cv2.aruco.DICT_5X5_1000,
"DICT_6X6_50": cv2.aruco.DICT_6X6_50,
"DICT_6X6_100": cv2.aruco.DICT_6X6_100,
"DICT_6X6_250": cv2.aruco.DICT_6X6_250,
"DICT_6X6_1000": cv2.aruco.DICT_6X6_1000,
"DICT_7X7_50": cv2.aruco.DICT_7X7_50,
"DICT_7X7_100": cv2.aruco.DICT_7X7_100,
"DICT_7X7_250": cv2.aruco.DICT_7X7_250,
"DICT_7X7_1000": cv2.aruco.DICT_7X7_1000,
"DICT_ARUCO_ORIGINAL": cv2.aruco.DICT_ARUCO_ORIGINAL,
"DICT_APRILTAG_16h5": cv2.aruco.DICT_APRILTAG_16h5,
"DICT_APRILTAG_25h9": cv2.aruco.DICT_APRILTAG_25h9,
"DICT_APRILTAG_36h10": cv2.aruco.DICT_APRILTAG_36h10,
"DICT_APRILTAG_36h11": cv2.aruco.DICT_APRILTAG_36h11
}
这些字典中的大多数遵循特定的命名约定,cv2.aruco.DICT_NxN_M,大小为 NxN ,后跟一个整数值, M — ,但是这些值是什么意思呢?
NxN 值是 ArUco 标记的 2D 位大小。例如,对于一个 6×6 标记,我们总共有 36 位。
网格大小后面的整数 M 指定可以用该字典生成的唯一 ArUco IDs 的总数。
为了使命名约定更加具体,请考虑以下示例:
那么,你如何决定使用哪一个 ArUco 标记字典呢?
- 首先,考虑字典中需要多少个唯一值。只需要一小把马克笔?那么选择一个唯一值数量较少的字典。需要检测很多标志物?选择具有更多唯一 ID 值的字典。本质上,选择一本有你需要的最少数量的身份证的字典——不要拿超过你实际需要的。
- 查看您的输入图像/视频分辨率大小。请记住,您的网格尺寸越大,您的相机拍摄的 ArUco 标记就需要越大。如果你有一个大的网格,但是有一个低分辨率的输入,那么这个标记可能是不可检测的(或者可能被误读)。
- 考虑标记间距离。 OpenCV 的 ArUco 检测实现利用误差校正来提高标记检测的准确性和鲁棒性。误差校正依赖于标记间距离的概念。 较小的字典尺寸与较大的 NxN 标记尺寸增加了标记间的距离,从而使它们不容易出现错误读数。
ArUco 字典的理想设置包括:
- 需要生成和读取的少量唯一 ArUco IDs
- 包含将被检测的 ArUco 标记的高质量图像输入
- 更大的 NxN 网格尺寸,与少量唯一 ArUco IDs 相平衡,这样标记间的距离可用于纠正误读的标记
关于 ArUco 字典的更多细节,请务必参考 OpenCV 文档。
注意:我将通过说 ARUCO_DICT 变量中的最后几个条目表明我们也可以生成和检测 AprilTags 来结束这一节!
配置您的开发环境
为了生成和检测 ArUco 标记,您需要安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助配置 OpenCV 的开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们开始用 OpenCV 生成 ArUco 标记之前,让我们先回顾一下我们的项目目录结构。
使用本教程的 “下载” 部分将源代码和示例图像下载到本教程。从那里,让我们检查我们有什么:
$ tree . --dirsfirst
.
├── tags
│ ├── DICT_5X5_100_id24.png
│ ├── DICT_5X5_100_id42.png
│ ├── DICT_5X5_100_id66.png
│ ├── DICT_5X5_100_id70.png
│ └── DICT_5X5_100_id87.png
└── opencv_generate_aruco.py
1 directory, 6 files
顾名思义,opencv_generate_aruco.py脚本用于生成 ArUco 标记。然后将生成的 ArUco 标记保存到任务的tags/目录中。
下周我们将学习如何真正地检测和识别这些(和其他)阿鲁科标记。
使用 OpenCV 和 Python 实现我们的 ArUco 标记生成脚本
让我们学习如何用 OpenCV 生成 ArUco 标记。
打开项目目录结构中的opencv_generate_aruco.py文件,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
import sys
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output image containing ArUCo tag")
ap.add_argument("-i", "--id", type=int, required=True,
help="ID of ArUCo tag to generate")
ap.add_argument("-t", "--type", type=str,
default="DICT_ARUCO_ORIGINAL",
help="type of ArUCo tag to generate")
args = vars(ap.parse_args())
# define names of each possible ArUco tag OpenCV supports
ARUCO_DICT = {
"DICT_4X4_50": cv2.aruco.DICT_4X4_50,
"DICT_4X4_100": cv2.aruco.DICT_4X4_100,
"DICT_4X4_250": cv2.aruco.DICT_4X4_250,
"DICT_4X4_1000": cv2.aruco.DICT_4X4_1000,
"DICT_5X5_50": cv2.aruco.DICT_5X5_50,
"DICT_5X5_100": cv2.aruco.DICT_5X5_100,
"DICT_5X5_250": cv2.aruco.DICT_5X5_250,
"DICT_5X5_1000": cv2.aruco.DICT_5X5_1000,
"DICT_6X6_50": cv2.aruco.DICT_6X6_50,
"DICT_6X6_100": cv2.aruco.DICT_6X6_100,
"DICT_6X6_250": cv2.aruco.DICT_6X6_250,
"DICT_6X6_1000": cv2.aruco.DICT_6X6_1000,
"DICT_7X7_50": cv2.aruco.DICT_7X7_50,
"DICT_7X7_100": cv2.aruco.DICT_7X7_100,
"DICT_7X7_250": cv2.aruco.DICT_7X7_250,
"DICT_7X7_1000": cv2.aruco.DICT_7X7_1000,
"DICT_ARUCO_ORIGINAL": cv2.aruco.DICT_ARUCO_ORIGINAL,
"DICT_APRILTAG_16h5": cv2.aruco.DICT_APRILTAG_16h5,
"DICT_APRILTAG_25h9": cv2.aruco.DICT_APRILTAG_25h9,
"DICT_APRILTAG_36h10": cv2.aruco.DICT_APRILTAG_36h10,
"DICT_APRILTAG_36h11": cv2.aruco.DICT_APRILTAG_36h11
}
我在上面的“OpenCV 中 ArUco 字典的类型”一节中回顾了 ArUco 字典,所以如果您想了解关于这个代码块的更多解释,请务必参考那里。
定义了ARUCO_DICT映射后,现在让我们使用 OpenCV 加载 ArUco 字典:
# verify that the supplied ArUCo tag exists and is supported by
# OpenCV
if ARUCO_DICT.get(args["type"], None) is None:
print("[INFO] ArUCo tag of '{}' is not supported".format(
args["type"]))
sys.exit(0)
# load the ArUCo dictionary
arucoDict = cv2.aruco.Dictionary_get(ARUCO_DICT[args["type"]])
# allocate memory for the output ArUCo tag and then draw the ArUCo
# tag on the output image
print("[INFO] generating ArUCo tag type '{}' with ID '{}'".format(
args["type"], args["id"]))
tag = np.zeros((300, 300, 1), dtype="uint8")
cv2.aruco.drawMarker(arucoDict, args["id"], 300, tag, 1)
# write the generated ArUCo tag to disk and then display it to our
# screen
cv2.imwrite(args["output"], tag)
cv2.imshow("ArUCo Tag", tag)
cv2.waitKey(0)
第 57 行为一张 300x300x1 灰度图像分配内存。我们在这里使用灰度,因为 ArUco 标签是一个二进制图像。
此外,您可以使用任何您想要的图像尺寸。我在这里硬编码了 300 个像素,但是同样,你可以根据自己的项目随意增减分辨率。
OpenCV ArUco 生成结果
我们现在准备用 OpenCV 生成 ArUco 标记!
首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python opencv_generate_aruco.py --id 24 --type DICT_5X5_100 \
--output tags/DICT_5X5_100_id24.png
[INFO] generating ArUCo tag type 'DICT_5X5_100' with ID '24'
$ python opencv_generate_aruco.py --id 42 --type DICT_5X5_100 \
--output tags/DICT_5X5_100_id42.png
[INFO] generating ArUCo tag type 'DICT_5X5_100' with ID '42'
$ python opencv_generate_aruco.py --id 66 --type DICT_5X5_100 \
--output tags/DICT_5X5_100_id66.png
[INFO] generating ArUCo tag type 'DICT_5X5_100' with ID '66'
$ python opencv_generate_aruco.py --id 87 --type DICT_5X5_100 \
--output tags/DICT_5X5_100_id87.png
[INFO] generating ArUCo tag type 'DICT_5X5_100' with ID '87'
$ python opencv_generate_aruco.py --id 70 --type DICT_5X5_100 \
--output tags/DICT_5X5_100_id70.png
[INFO] generating ArUCo tag type 'DICT_5X5_100' with ID '70'
此时,我们已经生成了五个 ArUco 标记,这是我在下面创建的一个蒙太奇:
但那又怎样?马克笔放在我们的磁盘上没什么用。
我们如何获取这些标记,然后在图像和实时视频流中检测?
我将在下周的教程中讨论这个问题。
敬请关注。
最后一点,如果你想自己创建 ArUco 标记,你需要将本教程中的 ArUco 标记放在白色背景上,以确保代码在下一篇博文中正常工作。
如果你的 ArUco 马克笔没有白色背景,我不能保证它能正常工作。
总结
在本教程中,您学习了如何使用 OpenCV 和 Python 生成 ArUco 标记。
在 OpenCV 中使用 ArUco 标签非常简单,因为 OpenCV 库中内置了方便的cv2.aruco 子模块(即,您不需要任何额外的 Python 包或依赖项来检测 ArUco 标签)。
现在我们已经实际上生成了一些 ArUco 标签,下周我将向你展示如何获取生成的标签,并实际上在图像和实时视频流中检测它们。
在本系列教程结束时,您将拥有在自己的 OpenCV 项目中自信而成功地使用 ArUco 标签所必需的知识。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
用 OpenCV 和 Python 生成电影条形码
原文:https://pyimagesearch.com/2017/01/16/generating-movie-barcodes-with-opencv-and-python/

在上周的博文中,我演示了如何计算视频文件中的帧数。
今天,我们将使用这些知识来帮助我们完成一项计算机视觉和图像处理任务— 可视化电影条形码,类似于本文顶部的任务。
几年前,我第一次意识到电影条形码,是从这个软件开始的,这个软件被用来为 2013 年 T2 布鲁克林电影节制作海报和预告片。
自从我开始 PyImageSearch 以来,我已经收到了一些关于生成电影条形码的电子邮件,有一段时间我通常不涉及可视化方法,我最终决定就此写一篇博文。毕竟这是一个非常巧妙的技术!
在本教程的剩余部分,我将演示如何编写自己的 Python + OpenCV 应用程序来生成自己的电影条形码。
用 OpenCV 和 Python 生成电影条形码
为了构建电影条形码,我们需要完成三项任务:
- 任务#1:确定视频文件中的帧数。计算电影中的总帧数可以让我们知道在电影条形码可视化中我们应该有多少帧包括。太多的框架和我们的条形码将巨大;太少的帧和电影条形码将是不美观的。
- 任务#2:生成电影条形码数据。一旦我们知道了我们想要包含在电影条形码中的视频帧的总数,我们就可以循环每第 N 帧并计算 RGB 平均值,同时维护一个平均值列表。这是我们实际的电影条形码数据。
- 任务#3:显示电影条形码。给定一组帧的 RGB 平均值列表,我们可以获取这些数据并创建显示在屏幕上的实际的电影条形码可视化。
这篇文章的其余部分将演示如何完成这些任务。
电影条形码项目结构
在我们深入本教程之前,让我们先来讨论一下我们的项目/目录结构,具体如下:
|--- output/
|--- videos/
|--- count_frames.py
|--- generate_barcode.py
|--- visualize_barcode.py
output目录将存储我们实际的电影条形码(生成的电影条形码图像和序列化的 RGB 平均值)。
然后我们有了videos文件夹,我们的输入视频文件就存放在这个文件夹中。
最后,我们需要三个助手脚本:count_frames.py、generate_barcode.py和visualize_barcode.py。我们将在接下来的章节中讨论每一个 Python 文件。
安装先决条件
我假设您的系统上已经安装了 OpenCV(如果没有,请参考本页中的,我在这里提供了在各种不同平台上安装 OpenCV 的教程)。
除了 OpenCV,你还需要 scikit-image 和 imutils 。您可以使用pip安装两者:
$ pip install --upgrade scikit-image imutils
现在花点时间安装/升级这些包,因为我们在本教程的后面会用到它们。
计算视频中的帧数
在上周的博文中,我讨论了如何(有效地)确定视频文件中的帧数。因为我已经深入讨论了这个主题,所以今天我不打算提供完整的代码概述。
也就是说,你可以在下面找到count_frames.py的源代码:
# import the necessary packages
from imutils.video import count_frames
import argparse
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
ap.add_argument("-o", "--override", type=int, default=-1,
help="whether to force manual frame count")
args = vars(ap.parse_args())
# count the total number of frames in the video file
override = False if args["override"] < 0 else True
total = count_frames(args["video"], override=override)
# display the frame count to the terminal
print("[INFO] {:,} total frames read from {}".format(total,
args["video"][args["video"].rfind(os.path.sep) + 1:]))
顾名思义,这个脚本只计算视频文件中的帧数。
举个例子,让我们看看我最喜欢的电影《侏罗纪公园》的预告片:
https://www.youtube.com/embed/lc0UehYemQA?feature=oembed
摆脱深度学习潮流,获得一些视角
原文:https://pyimagesearch.com/2014/06/09/get-deep-learning-bandwagon-get-perspective/

免责声明:这篇帖子的语气有点玩世不恭。老实说,我支持深度学习研究,我支持这些发现,我相信通过研究深度学习,我们只能进一步改进我们的分类方法,并开发更好的方法。我们都知道研究是反复的。有时,我们甚至探索几十年前的方法,仅应用稍微不同的扭曲,产生显著不同的结果——因此一个新的研究领域诞生了。 这就是机器学习研究的工作方式,理应如此。
下面的咆哮实际上更像是对我们如何对待当前“热门”机器学习算法的控诉——就像“银弹”和治愈我们分类疾病的神奇药丸。但是,这些算法不是银弹,它们不是神奇的药丸,它们也不是工具箱中的工具——它们是由理性思维过程支持的方法,带有关于它们所应用的数据集的假设。通过多花一点时间思考实际问题,而不是盲目地把一堆算法扔向墙壁,看看有什么坚持,我相信我们只能进一步研究。
我觉得每次我上/r/machinelearning、HN 或 DataTau 时,都有人在谈论深度学习——而更多时候,这感觉就像是炒作。
我不是消极,因为我认为这项研究是一个死胡同。远非如此。这是一个 奇妙的 研究领域,还有 遥远的 更多的 有待探索。
我只是厌倦了炒作。
真的,停止将深度学习视为受限的玻尔兹曼机器和卷积神经网络将解决你所有的图像分类困境。
是的。他们很强大。
是的,如果它们被应用到正确的问题类型中,它们有巨大的分类准确性。
但也要意识到深度学习是现在机器学习的热门话题。在某种程度上,在机器学习社区中有一种“赶时髦”的趋势——它也不是从深度网络开始的。
不相信我?请继续阅读。
为什么我在一个计算机视觉博客上谈论深度学习?
因为面对现实吧。除非你正在做一些非常严格形式的图像处理,否则如果没有某种机器学习,你就不可能拥有计算机视觉。
从聚类,到形成词袋模型,到软码字分配,到学习距离度量,到降维,到分类,回归(即使用回归森林的姿势估计,从而使 Xbox 360 Kinect 成为可能),计算机视觉在数量惊人的任务中利用机器学习。
也就是说,如果你在用计算机视觉工作,你也可能会利用某种机器学习。
就深度网络而言,计算机视觉和机器学习变得更加交织——只要看看我们试图学习一组内核的卷积神经网络就知道了。
随着机器学习的兴起和衰落,这一潮流也将影响计算机视觉。
随着潮流,趋势也来了…
永久感知器故障
让我提醒你注意罗森布拉特的感知机算法(1958)。在他出版之后,基于感知的技术风靡一时。
但随后,明斯基和帕佩特 1969 年的论文实际上让神经网络研究停滞了近十年,证明了感知机无法解决异或(XOR)问题。此外,作者认为我们没有建立和维护大型神经网络所需的计算资源。
光是这一篇论文就差点要了神经网络研究的命。
真扫兴。
幸运的是,反向传播算法和 Rumelhart (1986 年)和 Werbos (1974 年)的研究能够使神经网络从可能过早死亡的状态中恢复过来。
可以说,如果没有这些研究人员的贡献,深度学习可能永远不会存在。
支持向量机
下一个潮流是:支持向量机。
在 90 年代中期,科尔特斯和瓦普尼克发表了他们开创性的支持向量网络论文。
你可能会认为机器学习已经解决了,甚至促使 Lipo Wang 博士说:
支持向量机的开发顺序与神经网络的开发顺序相反。支持向量机从完善的理论发展到实现和实验,而神经网络遵循更多的启发式路径,从应用和广泛的实验到理论。
这是一个非常强有力的说法,特别是在今天的深度学习背景下。
虽然我(稍微)断章取义地引用了这句话,但我使用这句话的真正原因是为了证明,曾经有一段时间,机器学习研究人员认为支持向量机有效地“解决”了分类问题。
支持向量机是未来。没有什么能打败他们… 包括神经网络。
很讽刺,不是吗?因为现在我们所能谈论的就是堆叠受限玻尔兹曼机器和训练大规模卷积神经网络。
但是让我们保持这股潮流。
树木。树木。树木。
然后,随着 SVM 热,我们有了基于系综的方法。
基于 Amit 和 Geman (1997)、Ho (1998)和 Dietterich (2000)的工作,已故的 Leo Brieman 在 2001 年向机器学习社区贡献了他的 Random Forests 论文。
我们又跳上了马车,装上一堆树,扔上我们的铲子,前往壁橱苗圃建立营地。
老实说, 我和 没什么不同——可以说,我喝了随机森林的 Kool-Aid。我的整篇论文涉及如何利用随机森林和弱特征表示来胜过专注于单个数据集的大量工程化的最新方法。
直到今天,我仍然发现自己稍微偏向于集合和基于森林的方法。
这种偏见是坏事吗?
我不这么认为。我认为这是自然的,甚至在一定程度上是人类的,偏向于你一生中很大一部分时间都在苦心研究的东西。
真正的问题是:你能在没有大肆宣传的情况下做到吗?
现在我们在当代。还有另一种“热门”学习模式。

深度学习,深度有缺陷?
但是事实证明,也许我们可以做得更好。
也许我们可以使用深度学习来学习分层特征表示。
听起来很棒,对吧?
但是现在我们又赶上了另一个潮流。我们就堆一堆 RBM,看看会发生什么!
我告诉你会发生什么。你让你的模型训练、交叉验证和网格搜索参数一个多星期(或者更长,取决于你的网络有多大和你可以支配的计算资源),仅仅是为了让你在 ImageNet 上的准确度提高 0 . 1%。
好吧,我现在很愤世嫉俗。我承认这一点。
但问题来了: 我们需要停止把机器学习算法当成银弹。
事实是,谈到机器学习,没有什么灵丹妙药。
相反,我们拥有的是一套惊人的、不可思议的算法,既有理论假设,又有经验证据,证明它们有能力解决分类问题的某个子集。
这里的目标是能够识别在某些领域表现良好的算法,而不是声称一种方法是机器学习的终极目标,将分类标记为“结案”。
尽管如此,老实说,我并不想抨击深度学习。正如科学界所展示的那样,这些深网非常强大。我全心全意支持他们的研究和发现。
神经网络的有趣特性
然而,谷歌的最新文章神经网络的有趣特性表明,在每一个深层神经网络中都潜伏着一个巨大的漏洞。
在他们的论文中,作者能够构建“敌对图像”——即,拍摄一幅图像并扰乱像素值,使其(有效地)与人眼相同,但可能导致深度网络的错误分类。
这些对立图像是以一种相当复杂的方式构建的——作者故意调整图像中的像素值,以最大化网络的预测误差,导致“对立图像”,当用作网络的输入时,几乎总是被错误分类,即使应用于在不同数据子集上训练的不同神经网络。
如果图像中的这些微小变化(实际上,人眼完全无法察觉)会导致性能完全下降,这对真实世界的数据集意味着什么?
因为让我们面对现实吧,真实世界的数据集 并不像 MNIST 的 那样干净。它们很脏。它们通常包含噪声。而且它们远非完美——当我们将算法从学术界移植到工业界时,这一点尤其如此。
那么,在实践中,这意味着什么呢?
这意味着从基于原始像素的特征中学习的方法还有很长的路要走。
深度学习会一直存在。老实说,我认为这是件好事。
目前正在进行一些令人难以置信的研究,我个人对卷积神经网络感到兴奋——我认为在未来五年内,卷积神经网络将继续在某些图像分类挑战中占据主导地位,如 ImageNet。
我也希望深度学习领域保持活跃(我相信它会),因为无论如何,我们从研究深度网络中获得的研究和见解只会帮助我们在多年后创造出更好的方法。
但与此同时,也许我们可以把声音调小一点?
要点:
没有单一的机器学习模型是解决所有问题的“银弹”。
事实上,如果我们完全不把机器学习模型视为我们工具箱中的工具,那是最好的——我相信这是我们大多数问题的来源。
相反,我们需要花更多的时间来思考我们试图解决的实际问题,而不是用一堆算法来解决问题,看看什么可行。
因为当我们坐下来思考一个问题时,当我们花时间不仅理解我们的特征空间“是”什么以及它在现实世界中“暗示”什么时——那么我们就像机器学习的科学家一样。否则我们只是一堆机器学习工程师,盲目进行黑盒学习,操作一套 R,MATLAB,Python 库。
要点是:机器学习不是工具。这是一种具有理性思维过程的方法,完全依赖于我们试图解决的问题。我们不应该盲目地应用算法,看看什么能坚持下来。我们需要坐下来,探索特征空间(根据经验和现实世界的含义),然后考虑我们的最佳行动模式。
坐下,深呼吸。花时间好好想想。
最重要的是,避免炒作。
接下来:
在我的下一篇文章中,我将向你展示一幅图像中仅仅一个像素的移动是如何扼杀你受限的玻尔兹曼机器的性能的。
开始行动:时尚 DCGAN-MNIST
原文:https://pyimagesearch.com/2021/11/11/get-started-dcgan-for-fashion-mnist/
在本教程中,我们使用 TensorFlow 2 / Keras 实现了一个深度卷积 GAN (DCGAN),基于论文使用深度卷积生成对抗网络的无监督表示学习(拉德福德等人,2016) 。这是最早的 GAN 论文之一,也是你开始学习 GAN 的典型读物。
这是我们 GAN 教程系列的第二篇文章:
- 生成对抗网络简介
- 入门:时尚 DCGAN-MNIST(本帖)
- GAN 训练挑战:针对彩色图像的 DCGAN
我们将在本帖中讨论这些关键话题:
- DCGAN 架构指南
- 使用 Keras 定制
train_step()``model.fit() - 用 TensorFlow 2 / Keras 实现 DCGAN
在我们开始之前,你熟悉 GANs 的工作方式吗?
如果没有,一定要看看我以前的帖子“GANs 简介”,从高层次上了解 GANs 一般是如何工作的。每个 GAN 至少有一个发生器和一个鉴别器。虽然发生器和鉴别器相互竞争,但发生器在生成接近训练数据分布的图像方面做得更好,因为它从鉴别器获得了反馈。
要了解如何使用 TensorFlow 2 / Keras 训练 DCGAN 生成时尚 MNIST 般的灰度图像,继续阅读。
架构指南
DCGAN 论文介绍了一种 GAN 架构,其中鉴别器和发生器由卷积神经网络(CNN)定义。
它提供了几个架构指南来提高培训稳定性(参见图 1 ):
让我们看一下上面的指导方针。为简洁起见,我将生成器称为 G,鉴别器称为 d。
回旋
-
步长卷积:步长为 2 的卷积层,用于 d 中的下采样,见图 2 ( 左)。
-
分数步长卷积:
Conv2DTranspose步长为 2 的层,以 g 为单位进行上采样,见图 2 ( 右)。 -
![]()
-
![]()


Figure 2: Left: Strided convolutions (downsampling in D). Right: Fractional-strided convolutions (upsampling in G). Image source: https://github.com/vdumoulin/conv_arithmetic.
批量归一化
该论文建议在 G 和 D 中使用批量标准化(batchnorm)来帮助稳定 GAN 训练。Batchnorm 将输入图层标准化为具有零均值和单位方差。它通常被添加在隐藏层之后和激活层之前。随着我们在 GAN 系列中的进展,您将学到更好的 GAN 规范化技术。目前,我们将坚持使用 batchnorm 的 DCGAN 论文建议。
激活
DCGAN 发生器和鉴别器中有四个常用的激活函数:sigmoidtanhReLU****leakyReLU如图图 3 所示:
sigmoid:将数字挤压成0(假的)和1(真的)。由于 DCGAN 鉴别器做的是二进制分类,所以我们在 d 的最后一层使用 sigmoid。tanh(双曲正切):也是 s 形像乙状结肠;事实上,它是一个缩放的 sigmoid,但以0为中心,并将输入值压缩到[-1, 1]。正如论文所推荐的,我们在 g 的最后一层使用tanh,这就是为什么我们需要预处理我们的训练图像到[-1, 1]的范围。ReLU(整流线性激活):输入值为负时返回0;否则,它返回输入值。本文建议对 G 中除输出层之外的所有层激活ReLU,输出层使用tanh。LeakyReLU:类似于ReLU除了当输入值为负的时候,它使用一个常数 alpha 给它一个非常小的斜率。正如论文所建议的,我们将斜率(alpha)设置为 0.2。除了最后一层,我们对所有层都使用了 D 中的LeakyReLU激活。
DCGAN Code in Keras
现在我们已经很好地理解了论文中的指导方针,让我们浏览一下代码,看看如何在 TensorFlow 2 / Keras 中实现 DCGAN(参见图 4 )。
和最初的 GAN 一样,我们同时训练两个网络:一个生成器和一个鉴别器。为了创建 DCGAN 模型,我们首先需要用 Keras Sequential API 为生成器和鉴别器定义模型架构。然后我们使用 Keras 模型子类化来创建 DCGAN。
请跟随这个 Colab 笔记本这里的教程。
依赖关系
我们先启用 Colab GPU,导入需要的库。
启用 Colab GPU
本教程的代码在一个 Google Colab 笔记本里,最好启用 Colab 提供的免费 GPU。要在 Colab 中启用 GPU 运行时,请转到编辑→笔记本设置或运行时→更改运行时类型,然后从硬件加速器下拉菜单中选择“GPU”。
进口
Colab 应该已经预装了本教程所需的所有包。我们将在 TensorFlow 2 / Keras 中编写代码,并使用 matplotlib 进行可视化。我们只需要导入这些库,如下所示:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from matplotlib import pyplot as plt
数据
第一步是为训练准备好数据。在这篇文章中,我们将使用时尚 MNIST 的数据来训练 DCGAN。
数据加载
时尚-MNIST 数据集具有训练/测试分割。对于训练 DCGAN,我们不需要这样的数据拆分。我们可以只使用训练数据,或者为了训练的目的而加载训练/测试数据集。
对于具有时尚 MNIST 的 DCGAN,仅使用训练数据集进行训练就足够了:
(train_images, train_labels), (_, _) = tf.keras.datasets.fashion_mnist.load_data()
看一下带有train_images.shape的时尚-MNIST 训练数据形状,注意(60000, 28, 28)的形状,意味着有 60000 个训练灰度图像,大小为28x28。
数据可视化
我总是喜欢将训练数据可视化,以了解图像是什么样子的。让我们看一个图像,看看时尚 MNIST 灰度图像是什么样子的(见图 5)。
plt.figure()
plt.imshow(train_images[0], cmap='gray')
plt.show()
数据预处理
加载的数据呈(60000, 28, 28)形状,因为它是灰度的。所以我们需要为通道添加第四维为 1,并将数据类型(来自 NumPy 数组)转换为 TensorFlow 中训练所需的float32。
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
我们将输入图像归一化到[-1, 1]的范围,因为生成器的最终层激活使用了前面提到的tanh。
train_images = (train_images - 127.5) / 127.5
发电机型号
生成器的工作是生成可信的图像。它的目标是试图欺骗鉴别者,让他们认为它生成的图像是真实的。
生成器将随机噪声作为输入,并输出类似于训练图像的图像。因为我们在这里生成一个28x28灰度图像,模型架构需要确保我们达到一个形状,使得生成器输出应该是28x28x1(参见图 6 )。
所以为了能够创建图像,生成器的主要任务是:
- 用
Reshape图层将 1D 随机噪声(潜在矢量)转换为 3D - 使用 Keras
Conv2DTranspose层(本文中提到的分数步长卷积)向上采样几次,以输出图像大小,在时尚 MNIST 的情况下,是一个形状为28x28x1的灰度图像。
有几层构成了 G:
Dense(全连通)层:仅用于整形和平坦化噪声矢量Conv2DTranspose:上采样BatchNormalization:稳定训练;在 conv 层之后和激活功能之前。- 使用 G 中的
ReLU激活所有层,除了使用tanh的输出层。
让我们创建一个用于构建生成器模型架构的函数def build_generator()。
定义几个参数:
- 随机噪声的潜在维数
Con2DTranspose层的权重初始化- 图像的颜色通道。
# latent dimension of the random noise
LATENT_DIM = 100
# weight initializer for G per DCGAN paper
WEIGHT_INIT = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
# number of channels, 1 for gray scale and 3 for color images
CHANNELS = 1
使用 Keras Sequential API 创建模型,这是创建模型最简单的方法:
model = Sequential(name='generator')
然后我们创建一个Dense层,为 3D 整形做准备,同时确保在模型架构的第一层定义输入形状。添加BatchNormalization和ReLU图层:
model.add(layers.Dense(7 * 7 * 256, input_dim=LATENT_DIM))
model.add(layers.BatchNormalization())
model.add(layers.ReLU())
现在我们将之前的图层从 1D 重塑为 3D。
model.add(layers.Reshape((7, 7, 256)))
用2的stride对Conv2DTranspose进行两次上采样,从7x7到14x14再到28x28。在每个Conv2DTranspose层后添加一个BatchNormalization层,然后再添加一个ReLU层。
# upsample to 14x14: apply a transposed CONV => BN => RELU
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(2, 2),padding="same", kernel_initializer=WEIGHT_INIT))
model.add(layers.BatchNormalization())
model.add((layers.ReLU()))
# upsample to 28x28: apply a transposed CONV => BN => RELU
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2),padding="same", kernel_initializer=WEIGHT_INIT))
model.add(layers.BatchNormalization())
model.add((layers.ReLU()))
最后,我们使用激活了tanh的Conv2D层。注意CHANNELS早先被定义为1,它将制作一个28x28x1的图像,与我们的灰度训练图像相匹配。
model.add(layers.Conv2D(CHANNELS, (5, 5), padding="same", activation="tanh"))
看看我们刚刚用generator.summary()定义的生成器模型架构,确保每一层都是我们想要的形状(参见图 7 ):
鉴别器型号
鉴别器是一个简单的二进制分类器,可以辨别图像是真是假。它的目标是试图对图像进行正确的分类。但是,鉴别器和常规分类器之间有一些区别:
- 我们使用
LeakyReLU作为每个 DCGAN 文件的激活函数。 - 鉴别器有两组输入图像:标记为 1 的训练数据集或真实图像,以及标记为 0 的生成器创建的假图像。
注: 鉴频器网络通常比发生器小或简单,因为鉴频器的工作比发生器容易得多。如果鉴别器太强,那么发电机就不会有很好的改善。
下面是鉴别器架构的样子(参见图 8 ):
我们将再次创建一个函数来构建鉴别器模型。鉴别器的输入是真实图像(训练数据集)或生成器生成的假图像,因此对于时尚 MNIST,图像大小是28x28x1,它作为 argos 传递到函数中作为宽度、高度和深度。alpha 用于LeakyReLU定义泄漏的斜率。
def build_discriminator(width, height, depth, alpha=0.2):
使用 Keras Sequential API 来定义鉴别器架构。
model = Sequential(name='discriminator')
input_shape = (height, width, depth)
我们使用Conv2D、BatchNormalization和LeakyReLU两次进行下采样。
# first set of CONV => BN => leaky ReLU layers
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding="same",
input_shape=input_shape))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU(alpha=alpha))
# second set of CONV => BN => leacy ReLU layers
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding="same"))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU(alpha=alpha))
展平并应用 dropout:
model.add(layers.Flatten())
model.add(layers.Dropout(0.3))
然后在最后一层,我们使用 sigmoid 激活函数输出单个值用于二进制分类。
model.add(layers.Dense(1, activation="sigmoid"))
调用model.summary()查看我们刚刚定义的鉴别器架构(参见图 9 ):
损失函数
在继续创建 DCGAN 模型之前,我们先讨论一下损失函数。
计算损耗是 DCGAN(或任何 GAN)训练的核心。对于 DCGAN,我们将实现改进的 minimax 损失,它使用二进制交叉熵(BCE)损失函数。随着我们在 GAN 系列中的进展,您将了解不同 GAN 变体中的其他损失函数。
我们需要计算两个损耗:一个是鉴频器损耗,另一个是发电机损耗。
鉴频器损耗
由于有两组图像被送入鉴别器(真实图像和虚假图像),我们将计算每组图像的损失,并将它们合并为鉴别器损失。
总损失=损失真实图像+损失虚假图像
发电机损耗
对于发生器损耗,我们可以训练 G 使log D(G(z))最大化,而不是训练 G 使log(1 − D(G(z)))(D 将假图像分类为假图像的概率)最小化(0),我们可以训练 G 使log D(G(z))(D 将假图像错误分类为真图像的概率)最大化(1)。这就是修正的极大极小损失。
DCGAN 模型:覆盖train_step
我们已经定义了发生器和鉴别器架构,并了解了损失函数的工作原理。我们准备将 D 和 G 放在一起,通过子类化keras.Model并覆盖train_step()来训练鉴别器和生成器,从而创建 DCGAN 模型。这里是关于如何编写底层代码定制model.fit()的文档。这种方法的优点是,您仍然可以使用GradientTape进行定制的训练循环,同时仍然可以受益于fit()的便利特性(例如,回调和内置的分发支持等)。).
所以我们子类化keras.Model来创建 DCGAN 类—class DCGAN(keras.Model):
DCGAN 类的细节请参考 Colab 笔记本这里,这里我只重点讲解如何为训练 D 和 g 重写train_step()
在train_step()中,我们首先创建随机噪声,作为发生器的输入:
batch_size = tf.shape(real_images)[0]
noise = tf.random.normal(shape=(batch_size, self.latent_dim))
然后我们用真实图像(标记为 1)和虚假图像(标记为 0)来训练鉴别器。
with tf.GradientTape() as tape:
# Compute discriminator loss on real images
pred_real = self.discriminator(real_images, training=True)
d_loss_real = self.loss_fn(tf.ones((batch_size, 1)), pred_real)
# Compute discriminator loss on fake images
fake_images = self.generator(noise)
pred_fake = self.discriminator(fake_images, training=True)
d_loss_fake = self.loss_fn(tf.zeros((batch_size, 1)), pred_fake)
# total discriminator loss
d_loss = (d_loss_real + d_loss_fake)/2
# Compute discriminator gradients
grads = tape.gradient(d_loss, self.discriminator.trainable_variables)
# Update discriminator weights
self.d_optimizer.apply_gradients(zip(grads, self.discriminator.trainable_variables))
我们训练生成器,而不更新鉴别器的权重。
misleading_labels = tf.ones((batch_size, 1))
with tf.GradientTape() as tape:
fake_images = self.generator(noise, training=True)
pred_fake = self.discriminator(fake_images, training=True)
g_loss = self.loss_fn(misleading_labels, pred_fake)
# Compute generator gradients
grads = tape.gradient(g_loss, self.generator.trainable_variables)
# Update generator weights
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_variables))
self.d_loss_metric.update_state(d_loss)
self.g_loss_metric.update_state(g_loss)
训练期间的监控和可视化
我们将覆盖 Keras Callback()来监控:
- 鉴频器损耗
- 发电机损耗
- 训练过程中生成的图像
例如,对于图像分类,损失可以帮助我们理解模型的表现如何。对于 GAN,D 损失和 G 损失表示每个模型的单独表现,可能是也可能不是 GAN 模型总体表现的准确衡量。我们将在下一篇文章“GAN 训练挑战”中进一步讨论这个问题
对于 GAN 评估,我们必须目视检查训练期间生成的图像。我们将在以后的帖子中学习其他评估方法。
编译和训练模型
现在我们终于可以组装 DCGAN 模型了!
dcgan = DCGAN(discriminator=discriminator, generator=generator, latent_dim=LATENT_DIM)
正如 DCGAN 论文所建议的,我们对生成器和鉴别器都使用了具有 0.0002 的learning rate的Adam优化器。如前所述,我们对 D 和 g 都使用二元交叉熵损失函数。
LR = 0.0002 # learning rate
dcgan.compile(
d_optimizer=keras.optimizers.Adam(learning_rate=LR, beta_1 = 0.5),
g_optimizer=keras.optimizers.Adam(learning_rate=LR, beta_1 = 0.5),
loss_fn=keras.losses.BinaryCrossentropy(),
)
我们已经准备好训练 DCGAN 模型了,只需调用model.fit!
NUM_EPOCHS = 50 # number of epochs
dcgan.fit(train_images, epochs=NUM_EPOCHS,
callbacks=[GANMonitor(num_img=16, latent_dim=LATENT_DIM)])
训练 50 个历元,每个历元用 Colab 笔记本的 GPU 只需要 25 秒左右。
在训练期间,我们可以目视检查生成的图像,以确保生成器生成的图像质量良好。
查看图 10 中第 1 个历元、第 25 个历元和第 50 个历元的训练期间生成的图像,我们看到生成器在生成时尚 MNIST 相似图像方面变得越来越好。
总结
在这篇文章中,我们讨论了如何训练一个稳定的 DCGAN 的 DCGAN 架构指南。伴随着一个 Colab 笔记本,我们在 TensorFlow 2 / Keras 中用灰度时尚 MNIST 图像完成了 DCGAN 代码的实现。我讨论了如何用 Keras 模型子类化定制train_step,然后调用 Keras model.fit()进行训练。在下一篇文章中,我将通过实现一个用流行色图像训练的 DCGAN 来演示 GAN 训练的挑战。
引用信息
梅纳德-里德,M. 《入门:DCGAN for Fashion-MNIST》, PyImageSearch ,2021 年,https://PyImageSearch . com/2021/11/11/Get-Started-DCGAN-for-Fashion-mnist/
@article{Maynard-Reid_2021_DCGAN_MNIST,
author = {Margaret Maynard-Reid},
title = {Get Started: {DCGAN} for Fashion-{MNIST}},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/11/11/get-started-dcgan-for-fashion-mnist/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
使用 Python 开始计算机视觉的深度学习
原文:https://pyimagesearch.com/2017/09/23/getting-started-deep-learning-computer-vision-python/

这篇博文是为那些已经购买了我的新书《Python 计算机视觉深度学习》 的读者准备的。
在本教程中,您将学习如何:
- 下载书籍、代码、数据集和任何与您的购买相关的额外内容。
- 获取您的电子邮件收据和发票。
- 使用 Python 访问与计算机视觉深度学习相关的配套网站。
- 使用配套网站发布问题、提交 bug 或报告打字错误。
- 重新激活过期的下载链接。
如果您有任何与本书相关的其他问题,请给我发电子邮件或使用联系表。
使用 Python 开始计算机视觉的深度学习
感谢你用 Python 拿起一本 计算机视觉深度学习!
我感谢你对我和 PyImageSearch 博客的支持。没有你,PyImageSearch 就不可能实现。
我的目标是确保你在时间和金钱上的投资都能获得巨大的回报。为了确保你有一个良好的开端,本指南将帮助你开始使用全新的Python 计算机视觉深度学习。
下载文件
在您成功结帐并购买了使用 Python 进行计算机视觉的深度学习之后,您将被重定向到一个看起来与下图类似的页面:

Figure 1: The “Downloads Page” you can use to download the files associated with your purchase of Deep Learning for Computer Vision with Python.
这是你的 购买页面 ,在这里你可以下载你的文件。左键点击每个文件,你的下载将开始。
所有以前缀SB开头的文件都是启动包的一部分。以PB开头的文件是从业者包的一部分。最后,以IB开头的文件名是 ImageNet 包的一部分。
包含*_Book.zip的文件名包含相应包的 PDF。包含*_Videos.zip的文件名包含捆绑包的视频。包括*_Code.zip在内的文件名包含您的代码/与包相关的数据集。例如,文件名SB_Code.zip包含与启动包相关的所有代码/数据集。文件名SB_Book.zip包含您的启动包的 PDF。
最后,VirtualMachine.zip文件包含你的预配置的 Ubuntu VirtualBox 虚拟机。
注:此时只有启动包的内容已经发布。从业者捆绑包和 ImageNet 捆绑包的内容将于 10 月发布。
如果您在浏览器中关闭了此选项卡,并需要再次访问它,只需:
- 打开你的收件箱。
- 找到电子邮件收据(见下一节)。
- 点击“在线查看购买”链接。
从那里,您将能够访问下载页面。
请尽快下载这些文件。出于安全原因,我用来处理支付和分发数字下载的服务会在四天后自动过期。如果你的下载过期了,完全没问题,只需参考下面的“重新激活过期的下载” 一节。
您的电子邮件收据和发票
在你购买了用 Python 编写的用于计算机视觉的深度学习的副本几分钟后,你会收到一封电子邮件,主题是: “你从 PyImageSearch 的购买已完成” 。
在这封电子邮件中,您可以找到查看/打印发票以及访问下载页面的链接:

Figure 2: After purchasing your copy of Deep Learning for Computer Vision with Python you will receive an email containing your receipt/invoice and link to re-access the downloads page.
如果您没有收到这封电子邮件,请确保您正在检查退房时使用的收件箱/电子邮件地址。如果您使用 PayPal,您需要检查与您的 PayPal 帐户相关的电子邮件地址。
如果你仍然找不到邮件,不要担心!请通过联系表向我发送电子邮件或信息,并附上任何相关信息,例如:
- 电子邮件地址的购买应在其下列出。
- 你的名字。
- 您可能拥有的任何其他相关信息(购买号、是否通过信用卡或 PayPal 付款、是否有朋友/同事为您购买等。).
从那里,我可以仔细检查数据库,并确保您收到您的电子邮件收据和下载链接。
访问配套网站
您购买的用于 Python 计算机视觉的深度学习包括访问补充材料/配套网站。
要访问配套网站:
- 下载启动包的 PDF 文件。
- 打开入门包至“伙伴网站”部分(PDF 第 15 页)。
- 跟随到伙伴网站的链接。
- 通过创建用户名和密码在配套网站上注册您的帐户。
从那里,您可以访问配套网站:

Figure 3: The Deep Learning for Computer Vision with Python companion website.
现在,配套网站包括链接到(1)配置您的开发环境和(2)报告一个错误。今后,本网站将包含额外的补充材料。
发布问题、错误报告或打字错误
你应该在同伴网站上创建你的账户的最重要的原因是 报告问题 、 bug ,或者 错别字 。
您可以点击配套网站标题中的“问题”按钮来完成此操作:

Figure 4: If you encounter an error when using the book, please check the “Issues” page inside the companion website.
然后,您将看到所有未结票证的列表。
您可以通过点击“应用过滤器”按钮来搜索这些票证。
如果没有与您的查询相匹配的票证,请点击“创建新票证”并填写必填字段:

Figure 5: If no (already submitted) bug report matches your error, please create a new ticket so myself and others in the PyImageSearch community can help you.
从那里,我和 PyImageSearch 社区的其他人可以帮助你解决这个问题。
关于任何问题,你也可以随时给我发邮件;但是,我可能会建议您参考配套网站来发布错误:
- 我可以跟踪问题,并确保您的问题得到及时解决。
- 如果其他读者也遇到这个问题,他们可以从中吸取教训。
由于用 Python 进行计算机视觉的深度学习是一本全新的书,必然会有很多疑问。通过使用问题追踪器,我们可以组织所有的 bug,同时确保社区也可以从其他问题中学习。
重新激活过期的下载
出于安全原因,我用来处理支付和分发数字下载的服务会在四天后自动过期。
如果你的网址过期了,完全没问题— 只需给我发电子邮件或给我发信息,我可以为你重新激活购买。
摘要
在本教程中,您学习了如何使用 Python 开始使用新购买的 计算机视觉深度学习。
如果你有本指南中没有讨论的问题,请给我发电子邮件或给我发信息,我很乐意和你讨论这个问题。
否则,如果您的问题是特别是与一章、一段代码、一条错误消息或任何与本书的实际内容相关的内容,请参考上面的“发布问题、错误报告或错别字”部分。
再次感谢您使用 Python 购买计算机视觉深度学习的副本。
我感到无比兴奋和荣幸,能够在你的深度学习掌握之旅中指导你。
没有 你 ,这个博客就不可能。
祝你有美好的一天和快乐的阅读!
附言:如果你还没有用 Python、 购买用于计算机视觉的深度学习的副本,你可以在这里 购买。
深度学习和 Python 入门
原文:https://pyimagesearch.com/2014/09/22/getting-started-deep-learning-python/
https://www.youtube.com/embed/E9ZPD_T639c?feature=oembed
开始使用 EasyOCR 进行光学字符识别
原文:https://pyimagesearch.com/2020/09/14/getting-started-with-easyocr-for-optical-character-recognition/
在本教程中,您将学习如何使用 EasyOCR 包通过 Python 轻松执行光学字符识别和文本检测。
EasyOCR,顾名思义,是一个 Python 包,允许计算机视觉开发人员毫不费力地执行光学字符识别。
说到 OCR,EasyOCR 是迄今为止应用光学字符识别最直接的方式:
- EasyOCR 包可以用一个简单的
pip命令安装。 - 对 EasyOCR 包的依赖性很小,这使得配置 OCR 开发环境变得很容易。
- 一旦安装了 EasyOCR,只需要一个
import语句就可以将包导入到您的项目中。 - 从那里,你需要的只是两行代码来执行 OCR——一行初始化
Reader类,另一行通过readtext函数对图像进行 OCR。
听起来好得难以置信?
幸运的是,它不是——今天我将向您展示如何使用 EasyOCR 在您自己的项目中实现光学字符识别。
要了解如何使用 EasyOCR 进行光学字符识别,继续阅读。
开始使用 EasyOCR 进行光学字符识别
在本教程的第一部分,我们将简要讨论 EasyOCR 包。从那里,我们将配置我们的 OCR 开发环境并在我们的机器上安装 EasyOCR。
接下来,我们将实现一个简单的 Python 脚本,它通过 EasyOCR 包执行光学字符识别。您将直接看到实现 OCR(甚至是多种语言的 OCR 文本)是多么简单和直接。
我们将用 EasyOCR 结果的讨论来结束本教程。
什么是 EasyOCR 包?
EasyOCR 包由一家专门从事光学字符识别服务的公司 Jaided AI 创建和维护。
EasyOCR 是使用 Python 和 PyTorch 库实现的。如果你有一个支持 CUDA 的 GPU,底层的 PyTorch 深度学习库可以大大加快你的文本检测和 OCR 速度。
截至本文撰写之时,EasyOCR 可以识别 58 种语言的文本,包括英语、德语、印地语、俄语、等等!easy ocr 的维护者计划在未来添加更多的语言。你可以在下一页找到 EasyOCR 支持的语言的完整列表。
目前,EasyOCR 仅支持对键入的文本进行 OCR。2020 年晚些时候,他们还计划发布一款手写识别模型。
如何在你的机器上安装 easy ocr
要开始安装 EasyOCR,我的建议是遵循我的 pip install opencv 教程和重要警告:
一定要在你的虚拟环境中安装opencv-python而不是 opencv-contrib-python 。此外,如果您在同一个环境中有这两个包,可能会导致意想不到的后果。如果你两个都安装了,pip 不太可能会抱怨,所以要注意检查一下pip freeze命令。
当然,这两个 OpenCV 包在前面提到的教程中都有讨论;一定要安装正确的。
并且我的建议是你在你的系统上为 EasyOCR 专用一个单独的 Python 虚拟环境( pip 安装 opencv 指南的选项 B )。
然而,尽管选项 B 建议将您的虚拟环境命名为cv,我还是建议将其命名为easyocr、ocr_easy,或者类似的名称。如果您看过我的个人系统,您会惊讶地发现,在任何给定的时间,我的系统上都有 10-20 个用于不同目的的虚拟环境,每个虚拟环境都有一个对我有意义的描述性名称。
您的安装步骤应该如下所示:
- 步骤#1: 安装 Python 3
- 步骤#2: 安装 pip
- 第三步:在你的系统上安装
virtualenv和virtualenvwrapper,,包括按照指示编辑你的 Bash/ZSH 档案 - 步骤#4: 创建一个名为
easyocr的 Python 3 虚拟环境(或者选择一个您自己选择的名称),并使用workon命令确保它是活动的 - 步骤#5: 根据以下信息安装 OpenCV 和 EasyOCR
为了完成步骤#1-#4,确保首先遵循上面链接的安装指南。
当您准备好进行第五步时,只需执行以下操作:
$ pip install opencv-python # NOTE: *not* opencv-contrib-python
$ pip install easyocr
$ workon easyocr # replace `easyocr` with your custom environment name
$ pip freeze
certifi==2020.6.20
cycler==0.10.0
decorator==4.4.2
easyocr==1.1.7
future==0.18.2
imageio==2.9.0
kiwisolver==1.2.0
matplotlib==3.3.1
networkx==2.4
numpy==1.19.1
opencv-python==4.4.0.42
Pillow==7.2.0
pyparsing==2.4.7
python-bidi==0.4.2
python-dateutil==2.8.1
PyWavelets==1.1.1
scikit-image==0.17.2
scipy==1.5.2
six==1.15.0
tifffile==2020.8.13
torch==1.6.0
torchvision==0.7.0
请注意,安装了以下软件包:
easyocropencv-pythontorch和torchvision
还有一些其他的 EasyOCR 依赖项会自动为您安装。
最重要的是,正如我上面提到的,确保你的虚拟环境中安装了opencv-python和 而不是 opencv-contrib-python。
如果你仔细按照我列出的步骤去做,你很快就可以开始工作了。一旦您的环境准备就绪,您就可以开始使用 EasyOCR 进行光学字符识别。
项目结构
花点时间找到这篇博文的 【下载】 部分。在项目文件夹中,您会找到以下文件:
$ tree --dirsfirst
.
├── images
│ ├── arabic_sign.jpg
│ ├── swedish_sign.jpg
│ └── turkish_sign.jpg
└── easy_ocr.py
1 directory, 4 files
今天的 EasyOCR 项目已经名副其实了。如你所见,我们有三个测试images/和一个 Python 驱动脚本easy_ocr.py。我们的驱动程序脚本接受任何输入图像和所需的 OCR 语言,以便很容易地完成工作,我们将在实现部分看到这一点。
使用 EasyOCR 进行光学字符识别
配置了开发环境并检查了项目目录结构后,我们现在可以在 Python 脚本中使用 EasyOCR 包了!
打开项目目录结构中的easy_ocr.py文件,插入以下代码:
# import the necessary packages
from easyocr import Reader
import argparse
import cv2
def cleanup_text(text):
# strip out non-ASCII text so we can draw the text on the image
# using OpenCV
return "".join([c if ord(c) < 128 else "" for c in text]).strip()
如您所见,cleanup_text助手函数只是确保text字符串参数中的字符序数小于128,去掉任何其他字符。如果你对128的意义感到好奇,一定要看看任何标准的 ASCII 字符表,比如这个。
输入和便利实用程序准备就绪,现在让我们定义命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-l", "--langs", type=str, default="en",
help="comma separated list of languages to OCR")
ap.add_argument("-g", "--gpu", type=int, default=-1,
help="whether or not GPU should be used")
args = vars(ap.parse_args())
我们的脚本接受三个命令行参数:
--image:包含 OCR 文字的输入图像的路径。--langs:逗号分隔的语言代码列表(无空格)。到default时,我们的脚本采用英语(en)。如果你想使用英国和法国模式,你可以通过en,fr。或者也许你想通过es,pt,it使用西班牙语、葡萄牙语和意大利语。请务必参考 EasyOCR 列出的支持的语言。--gpu:是否要用 GPU。我们的default是-1,这意味着我们将使用我们的 CPU 而不是 GPU。如果您有支持 CUDA 的 GPU,启用此选项将允许更快的 OCR 结果。
给定我们的命令行参数,让我们执行 OCR:
# break the input languages into a comma separated list
langs = args["langs"].split(",")
print("[INFO] OCR'ing with the following languages: {}".format(langs))
# load the input image from disk
image = cv2.imread(args["image"])
# OCR the input image using EasyOCR
print("[INFO] OCR'ing input image...")
reader = Reader(langs, gpu=args["gpu"] > 0)
results = reader.readtext(image)
# loop over the results
for (bbox, text, prob) in results:
# display the OCR'd text and associated probability
print("[INFO] {:.4f}: {}".format(prob, text))
# unpack the bounding box
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
# cleanup the text and draw the box surrounding the text along
# with the OCR'd text itself
text = cleanup_text(text)
cv2.rectangle(image, tl, br, (0, 255, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
EasyOCR 结果
我们现在可以看到 EasyOCR 库应用光学字符识别的结果了。
首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python easy_ocr.py --image images/arabic_sign.jpg --langs en,ar
[INFO] OCR'ing with the following languages: ['en', 'ar']
[INFO] OCR'ing input image...
Using CPU. Note: This module is much faster with a GPU.
[INFO] 0.8129: خروج
[INFO] 0.7237: EXIT
EasyOCR 能够检测并正确识别输入图像中的英文和阿拉伯文文本。
注意:如果您是第一次使用 EasyOCR,您会看到在您的终端上打印出一个指示,说明 EasyOCR 正在“下载检测模型”下载文件时请耐心等待。一旦这些模型被缓存到您的系统中,您就可以无缝、快速地反复使用它们。
让我们尝试另一个图像,这个图像包含一个瑞典标志:
$ python easy_ocr.py --image images/swedish_sign.jpg --langs en,sv
[INFO] OCR'ing with the following languages: ['en', 'sv']
[INFO] OCR'ing input image...
Using CPU. Note: This module is much faster with a GPU.
[INFO] 0.7078: Fartkontrol
这里我们要求 EasyOCR 对英语(en)和瑞典语(sv)进行 OCR。
对于那些还不熟悉这个标志的人来说,“Fartkontrol”是瑞典人和丹麦人之间的一个小笑话。
直译过来,Fartkontrol在英文中的意思是【速度控制】(或者简称速度监控)。
但是当发音时,“【屁控】听起来像“屁控”——也许有人在控制自己的胀气方面有问题。在大学里,我有一个朋友在他们的浴室门上挂了一个瑞典【法特控】的标志——也许你不觉得这个笑话好笑,但每当我看到那个标志时,我都会暗自发笑(也许我只是一个不成熟的 8 岁小孩)。
最后一个例子,让我们看看土耳其的停车标志:
$ python easy_ocr.py --image images/turkish_sign.jpg --langs en,tr
[INFO] OCR'ing with the following languages: ['en', 'tr']
[INFO] OCR'ing input image...
Using CPU. Note: This module is much faster with a GPU.
[INFO] 0.9741: DUR
我让 EasyOCR 对英语(en)和土耳其语(tr)文本进行 OCR,通过--langs命令行参数以逗号分隔列表的形式提供这些值。
EasyOCR 能够检测文本,“DUR”,,当从土耳其语翻译成英语时,该文本是“停止”
正如你所看到的,EasyOCR 名副其实——最后,一个易于使用的光学字符识别包!
此外,如果您有支持 CUDA 的 GPU,您可以通过提供--gpu命令行参数来获得甚至更快的 OCR 结果,如下所示:
$ python easy_ocr.py --image images/turkish_sign.jpg --langs en,tr --gpu 1
但是同样,您需要为 PyTorch 库配置一个 CUDA GPU(easy ocr 使用 PyTorch 深度学习库)。
总结
在本教程中,您学习了如何使用 EasyOCR Python 包执行光学字符识别。
与 Tesseract OCR 引擎和 pytesseract 包不同,如果您是光学字符识别领域的新手,使用它们可能会有点乏味,EasyOCR 包名副其实——easy OCR 使 Python 的光学字符识别变得“简单”
此外,EasyOCR 还有许多好处:
- 您可以使用 GPU 来提高光学字符识别管道的速度。
- 您可以使用 EasyOCR 同时对多种语言的文本进行 OCR。
- EasyOCR API 是 Pythonic 式的,使用起来简单直观。
我在我的书 OCR with OpenCV、Tesseract 和 Python 中介绍了 EasyOCR 如果您有兴趣了解更多关于光学字符识别的知识,一定要看看!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
开始使用谷歌珊瑚的 TPU USB 加速器
原文:https://pyimagesearch.com/2019/04/22/getting-started-with-google-corals-tpu-usb-accelerator/
在本教程中,您将学习如何在 Raspberry Pi 和 Ubuntu 上配置您的谷歌珊瑚 TPU USB 加速器。然后,您将学习如何使用 Google Coral 的 USB 加速器执行分类和对象检测。
几周前,谷歌发布了“Coral”,这是一种超快、“不需要互联网”的开发板和 USB 加速器,使深度学习从业者能够“在边缘”和“更接近数据”地部署他们的模型。
使用 Coral,深度学习开发人员不再需要拥有互联网连接,这意味着 Coral TPU 足够快,可以直接在设备上执行推理,而不是将图像/帧发送到云端进行推理和预测。
谷歌珊瑚有两种口味:
- 带有板载 Edge TPU 的单板计算机。开发板可以被认为是“人工智能的高级树莓 Pi”或 NVIDIA 的 Jetson Nano 的竞争对手。
- 一个 USB 加速器可以插入一个设备(比如树莓派)。u 盘内置了一个 Edge TPU。可以把谷歌的 Coral USB 加速器看作是英特尔的 Movidius NCS 的竞争对手。
今天,我们将重点关注 Coral USB 加速器,因为它更容易上手(而且它非常符合我们过去几周树莓 Pi 相关帖子的主题)。
要了解如何配置您的 Google Coral USB 加速器(并执行分类+对象检测),继续阅读!
开始使用谷歌珊瑚的 TPU USB 加速器

Figure 1: The Google Coral TPU Accelerator adds deep learning capability to resource-constrained devices like the Raspberry Pi (source).
在这篇文章中,我假设你有:
- 您的谷歌珊瑚 USB 加速棒
- 全新安装基于 Debian 的 Linux 发行版(例如, Raspbian、Ubuntu、等)。)
- 了解基本的 Linux 命令和文件路径
如果你还没有谷歌珊瑚加速器,你可以通过谷歌官方网站购买。
我将在 Raspbian 上配置 Coral USB 加速器,但是同样,如果您有基于 Debian 的操作系统,这些命令仍然可以工作。
我们开始吧!
更新 2019-12-30: 安装步骤 1-6 已经完全重构并更新,以符合谷歌关于安装 Coral 的 EdgeTPU 运行时库的建议说明。我的主要贡献是添加了 Python 虚拟环境。我还更新了关于如何运行示例脚本的部分。
步骤 1:安装 Coral EdgeTPU 运行时和 Python API
在这一步,我们将使用您的 Aptitude 包管理器来安装 Google Coral 的 Debian/Raspbian 兼容包。
首先,让我们添加包存储库:
$ echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list
$ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ sudo apt-get update
注意:小心换行,确保你复制了每个完整的命令,并在你的终端中输入,如图所示。
现在我们准备好安装 EdgeTPU 运行时库:
$ sudo apt-get install libedgetpu1-std
接着是安装 EdgeTPU Python API:
$ sudo apt-get install python3-edgetpu
第二步:重启你的设备
重新启动您的 Raspberry Pi 或计算机是安装完成的关键。您可以使用以下命令:
$ sudo reboot now
步骤 3:设置你的谷歌珊瑚虚拟环境
我们将使用 Python 虚拟环境,这是使用 Python 时的最佳实践。
Python 虚拟环境是您系统上的一个隔离的开发/测试/生产环境——它与其他环境完全隔离。最重要的是,您可以使用 pip (Python 的包管理器)管理虚拟环境中的 Python 包。
当然,也有管理虚拟环境和包的替代方法(即 Anaconda/conda 和 venv)。我已经使用/尝试了所有这些工具,但最终选定 pip、 virtualenv 和 virtualenvwrapper 作为我安装在所有系统上的首选工具。如果你使用和我一样的工具,你会得到我最好的支持。
您可以使用以下命令安装 pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo python3 get-pip.py
$ sudo rm -rf ~/.cache/pip
现在让我们安装virtualenv和virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper
一旦virtualenv和virtualenvwrapper都安装好了,打开你的~/.bashrc文件:
$ nano ~/.bashrc
…并将以下几行附加到文件的底部:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
通过ctrl + x、y、enter保存并退出。
从那里,重新加载您的~/.bashrc文件,将更改应用到您当前的 bash 会话:
$ source ~/.bashrc
接下来,创建您的 Python 3 虚拟环境:
$ mkvirtualenv coral -p python3
这里我们使用 Python 3 创建了一个名为coral的 Python 虚拟环境。展望未来,我推荐 Python 3。
注意: Python 3 将在 2020 年 1 月 1 日到达生命的尽头,所以我不*推荐使用 Python 2.7。*
步骤 4:将 EdgeTPU 运行时符号链接到您的虚拟环境中
符号链接是从一个文件/文件夹到另一个文件/文件夹的虚拟链接。你可以在维基百科的文章上了解更多。
我们将创建一个从包含 EdgeTPU 运行时库的 system packages 文件夹到我们的虚拟环境的符号链接。
首先,让我们找到 Python EdgeTPU 包的安装路径:
$ dpkg -L python3-edgetpu
/.
/usr
/usr/lib
/usr/lib/python3
/usr/lib/python3/dist-packages
/usr/lib/python3/dist-packages/edgetpu
/usr/lib/python3/dist-packages/edgetpu/__init__.py
/usr/lib/python3/dist-packages/edgetpu/basic
/usr/lib/python3/dist-packages/edgetpu/basic/__init__.py
/usr/lib/python3/dist-packages/edgetpu/basic/basic_engine.py
/usr/lib/python3/dist-packages/edgetpu/basic/edgetpu_utils.py
/usr/lib/python3/dist-packages/edgetpu/classification
/usr/lib/python3/dist-packages/edgetpu/classification/__init__.py
/usr/lib/python3/dist-packages/edgetpu/classification/engine.py
/usr/lib/python3/dist-packages/edgetpu/detection
/usr/lib/python3/dist-packages/edgetpu/detection/__init__.py
/usr/lib/python3/dist-packages/edgetpu/detection/engine.py
/usr/lib/python3/dist-packages/edgetpu/learn
/usr/lib/python3/dist-packages/edgetpu/learn/__init__.py
/usr/lib/python3/dist-packages/edgetpu/learn/backprop
/usr/lib/python3/dist-packages/edgetpu/learn/backprop/__init__.py
/usr/lib/python3/dist-packages/edgetpu/learn/backprop/ops.py
/usr/lib/python3/dist-packages/edgetpu/learn/backprop/softmax_regression.py
/usr/lib/python3/dist-packages/edgetpu/learn/imprinting
/usr/lib/python3/dist-packages/edgetpu/learn/imprinting/__init__.py
/usr/lib/python3/dist-packages/edgetpu/learn/imprinting/engine.py
/usr/lib/python3/dist-packages/edgetpu/learn/utils.py
/usr/lib/python3/dist-packages/edgetpu/swig
/usr/lib/python3/dist-packages/edgetpu/swig/__init__.py
/usr/lib/python3/dist-packages/edgetpu/swig/_edgetpu_cpp_wrapper.cpython-35m-arm-linux-gnueabihf.so
/usr/lib/python3/dist-packages/edgetpu/swig/_edgetpu_cpp_wrapper.cpython-36m-arm-linux-gnueabihf.so
/usr/lib/python3/dist-packages/edgetpu/swig/_edgetpu_cpp_wrapper.cpython-37m-arm-linux-gnueabihf.so
/usr/lib/python3/dist-packages/edgetpu/swig/edgetpu_cpp_wrapper.py
/usr/lib/python3/dist-packages/edgetpu/utils
/usr/lib/python3/dist-packages/edgetpu/utils/__init__.py
/usr/lib/python3/dist-packages/edgetpu/utils/dataset_utils.py
/usr/lib/python3/dist-packages/edgetpu/utils/image_processing.py
/usr/lib/python3/dist-packages/edgetpu/utils/warning.py
/usr/lib/python3/dist-packages/edgetpu-2.12.2.egg-info
/usr/lib/python3/dist-packages/edgetpu-2.12.2.egg-info/PKG-INFO
/usr/lib/python3/dist-packages/edgetpu-2.12.2.egg-info/dependency_links.txt
/usr/lib/python3/dist-packages/edgetpu-2.12.2.egg-info/requires.txt
/usr/lib/python3/dist-packages/edgetpu-2.12.2.egg-info/top_level.txt
/usr/share
/usr/share/doc
/usr/share/doc/python3-edgetpu
/usr/share/doc/python3-edgetpu/changelog.Debian.gz
/usr/share/doc/python3-edgetpu/copyright
注意,在第 7 行的命令输出中,我们发现 edgetpu 库的根目录是:/usr/lib/python 3/dist-packages/edge TPU。我们将从虚拟环境站点包创建一个指向该路径的符号链接。
现在让我们创建我们的符号链接:
$ cd ~/.virtualenvs/coral/lib/python3.7/site-packages
$ ln -s /usr/lib/python3/dist-packages/edgetpu/ edgetpu
$ cd ~
步骤 5:测试您的 Coral EdgeTPU 安装
让我们启动 Python shell 来测试我们的 Google Coral 安装:
$ workon coral
$ python
>>> import edgetpu
>>> edgetpu.__version__
'2.12.2'
步骤 5b:您可能希望为 Google Coral 安装的可选 Python 包
随着您继续使用 Google Coral,您会发现您需要在虚拟环境中安装一些其他的包。
让我们安装用于 PiCamera(仅限 Raspberry Pi)和图像处理的软件包:
$ workon coral
$ pip install "picamera[array]" # Raspberry Pi only
$ pip install numpy
$ pip install opencv-contrib-python==4.1.0.25
$ pip install imutils
$ pip install scikit-image
$ pip install pillow
步骤 6:安装 EdgeTPU 示例
现在我们已经安装了 TPU 运行时库,让我们来测试一下 Coral USB 加速器吧!
首先让我们安装 EdgeTPU 示例包:
$ sudo apt-get install edgetpu-examples
从那里,我们需要添加写权限到示例目录:
$ sudo chmod a+w /usr/share/edgetpu/examples
项目结构
今天教程的例子是独立的,不需要额外下载。
继续激活您的环境,并切换到示例目录:
$ workon coral
$ cd /usr/share/edgetpu/examples
examples 目录包含图像和模型的目录,以及一些 Python 脚本。让我们用tree命令检查我们的项目结构:
$ tree --dirsfirst
.
├── images
│ ├── bird.bmp
│ ├── cat.bmp
│ ├── COPYRIGHT
│ ├── grace_hopper.bmp
│ ├── parrot.jpg
│ └── sunflower.bmp
├── models
│ ├── coco_labels.txt
│ ├── deeplabv3_mnv2_pascal_quant_edgetpu.tflite
│ ├── inat_bird_labels.txt
│ ├── mobilenet_ssd_v1_coco_quant_postprocess_edgetpu.tflite
│ ├── mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite
│ ├── mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite
│ └── mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite
├── backprop_last_layer.py
├── classify_capture.py
├── classify_image.py
├── imprinting_learning.py
├── object_detection.py
├── semantic_segmetation.py
└── two_models_inference.py
2 directories, 20 files
在下一节中,我们将使用以下基于 MobileNet 的 TensorFlow Lite 模型:
mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite:在鸟类数据集上训练的分类模型。mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite:人脸检测模型。mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite:在 COCO 数据集上训练的物体检测模型。
第一个模型将与classify_image.py分类 Python 脚本一起使用。
模型 2 和 3 都将与object_detection.py Python 脚本一起用于对象检测。请记住,面部检测是对象检测的一种形式。
使用 Google Coral USB 加速器进行分类、对象检测和人脸检测
此时,我们已经准备好测试我们的 Google Coral 协处理器了!
让我们首先执行一个简单的图像分类示例:
$ python classify_image.py \
--mode models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \
--label models/inat_bird_labels.txt \
--image images/parrot.jpg
---------------------------
Ara macao (Scarlet Macaw)
Score : 0.61328125
---------------------------
Platycercus elegans (Crimson Rosella)
Score : 0.15234375
Figure 2: Getting started with Google’s Coral TPU accelerator and the Raspberry Pi to perform bird classification.
正如你所看到的,MobileNet(训练过 iNat 鸟类)已经正确地将图像标记为“金刚鹦鹉”,一种鹦鹉。
让我们尝试第二个分类示例:
$ python classify_image.py \
--mode models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \
--label models/inat_bird_labels.txt \
--image images/bird.bmp
---------------------------
Poecile carolinensis (Carolina Chickadee)
Score : 0.37109375
---------------------------
Poecile atricapillus (Black-capped Chickadee)
Score : 0.29296875
Figure 3: Bird classification using Python and the Google Coral. Read this tutorial to get started with Google’s Coral TPU accelerator and the Raspberry Pi. Learn to install the necessary software and run example code.
请注意,山雀的图像已被正确分类。事实上,前两个结果都是山雀的形式:(1)卡罗莱纳州,和(2)黑帽。
现在让我们尝试使用 Google Coral USB 加速器执行面部检测:
$ python object_detection.py \
--mode models/mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite \
--input images/grace_hopper.bmp
-----------------------------------------
score = 0.99609375
box = [143.88912090659142, 40.834905445575714, 381.8060402870178, 365.49142384529114]
Please check object_detection_result.jpg
Figure 4: Face detection with the Google Coral and Raspberry Pi is very fast. Read this tutorial to get started.
在这里,MobileNet + SSD 面部检测器能够检测到图像中格蕾丝·赫柏的面部。Grace 的脸部周围有一个非常微弱的红色方框(我推荐点击图片放大,这样就可以看到脸部检测方框)。在未来,我们将学习如何执行自定义对象检测,在此期间,您可以绘制一个更厚的检测框。
下一个示例显示了如何使用在 COCO 数据集上训练的 MobileNet + SSD 来执行对象检测:
$ python object_detection.py \
--mode models/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite \
--input images/cat.bmp
-----------------------------------------
score = 0.96484375
box = [52.70467400550842, 37.87856101989746, 448.4963893890381, 391.3172245025635]
-----------------------------------------
score = 0.2109375
box = [0.0, 0.5118846893310547, 191.08786582946777, 194.69362497329712]
-----------------------------------------
score = 0.2109375
box = [300.4741072654724, 38.08128833770752, 382.5985550880432, 169.52738761901855]
-----------------------------------------
score = 0.16015625
box = [359.85671281814575, 46.61980867385864, 588.858425617218, 357.5845241546631]
-----------------------------------------
score = 0.16015625
box = [0.0, 10.966479778289795, 191.53071641921997, 378.33733558654785]
-----------------------------------------
score = 0.12109375
box = [126.62454843521118, 4.192984104156494, 591.4307713508606, 262.3262882232666]
-----------------------------------------
score = 0.12109375
box = [427.05928087234497, 84.77717638015747, 600.0, 332.24596977233887]
-----------------------------------------
score = 0.08984375
box = [258.74093770980835, 3.4015893936157227, 600.0, 215.32137393951416]
-----------------------------------------
score = 0.08984375
box = [234.9416971206665, 33.762264251708984, 594.8572397232056, 383.5402488708496]
-----------------------------------------
score = 0.08984375
box = [236.90505623817444, 51.90783739089966, 407.265830039978, 130.80371618270874]
Please check object_detection_result.jpg
Figure 5: Getting started with object detection using the Google Coral EdgeTPU USB Accelerator device.
注意图 5 中有 十个 检测(淡红色方框;点击放大),但图中只有一只猫— 这是为什么?
原因是object_detection.py脚本没有按照最小概率进行过滤。您可以很容易地修改脚本,忽略概率为 < 50% 的检测(我们将在下个月使用 Google coral 进行自定义对象检测)。
为了好玩,我决定尝试一个不包含在示例 TPU 运行时库演示中的图片。
下面是一个将人脸检测器应用于自定图像的示例:
$ python object_detection.py \
--mode models/mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite \
--input ~/IMG_7687.jpg
-----------------------------------------
score = 0.98046875
box = [190.66683948040009, 0.0, 307.4474334716797, 125.00646710395813]
Figure 6: Testing face detection (using my own face) with the Google Coral and Raspberry Pi.
果然我的脸被检测到了!
最后,这里有一个在同一映像上运行 MobileNet + SSD 的示例:
$ python object_detection.py \
--mode models/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite \
--label models/coco_labels.txt \
--input ~/IMG_7687.jpg
-----------------------------------------
person
score = 0.87890625
box = [58.70787799358368, 10.639026761054993, 371.2196350097656, 494.61638927459717]
-----------------------------------------
dog
score = 0.58203125
box = [50.500258803367615, 358.102411031723, 162.57299482822418, 500.0]
-----------------------------------------
dog
score = 0.33984375
box = [13.502731919288635, 287.04309463500977, 152.83603966236115, 497.8201985359192]
-----------------------------------------
couch
score = 0.26953125
box = [0.0, 88.88640999794006, 375.0, 423.55993390083313]
-----------------------------------------
couch
score = 0.16015625
box = [3.753773868083954, 64.79595601558685, 201.68977975845337, 490.678071975708]
-----------------------------------------
dog
score = 0.12109375
box = [65.94736874103546, 335.2701663970947, 155.95845878124237, 462.4992609024048]
-----------------------------------------
dog
score = 0.12109375
box = [3.5936199128627777, 335.3758156299591, 118.05401742458344, 497.33099341392517]
-----------------------------------------
couch
score = 0.12109375
box = [49.873560667037964, 97.65596687793732, 375.0, 247.15487658977509]
-----------------------------------------
dog
score = 0.12109375
box = [92.47469902038574, 338.89272809028625, 350.16247630119324, 497.23270535469055]
-----------------------------------------
couch
score = 0.12109375
box = [20.54794132709503, 99.93192553520203, 375.0, 369.604617357254]

Figure 7: An example of running the MobileNet SSD object detector on the Google Coral + Raspberry Pi.
同样,我们可以通过以最小概率过滤来去除无关的检测来改善结果。这样做将只留下两个检测:人(87.89%)和狗(58.20%)。
为谷歌的珊瑚训练定制模型怎么样?
你会注意到,在这篇文章中,我只在谷歌珊瑚上使用了预先训练的深度学习模型——你自己训练的定制模型呢?
Google 确实提供了一些关于那个的文档,但是它要高级得多,对我来说太多了,以至于我不能在这篇博文中包含。
如果你有兴趣学习如何为谷歌的 Coral 训练你自己的定制模型,我会推荐你看看我即将出版的书, 计算机视觉的树莓派 (完整捆绑包),在那里我将详细介绍谷歌 Coral。
如何在自己的自定义脚本中使用 Google Coral 的 Python 运行时库?
结合 OpenCV 和您自己的定制 Python 脚本使用edgetpu库超出了本文的范围。
下个月,我将介绍用于谷歌珊瑚分类和物体检测的定制 Python 脚本,以及我的用于计算机视觉的书 【树莓 Pi】。
使用谷歌 TPU USB 加速器的想法、提示和建议
总的来说,我真的很喜欢 Coral USB 加速器。我认为它非常容易配置和安装,虽然不是所有的演示都能开箱即用,但凭借一些文件路径的基本知识,我能够在几分钟内让它们运行起来。
在未来,我希望看到谷歌 TPU 运行时库与 Python 虚拟环境更加兼容。要求符号链接并不理想。
我还要补充一点,关于树莓派的推断比谷歌珊瑚 TPU 加速器宣传的要慢一点——这实际上不是 TPU 加速器的问题,而是树莓派的问题。
我这么说是什么意思?
请记住,树莓派 3B+使用的是 USB 2.0,但为了获得更好的推理速度,谷歌珊瑚 USB 加速器建议使用 USB 3。
由于 RPi 3B+没有 USB 3,所以在 RPi 4 出来之前我们对此无能为力——一旦它出来,我们将使用 Coral USB 加速器在 Pi 上进行更快的推断。
更新 2019-12-30:树莓 Pi 4B** 包含 USB 3.0 能力。传输图像、执行推理和获得结果所需的总时间要快得多。请务必参考Raspberry Pi for Computer Vision中的第 23.2 章“测试和分析您的脚本”,以了解如何在 Raspberry Pi 上测试您的深度学习脚本。
最后,我将注意到,在对象检测示例中,有一两次 Coral USB 加速器似乎“锁定”并且不执行推理(我认为它在尝试加载模型时“卡住了”),迫使我ctrl + c退出脚本。
终止该脚本一定会阻止关键的“关闭”脚本在 Coral 上运行——演示 Python 脚本的任何后续执行都会导致错误。
为了解决这个问题,我必须拔掉 Coral USB 加速器,然后再插回去。同样,我不确定为什么会发生这种情况,我在 Google Coral 网站上也找不到任何提到这个问题的文档。
摘要
在本教程中,您学习了如何开始使用 Google Coral USB 加速器。
我们从在基于 Debian 的操作系统上安装 Edge TPU 运行时库开始(我们专门用 Raspbian 来安装 Raspberry Pi)。
之后,我们学习了如何运行 Edge TPU 库下载中包含的示例演示脚本。
我们还学习了如何将edgetpu库安装到 Python 虚拟环境中(这样我们可以保持我们的包/项目整洁)。
我们讨论了我在使用 Coral USB 加速器时的一些想法、反馈和建议,从而结束了本教程(如果您有任何问题,请务必首先参考它们)。
我希望你喜欢这个教程!
要在 PyImageSearch 上发布未来教程时得到通知,只需在下表中输入您的电子邮件地址!
开始使用英特尔 Movidius 神经计算棒
原文:https://pyimagesearch.com/2018/02/12/getting-started-with-the-intel-movidius-neural-compute-stick/

让我问你三个问题:
- 如果你能在 T2 的 u 盘上运行最先进的神经网络会怎么样?
- 如果你能看到这个 u 盘上的性能比你的 CPU 高 10 倍会怎么样?
*** 如果整个设备的价格低于 100 美元呢?**
**听起来有趣吗?
进入英特尔的 Movidius 神经计算棒(NCS)。
Raspberry Pi 用户将特别是欢迎这款设备,因为它可以显著提高图像分类和物体检测的速度和能力。您可能会发现,Movidius“正是您所需要的”,它(1)外形小巧,( 2)价格实惠,可以加快网络推理时间。
在今天的帖子中,我们将讨论:
- Movidius 神经计算棒的能力
- 如果你应该买一个
- 如何快速、轻松地使用 Movidius 开始跑步
- 在 MacBook Pro 和 Raspberry Pi 上比较网络推理时间的基准测试
下周,我将使用 Movidius 提供额外的基准和对象检测脚本。
要开始使用英特尔 Movidius 神经计算棒并了解如何将 CNN 模型部署到您的 Raspberry Pi + NCS,请继续阅读。
弃用声明: 本文使用的是 Movidius APIv1 和 APIv2,现在已经被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。
开始使用英特尔 Movidius 神经计算棒
今天的博文分为五个部分。
首先,我来回答:
什么是英特尔 Movidius 神经计算棒,我是否应该购买一个?
接下来,我将解释使用 Movidius 神经计算棒的工作流程。整个过程相对简单,但需要详细说明,以便我们了解如何与 NCS 合作
然后,我们将把我们的 Raspberry Pi 与 NCS 一起设置为纯 API 模式。我们还会做一个快速的健全性检查,以确保我们与 NCS 有沟通。
接下来,我将介绍我的自定义 Raspberry Pi + Movidius NCS 图像分类基准脚本。我们将使用 SqueezeNet、GoogLeNet 和 AlexNet。
我们将通过比较基准测试结果来结束这篇博文。
什么是英特尔 Movidius 神经计算棒?
英特尔的神经计算棒是一个 u 盘大小的深度学习机器。
你可以把 NCS 想象成一个 USB 驱动的 GPU,尽管这有点言过其实——它不是 GPU,它只能用于预测/推理,而不是训练。
实际上,我会将 NCS 归类为协处理器。它只有一个目的:运行(向前传递)神经网络计算。在我们的例子中,我们将使用 NCS 进行图像分类。
NCS 应该而不是用于训练神经网络模型,而是为可部署模型而设计的。由于该设备旨在用于单板计算机,如 Raspberry Pi,因此功耗极低,因此不适合实际训练网络。
所以现在你在想:我应该买 Movidius NCS 吗?
在只有 77 美元时,NCS 打出了一记重拳。你可以在亚马逊或者英特尔网站上列出的任何一家零售商那里购买这款设备。
在 NCS 的引擎盖下是一个能够提供 80-150 GFLOPS 性能的 Myriad 2 处理器。这种处理器也被称为视觉处理单元(或视觉加速器),它仅消耗 1W 的功率(作为参考,Raspberry Pi 3 B 在 HDMI 关闭、led 关闭和 WiFi 打开的情况下消耗 1.2W 的功率)。
对您来说,购买 NCS 是否值得取决于几个问题的答案:
- 你有立即使用的案例吗?或者你有 77 美元可以花在另一个玩具上吗?
- 你愿意处理加入一个年轻社区的成长烦恼吗?虽然肯定有效,但我们不知道这些“视觉处理单元”是否会一直存在。
- 你愿意为 SDK 贡献一台机器(或虚拟机)吗?
- Pi 用户:你愿意为 NCS 提供一个单独的 Pi 或至少一个单独的 microSD 吗?您是否知道,基于其外形尺寸,该设备将阻塞 3 个 USB 端口,除非您使用电缆连接 NCS 加密狗?
问题 1 由你决定。
我问问题 2 的原因是因为英特尔因文档质量差而臭名昭著,甚至像他们停止生产英特尔 Galileo 一样停止生产他们的产品。
我并不是说 NCS 会出现这两种情况。NCS 处于深度学习领域,目前正全速前进,因此该产品的未来看起来很光明。没有太多竞品也无妨。
问题 2 和问题 3(及其答案)是相关的。简而言之,您不能将开发环境与虚拟环境隔离开来,安装程序实际上会从您的系统中删除以前安装的 OpenCV。因此,您不应该在当前项目和工作环境附近获取安装程序脚本。我得到了惨痛的教训。相信我。
希望我没有把你吓跑——那不是我的本意。大多数人会购买 Movidius NCS 来搭配 Raspberry Pi 或其他单板电脑。
问题 4 是针对 Pi 用户的。说到 Pi,如果你一直在关注 PyImageSearch.com 的其他教程,你会知道我推荐 Python 虚拟环境来隔离你的 Python 项目和相关的依赖项。 Python 虚拟环境是 Python 社区中的最佳实践。
我对神经计算棒最大的不满之一是,英特尔的安装脚本实际上会让你的虚拟环境几乎无法使用。安装程序从 Debian/Ubuntu Aptitude repos 下载软件包,并更改 PYTHONPATH 系统变量。
它会很快变得很乱,为了安全起见,你应该使用一个新的 microSD ( 在亚马逊上购买一个 32GB 98MB/s 的 microSD)和 Raspbian Stretch。如果你在一个可部署的项目中工作,你甚至可以再买一个 Pi 来嫁给 NCS。
当我收到 NCS 时,我很兴奋地把它插入我的 Pi… 中,但不幸的是,我有了一个糟糕的开始。
看看下面的图片。
我发现,随着 NCS 的插入,它阻塞了我的 Pi 上的所有其他 3 个 USB 端口。我甚至不能将我的无线键盘/鼠标转换器插入另一个端口!
现在,我知道 NCS 是为了与除 Raspberry Pi 之外的其他设备一起使用,但鉴于 Raspberry Pi 是最常用的单板系统之一,我有点惊讶英特尔没有考虑这一点——可能是因为该设备消耗大量电力,他们希望您在为您的 Pi 插入额外的外围设备时三思而行。

Figure 1: The Intel Movidius NCS blocks the 3 other USB ports from easy access.
这非常令人沮丧。解决办法是买一个 6 英寸的 USB 3.0 扩展接口,比如这个:

Figure 2: Using a 6in USB extension dongle with the Movidius NCS and Raspberry Pi allows access the other 3 USB ports.
考虑到这些因素,Movidius NCS 实际上是一款物有所值的好设备。让我们深入工作流程。
Movidius NCS 工作流程
Figure 3: The Intel Movidius NCS workflow (image credit: Intel)
弃用声明: 本文使用的是 Movidius APIv1 和 APIv2,现在已经被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。
一旦你理解了工作流程,使用 NCS 就很容易了。
底线是您需要一个 图形文件 来部署到 NCS。如果您愿意,这个图形文件可以与您的 Python 脚本放在同一个目录中——它将使用 NCS API 发送到 NCS。我包含了一些与这篇博文相关的带有 【下载】 的图形文件。
一般来说,使用 NCS 的工作流程是:
- 使用一个预先训练好的 TensorFlow/Caffe 模型或者 在 Ubuntu 或者 Debian 上用 TensorFlow/Caffe 训练一个网络。
- 使用 NCS SDK 工具链生成图形文件。
- 将图形文件和 NCS 部署到运行 Debian 风格的 Linux 的单板计算机上。我用的是运行 Raspbian(基于 Debian)的 Raspberry Pi 3 B。
- 使用 Python,使用 NCS API 将图形文件发送到 NCS,并请求对图像进行预测。处理预测结果,并根据结果采取(任意)行动。
今天,我们将使用 NCS API-only 模式工具链在中设置 Raspberry Pi。这个设置不包括生成图形文件的工具,也不安装 Caffe、Tensorflow 等。
然后,我们将创建自己的自定义图像分类基准脚本。你会注意到这个脚本在很大程度上基于之前的一篇关于使用树莓 Pi 和 OpenCVT3 进行深度学习的文章。
首先,让我们准备我们的树莓派。
在纯 API 模式下设置您的 Raspberry Pi 和 NCS
我吃了苦头才知道树莓派处理不了 SDK(我当时在想什么?)通过看一些稀疏的文档。
后来我从头开始,找到了更好的文档,指导我在纯 API 模式下设置我的 Pi(现在这有意义了)。我很快就以这种方式运行起来,我将向您展示如何做同样的事情。
对于您的 Pi,我建议您在全新安装的 Raspbian Stretch 上以仅 API 模式安装 SDK。
要在你的 Pi 上安装 Raspbian Stretch OS,在这里抓取 Stretch 镜像,然后使用这些指令刷新卡。
从那里,启动您的 Pi 并连接到 WiFi。如果您愿意,您可以通过 SSH 连接或使用显示器+键盘/鼠标(使用上面列出的 6 英寸加密狗,因为 USB 端口被 NCS 阻塞)来完成以下所有操作。
让我们更新系统:
$ sudo apt-get update && sudo apt-get upgrade
然后让我们安装一堆软件包:
$ sudo apt-get install -y libusb-1.0-0-dev libprotobuf-dev
$ sudo apt-get install -y libleveldb-dev libsnappy-dev
$ sudo apt-get install -y libopencv-dev
$ sudo apt-get install -y libhdf5-serial-dev protobuf-compiler
$ sudo apt-get install -y libatlas-base-dev git automake
$ sudo apt-get install -y byacc lsb-release cmake
$ sudo apt-get install -y libgflags-dev libgoogle-glog-dev
$ sudo apt-get install -y liblmdb-dev swig3.0 graphviz
$ sudo apt-get install -y libxslt-dev libxml2-dev
$ sudo apt-get install -y gfortran
$ sudo apt-get install -y python3-dev python-pip python3-pip
$ sudo apt-get install -y python3-setuptools python3-markdown
$ sudo apt-get install -y python3-pillow python3-yaml python3-pygraphviz
$ sudo apt-get install -y python3-h5py python3-nose python3-lxml
$ sudo apt-get install -y python3-matplotlib python3-numpy
$ sudo apt-get install -y python3-protobuf python3-dateutil
$ sudo apt-get install -y python3-skimage python3-scipy
$ sudo apt-get install -y python3-six python3-networkx
注意,我们已经从 Debian 仓库安装了libopencv-dev。这是我第一次推荐它,希望也是最后一次。通过 apt-get 安装 OpenCV(1)安装旧版本的 OpenCV,(2)不安装完整版本的 OpenCV,(3)不利用各种系统操作。再次声明,我不推荐这种方法安装 OpenCV。
此外,您可以看到我们正在安装一大堆包,我通常更喜欢在 Python 虚拟环境中使用 pip 来管理这些包。确保你使用的是一个新的存储卡,这样你就不会弄乱你 Pi 上正在做的其他项目。
由于我们使用 OpenCV 和 Python,我们将需要python-opencv绑定。Movidius 博客上的安装说明不包括这个工具。您可以通过输入以下内容来安装python-opencv绑定:
$ sudo apt-get install -y python-opencv
让我们也安装 imutils 和 picamera API:
$ pip install imutils
$ pip install “picamera[array]”
对于上面的pip install命令,我安装到了全局 Python 站点包中(没有虚拟环境)。
从这里,让我们创建一个工作区目录并克隆 NCSDK:
$ cd ~
$ mkdir workspace
$ cd workspace
$ git clone https://github.com/movidius/ncsdk
现在,让我们克隆 NC 应用程序 Zoo,因为我们以后会用到它。
$ git clone https://github.com/movidius/ncappzoo
从那里,导航到以下目录:
$ cd ~/workspace/ncsdk/api/src
在该目录中,我们将使用 Makefile 以纯 API 模式安装 SDK:
$ make
$ sudo make install
测试 NCS 上的 Raspberry Pi 安装
让我们使用 NC 应用程序 Zoo 中的代码来测试安装。确保 NCS 在这一点上插入到您的 Pi 中。
$ cd ~/workspace/ncappzoo/apps/hello_ncs_py
$ make run
making run
python3 hello_ncs.py;
Hello NCS! Device opened normally.
Goodbye NCS! Device closed normally.
NCS device working.
您应该会看到如上所示的确切输出。
使用预编译的图形文件
因为我们的 PI 上只有 API,所以我们必须依赖一个预先生成的图形文件来执行我们今天的分类项目。我已经在这篇博文的 【下载】 部分包含了相关的图形文件。
下周,我将向您展示如何使用安装在 Ubuntu 台式机/笔记本电脑上的成熟 SDK 来生成您自己的图形文件。
用 Movidius NCS 分类
如果您打开我们刚刚用 Makefile 创建的run.py文件,您会注意到大多数输入都是硬编码的,并且该文件通常很难看。
相反,我们将为分类和基准测试创建自己的文件。
在之前的一篇帖子 用 OpenCV 对树莓 Pi 进行深度学习中,我描述了如何使用 OpenCV 的 DNN 模块进行物体分类。
今天,我们将修改完全相同的脚本,使其与 Movidius NCS 兼容。
如果你比较一下这两个脚本,你会发现它们几乎是一样的。出于这个原因,我将简单地指出不同之处,所以我鼓励你参考之前的帖子以获得完整的解释。
每一个脚本都包含在这篇博文的 【下载】 部分,所以请务必打开 zip 并跟随它。
让我们回顾一下名为pi_ncs_deep_learning.py的修改后的文件的不同之处:
# import the necessary packages
from mvnc import mvncapi as mvnc
import numpy as np
import argparse
import time
import cv2
这里我们正在导入我们的包——唯一的不同是在行 2 ,在这里我们导入mvncapi as mvnc。这个导入是针对 NCS API 的。
从那里,我们需要解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-g", "--graph", required=True,
help="path to graph file")
ap.add_argument("-d", "--dim", type=int, required=True,
help="dimension of input to network")
ap.add_argument("-l", "--labels", required=True,
help="path to ImageNet labels (i.e., syn-sets)")
args = vars(ap.parse_args())
在这个模块中,删除了两个参数(--prototxt和--model),而添加了两个参数(--graph和--dim)。
--graph参数是我们的图形文件的路径——它代替了 prototxt 和 model。
图形文件可以通过 NCS SDK 生成,我们将在下周的博客文章中介绍。为了方便起见,我在 “下载中包含了本周的图形文件。在 Caffe 的情况下,图形是通过 SDK 从 prototxt 和模型文件中生成的。
**--dim参数简单地指定了我们将通过神经网络发送的(正方形)图像的像素尺寸。图片的尺寸在之前的文章中被硬编码。
接下来,我们将从磁盘加载类标签和输入图像:
# load the class labels from disk
rows = open(args["labels"]).read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
# load the input image from disk, make a copy, resize it, and convert to float32
image_orig = cv2.imread(args["image"])
image = image_orig.copy()
image = cv2.resize(image, (args["dim"], args["dim"]))
image = image.astype(np.float32)
这里我们用和前面一样的方法从synset_words.txt加载类标签。
然后,我们利用 OpenCV 加载图像。
一个微小的变化是我们在第 26 行制作了原始图像的副本。我们需要两份拷贝——一份用于预处理/标准化/分类,一份用于稍后在屏幕上显示。
第 27 行调整我们的图像大小,你会注意到我们使用了args["dim"]——我们的命令行参数值。
输入到卷积神经网络的宽度和高度图像尺寸的常见选择包括 32 × 32、64 × 64、224 × 224、227 × 227、256 × 256 和 299 × 299。您的确切图像尺寸将取决于您使用的 CNN。
第 28 行将图像数组数据转换为float32格式,这是NCS 和我们正在处理的图形文件的要求。
接下来,我们执行均值减法,但我们将以稍微不同的方式进行:
# load the mean file and normalize
ilsvrc_mean = np.load("ilsvrc_2012_mean.npy").mean(1).mean(1)
image[:,:,0] = (image[:,:,0] - ilsvrc_mean[0])
image[:,:,1] = (image[:,:,1] - ilsvrc_mean[1])
image[:,:,2] = (image[:,:,2] - ilsvrc_mean[2])
我们在第 31 行的处加载ilsvrc_2012_mean.npy文件。这来自 ImageNet 大规模视觉识别挑战,可用于 SqueezeNet、GoogLeNet、AlexNet,以及通常在 ImageNet 上训练的所有其他利用均值减法的网络(为此我们硬编码了路径)。
在第 32-34 行上计算图像均值减影(使用 GitHub 上的 Movidius 示例脚本中显示的相同方法)。
从那里,我们需要与 NCS 建立通信,并将图形加载到 NCS 中:
# grab a list of all NCS devices plugged in to USB
print("[INFO] finding NCS devices...")
devices = mvnc.EnumerateDevices()
# if no devices found, exit the script
if len(devices) == 0:
print("[INFO] No devices found. Please plug in a NCS")
quit()
# use the first device since this is a simple test script
print("[INFO] found {} devices. device0 will be used. "
"opening device0...".format(len(devices)))
device = mvnc.Device(devices[0])
device.OpenDevice()
# open the CNN graph file
print("[INFO] loading the graph file into RPi memory...")
with open(args["graph"], mode="rb") as f:
graph_in_memory = f.read()
# load the graph into the NCS
print("[INFO] allocating the graph on the NCS...")
graph = device.AllocateGraph(graph_in_memory)
可以看出,上面的代码块完全不同,因为上次我们根本没有使用 NCS。
让我们走一遍——它实际上非常简单。
为了准备在 NCS 上使用神经网络,我们需要执行以下操作:
- 列出所有连接的 NCS 设备(行 38 )。
- 如果发现一个 NCS 有问题,就完全脱离脚本(第 41-43 行)。
- 选择并打开
device0( 线 48 和 49 )。 - 将图形文件加载到 Raspberry Pi 内存中,以便我们可以使用 API 将其传输到 NCS(第 53 行和第 54 行)。
- 在 NCS 上加载/分配图表(行 58 )。
m ovidius 的开发者肯定说对了— 他们的 API 非常容易使用!
如果你在上面错过了,这里值得注意的是,我们正在加载一个预训练的图。训练步骤已经在一台更强大的机器上执行过,图形是由 NCS SDK 生成的。训练你自己的网络不在这篇博文的讨论范围之内,但是在 PyImageSearch 大师和用 Python 进行计算机视觉深度学习 中有详细介绍。
如果你读了前一篇文章,你会认出下面的代码块,但是你会注意到三个变化:
# set the image as input to the network and perform a forward-pass to
# obtain our output classification
start = time.time()
graph.LoadTensor(image.astype(np.float16), "user object")
(preds, userobj) = graph.GetResult()
end = time.time()
print("[INFO] classification took {:.5} seconds".format(end - start))
# clean up the graph and device
graph.DeallocateGraph()
device.CloseDevice()
# sort the indexes of the probabilities in descending order (higher
# probabilitiy first) and grab the top-5 predictions
preds = preds.reshape((1, len(classes)))
idxs = np.argsort(preds[0])[::-1][:5]
这里我们将使用 NCS 和 API 对图像进行分类。
使用我们的 graph 对象,我们调用graph.LoadTensor进行预测,调用graph.GetResult获取结果预测。这是一个两步操作,之前我们只是在一行中简单地调用了net.forward。
我们对这些操作进行计时,以计算我们的基准,同时像前面一样向终端显示结果。
接下来,我们通过清除图形存储器并关闭线 69 和 70 上的 NCS 连接来执行我们的内务处理任务。
从这里开始,我们还有一个剩余的块来将我们的图像显示到屏幕上(有一个非常小的变化):
# loop over the top-5 predictions and display them
for (i, idx) in enumerate(idxs):
# draw the top prediction on the input image
if i == 0:
text = "Label: {}, {:.2f}%".format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image_orig, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# display the predicted label + associated probability to the
# console
print("[INFO] {}. label: {}, probability: {:.5}".format(i + 1,
classes[idx], preds[0][idx]))
# display the output image
cv2.imshow("Image", image_orig)
cv2.waitKey(0)
在这个块中,我们在图像的顶部绘制最高的预测和概率。我们还在终端中打印前 5 个预测+概率。
这个模块中非常小的变化是我们在image_orig而不是image上绘制文本。
最后,我们在屏幕上显示输出image_orig。如果你使用 SSH 来连接你的 Raspberry Pi,只有当你在 SSH 连接到你的 Pi 时为 X11 转发提供了-X标志,这才会起作用。
要查看使用英特尔 Movidius 神经计算棒和 Python 在 Raspberry Pi 上应用深度学习图像分类的结果,请进入下一部分。
树莓 Pi 和深度学习结果
对于该基准测试,我们将比较使用 Pi CPU 和使用 Pi 与 NCS 协处理器的对比。
只是为了好玩,我还加入了我的 Macbook Pro 使用和不使用 NCS 的结果(这需要一个 Ubuntu 16.04 VM,我们将在下周构建和配置)。
我们将使用三种模型:
- 斯奎泽尼
- 谷歌网
- AlexNet
为了简单起见,我们每次都会对同一张图片进行分类——理发椅:

Figure 4: A barber chair in a barbershop is our test input image for deep learning on the Raspberri Pi with the Intel Movidius Neural Compute Stick.
由于终端输出结果相当长,我将把它们排除在后面的块之外。相反,为了便于比较,我将分享一个结果表。
下面是个 CPU 命令(尽管文件名中有pi,但实际上你可以在你的 Pi 或台式机/笔记本电脑上运行这个命令):
# SqueezeNet with OpenCV DNN module using the CPU
$ python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \
--model models/squeezenet_v1.0.caffemodel --dim 227 \
--labels synset_words.txt --image images/barbershop.png
[INFO] loading model...
[INFO] classification took 0.42588 seconds
[INFO] 1\. label: barbershop, probability: 0.8526
[INFO] 2\. label: barber chair, probability: 0.10092
[INFO] 3\. label: desktop computer, probability: 0.01255
[INFO] 4\. label: monitor, probability: 0.0060597
[INFO] 5\. label: desk, probability: 0.004565
# GoogLeNet with OpenCV DNN module using the CPU
$ python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt \
--model models/bvlc_googlenet.caffemodel --dim 224 \
--labels synset_words.txt --image images/barbershop.png
...
# AlexNet with OpenCV DNN module using the CPU
$ python pi_deep_learning.py --prototxt models/bvlc_alexnet.prototxt \
--model models/bvlc_alexnet.caffemodel --dim 227 \
--labels synset_words.txt --image images/barbershop.png
...
注意:为了使用 OpenCV DNN 模块,您必须至少安装 OpenCV 3.3。你可以使用这些指令在你的树莓 Pi 上安装一个优化的 OpenCV 3.3。
这里是 NCS 命令,使用我们刚刚走过的新的修改过的脚本(你实际上可以在你的 Pi 或你的桌面/笔记本电脑上运行这个,尽管文件名中有pi):
# SqueezeNet on NCS
$ python pi_ncs_deep_learning.py --graph graphs/squeezenetgraph \
--dim 227 --labels synset_words.txt --image images/barbershop.png
[INFO] finding NCS devices...
[INFO] found 1 devices. device0 will be used. opening device0...
[INFO] loading the graph file into RPi memory...
[INFO] allocating the graph on the NCS...
[INFO] classification took 0.085902 seconds
[INFO] 1\. label: barbershop, probability: 0.94482
[INFO] 2\. label: restaurant, probability: 0.013901
[INFO] 3\. label: shoe shop, probability: 0.010338
[INFO] 4\. label: tobacco shop, probability: 0.005619
[INFO] 5\. label: library, probability: 0.0035152
# GoogLeNet on NCS
$ python pi_ncs_deep_learning.py --graph graphs/googlenetgraph \
--dim 224 --labels synset_words.txt --image images/barbershop.png
...
# AlexNet on NCS
$ python pi_ncs_deep_learning.py --graph graphs/alexnetgraph \
--dim 227 --labels synset_words.txt --image images/barbershop.png
...
注意:为了使用 NCS,你必须有一个装载了 Raspbian(最好是 Stretch)的 Raspberry Pi,并且按照这篇博文中的说明安装了 NCS API-only 模式工具链。或者,你可以使用 Ubuntu 机器或虚拟机。
请注意两个Notes 以上。你需要两张 独立的 microSD 卡来完成这些实验。NCS 纯 API 模式工具链使用 OpenCV 2.4,因此没有新的 DNN 模块。您不能在 NCS 中使用虚拟环境,因此您需要完全隔离的系统。帮自己一个忙,弄几张备用的 microSD 卡——我喜欢 32 GB 98MB/s 卡。双引导你的 Pi 可能是一个选择,但我从未尝试过,也不想处理分区 microSD 卡的麻烦。
现在将结果汇总在一张表中:
Figure 5: Intel NCS with the Raspberry Pi benchmarks. I compared classification using the Pi CPU and using the Movidius NCS. On ImageNet, the NCS achieves a 395 to 545% speedup.
与使用 Pi 的 CPU 进行分类相比,NCS 在 Pi 上的速度明显更快,在 GoogLeNet 上实现了 6.45 倍的加速(545%)。NCS 肯定会给更大的网络带来显著的速度,比如这里比较的三个网络。
注:树莓 Pi 上收集的结果使用了我的优化的 OpenCV 安装指令。如果你没有使用优化的 OpenCV 安装,你会看到加速在 10-11x 的范围内!
当比较我的 MacBook Pro 和 Ubuntu 虚拟机与我的 MBP 上的 SDK 虚拟机时,性能更差——这是意料之中的,原因有很多。
首先,我的 MBP 有一个更强大的 CPU。事实证明,在 CPU 上运行完整的推理要比将图像从 CPU 移动到 NCS,然后将结果拉回来的额外开销更快。
第二,当对虚拟机进行 USB 直通时,存在 USB 开销。VirtualBox USB passthrough 也不支持 USB 3。
值得注意的是,树莓派 3 B 有 USB 2.0。如果你真的想要单板计算机设置的速度,选择支持 USB 3.0 的机器。如果您进行基准测试,数据传输速度本身就很明显。
当我们比较实时视频 FPS 基准时,下周的结果将更加明显,所以请务必在周一回来查看。
从这里去哪里?
我很快会带着另一篇博文回来,与你分享如何为 Movidius NCS 生成你自己的自定义图形文件。
我还将描述如何使用 Movidius NCS 在实时视频中执行对象检测,我们将对 FPS 加速进行基准测试和比较,我想您会对此印象深刻。
与此同时,请务必查看 Movidius 博客和 TopCoder 竞赛。
GitHub 上的 Movidus 博客
英特尔和 Movidius 正在 GitHub 上更新他们的博客。请务必将他们的页面加入书签和/或订阅 RSS:
你也可以登录 GitHub,点击 Movidius repos 上的“观看”按钮:
TopCoder 竞赛

Figure 5: Earn up to $8,000 with the Movidius NCS on TopCoder.
您有兴趣挑战英特尔 Movidius 神经计算棒的极限吗?
英特尔正在赞助一项关于 TopCoder 的竞赛。
有 $20,000 的奖品可供争夺(第一名赢得$8,000 )!
注册和提交截止日期为2018 年 2 月 26 日。
跟踪排行榜和排名!
摘要
今天,我们探索了英特尔的新 Movidius 神经计算棒。我今天在这里的目标是向您展示这种新的深度学习设备(我们也将在未来的博客帖子中使用)。我还演示了如何使用 NCS 工作流和 API。
一般来说,NCS 工作流程包括:
- 使用运行 Ubuntu/Debian 的机器用 Tensorflow 或 Caffe 训练网络(或使用预训练的网络)。
- 使用 NCS SDK 生成图形文件。
- 将图形文件和 NCS 部署到运行 Debian 风格的 Linux 的单板计算机上。我们使用了运行 Raspbian(基于 Debian)的 Raspberry Pi 3 B。
- 执行推理、分类、对象检测等。
今天,我们跳过了第 1 步和第 2 步。相反,我提供图形文件,你可以立即在你的 Pi 上开始使用。
然后,我们编写了自己的分类基准测试 Python 脚本,并对结果进行了分析,结果表明在 Raspberry Pi 上实现了显著的 10 倍加速。
到目前为止,NCS 的功能给我留下了非常深刻的印象——它与 Raspberry Pi 配合得非常好,我认为如果(1)你有它的用例,或者(2)你只是想修改和修补,它就有很大的价值。
我希望您喜欢今天关于英特尔新的 Movidius 神经计算棒的介绍文章!
为了及时了解 PyImageSearch 博客帖子、销售和活动,例如 PyImageConf 、,请务必在下表中输入您的电子邮件地址。
弃用声明: 本文使用的是 Movidius APIv1 和 APIv2,现在已经被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。****
NVIDIA Jetson Nano 入门
原文:https://pyimagesearch.com/2019/05/06/getting-started-with-the-nvidia-jetson-nano/

在本教程中,您将了解如何开始使用 NVIDIA Jetson Nano,包括:
- 第一次开机
- 安装系统软件包和先决条件
- 配置 Python 开发环境
- 在 Jetson Nano 上安装 Keras 和 TensorFlow
- 更改默认摄像机
- 利用 Jetson Nano 进行分类和目标探测
我还会一路提供我的评论,包括当我设置我的 Jetson Nano 时是什么绊倒了我,确保你避免我犯的同样的错误。
当您完成本教程时,您的 NVIDIA Jetson Nano 将配置完毕,并准备好进行深度学习!
要了解如何开始使用 NVIDIA Jetson Nano,请继续阅读!
NVIDIA Jetson Nano 入门

Figure 1: In this blog post, we’ll get started with the NVIDIA Jetson Nano, an AI edge device capable of 472 GFLOPS of computation. At around $100 USD, the device is packed with capability including a Maxwell architecture 128 CUDA core GPU covered up by the massive heatsink shown in the image. (image source)
在本教程的第一部分,您将学习如何下载和刷新 NVIDIA Jetson Nano。img 文件到你的微型 SD 卡。然后,我将向您展示如何安装所需的系统包和先决条件。
在那里,您将配置您的 Python 开发库,并学习如何在您的设备上安装 Jetson 纳米优化版的 Keras 和 TensorFlow 。
然后,我将向您展示如何在您的 Jetson Nano 上使用摄像头,甚至在 Nano 上执行图像分类和物体检测。
然后,我们将通过对 Jetson Nano 的简短讨论来结束本教程,NVIDIA Jetson Nano、Google Coral 和 Movidius NCS 之间的完整基准测试和比较将在未来的博客文章中发布。
在开始使用杰特森纳米之前
在你启动你的 NVIDIA Jetson Nano 之前,你需要三样东西:
- 一张 micro-SD 卡( )最低 16GB
- 5V 2.5A 微型 USB 电源
- 以太网电缆
我很想强调一下 16GB micro-SD 卡的最小值。我第一次配置我的 Jetson Nano 时,我使用了 16GB 的卡,但这个空间很快就被耗尽了,特别是当我安装了 Jetson 推理库,它将下载几千兆字节的预训练模型。
因此,我向*推荐一款 32GB 的微型 SD 卡给你的 Nano。
其次,当谈到你的 5V 2.5A MicroUSB 电源时,在他们的文档中 NVIDIA 特别推荐了 Adafruit 的这款。
最后,你 将需要一个以太网电缆 时,与杰特森纳米,我觉得真的,真的令人沮丧。
NVIDIA Jetson Nano 被宣传为一款强大的物联网和人工智能边缘计算设备…
…如果是这样的话,为什么设备上没有 WiFi 适配器?
我不理解英伟达的决定,我也不认为应该由产品的最终用户来决定“自带 WiFi 适配器”。
如果目标是将人工智能引入物联网和边缘计算,那么应该有 WiFi。
但是我跑题了。
你可以在这里阅读更多关于 NVIDIA 对 Jetson Nano 的推荐。
下载并闪存。img 文件到您的微型 SD 卡
在我们开始在 Jetson Nano 上安装任何软件包或运行任何演示之前,我们首先需要从 NVIDIA 的网站上下载 Jetson Nano 开发者套件 SD 卡映像 。
NVIDIA 提供了用于刷新的文档。img 文件保存到 micro-SD 卡,适用于 Windows、macOS 和 Linux——您应该选择适合您特定操作系统的闪存指令。
NVIDIA Jetson Nano 的第一次启动
下载并刷新了。img 文件到您的 micro-SD 卡,将卡插入 micro-SD 卡插槽。
我费了好大劲才找到卡槽——它实际上在热同步下面,就在我手指指向的地方:

Figure 2: Where is the microSD card slot on the NVIDIA Jetson Nano? The microSD receptacle is hidden under the heatsink as shown in the image.
我认为英伟达可以让这个槽更明显一点,或者至少在他们的网站上更好地记录下来。
将 micro-SD 卡滑回家后,接上电源,开机。
假设您的 Jetson Nano 连接到 HDMI 输出,您应该会看到屏幕上显示以下内容(或类似内容):
Figure 3: To get started with the NVIDIA Jetson Nano AI device, just flash the .img (preconfigured with Jetpack) and boot. From here we’ll be installing TensorFlow and Keras in a virtual environment.
然后,Jetson Nano 将引导您完成安装过程,包括设置您的用户名/密码、时区、键盘布局等。
安装系统软件包和先决条件
在本指南的剩余部分,我将向您展示如何为深度学习配置您的 NVIDIA Jetson Nano,包括:
- 安装系统软件包先决条件。
- 在 Jetson Nano 上安装 Keras、TensorFlow 和 Keras。
- 安装 Jetson 推理引擎。
让我们从安装所需的系统包开始:
$ sudo apt-get install git cmake
$ sudo apt-get install libatlas-base-dev gfortran
$ sudo apt-get install libhdf5-serial-dev hdf5-tools
$ sudo apt-get install python3-dev
如果你有一个良好的互联网连接,上述命令应该只需要几分钟就可以完成。
配置 Python 环境
下一步是配置我们的 Python 开发环境。
我们先安装pip,Python 的包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
$ rm get-pip.py
在本指南中,我们将使用 Python 虚拟环境来保持我们的 Python 开发环境相互独立和相互分离。
使用 Python 虚拟环境是最佳实践,并且将帮助您避免为您想要在 Jetson Nano 上使用的每个开发环境维护微 SD。
为了管理我们的 Python 虚拟环境,我们将使用 virtualenv 和 virtualenvwrapper ,我们可以使用以下命令安装它们:
$ sudo pip install virtualenv virtualenvwrapper
一旦我们安装了virtualenv和virtualenvwrapper,我们需要更新我们的~/.bashrc文件。我选择使用nano,但是你可以使用你最喜欢的编辑器:
$ nano ~/.bashrc
向下滚动到~/.bashrc文件的底部,添加以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
添加完以上几行后,保存并退出编辑器。
接下来,我们需要使用source命令重新加载~/.bashrc文件的内容:
$ source ~/.bashrc
我们现在可以使用mkvirtualenv命令创建一个 Python 虚拟环境——我将我的虚拟环境命名为deep_learning,但是您可以随意命名:
$ mkvirtualenv deep_learning -p python3
在 NVIDIA Jetson Nano 上安装 TensorFlow 和 Keras
在我们可以在 Jetson Nano 上安装 TensorFlow 和 Keras 之前,我们首先需要安装 NumPy。
首先,使用workon命令确保您在deep_learning虚拟环境中:
$ workon deep_learning
从那里,您可以安装 NumPy:
$ pip install numpy
在我的 Jetson Nano 上安装 NumPy 需要大约 10-15 分钟,因为它必须在系统上编译(目前没有针对 Jetson Nano 的预建版本的 NumPy)。
下一步是在 Jetson Nano 上安装 Keras 和 TensorFlow。你可能很想做一个简单的pip install tensorflow-gpu——不要这样做!
相反,NVIDIA 已经为 Jetson Nano 提供了一个 T2 官方的 TensorFlow 版本。
您可以使用以下命令安装正式的 Jetson Nano TensorFlow:
$ pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu==1.13.1+nv19.3
在我的 Jetson Nano 上安装 NVIDIA 的tensorflow-gpu包花了大约 40 分钟。
这里的最后一步是安装 SciPy 和 Keras:
$ pip install scipy
$ pip install keras
这些安装需要大约 35 分钟。
在 Nano 上编译和安装 Jetson 推理
杰特森纳米。img 已经安装了 JetPack,所以我们可以立即跳到构建 Jetson 推理引擎。
第一步是克隆出jetson-inference回购:
$ git clone https://github.com/dusty-nv/jetson-inference
$ cd jetson-inference
$ git submodule update --init
然后我们可以使用cmake来配置构建。
$ mkdir build
$ cd build
$ cmake ..
运行cmake时有两件重要的事情需要注意:
cmake命令将要求 root 权限,所以在您提供 root 凭证之前不要离开 Nano。- 在配置过程中,
cmake还将下载几千兆字节的预训练样本模型。确保你的微型 SD 卡上有几个 GB 的空间。(这也是为什么我推荐一张 32GB microSD 卡而不是 16GB 卡)。
在cmake完成构建配置后,我们可以编译并安装 Jetson 推理引擎:
$ make
$ sudo make install
在 Nano 上编译和安装 Jetson 推理引擎只花了 3 分多钟。
安装 OpenCV 怎么样?
我决定在以后的教程中介绍如何在 Jetson Nano 上安装 OpenCV。为了在 Nano 上充分利用 OpenCV,需要设置许多cmake配置,坦率地说,这篇文章已经够长了。
同样,我将在未来的教程中介绍如何在 Jetson Nano 上配置和安装 OpenCV。
运行 NVIDIA Jetson Nano 演示
使用 NVIDIA Jetson Nano 时,您有两种输入相机设备选项:
- CSI 相机模块,如 Raspberry Pi 相机模块(顺便说一下,该模块与 Jetson Nano 兼容)
- USB 网络摄像头
我目前正在为我即将出版的书使用我所有的树莓 Pi 相机模块, 树莓 Pi 用于计算机视觉 ,所以我决定使用我的罗技 C920 ,它与 Nano 即插即用兼容(你也可以使用更新的罗技 C960 )。
Jetson Nano 推理库包含的示例可在jetson-inference中找到:
detectnet-camera:使用摄像机作为输入进行物体检测。detectnet-console:也执行物体检测,但是使用输入的图像而不是摄像机。imagenet-camera:使用摄像机进行图像分类。imagenet-console:使用在 ImageNet 数据集上预先训练的网络对输入的图像进行分类。segnet-camera:对输入的摄像头进行语义分割。segnet-console:也执行语义分割,但是是在图像上。- 其他一些例子也包括在内,包括深度单应估计和超分辨率。
然而,为了运行这些例子,我们需要稍微修改一下各个摄像机的源代码。
在每个示例中,您会看到DEFAULT_CAMERA值被设置为-1,这意味着应该使用连接的 CSI 摄像机。
然而,由于我们使用的是 USB 摄像头,我们需要将DEFAULT_CAMERA值从-1更改为 0(或者任何正确的/dev/video V4L2 摄像头)。
幸运的是,这个改变超级容易做到!
先以图像分类为例。
首先,将目录更改为~/jetson-inference/imagenet-camera:
$ cd ~/jetson-inference/imagenet-camera
从那里,打开imagenet-camera.cpp:
$ nano imagenet-camera.cpp
然后,您需要向下滚动到大约 的第 37 行,在那里您将看到DEFAULT_CAMERA值:
#define DEFAULT_CAMERA -1 // -1 for onboard camera, or change to index of /dev/video V4L2 camera (>=0)
只需将该值从-1更改为 0:
#define DEFAULT_CAMERA 0 // -1 for onboard camera, or change to index of /dev/video V4L2 camera (>=0)
从那里,保存并退出编辑器。
编辑完 C++文件后,您需要重新编译示例,简单如下:
$ cd ../build
$ make
$ sudo make install
请记住,make足够聪明,不会让而不是重新编译整个库。它将只重新编译已经改变的文件(在这种情况下,ImageNet 分类的例子)。
编译完成后,转到aarch64/bin目录并执行imagenet-camera二进制文件:
$ cd aarch64/bin/
$ ./imagenet-camera
imagenet-camera
args (1): 0 [./imagenet-camera]
[gstreamer] initialized gstreamer, version 1.14.1.0
[gstreamer] gstCamera attempting to initialize with GST_SOURCE_NVCAMERA
[gstreamer] gstCamera pipeline string:
v4l2src device=/dev/video0 ! video/x-raw, width=(int)1280, height=(int)720, format=YUY2 ! videoconvert ! video/x-raw, format=RGB ! videoconvert !appsink name=mysink
[gstreamer] gstCamera successfully initialized with GST_SOURCE_V4L2
imagenet-camera: successfully initialized video device
width: 1280
height: 720
depth: 24 (bpp)
imageNet -- loading classification network model from:
-- prototxt networks/googlenet.prototxt
-- model networks/bvlc_googlenet.caffemodel
-- class_labels networks/ilsvrc12_synset_words.txt
-- input_blob 'data'
-- output_blob 'prob'
-- batch_size 2
[TRT] TensorRT version 5.0.6
[TRT] detected model format - caffe (extension '.caffemodel')
[TRT] desired precision specified for GPU: FASTEST
[TRT] requested fasted precision for device GPU without providing valid calibrator, disabling INT8
[TRT] native precisions detected for GPU: FP32, FP16
[TRT] selecting fastest native precision for GPU: FP16
[TRT] attempting to open engine cache file networks/bvlc_googlenet.caffemodel.2.1.GPU.FP16.engine
[TRT] loading network profile from engine cache... networks/bvlc_googlenet.caffemodel.2.1.GPU.FP16.engine
[TRT] device GPU, networks/bvlc_googlenet.caffemodel loaded
在这里,您可以看到 GoogLeNet 被加载到内存中,之后推理开始:
https://www.youtube.com/embed/vnpUmI0xy0g?feature=oembed*
Grad-CAM:使用 Keras、TensorFlow 和深度学习可视化类激活图

在本教程中,您将学习如何使用一种称为 Grad-CAM 的算法来可视化用于调试深度神经网络的类激活图。然后我们将使用 Keras 和 TensorFlow 实现 Grad-CAM。
虽然深度学习在图像分类、对象检测和图像分割方面促进了前所未有的准确性,但他们最大的问题之一是模型可解释性,这是模型理解和模型调试的核心组件。
在实践中,深度学习模型被视为“黑盒”方法,很多时候我们对以下方面没有合理的想法:
- 其中网络在输入图像中“寻找”
- 在推理/预测过程中,哪一系列神经元在正向传递中被激活
- 网络如何获得最终输出
这就提出了一个有趣的问题——如果你不能正确验证一个模型是如何到达那里的,你怎么能相信它的决定呢?
为了帮助深度学习实践者在视觉上调试他们的模型,并正确理解它在图像中“看”的地方,Selvaraju 等人创建了梯度加权类激活映射,或者更简单地说, Grad-CAM:
Grad-CAM 使用任何目标概念的梯度(比如“狗”的 logits,甚至是一个标题),流入最终的卷积层,以产生一个粗略的定位图,突出显示图像中的重要区域,用于预测概念。"
使用 Grad-CAM,我们可以直观地验证我们的网络在看哪里,验证它确实在看图像中的正确模式,并在这些模式周围激活。
如果网络不是围绕图像中适当的模式/对象激活的,那么我们知道:
- 我们的网络还没有正确地学习我们数据集中的潜在模式
- 我们的训练程序需要重新审视
- 我们可能需要收集额外的数据
- 最重要的是,我们的模型还没有准备好部署。
Grad-CAM 是一个应该在任何深度学习实践者的工具箱中的工具——现在就花时间学习如何应用它。
要了解如何使用 Grad-CAM 来调试您的深度神经网络,并使用 Keras 和 TensorFlow 可视化类激活图,请继续阅读!
Grad-CAM:使用 Keras、TensorFlow 和深度学习可视化类激活图
在本文的第一部分,我将与您分享一个警示故事,说明调试和视觉验证您的卷积神经网络“看”在图像中正确位置的重要性。
从那里,我们将深入 Grad-CAM,这是一种可用于可视化卷积神经网络(CNN)的类激活图的算法,从而允许您验证您的网络正在正确的位置“查看”和“激活”。
然后我们将使用 Keras 和 TensorFlow 实现 Grad-CAM。
在我们的 Grad-CAM 实现完成之后,我们将看一些可视化类激活图的例子。
为什么我们要在卷积神经网络中可视化类激活图?

Figure 1: Deep learning models are often criticized for being “black box” algorithms where we don’t know what is going on under the hood. Using a gradient camera (i.e., Grad-CAM), deep learning practitioners can visualize CNN layer activation heatmaps with Keras/TensorFlow. Visualizations like this allow us to peek at what the “black box” is doing, ensuring that engineers don’t fall prey to the urban legend of an unfortunate AI developer who created a cloud detector rather than the Army’s desire of a tank detector. (image source)
在计算机视觉社区中有一个古老的城市传说,研究人员用它来警告初学机器学习的从业者,在没有首先验证它正常工作的情况下部署一个模型的危险。
在这个故事中,美国陆军想使用神经网络来自动探测伪装的坦克。
该项目的研究人员收集了 200 幅图像的数据集:
- 其中 100 辆载有隐藏在树上的伪装坦克
- 其中 100 张不包含坦克,仅仅是树木/森林的图像
研究人员获取了这个数据集,然后将其分成 50/50 的训练和测试部分,确保类别标签平衡。
在训练集上训练神经网络,并获得 100%的准确度。研究人员对这一结果非常满意,并急切地将其应用到他们的测试数据中。他们再次获得了 100%的准确率。
研究人员给五角大楼打电话,对他们刚刚“解决”伪装坦克探测的消息感到兴奋。
几周后,研究小组接到了来自五角大楼的电话——他们对伪装坦克探测器的性能非常不满。在实验室中表现如此出色的神经网络在野外表现糟糕。
困惑中,研究人员回到他们的实验中,使用不同的训练程序训练一个又一个模型,只得到相同的结果——训练集和测试集的准确率都是 100%。
直到一位聪明的研究人员目测了他们的数据集,才最终意识到问题所在:
- 伪装坦克的照片是在阳光明媚的日子拍摄的
- 森林(没有坦克)的图像是在阴天拍摄的
本质上,美国陆军已经制造了一个价值数百万美元的云探测器。
虽然不是真的,但这个古老的城市传说很好地说明了模型互操作性的重要性。
如果研究团队有 Grad-CAM 这样的算法,他们会注意到模型是在有云/无云的情况下激活的,而不是坦克本身(这就是他们的问题)。
Grad-CAM 将为纳税人节省数百万美元,更不用说,让研究人员在五角大楼挽回面子——在那样的灾难之后,他们不太可能获得更多的工作或研究拨款。
什么是梯度加权类激活映射(Grad-CAM ),我们为什么要使用它?
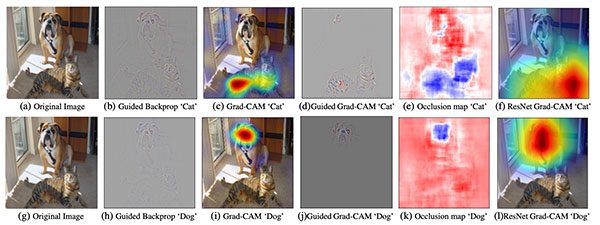
Figure 2: Visualizations of Grad-CAM activation maps applied to an image of a dog and cat with Keras, TensorFlow and deep learning. (image source: Figure 1 of Selvaraju et al.)
作为深度学习实践者,确保你的模型正确运行是你的责任。你可以这样做的一个方法是调试你的模型,并在视觉上验证它在图像中的正确位置“看”和“激活”。
为了帮助深度学习实践者调试他们的网络,Selvaraju 等人发表了一篇题为 Grad-CAM:通过基于梯度的定位 从深度网络进行可视化解释的新颖论文。
这种方法是:
- 易于实施
- 几乎适用于任何卷积神经网络架构
- 可用于直观调试网络在图像中的位置
Grad-CAM 的工作原理是(1)找到网络中的最终卷积层,然后(2)检查流入该层的梯度信息。
Grad-CAM 的输出是给定类标签(顶部、预测标签或我们选择用于调试的任意标签)的热图可视化。我们可以使用这张热图来直观地验证 CNN 在图像中的位置。
有关 Grad-CAM 如何工作的更多信息,我建议您阅读 Selvaraju 等人的论文以及Divyanshu Mishra的这篇优秀文章(只需注意, 他们的 实现不会与 TensorFlow 2.0 一起工作,而 我们的 会与 TF 2.0 一起工作)。
配置您的开发环境
为了使用我们的 Grad-CAM 实施,我们需要用几个软件包配置我们的系统,包括:
幸运的是,这些包都是 pip 可安装的。我个人建议您遵循我的 TensorFlow 2.0 安装教程之一:
- 如何在 UbuntuT3 上安装 tensor flow 2.0【Ubuntu 18.04 OS;CPU 和可选的 NVIDIA GPU)
- 如何在 macOS 上安装 tensor flow 2.0(Catalina 和 Mojave OSes)
请注意: PyImageSearch 不支持 Windows — 参考我们的 FAQ 。虽然我们不支持 Windows,但是这篇博文中的代码可以在配置正确的 Windows 上运行。
这两个教程都将教您如何使用本教程所需的所有软件来配置 Python 虚拟环境。我非常鼓励在虚拟环境中使用 Python 业界也认为这是一种最佳实践。如果你从未使用过 Python 虚拟环境,你可以在这篇 RealPython 文章中了解更多。
一旦您的系统配置完毕,您就可以开始学习本教程的其余部分了。
项目结构
让我们检查一下我们教程的项目结构。但是首先,一定要从这篇博文的 【下载】 部分获取代码和示例图片。从那里,提取文件,并在您的终端中使用tree命令:
$ tree --dirsfirst
.
├── images
│ ├── beagle.jpg
│ ├── soccer_ball.jpg
│ └── space_shuttle.jpg
├── pyimagesearch
│ ├── __init__.py
│ └── gradcam.py
└── apply_gradcam.py
2 directories, 6 files
今天的pyimagesearch模块包含了GradCAM类中的 Grad-CAM 实现。
我们的apply_gradcam.py驱动程序脚本接受我们的任何样本images/,并应用在 ImageNet 上训练的 VGG16 或 ResNet CNN 来(1)计算 Grad-CAM 热图和(2)在 OpenCV 窗口中显示结果。
让我们深入研究一下实现。
用 Keras 和 TensorFlow 实现 Grad-CAM
尽管 Grad-CAM 算法相对简单,但我还是努力寻找一个与 TensorFlow 2.0 兼容的实现。
我找到的最接近的一个在TF-explain;然而,那种方法只能在训练时使用——它不能在训练完一个模特之后使用。
因此,我决定基于 tf-explain 的工作创建自己的 Grad-CAM 实现,确保我的 Grad-CAM 实现:
- 与 Keras 和 TensorFlow 2.0 兼容
- 可以在模型已经被训练后使用
- 也可以很容易地修改,以便在培训期间进行回调(不在本文讨论范围内)
让我们深入研究我们的 Keras 和 TensorFlow Grad-CAM 实现。
打开项目目录结构中的gradcam.py文件,让我们开始吧:
# import the necessary packages
from tensorflow.keras.models import Model
import tensorflow as tf
import numpy as np
import cv2
class GradCAM:
def __init__(self, model, classIdx, layerName=None):
# store the model, the class index used to measure the class
# activation map, and the layer to be used when visualizing
# the class activation map
self.model = model
self.classIdx = classIdx
self.layerName = layerName
# if the layer name is None, attempt to automatically find
# the target output layer
if self.layerName is None:
self.layerName = self.find_target_layer()
在我们定义GradCAM类之前,我们需要导入几个包。其中包括一个 TensorFlow Model,我们将为其构建梯度模型,用于数学计算的 NumPy,以及 OpenCV。
我们的GradCAM类和构造函数从第 7 行和第 8 行开始定义。构造函数接受并存储:
- 我们将用来计算热图的张量流
model classIdx—我们将用来测量我们的类激活热图的特定类索引- 一个可选的 CONV
layerName模型,以防我们想要可视化 CNN特定层的热图;否则,如果没有提供具体的层名,我们将自动推断出model架构的最终 conv/池层(第 18 行和第 19 行)
既然我们的构造函数已经定义好了,我们的类属性也已经设置好了,那么让我们定义一个方法来找到我们的目标层:
def find_target_layer(self):
# attempt to find the final convolutional layer in the network
# by looping over the layers of the network in reverse order
for layer in reversed(self.model.layers):
# check to see if the layer has a 4D output
if len(layer.output_shape) == 4:
return layer.name
# otherwise, we could not find a 4D layer so the GradCAM
# algorithm cannot be applied
raise ValueError("Could not find 4D layer. Cannot apply GradCAM.")
我们的find_target_layer函数以逆序遍历网络中的所有层,在此期间,它检查当前层是否有 4D 输出(暗示 CONV 或池层)。
如果找到这样一个 4D 输出,我们把那层命名为return(第 24-27 行)。
否则,如果网络没有 4D 输出,那么我们不能应用 Grad-CAM,,此时,我们raise一个ValueError异常,导致我们的程序停止(第 31 行)。
在我们的下一个函数中,我们将计算我们的可视化热图,给定一个输入image:
def compute_heatmap(self, image, eps=1e-8):
# construct our gradient model by supplying (1) the inputs
# to our pre-trained model, (2) the output of the (presumably)
# final 4D layer in the network, and (3) the output of the
# softmax activations from the model
gradModel = Model(
inputs=[self.model.inputs],
outputs=[self.model.get_layer(self.layerName).output,
self.model.output])
第 33 行定义了compute_heatmap方法,这是我们 Grad-CAM 的核心。让我们一步一步地来了解这个实现是如何工作的。
首先,我们的 Grad-CAM 要求我们传入image,我们希望为其可视化类激活映射。
从那里,我们构造了我们的gradModel ( 第 38-41 行,它由一个输入和一个输出组成:
inputs: 将标准图像输入到modeloutputs: 用于生成类激活映射的layerName类属性的输出。注意我们是如何调用model上的get_layer的,同时也抓取了那个特定层的output
一旦构建了梯度模型,我们将继续计算梯度:
# record operations for automatic differentiation
with tf.GradientTape() as tape:
# cast the image tensor to a float-32 data type, pass the
# image through the gradient model, and grab the loss
# associated with the specific class index
inputs = tf.cast(image, tf.float32)
(convOutputs, predictions) = gradModel(inputs)
loss = predictions[:, self.classIdx]
# use automatic differentiation to compute the gradients
grads = tape.gradient(loss, convOutputs)
接下来,我们需要理解自动微分的定义以及 TensorFlow 所说的梯度带。
首先,自动微分是计算一个值并计算该值的导数的过程( CS321 Toronto , Wikipedia )。
TenorFlow 2.0 通过他们所谓的渐变带提供了自动 微分的实现
TensorFlow 提供了用于自动微分的
tf.GradientTapeAPI——计算计算相对于其输入变量的梯度。TensorFlow 将在tf.GradientTape上下文中执行的所有操作“记录”到“磁带”上。TensorFlow 然后使用该磁带和与每个记录的操作相关联的梯度来计算使用反向模式微分的“记录”计算的梯度( TensorFlow 的自动微分和梯度磁带教程)。
我建议你花一些时间在 TensorFlow 的 GradientTape 文档上,特别是我们现在要使用的 T2 梯度法。
我们使用GradientTape ( 线 44 )开始自动微分的记录操作。
线 48 接受输入image并将其转换为 32 位浮点类型。向前通过梯度模型(线 49 )产生layerName层的convOutputs和predictions。
然后我们提取与我们的predictions相关联的loss和我们感兴趣的特定的classIdx(第 50 行)。
请注意,我们的 推论停留在我们关注的特定层。我们不需要计算完整的向前传球。
第 53 行使用自动微分计算梯度,我们称之为grads ( 第 53 行)。
给定我们的梯度,我们现在将计算引导梯度:
# compute the guided gradients
castConvOutputs = tf.cast(convOutputs > 0, "float32")
castGrads = tf.cast(grads > 0, "float32")
guidedGrads = castConvOutputs * castGrads * grads
# the convolution and guided gradients have a batch dimension
# (which we don't need) so let's grab the volume itself and
# discard the batch
convOutputs = convOutputs[0]
guidedGrads = guidedGrads[0]
首先,我们找到值为> 0的所有输出和梯度,并将它们从二进制掩码转换为 32 位浮点数据类型(第 56 行和第 57 行)。
然后我们通过乘法(线 58 )计算引导梯度。
记住castConvOutputs和castGrads都只包含 1 的和 0 的的值;因此,在这个乘法期间,如果castConvOutputs、castGrads和grads中的任何一个是零,则卷中该特定索引的输出值将是零。
本质上,我们在这里所做的是找到castConvOutputs和castGrads的正值,然后将它们乘以微分的梯度——这个操作将允许我们在compute_heatmap函数中可视化网络在体积中的哪个位置被激活。
卷积和导向渐变有一个我们不需要的批量维度。线 63 和 64 抓取卷本身并丢弃来自convOutput和guidedGrads的批次。
我们正在接近我们的可视化热图。让我们继续:
# compute the average of the gradient values, and using them
# as weights, compute the ponderation of the filters with
# respect to the weights
weights = tf.reduce_mean(guidedGrads, axis=(0, 1))
cam = tf.reduce_sum(tf.multiply(weights, convOutputs), axis=-1)
第 69 行通过计算guidedGrads的平均值来计算梯度值的weights,其本质上是整个体积的1×1×N平均值。
然后,我们将这些weights和有重量的(即数学加权的)地图加到 Grad-CAM 可视化(cam)的第 70 行。
我们的下一步是生成与我们的图像相关的输出热图:
# grab the spatial dimensions of the input image and resize
# the output class activation map to match the input image
# dimensions
(w, h) = (image.shape[2], image.shape[1])
heatmap = cv2.resize(cam.numpy(), (w, h))
# normalize the heatmap such that all values lie in the range
# [0, 1], scale the resulting values to the range [0, 255],
# and then convert to an unsigned 8-bit integer
numer = heatmap - np.min(heatmap)
denom = (heatmap.max() - heatmap.min()) + eps
heatmap = numer / denom
heatmap = (heatmap * 255).astype("uint8")
# return the resulting heatmap to the calling function
return heatmap
我们获取输入图像的原始尺寸,并将我们的cam映射缩放到原始图像尺寸(行 75 和 76 )。
从那里,我们执行[最小-最大重新缩放](https://en.wikipedia.org/wiki/Feature_scaling#Rescaling_(min-max_normalization)到范围【0,1】,然后将像素值转换回范围【0,255】(第 81-84 行)。
最后,我们的compute_heatmap方法的最后一步将heatmap返回给调用者。
假设我们已经计算了热图,现在我们希望有一种方法可以将 Grad-CAM 热图透明地叠加到我们的输入图像上。
让我们继续定义这样一个实用程序:
def overlay_heatmap(self, heatmap, image, alpha=0.5,
colormap=cv2.COLORMAP_VIRIDIS):
# apply the supplied color map to the heatmap and then
# overlay the heatmap on the input image
heatmap = cv2.applyColorMap(heatmap, colormap)
output = cv2.addWeighted(image, alpha, heatmap, 1 - alpha, 0)
# return a 2-tuple of the color mapped heatmap and the output,
# overlaid image
return (heatmap, output)
我们通过前面的compute_heatmap函数生成的热图是图像中网络激活位置的单通道灰度表示——较大的值对应较高的激活,较小的值对应较低的激活。
为了覆盖热图,我们首先需要对热图应用伪/假颜色。为此,我们将使用 OpenCV 内置的 VIRIDIS colormap(即cv2.COLORMAP_VIRIDIS)。
病毒的温度如下所示:

Figure 3: The VIRIDIS color map will be applied to our Grad-CAM heatmap so that we can visualize deep learning activation maps with Keras and TensorFlow. (image source)
请注意,较暗的输入灰度值会产生深紫色的 RGB 颜色,而较亮的输入灰度值会映射到浅绿色或黄色。
第 93 行使用维里迪斯将颜色映射应用到输入heatmap。
从那里,我们透明地将热图覆盖在我们的output可视化上(第 94 行)。阿尔法通道是直接加权到 BGR 图像中(即,我们没有给图像添加阿尔法通道)。要了解更多关于透明叠加的知识,我建议你阅读我的 带 OpenCV 的透明叠加教程。
最后,行 98 返回heatmap的 2 元组(应用了 VIRIDIS 色图)以及output可视化图像。
创建 Grad-CAM 可视化脚本
随着 Grad-CAM 实现的完成,我们现在可以转到驱动程序脚本来应用它进行类激活映射。
如前所述,我们的apply_gradcam.py驱动程序脚本接受一个图像,并使用在 ImageNet 上训练的 VGG16 或 ResNet CNN 进行推理,以(1)计算 Grad-CAM 热图和(2)在 OpenCV 窗口中显示结果。
你将能够使用这个可视化脚本来实际“看到”你的深度学习模型下正在发生的事情,许多批评者认为这是一个太多的“黑匣子”,特别是在涉及到自动驾驶汽车等公共安全问题时。
让我们打开项目结构中的apply_gradcam.py,插入以下代码:
# import the necessary packages
from pyimagesearch.gradcam import GradCAM
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.applications import imagenet_utils
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-m", "--model", type=str, default="vgg",
choices=("vgg", "resnet"),
help="model to be used")
args = vars(ap.parse_args())
这个脚本最显著的引入是我们的GradCAM实现、ResNet/VGG 架构和 OpenCV。
我们的脚本接受两个命令行参数:
- 通往我们的输入图像的路径,我们试图对其进行分类并应用 Grad-CAM。
--model:我们想要应用的深度学习模型。默认情况下,我们将在 Grad-CAM 中使用 VGG16。或者,您可以指定 ResNet50。在这个例子中,当您键入命令时,您的choices被限制为直接在终端中输入的vgg或resenet,但是您也可以修改这个脚本来与您自己的架构一起工作。
给定--model参数,让我们加载我们的模型:
# initialize the model to be VGG16
Model = VGG16
# check to see if we are using ResNet
if args["model"] == "resnet":
Model = ResNet50
# load the pre-trained CNN from disk
print("[INFO] loading model...")
model = Model(weights="imagenet")
第 23-31 行使用预先训练的 ImageNet 权重加载 VGG16 或 ResNet50。
或者,您可以加载自己的模型;为了简单起见,我们在示例中使用 VGG16 和 ResNet50。
接下来,我们将加载并预处理我们的--image:
# load the original image from disk (in OpenCV format) and then
# resize the image to its target dimensions
orig = cv2.imread(args["image"])
resized = cv2.resize(orig, (224, 224))
# load the input image from disk (in Keras/TensorFlow format) and
# preprocess it
image = load_img(args["image"], target_size=(224, 224))
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
image = imagenet_utils.preprocess_input(image)
给定我们的输入图像(通过命令行参数提供),行 35 以 OpenCV BGR 格式从磁盘加载它,而行 40 以 TensorFlow/Keras RGB 格式加载相同的图像。
我们的第一个预处理步骤将图像的大小调整为 224×224 像素(第 36 行和第 40 行)。
如果在这个阶段我们检查。我们的图像的形状,你会注意到 NumPy 数组的形状是(224, 224, 3)——每个图像是 224 像素宽和 224 像素高,有 3 个通道(分别用于红色、绿色和蓝色通道)。
然而,在我们可以通过我们的 CNN 将我们的image进行分类之前,我们需要将维度扩展为(1, 224, 224, 3)。
我们为什么要这样做?
当使用深度学习和卷积神经网络对图像进行分类时,为了提高效率,我们经常通过网络“批量”发送图像。因此,通过网络一次只传递一幅图像的情况实际上非常罕见——当然,除非你只有一幅图像要分类并应用梯度图(就像我们一样)。
因此,我们将图像转换为一个数组,并添加一个批处理维度(第 41 行和第 42 行)。
然后,我们通过减去从 ImageNet 数据集计算的平均 RGB 像素强度(即,平均减法)来预处理第 43 行上的图像。
出于分类的目的(即,还不是 Grad-CAM),接下来我们将使用我们的模型对图像进行预测:
# use the network to make predictions on the input image and find
# the class label index with the largest corresponding probability
preds = model.predict(image)
i = np.argmax(preds[0])
# decode the ImageNet predictions to obtain the human-readable label
decoded = imagenet_utils.decode_predictions(preds)
(imagenetID, label, prob) = decoded[0][0]
label = "{}: {:.2f}%".format(label, prob * 100)
print("[INFO] {}".format(label))
第 47 行执行推理,通过我们的 CNN 传递我们的image。
然后我们找到对应概率最大的类别label索引(第 48-53 行)。
或者,如果您认为您的模型正在与一个特定的类标签进行斗争,并且您想要可视化它的类激活映射,那么您可以硬编码您想要可视化的类标签索引。
此时,我们已经准备好计算 Grad-CAM 热图可视化:
# initialize our gradient class activation map and build the heatmap
cam = GradCAM(model, i)
heatmap = cam.compute_heatmap(image)
# resize the resulting heatmap to the original input image dimensions
# and then overlay heatmap on top of the image
heatmap = cv2.resize(heatmap, (orig.shape[1], orig.shape[0]))
(heatmap, output) = cam.overlay_heatmap(heatmap, orig, alpha=0.5)
为了应用 Grad-CAM,我们用我们的model和最高概率类索引i ( 第 57 行)实例化一个GradCAM对象。
然后我们计算热图——Grad-CAM 的核心在于compute_heatmap方法(第 58 行)。
然后,我们将热图缩放/调整到我们的原始输入尺寸,并在我们的output图像上覆盖热图,透明度为 50%(行 62 和 63 )。
最后,我们生成一个堆叠的可视化,包括(1)原始图像,(2)热图,以及(3)透明地覆盖在原始图像上的带有预测类标签的热图:
# draw the predicted label on the output image
cv2.rectangle(output, (0, 0), (340, 40), (0, 0, 0), -1)
cv2.putText(output, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.8, (255, 255, 255), 2)
# display the original image and resulting heatmap and output image
# to our screen
output = np.vstack([orig, heatmap, output])
output = imutils.resize(output, height=700)
cv2.imshow("Output", output)
cv2.waitKey(0)
第 66-68 行在output Grad-CAM 图像的顶部绘制预测类别标签。
然后,我们将这三幅图像进行可视化,调整到适合我们屏幕的已知尺寸height,并在 OpenCV 窗口中显示结果(第 72-75 行)。
在下一节中,我们将 Grad-CAM 应用于三个样本图像,看看结果是否符合我们的预期。
用 Grad-CAM、Keras 和 TensorFlow 可视化类激活图
要使用 Grad-CAM 可视化类激活图,请确保使用本教程的 【下载】 部分下载我们的 Keras 和 TensorFlow Grad-CAM 实现。
从那里,打开一个终端,并执行以下命令:
$ python apply_gradcam.py --image images/space_shuttle.jpg
[INFO] loading model...
[INFO] space_shuttle: 100.00%
Figure 4: Visualizing Grad-CAM activation maps with Keras, TensorFlow, and deep learning applied to a space shuttle photo.
这里你可以看到 VGG16 以 100%的置信度正确地将我们的输入图像分类为space shuttle——通过查看我们在图 4 中的 Grad-CAM 输出,我们可以看到 VGG16 在航天飞机上的模式周围正确地激活,验证了网络的行为符合预期。
让我们尝试另一个图像:
$ python apply_gradcam.py --image images/beagle.jpg
[INFO] loading model...
[INFO] beagle: 73.94%
Figure 5: Applying Grad-CAM to visualize activation maps with Keras, TensorFlow, and deep learning applied to a photo of my beagle, Janie.
这一次,我们传入我的狗 Janie 的图像。VGG16 正确地将图像标记为beagle。
检查图 5 中的 Grad-CAM 输出,我们可以看到 VGG16 正在 Janie 的脸部周围激活,这表明我的狗的脸是网络用来将她归类为小猎犬的重要特征。
让我们检查最后一个图像,这次使用 ResNet 架构:
$ python apply_gradcam.py --image images/soccer_ball.jpg --model resnet
[INFO] loading model...
[INFO] soccer_ball: 99.97%
Figure 6: In this visualization, we have applied Grad-CAM with Keras, TensorFlow, and deep learning applied to a soccer ball photo.
我们的soccer ball以 99.97%的准确率被正确分类,但更有趣的是图 6 中的类激活可视化——注意我们的网络如何有效地忽略足球场,仅激活足球周围的。
*这种激活行为验证了我们的模型在训练期间已经正确地学习了soccer ball类。
在训练完你自己的 CNN 之后,我强烈建议你使用 Grad-CAM,并从视觉上验证你的模型正在学习你认为它正在学习的模式(以及而不是你的数据集中偶然出现的其他模式)。
摘要
在本教程中,您学习了 Grad-CAM,这是一种可用于可视化类激活图和调试卷积神经网络的算法,可确保您的网络“看到”图像中的正确位置。
请记住,如果您的网络在您的训练和测试集上表现良好,仍然有的机会,您的准确性是由意外或偶然事件造成的!
你的“高精度”模型可能在图像数据集中你没有注意到或察觉到的模式下被激活。
我建议你有意识地将 Grad-CAM 整合到你自己的深度学习管道中,并从视觉上验证你的模型是否正确运行。
你要做的最后一件事是部署一个模型,你认为表现很好,但在现实中在与你想要识别的图像中的物体无关的模式下激活。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
梯度下降算法和变体
原文:https://pyimagesearch.com/2021/05/05/gradient-descent-algorithms-and-variations/
在本教程中,您将学习:
- 什么是梯度下降
- 梯度下降如何让我们训练神经网络
- 梯度下降的变化,包括随机梯度下降(SGD)
- 如何利用动量和内斯特罗夫加速度提高 SGD
要了解梯度下降及其变化, 只需继续阅读。
梯度下降算法和变体
当涉及到训练神经网络时,梯度下降不仅仅是主力——它是耕地的犁和控制犁走向的农民。
梯度下降和优化器有大量的变化,从普通梯度下降、小批量梯度下降、随机梯度下降(SGD)和小批量 SGD,仅举几例。
此外,考虑到对 SGD 的改进,设计了全新的模型优化器,包括 Adam、Adadelta、RMSprop 等。
今天我们将回顾梯度下降的基本原理,并主要关注 SGD,包括对 SGD 的两项改进,动量和内斯特罗夫加速。
什么是梯度下降?
梯度下降是一种一阶优化算法。梯度下降的目标是找到一个可微函数的局部最小值。
我们迭代执行梯度下降:
- 我们从成本/损失函数(即负责计算我们想要最小化的值的函数)开始
- 然后我们计算损失的梯度
- 最后,我们在与梯度方向相反的方向迈出一步(因为这将把我们带到局部最小值的路径上)
下图简要总结了梯度下降:
但是这如何应用于神经网络和深度学习呢?
让我们在下一部分解决这个问题。
梯度下降如何为神经网络和深度学习提供动力?
神经网络由一个或多个隐藏层组成。每一层都由一组参数组成。我们的目标是优化这些参数,使我们的损失最小化。
典型的损失函数包括二元交叉熵(两类分类)、分类交叉熵(多类分类)、均方误差(回归)等。
损失函数有多种类型,每一种都用于特定的角色。不要太纠结于正在使用哪个损失函数的,而是这样想:
- 我们用一组随机的权重初始化我们的神经网络
- 我们要求神经网络对我们训练集中的数据点进行预测
- 我们计算预测,然后计算损失/成本函数,它告诉我们在做出正确预测时做得有多好/多差
- 我们计算损失的梯度
- 然后我们稍微调整一下神经网络的参数,这样我们的预测会更好
我们一遍又一遍地这样做,直到我们的模型被称为“收敛”并能够做出可靠、准确的预测。
梯度下降算法有很多种,但我们今天将重点介绍的是:
- 香草梯度下降
- 随机梯度下降
- 小批量 SGD
- 带动量的 SGD
- 带内斯特罗夫加速的 SGD
香草梯度下降
考虑一个由 N=10,000 幅图像组成的图像数据集。我们的目标是训练一个神经网络,将这 10,000 张图像中的每一张分类成总共 T=10 个类别。
为了在这个数据集上训练神经网络,我们将利用梯度下降。
梯度下降的最基本形式,我喜欢称之为香草梯度下降,我们每次更新只更新网络的权重一次。
这意味着:
- 我们通过我们的网络运行所有 10,000 张图片
- 我们计算损耗和梯度
- 我们更新网络的参数
在普通梯度下降中,我们每次迭代只更新网络的权重一次,这意味着每次执行权重更新时,网络都会看到整个数据集。
实际上,这没什么用。
如果训练样本的数量很大,那么香草梯度下降将花费 很长时间来收敛 ,因为权重更新在每个数据周期仅发生 一次 。
此外,你的数据集变得越大,你的梯度就变得越细微,如果你每个时期只更新一次权重,那么你将花费大部分时间来计算预测,而不是花费太多时间来学习(这是优化问题的目标,对吗?)
*幸运的是,还有其他梯度下降的变体可以解决这个问题。
随机梯度下降(SGD)
与每个历元仅进行一次权重更新的普通梯度下降不同,随机梯度下降(SGD)进行多次权重更新。
SGD 的原始公式将在每个历元进行 N 权重更新,其中 N 等于数据集中数据点的总数。因此,使用我们上面的例子,如果我们有 N=10,000 个图像,那么我们每个时期将有 10,000 个权重更新。
SGD 算法变成:
- 直到收敛:
- 从数据集中随机选择一个数据点
- 对此做一个预测
- 计算损耗和梯度
- 更新网络的参数
SGD 趋向于收敛 快得多 因为它能够在每次权重更新后开始自我改进。
也就是说,在每个时期执行 N 权重更新(其中 N 等于我们数据集中的数据点总数)在计算上也有点浪费——我们现在已经转到了钟摆的另一边。
相反,我们需要一个介于两者之间的中间值。
小批量新币
虽然 SGD 可以更快地收敛于大型数据集,但我们实际上遇到了另一个问题——我们无法利用我们的矢量化库来实现超快训练(同样,因为我们一次只能通过网络传递一个数据点)。
有一种称为小批量 SGD 的 SGD 变体解决了这个问题。当你听到人们谈论新币时,他们几乎总是指的是 迷你批量新币。
小批量 SGD 引入了批量大小的概念。现在,给定一个大小为 N 的数据集,总共会有 N / S 次网络更新。
我们可以将小批量 SGD 算法总结为:
- 随机打乱输入数据
- 直到收敛:
- 选择大小为 S 的下一批数据
- 对子集进行预测
- 计算小批量的损耗和平均梯度
- 更新网络的参数
如果您直接可视化每个小批量,那么您将看到一个非常嘈杂的图,如下图所示:
但是当你平均所有小批量的损失时,曲线实际上是相当稳定的:
注意: 根据你使用的深度学习库,你可能会看到这两种类型的图。
当你听到深度学习实践者谈论 SGD 时,他们更有可能谈论小批量 SGD。
带动量的新币
SGD 的一个问题是,在亏损领域的某个维度比其他维度明显更陡(你会在 local optima 附近看到这种情况)。
当这种情况发生时,似乎 SGD 只是振荡谷,而不是下降到较低损耗和理想情况下较低精度的区域(参见 Sebastian Ruder 的精彩文章了解关于这一现象的更多详细信息)。
通过施加动量(图 6 ),我们在一个方向上建立了一个蒸汽头,然后让重力使我们越滚越快地下山。
通常,在大多数 SGD 应用中,您会看到动量值为0.9。
习惯于在使用 SGD 时看到动量——它用于大多数应用 SGD 的神经网络实验中。
带内斯特罗夫加速度的 SGD
动量的问题是,一旦你形成一股蒸汽,火车很容易失去控制,滚过我们当地的最小值,再次回到山上。
基本上,我们不应该盲目地跟随梯度的斜率。
内斯特罗夫加速说明了这一点,并帮助我们认识到亏损的局面何时开始再次上升。
几乎所有包含 SGD 实现的深度学习库也包括动量和内斯特罗夫加速项。
势头几乎总是一个好主意。内斯特罗夫加速在某些情况下有效,但在其他情况下无效。在训练神经网络时,您会希望将它们视为需要调整的超参数(即,为每个超参数选择值,运行实验,记录结果,更新参数,并重复进行,直到找到一组产生良好结果的超参数)。
总结
在本教程中,您学习了梯度和下降及其变体,即随机梯度下降(SGD)。
SGD 是深度学习的主力。所有优化器,包括 Adam,Adadelta,RMSprop 等。这些优化器中的每一个都为 SGD 提供了调整和变化,理想地改善了收敛性,并使模型在训练过程中更加稳定。
我们将很快介绍这些更高级的优化器,但是目前,要理解 SGD 是所有这些优化器的基础。
我们可以通过引入动量项来进一步改进 SGD(几乎总是被推荐)。
有时,内斯特罗夫加速可以进一步提高 SGD(取决于您的具体项目)。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 Python 进行梯度下降
原文:https://pyimagesearch.com/2016/10/10/gradient-descent-with-python/
几乎所有的深度学习都是由一个非常重要的算法驱动的:随机梯度下降(SGD) 。
至此,我们对参数化学习的概念有了很强的理解。我们之前讨论了参数化学习的概念,以及这种类型的学习如何使我们能够定义将输入数据映射到输出类标签的评分函数。
该评分函数由两个重要的参数定义;具体来说,我们的权重矩阵 W 和我们的偏置向量 b 。我们的评分函数接受这些参数作为输入,并返回每个输入数据点 x [i] 的预测。
我们还讨论了两种常见的损失函数:多类 SVM 损失和交叉熵损失。最基本的损失函数用于量化给定预测器(即一组参数)在对数据中的输入数据点进行分类时的“好”或“坏”程度。
鉴于这些构建模块,我们现在可以继续进行机器学习、神经网络和深度学习的最重要的方面——优化 。优化算法是为神经网络提供动力并使其能够从数据中学习模式的引擎。在整个讨论中,我们已经了解到,获得高精度分类器是依赖于找到一组权重 W 和 b ,这样我们的数据点被正确分类。
但是我们如何去寻找获得 一个权重矩阵 W 和偏置向量 b 从而获得高的分类精度呢?我们是否随机地初始化它们,评估,并一遍又一遍地重复,希望在某个点我们找到一组获得合理分类的参数?我们可以——但鉴于现代深度学习网络的参数数以千万计,我们可能需要很长时间才能盲目地发现一组合理的参数。
我们需要定义一个优化算法,而不是依靠纯粹的随机性,让我们字面上改进* W 和 b 。在这一课中,我们将研究用于训练神经网络和深度学习模型的最常用算法— 梯度下降。梯度下降有许多变体(我们也将谈到),但是,在每种情况下,想法都是相同的:迭代地评估你的参数,计算你的损失,然后在将你的损失最小化的方向上迈出一小步。
使用 Python 进行梯度下降
梯度下降算法有两种主要风格:
- 标准的“普通”实现。
- 更常用的优化“随机”版本。
在这一课中,我们将回顾基本的香草实现,以形成我们理解的基线。在我们理解了梯度下降的基础之后,我们将转向随机版本。然后我们将回顾一些可以添加到梯度下降中的“附加功能”,包括动量和内斯特罗夫加速度。
损失景观和优化面
梯度下降法是一种在损失景观(也称为优化表面)上运行的迭代优化算法。典型的梯度下降示例是沿着 x 轴可视化我们的权重,然后沿着 y 轴可视化一组给定权重的损失(图 1 、左):
正如我们所看到的,我们的损失情况有许多峰值和谷值,这取决于我们的参数值。每个峰值都是代表极高损失区域的局部最大值——在整个损失范围内损失最大的局部最大值是全局最大值。类似地,我们也有局部最小值,它代表许多小的损失区域。
损失范围内损失最小的局部最小值就是我们的全局最小值。在理想世界中,我们希望找到这个全局最小值,确保我们的参数取最佳值。
所以这就提出了一个问题:“如果我们想达到一个全局最小值,为什么不直接跳到 上去呢?在剧情上清晰可见?”
这就是问题所在——我们看不到损失景观。我们不知道它看起来像什么。如果我们是一个优化算法,我们将被盲目地放置在地块上的某个地方,不知道我们面前的风景是什么样子,我们将不得不导航到损失最小,而不会意外地爬到局部最大值的顶部。
就我个人而言,我从来不喜欢这种损失景观的可视化——它太简单了,而且它经常让读者认为梯度下降(及其变体)最终会找到局部或全局最小值。这种说法是不正确的,尤其是对于复杂的问题来说。相反,让我们来看一个不同的损失景观的可视化,我相信它能更好地描述这个问题。这里我们有一个碗,类似于你用来吃麦片或喝汤的碗(图一、右)。
我们碗的表面是损失景观,是损失函数的一个图。我们的损失景观和你们的谷物碗的区别在于,你们的谷物碗只存在于三维空间,而你们的损失景观存在于多维度,可能是几十、几百、几千维。
给定一组参数(权重矩阵)和 b (偏置向量),沿碗表面的每个位置对应于一个特定损失值。我们的目标是尝试 W 和 b 的不同值,评估它们的损失,然后向(理想情况下)损失更低的更优值迈进一步。
**### 梯度下降中的“梯度”
为了让我们对梯度下降的解释更直观一点,让我们假设我们有一个机器人——让我们把他命名为乍得(图二,左)。当执行梯度下降时,我们随机地将 Chad 放在损失图的某个地方(图 2 ,右)。
现在乍得的工作是航行到盆地的底部(那里损失最小)。看起来很简单,对吗?查德所要做的就是调整自己的方向,让自己面向“下坡”,然后沿着斜坡一直走到碗的底部。
但问题是:乍得不是一个非常聪明的机器人。查德只有一个传感器——这个传感器允许他获取自己的参数【W】和 b ,然后计算损失函数 L 。因此,查德能够计算出他在损失地形上的相对位置,但是他完全不知道他应该朝哪个方向走一步才能更接近盆地的底部。
*查德要做什么? 答案是应用梯度下降。 查德需要做的就是顺着坡度的斜率 W 。我们可以使用以下等式计算所有维度上的梯度 W :
【①
**在维度 > 1 中,我们的梯度变成了偏导数的向量。这个等式的问题是:
- 这是梯度的近似值。
- 它慢得令人痛苦。
实际上,我们使用解析梯度来代替。该方法精确而快速,但由于偏导数和多变量微积分,实施起来极具挑战性。证明梯度下降的多变量微积分的完整推导不在本课范围内。如果你有兴趣学习更多关于数值和解析梯度的知识,我会推荐齐布列夫斯基的这个讲座,吴恩达的 CS229 机器学习笔记,以及的 CS231n 笔记。
为了便于讨论,简单地内化梯度下降是什么:通过在损失最小化的方向上迈出一步的迭代过程,尝试优化我们的参数以获得低损失和高分类精度。
把它当成凸问题(即使不是)
使用图 1 ( 右)中的碗作为损失景观的可视化也允许我们在现代神经网络中得出一个重要的结论——我们将损失景观作为凸问题来处理, 即使它不是 。如果某个函数 F 是凸的,那么所有局部极小值也是全局极小值。这个想法非常符合碗的形象。我们的优化算法只需在碗的顶部绑上一对滑雪板,然后慢慢滑下斜坡,直到我们到达底部。
问题是,我们应用神经网络和深度学习算法解决的几乎所有问题都是而不是简洁的凸函数。相反,在这个碗中,我们会发现尖峰状的峰,更像峡谷的谷,陡峭的下降,甚至是损耗急剧下降但又急剧上升的槽。
鉴于我们的数据集的非凸性质,为什么我们要应用梯度下降?答案很简单:因为它做得足够好。引用古德菲勒等人(2016) :
优化算法可能不能保证在合理的时间内达到局部最小值,但它通常能足够快地找到[loss]函数的一个非常低的值。
在训练深度学习网络时,我们可以设定找到局部/全局最小值的高期望,但这种期望很少与现实相符。相反,我们最终找到了一个低损耗的区域— 这个区域甚至可能不是局部最小值,但实际上,这证明了足够好。
偏见的诡计
在我们继续实现梯度下降之前,我想花时间讨论一种称为“偏差技巧”的技术,这是一种将我们的权重矩阵【W】和偏差向量 b 组合成一个单个参数的方法。回想一下我们之前的决策,我们的评分函数定义为:
*② = Wx_{i} + b")
**无论是从解释还是从实现的角度来看,跟踪两个独立的变量通常都很繁琐——为了完全避免这种情况,我们可以将 W 和 b 组合在一起。为了组合偏差和权重矩阵,我们向我们的输入数据 X 添加一个额外的维度(即列),该维度保持常数 1,这就是我们的偏差维度。
通常我们会将新的维度添加到每个单独的x[I]中,作为第一个维度或最后一个维度。实际上,这并不重要。我们可以选择任意位置将一列 1 插入到我们的设计矩阵中,只要它存在。这样做允许我们通过单个矩阵乘法来重写我们的评分函数:
(3)  = Wx_{i}")
同样,我们可以在这里省略掉 b 项,因为它是嵌入到我们的权重矩阵中的。
在我们之前的“动物”数据集中的例子的上下文中,我们已经处理了 32 张 × 32 张 × 3 张总共 3072 像素的图像。每一个x[I]都用一个矢量【3072 × 1】来表示。现在,添加一个常数值为 1 的维度会将向量扩展为[3073 × 1]。类似地,组合偏差和权重矩阵也将我们的权重矩阵 W 扩展为【3】×3073】而不是【3】××3072】。这样,我们可以将偏差视为权重矩阵中的一个可学习参数,我们不必在单独的变量中明确跟踪它。
为了形象化偏差技巧,考虑图 3 ( 左)中我们分离权重矩阵和偏差。到目前为止,这个图描述了我们如何考虑我们的得分函数。但是相反,我们可以将W和 b 组合在一起,前提是我们在每个 x [i] 中插入一个新列,其中每个条目都是一个(图 3 ,右)。应用偏差技巧允许我们只学习单一的权重矩阵,因此我们倾向于使用这种方法来实现。对于所有未来的例子,每当我提到 W 时,假设偏差向量 b 也隐式包含在权重矩阵中。
备注: 我们实际上是在图 3 的特征向量中插入一个新的行,其值为1。你也可以添加一个列*到我们的填充了 1 的特征矩阵中。那么,哪个是正确的呢?这实际上取决于你如何执行你的线性代数,以及你如何转置每个矩阵。您将看到两者都在实施中使用,我想确保您现在已为此做好准备。
梯度下降的伪代码
下面我为标准的普通梯度下降算法添加了类似 Python 的伪代码(伪代码,灵感来自 cs231n 幻灯片):
while True:
Wgradient = evaluate_gradient(loss, data, W)
W += -alpha * Wgradient
这个伪代码就是梯度下降的所有变体的基础。我们从线 1 开始循环,直到满足某些条件,通常是:
- 指定数量的时期已经过去(意味着我们的学习算法已经“看到”每个训练数据点 N 次)。
- 我们的损失已经变得足够低或者训练精度令人满意的高。
- 损失在随后的 M 个时期没有改善。
第 2 行然后调用一个名为evaluate_gradient的函数。该函数需要三个参数:
loss:用于计算超过当前参数W和输入data的损失的函数。data:我们的训练数据,其中每个训练样本由一个图像(或特征向量)表示。- 我们正在优化的实际权重矩阵。我们的目标是应用梯度下降来找到一个产生最小损失的
W。
evaluate_gradient函数返回一个 K 维的向量,其中 K 是我们的图像/特征向量的维数。Wgradient变量是实际的梯度,其中我们为每个维度都有一个梯度条目。
然后我们在线 3 上应用渐变下降。我们把我们的Wgradient乘以alpha ( α ,就是我们的学习率。学习率控制着我们一步的大小。
实际上,你会花很多时间来寻找 α 的最优值——这是到目前为止你的模型中最重要的参数。如果 α 太大,你会花所有的时间在亏损的情况下反弹,而不会真正“下降”到谷底(除非你的随机反弹纯属运气)。相反,如果 α 太小,那么将需要多次(可能是非常多次)迭代才能到达盆地底部。寻找 α 的最佳值将会给你带来很多麻烦——你将会花费大量的时间来为你的模型和数据集寻找这个变量的最佳值。
在 Python 中实现基本梯度下降
现在我们知道了梯度下降的基础知识,让我们用 Python 实现它,并用它对一些数据进行分类。打开一个新文件,将其命名为gradient_descent.py,并插入以下代码:
# import the necessary packages
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
import argparse
def sigmoid_activation(x):
# compute the sigmoid activation value for a given input
return 1.0 / (1 + np.exp(-x))
def sigmoid_deriv(x):
# compute the derivative of the sigmoid function ASSUMING
# that the input `x` has already been passed through the sigmoid
# activation function
return x * (1 - x)
第 2-7 行导入我们需要的 Python 包。我们之前已经看到了所有这些导入,除了make_blobs,一个用于创建正态分布数据点的“blobs”的函数——当从头开始测试或实现我们自己的模型时,这是一个方便的函数。
然后我们在第 9 行的上定义sigmoid_activation函数。绘制时,该函数将类似于一条“S”形曲线(图 4** )。我们称之为 激活函数 是因为该函数会“激活”并触发“on”(输出值 > 0 )。 5)或“关”(输出值 < = 0 )。 5)基于输入x。**
第 13-17 行定义了 sigmoid 函数的导数。我们需要计算这个函数的导数来得到实际的梯度。梯度使我们能够沿着优化曲面的斜坡向下行进。我们将在单独的课程中更详细地讲述这一点。
predict函数应用我们的 sigmoid 激活函数,然后根据神经元是否触发(1)来设定阈值(0):
def predict(X, W):
# take the dot product between our features and weight matrix
preds = sigmoid_activation(X.dot(W))
# apply a step function to threshold the outputs to binary
# class labels
preds[preds <= 0.5] = 0
preds[preds > 0] = 1
# return the predictions
return preds
给定一组输入数据点X和权重W,我们对它们调用sigmoid_activation函数来获得一组预测(行 21 )。然后,我们对预测进行阈值处理:值为 < = 0 的任何预测。 5 被设置为0,而任何具有值 > 0 的预测。 5 设置为1 ( 第 25 行和第 26 行)。然后预测返回到行 29 上的调用函数。
虽然有其他(更好的)替代 sigmoid 激活函数的方法,但它为我们讨论神经网络、深度学习和基于梯度的优化提供了一个极好的起点。我将在以后的课程中讨论其他激活函数,但目前,只要记住 sigmoid 是一个非线性激活函数,我们可以用它来设定预测阈值。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--epochs", type=float, default=100,
help="# of epochs")
ap.add_argument("-a", "--alpha", type=float, default=0.01,
help="learning rate")
args = vars(ap.parse_args())
我们可以为脚本提供两个(可选的)命令行参数:
- 当我们使用梯度下降来训练我们的分类器时,我们将使用的历元数。
--alpha:梯度下降的学习率。我们通常将 0.1、0.01 和 0.001 视为初始学习率值,但同样,这是一个超参数,您需要针对自己的分类问题进行调整。
既然我们的命令行参数已被解析,让我们生成一些数据进行分类:
# generate a 2-class classification problem with 1,000 data points,
# where each data point is a 2D feature vector
(X, y) = make_blobs(n_samples=1000, n_features=2, centers=2,
cluster_std=1.5, random_state=1)
y = y.reshape((y.shape[0], 1))
# insert a column of 1's as the last entry in the feature
# matrix -- this little trick allows us to treat the bias
# as a trainable parameter within the weight matrix
X = np.c_[X, np.ones((X.shape[0]))]
# partition the data into training and testing splits using 50% of
# the data for training and the remaining 50% for testing
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.5, random_state=42)
在第 41 行的上,我们调用make_blobs,它生成 1000 个数据点,分成两类。这些数据点是 2D,意味着“特征向量”的长度是 2。这些数据点的标签不是0就是1。我们的目标是训练一个正确预测每个数据点的类别标签的分类器。
第 48 行应用了“偏差技巧”(详见上文),通过插入一个全新的 1 列作为我们设计矩阵X的最后一项,允许我们明确跳过跟踪我们的偏差向量 b 。添加包含跨越所有特征向量的常量值的列允许我们将我们的偏差视为权重矩阵 内的可训练参数* ,而不是视为完全独立的变量。*
*一旦我们插入了 1 的列,我们就将数据划分到第 52 行和第 53 行的训练和测试部分,使用 50%的数据进行训练,50%的数据进行测试。
我们的下一个代码块使用均匀分布处理随机初始化我们的权重矩阵,使其具有与我们的输入特征相同的维数(包括偏差):
# initialize our weight matrix and list of losses
print("[INFO] training...")
W = np.random.randn(X.shape[1], 1)
losses = []
你可能还会看到零和一权重初始化,但正如我们将在后面的课程中发现的,良好的初始化对于在合理的时间内训练神经网络来说是关键的,因此随机初始化和简单的启发式算法在绝大多数情况下都会胜出( Mishkin 和 Matas,2016 )。
**初始化一个列表来记录每个时期后我们的损失。在 Python 脚本的最后,我们将绘制损失图(理想情况下,损失会随着时间的推移而减少)。
我们所有的变量现在都已初始化,所以我们可以继续实际的训练和梯度下降程序:
# loop over the desired number of epochs
for epoch in np.arange(0, args["epochs"]):
# take the dot product between our features "X" and the weight
# matrix "W", then pass this value through our sigmoid activation
# function, thereby giving us our predictions on the dataset
preds = sigmoid_activation(trainX.dot(W))
# now that we have our predictions, we need to determine the
# "error", which is the difference between our predictions and
# the true values
error = preds - trainY
loss = np.sum(error ** 2)
losses.append(loss)
在61 号线上,我们开始循环--epochs的供应数量。默认情况下,我们允许训练程序总共“看到”每个训练点 100 次(因此,100 个纪元)。
行 65 取我们的整个训练集trainX和我们的权重矩阵W之间的点积。这个点积的输出通过 sigmoid 激活函数,产生我们的预测。
给定我们的预测,下一步是确定预测的“误差”,或者更简单地说,我们的预测和真实值 ( 行 70 )之间的差异。第 71 行计算我们预测的最小平方误差,这是一个简单的损失,通常用于二元分类问题。这个训练程序的目标是最小化我们的最小平方误差。我们将这个loss添加到第 72 行列表的losses中,这样我们就可以随时间绘制损失图。
现在我们有了error,我们可以计算gradient,然后用它来更新我们的权重矩阵W:
# the gradient descent update is the dot product between our
# (1) features and (2) the error of the sigmoid derivative of
# our predictions
d = error * sigmoid_deriv(preds)
gradient = trainX.T.dot(d)
# in the update stage, all we need to do is "nudge" the weight
# matrix in the negative direction of the gradient (hence the
# term "gradient descent" by taking a small step towards a set
# of "more optimal" parameters
W += -args["alpha"] * gradient
# check to see if an update should be displayed
if epoch == 0 or (epoch + 1) % 5 == 0:
print("[INFO] epoch={}, loss={:.7f}".format(int(epoch + 1),
loss))
第 77 行和第 78 行处理梯度的计算,梯度是我们的数据点和误差之间的点积乘以我们预测的 sigmoid 导数。
第 84 行是我们算法中最关键的一步,也是实际梯度下降发生的地方。这里,我们通过在梯度的负方向上迈出一步来更新我们的权重矩阵W,从而允许我们向损失景观的盆地底部移动(因此,术语,梯度下降)。在更新我们的权重矩阵之后,我们检查是否应该向我们的终端显示更新(第 87-89 行),然后继续循环,直到达到期望的历元数——梯度下降因此是一个迭代算法。
我们的分类器现在已经训练好了。下一步是评估:
# evaluate our model
print("[INFO] evaluating...")
preds = predict(testX, W)
print(classification_report(testY, preds))
为了实际使用我们的权重矩阵W进行预测,我们在testX上调用了predict方法,在的第 93 行上调用了W方法。给定预测,我们在终端的第 94 行上显示一个格式良好的分类报告。
我们的最后一个代码块处理(1)绘制测试数据以便我们可以可视化我们试图分类的数据集,以及(2)我们随时间的损失:
# plot the (testing) classification data
plt.style.use("ggplot")
plt.figure()
plt.title("Data")
plt.scatter(testX[:, 0], testX[:, 1], marker="o", c=testY[:, 0], s=30)
# construct a figure that plots the loss over time
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, args["epochs"]), losses)
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.show()
简单梯度下降结果
要执行我们的脚本,只需发出以下命令:
$ python gradient_descent.py
[INFO] training...
[INFO] epoch=1, loss=194.3629849
[INFO] epoch=5, loss=9.3225755
[INFO] epoch=10, loss=5.2176352
[INFO] epoch=15, loss=3.0483912
[INFO] epoch=20, loss=1.8903512
[INFO] epoch=25, loss=1.3532867
[INFO] epoch=30, loss=1.0746259
[INFO] epoch=35, loss=0.9074719
[INFO] epoch=40, loss=0.7956885
[INFO] epoch=45, loss=0.7152976
[INFO] epoch=50, loss=0.6547454
[INFO] epoch=55, loss=0.6078759
[INFO] epoch=60, loss=0.5711027
[INFO] epoch=65, loss=0.5421195
[INFO] epoch=70, loss=0.5192554
[INFO] epoch=75, loss=0.5011559
[INFO] epoch=80, loss=0.4866579
[INFO] epoch=85, loss=0.4747733
[INFO] epoch=90, loss=0.4647116
[INFO] epoch=95, loss=0.4558868
[INFO] epoch=100, loss=0.4478966
从图 5 ( 左我们可以看到,我们的数据集是明显线性可分的(即我们可以画一条线将两类数据分开)。我们的损失也急剧下降,开始非常高,然后迅速下降(右)。通过研究上面的终端输出,我们可以看到损耗下降的速度有多快。请注意,损失最初是 > 194,但下降到≈ 0 。 6 按纪元 50。到第 100 纪元训练终止时,我们的损失已经到 0 。45。
该图验证了我们的权重矩阵正在以允许分类器从训练数据中学习的方式被更新。我们可以在下面看到数据集的分类报告:
[INFO] evaluating...
precision recall f1-score support
0 1.00 1.00 1.00 250
1 1.00 1.00 1.00 250
avg / total 1.00 1.00 1.00 500
请注意和这两个类别是如何在 100%的时间内被正确分类的,这再次表明我们的数据集是:(1)线性可分的,以及(2)我们的梯度下降算法能够下降到低损失的区域,能够分离这两个类别。
也就是说,记住普通梯度下降算法的工作原理是很重要的。普通梯度下降只对每个历元执行一次权重更新——在这个例子中,我们为我们的模型训练了 100 个历元,所以只发生了 100 次更新。根据权重矩阵的初始化和学习率的大小,我们可能无法学习到可以分离这些点的模型(即使它们是线性可分离的)。
对于简单的梯度下降,你最好训练更多的周期和更小的学习率来帮助克服这个问题。然而,称为随机梯度下降的梯度下降的变体对每批训练数据的执行权重更新,这意味着每个时期有多个权重更新。这种方法导致更快、更稳定的收敛。***************
使用 scikit-learn ( GridSearchCV)调整网格搜索超参数
在本教程中,您将学习如何使用 scikit-learn 机器学习库和GridSearchCV类来网格搜索超参数。我们将把网格搜索应用于一个计算机视觉项目。

这篇博客文章是我们关于超参数调优的四部分系列文章的第二部分:
- 用 scikit-learn 和 Python 调优超参数简介(上周教程)
- 使用 scikit-learn ( GridSearchCV)进行网格搜索超参数调整(今天的帖子)
- 使用 scikit-learn、Keras 和 TensorFlow 进行深度学习的超参数调整(下周发布)
- 使用 Keras 调谐器和 TensorFlow 进行简单的超参数调谐(从现在起两周后的教程)
上周,我们学习了如何将超参数调整到支持向量机(SVM ),该机器被训练用于预测海洋蜗牛的年龄。这是对超参数调整概念的一个很好的介绍,但是它没有演示如何将超参数调整应用到计算机视觉项目中。
今天,我们将建立一个计算机视觉系统来自动识别图像中物体的纹理 T2。我们将使用超参数调整来找到产生最高精度的最佳超参数集。
当您需要在自己的项目中调优超参数时,可以使用本文包含的代码作为起点。
要学习如何用GridSearchCV和 scikit-learn、网格搜索超参数,继续阅读。
使用 scikit-learn ( GridSearchCV)调整网格搜索超参数
在本教程的第一部分,我们将讨论:
- 什么是网格搜索
- 网格搜索如何应用于超参数调谐
- scikit-learn 机器学习库如何通过
GridSearchCV类实现网格搜索
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我将向您展示如何使用计算机视觉、机器学习和网格搜索超参数调整来调整纹理识别管道的参数,从而实现接近 100%纹理识别精度的系统。
本指南结束时,你将对如何将网格搜索应用于计算机视觉项目的超参数有深刻的理解。
什么是超参数网格搜索?
网格搜索允许我们详尽地测试我们感兴趣的所有可能的超参数配置。
在本教程的后面,我们将调整支持向量机(SVM)的超参数,以获得高精度。SVM 的超参数包括:
- 核选择:线性、多项式、径向基函数
- 严格(
C): 典型值在0.0001到1000的范围内 - 内核特定参数:次数(对于多项式)和伽玛(RBF)
例如,考虑以下可能的超参数列表:
parameters = [
{"kernel":
["linear"],
"C": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]},
{"kernel":
["poly"],
"degree": [2, 3, 4],
"C": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]},
{"kernel":
["rbf"],
"gamma": ["auto", "scale"],
"C": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]}
]
网格搜索将 详尽地 测试这些超参数的所有可能组合,为每组训练一个 SVM。网格搜索将报告最佳超参数(即最大化精度的参数)。
配置您的开发环境
要遵循本指南,您需要在计算机上安装以下库:
幸运的是,这两个包都是 pip 可安装的:
$ pip install opencv-contrib-python
$ pip install scikit-learn
$ pip install scikit-image
$ pip install imutils
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
我们的示例纹理数据集
我们将创建一个计算机视觉和机器学习模型,能够自动识别图像中对象的纹理。
我们将训练模型识别三种纹理:
- 砖
- 大理石
- 沙
每个类有 30 幅图像,数据集中总共有 90 幅图像。
我们现在的目标是:
- 量化数据集中每个图像的纹理
- 定义我们要搜索的超参数集
- 使用网格搜索来调整超参数,并找到最大化纹理识别准确性的值
注: 这个数据集是按照我关于 用 Google Images 创建图像数据集的教程创建的。 我已经在与本教程相关的 【下载】 中提供了示例纹理数据集。这样,您就不必自己重新创建数据集。
项目结构
在我们为超参数调优实现网格搜索之前,让我们花点时间回顾一下我们的项目目录结构。
从本教程的 【下载】 部分开始,访问源代码和示例纹理数据集。
从那里,解压缩档案文件,您应该会找到下面的项目目录:
$ tree . --dirsfirst --filelimit 10
.
├── pyimagesearch
│ ├── __init__.py
│ └── localbinarypatterns.py
├── texture_dataset
│ ├── brick [30 entries exceeds filelimit, not opening dir]
│ ├── marble [30 entries exceeds filelimit, not opening dir]
│ └── sand [30 entries exceeds filelimit, not opening dir]
└── train_model.py
5 directories, 3 files
texture_dataset包含我们将在其中训练模型的数据集。我们有三个子目录,brick、marble,和sand,每个子目录有 30 张图片。
我们将使用局部二进制模式(LBPs) 来量化纹理数据集中每个图像的内容。LBP 图像描述符在pyimagesearch模块内的localbinarypatterns.py文件中实现。
train_model.py脚本负责:
- 从磁盘加载
texture_dataset中的所有图像 - 使用 LBPs 量化每个图像
- 在超参数空间上执行网格搜索,以确定优化精度的值
让我们开始实现我们的 Python 脚本。
我们的本地二进制模式(LBP)描述符
我们今天要遵循的本地二进制模式实现来自我之前的教程。虽然为了完整起见,我在这里包含了完整的代码,但我将把对实现的详细回顾推迟到我以前的博客文章中。
说完了,打开你的项目目录结构的pyimagesearch模块中的localbinarypatterns.py文件,我们就可以开始了:
# import the necessary packages
from skimage import feature
import numpy as np
class LocalBinaryPatterns:
def __init__(self, numPoints, radius):
# store the number of points and radius
self.numPoints = numPoints
self.radius = radius
2 号线和 3 号线导入我们需要的 Python 包。scikit-image 的feature子模块包含local_binary_pattern函数——该方法根据输入图像计算 LBPs。
接下来,我们定义我们的describe函数:
def describe(self, image, eps=1e-7):
# compute the Local Binary Pattern representation
# of the image, and then use the LBP representation
# to build the histogram of patterns
lbp = feature.local_binary_pattern(image, self.numPoints,
self.radius, method="uniform")
(hist, _) = np.histogram(lbp.ravel(),
bins=np.arange(0, self.numPoints + 3),
range=(0, self.numPoints + 2))
# normalize the histogram
hist = hist.astype("float")
hist /= (hist.sum() + eps)
# return the histogram of Local Binary Patterns
return hist
这个方法接受一个输入image(即我们想要计算 LBPs 的图像)和一个小的 epsilon 值。正如我们将看到的,当将结果 LBP 直方图归一化到范围 [0,1]时,eps值防止被零除的错误。
从那里,行 15 和 16 从输入图像计算均匀 LBPs。给定 LBP,然后我们使用 NumPy 构建每个 LBP 类型的直方图(第 17-19 行)。
然后将得到的直方图缩放到范围【0,1】(第 22 行和第 23 行)。
要更详细地回顾我们的 LBP 实现,请务必参考我的教程, 使用 Python 的本地二进制模式& OpenCV。
为超参数调整实施网格搜索
实现 LBP 图像描述符后,我们可以创建网格搜索超参数调优脚本。
打开项目目录中的train_model.py文件,我们将开始:
# import the necessary packages
from pyimagesearch.localbinarypatterns import LocalBinaryPatterns
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from imutils import paths
import argparse
import time
import cv2
import os
第 2-11 行导入我们需要的 Python 包。我们的主要进口产品包括:
LocalBinaryPatterns:负责计算每个输入图像的 LBPs,从而量化纹理GridSearchCV: scikit-learn 实现了超参数调谐的网格搜索SVC:我们的支持向量机(SVM)用于分类(SVC)paths:获取输入数据集目录中所有图像的路径time:用于计时网格搜索需要多长时间
接下来,我们有命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
这里我们只有一个命令行参数,--dataset,它将指向驻留在磁盘上的texture_dataset。
让我们获取图像路径并初始化 LBP 描述符:
# grab the image paths in the input dataset directory
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the local binary patterns descriptor along with
# the data and label lists
print("[INFO] extracting features...")
desc = LocalBinaryPatterns(24, 8)
data = []
labels = []
第 20 行获取我们的--dataset目录中所有输入图像的路径。
然后我们初始化我们的LocalBinaryPatterns描述符,以及两个列表:
data:存储从每个图像中提取的 LBPlabels:包含特定图像的类别标签
现在让我们填充data和labels:
# loop over the dataset of images
for imagePath in imagePaths:
# load the image, convert it to grayscale, and quantify it
# using LBPs
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
hist = desc.describe(gray)
# extract the label from the image path, then update the
# label and data lists
labels.append(imagePath.split(os.path.sep)[-2])
data.append(hist)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
print("[INFO] constructing training/testing split...")
(trainX, testX, trainY, testY) = train_test_split(data, labels,
random_state=22, test_size=0.25)
在第 30 行,我们循环输入图像。
对于每幅图像,我们:
- 从磁盘加载(第 33 行)
- 将其转换为灰度(第 34 行)
- 计算图像的 LBPs(行 35 )
然后,我们用特定图像的类别标签更新我们的labels列表,并用计算出的 LBP 直方图更新我们的data列表。
注: 困惑于我们如何从图像路径中确定类标签?回想一下在texture_dataset目录中,有三个子目录,分别对应三个纹理类:砖、大理石和沙子。由于给定图像的类标签包含在文件路径中,我们需要做的就是提取子目录名称,这正是第 39 行 所做的。
在运行网格搜索之前,我们首先需要定义要搜索的超参数:
# construct the set of hyperparameters to tune
parameters = [
{"kernel":
["linear"],
"C": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]},
{"kernel":
["poly"],
"degree": [2, 3, 4],
"C": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]},
{"kernel":
["rbf"],
"gamma": ["auto", "scale"],
"C": [0.0001, 0.001, 0.1, 1, 10, 100, 1000]}
]
第 49 行定义了网格搜索将运行的parameters列表。如你所见,我们正在测试三种不同类型的 SVM 核:线性、多项式和径向基函数(RBF)。
每个内核都有自己的一组相关超参数要搜索。
支持向量机往往对超参数选择非常敏感;对于非线性内核来说,尤其如此。如果我们想要高纹理分类精度,我们需要来获得这些正确的超参数选择。
上面列出的值是您通常想要针对 SVM 和给定内核进行调优的值。
现在让我们在超参数空间上运行网格搜索:
# tune the hyperparameters via a cross-validated grid search
print("[INFO] tuning hyperparameters via grid search")
grid = GridSearchCV(estimator=SVC(), param_grid=parameters, n_jobs=-1)
start = time.time()
grid.fit(trainX, trainY)
end = time.time()
# show the grid search information
print("[INFO] grid search took {:.2f} seconds".format(
end - start))
print("[INFO] grid search best score: {:.2f}%".format(
grid.best_score_ * 100))
print("[INFO] grid search best parameters: {}".format(
grid.best_params_))
第 65 行初始化我们的GridSearchCV,它接受三个参数:
estimator:我们正在调整的模型(在这种情况下,是支持向量机分类器)。param_grid:我们希望搜索的超参数空间(即我们的parameters列表)。n_jobs:要运行的并行作业的数量。值-1意味着将使用机器的所有处理器/内核,从而加快网格搜索过程。
第 67 行开始超参数空间的网格搜索。我们用time()函数包装.fit调用来测量超参数搜索空间需要多长时间。
一旦网格搜索完成,我们将在终端上显示三条重要信息:
- 网格搜索花了多长时间
- 我们在网格搜索中获得的最佳精度
- 与我们最高精度模型相关的超参数
从那里,我们对最佳模型进行全面评估:
# grab the best model and evaluate it
print("[INFO] evaluating...")
model = grid.best_estimator_
predictions = model.predict(testX)
print(classification_report(testY, predictions))
行 80 从网格搜索中抓取best_estimator_。这是精确度最高的 SVM。
注: 超参数搜索完成后,scikit-learn 库总是用我们最高精度的模型填充grid的best_estimator_变量。
第 81 行使用找到的最佳模型对我们的测试数据进行预测。然后我们在的第 82 行显示一个完整的分类报告。
计算机视觉项目结果网格搜索
我们现在准备应用网格搜索来调整纹理识别系统的超参数。
请务必访问本教程的 “下载” 部分,以检索源代码和示例纹理数据集。
从那里,您可以执行train_model.py脚本:
$ time python train_model.py --dataset texture_dataset
[INFO] extracting features...
[INFO] constructing training/testing split...
[INFO] tuning hyperparameters via grid search
[INFO] grid search took 1.17 seconds
[INFO] grid search best score: 86.81%
[INFO] grid search best parameters: {'C': 1000, 'degree': 3,
'kernel': 'poly'}
[INFO] evaluating...
precision recall f1-score support
brick 1.00 1.00 1.00 10
marble 1.00 1.00 1.00 5
sand 1.00 1.00 1.00 8
accuracy 1.00 23
macro avg 1.00 1.00 1.00 23
weighted avg 1.00 1.00 1.00 23
real 1m39.581s
user 1m45.836s
sys 0m2.896s
正如你所看到的,我们已经在测试集上获得了 100%的准确率,这意味着我们的 SVM 能够识别我们每一张图像中的纹理。
此外,运行调优脚本只需要 1 分 39 秒。
网格搜索在这里工作得很好,但正如我在上周的教程中提到的那样,随机搜索往往工作得一样好,并且需要更少的时间运行——搜索空间中的超参数越多,网格搜索需要的时间就越长(呈指数增长)。
为了说明这一点,下周,我将向您展示如何使用随机搜索来调整深度学习模型中的超参数。
总结
在本教程中,您学习了如何使用网格搜索来自动调整机器学习模型的超参数。为了实现网格搜索,我们使用了 scikit-learn 库和GridSearchCV类。
我们的目标是训练一个计算机视觉模型,它可以自动识别图像中对象的纹理(砖、大理石或沙子)。
培训渠道本身包括:
- 循环我们数据集中的所有图像
- 使用局部二元模式描述符(一种常用于量化纹理的图像描述符)量化每幅图像的纹理
- 使用网格搜索来探索支持向量机的超参数
在调整我们的 SVM 超参数后,我们在纹理识别数据集上获得了 100%的分类准确率。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
在 PyImageSearch 博客上提问的指南
原文:https://pyimagesearch.com/2017/03/06/guide-asking-questions-pyimagesearch-blog/

在过去三年的《PyImageSearch.com》中,我收到并回答了来自读者的数万个问题,就像你自己一样,他们对研究计算机视觉、OpenCV 和深度学习感兴趣。
回顾这段时间,我可以说我回答的绝大多数问题都是一种真正的快乐。
其他的问题需要一点挖掘并且和读者来来回回地解决真正的潜在问题是什么。那也没关系。有些问题很复杂,需要稍微“巧妙处理”一下,直到我们能哄出主要问题。
另一方面,一小部分问题有点难,有点乏味,需要我自己和提问者的耐心。这些棘手的问题在内容或主题上并不“困难”,而是要弄清楚读者想要达到什么目的,并以尊重我的时间和他们的时间的方式来完成。
在上周的博客文章中,我讨论了提出有洞察力的计算机视觉问题的五个关键组成部分(最终目标是让你得到更好的答案,T2,T3)。
今天我们将更进一步,将这些组件应用到我在 PyImageSearch 博客上收到的个实际问题中。
我的目标是:
- 提供一套指导方针,您可以在联系我(或任何其他主题专家)时使用,以确保您的计算机视觉问题得到回答。
- 提供问题的正面和负面品质的例子,你可以在设计自己的询问时使用并从中学习。
- 帮助我更好地帮助你确保以尊重你我时间的方式提问。
要了解更多关于如何在 PyImageSearch 博客上提问的信息(并获得你的问题的最佳答案),请继续阅读。
在 PyImageSearch 博客上提问的指南
你可能想知道为什么我要在 PyImageSearch 博客上写一个完整的提问指南?
原因是 PyImageSearch 在过去三年里增长了很多。
我现在每天收到数百封电子邮件询问关于计算机视觉、OpenCV 和深度学习的问题。
*不要误会我的意思:
很高兴与你互动,回答你的问题,并向你学习:
这是我一天中最重要的时刻。
然而,问题的绝对数量要求我将这个过程正式化一点,以帮助 T2 尽可能地提高效率。
由于我不想求助于尴尬的、非个人化的调查或热门问题的“每周综述”(其中只有一小部分问题得到回答),我决定最好的行动是创建一个指南,提供:
- 一个 大纲 和 模板 ,你可以在制作自己的问题时使用。
- 真题 正反两面品质的例子我都收到了,你可以从中学习。
通过使用这些资源,我相信我们可以通过更有效的提问和回答而受益。
记住,我的最终目标是 帮你 ,但是你需要 先帮我 理解你的问题。
注:为了保护提问读者的身份,在这篇博文中,所有的名字、大学和机构都被匿名了。任何与姓名、问题或从属关系相关的现实生活纯属巧合。
为什么问问题(并从中学习)对你最有利
提问是计算机科学(以及所有科学)的一个基本方面。
事实上,问题是科学方法的基石:

Figure 1: The five fundamental steps of the scientific method.
这个提出问题、进行实验、测量/评估结果、得出结论以及重复这个过程的过程让我们获得了新的知识。
通过这些问题,我们发现成长不仅是就我们自身而言,也是就一般的科学方法而言。
作为一名计算机视觉的学生,提问对你最有利——这使你能够获得新的见解,消除困惑,以及解决你正在从事的项目。****
**也就是说,我们可以应用一些最佳实践来确保我们提出正确的问题。
你看,提问是一种后天习得的技能,类似于一门艺术。
这需要时间来掌握——但一旦你掌握了,它就开启了一个世界,在那里其他人(比如我自己)可以更好地帮助你理解计算机视觉。
要点:你对你的问题提供的信息越清晰,我就能更好地帮助你找到正确的方向并解决你的问题(但你仍然需要自己做艰苦的工作)。
要了解在 PyImageSearch 博客上提问的最佳实践,请继续阅读。
提问提纲
无论是给我自己还是其他主题专家发邮件,我都建议遵循这个简单的提纲:
- 自我介绍一下。
- 问你的问题。
- 解释你为什么要问。
- 提及你有什么计算机视觉经验(如果有的话)。
让我们深入探讨这些要点。
所有好问题都以介绍开始
我认为运行 PyImageSearch 博客是一种特权和 T2 的荣誉,我想了解你。
告诉我你的名字。说说你对计算机视觉的体验水平?让我知道你是计算机视觉的学生、研究人员、爱好者还是仅仅对计算机视觉感兴趣的程序员。
另外,如果你是第一次给我发邮件,知道你是如何找到 PyImageSearch 博客(例如、Google、朋友/同事推荐、stack overflow/Reddit/等链接。).
从那里,问你的问题
花点时间来阐述你的问题,并仔细思考。
我已经写了一个完全独立的指南,关于如何更好地回答你的计算机视觉问题——在写问题之前,请务必阅读它。
在你提问之前阅读本指南将为我们双方节省大量时间,并确保你的问题得到正确回答。
问完问题后,解释你为什么要问
理解为什么你会问一个特定问题的背景不仅对我(对你自己也是)至关重要。
如果你是一个计算机视觉爱好者,周末会在你的 Raspberry Pi 上玩黑客游戏,那么我建议使用的技术将会与一个在大学里寻找最先进研究的研究人员大不相同。
花点时间去理解你问题背后的 why 并确保你把它转述给我——我对你的问题产生的背景了解得越多,我就能更好地帮助你。
最后,一定要让我知道你的计算机视觉经验(如果有的话)
就像问题背后的背景和为什么很重要一样,了解你对计算机视觉的经验水平也很关键。
如果你没有计算机视觉方面的任何经验,那 100%没问题——但我确实需要知道这一点,以便我可以为你推荐一条包括基础知识的前进道路。
同样,如果你知道计算机视觉和 OpenCV 的基础知识,一定要让我知道,这样我才能向你推荐更高级的技术。
最后,如果你在一所大学机构里做研究,那对我来说也很有帮助,我可以试着给你介绍一些你可能感兴趣的出版物。
提问的模板
结合上面的提问提纲,我制作了一个“填空”模板,帮助你在构思问题和给我(或任何其他主题专家)发电子邮件时解决问题:
嗨阿德里安,
我的名字是{{名字}}。我第一次找到你是因为{{ source }}。
我对{{ topic }}感兴趣。
我的问题是:
{{问题}}
我这么问的原因是因为{{ question_reason }}。
我对{{ topic }}的体验是{{ experience_level }}。
谢谢,
{{名字}}
为了理解应用这个模板的重要性,让我们考虑一个与计算机视觉完全分离的主题——计划一次旅行。让我们假设我想去柬埔寨,为了计划这次旅行,我要给我的(虚构的)旅行社 Karen 发电子邮件。
不使用 模板,我最初给凯伦的邮件可能是这样的:
嗨,凯伦,
我想去柬埔寨。请帮助我。
艾德里安(男子名)
这封邮件对凯伦没什么帮助。除了我说我想去柬埔寨,她没什么可说的:
- 我为什么要去柬埔寨?
- 我想在一年中的什么时候游览?
- 这次旅行是出差还是游玩?
- 我的旅行预算是多少?
- 我以前去过柬埔寨吗?
- 我有兴趣在柬埔寨观光吗?
显而易见,根据我最初的询问,我和 Karen 之间需要通过几封电子邮件才能清楚地了解我访问柬埔寨的意图。
然而, 如果我使用上面的模板 ,我最初的邮件会变得更加清晰:
嗨,凯伦,
我叫艾德里安。我的朋友特里莎介绍我认识你,她说你是一个出色的旅行社代理人。
明年的某个时候,我想去柬埔寨看看。
我以前从未去过柬埔寨,但我有亲戚住在那里,我想去看看他们。他们不太会说英语,所以我很好地掌握这次旅行的方式(航班、租车、住宿等)是很重要的。).
我也不知道一年中什么时候去柬埔寨最好。你能提供一年中最佳旅游时间的建议吗?
我这次旅行的预算是 1500 美元。我可以用这笔预算做些什么,以确保我能负担得起一趟航班,并在我在那里的时候仍然能看到所有主要的网站?
谢谢!
阿德里安
在这一点上,凯伦确切地知道了我的意图,并且可以更好地帮助我。她可能还有一些问题需要澄清,但至少基础已经打好了。
这里的要点是,我需要首先帮助自己提出一个凯伦能更好回答的问题。从那里,凯伦可以更好地帮助我。
如何将此模板应用于您在 PyImageSearch 博客上的问题
让我们假设我的名字叫史蒂夫,我对基于内容的图像检索(CBIR) 或者更简单地说,图像搜索引擎感兴趣。
刚刚在 Google 上通过查询“图片搜索引擎 python”找到了 PyImageSearch 博客,登陆 《用 Python 和 OpenCV 构建图片搜索引擎的完整指南》教程。
我们还假设我有一些 Python 编程语言的经验,但是没有 OpenCV 的先验知识。
然后,我可以像这样填写模板:
嗨阿德里安,
我叫史蒂夫。当我在搜索“图片搜索引擎 python”时,我通过谷歌找到了你的博客。
我对构建图像搜索引擎很感兴趣,并且通读了你的图像搜索引擎指南教程。看到一个基本的图片搜索引擎是如何构建和组装的真的很有帮助。非常感谢。
我的问题是:
在该教程中,您使用了颜色直方图来量化图像内容。如果我想识别纹理或形状呢?
我这样问的原因是因为我为一家大型股票照片公司工作,我们需要建立一个系统,可以(自动)根据图像内容搜索相似的图像。
我之前没有任何计算机视觉或 OpenCV 的经验,但我知道如何用 Python、PHP 和 C++编写代码。
如果你能给我指出正确的方向,我将不胜感激。
谢谢!
史蒂夫(男子名)
史蒂夫的问题是一个很好的有见地的计算机视觉问题的例子:
- 这是经过深思熟虑的,切中要害的。
- 它有具体的目标:
- 史蒂夫想了解更多关于图像搜索引擎的知识。
- 利用这些知识,他想为他工作的公司建立一个图像搜索引擎。
- 它提供了足够的上下文和背景(包括以前的编程经验)。
鉴于 Steve 刚刚开始接触计算机视觉和 OpenCV,我可以向他推荐一条途径:
- 教他计算机视觉和图像处理的基础知识。
- 教育他各种颜色、形状和纹理图像描述符。
- 指导史蒂夫如何建立一个可扩展的图像搜索引擎。
再次,史蒂夫带着开放的心态走进这个问题。
他不是在寻找一个“替他完成”的解决方案,而是 一条通往理解 图像搜索引擎 的道路,以便他可以完成他的项目。
正如我们将在这些示例方程的其余部分中看到的,在计算机视觉领域很少有(如果有的话)“替你完成”的解决方案。即使有,这些解决方案可能需要你调整各种旋钮和杠杆。如果没有计算机视觉和图像处理的基础知识,你可能会很难将这些旋钮拨到正确的位置。
我在 PyImageSearch 博客上收到的问题示例
在本指南的剩余部分,我们将看看我在 PyImageSearch 博客上收到的个实际问题。
我们将检查这些问题中的每一个,并找出问题的积极和消极方面,以便您可以使用这些知识来制作自己的出色的计算机视觉问题。
每个示例问题都属于提出一个好的计算机视觉问题的五个组成部分:
- 成分#1: 知道目的。
- 组件#2: 提供上下文。
- 第三部分:做你的调查。
- 组件#4: 提出问题(并尊重他人的时间)。
- 组件#5: 根据需要重复该过程。

Figure 2: The five components of a practical insightful question.
其中一些问题是上述各个部分的极好的例子。
其他人在某些方面有所欠缺。
不管是哪种情况,我都会把这两种品质都说出来,这样你就可以从中学习了——这将使我能够通过理解你的问题来更好地帮助你。
第一部分:知道问题的目的
我们的第一个例子来自 Jason:
主题:Jason 提交的联系表单
如何追踪杯赛?请回答我。
Jason 的邮件非常简短——老实说,这是一个对我来说极具挑战性的问题。
原因是因为我提取不出问题的目的。
我不知道 Jason 想要识别和跟踪哪些类型的杯子:
- 每一款类型的杯子?
- 这包括玻璃杯和高脚杯吗?
- 啤酒杯呢?
- 这些杯子是什么材料的?它们是玻璃、陶瓷、塑料、金属等吗??
- 还是我们只局限于杰森家里厨房橱柜里的某一种杯子?
我也不知道Jason 想要建立他的杯子识别和跟踪系统的原因:
- 他是在为毕业做准备吗?这个杯子追踪器应该是他最后的顶点项目了吧?
- 他是否在一家大规模生产杯子并需要检测、跟踪和统计传送带上杯子数量的公司工作?
- 还是他只是单纯好奇如何跟踪识别杯子这个爱好项目?
选项是无止境的,对我来说不可能从杰森的电子邮件中辨别出【为什么】。
除了从根本上很难回答之外,这些类型的问题还会使人精神疲惫,令人生厌。
因为 Jason 的电子邮件缺乏上下文和细节,所以我和他之间需要多次电子邮件往来才能确定他项目的最终目标。
如果 Jason 能花更多的时间来形成一个问题,其中包括他希望完成的目标的具体细节,那么我可能会给他更多的帮助。否则,我很难对他的问题做出回应(甚至证明所花时间的合理性)。
像这样的电子邮件,我可能会回复,询问更多的细节,但在未来,这些问题将获得较低的优先级,可能根本不会回答。
如果我按照上面的模板重写这封邮件(对 Jason 进行假设,因为我不知道他的动机是什么),它看起来会像这样:
主题:Jason 提交的联系表单
嗨阿德里安,
我是计算机视觉和 OpenCV 的新手。我几个小时前才发现你的博客,并读过几篇文章。
我心中有一个爱好项目,我想检测和跟踪视频中的杯子。
为什么是杯子?
我有一个 2 岁的女儿,我最近给她买了颜色鲜艳的红色、黄色和蓝色的塑料吸管杯,以确保她不会把果汁洒在地板上。
从我读过的帖子来看,颜色似乎可以用来寻找图像中的物体,这些杯子似乎是一个很好的候选物。
同样,我是计算机视觉的新手,所以这个项目只是我自学基础知识的一种方式。
我如何应用你的技术来检测和跟踪视频中的杯子?
我应该从哪里开始?
伊阿宋
在这个重写的示例中,我将拥有回答 Jason 的问题所需的所有信息:
- 我知道他的计算机视觉和 OpenCV 经验。
- 我知道他对追踪一种特定类型的杯子感兴趣。
- 我知道这是他的爱好项目。
根据这些信息,我可以为 Jason 提供启动项目的建议,而不像在最初的例子中,我必须花费至少 3-4 封电子邮件来来回回地试图理解项目的目的。
对你项目的目标直言不讳会为我们双方节省很多时间。
#### 第 2 部分:提供背景(即“为什么”*你在问问题)
下一封电子邮件来自马克:
我正在做一个项目。我需要计算视频中越线的人数。请发送代码。提前谢了。
标记
Mark 的问题(实际上不是一个问题)与 Jason 的问题类似:非常简短,没有太多细节。
同样,我也很难回答这个问题。
我不确定为什么马克要数视频中的人数,甚至不知道所说的“数人数”是指什么。
然而,根据我在计算机视觉领域的经验(以及回答过 100 个类似的问题),我认为 Mark 想要做这样的东西:
https://www.youtube.com/embed/OWab2_ete7s?feature=oembed****
使用 NVIDIA DIGITS DevBox 进行深度学习
原文:https://pyimagesearch.com/2016/06/06/hands-on-with-the-nvidia-digits-devbox-for-deep-learning/

我今天有一个重要的宣布:
未来几个月,我将在 PyImageSearch 博客上做更多深度学习和卷积神经网络教程。
我对此非常认真——并且我已经把我的钱用在了我的嘴上和投资了一些用于深度学习的真正硬件。
要了解更多关于我的投资,NVIDIA DIGITS DevBox 和 PyImageSearch 博客的新教程,请继续阅读。
使用 NVIDIA DIGITS DevBox 进行深度学习
对于任何对 NVIDIA DIGITS DevBox for deep learning 感兴趣的人来说,也许更重要的是,导致我购买预配置深度学习系统而不是构建自己的的理性,我已经包括了我在决策过程中的工作经验,进行了购买,并打开了系统。在以后的博客文章中,我将回顾我是如何设置和配置系统来实现我自己的最佳设置的。
NVIDIA DIGITS DevBox 规格
让我告诉你:NVIDIA DIGITS DevBox 是个 野兽。
就系统规格而言,DevBox sports:
- 4 个 Titan X GPU(每块板 12GB 内存
** 64GB DDR4 内存* 华硕 X99-E WS 主板* 工作频率为 3.5GHz 的酷睿 i7-5930K 6 核处理器* RAID5 中配置的三个 3TB SATA 3.5 英寸硬盘(适用于存储海量数据集)* 用于 RAID 的 512GB 固态硬盘高速缓存* 250GB SATA 内置固态硬盘(用于存储系统文件、源代码和其他“最常访问”的文件)* 1600W 电源*
但是是而不是仅仅是硬件*让 NVIDIA DIGITS DevBox 变得令人敬畏。它还预配置了:
- Ubuntu 14.04
- NVIDIA 驱动程序
- NVIDIA CUDA 工具包 6.0-7.5
- cuDNN 4.0
- 咖啡,茶,托奇
这台机器可不是闹着玩的— 而且也不便宜。
在 称重,15000 美元 ,这不是你的标准台式机——这个系统是为在深度学习领域做实际工作的研究人员、公司和大学设计的。
所以,你可能想知道…
“你不是深度学习研究者,阿德里安。虽然你拥有涉及计算机视觉+机器学习的公司,但你为什么需要这样一台糟糕的机器?”
问得好。
这让我想到了这篇博文的下一部分…
投资 PyImageSearch、我的公司和我自己的未来
表面上,你可能会看到阿德里安·罗斯布鲁克的两面:
- 写每周博客和电子邮件公告的博主。
- 著有 实用 Python 和 OpenCV 以及 PyImageSearch 大师课程 的语言大师、老师和教育家。
但是还有一个第三方并不经常在 PyImageSearch 博客上被讨论(除了偶尔在这里或那里提到的): 企业家和(偶尔的)顾问。
我能承担新的咨询/承包工作的机会越来越少,但当我这样做的时候,我会对项目和预算非常挑剔。在过去的几年里,我注意到我越来越多地在我的项目中使用深度学习(无论是承包工作还是个人/商业项目)。
这可能与我关于摆脱深度学习潮流——的博文形成鲜明对比(表面上看,可能有点虚伪),但那篇文章的标题不是重点。
相反,这篇(有争议的)博文的目的是要说明一个细节:
“机器学习不是工具。这是一种具有理性思维过程的方法论,完全依赖于我们试图解决的问题。我们不应该盲目地应用算法,看看(除了抽查之外)还有什么可以坚持。我们需要坐下来,探索特征空间(根据经验和现实世界的影响),然后考虑我们的最佳行动模式。”
深度学习,就像支持向量机、随机森林和其他机器学习算法一样,都有一个合理的过程和假设,以确定我们何时应该使用每个特定的模型。我们在某个时间和地点使用深度学习— 你只需要在为特定程序选择算法时留心。
我在 PyImageSearch 博客上发布深度学习教程的希望是更好地阐明何时和哪里深度学习适合计算机视觉任务。
那么这和 PyImageSearch 博客有什么关系呢?
问得好。
我以前在其他博客中说过,今天我在这里再说一遍:
经营 PyImageSearch 博客让我喜欢的是写一些与读者你想听的内容相关的教程。
每天我都会收到越来越多的深度学习教程的请求。直到两个月前,我还在写视频搜索大师课程。我根本没有时间、精力或注意力来开始计划深度学习教程——就其定义而言,我需要花费更多的时间和精力(在思维过程、计算工作和实验方面)来创建这些教程。
现在我已经写完了 PyImageSearch 大师课程,我已经收回了一些时间。
但是更重要的是,我已经回收了一堆我的能量和注意力——这两者都是创作高质量教程的关键。在我读研的这些年里,我写论文,运行 PyImageSearch 博客,创作 实用 Python 和 OpenCV ,并创建了 PyImageSearch 大师课程,我已经掌握了一口气写出 5000 多个单词的能力。对于写作来说,时间不是问题——真正重要的是我的精力和注意力。
在接下来的一年里,你可以期待更多的深度学习教程发布在 PyImageSearch 博客上。这不会是一个立即发生的变化,但它会在接下来的 3-4 个月里慢慢增加,因为我开始创建积压的帖子。
重点是:
如果你对深度学习感兴趣,特别是深度学习和计算机视觉,PyImageSearch 是你应该去的地方。
计算数字
好的,我已经提到过我在 NVIDIA DIGITS DevBox 上投资了 15,000 美元——无论如何这都不是一笔小数目。
那么,我是如何证明这个巨大的数字的呢?
正如我上面提到的,我是一名企业家,一名科学家,本质上是一名商人——这意味着我的行为背后有(某种)逻辑。如果你给我看这些数字,它们就能算出来,并且与我的目标——一致,我就能证明投资是合理的,并据此制定计划。
我从事实开始评估:
- 事实#1: 我目前要么在亚马逊 ec2g 2.2x 大型实例上花费每小时 0.65 美元,要么在 g 2.8x 大型实例上花费每小时 2.60 美元。我的大部分 EC2 时间都是在使用 g2.8xlarge 实例上度过的。
- 事实#2: 这两个 EC2 实例的内存都比 NVIDIA DIGITS DevBox 少。根据 Amazon 计算虚拟 CPU 的方式,g2.8xlarge 的 CPU 仅略好于它(如果你信任 vCPU 分配的话)。
- 事实#3: 目前, EC2 GPU 实例只有 4GB 内存,1536 个内核(泰坦 X 有 12GB 内存,3072 个内核)。
- 事实# 4:NVIDIA DIGITS dev box 有 4 个 Titan X GPUs(总共 48GB 内存)。g2.8xlarge 有 4 个 K520 GPUs(总共 16GB 内存)。
- 事实#5: 如果不将计算分散到多个 GPU 上,4GB 无法满足大型数据集的需求。这很好,但从长远来看似乎不值得。理想情况下,我可以在 并行运行四个实验**或者将计算分散到四个卡上,从而减少训练给定模型所需的时间。泰坦 X 显然是这里的赢家。
接下来,我计算了这些数字,以确定一个 g2.8xlarge 实例的小时费率和 15,000 美元的前期投资之间的交集:

Figure 1: Plotting the intersection between the EC2 g2.8xlarge hourly rate and the upfront cost of $15,000 for the NVIDIA DIGITS DevBox. The break-even point is at approximately 240 days.
在一个 g2.8xlarge 实例上,这给了我大约 5,769 小时(约 240 天)的计算时间。
注意:这是在一个 g 2.2x 大型实例上的 23,076 小时(2.6 年)——再次重申,我主要使用 g 2.8x 大型实例。
由于盈亏平衡点只有 240 天(单个模型的训练可能需要几天到几周),决策开始变得更加清晰。
现在,我必须问自己的下一个问题是:
“我订购硬件,自己组装,省钱吗?还是说,我要为一台预先配置好的机器支付一点加价?”
在这一点上,我会得到相当多的负面反馈,,但在我看来,我倾向于“为你完成解决方案”。
为什么?
三个原因:我限制了时间、精力、注意力。
每当我可以花钱请专业人士外包一项我(1)不擅长,(2)不喜欢做,或者(3)不值得我花费时间/精力的任务时,我都会倾向于把任务从我的盘子上移开——这正是让我能够更聪明地工作而不是更努力地工作的基本原理。
因此,让我们假设我可以用大约 8,000 美元购买硬件来创建一个与 NVIDIA DIGITS DevBox 相当的系统,这为我节省了 7,000 美元,对吗?
嗯,没那么快。
我不打算说我每小时的咨询费率是多少,但是让我们(为了这个论点)假设我对我的时间每小时收费 250 美元:$ 7000/250 每小时= 28 小时。
为了这种时间和金钱的权衡(更不用说它需要的注意力和精力),在我自己的 28 小时时间内,我需要:
- 研究我需要的硬件。
- 购买它。
- 请到我的办公室来。
- 组装机器。
- 安装操作系统、软件、驱动程序等。
我能在 28 小时内用最少的上下文切换完成所有这些吗?
老实说,我不知道。我可能可以。
但是如果我错了呢?
更好的问题是:
如果东西坏了怎么办?
我不是一个硬件爱好者,我不喜欢与硬件打交道,这是我一贯的风格。
如果我建立自己的系统,我就是自己的支持人员。但如果我选择 NVIDIA,我会让整个 DevBox 团队帮助我排除故障,解决问题。
所以,假设我总共花了 15 个小时来订购硬件、组装硬件、安装所需的组件并确保其正常工作。
这样我就剩下28–15 = 13 小时的时间来处理在机器寿命期间出现的任何故障排除问题。
这现实吗?
不,不是的。
而且从这个角度(也就是我的角度)来看,这个投资是有意义的。你可能处于完全不同的情况——但是在我目前从事的项目、我运营的公司和 PyImageSearch 博客之间,我将在未来更多地利用深度学习。
*考虑到我不仅重视自己的时间,还受到注意力 的影响,这进一步证明了前期成本的合理性。另外,这更好地使我能够为 PyImageSearch 博客创建令人敬畏的深度学习教程。
注意:我没有考虑将*发生的水电费增加,但从长远来看,这变得边缘化了,因为我有能力节省时间,提高效率,加快运输速度。*
订购 NVIDIA DIGITS DevBox
订购 NVIDIA DIGITS DevBox 并不像打开网页、输入您的信用卡信息并点击“check out”按钮那么简单。相反,我需要联系 NVIDIA 并填写访问表格。
在 48 小时内,我与一名代表进行了会谈,并创建了 PO(采购订单)和发货。一旦条款达成一致,我就开了一张支票,连夜汇给了英伟达。总的来说,这是一个相当无痛的过程。
然而,我会注意到,如果你没有进行大量的发货/收货,DevBox 的实际发货可能会有点混乱。我个人没有太多的物流经验,但幸运的是,我父亲有。
我打电话给他,想弄清楚“运费条款”和“出厂价”。
从本质上讲,工厂交货可归结为:
工厂交货(EXW)是一个国际贸易术语,描述的是一项要求卖方准备好在自己的营业地提货的协议。所有其他运输费用和风险由买方承担。(来源)
归结起来很简单:
- NVIDIA 将会组装你的系统。
- 但是一旦它被装箱,放到他们的装货区,责任就在你身上了。
我是怎么处理的?
我用我的联邦快递商业账户支付了额外的现金来购买货物保险。没什么大不了的。
我在博文中包含这一部分的唯一原因是为了帮助那些处于类似情况、可能不熟悉这些术语的人。
打开 NVIDIA DIGITS DevBox
DevBox 装在一个大约 55 磅的大箱子里,但是纸板非常厚而且构造良好:

Figure 2: The box the NVIDIA Digits DevBox ships in.
DevBox 还非常安全地包装在聚苯乙烯泡沫容器中,以防止对您的机器造成任何损坏。
虽然打开 DevBox 可能没有第一次打开苹果新产品那么令人兴奋,但这仍然是一种乐趣。拆箱后,NVIDIA DIGITS DevBox 机器本身的尺寸为 18 英寸高、13 英寸宽、16.3 英寸深:

Figure 3: The NVIDIA DIGITS DevBox fully unboxed.
您会注意到机器前面有三个硬盘插槽:

Figure 4: Three hard drive slots on the front of the DevBox.
在这里,您可以滑入 DevBox 附带的三个 3TB 硬盘:

Figure 5: The DevBox ships with your 3TB hard drives. Luckily, you don’t need to purchase these separately.
插入驱动器再简单不过了:

Figure 6: Slotting the drives into their respective bays is easy. After slotting, the drives are securely locked in place.
第一次启动时,您需要连接显示器、键盘和鼠标来配置机器:

Figure 7: Make sure you connect your monitor to the first graphics card in the system.
按下电源按钮开始魔法:

Figure 8: Booting the DevBox.
接下来,您将看到引导序列:

Figure 9: Going through the motions and booting the NVIDIA DIGITS DevBox.
机器完成启动后,您需要配置 Ubuntu(就像标准安装一样)。设置键盘布局、时区、用户名、密码等之后。,剩下的配置就自动完成了。
另外值得一提的是,BIOS 仪表板非常有用,非常漂亮:

Figure 10: The BIOS dashboard on the NVIDIA DIGITS DevBox.
总的来说,我对设置过程很满意。不到 30 分钟,我就完成了整个系统的设置并准备就绪。
你不会把它直接插到墙上吧?
保护您的投资—获得优质的不间断电源(UPS)。我将在下一篇博文中详细介绍我选择的 UPS(和机架)。为这篇博文收集的图片主要是为了在初始拆箱时进行演示。
简而言之,我不会建议你将 DevBox 直接放在地毯上或者插在没有 UPS 的插座上——那只是自找麻烦。
摘要
诚然,这是一篇冗长的博文,所以如果你在寻找 TLDR,其实很简单:
- 明年我会在 PyImageSearch 博客上做更多的深度学习教程。它将在接下来的 3-4 个月内开始缓慢增长,并在年底前建立更多的一致性。
*** 为了促进更好的深度学习教程的创建(并用于我自己的项目),我已经把我的钱用在了我的嘴上,投资了一个 NVIDIA DIGITS DevBox 。* 安装 DevBox 是一件令人愉快的事情……尽管有一些实用的技巧和窍门,我会在下周的博文中分享。* 如果你对深度学习的世界感兴趣,PyImageSearch 博客是你应该去的地方。**
**值得注意的是,我已经在 PyImageSearch 大师课程 中涵盖了深度学习,所以如果你有兴趣学习更多关于神经网络、深度信念网络和卷积神经网络的知识,请务必加入该课程。
否则,我会在 PyImageSearch 博客上慢慢增加深度学习教程的频率。
最后,请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在这些新的深度学习帖子发布时得到通知!******
使用 OpenCV、scikit-image 和 Python 进行直方图匹配
原文:https://pyimagesearch.com/2021/02/08/histogram-matching-with-opencv-scikit-image-and-python/
在本教程中,您将学习如何使用 OpenCV 和 scikit-image 执行直方图匹配。
上周我们讨论了直方图均衡化,这是一种基本的图像处理技术,可以提高输入图像的对比度。
但是如果你想让两幅图像的对比度或颜色分布自动匹配,那该怎么办呢?
例如,假设我们有一个输入图像和一个参考图像。我们的目标是:
- 计算每个图像的直方图
- 取参考图像直方图
- 使用参考直方图更新输入图像中的像素亮度值,使它们匹配
我们在这篇博文顶部的图中看到了结果。请注意输入图像是如何更新以匹配参考图像的颜色分布的。
当将图像处理流水线应用于在不同照明条件下捕获的图像时,直方图匹配是有益的,从而创建图像的“标准化”表示,而不管它们是在什么照明条件下捕获的(当然,对照明条件变化的程度设置合理的预期)。
今天我们将详细讨论直方图匹配。下周我将展示如何使用直方图均衡化进行色彩校正和色彩恒常性。
要了解如何使用 OpenCV 和 scikit-image 执行直方图匹配,继续阅读。
使用 OpenCV、scikit-image 和 Python 进行直方图匹配
在本教程的第一部分,我们将讨论直方图匹配,并使用 OpenCV 和 scikit-image 实现直方图匹配。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
一旦我们理解了我们的项目结构,我们将实现一个 Python 脚本,它将:
- 加载输入图像(即“源”图像)
- 加载参考图像
- 计算两幅图像的直方图
- 获取输入图像并将其与参考图像进行匹配,从而将颜色/强度分布从参考图像转移到源图像中
我们将讨论我们的结果来结束本教程。
什么是直方图匹配?
直方图匹配最好被认为是一种“转换”我们的目标是获取一幅输入图像(“源”)并更新其像素强度,使输入图像直方图的分布与参考图像的分布相匹配。
虽然输入图像的实际内容没有改变,但是像素分布改变,从而基于参考图像的分布来调整输入图像的亮度和对比度。
应用直方图匹配可以让我们获得有趣的美学效果(我们将在本教程的后面看到)。
此外,我们可以使用直方图匹配作为基本颜色校正/颜色恒常性的一种形式,允许我们建立更好、更可靠的图像处理管道,而无需利用复杂、计算昂贵的机器学习和深度学习算法。我们将在下周的指南中讨论这个概念。
OpenCV 和 scikit-image 如何用于直方图匹配?
手工实现直方图匹配可能很痛苦,但对我们来说幸运的是,scikit-image 库已经有了一个match_histograms函数(你可以在这里找到的文档)。
因此,应用直方图匹配就像用 OpenCV 的cv2.imread加载两幅图像,然后调用 scikit-image 的match_histograms函数一样简单:
src = cv2.imread(args["source"])
ref = cv2.imread(args["reference"])
multi = True if src.shape[-1] > 1 else False
matched = exposure.match_histograms(src, ref, multichannel=multi)
我们将在本指南的后面更详细地介绍如何使用match_histograms函数。
配置您的开发环境
要了解如何执行直方图匹配,您需要安装 OpenCV 和 scikit-image:
两者都可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install scikit-image==0.18.1
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们可以用 OpenCV 和 scikit-image 实现直方图匹配之前,让我们首先使用我们的项目目录结构。
请务必访问本指南的 “下载” 部分,以检索源代码和示例图像。
从那里,看看我们的项目目录结构:
$ tree . --dirsfirst
.
├── empire_state_cloudy.png
├── empire_state_sunset.png
└── match_histograms.py
0 directories, 3 files
我们今天只需要查看一个 Python 脚本match_histograms.py,它将加载empire_state_cloud.png(即源图像)和empire_state_sunset.png(即引用图像)。
然后,我们的脚本将应用直方图匹配将颜色分布从参考图像转移到源图像。
在这种情况下,我们可以将阴天拍摄的照片转换成美丽的日落!
用 OpenCV 和 scikit-image 实现直方图匹配
准备好实现直方图匹配了吗?
太好了,我们开始吧。
打开match_histograms.py并插入以下代码:
# import the necessary packages
from skimage import exposure
import matplotlib.pyplot as plt
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--source", required=True,
help="path to the input source image")
ap.add_argument("-r", "--reference", required=True,
help="path to the input reference image")
args = vars(ap.parse_args())
我们从第 2-5 行开始,导入我们需要的 Python 包。
我们需要 scikit-image 的exposure库来计算图像直方图、累积分布函数,并应用直方图匹配。
我们将使用matplotlib来绘制直方图,这样我们可以在应用直方图匹配之前和之后可视化它们。
我们导入argparse用于命令行参数解析,导入cv2用于 OpenCV 绑定。
接下来是我们的命令行参数:
--source:我们输入图像的路径。--reference:参考图像的路径。
请记住,我们在这里做的是从参考获取颜色分布,然后将其传输到源。 源图像本质上是将更新其颜色分布的图像。
现在让我们从磁盘加载源图像和参考图像:
# load the source and reference images
print("[INFO] loading source and reference images...")
src = cv2.imread(args["source"])
ref = cv2.imread(args["reference"])
# determine if we are performing multichannel histogram matching
# and then perform histogram matching itself
print("[INFO] performing histogram matching...")
multi = True if src.shape[-1] > 1 else False
matched = exposure.match_histograms(src, ref, multichannel=multi)
# show the output images
cv2.imshow("Source", src)
cv2.imshow("Reference", ref)
cv2.imshow("Matched", matched)
cv2.waitKey(0)
第 17 行和第 18 行加载我们的src和ref图像。
加载这两幅图像后,我们可以对第 23 行和第 24 行进行直方图匹配。
直方图匹配可应用于单通道和多通道图像。第 23 行设置一个布尔值multi,这取决于我们使用的是多通道图像(True)还是单通道图像(False)。
从此,应用直方图匹配就像调用 scikit-image 的exposure子模块中的match_histogram函数一样简单。
从那里,行 27-30 显示我们的源,参考,并输出直方图matched图像到我们的屏幕上。
至此,我们在技术上已经完成了,但是为了充分理解直方图匹配的作用,让我们来检查一下src、ref和matched图像的颜色直方图:
# construct a figure to display the histogram plots for each channel
# before and after histogram matching was applied
(fig, axs) = plt.subplots(nrows=3, ncols=3, figsize=(8, 8))
# loop over our source image, reference image, and output matched
# image
for (i, image) in enumerate((src, ref, matched)):
# convert the image from BGR to RGB channel ordering
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# loop over the names of the channels in RGB order
for (j, color) in enumerate(("red", "green", "blue")):
# compute a histogram for the current channel and plot it
(hist, bins) = exposure.histogram(image[..., j],
source_range="dtype")
axs[j, i].plot(bins, hist / hist.max())
# compute the cumulative distribution function for the
# current channel and plot it
(cdf, bins) = exposure.cumulative_distribution(image[..., j])
axs[j, i].plot(bins, cdf)
# set the y-axis label of the current plot to be the name
# of the current color channel
axs[j, 0].set_ylabel(color)
第 34 行创建一个3 x 3图形,分别显示src、ref和matched图像的红色、绿色和蓝色通道的直方图。
从那里,行 38 在我们的src、ref和matched图像上循环。然后我们将当前的image从 BGR 转换到 RGB 通道排序。
接下来是实际的绘图:
- 第 45 和 46 行计算当前
image的当前通道的直方图 - 然后我们在第 47 行绘制直方图
- 类似地,行 51 和 52 计算当前通道的累积分布函数,然后将其绘制出来
- 第 56 行设置颜色的 y 轴标签
最后一步是显示绘图:
# set the axes titles
axs[0, 0].set_title("Source")
axs[0, 1].set_title("Reference")
axs[0, 2].set_title("Matched")
# display the output plots
plt.tight_layout()
plt.show()
这里,我们设置每个轴的标题,然后在屏幕上显示直方图。
直方图匹配结果
我们现在准备用 OpenCV 应用直方图匹配!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,我们打开一个 shell 并执行以下命令:
$ python match_histograms.py --source empire_state_cloudy.png \
--reference empire_state_sunset.png
[INFO] loading source and reference images...
[INFO] performing histogram matching...
假设我们正在纽约市进行家庭度假,我们想要捕捉日落时帝国大厦的美丽照片。今天是我们假期的最后一天,我们的航班计划在午饭前起飞。
在去机场之前,我们很快拍了一张帝国大厦的照片——但这是一个多云、沉闷的日子。这与我们想要的天堂般的日落照片相去甚远。
我们该怎么办?
答案是应用直方图匹配。
在回家的飞机上,我们打开笔记本电脑开始工作:
- 我们从从磁盘(左)加载原始输入图像开始
- 然后我们打开谷歌图片,找到一张日落时帝国大厦的照片(右)
- 最后,我们应用直方图匹配将色彩强度分布从日落照片(参考图像)转移到我们的输入图像(源图像)
结果是它现在看起来像我们在白天拍摄的原始图像,现在看起来像是在黄昏时拍摄的(图 4)!
图 5 分别显示了图像的红色、绿色和蓝色通道的源图像、参考图像和匹配图像的直方图:
“Source”列显示了我们的输入源图像中像素强度的分布。“参考”栏显示了我们从磁盘加载的参考图像的分布。最后,【匹配】栏显示应用直方图匹配的输出。
注意源像素强度是如何调整的,以匹配参考图像的分布!那个操作,本质上就是直方图匹配。
虽然本教程从美学角度关注直方图匹配,但直方图匹配还有更重要的实际应用。
直方图匹配可用作图像处理管道中的归一化技术,作为一种颜色校正和颜色匹配的形式,从而使您能够获得一致的归一化图像表示,即使光照条件发生变化。
在下周的博客文章中,我将向您展示如何执行这种类型的规范化。
学分
本教程的来源和参考图片分别来自这篇文章和这篇文章。感谢你让我有机会使用这些示例图像来教授直方图匹配。
此外,我想亲自感谢 scikit-image 库的开发人员和维护人员。我的直方图匹配实现基于 scikit-image 的官方示例。
我的主要贡献是演示了如何将 OpenCV 与 scikit-image 的match_histograms函数一起使用,并提供了对代码的更详细的讨论。
总结
在本教程中,您学习了如何使用 OpenCV 和 scikit-image 执行直方图匹配。
直方图匹配是一种图像处理技术,它将像素强度分布从一幅图像(“参考”图像)转移到另一幅图像(“源”图像)。
虽然直方图匹配可以改善输入图像的美观,但它也可以用作归一化技术,其中我们“校正”输入图像,以使输入分布与参考分布匹配,而不管光照条件的变化。
执行这种标准化使我们作为计算机视觉从业者的生活更加轻松。如果我们可以安全地假设特定范围的光照条件,我们可以硬编码参数,包括 Canny 边缘检测阈值、高斯模糊大小等。
我将在下周的教程中向你展示如何执行这种类型的颜色匹配和规范化。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
方向梯度直方图和目标检测
原文:https://pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/

如果你最近一直关注我的 Twitter 账户,你可能已经注意到了我一直在做的一个或两个预告片——一个 Python 框架/包,使用方向梯度直方图和线性支持向量机快速构建对象检测器。
老实说,我真的无法忍受使用 OpenCV 提供的 Haar 级联分类器(即 Viola-Jones 检测器)——因此我正在开发自己的分类器套件。虽然级联方法非常快,但它们仍有许多不足之处。如果你曾经使用过 OpenCV 来检测人脸,你就会知道我在说什么。

Figure 1: Example of falsely detecting a face in an image. This is a common problem when using cv2.detectMultiScale.
为了检测 OpenCV 中的人脸/人/物体/任何东西(并消除误报),您将花费大量时间调整cv2.detectMultiScale参数。同样,也不能保证图像与图像之间的参数完全相同。这使得批量处理大型数据集进行人脸检测成为一项乏味的任务,因为你会非常担心(1)错误地检测到人脸或(2)完全丢失人脸,这仅仅是因为每个图像的参数选择不当。
还有一个问题是维奥拉-琼斯探测器 已经接近 15 年了。 如果这台探测器是一瓶上好的赤霞珠葡萄酒,我现在可能会非常兴奋。但是从那以后,这个领域已经取得了实质性的进展。早在 2001 年,Viola-Jones 探测器就是最先进的,它们无疑是我们今天在物体探测方面取得令人难以置信的新进展的巨大推动力。
Viola-Jones 探测器并不是我们探测物体的唯一选择。我们使用关键点、局部不变描述符和视觉单词包模型进行对象检测。我们有方向梯度直方图。我们有可变形零件模型。模范模特。我们现在正在利用金字塔的深度学习来识别不同尺度的物体!
尽管如此,尽管用于对象识别的梯度方向直方图描述符已经有近十年的历史了,但它今天仍然被大量使用,并且产生了惊人的结果。Dalal 和 Triggs 在他们 2005 年的开创性论文 用于人体检测的定向梯度直方图 中提出的定向梯度直方图方法证明了定向梯度直方图(HOG)图像描述符和线性支持向量机(SVM)可以用于训练高度精确的物体分类器,或者在他们的特定研究中,训练人体检测器。
方向梯度直方图和目标检测
我不打算回顾使用梯度方向直方图训练对象检测器的整个详细过程,因为每个步骤都相当详细。但我想花一分钟,详细说明使用梯度方向直方图训练对象检测器的一般算法。事情大概是这样的:
第一步:
Sample P 从您想要检测的对象的训练数据中提取阳性样本,并从这些样本中提取 HOG 描述符。
第二步:
样本 N 来自负训练集的负样本,该负训练集 不包含 任何你想要检测的对象,并从这些样本中提取 HOG 描述符。在实践中N>p
第三步:
在你的正负样本上训练一个线性支持向量机。
第四步:

Figure 2: Example of the sliding a window approach, where we slide a window from left-to-right and top-to-bottom. Note: Only a single scale is shown. In practice this window would be applied to multiple scales of the image.
应用硬负挖掘。对于每幅图像和负训练集中每幅图像的每种可能比例,应用滑动窗口技术,在图像上滑动窗口。在每个窗口计算你的 HOG 描述符并应用你的分类器。如果你的分类器(不正确地)将给定的窗口分类为一个对象(它会,绝对会有假阳性),记录与假阳性补丁相关的特征向量以及分类的概率。这种方法被称为硬负开采。
第五步:
获取在硬阴性挖掘阶段发现的假阳性样本,根据它们的置信度(即概率)对它们进行排序,并使用这些硬阴性样本重新训练您的分类器。(注意:你可以迭代地应用步骤 4-5,但是在实践中,一个阶段的硬负挖掘通常就足够了。在随后的硬负挖掘运行中,准确性的提高往往是最小的。)
第六步:
您的分类器现在已经训练好了,可以应用于您的测试数据集。同样,就像在步骤 4 中一样,对于测试集中的每个图像,以及图像的每个比例,应用滑动窗口技术。在每个窗口提取 HOG 描述符并应用你的分类器。如果你的分类器以足够大的概率检测到一个对象,记录窗口的边界框。扫描完图像后,应用非最大抑制来移除多余和重叠的边界框。
这些是需要的最少步骤,但是通过使用这 6 个步骤的过程,你可以训练和建立你自己的物体检测分类器!这种方法的扩展包括一个可变形部件模型和样本支持向量机,在这里你为的每个 正实例训练一个分类器,而不是它们的集合。
然而,如果你曾经处理过图像中的对象检测,你可能会遇到这样的问题:检测图像中你想要检测的对象周围的多个 边界框。
这里有一个重叠边界框问题的例子:

Figure 3: (Left) Detecting multiple overlapping bounding boxes around the face we want to detect. (Right) Applying non-maximum suppression to remove the redundant bounding boxes.
注意左边的我们有 6 个重叠的边界框,它们正确地检测到了奥黛丽·赫本的脸。然而,这 6 个边界框都指向同一个面——我们需要一种方法来抑制该区域中 5 个最小的边界框,只保留最大的一个,如右边的所示。
这是一个常见的问题,不管你是使用基于 Viola-Jones 的方法还是遵循 Dalal-Triggs 的论文。
有多种方法可以解决这个问题。Triggs 等人建议使用 Mean-Shift 算法通过利用包围盒的 (x,y) 坐标以及图像当前尺度的对数来检测包围盒空间中的多个模式。
我个人试过这种方法,对结果不满意。相反,你最好依靠一个强分类器和更高的精确度(意味着很少有假阳性),然后对边界框应用非最大抑制。
我花了一些时间在 Python 中寻找一个好的非最大值抑制(有时称为非最大值抑制)实现。当我找不到的时候,我就和我的朋友 Tomasz Malisiewicz 博士聊天,他整个职业生涯都在研究物体探测器算法和猪描述符。在 T2,我知道没有人比托马斯在这方面更有经验。如果你读过他的论文,你就会知道为什么。他的工作棒极了。
反正跟他聊完之后,他给我指了两个 MATLAB 实现。第一部基于 Felzenszwalb 等人的作品。和它们的可变形部分模型。
第二种方法由 Tomasz 自己为他的 Exemplar SVM 项目实现,他在他的论文和他的 ICCV 2011 年论文Exemplar-SVMs 集合用于对象检测和超越 。值得注意的是,Tomasz 的方法比 Felzenszwalb 等人的方法快 100 多倍。当您执行非最大抑制函数数百万次时,100 倍的加速非常重要。
我已经实现了 Felzenszwalb 等人和 Tomasz 等人的方法,并将它们从 MATLAB 移植到 Python。下周我们将从 Felzenszwalb 方法开始,然后下周我将介绍 Tomasz 的方法。虽然 Tomasz 的方法要快得多,但我认为看到这两种实现方式很重要,这样我们就能准确理解为什么他的方法获得如此大的加速。
一定要留下来看看这些帖子!这些绝对是构建你自己的物体探测器的关键步骤!
摘要
在这篇博文中,我们上了一堂关于物体探测器的历史课。我们还偷偷看了一眼我正在开发的用于图像中物体检测的 Python 框架。
从那里,我们快速回顾了如何结合线性 SVM 使用梯度方向直方图方法来训练鲁棒的对象检测器。
但是,无论您使用哪种对象检测方法,您都可能会在要检测的对象周围出现多个边界框。为了移除这些多余的盒子,你需要应用非最大抑制。
在接下来的两周里,我将向您展示非最大抑制的两种实现,您可以在自己的对象检测项目中使用它们。
请务必在下面的表格中输入您的电子邮件地址,以便在这些帖子发布时收到通知!非最大抑制对于使用 HOG 获得精确和鲁棒的对象检测系统是绝对关键的,所以你绝对不想错过这些帖子!
霍比特人和直方图——如何用 Python 构建你的第一个图像搜索引擎
一枚戒指统治他们,一枚戒指寻找他们;一枚戒指将他们带到一起,在黑暗中将他们捆绑。
我们将要建立的图像搜索引擎将会是如此的令人敬畏,如果没有末日火山的帮助,它可能已经摧毁了至尊魔戒本身。
好吧,在过去的一周里,我显然看了很多《霍比特人》和《T2》《指环王》。
我心想,你知道什么最棒吗?
使用电影截图建立一个简单的图像搜索引擎。这正是我所做的。
这里有一个快速概述:
- 我们要做的:建立一个图片搜索引擎,从开始到结束,使用的霍比特人和的指环王截图。
- 你将学到:建立一个图片搜索引擎所需的 4 个步骤,包括代码示例。从这些例子中,你将能够建立你自己的图像搜索引擎。
- 你需要的: Python,NumPy,和 OpenCV 。了解一些基本的图像概念,比如像素和直方图,会有所帮助,但是绝对不是必需的。这篇博客文章旨在成为构建图像搜索引擎的实践指南。
霍比特人和直方图——如何用 Python 构建你的第一个图像搜索引擎
我以前从未见过如何建立一个简单的图片搜索引擎的指南。但这正是这篇文章的内容。我们将使用(可以说是)最基本的图像描述符之一来量化和描述这些截图——颜色直方图。
我在上一篇文章中讨论了颜色直方图,在计算机视觉和图像搜索引擎中使用颜色直方图的指南。如果你没有读过,没关系,但是我建议你在看完这篇博文后回去读一读,以进一步了解颜色直方图。
但在我深入研究构建图像搜索引擎的细节之前,让我们先来看看我们的数据集《霍比特人》和《T2》的《指环王》截图:

Figure 1: Our dataset of The Hobbit and Lord of the Rings screenshots. We have 25 total images of 5 different categories including Dol Guldur, the Goblin Town, Mordor/The Black Gate, Rivendell, and The Shire.
如你所见,我们的数据集中共有 25 张不同的图片,每类 5 张。我们的类别包括:
- 多尔·古尔杜尔:《死灵法师地牢》,索隆在幽暗密林的据点。
- 妖精小镇:迷雾山脉中的兽人小镇,妖精王的故乡。
- 魔多/黑门:索隆的要塞,周围是山脉和火山平原。
- 中土世界的精灵前哨站。
- 夏尔:霍比特人的故乡。
这些图片来自《霍比特人:意想不到的旅程》。我们的夏尔图片来自《指环王:指环王联盟。最后,我们的魔多/黑门截图来自指环王:王者归来。
目标是:
我们要做的第一件事是索引我们数据集中的 25 张图片。索引是通过使用图像描述符从每个图像中提取特征来量化我们数据集的过程,并存储所得到的特征以备后用,例如执行搜索。
一个图像描述符定义了我们如何量化一幅图像,因此从一幅图像中提取特征被称为描述一幅图像。图像描述符的输出是一个特征向量,一个图像本身的抽象。简单来说,就是用来表示一个图像的数字列表。
可以使用距离度量来比较两个特征向量。距离度量用于通过检查两个特征向量之间的距离来确定两幅图像有多“相似”。在图像搜索引擎的情况下,我们给我们的脚本一个查询图像,并要求它根据图像与我们的查询的相关程度,对索引中的图像进行排序。
这么想吧。当你去谷歌并在搜索框中输入“指环王”时,你会期望谷歌返回给你与托尔金的书和电影系列相关的页面。类似地,如果我们提供一个带有查询图像的图像搜索引擎,我们希望它返回与图像内容相关的图像——因此,我们有时称图像搜索引擎为学术界更普遍的名称基于内容的图像检索(CBIR) 系统。
那么我们指环王图片搜索引擎的总体目标是什么呢?
我们的目标是,给定来自五个不同类别之一的查询图像,返回该类别对应的前 10 个结果中的图像。
那是一口。我们用一个例子来说明一下。
如果我向我们的系统提交一个 Shire 的查询图像,我希望它能在我们的数据集中返回前 10 个结果,给出所有 5 个 Shire 图像。同样,如果我提交一个瑞文戴尔的查询图片,我希望我们的系统在前 10 个结果中给出所有 5 个瑞文戴尔的图片。
有道理吗?很好。让我们来谈谈建立图像搜索引擎的四个步骤。
构建图像搜索引擎的 4 个步骤
在最基本的层面上,构建图像搜索引擎有四个步骤:
- 定义您的描述符:您将使用哪种类型的描述符?你是在描述颜色吗?质感?外形?
- 索引您的数据集:将您的描述符应用到您的数据集中的每个图像,提取一组特征。
- 定义你的相似度:你将如何定义两幅图像有多“相似”?你可能会使用某种距离度量。常见的选择包括欧几里德、Cityblock(曼哈顿)、余弦和卡方等等。
- 搜索:要执行搜索,请将您的描述符应用到您的查询图像,然后询问您的距离度量来对您的图像在索引中与您的查询图像的相似程度进行排序。通过相似性对结果进行排序,然后检查它们。
步骤 1:描述符——3D RGB 颜色直方图
我们的图像描述符是 RGB 颜色空间中的 3D 颜色直方图,每个红色、绿色和蓝色通道有 8 个面元。
解释 3D 直方图的最佳方式是使用连接词和。该图像描述符将询问给定图像有多少像素具有落入面元#1 的红色值和落入面元#2 的绿色值以及落入面元#1 的蓝色像素。这个过程将对每个箱的组合重复进行;然而,这将以计算高效的方式完成。
当计算具有 8 个面元的 3D 直方图时,OpenCV 会将特征向量存储为一个(8, 8, 8)数组。我们将简单地把它弄平,并将其整形为(512,)。一旦它变平,我们就可以很容易地比较特征向量的相似性。
准备好看代码了吗?好了,我们开始吧:
# import the necessary packages
import imutils
import cv2
class RGBHistogram:
def __init__(self, bins):
# store the number of bins the histogram will use
self.bins = bins
def describe(self, image):
# compute a 3D histogram in the RGB colorspace,
# then normalize the histogram so that images
# with the same content, but either scaled larger
# or smaller will have (roughly) the same histogram
hist = cv2.calcHist([image], [0, 1, 2],
None, self.bins, [0, 256, 0, 256, 0, 256])
# normalize with OpenCV 2.4
if imutils.is_cv2():
hist = cv2.normalize(hist)
# otherwise normalize with OpenCV 3+
else:
hist = cv2.normalize(hist,hist)
# return out 3D histogram as a flattened array
return hist.flatten()
如您所见,我定义了一个RGBHistogram类。我倾向于将我的图像描述符定义为类,而不是函数。这是因为你很少单独从一幅图像中提取特征。而是从整个图像数据集中提取特征。此外,您希望从所有图像中提取的特征使用相同的参数,在这种情况下,就是直方图的箱数。如果您打算比较它们的相似性,那么从一幅图像中使用 32 个柱,然后从另一幅图像中使用 128 个柱来提取直方图是没有多大意义的。
让我们把代码拆开,了解一下发生了什么:
- 第 6-8 行:这里我定义了
RGBHistogram的构造函数。我们需要的唯一参数是直方图中每个通道的仓数量。同样,这也是为什么我更喜欢使用类而不是函数作为图像描述符——通过将相关参数放在构造函数中,可以确保每个图像都使用相同的参数。 - 第 10 行:你猜对了。describe 方法用于“描述”图像并返回特征向量。
- 第 15 行和第 16 行:这里我们提取实际的 3D RGB 直方图(或者实际上是 BGR,因为 OpenCV 将图像存储为 NumPy 数组,但是通道顺序相反)。我们假设
self.bins是三个整数的列表,指定每个通道的仓数量。 - 第 19-24 行:重要的是,我们要根据像素数来标准化直方图。如果我们使用图像的原始(整数)像素计数,然后将其缩小 50%并再次描述,那么对于相同的图像,我们将有两个不同的特征向量。在大多数情况下,您希望避免这种情况。我们通过将原始整数像素计数转换成实数值百分比来获得比例不变性。例如,不是说面元#1 中有 120 个像素,而是说面元#1 中有所有像素的 20%。同样,通过使用像素计数的百分比而不是原始的整数像素计数,我们可以确保两个相同的图像(仅大小不同)将具有(大致)相同的特征向量。
- 第 27 行:当计算一个 3D 直方图时,直方图将被表示为一个带有
(N, N, N)个面元的 NumPy 数组。为了更容易地计算直方图之间的距离,我们简单地将这个直方图展平成一个形状(N ** 3,)。示例:当我们实例化我们的 RGBHistogram 时,我们将使用每个通道 8 个面元。没有展平我们的直方图,形状将是(8, 8, 8)。但是把它展平,形状就变成了(512,)。
既然我们已经定义了我们的图像描述符,我们可以继续我们的数据集的索引过程。
步骤 2:索引我们的数据集
好了,我们已经决定我们的图像描述符是一个三维 RGB 直方图。下一步是将我们的图像描述符应用到数据集中的每个图像。
这意味着我们将遍历 25 个图像数据集,从每个图像中提取 3D RGB 直方图,将特征存储在字典中,并将字典写入文件。
对,就是这样。
实际上,您可以根据需要使索引变得简单或复杂。索引是一项很容易实现并行的任务。如果我们有一个四核机器,我们可以在四个核之间分配工作,加快索引过程。但是因为我们只有 25 张图像,这是相当愚蠢的,尤其是考虑到计算直方图的速度有多快。
让我们深入了解一下index.py:
# import the necessary packages
from pyimagesearch.rgbhistogram import RGBHistogram
from imutils.paths import list_images
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory that contains the images to be indexed")
ap.add_argument("-i", "--index", required = True,
help = "Path to where the computed index will be stored")
args = vars(ap.parse_args())
# initialize the index dictionary to store our our quantifed
# images, with the 'key' of the dictionary being the image
# filename and the 'value' our computed features
index = {}
好的,我们要做的第一件事是导入我们需要的包。我决定将RGBHistogram类存储在一个名为pyimagesearch的模块中。我是说,这才有意义,对吧?我们将使用cPickle将我们的索引转储到磁盘。我们将使用glob来获取我们要索引的图像的路径。
--dataset参数是我们的图像在磁盘上存储的路径,而--index选项是索引计算后我们将存储索引的路径。
最后,我们将初始化我们的index —一个内置的 Python 字典类型。字典的关键字将是图像文件名。我们假设所有文件名都是唯一的,事实上,对于这个数据集,它们是唯一的。字典的值将是图像的计算直方图。
在这个例子中使用字典是最有意义的,尤其是为了解释的目的。给定一个键,字典指向另一个对象。当我们使用图像文件名作为关键字,直方图作为值时,我们暗示给定的直方图 H 用于量化和表示文件名为 K 的图像。
同样,您可以根据自己的意愿让这个过程变得简单或复杂。更复杂的图像描述符使用术语频率-逆文档频率加权( tf-idf )和一个倒排索引,但是我们现在要避开它。不过不要担心,我会有很多的博客文章讨论我们如何利用更复杂的技术,但是目前,让我们保持简单。
# initialize our image descriptor -- a 3D RGB histogram with
# 8 bins per channel
desc = RGBHistogram([8, 8, 8])
这里我们实例化我们的RGBHistogram。同样,我们将分别为红色、绿色和蓝色通道使用 8 个箱。
# use list_images to grab the image paths and loop over them
for imagePath in list_images(args["dataset"]):
# extract our unique image ID (i.e. the filename)
k = imagePath[imagePath.rfind("/") + 1:]
# load the image, describe it using our RGB histogram
# descriptor, and update the index
image = cv2.imread(imagePath)
features = desc.describe(image)
index[k] = features
这里是实际索引发生的地方。让我们来分解一下:
- 第 26 行:我们使用
list_images来获取图像路径,并开始遍历我们的数据集。 - 第 28 行:我们提取字典的“关键字”。在这个样本数据集中,所有的文件名都是唯一的,所以文件名本身就足以作为键。
- 第 32-34 行:图像从磁盘上下载,然后我们使用
RGBHistogram从图像中提取直方图。直方图然后存储在索引中。
# we are now done indexing our image -- now we can write our
# index to disk
f = open(args["index"], "wb")
f.write(pickle.dumps(index))
f.close()
# show how many images we indexed
print("[INFO] done...indexed {} images".format(len(index)))
现在我们的索引已经被计算出来了,我们把它写到磁盘上,这样我们就可以在以后的搜索中使用它。
要索引您的图像搜索引擎,只需在终端中输入以下内容(注意命令行参数):
$ python index.py --dataset images --index index.cpickle
[INFO] done...indexed 25 images
第三步:搜索
现在,我们已经将索引放在了磁盘上,可以随时进行搜索。
问题是,我们需要一些代码来执行实际的搜索。我们如何比较两个特征向量,如何确定它们有多相似?
这个问题最好先在searcher.py里面解决,然后我再分解一下。
# import the necessary packages
import numpy as np
class Searcher:
def __init__(self, index):
# store our index of images
self.index = index
def search(self, queryFeatures):
# initialize our dictionary of results
results = {}
# loop over the index
for (k, features) in self.index.items():
# compute the chi-squared distance between the features
# in our index and our query features -- using the
# chi-squared distance which is normally used in the
# computer vision field to compare histograms
d = self.chi2_distance(features, queryFeatures)
# now that we have the distance between the two feature
# vectors, we can udpate the results dictionary -- the
# key is the current image ID in the index and the
# value is the distance we just computed, representing
# how 'similar' the image in the index is to our query
results[k] = d
# sort our results, so that the smaller distances (i.e. the
# more relevant images are at the front of the list)
results = sorted([(v, k) for (k, v) in results.items()])
# return our results
return results
def chi2_distance(self, histA, histB, eps = 1e-10):
# compute the chi-squared distance
d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps)
for (a, b) in zip(histA, histB)])
# return the chi-squared distance
return d
首先,大部分代码只是注释。不要害怕是 41 行。如果你还没有猜到,我喜欢注释良好的代码。让我们调查一下发生了什么:
- 第 4-7 行:我做的第一件事是定义一个
Searcher类和一个只有一个参数的构造函数——T1。这个index被认为是我们在索引步骤中写入文件的索引字典。 - 第 11 行:我们定义了一个字典来存储我们的
results。关键字是图像文件名(来自索引),值是给定图像与查询图像的相似程度。 - 第 14-26 行:这是实际搜索发生的部分。我们在索引中循环遍历图像文件名和相应的特征。然后,我们使用卡方距离来比较我们的颜色直方图。计算出的距离随后被存储在
results字典中,表明两幅图像彼此有多相似。 - 第 30-33 行:结果按照相关性排序(卡方距离越小,相关/相似)并返回。
- 第 35-41 行:这里我们定义了用于比较两个直方图的卡方距离函数。一般而言,大箱与小箱之间的差异不太重要,应同样进行加权。这正是卡方距离的作用。我们提供了一个
epsilon虚拟值来避免那些讨厌的“被零除”错误。如果图像的特征向量的卡方距离为零,则认为图像是相同的。距离越大,它们越不相似。
现在你有了它,一个 Python 类,它可以获取索引并执行搜索。现在是时候让这个搜索器发挥作用了。
注意:对于那些更倾向于学术的人来说,如果你对直方图距离度量感兴趣,你可能想看看来自 ECCV 10 会议的 二次卡方直方图距离族 。
步骤 4:执行搜索
最后。我们正在接近一个功能图像搜索引擎。
但是我们还没到那一步。我们在search.py中需要一点额外的代码来处理从磁盘上加载图像和执行搜索:
# import the necessary packages
from pyimagesearch.searcher import Searcher
import numpy as np
import argparse
import os
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory that contains the images we just indexed")
ap.add_argument("-i", "--index", required = True,
help = "Path to where we stored our index")
args = vars(ap.parse_args())
# load the index and initialize our searcher
index = pickle.loads(open(args["index"], "rb").read())
searcher = Searcher(index)
重要的事情先来。导入我们将需要的包。如您所见,我已经将我们的Searcher类存储在了pyimagesearch模块中。然后,我们以与索引步骤中相同的方式定义我们的参数。最后,我们使用cPickle从磁盘上加载我们的索引并初始化我们的Searcher。
# loop over images in the index -- we will use each one as
# a query image
for (query, queryFeatures) in index.items():
# perform the search using the current query
results = searcher.search(queryFeatures)
# load the query image and display it
path = os.path.join(args["dataset"], query)
queryImage = cv2.imread(path)
cv2.imshow("Query", queryImage)
print("query: {}".format(query))
# initialize the two montages to display our results --
# we have a total of 25 images in the index, but let's only
# display the top 10 results; 5 images per montage, with
# images that are 400x166 pixels
montageA = np.zeros((166 * 5, 400, 3), dtype = "uint8")
montageB = np.zeros((166 * 5, 400, 3), dtype = "uint8")
# loop over the top ten results
for j in range(0, 10):
# grab the result (we are using row-major order) and
# load the result image
(score, imageName) = results[j]
path = os.path.join(args["dataset"], imageName)
result = cv2.imread(path)
print("\t{}. {} : {:.3f}".format(j + 1, imageName, score))
# check to see if the first montage should be used
if j < 5:
montageA[j * 166:(j + 1) * 166, :] = result
# otherwise, the second montage should be used
else:
montageB[(j - 5) * 166:((j - 5) + 1) * 166, :] = result
# show the results
cv2.imshow("Results 1-5", montageA)
cv2.imshow("Results 6-10", montageB)
cv2.waitKey(0)
大部分代码处理结果的显示。实际的“搜索”是在一行中完成的(#31)。不管怎样,让我们来看看发生了什么:
- 第 23 行:我们将把索引中的每张图片视为一个查询,看看我们会得到什么结果。通常,查询是外部的,不是数据集的一部分,但是在我们开始之前,让我们先执行一些示例搜索。
- 第 25 行:这里是实际搜索发生的地方。我们将当前图像视为我们的查询并执行搜索。
- 第 28-31 行:加载并显示我们的查询图像。
- 第 37-55 行:为了显示前 10 个结果,我决定使用两个蒙太奇图像。第一个蒙太奇显示结果 1-5,第二个蒙太奇显示结果 6-10。第 27 行提供了图像的名称和距离。
- 第 58-60 行:最后,我们向用户显示搜索结果。
所以你有它。一个完整的 Python 图像搜索引擎。
让我们看看这东西的表现如何:
$ python search.py --dataset images --index index.cpickle
最后,在窗口处于活动状态时按下一个键后,您将看到这个魔多查询和结果:
query: Mordor-002.png
1\. Mordor-002.png : 0.000
2\. Mordor-004.png : 0.296
3\. Mordor-001.png : 0.532
4\. Mordor-003.png : 0.564
5\. Mordor-005.png : 0.711
6\. Goblin-002.png : 0.825
7\. Rivendell-002.png : 0.838
8\. Rivendell-004.png : 0.980
9\. Goblin-001.png : 0.994
10\. Rivendell-005.png : 0.996

图 2: 使用【Mordor-002.png 作为查询的搜索结果。我们的图像搜索引擎能够返回来自魔多和黑门的图像。让我们从《T4:王者归来》的结尾开始,用弗罗多和山姆爬上火山作为我们的查询图像。如你所见,我们的前 5 个结果来自“魔多”类别。
也许你想知道为什么 Frodo 和 Sam 的查询图像也是在#1 结果位置的图像?让我们回想一下卡方距离。我们说过,如果两个特征向量之间的距离为零,则认为图像是“相同的”。因为我们使用已经作为查询索引的图像,所以它们实际上是相同的,并且距离为零。因为零值表示完全相似,所以查询图像出现在#1 结果位置。
现在,让我们尝试另一个图像,这一次使用妖精镇中的妖精王。当你准备好了,只要在 OpenCV 窗口激活时按一个键,直到你看到这个妖精王的查询:
query: Goblin-004.png
1\. Goblin-004.png : 0.000
2\. Goblin-003.png : 0.103
3\. Golbin-005.png : 0.188
4\. Goblin-001.png : 0.335
5\. Goblin-002.png : 0.363
6\. Mordor-005.png : 0.594
7\. Rivendell-001.png : 0.677
8\. Mordor-003.png : 0.858
9\. Rivendell-002.png : 0.998
10\. Mordor-001.png : 0.999

图 3: 使用【Goblin-004.png 作为查询的搜索结果。返回的前 5 张图片来自地精镇。妖精王看起来不太高兴。但是我们很高兴地精镇的五张照片都进入了前十名。
最后,这里还有三个搜索 Dol-Guldur、Rivendell 和 Shire 的示例。同样,我们可以清楚地看到,来自各自类别的所有五张图片都位于前 10 名结果中。

Figure 4: Using images from Dol-Guldur (Dol-Guldur-004.png), Rivendell (Rivendell-003.png), and The Shire (Shire-002.png) as queries.
额外收获:外部查询
到目前为止,我只向你展示了如何使用已经在你的索引中的图片进行搜索。但显然,这并不是所有图像搜索引擎的工作方式。谷歌允许你上传自己的图片。TinEye 允许你上传自己的图片。为什么我们不能?让我们看看如何使用search_external.py来执行搜索,使用一个我们还没有索引的图像:
# import the necessary packages
from pyimagesearch.rgbhistogram import RGBHistogram
from pyimagesearch.searcher import Searcher
import numpy as np
import argparse
import os
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory that contains the images we just indexed")
ap.add_argument("-i", "--index", required = True,
help = "Path to where we stored our index")
ap.add_argument("-q", "--query", required = True,
help = "Path to query image")
args = vars(ap.parse_args())
# load the query image and show it
queryImage = cv2.imread(args["query"])
cv2.imshow("Query", queryImage)
print("query: {}".format(args["query"]))
# describe the query in the same way that we did in
# index.py -- a 3D RGB histogram with 8 bins per
# channel
desc = RGBHistogram([8, 8, 8])
queryFeatures = desc.describe(queryImage)
# load the index perform the search
index = pickle.loads(open(args["index"], "rb").read())
searcher = Searcher(index)
results = searcher.search(queryFeatures)
# initialize the two montages to display our results --
# we have a total of 25 images in the index, but let's only
# display the top 10 results; 5 images per montage, with
# images that are 400x166 pixels
montageA = np.zeros((166 * 5, 400, 3), dtype = "uint8")
montageB = np.zeros((166 * 5, 400, 3), dtype = "uint8")
# loop over the top ten results
for j in range(0, 10):
# grab the result (we are using row-major order) and
# load the result image
(score, imageName) = results[j]
path = os.path.join(args["dataset"], imageName)
result = cv2.imread(path)
print("\t{}. {} : {:.3f}".format(j + 1, imageName, score))
# check to see if the first montage should be used
if j < 5:
montageA[j * 166:(j + 1) * 166, :] = result
# otherwise, the second montage should be used
else:
montageB[(j - 5) * 166:((j - 5) + 1) * 166, :] = result
# show the results
cv2.imshow("Results 1-5", montageA)
cv2.imshow("Results 6-10", montageB)
cv2.waitKey(0)
- 第 2-18 行:到现在为止,这应该感觉像是非常标准的东西。我们正在导入我们的包并设置我们的参数解析器,但是,您应该注意到新的参数
--query。这是我们的查询图像的路径。 - 第 21 行和第 22 行:我们将加载您的查询图像并向您展示,以防您忘记您的查询图像是什么。
- 第 28 和 29 行:用与索引步骤 中完全相同的 bin 数实例化我们的
RGBHistogram。我用粗体和斜体来说明使用相同参数的重要性。然后,我们从查询图像中提取特征。 - 第 32-34 行:使用
cPickle从磁盘上加载我们的索引并执行搜索。 - 第 40-63 行:就像在上面的代码中执行搜索一样,这段代码只是向我们显示我们的结果。
在写这篇博文之前,我在谷歌上下载了两张索引中没有的图片。一辆瑞文戴尔和一辆夏尔。这两个图像将是我们的查询。
要运行该脚本,只需在终端中提供正确的命令行参数:
$ python search_external.py --dataset images --index index.cpickle \
--query queries/rivendell-query.png
query: queries/rivendell-query.png
1\. Rivendell-002.png : 0.195
2\. Rivendell-004.png : 0.449
3\. Rivendell-001.png : 0.643
4\. Rivendell-005.png : 0.757
5\. Rivendell-003.png : 0.769
6\. Mordor-001.png : 0.809
7\. Mordor-003.png : 0.858
8\. Goblin-002.png : 0.875
9\. Mordor-005.png : 0.894
10\. Mordor-004.png : 0.909
$ python search_external.py --dataset images --index index.cpickle \
--query queries/shire-query.png
query: queries/shire-query.png
1\. Shire-004.png : 1.077
2\. Shire-003.png : 1.114
3\. Shire-001.png : 1.278
4\. Shire-002.png : 1.376
5\. Shire-005.png : 1.779
6\. Rivendell-001.png : 1.822
7\. Rivendell-004.png : 2.077
8\. Rivendell-002.png : 2.146
9\. Golbin-005.png : 2.170
10\. Goblin-001.png : 2.198
查看以下两个查询图像的结果:

Figure 5: Using external Rivendell (Left) and the Shire (Right) query images. For both cases, we find the top 5 search results are from the same category.
在这种情况下,我们使用了两张以前没有见过的图像进行搜索。左边的是瑞文戴尔的。我们可以从结果中看到,我们的索引中的其他 5 个 Rivendell 图像被返回,这表明我们的图像搜索引擎工作正常。
在右边,我们有一个来自夏尔的查询图像。同样,这张图片没有出现在我们的索引中。但是当我们查看搜索结果时,我们可以看到其他 5 个 Shire 图像是从图像搜索引擎返回的,这再次证明了我们的图像搜索引擎正在返回语义相似的图像。
摘要
在这篇博文中,我们从头到尾探索了如何创建一个图片搜索引擎。第一步是选择图像描述符——我们使用 3D RGB 直方图来描述图像的颜色。然后,我们通过提取特征向量(即直方图),使用我们的描述符对数据集中的每个图像进行索引。从那里,我们使用卡方距离来定义两幅图像之间的“相似性”。最后,我们把所有的碎片粘在一起,创建了一个指环王图片搜索引擎。
那么,下一步是什么?
我们才刚刚开始。现在,我们只是触及了图像搜索引擎的皮毛。这篇博文中的技巧非常简单。有很多可以借鉴的地方。例如,我们专注于仅使用直方图来描述颜色。但是我们如何描述纹理呢?还是外形?这个神秘的 SIFT 描述符是什么?
所有这些问题以及更多的问题,都将在未来几个月得到解答。
如果你喜欢这篇博文,请考虑与他人分享。
HOG 检测多尺度参数解释
原文:https://pyimagesearch.com/2015/11/16/hog-detectmultiscale-parameters-explained/
上周我们讨论了如何使用 OpenCV 和 Python 来执行行人检测。
为了实现这一点,我们利用 OpenCV 自带的内置 HOG +线性 SVM 检测器,允许我们检测图像中的人。
然而,我们没有详细讨论的猪人检测器的一个方面是detectMultiScale功能;具体来说,该功能的 参数 可以:
- 增加假阳性检测的数量(即,报告图像中的位置包含人,但实际上不包含人)。
- 导致完全错过检测。
- 显著地影响检测过程的速度。
在这篇博文的剩余部分,我将把每个detectMultiScale参数分解成梯度方向直方图描述符和 SVM 检测器。
我还将解释如果我们希望我们的行人检测器实时运行,我们必须在速度和精度之间做出的 权衡 。如果您想在资源受限的设备(如 Raspberry Pi)上实时运行行人检测器,这种权衡尤其重要。
访问 HOG 检测多比例参数
要查看detectMultiScale函数的参数,只需启动一个 shell,导入 OpenCV,然后使用help函数:
$ python
>>> import cv2
>>> help(cv2.HOGDescriptor().detectMultiScale)
Figure 1: The available parameters to the detectMultiScale function.
您可以在任何 OpenCV 函数上使用内置的 Python help方法来获得参数和返回值的完整列表。
HOG 检测多尺度参数解释
在我们探索detectMultiScale参数之前,让我们首先创建一个简单的 Python 脚本(基于我们上周的行人检测器),它将允许我们轻松地进行实验:
# import the necessary packages
from __future__ import print_function
import argparse
import datetime
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-w", "--win-stride", type=str, default="(8, 8)",
help="window stride")
ap.add_argument("-p", "--padding", type=str, default="(16, 16)",
help="object padding")
ap.add_argument("-s", "--scale", type=float, default=1.05,
help="image pyramid scale")
ap.add_argument("-m", "--mean-shift", type=int, default=-1,
help="whether or not mean shift grouping should be used")
args = vars(ap.parse_args())
因为这个脚本的大部分是基于上周的帖子,所以我将对代码做一个更快速的概述。
第 9-20 行处理解析我们的命令行参数--image开关是我们想要检测行人的输入图像的路径。--win-stride是滑动窗口在 x 和 y 方向的步长。--padding开关控制在 HOG 特征向量提取和 SVM 分类之前填充 ROI 的像素数量。为了控制图像金字塔的比例(允许我们在多个比例下检测图像中的人),我们可以使用--scale参数。最后,如果我们想要对检测到的边界框应用均值漂移分组,可以指定--mean-shift。
# evaluate the command line arguments (using the eval function like
# this is not good form, but let's tolerate it for the example)
winStride = eval(args["win_stride"])
padding = eval(args["padding"])
meanShift = True if args["mean_shift"] > 0 else False
# initialize the HOG descriptor/person detector
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# load the image and resize it
image = cv2.imread(args["image"])
image = imutils.resize(image, width=min(400, image.shape[1]))
既然我们已经解析了命令行参数,我们需要分别在第 24-26 行的上提取它们的元组和布尔值。使用eval函数,尤其是在命令行参数中,并不是一种好的做法,但是为了这个例子,让我们容忍它(并且为了便于我们使用不同的--win-stride和--padding值)。
第 29 行和第 30 行初始化方向梯度直方图检测器,并将支持向量机检测器设置为 OpenCV 中包含的默认行人检测器。
从那里,第 33 行和第 34 行加载我们的图像并将其调整到最大宽度为 400 像素——我们的图像越小,处理和检测图像中的人就越快。
# detect people in the image
start = datetime.datetime.now()
(rects, weights) = hog.detectMultiScale(image, winStride=winStride,
padding=padding, scale=args["scale"], useMeanshiftGrouping=meanShift)
print("[INFO] detection took: {}s".format(
(datetime.datetime.now() - start).total_seconds()))
# draw the original bounding boxes
for (x, y, w, h) in rects:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Detections", image)
cv2.waitKey(0)
第 37-41 行使用detectMultiScale函数和我们通过命令行参数提供的参数检测我们的image中的行人。我们将在第 37 行和第 41 行上启动和停止一个计时器,允许我们确定在给定的一组参数下处理一个图像需要多长时间。
最后,第 44-49 行在我们的image上画出边界框检测,并将输出显示到我们的屏幕上。
要获得对象检测计时的默认基线,只需执行以下命令:
$ python detectmultiscale.py --image images/person_010.bmp
在我的 MacBook Pro 上,检测过程总共需要 0.09 秒,这意味着我每秒可以处理大约 10 张图像:
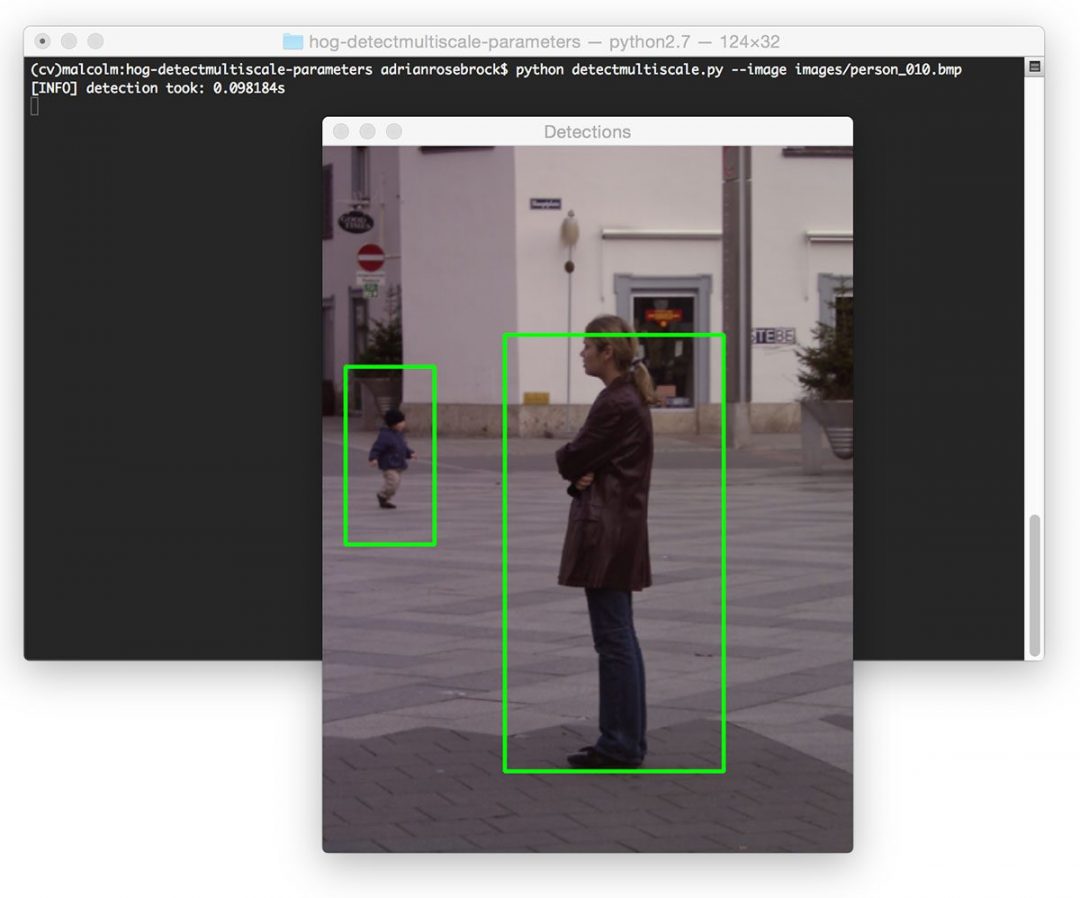
Figure 2: On my system, it takes approximately 0.09s to process a single image using the default parameters.
在本课的剩余部分,我们将详细探讨detectMultiScale的参数,以及这些参数对检测时间的影响。
img(必需)
这个参数非常明显——它是我们想要检测对象(在这个例子中是人)的图像。这是detectMultiScale函数的唯一的必需参数。我们传入的图像可以是彩色或者灰度。
hitThreshold(可选)
hitThreshold参数是可选的,在detectMultiScale功能中默认不使用。
当我查看这个函数的 OpenCV 文档时,对参数的唯一描述是:“特征和 SVM 分类平面之间距离的阈值”。
鉴于该参数的稀疏文档(以及我在使用它进行行人检测时的奇怪行为),我认为该参数控制输入 HOG 要素和 SVM 分类平面之间的最大欧氏距离。如果欧几里德距离超过该阈值,则检测被拒绝。然而,如果距离低于该阈值,则检测被接受。
我个人的观点是,你不应该费心去摆弄这个参数,除非你在你的图像中看到了极高的误报检测率。在这种情况下,可能值得尝试设置这个参数。否则,就让非最大值抑制处理任何重叠的边界框,就像我们在上一课中做的那样。
winStride(可选)
winStride参数是一个二元组,它规定了滑动窗口的 x 和 y 位置的“步长”。
winStride和scale都是 非常重要的参数 ,需要正确设置。这些参数 不仅对探测器的精度有巨大影响** ,而且对探测器运行的速度也有巨大影响。
在对象检测的上下文中,滑动窗口是一个固定宽度和高度的矩形区域,它在图像上“滑动”,如下图所示:
Figure 3: An example of applying a sliding window to an image for face detection.
在滑动窗口的每一个停止点(对于图像金字塔的每一层,在下面的scale部分讨论),我们(1)提取 HOG 特征并且(2)将这些特征传递给我们的线性 SVM 用于分类。特征提取和分类器决定的过程是一个昂贵的过程,所以如果我们打算近实时地运行我们的 Python 脚本,我们更愿意评估尽可能少的窗口。
winStride越小,需要评估的窗口就越多(这可能很快变成相当大的计算负担):
$ python detectmultiscale.py --image images/person_010.bmp --win-stride="(4, 4)"
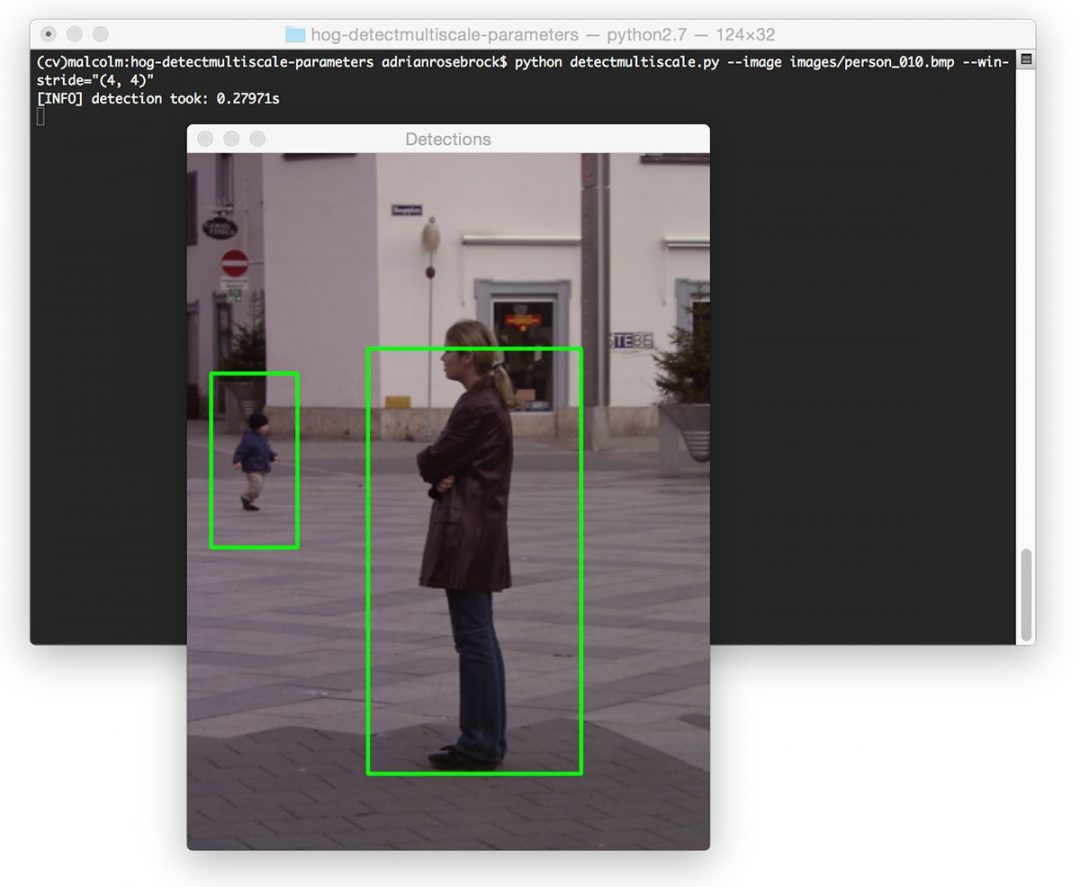
Figure 4: Decreasing the winStride increases the amount of time it takes it process each each.
这里我们可以看到,将winStride减少到 (4,4) 实际上已经将我们的检测时间大大增加到 0.27 秒
类似地,较大的 winStride是需要评估的较少的窗口(允许我们显著地加速我们的检测器)。然而,如果winStride变得太大,那么我们很容易完全错过检测:
$ python detectmultiscale.py --image images/person_010.bmp --win-stride="(16, 16)"
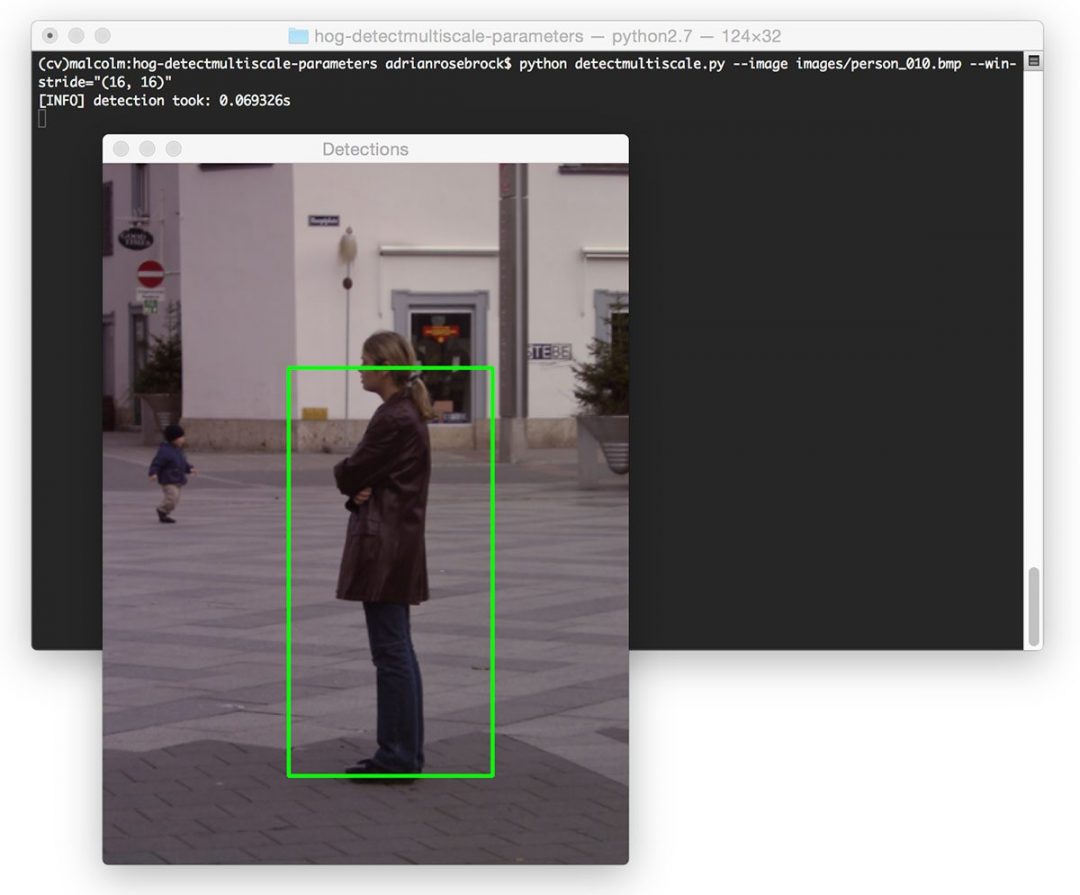
Figure 5: Increasing the winStride can reduce our pedestrian detection time (0.09s down to 0.06s, respectively), but as you can see, we miss out on detecting the boy in the background.
我倾向于从使用 (4,4) 的winStride值开始,并增加该值,直到我在速度和检测精度之间获得合理的平衡。
填充(可选)
padding参数是一个元组,其指示在 HOG 特征提取之前滑动窗口 ROI 被“填充”的 x 和 y 方向上的像素数。
正如 Dalal 和 Triggs 在他们 2005 年的 CVPR 论文中所建议的,在之前,在图像 ROI 周围添加一点填充,以进行特征提取和分类,实际上可以提高检测器的准确性。
填充的典型值包括 (8,8) 、 (16,16) 、 (24,24) 和 (32,32) 。
比例(可选)
图像金字塔是图像的多尺度表示:
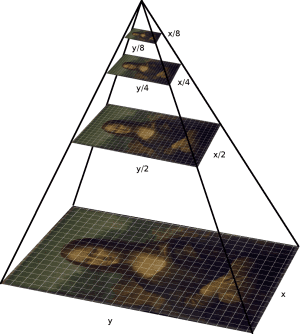
Figure 6: An example image pyramid.
在图像金字塔的每一层,图像被缩小并且(可选地)通过高斯滤波器被平滑。
这个scale参数控制着我们的图像在图像金字塔的每一层被调整大小的因子,最终影响图像金字塔中等级的数量。
一个变小 scale将 增加 图像金字塔中的层数和 增加 处理图像所需的时间:
$ python detectmultiscale.py --image images/person_010.bmp --scale 1.01
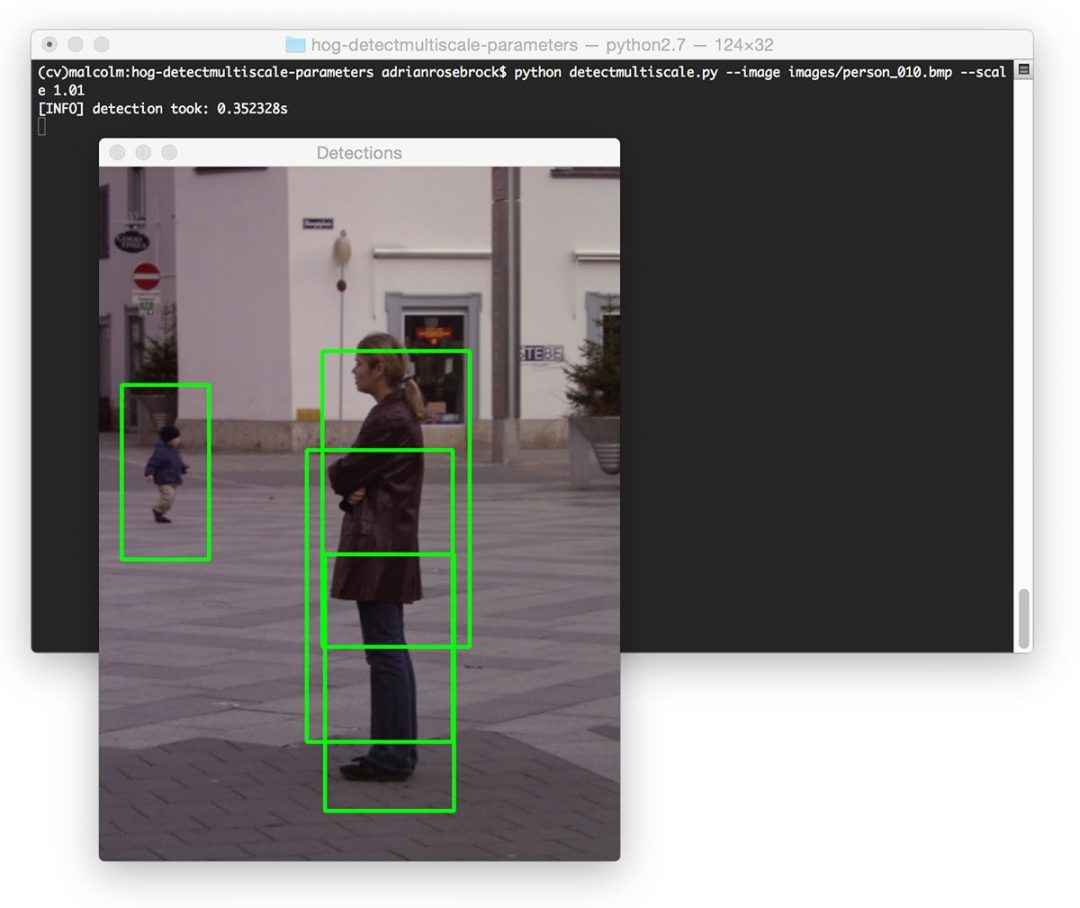
Figure 7: Decreasing the scale to 1.01
处理我们的图像所花费的时间已经大幅增加到 0.3 秒。我们现在还有一个重叠边界框的问题。然而,使用非最大值抑制可以很容易地解决这个问题。
与此同时,更大的比例将 减少 金字塔中的层数,以及 减少 检测图像中的物体所需的时间:
$ python detectmultiscale.py --image images/person_010.bmp --scale 1.5
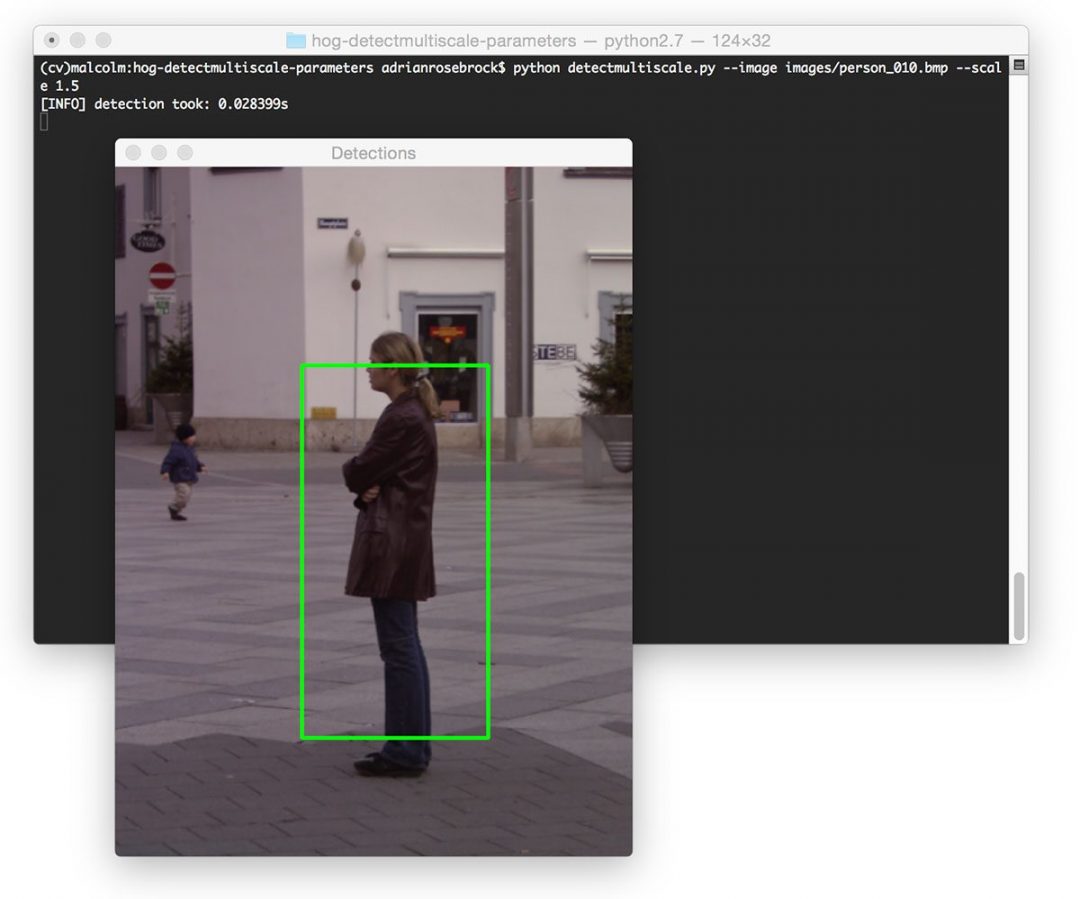
Figure 8: Increasing our scale allows us to process nearly 20 images per second — at the expense of missing some detections.
这里我们可以看到,我们仅用 0.02 秒就完成了行人检测,这意味着我们每秒可以处理近 50 张图像。然而,这是以错过一些检测为代价的,如上图所示。
最后,如果你同时减少winStride和scale,你将显著增加执行物体检测的时间:
$ python detectmultiscale.py --image images/person_010.bmp --scale 1.03 \
--win-stride="(4, 4)"
Figure 9: Decreasing both the scale and window stride.
我们能够检测到图像中的两个人——但执行这种检测几乎需要半秒钟,这绝对不适合实时应用。
请记住,对于金字塔的每一层,一个带有winStride台阶的滑动窗口会在整个层上移动。虽然评估图像金字塔的多个层很重要,使我们能够在不同尺度下找到图像中的对象,但这也增加了大量的计算负担,因为每一层还意味着必须执行一系列滑动窗口、HOG 特征提取和 SVM 决策。
scale的典型值通常在【1.01,1.5】范围内。如果您打算实时运行detectMultiScale,这个值应该尽可能大,而不显著牺牲检测精度。
同样,除了winStride,scale是检测速度方面最重要的参数。
finalThreshold (optional)
老实说,我甚至无法在 OpenCV 文档中找到finalThreshold(特别是针对 Python 绑定的),我也不知道它是做什么的。我假设它与hitThreshold有些关系,允许我们对潜在的命中应用“最终阈值”,剔除潜在的误报,但同样,这只是基于参数名称的推测。
如果有人知道这个参数控制什么,请在这篇文章的底部留下评论。
useMeanShiftGrouping(可选)
useMeanShiftGrouping参数是一个布尔值,指示是否应该执行均值偏移分组来处理潜在的重叠边界框。这个值默认为False,在我看来,永远不要设置为True —用非极大值抑制代替;你会得到更好的结果。
当使用 HOG +线性 SVM 物体检测器时,您无疑会遇到多个重叠边界框的问题,其中检测器在我们试图检测的物体周围的区域中多次触发:
Figure 10: An example of detecting multiple, overlapping bounding boxes.
为了抑制这些多重边界框, Dalal 建议使用均值偏移(幻灯片 18)。然而,根据我的经验,均值偏移的性能次优,不应用作边界框抑制的方法,如下图所示:
Figure 11: Applying mean-shift to handle overlapping bounding boxes.
相反,利用非最大值抑制 (NMS)。NMS 不仅速度更快,而且最终检测更加准确:

Figure 12: Instead of applying mean-shift, utilize NMS instead. Your results will be much better.
加快物体检测过程的提示
无论您是批量处理图像数据集,还是希望实时(或尽可能接近实时)运行 HOG 检测机,以下三个技巧都可以帮助您尽可能提高检测机的性能:
- 在不影响检测精度的情况下,尽可能缩小图像或帧的尺寸。在调用
detectMultiScale功能之前,减小你的图像的宽度和高度。您的图像越小,需要处理的数据就越少,因此检测器的运行速度会更快。 - 调整您的
scale和winStride参数。这两个参数对你的物体探测器速度有 巨大的影响 。scale和winStride都应该尽可能大,同样,不牺牲探测器的精度。 - 如果你的检测器仍然不够快……你可能要考虑用 C/C++重新实现你的程序。Python 很棒,你可以用它做很多事情。但是有时您需要 C 或 C++的编译二进制速度——对于资源受限的环境尤其如此。
摘要
在本课中,我们复习了 HOG 描述符和 SVM 检测器的detectMultiScale函数的参数。具体来说,我们在行人检测的背景下检查了这些参数值。我们还讨论了使用 HOG 检测器时必须考虑的 速度和精度权衡 。
如果你的目标是在(近)实时应用中应用 HOG +线性 SVM,你首先要做的是在不牺牲检测精度的情况下,将图像尺寸调整到尽可能小:图像越小,需要处理的数据就越少。你可以一直跟踪你的尺寸调整因子,并将返回的边界框乘以这个因子,以获得与原始图像尺寸相关的边界框尺寸。
其次,一定要玩好你的scale和winStride参数。这些值会极大地影响检测机的检测准确性(以及假阳性率)。
最后,如果您仍然没有获得想要的每秒帧数(假设您正在处理一个实时应用程序),您可能需要考虑用 C/C++重新实现您的程序。虽然 Python 非常快(从各方面考虑),但有时你无法超越二进制可执行文件的速度。**
基于 OpenCV 和深度学习的整体嵌套边缘检测

在本教程中,您将学习如何通过 OpenCV 和深度学习应用整体嵌套边缘检测(HED)。我们将对图像和视频流应用整体嵌套边缘检测,然后将结果与 OpenCV 的标准 Canny 边缘检测器进行比较。
边缘检测使我们能够找到图像中物体的边界,是图像处理和计算机视觉的第一个应用用例之一。
当使用 OpenCV 进行边缘检测时,你很可能会使用 Canny 边缘检测器;然而,Canny 边缘检测器有几个问题,即:
- 设置滞后阈值的下限值和上限值是一个手动过程,需要实验和视觉验证。
- 适用于一幅图像的滞后阈值可能不适用于另一幅图像(对于在不同光照条件下拍摄的图像来说,几乎总是如此)。
- Canny 边缘检测器通常需要多个预处理步骤(即转换为灰度、模糊/平滑等。)以便获得良好的边缘图。
整体嵌套边缘检测 (HED)试图通过端到端深度神经网络解决 Canny 边缘检测器的局限性。
该网络接受 RGB 图像作为输入,然后产生边缘图作为输出。此外,HED 制作的边缘图在保留图像中的对象边界方面做得更好。
要了解关于 OpenCV 整体嵌套边缘检测的更多信息,请继续阅读!
基于 OpenCV 和深度学习的整体嵌套边缘检测
在本教程中,我们将学习使用 OpenCV 和深度学习的整体嵌套边缘检测(HED)。
我们将从讨论整体嵌套边缘检测算法开始。
从那里我们将回顾我们的项目结构,然后在图像和视频中利用 HED 进行边缘检测。
让我们开始吧!
什么是整体嵌套边缘检测?
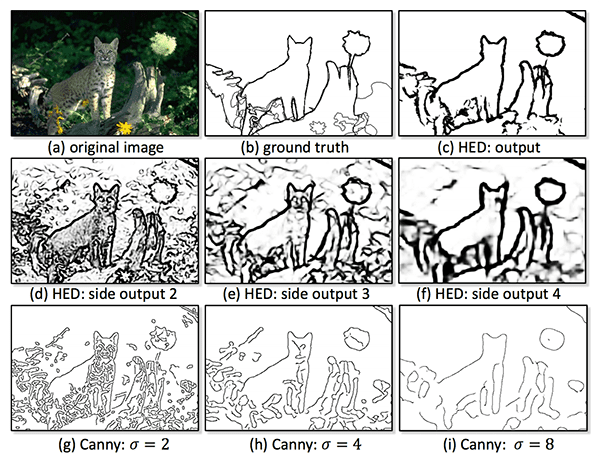
Figure 1: Holistically-Nested Edge Detection with OpenCV and Deep Learning (source: 2015 Xie and Tu Figure 1)
我们今天要用的算法来自谢和涂 2015 年的论文, 【整体嵌套边缘检测】,简称“”。
谢和涂的工作描述了能够自动学习丰富的分层边缘图的深度神经网络,所述分层边缘图能够确定图像中对象的边缘/对象边界。
这个边缘检测网络能够在 Berkely BSDS500 和 NYU 深度数据集上获得最先进的结果。
对网络架构和算法的全面回顾超出了本帖的范围,因此请参考官方出版物了解更多细节。
项目结构
继续抓取今天的 【下载】 并解压文件。
在那里,您可以使用以下命令检查项目目录:
$ tree --dirsfirst
.
├── hed_model
│ ├── deploy.prototxt
│ └── hed_pretrained_bsds.caffemodel
├── images
│ ├── cat.jpg
│ ├── guitar.jpg
│ └── janie.jpg
├── detect_edges_image.py
└── detect_edges_video.py
2 directories, 7 files
我们的 HED 咖啡模型包含在hed_model/目录中。
我提供了一些样本,包括我自己的一张照片,我的狗,还有我在网上找到的一张猫的图片样本。
今天我们将回顾一下detect_edges_image.py和detect_edges_video.py脚本。两个脚本共享相同的边缘检测过程,所以我们将花大部分时间在 HED 图像脚本上。
图像整体嵌套边缘检测
我们今天讨论的 Python 和 OpenCV 整体嵌套的边缘检测示例与 OpenCV 官方报告中的 HED 示例非常相似。
我在这里的主要贡献是:
- 提供一些额外的文档(在适当的时候)
- 最重要的是,向您展示如何在您自己的项目中使用整体嵌套边缘检测。
让我们开始吧——打开detect_edge_image.py文件并插入以下代码:
# import the necessary packages
import argparse
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--edge-detector", type=str, required=True,
help="path to OpenCV's deep learning edge detector")
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
args = vars(ap.parse_args())
我们的进口货物是在2-4 号线处理的。我们将使用 argparse来解析命令行参数。OpenCV 函数和方法通过cv2导入来访问。我们的os导入将允许我们在任何操作系统下构建文件路径。
该脚本需要两个命令行参数:
--edge-detector:OpenCV 深度学习边缘检测器的路径。该路径包含两个 Caffe 文件,稍后将用于初始化我们的模型。--image:测试用输入图像的路径。就像我之前说的——我已经在 【下载】 中提供了一些图片,但是你也应该在你自己的图片上尝试一下这个脚本。
让我们定义一下我们的CropLayer类:
class CropLayer(object):
def __init__(self, params, blobs):
# initialize our starting and ending (x, y)-coordinates of
# the crop
self.startX = 0
self.startY = 0
self.endX = 0
self.endY = 0
为了利用 OpenCV 的整体嵌套边缘检测模型,我们需要定义一个自定义的层裁剪类——我们将这个类恰当地命名为CropLayer。
在这个类的构造函数中,我们存储了开始和结束的坐标 (x,y)——分别是裁剪开始和结束的坐标(第 15-21 行)。
使用 OpenCV 应用 HED 的下一步是定义getMemoryShapes函数,这个方法负责计算inputs的卷大小:
def getMemoryShapes(self, inputs):
# the crop layer will receive two inputs -- we need to crop
# the first input blob to match the shape of the second one,
# keeping the batch size and number of channels
(inputShape, targetShape) = (inputs[0], inputs[1])
(batchSize, numChannels) = (inputShape[0], inputShape[1])
(H, W) = (targetShape[2], targetShape[3])
# compute the starting and ending crop coordinates
self.startX = int((inputShape[3] - targetShape[3]) / 2)
self.startY = int((inputShape[2] - targetShape[2]) / 2)
self.endX = self.startX + W
self.endY = self.startY + H
# return the shape of the volume (we'll perform the actual
# crop during the forward pass
return [[batchSize, numChannels, H, W]]
第 27 行导出输入体积的形状以及目标形状。
第 28 行也从inputs中提取批次大小和通道数量。
最后,行 29 分别提取目标形状的高度和宽度。
给定这些变量,我们可以计算开始和结束作物 (x,y)-线 32-35 上的坐标。
然后,我们将体积的形状返回给第 39 行上的调用函数。
我们需要定义的最后一个方法是forward函数。该功能负责在网络的正向传递(即推理/边缘预测)过程中执行裁剪:
def forward(self, inputs):
# use the derived (x, y)-coordinates to perform the crop
return [inputs[0][:, :, self.startY:self.endY,
self.startX:self.endX]]
第 43 行和第 44 行利用了 Python 和 NumPy 方便的列表/数组切片语法。
给定我们的CropLayer类,我们现在可以从磁盘加载我们的 HED 模型,并用net注册CropLayer:
# load our serialized edge detector from disk
print("[INFO] loading edge detector...")
protoPath = os.path.sep.join([args["edge_detector"],
"deploy.prototxt"])
modelPath = os.path.sep.join([args["edge_detector"],
"hed_pretrained_bsds.caffemodel"])
net = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# register our new layer with the model
cv2.dnn_registerLayer("Crop", CropLayer)
我们的 prototxt 路径和模型路径是使用通过args["edge_detector"] ( 第 48-51 行)可用的--edge-detector命令行参数构建的。
从那里,protoPath和modelPath都用于在线 52 上加载和初始化我们的 Caffe 模型。
让我们继续加载我们的输入内容image:
# load the input image and grab its dimensions
image = cv2.imread(args["image"])
(H, W) = image.shape[:2]
# convert the image to grayscale, blur it, and perform Canny
# edge detection
print("[INFO] performing Canny edge detection...")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
canny = cv2.Canny(blurred, 30, 150)
我们的原始数据image被加载,空间尺寸(宽度和高度)在行 58 和 59 被提取。
我们还计算 Canny 边缘图(第 64-66 行),这样我们可以将我们的边缘检测结果与 HED 进行比较。
最后,我们准备应用 HED:
# construct a blob out of the input image for the Holistically-Nested
# Edge Detector
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(W, H),
mean=(104.00698793, 116.66876762, 122.67891434),
swapRB=False, crop=False)
# set the blob as the input to the network and perform a forward pass
# to compute the edges
print("[INFO] performing holistically-nested edge detection...")
net.setInput(blob)
hed = net.forward()
hed = cv2.resize(hed[0, 0], (W, H))
hed = (255 * hed).astype("uint8")
# show the output edge detection results for Canny and
# Holistically-Nested Edge Detection
cv2.imshow("Input", image)
cv2.imshow("Canny", canny)
cv2.imshow("HED", hed)
cv2.waitKey(0)
为了将整体嵌套边缘检测(HED)与 OpenCV 和深度学习一起应用,我们:
- 从我们的图像中构造一个
blob(第 70-72 行)。 - 将斑点通过 HED 网,获得
hed输出(行 77 和 78 )。 - 将输出调整到我们的原始图像尺寸( Line 79 )。
- 将我们的图像像素缩放回范围【0,255】,并确保类型为
"uint8"( 第 80 行)。
最后,我们将展示:
- 原始输入图像
- Canny 边缘检测图像
- 我们的整体嵌套边缘检测结果
图像和 HED 结果
要使用 OpenCV 将整体嵌套的边缘检测应用到您自己的图像,请确保您使用本教程的 【下载】 部分来获取源代码、经过训练的 HED 模型和示例图像文件。从那里,打开一个终端并执行以下命令:
$ python detect_edges_image.py --edge-detector hed_model --image images/cat.jpg
[INFO] loading edge detector...
[INFO] performing Canny edge detection...
[INFO] performing holistically-nested edge detection...
Figure 2: Edge detection via the HED approach with OpenCV and deep learning ([input image source](https://www.boredpanda.com/cat-guide-man- mountain-gimmelwald-switzerland/? utm_source=google&utm_medium=organic&utm_cam paign=organic)).
左边的是我们的输入图像。
在中心我们有一个灵敏的边缘检测器。
右边的是我们应用整体嵌套边缘检测后的最终输出。
请注意,精明的边缘检测器无法保留猫、山脉或猫所坐的岩石的对象边界。
另一方面,HED 能够保留所有这些物体的边界。
让我们尝试另一个图像:
$ python detect_edges_image.py --edge-detector hed_model --image images/guitar.jpg
[INFO] loading edge detector...
[INFO] performing Canny edge detection...
[INFO] performing holistically-nested edge detection...

Figure 3: Me playing guitar in my office (left). Canny edge detection (center). Holistically-Nested Edge Detection (right).
在上面的图 3 中,我们可以看到一个我弹吉他的例子。使用 Canny 边缘检测器,会有许多由地毯的纹理和图案引起的“噪声”——相反,HED 没有这样的噪声。
此外,HED 在捕捉我的衬衫、牛仔裤(包括牛仔裤上的洞)和吉他的对象边界方面做得更好。
让我们做最后一个例子:
$ python detect_edges_image.py --edge-detector hed_model --image images/janie.jpg
[INFO] loading edge detector...
[INFO] performing Canny edge detection...
[INFO] performing holistically-nested edge detection...
Figure 4: My beagle, Janie, undergoes Canny and Holistically-Nested Edge Detection (HED) with OpenCV and deep learning.
这幅图像中有两个物体:(1)珍妮,一只狗,和(2)她身后的椅子。
精明的边缘检测器(中心)在突出椅子的轮廓方面做得很好,但不能正确地捕捉到狗的对象边界,主要是因为她的外套中的亮/暗和暗/亮过渡。
HED ( 右)更容易捕捉到简妮的整个轮廓。
视频中整体嵌套的边缘检测
我们已经用 OpenCV 对图像应用了整体嵌套边缘检测——对视频也可以这样做吗?
让我们找出答案。
打开detect_edges_video.py文件并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import imutils
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--edge-detector", type=str, required=True,
help="path to OpenCV's deep learning edge detector")
ap.add_argument("-i", "--input", type=str,
help="path to optional input video (webcam will be used otherwise)")
args = vars(ap.parse_args())
我们的视频脚本需要三个额外的导入:
VideoStream:从网络摄像头、视频文件或其他输入源读取帧。imutils:我在 GitHub 和 PyPi 上提供的便利功能包。我们正在使用我的resize函数。time:该模块允许我们发出睡眠命令,以允许我们的视频流建立并“预热”。
第 10-15 行上的两个命令行参数非常相似:
--edge-detector:OpenCV 的 HED 边缘检测器之路。--input:输入视频文件的可选路径。如果没有提供路径,将使用网络摄像头。
我们的CropLayer类与我们之前定义的相同:
class CropLayer(object):
def __init__(self, params, blobs):
# initialize our starting and ending (x, y)-coordinates of
# the crop
self.startX = 0
self.startY = 0
self.endX = 0
self.endY = 0
def getMemoryShapes(self, inputs):
# the crop layer will receive two inputs -- we need to crop
# the first input blob to match the shape of the second one,
# keeping the batch size and number of channels
(inputShape, targetShape) = (inputs[0], inputs[1])
(batchSize, numChannels) = (inputShape[0], inputShape[1])
(H, W) = (targetShape[2], targetShape[3])
# compute the starting and ending crop coordinates
self.startX = int((inputShape[3] - targetShape[3]) / 2)
self.startY = int((inputShape[2] - targetShape[2]) / 2)
self.endX = self.startX + W
self.endY = self.startY + H
# return the shape of the volume (we'll perform the actual
# crop during the forward pass
return [[batchSize, numChannels, H, W]]
def forward(self, inputs):
# use the derived (x, y)-coordinates to perform the crop
return [inputs[0][:, :, self.startY:self.endY,
self.startX:self.endX]]
在定义了我们的相同的 CropLayer类之后,我们将继续初始化我们的视频流和 HED 模型:
# initialize a boolean used to indicate if either a webcam or input
# video is being used
webcam = not args.get("input", False)
# if a video path was not supplied, grab a reference to the webcam
if webcam:
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# otherwise, grab a reference to the video file
else:
print("[INFO] opening video file...")
vs = cv2.VideoCapture(args["input"])
# load our serialized edge detector from disk
print("[INFO] loading edge detector...")
protoPath = os.path.sep.join([args["edge_detector"],
"deploy.prototxt"])
modelPath = os.path.sep.join([args["edge_detector"],
"hed_pretrained_bsds.caffemodel"])
net = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# register our new layer with the model
cv2.dnn_registerLayer("Crop", CropLayer)
无论我们选择使用我们的webcam还是一个视频文件,脚本都将动态地为这两者工作(第 51-62 行)。
我们的 HED 模型被加载,CropLayer被注册在行 65-73 。
让我们循环获取帧并应用边缘检测!
# loop over frames from the video stream
while True:
# grab the next frame and handle if we are reading from either
# VideoCapture or VideoStream
frame = vs.read()
frame = frame if webcam else frame[1]
# if we are viewing a video and we did not grab a frame then we
# have reached the end of the video
if not webcam and frame is None:
break
# resize the frame and grab its dimensions
frame = imutils.resize(frame, width=500)
(H, W) = frame.shape[:2]
我们开始在第 76-80 行的帧上循环。如果我们到达一个视频文件的结尾(当一帧是None时就会发生),我们将从循环中断开(第 84 行和第 85 行)。
第 88 行和第 89 行调整我们的框架大小,使其宽度为 500 像素。然后,我们在调整大小后获取框架的尺寸。
现在,让我们像在之前的脚本中一样处理帧和:
# convert the frame to grayscale, blur it, and perform Canny
# edge detection
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
canny = cv2.Canny(blurred, 30, 150)
# construct a blob out of the input frame for the Holistically-Nested
# Edge Detector, set the blob, and perform a forward pass to
# compute the edges
blob = cv2.dnn.blobFromImage(frame, scalefactor=1.0, size=(W, H),
mean=(104.00698793, 116.66876762, 122.67891434),
swapRB=False, crop=False)
net.setInput(blob)
hed = net.forward()
hed = cv2.resize(hed[0, 0], (W, H))
hed = (255 * hed).astype("uint8")
在输入帧上计算坎尼边缘检测(行 93-95 )和 HED 边缘检测(行 100-106 )。
从那里,我们将显示边缘检测结果:
# show the output edge detection results for Canny and
# Holistically-Nested Edge Detection
cv2.imshow("Frame", frame)
cv2.imshow("Canny", canny)
cv2.imshow("HED", hed)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# if we are using a webcam, stop the camera video stream
if webcam:
vs.stop()
# otherwise, release the video file pointer
else:
vs.release()
# close any open windows
cv2.destroyAllWindows()
我们的三个输出帧显示在行 110-112 : (1)原始的、调整大小的帧,(Canny 边缘检测结果,以及(3)HED 结果。
按键通过线 113 捕获。如果按下"q",我们将中断循环并清理(第 116-128 行)。
视频和 HED 结果
那么,如何使用 OpenCV 实时执行整体嵌套边缘检测呢?
让我们找出答案。
请务必使用这篇博文的 【下载】 部分下载源代码和 HED 模型。
从那里,打开一个终端并执行以下命令:
$ python detect_edges_video.py --edge-detector hed_model
[INFO] starting video stream...
[INFO] loading edge detector...
在上面简短的 GIF 演示中,你可以看到 HED 模型的演示。
请特别注意,当使用 Canny 边缘检测器时,背景中的灯边界是如何完全丢失的;然而,当使用 HED 时,边界被保留。
在性能方面,我在收集上面的演示时使用的是我的 3Ghz 英特尔至强 W 处理器。我们使用 HED 模型在 CPU 上获得了接近实时的性能。
要获得真正的实时性能,您需要利用 GPU 但是,请记住,OpenCV 的“dnn”模块的 GPU 支持特别有限(具体来说,目前不支持 NVIDIA GPUs)。
与此同时,如果您需要实时性能,您可以考虑使用 Caffe + Python 绑定。
摘要
在本教程中,您学习了如何使用 OpenCV 和深度学习来执行整体嵌套边缘检测(HED)。
与 Canny 边缘检测器不同,Canny 边缘检测器需要预处理步骤、手动调整参数,并且通常在使用不同照明条件捕获的图像上表现不佳,整体嵌套边缘检测寻求创建一个端到端深度学习边缘检测器。
正如我们的结果显示,HED 产生的输出边缘图比简单的 Canny 边缘检测器更好地保留了对象边界。整体嵌套边缘检测可以在环境和光照条件潜在地未知或简单地不可控的应用中潜在地替代 Canny 边缘检测。
不利的一面是,HED 的计算成本比 Canny 高得多。Canny 边缘检测器可以在 CPU 上超实时运行;然而,HED 的实时性能需要 GPU。
我希望你喜欢今天的帖子!
要下载本指南的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下表中输入您的电子邮件地址!
利用 Raspberry Pi、Python、OpenCV 和 Dropbox 实现家庭监控和运动检测

哇,上周关于构建基本运动检测系统的博文居然是 牛逼 。写这本书很有趣,我从像你一样的读者那里得到的反馈让我觉得很值得努力去收集。
对于那些刚刚开始调整的人来说,上周关于使用计算机视觉构建运动检测系统的帖子是由我的朋友詹姆斯溜进我的冰箱和偷了我最后一瓶令人垂涎的啤酒激发的。虽然我不能证明是他,但我想看看是否有可能使用计算机视觉和树莓酱来当场抓住他如果他再次试图偷我的啤酒。
正如你在这篇文章的结尾所看到的,我们将要构建的家庭监控和运动检测系统不仅是简单的 ,而且是 非常强大的 来实现这个特定的目标。
*今天,我们将扩展我们的基本运动检测方法,并:
- 让我们的运动检测系统更加鲁棒,这样它就可以全天连续运行****而不受光照条件变化的影响。
*** 更新我们的代码,这样我们的家庭监控系统就可以在树莓派上运行了。* 与 Dropbox API 集成,这样我们的 Python 脚本就可以自动将安全照片上传到我们的个人 Dropbox 账户。**
**在这篇文章中,我们将会看到很多代码,所以请做好准备。但是我们会学到很多东西。更重要的是,在这篇文章结束时,你将拥有一个自己的可以工作的 Raspberry Pi 家庭监控系统。
你可以直接在下面找到完整的演示视频,以及这篇文章底部的一堆其他例子。
更新:2017 年 8 月 24 日— 这篇博文中的所有代码都已更新,可以与 Dropbox V2 API 配合使用,因此您不再需要复制和粘贴视频中使用的验证密钥。更多细节请见这篇博文的剩余部分。
https://www.youtube.com/embed/BhD1aDEV-kg?feature=oembed***
如何构建自定义人脸识别数据集
原文:https://pyimagesearch.com/2018/06/11/how-to-build-a-custom-face-recognition-dataset/
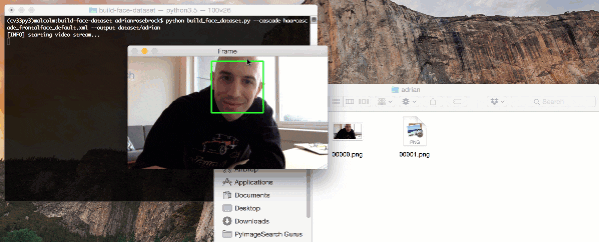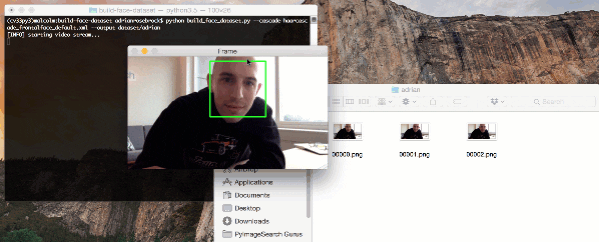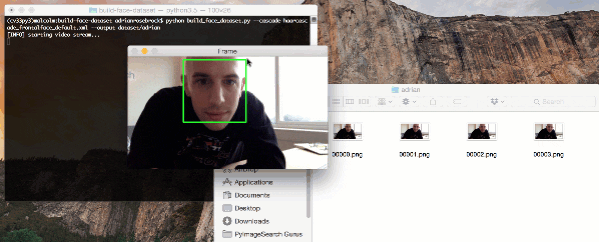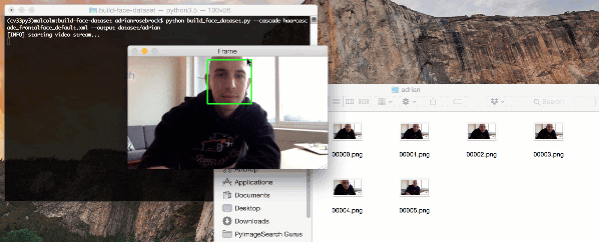
在接下来的几篇博文中,我们将训练一个计算机视觉+深度学习模型来执行 面部识别……
…但是在我们能够训练我们的模型识别图像和视频流中的人脸之前,我们首先需要 收集人脸数据集本身。
如果你已经在使用一个预先准备好的数据集,比如《野生人脸标签》( LFW ),那么艰苦的工作已经为你完成了。您将能够使用下周的博客文章来创建您的面部识别应用程序。
但是对于我们大多数人来说,我们反而想要识别不属于任何当前数据集的面孔并且识别我们自己、朋友、家庭成员、同事和同事等的面孔。
为了做到这一点,我们需要收集我们想要识别的人脸样本,然后以某种方式量化它们。
这个过程通常被称为面部识别注册。我们称之为“注册”,因为我们将用户作为数据集和应用程序中的示例人员进行“注册”。
今天的博文将关注注册过程的第一步:创建一个自定义的样本人脸数据集。
在下周的博客文章中,你将学习如何获取这个示例图像数据集,量化人脸,并创建自己的面部识别+ OpenCV 应用程序。
要了解如何创建自己的人脸识别数据集,请继续阅读!
如何创建自定义人脸识别数据集
在本教程中,我们将回顾三种为面部识别创建自定义数据集的方法。
第一种方法将使用 OpenCV 和网络摄像头来(1)检测视频流中的人脸,以及(2)将示例人脸图像/帧保存到磁盘。
第二种方法将讨论如何以编程方式下载人脸图像。
最后,我们将讨论图像的手动收集以及这种方法何时合适。
让我们开始构建人脸识别数据集吧!
方法 1:通过 OpenCV 和网络摄像头进行面部注册
Figure 1: Using OpenCV and a webcam it’s possible to detect faces in a video stream and save the examples to disk. This process can be used to create a face recognition dataset on premises.
这是创建您自己的自定义人脸识别数据集的第一种方法,适用于:
- 您正在构建一个“现场”人脸识别系统
- 而且你需要和特定的人有物理接触来收集他们面部的图像
这种系统对于公司、学校或其他组织来说是典型的,在这些组织中,人们需要每天亲自出现和参加。
为了收集这些人的示例面部图像,我们可以护送他们到一个特殊的房间,在那里安装了一台摄像机,以(1)检测他们面部在视频流中的 (x,y)-坐标,以及(2)将包含他们面部的帧写入磁盘。
我们甚至可能在几天或几周内执行这一过程,以收集他们面部的样本:
- 不同的照明条件
- 一天中的时间
- 心情和情绪状态
…创建一组更多样化的图像,代表特定人物的面部。
让我们继续构建一个简单的 Python 脚本,以便于构建我们的自定义人脸识别数据集。该 Python 脚本将:
- 访问我们的网络摄像头
- 检测人脸
- 将包含该面的帧写入磁盘
要获取今天博文的代码,请务必滚动到 【下载】 部分。
当你准备好了,打开build_face_dataset.py让我们一步步来:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import imutils
import time
import cv2
import os
在2-7 行,我们导入我们需要的包。值得注意的是,我们需要 OpenCV 和imutils。
要安装 OpenCV,请务必遵循我在本页上的安装指南。
您可以通过 pip 轻松安装或升级 imutils :
$ pip install --upgrade imutils
如果您正在使用 Python 虚拟环境,不要忘记使用workon命令!
现在您的环境已经设置好了,让我们来讨论两个必需的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", required=True,
help = "path to where the face cascade resides")
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
args = vars(ap.parse_args())
命令行参数在运行时由一个名为argparse的便利包解析(它包含在所有 Python 安装中)。如果你不熟悉argparse和命令行参数,我强烈推荐你给一个快速阅读这篇博文的机会。
我们有两个必需的命令行参数:
--cascade:磁盘上 Haar cascade 文件的路径。--output:输出目录的路径。人脸图像将存储在此目录中,我建议您以人名命名此目录。如果您的名字是“John Smith”,您可以将所有图像放在dataset/john_smith中。
让我们加载我们的脸哈尔级联和初始化我们的视频流:
# load OpenCV's Haar cascade for face detection from disk
detector = cv2.CascadeClassifier(args["cascade"])
# initialize the video stream, allow the camera sensor to warm up,
# and initialize the total number of example faces written to disk
# thus far
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
total = 0
在的第 18 行我们加载了 OpenCV 的 Haar face detector。这个detector将在我们即将到来的逐帧循环中完成繁重的工作。
我们在第 24 行的上实例化并启动我们的VideoStream。
注意:如果你使用的是 Raspberry Pi,注释掉第 24 行*并取消后面一行的注释。*
为了让我们的相机预热,我们简单地暂停两秒钟(第 26 行)。
我们还初始化了一个代表存储在磁盘上的人脸图像数量的total计数器(第 27 行)。
现在让我们逐帧循环视频流:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream, clone it, (just
# in case we want to write it to disk), and then resize the frame
# so we can apply face detection faster
frame = vs.read()
orig = frame.copy()
frame = imutils.resize(frame, width=400)
# detect faces in the grayscale frame
rects = detector.detectMultiScale(
cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY), scaleFactor=1.1,
minNeighbors=5, minSize=(30, 30))
# loop over the face detections and draw them on the frame
for (x, y, w, h) in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
在行 30 处,我们开始循环(当按下“q”键时,循环退出)。
从那里,我们抓取一个frame,创建一个副本,并调整它的大小(第 34-36 行)。
现在该进行人脸检测了!
使用detectMultiScale方法,我们可以在frame中检测人脸。该函数需要多个参数:
image:灰度图像scaleFactor:指定图像尺寸在每个比例下缩小多少minNeighbor:指定每个候选边界框矩形应该有多少个邻居以保持有效检测的参数minSize:可能的最小面部图像尺寸
不幸的是,有时这种方法需要调整以消除假阳性或检测人脸,但对于“近距离”人脸检测,这些参数应该是一个很好的起点。
也就是说,你在寻找更先进、更可靠的方法吗?在之前的一篇博文中,我用 OpenCV 和深度学习 覆盖了 人脸检测。你可以很容易地用深度学习方法更新今天的脚本,这种方法使用预先训练好的模型。这种方法的好处是不需要调整参数,而且速度非常快。
我们的人脸检测方法的结果是一个rects(包围盒矩形)列表。在第 44 和 45 行的上,我们循环遍历rects并在frame上画出矩形用于显示。
我们将在循环中采取的最后步骤是(1)在屏幕上显示帧,以及(2)处理按键:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `k` key was pressed, write the *original* frame to disk
# so we can later process it and use it for face recognition
if key == ord("k"):
p = os.path.sep.join([args["output"], "{}.png".format(
str(total).zfill(5))])
cv2.imwrite(p, orig)
total += 1
# if the `q` key was pressed, break from the loop
elif key == ord("q"):
break
在行 48 上,我们将帧显示到屏幕上,然后捕捉行 49 上的按键。
根据是否按下“k”或“q”键,我们将:
- 保留
frame并保存到磁盘中(第 53-56 行)。我们还增加我们捕获的total帧(行 57 )。对于每个我们想要“保留”的frame,必须按下“k”键。我建议让你的脸保持在不同的角度,不同的部位,戴/不戴眼镜,等等。 - 退出循环,准备退出脚本(quit)。
如果没有键被按下,我们从循环的顶部开始,从流中抓取一个frame。
最后,我们将打印终端中存储的图像数量并执行清理:
# print the total faces saved and do a bit of cleanup
print("[INFO] {} face images stored".format(total))
print("[INFO] cleaning up...")
cv2.destroyAllWindows()
vs.stop()
现在让我们运行脚本并收集面孔!
确保你已经从这篇博文的 “下载” 部分下载了代码和 Haar cascade。
从那里,在您的终端中执行以下命令:
$ python build_face_dataset.py --cascade haarcascade_frontalface_default.xml \
--output dataset/adrian
[INFO] starting video stream...
[INFO] 6 face images stored
[INFO] cleaning up...
https://www.youtube.com/embed/K0l0cs7ekeo?feature=oembed
如何为计算机视觉和深度学习配置您的 NVIDIA Jetson Nano

在今天的教程中,您将了解如何使用 TensorFlow、Keras、TensorRT 和 OpenCV 为计算机视觉和深度学习配置您的 NVIDIA Jetson Nano。
两周前,我们讨论了如何使用我的 预配置的 Nano。img 文件 — 今天,你将从开始学习如何配置自己的 Nano。
这个指南要求你在自己配置你的 NVIDIA Jetson Nano 时,有至少 48 小时的时间来消磨(是的,这真的很有挑战性
如果你决定要跳过麻烦,使用我预先配置的纳米。img,你可以在我的新书中找到它, 计算机视觉的树莓派。
但是对于那些足够勇敢的人来说,这篇文章是给你的!
要了解如何为计算机视觉和深度学习配置你的 NVIDIA Jetson Nano,继续阅读。
如何为计算机视觉和深度学习配置您的 NVIDIA Jetson Nano
NVIDIA Jetson Nano 拥有 472GFLOPS 的计算能力。虽然它是一台非常强大的机器,但配置它却不容易(复杂的机器通常不容易配置)。
在本教程中,我们将通过 16 个步骤来配置您的 Jetson Nano,以实现计算机视觉和深度学习。
做好准备,这将是一个漫长而艰苦的过程——按照这个指南,你可能需要 2-5 天的时间来配置你的 Nano。
一旦完成,我们将测试我们的系统,以确保它配置正确,TensorFlow/Keras 和 OpenCV 按预期运行。我们还将使用 OpenCV 测试我们的 Nano 的摄像头,以确保我们可以访问我们的视频流。
如果您在最后的测试步骤中遇到问题,那么您可能需要返回并解决它;或者更糟,从第一步开始,忍受另外 2-5 天的痛苦,通过配置教程开始运行(但是不要担心,我在 16 个步骤的结尾提供了一个替代方案)。
第一步:Flash NVIDIA 的 Jetson Nano 开发者套件。为 Jetson Nano 向 microSD 进行 img
在这一步,我们将下载 NVIDIA 的基于 Jetpack 4.2 Ubuntu 的操作系统映像,并将其闪存到 microSD。您需要刷新 microSD,并准备好执行后续步骤。
点击此处开始下载,确保下载“Jetson Nano Developer Kit SD 卡映像”,如下图所示:

Figure 1: The first step to configure your NVIDIA Jetson Nano for computer vision and deep learning is to download the Jetpack SD card image.
我们推荐 Jetpack 4.2 兼容 的完整捆绑计算机视觉 的【树莓 Pi】(我们的推荐未来必然会有变化)。
下载 Nano SD 映像时,继续下载并安装 balenaEtcher ,这是一个磁盘映像刷新工具:

Figure 2: Download and install balenaEtcher for your OS. You will use it to flash your Nano image to a microSD card.
一旦(1)下载了您的 Nano Jetpack 映像,并且(2)安装了 balenaEtcher,您就可以将映像刷新到 microSD 了。
您需要合适的 microSD 卡和 microSD 读卡器硬件。我们推荐 32GB 或 64GB 的 microSD 卡(SanDisk 的 98MB/s 卡是高质量的,如果他们是您所在地区的经销商,亚马逊也会提供这些卡)。任何 microSD 读卡器都应该能用。
将 microSD 插入读卡器,然后将读卡器插入电脑的 USB 端口。从那里,启动 balenaEtcher 并开始闪光。

Figure 3: Flashing NVIDIA’s Jetpack image to a microSD card with balenaEtcher is one of the first steps for configuring your Nano for computer vision and deep learning.
当闪烁成功完成时,您准备好继续进行步骤#2 。
第二步:用 microSD 启动你的 Jetson Nano 并连接到网络

Figure 4: The NVIDIA Jetson Nano does not come with WiFi capability, but you can use a USB WiFi module (top-right) or add a more permanent module under the heatsink (bottom-center). Also pictured is a 5V 4A (20W) power supply (top-left) that you may wish to use to power your Jetson Nano if you have lots of hardware attached to it.
在此步骤中,我们将启动 Jetson Nano 并建立网络连接。
这一步需要以下内容:
- 从步骤#1 开始闪烁的 microSD
- NVIDIA Jetson Nano 开发板
- HDMI 屏幕
- USB 键盘+鼠标
- 电源——1)5V 2.5A(12.5 瓦)microSD 电源或 2)5V 4A(20W)筒式插头电源,在 J48 连接器处有跳线
- 网络连接——要么是(1)将 Nano 连接到网络的以太网电缆,要么是(2)无线模块。无线模块可以以 USB WiFi 适配器或安装在 Jetson Nano 散热器下的 WiFi 模块的形式出现
如果你想要 WiFi(大部分人都有),你必须自己加一个 WiFi 模块。为您的 Jetson Nano 添加 WiFi 的两个绝佳选择包括:
- USB 转 WiFi 适配器(图四、右上)。不需要任何工具,可以移植到其他设备上。图为 Geekworm 双频 USB 1200m
- WiFi 模块如 Intel 双频 Wireless-Ac 8265 W/Bt(Intel 8265 NGW)和 2xMolex Flex 2042811100 Flex 天线 ( 图 5 、中底)。您必须在 Jetson Nano 的主散热器下安装 WiFi 模块和天线。这种升级需要 2 号十字螺丝刀、无线模块和天线(更不用说大约 10-20 分钟的时间)
如果您需要在 Jetson Nano 上使用 WiFi,我们建议您使用 USB WiFi 适配器。网上有很多选择,所以尽量购买一个在操作系统上预装了 Ubuntu 18.04 驱动程序的,这样你就不需要手忙脚乱地下载和安装驱动程序了。
一旦你收集好所有的装备,将你的 microSD 插入你的 Jetson Nano,如图 5 所示

Figure 5: To insert your Jetpack-flashed microSD after it has been flashed, find the microSD slot as shown by the red circle in the image. Insert your microSD until it clicks into place.
从那里,连接您的屏幕,键盘,鼠标和网络接口。
最后,施加力量。将电源适配器的电源插头插入 Jetson Nano(如果您使用 20W 桶形插头电源,请使用 J48 跳线)。
Figure 6: Use the icon near the top right corner of your screen to configure networking settings on your NVIDIA Jetson Nano. You will need internet access to download and install computer vision and deep learning software.
一旦你看到你的 NVIDIA + Ubuntu 18.04 桌面,你应该使用菜单栏中的图标根据需要配置你的有线或无线网络设置,如图 6 所示。
当您确认您的 NVIDIA Jetson Nano 可以访问互联网时,您可以进入下一步。
步骤 3:打开一个终端或启动一个 SSH 会话
在此步骤中,我们将执行以下操作之一:
- 选项 1: 在 Nano 桌面上打开一个终端,假设您将使用连接到 Nano 的键盘和鼠标执行从这里开始的所有步骤
- 选项 2: 从不同的计算机启动 SSH 连接,以便我们可以远程配置我们的 NVIDIA Jetson Nano,用于计算机视觉和深度学习
两种选择都一样好。
选项 1:使用 Nano 桌面上的终端
对于选项 1 ,打开应用启动器,选择终端应用。您可能希望在左侧菜单中右键单击它,并将其锁定到启动器,因为您可能会经常使用它。
您现在可以继续步骤#4 ,同时保持终端打开以输入命令。
选项 2:启动 SSH 远程会话
对于选项 2 ,您必须首先确定您的 Jetson Nano 的用户名和 IP 地址。在您的 Nano 上,从应用程序启动器启动终端,并在提示符下输入以下命令:
$ whoami
nvidia
$ ifconfig
en0: flags=8863 mtu 1500
options=400
ether 8c:85:90:4f:b4:41
inet6 fe80::14d6:a9f6:15f8:401%en0 prefixlen 64 secured scopeid 0x8
inet6 2600:100f:b0de:1c32:4f6:6dc0:6b95:12 prefixlen 64 autoconf secured
inet6 2600:100f:b0de:1c32:a7:4e69:5322:7173 prefixlen 64 autoconf temporary
inet 192.168.1.4 netmask 0xffffff00 broadcast 192.168.1.255
nd6 options=201
media: autoselect
status: active
获取您的 IP 地址(在突出显示的行中)。我的 IP 地址是192 . 168 . 1 . 4;然而,你的 IP 地址将是不同的,所以一定要检查和验证你的 IP 地址!
然后,在一台 单独的 计算机上,如您的笔记本电脑/台式机,启动 SSH 连接,如下所示:
$ ssh nvidia@192.168.1.4
请注意我是如何在命令中输入 Jetson Nano 的用户名和 IP 地址来进行远程连接的。您现在应该已经成功连接到您的 Jetson Nano,并且您可以继续进行步骤#4 。
第四步:更新你的系统并删除程序以节省空间
在这一步,我们将删除我们不需要的程序,并更新我们的系统。
首先,让我们将 Nano 设置为使用最大功率容量:
$ sudo nvpmodel -m 0
$ sudo jetson_clocks
命令为你的 Jetson Nano 处理两个功率选项:(1) 5W 是模式1和(2) 10W 是模式 0。默认为高功率模式,但最好在运行jetson_clocks命令前强制该模式。
根据 NVIDIA devtalk 论坛:
jetson_clocks脚本禁用 DVFS 调控器,并将时钟锁定到活动nvpmodel电源模式定义的最大值。因此,如果您的活动模式是 10W,jetson_clocks将锁定时钟到 10W 模式的最大值。如果你的活动模式是 5W,jetson_clocks会将时钟锁定到 5W 模式的最大值 ( NVIDIA DevTalk Forums )。
注: 有两种典型的方式为你的杰特森 Nano 提供动力。5V 2.5A (10W) microUSB 电源适配器是一个不错的选择。如果您有许多由 Nano 供电的设备(键盘、鼠标、WiFi、相机),那么您应该考虑 5V 4A (20W)电源,以确保您的处理器可以全速运行,同时为您的外围设备供电。从技术上讲,如果您想直接在接头引脚上供电,还有第三种电源选项。
在你将 Nano 设置为最大功率后,继续移除 libre office——它会占用大量空间,我们不需要它来进行计算机视觉和深度学习:
$ sudo apt-get purge libreoffice*
$ sudo apt-get clean
接下来,让我们继续更新系统级软件包:
$ sudo apt-get update && sudo apt-get upgrade
下一步,我们将开始安装软件。
步骤#5:安装系统级依赖项
我们需要安装的第一套软件包括一系列开发工具:
$ sudo apt-get install git cmake
$ sudo apt-get install libatlas-base-dev gfortran
$ sudo apt-get install libhdf5-serial-dev hdf5-tools
$ sudo apt-get install python3-dev
$ sudo apt-get install nano locate
接下来,我们将安装 SciPy 先决条件(从 NVIDIA 的 devtalk 论坛收集)和一个系统级 Cython 库:
$ sudo apt-get install libfreetype6-dev python3-setuptools
$ sudo apt-get install protobuf-compiler libprotobuf-dev openssl
$ sudo apt-get install libssl-dev libcurl4-openssl-dev
$ sudo apt-get install cython3
我们还需要一些 XML 工具来处理 TensorFlow 对象检测(TFOD) API 项目:
$ sudo apt-get install libxml2-dev libxslt1-dev
步骤 6:更新 CMake
现在我们将更新 CMake 预编译器工具,因为我们需要一个新的版本来成功编译 OpenCV。
首先,下载并解压缩 CMake 更新:
$ wget http://www.cmake.org/files/v3.13/cmake-3.13.0.tar.gz
$ tar xpvf cmake-3.13.0.tar.gz cmake-3.13.0/
接下来,编译 CMake:
$ cd cmake-3.13.0/
$ ./bootstrap --system-curl
$ make -j4
最后,更新 bash 概要文件:
$ echo 'export PATH=/home/nvidia/cmake-3.13.0/bin/:$PATH' >> ~/.bashrc
$ source ~/.bashrc
CMake 现在可以在您的系统上运行了。确保您没有删除个人文件夹中的cmake-3.13.0/目录。
步骤 7:安装 OpenCV 系统级依赖项和其他开发依赖项
现在,让我们在我们的系统上安装 OpenCV 依赖项,从构建和编译具有并行性的 OpenCV 所需的工具开始:
$ sudo apt-get install build-essential pkg-config
$ sudo apt-get install libtbb2 libtbb-dev
接下来,我们将安装一些编解码器和图像库:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev
$ sudo apt-get install libxvidcore-dev libavresample-dev
$ sudo apt-get install libtiff-dev libjpeg-dev libpng-dev
然后,我们将安装一系列 GUI 库:
$ sudo apt-get install python-tk libgtk-3-dev
$ sudo apt-get install libcanberra-gtk-module libcanberra-gtk3-module
最后,我们将安装 Video4Linux (V4L ),这样我们就可以使用 USB 网络摄像头,并为 FireWire 摄像头安装一个库:
$ sudo apt-get install libv4l-dev libdc1394-22-dev
步骤 8:在你的 Jetson Nano 上设置 Python 虚拟环境

Figure 7: Each Python virtual environment you create on your NVIDIA Jetson Nano is separate and independent from the others.
我怎么强调都不为过: Python 虚拟环境是开发和部署 Python 软件项目的最佳实践。
虚拟环境允许独立安装不同的 Python 包。当您使用它们时,您可以在一个环境中拥有一个版本的 Python 库,而在一个单独的隔离环境中拥有另一个版本。
在本教程的剩余部分,我们将创建一个这样的虚拟环境;不过,完成这个步骤#8 后,你可以根据自己的需要创建多个环境。如果你不熟悉虚拟环境,请务必阅读 RealPython 指南。
首先,我们将安装事实上的 Python 包管理工具,pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
$ rm get-pip.py
然后我们将安装我最喜欢的管理虚拟环境的工具,virtualenv和virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper
在您向 bash 概要文件添加信息之前,virtualenvwrapper工具并没有完全安装。继续使用nano编辑器打开您的~/.bashrc:
$ nano ~/.bashrc
然后在文件的底部插入以下内容:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
使用nano编辑器底部显示的快捷键保存并退出文件,然后加载 bash 概要文件以完成virtualenvwrapper安装:
$ source ~/.bashrc

Figure 8: Terminal output from the virtualenvwrapper setup installation indicates that there are no errors. We now have a virtual environment management system in place so we can create computer vision and deep learning virtual environments on our NVIDIA Jetson Nano.
只要您没有遇到任何错误消息,virtualenv和virtualenvwrapper现在都准备好了,您可以在步骤#9 中根据需要创建和销毁虚拟环境。
步骤 9:创建您的“py3cv4”虚拟环境
一旦你在前一步安装了virtualenv和virtualenvwrapper,这一步就非常简单了。virtualenvwrapper工具提供了以下命令来处理虚拟环境:
mkvirtualenv:创建一个 Python 虚拟环境lsvirtualenv:列出您系统上安装的虚拟环境rmvirtualenv:删除虚拟环境workon:激活 Python 虚拟环境deactivate:退出虚拟环境,返回系统环境
假设步骤#8 进展顺利,让我们在我们的 Nano: 上创建一个 Python 虚拟环境
$ mkvirtualenv py3cv4 -p python3
我将虚拟环境命名为py3cv4,表明我们将使用 Python 3 和 OpenCV 4。你可以根据你的项目和软件需求,甚至你自己的创造力来命名你的。
当您的环境准备就绪时,bash 提示符前面会有(py3cv4)。如果您的提示前面没有您的虚拟环境名称,您可以随时使用如下的workon命令:
$ workon py3cv4

Figure 9: Ensure that your bash prompt begins with your virtual environment name for the remainder of this tutorial on configuring your NVIDIA Jetson Nano for deep learning and computer vision.
对于本教程中的其余步骤,您必须处于py3cv4虚拟环境中。
步骤 10:安装 Protobuf 编译器
本节将带您逐步完成配置protobuf的过程,以便 TensorFlow 能够快速运行。
如果protobuf和libprotobuf的有效实现不存在,TensorFlow 的性能会受到显著影响(以负面方式)。
当我们 pip-install TensorFlow 时,它会自动安装一个可能不是理想版本的protobuf版本。关于【TensorFlow 性能慢的问题已经在这个 NVIDIA 开发者论坛中详细说明了。
首先,下载并安装 protobuf 编译器的高效实现( source ):
$ wget https://raw.githubusercontent.com/jkjung-avt/jetson_nano/master/install_protobuf-3.6.1.sh
$ sudo chmod +x install_protobuf-3.6.1.sh
$ ./install_protobuf-3.6.1.sh
这将需要大约一个小时来安装,所以去散散步,或者读一本好书,如用于计算机视觉的 【树莓派】 或用于计算机视觉的 深度学习与 Python 。
一旦protobuf安装到您的系统上,您需要将其安装到您的虚拟环境中:
$ workon py3cv4 # if you aren't inside the environment
$ cd ~
$ cp -r ~/src/protobuf-3.6.1/python/ .
$ cd python
$ python setup.py install --cpp_implementation
注意,我们没有使用 pip 来安装protobuf包,而是使用了setup.py安装脚本。使用setup.py的好处是我们专门为纳米处理器编译软件,而不是使用通用的预编译二进制文件。
*在剩下的步骤中,我们将混合使用setup.py(当我们需要优化编译时)和 pip(当通用编译足够时)。
让我们继续进行步骤#11 ,在这里我们将安装深度学习软件。
步骤 11:在 Jetson Nano 上安装 TensorFlow、Keras、NumPy 和 SciPy
在本节中,我们将安装 TensorFlow/Keras 及其依赖项。
首先,确保您在虚拟环境中:
$ workon py3cv4
然后安装 NumPy 和 Cython:
$ pip install numpy cython
您可能会遇到以下错误信息:
ERROR: Could not build wheels for numpy which use PEP 517 and cannot be installed directly.
如果您看到该消息,请遵循以下附加步骤。首先,用超级用户权限安装 NumPy:
$ sudo pip install numpy
然后,创建一个从系统的 NumPy 到虚拟环境站点包的符号链接。要做到这一点,您需要numpy的安装路径,可以通过发出 NumPy uninstall 命令找到,然后和取消它,如下所示:
$ sudo pip uninstall numpy
Uninstalling numpy-1.18.1:
Would remove:
/usr/bin/f2py
/usr/local/bin/f2py
/usr/local/bin/f2py3
/usr/local/bin/f2py3.6
/usr/local/lib/python3.6/dist-packages/numpy-1.18.1.dist-info/*
/usr/local/lib/python3.6/dist-packages/numpy/*
Proceed (y/n)? n
注意,您应该在提示符下键入n,因为我们不想继续卸载 NumPy。然后,记下安装路径(高亮显示),并执行以下命令(根据需要替换路径):
$ cd ~/.virtualenvs/py3cv4/lib/python3.6/site-packages/
$ ln -s ~/usr/local/lib/python3.6/dist-packages/numpy numpy
$ cd ~
此时,NumPy 通过符号链接到您的虚拟环境中。我们应该快速测试它,因为 NumPy 在本教程的剩余部分是需要的。在终端中发出以下命令:
$ workon py3cv4
$ python
>>> import numpy
现在已经安装了 NumPy,让我们安装 SciPy。我们需要 SciPy v1.3.3 才能在 Nano 上兼容 TensorFlow 1.13.1。因此,我们不能使用 pip。相反,我们将直接从 GitHub 获取一个版本(正如在 DevTalk 链接中向我们推荐的)并安装它:
$ wget https://github.com/scipy/scipy/releases/download/v1.3.3/scipy-1.3.3.tar.gz
$ tar -xzvf scipy-1.3.3.tar.gz scipy-1.3.3
$ cd scipy-1.3.3/
$ python setup.py install
安装 SciPy 大约需要 35 分钟。观看并等待它安装就像看着油漆变干,所以你不妨打开我的书籍或课程,温习一下你的计算机视觉和深度学习技能。
现在我们将安装 NVIDIA 针对 Jetson Nano 优化的 TensorFlow 1.13。你当然想知道:
为什么我不应该在 NVIDIA Jetson Nano 上使用 TensorFlow 2.0?
这是一个很好的问题,我将邀请我的 NVIDIA Jetson Nano 专家 Sayak Paul 来回答这个问题:
虽然 TensorFlow 2.0 可安装在 Nano 上,但不建议安装,因为它可能与 Jetson Nano 基本操作系统附带的 TensorRT 版本不兼容。此外,用于 Nano 的 TensorFlow 2.0 车轮有许多内存泄漏问题,可能会使 Nano 冻结和挂起。基于这些原因,我们在这个时间点推荐 TensorFlow 1.13。
鉴于 Sayak 的专家解释,现在让我们继续安装 TF 1.13:
$ pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu==1.13.1+nv19.3
现在让我们转到 Keras,我们可以通过 pip 简单地安装它:
$ pip install keras
接下来,我们将在 Jetson Nano 上安装 TFOD API。
步骤#12:在 Jetson Nano 上安装 TensorFlow 对象检测 API
在这一步中,我们将在 Jetson Nano 上安装 TFOD API。
TensorFlow 的对象检测 API (TFOD API)是一个库,我们通常知道它用于开发对象检测模型。我们还需要它来优化 Nano 的 GPU 模型。
NVIDIA 的tf_trt_models是 TFOD API 的包装器,它允许构建冻结图,这是模型部署的必要条件。更多关于tf_trt_models的信息可以在这个 NVIDIA 仓库中找到。
同样,确保所有操作都发生在您的py3cv4虚拟环境中:
$ cd ~
$ workon py3cv4
首先,从 TensorFlow 克隆models存储库:
$ git clone https://github.com/tensorflow/models
为了能够重现,您应该检查以下支持 TensorFlow 1.13.1 的提交:
$ cd models && git checkout -q b00783d
在那里,安装 COCO API 以使用 COCO 数据集,特别是对象检测:
$ cd ~
$ git clone https://github.com/cocodataset/cocoapi.git
$ cd cocoapi/PythonAPI
$ python setup.py install
下一步是编译 TFOD API 使用的 Protobuf 库。Protobuf 库使我们(以及 TFOD API)能够以一种与语言无关的方式序列化结构化数据:
$ cd ~/models/research/
$ protoc object_detection/protos/*.proto --python_out=.
从那里,让我们配置一个有用的脚本,我称之为setup.sh。每次在 Nano 上使用 TFOD API 进行部署时,都需要这个脚本。使用 Nano 编辑器创建这样一个文件:
$ nano ~/setup.sh
在新文件中插入以下行:
#!/bin/sh
export PYTHONPATH=$PYTHONPATH:/home/`whoami`/models/research:\
/home/`whoami`/models/research/slim
顶部的符号表示这个文件是可执行的,然后脚本根据 TFOD API 安装目录配置您的PYTHONPATH。使用nano编辑器底部显示的快捷键保存并退出文件。
第 13 步:为 Jetson Nano 安装 NVIDIA 的“tf_trt_models”
在这一步,我们将从 GitHub 安装tf_trt_models库。该套件包含针对 Jetson Nano 的 TensorRT 优化模型。
首先,确保您在py3cv4虚拟环境中工作:
$ workon py3cv4
继续克隆 GitHub repo,并执行安装脚本:
$ cd ~
$ git clone --recursive https://github.com/NVIDIA-Jetson/tf_trt_models.git
$ cd tf_trt_models
$ ./install.sh
这就是全部了。下一步,我们将安装 OpenCV!
步骤 14:在 Jetson Nano 上安装 OpenCV 4.1.2
在本节中,我们将在我们的 Jetson Nano 上安装支持 CUDA 的 OpenCV 库。
OpenCV 是我们用于图像处理、通过 DNN 模块进行深度学习以及基本显示任务的通用库。如果你有兴趣学习一些基础知识,我为你创建了一个 OpenCV 教程。
CUDA 是 NVIDIA 的一套库,用于处理他们的 GPU。一些非深度学习任务实际上可以在支持 CUDA 的 GPU 上比在 CPU 上运行得更快。因此,我们将安装支持 CUDA 的 OpenCV,因为 NVIDIA Jetson Nano 有一个支持 CUDA 的小 GPU。
这一段教程是基于python PS 网站的所有者们的辛勤工作。
我们将从源代码进行编译,所以首先让我们从 GitHub 下载 OpenCV 源代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.1.2.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.1.2.zip
注意 OpenCV 和 OpenCV-contrib 的版本是匹配的。为了兼容性,版本必须与匹配。
为了方便起见,从那里提取文件并重命名目录:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
$ mv opencv-4.1.2 opencv
$ mv opencv_contrib-4.1.2 opencv_contrib
如果您的 Python 虚拟环境尚未激活,请继续激活它:
$ workon py3cv4
并切换到 OpenCV 目录,然后创建并输入一个构建目录:
$ cd opencv
$ mkdir build
$ cd build
当您在(1)~/opencv/build目录和(2)py3cv4虚拟环境中时,输入下一个 CMake 命令非常重要。现在花点时间来验证:
(py3cv4) $ pwd
/home/nvidia/opencv/build
我通常不会在 bash 提示符中显示虚拟环境的名称,因为这会占用空间,但是请注意我是如何让在上面的提示符的开头显示它,以表明我们“在”虚拟环境中。
此外,pwd命令的结果表明我们在build/目录中。
如果您满足了这两个要求,现在就可以使用 CMake 编译准备工具了:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D WITH_CUDA=ON \
-D CUDA_ARCH_PTX="" \
-D CUDA_ARCH_BIN="5.3,6.2,7.2" \
-D WITH_CUBLAS=ON \
-D WITH_LIBV4L=ON \
-D BUILD_opencv_python3=ON \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_java=OFF \
-D WITH_GSTREAMER=ON \
-D WITH_GTK=ON \
-D BUILD_TESTS=OFF \
-D BUILD_PERF_TESTS=OFF \
-D BUILD_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D OPENCV_EXTRA_MODULES_PATH=/home/`whoami`/opencv_contrib/modules ..
这里有很多编译器标志,我们来回顾一下。注意WITH_CUDA=ON被设置,表明我们将使用 CUDA 优化进行编译。
其次,请注意,我们已经在我们设置的OPENCV_EXTRA_MODULES_PATH、和中提供了到我们的opencv_contrib文件夹的路径,这表明我们正在安装对外部和专利算法具有完全支持的 OpenCV 库。
确保复制上面的整个命令,包括最底部的..。当 CMake 完成时,您将在终端中看到以下输出:

Figure 10: It is critical to inspect your CMake output when installing the OpenCV computer vision library on an NVIDIA Jetson Nano prior to kicking off the compile process.
我强烈建议您向上滚动,用敏锐的眼光阅读终端输出,看看是否有错误。在继续之前,需要解决错误。如果您确实遇到错误,很可能是来自步骤#5-#11 的一个或多个先决条件没有正确安装。尝试确定问题并解决它。
如果您确实修复了一个问题,那么在再次运行 CMake 之前,您需要删除并重新创建您的构建目录:
$ cd ..
$ rm -rf build
$ mkdir build
$ cd build
# run CMake command again
当您对 CMake 输出感到满意时,就该用 Make:
$ make -j4
编译 OpenCV 大约需要 2.5 小时。完成后,您将看到 100%,您的 bash 提示符将返回:

Figure 11: Once your make command reaches 100% you can proceed with setting up your NVIDIA Jetson Nano for computer vision and deep learning.
从那里,我们需要完成安装。首先,运行安装命令:
$ sudo make install
然后,我们需要创建一个从 OpenCV 的安装目录到虚拟环境的符号链接。符号链接就像一个指针,一个特殊的操作系统文件在你的计算机上从一个地方指向另一个地方(在这里是我们的 Nano)。现在让我们创建符号链接:
$ cd ~/.virtualenvs/py3cv4/lib/python3.6/site-packages/
$ ln -s /usr/local/lib/python3.6/site-packages/cv2/python3.6/cv2.cpython-36m-aarch64-linux-gnu.so cv2.so
OpenCV 正式安装。在下一节中,我们将安装一些有用的库来补充我们目前已经安装的所有东西。
步骤#15:通过 pip 安装其他有用的库
在本节中,我们将使用 pip 将附加的软件包安装到我们的虚拟环境中。
继续并激活您的虚拟环境:
$ workon py3cv4
然后安装以下用于机器学习、图像处理和绘图的软件包:
$ pip install matplotlib scikit-learn
$ pip install pillow imutils scikit-image
其次是戴维斯·金的 dlib 库:
$ pip install dlib
注: 虽然你可能很想为你的 NVIDIA Jetson Nano 编译具有 CUDA 功能的 dlib,但目前 dlib 不支持 Nano 的 GPU。来源:(1) dlib GitHub 问题和(2) NVIDIA devtalk 论坛。
现在继续安装 Flask,这是一个 Python 微型 web 服务器;还有 Jupyter,一个基于网络的 Python 环境:
$ pip install flask jupyter
最后,为 TFOD API 安装我们的 XML 工具,并安装 progressbar 来跟踪需要很长时间的终端程序:
$ pip install lxml progressbar2
干得好,但派对还没结束。在下一步中,我们将测试我们的安装。
步骤#16:测试和验证
我总是喜欢在这一点上测试我的安装,以确保一切如我所愿。当您准备在您的 NVIDIA Jetson Nano 上部署计算机视觉和深度学习项目时,这种快速验证可以节省时间。
测试张量流和 Keras
要测试 TensorFlow 和 Keras,只需在 Python shell 中导入它们:
$ workon py3cv4
$ python
>>> import tensorflow
>>> import keras
>>> print(tensorflow.__version__)
1.13.1
>>> print(keras.__version__)
2.3.0
同样,我们故意不使用 TensorFlow 2.0。截至 2020 年 3 月,当我写这篇文章时,TensorRT 支持/不支持 TensorFlow 2.0,它有内存泄漏问题。
测试 TFOD API
为了测试 TFOD API,我们首先需要运行安装脚本:
$ cd ~
$ source ./setup.sh
然后执行测试程序,如图 12: 所示

Figure 12: Ensure that your NVIDIA Jetson Nano passes all TensorFlow Object Detection (TFOD) API tests before moving on with your embedded computer vision and deep learning install.
假设您在运行的每个测试旁边看到“好”,您就可以开始了。
测试 OpenCV
为了测试 OpenCV,我们将简单地将其导入 Python shell 并加载和显示一个图像:
$ workon py3cv4
$ wget -O penguins.jpg http://pyimg.co/avp96
$ python
>>> import cv2
>>> import imutils
>>> image = cv2.imread("penguins.jpg")
>>> image = imutils.resize(image, width=400)
>>> message = "OpenCV Jetson Nano Success!"
>>> font = cv2.FONT_HERSHEY_SIMPLEX
>>> _ = cv2.putText(image, message, (30, 130), font, 0.7, (0, 255, 0), 2)
>>> cv2.imshow("Penguins", image); cv2.waitKey(0); cv2.destroyAllWindows()
Figure 13: OpenCV (compiled with CUDA) for computer vision with Python is working on our NVIDIA Jetson Nano.
测试您的网络摄像头
在这一节中,我们将开发一个快速而简单的脚本,使用(1)PiCamera 或(2)USB 摄像头来测试您的 NVIDIA Jetson Nano 摄像头。
您知道 NVIDIA Jetson Nano 与您的 Raspberry Pi picamera 兼容吗?
事实上是的,但是它需要一个长的源字符串来与驱动程序交互。在本节中,我们将启动一个脚本来看看它是如何工作的。
首先,用带状电缆将 PiCamera 连接到 Jetson Nano,如图所示:

Figure 14: Your NVIDIA Jetson Nano is compatible with your Raspberry Pi’s PiCamera connected to the MIPI port.
接下来,一定要抓取与这篇博文相关的 【下载】 作为测试脚本。现在让我们回顾一下test_camera_nano.py脚本:
# import the necessary packages
from imutils.video import VideoStream
import imutils
import time
import cv2
# grab a reference to the webcam
print("[INFO] starting video stream...")
#vs = VideoStream(src=0).start()
vs = VideoStream(src="nvarguscamerasrc ! video/x-raw(memory:NVMM), " \
"width=(int)1920, height=(int)1080,format=(string)NV12, " \
"framerate=(fraction)30/1 ! nvvidconv ! video/x-raw, " \
"format=(string)BGRx ! videoconvert ! video/x-raw, " \
"format=(string)BGR ! appsink").start()
time.sleep(2.0)
这个脚本同时使用了 OpenCV 和imutils,如第 2-4 行的中的导入所示。
使用imutils的video模块,让我们在行的第 9-14 行创建一个VideoStream:
- USB 摄像头:目前已在第 9 行中注释掉,要使用您的 USB 网络摄像头,您只需提供
src=0或另一个设备序号,如果您有多个 USB 摄像头连接到您的 Nano - PiCamera: 目前活跃在线 10-14 上,一个很长的
src字符串用于与 Nano 上的驱动程序一起工作,以访问插入 MIPI 端口的 PiCamera。如您所见,格式字符串中的宽度和高度表示 1080p 分辨率。您也可以使用 PiCamera 兼容的其他分辨率
我们现在对皮卡梅拉更感兴趣,所以让我们把注意力集中在第 10-14 行。这些行为 Nano 激活一个流以使用 PiCamera 接口。注意逗号、感叹号和空格。您肯定希望得到正确的src字符串,所以请仔细输入所有参数!
接下来,我们将捕获并显示帧:
# loop over frames
while True:
# grab the next frame
frame = vs.read()
# resize the frame to have a maximum width of 500 pixels
frame = imutils.resize(frame, width=500)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# release the video stream and close open windows
vs.stop()
cv2.destroyAllWindows()
在这里,我们开始在帧上循环。我们resize了frame,并在 OpenCV 窗口中将它显示到我们的屏幕上。如果按下q键,我们退出循环并清理。
要执行该脚本,只需输入以下命令:
$ workon py3cv4
$ python test_camera_nano.py

Figure 15: Testing a PiCamera with the NVIDIA Jetson Nano configured for computer vision and deep learning.
正如你所看到的,现在我们的 PiCamera 与 NVIDIA Jetson Nano 一起工作正常。
有没有更快的方法来启动和运行?

Figure 16: Pick up your copy of Raspberry Pi for Computer Vision to gain access to the book, code, and three pre-configured .imgs: (1) NVIDIA Jetson Nano, (2) Raspberry Pi 3B+ / 4B, and (3) Raspberry Pi Zero W. This book will help you get your start in edge, IoT, and embedded computer vision and deep learning.
作为痛苦、乏味且耗时 2 天多的 Nano 配置过程的替代,我建议从计算机视觉 的 的完整捆绑包中抓取一份副本。
我的书里有一个预配置的 Nano。img 是由我的团队开发的,随时可以开箱即用。它包括 TensorFlow/Keras、TensorRT、OpenCV、scikit-image、scikit-learn 等等。
你需要做的只是:
- 下载杰特森纳米。img 文件
- 闪存到您的 microSD 卡
- 启动你的 Nano
- 开始你的项目
The。img 文件抵得上完整捆绑单独捆绑的价格。
正如资深软件顾问彼得·兰斯所说:
为 Jetson Nano 建立一个开发环境是一件可怕的事情。试了几次后,我放弃了,又放了一天。
直到现在,我的儿子都在做它最擅长的事情:在抽屉里收集灰尘。但现在我有借口清洗它,让它再次运行。
除了阿德里安的材料牛逼全面,预配置的 Nano。img 奖金是馅饼上的樱桃,使得计算机视觉的树莓 Pi 的价格更具吸引力。
对任何对 Adrian 的 RPi4CV 书感兴趣的人,对自己公平一点,计算一下你浪费在无所事事上的时间。它会让你意识到,你浪费的时间会比花在书本上的时间还多。
我的一个推特粉丝附和说:

我的。img 文件定期更新并分发给客户。我还为我的书籍和课程的客户提供优先支持,这是我无法免费提供给互联网上每个访问这个网站的人的。
简而言之,如果你需要我为你的 Jetson Nano 提供支持,我建议你买一本用于计算机视觉的 【树莓 Pi】,,它提供了互联网上最好的嵌入式计算机视觉和深度学习教育。
除了。img 文件,RPi4CV 涵盖了如何将计算机视觉、深度学习和 OpenCV 成功应用于嵌入式设备,例如:
- 树莓派
- 英特尔 Movidus NCS
- 谷歌珊瑚
- NVIDIA Jetson Nano
在里面,你会发现超过 40 个关于嵌入式计算机视觉和深度学习的项目(包括 60 多个章节)。
一些突出的项目包括:
- 交通计数和车速检测
- 实时人脸识别
- 建立课堂考勤系统
- 自动手势识别
- 白天和夜间野生动物监测
- 安全应用
- 资源受限设备上的深度学习分类、物体检测、和人体姿态估计
- …还有更多!
如果你和我一样兴奋,请通过点击此处获取免费目录:
摘要
在本教程中,我们为基于 Python 的深度学习和计算机视觉配置了我们的 NVIDIA Jetson Nano。
我们从刷新 NVIDIA Jetpack .img 开始,从那里我们安装了先决条件。然后,我们配置了一个 Python 虚拟环境,用于部署计算机视觉和深度学习项目。
在我们的虚拟环境中,我们安装了 TensorFlow、TensorFlow 对象检测(TFOD) API、TensorRT 和 OpenCV。
我们最后测试了我们的软件安装。我们还开发了一个快速的 Python 脚本来测试 PiCamera 和 USB 摄像头。
如果你对计算机视觉和深度学习的 Raspberry Pi 和 NVIDIA Jetson Nano 感兴趣,一定要拿起一份用于计算机视觉的 Raspberry Pi。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
如何使用 Google Images 创建深度学习数据集
原文:https://pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/
https://www.youtube.com/embed/JrVZ0QM_z-o?feature=oembed
如何在 OpenCV 中通过名字查找函数
原文:https://pyimagesearch.com/2015/08/31/how-to-find-functions-by-name-in-opencv/
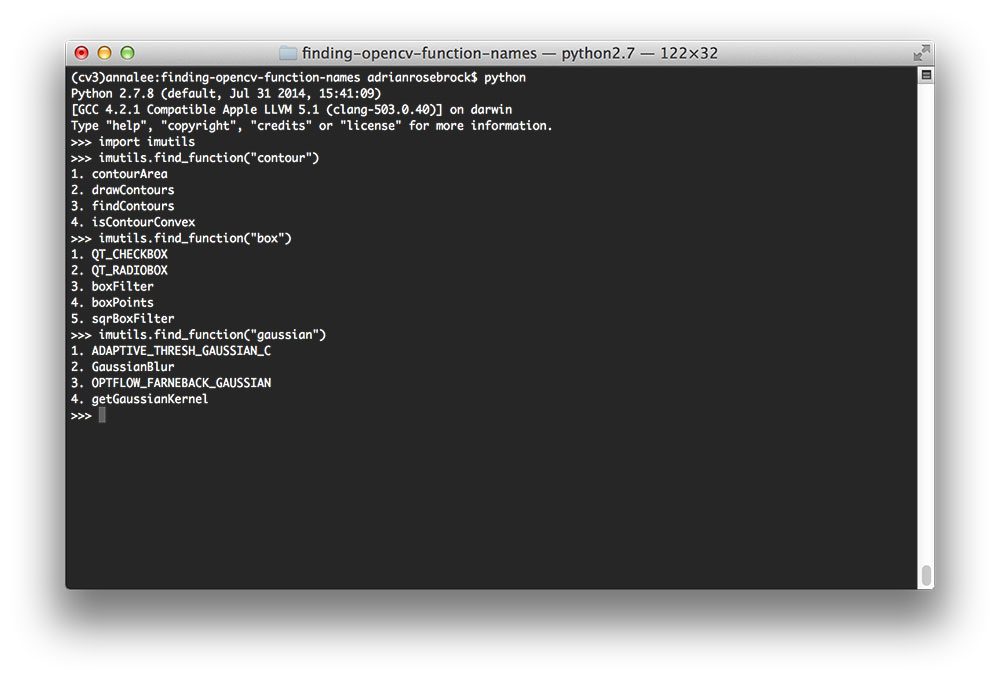
OpenCV 可能是一个很大、很难导航的库,尤其是如果你刚刚开始学习计算机视觉和图像处理。
OpenCV 3 的版本只是使事情变得更加复杂,移动了一些重要的函数,甚至稍微改变了它们的名字(我马上想到了cv2.cv.BoxPoints vs. cv2.boxPoints方法)。
虽然一个好的 IDE 可以帮助你只通过几次击键就能搜索和找到一个特定的功能,但有时你无法访问你的 IDE。如果你试图开发与OpenCV 2.4 和 OpenCV 3 兼容的代码,那么你需要以编程方式确定给定的函数是否可用(无论是通过版本检测还是函数列表)。
**进入find_function方法,现在是 imutils 库的一部分,它可以帮助你简单地通过提供一个查询字符串来搜索和查找 OpenCV 方法。
在这篇博文的剩余部分,我将向你展示如何在 OpenCV 库中使用简单的 Python 方法快速地和**搜索和查找函数。
*## 转储所有 OpenCV 函数名和属性
查看暴露给 Python 绑定的所有 OpenCV 函数和属性的一种快速方法是使用内置的 Python dir函数,该函数用于返回当前本地范围内的名称列表。
假设您已经安装了 OpenCV 并准备好了 Python shell,我们可以使用dir方法创建一个所有 OpenCV 方法和属性的列表:
>>> import cv2
>>> funcs = dir(cv2)
>>> for f in funcs:
... print(f)
...
ACCESS_FAST
ACCESS_MASK
ACCESS_READ
ACCESS_RW
ACCESS_WRITE
ADAPTIVE_THRESH_GAUSSIAN_C
ADAPTIVE_THRESH_MEAN_C
AGAST_FEATURE_DETECTOR_AGAST_5_8
AGAST_FEATURE_DETECTOR_AGAST_7_12D
AGAST_FEATURE_DETECTOR_AGAST_7_12S
AGAST_FEATURE_DETECTOR_NONMAX_SUPPRESSION
AGAST_FEATURE_DETECTOR_OAST_9_16
AGAST_FEATURE_DETECTOR_THRESHOLD
AKAZE_DESCRIPTOR_KAZE
AKAZE_DESCRIPTOR_KAZE_UPRIGHT
AKAZE_DESCRIPTOR_MLDB
AKAZE_DESCRIPTOR_MLDB_UPRIGHT
AKAZE_create
...
waitKey
warpAffine
warpPerspective
watershed
xfeatures2d
ximgproc
xphoto
虽然这个方法确实给了我们 OpenCV 中的属性和函数列表,但是它需要对列表进行手动扫描或 grep 来找到特定的函数。
就我个人而言,如果我对你要找的东西有一个粗略的想法,我喜欢使用这个方法名称的原始列表(有点像“当我看到它的时候我就知道了”类型的情况);否则,我会使用imutils的find_function方法来快速缩小搜索空间——类似于搜索dir(cv2)的输出。
在 OpenCV 库中搜索(部分)函数名
让我们从定义我们的find_function方法开始这一部分:
# import the necessary packages
from __future__ import print_function
import cv2
import re
def find_function(name, pretty_print=True, module=None):
# if the module is None, initialize it to to the root `cv2`
# library
if module is None:
module = cv2
# grab all function names that contain `name` from the module
p = ".*{}.*".format(name)
filtered = filter(lambda x: re.search(p, x, re.IGNORECASE), dir(module))
# check to see if the filtered names should be returned to the
# calling function
if not pretty_print:
return filtered
# otherwise, loop over the function names and print them
for (i, funcName) in enumerate(filtered):
print("{}. {}".format(i + 1, funcName))
if __name__ == "__main__":
find_function("blur")
2-4 线从进口我们需要的包装开始。我们将需要cv2用于 OpenCV 绑定,需要re用于 Python 内置的正则表达式功能。
我们在第 6 行的上定义了我们的find_function方法。这个方法需要一个必需的参数,即我们要搜索cv2的函数的(部分)name。我们还将接受两个可选参数:pretty_print这是一个布尔值,它指示结果应该作为列表返回还是整齐地格式化到我们的控制台;和module,它是 OpenCV 库的根模块或子模块。
我们将把module初始化为根模块cv2,但是我们也可以传入一个子模块,比如xfeatures2d。在任一情况下,将在module中搜索与name匹配的部分功能/属性。
实际的搜索发生在的第 13 行和第 14 行,在这里我们应用一个正则表达式来确定module中的任何属性/函数名是否包含所提供的name。
第 18 行和第 19 行检查我们是否应该将filtered函数的列表返回给调用函数;否则,我们循环函数名并将它们打印到我们的控制台(第 22 行和第 23 行)。
最后, Line 26 通过搜索名字中包含blur的函数来测试我们的find_function方法。
要查看我们的find_function方法的运行情况,只需打开一个终端并执行以下命令:
$ python find_function.py
1\. GaussianBlur
2\. blur
3\. medianBlur
正如我们的输出所示,OpenCV 中似乎有三个函数包含文本blur,包括cv2.GaussianBlur、cv2.blur和cv2.medianBlur。
通过名称查找 OpenCV 函数的真实例子
正如我在这篇文章前面提到的,find_functions方法已经是 imutils 库的一部分。您可以通过pip安装imutils:
$ pip install imutils
如果您的系统上已经安装了imutils,请务必将其升级到最新版本:
$ pip install --upgrade imutils
我们在这个项目中的目标是编写一个 Python 脚本来检测实用 Python 和 OpenCV +案例研究 的 硬拷贝版本(该版本将于美国东部时间8 月 16 日周三 12:00 发布,所以请务必标记您的日历!)并绘制一个它的边界轮廓围绕它:**

Figure 1: Our goal is to find the original book in the image (left) and then draw the outline on the book (right).
打开一个新文件,命名为find_book.py,让我们开始编码:
# import the necessary packages
import numpy as np
import imutils
import cv2
# load the image containing the book
image = cv2.imread("ppao_hardcopy.png")
orig = image.copy()
# convert the image to grayscale, threshold it, and then perform a
# series of erosions and dilations to remove small blobs from the
# image
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 40, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.erode(thresh, None, iterations=2)
thresh = cv2.dilate(thresh, None, iterations=2)
我们从在第 7 行从磁盘加载我们的映像开始。然后我们在的第 13-16 行做一些基本的图像处理,包括转换成灰度,阈值处理,以及一系列的腐蚀和膨胀,从阈值图像中去除任何小斑点。我们的输出阈值图像如下所示:
Figure 3: The thresholded, binary representation of the book image.
然而,为了画出包围书的轮廓,我首先需要找到书本身的轮廓。
假设我被困住了,我不知道在图像中寻找物体轮廓的函数的名字是什么,但是我记得在 OpenCV 中“轮廓”被称为“轮廓”。
通过启动一个 shell 并使用imutils中的find_function,我很快确定我正在寻找cv2.findContours函数:
$ python
>>> import imutils
>>> imutils.find_function("contour")
1\. contourArea
2\. drawContours
3\. findContours
4\. isContourConvex
现在我知道我正在使用cv2.findContours方法,我需要弄清楚这个函数应该使用什么轮廓提取标志。我只想返回外部轮廓(即最外面的轮廓),所以我也需要查找那个属性:
>>> imutils.find_function("external")
1\. RETR_EXTERNAL
明白了。我需要使用cv2.RETR_EXTERNAL标志。现在我已经解决了这个问题,我可以完成我的 Python 脚本了:
# find contours in the thresholded image, keeping only the largest
# one
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
cv2.drawContours(image, [c], -1, (0, 255, 255), 3)
# show the output image
thresh = np.dstack([thresh] * 3)
cv2.imshow("Output", np.hstack([orig, thresh, image]))
cv2.waitKey(0)
第 20-22 行调用cv2.findContours找到阈值图像中物体的外部轮廓(感谢cv2.RETR_EXTERNAL属性)。
然后,我们将找到最大的轮廓(假定是书的轮廓),并在我们的图像上画出轮廓(第 23 行和第 24 行)。
最后,行 27-29 显示了我们的输出图像。
要查看我的脚本的运行情况,我只需启动一个终端并发出以下命令:
$ python find_book.py

Figure 3: Our original input image (left), the thresholded, binary representation of the image (center), and the contour drawn surrounding the book (right).
果然,我们已经能够毫无问题地探测并画出这本书的轮廓了!
摘要
在这篇博文中,我们学习了如何获取 OpenCV 中所有暴露于 Python 绑定的函数和属性的名称。
然后,我们构建了一个 Python 函数,通过文本查询以编程方式搜索这些函数/属性名。该功能已包含在 imutils 包中。
最后,我们探讨了如何在日常工作流程中使用 OpenCV 函数过滤来提高生产率和促进快速函数查找。我们通过构建一个小的 Python 脚本来检测图片中是否有书,从而演示了这一点。***
如何更好地回答您的计算机视觉问题
原文:https://pyimagesearch.com/2017/02/27/how-to-get-better-answers-to-your-computer-vision-questions/
今天的博客文章是两部分系列文章的第一部分,灵感来自我周末收到的 Aarav 的一封电子邮件,他是一位对研究计算机视觉感兴趣的 PyImageSearch 读者:
主题:我如何提出好的计算机视觉问题?
嘿阿德里安,
我叫 Aarav。首先,我只想说我有多喜欢你的博客。这对我是一个巨大的资源。
我目前在 IIT 孟买大学学习计算机科学。我对计算机视觉和深度学习非常感兴趣,但对这些领域很陌生。
我知道我还有很多东西要学,但我在提问时会感到难为情。
我在顶级计算机视觉 LinkedIn 小组、StackOverflow 和 reddit 上发布了一些问题:
(考虑到 Aarav 的隐私,省略了链接)
但是我经常得不到回应。我得到的回答都很简短,有时令人不快,而且对我毫无帮助。
老实说,这让我怀疑我是否想研究这个领域。
阿德里安,你能帮我吗?我做错什么了吗?
如果你能写一篇关于如何提出好的计算机视觉问题的博文,那会很有帮助。
谢谢,
Aarav
我能理解 Aarav——学会问一个好问题是一种后天的技能,几乎可以说是一种“艺术”。
我怎么知道这个?
除了花七年时间在学校获得学士学位和博士学位(在此过程中,我也提出了一些问题),每天我还花大量时间回答 PyImageSearch 读者的问题,这些读者就像你一样,对研究计算机视觉感兴趣,但对某个特定主题感到困惑。
在过去三年运行 PyImageSearch 的过程中,我已经回答了成千上万个计算机视觉问题……但我从未真正解决过什么是“好的”计算机视觉问题。
正如 Aarav 所提出的,你如何知道你在问一个“好”的问题?
你怎样问这个问题才能:
- 获得你所寻求的知识/清晰。
- 在认可和尊重他人时间的同时?
有这样神奇的公式吗?
不幸的是,没有放之四海而皆准的解决方案。
但是当你问关于计算机视觉(或者任何一般的技术主题)的问题时,你可以(并且应该)使用一些通用的技术。
在今天的博文中,我们将讨论提出一个好的计算机视觉问题的五个关键组成部分。
下周,我们将应用这些组件来分析和剖析实际的 PyImageSearch 问题,以更好地理解如何提出有见地的问题。
无论你是在 StackOverflow 上发帖,给我发邮件,还是联系任何其他的主题专家,我希望你能使用这些技巧来更好地帮助你自己和那些回答你问题的人。
注: Aarav 的姓名、大学和所属机构均已匿名,以保护提问读者的身份。任何与名字、问题或隶属关系的现实关联纯属巧合。
如何提出好的计算机视觉问题
在开始今天的博文之前,我想和你分享一个我在大学学习计算机视觉时的个人故事。
然后我们将讨论什么是“好”的问题,接着回顾在问任何 问题时需要的五个关键要素。
个人故事

Figure 1: As an undergraduate student I had trouble grasping the concept of kernels and convolutions, one of the cornerstones of computer vision and image processing.
当我刚开始学习计算机视觉和图像处理时,我有很多问题。
*特别是,我清楚地记得与核的概念 和卷积的概念 的斗争——我根本无法将教科书上的数学知识转化为实际的应用。
在我的教授第一次在课堂上讨论了核和旋积之后,我花了两天的时间转着轮子,徒劳地重读了课本上的同一章,复习了同样的课堂笔记,却一无所获。
在我们的下一次讲座之前,我在办公时间夹着尾巴去找我的教授,对我不能掌握这么简单的概念感到一半羞愧(我甚至怀疑我是否有能力将计算机视觉作为职业来研究)。
我的教授给了我很大的帮助,对我非常耐心。
他帮助消除了我的疑虑。
回想起来,我记得当时感觉 极度紧张和拘谨 要去见我的教授:
我不想把他的时间浪费在我自己应该能够理解和回答的问题上。
我与事实相去甚远。
像我的计算摄影教授(以及我的许多其他老师)这样的人真心希望帮助我——他们所要求的回报是:
- 尊重他们的时间。
- 我明白,虽然他们可以指引我,给我指出正确的方向,但我还是得自己做艰苦的工作。
很久以前,我就开始思考与我的计算摄影教授的互动,但上周末,当我收到 Aarav 发来的电子邮件时,我想起了这件事。
Aarav 的问题让我停下来思考了一会儿:
在某种程度上,我和我的教授又回到了原点。虽然我会一直认为自己是一名学生(我从来没有学过东西,而且 T2 总是坚持学习和尝试新事物),但 T4 已经成为计算机视觉领域的专家。
在过去三年运行 PyImageSearch 的过程中,我看到了一些好问题——那些经过深思熟虑、有特定目的和最终目标的问题。
我也回答了一些问题,这些问题需要一点挖掘,并与读者反复讨论,以了解实际的潜在问题是什么。
我甚至回答了一些非常棘手的问题,需要我自己和读者的耐心。
我个人的观点是,无论我们已经有多好,我们都可以在提问方面变得更好。
我们问的问题越多,我们能学到的就越多——但我们需要以尊重周围人的方式来这样做。
什么是好问题?
你可能对这句老话很熟悉:

Figure 2: “There is no such thing as a stupid question”
在很大程度上,这是真的。
然而,我认为天文学家、宇宙学家和天体物理学家卡尔·萨根说得好:

Figure 3: “…every question is a cry to understand the world. There is no such thing as a dumb question” — Carl Sagan
在高度技术化的先进领域,比如计算机视觉,有 绑定 成为问题——正是这些问题的本质和存在使得计算机科学(以及所有其他科学)成为可能。
先进科学领域的专家一直在问问题。
事实上,研究人员真的是以提问为工作的。
他们质疑他们的研究。
他们质疑同行的研究。
他们从他们的原始问题中衍生出更多的问题。
你可能已经熟悉了这个过程——它被称为科学方法:
Figure 4: Whether we are just getting started in our science careers or already performing state-of-the-art research, we can all apply the scientific method.
- 步骤#1: 提出一个问题,发展一个假设。
- 第二步:做一个实验来测试你的假设。
- 第三步:测量并记录你的实验结果。
- 第四步:从你的结果中得出结论。
- 第五步:回到第一步,用你新发现的知识重复。
这些精确的步骤允许我们进行新的研究并推进当前最先进的…
…但是这个过程不仅仅是研究人员的,任何参与计算机科学的人都可以参与。
当研究人员正在推进他们各自的领域时,在光谱的另一端,我们有学生,我们只是试图通过询问关于计算机视觉的非常基础的问题开始。这些最初的问题为他们日后在职业生涯中问更高级的问题打下了基础。
简单来说:
我们需要提出问题。我们需要的问题来回答。没有这个过程,科学就不可能进步。
鉴于问题的不可避免性,无论是在非常高的层面(即,最先进的研究)还是在非常基础的层面(即,计算机视觉的构建模块),我们都需要专注于如何写出更有洞察力、更有智慧的问题以及可以由他人回答的具体目标。
一个实用的、有见地的问题的五个组成部分
Figure 5: The five components of a practical insightful question.
我将不再关注什么是“好”的问题,而是关注什么是“有见地”的问题。
问一个有见地的问题从开始,远远早于它被输入到电子邮件或评论表格中。
我在下面列出了编写实用、有见地的计算机视觉问题的要素:
- 知道目的。
- 理解上下文。
- 做你的研究。
- 提出你的问题(并尊重他人的时间)
- 必要时重复该过程。
我们将在这篇文章的剩余部分详细回顾这些组件。
第一部分:了解目的
在你问问题之前,你应该先退一步,问自己 为什么 你首先要问这个问题。
更具体地说,问自己:“问完这个问题后,我希望获得什么知识/洞察力?”
你看,所有有见地、有智慧的问题都有一个目的——它们所有都有一个最终目标。什么是你的最终目标在提问?
通过将目的(组件#1)与背景(组件#2)结合起来,主题专家可以更好地帮助你。
组件#2:理解上下文
理解你的问题背后的“为什么”很有帮助,但这还不够——**我还需要你问题的背景。**
我说的上下文是什么意思?
背景是构成你的问题的背景的环境。
有哪些相关的生活环境在提示这个问题?
你是一个正在做棘手的家庭作业的学生吗?
你是一个正在进行最先进的实验并希望发表你的结果的研究人员吗?
或者你只是对某个特定的计算机视觉主题感到好奇,想了解更多?
不仅要理解为什么你会问这个问题,还要理解背后的背景会让你的问题更容易回答。
关于你的问题,你能提供的背景信息越多越好。
第三部分:做研究
理解了你提问的目的后,你应该花些时间做一些初步的研究,即使只是在内部层面上。
问自己:
- 关于这个话题,我有什么预先存在的知识吗?如果是,我已经知道了什么?
- 在哪里可以找到与此问题/主题相关的资源?
- 是否有任何现有的教程、博客帖子、研究论文等。这回答了我的问题吗?
- 我是否花了 15-20 分钟在谷歌上查询与我的问题相似的内容,并阅读了别人在我之前问过的内容?
你可能能够回答所有这些问题中的——或者你可能只能回答其中的个问题。
这个练习的重点不是“核对每一项”,而是后退一步批判性地思考你的问题。
第四部分:提出你的问题(并尊重他人的时间)
当你真正问你的问题时,你应该已经准备好了。
通过提问,你应该明白你的最终目标是什么,你希望学到/完成什么。
你应该在这个问题上做足功课,看看其他人是否问过类似的问题(以及查看回答)。
最后,也是最重要的:
在尊重他人的情况下提问。
不管你是在 StackOverflow、LinkedIn 上发帖,还是询问某个主题专家(比如我自己), 尊重他们的时间。
- 不要指望你询问的人会写一份多页的电子邮件回复你的问题,分析每一个小细节,并包括你应该阅读的论文的详尽清单。
- 不要指望他们为你写代码。
- 别指望他们会牵你的手。
现实一点,相应地设定你的期望:
- 问问题时,要考虑到你的具体最终目标和背景。
- 并且你会收到一个帮助你指明正确方向的回复(但不会为你做所有的艰苦工作)。你需要自己做这项艰苦的工作。
一个问题的好坏取决于对它的思考、时间和努力。
如果你花时间带着深思熟虑的目的和最终目标提出问题,你会发现你得到的回应会更好,对完成你的特定项目/任务更有帮助。
组件#5:必要时重复该过程
很多时候,一个问题引出另一个问题。
我们问了一个问题,澄清了一个特定的问题,却发现它进一步混淆了下游另一个概念的水——我们再次需要帮助和解释。
这种情况下,就要重复这个过程了。
评估你的新问题。
你为什么问这个?
你的最终目标是什么?
对这个问题进行研究。
然后问(同时尊重他人时间)。
冲洗并重复。
问好问题需要练习
随着你越来越擅长问有见地的问题,你会开始注意到别人问问题的模式。
当一个同事或同事已经做了充分的研究来准备他们的问题时,或者当他们凭感觉飞行,希望从一个考虑不周的调查中突然实现一个解决方案时,你会开始感觉到。
作为一名主题专家,我可以告诉你回答有特定目的和最终目标的问题是多么令人愉快的事情。
我喜欢回答这些问题,因为我不仅可以澄清任何疑问,还可以就如何解决读者正在研究的整体问题提供建议。
读者总是很开心,不仅因为他们的问题得到了解答,还因为他们有更多的资源来帮助解决他们的问题。
相反,我还可以告诉你 如何令人厌烦而又乏味 它可以回答读者提出的问题:
- 不尊重我的时间。
- 他们自己没有花时间考虑为什么他们会问这个问题(即最终目标+背景)。
在下周的博客文章中,我们将分析我在 PyImageSearch 博客上收到的个实际问题,一条一条地回顾它们,看看如何提出一个好问题的五个组成部分。这些例子将帮助你提高自己提问的能力——因为让我们面对它,我们都可以使用一点实践。
摘要
今天的博文讨论了如何提出好的计算机视觉问题。
问一个好问题的五个组成部分包括:
- 了解你问题的目的(即最终目标)。
- 转述问题的语境(你所处的情境提示了要问的问题)。
- 做你的研究。
- 在尊重他人的情况下提问。
- 必要时重复该过程。
这个公式也可以扩展到计算机科学之外的其他技术领域。
在这个由两部分组成的系列的第二篇教程中,我将讨论如何在 PyImageSearch 博客上提问特别是。
我们将看看我在 PyImageSearch 博客上收到的实际电子邮件,并把它们分开,讨论这个问题的积极(和消极)方面——我甚至会建议一些方法来更好地表达你的查询,以帮助确保你找到你正在寻找的信息。
要在下一篇“不容错过”的博文发布时收到通知,请务必在下表中输入您的电子邮件地址,加入 PyImageSearch 时事通讯!*
深度学习如何安装 CUDA 工具包和 cuDNN
原文:https://pyimagesearch.com/2016/07/04/how-to-install-cuda-toolkit-and-cudnn-for-deep-learning/

如果你真的想做任何类型的深度学习,你应该利用你的 GPU 而不是 T2 的 CPU。你的 GPU 越多,你就越富裕。
如果你已经有一个 NVIDIA 支持的 GPU,那么下一个合乎逻辑的步骤是安装两个重要的库:
- NVIDIA CUDA Toolkit:用于构建 GPU 加速应用的开发环境。这个工具包包括一个专门为 NVIDIA GPUs 设计的编译器和相关的数学库+优化例程。
- cud nn 库:深度神经网络的 GPU 加速原语库。使用 cuDNN 软件包,你可以将训练速度提高 44%以上,在火炬和咖啡馆的速度提升超过6 倍。
在这篇博文的剩余部分,我将演示如何安装 NVIDIA CUDA Toolkit 和 cuDNN 库来进行深度学习。
具体来说,我将使用运行 Ubuntu 14.04 的 Amazon EC2 g 2.2x 大型机器。请随意创建一个自己的实例并跟随它。
当你完成本教程时,你将拥有一个全新的系统,为深度学习做好准备。
深度学习如何安装 CUDA 工具包和 cuDNN
正如我在之前的一篇博文中提到的,Amazon 提供了一个 EC2 实例,该实例提供了对 GPU 的访问,用于计算目的。
这个实例被命名为g 2.2x 大型实例,成本大约为每小时 0.65 美元。系统中包含的 GPU 是 K520,具有 4GB 内存和 1,536 个内核。
你也可以升级到g 2.8x 大型实例 ( $2.60 每小时)获得四个K520 GPU(总计 16GB 内存)。
对于我们大多数人来说,g2.8xlarge 有点贵,尤其是如果你只是将深度学习作为一种爱好的话。另一方面,g2.2xlarge 实例是一个完全合理的选择,允许你放弃下午的星巴克咖啡,用咖啡因换取一点深度学习的乐趣和教育。
在这篇博文的剩余部分,我将详细介绍如何在 Amazon EC2 上的 g 2.2x 大型 GPU 实例中安装 NVIDIA CUDA Toolkit v7.5 和 cuDNN v5。
如果你对深度学习感兴趣,我强烈建议你使用这篇博客文章中的详细说明来设置自己的 EC2 系统——你将能够使用你的 GPU 实例来跟随 PyImageSearch 博客上的未来深度学习教程(相信我,会有很多这样的教程)。
注:你是亚马逊 AWS 和 EC2 的新手吗?在继续之前,你可能想阅读亚马逊 EC2 GPU 上的深度学习和 Python 以及 nolearn 。这篇博客文章提供了关于如何启动第一个 EC2 实例并将其用于深度学习的分步说明(带有大量截图)。
安装 CUDA 工具包
假设你有(1)一个支持 GPU 的 EC2 系统或者(2)你自己的支持 NVIDIA 的 GPU 硬件,下一步是安装 CUDA 工具包。
但是在我们这样做之前,我们需要先安装一些必需的包:
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get install build-essential cmake git unzip pkg-config
$ sudo apt-get install libopenblas-dev liblapack-dev
$ sudo apt-get install linux-image-generic linux-image-extra-virtual
$ sudo apt-get install linux-source linux-headers-generic
我在亚马逊 EC2 GPU 实例上遇到的一个问题是,我们需要禁用新的内核驱动,因为它与我们即将安装的 NVIDIA 内核模块冲突。
注意:我只需要禁用亚马逊 EC2 GPU 实例上的新内核驱动程序——我不确定是否需要在 Ubuntu 的标准桌面安装上这样做。根据你自己的硬件和设置,你可以潜在地跳过这一步。
要禁用新内核驱动程序,首先创建一个新文件:
$ sudo nano /etc/modprobe.d/blacklist-nouveau.conf
然后将以下几行添加到文件中:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
保存这个文件,退出您的编辑器,然后更新初始 RAM 文件系统,然后重新启动您的机器:
$ echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
$ sudo update-initramfs -u
$ sudo reboot
重新启动后,新的内核驱动程序应该被禁用。
下一步是安装 CUDA 工具包。我们将为 Ubuntu 14.04 安装 CUDA Toolkit v7.5 。安装 CUDA 实际上是一个相当简单的过程:
- 下载安装归档文件并将其解压缩。
- 运行相关的脚本。
- 出现提示时,选择默认选项/安装目录。
首先,我们先下载适用于 CUDA 7.5 的.run文件:
$ wget http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run
通过超快的 EC2 连接,我能够在不到 30 秒的时间内下载完整的 1.1GB 文件:

Figure 1: Downloading the CUDA Toolkit from NVIDIA’s official website.
接下来,我们需要使.run文件可执行:
$ chmod +x cuda_7.5.18_linux.run
然后将各个安装脚本提取到installers目录中:
$ mkdir installers
$ sudo ./cuda_7.5.18_linux.run -extract=`pwd`/installers
您的installers目录现在应该是这样的:

Figure 2: Extracting the set of .run files into the ‘installers’ directory.
请注意我们有三个独立的.run文件——我们需要按照正确的顺序单独执行每个文件:
NVIDIA-Linux-x86_64-352.39.runcuda-linux64-rel-7.5.18-19867135.runcuda-samples-linux-7.5.18-19867135.run
下面一组命令将负责实际安装 CUDA 工具包:
$ sudo ./NVIDIA-Linux-x86_64-352.39.run
$ modprobe nvidia
$ sudo ./cuda-linux64-rel-7.5.18-19867135.run
$ sudo ./cuda-samples-linux-7.5.18-19867135.run
再次提醒,确保在出现提示时选择默认选项和目录。
为了验证是否安装了 CUDA 工具包,您应该检查您的/usr/local目录,其中应该包含一个名为cuda-7.5的子目录,后面是一个名为cuda的符号链接,它指向这个子目录:

Figure 3: Verifying that the CUDA Toolkit has been installed.
既然安装了 CUDA 工具包,我们需要更新我们的~/.bashrc配置:
$ nano ~/.bashrc
然后添加下面几行来定义 CUDA 工具包PATH变量:
# CUDA Toolkit
export CUDA_HOME=/usr/local/cuda-7.5
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:$LD_LIBRARY_PATH
export PATH=${CUDA_HOME}/bin:${PATH}
您的.bashrc文件会在您每次登录或打开新终端时自动source更新,但由于我们刚刚修改了它,我们需要手动source它:
$ source ~/.bashrc
接下来,让我们安装 cuDNN!
安装 cuDNN
我们现在准备安装 NVIDIA CUDA 深度神经网络库,这是一个 GPU 加速的深度神经网络库。诸如 Caffe 和 Keras(以及较低层次的 Theano)这样的软件包使用 cuDNN 来显著加速网络培训过程。
要获得 cuDNN 库,你首先需要用 NVIDIA 创建一个(免费)账户。从那里,你可以下载 cuDNN 。
对于本教程,我们将使用 cuDNN v5:

Figure 4: We’ll be installing the cuDNN v5 library for deep learning.
确保您下载了用于 Linux 的 cuDNN v5 库:

Figure 5: Since we’re installing the cuDNN on Ubuntu, we download the library for Linux.
这是一个 75MB 的小下载,你应该把它保存到你的本地机器(也就是你用来阅读本教程的笔记本电脑/台式机),然后把上传到你的 EC2 实例。为此,只需使用scp,根据需要替换路径和 IP 地址:
$ scp -i EC2KeyPair.pem ~/Downloads/cudnn-7.5-linux-x64-v5.0-ga.tgz ubuntu@<ip_address>:~
安装 cuDNN 非常简单——我们所需要做的就是将lib64和include目录中的文件复制到我们 EC2 机器上相应的位置:
$ cd ~
$ tar -zxf cudnn-7.5-linux-x64-v5.0-ga.tgz
$ cd cuda
$ sudo cp lib64/* /usr/local/cuda/lib64/
$ sudo cp include/* /usr/local/cuda/include/
恭喜您,cuDNN 现已安装!
做一些清理工作
现在我们已经(1)安装了 NVIDIA CUDA Toolkit ,( 2)安装了 cuDNN,让我们做一些清理工作来回收磁盘空间:
$ cd ~
$ rm -rf cuda installers
$ rm -f cuda_7.5.18_linux.run cudnn-7.5-linux-x64-v5.0-ga.tgz
在未来的教程中,我将演示如何使用 CUDA 和 cuDNN 来加快深度神经网络的训练。
摘要
在今天的博文中,我演示了如何安装用于深度学习的 CUDA 工具包和 cuDNN 库。如果你对深度学习感兴趣,我强烈推荐安装一台支持 GPU 的机器。
如果你还没有兼容 NVIDIA 的 GPU,不要担心——亚马逊 EC2 提供了 g 2.2 x large(0.65 美元/小时)和 g 2.8 x large(2.60 美元/小时)实例,这两种实例都可以用于深度学习。
这篇博客文章中详细描述的步骤将在 Ubuntu 14.04 的 g2.2xlarge 和 g2.8xlarge 实例上工作,请随意选择一个实例并设置您自己的深度学习开发环境(事实上,我鼓励您这样做!)
如果您熟悉命令行和 Linux 系统(并且在 EC2 生态系统方面有少量经验),那么完成整个过程只需要 1-2 个小时。
最重要的是,您可以使用这个 EC2 实例来关注 PyImageSearch 博客上未来的深度学习教程。
请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在新的深度学习文章发布时获得通知!*


 浙公网安备 33010602011771号
浙公网安备 33010602011771号