PyImgSearch-博客中文翻译-十一-
PyImgSearch 博客中文翻译(十一)
竖起大拇指:手势识别。
原文:https://pyimagesearch.com/2015/02/05/thumbs-hand-gesture-recognition/

我需要为这篇文章道歉——如果有一些明显的语法错误,我很抱歉。
你看,我熬了一个通宵。
我的眼睛布满血丝,呆滞无神,就像《行尸走肉》里的某样东西。我的大脑感觉像被大锤敲打的土豆泥。我真的真的需要洗个澡——出于某种原因,我认为在从健身房回来后立即开始黑客马拉松是个好主意。
但是在接下来的 10 个小时里,我想发布一个关于这个通宵黑客马拉松的目的的快速更新…
昨天,PyImageSearch 大师 Kickstarter 实现了它的第一个目标(为你的移动设备开发计算机视觉应用)。我需要想出第二个连续目标。经过几分钟的反复思考,我想到了:
手势识别。
手势识别是 PyImageSearch 博客上 点击率最高的教程 之一。每天我都会收到至少 2-3 封邮件,询问如何用 Python 和 OpenCV 进行手势识别。
让我告诉你,如果我们达到了 PyImageSearch 大师 Kickstarter 的第二个延伸目标,我将在课程中介绍手势识别!
因此,如果你对加入 PyImageSearch 大师计算机视觉课程犹豫不决,现在是时候了!在你们的帮助下,我们将能够在 PyImageSearch Gurus 中实现手势识别。
记住,PyImageSearch 大师们的大门将在一周后关闭,直到八月才会再次打开。
课程还有一些空位, 所以不要等着错过!
现在就行动起来,在大门关闭之前,在 PyImageSearch 大师中获得自己的一席之地。
是时候了。PyImageSearch 大师 Kickstarter 正式上线。
原文:https://pyimagesearch.com/2015/01/14/time-pyimagesearch-gurus-kickstarter-officially-live/

PyImageSaerch Gurus Kickstarter 正式上线了!
您可以使用以下链接支持 PyImageSearch 大师 Kickstarter 活动:
记住,只有为数不多的低价早鸟名额&提前入场 — 如果你想得到你的位置,你一定要马上行动!
非常感谢你对我和 PyImageSearch 博客的支持。
希望能在另一边见到你!
火炬中心系列#1:火炬中心简介
原文:https://pyimagesearch.com/2021/12/20/torch-hub-series-1-introduction-to-torch-hub/
在本教程中,您将学习 PyTorch 火炬中心的基础知识。
本课是关于火炬中心的 6 部分系列的第 1 部分:
- 火炬轮毂系列#1:火炬轮毂简介(本教程)
- 火炬中心系列#2: VGG 和雷斯内特
- 火炬轮毂系列#3: YOLO v5 和 SSD——物体检测模型
- 火炬轮毂系列# 4:PGAN——甘模型
- 火炬轮毂系列# 5:MiDaS——深度估计模型
- 火炬中枢系列#6:图像分割
要学习如何使用火炬中枢, 只要坚持阅读。
火炬中心介绍
那是 2020 年,我和我的朋友们夜以继日地完成我们最后一年的项目。像我们这一年的大多数学生一样,我们决定把它留到最后是个好主意。
这不是我们最明智的想法。接下来是永无休止的模型校准和训练之夜,烧穿千兆字节的云存储,并维护深度学习模型结果的记录。
我们为自己创造的环境不仅损害了我们的效率,还影响了我们的士气。由于我的其他队友的个人才华,我们设法完成了我们的项目。
回想起来,我意识到如果我们选择了一个更好的生态系统来工作,我们的工作会更有效率,也更令人愉快。
幸运的是,你不必犯和我一样的错误。
PyTorch 的创建者经常强调,这一计划背后的一个关键意图是弥合研究和生产之间的差距。PyTorch 现在在许多领域与它的同时代人站在一起,在研究和生产生态系统中被平等地利用。
他们实现这一目标的方法之一是通过火炬中心。火炬中心作为一个概念,是为了进一步扩展 PyTorch 作为一个基于生产的框架的可信度。在今天的教程中,我们将学习如何利用 Torch Hub 来存储和发布预先训练好的模型,以便广泛使用。
什么是火炬中心?
在计算机科学中,许多人认为研究和生产之间桥梁的一个关键拼图是可重复性。基于这一理念,PyTorch 推出了 Torch Hub,这是一个应用程序可编程接口(API ),它允许两个程序相互交互,并增强了工作流程,便于研究再现。
Torch Hub 允许您发布预先训练好的模型,以帮助研究共享和再现。利用 Torch Hub 的过程很简单,但是在继续之前,让我们配置系统的先决条件!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
在转到目录之前,我们先来看看图 2 中的项目结构。
今天,我们将使用两个目录。这有助于您更好地理解 Torch Hub 的使用。
子目录是我们初始化和训练模型的地方。在这里,我们将创建一个hubconf.py脚本。hubconf.py脚本包含名为entry_points的可调用函数。这些可调用的函数初始化并返回用户需要的模型。因此,这个脚本将把我们自己创建的模型连接到 Torch Hub。
在我们的主项目目录中,我们将使用torch.hub.load从 Torch Hub 加载我们的模型。在用预先训练的权重加载模型之后,我们将在一些样本数据上对其进行评估。
火炬中心概观
Torch Hub 已经托管了一系列用于各种任务的模型,如图 3 所示。
如你所见,Torch Hub 在其官方展示中总共接受了 42 个研究模型。每个模型属于以下一个或多个标签:音频、生成、自然语言处理(NLP)、可脚本化和视觉。这些模型也已经在广泛接受的基准数据集上进行了训练(例如, Kinetics 400 和 COCO 2017 )。
使用torch.hub.load函数很容易在您的项目中使用这些模型。让我们来看一个它是如何工作的例子。
我们将查看火炬中心的官方文件using a DCGAN在 fashion-gen 上接受培训来生成一些图片。
(如果你想了解更多关于 DCGANs 的信息,一定要看看这个 博客 。)
# USAGE
# python inference.py
# import the necessary packages
import matplotlib.pyplot as plt
import torchvision
import argparse
import torch
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--num-images", type=int, default=64,
help="# of images you want the DCGAN to generate")
args = vars(ap.parse_args())
# check if gpu is available for use
useGpu = True if torch.cuda.is_available() else False
# load the DCGAN model
model = torch.hub.load("facebookresearch/pytorch_GAN_zoo:hub", "DCGAN",
pretrained=True, useGPU=useGpu)
在的第 11-14 行,我们创建了一个参数解析器,让用户可以更自由地选择生成图像的批量大小。
要使用脸书研究所预训练的 DCGAN 模型,我们只需要torch.hub.load函数,如第 20 和 21 行所示。这里的torch.hub.load函数接受以下参数:
repo_or_dir:如果source参数被设置为github,则格式为repo_owner/repo_name:branch/tag_name的存储库名称。否则,它将指向您的本地计算机中所需的路径。entry_point:要在 torch hub 中发布模型,您需要在您的存储库/目录中有一个名为hubconf.py的脚本。在该脚本中,您将定义称为入口点的普通可调用函数。调用入口点以返回期望的模型。稍后你会在这篇博客中了解更多关于entry_point的内容。pretrained和useGpu:这些属于这个函数的*args或参数旗帜。这些参数用于可调用模型。
现在,这不是火炬中心提供的唯一主要功能。您可以使用其他几个值得注意的函数,比如torch.hub.list来列出所有属于存储库的可用入口点(可调用函数),以及torch.hub.help来显示目标入口点的文档 docstring。
# generate random noise to input to the generator
(noise, _) = model.buildNoiseData(args["num_images"])
# turn off autograd and feed the input noise to the model
with torch.no_grad():
generatedImages = model.test(noise)
# reconfigure the dimensions of the images to make them channel
# last and display the output
output = torchvision.utils.make_grid(generatedImages).permute(
1, 2, 0).cpu().numpy()
plt.imshow(output)
plt.show()
在第 24 行的上,我们使用一个名为buildNoiseData的被调用模型专有的函数来生成随机输入噪声,同时牢记输入大小。
关闭自动渐变( Line 27 ),我们通过给模型添加噪声来生成图像。
在绘制图像之前,我们对第 32-35 行的图像进行了维度整形(由于 PyTorch 使用通道优先张量,我们需要使它们再次成为通道最后张量)。输出将类似于图 4** 。**
瞧吧!这就是你使用预先训练的最先进的 DCGAN 模型所需要的一切。在火炬中心使用预先训练好的模型是那容易。然而,我们不会就此止步,不是吗?
打电话给一个预先训练好的模型来看看最新的最先进的研究表现如何是好的,但是当我们使用我们的研究产生最先进的结果时呢?为此,我们接下来将学习如何在 Torch Hub 上发布我们自己创建的模型。
在 PyTorch 车型上使用 Torch Hub
让我们回到 2021 年 7 月 12 日,Adrian Rosebrock 发布了一篇博文,教你如何在 PyTorch 上构建一个简单的 2 层神经网络。该博客教你定义自己的简单神经网络,并在用户生成的数据上训练和测试它们。
今天,我们将训练我们的简单神经网络,并使用 Torch Hub 发布它。我不会对代码进行全面剖析,因为已经有相关教程了。关于构建一个简单的神经网络的详细而精确的探究,请参考这篇博客。
构建简单的神经网络
接下来,我们将检查代码的突出部分。为此,我们将进入子目录。首先,让我们在mlp.py中构建我们的简单神经网络!
# import the necessary packages
from collections import OrderedDict
import torch.nn as nn
# define the model function
def get_training_model(inFeatures=4, hiddenDim=8, nbClasses=3):
# construct a shallow, sequential neural network
mlpModel = nn.Sequential(OrderedDict([
("hidden_layer_1", nn.Linear(inFeatures, hiddenDim)),
("activation_1", nn.ReLU()),
("output_layer", nn.Linear(hiddenDim, nbClasses))
]))
# return the sequential model
return mlpModel
行 6 上的get_training_model函数接受参数(输入大小、隐藏层大小、输出类别)。在函数内部,我们使用nn.Sequential创建一个 2 层神经网络,由一个带有 ReLU activator 的隐藏层和一个输出层组成(第 8-12 行)。
训练神经网络
我们不会使用任何外部数据集来训练模型。相反,我们将自己生成数据点。让我们进入train.py。
# import the necessary packages
from pyimagesearch import mlp
from torch.optim import SGD
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
import torch.nn as nn
import torch
import os
# define the path to store your model weights
MODEL_PATH = os.path.join("output", "model_wt.pth")
# data generator function
def next_batch(inputs, targets, batchSize):
# loop over the dataset
for i in range(0, inputs.shape[0], batchSize):
# yield a tuple of the current batched data and labels
yield (inputs[i:i + batchSize], targets[i:i + batchSize])
# specify our batch size, number of epochs, and learning rate
BATCH_SIZE = 64
EPOCHS = 10
LR = 1e-2
# determine the device we will be using for training
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print("[INFO] training using {}...".format(DEVICE))
首先,我们在第 11 行创建一个路径来保存训练好的模型权重,稍后会用到。第 14-18 行上的next_batch函数将作为我们项目的数据生成器,产生用于高效训练的批量数据。
接下来,我们设置超参数(第 21-23 行),如果有兼容的 GPU 可用,则将我们的DEVICE设置为cuda(第 26 行)。
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
在的第 32 行和第 33 行,我们使用make_blobs函数来模拟实际三类数据集的数据点。使用 scikit-learn 的 train_test_split函数,我们创建数据的训练和测试分割。
# initialize our model and display its architecture
mlp = mlp.get_training_model().to(DEVICE)
print(mlp)
# initialize optimizer and loss function
opt = SGD(mlp.parameters(), lr=LR)
lossFunc = nn.CrossEntropyLoss()
# create a template to summarize current training progress
trainTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
在第 45 行上,我们从mlp.py模块调用get_training_model函数并初始化模型。
我们选择随机梯度下降作为优化器(第 49 行),交叉熵损失作为损失函数(第 50 行)。
第 53 行上的trainTemplate变量将作为字符串模板打印精度和损耗。
# loop through the epochs
for epoch in range(0, EPOCHS):
# initialize tracker variables and set our model to trainable
print("[INFO] epoch: {}...".format(epoch + 1))
trainLoss = 0
trainAcc = 0
samples = 0
mlp.train()
# loop over the current batch of data
for (batchX, batchY) in next_batch(trainX, trainY, BATCH_SIZE):
# flash data to the current device, run it through our
# model, and calculate loss
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# zero the gradients accumulated from the previous steps,
# perform backpropagation, and update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# update training loss, accuracy, and the number of samples
# visited
trainLoss += loss.item() * batchY.size(0)
trainAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current training batch
trainTemplate = "epoch: {} train loss: {:.3f} train accuracy: {:.3f}"
print(trainTemplate.format(epoch + 1, (trainLoss / samples),
(trainAcc / samples)))
循环训练时期,我们初始化损失(行 59-61 )并将模型设置为训练模式(行 62 )。
使用next_batch函数,我们遍历一批批训练数据(第 65 行)。在将它们加载到设备(线 68 )后,在线 69 上获得数据批次的预测。这些预测然后被输入到损失函数中进行损失计算(第 70 行)。
使用zero_grad ( 线 74 )冲洗梯度,然后在线 75 上反向传播。最后,在行 76 上更新优化器参数。
对于每个时期,训练损失、精度和样本大小变量被升级(行 80-82 ),并使用行 85 上的模板显示。
# initialize tracker variables for testing, then set our model to
# evaluation mode
testLoss = 0
testAcc = 0
samples = 0
mlp.eval()
# initialize a no-gradient context
with torch.no_grad():
# loop over the current batch of test data
for (batchX, batchY) in next_batch(testX, testY, BATCH_SIZE):
# flash the data to the current device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# run data through our model and calculate loss
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current test batch
testTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
print(testTemplate.format(epoch + 1, (testLoss / samples),
(testAcc / samples)))
print("")
# save model to the path for later use
torch.save(mlp.state_dict(), MODEL_PATH)
我们将模型设置为eval模式进行模型评估,并在训练阶段进行同样的操作,除了反向传播。
在第 121 行,我们有保存模型权重以备后用的最重要步骤。
让我们来评估我们的模型的划时代的性能!
[INFO] training using cpu...
[INFO] preparing data...
Sequential(
(hidden_layer_1): Linear(in_features=4, out_features=8, bias=True)
(activation_1): ReLU()
(output_layer): Linear(in_features=8, out_features=3, bias=True)
)
[INFO] epoch: 1...
epoch: 1 train loss: 0.798 train accuracy: 0.649
epoch: 1 test loss: 0.788 test accuracy: 0.613
[INFO] epoch: 2...
epoch: 2 train loss: 0.694 train accuracy: 0.665
epoch: 2 test loss: 0.717 test accuracy: 0.613
[INFO] epoch: 3...
epoch: 3 train loss: 0.635 train accuracy: 0.669
epoch: 3 test loss: 0.669 test accuracy: 0.613
...
[INFO] epoch: 7...
epoch: 7 train loss: 0.468 train accuracy: 0.693
epoch: 7 test loss: 0.457 test accuracy: 0.740
[INFO] epoch: 8...
epoch: 8 train loss: 0.385 train accuracy: 0.861
epoch: 8 test loss: 0.341 test accuracy: 0.973
[INFO] epoch: 9...
epoch: 9 train loss: 0.286 train accuracy: 0.980
epoch: 9 test loss: 0.237 test accuracy: 0.993
[INFO] epoch: 10...
epoch: 10 train loss: 0.211 train accuracy: 0.985
epoch: 10 test loss: 0.173 test accuracy: 0.993
因为我们是根据我们设定的范例生成的数据进行训练,所以我们的训练过程很顺利,最终达到了 0.985 的训练精度。
配置hubconf.py脚本
模型训练完成后,我们的下一步是在 repo 中配置hubconf.py文件,使我们的模型可以通过 Torch Hub 访问。
# import the necessary packages
import torch
from pyimagesearch import mlp
# define entry point/callable function
# to initialize and return model
def custom_model():
""" # This docstring shows up in hub.help()
Initializes the MLP model instance
Loads weights from path and
returns the model
"""
# initialize the model
# load weights from path
# returns model
model = mlp.get_training_model()
model.load_state_dict(torch.load("model_wt.pth"))
return model
如前所述,我们在 7 号线的上创建了一个名为custom_model的入口点。在entry_point内部,我们从mlp.py模块(第 16 行)初始化简单的神经网络。接下来,我们加载之前保存的权重(第 17 行)。当前的设置使得这个函数将在您的项目目录中寻找模型权重。您可以在云平台上托管权重,并相应地选择路径。
现在,我们将使用 Torch Hub 访问该模型,并在我们的数据上测试它。
用torch.hub.load来称呼我们的模型
回到我们的主项目目录,让我们进入hub_usage.py脚本。
# USAGE
# python hub_usage.py
# import the necessary packages
from pyimagesearch.data_gen import next_batch
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
import torch.nn as nn
import argparse
import torch
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-b", "--batch-size", type=int, default=64,
help="input batch size")
args = vars(ap.parse_args())
在导入必要的包之后,我们为用户创建一个参数解析器(第 13-16 行)来输入数据的批量大小。
# load the model using torch hub
print("[INFO] loading the model using torch hub...")
model = torch.hub.load("cr0wley-zz/torch_hub_test:main",
"custom_model")
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, Y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, Y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
在的第 20 行和第 21 行,我们使用torch.hub.load来初始化我们自己的模型,就像前面我们加载 DCGAN 模型一样。模型已经初始化,权重已经根据子目录中的hubconf.py脚本中的入口点加载。正如你所注意到的,我们给子目录github作为参数。
现在,为了评估模型,我们将按照我们在模型训练期间创建的相同方式创建数据(第 26 行和第 27 行),并使用train_test_split创建数据分割(第 31-36 行)。
# initialize the neural network loss function
lossFunc = nn.CrossEntropyLoss()
# set device to cuda if available and initialize
# testing loss and accuracy
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
testLoss = 0
testAcc = 0
samples = 0
# set model to eval and grab a batch of data
print("[INFO] setting the model in evaluation mode...")
model.eval()
(batchX, batchY) = next(next_batch(testX, testY, args["batch_size"]))
在第 39 行上,我们初始化交叉熵损失函数,如在模型训练期间所做的。我们继续初始化第 44-46 行的评估指标。
将模型设置为评估模式(行 50 ),并抓取单批数据供模型评估(行 51 )。
# initialize a no-gradient context
with torch.no_grad():
# load the data into device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# pass the data through the model to get the output and calculate
# loss
predictions = model(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
print("[INFO] test loss: {:.3f}".format(testLoss / samples))
print("[INFO] test accuracy: {:.3f}".format(testAcc / samples))
关闭自动梯度(行 54 ),我们将该批数据加载到设备中,并将其输入到模型中(行 56-60 )。lossFunc继续计算线 61 上的损耗。
在损失的帮助下,我们更新了第 66 行上的精度变量,以及一些其他度量,如样本大小(行 67** )。**
让我们看看这个模型的效果如何!
[INFO] loading the model using torch hub...
[INFO] preparing data...
[INFO] setting the model in evaluation mode...
Using cache found in /root/.cache/torch/hub/cr0wley-zz_torch_hub_test_main
[INFO] test loss: 0.086
[INFO] test accuracy: 0.969
由于我们使用训练模型时使用的相同范例创建了我们的测试数据,因此它的表现与预期一致,测试精度为 0.969 。
摘要
在当今的研究领域,结果的再现是多么重要,这一点我怎么强调都不为过。特别是在机器学习方面,我们已经慢慢地达到了一个新的研究想法变得日益复杂的地步。在这种情况下,研究人员拥有一个平台来轻松地将他们的研究和结果公之于众,这是一个巨大的负担。
作为一名研究人员,当您已经有足够多的事情要担心时,拥有一个工具,使用一个脚本和几行代码来公开您的模型和结果,对我们来说是一个巨大的福音。当然,作为一个项目,随着时间的推移,火炬中心将更多地根据用户的需求进行发展。尽管如此,Torch Hub 的创建所倡导的生态系统将帮助未来几代人的机器学习爱好者。
引用信息
Chakraborty,D. “火炬中心系列#1:火炬中心简介”, PyImageSearch ,2021,https://PyImageSearch . com/2021/12/20/Torch-Hub-Series-1-Introduction-to-Torch-Hub/
@article{dev_2021_THS1,
author = {Devjyoti Chakraborty},
title = {{Torch Hub} Series \#1: Introduction to {Torch Hub}},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/12/20/torch-hub-series-1-introduction-to-torch-hub/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
火炬中心系列#2: VGG 和雷斯内特
原文:https://pyimagesearch.com/2021/12/27/torch-hub-series-2-vgg-and-resnet/
在之前的教程中,我们学习了火炬中心背后的精髓及其概念。然后,我们使用 Torch Hub 的复杂性发布了我们的模型,并通过它进行访问。但是,当我们的工作需要我们使用 Torch Hub 上众多功能强大的模型之一时,会发生什么呢?
在本教程中,我们将学习如何利用最常见的模型称为使用火炬枢纽的力量:VGG 和 ResNet 模型家族。我们将学习这些模型背后的核心思想,并针对我们选择的任务对它们进行微调。
本课是关于火炬中心的 6 部分系列的第 2 部分:
- 火炬中心系列# 1:火炬中心介绍
- 火炬毂系列#2: VGG 和雷斯内特(本教程)
- 火炬轮毂系列#3: YOLO v5 和 SSD——实物检测模型
- 火炬轮毂系列# 4:—甘上模
- 火炬轮毂系列# 5:MiDaS——深度估计模型
- 火炬中枢系列#6:图像分割
要了解如何利用火炬枢纽来驾驭 VGG 网和雷斯网的力量, 继续阅读。
火炬中心系列#2: VGG 和雷斯内特
VGG 和雷斯内特
说实话,在每一个深度学习爱好者的生活中,迁移学习总会发挥巨大的作用。我们并不总是拥有从零开始训练模型的必要硬件,尤其是在千兆字节的数据上。云环境确实让我们的生活变得更轻松,但它们的使用显然是有限的。
现在,你可能想知道我们是否必须在机器学习的旅程中尝试我们所学的一切。使用图 1 可以最好地解释这一点。
在机器学习领域,理论和实践是同等重要的。按照这种观念,硬件限制会严重影响你的机器学习之旅。谢天谢地,机器学习社区的好心人通过在互联网上上传预先训练好的模型权重来帮助我们绕过这些问题。这些模型在巨大的数据集上训练,使它们成为非常强大的特征提取器。
您不仅可以将这些模型用于您的任务,还可以将它们用作基准。现在,您一定想知道在特定数据集上训练的模型是否适用于您的问题所特有的任务。
这是一个非常合理的问题。但是想一想完整的场景。例如,假设您有一个在 ImageNet 上训练的模型(1400 万个图像和 20,000 个类)。在这种情况下,由于您的模型已经是一个熟练的特征提取器,因此针对类似的和更具体的图像分类对其进行微调将会给您带来好的结果。由于我们今天的任务是微调一个 VGG/雷斯网模型,我们将看到我们的模型从第一个纪元开始是多么熟练!
由于网上有大量预先训练好的模型权重,Torch Hub 可以识别所有可能出现的问题,并通过将整个过程浓缩到一行来解决它们。因此,您不仅可以在本地系统中加载 SOTA 模型,还可以选择是否需要对它们进行预训练。
事不宜迟,让我们继续本教程的先决条件。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 PyTorch 框架。
幸运的是,它是 pip 可安装的:
$ pip install pytorch
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
$ tree .
.
├── inference.py
├── pyimagesearch
│ ├── classifier.py
│ ├── config.py
│ └── datautils.py
└── train.py
1 directory, 5 files
在pyimagesearch中,我们有 3 个脚本:
classifier.py:容纳项目的模型架构config.py:包含项目的端到端配置管道datautils.py:包含了我们将在项目中使用的两个数据实用函数
在父目录中,我们有两个脚本:
- 根据我们训练的模型权重进行推断
train.py:在所需数据集上训练模型
VGG 和 ResNet 架构概述
论文中介绍了 VGG16 架构的超深卷积网络用于大规模图像识别它借鉴了 AlexNet 的核心思想,同时用多个3×3卷积滤波器取代了大尺寸的卷积滤波器。在图 3 中,我们可以看到完整的架构。
过多卷积滤波器的小滤波器尺寸和网络的深度架构胜过当时的许多基准模型。因此,直到今天,VGG16 仍被认为是 ImageNet 数据集的最新模型。
不幸的是,VGG16 有一些重大缺陷。首先,由于网络的性质,它有几个权重参数。这不仅使模型更重,而且增加了这些模型的推理时间。
理解了 VGG 篮网的局限性,我们继续关注他们的精神继承者;雷斯网。由何和介绍,ResNets 的想法背后的纯粹天才不仅在许多情况下超过了 Nets,而且他们的架构也使推理时间更快。
ResNets 背后的主要思想可以在图 4 中看到。
这种架构被称为“剩余块”正如您所看到的,一层的输出不仅会被提供给下一层,还会进行一次跳跃,并被提供给架构中的另一层。
现在,这个想法立刻消除了渐变消失的可能性。但是这里的主要思想是来自前面层的信息在后面的层中保持活跃。因此,精心制作的特征映射阵列在自适应地决定这些残余块层的输出中起作用。
ResNet 被证明是机器学习社区的一次巨大飞跃。ResNet 不仅在构思之初就超越了许多深度架构,而且还引入了一个全新的方向,告诉我们如何让深度架构变得更好。
有了这两个模型的基本思想之后,让我们开始编写代码吧!
熟悉我们的数据集
对于今天的任务,我们将使用来自 Kaggle 的简单二元分类狗&猫数据集。这个 217.78 MB 的数据集包含 10,000 幅猫和狗的图像,以 80-20 的训练与测试比率分割。训练集包含 4000 幅猫和 4000 幅狗的图像,而测试集分别包含 1000 幅猫和 1000 幅狗的图像。使用较小的数据集有两个原因:
- 微调我们的分类器将花费更少的时间
- 展示预训练模型适应具有较少数据的新数据集的速度
配置先决条件
首先,让我们进入存储在pyimagesearch目录中的config.py脚本。该脚本将包含完整的训练和推理管道配置值。
# import the necessary packages
import torch
import os
# define the parent data dir followed by the training and test paths
BASE_PATH = "dataset"
TRAIN_PATH = os.path.join(BASE_PATH, "training_set")
TEST_PATH = os.path.join(BASE_PATH, "test_set")
# specify ImageNet mean and standard deviation
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
# specify training hyperparameters
IMAGE_SIZE = 256
BATCH_SIZE = 128
PRED_BATCH_SIZE = 4
EPOCHS = 15
LR = 0.0001
# determine the device type
DEVICE = torch.device("cuda") if torch.cuda.is_available() else "cpu"
# define paths to store training plot and trained model
PLOT_PATH = os.path.join("output", "model_training.png")
MODEL_PATH = os.path.join("output", "model.pth")
我们首先在第 6 行初始化数据集的基本训练。然后,在第 7 行和第 8 行,我们使用os.path.join来指定数据集的训练和测试文件夹。
在第行第 11 和 12 行,我们指定了稍后创建数据集实例时所需的 ImageNet 平均值和标准偏差。这样做是因为模型是通过这些平均值和标准偏差值预处理的预训练数据,我们将尽可能使我们的当前数据与之前训练的数据相似。
接下来,我们为超参数赋值,如图像大小、批量大小、时期等。(第 15-19 行)并确定我们将训练我们模型的设备(第 22 行)。
我们通过指定存储训练图和训练模型权重的路径来结束我们的脚本(行 25 和 26 )。
为我们的数据管道创建实用函数
我们创建了一些函数来帮助我们处理数据管道,并在datautils.py脚本中对它们进行分组,以便更好地处理我们的数据。
# import the necessary packages
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader
from torch.datasets import Subset
def get_dataloader(dataset, batchSize, shuffle=True):
# create a dataloader
dl = DataLoader(dataset, batch_size=batchSize, shuffle=shuffle)
# return the data loader
return dl
我们的第一个效用函数是get_dataloader函数。它将数据集、批处理大小和一个布尔变量shuffle作为其参数(第 6 行),并返回一个 PyTorch dataloader实例(第 11 行)。
def train_val_split(dataset, valSplit=0.2):
# grab the total size of the dataset
totalSize = len(dataset)
# perform training and validation split
(trainIdx, valIdx) = train_test_split(list(range(totalSize)),
test_size=valSplit)
trainDataset = Subset(dataset, trainIdx)
valDataset = Subset(dataset, valIdx)
# return training and validation dataset
return (trainDataset, valDataset)
接下来,我们创建一个名为train_val_split的函数,它接受数据集和一个验证分割百分比变量作为参数(第 13 行)。由于我们的数据集只有训练和测试目录,我们使用 PyTorch dataset子集特性将训练集分成训练和验证集。
我们首先使用train_test_split函数为我们的分割创建索引,然后将这些索引分配给子集(第 20 行和第 21 行)。该功能将返回训练和验证数据子集(行 24 )。
为我们的任务创建分类器
我们的下一个任务是为猫狗数据集创建一个分类器。请记住,我们不是从零开始训练我们的调用模型,而是对它进行微调。为此,我们将继续下一个脚本,即classifier.py。
# import the necessary packages
from torch.nn import Linear
from torch.nn import Module
class Classifier(Module):
def __init__(self, baseModel, numClasses, model):
super().__init__()
# initialize the base model
self.baseModel = baseModel
# check if the base model is VGG, if so, initialize the FC
# layer accordingly
if model == "vgg":
self.fc = Linear(baseModel.classifier[6].out_features,
numClasses)
# otherwise, the base model is of type ResNet so initialize
# the FC layer accordingly
else:
self.fc = Linear(baseModel.fc.out_features, numClasses)
在我们的Classifier模块(第 5 行)中,构造函数接受以下参数:
- 因为我们将调用 VGG 或 ResNet 模型,我们已经覆盖了我们架构的大部分。我们将把调用的基础模型直接插入到我们的架构中的第 9 行上。
numClasses:将决定我们架构的输出节点。对于我们的任务,该值为 2。- 一个字符串变量,它将告诉我们我们的基本模型是 VGG 还是 ResNet。因为我们必须为我们的任务创建一个单独的输出层,所以我们必须获取模型的最终线性层的输出。但是,每个模型都有不同的方法来访问最终的线性图层。因此,该
model变量将有助于相应地选择特定于车型的方法(第 14 行和第 20 行)。
注意,对于 VGGnet,我们使用命令baseModel.classifier[6].out_features,而对于 ResNet,我们使用baseModel.fc.out_features。这是因为这些模型有不同的命名模块和层。所以我们必须使用不同的命令来访问每一层的最后一层。因此,model变量对于我们的代码工作非常重要。
def forward(self, x):
# pass the inputs through the base model to get the features
# and then pass the features through of fully connected layer
# to get our output logits
features = self.baseModel(x)
logits = self.fc(features)
# return the classifier outputs
return logits
转到forward函数,我们简单地在行 26 上获得基本模型的输出,并通过我们最终的完全连接层(行 27 )来获得模型输出。
训练我们的自定义分类器
先决条件排除后,我们继续进行train.py。首先,我们将训练我们的分类器来区分猫和狗。
# USAGE
# python train.py --model vgg
# python train.py --model resnet
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.classifier import Classifier
from pyimagesearch.datautils import get_dataloader
from pyimagesearch.datautils import train_val_split
from torchvision.datasets import ImageFolder
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torchvision.transforms import RandomResizedCrop
from torchvision.transforms import RandomHorizontalFlip
from torchvision.transforms import RandomRotation
from torchvision.transforms import Normalize
from torch.nn import CrossEntropyLoss
from torch.nn import Softmax
from torch import optim
from tqdm import tqdm
import matplotlib.pyplot as plt
import argparse
import torch
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="vgg",
choices=["vgg", "resnet"], help="name of the backbone model")
args = vars(ap.parse_args())
在第 6-23 行中,我们拥有培训模块所需的所有导入。不出所料,这是一个相当长的列表!
为了便于访问和选择,我们在第 26 行的处创建了一个参数解析器,在第 27-29 行的处添加了参数模型选项(VGG 或雷斯尼)。
接下来的一系列代码块是我们项目中非常重要的部分。例如,为了微调模型,我们通常冻结预训练模型的层。然而,在消融不同的场景时,我们注意到保持卷积层冻结,但是完全连接的层解冻以用于进一步的训练,这有助于我们的结果。
# check if the name of the backbone model is VGG
if args["model"] == "vgg":
# load VGG-11 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "vgg11",
pretrained=True, skip_validation=True)
# freeze the layers of the VGG-11 model
for param in baseModel.features.parameters():
param.requires_grad = False
从火炬中心调用的 VGG 模型架构(线 34 和 35 )被分成几个子模块,以便于访问。卷积层被分组在一个名为features的模块下,而下面完全连接的层被分组在一个名为classifier的模块下。由于我们只需要冻结卷积层,我们直接访问第 38 行上的参数,并通过将requires_grad设置为False来冻结它们,保持classifier模块层不变。
# otherwise, the backbone model we will be using is a ResNet
elif args["model"] == "resnet":
# load ResNet 18 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "resnet18",
pretrained=True, skip_validation=True)
# define the last and the current layer of the model
lastLayer = 8
currentLayer = 1
# loop over the child layers of the model
for child in baseModel.children():
# check if we haven't reached the last layer
if currentLayer < lastLayer:
# loop over the child layer's parameters and freeze them
for param in child.parameters():
param.requires_grad = False
# otherwise, we have reached the last layers so break the loop
else:
break
# increment the current layer
currentLayer += 1
在基本模型是 ResNet 的情况下,有几种方法可以解决这个问题。要记住的主要事情是,在 ResNet 中,我们只需要保持最后一个完全连接的层不冻结。相应地,在第 48 行和第 49 行,我们设置了最后一层和当前层索引。
在第 52 行的 ResNet 的可用层上循环,我们冻结所有层,除了最后一层(行 55-65** )。**
# define the transform pipelines
trainTransform = Compose([
RandomResizedCrop(config.IMAGE_SIZE),
RandomHorizontalFlip(),
RandomRotation(90),
ToTensor(),
Normalize(mean=config.MEAN, std=config.STD)
])
# create training dataset using ImageFolder
trainDataset = ImageFolder(config.TRAIN_PATH, trainTransform)
我们继续创建输入管道,从 PyTorch transform实例开始,它可以自动调整大小、规范化和增加数据,没有太多麻烦(第 68-74 行)。
我们通过使用另一个名为ImageFolder的 PyTorch 实用函数来完成它,该函数将自动创建输入和目标数据,前提是目录设置正确(第 77 行)。
# create training and validation data split
(trainDataset, valDataset) = train_val_split(dataset=trainDataset)
# create training and validation data loaders
trainLoader = get_dataloader(trainDataset, config.BATCH_SIZE)
valLoader = get_dataloader(valDataset, config.BATCH_SIZE)
使用我们的train_val_split效用函数,我们将训练数据集分成一个训练和验证集(第 80 行)。接下来,我们使用来自datautils.py的get_dataloader实用函数来创建我们数据的 PyTorch dataloader实例(第 83 行和第 84 行)。这将允许我们以一种类似生成器的方式无缝地向模型提供数据。
# build the custom model
model = Classifier(baseModel=baseModel.to(config.DEVICE),
numClasses=2, model=args["model"])
model = model.to(config.DEVICE)
# initialize loss function and optimizer
lossFunc = CrossEntropyLoss()
lossFunc.to(config.DEVICE)
optimizer = optim.Adam(model.parameters(), lr=config.LR)
# initialize the softmax activation layer
softmax = Softmax()
继续我们的模型先决条件,我们创建我们的定制分类器并将其加载到我们的设备上(第 87-89 行)。
我们已经使用交叉熵作为我们今天任务的损失函数和 Adam 优化器(第 92-94 行)。此外,我们使用单独的softmax损失来帮助我们增加培训损失(第 97 行)。
# calculate steps per epoch for training and validation set
trainSteps = len(trainDataset) // config.BATCH_SIZE
valSteps = len(valDataset) // config.BATCH_SIZE
# initialize a dictionary to store training history
H = {
"trainLoss": [],
"trainAcc": [],
"valLoss": [],
"valAcc": []
}
训练时期之前的最后一步是设置训练步骤和验证步骤值,然后创建一个存储所有训练历史的字典(行 100-109 )。
# loop over epochs
print("[INFO] training the network...")
for epoch in range(config.EPOCHS):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
在训练循环中,我们首先将模型设置为训练模式( Line 115 )。接下来,我们初始化训练损失、确认损失、训练和确认精度变量(第 118-124 行)。
# loop over the training set
for (image, target) in tqdm(trainLoader):
# send the input to the device
(image, target) = (image.to(config.DEVICE),
target.to(config.DEVICE))
# perform a forward pass and calculate the training loss
logits = model(image)
loss = lossFunc(logits, target)
# zero out the gradients, perform the backpropagation step,
# and update the weights
optimizer.zero_grad()
loss.backward()
optimizer.step()
# add the loss to the total training loss so far, pass the
# output logits through the softmax layer to get output
# predictions, and calculate the number of correct predictions
totalTrainLoss += loss.item()
pred = softmax(logits)
trainCorrect += (pred.argmax(dim=-1) == target).sum().item()
遍历完整的训练集,我们首先将数据和目标加载到设备中(行 129 和 130 )。接下来,我们简单地通过模型传递数据并获得输出,然后将预测和目标插入我们的损失函数(第 133 行和第 134 行),
第 138-140 行是标准 PyTorch 反向传播步骤,其中我们将梯度归零,执行反向传播,并更新权重。
接下来,我们将损失添加到我们的总训练损失中(行 145 ),通过 softmax 传递模型输出以获得孤立的预测值,然后将其添加到trainCorrect变量中。
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (image, target) in tqdm(valLoader):
# send the input to the device
(image, target) = (image.to(config.DEVICE),
target.to(config.DEVICE))
# make the predictions and calculate the validation
# loss
logits = model(image)
valLoss = lossFunc(logits, target)
totalValLoss += valLoss.item()
# pass the output logits through the softmax layer to get
# output predictions, and calculate the number of correct
# predictions
pred = softmax(logits)
valCorrect += (pred.argmax(dim=-1) == target).sum().item()
验证过程中涉及的大部分步骤与培训过程相同,除了以下几点:
- 模型被设置为评估模式(行 152 )
- 权重没有更新
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDataset)
valCorrect = valCorrect / len(valDataset)
# update our training history
H["trainLoss"].append(avgTrainLoss)
H["valLoss"].append(avgValLoss)
H["trainAcc"].append(trainCorrect)
H["valAcc"].append(valCorrect)
# print the model training and validation information
print(f"[INFO] EPOCH: {epoch + 1}/{config.EPOCHS}")
print(f"Train loss: {avgTrainLoss:.6f}, Train accuracy: {trainCorrect:.4f}")
print(f"Val loss: {avgValLoss:.6f}, Val accuracy: {valCorrect:.4f}")
在退出训练循环之前,我们计算平均损失(行 173 和 174 )以及训练和验证精度(行 177 和 178 )。
然后,我们继续将这些值添加到我们的训练历史字典中(行 181-184 )。
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["trainLoss"], label="train_loss")
plt.plot(H["valLoss"], label="val_loss")
plt.plot(H["trainAcc"], label="train_acc")
plt.plot(H["valAcc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
# serialize the model state to disk
torch.save(model.module.state_dict(), config.MODEL_PATH)
在完成我们的训练脚本之前,我们绘制所有的训练字典变量(行 192-201 )并保存图形(行 202 )。
我们最后的任务是将模型权重保存在之前定义的路径中( Line 205 )。
让我们看看每个时期的值是什么样的!
[INFO] training the network...
100%|██████████| 50/50 [01:24<00:00, 1.68s/it]
100%|██████████| 13/13 [00:19<00:00, 1.48s/it]
[INFO] EPOCH: 1/15
Train loss: 0.289117, Train accuracy: 0.8669
Val loss: 0.217062, Val accuracy: 0.9119
100%|██████████| 50/50 [00:47<00:00, 1.05it/s]
100%|██████████| 13/13 [00:11<00:00, 1.10it/s]
[INFO] EPOCH: 2/15
Train loss: 0.212023, Train accuracy: 0.9039
Val loss: 0.223640, Val accuracy: 0.9025
100%|██████████| 50/50 [00:46<00:00, 1.07it/s]
100%|██████████| 13/13 [00:11<00:00, 1.15it/s]
[INFO] EPOCH: 3/15
...
Train loss: 0.139766, Train accuracy: 0.9358
Val loss: 0.187595, Val accuracy: 0.9194
100%|██████████| 50/50 [00:46<00:00, 1.07it/s]
100%|██████████| 13/13 [00:11<00:00, 1.15it/s]
[INFO] EPOCH: 13/15
Train loss: 0.134248, Train accuracy: 0.9425
Val loss: 0.146280, Val accuracy: 0.9437
100%|██████████| 50/50 [00:47<00:00, 1.05it/s]
100%|██████████| 13/13 [00:11<00:00, 1.12it/s]
[INFO] EPOCH: 14/15
Train loss: 0.132265, Train accuracy: 0.9428
Val loss: 0.162259, Val accuracy: 0.9319
100%|██████████| 50/50 [00:47<00:00, 1.05it/s]
100%|██████████| 13/13 [00:11<00:00, 1.16it/s]
[INFO] EPOCH: 15/15
Train loss: 0.138014, Train accuracy: 0.9409
Val loss: 0.153363, Val accuracy: 0.9313
我们预训练的模型精度在第一个历元就已经接近 90% 。到了第 13个时期,数值在大约**~94%**处饱和。从这个角度来看,在不同数据集上训练的预训练模型在它以前没有见过的数据集上以大约 86% 的精度开始。这就是它学会提取特征的程度。
在图 5 中绘制了指标的完整概述。
测试我们微调过的模型
随着我们的模型准备就绪,我们将继续我们的推理脚本,inference.py。
# USAGE
# python inference.py --model vgg
# python inference.py --model resnet
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.classifier import Classifier
from pyimagesearch.datautils import get_dataloader
from torchvision.datasets import ImageFolder
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torchvision.transforms import Resize
from torchvision.transforms import Normalize
from torchvision import transforms
from torch.nn import Softmax
from torch import nn
import matplotlib.pyplot as plt
import argparse
import torch
import tqdm
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="vgg",
choices=["vgg", "resnet"], help="name of the backbone model")
args = vars(ap.parse_args())
因为我们必须在加载权重之前初始化我们的模型,所以我们需要正确的模型参数。为此,我们在第 23-26 行的中创建了一个参数解析器。
# initialize test transform pipeline
testTransform = Compose([
Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
ToTensor(),
Normalize(mean=config.MEAN, std=config.STD)
])
# calculate the inverse mean and standard deviation
invMean = [-m/s for (m, s) in zip(config.MEAN, config.STD)]
invStd = [1/s for s in config.STD]
# define our denormalization transform
deNormalize = transforms.Normalize(mean=invMean, std=invStd)
# create the test dataset
testDataset = ImageFolder(config.TEST_PATH, testTransform)
# initialize the test data loader
testLoader = get_dataloader(testDataset, config.PRED_BATCH_SIZE)
由于我们将在完整的测试数据集上计算我们的模型的准确性,我们在第 29-33 行的上为我们的测试数据创建一个 PyTorch transform实例。
因此,我们计算反平均值和反标准偏差值,我们用它们来创建一个transforms.Normalize实例(第 36-40 行)。这样做是因为数据在输入到模型之前经过了预处理。出于显示目的,我们必须将图像恢复到原始状态。
使用ImageFolder实用函数,我们创建我们的测试数据集实例,并将其提供给之前为测试dataLoader实例创建的get_dataloader函数(第 43-46 行)。
# check if the name of the backbone model is VGG
if args["model"] == "vgg":
# load VGG-11 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "vgg11",
pretrained=True, skip_validation=True)
# otherwise, the backbone model we will be using is a ResNet
elif args["model"] == "resnet":
# load ResNet 18 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "resnet18",
pretrained=True, skip_validation=True)
如前所述,由于我们必须再次初始化模型,我们检查给定的模型参数,并相应地使用 Torch Hub 加载模型(第 49-58 行)。
# build the custom model
model = Classifier(baseModel=baseModel.to(config.DEVICE),
numClasses=2, vgg = False)
model = model.to(config.DEVICE)
# load the model state and initialize the loss function
model.load_state_dict(torch.load(config.MODEL_PATH))
lossFunc = nn.CrossEntropyLoss()
lossFunc.to(config.DEVICE)
# initialize test data loss
testCorrect = 0
totalTestLoss = 0
soft = Softmax()
在第 61-66 行上,我们初始化模型,将其存储在我们的设备上,并在模型训练期间加载先前获得的权重。
正如我们在train.py脚本中所做的,我们选择交叉熵作为我们的损失函数(第 67 行,并初始化测试损失和准确性(第 71 行和第 72 行)。
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (image, target) in tqdm(testLoader):
# send the input to the device
(image, target) = (image.to(config.DEVICE),
target.to(config.DEVICE))
# make the predictions and calculate the validation
# loss
logit = model(image)
loss = lossFunc(logit, target)
totalTestLoss += loss.item()
# output logits through the softmax layer to get output
# predictions, and calculate the number of correct predictions
pred = soft(logit)
testCorrect += (pred.argmax(dim=-1) == target).sum().item()
关闭自动梯度(行 76 ),我们在行 78 将模型设置为评估模式。然后,在测试图像上循环,我们将它们提供给模型,并通过损失函数传递预测和目标(第 81-89 行)。
通过 softmax 函数(第 95 和 96 行)传递预测来计算精确度。
# print test data accuracy
print(testCorrect/len(testDataset))
# initialize iterable variable
sweeper = iter(testLoader)
# grab a batch of test data
batch = next(sweeper)
(images, labels) = (batch[0], batch[1])
# initialize a figure
fig = plt.figure("Results", figsize=(10, 10 ))
现在我们将看看测试数据的一些具体情况并显示它们。为此,我们在行 102 上初始化一个可迭代变量,并抓取一批数据(行 105 )。
# switch off autograd
with torch.no_grad():
# send the images to the device
images = images.to(config.DEVICE)
# make the predictions
preds = model(images)
# loop over all the batch
for i in range(0, config.PRED_BATCH_SIZE):
# initialize a subplot
ax = plt.subplot(config.PRED_BATCH_SIZE, 1, i + 1)
# grab the image, de-normalize it, scale the raw pixel
# intensities to the range [0, 255], and change the channel
# ordering from channels first tp channels last
image = images[i]
image = deNormalize(image).cpu().numpy()
image = (image * 255).astype("uint8")
image = image.transpose((1, 2, 0))
# grab the ground truth label
idx = labels[i].cpu().numpy()
gtLabel = testDataset.classes[idx]
# grab the predicted label
pred = preds[i].argmax().cpu().numpy()
predLabel = testDataset.classes[pred]
# add the results and image to the plot
info = "Ground Truth: {}, Predicted: {}".format(gtLabel,
predLabel)
plt.imshow(image)
plt.title(info)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
我们再次关闭自动渐变,并对之前获取的一批数据进行预测(第 112-117 行)。
在批处理中循环,我们抓取单个图像,反规格化它们,重新缩放它们,并固定它们的尺寸以使它们可显示(行 127-130 )。
基于当前正在考虑的图像,我们首先抓取它的地面真实标签(行 133 和 134 )以及它们在行 137 和 138 上对应的预测标签,并相应地显示它们(行 141-145 )。
微调模型的结果
在整个测试数据集上,我们的 ResNet 支持的定制模型产生了 97.5%的准确率。在图 6-9 中,我们看到显示的一批数据,以及它们对应的基础事实和预测标签。
凭借 97.5%的准确度,您可以放心,这一性能水平不仅适用于该批次,还适用于所有T2 批次。您可以重复运行sweeper变量来获得不同的数据批次,以便自己查看。
总结
今天的教程不仅展示了如何利用 Torch Hub 的模型库,还提醒了我们预先训练的模型在我们日常的机器学习活动中有多大的帮助。
想象一下,如果您必须为您选择的任何任务从头开始训练一个像 ResNet 这样的大型架构。这将需要更多的时间,而且肯定需要更多的纪元。至此,您肯定会欣赏 PyTorch Hub 背后的理念,即让使用这些最先进模型的整个过程更加高效。
从我们上一周的教程中离开的地方继续,我想强调 PyTorch Hub 仍然很粗糙,它仍然有很大的改进空间。当然,我们离完美的版本越来越近了!
引用信息
Chakraborty,D. “火炬中心系列#2: VGG 和雷斯内特”, PyImageSearch ,2021,https://PyImageSearch . com/2021/12/27/Torch-Hub-Series-2-vgg-and-ResNet/
@article{dev_2021_THS2,
author = {Devjyoti Chakraborty},
title = {{Torch Hub} Series \#2: {VGG} and {ResNet}},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/12/27/torch-hub-series-2-vgg-and-resnet/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
Torch Hub 系列#3: YOLOv5 和 SSD——对象检测模型
原文:https://pyimagesearch.com/2022/01/03/torch-hub-series-3-yolov5-and-ssd-models-on-object-detection/
在我的童年,电影《间谍小子》是我最喜欢看的电视节目之一。看到我这个年龄的孩子使用未来的小工具来拯救世界并赢得胜利可能是一个常见的比喻,但看起来仍然很有趣。在像喷气背包和自动驾驶汽车这样的东西中,我最喜欢的是智能太阳镜,它可以识别你周围的物体和人(它还可以兼作双目望远镜),有点像图 1 。
可以理解的是,这些小玩意在现实生活中的概念在当时很难理解。但是,现在已经到了 2022 年,一家自动驾驶汽车公司(特斯拉)已经处于电机行业的顶端,从实时视频中检测物体简直易如反掌!
所以今天,除了理解一个年轻的我的狂热梦想,我们将看到 PyTorch Hub 如何使探索这些领域变得容易。
在本教程中,我们将学习 YOLOv5 和 SSD300 等模型背后的直觉,并使用 Torch Hub 驾驭它们的力量。
本课是关于火炬中心的 6 部分系列的第 3 部分:
- 火炬中心系列# 1:火炬中心介绍
- 火炬枢纽系列#2: VGG 和雷斯内特
- 火炬轮毂系列#3: YOLOv5 和 SSD——物体检测模型(本教程)
- 火炬轮毂系列# 4:—甘上模
- 火炬轮毂系列# 5:MiDaS——深度估计模型
- 火炬中枢系列#6:图像分割
要学习如何使用 YOLOv5 和 SSD300, 继续阅读。
火炬轮毂系列#3: YOLOv5 和****SSD——物体检测模型
物体检测一目了然
乍一看,物体检测无疑是一个非常诱人的领域。让机器识别图像中某个对象的确切位置,让我相信我们离实现模仿人脑的梦想又近了一步。但即使我们把它放在一边,它在当今世界也有各种各样的重要用法。从人脸检测系统到帮助自动驾驶汽车安全导航,这样的例子不胜枚举。但是它到底是如何工作的呢?
实现物体检测的方法有很多,以机器学习为核心思想。例如,在这篇关于在 PyTorch 中从头开始训练一个物体检测器的博客文章中,我们有一个简单的架构,它接收图像作为输入并输出 5 样东西;检测到的对象的类别以及对象边界框的高度和宽度的起始值和结束值。
本质上,我们获取带注释的图像,并通过一个简单的输出大小为 5 的 CNN 传递它们。因此,就像机器学习中开发的每一个新事物一样,更复杂和错综复杂的算法随之而来,以改进它。
请注意,如果您考虑我在上一段中提到的方法,它可能只适用于检测单个对象的图像。然而,当多个物体在一张图像中时,这几乎肯定会遇到障碍。因此,为了解决这一问题以及效率等其他限制,我们转向 YOLO(v1)。
YOLO,或“你只看一次”(2015),介绍了一种巧妙的方法来解决简单的 CNN 探测器的缺点。我们将每幅图像分割成一个 S × S 网格,得到每个细胞对应的物体位置。当然,有些单元格不会有任何对象,有些则会出现在多个单元格中。看一下图二。
了解完整图像中对象的中点、高度和宽度非常重要。然后,每个像元将输出一个概率值(像元中有一个对象的概率)、检测到的对象类以及像元特有的边界框值。
即使每个单元只能检测一个对象,多个单元的存在也会使约束无效。结果可以在图 3 中看到。
尽管取得了巨大的成果,但 YOLOv1 有一个重大缺陷;图像中对象的接近程度经常会使模型错过一些对象。自问世以来,已经出版了几个后继版本,如 YOLOv2、YOLOv3 和 YOLOv4,每一个都比前一个版本更好更快。这就把我们带到了今天的焦点之一,YOLOv5。
YOLOv5 的创造者 Glenn Jocher 决定不写论文,而是通过 GitHub 开源该模型。最初,这引起了很多关注,因为人们认为结果是不可重复的。然而,这种想法很快被打破了,今天,YOLOv5 是火炬中心展示区的官方最先进的模型之一。
要了解 YOLOv5 带来了哪些改进,我们还得回到 YOLOv2。其中,YOLOv2 引入了锚盒的概念。一系列预定的边界框、锚框具有特定的尺寸。根据训练数据集中的对象大小选择这些框,以捕捉要检测的各种对象类的比例和纵横比。网络预测对应于锚框而不是边界框本身的概率。
但在实践中,悬挂 YOLO 模型通常是在 COCO 数据集上训练的。这导致了一个问题,因为自定义数据集可能没有相同的锚框定义。YOLOv5 通过引入自动学习锚盒来解决这个问题。它还利用镶嵌增强,混合随机图像,使您的模型擅长识别较小比例的对象。
今天的第二个亮点是用于物体检测的固态硬盘或单次多盒探测器型号。SSD300 最初使用 VGG 主干进行娴熟的特征检测,并利用了 Szegedy 在 MultiBox 上的工作,这是一种快速分类不可知边界框坐标建议的方法,启发了 SSD 的边界框回归算法。图 4 展示了 SSD 架构。
受 inception-net 的启发,Szegedy 创建的多盒架构利用了多尺度卷积架构。Multibox 使用一系列正常的卷积和1×1过滤器(改变通道大小,但保持高度和宽度不变)来合并多尺度边界框和置信度预测模型。
SSD 以利用多尺度特征地图而不是单一特征地图进行检测而闻名。这允许更精细的检测和更精细的预测。使用这些特征图,生成了用于对象预测的锚框。
它问世时就已经超越了它的同胞,尤其是在速度上。今天我们将使用 Torch Hub 展示的 SSD,它使用 ResNet 而不是 VGG 网络作为主干。此外,其他一些变化,如根据现代卷积物体探测器论文的速度/精度权衡移除一些层,也被应用到模型中。
今天,我们将学习如何使用 Torch Hub 利用这些模型的功能,并使用我们的自定义数据集对它们进行测试!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── output
│ ├── ssd_output
│ │ └── ssd_output.png
│ └── yolo_output
│ └── yolo_output.png
├── pyimagesearch
│ ├── config.py
│ ├── data_utils.py
├── ssd_inference.py
└── yolov5_inference.py
首先,我们有output目录,它将存放我们将从每个模型获得的输出。
在pyimagesearch目录中,我们有两个脚本:
- 这个脚本包含了项目的端到端配置管道
- 这个脚本包含了一些用于数据处理的帮助函数
在主目录中,我们有两个脚本:
ssd_inference.py:这个脚本包含自定义映像的 SSD 模型推断。yolov5_inference.py:这个脚本包含了定制图像的 YOLOv5 模型推理。
下载数据集
第一步是根据我们的需求配置数据集。像在之前的教程中一样,我们将使用来自 Kaggle 的狗&猫图像数据集,因为它相对较小。
$ mkdir ~/.kaggle
$ cp <path to your kaggle.json> ~/.kaggle/
$ chmod 600 ~/.kaggle/kaggle.json
$ kaggle datasets download -d chetankv/dogs-cats-images
$ unzip -qq dogs-cats-images.zip
$ rm -rf "/content/dog vs cat"
要使用数据集,您需要有自己独特的kaggle.json文件来连接到 Kaggle API ( 第 2 行)。线 3 上的chmod 600命令给予用户读写文件的完全权限。
接下来是kaggle datasets download命令(第 4 行)允许你下载他们网站上的任何数据集。最后,解压文件并删除不必要的附加内容(第 5 行和第 6 行)。
让我们转到配置管道。
配置先决条件
在pyimagesearch目录中,您会发现一个名为config.py的脚本。这个脚本将包含我们项目的完整的端到端配置管道。
# import the necessary packages
import torch
import os
# define the root directory followed by the test dataset paths
BASE_PATH = "dataset"
TEST_PATH = os.path.join(BASE_PATH, "test_set")
# specify image size and batch size
IMAGE_SIZE = 300
PRED_BATCH_SIZE = 4
# specify threshold confidence value for ssd detections
THRESHOLD = 0.50
# determine the device type
DEVICE = torch.device("cuda") if torch.cuda.is_available() else "cpu"
# define paths to save output
OUTPUT_PATH = "output"
SSD_OUTPUT = os.path.join(OUTPUT_PATH, "ssd_output")
YOLO_OUTPUT = os.path.join(OUTPUT_PATH, "yolo_output")
在第 6 行的上,我们有指向数据集目录的BASE_PATH变量。由于我们将只使用模型来运行推理,我们将只需要测试集(第 7 行)。
在第 10 行,我们有一个名为IMAGE_SIZE的变量,设置为300。这是 SSD 模型的一个要求,因为它是根据大小300 x 300图像训练的。预测批量大小设置为4 ( 第 11 行),但是鼓励读者尝试不同的大小。
接下来,我们有一个名为THRESHOLD的变量,它将作为 SSD 模型结果的置信度值阈值,即只保留置信度值大于阈值的结果(第 14 行)。
建议您为今天的项目准备一个兼容 CUDA 的设备( Line 17 ),但是由于我们不打算进行任何繁重的训练,CPU 应该也能正常工作。
最后,我们创建了路径来保存从模型推断中获得的输出(第 20-22 行)。
为数据管道创建辅助函数
在我们看到运行中的模型之前,我们还有一项任务;为数据处理创建辅助函数。为此,转到位于pyimagesearch目录中的data_utils.py脚本。
# import the necessary packages
from torch.utils.data import DataLoader
def get_dataloader(dataset, batchSize, shuffle=True):
# create a dataloader and return it
dataLoader= DataLoader(dataset, batch_size=batchSize,
shuffle=shuffle)
return dataLoader
get_dataloader ( 第 4 行)函数接受数据集、批量大小和随机参数,返回一个PyTorch Dataloader ( 第 6 行和第 7 行)实例。Dataloader实例解决了许多麻烦,这需要为巨大的数据集编写单独的定制生成器类。
def normalize(image, mean=128, std=128):
# normalize the SSD input and return it
image = (image * 256 - mean) / std
return image
脚本中的第二个函数normalize,专门用于我们将发送到 SSD 模型的图像。它将image、平均值和标准偏差值作为输入,对它们进行归一化,并返回归一化图像(第 10-13 行)。
在 YOLOv5 上测试自定义图像
先决条件得到满足后,我们的下一个目的地是yolov5_inference.py。我们将准备我们的自定义数据,并将其提供给 YOLO 模型。
# import necessary packages
from pyimagesearch.data_utils import get_dataloader
import pyimagesearch.config as config
from torchvision.transforms import Compose, ToTensor, Resize
from sklearn.model_selection import train_test_split
from torchvision.datasets import ImageFolder
from torch.utils.data import Subset
import matplotlib.pyplot as plt
import numpy as np
import random
import torch
import cv2
import os
# initialize test transform pipeline
testTransform = Compose([
Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), ToTensor()])
# create the test dataset
testDataset = ImageFolder(config.TEST_PATH, testTransform)
# initialize the test data loader
testLoader = get_dataloader(testDataset, config.PRED_BATCH_SIZE)
首先,我们在第 16 行和第 17 行上创建一个 PyTorch 转换实例。使用 PyTorch 的另一个名为ImageFolder的恒星数据实用函数,我们可以直接创建一个 PyTorch 数据集实例(第 20 行)。然而,为了使这个函数工作,我们需要数据集与这个项目具有相同的格式。
一旦我们有了数据集,我们就将它传递给预先创建的get_dataloader函数,以获得一个类似 PyTorch Dataloader 实例的生成器(第 23 行)。
# initialize the yolov5 using torch hub
yoloModel = torch.hub.load("ultralytics/yolov5", "yolov5s")
# initialize iterable variable
sweeper = iter(testLoader)
# initialize image
imageInput = []
# grab a batch of test data
print("[INFO] getting the test data...")
batch = next(sweeper)
(images, _) = (batch[0], batch[1])
# send the images to the device
images = images.to(config.DEVICE)
在线 26 上,使用焊炬集线器调用 YOLOv5。简单回顾一下,torch.hub.load函数将 GitHub 存储库和所需的入口点作为它的参数。入口点是函数的名称,在这个名称下,模型调用位于所需存储库的hubconf.py脚本中。
下一步对我们的项目至关重要。我们有很多方法可以从数据集中随机获取一批图像。然而,当我们处理越来越大的数据集时,依靠循环获取数据的效率会降低。
记住这一点,我们将使用一种比循环更有效的方法。我们可以选择使用第 29 行的可迭代变量随机抓取数据。所以每次你运行第 36 行上的命令,你会得到不同的一批数据。
在行 40 上,我们将抓取的数据加载到我们将用于计算的设备上。
# loop over all the batch
for index in range(0, config.PRED_BATCH_SIZE):
# grab each image
# rearrange dimensions to channel last and
# append them to image list
image = images[index]
image = image.permute((1, 2, 0))
imageInput.append(image.cpu().detach().numpy()*255.0)
# pass the image list through the model
print("[INFO] getting detections from the test data...")
results = yoloModel(imageInput, size=300)
在第 43 行,我们有一个循环,在这个循环中我们检查抓取的图像。然后,取每幅图像,我们重新排列维度,使它们成为通道最后的,并将结果添加到我们的imageInput列表中(第 47-49 行)。
接下来,我们将列表传递给 YOLOv5 模型实例(第 53 行)。
# get random index value
randomIndex = random.randint(0,len(imageInput)-1)
# grab index result from results variable
imageIndex= results.pandas().xyxy[randomIndex]
# convert the bounding box values to integer
startX = int(imageIndex["xmin"][0])
startY = int(imageIndex["ymin"][0])
endX = int(imageIndex["xmax"][0])
endY = int(imageIndex["ymax"][0])
# draw the predicted bounding box and class label on the image
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(imageInput[randomIndex], imageIndex["name"][0],
(startX, y+10), cv2.FONT_HERSHEY_SIMPLEX,0.65, (0, 255, 0), 2)
cv2.rectangle(imageInput[randomIndex],
(startX, startY), (endX, endY),(0, 255, 0), 2)
# check to see if the output directory already exists, if not
# make the output directory
if not os.path.exists(config.YOLO_OUTPUT):
os.makedirs(config.YOLO_OUTPUT)
# show the output image and save it to path
plt.imshow(imageInput[randomIndex]/255.0)
# save plots to output directory
print("[INFO] saving the inference...")
outputFileName = os.path.join(config.YOLO_OUTPUT, "output.png")
plt.savefig(outputFileName)
第 56 行上的randomIndex变量将作为我们选择的索引,同时访问我们将要显示的图像。使用其值,在行 59** 上访问相应的边界框结果。**
我们在行 62-65 上分割图像的特定值(起始 X、起始 Y、结束 X 和结束 Y 坐标)。我们必须使用imageIndex["Column Name"][0]格式,因为results.pandas().xyxy[randomIndex]返回一个数据帧。假设在给定的图像中有一个检测,我们必须通过调用所需列的第零个索引来访问它的值。
使用这些值,我们分别使用cv2.putText和cv2.rectangle在第 69-72 行的上绘制标签和边界框。给定坐标,这些函数将获取所需的图像并绘制出所需的必需品。
最后,在使用plt.imshow绘制图像时,我们必须缩小数值(第 80 行)。
这就是 YOLOv5 在自定义图像上的结果!我们来看看图 6-8 中的一些结果。
正如我们从结果中看到的,预训练的 YOLOv5 模型在所有图像上定位得相当好。
在固态硬盘型号上测试定制映像
对于 SSD 模型的推理,我们将遵循类似于 YOLOv5 推理脚本中的模式。
# import the necessary packages
from pyimagesearch.data_utils import get_dataloader
from pyimagesearch.data_utils import normalize
from pyimagesearch import config
from torchvision.datasets import ImageFolder
from torch.utils.data import Subset
from sklearn.model_selection import train_test_split
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torchvision.transforms import Resize
import matplotlib.patches as patches
import matplotlib.pyplot as plt
import numpy as np
import random
import torch
import cv2
import os
# initialize test transform pipeline
testTransform = Compose([
Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), ToTensor()])
# create the test dataset and initialize the test data loader
testDataset = ImageFolder(config.TEST_PATH, testTransform)
testLoader = get_dataloader(testDataset, config.PRED_BATCH_SIZE)
# initialize iterable variable
sweeper = iter(testLoader)
# list to store permuted images
imageInput = []
如前所述,我们在的第 20 和 21 行创建 PyTorch 转换实例。然后,使用ImageFolder实用函数,我们根据需要创建数据集实例,然后在第 24 和 25 行的上创建Dataloader实例。
可迭代变量sweeper在线 28 上初始化,以便于访问测试数据。接下来,为了存储我们将要预处理的图像,我们初始化一个名为imageInput ( 第 31 行)的列表。
# grab a batch of test data
print("[INFO] getting the test data...")
batch = next(sweeper)
(images, _ ) = (batch[0], batch[1])
# switch off autograd
with torch.no_grad():
# send the images to the device
images = images.to(config.DEVICE)
# loop over all the batch
for index in range(0, config.PRED_BATCH_SIZE):
# grab the image, de-normalize it, scale the raw pixel
# intensities to the range [0, 255], and change the channel
# ordering from channels first tp channels last
image = images[index]
image = image.permute((1, 2, 0))
imageInput.append(image.cpu().detach().numpy())
从 YOLOv5 推理脚本再次重复上面代码块中显示的过程。我们抓取一批数据(第 35 行和第 36 行)并循环遍历它们,将每个数据重新排列到最后一个通道,并将它们添加到我们的imageInput列表(第 39-50 行)。
# call the required entry points
ssdModel = torch.hub.load("NVIDIA/DeepLearningExamples:torchhub",
"nvidia_ssd")
utils = torch.hub.load("NVIDIA/DeepLearningExamples:torchhub",
"nvidia_ssd_processing_utils")
# flash model to the device and set it to eval mode
ssdModel.to(config.DEVICE)
ssdModel.eval()
# new list for processed input
processedInput = []
# loop over images and preprocess them
for image in imageInput:
image = normalize (image)
processedInput.append(image)
# convert the preprocessed images into tensors
inputTensor = utils.prepare_tensor(processedInput)
在第 53 行和第 54 行上,我们使用torch.hub.load函数来:
- 通过调用相应的存储库和入口点名称来调用 SSD 模型
- 根据 SSD 模型的需要,调用一个额外的实用函数来帮助预处理输入图像。
然后将模型加载到我们正在使用的设备中,并设置为评估模式(第 59 行和第 60 行)。
在第 63 行的上,我们创建了一个空列表来保存预处理后的输入。然后,循环遍历这些图像,我们对它们中的每一个进行归一化,并相应地添加它们(第 66-68 行)。最后,为了将预处理后的图像转换成所需的张量,我们使用了之前调用的效用函数(第 71 行)。
# turn off auto-grad
print("[INFO] getting detections from the test data...")
with torch.no_grad():
# feed images to model
detections = ssdModel(inputTensor)
# decode the results and filter them using the threshold
resultsPerInput = utils.decode_results(detections)
bestResults = [utils.pick_best(results,
config.THRESHOLD) for results in resultsPerInput]
关闭自动梯度,将图像张量输入 SSD 模型(第 75-77 行)。
在第 80 行的上,我们使用来自utils的另一个名为decode_results的函数来获得对应于每个输入图像的所有结果。现在,由于 SSD 为您提供了 8732 个检测,我们将使用之前在config.py脚本中设置的置信度阈值,只保留置信度超过 50%的检测(第 81 行和第 82 行)。
这意味着bestResults列表包含边界框值、对象类别和置信度值,对应于它在给出检测输出时遇到的每个图像。这样,这个列表的索引将直接对应于我们的输入列表的索引。
# get coco labels
classesToLabels = utils.get_coco_object_dictionary()
# loop over the image batch
for image_idx in range(len(bestResults)):
(fig, ax) = plt.subplots(1)
# denormalize the image and plot the image
image = processedInput[image_idx] / 2 + 0.5
ax.imshow(image)
# grab bbox, class, and confidence values
(bboxes, classes, confidences) = bestResults[image_idx]
由于我们没有办法将类的整数结果解码成它们对应的标签,我们将借助来自utils的另一个函数get_coco_object_dictionary ( 第 85 行)。
下一步是将结果与其对应的图像进行匹配,并在图像上绘制边界框。相应地,使用图像索引抓取相应的图像并将其反规格化(第 88-93 行)。
使用相同的索引,我们从结果中获取边界框结果、类名和置信度值(第 96 行)。
# loop over the detected bounding boxes
for idx in range(len(bboxes)):
# scale values up according to image size
(left, bot, right, top) = bboxes[idx ] * 300
# draw the bounding box on the image
(x, y, w, h) = [val for val in [left, bot, right - left,
top - bot]]
rect = patches.Rectangle((x, y), w, h, linewidth=1,
edgecolor="r", facecolor="none")
ax.add_patch(rect)
ax.text(x, y,
"{} {:.0f}%".format(classesToLabels[classes[idx] - 1],
confidences[idx] * 100),
bbox=dict(facecolor="white", alpha=0.5))
由于单个图像可能有多个检测,我们创建一个循环并开始迭代可用的边界框(行 99 )。边界框结果在 0 和 1 的范围内。所以在解包边界框值时,根据图像的高度和宽度缩放它们是很重要的(第 101 行)。
现在,SSD 模型输出左、下、右和上坐标,而不是 YOLOv5s 的起始 X、起始 Y、结束 X 和结束 Y 值。因此,我们必须计算起始 X、起始 Y、宽度和高度,以便在图像上绘制矩形(行 104-107 )。
最后,我们在第 109-112 行的函数的帮助下添加对象类名。
# check to see if the output directory already exists, if not
# make the output directory
if not os.path.exists(config.SSD_OUTPUT):
os.makedirs(config.SSD_OUTPUT)
# save plots to output directory
print("[INFO] saving the inference...")
outputFileName = os.path.join(config.SSD_OUTPUT, "output.png")
plt.savefig(outputFileName)
我们通过将输出图像文件保存到我们之前设置的位置(行 121 和 120 )来结束脚本,并绘制出我们的图像。
让我们看看脚本的运行情况!
在图 9-11 中,我们有 SSD 模型对来自自定义数据集的图像预测的边界框。
在图 11 中,SSD 模型设法找出了小狗,这是值得称赞的,它几乎将自己伪装成了它的父母。否则,SSD 模型在大多数图像上表现得相当好,置信度值告诉我们它对其预测的确信程度。
总结
由于物体检测已经成为我们生活的一个主要部分,因此能够获得可以复制高水平研究/行业水平结果的模型对于学习人群来说是一个巨大的福音。
本教程再次展示了 Torch Hub 简单而出色的入口点调用系统,在这里,我们可以调用预训练的全能模型及其辅助助手函数来帮助我们更好地预处理数据。这整个过程的美妙之处在于,如果模型所有者决定将更改推送到他们的存储库中,而不是通过许多过程来更改托管数据,他们需要将他们的更改推送到他们的存储库本身。
随着处理托管数据的整个过程的简化,PyTorch 在与 GitHub 的整个合作过程中取得了成功。这样,即使是调用模型的用户也可以在存储库中了解更多信息,因为它必须是公开的。
我希望本教程可以作为在您的定制任务中使用这些模型的良好起点。指导读者尝试他们的图像或考虑使用这些模型来完成他们的定制任务!
引用信息
Chakraborty,D. “火炬中心系列#3: YOLOv5 和 SSD-物体探测模型”, PyImageSearch ,2022 年,https://PyImageSearch . com/2022/01/03/Torch-Hub-Series-3-yolov 5-SSD-物体探测模型/
@article{dev_2022_THS3,
author = {Devjyoti Chakraborty},
title = {{Torch Hub} Series \#3: {YOLOv5} and {SSD} — Models on Object Detection},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimagesearch.com/2022/01/03/torch-hub-series-3-yolov5-and-ssd-models-on-object-detection/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
火炬中心系列# 4:PGAN——GAN 上的模型
原文:https://pyimagesearch.com/2022/01/10/torch-hub-series-4-pgan-model-on-gan/
在本教程中,您将了解渐进式 GAN 的架构细节,这使其能够生成高分辨率图像。此外,我们将了解如何使用 Torch Hub 导入预训练的 PGAN 模型,并在我们的项目中使用它来生成高质量的图像。
本课是关于火炬中心的 6 部分系列的第 4 部分:
- 火炬中心系列# 1:火炬中心介绍
- 火炬枢纽系列#2: VGG 和雷斯内特
- 火炬轮毂系列#3: YOLO v5 和 SSD——物体检测模型
- 火炬轮毂系列# 4:——甘模型(本教程)
- 火炬轮毂系列# 5:MiDaS——深度估计模型
- 火炬中枢系列#6:图像分割
要了解渐进式 GAN 如何工作并可用于生成高分辨率图像, 继续阅读。
火炬轮毂系列# 4:PGAN——甘模型
话题描述
2014 年,生成对抗网络的出现及其有效地对任意数据分布进行建模的能力,在计算机视觉界掀起了风暴。双人游戏范式的简单性和推理时惊人的快速样本生成是 GANs 成为现实世界中实际应用的理想选择的两个主要因素。
然而,在它们出现后的很长一段时间内,GAN 的生成能力局限于为相对低分辨率的数据集(例如,MNIST ( 28×28图像)、CIFAR10 ( 32×32图像)等生成样本。).这可以归因于这样一个事实,即生成性对抗网络难以捕捉高分辨率图像中潜在数据分布的几种模式和复杂的低级细节。这在实践中受到限制,因为现实世界中的应用通常要求以高分辨率生成样本。
正因为如此,计算机视觉社区共同努力改进底层网络架构,并引入新的训练技术来稳定训练过程和提高生成样本的质量。
在本教程中,我们将研究一种这样的技术,即渐进式生长,它在弥补这一差距和使 GANs 能够以更高分辨率生成高质量样品方面发挥了关键作用,这对于各种实际应用来说是必不可少的。具体来说,我们将详细讨论以下内容:
- 前卫的甘()建筑细部
- 渐进生长技术和显著特征使 PGAN 能够通过稳定高效的训练生成高分辨率样品
- 从 Torch Hub 导入预先训练的生成模型,如 PGAN,以便快速无缝地集成到我们的深度学习项目中
- 利用预训练的 PGAN 模型生成高分辨率人脸图像
- 走过训练有素的 PGAN 的潜在空间
渐进式氮化镓架构
长期以来,生成式对抗网络一直难以生成高分辨率的图像。这主要是因为高分辨率图像包含大量高层结构形式的信息和错综复杂的低层细节,很难一下子学会。
这可以从多玩家训练范例的角度来理解,该范例形成了训练 GAN 的整体部分。正如在之前的教程中所讨论的,GAN 的主要组件是更新生成器,以在每一步欺骗鉴别器。然而,当采用 GAN 来生成高分辨率图像时,生成器很难同时对图像的高级和复杂的低级细节进行整体建模。这是真的,尤其是在训练的初始阶段,此时它的权重或多或少是随机的。
这使得鉴别器更强,因为它可以很容易地将发生器样本与干扰发生器和鉴别器平衡的真实样本区分开,这对于 GAN 的最佳收敛是至关重要的。
渐进式 GAN 旨在通过将生成高分辨率图像的复杂任务划分为更简单的子任务来缓解上述问题。这主要是通过要求生成器在每一步解决更简单的生成任务来实现的。
具体地,在训练过程中,最初要求生成器学习图像的低分辨率版本。随着它在以较低分辨率生成图像方面慢慢变得更好,要求生成器生成的图像的分辨率会增加。这使生成高分辨率图像的最终目标保持不变,但不会立即使生成器负担过重,并允许它逐渐捕捉图像中的高层次和低层次细节。这项技术背后的动机在图 1 中被有效地捕捉到。
图 2 展示了构成 PGAN 基础的渐进增长模式。具体来说,我们从一个生成低分辨率图像(比如说,8×8)的生成器和一个相应的鉴别器开始,该鉴别器将生成的8×8图像与调整到8×8维度的真实图像(最初是1024×1024)一起作为输入。
此时,生成器学习对图像分布的高层结构进行建模。渐渐地,新层被同步添加到发生器和鉴别器,使它们能够以更高的分辨率处理图像。这使得发生器能够遵循平滑和渐进的学习曲线,并慢慢学习更高分辨率图像中的精细细节。
渐进增长的范式也可以从假设估计的角度来看。我们不是要求生成器一次学习一个复杂的函数,而是要求它在每一步学习更简单的子函数。由于这个原因,要求发生器在特定的时间步长捕获更少的模式。因此,随着训练的进行,它可以逐渐捕获不同的数据分布模式。
此外,由于发生器具有生成低分辨率图像的更简单的任务,特别是在训练的初始阶段,所以发生器可以在这些任务上做得相当好,保持鉴别器和发生器的强度之间的平衡。
渐进生长技术
在上一节中,我们讨论了 PGAN 网络如何通过将高分辨率图像分成更简单的任务来处理生成高分辨率图像的复杂问题。此外,我们观察到,这需要发生器和鉴别器架构同步渐进增长,以从低分辨率图像开始逐渐处理更高分辨率的图像。
在教程的这一部分,我们将讨论 PGAN 建筑如何实现渐进增长技术。具体来说,总体目标是在每个阶段缓慢地向生成器和鉴别器添加层。
图 3 显示了渐进增长模式的要点。在形式上,我们希望在生成器和鉴别器中逐步添加层,并确保它们平滑地、逐步地与网络集成,而不对训练过程进行任何突然的改变。
在发生器的情况下(即图 3 、上),我们假设在给定的阶段,我们得到如图所示的输入,我们希望发生器的输出分辨率加倍。为了实现这一点,我们首先使用Upsample()操作,它将图像的空间维度增加了一个因子×2。此外,我们添加一个新的卷积层,输出一个2N×2N维度图像(显示在右边的分支)。请注意,最终输出是左右分支输出与 的加权和
的加权和
and  weighting coefficients, respectively.
weighting coefficients, respectively.
现在让我们来了解一下的作用
in the architecture shown above. As we can see from the plot on the right side, increases linearly as training progresses, and thus, decays linearly.
最初,卷积层是随机初始化的,它不会计算任何有意义的函数或输出。因此,卷积层的输出被赋予一个低的非零加权系数(例如,
), and the entire output is nearly from the Upsampling layer. Note that the upsampling layer is not learnable or parameterized and uses a technique such as nearest-neighbor interpolation to increase the spatial dimensions.
即使系数
is initially low, the gradients flow through the convolution layer. As the training progresses, the weights of the newly added layer gradually start to learn and output meaningful images. Thus, slowly, the weight of the convolution layer (i.e., ) is increased as shown, and the contribution from the non-learnable Upsample layer (i.e., ) is reduced. This allows the newly added convolution layer to smoothly integrate with the network and learn more complex functions than a simple nearest interpolation-based upsampling.
鉴别器也遵循类似的方法,如图图 3 ( 底部)所示,逐渐增加层数。这里唯一的区别是鉴别器从发生器获取输出图像,并对空间维度进行下采样,如图所示。注意,在给定阶段,层被同时添加到鉴别器和发生器,因为鉴别器必须在任何给定的时间步长处理来自发生器的输出图像。
既然我们已经讨论了 PGAN 体系结构,那就让我们来看看网络的运行情况吧!!
CelebA 数据集
在本教程中,我们将使用 CelebA 数据集,它由各种名人的高分辨率面部图像组成,是我们教程的合适选择。具体来说,CelebA 数据集是由香港中文大学 MMLAB 的研究人员收集的,由 202,599 张人脸图像组成,属于 10,177 位独特的名人。此外,数据集还为图像提供面部标志和二元属性注释,这有助于定位面部特征和表示语义特征。
配置您的开发环境
要遵循本指南,您需要在系统上安装 PyTorch 库、torchvision模块和matplotlib库。
幸运的是,使用 pip 很容易安装这些包:
$ pip install torch torchvision
$ pip install matplotlib
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
既然我们已经讨论了 PGAN 和渐进式增长技术背后的直觉,我们就准备深入代码,看看我们的 PGAN 模型在起作用。我们从描述目录的项目结构开始。
├── output
├── pyimagesearch
│ ├── config.py
├── predict.py
└── analyze.py
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
我们从理解项目目录的结构开始。具体来说,输出文件夹将存储从我们预先训练的 PGAN 模型和我们的潜在空间分析生成的图像的绘图。
pyimagesearch文件夹中的config.py文件存储了我们代码的参数、初始设置和配置。
最后,predict.py文件使我们能够从我们的火炬中心预训练的 PGAN 模型生成高分辨率图像,analyze.py文件存储用于分析和遍历 PGAN 模型的潜在空间的代码。
创建配置文件
我们从讨论config.py文件开始,它包含我们将在教程中使用的参数配置。
# import the necessary packages
import torch
import os
# define gpu or cpu usage
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
USE_GPU = True if DEVICE == "cuda" else False
# define the number of images to generate and interpolate
NUM_IMAGES = 8
NUM_INTERPOLATION = 8
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the output model output and latent
# space interpolation
SAVE_IMG_PATH = os.path.join(BASE_OUTPUT, "image_samples.png")
INTERPOLATE_PLOT_PATH = os.path.sep.join([BASE_OUTPUT,
"interpolate.png"])
我们从进口2 号线和 3 号线的必要包装开始。然后,在的第 6 行和第 7 行,我们定义了DEVICE和USE_GPU参数,它们决定了我们是使用 GPU 还是 CPU 来根据可用性生成图像。
在的第 10 行,我们定义了NUM_IMAGES参数,它定义了我们将为 PGAN 模型可视化的输出图像的数量。此外,NUM_INTERPOLATION参数定义了我们将用于线性插值和遍历潜在空间的点数(第 11 行)。
最后,我们在行 14 上定义了到输出文件夹(即BASE_OUTPUT)的路径,并在行 18 和 19 上定义了存储生成图像(即SAVE_IMG_PATH)和潜在空间插值图(即INTERPOLATE_PLOT_PATH)的相应路径。
使用 PGAN 模型生成图像
现在我们已经定义了我们的配置参数,我们可以使用预训练的 PGAN 模型生成人脸图像。
在本系列之前的教程中,我们观察了 Torch Hub 如何用于将预先训练的 PyTorch 模型导入并无缝集成到我们的深度学习管道和项目中。这里,我们将使用 Torch Hub API 的功能来导入在 CelebAHQ 数据集上预先训练的 PGAN 模型。
让我们从项目目录中打开predict.py文件并开始吧。
# USAGE
# python predict.py
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import torchvision
import torch
# load the pre-trained PGAN model
model = torch.hub.load("facebookresearch/pytorch_GAN_zoo:hub",
"PGAN", model_name="celebAHQ-512", pretrained=True,
useGPU=config.USE_GPU)
# sample random noise vectors
(noise, _) = model.buildNoiseData(config.NUM_IMAGES)
# pass the sampled noise vectors through the pre-trained generator
with torch.no_grad():
generatedImages = model.test(noise)
# visualize the generated images
grid = torchvision.utils.make_grid(
generatedImages.clamp(min=-1, max=1), nrow=config.NUM_IMAGES,
scale_each=True, normalize=True)
plt.figure(figsize = (20,20))
plt.imshow(grid.permute(1, 2, 0).cpu().numpy())
# save generated image visualizations
torchvision.utils.save_image(generatedImages.clamp(min=-1, max=1),
config.SAVE_IMG_PATH, nrow=config.NUM_IMAGES, scale_each=True,
normalize=True)
在的第 5-8 行,我们导入必要的包和模块,包括来自pyimagesearch文件夹(第 5 行)和matplotlib库(第 6 行)的配置文件,以可视化我们生成的图像。此外,我们导入了torchvision模块(行 7 )和torch库(行 8 )来访问 PyTorch 的各种功能。
在的第 11-13 行,我们使用torch.hub.load函数加载我们预先训练好的 PGAN 模型。请注意,该函数采用以下参数:
- 存储模型的位置。这对应于 PyTorch GAN zoo(即
facebookresearch/pytorch_GAN_zoo:hub),它提供了在不同数据集上训练的各种 GAN 模型的模型和训练权重。 - 我们打算加载的模型的名称(即
PGAN) - 数据集名称(即
celebAHQ-512)允许我们为给定模型加载特定于数据集的预训练权重。 pretrained参数,当设置为 True 时,指示 Torch Hub API 下载所选模型的预训练权重并加载它们。useGPU布尔参数表示模型是否必须加载到 GPU 或 CPU 上进行推理(由config.USE_GPU定义)。
由于我们已经选择了celebAHQ-512数据集,该模型将生成维度为512×512的图像。
接下来,在第 16 行上,我们使用我们的 PGAN 模型的内置buildNoiseData()函数,它将我们打算生成的图像数量(即config.NUM_IMAGES)作为参数,并对这些 512 维随机噪声向量进行采样。
由于我们仅使用预训练的模型进行推断,我们指导 PyTorch 在torch.no_grad()的帮助下关闭梯度计算,如第 19 行所示。然后,我们将随机噪声向量作为输入提供给火炬中心 PGAN 模型的内置test()函数,该函数通过预训练的 PGAN 处理输入,并将输出图像存储在变量generatedImages ( 第 20 行)中。
在第 23-25 行,我们使用 torchvision.utils 包的make_grid()函数以网格的形式绘制我们的图像。该函数将待绘制图像的张量(即generatedImages)、单行中显示的图像数量(即config.NUM_IMAGES)和另外两个布尔参数(即scale_each和normalize)作为参数,它们对张量中的图像值进行缩放和归一化。
注意,在将张量传递给make_grid函数之前,我们将张量generatedImages限制在范围[-1, 1]内。此外,设置normalize=True参数会将图像移动到(0, 1)范围。scale_each=True参数确保在实例级别缩放图像,而不是基于所有图像进行缩放。设置这些参数可确保图像在make_grid功能要求的特定范围内标准化,以获得最佳的可视化结果。
最后,在的第 26 行和第 27 行,我们使用 matplotlib 的imshow()函数设置图形的大小并显示我们生成的图像。我们使用如图所示的torchvision.utils模块的save_image()功能,将我们的输出保存在config.SAVE_IMG_PATH定义的位置,在的第 30-32 行上。
图 5 显示了从 PGAN 模型生成的图像。请注意,即使在512×512的高分辨率下,模型也可以捕捉到高层次的结构和细节(如肤色、性别、发型、表情等)。)来确定特定人脸的语义。
行走潜在空间
我们已经讨论了渐进生长技术如何帮助 PGAN 捕捉图像中的高级结构和精细细节,并生成高分辨率的人脸。进一步分析 GAN 如何很好地捕获数据分布的语义的潜在方法是遍历网络的潜在空间并分析生成的图像中的转变。对于已经成功捕获底层数据分布的网络来说,图像之间的过渡应该是平滑的。具体地,在这种情况下,估计的概率分布函数将是平滑的,适当的概率质量均匀地分布在分布的图像上。
预训练的 PGAN 网络是从噪声空间中的点到图像空间的确定性映射。这仅仅意味着如果一个特定的噪声矢量(比如,
) is input multiple times to the pre-trained PGAN, it will always output the same image corresponding to that particular noise vector.
上述事实意味着,给定两个不同的噪声向量,
and  , we get two separate outputs (i.e., images
, we get two separate outputs (i.e., images  and
and  ) corresponding to the input vectors. In addition, if we take any point on the line joining the vectors and in the noise space, it will have a corresponding mapping in the image space.
) corresponding to the input vectors. In addition, if we take any point on the line joining the vectors and in the noise space, it will have a corresponding mapping in the image space.
因此,为了分析 PGAN 的输出图像空间中的图像之间的过渡,我们在噪声潜在空间中行走。我们可以取 2 个随机噪声向量,
and , and get points on the line joining and via a simple linear interpolation operation:
 * \mathbf{z_1} + (1-\lambda) * \mathbf{z_2}")
其中
is a number in the range (0, 1).
最后,我们可以通过插值向量
through the PGAN to get the corresponding image on the line joining and . To walk and analyze the latent space, we will do this for multiple points on the line joining the noise vectors by varying the value in the interval (0, 1).
接下来,让我们打开analyze.py文件并在代码中实现它,以分析我们的 PGAN 学习到的结构。
# USAGE
# python analyze.py
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import torchvision
import numpy as np
import torch
def interpolate(n):
# sample the two noise vectors z1 and z2
(noise, _) = model.buildNoiseData(2)
# define the step size and sample numbers in the range (0, 1) at
# step intervals
step = 1 / n
lam = list(np.arange(0, 1, step))
# initialize a tensor for storing interpolated images
interpolatedImages = torch.zeros([n, 3, 512, 512])
# iterate over each value of lam
for i in range(n):
# compute interpolated z
zInt = (1 - lam[i]) * noise[0] + lam[i] * noise[1]
# generate the corresponding in the images space
with torch.no_grad():
outputImage = model.test(zInt.reshape(-1, 512))
interpolatedImages[i] = outputImage
# return the interpolated images
return interpolatedImages
# load the pre-trained PGAN model
model = torch.hub.load("facebookresearch/pytorch_GAN_zoo:hub",
"PGAN", model_name="celebAHQ-512", pretrained=True, useGPU=True)
# call the interpolate function
interpolatedImages = interpolate(config.NUM_INTERPOLATION)
# visualize output images
grid = torchvision.utils.make_grid(
interpolatedImages.clamp(min=-1, max=1), scale_each=True,
normalize=True)
plt.figure(figsize = (20, 20))
plt.imshow(grid.permute(1, 2, 0).cpu().numpy())
# save visualizations
torchvision.utils.save_image(interpolatedImages.clamp(min=-1, max=1),
config.INTERPOLATE_PLOT_PATH, nrow=config.NUM_IMAGES,
scale_each=True, normalize=True)
正如我们之前看到的,我们在第 5-9 行导入必要的包。
在的第 11-34 行,我们定义了我们的插值函数,该函数将参数n作为输入,该参数是我们想要在连接两个噪声向量的线上采样的点数;并返回从我们的 GAN 模型输出的插值图像(即interpolatedImages)。
在第 13 行,我们对两个噪声向量进行采样,我们将使用内置的buildNoiseData()函数进行插值。然后,在行 17 上,我们将定义步长(即1/n,因为我们希望在大小为 1 的区间内均匀采样点),在行 18 上,我们使用np.arange()函数采样点(即我们的
values) in the interval (0, 1) at intervals defined by step. Notice that the np.arange() function takes as input the starting and ending points of the interval we want to sample in (i.e., 0 and 1) and the step size (i.e., step).
在第 21 行上,我们初始化了一个张量(即interpolatedImages),这有助于我们将来自 GAN 的输出插值存储在图像空间中。
从第 24 行开始,我们迭代由lam定义的 lambdas 列表中的每个值,以获得相应的插值。在第 26 行的上,我们使用列表lam中的第i个值,并用它来得到连接的线上相应的插值点
and (i.e., noise[0] and noise[1] vector). Then, on Lines 29-31, we invoke the torch.no_grad() mode as discussed earlier and pass the interpolated zInt through the PGAN model to get the corresponding output image and store it in the outputImage variable. Finally, we store the outputImage at the ith index of our interpolateImages tensor, which collects all interpolations in the image space in sequence. Finally, on Line 34, we return the interpolatedImages tensor.
现在我们已经定义了我们的interpolation()函数,我们准备在我们的潜在空间中行走,并在图像空间中分析相应输出中的转换。
在第 37 和 38 行,我们从火炬中心导入我们预先训练的 PGAN 模型,如前所述。
在第 41 行上,我们将config.NUM_INTERPOLATION参数(它定义了我们想要在连接两个噪声向量的线上采样的点数)传递给我们的 interpolate()函数,并将相应的输出存储在interpolatedImages变量中。
最后,在的第 44-48 行,我们使用make_grid()函数和matplotlib库来显示我们的插值输出,就像我们之前在文章中看到的那样。我们使用前面详细讨论过的torchvision.utils模块的save_image()函数将可视化保存在config.INTERPOLATE_PLOT_PATH定义的位置(第 51-53 行)。
图 6 显示了当直线上的插值点连接时,PGAN 图像空间中的相应输出
and are passed through the generator. Notice the transition of images happens smoothly, without any abrupt changes, as we move from left to right in the figure. This clearly shows that the PGAN has done a good job at learning the semantic structure of the underlying data distribution.
总结
在本教程中,我们讨论了渐进式 GAN 网络的架构细节,使其能够产生高分辨率图像。具体来说,我们讨论了渐进增长范式,它允许 PGAN 生成器逐渐学习生成高分辨率图像的精细细节积分。此外,我们了解了如何使用 Torch Hub 导入预训练的 GAN 模型,并在没有深度学习项目的情况下无缝集成它们。此外,我们通过可视化生成的图像和穿越其潜在空间,看到了 PGAN 网络的运行。
引用信息
Chandhok,S. “火炬中心系列#4: PGAN”, PyImageSearch ,2022 年,https://PyImageSearch . com/2022/01/10/Torch-Hub-Series-4-pgan-model-on-gan/
@article{shivam_2022_THS4,
author = {Shivam Chandhok},
title = {Torch Hub Series \#4: {PGAN}},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimagesearch.com/2022/01/10/torch-hub-series-4-pgan-model-on-gan/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
火炬中心系列# 5:MiDaS——深度估计模型
原文:https://pyimagesearch.com/2022/01/17/torch-hub-series-5-midas-model-on-depth-estimation/
在本系列的前一部分中,我们讨论了一些最新的对象检测模型;YOLOv5 和 SSD。在今天的教程中,我们将讨论 MiDaS,这是一种帮助图像深度估计的巧妙尝试。
通过本教程,我们将创建一个关于 MiDaS 背后思想的基本直觉,并学习如何将其用作深度估计推理工具。
本课是关于火炬中心的 6 部分系列的第 5 部分:
- 火炬中心系列# 1:火炬中心介绍
- 火炬枢纽系列#2: VGG 和雷斯内特
- 火炬轮毂系列#3: YOLO v5 和 SSD——实物检测上的型号
- 火炬轮毂系列# 4:—甘上模型
- 火炬轮毂系列# 5:MiDaS——深度估计模型(本教程)
- 火炬中枢系列#6:图像分割
要了解如何使用 MiDaS 对您的数据进行自定义, 只要继续阅读。
火炬轮毂系列# 5:MiDaS——深度估计模型
简介
首先,让我们了解什么是深度估计,或者为什么它很重要。图像的深度估计从 2D 图像本身预测对象的顺序(如果图像以 3D 格式扩展)。这无疑是一项艰巨的任务,因为获得这个领域的带注释的数据和数据集本身就是一项艰巨的任务。深度估计的用途非常广泛,最引人注目的是在自动驾驶汽车领域,估计汽车周围物体的距离有助于导航(图 1 )。
迈达斯背后的研究人员以非常简单的方式解释了他们的动机。他们坚定地断言,在处理包含现实生活问题的问题陈述时,单一数据集上的训练模型将是不健壮的。当实时使用的模型被创建时,它们应该足够健壮以处理尽可能多的情况和异常值。
牢记这一点,MiDaS 的创造者决定在多个数据集上训练他们的模型。这包括具有不同类型标签和目标函数的数据集。为了实现这一点,他们设计了一种方法,在与所有地面实况表示兼容的适当输出空间中进行计算。
这个想法在理论上非常巧妙,但作者必须仔细设计损失函数,并考虑使用多个数据集所带来的挑战。由于这些数据集在不同程度上具有不同的深度估计表示,正如论文作者所述,出现了固有的比例模糊和移位模糊。
现在,因为所有的数据集都可能遵循彼此不同的分布。因此,这些问题在意料之中。然而,作者对每个挑战都提出了解决方案。最终产品是一个强大的深度估计器,既高效又准确。在图 2 中,我们看到了论文中显示的一些结果。
跨数据集学习的想法并不新鲜,但是将基础事实放到一个公共输出空间中所带来的复杂性是非常难以克服的。然而,这篇论文详尽地解释了每一步,从直觉到所用损失的数学定义。
让我们看看如何使用 MiDaS 模型来找到自定义图像的反向深度。
配置您的开发环境****
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了个问题?****
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构****
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── midas_inference.py
├── output
│ └── midas_output
│ └── output.png
└── pyimagesearch
├── config.py
└── data_utils.py
在pyimagesearch目录中,我们有 2 个脚本:
config.py:包含项目的端到端配置管道data_utils.py:包含了我们将在项目中使用的两个数据实用函数
在父目录中,我们有一个脚本:
midas_inference.py:根据预训练的 MiDaS 模型进行推断
最后,我们有output目录,它将存放从运行脚本中获得的结果图。
下载数据集
由于其紧凑性,我们将再次使用来自 Kaggle 的狗&猫图像数据集。
$ mkdir ~/.kaggle
$ cp <path to your kaggle.json> ~/.kaggle/
$ chmod 600 ~/.kaggle/kaggle.json
$ kaggle datasets download -d chetankv/dogs-cats-images
$ unzip -qq dogs-cats-images.zip
$ rm -rf "/content/dog vs cat"
正如在本系列的前几篇文章中所解释的,您需要自己独特的kaggle.json文件来连接 Kaggle API ( 第 2 行)。第 3 行上的chmod 600命令将允许你的脚本完全访问读写文件。
下面的kaggle datasets download命令(第 4 行)允许您下载他们网站上托管的任何数据集。最后,我们有 unzip 命令和一个用于不必要添加的辅助 delete 命令(第 5 行和第 6 行)。
让我们转到配置管道。
配置先决条件
在pyimagesearch目录中,您会发现一个名为config.py的脚本。这个脚本将包含我们项目的完整的端到端配置管道。
# import the necessary packages
import torch
import os
# define the root directory followed by the test dataset paths
BASE_PATH = "dataset"
TEST_PATH = os.path.join(BASE_PATH, "test_set")
# specify image size and batch size
IMAGE_SIZE = 384
PRED_BATCH_SIZE = 4
# determine the device type
DEVICE = torch.device("cuda") if torch.cuda.is_available() else "cpu"
# define paths to save output
OUTPUT_PATH = "output"
MIDAS_OUTPUT = os.path.join(OUTPUT_PATH, "midas_output")
首先,我们将BASE_PATH变量作为数据集目录的指针(第 6 行)。我们没有对我们的模型做任何额外的修改,所以我们将只使用测试集(第 7 行)。
在第 10 行上,我们有一个名为IMAGE_SIZE的变量,设置为384,作为我们 MiDaS 模型输入的指令。预测批量大小设置为4 ( 第 11 行),但是鼓励读者尝试不同的大小。
建议您为今天的项目准备一个兼容 CUDA 的设备( Line 14 ),但是由于我们不打算进行任何繁重的训练,CPU 应该也能正常工作。
最后,我们创建了路径来保存从模型推断中获得的输出(第 17 行和第 18 )。
在今天的任务中,我们将只使用一个助手函数来帮助我们的管道。为此,我们将转到pyimagesearch目录中的第二个脚本data_utils.py。
# import the necessary packages
from torch.utils.data import DataLoader
def get_dataloader(dataset, batchSize, shuffle=True):
# create a dataloader and return it
dataLoader= DataLoader(dataset, batch_size=batchSize,
shuffle=shuffle)
return dataLoader
在第 4 行的上,我们有get_dataloader函数,它接受数据集、批量大小和随机变量作为它的参数。这个函数返回一个类似 PyTorch Dataloader 实例的生成器,它将帮助我们处理大量数据(第 6 行)。
这就是我们的公用事业。让我们继续推理脚本。
使用 MiDaS 进行反向深度估计
这个时候,你的脑海里可能会蹦出一个很符合逻辑的问题;为什么我们要花如此大的力气从一堆图片中得出结论呢?
我们在这里选择的方法是一种处理大型数据集的完全可靠的方法,即使您选择训练模型以便稍后进行微调,管道也是有用的。我们还考虑在不调用 MiDaS 储存库的预制功能的情况下尽可能准备数据。
# import necessary packages
from pyimagesearch.data_utils import get_dataloader
from pyimagesearch import config
from torchvision.transforms import Compose, ToTensor, Resize
from torchvision.datasets import ImageFolder
import matplotlib.pyplot as plt
import torch
import os
# create the test dataset with a test transform pipeline and
# initialize the test data loader
testTransform = Compose([
Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), ToTensor()])
testDataset = ImageFolder(config.TEST_PATH, testTransform)
testLoader = get_dataloader(testDataset, config.PRED_BATCH_SIZE)
如前所述,由于我们将只使用测试集,我们已经创建了一个 PyTorch 测试转换实例,我们正在对图像进行整形,并将它们转换为张量(行 12 和 13 )。
如果你的数据集的格式与我们在项目中使用的格式相同(例如,文件夹下的图像命名为 labels),那么我们可以使用ImageFolder函数创建一个 PyTorch 数据集实例(第 14 行)。最后,我们使用之前定义的get_dataloader函数来生成一个数据加载器实例(第 15 行)。
# initialize the midas model using torch hub
modelType = "DPT_Large"
midas = torch.hub.load("intel-isl/MiDaS", modelType)
# flash the model to the device and set it to eval mode
midas.to(device)
midas.eval()
接下来,我们使用torch.hub.load函数在本地运行时加载 MiDaS 模型(第 18 行和第 19 行)。同样,几个可用的选择可以在这里调用,所有这些都可以在这里找到。最后,我们将模型加载到我们的设备中,并将其设置为评估模式(第 22 行和第 23 行)。
# initialize iterable variable
sweeper = iter(testLoader)
# grab a batch of test data send the images to the device
print("[INFO] getting the test data...")
batch = next(sweeper)
(images, _) = (batch[0], batch[1])
images = images.to(config.DEVICE)
# turn off auto grad
with torch.no_grad():
# get predictions from input
prediction = midas(images)
# unsqueeze the predictions batchwise
prediction = torch.nn.functional.interpolate(
prediction.unsqueeze(1), size=[384,384], mode="bicubic",
align_corners=False).squeeze()
# store the predictions in a numpy array
output = prediction.cpu().numpy()
第 26 行上的sweeper变量将作为testLoader的可迭代变量。每次我们运行第 30 行上的命令,我们将从testLoader获得新的一批数据。在第 31 行上,我们将该批产品拆包成图像和标签,仅保留图像。
在将图像加载到我们的设备(第 32 行)后,我们关闭自动渐变并让图像通过模型(第 35-37 行)。在第 40 行上,我们使用一个漂亮的效用函数torch.nn.functional.interpolate将我们的预测解包成一个有效的 3 通道图像格式。
最后,我们将重新格式化的预测存储到 numpy 格式的输出变量中(第 45 行)。
# define row and column variables
rows = config.PRED_BATCH_SIZE
cols = 2
# define axes for subplots
axes = []
fig=plt.figure(figsize=(10, 20))
# loop over the rows and columns
for totalRange in range(rows*cols):
axes.append(fig.add_subplot(rows, cols, totalRange+1))
# set up conditions for side by side plotting
# of ground truth and predictions
if totalRange % 2 == 0:
plt.imshow(images[totalRange//2]
.permute((1, 2, 0)).cpu().detach().numpy())
else :
plt.imshow(output[totalRange//2])
fig.tight_layout()
# build the midas output directory if not already present
if not os.path.exists(config.MIDAS_OUTPUT):
os.makedirs(config.MIDAS_OUTPUT)
# save plots to output directory
print("[INFO] saving the inference...")
outputFileName = os.path.join(config.MIDAS_OUTPUT, "output.png")
plt.savefig(outputFileName)
为了绘制我们的结果,我们首先定义行和列变量来定义网格格式(行 48 和 49 )。在的第 52 行和第 53 行,我们定义了支线剧情列表和人物大小。
在行和列上循环,我们定义了一种方法,其中逆深度估计和地面真实图像并排绘制(行 56-66 )。
最后,我们将图形保存到我们想要的路径中(第 69 行和第 75 行)。
我们的推理脚本完成后,让我们检查一些结果。
MiDaS 推断结果
在我们的数据集中,大多数图像的最前面都有一只猫或一只狗。可能没有足够的背景图像,但 MiDaS 模型应该会给我们一个输出,明确地描绘出前景中的猫或狗。这正是在我们的推理图像中发生的事情(图 4-7 )。
虽然 MiDaS 的惊人能力可以在所有的推理图像中看到,但我们可以深入研究它们,并得出一些更多的观察结果。
在图 4 中,不仅猫被描绘在前景中,而且它的头部比身体更靠近相机(通过颜色的变化来显示)。在图 5 中,由于场地主要覆盖图像,所以狗和场地有明显的区别。在图 6 和图 7 中,猫的头部被描绘得比身体更近。
总结
把握迈达斯在当今世界的重要性,对我们来说是重要的一步。想象一下,一个完美的深度估计器对自动驾驶汽车会有多大的帮助。因为自动驾驶汽车几乎完全依赖于激光雷达(光探测和测距)、相机、声纳(声音导航和测距)等实用工具。拥有对其周围环境进行深度估计的完全可靠的系统将使旅行更加安全,并减轻其他传感器系统的负担。
关于 MiDaS 要注意的第二件最重要的事情是跨数据集混合的使用。虽然它最近获得了动力,但完美地执行它需要相当多的时间和计划。此外,MiDaS 是在一个对现实世界问题有重大影响的领域中做到这一点的。
我希望这篇教程能够激发你对自治系统和深度估计的兴趣。请随意使用您的自定义数据集进行尝试,并分享结果。
引文信息
Chakraborty,D. “火炬中心系列# 5:MiDaS-深度估计模型”, PyImageSearch ,2022 年,https://PyImageSearch . com/2022/01/17/Torch-Hub-Series-5-MiDaS-深度估计模型/
@article{Chakraborty_2022_THS5,
author = {Devjyoti Chakraborty},
title = {Torch Hub Series \#5: {MiDaS} — Model on Depth Estimation},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimagesearch.com/2022/01/17/torch-hub-series-5-midas-model-on-depth-estimation/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
火炬中心系列#6:图像分割
原文:https://pyimagesearch.com/2022/01/24/torch-hub-series-6-image-segmentation/
在本教程中,您将了解用于分段的全卷积网络(fcn)背后的概念。此外,我们将了解如何使用 Torch Hub 导入预训练的 FCN 模型,并在我们的项目中使用它来获得输入图像的实时分割输出。
本课是关于火炬中心的 6 部分系列的最后一部分:
- 火炬中心系列# 1:火炬中心介绍
- 火炬枢纽系列#2: VGG 和雷斯内特
- 火炬轮毂系列#3: YOLO v5 和 SSD——物体检测模型
- 火炬轮毂系列# 4:——甘模型
- 火炬中枢系列# 5:MiDaS——深度估计模型
- 火炬中枢系列#6:图像分割(本教程)
要了解完全卷积网络背后的概念并将其用于图像分割,继续阅读。
火炬中枢系列#6:图像分割
话题描述
在本系列的前几篇文章中,我们研究了不同的计算机视觉任务(例如,分类、定位、深度估计等。),这使我们能够理解图像中的内容及其相关语义。此外,在过去的教程中,我们对图像分割任务及其在理解像素级图像中复杂细节和信息的有用性有了深入的了解。此外,我们还研究了 UNET 等分割模型,这些模型利用跳跃连接等显著的架构特征来实时有效地分割图像。
在今天的教程中,我们将看看另一种分割图像的方法(即,使用全卷积网络(fcn))。图 1 展示了 FCN 的高层建筑。这些网络遵循一种训练范式,该范式使它们能够使用从除分割(例如,分类)之外的计算机视觉任务中学习到的特征来有效地分割图像。具体来说,我们将详细讨论以下内容:
- 为 FCN 模型提供动力的监督预培训范例
- 允许 FCN 模型处理任何大小的输入图像并有效计算分割输出的架构修改
- 从 Torch Hub 导入预训练的 FCN 细分模型,以便快速无缝地集成到我们的深度学习项目中
- 使用不同编码器的 FCN 模型实时分割图像,用于我们自己的深度学习应用
FCN 分割模型
针对不同的计算机视觉任务(例如,分类、定位等)训练的深度学习模型。)努力从图像中提取相似的特征以理解图像内容,而不考虑手边的下游任务。从以下事实可以进一步理解这一点:只为对象分类而训练的模型的注意力图也可以指向图像中特定类别对象出现的位置,如在之前的教程中所见。这意味着分类模型具有关于全局对象类别以及它在图像中所处位置的信息。
FCN 分割模型旨在利用这一事实,并遵循一种基于重新利用已训练好的分类模型进行分割的方法。这需要对分类模型层进行仔细的设计和修改,以便将模型无缝地转换成分段管道。
从形式上看,FCN 方法大体上采用了两个步骤来实现这一目标。首先,它获取在图像分类任务上训练的现成模型(即 ResNet)。接下来,为了将其转换为分段模型,它用卷积层替换最后完全连接的层。注意,这可以通过简单地使用内核大小与输入特征映射维数相同的卷积层来实现(如图 2 所示)。
由于网络现在只由卷积层组成,而没有固定节点数的静态全连接层,因此它可以将任何维度的图像作为输入并进行处理。此外,我们在改进的分类模型的最终层之后添加去卷积层,以将特征图映射回输入图像的原始维度,从而获得具有与输入对应的像素的分割输出。
现在,我们已经了解了 FCN 背后的方法,让我们继续设置我们的项目目录,并查看我们预先培训的 FCN 模型的运行情况。
配置您的开发环境
要遵循本指南,您需要在系统上安装 PyTorch 库、torchvision模块和matplotlib库。
幸运的是,使用 pip 很容易安装这些包:
$ pip install torch torchvision
$ pip install matplotlib
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
.
├── dataset
│ ├── test_set
│ └── training_set
├── output
├── predict.py
└── pyimagesearch
└── config.py
└── utils.py
我们从理解项目目录的结构开始。具体来说,数据集文件夹存储了我们的狗和猫数据集的test_set和training_set图像。对于本教程,我们将使用test_set图像进行推理,并使用我们的 FCN 模型进行分割掩模预测。
像往常一样,输出文件夹存储输入图像的可视化和来自我们预训练的 FCN 模型的预测分割掩模。
此外,predict.py文件使我们能够从 Torch Hub 加载预训练的 FCN 分割模型,并将它们集成到我们的项目中,用于实时分割掩模预测和可视化。
最后,pyimagesearch文件夹中的config.py文件存储了我们代码的参数、初始设置和配置,utils.py文件定义了帮助函数,使我们能够有效地可视化我们的分段输出。
下载数据集
在本系列前面的教程之后,我们将使用来自 Kaggle 的狗&猫图像数据集。该数据集是作为狗与猫图像分类挑战的一部分引入的,由属于两个类别(即,狗和猫)的图像组成。训练集包括 8000 幅图像(即,每类 4000 幅图像),测试集包括 2000 幅图像(即,每类 1000 幅图像)。
在本教程中,我们将使用来自数据集的测试集图像进行推理,并使用来自 Torch Hub 的预训练 FCN 模型生成分段掩码。猫狗数据集简洁易用。此外,它由深度学习社区中的分类模型训练的两个最常见的对象类(即,狗和猫图像)组成,这使得它成为本教程的合适选择。
创建配置文件
我们从讨论config.py文件开始,它包含我们将在教程中使用的参数配置。
# import the necessary packages
import os
# define gpu or cpu usage
DEVICE = "cpu"
# define the root directory followed by the test dataset paths
BASE_PATH = "dataset"
TEST_PATH = os.path.join(BASE_PATH, "test_set")
#define pre-trained model name and number of classes it was trained on
MODEL = ["fcn_resnet50", "fcn_resnet101"]
NUM_CLASSES = 21
# specify image size and batch size
IMAGE_SIZE = 224
BATCH_SIZE = 4
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the input image and output segmentation
# mask visualizations
SAVE_IMAGE_PATH = os.path.join(BASE_OUTPUT, "image_samples.png")
SEGMENTATION_OUTPUT_PATH = os.path.sep.join([BASE_OUTPUT,
"segmentation_output.png"])
我们首先在线 2 上导入必要的包,其中包括用于文件处理功能的os模块。然后,在第 5 行上,我们定义了将用于计算的DEVICE。请注意,由于我们将使用来自 Torch Hub 的预训练 FCN 模型进行推理,我们将设备设置为 CPU,如图所示。
在的第 8 行,我们定义了BASE_PATH参数,它指向存储数据集的根文件夹的位置。此外,我们在第 9 行上定义了TEST_PATH参数,它指向我们的测试集在根数据集文件夹中的位置。
接下来,我们定义MODEL参数,它决定了我们将用来执行分割任务的 FCN 模型(第 12 行)。请注意,火炬中心为我们提供了访问具有不同分类主干的 FCN 模型的途径。例如,fcn_resnet50对应于具有 ResNet50 分类主干的预训练 FCN 模型,而fcn_resnet101对应于具有 ResNet101 分类主干的预训练 FCN 模型。
Torch Hub 上托管的 FCN 模型在 COCO train2017 的一个子集上进行预训练,在 Pascal 视觉对象类(VOC)数据集中存在 20 个类别。这使得包括背景类在内的类别总数为 21 个。在第 13 行,我们定义了火炬中心 FCN 模型预训练的总类别数(即 21)。
此外,我们定义我们将输入到我们的模型(行 16 )的图像的空间维度(即IMAGE_SIZE)以及我们将用于加载我们的图像样本(行 17 )的BATCH_SIZE。
最后,我们在行 20 上定义到输出文件夹(即BASE_OUTPUT)的路径,并在行 24 和 25 上定义用于存储输入图像可视化(即SAVE_IMG_PATH)和最终分割输出图(即SEGMENTATION_OUTPUT_PATH)的相应路径。
使用 FCN 模型的图像分割
现在,我们已经定义了参数配置,我们准备设置项目管道,并查看预训练的 FCN 模型的运行情况。
正如在本系列前面的教程中所讨论的,Torch Hub 为访问模型提供了一个简单的 API。它可以导入预先训练好的模型,用于各种计算机视觉任务,从分类、定位、深度估计到生成建模。在这里,我们将更进一步,学习从 Torch Hub 导入和使用细分模型。
让我们从项目目录的 pyimagesearch 文件夹中打开utils.py文件,并从定义函数开始,这些函数将帮助我们从我们的 FCN 分割模型中绘制和可视化我们的分割任务预测。
# import the necessary packages
from torchvision.utils import draw_segmentation_masks
import torchvision.transforms.functional as F
import matplotlib.pyplot as plt
import numpy as np
import torch
def visualize_segmentation_masks(allClassMask, images, numClasses,
inverseTransforms, device):
# convert to boolean masks and batch dimension first format
booleanMask = (
allClassMask == torch.arange(numClasses, device=device)[:, None, None, None])
booleanMask = booleanMask.transpose(1,0)
# initialize list to store our output masks
outputMasks = []
# loop over all images and corresponding boolean masks
for image, mask in zip(images, booleanMask):
# plot segmentation masks over input images
outputMasks.append(
draw_segmentation_masks(
(inverseTransforms(image) * 255).to(torch.uint8),
masks=mask,
alpha=0.6
)
)
# return segmentation plots
return outputMasks
在的第 2-6 行上,我们首先导入必要的包,其中包括来自torchvision.utils的用于分割掩模可视化的draw_segmentation_masks函数(第 2 行)、来自torchvision.transforms的用于图像格式转换操作的功能模块(第 3 行)和matplotlib库(第 4 行),以创建和可视化我们的图,我们将在后面详细讨论。最后,我们还导入了用于张量和数组操作的 Numpy 和 PyTorch 库(第 5 行和第 6 行)。
我们现在准备定义我们的助手函数来可视化来自我们的 FCN 分割模型的分割掩码输出。
我们定义了visualize_segmentation_masks()函数(第 8-29 行),它绘制了输入图像上的预测遮罩,每个类像素用不同的颜色表示,我们将在后面看到。
该函数将按像素的类级分割掩码(即allClassMask)、我们想要分割的输入图像(即images)、我们的火炬中心 FCN 模型已被训练的类的总数(即numClasses)、将图像转换回非标准化形式所需的逆变换(即inverseTransforms)以及我们将用于计算的设备(即device)作为输入,如第 8 行和第 9 行所示。
在第 11 行和第 12 行,我们开始为数据集中的每个类创建一个布尔分段掩码,使用输入的类级分段掩码(即allClassMask)。这对应于布尔掩码的数量numClasses,存储在booleanMask变量(行 11 )中。
使用条件语句allClassMask == torch.arange(numClasses, device=device)[:, None, None, None])创建布尔掩码。
语句的左侧(LHS)就是我们的类级分段掩码,维度为[batch_size, height=IMG_SIZE,width=IMG_SIZE]。另一方面,右侧(RHS)创建一个 dim 张量[numClasses,1,1,1],其中条目0, 1, 2, …, (numClasses-1)按顺序排列。
为了匹配语句两边的维度,RHS 张量自动在空间上(即高度和宽度)传播到维度[numClasses,batch_size,height=IMG_SIZE,width=IMG_SIZE]。此外,LHS allClassMask在频道维度播放,有numClasses个频道,最终形状为[numClasses,batch_size,height=IMG_SIZE,width=IMG_SIZE]。
最后,执行条件语句,这给了我们numClasses个对应于每个类的布尔分段掩码。然后掩码被存储在booleanMask变量中。
注意第 12 行一开始形象化有点复杂。为了理解12 号线的工作原理,我们从一个简单的例子开始。我们将使用图 4 来更好地理解这个过程。
假设我们有一个具有三个类别(类别 0、类别 1 和类别 2)的分割任务,并且在我们的批处理中有一个输入图像(即batch_size, bs=1)。如图所示,我们有一个分段掩码S,它是我们的分段模型的预测输出,代表我们示例中第 12 行的 LHS。注意S是一个逐像素的类级分割掩码,其中每个像素条目对应于该像素所属的类(即 0、1 或 2)。
另一方面,所示的 RHS 是具有条目 0、1、2 的 dim [numClasses = 3,1,1,1]的张量。
如图所示,掩码S在信道维度上广播为[numClasses=3,bs=1,height, width]的形状。此外,RHS 张量在空间上传播(即,高度和宽度)以具有最终形状[numClasses=3,bs=1,height, width]。
注意,该语句的输出是对应于每个类的布尔分段掩码的数量。
我们现在继续解释visualize_segmentation_masks()函数。
在第 13 行,我们转置到从第 12 行输出的booleanMask,将其转换为形状为[batch_size,numClasses, height=IMG_SIZE,width=IMG_SIZE]的批量尺寸优先格式。
接下来,我们在第 15 行的上创建一个空列表outputMasks来存储每幅图像的最终分割蒙版。
在第 18 行上,我们开始遍历所有图像及其对应的布尔遮罩,如图所示。对于每个(image,mask)对,我们将输入image和mask传递给draw_segmentation_masks()函数(第 21-26 行)。
该函数在输入image上用不同的颜色覆盖每个类的布尔掩码。它还采用一个阿尔法参数,该参数是范围[0, 1]内的一个值,并且对应于当掩模覆盖在输入图像上时的透明度值(行 24 )。
注意,draw_segmentation_masks()函数期望输入图像采用范围[0, 255]和uint8格式。为了实现这一点,我们使用inverseTransforms函数对我们的图像进行非规格化,并将其转换到范围[0, 1],然后乘以 255,以获得范围[0, 255] ( 第 22 行)中的最终像素值。此外,我们还按照函数的预期将图像的数据类型设置为torch.uint8。
最后,在第 29 行,我们返回输出分段掩码列表,如下所示。
现在我们已经定义了我们的可视化助手函数,我们准备设置我们的数据管道,并使用我们的 FCN 模型来完成图像分割的任务。
让我们打开predict.py文件开始吧。
# USAGE
# python predict.py
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
from torchvision.datasets import ImageFolder
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import transforms
import torch
import os
在第 5-12 行,我们导入必要的包和模块,包括我们的config文件(第 5 行)和来自pyimagesearch文件夹(第 6 行)的用于可视化助手功能的utils模块。
我们还从torchvision.datasets模块导入了ImageFolder类来创建我们的数据集(第 7 行),导入了save_image函数来保存我们的可视化绘图(第 8 行),导入了torch.utils.data的DataLoader类来访问 PyTorch 提供的特定于数据的功能,以建立我们的数据加载管道(第 9 行)。
最后,我们从torchvision导入transforms模块来应用图像转换,同时加载图像(第 10 行)以及 PyTorch 和 os 库,用于基于张量和文件处理的功能(第 11 行和第 12 行)。
# create image transformations and inverse transformation
imageTransforms = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)])
imageInverseTransforms = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225]
)
# initialize dataset and dataloader
print("[INFO] creating data pipeline...")
testDs = ImageFolder(config.TEST_PATH, imageTransforms)
testLoader = DataLoader(testDs, shuffle=True,
batch_size=config.BATCH_SIZE)
# load the pre-trained FCN segmentation model, flash the model to
# the device, and set it to evaluation mode
print("[INFO] loading FCN segmentation model from Torch Hub...")
torch.hub._validate_not_a_forked_repo=lambda a,b,c: True
model = torch.hub.load("pytorch/vision:v0.10.0", config.MODEL[0],
pretrained=True)
model.to(config.DEVICE)
model.eval()
# initialize iterator and grab a batch from the dataset
batchIter = iter(testLoader)
print("[INFO] getting the test data...")
batch = next(batchIter)
# unpack images and labels and move to device
(images, labels) = (batch[0], batch[1])
images = images.to(config.DEVICE)
# initialize a empty list to store images
imageList =[]
# loop over all images
for image in images:
# add de-normalized images to the list
imageList.append(
(imageInverseTransforms(image) * 255).to(torch.uint8)
)
现在我们已经导入了基本的包,是时候设置我们的图像转换了。
我们定义了加载输入图像时想要应用的变换,并在第 15-21 行的函数的帮助下合并它们。我们的imageTransforms包括:
Resize():允许我们将图像调整到我们的模型可以接受的特定输入尺寸(即config.IMAGE_SIZE、config.IMAGE_SIZE)ToTensor():使我们能够将输入图像转换为 PyTorch 张量,并将输入的 PIL 图像从最初的[0, 255]转换为[0, 1]。Normalize():它有两个参数,即均值和标准差(即分别为mean和std),使我们能够通过减去均值并除以给定的标准差来归一化图像。注意,我们使用 ImageNet 统计数据来标准化图像。
此外,在的第 22-25 行,我们定义了一个逆变换(即imageInverseTransforms),它只是执行上面定义的规格化变换的相反操作。当我们想要将图像非规格化回范围[0, 1]以便可视化时,这将很方便。
我们现在准备使用 PyTorch 构建我们的数据加载管道。
在第 29 行,我们使用ImageFolder功能为我们的测试集图像创建 PyTorch 数据集,我们将使用它作为分割任务的输入。ImageFolder将测试集的路径(即config.TEST_PATH)和我们想要应用于图像的变换(即imageTransforms)作为输入。
在第 30 行和第 31 行,我们通过将我们的测试数据集(即testDs)传递给 PyTorch DataLoader类来创建我们的数据加载器(即testLoader)。我们将shuffle参数True保存在数据加载器中,因为我们想在每次运行脚本时处理一组不同的混洗图像。此外,我们使用config.BATCH_SIZE来定义batch_size参数,以确定数据加载器输出的单个批次中的图像数量。
既然我们已经构建并定义了数据加载管道,我们将从 Torch Hub 初始化我们预先训练的 FCN 细分模型。
在第 37 行的上,我们使用torch.hub.load函数来加载我们预先训练好的 FCN 模型。请注意,该函数采用以下参数:
- 模型存储的位置(即
pytorch/vision:v0.10.0) - 我们想要加载的模型的名称(即
config.MODEL[0]对应于带有 ResNet50 编码器的 FCN 模型,或者config.MODEL[1]对应于带有 ResnNet101 编码器的 FCN 模型) pretrained参数,当设置为 True 时,指示 Torch Hub API 下载所选模型的预训练权重并加载它们。
最后,我们使用to()函数将我们的模型传输到config.DEVICE,在提到的设备上注册我们的模型及其参数(第 39 行)。由于我们将使用我们预先训练的模型进行推理,我们在行 40 上将模型设置为eval()模式。
在完成我们的模型定义之后,现在是时候从我们的数据加载器访问样本,并查看我们的火炬中心 FCN 细分模型的运行情况。
我们首先使用第 43 行的方法将testLoader iterable 转换为 python 迭代器。这允许我们在next()方法( Line 45 )的帮助下简单地迭代我们的数据集批次,正如在之前关于使用 PyTorch 加载数据的教程中详细讨论的。
由于我们批次中的每个数据样本都是一个形式为(images, labels)的元组,我们在第 48 行解包测试图像(即batch[0])和相应的标签(即batch[1])。然后,我们将这批图像传输到我们模型的设备,由第行 49 上的config.DEVICE定义。
在第 55-59 行上,我们通过迭代images张量中的每个图像并将其转换为范围[0, 255]内的像素值来创建一个imageList。为了实现这一点,我们使用inverseTransforms函数对我们的图像进行非规格化,并将其转换到范围[0, 1],然后乘以 255,以获得范围[0, 255]中的最终像素值。
此外,我们还将图像的数据类型设置为torch.uint8,这是我们的可视化函数所期望的。
# create the output directory if not already exists
if not os.path.exists(config.BASE_OUTPUT):
os.makedirs(config.BASE_OUTPUT)
# turn off auto grad
with torch.no_grad():
# compute prediction from the model
output = model(images)["out"]
# convert predictions to class probabilities
normalizedMasks = torch.nn.functional.softmax(output, dim=1)
# convert to pixel-wise class-level segmentation masks
classMask = normalizedMasks.argmax(1)
# visualize segmentation masks
outputMasks = utils.visualize_segmentation_masks(
allClassMask=classMask,
images=images,
numClasses=config.NUM_CLASSES,
inverseTransforms=imageInverseTransforms,
device=config.DEVICE
)
# convert input images and output masks to tensors
inputImages = torch.stack(imageList)
generatedMasks = torch.stack(outputMasks)
# save input image visualizations and the mask visualization
print("[INFO] saving the image and mask visualization to disk...")
save_image(inputImages.float() / 255,
config.SAVE_IMAGE_PATH, nrow=4, scale_each=True,
normalize=True)
save_image(generatedMasks.float() / 255,
config.SEGMENTATION_OUTPUT_PATH, nrow=4, scale_each=True,
normalize=True)
现在是时候看看我们的预训练 FCN 模型的行动,并使用它来生成我们的批处理输入图像的分割掩模。
我们首先确保我们将存储分割预测的输出目录存在,如果不存在,我们创建它,如第62 和 63 行所示。
由于我们仅使用预训练的模型进行推断,我们指导 PyTorch 在torch.no_grad()的帮助下关闭梯度计算,如第 66 行所示。然后,我们将图像传递给我们预先训练好的 FCN 模型,并将输出图像存储在维度为[batch_size, config.NUM_CLASSES,config.IMAGE_SIZE,config.IMAGE_SIZE] ( 第 68 行)的变量output中。
如第 71 行所示,我们使用softmax函数将来自 FCN 模型的预测分割转换为分类概率。最后,在第 74 行上,我们通过在我们的normalizedMasks的类维度上使用argmax()函数为每个像素位置选择最可能的类来获得逐像素的类级分割掩模。
然后,我们使用来自utils模块的visualize_segmentation_masks()函数来可视化我们的classMask ( 第 77-83 行)并将输出分段掩码存储在outputMasks变量中。(第 77 行)。
在第行第 86 和 87 行,我们通过使用torch.stack()函数将各自列表中的条目进行堆栈,将输入图像列表imageList和最终列表outputMasks转换为张量。最后,我们使用来自torchvision.utils的save_image函数来保存我们的inputImages张量(第 91-93 行)和generatedMasks张量(第 94-96 行)。
请注意,我们将张量转换为float(),并通过用save_image函数将它们除以255来归一化它们。
此外,我们还注意到,save_image函数将我们想要保存图像的路径(即config.SAVE_IMG_PATH和config.SEGMENTATION_OUTPUT_PATH)、单行中显示的图像数量(即nrow=4)以及另外两个布尔参数(即scale_each和normalize)作为输入,它们对张量中的图像值进行缩放和归一化。
设置这些参数可确保图像在save_image功能要求的特定范围内标准化,以获得最佳的可视化结果。
图 5 在左侧示出了我们批次中的输入图像(即inputImages)的可视化,并且在右侧示出了来自我们预训练的 FCN 分割模型的对应预测分割掩模(即generatedMasks),用于四个不同的批次。
请注意,我们的 FCN 模型可以在所有情况下正确识别对应于类别猫(青色)和狗(绿色)的像素。此外,我们还注意到,即使一个对象的多个实例(比如,第二行第三幅图像中的猫)出现在一幅图像中,我们的模型也表现得相当好。
此外,我们观察到,在图像包含人形和狗/猫(第 4 行,第二幅图像)的情况下,我们的模型可以有效地分割我们的人(深蓝色)。
这可以主要归因于我们的 FCN 模型已经预先训练的 21 个类别,包括类别cat、dog和person。然而,假设我们想要分割不包括在 21 个类别中的对象。在这种情况下,我们可以使用来自 Torch Hub 的预训练权重来初始化 FCN 模型,并使用迁移学习范式来微调我们想要细分的新类别,如在之前的帖子中所讨论的。
总结
在本教程中,我们研究了另一种图像分割方法,该方法依赖于利用从图像分类任务中学到的特征,并重新利用它们来增强分割预测。我们还了解了将预训练分类模型转换为用于分割的完全卷积网络模型所需的架构变化,这使我们能够高效地处理不同大小的输入图像,并实时输出准确的分割预测。
此外,我们使用 Torch Hub API 来导入预训练的 FCN 分割模型,并使用它来实时预测自定义输入图像的分割输出。
引用信息
钱德霍克,S. “火炬中心系列#6:图像分割”, PyImageSearch ,2022,【https://pyimg.co/uk1oa】T4
@article{Chandhok_2022_THS6,
author = {Shivam Chandhok},
title = {Torch Hub Series \#6: Image Segmentation},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimg.co/uk1oa},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!【T2*
使用 OpenCV 跟踪多个对象
原文:https://pyimagesearch.com/2018/08/06/tracking-multiple-objects-with-opencv/

在今天的教程中,你将学习如何使用 OpenCV 和 Python 来跟踪多个对象。
这篇文章的灵感来自于我从 PyImageSearch 读者 Ariel 那里收到的一个问题。
阿里尔写道:
你好,阿德里安,感谢你上周发表的关于物体跟踪的博文。
我有一个需要跟踪多个对象的情况,但是上周的代码似乎没有处理这个用例。我对如何修改代码来跟踪多个对象有点困惑。
我该怎么办?
问得好,Ariel——我们将会发现,跟踪多个对象与跟踪单个对象非常相似,我们只需要记住一两个警告。
要了解如何使用 OpenCV 跟踪多个对象,继续阅读!
使用 OpenCV 跟踪多个对象
https://www.youtube.com/embed/Tjx8BGoeZtI?feature=oembed
基于 Keras 和深度学习的交通标志分类
原文:https://pyimagesearch.com/2019/11/04/traffic-sign-classification-with-keras-and-deep-learning/
在本教程中,您将学习如何使用 Keras 和深度学习训练自己的交通标志分类器/识别器,能够获得 95%以上的准确率。

上周末,我开车去马里兰看望我的父母。当我把车开进他们家的车道时,我注意到一件奇怪的事情——有一辆我不认识的车停在我爸爸的停车位上。
我停好车,从后备箱里拿出包,甚至还没来得及进前门,我爸就出来了,兴奋又活泼,大声说他刚从车行回来,把他的旧车折价换了一辆全新的 2020 款本田雅阁。
大多数人都喜欢拥有一辆新车,但对我爸爸来说,他每年为了工作都要开很多英里的车,拥有一辆新车对 T2 来说是一件大事,尤其是对 T3 来说。
我爸爸想让我们一家人去开车兜风,检查一下汽车,所以我爸爸、我妈妈和我爬进车里,“新车味”像难闻的古龙水一样扑面而来,你羞于承认自己喜欢这种味道。
当我们在路上行驶时,我妈妈注意到汽车的仪表盘上自动显示出了限速— 这是怎么回事?
答案?
交通标志识别。
在 2020 款本田雅阁车型中,前摄像头传感器安装在后视镜后面的挡风玻璃内部。
那个摄像头轮询帧,沿路寻找标志,然后对它们进行分类。
识别出的交通标志会显示在 LCD 仪表盘上,提醒驾驶员。
无可否认,这是一个非常漂亮的功能,其余的驾驶很快就从车辆试驾变成了一场关于如何使用计算机视觉和深度学习算法来识别交通标志的讲座(我不确定我的父母是否想要这场讲座,但他们还是得到了它)。
当我拜访我的父母回来时,我决定写一个关于交通标志识别的教程会很有趣(并且有教育意义)——你可以使用这个代码作为你自己的交通标志识别项目的起点。
要了解更多关于 Keras 和深度学习的交通标志分类,继续阅读!
基于 Keras 和深度学习的交通标志分类
在本教程的第一部分,我们将讨论交通标志分类和识别的概念,包括我们将用来训练我们自己的自定义交通标志分类器的数据集。
从那里,我们将审查我们的项目目录结构。
然后我们将实现TrafficSignNet,这是一个卷积神经网络,我们将在我们的数据集上训练它。
给定我们训练好的模型,我们将评估它在测试数据上的准确性,甚至学习如何对新的输入数据进行预测。
什么是交通标志分类?

Figure 1: Traffic sign recognition consists of object detection: (1) detection/localization and (2) classification. In this blog post we will only focus on classification of traffic signs with Keras and deep learning.
交通标志分类是自动识别道路沿线交通标志的过程,包括限速标志、让行标志、并线标志等。能够自动识别交通标志使我们能够制造“更智能的汽车”。
自动驾驶汽车需要交通标志识别,以便正确解析和理解道路。同样,汽车内部的“驾驶员警报”系统需要了解周围的道路,以帮助和保护驾驶员。
交通标志识别只是计算机视觉和深度学习可以解决的问题之一。
我们的交通标志数据集

Figure 2: The German Traffic Sign Recognition Benchmark (GTSRB) dataset will be used for traffic sign classification with Keras and deep learning. (image source)
我们将用来训练我们自己的自定义交通标志分类器的数据集是德国交通标志识别基准(GTSRB) 。
GTSRB 数据集由 43 个交通标志类别和近 50,000 张图像组成。
数据集的样本可以在上面的 图 2 中看到——注意交通标志是如何被预先裁剪给我们的,这意味着数据集注释者/创建者已经手动标记了图像中的标志并且为我们提取了交通标志感兴趣区域(ROI ),从而简化了项目。
在现实世界中,交通标志识别是一个两阶段的过程:
- 定位:检测并定位交通标志在输入图像/帧中的位置。
- 识别:取定位的 ROI,实际上识别,分类交通标志。
深度学习对象检测器可以在网络的单次前向传递中执行定位和识别——如果你有兴趣了解更多关于使用更快的 R-CNN、单次检测器(SSD)和 RetinaNet 的对象检测和交通标志定位的信息,请务必参考我的书, 使用 Python 进行计算机视觉的深度学习,我在其中详细讨论了该主题。
GTSRB 数据集面临的挑战
在 GTSRB 数据集中有许多挑战,首先是图像分辨率低,更糟糕的是,对比度差(如上面的 图 2 所示)。这些图像是像素化的,在某些情况下,人类的眼睛和大脑要识别这个标志即使不是不可能,也是非常具有挑战性的。
数据集的第二个挑战是处理类偏斜:
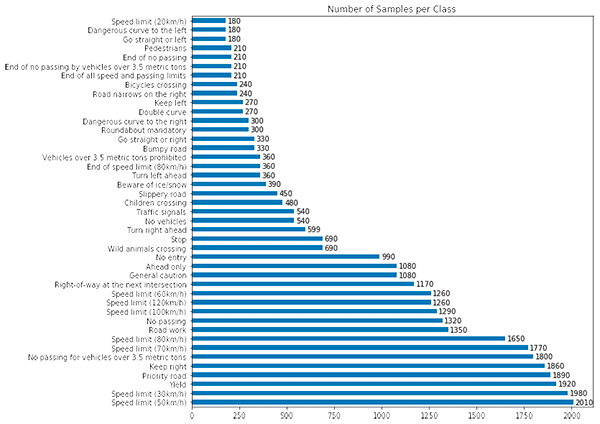
Figure 3: The German Traffic Sign Recognition Benchmark (GTSRB) dataset is an example of an unbalanced dataset. We will account for this when training our traffic sign classifier with Keras and deep learning. (image source)
最高级别(限速 50 公里/小时)有超过 2000 个例子,而最少代表级别(限速 20 公里/小时)只有不到 200 个例子——这是一个数量级的差异!
为了成功训练一个准确的交通标志分类器,我们需要设计一个实验来:
- 预处理我们的输入图像,以提高对比度。
- 说明类别标签倾斜。
项目结构
继续使用本文的 【下载】 部分下载源代码。下载完成后,在你的机器上解压文件。
从这里我们将 从 Kaggle 下载 GTSRB 数据集。只需点击 Kaggle 菜单栏中的“下载(300 MB)”按钮,按照提示使用第三方认证合作伙伴或您的电子邮件地址登录 Kaggle。然后,您可以再次单击“下载(300 MB)”按钮,您的下载将开始,如下所示:

Figure 4: How to download the GTSRB dataset from Kaggle for traffic sign recognition with Keras and deep learning.
我将数据集提取到我的项目目录中,您可以在这里看到:
$ tree --dirsfirst --filelimit 10
.
├── examples [25 entries]
├── gtsrb-german-traffic-sign
│ ├── Meta [43 entries]
│ ├── Test [12631 entries]
│ ├── Train [43 entries]
│ ├── meta-1 [43 entries]
│ ├── test-1 [12631 entries]
│ ├── train-1 [43 entries]
│ ├── Meta.csv
│ ├── Test.csv
│ └── Train.csv
├── output
│ ├── trafficsignnet.model
│ │ ├── assets
│ │ ├── variables
│ │ │ ├── variables.data-00000-of-00002
│ │ │ ├── variables.data-00001-of-00002
│ │ │ └── variables.index
│ │ └── saved_model.pb
│ └── plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── trafficsignnet.py
├── train.py
├── signnames.csv
└── predict.py
13 directories, 13 files
我们的项目包含三个主要目录和一个 Python 模块:
gtsrb-german-traffic-sign/:我们的 GTSRB 数据集。output/:包含我们的输出模型和train.py生成的训练历史图。examples/:包含由predict.py生成的 25 个带注释图像的随机样本。pyimagesearch:组成我们 TrafficSignNet CNN 的一个模块。
我们还将演练train.py和predict.py。我们的训练脚本加载数据,编译模型,训练,并将序列化的模型和绘图图像输出到磁盘。从那里,我们的预测脚本生成带注释的图像用于视觉验证目的。
配置您的开发环境
对于本文,您需要安装以下软件包:
- OpenCV
- NumPy
- scikit-learn
- scikit-image
- imutils
- matplotlib
- TensorFlow 2.0 (CPU 或 GPU)
幸运的是,每一个都很容易用 pip 安装,pip 是一个 Python 包管理器。
现在让我们安装软件包,理想情况下安装到如图所示的虚拟环境中(您需要创建环境):
$ workon traffic_signs
$ pip install opencv-contrib-python
$ pip install numpy
$ pip install scikit-learn
$ pip install scikit-image
$ pip install imutils
$ pip install matplotlib
$ pip install tensorflow==2.0.0 # or tensorflow-gpu
使用 pip 安装 OpenCV 无疑是开始使用 OpenCV 的最快和最简单的方法。关于如何创建你的虚拟环境的说明包含在这个链接的教程中。这种方法(与从源代码编译相反)只是检查先决条件,并将在大多数系统上都能工作的预编译二进制文件放入虚拟环境站点包中。优化可能处于活动状态,也可能不处于活动状态。请记住,维护者已经选择不包括专利算法,因为害怕诉讼。有时在 PyImageSearch 上,我们出于教育和研究目的使用专利算法(有一些免费的替代品,你可以在商业上使用)。然而,pip 方法对于初学者来说是一个很好的选择——只是要记住你没有完整的安装。如果您需要完整安装,请参考我的安装教程页面。
如果你对(1)我们为什么使用 TensorFlow 2.0 感到好奇,以及(2)想知道为什么我没有指导你安装 Keras,你可能会惊讶地知道,Keras 现在实际上是作为 TensorFlow 的一部分包含在内的。诚然,TensorFlow 和 Keras 的婚姻是建立在一个有趣的过去。一定要看Keras vs . TF . Keras:tensor flow 2.0 有什么不同? 如果你很好奇 TensorFlow 为什么现在包含 Keras。
一旦您的环境准备就绪,是时候使用 Keras 识别交通标志了!
实施交通标志网,我们的 CNN 交通标志分类器

Figure 5: The Keras deep learning framework is used to build a Convolutional Neural Network (CNN) for traffic sign classification.
让我们来实现一个卷积神经网络来分类和识别交通标志。
注:如果这是你第一次用 Keras 建 CNN,一定要复习我的 Keras 教程。
我已经决定将这个分类器命名为TrafficSignNet —打开项目目录中的trafficsignnet.py文件,然后插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
class TrafficSignNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
我们的tf.keras进口列在2-9 线。我们将利用 Keras 的顺序 API 来构建我们的TrafficSignNet CNN ( Line 2 )。
第 11 行定义了我们的TrafficSignNet类,接着是第 13 行定义了我们的build方法。build方法接受四个参数:图像尺寸、depth和数据集中classes的数量。
第 16-19 行初始化我们的Sequential模型并指定 CNN 的inputShape。
让我们定义我们的CONV => RELU => BN => POOL层集:
# CONV => RELU => BN => POOL
model.add(Conv2D(8, (5, 5), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
这组图层使用一个 5×5 内核来学习更大的特征——这将有助于区分不同的交通标志形状和交通标志本身上的颜色斑点。
在这里,我们定义了两组(CONV => RELU => CONV => RELU) * 2 => POOL层:
# first set of (CONV => RELU => CONV => RELU) * 2 => POOL
model.add(Conv2D(16, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(16, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
# second set of (CONV => RELU => CONV => RELU) * 2 => POOL
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
这些层集合通过在应用 max-pooling 以减少体积维度之前堆叠两组CONV => RELU => BN层来加深网络。
我们网络的头部由两组完全连接的层和一个 softmax 分类器组成:
# first set of FC => RELU layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# second set of FC => RELU layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
辍学是一种正规化的形式,旨在防止过度拟合。结果往往是一个更一般化的模型。
第 54 行返回我方model;接下来,我们将在我们的train.py脚本中编译和训练模型。
如果你很难理解本课程中的术语,请务必参考 使用 Python 进行计算机视觉的深度学习 了解图层类型的概念性知识。我的 Keras 教程也提供了一个简要的概述。
实施我们的培训脚本
现在我们的TrafficSignNet架构已经实现,让我们创建我们的 Python 训练脚本,它将负责:
- 从 GTSRB 数据集加载我们的训练和测试分割
- 图像预处理
- 训练我们的模型
- 评估我们模型的准确性
- 将模型序列化到磁盘,以便我们稍后可以使用它来预测新的交通标志数据
让我们开始吧——打开项目目录中的train.py文件,添加以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.trafficsignnet import TrafficSignNet
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from sklearn.metrics import classification_report
from skimage import transform
from skimage import exposure
from skimage import io
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import os
第 2-18 行导入我们必需的包:
matplotlib:Python 事实上的绘图包。我们使用"Agg"后端,确保我们能够将我们的绘图作为图像文件导出到磁盘(第 2 行和第 3 行)。TrafficSignNet:我们前面用 Keras 编码的交通标志卷积神经网络(第 6 行)。tensorflow.keras:确保我们可以处理数据扩充、Adam优化和一键编码(第 7-9 行)。classification_report:sci kit-learn 方法,用于打印方便的培训评估(第 10 行)。skimage:我们将使用 scikit-image 代替 OpenCV 预处理我们的数据集,因为 scikit-image 提供了 OpenCV 没有的一些额外的预处理算法(第 11-13 行)。numpy:用于数组和数值运算(第 15 行)。argparse:处理解析命令行参数 ( 第 16 行)。random:随机打乱我们的数据集(第 17 行)。os:我们将使用这个模块来获取我们操作系统的路径分隔符(第 18 行)。
让我们继续定义一个从磁盘加载数据的函数:
def load_split(basePath, csvPath):
# initialize the list of data and labels
data = []
labels = []
# load the contents of the CSV file, remove the first line (since
# it contains the CSV header), and shuffle the rows (otherwise
# all examples of a particular class will be in sequential order)
rows = open(csvPath).read().strip().split("\n")[1:]
random.shuffle(rows)
我们将 GTSRB 数据集预先分为训练/测试部分。第 20 行定义load_split分别加载每个训练片段。它接受一个到数据集基础的路径以及一个包含每个图像的类标签的.csv文件路径。
第 22 行和第 23 行初始化我们的data和labels列表,该函数将很快填充并返回这些列表。
第 28 行加载我们的.csv文件,去掉空白,通过换行符抓取每一行,跳过第一个标题行。结果是一个rows列表,然后行 29 随机洗牌。
这里可以看到第 28 行和第 29 行的结果(即,如果你通过print(rows[:3])打印列表中的前三行):
['33,35,5,5,28,29,13,Train/13/00013_00001_00009.png',
'36,36,5,5,31,31,38,Train/38/00038_00049_00021.png',
'75,77,6,7,69,71,35,Train/35/00035_00039_00024.png']
数据的格式为:Width, Height, X1, Y1, X2, Y2, ClassID, Image Path。
现在让我们继续遍历rows,提取并预处理我们需要的数据:
# loop over the rows of the CSV file
for (i, row) in enumerate(rows):
# check to see if we should show a status update
if i > 0 and i % 1000 == 0:
print("[INFO] processed {} total images".format(i))
# split the row into components and then grab the class ID
# and image path
(label, imagePath) = row.strip().split(",")[-2:]
# derive the full path to the image file and load it
imagePath = os.path.sep.join([basePath, imagePath])
image = io.imread(imagePath)
32 号线绕过rows。在循环中,我们继续:
- 每处理 1000 幅图像,向终端显示一次状态更新(第 34 行和第 35 行)。
- 从
row( 第 39 行)中提取 ClassID (label)和imagePath)。 - 导出图像文件的完整路径+用 scikit-image 加载图像(第 42 行和第 43 行)。
正如上面的“gt SRB 数据集的挑战”一节中提到的那样,数据集的一个最大问题是,许多图像具有低对比度,使得人眼识别给定的标志具有挑战性(更不用说计算机视觉/深度学习模型了)。
我们可以通过应用一种叫做对比度受限自适应直方图均衡化 (CLAHE)的算法来自动提高图像对比度,其实现可以在 scikit-image 库中找到。
使用 CLAHE,我们可以提高交通标志图像的对比度:

Figure 6: As part of preprocessing for our GTSRB dataset for deep learning classification of traffic signs, we apply a method known as Contrast Limited Adaptive Histogram Equalization (CLAHE) to improve image contrast. Original images input images can be seen on the left — notice how contrast is very low and some signs cannot be recognize. By applying CLAHE (right) we can improve image contrast.
虽然我们的图像对人眼来说可能有点“不自然”,但对比度的提高将更好地帮助我们的计算机视觉算法自动识别我们的交通标志。
注:非常感谢 Thomas Tracey 在他 2017 年的文章中提出使用 CLAHE 来改善交通标志识别。
现在让我们通过应用 CLAHE 来预处理我们的图像:
# resize the image to be 32x32 pixels, ignoring aspect ratio,
# and then perform Contrast Limited Adaptive Histogram
# Equalization (CLAHE)
image = transform.resize(image, (32, 32))
image = exposure.equalize_adapthist(image, clip_limit=0.1)
# update the list of data and labels, respectively
data.append(image)
labels.append(int(label))
# convert the data and labels to NumPy arrays
data = np.array(data)
labels = np.array(labels)
# return a tuple of the data and labels
return (data, labels)
为了完成对rows的循环,我们:
- 将图像尺寸调整为 32×32 像素(第 48 行)。
- 应用 CLAHE 图像对比度校正(第 49 行)。
- 用
image本身和等级label( 行 52 和 53 )更新data和labels列表。
然后,行 56-60 将data和labels转换成 NumPy 数组,return将它们转换成调用函数。
定义了我们的load_split函数后,现在我们可以继续用解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input GTSRB")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to training history plot")
args = vars(ap.parse_args())
我们的三个命令行参数包括:
--dataset:gt SRB 数据集的路径。--model:输出模型的路径/文件名。- 通往我们训练历史的路径。
让我们初始化一些超参数并加载我们的类标签名:
# initialize the number of epochs to train for, base learning rate,
# and batch size
NUM_EPOCHS = 30
INIT_LR = 1e-3
BS = 64
# load the label names
labelNames = open("signnames.csv").read().strip().split("\n")[1:]
labelNames = [l.split(",")[1] for l in labelNames]
第 74-76 行初始化要训练的时期数、我们的初始学习率和批量大小。
第 79 行和第 80 行从一个.csv文件中加载类labelNames。文件中不必要的标记会被自动丢弃。
现在让我们继续加载并预处理我们的数据:
# derive the path to the training and testing CSV files
trainPath = os.path.sep.join([args["dataset"], "Train.csv"])
testPath = os.path.sep.join([args["dataset"], "Test.csv"])
# load the training and testing data
print("[INFO] loading training and testing data...")
(trainX, trainY) = load_split(args["dataset"], trainPath)
(testX, testY) = load_split(args["dataset"], testPath)
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# one-hot encode the training and testing labels
numLabels = len(np.unique(trainY))
trainY = to_categorical(trainY, numLabels)
testY = to_categorical(testY, numLabels)
# calculate the total number of images in each class and
# initialize a dictionary to store the class weights
classTotals = trainY.sum(axis=0)
classWeight = dict()
# loop over all classes and calculate the class weight
for i in range(0, len(classTotals)):
classWeight[i] = classTotals.max() / classTotals[i]
在这一部分中,我们:
- 导出到训练和测试分割的路径(行 83 和 84 )。
- 使用我们的
load_split函数来分别加载每个训练/测试分割(行 88 和 89 )。 - 通过将图像缩放到范围【0,1】(第 92 行和第 93 行)来预处理图像。
- 对培训/测试类别标签进行一次性编码(第 96-98 行)。
- 考虑我们的数据集中的倾斜(即,事实上我们有比其他类别多多得多的图像)。第 102-107 行为每个类分配一个权重,供训练时使用。
从这里,我们将准备+训练我们的model:
# construct the image generator for data augmentation
aug = ImageDataGenerator(
rotation_range=10,
zoom_range=0.15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.15,
horizontal_flip=False,
vertical_flip=False,
fill_mode="nearest")
# initialize the optimizer and compile the model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / (NUM_EPOCHS * 0.5))
model = TrafficSignNet.build(width=32, height=32, depth=3,
classes=numLabels)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // BS,
epochs=NUM_EPOCHS,
class_weight=classWeight,
verbose=1)
第 110-118 行用随机旋转、缩放、移动、剪切和翻转设置初始化我们的数据扩充对象。请注意,我们在这里没有应用水平或垂直翻转,因为野外的交通标志不会翻转。
第 121-126 行用Adam优化器和学习率衰减编译我们的TraffigSignNet模型。
130-136 线使用Keras’fit方法训练model。注意,class_weight参数被传递以适应我们数据集中的倾斜。
接下来,我们将评估model并将其序列化到磁盘:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BS)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# save the network to disk
print("[INFO] serializing network to '{}'...".format(args["model"]))
model.save(args["model"])
行 140 对测试集上的model进行评估。从那里,行 141 和 142 在终端打印分类报告。
第 146 行将 Keras model序列化到磁盘,以便我们稍后可以在预测脚本中使用它进行推断。
最后,下面的代码块绘制了训练精度/损失曲线,并将该图导出到磁盘上的图像文件中:
# plot the training loss and accuracy
N = np.arange(0, NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
请特别注意,TensorFlow 2.0 已将训练历史键重命名为:
H.history["acc"]现在是H.history["accuracy"]。H.history["val_acc"]现在是H.history["val_accuracy"]。
此时,您应该正在使用 TensorFlow 2.0(内置了 Keras),但如果不是,您可以调整键名(第 154 行和第 155 行)。
就我个人而言,我仍然没有弄明白为什么 TensorFlow 的开发人员做出了更改,以拼出“准确性”,但没有拼出“验证”。对我来说,这似乎违反直觉。也就是说,所有的框架和代码库都有我们需要学会处理的细微差别。
在交通标志数据集上训练 TrafficSignNet
要训练我们的交通标志分类模型,请确保您具有:
- 使用本教程的 【下载】 部分下载源代码。
- 按照上面的“项目结构”部分下载我们的交通标志数据集。
从那里,打开一个终端并执行以下命令:
$ python train.py --dataset gtsrb-german-traffic-sign \
--model output/trafficsignnet.model --plot output/plot.png
[INFO] loading training and testing data...
[INFO] compiling model...
[INFO] training network...
Epoch 1/30
612/612 [==============================] - 49s 81ms/step - loss: 2.6584 - accuracy: 0.2951 - val_loss: 2.1152 - val_accuracy: 0.3513
Epoch 2/30
612/612 [==============================] - 47s 77ms/step - loss: 1.3989 - accuracy: 0.5558 - val_loss: 0.7909 - val_accuracy: 0.7417
Epoch 3/30
612/612 [==============================] - 48s 78ms/step - loss: 0.9402 - accuracy: 0.6989 - val_loss: 0.5147 - val_accuracy: 0.8302
Epoch 4/30
612/612 [==============================] - 47s 76ms/step - loss: 0.6940 - accuracy: 0.7759 - val_loss: 0.4559 - val_accuracy: 0.8515
Epoch 5/30
612/612 [==============================] - 47s 76ms/step - loss: 0.5521 - accuracy: 0.8219 - val_loss: 0.3004 - val_accuracy: 0.9055
...
Epoch 26/30
612/612 [==============================] - 46s 75ms/step - loss: 0.1213 - accuracy: 0.9627 - val_loss: 0.7386 - val_accuracy: 0.8274
Epoch 27/30
612/612 [==============================] - 46s 75ms/step - loss: 0.1175 - accuracy: 0.9633 - val_loss: 0.1931 - val_accuracy: 0.9505
Epoch 28/30
612/612 [==============================] - 46s 75ms/step - loss: 0.1101 - accuracy: 0.9664 - val_loss: 0.1553 - val_accuracy: 0.9575
Epoch 29/30
612/612 [==============================] - 46s 76ms/step - loss: 0.1098 - accuracy: 0.9662 - val_loss: 0.1642 - val_accuracy: 0.9581
Epoch 30/30
612/612 [==============================] - 47s 76ms/step - loss: 0.1063 - accuracy: 0.9684 - val_loss: 0.1778 - val_accuracy: 0.9495
[INFO] evaluating network...
precision recall f1-score support
Speed limit (20km/h) 0.94 0.98 0.96 60
Speed limit (30km/h) 0.96 0.97 0.97 720
Speed limit (50km/h) 0.95 0.98 0.96 750
Speed limit (60km/h) 0.98 0.92 0.95 450
Speed limit (70km/h) 0.98 0.96 0.97 660
Speed limit (80km/h) 0.92 0.93 0.93 630
End of speed limit (80km/h) 0.96 0.87 0.91 150
Speed limit (100km/h) 0.93 0.94 0.93 450
Speed limit (120km/h) 0.90 0.99 0.94 450
No passing 1.00 0.97 0.98 480
No passing veh over 3.5 tons 1.00 0.96 0.98 660
Right-of-way at intersection 0.95 0.93 0.94 420
Priority road 0.99 0.99 0.99 690
Yield 0.98 0.99 0.99 720
Stop 1.00 1.00 1.00 270
No vehicles 0.99 0.90 0.95 210
Veh > 3.5 tons prohibited 0.97 0.99 0.98 150
No entry 1.00 0.94 0.97 360
General caution 0.98 0.77 0.86 390
Dangerous curve left 0.75 0.60 0.67 60
Dangerous curve right 0.69 1.00 0.81 90
Double curve 0.76 0.80 0.78 90
Bumpy road 0.99 0.78 0.87 120
Slippery road 0.66 0.99 0.79 150
Road narrows on the right 0.80 0.97 0.87 90
Road work 0.94 0.98 0.96 480
Traffic signals 0.87 0.95 0.91 180
Pedestrians 0.46 0.55 0.50 60
Children crossing 0.93 0.94 0.94 150
Bicycles crossing 0.92 0.86 0.89 90
Beware of ice/snow 0.88 0.75 0.81 150
Wild animals crossing 0.98 0.95 0.96 270
End speed + passing limits 0.98 0.98 0.98 60
Turn right ahead 0.97 1.00 0.98 210
Turn left ahead 0.98 1.00 0.99 120
Ahead only 0.99 0.97 0.98 390
Go straight or right 1.00 1.00 1.00 120
Go straight or left 0.92 1.00 0.96 60
Keep right 0.99 1.00 0.99 690
Keep left 0.97 0.96 0.96 90
Roundabout mandatory 0.90 0.99 0.94 90
End of no passing 0.90 1.00 0.94 60
End no passing veh > 3.5 tons 0.91 0.89 0.90 90
accuracy 0.95 12630
macro avg 0.92 0.93 0.92 12630
weighted avg 0.95 0.95 0.95 12630
[INFO] serializing network to 'output/trafficsignnet.model'...
注意:在终端输出块中,为了可读性,一些类名被缩短了。
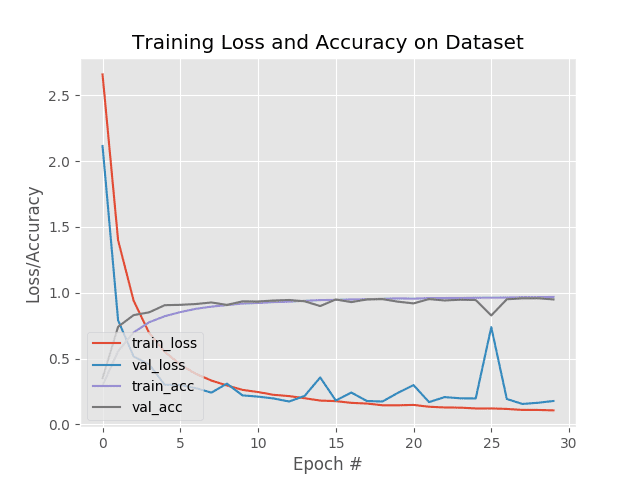
Figure 7: Keras and deep learning is used to train a traffic sign classifier.
在这里你可以看到我们在测试集上获得了 95%的准确率!
*### 实现我们的预测脚本
现在,我们的交通标志识别模型已经训练完毕,让我们学习如何:
- 从磁盘加载模型
- 从磁盘加载样本图像
- 以与训练相同的方式预处理样本图像
- 将我们的图像通过我们的交通标志分类器
- 获得我们的最终产量预测
为了实现这些目标,我们需要检查predict.py的内容:
# import the necessary packages
from tensorflow.keras.models import load_model
from skimage import transform
from skimage import exposure
from skimage import io
from imutils import paths
import numpy as np
import argparse
import imutils
import random
import cv2
import os
第 2-12 行导入我们必需的包、模块和函数。最值得注意的是,我们从tensorflow.keras.models导入load_model,确保我们可以从磁盘加载我们的序列化模型。你可以在这里了解更多关于保存和加载 Keras 模型的信息。
我们将使用 scikit-image 来预处理我们的图像,就像我们在训练脚本中所做的那样。
但是与我们的训练脚本不同,我们将利用 OpenCV 来注释并将输出图像写入磁盘。
让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to pre-trained traffic sign recognizer")
ap.add_argument("-i", "--images", required=True,
help="path to testing directory containing images")
ap.add_argument("-e", "--examples", required=True,
help="path to output examples directory")
args = vars(ap.parse_args())
第 15-22 行解析三个命令行参数:
--model:磁盘上序列化交通标志识别器 Keras 模型的路径(我们在上一节对模型进行了训练)。--images:测试图像目录的路径。--examples:我们的路径到我们的注释输出图像将被存储的目录。
有了args字典中的每一条路径,我们就可以继续了:
# load the traffic sign recognizer model
print("[INFO] loading model...")
model = load_model(args["model"])
# load the label names
labelNames = open("signnames.csv").read().strip().split("\n")[1:]
labelNames = [l.split(",")[1] for l in labelNames]
# grab the paths to the input images, shuffle them, and grab a sample
print("[INFO] predicting...")
imagePaths = list(paths.list_images(args["images"]))
random.shuffle(imagePaths)
imagePaths = imagePaths[:25]
第 26 行将我们训练过的交通标志model从磁盘载入内存。
第 29 行和第 30 行加载并解析类labelNames。
第 34-36 行抓取输入图像的路径,shuffle它们,并抓取25样本图像。
我们现在将对样本进行循环:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the image, resize it to 32x32 pixels, and then apply
# Contrast Limited Adaptive Histogram Equalization (CLAHE),
# just like we did during training
image = io.imread(imagePath)
image = transform.resize(image, (32, 32))
image = exposure.equalize_adapthist(image, clip_limit=0.1)
# preprocess the image by scaling it to the range [0, 1]
image = image.astype("float32") / 255.0
image = np.expand_dims(image, axis=0)
# make predictions using the traffic sign recognizer CNN
preds = model.predict(image)
j = preds.argmax(axis=1)[0]
label = labelNames[j]
# load the image using OpenCV, resize it, and draw the label
# on it
image = cv2.imread(imagePath)
image = imutils.resize(image, width=128)
cv2.putText(image, label, (5, 15), cv2.FONT_HERSHEY_SIMPLEX,
0.45, (0, 0, 255), 2)
# save the image to disk
p = os.path.sep.join([args["examples"], "{}.png".format(i)])
cv2.imwrite(p, image)
在我们的imagePaths循环中(从第 39 行开始),我们:
- 用 scikit-image 加载输入图像(第 43 行)。
- 预处理图像的方式与我们处理训练数据 ( 第 44-48 行)的方式相同。用和训练一样的方式预处理我们的图像是绝对重要的,包括(1)调整大小,(2)调整对比度,(3)缩放到范围 [0,1] 。如果我们不像对待训练数据一样对测试数据进行预处理,那么我们的模型预测就没有意义。
- 向图像添加一个维度——我们将对批量大小 1 进行推断( Line 49 )。
- 做一个预测,抓取概率最高的类标签(第 52-54 行)。
- 使用 OpenCV,我们加载图像,调整图像大小,用标签对图像进行注释,并将输出图像写入磁盘(第 58-65 行)。
对所有 25 个图像样本重复该过程。
对交通标志数据进行预测
要使用我们训练的TrafficSignNet模型对交通标志数据进行预测,请确保您已经使用本教程的 “下载” 部分下载源代码和预训练模型。
从那里,打开一个终端并执行以下命令:
$ python predict.py --model output/trafficsignnet.model \
--images gtsrb-german-traffic-sign/Test \
--examples examples
[INFO] loading model...
[INFO] predicting...

Figure 8: Keras deep learning traffic sign classification results.
如您所见,我们的交通标志分类器正在正确识别我们输入的交通标志!
接下来是什么?我推荐 PyImageSearch 大学。
 课程信息:
课程信息:
60+总课时 64+学时点播代码演练视频最后更新:2022 年 12 月
★★★4.84(128 评分)15800+学员报名人数
我强烈
你是否认为学习计算机视觉和深度学习必须是耗时的、势不可挡的、复杂的?还是必须涉及复杂的数学和方程?还是需要计算机科学的学位?
那是而不是的情况。
要掌握计算机视觉和深度学习,你需要的只是有人用简单、直观的术语向你解释事情。而这正是我做的。我的使命是改变教育和复杂的人工智能主题的教学方式。
如果你是认真学习计算机视觉的,你的下一站应该是 PyImageSearch 大学,最全面的计算机视觉,深度学习,以及今天在线的 OpenCV 课程。在这里,你将学习如何成功地将计算机视觉应用到你的工作、研究和项目中。和我一起掌握计算机视觉。
PyImageSearch 大学里面你会发现:
- & check; 60+Course About basic computer vision, deep learning, and OpenCV topics
- & check; 60+completion certificate
- & check; 64+hours of video on demand
- & check; The new course will be published regularly to ensure that you can keep up with the latest technology.
- Check of&; The pre-configured Jupyter notebook is in Google Colab 【T1]
- & check; Run all code examples in your web browser—for Windows, macOS and Linux (no development environment configuration required! )
- &检查;访问 PyImageSearch
- & check in the centralized code warehouse of all 500+tutorials on ; Easily click to download code, data set, pre-training model, etc.
- & check; Access on mobile phones, notebooks, desktops and other devices.
摘要
在本教程中,您学习了如何使用 Keras 和深度学习来执行交通标志分类和识别。
为了创建我们的交通标志分类器,我们:
- 利用流行的德国交通标志识别基准 (GTSRB) 作为我们的数据集。
- 使用 Keras 深度学习库实现了一个名为
TrafficSignNet的卷积神经网络。 - 在 GTSRB 数据集上训练
TrafficSignNet,获得 95%的准确率。 - 创建了一个 Python 脚本来加载我们训练过的
TrafficSignNet模型,然后对新的输入图像进行分类。
我希望你喜欢今天关于 Keras 交通标志分类的帖子!
如果你有兴趣了解更多关于为交通标志识别和检测训练你自己的定制深度学习模型的信息,请务必参考 使用 Python 进行计算机视觉的深度学习 ,在那里我会更详细地介绍这个主题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
训练您自己的自定义图像分类器、对象检测器和对象跟踪器。

你看了上周末的超级碗吗?
我做到了。算是吧。
我在我最喜欢的印度酒吧度过了超级碗周日(这实际上是美国的一个假期)。
捣翠鸟啤酒。
品尝美味的坦杜里鸡…
…所有这一切都发生在我的笔记本电脑上,为的 PyImageSearch 大师计算机视觉课程编写一些定制的图像分类器、物体检测器、&物体跟踪器。
哦,对了——背景音乐是超级碗比赛。虽然不能说我看了很多,但我太忙于我的笔记本电脑,看起来像一个疯狂的程序员!我肯定这是一幅奇特的景象。
无论如何,我今天发布这篇文章是因为我想与你分享我的印度啤酒燃料黑客狂欢的结果… 我们将在 PyImageSearch 大师内部构建的图像分类器、物体检测器和物体跟踪器的预览。
让我们从简单的事情开始,训练你自己的面部检测器:

Figure 1: Inside PyImageSearch Gurus you’ll learn how to train your own custom object detector to detect faces in images.
在这里,你可以看到我已经使用梯度方向直方图描述符和线性 SVM 训练了我的自定义对象检测器,以检测从回到未来的演员阵容中的人脸。
在这里,我训练了另一个自定义对象检测器,它使用梯度方向直方图来检测图像中是否存在汽车:

Figure 2: Learn how to detect a car in an image inside the PyImageSearch Gurus course.
现在让我们做一些稍微复杂一点的事情。在下图中,我训练了一个视觉词汇金字塔(PBOW)和一个梯度方向直方图金字塔(PHOG ),以识别来自流行的 CALTECH-101 数据集的图像:
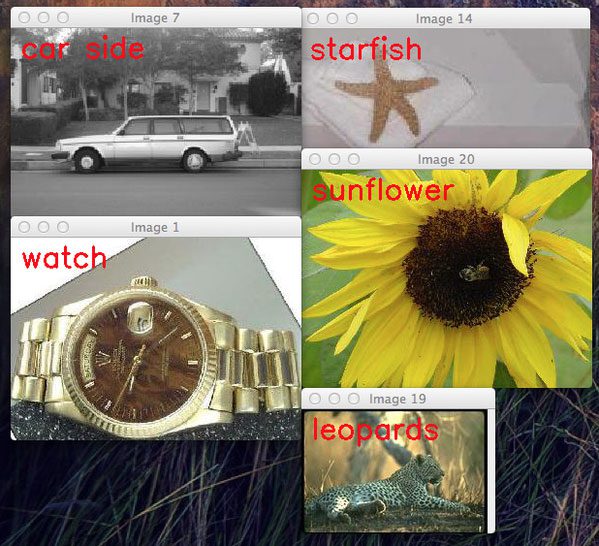
Figure 3: Learn how to train an image classifier on the popular 101 category CALTECH dataset.
作为另一个例子,我训练了一个分类器来区分 ASIRRA 猫和狗数据集上 Fido 和 Whiskers 夫人之间的差异:

Figure 4: You’ll learn how to train a custom image classifier to recognize the difference between cats and dogs.
最后,我利用关键点检测、局部不变描述符和关键点匹配在实时视频流中跟踪视频游戏盒的盖子:
![]()
Figure 5: Training your own custom object tracker for use in real-time video is a breeze. Discover how inside PyImageSearch Gurus.
很酷,对吧?
这些技巧并不神奇——我保证你可以自己学会。
在门关上之前加入 PyImageSearch 大师们吧…
正如你所看到的,我们将在 PyImageSearch 大师课程中学到很多实用的技能。从自定义图像分类器到物体检测器,再到实时物体跟踪,在 PyImageSearch 大师课程中,你一定会成为计算机视觉大师。
因此,如果你对揭示这些技术感兴趣,并成为一名计算机视觉大师,我肯定会建议加入我的 PyImageSearch Gurus!
一旦 Kickstarter 结束,您将无法再次注册 PyImageSearch 大师,直到 8 月份!这是你的机会!现在一定要进去…
PyImageSearch 大师课程仍有几个名额,所以请立即行动起来, 抢占你的位置!
训练自定义 dlib 形状预测器
原文:https://pyimagesearch.com/2019/12/16/training-a-custom-dlib-shape-predictor/
在本教程中,您将学习如何训练您自己的自定义 dlib 形状预测器。然后,您将学习如何使用经过培训的 dlib 形状预测器,并使用它来预测输入图像和实时视频流上的地标。
今天开始一个全新的两部分系列用 dlib: 训练自定义形状预测器
- 第 1 部分:训练自定义 dlib 形状预测器(今天的教程)
- 第 2 部分:调整 dlib 形状预测超参数以平衡速度、精度和模型大小(下周的教程)
形状预测器,也称为标志预测器,用于预测给定“形状”的关键 (x,y)-坐标。
最常见、最著名的形状预测器是 dlib 的面部标志预测器,用于定位个人面部结构,包括:
*** 眼睛
- 眉毛
- 鼻子
- 嘴唇/嘴
- 下颌的轮廓
面部标志用于面部对齐(一种提高面部识别准确性的方法),建立一个“睡意检测器”来检测疲劳、困倦的驾驶员,面部交换,虚拟改造应用,等等。
然而,仅仅因为面部标志是最流行的形状预测器,并不意味着我们不能训练一个形状预测器来定位图像中的其他形状!
例如,您可以使用形状预测器来:
- 在构建基于计算机视觉的文档扫描仪时自动定位一张纸的四个角。
- 检测人体的关键、结构关节(脚、膝、肘等。).
- 构建 AR/VR 应用时,将指尖本地化。
今天,我们将更详细地探讨形状预测器,包括如何使用 dlib 库训练您自己的自定义形状预测器。
要学习如何训练自己的 dlib 形状预测器,继续阅读!
调整自定义 dlib 形状预测器
在本教程的第一部分,我们将简要讨论什么是形状/标志预测器,以及如何使用它们来预测结构对象上的特定位置。
从那里,我们将回顾 iBUG 300-W 数据集,这是一个用于训练形状预测器的常见数据集,形状预测器用于定位人脸上的特定位置(即,面部标志)。
然后,我将向您展示如何训练您自己的自定义 dlib 形状预测器,从而得到一个可以平衡速度、准确性和模型大小的模型。
最后,我们将测试我们的形状预测器,并将其应用于一组输入图像/视频流,证明我们的形状预测器能够实时运行。
我们将讨论后续步骤来结束本教程。
什么是形状/地标预测?

Figure 1: Training a custom dlib shape predictor on facial landmarks (image source).
形状/标志预测器用于在输入“形状”上定位特定的 (x,y)-坐标。术语“形状”是任意的,但是它被认为是结构性的。
结构形状的例子包括:
- 表面
- 手
- 手指
- 脚趾
- 等等。
例如,脸有各种不同的形状和大小,它们都有共同的结构特征——眼睛在鼻子上面,鼻子在嘴巴上面,等等。
形状/标志预测器的目标是利用这种结构知识,并给出足够的训练数据,学习如何自动预测这些结构的位置。
形状/地标预测器如何工作?
Figure 2: How do shape/landmark predictors work? The dlib library implements a shape predictor algorithm with an ensemble of regression trees approach using the method described by Kazemi and Sullivan in their 2014 CVPR paper (image source).
有多种形状预测算法。具体使用哪一种取决于:
- 您正在处理 2D 或 3D 数据
- 你需要利用深度学习
- 或者,如果传统的计算机视觉和机器学习算法就足够了
dlib 库中实现的形状预测器算法来自卡泽米和沙利文 2014 年的 CVPR 论文, 用回归树集合进行 1 毫秒人脸对齐。
为了估计界标位置,算法:
- 检查一组稀疏的输入像素强度(即输入模型的“特征”)
- 将特征传递到回归树集合(ERT)中
- 细化预测位置,通过一系列回归变量提高准确性
最终的结果是一个可以超实时运行的形状预测器!
关于里程碑式预测内部运作的更多细节,请务必参考卡泽米和沙利文 2014 年的出版物。
iBUG 300-W 数据集

Figure 3: In this tutorial we will use the iBUG 300-W face landmark dataset to learn how to train a custom dlib shape predictor.
为了训练我们的自定义 dlib 形状预测器,我们将利用 iBUG 300-W 数据集(但是有一点变化)。
iBUG-300W 的目标是训练一个形状预测器,能够定位每个单独的面部结构,包括眼睛、眉毛、鼻子、嘴和下颌线。
数据集本身由 68 对整数值组成— 这些值是上面图 2 中描绘的面部结构的 (x,y)—坐标。
为了创建 iBUG-300W 数据集,研究人员手工并费力地在总共 7764 张图像上标注了 68 个坐标中的每个。
在 iBUG-300W 上训练的模型可以预测这 68 个 (x,y)-坐标对中的每一个的位置,并且因此可以定位面部上的每一个位置。
这一切都很好……
但是如果我们想训练一个形状预测器来定位眼睛呢?
我们如何着手做那件事?
平衡形状预测模型的速度和精度

Figure 4: We will train a custom dlib shape/landmark predictor to recognize just eyes in this tutorial.
让我们假设一下,你想训练一个定制的形状预测器来定位仅仅是眼睛的位置。
我们有两种选择来完成这项任务:
- 利用 dlib 的预先训练好的面部标志检测器来定位所有面部结构,然后丢弃除眼睛以外的所有定位。
- 训练我们自己的自定义 dlib 路标预测器,它返回仅仅是眼睛的位置。
在某些情况下,你也许能够摆脱第一种选择;然而,这里有两个问题,即关于你的模型速度和你的模型尺寸。
模型速度:即使你只对地标预测的子集感兴趣,你的模型仍然负责预测整个地标集。你不能只告诉你的模型“哦,嘿,只要给我那些位置,不要计算其余的。”事情并不是这样的——这是一种“全有或全无”的计算。
模型大小:由于你的模型需要知道如何预测所有被训练的地标位置,因此它需要存储关于如何预测这些位置的量化信息。它需要存储的信息越多,你的模型就越大。
把你的 shape predictor 模型尺寸想象成一张购物清单——在 20 件商品的清单中,你可能只需要鸡蛋和一加仑牛奶,但是如果你去商店,你将会购买清单上的所有商品,因为这是你的家人希望你做的!
模型大小也是这样。
您的模型并不“关心”您只真正“需要”地标预测的子集;它被训练来预测所有这些,所以你会得到所有的回报!
如果你只需要特定地标的子集,你应该考虑训练你自己的定制形状预测器——你最终会得到一个既更小又更快的模型。
在今天的教程中,我们将训练一个定制的 dlib 形状预测器来定位来自 iBUG 300-W 数据集中的眼睛位置。
这种模型可以用在虚拟改造应用程序中,用于只涂眼线笔/睫毛膏或 T2 或 T3。它可以用在 T4 睡意检测器中,用于检测汽车方向盘后疲劳的司机。
配置您的 dlib 开发环境
为了完成今天的教程,您需要一个安装了以下软件包的虚拟环境:
- dlib
- OpenCV
- imutils
幸运的是,这些包都是 pip 可安装的,但是有一些先决条件,包括虚拟环境。有关其他信息,请务必遵循以下两个指南:
pip 安装命令包括:
$ workon <env-name>
$ pip install dlib
$ pip install opencv-contrib-python
$ pip install imutils
一旦你按照我的 dlib 或 OpenCV 安装指南安装了virtualenv和virtualenvwrapper,那么workon命令就变得可用。
下载 iBUG 300-W 数据集
在我们深入本教程之前,现在花点时间下载 iBUG 300-W 数据集(~1.7GB):
http://dlib . net/files/data/ibug _ 300 w _ large _ face _ landmark _ dataset . tar . gz
你可能还想使用这篇博文的 【下载】 部分来下载源代码。
我建议将 iBug 300W 数据集放入与本教程下载相关的 zip 文件中,如下所示:
$ unzip custom-dlib-shape-predictor.zip
...
$ cd custom-dlib-shape-predictor
$ mv ~/Downloads/ibug_300W_large_face_landmark_dataset.tar.gz .
$ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz
...
或者(即,不点击上面的超链接),在您的终端中使用wget直接下载数据集:
$ unzip custom-dlib-shape-predictor.zip
...
$ cd custom-dlib-shape-predictor
$ wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
$ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz
...
从这里开始,您可以跟随教程的其余部分。
项目结构
假设您已经遵循了上一节中的说明,您的项目目录现在组织如下:
$ tree --dirsfirst --filelimit 10
.
├── ibug_300W_large_face_landmark_dataset
│ ├── afw [1011 entries]
│ ├── helen
│ │ ├── testset [990 entries]
│ │ └── trainset [6000 entries]
│ ├── ibug [405 entries]
│ ├── image_metadata_stylesheet.xsl
│ ├── labels_ibug_300W.xml
│ ├── labels_ibug_300W_test.xml
│ ├── labels_ibug_300W_train.xml
│ └── lfpw
│ ├── testset [672 entries]
│ └── trainset [2433 entries]
├── ibug_300W_large_face_landmark_dataset.tar.gz
├── eye_predictor.dat
├── parse_xml.py
├── train_shape_predictor.py
├── evaluate_shape_predictor.py
└── predict_eyes.py
9 directories, 10 files
iBug 300-W 数据集在ibug_300W_large_face_landmark_dataset/目录中提取。我们将按此顺序回顾以下 Python 脚本:
parse_xml.py:解析训练/测试 XML 数据集文件以获得只看得见的地标坐标。train_shape_predictor.py:接受解析后的 XML 文件,用 dlib 训练我们的形状预测器。evaluate_shape_predictor.py:计算我们定制的形状预测器的平均误差(MAE)。predict_eyes.py:使用我们定制的 dlib 形状预测器进行形状预测,该预测器经过训练,仅识别眼睛标志。
在下一节中,我们将从检查输入 XML 文件开始。
了解 iBUG-300W XML 文件结构
我们将使用 iBUG-300W 来训练我们的形状预测器;然而,我们有一个小问题:
iBUG-300W 为数据集中的所有 面部结构(即眉毛、眼睛、鼻子、嘴和下颌线) (x,y)-坐标对…
…然而,我们想在只训练眼睛的形状预测器!
那我们怎么做?
我们会找到另一个不包含我们不关心的面部结构的数据集吗?
手动打开训练文件并删除我们不需要的面部结构的坐标对?
干脆放弃,拿着我们的球,回家?
当然不是!
我们是程序员和工程师——我们所需要的只是一些基本的文件解析,以创建一个新的训练文件,该文件只包括眼睛坐标。
为了理解我们如何做到这一点,让我们首先通过检查labels_ibug_300W_train.xml训练文件来考虑如何在 iBUG-300W 数据集中注释面部标志:
...
<images>
<image file='lfpw/trainset/image_0457.png'>
<box top='78' left='74' width='138' height='140'>
<part name='00' x='55' y='141'/>
<part name='01' x='59' y='161'/>
<part name='02' x='66' y='182'/>
<part name='03' x='75' y='197'/>
<part name='04' x='90' y='209'/>
<part name='05' x='108' y='220'/>
<part name='06' x='131' y='226'/>
<part name='07' x='149' y='232'/>
<part name='08' x='167' y='230'/>
<part name='09' x='181' y='225'/>
<part name='10' x='184' y='208'/>
<part name='11' x='186' y='193'/>
<part name='12' x='185' y='179'/>
<part name='13' x='184' y='167'/>
<part name='14' x='186' y='152'/>
<part name='15' x='185' y='142'/>
<part name='16' x='181' y='133'/>
<part name='17' x='95' y='128'/>
<part name='18' x='105' y='121'/>
<part name='19' x='117' y='117'/>
<part name='20' x='128' y='115'/>
<part name='21' x='141' y='116'/>
<part name='22' x='156' y='115'/>
<part name='23' x='162' y='110'/>
<part name='24' x='169' y='108'/>
<part name='25' x='175' y='108'/>
<part name='26' x='180' y='109'/>
<part name='27' x='152' y='127'/>
<part name='28' x='157' y='136'/>
<part name='29' x='162' y='145'/>
<part name='30' x='168' y='154'/>
<part name='31' x='152' y='166'/>
<part name='32' x='158' y='166'/>
<part name='33' x='163' y='168'/>
<part name='34' x='167' y='166'/>
<part name='35' x='171' y='164'/>
<part name='36' x='111' y='134'/>
<part name='37' x='116' y='130'/>
<part name='38' x='124' y='128'/>
<part name='39' x='129' y='130'/>
<part name='40' x='125' y='134'/>
<part name='41' x='118' y='136'/>
<part name='42' x='161' y='127'/>
<part name='43' x='166' y='123'/>
<part name='44' x='173' y='122'/>
<part name='45' x='176' y='125'/>
<part name='46' x='173' y='129'/>
<part name='47' x='167' y='129'/>
<part name='48' x='139' y='194'/>
<part name='49' x='151' y='186'/>
<part name='50' x='159' y='180'/>
<part name='51' x='163' y='182'/>
<part name='52' x='168' y='180'/>
<part name='53' x='173' y='183'/>
<part name='54' x='176' y='189'/>
<part name='55' x='174' y='193'/>
<part name='56' x='170' y='197'/>
<part name='57' x='165' y='199'/>
<part name='58' x='160' y='199'/>
<part name='59' x='152' y='198'/>
<part name='60' x='143' y='194'/>
<part name='61' x='159' y='186'/>
<part name='62' x='163' y='187'/>
<part name='63' x='168' y='186'/>
<part name='64' x='174' y='189'/>
<part name='65' x='168' y='191'/>
<part name='66' x='164' y='192'/>
<part name='67' x='160' y='192'/>
</box>
</image>
...
iBUG-300W 数据集中的所有训练数据都由结构化的 XML 文件表示。
每个图像都有一个image标签。
在image标签中有一个file属性,它指向示例图像文件在磁盘上的位置。
此外,每个image都有一个与之相关联的box元素。
box元素表示图像中面部的边界框坐标。为了理解box元素如何表示面部的边界框,考虑它的四个属性:
top:包围盒的起始 y 坐标。left:包围盒的起始 x 坐标。width:边框的宽度。height:边框的高度。
在box元素中,我们总共有 68 个part元素— 这些part元素表示 iBUG-300W 数据集中的各个 (x,y)—面部标志的坐标。
注意,每个part元素都有三个属性:
name:特定面部标志的索引/名称。x:地标的 x 坐标。y:地标的 y 坐标。
那么,这些地标是如何映射到特定的面部结构的呢?
答案就在下图中:

Figure 5: Visualizing the 68 facial landmark coordinates from the iBUG 300-W dataset.
图 5 中的坐标是 1 索引的,因此要将坐标name映射到我们的 XML 文件,只需从值中减去 1(因为我们的 XML 文件是 0 索引的)。
基于可视化,我们可以得出哪个name坐标映射到哪个面部结构:
- 通过【48,68】可以进入口。
- 右眉通穴【17、22】。
- 左眉经穴【22、27】。
- 右眼使用【36,42】。
- 左眼与【42,48】。
- 鼻使用【27,35】。
- 通过【0,17】控制钳口。
由于我们只对眼睛感兴趣,因此我们需要解析出点【36,48】,再次记住:
- 我们的坐标在 XML 文件中是零索引的
- 而【36,48】中的右括号)是暗示“非包含”的数学符号。
既然我们理解了 iBUG-300W 训练文件的结构,我们可以继续解析出只眼睛坐标。
构建“仅眼睛”形状预测数据集
让我们创建一个 Python 脚本来解析 iBUG-300W XML 文件,并仅提取眼睛坐标(我们将在下一节中训练一个自定义 dlib 形状预测器)。
打开parse_xml.py文件,我们开始吧:
# import the necessary packages
import argparse
import re
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to iBug 300-W data split XML file")
ap.add_argument("-t", "--output", required=True,
help="path output data split XML file")
args = vars(ap.parse_args())
2 号线和 3 号线导入必要的包。
我们将使用 Python 的两个内置模块:(1) argparse用于解析命令行参数,以及(2) re用于正则表达式匹配。如果你在开发正则表达式时需要帮助,regex101.com是一个很好的工具,它也支持除 Python 之外的其他语言。
我们的脚本需要两个命令行参数:
--input:输入数据分割 XML 文件的路径(即来自 iBug 300-W 数据集)。--output:我们输出的只看 XML 文件的路径。
让我们继续定义我们的眼睛坐标的索引:
# in the iBUG 300-W dataset, each (x, y)-coordinate maps to a specific
# facial feature (i.e., eye, mouth, nose, etc.) -- in order to train a
# dlib shape predictor on *just* the eyes, we must first define the
# integer indexes that belong to the eyes
LANDMARKS = set(list(range(36, 48)))
我们的眼标指定在17 线上。参考图 5 ,记住该图是 1 索引的,而 Python 是 0 索引的。
我们将在眼睛位置上训练我们的自定义形状预测器;然而,通过修改LANDMARKS列表并包括您想要检测的地标的 0 索引名称,您可以轻松地训练眉毛、鼻子、嘴或下颌线预测器,包括这些结构的任何组合或子集,。
现在让我们定义正则表达式并加载原始的输入 XML 文件:
# to easily parse out the eye locations from the XML file we can
# utilize regular expressions to determine if there is a 'part'
# element on any given line
PART = re.compile("part name='[0-9]+'")
# load the contents of the original XML file and open the output file
# for writing
print("[INFO] parsing data split XML file...")
rows = open(args["input"]).read().strip().split("\n")
output = open(args["output"], "w")
我们在第 22 行上的正则表达式将很快支持提取part元素及其名称/索引。
第 27 行加载输入 XML 文件的内容。
第 28 行打开我们的输出 XML 文件进行写入。
现在我们准备好循环遍历输入的 XML 文件,让找到并提取眼睛标志:
# loop over the rows of the data split file
for row in rows:
# check to see if the current line has the (x, y)-coordinates for
# the facial landmarks we are interested in
parts = re.findall(PART, row)
# if there is no information related to the (x, y)-coordinates of
# the facial landmarks, we can write the current line out to disk
# with no further modifications
if len(parts) == 0:
output.write("{}\n".format(row))
# otherwise, there is annotation information that we must process
else:
# parse out the name of the attribute from the row
attr = "name='"
i = row.find(attr)
j = row.find("'", i + len(attr) + 1)
name = int(row[i + len(attr):j])
# if the facial landmark name exists within the range of our
# indexes, write it to our output file
if name in LANDMARKS:
output.write("{}\n".format(row))
# close the output file
output.close()
第 31 行开始对输入 XML 文件的rows进行循环。在循环内部,我们执行以下任务:
- 通过正则表达式匹配(第 34 行)确定当前
row是否包含part元素。- 如果 不包含
part元素,将该行写回文件(第 39 行和第 40 行)。 - 如果它 确实包含了一个
part元素 ,我们需要进一步解析它(第 43-53 行)。- 这里我们从
part中提取name属性。 - 然后检查
name是否存在于我们想要训练形状预测器来定位的LANDMARKS中。如果是,我们将row写回磁盘(否则我们忽略特定的name,因为它不是我们想要定位的地标)。
- 这里我们从
- 如果 不包含
- 通过关闭我们的
outputXML 文件(第 56 行)来结束这个脚本。
注:我们大部分parse_xml.py脚本的灵感来自于 Luca Anzalone 的slice_xml函数,来自于他们的 GitHub repo 。非常感谢 Luca 编写了这样一个简单、简洁、高效的脚本!
创建我们的培训和测试拆分

Figure 6: Creating our “eye only” face landmark training/testing XML files for training a dlib custom shape predictor with Python.
在本教程的这一点上,我假设您两者都具备:
- 从上面的“下载 iBUG 300-W 数据集”部分下载了 iBUG-300W 数据集
- 使用本教程的 【下载】 部分下载源代码。
您可以使用以下命令,通过仅解析原始训练文件中的眼睛标志坐标来生成新的训练文件:
$ python parse_xml.py \
--input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml \
--output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml
[INFO] parsing data split XML file...
类似地,您可以做同样的事情来创建我们新的测试文件:
$ python parse_xml.py \
--input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test.xml \
--output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test_eyes.xml
[INFO] parsing data split XML file...
要验证我们的新培训/测试文件是否已创建,请检查 iBUG-300W 根数据集目录中的labels_ibug_300W_train_eyes.xml和labels_ibug_300W_test_eyes.xml文件:
$ cd ibug_300W_large_face_landmark_dataset
$ ls -lh *.xml
-rw-r--r--@ 1 adrian staff 21M Aug 16 2014 labels_ibug_300W.xml
-rw-r--r--@ 1 adrian staff 2.8M Aug 16 2014 labels_ibug_300W_test.xml
-rw-r--r-- 1 adrian staff 602K Dec 12 12:54 labels_ibug_300W_test_eyes.xml
-rw-r--r--@ 1 adrian staff 18M Aug 16 2014 labels_ibug_300W_train.xml
-rw-r--r-- 1 adrian staff 3.9M Dec 12 12:54 labels_ibug_300W_train_eyes.xml
$ cd ..
请注意,我们的*_eyes.xml文件被高亮显示。这两个文件的文件大小都比它们原始的、未解析的副本小得多。
实现我们定制的 dlib 形状预测器训练脚本
我们的 dlib 形状预测器训练脚本大致基于(1) dlib 的官方示例和(2) Luca Anzalone 的 2018 年优秀文章。
我在这里的主要贡献是:
- 提供一个创建自定义 dlib 形状预测器的完整端到端示例,包括:
- 在训练集上训练形状预测器
- 在测试集上评估形状预测器
- 使用形状预测器对自定义图像/视频流进行预测。
- 对您应该调整的超参数提供更多注释。
- 演示如何系统地调整你的形状预测器超参数来平衡速度、模型大小和精确度 (下周的教程)。
要了解如何训练自己的 dlib 形状预测器,请打开项目结构中的train_shape_predictor.py文件并插入以下代码:
# import the necessary packages
import multiprocessing
import argparse
import dlib
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--training", required=True,
help="path to input training XML file")
ap.add_argument("-m", "--model", required=True,
help="path serialized dlib shape predictor model")
args = vars(ap.parse_args())
2-4 行导入我们的包,即 dlib。dlib 工具包是由 PyImageConf 2018 演讲人、 Davis King 开发的一个包。我们将使用 dlib 来训练形状预测器。
多重处理库将用于获取和设置我们将用于训练我们的形状预测器的线程/进程的数量。
我们的脚本需要两个命令行参数(第 7-12 行):
--training:我们输入的训练 XML 文件的路径。我们将使用前面两个部分生成的仅供参考的 XML 文件。--model:序列化 dlib 形状预测器输出文件的路径。
从这里开始,我们需要在训练形状预测器之前设置选项(即超参数)。
虽然下面的代码块可以压缩成只有 11 行代码,但是代码和本教程中的注释提供了额外的信息来帮助您(1)理解关键选项,以及(2)配置和调整选项/超参数以获得最佳性能。
在本节的剩余代码块中,我将讨论在训练您自己的自定义 dlib 形状预测器时,您可以调整/设置的 7 个最重要的超参数。这些值是:
tree_depthnucascade_depthfeature_pool_sizenum_test_splitsoversampling_amountoversampling_translation_jitter
我们将从默认的 dlib 形状预测器选项开始:
# grab the default options for dlib's shape predictor
print("[INFO] setting shape predictor options...")
options = dlib.shape_predictor_training_options()
在那里,我们将配置tree_depth选项:
# define the depth of each regression tree -- there will be a total
# of 2^tree_depth leaves in each tree; small values of tree_depth
# will be *faster* but *less accurate* while larger values will
# generate trees that are *deeper*, *more accurate*, but will run
# *far slower* when making predictions
options.tree_depth = 4
这里我们定义了tree_depth,顾名思义,它控制回归树集合(ERTs)中每个回归树的深度。每棵树上都有2^tree_depth片叶子——你必须小心平衡深度和速度。
更小的值tree_depth将导致更浅的树,其更快,但是潜在地更不准确。更大的值tree_depth将创建更深的树,这些树更慢,但潜在地更准确。
tree_depth的典型值在范围 [2,8]内。
我们要探索的下一个参数是nu,一个正则化参数:
# regularization parameter in the range [0, 1] that is used to help
# our model generalize -- values closer to 1 will make our model fit
# the training data better, but could cause overfitting; values closer
# to 0 will help our model generalize but will require us to have
# training data in the order of 1000s of data points
options.nu = 0.1
nu选项是一个浮点值(在范围 [0,1] 内),用作正则化参数来帮助我们的模型泛化。
更接近于1的值将使我们的模型更接近于训练数据,但是可能会导致过度拟合。更接近于 0的值将帮助我们的模型一般化;然而,泛化能力有一个警告—nu越接近 0,你就需要越多的训练数据。
通常,对于小的nu值,你需要 1000 个训练样本。
我们的下一个参数是cascade_depth:
# the number of cascades used to train the shape predictor -- this
# parameter has a *dramtic* impact on both the *accuracy* and *output
# size* of your model; the more cascades you have, the more accurate
# your model can potentially be, but also the *larger* the output size
options.cascade_depth = 15
一系列级联用于细化和调整来自专家审评组的初始预测—cascade_depth将对你的模型的准确性和输出文件大小产生巨大影响。
您允许的级联越多,您的模型将变得越大(但可能更准确)。你允许的层叠越少,你的模型就越小(但可能不太精确)。
卡泽米和沙利文论文中的下图展示了cascade_depth对面部标志对齐的影响:

Figure 7: The cascade_depth parameter has a significant impact on the accuracy of your custom dlib shape/landmark predictor model.
可以清楚地看到,层叠越深,面部标志对齐得越好。
通常情况下,您会希望根据所需的目标模型大小和精度,在【6,18】范围内探索cascade_depth值。
现在让我们继续讨论feature_pool_size:
# number of pixels used to generate features for the random trees at
# each cascade -- larger pixel values will make your shape predictor
# more accurate, but slower; use large values if speed is not a
# problem, otherwise smaller values for resource constrained/embedded
# devices
options.feature_pool_size = 400
feature_pool_size控制用于为每个级联中的随机树生成特征的像素数。
你包含的像素越多,你的模型运行的越慢(但是可能会更精确)。你考虑的像素越少,你的模型运行越快(但也可能不太准确)。
我在这里的建议是,如果推理速度是而不是所关心的,你应该为feature_pools_size使用较大的值。否则,您应该使用较小的值来加快预测速度(通常用于嵌入式/资源受限的设备)。
我们要设置的下一个参数是num_test_splits:
# selects best features at each cascade when training -- the larger
# this value is, the *longer* it will take to train but (potentially)
# the more *accurate* your model will be
options.num_test_splits = 50
num_test_splits参数对你的模型需要多长时间训练 ( 即训练/挂钟时间,不是推断速度)有着巨大的影响。
你考虑的越多,你就越有可能有一个准确的形状预测器——但是,再次重申,要小心这个参数,因为它可能会导致训练时间激增。
接下来让我们来看看oversampling_amount:
# controls amount of "jitter" (i.e., data augmentation) when training
# the shape predictor -- applies the supplied number of random
# deformations, thereby performing regularization and increasing the
# ability of our model to generalize
options.oversampling_amount = 5
oversampling_amount控制应用于我们训练数据的数据增加的数量。dlib 库导致数据扩充抖动,但它本质上和数据扩充的想法是一样的。
这里我们告诉 dlib 对每个输入图像应用总共5个随机变形。
您可以将oversampling_amount视为一个正则化参数,因为它可能降低训练精度,但增加测试精度,从而允许我们的模型更好地泛化。
典型的oversampling_amount值位于【0,50】范围内,其中 0表示没有增加,50表示训练数据集中增加了 50 倍。
小心这个参数!更大的oversampling_amount值可能看起来是个好主意,但是它们会显著增加你的训练时间。
接下来是oversampling_translation_jitter选项:
# amount of translation jitter to apply -- the dlib docs recommend
# values in the range [0, 0.5]
options.oversampling_translation_jitter = 0.1
oversampling_translation_jitter控制应用于我们的训练数据集的翻译增强量。
平移抖动的典型值在范围 [0,0.5]内。
be_verbose选项简单地指示 dlib 在我们的形状预测器训练时打印出状态信息:
# tell the dlib shape predictor to be verbose and print out status
# messages our model trains
options.be_verbose = True
最后,我们有了num_threads参数:
# number of threads/CPU cores to be used when training -- we default
# this value to the number of available cores on the system, but you
# can supply an integer value here if you would like
options.num_threads = multiprocessing.cpu_count()
这个参数 极其重要 因为它可以 显著地 加快训练你的模型所需要的时间!
向 dlib 提供的 CPU 线程/内核越多,模型的训练速度就越快。我们将把这个值默认为系统中 CPU 的总数;但是,您可以将该值设置为任意整数(前提是它小于或等于系统中 CPU 的数量)。
既然我们的options已经设置好了,最后一步就是简单地调用train_shape_predictor:
# log our training options to the terminal
print("[INFO] shape predictor options:")
print(options)
# train the shape predictor
print("[INFO] training shape predictor...")
dlib.train_shape_predictor(args["training"], args["model"], options)
dlib 库接受(1)我们的训练 XML 文件的路径,(2)我们的输出形状预测器模型的路径,以及(3)我们的选项集。
一旦定型,形状预测器将被序列化到磁盘上,这样我们以后就可以使用它了。
虽然这个脚本看起来特别简单,但是一定要花时间配置您的选项/超参数以获得最佳性能。
定型自定义 dlib 形状预测器
我们现在准备训练我们的自定义 dlib 形状预测器!
确保您已经(1)下载了 iBUG-300W 数据集,并且(2)使用了本教程的 “下载” 部分来下载这篇文章的源代码。
完成后,您就可以训练形状预测器了:
$ python train_shape_predictor.py \
--training ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml \
--model eye_predictor.dat
[INFO] setting shape predictor options...
[INFO] shape predictor options:
shape_predictor_training_options(be_verbose=1, cascade_depth=15, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1, oversampling_amount=5, oversampling_translation_jitter=0.1, feature_pool_size=400, lambda_param=0.1, num_test_splits=50, feature_pool_region_padding=0, random_seed=, num_threads=20, landmark_relative_padding_mode=1)
[INFO] training shape predictor...
Training with cascade depth: 15
Training with tree depth: 4
Training with 500 trees per cascade level.
Training with nu: 0.1
Training with random seed:
Training with oversampling amount: 5
Training with oversampling translation jitter: 0.1
Training with landmark_relative_padding_mode: 1
Training with feature pool size: 400
Training with feature pool region padding: 0
Training with 20 threads.
Training with lambda_param: 0.1
Training with 50 split tests.
Fitting trees...
Training complete
Training complete, saved predictor to file eye_predictor.dat
整个训练过程在我的 3 GHz 英特尔至强 W 处理器上花费了 9m11s 。
要验证您的形状预测器是否已序列化到磁盘,请确保已在您的目录结构中创建了eye_predictor.dat:
$ ls -lh *.dat
-rw-r--r--@ 1 adrian staff 18M Dec 4 17:15 eye_predictor.dat
正如你所看到的,输出模型只有18MB——与 dlib 的标准/默认面部标志预测器 99.7MB 相比,文件大小减少了很多!
实现我们的形状预测评估脚本
现在我们已经训练了 dlib 形状预测器,我们需要评估它在训练集和测试集上的性能,以验证它没有过度拟合,并且我们的结果将(理想地)推广到训练集之外的我们自己的图像。
打开evaluate_shape_predictor.py文件并插入以下代码:
# import the necessary packages
import argparse
import dlib
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--predictor", required=True,
help="path to trained dlib shape predictor model")
ap.add_argument("-x", "--xml", required=True,
help="path to input training/testing XML file")
args = vars(ap.parse_args())
# compute the error over the supplied data split and display it to
# our screen
print("[INFO] evaluating shape predictor...")
error = dlib.test_shape_predictor(args["xml"], args["predictor"])
print("[INFO] error: {}".format(error))
第 2 行和第 3 行表示我们需要argparse和dlib来评估我们的形状预测器。
我们的命令行参数包括:
--predictor:我们通过前面两个“训练”部分生成的序列化形状预测器模型的路径。--xml:输入训练/测试 XML 文件的路径(即我们的只看解析的 XML 文件)。
当这两个参数都通过命令行提供时,dlib 将处理求值(行 16 )。Dlib 处理在 预测的 标志坐标和 地面实况 标志坐标之间的平均误差(MAE)的计算。
越小越美,越好越预言。**
形状预测精度结果
如果你还没有,使用本教程的 “下载” 部分下载源代码和预训练的形状预测器。
从那里,执行下面的命令来评估我们在训练集上的眼睛界标预测器:
$ python evaluate_shape_predictor.py --predictor eye_predictor.dat \
--xml ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml
[INFO] evaluating shape predictor...
[INFO] error: 3.631152776257545
这里我们得到了大约 3.63 的 MAE。
现在让我们在我们的测试集上运行相同的命令:
$ python evaluate_shape_predictor.py --predictor eye_predictor.dat \
--xml ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test_eyes.xml
[INFO] evaluating shape predictor...
[INFO] error: 7.568211111799696
正如你所看到的, MAE 在我们的测试集上比在我们的训练集上大两倍。
如果你以前有过使用机器学习或深度学习算法的经验,你会知道在大多数情况下,你的训练损失会低于测试损失。这并不意味着您的模型表现很差,相反,这只是意味着您的模型在模拟训练数据和测试数据方面做得更好。
形状预测器的评估特别有趣,因为需要检查的不仅仅是 MAE!
你还需要视觉验证结果和验证形状预测器是否按预期工作——我们将在下一节讨论这个主题。
实现形状预测器推理脚本
现在我们已经训练好了形状预测器,我们需要通过将它应用到我们自己的示例图像/视频中来直观地验证结果看起来不错。
在本节中,我们将:
- 从磁盘加载我们训练过的 dlib 形状预测器。
- 访问我们的视频流。
- 将形状预测应用于每个单独的帧。
- 验证结果看起来不错。
让我们开始吧。
打开predict_eyes.py并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from imutils import face_utils
import argparse
import imutils
import time
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
args = vars(ap.parse_args())
2-8 线导入必要的包。特别是,我们将在这个脚本中使用imutils和 OpenCV ( cv2)。我们的VideoStream类将允许我们访问我们的网络摄像头。face_utils模块包含一个助手函数,用于将 dlib 的地标预测转换为 NumPy 数组。
这个脚本唯一需要的命令行参数是我们训练过的面部标志预测器的路径,--shape-predictor。
让我们执行三个初始化:
# initialize dlib's face detector (HOG-based) and then load our
# trained shape predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# initialize the video stream and allow the cammera sensor to warmup
print("[INFO] camera sensor warming up...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
我们的初始化包括:
- 加载人脸
detector( 第 19 行)。检测器允许我们在定位面部标志之前在图像/视频中找到面部。我们将使用 dlib 的 HOG +线性 SVM 人脸检测器。或者,你可以使用 Haar cascades(非常适合资源受限的嵌入式设备)或更准确的深度学习人脸检测器。 - 加载面部标志
predictor( 第 20 行)。 - 初始化我们的网络视频流(第 24 行)。
现在我们准备好循环我们相机中的帧:
# loop over the frames from the video stream
while True:
# grab the frame from the video stream, resize it to have a
# maximum width of 400 pixels, and convert it to grayscale
frame = vs.read()
frame = imutils.resize(frame, width=400)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
第 31-33 行抓取一帧,调整大小,转换成灰度。
第 36 行使用 dlib 的 HOG +线性 SVM 算法进行人脸检测。
让我们通过预测和绘制面部标志:来处理帧中检测到的面部
# loop over the face detections
for rect in rects:
# convert the dlib rectangle into an OpenCV bounding box and
# draw a bounding box surrounding the face
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# use our custom dlib shape predictor to predict the location
# of our landmark coordinates, then convert the prediction to
# an easily parsable NumPy array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates from our dlib shape
# predictor model draw them on the image
for (sX, sY) in shape:
cv2.circle(frame, (sX, sY), 1, (0, 0, 255), -1)
第 39 行开始在检测到的人脸上循环。在循环内部,我们:
- 取 dlib 的
rectangle对象,转换成 OpenCV 的标准(x, y, w, h)包围盒排序(第 42 行)。 - 画出包围面部的边界框(线 43 )。
- 使用我们定制的 dlib 形状
predictor通过线 48 预测我们的地标(即眼睛)的位置。 - 将返回的坐标转换成一个 NumPy 数组(第 49 行)。
- 循环预测的地标坐标,并在输出帧上将它们分别绘制为小点(行 53 和 54 )。
如果你需要复习画矩形和实心圆,请参考我的 OpenCV 教程。
最后,我们将显示结果!
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
第 57 行向屏幕显示画面。
如果在我们处理视频流中的帧时按下了q键,我们将暂停并执行清理。
用我们的 dlib 形状预测器进行预测
您准备好观看我们的定制形状预测器了吗?
如果是这样,请确保使用本教程的 “下载” 部分下载源代码和预训练的 dlib shape predictor。
从那里,您可以执行以下命令:
$ python predict_eyes.py --shape-predictor eye_predictor.dat
[INFO] loading facial landmark predictor...
[INFO] camera sensor warming up...
如你所见,我们的形状预测器是:
- 在输入视频流中正确定位我的眼睛
- 实时运行
再一次,我想把你的注意力引回到本教程的“平衡形状预测器模型速度和准确性”部分— 我们的模型并没有预测面部可能的 68 个地标位置的全部!
相反,我们训练了一个定制的 dlib 形状预测器,只对的眼睛区域进行定位。(即,我们的模型没有在 iBUG-300W 数据集中的其他面部结构上进行训练,包括眉毛、鼻子、嘴和下颌线)。
我们定制的眼睛预测器可以用于我们不需要额外的面部结构,而只需要眼睛的情况,例如建立一个睡意检测器,为眼线/睫毛膏建立一个虚拟改造应用程序,或者创建计算机辅助软件来帮助残疾用户使用他们的计算机。
在下周的教程中,我将向你展示如何调整 dlib 的形状预测器的超参数,以获得最佳的 性能。
如何为形状预测器训练创建自己的数据集?
要创建自己的形状预测数据集,您需要使用 dlib 的 imglab 工具。关于如何为形状预测器训练创建和注释你自己的数据集超出了这篇博文的范围。我将在 PyImageSearch 的未来教程中介绍它。
摘要
在本教程中,您学习了如何训练您自己的自定义 dlib 形状/地标预测器。
为了训练我们的形状预测器,我们利用了 iBUG-300W 数据集,只是不是训练我们的模型来识别所有面部结构(即,眼睛、眉毛、鼻子、嘴和下颌线),而是训练模型来定位仅仅是眼睛。
最终结果是一个模型:
- 准确:我们的形状预测器可以准确预测/定位人脸上眼睛的位置。
- 小:我们的眼睛标志预测器比预训练的 dlib 面部标志预测器小(分别为 18MB 和 99.7MB)。
- 快速:我们的模型比 dlib 的预训练面部标志预测器更快,因为它预测的位置更少(模型的超参数也被选择来提高速度)。
在下周的教程中,我将教你如何系统地调整 dlib 的形状预测器训练程序的超参数,以平衡预测速度,模型大小和定位精度。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
在 PyTorch 训练 DCGAN
原文:https://pyimagesearch.com/2021/10/25/training-a-dcgan-in-pytorch/
在本教程中,我们将学习如何使用 PyTorch 生成图像来训练我们的第一个 DCGAN 模型。
本课是高级 PyTorch 技术 3 部分系列的第 1 部分:
- 在 PyTorch 中训练 DCGAN(今天的教程)
- 在 PyTorch 中从头开始训练物体探测器(下周课)
- U-Net:在 PyTorch 中训练图像分割模型(两周内)
到 2014 年,机器学习的世界已经取得了相当大的进步。几个新概念(如关注和 R-CNN)被引入。然而,机器学习的想法已经成型,因此它们都以某种方式被期待。
那是直到 Ian Goodfellow 等人写了一篇论文改变了机器学习的世界;生成性对抗网络。
深度卷积网络在图像领域取得成功后,没过多久,这个想法就和 GANs 融合在一起了。于是,DCGANs 诞生了。
学习如何使用 PyTorch 编写的 DCGAN 生成图像, 继续阅读。
在 PyTorch 中训练 DCGAN
教程的结构:
- gan 和 DCGANs 介绍
- 了解 DCGAN 架构
- PyTorch 实现和演练
- 关于下一步尝试什么的建议
生成性对抗网络
GANs 的突出因素是它们能够生成真实的图像,类似于您可能使用的数据分布。
GANs 的概念简单而巧妙。让我们用一个简单的例子来理解这个概念(图 1 )。
你最近报了一个艺术班,那里的艺术老师极其苛刻和严格。当你交第一幅画时,美术老师惊呆了。他威胁要把你开除,直到你能创作出一幅壮观的杰作。
不用说,你心烦意乱。这项任务非常困难,因为你还是个新手。唯一对你有利的是,你讨厌的艺术老师说,这幅杰作不必是他的收藏的直接复制品,但它必须看起来像是属于它们的。
你急切地开始改进你的作品。在接下来的几天里,你提交了几份试用版,每一份都比上一次好,但还不足以让你通过这次测试。
与此同时,你的美术老师也开始成为展示给他的画作的更好的评判者。只需一瞥,他就能说出你试图复制的艺术家和艺术品的名字。最后,清算日到了,你提交你的最终作品(图 2 )。
你画了一幅非常好的画,你的美术老师把它放在他的收藏中。他夸你,收你为全日制学生(但到了那个时候,你意识到你已经不需要他了)。
GAN 的工作原理也是如此。“你”是试图生成模拟给定输入数据集的图像的生成者。而“美术老师”是鉴别者,他的工作是判断您生成的图像是否可以与输入数据集进行分组。上述示例与 GAN 的唯一区别在于,发生器和鉴别器都是从零开始一起训练的。
这些网络相互提供反馈,当我们训练 GAN 模型时,两者都得到了改善,我们得到了更好的输出图像质量。
关于在 Keras 和 Tensorflow 中实现 GAN 模型的完整教程,我推荐 Adrian Rosebrock 的教程。
什么是 DCGANs?
拉德福德等人(2016) 发表了一篇关于深度卷积生成对抗网络(DCGANs)的论文。
当时的 DCGANs 向我们展示了如何在没有监督的情况下有效地使用 GANs 的卷积技术来创建与我们的数据集中的图像非常相似的图像。
在这篇文章中,我将解释 DCGANs 及其关键研究介绍,并带您在 MNIST 数据集上完成相同的 PyTorch 实现。顺便说一下,这真的很酷,因为论文的合著者之一是 Soumith Chintala,PyTorch 的核心创建者!
DCGANs 架构
让我们深入了解一下架构:
图 3 包含了 DCGAN 中使用的发生器的架构,如文中所示。
如图 3 所示,我们将一个随机噪声向量作为输入,并将一幅完整的图像作为输出。让我们看看图 4 中的鉴别器架构。
鉴别器充当正常的确定性模型,其工作是将输入图像分类为真或假。
该论文的作者创建了一个不同的部分,解释他们的方法和香草甘之间的差异。
- 普通 GAN 的池层由分数阶卷积(在发生器的情况下)和阶卷积(在鉴别器的情况下)代替。对于前者,我绝对推荐塞巴斯蒂安·拉什卡的这个视频教程。分数步长卷积是标准向上扩展的替代方案,允许模型学习自己的空间表示,而不是使用不可训练的确定性池图层。
- 与传统 GANs 的第二个最重要的区别是,它排除了完全连接的层,而支持更深层次的架构。
- 第三, Ioffe 和 Szegedy (2015) 强调了批量标准化的重要性,以确保更深网络中梯度的正确流动。
- 最后,拉德福德等人解释了 ReLU 和 leaky ReLU 在其架构中的使用,引用了有界函数的成功,以帮助更快地了解训练分布。
让我们看看这些因素是如何影响结果的!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── dcgan_mnist.py
├── output
│ ├── epoch_0002.png
│ ├── epoch_0004.png
│ ├── epoch_0006.png
│ ├── epoch_0008.png
│ ├── epoch_0010.png
│ ├── epoch_0012.png
│ ├── epoch_0014.png
│ ├── epoch_0016.png
│ ├── epoch_0018.png
│ └── epoch_0020.png
├── output.gif
└── pyimagesearch
├── dcgan.py
└── __init__.py
在pyimagesearch目录中,我们有两个文件:
dcgan.py:包含完整的 DCGAN 架构__init__.py:将pyimagesearch转换成 python 目录
在父目录中,我们有dcgan_mnist.py脚本,它将训练 DCGAN 并从中得出推论。
除此之外,我们还有output目录,它包含 DCGAN 生成器生成的图像的按时间顺序的可视化。最后,我们有output.gif,它包含转换成 gif 的可视化效果。
在 PyTorch 中实现 DCGAN
我们的第一个任务是跳转到pyimagesearch目录并打开dcgan.py脚本。该脚本将包含完整的 DCGAN 架构。
# import the necessary packages
from torch.nn import ConvTranspose2d
from torch.nn import BatchNorm2d
from torch.nn import Conv2d
from torch.nn import Linear
from torch.nn import LeakyReLU
from torch.nn import ReLU
from torch.nn import Tanh
from torch.nn import Sigmoid
from torch import flatten
from torch import nn
class Generator(nn.Module):
def __init__(self, inputDim=100, outputChannels=1):
super(Generator, self).__init__()
# first set of CONVT => RELU => BN
self.ct1 = ConvTranspose2d(in_channels=inputDim,
out_channels=128, kernel_size=4, stride=2, padding=0,
bias=False)
self.relu1 = ReLU()
self.batchNorm1 = BatchNorm2d(128)
# second set of CONVT => RELU => BN
self.ct2 = ConvTranspose2d(in_channels=128, out_channels=64,
kernel_size=3, stride=2, padding=1, bias=False)
self.relu2 = ReLU()
self.batchNorm2 = BatchNorm2d(64)
# last set of CONVT => RELU => BN
self.ct3 = ConvTranspose2d(in_channels=64, out_channels=32,
kernel_size=4, stride=2, padding=1, bias=False)
self.relu3 = ReLU()
self.batchNorm3 = BatchNorm2d(32)
# apply another upsample and transposed convolution, but
# this time output the TANH activation
self.ct4 = ConvTranspose2d(in_channels=32,
out_channels=outputChannels, kernel_size=4, stride=2,
padding=1, bias=False)
self.tanh = Tanh()
在这里,我们创建了生成器类(第 13 行)。在我们的__init__构造函数中,我们有 2 个重要的事情要记住(第 14 行):
inputDim:通过发生器的噪声矢量的输入大小。outputChannels:输出图像的通道数。因为我们使用的是 MNIST 数据集,所以图像将是灰度的。因此它只有一个频道。
由于 PyTorch 的卷积不需要高度和宽度规格,所以除了通道尺寸之外,我们不必指定输出尺寸。然而,由于我们使用的是 MNIST 数据,我们需要一个大小为1×28×28的输出。
记住,生成器将随机噪声建模成图像。记住这一点,我们的下一个任务是定义生成器的层。我们将使用CONVT(转置卷积)、ReLU(整流线性单元)、BN(批量归一化)(第 18-34 行)。最终的转置卷积之后是一个tanh激活函数,将我们的输出像素值绑定到1到-1 ( 行 38-41 )。
def forward(self, x):
# pass the input through our first set of CONVT => RELU => BN
# layers
x = self.ct1(x)
x = self.relu1(x)
x = self.batchNorm1(x)
# pass the output from previous layer through our second
# CONVT => RELU => BN layer set
x = self.ct2(x)
x = self.relu2(x)
x = self.batchNorm2(x)
# pass the output from previous layer through our last set
# of CONVT => RELU => BN layers
x = self.ct3(x)
x = self.relu3(x)
x = self.batchNorm3(x)
# pass the output from previous layer through CONVT2D => TANH
# layers to get our output
x = self.ct4(x)
output = self.tanh(x)
# return the output
return output
在生成器的forward通道中,我们使用了三次CONVT = >、ReLU = > BN图案,而最后的CONVT层之后是tanh层(行 46-65 )。
class Discriminator(nn.Module):
def __init__(self, depth, alpha=0.2):
super(Discriminator, self).__init__()
# first set of CONV => RELU layers
self.conv1 = Conv2d(in_channels=depth, out_channels=32,
kernel_size=4, stride=2, padding=1)
self.leakyRelu1 = LeakyReLU(alpha, inplace=True)
# second set of CONV => RELU layers
self.conv2 = Conv2d(in_channels=32, out_channels=64, kernel_size=4,
stride=2, padding=1)
self.leakyRelu2 = LeakyReLU(alpha, inplace=True)
# first (and only) set of FC => RELU layers
self.fc1 = Linear(in_features=3136, out_features=512)
self.leakyRelu3 = LeakyReLU(alpha, inplace=True)
# sigmoid layer outputting a single value
self.fc2 = Linear(in_features=512, out_features=1)
self.sigmoid = Sigmoid()
请记住,当生成器将随机噪声建模到图像中时,鉴别器获取图像并输出单个值(确定它是否属于输入分布)。
在鉴别器的构造函数__init__中,只有两个参数:
depth:决定输入图像的通道数alpha:给予架构中使用的泄漏 ReLU 函数的值
我们初始化一组卷积层、漏 ReLU 层、两个线性层,然后是最终的 sigmoid 层(行 75-90 )。这篇论文的作者提到,泄漏 ReLU 允许一些低于零的值的特性有助于鉴别器的结果。当然,最后的 sigmoid 层是将奇异输出值映射到 0 或 1。
def forward(self, x):
# pass the input through first set of CONV => RELU layers
x = self.conv1(x)
x = self.leakyRelu1(x)
# pass the output from the previous layer through our second
# set of CONV => RELU layers
x = self.conv2(x)
x = self.leakyRelu2(x)
# flatten the output from the previous layer and pass it
# through our first (and only) set of FC => RELU layers
x = flatten(x, 1)
x = self.fc1(x)
x = self.leakyRelu3(x)
# pass the output from the previous layer through our sigmoid
# layer outputting a single value
x = self.fc2(x)
output = self.sigmoid(x)
# return the output
return output
在鉴别器的forward通道中,我们首先添加一个卷积层和一个漏 ReLU 层,并再次重复该模式(第 94-100 行)。接下来是一个flatten层、一个全连接层和另一个泄漏 ReLU 层(线 104-106 )。在最终的 sigmoid 层之前,我们添加另一个完全连接的层(行 110 和 111 )。
至此,我们的 DCGAN 架构就完成了。
训练 DCGAN
dcgan_mnist.py不仅包含 DCGAN 的训练过程,还将充当我们的推理脚本。
# USAGE
# python dcgan_mnist.py --output output
# import the necessary packages
from pyimagesearch.dcgan import Generator
from pyimagesearch.dcgan import Discriminator
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torchvision import transforms
from sklearn.utils import shuffle
from imutils import build_montages
from torch.optim import Adam
from torch.nn import BCELoss
from torch import nn
import numpy as np
import argparse
import torch
import cv2
import os
# custom weights initialization called on generator and discriminator
def weights_init(model):
# get the class name
classname = model.__class__.__name__
# check if the classname contains the word "conv"
if classname.find("Conv") != -1:
# intialize the weights from normal distribution
nn.init.normal_(model.weight.data, 0.0, 0.02)
# otherwise, check if the name contains the word "BatcnNorm"
elif classname.find("BatchNorm") != -1:
# intialize the weights from normal distribution and set the
# bias to 0
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
在第 23-37 行上,我们定义了一个名为weights_init的函数。这里,我们根据遇到的层初始化自定义权重。稍后,在推断步骤中,我们将看到这改进了我们的训练损失值。
对于卷积层,我们将0.0和0.02作为该函数中的平均值和标准差。对于批量标准化图层,我们将偏差设置为0,并将1.0和0.02作为平均值和标准偏差值。这是论文作者提出的,并认为最适合理想的训练结果。
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-e", "--epochs", type=int, default=20,
help="# epochs to train for")
ap.add_argument("-b", "--batch-size", type=int, default=128,
help="batch size for training")
args = vars(ap.parse_args())
# store the epochs and batch size in convenience variables
NUM_EPOCHS = args["epochs"]
BATCH_SIZE = args["batch_size"]
在第 40-47 行上,我们构建了一个扩展的参数解析器来解析用户设置的参数并添加默认值。
我们继续将epochs和batch_size参数存储在适当命名的变量中(第 50 行和第 51 行)。
# set the device we will be using
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# define data transforms
dataTransforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))]
)
# load the MNIST dataset and stack the training and testing data
# points so we have additional training data
print("[INFO] loading MNIST dataset...")
trainData = MNIST(root="data", train=True, download=True,
transform=dataTransforms)
testData = MNIST(root="data", train=False, download=True,
transform=dataTransforms)
data = torch.utils.data.ConcatDataset((trainData, testData))
# initialize our dataloader
dataloader = DataLoader(data, shuffle=True,
batch_size=BATCH_SIZE)
由于 GAN 训练确实涉及更多的复杂性,如果有合适的 GPU 可用,我们将默认设备设置为cuda(Line 54)。
为了预处理我们的数据集,我们简单地在第 57-60 行的上定义了一个torchvision.transforms实例,在这里我们将数据集转换成张量并将其归一化。
PyTorch 托管了许多流行的数据集供即时使用。它省去了在本地系统中下载数据集的麻烦。因此,我们从先前从torchvision.datasets ( 第 65-69 行)导入的 MNIST 包中准备训练和测试数据集实例。MNIST 数据集是一个流行的数据集,包含总共 70,000 个手写数字。
在连接训练和测试数据集(第 69 行)之后,我们创建一个 PyTorch DataLoader实例来自动处理输入数据管道(第 72 行和第 73 行)。
# calculate steps per epoch
stepsPerEpoch = len(dataloader.dataset) // BATCH_SIZE
# build the generator, initialize it's weights, and flash it to the
# current device
print("[INFO] building generator...")
gen = Generator(inputDim=100, outputChannels=1)
gen.apply(weights_init)
gen.to(DEVICE)
# build the discriminator, initialize it's weights, and flash it to
# the current device
print("[INFO] building discriminator...")
disc = Discriminator(depth=1)
disc.apply(weights_init)
disc.to(DEVICE)
# initialize optimizer for both generator and discriminator
genOpt = Adam(gen.parameters(), lr=0.0002, betas=(0.5, 0.999),
weight_decay=0.0002 / NUM_EPOCHS)
discOpt = Adam(disc.parameters(), lr=0.0002, betas=(0.5, 0.999),
weight_decay=0.0002 / NUM_EPOCHS)
# initialize BCELoss function
criterion = BCELoss()
因为我们已经将BATCH_SIZE值提供给了DataLoader实例,所以我们在行 76 上计算每个时期的步数。
在第 81-83 行,我们初始化生成器,应用自定义权重初始化,并将其加载到我们当前的设备中。正如在dcgan.py中提到的,我们在初始化期间传递适当的参数。
类似地,在第 87-90 行,我们初始化鉴别器,应用自定义权重,并将其加载到我们当前的设备上。唯一传递的参数是depth(即输入图像通道)。
我们选择Adam作为生成器和鉴别器的优化器(第 88-96 行),传递
- 模型参数:标准程序,因为模型权重将在每个时期后更新。
- 学习率:控制模型自适应的超参数。
- β衰变变量:初始衰变率。
- 权重衰减值,通过历元数进行调整:一种正则化方法,增加一个小的惩罚来帮助模型更好地泛化。
最后,我们损失函数的二元交叉熵损失(第 99 行)。
# randomly generate some benchmark noise so we can consistently
# visualize how the generative modeling is learning
print("[INFO] starting training...")
benchmarkNoise = torch.randn(256, 100, 1, 1, device=DEVICE)
# define real and fake label values
realLabel = 1
fakeLabel = 0
# loop over the epochs
for epoch in range(NUM_EPOCHS):
# show epoch information and compute the number of batches per
# epoch
print("[INFO] starting epoch {} of {}...".format(epoch + 1,
NUM_EPOCHS))
# initialize current epoch loss for generator and discriminator
epochLossG = 0
epochLossD = 0
在线 104 上,我们使用torch.randn给发电机馈电,并在可视化发电机训练期间保持一致性。
对于鉴别器,真标签和假标签值被初始化(行 107 和 108 )。
随着必需品的离开,我们开始在行 111 上的历元上循环,并初始化逐历元发生器和鉴别器损耗(行 118 和 119 )。
for x in dataloader:
# zero out the discriminator gradients
disc.zero_grad()
# grab the images and send them to the device
images = x[0]
images = images.to(DEVICE)
# get the batch size and create a labels tensor
bs = images.size(0)
labels = torch.full((bs,), realLabel, dtype=torch.float,
device=DEVICE)
# forward pass through discriminator
output = disc(images).view(-1)
# calculate the loss on all-real batch
errorReal = criterion(output, labels)
# calculate gradients by performing a backward pass
errorReal.backward()
启动前,使用zero_grad ( 线 123 )冲洗电流梯度。
从DataLoader实例(第 121 行)中获取数据,我们首先倾向于鉴别器。我们将并发批次的所有图像发送至设备(第 126 和 127 行)。由于所有图像都来自数据集,因此它们被赋予了realLabel ( 第 131 和 132 行)。
在行 135 上,使用图像执行鉴别器的一次正向通过,并计算误差(行 138 )。
backward函数根据损失计算梯度(行 141 )。
# randomly generate noise for the generator to predict on
noise = torch.randn(bs, 100, 1, 1, device=DEVICE)
# generate a fake image batch using the generator
fake = gen(noise)
labels.fill_(fakeLabel)
# perform a forward pass through discriminator using fake
# batch data
output = disc(fake.detach()).view(-1)
errorFake = criterion(output, labels)
# calculate gradients by performing a backward pass
errorFake.backward()
# compute the error for discriminator and update it
errorD = errorReal + errorFake
discOpt.step()
现在,我们继续讨论发电机的输入。在线 144 上,基于发电机输入大小的随机噪声被产生并馈入发电机(线 147 )。
由于生成器生成的所有图像都是假的,我们用fakeLabel值(第 148 行)替换标签张量的值。
在行 152 和 153 上,伪图像被馈送到鉴别器,并且计算伪预测的误差。
假图像产生的误差随后被送入backward函数进行梯度计算(行 156 )。然后根据两组图像产生的总损失更新鉴别器(第 159 和 160 行)。
# set all generator gradients to zero
gen.zero_grad()
# update the labels as fake labels are real for the generator
# and perform a forward pass of fake data batch through the
# discriminator
labels.fill_(realLabel)
output = disc(fake).view(-1)
# calculate generator's loss based on output from
# discriminator and calculate gradients for generator
errorG = criterion(output, labels)
errorG.backward()
# update the generator
genOpt.step()
# add the current iteration loss of discriminator and
# generator
epochLossD += errorD
epochLossG += errorG
继续发电机的训练,首先使用zero_grad ( 线 163 )冲洗梯度。
现在在第 168-173 行,我们做了一件非常有趣的事情:由于生成器必须尝试生成尽可能真实的图像,我们用realLabel值填充实际标签,并根据鉴别器对生成器生成的图像给出的预测来计算损失。生成器必须让鉴别器猜测其生成的图像是真实的。因此,这一步非常重要。
接下来,我们计算梯度(行 174 )并更新生成器的权重(行 177 )。
最后,我们更新发生器和鉴别器的总损耗值(行 181 和 182 )。
# display training information to disk
print("[INFO] Generator Loss: {:.4f}, Discriminator Loss: {:.4f}".format(
epochLossG / stepsPerEpoch, epochLossD / stepsPerEpoch))
# check to see if we should visualize the output of the
# generator model on our benchmark data
if (epoch + 1) % 2 == 0:
# set the generator in evaluation phase, make predictions on
# the benchmark noise, scale it back to the range [0, 255],
# and generate the montage
gen.eval()
images = gen(benchmarkNoise)
images = images.detach().cpu().numpy().transpose((0, 2, 3, 1))
images = ((images * 127.5) + 127.5).astype("uint8")
images = np.repeat(images, 3, axis=-1)
vis = build_montages(images, (28, 28), (16, 16))[0]
# build the output path and write the visualization to disk
p = os.path.join(args["output"], "epoch_{}.png".format(
str(epoch + 1).zfill(4)))
cv2.imwrite(p, vis)
# set the generator to training mode
gen.train()
这段代码也将作为我们的训练可视化和推理片段。
对于某个纪元值,我们将生成器设置为评估模式(行 190-194 )。
使用之前初始化的benchmarkNoise,我们让生成器产生图像(行 195 和 196 )。然后首先对图像进行高度整形,并按比例放大到其原始像素值(第 196 和 197 行)。
使用一个名为build_montages的漂亮的imutils函数,我们显示每次调用期间生成的批处理图像(第 198 和 199 行)。build_montages函数接受以下参数:
- 形象
- 正在显示的每个图像的大小
- 将显示可视化效果的网格的大小
在行 202-207 上,我们定义了一个输出路径来保存可视化图像并将生成器设置回训练模式。
至此,我们完成了 DCGAN 培训!
DCGAN 训练结果和可视化
让我们看看 DCGAN 在损耗方面的划时代表现。
$ python dcgan_mnist.py --output output
[INFO] loading MNIST dataset...
[INFO] building generator...
[INFO] building discriminator...
[INFO] starting training...
[INFO] starting epoch 1 of 20...
[INFO] Generator Loss: 4.6538, Discriminator Loss: 0.3727
[INFO] starting epoch 2 of 20...
[INFO] Generator Loss: 1.5286, Discriminator Loss: 0.9514
[INFO] starting epoch 3 of 20...
[INFO] Generator Loss: 1.1312, Discriminator Loss: 1.1048
...
[INFO] Generator Loss: 1.0039, Discriminator Loss: 1.1748
[INFO] starting epoch 17 of 20...
[INFO] Generator Loss: 1.0216, Discriminator Loss: 1.1667
[INFO] starting epoch 18 of 20...
[INFO] Generator Loss: 1.0423, Discriminator Loss: 1.1521
[INFO] starting epoch 19 of 20...
[INFO] Generator Loss: 1.0604, Discriminator Loss: 1.1353
[INFO] starting epoch 20 of 20...
[INFO] Generator Loss: 1.0835, Discriminator Loss: 1.1242
现在,在没有初始化自定义权重的情况下重新进行整个训练过程后,我们注意到损失值相对较高。因此,我们可以得出结论自定义重量初始化确实有助于改善训练过程。
让我们看看我们的生成器在图 6-9 中的一些改进图像。
在图 6 中,我们可以看到,由于生成器刚刚开始训练,生成的图像几乎是胡言乱语。在图 7 中,我们可以看到随着图像慢慢成形,生成的图像略有改善。
在图 8 和 9 中,我们看到完整的图像正在形成,看起来就像是从 MNIST 数据集中提取出来的,这意味着我们的生成器学习得很好,最终生成了一些非常好的图像!
总结
GANs 为机器学习打开了一扇全新的大门。我们不断看到 GANs 产生的许多新概念和许多旧概念以 GANs 为基础被复制。这个简单而巧妙的概念足够强大,在各自的领域胜过大多数其他算法。
在训练图中,我们已经看到,到 20 世纪本身,我们的 DCGAN 变得足够强大,可以产生完整和可区分的图像。但是我鼓励您将您在这里学到的编码技巧用于各种其他任务和数据集,并亲自体验 GANs 的魔力。
通过本教程,我试图使用 MNIST 数据集解释 gan 和 DCGANs 的基本本质。我希望这篇教程能帮助你认识到甘是多么的伟大!
引用信息
Chakraborty,d .“在 PyTorch 训练一名 DCGAN”, PyImageSearch ,2021 年,https://PyImageSearch . com/2021/10/25/Training-a-DCGAN-in-py torch/
@article{Chakraborty_2021_Training_DCGAN,
author = {Devjyoti Chakraborty},
title = {Training a {DCGAN} in {PyTorch}},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/10/25/training-a-dcgan-in-pytorch/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
在 PyTorch 中从头开始训练对象检测器
原文:https://pyimagesearch.com/2021/11/01/training-an-object-detector-from-scratch-in-pytorch/
在本教程中,您将学习如何使用 PyTorch 从头开始训练自定义对象检测器。
本课是高级 PyTorch 技术 3 部分系列的第 2 部分:
- 在 PyTorch 训练一个 DCGAN(上周教程)
- 在 PyTorch 中从头开始训练一个物体探测器(今天的教程)
- U-Net:在 PyTorch 中训练图像分割模型(下周博文)
从童年开始,人工智能(AI)的想法就吸引了我(就像其他孩子一样)。但是,当然,我对人工智能的概念与它的实际情况有很大的不同,毫无疑问是由于流行文化。直到我少年时代的末期,我坚信 AI 不受抑制的成长会导致 T-800(终结者中的终结者)之类的东西。幸运的是,使用图 1 可以更好地解释实际场景:
不过,不要误会我的意思。机器学习可能是一堆矩阵和微积分结合在一起,但我们可以用一个词来最好地描述这些东西的数量:无限。
我一直感兴趣的一个这样的应用是对象检测。注入图像数据来获取标签是一回事,但是让我们的模型知道标签在哪里呢?那是完全不同的一场球赛,就像一些间谍电影一样。这正是我们今天要经历的!
在今天的教程中,我们将学习如何在 PyTorch 中从头开始训练我们自己的物体检测器。这个博客将帮助你:
- 理解物体检测背后的直觉
- 了解构建您自己的对象检测器的逐步方法
- 了解如何微调参数以获得理想的结果
要学习如何在 Pytorch 中从头开始训练物体检测器,继续阅读。
在 PyTorch 中从头开始训练物体检测器
在今天强大的深度学习算法存在之前,物体检测是一个历史上广泛研究的领域。从 20 世纪 90 年代末到 21 世纪 20 年代初,提出了许多新的想法,这些想法至今仍被用作深度学习算法的基准。不幸的是,在那个时候,研究人员没有太多的计算能力可供他们支配,所以大多数这些技术都依赖于大量的额外数学来减少计算时间。谢天谢地,我们不会面临这个问题。
我们的目标检测方法
我们先来了解一下物体检测背后的直觉。我们将要采用的方法非常类似于训练一个简单的分类器。分类器的权重不断变化,直到它为给定数据集输出正确的标签并减少损失。对于今天的任务,我们将做与完全相同的事情,除了我们的模型将输出 5 个值, 4 个是围绕我们对象的边界框的 坐标。第 5 个值是被检测对象的标签。注意图 2 中的架构。
主模型将分为两个子集:回归器和分类器。前者将输出边界框的起始和结束坐标,而后者将输出对象标签。由这些值产生的组合损耗将用于我们的反向传播。很简单的开始方式,不是吗?
当然,多年来,一些强大的算法接管了物体检测领域,如 R-CNN 和 YOLO 。但是我们的方法将作为一个合理的起点,让你的头脑围绕物体检测背后的基本思想!
配置您的开发环境
要遵循这个指南,首先需要在系统中安装 PyTorch。要访问 PyTorch 自己的视觉计算模型,您还需要在您的系统中安装 Torchvision。对于一些数组和存储操作,我们使用了numpy。我们也使用imutils包进行数据处理。对于我们的情节,我们将使用matplotlib。为了更好地跟踪我们的模型训练,我们将使用tqdm,最后,我们的系统中需要 OpenCV!
幸运的是,上面提到的所有包都是 pip-installable!
$ pip install opencv-contrib-python
$ pip install torch
$ pip install torchvision
$ pip install imutils
$ pip install matplotlib
$ pip install numpy
$ pip install tqdm
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── dataset.zip
├── output
│ ├── detector.pth
│ ├── le.pickle
│ ├── plots
│ │ └── training.png
│ └── test_paths.txt
├── predict.py
├── pyimagesearch
│ ├── bbox_regressor.py
│ ├── config.py
│ ├── custom_tensor_dataset.py
│ └── __init__.py
└── train.py
目录中的第一项是dataset.zip。这个 zip 文件包含完整的数据集(图像、标签和边界框)。在后面的章节中会有更多的介绍。
接下来,我们有了output目录。这个目录是我们所有保存的模型、结果和其他重要需求被转储的地方。
父目录中有两个脚本:
- 用于训练我们的目标探测器
predict.py:用于从我们的模型中进行推断,并查看运行中的对象检测器
最后,我们有最重要的目录,即pyimagesearch目录。它包含了 3 个非常重要的脚本。
bbox_regressor.py:容纳完整的物体检测器架构config.py:包含端到端训练和推理管道的配置custom_tensor_dataset.py:包含数据准备的自定义类
我们的项目目录审查到此结束。
配置物体检测的先决条件
我们的第一个任务是配置我们将在整个项目中使用的几个超参数。为此,让我们跳到pyimagesearch文件夹并打开config.py脚本。
# import the necessary packages
import torch
import os
# define the base path to the input dataset and then use it to derive
# the path to the input images and annotation CSV files
BASE_PATH = "dataset"
IMAGES_PATH = os.path.sep.join([BASE_PATH, "images"])
ANNOTS_PATH = os.path.sep.join([BASE_PATH, "annotations"])
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the output model, label encoder, plots output
# directory, and testing image paths
MODEL_PATH = os.path.sep.join([BASE_OUTPUT, "detector.pth"])
LE_PATH = os.path.sep.join([BASE_OUTPUT, "le.pickle"])
PLOTS_PATH = os.path.sep.join([BASE_OUTPUT, "plots"])
TEST_PATHS = os.path.sep.join([BASE_OUTPUT, "test_paths.txt"])
我们首先定义几个路径,我们稍后会用到它们。然后在第 7-12 行,我们为数据集(图像和注释)和输出定义路径。接下来,我们为我们的检测器和标签编码器创建单独的路径,然后是我们的绘图和测试图像的路径(第 16-19 行)。
# determine the current device and based on that set the pin memory
# flag
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
PIN_MEMORY = True if DEVICE == "cuda" else False
# specify ImageNet mean and standard deviation
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
# initialize our initial learning rate, number of epochs to train
# for, and the batch size
INIT_LR = 1e-4
NUM_EPOCHS = 20
BATCH_SIZE = 32
# specify the loss weights
LABELS = 1.0
BBOX = 1.0
由于我们正在训练一个对象检测器,建议在 GPU 上训练,而不是在 CPU 上,因为计算更复杂。因此,如果我们的系统中有兼容 CUDA 的 GPU,我们就将 PyTorch 设备设置为 CUDA(第 23 行和第 24 行)。
当然,我们将在数据集准备期间使用 PyTorch 变换。因此,我们指定平均值和标准偏差值(第 27 行和第 28 行)。这三个值分别代表通道方向、宽度方向和高度方向的平均值和标准偏差。最后,我们为我们的模型初始化超参数,如学习速率、时期、批量大小和损失权重(第 32-38 行)。
创建自定义对象检测数据处理器
让我们看看我们的数据目录。
!tree .
.
├── dataset
│ ├── annotations
│ └── images
│ ├── airplane
│ ├── face
│ └── motorcycle
数据集细分为两个文件夹:annotations(包含边界框起点和终点的 CSV 文件)和 images(进一步分为三个文件夹,每个文件夹代表我们今天将使用的类)。
因为我们将使用 PyTorch 自己的数据加载器,所以以数据加载器能够接受的方式预处理数据是很重要的。custom_tensor_dataset.py脚本将完全做到这一点。
# import the necessary packages
from torch.utils.data import Dataset
class CustomTensorDataset(Dataset):
# initialize the constructor
def __init__(self, tensors, transforms=None):
self.tensors = tensors
self.transforms = transforms
我们创建了一个定制类CustomTensorDataset,它继承自torch.utils.data.Dataset类(第 4 行)。这样,我们可以根据需要配置内部函数,同时保留torch.utils.data.Dataset类的核心属性。
在的第 6-8 行,构造函数__init__被创建。构造函数接受两个参数:
tensors:三个张量的元组,即图像、标签和边界框坐标。transforms:将用于处理图像的torchvision.transforms实例。
def __getitem__(self, index):
# grab the image, label, and its bounding box coordinates
image = self.tensors[0][index]
label = self.tensors[1][index]
bbox = self.tensors[2][index]
# transpose the image such that its channel dimension becomes
# the leading one
image = image.permute(2, 0, 1)
# check to see if we have any image transformations to apply
# and if so, apply them
if self.transforms:
image = self.transforms(image)
# return a tuple of the images, labels, and bounding
# box coordinates
return (image, label, bbox)
因为我们使用的是自定义类,所以我们将覆盖父类(Dataset)的方法。因此,根据我们的需要改变了__getitem__方法。但是,首先,tensor元组被解包到它的组成元素中(第 12-14 行)。
图像张量最初的形式是Height × Width × Channels。然而,所有 PyTorch 模型都需要他们的输入成为“通道优先”相应地,image.permute方法重新排列图像张量(行 18 )。
我们在第 22 行和第 23 行上为torchvision.transforms实例添加了一个检查。如果检查结果为true,图像将通过transform实例传递。此后,__getitem__方法返回图像、标签和边界框。
def __len__(self):
# return the size of the dataset
return self.tensors[0].size(0)
我们要覆盖的第二个方法是__len__方法。它返回图像数据集张量的大小(第 29-31 行)。这就结束了custom_tensor_dataset.py脚本。
构建异议检测架构
谈到这个项目需要的模型,我们需要记住两件事。首先,为了避免额外的麻烦和有效的特征提取,我们将使用一个预先训练的模型作为基础模型。其次,基础模型将被分成两部分;盒式回归器和标签分类器。这两者都是独立的模型实体。
要记住的第二件事是,只有盒子回归器和标签分类器具有可训练的权重。预训练模型的重量将保持不变,如图图 4 所示。
考虑到这一点,让我们进入bbox_regressor.py!
# import the necessary packages
from torch.nn import Dropout
from torch.nn import Identity
from torch.nn import Linear
from torch.nn import Module
from torch.nn import ReLU
from torch.nn import Sequential
from torch.nn import Sigmoid
class ObjectDetector(Module):
def __init__(self, baseModel, numClasses):
super(ObjectDetector, self).__init__()
# initialize the base model and the number of classes
self.baseModel = baseModel
self.numClasses = numClasses
对于定制模型ObjectDetector,我们将使用torch.nn.Module作为父类(第 10 行)。对于构造函数__init__,有两个外部参数;基本型号和标签数量(第 11-16 行)。
# build the regressor head for outputting the bounding box
# coordinates
self.regressor = Sequential(
Linear(baseModel.fc.in_features, 128),
ReLU(),
Linear(128, 64),
ReLU(),
Linear(64, 32),
ReLU(),
Linear(32, 4),
Sigmoid()
)
继续讨论回归变量,记住我们的最终目标是产生 4 个单独的值:起始 x 轴值,起始 y 轴值,结束 x 轴值,以及结束 y 轴值。第一个Linear层输入基本模型的全连接层,输出尺寸设置为 128 ( 行 21 )。
接下来是几个Linear和ReLU层(行 22-27 ),最后以输出 4 值的Linear层结束,接下来是Sigmoid层(行 28 )。
# build the classifier head to predict the class labels
self.classifier = Sequential(
Linear(baseModel.fc.in_features, 512),
ReLU(),
Dropout(),
Linear(512, 512),
ReLU(),
Dropout(),
Linear(512, self.numClasses)
)
# set the classifier of our base model to produce outputs
# from the last convolution block
self.baseModel.fc = Identity()
下一步是对象标签的分类器。在回归器中,我们获取基本模型完全连接层的特征尺寸,并将其插入第一个Linear层(第 33 行)。接着重复ReLU、Dropout和Linear层(行 34-40 )。Dropout层通常用于帮助扩展概化和防止过度拟合。
初始化的最后一步是将基本模型的全连接层变成一个Identity层,这意味着它将镜像其之前的卷积块产生的输出(第 44 行)。
def forward(self, x):
# pass the inputs through the base model and then obtain
# predictions from two different branches of the network
features = self.baseModel(x)
bboxes = self.regressor(features)
classLogits = self.classifier(features)
# return the outputs as a tuple
return (bboxes, classLogits)
接下来是forward步骤(第 46 行)。我们简单地将基本模型的输出通过回归器和分类器(第 49-51 行)。
这样,我们就完成了目标检测器的架构设计。
训练目标检测模型
在我们看到物体探测器工作之前,只剩下最后一步了。因此,让我们跳到train.py脚本并训练模型!
# USAGE
# python train.py
# import the necessary packages
from pyimagesearch.bbox_regressor import ObjectDetector
from pyimagesearch.custom_tensor_dataset import CustomTensorDataset
from pyimagesearch import config
from sklearn.preprocessing import LabelEncoder
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.nn import CrossEntropyLoss
from torch.nn import MSELoss
from torch.optim import Adam
from torchvision.models import resnet50
from sklearn.model_selection import train_test_split
from imutils import paths
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import pickle
import torch
import time
import cv2
import os
# initialize the list of data (images), class labels, target bounding
# box coordinates, and image paths
print("[INFO] loading dataset...")
data = []
labels = []
bboxes = []
imagePaths = []
导入必要的包后,我们为数据、标签、边界框和图像路径创建空列表(第 29-32 行)。
现在是进行一些数据预处理的时候了。
# loop over all CSV files in the annotations directory
for csvPath in paths.list_files(config.ANNOTS_PATH, validExts=(".csv")):
# load the contents of the current CSV annotations file
rows = open(csvPath).read().strip().split("\n")
# loop over the rows
for row in rows:
# break the row into the filename, bounding box coordinates,
# and class label
row = row.split(",")
(filename, startX, startY, endX, endY, label) = row
# derive the path to the input image, load the image (in
# OpenCV format), and grab its dimensions
imagePath = os.path.sep.join([config.IMAGES_PATH, label,
filename])
image = cv2.imread(imagePath)
(h, w) = image.shape[:2]
# scale the bounding box coordinates relative to the spatial
# dimensions of the input image
startX = float(startX) / w
startY = float(startY) / h
endX = float(endX) / w
endY = float(endY) / h
# load the image and preprocess it
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
# update our list of data, class labels, bounding boxes, and
# image paths
data.append(image)
labels.append(label)
bboxes.append((startX, startY, endX, endY))
imagePaths.append(imagePath)
在第 35 行的处,我们开始遍历目录中所有可用的 CSV。打开 CSV,然后我们开始遍历这些行来分割数据(第 37-44 行)。
在将行值分割成一组单独的值之后,我们首先挑选出图像路径(行 48 )。然后,我们使用 OpenCV 读取图像并获得其高度和宽度(第 50 行和第 51 行)。
然后使用高度和宽度值将边界框坐标缩放到0和1的范围内(第 55-58 行)。
接下来,我们加载图像并做一些轻微的预处理(第 61-63 行)。
然后用解包后的值更新空列表,并且随着每次迭代的进行重复该过程(行 67-70 )。
# convert the data, class labels, bounding boxes, and image paths to
# NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)
bboxes = np.array(bboxes, dtype="float32")
imagePaths = np.array(imagePaths)
# perform label encoding on the labels
le = LabelEncoder()
labels = le.fit_transform(labels)
为了更快地处理数据,列表被转换成numpy数组(第 74-77 行)。由于标签是字符串格式,我们使用 scikit-learn 的LabelEncoder 将它们转换成各自的索引(第 80 行和第 81 行)。
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
split = train_test_split(data, labels, bboxes, imagePaths,
test_size=0.20, random_state=42)
# unpack the data split
(trainImages, testImages) = split[:2]
(trainLabels, testLabels) = split[2:4]
(trainBBoxes, testBBoxes) = split[4:6]
(trainPaths, testPaths) = split[6:]
使用另一个方便的 scikit-learn 工具train_test_split,我们将数据分成训练集和测试集,保持一个80-20比率(第 85 行和第 86 行)。由于拆分将应用于传递给train_test_split函数的所有数组,我们可以使用简单的行切片将它们解包为元组(第 89-92 行)。
# convert NumPy arrays to PyTorch tensors
(trainImages, testImages) = torch.tensor(trainImages),\
torch.tensor(testImages)
(trainLabels, testLabels) = torch.tensor(trainLabels),\
torch.tensor(testLabels)
(trainBBoxes, testBBoxes) = torch.tensor(trainBBoxes),\
torch.tensor(testBBoxes)
# define normalization transforms
transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
解包的训练和测试数据、标签和边界框然后从 numpy 格式转换成 PyTorch 张量(第 95-100 行)。接下来,我们继续创建一个torchvision.transforms实例来轻松处理数据集(第 103-107 行)。这样,数据集也将使用config.py中定义的平均值和标准偏差值进行标准化。
# convert NumPy arrays to PyTorch datasets
trainDS = CustomTensorDataset((trainImages, trainLabels, trainBBoxes),
transforms=transforms)
testDS = CustomTensorDataset((testImages, testLabels, testBBoxes),
transforms=transforms)
print("[INFO] total training samples: {}...".format(len(trainDS)))
print("[INFO] total test samples: {}...".format(len(testDS)))
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // config.BATCH_SIZE
valSteps = len(testDS) // config.BATCH_SIZE
# create data loaders
trainLoader = DataLoader(trainDS, batch_size=config.BATCH_SIZE,
shuffle=True, num_workers=os.cpu_count(), pin_memory=config.PIN_MEMORY)
testLoader = DataLoader(testDS, batch_size=config.BATCH_SIZE,
num_workers=os.cpu_count(), pin_memory=config.PIN_MEMORY)
记住,在custom_tensor_dataset.py脚本中,我们创建了一个定制的Dataset类来满足我们的确切需求。截至目前,我们所需的实体只是张量。因此,为了将它们转换成 PyTorch DataLoader 接受的格式,我们创建了CustomTensorDataset类的训练和测试实例,将图像、标签和边界框作为参数传递(第 110-113 行)。
在行 118 和 119 上,使用数据集的长度和config.py中设置的批量值计算每个时期的步骤值。
最后,我们通过DataLoader传递CustomTensorDataset实例,并创建训练和测试数据加载器(第 122-125 行)。
# write the testing image paths to disk so that we can use then
# when evaluating/testing our object detector
print("[INFO] saving testing image paths...")
f = open(config.TEST_PATHS, "w")
f.write("\n".join(testPaths))
f.close()
# load the ResNet50 network
resnet = resnet50(pretrained=True)
# freeze all ResNet50 layers so they will *not* be updated during the
# training process
for param in resnet.parameters():
param.requires_grad = False
因为我们稍后将使用测试映像路径进行评估,所以它被写入磁盘(行 129-132 )。
对于我们架构中的基本模型,我们将使用一个预先训练好的 resnet50 ( Line 135 )。然而,如前所述,基本模型的重量将保持不变。因此,我们冻结了权重(第 139 和 140 行)。
# create our custom object detector model and flash it to the current
# device
objectDetector = ObjectDetector(resnet, len(le.classes_))
objectDetector = objectDetector.to(config.DEVICE)
# define our loss functions
classLossFunc = CrossEntropyLoss()
bboxLossFunc = MSELoss()
# initialize the optimizer, compile the model, and show the model
# summary
opt = Adam(objectDetector.parameters(), lr=config.INIT_LR)
print(objectDetector)
# initialize a dictionary to store training history
H = {"total_train_loss": [], "total_val_loss": [], "train_class_acc": [],
"val_class_acc": []}
模型先决条件完成后,我们创建我们的定制模型实例,并将其加载到当前设备中(第 144 行和第 145 行)。对于分类器损失,使用交叉熵损失,而对于箱式回归器,我们坚持均方误差损失(第 148 和 149 行)。在行 153 ,Adam被设置为目标探测器优化器。为了跟踪训练损失和其他度量,字典H在行 157 和 158 上被初始化。
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.NUM_EPOCHS)):
# set the model in training mode
objectDetector.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
对于训练速度评估,记录开始时间(行 162 )。循环多个时期,我们首先将对象检测器设置为训练模式(第 165 行,并初始化正确预测的损失和数量(第 168-174 行)。
# loop over the training set
for (images, labels, bboxes) in trainLoader:
# send the input to the device
(images, labels, bboxes) = (images.to(config.DEVICE),
labels.to(config.DEVICE), bboxes.to(config.DEVICE))
# perform a forward pass and calculate the training loss
predictions = objectDetector(images)
bboxLoss = bboxLossFunc(predictions[0], bboxes)
classLoss = classLossFunc(predictions[1], labels)
totalLoss = (config.BBOX * bboxLoss) + (config.LABELS * classLoss)
# zero out the gradients, perform the backpropagation step,
# and update the weights
opt.zero_grad()
totalLoss.backward()
opt.step()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += totalLoss
trainCorrect += (predictions[1].argmax(1) == labels).type(
torch.float).sum().item()
在列车数据加载器上循环,我们首先将图像、标签和边界框加载到正在使用的设备中(行 179 和 180 )。接下来,我们将图像插入我们的对象检测器,并存储预测结果( Line 183 )。最后,由于模型将给出两个预测(一个用于标签,一个用于边界框),我们将它们索引出来并分别计算这些损失(第 183-185 行)。
这两个损失的组合值将作为架构的总损失。我们将在config.py中定义的边界框损失和标签损失的各自损失权重乘以损失,并将它们相加(第 186 行)。
在 PyTorch 的自动梯度功能的帮助下,我们简单地重置梯度,计算由于产生的损失而产生的权重,并基于当前步骤的梯度更新参数(第 190-192 行)。重置梯度是很重要的,因为backward函数一直在累积梯度。因为我们只想要当前步骤的梯度,所以opt.zero_grad清除了先前的值。
在第行第 196-198 行,我们更新损失值并修正预测。
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
objectDetector.eval()
# loop over the validation set
for (images, labels, bboxes) in testLoader:
# send the input to the device
(images, labels, bboxes) = (images.to(config.DEVICE),
labels.to(config.DEVICE), bboxes.to(config.DEVICE))
# make the predictions and calculate the validation loss
predictions = objectDetector(images)
bboxLoss = bboxLossFunc(predictions[0], bboxes)
classLoss = classLossFunc(predictions[1], labels)
totalLoss = (config.BBOX * bboxLoss) + \
(config.LABELS * classLoss)
totalValLoss += totalLoss
# calculate the number of correct predictions
valCorrect += (predictions[1].argmax(1) == labels).type(
torch.float).sum().item()
转到模型评估,我们将首先关闭自动渐变并切换到对象检测器的评估模式(行 201-203 )。然后,循环测试数据,除了更新权重之外,我们将重复与训练中相同的过程(第 212-214 行)。
以与训练步骤相同的方式计算组合损失(行 215 和 216 )。因此,总损失值和正确预测被更新(第 217-221 行)。
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(testDS)
# update our training history
H["total_train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_class_acc"].append(trainCorrect)
H["total_val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_class_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.NUM_EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
在一个时期之后,在行 224 和 225 上计算平均分批训练和测试损失。我们还使用正确预测的数量来计算历元的训练和测试精度(行 228 和 229 )。
在计算之后,所有的值都记录在模型历史字典H ( 第 232-235 行)中,同时计算结束时间以查看训练花费了多长时间以及退出循环之后(第 243 行)。
# serialize the model to disk
print("[INFO] saving object detector model...")
torch.save(objectDetector, config.MODEL_PATH)
# serialize the label encoder to disk
print("[INFO] saving label encoder...")
f = open(config.LE_PATH, "wb")
f.write(pickle.dumps(le))
f.close()
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["total_train_loss"], label="total_train_loss")
plt.plot(H["total_val_loss"], label="total_val_loss")
plt.plot(H["train_class_acc"], label="train_class_acc")
plt.plot(H["val_class_acc"], label="val_class_acc")
plt.title("Total Training Loss and Classification Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
# save the training plot
plotPath = os.path.sep.join([config.PLOTS_PATH, "training.png"])
plt.savefig(plotPath)
因为我们将使用对象检测器进行推理,所以我们将它保存到磁盘中( Line 249 )。我们还保存了已创建的标签编码器,因此模式保持不变(第 253-255 行
为了评估模型训练,我们绘制了存储在模型历史字典H ( 第 258-271 行)中的所有指标。
模型训练到此结束。接下来,我们来看看物体探测器训练的有多好!
评估物体探测训练
由于模型的大部分重量保持不变,训练不会花很长时间。首先,让我们来看看一些训练时期。
[INFO] training the network...
0%| | 0/20 [00:00<?,
5%|▌ | 1/20 [00:16<05:08, 16.21s/it][INFO] EPOCH: 1/20
Train loss: 0.874699, Train accuracy: 0.7608
Val loss: 0.360270, Val accuracy: 0.9902
10%|█ | 2/20 [00:31<04:46, 15.89s/it][INFO] EPOCH: 2/20
Train loss: 0.186642, Train accuracy: 0.9834
Val loss: 0.052412, Val accuracy: 1.0000
15%|█▌ | 3/20 [00:47<04:28, 15.77s/it][INFO] EPOCH: 3/20
Train loss: 0.066982, Train accuracy: 0.9883
...
85%|████████▌ | 17/20 [04:27<00:47, 15.73s/it][INFO] EPOCH: 17/20
Train loss: 0.011934, Train accuracy: 0.9975
Val loss: 0.004053, Val accuracy: 1.0000
90%|█████████ | 18/20 [04:43<00:31, 15.67s/it][INFO] EPOCH: 18/20
Train loss: 0.009135, Train accuracy: 0.9975
Val loss: 0.003720, Val accuracy: 1.0000
95%|█████████▌| 19/20 [04:58<00:15, 15.66s/it][INFO] EPOCH: 19/20
Train loss: 0.009403, Train accuracy: 0.9982
Val loss: 0.003248, Val accuracy: 1.0000
100%|██████████| 20/20 [05:14<00:00, 15.73s/it][INFO] EPOCH: 20/20
Train loss: 0.006543, Train accuracy: 0.9994
Val loss: 0.003041, Val accuracy: 1.0000
[INFO] total time taken to train the model: 314.68s
我们看到,该模型在训练和验证时分别达到了惊人的精度 0.9994 和 1.0000 。让我们看看训练图上划时代的变化图 5 !
该模型在训练值和验证值方面都相当快地达到了饱和水平。现在是时候看看物体探测器的作用了!
从物体检测器得出推论
这个旅程的最后一步是predict.py脚本。这里,我们将逐个循环测试图像,并用我们的预测值绘制边界框。
# USAGE
# python predict.py --input datasimg/face/image_0131.jpg
# import the necessary packages
from pyimagesearch import config
from torchvision import transforms
import mimetypes
import argparse
import imutils
import pickle
import torch
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input image/text file of image paths")
args = vars(ap.parse_args())
argparse模块用于编写用户友好的命令行界面命令。在的第 15-18 行,我们构建了一个参数解析器来帮助用户选择测试图像。
# determine the input file type, but assume that we're working with
# single input image
filetype = mimetypes.guess_type(args["input"])[0]
imagePaths = [args["input"]]
# if the file type is a text file, then we need to process *multiple*
# images
if "text/plain" == filetype:
# load the image paths in our testing file
imagePaths = open(args["input"]).read().strip().split("\n")
我们按照参数解析的步骤来处理用户给出的任何类型的输入。在行 22 和 23 上,imagePaths变量被设置为处理单个输入图像,而在行 27-29 上,处理多个图像的事件。
# load our object detector, set it evaluation mode, and label
# encoder from disk
print("[INFO] loading object detector...")
model = torch.load(config.MODEL_PATH).to(config.DEVICE)
model.eval()
le = pickle.loads(open(config.LE_PATH, "rb").read())
# define normalization transforms
transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
使用train.py脚本训练的模型被调用进行评估(第 34 和 35 行)。类似地,使用前述脚本存储的标签编码器被加载(第 36 行)。因为我们需要再次处理数据,所以创建了另一个torchvision.transforms实例,其参数与训练中使用的参数相同。
# loop over the images that we'll be testing using our bounding box
# regression model
for imagePath in imagePaths:
# load the image, copy it, swap its colors channels, resize it, and
# bring its channel dimension forward
image = cv2.imread(imagePath)
orig = image.copy()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
image = image.transpose((2, 0, 1))
# convert image to PyTorch tensor, normalize it, flash it to the
# current device, and add a batch dimension
image = torch.from_numpy(image)
image = transforms(image).to(config.DEVICE)
image = image.unsqueeze(0)
循环测试图像,我们读取图像并对其进行一些预处理(第 50-54 行)。这样做是因为我们的图像需要再次插入对象检测器。
我们继续将图像转换成张量,对其应用torchvision.transforms实例,并为其添加批处理维度(第 58-60 行)。我们的测试图像现在可以插入到对象检测器中了。
# predict the bounding box of the object along with the class
# label
(boxPreds, labelPreds) = model(image)
(startX, startY, endX, endY) = boxPreds[0]
# determine the class label with the largest predicted
# probability
labelPreds = torch.nn.Softmax(dim=-1)(labelPreds)
i = labelPreds.argmax(dim=-1).cpu()
label = le.inverse_transform(i)[0]
首先,从模型中获得预测(行 64 )。我们继续从boxPreds变量(第 65 行)解包边界框值。
标签预测上的简单 softmax 函数将为我们提供对应于类的值的更好的图片。为此,我们在69 线上使用 PyTorch 自己的torch.nn.Softmax。用argmax隔离索引,我们将它插入标签编码器le,并使用inverse_transform(索引到值)来获得标签的名称(第 69-71 行)。
# resize the original image such that it fits on our screen, and
# grab its dimensions
orig = imutils.resize(orig, width=600)
(h, w) = orig.shape[:2]
# scale the predicted bounding box coordinates based on the image
# dimensions
startX = int(startX * w)
startY = int(startY * h)
endX = int(endX * w)
endY = int(endY * h)
# draw the predicted bounding box and class label on the image
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(orig, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (0, 255, 0), 2)
cv2.rectangle(orig, (startX, startY), (endX, endY),
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", orig)
cv2.waitKey(0)
在第 75 行,我们已经调整了原始图像的大小以适应我们的屏幕。然后存储尺寸调整后的图像的高度和宽度,以基于图像缩放预测的边界框值(第 76-83 行)。之所以这样做,是因为我们在将注释与模型匹配之前,已经将它们缩小到了范围0和1。因此,出于显示目的,所有输出都必须放大。
显示边界框时,标签名称也将显示在它的顶部。为此,我们为第 86 行的文本设置了 y 轴的值。使用 OpenCV 的putText函数,我们设置了显示在图像上的标签(第 87 行和第 88 行)。
最后,我们使用 OpenCV 的rectangle方法在图像上创建边界框(第 89 行和第 90 行)。因为我们有起始 x 轴、起始 y 轴、结束 x 轴和结束 y 轴的值,所以很容易从它们创建一个矩形。这个矩形将包围我们的对象。
我们的推理脚本到此结束。让我们看看结果吧!
动作中的物体检测
让我们看看我们的对象检测器的表现如何,使用来自每个类的一个图像。我们首先使用一个飞机的图像(图 6 ),然后是一个人脸下的图像(图 7 ),以及一个属于摩托车类的图像(图 8 )。
事实证明,我们的模型的精度值没有说谎。我们的模型不仅正确地猜出了标签,而且生成的包围盒也几乎是完美的!
有了如此精确的检测和结果,我们都可以认为我们的小项目是成功的,不是吗?
摘要
在写这个物体检测教程的时候,回想起来我意识到了几件事。
老实说,我从来不喜欢在我的项目中使用预先训练好的模型。它会觉得我的工作不再是我的工作了。显然,这被证明是一个愚蠢的想法,事实上我的第一个一次性人脸分类器说我和我最好的朋友是同一个人(相信我,我们看起来一点也不相似)。
我认为本教程是一个很好的例子,说明了当你有一个训练有素的特征提取器时会发生什么。我们不仅节省了时间,而且最终的结果也是辉煌的。以图 6 和图 8 为例。预测的边界框具有最小的误差。
当然,这并不意味着没有改进的空间。在图 7 中,图像有许多元素,但物体探测器已经设法捕捉到物体的大致区域。然而,它可以更紧凑。我们强烈建议您修改参数,看看您的结果是否更好!
也就是说,物体检测在当今世界中扮演着重要的角色。自动交通、人脸检测、无人驾驶汽车只是物体检测蓬勃发展的现实世界应用中的一部分。每年,算法都被设计得更快更紧凑。我们已经达到了一个阶段,算法可以同时检测视频场景中的所有对象!我希望这篇教程激起了你对揭示这个领域复杂性的好奇心。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
在自定义数据集上训练 YOLOv5 对象检测器
原文:https://pyimagesearch.com/2022/06/20/training-the-yolov5-object-detector-on-a-custom-dataset/
目录
在自定义数据集上训练 YOLOv5 物体检测器
在深度学习的帮助下,我们都知道计算机视觉领域在最近十年里激增。因此,许多流行的计算机视觉问题,如图像分类、对象检测和具有真实工业用例的分割,开始实现前所未有的准确性。从 2012 年开始,每年都会设定一个新的基准。今天,我们将从实用的角度来看物体检测。
对象检测具有各种最先进的架构,可以在现实世界的数据集上使用现成的架构,以合理的准确度检测对象。唯一的条件是测试数据集与预训练的检测器具有相同的类。
但是,您经常构建的应用程序可能有不同于预训练对象检测器类的对象。例如,数据集分布与训练数据集检测器的地方非常不同。在这种情况下,我们经常使用迁移学习的概念,其中我们使用预先训练的检测器,并在较新的数据集上对其进行微调。在今天的教程中,您将学习在自定义数据集上训练预训练的 YOLOv5 对象检测器,而无需编写太多代码。
我们将不深入 YOLOv5 物体探测器的理论细节;然而,你可以查看我们的介绍 YOLO 家族的博客帖子,在那里我们涵盖了一些相关的内容。
这是我们关于 YOLO 的 7 集系列的最后一课:
- YOLO 家族简介
- 了解一个实时物体检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的物体探测器(YOLOv2)
- 使用 COCO 评估器 平均精度(mAP)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
- 【yolov 4】
- 在自定义数据集上训练 YOLOv5 物体检测器 (今日教程)
要了解如何在自定义数据集 上训练 YOLOv5 物体检测器,只需继续阅读。
在自定义数据集上训练 YOLOv5 物体检测器
2020 年, Ultralytics 的创始人兼 CEO 格伦·约彻(Glenn Jocher)在 GitHub 上发布了其 YOLOv5 的开源实现。YOLOv5 提供了一系列在 MS COCO 数据集上预先训练的对象检测架构。
今天,YOLOv5 是官方最先进的模型之一,拥有巨大的支持,并且在生产中更容易使用。最好的部分是 YOLOv5 是在 PyTorch 中原生实现的,消除了 Darknet 框架的限制(基于 C 编程语言)。
从 YOLO 到 PyTorch 框架的巨大变化使得开发人员更容易修改架构并直接导出到许多部署环境中。别忘了,YOLOv5 是火炬中心展示区的官方最先进车型之一。
表 1 显示了 Volta 100 GPU 上 640×640 图像分辨率下 MS COCO 验证数据集上五个 YOLOv5 变体的性能(mAP)和速度(FPS)基准。所有五个模型都是在 MS COCO 训练数据集上训练的。型号性能指标评测从 YOLOv5n 开始按升序显示(即,具有最小型号尺寸的 nano 变体到最大型号 YOLOv5x)。
| | | | | 速度 | 速度 | 速度 | | |
| | 大小 | | | CPU b1 | V100 b1 | V100 b32 | 参数 | 一偏 |
| 型号 | 【像素】 | 0.5:0.95 | 0.5 | (ms) | (ms) | (ms) | 【米】 | @ 640(B) |
| 约洛夫 5n | 640
| 28.4 | 46.0 | 45
| 6.3 | 0.6 | 1.9 | 4.5 |
| 约洛夫 5s | 640
| 37.2 | 56.0 | 98
| 6.4 | 0.9
| 7.2 | 16.5 |
| yolov 5m
| 640
| 45.2 | 63.9 | 224
| 8.2 | 1.7 | 21.2 | 49
|
| 约洛夫 5l | 640
| 48.8 | 67.2 | 430
| 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640
| 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| 表 1:MS COCO 数据集上五个 YOLOv5 变种的性能和速度基准。
|
今天,我们将通过在自定义数据集上迁移学习来学习如何在 PyTorch 框架中利用 YOLOv5 的强大功能!
配置您的开发环境
为了遵循这个指南,您需要克隆 Ultralytics YOLOv5 存储库并从requirements.txt安装所有必需的包pip。
幸运的是,要运行 YOLOv5 培训,您只需在requirements.txt文件上进行 pip 安装,这意味着所有的库都可以通过 pip 安装!
$ git clone https://github.com/ultralytics/yolov5.git #clone repo
$ cd yolov5/
$ pip install -r requirements.txt #install dependencies
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
关于数据集
对于今天的实验,我们将在两个不同的数据集上训练 YOLOv5 模型,即 Udacity 自动驾驶汽车数据集和 Vehicles-OpenImages 数据集。
这些数据集是公开的,但我们从 Roboflow 下载它们,它提供了一个很好的平台,可以用计算机视觉领域的各种数据集来训练你的模型。更有趣的是,你可以下载多种格式的数据集,如 COCO JSON、YOLO Darknet TXT 和 YOLOv5 PyTorch。这节省了编写助手函数的时间,以便将基本事实注释转换成模型所需的格式。
YOLOv5 标签格式
因为我们将训练 YOLOv5 PyTorch 模型,所以我们将以 YOLOv5 格式下载数据集。YOLOv5 的基本事实注释格式非常简单(图 2中显示了一个例子),因此您可以自己编写一个脚本来完成这项工作。每个图像的每个边界框都有一个单行的text文件。例如,如果一个图像中有四个对象,text文件将有四行包含类标签和边界框坐标。每行的格式是
class_id center_x center_y width height
其中字段以空格分隔,坐标从0到1标准化。要从像素值转换为标准化的xywh,将 x &框的宽度除以图像的宽度,将 y &框的高度除以图像的高度。
车辆-OpenImages 数据集
该数据集仅包含用于对象检测的各种车辆类别的 627 幅图像,如汽车、公共汽车、救护车、摩托车和卡车。这些图像来源于开放图像开源计算机视觉数据集。该数据集受知识共享许可的保护,它允许你共享和改编数据集,甚至将其用于商业用途。
图 3 显示了来自数据集的一些样本图像,带有用绿色标注的地面实况边界框。
在 627 幅图像中有 1194 个感兴趣区域(对象),这意味着每幅图像至少有 1.9 个对象。基于图 4 中所示的启发,汽车类贡献了超过 50%的对象。相比之下,其余的类别:公共汽车、卡车、摩托车和救护车,相对于小汽车类别来说代表性不足。
Udacity 自动驾驶汽车数据集
请注意,我们不会在此数据集上训练 YOLOv5 模型。相反,我们为你们所有人确定了这个伟大的数据集作为练习,以便一旦你们从本教程中学习完,你们可以使用这个数据集来训练对象检测器。
这个数据集来源于原始的 Udacity 自动驾驶汽车数据集。不幸的是,原始数据集缺少数以千计的行人、骑车人、汽车和交通灯的标注。因此,Roboflow 设法重新标记了数据集,以纠正错误和遗漏。
图 5 显示了 Roboflow 标注的数据集和原始数据集中缺失的标签的一些例子。如果你使用过自动驾驶城市场景数据集,如 Cityscapes 、 ApolloScape 和 Berkeley DeepDrive ,你会发现这个数据集与那些数据集非常相似。
该数据集包含 11 个类别的 97,942 个标签和 15,000 幅图像。该数据集在 Roboflow 上以两种不同的方式提供:具有1920x1200(下载大小~3.1 GB)的图像和适合大多数人的具有512x512(下载大小~580 MB)的降采样版本。我们将使用下采样版本,因为它的尺寸更小,符合我们对网络的要求。
像前面的 Vehicles-OpenImages 数据集一样,这个数据集拥有最多属于car类的对象(超过总对象的 60%)。图 6 显示了 Udacity 自动驾驶汽车数据集中的类别分布:
选择型号
图 7 显示了五种 YOLOv5 变体,从为在移动和嵌入式设备上运行而构建的最小 YOLOv5 nano 模型开始,到另一端的 YOLOv5 XLarge。对于今天的实验,我们将利用基本模型 YOLOv5s,它提供了准确性和速度之间的良好平衡。
约洛夫 5 训练
**这一部分是今天教程的核心,我们将涵盖大部分内容,从
- 下载数据集
- 创建数据配置
- 培训 YOLOv5 模型
- 可视化 YOLOv5 模型工件
- 定量结果
- 冻结初始图层并微调剩余图层
- 结果
下载车辆-打开图像数据集
# Download the vehicles-open image dataset
!mkdir vehicles_open_image
%cd vehicles_open_image
!curl -L "https://public.roboflow.com/ds/2Tb6yXY8l8?key=Eg82WpxUEr" > vehicles.zip
!unzip vehicles.zip
!rm vehicles.zip
在的第 2 行和第 3 行,我们创建了vehicles_open_image目录,并将cd放入我们下载数据集的目录中。然后,在的第 4 行,我们使用curl命令,并将从获得的数据集 URL 传递到这里。最后,我们解压缩数据集并删除第 5 行和第 6 行上的 zip 文件。
让我们看看vehicles_open_image文件夹的内容:
$tree /content/vehicles_open_image -L 2
/content/vehicles_open_image
├── data.yaml
├── README.dataset.txt
├── README.roboflow.txt
├── test
│ ├── images
│ └── labels
├── train
│ ├── images
│ └── labels
└── valid
├── images
└── labels
9 directories, 3 files
父目录有三个文件,其中只有data.yaml是必需的,还有三个子目录:
data.yaml:有数据相关的配置,如列车和有效数据目录路径,数据集中的类总数,每个类的名称train:带有训练标签的训练图像valid:带注释的验证图像test:测试图像和标签。如果带有标签的测试数据可用,评估模型的性能就变得容易了。
配置设置
接下来,我们将编辑data.yaml文件,为train和valid图像设置path和绝对路径。
# Create configuration
import yaml
config = {'path': '/content/vehicles_open_image',
'train': '/content/vehicles_open_image/train',
'val': '/content/vehicles_open_image/valid',
'nc': 5,
'names': ['Ambulance', 'Bus', 'Car', 'Motorcycle', 'Truck']}
with open("data.yaml", "w") as file:
yaml.dump(config, file, default_flow_style=False)
在行 2 上,我们导入yaml模块,这将允许我们以.yaml格式保存data.yaml配置文件。然后从第 3-7 行开始,我们在一个config变量中定义数据路径、训练、验证、类的数量和类名。所以config是一本字典。
最后,在的第 9 行和第 10 行,我们打开与数据集一起下载的现有data.yaml文件,用config中的内容覆盖它,并将其存储在磁盘上。
【yolo V5】训练超参数和模型配置
YOLOv5 有大约 30 个用于各种训练设置的超参数。这些在hyp.scratch-low.yaml中定义,用于从零开始的低增强 COCO 训练,放置在/data目录中。训练数据超参数如下所示,它们对于产生良好的结果非常重要,因此在开始训练之前,请确保正确初始化这些值。对于本教程,我们将简单地使用默认值,这些值是为 YOLOv5 COCO 培训从头开始优化的。
如您所见,它有learning rate、weight_decay和iou_t (IoU 训练阈值),以及一些数据增强超参数,如translate、scale、mosaic、mixup和copy_paste。mixup:0.0表示不应应用混合数据增强。
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
接下来,您可以简单地查看一下YOLOv5s网络架构的结构,尽管您几乎不会修改模型配置文件,这与训练数据超参数不同。对于 COCO 女士数据集,它将nc设置为80,将backbone设置为特征提取,然后将head设置为检测。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
训练约洛夫 5s 模型
我们几乎已经准备好训练 YOLOv5 模型了,正如上面讨论的,我们将训练 YOLOv5s 模型。但是,在我们运行培训之前,让我们定义几个参数:
SIZE = 640
BATCH_SIZE = 32
EPOCHS = 20
MODEL = "yolov5s"
WORKERS = 1
PROJECT = "vehicles_open_image_pyimagesearch"
RUN_NAME = f"{MODEL}_size{SIZE}_epochs{EPOCHS}_batch{BATCH_SIZE}_small"
我们定义了几个标准模型参数:
SIZE:训练时的图像尺寸或网络输入。图像在被传送到网络之前将被调整到这个值。预处理管道会将它们的大小调整为640像素。BATCH_SIZE:作为单个批次送入网络进行正向传送的图像数量。可以根据可用的 GPU 内存进行修改。我们已经将其设置为32。EPOCHS:我们想要在完整数据集上训练模型的次数。MODEL:我们希望用于训练的基础模型。我们使用 YOLOv5 系列的小型型号yolov5s。WORKERS:要使用的最大数据加载器工作进程。PROJECT:这将在当前目录下创建一个项目目录(yolov5)。RUN_NAME:每次运行这个模型时,它都会在项目目录下创建一个子目录,其中会有很多关于模型的信息,比如权重、样本输入图像、一些验证预测输出、度量图等。
!python train.py --img {SIZE}\
--batch {BATCH_SIZE}\
--epochs {EPOCHS}\
--data ../vehicles_open_image/data.yaml\
--weights {MODEL}.pt\
--workers {WORKERS}\
--project {PROJECT}\
--name {RUN_NAME}\
--exist-ok
如果没有错误,培训将如下所示开始。日志表明 YOLOv5 模型将在特斯拉 T4 GPU 上使用 Torch 版进行训练;除此之外,它还显示了初始化的hyperparameters。
下载了yolov5s.pt权重,这意味着用 MS COCO 数据集训练的参数来初始化 YOLOv5s 模型。最后,我们可以看到两个纪元已经用一个mAP@0.5=0.237完成了。
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 ? v6.1-236-gdcf8073 Python-3.7.13 torch-1.11.0+cu113 CUDA:0 (Tesla T4, 15110MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 ? runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir parking_lot_pyimagesearch', view at http://localhost:6006/
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
100% 755k/755k [00:00<00:00, 18.0MB/s]
YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected.
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 125MB/s]
Overriding model.yaml nc=80 with nc=5
Logging results to parking_lot_pyimagesearch/yolov5s_size640_epochs20_batch32_simple
Starting training for 20 epochs...
Epoch gpu_mem box obj cls labels img_size
0/19 7.36G 0.09176 0.03736 0.04355 31 640: 100% 28/28 [00:28<00:00, 1.03s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:03<00:00, 1.04it/s]
all 250 454 0.352 0.293 0.185 0.089
Epoch gpu_mem box obj cls labels img_size
1/19 8.98G 0.06672 0.02769 0.03154 45 640: 100% 28/28 [00:25<00:00, 1.09it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:05<00:00, 1.45s/it]
all 250 454 0.271 0.347 0.237 0.0735
瞧啊。这样,您已经学会了在从 Roboflow 下载的自定义数据集上训练对象检测器。是不是很神奇?
更令人兴奋的是,YOLOv5 将模型工件记录在runs目录中,我们将在下一节中看到这一点。
培训完成后,您将看到类似于下图的输出:
Epoch gpu_mem box obj cls labels img_size
19/19 7.16G 0.02747 0.01736 0.004772 46 640: 100% 28/28 [01:03<00:00, 2.27s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:05<00:00, 1.42s/it]
all 250 454 0.713 0.574 0.606 0.416
20 epochs completed in 0.386 hours.
Optimizer stripped from runs/train/exp/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp/weights/best.pt, 14.5MB
Validating runs/train/exp/weights/best.pt...
Fusing layers...
Model summary: 213 layers, 7023610 parameters, 0 gradients, 15.8 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:08<00:00, 2.23s/it]
all 250 454 0.715 0.575 0.606 0.416
Ambulance 250 64 0.813 0.814 0.853 0.679
Bus 250 46 0.771 0.652 0.664 0.44
Car 250 238 0.653 0.496 0.518 0.354
Motorcycle 250 46 0.731 0.478 0.573 0.352
Truck 250 60 0.608 0.433 0.425 0.256
以上结果表明,YOLOv5s 模型在所有类中都实现了0.606@0.5 IoU 和0.416@0.5:0.95 IoU 的映射。它还指示类-明智的地图,并且该模型获得了救护车类的最佳分数(即0.853 mAP@0.5 IoU)。该模型花了23.16分钟在特斯拉 T4 或特斯拉 K80 上完成了20时代的培训。
可视化模型构件
现在我们已经完成了模型的训练,让我们看看在yolov5/vehicles_open_pyimagesearch_model目录中生成的结果。
默认情况下,所有训练结果都记录到yolov5/runs/train中,并为每次运行创建一个新的递增目录,如runs/train/exp、runs/train/exp1等。然而,在训练模型时,我们通过了PROJECT和RUN_NAME,所以在这种情况下,它不会创建默认目录来记录训练结果。因此,在这个实验中runs是parking_lot_pyimagesearch。
接下来,让我们看看实验中创建的文件。
$tree parking_lot_pyimagesearch/yolov5s_size640_epochs20_batch32_small/
parking_lot_pyimagesearch/yolov5s_size640_epochs20_batch32_small/
├── confusion_matrix.png
├── events.out.tfevents.1652810418.f70b01be1223.864.0
├── F1_curve.png
├── hyp.yaml
├── labels_correlogram.jpg
├── labels.jpg
├── opt.yaml
├── P_curve.png
├── PR_curve.png
├── R_curve.png
├── results.csv
├── results.png
├── train_batch0.jpg
├── train_batch1.jpg
├── train_batch2.jpg
├── val_batch0_labels.jpg
├── val_batch0_pred.jpg
├── val_batch1_labels.jpg
├── val_batch1_pred.jpg
├── val_batch2_labels.jpg
├── val_batch2_pred.jpg
└── weights
├── best.pt
└── last.pt
1 directory, 23 files
在线 1 上,我们使用tree命令,后跟PROJECT和RUN_NAME,显示训练对象检测器的各种评估指标和权重文件。正如我们所看到的,它有一个精度曲线、召回曲线、精度-召回曲线、混淆矩阵、验证图像预测,以及 PyTorch 格式的权重文件。
现在让我们看一些来自runs目录的图片。
图 8 显示了具有镶嵌数据增强的训练图像批次。有 16 个图像聚集在一起;如果我们从第 3 行第 1 列中选择一个图像,那么我们可以看到该图像是四个不同图像的组合。我们在 YOLOv4 的文章中解释了镶嵌数据增强的概念,所以如果你还没有的话,一定要去看看。
接下来,我们看一下results.png,它包括边界框、对象和分类的训练和验证损失。它还具有用于训练的度量:精确度、召回率、mAP@0.5和mAP@0.5:0.95(图 9 )。
图 10 显示了 Vehicles-OpenImages 数据集上的地面实况图像和 YOLOv5s 模型预测。从下面的两张图片来看,很明显这个模型在检测物体方面做得很好。不幸的是,该模型在第二幅图像中没有检测到自行车,在第六幅图像中没有检测到汽车。在第一张图片中,把一辆卡车误归类为一辆汽车,但这是一个很难破解的问题,因为人类甚至很难正确预测它。但总的来说,它在这些图像上做得很好。


Figure 10: Ground-truth images (top) and YOLOv5s model prediction (bottom) fine-tuned with all layers.
冻结初始图层,微调剩余图层
我们学习了如何训练在 MS COCO 数据集上预先训练的对象检测器,这意味着我们微调了 Vehicles-OpenImages 数据集上的模型参数(所有层)。但问题是,我们需要在新的数据集上训练所有的模型层吗?也许不会,因为预训练模型已经在一个大型的、精确的 MS COCO 数据集上进行了训练。
在自定义数据集上经常微调模型时,冻结图层的好处是可以减少训练时间。如果自定义数据集不太复杂,那么即使不相同,也可以达到相当的精度。当我们比较这两个模型的训练时间时,你会自己看到。
在本节中,我们将再次在 Vehicles-OpenImages 数据集上训练或微调 YOLOv5s 模型,但冻结网络的初始11层,这与之前我们微调所有检测器层不同。感谢 YOLOv5 的创造者,冻结模型层非常容易。但是,首先,我们必须通过--freeze参数传递我们想要在模型中冻结的层数。
现在让我们通过执行train.py脚本来训练模型。首先我们把--name,也就是运行名改成freeze_layers,传递--freeze参数,其他参数都一样。
!python train.py --img {SIZE}\
--batch {BATCH_SIZE}\
--epochs {EPOCHS}\
--data ../vehicles_open_image/data.yaml\
--weights {MODEL}.pt\
--workers {WORKERS}\
--project {PROJECT}\
--name freeze_layers\
--exist-ok\
--freeze 0 1 2 3 4 5 6 7 8 9 10
运行培训脚本时会产生以下输出;如您所见,网络的前 11 层显示有一个freezing前缀,这意味着这些层的参数(权重和偏差)将保持不变。同时,剩余的 15 个图层将在自定义数据集上进行微调。
话虽如此,现在还是让我们来看看结果吧!
freezing model.0.conv.weight
freezing model.0.bn.weight
freezing model.0.bn.bias
freezing model.1.conv.weight
freezing model.1.bn.weight
freezing model.1.bn.bias
.
.
.
.
freezing model.10.conv.weight
freezing model.10.bn.weight
freezing model.10.bn.bias
我们可以从下面的输出中观察到,20个时期仅用了0.158个小时(即9.48分钟)就完成了,而我们在没有层冻结的情况下进行微调的模型用了23.16分钟。哇!这将时间缩短了近 2.5 倍。
但是等等,让我们来看看这个模型的映射,它是为所有类和类级显示的。
在冻结 11 层的情况下,模型实现了0.551 mAP@0.5 IoU 和0.336 mAP@0.5:0.95 IoU。这两个模型的精确度之间肯定有差异,但不太显著。
20 epochs completed in 0.158 hours.
Optimizer stripped from parking_lot_pyimagesearch/freeze_layers/weights/last.pt, 14.5MB
Optimizer stripped from parking_lot_pyimagesearch/freeze_layers/weights/best.pt, 14.5MB
Validating parking_lot_pyimagesearch/freeze_layers/weights/best.pt...
Fusing layers...
Model summary: 213 layers, 7023610 parameters, 0 gradients, 15.8 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:04<00:00, 1.25s/it]
all 250 454 0.579 0.585 0.551 0.336
Ambulance 250 64 0.587 0.688 0.629 0.476
Bus 250 46 0.527 0.696 0.553 0.304
Car 250 238 0.522 0.462 0.452 0.275
Motorcycle 250 46 0.733 0.478 0.587 0.311
Truck 250 60 0.527 0.6 0.533 0.313
最后,在图 11 中,我们可以在验证图像上看到探测器预测。结果清楚地表明,它们不如用所有层训练的检测器好。例如,它错过了第一幅图像中的对象,在第二幅图像中,它将一个motorcycle误归类为一个car,在第四幅图像中未能检测到car,甚至在第六幅图像中,它只看到了三个cars。也许多训练一点时间或者少冻结几层可以提高探测器的性能。
汇总
恭喜你走到这一步!让我们快速总结一下我们在本教程中学到的内容。
- 我们首先简要介绍了 YOLOv5,并讨论了 YOLOv5 变体的性能和速度基准。
- 然后我们讨论了两个数据集:Vehicles-OpenImages 数据集和 Udacity 自动驾驶汽车数据集。除此之外,我们还介绍了 YOLOv5 基本事实注释格式。
- 在最终确定 YOLOv5 模型变体用于训练之后,我们进入了本教程的实践部分,在这里我们讨论了一些方面,比如下载数据集、为给定数据创建
configuration.yaml,以及训练和可视化 YOLOv5 模型工件。 - 最后,我们第二次训练 YOLOv5 模型,但是模型的最初 11 层被冻结,并且将结果与完全训练的 YOLOv5 模型进行比较。
引用信息
Sharma,A. “在自定义数据集上训练 YOLOv5 对象检测器”, PyImageSearch ,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/fq0a3
@incollection{Sharma_2022_Custom_Dataset,
author = {Aditya Sharma},
title = {Training the {YOLOv5} Object Detector on a Custom Dataset},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/fq0a3},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
利用 Keras 和深度学习进行迁移学习
原文:https://pyimagesearch.com/2019/05/20/transfer-learning-with-keras-and-deep-learning/

在本教程中,您将学习如何使用 Keras、深度学习和 Python 在您自己的自定义数据集上执行迁移学习。
想象一下:
你刚刚被 Yelp 雇佣到他们的计算机视觉部门工作。
Yelp 刚刚在其网站上推出了一项新功能,允许评论者为他们的食物/菜肴拍照,然后将它们与餐厅菜单上的特定项目相关联。
这是一个很好的功能…
…但是他们收到了很多垃圾图片。
某些邪恶的用户没有给他们的菜肴拍照…相反,他们在给…(嗯,你大概可以猜到)拍照。
你的任务?
弄清楚如何创建一个自动化的计算机视觉应用程序,可以区分“食物”和“非食物”,从而允许 Yelp 继续推出他们的新功能,并为他们的用户提供价值。
那么,您将如何构建这样一个应用程序呢?
答案在于通过深度学习进行迁移学习。
今天标志着使用 Keras 进行 迁移学习的一套全新教程的开始。迁移学习是这样的过程:
- 在数据集上对网络进行预训练
- 并且利用它来识别它没有被训练过的图像/对象类别
从本质上讲,我们可以利用最先进的网络在具有挑战性的数据集(如 ImageNet 或 COCO)上学习到的强大、有鉴别能力的过滤器,然后应用这些网络来识别模型从未训练过的对象。
一般来说,在深度学习的背景下,有两种类型的迁移学习:
- 通过特征提取转移学习
- 通过微调转移学习
在执行特征提取时,我们将预训练的网络视为一个任意的特征提取器,允许输入图像向前传播,在预先指定的层停止,并将该层的输出作为我们的特征。
另一方面,微调要求我们通过移除之前的全连接层头,提供新的、刚初始化的层头,然后训练新的 FC 层来预测我们的输入类,从而更新模型架构本身。
我们将在 PyImageSearch 博客上讨论本系列的两种技术,但今天我们将重点讨论特征提取。
要了解如何使用 Keras 通过特征提取进行迁移学习,继续阅读!
利用 Keras 和深度学习进行迁移学习
2020-05-13 更新:此博文现已兼容 TensorFlow 2+!
注意:我将在本系列教程中介绍的许多迁移学习概念也出现在我的书《用 Python 进行计算机视觉的深度学习》中。在这本书里,我进行了更详细的讨论(包括更多我的技巧、建议和最佳实践)。*如果你想在阅读完本指南后了解更多关于迁移学习的细节,请务必看看我的书。*
在本教程的第一部分,我们将回顾迁移学习的两种方法:特征提取和微调。
然后,我将详细讨论如何通过特征提取进行迁移学习(本教程的主要焦点)。
从那里,我们将回顾 Food-5k 数据集,该数据集包含分为两类的 5000 张图像:“食物”和“非食物”。
在本教程中,我们将通过特征提取利用迁移学习来识别这两个类。
一旦我们很好地处理了数据集,我们将开始编码。
我们将回顾许多 Python 文件,每个文件完成一个特定的步骤,包括:
- 创建配置文件。
- 构建我们的数据集(即,将图像放入正确的目录结构中)。
- 使用 Keras 和预训练的 CNN 从我们的输入图像中提取特征。
- 在提取的特征之上训练逻辑回归模型。
我们今天将在这里复习的部分代码也将在迁移学习系列的剩余部分中使用——如果你打算跟随教程,现在花点时间来确保你理解代码。
两种迁移学习:特征提取和微调
![]()
Figure 1: Via “transfer learning”, we can utilize a pre-existing model such as one trained to classify dogs vs. cats. Using that pre-trained model we can break open the CNN and then apply “transfer learning” to another, completely different dataset (such as bears). We’ll learn how to apply transfer learning with Keras and deep learning in the rest of this blog post.
注:以下章节改编自我的书,用 Python 进行计算机视觉的深度学习。关于迁移学习的全套章节,请参考课文。
考虑一个传统的机器学习场景,其中我们面临两个分类挑战。
在第一个挑战中,我们的目标是训练一个卷积神经网络来识别图像中的狗和猫。
然后,在第二个项目中,我们的任务是识别三种不同的熊:灰熊、北极熊和大熊猫。
使用机器学习/深度学习中的标准实践,我们可以将这些挑战视为两个独立的问题:
- 首先,我们将收集足够的狗和猫的标记数据集,然后在数据集上训练模型
- 然后,我们将重复这个过程第二次,只是这一次,收集我们的熊品种的图像,然后在标记的数据集上训练一个模型。
迁移学习提出了一种不同的范式 — 如果我们可以利用现有的预训练分类器作为新分类、对象检测或实例分割任务的起点,会怎么样?
在上述挑战的背景下使用迁移学习,我们将:
- 首先训练一个卷积神经网络来识别狗和猫
- 然后,使用对狗和猫数据训练的相同的 CNN,并使用它来区分熊类,即使在初始训练期间没有熊数据与狗和猫数据混合
这听起来好得令人难以置信吗?
其实不是。
在 ImageNet 和 COCO 等大规模数据集上训练的深度神经网络已经被证明在迁移学习的任务上优秀。
这些网络学习一组丰富的、有辨别能力的特征,能够识别 100 到 1000 个对象类别——只有这些过滤器可以重复用于 CNN 最初训练以外的任务才有意义。
一般来说,当应用于计算机视觉的深度学习时,有两种类型的迁移学习:
- 将网络视为任意特征提取器。
- 移除现有网络的全连接层,在 CNN 上放置一组新的 FC 层,然后微调这些权重(以及可选的先前层)以识别新的对象类。
在这篇博文中,我们将主要关注迁移学习的第一种方法,将网络视为特征提取器。
我们将在本系列关于深度学习的迁移学习的后面讨论微调网络。
通过特征提取进行迁移学习
![]()
Figure 2: Left: The original VGG16 network architecture that outputs probabilities for each of the 1,000 ImageNet class labels. Right: Removing the FC layers from VGG16 and instead of returning the final POOL layer. This output will serve as our extracted features.
注:以下章节改编自我的书,用 Python 进行计算机视觉的深度学习。有关特征提取的完整章节,请参考正文。
通常,您会将卷积神经网络视为端到端图像分类器:
- 我们将图像输入网络。
- 图像通过网络向前传播。
- 我们在网络的末端获得最终的分类概率。
然而,没有“规则”说我们必须允许图像通过整个 T2 网络向前传播。
相反,我们可以:
- 在任意但预先指定的层(如激活层或池层)停止传播。
- 从指定图层中提取值。
- 将这些值视为特征向量。
例如,让我们考虑本节顶部的图 2 ( 左)中 Simonyan 和 Zisserman 的 VGG16 网络。
除了网络中的层,我还包括了每个层的输入和输出体积形状。
当将网络视为特征提取器时,我们本质上是在预先指定的层处“切断”网络(通常在完全连接的层之前,但这实际上取决于您的特定数据集)。
如果我们在 VGG16 的全连接层之前停止传播,网络中的最后一层将成为最大池层(图 2 ,右),其输出形状将为 7 x 7 x 512 。将该体积展平成特征向量,我们将获得一列 7 x 7 x 512 = 25,088 值— 该数字列表用作我们的特征向量,用于量化输入图像。
然后,我们可以对整个图像数据集重复这个过程。
给定我们网络中总共的 N 幅图像,我们的数据集现在将被表示为一列 N 个向量,每个向量有 25,088 维。
一旦我们有了我们的特征向量,我们就可以在这些特征的基础上训练现成的机器学习模型,如线性 SVM、逻辑回归、决策树或随机森林,以获得可以识别新类别图像的分类器。
也就是说,通过特征提取进行迁移学习的两种最常见的机器学习模型是:
- 逻辑回归
- 线性 SVM
为什么是那两种型号?
首先,记住我们的特征提取器是 CNN。
CNN 是能够学习非线性特征的非线性模型——我们假设 CNN 所学习的特征已经健壮且有辨别能力。
第二个原因,也可能是更重要的原因,是我们的特征向量往往非常大,而且维数很高。
因此,我们需要一个可以在特征之上训练的快速模型— 线性模型往往训练起来非常快。
例如,我们的 5000 幅图像的数据集,每幅图像由 25088 维的特征向量表示,可以在几秒钟内使用逻辑回归模型进行训练。
作为这一部分的总结,我希望你记住,CNN 本身是而不是能够识别这些新的阶级。
相反,我们使用 CNN 作为中间特征提取器。
下游机器学习分类器将负责学习从 CNN 提取的特征的潜在模式。
Foods-5K 数据集
![]()
Figure 3: We will apply transfer learning to the Foods-5K dataset using Python, Keras, and Deep Learning.
我们今天将在这里使用的数据集是由瑞士联邦理工学院的多媒体信号处理小组(MSPG) 策划的 Food-5K 数据集 。
顾名思义,该数据集由 5000 幅图像组成,分为两类:
- 食物
- 非食品
我们的目标是训练一个分类器,这样我们就可以区分这两个类。
MSPG 为我们提供了拆分前培训、验证和测试拆分。我们将在本指南中通过抽取进行迁移学习,并在其余的特征抽取教程中使用这些拆分。
下载 Food-5K 数据集
由于 不可靠 Food-5K 数据集下载方法最初发布在以下带密码的 FTP 站点:
- 主持人:treplin . epfl . ch
- 用户名: FoodImage@grebvm2.epfl.ch
- 密码: Cahc1moo
…我现在已经将数据集直接包含在这里:
项目结构
在继续之前,请继续:
- 找到这篇博文的 【下载】 部分,抓取代码。
- 使用上面的链接下载 Food-5K 数据集。
然后你会有两个。压缩文件。首先,提取transfer-learning-keras.zip。在里面,您会发现一个名为Food-5K/的空文件夹。第二,把Food-5K.zip文件放在那个文件夹里,然后解压。
完成这些步骤后,您将看到以下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── Food-5K
│ ├── evaluation [1000 entries]
│ ├── training [3000 entries]
│ ├── validation [1000 entries]
│ └── Food-5K.zip
├── dataset
├── output
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── build_dataset.py
├── extract_features.py
└── train.py
7 directories, 6 files
如你所见,Food-5K/包含了evaluation/、training/和validation/子目录(这些将出现在你提取Food-5K.zip的 之后的)。每个子目录包含 1000 个.jpg图像文件。
我们的dataset/目录虽然现在是空的,但很快就会以更有组织的形式包含 Food-5K 图像(将在章节“为特征提取构建数据集”中讨论)。
成功执行今天的 Python 脚本后,output/目录将存放我们提取的特征(存储在三个独立的.csv文件中)以及我们的标签编码器和模型(两者都是.cpickle格式)。这些文件有意不包含在中。zip 您必须按照本教程来创建它们。
我们的 Python 脚本包括:
- 我们的定制配置文件将帮助我们管理数据集、类名和路径。它是直接用 Python 编写的,所以我们可以使用
os.path直接在脚本中构建特定于操作系统的格式化文件路径。 - 使用这个配置,这个脚本将在磁盘上创建一个有组织的数据集,使得从其中提取特征变得容易。
extract_features.py:迁移学习魔法从这里开始。这个 Python 脚本将使用预先训练的 CNN 来提取原始特征,并将结果存储在一个.csv文件中。标签编码器.cpickle文件也将通过该脚本输出。- 我们的训练脚本将在先前计算的特征之上训练一个逻辑回归模型。我们将评估生成的模型并将其保存为
.cpickle。
config.py和build_dataset.py脚本将在迁移学习系列的剩余部分重复使用,所以请务必密切关注它们!
我们的配置文件
让我们从查看配置文件开始。
打开pyimagesearch子模块中的config.py,插入以下代码:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = "Food-5K"
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = "dataset"
我们从单个导入开始。我们将在这个配置中使用os模块( Line 2 )来正确地连接路径。
ORIG_INPUT_DATASET是到原始输入数据集的路径(即,您下载和解压缩 Food-5K 数据集的位置)。
下一个路径BASE_PATH,将是我们的数据集被组织的地方(执行build_dataset.py的结果)。
注意:目录结构对于这篇文章来说不是特别有用,但是一旦我们开始微调,它将*放在系列文章的后面。同样,我认为以这种方式组织数据集是“最佳实践”,原因您将在本系列文章中看到。*
让我们指定更多数据集配置以及我们的类标签和批量大小:
# define the names of the training, testing, and validation
# directories
TRAIN = "training"
TEST = "evaluation"
VAL = "validation"
# initialize the list of class label names
CLASSES = ["non_food", "food"]
# set the batch size
BATCH_SIZE = 32
输出训练、评估和验证目录的路径在第 13-15 行中指定。
在第 18 行的上以列表形式指定了CLASSES。如前所述,我们将使用"food"和"non_food"图像。
在提取特征时,我们将把数据分成称为批次的小块。BATCH_SIZE指定在线 21 上。
最后,我们可以建立其余的路径:
# initialize the label encoder file path and the output directory to
# where the extracted features (in CSV file format) will be stored
LE_PATH = os.path.sep.join(["output", "le.cpickle"])
BASE_CSV_PATH = "output"
# set the path to the serialized model after training
MODEL_PATH = os.path.sep.join(["output", "model.cpickle"])
我们的标签编码器路径连接在第 25 行的上,其中连接路径的结果是 Linux/Mac 上的output/le.cpickle或 Windows 上的output\le.cpickle。
提取的特征将存在于BASE_CSV_PATH中指定路径的 CSV 文件中。
最后,我们在MODEL_PATH中组装导出模型文件的路径。
构建用于特征提取的数据集
在我们从输入图像集中提取特征之前,让我们花点时间在磁盘上组织我们的图像。
我更喜欢将磁盘上的数据集组织成以下格式:
dataset_name/class_label/example_of_class_label.jpg
维护此目录结构:
- 不仅在磁盘上组织我们的数据集…
- …但是也使我们能够利用 Keras 的
flow_from_directory函数,当我们在本系列教程的后面进行微调时。
由于 Food-5K 数据集还提供了预先提供的数据分割,我们最终的目录结构将具有以下形式:
dataset_name/split_name/class_label/example_of_class_label.jpg
现在让我们继续构建我们的数据集+目录结构。
打开build_dataset.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import shutil
import os
# loop over the data splits
for split in (config.TRAIN, config.TEST, config.VAL):
# grab all image paths in the current split
print("[INFO] processing '{} split'...".format(split))
p = os.path.sep.join([config.ORIG_INPUT_DATASET, split])
imagePaths = list(paths.list_images(p))
我们的包装是在2-5 线进口的。我们将在整个脚本中使用我们的config ( Line 2 )来调用我们的设置。其他三个导入——paths、shutil和os——将允许我们遍历目录、创建文件夹和复制文件。
在第 8 行,我们开始循环我们的培训、测试和验证部分。
第 11 行和第 12 行创建了一个所有imagePaths在 split 中的列表。
从这里开始,我们将继续遍历imagePaths:
# loop over the image paths
for imagePath in imagePaths:
# extract class label from the filename
filename = imagePath.split(os.path.sep)[-1]
label = config.CLASSES[int(filename.split("_")[0])]
# construct the path to the output directory
dirPath = os.path.sep.join([config.BASE_PATH, split, label])
# if the output directory does not exist, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
# construct the path to the output image file and copy it
p = os.path.sep.join([dirPath, filename])
shutil.copy2(imagePath, p)
对于分割中的每个imagePath,我们继续:
- 从文件名中提取类
label(第 17 行和第 18 行)。 - 根据
BASE_PATH、split和label( 第 21 行)构建输出目录的路径。 - 通过线 24 和 25 创建
dirPath(如有必要)。 - 将图像复制到目标路径(第 28 行和第 29 行)。
既然build_dataset.py已经被编码,使用教程的 “下载” 部分下载源代码的档案。
然后,您可以使用以下命令执行build_dataset.py:
$ python build_dataset.py
[INFO] processing 'training split'...
[INFO] processing 'evaluation split'...
[INFO] processing 'validation split'...
在这里,您可以看到我们的脚本成功执行。
要验证磁盘上的目录结构,请使用ls命令:
$ ls dataset/
evaluation training validation
在数据集目录中,我们有培训、评估和验证部分。
在每个目录中,我们都有类别标签目录:
$ ls dataset/training/
food non_food
使用 Keras 和预训练的 CNN 从我们的数据集中提取特征
让我们转到迁移学习的实际特征提取部分。
使用预先训练的 CNN 进行特征提取的所有代码将存在于extract_features.py中—打开该文件并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.applications import VGG16
from tensorflow.keras.applications.vgg16 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from pyimagesearch import config
from imutils import paths
import numpy as np
import pickle
import random
import os
# load the VGG16 network and initialize the label encoder
print("[INFO] loading network...")
model = VGG16(weights="imagenet", include_top=False)
le = None
在第 2-12 行,提取特征所需的所有包都被导入。最值得注意的是这包括VGG16。
VGG16 是我们用来进行迁移学习的卷积神经网络(CNN)(第 3 行)。
在第 16 行的上,我们加载model,同时指定两个参数:
weights="imagenet":加载预训练的 ImageNet 权重用于迁移学习。include_top=False:我们不包括 softmax 分类器的全连接头部。换句话说,我们砍掉了网络的头。
随着重量的拨入和无头部模型的加载,我们现在准备好进行迁移学习了。我们将直接使用网络的输出值,将结果存储为特征向量。
最后,我们的标签编码器在行 17 被初始化。
让我们循环一下我们的数据分割:
# loop over the data splits
for split in (config.TRAIN, config.TEST, config.VAL):
# grab all image paths in the current split
print("[INFO] processing '{} split'...".format(split))
p = os.path.sep.join([config.BASE_PATH, split])
imagePaths = list(paths.list_images(p))
# randomly shuffle the image paths and then extract the class
# labels from the file paths
random.shuffle(imagePaths)
labels = [p.split(os.path.sep)[-2] for p in imagePaths]
# if the label encoder is None, create it
if le is None:
le = LabelEncoder()
le.fit(labels)
# open the output CSV file for writing
csvPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(split)])
csv = open(csvPath, "w")
每个split(训练、测试和验证)的循环从第 20 行开始。
首先,我们为split ( 第 23 行和第 24 行)抓取所有的imagePaths。
路径通过行 28 被随机打乱,从那里,我们的类labels被从路径本身中提取出来(行 29 )。
如果有必要,我们的标签编码器被实例化和安装(第 32-34 行),确保我们可以将字符串类标签转换为整数。
接下来,我们构建输出 CSV 文件的路径(第 37-39 行)。我们将有三个 CSV 文件—每个数据分割一个。每个 CSV 将有 N 个行数——数据分割中的每个图像一行。
下一步是循环遍历BATCH_SIZE块中的imagePaths:
# loop over the images in batches
for (b, i) in enumerate(range(0, len(imagePaths), config.BATCH_SIZE)):
# extract the batch of images and labels, then initialize the
# list of actual images that will be passed through the network
# for feature extraction
print("[INFO] processing batch {}/{}".format(b + 1,
int(np.ceil(len(imagePaths) / float(config.BATCH_SIZE)))))
batchPaths = imagePaths[i:i + config.BATCH_SIZE]
batchLabels = le.transform(labels[i:i + config.BATCH_SIZE])
batchImages = []
为了创建我们的批处理imagePaths,我们使用 Python 的range函数。该函数接受三个参数:start、stop和step。你可以在这篇详解中读到更多关于range的内容。
我们的批处理将遍历整个列表imagePaths。step是我们的批量大小(32,除非您在配置设置中调整它)。
在行 48 和 49 上,使用数组切片提取当前一批图像路径和标签。然后我们的batchImages列表在第 50 行被初始化。
现在让我们继续填充我们的batchImages:
# loop over the images and labels in the current batch
for imagePath in batchPaths:
# load the input image using the Keras helper utility
# while ensuring the image is resized to 224x224 pixels
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
# preprocess the image by (1) expanding the dimensions and
# (2) subtracting the mean RGB pixel intensity from the
# ImageNet dataset
image = np.expand_dims(image, axis=0)
image = preprocess_input(image)
# add the image to the batch
batchImages.append(image)
循环遍历batchPaths ( 第 53 行,我们将加载每个image,对其进行预处理,并将其聚集到batchImages。
image本身装载在线 56 上。
预处理包括:
- 通过行 56 上的
target_size参数调整到 224×224 像素。 - 转换成数组格式(第 57 行)。
- 添加批次尺寸(行 62 )。
- 均值减法(第 63 行)。
如果这些预处理步骤出现外来,请参考用 Python 进行计算机视觉的深度学习。
最后,通过线 66 将image添加到批次中。
现在,我们将通过我们的网络将该批图像传递给以提取特征:
# pass the images through the network and use the outputs as
# our actual features, then reshape the features into a
# flattened volume
batchImages = np.vstack(batchImages)
features = model.predict(batchImages, batch_size=config.BATCH_SIZE)
features = features.reshape((features.shape[0], 7 * 7 * 512))
我们的一批图像经由线 71 和 72 通过网络发送。
请记住,我们已经删除了网络的全连接层头。相反,正向传播在最大池层停止。我们将把 max-pooling 层的输出视为一个列表features,也称为“特征向量”。
最大池层的输出尺寸为 (batch_size,7 x 7 x 512) 。因此,我们可以将features转换成一个形状为(batch_size, 7 * 7 * 512)、、的 NumPy 数组,将 CNN 的输出视为一个特征向量。
让我们总结一下这个脚本:
# loop over the class labels and extracted features
for (label, vec) in zip(batchLabels, features):
# construct a row that exists of the class label and
# extracted features
vec = ",".join([str(v) for v in vec])
csv.write("{},{}\n".format(label, vec))
# close the CSV file
csv.close()
# serialize the label encoder to disk
f = open(config.LE_PATH, "wb")
f.write(pickle.dumps(le))
f.close()
为了保持我们的批处理效率,features和相关的类标签被写入我们的 CSV 文件(第 76-80 行)。
在 CSV 文件中,类label是每一行中的第一个字段(使我们能够在训练期间轻松地从该行中提取它)。特征vec如下。
每个 CSV 文件将通过行 83 关闭。回想一下,在完成后,我们将为每个数据分割创建一个 CSV 文件。
最后,我们可以将标签编码器转储到磁盘中(第 86-88 行)。
让我们使用在 ImageNet 上预先训练的 VGG16 网络从数据集中提取特征。
使用本教程的 “下载” 部分下载源代码,并从那里执行以下命令:
$ python extract_features.py
[INFO] loading network...
[INFO] processing 'training split'...
...
[INFO] processing batch 92/94
[INFO] processing batch 93/94
[INFO] processing batch 94/94
[INFO] processing 'evaluation split'...
...
[INFO] processing batch 30/32
[INFO] processing batch 31/32
[INFO] processing batch 32/32
[INFO] processing 'validation split'...
...
[INFO] processing batch 30/32
[INFO] processing batch 31/32
[INFO] processing batch 32/32
在 NVIDIA K80 GPU 上,从 Food-5K 数据集中的 5000 张图像中提取特征需要 2m55s。
你可以用 CPU 来代替,但是它会花费更多的时间。
实施我们的培训脚本
通过特征提取进行迁移学习的最后一步是实现一个 Python 脚本,该脚本将从 CNN 中提取特征,然后在这些特征的基础上训练一个逻辑回归模型。
再次提醒,请记住我们的 CNN 没有预测任何事情!相反,CNN 被视为一个任意的特征提取器。
我们向网络输入一幅图像,它被正向传播,然后我们从最大池层提取层输出——这些输出作为我们的特征向量。
要了解我们如何在这些特征向量上训练一个模型,打开train.py文件,让我们开始工作:
# import the necessary packages
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from pyimagesearch import config
import numpy as np
import pickle
import os
def load_data_split(splitPath):
# initialize the data and labels
data = []
labels = []
# loop over the rows in the data split file
for row in open(splitPath):
# extract the class label and features from the row
row = row.strip().split(",")
label = row[0]
features = np.array(row[1:], dtype="float")
# update the data and label lists
data.append(features)
labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data)
labels = np.array(labels)
# return a tuple of the data and labels
return (data, labels)
在2-7 行,我们导入我们需要的包。值得注意的是,我们将使用LogisticRegression作为我们的机器学习分类器。与提取特征相比,我们的训练脚本需要更少的导入。这部分是因为训练脚本本身实际上更简单。
让我们在第 9 行上定义一个名为load_data_split的函数。该函数负责加载给定数据分割 CSV 文件路径的所有数据和标签(参数splitPath)。
在函数内部,我们首先初始化我们的data和labels列表(第 11 行和第 12 行)。
从那里,我们打开 CSV,并从第 15 行的开始循环所有行。在循环中,我们:
- 将
row中所有逗号分隔的值加载到一个列表中(第 17 行)。 - 通过行 18 抓取类
label(列表中的第一个值)。 - 提取该行中的所有
features(行 19 )。这些都是列表中的值,除了类标签。结果就是我们的特征向量。 - 从那里,我们将特征向量和
label分别添加到data和labels列表中(第 22 和 23 行)。
最后,data和labels返回到调用函数(第 30 行)。
随着load_data_spit函数准备就绪,让我们通过加载我们的数据来让它工作:
# derive the paths to the training and testing CSV files
trainingPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(config.TRAIN)])
testingPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(config.TEST)])
# load the data from disk
print("[INFO] loading data...")
(trainX, trainY) = load_data_split(trainingPath)
(testX, testY) = load_data_split(testingPath)
# load the label encoder from disk
le = pickle.loads(open(config.LE_PATH, "rb").read())
第 33-41 行从磁盘加载我们的训练和测试特征数据。我们使用前面代码块中的函数来处理加载过程。
第 44 行加载我们的标签编码器。
有了内存中的数据,我们现在准备好训练我们的机器学习分类器:
# train the model
print("[INFO] training model...")
model = LogisticRegression(solver="lbfgs", multi_class="auto",
max_iter=150)
model.fit(trainX, trainY)
# evaluate the model
print("[INFO] evaluating...")
preds = model.predict(testX)
print(classification_report(testY, preds, target_names=le.classes_))
# serialize the model to disk
print("[INFO] saving model...")
f = open(config.MODEL_PATH, "wb")
f.write(pickle.dumps(model))
f.close()
48-50 线负责初始化和训练我们的逻辑回归 model。
注:要详细了解逻辑回归和其他机器学习算法,一定要参考 PyImageSearch 大师,我的旗舰计算机视觉课程和社区。
线 54 和 55 便于在测试机上评估model并在终端打印分类统计。
最后,model以 Python 的 pickle 格式输出(第 59-61 行)。
我们的培训脚本到此结束!如您所知,在要素数据的基础上编写用于训练逻辑回归模型的代码非常简单。在下一部分中,我们将运行培训脚本。
如果你想知道我们如何处理如此多的特征数据,以至于它不能一次全部放入内存,请继续关注下周的教程。
注意:本教程已经够长了,所以我还没有介绍如何调整逻辑回归模型的超参数,这是我肯定推荐的,以确保获得尽可能高的精度。如果您有兴趣了解更多关于迁移学习的知识,以及如何在特征提取过程中调整超参数,请务必参考使用 Python 进行计算机视觉的深度学习,其中我将更详细地介绍这些技术。
在提取的特征上训练模型
此时,我们已经准备好通过 Keras 的特征提取来执行迁移学习的最后一步。
让我们简要回顾一下到目前为止我们所做的工作:
- 下载了 Food-5K 数据集(分别属于“食物”和“非食物”两类的 5000 张图片)。
- 以一种更适合迁移学习的格式重构了数据集的原始目录结构(特别是微调,我们将在本系列的后面讨论)。
- 使用在 ImageNet 上预先训练的 VGG16 从图像中提取特征。
现在,我们将在这些提取特征的基础上训练一个逻辑回归模型。
请再次记住,VGG16 没有经过训练,无法识别“食物”和“非食物”类别。相反,它被训练识别 1000 个 ImageNet 类。
但是,通过利用:
- 用 VGG16 进行特征提取
- 并且在那些提取的特征之上应用逻辑回归分类器
我们将能够识别新的职业,尽管 VGG16 从未被训练来识别它们!
继续使用本教程的 【下载】 部分下载本指南的源代码。
从那里,打开一个终端并执行以下命令:
$ python train.py
[INFO] loading data...
[INFO] training model...
[INFO] evaluating...
precision recall f1-score support
food 0.99 0.98 0.98 500
non_food 0.98 0.99 0.99 500
accuracy 0.98 1000
macro avg 0.99 0.98 0.98 1000
weighted avg 0.99 0.98 0.98 1000
[INFO] saving model...
在我的机器上的训练只花了 27 秒,正如你可以从我们的输出中看到的,我们在测试集上获得了 98-99%的准确率!
什么时候应该使用迁移学习和特征提取?
通过特征提取进行迁移学习通常是在你自己的项目中获得基线准确度的最简单的方法之一。
每当我面对一个新的深度学习项目时,我经常用 Keras 进行特征提取,只是为了看看会发生什么:
- 在某些情况下,精确度是足够的。
- 在其他情况下,它需要我根据我的逻辑回归模型调整超参数,或者尝试另一个预先训练好的 CNN。
- 在其他情况下,我需要探索微调,甚至用定制的 CNN 架构从头开始训练。
无论如何,在最好的情况下通过特征提取的迁移学习给了我很好的准确性,项目可以完成。
在最糟糕的情况下,我将获得一个基线,在未来的实验中超越它。
摘要
今天标志着我们关于 Keras 和深度学习的迁移学习系列的开始。
通过深度学习进行特征提取的两种主要形式是:
- 特征抽出
- 微调
今天教程的重点是特征提取,将预先训练好的网络视为任意特征提取器的过程。
通过特征提取执行迁移学习的步骤包括:
- 从预先训练的网络开始(通常在诸如 ImageNet 或 COCO 的数据集上;大到足以让模型学习区分滤波器)。
- 允许输入图像向前传播到任意(预先指定的)层。
- 获取该层的输出,并将其作为 f 特征向量。
- 在提取特征的数据集上训练“标准”机器学习模型。
通过特征提取执行迁移学习的好处是,我们不需要训练(或重新训练)我们的神经网络。
相反,网络充当黑盒特征提取器。
那些被提取的特征被假设为本质上是非线性的(因为它们是从 CNN 中提取的),然后被传递到线性模型中用于分类。
如果你有兴趣学习更多关于迁移学习、特征提取和微调的知识,一定要参考我的书, 用 Python 进行计算机视觉的深度学习 ,我在那里更详细地讨论了这个主题。
我希望你喜欢今天的帖子!下周我们将讨论当我们的数据集太大而无法放入内存时如何进行特征提取,敬请关注。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV 透明覆盖
原文:https://pyimagesearch.com/2016/03/07/transparent-overlays-with-opencv/
# import the necessary packages
from __future__ import print_function
import numpy as np
import cv2
# load the image
image = cv2.imread("mexico.jpg")
第 2-4 行处理导入我们需要的 Python 包。
第 7 行使用cv2.imread函数从磁盘加载我们的图像。
下一步是在范围【0,1.0】之间循环不同的 alpha 透明度值,让我们可以直观地理解alpha值如何影响我们的输出图像:
# loop over the alpha transparency values
for alpha in np.arange(0, 1.1, 0.1)[::-1]:
# create two copies of the original image -- one for
# the overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# draw a red rectangle surrounding Adrian in the image
# along with the text "PyImageSearch" at the top-left
# corner
cv2.rectangle(overlay, (420, 205), (595, 385),
(0, 0, 255), -1)
cv2.putText(overlay, "PyImageSearch: alpha={}".format(alpha),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 3)
为了应用透明覆盖,我们需要制作输入图像的两个副本:
- 一个用于最终的
output图像。 - 另一个是我们将要建造的
overlay。
使用cv2.rectangle功能,我们在图像的右下角画一个围绕我的矩形。然后我们应用cv2.putText在左上角绘制文本PyImageSearch。
我们现在准备使用cv2.addWeighted函数应用透明叠加:
# apply the overlay
cv2.addWeighted(overlay, alpha, output, 1 - alpha,
0, output)
cv2.addWeighted方法需要六个参数。
第一个是我们的overlay,我们想要使用提供的 alpha 透明度“覆盖”在原始图像上的图像。
第二个参数是叠加层的实际 alpha 透明度。alpha越接近 1.0 ,叠加的越不透明。同样的,alpha越接近 0.0 ,叠加的越透明就会出现。
cv2.addWeighted的第三个参数是源映像——在本例中,是从磁盘加载的原始映像。
我们提供 beta 值作为第四个参数。β定义为1 - alpha。我们需要定义α和β,这样alpha + beta = 1.0。
第五个参数是 gamma 值——一个加到加权和上的标量。您可以将 gamma 视为应用加权加法后添加到输出图像的常数。在这种情况下,我们将其设置为零,因为我们不需要应用常数值的加法。
最后,我们有最后一个参数,output,它是应用加权求和运算后的输出目的地——这个值是我们最终的输出图像。
我们的最后一个代码块处理向屏幕显示最终输出图像,以及显示相关的 alpha 和 beta 值:
# show the output image
print("alpha={}, beta={}".format(alpha, 1 - alpha))
cv2.imshow("Output", output)
cv2.waitKey(0)
要执行我们的 Python 脚本,将源代码+示例图像下载到本文(使用本课底部的 “下载” 表单)并执行以下命令:
$ python overlay.py
您应该会在屏幕上看到以下图像:
Figure 3: Notice how for alpha=1.0, the text and rectangle are entirely opaque (i.e., not transparent).
然而,一旦我们到达alpha=0.5,“PyImageSearch”文本和矩形都变得更加透明:

Figure 4: Constructing transparent overlays with Python and OpenCV.
在alpha=0.1处,文本和矩形几乎不可见:

Figure 5: The smaller alpha gets, the more transparent the overlay will be.
下面您可以看到一个 GIF 动画,它将每个透明度级别可视化:
摘要
在这篇博文中,我们学习了如何使用 Python、OpenCV 和cv2.addWeighted函数构建透明的覆盖图。
未来的博客文章将使用这种透明叠加功能在输出图像上绘制平视显示器(hud ),并使输出更加美观。
调整 dlib 形状预测超参数以平衡速度、精度和模型尺寸

在本教程中,您将学习如何优化 dlib 的形状预测器超参数和选项,以获得平衡速度、精度和模型大小的形状预测器。
今天是我们关于用 dlib 训练自定义形状预测器的两部分系列的第二部分:
- Part #1: 训练自定义 dlib 形状预测器 (上周教程)
- 第 2 部分: 调整 dlib 形状预测超参数以平衡速度、精度和模型大小(今天的教程)
许多软件开发人员和项目经理都熟悉“铁三角”的概念。构建软件时,我们需要平衡:
- 好,优质软件
- 可以快速交付给客户的软件
*** 软件有多贵(即,它是否**便宜****
**需要注意的是,我们只能从上面选择两个。
快速交付给客户的好的、高质量的软件肯定不便宜。类似地,开发成本低、交付速度快的软件也不一定好。
当训练我们自己的定制 dlib 形状预测器时,我们有一个类似的问题——我们需要平衡:
- 速度:模型能做出预测的速度(即推理速度)。
- 准确性:我们的模型在预测中的精确程度。
- 模型大小:模型越大,占用的空间越多,需要的计算资源也越多。因此,更小的型号是首选。
但是不像软件开发的铁三角只有三个顶点, dlib 的形状预测器包括 7-10 个选项,你通常会想要调整。
那么,我们如何去调整这些形状预测选项和超参数呢?
我将在这篇文章的剩余部分讨论这个话题。
注意:如果你还没有读过 上周关于训练 dlib 形状预测器 的帖子,确保你现在就去读,因为本教程的其余部分都是以它为基础的。
要了解如何调整 dlib 的形状预测器选项,以最佳地平衡速度、精度和模型大小,请继续阅读!
调整 dlib 形状预测超参数以平衡速度、精度和模型尺寸
在本教程的第一部分,我们将讨论为什么我们需要调整 dlib 的形状预测选项,以获得一个适合我们特定项目要求和应用的最佳模型。
接下来,我们将回顾和讨论今天用来训练 dlib 形状预测器的数据集。
然后我将向你展示如何实现一个 Python 脚本来自动探索 dlib 的形状预测器选项。
*我们将讨论如何使用这个脚本的结果来设置 dlib 的形状预测器的选项,训练它,并获得一个最佳模型,从而结束本教程。
我们开始吧!
为什么我们需要调整我们的形状预测超参数?

Figure 1: In this tutorial, we will learn how to tune custom dlib shape predictor hyperparameters to balance speed, accuracy, and model size.
当训练我们自己的自定义 dlib 形状预测器时,我们需要平衡:
- 模型速率
- 模型精度
- 模型尺寸
通常我们只能有 1-2 个选择。
在你打开你的代码编辑器或命令行之前,首先考虑项目的目标和你的 shape predictor 将被部署在哪里:
- 形状预测器会在嵌入式设备上使用吗?如果是,就在精度上稍微妥协一下,寻求一个又快又小的模型。
- 您是否将该模型部署到现代笔记本电脑/台式机上?您可能能够获得计算成本更高的大型模型,因此不要太担心模型的大小,而是专注于最大限度地提高准确性。
- 模型的输出大小是一个问题吗?如果您的模型需要通过网络连接进行部署/更新,那么您应该寻求尽可能小但仍能达到合理精度的模型。
- 训练模型所需的时间是一个问题吗?如果是,请注意在训练过程中应用的任何抖动/数据增强。
提前考虑这些选项将使更容易为 dlib 的形状预测器调整选项——我还将向您展示我自己的调整脚本,我用它来帮助缩小形状预测器选项的范围,这些选项将很好地适用于我各自的用例。
*### iBUG-300W 数据集
Figure 2: The iBug 300-W face landmark dataset is used to train a custom dlib shape predictor. We will tune custom dlib shape predictor hyperparameters in an effort to balance speed, accuracy, and model size.
为了训练和调整我们自己的自定义 dlib 形状预测器,我们将使用 iBUG 300-W 数据集,与我们在上周的教程中使用的数据集相同。
iBUG 300-W 数据集用于训练面部标志预测器并定位面部的各个结构,包括:
- 眉毛
- 眼睛
- 鼻子
- 口
- 下颌的轮廓
然而,我们将训练我们的形状预测器来定位只有眼睛——我们的模型将而不是在其他面部结构上进行训练。
有关 iBUG 300-W 数据集的更多细节,请参考上周的博文。
配置您的 dlib 开发环境
为了完成今天的教程,您需要一个安装了以下软件包的虚拟环境:
- dlib
- OpenCV
- imutils
- scikit-learn
幸运的是,这些包都是 pip 可安装的,但是有一些先决条件(包括 Python 虚拟环境)。有关配置开发环境的更多信息,请务必遵循以下两个指南:
pip 安装命令包括:
$ workon <env-name>
$ pip install dlib
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install scikit-learn
一旦你按照我的 dlib 或 OpenCV 安装指南安装了virtualenv和virtualenvwrapper,那么workon命令就变得可用。
下载 iBUG 300-W 数据集
在我们深入本教程之前,现在花点时间下载 iBUG 300-W 数据集(~1.7GB):
http://dlib . net/files/data/ibug _ 300 w _ large _ face _ landmark _ dataset . tar . gz
你可能还想使用这篇博文的 【下载】 部分下载源代码。
我建议将 iBug 300-W 数据集放入与本教程下载相关的 zip 文件中,如下所示:
$ unzip tune-dlib-shape-predictor.zip
...
$ cd tune-dlib-shape-predictor
$ mv ~/Downloads/ibug_300W_large_face_landmark_dataset.tar.gz .
$ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz
...
或者(即,不点击上面的超链接),在您的终端中使用wget直接下载数据集:
$ unzip tune-dlib-shape-predictor.zip
...
$ cd tune-dlib-shape-predictor
$ wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
$ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz
...
从这里开始,您可以跟随教程的其余部分。
项目结构
假设您已经遵循了上一节中的说明,您的项目目录现在组织如下:
$ tree --dirsfirst --filelimit 15
.
├── ibug_300W_large_face_landmark_dataset
│ ├── afw [1011 entries]
│ ├── helen
│ │ ├── testset [990 entries]
│ │ └── trainset [6000 entries]
│ ├── ibug [405 entries]
│ ├── image_metadata_stylesheet.xsl
│ ├── labels_ibug_300W.xml
│ ├── labels_ibug_300W_test.xml
│ ├── labels_ibug_300W_train.xml
│ └── lfpw
│ ├── testset [672 entries]
│ └── trainset [2433 entries]
├── ibug_300W_large_face_landmark_dataset.tar.gz
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── example.jpg
├── ibug_300W_large_face_landmark_dataset.tar.gz
├── optimal_eye_predictor.dat
├── parse_xml.py
├── predict_eyes.py
├── train_shape_predictor.py
├── trials.csv
└── tune_predictor_hyperparams.py
2 directories, 15 files
上周,我们回顾了以下 Python 脚本:
parse_xml.py:解析训练/测试 XML 数据集文件以获得只看得见的地标坐标。train_shape_predictor.py:接受解析后的 XML 文件,用 dlib 训练我们的形状预测器。evaluate_shape_predictor.py:计算我们定制的形状预测器的平均误差(MAE)。不包括在今天的下载中 —类似/附加功能在今天的调整脚本中提供。predict_eyes.py:使用我们定制的 dlib 形状预测器进行形状预测,该预测器经过训练,仅识别眼睛标志。
今天,我们将回顾以下 Python 文件:
- 我们的配置路径、常量和变量都在一个方便的位置。
- 今天教程的核心就在这里。该脚本确定 dlib 形状预测超参数的所有6075 个组合。从那里,我们将随机抽样 100 个组合,并继续训练和评估这 100 个模型。超参数和评估标准输出到 CSV 文件,以便在您选择的电子表格应用程序中进行检查。
为培训准备 iBUG-300W 数据集
Figure 3: Our custom dlib shape/landmark predictor recognizes just eyes.
正如上面的“iBUG-300 w 数据集”部分提到的,我们将在只在眼睛上训练我们的 dlib 形状预测器(即而不是眉毛、鼻子、嘴或下颌)。
为了完成这项任务,我们首先需要从 iBUG 300-W 训练/测试 XML 文件中解析出我们不感兴趣的任何面部结构。
要开始,请确保您已经:
- 使用本教程的 【下载】 部分下载源代码。
- 已使用上面的“下载 iBUG-300W 数据集”部分下载 iBUG-300W 数据集。
- 查看了“项目结构”部分。
您会注意到在项目的目录结构中有一个名为parse_xml.py的脚本——这个脚本用于从 XML 文件中解析出也就是眼睛的位置。
我们在上周的教程中详细回顾了这个文件,所以我们今天不打算在这里再次回顾(参考上周的帖子以了解它是如何工作的)。
在继续本教程的其余部分之前,您需要执行以下命令来准备我们的“仅供参考”的培训和测试 XML 文件:
$ python parse_xml.py \
--input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml \
--output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml
[INFO] parsing data split XML file...
$ python parse_xml.py \
--input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test.xml \
--output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test_eyes.xml
[INFO] parsing data split XML file...
要验证我们的新培训/测试文件是否已创建,请检查 iBUG-300W 根数据集目录中的labels_ibug_300W_train_eyes.xml和labels_ibug_300W_test_eyes.xml文件:
$ cd ibug_300W_large_face_landmark_dataset
$ ls -lh *.xml
-rw-r--r--@ 1 adrian staff 21M Aug 16 2014 labels_ibug_300W.xml
-rw-r--r--@ 1 adrian staff 2.8M Aug 16 2014 labels_ibug_300W_test.xml
-rw-r--r-- 1 adrian staff 602K Dec 12 12:54 labels_ibug_300W_test_eyes.xml
-rw-r--r--@ 1 adrian staff 18M Aug 16 2014 labels_ibug_300W_train.xml
-rw-r--r-- 1 adrian staff 3.9M Dec 12 12:54 labels_ibug_300W_train_eyes.xml
$ cd ..
请注意,我们的*_eyes.xml文件被高亮显示。这两个文件的文件大小都比它们原始的、未解析的副本小得多。
一旦完成了这些步骤,您就可以继续本教程的其余部分。
查看我们的配置文件
在我们深入了解这个项目之前,让我们先回顾一下我们的配置文件。
打开config.py文件并插入以下代码:
# import the necessary packages
import os
# define the path to the training and testing XML files
TRAIN_PATH = os.path.join("ibug_300W_large_face_landmark_dataset",
"labels_ibug_300W_train_eyes.xml")
TEST_PATH = os.path.join("ibug_300W_large_face_landmark_dataset",
"labels_ibug_300W_test_eyes.xml")
这里我们有训练和测试 XML 文件的路径(即在我们已经解析出眼睛区域的之后生成的)。
接下来,我们将定义一些用于调整 dlib 形状预测超参数的常数:
# define the path to the temporary model file
TEMP_MODEL_PATH = "temp.dat"
# define the path to the output CSV file containing the results of
# our experiments
CSV_PATH = "trials.csv"
# define the path to the example image we'll be using to evaluate
# inference speed using the shape predictor
IMAGE_PATH = "example.jpg"
# define the number of threads/cores we'll be using when trianing our
# shape predictor models
PROCS = -1
# define the maximum number of trials we'll be performing when tuning
# our shape predictor hyperparameters
MAX_TRIALS = 100
我们的 dlib 调谐路径包括:
- 选项/超参数调整期间使用的临时形状预测文件(第 11 行)。
- 用于存储我们个人试验结果的 CSV 文件(第 15 行)。
- 我们将使用一个示例图像来评估给定模型的推理速度(第 19 行)。
接下来,我们将定义一个多处理变量——训练我们的形状预测器时将使用的并行线程/内核的数量(第 23 行)。值-1表示所有的处理器内核都将用于训练。
我们将通过超参数的组合来寻找性能最佳的模型。第 27 行定义了在探索形状预测器超参数空间时我们将执行的最大试验次数:
- 较小的值会导致
tune_predictor_hyperparams.py脚本完成得更快,但也会探索更少的选项。 - 更大的值将需要更多的时间来完成
tune_predictor_hyperparams.py脚本,并将探索更多的选项,为您提供更多的结果,然后您可以使用这些结果来做出更好、更明智的决定,以选择您的最终形状预测器超参数。
如果我们要从6000+中找出最好的模型,即使在强大的计算机上,也需要多周/数月的时间来训练和评估形状预测模型;所以你要用MAX_TRIALS参数寻求平衡。
实现我们的 dlib 形状预测器调整脚本
如果你关注了上周关于训练自定义 dlib 形状预测器的帖子,你会注意到我们将所有选项硬编码到了我们的形状预测器中。
硬编码我们的超参数值有点问题,因为它要求我们手动:
- 步骤#1: 更新任何培训选项。
- 步骤#2: 执行用于训练形状预测器的脚本。
- 步骤#3: 在我们的形状模型上评估新训练的形状预测器。
- 步骤#4: 返回步骤#1,必要时重复。
这里的问题是这些步骤是一个手动过程,要求我们在每一步都进行干预。
相反,如果我们可以创建一个 Python 脚本,让 自动 为我们处理调优过程,那就更好了。
我们可以定义我们想要探索的选项和相应的值。我们的脚本将确定这些参数的所有可能组合。然后,它会在这些选项上训练一个形状预测器,对其进行评估,然后继续下一组选项。一旦脚本完成运行,我们就可以检查结果,选择最佳参数来实现模型速度、大小和准确性的平衡,然后训练最终的模型。
要了解如何创建这样的脚本,打开tune_predictor_hyperparams.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch import config
from sklearn.model_selection import ParameterGrid
import multiprocessing
import numpy as np
import random
import time
import dlib
import cv2
import os
第 2-10 行导入我们的包装,包括:
config:我们的配置。ParameterGrid:生成一个可迭代的参数组合列表。参考 scikit-learn 的参数表格文件。multiprocessing: Python 内置的多处理模块。dlib: 戴维斯·金的图像处理工具包,其中包括一个形状预测器的实现。- OpenCV 现在被用于图像输入输出和预处理。
现在让我们定义我们的函数来评估我们的模型精度:
def evaluate_model_acc(xmlPath, predPath):
# compute and return the error (lower is better) of the shape
# predictor over our testing path
return dlib.test_shape_predictor(xmlPath, predPath)
第 12-15 行定义了一个辅助工具来评估我们的平均误差(MAE),或者更简单地说,模型的准确性。
就像我们有一个评估模型精度的函数,我们也需要一个评估模型推理速度的方法:
def evaluate_model_speed(predictor, imagePath, tests=10):
# initialize the list of timings
timings = []
# loop over the number of speed tests to perform
for i in range(0, tests):
# load the input image and convert it to grayscale
image = cv2.imread(config.IMAGE_PATH)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
detector = dlib.get_frontal_face_detector()
rects = detector(gray, 1)
# ensure at least one face was detected
if len(rects) > 0:
# time how long it takes to perform shape prediction
# using the current shape prediction model
start = time.time()
shape = predictor(gray, rects[0])
end = time.time()
# update our timings list
timings.append(end - start)
# compute and return the average over the timings
return np.average(timings)
我们从第 17 行开始的evaluate_model_speed函数接受以下参数:
predictor:dlib 形状/标志检测器的路径。imagePath:输入图像的路径。tests:要执行的测试数量和平均值。
第 19 行初始化一个timings列表。我们将在从第 22 行开始的循环中填充timings。在循环中,我们继续:
- 加载一个
image并将其转换为灰度(第 24 行和第 25 行)。 - 使用 dlib 的 HOG +线性 SVM 人脸
detector( 第 28 行和第 29 行)进行人脸检测。 - 确保至少检测到一张脸(第 32 行)。
- 计算形状/地标预测的推断时间,并将结果添加到
timings( 第 35-40 行)。
最后,我们将我们的timings平均值返回给调用者(行 43) 。
让我们为超参数 CSV 文件定义一个列列表:
# define the columns of our output CSV file
cols = [
"tree_depth",
"nu",
"cascade_depth",
"feature_pool_size",
"num_test_splits",
"oversampling_amount",
"oversampling_translation_jitter",
"inference_speed",
"training_time",
"training_error",
"testing_error",
"model_size"
]
记住,这个 CSV 将保存我们的脚本调整的所有超参数的值。第 46-59 行定义了 CSV 文件的列,包括:
- 给定试验的超参数值:
tree_depth:控制树的深度。nu:帮助我们模型一般化的正则化参数。cascade_depth:细化和调整初始预测的级联数量。feature_pool_size:控制用于为级联中的随机树生成特征的像素数。num_test_splits:测试分割的数量影响训练时间和模型精度。oversampling_amount:控制训练形状预测器时应用的“抖动”量。oversampling_translation_jitter:控制应用于数据集的平移“抖动”/增强量。
- 评估标准:
inference_speed:经过训练的形状预测器的推理速度。training_time:训练形状预测器所花费的时间。training_error:训练集错误。testing_error:测试集错误。model_size:模型文件大小。
注:请继续阅读,了解超参数值的简要回顾,包括如何初始化它们的指南。
然后,我们打开输出 CSV 文件并将cols写入磁盘:
# open the CSV file for writing and then write the columns as the
# header of the CSV file
csv = open(config.CSV_PATH, "w")
csv.write("{}\n".format(",".join(cols)))
# determine the number of processes/threads to use
procs = multiprocessing.cpu_count()
procs = config.PROCS if config.PROCS > 0 else procs
第 63 行和第 64 行将cols写入 CSV 文件。
第 67 行和第 68 行确定训练时使用的进程/线程的数量。这个数字是基于您的计算机拥有的 CPUs 内核的数量。我的 3GHz 英特尔至强 W 有 20 个内核,但大多数笔记本电脑 CPU 将有 2-8 个内核。
下一个代码块初始化集合超参数/选项以及我们将探索的对应值:
# initialize the list of dlib shape predictor hyperparameters that
# we'll be tuning over
hyperparams = {
"tree_depth": list(range(2, 8, 2)),
"nu": [0.01, 0.1, 0.25],
"cascade_depth": list(range(6, 16, 2)),
"feature_pool_size": [100, 250, 500, 750, 1000],
"num_test_splits": [20, 100, 300],
"oversampling_amount": [1, 20, 40],
"oversampling_translation_jitter": [0.0, 0.1, 0.25]
}
正如在上周的帖子中所讨论的,有 7 个形状预测器选项可供你探索。
我们上周详细回顾了它们,但您可以在下面找到每一个的简短摘要:
tree_depth:每棵树都会有2^tree_depth片叶子。更小的tree_depth值将导致更浅的树,更快,但是潜在地更不准确。更大的tree_depth值将创建更深的树,这些树更慢,但潜在地更准确。**
**nu:用于帮助我们模型一般化的正则化参数。更接近于1的值将使我们的模型更接近于训练数据,但是可能会导致过度拟合。更接近0的值将帮助我们的模型一般化;然而,这里有一个警告——nu越接近0你将需要更多的训练数据。*cascade_depth:用于改进和调整初始预测的级联数量。该参数将对模型的精度和输出文件大小产生 的显著影响。你允许的级联越多,你的模型就会变得越大(也可能更精确)。您允许的级联越少,您的模型就越小(但也可能导致精度降低)。***feature_pool_size:控制用于为级联中的每个随机树生成特征的像素数。你包含的像素越多,你的模型运行的就越慢(但也能产生更精确的形状预测器)。你考虑的像素越少,你的模型运行越快(但也可能不太准确)。*num_test_splits:影响训练时间和模型精度。你考虑的越多,你就越有可能有一个准确的形状预测器,但是要小心!较大的值将导致训练时间激增,并且需要更长的时间来完成形状预测器训练。*oversampling_amount:控制在训练形状预测器时应用的“抖动”量(即数据增加)。典型值在【0,50】范围内。例如,5的值会导致您的训练数据增加5 倍。这里要小心,因为oversampling_amount越大,你的模型训练的时间就越长。*oversampling_translation_jitter:控制应用于数据集的平移抖动/增强量。*
*现在我们有了将要探索的hyperparams集合,我们需要构造这些选项的所有可能组合——为此,我们将使用 scikit-learn 的ParameterGrid类:
# construct the set of hyperparameter combinations and randomly
# sample them as trying to test *all* of them would be
# computationally prohibitive
combos = list(ParameterGrid(hyperparams))
random.shuffle(combos)
sampledCombos = combos[:config.MAX_TRIALS]
print("[INFO] sampling {} of {} possible combinations".format(
len(sampledCombos), len(combos)))
给定上面第 72-80 行上的hyperparams集合,总共有6075 种可能的组合可供我们探索。
在单台机器上,这将需要花费周的时间来探索,因此我们将随机对参数进行采样,以获得可能值的合理范围。
第 85 行和第 86 行构建了所有可能的选项/值组合的集合,并对它们进行随机洗牌。然后我们对MAX_TRIALS组合进行采样(第 87 行)。
现在让我们继续循环我们的sampledCombos:
# loop over our hyperparameter combinations
for (i, p) in enumerate(sampledCombos):
# log experiment number
print("[INFO] starting trial {}/{}...".format(i + 1,
len(sampledCombos)))
# grab the default options for dlib's shape predictor and then
# set the values based on our current hyperparameter values
options = dlib.shape_predictor_training_options()
options.tree_depth = p["tree_depth"]
options.nu = p["nu"]
options.cascade_depth = p["cascade_depth"]
options.feature_pool_size = p["feature_pool_size"]
options.num_test_splits = p["num_test_splits"]
options.oversampling_amount = p["oversampling_amount"]
otj = p["oversampling_translation_jitter"]
options.oversampling_translation_jitter = otj
# tell dlib to be verbose when training and utilize our supplied
# number of threads when training
options.be_verbose = True
options.num_threads = procs
第 99 行抓取 dlib 的形状预测器的默认options。我们需要将默认选项属性加载到内存中,然后才能单独更改它们。
第 100-107 行根据这组特定的超参数设置每个 dlib 形状预测超参数options。
第 111 行和第 112 行告诉 dlib 在训练时要详细,并使用配置的线程数(关于线程/进程数请参考第 67 行和第 68 行)。
从这里开始,我们将用 dlib: 训练和评估我们的形状预测器
# train the model using the current set of hyperparameters
start = time.time()
dlib.train_shape_predictor(config.TRAIN_PATH,
config.TEMP_MODEL_PATH, options)
trainingTime = time.time() - start
# evaluate the model on both the training and testing split
trainingError = evaluate_model_acc(config.TRAIN_PATH,
config.TEMP_MODEL_PATH)
testingError = evaluate_model_acc(config.TEST_PATH,
config.TEMP_MODEL_PATH)
# compute an approximate inference speed using the trained shape
# predictor
predictor = dlib.shape_predictor(config.TEMP_MODEL_PATH)
inferenceSpeed = evaluate_model_speed(predictor,
config.IMAGE_PATH)
# determine the model size
modelSize = os.path.getsize(config.TEMP_MODEL_PATH)
第 115-118 行训练我们定制的 dlib 形状预测器,包括计算经过的训练时间。
然后,我们使用新训练的形状预测器来分别计算我们的训练和测试分割的误差(行 121-124 )。
为了估计inferenceSpeed,我们确定形状预测器执行推断需要多长时间(即,给定检测到的面部示例图像,模型需要多长时间来定位眼睛?)经由线路 128-130 。
第 133 行获取模型的文件大小。
接下来,我们将将超参数选项和评估指标输出到 CSV 文件:
# build the row of data that will be written to our CSV file
row = [
p["tree_depth"],
p["nu"],
p["cascade_depth"],
p["feature_pool_size"],
p["num_test_splits"],
p["oversampling_amount"],
p["oversampling_translation_jitter"],
inferenceSpeed,
trainingTime,
trainingError,
testingError,
modelSize,
]
row = [str(x) for x in row]
# write the output row to our CSV file
csv.write("{}\n".format(",".join(row)))
csv.flush()
# delete the temporary shape predictor model
if os.path.exists(config.TEMP_MODEL_PATH):
os.remove(config.TEMP_MODEL_PATH)
# close the output CSV file
print("[INFO] cleaning up...")
csv.close()
第 136-150 行生成训练超参数和评估结果的基于字符串的列表。
然后,我们将该行写入磁盘,删除临时模型文件,并进行清理(第 153-162 行)。
同样,这个循环将最多运行100次迭代,以构建我们的超参数和评估数据的 CSV 行。如果我们评估了所有的6075 个组合,我们的计算机将会在周内产生大量数据。
探索形状预测超参数空间
现在,我们已经实现了 Python 脚本来探索 dlib 的形状预测器超参数空间,让我们将它投入使用。
确保你有:
- 使用本教程的 【下载】 部分下载源代码。
- 使用上面的“下载 iBUG-300W 数据集”部分下载 iBUG-300W 数据集。
- 在“为培训准备 iBUG-300W 数据集”一节中,为培训和测试 XML 文件执行了
parse_xml.py。
假设您已经完成了这些步骤中的每一步,现在您可以执行tune_predictor_hyperparams.py脚本:
$ python tune_predictor_hyperparams.py
[INFO] sampling 100 of 6075 possible combinations
[INFO] starting trial 1/100...
...
[INFO] starting trial 100/100...
Training with cascade depth: 12
Training with tree depth: 4
Training with 500 trees per cascade level.
Training with nu: 0.25
Training with random seed:
Training with oversampling amount: 20
Training with oversampling translation jitter: 0.1
Training with landmark_relative_padding_mode: 1
Training with feature pool size: 1000
Training with feature pool region padding: 0
Training with 20 threads.
Training with lambda_param: 0.1
Training with 100 split tests.
Fitting trees...
Training complete
Training complete, saved predictor to file temp.dat
[INFO] cleaning up...
real 3052m50.195s
user 30926m32.819s
sys 338m44.848s
在我配有 3GHz 英特尔至强 W 处理器的 iMac Pro 上,整个训练时间花费了 ~3,052 分钟,相当于 ~2.11 天。确保运行脚本一整夜,并根据您的计算能力,计划在 2-5 天内检查状态。
脚本完成后,您的工作目录中应该有一个名为trials.csv的文件:
$ ls *.csv
trials.csv
我们的trials.csv文件包含了我们的实验结果。
在下一节中,我们将检查该文件,并使用它来选择最佳形状预测器选项,以平衡速度、准确性和模型大小。
确定最佳形状预测参数以平衡速度、精度和模型大小
此时,我们有了输出trials.csv文件,它包含(1)输入形状预测器选项/超参数值和(2)相应的输出精度、推理时间、模型大小等的组合。
我们的目标是分析这个 CSV 文件,并为我们的特定任务确定最合适的值。
首先,在您最喜欢的电子表格应用程序(例如、微软 Excel、macOS Numbers、Google Sheets 等。):
Figure 4: Hyperparameter tuning a dlib shape predictor produced the following data to analyze in a spreadsheet. We will analyze hyperparameters and evaluation criteria to balance speed, accuracy, and shape predictor model size.
现在假设我的目标是训练和部署一个形状预测器到嵌入式设备。
对于嵌入式设备,我们的模型应该:
- 尽可能小
- 在进行预测时,小模型也将是 快速的,在使用资源受限的设备时,是必需的
- 有合理的精确度,但是我们需要牺牲一点精确度来得到一个小而快的模型。
为了确定 dlib 的形状预测器的最佳超参数,我将首先按照模型大小: 对我的电子表格进行排序

Figure 5: Sort your dlib shape predictors by model size when you are analyzing the results of tuning your model to balance speed, accuracy, and model size.
然后我会检查inference_speed、training_error和testing_error列,寻找一个既快速又具有合理准确性的模型。
这样,我找到了下面的模型,粗体,并在电子表格中选择了:

Figure 6: After sorting your dlib shape predictor turning by model_size, examine the inference_speed, training_error, and testing_error columns, looking for a model that is fast but also has reasonable accuracy.
这种模式是:
- 大小只有 3.85MB
- 在测试误差方面前 25 名
- 极速,能够在单秒内进行1875 次预测
下面我包括了这个模型的形状预测超参数:
tree_depth: 2nu: 0.25cascade_depth: 12feature_pool_size: 500num_test_splits: 100oversampling_amount: 20oversampling_translation_jitter: 0
更新我们的形状预测器训练脚本
我们快完成了!
我们需要做的最后一个更新是对我们的train_shape_predictor.py文件的更新。
打开该文件并插入以下代码:
# import the necessary packages
import multiprocessing
import argparse
import dlib
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--training", required=True,
help="path to input training XML file")
ap.add_argument("-m", "--model", required=True,
help="path serialized dlib shape predictor model")
args = vars(ap.parse_args())
# grab the default options for dlib's shape predictor
print("[INFO] setting shape predictor options...")
options = dlib.shape_predictor_training_options()
# update our hyperparameters
options.tree_depth = 2
options.nu = 0.25
options.cascade_depth = 12
options.feature_pool_size = 500
options.num_test_splits = 20
options.oversampling_amount = 20
options.oversampling_translation_jitter = 0
# tell the dlib shape predictor to be verbose and print out status
# messages our model trains
options.be_verbose = True
# number of threads/CPU cores to be used when training -- we default
# this value to the number of available cores on the system, but you
# can supply an integer value here if you would like
options.num_threads = multiprocessing.cpu_count()
# log our training options to the terminal
print("[INFO] shape predictor options:")
print(options)
# train the shape predictor
print("[INFO] training shape predictor...")
dlib.train_shape_predictor(args["training"], args["model"], options)
注意在第 19-25 行中,我们如何使用在上一节中找到的最佳值来更新我们的形状预测器选项。
我们脚本的其余部分负责使用这些值训练形状预测器。
关于train_shape_predictor.py脚本的详细回顾,请务必参考上周的博客文章。
根据我们的最优选项值训练 dlib 形状预测器
既然我们已经确定了最佳形状预测器选项,并且用这些值更新了我们的train_shape_predictor.py文件,我们可以继续训练我们的模型。
打开终端并执行以下命令:
$ time python train_shape_predictor.py \
--training ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml \
--model optimal_eye_predictor.dat
[INFO] setting shape predictor options...
[INFO] shape predictor options:
shape_predictor_training_options(be_verbose=1, cascade_depth=12, tree_depth=2, num_trees_per_cascade_level=500, nu=0.25, oversampling_amount=20, oversampling_translation_jitter=0, feature_pool_size=500, lambda_param=0.1, num_test_splits=20, feature_pool_region_padding=0, random_seed=, num_threads=20, landmark_relative_padding_mode=1)
[INFO] training shape predictor...
Training with cascade depth: 12
Training with tree depth: 2
Training with 500 trees per cascade level.
Training with nu: 0.25
Training with random seed:
Training with oversampling amount: 20
Training with oversampling translation jitter: 0
Training with landmark_relative_padding_mode: 1
Training with feature pool size: 500
Training with feature pool region padding: 0
Training with 20 threads.
Training with lambda_param: 0.1
Training with 20 split tests.
Fitting trees...
Training complete
Training complete, saved predictor to file optimal_eye_predictor.dat
real 10m49.273s
user 83m6.673s
sys 0m47.224s
一旦经过训练,我们可以使用predict_eyes.py文件(在上周的博客文章中回顾过)来直观地验证我们的模型是否工作正常:
如你所见,我们训练了一个 dlib 形状预测器:
- 精确地定位眼睛
- 就推断/预测速度而言,快吗
- 就模型尺寸而言,小吗
在训练您自己的自定义 dlib 形状预测器时,您也可以执行相同的分析。
我们如何加快我们的形状预测器调整脚本?

Figure 7: Tuning dlib shape predictor hyperparameters allows us to balance speed, accuracy, and model size.
这里明显的瓶颈是tune_predictor_hyperparams.py脚本— 只探索了 1.65%的可能选项,花了 2 天多才完成。
因此,探索所有可能的超参数将花费 个月的时间!
记住,我们正在训练一个只用眼睛的地标预测器。如果我们为所有 68 个典型的地标训练模型,训练将花费更长的时间。
在大多数情况下,我们根本没有那么多时间(或耐心)。
那么,我们能做些什么呢?
首先,我建议减少你的超参数空间。
例如,让我们假设您正在训练一个 dlib shape predictor 模型,该模型将被部署到嵌入式设备,如 Raspberry Pi、Google Coral 或 NVIDIA Jetson Nano。在这种情况下,你会想要一个快和小的模型——因此知道你需要包含一点准确性,以获得一个又快又小的模型。
在这种情况下,您将希望避免探索超参数空间的区域,这将导致模型更大且进行预测更慢。考虑限制你的tree_depth、cascade_depth和feature_pool_size探索,并专注于将导致更小、更快模型的值。
不要混淆部署和培训。你应该在一台功能强大的全尺寸机器上(即不是嵌入式设备)调整/训练你的形状预测器。从那里开始,假设你的模型对于一个嵌入式设备来说相当小,那么你应该部署这个模型到目标设备。
其次,我建议利用分布式计算。
为模型调整超参数是线性扩展问题的一个很好的例子,可以通过增加硬件来解决。
例如,你可以使用亚马逊、微软、谷歌等。云加速旋转多台机器。然后,每台机器可以负责探索超参数的非重叠子集。给定 N 台机器总数,你可以通过因子 N 减少调整你的形状预测器选项所花费的时间。
当然,我们可能没有预算来利用云,在这种情况下,你应该看到我上面的第一个建议。
摘要
在本教程中,您学习了如何自动调整 dlib 的形状预测器的选项和超参数,使您能够正确地平衡:
- 模型推断/预测速度
- 模型精度
- 模型尺寸
调整超参数在计算上非常,因此建议您:
- 在您的个人笔记本电脑或台式机上安排足够的时间(2-4 天)来运行 hyperparameter 调整脚本。
- 利用分布式系统和潜在的云来加速多个系统,每个系统处理超参数的非重叠子集。
运行优化脚本后,您可以打开生成的 CSV/Excel 文件,按照您最感兴趣的列(即速度、准确性、大小)对其进行排序,并确定您的最佳超参数。
给定参数,您从排序中发现您可以更新形状预测器训练脚本,然后训练您的模型。
我希望你喜欢今天的教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
使用 Keras、TensorFlow 和 OpenCV 将任何 CNN 图像分类器转换为对象检测器
在本教程中,您将学习如何使用 Keras、TensorFlow 和 OpenCV 将任何预先训练的深度学习图像分类器转化为对象检测器。
今天,我们开始一个关于深度学习和物体检测的四部分系列:
- 第一部分: 用 Keras 和 TensorFlow 把任何深度学习图像分类器变成物体检测器(今日帖)
- 第二部分: OpenCV 对象检测选择性搜索
- 第三部分: 使用 OpenCV、Keras 和 TensorFlow 进行目标检测的区域提议
- 第四部分: 用 Keras 和 TensorFlow 进行 R-CNN 物体检测
这一系列帖子的目标是更深入地了解基于深度学习的对象检测器是如何工作的,更具体地说:
- 传统的计算机视觉对象检测算法如何与深度学习相结合
- 端到端可训练物体检测器背后的动机是什么,以及与之相关的挑战是什么
- 最重要的是,开创性的更快的 R-CNN 架构是如何形成的(我们将在本系列中构建 R-CNN 架构的变体)
今天,我们将从物体检测的基础开始,包括如何采用预先训练的图像分类器,并利用图像金字塔、滑动窗口和非极大值抑制来构建一个基本的物体检测器(想想猪+线性 SVM 启发)。
在接下来的几周里,我们将学习如何从头开始构建一个端到端的可训练网络。
但是今天,让我们从基础开始。
要学习如何用 Keras 和 TensorFlow 将任何卷积神经网络图像分类器变成对象检测器,继续阅读。
使用 Keras、TensorFlow 和 OpenCV 将任何 CNN 图像分类器转变为对象检测器
在本教程的第一部分,我们将讨论图像分类和目标检测任务之间的主要区别。
然后,我将向您展示如何用大约 200 行代码将任何为图像分类而训练的卷积神经网络变成一个对象检测器。
在此基础上,我们将使用 Keras、TensorFlow 和 OpenCV 实现必要的代码,将图像分类器转换为对象检测器。
最后,我们将回顾我们的工作结果,指出我们的实现中的一些问题和限制,包括我们如何改进这种方法。
图像分类与目标检测
当执行图像分类时,给定一个输入图像,我们将其呈现给我们的神经网络,并且我们获得单个类别标签和与类别标签预测相关联的概率(图 1 ,左)。
此类标签旨在表征整个图像的内容,或者至少是图像中最主要的可见内容。
因此我们可以把图像分类看作:
- 一个图像在
- 一类标签出来了
对象检测,另一方面,不仅通过边界框 (x,y)-坐标(图 1, 右)告诉我们图像中的是什么(即类别标签),还告诉我们图像中的位置。
因此,物体检测算法允许我们:
- 输入一幅图像
- 获得多个边界框和类标签作为输出
最核心的是,任何对象检测算法(无论传统的计算机视觉还是最先进的深度学习)都遵循相同的模式:
- 1。输入:我们希望对其应用对象检测的图像
- 2。输出:三个值,包括:
- 2a。图像中每个对象的边界框列表、或(x,y)坐标
- 2b。与每个边界框相关联的类标签
- 2c。与每个边界框和类别标签相关联的概率/置信度得分
今天,您将看到这种模式的一个实例。
怎样才能把任何深度学习图像分类器变成物体检测器?
在这一点上,你可能想知道:
嘿,阿德里安,如果我有一个为图像分类而训练的卷积神经网络,我到底要怎么用它来进行物体检测呢?
根据你上面的解释,图像分类和目标检测似乎是根本不同的,需要两种不同类型的网络架构。
从本质上说,是正确的——物体检测不需要专门的网络架构。
任何读过关于更快的 R-CNN、单发探测器(SSDs)、YOLO、RetinaNet 等的论文的人。知道与传统的图像分类相比,目标检测网络更复杂,涉及面更广,需要多倍的数量级和更多的工作来实施。
也就是说,我们可以利用一种黑客技术将我们的 CNN 图像分类器变成一个物体检测器——秘方在于传统的计算机视觉 T2 算法。
回到基于深度学习的对象检测器之前,最先进的技术是使用 HOG +线性 SVM 来检测图像中的对象。
我们将借用 HOG +线性 SVM 的元素,将任何深度神经网络图像分类器转换为对象检测器。
HOG+线性 SVM 的第一个关键要素是使用图像金字塔。
“图像金字塔”是图像的多尺度表示:
利用图像金字塔允许我们在图像的不同比例(即大小)(图 2 )下找到图像中的对象。
在金字塔的底部,我们有原始大小的原始图像(就宽度和高度而言)。
并且在每个后续层,图像被调整大小(二次采样)并且可选地被平滑(通常通过高斯模糊)。
图像被渐进地二次采样,直到满足某个停止标准,这通常是当已经达到最小尺寸并且不再需要进行二次采样时。
我们需要的第二个关键要素是滑动窗口:
顾名思义,滑动窗口是一个固定大小的矩形,在一幅图像中从左到右和从上到下滑动。(正如图 3 所示,我们的滑动窗口可以用来检测输入图像中的人脸)。
在窗口的每一站,我们将:
- 提取 ROI
- 通过我们的图像分类器(例如。、线性 SVM、CNN 等。)
- 获得输出预测
结合图像金字塔,滑动窗口允许我们在输入图像的不同位置和多尺度定位物体
我们需要的最后一个关键因素是非极大值抑制。
当执行对象检测时,我们的对象检测器通常会在图像中的对象周围产生多个重叠的边界框。
这种行为完全正常——它只是意味着随着滑动窗口接近图像,我们的分类器组件返回越来越大的肯定检测概率。
当然,多个边界框带来了一个问题——那里只有一个对象,我们需要以某种方式折叠/移除无关的边界框。
该问题的解决方案是应用非最大值抑制(NMS ),它折叠弱的、重叠的边界框,支持更有把握的边界框:
在左边的,我们有多个检测,而在右边的,我们有非最大值抑制的输出,其将多个边界框折叠成一个单个检测。
结合传统计算机视觉和深度学习构建物体检测器
为了采用任何为图像分类而训练的卷积神经网络,并将其用于物体检测,我们将利用传统计算机视觉的三个关键要素:
- 图像金字塔:以不同的比例/大小定位对象。
- 滑动窗口:精确检测给定物体在图像中的位置。
- 非最大值抑制:折叠弱的重叠包围盒。
我们算法的一般流程是:
- 步骤#1: 输入图像
- 步骤#2: 构建图像金字塔
- 步骤#3: 对于图像金字塔的每个比例,运行一个滑动窗口
- 步骤#3a: 对于滑动窗口的每次停止,提取 ROI
- 步骤#3b: 获取感兴趣区域,并将其通过我们最初为图像分类而训练的 CNN
- 步骤#3c: 检查 CNN 的顶级类别标签的概率,并且如果满足最小置信度,则记录(1)类别标签和(2)滑动窗口的位置
- 步骤#4: 对边界框应用类别式非最大值抑制
- 步骤#5: 将结果返回给调用函数
这看起来似乎是一个复杂的过程,但是正如你将在这篇文章的剩余部分看到的,我们可以用< 200 行代码实现整个物体检测过程!
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
一旦你提取了。zip 从这篇博文的 【下载】 部分,你的目录将被组织如下:
.
├── images
│ ├── hummingbird.jpg
│ ├── lawn_mower.jpg
│ └── stingray.jpg
├── pyimagesearch
│ ├── __init__.py
│ └── detection_helpers.py
└── detect_with_classifier.py
2 directories, 6 files
实现我们的图像金字塔和滑动窗口实用功能
为了将我们的 CNN 图像分类器变成一个对象检测器,我们必须首先实现助手工具来构造滑动窗口和图像金字塔。
现在让我们实现这个助手函数——打开pyimagesearch模块中的detection_helpers.py文件,并插入以下代码:
# import the necessary packages
import imutils
def sliding_window(image, step, ws):
# slide a window across the image
for y in range(0, image.shape[0] - ws[1], step):
for x in range(0, image.shape[1] - ws[0], step):
# yield the current window
yield (x, y, image[y:y + ws[1], x:x + ws[0]])
def image_pyramid(image, scale=1.5, minSize=(224, 224)):
# yield the original image
yield image
# keep looping over the image pyramid
while True:
# compute the dimensions of the next image in the pyramid
w = int(image.shape[1] / scale)
image = imutils.resize(image, width=w)
# if the resized image does not meet the supplied minimum
# size, then stop constructing the pyramid
if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]:
break
# yield the next image in the pyramid
yield image
更多细节,请参考我的 用 Python 和 OpenCV 实现图像金字塔的文章,其中还包括一个替代的 scikit-image 图像金字塔实现,可能对你有用。
使用 Keras 和 TensorFlow 将预先训练的图像分类器转变为对象检测器
# import the necessary packages
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.applications import imagenet_utils
from imutils.object_detection import non_max_suppression
from pyimagesearch.detection_helpers import sliding_window
from pyimagesearch.detection_helpers import image_pyramid
import numpy as np
import argparse
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-s", "--size", type=str, default="(200, 150)",
help="ROI size (in pixels)")
ap.add_argument("-c", "--min-conf", type=float, default=0.9,
help="minimum probability to filter weak detections")
ap.add_argument("-v", "--visualize", type=int, default=-1,
help="whether or not to show extra visualizations for debugging")
args = vars(ap.parse_args())
# initialize variables used for the object detection procedure
WIDTH = 600
PYR_SCALE = 1.5
WIN_STEP = 16
ROI_SIZE = eval(args["size"])
INPUT_SIZE = (224, 224)
理解上述每个常量控制什么,对于理解如何使用 Keras、TensorFlow 和 OpenCV 将图像分类器转变为对象检测器至关重要。在继续下一步之前,一定要在心里区分这些。
让我们加载我们的 ResNet 分类 CNN 并输入图像:
# load our network weights from disk
print("[INFO] loading network...")
model = ResNet50(weights="imagenet", include_top=True)
# load the input image from disk, resize it such that it has the
# has the supplied width, and then grab its dimensions
orig = cv2.imread(args["image"])
orig = imutils.resize(orig, width=WIDTH)
(H, W) = orig.shape[:2]
36 线加载 ImageNet 上预训练的 ResNet。如果您选择使用不同的预训练分类器,您可以在这里为您的特定项目替换一个。要学习如何训练自己的分类器,建议你阅读 用 Python 进行计算机视觉的深度学习 。
# initialize the image pyramid
pyramid = image_pyramid(orig, scale=PYR_SCALE, minSize=ROI_SIZE)
# initialize two lists, one to hold the ROIs generated from the image
# pyramid and sliding window, and another list used to store the
# (x, y)-coordinates of where the ROI was in the original image
rois = []
locs = []
# time how long it takes to loop over the image pyramid layers and
# sliding window locations
start = time.time()
# loop over the image pyramid
for image in pyramid:
# determine the scale factor between the *original* image
# dimensions and the *current* layer of the pyramid
scale = W / float(image.shape[1])
# for each layer of the image pyramid, loop over the sliding
# window locations
for (x, y, roiOrig) in sliding_window(image, WIN_STEP, ROI_SIZE):
# scale the (x, y)-coordinates of the ROI with respect to the
# *original* image dimensions
x = int(x * scale)
y = int(y * scale)
w = int(ROI_SIZE[0] * scale)
h = int(ROI_SIZE[1] * scale)
# take the ROI and preprocess it so we can later classify
# the region using Keras/TensorFlow
roi = cv2.resize(roiOrig, INPUT_SIZE)
roi = img_to_array(roi)
roi = preprocess_input(roi)
# update our list of ROIs and associated coordinates
rois.append(roi)
locs.append((x, y, x + w, y + h))
# check to see if we are visualizing each of the sliding
# windows in the image pyramid
if args["visualize"] > 0:
# clone the original image and then draw a bounding box
# surrounding the current region
clone = orig.copy()
cv2.rectangle(clone, (x, y), (x + w, y + h),
(0, 255, 0), 2)
# show the visualization and current ROI
cv2.imshow("Visualization", clone)
cv2.imshow("ROI", roiOrig)
cv2.waitKey(0)
# show how long it took to loop over the image pyramid layers and
# sliding window locations
end = time.time()
print("[INFO] looping over pyramid/windows took {:.5f} seconds".format(
end - start))
# convert the ROIs to a NumPy array
rois = np.array(rois, dtype="float32")
# classify each of the proposal ROIs using ResNet and then show how
# long the classifications took
print("[INFO] classifying ROIs...")
start = time.time()
preds = model.predict(rois)
end = time.time()
print("[INFO] classifying ROIs took {:.5f} seconds".format(
end - start))
# decode the predictions and initialize a dictionary which maps class
# labels (keys) to any ROIs associated with that label (values)
preds = imagenet_utils.decode_predictions(preds, top=1)
labels = {}
# loop over the predictions
for (i, p) in enumerate(preds):
# grab the prediction information for the current ROI
(imagenetID, label, prob) = p[0]
# filter out weak detections by ensuring the predicted probability
# is greater than the minimum probability
if prob >= args["min_conf"]:
# grab the bounding box associated with the prediction and
# convert the coordinates
box = locs[i]
# grab the list of predictions for the label and add the
# bounding box and probability to the list
L = labels.get(label, [])
L.append((box, prob))
labels[label] = L
# loop over the labels for each of detected objects in the image
for label in labels.keys():
# clone the original image so that we can draw on it
print("[INFO] showing results for '{}'".format(label))
clone = orig.copy()
# loop over all bounding boxes for the current label
for (box, prob) in labels[label]:
# draw the bounding box on the image
(startX, startY, endX, endY) = box
cv2.rectangle(clone, (startX, startY), (endX, endY),
(0, 255, 0), 2)
# show the results *before* applying non-maxima suppression, then
# clone the image again so we can display the results *after*
# applying non-maxima suppression
cv2.imshow("Before", clone)
clone = orig.copy()
# extract the bounding boxes and associated prediction
# probabilities, then apply non-maxima suppression
boxes = np.array([p[0] for p in labels[label]])
proba = np.array([p[1] for p in labels[label]])
boxes = non_max_suppression(boxes, proba)
# loop over all bounding boxes that were kept after applying
# non-maxima suppression
for (startX, startY, endX, endY) in boxes:
# draw the bounding box and label on the image
cv2.rectangle(clone, (startX, startY), (endX, endY),
(0, 255, 0), 2)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(clone, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
# show the output after apply non-maxima suppression
cv2.imshow("After", clone)
cv2.waitKey(0)
为了应用 NMS,我们首先通过行 159 和 160 提取边界boxes和相关的预测概率(proba)。然后,我们将这些结果传递给我的 NMS 的模拟实现(第 161 行)。关于非极大值抑制的更多细节,请务必参考我的博文。
应用 NMS 后,行 165-171 在“之后”图像上标注边界框矩形和标签。第 174 和 175 行显示结果,直到按下一个键,此时所有 GUI 窗口关闭,脚本退出。
干得好!在下一节中,我们将分析使用图像分类器进行对象检测的方法的结果。
使用 Keras 和 TensorFlow 对物体检测器结果进行图像分类
在这一点上,我们准备看到我们努力工作的成果。
确保使用本教程的 【下载】 部分下载这篇博文的源代码和示例图片。
从那里,打开一个终端,并执行以下命令:
$ python detect_with_classifier.py --image images/stingray.jpg --size "(300, 150)"
[INFO] loading network...
[INFO] looping over pyramid/windows took 0.19142 seconds
[INFO] classifying ROIs...
[INFO] classifying ROIs took 9.67027 seconds
[INFO] showing results for 'stingray'
在这里,您可以看到我输入了一个包含一个“stingray”的示例图像,在 ImageNet 上训练的 CNN 将能够识别该图像(因为 ImageNet 包含一个“stingray”类)。
图 7 (上) 显示了我们的目标检测程序的原始输出。
注意黄貂鱼周围有多个重叠的边界框。
应用非最大值抑制(图 7,底部 )将边界框折叠成单个检测。
让我们尝试另一个图像,这是一只蜂鸟(同样,在 ImageNet 上训练的网络将能够识别):
$ python detect_with_classifier.py --image images/hummingbird.jpg --size "(250, 250)"
[INFO] loading network...
[INFO] looping over pyramid/windows took 0.07845 seconds
[INFO] classifying ROIs...
[INFO] classifying ROIs took 4.07912 seconds
[INFO] showing results for 'hummingbird'
图 8 (上) 显示了我们检测程序的原始输出,而底部显示了应用非极大值抑制后的输出。
同样,我们的“图像分类器转物体探测器”程序在这里表现良好。
但是,现在让我们尝试一个示例图像,其中我们的对象检测算法没有以最佳方式执行:
$ python detect_with_classifier.py --image images/lawn_mower.jpg --size "(200, 200)"
[INFO] loading network...
[INFO] looping over pyramid/windows took 0.13851 seconds
[INFO] classifying ROIs...
[INFO] classifying ROIs took 7.00178 seconds
[INFO] showing results for 'lawn_mower'
[INFO] showing results for 'half_track'
乍一看,这种方法似乎非常有效——我们能够在输入图像中定位“割草机”。
但是对于一辆“半履带”(一辆前面有普通车轮,后面有坦克状履带的军用车辆),实际上有一个秒检测:
$ python detect_with_classifier.py --image images/lawn_mower.jpg --size "(200, 200)" --min-conf 0.95
[INFO] loading network...
[INFO] looping over pyramid/windows took 0.13618 seconds
[INFO] classifying ROIs...
[INFO] classifying ROIs took 6.99953 seconds
[INFO] showing results for 'lawn_mower'
通过将最小置信度提高到 95%,我们过滤掉了不太有信心的【半履带】预测,只留下(正确的)【割草机】物体检测。
虽然我们将预先训练的图像分类器转变为对象检测器的过程并不完美,但它仍然可以用于某些情况,特别是在受控环境中捕捉图像时。
在本系列的剩余部分中,我们将学习如何改进我们的对象检测结果,并构建一个更加健壮的基于深度学习的对象检测器。
问题、限制和后续步骤
如果您仔细检查我们的对象检测程序的结果,您会注意到一些关键的要点:
- 实际物体探测器是慢。构建所有图像金字塔和滑动窗口位置需要大约 1/10 秒,这还不包括网络对所有感兴趣区域进行预测所需的时间(在 3 GHz CPU 上为 4-9 秒)!
- 边界框的位置不一定准确。这种对象检测算法的最大问题是,我们检测的准确性取决于我们对图像金字塔比例、滑动窗口步长和 ROI 大小的选择。如果这些值中的任何一个是关闭的,那么我们的检测器将执行次优。
- 网络不是端到端可训练的。原因基于深度学习的物体检测器如更快的 R-CNN、SSDs、YOLO 等。表现如此之好是因为它们是端到端可训练的,这意味着边界框预测中的任何误差都可以通过反向传播和更新网络的权重来变得更准确——因为我们使用的是具有固定权重的预训练图像分类器,所以我们不能通过网络反向传播误差项。
在这个由四部分组成的系列中,我们将研究如何解决这些问题,并构建一个类似于 R-CNN 网络家族的对象检测器。
总结
在本教程中,您学习了如何使用 Keras、TensorFlow 和 OpenCV 将任何预先训练的深度学习图像分类器转化为对象检测器。
为了完成这项任务,我们将深度学习与传统计算机视觉算法结合起来:
- 为了检测在不同比例(即尺寸)的物体,我们利用了图像金字塔、,其获取我们的输入图像并对其重复下采样。
- 为了检测在不同位置的物体,我们使用了滑动窗口,它从左到右和从上到下在输入图像上滑动一个固定大小的窗口——在窗口的每一站,我们提取 ROI 并将其通过我们的图像分类器。
- 对象检测算法为图像中的对象产生多个重叠的边界框是很自然的;为了将这些重叠的边界框“折叠”成单个检测,我们应用了非最大值抑制。
我们拼凑的对象检测例程的最终结果相当合理,但是有两个主要问题:
- 网络不是端到端可训练的。我们实际上并不是在“学习”探测物体;相反,我们只是采用感兴趣区域,并使用为图像分类而训练的 CNN 对它们进行分类。
- 物体检测结果慢得令人难以置信。在我的英特尔至强 W 3 Ghz 处理器上,根据输入图像的分辨率,对单幅图像应用物体检测大约需要 4-9.5 秒。这种物体检测器不能实时应用。
为了解决这两个问题,下周,我们将开始探索从 R-CNN、快速 R-CNN 和更快 R-CNN 家族构建对象检测器所需的算法。
这将是一个伟大的系列教程,所以你不会想错过它们!
要下载这篇文章的源代码(并在本系列的下一篇教程发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
Keras 中的 U-Net 图像分割
原文:https://pyimagesearch.com/2022/02/21/u-net-image-segmentation-in-keras/
https://www.youtube.com/embed/viG6SzmqX1c?feature=oembed
U-Net:在 PyTorch 中训练图像分割模型
原文:https://pyimagesearch.com/2021/11/08/u-net-training-image-segmentation-models-in-pytorch/
在今天的教程中,我们将研究图像分割,并基于流行的 U-Net 架构从头构建我们自己的分割模型。
本课是高级 PyTorch 技术 3 部分系列的最后一课:
计算机视觉社区已经设计了各种任务,例如图像分类、对象检测、定位等。,用于理解图像及其内容。这些任务让我们对对象类及其在图像中的位置有了更高层次的理解。
在图像分割中,我们更进一步,要求我们的模型将图像中的每个像素分类到它所代表的对象类别。这可以被视为像素级图像分类,并且是比简单的图像分类、检测或定位困难得多的任务。我们的模型必须自动确定图像中像素级的所有对象及其精确位置和边界。
因此,图像分割提供了对图像的复杂理解,并广泛用于医学成像、自动驾驶、机器人操纵等。
要学习如何在 PyTorch 中训练一个基于 U-Net 的分割模型, 继续阅读。
U-Net:在 PyTorch 中训练图像分割模型
在本教程中,我们将学习图像分割,并在 PyTorch 中构建和训练一个分割模型。我们将重点介绍一个非常成功的架构,U-Net,它最初是为医学图像分割而提出的。此外,我们将了解 U-Net 模型的显著特征,这使得它成为图像分割任务的合适选择。
具体来说,我们将在本教程中详细讨论以下内容:
- U-Net 的架构细节使其成为一个强大的细分模型
- 为我们的图像分割任务创建自定义 PyTorch 数据集
- 从头开始训练 U-Net 分段模型
- 用我们训练好的 U-Net 模型对新图像进行预测
U-Net 架构概述
U-Net 架构(见图 1 )遵循编码器-解码器级联结构,其中编码器逐渐将信息压缩成低维表示。然后,解码器将该信息解码回原始图像尺寸。由于这一点,该架构获得了一个整体的 U 形,这导致了名称 U-Net。
除此之外,U-Net 架构的一个显著特征是跳过连接(在图 1 中用灰色箭头表示),这使得信息能够从编码器端流向解码器端,从而使模型能够做出更好的预测。
具体来说,随着我们的深入,编码器在更高的抽象层次上处理信息。这仅仅意味着在初始层,编码器的特征映射捕获关于对象纹理和边缘的低级细节,并且随着我们逐渐深入,特征捕获关于对象形状和类别的高级信息。
值得注意的是,要分割图像中的对象,低层和高层信息都很重要。例如,对象和边缘信息之间的纹理变化可以帮助确定各种对象的边界。另一方面,关于对象形状所属类别的高级信息可以帮助分割相应的像素,以校正它们所代表的对象类别。
因此,为了在预测期间使用这两条信息,U-Net 架构在编码器和解码器之间实现了跳跃连接。这使我们能够在编码器端从不同深度获取中间特征图信息,并在解码器端将其连接起来,以处理和促进更好的预测。
在本教程的后面,我们将更详细地研究 U-Net 模型,并在 PyTorch 中从头开始构建它。
我们的 TGS 盐分割数据集
对于本教程,我们将使用 TGS 盐分割数据集。该数据集是作为 Kaggle 上的 TGS 盐鉴定挑战赛的一部分推出的。
实际上,即使有人类专家的帮助,也很难从图像中准确地识别盐沉积的位置。因此,挑战要求参与者帮助专家从地球表面下的地震图像中精确地确定盐沉积的位置。这实际上很重要,因为对盐存在的不正确估计会导致公司在错误的地点设置钻探机进行开采,导致时间和资源的浪费。
我们使用这个数据集的一个子部分,它包括 4000 张大小为101×101像素的图像,取自地球上的不同位置。这里,每个像素对应于盐沉积或沉积物。除了图像,我们还提供了与图像相同尺寸的地面实况像素级分割掩模(见图 2)。
蒙版中的白色像素代表盐沉积,黑色像素代表沉积物。我们的目标是正确预测图像中对应于盐沉积的像素。因此,我们有一个二元分类问题,其中我们必须将每个像素分类到两个类别之一,类别 1:盐或类别 2:非盐(或者,换句话说,沉积物)。
配置您的开发环境
要遵循本指南,您需要在系统上安装 PyTorch 深度学习库、matplotlib、OpenCV、imutils、scikit-learn 和 tqdm 软件包。
幸运的是,使用 pip 安装这些包非常容易:
$ pip install torch torchvision
$ pip install matplotlib
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install scikit-learn
$ pip install tqdm
如果你在为 PyTorch 配置开发环境时需要帮助,我强烈推荐阅读 PyTorch 文档 — PyTorch 的文档很全面,可以让你快速上手。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
.
├── dataset
│ └── train
├── output
├── pyimagesearch
│ ├── config.py
│ ├── dataset.py
│ └── model.py
├── predict.py
└── train.py
dataset文件夹存储我们将用于训练我们的细分模型的 TGS 盐细分数据集。
此外,我们将在output文件夹中存储我们的训练模型和训练损失图。
pyimagesearch文件夹中的config.py 文件存储了我们代码的参数、初始设置和配置。
另一方面,dataset.py文件由我们的定制分段数据集类组成,model.py文件包含我们的 U-Net 模型的定义。
最后,我们的模型训练和预测代码分别在train.py和predict.py文件中定义。
创建我们的配置文件
我们从讨论config.py文件开始,它存储了教程中使用的配置和参数设置。
# import the necessary packages
import torch
import os
# base path of the dataset
DATASET_PATH = os.path.join("dataset", "train")
# define the path to the images and masks dataset
IMAGE_DATASET_PATH = os.path.join(DATASET_PATH, "images")
MASK_DATASET_PATH = os.path.join(DATASET_PATH, "masks")
# define the test split
TEST_SPLIT = 0.15
# determine the device to be used for training and evaluation
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# determine if we will be pinning memory during data loading
PIN_MEMORY = True if DEVICE == "cuda" else False
我们从进口2 号线和3 号线的必要包装开始。然后,我们在第 6 行的上定义数据集(即DATASET_PATH)的路径,并在第 9行和第 10** 行的IMAGE_DATASET_PATH和MASK_DATASET_PATH上定义数据集文件夹内图像和蒙版的路径。**
在第 13 行,我们定义了数据集的一部分,我们将为测试集保留。然后,在行第 16 处,我们定义了DEVICE参数,该参数根据可用性决定我们是使用 GPU 还是 CPU 来训练我们的分割模型。在这种情况下,我们使用支持 CUDA 的 GPU 设备,并且在第 19 行将PIN_MEMORY参数设置为True。
# define the number of channels in the input, number of classes,
# and number of levels in the U-Net model
NUM_CHANNELS = 1
NUM_CLASSES = 1
NUM_LEVELS = 3
# initialize learning rate, number of epochs to train for, and the
# batch size
INIT_LR = 0.001
NUM_EPOCHS = 40
BATCH_SIZE = 64
# define the input image dimensions
INPUT_IMAGE_WIDTH = 128
INPUT_IMAGE_HEIGHT = 128
# define threshold to filter weak predictions
THRESHOLD = 0.5
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the output serialized model, model training
# plot, and testing image paths
MODEL_PATH = os.path.join(BASE_OUTPUT, "unet_tgs_salt.pth")
PLOT_PATH = os.path.sep.join([BASE_OUTPUT, "plot.png"])
TEST_PATHS = os.path.sep.join([BASE_OUTPUT, "test_paths.txt"])
接下来,我们在第 23-25 行的上定义NUM_CHANNELS、NUM_CLASSES和NUM_LEVELS参数,我们将在本教程稍后详细讨论。最后,在第 29-31 行,我们定义了初始学习率(即INIT_LR)、总时期数(即NUM_EPOCHS)和批量大小(即BATCH_SIZE)等训练参数。
在第 34 行和第 35 行,我们还定义了输入图像的尺寸,我们的图像应该调整到这个尺寸,以便我们的模型处理它们。我们在第 38 行上进一步定义了一个阈值参数,这将有助于我们在基于二元分类的分割任务中将像素分类为两类中的一类。
最后,我们在第 41 行的上定义到输出文件夹(即BASE_OUTPUT)的路径,并在第 45-47 行的上定义到输出文件夹内的训练模型权重、训练图和测试图像的对应路径。
创建我们的自定义分段数据集类
既然我们已经定义了初始配置和参数,我们就可以理解将用于分段数据集的自定义数据集类了。
让我们从项目目录的pyimagesearch文件夹中打开dataset.py文件。
# import the necessary packages
from torch.utils.data import Dataset
import cv2
class SegmentationDataset(Dataset):
def __init__(self, imagePaths, maskPaths, transforms):
# store the image and mask filepaths, and augmentation
# transforms
self.imagePaths = imagePaths
self.maskPaths = maskPaths
self.transforms = transforms
def __len__(self):
# return the number of total samples contained in the dataset
return len(self.imagePaths)
def __getitem__(self, idx):
# grab the image path from the current index
imagePath = self.imagePaths[idx]
# load the image from disk, swap its channels from BGR to RGB,
# and read the associated mask from disk in grayscale mode
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(self.maskPaths[idx], 0)
# check to see if we are applying any transformations
if self.transforms is not None:
# apply the transformations to both image and its mask
image = self.transforms(image)
mask = self.transforms(mask)
# return a tuple of the image and its mask
return (image, mask)
我们首先从行 2 上的torch.utils.data模块导入Dataset类。这很重要,因为所有 PyTorch 数据集都必须从这个基本数据集类继承。此外,在第 3 行,我们导入了 OpenCV 包,这将使我们能够使用其图像处理功能。
我们现在准备定义我们自己的自定义分段数据集。每个 PyTorch 数据集都需要从Dataset类(第 5 行)继承,并且应该有一个 __len__ ( 第 13-15 行)和一个 __getitem__ ( 第 17-34 行)方法。下面我们将逐一讨论这些方法。
我们从定义我们的初始化器构造函数开始,也就是第 6-11 行的 __init__ 方法。该方法将我们的数据集的图像路径列表(即imagePaths)、相应的地面真相遮罩(即maskPaths)以及我们想要应用于我们的输入图像(行 6 )的变换集(即transforms)作为输入。
在的第 9-11 行,我们用输入到 __init__ 构造函数的参数来初始化我们的SegmentationDataset类的属性。
接下来,我们定义 __len__ 方法,该方法返回数据集中图像路径的总数,如第 15 行所示。
__getitem__ 方法的任务是将一个索引作为输入(第 17 行)并从数据集中返回相应的样本。在第 19 行,我们简单地在输入图像路径列表中的idx索引处抓取图像路径。然后,我们使用 OpenCV 加载图像(第 23 行)。默认情况下,OpenCV 加载 BGR 格式的图像,我们将其转换为 RGB 格式,如第 24 行所示。我们还在第 25 行的中加载了相应的灰度模式的地面实况分割蒙版。
最后,我们检查想要应用于数据集图像的输入变换(第 28 行),并分别在第 30 行和第 31 行用所需的变换来变换图像和蒙版。这是很重要的,因为我们希望我们的图像和地面真相面具对应,并有相同的维度。在行第 34 处,我们返回包含图像及其对应遮罩(即(image, mask))的元组,如图所示。
这就完成了我们的定制分段数据集的定义。接下来,我们将讨论 U-Net 架构的实现。
在 PyTorch 中构建我们的 U-Net 模型
是时候详细研究我们的 U-Net 模型架构,并在 PyTorch 中从头开始构建它了。
我们从项目目录的pyimagesearch文件夹中打开我们的model.py文件,然后开始。
# import the necessary packages
from . import config
from torch.nn import ConvTranspose2d
from torch.nn import Conv2d
from torch.nn import MaxPool2d
from torch.nn import Module
from torch.nn import ModuleList
from torch.nn import ReLU
from torchvision.transforms import CenterCrop
from torch.nn import functional as F
import torch
在第 2-11 行,我们从 PyTorch 导入必要的层、模块和激活函数,我们将使用它们来构建我们的模型。
总的来说,我们的 U-Net 模型将由一个Encoder类和一个Decoder类组成。编码器将逐渐减小空间维度来压缩信息。此外,它将增加通道的数量,即每个阶段的特征图的数量,使我们的模型能够捕捉我们图像中的不同细节或特征。另一方面,解码器将采用最终的编码器表示,并逐渐增加空间维度和减少通道数量,以最终输出与输入图像具有相同空间维度的分割掩模。
接下来,我们定义一个Block模块作为编码器和解码器架构的构建单元。值得注意的是,我们定义的所有模型或模型子部分都需要从 PyTorch Module类继承,该类是 PyTorch 中所有神经网络模块的父类。
class Block(Module):
def __init__(self, inChannels, outChannels):
super().__init__()
# store the convolution and RELU layers
self.conv1 = Conv2d(inChannels, outChannels, 3)
self.relu = ReLU()
self.conv2 = Conv2d(outChannels, outChannels, 3)
def forward(self, x):
# apply CONV => RELU => CONV block to the inputs and return it
return self.conv2(self.relu(self.conv1(x)))
我们从在第 13-23 行的上定义我们的Block类开始。该模块的功能是获取具有inChannels个通道的输入特征图,应用两个卷积运算并在它们之间进行 ReLU 激活,并返回具有outChannels个通道的输出特征图。
__init__ 构造器将两个参数inChannels和outChannels ( 第 14 行)作为输入,这两个参数分别确定输入特征图和输出特征图中的通道数。
我们初始化两个卷积层(即self.conv1和self.conv2)以及第 17-19 行上的一个 ReLU 激活。在第 21-23 行上,我们定义了forward函数,该函数将我们的特征图x作为输入,应用self.conv1 => self.relu => self.conv2操作序列并返回输出特征图。
class Encoder(Module):
def __init__(self, channels=(3, 16, 32, 64)):
super().__init__()
# store the encoder blocks and maxpooling layer
self.encBlocks = ModuleList(
[Block(channels[i], channels[i + 1])
for i in range(len(channels) - 1)])
self.pool = MaxPool2d(2)
def forward(self, x):
# initialize an empty list to store the intermediate outputs
blockOutputs = []
# loop through the encoder blocks
for block in self.encBlocks:
# pass the inputs through the current encoder block, store
# the outputs, and then apply maxpooling on the output
x = block(x)
blockOutputs.append(x)
x = self.pool(x)
# return the list containing the intermediate outputs
return blockOutputs
接下来,我们在第 25-47 行的上定义我们的Encoder类。类构造器(即 __init__ 方法)将通道维度(行 26** )的元组(即channels)作为输入。请注意,第一个值表示我们的输入图像中的通道数量,随后的数字逐渐使通道尺寸加倍。**
我们首先在第 29-31 行的上 PyTorch 的ModuleList功能的帮助下初始化编码器的块列表(即self.encBlocks)。每个Block获取前一个块的输入通道,并将输出特征图中的通道加倍。我们还初始化了一个MaxPool2d()层,它将特征图的空间维度(即高度和宽度)减少了 2 倍。
最后,我们在第 34-47 行的上为我们的编码器定义了forward函数。该功能将图像x作为输入,如行 34** 所示。在第 36行上,我们初始化一个空的blockOutputs列表,存储来自编码器模块的中间输出。请注意,这将使我们能够稍后将这些输出传递给解码器,在那里可以用解码器特征映射来处理它们。**
在第 39-44 行上,我们循环通过编码器中的每个块,通过该块处理输入特征图(第 42 行,并将该块的输出添加到我们的blockOutputs列表中。然后,我们对我们的块输出应用最大池操作(行 44 )。这是对编码器中的每个块进行的。
最后,我们在第 47 行的返回我们的blockOutputs列表。
class Decoder(Module):
def __init__(self, channels=(64, 32, 16)):
super().__init__()
# initialize the number of channels, upsampler blocks, and
# decoder blocks
self.channels = channels
self.upconvs = ModuleList(
[ConvTranspose2d(channels[i], channels[i + 1], 2, 2)
for i in range(len(channels) - 1)])
self.dec_blocks = ModuleList(
[Block(channels[i], channels[i + 1])
for i in range(len(channels) - 1)])
def forward(self, x, encFeatures):
# loop through the number of channels
for i in range(len(self.channels) - 1):
# pass the inputs through the upsampler blocks
x = self.upconvs[i](x)
# crop the current features from the encoder blocks,
# concatenate them with the current upsampled features,
# and pass the concatenated output through the current
# decoder block
encFeat = self.crop(encFeatures[i], x)
x = torch.cat([x, encFeat], dim=1)
x = self.dec_blocks[i](x)
# return the final decoder output
return x
def crop(self, encFeatures, x):
# grab the dimensions of the inputs, and crop the encoder
# features to match the dimensions
(_, _, H, W) = x.shape
encFeatures = CenterCrop([H, W])(encFeatures)
# return the cropped features
return encFeatures
现在我们定义我们的Decoder类(第 50-87 行)。类似于编码器定义,解码器 __init__ 方法将信道维度(行 51 )的元组(即channels)作为输入。请注意,与编码器端相比,这里的不同之处在于通道逐渐减少 2 倍,而不是增加。
我们初始化线 55 上的通道数。此外,在第 56-58 行,我们定义了一列上采样块(即self.upconvs),它们使用ConvTranspose2d层以因子 2 对特征图的空间维度(即高度和宽度)进行上采样。此外,该层还将通道数量减少了 1/2。
最后,我们为解码器初始化一个类似于编码器端的块列表(即self.dec_Blocks)。
在第 63-75 行,我们定义了forward函数,它将我们的特征图x和来自编码器的中间输出列表(即encFeatures)作为输入。从行 65 开始,我们循环遍历多个通道,并执行以下操作:
- 首先,我们通过我们的第 i 上采样块(行 67 )对解码器的输入(即
x)进行上采样 - 由于我们必须(沿着通道维度)将来自编码器的第 i (即
encFeatures[i])个中间特征图与来自上采样块的当前输出x连接起来,我们需要确保encFeatures[i]和x的空间维度匹配。为了完成这个,我们在第 73 行使用了我们的crop函数。 - 接下来,我们沿着行 74 上的通道维度,将我们裁剪的编码器特征图(即
encFeat)与我们当前的上采样特征图x连接起来 - 最后,我们将级联的输出通过我们的第 i 个解码器模块(线 75
循环完成后,我们在线 78 上返回最终的解码器输出。
在第 80-87 行,我们定义了我们的裁剪函数,该函数从编码器(即encFeatures)获取一个中间特征图,从解码器(即x)获取一个特征图输出,并在空间上将前者裁剪为后者的尺寸。
为此,我们首先获取第 83 行上x的空间尺寸(即高度H和宽度W)。然后,我们使用CenterCrop函数(行 84** )将encFeatures裁剪到空间维度[H, W],并最终在行 87 上返回裁剪后的输出。**
既然我们已经定义了组成我们的 U-Net 模型的子模块,我们就准备构建我们的 U-Net 模型类。
class UNet(Module):
def __init__(self, encChannels=(3, 16, 32, 64),
decChannels=(64, 32, 16),
nbClasses=1, retainDim=True,
outSize=(config.INPUT_IMAGE_HEIGHT, config.INPUT_IMAGE_WIDTH)):
super().__init__()
# initialize the encoder and decoder
self.encoder = Encoder(encChannels)
self.decoder = Decoder(decChannels)
# initialize the regression head and store the class variables
self.head = Conv2d(decChannels[-1], nbClasses, 1)
self.retainDim = retainDim
self.outSize = outSize
我们首先定义 __init__ 构造函数方法(第 91-103 行)。它将以下参数作为输入:
encChannels:元组定义了当我们的输入通过编码器时通道维度的逐渐增加。我们从 3 个通道(即 RGB)开始,然后将通道数量增加一倍。decChannels:元组定义了当我们的输入通过解码器时,信道维度的逐渐减小。我们每走一步都将通道减少 2 倍。nbClasses:这定义了我们必须对每个像素进行分类的分割类别的数量。这通常对应于我们的输出分割图中的通道数,其中每个类有一个通道。- 因为我们正在处理两个类(即,二进制分类),所以我们保持单个通道并使用阈值进行分类,这将在后面讨论。
retainDim:表示是否要保留原来的输出尺寸。outSize:决定输出分割图的空间尺寸。我们将其设置为与输入图像相同的尺寸(即(config.INPUT_IMAGE_HEIGHT, config.INPUT_IMAGE_WIDTH))。
在第 97 和 98 行上,我们初始化我们的编码器和解码器网络。此外,我们初始化一个卷积头,稍后通过它将我们的解码器输出作为输入,并输出我们的具有nbClasses个通道的分割图(行 101 )。
我们还在行 102 和 103 上初始化self.retainDim和self.outSize属性。
def forward(self, x):
# grab the features from the encoder
encFeatures = self.encoder(x)
# pass the encoder features through decoder making sure that
# their dimensions are suited for concatenation
decFeatures = self.decoder(encFeatures[::-1][0],
encFeatures[::-1][1:])
# pass the decoder features through the regression head to
# obtain the segmentation mask
map = self.head(decFeatures)
# check to see if we are retaining the original output
# dimensions and if so, then resize the output to match them
if self.retainDim:
map = F.interpolate(map, self.outSize)
# return the segmentation map
return map
最后,我们准备讨论我们的 U-Net 模型的forward功能(第 105-124 行)。
我们从通过编码器传递输入x开始。这将输出编码器特征图列表(即encFeatures,如行 107 所示。注意encFeatures列表包含从第一个编码器模块输出到最后一个的所有特征映射,如前所述。所以我们可以把这个列表中的特征图顺序倒过来:encFeatures[::-1]。
现在encFeatures[::-1]列表包含逆序的特征映射输出(即从最后一个到第一个编码器模块)。请注意,这一点很重要,因为在解码器端,我们将从最后一个编码器模块输出到第一个编码器模块输出开始利用编码器特征映射。
接下来,我们通过线 111 将最终编码器块的输出(即encFeatures[::-1][0])和所有中间编码器块的特征映射输出(即encFeatures[::-1][1:])传递给解码器。解码器的输出存储为decFeatures。
我们将解码器输出传递给我们的卷积头(行 116 )以获得分段掩码。
最后,我们检查self.retainDim属性是否为True ( 第 120 行)。如果是,我们将最终分割图插值到由self.outSize ( 行 121 )定义的输出尺寸。我们在第 124 行返回最终的分割图。
这就完成了我们的 U-Net 模型的实现。接下来,我们将了解细分渠道的培训程序。
训练我们的细分模型
现在我们已经实现了数据集类和模型架构,我们准备在 PyTorch 中构建和训练我们的分段管道。让我们从项目目录中打开train.py文件。
具体来说,我们将详细了解以下内容:
- 构建数据加载管道
- 初始化模型和训练参数
- 定义训练循环
- 可视化训练和测试损失曲线
# USAGE
# python train.py
# import the necessary packages
from pyimagesearch.dataset import SegmentationDataset
from pyimagesearch.model import UNet
from pyimagesearch import config
from torch.nn import BCEWithLogitsLoss
from torch.optim import Adam
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_split
from torchvision import transforms
from imutils import paths
from tqdm import tqdm
import matplotlib.pyplot as plt
import torch
import time
import os
我们首先在5 号线和 6 号线上导入我们自定义的SegmentationDataset类和UNet模型。接下来,我们在第 7 行导入我们的配置文件。
由于我们的盐分割任务是像素级二进制分类问题,我们将使用二进制交叉熵损失来训练我们的模型。在第 8 行,我们从 PyTorch nn模块导入二值交叉熵损失函数(即BCEWithLogitsLoss)。除此之外,我们从 PyTorch optim模块导入了Adam优化器,我们将使用它来训练我们的网络( Line 9 )。
接下来,在的第 11 行,我们从sklearn库中导入内置的train_test_split函数,使我们能够将数据集分成训练集和测试集。此外,我们从第 12 行的上的torchvision导入transforms模块,对我们的输入图像应用图像变换。
最后,我们导入其他有用的包来处理我们的文件系统,在训练过程中跟踪进度,为我们的训练过程计时,并在第行第 13-18 绘制损失曲线。
一旦我们导入了所有必需的包,我们将加载我们的数据并构建数据加载管道。
# load the image and mask filepaths in a sorted manner
imagePaths = sorted(list(paths.list_images(config.IMAGE_DATASET_PATH)))
maskPaths = sorted(list(paths.list_images(config.MASK_DATASET_PATH)))
# partition the data into training and testing splits using 85% of
# the data for training and the remaining 15% for testing
split = train_test_split(imagePaths, maskPaths,
test_size=config.TEST_SPLIT, random_state=42)
# unpack the data split
(trainImages, testImages) = split[:2]
(trainMasks, testMasks) = split[2:]
# write the testing image paths to disk so that we can use then
# when evaluating/testing our model
print("[INFO] saving testing image paths...")
f = open(config.TEST_PATHS, "w")
f.write("\n".join(testImages))
f.close()
在的第 21 行和第 22 行,我们首先定义两个列表(即imagePaths和maskPaths),分别存储所有图像的路径和它们对应的分割掩膜。
然后,我们在 scikit-learn 的第 26 行的train_test_split的帮助下,将我们的数据集划分为一个训练和测试集。注意,该函数将一系列列表(此处为imagePaths和maskPaths)作为输入,同时返回训练和测试集图像以及相应的训练和测试集掩码,我们在行的第 30 和 31 行对其进行解包。
我们将testImages列表中的路径存储在由第 36 行上的config.TEST_PATHS定义的测试文件夹路径中。
现在,我们已经准备好设置数据加载管道了。
# define transformations
transforms = transforms.Compose([transforms.ToPILImage(),
transforms.Resize((config.INPUT_IMAGE_HEIGHT,
config.INPUT_IMAGE_WIDTH)),
transforms.ToTensor()])
# create the train and test datasets
trainDS = SegmentationDataset(imagePaths=trainImages, maskPaths=trainMasks,
transforms=transforms)
testDS = SegmentationDataset(imagePaths=testImages, maskPaths=testMasks,
transforms=transforms)
print(f"[INFO] found {len(trainDS)} examples in the training set...")
print(f"[INFO] found {len(testDS)} examples in the test set...")
# create the training and test data loaders
trainLoader = DataLoader(trainDS, shuffle=True,
batch_size=config.BATCH_SIZE, pin_memory=config.PIN_MEMORY,
num_workers=os.cpu_count())
testLoader = DataLoader(testDS, shuffle=False,
batch_size=config.BATCH_SIZE, pin_memory=config.PIN_MEMORY,
num_workers=os.cpu_count())
我们首先定义加载输入图像时要应用的变换,并在第 41-44 行的Compose函数的帮助下合并它们。我们的转型包括:
- 它使我们能够将输入的图像转换成 PIL 图像格式。请注意,这是必要的,因为我们使用 OpenCV 在自定义数据集中加载图像,但是 PyTorch 希望输入图像样本是 PIL 格式的。
Resize():允许我们将图像调整到我们的模型可以接受的特定输入尺寸(即config.INPUT_IMAGE_HEIGHT、config.INPUT_IMAGE_WIDTH)ToTensor():使我们能够将输入图像转换为 PyTorch 张量,并将输入的 PIL 图像从最初的[0, 255]转换为[0, 1]。
最后,我们将训练和测试图像以及相应的掩码传递给我们的定制SegmentationDataset,以在第 47-50 行上创建训练数据集(即trainDS)和测试数据集(即testDS)。请注意,我们可以简单地将行 41 上定义的转换传递给我们的自定义 PyTorch 数据集,以便在自动加载图像时应用这些转换。
我们现在可以借助len()方法打印出trainDS和testDS中的样本数,如第 51 行和第 52 行所示。
在的第 55-60 行,我们通过将我们的训练数据集和测试数据集传递给 Pytorch DataLoader 类,直接创建我们的训练数据加载器(即trainLoader)和测试数据加载器(即testLoader)。我们将shuffle参数True保存在训练数据加载器中,因为我们希望来自所有类的样本均匀地出现在一个批次中,这对于基于批次梯度的优化方法的最佳学习和收敛非常重要。
既然我们已经构建并定义了数据加载管道,我们将初始化我们的 U-Net 模型和训练参数。
# initialize our UNet model
unet = UNet().to(config.DEVICE)
# initialize loss function and optimizer
lossFunc = BCEWithLogitsLoss()
opt = Adam(unet.parameters(), lr=config.INIT_LR)
# calculate steps per epoch for training and test set
trainSteps = len(trainDS) // config.BATCH_SIZE
testSteps = len(testDS) // config.BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "test_loss": []}
我们首先在行 63 定义我们的UNet()模型。注意,to()函数将我们的config.DEVICE作为输入,并在提到的设备上注册我们的模型及其参数。
在第 66 和 67 行,我们定义了我们的损失函数和优化器,我们将用它来训练我们的分割模型。Adam优化器类将我们模型的参数(即unet.parameters())和学习率(即config.INIT_LR)作为输入,我们将使用它们来训练我们的模型。
然后,我们定义迭代我们的整个训练和测试集所需的步骤数,即第 70 行和第 71 行上的trainSteps和testSteps。假设 dataloader 为我们的模型config.BATCH_SIZE提供了一次要处理的样本数,那么迭代整个数据集(即训练集或测试集)所需的步骤数可以通过将数据集中的样本总数除以批量大小来计算。
我们还在第 74 行的上创建了一个空字典H,我们将使用它来跟踪我们的训练和测试损失历史。
最后,我们已经准备好开始理解我们的训练循环。
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.NUM_EPOCHS)):
# set the model in training mode
unet.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalTestLoss = 0
# loop over the training set
for (i, (x, y)) in enumerate(trainLoader):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = unet(x)
loss = lossFunc(pred, y)
# first, zero out any previously accumulated gradients, then
# perform backpropagation, and then update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# add the loss to the total training loss so far
totalTrainLoss += loss
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
unet.eval()
# loop over the validation set
for (x, y) in testLoader:
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation loss
pred = unet(x)
totalTestLoss += lossFunc(pred, y)
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgTestLoss = totalTestLoss / testSteps
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["test_loss"].append(avgTestLoss.cpu().detach().numpy())
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.NUM_EPOCHS))
print("Train loss: {:.6f}, Test loss: {:.4f}".format(
avgTrainLoss, avgTestLoss))
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
为了给我们的训练过程计时,我们使用第 78 行的函数。这个函数在被调用时输出时间。因此,我们可以在训练过程开始时调用一次,在结束时调用一次,然后减去两次输出,得到经过的时间。
我们在训练循环中迭代config.NUM_EPOCHS,如第 79 行的所示。在我们开始训练之前,将我们的模型设置为训练模式是很重要的,正如我们在81线上看到的。这将指导 PyTorch 引擎跟踪我们的计算和梯度,并构建一个计算图,以便稍后进行反向传播。
我们初始化第 84 行和第 85 行上的变量totalTrainLoss和totalTestLoss,以跟踪我们在给定时期的损失。接下来,在行 88 上,我们迭代我们的trainLoader数据加载器,它一次提供一批样本。如第 88-103 行所示,训练循环包括以下步骤:
- 首先,在第 90 行的上,我们将数据样本(即
x和y)移动到由config.DEVICE定义的用于训练模型的设备上 - 然后,我们将输入图像样本
x通过线 93 上的unet模型,并获得输出预测(即pred - 在第 94 行,我们计算模型预测
pred和我们的地面实况标签y之间的损失 - 在第 98-100 行上,我们通过模型反向传播我们的损失并更新参数
- 这是在三个简单步骤的帮助下完成的;我们从清除线 98 上先前步骤的所有累积梯度开始。接下来,我们在计算的损失函数上调用
backward方法,如第 99 行所示。这将指导 PyTorch 计算我们的损失相对于计算图中涉及的所有变量的梯度。最后,我们调用opt.step()来更新我们的模型参数,如行 100 所示。
- 这是在三个简单步骤的帮助下完成的;我们从清除线 98 上先前步骤的所有累积梯度开始。接下来,我们在计算的损失函数上调用
- 最后,行 103 使我们能够通过将该步骤的损失添加到
totalTrainLoss变量来跟踪我们的训练损失,该变量累积所有样本的训练损失。
重复该过程,直到遍历所有数据集样本一次(即,完成一个时期)。
一旦我们处理了整个训练集,我们将希望在测试集上评估我们的模型。这很有帮助,因为它允许我们监控测试损失,并确保我们的模型不会过度适应训练集。
在测试集上评估我们的模型时,我们不跟踪梯度,因为我们不会学习或反向传播。因此,我们可以在torch.no_grad()的帮助下关闭梯度计算,并冻结模型权重,如行 106 所示。这将指示 PyTorch 引擎不计算和保存梯度,从而在评估期间节省内存和计算。
我们通过调用行 108 上的eval()函数将我们的模型设置为评估模式。然后,我们遍历测试集样本,并计算我们的模型对测试数据的预测(第 116 行)。然后将测试损失加到totalTestLoss中,该值累计整个测试集的测试损失。
然后,我们获得所有步骤的平均训练损失和测试损失,即第 120 和 121 行、上的avgTrainLoss和avgTestLoss,并将它们存储在第 124 和 125 行上的中,存储到我们的字典H中,该字典是我们在开始时创建的,用于跟踪我们的损失。
最后,我们打印当前的 epoch 统计数据,包括 128-130 线上的列车和测试损失。这使我们结束了一个时期,包括在我们的训练集上的一个完整的训练周期和在我们的测试集上的评估。整个过程重复config.NUM_EPOCHS次,直到我们的模型收敛。
在的第 133 行和第 134 行上,我们记下了我们训练循环的结束时间,并从startTime(我们在训练开始时初始化的)中减去endTime,以获得我们网络训练期间所用的总时间。
# plot the training loss
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["test_loss"], label="test_loss")
plt.title("Training Loss on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
# serialize the model to disk
torch.save(unet, config.MODEL_PATH)
接下来,我们使用 matplotlib 的 pyplot 包来可视化和保存我们在行 138-146 上的训练和测试损失曲线。我们可以简单地将损失历史字典H的train_loss和test_loss键传递给plot函数,如第行第 140 和 141 行所示。最后,我们设置我们的图的标题和图例(行 142-145 ),并将我们的可视化保存在行 146 。
最后,在第 149 行,我们在torch.save()函数的帮助下保存我们训练好的 U-Net 模型的权重,该函数将我们训练好的unet模型和config.MODEL_PATH作为我们想要保存模型的输入。
一旦我们的模型被训练,我们将看到一个类似于图 4所示的损失轨迹图。注意到train_loss随着时间的推移逐渐减少并慢慢收敛。此外,我们看到test_loss也随着train_loss遵循相似的趋势和值而持续减少,这意味着我们的模型概括得很好,并且不会过度适应训练集。
使用我们训练的 U-Net 模型进行预测
一旦我们训练并保存了我们的细分模型,我们就可以看到它的运行并将其用于细分任务。
从我们的项目目录中打开predict.py文件。
# USAGE
# python predict.py
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import numpy as np
import torch
import cv2
import os
def prepare_plot(origImage, origMask, predMask):
# initialize our figure
figure, ax = plt.subplots(nrows=1, ncols=3, figsize=(10, 10))
# plot the original image, its mask, and the predicted mask
ax[0].imshow(origImage)
ax[1].imshow(origMask)
ax[2].imshow(predMask)
# set the titles of the subplots
ax[0].set_title("Image")
ax[1].set_title("Original Mask")
ax[2].set_title("Predicted Mask")
# set the layout of the figure and display it
figure.tight_layout()
figure.show()
我们一如既往地在第 5-10 行导入必要的包和模块。
为了使用我们的分割模型进行预测,我们将需要一个函数,该函数可以获取我们的训练模型和测试图像,预测输出分割掩码,并最终可视化输出预测。
为此,我们首先定义prepare_plot函数来帮助我们可视化我们的模型预测。
这个函数将一幅图像、它的真实遮罩和我们的模型预测的分割输出,即origImage、origMask和predMask ( 第 12 行)作为输入,并创建一个单行三列的网格(第 14 行)来显示它们(第 17-19 行)。
最后,行 22-24 为我们的情节设置标题,在行 27 和 28 显示它们。
def make_predictions(model, imagePath):
# set model to evaluation mode
model.eval()
# turn off gradient tracking
with torch.no_grad():
# load the image from disk, swap its color channels, cast it
# to float data type, and scale its pixel values
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image.astype("float32") / 255.0
# resize the image and make a copy of it for visualization
image = cv2.resize(image, (128, 128))
orig = image.copy()
# find the filename and generate the path to ground truth
# mask
filename = imagePath.split(os.path.sep)[-1]
groundTruthPath = os.path.join(config.MASK_DATASET_PATH,
filename)
# load the ground-truth segmentation mask in grayscale mode
# and resize it
gtMask = cv2.imread(groundTruthPath, 0)
gtMask = cv2.resize(gtMask, (config.INPUT_IMAGE_HEIGHT,
config.INPUT_IMAGE_HEIGHT))
接下来,我们定义我们的make_prediction函数(第 31-77 行),它将把测试图像的路径和我们训练的分割模型作为输入,并绘制预测的输出。
由于我们仅使用我们训练过的模型进行预测,我们首先将我们的模型设置为eval模式,并分别关闭线 33 和线 36 上的 PyTorch 梯度计算。
在第 39-41 行上,我们使用 OpenCV ( 第 39 行)从imagePath加载测试图像(即image),将其转换为 RGB 格式(第 40 行),并将其像素值从标准[0-255]归一化到我们的模型被训练处理的范围[0, 1](第 41 行)。
然后在第 44 行将图像调整到我们的模型可以接受的标准图像尺寸。由于我们必须在将变量image传递给模型之前对其进行修改和处理,所以我们在行 45 上制作了一个额外的副本,并将其存储在orig变量中,我们将在以后使用它。
在第行第 49-51 行,我们获取测试图像的地面真相蒙版的路径,并将蒙版加载到第行第 55 行。注意,我们将遮罩调整到与输入图像相同的尺寸(第 56 行和第 57 行)。
现在,我们将我们的image处理成模型可以处理的格式。请注意,目前我们的image的形状是[128, 128, 3]。然而,我们的分割模型接受格式为[batch_dimension, channel_dimension, height, width]的四维输入。
# make the channel axis to be the leading one, add a batch
# dimension, create a PyTorch tensor, and flash it to the
# current device
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, 0)
image = torch.from_numpy(image).to(config.DEVICE)
# make the prediction, pass the results through the sigmoid
# function, and convert the result to a NumPy array
predMask = model(image).squeeze()
predMask = torch.sigmoid(predMask)
predMask = predMask.cpu().numpy()
# filter out the weak predictions and convert them to integers
predMask = (predMask > config.THRESHOLD) * 255
predMask = predMask.astype(np.uint8)
# prepare a plot for visualization
prepare_plot(orig, gtMask, predMask)
在第 62 行上,我们转置图像将其转换为通道优先格式,即[3, 128, 128],在第 63 行上,我们使用 numpy 的expand_dims函数添加额外的维度,将我们的图像转换为四维数组(即[1, 3, 128, 128])。请注意,这里的第一维表示等于 1 的批处理维,因为我们一次处理一个测试图像。然后,我们在torch.from_numpy()函数的帮助下将我们的图像转换为 PyTorch 张量,并在 Line 64 的帮助下将其移动到我们的模型所在的设备上。
最后,在第行第 68-70 行,我们通过将测试图像传递给我们的模型并将输出预测保存为predMask来处理测试图像。然后我们应用 sigmoid 激活来得到我们在范围[0, 1]内的预测。如前所述,分割任务是一个分类问题,我们必须将像素分类到两个离散类中的一个。由于 sigmoid 在[0, 1]范围内输出连续值,我们使用线 73 上的config.THRESHOLD将输出二进制化,并分配像素,值等于0或1。这意味着任何大于阈值的都将被赋值1,而其他的将被赋值0。
由于阈值输出(即(predMask > config.THRESHOLD))现在由值0或1组成,将其乘以255会使predMask中的最终像素值为0(即黑色像素值)或255(即白色像素值)。如前所述,白色像素对应于我们的模型检测到盐沉积的区域,黑色像素对应于不存在盐的区域。
我们借助于行 77 上的prepare_plot函数,绘制出我们的原始图像(即orig)、地面真实遮罩(即gtMask)和我们的预测输出(即predMask)。这就完成了我们的make_prediction函数的定义。
我们现在可以看到我们的模型在运行了。
# load the image paths in our testing file and randomly select 10
# image paths
print("[INFO] loading up test image paths...")
imagePaths = open(config.TEST_PATHS).read().strip().split("\n")
imagePaths = np.random.choice(imagePaths, size=10)
# load our model from disk and flash it to the current device
print("[INFO] load up model...")
unet = torch.load(config.MODEL_PATH).to(config.DEVICE)
# iterate over the randomly selected test image paths
for path in imagePaths:
# make predictions and visualize the results
make_predictions(unet, path)
在第 82 行和第 83 行,我们打开存储测试图像路径的文件夹,随机抓取 10 个图像路径。第 87 行在config.MODEL_PATH点从保存的检查点加载我们 U 网的训练重量。
我们最后迭代我们随机选择的测试imagePaths,并在第 90-92 行的make_prediction函数的帮助下预测输出。
图 5 显示了我们的make_prediction函数的示例可视化输出。黄色区域代表 1 类:盐,深蓝色区域代表 2 类:非盐(沉积物)。
我们看到,在案例 1 和案例 2(即,分别为行 1 和行 2)中,我们的模型正确识别了包含盐沉积的大多数位置。然而,一些存在盐矿床的地区没有被确定。
然而,在情况 3(即,行 3)中,我们的模型已经将一些区域识别为没有盐的盐沉积(中间的黄色斑点)。这是一个假阳性,其中我们的模型错误地预测了阳性类别,即盐的存在,在地面真相中不存在盐的区域。
值得注意的是,实际上,从应用的角度来看,情况 3 中的预测具有误导性,并且比其他两种情况中的预测风险更大。这可能是因为在前两种情况下,如果专家在预测的黄色标记位置设置钻探机开采盐矿床,他们将成功发现盐矿床。然而,如果他们在假阳性预测的位置进行同样的操作(如案例 3 所示),将会浪费时间和资源,因为在该位置不存在盐沉积。
学分
Aman Arora 的惊人文章 启发我们在model.py文件中实现 U-Net 模型。
总结
在本教程中,我们学习了图像分割,并在 PyTorch 中从头开始构建了一个基于 U-Net 的图像分割管道。
具体来说,我们讨论了 U-Net 模型的架构细节和显著特征,使其成为图像分割的实际选择。
此外,我们还了解了如何在 PyTorch 中为手头的分割任务定义自己的自定义数据集。
最后,我们看到了如何在 PyTorch 中训练基于 U-Net 的分割管道,并使用训练好的模型实时预测测试图像。
学习完教程后,您将能够理解任何图像分割管道的内部工作原理,并在 PyTorch 中从头开始构建自己的分割模型。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
Ubuntu 16.04:如何安装 OpenCV
原文:https://pyimagesearch.com/2016/10/24/ubuntu-16-04-how-to-install-opencv/

在过去两年运行 PyImageSearch 博客的过程中,我撰写了两篇教程,详细介绍了在 Ubuntu 上安装 OpenCV(带有 Python 绑定)所需的步骤。您可以在这里找到这两个教程:
然而,随着对 Ubuntu 14.04 winding down 的支持和 Ubuntu 16.04 被设定为下一个 LTS (支持到 2021 年 4 月),我认为应该创建一个 新的、更新的 Ubuntu + OpenCV 安装教程。
在本教程中,我将记录、演示、提供在 Ubuntu 16.04 上使用Python 2.7 或 Python 3.5 绑定安装 OpenCV 3 的详细步骤。
此外,这个文档已经从我之前的 Ubuntu 14.04 教程完全更新了,以使用来自apt-get库的最新更新包。
要了解如何在 Ubuntu 16.04 系统上安装 OpenCV,请继续阅读。
注意:不关心 Python 绑定,只想在你的系统上安装 OpenCV(可能是为了 C++编码)?别担心,这个教程对你仍然有效。遵循说明并执行步骤——到本文结束时,您的系统上已经安装了 OpenCV。从这里开始,忽略 Python 绑定,照常进行。
Ubuntu 16.04:如何安装 OpenCV
在我们进入本教程之前,我想提一下 Ubuntu 16.04 实际上已经安装了 Python 2.7 和 Python 3.5。实际版本(截至 2016 年 10 月 24 日)为:
- Python 2.7.12(在终端中键入
python时默认使用)。 - Python 3.5.2(可以通过
python3命令访问)。
再次重申,Python 2.7 仍然是 Ubuntu 使用的默认 Python 版本。有计划迁移到 Python 3 ,默认使用 Python 3;然而,据我所知,我们离真正成为现实还有很长的路要走。
无论哪种情况,本教程都将支持Python 2.7 和 Python 3。我强调了需要你做出决定的步骤,决定你想使用哪个版本的 Python。确保你与你的决定一致,否则你将不可避免地遇到编译、链接和导入错误。
**关于你应该使用哪一个 Python 版本……我不想讨论这个问题。我简单地说,你应该使用你日常使用的任何版本的 Python。请记住,Python 3 代表着未来——但也请记住,一旦您理解了 Python 版本之间的差异,将 Python 2.7 代码移植到 Python 3 也不是一件非常困难的事情。就 OpenCV 而言,OpenCV 3 并不关心您使用的是哪个版本的 Python:绑定将同样工作。
说了这么多,让我们开始在 Ubuntu 16.04 上安装带有 Python 绑定的 OpenCV。
步骤 1:在 Ubuntu 16.04 上安装 OpenCV 依赖项
本教程中的大多数(事实上,所有)步骤都将通过使用您的终端来完成。首先,打开你的命令行并更新apt-get包管理器来刷新和升级预安装的包/库:
$ sudo apt-get update
$ sudo apt-get upgrade
接下来,让我们安装一些开发人员工具:
$ sudo apt-get install build-essential cmake pkg-config
pkg-config包(很可能)已经安装在您的系统上,但是为了以防万一,请确保将它包含在上面的apt-get命令中。cmake程序用于自动配置我们的 OpenCV 构建。
OpenCV 是一个图像处理和计算机视觉库。因此,OpenCV 需要能够从磁盘加载 JPEG、PNG、TIFF 等各种图像文件格式。为了从磁盘加载这些图像,OpenCV 实际上调用了其他图像 I/O 库,这些库实际上方便了加载和解码过程。我们在下面安装了必要的组件:
$ sudo apt-get install libjpeg8-dev libtiff5-dev libjasper-dev libpng12-dev
好了,现在我们有了从磁盘加载图像的库,但是视频呢?使用以下命令安装用于处理视频流和访问摄像机帧的软件包:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
OpenCV 自带了一套非常有限的 GUI 工具。这些 GUI 工具允许我们在屏幕上显示图像(cv2.imshow)、等待/记录按键(cv2.waitKey)、跟踪鼠标事件(cv2.setMouseCallback),并创建简单的 GUI 元素,如滑块和跟踪条。同样,您不应该期望用 OpenCV 构建成熟的 GUI 应用程序——这些只是允许您调试代码和构建非常简单的应用程序的简单工具。
在内部,处理 OpenCV GUI 操作的模块的名称是highgui。highgui模块依赖于 GTK 库,您应该使用以下命令安装它:
$ sudo apt-get install libgtk-3-dev
接下来,我们安装用于优化 OpenCV 内部各种功能的库,例如矩阵运算:
$ sudo apt-get install libatlas-base-dev gfortran
我们将通过安装 Python 2.7 和 Python 3.5 的 Python 开发头文件和库来结束步骤#1(这样您就可以同时拥有这两个版本):
$ sudo apt-get install python2.7-dev python3.5-dev
注意: 如果你没有安装 Python 开发头文件和静态库,你会在步骤#4 中遇到问题,在那里我们运行cmake来配置我们的构建。如果没有安装这些头文件,那么cmake命令将无法自动确定 Python 解释器和 Python 库的正确值。简而言之,这一部分的输出看起来是“空的”,您将无法构建 Python 绑定。当您到达步骤#4 时,花时间将您的命令输出与我的进行比较。
步骤 2:下载 OpenCV 源代码
在本文发表时,OpenCV 的最新版本是3.1.0,我们下载了它的.zip,并使用以下命令将其解压缩:
$ cd ~
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.1.0.zip
$ unzip opencv.zip
当 OpenCV 的新版本发布时,你可以查看官方的 OpenCV GitHub ,并通过更改.zip的版本号下载最新版本。
然而,我们还没有下载完源代码——我们还需要 opencv_contrib 库:
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.1.0.zip
$ unzip opencv_contrib.zip
为什么我们还要费心下载 contrib repo 呢?
嗯,我们希望 OpenCV 3 的完全安装到能够访问诸如 SIFT 和 SURF 之类的特性(没有双关语的意思)。在 OpenCV 2.4 中,SIFT 和 SURF 包含在 OpenCV 的默认安装中。然而,随着 OpenCV 3+的发布,这些包已经被转移到 contrib 中,contrib 中包含(1)当前正在开发的模块或者(2)标记为“非自由的”(即专利的)模块。你可以在这篇博文的中了解更多关于 SIFT/SURF 重组背后的原因。
注意:在复制和粘贴过程中,您可能需要使用“< = >”按钮扩展上述命令。在较小的浏览器窗口中,3.1.0.zip中的.zip可能会被截断。为了方便起见,我在下面包含了opencv档案和opencv_contrib档案的完整 URL:
- https://github . com/itseez/opencv/archive/3 . 1 . 0 . zipT3]
- https://github . com/itseez/opencv _ contib/archive/3 . 1 . 0 . zipT3]
我还想提一下,两个你的opencv和opencv_contrib版本应该是一样的(这里是3.1.0)。如果版本号不匹配,您很容易遇到编译时错误(或者更糟,几乎无法调试的运行时错误)。
步骤 3:设置您的 Python 环境——Python 2.7 或 Python 3
我们现在准备开始为构建配置我们的 Python 开发环境。第一步是安装pip,一个 Python 包管理器:
$ cd ~
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
我在我做过的每一个 OpenCV + Python 安装教程中都提到过这一点,但今天我要在这里再说一遍:我是 virtualenv 和 virtualenvwrapper 的超级粉丝。这些 Python 包允许你为你正在进行的每个项目创建独立的 Python 环境。
简而言之,使用这些包可以让你解决“项目 X 依赖于 1.x 版本,但项目 Y 需要 4.x 的困境。使用 Python 虚拟环境的一个奇妙的副作用是,您可以让您的系统保持整洁,没有混乱。
虽然你当然可以在没有 Python 虚拟环境的情况下使用 Python 绑定来安装 OpenCV, 我强烈推荐你使用它们 ,因为其他 PyImageSearch 教程利用了 Python 虚拟环境。在本指南的剩余部分,我还假设您已经安装了virtualenv和virtualenvwrapper。
如果你想要一个完整、详细的解释,为什么 Python 虚拟环境是一个最佳实践,你绝对应该读一读这篇在 RealPython 上的精彩博文。在本教程的前半部分,我也提供了一些关于为什么我个人更喜欢 Python 虚拟环境的评论。
让我再次重申,在 Python 社区中,利用某种虚拟环境是的标准做法,所以我建议你也这样做:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
一旦我们安装了virtualenv和virtualenvwrapper,我们需要更新我们的~/.bashrc文件,在文件的底部包含以下行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
~/.bashrc文件只是一个 shell 脚本,每当您启动一个新的终端时,Bash 都会运行它。您通常使用该文件来设置各种配置。在本例中,我们设置了一个名为WORKON_HOME的环境变量,指向 Python 虚拟环境所在的目录。然后我们从virtualenvwrapper加载任何必要的配置。
要更新您的~/.bashrc文件,只需使用标准的文本编辑器。我会推荐使用nano、vim或emacs。你也可以使用图形编辑器,但是如果你刚刚开始使用,nano可能是最容易操作的。
一个更简单的解决方案是使用cat命令,完全避免编辑器:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.bashrc
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bashrc
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
编辑完我们的~/.bashrc文件后,我们需要重新加载修改:
$ source ~/.bashrc
注意: 在.bashrc上调用source对于我们当前的 shell 会话来说,只需要一次。每当我们打开一个新的终端,.bashrc的内容就会自动执行(包括我们的更新)。
现在我们已经安装了virtualenv和virtualenvwrapper,下一步是实际上创建Python 虚拟环境——我们使用mkvirtualenv命令来完成。
但是在执行这个命令之前,你需要做一个选择:是用 Python 2.7 还是 Python 3?
您选择的结果将决定您在下一节中运行哪个命令。
创建您的 Python 虚拟环境
如果您决定使用 Python 2.7,请使用以下命令创建 Python 2.7 虚拟环境:
$ mkvirtualenv cv -p python2
否则,使用此命令创建 Python 3 虚拟环境:
$ mkvirtualenv cv -p python3
无论您决定使用哪个 Python 命令,最终结果都是我们创建了一个名为cv(计算机视觉的简称)的 Python 虚拟环境。
您可以随意命名这个虚拟环境(并创建任意数量的 Python 虚拟环境),但是对于 bing,我建议坚持使用cv名称,因为这是我将在本教程的剩余部分中使用的名称。
验证您是否在“cv”虚拟环境中
如果你重启了你的 Ubuntu 系统;注销并重新登录;或者打开一个新的终端,您需要使用workon命令来重新访问您的cv虚拟环境。下面是一个workon命令的例子:
$ workon cv
要验证您是否在cv虚拟环境中,只需检查您的命令行— 如果您在提示前看到文本(cv),那么您**在cv虚拟环境中是**:

Figure 1: Make sure you see the “(cv)” text on your prompt, indicating that you are in the cv virtual environment.
否则,如果你 没有 看到cv文本,那么你 在cv虚拟环境中就不是 :

Figure 2: If you do not see the “(cv)” text on your prompt, then you are not in the cv virtual environment and need to run the “workon” command to resolve this issue.
要访问cv虚拟环境,只需使用上面提到的workon命令。
将 NumPy 安装到 Python 虚拟环境中
在我们编译 OpenCV 之前的最后一步是安装 NumPy ,一个用于数值处理的 Python 包。要安装 NumPy,请确保您处于cv虚拟环境中(否则 NumPy 将被安装到 Python 的系统版本中,而不是cv环境中)。从那里执行以下命令:
$ pip install numpy
步骤 4:在 Ubuntu 16.04 上配置和编译 OpenCV
至此,我们所有必要的先决条件都已经安装好了——我们现在可以编译 OpenCV 了!
但是在我们这样做之前,通过检查您的提示(您应该看到它前面的(cv)文本),再次检查您是否在cv虚拟环境中,如果不是,使用workon命令:
$ workon cv
确保您在cv虚拟环境中之后,我们可以使用 CMake 设置和配置我们的构建:
$ cd ~/opencv-3.1.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.1.0/modules \
-D PYTHON_EXECUTABLE=~/.virtualenvs/cv/bin/python \
-D BUILD_EXAMPLES=ON ..
上面的命令将目录更改为~/opencv-3.1.0,如果您一直在学习本教程,那么这里就是您下载和解压缩.zip文件的地方。
注意:如果您在本教程的cmake或make阶段遇到与stdlib.h: No such file or directory相关的错误,您还需要在 CMake 中包含以下选项:-D ENABLE_PRECOMPILED_HEADERS=OFF。在这种情况下,我建议删除您的build目录,重新创建它,然后重新运行包含上述选项的 CMake。这将解决stdlib.h错误。感谢 Carter Cherry 和 Marcin 在评论区指出这一点!
在这个目录中,我们创建一个名为build的子目录,并在其中进行更改。build目录是实际编译将要发生的地方。
最后,我们执行cmake来配置我们的构建。
在我们继续实际编译 OpenCV 之前,请确保检查 CMake 的输出!
为此,向下滚动标题为Python 2和Python 3的部分。
如果你正在使用 Python 2.7 支持 的 Ubuntu 16.04 上编译 OpenCV,确保Python 2部分包含到Interpreter、Libraries、numpy和packages path的有效路径。您的输出应该类似于下面的内容:

Figure 3: Ensuring that Python 2.7 will be used when compiling OpenCV 3 for Ubuntu 16.04.
检查这个输出,您可以看到:
Interpreter指向cv虚拟环境中的 Python 2.7 二进制文件。Libraries指向 Python 2.7 库(我们在步骤#1 的最后一步安装了这个库)。numpy值指向我们在cv虚拟环境中的 NumPy 安装。- 最后,
packages path指向lib/python2.7/site-packages。当与CMAKE_INSTALL_PREFIX结合时,这意味着编译 OpenCV 后,我们将在/usr/local/lib/python2.7/site-packages/中找到我们的cv2.so绑定。
类似地, 如果你正在用 Python 3 支持 编译 OpenCV 16.04,你会想要确保你的Python 3部分看起来类似于我的下面:

Figure 4: Validating that Python 3 will be used when compiling OpenCV 3 for Ubuntu 16.04.
同样,请注意我的Interpreter、Libraries、numpy和packages path是如何被正确设置的。
如果您 没有 看到这些变量路径中的cv虚拟环境, 几乎可以肯定是因为您在运行 CMake 之前不在cv虚拟环境中!
如果确实如此,只需通过调用workon cv访问cv虚拟环境,并重新运行上面提到的 CMake 命令。
假设 CMake 命令没有任何错误地退出,现在可以编译 OpenCV:
$ make -j4
-j开关控制编译 OpenCV 时要使用的进程数量——您可能希望将该值设置为您机器上的处理器/内核数量。在我的例子中,我有一个四核处理器,所以我设置了-j4。
使用多个进程可以让 OpenCV 编译得更快;然而,有时会遇到竞争条件,编译就会失败。如果没有以前编译 OpenCV 的大量经验,你真的无法判断这是不是真的,如果你真的遇到了错误,我的第一个建议是运行make clean刷新编译,然后只使用一个内核进行编译:
$ make clean
$ make
下面你可以找到一个成功的 OpenCV + Python 在 Ubuntu 16.04 上编译的截图:

Figure 5: Successfully compiling OpenCV 3 for Ubuntu 16.04.
最后一步是在 Ubuntu 16.04 上实际安装 OpenCV 3:
$ sudo make install
$ sudo ldconfig
步骤 5:完成 OpenCV 的安装
你已经到了最后阶段,只需要再走几步,你的 Ubuntu 16.04 系统就可以安装 OpenCV 3 了。
对于 Python 2.7:
运行sudo make install之后,您的 OpenCV 3 的 Python 2.7 绑定现在应该位于/usr/local/lib/python-2.7/site-packages/中。您可以使用ls命令来验证这一点:
$ ls -l /usr/local/lib/python2.7/site-packages/
total 1972
-rw-r--r-- 1 root staff 2016608 Sep 15 09:11 cv2.so
注意:在某些情况下,你可能会发现 OpenCV 安装在/usr/local/lib/python2.7/dist-packages而不是/usr/local/lib/python2.7/site-packages(注意dist-packages对site-packages)。如果您的cv2.so绑定不在site-packages目录中,请务必检查dist-pakages。
最后一步是 sym-link 我们的 OpenCV cv2.so绑定到我们的cvPython 2.7 虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
对于 Python 3.5:
运行sudo make install后,您的 OpenCV + Python 3 绑定应该位于/usr/local/lib/python3.5/site-packages/中。同样,您可以使用ls命令来验证这一点:
$ ls -l /usr/local/lib/python3.5/site-packages/
total 1972
-rw-r--r-- 1 root staff 2016816 Sep 13 17:24 cv2.cpython-35m-x86_64-linux-gnu.so
自从 OpenCV 3 发布以来,我一直对这种行为感到困惑,但是由于某种原因,当用 Python 3 支持编译 OpenCV 时,输出的cv2.so文件名是不同的。实际的文件名可能会因人而异,但它应该类似于cv2.cpython-35m-x86_64-linux-gnu.so。
同样,我不知道为什么会发生这种情况,但这是一个非常简单的解决方法。我们需要做的就是重命名文件:
$ cd /usr/local/lib/python3.5/site-packages/
$ sudo mv cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
将cv2.cpython-35m-x86_64-linux-gnu.so重命名为简单的cv2.so后,我们可以将 OpenCV 绑定符号链接到 Python 3.5 的cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2.so cv2.so
步骤 6:测试 OpenCV 安装
恭喜你,你现在已经在你的 Ubuntu 16.04 系统上安装了 OpenCV 3!
要验证您的安装正在运行,请执行以下操作:
- 打开一个新的终端。
- 执行
workon命令来访问cvPython 虚拟环境。 - 尝试导入 Python + OpenCV 绑定。
我在下面演示了如何执行这些步骤:
$ cd ~
$ workon cv
$ python
Python 3.5.2 (default, Jul 5 2016, 12:43:10)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.1.0'
>>>
如您所见,我可以将 OpenCV 绑定导入到 Python 3.5 shell 中。
下面是我利用本教程中概述的相同步骤将 OpenCV 绑定导入 Python 2.7 shell 的截图:

Figure 6: Ensuring that I can successfully import my Python + OpenCV bindings on Ubuntu 16.04.
因此,不管你决定使用哪个 Python 版本,只要按照本教程中详细描述的步骤,你就能在你的 Ubuntu 16.04 系统上安装 OpenCV + Python。
一旦安装了 OpenCV,您就可以删除opencv-3.1.0和opencv_contrib-3.1.0目录(以及它们相关的.zip文件):
$ cd ~
$ rm -rf opencv-3.1.0 opencv_contrib-3.1.0 opencv.zip opencv_contrib.zip
但是,运行这个命令时要小心!在浏览这些目录之前,您需要确保您已经在系统上正确安装了 OpenCV。否则,您将需要重新启动整个编译过程!
故障排除和常见问题
在本节中,我将解决一些在 Ubuntu 16.04 上安装 OpenCV 时出现的常见问题。
Q. 当我执行mkvirtualenv或workon时,我得到一个“命令未找到错误”。
答: 你会得到这个错误信息有三个主要原因,都与步骤#3: 有关
- 首先,确保你已经使用
pip软件包管理器安装了virtualenv和virtualenvwrapper。您可以通过运行pip freeze,检查输出,并确保在已安装包列表中看到virtualenv和virtualenvwrapper来验证这一点。 - 您的
~/.bashrc文件可能无法正确更新。要对此进行诊断,请使用文本编辑器,如nano,并查看您的~/.bashrc文件的内容。在文件的底部,您应该看到正确的export和source命令出现了(再次检查步骤#3 中应该附加到~/.bashrc的命令)。 - 编辑完您的
~/.bashrc文件后,您可能忘记对其进行source并重新加载其内容。确保在编辑完源代码~/.bashrc后运行它,以确保内容被重新加载——这将使你能够访问mkvirtualenv和workon命令。
问 每当我打开一个新的终端,注销或者重启我的 Ubuntu 系统,我都无法执行mkvirtualenv或者workon命令。
A. 见原因#2 来自上一题。
Q. 当我(1)打开一个导入 OpenCV 的 Python shell 或者(2)执行一个调用 OpenCV 的 Python 脚本时,我得到一个错误:Import Error: No module named cv2。
A. 不幸的是,这个错误消息的确切原因极难诊断,因为有多种原因可能导致这种情况发生。一般来说,我推荐以下建议来帮助诊断和解决错误:
- 使用
workon cv命令确保您处于cv虚拟环境中。如果这个命令给你一个错误,那么请看这个 FAQ 中的第一个问题。 - 如果在你确保你的
~/.bashrc文件已经被正确地更新和source之后,那么试着在你的cv虚拟环境中调查site-packages目录的内容。根据您的 Python 版本,您可以在~/.virtualenvs/cv/lib/python2.7/site-packages/或~/.virtualenvs/cv/lib/python3.5/site-packages/中找到site-packages目录。确保(1)这个site-packages目录中有一个cv2.so文件,以及(2)它正确地用符号链接到一个有效的现有文件。 - 请务必检查位于
/usr/local/lib/python2.7/site-packages/和/usr/local/lib/python3.5/site-packages/的 Python 系统安装的site-packages(甚至dist-packages)目录。理想情况下,你应该有一个cv2.so文件。 - 如果所有这些都失败了,检查 OpenCV 构建的
build/lib目录。那里的应该是那里的cv2.so文件(前提是cmake和make都执行无误)。如果cv2.so文件存在,手动将其复制到系统site-packages目录以及cv虚拟环境的site-packages目录中。
摘要
在今天的博文中,我演示了如何在你的 Ubuntu 16.04 系统 上安装带有 Python 2.7 或 Python 3 绑定的 OpenCV 3 。
更多其他操作系统上的 OpenCV 安装教程(如 OSX、Raspbian 等。),请参考本页,我在这里提供了额外的链接和资源。
但是在你走之前……
如果您有兴趣了解更多关于 OpenCV、计算机视觉和图像处理的知识,请务必在下面的表格中输入您的电子邮件地址,以便在新的博客文章发表时收到通知!****
Ubuntu 18.04:如何安装 OpenCV
原文:https://pyimagesearch.com/2018/05/28/ubuntu-18-04-how-to-install-opencv/

在这篇博文中,你将学习如何在 Ubuntu 18.04 上安装 OpenCV。
过去,我已经为 Ubuntu 编写了一些安装指南:
- Ubuntu 16.04:如何用 Python 2.7 和 Python 3.5+安装 OpenCV
- 在 Ubuntu 上安装 OpenCV 3.0 和 Python 2.7+
- 在 Ubuntu 上安装 OpenCV 3.0 和 Python 3.4+
- (…如果你正在寻找 macOS 和 Raspberry Pi 安装指南,请务必查看本页
Canonical 的员工一直在努力工作。
2018 年 4 月 26 日,他们为社区发布了新的长期支持(LTS)版本的 Ubuntu:Ubuntu 18.04 LTS(仿生海狸)。
对 Ubuntu 16.04 LTS 的支持将持续到 2021 年 4 月,所以请放心— 您不必升级 16.04 操作系统就可以继续进行您的图像处理项目。
也就是说,如果你想升级到 Ubuntu 18.04 并使用最新最好的,我想你会对 Ubuntu 18.04 的新变化感到非常满意。
让我们言归正传,用 Python 3 绑定安装 OpenCV。
要学习如何用 OpenCV 来支撑你的 Ubuntu 18.04 系统,继续阅读。
注意:虽然你不会在我的博客上看到 Ubuntu 17.10 的具体指南(非 -LTS),但这些说明可能适用于 17.10(你只需自担风险)。
Ubuntu 18.04:如何安装 OpenCV
Ubuntu 18.04 的一个主要变化是他们完全放弃了 Python 2.7。
如果需要的话,你仍然可以安装 Python 2.7,但是现在 Python 3 是操作系统的默认版本。
鉴于此,本指南支持 Python 3。如果你需要 Python 2.7 支持,请先阅读整个指南,然后查看这篇博文底部附近的安装故障排除(FAQ) 部分的第一个问题,寻找一些 Python 2.7 的指导。*
*### 第 0 步:放松——您将使用 Python 3.6
让我们在 Ubuntu 18.04 上熟悉一下 Python 3。
要在 Ubuntu 18.04 上运行 Python 3,必须显式调用python3。
让我们看看我们的系统上安装了哪个版本:
$ python3 --version
Python 3.6.5
现在,让我们启动一个 Python 3 shell 来测试一下:
$ python3
>> print("OpenCV + Ubuntu 18.04!")
OpenCV + Ubuntu 18.04!
>> quit()
这很简单,所以让我们继续在 Ubuntu 18.04 上安装 OpenCV。
步骤 1:在 Ubuntu 18.04 上安装 OpenCV 依赖项
今天的所有步骤都将在终端/命令行中完成。在我们开始之前,打开一个终端或通过 SSH 连接。
从那里,我们需要用 apt-get 包管理器刷新/升级预安装的包/库:
$ sudo apt-get update
$ sudo apt-get upgrade
然后安装开发人员工具:
$ sudo apt-get install build-essential cmake unzip pkg-config
你很可能已经在 Ubuntu 18.04 上安装了pkg-config,但是为了安全起见,一定要把它包含在 install 命令中。
接下来,我们需要安装一些特定于 OpenCV 的先决条件。OpenCV 是一个图像处理/计算机视觉库,因此它需要能够加载 JPEG、PNG、TIFF 等标准图像文件格式。以下图像 I/O 包将允许 OpenCV 处理图像文件:
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
现在让我们试着安装libjasper-dev:
$ sudo apt-get install libjasper-dev
如果您收到关于libjasper-dev丢失的错误,请遵循以下说明:
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
sudo apt update
sudo apt install libjasper1 libjasper-dev
否则(或者一旦libjasper-dev安装完毕),继续进行。
接下来,让我们包括视频 I/O 包,因为我们经常在 PyImageSearch 博客上处理视频。您将需要以下软件包,以便使用您的相机流和处理视频文件:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
OpenCV 的 highgui 模块依赖 GTK 库进行 gui 操作。highgui 模块将允许你创建基本的 gui 来显示图像,处理鼠标点击,创建滑块和跟踪条。高级 GUI 应该用 TK、Wx 或 QT 来构建。参见这篇博文来学习如何用 TK 制作 OpenCV GUI。
让我们安装 GTK:
$ sudo apt-get install libgtk-3-dev
我总是推荐以下两个库,它们将优化各种 OpenCV 函数:
$ sudo apt-get install libatlas-base-dev gfortran
最后,我们的最后一个要求是安装 Python 3 头文件和库:
$ sudo apt-get install python3.6-dev
步骤 2:下载官方 OpenCV 源代码
更新 2018-12-20:这些指令已经更新,可以与 OpenCV 3.4.4 一起使用。这些指令应该继续适用于未来的 OpenCV 3.x 版本。
既然我们继续在终端中工作,让我们使用wget下载官方 OpenCV 版本:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/3.4.4.zip
接着是opencv_contrib模块:
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/3.4.4.zip
注意:如果你的浏览器切断了完整的命令,要么使用上面工具栏中的<>按钮展开代码块,要么复制并粘贴以下 URL:https://github.com/opencv/opencv_contrib/archive/3.4.4.zip
那么,什么是贡献回购呢?
contrib 存储库包含 SIFT、SURF 等算法。在过去,这些实现包含在 OpenCV 2.4 的默认安装中;然而,从 OpenCV 3+开始,它们被转移了。
contrib 模块中包括正在积极开发的模块和/或已申请专利的模块(不能免费用于商业/工业用途)。筛选和冲浪属于这一类。你可以在下面的博文中进一步了解这一举动背后的思维过程:OpenCV 3 中 SIFT 和 SURF 去哪儿了?
重要:opencv和opencv_contrib版本必须相同。请注意,两个 URL 都指向 3.4.4。在使用本指南的同时,您可以随意安装不同的版本——只要确保更新两个网址即可。
现在,让我们解压缩归档文件:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
Figure 1: After downloading and unzipping opencv and opencv_contrib, our home directory listing should look similar to what is displayed in the terminal.
现在,让我们继续重命名目录:
$ mv opencv-3.4.4 opencv
$ mv opencv_contrib-3.4.4 opencv_contrib
步骤 3:配置您的 Python 3 环境
我们配置 Python 3 开发环境的第一步是安装 pip,这是一个 Python 包管理器。
要安装 pip,只需在终端中输入以下内容:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
利用虚拟环境进行 Python 开发
如果你熟悉我的博客并在其中安装了指南,下面的陈述可能会让我听起来像一张破唱片,但我还是会重复一遍:
我每天都使用 virtualenv 和 virtualenvwrapper ,你也应该这样做,除非你有非常具体的理由不这样做。这两个 Python 包便于为您的项目创建独立的 Python 环境。
使用虚拟环境是最佳实践。
为什么?
虚拟环境允许您在隔离的情况下处理项目,而不会占用大量资源,如虚拟机和 Docker 映像(我肯定会使用 VirtualBox 和 Docker,它们各有各的用处)。
例如,您可能有一个 Python + OpenCV 项目,它需要一个旧版本的 scikit-learn (v0.14),但是您希望在所有新项目中继续使用最新版本的 scikit-learn (0.19)。
使用虚拟环境,您可以分别处理这两个软件版本的依赖关系,这是使用 Python 的系统安装不可能做到的。
如果你想了解更多关于 Python 虚拟环境的信息,看看这篇关于 RealPython 的文章,或者阅读这篇关于 PyImageSearch 的博客的前半部分。
现在让我们继续安装virtualenv和virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
为了完成安装,我们需要更新我们的~/.bashrc文件。
使用终端文本编辑器,如vi / vim或nano,将下列行添加到您的~/.bashrc中:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
或者,您可以通过 bash 命令直接附加这些行:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.bashrc
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bashrc
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.bashrc
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
接下来,获取~/.bashrc文件:
$ source ~/.bashrc
创建一个虚拟环境来存放 OpenCV 和其他包
好了,虽然这看起来似乎需要做很多工作,但我们现在可以为 OpenCV 创建 Python 3 虚拟环境了:
$ mkvirtualenv cv -p python3
这一行简单地创建了一个名为cv的 Python 3 虚拟环境。你可以给你的环境起任何你喜欢的名字——我喜欢让它们简洁明了,同时提供足够的信息,这样我就能记住它们的用途。您可以在您的系统上拥有任意多的虚拟环境!
让我们使用 workon 命令来验证我们是否在 cv 环境中:
$ workon cv
图 2 显示了您的终端将会是什么样子(假设您没有更改任何 bash 提示符设置):
Figure 2: If you see the (cv) at the beginning of the bash prompt, then your virtual environment is active and you’re working “inside” the environment. You can now safely install OpenCV with correct Python bindings.
在您的环境中安装 NumPy
让我们将第一个包安装到环境中:NumPy。NumPy 是使用 Python 和 OpenCV 的必要条件。我们简单地使用 pip(当cv Python 虚拟环境处于活动状态时):
$ pip install numpy
步骤 4:为 Ubuntu 18.04 配置和编译 OpenCV
现在我们要搬家了。我们已经准备好编译和安装 OpenCV。
在我们开始之前,让我们确保我们在 cv 虚拟环境中:
$ workon cv
虚拟环境是活跃的(你在虚拟环境中)这是非常重要的,这也是我不断重申它的原因。如果在进入下一步之前,您在cv Python 虚拟环境中不是,那么您的构建文件将无法正确生成。
用 CMake 配置 OpenCV
让我们使用cmake来建立我们的 OpenCV 构建:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D WITH_CUDA=OFF \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D OPENCV_ENABLE_NONFREE=ON \
-D BUILD_EXAMPLES=ON ..
更新 2018-12-20: 一定要设置OPENCV_ENABLE_NONFREE=ON标志,这样你就可以访问我们有时在这个博客上回顾的专利算法(并在 PyImageSearch Gurus 中深入讨论)。同样,一定要更新虚拟环境的路径,以便使用正确的PYTHON_EXECUTABLE(注意路径中的cv,因为我们的虚拟环境名称是cv)。
我总是建议您滚动 CMake 输出,查看是否有任何异常。你不会看到每个设置旁边都标有“是”,这是正常的。确保您没有看到任何错误,否则您的编译可能会失败(警告是可以的)。
Figure 3: To compile OpenCV for Ubuntu 18.04, we make use of CMake. The CMake tool will configure settings prior to compilation.
花点时间注意一下图 3 中 Ubuntu 18.04 上的 CMake 输出中只显示了“Python 3”部分。这是故意的,因为我们只编译支持 Python 3 的 OpenCV。
更新 2018-12-20: 另外,向上滚动大约 20 行,确保“非自由算法”设置为“是”*。*
注意:如果您在本教程的cmake或make阶段遇到与stdlib.h: No such file or directory相关的问题,您还需要在 CMake 中包含以下选项:-D ENABLE_PRECOMPILED_HEADERS=OFF。在这种情况下,我建议删除您的构建目录,重新创建它,然后重新运行包含上述选项的cmake。这将解决stdlib.h错误。
在 Ubuntu 18.04 上编译 OpenCV
让我们用make来编译 OpenCV。
根据处理器/内核的数量,您可以通过改变命令中的标志来减少编译时间。我的计算机有 4 个内核,所以我使用的是-j4标志。您可以更新数字或完全关闭标志:
$ make -j4

Figure 4: To compile OpenCV with Python 3 on Ubuntu 18.04, we use make. Using make compiles OpenCV from source and is preferred over using package managers for installing OpenCV.
这个过程可能需要 30 分钟或更长时间,所以如果可以的话,去散散步吧。
如果您的编译受阻并挂起,这可能是由于线程竞争情况。如果您遇到这个问题,只需删除您的build目录,重新创建它,并重新运行cmake和make。这次不包括make旁边的旗帜。
安装和验证 OpenCV
成功完成 100%的编译后,您现在可以安装 OpenCV:
$ sudo make install
$ sudo ldconfig
为了验证安装,有时我喜欢在终端中输入以下命令:
$ pkg-config --modversion opencv
3.4.4
步骤 5:完成 Python+ OpenCV + Ubuntu 18.04 的安装
我们已经到达比赛的最后一圈,所以坚持下去。
更新 2018-12-20: 以下路径已更新。以前版本的 OpenCV 在不同的位置(/usr/local/lib/python3.6/site-packages)安装了绑定,所以一定要仔细看看下面的路径。
此时,OpenCV 的 Python 3 绑定应该位于以下文件夹中:
$ ls /usr/local/python/cv2/python-3.6
cv2.cpython-36m-x86_64-linux-gnu.so
让我们简单地将它们重命名为cv2.so:
$ cd /usr/local/python/cv2/python-3.6
$ sudo mv cv2.cpython-36m-x86_64-linux-gnu.so cv2.so
专业提示: 如果您同时安装 OpenCV 3 和 OpenCV 4 ,而不是将文件重命名为 cv2,那么您可以考虑将其命名为cv2.opencv3.4.4.so,然后在下一个子步骤中适当地将该文件 sym-link 到cv2.so。
我们的最后一个子步骤是将 OpenCV cv2.so绑定符号链接到我们的cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python3.6/site-packages/
$ ln -s /usr/local/python/cv2/python-3.6/cv2.so cv2.so
步骤 6:在 Ubuntu 18.04 上测试 OpenCV 3 的安装
比赛结束了,但是让我们来验证一下我们是否已经开足马力了。
为了验证我们的 OpenCV + Ubuntu 安装是否完成,我喜欢启动 Python,导入 OpenCV,并查询版本(如果您也安装了多个版本的 OpenCV,这对于保持理智很有用):
$ cd ~
$ workon cv
$ python
Python 3.6.5 (default, Apr 1 2018, 05:46:30)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.4.4'
>>> quit()
下面是它在我的系统上的样子:
Figure 5: To verify that OpenCV is correctly installed and configured in our Python 3 virtual environment, I like to run the Python interpreter in the terminal. From there you can import OpenCV (cv2) and verify the version number matches what you intended to install.
更新 2018-12-20: 我今天更新期间没有更新截图。版本应该反映您安装的 OpenCV 版本。
或者,此时,您可以安全地删除您的个人文件夹中的 zip 和目录:
$ cd ~
$ rm opencv.zip opencv_contrib.zip
$ rm -rf opencv opencv_contrib
安装疑难解答(常见问题)
在这一节中,我将解决在 Ubuntu 18.04 LTS 上安装 OpenCV 3 和 Python 3 时出现的一些常见问题。
q .Ubuntu 18.04 上 Python 2.7 在哪?
A. Python 3 是默认,Ubuntu 18.04 自带。Python 2.7 用户可以在步骤#1: 结束时手动安装 Python 2.7
$ sudo apt-get install python2.7 python2.7-dev
从那里,当您在步骤#3 中创建您的虚拟环境时,首先安装 Python 2.7 的 pip:
$ sudo python2.7 get-pip.py
然后(也是在步骤#3 中)当您创建虚拟环境时,只需使用相关的 Python 版本标志:
$ mkvirtualenv cv -p python2.7
从那以后,一切都应该是一样的。
Q. 为什么我不能直接 pip 安装 OpenCV?
A. 根据您的操作系统和架构,OpenCV 有许多可安装 pip 的版本。您可能遇到的问题是,它们可能在没有各种优化、图像 I/O 支持、视频 I/O 支持和opencv_contrib支持的情况下编译。使用它们——但是使用它们要自担风险。本教程旨在让你在 Ubuntu 18.04 上完全安装 OpenCV,同时让你完全控制编译。
Q. 执行mkvirtualenv或workon时,遇到“命令未找到错误”。
A. 你会看到这个错误消息的原因有很多,都来自于步骤#3:
- 首先,确保你已经使用
pip软件包管理器正确安装了virtualenv和virtualenvwrapper。通过运行pip freeze进行验证,确保在已安装包列表中看到virtualenv和virtualenvwrapper。 - 您的
~/.bashrc文件可能有错误。查看您的~/.bashrc文件的内容,查看正确的export和source命令是否存在(检查步骤#3 中应该附加到~/.bashrc的命令)。 - 你可能忘记了你的
~/.bashrc。确保编辑完source ~/.bashrc后运行它,以确保你可以访问mkvirtualenv和workon命令。
问 当我打开一个新的终端,注销或者重启我的 Ubuntu 系统时,我无法执行mkvirtualenv或者workon命令。
A. 见上一题的 #2 。
Q. 当我尝试导入 OpenCV 时,遇到了这个消息:Import Error: No module named cv2。
发生这种情况有多种原因,不幸的是,很难诊断。我推荐以下建议来帮助诊断和解决错误:
1. 使用workon cv命令确保您的cv虚拟环境处于活动状态。如果这个命令给你一个错误,那么请看这个 FAQ 中的第一个问题。
2. 尝试在您的cv虚拟环境中研究site-packages目录的内容。根据您的 Python 版本,您可以在~/.virtualenvs/cv/lib/python3.6/site-packages/中找到site-packages目录。确保(1)在site-packages目录中有一个cv2.so文件,并且(2)它被正确地符号链接到一个有效的文件。
3. 一定要检查位于/usr/local/lib/python3.6/site-packages/的 Python 的系统安装的site-packages(甚至dist-packages)目录。此外,请检查/usr/local/python/cv2。理想情况下,您应该在其中一个位置有一个cv2.so文件。
4. 作为最后一招,检查 OpenCV 构建的build/lib目录。那里的应该是那里的cv2.so文件(如果cmake和make都执行无误)。如果cv2.so文件存在,手动将其*复制到系统site-packages目录以及cv虚拟环境的site-packages目录中。
摘要
今天我们在 Ubuntu 18.04 LTS 上安装了 OpenCV 3 和 Python 3 绑定。
我希望这些说明对你用 OpenCV 3 配置你自己的 Ubuntu 18.04 机器有帮助。
如果您有兴趣了解关于 OpenCV、计算机视觉和图像处理的更多信息,请务必在下面的表格中输入您的电子邮件地址,以便在新的博客帖子和教程发布时收到通知!*****
Ubuntu 18.04:安装深度学习的 TensorFlow 和 Keras
原文:https://pyimagesearch.com/2019/01/30/ubuntu-18-04-install-tensorflow-and-keras-for-deep-learning/

在本教程中,您将学习如何使用 TensorFlow 和 Keras 配置您的 Ubuntu 18.04 机器进行深度学习。
在开始使用计算机视觉和深度学习时,配置深度学习装备是成功的一半。我以提供高质量的教程为荣,这些教程可以帮助您让您的环境为有趣的东西做好准备。
本指南将帮助你用必要的深度学习工具设置你的 Ubuntu 系统,用于(1)你自己的项目和(2)我的书, 用 Python 进行计算机视觉的深度学习 。
所需要的只是 Ubuntu 18.04,一些时间/耐心,以及可选的一个 NVIDIA GPU。
如果你是苹果用户,你可以按照我的 macOS Mojave 深度学习安装说明!
要了解如何用 TensorFlow、Keras、mxnet 配置 Ubuntu 进行深度学习,继续阅读。
Ubuntu 18.04:安装深度学习的 TensorFlow 和 Keras
2019 年 1 月 7 日,我向现有客户(一如既往免费升级)和新客户发布了我的深度学习书籍的 2.1 版本。
伴随兼容性代码更新的是全新的预配置环境,消除了配置您自己的系统的麻烦。换句话说,我将汗水和时间投入到创建近乎完美的可用环境中,您可以在不到 5 分钟的时间内启动这些环境。
这包括更新的(1) VirtualBox 虚拟机和(2) Amazon machine instance (AMI):
- 深度学习虚拟机是独立的,可以在任何运行 VirtualBox 的操作系统中独立运行。
- 我的深度学习 AMI 其实是互联网上所有人都可以免费使用的(收费当然适用于 AWS 收费)。如果你在家里/工作场所/学校没有 GPU,而你需要使用一个或多个 GPU 来训练深度学习模型,这是一个很好的选择。这是我用 GPU 在云端深度学习时用的 一模一样的系统 。
虽然有些人可以使用 VM 或 AMI,但你已经到达这里,因为你需要在你的 Ubuntu 机器上配置你自己的深度学习环境。
配置你自己系统的过程不适合胆小的人,尤其是第一次。如果你仔细按照步骤操作,并额外注意可选的 GPU 设置,我相信你会成功的。
如果你遇到困难,只需给我发信息,我很乐意帮忙。DL4CV 客户可以使用配套的网站门户获得更快的响应。
我们开始吧!
步骤 1:安装 Ubuntu 依赖项
在我们开始之前,启动一个终端或 SSH 会话。SSH 用户可能会选择使用一个名为screen的程序(如果你熟悉它的话)来确保你的会话在你的互联网连接中断时不会丢失。
准备好之后,继续更新您的系统:
$ sudo apt-get update
$ sudo apt-get upgrade
让我们安装开发工具、图像和视频 I/O 库、GUI 包、优化库和其他包:
$ sudo apt-get install build-essential cmake unzip pkg-config
$ sudo apt-get install libxmu-dev libxi-dev libglu1-mesa libglu1-mesa-dev
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libopenblas-dev libatlas-base-dev liblapack-dev gfortran
$ sudo apt-get install libhdf5-serial-dev
$ sudo apt-get install python3-dev python3-tk python-imaging-tk
CPU 用户:跳到 【第五步】 。
GPU 用户: CUDA 9 需要 gcc v6,但 Ubuntu 18.04 附带 gcc v7,因此我们需要安装 gcc 和 g++ v6:
$ sudo apt-get install gcc-6 g++-6
步骤 2:安装最新的 NVIDIA 驱动程序(仅限 GPU)

Figure 1: Steps 2-4 require that you have an NVIDIA CUDA-capable GPU. A GPU with 8GB memory is recommended. If you do not have a GPU, just skip to Step #5.
此步骤仅针对 GPU 用户。
注意: 这一节与我的 Ubuntu 16.04 深度学习安装指南有相当大的不同,所以确保你仔细地遵循它。
让我们继续将 NVIDIA PPA 库添加到 Ubuntu 的 Aptitude 包管理器中:
$ sudo add-apt-repository ppa:graphics-drivers/ppa
$ sudo apt-get update
现在,我们可以非常方便地安装我们的 NVIDIA 驱动程序:
$ sudo apt install nvidia-driver-396
继续并重新启动,以便在机器启动时激活驱动程序:
$ sudo reboot now
一旦您的计算机启动,您回到终端或重新建立了 SSH 会话,您将需要验证 NVIDIA 驱动程序是否已成功安装:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.54 Driver Version: 396.54 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A 58C P0 61W / 149W | 0MiB / 11441MiB | 99% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
在第一个表格的顶行,我们有 NVIDIA GPU 驱动程序版本。
接下来的两行显示了您的 GPU 类型(在我的例子中是 Tesla K80)以及使用了多少 GPU 内存——这个空闲的 K80 使用了大约 12GB 的 0Mb。
nvidi-smi命令还将向您展示使用下表中的 GPU 运行的进程。如果您在 Keras 或 mxnet 正在训练时发出这个命令,您会看到 Python 正在使用 GPU。
这里一切看起来都很好,所以我们可以前进到 【步骤 3】。
步骤 3:安装 CUDA 工具包和 cuDNN(仅限 GPU)
这一步是针对 GPU 用户的。
前往 NVIDIA 开发者网站下载 CUDA 9.0。您可以通过此直接链接访问下载内容:
https://developer.nvidia.com/cuda-90-download-archive
注意:TensorFlowv 1.12 需要 CUDA v9.0(除非你想从我不推荐的源码构建 tensor flow)。
NVIDIA 尚未正式支持 Ubuntu 18.04,但 Ubuntu 17.04 驱动程序仍将工作。
从 CUDA Toolkit 下载页面进行以下选择:
- “Linux”
- "x86_64"
- “Ubuntu”
- 【17.04】(也适用于 18.04)
- run file(本地)**
*…就像这样:

Figure 2: Downloading the NVIDIA CUDA Toolkit 9.0 for Ubuntu 18.04.
您可能只想将链接复制到剪贴板,并使用 wget 命令下载运行文件:
$ wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda_9.0.176_384.81_linux-run
请务必复制完整的 URL:
https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda_9.0.176_384.81_linux-run
从那里开始安装,让我们继续安装 CUDA 工具包。这要求我们首先通过chmod命令给脚本可执行文件权限,然后我们使用超级用户的凭证(可能会提示您输入 root 密码):
$ chmod +x cuda_9.0.176_384.81_linux-run
$ sudo ./cuda_9.0.176_384.81_linux-run --override
注意:需要–override开关,否则 CUDA 安装人员会抱怨 gcc-7 还在安装。
在安装过程中,您必须:
- 使用“空格”向下滚动并接受条款和条件
- 选择 y 为T3【在不支持的配置上安装】
- 选择 n 为T3“为 Linux-x86_64 384.81 安装 NVIDIA 加速图形驱动?”
- 保留所有其他默认值(有些是
y,有些是n)。对于路径,只需按下“回车”。
现在我们需要更新我们的 ~/。包含 CUDA 工具包的 bashrc 文件:
$ nano ~/.bashrc
nano 文本编辑器非常简单,但是您可以随意使用您喜欢的编辑器,如 vim 或 emacs。滚动到底部并添加以下行:
# NVIDIA CUDA Toolkit
export PATH=/usr/local/cuda-9.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64
Figure 3: Editing the ~/.bashrc profile for the CUDA Toolkit. CUDA allows you to use your GPU for deep learning and other computation.
用 nano 保存和退出,只需按“ctrl+o”,然后按“回车”,最后按“ctrl+x”。
保存并关闭 bash 概要文件后,继续重新加载文件:
$ source ~/.bashrc
从这里您可以确认 CUDA 工具包已经成功安装:
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176
第四步:安装 cuDNN (CUDA 深度学习神经网络库)(仅限 GPU)
对于这一步,您需要在 NVIDIA 网站上创建一个帐户+下载 cuDNN。
以下是链接:
https://developer.nvidia.com/cudnn
当您登录到该页面后,继续进行以下选择:
- “下载 cud nn”
- 登录并检查“我同意 cuDNN 软件许可协议的服务条款”
- “存档的 cuDNN 版本”
- “cud nn v 7 . 4 . 1(2018 . 11 . 8)for CUDA 9.0”
- 【cud nn Linux 库】
您的选择应该使您的浏览器页面看起来像这样:
Figure 4: Downloading cuDNN from the NVIDIA developer website in order to set up our Ubuntu system for deep learning.
一旦文件驻留在您的个人计算机上,您可能需要将它们放置到您的 GPU 系统中。您可以使用以下命令将文件 SCP 到您的 GPU 机器上(如果您使用 EC2 密钥对):
$ scp -i EC2KeyPair.pem ~/Downloads/cudnn-9.0-linux-x64-v7.4.1.5.tgz \
username@your_ip_address:~
在 GPU 系统上(通过 SSH 或在桌面上),以下命令会将 cuDNN 安装到 Ubuntu 18.04 系统的正确位置:
$ cd ~
$ tar -zxf cudnn-9.0-linux-x64-v7.4.1.5.tgz
$ cd cuda
$ sudo cp -P lib64/* /usr/local/cuda/lib64/
$ sudo cp -P include/* /usr/local/cuda/include/
$ cd ~
上面,我们有:
- 提取了我们主目录中的 cuDNN 9.0 v7.4.1.5 文件。
- 导航到
cuda/目录。 - 将
lib64/目录及其所有内容复制到所示路径。 - 将
include/文件夹也复制到所示的路径。
小心使用这些命令,因为如果 cuDNN 不在需要的地方,它们可能会成为一个棘手的问题。
步骤 5:创建您的 Python 虚拟环境
本节面向 两个 CPU 和 GPU 用户。
我是 Python 虚拟环境的倡导者,因为它们是 Python 开发世界中的最佳实践。
虚拟环境允许在您的系统上开发不同的项目,同时管理 Python 包的依赖性。
例如,我可能在我的 GPU DevBox 系统上有一个名为dl4cv_21的环境,对应于我的深度学习书籍的 2.1 版本。
但是当我以后发布 3.0 版本时,我会用不同版本的 TensorFlow、Keras、scikit-learn 等测试我的代码。因此,我只是将更新后的依赖项放在它们自己的环境中,名为dl4cv_30。我想你已经明白这使得开发变得容易多了。
另一个例子是两个独立的努力,例如(1)一个博客系列文章——我们现在正致力于预测房价;以及(2)一些其他项目,如 PyImageSearch Gurus 。
我有一个house_prices虚拟环境用于 3 部分房价系列,还有一个gurus_cv4虚拟环境用于我最近对整个大师课程的 OpenCV 4 更新。
换句话说,您可以根据需要构建尽可能多的虚拟环境,而无需让资源饥渴的虚拟机来测试代码。
对于 Python 开发来说,这是显而易见的。
我使用并推广以下工具来完成工作:
- 虚拟人
- 虚拟包装
注:我并不反对替代品(蟒蛇,venv 等。),但是您将独自解决这些替代方案的任何问题。此外,如果您混合使用不同的环境系统,这可能会引起一些麻烦,所以当您遵循网上找到的教程时,请注意您在做什么。
事不宜迟,让我们在您的系统上设置虚拟环境——如果您以前已经做过,只需选择我们实际创建新环境的位置。
首先,让我们安装 pip,一个 Python 包管理工具:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
现在已经安装了 pip,让我们继续安装我推荐的两个虚拟环境工具— virtualenv 和 virtualenvwrapper :
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
我们需要用一些 virtualenvwrapper 设置来更新 bash 概要文件,以使这些工具能够协同工作。
请打开您的 ~/。bashrc 文件,并在最底部添加以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
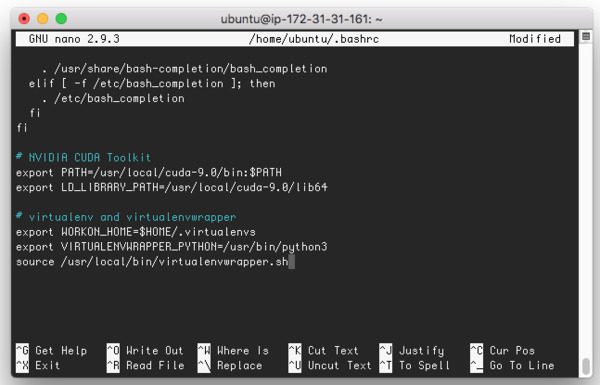
Figure 5: Using Python virtual environments is a necessity for deep learning development with Python on Ubuntu. In this screenshot, we have edited our ~/.bashrc to use virtualenv and virtualenvwrapper (two of my preferred tools).
让我们继续加载我们的 ~/。bashrc 文件:
$ source ~/.bashrc
virtualenvwrapper 工具现在支持以下终端命令:
mkvirtualenv:创建一个虚拟环境。rmvirtualenv:删除虚拟环境。workon:激活指定的虚拟环境。如果未指定环境,将列出所有环境。deactivate:带你到你的系统环境。您可以随时再次激活任何虚拟环境。
创建dl4cv环境
使用上面列表中的第一个命令,让我们继续用 Python 3:
$ mkvirtualenv dl4cv -p python3
当您的虚拟环境处于活动状态时,您的终端 bash 提示符将如下所示:
Figure 6: My dl4cv environment is activated. The beginning of the bash prompt serves as my validation that I’m ready to install software for deep learning with Python.
如果您的环境不是活动的,只需使用workon命令:
$ workon dl4cv
从这里开始,您的 bash 提示符将相应地改变。
步骤 6:安装 Python 库
既然我们的 Python 虚拟环境已经创建并处于活动状态,让我们使用 pip 安装 NumPy 和 OpenCV:
$ pip install numpy
$ pip install opencv-contrib-python
或者,您可以从源代码安装 OpenCV,以获得带有专利算法的完整安装。但是对于我的深度学习书籍来说,那些额外的算法与深度学习无关。
让我们安装额外的计算机视觉、图像处理和机器学习所需的库:
$ pip install scipy matplotlib pillow
$ pip install imutils h5py requests progressbar2
$ pip install scikit-learn scikit-image
用 Python 安装 TensorFlow 进行计算机视觉深度学习
安装 TensorFlow 有两种选择:
选项#1: 安装 tensor flowT3GPU 支持:
$ pip install tensorflow-gpu==1.12.0
注意:来自读者的反馈让我们意识到 CUDA 的新版本不支持最新的 TensorFlow。我们建议安装 1.12.0 版,如图所示。
选项#2: 安装 tensor flowT3【无 GPU 支持:
$ pip install tensorflow
可以说,第三种选择是从源代码编译 TensorFlow,但对于 DL4CV 来说这是不必要的。
继续验证 TensorFlow 是否安装在您的dl4cv虚拟环境中:
$ python
>>> import tensorflow
>>>
为 DL4CV 安装 Keras
我们将再次使用 pip 将 Keras 安装到dl4cv环境中:
$ pip install keras
您可以通过启动 Python shell 来验证 Keras 是否已安装:
$ python
>>> import keras
Using TensorFlow backend.
>>>
现在,让我们退出 Python shell,然后在进入“第 7 步”之前停用环境:
>>> exit()
$ deactivate
注:针对 DL4CV ImageNet 捆绑包第 10 章“案例研究:情感识别”提出了一个问题。解决方案是为了兼容性需要安装来自 Keras 主分支的以下 commit-ID:9d33a024e3893ec2a4a15601261f44725c6715d1。要实现修复,您可以(1)使用 commit-ID 克隆 Keras repo,以及(2)使用setup.py安装 Keras。最终,PyPi 将被更新,上面描述的 pip 安装方法将起作用。错误/修复并不影响所有章节。参考:*DL4CV 问题跟踪器中的 798 号票证。*
第 7 步:安装 mxnet(仅限于 DL4CV ImageNet 包)

Figure 7: mxnet is a great deep learning framework and is highly efficient for multi-GPU and distributed network training.
我们在使用 Python 的计算机视觉深度学习的 ImageNet 捆绑包中使用 mxnet ,这是因为(1)它的速度/效率以及(2)它处理多个 GPU 的强大能力。
当处理 ImageNet 数据集以及其他大型数据集时,使用多个 GPU 进行训练至关重要。
并不是说用 TensorFlow GPU 后端就不能用 Keras 完成同样的事情,而是 mxnet 做的更有效率。语法是相似的,但是 mxnet 的某些方面不如 Keras 用户友好。在我看来,权衡是值得的,精通一个以上的深度学习框架总是好的。
让我们开始行动,安装 mxnet。
安装 mxnet 需要 OpenCV + mxnet 编译
为了有效地使用 mxnet 的数据扩充功能和 im2rec 实用程序,我们需要从源代码编译 mxnet ,而不是简单的 mxnet 的 pip 安装。
由于 mxnet 是一个编译过的 C++库(带有 Python 绑定),这就意味着我们必须像井一样从源代码编译 OpenCV。
让我们继续下载 OpenCV(我们将使用版本 3.4.4):
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/3.4.4.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/3.4.4.zip
然后解压缩归档文件:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
我喜欢重命名目录,这样我们的路径将是相同的,即使您使用的是 OpenCV 3 . 4 . 4 以外的版本:
$ mv opencv-3.4.4 opencv
$ mv opencv_contrib-3.4.4 opencv_contrib
然后,让我们创建一个新的虚拟环境(假设您遵循了 步骤#2 中的 virtualenv 和 virtualenvwrapper 指令)。
mxnet虚拟环境将包含完全独立于我们的dl4cv环境的包:
$ mkvirtualenv mxnet -p python3
现在已经创建了 mxnet 环境,请注意 bash 提示符:
Figure 8: The virtualenvwrapper tool coupled with the workon mxnet command activates our mxnet virtual environment for deep learning.
我们可以继续将 DL4CV 所需的软件包安装到环境中:
$ pip install numpy scipy matplotlib pillow
$ pip install imutils h5py requests progressbar2
$ pip install scikit-learn scikit-image
让我们用 cmake 配置 OpenCV:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON_EXECUTABLE=~/.virtualenvs/mxnet/bin/python \
-D OPENCV_ENABLE_NONFREE=ON \
-D BUILD_EXAMPLES=ON ..
Figure 9: OpenCV’s CMake output shows us that we’re using a Python 3.6 interpreter inside the mxnet environment. NumPy in the mxnet environment is also being utilized.
假设您的输出与我的匹配,让我们开始编译过程:
$ make -j4
编译 OpenCV 可能需要相当长的时间,但是由于您可能有 GPU,您的系统规格可能已经能够在不到 30 分钟的时间内编译 OpenCV。然而,这是你想去散步或喝杯咖啡的时候。
当 OpenCV 被 100%编译后,还有一些子步骤要执行,从我们实际的安装命令开始:
$ sudo make install
$ sudo ldconfig
您可以通过以下方式确认 OpenCV 已成功安装:
$ pkg-config --modversion opencv
3.4.4
现在是关键的子步骤。
我们需要做的是创建一个从 OpenCV 安装位置到虚拟环境本身的链接。这就是所谓的符号链接。
让我们现在就着手解决这个问题:
$ cd /usr/local/python/cv2/python-3.6
$ ls
cv2.cpython-36m-x86_64-linux-gnu.so
现在让我们把。因此,文件到一些更有意义的东西+创建一个符号链接到我们的 mxnet 站点包:
$ sudo mv cv2.cpython-36m-x86_64-linux-gnu.so cv2.opencv3.4.4.so
$ cd ~/.virtualenvs/mxnet/lib/python3.6/site-packages
$ ln -s /usr/local/python/cv2/python-3.6/cv2.opencv3.4.4.so cv2.so
注意:如果您的系统中安装了多个 OpenCV 版本,您可以使用相同的命名约定和符号链接方法。
为了测试 OpenCV 是否正确安装和链接,在 mxnet 环境中启动一个 Python shell:
$ cd ~
$ workon mxnet
$ python
>>> import cv2
>>> cv2.__version__
'3.4.4'
我们现在准备将 mxnet 安装到环境中。
克隆和安装mxnet
我们为 CUDA 安装了 gcc 和 g++ V7;不过有个问题 — mxnet 需要 gcc v6 和 g++ v6 从源码编译。
解决方案是移除 gcc 和 g++ 符号链接:
$ cd /usr/bin
$ sudo rm gcc g++
然后创建新的,这次指向 gcc-6 和g++-6:
$ sudo ln -s gcc-6 gcc
$ sudo ln -s g++-6 g++
现在我们已经链接了正确的编译器工具,让我们下载并安装 mxnet。
继续克隆 mxnet 存储库,并检查版本 1.3:
$ cd ~
$ git clone --recursive --no-checkout https://github.com/apache/incubator-mxnet.git mxnet
$ cd mxnet
$ git checkout v1.3.x
$ git submodule update --init
随着 mxnet 1.3 版本的发布,我们将编译支持 BLAS、OpenCV、CUDA 和 cuDNN 的 mxnet:
$ workon mxnet
$ make -j4 USE_OPENCV=1 USE_BLAS=openblas USE_CUDA=1 USE_CUDA_PATH=/usr/local/cuda USE_CUDNN=1
编译过程可能会在不到 40 分钟内完成。
然后,我们将为 mxnet 创建一个到虚拟环境站点包的符号链接:
$ cd ~/.virtualenvs/mxnet/lib/python3.6/site-packages/
$ ln -s ~/mxnet/python/mxnet mxnet
更新 2019-06-04:sym-link 更新支持 mxnet 的io模块。
让我们继续测试我们的 mxnet 安装:
$ workon mxnet
$ cd ~
$ python
>>> import mxnet
>>>
注意:不要删除你 home 文件夹中的 ~/mxnet 目录。不仅我们的 Python 绑定在那里,而且在创建序列化图像数据集时,我们还需要 ~/mxnet/bin 中的文件(即im2rec命令)。
现在 mxnet 已经完成了编译,我们可以重置我们的 gcc 和 g++ 符号链接来使用 v7:
$ cd /usr/bin
$ sudo rm gcc g++
$ sudo ln -s gcc-7 gcc
$ sudo ln -s g++-7 g++
我们也可以从我们的主文件夹中删除 OpenCV 源代码:
$ cd ~
$ rm -rf opencv/
$ rm -rf opencv_contrib/
在这里,您可以停用此环境,选择不同的环境,或者创建另一个环境。在 DL4CV companion 网站的补充材料页面中,我有关于如何为 TensorFlow 对象检测 API、Mask R-CNN 和 RetinaNet 代码设置环境的说明。
mxnet + OpenCV 4.1 解决方法
更新 2019-08-08: OpenCV 4.1 已经引起了 mxnet 的大量读者问题。在本节中,我将介绍 PyImageSearch 阅读器 Gianluca 的一个解决方法。谢谢你,吉安卢卡!
问题是最新的 OpenCV (4.1.0)没有创建 pkg-config 命令(在 mxnet 构建中使用)需要的opencv4.pc文件来识别安装的库和文件夹。
修复的方法是除了稍后添加一个符号链接之外,再添加一个 CMake 标志。
让我们回顾一下 CMake 标志:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_GENERATE_PKGCONFIG=YES \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON_EXECUTABLE=~/.virtualenvs/mxnet/bin/python \
-D OPENCV_ENABLE_NONFREE=ON \
-D BUILD_EXAMPLES=ON ..
注意行 5 被高亮显示。
然而,从这一点开始遵循上述说明,还有一个额外的步骤。
一旦安装完毕(通过make命令),我们需要将文件opencv4.pc从/usr/local/lib符号链接到默认的/usr/share/pkgconfig文件夹:
$ cd /usr/share/pkgconfig
$ ln -s /usr/local/lib/opencv4.pc opencv4.pc
如果您对 OpenCV 4.1 和 mxnet 有任何问题,请务必在下面的表格中提供您的意见。
干得好的工作
在这一点上,依次“祝贺”——你已经成功地为深度学习配置了你的 Ubuntu 18.04 盒子!
干得好!
您在配置深度学习系统时遇到过困难吗?
如果您在这个过程中遇到了困难,我鼓励您重新阅读一遍说明,并尝试调试。如果你真的陷入困境,你可以在 DL4CV 伴侣网站问题跟踪者(在你的书的前面有一个注册链接)或者通过联系我来寻求帮助。
我还想借此机会提醒您一下本书附带的预配置实例:
- DL4CV VirtualBox 虚拟机已经过预先配置,可以使用了。它将帮助你通过初学者和实践者包中几乎所有的实验。对于 ImageNet 捆绑包,GPU 是必需的,而该虚拟机不支持 GPU。
- 我的用于 AWS 云的 DL4CV 亚马逊机器映像对互联网免费开放——不需要购买(当然,除了 AWS 收费)。在云中开始使用 GPU 只需要大约 4-6 分钟。以不到一杯咖啡的价格,您可以使用一个 GPU 实例一两个小时,这刚好够完成 DL4CV 中一些(肯定不是全部)更高级的课程。预先配置了以下环境:
dl4cv、mxnet、tfod_api、mask_rcnn、retinanet。
Azure 用户应该考虑 Azure DSVM。你可以点击阅读我对微软 Azure DSVM 的评论。2017 年 DL4CV 第一个版本中的所有代码都是使用微软的 DSVM 进行测试的。这是一个选项,而且是一个非常好的选项,但是目前它还不准备支持 DL4CV 的奖励捆绑包,没有额外的配置。如果 Azure 是你首选的云提供商,我鼓励你留在那里,利用 DSVM 所提供的优势。
摘要
今天我们学习了如何用 TensorFlow 和 Keras 设置一台 Ubuntu 18.04 + CUDA + GPU 的机器(以及一台纯 CPU 的机器)进行深度学习。
请记住,你不需要一个 GPU 来学习深度学习是如何工作的!GPU 非常适合更深层次的神经网络和用大量数据进行训练,但如果你只是需要学习基础知识并在笔记本电脑上进行一些实践,你的 CPU 就很好。
我们实现了在两个独立的虚拟环境中设置以下工具的目标:
- Keras + TensorFlow
- mxnet
这些深度学习框架中的每一个都需要额外的 Python 包才能成功,例如:
- scikit-learn,SciPy,matplotlib
- OpenCV、枕头、sci kit-图像
- imutils(我个人的便利功能和工具包)
- …还有更多!
这些库现在可以在我们今天设置的每个虚拟环境中使用。现在,您已经准备好使用 TensorFlow、Keras 和 mxnet 训练最先进的模型。你的系统已经准备好用我的深度学习书中的代码以及你自己的项目进行黑客攻击了。
设置所有这些软件肯定是令人生畏的,尤其是对于新手用户。如果您在这个过程中遇到了任何问题,我强烈建议您检查一下是否跳过了任何步骤。如果你仍然被卡住,请取得联系。
希望这篇教程对你的深度学习之旅有所帮助!
为了在 PyImageSearch 上发布未来的博客文章时得到通知(并获取我的 17 页深度学习和计算机视觉资源指南 PDF),只需在下面的表格中输入您的电子邮件地址!*
了解实时物体探测网络:你只看一次
了解一个实时物体检测网络:你只看一次(YOLOv1)
对象检测已经变得越来越流行,并且得到了广泛的发展,尤其是在深度学习时代。从我们以前的帖子“YOLO 家族介绍”中,我们知道对象检测分为三类算法:传统的计算机视觉,两阶段检测器和单阶段检测器。
今天,我们将讨论第一批单级检测器之一,名为“了解实时物体检测网络:你只看一次(YOLOv1)”。YOLOv1 是一个无锚点架构,它是对象检测领域的一个突破,将对象检测作为一个简单的回归问题来解决。它比 Faster-RCNN 等流行的两级检测器快许多倍,但代价是精度较低。
这一课是我们关于 YOLO 的七集系列的第二集:
- YOLO 家族简介
- 了解一个实时物体检测网络:你只看一次(YOLOv1) (今日教程)
- 更好、更快、更强的物体探测器(YOLOv2)
- 使用 COCO 评估器 平均精度(mAP)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
- 【yolov 4】
- 在自定义数据集上训练 YOLOv5 物体检测器
今天的帖子将讨论首批单级探测器之一(即 YOLOv1),该探测器能够以非常高的速度探测物体,同时还能达到相当高的精度。
理解对象检测架构有时会令人望而生畏。
但是不要担心,我们会让你很容易,我们会解开每一个细节,这将有助于你加快学习这个话题!
要了解 YOLOv1 物体探测器的所有信息并观看实时探测物体的演示,请继续阅读。
了解一个实时物体检测网络:你只看一次(YOLOv1)
在 YOLO 系列的第二部分,我们将首先讨论什么是单级目标探测器。然后,我们将对 YOLOv1 进行简单介绍,并讨论其端到端的检测过程。
在此基础上,我们将 YOLOv1 与其他架构进行比较,了解网络架构和训练过程,以及用于检测和分类的组合损失函数。最后,我们将回顾定性和定量基准,并反思 YOLOv1 的局限性和自然与艺术图像的普遍性。
最后,我们将通过在 Tesla V100 GPU 上安装 darknet 框架并使用 YOLOv1 预训练模型对图像和视频运行推理来结束本教程。
配置您的开发环境
要遵循这个指南,您需要在您的系统上编译并安装 Darknet 框架。在本教程中,我们将使用 AlexeyAB 的 Darknet 库。
我们将逐步介绍如何在 Google Colab 上安装 darknet 框架。但是,如果您想现在配置您的开发环境,可以考虑前往配置 Darknet 框架并使用预训练的 YOLOv1 模型运行推理部分。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
什么是单级物体探测器?
单级对象检测器是一类单级对象检测架构。他们将目标检测视为简单的回归问题;例如,输入图像被馈送到网络,直接输出类别概率和边界框坐标。
这些模型跳过区域提议阶段,也称为区域提议网络,它通常是两阶段对象检测器的一部分,是图像中可能包含对象的区域。
图 2 显示了单级和两级探测器的工作流程。在单阶段中,我们直接在特征图上应用检测头,而在两阶段中,我们首先在特征图上应用区域建议网络。
然后,这些区域被进一步传递到对每个区域进行预测的第二阶段。fast-RCNN 和 Mask-RCNN 是一些最流行的两阶段对象检测器。
虽然两级检测器被认为比单级对象检测器更准确,但是它们涉及多级时推理速度较慢。另一方面,单级检测器比两级检测器快得多。
【YOLO】你只看一次
由 Joseph Redmon 领导的一组作者在 2016 年 CVPR 会议上发表了 You Only Look Once: Unified,Real-Time Object Detection 。
你只看了一次或者俗称的 YOLO ,就在物体探测领域取得了突破。这是第一种将目标检测视为回归问题的方法。使用这个模型,你只需要看一次图像就可以预测出有什么物体存在,以及它们在哪里。
与两阶段检测器方法不同,YOLO 没有建议生成器和提炼阶段;它使用一个单一的神经网络,从一个完整的图像中预测类别概率和边界框坐标。因为检测管道本质上是一个网络,所以它可以被端到端地优化;可以把它想象成一个图像分类网络。
由于该网络旨在以类似于图像分类的端到端方式进行训练,因此该架构速度极快,并且基本 YOLO 模型在 Titan X GPU 上以 45 FPS(每秒帧数)的速度预测图像。作者还提出了一种更轻便的 YOLO 版本,称为快速 YOLO,具有更少的以 155 FPS 处理图像的层。是不是很神奇?
YOLO 实现了 63.4 mAP(平均精度),是其他实时探测器的两倍多,使其更加特殊。
我们即将发布一篇关于使用 COCO 评估器计算地图的博客文章,如果你有兴趣了解地图是如何计算的,那就去看看吧。
尽管与其他先进的模型(如 fast-RCNN)相比,YOLO 会产生更多的定位错误(假阴性),尤其是小物体,但它在预测背景中的假阳性较少方面表现良好。然而,YOLO 在准确性方面仍然落后于最先进的检测系统,如 fast-RCNN。虽然它可以快速识别图像中的对象,但它很难定位一些对象,尤其是小对象。
来自 Redmon et al. (2016) 的另一个令人兴奋的发现是 YOLO 对来自互联网的艺术品和自然图像的概括。此外,它比可变形部分模型(DPM)和基于区域的卷积神经网络(RCNN)等检测方法好得多。
端到端统一检测流程
YOLO 基于单阶段检测原理工作,这意味着它将物体检测管道的所有组件统一到单个神经网络中。它使用来自整个图像的特征来预测类别概率和包围盒坐标。
这种方法有助于对整个图像和图像中的对象进行全局建模推理。然而,在以前的两级检测器中,如 RCNN,我们有一个建议生成器,它为图像生成粗略的建议,然后将这些建议传递到下一级进行分类和回归。
图 4 显示整个检测过程由三个步骤组成:将输入图像调整到
, running a single convolutional network on the complete image, and thresholding the resulting detections by the model’s confidence, thereby removing duplicate detections.
这种端到端的统一检测设计使 YOLO 架构能够更快地训练,并在推理过程中实现实时速度,同时确保高平均精度(接近两级检测器)。
传统方法(例如 DPM)使用滑动窗口方法。然而,分类器在整个图像上以均匀间隔的位置运行,因此使得它在训练和测试时间非常慢,并且对优化具有挑战性,尤其是 RCNN 架构,因为每个阶段都需要单独训练。
我们知道 YOLO 致力于统一的端到端检测方法,但它是如何实现的呢?让我们来了解一下!
YOLO 模型将图像分成一个
grid, shown in Figure 5, where  . If the center of an object falls into one of the 49 grids, then that cell is responsible for detecting that object.
. If the center of an object falls into one of the 49 grids, then that cell is responsible for detecting that object.
但是一个网格单元能负责检测多少物体呢?嗯,每个网格单元可以检测 B 个边界框和这些边界框的置信度得分,
.
总之,该模型可以检测
bounding boxes; however, later, we will see that during the training, the model tries to suppress one of the two boxes in each cell that has less Intersection over Union (IOU) with the ground-truth box.
置信度得分被分配给每个框,它告诉模型对于边界框包含对象的置信度。
置信度得分可以定义为:
 \times \text{IOU}^\text{truth}_\text{pred}")
其中")
is 1 if the object exists, and 0 otherwise; when an object is present, the confidence score equals the IOU between the ground truth and the predicted bounding box.
这是有意义的,因为当预测的框不完全与基本事实框对齐时,我们不希望置信度得分为 100% ( 1),这允许我们的网络为每个边界框预测更真实的置信度。
每个边界框输出五个预测:
.
-
目标
") 坐标表示边界框的中心相对于网格单元的边界,意味着
坐标表示边界框的中心相对于网格单元的边界,意味着") 的值将在
的值将在[0, 1]之间变化。值为(0.5, 0.5)的") 表示对象的中心是特定网格单元的中心。
表示对象的中心是特定网格单元的中心。 -
目标
") 是边框相对于整个图像的宽度和高度。这意味着预测的
是边框相对于整个图像的宽度和高度。这意味着预测的") 也会相对于整个图像。边界框的宽度和高度可以大于
也会相对于整个图像。边界框的宽度和高度可以大于1。 -
 是网络预测的置信度得分。
是网络预测的置信度得分。
") 坐标表示边界框的中心相对于网格单元的边界,意味着
坐标表示边界框的中心相对于网格单元的边界,意味着") 是边框相对于整个图像的宽度和高度。这意味着预测的
是边框相对于整个图像的宽度和高度。这意味着预测的") 也会相对于整个图像。边界框的宽度和高度可以大于
也会相对于整个图像。边界框的宽度和高度可以大于 是网络预测的置信度得分。
是网络预测的置信度得分。除了边界框坐标和置信度得分,每个网格单元预测
conditional class probabilities ") , where
, where  for PASCAL VOC classes.
for PASCAL VOC classes.  is conditioned on the grid cell containing an object; hence, it only exists when there is an object.
is conditioned on the grid cell containing an object; hence, it only exists when there is an object.
我们了解到每个网格单元负责预测两个盒子。然而,只考虑具有最高 IOU 和地面真值的一个;因此,模型预测每个网格单元的一组类别概率,忽略盒子的数量
.
要培养更多的直觉,参考图 6;我们可以观察
grids, and each grid cell has output predictions for Box 1 and Box 2 and class probabilities.
每个边界框有五个值![[\text{confidence}, X, Y, \text{Width}, \text{Height}]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/1f07f495d131496ae8e5a88f4aa2a745.png "[\text{confidence}, X, Y, \text{Width}, \text{Height}]")
in total ten values for both bounding boxes and 20 class probabilities. Hence, the final prediction is a  tensor.
tensor.
比较 YOLOv1 与其他架构
本节将 YOLO 检测架构与几个顶级检测框架进行比较,如 DPM、RCNN、Overfeat 等。
-
DPM: Girshick,Iandola 等人(2014) 使用滑动窗口方法,根据窗口的跨度对每个图像区域进行分类。管道是不相交的,涉及提取静态特征、对区域分类和预测高分区域。
然而,在 YOLO, Redmon 等人使用统一的方法,其中单个 CNN 模型提取特征来执行包围盒预测和非最大值抑制。同样重要的是要注意,YOLO 不依赖于静态特性;他们是通过网络培训学会的。此外,YOLO 侧重于全局上下文信息,而不仅仅是局部区域,如 DPM 中所见,这有助于减少误报。不幸的是,与基准相比,DPM 在速度和准确性上都远远落后于 YOLO 网络。
-
RCNN ( Girshick,Donahue 等人,2014 ): 家庭使用区域建议在图像中寻找对象。RCNN 使用选择性搜索来生成潜在的包围盒。CNN 从每个区域提取特征,支持向量机(SVM)对盒子进行分类,并且完全连接的线性层校准边界盒子。它有如此多的组件,这使得它很难优化和缓慢的训练。RCNN 花费了超过 45 秒的时间,这对一个需要实时速度的应用来说太多了。此外,RCNN 的选择性搜索方法提出了 2000 个包围盒,而 YOLO 每幅图像有 98 个提议。YOLO 将所有这些不相关的步骤合并成一个单一的端到端联合优化模型。
-
过吃: Sermanet 等人(2014) 使用了与 DPM 类似的方法(即滑动窗口检测,但执行效率更高)。它训练 CNN 来执行定位,无法学习全球环境,并且需要大量的后处理来产生一致的检测。总的来说,这也是一个分离的架构。
-
更快-RCNN ( 任等,2016):比 RCNN 好得多。它消除了对建议区域的选择性搜索,但仍然有两个不同的对象检测网络。这很难优化,因为它有四个损失函数:两个用于区域建议网络,两个用于快速 R-CNN。
使用了相当多的全连接层,增加了参数,减少了推理时间。因此,虽然 fast-RCNN 在地图上超过了 YOLO,但它的 FPS 比 YOLO 少了 5-6。
在将 YOLO 与四种不同的架构进行比较后,我们可以得出结论,这些架构中的大多数专注于学习本地信息,而不是全局信息。他们只看图像的一部分,而不是图像的整体。对象检测管道不是端到端的;各种组件可能会使这些网络难以优化,并且在测试时速度较慢。
另一方面,YOLO 通过设计用于同时执行检测和分类的单个卷积神经网络,在将对象检测作为回归或图像分类问题来处理方面做得非常好。
YOLO 的网络架构
相信我,YOLO 的网络架构很简单!它类似于您过去可能训练过的图像分类网络。但是,令您惊讶的是,这个架构的灵感来自于图像分类任务中使用的 GoogLeNet 模型。
它主要由三种类型的层组成:卷积层、最大池层和全连接层。YOLO 网络有 24 个卷积层,它们进行图像特征提取,然后是两个完全连接的层,用于预测边界框坐标和分类分数。
Redmon 等人修改原 GoogLenet 架构。首先,他们使用了
convolutional layers instead of inception modules for reducing feature space, followed by a  convolutional layer (see Figure 7).
convolutional layer (see Figure 7).
YOLO 的第二种变体,称为快速 YOLO,具有 9 个卷积层而不是 24 个,并且使用更小的滤波器尺寸。它主要是设计来进一步推动推理速度到一个你永远无法想象的程度。通过这种设置,作者能够实现 155 FPS !
训练流程
作为第一步, Redmon 等人在 ImageNet 1000 类数据集上训练网络。然后,在预训练步骤中,他们考虑了前 20 个卷积层,随后是平均池和全连接层。
他们对这个模型进行了近 7 天的训练,并在 ImageNet 验证集上取得了 88%的前 5 名准确率。它是用 的输入分辨率训练的
的输入分辨率训练的
, half the resolution used for object detection. Figure 8 shows the network summary of YOLOv1 that has the detection layer at the end.
PASCAL VOC 2007 和 2012 数据集用于训练检测任务的神经网络。该网络被训练了大约 135 个时期,批次大小为 64,动量为 0.9。从 开始,学习率随着培训的进行而变化
开始,学习率随着培训的进行而变化
to  . Standard data augmentation and dropout techniques were used to avoid overfitting.
. Standard data augmentation and dropout techniques were used to avoid overfitting.
作者用C 语言编写了他们的框架,用于训练和测试被称为暗网的模型。预训练的分类网络堆叠有四个卷积层和两个全连接层,具有用于检测任务的随机初始化。
由于检测是一项更具挑战性的任务,需要细粒度的上下文信息,因此输入被上采样到
.
地面实况边界框的高度和宽度被标准化为![[0, 1]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/70c03e11df59f07f35779b889bcc19d4.png "[0, 1]")
by dividing it with the image height and width. All the layers except the last used LeakyReLU as the activation function with , and the final layer is linear.
损失函数
现在让我们剖析图 9 中所示的 YOLO 损失函数。乍一看,下面的等式可能看起来有点冗长和复杂,但是不要担心;很容易理解。
你会注意到,在这个损耗方程中,我们正在用误差平方和(SSE)优化网络, Redmon 等人认为这很容易优化。然而,使用它有一些注意事项,他们试图通过增加一个叫做的权重项来克服这些注意事项
.
让我们一部分一部分地理解上面的等式:
-
等式的第一部分计算预测边界框中点(
 ,
, )和地面真实边界框中点(
)和地面真实边界框中点( ,
, )之间的损失。
)之间的损失。对所有 49 个网格单元进行计算,损失中只考虑两个包围盒中的一个。请记住,它只会惩罚对地面实况框“负责”的预测值的边界框坐标误差(即,在该格网像元中具有任何预测值的最高 IOU)。
简而言之,我们将找出与目标边界框具有最高 IOU 的两个边界框,并且这将被优先用于损失计算。
最后,我们用一个常数
 来衡量损失,以确保我们的包围盒预测尽可能接近目标。最后,恒等式函数
来衡量损失,以确保我们的包围盒预测尽可能接近目标。最后,恒等式函数 表示单元
表示单元 中的第
中的第 个边界框预测器负责该预测。因此,如果目标对象存在,则为
个边界框预测器负责该预测。因此,如果目标对象存在,则为1,否则为0。 -
第二部分与第一部分颇为相似,让我们来了解一下不同之处。这里,我们计算预测的边界框宽度和高度
") 与目标宽度和高度
与目标宽度和高度") 之间的损失。
之间的损失。小盒子中的显著偏差会很小,而大盒子中的微小变化会很大,这将导致小盒子不那么重要。因此,作者增加了一个平方根,以反映大盒子中的轻微偏差小于小盒子中的偏差。
-
在等式的第三部分中,假设一个对象存在
 ,我们计算包围盒
,我们计算包围盒 的预测置信度得分和目标置信度得分
的预测置信度得分和目标置信度得分 之间的损失。
之间的损失。这里,目标置信度得分
 等于预测包围盒与目标之间的 IOU。我们选择与目标具有较高 IOU 的盒子的置信度得分。
等于预测包围盒与目标之间的 IOU。我们选择与目标具有较高 IOU 的盒子的置信度得分。 -
接下来,如果网格单元
 中不存在对象,那么
中不存在对象,那么 和
和 将使方程的第三部分为零。在具有较高 IOU 的框和目标
将使方程的第三部分为零。在具有较高 IOU 的框和目标 之间计算损失,目标为
之间计算损失,目标为0,因为我们希望没有对象的单元格的置信度为0。我们也用
 来衡量这部分,因为可能有许多没有对象的网格单元,我们不希望这个术语压倒包含对象的单元的渐变。正如本文所强调的,这可能会导致模型不稳定,并且更难优化。
来衡量这部分,因为可能有许多没有对象的网格单元,我们不希望这个术语压倒包含对象的单元的渐变。正如本文所强调的,这可能会导致模型不稳定,并且更难优化。 -
最后,对于每个单元,
 ,如果对象出现在单元
,如果对象出现在单元 中,我们计算所有 20 个类别的损失(条件类别概率)。这里,
中,我们计算所有 20 个类别的损失(条件类别概率)。这里,") 是预测的条件类概率,
是预测的条件类概率,") 是目标条件类概率。
是目标条件类概率。
 ,
, )和地面真实边界框中点(
)和地面真实边界框中点( ,
, )之间的损失。
)之间的损失。 来衡量损失,以确保我们的包围盒预测尽可能接近目标。最后,恒等式函数
来衡量损失,以确保我们的包围盒预测尽可能接近目标。最后,恒等式函数 表示单元
表示单元 中的第
中的第 个边界框预测器负责该预测。因此,如果目标对象存在,则为
个边界框预测器负责该预测。因此,如果目标对象存在,则为 ,我们计算包围盒
,我们计算包围盒 之间的损失。
之间的损失。 和
和 将使方程的第三部分为零。在具有较高 IOU 的框和目标
将使方程的第三部分为零。在具有较高 IOU 的框和目标 来衡量这部分,因为可能有许多没有对象的网格单元,我们不希望这个术语压倒包含对象的单元的渐变。正如本文所强调的,这可能会导致模型不稳定,并且更难优化。
来衡量这部分,因为可能有许多没有对象的网格单元,我们不希望这个术语压倒包含对象的单元的渐变。正如本文所强调的,这可能会导致模型不稳定,并且更难优化。 ,如果对象出现在单元
,如果对象出现在单元") 是预测的条件类概率,
是预测的条件类概率,") 是目标条件类概率。
是目标条件类概率。量化基准
现在,我们已经涵盖了 YOLO 架构的几乎所有方面,让我们看看 YOLO 及其变体快速 YOLO 与其他实时和非实时对象检测器相比所实现的一些量化基准。
表 1 有四个属性:实时检测器、训练数据、评估度量和 FPS 我们使用这四个属性进行定量比较。用于训练所有四个模型的训练数据是 Pascal VOC。我们可以看到,在平均精度(接近 2 倍)和 FPS 方面,YOLO 和快速 YOLO 都远远超过 DPM 的实时对象检测器变体。
具有九个卷积层的快速 YOLO 实现了52.7和155 FPS 的映射。另一方面,YOLO 获得了63.4地图和45 FPS。这两种型号在 2016 年都会改变游戏规则,是目标部署为嵌入式或移动设备的对象检测应用的明确选择,尤其是快速 YOLO 变体。
在表 2 中,我们将 YOLO 与其他非实时物体检测器进行了比较。更快-RCNN 在 mAP 方面表现最好,但仅达到 7 FPS,对于需要实时处理的应用来说太少;加上预处理和后处理,FPS 将进一步降低。而以 VGG-16 为骨干的 YOLO 比以谷歌网络为骨干的 YOLO 获得+3%的地图增益。
对艺术形象的概括
本节讨论 Redmon 等人对 YOLO、RCNN、DPM 和其他两个模型的概化测试。结果很有意思,所以让我们快速了解一下。
作者提出了一个很好的观点,即测试数据通常不来自模型在现实世界中接受训练的同一分布,或者它可能与模型之前看到的有所不同。
图 10 显示了用 Pascal VOC 数据集训练时 YOLOv1 在艺术和自然图像上的定性结果。这个模型做得相当好,尽管它确实认为一个人是一架飞机。
类似地,考虑到 YOLO 是在 Pascal VOC 数据集上训练的,他们在另外两个数据集上测试了该模型:Picasso 和 People-Art 数据集,用于测试艺术品上的人物检测。
表 3 显示了 YOLO 和其他检测方法之间的比较。YOLO 在所有三个数据集上都优于 R-CNN 和 DPM。VOC 2007 AP 仅在 person 类上评估,所有三个模型都在 VOC 2007 数据集上训练。
对于毕加索评估,模型在 VOC 2012 上训练,对于人艺测试数据,在 VOC 2010 上训练。
观察到在 VOC 2007 上 RCNN 的 AP 很高,但是当在 Picasso 和 People-Art 数据上测试时,准确性显著下降。一个可能的原因是,RCNN 使用选择性搜索来生成建议,这是针对自然图像而言的,而这是艺术作品。此外,RCNN 中的分类器步骤只看到局部区域,需要更好的建议。
YOLO 在这三个数据集上都表现良好;与其他两种型号相比,它的 AP 没有显著下降。作者指出,YOLO 能很好地学习物体的大小和形状以及它们之间的关系。自然图像和艺术品在像素级别上可能是不同的,但是它们在语义上是相似的,并且对象的大小和形状也保持一致。
YOLO 建筑的局限性
在讨论 YOLO 的局限性之前,我们都应该花点时间来欣赏一下这种新的单级检测技术,它通过提供一种运行速度如此之快并设定新基准的架构,在对象检测领域取得了突破!
但没有什么是完美的,总有改进的余地,YOLOv1 也是如此。
一些限制是:
- 该模型限制了在给定图像中检测到的对象的数量:最多只能检测 49 个对象。
- 由于每个网格单元只能预测两个盒子,只能有一个类别,这就限制了 YOLO 可以预测的附近物体的数量,尤其是成群出现的小物体,比如一群鸟。
- 它也很难探测到更小的物体。该模型使用相对粗糙的特征来预测对象,因为该架构具有来自输入图像的多个下采样层。因此,相对较小的对象在最后一层会变得更小,导致网络更难定位。
- Redmon 等人认为错误的主要来源是不正确的定位,因为损失函数在小边界框和大边界框中对待错误是一样的。
这么多理论就行了。让我们继续配置 darknet 框架,并使用预训练的 YOLOv1 模型运行推理。
配置暗网框架,用预先训练好的 YOLOv1 模型运行推理
我们已经将 Darknet 框架配置划分为 8 个易于遵循的步骤,并使用 YOLOv1 对图像和视频进行了推理。所以,让我们开始吧!
注意: 请确保您的机器上安装了匹配的 CUDA、CUDNN 和 NVIDIA 驱动程序。对于这个实验,我们使用 CUDA-10.2,CUDNN-8.0.3。但是如果你计划在 Google Colab 上运行这个实验,不要担心,因为所有这些库都预装了它。
第 1 步:本实验使用 GPU,确保 GPU 正常运行。
# Sanity check for GPU as runtime
$ nvidia-smi
图 11 显示了 machine(即 V100)、driver 和 CUDA 版本中可用的 GPU。
第二步:我们将安装一些库,比如 OpenCV,FFmpeg 等等。,这在编译和安装 darknet 之前是必需的。
# Install OpenCV, ffmpeg modules
$ apt install libopencv-dev python-opencv ffmpeg
步骤#3: 接下来,我们从 AlexyAB 存储库中克隆 darknet 框架的修改版本。如前所述,Darknet 是由 Joseph Redmon 编写的开源神经网络。用 C 和 CUDA 编写,同时支持 CPU 和 GPU 计算。暗网的官方实现可在:【https://pjreddie.com/darknet/;我们会下载官网提供的 YOLOv1 砝码。
# Clone AlexeyAB darknet repository
$ git clone https://github.com/AlexeyAB/darknet/
$ cd darknet/
确保将目录更改为 darknet,因为在下一步中,我们将配置Makefile并编译它。使用!pwd进行健全性检查;我们应该在/content/darknet目录里。
步骤#4: 使用流编辑器(sed),我们将编辑 make 文件并启用标志:GPU、CUDNN、OPENCV和LIBSO。
图 12 显示了Makefile的一个片段,其内容将在后面讨论:
- 我们让
GPU=1和CUDNN=1与CUDA一起构建暗网来执行和加速对GPU的推理。注意CUDA应该在/usr/local/cuda;否则,编译将导致错误,但如果您正在 Google Colab 上编译,请不要担心。 - 如果你的
GPU有张量核,使CUDNN_HALF=1获得最多3X推理和2X训练加速。由于我们使用带张量内核的 Tesla V100 GPU,因此我们将启用此标志。 - 我们使
OPENCV=1能够与OpenCV一起构建暗网。这将允许我们检测视频文件、IP 摄像头和其他 OpenCV 现成的功能,如读取、写入和在帧上绘制边界框。 - 最后,我们让
LIBSO=1构建darknet.so库和使用这个库的二进制可执行文件uselib。允许该标志使用 Python 脚本对图像和视频进行推理将使我们能够在其中导入darknet。
现在,让我们编辑Makefile并编译它。
# Enable the OpenCV, CUDA, CUDNN, CUDNN_HALF & LIBSO Flags and Compile Darknet
$ sed -i 's/OPENCV=0/OPENCV=1/g' Makefile
$ sed -i 's/GPU=0/GPU=1/g' Makefile
$ sed -i 's/CUDNN=0/CUDNN=1/g' Makefile
$ sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/g' Makefile
$ sed -i 's/LIBSO=0/LIBSO=1/g' Makefile
$ make
make命令将需要大约 90 秒来完成执行。既然编译已经完成,我们就可以下载 YOLOv1 权重并运行推理了。
你不兴奋吗?
步骤#5: 我们现在将从官方 YOLOv1 文档中下载 YOLOv1 砝码。
# Download YOLOv1 Weights
$ wget http://pjreddie.com/media/files/yolov1/yolov1.weights
步骤#6: 现在,我们将运行darknet_images.py脚本来推断图像。
# Run the darknet image inference script
$ python3 darknet_images.py --in hun put data --weights \
yolov1.weights --config_file cfg/yolov1/yolo.cfg \
--data_file cfg/voc.data --dont_show
让我们来看看传递给darknet_images.py的命令行参数:
--input:图像目录或文本文件的路径,带有图像路径或单个图像名称。支持jpg、jpeg和png图像格式。在本例中,我们将路径传递给名为data的图像文件夹。--weights: YOLOv1 重量路径。--config_file:yolo v1 的配置文件路径。在抽象层次上,该文件存储神经网络模型架构和一些其他参数,如batch_size、classes, input_size等。我们建议您通过在文本编辑器中打开该文件来快速阅读它。- 这里,我们传递 Pascal VOC 标签文件。
- 这将禁止 OpenCV 显示推理结果,我们使用它是因为我们正在使用 colab。
以下是 YOLOv1 模型对一组图像的对象检测推断结果。
我们可以从图 13 中看到,该模型表现良好,因为它正确预测了狗、自行车和汽车。
在图 14 中,该模型通过将一匹马归类为一只羊来预测一个假阳性,同时正确预测了另外两个对象。
在图 15 中,该模型再次通过正确检测几匹马完成了不错的工作。但是定位不是很准,确实漏了几匹马。在我们的下一篇文章中,你会看到 YOLOv2 在预测下图方面做得稍微好一点。
图 16 是一只鹰的图像,被模型很好的定位,归类为鸟。不幸的是,Pascal VOC 数据集没有 Eagle 类,但该模型很好地预测了它是一只鸟。
步骤#7: 现在,我们将在电影《天降》的视频上运行预训练的 YOLOv1 模型;这是雷德蒙等人在他们的一次 YOLOv1 实验中使用的同一段视频。
在运行darknet_video.py演示脚本之前,我们将首先使用pytube库从 YouTube 下载视频,并使用moviepy库裁剪视频。所以让我们快速安装这些模块并下载视频。
# Install pytube and moviepy for downloading and cropping the video
$ pip install git+https://github.com/rishabh3354/pytube@master
$ pip install moviepy
# Import the necessary packages
$ from pytube import YouTube
$ from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
# Download the video in 720p and Extract a subclip
$ YouTube('https://www.youtube.com/watch?v=tHRLX8jRjq8'). \ streams.filter(res="720p").first().download()
$ ffmpeg_extract_subclip("/content/darknet/Skyfall.mp4", \
0, 30, targetname="/content/darknet/Skyfall-Sample.mp4")
第 8 步:最后,我们将运行darknet_video.py脚本来为天崩地裂的视频生成预测。我们打印输出视频每一帧的 FPS 信息。
如果使用 mp4 视频文件,将 darknet 文件夹中darknet_video.py脚本的第 57 行的set_saved_video功能中的视频编解码器由MJPG更改为mp4v;否则,播放推理视频时会出现解码错误。
# Change the VideoWriter Codec
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
既然所有必要的安装和修改都已完成,我们将运行darknet_video.py脚本:
# Run the darknet video inference script
$ python darknet_video.py --input \
/content/darknet/Skyfall-Sample.mp4 \
--weights yolov1.weights --config_file \
cfg/yolov1/yolo.cfg --data_file ./cfg/voc.data \
--dont_show --out_filename pred-skyfall.mp4
让我们看看传递给darknet_video.py的命令行参数:
--input:视频文件的路径,如果使用网络摄像头,则为0--weights: YOLO 重量路径--config_file:配置文件路径--data_file:通过 Pascal VOC 标签文件--dont_show:禁止 OpenCV 显示推理结果--out_filename:未保存空输出视频时输出视频名称的推断结果。
瞧啊。下面是天崩地裂动作场景视频上的推断结果,预测似乎不错。YOLOv1 网络在特斯拉 V100 上实现了平均 140 FPS 的混合精度。
https://www.youtube.com/embed/p2dt4lljyLc*
理解图像分类和机器学习的正则化
机器学习中使用的许多策略被明确地设计成减少测试误差,可能以增加训练误差为代价。这些策略统称为规则化。
在之前的课程中,我们讨论了两个重要的损失函数:多类 SVM 损失和交叉熵损失。然后,我们讨论了梯度下降以及网络如何通过更新模型的权重参数来学习。虽然我们的损失函数允许我们确定我们的参数集在给定的分类任务上执行得有多好(或多差),但是损失函数本身并不考虑权重矩阵的“外观”
我说的“长相”是什么意思?嗯,请记住,我们是在实值空间中工作,因此有一组无限的参数将在我们的数据集上获得合理的分类精度(对于“合理”的一些定义)。
我们如何着手选择一组参数来帮助确保我们的模型能够很好地推广?或者至少减轻过度拟合的影响。 答案是正规化。 仅次于你的学习速率,正则化是你可以调优的模型中最重要的参数。
有各种类型的正则化技术,如 L1 正则化、L2 正则化(通常称为“权重衰减”)和弹性网,它们通过更新损失函数本身来使用,添加一个附加参数来约束模型的容量。
我们也有可以明确地添加到网络架构中的正则化类型——dropout 就是这种正则化的典型例子。然后,我们有在训练过程中应用的隐式正则化形式。隐式正则化的例子包括数据扩充和提前停止。
什么是正规化,我们为什么需要正规化?
正则化有助于我们控制我们的模型容量,确保我们的模型更擅长于在数据点上做出(正确的)分类,这些数据点是而不是训练出来的,我们称之为 概括 的能力。如果我们不应用正则化,我们的分类器很容易变得过于复杂,并且过度适应我们的训练数据,在这种情况下,我们失去了归纳我们的测试数据的能力(以及测试集之外的数据点,例如野外的新图像)。
然而,过多的正规化可能是一件坏事。我们可能会冒欠拟合的风险,在这种情况下,我们的模型在训练数据上表现不佳,并且无法对输入数据和输出类标签之间的关系进行建模(因为我们对模型容量的限制太多)。例如,考虑下面的点图,以及适合这些点的各种函数(图 1 )。
橙色线是欠拟合的一个例子——我们没有捕捉到点之间的关系。另一方面,蓝线是过度拟合的一个例子——我们的模型中有太多的参数,虽然它击中了数据集中的所有点,但它也在点之间变化很大。这不是我们想要的平滑、简单的拟合。然后我们有格林函数,它也命中数据集中的所有点,但是以一种更可预测、更简单的方式。
正则化的目标是获得这些类型的“格林函数”,它们很好地适应我们的训练数据,但避免过度适应我们的训练数据(蓝色)或未能对底层关系建模(橙色)。正则化是机器学习的一个重要方面,我们使用正则化来控制模型泛化。为了理解正则化及其对损失函数和权重更新规则的影响,让我们继续下一课。
更新我们的减肥和体重更新,以纳入正规化
让我们从交叉熵损失函数开始:
【①
**整个训练集的损失可以写成:
②
现在,假设我们已经获得了一个权重矩阵【W】,使得我们训练集中的每一个数据点都被正确分类,这意味着我们的 lossL= 0 for allL**[I]。
太棒了,我们获得了 100%的准确性,但让我问你一个关于这个权重矩阵的问题— 它是唯一的吗? 或者换句话说,有没有更好的W的选择,可以提高我们模型的泛化能力,减少过拟合?***
如果真有这么一个 W ,我们怎么知道?我们怎样才能把这种惩罚纳入我们的损失函数呢?答案是定义一个正则化惩罚,一个作用于我们权重矩阵的函数。正则化罚函数一般写成函数, R ( W )。等式( 3) 显示了最常见的正则化惩罚,L2 正则化(也称为权重* 衰减):
(3)  = \sum\limits_{i}\sum\limits_{j} W_{i,j}^{2}")
这个函数到底在做什么?就 Python 代码而言,它只是对数组求平方和:
penalty = 0
for i in np.arange(0, W.shape[0]):
for j in np.arange(0, W.shape[1]):
penalty += (W[i][j] ** 2)
我们在这里做的是循环遍历矩阵中的所有条目,并计算平方和。L2 正则化惩罚中的平方和不鼓励我们的矩阵中的大权重,而偏好较小的权重。为什么我们要阻止大的重量值?简而言之,通过惩罚大的权重,我们可以提高泛化能力,从而减少过度拟合。
*可以这样想,权重值越大,对输出预测的影响就越大。具有较大权重值的维度几乎可以单独控制分类器的输出预测(当然,假设权重值足够大),这几乎肯定会导致过度拟合。
为了减轻各种维度对我们的输出分类的影响,我们应用正则化,从而寻求考虑到所有维度而不是少数具有大值的维度的【W】值。在实践中,你可能会发现正规化会稍微损害你的训练精度,但实际上会增加你的测试精度。**
*同样,我们的损失函数具有相同的基本形式,只是现在我们加入了正则化:
(4) ")
我们之前见过的第一项是我们训练集中所有样本的平均损失。
第二个术语是新的——这是我们的正规化处罚 。λ变量是一个超参数,它控制我们正在应用的正则化的数量或强度。在实践中,学习率 α 和正则项 λ 都是您将花费最多时间调整的超参数。
扩展交叉熵损失以包括 L2 正则化产生以下等式:
(5) ![L = \displaystyle\frac{1}{N} \sum\limits^{N}_{i=1}\left [-\log\left(\displaystyle\frac{e^{s_{y_{i}}}}{\sum\limits_{j} e^{s_{j}}}\right)\right] +\lambda \sum\limits_{i} \sum\limits_{j} W_{i, j}^{2}](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/2abd0880de1a518c39fa194d21621dd5.png "L = \displaystyle\frac{1}{N} \sum\limits^{N}_{i=1}\left [-\log\left(\displaystyle\frac{e^{s_{y_{i}}}}{\sum\limits_{j} e^{s_{j}}}\right)\right] +\lambda \sum\limits_{i} \sum\limits_{j} W_{i, j}^{2}")
我们也可以扩展多级 SVM 损耗:
(6) ![L = \displaystyle\frac{1}{N} \sum\limits^{N}_{i=1} \sum\limits_{j \neq y_{i}} \left[\max\left(0, s_{j} - s_{y_{i}} + 1\right)\right] + \lambda \sum\limits_{i} \sum\limits_{j} W_{i, j}^{2}](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/9b99d3185e3b0cbef889c38793d21623.png "L = \displaystyle\frac{1}{N} \sum\limits^{N}_{i=1} \sum\limits_{j \neq y_{i}} \left[\max\left(0, s_{j} - s_{y_{i}} + 1\right)\right] + \lambda \sum\limits_{i} \sum\limits_{j} W_{i, j}^{2}")
现在,让我们来看看我们的标准权重更新规则:
(7)【w】=【w】-[【w】]
*该方法基于梯度乘以学习速率 α 来更新我们的权重。考虑到正则化,权重更新规则变为:
(8)【w】=【w】-[【w】]
*这里,我们将负线性项添加到我们的梯度(即梯度下降),惩罚大权重,最终目标是使我们的模型更容易泛化。
正则化技术的类型
一般来说,您会看到直接应用于损失函数的三种常见正则化类型。第一种,我们前面提到过,L2 正则化(又名“权重衰减”):
(9)  = \sum\limits_{i}\sum\limits_{j} W_{i,j}^{2}")
我们还有 L1 正则化,它采用绝对值而不是平方:
 = \sum\limits_{i}\sum\limits_{j} |W_{i,j}|") (10)
(10)
**弹性网正则化寻求结合 L1 正则化和 L2 正则化:
 = \sum\limits_{i}\sum\limits_{j} \beta W_{i,j}^{2} + \left|W_{i,j}\right|") (11)
(11)
**还存在其他类型的正则化方法,例如直接修改网络的架构以及网络的实际训练方式,我们将在后面的课程中回顾这些方法。
就您应该使用哪种正则化方法而言(包括根本不使用),您应该将此选择视为一个超参数,您需要优化并执行实验来确定是否应该应用正则化,如果应该应用正则化的哪种方法,以及 λ 的适当值是多少。有关正则化的更多详细信息,请参考 Goodfellow 等人(2016) 的第 7 章,DeepLearning.net 教程的“正则化”部分,以及 Karpathy 的 cs231n 神经网络 II 讲座的笔记。
正则化应用于图像分类
为了实际演示正则化,让我们编写一些 Python 代码,将其应用于我们的“Animals”数据集。打开一个新文件,将其命名为regularization.py,并插入以下代码:
# import the necessary packages
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from pyimagesearch.preprocessing import SimplePreprocessor
from pyimagesearch.datasets import SimpleDatasetLoader
from imutils import paths
import argparse
第 2-8 行导入我们需要的 Python 包。除了 scikit-learn SGDClassifier之外,我们以前见过所有这些导入。正如这个类的名字所暗示的,这个实现包含了我们在课程中复习过的所有概念,包括:
- 损失函数
- 时代数
- 学习率
- 正则项
从而使它成为在实践中展示所有这些概念的完美例子。
接下来,我们可以解析我们的命令行参数并从磁盘中获取图像列表:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
# grab the list of image paths
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
给定图像路径,我们将调整它们的大小为 32×32 像素,将它们从磁盘加载到内存中,然后将它们展平为一个 3072 维的数组:
# initialize the image preprocessor, load the dataset from disk,
# and reshape the data matrix
sp = SimplePreprocessor(32, 32)
sdl = SimpleDatasetLoader(preprocessors=[sp])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.reshape((data.shape[0], 3072))
我们还将标签编码为整数,并执行训练测试分割,使用 75%的数据进行训练,剩余的 25%进行测试:
# encode the labels as integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, random_state=42)
让我们在训练我们的SGDClassifier时应用一些不同类型的正则化:
# loop over our set of regularizers
for r in (None, "l1", "l2"):
# train a SGD classifier using a softmax loss function and the
# specified regularization function for 10 epochs
print("[INFO] training model with '{}' penalty".format(r))
model = SGDClassifier(loss="log", penalty=r, max_iter=10,
learning_rate="constant", tol=1e-3, eta0=0.01, random_state=12)
model.fit(trainX, trainY)
# evaluate the classifier
acc = model.score(testX, testY)
print("[INFO] {} penalty accuracy: {:.2f}%".format(r,
acc * 100))
第 37 行循环遍历我们的正则化函数,包括无正则化。然后我们初始化并训练第 41-43 号线上的SGDClassifier。
我们将使用交叉熵损失,正则化罚值为r,默认的 λ 为 0.0001。我们将使用 SGD 以 α = 0 的学习率对模型进行 10 个历元的训练。 01。然后,我们评估分类器,并在屏幕的第 46-48 行显示准确度结果。
要查看用各种正则化类型训练的 SGD 模型,只需执行以下命令:
$ python regularization.py --dataset dataset/animals
[INFO] loading images...
...
[INFO] training model with 'None' penalty
[INFO] 'None' penalty accuracy: 50.13%
[INFO] training model with 'l1' penalty
[INFO] 'l1' penalty accuracy: 52.67%
[INFO] training model with 'l2' penalty
[INFO] 'l2' penalty accuracy: 57.20%
我们可以看到,在没有正则化的情况下,我们获得了 50.13%的精度。使用 L1 正则化,我们的精度增加到 52.67% 。L2 正则化获得最高精度 57.20% 。
备注: 对train_test_split使用不同的random_state值会产生不同的结果。这里的数据集太小,分类器太简单,看不到正则化的全部影响,所以把它当作一个“工作示例”随着我们继续阅读这本书,你会看到正则化的更高级的应用,这将对你的准确性产生巨大的影响。
实际上,这个例子太小,无法显示应用正则化的所有优势——为此,我们必须等到我们开始训练卷积神经网络。然而,与此同时,简单地理解正则化可以提高我们的测试精度并减少过度拟合,假设我们可以正确地调整超参数。
总结
在这些课程中,我们打开了深度学习的引擎盖,深入研究了为现代神经网络提供动力的引擎— 梯度下降。我们研究了两种类型的梯度下降:
- 标准的香草味。
- 更常用的随机版本。
普通梯度下降每个历元只执行一次权重更新,这使得在大型数据集上收敛非常慢(如果不是不可能的话)。相反,随机版本通过计算小批量的梯度,在每个时期应用多重权重更新。通过使用 SGD,我们可以大大减少训练模型所需的时间,同时还可以享受更低的损失和更高的准确性。典型的批量大小包括 32、64、128 和 256。
梯度下降算法通过一个 学习速率 来控制:这是迄今为止在训练你自己的模型时要正确调整的最重要的参数。
如果你的学习速度太快,你只会在亏损的情况下徘徊,而不会从数据中“学习”到任何模式。另一方面,如果你的学习率太小,要达到一个合理的损失,将需要令人望而却步的迭代次数。为了得到正确的结果,你需要花大部分时间来调整学习速度。
然后我们讨论了 正则化 ,正则化被定义为“任何可能以训练精度为代价来提高测试精度的方法。”正规化包含一系列广泛的技术。我们特别关注应用于损失函数和权重更新规则的正则化方法,包括 L1 正则化、L2 正则化和弹性网。
就深度学习和神经网络而言,你通常会看到 L2 正则化用于图像分类——技巧是调整 λ 参数,以包括适量的正则化。
在这一点上,我们有一个良好的机器学习基础,但我们还没有研究神经网络或从头训练一个定制的神经网络。在以后的课程中,这一切都将改变,我们将讨论神经网络、反向传播算法以及如何在自定义数据集上训练您自己的神经网络。****************
了解神经网络的权重初始化
原文:https://pyimagesearch.com/2021/05/06/understanding-weight-initialization-for-neural-networks/
在本教程中,我们将讨论权重初始化的概念,或者更简单地说,我们如何初始化我们的权重矩阵和偏差向量。
本教程并不意味着是一个全面的初始化技术;然而,它确实突出了流行的方法,但是来自神经网络文献和一般的经验法则。为了说明这些权重初始化方法是如何工作的,我在适当的时候加入了基本的类似 Python/NumPy 的伪代码。
常量初始化
当应用常数初始化时,神经网络中的所有权重都用常数值 C 初始化。通常情况下, C 等于零或一。
为了用伪代码形象化这一点,让我们考虑具有 64 个输入和 32 个输出的神经网络的任意层(为了概念上的方便,排除任何偏差)。为了通过 NumPy 和 zero 初始化(Caffe 使用的默认设置,一个流行的深度学习框架)初始化这些权重,我们将执行:
>>> W = np.zeros((64, 32))
类似地,可以通过以下方式完成一次初始化:
>>> W = np.ones((64, 32))
我们可以使用任意的 C 应用常量初始化,使用:
>>> W = np.ones((64, 32)) * C
虽然常量初始化很容易掌握和理解,但使用这种方法的问题是,我们几乎不可能打破激活的对称性( 海因里希,2015 )。所以很少用作神经网络权重初始化器。
均匀和正态分布
一个均匀分布从范围[lower, upper]中抽取一个随机值,其中该范围内的每个值被抽取的概率相等。
再次,让我们假设对于神经网络中的给定层,我们有 64 个输入和 32 个输出。然后,我们希望在范围lower=-0.05和upper=0.05内初始化我们的权重。应用以下 Python + NumPy 代码将允许我们实现所需的规范化:
>>> W = np.random.uniform(low=-0.05, high=0.05, size=(64, 32))
执行 NumPy 上面的代码将从范围【0.05,0.05】,中随机生成64×32 = 2048个值,其中该范围中的每个值具有相等的概率。
然后我们有一个正态分布,其中我们将高斯分布的概率密度定义为:
【①
**这里最重要的参数是(均值)和【σ】(标准差)。标准差的平方,σ2,称为方差。
当使用 Keras 库时,RandomNormal类从正态分布中抽取随机值,其中 = 0 ,而 σ = 0.05 。我们可以使用下面的 NumPy 来模拟这种行为:
>>> W = np.random.normal(0.0, 0.05, size=(64, 32))
均匀分布和正态分布都可以用来初始化神经网络中的权重;然而,我们通常采用各种启发式方法来创建“更好的”初始化方案(我们将在剩余部分讨论)。
乐村制服和正常
如果您曾经使用过 Torch7 或 PyTorch 框架,您可能会注意到默认的权重初始化方法被称为“高效反向投影”,它是由 LeCun et al. (1998) 的工作派生而来的。
这里,作者在 T3 中定义了一个参数 F[input] (称为“扇入”,或者层的输入的数量)以及 F[output] (“扇出”,或者层的输出的数量)。使用这些值,我们可以通过以下方式应用统一初始化:
>>> F_in = 64
>>> F_out = 32
>>> limit = np.sqrt(3 / float(F_in))
>>> W = np.random.uniform(low=-limit, high=limit, size=(F_in, F_out))
我们也可以使用正态分布。Keras 库在构建下限和上限时使用截尾正态分布以及零均值:
>>> F_in = 64
>>> F_out = 32
>>> limit = np.sqrt(1 / float(F_in))
>>> W = np.random.normal(0.0, limit, size=(F_in, F_out))
Glorot/Xavier 制服和正常
Keras 库中使用的默认权重初始化方法称为“Glorot 初始化”或“Xavier 初始化”,以论文第一作者 Xavier Glorot理解深度前馈神经网络 训练难度命名。
对于正态分布,limit值是通过将 中的F[和F相加,然后求平方根( Jones,2016 )得到的。然后使用零中心(= 0):]
>>> F_in = 64
>>> F_out = 32
>>> limit = np.sqrt(2 / float(F_in + F_out))
>>> W = np.random.normal(0.0, limit, size=(F_in, F_out))
Glorot/Xavier 初始化也可以用均匀分布来完成,我们对limit设置了更强的限制:
>>> F_in = 64
>>> F_out = 32
>>> limit = np.sqrt(6 / float(F_in + F_out))
>>> W = np.random.uniform(low=-limit, high=limit, size=(F_in, F_out))
使用这种初始化方法,学习往往是非常有效的,我推荐它用于大多数神经网络。
何等人/和的制服正常
通常被称为“何等人初始化”、“明凯初始化”,或简称为“初始化”,这种技术是以论文第一作者何的名字命名的, 深入研究整流器:在 ImageNet 分类上超越人类水平的性能 。
我们通常在训练使用类似 ReLU 的激活函数(特别是“PReLU”,或参数校正线性单元)的非常深的神经网络时使用这种方法。
为了使用 he 等人的具有均匀分布的初始化来初始化层中的权重,我们将limit设置为
, where F**[in] is the number of input units in the layer:
>>> F_in = 64
>>> F_out = 32
>>> limit = np.sqrt(6 / float(F_in))
>>> W = np.random.uniform(low=-limit, high=limit, size=(F_in, F_out))
我们也可以通过设置= 0 和 来使用正态分布
来使用正态分布
>>> F_in = 64
>>> F_out = 32
>>> limit = np.sqrt(2 / float(F_in))
>>> W = np.random.normal(0.0, limit, size=(F_in, F_out))
初始化实现的差异
LeCun 均匀/正常、Xavier 均匀/正常和 he 等人均匀/正常的实际limit值可能有所不同。比如在 Caffe 使用 Xavier 制服时,limit = np.sqrt(3/n) ( Heinrich,2015 ),其中 n 要么是 中的 F[input], F[output] ,要么是它们的平均值。
另一方面,Keras 的默认 Xaiver 初始化使用np.sqrt(6/(F_in + F_out)) ( Keras contributors,2016 )。没有一种方法比另一种方法“更正确”,但你应该阅读各自深度学习库的文档。
总结
在本教程中,我们回顾了神经网络的基础知识。具体来说,我们关注神经网络的历史和与生物学的关系。
从那里,我们转移到人工神经网络,比如感知器算法。虽然从历史的角度来看很重要,但感知器算法有一个主要缺陷——它不能准确地分类非线性可分离点。为了处理更具挑战性的数据集,我们需要(1)非线性激活函数和(2)多层网络。
为了训练多层网络,我们必须使用反向传播算法。然后,我们手动实现了反向传播,并证明了当使用非线性激活函数训练多层网络时,我们可以对非线性可分离数据集进行建模,如 XOR。
当然,手工实现反向传播是一个艰苦的过程,容易出现错误——因此,我们经常依赖现有的库,如 Keras、Theano、TensorFlow 等。这使我们能够专注于实际的架构,而不是用于训练网络的底层算法。
最后,我们回顾了使用任何神经网络时的四个关键要素,包括数据集、损失函数、模型/架构,以及优化方法。
不幸的是,正如我们的一些结果所证明的(例如,CIFAR-10 ),当处理在平移、旋转、视点等方面表现出变化的挑战性图像数据集时,标准神经网络无法获得高分类精度。为了在这些数据集上获得合理的准确性,我们需要使用一种特殊类型的前馈神经网络,称为卷积神经网络(CNN),我们将在单独的教程中介绍。**
统一 picamera 和 cv2。使用 OpenCV 将视频捕获到单个类中
在过去两周的 PyImageSearch 博客上,我们讨论了如何使用线程来提高我们在内置/USB 网络摄像头以及 Raspberry Pi 摄像头模块上的 FPS 处理速率。
*通过利用线程,我们了解到我们可以显著降低 I/O 延迟的影响,让主线程在等待 I/O 操作完成(即从摄像头传感器读取最新帧)时不会被阻塞。
使用这种线程模型,我们可以将帧处理速率大幅提高 200%以上。
虽然 FPS 处理速度的提高是惊人的,但仍有一个(有点不相关的)问题困扰我很久了。
你看,在 PyImageSearch 博客上,我写了很多关于内置或 USB 摄像头的帖子,比如:
所有这些帖子都依赖于cv2.VideoCapture方法。
然而,如果您想在我们的 Raspberry Pi 上使用代码,这种对cv2.VideoCapture的依赖就成了一个问题。假设你是而不是使用带 Pi 的 USB 摄像头,并且实际上使用的是 picamera 模块,你需要修改代码以兼容picamera,如使用 Python 和 OpenCV 访问 Raspberry Pi 摄像头一文中所讨论的。
虽然只需要对代码做一些修改(例如,实例化PiCamera类并交换出帧读取循环),但这仍然很麻烦,尤其是如果您刚刚开始使用 Python 和 OpenCV 的话。
相反,PyImageSearch 博客上有其他帖子使用了picamera模块而不是 cv2.VideoCapture。这种帖子的一个很好的例子是 用树莓派、Python、OpenCV 和 Dropbox 实现家庭监控和运动检测。如果你没有 Raspberry Pi(或者想要使用内置或 USB 网络摄像头而不是 Raspberry Pi 摄像头模块),你将不得不再次换出几行代码。
因此,这篇文章的目标是构建一个 统一接口 给picamera和cv2.VideoCapture,只用一个名为VideoStream的 类 。这个类将根据提供给构造函数的参数调用WebcamVideoStream或PiVideoStream。
最重要的是,我们对VideoStream类的实现将允许 PyImageSearch 博客上未来的视频处理帖子在内置网络摄像头、 USB 摄像头或树莓 Pi 摄像头模块 — 上运行,而无需更改一行代码!
请继续阅读,了解更多信息。
https://www.youtube.com/embed/--90GjhAFH4?feature=oembed*
利用计算机视觉和光学字符识别进行移民文件分类(文斯·迪马斯西奥访谈)

在这篇文章中,我采访了专门从事企业移民的律师事务所 Berry Appleman & Leiden 的首席信息官/首席技术官 Vince DiMascio。
BAL 正在使用计算机视觉、机器学习和人工智能对移民文件进行自动分类,从而帮助加快收集和验证文件的艰巨任务。
最近,Vince 和 Tim Oates 博士(我以前的博士导师)发表了一篇关于他们工作的论文, 移民文件分类和自动响应生成。 这项工作是 BAL 和 Synaptiq 的共同努力,由奥茨博士和他的合作伙伴斯蒂芬·斯克雷乌(Stephen Sklarew)共同创立。
今天,我们将与 Vince 坐下来讨论他们的论文,包括他们的技术如何帮助移民团队提高效率,减少管理费用,并确保他们的客户成功。
贝瑞·阿普尔曼&莱顿公司首席信息官兼首席技术官文斯·迪马西奥访谈
阿德里安:嗨,文斯!感谢您来到 PyImageSearch 博客。我知道你作为 T2 莱顿公司的首席信息官非常忙。我们都很感谢你抽出时间来这里。
文斯:谢谢你邀请我。很高兴和你聊天,阿德里安。
阿德里安:你能告诉我们一些关于你自己和你在 BAL 的角色吗?
Vince: 我是 BAL 的首席信息官兼首席技术官。我们是一家全球性的企业移民律师事务所。我们已经存在 40 年了。技术一直是我们运营和服务客户的核心。
大约五年前,我加入了这家公司,负责制定技术战略,并带领团队执行这一战略。在我的岗位上,我处理与技术相关的任何事情。这些职责包括桌面支持、人工智能(AI)和自动化、专业服务团队以及处理尖端产品开发和推出的数字产品组织。
阿德里安:我很好奇,鉴于你在一家律师事务所工作,你最初是如何对计算机视觉和机器学习产生兴趣的?
文斯:我碰巧足够幸运,在正确的时间把正确的技能带到了正确的地方。
在 BAL 之前,我从事咨询工作。我经常参与律师事务所和法律部门对技术的使用。当联邦规则在 21 世纪初发生变化时,我开始研究机器学习,这真正催生了电子发现。当时,我们使用机器学习来做概念聚类、自然语言处理,甚至预测编码等事情,以找到相关文档并加快发现。这项工作使我走上了在严格监管和高风险环境中负责任地应用尖端技术来帮助企业的道路。
当我来到 BAL 时,我们制定了 2020 年战略。我们知道,通过很好地利用数据,应用机器学习,并将这些与伟大的设计结合起来,提供无与伦比的产品、见解和体验,我们可以为我们的客户做很多事情。像诉讼一样,移民法可能很繁琐,所以我知道我们可以通过处理非结构化数据、利用技术优化法律工作流程以及利用人工智能来产生影响。这包括开发和运营使用计算机视觉和机器学习的系统。
阿德里安:你是如何发现 PyImageSearch 的?
文斯:当我们开始将此视为一个机会时,我发现了 PyImageSearch。我一直在寻找对文档图像进行分类的方法,以便将它们分类,并沿着不同的工作流程进行传送,包括提取信息。例如,一个护照可以通过某一路径,并从其机器可读区域提取信息。但是政府表单可能会走不同的路,有不同的提取方法。我的搜索把我带到了 PyImageSearch,这是一个关于计算机视觉的信息、代码和社区的宝库。它帮助我们继续研究如何在 BAL 内部利用 CV。从那以后,我们一直是 PyImageSearch 社区的订户。
Adrian: 您与 PyImageSearch 的咨询合作伙伴 Synaptiq 合作的体验如何?你为什么选择与他们合作,而不是使用打包的人工智能(AI)和机器人处理自动化(RPA)解决方案?
文斯:这种体验非常棒,这也是我们保持客户关系的原因。Synaptiq 是我们的合作伙伴,而不是传统的供应商。他们专注于理解我们面临的问题和机遇。他们与我们的法律、数据和产品人员合作,与我们一起开发可以共同推动的解决方案。我们选择了它们,而不是利用打包的解决方案。我们发现,虽然打包的 AI 和 RPA 擅长很多事情,但它们在我们专注的领域并不出色。我们需要在我们所做的有限的事情上做到最好。因为我们正在做的事情是在未知的领域,所以有时构建是有意义的。我们确实利用适合商品工作的打包解决方案。在我们需要通过新技术提供独特、卓越价值的领域,我们自己设计 it。
当你这样做时,与一个在各行业拥有多年数据科学、机器学习和计算机视觉技能的合作伙伴合作,并确定使用哪种模型、遵循哪种方法或什么框架是至关重要的。除此之外,我们需要决定如何构建我们的团队,交付模型,并将其操作化。在实验室里做是一回事。我们到处都能看到这种实验室模型,尤其是在法律领域。但是,要真正将人工智能引入业务并将其投入运营,你需要强大的业务一致性和正确的技术能力。
Adrian: 你和 Synaptiq 最近发表了一篇关于使用计算机视觉和 OCR 自动处理和准备美国签证申请的支持文件的论文,这些申请是在 11 月举行的 IEEE / MLLD 2020 法律领域采矿和学习国际研讨会上提交的。你能解释一下什么是 MLLD,为什么它对有科学背景的法律专业人士很重要吗?
*文斯:首先,我想澄清一下这个项目是什么。该系统为我们的客户提供了第二双眼睛,帮助他们完成一些与移民案件处理相关的机械工作。系统不会独立地自动处理和准备文档。它通过对我们收到的邮件进行分类来提高质量和缩短周转时间。然后,它会读取这些文档来识别请求的内容。最后一步是将这些信息传递给一个系统,该系统像复制-粘贴操作一样创建一个法律专业人员可以用来开始法律工作的草稿。
这对法律专业人士来说很重要,所以它被选中在 IEEE-MLLD 会议上展示。这是真正的机器学习,适用于移民法以外的领域。另一个上下文的例子是处理第三方传票。在这种情况下,一方接收对文档的请求。第三方将仔细阅读请求,确定请求的内容,并经常对这些请求提出书面异议。因此,在类似的工作流程中,这项技术将帮助此类第三方看到他们已经使用批准的标准表单模板和内容识别并处理了所请求的内容。
阿德里安:未来员工申请美国工作签证的典型流程是什么?我想会生成很多文档,并且会有大量的文档记录。
Vince: 这个过程可能需要大量纸张,这就是为什么拥有高性能的精确机器学习系统非常重要,这些系统能够以远远超出 OCR 的方式处理文档和文档图像,并且可以不断发展。我不是律师,这个过程在某种程度上有所不同,取决于签证类型和情况。我认为这个过程分为几个阶段:接收、准备、归档和决定。
首先,有一个“接收”过程,你需要收集材料来提交请愿书。这是一系列文档和表格,其中一些以电子方式收集为 PDF、Word 或图像文件。当你有了你需要的材料,你进入“准备”阶段,在那里你填写各种表格,有些是在线的,有些是 PDF 文件。在此阶段,您将信息组合成特定的归档顺序。当材料准备好了,你就进入了“归档”阶段,在这里你进行最后的审查,然后向代理机构归档,通常会有一张归档费的支票。在这一点上,它是与政府,你开始监督的状态申请。这时,美国公民和移民服务局(USCIS)可能会发送证据请求(RFE),这是我们训练机器学习系统进行分类和阅读的文件类型。当 USCIS 没有足够的信息来决定申请时,他们将发送 rfe。所以如果你收到了 RFE,你需要写下地址。最终,你会到达“决定”阶段,你会得到移民局的决定。
阿德里安:什么是 RFE,它在每个求职者身上有多普遍?
Vince:RFE 是一种证据请求,即政府要求外国公民提供额外信息,以确定申请是否被批准。这可能只是一个丢失的文档,也可能是需要花费更多精力来响应的东西。
Adrian: 告诉我们你是如何想到在这个过程中使用计算机视觉和光学字符识别的?
文斯:这个想法来自我们的创新渠道。我们有专门定义、引导和扩展人工智能用例的功能。与我们在各行各业屡遭失败的“实验室”模式不同,我们将创新和人工智能直接嵌入到我们的业务中,因此我们与客户的需求保持一致。我们有一个正式的创新计划,我们邀请各级员工和领导加入并参与创造新的解决方案,以应对公司管理和客户的挑战。我们的技术和产品团队从可行性和价值方面审查和评估这些想法。我们使用产品管理方法回到实际问题中,看看我们是否能最大程度地概括它。然后我们冲刺,迭代。这个最初的想法来自于这个管道,一旦我们把它作为一个概念来评估,就有理由去做。
阿德里安:你提到了不同的阶段:接收、准备、归档以及将各种文件输入这些流程。所以你正在开发的系统可以区分文档类型?
文斯:这是个好问题。在我们这边,我们通过各种安全渠道接收材料。这些材料通常是 PDF 文件、扫描图像或从移动设备上拍摄的照片。我们得到了这份文件的图像。它是固定的,是一个像素网格,我们需要把它转化成我们可以使用的信息。我们必须将图像转换成文本信息,有时还要将其转换成政府表格。我们使用新颖的自动化方法为客户提供高质量的数据服务和卓越的体验。举个简单的例子,当一个外国人上传一张护照的照片时,他们不需要输入文字。它会被自动提取并放入字段中。我们在整个旅程中都有这样的自动化来提高质量和体验。
Adrian: 你能给我们一个你和 Synaptiq 开发的系统的概要吗?
文斯:我们创造了两个系统,它们可以独立工作,也可以协同工作。
第一个系统对美国工作签证申请中常见的文档图像进行分类。因此,您可以向我们的服务提交文档图像,服务将告诉您您提交的文档的类型。例如,护照、出生证明、某种政府表格或 RFE。该系统单独帮助标记或分类文档,或者启动下游的文本提取系统,以知道在提取相关文本时要查找什么以及在哪里查找。
第二个系统读取 rfe,也就是我前面提到的字母。当美国公民及移民服务局需要更多的信息来决定一项申请时,就会发出 rfe。你可以将 RFE 的信邮寄到第二个系统,它会阅读这封信,然后回复一份清单,列出 USCIS 在 RFE 需要的额外信息。一起使用,我们可以给我们的员工和客户一双额外的眼睛,在整个纸张处理过程中提高质量。这也使我们能够对政府请求的类型以及最有可能导致这些请求的因素组合进行分类。
嵌入在分类器和 RFE 阅读器中的文本提取组件是系统的无名英雄。机器学习技术,如用于消除噪声、消除偏斜或利用自定义语言模型来正确提取文本的技术,对于实现高质量的结果至关重要。所有这些都可以在 PyImageSearch 书籍中找到,包括理解书籍、交付代码和运行代码的虚拟机。
Adrian: 在最初的申请处理过程中,第一遍的准确性如何,建议律师进行哪种类型的质量控制?
文斯:重申一点非常重要,这里没有任何东西是独立自主地工作的。考虑到风险,我们每一步都有人参与。实验结果表明,我们的方法达到了相当的准确性。
我们的律师没有资格。他们在做法律工作。这些系统会反复检查与该工作相关的处理和生成的材料,因此我们在操作中增加了另一层审查和第二组手。它赋予我们的人民“超能力”
Adrian: 在最初的申请处理过程中,您的方法是代表律师收集数据和填写表格,还是也检测潜在的问题或争议点(例如,它是否会标记护照是否即将到期,或者个人的工作授权是否出现缺口?)
文斯:这是一个很好的问题,因为这个解决方案不是填写表格。首先,它对文档进行分类。如果它找到一个 RFE,它就可以从信件中读取文本,解释文本,并选择一个专门策划的表单模板供律师使用。它还可以将我们案例管理系统中的一些数据合并到文档中,就像 Microsoft Word 或 Google Docs 一样,但它不会起草响应。我们在申报流程中还有其他数据健康机制,可以解决您提到的与日期相关的问题。
Adrian: 您的解决方案可以在所有rfe 上使用吗,还是需要先针对特定的 RFE 类型进行培训?
文斯:它很灵活。RFE 通常基于 USCIS 提供给其官员的模板作为起点。官员根据应用定制 RFE。因此,我们为每种类型的 RFE 维护了一个 RFE 原因表,当我们向系统发送信件时,我们还告诉系统这是哪种签证。并且它使用该信息来确定在语言模型中使用哪组已知原因。同样,我们可以轻松地加载一个常见传票请求及其分类的表,并将其用于传票响应流程。
阿德里安:对于更复杂的 RFE,如专业职业 RFE,这如何生成初始响应供律师审阅和编辑?它从什么文件中提取来对抗 RFE?特别是对于这种 RFE 类型,对人类律师的回应的初稿有多“完整”?
文斯:就像美国公民及移民服务局一样,我们维护模型文档,这是标准的表单模板,有地址、称呼、格式、标准段落等类似内容的占位符。有一个标准的邮件合并来插入数据,如客户公司名称、外国人姓名等。,这已经存在很长时间了。这就是与模板使用相关的所有内容。律师撰写回应的实质内容。它只是从人类开始关注完整性的地方创建一个框架。你可以把它想象成一个更加“增强的草稿”,以及一个请求列表。
阿德里安:处理重复性行政工作的机器如何让律师专注于为客户处理更耗时、更专业的法律工作?
Vince: 系统增加了额外的审核人来推动工作质量。因此,这个工具的真正商业价值是一个更大的,也许是更强有力的回应,如果没有后续的眼睛捕捉每一个细微差别,你可能会从另一家公司那里得到。我们还可以推动分析,为回应语言背后的法律策略提供信息。我们的目标是创造一个良性循环,在这个循环中,我们不断改进对不断变化的政府要求的响应,并尽可能以最有效的方式做到这一点。然后,我们将数据库中的数据合并到模板中,这是标准做法。
Adrian: 您的解决方案如何帮助 BAL,更重要的是,它如何帮助您的客户更加成功?
Vince: 鉴于它提高了我们工作的质量,特别是在 rfe 和入口方面,它允许我们捕获和标记更多信息,以了解特定职业、特定行业或更广泛领域的攻击趋势。这有助于我们向客户提供宝贵的人才管理见解。
阿德里安:你对这个项目的下一步计划是什么?你会继续开发和完善这个系统吗?
文斯:我们将继续运营它,培训它,并找到用它为我们的客户创造价值的方法。这个想法是,如果我们知道关于 RFE 量的一切,字母中有什么,如果有季节性或峰值,等等。,我们可以马上得到这些信息来给我们的客户提供建议。我们的客户希望数据驱动的洞察力成为我们服务的一部分。奇闻轶事的日子已经过去了。
Adrian: 对于想跟随你的脚步,学习计算机视觉和深度学习,然后发表论文或在法律领域工作的人,你有什么建议吗?
Vince: 挑一个你关心的项目,开始建设。注册 PyImageSearch,浏览那里提供的培训,获取书籍,注册社区,开始合作。这是一组非常有价值的资源和一个活跃的大型社区。这些资源是理解、开发和部署这些能力的加速器。而文档可能是最无聊的章节。有关于处理视频流、照片、车牌、野生动物、侦探监视的课程和代码,以找出谁在从你的冰箱里偷啤酒。它很神奇,容易理解,实用,有趣。找到有商业价值的东西,科学地执行它,并花时间把它写下来。应用人工智能仍然很少见,尽管你听到了所有关于它的宣传,所以如果你建立了一些东西并使用它,你被这样一个主要和有声望的会议接受的机会可能比你想象的更好。
Adrian:2021 年 BAL 和 AI 的下一步是什么?
Vince: 这是关于挑战极限,继续引领我们的行业,为我们的客户提供技术、经验和见解。这意味着在我们发展人工智能优先的运营模式时,将智能嵌入到每一个地方。为此,我们正在壮大我们的技术、产品和设计团队,以保持与竞争对手的距离。
一个有趣的追求领域是在不破坏律师-客户关系的重要性的情况下利用人工智能。人际交往是我们工作的基础。因此,我们提高了帮助客户回答问题、查询和解决问题的质量和速度,并看到了数据交互的发生,所以这不是一个障碍。我们还使用人工智能使我们的专业人员能够比任何其他公司更好地提供法律服务。
BAL 在技术创新方面一直处于行业领先地位。举几个例子,就在今年,我们的 Cobalt 数字平台获得了最佳法律解决方案奖,我们的技术团队获得了 IDG CIO 100 奖,我们的创新工作获得了 Constellation Research 颁发的业务转型 150 奖。我们将继续提供尖端技术支持的服务和数字产品,在全球范围内推动人类成就。
阿德里安:如果一个 PyImageSearch 的读者想浏览报纸,他们可以在哪里找到它?
文斯:你可以在这里从 arXiv 下载这篇论文的 PDF 文档:【https://arxiv.org/abs/2010.01997
阿德里安:非常好。再次祝贺你的论文,感谢你今天抽出时间和我聊天。我期待保持联系。
文斯:谢谢你,阿德里安,我也是。期待很快再次和你聊天。
摘要
在这篇博文中,我们采访了专门从事企业移民的律师事务所 Berry Appleman & Leiden (BAL)的首席信息官/首席技术官文斯·迪马西奥(Vince DiMascio)。
巴尔最近与 Synaptiq 合作,Synaptiq 是一家人工智能咨询公司,由我的前博士顾问蒂姆·奥茨博士共同创立。
BAL 和 Synaptiq 共同发表了一篇关于自动移民文件分类的论文,该系统允许移民公司在回应美国政府的证据请求时更加有效。
他们的系统非常成功,展示了人工智能是如何应用到世界上几乎每一个领域的。
如果你有兴趣与 Synaptiq 合作,看看如何利用人工智能来提高公司的效率和利润,只需填写这张表格,进行免费的初步咨询。
PyImageSearch 咨询服务
我与我以前的博士顾问 Tim Oates 博士以及产品和技术执行顾问 Stephen Sklarew 合作,通过 Synaptiq 为计算机视觉、深度学习和人工智能提供 PyImageSearch 咨询。
Synaptiq 成立于 2015 年,是一家全面的人工智能咨询公司,在全球 20 多个行业拥有 40 多家客户。我们经验丰富的专家团队,包括 16 名数据科学家(6 名拥有博士学位),直接与每个客户合作,以识别和提供人工智能最擅长解决的现实世界问题的有效解决方案。
如果您有兴趣与 Synaptiq 合作,咨询公司 Vince DiMascio 与该解决方案合作(也是 PyImageSearch 的官方咨询合作伙伴),请使用此链接告诉我们有关您项目的更多信息。
我们期待着您的来信,并了解更多关于您的项目。*
使用机器学习对图像去噪以获得更好的 OCR 准确度
应用光学字符识别(OCR)最具挑战性的方面之一不是 OCR 本身。相反,它是预处理、去噪和清理图像的过程,这样它们就可以被 OCR 识别。
要学习如何对你的图像去噪以获得更好的光学字符识别, 继续阅读。
使用机器学习对图像进行去噪以获得更好的 OCR 准确度
当处理由计算机生成的文档、屏幕截图或基本上任何从未接触过打印机然后扫描的文本时,OCR 变得容易得多。文字干净利落。背景和前景之间有足够的对比。而且大多数时候,文字并不存在于复杂的背景上。
一旦一段文字被打印和扫描,一切都变了。从那里开始,OCR 变得更具挑战性。
- 打印机可能碳粉或墨水不足,导致文本褪色且难以阅读。
- 扫描文档时可能使用了旧扫描仪,导致图像分辨率低和文本对比度差。
- 一个手机扫描仪应用程序可能在光线不好的情况下使用,这使得人眼阅读文本变得非常困难,更不用说计算机了。
- 太常见的是真实的人类触摸过纸张的清晰迹象,包括角落上的咖啡杯污渍、纸张起皱、破裂、撕裂等。
对于人类思维所能做的所有惊人的事情,当涉及到印刷材料时,我们似乎都只是等待发生的行走事故。给我们一张纸和足够的时间,我保证即使我们中最有条理的人也会从原始状态中取出文件,并最终在其上引入一些污点、裂口、褶皱和皱纹。
这些问题不可避免地会出现,当这些问题出现时,我们需要利用我们的计算机视觉、图像处理和 OCR 技能来预处理和提高这些受损文档的质量。从那里,我们将能够获得更高的 OCR 准确性。
在本教程的剩余部分,您将了解即使是以新颖方式构建的简单机器学习算法也可以帮助您在应用 OCR 之前对图像进行降噪。
学习目标
在本教程中,您将:
- 获得处理嘈杂、损坏的文档数据集的经验
- 了解机器学习如何用于对这些损坏的文档进行降噪
- 使用 Kaggle 的去噪脏文档数据集
- 从该数据集中提取要素
- 根据我们提取的特征训练一个随机森林回归器(RFR)
- 用这个模型去噪我们测试集中的图像(然后也能去噪你的数据集)
利用机器学习进行图像去噪
在本教程的第一部分,我们将回顾数据集,我们将使用去噪文件。从那里,我们将回顾我们的项目结构,包括我们将使用的五个单独的 Python 脚本,包括:
- 存储跨多个 Python 脚本使用的变量的配置文件
- 一个助手功能,用来模糊和限制我们的文件
- 用于从数据集中提取要素和目标值的脚本
- 用于训练 RFR 的另一个脚本
- 以及用于将我们的训练模型应用到我们的测试集中的图像的最终脚本
这是我的一个较长的教程,虽然它很简单,并遵循线性进展,这里也有许多微妙的细节。因此,我建议你将本教程复习两遍,一遍从高层次理解我们在做什么,然后再从低层次理解实现。
说完了,我们开始吧!
我们嘈杂的文档数据集
在本教程中,我们将使用 Kaggle 的去噪脏文档数据集。该数据集是 UCI 机器学习库的一部分,但被转换成了 Kaggle 竞赛。在本教程中,我们将使用三个文件。这些文件是 Kaggle 竞赛数据的一部分,并被命名为:test.zip、train.zip和train_cleaned.zip。
该数据集相对较小,只有 144 个训练样本,因此很容易处理并用作教育工具。但是,不要让小数据集欺骗了你!我们要对这个数据集做的是远离基础的或介绍性的。
图 1 显示了脏文档数据集的示例。对于样本文档,顶部显示文档的噪声版本,包括污点、褶皱、折叠等。然后,底部的显示了我们希望生成的文档的目标原始版本。
我们的目标是在 顶部 输入图像,并训练机器学习模型在 底部产生干净的输出。现在看来这似乎是不可能的,但是一旦你看到我们将要使用的一些技巧和技术,这将比你想象的要简单得多。
文档去噪算法
我们的去噪算法依赖于训练 RFR 接受有噪声的图像,并自动预测输出像素值。这种算法的灵感来自科林·普里斯特介绍的去噪技术。
这些算法通过应用一个从从左到右和从上到下滑动的5 x 5 窗口来工作,一次一个像素(图 2 )穿过噪声图像(即,我们想要自动预处理和清理的图像)和目标输出图像(即,图像在清理后应该出现的“黄金标准”)。
*在每个滑动窗口停止时,我们提取:
- 噪声输入图像的
5 x 5区域。然后,我们将5 x 5区域展平成一个25-d列表,并将其视为一个特征向量。 - 同样的
5 x 5区域的被清理过的图像,但这次我们只取中心(x, y)-坐标,用位置(2, 2)表示。
给定来自噪声输入图像的25-d(维度)特征向量,这个单个像素值就是我们想要我们的 RFR 预测的。
为了使这个例子更具体,再次考虑图 2 中的、,这里我们有下面的5 x 5、、来自噪声图像的网格像素值:
[[247 227 242 253 237]
[244 228 225 212 219]
[223 218 252 222 221]
[242 244 228 240 230]
[217 233 237 243 252]]
然后,我们将其展平成一个由5 x 5 = 25-d 值组成的列表:
[247 227 242 253 237 244 228 225 212 219 223 218 252 222 221 242 244 228
240 230 217 233 237 243 252]
这个25-d向量是我们的特征向量,我们的 RFR 将在其上被训练。
但是,我们仍然需要定义 RFR 的目标产值。我们的回归模型应该接受输入的25-d向量,并输出干净的、去噪的像素。
现在,让我们假设我们的黄金标准/目标图像中有以下5 x 5 窗口:
[[0 0 0 0 0]
[0 0 0 0 1]
[0 0 1 1 1]
[0 0 1 1 1]
[0 0 0 1 1]]
我们只对这个5 x 5 区域的中心感兴趣,记为位置x = 2、y = 2 。 因此,我们提取1(前景,相对于0,是背景)的这个值,并把它作为我们的 RFR 应该预测的目标值。
将整个示例放在一起,我们可以将以下视为样本训练数据点:
trainX = [[247 227 242 253 237 244 228 225 212 219 223 218 252 222 221 242 244 228
240 230 217 233 237 243 252]]
trainY = [[1]]
给定我们的trainX变量(我们的原始像素强度),我们想要预测trainY中相应的净化/去噪像素值。
我们将以这种方式训练我们的 RFR,最终得到一个模型,该模型可以接受有噪声的文档输入,并通过检查局部5 x 5 区域,然后预测中心(干净的)像素值,自动去噪。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
本教程的项目目录结构比其他教程稍微复杂一点,因为有五个 Python 脚本需要查看(三个脚本、一个助手函数和一个配置文件)。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
在我们继续之前,让我们熟悉一下这些文件:
|-- pyimagesearch
| |-- __init__.py
| |-- denoising
| | |-- __init__.py
| | |-- helpers.py
|-- config
| |-- __init__.py
| |-- denoise_config.py
|-- build_features.py
|-- denoise_document.py
|-- denoiser.pickle
|-- denoising-dirty-documents
| |-- test
| | |-- 1.png
| | |-- 10.png
| | |-- ...
| | |-- 94.png
| | |-- 97.png
| |-- train
| | |-- 101.png
| | |-- 102.png
| | |-- ...
| | |-- 98.png
| | |-- 99.png
| |-- train_cleaned
| | |-- 101.png
| | |-- 102.png
| | |-- ...
| | |-- 98.png
| | |-- 99.png
|-- train_denoiser.py
denoising-dirty-documents directory包含来自 Kaggle 去噪脏文档数据集的所有图像。
在pyimagesearch的denoising子模块中,有一个helpers.py文件。该文件包含一个函数blur_and_threshold,顾名思义,该函数用于将平滑和阈值处理相结合,作为我们文档的预处理步骤。
然后我们有了denoise_config.py文件,它存储了一些指定训练数据文件路径、输出特征 CSV 文件和最终序列化 RFR 模型的配置。
我们将完整回顾三个 Python 脚本:
build_features.py:接受我们的输入数据集并创建一个 CSV 文件,我们将使用它来训练我们的 RFR。train_denoiser.py:训练实际的 RFR 模型,并将其序列化到磁盘中作为denoiser.pickle。denoise_document.py:从磁盘接受输入图像,加载训练好的 RFR,然后对输入图像去噪。
在本教程中,我们需要回顾几个 Python 脚本。因此,我建议你将本教程复习两遍,以便更好地理解我们正在实现什么,然后在更深层次上掌握实现。
实现我们的配置文件
实现降噪文档的第一步是创建配置文件。打开项目目录结构的config子目录下的denoise_config.py文件,插入以下代码:
# import the necessary packages
import os
# initialize the base path to the input documents dataset
BASE_PATH = "denoising-dirty-documents"
# define the path to the training directories
TRAIN_PATH = os.path.sep.join([BASE_PATH, "train"])
CLEANED_PATH = os.path.sep.join([BASE_PATH, "train_cleaned"])
第 5 行定义了我们的denoising-dirty-documents数据集的基本路径。如果您从 Kaggle 下载该数据集,请确保解压缩该目录下的所有.zip文件,以使数据集中的所有图像解压缩并驻留在磁盘上。
然后我们分别定义到原始噪声图像目录和相应的清洁图像*目录的路径(第 8 行和第 9 行)。
TRAIN_PATH图像包含有噪声的文档,而CLEANED_PATH图像包含我们的“黄金标准”,即在通过我们训练的模型应用文档去噪后,我们的输出图像应该是什么样子。我们将在我们的train_denoiser.py脚本中构建测试集。
让我们继续定义配置文件:
# define the path to our output features CSV file then initialize
# the sampling probability for a given row
FEATURES_PATH = "features.csv"
SAMPLE_PROB = 0.02
# define the path to our document denoiser model
MODEL_PATH = "denoiser.pickle"
第 13 行定义了输出features.csv文件的路径。我们的特色包括:
- 通过滑动窗口从有噪声的输入图像中采样的局部
5 x 5区域 5 x 5区域的中心,记为(x, y)-坐标(2, 2),对应于清洗后的图像
然而,如果我们将每个特性/目标组合的写到磁盘上,我们最终会得到数百万行和一个几千兆字节大小的 CSV。因此,我们不是穷尽地计算所有的滑动窗口和目标组合,而是以SAMPLES_PROB的概率将它们写入磁盘。
最后,第 17 行指定了到MODEL_PATH的路径,我们的输出序列化模型。
创建我们的模糊和阈值辅助函数
为了帮助我们的 RFR 从前景(即文本)像素中预测背景(即噪声),我们需要定义一个助手函数,该函数将在我们训练模型并使用它进行预测之前预处理我们的图像。
我们的图像处理操作流程可以在图 4 中看到。首先,我们将输入图像模糊化(左上),然后从输入图像中减去模糊的图像(右上)。我们这样做是为了逼近图像的前景,因为本质上,模糊会模糊聚焦的特征,并显示图像的更多“结构”成分。
接下来,我们通过将任何大于零的像素值设置为零来对近似的前景区域进行阈值化(图 4 ,左下方)。
最后一步是执行最小-最大缩放(右下角),这将使像素亮度回到范围[0, 1](或[0, 255],取决于您的数据类型)。当我们执行滑动窗口采样时,这个最终图像将作为噪声输入。
现在我们已经了解了一般的预处理步骤,让我们用 Python 代码来实现它们。
在pyimagesearch的denoising子模块中打开helpers.py文件,让我们开始定义我们的blur_and_threshold功能:
# import the necessary packages
import numpy as np
import cv2
def blur_and_threshold(image, eps=1e-7):
# apply a median blur to the image and then subtract the blurred
# image from the original image to approximate the foreground
blur = cv2.medianBlur(image, 5)
foreground = image.astype("float") - blur
# threshold the foreground image by setting any pixels with a
# value greater than zero to zero
foreground[foreground > 0] = 0
blur_and_threshold函数接受两个参数:
image:我们将要预处理的输入图像。eps:用于防止被零除的ε值。
然后,我们对图像应用中值模糊以减少噪声,并从原始的image中减去blur,得到一个foreground近似值(第 8 行和第 9 行)。
从那里,我们通过将任何大于零的像素强度设置为零来对foreground图像进行阈值处理(行 13 )。
这里的最后一步是执行最小-最大缩放:
# apply min/max scaling to bring the pixel intensities to the
# range [0, 1]
minVal = np.min(foreground)
maxVal = np.max(foreground)
foreground = (foreground - minVal) / (maxVal - minVal + eps)
# return the foreground-approximated image
return foreground
这里,我们找到了foreground图像中的最小值和最大值。我们使用这些值将foreground图像中的像素强度缩放到范围[0, 1] 。
这个前景近似的图像然后被返回给调用函数。
实现特征提取脚本
定义了我们的blur_and_threshold函数后,我们可以继续我们的build_features.py脚本。
顾名思义,这个脚本负责从有噪图像中创建我们的5 x 5 - 25-d 特征向量,然后从相应的黄金标准图像中提取目标(即清理后的)像素值。
我们将以 CSV 格式将这些特征保存到磁盘,然后在“实现我们的去噪训练脚本”一节中对它们训练一个随机森林回归模型
现在让我们开始实施:
# import the necessary packages
from config import denoise_config as config
from pyimagesearch.denoising import blur_and_threshold
from imutils import paths
import progressbar
import random
import cv2
第 2 行导入我们的config来访问我们的数据集文件路径并输出 CSV 文件路径。注意,我们在这里使用了blur_and_threshold函数。
下面的代码块获取我们的TRAIN_PATH(噪声图像)和CLEANED_PATH(我们的 RFR 将学习预测的干净图像)中所有图像的路径:
# grab the paths to our training images
trainPaths = sorted(list(paths.list_images(config.TRAIN_PATH)))
cleanedPaths = sorted(list(paths.list_images(config.CLEANED_PATH)))
# initialize the progress bar
widgets = ["Creating Features: ", progressbar.Percentage(), " ",
progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(trainPaths),
widgets=widgets).start()
注意trainPaths包含了我们所有的噪音图像。cleanedPaths包含相应的清洗过的图像。
图 5 显示了一个例子。在顶部是我们的输入训练图像。在底部,我们有相应的图像清理版本。我们将从trainPaths和cleanedPaths中提取5 x 5 区域——目标是使用有噪声的5 x 5 区域来预测干净的版本。
现在让我们开始循环这些图像组合:
# zip our training paths together, then open the output CSV file for
# writing
imagePaths = zip(trainPaths, cleanedPaths)
csv = open(config.FEATURES_PATH, "w")
# loop over the training images together
for (i, (trainPath, cleanedPath)) in enumerate(imagePaths):
# load the noisy and corresponding gold-standard cleaned images
# and convert them to grayscale
trainImage = cv2.imread(trainPath)
cleanImage = cv2.imread(cleanedPath)
trainImage = cv2.cvtColor(trainImage, cv2.COLOR_BGR2GRAY)
cleanImage = cv2.cvtColor(cleanImage, cv2.COLOR_BGR2GRAY)
在第 21 行,我们使用 Python 的zip函数将trainPaths和cleanedPaths组合在一起。然后,我们打开我们的输出csv文件,写入第行 22。
第 25 行在我们的imagePaths组合上开始一个循环。对于每个trainPath,我们也有相应的cleanedPath。
我们从磁盘中加载我们的trainImage和cleanImage,并将它们转换成灰度(第 28-31 行)。
接下来,我们需要在每个方向用 2 像素的边框填充trainImage和cleanImage:
# apply 2x2 padding to both images, replicating the pixels along
# the border/boundary
trainImage = cv2.copyMakeBorder(trainImage, 2, 2, 2, 2,
cv2.BORDER_REPLICATE)
cleanImage = cv2.copyMakeBorder(cleanImage, 2, 2, 2, 2,
cv2.BORDER_REPLICATE)
# blur and threshold the noisy image
trainImage = blur_and_threshold(trainImage)
# scale the pixel intensities in the cleaned image from the range
# [0, 255] to [0, 1] (the noisy image is already in the range
# [0, 1])
cleanImage = cleanImage.astype("float") / 255.0
为什么我们要为填充物费心呢?我们从输入图像的从左到右和从上到下滑动一个窗口,并使用窗口内的像素来预测位于x = 2、y = 2的输出中心像素,这与卷积运算没有什么不同(只有卷积我们的滤波器是固定和定义的)。
像卷积一样,您需要填充输入图像,以便输出图像的大小不会变小。如果你不熟悉这个概念,请参考我的关于 OpenCV 和 Python 卷积的指南。
填充完成后,我们对trainImage进行模糊和阈值处理,并手动将cleanImage缩放到范围[0, 1]。由于blur_and_threshold内的最小-最大缩放,trainImage已经缩放到[0, 1] 范围。
对我们的图像进行预处理后,我们现在可以在图像上滑动一个5 x 5 窗口:
# slide a 5x5 window across the images
for y in range(0, trainImage.shape[0]):
for x in range(0, trainImage.shape[1]):
# extract the window ROIs for both the train image and
# clean image, then grab the spatial dimensions of the
# ROI
trainROI = trainImage[y:y + 5, x:x + 5]
cleanROI = cleanImage[y:y + 5, x:x + 5]
(rH, rW) = trainROI.shape[:2]
# if the ROI is not 5x5, throw it out
if rW != 5 or rH != 5:
continue
49 线和 50 线从左右和上下滑动一个5 x 5 窗口穿过trainImage和cleanImage。在每次滑动窗口停止时,我们提取训练图像和干净图像的5 x 5ROI(行 54 和 55 )。
*我们获取第 56行上trainROI的宽度和高度,如果宽度或高度不是五个像素(由于我们在图像的边界上),我们丢弃 ROI(因为我们只关心5 x 5 区域)。
接下来,我们构建我们的特征向量,并将该行保存到 CSV 文件中:
# our features will be the flattened 5x5=25 raw pixels
# from the noisy ROI while the target prediction will
# be the center pixel in the 5x5 window
features = trainROI.flatten()
target = cleanROI[2, 2]
# if we wrote *every* feature/target combination to disk
# we would end up with millions of rows -- let's only
# write rows to disk with probability N, thereby reducing
# the total number of rows in the file
if random.random() <= config.SAMPLE_PROB:
# write the target and features to our CSV file
features = [str(x) for x in features]
row = [str(target)] + features
row = ",".join(row)
csv.write("{}\n".format(row))
# update the progress bar
pbar.update(i)
# close the CSV file
pbar.finish()
csv.close()
第 65 行从trainROI中取出5 x 5 像素区域,将其展平成一个5 x 5 = 25-d 列表— 这个列表作为我们的特征向量。
行 66 然后从cleanROI的中心提取清洁/黄金标准像素值。这个像素值就是我们希望 RFR 预测的值。
此时,我们可以将特征向量和目标值的组合写入磁盘;然而,如果我们将每个特性/目标组合的写到 CSV 文件中,我们最终会得到一个几千兆字节大小的文件。
为了避免产生大量的 CSV 文件,我们需要在下一步中处理它。因此,我们改为只允许将SAMPLE_PROB(在本例中,2%)行写入磁盘(行 72 )。进行这种采样可以减小生成的 CSV 文件的大小,并使其更易于管理。
第 74 行构建了我们的features行,并在前面加上了target像素值。然后,我们将该行写入 CSV 文件。我们对所有imagePaths重复这个过程。
运行特征提取脚本
我们现在准备运行我们的特征提取器。首先,打开一个终端,然后执行build_features.py脚本:
$ python build_features.py
Creating Features: 100% |#########################| Time: 0:01:05
在我的 3 GHz 英特尔至强 W 处理器上,整个特征提取过程只花了一分多钟。
检查我的项目目录结构,您现在可以看到结果 CSV 文件的特性:
$ ls -l *.csv
adrianrosebrock staff 273968497 Oct 23 06:21 features.csv
如果您打开系统中的features.csv文件,您会看到每行包含 26 个条目。
行中的第一个条目是目标输出像素。我们将尝试根据该行剩余部分的内容预测输出像素值,这些内容是输入 ROI 像素的5 x 5 = 25 。
下一节将介绍如何训练一个 RFR 模型来做到这一点。
实施我们的去噪训练脚本
现在我们的features.csv文件已经生成,我们可以继续学习训练脚本了。这个脚本负责加载我们的features.csv文件,训练一个 RFR 接受一个有噪图像的5 x 5 区域,然后预测清理后的中心像素值。
让我们开始检查代码:
# import the necessary packages
from config import denoise_config as config
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import numpy as np
import pickle
第 2-7 行处理我们需要的 Python 包,包括:
config:我们的项目配置保存了我们的输出文件路径和训练变量RandomForestRegressor:我们将用来预测像素值的回归模型的 scikit-learn 实现- 我们的误差/损失函数——这个值越低,我们在图像去噪方面做得越好
train_test_split:用于从我们的features.csv文件创建培训/测试分割pickle:用于将我们训练过的 RFR 序列化到磁盘
让我们继续从磁盘加载我们的 CSV 文件:
# initialize lists to hold our features and target predicted values
print("[INFO] loading dataset...")
features = []
targets = []
# loop over the rows in our features CSV file
for row in open(config.FEATURES_PATH):
# parse the row and extract (1) the target pixel value to predict
# along with (2) the 5x5=25 pixels which will serve as our feature
# vector
row = row.strip().split(",")
row = [float(x) for x in row]
target = row[0]
pixels = row[1:]
# update our features and targets lists, respectively
features.append(pixels)
targets.append(target)
第 11 行和第 12 行初始化我们的features ( 5 x 5 像素区域)和目标(我们要预测的目标输出像素值)。
我们在第 15 行开始循环 CSV 文件的所有行。对于每个row,我们提取target和pixel值(第 19-22 行)。然后我们分别更新我们的features和targets列表。
将 CSV 文件加载到内存中后,我们可以构建我们的训练和测试分割:
# convert the features and targets to NumPy arrays
features = np.array(features, dtype="float")
target = np.array(targets, dtype="float")
# construct our training and testing split, using 75% of the data for
# training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(features, target,
test_size=0.25, random_state=42)
这里,我们使用 75%的数据进行训练,剩下的 25%用于测试。这种类型的分割在机器学习领域是相当标准的。
最后,我们可以训练我们的 RFR:
# train a random forest regressor on our data
print("[INFO] training model...")
model = RandomForestRegressor(n_estimators=10)
model.fit(trainX, trainY)
# compute the root mean squared error on the testing set
print("[INFO] evaluating model...")
preds = model.predict(testX)
rmse = np.sqrt(mean_squared_error(testY, preds))
print("[INFO] rmse: {}".format(rmse))
# serialize our random forest regressor to disk
f = open(config.MODEL_PATH, "wb")
f.write(pickle.dumps(model))
f.close()
第 39 行初始化我们的RandomForestRegressor,指示它训练10独立的回归树。然后在线 40 上训练该模型。
训练完成后,我们计算均方根误差(RMSE)来衡量我们在预测干净、去噪的图像方面做得有多好。降低 的误差值,把的工作做好。****
***最后,我们将训练好的 RFR 模型序列化到磁盘上,这样我们就可以用它来预测我们的噪声图像。
训练我们的文档去噪模型
随着我们的train_denoiser.py脚本的实现,我们现在准备训练我们的自动图像降噪器!首先,打开一个 shell,然后执行train_denoiser.py脚本:
$ time python train_denoiser.py
[INFO] loading dataset...
[INFO] training model...
[INFO] evaluating model...
[INFO] rmse: 0.04990744293857625
real 1m18.708s
user 1m19.361s
sys 0m0.894s
训练我们的脚本只需要一分多钟,产生了一个≈0.05的 RMSE。这是一个非常低的损失值,表明我们的模型成功地接受了有噪声的输入像素 ROI,并正确地预测了目标输出值。
检查我们的项目目录结构,您会看到 RFR 模型已经被序列化到磁盘上,名为denoiser.pickle:
$ ls -l *.pickle
adrianrosebrock staff 77733392 Oct 23 denoiser.pickle
在下一节中,我们将从磁盘中加载经过训练的denoiser.pickle模型,然后使用它来自动清理和预处理我们的输入文档。
创建文档降噪脚本
这个项目的最后一步是采用我们训练过的 denoiser 模型来自动清理我们的输入图像。
现在打开denoise_document.py,我们将看到这个过程是如何完成的:
# import the necessary packages
from config import denoise_config as config
from pyimagesearch.denoising import blur_and_threshold
from imutils import paths
import argparse
import pickle
import random
import cv2
第 2-8 行处理导入我们需要的 Python 包。然后我们继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--testing", required=True,
help="path to directory of testing images")
ap.add_argument("-s", "--sample", type=int, default=10,
help="sample size for testing images")
args = vars(ap.parse_args())
我们的denoise_document.py脚本接受两个命令行参数:
--testing:包含 Kaggle 的 去噪脏文档 数据集测试图像的目录路径- 当应用我们的去噪模型时,我们将采样的测试图像的数量
说到我们的去噪模型,让我们从磁盘加载序列化模型:
# load our document denoiser from disk
model = pickle.loads(open(config.MODEL_PATH, "rb").read())
# grab the paths to all images in the testing directory and then
# randomly sample them
imagePaths = list(paths.list_images(args["testing"]))
random.shuffle(imagePaths)
imagePaths = imagePaths[:args["sample"]]
我们还抓取测试集的所有imagePaths部分,随机洗牌,然后选择总共--sample个图像,在这些图像中应用我们的自动降噪模型。
让我们循环一遍imagePaths的样本:
# loop over the sampled image paths
for imagePath in imagePaths:
# load the image, convert it to grayscale, and clone it
print("[INFO] processing {}".format(imagePath))
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
orig = image.copy()
# pad the image followed by blurring/thresholding it
image = cv2.copyMakeBorder(image, 2, 2, 2, 2,
cv2.BORDER_REPLICATE)
image = blur_and_threshold(image)
这里,我们执行的预处理步骤与我们在培训阶段使用的步骤相同:
- 我们从磁盘加载输入图像
- 将其转换为灰度
- 在每个方向用两个像素填充图像
- 应用
blur_and_threshold功能
现在我们需要循环处理过的image并提取每个 5 x 5 像素邻域的 :
# initialize a list to store our ROI features (i.e., 5x5 pixel
# neighborhoods)
roiFeatures = []
# slide a 5x5 window across the image
for y in range(0, image.shape[0]):
for x in range(0, image.shape[1]):
# extract the window ROI and grab the spatial dimensions
roi = image[y:y + 5, x:x + 5]
(rH, rW) = roi.shape[:2]
# if the ROI is not 5x5, throw it out
if rW != 5 or rH != 5:
continue
# our features will be the flattened 5x5=25 pixels from
# the training ROI
features = roi.flatten()
roiFeatures.append(features)
第 42 行初始化一个列表roiFeatures,以存储每个5 x 5 邻域。
然后我们将一个5 x 5 窗口从左右和上下滑过image。在窗口的每一步,我们提取roi ( 第 48 行),抓取它的空间维度(第 49 行),如果 ROI 大小不是5 x 5 ( 第 52 行和第 53 行)。
然后我们取我们的5 x 5 像素邻域,展平成一个features的列表,更新我们的roiFeatures列表(第 57 行和第 58 行)。
现在,在我们的滑动窗口for循环之外,我们用每一个可能的5 x 5 像素邻域填充了我们的roiFeatures。
然后我们可以对这些roiFeatures进行预测,得到最终的清洁图像:
# use the ROI features to predict the pixels of our new denoised
# image
pixels = model.predict(roiFeatures)
# the pixels list is currently a 1D array so we need to reshape
# it to a 2D array (based on the original input image dimensions)
# and then scale the pixels from the range [0, 1] to [0, 255]
pixels = pixels.reshape(orig.shape)
output = (pixels * 255).astype("uint8")
# show the original and output images
cv2.imshow("Original", orig)
cv2.imshow("Output", output)
cv2.waitKey(0)
第 62 行调用.predict方法作为我们的 RFR,产生pixels,我们的前景对背景预测。
然而,我们的pixels列表目前是一个 1D 数组,所以我们必须注意将reshape数组转换成 2D 图像,然后将像素亮度缩放回[0, 255] ( 第 67 行和第 68 行)。
最后,我们可以在屏幕上显示原始图像(有噪声的图像)和输出图像(干净的图像)。
运行我们的文档降噪器
你成功了!这是一个很长的章节,但是我们终于准备好将我们的文档 denoiser 应用于我们的测试数据。
要查看我们的denoise_document.py脚本的运行情况,请打开一个终端并执行以下命令:
$ python denoise_document.py --testing denoising-dirty-documents/test
[INFO] processing denoising-dirty-documents/test/133.png
[INFO] processing denoising-dirty-documents/test/160.png
[INFO] processing denoising-dirty-documents/test/40.png
[INFO] processing denoising-dirty-documents/test/28.png
[INFO] processing denoising-dirty-documents/test/157.png
[INFO] processing denoising-dirty-documents/test/190.png
[INFO] processing denoising-dirty-documents/test/100.png
[INFO] processing denoising-dirty-documents/test/49.png
[INFO] processing denoising-dirty-documents/test/58.png
[INFO] processing denoising-dirty-documents/test/10.png
我们的结果可以在图 6 中看到。每个样本的左侧图像显示有噪声的输入文档,包括污点、褶皱、折叠等。右边的显示了我们的 RFR 生成的清晰图像。
如你所见,我们的 RFR 在自动清理这些图像方面做得非常好!
总结
在本教程中,您学习了如何使用计算机视觉和机器学习对脏文档进行降噪。
使用这种方法,我们可以接受已经“损坏”的文档图像,包括裂口、撕裂、污点、起皱、折叠等。然后,通过以一种新的方式应用机器学习,我们可以将这些图像清理到接近原始状态,使 OCR 引擎更容易检测文本,提取文本,并正确地进行 OCR。
当你发现自己将 OCR 应用于真实世界的图像时,尤其是扫描的文档,你将不可避免地遇到质量差的文档。不幸的是,当这种情况发生时,您的 OCR 准确性可能会受到影响。
与其认输,不如考虑一下本教程中使用的技术会有什么帮助。是否可以手动预处理这些图像的子集,然后将它们用作训练数据?在此基础上,您可以训练一个模型,该模型可以接受有噪声的像素 ROI,然后生成原始、干净的输出。
通常,我们不使用原始像素作为机器学习模型的输入(当然,卷积神经网络除外)。通常,我们会使用一些特征检测器或描述符提取器来量化输入图像。从那里,产生的特征向量被交给机器学习模型。
很少有人看到标准的机器学习模型对原始像素强度进行操作。这是一个巧妙的技巧,但感觉在实践中并不可行。然而,正如你在这里看到的,这个方法是有效的!
我希望在实现文档去噪管道时,您可以将本教程作为一个起点。
更深入地说,您可以使用去噪自动编码器来提高去噪质量。在这一章中,我们使用了一个随机森林回归器,一个不同决策树的集合。你可能想探索的另一个系综是极端梯度增强,简称 XGBoost。
引用信息
A. Rosebrock ,“使用机器学习对图像去噪以获得更好的 OCR 准确度”, PyImageSearch ,2021,https://PyImageSearch . com/2021/10/20/Using-Machine-Learning-to-de-noise-Images-for-Better-OCR-Accuracy/
@article{Rosebrock_2021_Denoise, author = {Adrian Rosebrock}, title = {Using Machine Learning to Denoise Images for Better {OCR} Accuracy}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/10/20/using-machine-learning-to-denoise-images-for-better-ocr-accuracy/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*******
使用拼写检查提高 Tesseract OCR 的准确性
原文:https://pyimagesearch.com/2021/11/29/using-spellchecking-to-improve-tesseract-ocr-accuracy/
在之前的教程中,您学习了如何使用textblob库和 Tesseract 自动 OCR 文本,然后将其翻译成不同的语言。本教程也将使用textblob,但这次是通过自动拼写检查 OCR 文本来提高 OCR 的准确性。
要了解如何使用拼写检查对结果进行 OCR,请继续阅读。
使用拼写检查来提高立方体 OCR 的准确性
期望 任何 OCR 系统,即使是最先进的 OCR 引擎,做到 100%准确也是不现实的。这在实践中是不会发生的。不可避免的是,输入图像中的噪声、Tesseract 没有训练过的非标准字体或低于理想的图像质量都会导致 Tesseract 出错并错误地对一段文本进行 OCR。
当这种情况发生时,您需要创建规则和试探法来提高输出 OCR 质量。你应该关注的第一个规则和启发是自动拼写检查。例如,如果您正在对一本书进行 OCR,您可以使用拼写检查来尝试在 OCR 过程后自动更正,从而创建更好、更准确的数字化文本版本。
学习目标
在本教程中,您将:
- 了解如何使用
textblob包进行拼写检查 - 包含不正确拼写的一段文本
- 自动更正 OCR 文本的拼写
OCR 和拼写检查
我们将从回顾我们的项目目录结构开始本教程。然后,我将向您展示如何实现一个 Python 脚本,该脚本可以自动对一段文本进行 OCR,然后使用textblob库对其进行拼写检查。一旦我们的脚本被实现,我们将把它应用到我们的示例图像。我们将讨论拼写检查的准确性,包括一些与自动拼写检查相关的限制和缺点,从而结束本教程。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们的 OCR 拼写检查器的项目目录结构非常简单:
|-- comic_spelling.png
|-- ocr_and_spellcheck.py
我们这里只有一个 Python 脚本,ocr_and_spellcheck.py。该脚本执行以下操作:
- 从磁盘加载
comic_spelling.png - 对图像中的文本进行 OCR
- 对其应用拼写检查
通过应用拼写检查,我们将理想地能够提高我们脚本的 OCR 准确性,不管如果:
- 输入图像中有不正确的拼写
- 对字符进行不正确的 OCR 处理
实现我们的 OCR 拼写检查脚本
让我们开始实现我们的 OCR 和拼写检查脚本。
打开一个新文件,将其命名为ocr_and_spellcheck.py,并插入以下代码:
# import the necessary packages
from textblob import TextBlob
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
args = vars(ap.parse_args())
第 2-5 行导入我们需要的 Python 包。你应该注意到textblob包的使用,我们在的前一课中利用它将 OCR 文本从一种语言翻译成另一种语言。我们将在本教程中使用textblob,,但这次是为了它的自动拼写检查实现。
第 8-11 行然后解析我们的命令行参数。我们只需要一个参数,--image,它是输入图像的路径:
接下来,我们可以从磁盘加载图像并对其进行 OCR:
# load the input image and convert it from BGR to RGB channel
# ordering
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# use Tesseract to OCR the image
text = pytesseract.image_to_string(rgb)
# show the text *before* ocr-spellchecking has been applied
print("BEFORE SPELLCHECK")
print("=================")
print(text)
print("\n")
第 15 行使用提供的路径从磁盘加载我们的输入image。然后,我们将颜色通道排序从 BGR (OpenCV 的默认排序)交换到 RGB(这是 Tesseract 和pytesseract所期望的)。
一旦图像被加载,我们调用image_to_string来 OCR 图像。然后我们在屏幕上显示在拼写检查之前经过 OCR 处理的text(第 19-25 行)。
但是,可能会有拼写错误,例如用户在创建图像时拼写错误的文本,或者由于 Tesseract 错误地对一个或多个字符进行 OCR 而导致的“输入错误”——为了解决这个问题,我们需要利用textblob:
# apply spell checking to the OCR'd text
tb = TextBlob(text)
corrected = tb.correct()
# show the text after ocr-spellchecking has been applied
print("AFTER SPELLCHECK")
print("================")
print(corrected)
第 28 行从 OCR 识别的文本中构造一个TextBlob。然后,我们通过correct()方法(第 29 行)应用自动拼写检查纠正。然后corrected文本(即拼写检查后的)显示在终端上(第 32-34 行)。
OCR 拼写检查结果
我们现在准备对示例图像应用 OCR 拼写检查。
打开终端并执行以下命令:
$ python ocr_and_spellcheck.py --image comic_spelling.png
BEFORE SPELLCHECK
=================
Why can't yu
spel corrctly?
AFTER SPELLCHECK
================
Why can't you
spell correctly?
图 2 显示了我们的示例图像(通过 Explosm 漫画生成器创建),其中包括拼写错误的单词。使用 Tesseract,我们可以用 OCR 识别出有拼写错误的文本。
值得注意的是,这些拼写错误是故意引入的——在您的 OCR 应用程序中,这些拼写错误可能自然存在于您的输入图像中或 Tesseract 可能会错误地 OCR 某些字符。
正如我们的输出所示,我们能够使用textblob来纠正这些拼写错误,正确地纠正单词“Yu you”、“spel spel”、和【T3”
局限性和缺点
拼写检查算法的最大问题之一是大多数拼写检查器需要 一些 人工干预才能准确。当我们犯了拼写错误时,我们的文字处理器会自动检测错误并提出候选修正——通常是拼写检查器认为我们应该拼写的两三个单词。除非我们十有八九拼错了一个单词,否则我们可以在拼写检查器建议的候选词中找到我们想要使用的单词。
我们可以选择移除人工干预部分,而是允许拼写检查器使用它基于内部拼写检查算法认为最有可能的单词。我们冒着用在句子或段落的原始上下文中没有意义的单词替换只有小拼写错误的单词的风险。因此,在依赖全自动拼写检查器时,你应该小心谨慎。存在在输出的 OCR 文本中插入不正确的单词(相对于正确的单词,但是有小的拼写错误)的风险。
如果您发现拼写检查损害了 OCR 的准确性,您可能需要:
- 除了包含在
textblob库中的通用算法之外,寻找替代的拼写检查算法 - 用基于启发的方法替换拼写检查(例如,正则表达式匹配)
- 允许拼写错误存在,记住没有一个 OCR 系统是 100%准确的
总结
在本教程中,您学习了如何通过应用自动拼写检查来改善 OCR 结果。虽然我们的方法在我们的特定示例中运行良好,但在其他情况下可能不太适用!请记住,拼写检查算法通常需要少量的人工干预。大多数拼写检查器会自动检查文档中的拼写错误,然后会向用户建议一个候选更正列表。由人做出最终的拼写检查决定。
当我们去除人工干预的成分,转而允许拼写检查算法选择它认为最合适的纠正时,只有轻微拼写错误的单词将被替换为在句子的原始上下文中没有意义的单词。在您自己的 OCR 应用程序中,谨慎使用拼写检查,尤其是自动拼写检查——在某些情况下,它将有助于您的 OCR 准确性,但在其他情况下,它可能会损害准确性。
引用信息
罗斯布鲁克,一。“使用拼写检查提高 Tesseract OCR 准确度”, PyImageSearch ,2021,https://PyImageSearch . com/2021/11/29/Using-spell checking-to-improve-tessera CT-OCR-accuracy/
@article{Rosebrock_2021_Spellchecking,
author = {Adrian Rosebrock},
title = {Using spellchecking to improve {T}esseract {OCR} accuracy},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/11/29/using-spellchecking-to-improve-tesseract-ocr-accuracy/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 tensorflow 和 gradienttype 训练 keras 模型
原文:https://pyimagesearch.com/2020/03/23/using-tensorflow-and-gradienttape-to-train-a-keras-model/

在本教程中,您将学习如何使用 TensorFlow 的GradientTape函数创建自定义训练循环来训练 Keras 模型。
今天的教程受到了 PyImageSearch 读者 Timothy 给我的一个问题的启发:
你好,阿德里安,我刚刚看了你在 Grad-CAM 上的教程,注意到你在计算梯度时使用了一个名为
GradientTape的函数。我听说
GradientTape是 TensorFlow 2.0 中的一个全新功能,它可以用于自动微分 模拟和编写自定义训练循环,但我在网上找不到太多这样的例子。你能解释一下如何使用
GradientTape来定制训练循环吗?
蒂莫西在两方面都是正确的:
GradientTape是 TensorFlow 2.0 中的全新功能- 它还可以用来编写定制的训练循环(适用于 Keras 模型和在“纯”TensorFlow 中实现的模型)
对 TensorFlow 1.x 低级 API 以及 Keras 高级 API 的最大批评之一是,它使深度学习研究人员编写定制训练循环变得非常具有挑战性,这些循环可以:
- 自定义数据批处理过程
- 处理具有不同空间尺寸的多个输入和/或输出
- 利用定制损失函数
- 访问特定图层的渐变,并以独特的方式更新它们
这并不是说你不能用 Keras 和 TensorFlow 1.x 创建定制的训练循环。你可以;这是一个棘手的问题,也是一些研究人员最终转向 PyTorch 的原因之一——他们只是不想再头疼了,希望有更好的方法来实施他们的培训程序。
在 TensorFlow 2.0 中,这一切都改变了。
随着 TensorFlow 2.0 版本的发布,我们现在有了GradientTape功能,这使得比以往任何时候都更容易为 TensorFlow 和 Keras 模型编写定制训练循环,这要归功于自动微分。
无论你是深度学习实践者还是经验丰富的研究人员,你都应该学习如何使用GradientTape函数——它允许你为 Keras 易用的 API 中实现的模型创建定制的训练循环,让你两全其美。你就是无法打败这种组合。
要学习如何使用 TensorFlow 的GradientTape功能训练 Keras 模型,继续阅读!
使用 tensorflow 和 gradienttype 训练 keras 模型
在本教程的第一部分,我们将讨论自动微分,包括它与经典微分方法的不同,如符号微分和数值微分。
然后,我们将讨论创建自定义训练循环来训练深度神经网络所需的四个组件,最起码是这样。
之后,我们将向您展示如何使用 TensorFlow 的GradientTape函数来实现这样一个定制的训练循环。最后,我们将使用我们的自定义训练循环来训练一个 Keras 模型并检查结果。
GradientTape:什么是自动微分?

Figure 1: Using TensorFlow and GradientTape to train a Keras model requires conceptual knowledge of automatic differentiation — a set of techniques to automatically compute the derivative of a function by applying the chain rule. (image source)
自动微分 运算(也叫计算微分)是指通过反复应用链式法则,自动计算函数导数的一套技术。
自动微分利用了这样一个事实,即每个计算机程序,不管有多复杂,都执行一系列的基本算术运算(加、减、乘、除等)。)和初等函数(exp、log、sin、cos 等。).
通过将链式法则反复应用于这些运算,可以自动计算任意阶导数,精确到工作精度,并且最多使用一个小的常数因子比原程序多进行算术运算。
与经典的微分算法如符号微分(效率低)和数值微分****(容易出现离散化和舍入误差)不同,自动微分快速高效,最棒的是可以计算关于多个输入的偏导数(这正是我们在应用梯度下降来训练我们的模型时所需要的)。
***要了解更多关于自动微分算法的内部工作原理,我建议回顾一下多伦多大学讲座的幻灯片,以及研究一下这个由奇-汪锋做的例子。
具有 TensorFlow、GradientTape 和 Keras 的深度神经网络训练循环的 4 个组件
当使用 Keras 和 TensorFlow 实现自定义训练循环时,您至少需要定义四个组件:
- 组件 1: 模型架构
- 组件 2: 计算模型损失时使用的损失函数
- 组件 3:****优化器用于更新模型权重
- 组件 4:****阶跃函数,封装了网络的前向和后向通路
这些组件中的每一个都可能简单或复杂,但在为您自己的模型创建自定义训练循环时,您至少需要所有这四个组件。
一旦你定义了它们,GradientTape就会处理剩下的事情。
项目结构
继续抓取 【下载】 到今天的博文并解压代码。您将看到以下项目:
$ tree
.
└── gradient_tape_example.py
0 directories, 1 file
今天的 zip 只包含一个 Python 文件——我们的GradientTape示例脚本。
我们的 Python 脚本将使用GradientTape在 MNIST 数据集上训练一个定制的 CNN(如果您的系统上还没有缓存 MNIST,TensorFlow 将下载它)。
接下来让我们跳到GradientTape的实现。
实施 TensorFlow 和 GradientTape 培训脚本
让我们学习如何使用 TensorFlow 的GradientTape函数来实现一个定制的训练循环来训练一个 Keras 模型。
打开项目目录结构中的gradient_tape_example.py文件,让我们开始吧:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import tensorflow as tf
import numpy as np
import time
import sys
我们从 TensorFlow 2.0 和 NumPy 的导入开始。
如果你仔细检查,你不会看到GradientTape;我们可以通过tf.GradientTape访问它。在本教程中,我们将使用 MNIST 数据集(mnist)作为示例。
让我们继续使用 TensorFlow/Keras 的顺序 API 构建我们的模型:
def build_model(width, height, depth, classes):
# initialize the input shape and channels dimension to be
# "channels last" ordering
inputShape = (height, width, depth)
chanDim = -1
# build the model using Keras' Sequential API
model = Sequential([
# CONV => RELU => BN => POOL layer set
Conv2D(16, (3, 3), padding="same", input_shape=inputShape),
Activation("relu"),
BatchNormalization(axis=chanDim),
MaxPooling2D(pool_size=(2, 2)),
# (CONV => RELU => BN) * 2 => POOL layer set
Conv2D(32, (3, 3), padding="same"),
Activation("relu"),
BatchNormalization(axis=chanDim),
Conv2D(32, (3, 3), padding="same"),
Activation("relu"),
BatchNormalization(axis=chanDim),
MaxPooling2D(pool_size=(2, 2)),
# (CONV => RELU => BN) * 3 => POOL layer set
Conv2D(64, (3, 3), padding="same"),
Activation("relu"),
BatchNormalization(axis=chanDim),
Conv2D(64, (3, 3), padding="same"),
Activation("relu"),
BatchNormalization(axis=chanDim),
Conv2D(64, (3, 3), padding="same"),
Activation("relu"),
BatchNormalization(axis=chanDim),
MaxPooling2D(pool_size=(2, 2)),
# first (and only) set of FC => RELU layers
Flatten(),
Dense(256),
Activation("relu"),
BatchNormalization(),
Dropout(0.5),
# softmax classifier
Dense(classes),
Activation("softmax")
])
# return the built model to the calling function
return model
这里我们定义了用于构建模型架构的build_model函数(创建定制训练循环的组件#1 )。该函数接受我们数据的形状参数:
width和height:每个输入图像的空间尺寸depth:我们图像的通道数(灰度为 1,如 MNIST 的情况 RGB 彩色图像为 3)classes:数据集中唯一类标签的数量
我们的模型是 VGG 式架构的代表(即,受 VGGNet 变体的启发),因为它包含 3×3 卷积和在POOL之前堆叠CONV => RELU => BN层以减少体积大小。
50%的丢弃(随机断开神经元)被添加到一组FC => RELU层,因为它被证明可以提高模型的泛化能力。
一旦我们的model被构建,行 67 将它返回给调用者。
让我们来研究组件 2、3 和 4:
def step(X, y):
# keep track of our gradients
with tf.GradientTape() as tape:
# make a prediction using the model and then calculate the
# loss
pred = model(X)
loss = categorical_crossentropy(y, pred)
# calculate the gradients using our tape and then update the
# model weights
grads = tape.gradient(loss, model.trainable_variables)
opt.apply_gradients(zip(grads, model.trainable_variables))
我们的step函数接受训练图像X和它们相应的类标签y(在我们的例子中,是 MNIST 图像和标签)。
现在让我们通过以下方式记录我们的梯度:
- 使用我们的
model( 第 74 行)收集关于我们训练数据的预测 - 计算 行 75 上的
loss( 组件#2 创建自定义训练循环)
然后使用tape.gradients并通过传递我们的loss和可训练变量(第 79 行)来计算我们的梯度。
我们使用我们的优化器,使用第 80 ( 组件#3 )行上的梯度来更新模型权重。
作为一个整体,step函数完成了组件#4 ,使用我们的GradientTape封装了我们向前和向后传递的数据,然后更新了我们的模型权重。
定义了我们的build_model和step函数后,现在我们将准备数据:
# initialize the number of epochs to train for, batch size, and
# initial learning rate
EPOCHS = 25
BS = 64
INIT_LR = 1e-3
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, trainY), (testX, testY)) = mnist.load_data()
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# one-hot encode the labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
第 84-86 行初始化我们的训练时期、批量和初始学习率。
然后,我们加载 MNIST 数据(第 90 行),并通过以下方式对其进行预处理:
- 添加单通道尺寸(行 94 和 95 )
- 将像素强度缩放到范围【0,1】(行 96 和 97 )
- 一键编码我们的标签(行 100 和 101 )
注: 由于GradientTape是一个高级概念,你应该熟悉这些预处理步骤。如果你需要温习这些基础知识,一定要考虑拿一本用 Python 编写的计算机视觉深度学习。
有了现成的数据,我们将构建我们的模型:
# build our model and initialize our optimizer
print("[INFO] creating model...")
model = build_model(28, 28, 1, 10)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
在这里,我们利用我们的build_model函数构建我们的 CNN 架构,同时传递我们数据的形状。形状由单通道的 28×28 像素图像和 MNIST 数字 0-9 对应的10类组成。
然后我们用一个标准的学习率衰减时间表初始化我们的Adam优化器。
我们现在准备好用我们的 GradientTape 训练我们的模型:
# compute the number of batch updates per epoch
numUpdates = int(trainX.shape[0] / BS)
# loop over the number of epochs
for epoch in range(0, EPOCHS):
# show the current epoch number
print("[INFO] starting epoch {}/{}...".format(
epoch + 1, EPOCHS), end="")
sys.stdout.flush()
epochStart = time.time()
# loop over the data in batch size increments
for i in range(0, numUpdates):
# determine starting and ending slice indexes for the current
# batch
start = i * BS
end = start + BS
# take a step
step(trainX[start:end], trainY[start:end])
# show timing information for the epoch
epochEnd = time.time()
elapsed = (epochEnd - epochStart) / 60.0
print("took {:.4} minutes".format(elapsed))
第 109 行计算我们将在每个时期进行的批量更新的次数。
从那里,我们开始循环从第行第 112 开始的训练时期的数量。在内部,我们:
- 打印纪元编号并获取
epochStart时间戳(第 114-117 行) - 以批量增量循环我们的数据(第 120 行)。在内部,我们使用
step函数来计算向前和向后传递,然后更新模型权重 - 显示训练周期所用的
elapsed时间(第 130-132 行
最后,我们将计算测试集的损失和准确性:
# in order to calculate accuracy using Keras' functions we first need
# to compile the model
model.compile(optimizer=opt, loss=categorical_crossentropy,
metrics=["acc"])
# now that the model is compiled we can compute the accuracy
(loss, acc) = model.evaluate(testX, testY)
print("[INFO] test accuracy: {:.4f}".format(acc))
为了使用 Keras 的evaluate辅助函数在我们的测试集上评估model的准确性,我们首先需要compile我们的模型(第 136 行和第 137 行)。
第 140 和 141 行,然后evaluate,在我们的终端打印出我们模型的精度。
此时,我们已经用 GradientTape 训练和评估了一个模型。在下一节中,我们将让我们的脚本为我们服务。
用 TensorFlow 和 GradientTape 训练我们的 Keras 模型
要查看我们的GradientTape自定义训练循环,请确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端并执行以下命令:
$ time python gradient_tape_example.py
[INFO] loading MNIST dataset...
[INFO] creating model...
[INFO] starting epoch 1/25...took 1.039 minutes
[INFO] starting epoch 2/25...took 1.039 minutes
[INFO] starting epoch 3/25...took 1.023 minutes
[INFO] starting epoch 4/25...took 1.031 minutes
[INFO] starting epoch 5/25...took 0.9819 minutes
[INFO] starting epoch 6/25...took 0.9909 minutes
[INFO] starting epoch 7/25...took 1.029 minutes
[INFO] starting epoch 8/25...took 1.035 minutes
[INFO] starting epoch 9/25...took 1.039 minutes
[INFO] starting epoch 10/25...took 1.019 minutes
[INFO] starting epoch 11/25...took 1.029 minutes
[INFO] starting epoch 12/25...took 1.023 minutes
[INFO] starting epoch 13/25...took 1.027 minutes
[INFO] starting epoch 14/25...took 0.9743 minutes
[INFO] starting epoch 15/25...took 0.9678 minutes
[INFO] starting epoch 16/25...took 0.9633 minutes
[INFO] starting epoch 17/25...took 0.964 minutes
[INFO] starting epoch 18/25...took 0.9634 minutes
[INFO] starting epoch 19/25...took 0.9638 minutes
[INFO] starting epoch 20/25...took 0.964 minutes
[INFO] starting epoch 21/25...took 0.9638 minutes
[INFO] starting epoch 22/25...took 0.9636 minutes
[INFO] starting epoch 23/25...took 0.9631 minutes
[INFO] starting epoch 24/25...took 0.9629 minutes
[INFO] starting epoch 25/25...took 0.9633 minutes
10000/10000 [==============================] - 1s 141us/sample - loss: 0.0441 - acc: 0.9927
[INFO] test accuracy: 0.9927
real 24m57.643s
user 72m57.355s
sys 115m42.568s
在我们使用我们的GradientTape定制训练程序训练它之后,我们的模型在我们的测试集上获得了 99.27%的准确度。
正如我在本教程前面提到的,本指南旨在温和地介绍如何使用GradientTape进行定制训练循环。
最起码,你需要定义一个训练程序的四个组成部分,包括模型架构、损失函数、优化器和阶跃函数——这些组成部分中的每一个都可能极其简单或极其复杂,但它们中的每一个都必须存在。
在未来的教程中,我将涵盖更多关于GradientTape的高级用例,但同时,如果你有兴趣了解更多关于GradientTape方法的知识,我建议你参考官方 TensorFlow 文档以及塞巴斯蒂安·蒂勒的这篇优秀文章。
摘要
在本教程中,您学习了如何使用 TensorFlow 的GradientTape函数,这是 TensorFlow 2.0 中的一种全新方法,用于实现自定义训练循环。
然后,我们使用自定义训练循环来训练 Keras 模型。
使用GradientTape可以让我们两全其美:
- 我们可以实施我们自己的定制培训程序
- 我们仍然可以享受易于使用的 Keras API
本教程涵盖了一个基本的定制训练循环——以后的教程将探索更高级的用例。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
通过 Python 使用 Tesseract OCR
原文:https://pyimagesearch.com/2017/07/10/using-tesseract-ocr-python/
最后更新于 2021 年 7 月 2 日。
在上周的博客文章中,我们学习了如何安装用于光学字符识别(OCR)的宇宙魔方二进制文件。
然后,我们应用 Tesseract 程序来测试和评估 OCR 引擎在一个非常小的示例图像集上的性能。
正如我们的结果所表明的,当前景文本从背景中(非常)清晰地分割出来时,Tesseract 效果最好。在实践中,保证这些类型的分段是极具挑战性的。因此,我们倾向于训练特定领域的图像分类器和检测器。
然而,在我们需要将 OCR 应用到我们自己的项目的情况下,我们理解如何通过 Python 编程语言访问 Tesseract OCR 是很重要的(假设我们可以获得 Tesseract 所需的良好、干净的分段)。
涉及 OCR 的示例项目可能包括构建一个移动文档扫描仪,您希望从中提取文本信息,或者您正在运行一项扫描纸质医疗记录的服务,您希望将信息放入符合 HIPA 标准的数据库中。
在这篇博文的剩余部分,我们将学习如何安装 Tesseract OCR + Python“绑定”,然后编写一个简单的 Python 脚本来调用这些绑定。本教程结束时,您将能够将图像中的文本转换为 Python 字符串数据类型。
要了解更多关于将 Tesseract 和 Python 与 OCR 一起使用的信息,请继续阅读。
- 【2021 年 7 月更新:添加了详细说明宇宙魔方版本如何对 OCR 准确性产生巨大影响的部分。
通过 Python 使用 Tesseract OCR
这篇博文分为三个部分。
首先,我们将学习如何安装pyTesseract 包,以便我们可以通过 Python 编程语言访问 tesserac。
接下来,我们将开发一个简单的 Python 脚本来加载图像,将其二进制化,并通过 Tesseract OCR 系统传递。
最后,我们将在一些示例图像上测试我们的 OCR 管道,并查看结果。
要下载这篇博文的源代码+示例图片,请务必使用下面的 “下载” 部分。
安装宇宙魔方+ Python“绑定”
让我们从安装pytesseract开始。为了安装pytesseract,我们将利用pip。
如果您正在使用一个虚拟环境(我强烈建议您这样做,以便您可以分离不同的项目),使用workon命令,后跟适当的虚拟环境名称。在这种情况下,我们的 virtualenv 被命名为cv。
$ workon cv
接下来让我们安装 Pillow ,一个对 Python 更友好的 PIL(一个依赖项)端口,后面是pytesseract。
$ pip install pillow
$ pip install pytesseract
注意 : pytesseract不提供真正的 Python 绑定。相反,它只是提供了一个到tesseract二进制文件的接口。如果你在 GitHub 上看一下这个项目,你会看到这个库正在将图像写到磁盘上的一个临时文件中,然后调用文件上的tesseract二进制文件并捕获结果输出。这确实有点粗糙,但它为我们完成了工作。
让我们通过查看一些将前景文本从背景中分割出来的代码,然后利用我们新安装的pytesseract来继续。
将 OCR 与 Tesseract 和 Python 结合使用
让我们首先创建一个名为ocr.py的新文件:
# import the necessary packages
from PIL import Image
import pytesseract
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-p", "--preprocess", type=str, default="thresh",
help="type of preprocessing to be done")
args = vars(ap.parse_args())
2-6 号线办理我们的进口业务。需要使用Image类,这样我们就可以以 PIL 格式从磁盘加载输入图像,这是使用pytesseract时的一个要求。
我们的命令行参数在第 9-14 行中解析。我们有两个命令行参数:
- 我们通过 OCR 系统发送的图像的路径。
--preprocess:预处理方法。对于本教程,该开关是可选的,可以接受两个值:thresh(阈值)或blur。
接下来,我们将加载图像,将其二进制化,并将其写入磁盘。
# load the example image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# check to see if we should apply thresholding to preprocess the
# image
if args["preprocess"] == "thresh":
gray = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# make a check to see if median blurring should be done to remove
# noise
elif args["preprocess"] == "blur":
gray = cv2.medianBlur(gray, 3)
# write the grayscale image to disk as a temporary file so we can
# apply OCR to it
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
首先,我们将--image从磁盘载入内存(第 17 行),然后将其转换为灰度(第 18 行)。
接下来,根据我们的命令行参数指定的预处理方法,我们将对图像进行阈值处理或模糊处理。这是您想要添加更多高级预处理方法的地方(取决于 OCR 的具体应用),这超出了本文的范围。
第 22-24 行上的if语句和主体执行一个阈值,以便将前景从背景中分割出来。我们同时使用了cv2.THRESH_BINARY和cv2.THRESH_OTSU标志。关于 Otsu 方法的详细信息,请参见官方 OpenCV 文档中的“Otsu 的二值化”。
我们将在后面的结果部分中看到,这种阈值方法对于读取覆盖在灰色形状上的深色文本很有用。
或者,可以应用模糊方法。当--preprocess标志设置为blur时,第 28-29 行执行中值模糊。应用中值模糊有助于减少椒盐噪声,再次使 Tesseract 更容易正确地对图像进行 OCR。
在对图像进行预处理之后,我们使用os.getpid来根据我们的 Python 脚本的进程 ID(第 33 行)导出一个临时图像filename。
使用pytesseract进行 OCR 之前的最后一步是将预处理后的图像gray写入磁盘,用上面的filename保存(第 34 行)。
我们最终可以使用 Tesseract Python“绑定”将 OCR 应用于我们的图像:
# load the image as a PIL/Pillow image, apply OCR, and then delete
# the temporary file
text = pytesseract.image_to_string(Image.open(filename))
os.remove(filename)
print(text)
# show the output images
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
使用第 38 行上的pytesseract.image_to_string,我们将图像的内容转换成我们想要的字符串text。请注意,我们传递了对驻留在磁盘上的临时映像文件的引用。
接下来是在第 39 行的一些清理,我们删除了临时文件。
第 40 行是我们将文本打印到终端的地方。在您自己的应用程序中,您可能希望在这里进行一些额外的处理,如 OCR 错误的拼写检查或自然语言处理,而不是像我们在本教程中所做的那样简单地将其打印到控制台。
最后,行 43 和 44 处理在单独的窗口中在屏幕上显示原始图像和预处理图像。第 34 行上的cv2.waitKey(0)表示我们应该等到键盘上的一个键被按下后才退出脚本。
让我们看看我们的手工作品。
Tesseract OCR 和 Python 结果
现在已经创建了ocr.py,是时候应用 Python + Tesseract 对一些示例输入图像执行 OCR 了。
在本节中,我们将尝试使用以下过程对三个样本图像进行 OCR:
- 首先,我们将按原样运行每个图像。
- 然后我们将通过
ocr.py运行每个图像(它在通过 Tesseract 发送之前执行预处理)。 - 最后,我们将比较这两种方法的结果,并记录任何错误。
我们的第一个例子是一个“嘈杂”的图像。该图像包含我们期望的前景黑色文本,背景部分是白色,部分散布着人工生成的圆形斑点。斑点充当我们简单算法的“干扰物”。

Figure 1: Our first example input for Optical Character Recognition using Python.
使用宇宙魔方二进制码,正如我们上周学过的,我们可以对原始的、未加工的图像应用 OCR:
$ tesseract images/example_01.png stdout
Noisy image
to test
Tesseract OCR
在这种情况下,Tesseract 表现良好,没有错误。
现在让我们确认一下我们新制作的脚本ocr.py,也可以工作:
$ python ocr.py --image images/example_01.png
Noisy image
to test
Tesseract OCR

Figure 2: Applying image preprocessing for OCR with Python.
从这张截图中可以看到,经过阈值处理的图像非常清晰,背景已经被移除。我们的脚本正确地将图像内容打印到控制台。
接下来,让我们在背景中带有“盐和胡椒”噪声的图像上测试 Tesseract 和我们的预处理脚本:

Figure 3: An example input image containing noise. This image will “confuse” our OCR algorithm, leading to incorrect OCR results.
我们可以看到下面的tesseract二进制输出:
$ tesseract images/example_02.png stdout
Detected 32 diacritics
" Tesséra‘c't Will
Fail With Noisy
Backgrounds
不幸的是,Tesseract 没有成功地对图像中的文本进行 OCR。
然而,通过使用ocr.py中的blur预处理方法,我们可以获得更好的结果:
$ python ocr.py --image images/example_02.png --preprocess blur
Tesseract Will
Fail With Noisy
Backgrounds

Figure 4: Applying image preprocessing with Python and OpenCV to improve OCR results.
成功!我们的模糊预处理步骤使 Tesseract 能够正确地进行 OCR 并输出我们想要的文本。
最后,让我们尝试另一个图像,这个有更多的文字:

Figure 5: Another example input to our Tesseract + Python OCR system.
上图是我的书【先决条件】**实用 Python 和 OpenCV 中的截图——我们来看看宇宙魔方二进制是如何处理这张图的:
$ tesseract images/example_03.png stdout
PREREQUISITES
In order In make the rnosi of this, you will need (a have
a little bit of pregrarrmung experience. All examples in this
book are in the Python programming language. Familiarity
with Pyihon or other scriphng languages is suggesied, but
mm required.
You'll also need (a know some basic mathematics. This
book is handson and example driven: leis of examples and
lots of code, so even if your math skills are noi up to par.
do noi worry! The examples are very damned and heavily
documented (a help yuu follaw along.
接着用ocr.py测试图像:
$ python ocr.py --image images/example_03.png
PREREQUISITES
Lu order to make the most ol this, you will need to have
a little bit ol programming experience. All examples in this
book are in the Python programming language. Familiarity
with Python or other scripting languages is suggested, but
not requixed.
You’ll also need to know some basic mathematics. This
book is handson and example driven: lots of examples and
lots ol code, so even ii your math skills are not up to par,
do not worry! The examples are very detailed and heavily
documented to help you tollow along.
注意两个输出中的拼写错误,包括但不限于“中的“”、“、、【必需】、、、【编程】、、、【跟随】、。
这两者的输出不匹配;然而,有趣的是,预处理版本只有 8 个单词错误,而非预处理图像有 17 个单词错误(两倍多的错误)。我们的预处理甚至在干净的背景上也有帮助!
Python + Tesseract 在这里做了合理的工作,但是我们再一次展示了库作为现成分类器的局限性。
对于 OCR,我们可能会获得好的或可接受的结果,但是最佳准确度将来自于在真实世界图像中出现的特定字体集上训练自定义字符分类器。
不要让 Tesseract OCR 的结果让你气馁——简单地管理你的期望,并对 Tesseract 的性能持现实态度。没有一个真正的“现成的”OCR 系统会给你完美的结果(肯定会有一些错误)。
注意:如果你的文本被旋转,你可能希望做额外的预处理,就像这篇关于纠正文本倾斜的博文中所做的那样。否则,如果您对构建一个移动文档扫描仪感兴趣,您现在已经有一个相当好的 OCR 系统可以集成到其中。
提示:通过升级您的宇宙魔方版本 来提高 OCR 准确度
确保使用tesseract -v命令:检查你机器上安装的宇宙魔方版本
$ tesseract -v
tesseract 4.1.1
如果您在输出中看到 Tesseract v4 或更高版本,那么恭喜您,您使用的是长短期记忆(LSTM) OCR 模型,它的 比之前版本的 Tesseract 更加精确 !
如果您看到任何版本比 v4 少,那么您应该升级您的宇宙魔方安装——使用宇宙魔方 v4 LSTM 引擎将导致更准确的 OCR 结果。
摘要
在今天的博文中,我们学习了如何使用 Python 编程语言应用 Tesseract OCR 引擎。这使我们能够在 Python 脚本的中应用来自的 OCR 算法。
最大的缺点是宇宙魔方本身的局限性。当前景文本从背景中出现极其清晰的分割时,镶嵌效果最佳。
**此外,这些分割需要尽可能高的分辨率(DPI)和输入图像中的字符在分割后不能出现“像素化”。如果字符确实出现像素化,那么 Tesseract 将很难正确识别文本——我们甚至在应用理想条件下捕获的图像时也发现了这一点(PDF 截图)。
OCR 虽然不再是一项新技术,但在计算机视觉文献中仍然是一个活跃的研究领域尤其是在将 OCR 应用于现实世界中不受约束的图像时。深度学习和卷积神经网络(CNN)当然能够让我们获得更高的准确性,但我们距离看到“近乎完美”的 OCR 系统还有很长的路要走。此外,由于 OCR 在许多领域都有许多应用,因此一些用于 OCR 的最佳算法是商业化的,需要获得许可才能在您自己的项目中使用。
我给读者的主要建议是,在将 OCR 应用于他们自己的项目时,首先尝试 Tesseract,如果结果不理想,就继续使用 Google Vision API。
如果宇宙魔方和谷歌视觉 API 都没有获得合理的准确性,你可能想要重新评估你的数据集,并决定是否值得训练你自己的自定义字符分类器——如果你的数据集有噪音和/或包含你希望检测和识别的非常特定的字体,这尤其是正确。特定字体的示例包括信用卡上的数字、支票底部的帐户和银行编号,或者图形设计中使用的风格化文本。
我希望你喜欢这一系列关于使用 Python 和 OpenCV 进行光学字符识别(OCR)的博文!
如果 PyImageSearch 上有新的博客文章发布,请务必在下面的表格中输入您的电子邮件地址!**
基于 Keras 和深度学习的视频分类
原文:https://pyimagesearch.com/2019/07/15/video-classification-with-keras-and-deep-learning/
在本教程中,您将学习如何使用 Keras、Python 和深度学习来执行视频分类。
具体来说,您将学习:
- 视频分类和标准图像分类的区别
- 如何使用 Keras 训练用于图像分类的卷积神经网络
- 如何获取 CNN 然后用它进行视频分类
- 如何使用滚动预测平均来减少结果中的“闪烁”
本教程将介绍在时间性质上使用深度学习的概念,为我们讨论长短期记忆网络(LSTMs)以及最终的人类活动识别铺平道路。
要学习如何使用 Keras 和深度学习进行视频分类,继续阅读!
基于 Keras 和深度学习的视频分类
2020-06-12 更新:此博文现已兼容 TensorFlow 2+!
视频可以理解为一系列单独的图像;因此,许多深度学习实践者会很快将视频分类视为执行总共 N 次图像分类,其中 N 是视频中的总帧数。
然而,这种方法有一个问题。
视频分类比简单的图像分类更—对于视频,我们通常可以假设视频中的后续帧相对于它们的语义内容相关。
如果我们能够利用视频的时间特性,我们可以改善我们实际的视频分类结果。
长短期记忆(LSTMs)和递归神经网络(RNNs)等神经网络架构适用于时间序列数据,这是我们将在后面的教程中讨论的两个主题,但在某些情况下,它们可能有些过头了。正如你可以想象的那样,当训练成千上万的视频文件时,他们也是资源饥渴和耗时的。
相反,在一些应用中,你需要的只是预测的滚动平均。
在本教程的剩余部分,你将学习如何为图像分类(特别是体育分类)训练一个 CNN,然后通过使用滚动平均将它变成一个更准确的视频分类器*。
视频分类和图像分类有什么不同?
在执行图像分类时,我们:
- 给我们的 CNN 输入一张图片
- 从 CNN 获得预测
- 选择对应概率最大的标签
由于视频只是一系列帧,一种简单的视频分类方法是:
- 循环播放视频文件中的所有帧
- 对于每个帧,将该帧通过 CNN
- 将每一帧单独分类和相互独立
- 选择对应概率最大的标签
- 标记帧并将输出帧写入磁盘
然而,这种方法有一个问题——如果你曾经试图将简单的图像分类应用于视频分类,你可能会遇到一种“预测闪烁”,如本节顶部的视频所示。请注意,在这个可视化中,我们看到 CNN 在两个预测之间切换:【足球】和正确的标签【举重】。
这个视频显然是关于举重的,我们希望我们的整个视频都被贴上举重的标签——但是我们如何防止 CNN 在这两个标签之间“闪烁”?
一个简单而优雅的解决方案是利用滚动预测平均值。
我们的算法现在变成了:
- 循环播放视频文件中的所有帧
- 对于每个帧,将该帧通过 CNN
- 从 CNN 获得预测
- 维护最近的 K 个预测的列表
- 计算最后 K 个预测的平均值,并选择具有最大相应概率的标签
- 标记帧并将输出帧写入磁盘
这个算法的结果可以在这篇文章顶部的视频中看到——注意预测闪烁是如何消失的,整个视频剪辑都被正确标记了!
在本教程的剩余部分,您将学习如何使用 Keras 实现这种视频分类算法。
运动分类数据集

Figure 1: A sports dataset curated by GitHub user “anubhavmaity” using Google Image Search. We will use this image dataset for video classification with Keras. (image source)
我们今天将在这里使用的数据集用于运动/活动分类。这个数据集是由阿努巴夫·梅蒂通过从谷歌图片 ( 你也可以使用必应)下载照片整理出来的,分为以下几类:
为了节省时间和计算资源,并演示实际的视频分类算法(本教程的实际要点),我们将在体育类型数据集的子集上进行训练:
- 足球(即英式足球): 799 张图片
- 网球: 718 图片
- 举重: 577 图片
让我们开始下载我们的数据集吧!
下载运动分类数据集
继续从 “下载” 链接下载今天这篇博文的源代码。
提取。压缩并从您的终端导航到项目文件夹:
$ unzip keras-video-classification.zip
$ cd keras-video-classification
我已经决定在Sports-Type-Classifier/data/目录中用今天的 【下载】 包含数据集的子集,因为 Anubhav Maity 的原始数据集在 GitHub 上不再可用(一个几乎相同的体育数据集在这里可用)。
我们今天将使用的数据位于以下路径:
$ cd keras-video-classification
$ ls Sports-Type-Classifier/data | grep -Ev "urls|models|csv|pkl"
football
tennis
weight_lifting
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
现在我们已经有了项目文件夹和 Anubhav Maity 的回购,让我们回顾一下我们的项目结构:
$ tree --dirsfirst --filelimit 50
.
├── Sports-Type-Classifier
│ ├── data
│ │ ├── football [799 entries]
│ │ ├── tennis [718 entries]
│ │ └── weight_lifting [577 entries]
├── example_clips
│ ├── lifting.mp4
│ ├── soccer.mp4
│ └── tennis.mp4
├── model
│ ├── activity.model
│ └── lb.pickle
├── output
├── plot.png
├── predict_video.py
└── train.py
8 directories, 8 files
我们的训练图像数据在Sports-Type-Classifier/data/目录下,按类组织。
我从 YouTube 上提取了三个example_clips/来测试我们的模型。三个剪辑的演职员表位于“Keras 视频分类结果”部分的底部。
我们的分类器文件在model/目录中。包括activity.model(训练好的 Keras 模型)和lb.pickle(我们的标签二值化器)。
一个空的output/文件夹是我们存储视频分类结果的地方。
在今天的教程中,我们将讨论两个 Python 脚本:
train.py:一个 Keras 训练脚本,抓取我们关心的数据集类图像,加载 ResNet50 CNN,应用ImageNet 权重的转移学习/微调来训练我们的模型。训练脚本生成/输出三个文件:model/activity.model:基于 ResNet50 的用于识别运动的微调分类器。model/lb.pickle:一个序列化的标签二进制化器,包含我们唯一的类标签。plot.png:准确度/损失训练历史图。
predict_video.py:从example_clips/加载一个输入视频,并使用当今的滚动平均法对视频进行分类。
实施我们的 Keras 培训脚本
让我们继续执行用于训练 Keras CNN 识别每项体育活动的训练脚本。
打开train.py文件并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import pickle
import cv2
import os
在第 2-24 行,我们导入必要的包来训练我们的分类器:
matplotlib:用于绘图。第 3 行设置后端,这样我们可以将我们的训练图输出到一个. png 图像文件。tensorflow.keras:用于深度学习。也就是说,我们将使用ResNet50CNN。我们还将和ImageDataGenerator一起工作,你可以在上周的教程中读到。- 从 scikit-learn 中,我们将使用他们实现的一个
LabelBinarizer对我们的类标签进行一次性编码。train_test_split函数将把我们的数据集分割成训练和测试两部分。我们还将以传统格式打印一个classification_report。 paths:包含列出给定路径下所有图像文件的便捷函数。从那里我们可以将我们的图像加载到内存中。numpy: Python 的事实上的数值加工库。argparse:解析命令行参数。pickle:用于将我们的标签二进制化器序列化到磁盘。cv2: OpenCV。- 操作系统模块将被用来确保我们获得正确的文件/路径分隔符,这是依赖于操作系统的。
现在让我们继续解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to output serialized model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-e", "--epochs", type=int, default=25,
help="# of epochs to train our network for")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们的脚本接受五个命令行参数,其中前三个是必需的:
--dataset:输入数据集的路径。- 我们输出的 Keras 模型文件的路径。
--label-bin:我们输出标签二进制化器 pickle 文件的路径。--epochs:训练我们的网络多少个纪元——默认情况下,我们将训练25个纪元,但正如我将在本教程稍后展示的那样,50个纪元可以带来更好的结果。--plot:我们的输出绘图图像文件的路径——默认情况下,它将被命名为plot.png,并放置在与该训练脚本相同的目录中。
有了解析的命令行参数,让我们继续初始化我们的LABELS并加载我们的data:
# initialize the set of labels from the spots activity dataset we are
# going to train our network on
LABELS = set(["weight_lifting", "tennis", "football"])
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# if the label of the current image is not part of of the labels
# are interested in, then ignore the image
if label not in LABELS:
continue
# load the image, convert it to RGB channel ordering, and resize
# it to be a fixed 224x224 pixels, ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
第 42 行包含类LABELS的集合,我们的数据集将由它组成。不在这个集合中的所有标签将被排除成为我们数据集的一部分。为了节省训练时间,我们的数据集将只包含举重、和足球/英式足球。通过对LABELS集合进行修改,您可以随意使用其他类。
所有数据集imagePaths都是通过线 47 和args["dataset"]中包含的值(来自我们的命令行参数)收集的。
第 48 和 49 行初始化我们的data和labels列表。
从那里,我们将开始循环第 52 条线上的所有imagePaths。
在循环中,首先我们从imagePath ( 第 54 行)中提取类label。第 58 行和第 59 行然后忽略任何不在LABELS集合中的label。
第 63-65 行加载并预处理一个image。预处理包括交换颜色通道以兼容 OpenCV 和 Keras,以及调整大小为 224×224 T4 像素。点击阅读更多关于为 CNN 调整图像大小的信息。要了解更多关于预处理的重要性,请务必参考 使用 Python 进行计算机视觉的深度学习 。
然后将image和label添加到data和labels列表中,分别在行 68 和 69 上。
接下来,我们将对我们的labels进行一次性编码,并对我们的data进行分区:
# convert the data and labels to NumPy arrays
data = np.array(data)
labels = np.array(labels)
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, stratify=labels, random_state=42)
第 72 行和第 73 行将我们的data和labels列表转换成 NumPy 数组。
labels的一次加热编码发生在行 76 和 77 上。一键编码是一种通过二进制数组元素标记活动类标签的方法。例如,“足球”可能是array([1, 0, 0]),而“举重”可能是array([0, 0, 1])。请注意,在任何给定时间,只有一个类是“热门”的。
第 81 行和第 82 行然后将我们的data分割成训练和测试部分,使用 75%的数据进行训练,剩下的 25%用于测试。
让我们初始化我们的数据扩充对象:
# initialize the training data augmentation object
trainAug = ImageDataGenerator(
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# initialize the validation/testing data augmentation object (which
# we'll be adding mean subtraction to)
valAug = ImageDataGenerator()
# define the ImageNet mean subtraction (in RGB order) and set the
# the mean subtraction value for each of the data augmentation
# objects
mean = np.array([123.68, 116.779, 103.939], dtype="float32")
trainAug.mean = mean
valAug.mean = mean
第 85-96 行初始化两个数据扩充对象——一个用于训练,一个用于验证。在计算机视觉的深度学习中,几乎总是建议使用数据增强来提高模型的泛化能力。
trainAug对象对我们的数据进行随机旋转、缩放、移动、剪切和翻转。你可以在这里阅读更多关于ImageDataGenerator和fit的内容。正如我们上周所强调的,请记住,使用 Keras 的,图像将动态生成(它不是加法运算)。
对验证数据(valAug)不进行增强,但我们将进行均值减法。
在线 101 上设置mean像素值。从那里,行 102 和 103 为trainAug和valAug设置mean属性,以便在训练/评估期间生成图像时进行均值相减。
现在我们将执行我称之为“网络手术”的操作,作为微调的一部分:
# load the ResNet-50 network, ensuring the head FC layer sets are left
# off
baseModel = ResNet50(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(512, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(len(lb.classes_), activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the training process
for layer in baseModel.layers:
layer.trainable = False
第 107 和 108 行装载用 ImageNet 重量预先训练的ResNet50,同时切断网络的头部。
从那里,线 112-121 组装一个新的headModel并将其缝合到baseModel上。
我们现在将冻结baseModel,以便通过反向传播(行 125 和 126 )来训练 而不是 。
让我们继续编译+训练我们的model:
# compile our model (this needs to be done after our setting our
# layers to being non-trainable)
print("[INFO] compiling model...")
opt = SGD(lr=1e-4, momentum=0.9, decay=1e-4 / args["epochs"])
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network for a few epochs (all other layers
# are frozen) -- this will allow the new FC layers to start to become
# initialized with actual "learned" values versus pure random
print("[INFO] training head...")
H = model.fit(
x=trainAug.flow(trainX, trainY, batch_size=32),
steps_per_epoch=len(trainX) // 32,
validation_data=valAug.flow(testX, testY),
validation_steps=len(testX) // 32,
epochs=args["epochs"])
2020-06-12 更新: 以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
第 131-133 行 compile我们的model用随机梯度下降(SGD)优化器,初始学习速率为1e-4,学习速率衰减。我们使用"categorical_crossentropy"损失进行多类训练。如果您只处理两个类,请确保使用"binary_crossentropy" loss。
对我们的model ( 第 139-144 行)上的fit_generator函数的调用用数据扩充和均值减法训练我们的网络。
请记住,我们的baseModel是冻结的,我们只是在训练头部。这就是所谓的“微调”。要快速了解微调,请务必阅读我的前一篇文章。为了更深入地进行微调,请使用 Python 选择从业者捆绑 用于计算机视觉的副本。
我们将从评估我们的网络和绘制培训历史开始总结:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX.astype("float32"), batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = args["epochs"]
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-12 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
在我们在测试集上评估我们的网络并打印出classification_report ( 第 148-150 行)之后,我们继续用 matplotlib ( 第 153-163 行)绘制我们的精度/损耗曲线。该图通过线 164 保存到磁盘。
总结将序列化我们的model和标签二进制化器(lb)到磁盘:
# serialize the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
# serialize the label binarizer to disk
f = open(args["label_bin"], "wb")
f.write(pickle.dumps(lb))
f.close()
2020-06-12 更新:注意,对于 TensorFlow 2.0+我们建议明确设置save_format="h5" (HDF5 格式)。
168 线拯救我们微调过的 Keras model。
最后,第 171-173 行以 Python 的 pickle 格式序列化并存储我们的标签二进制化器。
培训结果
在我们能够(1)用我们的 CNN 对视频中的帧进行分类,然后(2)利用我们的 CNN 进行视频分类之前,我们首先需要训练模型。
确保您已经使用本教程的 【下载】 部分将源代码下载到该图像(以及下载运动类型数据集)。
从那里,打开一个终端并执行以下命令:
$ python train.py --dataset Sports-Type-Classifier/data --model model/activity.model \
--label-bin output/lb.pickle --epochs 50
[INFO] loading images...
[INFO] compiling model...
[INFO] training head...
Epoch 1/50
48/48 [==============================] - 10s 209ms/step - loss: 1.4184 - accuracy: 0.4421 - val_loss: 0.7866 - val_accuracy: 0.6719
Epoch 2/50
48/48 [==============================] - 10s 198ms/step - loss: 0.9002 - accuracy: 0.6086 - val_loss: 0.5476 - val_accuracy: 0.7832
Epoch 3/50
48/48 [==============================] - 9s 198ms/step - loss: 0.7188 - accuracy: 0.7020 - val_loss: 0.4690 - val_accuracy: 0.8105
Epoch 4/50
48/48 [==============================] - 10s 203ms/step - loss: 0.6421 - accuracy: 0.7375 - val_loss: 0.3986 - val_accuracy: 0.8516
Epoch 5/50
48/48 [==============================] - 10s 200ms/step - loss: 0.5496 - accuracy: 0.7770 - val_loss: 0.3599 - val_accuracy: 0.8652
...
Epoch 46/50
48/48 [==============================] - 9s 192ms/step - loss: 0.2066 - accuracy: 0.9217 - val_loss: 0.1618 - val_accuracy: 0.9336
Epoch 47/50
48/48 [==============================] - 9s 193ms/step - loss: 0.2064 - accuracy: 0.9204 - val_loss: 0.1622 - val_accuracy: 0.9355
Epoch 48/50
48/48 [==============================] - 9s 192ms/step - loss: 0.2092 - accuracy: 0.9217 - val_loss: 0.1604 - val_accuracy: 0.9375
Epoch 49/50
48/48 [==============================] - 9s 195ms/step - loss: 0.1935 - accuracy: 0.9290 - val_loss: 0.1620 - val_accuracy: 0.9375
Epoch 50/50
48/48 [==============================] - 9s 192ms/step - loss: 0.2109 - accuracy: 0.9164 - val_loss: 0.1561 - val_accuracy: 0.9395
[INFO] evaluating network...
precision recall f1-score support
football 0.93 0.96 0.95 196
tennis 0.92 0.92 0.92 179
weight_lifting 0.97 0.92 0.95 143
accuracy 0.94 518
macro avg 0.94 0.94 0.94 518
weighted avg 0.94 0.94 0.94 518
[INFO] serializing network...
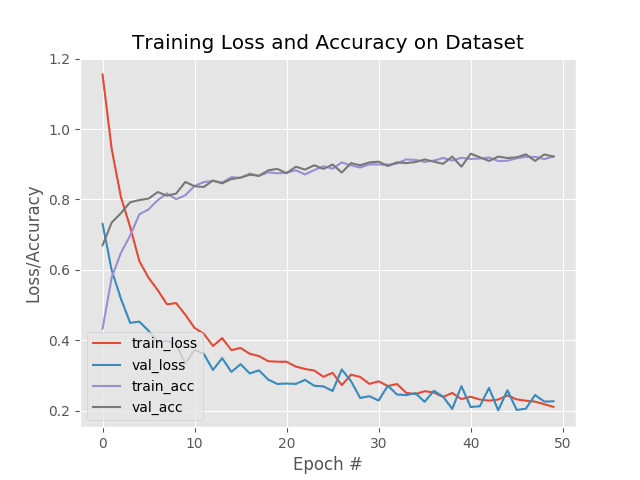
Figure 2: Sports video classification with Keras accuracy/loss training history plot.
如你所见,在体育数据集上对 ResNet50 进行微调后,我们获得了 ~94%的准确率。
检查我们的模型目录,我们可以看到微调模型和标签二进制化器已经序列化到磁盘:
$ ls model/
activity.model lb.pickle
然后,我们将在下一节中使用这些文件来实现滚动预测平均。
基于 Keras 和滚动预测平均的视频分类
我们现在已经准备好通过滚动预测精度用 Keras 实现视频分类了!
为了创建这个脚本,我们将利用视频的时间特性,特别是视频中的后续帧将具有相似语义内容的假设。
通过执行滚动预测准确性,我们将能够“平滑”预测并避免“预测闪烁”。
让我们开始吧——打开predict_video.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import load_model
from collections import deque
import numpy as np
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained serialized model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--input", required=True,
help="path to our input video")
ap.add_argument("-o", "--output", required=True,
help="path to our output video")
ap.add_argument("-s", "--size", type=int, default=128,
help="size of queue for averaging")
args = vars(ap.parse_args())
2-7 线装载必要的包和模块。特别是,我们将使用 Python 的collections模块中的deque来辅助我们的滚动平均算法。
然后,行 10-21 解析五个命令行参数,其中四个是必需的:
--model:从我们之前的训练步骤生成的输入模型的路径。--label-bin:前面脚本生成的序列化 pickle 格式标签二进制化器的路径。--input:用于视频分类的输入视频的路径。--output:我们将保存到磁盘的输出视频的路径。--size:滚动平均队列的最大长度(默认为128)。对于我们后面的一些示例结果,我们将把大小设置为1,这样就不会执行平均。
有了导入和命令行args,我们现在准备执行初始化:
# load the trained model and label binarizer from disk
print("[INFO] loading model and label binarizer...")
model = load_model(args["model"])
lb = pickle.loads(open(args["label_bin"], "rb").read())
# initialize the image mean for mean subtraction along with the
# predictions queue
mean = np.array([123.68, 116.779, 103.939][::1], dtype="float32")
Q = deque(maxlen=args["size"])
线 25 和 26 装载我们的model和标签二进制化器。
第 30 行然后设置我们的mean减数值。
我们将使用一个deque来实现我们的滚动预测平均。我们的队列Q,用等于args["size"]值的maxlen初始化(行 31 )。
让我们初始化我们的cv2.VideoCapture对象,并开始循环视频帧:
# initialize the video stream, pointer to output video file, and
# frame dimensions
vs = cv2.VideoCapture(args["input"])
writer = None
(W, H) = (None, None)
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# if the frame dimensions are empty, grab them
if W is None or H is None:
(H, W) = frame.shape[:2]
第 35 行抓取了一个指向我们输入视频文件流的指针。我们使用 OpenCV 中的VideoCapture类从视频流中读取帧。
然后我们的视频writer和尺寸通过线 36 和 37 被初始化为None。
第 40 行开始我们的视频分类while循环。
首先,我们抓一个frame ( 第 42-47 行)。如果frame是not grabbed,那么我们已经到达视频的结尾,此时我们将break从循环中退出。
第 50-51 行然后根据需要设置我们的框架尺寸。
让我们预处理一下我们的frame:
# clone the output frame, then convert it from BGR to RGB
# ordering, resize the frame to a fixed 224x224, and then
# perform mean subtraction
output = frame.copy()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (224, 224)).astype("float32")
frame -= mean
我们框架的一个copy是为了output的目的(线 56 )。
然后,我们使用与训练脚本相同的步骤对frame进行预处理,包括:
- 交换颜色通道(第 57 行)。
- 调整到 224×224 px ( 线 58 )。
- 均值减法(第 59 行)。
帧分类推断和滚动预测平均接下来:
# make predictions on the frame and then update the predictions
# queue
preds = model.predict(np.expand_dims(frame, axis=0))[0]
Q.append(preds)
# perform prediction averaging over the current history of
# previous predictions
results = np.array(Q).mean(axis=0)
i = np.argmax(results)
label = lb.classes_[i]
第 63 行在当前帧上进行预测。预测结果通过线 64** 加到QT6。**
从那里,行 68-70 对Q 历史执行预测平均,产生滚动平均的等级label。分解后,这些线在平均预测中找到对应概率最大的标签。
现在我们已经得到了结果label,让我们注释我们的output帧并将其写入磁盘:
# draw the activity on the output frame
text = "activity: {}".format(label)
cv2.putText(output, text, (35, 50), cv2.FONT_HERSHEY_SIMPLEX,
1.25, (0, 255, 0), 5)
# check if the video writer is None
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(W, H), True)
# write the output frame to disk
writer.write(output)
# show the output image
cv2.imshow("Output", output)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# release the file pointers
print("[INFO] cleaning up...")
writer.release()
vs.release()
第 73-75 行在output帧上绘制预测。
第 78-82 行如有必要,初始化视频writer。output帧被写入文件(第 85 行)。点击阅读更多关于使用 OpenCV 写入视频文件的信息。
通过线 88-93,output也显示在屏幕上,直到按下q键(或者直到如上所述到达视频文件的结尾)。
最后,我们将执行清理(行 97 和 98 )。
Keras 视频分类结果
现在我们已经用 Keras 实现了我们的视频分类器,让我们把它投入工作。
确保您已经使用本教程的 【下载】 部分下载了源代码。
接下来,让我们将视频分类应用于一个“网球”剪辑,但是让我们将队列的--size设置为1,将视频分类简单地转换为标准图像分类:
$ python predict_video.py --model model/activity.model \
--label-bin model/lb.pickle \
--input example_clips/tennis.mp4 \
--output output/tennis_1frame.avi \
--size 1
Using TensorFlow backend.
[INFO] loading model and label binarizer...
[INFO] cleaning up...
如你所见,有相当多的标签闪烁——我们的 CNN 认为某些帧是“网球”(正确),而其他帧是“足球”(不正确)。
现在让我们使用128的默认队列--size,从而利用我们的预测平均算法来平滑结果:
$ python predict_video.py --model model/activity.model \
--label-bin model/lb.pickle \
--input example_clips/tennis.mp4 \
--output output/tennis_128frames_smoothened.avi \
--size 128
Using TensorFlow backend.
[INFO] loading model and label binarizer...
[INFO] cleaning up...
请注意我们是如何正确地将该视频标记为“网球”的!
让我们尝试一个不同的例子,这个“举重”的例子。同样,我们将从使用1的队列--size开始:
$ python predict_video.py --model model/activity.model \
--label-bin model/lb.pickle \
--input example_clips/lifting.mp4 \
--output output/lifting_1frame.avi \
--size 1
Using TensorFlow backend.
[INFO] loading model and label binarizer...
[INFO] cleaning up...
我们再次遭遇预测闪烁。
然而,如果我们使用128的帧--size,我们的预测平均将获得期望的结果:
$ python predict_video.py --model model/activity.model \
--label-bin model/lb.pickle \
--input example_clips/lifting.mp4 \
--output output/lifting_128frames_smoothened.avi \
--size 128
Using TensorFlow backend.
[INFO] loading model and label binarizer...
[INFO] cleaning up...
让我们试试最后一个例子:
$ python predict_video.py --model model/activity.model \
--label-bin model/lb.pickle \
--input example_clips/soccer.mp4 \
--output output/soccer_128frames_smoothened.avi \
--size 128
Using TensorFlow backend.
[INFO] loading model and label binarizer...
[INFO] cleaning up...
```*
# 可视化日志,我调试 OpenCV 和 Python 应用程序的新宠工具
> 原文:<https://pyimagesearch.com/2014/12/22/visual-logging-new-favorite-tool-debugging-opencv-python-apps/>
[](https://github.com/dchaplinsky/visual-logging)
几个月前,我的朋友 Dmitry Chaplinsky 给我发了一封电子邮件,告诉我一个我必须去看看的新图书馆。我总是对新的计算机视觉和图像处理软件包感到好奇,因此产生了兴趣。
你看,德米特里的工作包括应用 Python 和 OpenCV 对粉碎的文件进行标记和分类,以期揭露乌克兰的腐败。他的图书馆[unthred](https://github.com/dchaplinsky/unshred),做了很多脏活累活。
但是为了构建 unshred,他需要一种简单的方法来调试 OpenCV 应用程序。
就像我们使用`print`语句调试简单的 Python 应用程序一样,我们使用 OpenCV `cv2.imshow`和`cv2.waitKey`函数在屏幕上直观地显示我们的图像,以便我们可以调试它们。
老实说,这真的很让人头疼,在你意识到之前,你的管道已经完全被`cv2.imshow`电话填满了。
为了修复这个`cv2.imshow`地狱,Dmitry 创建了[视觉记录](https://github.com/dchaplinsky/visual-logging),一个让你调试并直接记录你的 OpenCV 管道到文件的库。它使用一个漂亮的 HTML 结构对其进行格式化。
几个月前,我甚至不知道有这样的工具存在——现在我正在将它纳入我的日常计算机视觉工作流程。
因此,如果您对如何(更好地)调试和记录 OpenCV + Python 应用程序感兴趣,请继续阅读。你不会想错过这个令人敬畏的图书馆。
***再次感谢德米特里!***
**OpenCV 和 Python 版本:**
这个例子将运行在 **Python 2.7** 和 **OpenCV 2.4.X/OpenCV 3.0+** 上。
# 可视化日志,我调试 OpenCV 和 Python 应用程序的新宠工具
在撰写本文时,[视觉记录](https://github.com/dchaplinsky/visual-logging)文档声称这个包是`pip`可安装的:
```py
$ pip install visual-logging
然而,当我执行上面的命令时,我得到了可怕的“没有为可视化日志找到任何发行版”。我假设这个包还没有向 PyPi 注册。
不管怎样,这没什么大不了的。我们可以简单地从 GitHub repo 克隆并以“老式”的方式安装:
(cv)annalee:VisualLogging adrianrosebrock$ git clone https://github.com/dchaplinsky/visual-logging.git
Cloning into 'visual-logging'...
remote: Counting objects: 137, done.
remote: Total 137 (delta 0), reused 0 (delta 0)
Receiving objects: 100% (137/137), 361.23 KiB | 0 bytes/s, done.
Resolving deltas: 100% (70/70), done.
Checking connectivity... done.
(cv)annalee:VisualLogging adrianrosebrock$ cd visual-logging/
(cv)annalee:visual-logging adrianrosebrock$ python setup.py install
现在我们已经安装了visual-logging,让我们创建一个简单的脚本来演示如何使用visual-logging来帮助我们可视化我们的管道:
# import the necessary packages
from logging import FileHandler
from vlogging import VisualRecord
import logging
import cv2
# open the logging file
logger = logging.getLogger("visual_logging_example")
fh = FileHandler("demo.html", mode = "w")
# set the logger attributes
logger.setLevel(logging.DEBUG)
logger.addHandler(fh)
# load our example image and convert it to grayscale
image = cv2.imread("lex.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# loop over some varying sigma sizes
for s in xrange(3, 11, 2):
# blur the image and detect edges
blurred = cv2.GaussianBlur(image, (s, s), 0)
edged = cv2.Canny(blurred, 75, 200)
logger.debug(VisualRecord(("Detected edges using sigma = %d" % (s)),
[blurred, edged], fmt = "png"))
这里的代码相当简单。在第 2-5 行上,我们导入我们需要的包。
然后,我们在第 8-13 行中设置我们的日志处理程序和属性。
我们在的第 16 行加载一个莱克斯·墨菲(来自侏罗纪公园,duh)的示例图像,并在的第 17 行将图像转换成灰度。
第 20-25 行测试我们的视觉记录器。我们将使用越来越大的西格玛尺寸来逐渐模糊图像。然后我们检测模糊图像中的边缘。
通常,要查看我们的模糊和边缘检测的输出,我们必须调用cv2.imshow和cv2.waitKey。
但是那些日子已经过去了。
相反,我们将创建一个VisualRecord并将高斯模糊和边缘贴图记录到文件中。这将允许我们调试我们的管道,并轻松地查看我们的结果。
说到结果,执行以下命令来生成可视化日志文件:
$ python visual_logging_example.py
假设脚本执行无误,那么在当前工作目录中应该有一个名为demo.html的新文件。
下面是我的demo.html文件的截图:

Figure 1: Example of using visual-logger to log and debug OpenCV + Python computer vision pipelines.
从这个例子中我们可以看出,随着高斯西格玛的大小增加,图像变得越来越模糊。随着图像变得越来越模糊,检测到的边缘越来越少。
当然,这是调试和记录 OpenCV + Python 应用程序的一个相当简单的例子。但是我想你明白了——用cv2.imshow和cv2.waitKey语句堵塞代码的日子已经一去不复返了!
相反,只需使用视觉记录——你的生活会简单得多。
摘要
在这篇博文中,我们探索了可视化日志,这是我调试 Python + OpenCV 应用程序的新宠工具。
到目前为止,调试 OpenCV 应用程序一直是一堆cv2.imshow和cv2.waitKey调用。所有这些函数调用都很难管理,对于调试来说更是如此。你将会对你的计算机视觉管道的每一次迭代进行一次又一次的截图。
但是现在我们有了更好的方法。我们可以利用 Dmitry Chaplinsky 的可视化日志包来帮助我们轻松地调试和记录 OpenCV 应用程序。
感谢 Dmitry 提供了这么棒的图书馆!
使用 Keras 和 TensorFlow 可视化网络架构
原文:https://pyimagesearch.com/2021/05/22/visualizing-network-architectures-using-keras-and-tensorflow/
我们尚未讨论的一个概念是架构可视化,即构建网络中节点和相关连接的图并将该图保存到磁盘作为图像(即,PNG、JPG 等)的过程。).图中的节点表示层,而节点之间的连接表示网络中的数据流。
这些图表通常包括每个图层的以下组成部分:
- 输入音量大小。
- 输出音量大小。
- 以及可选的层的名称。
我们通常在以下情况下使用网络体系结构可视化:( 1)调试我们自己的定制网络体系结构;( 2)发布,在这种情况下,体系结构的可视化比包含实际源代码或试图构建表格来传达相同信息更容易理解。在本教程的剩余部分,您将学习如何使用 Keras 构建网络架构可视化图形,然后将图形作为实际图像序列化到磁盘。
要了解如何使用 Keras 和 TensorFlow** ,可视化网络架构,请继续阅读。**
建筑可视化的重要性
可视化一个模型的架构是一个关键的调试工具,尤其是如果你是:
- 在出版物中实现体系结构,但不熟悉它。
- 实现您自己的定制网络架构。
简而言之,网络可视化验证了我们的假设,即我们的代码正在正确地构建我们想要构建的模型。通过检查输出图形图像,您可以看到您的逻辑中是否有缺陷。最常见的缺陷包括:
- 网络中的图层排序不正确。
- 假设在
CONV或POOL层之后有一个(不正确的)输出音量大小。
每当实现一个网络架构时,我建议您在每一个CONV和POOL层的块之后都要可视化网络架构,这将使您能够验证您的假设(更重要的是,在早期捕捉网络中的“bug”)。
卷积神经网络中的错误不同于应用程序中由边缘情况导致的其他逻辑错误。相反,CNN 很可能训练并获得合理的结果,即使层排序不正确,但是如果你没有意识到这个错误已经发生,你可能会报告你的结果,认为你做了一件事,但实际上做了另一件事。
在本教程的剩余部分,我将帮助您可视化您自己的网络架构,以避免这些类型的问题情况。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
安装 graphviz 和 pydot
要构建我们的网络图并使用 Keras 将其保存到磁盘,我们需要安装graphviz先决条件:
在 Ubuntu 上,这很简单:
$ sudo apt-get install graphviz
在 macOS 上,我们可以通过自制软件安装graphviz:
$ brew install graphviz
一旦安装了graphviz库,我们需要安装两个 Python 包:
$ pip install graphviz
$ pip install pydot
可视化 Keras 网络
用 Keras 可视化网络架构非常简单。要了解这有多简单,请打开一个新文件,将其命名为visualize_architecture.py,并插入以下代码:
# import the necessary packages
from pyimagesearch.nn.conv import LeNet
from tensorflow.keras.utils import plot_model
# initialize LeNet and then write the network architecture
# visualization graph to disk
model = LeNet.build(28, 28, 1, 10)
plot_model(model, to_file="lenet.png", show_shapes=True)
第 2 行导入了我们对 LeNet ( 早期教程 )的实现——这是我们将要可视化的网络架构。第 3 行从 Keras 导入plot_model函数。正如这个函数名所示,plot_model负责基于输入模型内部的层构建一个图,然后将这个图写到磁盘上作为一个图像。
在第 7 行,我们实例化了 LeNet 架构,就好像我们要将它应用于 MNIST 进行数字分类。这些参数包括输入体积的宽度(28 像素)、高度(28 像素)、深度(1 个通道)和类别标签的总数(10)。
最后,第 8 行绘制了我们的model并以lenet.png的名字保存到磁盘。
要执行我们的脚本,只需打开一个终端并发出以下命令:
$ python visualize_architecture.py
命令成功存在后,检查您当前的工作目录:
$ ls
lenet.png visualize_architecture.py
正如您将看到的,有一个名为lenet.png的文件—这个文件是我们实际的网络可视化图形。打开并检查它(图 2 和图 3 )。
在这里,我们可以看到通过我们的网络的数据流的可视化。每一层都表示为体系结构中的一个节点,然后连接到其他层,最终在应用 softmax 分类器后终止。请注意网络中的每个层如何包括一个input和output属性——这些值是当进入该层时以及在退出该层之后各自体积的空间维度的大小。
走过 LeNet 架构,我们看到第一层是我们的InputLayer,它接受 28 × 28 × 1 输入图像。图层输入和输出的空间维度是相同的,因为这只是输入数据的一个“占位符”。
您可能想知道数据形状(None, 28, 28, 1)中的None代表什么。None实际上是我们的批量。当可视化网络架构时,Keras 不知道我们想要的批量大小,所以它保留值为None。训练时,该值将变为 32、64、128 等。或我们认为合适的任何批量。
接下来,我们的数据流向第一个CONV层,在那里我们学习 28 × 28 × 1 输入上的 20 个内核。这个第一层CONV的输出是 28 × 28 × 20。由于零填充,我们保留了原始的空间维度,但是通过学习 20 个过滤器,我们改变了体积大小。
激活层跟在CONV层之后,根据定义,它不能改变输入音量大小。然而,一个POOL操作可以减少音量大小——这里我们的输入音量从 28 × 28 × 20 减少到 14 × 14 × 20。
第二个CONV接受 14 × 14 × 20 音量作为输入,但随后学习 50 个滤波器,将输出音量大小更改为 14 × 14 × 50(再次利用零填充来确保卷积本身不会降低输入的宽度和高度)。在另一个POOL操作之前应用激活,该操作再次将宽度和高度从 14 × 14 × 50 减半至 7 × 7 × 50。
在这一点上,我们准备好应用我们的FC层。为了实现这一点,我们的 7 × 7 × 50 输入被展平为一系列2450值(因为 7×7×50 = 2, 450)。既然我们已经展平了网络卷积部分的输出,我们可以应用一个接受 2450 个输入值并学习 500 个节点的FC层。接着是激活,接着是另一个FC层,这次将 500 个减少到 10 个(MNIST 数据集的类标签总数)。
最后,将 softmax 分类器应用于 10 个输入节点中的每一个,给出我们最终的分类概率。
总结
正如我们可以用代码表达 LeNet 架构一样,我们也可以将模型本身可视化为图像。当你开始你的深度学习之旅时,我强烈鼓励你使用这个代码来可视化你正在工作的任何网络,尤其是如果你不熟悉它们的话。确保您了解网络中的数据流以及卷大小如何基于CONV、POOL和FC层发生变化,这将使您对架构有更加深入的了解,而不仅仅是依赖代码。
当实现我自己的网络架构时,我通过每 2-3 个层块可视化架构来验证我是否在正确的轨道上,因为我实际上是在对网络进行编码——这个动作帮助我在早期发现我的逻辑中的错误或缺陷。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
用 OpenCV 和 Python 实现图像水印
原文:https://pyimagesearch.com/2016/04/25/watermarking-images-with-opencv-and-python/

A few weeks ago, I wrote a blog post on creating transparent overlays with OpenCV. This post was meant to be a gentle introduction to a neat little trick you can use to improve the aesthetics of your processed image(s), such as creating a Heads-up Display (HUD) on live video streams.
但是还有另一个更实际的原因,我想向你介绍透明的覆盖图,即水印图像。 给一幅图像或视频加水印称为 数字水印 ,是在图像本身上嵌入一个唯一的和识别图案的过程。
例如,专业摄影师倾向于给发送给客户的数字样张(包括相关信息,如他们的姓名和/或设计工作室)加水印,直到客户同意购买照片,在此发布原始的、未经修改的图像。这使得摄影师可以分发他们作品的演示和样本,而不用真正“放弃”原始作品。
我们还在受版权保护的视频中看到数字水印——在这种情况下,水印被嵌入视频的每一帧,从而证明了作品的原始制作者。
在这两种情况下,水印的目标是在图像上创建一个独特的可识别的图案,将属性赋予原始创作者,但不破坏图像本身的内容。
要了解如何利用 OpenCV 为您自己的图像数据集添加水印,请继续阅读。
用 OpenCV 和 Python 实现图像水印
这篇博文的目的是演示如何使用 OpenCV 和 Python 为图像添加水印。首先,我们需要一个水印,出于本教程的目的,我选择它作为 PyImageSearch 徽标:

Figure 1: Our example watermark image — the PyImageSearch logo.
这个水印是一个 PNG 图像带有 四个通道 :一个红色通道、一个绿色通道、一个蓝色通道和一个 Alpha 通道 用于控制图像中每个像素的透明度。
我们的 alpha 通道中的值可以在【0,255】范围内,其中 255 的值是 100%不透明 (即根本不透明),而 0 的值是 100%透明 。介于 0 和 255 之间的值具有不同的透明度级别,其中 alpha 值越小,像素越透明。
在上图中,不是白色“PyImageSearch”标志的部分的所有像素都是完全透明的,这意味着您可以“透过它们”看到图像所覆盖的背景。在本例中,我将图像设置为蓝色背景,这样我们就可以看到徽标本身(显然,如果我将它放在白色背景上,您将看不到白色的 PyImageSearch 徽标——因此在本例中使用了蓝色背景)。
*一旦我们在图像上覆盖水印,水印将是半透明的,允许我们(部分)看到原始图像的背景。
现在我们已经了解了水印的过程,让我们开始吧。
用 OpenCV 创建水印
打开一个新文件,命名为watermark_dataset.py,让我们开始吧:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-w", "--watermark", required=True,
help="path to watermark image (assumed to be transparent PNG)")
ap.add_argument("-i", "--input", required=True,
help="path to the input directory of images")
ap.add_argument("-o", "--output", required=True,
help="path to the output directory")
ap.add_argument("-a", "--alpha", type=float, default=0.25,
help="alpha transparency of the overlay (smaller is more transparent)")
ap.add_argument("-c", "--correct", type=int, default=1,
help="flag used to handle if bug is displayed or not")
args = vars(ap.parse_args())
第 2-6 行导入我们需要的 Python 包。我们将在这里使用 imutils 包,所以如果你还没有安装它,让pip为你安装它:
$ pip install imutils
第 9-20 行然后处理解析我们需要的命令行参数。我们需要三个命令行参数,并且可以提供两个额外的(可选的)参数。下面是每个命令行参数的完整分类:
- 在这里,我们提供我们希望用作水印的图像的路径。我们假设(1)这个图像是一个具有 alpha 透明度的 PNG 图像,以及(2)我们的水印比我们将要应用水印的数据集中的所有图像小(就宽度和高度而言)。
--input:这是我们要水印的图像的输入目录的路径。--output:然后我们需要提供一个输出目录来存储我们的水印图像。--alpha:可选的--alpha值控制水印的透明度。 1.0 的值表示水印应该 100%不透明(即不透明)。值 0.0 表示水印应该 100%透明。您可能希望为自己的数据集调整这个值,但是我发现 25%的值在大多数情况下都很好。- 最后,这个开关用来控制我们是否应该保留一个 OpenCV 处理 alpha 透明度的“bug”。我包含这个开关的唯一原因是关于 OpenCV 库的教育问题。除非您想自己研究这个 bug,否则您很可能会忽略这个参数。
现在我们已经解析了我们的命令行参数,我们可以从磁盘加载我们的水印图像:
# load the watermark image, making sure we retain the 4th channel
# which contains the alpha transparency
watermark = cv2.imread(args["watermark"], cv2.IMREAD_UNCHANGED)
(wH, wW) = watermark.shape[:2]
第 24 行使用cv2.imread函数从磁盘加载我们的watermark图像。注意我们是如何使用cv2.IMREAD_UNCHANGED标志的——提供这个值是为了让我们能够读取 PNG 图像的 alpha 透明通道(以及标准的红色、绿色和蓝色通道)。
第 25 行然后获取watermark图像的空间尺寸(即高度和宽度)。
下一个代码块解决了我在使用 alpha transparency 和 OpenCV 时遇到的一些奇怪的问题:
# split the watermark into its respective Blue, Green, Red, and
# Alpha channels; then take the bitwise AND between all channels
# and the Alpha channels to construct the actaul watermark
# NOTE: I'm not sure why we have to do this, but if we don't,
# pixels are marked as opaque when they shouldn't be
if args["correct"] > 0:
(B, G, R, A) = cv2.split(watermark)
B = cv2.bitwise_and(B, B, mask=A)
G = cv2.bitwise_and(G, G, mask=A)
R = cv2.bitwise_and(R, R, mask=A)
watermark = cv2.merge([B, G, R, A])
当我第一次实现这个例子时,我注意到在具有 alpha 透明度的cv2.imread和 PNG 文件类型上有一些非常奇怪的行为。
首先,我注意到即使有了的cv2.IMREAD_UNCHANGED标志,alpha 通道中的透明度值也没有得到任何红色、绿色或蓝色通道的的的尊重——这些通道看起来要么是完全不透明的要么是半透明的,但从来没有达到我假设的正确的透明度水平。
然而,在研究 alpha 通道本身时,我注意到 alpha 通道本身没有问题—alpha 通道被加载并完美地呈现了。
因此,为了确保红色、绿色和蓝色通道尊重阿尔法通道,我在各个颜色通道和阿尔法通道之间进行了按位AND,将阿尔法通道视为一个遮罩(第 33-37 行 ) — ),这解决了奇怪的行为,并允许我继续进行水印处理。
我在这里加入了--correct标志,这样你就可以调查当没有应用这种类型的修正时会发生什么(更多信息请见“水印结果”部分)。
接下来,让我们继续处理我们的图像数据集:
# loop over the input images
for imagePath in paths.list_images(args["input"]):
# load the input image, then add an extra dimension to the
# image (i.e., the alpha transparency)
image = cv2.imread(imagePath)
(h, w) = image.shape[:2]
image = np.dstack([image, np.ones((h, w), dtype="uint8") * 255])
# construct an overlay that is the same size as the input
# image, (using an extra dimension for the alpha transparency),
# then add the watermark to the overlay in the bottom-right
# corner
overlay = np.zeros((h, w, 4), dtype="uint8")
overlay[h - wH - 10:h - 10, w - wW - 10:w - 10] = watermark
# blend the two images together using transparent overlays
output = image.copy()
cv2.addWeighted(overlay, args["alpha"], output, 1.0, 0, output)
# write the output image to disk
filename = imagePath[imagePath.rfind(os.path.sep) + 1:]
p = os.path.sep.join((args["output"], filename))
cv2.imwrite(p, output)
在第 40 行我们开始循环浏览--input目录中的每一张图片。对于这些图像中的每一个,我们从磁盘中加载它并获取它的宽度和高度。
理解每个image被表示为一个形状为 (h,w,3) 的 NumPy 数组是很重要的,其中 3 是我们图像中通道的数量——红色、绿色和蓝色通道各一个。
然而,由于我们使用的是阿尔法透明度,我们需要给图像添加一个第四维度来存储阿尔法值(第 45 行)。该 alpha 通道与我们的原始图像具有相同的空间维度,并且 alpha 通道中的所有值都被设置为 255 ,这表示像素完全不透明并且不透明。
第 51 行和第 52 行为我们的水印构造了overlay。同样,overlay与我们的输入图像具有完全相同的宽度和高度。
注:要了解更多关于透明叠加的信息,请参考这篇博文。
最后,第 55 行和第 56 行通过应用cv2.addWeighted函数来构造我们的水印图像。
第 59-61 行然后获取我们的output图像并将其写入--output目录。
水印结果
为了试试我们的watermark_dataset.py脚本,使用本教程底部的“下载”表单下载与本文相关的源代码和图片。然后,导航到代码目录并执行以下命令:
$ python watermark_dataset.py --watermark pyimagesearch_watermark.png \
--input input --output output
脚本执行完毕后,您的output目录应该包含以下五个图像:

Figure 2: The output from our watermarking script.
您可以在下面看到每个带水印的图像:

Figure 3: Watermarking images with OpenCV and Python.
在上面的图像中,你可以看到白色的 PyImageSearch 标志已经作为水印添加到原始图像中。
下面是用 OpeCV 给图像加水印的第二个例子。同样,请注意 PyImageSearch 徽标是如何出现的(1)半透明和(2)在图像的右下角:

Figure 4: Creating watermarks with OpenCV and Python.
大约一年前,我去亚利桑那州欣赏红岩。一路上,我在凤凰动物园停下来,抚摸并喂养一只长颈鹿:

Figure 5: Feeding a giraffe…and watermarking the image with computer vision.
我也是一个中世纪现代建筑的狂热爱好者,所以我不得不去参观西方的 T2 塔里耶辛。

Figure 6: Watermarking images with OpenCV.
最后,这里有一张亚利桑那州风景的美丽照片(即使那天有点多云):

Figure 7: Creating watermarks with OpenCV is easy!
请注意在上面的每张图片中,“PyImageSearch”徽标是如何放置在输出图片的右下角的。再者,这个水印是半透明,让我们透过前景水印看到背景图像的内容。
具有 alpha 透明度的奇怪行为
所以,还记得我在第 32-37 行中提到的,如果我们不在每个相应的红色、绿色和蓝色通道与 alpha 通道之间进行按位AND运算,alpha 透明度会发生一些奇怪的行为吗?
让我们来看看这种陌生感。
再次执行watermark_dataset.py脚本,这次提供--correct 0标志来跳过逐位AND步骤:
$ python watermark_dataset.py --correct 0 --watermark pyimagesearch_watermark.png \
--input input --output output
然后,打开您选择的输出图像,您将看到如下内容:

Figure 8: (Incorrectly) creating a watermark with OpenCV.
请注意整个水印图像是如何被视为半透明的,而不仅仅是相应的阿尔法像素值!
莫名其妙吧?
老实说,我不确定为什么会发生这种情况,我在 OpenCV 文档中找不到任何关于这种行为的信息。如果任何人对这个问题有任何额外的细节,请在这篇文章底部的评论区留言。
否则,如果您在任何自己的 OpenCV 图像处理管道中使用 alpha 透明度,请确保您特别注意使用 alpha 遮罩单独遮罩每个红色、绿色和蓝色通道。
摘要
在这篇博文中,我们学习了如何使用 OpenCV 和 Python 为图像数据集添加水印。使用数字水印,您可以将自己的名字、徽标或公司品牌覆盖在您的原创作品上,从而保护内容并表明您是原创者。
为了用 OpenCV 创建这些数字水印,我们利用了具有 alpha 透明度的 PNG。利用 alpha 透明度可能非常棘手,尤其是,因为 OpenCV 似乎不会自动屏蔽每个通道的透明像素。
相反,你需要手动通过在输入通道和 alpha 蒙版之间进行逐位AND来执行这个蒙版(如这篇博文中所示)。
*无论如何,我希望你喜欢这个教程!
在你离开之前,请务必在下面的表格中输入你的电子邮件地址,以便在有新的博文发表时得到通知!**
分水岭 OpenCV

分水岭算法是一种用于分割的经典算法,在提取图像中的接触或重叠物体时特别有用,比如上图中的硬币。
使用传统的图像处理方法,如阈值处理和轮廓检测,我们无法从图像中提取每枚硬币,但通过利用分水岭算法,我们能够毫无问题地检测和提取每枚硬币。
使用分水岭算法时,我们必须从用户定义的标记开始。这些标记既可以是通过点击手动定义的,也可以是自动定义的或启发式定义的。**
**基于这些标记,分水岭算法将我们输入图像中的像素视为局部高程(称为 地形 ) —该方法“淹没”山谷,从标记开始并向外移动,直到不同标记的山谷彼此相遇。为了获得准确的分水岭分割,必须正确放置标记。
在这篇文章的剩余部分,我将向您展示如何使用分水岭算法来分割和提取图像中既接触又重叠的对象。为此,我们将使用各种 Python 包,包括 SciPy 、 scikit-image 和 OpenCV。
分水岭 OpenCV

Figure 1: An example image containing touching objects. Our goal is to detect and extract each of these coins individually.
在上面的图像中,您可以看到使用简单的阈值处理和轮廓检测无法提取的对象示例,因为这些对象是接触的、重叠的或两者兼有,轮廓提取过程会将每组接触的对象视为一个单个对象而不是多个对象。
基本阈值和轮廓提取的问题
让我们继续演示简单阈值处理和轮廓检测的局限性。打开一个新文件,命名为contour_only.py,让我们开始编码:
# import the necessary packages
from __future__ import print_function
from skimage.feature import peak_local_max
from skimage.segmentation import watershed
from scipy import ndimage
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the image and perform pyramid mean shift filtering
# to aid the thresholding step
image = cv2.imread(args["image"])
shifted = cv2.pyrMeanShiftFiltering(image, 21, 51)
cv2.imshow("Input", image)
我们从线 2-8 开始,导入我们需要的包。第 11-14 行然后解析我们的命令行参数。这里我们只需要一个开关,--image,它是我们想要处理的图像的路径。
从那里,我们将在第 18 行上从磁盘加载我们的图像,应用金字塔均值漂移滤波 ( 第 19 行)来帮助我们的阈值步骤的准确性,并最终在我们的屏幕上显示我们的图像。到目前为止,我们的输出示例如下:
Figure 2: Output from the pyramid mean shift filtering step.
现在,让我们对均值偏移图像进行阈值处理:
# convert the mean shift image to grayscale, then apply
# Otsu's thresholding
gray = cv2.cvtColor(shifted, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv2.imshow("Thresh", thresh)
给定我们的输入image,然后我们将它转换为灰度,并应用 Otsu 的阈值处理将背景从前景中分割出来:
Figure 3: Applying Otsu’s automatic thresholding to segment the foreground coins from the background.
最后,最后一步是检测阈值图像中的轮廓,并绘制每个单独的轮廓:
# find contours in the thresholded image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
print("[INFO] {} unique contours found".format(len(cnts)))
# loop over the contours
for (i, c) in enumerate(cnts):
# draw the contour
((x, y), _) = cv2.minEnclosingCircle(c)
cv2.putText(image, "#{}".format(i + 1), (int(x) - 10, int(y)),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
cv2.drawContours(image, [c], -1, (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
下面我们可以看到我们的图像处理管道的输出:
Figure 4: The output of our simple image processing pipeline. Unfortunately, our results are pretty poor — we are not able to detect each individual coin.
如你所见,我们的结果相当糟糕。使用简单的阈值和轮廓检测,我们的 Python 脚本报告说图像中只有两个硬币,尽管很明显有九个硬币。
这个问题的原因来自于硬币边界在图像中彼此接触的事实——因此,cv2.findContours函数仅将硬币组视为单个对象,而事实上它们是多个独立的硬币。
注意:一系列的形态学操作(具体来说,腐蚀)将帮助我们获得这个特定的图像。然而,对于重叠的物体来说,这些腐蚀是不够的。为了这个例子,让我们假设形态学操作不是一个可行的选择,以便我们可以探索分水岭算法。
使用分水岭算法进行分割
既然我们已经了解了简单阈值处理和轮廓检测的局限性,让我们继续讨论分水岭算法。打开一个新文件,将其命名为watershed.py,并插入以下代码:
# import the necessary packages
from skimage.feature import peak_local_max
from skimage.morphology import watershed
from scipy import ndimage
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the image and perform pyramid mean shift filtering
# to aid the thresholding step
image = cv2.imread(args["image"])
shifted = cv2.pyrMeanShiftFiltering(image, 21, 51)
cv2.imshow("Input", image)
# convert the mean shift image to grayscale, then apply
# Otsu's thresholding
gray = cv2.cvtColor(shifted, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv2.imshow("Thresh", thresh)
同样,我们将从行 2-8 开始,导入我们需要的包。我们将使用来自 SciPy 、 scikit-image 、 imutils 和 OpenCV 的函数。如果您的系统上还没有安装 SciPy 和 scikit-image,您可以使用pip为您安装它们:
$ pip install --upgrade scipy
$ pip install --upgrade scikit-image
$ pip install --upgrade imutils
第 11-14 行处理解析我们的命令行参数。就像前面的例子一样,我们只需要一个开关,即我们要应用分水岭算法的图像路径--image。
从那里,行 18 和 19 从磁盘加载我们的图像,并应用金字塔平均移动滤波。第 24-26 行执行灰度转换和阈值处理。
给定我们的阈值图像,我们现在可以应用分水岭算法:
# compute the exact Euclidean distance from every binary
# pixel to the nearest zero pixel, then find peaks in this
# distance map
D = ndimage.distance_transform_edt(thresh)
localMax = peak_local_max(D, indices=False, min_distance=20,
labels=thresh)
# perform a connected component analysis on the local peaks,
# using 8-connectivity, then appy the Watershed algorithm
markers = ndimage.label(localMax, structure=np.ones((3, 3)))[0]
labels = watershed(-D, markers, mask=thresh)
print("[INFO] {} unique segments found".format(len(np.unique(labels)) - 1))
应用分水岭算法进行分割的第一步是通过distance_transform_edt函数(第 32 行)计算欧几里德距离变换(EDT)。顾名思义,这个函数计算每个前景像素到最近的零(即背景像素)的欧几里德距离。我们可以在下图中看到 EDT:
Figure 5: Visualizing the Euclidean Distance Transform.
在线 33 上,我们使用D,我们的距离地图,并在地图中找到峰值(即,局部最大值)。我们将确保每个峰值之间的距离至少为20 像素。
线 38 获取peak_local_max函数的输出,并使用 8-连通性应用连通分量分析。这个函数的输出给了我们markers,然后我们将它输入到线 39* 上的watershed函数中。由于分水岭算法假设我们的标记代表我们的距离图中的局部最小值(即山谷),所以我们取负值D。
watershed函数返回一个labels的矩阵,这是一个 NumPy 数组,其宽度和高度与我们的输入图像相同。每个像素值作为一个唯一的标签值。标签值相同的像素属于同一个对象。
最后一步是简单地遍历唯一标签值并提取每个唯一对象:
# loop over the unique labels returned by the Watershed
# algorithm
for label in np.unique(labels):
# if the label is zero, we are examining the 'background'
# so simply ignore it
if label == 0:
continue
# otherwise, allocate memory for the label region and draw
# it on the mask
mask = np.zeros(gray.shape, dtype="uint8")
mask[labels == label] = 255
# detect contours in the mask and grab the largest one
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
# draw a circle enclosing the object
((x, y), r) = cv2.minEnclosingCircle(c)
cv2.circle(image, (int(x), int(y)), int(r), (0, 255, 0), 2)
cv2.putText(image, "#{}".format(label), (int(x) - 10, int(y)),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
在第 44 行我们开始循环每个独特的labels。如果label是零,那么我们正在检查“背景成分”,所以我们简单地忽略它。
否则,行 52 和 53 为我们的mask分配内存,并将属于当前标签的像素设置为 255 (白色)。我们可以在下面的右侧看到一个这样的遮罩示例:
Figure 6: An example mask where we are detecting and extracting only a single object from the image.
在线 56-59 上,我们检测mask中的轮廓并提取最大的一个——该轮廓将代表图像中给定对象的轮廓/边界。
最后,给定物体的轮廓,我们需要做的就是在第 62-65 行上画出围绕物体的圆圈边界。我们还可以计算对象的边界框,应用位运算,并提取每个单独的对象。
最后,行 68 和 69 向我们的屏幕显示输出图像:

Figure 7: The final output of our watershed algorithm — we have been able to cleanly detect and draw the boundaries of each coin in the image, even though their edges are touching.
正如你所看到的,我们已经成功地检测到图像中的所有九个硬币。此外,我们还能够清晰地画出每枚硬币周围的边界。这与使用简单阈值和轮廓检测的先前示例形成鲜明对比,在先前示例中,仅两个对象被(不正确地)检测到。
将分水岭算法应用于图像
既然我们的watershed.py脚本已经完成,让我们将它应用到更多的图像并研究结果:
$ python watershed.py --image images/coins_02.png

Figure 8: Again, we are able to cleanly segment each of the coins in the image.
让我们尝试另一个图像,这次是重叠的硬币:
$ python watershed.py --image images/coins_03.png

Figure 9: The watershed algorithm is able to segment the overlapping coins from each other.
在下图中,我决定将分水岭算法应用于药丸计数任务:
$ python watershed.py --image images/pills_01.png

Figure 10: We are able to correctly count the number of pills in the image.
这张图片也是如此:
$ python watershed.py --image images/pills_02.png

Figure 11: Applying the watershed algorithm with OpenCV to count the number of pills in an image.
摘要
在这篇博文中,我们学习了如何应用分水岭算法,这是一种经典的分割算法,用于检测和提取图像中接触和/或重叠的对象。
为了应用分水岭算法,我们需要定义与我们图像中的物体相对应的标记。这些标记可以是用户定义的,或者我们可以应用图像处理技术(如阈值处理)来为我们找到标记。当应用分水岭算法时,获得准确的标记是绝对关键的。
给定我们的标记,我们可以计算欧几里德距离变换并将距离图传递给分水岭函数本身,该函数在距离图中“淹没”山谷,从初始标记开始并向外移动。在分割过程中,水的“池”相遇的地方可以被认为是边界线。
分水岭算法的输出是一组标签,其中每个标签对应于图像中的一个唯一对象。从那里开始,我们需要做的就是分别遍历每个标签并提取每个对象。
无论如何,我希望你喜欢这篇文章!请务必下载代码并尝试一下。尝试使用各种参数,特别是peak_local_max函数的min_distance参数。请注意改变该参数的值会如何改变输出图像。***
什么是深度学习?
原文:https://pyimagesearch.com/2021/04/17/what-is-deep-learning/
深度学习方法是具有多级表示的表示学习方法,通过组合简单但非线性的模块获得,每个模块将一级(从原始输入开始)的表示转换为更高、稍微更抽象级别的表示。[.。。深度学习的关键在于,这些层不是由人类工程师设计的:它们是使用通用学习程序从数据中学习的。
— Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, Nature (2015), p. 436
深度学习是机器学习的一个子领域,而机器学习又是人工智能(AI)的一个子领域。有关这种关系的图示,请参考图 1 。
人工智能的核心目标是提供一套算法和技术,可以用来解决人类直观地执行和近乎自动地执行的问题,但在其他方面对计算机来说非常具有挑战性。这类人工智能问题的一个很好的例子是解释和理解图像的内容——这项任务人类可以不费吹灰之力完成,但事实证明机器完成这项任务极其困难。**
而人工智能包含了大量不同的与自动机器推理相关的工作(推理、计划、启发等)。),机器学习子领域往往是*对模式识别和从数据中学习**特别感兴趣*。
人工神经网络(ann)是一类机器学习算法,从数据中学习,专门从事模式识别,受大脑结构和功能的启发。正如我们将发现的那样,深度学习属于 ANN 算法家族,在大多数情况下,这两个术语可以互换使用。事实上,你可能会惊讶地发现,深度学习领域已经存在了超过 60 年,根据研究趋势、可用的硬件和数据集以及当时杰出研究人员的流行选择,它有不同的名称和化身。
*在本章的剩余部分,我们将回顾深度学习的简史,讨论什么使神经网络“深度”,并发现“分层学习”的概念,以及它如何使深度学习成为现代机器学习和计算机视觉的主要成功故事之一。
神经网络和深度学习的简明历史
神经网络和深度学习的历史很长,有点令人困惑。你可能会惊讶地知道,“深度学习”自 20 世纪 40 年代以来就存在了,经历了各种名称的变化,包括控制论、连接主义,以及最熟悉的人工神经网络 (ANNs)。
虽然受到人类大脑及其神经元如何相互作用的启发,但人工神经网络不是大脑的现实模型。相反,它们是一种灵感,让我们能够在一个非常基本的大脑模型和我们如何通过人工神经网络模仿这种行为之间进行比较。
第一个神经网络模型来自于 1943 年 麦卡洛克和皮茨。这个网络是一个二元分类器,能够根据一些输入识别两个不同的类别。问题是,用于确定给定输入的类别标签的权重需要由人工手动调整——如果需要人工操作员干预,这种类型的模型显然不能很好地扩展。
然后,在 20 世纪 50 年代,开创性的感知器算法由Rosenblatt(1958,1962)发表——这个模型可以自动学习对输入进行分类所需的权重(不需要人工干预)。感知器架构的一个例子可以在图 2 中看到。事实上,这种自动训练程序形成了随机梯度下降法(SGD)的基础,该方法至今仍用于训练深度神经网络。
在此期间,基于感知机的技术在神经网络社区中风靡一时。然而,Minsky 和 Papert 在 1969 年发表的一篇 实际上使神经网络研究停滞了近十年。他们的工作表明,具有线性激活函数(不考虑深度)的感知器仅仅是一个线性分类器,无法解决非线性问题。非线性问题的典型例子是图 3** 中的 XOR 数据集。现在花一点时间说服自己,尝试用一条单线把蓝色星星和红色圆圈分开是不可能的。**
此外,作者认为(当时)我们没有构建大型深度神经网络所需的计算资源(事后看来,他们是绝对正确的)。光是这一篇论文就差点要了神经网络研究的命。
幸运的是,反向传播算法和Werbos(1974)Rumelhart 等人(1986) 和 LeCun 等人(1998) 的研究能够使可能已经早期消亡的神经网络复苏。他们对反向传播算法的研究使得多层前馈神经网络能够被训练(图 4 )。
结合非线性激活函数,研究人员现在可以学习非线性函数并解决 XOR 问题,从而打开了神经网络研究的全新领域。进一步的研究表明,神经网络是 通用逼近器 ,能够逼近任何连续函数(但不能保证网络是否真的能够学习表示函数所需的参数)。
反向传播算法是现代神经网络的基石,允许我们有效地训练神经网络,并“教”它们从错误中学习。但即使如此,在这个时候,由于(1)缓慢的计算机(与现代机器相比)和(2)缺乏大的、有标签的训练集,研究人员无法(可靠地)训练具有两个以上隐藏层的神经网络——这在计算上是不可行的。
今天,我们所知的神经网络的最新化身被称为深度学习。将深度学习与其之前的化身区分开来的是,我们拥有更快、更专业的硬件,以及更多可用的训练数据。我们现在可以用训练更多隐藏层的网络,这些隐藏层能够进行分层学习,在较低层学习简单的概念,在网络的较高层学习更抽象的模式。
也许将深度学习应用于特征学习的典型例子是应用于手写字符识别的 卷积神经网络 (LeCun 等人,1998)自动从图像中学习区分模式(称为“过滤器”),方法是依次将层堆叠在彼此之上。网络中较低级别的过滤器表示边缘和角点,而较高级别的图层使用边缘和角点来学习更抽象的概念,这些概念对于区分图像类别非常有用。
在许多应用中,CNN 现在被认为是最强大的图像分类器,目前负责推动利用机器学习的计算机视觉子领域的最新发展。要更彻底地回顾神经网络和深度学习的历史,请参考 Goodfellow 等人(2016) 以及 Jason Brownlee (2016)在机器学习掌握 发表的这篇优秀博文。
分层特征学习
机器学习算法(一般)分为三个阵营——监督、非监督和半监督学习。我们将在本章讨论监督和非监督学习,而半监督学习留待将来讨论。
在受监督的情况下,机器学习算法被给予一组输入和目标 输出。然后,该算法尝试学习可用于将输入数据点自动映射到其正确目标输出的模式。监督学习类似于让老师看着你考试。鉴于你以前的知识,你尽最大努力在你的考试上标出正确答案;然而,如果你是不正确的,你的老师下次会引导你做出更好的、更有教育意义的猜测。
在无人监督的情况下,机器学习算法试图自动发现有区别的特征,而不需要任何关于输入是什么的提示。在这种情况下,我们的学生试图将相似的问题和答案组合在一起,即使学生不知道正确答案是什么和老师不在那里为他们提供正确的答案。与监督学习相比,无监督学习显然是一个更具挑战性的问题——通过知道答案(即目标输出),我们可以更容易地定义可以将输入数据映射到正确目标分类的判别模式。
在应用于图像分类的机器学习的背景下,机器学习算法的目标是获取这些图像集,并识别可用于将各种图像类别/对象彼此区分开的模式。
过去,我们使用手工设计的特征来量化图像的内容——我们很少使用原始像素强度作为我们机器学习模型的输入,这在深度学习中很常见。对于我们数据集中的每张图像,我们都执行了特征提取,或获取输入图像,根据某种算法(称为特征提取器或图像描述符)对其进行量化,并返回旨在量化图像内容的向量(即一系列数字)的过程。图 5 描绘了通过一系列黑盒颜色、纹理和形状图像描述符来量化包含处方药丸药物的图像的过程。
我们手工设计的特征试图编码纹理(****、** 哈拉里克纹理 )、形状( 胡矩 、 泽尼克矩 )和颜色( 颜色矩、颜色直方图、颜色相关图 )。**
**其他方法如关键点检测器(、、FAST 、、、 Harris 、、、 DoG 、等)和局部不变描述符(、 SIFT 、、、 SURF 、T19、、T21【BRIEF】、、、 ORB 、等。)描述图像的显著(即最“有趣”)区域。
其他方法如 梯度方向直方图(HOG) 被证明在检测图像中的对象时非常好,当我们的图像的视角与我们的分类器被训练的视角没有显著变化时。使用 HOG +线性 SVM 检测器方法的一个例子可以在图 6 中看到,我们在图像中检测停车标志的存在。
有一段时间,图像中对象检测的研究是由 HOG 及其变体指导的,包括计算昂贵的方法,如 可变形部分模型 和 样本支持向量机 。
在每一种情况下,算法都是由手工定义的来量化和编码图像的特定方面(即形状、纹理、颜色等)。).给定像素的输入图像,我们将对像素应用我们手动定义的算法,并作为回报接收量化图像内容的特征向量——图像像素本身除了作为我们特征提取过程的输入之外,没有其他用途。从特征提取中得到的特征向量是我们真正感兴趣的,因为它们是我们机器学习模型的输入。
深度学习,特别是卷积神经网络,采取了不同的方法。不是手动定义一组规则和算法来从图像中提取特征,而是从训练过程中自动学习这些特征。
再次,让我们回到机器学习的目标:计算机应该能够从 的经验(即例子)中学习它们试图解决的问题。
利用深度学习,我们试图从概念的层次来理解问题。每个概念都建立在其他概念的基础上。网络低层中的概念对问题的一些基本表示进行编码,而高层使用这些基本层来形成更抽象的概念。这种分层学习允许我们完全去除手工设计的特征提取过程,并将 CNN 视为端到端学习器。
给定一幅图像,我们将像素亮度值作为输入提供给 CNN。一系列的隐藏层被用来从我们的输入图像中提取特征。这些隐藏层以分层的方式建立在彼此之上。首先,在网络的较低层中只检测到类似边缘的区域。这些边缘区域用于定义拐角(边缘相交的地方)和轮廓(对象的轮廓)。组合角和轮廓可以导致下一层中的抽象“对象部分”。
再次请记住,这些过滤器正在学习检测的概念类型是自动 人工学习的— 在学习过程中没有我们的干预。最后,输出层用于对图像进行分类,并获得输出类别标签——输出层或者直接受到网络中每个其他节点的影响或者间接受到网络中每个其他节点的影响。
我们可以将这一过程视为分层学习:网络中的每一层都使用前几层的输出作为“构建模块”,来构建越来越抽象的概念。这些层是自动学习的——在我们的网络中没有手工制作的特征工程。图 7 将使用手工制作特征的经典图像分类算法与通过深度学习和卷积神经网络的表示学习进行了比较。
深度学习和卷积神经网络的主要好处之一是,它允许我们跳过特征提取步骤,而是专注于训练我们的网络来学习这些过滤器的过程。然而,正如我们将在本书后面发现的,训练网络以在给定的图像数据集上获得合理的精度并不总是一件容易的事情。
“深”有多深?
引用 Jeff Dean 2016 年的演讲中的 深度学习构建智能计算机系统 :
当你听到深度学习这个术语时,只需想到一个大型的深度神经网络。深度指的是典型的层数,这是一个流行的术语,已经被媒体采用。
这是一个很好的引用,因为它允许我们将深度学习概念化为大型神经网络,其中各层建立在彼此之上,逐渐增加深度。问题是我们仍然没有一个具体的答案,“一个神经网络需要多少层才能被认为是 深?”
简而言之,专家们对一个网络的深度没有达成共识****(good fellow 等人,2016 ) 。
**现在我们需要看看网络类型的问题。根据定义,卷积神经网络(CNN)是一种深度学习算法。但假设我们有一个只有一个卷积层的 CNN 是一个浅层的网络,但仍然属于深度学习阵营中被认为是“深度”的算法家族?
我个人的观点是,任何大于两个隐藏层的网络都可以被认为是“深度的”我的推理是基于以前在人工神经网络中的研究,这些人工神经网络存在以下严重缺陷:
- 我们缺乏可用于训练的大规模、带标签的数据集
- 我们的计算机速度太慢,无法训练大型神经网络
- 激活功能不足
由于这些问题,在 20 世纪 80 年代和 90 年代(当然,还有更早的时期),我们不容易训练具有两个以上隐藏层的网络。事实上, Geoff Hinton 在他 2016 年的演讲中支持这种观点,他在演讲中讨论了为什么深度学习的前身在 20 世纪 90 年代没有起飞:
*1. 我们标记的数据集小了几千倍。
2. 我们的计算机慢了几百万倍。
3. 我们用一种愚蠢的方式初始化了网络权重。
4. 我们使用了错误类型的非线性激活函数。
所有这些原因都指向一个事实,即训练深度超过两个隐藏层的网络是徒劳的,如果不是计算上的,也是不可能的。
在当前的化身中,我们可以看到潮汐已经改变。我们现在有:
- 更快的计算机
- 高度优化的硬件(即 GPU)
- 数百万张图像数量级的大型标记数据集
- 更好地理解重量初始化功能以及哪些功能起作用/不起作用
- 优越的激活函数和理解为什么以前的非线性函数停滞不前的研究
套用吴恩达 2013 年的演讲, 深度学习,自学和无监督特征学习 ,我们现在能够构建更深层次的神经网络,并用更多的数据训练它们。
随着网络的深度增加,分类精度也增加。这种行为不同于传统的机器学习算法(即逻辑回归、支持向量机、决策树等。),在这种情况下,即使可用的训练数据增加,我们的性能也会达到一个稳定的水平。受 吴恩达 2015 年演讲启发的一个情节,关于深度学习 科学家应该知道的数据,可以在图 8 中看到,提供了这种行为的一个例子。
随着训练数据量的增加,我们的神经网络算法获得了更高的分类精度,而以前的方法在某一点上停滞不前。由于更高的准确性和更多数据之间的关系,我们倾向于将深度学习与大型数据集联系起来。
在开发自己的深度学习应用程序时,我建议使用以下经验法则来确定您给定的神经网络是否是深度的:
- 您是否正在使用一种专门的网络架构,如卷积神经网络、循环神经网络或长短期记忆(LSTM)网络?如果是这样,是的,你正在执行深度学习。
- 你的网络有深度 > 2 吗?如果是,你在做深度学习。
- 你的网络有深度 > 10 吗?如果是这样,你正在执行非常 深度学习 。
尽管如此,尽量不要陷入深度学习和什么是/不是深度学习的流行词汇中。最核心的是,在过去的 60 年里,深度学习已经经历了许多不同的化身,基于各种思想流派——但这些思想流派中的每一个都围绕着受大脑结构和功能启发的人工神经网络。不管网络深度、宽度或专门的网络架构如何,你仍然使用人工神经网络执行机器学习。
总结
这一章解决了复杂的问题“什么是深度学习?”
正如我们发现的那样,深度学习自 20 世纪 40 年代以来就已经存在,根据不同的思想流派和特定时间的流行研究趋势,它有不同的名称和化身。在最核心的地方,深度学习属于人工神经网络(ann)家族,这是一套学习受大脑结构和功能启发的模式的算法。
专家们对于究竟是什么让神经网络变得“深”没有达成一致意见;然而,我们知道:
- 深度学习算法以分层的方式学习,因此将多个层堆叠在彼此之上,以学习越来越多的抽象概念。
- 一个网络要有 > 2 层才算“深”(这是我基于几十年神经网络研究的坊间看法)。
- 具有 > 10 层的网络被认为是非常深(尽管这个数字会随着诸如 ResNet 之类的架构被成功训练超过 100 层而改变)。
如果你在阅读本章后感到有点困惑甚至不知所措,不要担心——这里的目的只是提供深度学习的一个非常高层次的概述以及“深度”的确切含义。
本章还介绍了一些你可能不熟悉的概念和术语,包括像素、边缘和拐角——我们的下一章将讨论这些类型的图像基础知识,并给你一个坚实的基础。然后,我们将开始进入神经网络的基础,使我们能够在本书的稍后部分过渡到深度学习和卷积神经网络。虽然这一章是公认的高级别,但本书的其余章节将非常实用,允许您掌握计算机视觉概念的深度学习。********
什么是人脸识别?
原文:https://pyimagesearch.com/2021/05/01/what-is-face-recognition/
在本教程中,您将了解人脸识别,包括:
- 人脸识别的工作原理
- 人脸识别与人脸检测有何不同
- 人脸识别算法的历史
- 当今用于人脸识别的最先进算法
下周我们将开始实施这些人脸识别算法。
要了解人脸识别,继续阅读。
什么是人脸识别?
人脸识别是在图像中拍摄一张人脸并实际上识别该人脸属于谁的过程。因此,面部识别是一种身份识别的形式。
早期的人脸识别系统依赖于从图像中提取的早期版本的面部标志,如眼睛、鼻子、颧骨和下巴的相对位置和大小。然而,这些系统通常非常主观,并且容易出错,因为这些面部量化是由运行面部识别软件的计算机科学家和管理员手动提取的。
随着机器学习算法变得更加强大和计算机视觉领域的成熟,人脸识别系统开始利用特征提取和分类模型来识别图像中的人脸。
这些系统不仅是非主观的,而且是自动的——不需要人工标记人脸。我们简单地从面部提取特征,训练我们的分类器,然后用它来识别后续的面部。
最近,我们已经开始利用深度学习算法进行人脸识别。FaceNet 和 OpenFace 等最先进的人脸识别模型依赖于一种叫做暹罗网络的专门深度神经网络架构。
这些神经网络能够获得曾经被认为不可能的人脸识别精度(而且它们可以在数据少得惊人的情况下达到这种精度)。
人脸 识别 与人脸 检测有何不同?
我经常看到新的计算机视觉和深度学习从业者混淆人脸检测和人脸识别之间的区别,有时(并不正确地)互换使用这两个术语。
人脸检测和人脸识别都是 截然不同的 算法 — 人脸检测会告诉你****在给定的图像/帧中一张人脸是属于谁的(而不是而
****让我们进一步分析一下:
与 人脸检测 不同,后者是简单的检测图像或视频流中人脸的存在的过程,人脸识别采用从定位阶段检测到的人脸,并试图识别该人脸属于谁。因此,人脸识别可以被认为是一种身份识别方法,我们在安全和监控系统中大量使用。
根据定义,人脸识别需要人脸检测,因此我们可以将人脸识别视为两个阶段的过程。
- 阶段#1: 使用诸如 Haar 级联、HOG +线性 SVM、深度学习或任何其他可以定位人脸的算法来检测图像或视频流中人脸的存在。
- 阶段#2: 获取定位阶段检测到的每一张人脸,并识别它们中的每一张——这是我们实际上为人脸指定名称的地方。
在本教程的剩余部分,我们将回顾人脸识别的快速历史,然后介绍人脸识别算法和技术,包括特征脸,用于人脸识别的局部二进制模式(LBPs),暹罗网络,FaceNet 等。
人脸识别简史
人脸识别现在似乎无处不在(大多数智能手机和主要社交媒体平台都在实施),但在 20 世纪 70 年代之前,人脸识别通常被视为科幻小说,与超未来时代的电影和书籍隔离开来。简而言之,人脸识别是一个幻想,它是否会成为现实还不清楚。
这一切都在 1971 年改变了,当时 Goldstein 等人发表了 人脸识别 。作为人脸识别的初步尝试,这种方法提出了 21 个主观面部特征,如头发颜色和嘴唇厚度,来识别照片中的人脸。
这种方法的最大缺点是,21 个测量值(除了高度主观之外)是手动计算的——这是计算机科学社区中的一个明显缺陷,该社区正在快速走向无监督计算和分类(至少在人类监督方面)。
*然后,十多年后,在 1987 年,西罗维奇和科比发表了他们的开创性工作, 一种用于描述人脸特征的低维程序 ,随后在 1991 年,特克和彭特兰使用特征脸 进行了 人脸识别。
Sirovich 和 Kirby 以及 Turk 和 Pentland 证明了一种称为主成分分析 (PCA)的标准线性代数降维技术可以用于使用小于 100 维的特征向量来识别人脸。
此外,“主成分”(即特征向量,或“特征脸”)可用于从原始数据集重建人脸。这意味着人脸可以被表示(并最终被识别)为特征脸的线性组合:
查询脸=特征脸#1 的 36%+-特征脸#2 的 8%…+特征脸 N 的 21%
继 Sirovich 和 Kirby 在 20 世纪 80 年代后期的工作之后,对人脸识别的进一步研究爆发了——另一种流行的基于线性代数的人脸识别技术利用了线性判别分析。基于 LDA 的人脸识别算法俗称鱼脸。
基于特征的方法,例如用于人脸识别的局部二进制模式也已经被提出,并且仍然在现实世界的应用中大量使用:
**深度学习现在负责人脸识别中前所未有的准确性。称为暹罗网络的专门架构用一种特殊类型的数据训练,称为图像三元组。然后,我们计算、监控并试图最小化我们的三重损失,从而最大化人脸识别的准确性。
流行的深度神经网络人脸识别模型有 FaceNet 和 OpenFace 。
特征脸
本征脸算法使用主成分分析来构建人脸图像的低维表示。
这个过程包括收集一个人脸数据集,其中每个人都有多个我们想要识别的人脸图像(就像在执行图像分类时,我们想要识别一个图像类别的多个训练示例)。
给定这个人脸图像的数据集,假设它们具有相同的宽度、高度,并且理想地,它们的眼睛和面部结构在相同的 (x,y)-坐标上对齐,我们应用数据集的特征值分解,保留具有最大对应特征值的特征向量。
给定这些特征向量,人脸就可以表示为 Sirovich 和 Kirby 所说的特征脸的线性组合。
可以通过计算特征脸表示之间的欧几里德距离并将人脸识别视为 k-最近邻分类问题来执行人脸识别,但是,我们通常倾向于对特征脸表示应用更高级的机器学习算法。
如果您对线性代数术语或特征脸算法的工作原理感到有点不知所措,不要担心,我们将在本系列人脸识别教程的后面详细介绍特征脸算法。
用于人脸识别的 LBPs】
本征脸算法依靠 PCA 来构建人脸图像的低维表示,而局部二进制模式(LBPs)方法,顾名思义,依靠特征提取。
Ahonen 等人在他们 2004 年的论文 中首次介绍了使用局部二进制模式 进行人脸识别,他们的方法建议将人脸图像分成大小相等的单元的 7×7 网格:
通过将图像分成单元,我们可以将位置引入到我们最终的特征向量中。此外,一些单元格被加权,使得它们对整体表示的贡献更多。与网格中心的细胞(包含眼睛、鼻子和嘴唇结构)相比,角落的细胞携带的识别面部信息较少。
最后,我们连接来自 49 个细胞的加权 LBP 直方图以形成我们的最终特征向量。
使用 通过 k-NN 分类进行实际的人脸识别
通过 k-NN 分类进行实际的人脸识别
distance between the query image and the dataset of labeled faces — since we are comparing histograms, the distance is a better choice than the Euclidean distance.
虽然用于人脸识别的特征脸和 LBP 都是用于人脸识别的相当简单的算法,但是基于特征的 LBP 方法往往对噪声更有弹性(因为它不对原始像素强度本身进行操作),并且通常会产生更好的结果。
我们将在本系列教程的后面详细实现 LBPs 人脸识别。
基于深度学习的人脸识别
深度学习几乎影响了计算机科学的每个方面和子领域。人脸识别也没什么不同。
多年来,LBP 和特征脸/鱼脸被认为是人脸识别的最新技术。这些技术很容易被愚弄,在研究实验室/受控环境之外,准确性很差。
深度学习改变了这一切。专门的神经网络架构和训练技术,包括暹罗网络、图像三元组和三元组丢失、使研究人员能够获得曾经被认为不可能的人脸识别准确性。
这些方法比以前的技术更加精确和稳健。尽管神经网络被认为是数据饥渴的野兽,但暹罗网络允许我们用很少的数据训练这些最先进的模型。
如果你有兴趣了解更多基于深度学习的人脸识别,我建议你阅读 PyImageSearch 上的以下指南:
总结
在本教程中,我们了解到人脸识别是一个分为两个阶段的过程,包括:
- 人脸检测和人脸感兴趣区域的提取
- 识别,在这里我们识别出这张脸属于谁
从那里,我们回顾了人脸识别算法的历史,包括:
- 由研究人员手动标记的粗糙的(通常是主观的)面部标志
- 基于线性代数的技术,如特征面和鱼面
- 用于人脸识别的 LBPs
- 基于深度学习的模型,包括 FaceNet 和 OpenFace
本系列的下一篇教程将介绍如何用 OpenCV 实现 Eigenfaces。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!*********
什么是光学字符识别(OCR)?
原文:https://pyimagesearch.com/2021/08/09/what-is-optical-character-recognition-ocr/
光学字符识别,简称或 OCR ,是用来描述将 图像 文本转换为 机器编码 文本的算法和技术(既有电子的也有机械的)。我们通常认为 OCR 是一种软件。也就是说,这些系统:
- 接受输入图像(扫描、拍摄或计算机生成)
- 自动检测文本并像人一样“阅读”它
- 将文本转换成机器可读的格式,以便在更大的计算机视觉系统范围内进行搜索、索引和处理
什么是光学字符识别(OCR)?
然而,OCR 系统也可以是机械和物理。例如,你可能很熟悉电子铅笔,当你写 T5 时,会自动扫描你的笔迹。一旦你写完了,你把笔连接到你的电脑(通用串行总线(USB),蓝牙,或其他)。然后,OCR 软件会分析智能笔记录的动作和图像,生成机器可读的文本。
如果你使用过任何一种光学字符识别系统,不管是像宇宙魔方这样的软件还是一种物理光学字符识别设备,你都会知道光学字符识别系统离精确还有很大的差距。但这是为什么呢?从表面上看,OCR 是一个如此简单的想法,可以说是整个计算机视觉领域中最简单的。拍摄文本图像,并将其转换为机器可读的文本,以便软件对其进行操作。然而,自从 20 世纪 60 年代计算机视觉领域开始以来( Papert,1966 ),研究人员一直在努力创造通用的 OCR 系统,在通用的用例中工作。**
简单的事实是,OCR 是 硬的。
人类通过书写交流的方式有很多细微差别——我们有自然语言处理(NLP)的所有问题,加上计算机视觉系统在从图像中读取一段文本时永远不会获得 100%的准确性。噪点、文笔、画质等方面的变量太多。我们离解决 OCR 还有很长的路要走。
如果 OCR 已经被解决了,这个教程就不会存在了——你的第一个谷歌搜索会带你找到你需要的软件包,你可以毫不费力地自信而准确地将 OCR 应用到你的项目中。但这不是我们生活的世界。虽然我们在解决 OCR 问题方面做得越来越好,但仍然需要一个熟练的从业者来理解如何操作现有的 OCR 工具。这就是本教程存在的原因——我迫不及待地想和你一起踏上这段旅程。
学习目标
在本教程中,您将:
- 了解什么是 OCR
- 接受一堂简短的 OCR 历史课
- 发现 OCR 的常见真实应用
- 了解 OCR 与方向和文字检测(OSD)之间的区别,OSD 是许多最先进的 OCR 引擎中的常见组件
- 了解图像预处理和后处理对改善 OCR 结果的重要性
要了解什么是 OCR,熟悉 OCR 工具, 只要坚持阅读。
OCR 简介
我们将从 OCR 的简史开始这一部分,包括这个计算机视觉子领域是如何产生的。接下来,我们将回顾 OCR 的一些实际应用(其中一些我们将在教程中构建)。然后,我们将简要讨论 OSD 的概念,它是任何 OCR 系统的基本组件。本教程的最后一部分将介绍图像预处理和 OCR 结果后处理的概念,这是两种用于提高 OCR 准确性的常用技术。
OCR 简史
早期的 OCR 技术是纯机械的,可以追溯到 1914 年“伊曼纽尔·戈德堡(Emanuel Goldberg)开发了一种可以读取字符,然后将其转换成标准电报代码的机器” ( Dhavale,2017,第 91 页)。戈德堡在 20 世纪 20 年代和 30 年代继续他的研究,当时他开发了一个搜索缩微胶片(按比例缩小的文件,通常是电影、报纸、杂志等)的系统。)中的字符,然后进行 OCR 识别。
1974 年, Ray Kurzweil 和 Kurzweil Computer Products,Inc. 继续开发 OCR 系统,主要致力于创造一种“盲人阅读机器”库兹韦尔的工作引起了行业领导者施乐的注意,施乐希望将该软件进一步商业化,并开发用于文档理解的 OCR 应用程序。
惠普实验室从 20 世纪 80 年代开始研究宇宙魔方。惠普的工作在 2005 年被开源,迅速成为世界上最受欢迎的 OCR 引擎。宇宙魔方库很可能是你现在阅读这篇教程的原因。
随着深度学习在 2010 年代彻底改变了计算机视觉领域(以及几乎所有其他计算机科学领域),OCR 准确性从称为长短期记忆(LSTM)网络的专门架构中获得了巨大的提升。
现在,在 21 世纪 20 年代,我们看到 OCR 已经越来越多地被科技巨头商业化,例如谷歌、T2、微软、T4、亚马逊等等。我们生活在计算机科学领域的一个奇妙时代——以前我们从未有过如此强大和准确的 OCR 系统。但事实仍然是,这些 OCR 引擎仍然需要一个有知识的计算机视觉从业者来操作。这篇课文将教你如何做到这一点。
光学字符识别的应用
OCR 的应用有很多,其初衷是为盲人创造阅读机器( Schantz,1982 )。从那时起,OCR 应用程序已经发生了的重大变化,包括(但不限于):
- 自动牌照/车牌识别(ALPR/ANPR)
- 交通标志识别
- 分析并击败网站上的验证码(区分计算机和人类的完全自动化的公共图灵测试)
- 从名片中提取信息
- 自动读取护照的机器可读区(MRZ)和其他相关部分
- 解析银行支票中的银行代号、帐号和货币金额
- 理解自然场景中的文本,例如从智能手机拍摄的照片
如果输入图像中有文本,我们很可能会对其应用 OCR—我们需要知道使用哪种技术!
方向和脚本检测
在我们详细讨论 OCR 之前,我们需要简单介绍一下方向和文字检测(OSD) ,我们将在以后的教程中详细介绍。如果 OCR 是获取输入图像并以人类可读和机器可读两种格式返回文本的过程,那么 OSD 就是分析图像的文本元数据的过程,特别是 方向 和 脚本/书写风格。
文本的方向是输入图像中文本的角度(以度为单位)。为了获得更高的 OCR 准确性,我们可能需要应用 OSD 来确定文本方向,纠正它,然后应用 OCR。
脚本和写作风格是指一套字符和符号用于书面和打字交流。我们大多数人都熟悉拉丁字符,它构成了许多欧洲和西方国家使用的字符和符号;然而,还有许多其他形式的写作风格被广泛使用,包括阿拉伯语、希伯来语、汉语等等。拉丁字符与阿拉伯语非常不同,而阿拉伯语又不同于日本汉字,后者是一种用汉字书写的系统。
OCR 系统可以对特定的文字或书写系统做出的任何规则、启发或假设都将使 OCR 引擎在应用于给定的文字时更加准确。因此,我们可以使用 OSD 信息作为提高 OCR 准确性的前兆。
预处理和后处理的重要性
如果您可以应用计算机视觉和图像处理技术来清理您的图像,许多 OCR 引擎(无论是 Tesseract 还是基于云的 API)都会更加准确。
例如,考虑图 1 。作为人类,我们可以在图 1 (左上)中看到文本“12-14”,但是如果您通过 Tesseract OCR 引擎运行相同的图像,您将得到“12:04”(底部)。
然而,如果您要应用一些基本的图像处理操作,如阈值处理、距离变换和形态学操作,您最终会得到一个清晰的图像(图 1 、右上)。当我们通过 Tesseract 传递清理后的图像时,我们正确地获得了文本“12-14。”
我看到计算机视觉和深度学习从业者犯的最常见的错误之一是,他们假设他们正在利用的 OCR 引擎是也是一种广义的图像处理器,能够自动清理他们的图像。由于 Tesseract OCR 引擎的进步,OCR 系统可以进行自动分割和页面分析;然而,这些系统远没有人类那么聪明,人类几乎可以即时解析复杂背景中的文本。
OCR 引擎应该像四年级学生一样被对待,他们能够阅读文本,并且经常需要正确方向的推动。
作为一名计算机视觉和深度学习从业者,使用你的 CV/DL 知识来协助OCR 引擎是你的责任。请记住,如果先对一段文本进行适当的清理和分割,OCR 系统识别这段文本会容易得多。
你还应该考虑对你的 OCR 文本进行后处理。OCR 系统永远不会 100%准确,所以你应该假设会有一些错误。要做到这一点,问问自己是否有可能应用规则和启发法。一些需要考虑的示例问题:
- 我可以应用自动拼写检查来纠正 OCR 过程中拼错的单词吗?
- 我能否利用正则表达式来确定输出 OCR 数据中的模式,并仅提取我感兴趣的信息(如发票中的日期或价格)?
- 我能否利用我的领域知识来创建启发法,自动为我更正 OCR 文本?
创建一个成功的 OCR 应用程序一部分是科学,一部分是艺术。让我们换个话题,谈谈成为一名成功的 OCR 从业者所需的工具。
用于 OCR 的工具、库和包
在构建我们的光学字符识别(OCR)项目之前,我们首先需要熟悉我们可用的 OCR 工具。
教程的这一部分将回顾我们将在本课中使用的主要 OCR 引擎、软件和 API。这些工具将作为我们构建 OCR 项目的基础。
发现 OCR 工具和 API
在本教程的其余部分,您将:
- 探索宇宙魔方 OCR 引擎,世界上最受欢迎的 OCR 软件包
- 了解 Python 和
pytesseract库如何使用 Tesseract 进行推理 - 了解计算机视觉和图像处理算法对 OCR 准确性的影响
- 发现可用于 OCR 的基于云的 API
OCR 工具和库
我们将从简要讨论 Tesseract OCR 引擎开始本节教程,tessera CT OCR 引擎是一个 OCR 包,最初开发于 20 世纪 80 年代,经历了多次修订和更新,现在是世界上最流行的 OCR 系统。
当然,如果 Tesseract 只能用作命令行工具,它就没什么用了——我们的编程语言需要 API 来与它交互。幸运的是,几乎每一种流行的编程语言(Java、C/C++、PHP 等)都有可用的宇宙魔方绑定。),但是我们将使用 Python 编程语言。
Python 不仅是一种简单(且宽容)的编码语言,而且被许多计算机视觉和深度学习从业者使用,非常适合 OCR。为了通过 Python 与 Tesseract OCR 引擎交互,我们将使用pytesseract。但是,光靠宇宙魔方和pytesseract是不够的。OCR 的准确性倾向于严重依赖于我们能够多好地“清理”我们的输入图像,让 Tesseract 更容易对它们进行 OCR。
为了清理和预处理我们的图像,我们将使用 OpenCV,即用于计算机视觉和图像处理的事实上的标准库。我们还将使用机器学习和深度学习 Python 库,包括 scikit-learn、scikit-image、Keras、TensorFlow 等。,来训练我们的自定义 OCR 模型。最后,我们将简要回顾一下基于云的 OCR APIs,我们将在本教程的后面部分进行介绍。
宇宙魔方
Tesseract OCR 引擎最初是由惠普(HP)实验室在 20 世纪 80 年代开发的闭源软件。惠普在 OCR 项目中使用了 Tesseract,大部分 Tesseract 软件都是用 c 语言编写的。然而,当 Tesseract 最初开发时,很少对软件进行更新、修补或加入最新的 OCR 算法。宇宙魔方虽然仍在使用,但基本上处于休眠状态,直到 2005 年被开源。2006 年,谷歌开始赞助开发宇宙魔方。你可能会在图 2 中认出宇宙魔方的标志。
2000 年代后期,传统的 Tesseract 用户和谷歌的赞助为该项目带来了新的生命,允许 OCR 软件更新、修补和添加新功能。最突出的新功能出现在 2018 年 10 月 宇宙魔方 v4 发布时,其中包括一个新的基于长短期记忆(LSTM)网络的深度学习 OCR 引擎。新的 LSTM 引擎提供了显著的准确性增益,使得准确的 OCR 文本成为可能,即使在恶劣的非最佳条件下。
此外,新的 LSTM 引擎接受了超过 123 种语言的训练,使其更容易识别除英语之外的其他语言文本(包括基于脚本的语言,如中文、阿拉伯语等)。).长期以来,宇宙魔方一直是开源 OCR 的事实上的标准,随着 v4 的发布,我们现在看到甚至有更多的计算机视觉开发人员使用这个工具。如果您有兴趣了解如何将 OCR 应用到您的项目中,您需要知道如何操作 Tesseract OCR 引擎。
Python
我们将在本教程的所有例子中使用 Python 编程语言。Python 是一门容易学习的语言。它也是用于计算机视觉、机器学习和深度学习的最广泛使用的语言——这意味着我们需要的任何额外的计算机视觉/深度学习功能都只是一种import陈述方式。因为 OCR 本质上是一个计算机视觉问题,所以使用 Python 编程语言是一个自然的选择。
中小企业〔t1〕
pytesserac是由马蒂亚斯·李开发的 Python 包,他是计算机科学博士,专注于软件工程性能。PyTesseract 库是一个 Python 包,它与tesseract命令行二进制文件接口。仅使用一两个函数调用,我们就可以轻松地将 Tesseract OCR 应用到我们的 OCR 项目中。
OpenCV
为了提高我们的 OCR 准确性,我们需要利用计算机视觉和图像处理来“清理”我们的输入图像,使 Tesseract 更容易正确地对图像中的文本进行 OCR。
为了方便我们的计算机视觉和图像处理操作,我们将使用 OpenCV 库,即事实上的计算机视觉和图像处理标准。OpenCV 库提供了 Python 绑定,这使得它自然地适合我们的 OCR 生态系统。OpenCV 的标志如图图 3 所示。
Keras, TensorFlow, and scikit-learn
有时应用基本的计算机视觉和图像处理操作不足以获得足够的 OCR 准确度。到那时,我们将需要应用机器学习和深度学习。
scikit-learn 库是用 Python 训练机器学习模型时使用的标准包。Keras 和 TensorFlow 在一个易于使用的 API 中为我们提供了深度学习的所有功能。您可以在图 4 中看到这些工具的标志。
云 OCR API
有时候,再多的图像处理/清理和镶嵌选项的组合也无法为我们提供准确的 OCR 结果:
- 也许宇宙魔方从来没有在你的输入图像的字体上训练过
- 也许没有预先训练好的“现成”模型可以正确地定位图像中的文本
- 或者,开发一个定制的 OCR 管道可能会花费太多的精力,而您正在寻找捷径
当这些类型的场景出现时,您应该考虑使用基于云的 OCR APIs,如微软 Azure 认知服务、亚马逊 Rekognition 和谷歌云平台(GCP) API。常用 API 的标志如图图 5 所示。这些 API 是在大规模文本数据集上训练的,潜在地允许你用的一小部分的努力准确地 OCR 复杂的图像。
当然,缺点是:
- 这些都是付费的 API,意味着你需要付费才能使用它们
- 向他们提交图像和检索结果需要互联网连接
- 网络连接意味着在提交图像和获得 OCR 结果之间会有延迟,这使得它可能无法用于实时应用
- 您并不“拥有”整个 OCR 管道。您将被锁定到您用于 OCR 的供应商。
也就是说,在开发 OCR 项目时,这些 OCR APIs 会非常有用,所以我们将在后面的教程中介绍它们。
总结
在本教程中,向您介绍了光学字符识别(OCR)领域。从我的经验来看,我可以证明 OCR 表面上看起来很容易,但当你需要开发一个工作系统时,它绝对是一个 具有挑战性的 领域。请记住,计算机视觉领域已经存在了 50 多年,然而研究人员还没有创造出高度精确的通用 OCR 系统。我们当然离著名的云服务提供商 API 越来越近了,但我们还有很长的路要走。
您还了解了 OCR 中常用的工具、编程语言和库。如果您对可用的工具数量感到不知所措,不要担心,我们将有条不紊地构建每一个工具,将您的知识从 OCR 初学者逐步提升到有经验的 OCR 从业者,他们有信心将 OCR 应用到您的项目中。
PyTorch 是什么?
在本教程中,您将了解 PyTorch 深度学习库,包括:
- PyTorch 是什么
- 如何在你的机器上安装 PyTorch
- 重要 PyTorch 功能,包括张量和亲笔签名
- PyTorch 如何支持 GPU
- PyTorch 为何如此受研究者欢迎
- PyTorch 是否比 Keras/TensorFlow 更好
- 您是否应该在项目中使用 PyTorch 或 Keras/TensorFlow
此外,本教程是 PyTorch 基础知识五部分系列的第一部分:
- py torch 是什么?(今日教程)
- PyTorch 简介:使用 PyTorch 训练你的第一个神经网络(下周教程)
- PyTorch:训练你的第一个卷积神经网络
- 使用预训练网络的 PyTorch 图像分类
- 使用预训练网络的 PyTorch 对象检测
在本教程结束时,您将对 PyTorch 库有一个很好的介绍,并且能够与其他深度学习实践者讨论该库的优缺点。
了解 PyTorch 深度学习库, 继续阅读。
py torch 是什么?
PyTorch 是一个开源的机器学习库,专门从事张量计算、自动微分和 GPU 加速。由于这些原因, PyTorch 是最受欢迎的深度学习库之一,与 Keras 和 TensorFlow 竞争“最常用”深度学习包的奖项:
PyTorch 趋向于特别是在研究社区中流行,因为它的 Pythonic 性质和易于扩展(例如,实现定制的层类型、网络架构等)。).
在本教程中,我们将讨论 PyTorch 深度学习库的基础知识。从下周开始,您将获得使用 PyTorch 训练神经网络、执行图像分类以及对图像和实时视频应用对象检测的实践经验。
让我们开始了解 PyTorch 吧!
PyTorch、深度学习和神经网络
PyTorch 基于 Torch,一个用于 Lua 的科学计算框架。在 PyTorch 和 Keras/TensorFlow 之前,Caffe 和 Torch 等深度学习包往往最受欢迎。
然而,随着深度学习开始彻底改变计算机科学的几乎所有领域,开发人员和研究人员希望有一个高效、易用的库来用 Python 编程语言构建、训练和评估神经网络。
Python 和 R 是数据科学家和机器学习最受欢迎的两种编程语言,因此研究人员希望在他们的 Python 生态系统中使用深度学习算法是很自然的。
谷歌人工智能研究员弗朗索瓦·乔莱(Franç ois Chollet)于 2015 年 3 月开发并发布了 Keras,这是一个开源库,提供了用于训练神经网络的 Python API。 Keras 因其易于使用的 API 而迅速受到欢迎,该 API 模仿了 scikit-learn 的大部分工作方式,事实上的Python 的标准机器学习库。
很快,谷歌在 2015 年 11 月发布了第一个 TensorFlow 版本。 TensorFlow 不仅成为 Keras 库的默认后端/引擎,还实现了高级深度学习实践者和研究人员创建最先进的网络和进行新颖研究所需的许多低级功能。
然而,有一个问题 TensorFlow v1.x API 不是很 Pythonic 化,也不是很直观和易于使用。为了解决这个问题,PyTorch 于 2016 年 9 月发布,由脸书赞助,Yann LeCun(现代神经网络复兴的创始人之一,脸书的人工智能研究员)支持。
PyTorch 解决了研究人员在 Keras 和 TensorFlow 中遇到的许多问题。虽然 Keras 非常容易使用,但就其本质和设计而言,Keras 并没有公开研究人员需要的一些低级功能和定制。
另一方面,TensorFlow 当然提供了对这些类型函数的访问,但它们不是 Pythonic 式的,而且通常很难梳理 TensorFlow 文档来找出到底需要什么函数。简而言之,Keras 没有提供研究人员需要的低级 API,TensorFlow 的 API 也不那么友好。
PyTorch 通过创建一个既 Pythonic 化又易于定制的 API 解决了这些问题,允许实现新的层类型、优化器和新颖的架构。研究小组慢慢开始接受 PyTorch,从 TensorFlow 转变过来。本质上,这就是为什么今天你会看到这么多研究人员在他们的实验室里使用 PyTorch。
也就是说,自从 PyTorch 1.x 和 TensorFlow 2.x 发布以来,各自库的 API 基本上已经(双关语)。PyTorch 和 TensorFlow 现在实现了本质上相同的功能,并提供 API 和函数调用来完成相同的事情
*这种说法甚至得到了伊莱·史蒂文斯、卢卡·安提卡和托马斯·维赫曼的支持,他们在《PyTorch》一书中写道:
有趣的是,随着 TorchScript 和 eager mode 的出现,py torch 和 TensorFlow 都已经看到它们的功能集开始与对方的 融合,尽管两者之间这些功能的呈现和整体体验仍然有很大不同。
— Deep Learning with PyTorch (Chapter 1, Section 1.3.1, Page 9)
我在这里的观点是不要陷入 PyTorch 或 Keras/TensorFlow 哪个“更好”的争论中——这两个库实现了非常相似的特性,只是使用了不同的函数调用和不同的训练范式。
如果你是深度学习的初学者,不要陷入哪个库更好的争论(有时是敌意的)中是正确的。正如我在本教程后面讨论的,你最好选择一个并学习它。不管你用 PyTorch 还是 Keras/TensorFlow,深度学习的基础都是一样的。
如何安装 PyTorch?
PyTorch 库可以使用 Python 的包管理器 pip 安装:
$ pip install torch torchvision
从那里,您应该启动一个 Python shell 并验证您可以导入torch和torchvision:
$ python
>>> import torch
>>> torch.__version__
'1.8.1'
>>>
恭喜你现在已经在你的机器上安装了 PyTorch!
注: 需要帮忙安装 PyTorch?要开始, 一定要查阅 PyTorch 官方文档 。不然你可能会对我预装 PyTorch 自带的 PyImageSearch 大学 里面预配置的 Jupyter 笔记本感兴趣。
PyTorch 和 Tensors
PyTorch 将数据表示为多维的类似 NumPy 的数组,称为张量。张量将输入存储到你的神经网络、隐藏层表示和输出中。
下面是一个用 NumPy 初始化数组的例子:
>>> import numpy as np
>>> np.array([[0.0, 1.3], [2.8, 3.3], [4.1, 5.2], [6.9, 7.0]])
array([[0\. , 1.3],
[2.8, 3.3],
[4.1, 5.2],
[6.9, 7\. ]])
我们可以使用 PyTorch 初始化同一个数组,如下所示:
>>> import torch
>>> torch.tensor([[0.0, 1.3], [2.8, 3.3], [4.1, 5.2], [6.9, 7.0]])
tensor([[0.0000, 1.3000],
[2.8000, 3.3000],
[4.1000, 5.2000],
[6.9000, 7.0000]])
这看起来没什么大不了的,但是在幕后,PyTorch 可以从这些张量动态生成一个图形,然后在其上应用自动微分:
PyTorch 的亲笔签名特稿
说到自动微分,PyTorch 让使用torch.autograd训练神经网络变得超级简单。
在引擎盖下,PyTorch 能够:
- 组装一个神经网络图
- 执行向前传递(即,进行预测)
- 计算损失/误差
- 向后遍历网络(即反向传播)并调整网络参数,使其(理想情况下)基于计算的损耗/输出做出更准确的预测
*第 4 步总是手工实现的最乏味和耗时的步骤。幸运的是,PyTorch 会自动完成这一步。
注意: Keras 用户通常只需调用model.fit来训练网络,而 TensorFlow 用户则利用GradientTape类。PyTorch 要求我们手工实现我们的训练循环,所以torch.autograd在幕后为我们工作的事实是一个巨大的帮助。感谢 PyTorch 开发人员实现了自动微分,这样您就不必这么做了。
PyTorch 和 GPU 支持
PyTorch 库主要支持基于 NVIDIA CUDA 的 GPU。GPU 加速允许您在很短的时间内训练神经网络。
此外,PyTorch 支持分布式训练,可以让你更快地训练你的模型。
py torch 为什么受科研人员欢迎?
PyTorch 在 2016 年(PyTorch 发布的时间)到 2019 年(TensorFlow 2.x 正式发布之前)之间在研究社区获得了立足点。
PyTorch 能够获得这个立足点的原因有很多,但最主要的原因是:
- Keras 虽然非常容易使用,但并没有提供研究人员进行新颖的深度学习研究所需的低级功能
- 同样,Keras 使得研究人员很难实现他们自己的定制优化器、层类型和模型架构
- TensorFlow 1.x 有没有提供这种底层访问和自定义实现;然而,这个 API 很难使用,也不是很 Pythonic 化
- PyTorch,特别是其亲笔签名的支持,帮助解决了 TensorFlow 1.x 的许多问题,使研究人员更容易实现他们自己的自定义方法
- 此外,PyTorch 让深度学习实践者完全控制训练循环
这两者之间当然有分歧。Keras 使得使用对model.fit的单个调用来训练神经网络变得微不足道,类似于我们如何在 scikit-learn 中训练标准机器学习模型。
缺点是研究人员无法(轻易地)修改这个model.fit调用,所以他们不得不使用 TensorFlow 的底层函数。但是这些方法并不容易让他们实施他们的训练程序。
PyTorch 解决了这个问题,从我们完全控制的意义上来说,这是好的(T1),但坏的(T3)是,因为我们可以轻易地用 PyTorch 搬起石头砸自己的脚(每个* PyTorch 用户以前都忘了将渐变归零)。*
尽管如此,关于 PyTorch 和 TensorFlow 哪个更适合研究的争论开始平息。PyTorch 1.x 和 TensorFlow 2.x APIs 实现了非常相似的特性,它们只是以不同的方式实现,有点像学习一种编程语言而不是另一种。每种编程语言都有其优点,但两者都实现了相同类型的语句和控制(即“if”语句、“for”循环等)。).
py torch 比 TensorFlow 和 Keras 好吗?
这个问题问错了, 尤其是 如果你是深度学习的新手。谁也不比谁强。 Keras 和 TensorFlow 有特定的用途,就像 PyTorch 一样。
例如,你不会一概而论地说 Java 绝对比 Python 好。当处理机器学习和数据科学时,有一个强有力的论点是 Python 优于 Java。但是如果您打算开发运行在多种高可靠性架构上的企业应用程序,那么 Java 可能是更好的选择。
不幸的是,一旦我们对某个特定的阵营或团体变得忠诚,我们人类就会变得“根深蒂固”。围绕 PyTorch 与 Keras/TensorFlow 的斗争有时会变得很难看,这曾促使 Keras 的创始人弗朗索瓦·乔莱(Franç ois Chollet)要求 PyTorch 用户停止向他发送仇恨邮件:
仇恨邮件也不仅限于弗朗索瓦。我在 PyImageSearch 上的大量深度学习教程中使用了 Keras 和 TensorFlow,我很难过地报告,我收到了批评我使用 Keras/TensorFlow 的仇恨邮件,称我愚蠢/愚蠢,告诉我关闭 PyImageSearch,我不是“真正的”深度学习实践者(不管这是什么意思)。
我相信其他教育工作者也经历过类似的行为,不管他们是用 Keras/TensorFlow 还是 PyTorch 写的教程。双方都变得丑陋,这不仅限于 PyTorch 用户。
我在这里的观点是,你不应该变得如此根深蒂固,以至于你根据别人使用的深度学习库来攻击他们。说真的,世界上有更重要的问题值得你关注——你真的不需要使用你的电子邮件客户端或社交媒体平台上的回复按钮来煽动和催化更多的仇恨进入我们已经脆弱的世界。
其次,如果你是深度学习的新手,那么从哪个库开始并不重要。PyTorch 1.x 和 TensorFlow 2.x 的 API 已经融合——两者都实现了相似的功能,只是实现方式不同。
你在一个库中学到的东西会转移到另一个库中,就像学习一门新的编程语言一样。你学习的第一种语言通常是最难的,因为你不仅要学习该语言的语法*,还要学习控制结构和程序设计。
你的第二编程语言通常容易学习一个数量级,因为到那时你已经理解了控制和程序设计的基础。
深度学习库也是如此。随便挑一个就学会了。如果你在挑选上有困难,抛硬币——这真的没关系,你的经验会转移。
是否应该用 PyTorch 代替 TensorFlow/Keras?
正如我在这篇文章中多次提到的,在 Keras/TensorFlow 和 PyTorch 之间进行选择并不涉及做出笼统的陈述,例如:
- “如果你在做研究,你绝对应该使用 PyTorch。”
- 如果你是初学者,你应该使用 Keras
- “如果你正在开发一个行业应用,使用 TensorFlow 和 Keras。”
PyTorch/Keras 和 TensorFlow 之间的许多功能集是融合的——两者本质上包含相同的功能集,只是以不同的方式实现。
如果你是全新的深度学习, 随便挑一个就学会了。 我个人做认为 Keras 是最适合教初露头角的深度学习从业者。我也认为 Keras 是快速原型化和部署深度学习模型的最佳选择。
也就是说,PyTorch 确实让更高级的实践者更容易实现定制的训练循环、层类型和架构。现在 TensorFlow 2.x API 出来了,这种争论有所减弱,但我相信它仍然值得一提。
最重要的是,无论你使用或选择学习什么深度学习库,不要成为一个狂热分子,不要 troll 留言板,总的来说,不要造成问题。这个世界上的仇恨已经够多了——作为一个科学界,我们应该超越仇恨邮件和揪头发。
总结
在本教程中,您了解了 PyTorch 深度学习库,包括:
- PyTorch 是什么
- 如何在你的机器上安装 PyTorch
- PyTorch GPU 支持
- PyTorch 为什么在研究界受欢迎
- 在项目中是使用 PyTorch 还是 Keras/TensorFlow
下周,您将通过实现和训练您的第一个神经网络,获得一些使用 PyTorch 的实践经验。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
OpenCV 3 中 SIFT 和 SURF 去哪了?
原文:https://pyimagesearch.com/2015/07/16/where-did-sift-and-surf-go-in-opencv-3/
如果你有机会体验 OpenCV 3(并在关键点检测器和特征描述符方面做了大量工作),你可能会注意到默认情况下,SIFT 和 SURF 实现不再包含在 OpenCV 3 库中。
不幸的是,您可能通过打开一个终端、导入 OpenCV,然后尝试实例化您最喜欢的关键点检测器(可能使用如下代码)来学习这一课:
$ python
>>> import cv2
>>> detector = cv2.FeatureDetector_create("SIFT")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'FeatureDetector_create'
哦不!再也没有cv2.FeatureDetector_create的方法了!
我们的cv2.DescriptorExtractor_create函数也是如此:
>>> extractor = cv2.DescriptorExtractor_create("SIFT")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'DescriptorExtractor_create'
此外,cv2.SIFT_create和cv2.SURF_create也将失败:
>>> cv2.SIFT_create()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'SIFT_create'
>>> cv2.SURF_create()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'SURF_create'
老实说,这一开始让我挠头。如果删除了cv2.FeatureDetector_create和cv2.DescriptorExtractor_create,我该如何访问 SIFT、SURF 和我喜欢的其他关键点检测器和局部不变描述符?
cv2.FeatureDetector_create和cv2.DescriptorExtractor_create是(现在仍然是)我一直使用的方法。就我个人而言,我非常喜欢 OpenCV 2.4.X 的实现。您所需要做的就是传入一个字符串,工厂方法就会为您构建实例化。然后,您可以使用关键点检测器或特性描述符的 getter 和 setter 方法来调整参数。
此外,这些方法多年来一直是 OpenCV 2.4.X 的一部分。为什么他们会从默认安装中被删除?他们被转移到哪里了?
在这篇博文的剩余部分,我将详细说明为什么 OpenCV 3.0 默认删除了某些关键点检测器和局部不变描述符。我还将向您展示在 OpenCV 的新版本中哪里可以找到 SIFT、SURF 以及其他检测器和描述符。
OpenCV 3.0 默认安装中为什么去掉了 SIFT 和 SURF?
SIFT 和 SURF 是 OpenCV 称之为“非自由”模块的算法的例子。这些算法由它们各自的创造者申请专利,虽然它们可以在学术和研究环境中免费使用,但如果你在商业(即盈利)应用中使用它们,你应该从技术上从创造者那里获得许可证/许可。
随着 OpenCV 3 的推出,许多“非自由”模块被移出默认的 OpenCV 安装,并被放入 opencv_contrib 包。opencv_contrib包包含算法的实现,这些算法要么是获得专利的,要么是实验开发的。
opencv_contrib 中的算法和相关实现不是默认安装的,您需要在编译和安装 OpenCV 时 显式启用它们以获得对它们的访问。
*就我个人而言,我对这一举措并不太感冒。
是的,我知道在开源库中包含专利算法可能会引起一些争议。但是像 SIFT 和 SURF 这样的算法在很多计算机视觉领域都很普遍。更重要的是,SIFT 和 SURF 的 OpenCV 实现每天都被学者和研究人员用来评估新的图像分类、基于内容的图像检索等。算法。默认不包含这些算法,弊大于利(至少在我看来是这样)。
如何在 OpenCV 3 中访问 SIFT 和 SURF?
要访问 OpenCV 2.4.X 中的原始 SIFT 和 SURF 实现,您需要从 GitHub 中下载OpenCV和 opencv_contrib 库,然后从源代码中编译并安装 OpenCV 3。
*幸运的是,从源代码编译 OpenCV 比以前更容易了。我在 OpenCV 3 教程、资源和指南页面上收集了许多流行操作系统的 Python 和 OpenCV 安装说明——只需向下滚动安装 OpenCV 3 和 Python 部分,找到适合您的操作系统的 Python 版本(Python 2.7+或 Python 3+)。
如何在 OpenCV 3 中使用 SIFT 和 SURF?
现在你已经用opencv_contrib包安装了 OpenCV 3,你应该可以访问 OpenCV 2.4.X 中最初的 SIFT 和 SURF 实现,只是这次它们将通过cv2.SIFT_create和cv2.SURF_create函数在xfeatures2d子模块中。
为了确认这一点,打开一个 shell,导入 OpenCV,并执行以下命令(当然,假设在当前目录中有一个名为test_image.jpg的图像):
$ python
>>> import cv2
>>> image = cv2.imread("test_image.jpg")
>>> gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
>>> sift = cv2.xfeatures2d.SIFT_create()
>>> (kps, descs) = sift.detectAndCompute(gray, None)
>>> print("# kps: {}, descriptors: {}".format(len(kps), descs.shape))
# kps: 274, descriptors: (274, 128)
>>> surf = cv2.xfeatures2d.SURF_create()
>>> (kps, descs) = surf.detectAndCompute(gray, None)
>>> print("# kps: {}, descriptors: {}".format(len(kps), descs.shape))
# kps: 393, descriptors: (393, 64)
如果一切顺利,您应该能够无误地实例化 SIFT 和 SURF 关键点检测器和局部不变描述符。
同样重要的是要注意,通过使用opencv_contrib,你将不会干扰 OpenCV 3 中包含的任何其他关键点检测器和局部不变描述符。您仍然可以访问 KAZE、AKAZE、BRISK 等。没有问题:
>>> kaze = cv2.KAZE_create()
>>> (kps, descs) = kaze.detectAndCompute(gray, None)
>>> print("# kps: {}, descriptors: {}".format(len(kps), descs.shape))
# kps: 359, descriptors: (359, 64)
>>> akaze = cv2.AKAZE_create()
>>> (kps, descs) = akaze.detectAndCompute(gray, None)
>>> print("# kps: {}, descriptors: {}".format(len(kps), descs.shape))
# kps: 192, descriptors: (192, 61)
>>> brisk = cv2.BRISK_create()
>>> (kps, descs) = brisk.detectAndCompute(gray, None)
>>> print("# kps: {}, descriptors: {}".format(len(kps), descs.shape))
# kps: 361, descriptors: (361, 64)
摘要
在这篇博文中,我们了解到 OpenCV 已经从库中移除了cv2.FeatureDetector_create和cv2.DescriptorExtractor_create函数。此外,SIFT 和 SURF 实现也已经从默认的 OpenCV 3 安装中删除。
移除 SIFT 和 SURF 的原因是 OpenCV 所谓的“非自由”算法。SIFT 和 SURF 都是专利算法,这意味着从技术上讲,你应该获得许可,才能在商业算法中使用它们(尽管它们可以免费用于学术和研究目的)。
正因为如此,OpenCV 决定将专利算法(以及实验性实现)转移到 opencv_contrib 包中。这意味着要访问 SIFT 和 SURF,您需要编译并安装 OpenCV 3,并启用opencv_contrib支持。幸运的是,在我的 OpenCV 3 安装指南的帮助下,这并不太具有挑战性。
一旦你安装了支持opencv_contrib的 OpenCV 3,你就可以通过cv2.xfeatures2d.SIFT_create()和cv2.xfeatures2d.SURF_create()功能在xfeatures2d包中找到你喜欢的 SIFT 和 SURF 实现。**
使用 Tesseract 和 Python 将角色列入白名单和黑名单
在我们的之前的教程中,你学习了如何从输入图像中只对个数字进行 OCR 。但是,如果您想对字符过滤过程进行更细粒度的控制,该怎么办呢?
例如,在构建发票应用程序时,您可能希望不仅提取数字和字母,还提取特殊字符,如美元符号、小数点分隔符(即句点)和逗号。为了获得更细粒度的控制,我们可以应用白名单和黑名单,这正是本教程的主题。
学习目标
在本教程中,您将了解到:
- 白名单和黑名单的区别
- 白名单和黑名单如何用于 OCR 问题
- 如何使用 Tesseract 应用白名单和黑名单
要了解如何在进行 OCR 时加入白名单和黑名单, 请继续阅读。
用于 OCR 的白名单和黑名单字符
在本教程的第一部分,我们将讨论白名单和黑名单之间的区别,这是在应用 OCR 和 Tesseract 时两种常见的字符过滤技术。从那里,我们将回顾我们的项目并实现一个可用于白名单/黑名单过滤的 Python 脚本。然后,我们将检查我们的字符过滤工作的结果。
什么是白名单和黑名单?
作为白名单和黑名单如何工作的例子,让我们考虑一个为 Google 工作的系统管理员。谷歌是全球最受欢迎的网站——几乎互联网上的每个人都使用谷歌——但随着它的受欢迎程度,邪恶的用户可能会试图攻击它,关闭它的服务器,或泄露用户数据。**系统管理员需要将恶意行为的* IP 地址列入黑名单,同时允许所有其他有效的传入流量。***
*现在,让我们假设同一个系统管理员需要配置一个开发服务器供 Google 内部使用和测试。该系统管理员将需要阻止所有传入的 IP 地址 ,除了谷歌开发者的 白名单 IP 地址的 。
出于 OCR 目的的白名单和黑名单的概念是相同的。白名单指定 OCR 引擎只允许识别的字符列表——如果一个字符不在白名单上,它就不能包含在输出的 OCR 结果中。
白名单的反义词是黑名单。黑名单中指定的人物,* 在任何情况下 ,都不能列入输出。
在本教程的其余部分,您将学习如何使用 Tesseract 应用白名单和黑名单。
项目结构
让我们从回顾本教程的目录结构开始:
|-- invoice.png
|-- pa_license_plate.png
|-- whitelist_blacklist.py
本教程将实现whitelist_blacklist.py Python 脚本,并使用两张图像——一张发票和一张牌照——进行测试。让我们深入研究代码。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
用魔方将角色列入白名单和黑名单
我们现在将学习如何使用 Tesseract OCR 引擎将字符列入白名单和黑名单。打开项目目录结构中的whitelist_blacklist.py文件,插入以下代码:
# import the necessary packages
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-w", "--whitelist", type=str, default="",
help="list of characters to whitelist")
ap.add_argument("-b", "--blacklist", type=str, default="",
help="list of characters to blacklist")
args = vars(ap.parse_args())
我们的导入没有什么特别之处——同样,我们使用的是 PyTesseract 和 OpenCV。白名单和黑名单功能通过基于字符串的配置选项内置到 PyTesseract 中。
我们的脚本接受一个输入--image路径。此外,它接受两个可选的命令行参数来直接从我们的终端驱动我们的白名单和黑名单功能:
--whitelist:作为我们的字符的字符串,可以传递给结果--blacklist:必须永不包含在结果中的字符
--whitelist和--blacklist参数都有空字符串的default值,因此我们可以使用一个、两个或两个都不使用作为我们的 Tesseract OCR 配置的一部分。
接下来,让我们加载我们的图像并构建我们的宇宙魔方 OCR options:
# load the input image, swap channel ordering, and initialize our
# Tesseract OCR options as an empty string
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
options = ""
# check to see if a set of whitelist characters has been provided,
# and if so, update our options string
if len(args["whitelist"]) > 0:
options += "-c tessedit_char_whitelist={} ".format(
args["whitelist"])
# check to see if a set of blacklist characters has been provided,
# and if so, update our options string
if len(args["blacklist"]) > 0:
options += "-c tessedit_char_blacklist={}".format(
args["blacklist"])
第 18 行和第 19 行以 RGB 格式加载我们的--image。我们的options变量首先被初始化为一个空字符串(第 20 行)。
从那里开始,如果--whitelist命令行参数至少有一个我们希望只允许 OCR 的字符,它将作为我们的options ( 第 24-26 行)的一部分被附加到-c tessedit_char_whitelist=。
类似地,如果我们通过--blacklist参数将任何字符列入黑名单,那么options会被附加上-c tessedit_char_blacklist=,后跟任何在任何情况下都不会出现在我们的结果中的字符(第 30-32 行)。
*同样,我们的options字符串可以包含一个、两个或者都不包含白名单/黑名单字符。
最后,我们对 PyTesseract 的image_to_string的调用执行 OCR:
# OCR the input image using Tesseract
text = pytesseract.image_to_string(rgb, config=options)
print(text)
在我们对image_to_string的调用中,唯一新的参数是config参数(第 35 行)。请注意我们是如何传递连接在一起的宇宙魔方options的。OCR 字符的白名单和黑名单的结果通过脚本的最后一行打印出来。
白名单和黑名单以及镶嵌结果
我们现在已经准备好用 Tesseract 应用白名单和黑名单了。打开终端并执行以下命令:
$ python whitelist_blacklist.py --image pa_license_plate.png
PENNSYLVANIA
ZIW*4681
visitPA.com
正如终端输出所展示的,我们有一个宾夕法尼亚州的牌照(图 2 ),除了车牌号码之间的星号(*)之外,所有内容都被正确地 OCR 识别了——这个特殊的符号被错误地 OCR 识别了。利用一点领域知识,我们知道车牌不能包含一个*作为字符,所以一个简单的解决问题的方法是将和*列入的黑名单:
$ python whitelist_blacklist.py --image pa_license_plate.png \
--blacklist "*#"
PENNSYLVANIA
ZIW4681
visitPA.com
如--blacklist命令行参数所示,我们将两个字符列入了黑名单:
*从上面- 还有
#符号(一旦你将*列入黑名单,宇宙魔方将试图将这个特殊符号标记为#,因此我们将和都列入黑名单)
通过使用黑名单,我们的 OCR 结果现在正确了!
*让我们试试另一个例子,这是一张发票,包括发票号、签发日期和到期日:
$ python whitelist_blacklist.py --image invoice.png
Invoice Number 1785439
Issue Date 2020-04-08
Due Date 2020-05-08
| DUE | $210.07
在图 3 的中,Tesseract 已经能够正确识别发票的所有字段。有趣的是,它甚至将底部框的边缘确定为竖条(|),这对多列数据可能很有用,但在这种情况下只是一个意外的巧合。
现在假设我们只想过滤出价格信息(即数字、美元符号和句点),以及发票号和日期(数字和破折号):
$ python whitelist_blacklist.py --image invoice.png \
--whitelist "0123456789.-"
1785439
2020-04-08
2020-05-08
210.07
结果正如我们所料!我们现在已经成功地使用了白名单来提取发票号、签发日期、到期日期和价格信息,同时丢弃其余信息。
如果需要,我们还可以组合白名单和黑名单:
$ python whitelist_blacklist.py --image invoice.png \
--whitelist "123456789.-" --blacklist "0"
1785439
22-4-8
22-5-8
21.7
这里,我们将数字、句点和破折号列入白名单,同时将数字0列入黑名单,正如我们的输出所示,我们有发票号、签发日期、到期日和价格,但是所有出现的0由于黑名单而被忽略。
当你对图像或文档结构有了先验知识后,你就可以使用白名单和黑名单作为简单而有效的方法来提高输出的 OCR 结果。当您试图提高项目的 OCR 准确性时,它们应该是您的第一站。
总结
在本教程中,您学习了如何使用 Tesseract OCR 引擎应用白名单和黑名单字符过滤。
白名单指定 OCR 引擎只允许识别的字符列表——如果一个字符不在白名单上,它就不能包含在输出的 OCR 结果中。白名单的反义词是黑名单。黑名单指定* 在任何情况下 都不能包含在输出中的字符。***
*使用白名单和黑名单是一种简单而强大的技术,可以在 OCR 应用程序中使用。为了让白名单和黑名单起作用,您需要一个具有可靠模式或结构的文档或图像。例如,如果你正在构建一个基本的收据扫描软件,你可以写一个白名单,只有允许数字、小数点、逗号和美元符号。
如果你已经建立了一个自动车牌识别(ALPR)系统,你可能会注意到宇宙魔方变得“混乱”,并输出图像中不是的特殊字符。
在我们的下一个教程中,我们将继续构建我们的 Tesseract OCR 知识,这一次我们将注意力转向检测和校正文本方向,这是提高 OCR 准确性的一个重要的预处理步骤。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!**********
为什么我的验证损失低于培训损失?
原文:https://pyimagesearch.com/2019/10/14/why-is-my-validation-loss-lower-than-my-training-loss/
在本教程中,您将了解在训练您自己的自定义深度神经网络时,验证损失可能低于训练损失的三个主要原因。
我第一次对研究机器学习和神经网络感兴趣是在高中后期。那时候没有很多可访问的机器学习库,当然也没有 scikit-learn。
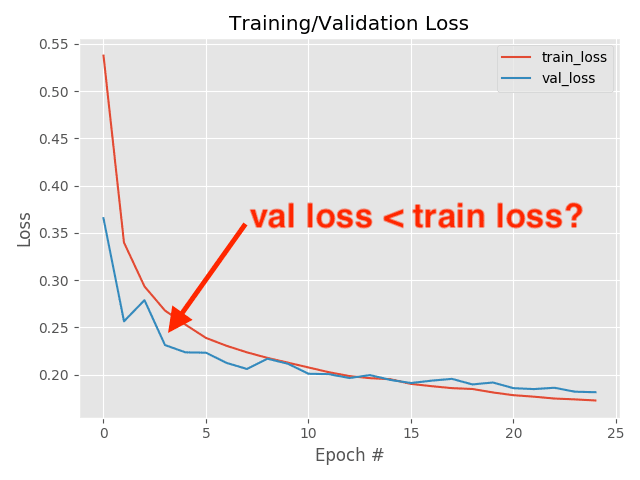
每天下午 2 点 35 分,我会离开高中,跳上回家的公交车,在 15 分钟内,我会在我的笔记本电脑前,研究机器学习,并试图用手实现各种算法。
我很少停下来休息,只是偶尔不吃晚饭,这样我就可以继续工作和学习到深夜。
在这些深夜会议中,我会手工实现模型和优化算法(用所有语言的 Java 当时我也在学 Java)。
由于它们是由一个初露头角的高中程序员手工实现的 ML 算法,而他只学过一门微积分课程,我的实现毫无疑问容易出现错误。
我特别记得一个晚上。
时间是凌晨 1 点半。我累了。我饿了(因为我没吃晚饭)。我很担心第二天的西班牙语考试,我肯定不是为了考试而学习的。
我试图训练一个简单的前馈神经网络,根据基本的颜色通道统计(即平均值和标准偏差)对图像内容进行分类。
我的网络正在训练…但是我遇到了一个非常奇怪的现象:
我的验证损失低于培训损失!
这怎么可能呢?
- 我是否不小心切换了训练和验证损失的图标签?潜在地。我没有像 matplotlib 这样的绘图库,所以我的损失日志被传输到一个 CSV 文件,然后在 Excel 中绘制。肯定容易出现人为错误。
- 我的代码中有错误吗?几乎可以肯定。我同时在自学 Java 和机器学习——那些代码中肯定有某种错误。
- 我是不是太累了以至于我的大脑无法理解?也很有可能。在我生命的那段时间里,我睡得不多,很容易忽略一些显而易见的东西。
但是,事实证明上面的情况都不是——**我的验证损失比我的培训损失要低。**
直到大学三年级,我第一次参加正式的机器学习课程,我才终于明白为什么验证损失可以低于训练损失。
几个月前,杰出的作者 aurélien Geron发布了一条 tweet 线程,简明地解释了为什么你可能会遇到验证损失低于培训损失的情况。
我受到 Aurélien 精彩解释的启发,想在这里用我自己的评论和代码来分享它,确保没有学生(像我多年前一样)必须挠头想知道“为什么我的验证损失低于我的培训损失?!"。
要了解验证损失可能低于培训损失的三个主要原因,请继续阅读!
为什么我的验证损失低于培训损失?
在本教程的第一部分,我们将讨论神经网络中“损失”的概念,包括损失代表什么以及我们为什么要测量它。
从那里,我们将实现一个基本的 CNN 和训练脚本,然后使用我们新实现的 CNN 运行一些实验(这将导致我们的验证损失低于我们的训练损失)。
根据我们的结果,我将解释您的验证损失可能低于培训损失的三个主要原因。
训练一个神经网络,什么是“损失”?
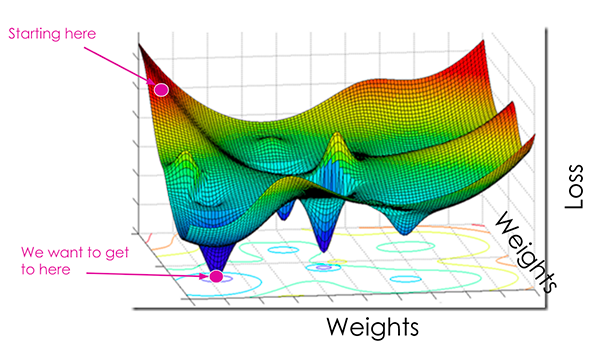
Figure 1: What is the “loss” in the context of machine/deep learning? And why is my validation loss lower than my training loss? (image source)
在最基本的层面上,损失函数量化了给定预测器在对数据集中的输入数据点进行分类时的“好坏”程度。
损失越小,分类器在对输入数据和输出目标之间的关系进行建模方面的工作就越好。
也就是说,有一点我们可以过度拟合我们的模型——通过对训练数据建模过于接近,我们的模型失去了概括的能力。
因此,我们寻求:
- 降低我们的损失,从而提高我们模型的准确性。
- 尽快完成并尽可能少地进行超参数更新/实验。
- 所有的都不会过度拟合我们的网络,也不会过于紧密地模拟训练数据。
这是一种平衡行为,我们对损失函数和模型优化器的选择会极大地影响我们最终模型的质量、准确性和可推广性。
典型的损失函数(也称为“目标函数”或“得分函数”)包括:
- 二元交叉熵
- 范畴交叉熵
- 稀疏分类交叉熵
- 均方误差
- 平均绝对误差
- 标准铰链
- 方形铰链
对损失函数的全面回顾超出了这篇文章的范围,但是目前,只要理解对于大多数任务:
- 损失衡量你的模型的“好”
- 损失越小越好
- 但是你需要小心不要吃太多
若要在训练您自己的自定义神经网络时了解有关损失函数的角色的更多信息,请确保:
- 阅读此关于参数化学习和线性分类的介绍。
- 浏览下面关于 Softmax 分类器的教程。
- 请参考本指南关于多级 SVM 损耗的内容。
此外,如果您想要一份关于损失函数在机器学习/神经网络中作用的完整、分步指南,请确保您阅读 使用 Python 对计算机视觉进行深度学习 ,在那里我详细解释了参数化学习和损失方法(包括代码和实验)。
项目结构
继续使用本文的 【下载】 部分下载源代码。从那里,通过tree命令检查项目/目录结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── minivggnet.py
├── fashion_mnist.py
├── plot_shift.py
└── training.pickle
1 directory, 5 files
今天我们将使用较小版本的 VGGNet,称为 MiniVGGNet。pyimagesearch模块包括这个 CNN。
我们的脚本在时尚 MNIST 数据集上训练 MiniVGGNet。我在之前的博客文章中写过关于在时尚 MNIST 上培训 MiniVGGNet 的文章,所以今天我们不会谈论太多细节。
今天的训练脚本生成一个training.pickle文件,记录训练准确度/损失历史。在下面的 原因#2 部分中,我们将使用plot_shift.py将培训损失图移动半个时期,以证明当验证损失低于培训损失时,测量损失的时间起作用。
现在让我们深入三个原因来回答这个问题,“为什么我的验证损失低于我的培训损失?”。
原因#1:在培训期间应用了正则化,但在验证/测试期间没有应用

Figure 2: Aurélien answers the question: “Ever wonder why validation loss > training loss?” on his twitter feed (image source). The first reason is that regularization is applied during training but not during validation/testing.
当训练深度神经网络时,我们经常应用正则化来帮助我们的模型:
- 获得更高的验证/测试精度
- 理想情况下,更好地概括验证和测试集之外的数据
正则化方法通常牺牲训练精度来提高验证/测试精度——在某些情况下,这可能导致验证损失低于训练损失。
其次,请记住,在验证/测试阶段,退出等正则化方法不会应用。
正如 Aurélien 在图 2 中所示,将正则化因素纳入验证损失(例如在验证/测试期间应用下降)可以使你的训练/验证损失曲线看起来更相似。
原因#2:在每个时期的期间测量训练损失,而在每个时期的之后测量验证损失
*
Figure 3: Reason #2 for validation loss sometimes being less than training loss has to do with when the measurement is taken (image source).
您可能看到验证损失低于培训损失的第二个原因是损失值的测量和报告方式:
- 在每个时期的期间测量训练损失
** 而验证损失是在每个时期的之后的*测量的**
你的训练损失在整个时期内不断被报告;然而,**验证度量仅在当前训练时期完成后才在验证集上计算。***
这意味着,平均而言,培训损失是在半个时期之前测量的。
如果将训练损失向左移动半个历元,您会看到训练值和损失值之间的差距要小得多。
有关这种行为的实际例子,请阅读下面一节。
实施我们的培训脚本
我们将实现一个简单的 Python 脚本,在时尚 MNIST 数据集上训练一个小型的类似 VGG 的网络(称为 MiniVGGNet)。在培训期间,我们会将培训和验证损失保存到磁盘。然后,我们将创建一个单独的 Python 脚本来比较未偏移和偏移损失图。
让我们从实施培训脚本开始:
# import the necessary packages
from pyimagesearch.minivggnet import MiniVGGNet
from sklearn.metrics import classification_report
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--history", required=True,
help="path to output training history file")
args = vars(ap.parse_args())
第 2-8 行导入我们需要的包、模块、类和函数。也就是说,我们导入MiniVGGNet(我们的 CNN)、fashion_mnist(我们的数据集)和pickle(确保我们可以为单独的脚本序列化我们的训练历史以处理绘图)。
命令行参数,--history,指向单独的.pickle文件,该文件将很快包含我们的训练历史(第 11-14 行)。
然后,我们初始化几个超参数,即我们要训练的时期数、初始学习速率和批量大小:
# initialize the number of epochs to train for, base learning rate,
# and batch size
NUM_EPOCHS = 25
INIT_LR = 1e-2
BS = 32
然后,我们加载并预处理我们的时尚 MNIST 数据:
# grab the Fashion MNIST dataset (if this is your first time running
# this the dataset will be automatically downloaded)
print("[INFO] loading Fashion MNIST...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# we are using "channels last" ordering, so the design matrix shape
# should be: num_samples x rows x columns x depth
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# one-hot encode the training and testing labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
# initialize the label names
labelNames = ["top", "trouser", "pullover", "dress", "coat",
"sandal", "shirt", "sneaker", "bag", "ankle boot"]
第 25-34 行加载并预处理训练/验证数据。
第 37 行和第 38 行将我们的类标签二进制化,而第 41 行和第 42 行列出了人类可读的类标签名称,用于稍后的分类报告。
在这里,我们拥有了根据 MNIST 时装数据编译和训练 MiniVGGNet 模型所需的一切:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9, decay=INIT_LR / NUM_EPOCHS)
model = MiniVGGNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training model...")
H = model.fit(trainX, trainY,
validation_data=(testX, testY),
batch_size=BS, epochs=NUM_EPOCHS)
第 46-49 行初始化并编译MiniVGGNet模型。
线 53-55 然后安装/训练model。
在这里,我们将评估我们的model并序列化我们的培训历史:
# make predictions on the test set and show a nicely formatted
# classification report
preds = model.predict(testX)
print("[INFO] evaluating network...")
print(classification_report(testY.argmax(axis=1), preds.argmax(axis=1),
target_names=labelNames))
# serialize the training history to disk
print("[INFO] serializing training history...")
f = open(args["history"], "wb")
f.write(pickle.dumps(H.history))
f.close()
第 59-62 行对测试集进行预测,并向终端打印分类报告。
第 66-68 行将我们的训练准确性/损失历史序列化到一个.pickle文件中。我们将使用单独的 Python 脚本中的训练历史来绘制损耗曲线,包括一个显示半个纪元偏移的图。
继续使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端并执行以下命令:
$ python fashion_mnist.py --history training.pickle
[INFO] loading Fashion MNIST...
[INFO] compiling model...
[INFO] training model...
Train on 60000 samples, validate on 10000 samples
Epoch 1/25
60000/60000 [==============================] - 200s 3ms/sample - loss: 0.5433 - accuracy: 0.8181 - val_loss: 0.3281 - val_accuracy: 0.8815
Epoch 2/25
60000/60000 [==============================] - 194s 3ms/sample - loss: 0.3396 - accuracy: 0.8780 - val_loss: 0.2726 - val_accuracy: 0.9006
Epoch 3/25
60000/60000 [==============================] - 193s 3ms/sample - loss: 0.2941 - accuracy: 0.8943 - val_loss: 0.2722 - val_accuracy: 0.8970
Epoch 4/25
60000/60000 [==============================] - 193s 3ms/sample - loss: 0.2717 - accuracy: 0.9017 - val_loss: 0.2334 - val_accuracy: 0.9144
Epoch 5/25
60000/60000 [==============================] - 194s 3ms/sample - loss: 0.2534 - accuracy: 0.9086 - val_loss: 0.2245 - val_accuracy: 0.9194
...
Epoch 21/25
60000/60000 [==============================] - 195s 3ms/sample - loss: 0.1797 - accuracy: 0.9340 - val_loss: 0.1879 - val_accuracy: 0.9324
Epoch 22/25
60000/60000 [==============================] - 194s 3ms/sample - loss: 0.1814 - accuracy: 0.9342 - val_loss: 0.1901 - val_accuracy: 0.9313
Epoch 23/25
60000/60000 [==============================] - 193s 3ms/sample - loss: 0.1766 - accuracy: 0.9351 - val_loss: 0.1866 - val_accuracy: 0.9320
Epoch 24/25
60000/60000 [==============================] - 193s 3ms/sample - loss: 0.1770 - accuracy: 0.9347 - val_loss: 0.1845 - val_accuracy: 0.9337
Epoch 25/25
60000/60000 [==============================] - 194s 3ms/sample - loss: 0.1734 - accuracy: 0.9372 - val_loss: 0.1871 - val_accuracy: 0.9312
[INFO] evaluating network...
precision recall f1-score support
top 0.87 0.91 0.89 1000
trouser 1.00 0.99 0.99 1000
pullover 0.91 0.91 0.91 1000
dress 0.93 0.93 0.93 1000
coat 0.87 0.93 0.90 1000
sandal 0.98 0.98 0.98 1000
shirt 0.83 0.74 0.78 1000
sneaker 0.95 0.98 0.97 1000
bag 0.99 0.99 0.99 1000
ankle boot 0.99 0.95 0.97 1000
accuracy 0.93 10000
macro avg 0.93 0.93 0.93 10000
weighted avg 0.93 0.93 0.93 10000
[INFO] serializing training history...
检查工作目录的内容,您应该有一个名为training.pickle的文件——该文件包含我们的培训历史日志。
$ ls *.pickle
training.pickle
在下一节中,我们将学习如何绘制这些值,并将我们的训练信息向左移动半个历元,从而使我们的训练/验证损失曲线看起来更相似。
转移我们的培训损失值
我们的plot_shift.py脚本用于绘制来自fashion_mnist.py的训练历史输出。使用这个脚本,我们可以研究如何将我们的训练损失向左移动半个历元,使我们的训练/验证图看起来更相似。
打开plot_shift.py文件并插入以下代码:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input training history file")
args = vars(ap.parse_args())
第 2-5 行导入matplotlib(用于绘图)、NumPy(用于简单的数组创建操作)、argparse ( 命令行参数)和pickle(用于加载我们的序列化训练历史)。
第 8-11 行解析--input命令行参数,该参数指向我们在磁盘上的.pickle训练历史文件。
让我们继续加载我们的数据并初始化我们的曲线图:
# load the training history
H = pickle.loads(open(args["input"], "rb").read())
# determine the total number of epochs used for training, then
# initialize the figure
epochs = np.arange(0, len(H["loss"]))
plt.style.use("ggplot")
(fig, axs) = plt.subplots(2, 1)
第 14 行使用--input命令行参数加载我们的序列化训练历史.pickle文件。
第 18 行为我们的 x 轴腾出空间,该轴在训练历史中的跨度从 0 到数字epochs。
第 19 行和第 20 行将我们的绘图图设置为同一图像中的两个堆叠图:
- 顶部的图将按原样包含损耗曲线。
- 另一方面,底部图将包括训练损失的偏移(但不包括验证损失)。正如奥雷连恩的推文中所说,训练损失将向左移动半个时代。然后我们将能够观察到这些图是否排列得更紧密。
让我们生成我们的顶部图:
# plot the *unshifted* training and validation loss
plt.style.use("ggplot")
axs[0].plot(epochs, H["loss"], label="train_loss")
axs[0].plot(epochs, H["val_loss"], label="val_loss")
axs[0].set_title("Unshifted Loss Plot")
axs[0].set_xlabel("Epoch #")
axs[0].set_ylabel("Loss")
axs[0].legend()
然后画出我们的底图:
# plot the *shifted* training and validation loss
axs[1].plot(epochs - 0.5, H["loss"], label="train_loss")
axs[1].plot(epochs, H["val_loss"], label="val_loss")
axs[1].set_title("Shifted Loss Plot")
axs[1].set_xlabel("Epoch #")
axs[1].set_ylabel("Loss")
axs[1].legend()
# show the plots
plt.tight_layout()
plt.show()
请注意第 32 行的**处的 培训损失被移至0.5时代的左侧——本例的中心。**
现在让我们分析我们的训练/验证图。
打开终端并执行以下命令:
$ python plot_shift.py --input training.pickle

Figure 4: Shifting the training loss plot 1/2 epoch to the left yields more similar plots. Clearly the time of measurement answers the question, “Why is my validation loss lower than training loss?”.
正如您所观察到的,将训练损失值向左移动半个历元(底部)使得训练/验证曲线与未移动(顶部)的曲线更加相似。
原因 3:验证集可能比训练集更容易(或者可能有漏洞)

Figure 5: Consider how your validation set was acquired/generated. Common mistakes could lead to validation loss being less than training loss. (image source)
验证损失低于训练损失的最后一个最常见的原因是由于数据分布本身。
考虑您的验证集是如何获得的:
- 您能保证验证集是从与定型集相同的分布中取样的吗?
- 你确定验证示例和你的训练图像一样具有挑战性吗?
- 你能保证没有“数据泄漏”(例如,训练样本偶然混入验证/测试样本)?
- 您确信您的代码正确地创建了训练、验证和测试分割吗?
每一个深度学习从业者在职业生涯中都至少犯过一次以上的错误。
是的,当这种情况发生时会很尴尬——但这就是问题的关键——这种情况确实会发生,所以现在花点时间研究一下你的代码。*
额外收获:你训练的够努力吗?

Figure 6: If you are wondering why your validation loss is lower than your training loss, perhaps you aren’t “training hard enough”.
奥雷连恩在他的推文中没有提到的一个方面是“足够努力地训练”的概念。
当训练深度神经网络时,我们最大的担忧几乎总是过拟合——为了克服过拟合,我们引入了正则化技术(在上面的原因#1 中讨论过)。我们以下列形式应用正则化:
- 拒绝传统社会的人
- L2 重量衰减
- 降低模型容量(即,更浅的模型)
我们还倾向于在学习率上更保守一点,以确保我们的模型不会超出损失景观中损失较低的区域。
这一切都很好,但有时我们最终会 过度规范我们的模型。
如果你经历了验证损失低于上述训练损失的所有三个原因,你可能过度规范了你的模型。通过以下方式开始放松你的正规化约束:
- 降低你的 L2 重量衰减强度。
- 减少你申请退学的数量。
- 增加您的模型容量(即,使其更深)。
你也应该尝试用更大的学习率来训练,因为你可能已经变得太保守了。
Summary
今天的教程很大程度上受到了作者 Aurélien Geron 的以下推文的启发。
在帖子中,Aurélien 专业而简洁地解释了在训练深度神经网络时,验证损失可能低于训练损失的三个原因:
- 原因#1: 正则化在训练期间应用,但不在验证/测试期间应用。如果您在验证/测试期间添加正则化损失,您的损失值和曲线将看起来更相似。
- 原因#2: 训练损失在每个历元期间测量,而验证损失在每个历元之后测量。平均而言,训练损失是在 1/2 个时期之前测量的。如果你把你的训练损失曲线向左移动半个纪元,你的损失会对齐得更好。
- 原因#3: 你的验证集可能比你的训练集容易或者你的数据有漏洞/你的代码有 bug。确保您的验证集相当大,并且是从与您的训练集相同的分布(和难度)中取样的。
- 奖励:你可能过度规范了你的模型。尝试减少您的正则化约束,包括增加您的模型容量(即,使用更多参数使其更深),减少压差,减少 L2 权重衰减强度等。
希望这有助于澄清为什么您的验证损失可能会低于您的培训损失的任何困惑!
当我第一次开始学习机器学习和神经网络时,这对我来说肯定是一个令人挠头的问题,直到我上了大学才明白这到底是为什么——而且当时没有一个解释像奥雷连恩的解释那样清晰简洁。
我希望你喜欢今天的教程!
要下载源代码(并在 PyImageSearch 上发布未来教程时得到通知),只需在下表中输入您的电子邮件地址!***
Word2Vec:自然语言处理中的嵌入研究
原文:https://pyimagesearch.com/2022/07/11/word2vec-a-study-of-embeddings-in-nlp/
目录
word 2 vec:NLP 中的嵌入研究
上周,我们看到了如何根据完整的语料库以受限的方式来表示文本,从而帮助计算机给单词赋予意义。我们的方法(单词袋)基于单词的频率,当输入文本变大时,需要复杂的计算。但是它所表达的思想值得探索。
随着今天的聚焦:Word2Vec,我们慢慢步入现代自然语言处理(NLP)的领域。
在本教程中,您将学习如何为文本实现 Word2Vec 方法。
作为一个小序言,Word2Vec 是我在自己的旅程中遇到的 NLP 中最简单但也是我最喜欢的主题之一。这个想法是如此简单,然而它在许多方面重新定义了 NLP 世界。让我们一起来探索和了解 Word2Vec 背后的本质。
本课是关于 NLP 101 的 4 部分系列的第 3 部分:
- 自然语言处理入门
- 介绍词袋(BoW)模型
- word 2 vec:NLP 中的嵌入研究 (今日教程)
- 【BagofWords 和 Word2Vec 的比较
*要学习如何实现 Word2Vec, 只要坚持阅读。
word 2 vec:NLP 中的嵌入研究
word 2 vec简介
让我们解决第一件事;Word2vec 这个名字是什么意思?
它正是你所想的(即,作为向量的词)。Word2Vec 本质上就是把你的文本语料库中的每一个单词都表达在一个 N 维空间(嵌入空间)中。单词在嵌入空间的每个维度中的权重为模型定义了它。
但是我们如何分配这些权重呢?向计算机教授语法和其他语义是一项艰巨的任务,这一点并不十分清楚,但表达每个单词的意思完全是另一回事。最重要的是,英语有几个词根据上下文有多种意思。那么这些权重是随机分配的吗(表 1 )?
|
| 活着 | 财富 | 性别 |
| 男人 | one | -1 | -1 |
| 女王 | one | one | one |
| 框 | -1 | Zero | Zero |
| 表 1: 嵌入。 |
信不信由你,答案就在最后一段本身。我们根据单词的上下文帮助定义单词的意思。
现在,如果这听起来让你困惑,让我们把它分解成更简单的术语。一个单词的上下文是由其相邻的单词定义的。因此,一个词的意义取决于它所联系的词。
如果您的文本语料库中有几个单词“read”与单词“book”出现在同一个句子中,Word2Vec 方法会自动将它们组合在一起。因此,这项技术完全依赖于一个好的数据集。
既然我们已经确定了 Word2Vec 的魔力在于单词联想,那么让我们更进一步,理解 Word2Vec 的两个子集。
【CBOW】
CBOW 是一种给定相邻单词,确定中心单词的技术。如果我们的输入句子是“我在看书。”,则窗口大小为 3 的输入对和标签将是:
I、reading,为标签amam、the,为标签readingreading、book,为标签the
看一看图 1 。
假设我们在图 1 中的输入句子是我们完整的输入文本。这使得我们的词汇量为 5,为了简单起见,我们假设有 3 个嵌入维度。
我们将考虑(I,reading)–(am)的输入标签对的例子。我们从I和reading(形状1x5)的一键编码开始,将这些编码与形状5x3的编码矩阵相乘。结果是一个1x3隐藏层。
这个隐藏层现在乘以一个3x5解码矩阵,给出我们对一个1x5形状的预测。这是比较实际的标签(am)一热编码相同的形状,以完成架构。
这里的星号是编码/解码矩阵。该损失影响这些矩阵在适应数据时的权重。矩阵提供了一个表达每个单词的有限空间。矩阵成为单词的矢量表示。
单个矩阵可以用于实现编码/解码两个目的。为了解开这两个任务之间的纠缠,我们将使用两个矩阵:当将单词视为相邻单词时,用上下文单词矩阵来表示单词;当将单词视为中心单词时,用中心单词矩阵来表示单词。
使用两个矩阵给每个单词两个不同的空间范围,同时给我们两个不同的视角来看待每个单词。
Skip-Gram
今天关注的第二种技术是跳格法。这里,给定中心词,我们必须预测它的相邻词。与 CBOW 完全相反,但效率更高。在此之前,让我们先了解一下什么是跳格。
假设我们给定的输入句子是“我正在看书”窗口大小为 3 时,相应的跳跃码对将是:
am,用于标签I和readingreading,用于标签am和thethe,用于标签reading和book
我们来分析一下图二。
就像在 CBOW 中一样,让我们假设我们在图 2 中的输入句子是我们完整的输入文本。这使得我们的词汇量为 5,为了简单起见,我们假设有 3 个嵌入维度。
从编码矩阵开始,我们获取位于中心词索引处的向量(在本例中为am)。转置它,我们现在有了单词am的一个3x1向量表示(因为我们直接抓取了编码矩阵的一行,所以这个不会是的一次性编码)。
我们将这个向量表示乘以形状5x3的解码矩阵,得到形状5x1的预测输出。现在,这个向量基本上是整个词汇表的 softmax 表示,指向属于输入中心单词的相邻单词的索引。在这种情况下,输出应该指向I和reading的索引。
同样,为了更好地表示,我们将使用两种不同的矩阵。Skip-Gram 直观上比 CBOW 工作得更好,因为我们基于单个输入单词对几个单词进行分组,而在 CBOW 中,我们试图基于几个输入单词将一个单词关联起来。
对这两种技术有了基本的了解之后,让我们看看如何实现 CBOW 和 Skip-Gram。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install tensorflow
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── data.txt
├── LICENSE
├── outputs
│ ├── loss_CBOW.png
│ ├── loss_skipgram.png
│ ├── output.txt
│ ├── TSNE_CBOW.png
│ └── tsne_skipgram.png
├── pyimagesearch
│ ├── config.py
│ ├── create_vocabulary.py
│ └── __init__.py
├── README.md
├── requirements.txt
├── train_CBOW.py
└── train_SkipGram.py
2 directories, 14 files
我们在主目录中有两个子目录,outputs和pyimagesearch。
目录包含了我们项目的所有结果和可视化。pyimagesearch目录包含几个脚本:
config.py:包含完整的配置管道。- 帮助创建我们项目的词汇。
__init__.py:使pyimagesearch目录作为 python 包工作。
在父目录中,我们有:
train_CBOW.py:CBOW 架构培训脚本。train_SkipGram.py:Skip-Gram 架构的训练脚本。- 包含我们项目的训练数据。
配置先决条件
在pyimagesearch目录中,config.py脚本存放了我们项目的配置管道。
# import the necessary packages
import os
# define the number of embedding dimensions
EMBEDDING_SIZE = 10
# define the window size and number of iterations
WINDOW_SIZE = 5
ITERATIONS = 1000
# define the path to the output directory
OUTPUT_PATH = "outputs"
# define the path to the skipgram outputs
SKIPGRAM_LOSS = os.path.join(OUTPUT_PATH, "loss_skipgram")
SKIPGRAM_TSNE = os.path.join(OUTPUT_PATH, "tsne_skipgram")
# define the path to the CBOW outputs
CBOW_LOSS = os.path.join(OUTPUT_PATH, "loss_cbow")
CBOW_TSNE = os.path.join(OUTPUT_PATH, "tsne_cbow")
在第 5 行,我们已经为你的嵌入矩阵定义了维数。接下来,我们定义上下文单词的窗口大小和迭代次数(第 8 行和第 9 行)。
输出路径在行 12 上定义,随后是 Skip-Gram 架构的损耗和 TSNE 图。我们对 CBOW 损失图和 TSNE 图做了同样的处理(第 19 行和第 20 行)。
建筑词汇
在我们的父目录中,有一个名为data.txt的文件,其中包含了我们将用来展示 Word2Vec 技术的文本。在这种情况下,我们使用的是关于诺贝尔奖获得者玛丽·居里的一段话。
然而,要应用 Word2Vec 算法,我们需要正确地处理数据。这涉及到符号化。pyimagesearch目录中的create_vocabulary.py脚本将帮助我们构建项目的词汇表。
# import the necessary packages
import tensorflow as tf
def tokenize_data(data):
# convert the data into tokens
tokenizedText = tf.keras.preprocessing.text.text_to_word_sequence(
input_text=data
)
# create and store the vocabulary of unique words along with the
# size of the tokenized texts
vocab = sorted(set(tokenizedText))
tokenizedTextSize = len(tokenizedText)
# return the vocabulary, size of the tokenized text, and the
# tokenized text
return (vocab, tokenizedTextSize, tokenizedText)
在第 4 行上,我们有一个名为tokenize_data的函数,它以文本数据为自变量。谢天谢地,由于tensorflow,我们可以使用tf.keras.preprocessing.text.text_to_word_sequence直接标记我们的数据。这将文本数据中的所有单词确认为标记。
现在,如果我们对标记化的文本进行排序,这将为我们提供词汇表(第 12 行)。这是因为令牌是基于字母顺序等范例创建的。所以我们最初的tokenizedText变量只有文本的标记化版本,没有排序的词汇。
在第 17 行上,我们返回创建的词汇、标记化文本的大小以及标记化文本本身。
培训 CBOW 架构
我们将从 CBOW 实现开始。在父目录中,train_CBOW.py脚本包含完整的 CBOW 实现。
# USAGE
# python -W ignore train_CBOW.py
# set seed for reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.create_vocabulary import tokenize_data
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from tqdm import tqdm
import pandas as pd
import numpy as np
import os
# read the text data from the disk
print("[INFO] reading the data from the disk...")
with open("data.txt") as filePointer:
lines = filePointer.readlines()
textData = "".join(lines)
首先,我们将首先获取数据,并将其转换成适合我们的create_vocabulary脚本的格式。在的第 20-22 行,我们打开data.txt文件并读取其中的行。但是,这将产生一个列表,其中包含单个字符串格式的所有行。
为了解决这个问题,我们简单地使用"".join函数,将所有的行连接成一个字符串。
# tokenize the text data and store the vocabulary, the size of the
# tokenized text, and the tokenized text
(vocab, tokenizedTextSize, tokenizedText) = tokenize_data(
data=textData
)
# map the vocab words to individual indices and map the indices to
# the words in vocab
vocabToIndex = {
uniqueWord:index for (index, uniqueWord) in enumerate(vocab)
}
indexToVocab = np.array(vocab)
# convert the tokens into numbers
textAsInt = np.array([vocabToIndex[word] for word in tokenizedText])
# create the representational matrices as variable tensors
contextVectorMatrix = tf.Variable(
np.random.rand(tokenizedTextSize, config.EMBEDDING_SIZE)
)
centerVectorMatrix = tf.Variable(
np.random.rand(tokenizedTextSize, config.EMBEDDING_SIZE)
)
有了正确格式的数据,我们现在可以在第 26-28 行的上使用tokenize_data函数对数据进行标记。
使用构建的词汇,我们可以将单词映射到它们的索引,并创建一个vocabToIndex字典,帮助我们将单词链接到它们的索引(第 32-34 行)。
类似地,我们在第 35 行的上创建一个indexToVocab变量。这里的最后一步是在第 38 行将我们的整个文本数据从 word 格式转换成 indices 格式。
现在,是时候创建我们的嵌入空间了。如前所述,我们将使用两个不同的矩阵,一个用于上下文单词表示,一个用于中心单词表示。每个单词都会用两个空格表示(第 41-46 行)。
# initialize the optimizer and create an empty list to log the loss
optimizer = tf.optimizers.Adam()
lossList = list()
# loop over the training epochs
print("[INFO] Starting CBOW training...")
for iter in tqdm(range(config.ITERATIONS)):
# initialize the loss per epoch
lossPerEpoch = 0
# the window for center vector prediction is created
for start in range(tokenizedTextSize - config.WINDOW_SIZE):
# generate the indices for the window
indices = textAsInt[start:start + config.WINDOW_SIZE]
在第 49 行上,我们已经初始化了Adam优化器和一个列表来存储我们的每历元损失(第 49 和 50 行)。
现在,我们开始在历元上循环,并初始化第 54-56 行上的每历元损失变量。
随后在第 59-61 行上初始化用于 CBOW 考虑的窗口。
# initialize the gradient tape
with tf.GradientTape() as tape:
# initialize the context vector
combinedContext = 0
# loop over the indices and grab the neighboring
# word representation from the embedding matrix
for count,index in enumerate(indices):
if count != config.WINDOW_SIZE // 2:
combinedContext += contextVectorMatrix[index, :]
# standardize the result according to the window size
combinedContext /= (config.WINDOW_SIZE-1)
# calculate the center word embedding predictions
output = tf.matmul(centerVectorMatrix,
tf.expand_dims(combinedContext, 1))
# apply softmax loss and grab the relevant index
softOut = tf.nn.softmax(output, axis=0)
loss = softOut[indices[config.WINDOW_SIZE // 2]]
# calculate the logarithmic loss
logLoss = -tf.math.log(loss)
# update the loss per epoch and apply
# the gradients to the embedding matrices
lossPerEpoch += logLoss.numpy()
grad = tape.gradient(
logLoss, [contextVectorMatrix, centerVectorMatrix]
)
optimizer.apply_gradients(
zip(grad, [contextVectorMatrix, centerVectorMatrix])
)
# update the loss list
lossList.append(lossPerEpoch)
对于梯度计算,我们在线 64 上初始化一个梯度带。在行 66 上,组合上下文向量变量被初始化。这将表示上下文向量的添加。
根据窗口循环遍历索引,我们从上下文向量矩阵中获取上下文向量表示(行 70-72 )。
这是一个有趣的方法。你可能注意到了,我们走的是一条不同于之前解释的路线。我们可以直接从嵌入矩阵中获取这些索引,而不是将独热编码与嵌入空间相乘,因为这实质上意味着将独热编码(只有一个 1 的 0 的向量)与矩阵相乘。
我们得到了所有上下文向量的总和。我们根据第 75 行的上考虑的上下文单词数(4)来标准化输出。
接下来,该输出乘以第 78 和 79 行上的中心字嵌入空间。我们对这个输出应用 softmax,通过抓取属于中心单词标签的相关索引来确定损失(第 82 行和第 83 行)。
由于我们必须在该指数下最大化输出,我们计算第 86 行的负对数损耗。
基于损失,我们将梯度应用于我们创建的两个嵌入空间(行 91-96 )。
一旦超出时期,我们就用每个时期计算的损失来更新损失列表(行 99 )。
# create output directory if it doesn't already exist
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# plot the loss for evaluation
print("[INFO] Plotting loss...")
plt.plot(lossList)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.savefig(config.CBOW_LOSS)
如果输出文件夹还不存在,我们将创建它(行 102 和 103 )。每个历元的损失被标绘并保存在输出文件夹中(第 106-110 行)。
# apply dimensional reductionality using tsne for the representation matrices
tsneEmbed = (
TSNE(n_components=2)
.fit_transform(centerVectorMatrix.numpy())
)
tsneDecode = (
TSNE(n_components=2)
.fit_transform(contextVectorMatrix.numpy())
)
# initialize a index counter
indexCount = 0
# initialize the tsne figure
plt.figure(figsize=(25, 5))
# loop over the tsne embeddings and plot the corresponding words
print("[INFO] Plotting TSNE embeddings...")
for (word, embedding) in tsneDecode[:100]:
plt.scatter(word, embedding)
plt.annotate(indexToVocab[indexCount], (word, embedding))
indexCount += 1
plt.savefig(config.CBOW_TSNE)
我们的嵌入空间已经准备好了,但是由于它们有许多维度,我们的肉眼将无法理解它们。解决这个问题的方法是降维。
维数约简是一种我们可以降低嵌入空间的维数,同时保持大部分重要信息(分离数据)完整的方法。在这种情况下,我们将应用TSNE(t-分布式随机邻居嵌入)。
使用 TSNE,我们将嵌入空间的维数减少到 2,从而使 2D 图成为可能(行 113-120 )。基于索引,我们在 2D 空间中绘制单词(第 129-134 行)。
在我们检查结果之前,让我们看一下 Skip-Gram 实现。
实现跳格架构
正如我们前面所解释的,Skip-Gram 是一个输入得到多个输出的地方。让我们转到train_SkipGram.py脚本来完成我们的 Skip-Gram 实现。
# USAGE
# python -W ignore train_skipgram.py
# set seed for reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.create_vocabulary import tokenize_data
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from tqdm import tqdm
import pandas as pd
import numpy as np
import os
# read the text data from the disk
print("[INFO] reading the data from the disk...")
with open("data.txt") as filePointer:
lines = filePointer.readlines()
textData = "".join(lines)
# tokenize the text data and store the vocabulary, the size of the
# tokenized text, and the tokenized text
(vocab, tokenizedTextSize, tokenizedText) = tokenize_data(
data=textData
)
最初的步骤类似于我们在 CBOW 实现中所做的。在将文本数据提供给tokenize_data函数之前,我们准备好文本数据,并获得词汇、文本大小和返回的标记化文本(第 20-28 行)。
# map the vocab words to individual indices and map the indices to
# the words in vocab
vocabToIndex = {
uniqueWord:index for (index, uniqueWord) in enumerate(vocab)
}
indexToVocab = np.array(vocab)
# convert the tokens into numbers
textAsInt = np.array([vocabToIndex[word] for word in tokenizedText])
# create the representational matrices as variable tensors
contextVectorMatrix = tf.Variable(
np.random.rand(tokenizedTextSize, config.EMBEDDING_SIZE)
)
centerVectorMatrix = tf.Variable(
np.random.rand(tokenizedTextSize, config.EMBEDDING_SIZE)
)
下一步是创建到词汇和文本的索引映射,这是重复的(第 32-38 行)。然后我们创建两个嵌入空间,我们将在第 41-46 行使用。
# initialize the optimizer and create an empty list to log the loss
optimizer = tf.optimizers.Adam()
lossList = list()
# loop over the training epochs
print("[INFO] Starting SkipGram training...")
for iter in tqdm(range(config.ITERATIONS)):
# initialize the loss per epoch
lossPerEpoch = 0
# the window for center vector prediction is created
for start in range(tokenizedTextSize - config.WINDOW_SIZE):
# generate the indices for the window
indices = textAsInt[start:start + config.WINDOW_SIZE]
在第 49 行上,我们已经初始化了Adam优化器和一个列表来存储我们的每历元损失(第 49 和 50 行)。
现在,我们开始在历元上循环,并初始化第 54-56 行上的每历元损失变量。
随后在行 59-61 上初始化窗口跳过程序考虑。
# initialize the gradient tape
with tf.GradientTape() as tape:
# initialize the context loss
loss = 0
# grab the center word vector and matrix multiply the
# context embeddings with the center word vector
centerVector = centerVectorMatrix[
indices[config.WINDOW_SIZE // 2],
:
]
output = tf.matmul(
contextVectorMatrix, tf.expand_dims(centerVector ,1)
)
# pass the output through a softmax function
softmaxOutput = tf.nn.softmax(output, axis=0)
# loop over the indices of the neighboring words and
# update the context loss w.r.t each neighbor
for (count, index) in enumerate(indices):
if count != config.WINDOW_SIZE // 2:
loss += softmaxOutput[index]
# calculate the logarithmic value of the loss
logLoss = -tf.math.log(loss)
# update the loss per epoch and apply the gradients to the
# embedding matrices
lossPerEpoch += logLoss.numpy()
grad = tape.gradient(
logLoss, [contextVectorMatrix, centerVectorMatrix]
)
optimizer.apply_gradients(
zip(grad, [contextVectorMatrix, centerVectorMatrix])
)
# update the loss list
lossList.append(lossPerEpoch)
在行 64 上,我们初始化一个梯度带,用于矩阵的梯度计算。这里,我们需要创建一个变量来存储每个上下文的损失(第 66 行)。
我们从中心词嵌入空间获取中心词表示,并将其乘以上下文向量矩阵(行 70-76 )。
该输出通过 softmax,并且相关的上下文索引被采样用于损失计算(行 79-85 )。
由于我们必须最大化相关指数,我们计算第 88 行的负对数损耗。
然后根据损失计算梯度,并应用于两个嵌入空间(行 93-99 )。每个时期的损失然后被存储在线 101 上。
# create output directory if it doesn't already exist
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# plot the loss for evaluation
print("[INFO] Plotting Loss...")
plt.plot(lossList)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.savefig(config.SKIPGRAM_LOSS)
如果输出文件夹还不存在,我们将创建它(行 104 和 105 )。每个历元的损失被标绘并保存在输出文件夹中(第 108-112 行)。
# apply dimensional reductionality using tsne for the
# representation matrices
tsneEmbed = (
TSNE(n_components=2)
.fit_transform(centerVectorMatrix.numpy())
)
tsneDecode = (
TSNE(n_components=2)
.fit_transform(contextVectorMatrix.numpy())
)
# initialize a index counter
indexCount = 0
# initialize the tsne figure
plt.figure(figsize=(25, 5))
# loop over the tsne embeddings and plot the corresponding words
print("[INFO] Plotting TSNE Embeddings...")
for (word, embedding) in tsneEmbed[:100]:
plt.scatter(word, embedding)
plt.annotate(indexToVocab[indexCount], (word, embedding))
indexCount += 1
plt.savefig(config.SKIPGRAM_TSNE)
如同对 CBOW 图所做的,我们应用维数约简并在 2D 空间中绘制单词(行 114-137 )。
可视化结果
让我们来看看损失(图 4 和图 5
不要被损失值震惊。如果从分类的角度来看,每个窗口都有不同的标签。损失肯定会很大,但谢天谢地,它已经降到了一个相当可观的价值。
对于跳格损耗来说,想法是类似的,但是因为我们有一个输入的多个输出,损耗下降得更快。
再来看嵌入空间本身(图 6 和图 7 )。
CBOW 嵌入空间相当分散,很少形成视觉联想。如果我们仔细观察,我们可能会发现类似的上下文单词,如组合在一起的年份等。,但一般来说,结果并不是那么好。
Skip-Gram 嵌入空间要好得多,因为我们可以看到已经形成的几个可视单词分组。这表明在我们特定的小数据集实例中,Skip-Gram 工作得更好。
汇总
Word2Vec 本质上是理解 NLP 中表征学习的一个重要里程碑。它提出的想法非常直观,为教会计算机如何理解单词的含义这一问题提供了有效的解决方案。
最棒的是,数据为我们做了大部分工作。这些关联是根据一个词与另一个词一起出现的频率形成的。虽然近年来出现了许多更好的算法,但嵌入空间的影响在所有这些算法中都可以找到。
引用信息
Chakraborty,d .“word 2 vec:自然语言处理中的嵌入研究”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki 编辑。,2022 年,【https://pyimg.co/2fb0z
@incollection{Chakraborty_2022_Word2Vec,
author = {Devjyoti Chakraborty},
title = {{Word2Vec}: A Study of Embeddings in {NLP}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/2fb0z},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
使用 OpenCV 写入视频
原文:https://pyimagesearch.com/2016/02/22/writing-to-video-with-opencv/
让我先说用 OpenCV 写视频是一件非常痛苦的事情。
本教程的目的是帮助你开始用 OpenCV 3 编写视频文件,提供(并解释)一些样板代码,并详细说明我是如何在自己的系统上编写视频的。
但是,如果您试图在自己的应用程序中使用 OpenCV 编写视频文件,请做好准备:
- 研究安装在您系统上的视频编解码器。
- 玩各种编解码器+文件扩展名,直到视频成功写入磁盘。
- 确保你在一个远离孩子的僻静地方——那里会有很多咒骂和诅咒。
你看,虽然用于用 OpenCV 创建视频文件的函数如cv2.VideoWriter、cv2.VideoWriter_fourcc和cv2.cv.FOURCC在中有很好的记录,但是没有有很好的记录的是成功编写视频文件所需的编解码器+文件扩展名的组合、、、。
我需要创建一个用 OpenCV 编写视频文件的应用程序已经有很长时间了,所以当我坐下来为这篇博文编写代码时,我对我花了这么长时间编写这个例子感到非常惊讶(也非常沮丧)。
事实上,我是唯一能够使用 OpenCV 3 的代码! 这篇文章中详细描述的代码与 OpenCV 2.4.X 不兼容(尽管我已经强调了在 OpenCV 2.4 上运行所需的代码更改,如果你想试一试的话)。
注意:如果您需要在您的系统上安装 OpenCV 的帮助,请查阅此页以获得各种平台的安装说明列表。另外,一定要看看 实用 Python 和 OpenCV 的 Quickstart 包和硬拷贝包,其中包括一个可下载的 Ubuntu VirtualBox 虚拟机,预配置和预安装了 Open 3。
无论如何,在这篇文章的剩余部分,我将演示如何使用 OpenCV 将视频写入文件。希望您能够在自己的应用程序中使用这些代码,而不会掉太多头发(我已经秃顶了,所以我没有这个问题)。
https://www.youtube.com/embed/HRXwqx1ep3M?feature=oembed
树莓派和 Movidius NCS 上的 YOLO 和微小 YOLO 目标检测
在本教程中,您将学习如何利用 YOLO 和蒂尼-YOLO 在带有 Movidius NCS 的 Raspberry Pi 上进行近实时对象检测。
YOLO 物体检测器经常被认为是最快的基于深度学习的物体检测器之一,比计算昂贵的两阶段检测器(例如更快的 R-CNN)和一些单级检测器(例如。RetinaNet 和一些(但不是全部)SSD 的变体)。
然而,即使有这样的速度,YOLO仍然不够快,无法在树莓 Pi 等嵌入式设备上运行——即使有 Movidius NCS 的帮助。
为了让 YOLO 变得更快,雷德蒙等人(《YOLO》的创造者),定义了一种被称为微小 YOLO 的 YOLO 架构变体。
小小的 YOLO 架构比它的大兄弟 快了大约 442% ,在单个 GPU 上实现了超过 244 FPS 。
小模型尺寸(< 50MB)和快速推理速度使微小 YOLO 物体探测器自然适合嵌入式计算机视觉/深度学习设备,如 Raspberry Pi、Google Coral 和 NVIDIA Jetson Nano。
今天,您将了解如何使用微型 YOLO,然后使用 Movidius NCS 将其部署到 Raspberry Pi,以获得近乎实时的对象检测。
要了解如何利用 YOLO 和 TinyYOLO 通过 Movidius NCS 在树莓 Pi 上进行物体检测,请继续阅读!
树莓派和 Movidius NCS 上的 YOLO 和微小 YOLO 目标检测
在本教程的第一部分,我们将了解 YOLO 和微小 YOLO 物体探测器。
在那里,我将向您展示如何配置您的 Raspberry Pi 和 OpenVINO 开发环境,以便它们可以利用微小的 YOLO。
然后我们将回顾项目的目录结构,包括正确访问 OpenVINO 环境所需的 shell 脚本。
一旦我们理解了项目结构,我们将继续实现一个 Python 脚本,它:
- 访问我们的 OpenVINO 环境。
- 从视频流中读取帧。
- 使用 Raspberry Pi、Movidius NCS 和 Tiny-YOLO 执行近实时对象检测。
我们将通过检查脚本的结果来结束本教程。
什么是 YOLO 和小 YOLO?
Figure 1: Tiny-YOLO has a lower mAP score on the COCO dataset than most object detectors. That said, Tiny-YOLO may be a useful object detector to pair with your Raspberry Pi and Movidius NCS. (image source)
Tiny-YOLO 是 Redmon 等人在其 2016 年的论文 中提出的“你只看一次”(YOLO)物体检测器的变体:统一、实时的物体检测 。
创建 YOLO 是为了帮助提高较慢的两级物体探测器的速度,如较快的 R-CNN。
虽然 R-CNN 是精确的,但是它们是非常慢的,即使在 GPU 上运行也是如此。
相反,YOLO 等单级探测器相当快,在 GPU 上获得超实时性能。
当然,缺点是 YOLO 往往是不太准确 (根据我的经验,比固态硬盘或 RetinaNet 更难训练)。
由于蒂尼-YOLO 是比它的大兄弟们更小的版本,这也意味着蒂尼-YOLO 不幸是 甚至更不准确的 。
作为参考,Redmon 等人在 COCO 基准数据集上报告了约 51-57%的 YOLO 地图,而 Tiny-YOLO 只有 23.7%的地图,不到其更大兄弟的一半精度。
也就是说,23%的 mAP 对于某些应用来说仍然是合理的。
使用 YOLO 时,我的一般建议是“简单地试一试”:
- 在某些情况下,它可能非常适合您的项目。
- 在其他情况下,您可能会寻求更准确的检测器(更快的 R-CNN、SSDs、RetinaNet 等)。).
要了解更多关于 YOLO、蒂尼-YOLO 和其他 YOLO 变种的信息,请务必参考雷德蒙等人的 2018 年出版物。
配置您的 Raspberry Pi + OpenVINO 环境

Figure 2: Configuring the OpenVINO toolkit for your Raspberry Pi and Movidius NCS to conduct TinyYOLO object detection.
这个教程需要一个树莓 Pi 4BT4 和m ovidius NC S2(NC S1 不支持)来复制我的结果。
在这个项目中,为您的 Raspberry Pi 配置英特尔 Movidius NCS 无疑具有挑战性。
建议你(1)拿一个 的副本给计算机视觉 ,还有(2)把预先配置好的 收录闪存。img 到你的 microSD。的。这本书附带的 img 是物有所值的,因为它会节省你无数个小时的辛苦和挫折。
对于那些想自己配置覆盆子 Pi + OpenVINO 的顽固少数人来说,这里有一个简单的指南:
- 前往我的 BusterOS 安装指南 并按照所有指示创建一个名为
cv的环境。 - 按照我的 OpenVINO 安装指南 创建第二个环境名为
openvino。一定要下载 OpenVINO 4.1.1 (4.1.2 有未解决的问题)。
您将需要一个名为 JSON-Minify 的包来解析我们的 JSON 配置。您可以将其安装到您的虚拟环境中:
$ pip install json_minify
在这一点上,你的 RPi 将有和一个普通的 OpenCV 环境以及一个 OpenVINO-OpenCV 环境。在本教程中,您将使用openvino环境。
现在,只需将 NCS2 插入蓝色 USB 3.0 端口(RPi 4B 具有 USB 3.0 以获得最高速度),并使用以下任一方法启动您的环境:
选项 A: 在我的 预配置的 Raspbian 上使用 shell 脚本。img (在我的 OpenVINO 安装指南的“推荐:创建一个用于启动您的 OpenVINO 环境的 shell 脚本”部分中描述了相同的 shell 脚本)。
从现在开始,您可以用一个简单的命令来激活您的 OpenVINO 环境(与上一步中的两个命令相反:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
选项 B: 一二冲法。
如果您不介意执行两个命令而不是一个,您可以打开一个终端并执行以下操作:
$ workon openvino
$ source ~/openvino/bin/setupvars.sh
第一个命令激活我们的 OpenVINO 虚拟环境。第二个命令用 OpenVINO 设置 Movidius NCS(这非常重要,否则您的脚本会出错)。
选项 A 和选项 B 都假设你要么使用我的 预配置的 Raspbian。img 或者说你按照我的 OpenVINO 安装指南自己安装了 OpenVINO 4.1.1。
注意事项:
- 某些版本的 OpenVINO 很难读取. mp4 视频。这是 PyImageSearch 已经向英特尔团队报告的一个已知 bug。我们的已预先配置。img 包含一个修复。Abhishek Thanki 编辑了源代码,并从 source 编译了 OpenVINO。这篇博文已经够长了,所以我不能包含从源代码编译的说明。如果您遇到这个问题,请鼓励英特尔解决这个问题,或者(A) 使用我们的客户门户说明从源代码编译,或者(B)拿一份Raspberry Pi for Computer Vision并使用预配置的. img
- NCS1 不支持本教程提供的 TinyYOLO 模型。这是不典型的——通常,NCS2 和 NCS1 非常兼容(NCS2 更快)。
- 如果我们发现其他注意事项,我们会添加到此列表中。
项目结构
继续并获取今天的可下载内容。zip 来自今天教程的“下载”部分。让我们用tree命令直接在终端中检查我们的项目结构:
$ tree --dirsfirst
.
├── config
│ └── config.json
├── intel
│ ├── __init__.py
│ ├── tinyyolo.py
│ └── yoloparams.py
├── pyimagesearch
│ ├── utils
│ │ ├── __init__.py
│ │ └── conf.py
│ └── __init__.py
├── videos
│ └── test_video.mp4
├── yolo
│ ├── coco.names
│ ├── frozen_darknet_tinyyolov3_model.bin
│ ├── frozen_darknet_tinyyolov3_model.mapping
│ └── frozen_darknet_tinyyolov3_model.xml
└── detect_realtime_tinyyolo_ncs.py
6 directories, 13 files
我们在 COCO 数据集上训练的 TinyYOLO 模型是通过yolo/目录提供的。
intel/目录包含英特尔公司提供的两个类:
TinyYOLOv3:解析、缩放和计算 TinyYOLO 结果的 Union 上的交集的类。TinyYOLOV3Params:用于建立层参数对象的类。
我们今天不会复习英特尔提供的任何一个脚本。我们鼓励您自己查看这些文件。
我们的pyimagesearch模块包含我们的Conf类,一个负责解析config.json的实用程序。
提供了一段人们走过公共场所的测试视频(摘自牛津大学的网站)供您执行 TinyYOLO 对象检测。我鼓励你也添加自己的videos/。
今天教程的核心在于detect_realtime_tinyyolo_ncs.py。该脚本加载 TinyYOLOv3 模型,并对实时视频流的每一帧执行推理。您可以使用您的 PiCamera、USB 摄像头或存储在磁盘上的视频文件。该脚本将在您的 Raspberry Pi 4B 和 NCS2 上计算接近实时的 TinyYOLOv3 推理的整体每秒帧数(FPS)基准。
我们的配置文件

Figure 3: Intel’s OpenVINO Toolkit is combined with OpenCV allowing for optimized deep learning inference on Intel devices such as the Movidius Neural Compute Stick. We will use OpenVINO for TinyYOLO object detection on the Raspberry Pi and Movidius NCS.
我们的配置变量存放在我们的config.json文件中。现在打开它,让我们检查一下里面的东西:
{
// path to YOLO architecture definition XML file
"xml_path": "yolo/frozen_darknet_tinyyolov3_model.xml",
// path to the YOLO weights
"bin_path": "yolo/frozen_darknet_tinyyolov3_model.bin",
// path to the file containing COCO labels
"labels_path": "yolo/coco.names",
第 3 行定义了我们的 TinyYOLOv3 架构定义文件路径,而第 6 行指定了预训练 TinyYOLOv3 COCO 权重的路径。
然后我们在第 9 行的上提供 COCO 数据集标签名称的路径。
现在让我们看看用于过滤检测的变量:
// probability threshold for detections filtering
"prob_threshold": 0.2,
// intersection over union threshold for filtering overlapping
// detections
"iou_threshold": 0.15
}
第 12-16 行定义概率和交集超过并集(IoU) 阈值,以便我们的驱动程序脚本可以过滤弱检测。如果您遇到太多的误报对象检测,您应该增加这些数字。一般来说,我喜欢在0.5开始我的概率阈值。
为 Movidius NCS 实现 YOLO 和小 YOLO 目标探测脚本
我们现在准备实施我们的微小 YOLO 物体检测脚本!
打开目录结构中的detect_realtime_tinyyolo_ncs.py文件,插入以下代码:
# import the necessary packages
from openvino.inference_engine import IENetwork
from openvino.inference_engine import IEPlugin
from intel.yoloparams import TinyYOLOV3Params
from intel.tinyyolo import TinyYOLOv3
from imutils.video import VideoStream
from pyimagesearch.utils import Conf
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import time
import cv2
import os
我们从第 2-14 行开始,导入必要的包;让我们回顾一下最重要的几个:
openvino:IENetwork和IEPlugin的进口让我们的 Movidius NCS 接管了 TinyYOLOv3 的推论。intel:TinyYOLOv3和TinyYOLOV3Params类是由英特尔公司提供的(即不是我们开发的)并协助解析 TinyYOLOv3 结果。imutils:VideoStream类是线程化的,用于快速的相机帧捕获。FPS类提供了一个计算每秒帧数的框架。Conf:解析注释 JSON 文件的类。cv2: OpenVINO 的改良版 OpenCV 针对英特尔设备进行了优化。
导入准备就绪,现在我们将加载配置文件:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True,
help="Path to the input configuration file")
ap.add_argument("-i", "--input", help="path to the input video file")
args = vars(ap.parse_args())
# load the configuration file
conf = Conf(args["conf"])
我们 Python 脚本的命令行参数包括:
--conf:我们在上一节中查看的输入配置文件的路径。--input:输入视频文件的可选路径。如果没有指定输入文件,脚本将使用摄像机。
指定了我们的配置路径后, Line 24 从磁盘加载我们的配置文件。
既然我们的配置驻留在内存中,现在我们将继续加载我们的 COCO 类标签:
# load the COCO class labels our YOLO model was trained on and
# initialize a list of colors to represent each possible class
# label
LABELS = open(conf["labels_path"]).read().strip().split("\n")
np.random.seed(42)
COLORS = np.random.uniform(0, 255, size=(len(LABELS), 3))
第 29-31 行加载我们的 COCO 数据集类标签,并将随机颜色与每个标签相关联。我们将使用颜色来注释我们生成的边界框和类标签。
接下来,我们将把 TinyYOLOv3 模型加载到我们的 Movidius NCS 上:
# initialize the plugin in for specified device
plugin = IEPlugin(device="MYRIAD")
# read the IR generated by the Model Optimizer (.xml and .bin files)
print("[INFO] loading models...")
net = IENetwork(model=conf["xml_path"], weights=conf["bin_path"])
# prepare inputs
print("[INFO] preparing inputs...")
inputBlob = next(iter(net.inputs))
# set the default batch size as 1 and get the number of input blobs,
# number of channels, the height, and width of the input blob
net.batch_size = 1
(n, c, h, w) = net.inputs[inputBlob].shape
我们与 OpenVINO API 的第一个交互是初始化 NCS 的 Myriad 处理器,并从磁盘加载预先训练好的 TinyYOLOv3】第 34-38 行)。
我们然后:
- 准备我们的
inputBlob( 第 42 行)。 - 将批量大小设置为
1,因为我们将一次处理一个帧(第 46 行)。 - 确定输入体积形状尺寸(行 47 )。
让我们继续初始化我们的摄像机或文件视频流:
# if a video path was not supplied, grab a reference to the webcam
if args["input"] is None:
print("[INFO] starting video stream...")
# vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# otherwise, grab a reference to the video file
else:
print("[INFO] opening video file...")
vs = cv2.VideoCapture(os.path.abspath(args["input"]))
# loading model to the plugin and start the frames per second
# throughput estimator
print("[INFO] loading model to the plugin...")
execNet = plugin.load(network=net, num_requests=1)
fps = FPS().start()
我们查询我们的--input参数,以确定我们是否将处理来自摄像机或视频文件的帧,并设置适当的视频流(第 50-59 行)。
由于 Intel 的 OpenCV-OpenVINO 实现中的一个 bug,如果你正在使用一个视频文件,你必须在cv2.VideoCapture函数中指定绝对路径。如果不这样做,OpenCV-OpenVINO 将无法处理该文件。
注意:如果没有提供--input命令行参数,将使用摄像机代替。默认情况下,您的 PiCamera ( Line 53 )处于选中状态。如果您喜欢使用 USB 摄像头,只需注释掉行 53* 并取消注释行 52 。*
我们与 OpenVINO API 的下一个交互是将 TinyYOLOv3 放到我们的 Movidius NCS ( 行 64 )上,同时行 65 开始测量 FPS 吞吐量。
至此,我们完成了设置,现在可以开始处理帧并执行 TinyYOLOv3 检测:
# loop over the frames from the video stream
while True:
# grab the next frame and handle if we are reading from either
# VideoCapture or VideoStream
orig = vs.read()
orig = orig[1] if args["input"] is not None else orig
# if we are viewing a video and we did not grab a frame then we
# have reached the end of the video
if args["input"] is not None and orig is None:
break
# resize original frame to have a maximum width of 500 pixel and
# input_frame to network size
orig = imutils.resize(orig, width=500)
frame = cv2.resize(orig, (w, h))
# change data layout from HxWxC to CxHxW
frame = frame.transpose((2, 0, 1))
frame = frame.reshape((n, c, h, w))
# start inference and initialize list to collect object detection
# results
output = execNet.infer({inputBlob: frame})
objects = []
第 68 行开始我们的实时 TinyYOLOv3 对象检测循环。
首先,我们抓取并预处理我们的frame ( 第 71-86 行)。
然后,我们执行对象检测推理(行 90 )。
第 91 行初始化一个objects列表,我们接下来将填充它:
# loop over the output items
for (layerName, outBlob) in output.items():
# create a new object which contains the required tinyYOLOv3
# parameters
layerParams = TinyYOLOV3Params(net.layers[layerName].params,
outBlob.shape[2])
# parse the output region
objects += TinyYOLOv3.parse_yolo_region(outBlob,
frame.shape[2:], orig.shape[:-1], layerParams,
conf["prob_threshold"])
为了填充我们的objects列表,我们循环遍历output项,创建我们的layerParams,并解析输出区域(第 94-103 行)。请注意,我们使用英特尔提供的代码来帮助解析我们的 YOLO 输出。
YOLO 和 TinyYOLO 往往会产生相当多的假阳性。为了解决这个问题,接下来,我们将设计两种弱检测滤波器:
# loop over each of the objects
for i in range(len(objects)):
# check if the confidence of the detected object is zero, if
# it is, then skip this iteration, indicating that the object
# should be ignored
if objects[i]["confidence"] == 0:
continue
# loop over remaining objects
for j in range(i + 1, len(objects)):
# check if the IoU of both the objects exceeds a
# threshold, if it does, then set the confidence of that
# object to zero
if TinyYOLOv3.intersection_over_union(objects[i],
objects[j]) > conf["iou_threshold"]:
objects[j]["confidence"] = 0
# filter objects by using the probability threshold -- if a an
# object is below the threshold, ignore it
objects = [obj for obj in objects if obj['confidence'] >= \
conf["prob_threshold"]]
第 106 行开始在我们的第一个过滤器的解析objects上循环
- 我们只允许置信度值不等于零的对象(行 110 和 111 )。
- 然后,我们实际上修改任何没有通过联合(IoU) 阈值上的交集的对象的置信度值(将其设置为零)(第 114-120 行)。
- 有效地,IoU 低的对象将被忽略。
第 124 和 125 行简洁地说明了我们的第二滤波器。仔细检查代码,这两行:
- 重建(覆盖)我们的
objects列表。 - 有效地,我们是 过滤掉不符合概率阈值的对象。
既然我们的objects只包含我们关心的那些,我们将用边界框和类标签来注释我们的输出帧:
# store the height and width of the original frame
(endY, endX) = orig.shape[:-1]
# loop through all the remaining objects
for obj in objects:
# validate the bounding box of the detected object, ensuring
# we don't have any invalid bounding boxes
if obj["xmax"] > endX or obj["ymax"] > endY or obj["xmin"] \
< 0 or obj["ymin"] < 0:
continue
# build a label consisting of the predicted class and
# associated probability
label = "{}: {:.2f}%".format(LABELS[obj["class_id"]],
obj["confidence"] * 100)
# calculate the y-coordinate used to write the label on the
# frame depending on the bounding box coordinate
y = obj["ymin"] - 15 if obj["ymin"] - 15 > 15 else \
obj["ymin"] + 15
# draw a bounding box rectangle and label on the frame
cv2.rectangle(orig, (obj["xmin"], obj["ymin"]), (obj["xmax"],
obj["ymax"]), COLORS[obj["class_id"]], 2)
cv2.putText(orig, label, (obj["xmin"], y),
cv2.FONT_HERSHEY_SIMPLEX, 1, COLORS[obj["class_id"]], 3)
第 128 行提取我们原始框架的高度和宽度。我们需要这些值来进行注释。
然后我们循环过滤后的objects。在从行 131 开始的循环中,我们:
- 检查检测到的 (x,y)-坐标是否超出原始图像尺寸的界限;如果是这样,我们丢弃检测(第 134-136 行)。
- 构建我们的包围盒
label,它由物体"class_id"和"confidence"组成。 - 使用输出帧(第 145-152 行)上的
COLORS(来自第 31 行)标注边界框矩形和标签。如果框的顶部接近框架的顶部,行 145 和 146 将标签向下移动15个像素。
最后,我们将显示我们的框架,计算统计数据,并清理:
# display the current frame to the screen and record if a user
# presses a key
cv2.imshow("TinyYOLOv3", orig)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# stop the video stream and close any open windows1
vs.stop() if args["input"] is None else vs.release()
cv2.destroyAllWindows()
结束后,我们显示输出帧并等待按下q键,此时我们将break退出循环(第 156-161 行)。
第 164 行更新我们的 FPS 计算器。
当(1)视频文件没有更多的帧,或者(2)用户在视频或相机流上按下q键时,循环退出。此时,第 167-169 行将 FPS 统计打印到您的终端。第 172 和 173 行停止流并破坏 GUI 窗口。
树莓 Pi 和 Movidius NCS 上的 YOLO 和小 YOLO 目标检测结果
要在树莓 Pi 上使用微小 YOLO 和 Movidius NCS,请确保:
- 按照“配置您的 Raspberry Pi + OpenVINO 环境”中的说明配置您的开发环境。
- 使用本教程的 【下载】 部分来下载源代码和预训练的模型权重。
在对源代码/模型权重进行解归档之后,您可以打开一个终端并执行以下命令:
$ python detect_realtime_tinyyolo_ncs.py --conf config/config.json \
--input videos/test_video.mp4
[INFO] loading models...
[INFO] preparing inputs...
[INFO] opening video file...
[INFO] loading model to the plugin...
[INFO] elapsed time: 199.86
[INFO] approx. FPS: 2.66
这里我们提供了输入视频文件的路径。
我们的 Raspberry Pi、Movidius NCS 和 Tiny-YOLO 的组合可以以 ~2.66 FPS 的速率应用对象检测。
视频鸣谢: 牛津大学。
现在让我们尝试使用一个相机而不是一个视频文件,简单地通过省略--input 命令行参数:
$ python detect_realtime_tinyyolo_ncs.py --conf config/config.json
[INFO] loading models...
[INFO] preparing inputs...
[INFO] starting video stream...
[INFO] loading model to the plugin...
[INFO] elapsed time: 804.18
[INFO] approx. FPS: 4.28
请注意,处理相机流会导致更高的 FPS(分别为 ~4.28 FPS 对 2.66 FPS )。
那么,为什么对摄像机流运行对象检测比对视频文件应用对象检测更快呢?
原因很简单,从视频文件中解码帧比从相机流中读取原始帧需要更多的 CPU 周期。
视频文件通常会应用某种级别的压缩来减小最终的视频文件大小。
虽然输出文件大小减小了,但读取时仍需要对帧进行解压缩 CPU 负责该操作。
相反,当从网络摄像头、USB 摄像头或 RPi 摄像头模块读取帧时,CPU 需要做的工作显著减少,这就是为什么我们的脚本在摄像头流上比在视频文件上运行得更快。
同样值得注意的是,使用树莓 Pi 相机模块可以获得最快速度。当使用 RPi 相机模块时,RPi 上的板载显示和流处理 GPU(不,不是深度学习 GPU)处理读取和处理帧,因此 CPU 不必参与。
我将把它作为一个实验留给读者,来比较 USB 摄像头与 RPi 摄像头模块的吞吐率。
注:在 RPi 4B 4GB、NCS2(连接到 USB 3.0)上收集的所有 FPS 统计数据,并在 VNC 显示的 Raspbian 桌面上的 OpenCV GUI 窗口上提供服务。如果您运行无头算法(即没有 GUI),您可能会获得 0.5 或更多的 FPS 增益,因为将帧显示到屏幕上也会占用宝贵的 CPU 周期。在比较结果时,请记住这一点。
微型 YOLO 的缺点和局限性
虽然小 YOLO 的速度更快,而且能够在树莓 Pi、**上运行,但你会发现它最大的问题是精度——较小的模型尺寸导致的精度大大低于的模型。
作为参考, Tiny-YOLO 在 COCO 数据集上仅实现了 23.7%的 mAP ,而更大的 YOLO 车型实现了 51-57%的 mAP ,远远超过了两倍于*Tiny-YOLO 的精度。
在测试 Tiny-YOLO 时,我发现它在一些图像/视频中工作得很好,而在另一些图像/视频中,它完全无法使用。
如果蒂尼-YOLO 没有给你想要的结果,不要气馁,很可能该模型只是不适合你的特定应用。
相反,可以考虑尝试更精确的物体检测器,包括:
- 更大、更精确的 YOLO 模型
- 单触发探测器(SSD)
- 更快的 R-CNN
- RetinaNet
对于 Raspberry Pi 之类的嵌入式设备,我通常会推荐带 MobileNet 底座的单次检测器(SSD)。这些模型很难训练(即优化超参数),但一旦你有了一个可靠的模型,速度和精度的权衡是非常值得的。
如果你有兴趣了解更多关于这些物体检测器的信息,我的书, 用 Python 进行计算机视觉的深度学习 ,向你展示了如何从头开始训练这些物体检测器,然后将它们部署到图像和视频流中进行物体检测。
在 计算机视觉树莓派 的内部,您将学习如何训练 MobileNet SSD 和 InceptionNet SSD 对象检测器,以及将模型部署到嵌入式设备。
摘要
在本教程中,您学习了如何在使用 Movidius NCS 的 Raspberry Pi 上利用微型 YOLO 进行近实时对象检测。
由于蒂尼-YOLO 的小尺寸(< 50MB)和快速推理速度(在 GPU 上约 244 FPS),该模型非常适合在嵌入式设备上使用,如 Raspberry Pi、Google Coral 和 NVIDIA Jetson Nano。
使用 Raspberry Pi 和 Movidius NCS,我们能够获得 ~4.28 FPS 。
我建议使用本教程中提供的代码和预先训练的模型作为您自己项目的模板/起点——扩展它们以满足您自己的需要。
要下载源代码和预训练的小 YOLO 模型(并在未来的教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
基于 OpenCV 的 YOLO 目标检测
原文:https://pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
在本教程中,您将学习如何使用深度学习、OpenCV 和 Python 来使用 YOLO 对象检测器检测图像和视频流中的对象。
通过应用对象检测,你不仅能够确定图像中的是什么,还能够确定给定对象的所在的!
我们将从简单讨论 YOLO 物体探测器开始,包括物体探测器是如何工作的。
接下来,我们将使用 OpenCV、Python 和深度学习来:
- 将 YOLO 对象检测器应用于图像
- 将 YOLO 应用于视频流
我们将通过讨论 YOLO 物体探测器的一些限制和缺点来结束本教程,包括一些我个人的技巧和建议。
要了解如何通过 OpenCV 使用 YOLO 进行物体检测,请继续阅读!
- 【2021 年 7 月更新: 增加了关于 YOLO v4 和 YOLO v5 的部分,包括如何将它们整合到 OpenCV 和 PyTorch 项目中。
基于 OpenCV 的 YOLO 目标检测
https://www.youtube.com/embed/eeIEH2wjvhg?feature=oembed
你的第一个图像分类器:使用 k-NN 分类图像
原文:https://pyimagesearch.com/2021/04/17/your-first-image-classifier-using-k-nn-to-classify-images/
最近,我们花了相当多的时间讨论图像基础知识、学习类型,甚至是构建我们自己的图像分类器时可以遵循的四步管道。但是我们还没有建立我们自己的真正的图像分类器。
这将在本课中改变。我们将从构建几个助手工具开始,以便于预处理和从磁盘加载图像。从那里,我们将讨论 k-最近邻(k-NN)分类器,这是您第一次接触使用机器学习进行图像分类。事实上,这个算法非常简单以至于它根本不做任何实际的“学习”——然而它仍然是一个重要的算法,因此我们可以在未来的课程中了解神经网络如何从数据中学习。
最后,我们将应用 k-NN 算法来识别图像中的各种动物。
使用图像数据集
在处理图像数据集时,我们首先必须考虑数据集的总大小(以字节为单位)。我们的数据集是否足够大,可以放入我们机器上的可用 RAM 中?我们可以像加载大型矩阵或数组一样加载数据集吗?还是数据集太大,超出了我们机器的内存,需要我们将数据集“分块”成段,一次只加载一部分?
对于较小的数据集,我们可以将它们加载到主存中,而不必担心内存管理;然而,对于更大的数据集,我们需要开发一些聪明的方法来有效地处理加载图像,以训练图像分类器(而不会耗尽内存)。
也就是说,在开始使用影像分类算法之前,您应该始终了解数据集的大小。正如我们将在本课的其余部分看到的,花时间组织、预处理和加载数据集是构建图像分类器的一个关键方面。
介绍“动物”数据集
“Animals”数据集是我整理的一个简单的示例数据集,用于演示如何使用简单的机器学习技术以及高级深度学习算法来训练图像分类器。
动物数据集中的图像属于三个不同的类别:狗、猫和熊猫正如你在图 1 中看到的,每个类别有 1000 个示例图像。狗和猫的图像是从 Kaggle 狗对猫挑战赛中采集的,而熊猫的图像是从 ImageNet 数据集中采集的。
动物数据集仅包含 3,000 张图像,可以很容易地放入我们机器的主内存中,这将使训练我们的模型更快,而不需要我们编写任何“开销代码”来管理否则无法放入内存的数据集。最重要的是,深度学习模型可以在 CPU 或 GPU 上的数据集上快速训练。无论你的硬件设置如何,你都可以使用这个数据集来学习机器学习和深度学习的基础知识。
我们在本课中的目标是利用 k-NN 分类器,尝试仅使用原始像素强度来识别图像中的每一个物种(即,不进行特征提取)。正如我们将看到的,原始像素亮度并不适合 k-NN 算法。尽管如此,这是一个重要的基准实验,因此我们可以理解为什么卷积神经网络能够在原始像素强度上获得如此高的精度,而传统的机器学习算法却无法做到这一点。
开始使用我们的深度学习工具包
让我们开始定义我们工具包的项目结构:
|--- pyimagesearch
如您所见,我们有一个名为pyimagesearch的模块。我们开发的所有代码都将存在于pyimagesearch模块中。出于本课的目的,我们需要定义两个子模块:
|--- pyimagesearch
| |--- __init__.py
| |--- datasets
| | |--- __init__.py
| | |--- simpledatasetloader.py
| |--- preprocessing
| | |--- __init__.py
| | |--- simplepreprocessor.py
datasets子模块将开始我们名为SimpleDatasetLoader的类的实现。我们将使用这个类从磁盘(可以放入主存)加载小的图像数据集,根据一组函数对数据集中的每个图像进行预处理,然后返回:
- 图像(即原始像素强度)
- 与每个图像关联的类别标签
然后我们有了preprocessing子模块。有许多预处理方法可以应用于我们的图像数据集,以提高分类精度,包括均值减法、随机面片采样或简单地将图像大小调整为固定大小。在这种情况下,我们的SimplePreprocessor类将执行后者——从磁盘加载一个图像,并将其调整为固定大小,忽略纵横比。在接下来的两节中,我们将手动实现SimplePreprocessor和SimpleDatasetLoader。
备注: 当我们在课程中复习整个pyimagesearch模块进行深度学习时,我特意将__init__.py文件的解释留给读者作为练习。这些文件只包含快捷方式导入,与理解应用于图像分类的深度学习和机器学习技术无关。如果你是 Python 编程语言的新手,我建议你温习一下包导入的基础知识。
基本图像预处理器
机器学习算法,如 k-NN,SVM,甚至卷积神经网络,都要求数据集中的所有图像都具有固定的特征向量大小。在图像的情况下,这个要求意味着我们的图像必须预处理和缩放,以具有相同的宽度和高度。
有许多方法可以实现这种调整大小和缩放,从尊重原始图像与缩放图像的纵横比的更高级的方法到忽略纵横比并简单地将宽度和高度压缩到所需尺寸的简单方法。确切地说,你应该使用哪种方法实际上取决于你的变异因素的复杂性——在某些情况下,忽略纵横比就可以了;在其他情况下,您可能希望保留纵横比。
让我们从基本的解决方案开始:构建一个调整图像大小的图像预处理器,忽略纵横比。打开simplepreprocessor.py,然后插入以下代码:
# import the necessary packages
import cv2
class SimplePreprocessor:
def __init__(self, width, height, inter=cv2.INTER_AREA):
# store the target image width, height, and interpolation
# method used when resizing
self.width = width
self.height = height
self.inter = inter
def preprocess(self, image):
# resize the image to a fixed size, ignoring the aspect
# ratio
return cv2.resize(image, (self.width, self.height),
interpolation=self.inter)
Line 2 导入我们唯一需要的包,我们的 OpenCV 绑定。然后我们在第 5 行的上定义了SimplePreprocessor类的构造函数。该构造函数需要两个参数,后跟第三个可选参数,每个参数的详细信息如下:
width:调整大小后输入图像的目标宽度。height:调整大小后输入图像的目标高度。inter:可选参数,用于控制调整大小时使用哪种插值算法。
preprocess函数在第 12 行上定义,需要一个参数——我们想要预处理的输入image。
第 15 行和第 16 行通过将图像调整到固定的大小width和height来预处理图像,然后我们返回到调用函数。
同样,这个预处理器根据定义是非常基本的——我们所做的就是接受一个输入图像,将它调整到一个固定的尺寸,然后返回它。然而,当与下一节中的图像数据集加载器结合使用时,该预处理器将允许我们从磁盘快速加载和预处理数据集,使我们能够快速通过我们的图像分类管道,并转移到更重要的方面,如训练我们的实际分类器。
构建图像加载器
既然我们的SimplePreprocessor已经定义好了,让我们继续讨论SimpleDatasetLoader:
# import the necessary packages
import numpy as np
import cv2
import os
class SimpleDatasetLoader:
def __init__(self, preprocessors=None):
# store the image preprocessor
self.preprocessors = preprocessors
# if the preprocessors are None, initialize them as an
# empty list
if self.preprocessors is None:
self.preprocessors = []
第 2-4 行导入我们需要的 Python 包:NumPy 用于数值处理,cv2用于 OpenCV 绑定,os用于提取图像路径中子目录的名称。
第 7 行定义了SimpleDatasetLoader的构造函数,在这里我们可以有选择地传入一列图像预处理程序(例如SimplePreprocessor),它们可以顺序地应用于给定的输入图像。
将这些preprocessors指定为一个列表而不是单个值是很重要的——有时我们首先需要将图像的大小调整到一个固定的大小,然后执行某种缩放(比如均值减法),接着将图像数组转换为适合 Keras 的格式。这些预处理程序中的每一个都可以独立实现,允许我们以一种高效的方式将它们依次应用到图像中。
*然后我们可以继续讨论load方法,这是SimpleDatasetLoader的核心:
def load(self, imagePaths, verbose=-1):
# initialize the list of features and labels
data = []
labels = []
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# load the image and extract the class label assuming
# that our path has the following format:
# /path/to/dataset/{class}/{image}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-2]
我们的load方法需要一个参数— imagePaths,它是一个指定驻留在磁盘上的数据集中图像的文件路径的列表。我们还可以为verbose提供一个值。这个“详细级别”可以用来打印控制台的更新,允许我们监控SimpleDatasetLoader已经处理了多少图像。
第 18 行和第 19 行初始化我们的data列表(即图像本身)以及labels,图像的类别标签列表。
在第 22 行上,我们开始循环每个输入图像。对于这些图像中的每一个,我们从磁盘中加载它(第 26 行)并基于文件路径提取类标签(第 27 行)。我们假设我们的数据集是根据以下目录结构在磁盘上组织的:
/dataset_name/class/image.jpg
dataset_name可以是数据集的任何名称,在本例中是animals。class应该是类标签的名称。对于我们的例子,class可以是dog、cat或panda。最后,image.jpg是实际图像本身的名称。
基于这种分层目录结构,我们可以保持数据集整洁有序。因此,假设dog子目录中的所有图像都是狗的例子是安全的。类似地,我们假设panda目录中的所有图像都包含熊猫的例子。
我们审查的几乎每个数据集都将遵循这种分层目录设计结构——我强烈鼓励你对自己的项目也这样做。
既然我们的映像已经从磁盘加载,我们可以对它进行预处理(如果需要的话):
# check to see if our preprocessors are not None
if self.preprocessors is not None:
# loop over the preprocessors and apply each to
# the image
for p in self.preprocessors:
image = p.preprocess(image)
# treat our processed image as a "feature vector"
# by updating the data list followed by the labels
data.append(image)
labels.append(label)
30 线快速检查,确保我们的preprocessors不是None。如果检查通过,我们对第 33 行上的每个preprocessors进行循环,并依次将它们应用于第 34 行上的图像——这个动作允许我们形成一个预处理程序链,它可以应用于数据集中的每个图像。
一旦图像经过预处理,我们就分别更新data和label列表(第 38 行和第 39 行)。
我们的最后一个代码块只是处理对控制台的打印更新,然后将一个由data和labels组成的二元组返回给调用函数:
# show an update every `verbose` images
if verbose > 0 and i > 0 and (i + 1) % verbose == 0:
print("[INFO] processed {}/{}".format(i + 1,
len(imagePaths)))
# return a tuple of the data and labels
return (np.array(data), np.array(labels))
如您所见,我们的数据集加载器设计简单;然而,它让我们能够轻松地将任意数量的图像预处理程序应用到我们数据集中的每张图像上。这个数据集加载器的唯一警告是,它假设数据集中的所有图像都可以一次放入主存。
对于太大而不适合系统内存的数据集,我们需要设计一个更复杂的数据集加载器。
k-NN:一个简单的分类器
k-最近邻分类器是迄今为止最简单的机器学习和图像分类算法。事实上,它的非常简单,它实际上并没有“学习”任何东西。相反,这种算法直接依赖于特征向量之间的距离(在我们的例子中,是图像的原始 RGB 像素强度)。
简单来说,k-NN 算法通过在 k 最接近的例子中找到最常见的类来对未知数据点进行分类。在 k 个最接近的数据点中的每个数据点进行投票,如图 2 所示,票数最高的类别获胜。
为了让 k-NN 算法工作,它首先假设具有相似视觉内容的图像在一个 n 维空间中靠近。在这里,我们可以看到三类图像,分别标记为狗、猫和熊猫。在这个假想的例子中,我们沿着 x 轴绘制了动物皮毛的“蓬松度”,沿着 y 轴绘制了皮毛的“亮度”。在我们的 n 维空间中,每一个动物数据点都相对紧密地组合在一起。这意味着两个猫图像之间的距离比一只猫和一只狗之间的距离小得多。
然而,为了应用 k-NN 分类器,我们首先需要选择一个距离度量或相似性函数。常见的选择包括欧几里德距离(通常称为 L2 距离):
【①
**但是,也可以使用其他距离度量,例如曼哈顿/城市街区(通常称为 L1 距离):
② = \sum\limits_{i=1}^{N}|q_{i} - p_{i}|")
**实际上,您可以使用最适合您的数据(并给出最佳分类结果)的任何距离度量/相似性函数。然而,在本课的剩余部分,我们将使用最流行的距离度量:欧几里德距离。
一个工作过的 k-NN 例子
至此,我们理解了 k-NN 算法的原理。我们知道它依赖于特征向量/图像之间的距离来进行分类。我们知道它需要一个距离/相似性函数来计算这些距离。
但是我们实际上如何让成为一个分类呢?要回答这个问题,我们来看看图 3 。这里我们有一个三种动物的数据集——狗、猫和熊猫——我们根据它们的蓬松度和皮毛亮度来绘制它们。
我们还插入了一个“未知动物”,我们试图只使用一个单邻居(即 k = 1)对其进行分类。在这种情况下,离输入图像最近的动物是狗数据点;因此我们的输入图像应该被归类为狗。
让我们尝试另一种“未知动物”,这次使用 k = 3 ( 图 4 )。我们在前三名结果中发现了两只猫和一只熊猫。由于猫类别的票数最多,我们将输入图像分类为猫。
我们可以针对不同的 k 值继续执行该过程,但是无论 k 变得多大或多小,原则都保持不变——在 k 个最接近的训练点中拥有最多票数的类别获胜,并被用作输入数据点的标签。
备注: 在平局的情况下,k-NN 算法随机选择一个平局的类标签。
k-NN 超参数
在运行 k-NN 算法时,我们关心两个明显的超参数。第一个很明显: k 的值。 k 的最优值是多少?如果它太小(例如, k = 1),那么我们会提高效率,但容易受到噪声和离群数据点的影响。然而,如果 k 太大,那么我们就有过度平滑我们的分类结果并增加偏差的风险。
我们应该考虑的第二个参数是实际距离度量。欧氏距离是最佳选择吗?曼哈顿距离呢?
在下一节中,我们将在动物数据集上训练 k-NN 分类器,并在测试集上评估该模型。我鼓励您尝试不同的k值和不同的距离指标,注意性能的变化。
实现 k-NN
本部分的目标是在动物数据集的原始像素亮度上训练一个 k-NN 分类器,并使用它对未知动物图像进行分类。
- 步骤#1 —收集我们的数据集:动物数据集由 3,000 张图像组成,每只狗、猫和熊猫分别有 1,000 张图像。每个图像都用 RGB 颜色空间表示。我们将对每张图片进行预处理,将其调整为 32×32 像素的。考虑到三个 RGB 通道,调整后的图像尺寸意味着数据集中的每个图像都由32×32×3 = 3072 个整数表示。
- 步骤# 2——拆分数据集:对于这个简单的例子,我们将使用对数据进行两次拆分。一部分用于培训,另一部分用于测试。我们将省略超参数调优的验证集,把它作为一个练习留给读者。
- 步骤# 3-训练分类器:我们的 k-NN 分类器将在训练集中的图像的原始像素强度上进行训练。
- 步骤#4 —评估:一旦我们的 k-NN 分类器被训练,我们就可以在测试集上评估性能。
让我们开始吧。打开一个新文件,将其命名为knn.py,并插入以下代码:
# import the necessary packages
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.preprocessing import SimplePreprocessor
from pyimagesearch.datasets import SimpleDatasetLoader
from imutils import paths
import argparse
第 2-9 行导入我们需要的 Python 包。需要注意的最重要的是:
- 第 2 行:
KNeighborsClassifier是我们对 k-NN 算法的实现,由 scikit-learn 库提供。 - 第 3 行:
LabelEncoder,一个帮助实用程序,将表示为字符串的标签转换为整数,其中每个类标签有一个唯一的整数(应用机器学习时的常见做法)。 - 第 4 行:我们将导入
train_test_split函数,这是一个方便的函数,用来帮助我们创建训练和测试分割。 - 第 5 行:
classification_report函数是另一个实用函数,用于帮助我们评估分类器的性能,并将格式良好的结果表打印到控制台。
您还可以看到我们分别在第 6 行和第 7 行上导入的SimplePreprocessor和SimpleDatasetLoader的实现。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-k", "--neighbors", type=int, default=1,
help="# of nearest neighbors for classification")
ap.add_argument("-j", "--jobs", type=int, default=-1,
help="# of jobs for k-NN distance (-1 uses all available cores)")
args = vars(ap.parse_args())
我们的脚本需要一个命令行参数,后面跟着两个可选参数,每个参数如下所示:
--dataset:输入图像数据集在磁盘上的路径。--neighbors:可选,使用 k-NN 算法时要应用的邻居数量 k 。--jobs:可选,计算输入数据点与训练集之间的距离时要运行的并发作业的数量。值-1将使用处理器上所有可用的内核。
既然我们的命令行参数已经被解析,我们就可以获取数据集中图像的文件路径,然后加载并预处理它们(分类管道中的步骤#1 ):
# grab the list of images that we'll be describing
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the image preprocessor, load the dataset from disk,
# and reshape the data matrix
sp = SimplePreprocessor(32, 32)
sdl = SimpleDatasetLoader(preprocessors=[sp])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.reshape((data.shape[0], 3072))
# show some information on memory consumption of the images
print("[INFO] features matrix: {:.1f}MB".format(
data.nbytes / (1024 * 1024.0)))
第 23 行获取数据集中所有图像的文件路径。然后我们初始化我们的SimplePreprocessor,用来在第 27 行上将每个图像的大小调整为 32×32 像素。
在第 28 行的上初始化SimpleDatasetLoader,为我们实例化的SimplePreprocessor提供一个参数(这意味着sp将被应用到数据集中的每个图像的)。
对第 29 行上的.load的调用从磁盘加载了我们实际的图像数据集。这个方法返回一个二元组的data(每张图片调整到 32×32 像素)以及每张图片的labels。
从磁盘加载我们的图像后,data NumPy 数组有一个.shape的(3000, 32, 32, 3),表示数据集中有 3000 个图像,每个 32×32 像素有 3 个通道。
然而,为了应用 k-NN 算法,我们需要将我们的图像从 3D 表示“展平”为像素强度的单一列表。我们完成这个,第 30 行调用data NumPy 数组上的.reshape方法,将 32×32×3 图像展平成一个形状为(3000, 3072)的数组。实际的图像数据一点也没有改变——图像被简单地表示为 3000 个条目的列表,每个条目为 3072-dim(32×32×3 = 3072)。
为了演示在内存中存储这 3,000 个图像需要多少内存,第 33 行和第 34 行计算数组消耗的字节数,然后将该数字转换为兆字节。
接下来,让我们构建我们的培训和测试分割(管道中的步骤#2 ):
# encode the labels as integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, random_state=42)
第 37 行和第 38 行将我们的labels(表示为字符串)转换成整数,其中我们每个类有个唯一的整数。这种转换允许我们将猫类映射到整数0,将狗类映射到整数1,将熊猫类映射到整数2。许多机器学习算法假设类别标签被编码为整数,所以我们养成执行这一步骤的习惯是很重要的。
计算我们的训练和测试分割是由第 42 行和第 43 行上的train_test_split函数处理的。这里,我们将我们的data和labels分成两个不同的集合:75%的数据用于训练,25%用于测试。
通常使用变量 X 来指代包含我们将用于训练和测试的数据点的数据集,而 y 指代类标签(您将在关于 参数化学习 的课程中了解更多)。因此,我们使用变量trainX和testX分别指代训练和测试示例。变量trainY和testY是我们的训练和测试标签。你会在我们的课程和以及你可能阅读的其他机器学习书籍、课程和教程中看到这些常见的符号。
最后,我们能够创建我们的 k-NN 分类器并评估它(图像分类管道中的步骤#3 和#4 ):
# train and evaluate a k-NN classifier on the raw pixel intensities
print("[INFO] evaluating k-NN classifier...")
model = KNeighborsClassifier(n_neighbors=args["neighbors"],
n_jobs=args["jobs"])
model.fit(trainX, trainY)
print(classification_report(testY, model.predict(testX),
target_names=le.classes_))
第 47 和 48 行初始化KNeighborsClassifier类。对第 49行上的.fit方法的调用“训练”了分类器,尽管这里没有实际的“学习”在进行——k-NN 模型只是在内部存储了trainX和trainY数据,因此它可以通过计算输入数据和trainX数据之间的距离,在测试集上创建预测。
第 50 行和第 51 行使用classification_report函数评估我们的分类器。这里我们需要提供testY类标签,来自model的预测类标签,以及可选的类标签名称(例如,“狗”、“猫”、“熊猫”)。
k-NN 结果
要运行我们的 k-NN 分类器,请执行以下命令:
$ python knn.py --dataset ../datasets/animals
然后,您应该会看到类似以下内容的输出:
[INFO] loading images...
[INFO] processed 500/3000
[INFO] processed 1000/3000
[INFO] processed 1500/3000
[INFO] processed 2000/3000
[INFO] processed 2500/3000
[INFO] processed 3000/3000
[INFO] features matrix: 8.8MB
[INFO] evaluating k-NN classifier...
precision recall f1-score support
cats 0.37 0.52 0.43 239
dogs 0.35 0.43 0.39 249
panda 0.70 0.28 0.40 262
accuracy 0.41 750
macro avg 0.47 0.41 0.41 750
weighted avg 0.48 0.41 0.40 750
请注意,我们的特征矩阵对于 3000 幅图像只消耗了 8.8MB 的内存,每幅图像的大小为 32×32×3(T1),这个数据集可以很容易地(T2)存储在现代机器的内存中,没有任何问题。
评估我们的分类器,我们看到我们获得了 48% 的准确度——对于一个根本不做任何真正“学习”的分类器来说,这个准确度还不错,因为随机猜测正确答案的概率是 1 / 3。
然而,检查每个类标签的准确性是很有趣的。“熊猫”类有 70%的时间被正确分类,可能是因为熊猫大部分是黑白的,因此这些图像在我们的 3 , 072-dim 空间中靠得更近。
狗和猫分别获得 35%和 37%的低得多的分类准确度。这些结果可以归因于这样一个事实,即狗和猫可能有非常相似的皮毛色调,它们皮毛的颜色不能用来区分它们。背景噪声(如后院的草地、动物休息的沙发的颜色等。)也可以“混淆”k-NN 算法,因为它不能学习这些物种之间的任何区别模式。这种混乱是 k-NN 算法的主要缺点之一:虽然它很简单,但它也无法从数据中学习。
k-NN 的利弊
k-NN 算法的一个主要优点是它的实现和理解非常简单。此外,训练分类器绝对不需要时间,因为我们需要做的只是存储我们的数据点,以便以后计算到它们的距离并获得我们的最终分类。
然而,我们在分类时为这种简单付出了代价。对新的测试点进行分类需要与我们训练数据中的每一个数据点进行比较,这会扩展 O(N) ,使得处理更大的数据集在计算上非常困难。
我们可以通过使用近似最近邻(ANN) 算法(例如 kd-trees 、 FLANN 、随机投影( Dasgupta,2000);宾汉姆和曼尼拉,2001;达斯古普塔和古普塔,2003);等等。);然而,使用这些算法要求我们用空间/时间复杂度来换取最近邻算法的“正确性”,因为我们是在执行近似。也就是说,在许多情况下,使用 k-NN 算法的努力和较小的精度损失是非常值得的。这种行为与大多数机器学习算法(以及所有神经网络)形成对比,在这些算法中,我们花费大量时间预先训练我们的模型以获得高精度,反过来,在测试时有非常快速的分类。
最后,k-NN 算法更适合低维特征空间(图像不是)。高维特征空间中的距离通常是不直观的,您可以在Pedro Domingos’(2012)的优秀论文中了解更多信息。
同样重要的是要注意,k-NN 算法实际上并没有“学习”任何东西——如果它犯了错误,它也不能让自己变得更聪明;它只是简单地依靠一个 n 维空间中的距离来进行分类。
考虑到这些缺点,为什么还要研究 k-NN 算法呢?原因是算法简单。这是容易理解的。最重要的是,它给了我们一个基准,我们可以用它来比较神经网络和卷积神经网络,因为我们将继续学习剩下的课程。**
**## 总结
在本课中,我们学习了如何构建一个简单的图像处理器并将图像数据集加载到内存中。然后我们讨论了k-最近邻分类器或者简称为 k-NN 。
k-NN 算法通过将未知数据点与训练集中的每个数据点进行比较来对未知数据点进行分类。使用距离函数或相似性度量来进行比较。然后从训练集中最 k 个相似的例子中,累计每个标签的“投票”数。最高票数的类别“胜出”,并被选为总体分类。
虽然简单直观,但 k-NN 算法有许多缺点。首先,它实际上并没有“学习”任何东西——如果算法出错,它没有办法为后面的分类“纠正”和“改进”自己。其次,在没有专门的数据结构的情况下,k-NN 算法随着数据点的数量而线性扩展,这不仅使其在高维中的使用具有实际挑战性,而且就其使用而言在理论上也是有问题的( Domingos,2012 )。现在我们已经使用 k-NN 算法获得了图像分类的基线,我们可以继续进行参数化学习,这是所有深度学习和神经网络建立的基础。使用参数化学习,我们实际上可以从我们的输入数据中学习,并发现潜在的模式。这个过程将使我们能够建立高精度的图像分类器,使 k-NN 的性能大打折扣。*******
您使用 Tesseract 和 Python 的第一个 OCR 项目
原文:https://pyimagesearch.com/2021/08/23/your-first-ocr-project-with-tesseract-and-python/
我第一次使用 Tesseract 光学字符识别(OCR)引擎是在我读大学的时候。

我正在上我的第一门计算机视觉课程。我们的教授希望我们为期末项目研究一个具有挑战性的计算机视觉主题,扩展现有的研究,然后就我们的工作写一篇正式的论文。我很难决定一个项目,所以我去见了教授,他是一名海军研究员,经常从事计算机视觉和机器学习的医学应用。他建议我研究自动处方药识别,这是一种在图像中自动识别处方药的过程。我考虑了一会儿这个问题,然后回答说:
你就不能用光学字符识别药片上的印记来识别它吗?
要学习如何在你的第一个项目中进行 OCR, 继续阅读。
您第一个使用 Tesseract 和 Python 的 OCR 项目
我仍然记得我的教授脸上的表情。
他笑了,一个小傻笑出现在他的嘴角。知道了我将要遇到的问题,他用回答道:“要是这么简单就好了。但你很快就会发现。”
然后我回家,立即开始玩 Tesseract 库,阅读手册/文档,并试图通过命令行 OCR 一些示例图像。但我发现自己在挣扎。一些图像得到了正确的 OCR 识别,而另一些图像则完全没有意义。
为什么 OCR 这么难?为什么我如此挣扎?
我花了一个晚上,熬到深夜,继续用各种图像测试宇宙魔方——对我来说,我无法辨别宇宙魔方可以正确 OCR 的图像和它可能失败的图像之间的模式。这里发生了什么巫术?!
*不幸的是,我看到许多计算机视觉从业者在刚开始学习 OCR 时也有这种感觉——也许你自己也有这种感觉:
- 你在你的机器上安装宇宙魔方
- 你可以通过谷歌搜索找到一些教程的基本例子
- 这些示例返回正确的结果
- …但是当你将同样的 OCR 技术应用于你的图像时,你会得到不正确的结果
听起来熟悉吗?
问题是这些教程没有系统的教 OCR。他们会向你展示如何,但他们不会向你展示为什么——这是一条关键的信息,它允许你辨别 OCR 问题中的模式,允许你正确地解决它们。
在本教程中,您将构建您的第一个 OCR 项目。它将作为执行 OCR 所需的“基本”Python 脚本。在以后的文章中,我们将基于你在这里学到的东西。
在本教程结束时,您将对自己在项目中应用 OCR 的能力充满信心。
让我们开始吧。
学习目标
在本教程中,您将:
- 获得使用 Tesseract 对图像进行 OCR 的实践经验
- 了解如何将
pytesseract包导入到 Python 脚本中 - 使用 OpenCV 从磁盘加载输入图像
- 通过
pytesseract库将图像传递到 Tesseract OCR 引擎 - 在我们的终端上显示 OCR 文本结果
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
宇宙魔方入门
在本教程的第一部分,我们将回顾这个项目的目录结构。从这里,我们将实现一个简单的 Python 脚本,它将:
- 通过 OpenCV 从磁盘加载输入图像
- 通过 Tesseract 和
pytesseract对图像进行光学字符识别 - 在屏幕上显示 OCR 文本
我们将讨论 OCR 处理的文本结果来结束本教程。
项目结构
|-- pyimagesearch_address.png
|-- steve_jobs.png
|-- whole_foods.png
|-- first_ocr.py
我们的第一个项目在组织方式上非常简单。在本教程的代码目录中,您会发现三个用于 OCR 测试的示例 PNG 图像和一个名为first_ocr.py的 Python 脚本。
让我们在下一节直接进入 Python 脚本。
带魔方的基本 OCR
让我们从你的第一个宇宙魔方 OCR 项目开始吧!打开一个新文件,将其命名为first_ocr.py,并插入以下代码:
# import the necessary packages
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments}
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
args = vars(ap.parse_args())
在这个脚本中,您将注意到的第一个 Python import是pytesseract ( Python Tesseract ),这是一个 Python 绑定,直接与您的系统上运行的 Tesseract OCR 应用程序绑定。pytesseract的力量在于我们能够与宇宙魔方交互,而不是依赖丑陋的os.cmd调用,这是在pytesseract存在之前我们需要做的。由于它的强大和易用性,我们将在本教程和以后的教程中使用pytesseract!
我们的脚本需要一个使用 Python 的argparse接口的命令行参数。当您执行这个示例脚本时,通过在终端中直接提供--image参数和图像文件路径值,Python 将动态加载您选择的图像。我在本教程的项目目录中提供了三个示例图像,您可以使用。我也强烈建议您通过这个 Python 示例脚本尝试使用 Tesseract 来 OCR 您的图像!
既然我们已经处理了导入和单独的命令行参数,让我们进入有趣的部分——用 Python 进行 OCR:
# load the input image and convert it from BGR to RGB channel
# ordering}
image = cv2.imread(args["image"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# use Tesseract to OCR the image
text = pytesseract.image_to_string(image)
print(text)
这里,行 14 和 15 从磁盘加载我们的输入--image并交换颜色通道排序。宇宙魔方期望 RGB 格式的图像;然而,OpenCV 以 BGR 顺序加载图像。这不是问题,因为我们可以使用 OpenCV 的cv2.cvtColor调用来修复它——只是要特别小心知道什么时候使用 RGB(红绿蓝)和 BGR(蓝绿红)。
备注 1。 我还想指出的是,很多时候当你在网上看到宇宙魔方的例子时,他们会使用PIL或pillow来加载图像。这些软件包以 RGB 格式加载图像,因此不需要转换步骤。
最后, Line 18 对我们的输入 RGB image执行 OCR,并将结果作为字符串存储在text变量中。
假设text现在是一个字符串,我们可以将它传递给 Python 的内置print函数,并在我们的终端中查看结果(第 19 行)。未来的例子将解释如何用文本本身注释输入图像(即,使用 OpenCV 将text结果叠加在输入--image的副本上,并显示在屏幕上)。
我们完了!
等等,真的吗?
哦,对了,如果你没有注意到的话,使用 PyTesseract 的 OCR 就像一个简单的函数调用一样简单,前提是你已经按照正确的 RGB 顺序加载了图像。所以现在,让我们检查结果,看看它们是否符合我们的期望。
宇宙魔方 OCR 结果
让我们测试一下新实现的 Tesseract OCR 脚本。打开您的终端,并执行以下命令:
$ python first_ocr.py --image pyimagesearch_address.png
PyImageSearch
PO Box 17598 #17900
Baltimore, MD 21297
在图 2 中,您可以看到我们的输入图像,它包含 PyImageSearch 的地址,背景是灰色的,有点纹理。如命令和终端输出所示,Tesseract 和pytesseract都正确地对文本进行了 OCR。
让我们试试另一张图片,这是史蒂夫·乔布斯的旧名片:
$ python first_ocr.py --image steve_jobs.png
Steven P. Jobs
Chairman of the Board
Apple Computer, Inc.
20525 Mariani Avenue, MS: 3K
Cupertino, California 95014
408 973-2121 or 996-1010.
图图 3 中史蒂夫·乔布斯的名片被正确地进行了 OCR 识别,尽管输入图像给 OCR 识别扫描文档带来了一些常见的困难,包括:
- 纸张因老化而发黄
- 图像上的噪声,包括斑点
- 开始褪色的文字
尽管有这些挑战,宇宙魔方仍然能够正确地识别名片。但这回避了一个问题——OCR这么简单吗? 我们是不是只要打开一个 Python shell,导入pytesseract包,然后在一个输入图片上调用image_to_string?不幸的是,OCR 并没有那么简单(如果是的话,本教程就没有必要了)。作为一个例子,让我们将同样的first_ocr.py脚本应用于一张更具挑战性的全食收据照片:
$ python first_ocr.py --image whole_foods.png
aie WESTPORT CT 06880
yHOLE FOODS MARKE
399 post RD WEST ~ ;
903) 227-6858
BACON LS NP
365
pacon LS N
图 4 中的全食杂货店收据没有使用 Tesseract 正确识别。你可以看到宇宙魔方要吐出一堆乱码的废话。OCR 并不总是完美的。
总结
在本教程中,您使用 Tesseract OCR 引擎、pytesseract包(用于与 Tesseract OCR 引擎交互)和 OpenCV 库(用于从磁盘加载输入图像)创建了您的第一个 OCR 项目。
然后,我们将我们的基本 OCR 脚本应用于三个示例图像。我们的基本 OCR 脚本适用于前两个版本,但在最后一个版本中却非常困难。那么是什么原因呢?为什么宇宙魔方能够完美地识别前两个例子,但是在第三张图片上却完全失败?秘密在于图像预处理步骤,以及底层的镶嵌模式和选项。
*祝贺您完成今天的教程,干得好!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***


 浙公网安备 33010602011771号
浙公网安备 33010602011771号