PyImgSearch-博客中文翻译-十-
PyImgSearch 博客中文翻译(十)
Raspbian Stretch:在您的 Raspberry Pi 上安装 OpenCV 3 + Python
原文:https://pyimagesearch.com/2017/09/04/raspbian-stretch-install-opencv-3-python-on-your-raspberry-pi/

拉斯比恩·杰西的释放已经过去两年多了。截止 2017 年 8 月 17 日,树莓 Pi 基金会正式发布了 Raspbian Jessie 的继任者— Raspbian Stretch。
正如我在以前的博客文章中所做的那样,我将展示如何在 Raspbian Stretch 上使用 Python 绑定安装 OpenCV 3。
如果您正在寻找不同平台的先前安装说明,请参考以下列表:
- 安装指南:Raspberry Pi 3+Raspbian Jessie+OpenCV 3
- 如何在 Raspbian Jessie 上安装 OpenCV 3.0?
- 在你的Raspberry Pi ZerorunningRaspbian Jessie 上安装 OpenCV。
- 在 拉斯边喘息上同时安装 Python 2.7 和 Python 3+的 OpenCV 3.0。
- 在 拉斯边喘息 上为 Python 2.7 安装 OpenCV 2.4。
否则,让我们继续在 Raspian Stretch 上安装带有 Python 绑定的 OpenCV 3!
快速入门视频教程
如果这是你第一次安装 OpenCV,或者你刚刚开始使用 Linux,我强烈建议你观看下面的视频,跟着我一步一步地指导你如何在运行 Raspbian Stretch 的 Raspberry Pi 上安装 OpenCV 3:
https://www.youtube.com/embed/j6RD3X94rEA?feature=oembed
使用 Python 和 OpenMV 读取条形码
原文:https://pyimagesearch.com/2018/03/19/reading-barcodes-with-python-and-openmv/

如果我说有一个摄像头:
- 是低成本的 $65 。
- 运行 MicroPython 。
- 并且可以像 Arduino/RPi 一样用护盾扩展。
相约 OpenMV !
2015 年 1 月,在视频搜索大师 Kickstarter 活动期间,我遇到了 OpenMV 的创始人夸贝纳·阿杰曼。那时,Kwabena 和 OpenMV 团队正在运行他们自己的的 Kickstarter。Kwabena 的 Kickstarter 筹集的资金比我多得多,这确实证明了(OpenMV 产品的价值和(2)嵌入式社区对使用这样一个工具的渴望。
自从 OpenMV Kickstarter 以来,OpenMV 团队一直致力于为从事嵌入式计算机视觉项目的开发人员和工程师提供低成本、Python 就绪且易于使用的相机系统。
鉴于 OpenMV 到目前为止的成功,有一个活跃的开发者社区也就不足为奇了。你肯定会得到项目成功所需的支持。当我开始为这篇文章构建条形码扫描系统时,他们的用户和论坛的响应速度给我留下了难以置信的印象。
在今天的博客文章中,将向您介绍 OpenMV,他们的花哨 IDE,我们甚至将构建您自己的条形码扫描系统。
要开始使用 OpenMV cam 和计算机视觉条形码解码,请继续阅读。
使用 Python 和 OpenMV 读取条形码

Figure 1: The OpenMV can read QR codes among many types of codes — all with built in libraries!
在今天的世界里,没有办法绕过条形码。
你收到的每一件杂货或亚马逊包裹都有它们。每次登机或租车时,都会用到条形码。但愿不会,在急诊时,医院腕带上的条形码可能会与你的身份相关联!
但是为什么呢?
简而言之,条形码是计算机将物品与数据库相关联的一种简单方式。因此,正确解码条形码非常重要,这样才能更新数据库。
典型的条形码阅读器使用光电管来“看到”代码。查看克里斯伍德福德关于 条形码和条形码扫描仪 的这篇文章。
鉴于当今时代相机的重要性,我们实际上可以使用图像处理来检测和解码条形码。
在 PyImageSearch 的上一篇文章中,我演示了如何用 Python 和 OpenCV 检测条形码。
探测是拼图的一部分。
另一部分是将条形码解码成有用的字符串。
遗憾的是,OpenCV 不包含内置的条形码检测+读取功能…
…但是有一些流行的条形码检测库,其中之一是 ZBar 。Satya Mallick, PyImageConf 2018 主持人,上个月在他的博客上写了一篇关于 ZBar 的精彩文章。
使用 ZBar 和其他类似的条形码读取库是完成这项任务的一种方法。
另一个选择是使用嵌入式工具和库,如 OpenMV。
事实上,OpenMV 让检测和读取条形码变得如此简单,以至于您可以:
- 构建您自己的条形码扫描设备
- 在装配线上创建自动化零件检测系统
- 在业余爱好项目中利用 OpenMV 来帮助您扫描和组织工作间中的组件和外围设备
- 使用 OpenMV 向初中或高中学生讲授嵌入式编程
OpenMV 摄像头
![]()
Figure 2: The OpenMV camera is a powerful embedded camera board that runs MicroPython.
OpenMV cam 的目标是成为 “机器视觉的 Arduino”,它是嵌入式的(没有操作系统),并且可以通过几个可用的屏蔽进行扩展(就像一个 Arduino )。
它使用起来也非常简单——你可以用 MicroPython 编写代码(不像 Arduino)。
Python 用户和本博客的读者在用 MicroPython 为 OpenMV 构建嵌入式计算机视觉项目时会有宾至如归的感觉。
OpenMV 摄像机非常强大,非常适合带有伺服电机的小型机器人项目,甚至是自动化零件检测装配线。
您可以通过 SPI、I2C、WiFi 和 USB 等通信协议轻松地将 OpenMV 与其他硬件、传感器、微控制器和 SBC 进行接口。
如果 OpenMV 只有一两个任务要执行,它通常会工作得最好,因为它的内存有限 (31KB 分配给脚本)。如果你需要录制静止图像或视频,你可以插入一个 microSD。
OpenMV 的图像处理能力包括:
- 瀑布式头发
- 阈值处理
- 斑点检测
- 画直线、圆和矩形
- 录制 gif 和 MJPEGs
- 阅读条形码(这篇文章)
- 模板匹配
- …还有更多!
如需完整列表,请务必查看文档。
你的应用需要特殊的镜头吗?一个不同点是标准 M12 镜头支架。现在,您可以为您的项目安装望远镜变焦镜头或鱼眼镜头。我真的希望树莓 Pi PiCamera 像 OpenMV 一样有一个镜头支架。
使用 OpenMV 和 Python 进行条形码检测和解码
一旦你安装了 OpenMV IDE,启动它。我们将在 OpenMV IDE 中完成所有的编码。
让我们首先创建一个名为openmv_barcode.py的文件:
# import necessary packages
import sensor
import time
import image
# import the lcd optionally
# to use the LCD, uncomment Lines 9, 24, 33, and 100
# and comment Lines 19 and 20
#import lcd
在第 2-4 行上,我们导入我们需要的 MicroPython/OpenMV 包。
可选地,在线 9 上,您可以导入lcd包,如果您想要使用 LCD 屏蔽,则需要该包。
接下来,让我们设置摄像头传感器:
# reset the camera
sensor.reset()
# sensor settings
sensor.set_pixformat(sensor.GRAYSCALE)
# non LCD settings
# comment the following lines if you are using the LCD
sensor.set_framesize(sensor.VGA)
sensor.set_windowing((640, 240))
# LCD settings
# uncomment this line to use the LCD with valid resolution
#sensor.set_framesize(sensor.QQVGA2)
# additional sensor settings
sensor.skip_frames(2000)
sensor.set_auto_gain(False)
sensor.set_auto_whitebal(False)
第 12-29 行上的设置是不言自明的,所以请阅读代码和注释。
我想指出的是,LCD 需要适合屏幕的分辨率。
注:我试了又试,想弄清楚如何使用全分辨率,然后制作一个适合 LCD 的缩放图像,但就是做不到。因此,如果您选择使用 LCD,您将尝试以较低的分辨率解码条形码(这对于传统的 1D 条形码来说不是最佳选择)。不用说,LCD 仍然是一个很好的调试工具,我想把它包括进来,这样你就可以看到它非常容易使用。一如既往,如果你能够解决这个问题,那么我鼓励你在帖子下面给我留下评论,与我和社区分享。
我还想指出27 号线。在“hello world”示例中,您将看到一个关键字参数time=2000到sensor.skip_frames。在这个上下文中不支持关键字参数,所以一定要使用在第 27 行显示的语法(特别是如果你正在处理“hello world”)。
接下来,让我们执行初始化:
# initialize the LCD
# uncomment if you are using the LCD
#lcd.init()
# initialize the clock
clock = time.clock()
如果你正在使用 LCD,你需要取消对第 33 行的注释(参见前面的代码块)。
第 36 行为 FPS 计算初始化我们的时钟
在这里,我们将创建(1)一个查找表和(2)一个用于确定条形码类型的便利函数:
# barcode type lookup table
barcode_type = {
image.EAN2: "EAN2",
image.EAN5: "EAN5",
image.EAN8: "EAN8",
image.UPCE: "UPCE",
image.ISBN10: "ISBN10",
image.EAN13: "EAN13",
image.ISBN13: "ISBN13",
image.I25: "I25",
image.DATABAR: "DATABAR",
image.DATABAR_EXP: "DATABAR_EXP",
image.CODABAR: "CODABAR",
image.CODE39: "CODE39",
image.PDF417: "PDF417",
image.CODE93: "CODE93",
image.CODE128: "CODE128"
}
def barcode_name(code):
# if the code type is in the dictionary, return the value string
if code.type() in barcode_type.keys():
return barcode_type[code.type()]
# otherwise return a "not defined" string
return "NOT DEFINED"
正如你在第 39 行看到的,我在那里定义了一个barcode_type字典,OpenMV 可以检测和解码相当多不同的条形码样式。
话虽如此,我并没有幸运地找到所有的条形码,所以这篇博文的 【下载】 部分包含的 PDF 并没有包括所有类型的条形码。
第 57-63 行定义了一个获取条形码类型的便利函数,没有抛出 Python key 异常的风险(OpenMV 不能很好地处理异常)。
从那里,让我们进入正题,开始捕捉和处理帧!我们将从开始一个while循环开始:
# loop over frames and detect + decode barcodes
while True:
# tick the clock for our FPS counter
clock.tick()
# grab a frame
img = sensor.snapshot()
第一步是为我们的 FPS 计数器滴答时钟(行 68 )。
从那里你应该用sensor.snapshot ( 线 71 )抓取一个画面。
现在,让乐趣开始吧!
我们已经有了一个图像,让我们看看我们能做些什么:
# loop over standard barcodes that are detected in the image
for code in img.find_barcodes():
# draw a rectangle around the barcode
img.draw_rectangle(code.rect(), color=127)
# print information in the IDE terminal
print("type: {}, quality: {}, payload: {}".format(
barcode_name(code),
code.quality(),
code.payload()))
# draw the barcode string on the screen similar to cv2.putText
img.draw_string(10, 10, code.payload(), color=127)
这里我们找到了标准的非二维码。我们需要做的就是调用img.find_barcodes(它封装了所有的条形码检测+读取功能)并循环结果(第 74 行)。
给定检测到的条形码,我们可以:
- 在检测到的条形码周围画一个边框矩形(行 76 )。
- 打印类型、质量和有效载荷(第 79-82 行)。
- 在屏幕上画出字符串(行 85 )。不幸的是(根据文档)目前没有办法用更大的字体来绘制字符串。
真的就是这么回事!
QR 码解码以类似的方式完成:
# loop over QR codes that are detected in the image
for code in img.find_qrcodes():
# draw a rectangle around the barcode
img.draw_rectangle(code.rect(), color=127)
# print information in the IDE terminal
print("type: QR, payload: {}".format(code.payload()))
# draw the barcode string on the screen similar to cv2.putText
img.draw_string(10, 10, code.payload(), color=127)
# display the image on the LCD
# uncomment if you are using the LCD
#lcd.display(img)
# print the frames per second for debugging
print("FPS: {}".format(clock.fps()))
此循环模拟标准条形码循环,因此请务必查看详细信息。
在循环之外,如果你正在使用 LCD,你将想要在它上面显示( Line 100 )。
最后,我们可以很容易地在终端的第 103 行上打印 FPS(每秒帧数)。
OpenMV 条形码解码结果。
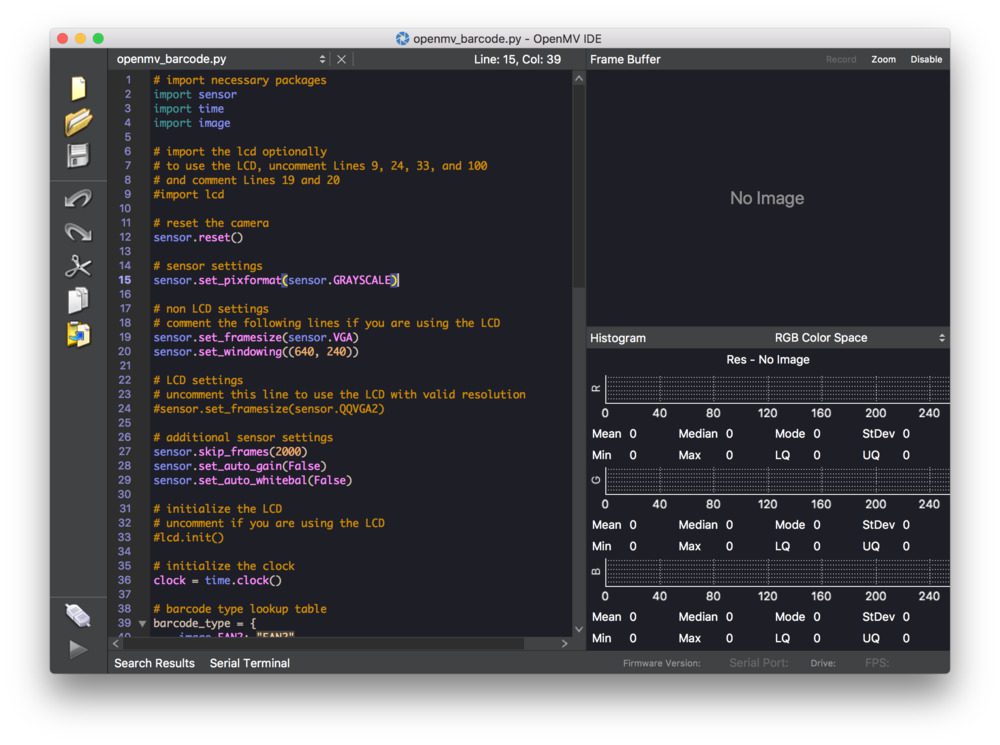
Figure 3: The OpenMV team has put together an awesome IDE for computer vision development. This is what you see when you first open the IDE and load a program.
首先,通过 USB 将您的 OpenMV cam 连接到您的计算机。
然后启动 IDE,如图 3 所示。
在那里,单击左下角的连接按钮。
IDE 可能会提示您更新固件(我通过单击按钮并等待大约 3-5 分钟就顺利完成了)。
当您准备好在编辑器中载入您的节目时,点按左下方的绿色播放/节目按钮。此按钮将使用您的代码设置 OpenMV。
耐心点。MicroPython 代码编译成机器代码并在处理器上刷新大约需要 45-90 秒。没有状态指示器,所以你只需要耐心。
不久,如果你正在打印到终端,你会看到数据,如 FPS 或条形码信息-这是你的队列,一切都在工作。你还可以在右上角的取景器中看到相机传感器的实时画面。
现在让我们来试试条形码!
在 “下载” 部分,我包含了一个 PDF 格式的条形码,供您打印和扫描。这是我们正在研究的东西:

Figure 4: Sample barcodes for testing with the OpenMV camera. Included are QR, CODE128, CODE93, CODE39, and DATABAR barcode images. You may print a PDF from the “Downloads” section of this blog post.
您可以从 IDE 的内置终端看到结果:
FPS: 2.793296
type: QR, payload: https://pyimagesearch.com/
FPS: 2.816901
type: QR, payload: https://openmv.io/
FPS: 2.941176
type: QR, payload: http://pyimg.co/dl4cv
FPS: 3.831418
type: CODE128, quality: 48, payload: guru
FPS: 4.484305
ype: CODE93, quality: 15, payload: OpenMV
FPS: 3.849856
type: CODE39, quality: 68, payload: DL4CV
FPS: 3.820961
type: DATABAR, quality: 83, payload: 0100000000020183
FPS: 4.191617
每个代码和终端的屏幕截图如下:
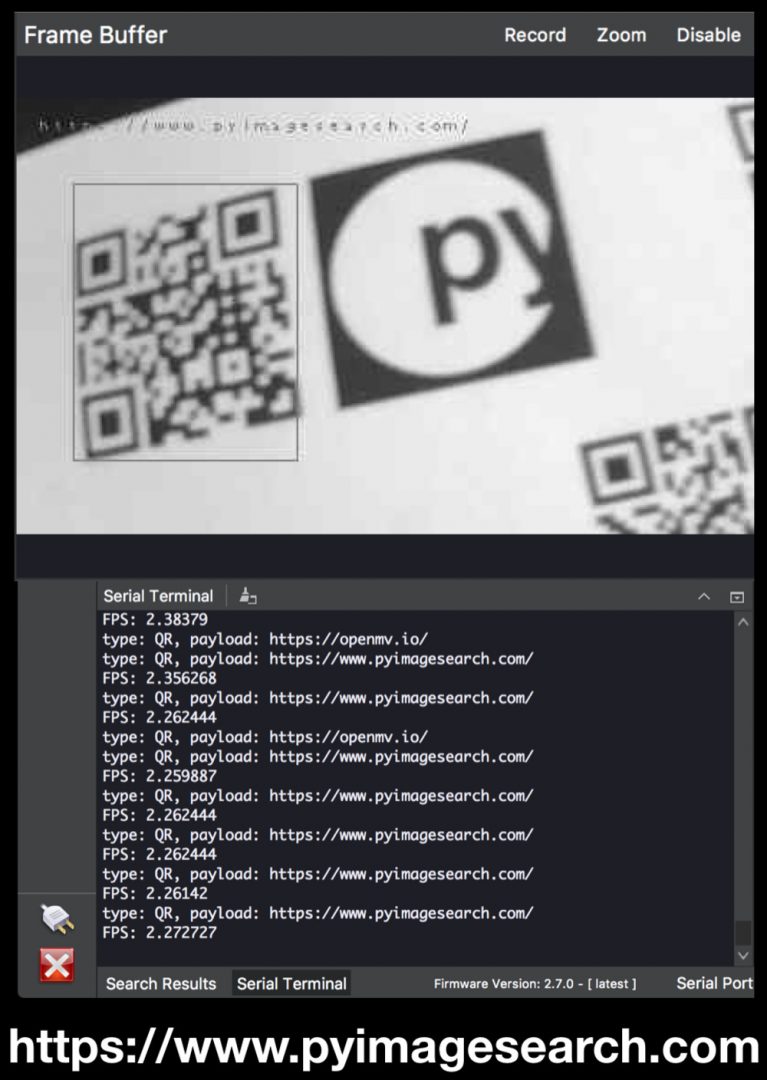
Figure 5: Scanning a QR code with a link to the PyImageSearch homepage.
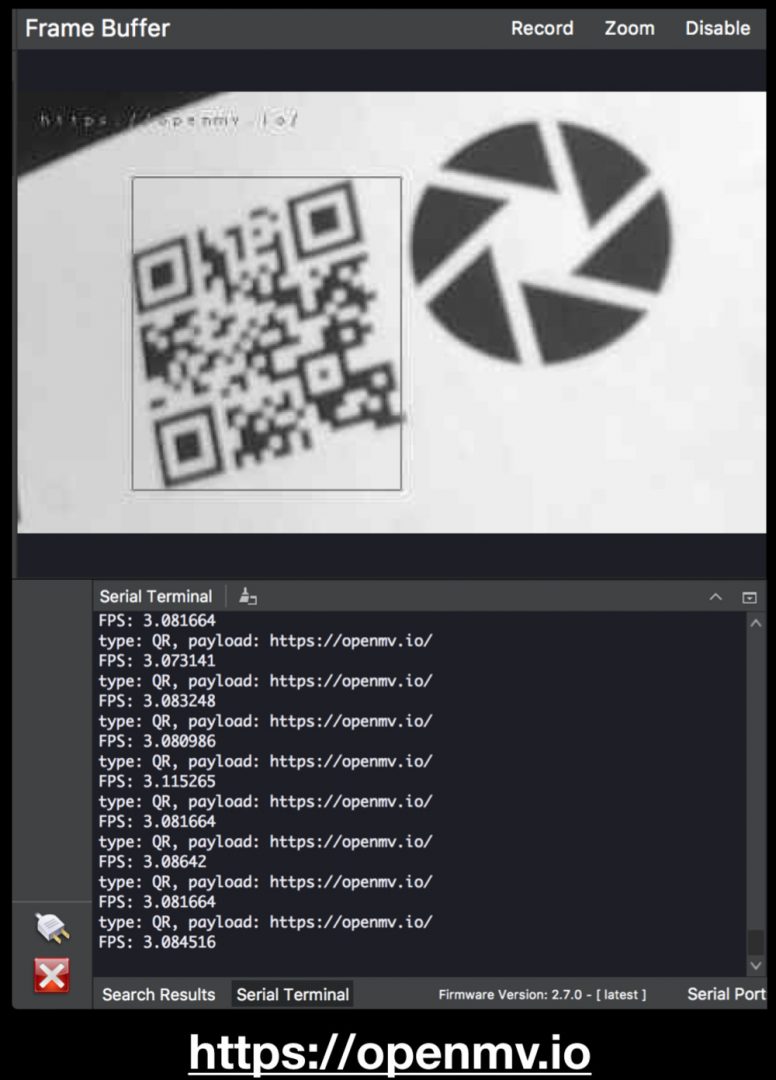
Figure 6: Scanning a QR code that contains a payload of “https://openmv.io” — the OpenMV homepage.
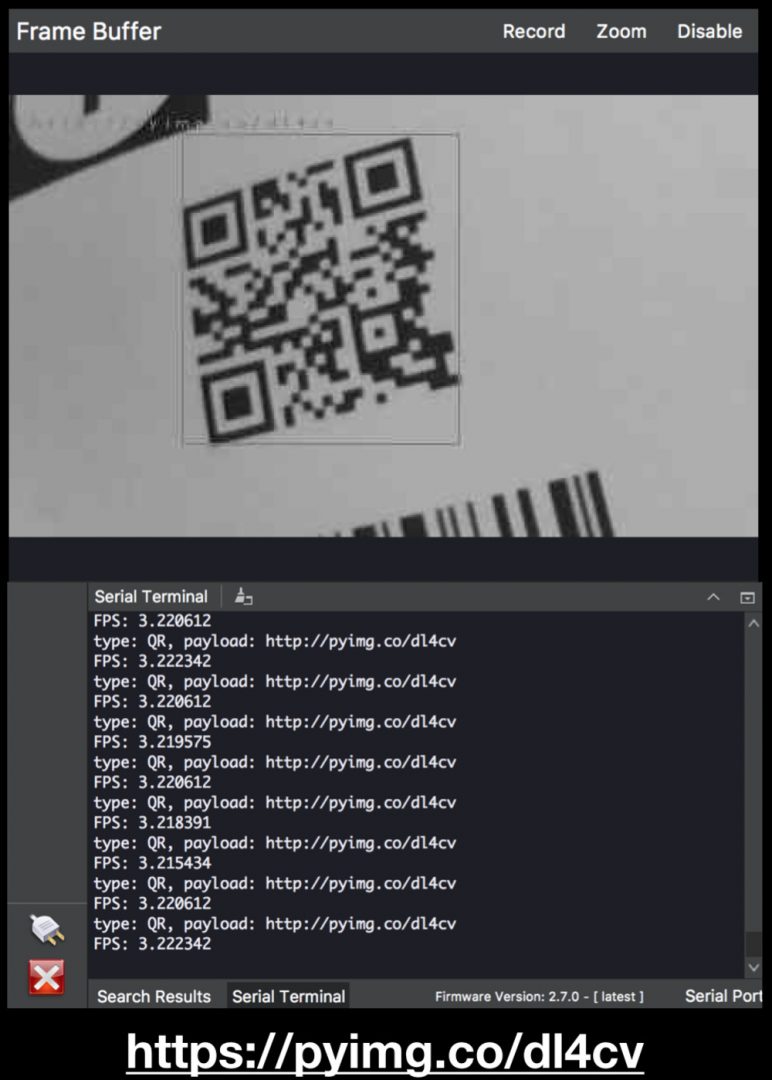
Figure 7: This QR code contains a payload directing you to the Deep Learning for Computer Vision with Python book information page.
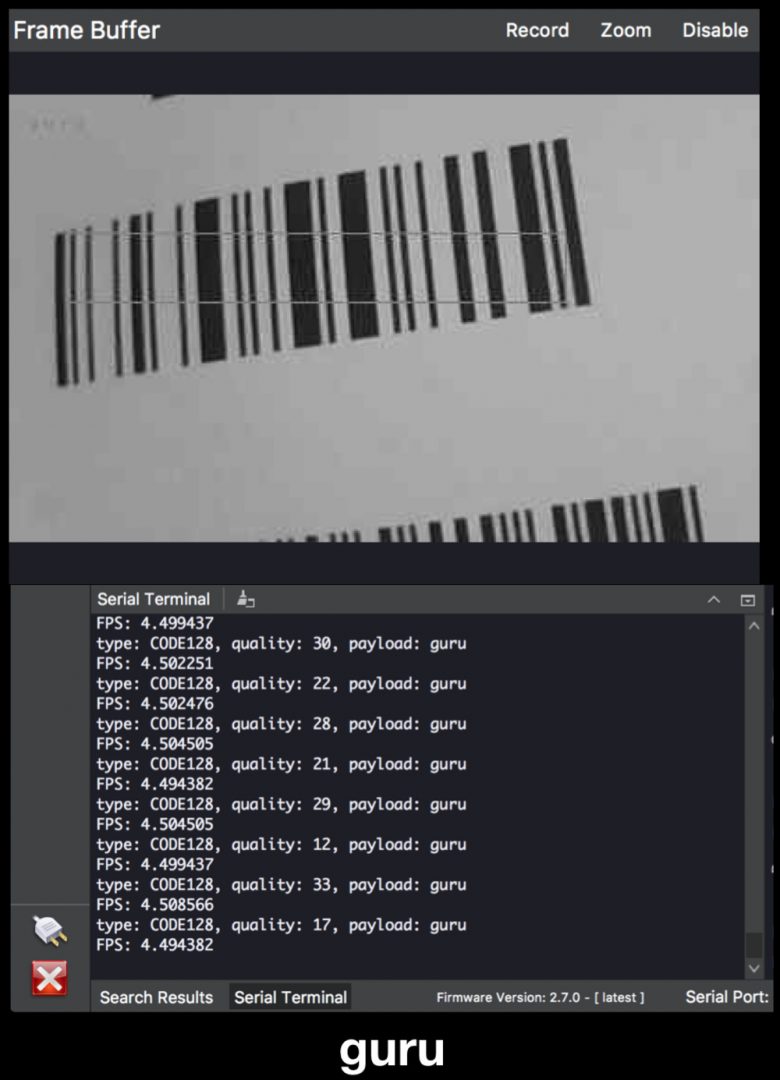
Figure 8: A CODE128 barcode that says “guru” is decoded by the OpenMV.
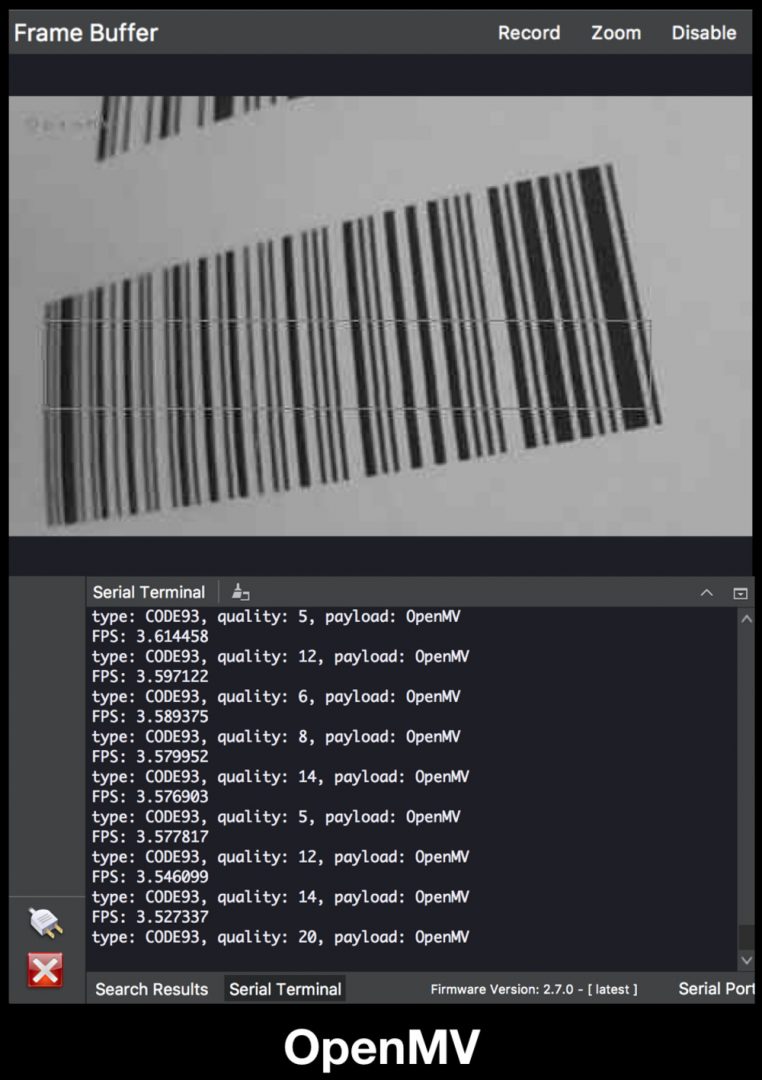
Figure 9: The OpenMV can decode CODE93 barcodes such as this one that has a payload of “OpenMV”.

Figure 10: CODE39 barcodes are easy with the OpenMV. The Payload here is “DL4CV”.
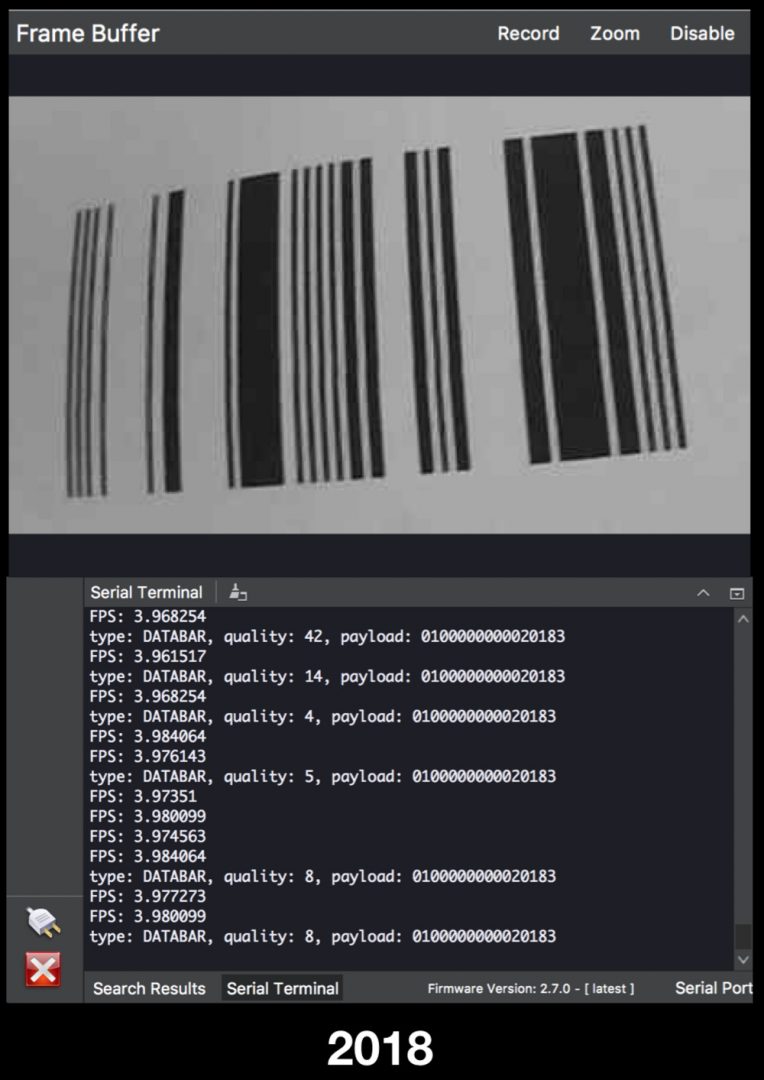
Figure 11: The OpenMV can decode DATABAR codes which are fixed-width and only contain digits. I coded “2018” into this barcode, but as you can see, the OpenMV camera actually reads 16 characters.
最后,这里有一张 IDE 运行的图片。请注意它是如何读取多个代码的,在条形码周围画出方框,还包含一个漂亮的颜色直方图。
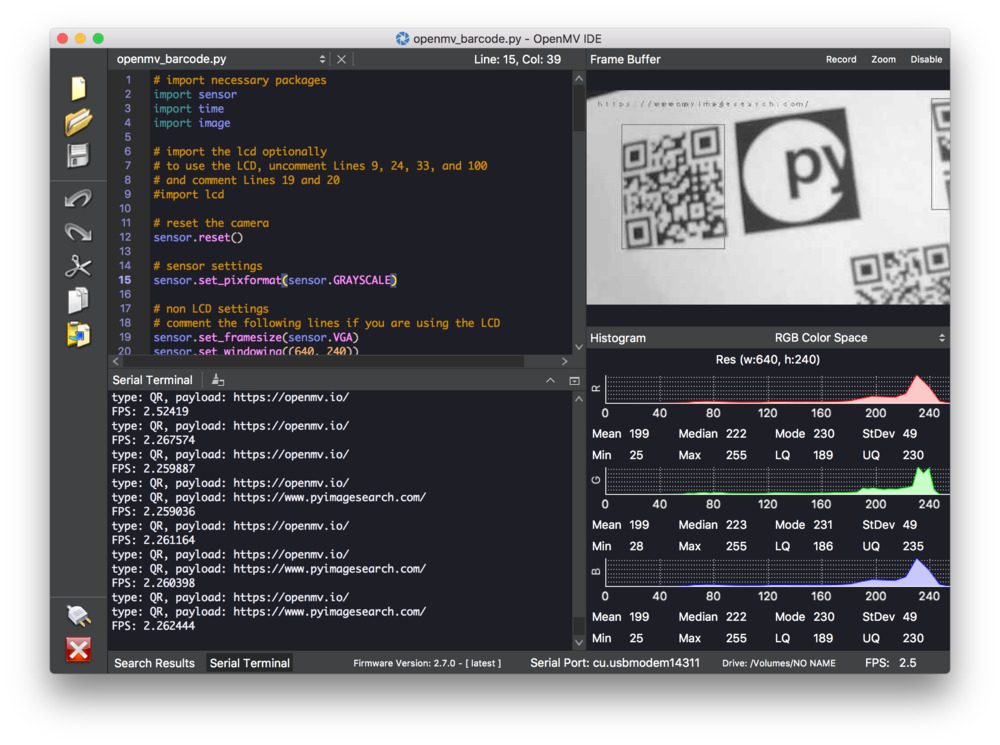
Figure 12: The OpenMV in action detecting barcodes and printing results to the IDE. As you can see, there’s a terminal in the bottom left which is scrolling data. There’s also a live view of the camera feed in the top right of the IDE and color histograms in the bottom right.
下面是使用 IDE 运行系统的视频:
https://www.youtube.com/embed/s6Jh7eJ1k7g?feature=oembed
用 Python 和 OpenCV 实现视频中的实时条码检测
原文:https://pyimagesearch.com/2014/12/15/real-time-barcode-detection-video-python-opencv/
https://www.youtube.com/embed/oooDn5SBUAg?feature=oembed
使用 OpenCV、Python 和 dlib 进行实时面部标志检测
原文:https://pyimagesearch.com/2017/04/17/real-time-facial-landmark-detection-opencv-python-dlib/
在过去的几周里,我们一直在讨论面部标志以及它们在计算机视觉和图像处理中的作用。

我们已经开始学习如何在图像中检测面部标志。
然后我们发现如何标记和注释每个面部区域 ,比如眼睛、眉毛、鼻子、嘴和下颌线。
今天,我们将扩展面部标志的实现,以在实时视频流中工作,为更多现实世界的应用铺平道路,包括下周关于眨眼检测的教程。
要了解如何实时检测视频流中的面部标志,请继续阅读。
使用 OpenCV、Python 和 dlib 进行实时面部标志检测
这篇博文的第一部分将利用 Python、OpenCV 和 dlib 实现视频流中的实时面部标志检测。
然后,我们将测试我们的实现,并使用它来检测视频中的面部标志。
视频流中的面部标志
让我们开始这个面部标志的例子。
打开一个新文件,将其命名为video_facial_landmarks.py,并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from imutils import face_utils
import datetime
import argparse
import imutils
import time
import dlib
import cv2
第 2-9 行导入我们需要的 Python 包。
我们将使用 imutils 的face_utils子模块,因此如果您还没有安装/升级到最新版本,请花一点时间现在就安装/升级:
$ pip install --upgrade imutils
注意: 如果您正在使用 Python 虚拟环境,请注意确保您正在正确的环境中安装/升级imutils。
我们还将在imutils中使用VideoStream实现,允许你以更高效的、更快的线程方式访问你的网络摄像头/USB 摄像头/Raspberry Pi 摄像头模块。在这篇博文中,你可以读到更多关于VideoStream类以及它如何实现一个更高的框架。**
如果你想使用视频文件而不是视频流,一定要参考这篇关于有效帧轮询的博文来自一个预先录制的视频文件,用FileVideoStream代替VideoStream。
对于我们的面部标志实现,我们将使用 dlib 库。你可以在本教程中学习如何在你的系统上安装 dlib(如果你还没有这样做的话)。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-r", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
args = vars(ap.parse_args())
我们的脚本需要一个命令行参数,后跟第二个可选参数,每个参数的详细信息如下:
--shape-predictor:dlib 预训练的面部标志检测器的路径。使用这篇博文的 “下载” 部分下载代码+面部标志预测器文件的存档。--picamera:可选命令行参数,此开关指示是否应该使用 Raspberry Pi 摄像头模块,而不是默认的网络摄像头/USB 摄像头。提供一个值 > 0 来使用你的树莓 Pi 相机。
既然已经解析了我们的命令行参数,我们需要初始化 dlib 的 HOG +基于线性 SVM 的面部检测器,然后从磁盘加载面部标志预测器:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
下一个代码块只是处理初始化我们的VideoStream并允许相机传感器预热:
# initialize the video stream and allow the cammera sensor to warmup
print("[INFO] camera sensor warming up...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
我们视频处理管道的核心可以在下面的while循环中找到:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream, resize it to
# have a maximum width of 400 pixels, and convert it to
# grayscale
frame = vs.read()
frame = imutils.resize(frame, width=400)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
在第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第 31 行第
第 35 行从我们的视频流中抓取下一帧。
然后我们预处理这个帧,将它的宽度调整为 400 像素,并将其转换为灰度(行 36 和 37 )。
在我们可以在我们的帧中检测面部标志之前,我们首先需要定位面部——这是通过返回边界框 (x,y) 的detector在行 40 上完成的——图像中每个面部的坐标。
既然我们已经在视频流中检测到了面部,下一步就是将面部标志预测器应用于每个面部 ROI:
# loop over the face detections
for rect in rects:
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
在第 43 行第 43 行第 43 行第 43 行第 43 行第 43 行第 43 行第 41 行,我们对每个检测到的人脸进行循环。
第 47 行将面部标志检测器应用到面部区域,返回一个shape对象,我们将其转换为一个 NumPy 数组(第 48 行)。
第 52 行和第 53 行然后在输出frame上画一系列圆圈,可视化每个面部标志。了解面部什么部位(即鼻子、眼睛、嘴巴等。)每个 (x,y)-坐标映射到,请参考这篇博文。
第 56 和 57 行显示输出frame到我们的屏幕。如果按下q键,我们从循环中断开并停止脚本(第 60 行和第 61 行)。
最后,行 64 和 65 做了一些清理工作:
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
正如你所看到的,在图像 中检测面部标志的与在视频流中检测面部标志的之间几乎没有区别——代码中的主要区别只是涉及设置我们的视频流指针,然后轮询视频流中的帧。
检测面部标志的实际过程是相同的,不同于在单一图像中检测面部标志,我们现在检测在系列帧中的面部标志。
实时面部标志结果
要使用 OpenCV、Python 和 dlib 测试我们的实时面部标志检测器,请确保您使用这篇博客文章的 【下载】 部分下载代码、项目结构和面部标志预测器模型的档案。
如果您使用标准网络摄像头/USB 摄像头,您可以执行以下命令来启动视频面部标志预测器:
$ python video_facial_landmarks.py \
--shape-predictor shape_predictor_68_face_landmarks.dat
否则,如果您使用的是 Raspberry Pi,请确保将--picamera 1开关附加到命令中:
$ python video_facial_landmarks.py \
--shape-predictor shape_predictor_68_face_landmarks.dat \
--picamera 1
这是一个简短的 GIF 输出,您可以看到面部标志已经成功地实时检测到我的面部:
Figure 1: A short demo of real-time facial landmark detection with OpenCV, Python, an dlib.
我已经包括了一个完整的视频输出如下:
https://www.youtube.com/embed/pD0gVP0aw3Q?feature=oembed
基于 Movidius NCS 的树莓派实时目标检测

今天的帖子是受丹妮尔的启发,丹妮尔是一位 PyImageSearch 的读者,她上周给我发了一封电子邮件,问我:
嗨阿德里安,
我很喜欢你的博客,我尤其喜欢上周关于英特尔 Movidius NCS 的图像分类的帖子。
我仍在考虑为个人项目购买一台英特尔 Movidius NCS。
我的项目包括使用 Raspberry Pi 进行对象检测,在这里我使用了自己定制的 Caffe 模型。您提供的用于在 Pi 的 CPU 上应用对象检测的基准脚本太慢了,我需要更快的速度。
NCS 对我的项目来说是个好选择吗?它能帮助我实现更高的 FPS 吗?
问得好,丹妮尔。谢谢你的关心。
简短的回答是肯定的,你可以使用 Movidius NCS 和你自己定制的 Caffe 模型进行物体检测。如果您正在处理直播或录制的视频,您甚至可以获得高帧速率。
但是有一个条件。
我告诉 Danielle,她需要在她的(Ubuntu 16.04)机器上安装成熟的 Movidius SDK。我还提到从 Caffe 模型生成图形文件并不总是简单明了的。
在今天的帖子中,你将学习如何:
- 在您的机器上安装 Movidius SDK
- 使用 SDK 生成对象检测图形文件
- 为 Raspberry Pi + NCS 编写一个实时对象检测脚本
看完这篇文章后,你会对 Movidius NCS 有一个很好的了解,并且知道它是否适合你的 Raspberry Pi +对象检测项目。
要开始在 Raspberry Pi 上进行实时物体检测,继续阅读。
弃用声明: 本文使用 Movidius SDK 和 APIv1/APIv2,API v1/API v2 现已被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。
树莓派上的实时目标检测
今天的博文分为五个部分。
首先,我们将安装 Movidius SDK,然后学习如何使用 SDK 来生成 Movidius 图形文件。
在此基础上,我们将编写一个脚本,使用英特尔 Movidius Neural compute stick 进行实时对象检测,该计算棒可用于 Pi(或稍加修改的替代单板计算机)。
接下来,我们将测试脚本并比较结果。
在之前的帖子中,我们学习了如何使用 CPU 和 OpenCV DNN 模块在 Raspberry Pi 上执行实时视频对象检测。我们实现了大约 0.9 FPS,这是我们的基准比较。今天,我们将看看与 Pi 配对的 NCS 如何与使用相同模型的 Pi CPU 进行比较。
最后,我收集了一些常见问题(FAQ)。请经常参考这一部分——我希望随着我收到的评论和电子邮件的增多,这一部分会越来越多。
安装英特尔 Movidius SDK
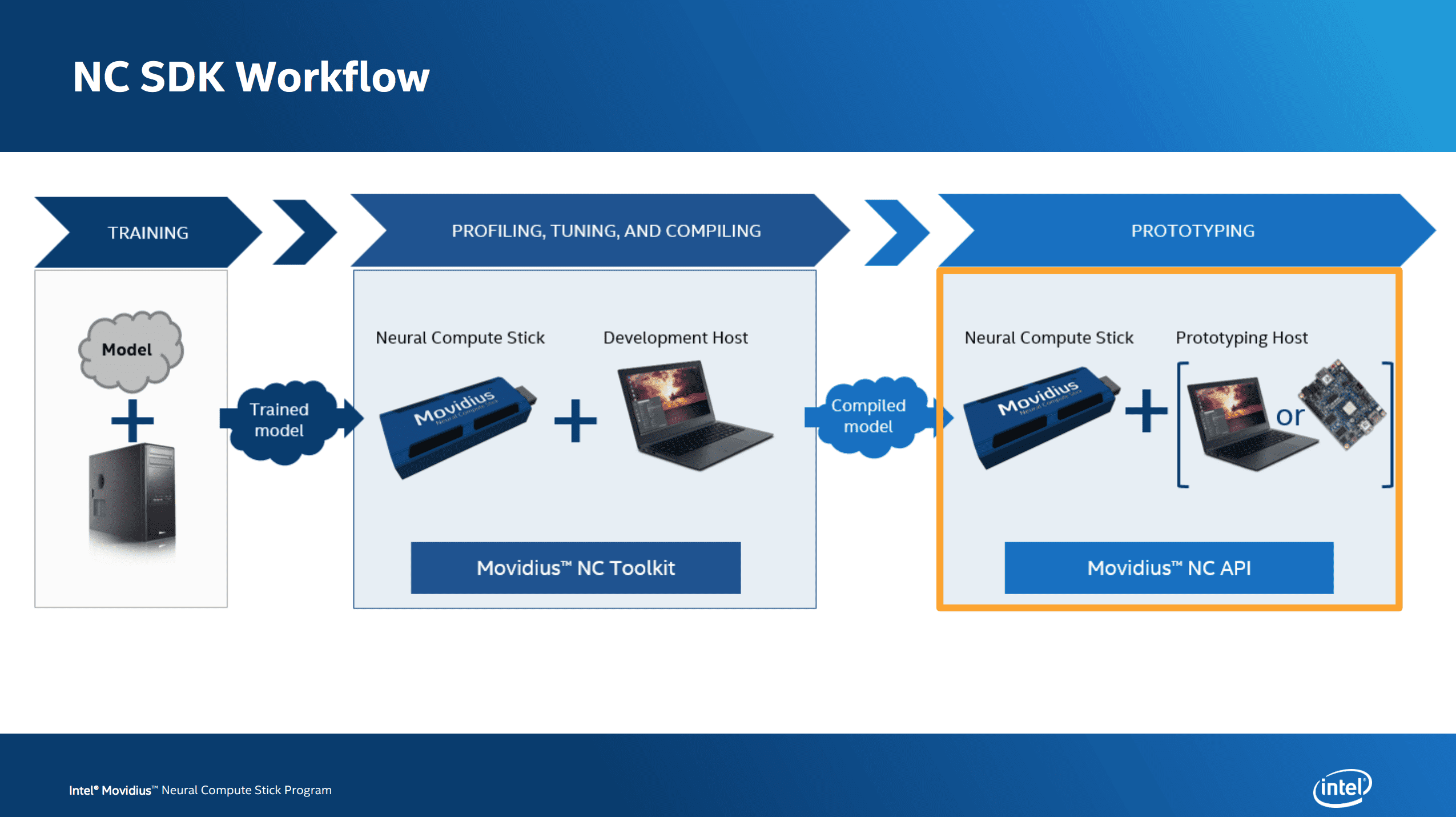
Figure 1: The Intel Movidius NCS workflow (image credit: Intel)
弃用声明: 本文使用 Movidius SDK 和 APIv1/APIv2,API v1/API v2 现已被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。
上周,我回顾了 Movidius 的工作流程。该工作流程有四个基本步骤:
- 使用全尺寸机器训练模型
- 使用 SDK 和 NCS 将模型转换成可部署的图形文件
- 编写一个 Python 脚本来部署图形文件并处理结果
- 将 Python 脚本和图形文件部署到配有英特尔 Movidius NCS 的单板计算机上
在本节中,我们将学习如何安装 SDK,其中包括 TensorFlow、Caffe、OpenCV 和英特尔的 Movidius 工具套件。
要求:
- 独立的机器或虚拟机。我们会在上面安装 Ubuntu 16.04 LTS
- 根据下载速度和机器性能,需要 30-60 分钟
- NCS USB stick 移动器
我强调了“单机”,因为这台机器仅用于 Movidius 开发非常重要。
换句话说,不要在“日常开发和生产力使用”的机器上安装 SDK,那里可能已经安装了 Python 虚拟环境和 OpenCV。安装过程并不是完全孤立的,它可能会改变系统中现有的库。
然而,还有一种选择:
使用 VirtualBox 虚拟机(或其他虚拟化系统)并在虚拟机中运行独立的 Ubuntu 16.04 操作系统。
VM 的优点是你可以把它安装在日常使用的机器上,并且仍然保持 SDK 的独立性。缺点是你不能通过虚拟机访问 GPU。
Danielle 想要使用 Mac,而 VirtualBox 在 Mac 上运行良好,所以让我们沿着这条路走下去。请注意,您也可以在 Windows 或 Linux 主机上运行 VirtualBox,这可能会更容易。
在我们开始之前,我想提醒大家注意我们将要进行的非标准虚拟机设置。我们将配置 USB 设置,这将允许 Movidius NCS 保持正常连接。
据我从论坛上看,这些是 Mac 专用的 VM USB 设置(但我不确定)。请在评论区分享你的经历。
下载 Ubuntu 和 Virtualbox
让我们开始吧。
首先,下载 Ubuntu 16.04 64 位。iso 图片来自这里LTS 官方 Ubuntu 16.04.3 下载页面。你可以抓住。iso 直接或种子也将适合更快的下载。
在 Ubuntu 下载的时候,如果你没有 Oracle VirtualBox,就抓取适合你操作系统的安装程序(我运行的是 macOS)。你可以在这里下载 VirtualBox。
非虚拟机用户:如果你不打算在虚拟机上安装 SDK,那么你可以跳过下载/安装 Virtualbox。相反,向下滚动到“安装操作系统”,但忽略关于虚拟机和虚拟光驱的信息——您可能会使用 USB 拇指驱动器进行安装。
当你下载了 VirtualBox,而 Ubuntu。iso 继续下载,可以安装 VirtualBox。通过向导安装非常容易。
从那里,因为我们将使用 USB 直通,我们需要扩展包。
安装扩展包
让我们导航回 VirtualBox 下载页面并下载 Oracle VM 扩展包(如果您还没有的话)。
扩展包的版本必须与您正在使用的 Virtualbox 的版本相匹配。如果您有任何正在运行的虚拟机,您会想要关闭它们以便安装扩展包。安装扩展包轻而易举。
创建虚拟机
一旦下载了 Ubuntu 16.04 映像,启动 VirtualBox,并创建一个新的虚拟机:

Figure 2: Creating a VM for the Intel Movidius SDK.
为您的虚拟机提供合理的设置:
- 我暂时选择了 2048MB 的内存。
- 我选择了 2 个虚拟 CPU。
- 我设置了一个 40Gb 的动态分配 VDI (Virtualbox 磁盘映像)。
前两个设置很容易在以后更改,以获得主机和来宾操作系统的最佳性能。
至于第三个设置,为操作系统和 SDK 提供足够的空间是很重要的。如果空间不足,您可以随时“连接”另一个虚拟磁盘并装载它,或者您可以扩展操作系统磁盘(仅限高级用户)。
USB 直通设置
根据定义,虚拟机实际上是作为软件运行的。本质上,这意味着它没有访问硬件的权限,除非您特别授予它权限。这包括相机、USB、磁盘等。
这是我必须在英特尔表单上做一些挖掘的地方,以确保 Movidius 可以与 MacOS 一起工作(因为最初它在我的设置上不工作)。
Ramana @ Intel 在论坛上提供了关于如何设置 USB 的“非官方”指导。您的里程可能会有所不同。
为了让虚拟机访问 USB NCS,我们需要更改设置。
转到虚拟机的“设置”,编辑“端口”>“USB”,以反映一个“USB 3.0 (xHCI)控制器”。
您需要为 Movidius 设置 USB2 和 USB3 设备过滤器,以无缝保持连接。
为此,点击“添加新 USB 过滤器”图标,如图所示:
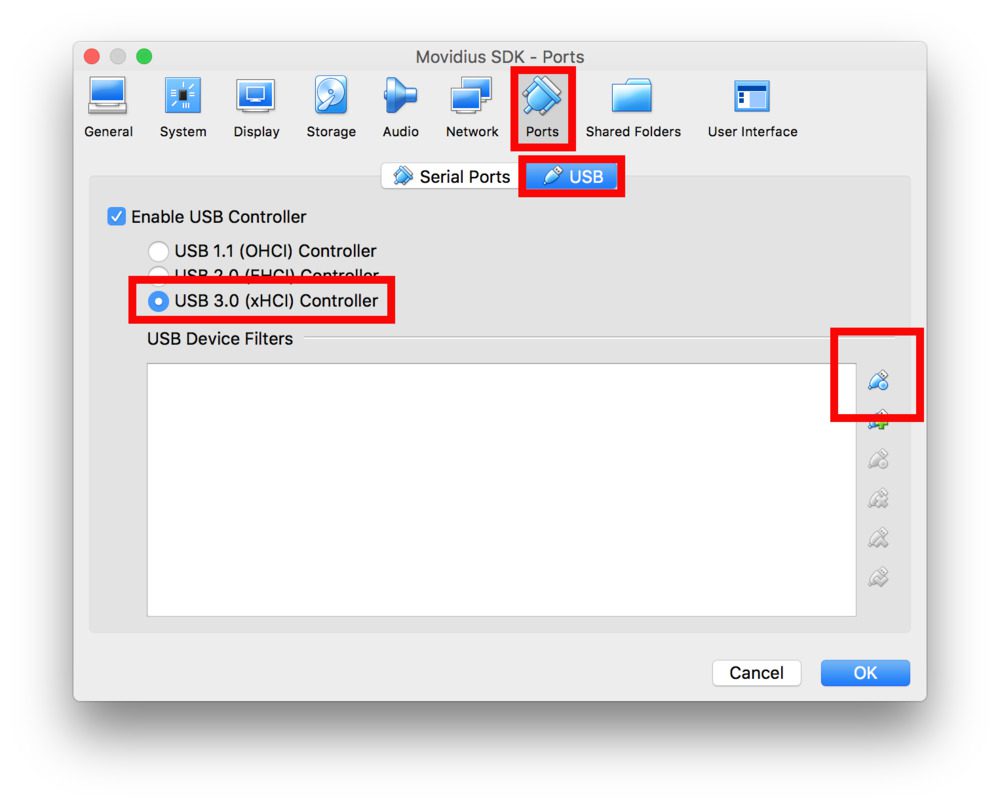
Figure 3: Adding a USB Filter in VirtualBox settings to accommodate the Intel Movidius NCS on MacOS.
在那里,您需要创建两个 USB 设备过滤器。大多数字段可以留空。我只是给了每个人一个名字,并提供了供应商 ID。
- 名称: Movidius1 ,厂商 ID: 03e7 ,其他字段: 空白
- 名称: Movidius2 ,厂商 ID: 040e ,其他字段: 空白
下面是第一个例子:
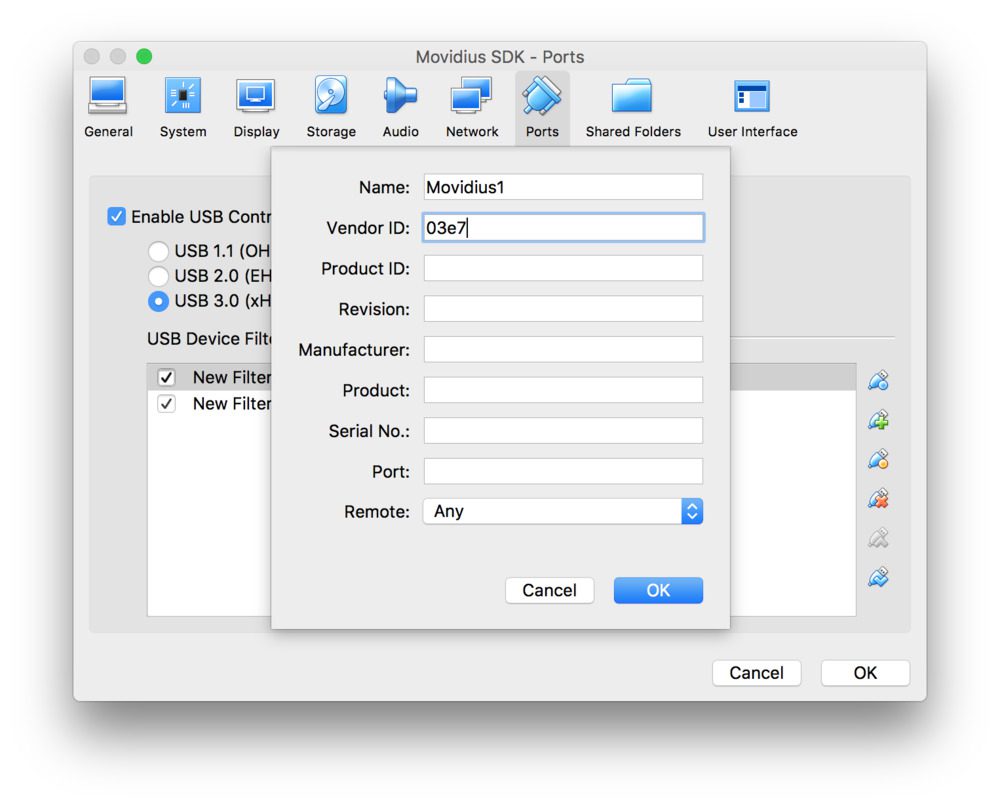
Figure 4: Two Virtualbox USB device filters are required for the Movidius NCS to work in a VM on MacOS.
请务必保存这些设置。
安装操作系统
要安装操作系统,请“插入”。iso 镜像到虚拟光驱中。为此,请转到“设置”,然后在“存储”下选择“控制器:IDE >空”,并点击磁盘图标(用红框标出)。然后找到并选择你新下载的 Ubuntu .iso。
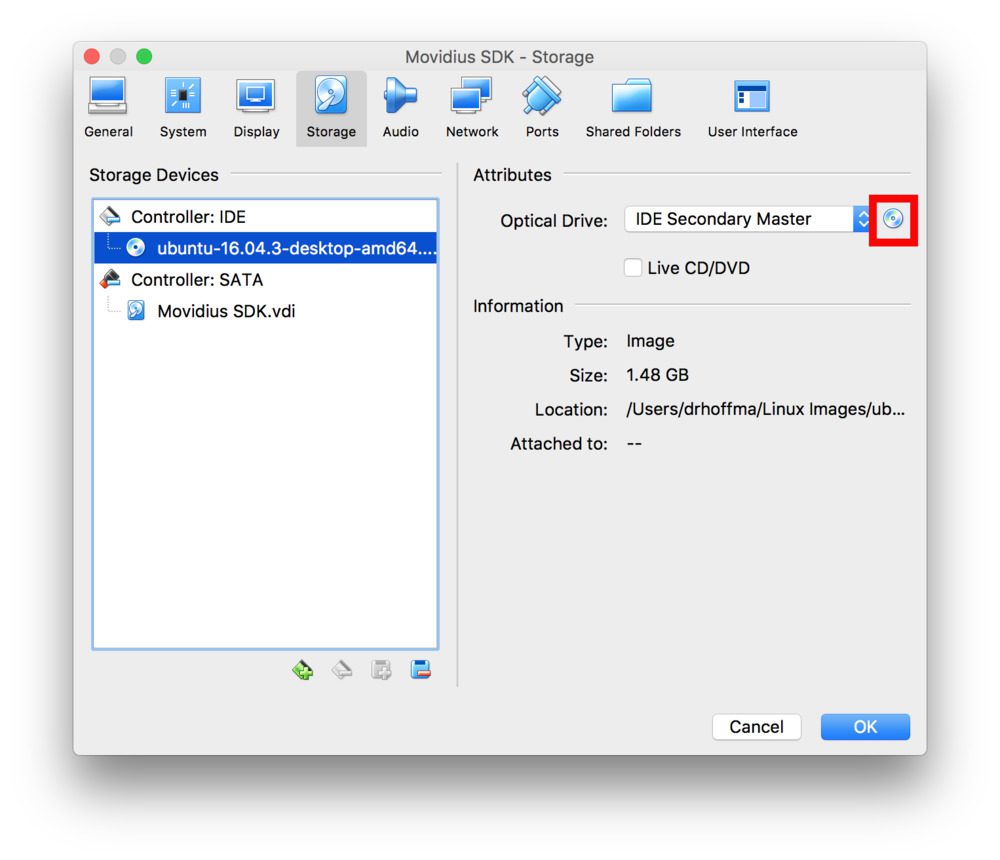
Figure 5: Inserting an Ubuntu 16.04 .iso file into a Virtualbox VM.
验证所有设置,然后启动您的机器。
按照提示进入“安装 Ubuntu”。如果您的互联网连接速度很快,您可以选择“安装 Ubuntu 时下载更新”。我没有选择“安装第三方软件……”选项。
下一步是“擦除磁盘并安装 Ubuntu”—这是一个安全的操作,因为我们刚刚创建了空的 VDI 磁盘。在那里,设置系统名称和用户名+密码。
一旦指示您重新启动并移除虚拟光盘,您就差不多准备好了。
首先,让我们更新我们的系统。打开终端并键入以下内容来更新您的系统:
$ sudo apt-get update && sudo apt-get upgrade
安装来宾附件
非虚拟机用户:您应该跳过这一部分。
从这里开始,因为我们将使用 USB 设备(Intel NCS),所以让我们安装来宾附件。Guest additions 还支持虚拟机和主机之间的双向复制/粘贴,以及其他不错的共享工具。
可以通过转到虚拟箱的设备菜单并点击“插入来宾附件 CD 映像……”来安装来宾附件:
Figure 6: Virtualbox Guest Additions for Ubuntu has successfully been installed.
按照提示按“返回关闭此窗口……”完成安装。
拍快照
非虚拟机用户:您可以跳过这一部分,或者通过您喜欢的方法备份您的台式机/笔记本电脑。
从那里开始,我喜欢重启,然后拍摄我的虚拟机的“快照”。
重启很重要,因为我们刚刚更新并安装了很多软件,希望确保更改生效。
此外,如果我们在安装过程中出现任何错误或问题,快照将允许我们进行回滚——正如我们将发现的那样,在安装过程中会遇到一些问题,可能会让您被 Movidius SDK 绊倒,因此这是一个值得的步骤。
一定要花时间给你的系统拍快照。进入 VirtualBox 菜单栏,按下“机器>拍摄快照”。
您可以为快照命名,如“已安装的操作系统和来宾添加项”,如下所示:
Figure 7: Taking a snapshot of the Movidius SDK VM prior to actually installing the SDK.
在 Ubuntu 上安装英特尔 Movidius SDK
本节假设你(a)按照上面的说明在虚拟机上安装了 Ubuntu 16.04 LTS,或者(b)正在台式机/笔记本电脑上使用全新安装的 Ubuntu 16.04 LTS 。
英特尔使安装 SDK 的过程变得非常简单。为此干杯!
但是就像我上面说的,我希望有一种先进的方法。我喜欢简单,但我也喜欢控制我的电脑。
让我们从终端安装 Git:
$ sudo apt-get install git
从那里开始,让我们非常紧密地遵循英特尔的指示,这样就不会有任何问题。
打开一个终端并跟随:
$ cd ~
$ mkdir workspace
$ cd workspace
现在我们在工作区中,让我们克隆出 NCSDK 和 NC App Zoo :
$ git clone https://github.com/movidius/ncsdk.git
$ git clone https://github.com/movidius/ncappzoo.git
从那里,您应该导航到ncsdk目录并安装 SDK:
$ cd ~/workspace/ncsdk
$ make install
你可能想出去呼吸点新鲜空气,或者给自己拿杯咖啡(或者啤酒,看时间了)。这个过程大约需要 15 分钟,取决于您的主机性能和下载速度。
Figure 8: The Movidius SDK has been successfully installed on our Ubuntu 16.04 VM.
虚拟机用户:现在安装已经完成,这是拍摄另一个快照的好时机,这样我们可以在将来需要时恢复。你可以按照上面同样的方法再拍一张快照(我把我的命名为“SDK installed”)。请记住,快照要求主机上有足够的磁盘空间。
将 NCS 连接到 USB 端口并验证连通性
此步骤应在您的台式机/笔记本电脑上执行。
非虚拟机用户:您可以跳过这一步,因为您可能不会遇到任何 USB 问题。相反,插入 NCS 并滚动到“测试 SDK”。
首先,将您的 NCS 连接到笔记本电脑或台式机上的物理 USB 端口。
注:鉴于我的 Mac 有雷电 3 / USB-C 端口,我最初插上了苹果的 USB-C 数字 AV 多端口适配器,它有一个 USB-A 和 HDMI 端口。这不管用。相反,我选择使用一个简单的适配器,而不是 USB 集线器。基本上,如果您正在使用 VM,您应该尝试消除对任何额外的必需驱动程序的需求。
然后,我们需要让虚拟机可以访问 u 盘。因为我们已经安装了访客插件和扩展包,所以我们可以从 VirtualBox 菜单中完成这项工作。在虚拟机菜单栏中,点击“设备>USB>' m ovidius ltd . m ovidius ma 2x5x '”(或一个类似名称的设备)。movid us 旁边可能已经有一个复选标记,表示它已连接到虚拟机。
在虚拟机中打开一个终端。您可以运行以下命令来验证操作系统是否知道 USB 设备:
$ dmesg
您应该看到,通过读取最近的 3 或 4 条日志消息,可以识别出 Movidius,如下所示:

Figure 9: Running the dmesg command in a terminal allows us to see that the Movidius NCS is associated with the OS.
如果您看到了 Movidius 设备,那么是时候测试安装了。
测试 SDK
此步骤应在您的台式机/笔记本电脑上执行。
既然已经安装了 SDK,您可以通过运行预构建的示例来测试安装:
$ cd ~/workspace/ncsdk
$ make examples
这可能需要大约五分钟的时间来运行,您将会看到大量的输出(上面的块中没有显示)。
如果您在所有示例运行时没有看到错误消息,这是好消息。您会注意到 Makefile 已经执行了代码,从 Github 下载模型和权重,并从那里运行 mvNCCompile。我们将在下一节学习 mvNCCompile。我对 Movidius 团队在 Makefiles 中所做的努力印象深刻。
另一项检查(这与我们上周对 Pi 进行的检查相同):
$ cd ~/workspace/ncsdk/examples/apps
$ make all
$ cd hello_ncs_py
$ python hello_ncs.py
Hello NCS! Device opened normally.
Goodbye NCS! Device closed normally.
NCS device working.
该测试确保到 API 的链接和到 NCS 的连接正常工作。
如果你没有遇到太多麻烦就走到了这一步,那么恭喜你!
从您自己的 Caffe 模型生成 Movidius 图形文件
弃用声明: 本文使用 Movidius SDK 和 APIv1/APIv2,API v1/API v2 现已被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。
此步骤应在您的台式机/笔记本电脑上执行。
借助英特尔的 SDK,生成图形文件变得非常容易。在某些情况下,您实际上可以使用 Pi 来计算图形。其他时候,你需要一台内存更大的机器来完成任务。
我想和你分享一个主要工具:mvNCCompile。
这个命令行工具同时支持 TensorFlow 和 Caffe。我希望 Keras 将来能得到英特尔的支持。
对于 Caffe,命令行参数采用以下格式(TensorFlow 用户应参考类似的文档):
$ mvNCCompile network.prototxt -w network.caffemodel \
-s MaxNumberOfShaves -in InputNodeName -on OutputNodeName \
-is InputWidth InputHeight -o OutputGraphFilename
让我们回顾一下论点:
network.prototxt:网络文件的路径/文件名-w network.caffemodel:caffe model 文件的路径/文件名-s MaxNumberOfShaves: SHAVEs (1、2、4、8 或 12)用于网络层(我想默认是 12,但是文档不清楚)-in InputNodeNodeName:您可以选择指定一个特定的输入层(它将匹配 prototxt 文件中的名称)-on OutputNodeName:默认情况下,网络通过输出张量进行处理,该选项允许用户选择网络中的替代端点-is InputWidth InputHeight:输入形状非常重要,应该与您的网络设计相匹配-o OutputGraphFilename:如果没有指定文件/路径,默认为当前工作目录中非常模糊的文件名graph
批量参数在哪里?
NCS 的批次大小始终为 1,颜色通道的数量假定为 3。
如果您以正确的格式向mvNCCompile提供命令行参数,并插入 NCS,那么您将很快拥有一个图形文件。
有一点需要注意(至少从我目前使用 Caffe 文件的经验来看)。mvNCCompile工具要求 prototxt 采用特定的格式。
你可能需要修改你的 prototxt 来让mvNCCompile工具工作。如果你有困难, Movidius 论坛也许可以指导你。
今天,我们将使用经过 Caffe 培训的 MobileNet 单次检测器(SSD)。GitHub 用户 chuanqui305 因在 MS-COCO 数据集上训练模型而获得积分。谢谢川 qui305!
我已经在 【下载】 部分提供了川奎 305 的文件。要编译图形,您应该执行以下命令:
$ mvNCCompile models/MobileNetSSD_deploy.prototxt \
-w models/MobileNetSSD_deploy.caffemodel \
-s 12 -is 300 300 -o graphs/mobilenetgraph
mvNCCompile v02.00, Copyright @ Movidius Ltd 2016
/usr/local/bin/ncsdk/Controllers/FileIO.py:52: UserWarning: You are using a large type. Consider reducing your data sizes for best performance
"Consider reducing your data sizes for best performance\033[0m")
你应该期待版权信息和可能的附加信息,或者像我上面遇到的警告。我毫不费力地忽略了警告。
使用英特尔 Movidius 神经计算棒进行物体检测
弃用声明: 本文使用 Movidius SDK 和 APIv1/APIv2,API v1/API v2 现已被 Intel 的 OpenVINO 软件取代,用于使用 Movidius NCS。在这篇 PyImageSearch 文章中了解更多关于 OpenVINO 的信息。
可以在您的台式机/笔记本电脑或您的 Pi 上编写此代码,但是您应该在下一节中在您的 Pi 上运行它。
让我们写一个实时对象检测脚本。该脚本与我们在上一篇文章中构建的非 NCS 版本非常接近。
你可以在这篇博文的 【下载】 部分找到今天的脚本和相关文件。如果您想继续学习,我建议您下载源代码和模型文件。
下载完文件后,打开ncs_realtime_objectdetection.py:
# import the necessary packages
from mvnc import mvncapi as mvnc
from imutils.video import VideoStream
from imutils.video import FPS
import argparse
import numpy as np
import time
import cv2
我们在第 2-8 行的中导入我们的包,注意到mvncapi,它是 Movidius NCS Python API 包。
从这里开始,我们将执行初始化:
# initialize the list of class labels our network was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "aeroplane", "bicycle", "bird",
"boat", "bottle", "bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
# frame dimensions should be sqaure
PREPROCESS_DIMS = (300, 300)
DISPLAY_DIMS = (900, 900)
# calculate the multiplier needed to scale the bounding boxes
DISP_MULTIPLIER = DISPLAY_DIMS[0] // PREPROCESS_DIMS[0]
我们的类标签和相关的随机颜色(每个类标签一种随机颜色)在第 12-16 行初始化。
我们的 MobileNet SSD 需要 300×300 的尺寸,但我们将以 900×900 显示视频流,以便更好地显示输出(第 19 行和第 20 )。
因为我们正在改变图像的尺寸,我们需要计算标量值来缩放我们的对象检测框( Line 23 )。
从这里我们将定义一个preprocess_image函数:
def preprocess_image(input_image):
# preprocess the image
preprocessed = cv2.resize(input_image, PREPROCESS_DIMS)
preprocessed = preprocessed - 127.5
preprocessed = preprocessed * 0.007843
preprocessed = preprocessed.astype(np.float16)
# return the image to the calling function
return preprocessed
该预处理功能中的操作是特定于我们的 MobileNet SSD 模型的。我们调整大小,执行均值减法,缩放图像,并将其转换为float16格式(第 27-30 行)。
然后我们将preprocessed图像返回给调用函数(第 33 行)。
要了解更多关于深度学习的预处理,一定要参考我的书, 用 Python 进行计算机视觉的深度学习 。
从这里我们将定义一个predict函数:
def predict(image, graph):
# preprocess the image
image = preprocess_image(image)
# send the image to the NCS and run a forward pass to grab the
# network predictions
graph.LoadTensor(image, None)
(output, _) = graph.GetResult()
# grab the number of valid object predictions from the output,
# then initialize the list of predictions
num_valid_boxes = output[0]
predictions = []
这个predict功能适用于 Movidius NC 的用户,它主要基于 Movidius NC 应用程序 Zoo GitHub 示例——我做了一些小的修改。
该函数需要一个image和一个graph对象(我们将在后面实例化)。
首先我们预处理图像(第 37 行)。
从那里,我们利用 NCS 向前通过神经网络,同时获取预测(行 41 和 42 )。
然后我们提取有效对象预测的数量(num_valid_boxes)并初始化我们的predictions列表(第 46 和 47 行)。
从这里开始,让我们遍历有效的结果:
# loop over results
for box_index in range(num_valid_boxes):
# calculate the base index into our array so we can extract
# bounding box information
base_index = 7 + box_index * 7
# boxes with non-finite (inf, nan, etc) numbers must be ignored
if (not np.isfinite(output[base_index]) or
not np.isfinite(output[base_index + 1]) or
not np.isfinite(output[base_index + 2]) or
not np.isfinite(output[base_index + 3]) or
not np.isfinite(output[base_index + 4]) or
not np.isfinite(output[base_index + 5]) or
not np.isfinite(output[base_index + 6])):
continue
# extract the image width and height and clip the boxes to the
# image size in case network returns boxes outside of the image
# boundaries
(h, w) = image.shape[:2]
x1 = max(0, int(output[base_index + 3] * w))
y1 = max(0, int(output[base_index + 4] * h))
x2 = min(w, int(output[base_index + 5] * w))
y2 = min(h, int(output[base_index + 6] * h))
# grab the prediction class label, confidence (i.e., probability),
# and bounding box (x, y)-coordinates
pred_class = int(output[base_index + 1])
pred_conf = output[base_index + 2]
pred_boxpts = ((x1, y1), (x2, y2))
# create prediciton tuple and append the prediction to the
# predictions list
prediction = (pred_class, pred_conf, pred_boxpts)
predictions.append(prediction)
# return the list of predictions to the calling function
return predictions
好吧,上面的代码可能看起来很丑。让我们后退一步。这个循环的目标是以一种有组织的方式将预测数据附加到我们的predictions列表中,以便我们以后使用它。这个循环只是为我们提取和组织数据。
但是base_index究竟是什么?
基本上,我们所有的数据都存储在一个长数组/列表中(output)。使用box_index,我们计算我们的base_index,然后我们将使用它(用更多的偏移量)来提取预测数据。
我猜写 Python API/绑定的人是 C/C++程序员。我可能选择了一种不同的方式来组织数据,比如我们将要构建的元组列表。
为什么我们要确保第 55-62 行上的值是有限的?
这确保了我们拥有有效的数据。如果无效,我们continue回到循环的顶部(第 63 行)并尝试另一个预测。
output列表的格式是什么?
输出列表具有以下格式:
output[0]:我们在第 46 行提取这个值为num_valid_boxesoutput[base_index + 1]:预测类索引output[base_index + 2]:预测置信度output[base_index + 3]:对象框点 x1 值(需要缩放)output[base_index + 4]:对象框点 y1 值(需要缩放)output[base_index + 5]:对象框点 x2 值(需要缩放)output[base_index + 6]:对象框点 y2 值(需要缩放)
第 68-82 行处理构建单个预测元组。预测由(pred_class, pred_conf, pred_boxpts)组成,我们将prediction添加到列表的第 83 行上。
在我们循环完数据后,我们将predictions列表return给行 86 上的调用函数。
从那里,让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-g", "--graph", required=True,
help="path to input graph file")
ap.add_argument("-c", "--confidence", default=.5,
help="confidence threshold")
ap.add_argument("-d", "--display", type=int, default=0,
help="switch to display image on screen")
args = vars(ap.parse_args())
我们在第 89-96 行解析我们的三个命令行参数。
我们需要图形文件的路径。可选地,我们可以指定一个不同的置信度阈值或将图像显示到屏幕上。
接下来,我们将连接到 NCS 并将图形文件加载到它上面:
# grab a list of all NCS devices plugged in to USB
print("[INFO] finding NCS devices...")
devices = mvnc.EnumerateDevices()
# if no devices found, exit the script
if len(devices) == 0:
print("[INFO] No devices found. Please plug in a NCS")
quit()
# use the first device since this is a simple test script
# (you'll want to modify this is using multiple NCS devices)
print("[INFO] found {} devices. device0 will be used. "
"opening device0...".format(len(devices)))
device = mvnc.Device(devices[0])
device.OpenDevice()
# open the CNN graph file
print("[INFO] loading the graph file into RPi memory...")
with open(args["graph"], mode="rb") as f:
graph_in_memory = f.read()
# load the graph into the NCS
print("[INFO] allocating the graph on the NCS...")
graph = device.AllocateGraph(graph_in_memory)
上面这个块和上周的是一样的,我就不详细回顾了。本质上,我们检查是否有可用的 NCS,连接并加载图形文件。
结果是我们在上面的预测函数中使用的一个graph对象。
让我们开始我们的视频流:
# open a pointer to the video stream thread and allow the buffer to
# start to fill, then start the FPS counter
print("[INFO] starting the video stream and FPS counter...")
vs = VideoStream(usePiCamera=True).start()
time.sleep(1)
fps = FPS().start()
我们启动相机VideoStream,让我们的相机预热,并实例化我们的 FPS 计数器。
现在让我们一帧一帧地处理摄像机画面:
# loop over frames from the video file stream
while True:
try:
# grab the frame from the threaded video stream
# make a copy of the frame and resize it for display/video purposes
frame = vs.read()
image_for_result = frame.copy()
image_for_result = cv2.resize(image_for_result, DISPLAY_DIMS)
# use the NCS to acquire predictions
predictions = predict(frame, graph)
在这里,我们从视频流中读取一帧,制作一个副本(这样我们以后可以在上面画画),并调整它的大小(第 135-137 行)。
然后,我们将该帧通过我们的对象检测器发送,该检测器将返回predictions给我们。
接下来让我们循环一遍predictions:
# loop over our predictions
for (i, pred) in enumerate(predictions):
# extract prediction data for readability
(pred_class, pred_conf, pred_boxpts) = pred
# filter out weak detections by ensuring the `confidence`
# is greater than the minimum confidence
if pred_conf > args["confidence"]:
# print prediction to terminal
print("[INFO] Prediction #{}: class={}, confidence={}, "
"boxpoints={}".format(i, CLASSES[pred_class], pred_conf,
pred_boxpts))
在predictions上循环,我们首先提取对象的类、置信度和盒点(行 145 )。
如果confidence高于阈值,我们将预测打印到终端,并检查我们是否应该在屏幕上显示图像:
# check if we should show the prediction data
# on the frame
if args["display"] > 0:
# build a label consisting of the predicted class and
# associated probability
label = "{}: {:.2f}%".format(CLASSES[pred_class],
pred_conf * 100)
# extract information from the prediction boxpoints
(ptA, ptB) = (pred_boxpts[0], pred_boxpts[1])
ptA = (ptA[0] * DISP_MULTIPLIER, ptA[1] * DISP_MULTIPLIER)
ptB = (ptB[0] * DISP_MULTIPLIER, ptB[1] * DISP_MULTIPLIER)
(startX, startY) = (ptA[0], ptA[1])
y = startY - 15 if startY - 15 > 15 else startY + 15
# display the rectangle and label text
cv2.rectangle(image_for_result, ptA, ptB,
COLORS[pred_class], 2)
cv2.putText(image_for_result, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 1, COLORS[pred_class], 3)
如果我们正在显示图像,我们首先构建一个label字符串,它将包含百分比形式的类名和置信度(第 160-161 行)。
从那里我们提取矩形的角,并计算出label相对于这些点的位置(第 164-168 行)。
最后,我们在屏幕上显示矩形和文本标签。如果框架中有多个相同类别的对象,则框和标签将具有相同的颜色。
从那里,让我们显示图像并更新我们的 FPS 计数器:
# check if we should display the frame on the screen
# with prediction data (you can achieve faster FPS if you
# do not output to the screen)
if args["display"] > 0:
# display the frame to the screen
cv2.imshow("Output", image_for_result)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# if "ctrl+c" is pressed in the terminal, break from the loop
except KeyboardInterrupt:
break
# if there's a problem reading a frame, break gracefully
except AttributeError:
break
在预测循环之外,我们再次检查是否应该在屏幕上显示该帧。如果是,我们显示该帧(行 181 )并等待“q”键被按下,如果用户想要退出(行 182-186 )。
我们在第 189 行更新我们的每秒帧数计数器。
从那里,我们很可能会继续逐帧循环的顶部,再次完成这个过程。
如果用户碰巧在终端中按下了“ctrl+c ”,或者在读取一个帧时出现了问题,我们就会跳出这个循环。
# stop the FPS counter timer
fps.stop()
# destroy all windows if we are displaying them
if args["display"] > 0:
cv2.destroyAllWindows()
# stop the video stream
vs.stop()
# clean up the graph and device
graph.DeallocateGraph()
device.CloseDevice()
# display FPS information
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
这最后一个代码块处理一些内务处理(行 200-211 ),最后将经过的时间和每秒帧数的流水线信息打印到屏幕上。这些信息允许我们对我们的脚本进行基准测试。
Movidius NCS 对象检测结果
这一步应该在您连接了 HDMI 线缆+屏幕的 Raspberry Pi + NCS 上执行。你还需要一个键盘和鼠标,正如我在图 2 中的之前的教程中所描述的,你可能需要一根加密狗延长线来为 USB 键盘/鼠标腾出空间。也可以在台式机/笔记本电脑上运行这个步骤,但是速度可能会比使用 CPU 慢。
让我们使用以下命令在 NCS 上运行我们的实时对象检测器:
$ python ncs_realtime_objectdetection.py --graph graph --display 1
预测结果将打印在终端上,图像将显示在我们的 Raspberry Pi 监视器上。
下面我提供了一个用智能手机拍摄视频,然后在 Raspberry Pi 上进行后期处理的 GIF 动画示例:
以及完整的视频剪辑示例:
https://www.youtube.com/embed/AfNZviiJYaA?feature=oembed
基于深度学习和 OpenCV 的实时物体检测
原文:https://pyimagesearch.com/2017/09/18/real-time-object-detection-with-deep-learning-and-opencv/
https://www.youtube.com/embed/e2M2mbLE1xU?feature=oembed
用 OpenCV 实现实时全景和图像拼接
原文:https://pyimagesearch.com/2016/01/25/real-time-panorama-and-image-stitching-with-opencv/
运行 PyImageSearch 博客我最喜欢的部分之一是能够将以前的博客文章和链接在一起,创建一个特定问题的解决方案 — 在这种情况下,使用 Python 和 OpenCV 进行实时全景和图像拼接。
在过去的一个半月里,我们已经学会了如何提高内置/USB 网络摄像头和 Raspberry Pi 摄像头模块的 FPS 处理速率。我们还学习了如何将对USB 网络摄像头和 Raspberry Pi 摄像头的访问统一到一个单个类 ,使得 PyImageSearch 博客上的所有视频处理和示例能够在 USB 和 Pi 摄像头设置上运行,而无需修改一行代码。
**就在几周前,我们讨论了如何使用关键点检测、局部不变描述符、关键点匹配和单应矩阵估计来构建全景并将图像拼接在一起。
今天我们将链接过去 1.5 个月的帖子,并使用 Python 和 OpenCV 使用它们来执行 实时全景和图像拼接 。我们的解决方案将能够运行在笔记本电脑/台式机系统上,以及树莓派。
此外,我们还将应用上周的帖子中的基本运动检测实现对全景图像进行运动检测。
这种解决方案尤其适用于您想要测量大范围运动,但又不想在相机视野中出现“盲点”的情况。
继续阅读以了解更多信息…
用 OpenCV 实现实时全景和图像拼接
正如我在这篇文章的介绍中提到的,我们将把我们在之前 1.5 个月的 PyImageSearch 文章中学到的概念联系起来:
- 使用我们改进的 FPS 处理速率 Python 类来访问我们的内置/USB 网络摄像头和/或 Raspberry Pi 摄像头模块。
- 一次访问多个摄像机流。
- 对这些视频流中的帧应用图像拼接和全景构建。
- 在全景图像中执行运动检测。
同样,在全景图像与两个独立的帧中执行运动检测的好处是,我们的视野中不会有任何“盲点”。
硬件设置
对于这个项目,我将使用我的 Raspberry Pi 2,虽然你当然可以使用你的笔记本电脑或台式机系统。我只是选择了 Pi 2,因为它的外形小巧,易于在空间有限的地方操作。
我还将使用我的罗技 C920 网络摄像头(即插即用,与树莓派兼容)以及树莓派相机模块。同样,如果你决定使用笔记本电脑/台式机系统,你可以简单地将多个网络摄像头连接到你的机器上——本文中讨论的相同概念仍然适用。
下面你可以看到我的设置:

Figure 1: My the Raspberry Pi 2 + USB webcam + Pi camera module setup.
这是另一个角度来看这个装置:

Figure 2: Placing my setup on top of a bookcase so it has a good viewing angle of my apartment.
这个装置正对着我的前门、厨房和走廊,让我可以看到我公寓里发生的一切:

Figure 3: Getting ready for real-time panorama construction.
目标是从我的两个视频流中获取帧,将它们拼接在一起,然后在全景图像中执行运动检测。
构建一个全景图,而不是使用多个摄像机并在每个流中独立执行运动检测确保了我的视野中没有任何“盲点”。
项目结构
在我们开始之前,让我们看一下我们的项目结构:
|--- pyimagesearch
| |---- __init__.py
| |--- basicmotiondetector.py
| |--- panorama.py
|--- realtime_stitching.py
如您所见,我们已经为组织目的定义了一个pyimagesearch模块。然后我们有了上周关于的帖子中的basicmotiondetector.py实现,用 Python 和 OpenCV 访问多个摄像机。这个类根本没有改变,所以我们不会在这篇文章中回顾它的实现。要彻底复习基本的运动检测器,请务必阅读上周的文章。
然后我们有了我们的panorama.py文件,它定义了用于将图像拼接在一起的Stitcher类。我们最初在 OpenCV 全景拼接教程中使用这个类。
然而,正如我们将在本文后面看到的,我对构造函数和stitch方法做了轻微的修改,以促进实时全景图的构建——我们将在本文后面了解更多关于这些轻微修改的内容。
最后,realtime_stitching.py文件是我们的主要 Python 驱动程序脚本,它将访问多个视频流(当然是以高效、线程化的方式),将帧拼接在一起,然后对全景图像执行运动检测。
更新图像拼接器
为了(1)创建实时图像拼接器和(2)在全景图像上执行运动检测,我们将假设两个摄像机都是固定的和非移动的,如上面的图 1 所示。
为什么固定不动的假设如此重要?
好吧,记得回到我们关于全景和图像拼接的课程。
执行关键点检测、局部不变量描述、关键点匹配和单应性估计是一项计算量很大的任务。如果我们使用我们以前的实现,我们将不得不对每组帧的执行拼接,这使得它几乎不可能实时运行(特别是对于资源受限的硬件,如 Raspberry Pi)。
然而,如果我们假设摄像机是固定的, 我们只需要执行一次单应矩阵估计!
在初始单应性估计之后,我们可以使用相同的矩阵来变换和扭曲图像,以构建最终的全景图——这样做使我们能够跳过关键点检测、局部不变特征提取和每组帧中的关键点匹配这些计算量大的步骤。
下面我提供了对Sticher类的相关更新,以便于缓存单应矩阵:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X and initialize the
# cached homography matrix
self.isv3 = imutils.is_cv3()
self.cachedH = None
这里唯一增加的是在第 11 行的上,我定义了cachedH,缓存的单应矩阵。
我们还需要更新stitch方法,以便在计算完单应矩阵后缓存它:
def stitch(self, images, ratio=0.75, reprojThresh=4.0):
# unpack the images
(imageB, imageA) = images
# if the cached homography matrix is None, then we need to
# apply keypoint matching to construct it
if self.cachedH is None:
# detect keypoints and extract
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
# cache the homography matrix
self.cachedH = M[1]
# apply a perspective transform to stitch the images together
# using the cached homography matrix
result = cv2.warpPerspective(imageA, self.cachedH,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# return the stitched image
return result
在第行第 19 处,我们检查单应矩阵之前是否已经计算过。如果不是,我们检测关键点并从两幅图像中提取局部不变描述符,然后应用关键点匹配。然后我们在第 34 行的缓存单应矩阵。
对stitch的后续调用将使用这个缓存的矩阵,允许我们避开检测关键点、提取特征以及对每一组帧的执行关键点匹配。
关于panorama.py的其余源代码,请参见图像拼接教程或使用本文底部的表格下载源代码。
执行实时全景拼接
既然我们的Stitcher类已经更新,让我们继续到realtime_stitching.py驱动程序脚本:
# import the necessary packages
from __future__ import print_function
from pyimagesearch.basicmotiondetector import BasicMotionDetector
from pyimagesearch.panorama import Stitcher
from imutils.video import VideoStream
import numpy as np
import datetime
import imutils
import time
import cv2
# initialize the video streams and allow them to warmup
print("[INFO] starting cameras...")
leftStream = VideoStream(src=0).start()
rightStream = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
我们从导入所需的 Python 包开始。BasicMotionDetector和Stitcher类是从pyimagesearch模块导入的。我们还需要 imutils 包中的VideoStream类。
如果您的系统上还没有安装imutils,您可以使用以下命令安装它:
$ pip install imutils
如果您已经安装了它,请确保您已经升级到了最新版本(该版本为video子模块添加了 Python 3 支持):
$ pip install --upgrade imutils
第 14 行和第 15 行然后初始化我们的两个VideoStream类。这里我假设leftStream是 USB 摄像头,rightStream是树莓 Pi 摄像头(用usePiCamera=True表示)。
如果您想使用两个 USB 摄像头,您只需将流初始化更新为:
leftStream = VideoStream(src=0).start()
rightStream = VideoStream(src=1).start()
src参数控制系统上摄像机的指数。
还是那句话,正确初始化leftStream和rightStream是命令式 T7。当站在相机后面时,leftStream应该是你左手边的相机,rightStream应该是你右手边的相机。
未能正确设置这些流变量将导致“全景图”只包含两个帧中的一个。
现在,让我们初始化图像拼接器和运动检测器:
# initialize the image stitcher, motion detector, and total
# number of frames read
stitcher = Stitcher()
motion = BasicMotionDetector(minArea=500)
total = 0
现在我们进入驱动程序脚本的主循环,在这里我们无限循环遍历帧,直到被指示退出程序:
# loop over frames from the video streams
while True:
# grab the frames from their respective video streams
left = leftStream.read()
right = rightStream.read()
# resize the frames
left = imutils.resize(left, width=400)
right = imutils.resize(right, width=400)
# stitch the frames together to form the panorama
# IMPORTANT: you might have to change this line of code
# depending on how your cameras are oriented; frames
# should be supplied in left-to-right order
result = stitcher.stitch([left, right])
# no homograpy could be computed
if result is None:
print("[INFO] homography could not be computed")
break
# convert the panorama to grayscale, blur it slightly, update
# the motion detector
gray = cv2.cvtColor(result, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
locs = motion.update(gray)
第 27 行和第 28 行从各自的视频流中读取left和right帧。然后,我们调整帧的大小,使其宽度为 400 像素,然后将它们拼接在一起,形成全景图。记住,提供给stitch方法的帧需要按照从左到右的顺序提供!
在图像不能被拼接的情况下(即,不能计算单应矩阵),我们从循环中脱离(行 41-43 )。
假设全景图可以被构建,那么我们通过将其转换为灰度并稍微模糊化来处理它(行 47 和 48 )。然后,处理后的全景图像被传送到运动检测器中(线 49 )。
然而,在我们能够检测任何运动之前,我们首先需要允许运动检测器“运行”一段时间,以获得背景模型的精确运行平均值:
# only process the panorama for motion if a nice average has
# been built up
if total > 32 and len(locs) > 0:
# initialize the minimum and maximum (x, y)-coordinates,
# respectively
(minX, minY) = (np.inf, np.inf)
(maxX, maxY) = (-np.inf, -np.inf)
# loop over the locations of motion and accumulate the
# minimum and maximum locations of the bounding boxes
for l in locs:
(x, y, w, h) = cv2.boundingRect(l)
(minX, maxX) = (min(minX, x), max(maxX, x + w))
(minY, maxY) = (min(minY, y), max(maxY, y + h))
# draw the bounding box
cv2.rectangle(result, (minX, minY), (maxX, maxY),
(0, 0, 255), 3)
我们使用初始视频流的前 32 帧作为背景的估计——在这 32 帧期间,不应该发生运动。
否则,假设我们已经处理了用于背景模型初始化的 32 个初始帧,我们可以检查locs的len以查看它是否大于零。如果是,那么我们可以假设全景图像中正在发生“运动”。
然后,我们初始化与包含运动的位置相关联的最小和最大 (x,y)- 坐标。给定该列表(即locs),我们逐个循环遍历轮廓区域,计算边界框,并确定包含所有轮廓的最小区域。然后在全景图像上绘制这个边界框。
正如上周的帖子中提到的,我们使用的运动检测器假设一次只有一个物体/人在移动。对于多个对象,需要一个更高级的算法(我们将在未来的 PyImageSearch 帖子中讨论)。
最后,最后一步是在 panorama 上绘制时间戳并显示输出图像:
# increment the total number of frames read and draw the
# timestamp on the image
total += 1
timestamp = datetime.datetime.now()
ts = timestamp.strftime("%A %d %B %Y %I:%M:%S%p")
cv2.putText(result, ts, (10, result.shape[0] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)
# show the output images
cv2.imshow("Result", result)
cv2.imshow("Left Frame", left)
cv2.imshow("Right Frame", right)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
print("[INFO] cleaning up...")
cv2.destroyAllWindows()
leftStream.stop()
rightStream.stop()
第 82-86 行检查q键是否被按下。如果是,我们就从视频流循环中脱离出来,做一些清理工作。
运行我们的 panorama builder +运动探测器
要执行我们的脚本,只需发出以下命令:
$ python realtime_stitching.py
下面你可以找到我的结果的 GIF 示例:
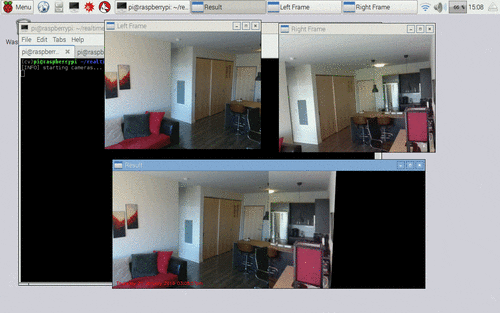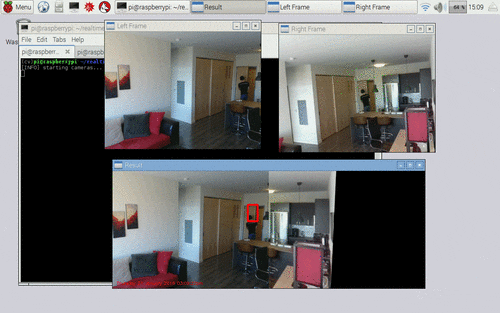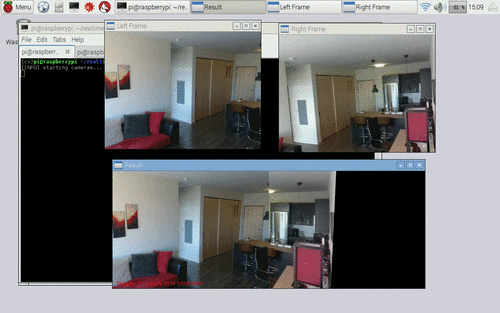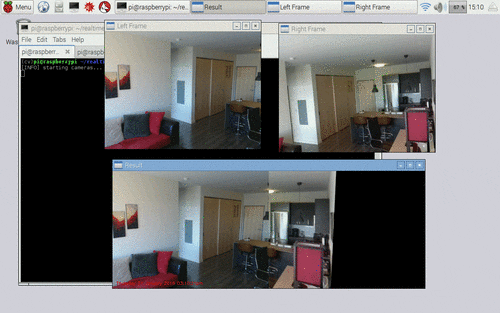
Figure 4: Applying motion detection on a panorama constructed from multiple cameras on the Raspberry Pi, using Python + OpenCV.
在左上角的我们有左边的视频流。在右上角的上,我们有右侧的视频流。**在底部,我们可以看到两个画面被拼接成一幅全景图。**然后对全景图像和围绕运动区域绘制的边界框执行运动检测。
*完整的视频演示可以在下面看到:
https://www.youtube.com/embed/n3CsQEC4Z3U?feature=oembed***
用 OpenCV 和 Python 识别数字
原文:https://pyimagesearch.com/2017/02/13/recognizing-digits-with-opencv-and-python/
https://www.youtube.com/embed/bFcSjNe0O8s?feature=oembed
修正了带有 Keras 的 Adam (RAdam)优化器
原文:https://pyimagesearch.com/2019/09/30/rectified-adam-radam-optimizer-with-keras/

在本教程中,您将学习如何使用 Keras 和修正的 Adam 优化器作为标准 Adam 优化器的替代产品,潜在地产生更高精度的模型(并且在更少的时期内)。
今天我们将开始一个关于修正亚当优化器的两部分系列:
- 修正了带有 Keras 的 Adam (RAdam)优化器(今天的帖子)
- 整流亚当真的比亚当更好吗?(下周教程)
整流亚当是一个全新的深度学习模型优化器,由伊利诺伊大学、佐治亚理工学院和微软研究院的成员合作推出。
调整后的 Adam 优化器有两个目标:
- 获得一个 更精确/更可推广的 深度神经网络
- 在完成训练更少的时期
听起来好得难以置信?
嗯,可能只是。
你需要阅读本教程的其余部分来找到答案。
要了解如何将修正的 Adam 优化器用于 Keras,请继续阅读!
修正了带有 Keras 的 Adam (RAdam)优化器
在本教程的第一部分,我们将讨论修正的 Adam 优化器,包括它与标准 Adam 优化器的不同之处(以及为什么我们应该关注它)。
从那以后,我将向您展示如何将修正的 Adam 优化器与 Keras 深度学习库一起使用。
然后,我们将运行一些实验,比较亚当和纠正亚当。
什么是修正的 Adam 优化器?
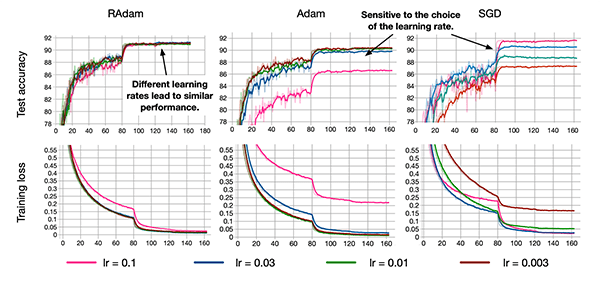
Figure 1: Using the Rectified Adam (RAdam) deep learning optimizer with Keras. (image source: Figure 6 from Liu et al.)
几周前,在刘等人发表了一篇名为 的关于自适应学习速率的方差和超越的全新论文之后,深度学习社区议论纷纷。
本文介绍了一种新的深度学习优化器,称为修正亚当(或简称雷达姆)。
修正的 Adam 旨在替代标准的 Adam 优化器。
那么,为什么刘等人的贡献如此重要呢?为什么深度学习社区对此如此兴奋?
这里有一个关于你为什么应该关心它的简要概述:
- 学习率热身试探法对稳定训练很有效。
- 这些试探法也能很好地提高泛化能力。
- 刘等人决定研究学习率热身背后的理论…
- …但是他们发现了自适应学习率的一个问题——在前几批中,模型没有很好地概括并且具有非常高的方差。
- 作者详细研究了该问题,并得出结论,该问题可以通过以下方式解决/缓解:
- 1.以较低的初始学习率进行热身。
- 2.或者,简单地关闭最初几组输入批次的动量项。
- 随着训练的继续,方差将稳定下来,从那里开始,学习率可以增加并且动量项可以添加回。
作者将这种优化器称为修正的 Adam (RAdam) ,Adam 优化器的一种变体,因为它“修正”(即纠正)了其他自适应学习率优化器中明显存在的差异/泛化问题。
但是问题依然存在——修正亚当真的比标准亚当更好吗?
要回答这个问题,你需要读完这篇教程,并阅读下周的帖子,其中包括一个完整的比较。
欲了解更多关于修正 Adam 的信息,包括理论和实证结果的细节,请务必参考刘等人的论文。
项目结构
让我们检查一下我们的项目布局:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── resnet.py
├── cifar10_adam.png
├── cifar10_rectified_adam.png
└── train.py
1 directory, 5 files
我们的 ResNet CNN 包含在pyimagesearch模块中。resnet.py文件包含使用 Python 进行计算机视觉深度学习的 中包含的精确 ResNet 模型类。
我们将使用train.py中的 Adam 或 RAdam 优化器在 CIFAR-10 数据集上训练 ResNet,我们将在本教程的稍后部分回顾这一点。训练脚本将在每次运行时生成一个精度/损失图—两个。每个 Adam 和整流 Adam 实验的 png 文件都包含在 【下载】 中。
为 keras 安装整流器 adam
本教程要求在您的环境中安装以下软件:
- TensorFlow
- Keras
- keras 整流器 adam
- scikit-learn
- matplotlib
幸运的是,所有的软件都是 pip 安装的。如果你曾经关注过我的安装教程,那么你会知道我是管理 Python 虚拟环境的 virtualenv 和 virtualenvwrapper 的粉丝。下面的第一个命令workon假设您已经安装了这些软件包,但是它是可选的。
让我们现在安装软件:
$ workon <env_name> # replace "<env_name>" with your environment
$ pip install tensorflow # or tensorflow-gpu
$ pip install keras
$ pip install scikit-learn
$ pip install matplotlib
刘等人的 RAdam 的最初实现是在 PyTorch 然而,的赵 HG 创造了一个 Keras 实现。
您可以通过以下命令安装修正 Adam 的 Keras 实现:
$ pip install keras-rectified-adam
要验证 Keras + RAdam 包是否已成功安装,请打开 Python shell 并尝试导入keras_radam:
$ python
>>> import keras_radam
>>>
如果导入过程中没有错误,您可以假设已修正的 Adam 已成功安装在您的深度学习设备上!
使用 Keras 实施修正的 Adam
现在,让我们学习如何将修正的 Adam 与 Keras 一起使用。
如果你对 Keras 和/或深度学习不熟悉,请参考我的 Keras 教程。关于深度学习优化器的完整回顾,请参考以下章节的 用 Python 进行计算机视觉的深度学习 :
- 启动包–第九章:“优化方法和正则化技术”
- 从业者捆绑包–第七章:“高级优化方法”
否则,如果你准备好了,让我们开始吧。
打开一个新文件,将其命名为train.py,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.resnet import ResNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras_radam import RAdam
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, required=True,
help="path to output training plot")
ap.add_argument("-o", "--optimizer", type=str, default="adam",
choices=["adam", "radam"],
help="type of optmizer")
args = vars(ap.parse_args())
第 2-15 行导入我们的包和模块。最值得注意的是,第 10 行和第 11 行导入了Adam和RAdam优化器。我们将使用 matplotlib 的 "Agg"后端,这样我们可以将我们的训练图保存到磁盘上( Line 3 )。
第 18-24 行然后解析两个命令行参数:
--plot:输出训练图的路径。--optimizer:我们将用于训练的优化器的类型(或者是adam或者是radam)。
从这里开始,让我们继续执行一些初始化:
# initialize the number of epochs to train for and batch size
EPOCHS = 75
BS = 128
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
第 27 行和第 28 行初始化要训练的时期数以及我们的批量大小。请随意调整这些超参数,只是要记住它们会影响结果。
第 33-35 行加载并预处理我们的 CIFAR-10 数据,包括缩放数据到范围 [0,1] 。
第 38-40 行然后将我们的类标签从整数二进制化为向量。
第 43-45 行构建我们的数据增强对象。如果你是数据增强的新手,请务必参考我的数据增强教程,它是如何工作的,或者我们为什么使用它。
我们的 CIFAR-10 级labelNames列在线 48 和 49 上。
现在我们进入本教程的核心部分— 初始化亚当或雷达姆优化器:
# check if we are using Adam
if args["optimizer"] == "adam":
# initialize the Adam optimizer
print("[INFO] using Adam optimizer")
opt = Adam(lr=1e-3)
# otherwise, we are using Rectified Adam
else:
# initialize the Rectified Adam optimizer
print("[INFO] using Rectified Adam optimizer")
opt = RAdam(total_steps=5000, warmup_proportion=0.1, min_lr=1e-5)
根据--optimizer命令行参数,我们将初始化:
Adam学习率为1e-3( 第 52-55 行)- 或者
RAdam以最小学习率1e-5热身(第 58-61 行)。务必参照原来的预热实施注意事项其中赵 HG 也实施了
优化器准备就绪,现在我们将编译和训练我们的模型:
# initialize our optimizer and model, then compile it
model = ResNet.build(32, 32, 3, 10, (9, 9, 9),
(64, 64, 128, 256), reg=0.0005)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // BS,
epochs=EPOCHS,
verbose=1)
我们通过第 64-67 行用我们指定的优化器(Adam 或 r Adam)编译ResNet。
第 70-75 行启动培训流程。如果你是使用这个函数来训练 Keras 深度神经网络的新手,请务必参考我关于 Keras 的 fit_generator 方法的教程。
最后,我们打印分类报告,并绘制训练期内的损失/准确度曲线:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BS)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# determine the number of epochs and then construct the plot title
N = np.arange(0, EPOCHS)
title = "Training Loss and Accuracy on CIFAR-10 ({})".format(
args["optimizer"])
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["acc"], label="train_acc")
plt.plot(N, H.history["val_acc"], label="val_acc")
plt.title(title)
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
标准 Adam 优化器结果
要使用 Adam optimizer 在 CIFAR-10 数据集上训练 ResNet,请确保使用本博客文章的 【下载】 部分下载本指南的源代码指南。
从那里,打开一个终端并执行以下命令:
$ python train.py --plot cifar10_adam.png --optimizer adam
[INFO] loading CIFAR-10 data...
[INFO] using Adam optimizer
Epoch 1/75
390/390 [==============================] - 205s 526ms/step - loss: 1.9642 - acc: 0.4437 - val_loss: 1.7449 - val_acc: 0.5248
Epoch 2/75
390/390 [==============================] - 185s 475ms/step - loss: 1.5199 - acc: 0.6050 - val_loss: 1.4735 - val_acc: 0.6218
Epoch 3/75
390/390 [==============================] - 185s 474ms/step - loss: 1.2973 - acc: 0.6822 - val_loss: 1.2712 - val_acc: 0.6965
Epoch 4/75
390/390 [==============================] - 185s 474ms/step - loss: 1.1451 - acc: 0.7307 - val_loss: 1.2450 - val_acc: 0.7109
Epoch 5/75
390/390 [==============================] - 185s 474ms/step - loss: 1.0409 - acc: 0.7643 - val_loss: 1.0918 - val_acc: 0.7542
...
Epoch 71/75
390/390 [==============================] - 185s 474ms/step - loss: 0.4215 - acc: 0.9358 - val_loss: 0.6372 - val_acc: 0.8775
Epoch 72/75
390/390 [==============================] - 185s 474ms/step - loss: 0.4241 - acc: 0.9347 - val_loss: 0.6024 - val_acc: 0.8819
Epoch 73/75
390/390 [==============================] - 185s 474ms/step - loss: 0.4226 - acc: 0.9350 - val_loss: 0.5906 - val_acc: 0.8835
Epoch 74/75
390/390 [==============================] - 185s 474ms/step - loss: 0.4198 - acc: 0.9369 - val_loss: 0.6321 - val_acc: 0.8759
Epoch 75/75
390/390 [==============================] - 185s 474ms/step - loss: 0.4127 - acc: 0.9391 - val_loss: 0.5669 - val_acc: 0.8953
[INFO] evaluating network...
[INFO] evaluating network...
precision recall f1-score support
airplane 0.81 0.94 0.87 1000
automobile 0.96 0.96 0.96 1000
bird 0.86 0.87 0.86 1000
cat 0.84 0.75 0.79 1000
deer 0.91 0.91 0.91 1000
dog 0.86 0.84 0.85 1000
frog 0.89 0.95 0.92 1000
horse 0.93 0.92 0.93 1000
ship 0.97 0.88 0.92 1000
truck 0.96 0.92 0.94 1000
micro avg 0.90 0.90 0.90 10000
macro avg 0.90 0.90 0.90 10000
weighted avg 0.90 0.90 0.90 10000

Figure 2: To achieve a baseline, we first train ResNet using the Adam optimizer on the CIFAR-10 dataset. We will compare the results to the Rectified Adam (RAdam) optimizer using Keras.
查看我们的输出,您可以看到我们在测试集上获得了 90%的准确率。
检查图 2 显示几乎没有过度配合的情况发生— 我们的训练进度相当稳定。
整流器 adam 优化器结果
现在,让我们使用修正的 Adam 优化器在 CIFAR-10 上训练 ResNet:
$ python train.py --plot cifar10_rectified_adam.png --optimizer radam
[INFO] loading CIFAR-10 data...
[INFO] using Rectified Adam optimizer
Epoch 1/75
390/390 [==============================] - 212s 543ms/step - loss: 2.4813 - acc: 0.2489 - val_loss: 2.0976 - val_acc: 0.3921
Epoch 2/75
390/390 [==============================] - 188s 483ms/step - loss: 1.8771 - acc: 0.4797 - val_loss: 1.8231 - val_acc: 0.5041
Epoch 3/75
390/390 [==============================] - 188s 483ms/step - loss: 1.5900 - acc: 0.5857 - val_loss: 1.4483 - val_acc: 0.6379
Epoch 4/75
390/390 [==============================] - 188s 483ms/step - loss: 1.3919 - acc: 0.6564 - val_loss: 1.4264 - val_acc: 0.6466
Epoch 5/75
390/390 [==============================] - 188s 483ms/step - loss: 1.2457 - acc: 0.7046 - val_loss: 1.2151 - val_acc: 0.7138
...
Epoch 71/75
390/390 [==============================] - 188s 483ms/step - loss: 0.6256 - acc: 0.9054 - val_loss: 0.7919 - val_acc: 0.8551
Epoch 72/75
390/390 [==============================] - 188s 482ms/step - loss: 0.6184 - acc: 0.9071 - val_loss: 0.7894 - val_acc: 0.8537
Epoch 73/75
390/390 [==============================] - 188s 483ms/step - loss: 0.6242 - acc: 0.9051 - val_loss: 0.7981 - val_acc: 0.8519
Epoch 74/75
390/390 [==============================] - 188s 483ms/step - loss: 0.6191 - acc: 0.9062 - val_loss: 0.7969 - val_acc: 0.8519
Epoch 75/75
390/390 [==============================] - 188s 483ms/step - loss: 0.6143 - acc: 0.9098 - val_loss: 0.7935 - val_acc: 0.8525
[INFO] evaluating network...
precision recall f1-score support
airplane 0.86 0.88 0.87 1000
automobile 0.91 0.95 0.93 1000
bird 0.83 0.76 0.79 1000
cat 0.76 0.69 0.72 1000
deer 0.85 0.81 0.83 1000
dog 0.79 0.79 0.79 1000
frog 0.81 0.94 0.87 1000
horse 0.89 0.89 0.89 1000
ship 0.94 0.91 0.92 1000
truck 0.88 0.91 0.89 1000
micro avg 0.85 0.85 0.85 10000
macro avg 0.85 0.85 0.85 10000
weighted avg 0.85 0.85 0.85 10000
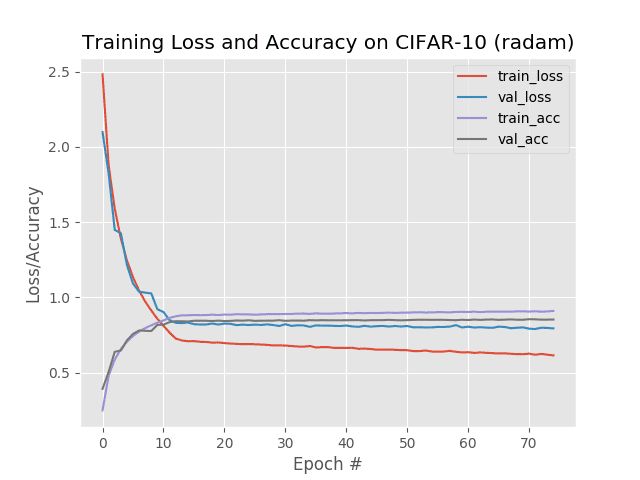
Figure 3: The Rectified Adam (RAdam) optimizer is used in conjunction with ResNet using Keras on the CIFAR-10 dataset. But how to the results compare to the standard Adam optimizer?
请注意,在第二次运行我们的训练脚本时,--optimizer开关是如何设置为radam的。
但是等一下,为什么我们只获得了 85%的准确率?
调整后的 Adam 优化器不是应该优于标准 Adam 吗?
为什么我们的准确性不知何故不如?
让我们在下一节讨论这个问题。
整流亚当真的比亚当好吗?
如果你看看我们的结果,你会发现标准的 Adam 优化器优于新的 Adam 优化器。
这是怎么回事?
大半年的亚当不是应该获得 更高的精度 而在 更少的历元吗?
为什么整流 Adam 的性能比标准 Adam 的性能差?
首先,请记住,我们在这里只查看来自一个单个数据集的结果——一个真实评估将查看来自多个数据集的结果。
这正是我下周要做的事情!
要查看 Adam 和 Rectified Adam 之间的全面比较,并确定哪个优化器更好,,您需要收听下周的博客帖子!
*## 摘要
在本教程中,您学习了如何使用修正的 Adam 优化器,作为使用 Keras 深度学习库的标准 Adam 优化器的替代产品。
然后,我们运行了一组实验,将 Adam 性能与修正后的 Adam 性能进行比较。我们的结果显示,标准 Adam 实际上优于RAdam 优化器。
那么是什么原因呢?
刘等人在他们的论文中报告了更高的精确度和更少的时期,我们做错了什么吗?
我们修正过的 Adam 优化器有什么问题吗?
要回答这些问题,你需要在下周收听,届时我将提供一整套比较亚当和修正亚当的基准实验。你不会想错过下周的帖子,这将是一篇好文章!
要下载这篇文章的源代码(并在下周教程上线时得到通知),请务必在下面的表格中输入您的电子邮件地址!*
基于 OpenCV、Keras 和 TensorFlow 的区域提议对象检测
在本教程中,您将学习如何使用 OpenCV、Keras 和 TensorFlow 利用区域建议进行对象检测。
今天的教程是我们关于深度学习和对象检测的 4 部分系列的第 3 部分:
- Part 1: 用 Keras 和 TensorFlow 把任何深度学习图像分类器变成物体检测器
- 第二部分: OpenCV 选择性搜索对象检测
- 第三部分: 用 OpenCV、Keras 和 TensorFlow 进行物体检测的区域建议(今天的教程)
- 第四部分: 用 Keras 和 TensorFlow 进行 R-CNN 物体检测
在上周的教程中,我们学习了如何利用选择性搜索来取代使用边界框和滑动窗口进行物体检测的传统计算机视觉方法。
但是问题仍然存在:我们如何获得区域提议(即,图像中可能包含感兴趣的对象的区域),然后实际上将它们分类为,以获得我们最终的对象检测?
我们将在本教程中讨论这个问题。
要了解如何使用 OpenCV、Keras 和 TensorFlow 使用区域建议执行对象检测,请继续阅读。
使用 OpenCV、Keras 和 TensorFlow 进行区域提议对象检测
在本教程的第一部分,我们将讨论区域提议的概念,以及如何在基于深度学习的对象检测管道中使用它们。
然后,我们将使用 OpenCV、Keras 和 TensorFlow 实现区域提议对象检测。
我们将通过查看我们的区域提议对象检测结果来结束本教程。
什么是区域提议,它们如何用于对象检测?
我们在上周的教程 中讨论了区域提议的概念和选择性搜索算法【OpenCV 用于对象检测的选择性搜索——我建议您在今天继续之前阅读一下该教程,但要点是传统的计算机视觉对象检测算法依赖于图像金字塔和滑动窗口来定位图像中的对象,并且改变比例和位置:
图像金字塔和滑动窗口方法存在一些问题,但主要问题是:
- 滑动窗口/图像金字塔非常慢
- 它们对超参数选择很敏感(即金字塔尺度大小、ROI 大小和窗口步长)
- 它们的计算效率很低
区域提议算法寻求取代传统的图像金字塔和滑动窗口方法。
这些算法:
- 接受输入图像
- 通过应用超像素聚类算法对其进行过度分割
- 基于五个分量(颜色相似性、纹理相似性、尺寸相似性、形状相似性/兼容性以及线性组合前述分数的最终元相似性)来合并超像素的片段
最终结果是指示在图像中的什么地方可能是的物体的提议:
请注意我是如何将图片上方句子中的“could”——记住,区域提议算法不知道给定的区域是否实际上包含一个对象。
相反,区域建议方法只是告诉我们:
嘿,这看起来像是输入图像的一个有趣区域。让我们应用计算量更大的分类器来确定这个区域中实际上有什么。
区域提议算法往往比图像金字塔和滑动窗口的传统对象检测技术更有效,因为:
- 检查的单个 ROI 更少
- 这比彻底检查输入图像的每个比例/位置要快
- 精确度的损失是最小的,如果有的话
在本教程的其余部分,您将学习如何实现区域建议对象检测。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
请务必从 “下载” 部分获取今天的文件,以便您可以跟随今天的教程:
$ tree
.
├── beagle.png
└── region_proposal_detection.py
0 directories, 2 files
如您所见,我们今天的项目布局非常简单,由一个 Python 脚本组成,对于今天的区域提议对象检测示例,这个脚本被恰当地命名为region_proposal_detection.py。
我还附上了我家的小猎犬杰玛的照片。我们将使用这张照片来测试我们的 OpenCV、Keras 和 TensorFlow 区域提议对象检测系统。
用 OpenCV、Keras 和 TensorFlow 实现区域提议对象检测
让我们开始实现我们的区域提议对象检测器。
打开一个新文件,将其命名为region_proposal_detection.py,并插入以下代码:
# import the necessary packages
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet50 import preprocess_input
from tensorflow.keras.applications import imagenet_utils
from tensorflow.keras.preprocessing.image import img_to_array
from imutils.object_detection import non_max_suppression
import numpy as np
import argparse
import cv2
def selective_search(image, method="fast"):
# initialize OpenCV's selective search implementation and set the
# input image
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(image)
# check to see if we are using the *fast* but *less accurate* version
# of selective search
if method == "fast":
ss.switchToSelectiveSearchFast()
# otherwise we are using the *slower* but *more accurate* version
else:
ss.switchToSelectiveSearchQuality()
# run selective search on the input image
rects = ss.process()
# return the region proposal bounding boxes
return rects
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-m", "--method", type=str, default="fast",
choices=["fast", "quality"],
help="selective search method")
ap.add_argument("-c", "--conf", type=float, default=0.9,
help="minimum probability to consider a classification/detection")
ap.add_argument("-f", "--filter", type=str, default=None,
help="comma separated list of ImageNet labels to filter on")
args = vars(ap.parse_args())
# grab the label filters command line argument
labelFilters = args["filter"]
# if the label filter is not empty, break it into a list
if labelFilters is not None:
labelFilters = labelFilters.lower().split(",")
# load ResNet from disk (with weights pre-trained on ImageNet)
print("[INFO] loading ResNet...")
model = ResNet50(weights="imagenet")
# load the input image from disk and grab its dimensions
image = cv2.imread(args["image"])
(H, W) = image.shape[:2]
# run selective search on the input image
print("[INFO] performing selective search with '{}' method...".format(
args["method"]))
rects = selective_search(image, method=args["method"])
print("[INFO] {} regions found by selective search".format(len(rects)))
# initialize the list of region proposals that we'll be classifying
# along with their associated bounding boxes
proposals = []
boxes = []
proposals:在第 68 行初始化,这个列表将保存来自我们的输入--image的足够大的预处理 ROI,我们将把这些 ROI 送入我们的 ResNet 分类器。boxes:在第 69 行初始化,这个包围盒坐标列表对应于我们的proposals,并且类似于rects,有一个重要的区别:只包括足够大的区域。
# loop over the region proposal bounding box coordinates generated by
# running selective search
for (x, y, w, h) in rects:
# if the width or height of the region is less than 10% of the
# image width or height, ignore it (i.e., filter out small
# objects that are likely false-positives)
if w / float(W) < 0.1 or h / float(H) < 0.1:
continue
# extract the region from the input image, convert it from BGR to
# RGB channel ordering, and then resize it to 224x224 (the input
# dimensions required by our pre-trained CNN)
roi = image[y:y + h, x:x + w]
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
roi = cv2.resize(roi, (224, 224))
# further preprocess by the ROI
roi = img_to_array(roi)
roi = preprocess_input(roi)
# update our proposals and bounding boxes lists
proposals.append(roi)
boxes.append((x, y, w, h))
# convert the proposals list into NumPy array and show its dimensions
proposals = np.array(proposals)
print("[INFO] proposal shape: {}".format(proposals.shape))
# classify each of the proposal ROIs using ResNet and then decode the
# predictions
print("[INFO] classifying proposals...")
preds = model.predict(proposals)
preds = imagenet_utils.decode_predictions(preds, top=1)
# initialize a dictionary which maps class labels (keys) to any
# bounding box associated with that label (values)
labels = {}
# loop over the predictions
for (i, p) in enumerate(preds):
# grab the prediction information for the current region proposal
(imagenetID, label, prob) = p[0]
# only if the label filters are not empty *and* the label does not
# exist in the list, then ignore it
if labelFilters is not None and label not in labelFilters:
continue
# filter out weak detections by ensuring the predicted probability
# is greater than the minimum probability
if prob >= args["conf"]:
# grab the bounding box associated with the prediction and
# convert the coordinates
(x, y, w, h) = boxes[i]
box = (x, y, x + w, y + h)
# grab the list of predictions for the label and add the
# bounding box + probability to the list
L = labels.get(label, [])
L.append((box, prob))
labels[label] = L
# loop over the labels for each of detected objects in the image
for label in labels.keys():
# clone the original image so that we can draw on it
print("[INFO] showing results for '{}'".format(label))
clone = image.copy()
# loop over all bounding boxes for the current label
for (box, prob) in labels[label]:
# draw the bounding box on the image
(startX, startY, endX, endY) = box
cv2.rectangle(clone, (startX, startY), (endX, endY),
(0, 255, 0), 2)
# show the results *before* applying non-maxima suppression, then
# clone the image again so we can display the results *after*
# applying non-maxima suppression
cv2.imshow("Before", clone)
clone = image.copy()
# extract the bounding boxes and associated prediction
# probabilities, then apply non-maxima suppression
boxes = np.array([p[0] for p in labels[label]])
proba = np.array([p[1] for p in labels[label]])
boxes = non_max_suppression(boxes, proba)
# loop over all bounding boxes that were kept after applying
# non-maxima suppression
for (startX, startY, endX, endY) in boxes:
# draw the bounding box and label on the image
cv2.rectangle(clone, (startX, startY), (endX, endY),
(0, 255, 0), 2)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(clone, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
# show the output after apply non-maxima suppression
cv2.imshow("After", clone)
cv2.waitKey(0)
NMS 之前的和 NMS 之后的都将保留在屏幕上,直到按下一个键(第 170 行)。
使用 OpenCV、Keras 和 TensorFlow 的区域提议对象检测结果
我们现在准备执行区域提议对象检测!
确保使用本教程的 “下载” 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python region_proposal_detection.py --image beagle.png
[INFO] loading ResNet...
[INFO] performing selective search with 'fast' method...
[INFO] 922 regions found by selective search
[INFO] proposal shape: (534, 224, 224, 3)
[INFO] classifying proposals...
[INFO] showing results for 'beagle'
[INFO] showing results for 'clog'
[INFO] showing results for 'quill'
[INFO] showing results for 'paper_towel'
最初,我们的结果看起来相当不错。
如果你看一下图 3 ,你会看到在左边我们有“小猎犬”类(一种狗)的对象检测,在右边我们有应用非最大值抑制后的输出。
从输出可以看出,我家的小猎犬 Jemma 被正确检测到了!
然而,正如我们的其余结果所示,我们的模型还报告我们检测到了“木屐”(一种木鞋):
以及【鹅毛笔】(用羽毛制成的书写笔):
最后,一张【纸巾】:
看看每一类的 ROI,可以想象我们的 CNN 在做这些分类的时候是如何的混乱。
但是我们实际上如何去除不正确的物体检测呢?
这里的解决方案是,我们可以只过滤掉我们关心的检测。
例如,如果我正在构建一个“beagle detector”应用程序,我将提供--filter beagle命令行参数:
$ python region_proposal_detection.py --image beagle.png --filter beagle
[INFO] loading ResNet...
[INFO] performing selective search with 'fast' method...
[INFO] 922 regions found by selective search
[INFO] proposal shape: (534, 224, 224, 3)
[INFO] classifying proposals...
[INFO] showing results for 'beagle'
在这种情况下,只找到“beagle”类(其余的都被丢弃)。
问题和局限
正如我们的结果部分所展示的,我们的区域提议对象检测器“只是有点儿工作”——当我们获得了正确的对象检测时,我们也获得了许多噪声。
在下周的教程中,我将向你展示我们如何使用选择性搜索和区域建议来构建一个完整的 R-CNN 物体检测器管道,它比我们今天在这里讨论的方法更加精确。
总结
在本教程中,您学习了如何使用 OpenCV、Keras 和 TensorFlow 执行区域提议对象检测。
使用区域建议进行对象检测是一个 4 步过程:
- 步骤#1: 使用选择性搜索(区域提议算法)来生成输入图像的候选区域,其中可能包含感兴趣的对象。
- 步骤#2: 获取这些区域,并通过预先训练的 CNN 对候选区域进行分类(同样,可能包含一个物体)。
- 步骤#3: 应用非最大值抑制(NMS)来抑制弱的、重叠的边界框。
- 步骤#4: 将最终的边界框返回给调用函数。
我们使用 OpenCV、Keras 和 TensorFlow 实现了上面的管道— 全部用了大约 150 行代码!
但是,您会注意到,我们使用了一个在 ImageNet 数据集上经过预训练的网络。
这就引出了问题:
- 如果我们想在我们自己的自定义数据集上训练一个网络会怎么样?
- 我们如何使用选择性搜索来训练网络?
- 这将如何改变我们用于物体检测的推理代码?
我将在下周的教程中回答这些问题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
带 Keras 的回归
原文:https://pyimagesearch.com/2019/01/21/regression-with-keras/
在本教程中,您将学习如何使用 Keras 和深度学习来执行回归。您将学习如何为回归和连续值预测训练 Keras 神经网络,特别是在房价预测的背景下。
今天的帖子开始了关于深度学习、回归和连续价值预测的 3 部分系列。
我们将在房价预测的背景下研究 Keras 回归预测:
- 第一部分:今天我们将训练一个 Keras 神经网络来根据分类和数字属性预测房价,例如卧室/浴室的数量、平方英尺、邮政编码等。
- 第二部分:下周我们将训练一个 Keras 卷积神经网络,根据房屋本身的输入图像(即房屋、卧室、浴室和厨房的正面视图)来预测房价。
- 第三部分:在两周内,我们将定义并训练一个神经网络, 将我们的分类/数字属性与我们的图像相结合,从而比单独的属性或图像更好、更准确地预测房价。
与分类(预测 标签 )不同,回归使我们能够预测 连续值 。
比如分类也许能预测出以下某个值:{便宜,买得起,贵} 。
另一方面,回归将能够预测精确的美元金额,例如“这栋房子的估计价格是 489,121 美元”。
在许多现实世界的情况下,比如房价预测或股市预测,应用回归而不是分类对于获得好的预测是至关重要的。
要了解如何使用 Keras 执行回归,请继续阅读!
带 Keras 的回归
2020-06-12 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将简要讨论分类和回归之间的区别。
然后,我们将探索我们在这一系列 Keras 回归教程中使用的房价数据集。
从那里,我们将配置我们的开发环境,并审查我们的项目结构。
在这个过程中,我们将学习如何使用 Pandas 加载我们的房价数据集,并定义一个用于 Keras 回归预测的神经网络。
最后,我们将训练我们的 Keras 网络,然后评估回归结果。
分类与回归
通常在 PyImageSearch 博客上,我们在分类的背景下讨论 Keras 和深度学习——预测一个标签来表征图像或输入数据集的内容。
回归,另一方面,使我们能够预测连续值。让我们再次考虑房价预测的任务。
我们知道,分类是用来预测一个类别标签的。
对于房价预测,我们可以将分类标签定义为:
labels = {very cheap, cheap, affordable, expensive, very expensive}
如果我们执行分类,我们的模型可以根据一组输入特征学习预测这五个值中的一个。
然而,这些标签仅仅是——代表房子潜在价格范围的类别,但并不代表房子的实际成本(T2)。
为了预测房屋的实际成本,我们需要进行回归分析。
使用回归,我们可以训练一个模型来预测一个连续值。
例如,虽然分类可能只能预测一个标签,但回归可以说:
根据我的输入数据,我估计这栋房子的价格是 781,993 美元
上面的图 1 提供了执行分类和回归的可视化。
在本教程的其余部分,您将学习如何使用 Keras 为回归训练神经网络。
房价数据集
我们今天要使用的数据集来自 Ahmed 和 Moustafa 于 2016 年发表的论文根据视觉和文字特征进行房价估算。
数据集包括 535 个数据点的数字/分类属性以及图像*,**使其成为研究回归和混合数据预测的优秀数据集。
房屋数据集包括四个数字和分类属性:
- 卧室数量
- 浴室数量
- 面积(即平方英尺)
- 邮政区码
这些属性以 CSV 格式存储在磁盘上。
我们将在本教程的后面使用pandas从磁盘加载这些属性,这是一个用于数据分析的流行 Python 包。
也为每个房屋提供总共四个图像:
- 卧室
- 浴室
- 厨房
- 房子的正面图
房屋数据集的最终目标是预测房屋本身的价格。
在今天的教程中,我们将使用和数字和分类数据。
下周的博客文章将讨论如何处理图像数据。
最后,两周后,我们将结合数字/分类数据和图像,以获得我们的最佳表现模型。
但是在我们为回归训练我们的 Keras 模型之前,我们首先需要配置我们的开发环境并获取数据。
配置您的开发环境
对于这个由 3 部分组成的博客文章系列,您需要安装以下软件包:
- NumPy
- scikit-learn
- 熊猫
- Keras 与 TensorFlow 后端(CPU 或 GPU)
- OpenCV (本系列接下来的两篇博文)
要为这一系列教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
下载房价数据集
在下载数据集之前,使用 “下载” 部分获取这篇文章的源代码。
从那里,解压缩文件并导航到目录:
$ cd path/to/downloaded/zip
$ unzip keras-regression.zip
$ cd keras-regression
在那里,您可以使用以下命令下载房价数据集:
$ git clone https://github.com/emanhamed/Houses-dataset
当我们准备好训练我们的 Keras 回归网络时,你需要通过命令行参数提供到Houses-dataset目录的路径。
项目结构
现在您已经有了数据集,接下来使用带有如下所示相同参数的tree命令来打印项目的目录+文件列表:
$ tree --dirsfirst --filelimit 10
.
├── Houses-dataset
│ ├── Houses Dataset [2141 entries]
│ └── README.md
├── pyimagesearch
│ ├── __init__.py
│ ├── datasets.py
│ └── models.py
└── mlp_regression.py
3 directories, 5 files
从 GitHub 下载的数据集现在位于Houses-dataset/文件夹中。
pyimagesearch/目录实际上是一个包含代码 【下载】 的模块,在里面你会发现:
datasets.py:我们从数据集加载数字/分类数据的脚本models.py:我们的多层感知器架构实现
这两个脚本将在今天复习。此外,我们将在接下来的两个教程中重用datasets.py和models.py(带修改),以保持我们的代码有组织和可重用。
regression + Keras 脚本包含在mlp_regression.py中,我们也将回顾它。
加载房价数据集
在训练我们的 Keras 回归模型之前,我们首先需要为 houses 数据集加载数值和分类数据。
打开datasets.py文件并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
import glob
import cv2
import os
def load_house_attributes(inputPath):
# initialize the list of column names in the CSV file and then
# load it using Pandas
cols = ["bedrooms", "bathrooms", "area", "zipcode", "price"]
df = pd.read_csv(inputPath, sep=" ", header=None, names=cols)
我们首先从 scikit-learn、pandas、NumPy 和 OpenCV 导入库和模块。OpenCV 将在下周使用,因为我们将添加加载图像到这个脚本的能力。
在第 10 行上,我们定义了接受输入数据集路径的load_house_attributes函数。
在函数内部,我们首先定义 CSV 文件中的列名(第 13 行)。从那里,我们使用 pandas 的函数,read_csv将 CSV 文件加载到内存中,作为第 14 行上的日期帧(df)。
下面您可以看到我们的输入数据示例,包括卧室数量、浴室数量、面积(即平方英尺)、邮政编码、代码,以及我们的模型应训练预测的最终目标价格:
bedrooms bathrooms area zipcode price
0 4 4.0 4053 85255 869500.0
1 4 3.0 3343 36372 865200.0
2 3 4.0 3923 85266 889000.0
3 5 5.0 4022 85262 910000.0
4 3 4.0 4116 85266 971226.0
让我们完成剩下的load_house_attributes函数:
# determine (1) the unique zip codes and (2) the number of data
# points with each zip code
zipcodes = df["zipcode"].value_counts().keys().tolist()
counts = df["zipcode"].value_counts().tolist()
# loop over each of the unique zip codes and their corresponding
# count
for (zipcode, count) in zip(zipcodes, counts):
# the zip code counts for our housing dataset is *extremely*
# unbalanced (some only having 1 or 2 houses per zip code)
# so let's sanitize our data by removing any houses with less
# than 25 houses per zip code
if count < 25:
idxs = df[df["zipcode"] == zipcode].index
df.drop(idxs, inplace=True)
# return the data frame
return df
在剩余的行中,我们:
- 确定唯一的邮政编码集,然后计算每个唯一邮政编码的数据点数(第 18 行和第 19 行)。
- 过滤掉低计数的邮政编码(第 28 行)。对于一些邮政编码,我们只有一两个数据点,这使得获得准确的房价估计非常具有挑战性,如果不是不可能的话。
- 将数据帧返回给调用函数(第 33 行)。
现在让我们创建用于预处理数据的process_house_attributes函数:
def process_house_attributes(df, train, test):
# initialize the column names of the continuous data
continuous = ["bedrooms", "bathrooms", "area"]
# performin min-max scaling each continuous feature column to
# the range [0, 1]
cs = MinMaxScaler()
trainContinuous = cs.fit_transform(train[continuous])
testContinuous = cs.transform(test[continuous])
我们在第 35 行定义函数。process_house_attributes函数接受三个参数:
df:我们由 pandas 生成的数据框(前面的函数帮助我们从数据框中删除一些记录)train:我们的房价数据集的训练数据- 我们的测试数据。
然后在第 37 行上,我们定义连续数据的列,包括卧室、浴室和房子的大小。
我们将获取这些值,并使用 scikit-learn 的MinMaxScaler将连续特征缩放到范围【0,1】(第 41-43 行)。
现在我们需要预处理我们的分类特征,即邮政编码:
# one-hot encode the zip code categorical data (by definition of
# one-hot encoing, all output features are now in the range [0, 1])
zipBinarizer = LabelBinarizer().fit(df["zipcode"])
trainCategorical = zipBinarizer.transform(train["zipcode"])
testCategorical = zipBinarizer.transform(test["zipcode"])
# construct our training and testing data points by concatenating
# the categorical features with the continuous features
trainX = np.hstack([trainCategorical, trainContinuous])
testX = np.hstack([testCategorical, testContinuous])
# return the concatenated training and testing data
return (trainX, testX)
首先,我们将对邮政编码进行一次性编码(第 47-49 行)。
然后,我们将使用 NumPy 的hstack函数(第 53 行和第 54 行)将分类特征与连续特征连接起来,将得到的训练和测试集作为元组(第 57 行)返回。
请记住,现在我们的分类特征和连续特征都在 [0,1]范围内所有。**
实现用于回归的神经网络
在我们为回归训练 Keras 网络之前,我们首先需要定义架构本身。
今天我们将使用一个简单的多层感知器(MLP),如图 5 所示。
打开models.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
def create_mlp(dim, regress=False):
# define our MLP network
model = Sequential()
model.add(Dense(8, input_dim=dim, activation="relu"))
model.add(Dense(4, activation="relu"))
# check to see if the regression node should be added
if regress:
model.add(Dense(1, activation="linear"))
# return our model
return model
首先,我们将从 Keras 导入所有必需的模块(第 2-11 行)。我们将在下周的教程的中给这个文件添加一个卷积神经网络,因此今天这里没有使用额外的导入。
让我们通过编写一个名为create_mlp的函数来定义 MLP 架构。
该函数接受两个参数:
dim:定义我们的输入尺寸regress:一个布尔值,定义是否应该添加我们的回归神经元
我们将着手开始用dim-8-4架构(第 15-17 行)建造我们的 MLP。
如果我们正在执行回归,我们添加一个包含具有线性激活函数的单个神经元的Dense层(行 20 和 21 )。通常我们使用基于 ReLU 的激活,但是因为我们正在执行回归,所以我们需要一个线性激活。
最后,我们的model在行 24 返回。
实现我们的 Keras 回归脚本
现在是时候把所有的碎片放在一起了!
打开mlp_regression.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from pyimagesearch import datasets
from pyimagesearch import models
import numpy as np
import argparse
import locale
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input dataset of house images")
args = vars(ap.parse_args())
我们从导入必要的包、模块和库开始。
也就是说,我们需要来自 Keras 的Adam优化器,来自 scikit-learn 的train_test_split,以及来自pyimagesearch模块的datasets + models函数。
此外,在评估我们的模型时,我们将使用 NumPy 的数学特性来收集统计数据。
argparse模块用于解析命令行参数。
我们的脚本只需要一个命令行参数--dataset ( 第 12-15 行)。当您在终端中运行训练脚本时,您需要提供--dataset开关和数据集的实际路径。
让我们加载房屋数据集属性,并构建我们的培训和测试拆分:
# construct the path to the input .txt file that contains information
# on each house in the dataset and then load the dataset
print("[INFO] loading house attributes...")
inputPath = os.path.sep.join([args["dataset"], "HousesInfo.txt"])
df = datasets.load_house_attributes(inputPath)
# construct a training and testing split with 75% of the data used
# for training and the remaining 25% for evaluation
print("[INFO] constructing training/testing split...")
(train, test) = train_test_split(df, test_size=0.25, random_state=42)
使用我们方便的load_house_attributes函数,并通过将inputPath传递给数据集本身,我们的数据被加载到内存中(第 20 行和第 21 行)。
我们的培训(75%)和测试(25%)数据是通过第 26 行和 scikit-learn 的train_test_split方法构建的。
让我们来衡量我们的房价数据:
# find the largest house price in the training set and use it to
# scale our house prices to the range [0, 1] (this will lead to
# better training and convergence)
maxPrice = train["price"].max()
trainY = train["price"] / maxPrice
testY = test["price"] / maxPrice
正如评论中所说,将我们的房价调整到范围【0,1】将使我们的模型更容易训练和收敛。将输出目标缩放至【0,1】将缩小我们的输出预测范围(相对于【0,maxPrice】),不仅使 更容易、更快地训练我们的网络 ,而且使我们的模型 也能获得更好的结果。
因此,我们获取训练集中的最高价格(行 31 ),并相应地扩展我们的训练和测试数据(行 32 和 33 )。
现在让我们处理房屋属性:
# process the house attributes data by performing min-max scaling
# on continuous features, one-hot encoding on categorical features,
# and then finally concatenating them together
print("[INFO] processing data...")
(trainX, testX) = datasets.process_house_attributes(df, train, test)
回想一下datasets.py脚本中的process_house_attributes函数:
- 预处理我们的分类和连续特征。
- 通过最小-最大缩放将我们的连续特征缩放到范围【0,1】。
- 一键编码我们的分类特征。
- 连接分类特征和连续特征以形成最终的特征向量。
现在,让我们根据数据拟合 MLP 模型:
# create our MLP and then compile the model using mean absolute
# percentage error as our loss, implying that we seek to minimize
# the absolute percentage difference between our price *predictions*
# and the *actual prices*
model = models.create_mlp(trainX.shape[1], regress=True)
opt = Adam(lr=1e-3, decay=1e-3 / 200)
model.compile(loss="mean_absolute_percentage_error", optimizer=opt)
# train the model
print("[INFO] training model...")
model.fit(x=trainX, y=trainY,
validation_data=(testX, testY),
epochs=200, batch_size=8)
我们的model被Adam优化器初始化(第 45 和 46 行,然后被编译(第 47 行)。注意,我们使用平均绝对百分比误差作为我们的损失函数,表明我们寻求最小化预测价格和实际价格之间的平均百分比差异。
实际培训过程从第 51-53 行开始。
培训完成后,我们可以评估我们的模型并总结我们的结果:
# make predictions on the testing data
print("[INFO] predicting house prices...")
preds = model.predict(testX)
# compute the difference between the *predicted* house prices and the
# *actual* house prices, then compute the percentage difference and
# the absolute percentage difference
diff = preds.flatten() - testY
percentDiff = (diff / testY) * 100
absPercentDiff = np.abs(percentDiff)
# compute the mean and standard deviation of the absolute percentage
# difference
mean = np.mean(absPercentDiff)
std = np.std(absPercentDiff)
# finally, show some statistics on our model
locale.setlocale(locale.LC_ALL, "en_US.UTF-8")
print("[INFO] avg. house price: {}, std house price: {}".format(
locale.currency(df["price"].mean(), grouping=True),
locale.currency(df["price"].std(), grouping=True)))
print("[INFO] mean: {:.2f}%, std: {:.2f}%".format(mean, std))
第 57 行指示 Keras 在我们的测试集上进行预测。
使用预测,我们计算:
- 预测房价与实际房价之差(62 线)。
- 百分比差异(第 63 行)。
- 绝对百分比差异(第 64 行)。
从那里,在第 68 和 69 行上,我们计算绝对百分比差的平均值和标准偏差。
结果通过行 73-76 打印出来。
用 Keras 回归并不困难,不是吗?
我们来训练模型,分析结果!
Keras 回归结果

Figure 6: For today’s blog post, our Keras regression model takes four numerical inputs, producing one numerical output: the predicted value of a home.
要训练我们自己的 Keras 网络进行回归和房价预测,请确保您:
- 根据上述指导配置您的开发环境。
- 使用本教程的 【下载】 部分下载源代码。
- 根据上面“房价数据集”部分的说明下载房价数据集。
从那里,打开一个终端并提供以下命令(确保--dataset 命令行参数指向您下载房价数据集的位置):
$ python mlp_regression.py --dataset Houses-dataset/Houses\ Dataset/
[INFO] loading house attributes...
[INFO] constructing training/testing split...
[INFO] processing data...
[INFO] training model...
Epoch 1/200
34/34 [==============================] - 0s 4ms/step - loss: 73.0898 - val_loss: 63.0478
Epoch 2/200
34/34 [==============================] - 0s 2ms/step - loss: 58.0629 - val_loss: 56.4558
Epoch 3/200
34/34 [==============================] - 0s 1ms/step - loss: 51.0134 - val_loss: 50.1950
Epoch 4/200
34/34 [==============================] - 0s 1ms/step - loss: 47.3431 - val_loss: 47.6673
Epoch 5/200
34/34 [==============================] - 0s 1ms/step - loss: 45.5581 - val_loss: 44.9802
Epoch 6/200
34/34 [==============================] - 0s 1ms/step - loss: 42.4403 - val_loss: 41.0660
Epoch 7/200
34/34 [==============================] - 0s 1ms/step - loss: 39.5451 - val_loss: 34.4310
Epoch 8/200
34/34 [==============================] - 0s 2ms/step - loss: 34.5027 - val_loss: 27.2138
Epoch 9/200
34/34 [==============================] - 0s 2ms/step - loss: 28.4326 - val_loss: 25.1955
Epoch 10/200
34/34 [==============================] - 0s 2ms/step - loss: 28.3634 - val_loss: 25.7194
...
Epoch 195/200
34/34 [==============================] - 0s 2ms/step - loss: 20.3496 - val_loss: 22.2558
Epoch 196/200
34/34 [==============================] - 0s 2ms/step - loss: 20.4404 - val_loss: 22.3071
Epoch 197/200
34/34 [==============================] - 0s 2ms/step - loss: 20.0506 - val_loss: 21.8648
Epoch 198/200
34/34 [==============================] - 0s 2ms/step - loss: 20.6169 - val_loss: 21.5130
Epoch 199/200
34/34 [==============================] - 0s 2ms/step - loss: 19.9067 - val_loss: 21.5018
Epoch 200/200
34/34 [==============================] - 0s 2ms/step - loss: 19.9570 - val_loss: 22.7063
[INFO] predicting house prices...
[INFO] avg. house price: $533,388.27, std house price: $493,403.08
[INFO] mean: 22.71%, std: 18.26%
正如您从我们的输出中看到的,我们的初始平均绝对百分比误差开始高达 73%,然后迅速下降到 30%以下。
当我们完成训练时,我们可以看到我们的网络开始有点超载。我们的培训损耗低至~ 20%;然而,我们的验证损失约为 23%。
计算我们的最终平均绝对百分比误差,我们得到最终值 22.71%。
这个值是什么意思?
我们的最终平均绝对百分比误差意味着,平均而言,我们的网络在房价预测中会有约 23%的误差,标准差约为 18%。
房价数据集的局限性
房价预测下降 22%是一个好的开始,但肯定不是我们想要的那种精确度。
也就是说,这种预测准确性也可以被视为房价数据集本身的一种限制。
请记住,数据集只包括四个属性:
- 卧室数量
- 浴室数量
- 面积(即平方英尺)
- 邮政区码
大多数其他房价数据集包括更多属性。
例如,波士顿房价数据集包括总共14 个属性,这些属性可用于房价预测(尽管该数据集确实有一些种族歧视)。
Ames House 数据集 包括超过 79 种不同的属性,可用于训练回归模型。
当你想到这一点,事实上,我们甚至能够获得 26%的平均绝对百分比误差,而没有一个专业的房地产经纪人的知识是相当合理的给定:
- 数据集中总共只有 535 栋房屋(出于本指南的目的,我们只使用了 362 栋房屋)。
- 我们只有四个属性来训练我们的回归模型。
- 这些属性本身,虽然在描述房屋本身时很重要,但对房屋周围区域的特征描述却很少。
- 房价的变化令人难以置信均值为 53.3 万美元,标准差为 49.3 万美元(基于我们过滤后的 362 套房屋的数据集)。
综上所述,学习如何使用 Keras 执行回归是一项重要的技能!
在本系列的下两篇文章中,我将向您展示如何:
- 利用房价数据集提供的图像来训练 CNN。
- 将我们的数字/分类数据与房屋图像相结合,得到一个优于我们之前所有 Keras 回归实验的模型。
摘要
在本教程中,您学习了如何使用 Keras 深度学习库进行回归。
具体来说,我们使用 Keras 和回归来预测基于四个数字和分类属性的房价:
- 卧室数量
- 浴室数量
- 面积(即平方英尺)
- 邮政区码
总体而言,我们的神经网络获得了 22.71%的平均绝对百分比误差,这意味着,平均而言,我们的房价预测将偏离 22.71%。
这就提出了问题:
- 怎样才能提高我们的房价预测准确率?
- 如果我们利用每栋房子的图片会怎么样?这会提高准确性吗?
- 有什么方法可以将我们的分类/数字属性和图像数据结合起来?
要回答这些问题,您需要继续关注 Keras 回归系列中的其他教程。
要下载这篇文章的源代码(下一篇教程在 PyImageSearch 上发布时会通知您),只需在下面的表格中输入您的电子邮件地址。*
Raspberry Pi(或 Amazon EC2)上的远程开发
原文:https://pyimagesearch.com/2019/07/01/remote-development-on-the-raspberry-pi-or-amazon-ec2/

在这篇博文中,您将学习如何在 Raspberry Pi(或 Amazon EC2 服务器)上执行远程开发。您将发现如何配置您的主机以连接到这些系统并远程执行 Python 开发。
今天的教程实际上是我即将出版的书的一个章节, 计算机视觉的树莓派 。
在我写这一章的时候,我意识到这个指南并不是专门针对 RPi 的,它实际上可以用于任何需要配置远程系统进行开发的人(特别是使用 Python 编程语言的人)。
因此,我决定把这一章转换成一篇博文。
通过本教程,您将学习如何配置:
- 用于远程计算机视觉开发的树莓 Pi
- 用于远程深度学习的亚马逊 AWS 服务器
- …或任何其他可以远程连接的系统!
要了解如何为远程 Python 开发配置您的 Raspberry Pi、Amazon EC2 实例或服务器,请继续阅读!
Raspberry Pi(或 Amazon EC2)上的远程开发
在本教程的第一部分,我们将讨论远程开发的概念,以及为什么它不仅对我们这些程序员来说方便,而且为什么你应该在你的非宿主机器上写代码时使用它。
在这里,我将向您提供我最喜欢的三种连接到 Raspberry Pi、AWS 实例或远程服务器的方法。
然后,我们将讨论将文件从主机传输到远程系统的两种简单易用的方法。
最后,我们将在文章的最后讨论可用于在远程系统上编写代码的 Python IDEs。
什么是远程开发?
Figure 1: Remote Python development flowchart.
远程开发假设您有两台计算机:
- 您的主机(也称为您的本地机器)连接了您的显示器、键盘和鼠标。
- 执行代码的远程机器。
或者,更简单地说:
- 你的主机是你的笔记本电脑/台式机,放在你平时工作的桌子上。
- 您的远程机器是您通过主机登录的机器。
要执行开发,首先要从主机连接到远程机器。
有许多方法可以连接到远程机器,包括 SSH、VNC、Jupyter 笔记本等等。我们将在本指南的后面介绍这些方法。
连接到远程机器后,您可以:
- 在远程机器上编写代码
- 在远程机器上执行代码
图 1 说明了使用您的主机登录到设备,在远程系统上编写代码,然后执行代码的概念。
当您仍然在本地系统上使用键盘输入时,命令/代码本身实际上正在远程机器上执行。
为什么我要远程编写我的代码?
如果你正在使用基于云的实例,比如 Amazon EC2、Microsoft Azure 等。,那么您没有物理接触到机器(意味着没有键盘/鼠标可以使用)。
在这种情况下,您需要登录到服务器并执行远程开发——并且您希望确保您的本地主机针对远程开发进行了正确配置。
如果你用的是树莓派,那么你当然可以连接键盘、显示器和鼠标,但这并不总是必要的!
首先,您会遇到设置额外硬件的麻烦—设置起来很笨重,您会失去桌面上的空间,最糟糕的是,您会不断地在 RPi 键盘和笔记本电脑/台式机键盘之间来回切换。
其次,即使发布了 Raspberry Pi 4,与您的笔记本电脑/台式机相比,RPi 本身仍然非常不够强大——您不会(也不应该)能够在 Pi 本身上利用强大的编程 ide。
说到 Python 开发, PyCharm 简直就是标准。
然而,像 PyCharm 这样的 IDE 虽然超级强大,但却是资源消耗大户,消耗相当多的 RAM 和 CPU 周期——在 RPi 这样的资源受限设备上,运行这样的 IDE 在计算上是很浪费的。
相反,您应该:
- 配置您的本地机器以连接到 Pi
- 笔记本电脑/台式机上的代码
- 然后将这些文件传输(可能是自动传输)到 Pi,这样您就可以在远程机器上运行代码本身。
在本教程的剩余部分,我将向你展示如何配置你的主机来创建一个无缝转换,让感觉到就像你在你的主机上写代码,但实际上是在远程系统上写代码。
连接到远程机器或 Raspberry Pi
有许多方法、协议和程序可以连接到远程机器。
本节中讨论的方法当然不是详尽的,但是它们是我最喜欢的,也是你在执行远程开发时绝对会遇到的。
安全外壳(SSH)

Figure 2: Secure Shell (SSH) is essential to remote development with Unix systems such as Ubuntu, macOS, EC2, and Raspbian.
第一种方法,也可以说是最简单的方法,是利用安全 Shell (SSH),这是 Unix 机器上的ssh命令。
要使用 SSH,您需要:
- 远程机器上安装并运行的 SSH 服务器。
- 安装在本地机器上的 SSH 客户端。
- 远程系统的 IP 地址、用户名和密码。
大多数系统都有 SSH 服务器。在 Ubuntu 上,如果需要安装 SSH 服务器,只需:
$ sudo apt-get install openssh-server
在 macOS 上,你只需要开启“远程登录”:
sudo systemsetup -setremotelogin on
参见下面的了解在 Raspberry Pi 上启用 SSH 服务器的两个选项。
如果你使用的是基于 Unix 的机器(比如 Linux 或 macOS),默认情况下会安装ssh 客户端。如果您使用的是 Windows,您可能需要安装它
注意:我已经 10 多年没用过 Windows 了,在 PyImageSearch 博客上也没有正式支持 Windows。我最后一次检查 PuTTY 仍然是一个很好的选择,但我会把 SSH 安装在 Windows 上留给你。
如果您已经安装了 SSH,首先在您的主机上打开一个终端/命令行。
然后,您将需要以下内容:
- 您正在连接的机器的 IP 地址。
- 您将在远程机器上登录的用户的用户名。
- 相应用户的密码。
获得这些信息后,您可以使用以下命令作为模板:
$ ssh username@ip_address
如果您使用的是 Amazon EC2,您可能需要提供一个私钥来代替密码:
$ ssh -i ~/keyfile.pem username@ip_address # AWS EC2
例如,如果我的远程机器的 IP 地址是10.0.0.90,我的用户名是adrian,那么ssh命令就变成:
$ ssh adrian@10.0.0.90
然后,我可以提供我的密码并登录到远程机器。登录后,我现在可以在远程机器上执行任何我想执行的命令(当然,前提是我有适当的权限)。
X11 转发

Figure 3: X11 forwarding allows a remote system to render a GUI window on your local system. X forwarding is useful for remote development over high-speed connections and when the GUI is relatively static. It does not perform well for animations and video.
您知道可以使用 SSH 从 Python 脚本和程序中查看基本的 GUI 窗口吗?
首先,您需要一个 X-Window 管理器:
- 如果你的主机是 Ubuntu (或者另一个 Linux 发行版),它是内置的。
- 如果你的主机是 macOS ,你要下载+安装 xQuartz 。
- 如果你的主机是 Windows ,我认为这些天你仍然需要 Xming (我使用 Windows 已经超过 10 年了,所以你应该自己做研究)。
您需要做的就是通过-X开关启用 X11 转发:
$ ssh -X username@ip_address
Figure 4: A remote X11 window displayed on my Mac using the Xquartz app and an SSH connection.
这里我启动了一个名为example.py的 Python 脚本。这个脚本从磁盘加载一个图像,并通过cv2.imshow调用将它显示到我的本地主机的屏幕上。
因为我启用了 X11 转发,所以通过 OpenCV 打开的窗口显示在我的主机上。请记住,代码是远程执行的,图像是远程呈现的,但在本地显示。
你可能想知道:
X11 转发对视频流有用吗?
简而言之,答案是“不,不用麻烦了。”X11 转发协议根本不压缩图像,也不能有效地使视频流成为可能。不要尝试将 X11 转发用于内容经常变化或有视频内容的应用。
树莓 Pi 上的 SSH 的一个快速注释
值得注意的是,SSH 在 Raspberry Pi 上默认是关闭的,这意味着如果不先启用它,您就不能通过 SSH 连接到您的 RPi。
有几种方法可以在 Raspberry Pi 上启用 SSH。
选项 1: 您可以通过桌面用户界面:启用

Figure 5: The Raspberry Pi Configuration desktop GUI is accessed from the main menu.
从那里,找到“Interfaces”选项卡并启用 SSH:

Figure 6: Enabling SSH on the Raspberry Pi via the Desktop. SSH is essential for remote development on the Raspberry Pi.
选项 2: 第二种方法是使用下面的命令来启用它:
$ sudo service ssh start
这种方法的问题是,需要物理访问 RPi 才能键入命令。
第二个问题是,如果您重新启动 Raspberry Pi,SSH 将不会自动启动(也就是说,启动 SSH 将不会在重新启动后持续)。
选项 3: 与选项 1 类似,您可以通过命令行:进入树莓 Pi 配置
Figure 7: The raspi-config command allows you to change system settings.
从那里,您将看到一个终端菜单:
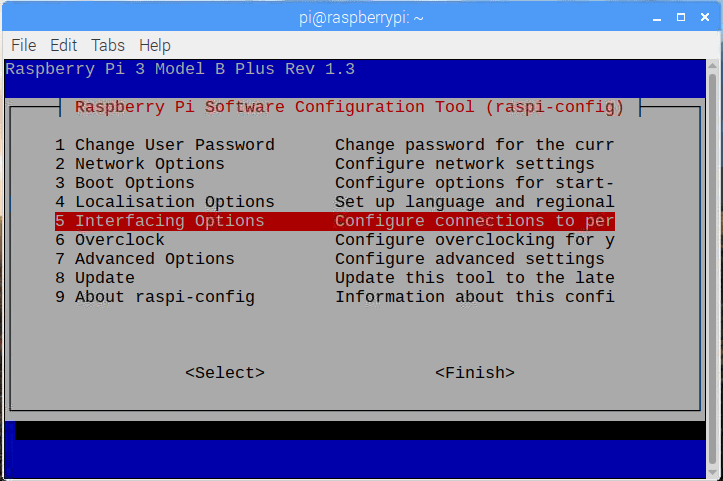
Figure 8: Select “5 Interfacing Options” to find SSH and other interface settings for the Raspberry Pi. Once you turn on SSH you can begin remote development with your Raspberry Pi.
然后您将看到一些界面,其中一个是 SSH:
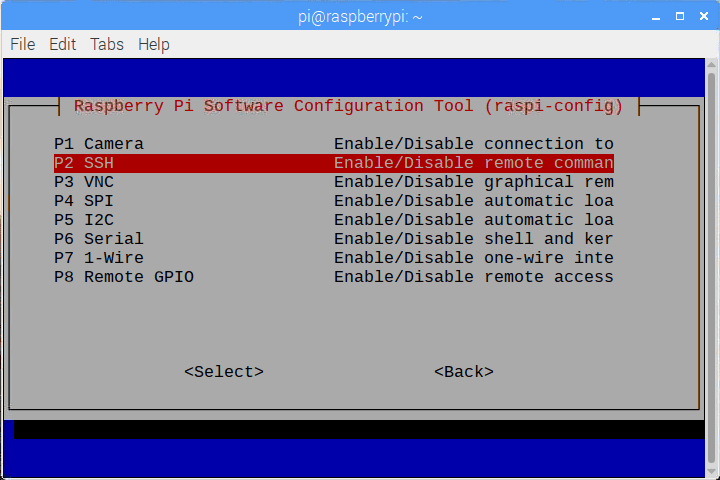
Figure 9: SSH for Raspberry Pi can be turned on from the “P2 SSH” menu item.
将需要重新启动。从那里你可以使用 Raspberry Pi 的 IP 地址远程连接到它。要找到您的 RPi 的 IP 地址,只需使用ifconfig命令:
Figure 10: To find the IP address of your Raspberry Pi, use the ifconfig command. Here my RPi is connected to my wlan0 interface on the 192.168.1.150 IP.
另一种在你的网络上找到 Raspberry Pi 的方法是访问我们路由器的客户端页面。如果您当时没有将屏幕和键盘/鼠标连接到 RPi,这将非常有用。
虚拟网络计算(VNC)

Figure 11: VNC is a graphical way to connect to remote systems such as the Raspberry Pi or another computer on your network that has a desktop environment.
如果您在远程机器上工作时更喜欢图形用户界面(GUI)而不是命令行,那么您可以使用 VNC。
要使用 VNC,您需要:
- 远程机器上安装并运行的 VNC 服务器。
- 安装在本地计算机上的 VNC 客户端。
- 远程系统的 IP 地址、用户名和密码。
然而,请记住,VNC 假设您的远程系统上运行着 GUI/桌面管理器。
对于 Raspberry Pi,这是一个非常好的假设 RPi 在启动时启动一个窗口管理器(当然,前提是您使用的是 Raspbian 的标准安装)。
然而,对于远程服务器,比如 Amazon EC2 或 Microsoft Azure,您可能没有窗口管理器。
在这些情况下,你不能使用 VNC,而应该使用 SSH。
如何安装 VNC 服务器取决于你的操作系统,所以你需要自己研究一下(因为我不能为每个操作系统提供指导)。
也就是说,我已经为 Raspbian 和 Ubuntu 提供了 VNC 服务器的安装说明,这是你想安装 VNC 服务器的两个最流行的操作系统。
在 Raspbian 上安装 VNC 服务器
对我们来说幸运的是,很容易让 VNC 运行 Raspbian 操作系统。
你有两个选择:
选项 1: 使用桌面配置更改设置:
参见图 5 打开“树莓派配置”用户界面。然后通过单选按钮启用 VNC:
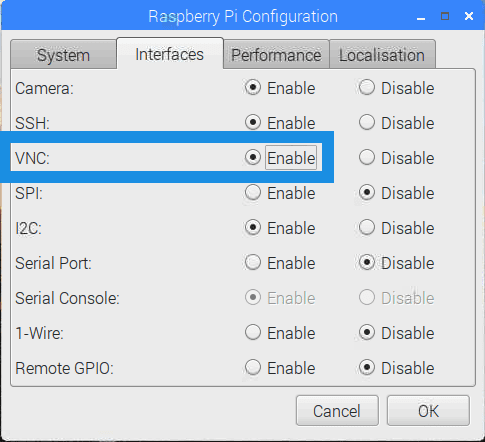
Figure 12: Enabling VNC on the Raspberry Pi via the desktop user interface.
这种方法需要重新启动。
选项 2: 使用命令行启用 VNC 服务器:
在命令行运行sudo raspi-config(参见图 7 )。
然后,导航到“5 接口选项”菜单项(参见图 8 )。
最后,选择“P3 VNC”:
Figure 13: Enabling VNC via the command line on the Raspberry Pi. We used the raspi-config command to open the configuration settings.
启用 VNC,重启后就可以运行了。
在 Ubuntu 上安装 VNC 服务器
在 Ubuntu 上安装 VNC 服务器有多种方法。
选项 1: 鉴于我的偏好是皇家 VNC (对于服务器和客户端),你可以从安装他们的。deb 文件为最简单的方法:
Figure 14: Installing the RealVNC branded VNC Server on Linux can be accomplished with their .deb package file.
要在 Ubuntu 中安装. deb 文件,可以双击文件浏览器/桌面中的图标。或者,你可以跑。命令行中的 deb 文件:
$ sudo dpkg -i VNC-Server-6.4.1-Linux-x64.deb
另外,关于如何从命令行手动安装 VNC 服务器,网上有很多信息。
我不会在这里重复别人的安装指南,而是提供一些有前途的教程的链接:
- https://www . cyber Citi . biz/FAQ/install-and-configure-tigervnc-server-on-Ubuntu-18-04/
- https://www . digital ocean . com/community/tutorials/how-to-install-and-configure-VNC-on-Ubuntu-18-04
如果你找到一个你特别喜欢的通过命令行安装 VNC 的教程,请在这篇文章的评论部分分享。
realvnc 客户端
我首选的 VNC 客户端是适用于 macOS、Linux、Windows 和其他操作系统的 皇家 VNC 。
您可以使用此链接下载适合您系统的 Real VNC 客户端。
一旦(1) VNC 服务器在您的远程机器上运行,并且(2)VNC 客户端在您的本地机器上运行,遵循图 11 中的步骤:
- 输入远程机器的 IP 地址。
- 输入远程系统上该帐户的用户名和密码。
- 享受您的 VNC 连接!
从那里,您可以远程访问远程机器上的桌面和 GUI 管理器。
那么,有什么条件呢?
VNC 的问题是它由于网络延迟而很慢。即使在本地网络上,VNC 有时也会显得有点“落后”。
我个人只在以下情况下使用 VNC:
- 我需要在本地网络上访问我的树莓派。
- 我需要运行利用
cv2.imshow的 Python 脚本,这样我就可以可视化输出。
如果你的网络连接比较强,可以使用 VNC 和cv2.imshow调用调试实时 Python 和 OpenCV 脚本;然而,如果您的连接很弱,并且您一直需要使用cv2.imshow,您应该简单地使用一个连接到您的“远程”机器的物理监视器。
jupyter 笔记本
Figure 15: Jupyter Notebooks are great environments if you can stay contained in your web browser. The community loves Jupyter Notebooks for sharing code demos. There are times when you’ll find that Jupyter limits your development, however.
Jupyter 笔记本已经成为 Python 开发的超级热门。
我鼓励你使用它们,只要你明白 Jupyter 笔记本是而不是命令 行的替代品——它们只是你工具箱里的一个不同的工具。
仅仅因为你可以通过 Jupyter 笔记本执行命令和代码,并不意味着你可以忽略学习命令行(反之亦然)。
要成为一名全面发展的开发人员,你需要学习如何使用两个。
Jupyter 笔记本电脑的优势在于,您可以通过网络浏览器访问一个交互式的空闲环境,只需将网络浏览器指向运行在远程机器上的 Jupyter 笔记本电脑的 IP 地址/端口,就可以访问它。要使用 Jupyter 笔记本,您首先需要将它安装在您的远程计算机上:
$ workon your_env_name
$ pip install jupyter
如果您使用的是 Python 虚拟环境(推荐),您需要将 jupyter 包安装到您在其中使用 Jupyter 笔记本的任何 Python 环境中。
作为快速检查,您可以通过以下方式启动 jupyter 笔记本:
$ jupyter notebook
如果您的笔记本在本地计算机上运行,并且您也在本地计算机上,您的 web 浏览器将自动启动。
Figure 16: To create a new Python Jupyter Notebook file, simply use the “New” menu in the corner. You may also launch a web-based terminal from this menu.
如果您的笔记本电脑正在远程运行,您需要启动网络浏览器,并在 URL 框中输入服务器 IP 地址和端口(http://10.0.0.90:8888)。
在那里,您可以通过点击【新建】和【Python 3】创建一个新的笔记本,如图图 16 所示。
您可以将 Python 代码或系统命令插入到“Cells”中的笔记本中。继续按下“插入” > “在下方插入单元格”几次。从那里,您可以正常地输入 Python 代码。系统命令以! 开头(参见图 15的【3】中的)。
在 Jupyter 中显示图像怎么样?
Jupyter 无权访问您的系统 GUI。
因此,cv2.imshow和任何其他 GUI 命令都不起作用。
如果你想在你的 Jupyter 笔记本上显示图片,我推荐你使用 matplotlib。
唯一需要注意的是,matplotlib 的默认显示通道顺序是 RGB。您可能知道,OpenCV 的默认名称是 BGR。因此,在 Jupyter 笔记本中使用 matplotlib 显示之前,您必须交换蓝色和红色通道(cv2.cvtColor)。这里有一个简单的例子:

Figure 17: Displaying images in Jupyter notebooks for remote computer vision development or developing tutorials.
要了解更多细节,请务必参考我之前的帖子。
将文件传输到远程机器或 Raspberry Pi
在本节中,您将学习如何将文件从您的主机传输到您的远程机器。
有许多方法可以完成这项任务,但我最喜欢的两种方法包括使用 SCP/SFTP 或使用远程安装的驱动器。
手动 SCP 或 SFTP
![]()
Figure 18: Transmit is a macOS app for uploading/downloading files to/from remote machines using FTP/SFTP.
如果你需要将文件转移到你的远程机器上(比如将与你购买的 计算机视觉树莓 Pi相关的代码从你的笔记本电脑转移到你的 RPi 上),我强烈推荐使用 SCP/SFTP。
如果您使用的是基于 Unix 的计算机,您可以使用 SCP 命令:
$ scp foo.py username@ip_address:~/foobar_project
我正在把一个名为foo.py 的文件从本地机器移动到我的远程机器的~/foobar_project文件夹中。
请注意我是如何提供文件名以及远程机器的 IP 地址和用户名的(密码是在我执行命令后提供的)。
同样,我可以将文件从我的远程机器传输回我的本地机器:
$ scp username@ip_address:~/foobar_project/bar.py ~/foobar_project
该命令将名为bar.py的文件传输回本地机器的~/foobar_project文件夹中。
如果你更喜欢为 SCP/SFTP 使用基于 GUI 的程序,我会推荐使用 FileZilla (所有操作系统)或 Transmit for macOS ( 图 18 )。
使用这些程序,你可以简单地来回“拖放”文件。
当然 SCP 和 SFTP 最大的问题就是手动——你无法自动来回传输文件(至少不需要额外的命令)。
本教程的“通过 IDE 远程开发 Python 脚本”部分将向您展示如何将文件从您的主机自动传输到您的远程系统,但是现在,让我们来看看远程安装的驱动器。
远程安装驱动器
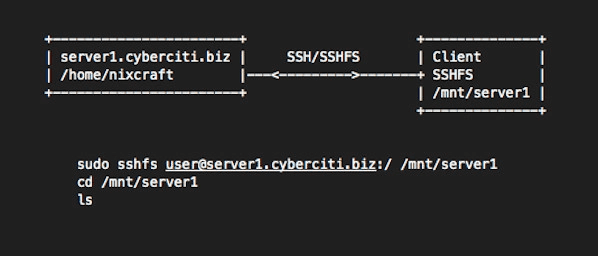
Figure 19: Using the SSH file system (SSHFS) you can remotely mount a remote system and access its file system, just like you would on your host machine (i.e., via macOS Finder, the Ubuntu/Raspbian GUI, Windows Explorer, etc.). (image source)
我不是远程安装机器或驱动器的最大粉丝,但它们在这里值得一提。
使用 SSH 文件系统(SSHFS ),您可以远程挂载远程系统并访问其文件系统,就像在您的主机上一样(例如,通过 macOS Finder、Ubuntu/Raspbian GUI、Windows Explorer 等)。).
我经常遇到的远程安装设备的问题是:
- 连接神秘地消失了。
- 文件并不总是传输。
相反,如果我想要一个文件自动同步(比如当我保存/更新一个文件时),我使用一个专用的 IDE,这正是我们将在下一节讨论的。
通过 IDE 远程开发 Python 脚本
在本节中,您将了解两个软件开发 ide,它们将使在远程机器上使用 Python 变得轻而易举。
崇高的文本与 SFTP 插件
崇高文字 是一个流行的代码编辑器。
编辑器是免费的,但是你可以购买一个可选的许可证(如果你发现自己在使用 Sublime Text,我建议你这么做——一定要支持那些开发你经常使用的软件的人!).
Sublime Text 的好处之一是它允许通过插件/包进行扩展。
对于远程开发你应该使用 崇高文本 SFTP 插件 。这个插件也是免费的,但有一个可选付费版本(如果你经常使用 SFTP 插件,你应该考虑购买)。此处列出了插件的安装说明。
安装后,您可以启动 Sublime 文本编辑器:
Figure 20: Sublime Text, a popular text/code editor can work with remote files using a plugin.
通过“shift+command+p”打开命令面板。
在那里,选择“SFTP:设置服务器…”:
Figure 21: Selecting the SFTP setup via Sublime Text’s command palette.
然后会提示您一个 JSON 模板文件,其中包含您可以填写的选项。
Figure 22: Sublime Text’s SFTP configuration file needs to be updated before you can connect to a remote system for development.
您需要将host和user编辑成您的远程机器的 IP 地址和用户名。如果您想避免每次都输入密码,也可以指定密码。
您还应该指定remote_path,这是您登录时的默认路径— 我通常建议将remote_path设置为用户主目录的路径。
编辑后,我的 SFTP 配置如下所示:
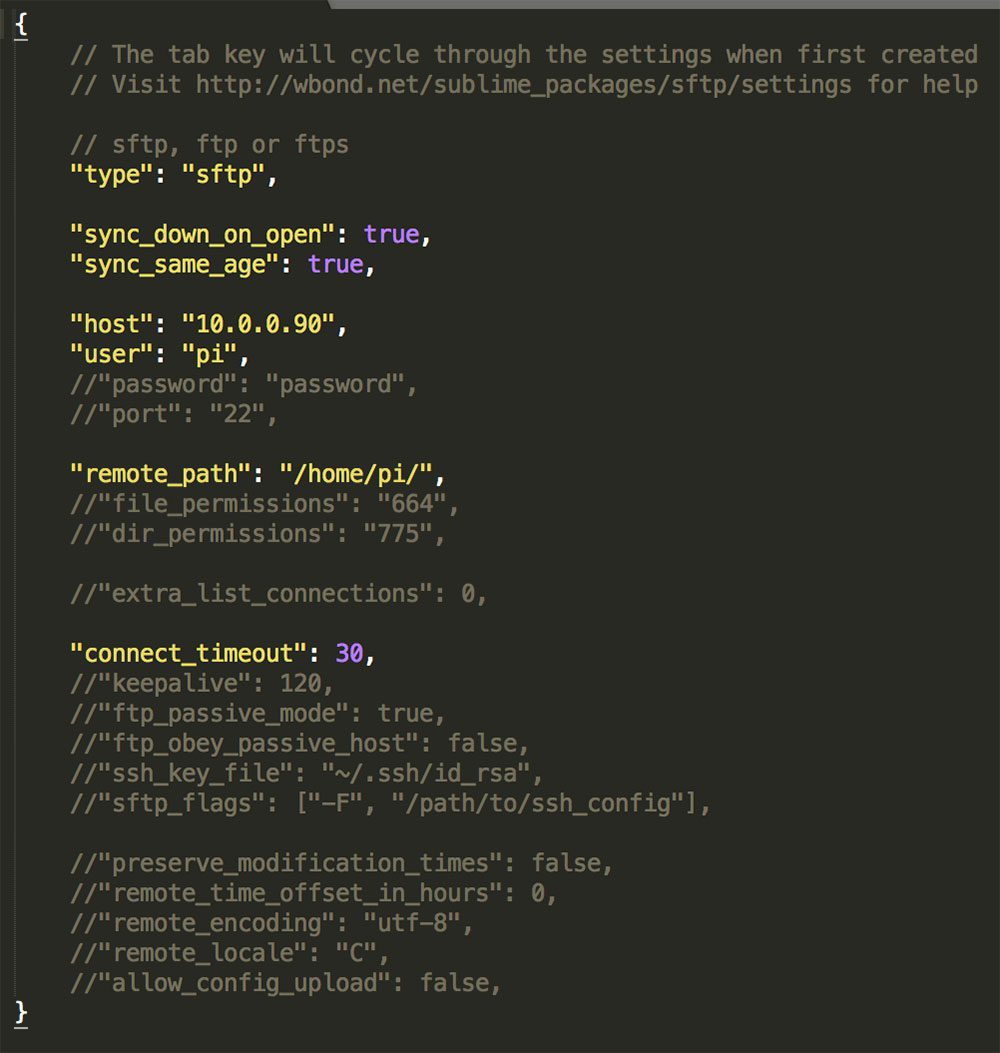
Figure 23: A custom Sublime Text SFTP configuration for a Raspberry Pi on my network.
接下来,保存文件:

Figure 24: Saving the SFTP configuration with a name that I’ll recognize later if I want to work on this remote system using Sublime Text again.
请注意,一个对话框会提示我如何给文件命名。你应该给这个文件一个描述性的名字。在这里,我将我的文件命名为rpi_office,以表明这是我办公室里的树莓派。
保存文件后,我可以选择“SFTP:浏览器服务器……”(再次通过命令面板):

Figure 25: From the Sublime Text command palette, select “SFTP: Browse Server…” so that you can log in to a remote system and list files.
然后选择我的“rpi _ office”:
Figure 26: Selecting my “rpi_office” remote SFTP configuration in Sublime Text.
然后我输入我的密码,进入了/home/pi目录。
在那里,我选择“文件夹操作”,然后选择“新文件”,创建一个名为test.py的新文件:

Figure 27: Creating plus naming a new file called test.py on a remote system (Raspberry Pi) via the Sublime Text SFTP plugin.
然后我可以保存这个文件,它的内容会在 Raspberry Pi 上自动更新。
从 SSH 连接执行脚本,您可以看到文本“您好,PyImageSearch Reader!”显示在我的终端上(再次注意,代码本身是在 Raspberry Pi 上执行的,而不是在我的本地机器上)。
Figure 28: As you can see, I’m SSH’ed into my remote Raspberry Pi. I’ve executed the Python script that was just saved to the remote system automatically via Sublime Text’s SFTP plugin.
给 Amazon EC2 用户的一个快速提示
如果您使用 Amazon EC2 或任何其他需要 SSH 密钥的认证方法,您需要在服务器设置期间编辑sftp_flags选项。
具体来说,您会希望编辑成如下所示:
Figure 29: Using Sublime Text’s SFTP plugin with Amazon EC2 systems requires that you insert the path to your encryption key (.pem file) in your configuration.
注意我是如何更新sftp_flags来包含-i选项的,后面是我的 SSH 密钥的路径。SFTP 插件然后知道使用这个文件来执行正确的认证。
注意: 当你在本地机器上编辑远程代码时,你的系统会自动生成/下载你在屏幕上看到的临时文件。当您“保存”您的代码时,它会自动更新到远程机器。如果您还需要本地系统上的这些文件,我建议您使用 SCP/SFTP 来传输这些文件。您也可以使用 Sublime 中的“另存为”命令在本地保存文件。
具有自动上传部署的 PyCharm
如果你正在寻找一个更加成熟的 IDE,我推荐使用 PyCharm ,它已经成为 Python IDEs 事实上的标准。
我是 PyCharm 的超级粉丝,如果我的 Python 代码跨越了 1-2 个以上的文件,我倾向于使用 PyCharm 而不是 Sublime Text。也就是说,PyCharm 是一个大的IDE——它是而不是小的和最小的,就像 Sublime Text 一样。
与 Sublime Text 类似,我们也可以将 PyCharm 配置为:
- 使用远程 Python 解释器(包括远程机器上的 Python 虚拟环境)。
- 自动传输编辑过的文件,确保代码在远程机器上得到更新。
这个功能要求你已经安装了py charm Professional(点击这里查看 PyCharm Professional 的功能和好处)。
假设您已经安装了 PyCharm,让我们创建一个执行自动上传部署的项目。
首先创建一个新项目:
Figure 30: Creating a new project in PyCharm locally prior to setting it up for remote development.
我将这个项目命名为“rpi test”。**
然后,您需要扩展“项目解释器”选项,以扩展 Python 解释器选项:
Figure 31: In PyCharm, select “Python Interpreter” to configure the Python environment for the project.
选择“现有解释器”单选按钮,然后点击“…”,将打开一个类似如下的新窗口:
Figure 32: Select the “Existing Interpreter” option in PyCharm.
选择“SSH 解释器”选项,然后选择“新服务器配置”:

Figure 33: Select “New server configuration” and enter the IP address, and username of the remote system.
在这里,我已经输入了 IP 地址和用户名我的树莓派。
点击“下一步”按钮,然后输入您的服务器的密码:
Figure 34: Enter your remote system’s password and ensure that you save the password (checkbox) so that you don’t need to enter it upon each save.
确保您选中了“保存密码”复选框,以确保您的密码被保存,否则每次您想要保存/修改文件时,您都必须重新输入密码(这将变得非常令人沮丧和乏味)。
下一个窗口将提示您选择一个 Python 解释器,默认为/usr/bin/python:
Figure 35: Be sure to select the virtual environment on the remote system that you’d like to use as your Python interpreter.
由于我们使用的是 Python 虚拟环境,我们应该点击“…”并导航到/home/pi/.virtualenvs/py3cv3/bin/python目录中的python二进制文件:
Figure 36: Navigate to the Python executable within the appropriate .virtualenvs folder to select your remote interpreter.
选择“确定”确认 Python 虚拟环境选择。注意 Python 解释器路径现在已经更新为/home/pi/.virtualenvs/py3cv3/bin/python。单击“完成”按钮,完成 Python 虚拟环境的创建。
PyCharm 现在将向我们提供关于我们的“现有口译员”以及“远程项目位置”的详细信息:
Figure 37: Be sure to edit the PyCharm “Remote project location” under the “Existing Interpreter” section so that your project files are stored in a known location.
然而,我们不希望我们的项目生活在树莓派的/tmp/pycharm_project_409里。相反,我们希望这个项目存在于/home/pi/RPiTest。要进行更新,您可以使用“…”按钮进行导航,或者直接在字段中手动输入路径。
点击“创建”按钮,然后 PyCharm IDE 将加载:
Figure 38: PyCharm Professional has now been configured for remote development over an SSH/SFTP connection.
PyCharm 在您的 Raspberry Pi 上索引 Python 虚拟环境和项目文件可能需要 5-10 分钟,请耐心等待。
让我们向项目添加一个新文件。
右键单击项目中的 RPiTest 目录,然后选择【新建】**【文件】:

Figure 39: Adding a new Python file to our PyCharm remote project.
我们将这个文件命名为pycharm_test.py:
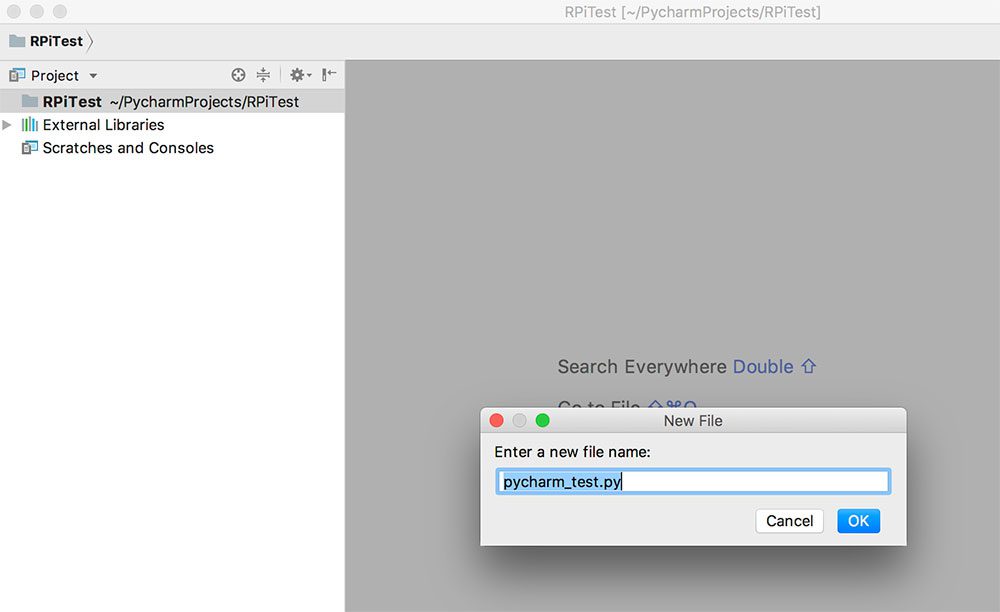
Figure 40: Saving a Python script on a remote machine via PyCharm called pycharm_test.py.
我已经更新了该文件,以包含以下代码:
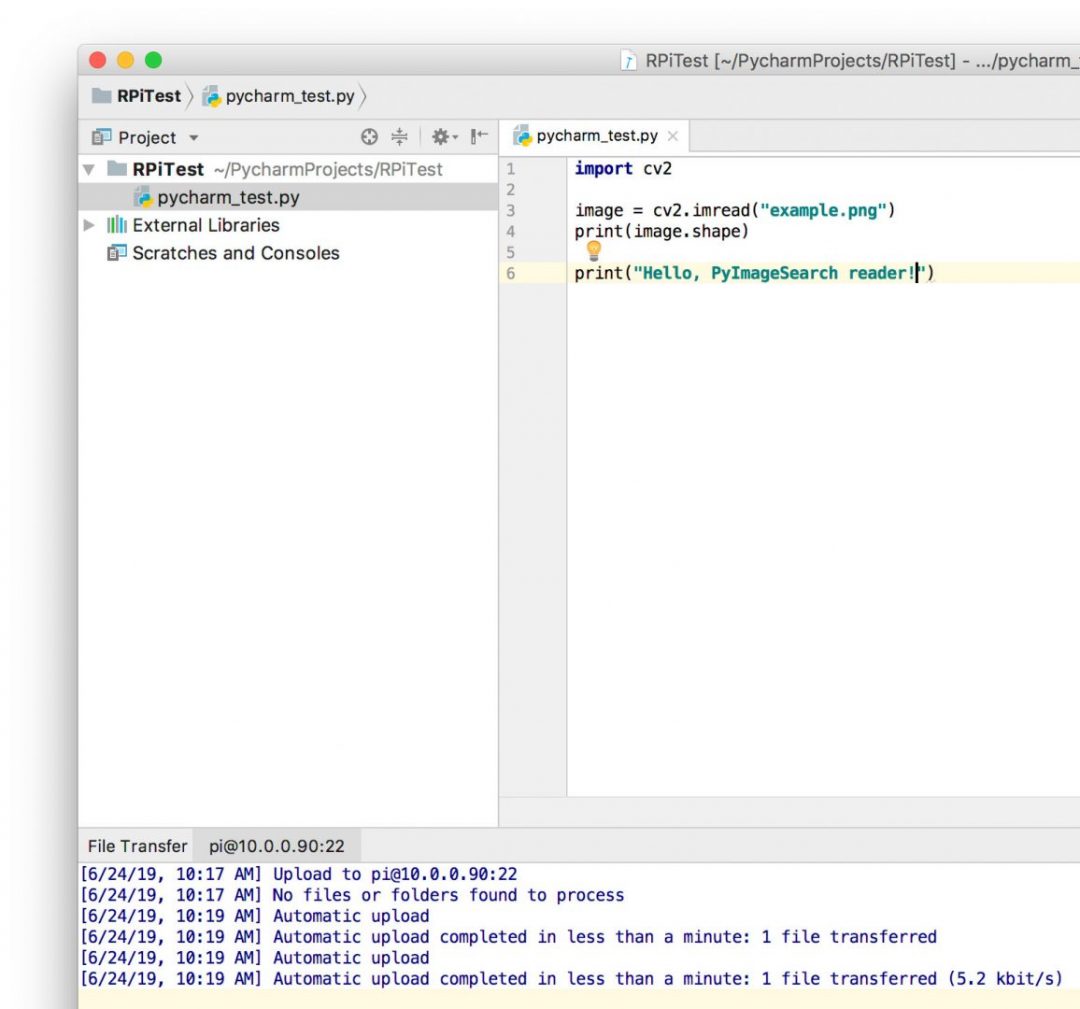
Figure 41: A test script was developed and saved to a remote system via PyCharm.
注意 PyCharm 是如何指示文件已经被自动上传到 Raspberry Pi 的。您可以通过终端登录 Raspberry Pi 并检查文件内容来验证文件是否已自动上传:
**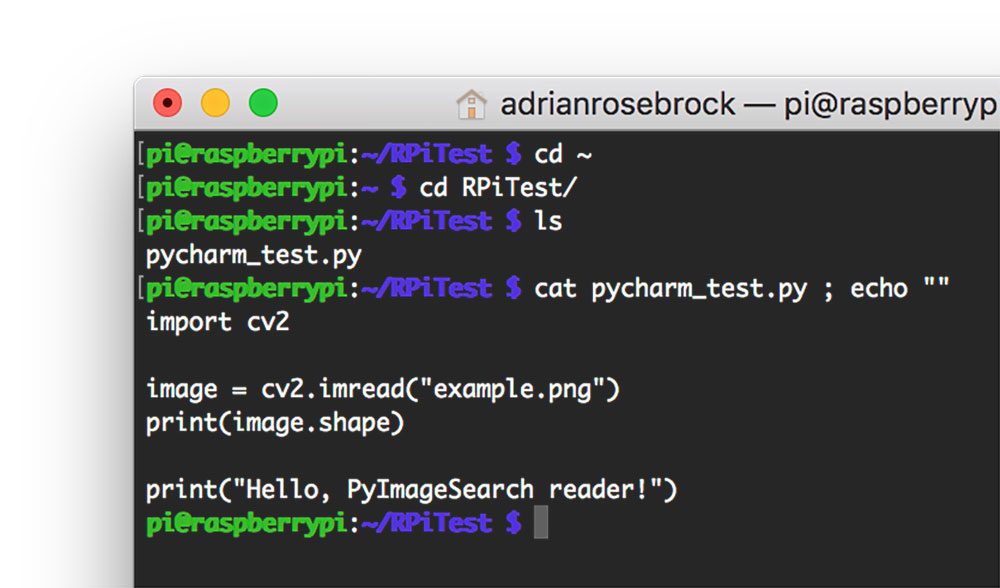
Figure 42: Over an SSH connection in my terminal, I’ve verified that after saving a file via PyCharm to my remote Raspberry Pi, that the file is, in fact, updated.
谈到远程 Python 开发,很难用自动上传来击败 PyCharm。
是的,这涉及到更多的步骤(至少与配置 Sublime 文本相比),但是一旦你让它工作起来,这是非常值得的!
注意: 当你在本地机器上编辑远程代码时,你的系统会自动生成/下载你在屏幕上看到的临时文件。当您“保存”您的代码时,它会自动更新到远程机器。
通过命令行执行代码
当执行远程 Python 开发时,我个人的建议是:
- 在启用自动 SFTP 的情况下,使用崇高文本或 PyCharm 。
- 使用 SSH 通过命令行执行我的 Python 脚本。
你可以自由选择你喜欢的选项。也许你喜欢用 Jupyter 笔记本。或者也许你觉得使用手动 SFTP 上传你有更多的控制权。所有选项都没问题,只是你自己的喜好问题。
也就是说,我将向您快速演示如何通过 SSH 命令行执行脚本。
首先,我将使用 SSH 登录到我的 Raspberry Pi(或 AWS 服务器):
$ ssh pi@192.168.1.150
$ ls *.py
simple_example.py
我已经列出了我的主目录的内容,并且看到我已经有了一个名为simple_example.py的文件。
我想编辑这个文件,所以我也要通过 Sublime Text 登录并打开它:
Figure 43: I’ve opened a file on my remote system using Sublime Text’s SFTP plugin. Now we’re going to edit the file an execute it.
这里你可以看到simple_example.py现在已经在 Sublime Text 中打开了。
我将借此机会编辑这个文件,并包含一个命令行参数 —代码清单现在看起来像这样:
# import the necessary packages
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--name", help="your name")
args = vars(ap.parse_args())
# greet the user
print("Hello there, {}!".format(args["name"]))
我通过 Sublime Text 保存文件,然后切换回我的终端。然后,我可以通过以下方式执行 Python 脚本:
$ python simple_example.py --name Adrian
Hello there, Adrian!
请注意我是如何向脚本提供命令行参数的——我们在 PyImageSearch 上经常使用命令行参数,所以请确保您现在花时间了解它们是如何工作的。
另外,请注意脚本不是在我的本地机器上执行的,而是在远程 Raspberry Pi 上执行的。
摘要
在本教程中,当在 Raspberry Pi、Amazon EC2 或任何其他远程服务器实例上执行远程 Python 开发时,您会发现我的个人建议。
当您连接到机器时,我推荐使用:
- 嘘
- VNC
- jupyter 笔记本
远程编辑代码时,我建议您使用:
- 崇高的文本与 SFTP 插件
- 具有自动上传部署的 PyCharm
我个人倾向于通过 Sublime Text 或 PyCharm 编辑代码,然后通过 SSH +命令行执行。也就是说,你应该花时间尝试每一个选项。一种方法并不总是比其他方法更好,你可能会发现在大多数情况下你更喜欢一种方法——这完全没问题!
请记住,这些都是你工具箱中的工具,学会如何使用它们,你会有更多的工具可供你使用。
我希望你喜欢这个教程!
为了在 PyImageSearch 上发布未来教程时得到通知(并获得我的免费计算机视觉和深度学习资源指南),*只需在下表中输入您的电子邮件地址!***
使用 Python 和 OpenCV 从图像中移除轮廓
原文:https://pyimagesearch.com/2015/02/09/removing-contours-image-using-python-opencv/

不久前,我在浏览 /r/computervision 时,偶然发现一个问题,问如何使用 OpenCV 从图像中移除轮廓。
出于好奇,我发了一个回复。从图像中移除轮廓的基本算法是这样的:
- 第一步:检测并找到图像中的轮廓。
- 第二步:逐个循环遍历轮廓。
- 第三步:根据某种标准确定轮廓是否“坏”并且应该被去除。
- 第四步:积累一个要去除的“坏”轮廓的蒙版。
- 第五步:使用逐位“与”运算将累积的坏轮廓掩模应用于原始图像。
就是这样!
该算法本身非常简单,你需要注意和考虑的主要步骤是步骤 3 ,确定是否应该移除一个轮廓。
这一步可能非常简单,也可能非常困难,具体取决于您的应用。虽然我无法猜测为什么要从图像中移除轮廓区域的标准,但这篇博文的剩余部分将展示一个玩具示例,您可以用它来从图像中移除轮廓。从这里开始,您将能够根据自己的需要使用这段代码并修改轮廓移除标准。
OpenCV 和 Python 版本:
这个例子将在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X 上运行。
使用 Python 和 OpenCV 从图像中移除轮廓

Figure 1: Our example toy image. Our goal is to remove all circles/ellipses while retaining the rectangles.
在这个玩具示例中,我们的目标是从上方的图像中移除圆形/椭圆形****,同时保留矩形。我们将通过对每个轮廓应用一个测试来决定它是否应该被删除来完成这个任务。
无论如何,让我们开始这个例子。打开一个新文件,命名为remove_contours.py,让我们开始编码:
# import the necessary packages
import numpy as np
import imutils
import cv2
def is_contour_bad(c):
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# the contour is 'bad' if it is not a rectangle
return not len(approx) == 4
我们要做的第一件事是导入我们需要的包。我们将使用 NumPy 进行数值处理,使用cv2进行 OpenCV 绑定。
然后我们在第 6 行的上定义我们的is_contour_bad函数。该函数处理上述步骤 3** 的执行,并定义一个轮廓应被标记为“坏”并从图像中移除的标准。**
is_contour_bad函数需要一个参数c,这是我们将要测试的轮廓,以确定它是否应该被移除。
请记住,在上面的玩具示例图像中,我们的目标是移除圆形/椭圆形,同时保持矩形完整。
因此,让我们花点时间考虑一下是否可以利用这个问题的几何学。
长方形有四条边。圆没有边。
所以如果我们 近似轮廓 ,然后 检查近似轮廓 内的点数,我们就能确定轮廓是否是正方形!
而这正是行 7-11 所做的。我们首先在的第 8 行和第 9 行上近似轮廓,而的第 12 行返回一个布尔值,指示是否应该移除轮廓。在这种情况下,如果近似有 4 个点(顶点),轮廓将保持不变,表明轮廓是一个矩形。
让我们完成解决这个问题的其他步骤:
# load the shapes image, convert it to grayscale, and edge edges in
# the image
image = cv2.imread("shapes.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edged = cv2.Canny(gray, 50, 100)
cv2.imshow("Original", image)
# find contours in the image and initialize the mask that will be
# used to remove the bad contours
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
mask = np.ones(image.shape[:2], dtype="uint8") * 255
# loop over the contours
for c in cnts:
# if the contour is bad, draw it on the mask
if is_contour_bad(c):
cv2.drawContours(mask, [c], -1, 0, -1)
# remove the contours from the image and show the resulting images
image = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Mask", mask)
cv2.imshow("After", image)
cv2.waitKey(0)
为了找到并检测我们图像中的轮廓(步骤 1 ),我们在第 16-19 行对我们的图像进行预处理,从磁盘加载,将其转换为灰度并检测边缘。
通过调用cv2.findContours,在行 23 找到实际轮廓。随后,我们用不同版本的 OpenCV 处理抓取轮廓(第 24 行)。
然后我们初始化第 25 行上的mask来存储我们累积的“坏”轮廓。我们将在后面的代码中使用这个掩码和位运算来执行轮廓的实际移除。
现在,我们可以继续进行步骤 2 ,在线 28 上的各个轮廓上循环。
对于每个轮廓,我们调用第 30 行上的is_contour_bad,如果轮廓确实是“坏的”,那么我们通过在掩膜上绘制轮廓,在第 31 行上累积要移除的轮廓。
最后,我们所要做的就是使用累积蒙版对图像进行逐位“与”运算,去除第 34 行上的轮廓。第 35-37 行然后显示我们的结果。
结果
要执行我们的脚本,只需发出以下命令:
$ python remove_contours.py
首先,你会看到我们的积累轮廓的面具将被删除:

Figure 2: Our accumulated mask of contours to be removed. Shapes to be removed appear as black whereas the regions of the image to be retained are white.
注意轮廓是如何在白色背景上显示为黑色形状。这是因为一旦我们应用cv2.bitwise_and功能,黑色形状将从原始图像中移除,而白色区域将被保留。
下面是应用累积遮罩后的输出:
Figure 3: We have successfully removed the circles/ellipses while retaining the rectangles.
显然,我们已经删除了图像中的圆形/椭圆形,同时保留了矩形!
摘要
在这篇博文中,我展示了如何使用 Python 和 OpenCV 从图像中移除轮廓区域。从图像中移除轮廓非常简单,可以通过以下 5 个步骤完成:
- 检测和寻找图像中的轮廓。
- 分别在每个轮廓上循环。
- 应用某种“测试”来确定是否应该移除轮廓。
- 累积要移除的轮廓的掩模。
- 将遮罩应用于原始图像。
要将这种算法应用到你自己的图像上,你需要花点时间考虑第三步,并确定你用来去除轮廓的标准。从那里,您可以按原样应用算法的其余部分。
已解决:Matplotlib 图形不显示或不显示
原文:https://pyimagesearch.com/2015/08/24/resolved-matplotlib-figures-not-showing-up-or-displaying/
我认为这篇博文更好的标题可能是: 我如何因为 Ubuntu、虚拟环境、matplotlib 和渲染后端而损失了一天的生产力。
周末,我在我的 Ubuntu 系统上玩深度学习,并绘制了我的分类器的准确度分数。我使用 matplotlib 编写了一个快速的 Python 脚本,执行了脚本,只是为了不让图形显示在我的屏幕上。
我的脚本执行得很好。没有错误消息。没有警告。 但是还是没有发现阴谋!
这实际上是我在过去几个月遇到的一个常见问题,尤其是在使用基于 Debian 的操作系统如 Ubuntu 和 Raspbian 时。当通过 virtualenv 和 virtualenvwrapper 软件包利用虚拟环境时,这个问题只会变得更加复杂。
这个问题实际上源于 matplotlib 后端没有正确设置,或者在编译和安装 matplotlib 时缺少依赖关系。幸运的是,经过大量的试验和错误(花了一整天的时间试图找到一个解决方案),我已经能够解决这个问题,并在 Ubuntu 和 Raspbian 操作系统上(以及使用 Python 虚拟环境时)让 matplotlib 图形出现在我的屏幕上。
虽然这篇文章与计算机视觉或 OpenCV 不完全相关,但我仍然想与其他 PyImageSearch 读者分享我的经验和解决方案。Matplotlib 是 Python 科学界广泛使用的一个包,我希望这篇文章能帮助其他读者解决这个奇怪且难以确定的问题。
搭建舞台
让我们开始布置舞台吧。
- 我们使用的是基于 Debian 的操作系统,比如 Ubuntu 或 Raspbian。
- 我们(可选地)通过 virtualenv 和 virtualenvwrapper 利用 Python 虚拟环境。
- 我们的目标是拍摄下面的图像(左),并使用 matplotlib (右)为其计算灰度像素强度直方图:
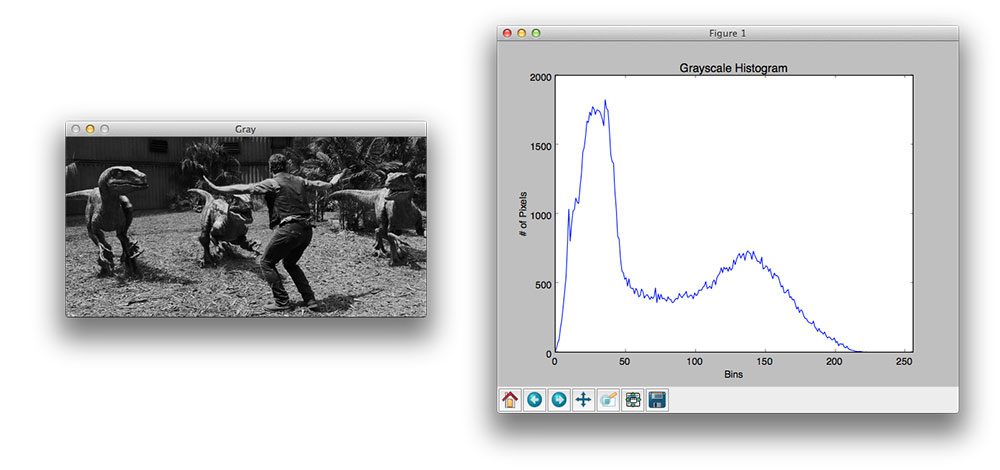
Figure 1: Our end goal is to utilize matplotlib to display a grayscale pixel intensity for the image on the left.
由于我们正在使用 matplotlib ,让我们创建一个名为plotting的新虚拟环境:
$ mkvirtualenv plotting
现在我们在plotting环境中,让我们安装numpy、scipy和matplotlib:
$ pip install numpy
$ pip install scipy
$ pip install matplotlib
太棒了——我们所有的 Python 依赖项都已安装。现在,让我们编写几行代码来加载图像,将其转换为灰度图像,计算灰度图像的直方图,最后将其显示在屏幕上。我将把所有这些代码放到一个名为grayscale_histogram.py的文件中:
# import the necessary packages
from matplotlib import pyplot as plt
import cv2
# load the image, convert it to grayscale, and show it
image = cv2.imread("raptors.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Image", image)
cv2.imshow("Gray", gray)
cv2.waitKey(0)
# construct a grayscale histogram
hist = cv2.calcHist([gray], [0], None, [256], [0, 256])
# plot the histogram
plt.figure()
plt.title("Grayscale Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
plt.plot(hist)
plt.xlim([0, 256])
plt.show()
cv2.waitKey(0)
这里的代码相当简单。1、2 号线导入matplotlib和cv2。然后,我们加载我们的图像并将其转换为灰度(第 4-9 行)。从那里,cv2.calcHist函数被用来计算灰度像素强度的直方图。最后,第 14-22 行使用matplotlib绘制直方图。
要执行我们的脚本,我们需要做的就是启动 shell 并发出以下命令:
$ python grayscale_histogram.py
当我在plotting虚拟环境中的 OSX 机器上执行代码时,直方图被计算出来,灰度图像和直方图都显示在我的屏幕上:

Figure 2: Using OSX, I can successfully plot and display my grayscale histogram using matplotlib.
然而,当我回到我的 Ubuntu 14.04 机器并执行完全相同的代码时,我看到的只是我的图像:

Figure 3: I have executed the exact same code on my Ubuntu system in the plotting virtual environment. All I see are my images — where did my histogram go? Why is there no error message?
这就引出了问题:“直方图在哪里?”
正如我们从终端输出中看到的,脚本执行得很好。未显示任何错误。没有警告信息打印到我的控制台。 但是还没有剧情!
已解决:Matplotlib 图形不显示或不显示
正如我在这篇文章的前面所暗示的,丢失数字的问题与 matplotlib 后端有关,它在幕后完成了准备数字的所有繁重工作。
进入 shell 后,我可以使用matplotlib.get_backend()访问 matplotlib 后端:
$ python
Python 3.4.0 (default, Apr 11 2014, 13:05:11)
[GCC 4.8.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import matplotlib
>>> matplotlib.get_backend()
'agg'
在我的 Ubuntu 机器上,这给了我一个值agg;但通过我的测试调试,对于 TkInter 窗口系统,这个值需要是TkAgg(至少在使用 Ubuntu 和 Raspbian 时)。
幸运的是,我们可以通过使用apt-get安装几个库来解决这个问题:
$ sudo apt-get install tcl-dev tk-dev python-tk python3-tk
但是我们还没有完成。为了让 matplotlib 识别 TkInter GUI 库,我们需要:
- 第一步:通过
workon plotting访问我们的plotting虚拟环境。 - 第二步:使用 pip 来 卸载
matplotlib(因为我们在本文前面已经通过 pip 安装了)。 - 第三步:从 GitHub repo 中下拉 matplotlib。
- 第四步:使用
setup.py从源代码安装matplotlib。
我可以使用以下命令完成这些步骤:
$ workon plotting
$ pip uninstall matplotlib
$ git clone https://github.com/matplotlib/matplotlib.git
$ cd matplotlib
$ python setup.py install
同样,在执行这些步骤之前,您需要确保已经通过apt-get安装了 TkInter。
在通过源代码安装了matplotlib之后,让我们再次执行get_backend()函数:
$ python
Python 3.4.0 (default, Apr 11 2014, 13:05:11)
[GCC 4.8.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import matplotlib
>>> matplotlib.get_backend()
'TkAgg'
果然,我们现在看到TkAgg正被用作matplotlib后端。
注意: 你可以通过调用matplotlib.use("TkAgg")来明确指示matplotlib使用TkAgg后端;然而,如果没有安装 TkInter 依赖项,这不会给你带来太多好处。
现在,当我们执行我们的grayscale_histogram.py脚本时,就像上面一样:
$ python grayscale_histogram.py
我们现在应该看到我们的灰度图像和直方图:
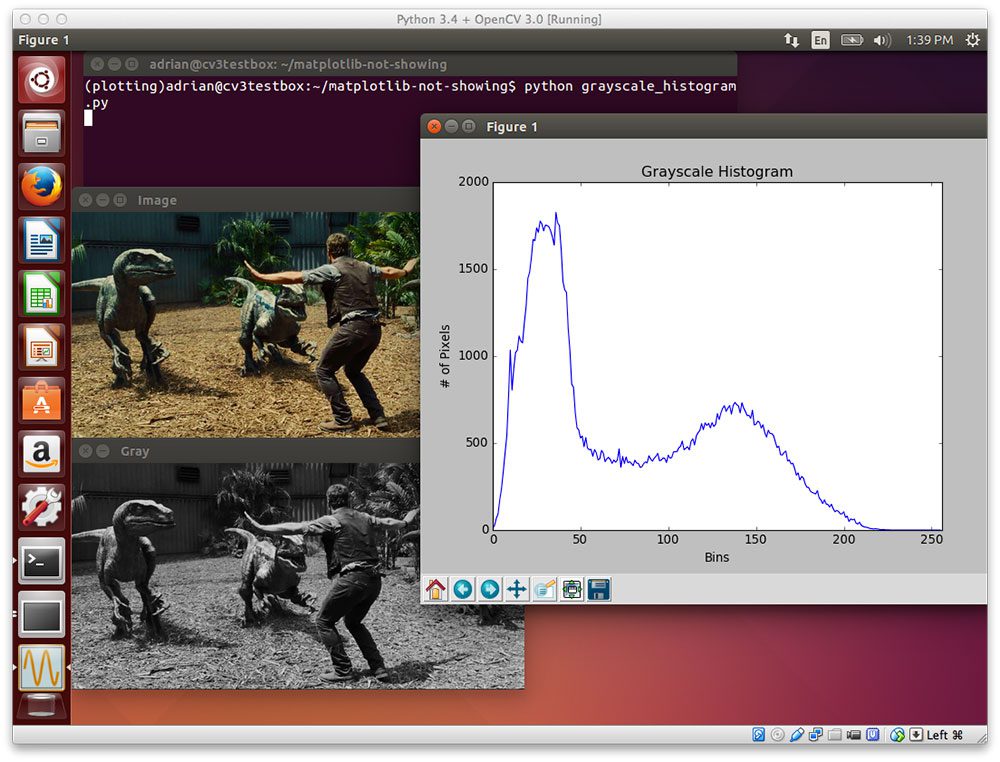
Figure 4: Success! Our matplotlib figure is now showing up! All we need to do was change the matplotlib backend.
我们现在已经修复了我们的问题— matplotlib 数字成功地显示在我们的屏幕上!
诚然,这种解决方案有点棘手,但它相当简单,可以完成工作。如果您有任何其他建议或意见,请随时在评论区留下。
树莓派怎么样?
Raspbian 操作系统,许多 Raspberry Pi 运行的,是基于 Debian 的,就像 Ubuntu 一样。如果你有同样的问题,matplotlib 图形不能在你的 Raspberry Pi 上显示,这篇博文中详细描述的修复方法将解决你的绘图问题。
不能直接通过 apt-get 安装 matplotlib 吗?
精明的 Debian 用户可能想知道为什么我不简单地通过apt-get安装matplotlib,就像这样:
$ sudo apt-get install python-matplotlib
原因是因为我是 Python 虚拟环境 的 重度用户,并且坚信保持我的 Python 环境的隔离和相互独立。如果你使用apt-get来安装matplotlib,你就失去了对你想要安装的matplotlib版本的控制——你只需要使用apt-get库中的任何版本。这也使你的 Python 系统安装变得混乱,我试图保持它尽可能的干净。
也就是说,每次我通过apt-get安装了matplotlib之后,我所有的依赖项都被正确地安装了,我可以毫无问题地显示我的数据,所以如果你不关心 Python 虚拟环境,那么apt-get解决方案是一个不错的选择。但是,我还是建议使用虚拟环境。
摘要
在这篇博文中,我详细介绍了如何解决一个棘手的问题,即matplotlib数字无法显示在屏幕上。此问题的症状包括清晰的脚本执行(即没有错误消息和警告)打印到您的终端,但您的绘图没有显示。我在使用基于 Debian 的操作系统如 Ubuntu 和 Raspbian 时经常遇到这个问题。当使用 Python 虚拟环境时,这个问题只会变得更加复杂。
解决这个matplotlib问题需要通过apt-get手动安装依赖项,并调整 matplotlib 后端以使用TkAgg,然后从源代码编译并安装matplotlib。后来,这个问题似乎解决了。
虽然这篇文章与计算机视觉无关,但是科学 Python 社区中大量使用了matplotlib库,因此没有显示您的matplotlib图会非常令人沮丧和烦恼。我希望这篇文章能帮助其他遇到类似问题的读者。
下周我会带着更多的计算机视觉帖子回来!
解决 macOS、OpenCV 和 Homebrew 安装错误
原文:https://pyimagesearch.com/2017/05/15/resolving-macos-opencv-homebrew-install-errors/

正如你无疑知道的,在你的 macOS 机器上配置和安装 OpenCV 可能有点痛苦。
为了帮助你和其他 PyImageSearch 读者更快地安装 OpenCV(并减少麻烦),我整理了一个关于使用 Homebrew 安装 OpenCV 的教程。
使用 Homebrew 允许您跳过手动配置您的构建并从源代码编译 OpenCV。
相反,你只需使用所谓的 brew 公式,它定义了如何自动配置和安装给定的软件包,类似于软件包管理器如何智能地在你的系统上安装库和软件。
然而,几周前出现了一个小问题,人们发现最近用于在 macOS 上构建和安装 OpenCV 的自制程序中有一些错误。
这个公式在通过自制程序在 macOS 上构建 OpenCV 时导致了 两类错误 :
- 错误#1: 报告称Python 2 和 Python 3 包装器都无法构建(这不是真的,你可以在同一个 Homebrew 命令中构建 Python 2.7 和 Python 3 绑定)。
** 错误#2: 一个丢失的downloader.cmake文件。*
*我自己,以及 PyImageSearch 的读者 Andreas Linnarsson、Francis 和 Patrick(血淋淋的细节见家酿 OpenCV 安装帖子的评论部分)深入研究了这个问题,并正面解决了它。
今天我将分享我们的发现,希望它能帮助你和其他 PyImageSearch 的读者在你的 macOS 机器上安装 OpenCV。
在理想情况下,随着用于配置和安装 OpenCV 的家酿公式被更新以纠正这些错误,这些说明最终会过时。
要了解更多关于安装 OpenCV 时解决自制软件错误的信息,继续阅读。
解决 macOS、OpenCV 和 Homebrew 安装错误
在这篇博文的剩余部分,我将讨论在 macOS 系统上通过自制软件安装 OpenCV 时可能遇到的常见错误。
我还将提供关于检查 Python 版本的额外建议,以帮助您进一步调试这些错误。
错误#1: opencv3:不支持构建 Python 2 和 3 包装器
假设您遵循了我的原始家酿+ OpenCV 安装帖子,您可能在尝试安装 OpenCV 时遇到了以下错误:
$ brew install opencv3 --with-contrib --with-python3 --HEAD
...
Error: opencv3: Does not support building both Python 2 and 3 wrappers
这个错误是由下面的提交引入的。我发现这个错误令人沮丧,原因有二:
- 没有必要进行这项检查…
- …因为 Homebrew 可以用来编译 OpenCV 两次:一次用于 Python 2.7,一次用于 Python 3。
首先,OpenCV 3 可以用 Python 2.7 和 Python 3 绑定来构建。它只需要两个单独的编译。
第一次编译 e 处理构建 OpenCV 3 + Python 2.7 绑定,而第二次编译生成 OpenCV 3 + Python 3 绑定。这样做可以正确安装 OpenCV 3,同时为每个 Python 版本生成正确的cv2.so绑定。
有两种方法可以解决这个错误,如 this StackOverflow thread 中所讨论的。
第一种方法可以说更简单,,但是没有解决真正的问题。这里我们只是更新了brew install opencv3命令,以表明我们想要在没有 Python 3 绑定 的情况下构建 OpenCV 3 :
$ brew install opencv3 --with-contrib
注意我们是如何忽略了--with-python3开关的。在这种情况下,自制自动为 OpenCV 3 构建 Python 2.7 绑定(没有--with-python2开关;这是自动假定的)。
类似地,如果我们想用 Python 3 绑定 构建 OpenCV 3 ,我们应该将brew install opencv3命令更新为:
$ brew install opencv3 --with-contrib --with-python3 --without-python
这里我们提供--with-python3来表示我们希望生成 OpenCV 3 + Python 3 绑定,但是使用--without-python开关跳过生成 OpenCV 3 + Python 2.7 绑定。
这个方法行得通;然而,我发现令人沮丧和令人困惑。开始,--without-python开关是极不明确。
如果我给 install 命令提供一个名为--without-python的开关,我会假设它会构建不 Python 绑定什么的,而不管 Python 版本 。然而,事实并非如此。相反,--without-python 真的是没有 Python 2.7 绑定的意思。
这些开关让像我这样的 OpenCV 安装老手和第一次尝试正确配置开发环境的新手感到困惑。
在我看来,一个 更好的解决方案 (当然直到一个补丁完全发布)是编辑 OpenCV 3 安装公式本身。
要编辑 OpenCV 3 Homebrew 安装公式,请执行以下命令:
$ brew edit opencv3
然后找到下面的配置块:
if build.with?("python3") && build.with?("python")
# Opencv3 Does not support building both Python 2 and 3 versions
odie "opencv3: Does not support building both Python 2 and 3 wrappers"
end
从我下面的截图可以看到,这个配置在第 187-190 行(不过,这些行会随着 OpenCV 3 家酿公式的更新而改变)。

Figure 1: Finding the Homebrew + OpenCV 3 formula that needs to be edited.
找到这一部分后,请将这四行注释掉:
#if build.with?("python3") && build.with?("python")
# # Opencv3 Does not support building both Python 2 and 3 versions
# odie "opencv3: Does not support building both Python 2 and 3 wrappers"
#end
我还提供了一个截图,展示了如何注释掉这些行:

Figure 2: Updating the Homebrew + OpenCV 3 install formula to resolve the error.
在注释掉这些行之后,保存并退出编辑器来更新 OpenCV 3 Homebrew 安装公式。
从那里,您应该能够使用以下命令通过 Homebrew 成功安装 OpenCV 3:
$ brew install opencv3 --with-contrib --with-python3

Figure 3: Successfully compiling OpenCV 3 with Python 2.7 and Python 3 bindings on macOS via Homebrew.
注意:如果您收到与downloader.cmake相关的错误信息,请确保进入下一节。
OpenCV 3 安装完成后,回到最初的教程,按照从“处理 Python 3 问题”部分开始的说明进行操作。
从那里开始,你将安装 OpenCV 3,同时绑定了 Python 2.7 和 Python 3:

Figure 4: Importing the cv2 library into a Python 2.7 and Python 3 shell.
再次请记住,为了生成这些绑定,进行了两次单独的编译。第一次编译生成了 OpenCV 3 + Python 2.7 绑定,而第二次编译创建了 OpenCV 3 + Python 3 绑定。
错误#2:没有这样的文件或目录 3rd party/IP picv/downloader . cmake
通过 Homebrew 安装 OpenCV 3 可能遇到的第二个错误与downloader.cmake文件有关。该错误仅在您向brew install opencv3命令提供--HEAD开关时出现。
该错误的原因是3rdparty/ippicv/downloader.cmake文件被从回购中移除;然而,家酿安装公式并没有更新,以反映这一点(来源)。
因此,避开这个错误的最简单的方法就是简单地将省略掉这个--HEAD开关。
例如,如果您之前的 OpenCV 3 + Homebrew 安装命令是:
$ brew install opencv3 --with-contrib --with-python3 --HEAD
只需将其更新为:
$ brew install opencv3 --with-contrib --with-python3
如果你已经遵循了上面的“错误# 1”部分的说明,Homebrew 现在应该安装 OpenCV 3 与 Python 2.7 和 Python 3 绑定。现在你会想回到最初的 Homebrew + OpenCV 教程,并遵循从“处理 Python 3 问题”部分开始的说明。
额外收获:检查您的 Python 版本并相应地更新路径
如果您是 Unix 环境和命令行的新手(或者如果这是您第一次一起使用 Python + OpenCV),我看到新手犯的一个常见错误是 忘记检查他们的 Python 版本号。
您可以使用以下命令检查您的 Python 2.7 版本:
$ python --version
Python 2.7.13
类似地,该命令将为您提供 Python 3 版本:
$ python3 --version
Python 3.6.1
为什么这如此重要?
原创家酿+ OpenCV 安装教程是为 Python 2.7 和 Python 3.5 编写的。但是,Python 版本会更新。Python 3.6 已经正式发布,正在很多机器上使用。事实上,如果你通过自制软件安装 Python 3(在撰写本文时),Python 3.6 就会被安装。
这很重要,因为你需要检查你的文件路径。
例如,如果我告诉您检查 Python 3 安装的site-packages目录,并提供一个示例命令:
$ ls /usr/local/opt/opencv3/lib/python3.5/site-packages/
你应该首先检查你的 Python 3 版本。上面执行的命令假设 Python 3.5。但是,如果在运行python3 --version之后,您发现您正在使用 Python 3.6,则需要将您的路径更新为:
$ ls /usr/local/opt/opencv3/lib/python3.6/site-packages/
注意python3.5是如何变成python3.6的。
忘记检查和验证文件路径是我看到的新手在用 Python 绑定安装和配置 OpenCV 时经常犯的错误。
不要在你的终端里盲目的复制粘贴命令。相反,花点时间去理解他们在做什么,这样你就可以根据你自己的开发环境来调整指令。
一般来说,在系统上安装 OpenCV + Python 的指令不会改变——但是 Python 和 OpenCV 版本会改变,因此一些文件路径会稍微改变。通常所有这些相当于改变一个文件路径中的一两个字符。
*## 摘要
在今天的博文中,我们回顾了通过自制软件安装 OpenCV 3 时可能会遇到的两个常见错误信息:
- 错误#1: 报告说Python 2 和 Python 3 的包装器都无法构建。
- 错误#2: 一个丢失的
downloader.cmake文件。
在 PyImageSearch 读者 Andreas Linnarsson、Francis 和 Patrick 的帮助下,我提供了这些错误的解决方案。
我希望这些说明可以帮助你在 macOS 机器上通过 Homebrew 安装 OpenCV 3 时避免这些常见错误!
出发前,请务必在下面的表格中输入您的电子邮件地址,以便在 PyImageSearch 上发布以后的博文时得到通知!**
使用 OpenCV 和 Python(正确地)旋转图像
原文:https://pyimagesearch.com/2017/01/02/rotate-images-correctly-with-opencv-and-python/

让我告诉你一个尴尬的故事,六年前我是如何浪费了 T2 三周的研究时间。
那是我第二学期课程结束的时候。
我很早就参加了所有的考试,这学期所有的项目都已经提交了。
由于我的学校义务基本上为零,我开始尝试在图像中(自动)识别处方药(T1),这是我知道的一件关于 T2 或 T4 的事情(但那时我才刚刚开始我的研究)。
当时,我的研究目标是找到并确定以旋转不变方式可靠量化药丸的方法。无论药丸如何旋转,我都希望输出的特征向量(近似)相同(由于光照条件、相机传感器、浮点误差等原因,特征向量永远不会与现实应用中的完全相同。).
第一周之后,我取得了惊人的进步。
我能够从我的药丸数据集中提取特征,对它们进行索引,然后识别我的测试药丸集,而不管它们是如何定位的…
…但是,有一个问题:
我的方法只对圆形药丸有效——对长方形药丸我得到了完全无意义的结果。
怎么可能呢?
我绞尽脑汁寻找解释。
我的特征提取算法的逻辑有缺陷吗?
是我没有正确匹配特征吗?
还是完全是别的什么… 比如我的图像预处理有问题。
虽然作为一名研究生,我可能羞于承认这一点,但问题是后者:
我搞砸了。
结果是,在图像预处理阶段,我错误地旋转了我的图像。
由于圆形药丸的长宽比接近正方形,所以旋转错误对他们来说不是问题。这里你可以看到一个圆形药丸旋转了 360 度,没有问题:

Figure 1: Rotating a circular pill doesn’t reveal any obvious problems.
但对于椭圆形药丸,它们会在旋转过程中被“切断”,就像这样:

Figure 2: However, rotating oblong pills using the OpenCV’s standard cv2.getRotationMatrix2D and cv2.warpAffine functions caused me some problems that weren’t immediately obvious.
本质上,我只是量化了旋转的长方形药丸的部分。因此我得出了奇怪的结果。
我花了三周和部分圣诞假期试图诊断这个 bug——当我意识到这是由于我疏忽了cv2.rotate功能时,我感到非常尴尬。
你看,输出图像的尺寸需要调整,否则,我的图像的角会被切掉。
我是如何做到这一点并彻底消灭这个 bug 的呢?
要学习如何用 OpenCV 旋转图像,使得整个图像被包含,而没有图像被切掉,继续阅读。
使用 OpenCV 和 Python(正确地)旋转图像
在这篇博文的剩余部分,我将讨论使用 OpenCV 和 Python 旋转图像时可能遇到的常见问题。
具体来说,我们将研究当图像的角在旋转过程中被“切掉”时会发生什么问题。
为了确保我们都理解 OpenCV 和 Python 的旋转问题,我将:
- 从演示旋转问题的简单示例开始。
- 提供旋转功能,确保图像在旋转过程中不会被切断。
- 讨论我是如何使用这种方法解决药片识别问题的。
OpenCV 的一个简单旋转问题
让我们从一个示例脚本开始这篇博文。
打开一个新文件,将其命名为rotate_simple.py,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the image file")
args = vars(ap.parse_args())
第 2-5 行从导入我们需要的 Python 包开始。
如果你还没有安装我的 OpenCV 便利功能系列 imutils ,你现在就可以安装了:
$ pip install imutils
如果您已经在安装了imutils,请确保您已经升级到最新版本:
$ pip install --upgrade imutils
从那里,第 8-10 行解析我们的命令行参数。这里我们只需要一个开关,--image,它是我们的映像驻留在磁盘上的路径。
让我们继续实际旋转我们的图像:
# load the image from disk
image = cv2.imread(args["image"])
# loop over the rotation angles
for angle in np.arange(0, 360, 15):
rotated = imutils.rotate(image, angle)
cv2.imshow("Rotated (Problematic)", rotated)
cv2.waitKey(0)
# loop over the rotation angles again, this time ensuring
# no part of the image is cut off
for angle in np.arange(0, 360, 15):
rotated = imutils.rotate_bound(image, angle)
cv2.imshow("Rotated (Correct)", rotated)
cv2.waitKey(0)
第 14 行从磁盘加载我们想要旋转的图像。
然后我们在范围【0,360】内以 15 度的增量循环各个角度(第 17 行)。
对于这些角度中的每一个,我们称之为imutils.rotate,它将我们的image围绕图像中心旋转指定数量的angle度。然后,我们在屏幕上显示旋转后的图像。
第 24-27 行执行相同的过程,但是这次我们调用imutils.rotate_bound(我将在下一节提供这个函数的实现)。
正如这个方法的名字所暗示的,我们将确保整个图像被绑定在窗口中,并且没有一个被切断。
要查看这个脚本的运行,请务必使用本文的 “下载” 部分下载源代码,然后执行下面的命令:
$ python rotate_simple.py --image images/saratoga.jpg
在非正方形图像上使用imutils.rotate功能的输出如下所示:

Figure 3: An example of corners being cut off when rotating an image using OpenCV and Python.
如您所见,图像在旋转时被“截断”——整个图像不在视野范围内。
但是如果我们使用imutils.rotate_bound我们可以解决这个问题:

Figure 4: We can ensure the entire image is kept in the field of view by modifying the matrix returned by cv2.getRotationMatrix2D.
太棒了,我们解决了问题!
那么这是否意味着我们应该总是使用.rotate_bound而不是.rotate方法?
是什么让它如此特别?
引擎盖下发生了什么?
我将在下一节回答这些问题。
实现一个旋转功能,使不会切断你的图像
首先,我要说的是,OpenCV 中用于旋转图像的cv2.getRotationMatrix2D和cv2.warpAffine函数没有任何问题。
实际上,这些函数给了我们更多的自由,这可能是我们不习惯的(有点像用 C 语言比较手动内存管理和用 Java 比较自动垃圾收集)。
cv2.getRotationMatrix2D函数 并不关心 是否希望保留整个旋转后的图像。
它 不在乎 是否图像被切断。
如果你在使用这个功能的时候搬起石头砸自己的脚,它 也帮不了你 (我发现这一点很难,花了 3 周才止住血)。
相反,你需要做的是理解什么是旋转矩阵以及如何构造它。
你看,当你用 OpenCV 旋转一个图像时,你调用cv2.getRotationMatrix2D,它返回一个矩阵 M ,看起来像这样:

Figure 5: The structure of the matrix M returned by cv2.getRotationMatrix2D.
这个矩阵看起来很恐怖,但我向你保证:它不是。
为了理解它,让我们假设我们想要旋转我们的图像
degrees about some center ") coordinates at some scale (i.e., smaller or larger).
coordinates at some scale (i.e., smaller or larger).
然后我们可以插入 的值
的值
and  :
:

and 
这对于简单的旋转来说很好,但它没有考虑到如果图像沿边界被切断会发生什么。我们如何补救?
答案在 imutils 的便利. py 中的rotate_bound函数里面:
def rotate_bound(image, angle):
# grab the dimensions of the image and then determine the
# center
(h, w) = image.shape[:2]
(cX, cY) = (w // 2, h // 2)
# grab the rotation matrix (applying the negative of the
# angle to rotate clockwise), then grab the sine and cosine
# (i.e., the rotation components of the matrix)
M = cv2.getRotationMatrix2D((cX, cY), -angle, 1.0)
cos = np.abs(M[0, 0])
sin = np.abs(M[0, 1])
# compute the new bounding dimensions of the image
nW = int((h * sin) + (w * cos))
nH = int((h * cos) + (w * sin))
# adjust the rotation matrix to take into account translation
M[0, 2] += (nW / 2) - cX
M[1, 2] += (nH / 2) - cY
# perform the actual rotation and return the image
return cv2.warpAffine(image, M, (nW, nH))
在第 41 行的上,我们定义了我们的rotate_bound函数。
这个方法接受一个输入image和一个angle来旋转它。
我们假设我们将围绕它的中心 (x,y)-坐标旋转我们的图像,所以我们在行 44 和 45 上确定这些值。
给定这些坐标,我们可以调用cv2.getRotationMatrix2D来获得我们的旋转矩阵 M ( 第 50 行)。
然而,为了调整任何图像边界截断问题,我们需要应用一些我们自己的手动计算。
我们首先从旋转矩阵 M ( 第 51 行和第 52 行)中获取余弦和正弦值。
这使我们能够计算旋转图像的新宽度和高度,确保图像没有任何部分被剪切掉。
一旦我们知道了新的宽度和高度,我们可以通过再次修改我们的旋转矩阵来调整第 59 行和第 60 行的平移。
最后,在第 63 行的上调用cv2.warpAffine来使用 OpenCV 旋转实际的图像,同时确保没有图像被切掉。
对于使用 OpenCV 时旋转切断问题的一些其他有趣的解决方案(有些比其他的更好),请务必参考这个 StackOverflow 线程和这个。
用 OpenCV 和 Python 修复旋转图像的“截断”问题
让我们回到我最初的旋转椭圆形药丸的问题,以及我如何使用.rotate_bound来解决这个问题(尽管那时我还没有创建imutils Python 包——它只是一个助手文件中的实用函数)。
我们将使用以下药丸作为我们的示例图像:

Figure 6: The example oblong pill we will be rotating with OpenCV.
首先,打开一个新文件,命名为rotate_pills.py。然后,插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the image file")
args = vars(ap.parse_args())
第 2-5 行导入我们需要的 Python 包。同样,在继续之前,确保你已经安装和/或升级了 imutils Python 包。
然后我们在第 8-11 行解析我们的命令行参数。就像博文开头的例子一样,我们只需要一个开关:--image,我们输入图像的路径。
接下来,我们从磁盘加载药丸图像,并通过将其转换为灰度、模糊和检测边缘对其进行预处理:
# load the image from disk, convert it to grayscale, blur it,
# and apply edge detection to reveal the outline of the pill
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (3, 3), 0)
edged = cv2.Canny(gray, 20, 100)
执行这些预处理函数后,我们的药丸图像现在看起来像这样:

Figure 7: Detecting edges in the pill.
药丸的轮廓清晰可见,因此让我们应用轮廓检测来找到药丸的轮廓:
# find contours in the edge map
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
我们现在准备从图像中提取药丸 ROI:
# ensure at least one contour was found
if len(cnts) > 0:
# grab the largest contour, then draw a mask for the pill
c = max(cnts, key=cv2.contourArea)
mask = np.zeros(gray.shape, dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1)
# compute its bounding box of pill, then extract the ROI,
# and apply the mask
(x, y, w, h) = cv2.boundingRect(c)
imageROI = image[y:y + h, x:x + w]
maskROI = mask[y:y + h, x:x + w]
imageROI = cv2.bitwise_and(imageROI, imageROI,
mask=maskROI)
首先,我们确保在边缘图(线 26 )中找到至少个轮廓。
假设我们至少有一个轮廓,我们在第 29 行和第 30 行上为最大轮廓区域构建一个mask。
我们的mask长这样:

Figure 8: The mask representing the entire pill region in the image.
给定轮廓区域,我们可以计算该区域的边界框的坐标 (x,y)(第 34 行)。
使用边界框和mask,我们可以提取实际药丸区域 ROI ( 第 35-38 行)。
现在,让我们继续对imageROI应用imutils.rotate和imutils.rotate_bound函数,就像我们在上面的简单例子中所做的一样:
# loop over the rotation angles
for angle in np.arange(0, 360, 15):
rotated = imutils.rotate(imageROI, angle)
cv2.imshow("Rotated (Problematic)", rotated)
cv2.waitKey(0)
# loop over the rotation angles again, this time ensure the
# entire pill is still within the ROI after rotation
for angle in np.arange(0, 360, 15):
rotated = imutils.rotate_bound(imageROI, angle)
cv2.imshow("Rotated (Correct)", rotated)
cv2.waitKey(0)
使用下面的 “下载” 部分将源代码下载到本教程后,您可以执行以下命令来查看输出:
$ python rotate_pills.py --image images/pill_01.png
imutils.rotate的输出将如下所示:
Figure 9: Incorrectly rotating an image with OpenCV causes parts of the image to be cut off.
注意药丸在旋转过程中是如何被切掉的——我们需要显式地计算旋转后图像的新尺寸,以确保边界不会被切掉。
通过使用imutils.rotate_bound,我们可以确保在使用 OpenCV 时图像的任何部分都不会被切掉:

Figure 10: By modifying OpenCV’s rotation matrix we can resolve the issue and ensure the entire image is visible.
使用这个功能,我终于能够完成寒假的研究——但在此之前,我对自己的新手错误感到非常尴尬。
摘要
在今天的博文中,我讨论了如何在用 OpenCV 和cv2.warpAffine旋转图像时切断图像边框。
图像边框可以被剪掉的事实是而不是OpenCV 中的一个 bug 事实上,cv2.getRotationMatrix2D和cv2.warpAffine就是这么设计的。
虽然计算新的图像尺寸以确保你不会失去你的边界似乎令人沮丧和繁琐,但这实际上是塞翁失马焉知非福。
OpenCV 给了我们如此多的控制权,以至于我们可以修改我们的旋转矩阵,让它完全按照我们想要的那样做。
当然,这需要我们知道我们的旋转矩阵 M 是如何形成的,它的每个分量代表什么(本教程前面已经讨论过)。如果我们理解了这一点,数学自然就会水落石出。
要了解更多关于图像处理和计算机视觉的知识,一定要看看 PyImageSearch 大师课程,在那里我会更详细地讨论这些话题。
否则,我鼓励您在下面的表格中输入您的电子邮件地址,以便在以后发布博文时得到通知。
重启时运行 Python + OpenCV 脚本
原文:https://pyimagesearch.com/2016/05/16/running-a-python-opencv-script-on-reboot/

这是我在 PyImageSearch 博客上被问到的一个常见问题:
如何让 Python + OpenCV 脚本在我的系统一启动就启动?
有很多方法可以实现。我最喜欢的是使用 crontab 和@reboot 选项。
我如此喜欢这种方法的主要原因是因为 crontab 存在于几乎每一台 Unix 机器上(另外,crontab 是一个非常好的工具,我认为每个人都应该至少有一些经验)。
无论您使用的是 Raspbian、Linux 还是 OSX,crontab 都有可能安装在您的系统上。
https://www.youtube.com/embed/yS-zke4xp_c?feature=oembed
使用 CoreML 在 iOS 上运行 Keras 模型
原文:https://pyimagesearch.com/2018/04/23/running-keras-models-on-ios-with-coreml/
 In last week’s blog post, you learned how to train a Convolutional Neural Network (CNN) with Keras.
In last week’s blog post, you learned how to train a Convolutional Neural Network (CNN) with Keras.
今天,我们将把这个经过训练的 Keras 模型部署到 iPhone 和 iOS 应用程序中,使用苹果公司称为“CoreML”、 的苹果应用程序的易用机器学习框架:
https://www.youtube.com/embed/Qqv4qOJ3RnU?feature=oembed
保存日期:PyImageConf 2018
原文:https://pyimagesearch.com/2017/11/20/save-date-pyimageconf-2018/

想象一下,采用 PyImageSearch 博客的实用、动手教学风格…
并将其转化为现场的面对面会议。
听起来有趣吗?
如果是这样,现在就在日历上标出日期:
PyImageConf 将于 2018 年 8 月 26 日至 28 日在三藩市凯悦酒店举行。****
确认的演讲者/研讨会主持人包括:
- 弗朗索瓦·乔莱(Keras 创始人,谷歌研究员)
- 凯瑟琳·斯科特(行星实验室 SimpleCV 的合著者)
- 戴维斯·金(dlib 的创建者)
- 萨提亚·马利克(LearnOpenCV 的作者)
- Joseph Howse(六部计算机视觉/OpenCV 书籍的作者)
- 亚当·盖特基(的作者机器学习很有趣!中等级数)
- 杰夫·巴斯(树莓派黑客)
- 阿德里安·罗斯布鲁克(就是我!)
- …更多精彩即将到来!
要了解更多关于 PyImageConf 的信息(以及为什么您应该参加),请继续阅读。
保存日期:PyImageConf 2018
PyImageConf 是一个实用的动手会议,以计算机视觉、深度学习和 OpenCV 专家为特色。
如果你想与领先的计算机视觉和深度学习专家交流、建立联系并向他们学习(并在旧金山与我们一起玩几天)……你现在就想加入等待名单。
谁在发言/发言?

Figure 1: PyImageConf 2018 speakers include Adrian Rosebrock, François Chollet, Katherine Scott, Davis King, Satya Mallick, Joseph Howse, Adam Geitgey, Jeff Bass, and more.
PyImageConf 汇集了计算机视觉、深度学习和 OpenCV 教育领域的知名人士,为您提供最佳的现场实践培训和讲座。
每个演讲者分别以他们的写作、教学、在线课程和对开源项目的贡献而闻名。
目前有八位已确认的演讲者/研讨会主持人,稍后还会增加更多:
- 弗朗索瓦·乔莱:谷歌人工智能研究员。 Keras 深度学习库的作者。作品在 CVPR、日本、ICLR 等地出版。
- Katherine Scott:行星实验室的图像分析团队负责人。Tempo Automation 和 Sight Machine 的前联合创始人。《T4》的合著者。
- 戴维斯·金:作者 dlib 库。机器学习,计算机视觉,自然语言处理。十多年来,开源开发者和从业者一直在构建行业 CV 系统。
- Satya Mallick:learn openv的作者和创作者。TAAZ 公司的联合创始人,在 CV 和 ML 工作的企业家。
- 约瑟夫·豪斯:帕克特出版社出版的六部计算机视觉/OpenCV 书籍的作者。通过他的公司nummit Media提供计算机视觉和咨询服务。
- 亚当·盖特吉:的作者机器学习很有趣!博客系列,领英学习,和 Lynda.com。喜欢用机器学习和计算机视觉来构建产品。
- Jeff Bass: Raspberry Pi 黑客,计算机视觉从业者,计量经济学向导,35 年统计学、经济学和生物技术经验。
- Adrian rose Brock:PyImageSearch.com 的作者和创造者, 实用 Python 和 OpenCV , PyImageSearch 大师 , 用 Python 进行计算机视觉的深度学习 。
如果你正在寻找一个由最重要的教育家和演讲者参加的计算机视觉/深度学习会议,这就是它。
什么时候?
PyImageConf 将于 2018 年 8 月 26-28 日举行。
门票将于 2018 年 1 月开始发售。
如果你想要一张票,请确保你在队伍中占有一席之地。
在哪里?
会议将在新改建的 旧金山凯悦 酒店举行,就在美丽的旧金山湾水线上。
会谈将在他们精致的最先进的宴会厅举行,研讨会/分组会议将利用酒店的专用工作区。
看看下面的照片,感受一下这个空间——我相信你会同意这将是今年的计算机视觉和深度学习事件:
**
Figure 1: PyImageConf 2018 will be held at the newly renovated Hyatt Regency in San Francisco CA. The hotel is right on the San Francisco Bay waterline and walking distance to popular attractions, restaurants, and bars.

Figure 2: The conference itself will be held the Grand Ballroom with state-of-the-art visual/audio and reliable high-speed WiFi.

Figure 3: Along with the talks we’ll have a number of smaller, intimate workshops where you’ll learn techniques you can apply to your work and projects.

Figure 4: Registration and evening events will take place in the Hyatt Regency ballroom.
多少钱?
我正在和我的会议协调员敲定门票价格,但预计价格会在 700-900 美元之间。
这可能看起来很多,但请记住,这包括两整天的会谈、研讨会和培训——大多数会议对此类活动的收费远远超过 1,500-2,500 美元。
如果你是 PyImageSearch Gurus 的会员,你将享有优先购票权(以及折扣)。
现在花点时间和你的利益相关者(配偶、孩子等)确认一下。)并专款抢票。
会有多少张票?
这个会议将会很小而且很私密,最多 200 名与会者。
我特意将会议开得很小,以便您能够:
- 向演讲者和演示者学习
- 与计算机视觉和深度学习领域的专家进行一对一的交流
- 更好地与你的同行和同事建立联系
一旦 200 张票卖光,它们就都没了,我不会再增加了。
门票将销售一空… 所以赶快加入早鸟名单吧!
如果你是一个长期的 PyImageSearch 读者,我不需要告诉你这些类型的销售销售有多快。
几年前,当我在 Kickstarter 上为 PyImageSearch 大师课程开展活动时,所有早期特价商品在 30 分钟内售罄。
今年 1 月,我用 Python Kickstarter 推出了用于计算机视觉的——所有早鸟特价商品都在 15 分钟内被认领 。
鉴于只有 200 张门票,我预计所有门票将在门票上线后 10 分钟内销售一空。
所以,如果你想要一张去 PyImageConf 的票…
总结
这是 TL。DR;
- PyImageConf 将于 2018 年 8 月 26 日至 28 日在旧金山凯悦酒店举行。
- 我将会议人数控制在 200 人以内,以保持会议的小型、私密和亲历性。
- 已确认的演讲嘉宾包括弗朗索瓦·乔莱(Keras)、戴维斯·金(dlib)凯瑟琳·斯科特(SimpleCV/Planet Labs)、萨提亚·马里克(LearnOpenCV)、阿德里安·罗斯布洛克(就是我!)等。
- 门票将于 2018 年 1 月开始发售。
- 如果你想要一张 的票,你需要排队 (票会很快卖光**)。****
将 Keras 和 TensorFlow 模型保存到磁盘
原文:https://pyimagesearch.com/2021/05/22/save-your-keras-and-tensorflow-model-to-disk/
在我们的之前的教程中,你学习了如何使用 Keras 库训练你的第一个卷积神经网络。但是,您可能已经注意到,每次您想要评估您的网络或在一组图像上测试它时,您首先需要在进行任何类型的评估之前训练它。这个要求可能会很麻烦。
我们只是在小数据集上使用浅层网络,可以相对快速地进行训练,但如果我们的网络很深,我们需要在更大的数据集上进行训练,因此需要花费许多小时甚至几天来训练,那该怎么办?我们每次都必须投入这么多的时间和资源来训练我们的网络吗?或者,有没有一种方法可以在训练完成后将我们的模型保存到磁盘,然后在我们想要对新图像进行分类时从磁盘加载它?
你肯定有办法。保存和加载已训练模型的过程称为模型序列化,是本教程的主要主题。
要学习如何序列化一个模型,继续阅读。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
将模型序列化到磁盘
使用 Keras 库,模型序列化就像在训练好的模型上调用model.save一样简单,然后通过load_model函数加载它。在本教程的第一部分,我们将修改来自之前教程的一个 ShallowNet 训练脚本,在动物数据集上训练后序列化网络。然后,我们将创建第二个 Python 脚本,演示如何从磁盘加载我们的序列化模型。
让我们从培训部分开始—打开一个新文件,将其命名为shallownet_train.py,并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.preprocessing import ImageToArrayPreprocessor
from pyimagesearch.preprocessing import SimplePreprocessor
from pyimagesearch.datasets import SimpleDatasetLoader
from pyimagesearch.nn.conv import ShallowNet
from tensorflow.keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-13 行 导入我们需要的 Python 包。这个例子中的大部分代码与“用 Keras 和 TensorFlow 训练你的第一个 CNN 的温和指南”中的shallownet_animals.py相同为了完整起见,我们将回顾整个文件,我一定会指出为完成模型序列化所做的重要更改,但关于如何在 Animals 数据集上训练 ShallowNet 的详细回顾,请参考之前的教程。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
args = vars(ap.parse_args())
我们之前的脚本只需要一个单个开关--dataset,这是输入动物数据集的路径。但是,如您所见,我们在这里添加了另一个交换机— --model,这是训练完成后我们希望保存网络的路径。
我们现在可以在--dataset中获取图像的路径,初始化我们的预处理器,并从磁盘加载我们的图像数据集:
# grab the list of images that we'll be describing
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the image preprocessors
sp = SimplePreprocessor(32, 32)
iap = ImageToArrayPreprocessor()
# load the dataset from disk then scale the raw pixel intensities
# to the range [0, 1]
sdl = SimpleDatasetLoader(preprocessors=[sp, iap])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.astype("float") / 255.0
下一步是将我们的数据划分为训练和测试部分,同时将我们的标签编码为向量:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, random_state=42)
# convert the labels from integers to vectors
trainY = LabelBinarizer().fit_transform(trainY)
testY = LabelBinarizer().fit_transform(testY)
通过下面的代码块处理 ShallowNet 训练:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.005)
model = ShallowNet.build(width=32, height=32, depth=3, classes=3)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=100, verbose=1)
现在我们的网络已经训练好了,我们需要把它保存到磁盘上。这个过程就像调用model.save并提供我们的输出网络保存到磁盘的路径一样简单:
# save the network to disk
print("[INFO] serializing network...")
model.save(args["model"])
.save方法获取优化器的权重和状态,并以 HDF5 格式将它们序列化到磁盘中。从磁盘加载这些权重就像保存它们一样简单。
在这里,我们评估我们的网络:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=["cat", "dog", "panda"]))
以及绘制我们的损失和准确性:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
要运行我们的脚本,只需执行以下命令:
$ python shallownet_train.py --dataset ../datasets/animals \
--model shallownet_weights.hdf5
网络完成训练后,列出您的目录内容:
$ ls
shallownet_load.py shallownet_train.py shallownet_weights.hdf5
并且你会看到一个名为shallownet_weights.hdf5的文件——这个文件就是我们的连载网络。下一步是获取这个保存的网络并从磁盘加载它。
摘要
恭喜你,现在你知道如何将你的 Keras 和 TensorFlow 模型保存到磁盘了。如您所见,这就像调用model.save并提供保存输出网络的路径一样简单。现在,您知道了如何训练模型并保存它,这样您就不需要每次训练模型时都从头开始。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
用 OpenCV 保存关键事件视频剪辑
原文:https://pyimagesearch.com/2016/02/29/saving-key-event-video-clips-with-opencv/

上周的博客文章教我们如何使用 OpenCV 和 Python 将视频写入文件。这是一项了不起的技能,但它也提出了一个问题:
我如何把包含*有趣事件的 视频剪辑到文件中而不是把*** 整个视频 ?
**在这种情况下,总体目标是构建一个 视频梗概 ,将视频流中最关键、最显著、最有趣的部分提取到一系列短视频文件中。
什么真正定义了“关键或有趣的事件”完全取决于您和您的应用程序。关键事件的潜在示例包括:
- 在限制进入区检测到运动。
- 入侵者进入你的房子或公寓。
- 一辆汽车在你家附近繁忙的街道上闯红灯。
在每一种情况下,你对整个视频捕捉——不感兴趣,相反,你只想要包含动作的视频剪辑!
要了解如何使用 OpenCV 捕获关键事件视频剪辑(并构建您自己的视频概要),请继续阅读。
用 OpenCV 保存关键事件视频剪辑
这篇博文的目的是演示当一个特定动作发生时,如何将短视频剪辑写到文件中。我们将利用从上周关于用 OpenCV 写视频到文件的博文中获得的知识来实现这一功能。
正如我在这篇文章的开头提到的,在视频流中定义“关键”和“有趣”的事件完全取决于你的应用程序和你试图构建的整体目标。
你可能对探测房间里的运动感兴趣。监控你的房子。或者创建一个系统来观察交通状况并存储机动车司机违反法律的片段。
作为两者的简单例子:
- 定义关键事件。
- 将视频剪辑写入包含事件的文件。
我们将处理一个视频流,并寻找这个绿色球的出现:

Figure 1: An example of the green ball we are going to detect in video streams.
如果这个绿色的球出现在我们的视频流中,我们将打开一个新的文件视频(基于发生的时间戳),将剪辑写入文件,然后一旦球从我们的视野中消失,就停止写入过程。
此外,我们的实现将具有许多理想的特性,包括:
- 在 动作发生前几秒 向我们的视频文件写入帧。
- 在 动作结束后几秒钟 编写帧文件——在这两种情况下,我们的目标不仅是捕捉整个事件,还包括事件的上下文。**
- 利用线程来确保我们的主程序在输入流和输出视频剪辑文件上执行 I/O 时不会变慢。
- 利用内置的 Python 数据结构,比如
deque和Queue,所以我们不需要依赖外部库(当然,除了 OpenCV 和 imutils )。
项目结构
在我们开始实现我们的关键事件视频编写器之前,让我们看一下项目结构:
|--- output
|--- pyimagesearch
| |--- __init__.py
| |--- keyclipwriter.py
|--- save_key_events.py
在pyimagesearch模块中,我们将在keyclipwriter.py文件中定义一个名为KeyClipWriter的类。这个类将处理从一个输入视频流中接收帧,并以一种安全、高效和线程化的方式将它们写入文件。
驱动程序脚本save_key_events.py将定义“有趣事件”的标准(即绿色球进入摄像机视野),然后将这些帧传递给KeyClipWriter,后者将创建我们的视频概要。
关于 Python + OpenCV 版本的快速说明
这篇博文假设你使用的是 Python 3+ 和 OpenCV 3 。正如我在上周的帖子的中提到的,我无法让cv2.VideoWriter函数在我的 OpenCV 2.4 安装上工作,所以在几个小时的摸索之后,我最终放弃了 OpenCV 2.4,坚持使用 OpenCV 3。
本课中的代码在技术上与 Python 2.7 的兼容(同样,假设你使用的是带有 OpenCV 3 绑定的 Python 2.7),但是你需要修改一些import语句(我会在后面指出)。
*### 使用 OpenCV 将关键/有趣的视频剪辑写入文件
让我们开始复习我们的KeyClipWriter课:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
我们从在2-6 行导入我们需要的 Python 包开始。本教程假设你使用的是 Python 3,所以如果你使用的是 Python 2.7,你需要将第 4 行从from queue import Queue改为简单的import Queue。
第 9 行定义了我们的KeyClipWriter的构造函数,它接受两个可选参数:
bufSize:内存缓冲区中缓存的最大帧数。timeout:一个整数,表示当(1)将视频剪辑写入文件和(2)没有准备好写入的帧时休眠的秒数。
然后我们在第 18-22 行初始化四个重要的变量:
frames:用于存储最近从视频流中读取的最多bufSize帧的缓冲器。Q:一个“先入先出”( FIFO ) Python 队列数据结构,用于保存等待写入视频文件的帧。writer:用于将帧实际写入输出视频文件的cv2.VideoWriter类的实例化。thread:一个 PythonThread实例,我们将在将视频写入文件时使用它(以避免代价高昂的 I/O 延迟)。recording:布尔值,表示我们是否处于“录制模式”。
接下来,让我们回顾一下update方法:
def update(self, frame):
# update the frames buffer
self.frames.appendleft(frame)
# if we are recording, update the queue as well
if self.recording:
self.Q.put(frame)
update函数需要一个参数,即从视频流中读取的frame。我们获取这个frame,并将其存储在我们的frames缓冲区中(第 26 行)。如果我们已经处于录制模式,我们还会将frame存储在Queue中,这样它就可以刷新到视频文件(第 29 行和第 30 行)。
为了开始实际的视频剪辑记录,我们需要一个start方法:
def start(self, outputPath, fourcc, fps):
# indicate that we are recording, start the video writer,
# and initialize the queue of frames that need to be written
# to the video file
self.recording = True
self.writer = cv2.VideoWriter(outputPath, fourcc, fps,
(self.frames[0].shape[1], self.frames[0].shape[0]), True)
self.Q = Queue()
# loop over the frames in the deque structure and add them
# to the queue
for i in range(len(self.frames), 0, -1):
self.Q.put(self.frames[i - 1])
# start a thread write frames to the video file
self.thread = Thread(target=self.write, args=())
self.thread.daemon = True
self.thread.start()
首先,我们更新我们的recording布尔值来表明我们处于“记录模式”。然后,我们使用提供给start方法的outputPath、fourcc和fps以及帧空间尺寸(即宽度和高度)来初始化cv2.VideoWriter。关于cv2.VideoWriter参数的完整回顾,请参考这篇博文。
第 39 行初始化我们的Queue,用来存储准备写入文件的帧。然后,我们循环我们的frames缓冲区中的所有帧,并将它们添加到队列中。
最后,我们生成一个单独的线程来处理将帧写入视频——这样我们就不会因为等待 I/O 操作完成而减慢我们的主视频处理流水线。
如上所述,start方法创建了一个新线程,调用用于将Q中的帧写入文件的write方法。让我们来定义这个write方法:
def write(self):
# keep looping
while True:
# if we are done recording, exit the thread
if not self.recording:
return
# check to see if there are entries in the queue
if not self.Q.empty():
# grab the next frame in the queue and write it
# to the video file
frame = self.Q.get()
self.writer.write(frame)
# otherwise, the queue is empty, so sleep for a bit
# so we don't waste CPU cycles
else:
time.sleep(self.timeout)
第 53 行开始一个无限循环,将继续轮询新帧并将它们写入文件,直到我们的视频录制完成。
第 55 和 56 行检查记录是否应该停止,如果是,我们从线程返回。
否则,如果Q不为空,我们抓取下一帧并将其写入视频文件(第 59-63 行)。
如果在Q中没有帧,我们就睡一会儿,这样我们就不会不必要地浪费 CPU 周期旋转(第 67 行和第 68 行)。这是特别重要的当使用Queue数据结构时,它是线程安全的,这意味着我们必须在更新内部缓冲区之前获取一个锁/信号量。如果我们在缓冲区为空时不调用time.sleep,那么write和update方法将不断地争夺锁。相反,最好让写入程序休眠一会儿,直到队列中有一堆帧需要写入文件。
我们还将定义一个flush方法,该方法简单地获取Q中剩余的所有帧,并将它们转储到文件中:
def flush(self):
# empty the queue by flushing all remaining frames to file
while not self.Q.empty():
frame = self.Q.get()
self.writer.write(frame)
当视频录制完成后,我们需要立即将所有帧刷新到文件中时,就会使用这样的方法。
最后,我们定义下面的finish方法:
def finish(self):
# indicate that we are done recording, join the thread,
# flush all remaining frames in the queue to file, and
# release the writer pointer
self.recording = False
self.thread.join()
self.flush()
self.writer.release()
这个方法表示记录已经完成,将 writer 线程与主脚本连接,将Q中的剩余帧刷新到文件,最后释放cv2.VideoWriter指针。
既然我们已经定义了KeyClipWriter类,我们可以继续讨论用于实现“关键/有趣事件”检测的驱动程序脚本。
用 OpenCV 保存关键事件
为了让这篇博文简单易懂,我们将把这个绿色球进入我们的视频流定义为“关键事件”:
Figure 2: An example of a key/interesting event in a video stream.
一旦我们看到这个绿球,我们将调用KeyClipWriter将包含绿球的所有帧写入文件。本质上,这将为我们提供一组简短的视频剪辑,它们巧妙地总结了整个视频流的事件——简而言之, 一个视频概要 。
当然,您可以使用这段代码作为样板/起点来定义您自己的操作——我们将简单地使用“绿球”事件,因为我们之前在 PyImageSearch 博客上多次报道过它,包括跟踪对象移动和球跟踪。
在您继续本教程的其余部分之前,请确保您的系统上安装了 imutils 软件包:
$ pip install imutils
这将确保您可以使用VideoStream类来创建对内置/USB 网络摄像头和 Raspberry Pi 摄像头模块的统一访问。
让我们开始吧。打开save_key_events.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())
第 2-8 行导入我们需要的 Python 包,而第 11-22 行解析我们的命令行参数。下面详细介绍了一组命令行参数:
--output:这是到输出目录的路径,我们将在这里存储输出的视频剪辑。--picamera:如果你想使用你的 Raspberry Pi 摄像头(而不是内置/USB 摄像头),那么提供一个值--picamera 1。你可以在这篇文章中阅读更多关于访问内置/USB 网络摄像头和 Raspberry Pi 摄像头模块的信息(无需更改一行代码)。--fps:此开关控制输出视频的所需 FPS。这个值应该类似于您的图像处理管道每秒可以处理的帧数。--codec:输出视频剪辑的 FourCC 编解码器。更多信息请见前贴。--buffer-size:内存缓冲区的大小,用于存储摄像头传感器最近轮询的帧。较大的--buffer-size将允许在输出视频剪辑中包含“关键事件”前后的更多上下文,而较小的--buffer-size将在“关键事件”前后存储较少的帧。
让我们执行一些初始化:
# initialize the video stream and allow the camera sensor to
# warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# define the lower and upper boundaries of the "green" ball in
# the HSV color space
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
# initialize key clip writer and the consecutive number of
# frames that have *not* contained any action
kcw = KeyClipWriter(bufSize=args["buffer_size"])
consecFrames = 0
第 26-28 行初始化我们的VideoStream并允许摄像机传感器预热。
从那里,行 32 和 33 定义了 HSV 颜色空间中绿色球的较低和较高颜色阈值边界。关于我们如何定义这些颜色阈值的更多信息,请看这篇文章。
第 37 行使用我们提供的--buffer-size实例化我们的KeyClipWriter,同时初始化一个整数,用于计数没有包含任何有趣事件的连续帧的数量。
我们现在准备开始处理视频流中的帧:
# keep looping
while True:
# grab the current frame, resize it, and initialize a
# boolean used to indicate if the consecutive frames
# counter should be updated
frame = vs.read()
frame = imutils.resize(frame, width=600)
updateConsecFrames = True
# blur the frame and convert it to the HSV color space
blurred = cv2.GaussianBlur(frame, (11, 11), 0)
hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)
# construct a mask for the color "green", then perform
# a series of dilations and erosions to remove any small
# blobs left in the mask
mask = cv2.inRange(hsv, greenLower, greenUpper)
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
# find contours in the mask
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
在第 41 行上,我们开始循环播放视频流中的帧。第 45 行和第 46 行从视频流中读取下一个frame,然后将它的宽度调整为 600 像素。
通过稍微模糊图像,然后将图像从 RGB 颜色空间转换到 HSV 颜色空间,对第 50 和 51 行进行进一步的预处理(因此我们可以应用我们的颜色阈值)。
使用cv2.inRange功能在线 56 上执行实际的颜色阈值处理。这个方法找到所有为greenLower <= p <= greenUpper的像素 p 。然后,我们执行一系列的腐蚀和扩张,以消除任何小斑点留在面具。
最后,行 61-63 在阈值图像中找到轮廓。
如果你对这个处理流程的任何一步感到困惑,我建议回到我们之前关于球跟踪和物体移动的帖子,进一步熟悉这个主题。
我们现在准备检查并查看是否在我们的图像中找到了绿色球:
# only proceed if at least one contour was found
if len(cnts) > 0:
# find the largest contour in the mask, then use it
# to compute the minimum enclosing circle
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
updateConsecFrames = radius <= 10
# only proceed if the radius meets a minimum size
if radius > 10:
# reset the number of consecutive frames with
# *no* action to zero and draw the circle
# surrounding the object
consecFrames = 0
cv2.circle(frame, (int(x), int(y)), int(radius),
(0, 0, 255), 2)
# if we are not already recording, start recording
if not kcw.recording:
timestamp = datetime.datetime.now()
p = "{}/{}.avi".format(args["output"],
timestamp.strftime("%Y%m%d-%H%M%S"))
kcw.start(p, cv2.VideoWriter_fourcc(*args["codec"]),
args["fps"])
第 66 行进行检查以确保至少找到一个轮廓,如果找到,则第 69 行和第 70 行在掩模中找到最大的轮廓(根据面积)并使用该轮廓计算最小封闭圆。
如果圆的半径满足 10 个像素的最小尺寸(第 74 行,那么我们将假设我们已经找到了绿色的球。第 78-80 行重置不包含任何有趣事件的consecFrames的数量(因为一个有趣的事件“当前正在发生”),并画一个圆圈突出显示我们在帧中的球。
最后,我们检查我们是否正在录制一个视频剪辑(第 83 行)。如果没有,我们基于当前时间戳为视频剪辑生成一个输出文件名,并调用KeyClipWriter的start方法。
否则,我们将假设没有关键/有趣的事件发生:
# otherwise, no action has taken place in this frame, so
# increment the number of consecutive frames that contain
# no action
if updateConsecFrames:
consecFrames += 1
# update the key frame clip buffer
kcw.update(frame)
# if we are recording and reached a threshold on consecutive
# number of frames with no action, stop recording the clip
if kcw.recording and consecFrames == args["buffer_size"]:
kcw.finish()
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
如果没有有趣的事件发生,我们更新consecFrames并将frame传递到我们的缓冲区。
第 101 行做了一个重要的检查——如果我们正在记录并且已经达到足够数量的连续帧 而没有关键事件 ,那么我们应该停止记录。
最后,行 105-110 将输出frame显示到我们的屏幕上,并等待按键。
我们的最后一个代码块确保视频已经成功关闭,然后执行一点清理:
# if we are in the middle of recording a clip, wrap it up
if kcw.recording:
kcw.finish()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
视频概要结果
要为关键事件生成视频剪辑(例如,视频流中出现的绿色球),只需执行以下命令:
$ python save_key_events.py --output output
我把完整的1 米 46 秒的视频(没有提取突出的剪辑)放在下面:
https://www.youtube.com/embed/QQxf0xV1WK0?feature=oembed***
可扩展的 Keras +深度学习 REST API
原文:https://pyimagesearch.com/2018/01/29/scalable-keras-deep-learning-rest-api/
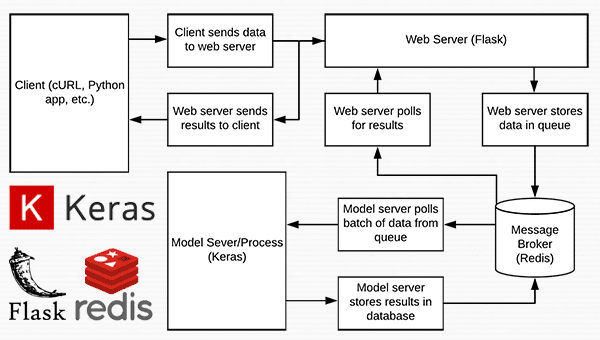
在今天的博客文章中,我们将创建一个深度学习 REST API,以高效、可扩展的方式包装 Keras 模型。
我们的 Keras +深度学习 REST API 将能够批量处理图像,扩展到多台机器(包括多台 web 服务器和 Redis 实例),并在置于负载平衡器之后时进行循环调度。
为此,我们将使用:
- Keras
- Redis (一个内存中的数据结构存储)
- 烧瓶(Python 的一个微型 web 框架)
- 消息队列和消息代理编程范例
这篇博文比 PyImageSearch 上的其他教程更高级一些,面向读者:
- 熟悉 Keras 深度学习库的人
- 了解 web 框架和 web 服务的人(最好以前编写过简单的网站/web 服务)
- 他们了解基本的数据结构,如散列表/字典、列表,以及它们相关的渐进复杂性
更简单的 Keras +深度学习 REST API,请参考我在官方 Keras.io 博客上做的这篇客座博文。
要了解如何创建自己的可扩展 Keras +深度学习 REST API,继续阅读!
可扩展的 Keras +深度学习 REST API
2020-06-16 更新:此博文现已兼容 TensorFlow 2+!
今天的教程分为多个部分。
我们将首先简要讨论一下 Redis 数据存储库,以及如何使用它来促进消息队列和消息代理。
从那里,我们将通过安装所需的 Python 包来配置我们的 Python 开发环境,以构建我们的 Keras 深度学习 REST API。
一旦我们配置好开发环境,我们就可以使用 Flask web 框架实现我们实际的 Keras 深度学习 REST API。实现之后,我们将启动 Redis 和 Flask 服务器,然后使用 cURL 和 Python 向我们的深度学习 API 端点提交推理请求。
最后,我们将对构建自己的深度学习 REST API 时应该记住的注意事项进行简短的讨论。
Redis 作为 REST API 消息代理/消息队列的简短介绍
Figure 1: Redis can be used as a message broker/message queue for our deep learning REST API
Redis 是内存中的数据存储。它不同于简单的键/值存储(如 memcached ),因为它可以存储实际的数据结构。
要阅读更多关于 Redis 的内容,我鼓励您阅读这篇简介。
为我们的 Keras REST API 配置和安装 Redis
Redis 非常容易安装。下面是在您的系统上下载、解压缩和安装 Redis 的命令:
$ wget http://download.redis.io/redis-stable.tar.gz
$ tar xvzf redis-stable.tar.gz
$ cd redis-stable
$ make
$ sudo make install
要启动 Redis 服务器,请使用以下命令:
$ redis-server
让此终端保持打开状态,以保持 Redis 数据存储运行。
在另一个终端中,您可以验证 Redis 已经启动并正在运行:
$ redis-cli ping
PONG
只要你从 Redis 得到一个PONG回复,你就可以开始了。
配置 Python 开发环境以构建 Keras REST API
我建议您在 Python 虚拟环境中处理这个项目,这样它就不会影响系统级 Python 和项目。
为此,您需要安装 pip、virtualenv 和 virtualenvwrapper(假设您尚未安装)。有关在您的环境中配置这些工具的说明,请参见:
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
您还需要在虚拟环境中安装以下软件包:
$ workon dl4cv
$ pip install flask
$ pip install gevent
$ pip install requests
$ pip install redis
就是这样!
实现可伸缩的 Keras REST API
Figure 2: Our deep learning Keras + Redis + Flask REST API data flow diagram
让我们开始构建我们的服务器脚本。为了方便起见,我在一个文件中实现了服务器,但是如果你认为合适的话,它也可以模块化。
为了获得最佳效果并避免复制/粘贴错误,我鼓励你使用这篇博文的 【下载】 部分来获取相关的脚本和图像。
让我们打开run_keras_server.py并一起走过它:
# import the necessary packages
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.applications.resnet50 import preprocess_input
from tensorflow.keras.applications.resnet50 import decode_predictions
from threading import Thread
from PIL import Image
import numpy as np
import base64
import flask
import redis
import uuid
import time
import json
import sys
import io
上面列出了不少进口,特别是ResNet50、flask、redis。
为了简单起见,我们将使用在 ImageNet 数据集上预先训练的 ResNet。我将指出在哪里可以用 ResNet 替换您自己的模型。
flask模块包含烧瓶库(用于构建我们的 web API)。redis模块将使我们能够与 Redis 数据存储接口。
从这里,让我们初始化将在整个run_keras_server.py中使用的常数:
# initialize constants used to control image spatial dimensions and
# data type
IMAGE_WIDTH = 224
IMAGE_HEIGHT = 224
IMAGE_CHANS = 3
IMAGE_DTYPE = "float32"
# initialize constants used for server queuing
IMAGE_QUEUE = "image_queue"
BATCH_SIZE = 32
SERVER_SLEEP = 0.25
CLIENT_SLEEP = 0.25
我们将向服务器传递尺寸为 224 x 224 并包含3个通道的float32个图像。
我们的服务器可以处理一个BATCH_SIZE = 32。如果您的生产系统上有 GPU,您会想要调整您的BATCH_SIZE以获得最佳性能。
我发现将SERVER_SLEEP和CLIENT_SLEEP都设置为0.25秒(分别是服务器和客户端在再次轮询 Redis 之前暂停的时间)在大多数系统上都可以很好地工作。如果你正在构建一个生产系统,一定要调整这些常量。
让我们启动 Flask 应用程序和 Redis 服务器:
# initialize our Flask application, Redis server, and Keras model
app = flask.Flask(__name__)
db = redis.StrictRedis(host="localhost", port=6379, db=0)
model = None
这里你可以看到启动 Flask 是多么容易。
我假设在您运行这个服务器脚本之前,您的 Redis 服务器正在运行。我们的 Python 脚本在端口6379上连接到我们的localhost上的 Redis 存储(Redis 的默认主机和端口值)。
不要忘记在这里初始化一个全局 Keras model到None。
接下来,让我们处理图像的序列化:
def base64_encode_image(a):
# base64 encode the input NumPy array
return base64.b64encode(a).decode("utf-8")
def base64_decode_image(a, dtype, shape):
# if this is Python 3, we need the extra step of encoding the
# serialized NumPy string as a byte object
if sys.version_info.major == 3:
a = bytes(a, encoding="utf-8")
# convert the string to a NumPy array using the supplied data
# type and target shape
a = np.frombuffer(base64.decodestring(a), dtype=dtype)
a = a.reshape(shape)
# return the decoded image
return a
Redis 将作为我们在服务器上的临时数据存储。图像将通过各种方法进入服务器,如 cURL、Python 脚本,甚至是移动应用程序。
此外,图像可能只是每隔一段时间出现一次(几小时或几天一次),或者以非常高的速率出现(每秒多次)。我们需要把图像放在某个地方,因为它们在被处理之前会排队。我们的 Redis 商店将充当临时存储。
为了在 Redis 中存储我们的图像,需要对它们进行序列化。由于图像只是 NumPy 数组,我们可以利用 base64 编码来序列化图像。使用 base64 编码还有一个好处,就是允许我们使用 JSON 来存储图像的附加属性。
我们的base64_encode_image函数处理序列化,并在第 36-38 行中定义。
类似地,我们需要在通过模型传递图像之前对它们进行反序列化。这由行 40-52 上的base64_decode_image函数处理。
让我们预处理我们的图像:
def prepare_image(image, target):
# if the image mode is not RGB, convert it
if image.mode != "RGB":
image = image.convert("RGB")
# resize the input image and preprocess it
image = image.resize(target)
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
image = preprocess_input(image)
# return the processed image
return image
在第 54 行上,我定义了一个prepare_image函数,它使用 Keras 中的 ResNet50 实现对我们的输入图像进行预处理以进行分类..当使用你自己的模型时,我建议修改这个函数来执行任何需要的预处理、缩放或归一化。
在这里,我们将定义我们的分类方法:
def classify_process():
# load the pre-trained Keras model (here we are using a model
# pre-trained on ImageNet and provided by Keras, but you can
# substitute in your own networks just as easily)
print("* Loading model...")
model = ResNet50(weights="imagenet")
print("* Model loaded")
正如我们将在下面的__main__中看到的,classify_process函数将在它自己的线程中被启动。该函数将从 Redis 服务器轮询图像批次,对图像进行分类,并将结果返回给客户端。
73 线加载model。我将此操作与终端print消息夹在一起——取决于您的 Keras 模型的大小,加载可以是瞬时的,也可能需要几秒钟。
当这个线程启动时,加载模型只发生一次——如果我们每次想要处理一个图像时都必须加载模型,这将会非常慢,此外,这可能会由于内存耗尽而导致服务器崩溃。
加载模型后,该线程将不断轮询新图像,然后对它们进行分类:
# continually pool for new images to classify
while True:
# attempt to grab a batch of images from the database, then
# initialize the image IDs and batch of images themselves
queue = db.lrange(IMAGE_QUEUE, 0, BATCH_SIZE - 1)
imageIDs = []
batch = None
# loop over the queue
for q in queue:
# deserialize the object and obtain the input image
q = json.loads(q.decode("utf-8"))
image = base64_decode_image(q["image"], IMAGE_DTYPE,
(1, IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANS))
# check to see if the batch list is None
if batch is None:
batch = image
# otherwise, stack the data
else:
batch = np.vstack([batch, image])
# update the list of image IDs
imageIDs.append(q["id"])
这里我们首先使用 Redis 数据库的lrange函数从我们的队列中获取最多BATCH_SIZE张图像(第 80 行)。
从那里我们初始化我们的imageIDs和batch ( 行 81 和 82 )并开始从行 85 开始在queue上循环。
在循环中,我们首先解码对象并将其反序列化为一个 NumPy 数组,image ( 第 87-89 行)。
接下来,在第 91-97 行,我们将把image加到batch(或者如果batch当前是None,我们就把batch设置为当前的image)。
我们还将图像的id附加到imageIDs ( 第 100 行)。
让我们完成循环和函数:
# check to see if we need to process the batch
if len(imageIDs) > 0:
# classify the batch
print("* Batch size: {}".format(batch.shape))
preds = model.predict(batch)
results = decode_predictions(preds)
# loop over the image IDs and their corresponding set of
# results from our model
for (imageID, resultSet) in zip(imageIDs, results):
# initialize the list of output predictions
output = []
# loop over the results and add them to the list of
# output predictions
for (imagenetID, label, prob) in resultSet:
r = {"label": label, "probability": float(prob)}
output.append(r)
# store the output predictions in the database, using
# the image ID as the key so we can fetch the results
db.set(imageID, json.dumps(output))
# remove the set of images from our queue
db.ltrim(IMAGE_QUEUE, len(imageIDs), -1)
# sleep for a small amount
time.sleep(SERVER_SLEEP)
在这个代码块中,我们检查我们的批处理中是否有任何图像(行 103 )。
如果我们有一批图像,我们通过将整批图像传递给模型来对其进行预测( Line 106 )。
从那里,我们循环遍历一个imageIDs和相应的预测results ( 第 111-123 行)。这些行将标签和概率附加到输出列表中,然后使用imageID作为键将输出存储在 Redis 数据库中(行 117-123 )。
我们使用第 126 行上的ltrim从队列中移除我们刚刚分类的图像集。
最后,我们在设定的SERVER_SLEEP时间内休眠,等待下一批图像进行分类。
接下来让我们处理 REST API 的/predict端点:
@app.route("/predict", methods=["POST"])
def predict():
# initialize the data dictionary that will be returned from the
# view
data = {"success": False}
# ensure an image was properly uploaded to our endpoint
if flask.request.method == "POST":
if flask.request.files.get("image"):
# read the image in PIL format and prepare it for
# classification
image = flask.request.files["image"].read()
image = Image.open(io.BytesIO(image))
image = prepare_image(image, (IMAGE_WIDTH, IMAGE_HEIGHT))
# ensure our NumPy array is C-contiguous as well,
# otherwise we won't be able to serialize it
image = image.copy(order="C")
# generate an ID for the classification then add the
# classification ID + image to the queue
k = str(uuid.uuid4())
d = {"id": k, "image": base64_encode_image(image)}
db.rpush(IMAGE_QUEUE, json.dumps(d))
稍后您会看到,当我们发布到 REST API 时,我们将使用/predict端点。当然,我们的服务器可以有多个端点。
我们使用函数上方的@app.route装饰器,格式如第 131 行所示,来定义我们的端点,以便 Flask 知道要调用什么函数。我们可以很容易地拥有另一个使用 AlexNet 而不是 ResNet 的端点,并且我们可以以类似的方式定义具有关联函数的端点。您明白这个想法,但是对于我们今天的目的,我们只有一个端点叫做/predict。
我们在行 132 定义的predict方法将处理对服务器的 POST 请求。这个函数的目标是构建 JSON data,我们将把它发送回客户端。
如果 POST 数据包含图像(行 138 和 139 ),我们将图像转换为 PIL/枕头格式,并对其进行预处理(行 142-144 )。
在开发这个脚本时,我花了相当多的时间来调试我的序列化和反序列化函数,结果发现我需要第 148 行来将数组转换成 C 连续排序(你可以在这里阅读更多关于的内容)。老实说,这是一个相当大的痛苦,但我希望它能帮助您快速启动和运行。
如果你想知道在行 100 上提到的id,它实际上是在这里使用uuid(一个通用唯一标识符)在行 152 上生成的。我们使用 UUID 来防止哈希/键冲突。
接下来,我们将image的id和base64编码添加到d字典中。使用rpush ( Line 154 )将这个 JSON 数据推送到 Redis db非常简单。
让我们轮询服务器以返回预测:
# keep looping until our model server returns the output
# predictions
while True:
# attempt to grab the output predictions
output = db.get(k)
# check to see if our model has classified the input
# image
if output is not None:
# add the output predictions to our data
# dictionary so we can return it to the client
output = output.decode("utf-8")
data["predictions"] = json.loads(output)
# delete the result from the database and break
# from the polling loop
db.delete(k)
break
# sleep for a small amount to give the model a chance
# to classify the input image
time.sleep(CLIENT_SLEEP)
# indicate that the request was a success
data["success"] = True
# return the data dictionary as a JSON response
return flask.jsonify(data)
我们将不断循环,直到模型服务器返回输出预测。我们开始一个无限循环,并试图得到第 158-160 行的预测。
从那里,如果output包含预测,我们反序列化结果,并将它们添加到将返回给客户端的data。
我们还从db中delete出结果(因为我们已经从数据库中取出了结果,不再需要将它们存储在数据库中)并将break从循环中取出(第 164-173 行)。
否则,我们没有任何预测,我们需要睡觉,继续投票( Line 177 )。
如果我们到达线 180 ,我们就成功获得了我们的预言。在这种情况下,我们将True的success值添加到客户端数据中。
注意:对于这个示例脚本,我没有在上面的循环中添加超时逻辑,这在理想情况下会将False的success值添加到数据中。我将把它留给你来处理和实现。
最后我们在data上调用flask.jsonify,并将其返回给客户端(行 183 )。这就完成了我们的预测功能。
为了演示我们的 Keras REST API,我们需要一个__main__函数来实际启动服务器:
# if this is the main thread of execution first load the model and
# then start the server
if __name__ == "__main__":
# load the function used to classify input images in a *separate*
# thread than the one used for main classification
print("* Starting model service...")
t = Thread(target=classify_process, args=())
t.daemon = True
t.start()
# start the web server
print("* Starting web service...")
app.run()
第 187-197 行定义了__main__函数,它将启动我们的classify_process线程(第 191-193 行)并运行 Flask app ( 第 197 行)。
为了测试我们的 Keras 深度学习 REST API,请务必使用这篇博客文章的 “下载” 部分下载源代码+示例图像。
从这里,让我们启动 Redis 服务器(如果它还没有运行的话):
$ redis-server
然后,在一个单独的终端中,让我们启动 REST API Flask 服务器:
$ python run_keras_server.py
Using TensorFlow backend.
* Loading Keras model and Flask starting server...please wait until server has fully started
...
* Running on http://127.0.0.1:5000
此外,我建议等到您的模型完全加载到内存中之后,再向服务器提交请求。
现在我们可以继续用 cURL 和 Python 测试服务器了。
使用 cURL 访问我们的 Keras REST API
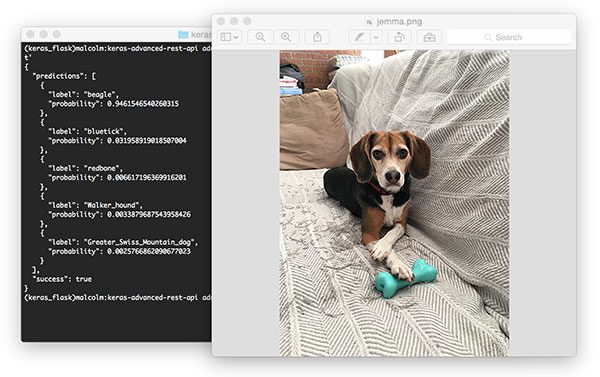
Figure 3: Using cURL to test our Keras REST API server. Pictured is my family beagle, Jemma. She is classified as a beagle with 94.6% confidence by our ResNet model.
cURL 工具预装在大多数(基于 Unix 的)操作系统上。我们可以通过使用以下命令在/predict端点将图像文件发布到我们的深度学习 REST API:
$ curl -X POST -F image=@jemma.png 'http://localhost:5000/predict'
您将在终端上收到 JSON 格式的预测:
{
"predictions": [
{
"label": "beagle",
"probability": 0.9461546540260315
},
{
"label": "bluetick",
"probability": 0.031958919018507004
},
{
"label": "redbone",
"probability": 0.006617196369916201
},
{
"label": "Walker_hound",
"probability": 0.0033879687543958426
},
{
"label": "Greater_Swiss_Mountain_dog",
"probability": 0.0025766862090677023
}
],
"success": true
}
让我们尝试传递另一个图像,这次是一架航天飞机:
$ curl -X POST -F image=@space_shuttle.png 'http://localhost:5000/predict'
{
"predictions": [
{
"label": "space_shuttle",
"probability": 0.9918227791786194
},
{
"label": "missile",
"probability": 0.006030891090631485
},
{
"label": "projectile",
"probability": 0.0021368064917623997
},
{
"label": "warplane",
"probability": 1.980597062356537e-06
},
{
"label": "submarine",
"probability": 1.8291866581421345e-06
}
],
"success": true
}
其结果可以在下面看到:

Figure 4: Submitting an input image to our Keras REST API and obtaining the prediction results.
我们的 Keras REST API 再次正确地对输入图像进行了分类。
使用 Python 向 Keras REST API 提交请求
如您所见,使用 cURL 进行验证非常容易。现在让我们构建一个 Python 脚本,它将发布一个图像并以编程方式解析返回的 JSON。
让我们回顾一下simple_request.py:
# import the necessary packages
import requests
# initialize the Keras REST API endpoint URL along with the input
# image path
KERAS_REST_API_URL = "http://localhost:5000/predict"
IMAGE_PATH = "jemma.png"
我们在这个脚本中使用 Python requests来处理向服务器发送数据。
我们的服务器运行在localhost上,可以通过端口5000访问,端点/predict由KERAS_REST_API_URL变量指定(第 6 行)。如果服务器远程运行或在不同的机器上运行,请确保指定适当的域/ip、端口和端点。
我们还定义了一个IMAGE_PATH ( 线 7 )。在这种情况下,jemma.png与我们的脚本在同一个目录中。如果您想使用其他图像进行测试,请确保指定输入图像的完整路径。
让我们加载图像并将其发送到服务器:
# load the input image and construct the payload for the request
image = open(IMAGE_PATH, "rb").read()
payload = {"image": image}
# submit the request
r = requests.post(KERAS_REST_API_URL, files=payload).json()
# ensure the request was sucessful
if r["success"]:
# loop over the predictions and display them
for (i, result) in enumerate(r["predictions"]):
print("{}. {}: {:.4f}".format(i + 1, result["label"],
result["probability"]))
# otherwise, the request failed
else:
print("Request failed")
我们在二进制模式下读取第 10 行的图像,并将其放入有效载荷字典中。
有效载荷通过行 14 上的requests.post发送到服务器。
如果我们得到一个success消息,我们可以循环预测并把它们打印到终端上。我把这个脚本做得很简单,但是如果你想变得有趣,你也可以使用 OpenCV 在图像上绘制最高预测文本。
运行简单请求脚本
将脚本投入使用很容易。打开一个终端并执行以下命令(当然,前提是我们的 Flask 服务器和 Redis 服务器都在运行)。
$ python simple_request.py
1\. beagle: 0.9462
2\. bluetick: 0.0320
3\. redbone: 0.0066
4\. Walker_hound: 0.0034
5\. Greater_Swiss_Mountain_dog: 0.0026

Figure 5: Using Python to programmatically consume the results of our Keras deep learning REST API.
对于space_shuttle.png,只需修改IMAGE_PATH变量:
IMAGE_PATH = "space_shuttle.png"
从那里,再次运行脚本:
$ python simple_request.py
1\. space_shuttle: 0.9918
2\. missile: 0.0060
3\. projectile: 0.0021
4\. warplane: 0.0000
5\. submarine: 0.0000

Figure 6: A second example of programmatically consuming our Keras deep learning REST API. Here a space shuttle is classified with 99% confidence by ResNet + Keras REST API.
扩展深度学习 REST API 时的注意事项
如果您预计 deep learning REST API 的负载会持续较长时间,您可能需要考虑负载平衡算法,如循环调度,以帮助在多个 GPU 机器和 Redis 服务器之间均匀地分配请求。
请记住,Redis 是一个内存中的数据存储,所以我们只能在队列中存储尽可能多的图像,我们有可用的内存。
数据类型为float32的单个 224 x 224 x 3 图像将消耗 602112 字节的内存。
假设一台服务器只有 16GB 的内存,这意味着我们的队列中可以容纳大约 26,500 张图像,但此时我们可能会希望添加更多的 GPU 服务器来更快地处理队列。
然而,有一个微妙的问题…
取决于你如何部署你的深度学习 REST API,将classify_process函数保存在与我们的 web API 代码的其余部分相同的文件中有一个微妙的问题。
大多数 web 服务器,包括 Apache 和 nginx,都允许多线程。
如果您将classify_process保存在与predict视图相同的文件中,那么您可以加载多个模型。如果您的服务器软件认为有必要创建一个新线程来服务传入的客户端请求,那么对于每个新线程,都会创建一个新视图,因此会加载一个新模型。
解决方案是将classify_process转移到一个完全独立的进程,然后和你的 Flask web 服务器和 Redis 服务器一起启动它。
在下周的博文中,我将基于今天的解决方案,展示如何解决这个问题,并演示:
- 如何配置 Apache web 服务器来服务我们的深度学习 REST API
- 如何将
classify_process作为一个完全独立的 Python 脚本运行,避免“多模型综合症” - 提供压力测试结果,确认和验证我们的深度学习 REST API 可以在高负载下扩展
摘要
在今天的博文中,我们学习了如何构建一个可扩展的 Keras +深度学习 REST API。
为了实现这一目标,我们:
- 构建了一个简单的 Flask 应用程序,将我们的 Keras 模型加载到内存中,并接受传入的请求。
- 利用 Redis 作为内存中的消息队列/消息代理。
- 利用线程来批处理输入图像,将它们写回消息队列,然后将结果返回给客户端。
这种方法可以扩展到多台机器,包括多台 web 服务器和 Redis 实例。
我希望你喜欢今天的博文!
请务必在下表中输入您的电子邮件地址,以便在 PyImageSearch 上发布未来教程时得到通知!
使用 XGBoost 扩展 Kaggle 竞赛:第 1 部分
原文:https://pyimagesearch.com/2022/11/21/scaling-kaggle-competitions-using-xgboost-part-1/
目录
用 XGBoost 缩放 Kaggle 比赛:第一部分
深入处理深度学习主题有时会很困难。你可以一次又一次地尝试,但是就像作家的瓶颈一样,研究者的瓶颈也是非常真实的!
在我探索深度学习的最初几天,我曾经半日一遇。当然,我们都说坚定不移的奉献是取得突破的关键,但有时采取不同的方法也是好的。
对我来说,一股新鲜空气正在(不经意地)卡格尔竞赛中竞争。由于深度学习研究和实用深度学习需要截然不同的思维方式,这对我来说是一个很好的改变,因为我获得了解决问题的不同视角,也看到了最高水平的数据科学家如何利用深度学习解决现实生活中的问题。
竞争性的“卡格灵”实际上是一个非常容易上瘾的习惯,深度学习者很容易陷入其中。然而,提供成长和几个奖项的比赛足以吸引人们致力于成为最好的“卡格勒”。
然而,这仅占我们博客文章标题的 50%。那么另一半呢?
卡格勒人总是在寻找方法,使他们的竞争提交比别人更好。今天的卡格勒人的能力是这样的,几乎每个人都达到 99%的准确率,但只有 99.1%的准确率至高无上。
XGBoost 是一个可扩展的梯度增强库,当几个获胜的 Kaggle 竞赛团队在提交的作品中使用它时,它就出现了。如果你对“梯度推进”这个术语不熟悉;别担心,我们会保护你的。
今天,我们将深入探讨 Kaggle 竞赛的前奏,看看 XGBoost 如何将您的梯度推向最大潜力。
在本教程中,您将学习如何使用 XGBoost 来缩放 Kaggle 比赛。
本课是关于深度学习 108 的 4 部分系列的第 1 部分:
- 缩放 Kaggle 招商会 Using XGBoost:Part 1(本教程)
- 使用 XGBoost 扩展 Kaggle 竞赛:第 2 部分
- 使用 XGBoost 扩展 Kaggle 竞赛:第 3 部分
- 使用 XGBoost 扩展 Kaggle 竞赛:第 4 部分
要了解如何使用 XGBoost 、来缩放 Kaggle 比赛,请继续阅读。
用 XGBoost 缩放 Kaggle 比赛:第一部分
前言
要理解 XGBoost,我们首先需要理解一些先决条件。你需要熟悉的第一个概念是决策树。
至此,我们都熟悉线性回归。如果没有,就在你的脑海中重新叙述一条线的方程式,
. Take a look at Figure 1.
在这里,我们试图使用X对Y建模。我们绘制了一些数据点。因为这是一个理想的设置,我们已经找到了一个穿过所有点的线性函数。
现在,如果我们通过进入适当的分类任务来使事情变得更复杂,我们必须处理对应于标签的几个特征。理想情况下,假设我们有给定数据集的特征X1和X2,当绘制时,它们完美地将数据集分割成其相应的标签(图 2 )。
这将是每个数据科学家的梦想,因为结果将在瞬间流动。然而,大多数现实生活中的数据集将具有极度非线性的数据,在这种情况下,使用线性函数对数据集进行分类将会很困难(图 3 )。
令人欣慰的是,在我们的回归函数中引入非线性对于这样的数据集来说是我们已经驾轻就熟了。因此,决策树是处理这类复杂数据集的一种非常熟练的算法。
决策树可以被认为是一棵二叉树,它递归地分割数据集,使得至少一个叶节点包含一个单独的类。就个人而言,决策树是我在经典机器学习中遇到的最酷、最具欺骗性的算法。
我最酷的,我指的是它的设计,是这样的,即使是最多样化的数据集也可以很容易地使用决策树来驯服。但另一方面,决策树的实际使用使我相信,在使用决策树时,很容易对训练数据进行过度拟合,特别是对于复杂的数据集。
让我们看一下图 4 ,它显示了一个决策树,该决策树将流行的 iris 数据集分成其相应的类。
十有八九,这张图片对你来说可能看起来超级复杂。所以,让我们破译它的意思;看根节点。我们在根节点中没有足够的信息来分离每个类。因此我们看到一个分布。
根节点的子节点根据花瓣长度条件进行分割。满足小于条件的数据点产生纯节点(即,引用单一类的节点)。在右边的孩子中,满足大于或等于条件的数据点下降,但它仍然是一个分布,因为还有两个类。
因此,在随后的节点中,分布将根据模型创建的条件进一步拆分,当我们沿着树向下移动时,我们会看到叶节点有单独的类。
让我们试着想象一下图 3 的示例数据集的决策树。
在图 5 中,我们尝试为给定数据集形成的可能决策树创建初始树结构。
现在,如果你仔细观察,我们有几个系统分割数据点的条件。虽然使用这些例子可以清楚决策树的一般思想,但直觉上,我们应该注意到许多条件可以极大地增加过度拟合的机会。
让我们继续下一个我们需要的重要前提:集成学习。
因此,决策树提供了一种由几个决策组成的方法,在这种方法中,我们可以将数据集分成相应的类。然而,这种方法有几个缺点,最明显的是过度拟合。
但是,如果我们不使用单一的树,而是使用多个决策树,它们互相帮助,消除薄弱环节,并确保一个健壮的树簇,也可以用来防止过度拟合,会怎么样?
答案在于使用多种机器学习模型来结合从它们的输出中获得的洞察力,以做出更加准确和改进的决策。让我们用多个决策树的例子来更好地理解它。
让我们假设您有一个包含X个特征的数据集。让我们从这些X特征中抽取K个特征,构建一个决策树。如果我们重复这个过程,每次我们的树将有随机数量的特征,并且结果树将是不同的。
现在,剩下的就是将结果汇总在一起,我们的准系统集合模型就准备好了。如果我们也为这一群决策树引入训练数据的随机采样,这就成为非常著名的决策树算法,现在仍在使用,称为随机森林(图 6 )。
这个难题的第三部分是理解什么是梯度增强。虽然我们将在本系列的后续博客中讨论这一概念的数学方面,但让我们试着理解它背后的思想。
假设我们有一些基本数据集,其中基于 3 个特征给出了一个标签。首先,我们将从创建基础树开始。如果我们的任务是一个回归任务,这个树可以是一个输出标签平均值的单个节点。这没多大帮助,但这是我们的起点。
从我们的起始树产生的损失将告诉我们离接近标签有多远。现在,我们创建第二棵树,这将是一个正确的决策树。正如我们已经看到的,决策树可能会过度拟合,导致对方差的考虑非常低。
为了缓解这个问题,我们将确定一棵树在我们的整体结果中所占的比重。结果将是我们的初始根树的输出(标签的平均值)和第二个树的输出的总和,用学习率修改。
如果我们的方向是正确的,那么这个总和产生的损耗将低于初始损耗。我们重复这个过程,直到达到指定的树的数量。如果你想用更简单的术语来理解这一点,一组弱学习者被组合成一个单一的强学习者。
XGBoost
有了对所有先决条件的基本理解,我们就可以继续这个博客的重点了;XGBoost。
XGBoost 代表极端梯度增强,是梯度增强训练的优化解决方案。可以说是当今最强大的经典机器学习算法,它有几个结合了我们迄今为止所学概念的功能:
- 具有防止过度拟合(调整)的步骤
- 可以并行处理
- 具有内置的交叉验证和提前停止功能
- 产生高度优化的结果(更深的树)
在本系列的后续部分中,我们将了解更多关于我们提到的一些概念背后的数学知识,但是现在,让我们在实际场景中使用 XGBoost,并惊叹它是多么简单!
配置您的开发环境
要遵循本指南,您需要在系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
配置先决条件
由于我们与 Kaggle 合作,我们将使用笔记本和 Kaggle 笔记本来编写代码。对于我们今天的数据集,我们直接使用了来自sklearn.datasets的iris数据集。我们的目标是看看在我们的代码中使用 XGBoost 有多简单。
# import necessary packages
import pandas as pd
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
在导入中,我们有pandas、xgboost和几个来自sklearn的帮助器包,其中包括 iris 数据集和train_test_split ( 第 2-6 行)。
插在 XGBoost
现在我们将在代码中直接使用 XGBoost。
# load the iris dataset and create the dataframe
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
在第 9 行,我们使用load_iris功能直接加载所需的数据集,并创建了一个由我们的数据组成的数据框架(第 10 行和第 11 行)。
# split the dataset
xTrain, xTest, yTrain, yTest = train_test_split(X, y)
# define the XGBoost regressor according to your specifications
xgbModel = xgb.XGBRegressor(
n_estimators=100,
reg_lambda=1,
gamma=0,
max_depth=4
)
在第 14 行,我们使用另一个sklearn函数来创建我们的训练和测试分割。随后定义 XGBoost 回归器,它接受以下参数(第 17-22 行):
n_estimators:树木数量reg_lambda:L2 正则化的λ值gamma:分支机构拆分损失的最小减少额max_depth:一棵树的最大深度
# fit the training data in the model
xgbModel.fit(xTrain, yTrain)
# Store the importance of features in a separate dataframe
impFeat = pd.DataFrame(xgbModel.feature_importances_.reshape(1, -1), columns=iris.feature_names)
在第 25 行上,我们将训练中的数据放入我们的回归模型,并让它进行训练。XGBoost 会自动让我们分离出特性的重要性,我们已经在第 28 行完成了。
# get predictions on test data
yPred = xgbModel.predict(xTest)
# store the msq error from the predictions
msqErr = mean_squared_error(yPred, yTest)
最后,我们可以使用训练好的模型对测试数据进行预测(行 31 ),并从预测中手动计算均方误差(行 34 )。
汇总
在这篇介绍性的文章中,我们回顾了理解 XGBoost 所需的一些关键概念。我们学习了决策树、集成模型和梯度提升背后的直觉,并使用 XGBoost 解决了一个解决 iris 数据集的基本问题。
像 XGBoost 这样强大的算法的易用性以及它在任何给定数据集上学习的能力都值得注意。
引用信息
Martinez,H. “使用 XGBoost 扩展 Kaggle 竞赛:第 1 部分”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022,https://pyimg . co/0c9pb
@incollection{Martinez_2022_XGBoost1,
author = {Hector Martinez},
title = {Scaling {Kaggle} Competitions Using {XGBoost}: Part 1},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/0c9pb},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 XGBoost 扩展 Kaggle 竞赛:第 2 部分
原文:https://pyimagesearch.com/2022/12/12/scaling-kaggle-competitions-using-xgboost-part-2/
目录
用 XGBoost 缩放 Kaggle 比赛:第二部分
在我们的之前的教程中,我们浏览了 XGBoost 背后的基本基础,并了解了将一个基本的 XGBoost 模型合并到我们的项目中是多么容易。我们讨论了理解 XGBoost 所需的核心要素,即决策树和集成学习器。
虽然我们学会了将 XGBoost 插入到我们的项目中,但是我们还没有触及到它背后的神奇之处。在本教程中,我们的目标是将 XGBoost 简化为一个黑体,并学习更多关于使它如此优秀的简单数学知识。
但是这个过程是一步一步来的。为了避免在一个教程中加入太多的数学知识,我们来看看今天这个概念背后的数学知识:AdaBoost。一旦清除了这个问题,我们将在下一个教程中最终解决 XGBoost 之前解决梯度增强问题。
在本教程中,您将学习 XGBoost 的一个先决条件背后的数学基础。
我们还将解决一个稍微更具挑战性的 Kaggle 数据集,并尝试使用 XGBoost 来获得更好的结果。
本课是关于深度学习 108 的 4 部分系列的第 2 部分:
- 用 XGBoost 缩放 Kaggle 比赛:第一部分
- 缩放 Kaggle 比赛使用 XGBoost: Part 2 (本教程)
- 使用 XGBoost 扩展 Kaggle 竞赛:第 3 部分
- 使用 XGBoost 扩展 Kaggle 竞赛:第 4 部分
要学习如何算出 AdaBoost 背后的数学,只要坚持读下去。**
用 XGBoost 缩放 Kaggle 比赛:第二部分
在本系列的前一篇博文中,我们简要介绍了决策树和梯度增强等概念,然后讨论了 XGBoost 的概念。
随后,我们看到在代码中使用它是多么容易。现在,让我们把手弄脏,更进一步了解背后的数学!
阿达布斯T3t
AdaBoost(自适应增强)的正式定义是“将弱学习器的输出组合成加权和,代表最终输出。”但这让很多事情变得模糊不清。让我们开始剖析理解这句话的意思。
由于我们一直在处理树,我们将假设我们的自适应提升技术正被应用于决策树。
数据集
为了开始我们的旅程,我们将考虑表 1 中所示的虚拟数据集。
这个数据集的特征主要是“课程”和“项目”,而“工作”列中的标签告诉我们这个人现在是否有工作。如果我们采用决策树方法,我们将需要找出一个合适的标准来将数据集分割成相应的标签。
现在,关于自适应增强,需要记住的一个关键点是,我们是按顺序创建树,并将每个树产生的错误传递给下一个树。在随机森林中,我们会创建全尺寸的树,但在自适应增强中,创建的树是树桩(深度为 1 的树)。
现在,一个总的思路是,一棵树基于某种标准产生的误差决定了第二棵树的性质。让一棵复杂的树过度适应数据将会破坏将许多弱学习者组合成强学习者的目的。然而,AdaBoost 在更复杂的树中也显示了结果。
样本权重
下一步是为数据集中的每个样本分配一个样本权重。最初,所有样本将具有相同的权重,并且它们的权重必须加起来为 1 ( 表 2 )。随着我们向最终目标迈进,样品重量的概念将更加清晰。
现在,由于我们有 7 个数据样本,我们将为每个样本分配 1/7。这意味着所有样本在决策树的最终结构中的重要性是同等重要的。
选择合适的特征
现在我们必须用一些信息初始化我们的第一个 stump。
粗略地看一下,我们可以看到,对于这个虚拟数据集,“courses”特性比“project”特性更好地分割了数据集。让我们在图 1 中亲眼看看这个。
这里的分割因子是一个学生所学课程的数量。我们注意到,在选修 7 门以上课程的学生中,所有人都有工作。相反,对于少于或等于 7 门课程的学生,大多数没有工作。
然而,这种分裂给了我们 6 个正确的预测和 1 个错误的预测。这意味着如果我们使用这个特殊的残肢,我们数据集中的一个样本会给我们错误的预测。
一个树桩的意义
现在,我们特别的树桩做了一个错误的预测。为了计算误差,我们必须将所有未正确分类的样本的权重相加,在本例中为 1/7,因为只有一个样本被错误分类。
现在,AdaBoost 和随机森林之间的一个关键区别是,在前者中,一个树桩在最终输出中可能比其他树桩具有更大的权重。所以这里的问题变成了如何计算
 \ln\left(\displaystyle\frac{1 - \text{loss}}{\text{loss}}\right).")
所以,如果我们把损失值(1/7)代入这个公式,我们得到 0.89。请注意,公式应该给出介于 0 和 1 之间的值。所以 0.89 是一个非常高的值,告诉我们这个特定的树桩对树桩组合的最终输出有很大的发言权。
计算新样本权重
如果我们已经建立了一个分类器,可以对除了一个样本之外的所有样本进行正确的预测,那么我们的自然行动应该是确保我们更多地关注那个特定的样本,以便将其分组到正确的类别中。
目前,所有样品的重量相同(1/7)。但是我们希望我们的分类器更多地关注错误分类的样本。为此,我们必须改变权重。
请记住,当我们改变样品的重量时,所有其他样品的重量也会改变,只要所有的重量加起来为 1。
计算错误分类样本的新权重的公式为
}")
.
插入虚拟数据集中的值就变成了
 \times e^{(0.89)}")
,
得出的值是 0.347。
以前,这个特定样本的样本重量是 1/7,现在变成≈0.142。新的权重为 0.347,意味着样本显著性增加。现在,我们需要相应地移动其余的样本权重。
这个公式是
 \times e^{(-0.89)}")
,
一共是 0.0586。所以现在,代替 1/7,6 个正确预测的样本将具有权重 0.0586,而错误预测的样本将具有权重 0.347。
这里的最后一步是归一化权重,因此它们相加为 1,这使得错误预测的样本的权重为 0.494,而其他样本的权重为 0.084。
向前移动:后续树桩
现在有几种方法可以确定下一个树桩会是什么样子。我们目前的首要任务是确保第二个 stump 用较大的权重对样本进行分类(我们在最后一次迭代中发现权重为 0.494)。
这个样本的重点是因为这个样本导致了我们之前残肢的错误。
虽然没有选择新残肢的标准方法,因为大多数都很好,但一种流行的方法是从我们当前的数据集及其样本权重创建一个新的数据集。
让我们回忆一下目前我们走了多远(表 3 )。
我们的新数据集将来自基于当前权重的随机采样。我们将创建范围的桶。范围如下:
- 我们选择值在 0 和 0.084 之间的第一个样本。
- 对于 0.084 和 0.168 之间的值,我们选择第二个样本。
- 我们选择第三个样本的值为 0.168 和 0.252。
- 我们选择第四个样本的值为 0.252 和 0.746。
到目前为止,我希望您已经理解了我们在这里遵循的模式。这些桶是基于权重形成的:0.084(第一样本)、0.084 + 0.084(第二样本)、0.084 + 0.084(第三样本)、0.084 + 0.084 + 0.494(第四样本),依此类推。
自然地,由于第四个样本具有更大的范围,如果应用随机抽样,它将在我们的下一个数据集中出现更多次。因此,我们的新数据集将有 7 个条目,但它可能有 4 个属于姓名“Tom”的条目我们重置了新数据集的权重,但是直觉上,由于“Tom”出现得更频繁,这将显著影响树的结果。
因此,我们重复这个过程来寻找创建残肢的最佳特征。这一次,由于数据集不同,我们将使用不同的特征而不是球场数量来创建树桩。
请注意,我们一直在说,第一个树桩的输出将决定第二棵树如何工作。这里我们看到了从第一个树桩上获得的重量是如何决定第二棵树如何工作的。对 N 个树桩冲洗并重复该过程。
**我们已经了解了树桩及其产出的重要性。假设我们给我们的树桩组喂一个测试样本。第一个树桩给 1,第二个给 1,第三个给 0,第四个也给 0。
但是由于每棵树都有一个重要值,我们将得到一个最终的加权输出,确定输入到树桩的测试样本的性质。
随着 AdaBoost 的完成,我们离理解 XGBoost 算法又近了一步。现在,我们将处理一个稍微中级的 Kaggle 任务,并使用 XGBoost 解决它。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
设置先决条件
今天,我们将处理美国房地产数据集。让我们从为我们的项目导入必要的包开始。
# import the necessary packages
import pandas as pd
import xgboost as xgb
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
在我们的进口中,我们有pandas、xgboost,以及来自scikit-learn的一些实用函数,如行 2-5 上的mean_squared_error和train_test_split。
# load the data in the form of a csv
estData = pd.read_csv("/content/realtor-data.csv")
# drop NaN values from the dataset
estData = estData.dropna()
# split the labels and remove non-numeric data
y = estData["price"].values
X = estData.drop(["price"], axis=1).select_dtypes(exclude=['object'])
在第 8 行的上,我们使用read_csv来加载 csv 文件作为熊猫数据帧。对数据集进行一些探索性数据分析(EDA)会显示许多 NaN(非数字或未定义的)值。这些会妨碍我们的训练,所以我们丢弃了第 11 行的中所有具有 NaN 值的元组。
我们继续准备第 14 行和第 15 行的标签和特征。我们在我们的特征集中排除任何不包含数值的列。包含这些数据是可能的,但是我们需要将它转换成一次性编码。
我们最终的数据集看起来类似于表 4 。
我们将使用这些特征来确定房子的价格(标签)。
建立模型
我们的下一步是初始化和训练 XGBoost 模型。
# create the train test split
xTrain, xTest, yTrain, yTest = train_test_split(X, y)
# define the XGBoost regressor according to your specifications
xgbModel = xgb.XGBRegressor(
n_estimators=1000,
reg_lambda=1,
gamma=0,
max_depth=4
)
# fit the data into the model
xgbModel.fit(xTrain, yTrain,
verbose = False)
# calculate the importance of each feature used
impFeat = pd.DataFrame(xgbModel.feature_importances_.reshape(1, -1), columns=X.columns)
在第 18 行的上,我们使用train_test_split函数将数据集分成训练集和测试集。对于 XGBoost 模型,我们使用 1000 棵树和最大树深度 4 来初始化它(第 21-26 行)。
我们在第 29 行和第 30 行将训练数据放入我们的模型中。一旦我们的培训完成,我们可以评估我们的模型更重视哪些特性(表 5 )。
表 5 显示特征“bath”最重要。
评估模型
我们的下一步是看看我们的模型在看不见的测试数据上表现如何。
# get predictions on test data
yPred = xgbModel.predict(xTest)
# store the msq error from the predictions
msqErr = mean_squared_error(yPred, yTest)
# assess your model’s results
xgbModel.score(xTest, yTest)
在第 36-39 行上,我们得到了我们的模型对测试数据集的预测,并计算了均方误差(MSE)。由于这是一个回归模型,因此高 MSE 值可以让您放心。
我们的最后一步是使用model.score函数获得测试集的精度值(第 42 行)。
准确率显示我们的模型在测试集上有将近 95%的准确率。
汇总
在本教程中,我们首先了解了 XGBoost 的先决条件之一——自适应增强背后的数学原理。然后,就像我们在本系列中的第一篇博文一样,我们处理了来自 Kaggle 的数据集,并使用 XGBoost 在测试数据集上获得了相当高的准确度,再次确立了 XGBoost 作为领先的经典机器学习技术之一的主导地位。
在我们最终剖析 XGBoost 的基础之前,我们的下一站将是找出梯度增强背后的数学原理。
引用信息
Martinez,H. “使用 XGBoost 扩展 Kaggle 竞赛:第 2 部分”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/2wiy7
@incollection{Martinez_2022_XGBoost2,
author = {Hector Martinez},
title = {Scaling {Kaggle} Competitions Using {XGBoost}: Part 2},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/2wiy7},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
用 Python 和 Scrapy 抓取图像
原文:https://pyimagesearch.com/2015/10/12/scraping-images-with-python-and-scrapy/
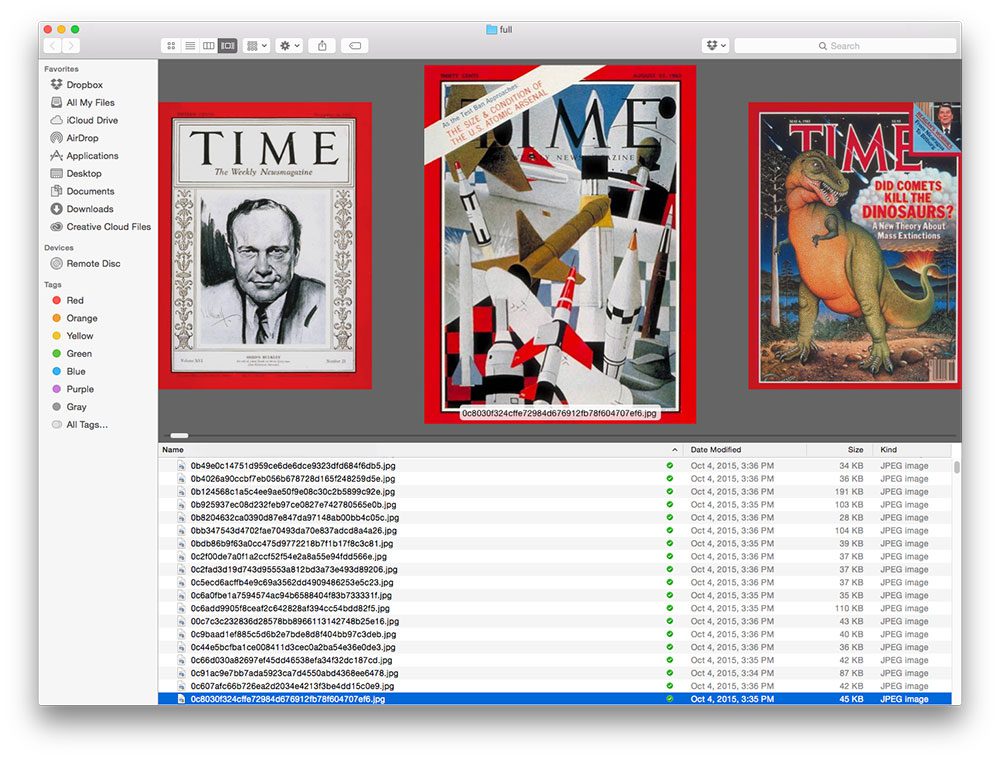 既然这是一个计算机视觉和 OpenCV 的博客,你可能会奇怪:“嘿,阿德里安,你到底为什么要谈论刮图像?”
既然这是一个计算机视觉和 OpenCV 的博客,你可能会奇怪:“嘿,阿德里安,你到底为什么要谈论刮图像?”
问得好。
原因是因为图像采集是计算机视觉领域最少被谈论的课题之一!
想想吧。无论您是利用机器学习来训练图像分类器,还是构建图像搜索引擎来在一组照片中找到相关图像,或者只是开发您自己的爱好计算机视觉应用程序— 这一切都始于图像本身。
这些图像从何而来?
嗯,如果你幸运的话,你可能会利用现有的图像数据集,如加州理工学院-256、 ImageNet 或 MNIST 。
但是在你找不到适合你需求的数据集的情况下(或者当你想要创建你自己的定制数据集时),你可能需要完成收集你的图像的任务。虽然从网站上抓取图片并不完全是一种计算机视觉技术,但 仍然是一项你可以随身携带的好技能。
*在这篇博文的剩余部分,我将向你展示如何使用 Scrapy 框架和 Python 编程语言从网页中抓取图像。
具体来说,我们会刮 所有【Time.com】杂志封面图片。然后,我们将在接下来的几篇博客文章中使用这个杂志封面图像数据集,因为我们应用了一系列图像分析和计算机视觉算法来更好地探索和理解数据集。
安装刮刀
实际上,在我的 OSX 机器上安装 Scrapy 时我遇到了一点问题——无论我做了什么,我就是无法正确安装依赖项(闪回到我在大学本科时第一次尝试安装 OpenCV)。
在几个小时的修补没有成功之后,我干脆放弃了,切换到我的 Ubuntu 系统,在那里我使用了 Python 2.7 。之后,安装变得轻而易举。
你需要做的第一件事是安装一些依赖项来帮助 Scrapy 解析文档(再次提醒,记住我是在我的 Ubuntu 系统上运行这些命令的):
$ sudo apt-get install libffi-dev
$ sudo apt-get install libssl-dev
$ sudo apt-get install libxml2-dev libxslt1-dev
注:这个下一步是可选的, 但是我 强烈建议你去做 。
然后,我使用 virtualenv 和 virtualenvwrapper 创建了一个名为scrapy的 Python 虚拟环境,以保持我的系统site-packages独立,并与我即将设置的新 Python 环境隔离。同样,这是可选的,但是如果你是一个virtualenv用户,这样做没有坏处:
$ mkvirtualenv scrapy
无论是哪种情况,现在我们都需要安装 Scrapy 和 Pillow ,如果您计划抓取实际的二进制文件(比如图像),这是一个必要条件:
$ pip install pillow
$ pip install scrapy
Scrapy 应该花几分钟的时间来删除它的依赖项、编译和安装。
您可以通过打开一个 shell(如有必要,访问scrapy虚拟环境)并尝试导入scrapy库来测试 Scrapy 是否安装正确:
$ python
>>> import scrapy
>>>
如果你得到一个导入错误(或任何其他错误),很可能 Scrapy 没有正确地链接到一个特定的依赖项。再说一次,我不是争斗专家,所以如果你遇到问题,我会建议你咨询一下文档或者在争斗社区上发帖。
创建 Scrapy 项目
如果你以前使用过 Django web 框架,那么你应该对 Scrapy 如鱼得水——至少在项目结构和模型-视图-模板模式方面;虽然,在这种情况下,它更像是一个模型——蜘蛛模式。
要创建我们的 Scrapy 项目,只需执行以下命令:
$ scrapy startproject timecoverspider
运行该命令后,您将在当前工作目录中看到一个timecoverspider。进入timecoverspider目录,你会看到下面这个杂乱的项目结构:
|--- scrapy.cfg
| |--- timecoverspider
| | |--- __init__.py
| | |--- items.py
| | |--- pipelines.py
| | |--- settings.py
| | |--- spiders
| | | |---- __init__.py
| | | |---- coverspider.py # (we need to manually create this file)
为了开发我们的时代杂志封面爬虫,我们需要编辑以下两个文件:items.py和settings.py。我们还需要在spiders目录中创建我们的客户蜘蛛coverspider.py
让我们从只需要快速更新的settings.py文件开始。第一个是找到ITEMS_PIPELINE元组,取消对它的注释(如果它被注释掉了),并添加如下设置:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy.contrib.pipeline.images.FilesPipeline': 1,
}
这个设置将激活 Scrapy 的默认文件抓取功能。
第二次更新可以附加到文件的底部。该值FILES_STORE只是输出目录的路径,下载图像将存储在该目录中:
FILES_STORE = "/home/adrian/projects/time_magazine/timecoverspider/output"
同样,随意将这个设置添加到settings.py文件的底部——放在文件的什么地方并不重要。
现在我们可以继续讨论items.py,它允许我们为蜘蛛抓取的网页定义一个数据对象模型:
# import the necessary packages
import scrapy
class MagazineCover(scrapy.Item):
title = scrapy.Field()
pubDate = scrapy.Field()
file_urls = scrapy.Field()
files = scrapy.Field()
这里的代码非常简单明了。在第 2 行我们导入我们的scrapy包,然后在第 4 行定义MagazineCover类。这个类封装了我们从每个time.com杂志封面网页上收集的数据。对于这些页面,我们将返回一个MagazineCover对象,其中包括:
title:当前时间杂志期的标题。例如,这可能是、【红色代码】、、【有用的文凭】、、、【无限机器】、等。pubDate:该字段以year-month-day格式存储问题发布的日期。file_urls:file_urls字段是一个 非常重要的 字段,你必须 显式 定义来抓取二进制文件(无论是图片、pdf、MP3)等。从一个网站上。你不能用不同的名字命名这个变量,它必须在你的Item子类中。files:同样,抓取二进制数据时需要files字段。不要给它起任何不同的名字。要了解更多关于用于将二进制数据保存到磁盘的Item子类结构的信息,请务必阅读 Scrapy Google Groups 上的这篇帖子。
现在我们已经更新了我们的设置并创建了我们的数据模型,我们可以继续进行最难的部分——实际实现蜘蛛抓取封面图片的时间。在spiders目录中创建一个新文件,将其命名为coverspider.py,然后我们开始工作:
# import the necessary packages
from timecoverspider.items import MagazineCover
import datetime
import scrapy
class CoverSpider(scrapy.Spider):
name = "pyimagesearch-cover-spider"
start_urls = ["http://search.time.com/results.html?N=46&Ns=p_date_range|1"]
2-4 线负责进口我们需要的包装。我们将确保导入我们的MagazineCover数据对象,datetime来解析来自Time.com网站的日期,然后是scrapy来访问我们实际的爬行和抓取工具。
从那里,我们可以定义行 6 上的CoverSpider类,它是scrapy.Spider的子类。这个类需要有两个预定义的值:
- 我们蜘蛛的名字。
name应该是描述蜘蛛做什么的;然而,不要让它太长,因为你必须手动输入到你的命令行来触发和执行它。 - 这是蜘蛛将首先抓取的种子 URL 列表。我们在这里提供的 URL 是【Time.com 封面浏览器的主页。
每个 Scrapy spider 都需要(至少)有一个处理解析start_urls的parse方法。这个方法反过来可以产生其他请求,触发其他页面被抓取和爬行,但至少,我们需要定义我们的parse函数:
# import the necessary packages
from timecoverspider.items import MagazineCover
import datetime
import scrapy
class CoverSpider(scrapy.Spider):
name = "pyimagesearch-cover-spider"
start_urls = ["http://search.time.com/results.html?N=46&Ns=p_date_range|1"]
def parse(self, response):
# let's only gather Time U.S. magazine covers
url = response.css("div.refineCol ul li").xpath("a[contains(., 'TIME U.S.')]")
yield scrapy.Request(url.xpath("@href").extract_first(), self.parse_page)
Scrapy 令人惊叹的一个方面是能够使用简单的 CSS 和 XPath 选择器遍历文档对象模型 (DOM)。在第 12 行,我们遍历 DOM 并获取包含文本TIME U.S.的链接的href(即 URL)。我在下面的截图中突出显示了“美国时间”链接:
Figure 1: The first step in our scraper is to access the “TIME U.S.” page.
通过使用 Chrome 浏览器,右键单击 link 元素,选择 Inspect 元素",并使用 Chrome 的开发工具遍历 DOM,我可以获得这个 CSS 选择器:
Figure 2: Utilizing Chrome’s Developer tools to navigate the DOM.
现在我们有了链接的 URL,我们产生了该页面的一个Request(这实际上是告诉 Scrapy“点击那个链接”),表明应该使用parse_page方法来处理对它的解析。
时间美国页面截图如下:
Figure 3: On this page we need to extract all “Large Cover” links, followed by following the “Next” link in the pagination.
我们解析这个页面有两个主要目标:
- 目标#1: 抓取所有带文字【大封面】(上图中以 突出显示绿色 )的链接的 URL。
- 目标#2: 一旦我们抓取了所有的【大封面】链接,我们需要点击【下一页】按钮(在中高亮显示),允许我们跟随分页并解析的所有 期并抓取它们各自的封面。
***下面是我们对parse_page方法的实现,以实现这一点:
def parse_page(self, response):
# loop over all cover link elements that link off to the large
# cover of the magazine and yield a request to grab the cove
# data and image
for href in response.xpath("//a[contains(., 'Large Cover')]"):
yield scrapy.Request(href.xpath("@href").extract_first(),
self.parse_covers)
# extract the 'Next' link from the pagination, load it, and
# parse it
next = response.css("div.pages").xpath("a[contains(., 'Next')]")
yield scrapy.Request(next.xpath("@href").extract_first(), self.parse_page)
我们从第 19 行的开始,遍历所有包含文本Large Cover的链接元素。对于这些链接中的每一个,我们“点击”它,并使用parse_covers方法(我们将在几分钟内定义)向该页面发出请求。
然后,一旦我们生成了对所有封面的请求,就可以安全地单击Next按钮,并使用相同的parse_page方法从下一页提取数据——这个过程一直重复,直到我们完成了杂志期的分页,并且在分页中没有其他页面要处理。
最后一步是提取title、pubDate,存储时间封面图像本身。从时间 开始的封面截图示例如下:
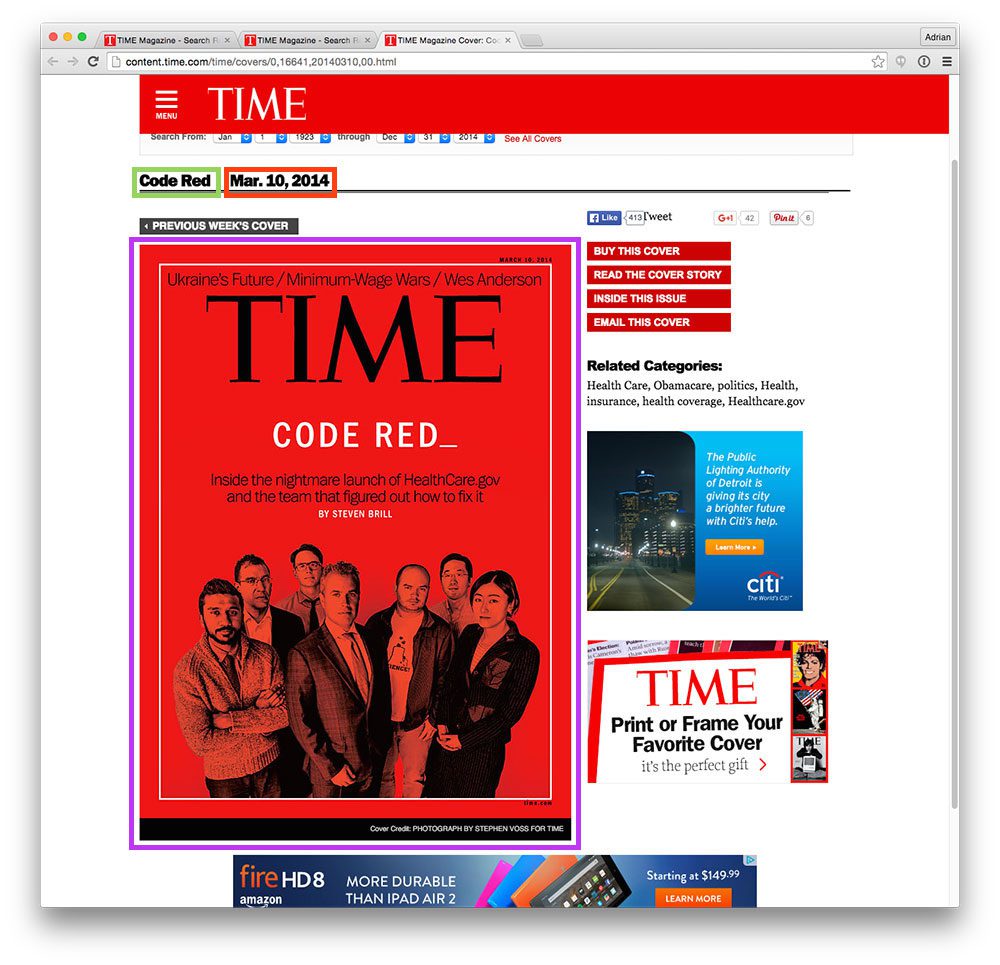
Figure 4: On the actual cover page, we need to extract the issue title, publish date, and cover image URL.
这里我用 绿色 突出显示了刊名,用 红色 突出显示了出版日期,用 紫色 突出显示了封面图片本身。剩下要做的就是定义parse_covers方法来提取这些数据:
def parse_covers(self, response):
# grab the URL of the cover image
img = response.css(".art-cover-photo figure a img").xpath("@src")
imageURL = img.extract_first()
# grab the title and publication date of the current issue
title = response.css(".content-main-aside h1::text").extract_first()
year = response.css(".content-main-aside h1 time a::text").extract_first()
month = response.css(".content-main-aside h1 time::text").extract_first()[:-2]
# parse the date
date = "{} {}".format(month, year).replace(".", "")
d = datetime.datetime.strptime(date, "%b %d %Y")
pub = "{}-{}-{}".format(d.year, str(d.month).zfill(2), str(d.day).zfill(2))
# yield the result
yield MagazineCover(title=title, pubDate=pub, file_urls=[imageURL])
正如其他解析方法一样,parse_covers方法也很简单。第 30 行和第 31 行提取封面图片的 URL。
第 33 行抓取杂志期的标题,而第 35 行和第 36 行提取出版年月。
然而,出版日期可以使用一点格式——让我们在year-month-day中创建一个组合格式。虽然目前还不完全清楚为什么这种日期格式是有用的,但在下周的帖子中,当我们实际上对杂志封面本身执行时间图像分析时,这将是非常明显的。
最后,第 44 行产生一个MagazineCover对象,包括title、pubDate和imageURL(它将被下载并存储在磁盘上)。
运行蜘蛛
要运行 Scrapy spider 来抓取图像,只需执行以下命令:
$ scrapy crawl pyimagesearch-cover-spider -o output.json
这将启动图像抓取过程,将每个MagazineCover项序列化为一个输出文件output.json。由此产生的图像将被保存在full中,这是 Scrapy 在output目录中自动创建的子目录,我们通过上面settings.py中的FILES_STORE选项指定该目录。
下面是图像抓取过程运行的屏幕截图:
Figure 5: Kicking off our image scraper and letting it run.
在我的系统上,整个刮抢 全部 时间杂志封面使用 Python + Scrapy 拍了一张迅疾的2m 23s——不差近 4000 张图片!
我们的全套时代杂志封面
既然我们的蜘蛛已经刮完了时代杂志封面,让我们来看看我们的output.json档案:
Figure 6: A screenshot of our output.json file.
为了逐个检查它们,让我们启动一个 Python shell,看看我们在做什么:
$ python
>>> import json
>>> data = open("output.json").read()
>>> data = json.loads(data)
>>> len(data)
3969
我们可以看到,我们总共刮到了3969 张图片。
data列表中的每个条目都是一个字典,它本质上映射到我们的MagazineCover数据模型:
>>> data[0]
{u'files': [{u'url': u'http://img.timeinc.net/time/magazine/archive/covers/2014/1101140113_600.jpg', u'path': u'full/78a2264fb6103aaf20ff13982a09cb182294709d.jpg', u'checksum': u'02a6b4d22402fd9d5642535bea950c5f'}], u'file_urls': [u'http://img.timeinc.net/time/magazine/archive/covers/2014/1101140113_600.jpg'], u'pubDate': u'2014-01-13', u'title': u'2014: The Year Ahead '}
>>> data[0].keys()
[u'files', u'file_urls', u'pubDate', u'title']
我们可以像这样轻松地获取到时间封面图像的路径:
>>> print("Title: {}\nFile Path: {}".format(data[0]["title"], data[0]["files"][0]["path"]))
Title: 2014: The Year Ahead
File Path: full/78a2264fb6103aaf20ff13982a09cb182294709d.jpg
检查output/full目录我们可以看到我们有自己的3969 张图片:
$ cd output/full/
$ ls -l *.jpg | wc -l
3969
Figure 7: Our dataset of Time magazine cover images.
现在我们有了所有这些图像,最大的问题是: “我们要用它们做什么?!"
我将在接下来的几篇博文中回答这个问题。我们将花一些时间使用计算机视觉和图像处理技术来分析这个数据集,所以不要担心,您的带宽没有白白浪费!
注意:如果 Scrapy 没有为你工作(或者如果你不想麻烦地设置它),不用担心——我已经在本页底部找到的帖子的源代码下载中包括了output.json和原始的、粗糙的.jpg图像。您仍然可以毫无问题地阅读即将发布的 PyImageSearch 帖子。
摘要
在这篇博文中,我们学习了如何使用 Python 抓取《时代》杂志的所有封面图片。为了完成这个任务,我们利用了 Scrapy ,一个快速而强大的网络抓取框架。总的来说,我们的整个蜘蛛文件由不到 44 行代码 组成,这真正展示了 Scrapy libray 背后的能力和抽象。
那么现在我们有了这个关于时代杂志封面、的数据集,我们该怎么处理它们呢?
好吧,这毕竟是一个计算机视觉博客——所以下周我们将从一个视觉分析项目开始,在那里我们对封面图像进行时间调查。这是一个非常酷的项目,我对此非常兴奋!
请务必使用本文底部的表格注册 PyImageSearch 时事通讯— 当我们分析时代杂志封面数据集时,你不会想错过后续的文章!****
使用 OpenCV、Python 和 scikit 进行线缝雕刻-图像
原文:https://pyimagesearch.com/2017/01/23/seam-carving-with-opencv-python-and-scikit-image/

很容易,我一直以来最喜欢的计算机视觉文献之一是三菱电机研究实验室(MERL)的 Avidan 和 Shamir 的Seam Carving for Content-Aware Image Resizing。
最初发表在 SIGGRAPH 2007 会议录上,我第一次读到这篇论文是在我的计算摄影课上,当时我还是一名本科生。
这篇论文,以及来自作者、、的演示视频,让该算法感觉像魔法、,尤其是对一个刚刚涉足计算机视觉和图像处理领域的学生来说。
接缝雕刻算法的工作原理是找到被称为接缝的具有低能量(即最不重要)的连接像素,这些像素从左到右或从上到下穿过整个图像。
然后从原始图像中移除这些接缝,允许我们在保留最显著区域的同时调整图像的大小(原始算法还支持添加接缝,允许我们增加图像大小)。
在今天博文的剩余部分,我将讨论 seam carving 算法,它是如何工作的,以及如何使用 Python、OpenCV 和 sickit-image 应用 seam carving。
要了解更多关于这个经典的计算机视觉算法,就继续阅读吧!
使用 OpenCV、Python 和 scikit 进行线缝雕刻-图像
这篇博文的第一部分将讨论什么是接缝雕刻算法以及为什么我们可能更喜欢使用它而不是传统的调整大小方法。
从那以后,我将使用 OpenCV、Python 和 scikit-image 演示如何使用 seam carving。
最后,我将通过提供一个实际的接缝雕刻算法演示来结束本教程。
接缝雕刻算法
由 Avidan 和 Shimar 在 2007 年引入的 seam carving 算法用于通过移除/添加具有低能量的接缝来调整(下采样和上采样)图像的大小。
接缝被定义为从左到右或从上到下流动的连接像素,只要它们穿过图像的整个宽度/高度。
因此,为了进行接缝雕刻,我们需要两个重要的输入:
- 原始图像。这是我们想要调整大小的输入图像。
- 能量地图。我们从原始图像中导出能量图。能量图应该代表图像中最显著的区域。通常,这是梯度幅度表示(即 Sobel、Scharr 等的输出)。算子)、熵图或显著图。
例如,让我们看看下面的图像:
![Figure 1: Our input image to the seam carving algorithm [source: Wikipedia].](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/c02560ae412de8ed74212660f82c48ba.png)
图 1: 我们将图像输入到缝雕算法中【来源:维基。
使用此图像作为输入,我们可以计算梯度幅度作为我们的能量图:![Figure 2: Computing the gradient magnitude representation of of the input image. This representation will serve as our energy map [source: Wikipedia].](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/44855e72570f8eb9e263e81e7c1f442f.png)
图 2: 计算输入图像的渐变幅度表示。这种表现将作为我们的能量图【来源:维基百科】。
给定我们的能量图,我们可以生成一组从左到右或从上到下跨越图像的接缝:![Figure 3: Generating seams from the energy map. Low energy seams can be removed/duplicated to perform the actual resizing [source: Wikipedia].](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/6240f5e00ff977c8320614c66bc1a072.png)
图 3: 从能量图中生成接缝。低能量接缝可以被移除/复制以执行实际的尺寸调整【来源:维基百科】。
这些接缝通过动态编程有效计算,并按其能量排序。低能焊缝位于列表的前面,而高能焊缝位于列表的后面。
为了调整图像的大小,我们或者用低能量移除接缝来下采样图像,或者我们用低能量复制接缝来上采样图像。
下面是一个示例,它获取原始图像,找到能量最低的接缝,然后移除它们以减小输出图像的最终大小:
![Figure 4: Removing low energy seams from an image using the seam carving algorithm [source: Wikipedia].](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/3108e377f1de2f4b01eb059998aa4ea1.png)
图 4: 使用线缝雕刻算法从图像中去除低能线缝【来源:维基百科。
关于接缝雕刻算法的更多信息,请参见原始出版物。
为什么使用传统的缝雕刻超过传统的调整大小?
请记住,线缝雕刻的目的是保留图像中最突出的(即“有趣的”)区域,同时仍然调整图像本身的大小。
使用传统的方法来调整大小会改变整个图像的尺寸——没有注意确定图像的哪个部分最重要或者最不重要。
相反,Seam carving 应用从能量图导出的试探法/路径查找来确定图像的哪些区域可以被移除/复制,以确保(1)图像的所有“感兴趣”区域被保留,以及(2)这是以美学上令人愉悦的方式完成的。
注意:以一种审美愉悦的方式保留图像中最有趣的区域比听起来要困难得多。虽然缝雕看起来像魔术,但实际上不是——它有其局限性。有关这些限制的更多信息,请参见“概述”部分。
要比较传统的调整大小和线缝雕刻,请考虑以下输入图像:

Figure 5: An example image to resize.
这张图片的宽度是 600 像素,我想把它的大小调整到大约 500 像素。
使用传统的插值方法,我调整后的图像看起来像这样:

Figure 6: Resizing an image using traditional interpolation techniques. Notice how the height changes along with the width to retain the aspect aspect ratio.
然而,通过应用缝雕,我可以沿水平方向“缩小”图像,并且仍然保留图像中最有趣的区域,而不需要改变图像的高度:

Figure 7: Resizing the image using seam carving.
缝雕在计算机视觉和图像处理中的应用
在这一节中,我将演示如何在 OpenCV、Python 和 scikit-image 中使用 seam carving。
我假设您的系统上已经安装了 OpenCV——如果没有,请参考本页,我在这里提供了在许多不同的操作系统上安装 OpenCV 的资源。
从那里,你应该确保你已经安装了 scikit-image 。本页提供了关于安装 scikit-image 的更多信息,但是对于大多数系统,您可以使用pip:
$ pip install --upgrade scikit-image
让我们来看看如何将缝雕应用到我们自己的图像中。
打开一个新文件,将其命名为seam_carving.py,并插入以下代码:
# import the necessary packages
from skimage import transform
from skimage import filters
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image file")
ap.add_argument("-d", "--direction", type=str,
default="vertical", help="seam removal direction")
args = vars(ap.parse_args())
第 2-5 行导入我们需要的 Python 包,而第 8-13 行解析我们的命令行参数。这个脚本需要一个参数,后面跟着第二个可选参数:
--image:我们要应用线缝雕刻的输入图像的路径。--direction:我们将应用缝雕的方向。值vertical将调整图像宽度,而值horizontal将调整图像高度。我们默认雕刻方向为vertical。
接下来,让我们从磁盘加载我们的输入图像,将其转换为灰度,并计算 Sobel 梯度幅度表示(即,我们的能量图):
# load the image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# compute the Sobel gradient magnitude representation
# of the image -- this will serve as our "energy map"
# input to the seam carving algorithm
mag = filters.sobel(gray.astype("float"))
# show the original image
cv2.imshow("Original", image)
为了应用 seam carving,我们将使用 scikit-image 库中的实现。seam_carve函数接受四个必需的参数:
- 我们正在应用线缝雕刻的输入
image。 - 能源地图。
- 我们将应用缝雕的方向(水平或垂直)。
- 要移除的接缝数量。此时,
seam_carve函数仅支持下采样图像——不支持上采样。
为了演示接缝雕刻的实际操作,让我们循环查看一些要移除的接缝:
# loop over a number of seams to remove
for numSeams in range(20, 140, 20):
# perform seam carving, removing the desired number
# of frames from the image -- `vertical` cuts will
# change the image width while `horizontal` cuts will
# change the image height
carved = transform.seam_carve(image, mag, args["direction"],
numSeams)
print("[INFO] removing {} seams; new size: "
"w={}, h={}".format(numSeams, carved.shape[1],
carved.shape[0]))
# show the output of the seam carving algorithm
cv2.imshow("Carved", carved)
cv2.waitKey(0)
我们调用第 33 行和第 34 行上的seam_carve函数,删除当前的numSeams数。
新雕刻的图像尺寸打印在我们终端的第 35-37 行上。
我们还在屏幕的第 40 行和第 41 行上显示接缝雕刻图像。
接缝雕刻结果
要亲自尝试这个 seam carving 示例,请务必使用本文底部的 【下载】 部分下载源代码和示例图像。
从那里,执行以下命令:
$ python seam_carving.py --image bryce_canyon.jpg

Figure 8: (Left) The original input image. (Right) Removing vertical seams from the image, thereby decreasing the image width.
在左边的你可以看到原始输入图像——一张布莱斯峡谷的照片,布莱斯峡谷是美国最美丽的国家公园之一。然后在右边我们有缝刻图像。正如你所看到的,我们已经从图像中移除了垂直接缝,从而减小了图像宽度。
我们可以通过移除水平接缝来降低图像高度:
$ python seam_carving.py --image bryce_canyon.jpg --direction horizontal

Figure 9: (Left) The original image. (Right) Removing horizontal seams from the image to decrease height.
我还在下面包含了一个 GIF 动画,演示了一次一个像素的接缝雕刻,让您对算法有更好的感觉:
Figure 10: Applying seam carving to an image using OpenCV, Python, and scikit-image.
摘要
在今天的博文中,我讨论了用于图像内容感知大小调整的开创性 seam carving 算法。
这是计算机视觉文献中的一个经典算法,所以如果你还没有读过原始出版物,我建议你把它加入你的阅读清单。
在这篇论文中,Avidan 和 Shimar 证明了线缝雕刻不仅可以用于缩小图像尺寸,还可以用于增大图像尺寸。然而,scikit-image 实现目前仅支持缩减采样。
虽然这个算法对我这个大学生来说可能感觉像是“魔法”,但我最终了解到,在计算机视觉世界中没有魔法这种东西——每种算法都有其局限性。
对于线缝雕刻,这些限制通常表现为视觉效果不佳,其中图像的重要语义信息被部分破坏或完全切除。一个很好的例子是将接缝雕刻应用于包含面的图像,并且面上的接缝被移除。
为了解决这个问题,我们可以注释我们的图像,为接缝雕刻算法提供“提示”,确保在接缝雕刻过程中标记的区域不会被切割。在理想情况下,我们可以提供更好地反映我们希望保留的图像的显著区域的能量图,从而不需要修改实际的接缝雕刻算法。
个人很有兴趣看看缝雕的未来景观。随着深度学习算法用于显著性检测等任务,这些显著图可以用于接缝雕刻。我们最终可能会看到一个端到端的缝雕网络。
无论如何,我希望你喜欢这篇经典计算机视觉论文的讨论!
为了在以后的博客文章发布时得到通知,请务必在下表中输入您的电子邮件地址。
基于 OpenCV 和深度学习的语义切分
原文:https://pyimagesearch.com/2018/09/03/semantic-segmentation-with-opencv-and-deep-learning/

在本教程中,您将学习如何使用 OpenCV、深度学习和 ENet 架构来执行语义分割。阅读完今天的指南后,您将能够使用 OpenCV 对图像和视频应用语义分割。
深度学习帮助促进了计算机视觉前所未有的准确性,包括图像分类、物体检测,现在甚至还有分割。
传统的分割包括将图像分割成多个部分(归一化切割、图形切割、抓取切割、超像素等)。);然而,算法没有真正的理解这些部分代表什么。
语义分割另一方面,算法试图:
- 将图像分割成有意义的部分
- 同时,将输入图像中的每个像素与类别标签(即,人、道路、汽车、公共汽车等)相关联。)
语义分割算法超级强大,有许多用例,包括无人驾驶汽车——在今天的帖子中,我将向你展示如何将语义分割应用于道路场景图像/视频!
要了解如何使用 OpenCV 和深度学习应用语义分割,继续阅读!
基于 OpenCV 和深度学习的语义切分
https://www.youtube.com/embed/1iK1gMOVZF0?feature=oembed
语义分割、实例分割和全景分割
原文:https://pyimagesearch.com/2022/06/29/semantic-vs-instance-vs-panoptic-segmentation/
目录
语义对比实例对比全景分割
在本教程中,您将了解语义分割、实例分割和全景分割。
这些图像分割技术有何不同?
基里洛夫等人(2018) 提出了一种新型的图像分割技术,称为全景分割,这为确定三种(即语义、实例和全景)图像分割技术中的最佳技术展开了辩论。
在我们深入这场辩论之前,理解图像分割的基础知识是很重要的,包括things和stuff之间的比较。
图像分割是一种计算机视觉和图像处理技术,涉及在像素级别上对图像中的相似区域或片段进行分组或标记。类别标签或遮罩表示每个像素段。
在图像分割中,一幅图像有两个主要成分:things和stuff。事物对应于图像中的可数对象(例如,人、花、鸟、动物等。).相比之下,stuff 表示相似材料的无定形区域(或重复模式),这是不可数的(例如,道路、天空和草地)。
在本课中,我们将根据语义、实例和全景图像分割技术如何对待things和stuff来区分它们。
我们开始吧!
区别
语义分割、实例分割和全景分割的区别在于它们如何处理图像中的things和stuff。
语义分割研究图像中的不可数stuff。它分析每个图像像素,并根据它所代表的纹理分配一个唯一的类别标签。例如,在图 1 的中,一幅图像包含两辆汽车、三个行人、一条道路和天空。两辆车和三个行人代表了相同的纹理。
语义分割将为这些纹理或类别中的每一个分配唯一的类别标签。然而,语义分割的输出不能分别区分或计数两辆汽车或三个行人。常用的语义分割技术包括 SegNet、U-Net、DeconvNet 和 FCNs。
实例分割通常处理与可计数things相关的任务。它可以检测图像中出现的每个对象或类的实例,并为其分配具有唯一标识符的不同遮罩或边界框。
例如,实例分段将把前一个例子中的两辆汽车分别标识为car_1和car_2。常用的实例分割技术有 Mask R-CNN、fast R-CNN、PANet 和 YOLACT。图 2 展示了不同的实例分割检测。
语义和实例分割技术的目标都是连贯地处理场景。自然,我们希望在场景中识别出stuff和things,以构建更实际的真实世界应用程序。研究人员设计了一种解决方案来协调场景中的stuff和things(即全景分割)。
全景分割两全其美。它提出了一种统一的图像分割方法,其中场景中的每个像素被分配一个语义标签(由于语义分割)和一个唯一的实例标识符(由于实例分割)。
全景分割只给每个像素分配一对语义标签和实例标识符。但是,对象可以有重叠的像素。在这种情况下,全景分割通过支持对象实例来解决差异,因为优先级是识别每个thing而不是stuff。图 3 展示了不同的全景分割检测。


Figure 3: Panoptic segmentation examples (source: FPSNet).
大多数全景分割模型都是基于掩模 R-CNN 方法。其骨干架构包括 UPSNet 、 FPSNet 、 EPSNet 和 VPSNet 。
评价指标
每种分割技术使用不同的评估度量来评估场景中的预测遮罩或标识符。这是因为stuff和things的处理方式不同。
语义分割通常采用联合 ( IoU )上的交集度量(也称为 Jaccard 索引),该度量检查预测的和基本事实掩码之间的相似性。它决定了两个遮罩之间有多少区域重叠。除了 IoU,我们还可以使用骰子系数、像素精度和平均精度指标来执行更鲁棒的评估。这些指标不考虑对象级标签。
另一方面,实例分割使用平均精度 (AP)作为标准评估度量。AP 指标对每个对象实例逐个像素地使用 IoU。
最后,全景分割使用全景质量 (PQ)度量,该度量评估things和stuff的预测遮罩和实例标识符。PQ 通过乘以分割质量(SQ)和识别质量(RQ)项来统一所有类别的评估。SQ 表示匹配片段的平均 IoU 分数,而 RQ 是使用预测掩码的精度和召回值计算的 F1 分数。
**所有这三种图像分割技术在计算机视觉和图像处理中有重叠的应用。它们共同提供了许多现实世界的应用,帮助人类增加认知带宽。语义和实例分割的一些实际应用包括:
- 自动驾驶汽车或自动驾驶汽车: 3D 语义分割通过识别街道上的不同物体,让车辆更好地了解自己的环境。同时,实例分割识别每个对象实例,以便为计算速度和距离提供更大的深度。
- 分析医学扫描:这两种技术都可以在 MRI、CT 和 X 射线扫描中识别肿瘤和其他异常。
- 卫星或航空图像:这两种技术都提供了一种从太空或高空绘制世界地图的方法。它们可以勾勒出世界物体的轮廓,如河流、海洋、道路、农田、建筑物等。这类似于它们在场景理解中的应用。
全景分割将自动驾驶汽车的视觉感知提升到了一个新的水平。它可以产生像素级精度的精细掩模,使自动驾驶汽车能够做出更准确的驾驶决策。此外,全景分割在医学图像分析、数据注释、数据扩充、UAV(无人驾驶飞行器)遥感、视频监控和人群计数等方面得到了更多的应用。在所有领域,全景分割提供了更大的深度和准确性,同时预测遮罩和边界框。
总结:该用哪个?
图像分割是人工智能革命的重要组成部分。它是各种行业(例如,制造业、零售业、医疗保健和运输业)的自主应用程序的核心组件。
历史上,由于硬件限制,图像分割在大范围内是无效的。如今,借助 GPU、云 TPUs 和边缘计算,普通消费者都可以使用图像分割应用。
在本课中,我们讨论了语义、实例和全景图像分割技术。这三种技术在学术界和现实世界中都有有效的应用。在过去的几年中,全景分割在研究人员中得到了更多的发展,以推进计算机视觉领域。相比之下,语义分割和实例分割有许多现实世界的应用,因为它们的算法更成熟。在任何形式下,图像分割对于推进各行业的超自动化都是至关重要的。
参考
Shiledarbaxi,n . .语义 vs 实例 vs 全景:选择哪种图像分割技术,开发者角落,2021 年。
用 Python 设置 Ubuntu 16.04 + CUDA + GPU 进行深度学习
原文:https://pyimagesearch.com/2017/09/27/setting-up-ubuntu-16-04-cuda-gpu-for-deep-learning-with-python/

欢迎回来!这是深度学习开发环境配置系列的第四篇文章,伴随我的新书, 用 Python 进行计算机视觉的深度学习。
今天,我们将为您配置 Ubuntu + NVIDIA GPU + CUDA,让您在 GPU 上训练自己的深度学习网络时获得成功。
相关教程的链接可在此处找到:
- 你的深度学习+ Python Ubuntu 虚拟机
- 用 Python 预配置亚马逊 AWS 深度学习 AMI
- 用 Python 为深度学习配置 Ubuntu(仅针对 CPU 的环境)
- 用 Python 设置 Ubuntu 16.04 + CUDA + GPU 进行深度学习(本帖)
- 用 Python 配置 macOS 进行深度学习(周五发布)
如果你有一个兼容 NVIDIA CUDA 的 GPU,你可以使用本教程来配置你的深度学习开发,以在你优化的 GPU 硬件上训练和执行神经网络。
让我们开始吧!
用 Python 设置 Ubuntu 16.04 + CUDA + GPU 进行深度学习
如果你已经达到了这一点,你可能对深度学习很认真,并希望用 GPU 来训练你的神经网络。
图形处理单元因其并行处理架构而在深度学习方面表现出色——事实上,如今有许多专门为深度学习而构建的 GPU——它们被用于计算机游戏领域之外。
NVIDIA 是深度学习硬件的市场领导者,坦率地说,如果你进入这个领域,这是我推荐的主要选择。熟悉他们的产品系列(硬件和软件)是值得的,这样你就知道如果你在云中使用一个实例或者自己构建一台机器,你要付出什么。请务必查看开发者页面。
在大学和公司共享高端 GPU 机器是很常见的。或者,你可以构建一个,购买一个(就像我曾经做的那样),或者在云中租用一个(就像我现在做的那样)。
如果你只是做几个实验,那么使用云服务提供商,如亚马逊、谷歌或 FloydHub,收取基于时间的使用费是一个不错的选择。
长期来看,如果你每天都在进行深度学习实验,那么出于节约成本的目的,手头上有一个是明智的(假设你愿意定期更新硬件和软件)。
注意:对于那些使用 AWS 的 EC2 的人,我建议你选择p2 . xlage、 p2.8xlarge 或p 2.16 xlage*机器,以与这些指令兼容(取决于你的用例场景和预算)。较旧的实例 g2.2xlarge 和 g2.8xlarge 与本教程中的 CUDA 和 cuDNN 版本不兼容。我还建议你在你的操作系统驱动器/分区上有大约 32GB 的空间。在我的 EC2 实例上,16GB 并没有为我削减它。*
需要特别指出的是 你不需要访问一台昂贵的 GPU 机器来开始深度学习 。大多数现代笔记本电脑的 CPU 可以很好地完成我书中前几章介绍的小实验。正如我所说的,“基础先于资金”——这意味着,在你用昂贵的硬件和云账单超出你的能力之前,先适应现代深度学习的基础和概念。我的书会让你做到这一点。
给 Ubuntu 配置 GPU 支持深度学习有多难?
你很快就会发现,配置一个 GPU 机器不是一件容易的事。事实上,事情变糟的步骤和可能性相当多。这就是为什么我构建了一个定制的 Amazon Machine Instance (AMI ),并为我的书附带的社区进行了预配置和预安装。
我在上一篇文章的中详细介绍了如何将它加载到你的 AWS 账户中,以及如何启动它。
使用 AMI 是迄今为止在 GPU 上开始深度学习的最快方式。即使你有的 GPU,也值得在 Amazon EC2 云中进行试验,这样你就可以拆除一个实例(如果你犯了一个错误),然后立即启动一个新的、全新的实例。
自行配置环境直接关系到您的:
- 使用 Linux 的经验
- 注意细节
- 耐心。
首先,您必须非常熟悉命令行。
下面的许多步骤都有命令,您可以简单地复制并粘贴到您的终端中;但是,在进入下一步之前,阅读输出、记录任何错误并尝试解决它们是很重要的。
你必须特别注意本教程中指令的顺序,此外还要注意命令本身。
实际上,我建议复制和粘贴,以确保你不会弄乱命令(在下面的一个例子中,反斜线和引号可能会让你卡住)。
如果您准备好迎接挑战,那么我会在那里与您一起准备好您的环境。事实上,我鼓励你留下评论,这样 PyImageSearch 社区可以为你提供帮助。在你发表评论之前,请务必查看帖子和评论,以确保你没有遗漏任何一步。
事不宜迟,让我们动手实践一下配置步骤。
步骤#0:关闭 X 服务器/X 窗口系统
在我们开始之前,我需要指出一个重要的先决条件。在遵循以下说明之前,您需要执行以下操作之一:
*1. SSH 到您的 GPU 实例中(关闭/禁用 X 服务器)。
** 直接在您的 GPU 机器上工作,无需运行您的 X 服务器(X 服务器,也称为 X11,是您在桌面上的图形用户界面)。我建议你试试本帖中概述的方法之一。
*有几种方法可以做到这一点,有些很简单,有些则比较复杂。
第一种方法有点笨拙,但是很有效:
- 关掉你的机器。
- 拔掉你的显示器。
- 重启。
- 从一个单独的系统 SSH 到您的机器。
- 执行安装说明。
这种方法非常有效,也是迄今为止最简单的方法。拔掉显示器的插头,X 服务器不会自动启动。从那里,你可以从一台单独的计算机 SSH 到你的机器,并遵循本文中概述的指示。
第二种方法假设你已经启动了你想要配置深度学习的机器:
- 关闭所有正在运行的应用程序。
- 按下
ctrl + alt + F2。 - 使用您的用户名和密码登录。
- 通过执行
sudo service lightdm stop停止 X 服务器。 - 执行安装说明。
请注意,你需要一台单独的电脑来阅读指令或执行命令。或者,您可以使用基于文本的 web 浏览器。
步骤 1:安装 Ubuntu 系统依赖项
现在我们已经准备好了,让我们更新我们的 Ubuntu 操作系统:
$ sudo apt-get update
$ sudo apt-get upgrade
然后,让我们安装一些必要的开发工具,图像/视频 I/O,GUI 操作和各种其他包:
$ sudo apt-get install build-essential cmake git unzip pkg-config
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng12-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libhdf5-serial-dev graphviz
$ sudo apt-get install libopenblas-dev libatlas-base-dev gfortran
$ sudo apt-get install python-tk python3-tk python-imaging-tk
接下来,让我们安装 Python 2.7 和 Python 3 头文件,这样我们就可以使用 Python 绑定来编译 OpenCV:
$ sudo apt-get install python2.7-dev python3-dev
我们还需要准备我们的系统,用 NVIDIA CUDA 驱动程序替换默认驱动程序:
$ sudo apt-get install linux-image-generic linux-image-extra-virtual
$ sudo apt-get install linux-source linux-headers-generic
第一步到此为止,让我们继续。
步骤 2:安装 CUDA 工具包
CUDA 工具包安装步骤需要注意细节,以便顺利进行。
首先通过创建一个新文件来禁用新的内核驱动程序:
$ sudo nano /etc/modprobe.d/blacklist-nouveau.conf
请随意使用您喜欢的终端文本编辑器,如vim或emacs,而不是nano。
添加以下行,然后保存并退出:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
您的会话应该如下所示(如果您使用的是 nano):
Figure 1: Editing the blacklist-nouveau.conf file with the nano text editor.
接下来,让我们更新初始 RAM 文件系统并重启机器:
$ echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
$ sudo update-initramfs -u
$ sudo reboot
您将在重启时失去 SSH 连接,所以请耐心等待,然后在继续之前重新连接。
您将需要通过 NVIDIA CUDA Toolkit 网站下载 CUDA Toolkit v8.0 版:
https://developer.nvidia.com/cuda-80-ga2-download-archive
进入下载页面后,选择Linux => x86_64 => Ubuntu => 16.04 => runfile (local)。
下面是下载页面的截图:
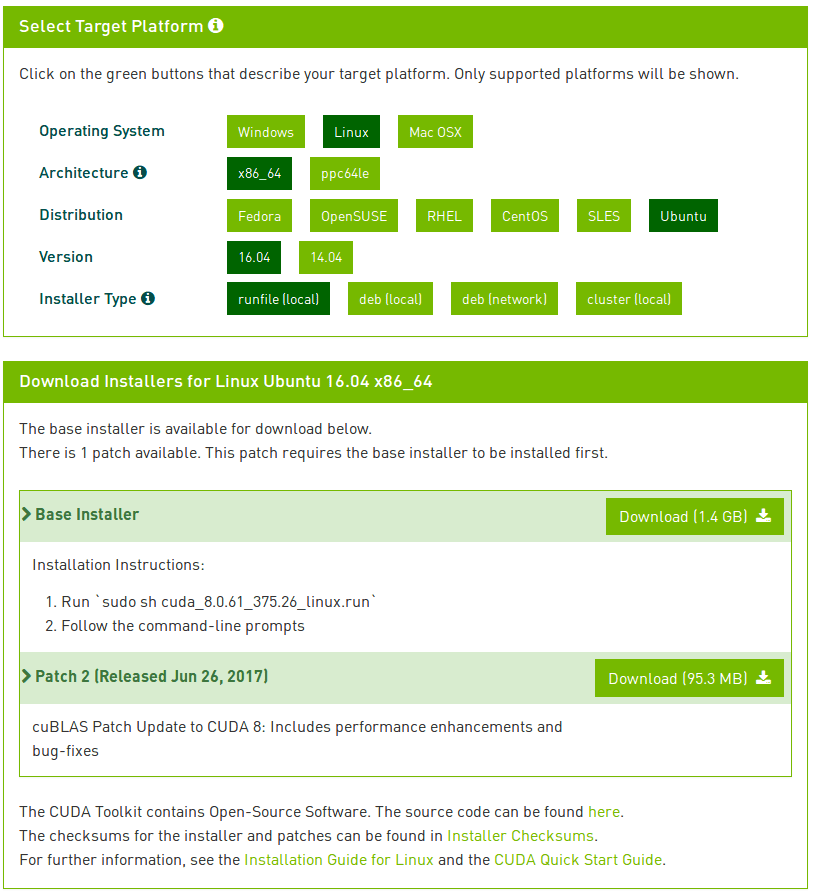
Figure 2: The CUDA Toolkit download page.
从那里下载文件名为cuda_8.0.61_375.26_linux-run或类似的-run文件。为此,只需右键单击复制下载链接,并在您的远程 GPU 框上使用wget:
$ wget https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda_8.0.61_375.26_linux-run
重要提示:在撰写本文时,NVIDIA 网站上有一个小的出入。如图 2* 所示,在“基础安装程序”下载下,文件名(如所写)以.run结尾。实际可下载的文件以-run结尾。你现在应该可以复制我的wget + URL 命令了,除非 NVIDIA 再次更改文件名。*
注意:您需要点击上面代码块工具栏中的< = >按钮来展开代码块。这将使您能够将的完整 URL* 复制到-run文件中。*
从那里,解压-run文件:
$ chmod +x cuda_8.0.61_375.26_linux-run
$ mkdir installers
$ sudo ./cuda_8.0.61_375.26_linux-run -extract=`pwd`/installers
上面程序块中的最后一步可能需要 30-60 秒,这取决于您机器的速度。
现在是时候安装 NVIDIA 内核驱动程序了:
$ cd installers
$ sudo ./NVIDIA-Linux-x86_64-375.26.run
在此过程中,接受许可证并按照屏幕上的提示进行操作。
Figure 3: Accepting the NVIDIA End User License Agreement.
从那里,将 NVIDIA 可加载内核模块(LKM)添加到 Linux 内核:
$ modprobe nvidia
安装 CUDA 工具包和示例:
$ sudo ./cuda-linux64-rel-8.0.61-21551265.run
$ sudo ./cuda-samples-linux-8.0.61-21551265.run
再次接受许可并遵循默认提示。你可能需要按“空格”来滚动许可协议,然后输入“接受”,就像我在上面的图片中所做的那样。当它询问您安装路径时,只需按<enter>接受默认值。
既然已经安装了 NVIDIA CUDA 驱动程序和工具,您需要更新您的~/.bashrc文件以包含 CUDA Toolkit(我建议使用终端文本编辑器,如vim、emacs或nano):
# NVIDIA CUDA Toolkit
export PATH=/usr/local/cuda-8.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64/
现在,重新加载您的~/.bashrc ( source ~/.bashrc),然后通过编译deviceQuery示例程序并运行它来测试 CUDA 工具包的安装:
$ source ~/.bashrc
$ cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
$ sudo make
$ ./deviceQuery
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = Tesla K80
Result = PASS
注意: 在~/.bashrc上调用source对于我们当前的 shell 会话来说,只需要一次。每当我们打开一个新的终端,~/.bashrc的内容就会自动执行(包括我们的更新)。
此时,如果你有Result = PASS,那么祝贺,因为你已经准备好进入下一步。
如果你看不到这个结果,我建议你重复第 2 步,仔细检查每一个命令的输出,以确保安装过程中没有错误。
第三步:安装 cuDNN (CUDA 深度学习神经网络库)
对于这一步,你需要在 NVIDIA 创建一个免费账户,并下载 cuDNN 。
对于本教程,我使用的是用于 Linux 的cud nn v 6.0也就是 TensorFlow 需要的 。
由于 NVIDIA 的要求认证访问下载,您可能无法在您的远程机器上使用wget进行下载。
相反,将文件下载到您的本地机器,然后(在您的本地机器上)使用scp(安全拷贝),同时用适当的值替换<username>和<password>,以将文件更新到您的远程实例(同样,假设您通过 SSH 访问您的机器):
scp -i EC2KeyPair.pem ~/Downloads/cudnn-8.0-linux-x64-v6.0.tgz \
username@your_ip_address:~
接下来,解压缩文件,然后将结果文件分别复制到lib64和include中,使用-P开关保留符号链接:
$ cd ~
$ tar -zxf cudnn-8.0-linux-x64-v6.0.tgz
$ cd cuda
$ sudo cp -P lib64/* /usr/local/cuda/lib64/
$ sudo cp -P include/* /usr/local/cuda/include/
$ cd ~
这就是步骤#3 的全部内容——这里没有太多可能出错的地方,所以您应该准备好继续进行。
步骤 4:创建您的 Python 虚拟环境
在本节中,我们将在您的系统上配置一个 Python 虚拟环境。
安装 pip
第一步是安装pip,一个 Python 包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo python3 get-pip.py
安装 virtualenv 和 virtualenvwrapper
使用pip,我们可以很容易地安装 Python 包索引中的任何包,包括 virtualenv 和 virtualenvwrapper 。如你所知,我是 Python 虚拟环境的粉丝,我鼓励你也将它们用于深度学习。
如果您的机器上有多个项目,使用虚拟环境将允许您隔离它们并安装不同版本的包。简而言之,同时使用virtualenv和virtualenvwrapper可以让你解决“项目 X 依赖于 1.x 版本,但项目 Y 需要 4.x 的困境。
如果我没有说服你,RealPython 的人也许能说服你,所以读一读 RealPython 上这篇精彩的博文。
让我再次重申,在 Python 社区中,利用某种虚拟环境是的标准做法,所以我建议你也这样做:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip get-pip.py
一旦我们安装了virtualenv和virtualenvwrapper,我们需要更新我们的~/.bashrc文件,在文件的底部包含以下行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
编辑完我们的~/.bashrc文件后,我们需要重新加载修改:
$ source ~/.bashrc
现在我们已经安装了virtualenv和virtualenvwrapper,下一步是实际上创建Python 虚拟环境——我们使用mkvirtualenv命令来完成。
创建 dl4cv 虚拟环境
在过去的安装教程中,我介绍了 Python 2.7 或 Python 3 的选择。在 Python 3 开发周期的这一点上,我认为它是稳定和正确的选择。如果您有特定的兼容性需求,您可以选择使用 Python 2.7,但是出于我的书的目的,我们将使用 Python 3 。
也就是说,对于下面的命令,确保将-p标志设置为python3。
$ mkvirtualenv dl4cv -p python3
您可以随意命名这个虚拟环境(并创建任意数量的 Python 虚拟环境),但是目前,我建议坚持使用dl4cv名称,因为这是我将在本教程的剩余部分中使用的名称。
验证您是否处于“dl4cv”虚拟环境中
如果你重启了你的 Ubuntu 系统;注销并重新登录;或者打开一个新的终端,您需要使用workon命令来重新访问您的dl4cv虚拟环境。下面是一个workon命令的例子:
$ workon dl4cv
要验证您是否在dl4cv虚拟环境中,只需检查您的命令行— 如果您在提示前看到文本(dl4cv),那么您**在dl4cv虚拟环境中是**:

Figure 4: Inside the dl4cv virtual environment.
否则,如果你 没有 看到dl4cv文本,那么你 在dl4cv虚拟环境中就不是 :

Figure 5: Outside the dl4cv virtual environment. Execute workon dl4cv to activate the environment.
安装 NumPy
在我们编译 OpenCV 之前的最后一步是安装 NumPy ,一个用于数值处理的 Python 包。要安装 NumPy,请确保您处于dl4cv虚拟环境中(否则 NumPy 将被安装到 Python 的系统版本中,而不是dl4cv环境中)。
从那里执行以下命令:
$ pip install numpy
一旦 NumPy 安装在您的虚拟环境中,我们就可以继续编译和安装 OpenCV。
步骤 5:编译并安装 OpenCV
首先你需要将 opencv 和 opencv_contrib 下载到你的主目录中。对于本安装指南,我们将使用 OpenCV 3.3:
$ cd ~
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.3.0.zip
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.3.0.zip
然后,解压缩这两个文件:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
运行 CMake
在这一步中,我们创建一个构建目录,然后运行 CMake:
$ cd ~/opencv-3.3.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D WITH_CUDA=OFF \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.3.0/modules \
-D BUILD_EXAMPLES=ON ..
注意:我关掉了 CUDA,因为它会导致一些机器上的编译错误。CUDA 优化将在内部用于 C++函数,所以它与 Python + OpenCV 没有太大区别。同样,CUDA 在这篇博文中的主要用途是优化我们的深度学习库,而不是 OpenCV 本身。
对于 CMake,为了兼容性,您的标志与我的标志匹配是很重要的。此外,确保你的opencv_contrib版本与你下载的opencv版本完全相同(这里是版本3.3.0)。
在我们进入实际的编译步骤之前,确保检查 CMake 的输出。
首先滚动到标题为Python 3的部分。
确保您的 Python 3 部分如下图所示:
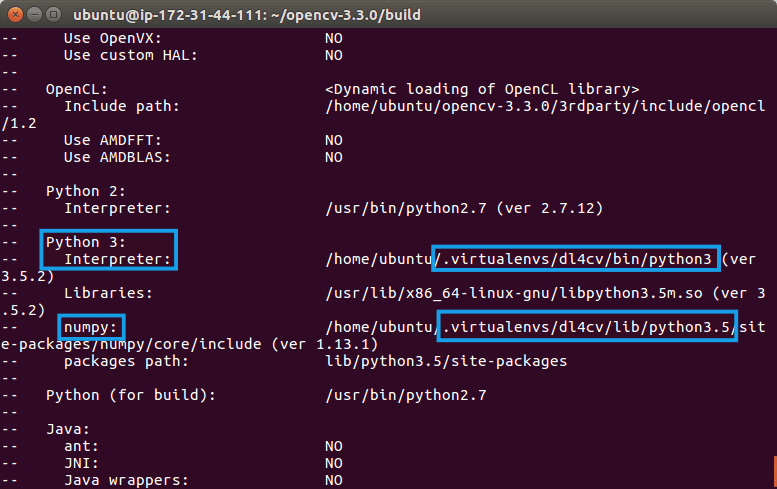
Figure 6: Verifying that CMake has properly set up the compile to use the correct Python 3 Interpreter and version of NumPy. Both Python 3 and NumPy should be pulled from the dl4cv virtual environment.
确保解释器指向位于虚拟环境中的二进制文件,而 T2 指向我们的 NumPy 安装。
在任何一种情况下,如果您 没有 看到这些变量路径中的dl4cv虚拟环境,那么 几乎肯定是因为您在运行 CMake 之前不在dl4cv虚拟环境中!
如果是这种情况,使用workon dl4cv访问dl4cv虚拟环境,并重新运行上述命令。
编译 OpenCV
现在我们已经准备好编译 OpenCV 了:
$ make -j4
注意: *如果遇到编译错误,可以运行命令make clean,然后只编译不加标志:make。你可以通过-j开关来调整编译 OpenCV 所使用的处理器内核数量(在上面的例子中,我用四个内核来编译 OpenCV)。
*
从那里,你需要做的就是安装 OpenCV 3.3:
$ sudo make install
$ sudo ldconfig
$ cd ~
您也可以删除您的opencv和opencv_contrib目录来释放系统空间;然而,我强烈建议等到本教程结束,并确保 OpenCV 已经正确安装之后再删除这些文件(否则你将不得不重新下载)。
将 OpenCV 符号链接到您的虚拟环境
要将我们的 OpenCV 绑定符号链接到dl4cv虚拟环境中,发出以下命令
$ cd ~/.virtualenvs/dl4cv/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
$ cd ~
注意:确保点击上方工具栏中的< = >按钮展开代码块。在那里,确保正确地复制并粘贴了ln命令,否则您将创建一个无效的符号链接,Python 将无法找到您的 OpenCV 绑定。
您的.so文件可能与上面显示的有些不同,所以一定要使用合适的文件。
测试您的 OpenCV 3.3 安装
现在我们已经安装并链接了 OpenCV 3.3,让我们做一个快速的健全性测试来看看事情是否正常:
$ python
>>> import cv2
>>> cv2.__version__
'3.3.0'
在启动 Python 之前,确保你处于dl4cv虚拟环境中。您可以通过运行workon dl4cv来实现这一点。
当您在 Python shell 中打印 OpenCV 版本时,它应该与您安装的 OpenCV 版本相匹配(在我们的例子中是 OpenCV 3.3.0)。
当您的编译 100%完成时,您应该会看到类似如下的输出:
就这样——假设您没有导入错误,那么您就准备好继续进行步骤#6 ,在这里我们将安装 Keras 。
Step #6: Install Keras
对于这一步,通过发出workon dl4cv命令,确保您处于dl4cv环境中。
从那里我们可以安装一些需要的计算机视觉、图像处理和机器学习库:
$ pip install scipy matplotlib pillow
$ pip install imutils h5py requests progressbar2
$ pip install scikit-learn scikit-image
接下来,安装 Tensorflow (GPU 版):
$ pip install tensorflow-gpu
您可以通过在 Python shell 中导入 TensorFlow 来验证它是否已安装:
$ python
>>> import tensorflow
>>>
现在我们准备安装 Keras :
$ pip install keras
同样,您可以通过 Python shell 验证 Keras 是否已经安装:
$ python
>>> import keras
Using TensorFlow backend.
>>>
您应该看到 Keras 已经被正确导入 和tensor flow 后端正在被使用。
在进入第 7 步之前,花点时间熟悉一下~/.keras/keras.json文件:
{
"image_data_format": "channels_last",
"backend": "tensorflow",
"epsilon": 1e-07,
"floatx": "float32"
}
确保image_data_format设置为channels_last并且backend为tensorflow。
恭喜你!你现在已经准备好开始你的用 Python 进行计算机视觉的深度学习之旅(初学者包和实践者包读者可以安全地跳过 步骤#7 )。
步骤 7 安装 mxnet(仅 ImageNet 捆绑包)
只有购买了使用 Python 进行计算机视觉的深度学习的 ImageNet 捆绑包的读者才需要这一步。如果您想在系统上配置 mxnet,也可以选择使用这些说明。
不管怎样,让我们首先克隆 mxnet 存储库和检出分支0.11.0:
$ cd ~
$ git clone --recursive https://github.com/apache/incubator-mxnet.git mxnet --branch 0.11.0
我们可以编译 mxnet:
$ cd mxnet
$ make -j4 USE_OPENCV=1 USE_BLAS=openblas USE_CUDA=1 USE_CUDA_PATH=/usr/local/cuda USE_CUDNN=1
然后是到我们 dl4cv 环境的符号链接。
$ cd ~/.virtualenvs/dl4cv/lib/python3.5/site-packages/
$ ln -s ~/mxnet/python/mxnet mxnet
$ cd ~
最后,您可以在您的环境中启动 Python 来测试安装是否成功:
$ python
>>> import mxnet
>>>
注意: 不要删除你的 home 文件夹中的mxnet目录。不仅我们的 Python 绑定在那里,而且当创建序列化的图像数据集时,我们还需要~/mxnet/bin中的文件。
干杯!当你阅读使用 Python 的计算机视觉深度学习 (ImageNet bundle)时,你已经完成并值得一杯冰啤酒。
注意: 为了避免大量的云费用(或者电费,如果你的盒子在桌子下面的话),我建议你关掉你的机器,直到你准备好使用它。
摘要
今天,我们学习了如何使用必要的工具来设置 Ubuntu + CUDA + GPU 机器,以便在训练自己的深度学习网络时取得成功。
如果您在这个过程中遇到了任何问题,我强烈建议您检查一下是否跳过了任何步骤。如果你还是被卡住了,请在下面留下评论。
我想重申,你不需要一台花哨、昂贵的 GPU 机器来开始你的计算机视觉深度学习之旅。你的 CPU 可以处理书中的介绍性例子。为了帮助你开始,我在这里为 Ubuntu CPU 用户提供了一个安装教程。如果你喜欢简单的、预先配置好的路线,我的书附带了一个 VirtualBox 虚拟机,随时可用。
希望这篇教程对你的深度学习之旅有所帮助!
如果你想深入研究深度学习,一定要看看我的新书, 用 Python 进行计算机视觉的深度学习。
为了在 PyImageSearch 博客上发布以后的博文和教程时得到通知,*请务必在下面的表格中输入您的电子邮件地址!******
包含 Keras、TensorFlow 和深度学习的暹罗网络
原文:https://pyimagesearch.com/2020/11/30/siamese-networks-with-keras-tensorflow-and-deep-learning/
在本教程中,您将学习如何使用 Keras、TensorFlow 和深度学习来实现和训练暹罗网络。
本教程是我们关于暹罗网络基础的三部分系列的第二部分:
- 第一部分: 用 Python 构建连体网络的图像对(上周的帖子)
- 第二部分: 用 Keras、TensorFlow 和深度学习训练暹罗网络(本周教程)
- 第三部分: 使用连体网络比较图像(下周教程)
使用我们的暹罗网络实施,我们将能够:
- 向我们的网络呈现两个输入图像。
- 网络将预测这两幅图像是否属于同一类(即验证)。
- 然后,我们将能够检查网络的置信度得分来确认验证。
暹罗网络的实际、真实使用案例包括人脸识别、签名验证、处方药识别、等等!
此外,暹罗网络可以用少得惊人的数据进行训练,使更高级的应用成为可能,如一次性学习和少量学习。
要学习如何用 Keras 和 TenorFlow 实现和训练暹罗网络,继续阅读。
包含 Keras、TensorFlow 和深度学习的连体网络
在本教程的第一部分,我们将讨论暹罗网络,它们如何工作,以及为什么您可能希望在自己的深度学习应用中使用它们。
从那里,您将学习如何配置您的开发环境,以便您可以按照本教程学习,并学习如何训练您自己的暹罗网络。
然后,我们将查看我们的项目目录结构,并实现一个配置文件,后面是三个助手函数:
- 一种用于生成图像对的方法,以便我们可以训练我们的连体网络
- 一个定制的 CNN 层,用于计算网络内向量之间的欧几里德距离
- 用于将暹罗网络训练历史记录绘制到磁盘的实用程序
给定我们的辅助工具,我们将实现用于从磁盘加载 MNIST 数据集的训练脚本,并根据数据训练一个暹罗网络。
我们将讨论我们的结果来结束本教程。
什么是暹罗网络,它们是如何工作的?
上周的教程涵盖了暹罗网络的基础知识,它们是如何工作的,以及有哪些现实世界的应用适用于它们。我将在这里对它们进行快速回顾,但我强烈建议你阅读上周的指南,以获得对暹罗网络的更深入的回顾。
本节顶部的图 1 显示了暹罗网络的基本架构。你会立即注意到暹罗网络架构与大多数标准分类架构不同。
注意网络有两个输入端和两个分支(即“姐妹网络”)。这些姐妹网络彼此完全相同。组合两个子网络的输出,然后返回最终的输出相似性得分。
为了使这个概念更具体一些,让我们在上面的图 1 中进一步分解它:
- 在左侧我们向暹罗模型展示了两个示例数字(来自 MNIST 数据集)。我们的目标是确定这些数字是否属于的同类。
- 中间的表示暹罗网络本身。**这两个子网络具有相同的架构和相同的参数,并且它们镜像彼此**——如果一个子网络中的权重被更新,则其他子网络中的权重也被更新。
- 每个子网的输出是全连接(FC)层。我们通常计算这些输出之间的欧几里德距离,并通过 sigmoid 激活来馈送它们,以便我们可以确定两个输入图像有多相似。更接近“1”的 sigmoid 激活函数值意味着更相似,而更接近“0”的值表示“不太相似”
为了实际训练暹罗网络架构,我们可以利用许多损失函数,包括二元交叉熵、三元损失和对比损失。
后两个损失函数需要图像三元组(网络的三个输入图像),这与我们今天使用的图像对(两个输入图像)不同。
今天我们将使用二进制交叉熵来训练我们的暹罗网络。在未来,我将涵盖中级/高级暹罗网络,包括图像三元组、三元组损失和对比损失——但现在,让我们先走后跑。
配置您的开发环境
在这一系列关于暹罗网络的教程中,我们将使用 Keras 和 TensorFlow。我建议你现在就花时间配置你的深度学习开发环境。
我建议您按照这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras(对于本指南,我建议您安装 TensorFlow 2.3 ):
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们可以训练我们的暹罗网络之前,我们首先需要回顾我们的项目目录结构。
首先使用本教程的 【下载】 部分下载源代码、预先训练好的暹罗网络模型等。
从那里,让我们来看看里面有什么:
$ tree . --dirsfirst
.
├── output
│ ├── siamese_model
│ │ ├── variables
│ │ │ ├── variables.data-00000-of-00001
│ │ │ └── variables.index
│ │ └── saved_model.pb
│ └── plot.png
├── pyimagesearch
│ ├── config.py
│ ├── siamese_network.py
│ └── utils.py
└── train_siamese_network.py
2 directories, 6 files
查看完项目目录结构后,让我们继续创建配置文件。
注:与本教程相关的“下载”中包含的预训练siamese_model是使用 TensorFlow 2.3 创建的。我建议您使用 TensorFlow 2.3 来完成本指南。如果您希望使用 TensorFlow 的另一个版本,这完全没问题,但是您需要执行train_siamese_network.py来训练和序列化模型。当我们使用训练好的暹罗网络来比较图像时,你还需要为下周的教程保留这个模型。
创建我们的暹罗网络配置文件
我们的配置文件短小精悍。打开config.py,插入以下代码:
# import the necessary packages
import os
# specify the shape of the inputs for our network
IMG_SHAPE = (28, 28, 1)
# specify the batch size and number of epochs
BATCH_SIZE = 64
EPOCHS = 100
第 5 行初始化我们输入的IMG_SHAPE空间维度。因为我们使用的是 MNIST 数字数据集,所以我们的图像是带有单一灰度通道的 28×28 像素。
然后我们定义我们的BATCH_SIZE和我们正在训练的纪元总数。
在我们自己的实验中,我们发现仅针对10个时期的训练产生了良好的结果,但是更长时间的训练产生了更高的准确性。如果你时间紧迫,或者如果你的机器没有 GPU,将EPOCHS升级到10仍然会产生好的结果。
接下来,让我们定义输出路径:
# define the path to the base output directory
BASE_OUTPUT = "output"
# use the base output path to derive the path to the serialized
# model along with training history plot
MODEL_PATH = os.path.sep.join([BASE_OUTPUT, "siamese_model"])
PLOT_PATH = os.path.sep.join([BASE_OUTPUT, "plot.png"])
使用 Keras 和 TensorFlow 实施暹罗网络架构
暹罗网络架构由两个或更多姐妹网络组成(在上面的图 3 中突出显示)。本质上,姐妹网络是一个基本的卷积神经网络,它产生一个全连接(FC)层,有时称为嵌入式层。
当我们开始构建暹罗网络架构本身时,我们将:
- 实例化我们的姐妹网络
- 创建一个
Lambda层,用于计算姐妹网络输出之间的欧几里德距离 - 创建具有单个节点和 sigmoid 激活函数的 FC 层
结果将是一个完全构建的连体网络。
但是在我们到达那里之前,我们首先需要实现我们的暹罗网络架构的姐妹网络组件。
打开项目目录结构中的siamese_network.py,让我们开始工作:
# import the necessary packages
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.layers import MaxPooling2D
我们从第 2-8 行开始,导入我们需要的 Python 包。如果你以前曾经用 Keras/TensorFlow 训练过 CNN,这些输入对你来说应该都很标准。
如果你需要复习 CNN,我推荐你阅读我的 Keras 教程以及我的书 用 Python 进行计算机视觉的深度学习。
考虑到我们的导入,我们现在可以定义负责构建姐妹网络的build_siamese_model函数:
def build_siamese_model(inputShape, embeddingDim=48):
# specify the inputs for the feature extractor network
inputs = Input(inputShape)
# define the first set of CONV => RELU => POOL => DROPOUT layers
x = Conv2D(64, (2, 2), padding="same", activation="relu")(inputs)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.3)(x)
# second set of CONV => RELU => POOL => DROPOUT layers
x = Conv2D(64, (2, 2), padding="same", activation="relu")(x)
x = MaxPooling2D(pool_size=2)(x)
x = Dropout(0.3)(x)
第 12 行初始化我们姐妹网络的输入空间维度。
从那里,第 15-22 行定义了两组CONV => RELU => POOL层集合。每个CONV层总共学习 64 个 2×2 滤镜。然后,我们应用一个 ReLU 激活函数,并使用一个 2×2 步距应用最大池。
我们现在可以完成构建姐妹网络架构了:
# prepare the final outputs
pooledOutput = GlobalAveragePooling2D()(x)
outputs = Dense(embeddingDim)(pooledOutput)
# build the model
model = Model(inputs, outputs)
# return the model to the calling function
return model
第 25 行将全局平均池应用于 7x7x64 卷(假设对网络的 28×28 输入),产生 64-d 的输出
我们取这个pooledOutput,然后用指定的embeddingDim(Line 26)——应用一个全连接层,这个 Dense 层作为姐妹网络的输出。
第 29 行然后建立姐妹网络Model,然后返回给调用函数。
我在下面提供了该模型的摘要:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 64) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 64) 16448
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
global_average_pooling2d (Gl (None, 64) 0
_________________________________________________________________
dense (Dense) (None, 48) 3120
=================================================================
Total params: 19,888
Trainable params: 19,888
Non-trainable params: 0
_________________________________________________________________
下面是我们刚刚构建的模型的快速回顾:
- 每个姐妹网络将接受一个 28x28x1 输入。
- 然后,我们应用 CONV 层学习总共 64 个过滤器。使用 2×2 步幅应用最大池,以将空间维度减少到14×14×64。
- 应用了另一个 CONV 层(再次学习 64 个过滤器)和池层,将空间维度进一步减少到 7x7x64。
- 全局平均池用于将 7x7x64 卷平均到 64-d。
- 这个 64-d 池化输出被传递到具有 48 个节点的 FC 层。
- 48 维向量作为我们姐妹网络的输出。
在train_siamese_network.py脚本中,您将学习如何实例化我们姐妹网络的两个实例,然后完成暹罗网络架构本身的构建。
实现我们的配对生成、欧几里德距离和绘图历史实用函数
# import the necessary packages
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import numpy as np
我们从第 2-4 行的开始,导入我们需要的 Python 包。
def make_pairs(images, labels):
# initialize two empty lists to hold the (image, image) pairs and
# labels to indicate if a pair is positive or negative
pairImages = []
pairLabels = []
# calculate the total number of classes present in the dataset
# and then build a list of indexes for each class label that
# provides the indexes for all examples with a given label
numClasses = len(np.unique(labels))
idx = [np.where(labels == i)[0] for i in range(0, numClasses)]
# loop over all images
for idxA in range(len(images)):
# grab the current image and label belonging to the current
# iteration
currentImage = images[idxA]
label = labels[idxA]
# randomly pick an image that belongs to the *same* class
# label
idxB = np.random.choice(idx[label])
posImage = images[idxB]
# prepare a positive pair and update the images and labels
# lists, respectively
pairImages.append([currentImage, posImage])
pairLabels.append([1])
# grab the indices for each of the class labels *not* equal to
# the current label and randomly pick an image corresponding
# to a label *not* equal to the current label
negIdx = np.where(labels != label)[0]
negImage = images[np.random.choice(negIdx)]
# prepare a negative pair of images and update our lists
pairImages.append([currentImage, negImage])
pairLabels.append([0])
# return a 2-tuple of our image pairs and labels
return (np.array(pairImages), np.array(pairLabels))
我不打算对这个函数进行全面的回顾,因为我们在关于暹罗网络的系列的第 1 部分中已经详细介绍过了;然而,高层次的要点是:
- 为了训练暹罗网络,我们需要正和负对
- 一个正对是属于同一类的两个图像(即数字“8”的两个例子)
- 一个负对是属于不同类的两个图像(即一个图像包含一个【1】,另一个图像包含一个【3】)
make_pairs函数接受一组images和相关联的labels的输入,然后构建这些用于训练的正负图像对,并将它们返回给调用函数
关于make_pairs函数更详细的回顾,请参考我的教程 用 Python 为暹罗网络构建图像对。
我们的下一个函数euclidean_distance接受一个 2 元组的vectors,然后利用 Keras/TensorFlow 函数计算它们之间的欧氏距离:
def euclidean_distance(vectors):
# unpack the vectors into separate lists
(featsA, featsB) = vectors
# compute the sum of squared distances between the vectors
sumSquared = K.sum(K.square(featsA - featsB), axis=1,
keepdims=True)
# return the euclidean distance between the vectors
return K.sqrt(K.maximum(sumSquared, K.epsilon()))
我们通过取平方差之和的平方根来舍入函数,得到欧几里德距离(第 57 行)。
请注意,我们使用 Keras/TensorFlow 函数来计算欧几里德距离,而不是使用 NumPy 或 SciPy。
这是为什么呢?
使用 NumPy 和 SciPy 内置的欧几里德距离函数不是更简单吗?
为什么要大费周章地用 Keras/TensorFlow 重新实现欧几里德距离呢?
一旦我们到达train_siamese_network.py脚本,,原因将变得更加清楚,但是要点是为了构建我们的暹罗网络架构,我们需要能够计算暹罗架构本身内部的姐妹网络输出之间的欧几里德距离。
为了完成这项任务,我们将使用一个自定义的Lambda层,该层可用于在模型中嵌入任意 Keras/TensorFlow 函数(因此,Keras/TensorFlow 函数用于实现欧几里德距离)。
我们的最后一个函数plot_training,接受(1)来自调用model.fit的训练历史和(2)一个输出plotPath:
def plot_training(H, plotPath):
# construct a plot that plots and saves the training history
plt.style.use("ggplot")
plt.figure()
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.plot(H.history["accuracy"], label="train_acc")
plt.plot(H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(plotPath)
给定我们的训练历史变量H,我们绘制我们的训练和验证损失和准确性。然后将输出图保存到磁盘的plotPath中。
使用 Keras 和 TensorFlow 创建我们的暹罗网络培训脚本
我们现在准备实施我们的暹罗网络培训脚本!
在内部train_siamese_network.py我们将:
- 从磁盘加载 MNIST 数据集
- 构建我们的训练和测试图像对
- 创建我们的
build_siamese_model的两个实例作为我们的姐妹网络 - 通过我们定制的
euclidean_distance函数(使用一个Lambda层)用管道传输姐妹网络的输出,完成暹罗网络架构的构建 - 对欧几里德距离的输出应用 sigmoid 激活
- 在我们的图像对上训练暹罗网络架构
这听起来像是一个复杂的过程,但是我们能够用不到 60 行代码完成所有这些任务!
打开train_siamese_network.py,让我们开始工作:
# import the necessary packages
from pyimagesearch.siamese_network import build_siamese_model
from pyimagesearch import config
from pyimagesearch import utils
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Lambda
from tensorflow.keras.datasets import mnist
import numpy as np
第 2-10 行导入我们需要的 Python 包。值得注意的进口包括:
build_siamese_model:构建连体网络架构的姊妹网络组件config:存储我们的训练配置utils:保存我们的辅助函数实用程序,用于创建图像对,绘制训练历史,并使用 Keras/TensorFlow 函数计算欧几里德距离Lambda:采用我们的欧几里德距离实现,并将其嵌入暹罗网络架构本身
导入工作完成后,我们可以继续从磁盘加载 MNIST 数据集,对其进行预处理,并构建图像对:
# load MNIST dataset and scale the pixel values to the range of [0, 1]
print("[INFO] loading MNIST dataset...")
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX / 255.0
testX = testX / 255.0
# add a channel dimension to the images
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
# prepare the positive and negative pairs
print("[INFO] preparing positive and negative pairs...")
(pairTrain, labelTrain) = utils.make_pairs(trainX, trainY)
(pairTest, labelTest) = utils.make_pairs(testX, testY)
第 14 行从磁盘加载 MNIST 数字数据集。
然后,我们对 MNIST 图像进行预处理,将它们从范围【0,255】缩放到【0,1】(第 15 行和第 16 行),然后添加通道维度(第 19 行和第 20 行)。
我们使用我们的make_pairs函数分别为我们的训练集和测试集创建正面和负面图像对(第 24 行和第 25 行)。如果你需要复习一下make_pairs功能,我建议你阅读本系列的第 1 部分,其中详细介绍了图像对。
现在让我们构建我们的连体网络架构:
# configure the siamese network
print("[INFO] building siamese network...")
imgA = Input(shape=config.IMG_SHAPE)
imgB = Input(shape=config.IMG_SHAPE)
featureExtractor = build_siamese_model(config.IMG_SHAPE)
featsA = featureExtractor(imgA)
featsB = featureExtractor(imgB)
第 29-33 行创建我们的姐妹网络:
- 首先,我们创建两个输入,一个用于图像对中的每个图像(行 29 和 30 )。
- 31 号线再搭建姊妹网架构,作为
featureExtractor。 - 该对中的每个图像将通过
featureExtractor,产生一个 48 维的特征向量(第 32 行和第 33 行)。由于在一对中有两个图像,因此我们有两个 48-d 特征向量。
也许你想知道为什么我们没有打两次电话?我们的架构中有两个姐妹网络,对吗?
好吧,请记住你上周学的内容:
“这两个姐妹网络具有相同的架构和相同的参数,并且相互镜像 —如果一个子网中的权重被更新,则其他网络中的权重也会被更新。”
因此,即使有两个姐妹网络,我们实际上还是将它们实现为一个单个实例。本质上,这个单一的网络被视为一个特征提取器(因此我们将其命名为featureExtractor)。然后,当我们训练网络时,通过反向传播来更新网络的权重。
现在,让我们完成暹罗网络架构的构建:
# finally, construct the siamese network
distance = Lambda(utils.euclidean_distance)([featsA, featsB])
outputs = Dense(1, activation="sigmoid")(distance)
model = Model(inputs=[imgA, imgB], outputs=outputs)
第 36 行利用一个Lambda层来计算featsA和featsB网络之间的euclidean_distance(记住,这些值是通过姐妹网络特征提取器传递图像对中的每个图像的输出)。
然后,我们应用一个带有单个节点的Dense层,该节点应用了一个 sigmoid 激活函数。
这里使用了 sigmoid 激活函数,因为该函数的输出范围是【0,1】。更接近0的输出意味着图像对不太相似(因此来自不同的类),而更接近1的值意味着它们更相似(并且更可能来自相同的类)。
线 38 然后构建连体网络Model。inputs由我们的图像对imgA和imgB组成。网络的outputs是乙状结肠激活。
既然我们的暹罗网络架构已经构建完毕,我们就可以继续训练它了:
# compile the model
print("[INFO] compiling model...")
model.compile(loss="binary_crossentropy", optimizer="adam",
metrics=["accuracy"])
# train the model
print("[INFO] training model...")
history = model.fit(
[pairTrain[:, 0], pairTrain[:, 1]], labelTrain[:],
validation_data=([pairTest[:, 0], pairTest[:, 1]], labelTest[:]),
batch_size=config.BATCH_SIZE,
epochs=config.EPOCHS)
第 42 行和第 43 行使用二进制交叉熵作为我们的损失函数来编译我们的暹罗网络。
我们在这里使用二进制交叉熵,因为这本质上是一个两类分类问题——给定一对输入图像,我们试图确定这两幅图像有多相似,更具体地说,它们是否来自相同的或不同的类。
这里也可以使用更高级的损失函数,包括三重损失和对比损失。我将在 PyImageSearch 博客的未来系列中介绍如何使用这些损失函数,包括构造图像三元组(将介绍更高级的暹罗网络)。
第 47-51 行然后在图像对上训练暹罗网络。
一旦模型被训练,我们可以将它序列化到磁盘并绘制训练历史:
# serialize the model to disk
print("[INFO] saving siamese model...")
model.save(config.MODEL_PATH)
# plot the training history
print("[INFO] plotting training history...")
utils.plot_training(history, config.PLOT_PATH)
恭喜你实现了我们的暹罗网络培训脚本!
使用 Keras 和 TensorFlow 训练我们的暹罗网络
我们现在准备使用 Keras 和 TensorFlow 来训练我们的暹罗网络!确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端,并执行以下命令:
$ python train_siamese_network.py
[INFO] loading MNIST dataset...
[INFO] preparing positive and negative pairs...
[INFO] building siamese network...
[INFO] training model...
Epoch 1/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.6210 - accuracy: 0.6469 - val_loss: 0.5511 - val_accuracy: 0.7541
Epoch 2/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.5433 - accuracy: 0.7335 - val_loss: 0.4749 - val_accuracy: 0.7911
Epoch 3/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.5014 - accuracy: 0.7589 - val_loss: 0.4418 - val_accuracy: 0.8040
Epoch 4/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.4788 - accuracy: 0.7717 - val_loss: 0.4125 - val_accuracy: 0.8173
Epoch 5/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.4581 - accuracy: 0.7847 - val_loss: 0.3882 - val_accuracy: 0.8331
...
Epoch 95/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.3335 - accuracy: 0.8565 - val_loss: 0.3076 - val_accuracy: 0.8630
Epoch 96/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.3326 - accuracy: 0.8564 - val_loss: 0.2821 - val_accuracy: 0.8764
Epoch 97/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.3333 - accuracy: 0.8566 - val_loss: 0.2807 - val_accuracy: 0.8773
Epoch 98/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.3335 - accuracy: 0.8554 - val_loss: 0.2717 - val_accuracy: 0.8836
Epoch 99/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.3307 - accuracy: 0.8578 - val_loss: 0.2793 - val_accuracy: 0.8784
Epoch 100/100
1875/1875 [==============================] - 11s 6ms/step - loss: 0.3329 - accuracy: 0.8567 - val_loss: 0.2751 - val_accuracy: 0.8810
[INFO] saving siamese model...
[INFO] plotting training history...
正如你所看到的,我们的模型在我们的验证集上获得了 ~88.10%的准确度,意味着 88%的时候,模型能够正确地确定两幅输入图像是否属于相同的类别。
上面的图 4 显示了我们在 100 个时期的训练历史。我们的模型看起来相当稳定,鉴于我们的验证损失低于我们的训练损失,似乎我们可以通过“更努力地训练”来进一步提高准确性(“T2”,我在这里提到了这个)。
检查您的output目录,您现在应该看到一个名为siamese_model的目录:
$ ls output/
plot.png siamese_model
$ ls output/siamese_model/
saved_model.pb variables
这个目录包含我们的序列化暹罗网络。下周你将学习如何利用这个训练好的模型,并使用它对输入图像进行预测— 敬请关注我们的暹罗网络介绍系列的最后部分;你不会想错过的!
总结
在本教程中,您学习了如何使用 Keras、TensorFlow 和深度学习来实现和训练暹罗网络。
我们在 MNIST 数据集上训练了我们的暹罗网络。我们的网络接受一对输入图像(数字),然后尝试确定这两个图像是否属于同一类。
例如,如果我们要向模型呈现两幅图像,每幅图像都包含一个“9”,那么暹罗网络将报告这两幅图像之间的高相似度,表明它们确实属于相同的类。
然而,如果我们提供两个图像,一个包含一个“9”,另一个包含一个“2”,那么网络应该报告低相似度,假定这两个数字属于单独的类。
为了方便起见,我们在这里使用了 MNIST 数据集,这样我们可以了解暹罗网络的基本原理;然而,这种相同类型的训练过程可以应用于面部识别、签名验证、处方药丸识别等。
下周,您将学习如何实际使用我们训练过的、序列化的暹罗网络模型,并使用它来进行相似性预测。
然后我会在未来的一系列文章中讨论更高级的暹罗网络,包括图像三联体、三联体损失和对比损失。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
使用 OpenCV 进行简单的对象跟踪
原文:https://pyimagesearch.com/2018/07/23/simple-object-tracking-with-opencv/
最后更新于 2021 年 7 月 8 日。
今天的教程开始了一系列关于物体跟踪的博客文章,可以说是 PyImageSearch 上最受欢迎的话题之一。
物体跟踪的过程是:
- 获取对象检测的初始集合(例如输入的一组边界框坐标)
- 为每个初始检测创建唯一的 ID
- 然后当每个对象在视频帧中移动时跟踪它们,保持唯一 id 的分配
此外,对象跟踪允许我们为每个被跟踪的对象应用一个唯一的 ID,这使我们能够计数视频中的唯一对象。对象跟踪对于构建一个人物计数器(我们将在本系列的后面完成)至关重要。
理想的对象跟踪算法将:
- 仅需要一次对象检测阶段(即,当最初检测到对象时)
- 将会非常快——比运行实际的物体探测器本身快得多
- 能够处理被跟踪对象“消失”或移出视频帧边界的情况
- 对闭塞具有鲁棒性
- 能够捡起它在帧之间“丢失”的对象
这对任何计算机视觉或图像处理算法来说都是一个很高的要求,我们可以玩各种各样的技巧来帮助改进我们的物体跟踪器。
但是,在我们能够建立这样一个稳健的方法之前,我们首先需要研究对象跟踪的基本原理。
在今天的博客文章中,你将学习如何用 OpenCV 实现质心跟踪,OpenCV是一种易于理解但高效的跟踪算法。
在这个对象跟踪系列的后续文章中,我将开始研究更高级的基于内核和基于相关性的跟踪算法。
要了解如何开始使用 OpenCV 构建您的第一个对象跟踪,请继续阅读!
- 【2021 年 7 月更新:添加了关于替代对象跟踪器的部分,包括直接内置于 OpenCV 库中的对象跟踪器。
使用 OpenCV 进行简单的对象跟踪
https://www.youtube.com/embed/H0ztMWR3C04?feature=oembed
使用 OpenCV 进行简单的场景边界/镜头转换检测
原文:https://pyimagesearch.com/2019/08/19/simple-scene-boundary-shot-transition-detection-with-opencv/
https://www.youtube.com/embed/EYyGN6F1tK0?feature=oembed
皮肤检测:使用 Python 和 OpenCV 的分步示例
原文:https://pyimagesearch.com/2014/08/18/skin-detection-step-step-example-using-python-opencv/
https://www.youtube.com/embed/IkgM1b1HLK0?feature=oembed
用 Python 和 OpenCV 实现对象检测的滑动窗口
原文:https://pyimagesearch.com/2015/03/23/sliding-windows-for-object-detection-with-python-and-opencv/
所以在上周的博客文章中,我们发现了如何构建一个图像金字塔。
在今天的文章中,我们将扩展这个例子,引入一个 滑动窗口 的概念。滑动窗口在对象分类中起着不可或缺的作用,因为它们允许我们精确定位图像中对象所在的位置。
*利用滑动窗口和图像金字塔,我们能够在不同的尺度和位置检测图像中的对象。
事实上,在我的 6 步 HOG +线性 SVM 对象分类框架中,滑动窗口和图像金字塔都被使用了!
要了解滑动窗口在对象分类和图像分类中的作用,请继续阅读。当你读完这篇博文时,你会对图像金字塔和滑动窗口如何用于分类有一个很好的理解。
什么是滑动窗口?
在计算机视觉的上下文中(顾名思义),滑动窗口是一个固定宽度和高度的矩形区域,它在图像上“滑动”,如下图所示:

Figure 1: Example of the sliding a window approach, where we slide a window from left-to-right and top-to-bottom.
对于这些窗口中的每一个,我们通常会获取窗口区域并应用一个图像分类器来确定窗口中是否有我们感兴趣的对象——在本例中是一张脸。
结合图像金字塔我们可以创建图像分类器,这些图像分类器能够识别图像中不同比例和位置的物体。
这些技术虽然简单,但在物体检测和图像分类中扮演着绝对关键的角色。
用 Python 和 OpenCV 实现对象检测的滑动窗口
让我们继续,在上周的形象金字塔示例的基础上继续。
但是首先要确保你已经安装了 OpenCV 和 imutils :
- 用我的一个向导安装 OpenCV
- 要安装
imutils,请使用 pip:pip install --upgrade imutils
还记得helpers.py文件吗?重新打开并插入sliding_window功能:
# import the necessary packages
import imutils
def pyramid(image, scale=1.5, minSize=(30, 30)):
# yield the original image
yield image
# keep looping over the pyramid
while True:
# compute the new dimensions of the image and resize it
w = int(image.shape[1] / scale)
image = imutils.resize(image, width=w)
# if the resized image does not meet the supplied minimum
# size, then stop constructing the pyramid
if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]:
break
# yield the next image in the pyramid
yield image
def sliding_window(image, stepSize, windowSize):
# slide a window across the image
for y in range(0, image.shape[0], stepSize):
for x in range(0, image.shape[1], stepSize):
# yield the current window
yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
sliding_window函数需要三个参数。第一个是我们将要循环的image。第二个论点是stepSize。
步长表示我们将在 (x,y) 两个方向上“跳过”多少像素。通常,我们会 而不是 想要循环图像的每个像素(即stepSize=1),因为如果我们在每个窗口应用图像分类器,这在计算上将是禁止的。
相反,stepSize是基于每个数据集的确定的,并根据您的图像数据集进行调整以提供最佳性能。实际上,通常使用 4 到 8 个像素的stepSize。请记住,你的步长越小,你需要检查的窗口就越多。
最后一个参数windowSize定义了我们要从image中提取的窗口的宽度和高度(以像素为单位)。
第 24-27 行相当简单,处理窗口的实际“滑动”。
第 24-26 行定义了两个for循环,它们在图像的 (x,y) 坐标上循环,按照提供的步长递增它们各自的x和y计数器。
然后,第 27 行返回包含滑动窗口的x和y坐标以及窗口本身的元组。
为了看到滑动窗口的运行,我们必须为它写一个驱动脚本。创建一个新文件,命名为sliding_window.py,我们将完成这个例子:
# import the necessary packages
from pyimagesearch.helpers import pyramid
from pyimagesearch.helpers import sliding_window
import argparse
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
# load the image and define the window width and height
image = cv2.imread(args["image"])
(winW, winH) = (128, 128)
在2-6 号线,我们进口必要的包装。我们将使用上周中的pyramid函数来构建我们的图像金字塔。我们还将使用刚刚定义的sliding_window函数。最后,我们导入argparse来解析命令行参数,导入cv2来解析 OpenCV 绑定。
第 9-12 行处理解析我们的命令行参数。我们在这里只需要一个开关,我们想要处理的--image。
从那里,行 14 从磁盘上加载我们的图像,行 15 分别定义我们的窗口宽度和高度为 128 像素。
现在,让我们继续结合我们的图像金字塔和滑动窗口:
# loop over the image pyramid
for resized in pyramid(image, scale=1.5):
# loop over the sliding window for each layer of the pyramid
for (x, y, window) in sliding_window(resized, stepSize=32, windowSize=(winW, winH)):
# if the window does not meet our desired window size, ignore it
if window.shape[0] != winH or window.shape[1] != winW:
continue
# THIS IS WHERE YOU WOULD PROCESS YOUR WINDOW, SUCH AS APPLYING A
# MACHINE LEARNING CLASSIFIER TO CLASSIFY THE CONTENTS OF THE
# WINDOW
# since we do not have a classifier, we'll just draw the window
clone = resized.copy()
cv2.rectangle(clone, (x, y), (x + winW, y + winH), (0, 255, 0), 2)
cv2.imshow("Window", clone)
cv2.waitKey(1)
time.sleep(0.025)
我们从第 18 行的开始循环图像金字塔的每一层。
对于图像金字塔的每一层,我们也将在第 20 行的sliding_window中循环每个窗口。我们还对第 22-23 行进行了检查,以确保我们的滑动窗口符合最小尺寸要求。
如果我们应用图像分类器来检测对象,我们将通过从窗口中提取特征并将它们传递给我们的分类器(这是在我们的 6 步 HOG +线性 SVM 对象检测框架中完成的)在行 25-27 上完成。
但是由于我们没有图像分类器,我们将通过在图像上绘制一个矩形来显示滑动窗口的结果,该矩形指示滑动窗口在第 30-34 行上的位置。
结果
要查看我们的图像金字塔和滑动窗口的运行情况,请打开一个终端并执行以下命令:
$ python sliding_window.py --image images/adrian_florida.jpg
如果一切顺利,您应该会看到以下结果:

Figure 2: An example of applying a sliding window to each layer of the image pyramid.
在这里你可以看到金字塔的每一层都有一个窗口滑过。同样,如果我们有一个准备好的图像分类器,我们可以对每个窗口进行分类。一个例子可以是“这个窗口是否包含人脸?”
这是另一个不同图像的例子:
$ python sliding_window.py --image images/stick_of_truth.jpg.jpg

Figure 3: A second example of applying a sliding window to each layer of the image pyramid.
我们可以再次看到,滑动窗口在金字塔的每一层滑过图像。金字塔的高级别(以及更小的层)需要检查的窗口更少。
摘要
在这篇博文中,我们了解了滑动窗口及其在物体检测和图像分类中的应用。
通过将滑动窗口与图像金字塔相结合,我们能够在多个和 位置 定位和检测图像中的对象。
*虽然滑动窗口和图像金字塔都是非常简单的技术,但它们在对象检测中是绝对关键的。
你可以在这篇博客文章中了解更多关于它们扮演的全球角色的信息,在这篇文章中,我详细介绍了如何使用梯度方向直方图图像描述符和线性 SVM 分类器来构建自定义对象检测器的框架。**
利用 OpenCV、Keras 和 TensorFlow 进行微笑检测
原文:https://pyimagesearch.com/2021/07/14/smile-detection-with-opencv-keras-and-tensorflow/
在本教程中,我们将构建一个完整的端到端应用程序,该应用程序可以使用深度学习和传统的计算机视觉技术实时检测视频流中的微笑。
为了完成这项任务,我们将在一个图像数据集上训练 LetNet 架构,该数据集包含了正在微笑的和没有微笑的的人脸。一旦我们的网络经过训练,我们将创建一个单独的 Python 脚本——这个脚本将通过 OpenCV 的内置 Haar cascade 人脸检测器检测图像中的人脸,从图像中提取人脸感兴趣区域(ROI ),然后将 ROI 通过 LeNet 进行微笑检测。
*要学习如何用 OpenCV、Keras 和 TensorFlow 检测微笑, 继续阅读。
使用 OpenCV、Keras 和 TensorFlow 进行微笑检测
当开发图像分类的真实应用程序时,您经常需要将传统的计算机视觉和图像处理技术与深度学习相结合。为了在学习和应用深度学习时取得成功,我尽了最大努力来确保本教程在算法、技术和你需要理解的库方面独立存在。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
微笑数据集
微笑数据集由脸的图像组成,这些脸或者是微笑的或者是不微笑的 ( 罗马达,2010 年)。数据集中总共有 13,165 幅灰度图像,每幅图像的大小为 64×64像素。
正如图 2 所展示的,这个数据集中的图像在脸部周围被紧密裁剪,这将使训练过程更容易,因为我们将能够直接从输入图像中学习“微笑”或“不微笑”的模式。
然而,近距离裁剪在测试过程中带来了一个问题——因为我们的输入图像不仅包含人脸,还包含图像的背景,我们首先需要定位图像中的人脸,并提取人脸 ROI,然后才能通过我们的网络进行检测。幸运的是,使用传统的计算机视觉方法,如 Haar cascades,这比听起来容易得多。
我们需要在 SMILES 数据集中处理的第二个问题是类不平衡。虽然数据集中有 13,165 幅图像,但是这些例子中有 9,475 幅是没有微笑,,而只有 3,690 幅属于微笑类。鉴于有超过 2 个。 5 x 把“不笑”的图片数量改为“笑”的例子,我们在设计训练程序时需要小心。
我们的网络可能自然地选择“不笑”的标签,因为(1)分布是不均匀的,以及(2)它有更多“不笑”的脸看起来像什么的例子。稍后,您将看到我们如何通过在训练期间计算每个职业的“权重”来消除职业不平衡。
训练微笑 CNN
构建我们的微笑检测器的第一步是在微笑数据集上训练 CNN,以区分微笑和不微笑的脸。为了完成这个任务,让我们创建一个名为train_model.py的新文件。从那里,插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.utils import to_categorical
from pyimagesearch.nn.conv import LeNet
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import imutils
import cv2
import os
第 2-14 行导入我们需要的 Python 包。我们以前使用过所有的包,但是我想提醒你注意第 7 行,在那里我们导入了 LeNet(LeNet Tutorial)类——这是我们在创建微笑检测器时将使用的架构。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of faces")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
args = vars(ap.parse_args())
# initialize the list of data and labels
data = []
labels = []
我们的脚本需要两个命令行参数,我在下面详细介绍了每个参数:
--dataset:位于磁盘上的 SMILES 目录的路径。--model:训练完成后,序列化 LeNet 权重的保存路径。
我们现在准备从磁盘加载 SMILES 数据集,并将其存储在内存中:
# loop over the input images
for imagePath in sorted(list(paths.list_images(args["dataset"]))):
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = imutils.resize(image, width=28)
image = img_to_array(image)
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-3]
label = "smiling" if label == "positives" else "not_smiling"
labels.append(label)
在第 29 行,上,我们遍历了--dataset输入目录中的所有图像。对于这些图像中的每一个,我们:
- 从磁盘加载(第 31 行)。
- 将其转换为灰度(第 32 行)。
- 调整它的大小,使其有一个像素的固定输入尺寸(第 33 行)。
- 将图像转换为与 Keras 及其通道排序兼容的数组(第 34 行)。
- 将
image添加到 LeNet 将接受培训的data列表中。
第 39-41 行处理从imagePath中提取类标签并更新labels列表。SMILES 数据集将微笑的人脸存储在SMILES/positives/positives7子目录中,而不微笑的人脸存储在SMILES/negatives/negatives7子目录中。
因此,给定图像的路径:
SMILEs/positives/positives7/10007.jpg
我们可以通过在图像路径分隔符上拆分并抓取倒数第三个子目录:positives来提取类标签。事实上,这正是线 39 所要完成的。
既然我们的data和labels已经构造好了,我们可以将原始像素强度缩放到范围[0, 1],然后对labels应用一键编码:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# convert the labels from integers to vectors
le = LabelEncoder().fit(labels)
labels = to_categorical(le.transform(labels), 2)
我们的下一个代码块通过计算类权重来处理我们的数据不平衡问题:
# calculate the total number of training images in each class and
# initialize a dictionary to store the class weights
classTotals = labels.sum(axis=0)
classWeight = dict()
# loop over all classes and calculate the class weight
for i in range(0, len(classTotals)):
classWeight[i] = classTotals.max() / classTotals[i]
第 53 行计算每个类的例子总数。在这种情况下,classTotals将是一个数组:[9475, 3690]分别表示“不笑”和“笑”。
然后我们缩放第 57 行和第 58 行上的这些总数,以获得用于处理类不平衡的classWeight,产生数组:[1, 2.56]。这种加权意味着我们的网络将把每个“微笑”的实例视为 2.56 个“不微笑”的实例,并通过在看到“微笑”的实例时用更大的权重放大每个实例的损失来帮助解决类别不平衡问题。
既然我们已经计算了我们的类权重,我们可以继续将我们的数据划分为训练和测试部分,将 80%的数据用于训练,20%用于测试:
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.20, stratify=labels, random_state=42)
最后,我们准备培训 LeNet:
# initialize the model
print("[INFO] compiling model...")
model = LeNet.build(width=28, height=28, depth=1, classes=2)
model.compile(loss="binary_crossentropy", optimizer="adam",
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
class_weight=classWeight, batch_size=64, epochs=15, verbose=1)
第 67 行初始化将接受28×28单通道图像的 LeNet 架构。假设只有两个类(微笑和不微笑),我们设置classes=2。
我们也将使用binary_crossentropy而不是categorical_crossentropy作为我们的损失函数。同样,分类交叉熵仅在类别数量超过两个时使用。
到目前为止,我们一直使用 SGD 优化器来训练我们的网络。在这里,我们将使用亚当(金玛和巴,2014 ) ( 第 68 行)。
同样,优化器和相关参数通常被认为是在训练网络时需要调整的超参数。当我把这个例子放在一起时,我发现 Adam 的表现比 SGD 好得多。
73 号线和 74 号线使用我们提供的classWeight训练 LeNet 总共 15 个时期,以对抗等级不平衡。
一旦我们的网络经过训练,我们就可以对其进行评估,并将权重序列化到磁盘中:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=64)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=le.classes_))
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"])
我们还将为我们的网络构建一条学习曲线,以便我们可以直观地了解性能:
# plot the training + testing loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 15), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 15), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 15), H.history["accuracy"], label="acc")
plt.plot(np.arange(0, 15), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
要训练我们的微笑检测器,请执行以下命令:
$ python train_model.py --dataset ../datasets/SMILEsmileD \
--model output/lenet.hdf5
[INFO] compiling model...
[INFO] training network...
Train on 10532 samples, validate on 2633 samples
Epoch 1/15
8s - loss: 0.3970 - acc: 0.8161 - val_loss: 0.2771 - val_acc: 0.8872
Epoch 2/15
8s - loss: 0.2572 - acc: 0.8919 - val_loss: 0.2620 - val_acc: 0.8899
Epoch 3/15
7s - loss: 0.2322 - acc: 0.9079 - val_loss: 0.2433 - val_acc: 0.9062
...
Epoch 15/15
8s - loss: 0.0791 - acc: 0.9716 - val_loss: 0.2148 - val_acc: 0.9351
[INFO] evaluating network...
precision recall f1-score support
not_smiling 0.95 0.97 0.96 1890
smiling 0.91 0.86 0.88 743
avg / total 0.93 0.94 0.93 2633
[INFO] serializing network...
在 15 个时期之后,我们可以看到我们的网络正在获得 93%的分类准确度。图 3 描绘了我们的学习曲线:
过了第六个时期,我们的确认损失开始停滞——过了第 15 个时期的进一步训练将导致过度拟合。如果需要,我们可以通过使用更多的训练数据来提高微笑检测器的准确性,方法是:
- 收集其他培训数据。
- 应用数据增强来随机平移、旋转和移动我们的现有的训练集。
实时运行微笑有线电视新闻网
既然我们已经训练了我们的模型,下一步是构建 Python 脚本来访问我们的网络摄像头/视频文件,并对每一帧应用微笑检测。为了完成这一步,打开一个新文件,将其命名为detect_smile.py,然后我们开始工作。
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import imutils
import cv2
第 2-7 行导入我们需要的 Python 包。img_to_array函数将用于将视频流中的每个单独的帧转换成一个适当的通道有序数组。load_model函数将用于从磁盘加载我们训练好的 LeNet 模型的权重。
detect_smile.py脚本需要两个命令行参数,后跟第三个可选参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", required=True,
help="path to where the face cascade resides")
ap.add_argument("-m", "--model", required=True,
help="path to pre-trained smile detector CNN")
ap.add_argument("-v", "--video",
help="path to the (optional) video file")
args = vars(ap.parse_args())
第一个参数,--cascade是用于检测图像中人脸的 Haar 级联的路径。保罗·维奥拉(Paul Viola)和迈克尔·琼斯(Michael Jones)于 2001 年首次发表了他们的工作,详细描述了哈尔级联 使用简单特征的增强级联 进行快速对象检测。该出版物已成为计算机视觉文献中被引用最多的论文之一。
Haar 级联算法能够检测图像中的对象,而不管它们的位置和比例。也许最有趣的(也是与我们的应用相关的)是,探测器可以在现代硬件上实时运行。事实上,Viola 和 Jones 工作背后的动机是创造一个面部检测器。
第二个常见的行参数是--model,它指定了我们在磁盘上序列化 LeNet 权重的路径。我们的脚本将默认从内置/USB 摄像头读取帧;然而,如果我们想从文件中读取帧,我们可以通过可选的--video开关来指定文件。
在检测微笑之前,我们首先需要执行一些初始化:
# load the face detector cascade and smile detector CNN
detector = cv2.CascadeClassifier(args["cascade"])
model = load_model(args["model"])
# if a video path was not supplied, grab the reference to the webcam
if not args.get("video", False):
camera = cv2.VideoCapture(0)
# otherwise, load the video
else:
camera = cv2.VideoCapture(args["video"])
第 20 行和第 21 行分别加载 Haar 级联人脸检测器和预训练的 LeNet 模型。如果没有提供视频路径,我们就抓取一个指向我们网络摄像头的指针(第 24 行和第 25 行)。否则,我们打开一个指向磁盘上视频文件的指针(第 28 行和第 29 行)。
现在,我们已经到达了应用程序的主要处理管道:
# keep looping
while True:
# grab the current frame
(grabbed, frame) = camera.read()
# if we are viewing a video and we did not grab a frame, then we
# have reached the end of the video
if args.get("video") and not grabbed:
break
# resize the frame, convert it to grayscale, and then clone the
# original frame so we can draw on it later in the program
frame = imutils.resize(frame, width=300)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frameClone = frame.copy()
第 32 行开始一个循环,这个循环将一直持续到(1)我们停止脚本或者(2)我们到达视频文件的结尾(假设应用了一个--video路径)。
第 34 行从视频流中抓取下一帧。如果frame不是grabbed,那么我们已经到达了视频文件的末尾。否则,我们通过调整frame的大小使其宽度为 300 像素(行 43 )并将其转换为灰度(行 44 )来预处理人脸检测。
.detectMultiScale方法处理检测边界框( x,y)—frame中面部的坐标:
# detect faces in the input frame, then clone the frame so that
# we can draw on it
rects = detector.detectMultiScale(gray, scaleFactor=1.1,
minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
这里,我们传入我们的灰度图像,并指出对于一个被认为是人脸的给定区域,它的必须具有最小宽度30×30像素。minNeighbors属性有助于删除误报,而scaleFactor控制生成的图像金字塔(http://pyimg.co/rtped)等级的数量。
同样,对用于物体检测的哈尔级联的详细回顾不在本教程的范围之内。
.detectMultiScale方法返回一个 4 元组的列表,这些元组组成了在frame中包围面部的矩形。列表中的前两个值是起始( x,y )坐标。在rects列表中的后两个值分别是边界框的宽度和高度。
我们循环下面的每组边界框:
# loop over the face bounding boxes
for (fX, fY, fW, fH) in rects:
# extract the ROI of the face from the grayscale image,
# resize it to a fixed 28x28 pixels, and then prepare the
# ROI for classification via the CNN
roi = gray[fY:fY + fH, fX:fX + fW]
roi = cv2.resize(roi, (28, 28))
roi = roi.astype("float") / 255.0
roi = img_to_array(roi)
roi = np.expand_dims(roi, axis=0)
对于每个边界框,我们使用 NumPy 数组切片来提取人脸 ROI ( 行 58 )。一旦我们有了 ROI,我们就对它进行预处理,并通过调整它的大小、缩放它、将其转换为 Keras 兼容的数组,并用一个额外的维度填充图像来准备通过 LeNet 进行分类(第 59-62 行)。
roi经过预处理后,可以通过 LeNet 进行分类:
# determine the probabilities of both "smiling" and "not
# smiling", then set the label accordingly
(notSmiling, smiling) = model.predict(roi)[0]
label = "Smiling" if smiling > notSmiling else "Not Smiling"
对行 66 上的.predict的调用分别返回“不笑”和“笑”的概率。第 67 行根据哪个概率大来设置label。
一旦我们有了label,我们就可以画出它,以及相应的边框:
# display the label and bounding box rectangle on the output
# frame
cv2.putText(frameClone, label, (fX, fY - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
cv2.rectangle(frameClone, (fX, fY), (fX + fW, fY + fH),
(0, 0, 255), 2)
我们最后的代码块处理在屏幕上显示输出帧:
# show our detected faces along with smiling/not smiling labels
cv2.imshow("Face", frameClone)
# if the 'q' key is pressed, stop the loop
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# cleanup the camera and close any open windows
camera.release()
cv2.destroyAllWindows()
如果按下q键,我们将退出脚本。
要使用您的网络摄像头运行detect_smile.py,请执行以下命令:
$ python detect_smile.py --cascade haarcascade_frontalface_default.xml \
--model output/lenet.hdf5
如果您想使用视频文件,您可以更新您的命令以使用--video开关:
$ python detect_smile.py --cascade haarcascade_frontalface_default.xml \
--model output/lenet.hdf5 --video path/to/your/video.mov
我已经将微笑检测脚本的结果包含在图 4 中:
请注意 LeNet 是如何根据我的面部表情正确预测“微笑”或“不微笑”的。
总结
在本教程中,我们学习了如何构建一个端到端的计算机视觉和深度学习应用程序来执行微笑检测。为此,我们首先在 SMILES 数据集上训练 LeNet 架构。由于 SMILES 数据集中的类不平衡,我们发现了如何计算类权重来帮助缓解这个问题。
训练完成后,我们在测试集上对 LeNet 进行了评估,发现该网络获得了相当高的 93%的分类准确率。通过收集更多的训练数据或者对现有的训练数据进行数据扩充,可以获得更高的分类精度。
然后,我们创建了一个 Python 脚本来从网络摄像头/视频文件中读取帧,检测人脸,然后应用我们预先训练好的网络。为了检测人脸,我们使用了 OpenCV 的哈尔级联。一旦检测到一张脸,就从画面中提取出来,然后通过 LeNet 来确定这个人是在笑还是没笑。作为一个整体,我们的微笑检测系统可以使用现代硬件在 CPU 上轻松地实时运行。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
先睹为快:用 Python 实现计算机视觉的深度学习
原文:https://pyimagesearch.com/2017/01/12/sneak-preview-deep-learning-for-computer-vision-with-python/
哇,1 月 18 日的 Kickstarter 发布日期这么快就要到了!
我仍然有大量的工作要做,我深陷在 Kickstarter logistics 中,但我今天早些时候花了几分钟,用 Python 为你录制了这个关于计算机视觉的深度学习的预览:
 这个视频相当短,只有 2m51s,绝对值得一看,但是如果你没有足够的时间看,你可以看看下面的要点:
这个视频相当短,只有 2m51s,绝对值得一看,但是如果你没有足够的时间看,你可以看看下面的要点:
** 0m09s:我展示了在大规模 ImageNet 数据集上从头开始训练 AlexNet 的输出结果——我将在我的书中向你展示确切地说如何做。
- 0m37s:我讨论这本书如何有一个目标:帮助开发者、研究人员和学生就像你自己成为深度学习计算机视觉的专家。
- 0m44s:无论这是你第一次使用深度学习和神经网络,还是已经是一名经验丰富的深度学习实践者,这本书都是从头开始设计的,旨在帮助你成为专家。
- 0m58s:我提供了我的《计算机视觉深度学习》一书中将要涉及的主题的高层次概述。
- 1m11s:我揭示了编程语言(Python)和我们将用来构建深度学习网络的库(Keras 和 mxnet)。
- 1m24s:由于我们将涵盖大量主题,我将把这本书分成卷称为 【捆绑】 。你将能够根据你想要研究深度学习的深度以及你的特定预算来选择一个捆绑包。
- 1m38s:每个捆绑包将包括电子书文件、视频教程和演练、源代码列表、配套网站的访问权限以及可下载的预配置 Ubuntu VM。
- Kickstarter 活动将于 1 月 18 日周三美国东部时间 上午 10 点开始——我希望能在 Kickstarter 支持者名单上看到你。
就像我说的,如果你有时间,先睹为快绝对值得一看。
我希望你支持 1 月 18 日美国东部时间周三上午 10 点举行的用 Python 进行计算机视觉深度学习 Kickstarter 活动——如果你真的想成为深度学习专家,那么这本书将是你的不二之选!
要在更多 Kickstarter 公告发布时收到通知, 请务必注册 Kickstarter 通知列表!*
预览:OCR 与 OpenCV、Tesseract 和 Python
原文:https://pyimagesearch.com/2020/08/13/sneak-preview-ocr-with-opencv-tesseract-and-python/
哇,8 月 19 日星期三的 IndieGoGo 发布日期越来越近了! ( 注:战役已经结束。但是你仍然可以在这里预定我即将出版的书的副本,该书使用了 Tesseract、OpenCV 和 Python 、T6。)
我仍然有大量的工作要做,目前我深陷在 IndieGoGo 竞选后勤中,但我花了几分钟时间,用 OpenCV、Tesseract 和 Python 录制了这个 OCR 的预览:
https://www.youtube.com/embed/fr9g86t8Uc4?feature=oembed
预览:PyImageSearch 大师
原文:https://pyimagesearch.com/2015/01/08/sneak-preview-pyimagesearch-gurus/
哇,1 月 14 日的 Kickstarter 发布日期这么快就到了!我还有一大堆事情要做,而且我深陷在 Kickstarter 的物流中,但今天早些时候我花了几分钟,为你录制了这个 PyImageSearch 大师的预览:

这段视频相当短,只有 1 分 08 秒,绝对值得一看,但是如果你没有足够的时间看,你可以阅读下面的要点:
- 0m07s:我演示了人脸检测和识别,我们将在 PyImageSearch Gurus 中介绍。
- 0m16s: 实用 Python 和 OpenCV 将作为 Kickstarter 独家奖励提供印刷版本。这本书将单独编号并亲笔签名——这可能是这本书第次出版了!
- 0m23s:PyImageSearch 大师计算机视觉课程将 6-8 个月和完全自定进度。
- 0m38s:我演示了自动车牌识别,我们也会在 PyImageSearch Gurus 里面涉及到。
- 0m45s:加入 PyImageSearch 大师们的行列,利用 Hadoop、Elasticsearch 和 Accumulo 来构建大规模的图片搜索引擎。
- 0m50s: 深度学习和卷积神经网络。是的,他们也会被覆盖。
- Kickstarter 将于美国东部时间1 月 14 日T3【上午 10 点】上线——我希望在 Kickstarter 支持者名单上看到你!
就像我说的,如果你有时间,先睹为快绝对值得一看。
我希望你支持 1 月 14 日美国东部时间上午 10 点的 PyImageSearch 大师 Kickstarter 活动——如果你真的想提升你的计算机视觉和 OpenCV 技能,那么这将是你的完美课程!
明天我将发布另一个公告,上面有最终确定的计算机视觉主题列表,你将在 PyImageSearch 大师中掌握这些主题。这是大单,你不会想错过的!
要在这些公告发布时收到通知, 请务必注册 Kickstarter 通知列表!
先睹为快:计算机视觉的树莓派
原文:https://pyimagesearch.com/2019/04/04/sneak-preview-raspberry-pi-for-computer-vision/
4 月 10 日星期三的 Kickstarter 发布日期越来越近了!
我仍然有大量的工作要做,我目前深陷在 Kickstarter 活动后勤中, ,但我花了几分钟,录制了这个用于计算机视觉的树莓派的预览,只为你:
该视频相当短,时长为 5 分 56 秒,绝对值得一看,但如果你没有足够的时间观看,你可以阅读下面的要点:
- 0m06s:我展示一个搭建 CV +物联网野生动物相机的例子。我们将在书中详细介绍的具体实施。
- 0m29s:我讨论了 Raspberry Pi,它与相机+计算机视觉库的兼容性,以及我们如何将 Pi 用于计算机视觉。
- 0m45:我们能否编写理解 Pi“看到”的内容并根据其采取行动的软件?当然,是的!我将向您展示如何通过人脸识别、客流量/交通计数器应用、手势识别、Pi 上的深度学习、等等!
- 1m01s:无论你是经验丰富的计算机视觉和深度学习实践者,还是计算机视觉和图像处理领域的新手,这本书都将帮助你在 Raspberry Pi 上构建实用的、真实世界的计算机视觉应用。
- 1 分 16 秒:我提供了 RPi + CV 手册中将涵盖的主题的高层次概述。
- 1m45s:由于这本书涵盖了如此大量、多样的内容,我决定将这本书分成三个卷,称为 【捆绑】。 你可以根据你想在 Pi 上学习 CV 和 DL 的深度,选择你最感兴趣的项目/章节,以及你的具体预算。
- 2m50s:我非常相信边做边学。您将卷起袖子,动手编写代码,并构建真实的项目。
- 3m03s:物联网野生动物监控、检测疲劳驾驶员、平移和倾斜物体跟踪以及物联网交通/人流计数的演示。
- 3m41s:更多演示,包括手势识别、车辆检测和识别、车速检测、多个 pi 和深度学习、自动驾驶汽车应用、Movidius NCS 和 OpenVINO、人脸识别安全摄像头、智能教室考勤系统。
- Kickstarter 活动将于美国东部时间 4 月 10 日周三上午 10 点T3 开始——我希望在 Kickstarter 支持者名单上看到你!
就像我说的,如果你有时间,预告视频绝对值得一看。
我希望你决定支持美国东部时间 4 月 10 日星期三上午 10 点在举行的计算机视觉树莓 PiKickstarter 活动——如果你准备好将 CV 和 DL 带到嵌入式/物联网设备上,那么这就是给你的完美书!
要在更多 Kickstarter 公告发布时获得通知, 请务必注册 RPi for CV Kickstarter 通知列表!
softmax 分类广告解释
原文:https://pyimagesearch.com/2016/09/12/softmax-classifiers-explained/

上周我们讨论了多级 SVM 损耗;具体来说,铰链损耗和平方铰链损耗函数。
在机器学习和深度学习的背景下,损失函数允许我们量化给定分类函数(也称为“得分函数”)在正确分类数据集中的数据点方面有多“好”或“坏”。
然而,虽然在训练机器学习/深度学习分类器时通常使用铰链损失和平方铰链损失,但还有另一种更常用的方法…
事实上,如果你以前做过深度学习方面的工作,你可能以前听说过这个函数——这些术语【soft max 分类器】 和 交叉熵损失 听起来熟悉吗?
我甚至可以说,如果你在深度学习(特别是卷积神经网络)中做任何工作,你都会遇到术语“软最大值”:正是网络末端的最后一层**为每个类别标签产生你的实际概率分数。
要了解更多关于 Softmax 分类器和交叉熵损失函数的信息,请继续阅读。
softmax 分类广告解释
虽然铰链损失非常普遍,但在深度学习和卷积神经网络的背景下,你更有可能遇到交叉熵损失和 Softmax 分类器。
这是为什么呢?
简单来说:
Softmax 分类器给你每个类别标签的概率,而铰链损耗给你余量 。
对我们人类来说,解释概率比解释差额分数(比如铰链损失和平方铰链损失)要容易得多。
此外,对于像 ImageNet 这样的数据集,我们经常查看卷积神经网络的 5 级精度(其中我们检查地面实况标签是否在网络为给定输入图像返回的前 5 个预测标签中)。
查看(1)真实类别标签是否存在于前 5 个预测中,以及(2)与预测标签相关联的概率是一个很好的属性。
了解多项式逻辑回归和 Softmax 分类器
Softmax 分类器是二进制形式的逻辑回归的推广。就像在铰链损失或平方铰链损失中一样,我们的映射函数 f 被定义为它获取一组输入数据 x 并通过数据 x 和权重矩阵 W 的简单(线性)点积将它们映射到输出类标签:
 = Wx_{i}")
然而,与铰链损失不同,我们将这些分数解释为每个类别标签的非标准化对数概率——这相当于用交叉熵损失替换我们的铰链损失函数:
")
那么,我是怎么来到这里的呢?让我们把功能拆开来看看。
首先,我们的损失函数应该最小化正确类别的负对数可能性:
")
这种概率陈述可以解释为:
 = e^{s_{y_{i}}} / \sum_{j} e^{s_{j}}")
我们使用标准的评分函数形式:
")
总的来说,这产生了一个单个数据点的最终损失函数,如上所示:
注: 你这里的对数其实是以 e 为底(自然对数)由于我们前面是取 e 的幂的倒数,
通过指数之和的实际取幂和归一化是我们实际的 Softmax 函数。负对数产生我们实际的交叉熵损失。
正如铰链损失或平方铰链损失一样,计算整个数据集的交叉熵损失是通过取平均值来完成的:

如果这些方程看起来很可怕,不要担心——在下一节中,我将给出一个实际的数值例子。
注意: 我特意省略了正则化术语,以免使本教程臃肿或迷惑读者。我们将在未来的博客文章中回到正则化,并解释它是什么,如何使用,以及为什么它对机器学习/深度学习很重要。
一个成功的 Softmax 示例
为了演示实际的交叉熵损失,请考虑下图:

Figure 1: To compute our cross-entropy loss, let’s start with the output of our scoring function (the first column).
我们的目标是分类上面的图像是否包含一只狗、猫、船或飞机。
我们可以清楚地看到,这个图像是一架“飞机”。但是我们的 Softmax 分类器呢?
为了找到答案,我在上面的图 1 中分别包含了四个类的评分函数 f 的输出。这些值是我们的四个类别的非标准化对数概率。
注意:我使用了一个随机数生成器来获得这个特定例子的这些值。这些值仅用于演示如何执行 Softmax 分类器/交叉熵损失函数的计算。实际上,这些值不是随机生成的——而是您的评分函数 f 的输出。
让我们对评分函数的输出进行指数运算,得到我们的非标准化概率:

Figure 2: Exponentiating the output values from the scoring function gives us our unnormalized probabilities.
下一步是取分母,对指数求和,然后除以总和,从而产生与每个类标签相关联的实际概率:

Figure 3: To obtain the actual probabilities, we divide each individual unnormalized probability by the sum of unnormalized probabilities.
最后,我们可以取负对数,得出我们的最终损失:
Figure 4: Taking the negative log of the probability for the correct ground-truth class yields the final loss for the data point.
在这种情况下,我们的 Softmax 分类器将以 93.15%的置信度正确地将图像报告为飞机。
Python 中的 Softmax 分类器
为了用实际的 Python 代码演示我们到目前为止学到的一些概念,我们将使用一个带有日志丢失函数的 SGDClassifier 。
注: 我们会在以后的博文中了解更多关于随机梯度下降和其他优化方法的内容。
对于这个示例,我们将再次使用 Kaggle 狗与猫数据集,因此在开始之前,请确保您已经:
- 使用本教程底部的 “下载” 表单下载了这篇博文的源代码。
- 下载了 Kaggle 狗对猫数据集。
在我们的特定示例中,Softmax 分类器实际上会简化为一种特殊情况——当有 K=2 个类时,Softmax 分类器会简化为简单的逻辑回归。如果我们有 > 2 类,那么我们的分类问题将变成多项式逻辑回归,或者更简单地说,一个 Softmax 分类器。
如上所述,打开一个新文件,将其命名为softmax.py,并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
import os
如果您在过去几周一直关注 PyImageSearch 博客,那么上面的代码可能看起来非常熟悉——我们在这里所做的只是导入我们需要的 Python 包。
我们将使用 scikit-learn 库,因此如果您还没有安装它,请务必现在安装它:
$ pip install scikit-learn
我们还将使用我的 imutils 包,这是一系列方便的功能,用于使执行常见的图像处理操作变得更容易。如果您没有安装imutils,您也可以安装它:
$ pip install imutils
接下来,我们定义我们的extract_color_histogram函数,该函数用于使用提供的bins的数量来量化我们的输入image的颜色分布:
def extract_color_histogram(image, bins=(8, 8, 8)):
# extract a 3D color histogram from the HSV color space using
# the supplied number of `bins` per channel
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
hist = cv2.calcHist([hsv], [0, 1, 2], None, bins,
[0, 180, 0, 256, 0, 256])
# handle normalizing the histogram if we are using OpenCV 2.4.X
if imutils.is_cv2():
hist = cv2.normalize(hist)
# otherwise, perform "in place" normalization in OpenCV 3 (I
# personally hate the way this is done
else:
cv2.normalize(hist, hist)
# return the flattened histogram as the feature vector
return hist.flatten()
这个功能我之前已经复习过几次了,所以就不详细复习了。关于extract_color_histogram,我们为什么使用它,以及它是如何工作的更深入的讨论,请看这篇博文。
同时,请记住,这个函数通过构建像素强度直方图来量化图像的内容。
让我们解析我们的命令行参数,并从磁盘中获取 25,000 张狗和猫的图像的路径:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
# grab the list of images that we'll be describing
print("[INFO] describing images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the data matrix and labels list
data = []
labels = []
这里我们只需要一个开关--dataset,它是我们输入狗和猫图像的路径。
一旦我们有了这些图像的路径,我们就可以逐个遍历它们,并提取每幅图像的颜色直方图:
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# load the image and extract the class label (assuming that our
# path as the format: /path/to/dataset/{class}.{image_num}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-1].split(".")[0]
# extract a color histogram from the image, then update the
# data matrix and labels list
hist = extract_color_histogram(image)
data.append(hist)
labels.append(label)
# show an update every 1,000 images
if i > 0 and i % 1000 == 0:
print("[INFO] processed {}/{}".format(i, len(imagePaths)))
同样,因为我已经在 PyImageSearch 博客上多次查看过这个样板代码,所以我会让你参考这篇博文以获得关于特征提取过程的更详细的讨论。
我们的下一步是构建培训和测试部分。我们将使用 75%的数据来训练我们的分类器,剩余的 25%用于测试和评估模型:
# encode the labels, converting them from strings to integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# partition the data into training and testing splits, using 75%
# of the data for training and the remaining 25% for testing
print("[INFO] constructing training/testing split...")
(trainData, testData, trainLabels, testLabels) = train_test_split(
np.array(data), labels, test_size=0.25, random_state=42)
# train a Stochastic Gradient Descent classifier using a softmax
# loss function and 10 epochs
model = SGDClassifier(loss="log", random_state=967, n_iter=10)
model.fit(trainData, trainLabels)
# evaluate the classifier
print("[INFO] evaluating classifier...")
predictions = model.predict(testData)
print(classification_report(testLabels, predictions,
target_names=le.classes_))
我们还使用log损失函数(第 75 行和第 76 行)来训练我们的SGDClassifier。使用log损失函数确保我们将在测试时获得每个类标签的概率估计值。
第 79-82 行然后为我们的分类器显示一个格式良好的准确性报告。
为了检查一些实际的概率,让我们循环几个随机抽样的训练示例,并检查分类器返回的输出概率:
# to demonstrate that our classifier actually "learned" from
# our training data, randomly sample a few training images
idxs = np.random.choice(np.arange(0, len(trainData)), size=(5,))
# loop over the training indexes
for i in idxs:
# predict class probabilities based on the extracted color
# histogram
hist = trainData[i].reshape(1, -1)
(catProb, dogProb) = model.predict_proba(hist)[0]
# show the predicted probabilities along with the actual
# class label
print("cat={:.1f}%, dog={:.1f}%, actual={}".format(catProb * 100,
dogProb * 100, le.inverse_transform(trainLabels[i])))
注意:我从训练数据而不是测试数据中随机抽样,以证明每个类别标签的概率之间应该有明显的巨大差距。每个分类是否正确是另一回事——但是即使我们的预测是错误的,我们仍然应该看到某种差距,这表明我们的分类器实际上正在从数据中学习。
第 93 行通过.predict_proba函数计算随机采样数据点的概率。
猫和狗类的预测概率随后显示在我们屏幕的第 97 和 98 行上。
Softmax 分类器结果
一旦你:
- 使用本教程底部的 “下载” 表单将源代码下载到这个博客。
- 下载了 Kaggle 狗对猫数据集。
您可以执行以下命令从我们的数据集中提取特征并训练我们的分类器:
$ python softmax.py --dataset kaggle_dogs_vs_cats
训练完我们的SGDClassifier,你应该会看到下面的分类报告:

Figure 5: Computing the accuracy of our SGDClassifier with log loss — we obtain 65% classification accuracy.
请注意,我们的分类器已经获得了 65%的准确度,比在我们的线性分类柱中使用线性 SVM 时的 64%的准确度有所提高。
要调查给定数据点的单个类别概率,请查看其余的softmax.py输出:

Figure 6: Investigating the class label probabilities for each prediction.
对于每一个随机采样的数据点,我们被给定了“狗”和“猫”的分类标签概率,以及实际地面实况标签。**
基于这个样本,我们可以看到我们获得了 4 / 5 = 80% 的准确率。
但更重要的是,注意在类别标签概率之间有一个特别大的差距。如果我们的 Softmax 分类器预测到“狗”,那么与“狗”相关联的概率将会很高。相反,与“猫”相关联的类别标签概率将会很低。
类似地,如果我们的 Softmax 分类器预测“猫”,那么与“猫”相关联的概率将是高的,而与“狗”相关联的概率将是“低的”。
这种行为意味着在我们的预测中有一些实际的置信度,并且我们的算法实际上是从数据集学习。
确切地说,学习如何发生涉及更新我们的权重矩阵 W ,这归结为一个优化问题。我们将在未来的博客文章中回顾如何执行梯度体面和其他优化算法。
摘要
在今天的博客文章中,我们看了 Softmax 分类器,它是二元逻辑回归分类器的简单推广。
当构建深度学习和卷积神经网络模型时,你将无疑遇到 Softmax 分类器和交叉熵损失函数。
虽然铰链损失和平方铰链损失都是受欢迎的选择,但我几乎可以绝对肯定地保证,你会看到更多频率的交叉熵损失——这主要是因为 Softmax 分类器输出概率而不是余量。概率对于我们人类来说更容易解释,所以这是 Softmax 分类器的一个特别好的特性。
现在我们理解了损失函数的基本原理,我们准备给我们的损失方法加上另一个术语— 正则化。
正则化项被附加到我们的损失函数中,并用于控制我们的权重矩阵 W 看起来如何。通过控制 W 并确保它“看起来”像某种方式,我们实际上可以提高分类的准确性。
在我们讨论正则化之后,我们可以继续进行优化——这个过程实际上采用我们的得分和损失函数的输出,并使用这个输出来调整我们的权重矩阵 W 以实际“学习”。
无论如何,我希望你喜欢这篇博文!
在您离开之前,请务必在下面的表格中输入您的电子邮件地址,以便在新博文发布时得到通知!
使用 Python 和 OpenCV 对等值线进行排序
原文:https://pyimagesearch.com/2015/04/20/sorting-contours-using-python-and-opencv/

好了,现在你已经在 PyImageSearch 博客上大量接触到轮廓了。
我们使用轮廓构建了一个强大的移动文档扫描仪。
轮廓使我们能够检测图像中的条形码。
我们甚至利用轮廓的力量来找到相机到物体或标记的距离。
但是仍然有一个我们没有解决的棘手问题: 我们究竟如何从左到右、从上到下等排序轮廓。**
奇怪的是,OpenCV 没有提供一个内置函数或方法来执行轮廓的实际排序。
但是不用担心。
在这篇博客的其余部分,你将像专业人士一样使用 Python 和 OpenCV 对轮廓进行排序。
请继续阅读,了解更多信息…
OpenCV 和 Python 版本:
为了运行这个例子,你需要 Python 2.7 和 OpenCV 2.4.X 。
使用 Python 和 OpenCV 对等值线进行排序
在这篇博客文章结束时,你将能够:
-
根据轮廓的大小/面积对轮廓进行分类,并使用一个模板根据任何其他任意标准对轮廓进行分类。
-
仅使用一个 单一函数 从从左到右、从右到左、从上到下和从下到上对轮廓区域进行排序。
所以让我们开始吧。打开您最喜欢的代码编辑器,将其命名为sorting_contours.py ,让我们开始吧:
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
def sort_contours(cnts, method="left-to-right"):
# initialize the reverse flag and sort index
reverse = False
i = 0
# handle if we need to sort in reverse
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
# handle if we are sorting against the y-coordinate rather than
# the x-coordinate of the bounding box
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# construct the list of bounding boxes and sort them from top to
# bottom
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b:b[1][i], reverse=reverse))
# return the list of sorted contours and bounding boxes
return (cnts, boundingBoxes)
我们将从导入必要的包开始:NumPy 用于数值处理,argparse用于解析命令行参数,而cv2用于 OpenCV 绑定。
让我们暂时跳过这些步骤,直接开始定义我们的sort_contours函数,这将使我们能够对轮廓进行排序,而不是从解析参数、加载图像和处理其他正常过程开始。
实际的sort_contours函数在第 7 行的上定义,有两个参数。第一个是cnts,我们要排序的轮廓列表,第二个是排序method,它表示我们要排序轮廓的方向(即从左到右、从上到下等)。).
从这里开始,我们将初始化第 9 行和第 10 行上的两个重要变量。这些变量只是指示排序顺序(升序或降序)和我们将要用来执行排序的边界框的索引(稍后将详细介绍)。我们将初始化这些变量,按照升序排序,并沿着轮廓边界框的 x 轴位置排序。
如果我们从右到左或从下到上排序,我们需要按照轮廓在图像中的位置(第 13 行和第 14 行)按降序排序。
*类似地,在第行的第 18 和 19 行,我们检查我们是从上到下还是从下到上进行排序。如果是这种情况,那么我们需要根据 y 轴的值而不是 x 轴的值进行排序(因为我们现在是垂直排序而不是水平排序)。
轮廓的实际分类发生在第 23-25 行的行。
我们首先计算每个轮廓的边界框,它只是边界框的起始 (x,y) 坐标,后跟宽度和高度(因此称为“边界框”)。(第 23 行)
boundingBoxes使我们能够对实际轮廓进行排序,我们在第 24 行和第 25 行使用一些 Python 魔法将两个列表排序在一起。使用这个代码,我们能够根据我们提供的标准对轮廓和边界框进行排序。
*最后,我们将(现在已排序的)边界框和轮廓列表返回给第 28 行上的调用函数。
现在,让我们继续定义另一个助手函数,draw_contour:
def draw_contour(image, c, i):
# compute the center of the contour area and draw a circle
# representing the center
M = cv2.moments(c)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
# draw the countour number on the image
cv2.putText(image, "#{}".format(i + 1), (cX - 20, cY), cv2.FONT_HERSHEY_SIMPLEX,
1.0, (255, 255, 255), 2)
# return the image with the contour number drawn on it
return image
该功能简单地计算第 33-35 行上所提供轮廓c的中心** (x,y)-坐标,然后使用该中心坐标在第 38 和 39** 行上绘制轮廓 IDi。
最后,传入的image被返回给行 42 上的调用函数。
同样,这只是一个辅助函数,我们将利用它在实际图像上绘制轮廓 ID 号,这样我们就可以可视化我们的工作结果。
现在,助手函数已经完成,让我们把驱动程序代码放在适当的位置,以获取我们的实际图像,检测轮廓,并对它们进行排序:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the input image")
ap.add_argument("-m", "--method", required=True, help="Sorting method")
args = vars(ap.parse_args())
# load the image and initialize the accumulated edge image
image = cv2.imread(args["image"])
accumEdged = np.zeros(image.shape[:2], dtype="uint8")
# loop over the blue, green, and red channels, respectively
for chan in cv2.split(image):
# blur the channel, extract edges from it, and accumulate the set
# of edges for the image
chan = cv2.medianBlur(chan, 11)
edged = cv2.Canny(chan, 50, 200)
accumEdged = cv2.bitwise_or(accumEdged, edged)
# show the accumulated edge map
cv2.imshow("Edge Map", accumEdged)
第 45-48 行并不十分有趣——它们只是解析我们的命令行参数,--image是我们的图像在磁盘上驻留的路径,--method是我们想要排序轮廓的方向的文本表示。
从那里,我们在行 51 上加载我们的图像,并在行 52 上为边缘图分配内存。
构建实际的边缘图发生在行 55-60 上,其中我们循环图像的每个蓝色、绿色和红色通道(行 55 ),稍微模糊每个通道以去除高频噪声(行 58 ),执行边缘检测(行 59 ),并在行 60 上更新累积的边缘图。
我们在行 63 上显示累积的边缘图,如下所示:

Figure 1: (Left) Our original image. (Right) The edge map of the Lego bricks.
正如你所看到的,我们已经检测到图像中乐高积木的实际边缘轮廓。
现在,让我们看看能否(1)找到这些乐高积木的轮廓,然后(2)对它们进行分类:
# find contours in the accumulated image, keeping only the largest
# ones
cnts = cv2.findContours(accumEdged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
orig = image.copy()
# loop over the (unsorted) contours and draw them
for (i, c) in enumerate(cnts):
orig = draw_contour(orig, c, i)
# show the original, unsorted contour image
cv2.imshow("Unsorted", orig)
# sort the contours according to the provided method
(cnts, boundingBoxes) = sort_contours(cnts, method=args["method"])
# loop over the (now sorted) contours and draw them
for (i, c) in enumerate(cnts):
draw_contour(image, c, i)
# show the output image
cv2.imshow("Sorted", image)
cv2.waitKey(0)
很明显,这里的第一步是在第 67-69 行的累积边缘图图像中找到实际轮廓。我们正在寻找乐高积木的外部轮廓,它仅仅对应于它们的轮廓。
基于这些轮廓,我们现在将通过使用 Python sorted函数和cv2.contourArea方法的组合,根据它们的大小 对它们进行 排序——这允许我们根据它们的面积(即大小)从最大到最小对我们的轮廓进行排序(行 70* )。***
我们获取这些排序后的轮廓(根据大小,而不是位置),在线 74 上循环,并使用我们的draw_contour辅助函数在线 76 上绘制每个单独的轮廓。
该图像随后通过线 78 显示在我们的屏幕上。
然而,正如你会注意到的,我们的轮廓仅仅是根据它们的大小来分类的——没有注意到它们在图像中的实际位置。
我们在第 81 行解决了这个问题,在那里我们调用了我们的自定义函数。该方法接受我们的轮廓列表和排序方向方法(通过命令行参数提供),并对它们进行排序,分别返回一组排序的边界框和轮廓。
最后,我们获取这些排序后的轮廓,循环遍历它们,画出每一个单独的轮廓,最后将输出图像显示到我们的屏幕上(行 84-89 )。
结果
让我们来检验一下我们的努力。
打开一个终端,导航到您的源代码并执行以下命令:
$ python sorting_contours.py --image images/image_01.png --method "top-to-bottom"
您的输出应该如下所示:
Figure 2: Sorting our Lego bricks from top-to-bottom.
在左边的上,我们有原始的未分类轮廓。很明显,我们可以看到轮廓非常混乱——第一个轮廓出现在最底部,第二个轮廓出现在最顶部!
然而,通过应用我们的sorted_contours函数,我们能够从上到下对乐高积木进行排序。
让我们看另一个例子。
$ python sorting_contours.py --image images/image_01.png --method "bottom-to-top"

Figure 3: Sorting our contours from bottom-to-top.
这里我们从下到上对轮廓进行了排序。
当然,我们也可以对轮廓进行水平排序:
$ python sorting_contours.py --image images/image_02.png --method "left-to-right"

Figure 4: Sorting our contours from left-to-right.
同样,在顶部的图像中,我们的轮廓是无序的。但是在底部的图像中,我们能够成功地对轮廓进行分类,没有任何问题。
最后一个例子:
$ python sorting_contours.py --image images/image_02.png --method "right-to-left"

Figure 5: Sorting our contours from right-to-left.
正如你所看到的,这没什么——我们只是利用图像中每个对象的边界框,使用 Python 和 OpenCV 按方向对轮廓进行排序。
将来,你只需要我们可靠的sorted_contours功能,你就可以毫无问题地根据方向对轮廓进行分类。
摘要
在这篇博客文章中,我们学习了如何从左到右、从右到左、从上到下和从下到上对轮廓进行排序。
实际上,我们只需要利用两个关键功能。
第一个关键函数是计算轮廓边界框区域的cv2.boundingRect方法。基于这些边界框,我们利用了一些 Python 魔法,并使用我们的第二个关键函数sorted,实际上按照我们想要的方向“排序”这些边界框。
这就是全部了!
如果你想玩这个帖子中的例子,只要在下面的表格中输入你的电子邮件地址,我会马上把代码通过电子邮件发给你。**
使用张量流的空间变压器网络
原文:https://pyimagesearch.com/2022/05/23/spatial-transformer-networks-using-tensorflow/
目录
卷积神经网络(CNN)无疑改变了技术世界的运作方式。在图像处理领域站稳脚跟后,它所影响的子域数量多得无法计数。
就好像我们仅仅通过矩阵乘法和一些微积分就解决了向计算机教授图像的问题。然而,它并不像看起来那么完美。
让我们看看我这样说是什么意思。在图 1 中,我们有一个标准的 CNN 数字预测器。
有了足够的数据,它将完全按照预期的方式工作,展示 CNN 的力量。但是,当你旋转图形并馈入模型时会发生什么(图 2 )?
尽管 CNN 具有独创性,但它并不是变换不变的。这意味着,如果我旋转图像,CNN 很可能会预测出错误的答案,让我们得出结论,CNN 是而不是 变换不变的。
现在你可能认为这不是一个大问题。然而,这就是现实世界的不确定性因素的来源。
让我们以车牌检测器为例。即使它估计了车牌的大致区域,如果检测到的区域不是水平的,它也可能错误标记数字。想象一下这在繁忙的收费广场通勤中会造成多大的不便。
这背后的直觉很有意思。无论你如何扭曲输入图像,我们的眼睛都能发现数字 7。一个很大的原因是,当我们在大脑中处理图像时,我们只关心数字,而不是背景。
对于机器学习模型,会考虑完整的像素方向,而不仅仅是数字。毕竟机器学习模型是矩阵。因此,这些权重矩阵的值是根据输入数据的完整像素方向形成的。
因此,对于一个如此出色的概念来说,这难道不是一个大败笔吗?
令人欣慰的是,深度学习世界的快速研究人员已经提出了一个解决方案,即空间转换器网络。
要了解如何实现空间转换网络,就继续阅读吧。
使用张量流的空间变压器网络
空间转换器网络模块背后的主要意图是帮助我们的模型选择图像的最相关 ROI。一旦模型成功计算出相关像素,空间变换模块将帮助模型决定图像成为标准格式所需的变换类型。
请记住,模型必须找出一种转换,使其能够预测图像的正确标签。对我们来说,这可能不是一个可以理解的变换,但是只要损失函数可以被降低,它对模型是有效的。
创建整个模块,以便模型可以根据情况访问各种变换:平移、裁剪、各向同性和倾斜。在下一节中,您将了解到更多相关信息。
将空间转换器模块视为模型的附加附件。在正向传递过程中,它会根据输入要求对要素地图应用特定的空间变换。对于特定的输入,我们有一个输出特征图。
它将帮助我们的模型决定像图 2 中的 7 这样的输入需要什么样的转换。对于多通道输入(例如,RGB 图像),相同的更改将应用于所有三个通道(以保持空间一致性)。最重要的是,这个模块将学习模型权重的其余部分(它是可区分的)。
图 3 显示了空间转换器模块的三个部分:定位网络、网格生成器和采样器。
定位网络:该网络接收宽度 W、高度 H、通道 c 的输入特征图 U ,其工作是输出
, the transformation parameters to be applied to the feature map.
本地化网络可以是任何网络:全连接网络或卷积网络。唯一重要的是它必须包含一个最终回归层,它输出
.
参数化采样网格:我们有参数变换
. Let’s assume our input feature map to be U, as shown in Figure 4. We can see that U is a rotated version of the number 9. Our output feature map V is a square grid. Hence we already know its indices (i.e., a normal rectangular grid).
虽然变换可以是任何东西,但让我们假设我们的输入特征需要仿射变换。
变换网格给我们:=A_{\theta} \times V")
. Let’s understand what this means. The matrix U is our input feature map. For each of its source coordinates, we are defining it as the transformation matrix  multiplied by each of the target coordinates from the output feature map V.
multiplied by each of the target coordinates from the output feature map V.
所以,综上所述,矩阵
maps the output pixel coordinates back to the source pixel coordinates.
但说到底,这些只是坐标。我们如何知道这些像素的值呢?为此,我们将转移到采样器。
采样器:现在我们有了坐标,输出的特征图 V 值将使用我们的输入像素值来估计。也就是说,我们将使用输入像素对输出像素执行线性/双线性插值。双线性插值使用最近的像素值,这些像素值位于给定位置的对角线方向,以便找到该像素的适当颜色强度值。
在我们浏览代码时,我们将分别处理这些模块。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install tensorflow
$ pip install matplotlib
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── create_gif.py
├── pyimagesearch
│ ├── callback.py
│ ├── classification_model.py
│ ├── config.py
│ └── stn.py
├── stn.gif
└── train.py
1 directory, 7 files
create_gif.py脚本将帮助我们从输出图像中创建一个 gif。
在pyimagesearch目录中,我们有 4 个脚本:
callback.py:包含模型训练时使用的回调。classification_model.py:包含用于训练的基础模型。config.py:包含项目的端到端配置管道。stn.py:包含空间变换块的定义。
在核心目录中,我们有train.py,在那里进行模型训练,还有stn.gif,它是我们的输出 gif。
准备配置脚本
在开始实现之前,让我们跳到pyimagesearch目录中的config.py脚本。这个脚本将定义在整个项目中使用的全局变量和路径。
# import the necessary packages
from tensorflow.data import AUTOTUNE
import os
# define AUTOTUNE
AUTO = AUTOTUNE
# define the image height, width and channel size
IMAGE_HEIGHT = 28
IMAGE_WIDTH = 28
CHANNEL = 1
# define the dataset path, dataset name, and the batch size
DATASET_PATH = "dataset"
DATASET_NAME = "emnist"
BATCH_SIZE = 1024
在第 6 行上,我们定义了tensorflow.data的AUTOTUNE特征。这样,tfds的运行时值(相关的参数在 CPU 中的分配)将被动态优化,以使用户受益。
接下来,我们定义输入图像的高度、宽度和通道值(第 9-11 行)。因为我们将使用黑白图像,我们的通道值是 1。
在第 14 行,我们已经定义了一个数据集路径,然后指定我们希望在我们的项目中使用哪个数据集(第 15 行)。最后,我们为我们的数据将被分割成的批次的大小定义一个值(第 16 行)。
# define the number of epochs
EPOCHS = 100
# define the conv filters
FILTERS = 256
# define an output directory
OUTPUT_PATH = "output"
# define the loss function and optimizer
LOSS_FN = "sparse_categorical_crossentropy"
OPTIMIZER = "adam"
# define the name of the gif
GIF_NAME = "stn.gif"
# define the number of classes for classification
CLASSES = 62
# define the stn layer name
STN_LAYER_NAME = "stn"
接下来,我们定义一些超参数,如历元数(第 19 行)和卷积滤波器数(第 22 行),后面是对输出文件夹路径的引用(第 25 行)。
对于今天的项目,我们将使用sparse_categorical_crossentropy作为我们的损失函数,使用adam作为我们的优化器(第 28 和 29 行)。
为了可视化我们的输出,我们将使用 GIF。我们在第 32 行的中定义了一个对 GIF 的引用。emnist数据集有 62 个类,如第 35 行所定义。这是一个使用与mnist数据集相同的格式创建的数据集,但它具有更复杂的数据条目,用于更强大的训练。
关于这个数据集的更多信息,请访问官方 arXiv 链接 。
最后,我们在第 38 行的上有我们的空间转换器网络变量名。
实现输出 GIF 的回调函数
这个函数将帮助我们建立我们的 GIF。它还允许我们在模型训练时跟踪模型的进度。这个函数可以在pyimagesearch中的callback.py脚本中找到。
# import the necessary packages
from tensorflow.keras.callbacks import Callback
from tensorflow.keras import Model
import matplotlib.pyplot as plt
def get_train_monitor(testDs, outputPath, stnLayerName):
# iterate over the test dataset and take a batch of test images
(testImg, _) = next(iter(testDs))
我们在第 6 行的上定义函数。它接受以下参数:
testDs:测试数据集outputPath:存储图像的文件夹stnLayerName:分层输出的层名
在的第 8 行,我们使用next(iter(dataset))来迭代我们的完整数据集。这是因为我们的数据集具有类似生成器的属性。当前批次图像存储在testImg变量中。
# define a training monitor
class TrainMonitor(Callback):
def on_epoch_end(self, epoch, logs=None):
model = Model(self.model.input,
self.model.get_layer(stnLayerName).output)
testPred = model(testImg)
# plot the image and the transformed image
_, axes = plt.subplots(nrows=5, ncols=2, figsize=(5, 10))
for ax, im, t_im in zip(axes, testImg[:5], testPred[:5]):
ax[0].imshow(im[..., 0], cmap="gray")
ax[0].set_title(epoch)
ax[0].axis("off")
ax[1].imshow(t_im[..., 0], cmap="gray")
ax[1].set_title(epoch)
ax[1].axis("off")
# save the figures
plt.savefig(f"{outputPath}/{epoch:03d}")
plt.close()
# instantiate the training monitor callback
trainMonitor = TrainMonitor()
# return the training monitor object
return trainMonitor
在第 11 行,我们定义了一个训练监视器类,继承自 TensorFlow 的回调模块。在它里面,我们有另一个叫做on_epoch_end的函数,它将在每一个纪元后被激活(第 12 行)。它将当前的纪元编号和日志作为其参数。
在第行第 13 和第 14 行,我们在函数内部定义了一个迷你模型。这个迷你模型将所有层从我们的主模型到空间变换层,因为我们需要这一层的输出。在15 号线,我们将当前测试批次通过迷你模型并获取其输出。
在第 18-26 行上,我们定义了一个完整的子图系统,其中前 5 个测试图像及其相应的预测并排绘制。然后我们将这个数字保存到我们的输出路径中(第 29 行)。
在我们关闭函数之前,我们实例化了一个trainMonitor类的对象(第 33 行)。
空间转换器模块
为了将空间转换器模块附加到我们的主模型,我们创建了一个单独的脚本,它将包含所有必要的辅助函数以及主stn层。因此,让我们转到stn.py脚本。
在我们进入代码之前,让我们简要回顾一下我们试图完成的任务。
- 我们的输入图像将为我们提供所需的转换参数。
- 我们将从输出要素地图映射输入要素地图。
- 我们将应用双线性插值来估计输出特征地图像素值。
如果你还记得这些指针,我们来分析一下代码。
# import the necessary packages
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Layer
import tensorflow as tf
def get_pixel_value(B, H, W, featureMap, x, y):
# create batch indices and reshape it
batchIdx = tf.range(0, B)
batchIdx = tf.reshape(batchIdx, (B, 1, 1))
# create the indices matrix which will be used to sample the
# feature map
b = tf.tile(batchIdx, (1, H, W))
indices = tf.stack([b, y, x], 3)
# gather the feature map values for the corresponding indices
gatheredPixelValue = tf.gather_nd(featureMap, indices)
# return the gather pixel values
return gatheredPixelValue
这个脚本中第一个重要的函数是get_pixel_value ( 第 11 行)。它包括:
- 批次大小、高度和宽度值
- 输入要素地图
- 给定像素的
x和y坐标。
该函数将帮助您通过直接从特征图中访问角坐标来挽救像素值。
在行的第 13 和第 14 行,我们正在创建占位符批次索引。接下来,我们创建一个索引矩阵,我们将使用它从特征图中进行采样(第 18 行和第 19 行)。在第 22 行上,我们使用tf.gather_nd获得相应坐标的特征映射值。
def affine_grid_generator(B, H, W, theta):
# create normalized 2D grid
x = tf.linspace(-1.0, 1.0, H)
y = tf.linspace(-1.0, 1.0, W)
(xT, yT) = tf.meshgrid(x, y)
# flatten the meshgrid
xTFlat = tf.reshape(xT, [-1])
yTFlat = tf.reshape(yT, [-1])
# reshape the meshgrid and concatenate ones to convert it to
# homogeneous form
ones = tf.ones_like(xTFlat)
samplingGrid = tf.stack([xTFlat, yTFlat, ones])
# repeat grid batch size times
samplingGrid = tf.broadcast_to(samplingGrid, (B, 3, H * W))
# cast the affine parameters and sampling grid to float32
# required for matmul
theta = tf.cast(theta, "float32")
samplingGrid = tf.cast(samplingGrid, "float32")
# transform the sampling grid with the affine parameter
batchGrids = tf.matmul(theta, samplingGrid)
# reshape the sampling grid to (B, H, W, 2)
batchGrids = tf.reshape(batchGrids, [B, 2, H, W])
# return the transformed grid
return batchGrids
显微镜下的下一个功能是第 27 行上的affine_grid_generator。它接受以下参数:
- 批量
- 高度
- 宽度
- 变换参数θ
让我们理解我们在这里试图做什么。在这篇博客的开始,我们已经告诉你网格生成器给了我们下面的公式:
, where U is our input feature map and V is our output feature map.
因此,我们将输出坐标映射回输入坐标的这一步是我们在这里尝试完成的。
为此,我们首先在第 29-31 行的上创建一个标准化的 2D 网格。然后我们展平并创建一个均匀的网格(第 34-40 行)。注意,这些变量被命名为xT, yT,与我们在本教程第一部分中解释的目标坐标相呼应。
由于我们需要与批量大小相等的网格,我们在行 43 重复网格大小。
我们的下一步是目标坐标和变换参数θ之间的矩阵乘法。为此,我们首先将它们转换为浮点型(第 47 行和第 48 行),然后使用tf.matmul将它们相乘(第 51 行)。
最后,我们重塑batchGrids变量,让函数返回值(第 54-57 行)。注意,整形值是(B, 2, H, W)。值2是因为我们必须得到 X 坐标网格和 Y 坐标网格。
def bilinear_sampler(B, H, W, featureMap, x, y):
# define the bounds of the image
maxY = tf.cast(H - 1, "int32")
maxX = tf.cast(W - 1, "int32")
zero = tf.zeros([], dtype="int32")
# rescale x and y to feature spatial dimensions
x = tf.cast(x, "float32")
y = tf.cast(y, "float32")
x = 0.5 * ((x + 1.0) * tf.cast(maxX-1, "float32"))
y = 0.5 * ((y + 1.0) * tf.cast(maxY-1, "float32"))
# grab 4 nearest corner points for each (x, y)
x0 = tf.cast(tf.floor(x), "int32")
x1 = x0 + 1
y0 = tf.cast(tf.floor(y), "int32")
y1 = y0 + 1
# clip to range to not violate feature map boundaries
x0 = tf.clip_by_value(x0, zero, maxX)
x1 = tf.clip_by_value(x1, zero, maxX)
y0 = tf.clip_by_value(y0, zero, maxY)
y1 = tf.clip_by_value(y1, zero, maxY)
继续我们的bilinear_sampler函数将帮助我们获得完整的输出特征图。它接受以下参数:
- 批次大小、高度和宽度
- 输入要素地图
- 从前一个函数
affine_grid_generator中获得的x和y坐标
在第 61-63 行上,我们根据高度和宽度索引定义了图像的边界。
在的第 66-69 行,我们正在重新调整x和y的比例,以匹配特征地图的空间维度(即,在从 0 到 400 的区间内)。
在线 72-75 上,我们为每个给定的x和y坐标抓取 4 个最近的角点。
接下来是剪切这些值,使它们不违反特征图边界(行 78-81 )。
# get pixel value at corner coords
Ia = get_pixel_value(B, H, W, featureMap, x0, y0)
Ib = get_pixel_value(B, H, W, featureMap, x0, y1)
Ic = get_pixel_value(B, H, W, featureMap, x1, y0)
Id = get_pixel_value(B, H, W, featureMap, x1, y1)
# recast as float for delta calculation
x0 = tf.cast(x0, "float32")
x1 = tf.cast(x1, "float32")
y0 = tf.cast(y0, "float32")
y1 = tf.cast(y1, "float32")
# calculate deltas
wa = (x1-x) * (y1-y)
wb = (x1-x) * (y-y0)
wc = (x-x0) * (y1-y)
wd = (x-x0) * (y-y0)
# add dimension for addition
wa = tf.expand_dims(wa, axis=3)
wb = tf.expand_dims(wb, axis=3)
wc = tf.expand_dims(wc, axis=3)
wd = tf.expand_dims(wd, axis=3)
# compute transformed feature map
transformedFeatureMap = tf.add_n(
[wa * Ia, wb * Ib, wc * Ic, wd * Id])
# return the transformed feature map
return transformedFeatureMap
现在我们有了角坐标,我们使用之前创建的get_pixel_value函数获取像素值。这就结束了插值步骤(第 84-87 行)。
在第 90-93 行的上,我们将坐标重新转换为float用于增量计算。最后,在第 96-99 行计算增量。
让我们明白这是怎么回事。首先,我们的图像将根据我们的变换矩阵在某些区域进行插值。像素值将是这些区域中它们的角点的平均值。但是为了得到我们的实际输出,我们需要将我们修改过的特征图除以实际的特征图来得到想要的结果。
在行 102-109 上,我们使用增量来计算我们的转换后的最终特征图。
class STN(Layer):
def __init__(self, name, filter):
# initialize the layer
super().__init__(name=name)
self.B = None
self.H = None
self.W = None
self.C = None
# create the constant bias initializer
self.output_bias = tf.keras.initializers.Constant(
[1.0, 0.0, 0.0,
0.0, 1.0, 0.0]
)
# define the filter size
self.filter = filter
现在是时候把我们的完整设置放在一起了。我们在行 114 上创建了一个名为stn的类,它继承了keras.layer类。
__init__函数用于初始化和分配我们将在call函数中使用的变量(第 117-130 行)。output_bias将在后面的密集函数中使用。
def build(self, input_shape):
# get the batch size, height, width and channel size of the
# input
(self.B, self.H, self.W, self.C) = input_shape
# define the localization network
self.localizationNet = Sequential([
Conv2D(filters=self.filter // 4, kernel_size=3,
input_shape=(self.H, self.W, self.C),
activation="relu", kernel_initializer="he_normal"),
MaxPool2D(),
Conv2D(filters=self.filter // 2, kernel_size=3,
activation="relu", kernel_initializer="he_normal"),
MaxPool2D(),
Conv2D(filters=self.filter, kernel_size=3,
activation="relu", kernel_initializer="he_normal"),
MaxPool2D(),
GlobalAveragePooling2D()
])
# define the regressor network
self.regressorNet = tf.keras.Sequential([
Dense(units = self.filter, activation="relu",
kernel_initializer="he_normal"),
Dense(units = self.filter // 2, activation="relu",
kernel_initializer="he_normal"),
Dense(units = 3 * 2, kernel_initializer="zeros",
bias_initializer=self.output_bias),
Reshape(target_shape=(2, 3))
])
如前所述,本地化网络会给我们转换参数theta作为输出。我们已经将本地化网络分成两个独立的部分。在第 138-150 行,我们有卷积定位网络,它会给我们特征图作为输出。
在第 153-161 行,我们有回归器网络,它将卷积输出作为其输入,并给我们变换参数theta。在这里,我们可以有把握地说theta成为一个可学习的参数。
def call(self, x):
# get the localization feature map
localFeatureMap = self.localizationNet(x)
# get the regressed parameters
theta = self.regressorNet(localFeatureMap)
# get the transformed meshgrid
grid = affine_grid_generator(self.B, self.H, self.W, theta)
# get the x and y coordinates from the transformed meshgrid
xS = grid[:, 0, :, :]
yS = grid[:, 1, :, :]
# get the transformed feature map
x = bilinear_sampler(self.B, self.H, self.W, x, xS, yS)
# return the transformed feature map
return x
最后,我们来看一下call函数(第 163 行)。在这里,我们首先在行 165 上创建特征图,通过regressorNet传递它并获得我们的变换参数(行 168 )。
现在我们有了θ,我们可以使用第 171 行的函数来创建网格。现在,我们可以将x和y源坐标从网格中分离出来,方法是将它们编入索引,并通过我们的双线性采样器(第 174-178 行)。
分类模式
我们完整的分类模型相对简单,因为我们已经创建了空间转换器模块。因此,让我们转到classification_model.py脚本并分析架构。
# import the necessary packages
from tensorflow.keras import Input
from tensorflow.keras import Model
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
import tensorflow as tf
def get_training_model(batchSize, height, width, channel, stnLayer,
numClasses, filter):
# define the input layer and pass the input through the STN
# layer
inputs = Input((height, width, channel), batch_size=batchSize)
x = Lambda(lambda image: tf.cast(image, "float32")/255.0)(inputs)
x = stnLayer(x)
我们的主训练模型是使用第 14 行上的函数get_training_model获得的。它接受以下参数:
- 批次大小、高度、宽度和通道值
- 空间变换层
- 输出类的数量和过滤器的数量
在第 18 行上,我们初始化模型输入。接下来,我们将图像缩放到 0 和 1 ( 第 19 行)。
接下来,我们在第 20 行添加空间变换层。创建一个模块的额外好处是我们的主架构脚本不那么杂乱。
# apply a series of conv and maxpool layers
x = Conv2D(filter // 4, 3, activation="relu",
kernel_initializer="he_normal")(x)
x = MaxPool2D()(x)
x = Conv2D(filter // 2, 3, activation="relu",
kernel_initializer="he_normal")(x)
x = MaxPool2D()(x)
x = Conv2D(filter, 3, activation="relu",
kernel_initializer="he_normal")(x)
x = MaxPool2D()(x)
# global average pool the output of the previous layer
x = GlobalAveragePooling2D()(x)
# pass the flattened output through a couple of dense layers
x = Dense(filter, activation="relu",
kernel_initializer="he_normal")(x)
x = Dense(filter // 2, activation="relu",
kernel_initializer="he_normal")(x)
# apply dropout for better regularization
x = Dropout(0.5)(x)
# apply softmax to the output for a multi-classification task
outputs = Dense(numClasses, activation="softmax")(x)
# return the model
return Model(inputs, outputs)
其余的层非常简单。在第 23-31 行,我们有一个Conv2D层和一个最大池层的重复设置。
接下来是第 34 行的全局平均池层。
我们添加两个密集层,然后添加一个下降层,最后添加输出层,这样我们就可以得到一个关于类数量的 soft max(37-46 行)。
该函数然后返回一个初始化的模型(行 49 )。
训练模型
完成所有的配置管道、助手函数和模型架构后,我们只需要插入数据并查看结果。为此,让我们继续讨论train.py。
# USAGE
# python train.py
# setting seed for reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch.stn import STN
from pyimagesearch.classification_model import get_training_model
from pyimagesearch.callback import get_train_monitor
from pyimagesearch import config
from tensorflow.keras.callbacks import EarlyStopping
import tensorflow_datasets as tfds
import os
# load the train and test dataset
print("[INFO] loading the train and test dataset...")
trainingDs = tfds.load(name=config.DATASET_NAME,
data_dir=config.DATASET_PATH, split="train", shuffle_files=True,
as_supervised=True)
testingDs = tfds.load(name=config.DATASET_NAME,
data_dir=config.DATASET_PATH, split="test", as_supervised=True)
记住在导入部分调用我们的脚本很重要(第 5-15 行)。接下来,我们使用tfds.load直接下载我们需要的数据集(第 19-23 行)。我们这样做是为了同时获得训练和测试拆分。
# preprocess the train and test dataset
print("[INFO] preprocessing the train and test dataset...")
trainDs = (
trainingDs
.shuffle(config.BATCH_SIZE*100)
.batch(config.BATCH_SIZE, drop_remainder=True)
.prefetch(config.AUTO)
)
testDs = (
testingDs
.batch(config.BATCH_SIZE, drop_remainder=True)
.prefetch(config.AUTO)
)
# initialize the stn layer
print("[INFO] initializing the stn layer...")
stnLayer = STN(name=config.STN_LAYER_NAME, filter=config.FILTERS)
# get the classification model for cifar10
print("[INFO] grabbing the multiclass classification model...")
model = get_training_model(batchSize=config.BATCH_SIZE,
height=config.IMAGE_HEIGHT, width=config.IMAGE_WIDTH,
channel=config.CHANNEL, stnLayer=stnLayer,
numClasses=config.CLASSES, filter=config.FILTERS)
一旦我们有了训练和测试数据集,我们就在第 27-37 行对它们进行预处理。
在第行第 41 处,我们使用预先创建的脚本和配置变量初始化一个空间转换器模块层。
然后我们通过传递stn层和所需的配置变量来初始化我们的主模型(第 45-48 行)。
# print the model summary
print("[INFO] the model summary...")
print(model.summary())
# create an output images directory if it not already exists
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# get the training monitor
trainMonitor = get_train_monitor(testDs=testDs,
outputPath=config.OUTPUT_PATH, stnLayerName=config.STN_LAYER_NAME)
# compile the model
print("[INFO] compiling the model...")
model.compile(loss=config.LOSS_FN, optimizer=config.OPTIMIZER,
metrics=["accuracy"])
# define an early stopping callback
esCallback = EarlyStopping(patience=5, restore_best_weights=True)
# train the model
print("[INFO] training the model...")
model.fit(trainDs, epochs=config.EPOCHS,
callbacks=[trainMonitor, esCallback], validation_data=testDs)
为了进行健全性检查,我们在第 52 行的处显示了模型概要。
接下来,我们在第 55 和 56 行的上使用os.makedirs创建一个输出目录。
由于我们的模型已经创建,我们在第 59 和 60 行的上初始化回调脚本的对象trainMonitor。总的来说,这将使我们可视化我们的训练如何影响我们的测试数据集的输出。
然后,我们用我们的配置变量编译模型,并选择准确性作为我们的度量标准(第 64 行和第 65 )。
为了提高效率,我们在第 68 行的上定义了一个提前停止的回调函数。如果已经达到中等精度值,这将停止模型训练。
在第 72 行和第 73 行,我们通过将数据集和回调函数放入我们的模型并开始训练步骤来结束脚本。
模型训练和可视化
让我们看看我们的模特训练进展如何!
[INFO] compiling the model...
[INFO] training the model...
Epoch 1/100
681/681 [==============================] - 104s 121ms/step - loss: 0.9146 - accuracy: 0.7350 - val_loss: 0.4381 - val_accuracy: 0.8421
Epoch 2/100
681/681 [==============================] - 84s 118ms/step - loss: 0.4705 - accuracy: 0.8392 - val_loss: 0.4064 - val_accuracy: 0.8526
Epoch 3/100
681/681 [==============================] - 85s 119ms/step - loss: 0.4258 - ...
Epoch 16/100
681/681 [==============================] - 85s 119ms/step - loss: 0.3192 - accuracy: 0.8794 - val_loss: 0.3483 - val_accuracy: 0.8725
Epoch 17/100
681/681 [==============================] - 85s 119ms/step - loss: 0.3151 - accuracy: 0.8803 - val_loss: 0.3487 - val_accuracy: 0.8736
Epoch 18/100
681/681 [==============================] - 85s 118ms/step - loss: 0.3113 - accuracy: 0.8814 - val_loss: 0.3503 - val_accuracy: 0.8719
我们可以看到,到了第 18 纪元,早期停止生效并停止了模型训练。最终的训练和验证准确率分别为 88.14%和 87.19%。
让我们来看看图 6 中的一些可视化效果。
在图 6 中,我们可以看到一批数字在每个历元中被转换。您可能会注意到,这些转换对于人眼来说不是很容易理解。
然而,你必须记住,这种转换不会总是基于我们对数字的看法而发生。这取决于哪种转换使损失更低。所以这可能不是我们理解的东西,但是如果它对损失函数有效,它对模型来说就足够好了!
汇总
转换不变性是当今深度学习世界中高度相关的因素。视觉任务以某种形式使用深度学习。当现实生活中的因素受到威胁时,创建健壮的、构建好的系统来处理尽可能多的场景是很重要的。
我们的结果表明,该系统协调工作;反向传播为我们提供了正确的变换参数,同时初始网格开始在每个时期固定自己。
如果你想想,我们从图像中识别一个数字,而整个画面对于深度学习系统来说很重要。因此,如果它能够识别出要处理的确切像素,那肯定会更有效率。
具有变换不变性的卷积网络确实有助于建立稳健的人工智能(AI)系统。额外的好处是,我们朝着让人工智能系统更接近人脑的方向迈进了一步。
CNN 的可连接模块最近越来越受欢迎。你可以在下周的博客上关注特色地图频道,它使用了另一个可连接的模块来改善你的模型。
信用点
本教程的灵感来自于塞亚克保罗和 T2 凯文扎克卡的作品。
引用信息
Chakraborty,D. “使用 TensorFlow 的空间变压器网络”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/4ham6
@incollection{Chakraborty_2022_Spatial_Transformer,
author = {Devjyoti Chakraborty},
title = {Spatial Transformer Networks Using {TensorFlow}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/4ham6},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 OpenCV 拆分和合并通道
原文:https://pyimagesearch.com/2021/01/23/splitting-and-merging-channels-with-opencv/
在本教程中,您将学习如何使用 OpenCV 分割和合并通道。
我们知道,图像由三个部分表示:红色、绿色和蓝色通道。
虽然我们已经简要讨论了图像的灰度和二进制表示,但您可能想知道:
如何访问图像的每个单独的红色、绿色和蓝色通道?
由于 OpenCV 中的图像在内部表示为 NumPy 数组,因此可以通过多种方式来访问每个通道,这意味着可以通过多种方式来获取图像。然而,我们将关注您应该使用的两个主要方法:cv2.split和cv2.merge。
在本教程结束时,你会很好地理解如何使用cv2.split将图像分割成通道,并使用cv2.merge将各个通道合并在一起。
要学习如何使用 OpenCV 拆分和合并频道,继续阅读。
使用 OpenCV 拆分和合并频道
在本教程的第一部分,我们将配置我们的开发环境并回顾我们的项目结构。
然后,我们将实现一个 Python 脚本,它将:
- 从磁盘加载输入图像
- 将它分成各自的红色、绿色和蓝色通道
- 将每个频道显示在我们的屏幕上,以便可视化
- 将各个通道合并在一起,形成原始图像
我们开始吧!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从回顾我们的项目目录结构开始。请务必使用本教程的 【下载】 部分下载源代码和示例图像:
$ tree . --dirsfirst
.
├── adrian.png
├── opencv_channels.py
└── opencv_logo.png
0 directories, 3 files
在我们的项目中,您会看到我们有一个单独的 Python 脚本,opencv_channels.py,它将向我们展示:
- 如何将输入图像(
adrian.png和opencv_logo.png)分割成各自的红色、绿色和蓝色通道 - 可视化每个 RGB 通道
- 将 RGB 通道合并回原始图像
我们开始吧!
如何用 OpenCV 拆分和合并频道
彩色图像由多个通道组成:红色、绿色和蓝色分量。我们已经看到,我们可以通过索引 NumPy 数组来访问这些组件。但是如果我们想把一幅图像分割成各个部分呢?
正如您将看到的,我们将利用cv2.split函数。
但是现在,让我们来看看图 2 中的一个示例图像:
这里,我们有(按外观顺序)红色、绿色、蓝色和我去佛罗里达旅行的原始图像。
但是给定这些表征,我们如何解释图像的不同通道呢?
让我们来看看原始图像(右下)中天空的颜色。请注意天空是如何略带蓝色的。当我们看蓝色通道的图像(左下角,我们看到蓝色通道在对应天空的区域非常亮。这是因为蓝色通道像素非常亮,表明它们对输出图像的贡献很大。
然后,看看我穿的黑色连帽衫。在图像的红色、绿色和蓝色通道中,我的黑色连帽衫非常暗,这表明这些通道对输出图像的连帽衫区域的贡献非常小(赋予它非常暗的黑色)。
当你单独调查每个通道而不是作为一个整体时,你可以想象每个通道对整体输出图像的贡献。执行此练习非常有帮助,尤其是在应用阈值处理和边缘检测等方法时,我们将在本模块的后面介绍这些方法。**
**现在我们已经可视化了我们的通道,让我们检查一些代码来完成这个任务:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="opencv_logo.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包。然后我们在的第 7-10 行解析我们的命令行参数。
这里我们只需要一个参数,--image,它指向驻留在磁盘上的输入图像。
现在让我们加载这个图像,并把它分成各自的通道:
# load the input image and grab each channel -- note how OpenCV
# represents images as NumPy arrays with channels in Blue, Green,
# Red ordering rather than Red, Green, Blue
image = cv2.imread(args["image"])
(B, G, R) = cv2.split(image)
# show each channel individually
cv2.imshow("Red", R)
cv2.imshow("Green", G)
cv2.imshow("Blue", B)
cv2.waitKey(0)
第 15 行从磁盘加载我们的image。然后我们在第 16 行上通过调用cv2.split将其分成红色、绿色和蓝色通道分量。
通常,我们会想到 RGB 色彩空间中的图像——红色像素第一,绿色像素第二,蓝色像素第三。但是,OpenCV 按照相反的通道顺序将 RGB 图像存储为 NumPy 数组。它不是以 RGB 顺序存储图像,而是以 BGR 顺序存储图像。因此,我们以相反的顺序解包元组。
第 19-22 行分别显示每个通道,如图图 2 所示。
我们还可以使用cv2.merge功能将通道重新合并在一起:
# merge the image back together again
merged = cv2.merge([B, G, R])
cv2.imshow("Merged", merged)
cv2.waitKey(0)
cv2.destroyAllWindows()
我们只是简单地指定我们的频道,还是按照 BGR 的顺序,然后cv2.merge为我们处理剩下的事情( Line 25 )!
请注意我们是如何从每个单独的 RGB 通道重建原始输入图像的:
还有一个秒的方法来可视化每个通道的颜色贡献。在图 3 中,我们简单地检查了图像的单通道表示,它看起来像一个灰度图像。
但是,我们也可以将图像的颜色贡献想象为完整的 RGB 图像,如下所示:
使用这种方法,我们可以用“彩色”而不是“灰度”来可视化每个通道这是一种严格的可视化技术,我们不会在标准的计算机视觉或图像处理应用程序中使用。
但是,让我们研究一下代码,看看如何构造这种表示:
# visualize each channel in color
zeros = np.zeros(image.shape[:2], dtype="uint8")
cv2.imshow("Red", cv2.merge([zeros, zeros, R]))
cv2.imshow("Green", cv2.merge([zeros, G, zeros]))
cv2.imshow("Blue", cv2.merge([B, zeros, zeros]))
cv2.waitKey(0)
为了显示通道的实际“颜色”,我们首先需要使用cv2.split分解图像。我们需要重建图像,但是这一次,除了当前通道之外,所有像素都为零。
在第 31 行,我们构造了一个 NumPy 的零数组,宽度和高度与最初的image相同。
然后,为了构建图像的红色通道表示,我们调用cv2.merge,为绿色和蓝色通道指定我们的zeros数组。
我们对第 33 行和第 34 行的其他通道采取了类似的方法。
您可以参考图 5 来查看这段代码的输出可视化。
通道拆分和合并结果
要使用 OpenCV 拆分和合并通道,请务必使用本教程的 【下载】 部分下载源代码。
让我们执行我们的opencv_channels.py脚本来分割每个单独的通道并可视化它们:
$ python opencv_channels.py
您可以参考上一节来查看脚本的输出。
如果您希望向opencv_channels.py脚本提供不同的图像,您需要做的就是提供--image命令行参数:
$ python opencv_channels.py --image adrian.png
在这里,您可以看到我们已经将输入图像分割为相应的红色、绿色和蓝色通道分量:
这是每个频道的第二个可视化效果:
总结
在本教程中,您学习了如何使用 OpenCV 以及cv2.split和cv2.merge函数来分割和合并图像通道。
虽然有 NumPy 函数可以用于拆分和合并,但是我强烈建议您使用cv2.split和cv2.merge函数——从代码的角度来看,它们更容易阅读和理解。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
我为什么要开一个计算机视觉和深度学习会议
原文:https://pyimagesearch.com/2018/01/15/started-computer-vision-deep-learning-conference/

PyImageSearch 上的绝大多数博文都非常实用,并且遵循一种特定的模式:
- 我们探索一个问题。
- 我们写一些代码来解决这个问题。
- 我们查看结果,解释哪些可行,哪些不可行,以及我们如何改进解决方案。
我喜欢这种方法,因为它使我能够分享你可以应用到你自己的项目和研究中的算法和技术。
然而,我时不时会写一篇更加个人化的文章,然后 T2 拉开窗帘,向大家展示运行 PyImageSearch 的过程。
今天就是其中之一。
在这篇文章中,我将近距离观察 PyImageConf 2018 ,包括我的想法和背后的理性:
- 为什么我参加的第一次机器学习会议完全是一场灾难…
- …为什么这完全是我的错
- 我为什么启动 PyImageConf
- 我参加的任何会议的两个“必备”特征
- 为什么您应该参加 PyImageConf 以及您将从中获得的价值
看看 PyImageSearch 的幕后,以及我开始一场会议的思维过程,继续阅读。
我参加的第一次机器学习会议完全是一场灾难

Figure 1: ICMLA 2013, the first conference I presented at, was a complete disaster. And it was totally my fault (but not for the reasons you might think).
发生了什么事?
基本没有。
这是我的错。
我参加的第一个计算机视觉/机器学习会议是 IEEE 机器学习与应用国际会议(ICMLA) 2013。
会议于 2013 年 12 月 4 日至 7 日在佛罗里达州迈阿密举行。那年马里兰州的冬天特别寒冷,我很感激有机会逃到温暖的地方(享受世界闻名的迈阿密海滩)。
我提前一天到达会场进行登记,继续准备/练习我的演讲。至少可以说,我有点紧张,因为这是我提交的第一篇论文。这篇论文后来成为我博士论文的关键。
第二天,我做了报告——我肯定是那天第二个或第三个发言的人,这让我更加紧张。
当我的时间到了,我振作起来,发表了讲话。
会谈进行得很顺利。这篇论文很受欢迎。批评是次要的,但也是合理的。这几乎是每个发表第一篇论文的年轻研究生都希望的经历。
但是积极的一面也到此为止了。
会议的其余部分是一场灾难,我只能怪自己。
那时我是一个害羞、内向的人——我努力接近人们,进行基本的对话。在晚上的活动中,我不喜欢用酒精来帮助我放松和与人交往。作为一个内向的人,我倾向于从独处中获取能量,那是我最舒服的地方。
整个会议期间,我一共和五个人谈过话。其中一个是管理前台的人。当我要更多毛巾时,另一个是清洁工。其中只有三个是真正的与会者。
我花了会议的剩余时间:
- 独自走在沙滩上
- 独自坐在酒吧里
- 或者被拖进我的房间,看报纸(再次,你猜对了:独自一人)
2013 年对我来说是非常艰难的一年。有很多挑战性的个人/家庭问题正在发生,其中一些我在这篇文章中讨论过。我有许多个人事务,这使我无法充分利用这次会议。
但更重要的是,我没有学到一项有价值的技能:
走出去,真正向他人学习。
从大学的老师那里学习让我感觉很舒服……但从我刚在一次会议上认识的“陌生人”那里却不舒服。
在回家的飞机上,我记得那次经历让我感到沮丧和气馁。
我发誓再也不会让这种事发生了。
下一次会议不是一场灾难…我不会让它发生的

Figure 2: At my next conference, I vowed to never let my ICMLA experience happen again.
我在 2014 年 4 月得到了我的救赎。
这一次我不是在参加计算机视觉或机器学习会议——而是在拉斯维加斯参加一个小型企业家会议( MicroConf )。
我对是否去犹豫不决。
当时,内向的我几乎是在编造借口,避免去拉斯维加斯这样高度刺激、令人无法抗拒的地方。
但我记得我在 ICMLA 的誓言:
我不会让另一场会议成为一场灾难。
我收拾好行李,出发去拉斯维加斯。
在注册过程中,我和会议协调员史云光·卡斯楚聊了聊(他现在是 PyImageConf 的会议协调员,也是你见过的最好的人之一),问他在拉斯维加斯最喜欢去哪里吃饭。
然后,我走向我看到的第一组人,介绍了我自己,问他们每个人是做什么的。我和这个团队谈了大约 45 分钟,了解了他们的每一项业务。
当我的能量水平开始下降,我感到内向的借口开始出现,告诉我回到我的房间,独自一人,我走到酒吧,点了一杯啤酒。我立刻喝了三分之一的啤酒,然后在接下来的一个半小时里慢慢地啜饮剩下的。这次会议没有任何借口——我不会让我内向的习惯占上风,当我周围有这么多我可以学习的人时,我不会强迫我回到自己的房间。
我继续社交,与他人交谈,最重要的是,倾听他人,T3整个接待的其余时间。我从听别人的技术、方法和战争故事中获得的价值,抵得上光是会议门票的价格。
会议的其余部分取得了巨大的成功。
我不仅没有让历史重演,而且我也打破了自己的外壳。
你会得到你在会议中投入的东西
从那以后,我参加了无数的会议。有些很棒,有些简直是浪费我的时间。
但是总的来说,我发现让一个会议变得伟大有两个关键因素:
- 你得到你所投入的
- 更小型、更私密的会议通常更好
就像大学或练习一项运动/器械一样,你付出多少就会得到多少。
如果你总是逃课,不交任何朋友,很可能你不会喜欢上大学。
同样,如果你开始学习吉他,然后每月只练习一次,每次 30 分钟,你就不能指望在这方面有任何进步。
会议也是如此。
你需要带着一张清单去参加会议,上面列有你想从中得到的东西。带着目标进去,比如:
- 我想从戴维斯·金的演讲和研讨会中学习如何训练我自己的自定义对象检测器
- 我想问凯瑟琳·斯科特关于卫星图像分析的问题
- 我想问问 Adrian 关于创办一家计算机视觉/深度学习公司是什么感觉的建议
在你上飞机之前,花点时间写下你参加会议的目标。这个列表将指导你,并帮助确保你充分利用这次经历。
其次,我发现小型私密会议通常比大型会议更好。
大型会议人太多(> 500-1000 人)。你不可能见到所有的人——你见到的那些人你只能和他们聊 30 秒钟,然后继续下一个话题。这没有足够的时间去了解这个人,他们的项目,以及你们如何能够互相帮助。这些是遗漏的连接。能对你的职业和项目产生重大影响的人脉。
此外,小型会议有助于您更好地计划(并实现)参加会议的目标:
- 如果与会者人数较少,你就有更多的时间适应演讲者和研讨会主持人。
- 出席的人越少,你就能和出席的人进行越亲密的交谈。
现在,不要误会我的意思——你不能举办一个计划不周的会议,包括不太合适的场地和不合格的发言者,并期望它比 NIPS 好。
但是你能做的是精心策划一个包含两个世界最佳部分的会议:
- 非常著名的演讲者
- 与该领域的专家一对一交流
- 实践讲座和研讨会,在那里你可以学到当晚可以应用到自己的数据集或项目中的技能和技术
- 一个有很多额外待遇的一流场所(美丽的酒店,旧金山湾的景色,供应午餐,晚上的活动,开放的酒吧,数不清的步行距离,旧金山的优秀餐厅,等等。)
这就是 PyImageConf 的确切地说是:小巧、私密、实用。
我创建了 PyImageConf 作为我想参加的会议(你也会想参加)

Figure 3: PyImageConf, the practical, hands-on computer vision and deep learning conference.
在参加了许多会议之后,无论是在计算机视觉/深度学习领域还是在创业领域,我都在寻找两个必须具备的特征:
- 小型私密活动(少于 250 名与会者)
- 动手实践——那天晚上在你的酒店房间里,讨论的想法和算法可以应用到你的简历/毫升(或业务,如果是企业家会议)
作为一名与会者,最糟糕的感觉之一就是感觉自己只是另一个统计数字,迷失在人群中。
如果你以前参加过大型会议,你就会知道在这些更大的场所很难建立联系。您可以:
- 和一群人一起参加会议/快速结交一群朋友,在整个会议期间一起闲逛,以便在几乎势不可挡的与会者海洋中导航。
- 玩一个永无止境的“快速约会”游戏,你试着花 30 秒和每个人聊天。你不仅不能和每个人聊天,而且(最重要的是)30 秒对你来说太短了,不足以发展一段持久的关系。
关于小型会议,我喜欢的另一个方面是 专家更愿意分享他们不能公开分享的技术 ,无论这是他们用来获得比竞争对手更高准确性的新算法,还是由于雇主规定或害怕嘲笑而不能公布的新方法。包括我自己在内的专家们更愿意开放,在微小的群体中分享。
分享的技术会对你自己的项目产生巨大的影响。
我无法告诉你有多少次我在会议上学会了一种新方法,然后在从会议回家的飞机上将其应用到我的技术工作或业务(并且能够很快看到结果)。
总的来说,我参加过的企业家会议在这些实用的技巧和技术方面胜过。更大的计算机视觉和机器学习会议在这方面有很多值得学习的地方。
注:我在这里做一个概括来说明一个观点,请见谅。并非所有的企业家会议都是动手实践的(老实说,有相当多的会议非常糟糕)。同样,并不是所有的大型 CV 和 ML 会议都只关注理论。但是当你坚持我上面建议的两个特征时,你会发现小型企业家会议在战术内容方面做得非常好。
PyImageConf 的目标是融合我在这两种类型的会议上获得的积极经验,并将它们应用到计算机视觉和深度学习领域。
你将学习真实世界的计算机视觉和深度学习技术,然后你可以在晚上将它们应用到你自己的数据集/项目中(尽管我会建议你等到回家的飞机上,这样你就可以通过在晚上聚会和公开酒吧建立持久的联系来充分利用会议)。
为什么要开始一个会议呢?
相信我,这不是钱的问题。
会议的利润率低得离谱,尤其是像 PyImageConf 这样有与会者名单上限的会议。
除非你的全职工作是通过吸引尽可能多的与会者来使会议盈利,否则经营会议不是一种长期谋生的方式。如果算上你自己花在计划和执行会议上的时间,你所获得的任何利润(小型会议通常在 10-20%的范围内)都将完全失去。
在这一点上,你可能想知道:
阿德里安,如果对你来说开一个会议都不经济,你为什么还要费事呢?为什么不把你的时间投入到写另一本书或者组织一门新课程上呢?
答案很简单:
这不是关于我,而是关于你,PyImageSearch 的读者(希望还有 PyImageConf attendee)。
PyImageSearch 不仅仅是我。
是的,我写博客、书和课程。但从长远和宏观的角度来看,这并不重要。
真正重要的是 PyImageSearch 的社区。
我们互相学习。
我们在评论区互动。
我们通过电子邮件聊天。
PyImageSearch 大师的成员们每天在论坛上分享项目、算法和技术。
每天,我都会从一个读者的问题中学到一些新东西,这要求我阅读新技术,探索数据集,或者从不同的角度看待计算机视觉/深度学习问题。
这是一个令人难以置信的社区,我相信我有责任继续发展和培育它。虽然我可能是 PyImageSearch 的代言人,但我也谦卑地接受我作为社区管理者的角色——你是真正的PyImageSearch。
简单来说:
PyImageConf 是关于我通过创建一个会议来促进计算机视觉和深度学习社区的发展,这个会议以前在这种实际动手的水平上是不存在的。
会议,以及我在会议上建立的联系,改变了我的生活,这次会议也将为你做同样的事情。
在 PyImageConf 会议上,我会确保你在会议开始前至少见到一位出色的与会者,这样你会感觉自己是这个家庭的一员,而不是一个害羞的局外人,不得不鼓起勇气开始一场对话。
我很想在那里见到你,我希望你能来。
我为什么要参加 PyImageConf?
您应该参加 PyImageConf,如果您:
- 是一个准备好构建下一个计算机视觉或深度学习应用的企业家
- 你是一名不确定你职业道路的学生,但准备探索计算机视觉、深度学习和人工智能吗
- 是一个计算机视觉爱好者,喜欢构建新的项目和工具
- 渴望向顶级计算机视觉和深度学习教育家学习
- 享受 PyImageSearch 的教学风格,想要个性化的现场培训
如果这听起来像你,请放心,这次会议将是值得你投资的时间,资金和旅行。
我怎么知道这个?
因为我知道像这样的会议有两个组成部分:
- 教育,包括讲座、研讨会等。
- 在招待会、会谈和晚间活动之间建立的联系。
例如:
在会议的某个时刻,你需要站起来出去喝杯咖啡,吃点零食,或者呼吸点新鲜空气。也许这是在你不太感兴趣的谈话中,在问答环节,或者在谈话结束后。
就在舞厅的门外,你还会发现少数其他与会者也在做同样的事情。其中一些与会者将参与关于算法、应用于数据集的技术,甚至他们的业务/咨询工作的深入对话。通俗地说,这在会议行话中被称为“走廊通道”。【T2
一些最有价值、最持久的联系可以在“走廊”上建立,因为没有干扰。很安静。很贴心。很容易开始交谈,了解你周围的一小群人在做什么——其他人会很乐意和你交谈。不要低估这些对话。
通过这些对话建立的联系能够:
- 你会遇到能帮助你完成当前项目的人
- 帮你找到下一份计算机视觉或者深度学习的工作
- 为您当前的图像处理业务寻找客户
- 在您的笔记本电脑上演示您的最新项目,获得建议,并继续将您的演示构建到实际的应用程序中
- 找一个也在努力读研究生,但有信心想从事人工智能或人工智能的与会者
以下是我如何确保您充分利用 PyImageConf 的方法…

Figure 4: Before PyImageConf starts I’ll be creating a Slack group to help you network, create your list of goals, and find attendees you need to meet up with.
为了帮助促进这些联系,在 PyImageConf 2018 前几个月,我将为 PyImageConf 与会者创建一个 Slack 群。
该群组将使您能够在会议开始前与其他与会者聊天。利用这段时间了解其他与会者正在做什么— ,然后利用这些信息来帮助你制定我上面建议的目标清单:
- “我想和哪些演讲者进行一对一的谈话?”
- “哪些与会者可以帮助我当前的项目?”
- “我需要会见哪些与会者,以便在我的笔记本电脑上演示我的新项目?”
- “我将和哪一组与会者共进晚餐,这样我就可以学习他们的专业知识了?”
- “哪些与会者正在招聘,这样我就可以在计算机视觉/深度学习领域找到一份新工作?”
- 哪些与会者可以给我一些关于研究生院的建议
我还会亲自接触每位与会者,询问你们的目标。如果你没有目标清单,我会帮你列出来。如果你不知道该和哪些与会者聊天来实现你的目标,我会确保帮你建立联系。
PyImageSearch 不仅仅是一个教育博客,它还是一个社区。
如果你想在更私人的层面上了解社区中的读者,并与你可以一起工作、咨询并帮助你实现计算机视觉目标的人会面,那么 PyImageConf 就是你要去的地方。
不要错过门票(它们很可能会很快售完)。 确保你现在就加入早鸟名单。
PyImageConf 听起来很棒,现在怎么办?
为了开一个小型的私人会议,我把与会者的总人数限制在 200 人。
PyImageConf 2018 go 发售的早鸟票本周五,1 月 19 日。公开发售将于 1 月 26 日星期五在开始。
在这一点上,我不确定大减价开始时是否还有剩余的票。
如果您有兴趣参加 PyImageConf 并想要一张门票,请务必点击以下链接并加入早到者名单:
不要错过获得 PyImageConf 门票的机会, 点击此处加入早鸟名单 。
有关更多信息,请参考:
- 【PyImageConf 2018 官方网站
- PyImageConf 公告博客帖子(包括完整的演讲人名单、研讨会、价格、暂定日程等。)
如果您有任何关于会议的其他问题,请使用下面的评论部分或通过我的联系表联系。
会议将会非常精彩,我希望你能来!
用 Python 实现随机梯度下降(SGD)
原文:https://pyimagesearch.com/2016/10/17/stochastic-gradient-descent-sgd-with-python/
在上一节中,我们讨论了梯度下降,这是一种一阶优化算法,可用于学习一组用于参数化学习的分类器权重。然而,梯度下降的这种“普通”实现在大型数据集上运行会非常慢——事实上,它甚至可以被认为是计算浪费。
相反,我们应该应用随机梯度下降(SGD) ,这是对标准梯度下降算法的一个简单修改,该算法由计算梯度,由更新权重矩阵 W 对小批训练数据,而不是整个训练集。虽然这种修改导致“更多噪声”的更新,但它也允许我们沿着梯度采取更多的步骤(每批一步对每个时期一步),最终导致更快的收敛,并且对损失和分类精度没有负面影响。
谈到训练深度神经网络,SGD 可以说是最重要的算法。即使 SGD 的最初版本是在 57 年前推出的(斯坦福电子实验室等,1960 ),它仍然是使我们能够训练大型网络从数据点学习模式的引擎。在本书涵盖的所有其他算法中,请花时间理解 SGD。
**### 小批量新币
回顾一下传统的梯度下降算法,很明显该方法在大型数据集上运行非常慢。这种缓慢的原因是因为梯度下降的每次迭代需要我们在允许我们更新我们的权重矩阵之前为我们的训练数据中的每个训练点计算预测。对于像 ImageNet 这样的图像数据集,我们有超过120 万张训练图像,这种计算可能需要很长时间。
事实证明,在沿着我们的权重矩阵前进之前,计算每个训练点的预测是计算上的浪费,并且对我们的模型覆盖没有什么帮助。
相反,我们应该做的是批量我们的更新。我们可以通过添加额外的函数调用来更新伪代码,将 vanilla gradient descent 转换为 SGD:
while True:
batch = next_training_batch(data, 256)
Wgradient = evaluate_gradient(loss, batch, W)
W += -alpha * Wgradient
普通梯度下降和 SGD 的唯一区别是增加了next_training_batch函数。我们不是在整个data集合上计算我们的梯度,而是对我们的数据进行采样,产生一个batch。我们评估batch上的梯度,并更新我们的权重矩阵W。从实现的角度来看,我们还试图在应用 SGD 之前随机化我们的训练样本,因为该算法对批次敏感。**
在查看了 SGD 的伪代码之后,您会立即注意到一个新参数的引入:。在 SGD 的“纯粹”实现中,您的小批量大小将是 1,这意味着我们将从训练集中随机抽取一个数据点,计算梯度,并更新我们的参数。然而,我们经常使用的小批量是 > 1。典型的批量大小包括 32、64、128 和 256。*
*那么,为什么要使用批量大小 > 1 呢?首先,批量大小 > 1 有助于减少参数更新(【http://pyimg.co/pd5w0】)中的方差,从而导致更稳定的收敛。其次,对于批量大小,2 的幂通常是可取的,因为它们允许内部线性代数优化库更有效。
一般来说,小批量不是一个你应该过分担心的超参数(http://cs231n.stanford.edu)。如果您使用 GPU 来训练您的神经网络,您可以确定有多少训练示例适合您的 GPU,然后使用最接近的 2 的幂作为批处理大小,以便该批处理适合 GPU。对于 CPU 培训,您通常使用上面列出的批量大小之一,以确保您获得线性代数优化库的好处。
实施小批量 SGD
让我们继续实现 SGD,看看它与标准的普通梯度下降有什么不同。打开一个新文件,将其命名为sgd.py,并插入以下代码:
# import the necessary packages
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
import argparse
def sigmoid_activation(x):
# compute the sigmoid activation value for a given input
return 1.0 / (1 + np.exp(-x))
def sigmoid_deriv(x):
# compute the derivative of the sigmoid function ASSUMING
# that the input "x" has already been passed through the sigmoid
# activation function
return x * (1 - x)
第 2-7 行导入我们需要的 Python 包,和本章前面的gradient_descent.py例子完全一样。第 9-17 行定义了我们的sigmoid_activation和sigmoid_deriv函数,这两个函数与之前版本的梯度下降相同。
事实上,predict方法也没有改变:
def predict(X, W):
# take the dot product between our features and weight matrix
preds = sigmoid_activation(X.dot(W))
# apply a step function to threshold the outputs to binary
# class labels
preds[preds <= 0.5] = 0
preds[preds > 0] = 1
# return the predictions
return preds
然而,改变的是增加了next_batch功能:
def next_batch(X, y, batchSize):
# loop over our dataset "X" in mini-batches, yielding a tuple of
# the current batched data and labels
for i in np.arange(0, X.shape[0], batchSize):
yield (X[i:i + batchSize], y[i:i + batchSize])
next_batch方法需要三个参数:
- 特征向量/原始图像像素强度的训练数据集。
y:与每个训练数据点相关联的类别标签。batchSize:将被退回的每个小批量的大小。
第 34 行和第 35 行然后遍历训练示例,产生X和y的子集作为小批量。
接下来,我们可以解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--epochs", type=float, default=100,
help="# of epochs")
ap.add_argument("-a", "--alpha", type=float, default=0.01,
help="learning rate")
ap.add_argument("-b", "--batch-size", type=int, default=32,
help="size of SGD mini-batches")
args = vars(ap.parse_args())
我们已经回顾了普通梯度下降示例中的--epochs(历元数)和--alpha(学习速率)开关,但也注意到我们引入了第三个开关:--batch-size,顾名思义,它是我们每个小批量的大小。我们将默认该值为每个小批量的32个数据点。
我们的下一个代码块处理生成具有 1,000 个数据点的 2 类分类问题,添加偏差列,然后执行训练和测试分割:
# generate a 2-class classification problem with 1,000 data points,
# where each data point is a 2D feature vector
(X, y) = make_blobs(n_samples=1000, n_features=2, centers=2,
cluster_std=1.5, random_state=1)
y = y.reshape((y.shape[0], 1))
# insert a column of 1's as the last entry in the feature
# matrix -- this little trick allows us to treat the bias
# as a trainable parameter within the weight matrix
X = np.c_[X, np.ones((X.shape[0]))]
# partition the data into training and testing splits using 50% of
# the data for training and the remaining 50% for testing
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.5, random_state=42)
然后,我们将初始化权重矩阵和损失,就像前面的例子一样:
# initialize our weight matrix and list of losses
print("[INFO] training...")
W = np.random.randn(X.shape[1], 1)
losses = []
接下来是真正的变化,我们循环期望的历元数,沿途采样小批量:
# loop over the desired number of epochs
for epoch in np.arange(0, args["epochs"]):
# initialize the total loss for the epoch
epochLoss = []
# loop over our data in batches
for (batchX, batchY) in next_batch(trainX, trainY, args["batch_size"]):
# take the dot product between our current batch of features
# and the weight matrix, then pass this value through our
# activation function
preds = sigmoid_activation(batchX.dot(W))
# now that we have our predictions, we need to determine the
# "error", which is the difference between our predictions
# and the true values
error = preds - batchY
epochLoss.append(np.sum(error ** 2))
在第 69 行,上,我们开始循环所提供的--epochs号。然后我们在行 74 上批量循环我们的训练数据。对于每个批次,我们计算批次和W之间的点积,然后将结果通过 sigmoid 激活函数来获得我们的预测。我们计算第行 83 上批次的误差,并使用该值更新第行 84 上的最小二乘epochLoss。
现在我们有了error,我们可以计算梯度下降更新,与从普通梯度下降计算梯度相同,只是这次我们对批而不是整个训练集执行更新:
# the gradient descent update is the dot product between our
# (1) current batch and (2) the error of the sigmoid
# derivative of our predictions
d = error * sigmoid_deriv(preds)
gradient = batchX.T.dot(d)
# in the update stage, all we need to do is "nudge" the
# weight matrix in the negative direction of the gradient
# (hence the term "gradient descent" by taking a small step
# towards a set of "more optimal" parameters
W += -args["alpha"] * gradient
第 96 行处理基于梯度更新我们的权重矩阵,由我们的学习速率--alpha缩放。注意重量更新阶段是如何在批处理循环中发生的——这意味着每个时期有多次重量更新。
然后,我们可以通过取时段中所有批次的平均值来更新我们的损失历史,然后在必要时向我们的终端显示更新:
# update our loss history by taking the average loss across all
# batches
loss = np.average(epochLoss)
losses.append(loss)
# check to see if an update should be displayed
if epoch == 0 or (epoch + 1) % 5 == 0:
print("[INFO] epoch={}, loss={:.7f}".format(int(epoch + 1),
loss))
评估我们的分类器的方式与普通梯度下降法相同——只需使用我们学习的W权重矩阵对testX数据调用predict:
# evaluate our model
print("[INFO] evaluating...")
preds = predict(testX, W)
print(classification_report(testY, preds))
我们将通过绘制测试分类数据以及每个时期的损失来结束我们的脚本:
# plot the (testing) classification data
plt.style.use("ggplot")
plt.figure()
plt.title("Data")
plt.scatter(testX[:, 0], testX[:, 1], marker="o", c=testY[:, 0], s=30)
# construct a figure that plots the loss over time
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, args["epochs"]), losses)
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.show()
SGD 结果
要可视化我们实现的结果,只需执行以下命令:
$ python sgd.py
[INFO] training...
[INFO] epoch=1, loss=0.1317637
[INFO] epoch=5, loss=0.0162487
[INFO] epoch=10, loss=0.0112798
[INFO] epoch=15, loss=0.0100234
[INFO] epoch=20, loss=0.0094581
[INFO] epoch=25, loss=0.0091053
[INFO] epoch=30, loss=0.0088366
[INFO] epoch=35, loss=0.0086082
[INFO] epoch=40, loss=0.0084031
[INFO] epoch=45, loss=0.0082138
[INFO] epoch=50, loss=0.0080364
[INFO] epoch=55, loss=0.0078690
[INFO] epoch=60, loss=0.0077102
[INFO] epoch=65, loss=0.0075593
[INFO] epoch=70, loss=0.0074153
[INFO] epoch=75, loss=0.0072779
[INFO] epoch=80, loss=0.0071465
[INFO] epoch=85, loss=0.0070207
[INFO] epoch=90, loss=0.0069001
[INFO] epoch=95, loss=0.0067843
[INFO] epoch=100, loss=0.0066731
[INFO] evaluating...
precision recall f1-score support
0 1.00 1.00 1.00 250
1 1.00 1.00 1.00 250
avg / total 1.00 1.00 1.00 500
SGD 示例使用学习率(0.1)和与普通梯度下降相同的历元数(100)。其结果可以在图 1 中看到。
调查第 100 个历元结束时的实际损耗值,您会注意到 SGD 获得的损耗比普通梯度下降(0 )低近两个数量级 。 006 vs 0 。分别为 447)。这种差异是由于每个时期的多个权重更新,给了我们的模型更多的机会从对权重矩阵的更新中学习。这种影响在大型数据集上更加明显,例如 ImageNet,我们有数百万个训练样本,参数的小规模增量更新可以产生低损失(但不一定是最佳)的解决方案。****
图像间的超快速色彩转换
原文:https://pyimagesearch.com/2014/06/30/super-fast-color-transfer-images/
大约一个月前,我在海边度过了一个早晨,沿着沙滩散步,让清凉的水拍打着我的脚。它是宁静的,放松的。然后我拿出我的 iPhone,抓拍了几张经过的海洋和云彩的照片。你知道,一些值得纪念的事情。因为我知道我一回到办公室,我的鼻子就要开始工作了。
回到家里,我把照片导入笔记本电脑,心想,嘿,一定有办法把我上午拍的这张海滩照片拍成黄昏时的样子。
由于我是一名计算机视觉科学家,我当然不会求助于 Photoshop。
不,这必须是一个手工设计的算法,可以拍摄任意两个图像,一个源图像和一个目标图像,然后将颜色空间从source图像转移到target图像。
几周前,我在浏览 reddit 时,看到了一个关于如何在两张图片之间转换颜色的帖子。作者的实现使用了基于直方图的方法,旨在平衡三种“类型”的箱:相等、过剩和不足。
这种方法取得了很好的效果——但是以速度为代价。使用这种算法将需要您对源图像中的每个像素执行查找,随着图像大小的增加,这将变得非常昂贵。虽然你可以用一点数字魔法来加速这个过程,但是你可以做得更好。
好得多,其实好得多。
如果我告诉你,你可以创建一个只使用图像通道的平均值和标准偏差 的 颜色转移算法,那会怎么样?
就是这样。没有复杂的代码。没有计算直方图。只是简单的统计。
顺便说一下,这种方法甚至可以轻松处理巨大的图像。
感兴趣吗?
请继续阅读。
你也可以通过 GitHub 下载代码或者通过 PyPI 安装(假设你已经安装了 OpenCV)。
颜色传递算法
我实现的颜色转换是(粗略地)基于赖因哈德等人 2001 年提出的图像间的颜色转换。
在这篇论文中,赖因哈德和他的同事证明了通过分别利用 Lab颜色空间和每个 L、a和 b*通道的平均值和标准偏差,颜色可以在两个图像之间转移。
算法是这样的:
- 第一步:输入一张
source和一张target图像。源图像包含您希望您的target图像模仿的色彩空间。在这个页面顶部的图中,左边的日落图像是我的source,中间的图像是我的target,右边的图像是应用到target的source的色彩空间。 - 第二步:将
source和target图像都转换到 Lab颜色空间。Lab颜色空间模拟感知均匀性,其中颜色值数量的小变化也应该产生颜色重要性的相对相等的变化。Lab*颜色空间在模仿人类如何解释颜色方面比标准 RGB 颜色空间做得好得多,正如您将看到的,它非常适合颜色传递。 - 第三步:为
source和target拆分通道。 - 步骤 4: 计算
source和target图像的 Lab*通道的平均值和标准偏差。 - 第五步:从
target通道中减去target图像的 Lab*通道的平均值。 - 第六步:按
target的标准差除以source的标准差,再乘以target通道的比值缩放target通道。 - 第七步:为
source添加 Lab*通道的含义。 - 第 8 步:裁剪掉范围【0,255】之外的任何值。(注:这一步不是原纸的一部分。我添加它是因为 OpenCV 处理色彩空间转换的方式。如果您要在不同的语言/库中实现该算法,您将不得不自己执行色彩空间转换,或者了解执行转换的库是如何工作的)。
- 第九步:合并频道。
- 第十步:从 Lab*空间转换回 RGB 颜色空间。
我知道这看起来需要很多步骤,但实际上并不多,特别是考虑到在使用 Python、NumPy 和 OpenCV 时实现这种算法是多么简单。
如果现在看起来有点复杂,不要担心。继续阅读,我将解释驱动算法的代码。
要求
我假设您的系统上安装了 Python、OpenCV(带有 Python 绑定)和 NumPy。
如果有人想帮我在 GitHub repo 中创建一个requirements.txt文件,那将会非常棒。
安装
假设您已经安装了 OpenCV(带有 Python 绑定)和 NumPy,最简单的安装方法是使用pip:
$ pip install color_transfer
代码解释
我创建了一个 PyPI 包,你可以用它在你自己的图片之间进行颜色转换。GitHub 上也有该代码。
无论如何,让我们卷起袖子,把手弄脏,看看在color_transfer包的引擎盖下发生了什么:
# import the necessary packages
import numpy as np
import cv2
def color_transfer(source, target):
# convert the images from the RGB to L*ab* color space, being
# sure to utilizing the floating point data type (note: OpenCV
# expects floats to be 32-bit, so use that instead of 64-bit)
source = cv2.cvtColor(source, cv2.COLOR_BGR2LAB).astype("float32")
target = cv2.cvtColor(target, cv2.COLOR_BGR2LAB).astype("float32")
2 号线和 3 号线输入我们需要的包裹。我们将使用 NumPy 进行数值处理,使用cv2进行 OpenCV 绑定。
从那里,我们在线 5 上定义我们的color_transfer函数。这个函数执行颜色从source图像(第一个参数)到target图像(第二个参数)的实际转换。
赖因哈德等人详述的算法表明,应该利用 Lab颜色空间,而不是标准的 RGB。为了处理这个问题,我们将源图像和目标图像都转换到 Lab颜色空间的第 9 行和第 10 行 ( 步骤 1 和 2 )。
OpenCV 将图像表示为多维 NumPy 数组,但默认为uint8数据类型。这对于大多数情况来说没问题,但是当执行颜色传输时,我们可能会有负值和十进制值,因此我们需要利用浮点数据类型。
现在,让我们开始执行实际的颜色转换:
# compute color statistics for the source and target images
(lMeanSrc, lStdSrc, aMeanSrc, aStdSrc, bMeanSrc, bStdSrc) = image_stats(source)
(lMeanTar, lStdTar, aMeanTar, aStdTar, bMeanTar, bStdTar) = image_stats(target)
# subtract the means from the target image
(l, a, b) = cv2.split(target)
l -= lMeanTar
a -= aMeanTar
b -= bMeanTar
# scale by the standard deviations
l = (lStdTar / lStdSrc) * l
a = (aStdTar / aStdSrc) * a
b = (bStdTar / bStdSrc) * b
# add in the source mean
l += lMeanSrc
a += aMeanSrc
b += bMeanSrc
# clip the pixel intensities to [0, 255] if they fall outside
# this range
l = np.clip(l, 0, 255)
a = np.clip(a, 0, 255)
b = np.clip(b, 0, 255)
# merge the channels together and convert back to the RGB color
# space, being sure to utilize the 8-bit unsigned integer data
# type
transfer = cv2.merge([l, a, b])
transfer = cv2.cvtColor(transfer.astype("uint8"), cv2.COLOR_LAB2BGR)
# return the color transferred image
return transfer
第 13 行和第 14 行调用了image_stats函数,我将在几个段落中详细讨论。但是现在,要知道这个函数只是分别计算 L、a和 b*通道的像素强度的平均值和标准偏差(步骤 3 和 4 )。
现在我们有了source和target图像的每个 Lab*通道的平均值和标准偏差,我们现在可以执行颜色转换。
在第 17-20 行,我们将目标图像分割成 L、a和 b*分量,并减去它们各自的平均值(步骤 5 )。
从那里,我们通过目标标准偏差除以源图像的标准偏差的比率进行缩放,在行 23-25 上执行步骤 6 。
然后,我们可以应用步骤 7 ,在行 28-30 添加源通道的平均值。
第 8 步在第 34-36 行上处理,在这里我们截取落在范围【0,255】之外的值(在 Lab颜色空间的 OpenCV 实现中,这些值被缩放到范围【0,255】,尽管这不是原始 Lab规范的一部分)。
最后,我们通过将缩放后的 Lab*通道合并在一起,并最终转换回原始 RGB 色彩空间,在行 41 和 42 上执行步骤 9 和步骤 10 。
最后,我们在第 45 行返回彩色传输图像。
让我们快速看一下image_stats函数,使这段代码解释更加完整:
def image_stats(image):
# compute the mean and standard deviation of each channel
(l, a, b) = cv2.split(image)
(lMean, lStd) = (l.mean(), l.std())
(aMean, aStd) = (a.mean(), a.std())
(bMean, bStd) = (b.mean(), b.std())
# return the color statistics
return (lMean, lStd, aMean, aStd, bMean, bStd)
这里我们定义了image_stats函数,它接受一个参数:我们想要计算统计数据的image。
在调用行 49 上的cv2.split将我们的图像分解到各自的通道之前,我们假设图像已经在 Lab*颜色空间中。
从那里,行 50-52 处理每个通道的平均值和标准偏差的计算。
最后,在线 55 上返回每个通道的一组平均值和标准偏差。
例子
要获取example.py文件并运行示例,只需从 GitHub 项目页面获取代码。
你已经在这篇文章的顶部看到了海滩的例子,但是让我们再看一看:
$ python example.py --source images/ocean_sunset.jpg --target images/ocean_day.jpg
执行该脚本后,您应该会看到以下结果:
Figure 1: The image on the left is the source, the middle image is the target, and the right is the output image after applying the color transfer from the source to the target. Notice how a nice sunset effect is created in the output image.
注意日落照片的橙色和红色是如何被转移到白天的海洋照片上的。

太棒了。但是让我们尝试一些不同的东西:
$ python example.py --source images/woods.jpg --target images/storm.jpg
Figure 2: Using color transfer to make storm clouds look much more ominous using the green foliage of a forest scene.
这里你可以看到在左边的我们有一张林地的照片——大部分是与植被相关的绿色和与树皮相关的深棕色。
然后在中间我们有一个不祥的雷雨云——但让我们让它更不祥!
如果你曾经经历过严重的雷雨或龙卷风,你可能已经注意到在暴风雨来临之前,天空会变成一片诡异的绿色。
正如你在右边看到的,我们已经成功地通过将森林区域的颜色空间映射到我们的云上来模拟这种不祥的绿色天空。
很酷,对吧?
再举一个例子:
$ python example.py --source images/autumn.jpg --target images/fallingwater.jpg

Figure 3: Using color transfer between images to create an autumn style effect on the output image.
在这里,我结合了我最喜欢的两件东西:秋叶(左)和中世纪的现代建筑,在这种情况下,弗兰克劳埃德赖特的流水别墅(中)。
流水别墅的中间照片展示了一些令人惊叹的中世纪建筑,但如果我想给它一个“秋天”风格的效果呢?
你猜对了——把秋天图像的色彩空间转移到流水上!正如你在右边的所看到的,结果非常棒。
改进算法的方法
虽然赖因哈德等人的算法非常快,但有一个特别的缺点——它依赖于全局颜色统计,因此具有相似像素强度值的大区域会显著影响平均值(从而影响整体颜色传递)。
为了解决这个问题,我们可以考虑两种解决方案:
选项 1: 在您想要模拟颜色的较小感兴趣区域(ROI)中计算源图像的平均值和标准偏差,而不是使用整个图像。采用这种方法将使您的平均值和标准差更好地代表您想要使用的色彩空间。
选项 2: 第二种方法是将 k 均值应用于两幅图像。您可以在 Lab*颜色空间中对每个图像的像素强度进行聚类,然后使用欧几里得距离确定最相似的两个图像之间的质心。然后,只计算这些区域内的统计数据。同样,这将使您的均值和标准差具有更“局部”的效果,并有助于缓解全球统计数据的过度代表性问题。当然,缺点是这种方法速度很慢,因为现在增加了一个昂贵的集群步骤。
摘要
在这篇文章中,我展示了如何使用 Python 和 OpenCV 在图像之间进行超快速的颜色转换。
然后,我提供了一个(大致)基于赖因哈德等人论文的实现。
与需要计算每个通道的 CDF 然后构建查找表(LUT)的基于直方图的颜色传递方法不同,这种方法严格依赖于 Lab*颜色空间中像素强度的平均值和标准偏差,这使得它非常高效,并且能够快速处理非常大的图像。
如果您希望改进此算法的结果,请考虑对源图像和目标图像应用 k-means 聚类,匹配具有相似质心的区域,然后在每个单独的区域内执行颜色传递。这样做将使用 局部 颜色统计,而不是 全局 统计,从而使颜色转移更具视觉吸引力。
GitHub 上提供的代码
寻找这篇文章的源代码?只需前往 GitHub 项目页面!
在一个周末学习计算机视觉的基础知识

如果你有兴趣学习计算机视觉的基础知识,但不知道从哪里开始,你绝对应该看看我的新电子书, 实用 Python 和 OpenCV 。
在这本书里,我涵盖了计算机视觉和图像处理的基础…我可以在一个周末教你!
我知道,这听起来好得难以置信。
但是我向你保证,这本书是你学习计算机视觉基础的快速入门指南。读完这本书后,你将很快成为一名 OpenCV 大师!
所以如果你想学习 OpenCV 的基础知识,一定要看看我的书。你不会失望的。*
超分辨率生成对抗网络
原文:https://pyimagesearch.com/2022/06/06/super-resolution-generative-adversarial-networks-srgan/
目录
**超分辨率(SR)是以最小的信息失真将低分辨率图像上采样到更高的分辨率。自从研究人员获得了足够强大的机器来计算大量数据,超分辨率领域已经取得了重大进展,双三次调整大小,高效的亚像素网络等。
要理解超分辨率的重要性,环顾一下当今的技术世界就会自动解释它。从保存旧媒体材料(电影和连续剧)到增强显微镜的视野,超分辨率的影响是广泛而又极其明显的。稳健的超分辨率算法在当今世界极其重要。
由于生成对抗网络(GANs)的引入在深度学习领域掀起了风暴,所以结合 GAN 的超分辨率技术的引入只是时间问题。
今天我们将学习 SRGAN,这是一种巧妙的超分辨率技术,结合了 GANs 的概念和传统的 SR 方法。
在本教程中,您将学习如何实现 SRGAN。
本课是 4 部分系列 GANs 201 的第 1 部分。
- 【超分辨率生成对抗网络(SRGAN) (本教程)
- 增强型超分辨率生成对抗网络(ESRGAN)
- 用于图像到图像转换的像素 2 像素氮化镓
- 用于图像到图像转换的 CycleGAN】
要学习如何实现 SRGANs,继续阅读。
**虽然 GANs 本身是一个革命性的概念,但其应用领域仍然是一个相当新的领域。在超分辨率中引入 GANs 并不像听起来那么简单。简单地在一个类似超分辨率的架构中添加 GANs 背后的数学将无法实现我们的目标。
SRGAN 的想法是通过结合有效的子像素网络的元素以及传统的 GAN 损失函数来构思的。在我们深入探讨这个问题之前,让我们先简要回顾一下生成敌对网络。
甘斯简介
用最常见的侦探和伪造者的例子(图 1 )来最好地描述甘的想法。
伪造者试图制造出逼真的艺术品,而侦探则负责辨别真假艺术品。造假者是生产者,侦探是鉴别者。
理想的训练将生成欺骗鉴别器的数据,使其相信该数据属于训练数据集。
注: 关于 GANs 最重要的直觉是,生成器产生的数据不一定是训练数据的复制品,但它必须 看起来 像它属于训练数据分布。
使用 GANs 的超分辨率
SRGANs 保留了 GANs 的核心概念(即 min-max 函数),使生成器和鉴别器通过相互对抗来一致学习。SRGAN 引入了一些自己独有的附加功能,这些功能是基于之前在该领域所做的研究。让我们先来看看 SRGAN 的完整架构(图 2 )。
一些要点要注意:
- 生成器网络采用残差块,其思想是保持来自先前层的信息有效,并允许网络自适应地从更多特征中进行选择。
- 我们传递低分辨率图像,而不是添加随机噪声作为发生器输入。
鉴别器网络非常标准,其工作原理与普通 GAN 中的鉴别器一样。
SRGANs 中的突出因素是感知损失函数。虽然生成器和鉴别器将基于 GAN 架构进行训练,但 SRGANs 使用另一个损失函数的帮助来达到其目的地:感知/内容损失函数。
这个想法是,SRGAN 设计了一个损失函数,通过计算出感知相关的特征来达到它的目标。因此,不仅对抗性的损失有助于调整权重,内容损失也在发挥作用。
内容损失被定义为 VGG 损失,这意味着然后按像素比较预训练的 VGG 网络输出。真实图像 VGG 输出和伪图像 VGG 输出相似的唯一方式是当输入图像本身相似时。这背后的直觉是,逐像素比较将有助于实现超分辨率的核心目标。
当 GAN 损失和含量损失相结合时,结果确实是正的。我们生成的超分辨率图像非常清晰,能够反映高分辨率(hr)图像。
在我们的项目中,为了展示 SRGAN 的威力,我们将它与预训练的发生器和原始高分辨率图像进行比较。为了使我们的训练更有效,我们将把我们的数据转换成 TFRecords 。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install tensorflow
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── create_tfrecords.py
├── inference.py
├── outputs
├── pyimagesearch
│ ├── config.py
│ ├── data_preprocess.py
│ ├── __init__.py
│ ├── losses.py
│ ├── srgan.py
│ ├── srgan_training.py
│ ├── utils.py
│ └── vgg.py
└── train_srgan.py
2 directories, 11 files
在pyimagesearch目录中,我们有:
config.py:包含完整项目的端到端配置管道,data_preprocess.py:包含辅助数据处理的功能。__init__.py:使目录的行为像一个 python 包。losses.py:初始化训练 SRGAN 所需的损耗。srgan.py:包含 SRGAN 架构。srgan_training.py:包含运行 SRGAN 训练的训练类。utils.py:包含附加实用程序vgg.py:初始化用于感知损失计算的 VGG 模型。
在根目录中,我们有:
create_tfrecords.py:从我们将要使用的数据集创建TFRecords。inference.py:使用训练好的模型进行推理。train_srgan.py:使用srgan.py和srgan_training.py脚本执行 SRGAN 训练。
创建配置管道
在实施 SRGAN 时,有许多因素在起作用。为此,我们创建了一个在整个项目中使用的全局配置文件。让我们转到位于pyimagesearch目录中的config.py文件。
# import the necessary packages
import os
# name of the TFDS dataset we will be using
DATASET = "div2k/bicubic_x4"
# define the shard size and batch size
SHARD_SIZE = 256
TRAIN_BATCH_SIZE = 64
INFER_BATCH_SIZE = 8
# dataset specs
HR_SHAPE = [96, 96, 3]
LR_SHAPE = [24, 24, 3]
SCALING_FACTOR = 4
# GAN model specs
FEATURE_MAPS = 64
RESIDUAL_BLOCKS = 16
LEAKY_ALPHA = 0.2
DISC_BLOCKS = 4
# training specs
PRETRAIN_LR = 1e-4
FINETUNE_LR = 1e-5
PRETRAIN_EPOCHS = 2500
FINETUNE_EPOCHS = 2500
STEPS_PER_EPOCH = 10
在第 5 行,引用了TFDS数据集。我们将在我们的项目中使用 div2k 数据集。该数据集的目的是帮助进行图像超分辨率研究,因为它包含各种高分辨率图像。
在第 8 行的上,我们已经定义了创建TFRecords所需的分片大小。随后是第 9 和第 10 行的训练和推理批量。
在行 13 上,定义高分辨率图像形状。这是我们的输出形状,图像将被放大。定义的下一个变量是低分辨率形状,它将作为我们的输入(第 14 行)。
相应地,比例因子被定义为4 (96/24) ( 第 15 行)。
在第 18-21 行中,定义了 GAN 型号规格。这些是:
FEATURE_MAPS:定义 CNN 的过滤器尺寸RESIDUAL_BLOCKS:如前所述,生成器利用残差块,这定义了残差块的数量LEAKY_ALPHA:为我们的激活函数值定义alpha参数DISC_BLOCKS:定义鉴别器的块
然后我们定义训练参数(第 24-28 行),包括:
PRETRAIN_LR:学习率定义预训练。FINETUNE_LR:用于微调的学习率PRETRAIN_EPOCHS:定义为预训练的时期数FINETUNE_EPOCHS:用于微调的时期数STEPS_PER_EPOCH:定义每个时期运行的步数
# define the path to the dataset
BASE_DATA_PATH = "dataset"
DIV2K_PATH = os.path.join(BASE_DATA_PATH, "div2k")
# define the path to the tfrecords for GPU training
GPU_BASE_TFR_PATH = "tfrecord"
GPU_DIV2K_TFR_TRAIN_PATH = os.path.join(GPU_BASE_TFR_PATH, "train")
GPU_DIV2K_TFR_TEST_PATH = os.path.join(GPU_BASE_TFR_PATH, "test")
# define the path to the tfrecords for TPU training
TPU_BASE_TFR_PATH = "gs://<PATH_TO_GCS_BUCKET>/tfrecord"
TPU_DIV2K_TFR_TRAIN_PATH = os.path.join(TPU_BASE_TFR_PATH, "train")
TPU_DIV2K_TFR_TEST_PATH = os.path.join(TPU_BASE_TFR_PATH, "test")
# path to our base output directory
BASE_OUTPUT_PATH = "outputs"
# GPU training SRGAN model paths
GPU_PRETRAINED_GENERATOR_MODEL = os.path.join(BASE_OUTPUT_PATH,
"models", "pretrained_generator")
GPU_GENERATOR_MODEL = os.path.join(BASE_OUTPUT_PATH, "models",
"generator")
# TPU training SRGAN model paths
TPU_OUTPUT_PATH = "gs://<PATH_TO_GCS_BUCKET>/outputs"
TPU_PRETRAINED_GENERATOR_MODEL = os.path.join(TPU_OUTPUT_PATH,
"models", "pretrained_generator")
TPU_GENERATOR_MODEL = os.path.join(TPU_OUTPUT_PATH, "models",
"generator")
# define the path to the inferred images and to the grid image
BASE_IMAGE_PATH = os.path.join(BASE_OUTPUT_PATH, "images")
GRID_IMAGE_PATH = os.path.join(BASE_IMAGE_PATH, "grid.png")
在第 31 行和第 32 行,我们已经定义了存储数据集的引用路径。
由于我们将在 GPU 和 TPU 上训练我们的数据,我们已经为每个训练选择分别创建了tfrecords。如你所知,这个项目是数据密集型的。因此,需要将我们的数据转换到tfrecords以进行优化和更快的训练。
首先,我们为 GPU 训练数据定义了到tfrecords的路径(第 35-37 行)。接下来是参考 TPU 训练数据的tfrecords的定义(第 40-42 行)。
训练和推断数据路径完成后,我们在第 45 行的上定义了全局输出目录。
我们将比较预训练的主干和我们完全训练的发电机模型。我们在行 48-51 定义了 GPU 预训练生成器和普通生成器。
如前所述,由于我们也将在 TPU 上训练,我们在线 54-58 上定义单独的 TPU 训练输出和发生器路径。
最后,我们在的第 61 行和第 62 行添加推断图像子目录以及网格图像子目录,以结束我们的config.py脚本。
搭建数据处理管道
由于数据无疑是我们项目中最重要的一块拼图,我们必须建立一个广泛的数据处理管道来处理我们所有的需求,这涉及到几种数据扩充方法。为此,让我们移到pyimagesearch目录中的data_preprocess.py。
我们创建了一系列函数来帮助我们扩充数据集。
# import the necessary packages
from tensorflow.io import FixedLenFeature
from tensorflow.io import parse_single_example
from tensorflow.io import parse_tensor
from tensorflow.image import flip_left_right
from tensorflow.image import rot90
import tensorflow as tf
# define AUTOTUNE object
AUTO = tf.data.AUTOTUNE
def random_crop(lrImage, hrImage, hrCropSize=96, scale=4):
# calculate the low resolution image crop size and image shape
lrCropSize = hrCropSize // scale
lrImageShape = tf.shape(lrImage)[:2]
# calculate the low resolution image width and height offsets
lrW = tf.random.uniform(shape=(),
maxval=lrImageShape[1] - lrCropSize + 1, dtype=tf.int32)
lrH = tf.random.uniform(shape=(),
maxval=lrImageShape[0] - lrCropSize + 1, dtype=tf.int32)
# calculate the high resolution image width and height
hrW = lrW * scale
hrH = lrH * scale
# crop the low and high resolution images
lrImageCropped = tf.slice(lrImage, [lrH, lrW, 0],
[(lrCropSize), (lrCropSize), 3])
hrImageCropped = tf.slice(hrImage, [hrH, hrW, 0],
[(hrCropSize), (hrCropSize), 3])
# return the cropped low and high resolution images
return (lrImageCropped, hrImageCropped)
考虑到我们将在这个项目中使用的 TensorFlow 包装器的数量,为空间优化定义一个tf.data.AUTOTUNE对象是一个好方法。
我们定义的第一个函数是random_crop ( 第 12 行)。它接受以下参数:
lrImage:低分辨率图像。hrImage:高分辨率图像。hrCropSize:用于低分辨率裁剪计算的高分辨率裁剪尺寸。scale:我们用来计算低分辨率裁剪的因子。
使用tf.random.uniform,我们计算行 18-21 上的低分辨率(lr)宽度和高度偏移。
为了计算相应的高分辨率值,我们简单地将低分辨率值乘以比例因子(行 24 和 25 )。
使用这些值,我们裁剪出低分辨率图像及其对应的高分辨率图像并返回它们(第 28-34 行)。
def get_center_crop(lrImage, hrImage, hrCropSize=96, scale=4):
# calculate the low resolution image crop size and image shape
lrCropSize = hrCropSize // scale
lrImageShape = tf.shape(lrImage)[:2]
# calculate the low resolution image width and height
lrW = lrImageShape[1] // 2
lrH = lrImageShape[0] // 2
# calculate the high resolution image width and height
hrW = lrW * scale
hrH = lrH * scale
# crop the low and high resolution images
lrImageCropped = tf.slice(lrImage, [lrH - (lrCropSize // 2),
lrW - (lrCropSize // 2), 0], [lrCropSize, lrCropSize, 3])
hrImageCropped = tf.slice(hrImage, [hrH - (hrCropSize // 2),
hrW - (hrCropSize // 2), 0], [hrCropSize, hrCropSize, 3])
# return the cropped low and high resolution images
return (lrImageCropped, hrImageCropped)
我们关注的下一个函数是get_center_crop ( 第 36 行),它接受以下参数:
lrImage:低分辨率图像hrImage:高分辨率图像hrCropSize:用于低分辨率裁剪计算的高分辨率裁剪尺寸scale:我们用来计算低分辨率裁剪的因子
就像我们为之前的函数创建裁剪大小值一样,我们在第 38 行和第 39 行得到 lr 裁剪大小值和图像形状。
在行 42 和 43 上,我们将低分辨率形状除以 2,得到中心点。
为了获得相应的高分辨率中心点,将 lr 中心点乘以比例因子(第 46 和 47 行)。
在第行第 50-53 行,我们得到低分辨率和高分辨率图像的中心裁剪并返回它们。
def random_flip(lrImage, hrImage):
# calculate a random chance for flip
flipProb = tf.random.uniform(shape=(), maxval=1)
(lrImage, hrImage) = tf.cond(flipProb < 0.5,
lambda: (lrImage, hrImage),
lambda: (flip_left_right(lrImage), flip_left_right(hrImage)))
# return the randomly flipped low and high resolution images
return (lrImage, hrImage)
在第 58 行的上,我们有random_flip功能来翻转图像。它接受低分辨率和高分辨率图像作为其参数。
基于使用tf.random.uniform的翻转概率值,我们翻转我们的图像并返回它们。
def random_rotate(lrImage, hrImage):
# randomly generate the number of 90 degree rotations
n = tf.random.uniform(shape=(), maxval=4, dtype=tf.int32)
# rotate the low and high resolution images
lrImage = rot90(lrImage, n)
hrImage = rot90(hrImage, n)
# return the randomly rotated images
return (lrImage, hrImage)
行 68 上的random_rotate功能将根据tf.random.uniform ( 行 70-77 )产生的值随机旋转一对高分辨率和低分辨率图像。
def read_train_example(example):
# get the feature template and parse a single image according to
# the feature template
feature = {
"lr": FixedLenFeature([], tf.string),
"hr": FixedLenFeature([], tf.string),
}
example = parse_single_example(example, feature)
# parse the low and high resolution images
lrImage = parse_tensor(example["lr"], out_type=tf.uint8)
hrImage = parse_tensor(example["hr"], out_type=tf.uint8)
read_train_example函数接受一个示例图像集(一个 lr 和一个 hr 图像集)作为参数(第 79 行)。在第 82-85 行,我们创建一个特征模板。
我们从示例集中解析低分辨率和高分辨率图像(第 86-90 行)。
# perform data augmentation
(lrImage, hrImage) = random_crop(lrImage, hrImage)
(lrImage, hrImage) = random_flip(lrImage, hrImage)
(lrImage, hrImage) = random_rotate(lrImage, hrImage)
# reshape the low and high resolution images
lrImage = tf.reshape(lrImage, (24, 24, 3))
hrImage = tf.reshape(hrImage, (96, 96, 3))
# return the low and high resolution images
return (lrImage, hrImage)
使用我们之前创建的函数,我们将数据扩充应用于我们的示例图像集(行 93-95 )。
一旦我们的图像被增强,我们就将图像重新整形为我们需要的输入和输出大小(行 98 和 99 )。
def read_test_example(example):
# get the feature template and parse a single image according to
# the feature template
feature = {
"lr": FixedLenFeature([], tf.string),
"hr": FixedLenFeature([], tf.string),
}
example = parse_single_example(example, feature)
# parse the low and high resolution images
lrImage = parse_tensor(example["lr"], out_type=tf.uint8)
hrImage = parse_tensor(example["hr"], out_type=tf.uint8)
# center crop both low and high resolution image
(lrImage, hrImage) = get_center_crop(lrImage, hrImage)
# reshape the low and high resolution images
lrImage = tf.reshape(lrImage, (24, 24, 3))
hrImage = tf.reshape(hrImage, (96, 96, 3))
# return the low and high resolution images
return (lrImage, hrImage)
我们创建一个类似的函数read_test_example,来读取一个推理图像集。从先前创建的read_train_example开始重复所有步骤。例外的是,由于这是为了我们的推断,我们不对数据进行任何扩充(**行 104-125** )。
def load_dataset(filenames, batchSize, train=False):
# get the TFRecords from the filenames
dataset = tf.data.TFRecordDataset(filenames,
num_parallel_reads=AUTO)
# check if this is the training dataset
if train:
# read the training examples
dataset = dataset.map(read_train_example,
num_parallel_calls=AUTO)
# otherwise, we are working with the test dataset
else:
# read the test examples
dataset = dataset.map(read_test_example,
num_parallel_calls=AUTO)
# batch and prefetch the data
dataset = (dataset
.shuffle(batchSize)
.batch(batchSize)
.repeat()
.prefetch(AUTO)
)
# return the dataset
return dataset
我们的数据处理管道脚本中的最后一个函数是load_dataset ( 第 127 行),它接受以下参数:
filenames:正在考虑的文件的名称batchSize:定义一次要考虑的批量train:告诉我们模式是否设置为训练的布尔变量
在的第 129 行,我们使用tf.data从文件名中获取TFRecords。
如果模式设置为train,我们将read_train_example函数映射到我们的数据集(第 133-136 行)。这意味着数据集中的所有记录都通过该函数传递。
如果模式设置为其他,我们将read_test_example函数映射到我们的数据集(第 138-141 行)。
我们的最后一步是批处理和预取数据集(行 144-149 )。
实现 SRGAN 损耗功能
尽管我们的实际损失计算将在以后进行,但是一个简单的实用脚本来存储损失函数将有助于更好地组织我们的项目。因为我们不需要写损失的数学方程(TensorFlow 会替我们写),我们只需要调用所需的包。
为此,让我们转到位于pyimagesearch目录中的losses.py脚本。
# import necessary packages
from tensorflow.keras.losses import MeanSquaredError
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.losses import Reduction
from tensorflow import reduce_mean
class Losses:
def __init__(self, numReplicas):
self.numReplicas = numReplicas
def bce_loss(self, real, pred):
# compute binary cross entropy loss without reduction
BCE = BinaryCrossentropy(reduction=Reduction.NONE)
loss = BCE(real, pred)
# compute reduced mean over the entire batch
loss = reduce_mean(loss) * (1\. / self.numReplicas)
# return reduced bce loss
return loss
创建一个专门用于损失的完整类(行 7 )。我们首先在第 11 行定义二元交叉熵损失函数,它接受真实值和预测值。
创建一个二元交叉熵对象,并计算损失(第 13 行和第 14 行)。然后计算整批的损失(第 17 行)。
def mse_loss(self, real, pred):
# compute mean squared error loss without reduction
MSE = MeanSquaredError(reduction=Reduction.NONE)
loss = MSE(real, pred)
# compute reduced mean over the entire batch
loss = reduce_mean(loss) * (1\. / self.numReplicas)
# return reduced mse loss
return loss
接下来,定义线 22 上的均方误差损失函数。创建一个 MSE 对象,并计算损失(第 24 和 25 行)。
正如在前面的函数中所做的,我们计算整批的损失并返回它(第 28-31 行)。
实现 SRGAN
为了开始实现 SRGAN 架构,让我们转到位于pyimagesearch目录中的srgan.py。
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import GlobalAvgPool2D
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Rescaling
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import PReLU
from tensorflow.keras.layers import Add
from tensorflow.nn import depth_to_space
from tensorflow.keras import Model
from tensorflow.keras import Input
class SRGAN(object):
@staticmethod
def generator(scalingFactor, featureMaps, residualBlocks):
# initialize the input layer
inputs = Input((None, None, 3))
xIn = Rescaling(scale=(1.0 / 255.0), offset=0.0)(inputs)
为了包含我们的生成器和鉴别器,我们创建了一个名为SRGAN ( 第 14 行)的类。
首先,我们在第 16 行上定义我们的生成器函数,它接受以下参数:
- 需要得到我们最终的升级输出。
featureMaps:决定我们想要的卷积滤波器的数量。residualBlocks:决定我们想要的剩余连接块数。
在的第 18 行和第 19 行,我们定义了生成器的输入,并将像素重新缩放到0和1的范围。
# pass the input through CONV => PReLU block
xIn = Conv2D(featureMaps, 9, padding="same")(xIn)
xIn = PReLU(shared_axes=[1, 2])(xIn)
# construct the "residual in residual" block
x = Conv2D(featureMaps, 3, padding="same")(xIn)
x = BatchNormalization()(x)
x = PReLU(shared_axes=[1, 2])(x)
x = Conv2D(featureMaps, 3, padding="same")(x)
x = BatchNormalization()(x)
xSkip = Add()([xIn, x])
我们首先将输入通过Conv2D层和一个参数化 ReLU 层(行 22 和 23 )。
接下来,我们建立一个基础剩余块网络。一个Conv2D层,一个批处理规范化层,接着是一个参数化 ReLU 层,Conv2D层,和另一个批处理规范化层(第 26-30 行)。
这里的最后一步是将我们的输入xIn与剩余块输出x相加,以完成剩余块网络(行 31 )。
# create a number of residual blocks
for _ in range(residualBlocks - 1):
x = Conv2D(featureMaps, 3, padding="same")(xSkip)
x = BatchNormalization()(x)
x = PReLU(shared_axes=[1, 2])(x)
x = Conv2D(featureMaps, 3, padding="same")(x)
x = BatchNormalization()(x)
xSkip = Add()([xSkip, x])
# get the last residual block without activation
x = Conv2D(featureMaps, 3, padding="same")(xSkip)
x = BatchNormalization()(x)
x = Add()([xIn, x])
我们使用 for 循环来自动化剩余块条目,并且基本上重复基本剩余块的过程(行 34-40 )。
一旦在循环之外,我们在添加跳过连接(第 43-45 行)之前添加最后的Conv2D和批处理规范化层。
# upscale the image with pixel shuffle
x = Conv2D(featureMaps * (scalingFactor // 2), 3, padding="same")(x)
x = depth_to_space(x, 2)
x = PReLU(shared_axes=[1, 2])(x)
# upscale the image with pixel shuffle
x = Conv2D(featureMaps * scalingFactor, 3,
padding="same")(x)
x = depth_to_space(x, 2)
x = PReLU(shared_axes=[1, 2])(x)
# get the output and scale it from [-1, 1] to [0, 255] range
x = Conv2D(3, 9, padding="same", activation="tanh")(x)
x = Rescaling(scale=127.5, offset=127.5)(x)
# create the generator model
generator = Model(inputs, x)
# return the generator
return generator
我们的输入通过一个Conv2D层,在那里比例因子值开始起作用(行 48 )。
depth_to_space函数是 TensorFlow 提供的一个漂亮的实用函数,它重新排列我们输入的像素,通过减少通道值来扩展它们的高度和宽度( Line 49 )。
之后是参数ReLU函数,之后是重复的Conv2D、depth_to_space和另一个参数ReLU函数(第 50-56 行)。
注意线 59 上的Conv2D功能将tanh作为其激活功能。这意味着特征地图的值现在被缩放到-1和1的范围。我们使用Rescaling ( 第 60 行)重新调整数值,并使像素回到 0 到 255 的范围内。
这就结束了我们的生成器,所以我们简单地初始化生成器并返回它(第 63-66 行)。
@staticmethod
def discriminator(featureMaps, leakyAlpha, discBlocks):
# initialize the input layer and process it with conv kernel
inputs = Input((None, None, 3))
x = Rescaling(scale=(1.0 / 127.5), offset=-1.0)(inputs)
x = Conv2D(featureMaps, 3, padding="same")(x)
# unlike the generator we use leaky relu in the discriminator
x = LeakyReLU(leakyAlpha)(x)
# pass the output from previous layer through a CONV => BN =>
# LeakyReLU block
x = Conv2D(featureMaps, 3, padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(leakyAlpha)(x)
我们继续讨论鉴别器,为此我们在第 69 行的上定义了一个函数。它接受以下参数:
featureMaps:决定一个Conv2D层内的滤镜数量。leakyAlpha:提供给泄漏ReLU激活函数的值,discBlocks:要添加到架构内部的鉴别器块的数量。
首先定义鉴频器的输入。然后,将像素重新缩放到范围-1到1 ( 行 71 和 72 )。接下来是在第 73-76 条线上的Conv2D层和LeakyReLU激活层。
接下来,我们创建一个 3 层的组合:第Conv2D层,接着是批量标准化,最后是一个LeakyReLU函数(第 80-82 行)。你会发现这种组合重复了很多次。
# create a number of discriminator blocks
for i in range(1, discBlocks):
# first CONV => BN => LeakyReLU block
x = Conv2D(featureMaps * (2 ** i), 3, strides=2,
padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(leakyAlpha)(x)
# second CONV => BN => LeakyReLU block
x = Conv2D(featureMaps * (2 ** i), 3, padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(leakyAlpha)(x)
基于之前的discBlocks值,我们开始一个循环,并不断添加鉴别器块。每个鉴别器块包含重复两次的Conv2D → BatchNormalization → LeakyReLU组合(第 85-95 行)。
# process the feature maps with global average pooling
x = GlobalAvgPool2D()(x)
x = LeakyReLU(leakyAlpha)(x)
# final FC layer with sigmoid activation function
x = Dense(1, activation="sigmoid")(x)
# create the discriminator model
discriminator = Model(inputs, x)
# return the discriminator
return discriminator
在循环之外,我们添加一个全局平均池层,然后是另一个LeakyReLU激活函数(第 98 行和第 99 行)。
由于鉴别器给我们关于输入真实性的信息,我们网络的最后一层是具有 sigmoid 激活函数的Dense层(行 102 )。
执行 SRGAN 训练脚本
正如本博客开头所解释的,SRGAN 训练需要同时进行两次损失;VGG 含量的损失以及 GAN 的损失。让我们转到pyimagesearch目录中的srgan_training脚本。
# import the necessary packages
from tensorflow.keras import Model
from tensorflow import GradientTape
from tensorflow import concat
from tensorflow import zeros
from tensorflow import ones
import tensorflow as tf
class SRGANTraining(Model):
def __init__(self, generator, discriminator, vgg, batchSize):
super().__init__()
# initialize the generator, discriminator, vgg model, and
# the global batch size
self.generator = generator
self.discriminator = discriminator
self.vgg = vgg
self.batchSize = batchSize
为了让我们的生活更轻松,我们已经在线 9 创建了一个 SRGAN 培训课程。
这个类的__init__函数接受以下参数(第 10 行):
generator:SRGAN 的发电机discriminator:SRGAN 的鉴别器vgg:用于内容丢失的 VGG 网络batchSize:训练时使用的批量
在第行第 14-17 行,我们简单地通过将类的生成器、鉴别器、VGG 和批处理大小值赋给参数来初始化它们。
def compile(self, gOptimizer, dOptimizer, bceLoss, mseLoss):
super().compile()
# initialize the optimizers for the generator
# and discriminator
self.gOptimizer = gOptimizer
self.dOptimizer = dOptimizer
# initialize the loss functions
self.bceLoss = bceLoss
self.mseLoss = mseLoss
在第 19 行的上,我们定义了 SRGAN 的compile函数。它接受以下参数:
gOptimizer:发电机优化器dOptimzer:鉴别器的优化器bceLoss:二元交叉熵损失mseLoss:均方误差损失
该函数的其余部分初始化相应的类变量(第 23-28 行)。
def train_step(self, images):
# grab the low and high resolution images
(lrImages, hrImages) = images
lrImages = tf.cast(lrImages, tf.float32)
hrImages = tf.cast(hrImages, tf.float32)
# generate super resolution images
srImages = self.generator(lrImages)
# combine them with real images
combinedImages = concat([srImages, hrImages], axis=0)
# assemble labels discriminating real from fake images where
# label 0 is for predicted images and 1 is for original high
# resolution images
labels = concat(
[zeros((self.batchSize, 1)), ones((self.batchSize, 1))],
axis=0)
在第 30 行的上,我们定义了train_step,它接受训练图像作为它的参数。
我们继续对图像进行解压缩,并将它们转换成float类型(第 32-34 行)。
将低分辨率图像通过发生器,我们获得我们的假超分辨率图像。这些与线 40 上的真实超分辨率图像相结合。
对于我们的鉴别器训练,我们必须为这组组合图像创建标签。生成器生成的假图像将有一个标签0,而真正的高分辨率图像将有一个标签1 ( 第 45-47 行)。
# train the discriminator
with GradientTape() as tape:
# get the discriminator predictions
predictions = self.discriminator(combinedImages)
# compute the loss
dLoss = self.bceLoss(labels, predictions)
# compute the gradients
grads = tape.gradient(dLoss,
self.discriminator.trainable_variables)
# optimize the discriminator weights according to the
# gradients computed
self.dOptimizer.apply_gradients(
zip(grads, self.discriminator.trainable_variables)
)
# generate misleading labels
misleadingLabels = ones((self.batchSize, 1))
为了训练鉴别器,打开GradientTape进行反向传播(线路 50 )。
组合图像集通过用于预测的鉴别器(行 52 )。使用bceLoss,我们通过将它们与标签(第 55 行)进行比较来计算鉴频器损耗。
我们计算梯度并根据梯度优化权重(行 58-65 )。
为了计算发电机重量,我们必须将发电机生成的图像标记为真实图像(行 68 )。
# train the generator (note that we should *not* update the
# weights of the discriminator)!
with GradientTape() as tape:
# get fake images from the generator
fakeImages = self.generator(lrImages)
# get the prediction from the discriminator
predictions = self.discriminator(fakeImages)
# compute the adversarial loss
gLoss = 1e-3 * self.bceLoss(misleadingLabels, predictions)
# compute the normalized vgg outputs
srVgg = tf.keras.applications.vgg19.preprocess_input(
fakeImages)
srVgg = self.vgg(srVgg) / 12.75
hrVgg = tf.keras.applications.vgg19.preprocess_input(
hrImages)
hrVgg = self.vgg(hrVgg) / 12.75
# compute the perceptual loss
percLoss = self.mseLoss(hrVgg, srVgg)
# calculate the total generator loss
gTotalLoss = gLoss + percLoss
# compute the gradients
grads = tape.gradient(gTotalLoss,
self.generator.trainable_variables)
# optimize the generator weights with the computed gradients
self.gOptimizer.apply_gradients(zip(grads,
self.generator.trainable_variables)
)
# return the generator and discriminator losses
return {"dLoss": dLoss, "gTotalLoss": gTotalLoss,
"gLoss": gLoss, "percLoss": percLoss}
在线 72 上,我们为发电机启动另一个GradientTape。
在行 74 上,我们从通过生成器的低分辨率图像生成假的高分辨率图像。
这些假图像通过鉴别器得到我们的预测。将这些预测与误导标签进行比较,以在第 80 行第 80 行得到我们的二元交叉熵损失。
对于内容损失,我们通过 VGG 网传递假的超分辨率图像和实际的高分辨率图像,并使用我们的均方损失函数对它们进行比较(第 83-91 行)。
如前所述,发电机总损耗为发电损耗和容量损耗之和(行 94 )。
接下来,我们计算生成器的梯度并应用它们(第 97-103 行)。
我们的 SRGAN 培训模块到此结束。
实现最终的实用脚本
正如您可以从srgan_training脚本中发现的,我们使用了一些助手脚本。在评估我们的产出之前,让我们快速浏览一遍。
首先,让我们转到位于pyimagesearch目录中的vgg.py脚本。
# import the necessary packages
from tensorflow.keras.applications import VGG19
from tensorflow.keras import Model
class VGG:
@staticmethod
def build():
# initialize the pre-trained VGG19 model
vgg = VGG19(input_shape=(None, None, 3), weights="imagenet",
include_top=False)
# slicing the VGG19 model till layer #20
model = Model(vgg.input, vgg.layers[20].output)
# return the sliced VGG19 model
return model
在里面,我们在第 5 行的上定义了一个名为VGG的类。在行第 7** 定义的构建函数使用tensorflow包来调用一个预训练的VGG模型,并用它来处理我们的内容丢失(行第 9-16 行)。**
在培训结束前,我们还有一个脚本要检查。为了帮助评估我们的输出图像,我们创建了一个放大脚本。为此,让我们转到位于pyimagesearch目录中的utils.py。
# import the necessary packages
from . import config
from matplotlib.pyplot import subplots
from matplotlib.pyplot import savefig
from matplotlib.pyplot import title
from matplotlib.pyplot import xticks
from matplotlib.pyplot import yticks
from matplotlib.pyplot import show
from tensorflow.keras.preprocessing.image import array_to_img
from mpl_toolkits.axes_grid1.inset_locator import zoomed_inset_axes
from mpl_toolkits.axes_grid1.inset_locator import mark_inset
import os
# the following code snippet has been taken from:
# https://keras.io/examples/vision/super_resolution_sub_pixel
def zoom_into_images(image, imageTitle):
# create a new figure with a default 111 subplot.
(fig, ax) = subplots()
im = ax.imshow(array_to_img(image[::-1]), origin="lower")
title(imageTitle)
# zoom-factor: 2.0, location: upper-left
axins = zoomed_inset_axes(ax, 2, loc=2)
axins.imshow(array_to_img(image[::-1]), origin="lower")
# specify the limits.
(x1, x2, y1, y2) = 20, 40, 20, 40
# apply the x-limits.
axins.set_xlim(x1, x2)
# apply the y-limits.
axins.set_ylim(y1, y2)
# remove the xticks and yticks
yticks(visible=False)
xticks(visible=False)
# make the line.
mark_inset(ax, axins, loc1=1, loc2=3, fc="none", ec="blue")
# build the image path and save it to disk
imagePath = os.path.join(config.BASE_IMAGE_PATH,
f"{imageTitle}.png")
savefig(imagePath)
# show the image
show()
我们在第 16 行的上实现我们的zoom_into_images函数。它接受图像和图像标题作为参数。
在第 18 行定义了多个图的子图。图像绘制在线 19** 处。在的第 21-24 行,我们绘制了相同的图像,但是放大了一个特定的补丁以供参考。**
在第 26-31 行,我们指定图像的x和y坐标限制。
该函数的其余部分涉及一些修饰,如删除记号、添加线条,并将图像保存到我们的输出路径(第 34-46 行)。
训练 SRGAN
完成所有必需的脚本后,最后一步是执行培训流程。为此,让我们进入根目录中的train_srgan.py脚本。
# USAGE
# python train_srgan.py --device tpu
# python train_srgan.py --device gpu
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch.data_preprocess import load_dataset
from pyimagesearch.srgan import SRGAN
from pyimagesearch.vgg import VGG
from pyimagesearch.srgan_training import SRGANTraining
from pyimagesearch import config
from pyimagesearch.losses import Losses
from tensorflow import distribute
from tensorflow.config import experimental_connect_to_cluster
from tensorflow.tpu.experimental import initialize_tpu_system
from tensorflow.keras.optimizers import Adam
from tensorflow.io.gfile import glob
import argparse
import sys
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("--device", required=True, default="gpu",
choices=["gpu", "tpu"], type=str,
help="device to use for training (gpu or tpu)")
args = vars(ap.parse_args())
创建一个参数解析器来接收来自用户的设备选择输入(行 26-30 )。
# check if we are using TPU, if so, initialize the TPU strategy
if args["device"] == "tpu":
# initialize the TPUs
tpu = distribute.cluster_resolver.TPUClusterResolver()
experimental_connect_to_cluster(tpu)
initialize_tpu_system(tpu)
strategy = distribute.TPUStrategy(tpu)
# ensure the user has entered a valid gcs bucket path
if config.TPU_BASE_TFR_PATH == "gs://<PATH_TO_GCS_BUCKET>/tfrecord":
print("[INFO] not a valid GCS Bucket path...")
sys.exit(0)
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for TPU training
tfrTrainPath = config.TPU_DIV2K_TFR_TRAIN_PATH
pretrainedGenPath = config.TPU_PRETRAINED_GENERATOR_MODEL
genPath = config.TPU_GENERATOR_MODEL
# otherwise, we are using multi/single GPU so initialize the mirrored
# strategy
elif args["device"] == "gpu":
# define the multi-gpu strategy
strategy = distribute.MirroredStrategy()
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for GPU training
tfrTrainPath = config.GPU_DIV2K_TFR_TRAIN_PATH
pretrainedGenPath = config.GPU_PRETRAINED_GENERATOR_MODEL
genPath = config.GPU_GENERATOR_MODEL
# else, invalid argument was provided as input
else:
# exit the program
print("[INFO] please enter a valid device argument...")
sys.exit(0)
由于我们可以用 TPU 或 GPU 来训练 SRGAN,因此我们会做出相应的安排。
我们的第一种情况是,如果device被设置为tpu,我们初始化 TPU 训练的要求(第 33-43 行):
TPUClusterResolver:与集群管理系统(AWS、GCP 等)进行高效通信。)- 为有效的 TPU 培训初始化正确的策略。
接下来,我们设置训练TFRecords路径、预训练生成器路径和最终生成器路径(第 47-49 行)。
如果device被设置为gpu,我们将训练策略设置为在多个 GPU 上镜像(第 53-55 行)。
定义了 GPU TFRecords路径、预训练生成器和最终生成器路径(第 59-61 行)。注意在每种情况下,这些变量是如何被排斥在案例本身之外的(例如,GPU_GENERATOR_MODEL或TPU_GENERATOR_MODEL)。
如果用户既没有给出gpu也没有给出tpu选择,程序简单地退出(第 64-67 行)。
# display the number of accelerators
print("[INFO] number of accelerators: {}..."
.format(strategy.num_replicas_in_sync))
# grab train TFRecord filenames
print("[INFO] grabbing the train TFRecords...")
trainTfr = glob(tfrTrainPath +"/*.tfrec")
# build the div2k datasets from the TFRecords
print("[INFO] creating train and test dataset...")
trainDs = load_dataset(filenames=trainTfr, train=True,
batchSize=config.TRAIN_BATCH_SIZE * strategy.num_replicas_in_sync)
# call the strategy scope context manager
with strategy.scope():
# initialize our losses class object
losses = Losses(numReplicas=strategy.num_replicas_in_sync)
# initialize the generator, and compile it with Adam optimizer and
# MSE loss
generator = SRGAN.generator(
scalingFactor=config.SCALING_FACTOR,
featureMaps=config.FEATURE_MAPS,
residualBlocks=config.RESIDUAL_BLOCKS)
generator.compile(
optimizer=Adam(learning_rate=config.PRETRAIN_LR),
loss=losses.mse_loss)
# pretraining the generator
print("[INFO] pretraining SRGAN generator...")
generator.fit(trainDs, epochs=config.PRETRAIN_EPOCHS,
steps_per_epoch=config.STEPS_PER_EPOCH)
在的第 70-80 行,我们从TFRecords构建div2k数据集。调用策略范围,我们从损失对象初始化损失函数(第 83-85 行)。
然后,使用我们的config.py脚本中的值初始化生成器,并用Adam优化器进行编译(第 89-95 行)。
为了获得更好的结果,我们在线 99 和 100 上对发电机网络进行了预处理。
# check whether output model directory exists, if it doesn't, then
# create it
if args["device"] == "gpu" and not os.path.exists(config.BASE_OUTPUT_PATH):
os.makedirs(config.BASE_OUTPUT_PATH)
# save the pretrained generator
print("[INFO] saving the SRGAN pretrained generator to {}..."
.format(pretrainedGenPath))
generator.save(pretrainedGenPath)
# call the strategy scope context manager
with strategy.scope():
# initialize our losses class object
losses = Losses(numReplicas=strategy.num_replicas_in_sync)
# initialize the vgg network (for perceptual loss) and discriminator
# network
vgg = VGG.build()
discriminator = SRGAN.discriminator(
featureMaps=config.FEATURE_MAPS,
leakyAlpha=config.LEAKY_ALPHA, discBlocks=config.DISC_BLOCKS)
# build the SRGAN training model and compile it
srgan = SRGANTraining(
generator=generator,
discriminator=discriminator,
vgg=vgg,
batchSize=config.TRAIN_BATCH_SIZE)
srgan.compile(
dOptimizer=Adam(learning_rate=config.FINETUNE_LR),
gOptimizer=Adam(learning_rate=config.FINETUNE_LR),
bceLoss=losses.bce_loss,
mseLoss=losses.mse_loss,
)
# train the SRGAN model
print("[INFO] training SRGAN...")
srgan.fit(trainDs, epochs=config.FINETUNE_EPOCHS,
steps_per_epoch=config.STEPS_PER_EPOCH)
# save the SRGAN generator
print("[INFO] saving SRGAN generator to {}...".format(genPath))
srgan.generator.save(genPath)
在行 104 和 105 上,我们检查我们的输出的输出路径是否存在。如果没有,我们创建一个。
一旦保存了预训练的生成器,我们就调用策略范围并再次初始化 loss 对象(第 110-115 行)。
由于我们将需要VGG网络来处理我们的内容丢失,我们初始化了一个VGG网络和鉴别器,后者的值在config.py脚本中(第 119-122 行)。
既然已经创建了生成器和鉴别器,我们就直接使用了SRGANTraining对象并编译了我们的 SRGAN 模型(第 125-135 行)。
初始化的 SRGAN 与启动训练的数据相匹配,然后保存训练的 SRGAN(行 139-144 )
为 SRGAN 创建推理脚本
我们的训练结束了,让我们看看结果吧!为此,我们将转向inference.py脚本。
# USAGE
# python inference.py --device gpu
# python inference.py --device tpu
# import the necessary packages
from pyimagesearch.data_preprocess import load_dataset
from pyimagesearch.utils import zoom_into_images
from pyimagesearch import config
from tensorflow import distribute
from tensorflow.config import experimental_connect_to_cluster
from tensorflow.tpu.experimental import initialize_tpu_system
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.io.gfile import glob
from matplotlib.pyplot import subplots
import argparse
import sys
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("--device", required=True, default="gpu",
choices=["gpu", "tpu"], type=str,
help="device to use for training (gpu or tpu)")
args = vars(ap.parse_args())
正如在训练脚本中所做的,我们需要创建另一个参数解析器,它从用户那里接受设备(TPU 或 GPU)的选择(行 21-25 )。
# check if we are using TPU, if so, initialize the strategy
# accordingly
if args["device"] == "tpu":
# initialize the tpus
tpu = distribute.cluster_resolver.TPUClusterResolver()
experimental_connect_to_cluster(tpu)
initialize_tpu_system(tpu)
strategy = distribute.TPUStrategy(tpu)
# ensure the user has entered a valid gcs bucket path
if config.TPU_BASE_TFR_PATH == "gs://<PATH_TO_GCS_BUCKET>/tfrecord":
print("[INFO] not a valid GCS Bucket path...")
sys.exit(0)
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for TPU training
tfrTestPath = config.TPU_DIV2K_TFR_TEST_PATH
pretrainedGenPath = config.TPU_PRETRAINED_GENERATOR_MODEL
genPath = config.TPU_GENERATOR_MODEL
# otherwise, we are using multi/single GPU so initialize the mirrored
# strategy
elif args["device"] == "gpu":
# define the multi-gpu strategy
strategy = distribute.MirroredStrategy()
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for GPU training
tfrTestPath = config.GPU_DIV2K_TFR_TEST_PATH
pretrainedGenPath = config.GPU_PRETRAINED_GENERATOR_MODEL
genPath = config.GPU_GENERATOR_MODEL
# else, invalid argument was provided as input
else:
# exit the program
print("[INFO] please enter a valid device argument...")
sys.exit(0)
下一步同样与训练步骤相同。根据设备的选择,我们初始化集群(用于 TPU)、策略(用于 GPU 和 TPU)和路径,同时为脚本设置退出子句(第 27-63 行)。
# get the dataset
print("[INFO] loading the test dataset...")
testTfr = glob(tfrTestPath + "/*.tfrec")
testDs = load_dataset(testTfr, config.INFER_BATCH_SIZE, train=False)
# get the first batch of testing images
(lrImage, hrImage) = next(iter(testDs))
# call the strategy scope context manager
with strategy.scope():
# load the SRGAN trained models
print("[INFO] loading the pre-trained and fully trained SRGAN model...")
srganPreGen = load_model(pretrainedGenPath, compile=False)
srganGen = load_model(genPath, compile=False)
# predict using SRGAN
print("[INFO] making predictions with pre-trained and fully trained SRGAN model...")
srganPreGenPred = srganPreGen.predict(lrImage)
srganGenPred = srganGen.predict(lrImage)
在第 67 行和第 68 行,我们获得了用于推理的数据集。
使用next(iter()),我们得到第一批测试图像(第 71 行)。接下来,预训练的 SRGAN 和完全训练的 SRGAN 模型权重被加载和初始化,第一个低分辨率图像通过它们(第 74-83 行)。
# plot the respective predictions
print("[INFO] plotting the SRGAN predictions...")
(fig, axes) = subplots(nrows=config.INFER_BATCH_SIZE, ncols=4,
figsize=(50, 50))
# plot the predicted images from low res to high res
for (ax, lowRes, srPreIm, srGanIm, highRes) in zip(axes, lrImage,
srganPreGenPred, srganGenPred, hrImage):
# plot the low resolution image
ax[0].imshow(array_to_img(lowRes))
ax[0].set_title("Low Resolution Image")
# plot the pretrained SRGAN image
ax[1].imshow(array_to_img(srPreIm))
ax[1].set_title("SRGAN Pretrained")
# plot the SRGAN image
ax[2].imshow(array_to_img(srGanIm))
ax[2].set_title("SRGAN")
# plot the high resolution image
ax[3].imshow(array_to_img(highRes))
ax[3].set_title("High Resolution Image")
在第 87 和 88 行上,我们初始化子情节。然后,循环子图的列,我们绘制低分辨率图像、SRGAN 预训练结果、完全 SRGAN 超分辨率图像和原始高分辨率图像(第 91-107 行)。
# check whether output image directory exists, if it doesn't, then
# create it
if not os.path.exists(config.BASE_IMAGE_PATH):
os.makedirs(config.BASE_IMAGE_PATH)
# serialize the results to disk
print("[INFO] saving the SRGAN predictions to disk...")
fig.savefig(config.GRID_IMAGE_PATH)
# plot the zoomed in images
zoom_into_images(srganPreGenPred[0], "SRGAN Pretrained")
zoom_into_images(srganGenPred[0], "SRGAN")
如果输出图像的目录还不存在,我们就创建一个用于存储输出图像的目录(行 111 和 112 )。
我们保存该图并绘制输出图像的放大版本(行 116-120 )。
SRGAN 的训练和可视化
让我们来看看我们训练过的 SRGAN 的一些图像。图 4-7 显示了在 TPU 和 GPU 上训练的 SRGANs 的输出。
我们可以清楚地看到,经过完全训练的 SRGAN 输出比未经训练的 SRGAN 输出显示出更多的细节。
汇总
SRGANs 通过将传统 GAN 元素与旨在提高视觉性能的配方相结合,非常巧妙地实现了更好的图像超分辨率效果。
与以前的工作相比,输出的像素比较的简单增加给了我们明显更强的结果。然而,由于 GANs 本质上是试图重新创建数据,使其看起来像是属于训练分布,因此需要大量的计算能力来实现这一点。SRGANs 可以帮助你实现你的目标,但是问题是你必须准备好大量的计算能力。
引用信息
Chakraborty,D. 【超分辨率生成对抗网络(SRGAN)】PyImageSearch,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki 合编。,2022 年,https://pyimg.co/lgnrx
@incollection{Chakraborty_2022_SRGAN,
author = {Devjyoti Chakraborty},
title = {Super-Resolution Generative Adversarial Networks {(SRGAN)}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/lgnrx},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
目录:使用 Python 进行计算机视觉的深度学习

几天前我提到在1 月 18 日星期三上午 10 点我将启动 Kickstarter 来资助我的新书——用 Python 进行计算机视觉的深度学习。
正如你将在这篇文章的后面看到的,我将会涵盖大量的内容,所以我决定将这本书分成三册【捆绑】。
*一个 包 包括给定卷的电子书、视频教程和源代码。
每个包建立在其他包和的基础上,包括来自较低包的所有内容。你应该根据你对深度学习和计算机视觉的研究深度来选择捆绑包:
- Starter Bundle: 非常适合那些向深度学习迈出第一步以掌握图像分类的人。
- 从业者捆绑包:非常适合准备深入学习深度学习、了解先进技术、发现常见最佳实践和经验法则的读者。
- ImageNet Bundle:完成计算机视觉体验的深度学习。在这个包中,我演示了如何在大规模 ImageNet 数据集上从头开始训练大规模神经网络。你不能打败这个包。
下一节列出了每个包的完整的目录。
起始捆绑包
入门包包括以下主题:
机器学习基础
迈出第一步:
- 了解如何设置和配置您的开发环境来研究深度学习。
- 了解图像基础知识,包括坐标系;宽度、高度、深度;和长宽比。
- 回顾用于测试机器学习、深度学习和卷积神经网络算法的流行图像数据集。
形成对机器学习基础知识的扎实理解,包括:
- 简单的 k-NN 分类器。
- 参数化学习(即“从数据中学习”)
- 数据和特征向量。
- 了解评分功能。
- 损失函数的工作原理。
- 定义权重矩阵和偏差向量(以及它们如何促进学习)。
通过学习基本的优化方法(即“学习”实际上是如何进行的)
- 梯度下降
- 随机梯度下降
- 分批随机梯度下降
神经网络基础
发现前馈网络架构:
- 手工实现经典感知器算法。
- 使用感知器算法学习实际的函数(并理解感知器算法的局限性)。
- 取一个 深入潜 进入 反向传播算法 。
- 用 Python + NumPy 手工实现反向传播。
- 利用工作表来帮助你练习反向传播算法。
- 掌握多层网络(并从头开始训练)。
- 用手工和 Keras 库实现神经网络。
卷积神经网络简介
从卷积的基础开始:
- 理解卷积(以及为什么它们比看起来容易理解)。
- 研究卷积神经网络(它们是用来做什么的,为什么它们对图像分类如此有效等等。).
- 从头开始训练你的第一个卷积神经网络。
回顾卷积神经网络的构建模块,包括:
- 卷积层
- 激活层
- 池层
- 批量标准化
- 拒绝传统社会的人
揭示通用架构和培训模式:
- 发现通用的网络体系结构模式,您可以使用这些模式来设计自己的体系结构,从而最大限度地减少挫折和麻烦。
- 利用现成的 CNN 进行分类,这些 CNN 已经过预训练并准备好应用于您自己的图像/图像数据集(VGG16、VGG19、ResNet50 等)。)
- 从磁盘保存和加载您自己的网络模型。
- 检查您的模型,发现高性能的时代,并重新开始训练。
- 了解如何发现欠拟合和过拟合,从而允许您纠正它们并提高分类精度。
- 利用衰减和学习率调度程序。
- 从零开始训练经典的 LeNet 架构来识别手写数字。
使用您自己的自定义数据集
使用自定义数据集+深度学习很简单:
- 了解如何收集您自己的培训图像。
- 了解如何注释和标注数据集。
- 在数据集的基础上从头开始训练一个卷积神经网络。
- 评估你的模型的准确性。
- 所有这些都通过演示如何收集、注释和训练 CNN 破解图像验证码来解释。
从业者捆绑包
从业者捆绑包括起步者捆绑中的 一切 。它还包括以下主题。
高级卷积神经网络
了解如何使用将学习转移到:
- 将预先训练的网络视为特征提取器,以不费吹灰之力获得高分类精度。
- 利用微调来提高预训练网络的准确性。
- 应用数据扩充来提高网络分类的准确性,而无需收集更多的训练数据。
使用更深层次的网络架构:
- 编写开创性的 AlexNet 架构。
- 实现 VGGNet 架构(以及的变体)。
探索更高级的优化算法,包括:
- RMSprop
- 阿达格拉德
- 阿达德尔塔
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
- 阿达马斯
- 那达慕
- …以及微调 SGD 参数的最佳实践。
提升网络性能的最佳实践
揭示通用技术&提高分类准确性的最佳实践:
- 了解等级 1 和等级 5 的准确性(以及我们如何使用它们来衡量给定网络的分类能力)。
- 利用图像裁剪这种简单的方法来提高测试集的准确性。
- 探索如何简单地通过训练多个网络使用网络集成来提高分类精度。
- 发现我应用深度学习技术的最佳途径最大化分类准确性(以及以何种顺序应用这些技术来实现最大的有效性)。
缩放至大型图像数据集
处理太大而无法放入内存的数据集:
- 了解如何将图像数据集从磁盘上的原始图像转换为 HDF5 格式,从而使网络训练更容易(更快)。
- 将大型图像数据集压缩到高效打包的记录文件中。
参加深度学习挑战和比赛:
- 参加斯坦福大学的 cs231n 微型图像网络分类挑战赛……并获得第一名 。
- 在 Kaggle Dogs vs. Cats challenge 上训练一个网络,不费吹灰之力就能在 25 强排行榜中占据一席之地。
目标检测和定位
通过以下方式使用深度学习检测图像中的对象:
- 利用朴素图像金字塔和滑动窗口进行目标检测。
imagenes 包
ImageNet 捆绑包包括初学者捆绑包和实践者捆绑包中的 一切 。它还包括以下附加主题:
ImageNet:大规模视觉识别挑战
在 ImageNet 数据集上训练最先进的网络:
- 了解什么是海量ImageNet(1000 个类别)数据集以及为什么它被认为是对基准图像分类算法的事实上的挑战。
- 获取 ImageNet 数据集。
- 将 ImageNet 转换成适合培训的格式。
- 学习如何利用多个 GPU在并行、中训练你的网络,大大减少训练时间。
- 从零开始在 ImageNet 上训练 AlexNet。
- 在 ImageNet 上从头开始训练 VGGNet。
- 将 SqueezeNet 架构应用于 ImageNet 以获得(高精度)模型,完全可部署到较小的设备,如 Raspberry Pi。
ImageNet:提示、技巧和经验法则
解锁深度学习专家在 ImageNet 上使用的相同技术:
- 通过发现实际有效的 学习进度,节省数周(甚至数月)的培训时间。
- 在 ImageNet 上发现过度拟合并在之前发现它,你会浪费几个小时(或几天)看着你的验证准确性停滞不前。
- 了解如何从保存的纪元重新开始训练,降低学习率,并提高准确性。
- 发现快速调整大规模网络超参数的方法。
个案研究
探索如何解决真实世界的深度学习问题,包括:
- 使用深度学习技术训练一个网络来预测图像中人的性别和年龄。
- 使用卷积神经网络自动分类汽车类型。
- 使用 CNN 确定(并校正)图像方向。
这就是你要的——用 Python 进行计算机视觉深度学习的完整目录。我希望看完这份清单后,你会和我一样兴奋!
我也有一些秘密奖金章节,在 Kickstarter 正式发布之前我会保密——请继续关注更多细节。
当更多的 Kickstarter 通知发布时(包括我不会在这个博客上发布的通知),请务必注册 Kickstarter 通知列表!*
目录–OCR 与 OpenCV、Tesseract 和 Python
原文:https://pyimagesearch.com/2020/08/14/table-of-contents-ocr-with-opencv-tesseract-and-python/

几天前我提到在8 月 19 日星期三上午 10 点我将为我的新书 OCR 与 OpenCV、Tesseract 和 Python 发起 IndieGoGo 众筹活动。注意:活动现在已经结束了。但是你仍然可以通过点击这里来预订你的副本。)
今天我要和大家分享:
- 这本书的目录
- 关于这本书结构的更多细节
- 书中包含的内容,包括源代码、预配置的 VM、访问私人社区论坛等。
- 完成所有与文本相关的测验/考试后,您将获得结业证书
让我们开始吧!
这是什么书?

OCR 与 OpenCV、Tesseract 和 Python 将教你如何成功地将光学字符识别应用到你的工作、项目和研究中。
您将通过实际的动手项目(包含大量代码)来学习,这样您不仅可以开发自己的 OCR 项目,而且在开发过程中会感到自信。
在本书中,我们将重点关注:
- OCR 入门
- 了解 Tesseract OCR 引擎的基础知识
- 探索如何使用镶嵌选项和配置提高 OCR 准确性
- 通过 Python 编程语言与 Tesseract 接口
- 使用 OpenCV 和 Tesseract 定位和检测图像中的文本
- 利用 OpenCV 和图像处理技术提高 OCR 准确率
- 使用机器学习对我们的图像去噪以获得更好的 OCR 准确度
- 建立发票扫描项目的图像/文件登记和校准
- 用 Keras 和 TensorFlow 训练我们自己的定制深度学习模型
- 用 OCR、OpenCV 和 Keras/TensorFlow 解决数独难题
- 自动牌照/车牌识别(ANPR)
- 手写识别
- 在实时视频流中执行 OCR
- 利用 GPU 加快 OCR 推理
- 在云中使用 OCR 引擎,包括 Amazon Rekognition、微软认知服务和 Google Vison API
- 执行 OCR 时的提示、建议和最佳实践
目前我已经计划了 35 章以上的章节,还会有更多!
这本书的结构是怎样的?
因为我们将深入讨论这么多 OCR 技术,所以我决定将这本书分成三册称为“捆绑”。****

我在下面列出了三个包的简短分类:


“OCR 简介”捆绑包适合您,如果:
- 你是 OCR 和计算机视觉领域的新手
- 你只是在测试 OCR 水域
- 你在预算之内
在这个包中,您将学习使用 Tesseract、OpenCV 和 Python 进行光学字符识别的基础知识。虽然这是最底层的捆绑包,但你仍然可以通过获得大量实践经验获得很好的教育。
本章主题的完整列表如下:
- 介绍
- 什么是光学字符识别(OCR)?
- 用于 OCR 的工具、库和包
- 安装我们的 OCR 库和工具
- 您的第一个使用宇宙魔方的 OCR 示例
- 用宇宙魔方检测数字
- 使用宇宙魔方将角色列入白名单和黑名单
- 使用 Tesseract 确定和校正文本方向
- OCR 文本并翻译成不同的语言
- 对非英语语言使用 Tesseract
- 使用 Tesseract 页面分割模式(PSM)提高 OCR 准确性
- 利用 OpenCV 和图像处理改善 OCR 结果
- 利用 OCR 进行拼写检查
- 用计算机视觉识别护照
- 使用 OpenCV 和模板匹配进行 OCR 字符识别
- 用基本的计算机视觉和图像处理来识别字符
- 文本包围盒定位和 OCR 与 Tesseract
- 用 OpenCV 实现旋转文本包围盒定位
- 完整的文本检测和 OCR 管道
- 结论
“OCR 简介”包中的章节将为您打下坚实的基础。要更深入地了解 OCR,我推荐“OCR 从业者”套装或“OCR 专家”套装。
我的建议:“OCR 简介”捆绑包是将 OCR 应用于现实项目的第一步。您将学习 OCR 和 Tesseract 的基础知识,使您能够将 OCR 应用到自己的项目中。
也就是说,如果你是计算机视觉和 OCR 领域的新手,那么你绝对应该看看实用 Python 和 OpenCV 和 PyImageSearch Gurus 插件。这两者都可以用来帮助你快速提升你的计算机视觉技能(并且在应用 OCR 时更加成功)。

“OCR 从业者”捆绑包建立在前一个捆绑包的基础上,包含了“OCR 简介”捆绑包中的每一章。该软件包面向更高级的 OCR 算法、技术和用例,包括深度学习、图像/文档对齐、实时视频流中的 OCR、使用 GPU 的 OCR、基于云的 OCR APIs、等等!
你不仅会获得“OCR 简介”捆绑包中的每一章,还会收到以下内容:
- 介绍
- 使用 Keras 和 TensorFlow 训练自定义 OCR 模型
- 使用机器学习对图像去噪以获得更好的 OCR 准确度
- 图像和文档注册
- 自动校准和识别文件、发票、表格等。
- 使用 OCR 构建 OpenCV 数独求解器
- 光学字符识别收据
- 使用 OCR 自动识别牌照/车牌
- 文本模糊检测
- OCR 实时视频流
- 利用 OpenCV 和 GPU 提高文本检测速度
- 手写识别
- 使用 Amazon Rekognition API 进行文本检测和 OCR
- 使用 Microsoft 认知服务 API 进行 OCR
- 使用 Google Vision API 进行 OCR
- 培训自定义立方体 OCR 模型
- 微调 Tesseract OCR 模型
- 利用 EasyOCR 软件包实现快速、高效的 OCR
- 结论
我的推荐:“OCR 从业者捆绑包”给你最好的回报。如果您想要对 OCR 进行超级深入的处理,但是负担不起“OCR 专家”软件包,您应该选择这个软件包。
如果你是计算机视觉和深度学习的新手,我强烈建议你还可以获得 PyImageSearch Gurus 和/或 带有 Python 插件的计算机视觉深度学习——这两种资源都将快速教会你计算机视觉和深度学习(确保你从购买 OCR 书籍中获得更多价值)。

“OCR 专家”捆绑包包括来自“OCR 入门”捆绑包和“OCR 从业者”捆绑包的所有内容。
**它还包括:
- IndieGoGo 活动期间延伸目标的所有奖励章节(包括活动结束后创作的章节)。
- 纸质印刷版本包含 OpenCV、Tesseract 和 Python 的全部三卷OCR—这是唯一包含硬拷贝版本的捆绑包。
- 访问我的私人社区论坛获取更多帮助和支持。你的问题会得到更快、更详细的答案,你也能更好地与我和其他读者交流。(同样,另外两个捆绑包没有访问这些论坛的权限)。
- 在成功完成与课文相关的所有课程和测验后,获得结业证书。
我的建议:如果(1)你想深入学习 OCR,并且(2)你想在学习过程中获得额外的帮助和支持,你应该选择“OCR 专家”套装。说到学习光学字符识别,你就是不能打败这个包袱!
此外,“OCR 专家”套装包含一份结业证书。要获得证书,您需要完成与该文本相关的所有课程和测验。

成功完成所有课程/测验后,您将获得证书,并能够将其直接嵌入到您的 LinkedIn 个人资料中,从而展示您的光学字符识别技能。
下一步是什么?
现在,您已经有了 OpenCV、Tesseract 和 Python 的 OCR 的完整目录。我希望看完这份清单后,你会和我一样兴奋!
我也有一些秘密奖励章节可用。
如果您对 OCR 感兴趣,已经有了 OCR 项目的想法,或者您的公司需要它,请点击下面的按钮获取您的特别预购本《我的 OCR 图书》😗*
目录–用于计算机视觉的树莓 Pi
原文:https://pyimagesearch.com/2019/04/05/table-of-contents-raspberry-pi-for-computer-vision/

几天前我提到过,美国东部时间 4 月 10 日星期三上午 10 点我将在 Kickstarter 上发布我的新书《计算机视觉的 T4 树莓 Pi》。
正如你将在这篇文章的后面看到的,我将会涵盖大量的内容,所以我决定将这本书分成三册【捆绑】。
*一个 捆绑包 包含给定卷的电子书和源代码(以及一个预配置的 Raspbian。img 文件,预装所有你需要的计算机视觉+深度学习库)。
每个包都建立在其他包和的基础上,包括来自较低包的所有内容。您应该根据您希望深入学习 Pi 中的 CV 和 DL、您最感兴趣的项目/章节以及您的具体预算来选择一个组合:
- 爱好者套装:如果这是你第一次使用计算机视觉或树莓派,这是一个很好的选择。在这里,您将学习可以轻松应用于 Pi 的基本计算机视觉算法。您将构建动手应用程序,包括野生动物监视器/探测器、家庭视频监控、平移/倾斜伺服跟踪、等等!
- Hacker Bundle: 非常适合希望学习更高级技术的读者,包括深度学习、使用 Movidius NCS、OpenVINO toolkit 和自动驾驶汽车应用程序。您还将了解我的技巧、建议和在 Raspberry Pi 上应用计算机视觉时的最佳实践。
- 完整捆绑:完整的树莓派和计算机视觉体验。你可以访问书中的每一章、视频教程、文本的硬拷贝,以及访问我的私人社区和论坛以获得额外的帮助和支持。
下一节列出了每个包的完整目录。
业余爱好者包

Figure 1: Raspberry Pi for Computer Vision – Hobbyist Bundle
爱好者包包括以下主题。
使用树莓派
- 为什么是树莓派?
- 为你的树莓 Pi 配置计算机视觉+深度学习(包括所有库、包等。)
- 或者,跳过安装过程,使用我的预配置的 Raspbian。img 文件,其中带有你需要的一切预装!只是闪了一下。img 文件和引导。
- 简化您的开发流程,了解如何在 Raspberry Pi 上以最佳方式编写代码(包括建议的 ide 和推荐的设置/配置)
- 在 Pi 上访问您的 USB 网络摄像头和/或 Raspberry Pi 摄像头模块
- 使用黑色摄像头模块
- 了解如何利用树莓 Pi 的多个摄像头
树莓派计算机视觉入门
- 通过在 Pi 上创建延时视频,体验 OpenCV 和您的 Raspberry Pi 相机
- 建立一个自动喂鸟监视器,当鸟出现时进行检测
- 建立自动处方药丸识别系统(减少每年因服用错误药丸而发生的 120 万起伤亡)
- 了解如何从树莓派向您的网络浏览器传输帧
树莓派的计算机视觉和物联网项目
- 回顾在物联网应用中使用 Raspberry Pi 时的硬件考虑和建议
- 了解如何在弱光条件下工作,包括相机和算法建议
- 建造并部署一个远程野生动物监视器,能够探测野生动物并保存野生动物活动的片段
- 了解如何在 Pi 上启动/重启时自动运行您的计算机视觉应用程序
- 从 Pi 向您的手机发送文本消息(包括带有图像和视频的消息)
- 创建一个车辆交通和行人流量计数系统,能够检测和计数道路上的车辆数量/进出一个区域的人员数量
伺服和 PID
- PID 是什么?
- 了解如何使用平移/倾斜伺服跟踪来跟踪面部和物体
人类活动和家庭监控
- 建立一个基本的视频监控系统,检测人们何时进入“未授权”区域
- 将你的树莓派部署到车辆上,检测疲劳、困倦的司机(并发出警报叫醒他们)
- 建造一个自动人/脚步计数器来计算进出商店、房子等的人数。
提示、建议和最佳实践
- 了解 OpenCV 优化、包括 OpenCL 以及如何访问树莓 Pi 的所有四个内核,提升您的系统性能
- 了解我关于如何设计您自己的计算机视觉+ Raspberry Pi 应用程序以获得最佳性能的蓝图
- 使用线程和多处理提高 FPS 吞吐率
黑客捆绑包

Figure 2: Raspberry Pi for Computer Vision – Hacker Bundle
黑客捆绑包包括爱好者捆绑包中的一切。还包括以下主题。
高级计算机视觉和物联网项目与 Pi
- 将帧从 Raspberry Pi 相机传输到您的笔记本电脑、台式机或云实例,处理这些帧,然后将结果返回给 Pi
- 建立一个邻居车辆速度监视器,检测车辆,估计它们的速度,并记录司机的活动
- 通过自动识别递送卡车和检测包裹递送来减少包裹盗窃
高级人类活动和面部应用
- 扩展您的视频监控系统,以包括基于深度学习的对象检测和带注释的输出视频剪辑
- 使用多个摄像头和多个树莓派在整个房子内追踪你的家人和宠物
- 利用树莓派进行手势识别
- 在树莓 Pi 上执行人脸识别
- 创建一个智能教室和自动考勤系统,能够检测哪些学生在场(和不在场)
- 利用 TensorFlow Lite 进行人体姿态估计
对树莓派的深度学习
- 了解如何在资源受限的设备上执行深度学习
- 利用 Movidius NCS 和 OpenVINO 在树莓 Pi 上进行更快、更高效的深度学习
- 使用 Pi 上的 TinyYOLO 物体检测器进行物体检测
- 在 Raspberry Pi 上使用单次检测器(SSDs)
- 在您的 Pi 上训练和部署一个深度学习手势识别模型
- 通过培训和部署深度学习模型来减少包裹盗窃识别送货卡车
- 使用深度学习和多个树莓 pi创建一个“智能摄像机”网络
- 回顾一下我的指南和最佳实践关于何时使用 Pi CPU、Movidius NCS 或者将帧传输到更强大的系统
Movidius NCS 和 OpenVINO
- 探索 OpenVINO 如何显著提高树莓 Pi 的推理时间
- 了解如何配置和安装支持 OpenVINO 的 OpenCV
- 在您的 Raspberry Pi 上配置 Movidius NCS 开发套件
- 在您的 Pi 上使用深度学习和 Movidius NCS 对图像进行分类
- 在 Movidius NCS 上执行物体检测,以创建人员计数器和跟踪器
- 在 Raspberry Pi 上使用 Movidius NCS 创建一个人脸识别系统
- 为 NCS 训练定制 Caffe + TensorFlow 模型,并将其部署到 RPi
自动驾驶汽车应用和树莓派
- 了解 GoPiGo3 以及它如何通过 Raspberry Pi 促进无人驾驶汽车的研究
- 了解如何用树莓派驾驶您的 GoPiGo3
- 使用 GoPiGo3 和 Raspberry Pi 驾驶课程
- 用树莓派识别红绿灯
- 使用 GoPiGo3 和 Raspberry Pi 驾驶至特定物体
- 用覆盆子 Pi 创建一个线路/车道跟随器
完全捆绑

Figure 3: Raspberry Pi for Computer Vision – Complete Bundle
完整套装包括爱好者套装和黑客套装中的一切。
此外,还包括:
- 所有附加的奖励章节、指南和教程
- 每章的视频教程和演练
- 访问我的私人 Raspberry Pi 和计算机视觉社区和论坛
- 一份送到你家门口的纸质文本
谷歌珊瑚和树莓派
- 配置您的谷歌珊瑚 USB 加速器
- 使用 Google Coral 执行图像分类
- 用 Coral 创建实时物体探测器
- 使用 Coral 训练和部署您自己的定制模型
NVIDIA Jetson Nano 实践教程和指南
- 配置您的 Jetson Nano
- 用 Nano 执行图像分类
- 使用 Jetson Nano 进行实时物体检测
- 培训并部署您自己的定制模型到 Nano
现在你有了——用于计算机视觉的树莓 Pi 的完整目录。我希望看完这份清单后,你会和我一样兴奋!
我也有一些秘密奖金章节,在 Kickstarter 发布之前我会保密。详情敬请关注。
为了在更多 Kickstarter 公告发布时得到通知(包括我不会在本博客上发布的公告), 请务必注册Raspberry Pi for Computer VisionKickstarter 通知列表!*
用 OpenCV 和 Python 截图
原文:https://pyimagesearch.com/2018/01/01/taking-screenshots-with-opencv-and-python/ 截图
新年快乐
现在正式 2018… 这也意味着 PyImageSearch(差不多)四岁了!
我在 2014 年 1 月 12 日星期一发表了第一篇博文。从那以后已经发布了 230 个帖子,还有两本书和一门成熟的课程。
每年新年伊始,我都会花些时间进行反思。
我抓起我的笔记本+几支笔(把我的笔记本电脑和手机留在家里;不要分心)然后去我家附近的咖啡馆。然后,我坐在那里,反思过去的一年,问自己以下问题:
- 什么顺利,给了我生命?
- 是什么让我的生活变得很糟糕?
- 我怎样才能在积极的、赋予生命的方面加倍努力呢?
- 我怎样才能摆脱消极的一面(或者至少最小化它们对我生活的影响)?
这四个问题(以及我对它们的想法)最终决定了即将到来的一年。
但最重要的是,在过去的四年里,运行 PyImageSearch 一直在我的“赋予生命”列表中名列前茅。
感谢您让 PyImageSearch 成为可能。运行这个博客是我一天中最美好的时光。
没有你,PyImageSearch 就不可能实现。
为此,今天我要回答一个来自 Shelby 的问题,她是一个 PyImageSearch 的读者:
嗨,阿德里安,过去几年我一直在阅读 PyImageSearch。我很好奇的一个话题是用 OpenCV 截图。这可能吗?
我想建立一个应用程序,可以自动控制用户的屏幕,它需要截图。但我不确定该如何着手。
谢尔比的问题很好。
构建一个计算机视觉系统来自动控制或分析用户屏幕上的内容是一个伟大的项目。
一旦有了屏幕截图,我们就可以使用模板匹配、关键点匹配或局部不变描述符来识别屏幕上的元素。
问题其实是首先获取截图。
我们称之为数据获取——在某些情况下,获取数据实际上比
应用计算机视觉或机器学习本身更难。
要学习如何用 OpenCV 和 Python 截图,继续阅读。
$ workon your_virtualenv
$ pip install pillow imutils
$ pip install pyobjc-core
$ pip install pyobjc
$ pip install pyautogui
Ubuntu 或 Raspbian
要为 Ubuntu(或 Raspbian)安装 PyAutoGUI,您需要同时使用 Aptitude 和 pip。同样,在执行 pip 命令之前,请确保您正在 Python 虚拟环境中工作:
$ sudo apt-get install scrot
$ sudo apt-get install python-tk python-dev
$ sudo apt-get install python3-tk python3-dev
$ workon your_virtualenv
$ pip install pillow imutils
$ pip install python3_xlib python-xlib
$ pip install pyautogui
OpenCV 和 Python 的屏幕截图和截屏
现在 PyAutoGUI 已经安装好了,让我们用 OpenCV 和 Python 来拍第一张截图。
打开一个新文件,将其命名为take_screenshot.py,并插入以下代码:
# import the necessary packages
import numpy as np
import pyautogui
import imutils
import cv2
在2-5 行我们正在导入我们需要的包,特别是pyautogui。
在那里,我们将通过两种不同的方法截取一个截图。
在第一种方法中,我们获取屏幕截图并将其存储在内存中以供立即使用:
# take a screenshot of the screen and store it in memory, then
# convert the PIL/Pillow image to an OpenCV compatible NumPy array
# and finally write the image to disk
image = pyautogui.screenshot()
image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
cv2.imwrite("in_memory_to_disk.png", image)
第 10 行显示我们正在用pyautogui.screenshot抓取一个屏幕截图,并将其存储为image(同样,这个图像存储在内存中,它是而不是保存到磁盘)。
简单吧。
没那么快!
PyAutoGUI 实际上将图像存储为 PIL/枕头图像,因此在图像可以与 OpenCV 一起使用之前,我们需要执行额外的步骤。
在第 11 行我们将图像转换成一个 NumPy 数组,并将颜色通道从 RGB 排序(PIL/枕头使用的)转换成 BGR(OpenCV 期望的)。这就是让我们的截图图像兼容 OpenCV 所需的全部内容。
从这里开始,天空是你能做的极限。您可以检测屏幕上显示的按钮,甚至可以确定鼠标在屏幕上的坐标。
这些任务我们今天都不做。相反,让我们用cv2.imwrite将映像写入磁盘,以确保进程正确运行(第 12 行)。
第二种方法(将屏幕截图写入磁盘)更简单:
# this time take a screenshot directly to disk
pyautogui.screenshot("straight_to_disk.png")
如图所示,这个一行程序将图像直接写入磁盘。说够了。
我们可以就此打住,但是为了检查一下,让我们确保 OpenCV 也可以打开并显示截图:
# we can then load our screenshot from disk in OpenCV format
image = cv2.imread("straight_to_disk.png")
cv2.imshow("Screenshot", imutils.resize(image, width=600))
cv2.waitKey(0)
在这里,我们从磁盘读取图像。然后我们调整它的大小并显示在屏幕上,直到按下一个键。
就是这样!
如你所知, PyAutoGui 非常简单多亏了阿尔·斯威加特的努力工作。
让我们看看它是否有效。
要测试这个脚本,请打开一个终端并执行以下命令:
$ python take_screenshot.py
这是我们的桌面截图,显示在我们的桌面内…证明截图已拍摄并显示:

Figure 1: Taking a screenshot with Python, OpenCV, and PyAutoGUI on macOS.
请注意 Python 脚本是如何在终端中运行的(暗示当前正在拍摄屏幕截图)。
脚本退出后,我的工作目录中有两个新文件:in_memory_to_disk.png和straight_to_disk.png。
让我们列出目录的内容:
$ ls -al
total 18760
drwxr-xr-x@ 5 adrian staff 160 Jan 01 10:04 .
drwxr-xr-x@ 8 adrian staff 256 Jan 01 20:38 ..
-rw-r--r--@ 1 adrian staff 4348537 Jan 01 09:59 in_memory_to_disk.png
-rw-r--r--@ 1 adrian staff 5248098 Jan 01 09:59 straight_to_disk.png
-rw-r--r--@ 1 adrian staff 703 Jan 01 09:59 take_screenshot.py
如你所见,我已经拿到了我的take_screenshot.py脚本和两张截图
现在我们有了 OpenCV 格式的截图,我们可以应用任何“标准”的计算机视觉或图像处理操作,包括边缘检测、模板匹配、关键点匹配、对象检测等。
在以后的博客文章中,我将展示如何检测屏幕上的元素,然后根据我们的计算机视觉算法检测到的内容从 PyAutoGUI 库中控制整个 GUI。
敬请关注 2018 年初本帖!
摘要
在今天的博文中,我们学习了如何使用 OpenCV、Python 和 PyAutoGUI 库来截图。
使用 PyAutoGUI,我们可以轻松地将截图直接捕获到磁盘或内存中,然后我们可以将其转换为 OpenCV/NumPy 格式。
在创建可以自动控制屏幕上 GUI 操作的计算机视觉软件时,截图是重要的第一步,包括自动移动鼠标、单击鼠标和注册键盘事件。
在未来的博客文章中,我们将学习如何通过计算机视觉和 PyAutoGUI 自动控制我们的整个计算机。
要在 PyImageSearch 上发布博客文章时得到通知,只需在下表中输入您的电子邮件地址!
获取目标:使用 Python 和 OpenCV 在无人机和四轴飞行器视频流中寻找目标
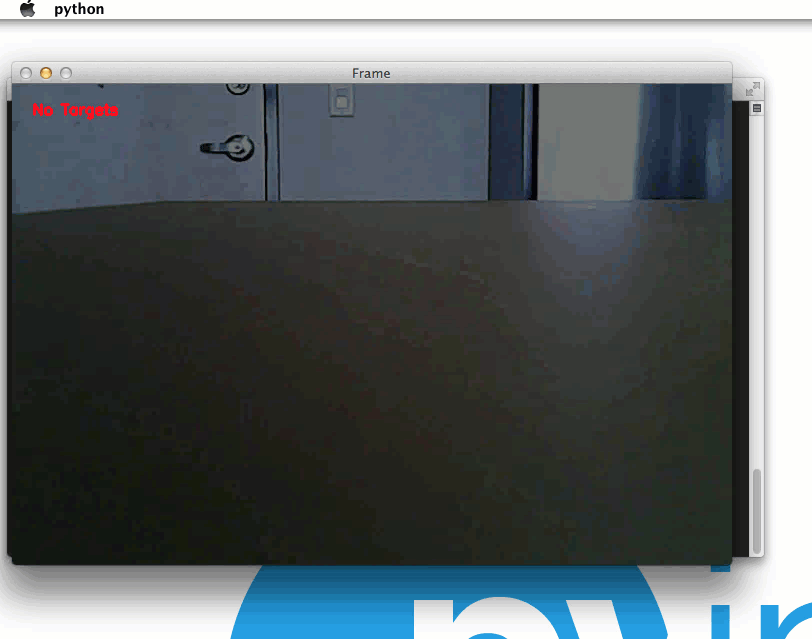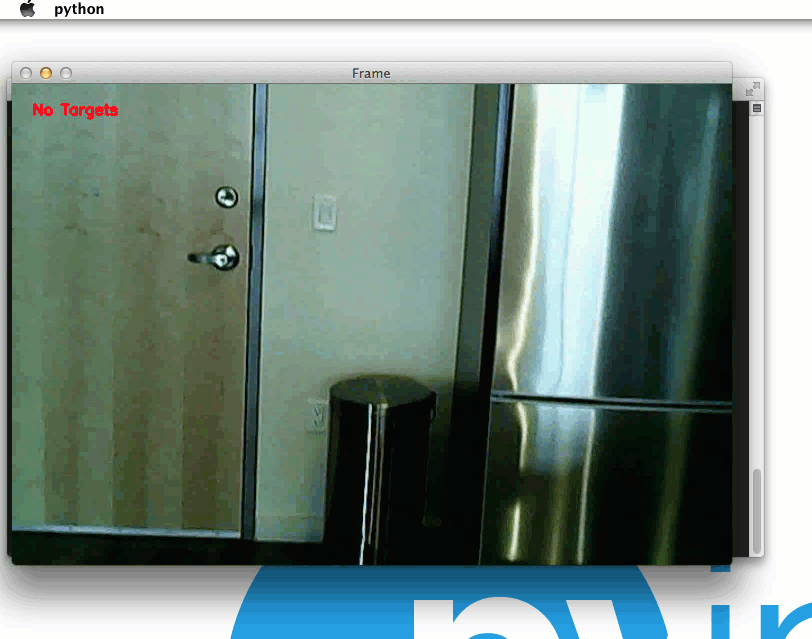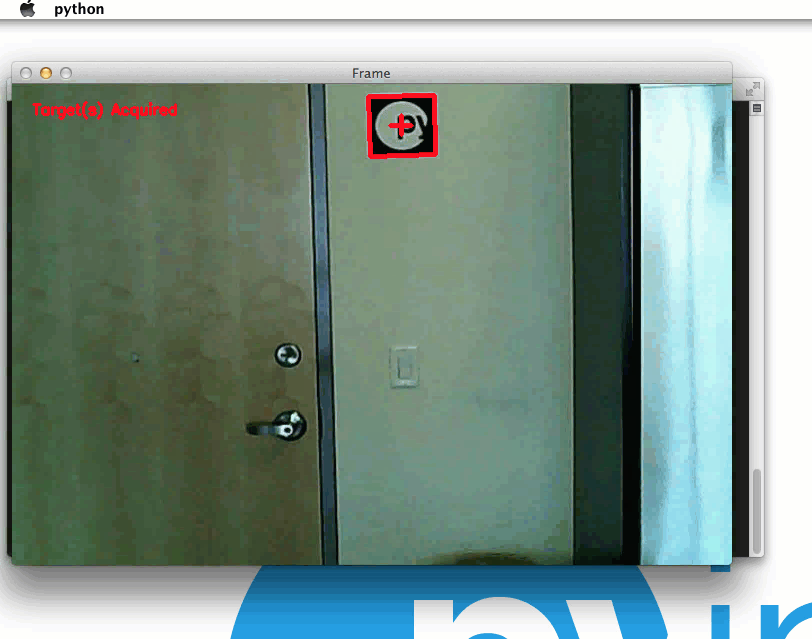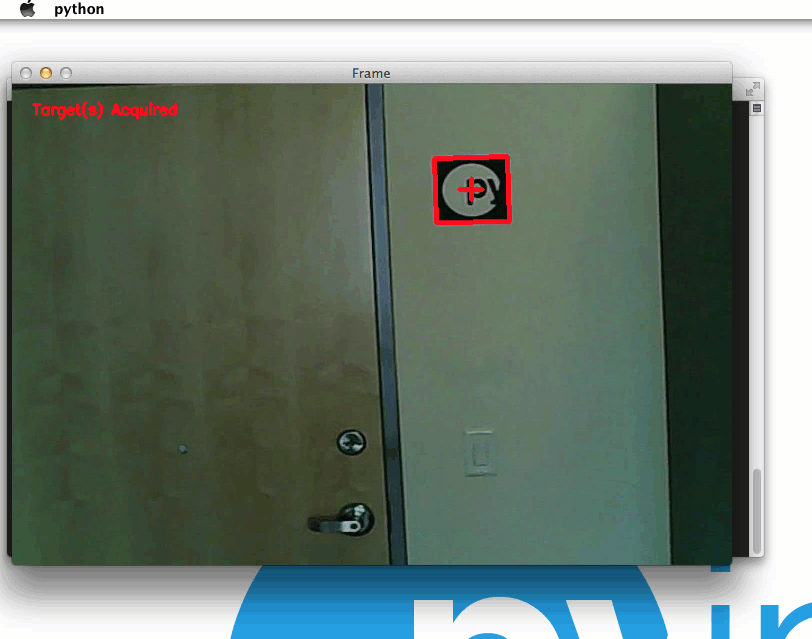
我将以一段很少有人知道的我的个人历史来开始这篇文章:当我还是个孩子的时候,在上高中的时候,每个周六我都会在离我家大约 25 英里的地方遥控赛道上几乎 度过。
你看,我曾经在业余水平上比赛 1/10 比例(电动)的遥控汽车。能够在每个周六花时间比赛绝对是我童年最喜欢的经历之一(如果不是最喜欢的话)。
我曾经驾驶联合车队的 TC3 赛车(现在已经过时了)。从普通引擎,到 19 转引擎,再到改装引擎(当我停止比赛的时候,我已经开始使用 9 转引擎了),我都有了。我甚至在美国东海岸参加了几次大型业余水平的比赛,并取得了好成绩。
但随着年龄的增长,赛车变得越来越昂贵,我开始花更少的时间在赛道上,更多的时间在编程上。最终,这可能是我做过的最聪明的决定之一,尽管我如此热爱赛车——我似乎不太可能以赛车为职业,但我确实以编程和创业为职业。
所以,现在我 26 岁了,我有回到 RC 的冲动,这也许并不奇怪。但我想做的不是汽车,而是我从未做过的事情——无人机和四轴飞行器 。
这就引出了这篇文章的目的:开发一个从四轴飞行器视频记录中自动检测目标的系统。
如果你想看目标收购的实际情况,我不会让你久等的。以下是完整视频:
https://www.youtube.com/embed/VoFcNkWMu08?feature=oembed
使用 Keras 和 TensorFlow 进行有针对性的对抗性攻击
原文:https://pyimagesearch.com/2020/10/26/targeted-adversarial-attacks-with-keras-and-tensorflow/
在本教程中,您将学习如何使用 Keras、TensorFlow 和深度学习来执行有针对性的对抗性攻击和构建有针对性的对抗性图像。
上周的教程涵盖了 无针对性的对抗性学习,它的过程是:
- 步骤#1: 接受输入图像并使用预训练的 CNN 确定其类别标签
- 步骤#2: 构造噪声向量,该噪声向量在被添加到输入图像时故意干扰结果图像,以这样的方式:
- 步骤#2a: 输入图像被预先训练的 CNN错误分类
- 步骤#2b: 然而,对于人眼来说,被扰乱的图像与原始图像是无法区分的
有了无目标的对抗性学习,我们就不在乎输入图像的新类标签是什么了,假设它被 CNN 错误分类了。例如,下图显示了我们已经应用了对抗性学习来获取被正确分类为“猪”的输入,并对其进行扰动,使得图像现在被错误地分类为“袋熊”:
在无目标的对抗性学习中,我们无法控制最终的、被扰乱的类别标签是什么。但是如果我们想要控制呢?这可能吗?
绝对是——为了控制扰动图像的类别标签,我们需要应用有针对性的对抗学习。
本教程的剩余部分将向你展示如何应用有针对性的对抗性学习。
要学习如何用 Keras 和 TensorFlow 进行有针对性的对抗性学习,继续阅读。
使用 Keras 和 TensorFlow 进行有针对性的对抗性攻击
在本教程的第一部分,我们将简要讨论什么是对抗性攻击和对抗性图像。然后我会解释有针对性的对抗性攻击和无针对性的攻击之间的区别。
接下来,我们将回顾我们的项目目录结构,从那里,我们将实现一个 Python 脚本,它将使用 Keras 和 TensorFlow 应用有针对性的对抗性学习。
我们将讨论我们的结果来结束本教程。
什么是对抗性攻击?什么是形象对手?
如果你是对抗性攻击的新手,以前没有听说过对抗性图像,我建议你在阅读本指南之前,先阅读我的博客文章, 对抗性图像和攻击与 Keras 和 TensorFlow 。
要点是,敌对的图像是故意构建的来愚弄预先训练好的模型。
例如,如果一个预先训练的 CNN 能够正确地分类一个输入图像,一个敌对的攻击试图采取完全相同的图像并且:
- 扰动它,使图像现在被错误分类…
- …然而,新的、被打乱的图像看起来与原始图像(至少在人眼看来)一模一样
理解对抗性攻击是如何工作的以及对抗性图像是如何构建的非常重要——了解这一点将有助于你训练你的 CNN,使它们能够抵御这些类型的对抗性攻击(这是我将在未来的教程中涉及的主题)。
有针对性的对抗性攻击与无针对性的攻击有何不同?**
**上面的图 3 直观地显示了无目标对抗性攻击和有目标攻击之间的区别。
当构建无目标的对抗性攻击时,我们无法控制扰动图像的最终输出类别标签将是什么— 我们唯一的目标是迫使模型对输入图像进行错误的分类。
图 3 (上) 是无针对性对抗性攻击的一个例子。在这里,我们输入一个“猪”的图像——对抗性攻击算法然后扰乱输入图像,使得它被错误地分类为“袋熊”,但是同样,我们没有指定目标类标签应该是什么(坦率地说,无目标算法不关心,只要输入图像现在被错误地分类)。
另一方面,有针对性的对抗性攻击让我们能够更好地控制被扰乱图像的最终预测标签。
图 3 (下) 是针对性对抗性攻击的一个例子。我们再次输入一个“pig”的图像,但是我们也提供了扰动图像的目标类标签(在本例中是一只“Lakeland terrier”,一种狗)。
然后,我们的目标对抗性攻击算法能够干扰猪的输入图像,使得它现在被错误地分类为莱克兰梗。
在本教程的剩余部分,你将学习如何进行这样有针对性的对抗性攻击。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
这样说来,你是:
- 时间紧迫?
- 在你雇主被行政锁定的笔记本电脑上学习?
- 想要跳过与包管理器、bash/ZSH 概要文件和虚拟环境的争论吗?
- 准备好运行代码了吗(并尽情体验它)?
那今天就加入 PyImageSearch 加吧!获得我们的 PyImageSearch 教程 Jupyter 笔记本,,它运行在谷歌的 Colab 生态系统上,在你的浏览器 — 中不需要安装。
项目结构
在我们开始用 Keras 和 TensorFlow 实现有针对性的对抗性攻击之前,我们首先需要回顾一下我们的项目目录结构。
首先使用本教程的 【下载】 部分下载源代码和示例图像。从那里,检查目录结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── imagenet_class_index.json
│ └── utils.py
├── adversarial.png
├── generate_targeted_adversary.py
├── pig.jpg
└── predict_normal.py
1 directory, 7 files
我们的目录结构与上周关于 敌对图像以及用 Keras 和 TensorFlow 攻击的指南相同。
pyimagesearch模块包含utils.py,这是一个帮助实用程序,它加载并解析位于imagenet_class_index.json中的 ImageNet 类标签索引。我们在上周的教程中介绍了这个助手函数,今天不会在这里介绍它的实现——我建议你阅读我的以前的教程来了解更多细节。
让我们开始实施有针对性的对抗性攻击吧!
步骤#1:使用我们预先训练的 CNN 获得原始类别标签预测
在我们能够执行有针对性的对抗性攻击之前,我们必须首先确定来自预训练 CNN 的预测类别标签是什么。
出于本教程的目的,我们将使用 ResNet 架构,在 ImageNet 数据集上进行了预训练。
对于任何给定的输入图像,我们需要:
- 加载图像
- 预处理它
- 通过 ResNet 传递
- 获得类别标签预测
- 确定类标签的整数索引
一旦我们有了预测的类标签的整数索引,以及目标类标签,我们希望网络预测图像是什么;然后我们就可以进行有针对性的对抗性攻击。
让我们从获得猪的以下图像的类别标签预测和索引开始:
为了完成这项任务,我们将在项目目录结构中使用predict_normal.py脚本。这个脚本在上周的教程中已经讨论过了,所以我们今天不会在这里讨论它——如果你有兴趣看这个脚本背后的代码,可以参考我之前的教程。
综上所述,首先使用本教程的 “下载” 部分下载源代码和示例图像。
$ python predict_normal.py --image pig.jpg
[INFO] loading image...
[INFO] loading pre-trained ResNet50 model...
[INFO] making predictions...
[INFO] hog => 341
[INFO] 1\. hog: 99.97%
[INFO] 2\. wild_boar: 0.03%
[INFO] 3\. piggy_bank: 0.00%
这里你可以看到我们输入的pig.jpg图像被归类为“猪”,置信度为 99.97%。
在我们的下一部分,你将学习如何干扰这张图片,使它被错误地归类为“莱克兰梗”(一种狗)。
但是现在,请注意我们终端输出的第 5 行,它显示了预测标签【猪】的 ImageNet 类标签索引是341——我们将在下一节中需要这个值。
步骤#2:使用 Keras 和 TensorFlow 实施有针对性的对抗性攻击
我们现在准备实施有针对性的对抗性攻击,并使用 Keras 和 TensorFlow 构建有针对性的对抗性图像。
打开项目目录结构中的generate_targeted_adversary.py文件,并插入以下代码:
# import necessary packages
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.resnet50 import preprocess_input
import tensorflow as tf
import numpy as np
import argparse
import cv2
def preprocess_image(image):
# swap color channels, resize the input image, and add a batch
# dimension
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
image = np.expand_dims(image, axis=0)
# return the preprocessed image
return image
def clip_eps(tensor, eps):
# clip the values of the tensor to a given range and return it
return tf.clip_by_value(tensor, clip_value_min=-eps,
clip_value_max=eps)
我们通过使用 TensorFlow 的clip_by_value方法来完成这个裁剪。我们提供tensor作为输入,然后将-eps设置为最小限幅值限制,将eps设置为正限幅值限制。
当我们构造扰动向量时,将使用该函数,确保我们构造的噪声向量落在可容忍的限度内,并且最重要的是,不会显著影响输出对抗图像的视觉质量。
请记住,对立的图像应该与它们的原始输入相同(对人眼而言)——通过在可容忍的限度内剪裁张量值,我们能够强制执行这一要求。
接下来,我们需要定义generate_targeted_adversaries函数,这是这个 Python 脚本的主要部分:
def generate_targeted_adversaries(model, baseImage, delta, classIdx,
target, steps=500):
# iterate over the number of steps
for step in range(0, steps):
# record our gradients
with tf.GradientTape() as tape:
# explicitly indicate that our perturbation vector should
# be tracked for gradient updates
tape.watch(delta)
# add our perturbation vector to the base image and
# preprocess the resulting image
adversary = preprocess_input(baseImage + delta)
接下来是应用有针对性的对抗性攻击的梯度下降部分:
# run this newly constructed image tensor through our
# model and calculate the loss with respect to the
# both the *original* class label and the *target*
# class label
predictions = model(adversary, training=False)
originalLoss = -sccLoss(tf.convert_to_tensor([classIdx]),
predictions)
targetLoss = sccLoss(tf.convert_to_tensor([target]),
predictions)
totalLoss = originalLoss + targetLoss
# check to see if we are logging the loss value, and if
# so, display it to our terminal
if step % 20 == 0:
print("step: {}, loss: {}...".format(step,
totalLoss.numpy()))
# calculate the gradients of loss with respect to the
# perturbation vector
gradients = tape.gradient(totalLoss, delta)
# update the weights, clip the perturbation vector, and
# update its value
optimizer.apply_gradients([(gradients, delta)])
delta.assign_add(clip_eps(delta, eps=EPS))
# return the perturbation vector
return delta
现在已经定义了所有的函数,我们可以开始解析命令行参数了:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to original input image")
ap.add_argument("-o", "--output", required=True,
help="path to output adversarial image")
ap.add_argument("-c", "--class-idx", type=int, required=True,
help="ImageNet class ID of the predicted label")
ap.add_argument("-t", "--target-class-idx", type=int, required=True,
help="ImageNet class ID of the target adversarial label")
args = vars(ap.parse_args())
让我们继续进行一些初始化:
EPS = 2 / 255.0
LR = 5e-3
# load image from disk and preprocess it
print("[INFO] loading image...")
image = cv2.imread(args["input"])
image = preprocess_image(image)
第 82 行定义了我们的ε(EPS)值,用于在构建对抗图像时裁剪张量。2 / 255.0的EPS值是敌对出版物和教程中使用的标准值。
然后我们在第 84 行定义我们的学习率。值LR = 5e-3是通过经验调整获得的— 在构建您自己的目标对抗性攻击时,您可能需要更新该值。
第 88 行和第 89 行加载我们的输入image,然后使用 ResNet 的预处理帮助函数对其进行预处理。
接下来,我们需要加载 ResNet 模型并初始化我们的损失函数:
# load the pre-trained ResNet50 model for running inference
print("[INFO] loading pre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# initialize optimizer and loss function
optimizer = Adam(learning_rate=LR)
sccLoss = SparseCategoricalCrossentropy()
# create a tensor based off the input image and initialize the
# perturbation vector (we will update this vector via training)
baseImage = tf.constant(image, dtype=tf.float32)
delta = tf.Variable(tf.zeros_like(baseImage), trainable=True)
如果你想了解更多关于这些变量和初始化的细节,请参考上周的教程,我会在那里详细介绍它们。
构建了所有变量后,我们现在可以应用有针对性的对抗性攻击:
# generate the perturbation vector to create an adversarial example
print("[INFO] generating perturbation...")
deltaUpdated = generate_targeted_adversaries(model, baseImage, delta,
args["class_idx"], args["target_class_idx"])
# create the adversarial example, swap color channels, and save the
# output image to disk
print("[INFO] creating targeted adversarial example...")
adverImage = (baseImage + deltaUpdated).numpy().squeeze()
adverImage = np.clip(adverImage, 0, 255).astype("uint8")
adverImage = cv2.cvtColor(adverImage, cv2.COLOR_RGB2BGR)
cv2.imwrite(args["output"], adverImage)
然后我们剪裁任何像素值,使所有像素都在范围【0,255】内,接着将图像转换为无符号的 8 位整数(这样 OpenCV 就可以对图像进行操作)。
最后的adverImage然后被写入磁盘。
问题依然存在——我们是否愚弄了我们最初的 ResNet 模型,做出了不正确的预测?
让我们在下面代码块中回答这个问题:
# run inference with this adversarial example, parse the results,
# and display the top-1 predicted result
print("[INFO] running inference on the adversarial example...")
preprocessedImage = preprocess_input(baseImage + deltaUpdated)
predictions = model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
label = predictions[0][1]
confidence = predictions[0][2] * 100
print("[INFO] label: {} confidence: {:.2f}%".format(label,
confidence))
# write the top-most predicted label on the image along with the
# confidence score
text = "{}: {:.2f}%".format(label, confidence)
cv2.putText(adverImage, text, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", adverImage)
cv2.waitKey(0)
第 120 行通过首先构建对抗图像,然后使用 ResNet 的预处理实用程序对其进行预处理,来构建一个preprocessedImage。
一旦图像经过预处理,我们就使用我们的model对其进行预测。这些预测随后被解码并获得排名第一的预测——类别标签和相应的概率随后被显示到我们的终端上(第 121-126 行)。
最后,我们用预测的标签和置信度注释输出图像,然后将输出图像显示到屏幕上。
要审查的代码太多了!花点时间祝贺自己成功实施了有针对性的对抗性攻击。在下一部分,我们将看到我们努力工作的成果。
步骤#3:有针对性的对抗性攻击结果
我们现在准备进行有针对性的对抗性攻击!确保您已经使用了本教程的 【下载】 部分来下载源代码和示例图像。
接下来,打开imagenet_class_index.json文件,确定我们想要“欺骗”网络进行预测的 ImageNet 类标签的整数索引——类标签索引文件的前几行如下所示:
{
"0": [
"n01440764",
"tench"
],
"1": [
"n01443537",
"goldfish"
],
"2": [
"n01484850",
"great_white_shark"
],
"3": [
"n01491361",
"tiger_shark"
],
...
滚动浏览文件,直到找到要使用的类别标签。
在这种情况下,我选择了索引189,它对应于一只“莱克兰梗”(一种狗):
...
"189": [
"n02095570",
"Lakeland_terrier"
],
...
从那里,您可以打开一个终端并执行以下命令:
$ python generate_targeted_adversary.py --input pig.jpg --output adversarial.png --class-idx 341 --target-class-idx 189
[INFO] loading image...
[INFO] loading pre-trained ResNet50 model...
[INFO] generating perturbation...
step: 0, loss: 16.111093521118164...
step: 20, loss: 15.760734558105469...
step: 40, loss: 10.959839820861816...
step: 60, loss: 7.728139877319336...
step: 80, loss: 5.327273368835449...
step: 100, loss: 3.629972219467163...
step: 120, loss: 2.3259339332580566...
step: 140, loss: 1.259613037109375...
step: 160, loss: 0.30303144454956055...
step: 180, loss: -0.48499584197998047...
step: 200, loss: -1.158257007598877...
step: 220, loss: -1.759873867034912...
step: 240, loss: -2.321563720703125...
step: 260, loss: -2.910153865814209...
step: 280, loss: -3.470625877380371...
step: 300, loss: -4.021825313568115...
step: 320, loss: -4.589465141296387...
step: 340, loss: -5.136003017425537...
step: 360, loss: -5.707150459289551...
step: 380, loss: -6.300693511962891...
step: 400, loss: -7.014866828918457...
step: 420, loss: -7.820181369781494...
step: 440, loss: -8.733556747436523...
step: 460, loss: -9.780607223510742...
step: 480, loss: -10.977422714233398...
[INFO] creating targeted adversarial example...
[INFO] running inference on the adversarial example...
[INFO] label: Lakeland_terrier confidence: 54.82%
在左边的,你可以看到我们的原始输入图像,它被正确地归类为“猪”。
然后,我们应用了一个有针对性的对抗性攻击(右),扰乱了输入图像,以至于它被错误地分类为一只具有 68.15%置信度的莱克兰梗(一种狗)!
作为参考,莱克兰梗看起来一点也不像猪:
在上周关于无目标对抗性攻击的教程中,我们看到无法控制扰动图像的最终预测类别标签;然而,通过应用有针对性的对抗性攻击,我们能够控制最终预测什么标签。
总结
在本教程中,您学习了如何使用 Keras、TensorFlow 和深度学习来执行有针对性的对抗性学习。
当应用无目标的对抗学习时,我们的目标是干扰输入图像,使得:
- 受干扰的图像被我们预先训练的 CNN 错误分类
- 然而,对于人眼来说,被扰乱的图像与原始图像是相同的
无目标的对抗学习的问题是,我们无法控制扰动的输出类别标签。例如,如果我们有一个“猪”的输入图像,并且我们想要扰乱该图像,使得它被错误分类,我们不能控制什么是新的类标签。
另一方面,有针对性的对抗性学习允许我们控制新的类别标签将是什么,这非常容易实现,只需要更新我们的损失函数计算。
到目前为止,我们已经讲述了如何构建对抗性攻击,但是如果我们想要防御攻击呢?这可能吗?
的确是这样——我将在以后的博客文章中讨论防御对抗性攻击。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
非英语语言的 Tesseract OCR
原文:https://pyimagesearch.com/2020/08/03/tesseract-ocr-for-non-english-languages/
在本教程中,您将学习如何使用 Tesseract OCR 引擎对非英语语言进行 OCR。
如果你参考我在 PyImageSearch 博客上的以前的光学字符识别(OCR)教程,你会注意到所有的 OCR 文本都是用英语语言编写的。
但是如果你想对非英语文本进行 OCR 呢?
你需要采取什么步骤?
宇宙魔方如何处理非英语语言?
我们将在本教程中回答所有这些问题。
要了解如何使用 Tesseract 对非英语语言的文本进行 OCR,请继续阅读。
非英语语言的光学字符识别(OCR)
在本教程的第一部分,您将学习如何为多种语言配置 Tesseract OCR 引擎,包括非英语语言。
然后,我将向您展示如何为 Tesseract 下载多个语言包,并验证它是否正常工作——我们将使用德语作为示例。
从那里,我们将配置 TextBlob 包,它将用于从一种语言翻译成另一种语言。
完成所有设置后,我们将为 Python 脚本实现项目结构,该脚本将:
- 接受输入图像
- 检测和 OCR 非英语语言的文本
- 将 OCR 识别的文本从给定的输入语言翻译成英语
- 将结果显示到我们的终端上
我们开始吧!
为多种语言配置 Tesseract OCR】
在本节中,我们将为多种语言配置 Tesseract OCR。我们将一步一步地分解它,看看它在 macOS 和 Ubuntu 上是什么样子。
如果您尚未安装宇宙魔方:
- 我已经在我的博文 OpenCV OCR 和使用 Tesseract 的文本识别中提供了安装Tesseract OCR 引擎* 以及 pytesseract (用于连接 tesseract 的 Python 绑定)的说明。***
- 按照该教程的如何安装宇宙魔方 4 部分的说明,确认您的宇宙魔方安装,然后回到这里学习如何为多种语言配置宇宙魔方。
从技术上讲,Tesseract 应该已经配置为处理多种语言,包括非英语语言;然而,根据我的经验,多语言支持可能有点不稳定。我们将回顾我的方法,它给出了一致的结果。
如果您通过自制软件在 macOS 上安装了宇宙魔方,那么您的宇宙魔方语言包应该在/usr/local/Cellar/tesseract/<version>/share/tessdata中可用,其中<version>是您的宇宙魔方安装的版本号(您可以使用tab键自动完成以获得您机器上的完整路径)。
如果你在 Ubuntu 上运行,你的宇宙魔方语言包应该位于目录/usr/share/tesseract-ocr/<version>/tessdata中,其中<version>是你的宇宙魔方安装的版本号。
让我们用下面的图 1、所示的ls命令快速查看一下这个tessdata目录的内容,它对应于我的 macOS 上的 Homebrew 安装,用于英语语言配置。
eng.traineddata是英语的语言包。osd.traineddata是与方位和脚本相关的特殊数据文件。snum.traineddata是宇宙魔方使用的内部序列号。pdf.ttf是一个支持 pdf 渲染的 True Type 格式字体文件。
下载语言包并添加到 Tesseract OCR
宇宙魔方的第一个版本只支持英语。在第二个版本中增加了对法语、意大利语、德语、西班牙语、巴西葡萄牙语和荷兰语的支持。
在第三个版本中,对表意(符号)语言(如中文和日文)以及从右向左书写的语言(如阿拉伯语和希伯来语)的支持显著增加。
我们现在使用的第四个版本支持 100 多种语言,并且支持字符和符号。
注:第四个版本包含 Tesseract 的传统和更新、更准确的长期短期记忆(LSTM) OCR 引擎的训练模型。
现在我们对支持的语言范围有了一个概念,让我们深入了解我发现的最简单的方法来配置 Tesseract 并释放这种巨大的多语言支持的力量:
- 从 GitHub 手动下载 Tesseract 的语言包并安装。
- 设置
TESSDATA_PREFIX环境变量指向包含语言包的目录。
这里的第一步是克隆 Tesseract 的 GitHub tessdata存储库,它位于:
https://github.com/tesseract-ocr/tessdata
我们希望移动到我们希望成为本地tessdata目录的父目录的目录。然后,我们将简单地发出下面的git命令来clone将回购文件发送到我们的本地目录。
$ git clone https://github.com/tesseract-ocr/tessdata
注意:注意,在撰写本文时,生成的 tessdata 目录将为 ~4.85GB ,因此请确保您的硬盘上有足够的空间。
第二步是设置环境变量TESSDATA_PREFIX指向包含语言包的目录。我们将把目录(cd)改为tessdata目录,并使用pwd命令确定到该目录的完整系统路径:
$ cd tessdata/
$ pwd
/Users/adrianrosebrock/Desktop/tessdata
你的tessdata目录将有一个不同于我的路径,所以确保你运行上面的命令来确定路径特定的到你的机器!
从那里,您需要做的就是设置TESSDATA_PREFIX环境变量指向您的tessdata目录,从而允许 Tesseract 找到语言包。为此,只需执行以下命令:
$ export TESSDATA_PREFIX=/Users/adrianrosebrock/Desktop/tessdata
同样,您的完整路径将与我的不同,所以要注意仔细检查和三次检查您的文件路径。
项目结构
让我们回顾一下项目结构。
一旦您从本文的 【下载】 部分获取文件,您将看到以下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── images
│ ├── arabic.png
│ ├── german.png
│ ├── german_block.png
│ ├── swahili.png
│ └── vietnamese.png
└── ocr_non_english.py
1 directory, 6 files
images/子目录包含几个我们将用于 OCR 的 PNG 文件。标题指示将用于 OCR 的母语。
Python 文件ocr_non_english.py,位于我们的主目录中,是我们的驱动文件。它将 OCR 我们的母语文本,然后从母语翻译成英语。
验证 Tesseract 对非英语语言的支持
此时,您应该已经将 Tesseract 正确配置为支持非英语语言,但是作为一项健全性检查,让我们通过使用echo命令来验证TESSDATA_PREFIX环境变量是否设置正确:
$ echo $TESSDATA_PREFIX
/Users/adrianrosebrock/Desktop/tessdata
$ tesseract german.png stdout -l deu
- 检查
tessdata目录。 - 参考宇宙魔方文档,其中列出了宇宙魔方支持的语言和对应的代码。
- 使用此网页确定主要使用某种语言的国家代码。
- 最后,如果你仍然不能得到正确的国家代码,使用一点 Google-foo,搜索你所在地区的三个字母的国家代码(在 Google 上搜索宇宙魔方<语言名称>代码也无妨)。
只要有一点耐心,再加上一些练习,你就可以用 Tesseract 对非英语语言的文本进行 OCR。
text blob 包的环境设置
现在我们已经设置了 Tesseract 并添加了对非英语语言的支持,我们需要设置 TextBlob 包。
注意:这一步假设你已经在 Python3 虚拟环境中工作(例如 $ workon cv 其中 cv 是一个虚拟环境的名称——你的可能会不同) )。
安装textblob只是一个快速命令:
$ pip install textblob
伟大的工作设置您的环境依赖!
用非英语语言脚本实现我们的宇宙魔方
我们现在已经准备好为非英语语言支持实现 Tesseract。让我们从下载小节回顾一下现有的ocr_non_english.py。
打开项目目录中的ocr_non_english.py文件,并插入以下代码:
# import the necessary packages
from textblob import TextBlob
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-l", "--lang", required=True,
help="language that Tesseract will use when OCR'ing")
ap.add_argument("-t", "--to", type=str, default="en",
help="language that we'll be translating to")
ap.add_argument("-p", "--psm", type=int, default=13,
help="Tesseract PSM mode")
args = vars(ap.parse_args())
第 5 行导入TextBlob,这是一个非常有用的处理文本数据的 Python 库。它可以执行各种自然语言处理任务,如标记词性。我们将使用它将 OCR 识别的外语文本翻译成英语。你可以在这里阅读更多关于 TextBlob 的内容:https://textblob.readthedocs.io/en/dev/
--image:要进行 OCR 的输入图像的路径。--lang:宇宙魔方在 ORC 图像时使用的本地语言。- 我们将把本地 OCR 文本翻译成的语言。
--psm:镶嵌的页面分割方式。我们的default是针对13、的页面分割模式,它将图像视为单行文本。对于我们今天的最后一个例子,我们将对一整块德语文本进行 OCR。对于这个完整的块,我们将使用一个页面分割模式3,这是一个没有方向和脚本检测(OSD)的全自动页面分割。
导入、便利函数和命令行args都准备好了,在循环遍历帧之前,我们只需要处理一些初始化:
# load the input image and convert it from BGR to RGB channel
# ordering
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# OCR the image, supplying the country code as the language parameter
options = "-l {} --psm {}".format(args["lang"], args["psm"])
text = pytesseract.image_to_string(rgb, config=options)
# show the original OCR'd text
print("ORIGINAL")
print("========")
print(text)
print("")
在本节中,我们将从文件中加载图像,更改图像颜色通道的顺序,设置 Tesseract 的选项,并以图像的母语对图像执行光学字符识别。
- Tesseract 用于 OCR 图像的本地语言(
-l)。 - 页面分割模式选项(
-psm)。这些对应于我们运行这个程序时在命令行上提供的输入参数。
接下来,我们将以本地语言显示 Tesseract 的 OCR 结果来结束这一部分(第 32-35 行):
# translate the text into a different language
tb = TextBlob(text)
translated = tb.translate(to=args["to"])
# show the translated text
print("TRANSLATED")
print("==========")
print(translated)
既然我们已经用本地语言对文本进行了 OCR,我们将把文本从我们的--lang命令行参数指定的本地语言翻译成我们的--to命令行参数描述的输出语言。
我们使用TextBlob ( 第 38 行)将文本抽象为 textblob。然后,我们使用tb.tranlsate翻译第 39 行的最终语言。我们最后打印翻译文本的结果(第 42-44 行)。现在,您有了一个完整的工作流程,其中包括对母语文本进行 OCR,并将其翻译成您想要的语言。
很好地实现了不同语言的 Tesseract 正如您所看到的,它相对简单。接下来,我们将确保我们的脚本和宇宙魔方正在所有的气缸上点火。
细分 OCR 和非英语语言结果
是时候让非英语语言的宇宙魔方发挥作用了!
打开终端,从主项目目录执行以下命令:
$ python ocr_non_english.py --image images/german.png --lang deu
ORIGINAL
========
Ich brauche ein Bier!
TRANSLATED
==========
I need a beer!
在图 3 的中,您可以看到一个带有文本的输入图像,“我是 brauche ein Bier!”这是德语中的“我需要一杯啤酒!”
$ python ocr_non_english.py --image images/swahili.png --lang swa
ORIGINAL
========
Jina langu ni Adrian
TRANSLATED
==========
My name is Adrian
--lang swa标志表示我们想要 OCR 斯瓦希里语文本(图 4 )。
宇宙魔方正确地 OCR 出了文本“纪娜·顾岚·尼·阿德里安”,翻译成英语就是“我的名字是阿德里安。”
此示例显示如何对越南语文本进行 OCR,越南语是一种不同于前面示例的脚本/书写系统:
$ python ocr_non_english.py --image images/vietnamese.png --lang vie
ORIGINAL
========
Tôi mến bạn..
TRANSLATED
==========
I love you..
$ python ocr_non_english.py --image images/arabic.png --lang ara
ORIGINAL
========
أنا أتحدث القليل من العربية فقط..
TRANSLATED
==========
I only speak a little Arabic ..
使用--lang ara标志,我们能够告诉 Tesseract 对阿拉伯文本进行 OCR。
在这里,我们可以看到,阿拉伯语“阿拉伯语”是“我只说一点阿拉伯语”。英语中“T1”是“roughly translates”,意思是“我是唯一一个阿拉伯语”是“T3”。
对于我们的最后一个示例,让我们对一大块德语文本进行 OCR:
$ python ocr_non_english.py --image images/german_block.png --lang deu --psm 3
ORIGINAL
========
Erstes Kapitel
Gustav Aschenbach oder von Aschenbach, wie seit seinem fünfzigsten
Geburtstag amtlich sein Name lautete, hatte an einem
Frühlingsnachmittag des Jahres 19.., das unserem Kontinent monatelang
eine so gefahrdrohende Miene zeigte, von seiner Wohnung in der Prinz-
Regentenstraße zu München aus, allein einen weiteren Spaziergang
unternommen. Überreizt von der schwierigen und gefährlichen, eben
jetzt eine höchste Behutsamkeit, Umsicht, Eindringlichkeit und
Genauigkeit des Willens erfordernden Arbeit der Vormittagsstunden,
hatte der Schriftsteller dem Fortschwingen des produzierenden
Triebwerks in seinem Innern, jenem »motus animi continuus«, worin
nach Cicero das Wesen der Beredsamkeit besteht, auch nach der
Mittagsmahlzeit nicht Einhalt zu tun vermocht und den entlastenden
Schlummer nicht gefunden, der ihm, bei zunehmender Abnutzbarkeit
seiner Kräfte, einmal untertags so nötig war. So hatte er bald nach dem
Tee das Freie gesucht, in der Hoffnung, daß Luft und Bewegung ihn
wieder herstellen und ihm zu einem ersprießlichen Abend verhelfen
würden.
Es war Anfang Mai und, nach naßkalten Wochen, ein falscher
Hochsommer eingefallen. Der Englische Garten, obgleich nur erst zart
belaubt, war dumpfig wie im August und in der Nähe der Stadt voller
Wagen und Spaziergänger gewesen. Beim Aumeister, wohin stillere und
stillere Wege ihn geführt, hatte Aschenbach eine kleine Weile den
volkstümlich belebten Wirtsgarten überblickt, an dessen Rande einige
Droschken und Equipagen hielten, hatte von dort bei sinkender Sonne
seinen Heimweg außerhalb des Parks über die offene Flur genommen
und erwartete, da er sich müde fühlte und über Föhring Gewitter drohte,
am Nördlichen Friedhof die Tram, die ihn in gerader Linie zur Stadt
zurückbringen sollte. Zufällig fand er den Halteplatz und seine
Umgebung von Menschen leer. Weder auf der gepflasterten
Ungererstraße, deren Schienengeleise sich einsam gleißend gegen
Schwabing erstreckten, noch auf der Föhringer Chaussee war ein
Fuhrwerk zu sehen; hinter den Zäunen der Steinmetzereien, wo zu Kauf
TRANSLATED
==========
First chapter
Gustav Aschenbach or von Aschenbach, like since his fiftieth
Birthday officially his name was on one
Spring afternoon of the year 19 .. that our continent for months
showed such a threatening expression from his apartment in the Prince
Regentenstrasse to Munich, another walk alone
undertaken. Overexcited by the difficult and dangerous, just
now a very careful, careful, insistent and
Accuracy of the morning's work requiring will,
the writer had the swinging of the producing
Engine inside, that "motus animi continuus", in which
according to Cicero the essence of eloquence persists, even after the
Midday meal could not stop and the relieving
Slumber not found him, with increasing wear and tear
of his strength once was necessary during the day. So he had soon after
Tea sought the free, in the hope that air and movement would find him
restore it and help it to a profitable evening
would.
It was the beginning of May and, after wet and cold weeks, a wrong one
Midsummer occurred. The English Garden, although only tender
leafy, dull as in August and crowded near the city
Carriages and walkers. At the Aumeister, where quiet and
Aschenbach had walked the more quiet paths for a little while
overlooks a popular, lively pub garden, on the edge of which there are a few
Stops and equipages stopped from there when the sun was down
made his way home outside the park across the open corridor
and expected, since he felt tired and threatened thunderstorms over Foehring,
at the northern cemetery the tram that takes him in a straight line to the city
should bring back. By chance he found the stopping place and his
Environment of people empty. Neither on the paved
Ungererstrasse, the rail tracks of which glisten lonely against each other
Schwabing extended, was still on the Föhringer Chaussee
See wagon; behind the fences of the stonemasons where to buy
摘要
在这篇博文中,您了解了如何将 Tesseract 配置为 OCR 非英语语言。
大多数 Tesseract 安装会自然地处理多种语言,不需要额外的配置;但是,在某些情况下,您需要:
- 手动下载宇宙魔方语言包
- 设置
TESSDATA_PREFIX环境变量来指向语言包 - 请验证语言包目录是否正确
未能完成以上三个步骤可能会阻止您在非英语语言中使用 Tesseract,所以请确保您严格遵循本教程中的步骤!
如果你这样做,你不应该有任何非英语语言的 OCR 问题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
Tesseract OCR:文本定位和检测
原文:https://pyimagesearch.com/2020/05/25/tesseract-ocr-text-localization-and-detection/
在本教程中,您将学习如何利用 Tesseract 来检测、本地化和 OCR 文本,所有这些都在一个有效的函数调用中完成。

回到九月份,我向您展示了如何使用 OpenCV 检测和 OCR 文本。该方法分为三个阶段:
- 使用 OpenCV 的东方文本检测模型来检测图像中文本的存在
- 使用基本图像裁剪/数字阵列切片从图像中提取文本感兴趣区域(ROI)
- 获取文本 ROI,然后将它传递到 Tesseract 中以实际 OCR 文本
我们的方法工作得很好,但由于多阶段的过程,有点复杂和效率较低。
PyImageSearch 读者 Bryan 想知道是否有更好、更简化的方法:
嗨,阿德里安,
我注意到 OpenCV 的使用了东文检测模型。我假设文本检测也存在于宇宙魔方内部?
如果是这样的话,我们是否可以利用 Tesseract 来检测文本并对其进行 OCR,而无需调用额外的 OpenCV 函数?
你很幸运,布莱恩。**宇宙魔方有能力在一个函数调用**中执行文本检测和 OCR 吗——你会发现,这很容易做到!
要了解如何使用 Tesseract 检测、定位和 OCR 文本,请继续阅读。*
Tesseract OCR:文本定位和检测
在本教程的第一部分,我们将讨论文本检测和定位的概念。
从这里开始,我将向您展示如何在您的系统上安装 Tesseract。
然后,我们将使用 Tesseract 和 Python 实现文本本地化、检测和 OCR。
最后,我们将回顾我们的结果。
什么是文本定位和检测?
文本检测是定位图像文本所在的过程。
您可以将文本检测视为对象检测的一种特殊形式。
在对象检测中,我们的目标是(1)检测并计算图像中所有对象的边界框,以及(2)确定每个边界框的类别标签,类似于下图:
在文本检测中,我们的目标是自动计算图像中每个文本区域的边界框:
一旦我们有了这些区域,我们就可以对它们进行 OCR。
如何为宇宙魔方 OCR 安装宇宙魔方
在我的博客文章 OpenCV OCR 和使用 Tesseract 的文本识别中,我已经提供了安装 Tesseract OCR 引擎以及 pytesseract (用于与 tesseract 接口的 Python 绑定)的说明。
按照该教程的“如何安装 Tesseract 4”部分中的说明,确认您的 Tesseract 安装,然后回到这里学习如何使用 tessera CT 检测和本地化文本。
项目结构
去拿今天的。这篇博文的 【下载】 部分的 zip 文件。提取文件后,您将看到一个特别简单的项目布局:
% tree
.
├── apple_support.png
└── localize_text_tesseract.py
0 directories, 2 files
使用 Tesseract 实现文本本地化、文本检测和 OCR
# import the necessary packages
from pytesseract import Output
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-c", "--min-conf", type=int, default=0,
help="mininum confidence value to filter weak text detection")
args = vars(ap.parse_args())
我们从导入包开始,即 pytesseract 和 OpenCV。有关安装链接,请务必参考上面的“如何为 Tesseract OCR 安装 pytessera CT”部分。
接下来,我们解析两个命令行参数:
# load the input image, convert it from BGR to RGB channel ordering,
# and use Tesseract to localize each area of text in the input image
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pytesseract.image_to_data(rgb, output_type=Output.DICT)
# loop over each of the individual text localizations
for i in range(0, len(results["text"])):
# extract the bounding box coordinates of the text region from
# the current result
x = results["left"][i]
y = results["top"][i]
w = results["width"][i]
h = results["height"][i]
# extract the OCR text itself along with the confidence of the
# text localization
text = results["text"][i]
conf = int(results["conf"][i])
# filter out weak confidence text localizations
if conf > args["min_conf"]:
# display the confidence and text to our terminal
print("Confidence: {}".format(conf))
print("Text: {}".format(text))
print("")
# strip out non-ASCII text so we can draw the text on the image
# using OpenCV, then draw a bounding box around the text along
# with the text itself
text = "".join([c if ord(c) < 128 else "" for c in text]).strip()
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX,
1.2, (0, 0, 255), 3)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
用宇宙魔方和宇宙魔方执行 OCR 非常棒。
镶嵌文本本地化、文本检测和 OCR 结果
我们现在准备好用 Tesseract 执行文本检测和定位了!
确保使用本教程的 “下载” 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python localize_text_tesseract.py --image apple_support.png
Confidence: 26
Text: a
Confidence: 96
Text: Apple
Confidence: 96
Text: Support
Confidence: 96
$ python localize_text_tesseract.py --image apple_support.png --min-conf 50
Confidence: 96
Text: Apple
Confidence: 96
Text: Support
Confidence: 96
Text: 1-800-275-2273
摘要
在本教程中,您学习了如何使用 Tesseract 来检测文本,将其本地化,然后进行 OCR。
使用 Tesseract 执行文本检测和 OCR 的好处是,我们可以在一个函数调用中完成,这比多级 OpenCV OCR 过程更容易。
也就是说,OCR 仍然是计算机视觉的一个远未解决的领域。
每当遇到 OCR 项目时,一定要应用这两种方法,看看哪种方法能给你最好的结果——让你的经验结果来指导你。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
Tesseract 页面分割模式(PSMs)解释:如何提高您的 OCR 准确性
大多数介绍 Tesseract 的教程都会向您提供在您的机器上安装和配置 Tesseract 的说明,提供一两个如何使用tesseract二进制文件的例子,然后可能会提供如何使用一个库(如pytesseract — )将 Tesseract 与 Python 集成的例子。这些介绍教程的问题在于它们没有抓住页面分段模式(PSM)的重要性。让我们用 OCR 找到靶心。
Tesseract 页面分割模式(PSMs)讲解:如何提高您的 OCR 准确度
在阅读完这些指南后,计算机视觉/深度学习实践者得到的印象是,无论图像有多简单或多复杂,OCR 识别都像打开外壳、执行tesseract命令并提供输入图像的路径一样简单(即,没有额外的选项或配置)。
大多数情况下(对于复杂的图像,几乎总是),宇宙魔方要么:
- 无法光学字符识别(OCR) 图像中的任何文本,返回空结果
- 尝试对文本进行 OCR,但是完全不正确,返回无意义的结果
事实上,当我在大学开始使用 OCR 工具时,情况就是这样。我在网上阅读了一两个教程,浏览了文档,当我不能获得正确的 OCR 结果时,我很快变得沮丧。我完全不知道如何以及何时使用不同的选项。我甚至不知道有一半的选项是控制什么的,因为文档是如此的稀疏,没有提供具体的例子!
我犯的错误,也可能是我看到的现在初露头角的 OCR 从业者犯的最大问题之一,是没有完全理解 Tesseract 的页面分割模式如何能够显著地影响 OCR 输出的准确性。
当使用 Tesseract OCR 引擎时,你绝对必须对 Tesseract 的 PSM感到舒适——没有它们,你很快就会变得沮丧,并且无法获得高 OCR 准确度。*
在本教程中,您将了解关于 Tesseract 的 14 种页面分割模式的所有信息,包括:
- 他们做什么
- 如何设置它们
- 何时使用它们(从而确保您能够正确地对输入图像进行 OCR)
让我们开始吧!
学习目标
在本教程中,您将:
- 了解什么是页面分段模式(PSM)
- 了解选择 PSM 是如何区分正确的 OCR 结果和不正确的 OCR 结果的
- 查看 Tesseract OCR 引擎内置的 14 个 PSM
- 查看 14 种 PSM 的实际应用示例
- 使用这些 PSM 时,发现我的提示、建议和最佳实践
要了解如何使用 PSM 提高 OCR 结果, 继续阅读。
镶嵌页面分割模式
在本教程的第一部分,我们将讨论什么是页面分割模式(PSM),为什么它们很重要,以及它们如何显著地影响我们的 OCR 准确度。
在这里,我们将回顾本教程的项目目录结构,然后探究 Tesseract OCR 引擎内置的 14 个 PSM 中的每一个。
本教程将以讨论我的技巧、建议和使用 Tesseract 应用各种 PSM 时的最佳实践作为结束。
什么是页面分割模式?
我看到初学 OCR 的从业者无法获得正确的 OCR 结果的首要原因是他们使用了不正确的页面分割模式。引用宇宙魔方文档,默认情况下,宇宙魔方在分割输入图像 ( 提高输出质量 )时,期望有一页的文本。
“一页文字”的假设非常重要。如果你正在对一本书的扫描章节进行 OCR,默认的 Tesseract PSM 可能会很适合你。但是如果你试图只对一个单行,一个单字,或者甚至一个单字进行 OCR,那么这个默认模式将会导致一个空字符串或者无意义的结果。
把宇宙魔方想象成你小时候长大的大哥哥。他真心实意地关心你,希望看到你快乐——但与此同时,他毫不犹豫地把你推倒在沙盒里,让你满嘴砂砾,也不会伸出援助之手让你重新站起来。
我的一部分认为这是一个用户体验(UX)的问题,可以由宇宙魔方开发团队来改善。包括一条短信说:
没有得到正确的 OCR 结果?尝试使用不同的页面分段模式。运行
tesseract --help-extra可以看到所有的 PSM 模式。
也许他们甚至可以链接到一个教程,用简单易懂的语言解释每个 PSM。从那里,最终用户可以更成功地将 Tesseract OCR 引擎应用到他们自己的项目中。
但是在那个时候到来之前,Tesseract 的页面分割模式,尽管是获得高 OCR 准确度的一个关键方面,对许多 OCR 新手来说还是一个谜。他们不知道它们是什么,如何使用它们,为什么它们很重要— 许多人甚至不知道在哪里可以找到各种页面分割模式!
要列出 Tesseract 中的 14 个 PSM,只需向tesseract二进制文件提供--help-psm参数:
$ tesseract --help-psm
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
然后,您可以通过为--psm参数提供相应的整数值来应用给定的 PSM。
例如,假设我们有一个名为input.png的输入图像,我们想要使用 PSM 7,它用于 OCR 单行文本。因此,我们对tesseract的调用如下所示:
$ tesseract input.png stdout --psm 7
在本教程的其余部分,我们将回顾 14 个宇宙魔方 PSM 的每一个。您将获得使用它们的实践经验,并且在完成本教程后,您会对使用 Tesseract OCR 引擎正确识别图像的能力更加有信心。
项目结构
不像大多数教程,其中包括一个或多个 Python 脚本来回顾,本教程是为数不多的不利用 Python 的教程之一。相反,我们将使用tesseract二进制来探索每种页面分段模式。
请记住,本教程旨在了解 PSM 并获得使用它们的第一手经验。一旦你对它们有了很深的理解,这些知识就直接转移到 Python 上了。要在 Python 中设置 PSM,就像设置一个选项变量一样简单— 简单得不能再简单了,实际上只需要几次击键!
因此,我们将首先从tesseract二进制开始。
说完这些,让我们看看我们的项目目录结构:
|-- psm-0
| |-- han_script.jpg
| |-- normal.png
| |-- rotated_90.png
|-- psm-1
| |-- example.png
|-- psm-3
| |-- example.png
|-- psm-4
| |-- receipt.png
|-- psm-5
| |-- receipt_rotated.png
|-- psm-6
| |-- sherlock_holmes.png
|-- psm-7
| |-- license_plate.png
|-- psm-8
| |-- designer.png
|-- psm-9
| |-- circle.png
| |-- circular.png
|-- psm-10
| |-- number.png
|-- psm-11
| |-- website_menu.png
|-- psm-13
| |-- the_old_engine.png
如您所见,我们有 13 个目录,每个目录中都有一个示例图像,它会突出显示何时使用该特定的 PSM。
但是等等 … 我之前在教程里不是说宇宙魔方有 14 ,没有 13 吗,页面分割模式?如果是,为什么没有 14 个目录?
答案很简单——其中一个 PSM 没有在 Tesseract 中实现。它本质上只是未来潜在实现的占位符。
让我们开始探索使用 Tesseract 的页面分段模式吧!
PSM 0。仅定向和脚本检测
--psm 0模式并不执行 OCR,至少在本书的上下文中我们是这样认为的。当我们想到 OCR 时,我们会想到一个软件,它能够定位输入图像中的字符,识别它们,然后将它们转换为机器编码的字符串。
方向和文字检测(OSD)检查输入图像,但 OSD 返回两个值,而不是返回实际的 OCR 文本:
- 页面的方向,以度为单位,其中
angle = {0, 90, 180, 270} - 文字的置信度(即图形符号/ 书写系统),如拉丁文、汉文、西里尔文等。
OSD 最好用一个例子来看。看一下图 1 ,这里有三个示例图像。第一个是我第一本书 实用 Python 和 OpenCV 的一段文字。第二张是同一段文字,这次顺时针旋转了 90 度,最后的图像包含了汉文。
让我们从将tesseract应用到normal.png图像开始,该图像显示在图 1 中左上角处:
$ tesseract normal.png stdout --psm 0
Page number: 0
Orientation in degrees: 0
Rotate: 0
Orientation confidence: 11.34
Script: Latin
Script confidence: 8.10
在这里,我们可以看到,宇宙魔方已经确定这个输入图像是未旋转的(即 0),并且脚本被正确地检测为Latin。
现在让我们把同样的图像旋转 90 度,如图 1(右上)所示:
$ tesseract rotated_90.png stdout --psm 0
Page number: 0
Orientation in degrees: 90
Rotate: 270
Orientation confidence: 5.49
Script: Latin
Script confidence: 4.76
宇宙魔方确定输入的图像已经旋转了 90,为了纠正图像,我们需要将其旋转 270。同样,脚本被正确地检测为Latin。
最后一个例子,我们现在将把 Tesseract OSD 应用于汉字图像(图 1,底):
$ tesseract han_script.jpg stdout --psm 0
Page number: 0
Orientation in degrees: 0
Rotate: 0
Orientation confidence: 2.94
Script: Han
Script confidence: 1.43
注意脚本是如何被正确标记为Han的。
你可以把--psm 0模式想象成一种“元信息”模式,在这种模式下,宇宙魔方只为你提供输入图像的脚本和旋转——当应用这种模式时,宇宙魔方不会 OCR 实际文本并返回给你。
如果你需要只是文本上的元信息,使用--psm 0是适合你的模式;然而,很多时候我们需要 OCR 文本本身,在这种情况下,您应该使用本教程中介绍的其他 PSM。
PSM 1。带 OSD 的自动页面分割
关于--psm 1的 Tesseract 文档和示例并不完整,因此很难提供关于这种方法的详细研究和示例。我对--psm 1的理解是:
- 应该执行 OCR 的自动页面分割
- 并且应该在 OCR 过程中推断和利用 OSD 信息
然而,如果我们采用图 1 的中的图像,并使用此模式将它们通过tesseract,您可以看到没有 OSD 信息:
$ tesseract example.png stdout --psm 1
Our last argument is how we want to approximate the
contour. We use cv2.CHAIN_APPROX_SIMPLE to compress
horizontal, vertical, and diagonal segments into their end-
points only. This saves both computation and memory. If
we wanted all the points along the contour, without com-
pression, we can pass in cv2\. CHAIN_APPROX_NONE; however,
be very sparing when using this function. Retrieving all
points along a contour is often unnecessary and is wasteful
of resources.
这个结果让我觉得 Tesseract 一定是在内部执行 OSD 但是没有返回给用户。根据我对--psm 1的实验和经验,我认为可能是--psm 2没有完全工作/实现。
简单地说:在我所有的实验中,我找不到一种情况是--psm 1获得了其他 PSM 不能获得的结果。如果以后我发现这样的情况,我会更新这一部分,并提供一个具体的例子。但在那之前,我认为不值得在你的项目中应用--psm 1。
PSM 2。自动页面分割,但没有 OSD 或 OCR
在 Tesseract 中没有实现--psm 2模式。您可以通过运行tesseract --help-psm命令查看模式二的输出来验证这一点:
$ tesseract --help-psm
Page segmentation modes:
...
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
...
目前还不清楚 Tesseract 是否或何时会实现这种模式,但就目前而言,您可以放心地忽略它。
PSM 3。全自动页面分割,但没有 OSD
PSM 3 是宇宙魔方的默认行为。如果你运行tesseract二进制而没有明确提供一个--psm,那么将使用一个--psm 3。
在这种模式下,宇宙魔方将:
- 自动尝试对文本进行分段,将其视为包含多个单词、多行、多段等的文本“页面”。
- 分割后,Tesseract 将对文本进行 OCR,并将其返回给您
然而,重要的是要注意,宇宙魔方不会执行任何方向/脚本检测。为了收集这些信息,您需要运行两次tesseract:
- 一次用
--psm 0模式收集 OSD 信息 - 然后再次使用
--psm 3对实际文本进行 OCR
以下示例显示了如何获取一段文本,并在两个单独的命令中同时应用 OSD 和 OCR:
$ tesseract example.png stdout --psm 0
Page number: 0
Orientation in degrees: 0
Rotate: 0
Orientation confidence: 11.34
Script: Latin
Script confidence: 8.10
$ tesseract example.png stdout --psm 3
Our last argument is how we want to approximate the
contour. We use cv2.CHAIN_APPROX_SIMPLE to compress
horizontal, vertical, and diagonal segments into their end-
points only. This saves both computation and memory. If
we wanted all the points along the contour, without com-
pression, we can pass in cv2\. CHAIN_APPROX_NONE; however,
be very sparing when using this function. Retrieving all
points along a contour is often unnecessary and is wasteful
of resources.
同样,如果您只想要 OCR 处理的文本,可以跳过第一个命令。
PSM 4。假设一列可变大小的文本
使用--psm 4的一个很好的例子是当您需要 OCR 列数据并要求文本按行连接时(例如,您将在电子表格、表格或收据中找到的数据)。
例如,考虑图 2,这是杂货店的收据。让我们尝试使用默认(--psm 3)模式对该图像进行 OCR:
$ tesseract receipt.png stdout
ee
OLE
YOSDS:
cea eam
WHOLE FOODS MARKET - WESTPORT,CT 06880
399 POST RD WEST - (203) 227-6858
365
365
365
365
BACON LS
BACON LS
BACON LS
BACON LS
BROTH CHIC
FLOUR ALMOND
CHKN BRST BNLSS SK
HEAVY CREAM
BALSMC REDUCT
BEEF GRND 85/15
JUICE COF CASHEW C
DOCS PINT ORGANIC
HNY ALMOND BUTTER
wee TAX
.00
BAL
NP 4.99
NP 4.99
NP 4.99
NP 4.99
NP 2.19
NP 91.99
NP 18.80
NP 3.39
NP. 6.49
NP 5.04
ne £8.99
np £14.49
NP 9.99
101.33
aaa AAAATAT
ie
结果不太好。使用默认的--psm 3模式,Tesseract 无法推断我们正在查看列数据,并且同一行的文本应该关联在一起。
为了解决这个问题,我们可以使用--psm 4模式:
$ tesseract receipt.png stdout --psm 4
WHOLE
FOODS.
cea eam
WHOLE FOODS MARKET - WESTPORT,CT 06880
399 POST RD WEST - (203) 227-6858
365 BACONLS NP 4.99
365 BACON LS NP 4.99
365 BACONLS NP 4.99
365 BACONLS NP 4,99
BROTH CHIC NP 2.19
FLOUR ALMOND NP 91.99
CHKN BRST BNLSS SK NP 18.80
HEAVY CREAM NP 3.39
BALSMC REDUCT NP 6.49
BEEF GRND 85/15 NP 6.04
JUICE COF CASHEW C NP £8.99
DOCS PINT ORGANIC NP 14,49
HNY ALMOND BUTTER NP 9,99
wee TAX = 00 BAL 101.33
如你所见,这里的结果要好得多。 Tesseract 能够理解文本应该按行进行分组,从而允许我们对收据中的项目进行 OCR。
PSM 5。假设一个单一的垂直对齐的文本块
围绕--psm 5的文档有些混乱,因为它声明我们希望对垂直对齐的单个文本块进行 OCR。问题是“垂直对齐文本”的实际含义有点模糊(因为没有显示垂直对齐文本示例的 Tesseract 示例)。
对我来说,垂直对齐的文本要么放在页面顶部的、页面中间的、页面底部的。在图 3 的中,是顶部对齐(左)、中间对齐(中间)和底部对齐(右)的文本示例。**
然而,在我自己的实验中,我发现--psm 5与--psm 4、的工作方式相似,只是对于旋转的图像。*考虑图 4、图中,我们将一张收据顺时针旋转了 90 度来看看这个例子。
让我们首先应用默认的--psm 3:
$ tesseract receipt_rotated.png stdout
WHOLE
FOODS.
(mM AR K E T)
WHOLE FOODS MARKET - WESTPORT,CT 06880
399 POST RD WEST - (203) 227-6858
365 BACON LS
365 BACON LS
365 BACON LS
365 BACON LS
BROTH CHIC
FLOUR ALMOND
CHKN BRST BNLSS SK
HEAVY CREAM
BALSMC REDUCT
BEEF GRND 85/15
JUICE COF CASHEW C
DOCS PINT ORGANIC
HNY ALMOND BUTTER
eee TAX =.00 BAL
ee
NP 4.99
NP 4.99
NP 4,99
NP 4.99
NP 2.19
NP 1.99
NP 18.80
NP 3.39
NP 6.49
NP 8.04
NP £8.99
np "14.49
NP 9.99
101.33
aAnMAIATAAT AAA ATAT
ie
再说一次,我们在这里的结果并不好。虽然宇宙魔方可以纠正旋转,但我们没有收据的行元素。
为了解决这个问题,我们可以使用--psm 5:
$ tesseract receipt_rotated.png stdout --psm 5
Cea a amD
WHOLE FOODS MARKET - WESTPORT, CT 06880
399 POST RD WEST - (203) 227-6858
* 365 BACONLS NP 4.99 F
* 365 BACON LS NP 4.99 F
* 365 BACONLS NP 4,99 F*
* 365 BACONLS NP 4.99 F
* BROTH CHIC NP 2.19 F
* FLOUR ALMOND NP 1.99 F
* CHKN BRST BNLSS SK NP 18.80 F
* HEAVY CREAM NP 3.39 F
* BALSMC REDUCT NP 6.49 F
* BEEF GRND 85/1§ NP {6.04 F
* JUICE COF CASHEW C NP [2.99 F
*, DOCS PINT ORGANIC NP "14.49 F
* HNY ALMOND BUTTER NP 9,99
wee TAX = 00 BAL 101.33
在旋转后的收据图像上,我们的 OCR 结果现在要好得多。
PSM 6。假设一个统一的文本块
我喜欢用--psm 6来识别简单书籍的页面(例如,一本平装小说)。书中的页面倾向于在整本书中使用单一、一致的字体。同样,这些书遵循简单的页面结构,这对于 Tesseract 来说很容易解析和理解。
这里的关键字是 统一文本, 的意思是文本是没有任何变化的单一字体。
下面显示了在默认--psm 3模式下,对夏洛克·福尔摩斯小说(图 5)中的单个统一文本块应用宇宙魔方的结果:
$ tesseract sherlock_holmes.png stdout
CHAPTER ONE
we
Mr. Sherlock Holmes
M: Sherlock Holmes, who was usually very late in the morn-
ings, save upon those not infrequent occasions when he
was up all night, was seated at the breakfast table. I stood upon
the hearth-rug and picked up the stick which our visitor had left
behind him the night before. It was a fine, thick piece of wood,
bulbous-headed, of the sort which is known as a “Penang lawyer.”
Just under the head was a broad silver band nearly an inch across.
“To James Mortimer, M.R.C.S., from his friends of the C.C.H.,”
was engraved upon it, with the date “1884.” It was just such a
stick as the old-fashioned family practitioner used to carry--dig-
nified, solid, and reassuring.
“Well, Watson, what do you make of it2”
Holmes w:
sitting with his back to me, and I had given him no
sign of my occupation.
“How did you know what I was doing? I believe you have eyes in
the back of your head.”
“L have, at least, a well-polished, silver-plated coffee-pot in front
of me,” said he. “But, tell me, Watson, what do you make of our
visitor's stick? Since we have been so unfortunate as to miss him
and have no notion of his errand, this
accidental souvenir be-
comes of importance, Let me hear you reconstruct the man by an
examination of it.”
为了节省空间,我从上面的输出中删除了许多换行符。如果您在自己的系统中运行上面的命令,您会看到输出比文本中显示的更加混乱。
通过使用--psm 6模式,我们能够更好地对这一大块文本进行 OCR:
$ tesseract sherlock_holmes.png stdout --psm 6
CHAPTER ONE
SS
Mr. Sherlock Holmes
M Sherlock Holmes, who was usually very late in the morn
ings, save upon those not infrequent occasions when he
was up all night, was seated at the breakfast table. I stood upon
the hearth-rug and picked up the stick which our visitor had left
behind him the night before. It was a fine, thick piece of wood,
bulbous-headed, of the sort which is known as a “Penang lawyer.”
Just under the head was a broad silver band nearly an inch across.
“To James Mortimer, M.R.C.S., from his friends of the C.C.H.,”
was engraved upon it, with the date “1884.” It was just such a
stick as the old-fashioned family practitioner used to carry--dig-
nified, solid, and reassuring.
“Well, Watson, what do you make of it2”
Holmes was sitting with his back to me, and I had given him no
sign of my occupation.
“How did you know what I was doing? I believe you have eyes in
the back of your head.”
“T have, at least, a well-polished, silver-plated coflee-pot in front
of me,” said he. “But, tell me, Watson, what do you make of our
visitor’s stick? Since we have been so unfortunate as to miss him
and have no notion of his errand, this accidental souvenir be-
comes of importance. Let me hear you reconstruct the man by an
examination of it.”
6
这个输出中的错误要少得多,从而演示了如何使用--psm 6来 OCR 统一文本块。
PSM 7。将图像视为单个文本行
当你处理一个单行的统一文本时,应该使用--psm 7模式。例如,让我们假设我们正在构建一个自动牌照/号码牌识别(ANPR)系统,并且需要对图图 6 中的牌照进行 OCR。
让我们从使用默认的--psm 3模式开始:
$ tesseract license_plate.png stdout
Estimating resolution as 288
Empty page!!
Estimating resolution as 288
Empty page!!
默认的宇宙魔方模式停滞不前,完全无法识别车牌。
但是,如果我们使用--psm 7并告诉 Tesseract 将输入视为单行统一文本,我们就能够获得正确的结果:
$ tesseract license_plate.png stdout --psm 7
MHOZDW8351
PSM 8。将图像视为一个单词
如果你有一个统一文本的单字,你应该考虑使用--psm 8。一个典型的使用案例是:
- 对图像应用文本检测
- 在所有文本 ROI 上循环
- 提取它们
- 将每个单独的文本 ROI 通过 Tesseract 进行 OCR
例如,让我们考虑一下图 7 ,这是一张店面的照片。我们可以尝试使用默认的--psm 3模式对该图像进行 OCR:
$ tesseract designer.png stdout
MS atts
但不幸的是,我们得到的都是胡言乱语。
为了解决这个问题,我们可以使用--psm 8,告诉 Tesseract 绕过任何页面分割方法,而是将该图像视为一个单词:
$ tesseract designer.png stdout --psm 8
Designer
果然,--psm 8能够解决问题!
此外,您可能会发现--psm 7和--psm 8可以互换使用的情况——两者的功能类似,因为我们分别在查看单行或单字。
PSM 9。将图像视为圆圈中的一个单词
我已经玩了几个小时的--psm 9模式,真的,我不知道它能做什么。我已经搜索了谷歌并阅读了宇宙魔方文档,但是一无所获——我找不到一个关于圆形 PSM 打算做什么的具体例子。
对我来说,这个参数有两种解读方式(图 8 ):
- 文字其实是圆圈内的(左)
- 文字被包裹在一个看不见的圆形/弧形区域(右)
对我来说,第二种选择似乎更有可能,但是无论我怎么努力,我都无法让这个参数起作用。我认为可以放心地假设这个参数很少使用——此外,实现可能会有一点问题。我建议尽量避免这种 PSM。
PSM 10。将图像视为单个字符
当已经从图像中提取出每个单独的字符时,就应该将图像视为单个字符。
回到我们在 ANPR 的例子,假设您已经在输入图像中定位了车牌,然后提取了车牌上的每个字符——然后您可以使用--psm 10将每个字符通过 Tesseract 进行 OCR。
图 9 显示了数字2的一个例子。让我们试着用默认的--psm 3进行 OCR:
$ tesseract number.png stdout
Estimating resolution as 1388
Empty page!!
Estimating resolution as 1388
Empty page!!
Tesseract 试图应用自动页面分割方法,但是由于没有实际的文本“页面”,默认的--psm 3失败并返回一个空字符串。
我们可以通过--psm 10将输入图像视为单个字符来解决这个问题:
$ tesseract number.png stdout --psm 10
2
果然,--psm 10解决了这件事!
PSM 11。稀疏文本:找到尽可能多的文本,不分先后
当图像中有大量文本需要提取时,检测稀疏文本会很有用。当使用这种模式时,你通常不关心文本的顺序/分组,而是关心文本本身的 T2。
如果您通过 OCR 在图像数据集中找到的所有文本来执行信息检索(即文本搜索引擎),然后通过信息检索算法(tf-idf、倒排索引等)构建基于文本的搜索引擎,则此信息非常有用。).
图 10 显示了一个稀疏文本的例子。这里有我在 PyImageSearch 上 【入门】 页面的截图。该页面提供按流行的计算机视觉、深度学习和 OpenCV 主题分组的教程。
让我们尝试使用默认的--psm 3来 OCR 这个主题列表:
$ tesseract website_menu.png stdout
How Do | Get Started?
Deep Learning
Face Applications
Optical Character Recognition (OCR)
Object Detection
Object Tracking
Instance Segmentation and Semantic
Segmentation
Embedded and lol Computer Vision
Computer Vision on the Raspberry Pi
Medical Computer Vision
Working with Video
Image Search Engines
Interviews, Case Studies, and Success Stories
My Books and Courses
虽然 Tesseract 可以对文本进行 OCR,但是有几个不正确的行分组和额外的空白。额外的空白和换行符是 Tesseract 的自动页面分割算法工作的结果——这里它试图推断文档结构,而实际上没有文档结构。
为了解决这个问题,我们可以用--psm 11将输入图像视为稀疏文本:
$ tesseract website_menu.png stdout --psm 11
How Do | Get Started?
Deep Learning
Face Applications
Optical Character Recognition (OCR)
Object Detection
Object Tracking
Instance Segmentation and Semantic
Segmentation
Embedded and lol Computer Vision
Computer Vision on the Raspberry Pi
Medical Computer Vision
Working with Video
Image Search Engines
Interviews, Case Studies, and Success Stories
My Books and Courses
这次来自宇宙魔方的结果要好得多。
PSM 12。带 OSD 的稀疏文本
--psm 12模式与--psm 11基本相同,但现在增加了 OSD(类似于--psm 0)。
也就是说,我在让这种模式正常工作时遇到了很多问题,并且找不到结果与--psm 11有意义不同的实际例子。
我觉得有必要说一下--psm 12的存在;然而,在实践中,如果您想要复制预期的--psm 12行为,您应该使用--psm 0(用于 OSD)后跟--psm 11(用于稀疏文本的 OCR)的组合。
PSM 13。原始行:将图像视为一个单独的文本行,绕过特定于宇宙魔方的 Hacks】
有时,OSD、分段和其他内部特定于 Tesseract 的预处理技术会通过以下方式损害 OCR 性能:
- 降低精确度
- 根本没有检测到文本
通常,如果一段文本被紧密裁剪,该文本是计算机生成的/以某种方式风格化的,或者它是 Tesseract 可能无法自动识别的字体,就会发生这种情况。当这种情况发生时,考虑将--psm 13作为“最后手段”
要查看这种方法的实际应用,请考虑图 11 中的文本“旧引擎”以风格化的字体打印,类似于旧时代的报纸。
让我们尝试使用默认的--psm 3来 OCR 这个图像:
$ tesseract the_old_engine.png stdout
Warning. Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 491
Estimating resolution as 491
Tesseract 无法对图像进行 OCR,返回一个空字符串。
现在让我们使用--psm 13,绕过所有页面分割算法和镶嵌预处理函数,从而将图像视为一行原始文本:
$ tesseract the_old_engine.png stdout --psm 13
Warning. Invalid resolution 0 dpi. Using 70 instead.
THE OLD ENGINE.
这一次我们能够正确地使用--psm 13对文本进行 OCR!
使用--psm 13有时有点麻烦,所以先尝试其他页面分割模式。
【Tips 的技巧、建议和最佳实践
习惯宇宙魔方中的页面分割模式需要 练习——没有别的办法。我强烈建议你:
- 多次阅读本教程
- 运行本教程文本中包含的示例
- 然后开始用你自己的图像练习
不幸的是,Tesseract 没有包括太多关于 PSM 的文档,也没有容易参考的具体例子。本教程尽我所能为您提供尽可能多的关于 PSM 的信息,包括您何时想要使用每种 PSM 的实际例子。
也就是说,这里有一些提示和建议可以帮助您快速使用 PSM:
- 总是从默认的
--psm 3开始,看看宇宙魔方吐出什么。在最好的情况下,OCR 结果是准确的,您就大功告成了。在最坏的情况下,你现在有一个基线要超越。 - 虽然我提到过
--psm 13是一种“最后手段”的模式,但我还是建议第二次使用它。这个模式出奇的好,尤其是如果你已经预处理了你的图像和二值化了你的文本。如果--psm 13起作用,你可以停止或者将你的努力集中在模式 4-8 上,因为它们中的一个很可能会代替模式 13。 - 接下来,应用
--psm 0验证旋转和脚本是否被正确检测。如果不是这样,期望 Tesseract 在不能正确检测旋转角度和脚本/书写系统的图像上表现良好是不合理的。 - 如果脚本和角度被正确检测,你需要遵循本教程中的指导方针。具体来说,您应该关注 PSM 4-8、10 和 11。避免 PSMs 1、2、9 和 12,除非您认为它们有特定的用例。
- 最后,您可能要考虑强制使用它。依次尝试 1-13 中的每种模式。这是一种“往墙上扔意大利面,看看会粘上什么”的黑客行为,但你有时会很幸运。
如果你发现宇宙魔方没有给你想要的精度不管你用的是什么页面分割模式,不要惊慌或沮丧——这都是过程的一部分。OCR 部分是艺术,部分是科学。列奥纳多·达·芬奇并没有一开始就画蒙娜丽莎。这是一项需要练习才能获得的技能。
*我们只是触及了 OCR 的皮毛。未来的教程将进行更深入的探讨,并帮助您更好地磨练这种艺术。通过实践,如图 12 所示,您也将通过您的 OCR 项目击中靶心。
总结
在本教程中,您学习了 Tesseract 的 14 种页面分段模式(PSM)。应用正确的 PSM 对于正确地对输入图像进行 OCR 是绝对关键的。
简而言之,你在 PSM 中的选择可能意味着一张精确 OCR 的图像与从宇宙魔方得到的无结果或无意义结果之间的差异。
Tesseract 中的 14 个 PSM 中的每一个都对您的输入图像做出假设,例如一个文本块(例如,扫描的一章)、一行文本(可能是一章中的一句话),甚至是一个单词(例如,牌照/车牌)。
获得准确 OCR 结果的关键是:
- 使用 OpenCV(或您选择的图像处理库)来清理您的输入图像,去除噪声,并可能从背景中分割文本
- 应用 Tesseract,注意使用与任何预处理输出相对应的正确 PSM
例如,如果您正在构建一个自动车牌识别器(我们将在以后的教程中完成),那么我们将利用 OpenCV 首先检测图像中的车牌。这可以使用图像处理技术或专用对象检测器来完成,例如 HOG +线性 SVM 、fast R-CNN、 SSD 、 YOLO 等。
一旦我们检测到车牌,我们将从车牌中分割出字符,这样字符在黑色背景下显示为白色(前景)。
最后一步是将二进制化的车牌字符通过 Tesseract 进行 OCR。我们在 PSM 中的选择将是正确的和错误的结果之间的差异。
因为牌照可以被看作是“单行文本”或“单个单词”,所以我们想要尝试使用--psm 7或--psm 8。一个--psm 13 可能也能工作,但是使用默认的(--psm 3)在这里不太可能工作,因为我们已经已经处理了我们的图像质量。
我强烈建议你花相当多的时间探索本教程中的所有例子,甚至回过头来再读一遍——从 Tesseract 的页面分割模式中可以获得如此多的知识。
从那里,开始应用各种 PSM 到你自己的图像。一路记录你的结果:
- 他们是你所期望的吗?
- 你得到正确的结果了吗?
- Tesseract 是否未能对图像进行 OCR,返回空字符串?
- 宇宙魔方是否返回了完全无意义的结果?
你对 PSM 的实践越多,你获得的经验就越多,这将使你更容易正确地将 OCR 应用到你自己的项目中。*****
使用 amazon 识别 api 进行文本检测和 ocr
原文:https://pyimagesearch.com/2022/03/21/text-detection-and-ocr-with-amazon-rekognition-api/
使用亚马逊 Rekognition API 进行文本检测和 OCR
在本教程中,您将:
- 了解 Amazon Rekognition API
- 了解如何将 amazon 识别 api 用于 ocr
- 获取您的亚马逊网络服务(AWS)认证密钥
- 安装 Amazon 的
boto3包来与 OCR API 接口 - 实现一个与 Amazon Rekognition API 接口的 Python 脚本来 OCR 图像
本课是关于 文本检测和 OCR 的 3 部分系列的第 1 部分:
- 使用亚马逊 Rekognition API 进行文本检测和 OCR(今日教程)
- 微软认知服务的文本检测和 OCR
- 使用谷歌云视觉 API 进行文本检测和 OCR
要了解文本检测和 OCR, 继续阅读。
使用亚马逊 Rekognition API 进行文本检测和 OCR
到目前为止,我们主要关注于使用 Tesseract OCR 引擎。然而,其他光学字符识别(OCR)引擎也是可用的,其中一些比 Tesseract 更精确,甚至在复杂、不受约束的条件下也能准确地识别文本。
通常,这些 OCR 引擎位于云中。许多是基于专利的。为了保持这些模型和相关数据集的私有性,公司并不自己分发模型,而是将它们放在 REST API 后面。
虽然这些模型确实比 Tesseract 更精确,但也有一些缺点,包括:
- OCR 图像需要互联网连接,这对于大多数笔记本电脑/台式机来说不是问题,但如果您在边缘工作,互联网连接可能是不可能的
- 此外,如果您正在使用边缘设备,那么您可能不希望在网络连接上消耗功率
- 网络连接会带来延迟
- OCR 结果需要更长时间,因为图像需要打包到 API 请求中并上传到 OCR API。API 将需要咀嚼图像并对其进行 OCR,然后最终将结果返回给客户端
- 由于 OCR 处理每幅图像的延迟和时间,这些 OCR APIs 能否实时运行是个疑问
- 它们是要花钱的(但是通常提供免费试用,或者每月有一定数量的 API 请求是免费的)
看着前面的列表,你可能想知道我们到底为什么要覆盖这些 APIs 好处是什么?
正如您将看到的,这里的主要好处是准确性。首先,考虑一下谷歌和微软运行各自的搜索引擎所获得的数据量。然后,考虑一下亚马逊每天从打印运输标签中产生的数据量。
这些公司拥有令人难以置信的数量的图像数据——当他们根据自己的数据训练他们新颖、先进的 OCR 模型时,结果是一个 令人难以置信的 健壮而准确的 OCR 模型。*
*在本教程中,您将学习如何使用 Amazon Rekognition API 来 OCR 图像。在即将到来的教程中,我们将涵盖微软 Azure 认知服务和谷歌云视觉 API。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install boto3
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
亚马逊用于 OCR 的识别 API
本教程的第一部分将着重于获取您的 AWS 重新识别密钥。这些密钥将包括一个公共访问密钥和一个秘密密钥,类似于 SSH、SFTP 等。
然后,我们将向您展示如何安装用于 Python 的亚马逊 Web 服务(AWS)软件开发工具包(SDK)boto3。最后,我们将使用boto3包与 Amazon Rekognition OCR API 接口。
接下来,我们将实现我们的 Python 配置文件(它将存储我们的访问密钥、秘密密钥和 AWS 区域),然后创建我们的驱动程序脚本,用于:
- 从磁盘加载输入图像
- 将其打包成一个 API 请求
- 将 api 请求发送到 aws 识别以进行 ocr
- 从 API 调用中检索结果
- 显示我们的 OCR 结果
我们将讨论我们的结果来结束本教程。
获取您的 AWS 识别密钥
您将需要从我们的伙伴网站获取更多信息,以获得有关获取您的 AWS 重新识别密钥的说明。你可以在这里找到说明。
安装亚马逊的 Python 包
为了与 Amazon Rekognition API 接口,我们需要使用boto3包:AWS SDK。幸运的是,boto3安装起来非常简单,只需要一个pip -install 命令:
$ pip install boto3
如果您正在使用 Python 虚拟环境或 Anaconda 环境,请确保在运行上述命令之前,使用适当的命令访问您的 Python 环境(否则,boto3将被安装在 Python 的系统安装中)。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
在使用 Amazon Rekognition API 执行文本检测和 OCR 之前,我们首先需要回顾一下我们的项目目录结构。
|-- config
| |-- __init__.py
| |-- aws_config.py
|-- images
| |-- aircraft.png
| |-- challenging.png
| |-- park.png
| |-- street_signs.png
|-- amazon_ocr.py
aws_config.py文件包含我们的 AWS 访问密钥、秘密密钥和区域。在 获取 AWS 识别密钥 一节中,您学习了如何获取这些值。
我们的amazon_ocr.py脚本将获取这个aws_config,连接到 Amazon Rekognition API,然后对我们的images目录中的每张图像执行文本检测和 OCR。
创建我们的配置文件
为了连接到 Amazon Rekognition API,我们首先需要提供我们的访问密钥、秘密密钥和区域。如果您尚未获得这些密钥,请转到 获取您的 AWS 重新识别密钥 部分,并确保按照步骤操作并记下值。
之后,您可以回到这里,打开aws_config.py,并更新代码:
# define our AWS Access Key, Secret Key, and Region
ACCESS_KEY = "YOUR_ACCESS_KEY"
SECRET_KEY = "YOUR_SECRET_KEY"
REGION = "YOUR_AWS_REGION"
共享我的 API 键会违反安全性,所以我在这里留了占位符值。确保用您的 API 密钥更新它们;否则,您将无法连接到 Amazon Rekognition API。
实现亚马逊 Rekognition OCR 脚本
实现了我们的aws_config之后,让我们转到amazon_ocr.py脚本,它负责:
- 连接到亚马逊识别 api
- 从磁盘载入输入图像
- 在 API 请求中打包图像
- 将包发送到 amazon recognition api 进行 ocr
- 从 Amazon Rekognition API 获取 OCR 结果
- 显示我们的输出文本检测和 OCR 结果
让我们开始实施:
# import the necessary packages
from config import aws_config as config
import argparse
import boto3
import cv2
第 2-5 行导入我们需要的 Python 包。值得注意的是,我们需要我们的aws_config,以及boto3,它是亚马逊的 Python 包,来与他们的 API 接口。
现在让我们定义draw_ocr_results,这是一个简单的 Python 实用程序,用于从 Amazon Rekognition API 中提取输出 OCR 结果:
def draw_ocr_results(image, text, poly, color=(0, 255, 0)):
# unpack the bounding box, taking care to scale the coordinates
# relative to the input image size
(h, w) = image.shape[:2]
tlX = int(poly[0]["X"] * w)
tlY = int(poly[0]["Y"] * h)
trX = int(poly[1]["X"] * w)
trY = int(poly[1]["Y"] * h)
brX = int(poly[2]["X"] * w)
brY = int(poly[2]["Y"] * h)
blX = int(poly[3]["X"] * w)
blY = int(poly[3]["Y"] * h)
draw_ocr_results函数接受四个参数:
- 我们正在其上绘制 OCR 文本的输入图像
text:OCR 识别的文本本身poly:Amazon Rekognition API 返回的文本包围盒的多边形对象/坐标color:边框的颜色
第 10 行获取我们正在绘制的image的宽度和高度。第 11-18 行然后抓取文本 ROI 的边界框坐标,注意按宽度和高度缩放坐标。
我们为什么要执行这个缩放过程?
嗯,正如我们将在本教程后面发现的,Amazon Rekognition API 返回范围[0, 1] 中的边界框。将边界框乘以原始图像的宽度和高度会使边界框回到原始图像的比例。
从那里,我们现在可以注释image:
# build a list of points and use it to construct each vertex
# of the bounding box
pts = ((tlX, tlY), (trX, trY), (brX, brY), (blX, blY))
topLeft = pts[0]
topRight = pts[1]
bottomRight = pts[2]
bottomLeft = pts[3]
# draw the bounding box of the detected text
cv2.line(image, topLeft, topRight, color, 2)
cv2.line(image, topRight, bottomRight, color, 2)
cv2.line(image, bottomRight, bottomLeft, color, 2)
cv2.line(image, bottomLeft, topLeft, color, 2)
# draw the text itself
cv2.putText(image, text, (topLeft[0], topLeft[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
# return the output image
return image
第 22-26 行建立对应于边界框每个顶点的点列表。给定顶点,第 29-32 行画出旋转文本的边界框。第 35 行和第 36 行绘制 OCR 文本本身。
然后,我们将带注释的输出image返回给调用函数。
定义了 helper 实用程序后,让我们继续讨论命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image that we'll submit to AWS Rekognition")
ap.add_argument("-t", "--type", type=str, default="line",
choices=["line", "word"],
help="output text type (either 'line' or 'word')")
args = vars(ap.parse_args())
--image命令行参数对应于我们想要提交给 Amazon Rekognition OCR API 的输入图像的路径。
--type参数可以是line或word,表示我们是否希望 Amazon Rekognition API 返回分组为行或单个单词的 OCR 结果。
接下来,让我们连接到亚马逊网络服务:
# connect to AWS so we can use the Amazon Rekognition OCR API
client = boto3.client(
"rekognition",
aws_access_key_id=config.ACCESS_KEY,
aws_secret_access_key=config.SECRET_KEY,
region_name=config.REGION)
# load the input image as a raw binary file and make a request to
# the Amazon Rekognition OCR API
print("[INFO] making request to AWS Rekognition API...")
image = open(args["image"], "rb").read()
response = client.detect_text(Image={"Bytes": image})
# grab the text detection results from the API and load the input
# image again, this time in OpenCV format
detections = response["TextDetections"]
image = cv2.imread(args["image"])
# make a copy of the input image for final output
final = image.copy()
51-55 号线连接到 AWS。在这里,我们提供访问密钥、秘密密钥和区域。
一旦连接好,我们就从磁盘中加载输入图像作为二进制对象(第 60 行),然后通过调用detect_text函数并提供我们的image将它提交给 AWS。
调用detect_text会导致来自 Amazon Rekognition API 的response。我们接着抓取TextDetections结果(第 65 行)。
第 66 行以 OpenCV 格式从磁盘加载输入--image,而第 69 行克隆图像以在其上绘制。
我们现在可以在 Amazon Rekognition API 的文本检测边界框上循环:
# loop over the text detection bounding boxes
for detection in detections:
# extract the OCR'd text, text type, and bounding box coordinates
text = detection["DetectedText"]
textType = detection["Type"]
poly = detection["Geometry"]["Polygon"]
# only draw show the output of the OCR process if we are looking
# at the correct text type
if args["type"] == textType.lower():
# draw the output OCR line-by-line
output = image.copy()
output = draw_ocr_results(output, text, poly)
final = draw_ocr_results(final, text, poly)
# show the output OCR'd line
print(text)
cv2.imshow("Output", output)
cv2.waitKey(0)
# show the final output image
cv2.imshow("Final Output", final)
cv2.waitKey(0)
第 72 行遍历亚马逊的 OCR API 返回的所有detections。然后,我们提取经过 OCR 处理的text、textType(或者是 "word" 或者是 "line" ),以及经过 OCR 处理的文本的边界框坐标(第 74 行和第 75 行)。
第 80 行进行检查,以验证我们正在查看的是word还是line OCR 文本。如果当前的textType匹配我们的--type命令行参数,我们在output映像和我们的final克隆映像上调用我们的draw_ocr_results函数(第 82-84 行)。
第 87-89 行在我们的终端和屏幕上显示当前 OCR 识别的行或单词。这样,我们可以很容易地看到每一行或每一个单词,而不会使输出图像变得过于混乱。
最后,行 92 和 93 显示了在我们的屏幕上一次绘制所有文本的结果(为了可视化的目的)。
亚马逊 Rekognition OCR 结果
恭喜你实现了一个 Python 脚本来与 Amazon Rekognition 的 OCR API 接口!
让我们看看实际效果,首先逐行对整个图像进行光学字符识别:
$ python amazon_ocr.py --image images/aircraft.png
[INFO] making request to AWS Rekognition API...
WARNING!
LOW FLYING AND DEPARTING AIRCRAFT
BLAST CAN CAUSE PHYSICAL INJURY
图 2 显示我们已经成功地逐行对输入的aircraft.png图像进行了 OCR,从而证明 Amazon Rekognition API 能够:
- 定位输入图像中的每个文本块
- OCR 每个文本 ROI
- 将文本块分组成行
但是如果我们想在单词级别而不是行级别获得我们的 OCR 结果呢?
这就像提供--type命令行参数一样简单:
$ python amazon_ocr.py --image images/aircraft.png --type word
[INFO] making request to AWS Rekognition API...
WARNING!
LOW
FLYING
AND
DEPARTING
AIRCRAFT
BLAST
CAN
CAUSE
PHYSICAL
INJURY
正如我们的输出和图 3 所示,我们现在在单词级别上对文本进行 OCR。
我是 Amazon Rekognition 的 OCR API 的忠实粉丝。而 AWS、EC2 等。确实有一点学习曲线,好处是一旦你知道了,你就理解了亚马逊的整个网络服务生态系统,这使得开始集成不同的服务变得更加容易。
我也很欣赏亚马逊 Rekognition API 的入门超级简单。其他服务(例如 Google Cloud Vision API)让“第一次轻松获胜”变得更加困难。如果这是您第一次尝试使用云服务 API,那么在使用微软认知服务或谷歌云视觉 API 之前,一定要考虑先使用 Amazon Rekognition API。
汇总
在本教程中,您学习了如何创建 Amazon Rekognition 密钥,安装boto3,这是一个用于与 AWS 接口的 Python 包,以及实现一个 Python 脚本来调用 Amazon Rekognition API。
Python 脚本很简单,只需要不到 100 行代码就可以实现(包括注释)。
我们的 Amazon Rekognition OCR API 结果不仅是正确的,而且我们还可以在行和字级别解析结果,比 EAST text 检测模型和 Tesseract OCR 引擎提供的粒度更细(至少不需要微调几个选项)。
在下一课中,我们将了解用于 OCR 的 Microsoft 认知服务 API。
引用信息
Rosebrock,A. “使用亚马逊 Rekognition API 的文本检测和 OCR”, PyImageSearch ,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki 编辑。,2022 年,https://pyimg.co/po6tf
@incollection{Rosebrock_2022_OCR_Amazon_Rekognition_API,
author = {Adrian Rosebrock},
title = {Text Detection and OCR with Amazon Rekognition API},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/po6tf},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 Google Cloud Vision API 进行文本检测和 OCR
原文:https://pyimagesearch.com/2022/03/31/text-detection-and-ocr-with-google-cloud-vision-api/
使用谷歌云视觉 API 进行文本检测和 OCR
在本课中,您将:
- 了解如何从 Google Cloud 管理面板获取您的 Google Cloud Vision API keys/JSON 配置文件
- 配置您的开发环境,以便与 Google Cloud Vision API 一起使用
- 实现用于向 Google Cloud Vision API 发出请求的 Python 脚本
本课是关于文本检测和 OCR 的 3 部分系列的最后一部分:
- 使用亚马逊 Rekognition API 进行文本检测和 OCR
- 微软认知服务的文本检测和 OCR
- 使用谷歌云视觉 API 进行文本检测和 OCR(本教程)
要了解谷歌云视觉 API 的文本检测和 OCR, 继续阅读。
使用谷歌云视觉 API 进行文本检测和 OCR
在今天的课程中,我们将了解 Google Cloud Vision API。代码方面,Google Cloud Vision API 很好用。不过,它要求我们使用他们的管理面板来生成一个客户端 JavaScript 对象符号(JSON)文件,该文件包含访问 Vision API 所需的所有信息。
我们对 JSON 文件有着复杂的感情。一方面,不必硬编码我们的私有和公共密钥是件好事。但是另一方面,使用管理面板来生成 JSON 文件本身也很麻烦。
实际上,这是一种“一个六个,另一个半打”的情况这并没有太大的区别(只是一些需要注意的事情)。
正如我们将发现的,谷歌云视觉 API,就像其他的一样,往往非常准确,在复杂图像的 OCR 方面做得很好。
让我们开始吧!
用于 OCR 的谷歌云视觉 API
在本课的第一部分,您将了解 Google Cloud Vision API,以及如何获取 API 密钥和生成 JSON 配置文件,以便使用 API 进行身份验证。
从那里,我们将确保您的开发环境正确配置了所需的 Python 包,以便与 Google Cloud Vision API 接口。
然后,我们将实现一个 Python 脚本,该脚本获取一个输入图像,将其打包到一个 API 请求中,并将其发送到用于 OCR 的 Google Cloud Vision API。
我们将通过讨论我们的结果来结束本课。
获取您的谷歌云视觉 API 密钥
先决条件
使用 Google Cloud Vision API 只需要一个启用了计费的 Google Cloud 帐户。你可以在这里找到关于如何修改你的账单设置的谷歌云指南。
启用 Google Cloud Vision API 并下载凭证的步骤
你可以在我们的书里找到获取密钥的指南, OCR with OpenCV,Tesseract,和 Python 。
为 Google Cloud Vision API 配置您的开发环境
为了遵循这个指南,您需要在您的系统上安装 OpenCV 库和google-cloud-vision Python 包。
幸运的是,两者都是 pip 可安装的:
$ pip install opencv-contrib-python
$ pip install --upgrade google-cloud-vision
如果您正在使用 Python 虚拟环境或 Anaconda 包管理器,请确保在运行上面的pip -install 命令之前,使用适当的命令访问您的 Python 环境。否则,google-cloud-vision包将被安装在您的系统 Python 中,而不是您的 Python 环境中。
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
让我们检查一下 Google Cloud Vision API OCR 项目的项目目录结构:
|-- images
| |-- aircraft.png
| |-- challenging.png
| |-- street_signs.png
|-- client_id.json
|-- google_ocr.py
我们将把我们的google_ocr.py脚本应用于images目录中的几个例子。
client_id.json文件提供了所有必要的凭证和认证信息。google_ocr.py脚本将加载这个文件,并将其提供给 Google Cloud Vision API 来执行 OCR。
实现谷歌云视觉 API 脚本
回顾了我们的项目目录结构后,我们可以继续实现google_ocr.py,Python 脚本负责:
- 加载我们的
client_id.json文件的内容 - 连接到 Google Cloud Vision API
- 将输入图像加载并提交给 API
- 检索文本检测和 OCR 结果
- 在屏幕上绘制和显示 OCR 文本
让我们开始吧:
# import the necessary packages
from google.oauth2 import service_account
from google.cloud import vision
import argparse
import cv2
import io
第 2-6 行导入我们需要的 Python 包。注意,我们需要service_account来连接到 Google Cloud Vision API,而vision包包含负责 OCR 的text_detection函数。
接下来,我们有draw_ocr_results,一个用来注释输出图像的便利函数:
def draw_ocr_results(image, text, rect, color=(0, 255, 0)):
# unpacking the bounding box rectangle and draw a bounding box
# surrounding the text along with the OCR'd text itself
(startX, startY, endX, endY) = rect
cv2.rectangle(image, (startX, startY), (endX, endY), color, 2)
cv2.putText(image, text, (startX, startY - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
# return the output image
return image
draw_ocr_results函数接受四个参数:
image:我们正在绘制的输入图像text:OCR 识别的文本rect:文本 ROI 的边界框坐标color:绘制的边框和文字的颜色
第 11 行解包 (x,y)-我们文本 ROI 的坐标。我们使用这些坐标绘制一个包围文本的边界框,以及 OCR 文本本身(第 12-14 行)。
然后我们将image返回给调用函数。
让我们检查一下我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image that we'll submit to Google Vision API")
ap.add_argument("-c", "--client", required=True,
help="path to input client ID JSON configuration file")
args = vars(ap.parse_args())
这里有两个命令行参数:
--image:输入图像的路径,我们将把它提交给 Google Cloud Vision API 进行 OCR。--client:包含我们认证信息的客户端 ID JSON 文件(确保按照 获取您的 Google Cloud Vision API 密钥 部分生成该 JSON 文件)。
是时候连接到谷歌云视觉 API 了:
# create the client interface to access the Google Cloud Vision API
credentials = service_account.Credentials.from_service_account_file(
filename=args["client"],
scopes=["https://www.googleapis.com/auth/cloud-platform"])
client = vision.ImageAnnotatorClient(credentials=credentials)
# load the input image as a raw binary file (this file will be
# submitted to the Google Cloud Vision API)
with io.open(args["image"], "rb") as f:
byteImage = f.read()
第 28-30 行连接到 Google Cloud Vision API,提供磁盘上 JSON 认证文件的--client路径。第 31 行然后为所有图像处理/计算机视觉操作创建我们的client。
然后,我们将我们的输入--image作为一个字节数组(byteImage)从磁盘加载,提交给 Google Cloud Vision API。
现在让我们将byteImage提交给 API:
# create an image object from the binary file and then make a request
# to the Google Cloud Vision API to OCR the input image
print("[INFO] making request to Google Cloud Vision API...")
image = vision.Image(content=byteImage)
response = client.text_detection(image=image)
# check to see if there was an error when making a request to the API
if response.error.message:
raise Exception(
"{}\nFor more info on errors, check:\n"
"https://cloud.google.com/apis/design/errors".format(
response.error.message))
第 41 行创建一个Image数据对象,然后提交给 Google Cloud Vision API 的text_detection函数(第 42 行)。
第 45-49 行检查我们的输入图像是否有错误,如果有,我们raise出错并退出脚本。
否则,我们可以处理 OCR 步骤的结果:
# read the image again, this time in OpenCV format and make a copy of
# the input image for final output
image = cv2.imread(args["image"])
final = image.copy()
# loop over the Google Cloud Vision API OCR results
for text in response.text_annotations[1::]:
# grab the OCR'd text and extract the bounding box coordinates of
# the text region
ocr = text.description
startX = text.bounding_poly.vertices[0].x
startY = text.bounding_poly.vertices[0].y
endX = text.bounding_poly.vertices[1].x
endY = text.bounding_poly.vertices[2].y
# construct a bounding box rectangle from the box coordinates
rect = (startX, startY, endX, endY)
Line 53 以 OpenCV/NumPy 数组格式从磁盘加载我们的输入图像(以便我们可以在上面绘图)。
第 57 行遍历来自 Google Cloud Vision API 响应的所有 OCR 结果text。第 60 行提取ocr文本本身,而第 61-64 行提取文本区域的边界框坐标。第 67 行然后从这些坐标构建一个矩形(rect)。
最后一步是在output和final图像上绘制 OCR 结果:
# draw the output OCR line-by-line
output = image.copy()
output = draw_ocr_results(output, ocr, rect)
final = draw_ocr_results(final, ocr, rect)
# show the output OCR'd line
print(ocr)
cv2.imshow("Output", output)
cv2.waitKey(0)
# show the final output image
cv2.imshow("Final Output", final)
cv2.waitKey(0)
每一段 OCR 文本都显示在我们屏幕上的第 75-77 行。带有所有 OCR 文本的final图像显示在行 80 和 81** 上。**
谷歌云视觉 API OCR 结果
现在让我们将 Google Cloud Vision API 投入使用吧!打开终端并执行以下命令:
$ python google_ocr.py --image images/aircraft.png --client client_id.json
[INFO] making request to Google Cloud Vision API...
WARNING!
LOW
FLYING
AND
DEPARTING
AIRCRAFT
BLAST
CAN
CAUSE
PHYSICAL
INJURY
图 2 显示了将 Google Cloud Vision API 应用于我们的飞机图像的结果,我们一直在对所有三种云服务的 OCR 性能进行基准测试。与亚马逊 Rekognition API 和微软认知服务一样,谷歌云视觉 API 可以正确地对图像进行 OCR。
让我们尝试一个更具挑战性的图像,您可以在图 3 中看到:
$ python google_ocr.py --image images/challenging.png --client client_id.json
[INFO] making request to Google Cloud Vision API...
LITTER
First
Eastern
National
Bus
Fimes
EMERGENCY
STOP
就像微软的认知服务 API 一样,谷歌云视觉 API 在我们具有挑战性的低质量图像上表现良好,这些图像具有像素化和低可读性(即使以人类的标准来看,更不用说机器了)。结果在图 3 中。
有趣的是,Google Cloud Vision API 确实出错了,以为【时代】中的【T】是一个【f】
让我们看最后一张图片,这是一个街道标志:
$ python google_ocr.py --image images/street_signs.png --client client_id.json
[INFO] making request to Google Cloud Vision API...
Old
Town
Rd
STOP
ALL
WAY
图 4 显示了将 Google Cloud Vision API 应用于我们的街道标志图像的输出。微软认知服务 API 对图像进行逐行 OCR,导致文本“老城路”和“一路”被 OCR 成单行。或者,Google Cloud Vision API 对文本进行逐字 ocr(Google Cloud Vision API 中的默认设置)。
汇总
在本课中,您学习了如何将基于云的 Google Cloud Vision API 用于 OCR。像我们在本书中讨论的其他基于云的 OCR APIs 一样,Google Cloud Vision API 可以不费吹灰之力获得高 OCR 准确度。当然,缺点是你需要一个互联网连接来利用这个 API。
当选择基于云的 API 时,我不会关注与 API 接口所需的 Python 代码量。相反,考虑你正在使用的云平台的 整体生态系统 。
假设您正在构建一个应用程序,要求您与 Amazon 简单存储服务(Amazon S3)进行数据存储。在这种情况下,使用 Amazon Rekognition API 更有意义。这使得你可以把所有东西都放在亚马逊的保护伞下。
另一方面,如果你正在使用谷歌云平台(GCP)实例来训练云中的深度学习模型,那么使用谷歌云视觉 API 更有意义。
这些都是构建应用程序时的设计和架构决策。假设您只是在“测试”这些 API 中的每一个。你不受这些考虑的约束。然而,如果你正在开发一个生产级的应用程序,那么花时间考虑每个云服务的权衡是非常值得的。你应该考虑更多的而不仅仅是 OCR 的准确性;考虑计算、存储等。,每个云平台提供的服务。
引用信息
Rosebrock,A. “使用谷歌云视觉 API 的文本检测和 OCR”, PyImageSearch ,D. Chakraborty,P. Chugh。A. R. Gosthipaty、S. Huot、K. Kidriavsteva、R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/evzxr
***@incollection{Rosebrock_2022_OCR_GCV,
author = {Adrian Rosebrock},
title = {Text Detection and {OCR} with {G}oogle Cloud Vision {API}},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki}, year = {2022},
note = {https://pyimg.co/evzxr},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 Microsoft 认知服务进行文本检测和 OCR
原文:https://pyimagesearch.com/2022/03/28/text-detection-and-ocr-with-microsoft-cognitive-services/
微软认知服务的文本检测和 OCR
本课是关于文本检测和 OCR 的 3 部分系列的一部分:
- 使用亚马逊 Rekognition API 进行文本检测和 OCR
- 微软认知服务的文本检测和 OCR(今日教程)
- 使用谷歌云视觉 API 进行文本检测和 OCR
在本教程中,您将:
- 了解如何获取您的 MCS API 密钥
- 创建一个配置文件来存储您的订阅密钥和 API 端点 URL
- 实现 Python 脚本来调用 MCS OCR API
- 查看将 MCS OCR API 应用于样本图像的结果
要了解文本检测和 OCR,继续阅读。
微软认知服务的文本检测和 OCR
在我们的之前的教程中,您学习了如何使用 Amazon Rekognition API 来 OCR 图像。使用 Amazon Rekognition API 最困难的部分是获取 API 密钥。然而,一旦你有了你的 API 密匙,事情就一帆风顺了。
本教程重点介绍一种不同的基于云的 API,称为微软认知服务(MCS),是微软 Azure 的一部分。与 Amazon Rekognition API 一样,MCS 也具有很高的 OCR 准确性,但不幸的是,实现稍微复杂一些(微软的登录和管理仪表板也是如此)。
与 MCS 相比,我们更喜欢 Amazon Web Services(AWS)Rekognition API,无论是对于管理仪表板还是 API 本身。然而,如果你已经根深蒂固地融入了 MCS/Azure 生态系统,你应该考虑留在那里。MCS API 并没有那么难用(只是不像 Amazon Rekognition API 那么简单)。
微软 OCR 认知服务
我们将从如何获得 MCS API 密钥的回顾开始本教程。您将需要这些 API 键来请求 MCS API 对图像进行 OCR。
一旦我们有了 API 密钥,我们将检查我们的项目目录结构,然后实现一个 Python 配置文件来存储我们的订阅密钥和 OCR API 端点 URL。
实现了配置文件后,我们将继续创建第二个 Python 脚本,这个脚本充当驱动程序脚本,它:
- 导入我们的配置文件
- 将输入图像加载到磁盘
- 将图像打包到 API 调用中
- 向 MCS OCR API 发出请求
- 检索结果
- 注释我们的输出图像
- 将 OCR 结果显示到我们的屏幕和终端上
让我们开始吧!
获取您的微软认知服务密钥
在继续其余部分之前,请确保按照此处所示的说明获取 API 密钥。
配置您的开发环境
要遵循本指南,您需要在系统上安装 OpenCV 和 Azure 计算机视觉库。
幸运的是,两者都是 pip 可安装的:
$ pip install opencv-contrib-python
$ pip install azure-cognitiveservices-vision-computervision
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
我们的 MCS OCR API 的目录结构类似于前面教程中的 Amazon Rekognition API 项目的结构:
|-- config
| |-- __init__.py
│ |-- microsoft_cognitive_services.py
|-- images
| |-- aircraft.png
| |-- challenging.png
| |-- park.png
| |-- street_signs.png
|-- microsoft_ocr.py
在config中,我们有我们的microsoft_cognitive_services.py文件,它存储了我们的订阅密钥和端点 URL(即,我们提交图像的 API 的 URL)。
microsoft_ocr.py脚本将获取我们的订阅密钥和端点 URL,连接到 API,将我们的images目录中的图像提交给 OCR,并显示我们的屏幕结果。
创建我们的配置文件
确保您已按照 获取您的 Microsoft 认知服务密钥 获取您的 MCS API 订阅密钥。从那里,打开microsoft_cognitive_services.py文件并更新您的SUBSCRPTION_KEY:
# define our Microsoft Cognitive Services subscription key
SUBSCRIPTION_KEY = "YOUR_SUBSCRIPTION_KEY"
# define the ACS endpoint
ENDPOINT_URL = "YOUR_ENDPOINT_URL"
您应该用从 获取您的 Microsoft 认知服务密钥 获得的订阅密钥替换字符串"YOUR_SUBSCRPTION_KEY"。
此外,确保你再次检查你的ENDPOINT_URL。在撰写本文时,端点 URL 指向最新版本的 MCS API 然而,随着微软发布新的 API 版本,这个端点 URL 可能会改变,因此值得仔细检查。
实现微软认知服务 OCR 脚本
现在,让我们学习如何向 MCS API 提交用于文本检测和 OCR 的图像。
打开项目目录结构中的microsoft_ocr.py脚本,插入以下代码:
# import the necessary packages
from config import microsoft_cognitive_services as config
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from msrest.authentication import CognitiveServicesCredentials
import argparse
import time
import sys
import cv2
注意第 2 行的我们导入我们的microsoft_cognitive_services配置来提供我们的订阅密钥和端点 URL。然后,我们将使用azure和msrest Python 包向 API 发送请求。
接下来,让我们定义draw_ocr_results,这是一个帮助函数,用于用 OCR 处理的文本注释我们的输出图像:
def draw_ocr_results(image, text, pts, color=(0, 255, 0)):
# unpack the points list
topLeft = pts[0]
topRight = pts[1]
bottomRight = pts[2]
bottomLeft = pts[3]
# draw the bounding box of the detected text
cv2.line(image, topLeft, topRight, color, 2)
cv2.line(image, topRight, bottomRight, color, 2)
cv2.line(image, bottomRight, bottomLeft, color, 2)
cv2.line(image, bottomLeft, topLeft, color, 2)
# draw the text itself
cv2.putText(image, text, (topLeft[0], topLeft[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
# return the output image
return image
我们的draw_ocr_results函数有四个参数:
image:我们将要绘制的输入图像。text:OCR 识别的文本。pts:左上、右上、右下、左下(x,y)-文本 ROI 的坐标color:我们在image上绘制的 BGR 颜色
第 13-16 行解包我们的边界框坐标。从那里,第 19-22 行画出图像中文本周围的边界框。然后我们在第 25 和 26 行的上绘制 OCR 文本本身。*
我们通过将输出image返回给调用函数来结束这个函数。
我们现在可以解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image that we'll submit to Microsoft OCR")
args = vars(ap.parse_args())
# load the input image from disk, both in a byte array and OpenCV
# format
imageData = open(args["image"], "rb").read()
image = cv2.imread(args["image"])
这里我们只需要一个参数,--image,它是磁盘上输入图像的路径。我们从磁盘中读取这个图像,两者都是二进制字节数组(这样我们就可以将它提交给 MCS API,然后再以 OpenCV/NumPy 格式提交(这样我们就可以利用/注释它)。
现在让我们构造一个对 MCS API 的请求:
# initialize the client with endpoint URL and subscription key
client = ComputerVisionClient(config.ENDPOINT_URL,
CognitiveServicesCredentials(config.SUBSCRIPTION_KEY))
# call the API with the image and get the raw data, grab the operation
# location from the response, and grab the operation ID from the
# operation location
response = client.read_in_stream(imageData, raw=True)
operationLocation = response.headers["Operation-Location"]
operationID = operationLocation.split("/")[-1]
第 43 和 44 行初始化 Azure 计算机视觉客户端。请注意,我们在这里提供了我们的ENDPOINT_URL和SUBSCRIPTION_KEY——现在是返回microsoft_cognitive_services.py并确保您已经正确插入了您的订阅密钥的好时机(否则,对 MCS API 的请求将会失败)。
然后,我们将图像提交给第 49-51 行的 MCS API 进行 OCR。
我们现在必须等待并轮询来自 MCS API 的结果:
# continue to poll the Cognitive Services API for a response until
# we get a response
while True:
# get the result
results = client.get_read_result(operationID)
# check if the status is not "not started" or "running", if so,
# stop the polling operation
if results.status.lower() not in ["notstarted", "running"]:
break
# sleep for a bit before we make another request to the API
time.sleep(10)
# check to see if the request succeeded
if results.status == OperationStatusCodes.succeeded:
print("[INFO] Microsoft Cognitive Services API request succeeded...")
# if the request failed, show an error message and exit
else:
print("[INFO] Microsoft Cognitive Services API request failed")
print("[INFO] Attempting to gracefully exit")
sys.exit(0)
老实说,对结果进行投票并不是我最喜欢的使用 API 的方式。它需要更多的代码,有点乏味,而且如果程序员不小心将break恰当地从循环中取出,它可能容易出错。
当然,这种方法也有好处,包括保持连接,提交更大块的数据,以及以批返回结果,而不是一次。
不管怎样,这就是微软实现 API 的方式,所以我们必须遵守他们的规则。
第 55 行开始一个while循环,连续检查来自 MCS API 的响应(第 57 行)。
如果我们没有在["notstarted", "running"] 列表中找到状态,我们可以从循环中安全地break并处理我们的结果(行 61 和 62 )。
如果不满足上述条件,我们睡眠一小段时间,然后再次轮询( Line 65 )。
检查请求是否成功,如果成功,我们就可以安全地继续处理我们的结果。否则,如果请求没有成功,那么我们就没有 OCR 结果可以显示(因为图像不能被处理),然后我们优雅地从脚本中退出(第 72-75 行)。
假设我们的 OCR 请求成功,现在让我们处理结果:
# make a copy of the input image for final output
final = image.copy()
# loop over the results
for result in results.analyze_result.read_results:
# loop over the lines
for line in result.lines:
# extract the OCR'd line from Microsoft's API and unpack the
# bounding box coordinates
text = line.text
box = list(map(int, line.bounding_box))
(tlX, tlY, trX, trY, brX, brY, blX, blY) = box
pts = ((tlX, tlY), (trX, trY), (brX, brY), (blX, blY))
# draw the output OCR line-by-line
output = image.copy()
output = draw_ocr_results(output, text, pts)
final = draw_ocr_results(final, text, pts)
# show the output OCR'd line
print(text)
cv2.imshow("Output", output)
# show the final output image
cv2.imshow("Final Output", final)
cv2.waitKey(0)
第 78 行用所有绘制的文本初始化我们的final输出图像。
我们开始遍历第 81 行的所有linesOCR 文本。在第 83 行上,我们开始遍历 OCR 文本的所有行。我们提取 OCR 处理过的text和每个line的边界框坐标,然后分别构造一个列表,包含左上角、右上角、右下角和左下角(第 86-89 行)。
然后我们在output和final图像上逐行绘制 OCR 文本(第 92-94 行)。我们在屏幕和终端上显示当前文本行(第 97 行和第 98 行 ) —最终的输出图像,上面绘制了所有经过 OCR 处理的文本,显示在第 101 行和第 102 行。
微软认知服务 OCR 结果
现在让我们让 MCS OCR API 为我们工作。打开终端并执行以下命令:
$ python microsoft_ocr.py --image images/aircraft.png
[INFO] making request to Microsoft Cognitive Services API...
WARNING!
LOW FLYING AND DEPARTING AIRCRAFT
BLAST CAN CAUSE PHYSICAL INJURY
图 2 显示了将 MCS OCR API 应用于我们的飞机警告标志的输出。如果你还记得,这是我们在之前的教程中应用亚马逊识别 API 时使用的同一张图片。因此,我在本教程中包含了相同的图像,以演示 MCS OCR API 可以正确地对该图像进行 OCR。
让我们尝试一个不同的图像,这个图像包含几个具有挑战性的文本:
$ python microsoft_ocr.py --image images/challenging.png
[INFO] making request to Microsoft Cognitive Services API...
LITTER
EMERGENCY
First
Eastern National
Bus Times
STOP
图 3 显示了将 MCS OCR API 应用于我们的输入图像的结果——正如我们所见,MCS 在图像 OCR 方面做了一件出色的工作。
在左边的上,我们有第一张东部国家公共汽车时刻表的样本图像(即公共汽车到达的时间表)。文件打印时采用了光面处理(可能是为了防止水渍)。尽管如此,由于光泽,图像仍然有明显的反射,特别是在“公交时间”文本中。尽管如此,MCS OCR API 可以正确地对图像进行 OCR。
在中间,,文本高度像素化且质量低下,但这并不影响 MCS OCR API!它能正确识别图像。
最后,右边的显示了一个垃圾桶,上面写着“垃圾”文本很小,由于图像质量很低,不眯着眼睛看很难。也就是说,MCS OCR API 仍然可以对文本进行 OCR(尽管垃圾桶底部的文本难以辨认——无论是人还是 API 都无法读取该文本)。
下一个样本图像包含一个国家公园标志,如图图 4 所示:
MCS OCR API 可以逐行 OCR 每个符号(图 4 )。我们还可以为每条线计算旋转的文本边界框/多边形。
$ python microsoft_ocr.py --image images/park.png
[INFO] making request to Microsoft Cognitive Services API...
PLEASE TAKE
NOTHING BUT
PICTURES
LEAVE NOTHING
BUT FOOT PRINTS
最后一个例子包含交通标志:
$ python microsoft_ocr.py --image images/street_signs.png
[INFO] making request to Microsoft Cognitive Services API...
Old Town Rd
STOP
ALL WAY
图 5 显示我们可以正确识别站牌和街道名称牌上的每一段文字。
汇总
在本教程中,您了解了 Microsoft 认知服务(MCS) OCR API。尽管比 Amazon Rekognition API 稍难实现和使用,但微软认知服务 OCR API 证明了它非常健壮,能够在许多情况下 OCR 文本,包括低质量图像。
当处理低质量图像时,MCS API 闪亮。通常,我建议你有计划地检测并丢弃低质量的图像(正如我们在之前的教程中所做的)。然而,如果你发现自己处于不得不处理低质量图像的情况下,使用微软 Azure 认知服务 OCR API 可能是值得的。
引用信息
罗斯布鲁克,A. “微软认知服务的文本检测和 OCR”, PyImageSearch ,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,https://pyimg.co/0r4mt
@incollection{Rosebrock_2022_OCR_MCS,
author = {Adrian Rosebrock},
title = {Text Detection and {OCR} with {M}icrosoft Cognitive Services},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/0r4mt},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
使用 OpenCV 和 Python 进行文本倾斜校正
原文:https://pyimagesearch.com/2017/02/20/text-skew-correction-opencv-python/

今天的教程是我最喜欢的博文的 Python 实现 Félix Abecassis 关于使用 OpenCV 和图像处理函数进行文本倾斜校正(即“文本去倾斜”)的过程。
给定一个包含未知角度的旋转文本块的图像,我们需要通过以下方式校正文本倾斜:
- 检测图像中的文本块。
- 计算旋转文本的角度。
- 旋转图像以校正倾斜。
我们通常在自动文档分析领域应用文本倾斜校正算法,但是该过程本身也可以应用于其他领域。
要了解更多关于文本倾斜校正的信息,请继续阅读。
使用 OpenCV 和 Python 进行文本倾斜校正
这篇博文的剩余部分将演示如何使用 Python 和 OpenCV 的基本图像处理操作来消除文本倾斜。
我们将从创建一个简单的数据集开始,我们可以用它来评估我们的文本倾斜校正器。
然后我们将编写 Python 和 OpenCV 代码来自动检测和校正图像中的文本倾斜角度。
创建简单的数据集
与 Félix 的例子类似,我准备了一个小数据集,其中包含四幅旋转了给定度数的图像:

Figure 1: Our four example images that we’ll be applying text skew correction to with OpenCV and Python.
文本块本身来自我的书的第 11 章, 实用 Python 和 OpenCV ,,我在这里讨论轮廓以及如何利用它们进行图像处理和计算机视觉。
四个文件的文件名如下:
$ ls images/
neg_28.png neg_4.png pos_24.png pos_41.png
文件名的第一部分指定我们的图像是逆时针旋转了(负)还是顺时针旋转了(正)。**
**文件名的第二部分是图像旋转的实际度数。
我们的文本倾斜校正算法的目标是正确地确定旋转的方向和角度*,然后进行校正。
要了解我们的文本倾斜校正算法是如何用 OpenCV 和 Python 实现的,请务必阅读下一节。
用 OpenCV 和 Python 实现文本去倾斜
首先,打开一个新文件,命名为correct_skew.py。
从那里,插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image file")
args = vars(ap.parse_args())
# load the image from disk
image = cv2.imread(args["image"])
第 2-4 行导入我们需要的 Python 包。我们将通过我们的cv2绑定来使用 OpenCV,所以如果你的系统上还没有安装 OpenCV,请参考我的 OpenCV 安装教程列表来帮助你设置和配置你的系统。
然后我们在第 7-10 行解析我们的命令行参数。这里我们只需要一个参数,--image,它是输入图像的路径。
然后从磁盘的线 13 载入图像。
我们的下一步是分离图像中的文本:
# convert the image to grayscale and flip the foreground
# and background to ensure foreground is now "white" and
# the background is "black"
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.bitwise_not(gray)
# threshold the image, setting all foreground pixels to
# 255 and all background pixels to 0
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
我们的输入图像包含在亮背景上暗的文本;然而,要应用我们的文本倾斜校正过程,我们首先需要反转图像(即,文本现在在暗背景上是亮——我们需要反转)。
在应用计算机视觉和图像处理操作时,前景通常表现为亮,而背景(图像中我们不感兴趣的部分)则表现为暗。
然后应用阈值操作(行 23 和 24 )来二值化图像:

Figure 2: Applying a thresholding operation to binarize our image. Our text is now white on a black background.
给定这个阈值图像,我们现在可以计算包含文本区域的最小旋转边界框:
# grab the (x, y) coordinates of all pixel values that
# are greater than zero, then use these coordinates to
# compute a rotated bounding box that contains all
# coordinates
coords = np.column_stack(np.where(thresh > 0))
angle = cv2.minAreaRect(coords)[-1]
# the `cv2.minAreaRect` function returns values in the
# range [-90, 0); as the rectangle rotates clockwise the
# returned angle trends to 0 -- in this special case we
# need to add 90 degrees to the angle
if angle < -45:
angle = -(90 + angle)
# otherwise, just take the inverse of the angle to make
# it positive
else:
angle = -angle
第 30 行找到thresh图像中作为前景一部分的所有 (x,y) 坐标。
我们将这些坐标传递给cv2.minAreaRect,然后它计算包含整个T2 文本区域的最小旋转矩形。
cv2.minAreaRect函数返回范围 [-90,0]内的角度值。当矩形顺时针旋转时,角度值向零增加。当达到零度时,角度被再次设置回-90 度,并且该过程继续。
注:更多关于cv2.minAreaRect的信息,请看这篇亚当古德温的精彩解说。
第 37 行和第 38 行处理角度小于-45 度的情况,在这种情况下,我们需要给角度加上 90 度,然后取反。
否则,行 42 和 43 简单取角度的倒数。
既然我们已经确定了文本倾斜角度,我们需要应用仿射变换来校正倾斜:
# rotate the image to deskew it
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h),
flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
第 46 和 47 行确定图像的中心 (x,y)-坐标。我们将center坐标和旋转角度传入cv2.getRotationMatrix2D ( 行 48 )。这个旋转矩阵M然后被用于在行 49 和 50 上执行实际的变换。
最后,我们将结果显示在屏幕上:
# draw the correction angle on the image so we can validate it
cv2.putText(rotated, "Angle: {:.2f} degrees".format(angle),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# show the output image
print("[INFO] angle: {:.3f}".format(angle))
cv2.imshow("Input", image)
cv2.imshow("Rotated", rotated)
cv2.waitKey(0)
第 53 行在我们的图像上画出了angle,这样我们就可以验证输出图像是否与旋转角度相匹配(很明显,您希望在文档处理管道中删除这一行)。
第 57-60 行处理显示输出图像。
歪斜校正结果
要获得这篇博文中使用的代码+示例图片,请务必使用这篇博文底部的 “下载” 部分。
从那里,执行以下命令来纠正我们的neg_4.png图像的倾斜:
$ python correct_skew.py --image images/neg_4.png
[INFO] angle: -4.086

Figure 3: Applying skew correction using OpenCV and Python.
这里我们可以看到输入图像有 4 度逆时针倾斜。通过 OpenCV 应用我们的偏斜校正可以检测到这种 4 度的偏斜,并对其进行校正。
这是另一个例子,这次逆时针倾斜 28 度:
$ python correct_skew.py --image images/neg_28.png
[INFO] angle: -28.009

Figure 4: Deskewing images using OpenCV and Python.
同样,我们的倾斜校正算法能够校正输入图像。
这一次,让我们试试顺时针倾斜:
$ python correct_skew.py --image images/pos_24.png
[INFO] angle: 23.974

Figure 5: Correcting for skew in text regions with computer vision.
最后是更极端的 41 度顺时针倾斜:
$ python correct_skew.py --image images/pos_41.png
[INFO] angle: 41.037
Figure 6: Deskewing text with OpenCV.
不管倾斜角度如何,我们的算法能够使用 OpenCV 和 Python 来校正图像中的倾斜。
摘要
在今天的博文中,我提供了菲利克斯·阿贝卡西斯的方法的 Python 实现。
该算法本身非常简单,仅依赖于基本的图像处理技术,例如阈值处理、计算最小面积旋转矩形,然后应用仿射变换来校正倾斜。
我们通常会在自动文档分析管道中使用这种类型的文本倾斜校正,我们的目标是数字化一组文档,校正文本倾斜,然后应用 OCR 将图像中的文本转换为机器编码的文本。
我希望你喜欢今天的教程!
为了在以后发表博文时得到通知,请务必在下面的表格中输入您的电子邮件地址!***
2023 年敏捷培训指南
原文:https://pyimagesearch.com/2022/12/29/the-2023-guide-to-grooming-in-agile/
整理是将产品的待办事项列表转化为产品待办事项。
如果你想学习如何整理或提炼你的积压工作,以便为你的冲刺做好准备,那就继续读吧。

Grooming your backlog
让我们从一个快速的工作定义开始。
梳理,在 Scrum 中也称为精化,是 接受名义上的工作,并阐明与该工作相关的范围、测试和工作量估计,直到准备好移交给开发人员开始。
当你整理你的积压工作时,你的团队从一个粗略定义的工作列表开始,以一个清晰定义的工作单元结束。这些定义清晰的工作单元已经被“修饰”过了。
一旦这个关键步骤完成,您的开发人员就可以开始工作了。
上面的定义很有帮助,但请注意它包含三个关键部分
- 充分理解工作范围
- 确保工作质量的明确测试标准
- 完成工作的工作量估计
整理积压工作指南
- 召集整个团队
- 让产品负责人解释产品愿景和目标
- 让产品负责人解释本次培训的目标
- 给每个人几分钟(5-10 分钟)来回顾整个产品待办事项
- 让产品负责人问:“我们想培养什么?”
- 观察团队行动起来,开始讨论想法和整理待办事项
- 如果进度停滞不前,Scrum Master 可以通过几个简短的动作来自由启动流程
- 当完成了至少两个冲刺阶段的准备工作后,产品负责人可以通过回顾完成了什么以及这些成就如何支持产品愿景和目标来总结。
- 然后,开发人员又开始工作了,只是现在他们对接下来的工作有了一个清晰的想法。
精心整理的待办事项列表示例
这里有一个简单的例子,展示了一些没有整理的产品待办事项(pbi)和一些已经整理的项目。
你能看出哪些是修饰过的,哪些不是吗?
PBI 1 启用双因素认证
PBI 2 通过将灯塔可访问性得分从 73 提高到 85 以上来提高可访问性。
PBI 3 将 CNN 模型训练并部署到云端点,并通过保持数据集得分高于 98%的准确性来验证结果。该模型必须比当前模型的 F1 分数高出 5%或更多。努力:21
如果你猜 PBI 3 你就猜对了😃。** 原因如下。
PBI 3 是唯一一个被修饰到定义明确的 PBI。很清楚需要做什么工作。这包括我可以验证的指标,如“车型必须比当前车型的 F1 分数高出 5%或更多”。
它还包括测试标准,以确保质量,“验证结果与维持数据集得分超过 98%的准确性”。
最后,对其进行了评估,并为其努力程度分配了“21”分。
那 21 是 21 个努力点,因为最好使用努力来估计,以便在项目早期获得更准确的估计。
具有良好定义的范围、测试标准和估计工作量的 PBI =经过培训。答对了。
PBI 3 有明确的范围✅
PBI 3 有✅的测试标准
PBI 3 有一个估计的工作范围✅
另一方面,PBI 1 号不符合任何修饰标准。
PBI 1 没有明确定义的范围❌(哪种类型的 2FA?)
PBI 1 没有测试标准❌(我们怎么知道 2FA 在 iOS/Android 上工作?)
PBI 1 没有估计的❌工作范围
十二个科学积压实践
根据对产品积压的研究,有 12 种实践值得理解。
- 平衡的团队允许所有领域的专家帮助构建 backlog
- 双轨敏捷一条轨道是理解客户,另一条轨道是理解如何构建产品
- 利益相关者映射明确了谁是利益相关者以及他们想要什么
- 访谈允许通过访谈对话与客户直接接触
- 个人建模创建功能性人物角色来指导产品开发
- 亲和力映射组织来自访谈的数据以显示聚类和趋势
- 设计工作室使用设计思维和原型来观察许多可能性
- 草图/模型可能产品的图纸和视觉展示
- 可用性测试让用户尝试你的模型
- 撰写用户故事描述客户将如何使用你的产品,以及为什么要引导开发
- 故事展示建立团队对故事的理解
- 接受故事评估故事并确保达成一致
这 12 个研究支持的 backlog 实践应该给你很多想法。
想象一下,你通过采访客户来获得灵感。然后,您使用相似性映射来围绕特征聚集想法。最后,你用素描把想法画出来。
转眼间。现在你有大量的以客户为中心的想法,这些想法被团队整理和理解。
做一个快速的 PBI 评估会议,你就有了干净的、准备好的、有价值的积压工作。
这只是一个例子。上面有 12 种不同的活动
理论上你应该有 12 个!选项或 479,000,600 种不同的选项。
那是期权!
更深入地了解产品积压
让我们更详细地研究一下积压工作。
待办事项中的每一件事都是要完成的工作的一般单元。这种最普通的“待办事项”是产品待办事项(PBI)。
PBI 是积压案件中最具包容性和一般性的一类。
让我们用一个类比来阐明 pbi。
称一辆汽车为“汽车”是最普通的称呼。
下一个层面的特殊性可能是通过品牌来称呼它,“这是一辆丰田”。
更具体地说,你可以说,“这是一辆丰田雅力士。”包括品牌和型号。
“丰田雅力士,2008”怎么样
现在我们变得非常具体,你的待办事项也是如此。
您可以将待办事项列表中的某样东西称为 PBI(比如称之为“汽车”)。
但是你也可以更具体一些,称之为用户故事。这是一种 PBI。在汽车类比中,这将是“丰田”。
然后你可以进一步描述它是否是一个特色用户故事。这是一个为你的产品添加功能的用户故事。想想,“丰田雅力士”。
还有其他类别的 pbi,如史诗、bug、数据收集、研究尖峰等等。
重点不是定义每种类型的 PBI,而是说明有多种类型的 pbi。
您想要知道这些名称和分类,以便能够跟踪关于 backlog 的对话。当有人谈论用户故事时,有助于理解这一类别。
你不需要给 pbi 贴标签或分类。重点是不要把一切都贴上标签,组织起来。关键是要知道有很多选择,并帮助你选择正确的选项,这样你就能制造出正确的产品。
Scrum 中的一切都是关于在正确的时间构建正确的产品。
验收准则
验收标准是 PBI 必须满足的一系列条件。
这些标准在广泛的工作中应该是相同的。
建设项目的验收标准应包括“工作现场清洁”。
每个建筑工程在完工前都需要清理。这意味着我们可以将这一验收标准应用于每一项工作。
有了验收标准,就可以更快更容易地完成 backlog 精化。
每个符合某一工作类别的 PBI 都应该得到相同的验收标准。
如果每个建设项目都有一个必须完成的事情的列表,那么将它们添加到每个新项目中几乎是自动化的。你只需要切割并通过每个 PBI 的验收标准。
许多团队忽略了验收标准,因此花费了更多的时间和精力来构建每个 PBI 的“完成”含义的共同愿景。
通过将你的接受标准存储在一个容易获取的地方并重复使用它们,可以更快更有效地行动。
评估和 pbi
评估用户故事既快速又有趣。你应该考虑两种经过测试的有效方法。
亲和上浆
亲和力大小真的很有趣。它是这样工作的
- 把你所有的 pbi 集中到一个地方
- 制作标签为 S、M、L、XL 的列
- 将每个人都认为是中等工作量的一项移入 M
- 每个小组成员将一个 PBI 移动到一列,然后走到队伍的后面
- 每个项目可以从一列移动到另一列 3 次,然后固定在该列中
- 这个练习一直持续到所有东西都在一列中
- 为这些列中的所有内容指定以下几点:S = 3;m = 5;l = 8;XL=13
- 搞定了。
如果你这样做,你的全部积压将是估计
Scrum 扑克
Scrum poker 让你更详细地讨论 pbi,这是我的偏好。
它是这样工作的。
- 选一个 PBI
- 描述一下 PBI
- 使用遵循斐波纳契数列的卡片投票
- 如果所有投票都在 3 以内(2,3,5 在 3 以内),平均投票并继续
- 如果票数相差超过 3 个序列空格(2,3,8 相差 4 个),则停止
- 让高票解释他们的投票
- 让票数低的人解释他们的投票
- 遥远的
- 重复多达三次,然后抛出低和高投票,平均其余的投票,并继续进行
我更喜欢这种方法,因为它允许团队更详细地讨论工作。
Scrum 角色
没有讨论这三个角色,任何关于 Scrum 的文章都是不完整的。
Scrum 大师
服务的领导者。这个人让团队保持专注,受到保护,并按计划进行。
他们的主要任务是通过消除障碍来提高生产率。
你可以通过参加认证的 Scrum Master 课程成为一名 Scrum Master。
下面是如何成为一名 scrum 大师。
产品所有者
产品所有者是对所生产的工作的价值负责的人。如果你的产品找到了适合市场的产品,并且获得了巨大的增长和利润,那是因为有一个伟大的产品所有者。
如果你的工作失败了,那也是产品所有者的责任。
关键任务包括积压整理、客户互动和产品愿景创建。
您可以通过参加几门产品所有者课程中的一门来成为产品所有者。
开发者
开发人员是团队的核心,因为他们创造了产品。
开发人员是一个软件角色,但是在 Scrum 中,它被用于团队中任何构建产品的人。
这就是为什么这个角色可以分配给团队中的测试人员。如果它是一个营销团队,它也可以应用于营销人员。
冲刺
冲刺是用来衡量工作进度的任意长度的时间。这是一到四个星期长。
Sprints 的原因是有一个可重复的时间单位来衡量完成了多少工作。
有了相同的时间单位,你就可以测量完成的工作量,并比较每次冲刺的工作量。
冲刺的时间应该足够完成有意义的工作,越短越好。
如果你能用一周冲刺,那就去做吧。你会得到更多的反馈。
2023 年的 Scrum 统计
摘要
在本教程中,我们已经回顾了什么是积压以及如何整理它。我们已经展示了 12 项活动,你可以做好准备工作,并确保它是客户驱动的。最后,我们回顾了 Scrum 的角色,并提供了一些统计数据供您考虑。
3 种类型的图像搜索引擎:元数据搜索、实例搜索和混合搜索
你想建立什么类型的图像搜索引擎?你的搜索引擎会依赖与图片相关的标签、关键词和文本吗?那么你可能正在建立一个通过元数据搜索图片的搜索引擎。
你真的在检查图像本身并试图理解图像包含的内容吗?你是否正在尝试量化图像并提取一组数字来表示图像的颜色、纹理或形状?然后,你可能会建立一个搜索的例子图像搜索引擎。
还是你结合了上面的两种方法?你是否依赖与图像相关的文本信息,然后量化图像本身?听起来像一个混合图像搜索引擎。
让我们继续下去,分解这些类型的图片搜索引擎,并试图更好地理解它们。
按元数据搜索
你去谷歌一下。你会看到一个非常熟悉的图标,一个可以输入关键词的文本框,以及两个按钮:“谷歌搜索”和“我感觉很幸运”。这就是我们喜欢和崇拜的文本搜索引擎。手动输入关键字并查找相关结果。
事实上,元数据图像搜索引擎与上面提到的文本搜索引擎只有微小的不同。元数据图像搜索引擎的搜索很少检查实际图像本身。相反,它依赖于文本线索。这些线索可以来自各种来源,但两种主要方法是:
1。手动标注:
在这种情况下,管理员或用户提供建议图像内容的标签和关键字。例如,让我们来看看我最喜欢的电影《侏罗纪公园》中的一个片头。

Figure 1: Let’s assign some keywords and tags to this image: dinosaur, velociraptors, kitchen, restaurant kitchen, boy, scared
我们会将什么类型的标签或关键词与这张图片联系起来?嗯,我们看到有两只恐龙,但更准确地说,它们是迅猛龙。显然,这是某种类型的厨房,但它不像你家或公寓里的厨房。一切都是不锈钢和工业级的——这显然是一个餐厅厨房。最后,我们看到提姆,一个看起来很害怕的男孩。仅仅看了这张图片一两秒钟,我们就想出了六个标签来描述这个图片:恐龙、迅猛龙、厨房、** 工业厨房、男孩和惊吓。这是一个手动注释图像的例子。我们正在做这项工作,我们向计算机提供暗示图像内容的关键词。
2。上下文提示:
通常,上下文提示仅适用于网页。与手工注释不同,在手工注释中,我们必须用手想出标签,上下文提示会自动检查图像周围的文本或图像出现的文本。这种方法的缺点是,我们假设图像的内容与网页上的文本相关。这可能适用于维基百科等网站,页面上的图像与文章内容相关,但如果我在这个博客上实现元数据搜索算法,它会(错误地)将上面的侏罗纪公园图像与一堆与图像搜索引擎相关的关键词关联起来。虽然我个人认为这很有趣,但它展示了上下文暗示方法的局限性。
通过使用文本关键词(无论是上下文提示的手动注释)来表征图像,我们实际上可以将一个图像搜索引擎构建为一个文本搜索引擎,并应用来自信息检索的标准实践。正如我上面提到的,图像搜索引擎通过元数据实现搜索的最好例子是标准的 Google、Bing 或 Yahoo 搜索,它们利用文本关键字而不是图像本身的内容。接下来,让我们研究一下考虑图像实际内容的图像搜索引擎。
按示例搜索
想象你是谷歌或者 TinEye。你有数十亿张可以搜索的图片。你要手动标记每一张图片吗?不会吧。那太费时、乏味而且昂贵。语境提示呢?这是一个自动的方法,对吗?当然,但是记住我上面提到的限制。你可能会得到一些非常奇怪的结果,如果你仅仅依靠图片所在网页上的文字。
相反,你可以建立一个“按例子搜索”的图像搜索引擎。这些类型的图像搜索引擎试图量化图像本身,被称为基于内容的图像检索系统。一个简单的例子是通过图像中像素强度的平均值、标准偏差和偏斜度来表征图像的颜色。(快速提示:如果您正在构建一个简单的图片搜索引擎,在许多情况下,这种方法实际上工作得相当好)。
给定一个图像数据集,我们将计算数据集中所有图像的这些矩,并将它们存储在磁盘上。当我们量化一幅图像时,我们是描述一幅图像并提取图像特征。这些图像特征是图像的抽象,用于表征图像的内容。从图像集合中提取特征的过程被称为索引。
好了,现在我们已经从数据集中的每张图片中提取了特征。如何执行搜索?嗯,第一步是为我们的系统提供一个查询图像,一个我们在数据集中寻找的例子。查询图像的描述方式与我们的索引图像完全相同。然后,我们使用一个距离函数,例如欧几里德距离,将我们的查询特征与我们的索引数据集中的特征进行比较。然后根据相关性对结果进行排序(欧几里德距离越小意味着越“相关”)并呈现给我们。
通过示例图片搜索引擎进行搜索的例子有 TinEye 、 Incogna 以及我自己的 Chic Engine 和 ID My Pill 。在所有这些示例中,从查询图像中提取特征,并将其与特征数据库进行比较。
混合工艺
让我们假设我们正在为 Twitter 构建一个图像搜索引擎。Twitter 允许你在推文中加入图片。当然,Twitter 允许你为你的推文提供标签。
如果我们使用标签来建立一个元数据图片搜索引擎,然后分析和量化图片本身来建立一个示例图片搜索引擎呢?如果我们采用这种方法,我们将构建一个混合图像搜索引擎,它包括文本关键词以及从图像中提取的特征。
我能想到的这种混合方法的最好例子是谷歌图片搜索。谷歌图片搜索实际上是分析图片本身吗?你打赌它是。但谷歌首先主要是一个文本搜索引擎,所以它也允许你通过元数据进行搜索。
摘要
如果你依赖于由真实的人提供的标签和关键词,你正在建立一个通过元数据搜索的图像搜索引擎。如果您的算法分析图像本身,并通过提取特征来量化图像,那么您正在创建一个按示例搜索的搜索引擎,并正在执行基于内容的图像检索(CBIR)。如果你同时使用关键字提示和特性,你就建立了两者的混合方法。
深度学习分类管道
原文:https://pyimagesearch.com/2021/04/17/the-deep-learning-classification-pipeline/
根据我们之前关于图像分类和学习算法类型的两节,您可能会开始对新术语、考虑事项以及构建图像分类器时看起来难以克服的大量变化感到有些不知所措,但事实是,一旦您理解了过程,构建图像分类器是相当简单的。
在这一部分,我们将回顾在使用机器学习时,你需要在思维模式上进行的一个重要转变。在那里,我将回顾构建基于深度学习的图像分类器的四个步骤,并比较和对比传统的基于特征的机器学习和端到端深度学习。
心态的转变
在我们进入任何复杂的事情之前,让我们从我们都(很可能)熟悉的东西开始:斐波那契数列。
斐波纳契数列是一系列的数字,序列的下一个数字是通过对它前面的两个整数求和得到的。例如,给定序列0, 1, 1,通过添加1 + 1 = 2找到下一个数字。同样,给定0, 1, 1, 2,序列中的下一个整数是1 + 2 = 3。
按照这种模式,序列中的前几个数字如下:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
当然,我们也可以使用递归在(极未优化的)Python 函数中定义这种模式:
>>> def fib(n):
... if n == 0:
... return 0
... elif n == 1:
... return 1
... else:
... return fib(n-1) + fib(n-2)
...
>>>
使用这段代码,我们可以通过向fib函数提供一个值n来计算序列中的第 n 个。例如,让我们计算斐波纳契数列中的第 7 个数字:
>>> fib(7)
13
第 13 个数字:
>>> fib(13)
233
最后是第 35 个数字:
>>> fib(35)
9227465
如您所见,斐波纳契数列非常简单,是一系列函数的示例:
- 接受输入,返回输出。
- 该过程被很好地定义。
- 很容易验证输出的正确性。
- 非常适合代码覆盖和测试套件。
一般来说,在你的一生中,你可能已经编写了成千上万个这样的过程函数。无论您是计算斐波纳契数列,从数据库中提取数据,还是从一系列数字中计算平均值和标准偏差,这些函数都是定义良好的,并且很容易验证其正确性。
可惜深度学习和图像分类就不是这样了!T3**
注意图 1 中一只猫和一只狗的图片。现在,想象一下,试着写一个程序函数,它不仅能区分和这两张照片,还能区分任何一张猫和狗的照片。你将如何着手完成这项任务?你会检查各个( x,y )坐标的像素值吗?写几百条if/else语句?你将如何维护和验证如此庞大的基于规则的系统的正确性?简而言之就是:你不。
与编写算法来计算斐波纳契数列或对一系列数字进行排序不同,如何创建算法来区分猫和狗的图片并不直观或显而易见。因此,与其试图构建一个基于规则的系统来描述每个类别“看起来像什么”,不如我们可以采取一种数据驱动的方法,通过提供每个类别看起来像什么的例子,然后教我们的算法使用这些例子来识别类别之间的差异。
我们将这些例子称为我们的标签图像的训练数据集,其中我们的训练数据集中的每个数据点包括:
- 一幅图像
- 标签/类别(如狗、猫、熊猫等。)的图像
同样,这些图像中的每一个都有与之相关联的标签是很重要的,因为我们的监督学习算法需要看到这些标签,以“教会自己”如何识别每个类别。记住这一点,让我们继续完成构建深度学习模型的四个步骤。
第一步:收集数据集
构建深度学习网络的第一个组成部分是收集我们的初始数据集。我们需要图像本身以及与每个图像相关联的标签。这些标签应该来自一组有限的类别,比如:categories = dog, cat, panda。
此外,每个类别的图像数量应该大致一致(即,每个类别的示例数量相同)。如果我们的猫图像的数量是狗图像的两倍,熊猫图像的数量是猫图像的五倍,那么我们的分类器将自然地偏向于过度适合这些大量表示的类别。
类别不平衡是机器学习中的一个常见问题,有许多方法可以克服它。我们将在本书的后面讨论其中的一些方法,但是请记住,避免由于班级失衡而导致的学习问题的最好方法是完全避免班级失衡。
第二步:分割你的数据集
现在我们有了初始数据集,我们需要将它分成两部分:
- 一个训练集
- 一个测试装置
我们的分类器使用训练集通过对输入数据进行预测来“学习”每个类别的样子,然后在预测错误时进行自我纠正。训练好分类器后,我们可以在测试集上评估性能。
训练集和测试集相互独立不要重叠,这一点非常重要! 如果您使用测试集作为训练数据的一部分,那么您的分类器就具有不公平的优势,因为它之前已经看过测试示例并从中“学习”。相反,你必须将这个测试集与你的训练过程完全分开,并且只使用它来评估你的网络。
训练集和测试集的常见拆分大小包括 66。 6 %/33。 3 %,75%/25%,90%/10%(图 2* ):
这些数据分割是有意义的,但是如果您有要调整的参数呢?神经网络有许多旋钮和杠杆(例如,学习率、衰减、正则化等。)需要被调谐和拨号以获得最佳性能。我们将这些类型的参数称为超参数,它们的正确设置是关键。
在实践中,我们需要测试一堆这些超参数,并确定最有效的参数集。您可能会尝试使用您的测试数据来调整这些值, ,但是同样,这是一个大禁忌! 测试集仅用于评估你的网络性能。
相反,你应该创建一个名为验证集的第三个数据分割。这组数据(通常)来自训练数据,并被用作“假测试数据”,因此我们可以调整我们的超参数。只有在我们使用验证集确定了超参数值之后,我们才能继续收集测试数据中的最终准确性结果。
我们通常分配大约 10-20%的训练数据进行验证。如果将数据分割成块听起来很复杂,实际上并不复杂。正如我们将在下一章看到的,这非常简单,多亏了 scikit-learn 库,只需一行代码就能完成。
第三步:训练你的人际网络
给定我们的训练图像集,我们现在可以训练我们的网络。这里的目标是让我们的网络学会如何识别我们的标签数据中的每个类别。当模型犯错误时,它会从这个错误中学习并改进自己。
那么,实际的“学习”是如何进行的呢?总的来说,我们应用一种梯度下降的形式,我们将在另一篇文章中详述。
步骤#4:评估
最后,我们需要评估我们训练有素的网络。对于我们测试集中的每一幅图像,我们将它们呈现给网络,并要求它预测它认为图像的标签是什么。然后,我们将测试集中图像的模型预测列表。
最后,将这些模型预测与来自我们测试集的地面实况标签进行比较。地面实况标签代表图像类别实际上是什么。从那里,我们可以计算我们的分类器获得正确预测的数量,并计算诸如精度、召回和 f-measure 之类的聚合报告,这些报告用于量化我们的网络作为一个整体的性能。
基于特征的学习与深度学习在图像分类中的比较
在传统的基于特征的图像分类方法中,实际上在步骤#2 和步骤#3 之间插入了一个步骤——这个步骤是 特征提取 。在这个阶段,我们应用手工设计的算法,如猪、 LBPs 等。,基于我们想要编码的图像的特定成分(即,形状、颜色、纹理)来量化图像的内容。给定这些特征,然后我们继续训练我们的分类器并评估它。
当构建卷积神经网络时,我们实际上可以跳过特征提取步骤。这样做的原因是因为 CNN 是端到端模型。我们将原始输入数据(像素)呈现给网络。然后网络学习隐藏层内的过滤器,可以用来区分物体类别。然后,网络的输出是类别标签上的概率分布。
使用 CNN 的一个令人兴奋的方面是,我们不再需要对手工设计的功能大惊小怪——我们可以让我们的网络学习这些功能。然而,这种权衡是有代价的。训练 CNN 可能是一个不平凡的过程,所以要准备好花相当多的时间来熟悉自己的经验,并进行许多实验来确定什么可行,什么不可行。
当我的预测不正确时会发生什么?
不可避免地,你会在你的训练集上训练一个深度学习网络,在你的测试集上评估它(发现它获得了很高的准确率),然后将它应用到你的训练集和测试集都在之外的——的图像上,却发现网络表现很差。
这个问题被称为一般化,网络能够一般化并正确预测不存在于其训练或测试数据中的图像的类别标签。网络的泛化能力实际上是深度学习研究最重要的方面——如果我们可以训练网络,使其能够泛化到外部数据集,而无需重新训练或微调,我们将在机器学习方面取得巨大进步,使网络能够在各种领域中重复使用。网络的泛化能力将在本书中多次讨论,但我现在想提出这个话题,因为你将不可避免地遇到泛化问题,特别是当你了解深度学习的诀窍时。
不要因为你的模型不能正确分类图像而沮丧,考虑一下上面提到的一系列变化因素。您的训练数据集是否准确地反映了这些变化因素的例子?如果没有,你需要收集更多的训练数据(并阅读本书的其余部分,学习其他技术,以减少偏差和打击过度拟合)。
总结
我们了解了什么是图像分类,以及为什么它对计算机来说是一项如此具有挑战性的任务(尽管人类似乎毫不费力地凭直觉做到了)。然后,我们讨论了机器学习的三种主要类型:监督学习、非监督学习和半监督学习。
最后,我们回顾了深度学习分类管道中的四个步骤。这些步骤包括收集数据集、将数据分为训练、测试和验证步骤、训练网络以及最终评估模型。
与传统的基于特征的方法不同,传统的方法需要我们利用手工制作的算法从图像中提取特征,图像分类模型,如卷积神经网络,是端到端的分类器,它在内部学习可用于区分图像类别的特征。****
训练任何神经网络时的四个关键因素
原文:https://pyimagesearch.com/2021/05/06/the-four-key-ingredients-when-training-any-neural-network/
在训练神经网络时,您可能已经开始注意到我们的 Python 代码示例中的一个模式。在你自己的神经网络和深度学习算法中,有四个主要成分需要放在一起:一个数据集,一个模型/架构,一个损失函数,一个优化方法。我们将在下面逐一回顾这些成分。
数据集
数据集是训练神经网络的第一要素——数据本身以及我们试图解决的问题定义了我们的最终目标。例如,我们是否正在使用神经网络进行回归分析,以预测特定郊区 20 年后的房价?我们的目标是执行无监督学习吗,比如降维?还是我们在尝试进行分类?
在本书的上下文中,我们严格地关注于图像分类;但是,数据集和您试图解决的问题的组合会影响您对损失函数、网络架构和用于训练模型的优化方法的选择。通常,我们在数据集中几乎没有选择的余地(除非你正在做一个业余爱好项目)——我们被给予一个数据集,这个数据集对我们项目的结果应该是什么有一些期望。然后由我们在数据集上训练一个机器学习模型,以便在给定的任务中表现良好。
损失函数
给定我们的数据集和目标,我们需要定义一个与我们试图解决的问题一致的损失函数。在几乎所有使用深度学习的图像分类问题中,我们将使用交叉熵损失。对于 > 2 类,我们称之为分类交叉熵。对于两类问题,我们称损失为二元交叉熵。
模型/架构
您的网络架构可以被认为是您必须做出的第一个实际“选择”。您的数据集很可能是为您选择的(或者至少您已经决定您想要使用给定的数据集)。如果你在进行分类,你很可能会使用交叉熵作为损失函数。
但是,您的网络架构可能会有很大的不同,尤其是当您选择使用哪种优化方法来训练网络时。在花时间研究您的数据集并查看:
- 你有多少数据点?
- 班级的数量。
- 这些课有多相似/不相似。
- 类内方差。
您应该开始对将要使用的网络体系结构有一种“感觉”。这需要实践,因为深度学习是部分科学,部分艺术。
请记住,随着您进行越来越多的实验,网络架构中的层数和节点数(以及任何类型的正则化)可能会发生变化。你收集的结果越多,你就越有能力做出明智的决定,决定下一步要尝试哪种技术。
优化方法
最后一个要素是定义一个优化方法。 随机梯度下降 使用频率相当高。还存在其他优化方法,包括 RMSprop ( Hinton、用于机器学习的神经网络 )、Adagrad ( 杜奇、哈赞和辛格,2011 )、Adadelta ( 泽勒,2012 )和 Adam ( 金玛和巴,2014);然而,这些是更高级的优化方法。
尽管有所有这些更新的优化方法,SGD 仍然是深度学习的主力——大多数神经网络都是通过 SGD 训练的,包括在 ImageNet 等具有挑战性的图像数据集上获得最先进精度的网络。
当训练深度学习网络时,特别是当你第一次开始学习时, SGD 应该是你的首选优化器。然后,您需要设置适当的学习速率和正则化强度、网络应接受训练的总时期数,以及是否应使用动量(如果是,使用哪个值)或内斯特罗夫加速度。花时间尽可能多地试验 SGD 和变得适应调整 参数。
熟悉给定的优化算法类似于掌握如何驾驶汽车——你驾驶自己的车比别人的车好,因为你花了太多时间驾驶它;你了解你的车及其复杂性。通常,选择给定的优化器在数据集而不是上训练网络,因为优化器本身更好,但是因为驱动者(即深度学习实践者)更熟悉优化器,并且理解调整其各自参数背后的“艺术”。
请记住,即使对于高级深度学习用户来说,在小型/中型数据集上获得性能合理的神经网络也可能需要 10 到 100 次的实验——当您的网络一开始就表现不佳时,不要气馁。精通深度学习将需要你投入时间和许多实验——但是一旦你掌握了这些要素是如何组合在一起的,这将是值得的。
完美的计算机视觉环境:PyCharm、OpenCV 和 Python 虚拟环境

你知道是什么造就了一个(不那么)有趣的周末吗?
在 MacBook Pro 上重新配置和安装 OSX。显然,我旅行时用的 13 英寸 MacBook Pro 决定拉屎了。
不过不用担心,我用的是复写克隆器和备份器,所以没有数据丢失。老实说,我考虑在我的旅行系统上重建开发环境已经有一段时间了。当我在旅行中使用我的 13 英寸 MacBook Pro 时,我有第二个 MacBook Pro,我每天都用它作为我的主要开发系统。在过去的两年里,两者之间的开发环境变得非常不同步,几乎无法使用。
周日晚上,当我坐下来,看着铁砧形状的雷雨云在长岛海峡翻滚,我花了一秒钟,啜饮了一些茶(掺有一些薄荷杜松子酒;这是周末,当然)从我的杯子里,看着闪电随意地划过天空。
看着雷雨滚滚而来,你会有一种平静的安详——当你设置 PyCharm 来玩 OpenCV 和虚拟环境时,希望本指南的其余部分能给你一些平静的安详。
PyCharm、虚拟环境和 OpenCV
这篇博文的其余部分将假设您已经在系统上安装了 OpenCV 和适当的 Python 绑定。我还将假设您已经安装了 virtualenv 和 virtualenvwrapper 。
这些安装说明和相关的截屏是在我的 OSX 机器上收集的,但是这些说明在 Linux 和 Windows 上都可以工作(对于 Windows,你当然必须改变文件的不同路径,但是没关系)。
我还会用 Python 2.7 和 OpenCV 2.4.X 来设置我的系统。然而,您也可以使用相同的指令来设置 Python 3 和 OpenCV 的环境,您只需要更改 Python 和 OpenCV 文件的路径。
步骤 1:创建您的虚拟环境
我们要做的第一件事是设置我们的虚拟环境。打开一个终端,创建你的虚拟环境。对于本例,我们将虚拟环境命名为pyimagesearch:
$ mkvirtualenv pyimagesearch
现在我们的虚拟环境已经设置好了,让我们安装 NumPy、Scipy、matplotlib、scikit-learn 和 scikit-image,它们都是计算机视觉开发中常用的工具:
$ pip install numpy
$ pip install scipy
$ pip install matplotlib
$ pip install scikit-learn
$ pip install -U scikit-image
第二步:符号链接你的 cv2.so 和 cv.py 文件
我相信您已经知道,OpenCV 不是 pip 可安装的。您需要手动将您的cv2.so和cv.py文件符号链接到pyimagesearch虚拟环境的站点包目录中。
在我的系统上,OpenCV 安装在/usr/local/lib/python2.7/site-packages/
对于您的系统来说可能不是这样,所以一定要找到您的 OpenCV 安装路径并记下来——在接下来的步骤中您将需要这个路径。
现在我们有了 OpenCV 安装的路径,我们可以将它符号链接到我们的虚拟环境中:
$ cd ~/.virtualenvs/pyimagesearch/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv.py cv.py
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
步骤 3:配置 PyCharm
如果你还没有使用 PyCharm IDE 来编辑你的代码,它绝对值得一看。他们有一个免费的社区版和一个付费版,都有一些漂亮的铃铛和哨子。
很难相信,但多年来我在 PyCharm 都是反其道而行之,不予理会。
你看,在大学的时候,我被迫使用 Eclipse 进行 Java 开发——由于我从来不喜欢 Java 或 Eclipse,我(无知地)拒绝了任何让我想起它的 IDE。伙计,那是个巨大的错误。
大约六个月前,我决定给皮查姆一个真正的机会,不要让我以前的经历影响我的看法。简而言之,这是我在开发环境方面做出的最好的选择之一。
不管怎样,现在我们的虚拟环境已经设置好了,让我们将它连接到 PyCharm 项目。
打开 PyCharm 并创建一个新的“纯 Python”项目:
Figure 1: Creating a new Pure Python project in PyCharm.
在这里,我们需要设置 Python 解释器的位置。在大多数情况下,这个位置将指向您的 Python 系统安装。但是,我们不想使用系统 Python —我们想使用属于我们的pyimagesearch虚拟环境的 Python,所以单击齿轮图标并选择“添加本地”:
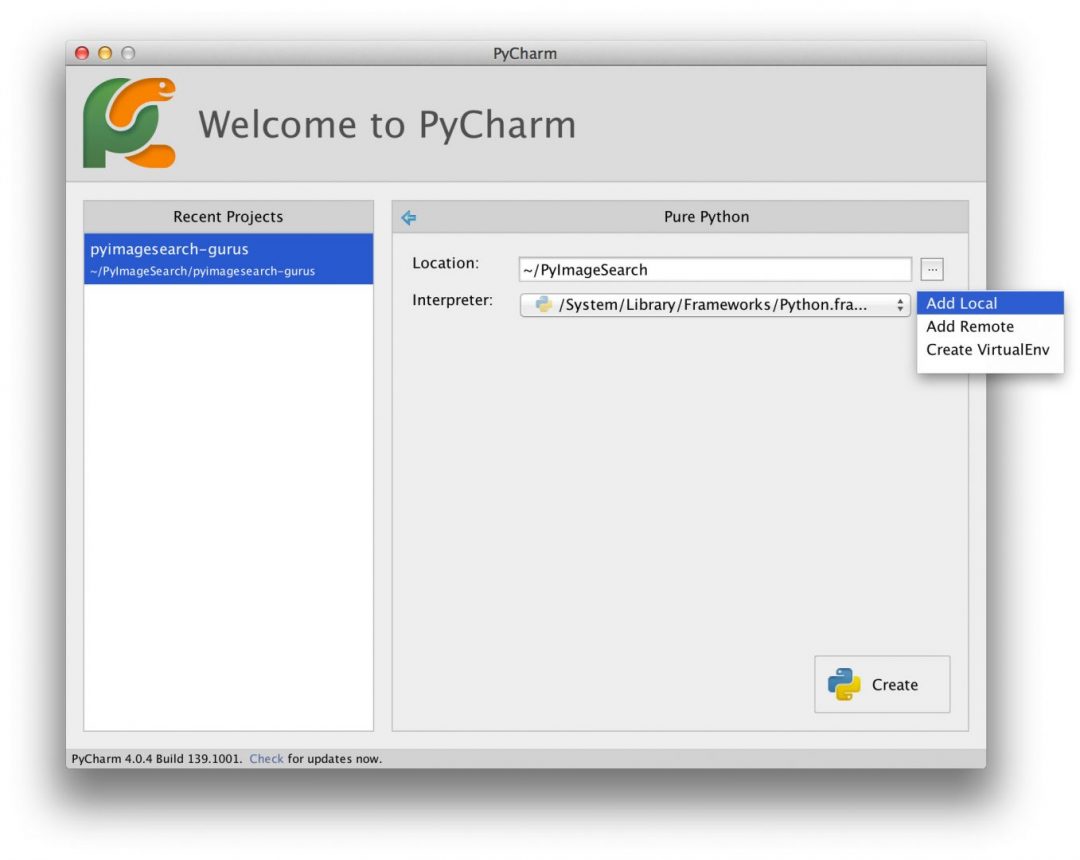
Figure 2: Specifying that we want to use a local Python environment rather than the default system Python.
接下来,我们需要指定虚拟环境中 Python 二进制文件 的路径。
在我的例子中,pyimagesearch虚拟环境位于~/.virtualenvs/pyimagesearch/中,而实际的 Python 二进制文件位于~/.virtualenvs/pyimagesearch/bin中。
在任何情况下,请确保导航到适用于您的虚拟环境的 Python 二进制文件,然后单击“选择”:
Figure 3: Selecting the pyimagesearch Python binary.
选择虚拟环境后,PyCharm 将花几秒钟时间更新项目框架:
Figure 4: PyCharm updating the project skeletons for our computer vision virtual environment.
一旦骨骼更新完成,点击“创建”按钮启动你的项目。
这就是全部了!
搞定了。
在这之后,你都设置好了。PyCharm 将使用您的pyimagesearch虚拟环境,并将识别 OpenCV 库。
如果您想要更新您正在使用的项目的虚拟环境,只需在 PyCharm 首选项面板中,选择左侧栏中的项目选项卡,然后选择“项目解释器”:
Figure 5: Updating the virtual environment for a project already created with PyCharm.
摘要
在这篇博文中,我向您展示了如何在我最喜欢的 IDEpy charm中利用虚拟环境和 OpenCV。
我希望这篇文章对你设置下一个 Python + OpenCV 项目有用!
如果您还没有使用 PyCharm,它绝对值得一看。
计算机视觉 Kickstarter 的树莓 Pi 现已上线!
原文:https://pyimagesearch.com/2019/04/10/the-raspberry-pi-for-computer-vision-kickstarter-is-now-live/

用于计算机视觉的树莓派 Kickstarter 正式上线!
要支持 Kickstarter 活动(并以 15-25%的折扣率索取您的 RPi for CV/my other books and courses ),只需使用以下链接:
请记住,我为活动的前 10 分钟在已经打折的捆绑价格基础上再提供15%的折扣。(美国东部时间上午 10:00-10:10)。这比整个 PyImageSearch 库节省了 30-35%。
但是一旦时钟指向美国东部时间上午 10:10,我就会取消额外的折扣。没有例外(但是你仍然可以从 Kickstarter 的特别定价中得到很多)。
如果您想利用特价优惠, 您肯定想现在就行动!
我希望你能利用这个机会充分利用这次销售,并继续学习计算机视觉、深度学习和 OpenCV。我会一直陪着你。
非常感谢你对我和 PyImageSearch 博客的支持。
我希望在另一边见到你。
热视觉:带 Python 和 OpenCV 的发热探测器(入门项目)
目录
热视觉:带 Python 和 OpenCV 的发热探测器(入门项目)
在本课中,您将把上两节课学到的知识应用到一个入门项目中,包括:
- 热图像中的简单人脸检测
- 发热检测(近似解决方案)
- 实时发烧检测您的树莓皮在 3 个步骤
本教程是关于红外视觉基础知识的 4 部分系列中的第 3 部分:
- 红外视觉介绍:近中远红外图像
- 热视觉:用 Python 和 OpenCV 从图像中测量你的第一个温度
- 热视觉:用 Python 和 OpenCV 实现的发热探测器(入门项目) (今日教程)
- 热视觉:用 PyTorch 和 YOLOv5 探测夜间物体(真实项目)
本课结束时,您将能够通过估计人脸的温度,在热图像、视频或摄像机视频流中实时检测人脸。
我们希望本教程能启发您将温度测量应用到项目中的图像。
免责声明 : 本教程试图利用热像来估计人体温度。这并不意味着新冠肺炎或其他疾病可以用建议的方法检测出来。我们鼓励您遵循美国美国食品药品监督管理局(FDA) 指南 来更深入地了解这个主题。
热图像中简单的人脸检测
简介
您可能已经注意到,由于 COVID 疫情的出现,用于大众门禁控制的热红外摄像机和热红外温度计的需求大幅增长。
我们可以找到这种设备,例如,在机场或其他群体事件中,如图图 1 所示。

Figure 1: Top: Manual thermal thermometer control in an airport (source). Bottom: Automatic thermal camera control in an airport (source).
正如我们已经了解到的,热感相机让我们能够通过应用我们作为计算机视觉初学者/从业者/研究人员/专家的知识,为这个现实生活中的问题做出贡献。
因此,让我们从我们的热图像中的面部检测开始!
计算机视觉为我们提供了许多方法来检测标准彩色可见光/RGB 图像中的人脸:哈尔级联、梯度方向直方图(HOG) +线性支持向量机(SVM)、深度学习方法等。
有大量的在线教程,但在这里你可以找到 4 种最流行的面部检测方法,并以简单明了的方式进行解释。
但是热成像发生了什么呢?
我们将尝试快速回答这个问题。
让我们通过将上述方法分为两组来简化问题:
- 人脸检测的传统机器学习: Haar 级联和梯度方向直方图(HOG) +线性支持向量机(SVM)。
- 深度学习(卷积神经网络)人脸检测方法:最大间隔对象检测器(MMOD)和单镜头检测器(SSD)。
乍一看,我们可以考虑使用其中任何一种。
尽管如此,看看面部检测技巧、建议和最佳实践,我们应该验证所使用的库 OpenCV 和 Dlib 是否实现了在热图像上训练的算法。
或者,我们可以训练自己的面部检测器模型,这显然超出了我们红外视觉基础课程的范围。
此外,我们应该考虑到,作为本教程的起始项目,我们希望将我们的解决方案集成到一个 Raspberry Pi 中。所以,我们需要一个又快又小的模型。
因此,出于这些原因并为了简化本教程,我们将使用哈尔级联方法(图 2 )。
热人脸检测与哈尔喀
保罗·维奥拉和迈克尔·琼斯在 2001 年的快速物体检测中提出了这个著名的物体检测器,使用简单特征的增强级联。
是的,2001 年,“几年前”。
是的。我们已经在热图像上测试过了,它不需要我们的任何培训就能工作!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
开始编码吧。
首先,看看我们的项目结构:
$ tree --dirsfirst
.
├── fever_detector_image.py
├── fever_detector_video.py
├── fever_detector_camera.py
├── faces_gray16_image.tiff
├── haarcascade_frontalface_alt2.xml
└── gray16_sequence
├── gray16_frame_000.tiff
├── gray16_frame_001.tiff
├── gray16_frame_002.tiff
├── ...
└── gray16_frame_069.tiff
1 directory, 76 files
我们将对热图像中的人脸应用 Haar 级联算法,然后是热视频序列,最后是使用 USB 视频类(UVC)热摄像机。这些部分分别在以下版本中实现:
fever_detector_image.py:对输入图像应用 Haar 级联人脸检测算法(faces_gray16_image.tiff)。fever_detector_video.py:将 Haar 级联人脸检测算法应用于输入视频帧(gray16_sequence文件夹)。fever_detector_camera.py:将 Haar 级联人脸检测应用于 UVC 热感摄像机的视频输入流。
整堂课我们都将遵循这个结构。
faces_gray16_image.tiff是我们的 raw gray16 热像,如图 3 、右所示,提取自热像仪RGM vision thermal cam 1。
gray16_sequence文件夹包含一个视频序列样本。
haarcascade_frontalface_alt2.xml文件是我们预先训练好的人脸检测器,由 OpenCV 库( GitHub )的开发者和维护者提供。
人脸检测
热图像中的人脸检测
打开您的fever_detector_image.py文件并导入 NumPy 和 OpenCV 库:
# import the necessary packages
import cv2
import numpy as np
您应该已经安装了 NumPy 和 OpenCV 库。
首先,我们将开始打开热灰色图像:
# open the gray16 image
gray16_image = cv2.imread("faces_gray16_image.tiff", cv2.IMREAD_ANYDEPTH)
cv2.IMREAD_ANYDEPTH标志允许我们以 16 位格式打开灰色 16 图像。
# convert the gray16 image into a gray8
gray8_image = np.zeros((120,160), dtype=np.uint8)
gray8_image = cv2.normalize(gray16_image, gray8_image, 0, 255, cv2.NORM_MINMAX)
gray8_image = np.uint8(gray8_image)
在第 9-11 行上,我们分别创建一个空的160x120图像,我们将 gray16 图像从 0-65,553 (16 位)归一化到 0-255 (8 位),我们确保最终图像是 8 位图像。
我们使用160x120分辨率,因为faces_gray16_image.tiff gray16 图像有这个尺寸。
然后,我们使用我们最喜欢的 OpenCV colormap*为 gray8 图像着色,以获得不同的热调色板(图 3 ,中间):
# color the gray8 image using OpenCV colormaps
gray8_image = cv2.applyColorMap(gray8_image, cv2.COLORMAP_INFERNO)
(*)请访问 OpenCV 中的色彩映射表,以确保您选择的色彩映射表在您的 OpenCV 版本中可用。在这种情况下,我们使用的是 OpenCV 4.5.4。
最后,我们实现了我们的 Haar 级联算法。
# load the haar cascade face detector
haar_cascade_face = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
在第 17 行上,加载了由 OpenCV 库(GitHub)的开发者和维护者提供的带有我们预先训练好的人脸检测器的 XML haarcascade_frontalface_alt2.xml文件。
# detect faces in the input image using the haar cascade face detector
faces = haar_cascade_face.detectMultiScale(gray8_image, scaleFactor=1.1, minNeighbors=5, minSize=(10, 10), flags=cv2.CASCADE_SCALE_IMAGE)
在第 20 行上,应用了哈尔级联检测器。
# loop over the bounding boxes
for (x, y, w, h) in faces:
# draw the rectangles
cv2.rectangle(gray8_image, (x, y), (x + w, y + h), (255, 255, 255), 1)
在第 23-25 行上,我们循环检测到的人脸,并绘制相应的矩形。
# show result
cv2.imshow("gray8-face-detected", gray8_image)
cv2.waitKey(0)
最后,我们展示结果(第 28 行和第 29 行)。
没错!我们正在检测热红外图像上的人脸(图三、右图)。



Figure 3: Left: Thermal gray16 image showing a face, faces_gray16_image.tiff. Middle: Thermal gray8 image after converting the gray16 faces_gray16_image.tiff and coloring it with the Inferno OpenCV colormap. Right: Haar Cascade face detector applied on the thermal gray8 image.
热视频序列中的人脸检测
假设我们手头没有热感相机,并且想要检测热感视频流中的人脸,我们遵循前面相同的步骤。
为了简化,我们将使用存储在我们的gray16_sequence中的视频序列。此文件夹包含 TIFF 帧而不是 gray16 视频文件,因为标准压缩视频文件容易丢失信息。灰色的 16 帧保持了每个像素的温度值,我们用它来估计面部温度。
在导入必要的库之后,我们使用fever_detector_video.py文件来遵循我们在上一节中看到的相同过程,在每一帧上循环:
# import the necessary packages
import numpy as np
import cv2
import os
import argparse
在本例中,我们还导入了 argparse 和 os 库。
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True, help="path of the video sequence")
args = vars(ap.parse_args())
如果您熟悉 PyImageSearch 教程,那么您已经知道 argparse Python 库。我们用它在运行时给程序提供额外的信息(例如,命令行参数)。在这种情况下,我们将使用它来指定我们的热视频路径(第 8-10 行)。
# load the haar cascade face detector
haar_cascade_face = cv2.CascadeClassifier("haarcascade_frontalface_alt2.xml")
# create thermal video fps variable (8 fps in this case)
fps = 8
让我们加载预训练的 Haar Cascade 人脸检测器,并定义每秒帧序列值(第 13-16 行):
# loop over the thermal video frames to detect faces
for image in sorted(os.listdir(args["video"])):
# filter .tiff files (gray16 images)
if image.endswith(".tiff"):
# define the gray16 frame path
file_path = os.path.join(args["video"], image)
# open the gray16 frame
gray16_image = cv2.imread(args["video"], cv2.IMREAD_ANYDEPTH)
# convert the gray16 image into a gray8
gray8_frame = np.zeros((120, 160), dtype=np.uint8)
gray8_frame = cv2.normalize(gray16_frame, gray8_frame, 0, 255, cv2.NORM_MINMAX)
gray8_frame = np.uint8(gray8_frame)
# color the gray8 image using OpenCV colormaps
gray8_frame = cv2.applyColorMap(gray8_frame, cv2.COLORMAP_INFERNO)
# detect faces in the input image using the haar cascade face detector
faces = haar_cascade_face.detectMultiScale(gray8_frame, scaleFactor=1.1, minNeighbors=5, minSize=(10, 10),
flags=cv2.CASCADE_SCALE_IMAGE)
# loop over the bounding boxes
for (x, y, w, h) in faces:
# draw the rectangles
cv2.rectangle(gray8_frame, (x, y), (x + w, y + h), (255, 255, 255), 1)
# show results
cv2.imshow("gray8-face-detected", gray8_frame)
# wait 125 ms: RGMVision ThermalCAM1 frames per second = 8
cv2.waitKey(int((1 / fps) * 1000))
第 19-50 行包括检测每帧人脸的循环过程。
图 4 显示了视频场景中的人脸检测。
发热检测
热图像中的发热检测
一旦我们学会了如何在我们的热图像中轻松地检测人脸,我们就需要测量每个像素的温度来决定一个人是否有正常值。
因此,我们将此过程分为两步:
- 测量我们感兴趣区域(ROI)的温度值,即检测到的人脸的特定区域。
- 为我们的 ROI 温度值设置一个阈值,以确定我们何时检测到发烧的人(或体温高于平时的人)。
我们继续编码吧!首先,我们打开我们的fever_detector_image.py文件。
# loop over the bounding boxes to measure their temperature
for (x, y, w, h) in faces:
# draw the rectangles
cv2.rectangle(gray8_image, (x, y), (x + w, y + h), (255, 255, 255), 1)
# define the roi with a circle at the haar cascade origin coordinate
# haar cascade center for the circle
haar_cascade_circle_origin = x + w // 2, y + h // 2
# circle radius
radius = w // 4
# get the 8 most significant bits of the gray16 image
# (we follow this process because we can't extract a circle
# roi in a gray16 image directly)
gray16_high_byte = (np.right_shift(gray16_image, 8)).astype('uint8')
# get the 8 less significant bits of the gray16 image
# (we follow this process because we can't extract a circle
# roi in a gray16 image directly)
gray16_low_byte = (np.left_shift(gray16_image, 8) / 256).astype('uint16')
# apply the mask to our 8 most significant bits
mask = np.zeros_like(gray16_high_byte)
cv2.circle(mask, haar_cascade_circle_origin, radius, (255, 255, 255), -1)
gray16_high_byte = np.bitwise_and(gray16_high_byte, mask)
# apply the mask to our 8 less significant bits
mask = np.zeros_like(gray16_low_byte)
cv2.circle(mask, haar_cascade_circle_origin, radius, (255, 255, 255), -1)
gray16_low_byte = np.bitwise_and(gray16_low_byte, mask)
# create/recompose our gray16 roi
gray16_roi = np.array(gray16_high_byte, dtype=np.uint16)
gray16_roi = gray16_roi * 256
gray16_roi = gray16_roi | gray16_low_byte
# estimate the face temperature by obtaining the higher value
higher_temperature = np.amax(gray16_roi)
# calculate the temperature
higher_temperature = (higher_temperature / 100) - 273.15
# higher_temperature = (higher_temperature / 100) * 9 / 5 - 459.67
# write temperature value in gray8
if higher_temperature < fever_temperature_threshold:
# white text: normal temperature
cv2.putText(gray8_image, "{0:.1f} Celsius".format(higher_temperature), (x - 10, y - 10), cv2.FONT_HERSHEY_PLAIN,
1, (255, 255, 255), 1)
else:
# - red text + red circle: fever temperature
cv2.putText(gray8_image, "{0:.1f} Celsius".format(higher_temperature), (x - 10, y - 10), cv2.FONT_HERSHEY_PLAIN,
1, (0, 0, 255), 2)
cv2.circle(gray8_image, haar_cascade_circle_origin, radius, (0, 0, 255), 2)
同样,我们在第 36-90 行上循环检测到的面部。这次我们将定义我们的投资回报。
当前的 ISO 标准确定内眼角是使用热面部图像来确定体温的最佳位置。
为此,为了简化过程,我们将围绕 Haar 级联人脸检测的中心点定义一个圆形 ROI。
# draw the rectangles
cv2.rectangle(gray8_image, (x, y), (x + w, y + h), (255, 255, 255), 1)
为此,首先,我们为每个检测到的人脸再次绘制一个 Haar Cascade 矩形(行 39 )。
# define the roi with a circle at the haar cascade origin coordinate
# haar cascade center for the circle
haar_cascade_circle_origin = x + w // 2, y + h // 2
# circle radius
radius = w // 4
然后,我们通过建立面部的中心来定义我们的 ROI 圆,即圆心(线 44 )和圆的半径(线 46 )。
由于 OpenCV 不允许我们在 16 位图像中画一个圆,并且我们需要 gray16 信息来测量温度,我们将使用下面的技巧。
首先,我们将 16 位热成像的每个像素值分成两组,每组 8 位(2 个字节),如图 5 所示。
# get the 8 most significant bits of the gray16 image
# (we follow this process because we can't extract a circle
# roi in a gray16 image directly)
gray16_high_byte = (np.right_shift(gray16_image, 8)).astype('uint8')
我们右移第 51 行上的 16 位,丢失 8 个较低有效位,并通过将图像转换为灰度 8 来删除新的最高有效位(8 个零)。
# get the 8 less significant bits of the gray16 image
# (we follow this process because we can't extract a circle
# roi in a gray16 image directly)
gray16_low_byte = (np.left_shift(gray16_image, 8) / 256).astype('uint16')
我们左移第 56 行上的 16 位,丢失 8 个最高有效位(msb ),并通过将值除以 256 来转换新的 8 个 msb。
# apply the mask to our 8 most significant bits
mask = np.zeros_like(gray16_high_byte)
cv2.circle(mask, haar_cascade_circle_origin, radius, (255, 255, 255), -1)
gray16_high_byte = np.bitwise_and(gray16_high_byte, mask)
# apply the mask to our 8 less significant bits
mask = np.zeros_like(gray16_low_byte)
cv2.circle(mask, haar_cascade_circle_origin, radius, (255, 255, 255), -1)
gray16_low_byte = np.bitwise_and(gray16_low_byte, mask)
然后,我们分别对我们的 2 个分割字节应用掩码和位运算,以隔离包含温度信息的 ROI(行 59-66 )。
如果您不熟悉这些操作,我们鼓励您遵循 OpenCV 按位 AND、OR、XOR 和 NOT 。
# create/recompose our gray16 roi
gray16_roi = np.array(gray16_high_byte, dtype=np.uint16)
gray16_roi = gray16_roi * 256
gray16_roi = gray16_roi | gray16_low_byte
在第行第 69-71 行,我们用内眼角区域的温度值重新组合图像,获得我们的 16 位圆形 ROI。
# estimate the face temperature by obtaining the higher value
higher_temperature = np.amax(gray16_roi)
# calculate the temperature
higher_temperature = (higher_temperature / 100) - 273.15
#higher_temperature = (higher_temperature / 100) * 9 / 5 - 459.67
最后,为了容易地确定检测到的面部是否具有高于正常范围的温度,即,超过 99-100.5 F(大约 37-38 C),我们在第 74-78 行上计算我们的圆形 ROI 的最高温度值。
# fever temperature threshold in Celsius or Fahrenheit
fever_temperature_threshold = 37.0
fever_temperature_threshold = 99.0
然后,如果该值(第 88 行)高于我们的阈值(fever_temperature_threshold、第 32 行和第 33 行),我们将显示发烧红色警报文本(第 81 行)。再次我们要记住上面提到的 免责声明 。
# write temperature value in gray8
if higher_temperature < fever_temperature_threshold:
# white text: normal temperature
cv2.putText(gray8_image, "{0:.1f} Celsius".format(higher_temperature), (x - 10, y - 10), cv2.FONT_HERSHEY_PLAIN,
1, (255, 255, 255), 1)
else:
# - red text + red circle: fever temperature
cv2.putText(gray8_image, "{0:.1f} Celsius".format(higher_temperature), (x - 10, y - 10), cv2.FONT_HERSHEY_PLAIN,
1, (0, 0, 255), 2)
cv2.circle(gray8_image, haar_cascade_circle_origin, radius, (0, 0, 255), 2)
# show result
cv2.imshow("gray8-face-detected", gray8_image)
cv2.waitKey(0)
就是这样:我们有了使用计算机视觉的发烧探测器!
图 6 显示了热灰 8 图像中的面部温度值。


Figure 6: Left: The face temperature measurement result in the thermal gray8 image (in °C). Right: The face temperature measurement result in the thermal gray8 image (in °F).
热视频序列中的发热检测
同样,和前面的教程部分一样,我们遵循与“静态”图像中相同的步骤。我们循环视频序列的每一帧,测量并显示每个检测到的人脸的 ROI 的最大温度值。
图 7 显示了结果。
分两步对您的树莓 Pi 进行实时发热检测
在这堂课的最后一节,我们将运用到目前为止我们在这门课中学到的所有东西。
我们将在我们的 Raspberry Pi 上使用 OpenCV 和 Python,并使用性价比最高的热感相机之一 RGMVision ThermalCAM 1 来实现我们的 easy fever detector 流程。
无论你有这台相机或任何其他 UVC 热感相机,你会很高兴实现一个实时发热探测器。如果您手头没有热感相机,您也可以在您的 Raspberry Pi 上运行本课程中迄今为止显示的所有内容。
只要遵循以下 3 个 CPP 步骤,您就能成功实施该项目:
- 密码
- 插头
- 玩
我们来编码吧!
打开fever_detector_camera.py并导入 NumPy 和 OpenCV 库:
# import the necessary packages
import cv2
import numpy as np
当然,您的 Raspberry Pi 应该安装了这两个库。如果没有,请看在树莓 Pi 4 上安装 OpenCV 4 和 Raspbian Buster 。
设置热感摄像机指数和分辨率,在我们的例子中,160x120:
# set up the thermal camera index (thermal_camera = cv2.VideoCapture(0, cv2.CAP_DSHOW) on Windows OS)
thermal_camera = cv2.VideoCapture(0)
# set up the thermal camera resolution
thermal_camera.set(cv2.CAP_PROP_FRAME_WIDTH, 160)
thermal_camera.set(cv2.CAP_PROP_FRAME_HEIGHT, 120)
在第 6 行,你应该选择你的相机 ID。如果您使用的是 Windows 操作系统,请确保指定您的后端视频库,例如,Direct Show (DSHOW): thermal_camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)。
欲了解更多信息,请访问带 OpenCV 概述的视频 I/O。
将热感摄像机设置为 gray16 源,并接收 raw 格式的数据:
# set up the thermal camera to get the gray16 stream and raw data
thermal_camera.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter.fourcc('Y','1','6',' '))
thermal_camera.set(cv2.CAP_PROP_CONVERT_RGB, 0)
第 14 行阻止 RGB 转换。
# load the haar cascade face detector
haar_cascade_face = cv2.CascadeClassifier("haarcascade_frontalface_alt2.xml")
# fever temperature threshold in Celsius or Fahrenheit
fever_temperature_threshold = 37.0
#fever_temperature_threshold = 99.0
让我们加载预训练的 Haar Cascade 人脸检测器,并定义我们的发烧阈值(fever_temperature_threshold、第 20 行和第 21 行)。
# loop over the thermal camera frames
while True:
# grab the frame from the thermal camera stream
(grabbed, gray16_frame) = thermal_camera.read()
# convert the gray16 image into a gray8
gray8_frame = np.zeros((120, 160), dtype=np.uint8)
gray8_frame = cv2.normalize(gray16_frame, gray8_frame, 0, 255, cv2.NORM_MINMAX)
gray8_frame = np.uint8(gray8_frame)
# color the gray8 image using OpenCV colormaps
gray8_frame = cv2.applyColorMap(gray8_frame, cv2.COLORMAP_INFERNO)
# detect faces in the input frame using the haar cascade face detector
faces = haar_cascade_face.detectMultiScale(gray8_frame, scaleFactor=1.1, minNeighbors=5, minSize=(10, 10),
flags=cv2.CASCADE_SCALE_IMAGE)
# loop over the bounding boxes to measure their temperature
for (x, y, w, h) in faces:
# draw the rectangles
cv2.rectangle(gray8_frame, (x, y), (x + w, y + h), (255, 255, 255), 1)
# define the roi with a circle at the haar cascade origin coordinate
# haar cascade center for the circle
haar_cascade_circle_origin = x + w // 2, y + h // 2
# circle radius
radius = w // 4
# get the 8 most significant bits of the gray16 image
# (we follow this process because we can't extract a circle
# roi in a gray16 image directly)
gray16_high_byte = (np.right_shift(gray16_frame, 8)).astype('uint8')
# get the 8 less significant bits of the gray16 image
# (we follow this process because we can't extract a circle
# roi in a gray16 image directly)
gray16_low_byte = (np.left_shift(gray16_frame, 8) / 256).astype('uint16')
# apply the mask to our 8 most significant bits
mask = np.zeros_like(gray16_high_byte)
cv2.circle(mask, haar_cascade_circle_origin, radius, (255, 255, 255), -1)
gray16_high_byte = np.bitwise_and(gray16_high_byte, mask)
# apply the mask to our 8 less significant bits
mask = np.zeros_like(gray16_low_byte)
cv2.circle(mask, haar_cascade_circle_origin, radius, (255, 255, 255), -1)
gray16_low_byte = np.bitwise_and(gray16_low_byte, mask)
# create/recompose our gray16 roi
gray16_roi = np.array(gray16_high_byte, dtype=np.uint16)
gray16_roi = gray16_roi * 256
gray16_roi = gray16_roi | gray16_low_byte
# estimate the face temperature by obtaining the higher value
higher_temperature = np.amax(gray16_roi)
# calculate the temperature
higher_temperature = (higher_temperature / 100) - 273.15
# higher_temperature = (higher_temperature / 100) * 9 / 5 - 459.67
# write temperature value in gray8
if higher_temperature < fever_temperature_threshold:
# white text: normal temperature
cv2.putText(gray8_frame, "{0:.1f} Celsius".format(higher_temperature), (x, y - 10), cv2.FONT_HERSHEY_PLAIN,
1, (255, 255, 255), 1)
else:
# - red text + red circle: fever temperature
cv2.putText(gray8_frame, "{0:.1f} Celsius".format(higher_temperature), (x, y - 10), cv2.FONT_HERSHEY_PLAIN,
1, (0, 0, 255), 2)
cv2.circle(gray8_frame, haar_cascade_circle_origin, radius, (0, 0, 255), 2)
# show the temperature results
cv2.imshow("final", gray8_frame)
cv2.waitKey(1)
# do a bit of cleanup
thermal_camera.release()
cv2.destroyAllWindows()
通过使用 Haar Cascade 算法检测面部,隔离圆形 ROI,并按照前面的章节设定最大温度值的阈值,循环热摄像机帧(第 24-100 行)。
让我们将您的热感相机插入您的 4 个 Raspberry Pi USB 插座中的一个(图 8 )!
最后,让我们通过命令或使用您最喜欢的 Python IDE 来播放/运行代码(图 9 )!
仅此而已!享受你的项目!
汇总
在本教程中,我们学习了如何实现一个简单的发热探测器作为热启动项目。
首先,为此目的,我们已经发现如何通过实现 Haar 级联机器学习算法来检测热图像/视频/相机流中的人脸。
然后,我们使用圆形遮罩在检测到的人脸中分离出感兴趣的区域(ROI ),而不会丢失灰度 16 温度信息。
之后,我们对定义的 ROI 的最大温度值进行阈值处理,以确定检测到的人脸是否属于温度高于正常范围的人。
最后,我们用 UVC 热感相机和你的 Raspberry Pi 分三步实现了一个实时发热探测器。
在下面的教程中,我们将进入应用于热视觉的深度学习,你将学会即使在晚上完全黑暗的情况下也能探测到不同的物体。
那里见!
引用信息
Garcia-Martin,R. “热视觉:使用 Python 和 OpenCV 的发热探测器(启动项目), PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/6nxs0
@incollection{Garcia-Martin_2022_Fever,
author = {Raul Garcia-Martin},
title = {Thermal Vision: Fever Detector with {P}ython and {OpenCV} (starter project)},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/6nxs0},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
热视觉:使用 Python 和 OpenCV 从图像中测量第一个温度
目录
热视觉:用 Python 和 OpenCV 从图像中测量你的第一个温度
在今天的课程中,您将学习热/中远红外视觉的基础知识。完成本课后,您将了解如何从热图像中的每个像素测量第一个温度值,包括:
- 热成像格式:灰色 8 与灰色 16
- 从热成像中测量你的第一次体温
- 通过热感摄像机/摄像机测量您的第一次体温
本教程是关于红外视觉基础知识的 4 部分系列中的第 2 部分:
- 红外视觉介绍:近红外与中远红外图像 (建议更好地理解今天的教程)
- 热视觉:用 Python 和 OpenCV (今日教程)
- 热视觉:使用 Python 和 OpenCV 的发热探测器(初始项目)
- 热视觉:用 PyTorch 和 YOLOv5 探测夜间物体(真实项目)
本课结束时,您将通过一种非常简单的方式,仅使用 Python 和 OpenCV,测量热图像和热视频中每个像素的温度值。此外,如果你手头有这样一台神奇的摄像机,你还可以从热感摄像机获得视频流和实时温度值。
要了解如何从热图像中的每个像素测量你的第一个温度值, 继续阅读。
热视觉:用 Python 和 OpenCV 从图像中测量你的第一个温度
热成像格式:灰色 8 对灰色 16
灰色 8
在我们开始测量每个像素的温度值之前,我们需要了解热感相机/图像提供的不同基本图像格式。



Figure 1: Color RGB visible-light image (left) vs. Black and White or Grayscale visible-light image (center) vs. Gray8 thermal image (right).
当图像在灰度空间中表示时(图 1 、中心),每个像素仅由单个通道或值表征,通常在 0 到 255 之间(即黑白)。
这种格式如图图 1 ( 右)所示,被称为灰度或灰色 8 (8 位= 0 到 255 的像素值),是热视觉中最广泛的格式。
如图图 2 所示,gray8 图像用不同的色图或色标着色,以增强热图像中温度分布的可视化。这些贴图被称为热调色板。




Figure 2: Gray8 thermal colored images. Colormaps from OpenCV: Grayscale (top-left), Inferno (top-right), Jet (bottom-left), and Viridis (bottom-right). For extra information, you can visit ColorMaps in OpenCV.
例如,Inferno 调色板显示紫色(0)和黄色(255)之间的温度变化。
灰色 16
太好了,现在我们明白这些令人惊叹的彩色图像是从哪里来的了,但是我们如何计算温度呢(你可能想知道)?
出于这个目的,热感相机也提供灰度图像。这种格式不是使用从 0 到 255 的像素值(图 3 、左),而是将信息编码为 16 位,即 0 到 65535 个值(图 3 、右)。
但是,为什么呢?
我们将在下一节中发现它,但首先,让我们应用到目前为止所学的知识。
在下面的一小段代码中,您将学习如何:
- 打开一个 gray16 热图像(
lighter_gray16_image.tiff) - 将其转换为灰色 8 图像
- 用不同的热调色板给它上色
您可能已经注意到,这个图像有一种特殊的格式,TIFF(标记图像文件格式),用来存储 16 位信息。它已经被一个负担得起的热感相机拍摄到:RGM vision thermal cam 1(如果你有兴趣发现热感视觉世界,这是一个极好的开始选项)。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
让我们检查一下简单的项目结构:
$ tree --dirsfirst
.
├── gray8_vs_gray16.py
├── measure_image_temperature.py
├── measure_video_temperature.py
├── measure_camera_video_temperature.py
├── lighter_gray16_image.tiff
└── gray16_sequence
├── gray16_frame_000.tiff
├── gray16_frame_001.tiff
├── gray16_frame_002.tiff
├── ...
└── gray16_frame_069.tiff
1 directory, 76 files
每个 Python 文件对应于教程的 4 个部分。lighter_gray16_image.tiff文件是我们的 16 位/灰度 16 热图像。
打开项目目录结构中的gray8_vs_gray16.py文件,插入以下代码导入 NumPy 和 OpenCV 库:
# import the necessary packages
import numpy as np
import cv2
首先,我们将开始打开 gray16 热图像:
# open the gray16 image
gray16_image = cv2.imread("lighter_gray16_image.tiff", cv2.IMREAD_ANYDEPTH)
标志允许我们以 16 位格式打开 gray16 图像。
然后,我们将它转换成灰色图像,以便能够正确处理和可视化:
# convert the gray16 image into a gray8
gray8_image = np.zeros((120, 160), dtype=np.uint8)
gray8_image = cv2.normalize(gray16_image, gray8_image, 0, 255, cv2.NORM_MINMAX)
gray8_image = np.uint8(gray8_image)
在的第 9、10 和 11 行上,我们分别创建了一个空的160x120图像,我们将 gray16 图像从 0-65,553 (16 位)归一化到 0-255 (8 位),并确保最终图像是 8 位图像。
我们使用我们最喜欢的 OpenCV colormap ***** 为 gray8 图像着色,以获得不同的热调色板:
# color the gray8 image using OpenCV colormaps
inferno_palette = cv2.applyColorMap(gray8_image, cv2.COLORMAP_INFERNO)
jet_palette = cv2.applyColorMap(gray8_image, cv2.COLORMAP_JET)
viridis_palette = cv2.applyColorMap(gray8_image, cv2.COLORMAP_VIRIDIS)
(*) 请访问 OpenCV 中的色彩图,确保您选择的色彩图在您的 OpenCV 版本中可用。在这种情况下,我们使用的是 OpenCV 4.5.4。
最后,我们展示结果:
# show the different thermal color palettes
cv2.imshow("gray8", gray8_image)
cv2.imshow("inferno", inferno_palette)
cv2.imshow("jet", jet_palette)
cv2.imshow("viridis", viridis_palette)
cv2.waitKey(0)
从热成像中测量你的第一个温度
既然我们已经了解了基本的热成像格式,我们就可以从热成像中测量我们的第一个温度了!
我们离开了上一节,想知道为什么灰色图像有助于确定温度。
答案很简单:16 位像素值为我们计算每个像素的温度提供了足够的信息。
重要: 此时,你应该检查信息是如何在你的热/图像相机中被编码的!
但是不用担心;我们将通过查看用 RGMVision ThermalCAM 1 拍摄的样本图像lighter_gray16_image.tiff中的温度来简化这一步骤。
这款相机遵循:
(1)温度(°C)=(Gray _ 16 _ value)/100(K)-绝对零度(K)。
例如,如果我们得到的 gray16 值为 40,000,则以摄氏度表示的结果温度为:
(2)温度(°C)= 40000/100(K)–273.15(K)= 126.85°C,
这意味着
(3)温度= 126.85 摄氏度= 260.33 华氏度
有了这些信息,我们开始编码吧!
打开measure_image_temperature.py文件,导入 NumPy 和 OpenCV 库:
# import the necessary packages
import numpy as np
import cv2
打开 gray16 热像,lighter_gray16_image.tiff如前一节:
# open the gray16 image
gray16_image = cv2.imread("lighter_gray16_image.tiff ", cv2.IMREAD_ANYDEPTH)
标志允许我们以 16 位格式打开 gray16 图像。
我们将测量所需像素的温度值。先说火焰中间的一个热值。由于 RGMVision ThermalCAM 1 提供160x120图像,我们可以选择例如x, y = (90, 40)值,如图图 4 所示。
# get the first gray16 value
# pixel coordinates
x = 90
y = 40
pixel_flame_gray16 = gray16_image [y, x]
现在,我们可以应用等式(1 ),得到以°C 或°F 为单位的温度值:
# calculate temperature value in ° C
pixel_flame_gray16 = (pixel_flame_gray16 / 100) - 273.15
# calculate temperature value in ° F
pixel_flame_gray16 = (pixel_flame_gray16 / 100) * 9 / 5 - 459.67
就是这样!就这么简单!
最后,我们显示灰度 16 和灰度 8 图像中的值:
# convert the gray16 image into a gray8 to show the result
gray8_image = np.zeros((120,160), dtype=np.uint8)
gray8_image = cv2.normalize(gray16_image, gray8_image, 0, 255, cv2.NORM_MINMAX)
gray8_image = np.uint8(gray8_image)
# write pointer
cv2.circle(gray8_image, (x, y), 2, (0, 0, 0), -1)
cv2.circle(gray16_image, (x, y), 2, (0, 0, 0), -1)
# write temperature value in gray8 and gray16 image
cv2.putText(gray8_image,"{0:.1f} Fahrenheit".format(pixel_flame_gray16),(x - 80, y - 15), cv2.FONT_HERSHEY_PLAIN, 1,(255,0,0),2)
cv2.putText(gray16_image,"{0:.1f} Fahrenheit".format(pixel_flame_gray16),(x - 80, y - 15), cv2.FONT_HERSHEY_PLAIN, 1,(255,0,0),2)
# show result
cv2.imshow("gray8-fahrenheit", gray8_image)
cv2.imshow("gray16-fahrenheit", gray16_image)
cv2.waitKey(0)
图 5 显示了结果。




Figure 5: Gray8 thermal image with the measured temperature value of a flame pixel in °C (top-left) and in °F (bottom-left). Gray16 thermal image with the measured temperature value of a flame pixel in °C (top-right) and in °F (bottom-right).
我们不显示度数符号“”,因为默认的 OpenCV 字体遵循有限的 ASCII,不提供这种符号。如果你对它感兴趣,请使用 PIL (Python 图像库)。
如果我们想验证这个值是否有意义,我们可以获得一个不同的温度点,在这种情况下,一个更冷的温度点:点燃打火机的手。
# get the second gray16 value
# pixel coordinates
x = 90
y = 100
我们简单地改变坐标,得到如图 6 所示的结果。




Figure 6: Gray8 thermal image with the measured temperature value of a hand pixel in °C (top-left) and in °F (bottom-left). Gray16 thermal image with the measured temperature value of a hand pixel in °C (top-right) and in °F (bottom-right).
用热感摄像机/照相机测量你的第一次体温
**在这最后一节,我们将再次应用我们在本教程中学到的东西,但来自一个热视频源:一个热摄像机或热视频文件。
测量来自热视频的温度
如果你手头没有这些令人难以置信的相机,不要担心,我们将使用一个样本视频序列,gray16_sequence文件夹,提取自 RGMVision ThermalCAM 1 。
在下面这段代码中,您将学会如何轻松地做到这一点。
打开measure_video_temperature.py并导入 NumPy、OpenCV、OS 和 argparse 库:
# import the necessary packages
import cv2
import numpy as np
import os
import argparse
如果您熟悉 PyImageSearch 教程,那么您已经知道 argparse Python 库。我们用它在运行时给程序提供额外的信息(例如,命令行参数)。在这种情况下,我们将使用它来指定我们的热视频路径:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True, help="path of the video sequence")
args = vars(ap.parse_args())
下面的代码向您展示了如何实现一个鼠标指针来轻松显示所选像素的温度,而不是选择一个固定点:
# create mouse global coordinates
x_mouse = 0
y_mouse = 0
# create thermal video fps variable (8 fps in this case)
fps = 8
# mouse events function
def mouse_events(event, x, y, flags, param):
# mouse movement event
if event == cv2.EVENT_MOUSEMOVE:
# update global mouse coordinates
global x_mouse
global y_mouse
x_mouse = x
y_mouse = y
# set up mouse events and prepare the thermal frame display
gray16_frame = cv2.imread("lighter_gray16_image.tiff", cv2.IMREAD_ANYDEPTH)
cv2.imshow('gray8', gray16_frame)
cv2.setMouseCallback('gray8', mouse_events)
从第 20-29 行,我们定义了鼠标事件函数。首先,当我们检测到鼠标移动(cv2.EVENT_MOUSEMOVE)时,我们更新先前的x和y像素坐标。
我们建议您查看使用 Python 和 OpenCV 捕获鼠标点击事件的教程,以更深入地了解鼠标捕获事件。
# loop over the thermal video frames
for image in sorted(os.listdir(args["video"])):
# filter .tiff files (gray16 images)
if image.endswith(".tiff"):
# define the gray16 frame path
file_path = os.path.join(args["video"], image)
# open the gray16 frame
gray16_frame = cv2.imread(file_path, cv2.IMREAD_ANYDEPTH)
# calculate temperature
temperature_pointer = gray16_frame[y_mouse, x_mouse]
temperature_pointer = (temperature_pointer / 100) - 273.15
temperature_pointer = (temperature_pointer / 100) * 9 / 5 - 459.67
# convert the gray16 frame into a gray8
gray8_frame = np.zeros((120, 160), dtype=np.uint8)
gray8_frame = cv2.normalize(gray16_frame, gray8_frame, 0, 255, cv2.NORM_MINMAX)
gray8_frame = np.uint8(gray8_frame)
# colorized the gray8 frame using OpenCV colormaps
gray8_frame = cv2.applyColorMap(gray8_frame, cv2.COLORMAP_INFERNO)
# write pointer
cv2.circle(gray8_frame, (x_mouse, y_mouse), 2, (255, 255, 255), -1)
# write temperature
cv2.putText(gray8_frame, "{0:.1f} Fahrenheit".format(temperature_pointer), (x_mouse - 40, y_mouse - 15), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1)
# show the thermal frame
cv2.imshow("gray8", gray8_frame)
# wait 125 ms: RGMVision ThermalCAM1 frames per second = 8
cv2.waitKey(int((1 / fps) * 1000))
循环热视频序列,gray16_sequence文件夹,并获得 gray16 温度值(第 37-46 行)。为了简化过程,我们使用 gray16 帧序列 TIFF 图像,而不是 gray16 视频文件(常见的压缩视频文件往往会丢失信息)。
在的第 49-51 行上,我们应用等式(1)并以 C(或 F)为单位计算我们的热感鼠标指针的温度:x_mouse和y_mouse。
然后,我们获得 gray8 图像来显示每帧的结果。
在第 71 行的上,我们等待了 125 毫秒,因为我们的 RGMVision ThermalCAM 1 提供了一个 8 fps 的流。
用热感相机测量温度
作为本教程的最后一点,我们将学习如何在 UVC (USB 视频类)热感摄像机的每一帧中循环,在我们的例子中,是 RGMVision ThermalCAM 1 ,同时测量和显示鼠标像素的温度。
打开measure_camera_video_temperature.py并导入 NumPy 和 OpenCV 库:
# import the necessary packages
import cv2
import numpy as np
按照上面的“从热视频测量温度”部分定义鼠标事件功能:
# create mouse global coordinates
x_mouse = 0
y_mouse = 0
# mouse events function
def mouse_events(event, x, y, flags, param):
# mouse movement event
if event == cv2.EVENT_MOUSEMOVE:
# update global mouse coordinates
global x_mouse
global y_mouse
x_mouse = x
y_mouse = y
设置热感摄像机指数和分辨率,在我们的例子中,160x120:
# set up the thermal camera index (thermal_camera = cv2.VideoCapture(0, cv2.CAP_DSHOW) on Windows OS)
thermal_camera = cv2.VideoCapture(0)
# set up the thermal camera resolution
thermal_camera.set(cv2.CAP_PROP_FRAME_WIDTH, 160)
thermal_camera.set(cv2.CAP_PROP_FRAME_HEIGHT, 120)
在第 22 行,你应该选择你的相机 ID。如果您使用的是 Windows 操作系统,请确保指定您的后端视频库,例如,Direct Show (DSHOW): thermal_camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)。
欲了解更多信息,请访问带 OpenCV 概述的视频 I/O。
将热感摄像机设置为 gray16 源,并接收 raw 格式的数据。
# set up the thermal camera to get the gray16 stream and raw data
thermal_camera.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter.fourcc('Y','1','6',' '))
thermal_camera.set(cv2.CAP_PROP_CONVERT_RGB, 0)
第 30 行阻止 RGB 转换。
设置鼠标事件并准备热帧显示(行 33-35 ):
# set up mouse events and prepare the thermal frame display
grabbed, frame_thermal = thermal_camera.read()
cv2.imshow('gray8', frame_thermal)
cv2.setMouseCallback('gray8', mouse_events)
循环热摄像机帧,计算灰度 16 温度值(第 38-63 行)。
# loop over the thermal camera frames
while True:
# grab the frame from the thermal camera stream
(grabbed, thermal_frame) = thermal_camera.read()
# calculate temperature
temperature_pointer = thermal_frame[y_mouse, x_mouse]
# temperature_pointer = (temperature_pointer / 100) - 273.15
temperature_pointer = (temperature_pointer / 100) * 9 / 5 - 459.67
# convert the gray16 image into a gray8
cv2.normalize(thermal_frame, thermal_frame, 0, 255, cv2.NORM_MINMAX)
thermal_frame = np.uint8(thermal_frame)
# colorized the gray8 image using OpenCV colormaps
thermal_frame = cv2.applyColorMap(thermal_frame, cv2.COLORMAP_INFERNO)
# write pointer
cv2.circle(thermal_frame, (x_mouse, y_mouse), 2, (255, 255, 255), -1)
# write temperature
cv2.putText(thermal_frame, "{0:.1f} Fahrenheit".format(temperature_pointer), (x_mouse - 40, y_mouse - 15), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1)
# show the thermal frame
cv2.imshow('gray8', thermal_frame)
cv2.waitKey(1)
# do a bit of cleanup
thermal_camera.release()
cv2.destroyAllWindows()
我们在第 49 行和第 50 行将灰色 16 图像转换为灰色 8,以显示结果。
然后我们应用我们最喜欢的热调色板,就像我们已经学过的,写下温度值和指针位置。
在这里!
一个使用热感相机和 OpenCV 的实时鼠标温度测量仪!
这最后一部分代码和 RGMVision ThermalCAM 1 可在 RGM 视觉上获得。
汇总
在本教程中,我们已经了解了灰度 8 和灰度 16 图像(即最常见的热成像格式)之间的差异。我们学会了从图像中测量我们的第一个温度,只使用 Python 和 OpenCV 在不同的调色板中显示结果。更进一步,我们还发现了如何实时计算视频流和 UVC 热感相机的每个像素温度。
在下一个教程中,我们将实现一个简化的面部温度测量解决方案,这是 COVID 疫情中一个有价值的方法。您将能够将这些知识应用到您自己的实际项目中,例如,以简单明了的方式使用您的 Raspberry Pi。
引用信息
Garcia-Martin,R. “热视觉:使用 Python 和 OpenCV 从图像中测量第一个温度”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/mns3e
@incollection{Garcia-Martin_2022_Measuring,
author = {Raul Garcia-Martin},
title = {Thermal Vision: Measuring Your First Temperature from an Image with {P}ython and {OpenCV}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/mns3e},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
热视觉:用 PyTorch 和 YOLOv5 探测夜间目标(真实项目)
目录
热视觉:用 PyTorch 和 YOLOv5 进行夜间目标探测
在今天的教程中,您将使用深度学习并结合 Python 和 OpenCV 来检测热图像中的对象。正如我们已经发现的,热感相机让我们在绝对黑暗的环境中也能看到东西,所以我们将学习如何在任何可见光条件下探测物体!
本课包括:
- 通过 PyTorch 和 YOLOv5 进行深度学习的对象检测
- 发现前视红外热启动器数据集
- 使用 PyTorch 和 YOLOv5 进行热目标检测
本教程是我们关于红外视觉基础知识的 4 部分课程的最后一部分:
- 红外视觉介绍:近中远红外图像
- 热视觉:用 Python 和 OpenCV 从图像中测量你的第一个温度
- 热视觉:带 Python 和 OpenCV 的发热探测器(入门项目)
- 热视觉:用 PyTorch 和 YOLOv5 进行夜间物体探测(真实项目) (今日教程)
在本课结束时,您将学习如何使用热图像和深度学习以非常快速、简单和最新的方式检测不同的对象,仅使用四段代码!
要了解如何利用 YOLOv5 使用您的自定义热成像数据集, 继续阅读 。
热视觉:用 PyTorch 和 YOLOv5 进行夜间目标探测
通过 PyTorch 和 YOLOv 进行深度学习的物体检测 5
在我们的上一篇教程中,我们介绍了如何在实际解决方案中应用使用 Python、OpenCV 和传统机器学习方法从热图像中测量的温度。
从这一点出发,并基于本课程中涵盖的所有内容,PyImageSearch 团队激发您的想象力,在任何热成像情况下脱颖而出,但之前会为您提供这种令人难以置信的组合的另一个强大而真实的例子:计算机视觉+热成像。
在这种情况下,我们将了解计算机如何在黑暗中实时区分不同的对象类别。
在开始本教程之前,为了更好地理解,我们鼓励你在 PyImageSearch 大学参加 Torch Hub 系列课程,或者获得一些 PyTorch 和深度学习的经验。和所有 PyImageSearch 大学课程一样,我们会一步一步涵盖各个方面。
正如在 Torch Hub 系列#3 中所解释的:YOLOv5 和 SSD——关于对象检测的模型,yolov 5————你只看一次 ( 图 1 ,2015)版本 5——是最强大的最先进的卷积神经网络模型之一的第五个版本。这种快速对象检测器模型通常在 COCO 数据集上训练,这是一个开放访问的微软 RGB 成像数据库,由 33 万张图像、91 个对象类和 250 万个标记实例组成。
这种强大的组合使 YOLOv5 成为即使在我们的定制成像数据集中检测对象的完美模型。为了获得热物体检测器,我们将使用迁移学习(即,在专门为自动驾驶汽车解决方案收集的真实热成像数据集上训练 COCO 预训练的 YOLOv5 模型)。
发现前视红外热启动器数据集
我们将用来训练预训练 YOLOv5 模型的热成像数据集是免费的 Teledyne FLIR ADAS 数据集。
该数据库由 14,452 张灰度 8 和灰度 16 格式的热图像组成,据我们所知,这允许我们测量任何像素温度。用车载热感相机在加州的一些街道上拍摄的 14452 张灰度图像都被手工加上了边框,如图 2 所示。我们将使用这些注释(标签+边界框)来检测该数据集中预定义的四个类别中的四个不同的对象类别:car、person、bicycle和dog。
提供了一个带有 COCO 格式注释的 JSON 文件。为了简化本教程,我们给出了 YOLOv5 PyTorch 格式的注释。你可以找到一个labels文件夹,里面有每个 gray8 图像的单独注释。
我们还将数据集减少到 1,772 张图像:1000 张用于训练我们预先训练的 YOLOv5 模型,772 张用于验证它(即,大约 60-40%的训练-验证分离)。这些图像是从原始数据集的训练部分中选择的。
利用 PyTorch 和 YOLOv 探测热物体 5
一旦我们学会了到目前为止看到的所有概念…我们来玩吧!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
$ tree --dirsfirst
.
└── yolov5
├── data
├── models
├── utils
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── ...
└── val.py
1 directory, XX files
我们通过克隆官方的 YOLOv5 库来建立这个结构。
# clone the yolov5 repository from GitHub and install some necessary packages (requirements.txt file)
!git clone https://github.com/ultralytics/yolov5
%cd yolov5
%pip install -qr requirements.txt
参见行 2 和 3 上的代码。
注意,我们还安装了在requirements.txt文件(第 4 行)中指出的所需库:Matplotlib、NumPy、OpenCV、PyTorch 等。
在yolov5文件夹中,我们可以找到在我们的任何项目中使用 YOLOv5 所需的所有文件:
data:包含管理 COCO 等不同数据集所需的信息。- 我们可以在另一种标记语言(YAML)格式中找到所有的 YOLOv5 CNN 结构,这是一种用于编程语言的对人类友好的数据序列化语言。
utils:包括一些必要的 Python 文件来管理训练、数据集、信息可视化和通用项目工具。
yolov5文件中的其余文件是必需的,但我们将只运行其中的两个:
- 是一个用来训练我们的模型的文件,它是我们上面克隆的存储库的一部分
[detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py):是一个通过推断检测到的对象来测试我们的模型的文件,它也是我们上面克隆的存储库的一部分
thermal_imaging_dataset文件夹包括我们的 1,772 张灰度热成像图片。该文件夹包含图像(thermal_imaging_dataset/images)和标签(thermal_imaging_dataset/labels),分别被分成训练集和验证集、train和val文件夹。
thermal_imaging_video_test.mp4是视频文件,我们将在其上测试我们的热目标检测模型。它包含 4,224 个以 30 帧/秒的速度获取的带有街道和高速公路场景的热帧。
# import PyTorch and check versions
import torch
from yolov5 import utils
display = utils.notebook_init()
打开您的yolov5.py文件并导入所需的包(第 7 行和第 8 行),如果您正在使用 Google Colab 上的 Jupyter 笔记本,请检查您的笔记本功能(第 9 行)。
检查您的环境是否包含 GPU ( 图 3 ),以便在合理的时间内成功运行我们的下一个培训流程。
预训练
正如我们已经提到的,我们将使用迁移学习在我们的热成像数据集上训练我们的对象检测器模型,使用在 COCO 数据集上预先训练的 YOLOv5 CNN 架构作为起点。
为此,所选的经过训练的 YOLOv5 型号是 YOLOv5s 版本,因为它具有高速度精度性能。
训练
在设置好环境并满足所有要求后,让我们来训练我们的预训练模型!
# train pretrained YOLOv5s model on the custom thermal imaging dataset,
# basic parameters:
# - image size (img): image size of the thermal dataset is 640 x 512, 640 passed
# - batch size (batch): 16 by default, 16 passed
# - epochs (epochs): number of epochs, 30 passed
# - dataset (data): dataset in .yaml file format, custom thermal image dataset passed
# - pre-trained YOLOv5 model (weights): YOLOv5 model version, YOLOv5s (small version) passed
!python train.py --img 640 --batch 16 --epochs 30 --data thermal_image_dataset.yaml --weights yolov5s.pt
在第 18 行上,导入 PyTorch 和 YOLOv5 实用程序(第 7-9 行)后,我们通过指定以下参数运行train.py文件:
-
img:要通过我们模型的训练图像的图像大小。在我们的例子中,热图像有一个640x512分辨率,所以我们指定最大尺寸,640 像素。 -
batch:批量大小。我们设置了 16 个图像的批量大小。 -
epochs:训练时代。在一些测试之后,我们将 30 个时期确定为一个很好的迭代次数。 -
data: YAML 数据集文件。图 4 显示了我们的数据集文件。它指向 YOLOv5 数据集的结构,前面解释过:thermal_imaging_datasimg/train
thermal_imaging_dataset/labels/train,用于训练,
thermal_imaging_datasimg/val
thermal_imaging_dataset/labels/val,用于验证。
还表示班级的数量
nc: 4,以及班级名称names: ['bicycle', 'car', 'dog', 'person']。这个 YAML 数据集文件应该位于
yolov5/data中。 -
weights:在 COCO 数据集上计算预训练模型的权重,在我们的例子中是 YOLOv5s。yolov5s.pt文件是包含这些权重的预训练模型,位于yolov5/models。
这就是我们训练模型所需要的!
让我们看看结果吧!
在 0.279 小时内在 GPU NVIDIA Tesla T4 中完成 30 个纪元后,我们的模型已经学会检测类别person、car、bicycle和dog,达到平均 50.7%的平均精度,mAP (IoU = 0.5) = 0.507,如图图 5 所示。这意味着我们所有类的平均预测值为 50.7%,交集为 0.5(IoU,图 6 )。
如图图 6 所示,当比较原始和预测时,并集上的交集(IoU)是边界框的右重叠。
因此,对于我们的person类,我们的模型平均正确地检测到 77.7%的情况,考虑到当有 50%或更高的边界框交集时的正确预测。
图 7 比较了两幅原始图像、它们的手绘边界框以及它们的预测结果。
尽管这超出了本教程的范围,但重要的是要注意我们的数据集是高度不平衡的,对于我们的bicycle和dog类,分别只有 280 和 31 个标签。这就是为什么我们分别得到 mAP bicycle (IoU = 0.5) = 0.456 和 mAP dog (IoU = 0.5) = 0.004。
最后,为了验证我们的结果,图 8 显示了在训练(左上)和验证(左下)过程中的分类损失,以及在 IoU 50% ( 中右)时的平均精度,mAP (IoU = 0.5),所有类别经过 30 个时期。
但是现在,让我们来测试我们的模型!
检测
为此,我们将使用位于项目根的thermal_imaging_video_test.mp4,通过 Python 文件detect.py将它传递到我们的模型层。
# test the trained model (night_object_detector.pt) on a thermal imaging video,
# parameters:
# - trained model (weights): model trained in the previous step, night_object_detector.pt passed
# - image size (img): frame size of the thermal video is 640 x 512, 640 passed
# - confidence (conf): confidence threshold, only the inferences higher than this value will be shown, 0.35 passed
# - video file (source): thermal imaging video, thermal_imaging_video.mp4 passed
!python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.35 --source ../thermal_imaging_video.mp4
第 27 行显示了如何做。
我们通过指定以下参数来运行detect.py:
- 指向我们训练好的模型。在
best.pt文件(runs/train/exp/weights/best.pt)中收集的计算重量。 img:将通过我们模型的测试图像的图像尺寸。在我们的例子中,视频中的热图像具有640x512分辨率,因此我们将最大尺寸指定为 640 像素。conf:每次检测的置信度。该阈值建立了检测的概率水平,根据该水平,检测被认为是正确的,因此被显示。我们设定置信度为 35%。source:测试模型的图像,在我们的例子中,是视频文件thermal_imaging_video.mp4。
来测试一下吧!
图 9 展示了我们良好结果的 GIF 图!
正如我们已经指出的,该视频的夜间物体检测已经获得了 35%的置信度。为了修改这个因素,我们应该检查图 10 中的曲线,该曲线绘制了精度与置信度的关系。
汇总
我们要感谢超极本的伟大工作。我们发现他们的[train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)和[detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)文件非常棒,所以我们把它们放在了这个帖子里。
在本教程中,我们学习了如何在任何光线条件下检测不同的物体,结合热视觉和深度学习,使用 CNN YOLOv5 架构和我们的自定义热成像数据集。
为此,我们发现了如何在 FLIR Thermal Starter 数据集上训练最先进的 YOLOv5 模型,该模型先前是使用 Microsoft COCO 数据集训练的。
尽管热图像与 COCO 数据集的常见 RGB 图像完全不同,但获得的出色性能和结果显示了 YOLOv5 模型的强大功能。
我们可以得出结论,人工智能如今经历了令人难以置信的有用范式。
本教程向您展示了如何在实际应用中应用热视觉和深度学习(例如,自动驾驶汽车)。如果你想了解这个令人敬畏的话题,请查看 PyImageSearch 大学的自动驾驶汽车课程。
PyImageSearch 团队希望您已经喜欢并深入理解了本红外视觉基础课程中教授的所有概念。
下节课再见!
引用信息
Garcia-Martin,R. “热视觉:用 PyTorch 和 YOLOv5 进行夜间目标探测”(真实项目), PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/p2zsm
@incollection{RGM_2022_PYTYv5,
author = {Raul Garcia-Martin},
title = {Thermal Vision: Night Object Detection with {PyTorch} and {YOLOv5} (real project)},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/p2zsm},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
阈值处理:使用 OpenCV 的简单图像分割
原文:https://pyimagesearch.com/2014/09/08/thresholding-simple-image-segmentation-using-opencv/

悲剧。令人心碎。无法忍受。
这是我用来形容过去一周的三个词。
大约一周前,我的一个儿时密友在一场悲惨的车祸中去世了。
我和他一起上小学和中学。我们夏天在我的车道上玩滑板,冬天在我的后院玩滑雪板和雪橇。
从上周开始,我一直在旅行,参加他的葬礼。每一刻都极度痛苦。我发现很难集中注意力,我的思绪总是回到十多年前的记忆中。
老实说,我写这篇博客是一个奇迹。
但是如果有什么是我相信的,那就是生活应该被庆祝。没有比对爱人的怀旧回忆更好的庆祝方式了。
早在中学时代,我和他曾经浏览过 CCS 目录(是的,实际目录;他们没有在网上列出他们所有的产品,即使他们列出了,我们的互联网是拨号上网的,使用是由父母控制的。
我们会幻想下一步要买哪种滑板,或者更确切地说,我们会要求父母给我们买哪种滑板作为生日礼物。
像在上学前、上学中和放学后翻阅 CCS 目录这样的小回忆让我喜笑颜开。它们让日子过得更轻松。
所以在这篇文章中,我将展示如何使用 Python 和 OpenCV 执行基本的图像分割。
我们还会给它一个小小的滑板主题,只是为了向一位朋友致敬,他的记忆在我脑海中占据了很重的位置。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
cv2.threshold功能
让我们先来看看 cv2.threshold 函数的签名:
(T, threshImage) = cv2.threshold(src, thresh, maxval, type)
第一个参数是我们的源图像,或者我们想要对其执行阈值处理的图像。这个图像应该是灰度的。
第二个参数thresh是用于对灰度图像中的像素强度进行分类的阈值。
第三个参数maxval,是图像中任何给定像素通过thresh测试时使用的像素值。
最后,第四个参数是要使用的阈值方法。type值可以是以下任一值:
cv2.THRESH_BINARYcv2.THRESH_BINARY_INVcv2.THRESH_TRUNCcv2.THRESH_TOZEROcv2.THRESH_TOZERO_INV
听起来很复杂?事实并非如此——我将为您展示每种阈值类型的示例。
然后,cv2.threshold返回一个由两个值组成的元组。第一个值T是用于阈值处理的值。在我们的例子中,这个值与我们传递给cv2.threshold函数的thresh值相同。
第二个值是我们实际的阈值图像。
无论如何,让我们继续探索一些代码。
阈值处理:使用 OpenCV 的简单图像分割
图像分割有多种形式。
聚类。压缩。边缘检测。区域增长。图形划分。分水岭。这样的例子不胜枚举。
但是在一开始,只有最基本的图像分割类型:阈值分割。
让我们看看如何使用 OpenCV 执行简单的图像分割。打开您最喜欢的编辑器,创建一个名为threshold.py的文件,让我们开始吧:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True,
help = "Path to the image to be thresholded")
ap.add_argument("-t", "--threshold", type = int, default = 128,
help = "Threshold value")
args = vars(ap.parse_args())
# load the image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# initialize the list of threshold methods
methods = [
("THRESH_BINARY", cv2.THRESH_BINARY),
("THRESH_BINARY_INV", cv2.THRESH_BINARY_INV),
("THRESH_TRUNC", cv2.THRESH_TRUNC),
("THRESH_TOZERO", cv2.THRESH_TOZERO),
("THRESH_TOZERO_INV", cv2.THRESH_TOZERO_INV)]
# loop over the threshold methods
for (threshName, threshMethod) in methods:
# threshold the image and show it
(T, thresh) = cv2.threshold(gray, args["threshold"], 255, threshMethod)
cv2.imshow(threshName, thresh)
cv2.waitKey(0)
我们将从导入我们需要的两个包开始,线 2 和 3 上的argparse和cv2。
从那里,我们将在第 6-11 行解析我们的命令行参数。这里我们需要两个参数。第一个,--image,是我们想要阈值化的图像的路径。第二个,--threshold,是将传递给cv2.threshold函数的阈值。
从那里,我们将从磁盘加载图像,并在第 14 行和第 15 行将其转换为灰度。我们转换为灰度,因为cv2.threshold期望一个单通道图像。
第 18-23 行定义了我们的阈值方法列表。
我们从第 26 行的开始循环我们的阈值方法。
从那里,我们在第 28 行的上应用实际阈值方法。我们将灰度图像作为第一个参数传递,将命令行提供的阈值作为第二个参数传递,将 255(白色)作为阈值测试通过时的值作为第三个参数传递,最后将阈值方法本身作为最后一个参数传递。
最后,阈值图像显示在行 29 和 30 上。
我们来看一些结果。打开您的终端,导航到我们的代码目录,并执行以下命令:
$ python threshold.py --image images/skateboard_decks.png --threshold 245
在本例中,我们使用值 245 进行阈值测试。如果输入图像中的像素通过了阈值测试,它的值将被设置为 255。
现在,让我们来看看结果:

Figure 1: Applying cv2.threshold with cv2.THRESH_BINARY.
使用cv2.THRESH_BINARY将滑板分割成白色背景的黑色。
要反转颜色,只需使用cv2.THRESH_BINARY_INV,如下所示:

Figure 2: Applying cv2.threshold with cv2.THRESH_BINARY_INV.
还不错。我们还能做什么?

Figure 3: Applying cv2.threshold with cv2.THRESH_TRUNC.
如果源像素不大于提供的阈值,使用cv2.THRESH_TRUNC保持像素强度不变。
然后我们有cv2.THRESH_TOZERO,如果源像素不大于提供的阈值,它将源像素设置为零:

Figure 4: Applying cv2.threshold with cv2.THRESH_TOZERO.
最后,我们也可以使用cv2.THRESH_TOZERO_INV来反转这个行为:

Figure 5: Applying cv2.threshold with cv2.THRESH_TOZERO_INV.
没什么!
摘要
在这篇博文中,我向你展示了如何执行最基本的图像分割形式:阈值分割。
为了执行阈值处理,我们使用了cv2.threshold函数。
OpenCV 为我们提供了五种基本的阈值分割方法,包括:cv2.THRESH_BINARY、cv2.THRESH_BINARY_INV、cv2.THRESH_TRUNC、cv2.THRESH_TOZERO、cv2.THRESH_TOZERO_INV。
最重要的是,确保使用thresh值,因为它会根据您提供的值给出不同的结果。
在以后的文章中,我将向你展示如何用自动确定阈值,不需要调整参数!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号