PyImgSearch-博客中文翻译-三-
PyImgSearch 博客中文翻译(三)
用 Python 和 OpenCV 将 URL 转换成图像
原文:https://pyimagesearch.com/2015/03/02/convert-url-to-image-with-python-and-opencv/

今天的博文直接来自我个人的效用函数库。
在过去的一个月里,我收到了一些 PyImageSearch 读者发来的电子邮件,询问如何从 URL 下载图像,然后将其转换为 OpenCV 格式(不需要将其写入磁盘,然后读取回来)——在本文中,我将向您展示具体的操作方法。
此外,我们还将看到如何利用 scikit-image 从 URL 下载图像,以及一个常见的“陷阱”,它可能会让您一路出错。
继续阅读,了解如何使用 Python 和 OpenCV 将 URL 转换为图像。
OpenCV 和 Python 版本:
为了运行这个例子,你需要 Python 2.7 和 OpenCV 2.4.X 。
方法 1: OpenCV、NumPy 和 urllib
我们将探索的第一种方法是使用 OpenCV、NumPy 和 urllib 库将 URL 转换成图像。打开一个新文件,命名为url_to_image.py,让我们开始吧:
# import the necessary packages
import numpy as np
import urllib
import cv2
# METHOD #1: OpenCV, NumPy, and urllib
def url_to_image(url):
# download the image, convert it to a NumPy array, and then read
# it into OpenCV format
resp = urllib.urlopen(url)
image = np.asarray(bytearray(resp.read()), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
# return the image
return image
我们要做的第一件事是导入我们需要的包。我们将使用 NumPy 将下载的字节序列转换为 NumPy 数组,urllib用于执行实际的请求,而cv2用于 OpenCV 绑定。
然后我们在第 7 行的上定义我们的url_to_image函数。这个函数需要一个参数url,它是我们想要下载的图片的 URL。
接下来,我们利用urllib库打开一个到第 10 行上提供的 URL 的连接。来自请求的原始字节序列然后在行 11 上被转换成一个 NumPy 数组。
此时,NumPy 数组是一维数组(即一长列像素)。为了将数组重新整形为 2D 格式,假设每个像素有 3 个分量(即,分别是红色、绿色和蓝色分量),我们调用行 12 上的cv2.imdecode。最后,我们将解码后的图像返回给第 15 行的调用函数。
好了,是时候让这个函数发挥作用了:
# initialize the list of image URLs to download
urls = [
"https://pyimagesearch.com/wp-content/uploads/2015/01/opencv_logo.png",
"https://pyimagesearch.com/wp-content/uploads/2015/01/google_logo.png",
"https://pyimagesearch.com/wp-content/uploads/2014/12/adrian_face_detection_sidebar.png",
]
# loop over the image URLs
for url in urls:
# download the image URL and display it
print "downloading %s" % (url)
image = url_to_image(url)
cv2.imshow("Image", image)
cv2.waitKey(0)
第 18-21 行定义了我们将要下载并转换成 OpenCV 格式的图像 URL 列表。
我们开始在第 25 行的上循环这些 URL,在第 28 行的上调用我们的url_to_image函数,然后最后在第 29 和 30 行的上将我们下载的图像显示到我们的屏幕上。此时,我们的图像可以像平常一样用任何其他 OpenCV 函数进行操作。
要查看我们的工作,打开一个终端并执行以下命令:
$ python url_to_image.py
如果一切顺利,您应该首先看到 OpenCV 徽标:
Figure 1: Downloading the OpenCV logo from a URL and converting it to OpenCV format.
接下来是谷歌标志:
Figure 2: Downloading the Google logo from a URL and converting it to OpenCV format.
这里有一个我在我的书《实用 Python 和 OpenCV 中演示人脸检测的例子:
Figure 3: Converting an image URL to OpenCV format with Python.
现在,让我们转到下载图像并将其转换为 OpenCV 格式的替代方法。
方法 2: scikit-image
第二种方法假设您的系统上安装了 scikit-image 库。让我们看看如何利用 scikit-image 从 URL 下载图像并将其转换为 OpenCV 格式:
# METHOD #2: scikit-image
from skimage import io
# loop over the image URLs
for url in urls:
# download the image using scikit-image
print "downloading %s" % (url)
image = io.imread(url)
cv2.imshow("Incorrect", image)
cv2.imshow("Correct", cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
cv2.waitKey(0)
scikit-image 库的一个优点是,io子包中的imread函数可以区分磁盘上图像的路径和 URL ( 第 39 行)。
然而,有一个重要的问题会让你犯错误!
OpenCV 以 BGR 顺序表示图像,而 scikit-image 以 RGB 顺序表示图像。如果您使用 scikit-image imread功能,并希望在下载图像后使用 OpenCV 功能,您需要特别注意将图像从 RGB 转换为 BGR ( Line 41 )。
如果不采取这一额外步骤,您可能会获得不正确的结果:

Figure 4: Special care needs to be taken to convert from RGB to BGR when using scikit-image to convert a URL to an image. The image on the left is incorrectly specified in the RGB order. The image on the right correctly displays the image after it is converted from RGB to BGR order.
看看下面的谷歌标志,让这一点更加清楚:

Figure 5: Order matters. Be sure to convert from RGB to BGR order or you might be tracking down a hard-to-find bug.
所以你有它!使用 Python、OpenCV、urllib 和 scikit-image 将 URL 转换为图像的两种方法。
摘要
在这篇博文中,我们了解了两种从 URL 下载图像并使用 Python 和 OpenCV 将其转换为 OpenCV 格式的方法。
第一种方法是使用urllib Python 包下载图像,使用 NumPy 将其转换为数组,最后使用 OpenCV 重塑数组来构造我们的图像。
第二种方法是使用 scikit-image 的io.imread函数。
那么哪种方法更好呢?
这完全取决于你的设置。
如果你已经安装了 scikit-image,我会使用io.imread函数(如果你使用 OpenCV 函数,别忘了从 RGB 转换到 BGR)。如果您没有安装 scikit-image,我会手工滚动本文开头详述的url_to_image函数。
我很快也会把这个功能添加到 GitHub 的 imutils 包中。
神经网络中的卷积和互相关
原文:https://pyimagesearch.com/2021/05/14/convolution-and-cross-correlation-in-neural-networks/
到目前为止,我们对机器学习和神经网络的整个回顾一直指向这一点: 了解卷积神经网络(CNN)以及它们在深度学习中扮演的角色。
在传统的前馈神经网络中,输入层的每个神经元都连接到下一层的每个输出神经元——我们称之为全连接* (FC)层。然而,在 CNN 中,我们直到网络中的最后一层才使用 FC 层。因此,我们可以将 CNN 定义为一个神经网络,它用一个专门的“卷积”层代替网络中至少一个层的(古德费勒、本吉奥和库维尔,2016 )。
然后将非线性激活函数(如 ReLU)应用于这些卷积的输出,卷积= >激活的过程继续进行(以及其他层类型的混合,以帮助减少输入体积的宽度和高度,并帮助减少过拟合),直到我们最终到达网络的末端,并应用一个或两个 FC 层,在那里我们可以获得最终的输出分类。
CNN 的每一层都使用一组不同的过滤器,通常是成百上千的过滤器,然后将结果组合起来,将输出送入网络的下一层。在训练期间,CNN 自动学习这些滤波器的值。
在图像分类的背景下,我们的 CNN 可以学习:
- 从第一层的原始像素数据中检测边缘。
- 使用这些边缘来检测第二层中的形状(即“斑点”)。
- 使用这些形状来检测更高层次的特征,如面部结构、汽车零件等。在网络的最高层。
CNN 的最后一层使用这些高级特征来预测图像的内容。实际上,CNN 给了我们两个关键的好处:局部不变性和合成性。局部不变性的概念允许我们将图像分类为包含特定对象,而不管该对象出现在图像中的什么位置。我们通过使用“池层”来获得这种局部不变性,池层识别对特定滤波器具有高响应的输入体积的区域。
第二个好处是组合性。每个过滤器将较低级别特征的局部补丁组成较高级别表示,类似于我们如何能够在先前函数的输出的基础上组成一组数学函数:f(g(h(x))——这种组成允许我们的网络在网络的更深处学习更丰富的特征。例如,我们的网络可以从像素构建边缘,从边缘构建形状,然后从形状构建复杂的对象——所有这些都是在训练过程中以自动方式自然发生的。从低级特征构建高级特征的概念正是 CNN 在计算机视觉中如此强大的原因。
理解卷积
在这一部分,我们将解决一些问题,包括:
- 什么是图像卷积?
- 他们做什么?
- 为什么我们要使用它们?
- 我们如何将它们应用到图像中?
- 而卷积在深度学习中起到什么作用?
“卷积”这个词听起来像是一个奇特而复杂的术语,但事实并非如此。如果你以前有过计算机视觉、图像处理或 OpenCV 的经验,不管你是否意识到,你已经应用了卷积、 !
曾经对图像应用过模糊或平滑吗?是的,这是一个卷积。边缘检测怎么样?是的,卷积。有没有打开 Photoshop 或者 GIMP 来锐化一张图片?你猜对了——卷积。卷积是计算机视觉和图像处理中最关键、最基本的构件之一。
但是这个词本身往往会把人吓跑——事实上,从表面上看,这个词甚至似乎有负面的含义(为什么会有人想“弄复杂”一些东西?相信我,回旋一点也不可怕。它们其实很容易理解。
在深度学习方面,an (image) 卷积是两个矩阵的逐元素乘法,后跟一个和 。
说真的。就是这样。你刚刚学习了什么是卷积:
- 取两个矩阵(都有相同的维数)。
- 将它们逐个元素相乘(即不是的点积,只是一个简单的乘法)。
- 将元素加在一起。
卷积与互相关
具有计算机视觉和图像处理背景的读者可能已经将我上面对卷积的描述识别为互相关运算。用互相关代替卷积,其实是故意的。卷积(由 表示)
表示)
operator) over a two-dimensional input image I and two-dimensional kernel K is defined as:
【①
**然而,几乎所有的机器学习和深度学习库都使用简化的互相关函数
② = (I \star K)(i, j) = \sum\limits_{m}\sum\limits_{n} I(i + m, j + n)K(m, n)")
**所有这些数学都意味着我们如何访问图像的坐标 I 的符号变化(即,当应用互相关时,我们不必相对于输入“翻转”内核)。
同样,许多深度学习库使用简化的互相关运算,并将其称为卷积— 我们在这里将使用相同的术语。对于有兴趣了解更多卷积与互相关背后的数学知识的读者,请参考 Szeliski (2011) 的计算机视觉:算法与应用第三章。
“大矩阵”与“小矩阵”比喻
一幅图像是一个多维矩阵。我们的图像有一个宽度(列数)和高度(行数),就像一个矩阵。但是与你在小学时使用的传统矩阵不同,图像也有一个深度——图像中通道的数量。
对于标准 RGB 图像,我们的深度为 3——红色、绿色和蓝色通道的每个对应一个通道。有了这些知识,我们可以将图像想象成大矩阵,将核或卷积矩阵想象成小矩阵,用于模糊、锐化、边缘检测和其他处理功能。本质上,这个小内核位于大图像的顶部,并从从左到右和从上到下滑动,在原始图像的每个( x,y )坐标处应用数学运算(即卷积)。
手工定义内核来获得各种图像处理功能是很正常的。事实上,你可能已经熟悉模糊(平均平滑,高斯平滑等)。)、边缘检测(拉普拉斯、索贝尔、沙尔、普鲁伊特等。),以及锐化— 所有这些操作都是手工定义内核的形式,是专门设计的来执行特定的功能。
这样就引出了一个问题:有没有办法让自动学习这些类型的滤镜?甚至使用这些滤镜进行图像分类和物体检测?* 肯定有。但是在我们到达那里之前,我们需要多理解一些内核和卷积。*
*### 内核
同样,让我们把一个图像想象成一个大矩阵,把一个内核想象成一个小矩阵(至少相对于原始的“大矩阵”图像而言),如图 1所示。如图所示,我们沿着原始图像从左到右和从上到下滑动内核(红色区域)。在原始图像的每个( x,y )坐标处,我们停下来检查位于图像核心的中心的像素邻域。然后,我们获取这个像素邻域,将它们与内核进行卷积,并获得单个输出值。输出值存储在与内核中心相同的( x,y )坐标的输出图像中。
在我们深入一个例子之前,让我们看一下内核是什么样子的(等式(3) ):
(3) ![K = \displaystyle\frac{1}{9} \left[\begin{tabular}{ccc}1 & 1 & 1 \ 1 & 1 & 1 \ 1 & 1 & 1\end{tabular}\right]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/0e5a37c58a74211b66b7c8686427f85d.png "K = \displaystyle\frac{1}{9} \left[\begin{tabular}{ccc}1 & 1 & 1 \ 1 & 1 & 1 \ 1 & 1 & 1\end{tabular}\right]")
上面,我们已经定义了一个 square 3 × 3 内核(有没有人猜到这个内核是用来做什么的?).内核可以是任意的矩形大小 M×N ,前提是的两个 M 和 N 都是奇数。
*备注: 大多数应用于深度学习和 CNN 的内核都是 N×N 平方矩阵,允许我们利用优化的线性代数库,这些库对平方矩阵的操作效率最高。
我们使用一个奇数的内核大小来确保在图像中心有一个有效的整数( x,y)-坐标(图 2 )。在左边,我们有一个 3 × 3 矩阵。矩阵的中心位于 x = 1 ,y = 1,这里矩阵的左上角作为原点,我们的坐标是零索引。但是在右边的,我们有一个 2 × 2 矩阵。该矩阵的中心将位于 x = 0 。 5 ,y = 0 。 5。
但我们知道,不应用插值,就没有像素位置(0 )这一说。 5 , 0 。 5) —我们的像素坐标必须是整数!这就是为什么我们使用奇数内核大小的原因:确保在内核的中心有一个有效的( x,y )坐标。
卷积的手算实例
现在我们已经讨论了内核的基础知识,让我们来讨论实际的卷积运算,看看它实际上是如何帮助我们巩固知识的。在图像处理中,卷积需要三个分量:
- 输入图像。
- 我们将应用于输入图像的核矩阵。
- 输出图像,用于存储与内核卷积的图像的输出。
卷积(或互相关)其实很简单。我们需要做的就是:
- 从原始图像中选择一个( x,y)-坐标。
- 将内核的中心放在这个( x,y )坐标上。
- 对输入图像区域和内核进行逐元素乘法运算,然后将这些乘法运算的值相加为单个值。这些乘法的总和被称为内核输出。
- 使用来自步骤#1 的相同的( x,y)-坐标,但是这次,将内核输出存储在与输出图像相同的( x,y)-位置。
下面,你可以找到一个卷积的例子(数学上表示为
operator) a 3×3 region of an image with a 3×3 kernel used for blurring:
(4) ![O_{i,j} = \displaystyle\frac{1}{9} \left[\begin{tabular}{ccc}1 & 1 & 1 \ 1 & 1 & 1 \ 1 & 1 & 1\end{tabular}\right] \star \left[\begin{tabular}{ccc}93 & 139 & 101 \ 26 & 252 & 196 \ 135 & 230 & 18\end{tabular}\right] = \left[\begin{tabular}{ccc} 1/9 \text{x} 93 & 1/9 \text{x} 139 & 1/9 \text{x} 101 \ 1/9 \text{x} 26 & 1/9 \text{x} 252 & 1/9 \text{x} 196 \ 1/9 \text{x} 135 & 1/9 \text{x} 230 & 1/9 \text{x} 18\end{tabular}\right]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/8b6d6538e03e118ad9d0beccad7f1a87.png "O_{i,j} = \displaystyle\frac{1}{9} \left[\begin{tabular}{ccc}1 & 1 & 1 \ 1 & 1 & 1 \ 1 & 1 & 1\end{tabular}\right] \star \left[\begin{tabular}{ccc}93 & 139 & 101 \ 26 & 252 & 196 \ 135 & 230 & 18\end{tabular}\right] = \left[\begin{tabular}{ccc} 1/9 \text{x} 93 & 1/9 \text{x} 139 & 1/9 \text{x} 101 \ 1/9 \text{x} 26 & 1/9 \text{x} 252 & 1/9 \text{x} 196 \ 1/9 \text{x} 135 & 1/9 \text{x} 230 & 1/9 \text{x} 18\end{tabular}\right]")
因此,
(5) ![O_{i,j} =\sum\left[\begin{tabular}{ccc}10.3 & 15.4 & 11.2 \ 2.8 & 28.0 & 21.7 \ 15.0 & 25.5 & 2.0\end{tabular}\right] \approx 132](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/79d634b9d034d894c60a4a55fafd4a75.png "O_{i,j} =\sum\left[\begin{tabular}{ccc}10.3 & 15.4 & 11.2 \ 2.8 & 28.0 & 21.7 \ 15.0 & 25.5 & 2.0\end{tabular}\right] \approx 132")
在应用这个卷积之后,我们将把位于输出图像 O 的坐标( i,j )处的像素设置为 O [i,j] = 132。
这就是全部了!卷积是内核和内核覆盖的输入图像的邻域之间的元素矩阵乘法的总和。
用 Python 实现卷积
为了帮助我们进一步理解卷积的概念,让我们看一些真实的代码,它们将揭示内核和卷积是如何实现的。这个源代码不仅能帮助你理解如何对图像应用卷积,还能让你理解在训练 CNN 的时候到底发生了什么。
打开一个新文件,命名为convolutions.py,让我们开始工作:
# import the necessary packages
from skimage.exposure import rescale_intensity
import numpy as np
import argparse
import cv2
我们从第 2-5 行开始,导入我们需要的 Python 包。我们将使用 NumPy 和 OpenCV 来实现我们的标准数值数组处理和计算机视觉功能,以及 scikit-image 库来帮助我们实现我们自己的自定义卷积功能。
接下来,我们可以开始定义这个convolve方法:
def convolve(image, K):
# grab the spatial dimensions of the image and kernel
(iH, iW) = image.shape[:2]
(kH, kW) = K.shape[:2]
# allocate memory for the output image, taking care to "pad"
# the borders of the input image so the spatial size (i.e.,
# width and height) are not reduced
pad = (kW - 1) // 2
image = cv2.copyMakeBorder(image, pad, pad, pad, pad,
cv2.BORDER_REPLICATE)
output = np.zeros((iH, iW), dtype="float")
convolve函数需要两个参数:我们希望与kernel卷积的(灰度)image。给定我们的image和kernel(我们假设它们是 NumPy 数组),然后我们确定每个(第 9 行和第 10 行)的空间维度(即宽度和高度)。
在我们继续之前,重要的是要理解卷积矩阵在图像上“滑动”的过程,应用卷积,然后存储输出,这实际上会减少输入图像的空间维度。这是为什么呢?
回想一下,我们将计算“集中”在输入图像的中心( x,y)-坐标上,内核当前位于该坐标上。这种定位意味着对于落在图像边缘的像素来说没有“中心”像素这种东西(因为内核的角会“悬挂”在值未定义的图像上),如图 3所示。
空间维度的减少仅仅是对图像应用卷积的副作用。有时这种效果是可取的,而其他时候不是,这只是取决于您的应用程序。
然而,在大多数情况下,我们希望我们的输出图像具有与我们的输入图像相同的尺寸。为了确保尺寸相同,我们应用 填充 ( 行 15-18 )。在这里,我们只是沿着图像的边界复制像素,这样输出图像将与输入图像的尺寸相匹配。
还存在其他填充方法,包括零填充(用零填充边界——在构建卷积神经网络时非常常见)和环绕(通过检查图像的反面来确定边界像素)。在大多数情况下,您会看到复制或零填充。考虑到美观,重复填充更常用,而零填充最有利于提高效率。
我们现在准备将实际卷积应用于我们的图像:
# loop over the input image, "sliding" the kernel across
# each (x, y)-coordinate from left-to-right and top-to-bottom
for y in np.arange(pad, iH + pad):
for x in np.arange(pad, iW + pad):
# extract the ROI of the image by extracting the
# *center* region of the current (x, y)-coordinates
# dimensions
roi = image[y - pad:y + pad + 1, x - pad:x + pad + 1]
# perform the actual convolution by taking the
# element-wise multiplication between the ROI and
# the kernel, then summing the matrix
k = (roi * K).sum()
# store the convolved value in the output (x, y)-
# coordinate of the output image
output[y - pad, x - pad] = k
第 22 行和第 23 行在我们的image上循环,从从左到右和从上到下滑动内核,一次一个像素。第 27 行使用 NumPy 数组切片从image中提取感兴趣区域(ROI)。roi将以image的当前( x,y )坐标为中心。roi也将与我们的kernel大小相同,这对下一步至关重要。
通过在roi和kernel之间进行逐元素乘法,接着对矩阵中的条目求和,在行 32 上执行卷积。然后,输出值k存储在output数组中相同的( x,y)-坐标(相对于输入图像)。
我们现在可以完成我们的convolve方法了:
# rescale the output image to be in the range [0, 255]
output = rescale_intensity(output, in_range=(0, 255))
output = (output * 255).astype("uint8")
# return the output image
return output
当处理图像时,我们通常处理范围在[0 , 255]内的像素值。然而,当应用卷积时,我们可以很容易地获得在这个范围之外的值。为了将我们的output图像带回到范围[0 , 255],我们应用了 scikit-image 的rescale_intensity函数( Line 39 )。
我们还在第 40 行将我们的图像转换回无符号的 8 位整数数据类型(以前,output图像是浮点类型,以便处理范围[0 , 255]之外的像素值)。最后,output图像返回到线 43 上的调用函数。
现在我们已经定义了我们的convolve函数,让我们继续脚本的驱动程序部分。本课的这一部分将处理解析命令行参数,定义一系列要应用于图像的内核,然后显示输出结果:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
我们的脚本只需要一个命令行参数--image,它是输入图像的路径。然后,我们可以定义两个用于模糊和平滑图像的内核:
# construct average blurring kernels used to smooth an image
smallBlur = np.ones((7, 7), dtype="float") * (1.0 / (7 * 7))
largeBlur = np.ones((21, 21), dtype="float") * (1.0 / (21 * 21))
为了说服自己这个内核正在执行模糊,请注意内核中的每个条目如何是 1 个 /S 的平均值,,其中 S 是矩阵中条目的总数。因此,这个内核将把每个输入像素乘以一个小分数,然后求和——这就是平均值的定义。
然后我们有一个负责锐化图像的内核:
# construct a sharpening filter
sharpen = np.array((
[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]), dtype="int")
然后使用拉普拉斯核来检测边缘状区域:
# construct the Laplacian kernel used to detect edge-like
# regions of an image
laplacian = np.array((
[0, 1, 0],
[1, -4, 1],
[0, 1, 0]), dtype="int")
索贝尔核可用于分别检测沿 x 和 y 轴的边缘状区域:
# construct the Sobel x-axis kernel
sobelX = np.array((
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]), dtype="int")
# construct the Sobel y-axis kernel
sobelY = np.array((
[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]), dtype="int")
最后,我们定义了浮雕内核:
# construct an emboss kernel
emboss = np.array((
[-2, -1, 0],
[-1, 1, 1],
[0, 1, 2]), dtype="int")
解释这些内核是如何形成的超出了本教程的范围,所以暂时简单地理解这些内核是手动构建的来执行给定的操作。
关于内核如何在数学上构造并被证明执行给定图像处理操作的完整处理,请参考 Szeliski(第 3 章)。我还推荐使用这个来自 Setosa.io 的优秀内核可视化工具。
给定所有这些内核,我们可以将它们集合成一组称为“内核库”的元组:
# construct the kernel bank, a list of kernels we're going to apply
# using both our custom 'convolve' function and OpenCV's 'filter2D'
# function
kernelBank = (
("small_blur", smallBlur),
("large_blur", largeBlur),
("sharpen", sharpen),
("laplacian", laplacian),
("sobel_x", sobelX),
("sobel_y", sobelY),
("emboss", emboss))
构建这个内核列表使我们能够循环遍历它们,并以有效的方式可视化它们的输出,如下面的代码块所示:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# loop over the kernels
for (kernelName, K) in kernelBank:
# apply the kernel to the grayscale image using both our custom
# 'convolve' function and OpenCV's 'filter2D' function
print("[INFO] applying {} kernel".format(kernelName))
convolveOutput = convolve(gray, K)
opencvOutput = cv2.filter2D(gray, -1, K)
# show the output images
cv2.imshow("Original", gray)
cv2.imshow("{} - convolve".format(kernelName), convolveOutput)
cv2.imshow("{} - opencv".format(kernelName), opencvOutput)
cv2.waitKey(0)
cv2.destroyAllWindows()
第 99 行和第 100 行从磁盘加载我们的图像并将其转换成灰度。卷积运算符可以应用于 RGB 或其他多通道体积,但为了简单起见,我们将只对灰度图像应用我们的过滤器。
我们开始在第行第 103 行的kernelBank中循环我们的内核集,然后通过调用我们的函数convolve方法,将当前的kernel应用到第行第 107 行的gray图像,该方法在脚本的前面定义。
作为检查,我们还调用了cv2.filter2D,这也将我们的kernel应用于gray图像。cv2.filter2D函数是 OpenCV 的convolve函数的优化版本。我在这里包括这两者的主要原因是为了让我们对我们的定制实现进行健全的检查。
最后,行 111-115 在屏幕上显示每种内核类型的输出图像。
卷积结果
要运行我们的脚本(并可视化各种卷积运算的输出),只需发出以下命令:
$ python convolutions.py --image jemma.png
然后你会在图 4 的中看到将smallBlur内核应用到输入图像的结果。在左边,我们有我们的原始图像。然后,在中心,我们得到了来自convolve函数的结果。而在右边的,则是来自cv2.filter2D的结果。快速的视觉检查将揭示我们的输出与cv2.filter2D匹配,这表明我们的convolve功能工作正常。此外,由于平滑内核,我们的图像现在看起来“模糊”和“平滑”。
让我们应用一个更大的模糊,结果可以在图 5 ( 左上)中看到。这次我省略了cv2.filter2D结果以节省空间。比较图 5和图 4的结果,注意随着平均内核的大小增加,输出图像中的模糊量也增加。****
我们还可以锐化我们的图像(图 5 、中上),并通过拉普拉斯算子(右上)检测边缘状区域。
sobelX内核用于寻找图像中的垂直边缘(图 5 、左下),而sobelY内核揭示水平边缘(中下)。最后,我们可以在右下方的中看到浮雕内核的结果。
卷积在深度学习中的作用
我们必须手动定义各种图像处理操作的内核,比如平滑、锐化和边缘检测。这一切都很好,但是如果有办法用 学 这些滤镜来代替呢?
有没有可能定义一种机器学习算法,它可以查看我们的输入图像,并最终学习这些类型的运算符?其实是有的——这类算法有:【卷积神经网络(CNN)。
通过应用卷积过滤器、非线性激活函数、池化和反向传播,CNN 能够学习能够检测网络低层中的边缘和斑点状结构的过滤器,然后使用边缘和结构作为“构建块”,最终检测高层对象(例如,脸、猫、狗、杯子等)。)在网络的更深层。
这种使用较低级别的层来学习高级特征的过程正是我们之前提到的 CNN 的组成性。但是 CNN 到底是怎么做的呢*?答案是通过有目的地堆叠一组特定的层。我们将在单独的课程中讨论这些类型的图层,然后研究在许多影像分类任务中广泛使用的常见图层堆叠模式。********
卷积神经网络(CNN)和层类型
原文:https://pyimagesearch.com/2021/05/14/convolutional-neural-networks-cnns-and-layer-types/
CNN 积木
神经网络接受输入图像/特征向量(每个条目一个输入节点),并通过一系列隐藏层对其进行变换,通常使用非线性激活函数。每个隐藏层也由一组神经元组成,其中每个神经元都与前一层中的所有神经元完全连接。神经网络的最后一层(即“输出层”)也是完全连接的,并代表网络的最终输出分类。
然而,神经网络直接对原始像素强度进行操作:
- 随着图像尺寸的增加,缩放效果不佳。
- 精度有待提高(即 CIFAR-10 上的标准前馈神经网络仅获得 52%的精度)。
为了证明标准神经网络如何不能随着图像大小的增加而很好地扩展,让我们再次考虑 CIFAR-10 数据集。CIFAR-10 中的每个图像是 32 × 32,具有红色、绿色和蓝色通道,总共产生 32 × 32 × 3 = 3 , 072 个输入到我们的网络。
总共 3 个, 072 个输入看起来不算多,但是考虑一下如果我们使用 250 个 × 250 像素的图像——输入和权重的总数将跳到 250 个 × 250 个 × 3 = 187 个, 500 个——并且这个数字仅针对输入层!当然,我们会希望添加多个隐藏层,每层的节点数各不相同——这些参数可以很快累加起来,鉴于标准神经网络在原始像素强度上的较差性能,这种膨胀几乎不值得。
相反,我们可以使用卷积神经网络(CNN)来利用输入图像结构,并以更明智的方式定义网络架构。与标准的神经网络不同,CNN 的层以三维方式排列在 3D 体积中:宽度、高度和深度(其中深度是指体积的第三维,例如图像中的通道数量或层中的过滤器数量)。
为了使这个例子更具体,再次考虑 CIFAR-10 数据集:输入体积将具有维度 32 × 32 × 3(分别是宽度、高度和深度)。后续层中的神经元将只连接到其前一层的小区域(而不是标准神经网络的完全连接结构)——我们称之为 局部连接 、,这使我们能够在我们的网络中保存大量参数。最后,输出层将是一个 1 × 1 ×N 的体积,它表示提取到类分数的单个向量中的图像。在 CIFAR-10 的情况下,给定十个等级, N = 10,产生 1 × 1 × 10 的体积。
图层类型
有许多类型的层用于构建卷积神经网络,但您最有可能遇到的层包括:
- 卷积(
CONV) - 激活(
ACT或RELU,我们使用相同或实际的激活功能) - 合用(
POOL) - 完全连接(
FC) - 批量标准化(
BN) - 辍学(
DO)
以特定的方式堆叠一系列这些层会产生 CNN。我们经常用简单的文字图来描述一个 CNN: INPUT => CONV => RELU => FC => SOFTMAX。
这里,我们定义了一个简单的 CNN,它接受输入,应用卷积层,然后是激活层,然后是全连接层,最后是 softmax 分类器,以获得输出分类概率。网络图中经常省略SOFTMAX激活层,因为它被认为直接跟在最后的FC之后。
在这些层类型中,CONV和FC(在较小程度上,BN)是唯一包含在训练过程中学习到的参数的层。激活层和脱落层本身并不被认为是真正的“层”,但通常被包含在网络图中,以使体系结构显式清晰。与CONV和FC同等重要的汇集层(POOL)也被包含在网络图中,因为它们在图像通过 CNN 时对图像的空间维度有着重大影响。
在定义您的实际网络架构时,、POOL、RELU和FC是最重要的。这并不是说其他层不重要,而是让位于这四个关键层,因为它们定义了实际架构本身。
备注: 激活函数本身实际上假设是架构的一部分,当定义 CNN 架构时,我们经常从表格/图表中省略激活层以节省空间;然而,激活层被隐含地假定为架构的一部分。
在本教程中,我们将详细回顾每一种层类型,并讨论与每一层相关的参数(以及如何设置它们)。在以后的教程中,我将更详细地讨论如何正确地堆叠这些层来构建您自己的 CNN 架构。
卷积层
CONV层是卷积神经网络的核心构建模块。CONV层参数由一组 K 可学习过滤器(即“内核”)组成,其中每个过滤器都有一个宽度和一个高度,并且几乎总是正方形。这些过滤器很小(就它们的空间尺寸而言),但是在体积的整个深度上延伸。
对于 CNN 的输入,深度是图像中通道的数量(即,当处理 RGB 图像时,深度为三,每个通道一个)。对于网络中较深的卷,深度将是在之前的层中应用的过滤器数量。
为了使这个概念更清楚,让我们考虑 CNN 的前向传递,其中我们在输入体积的宽度和高度上卷积每个 K 滤波器。更简单地说,我们可以想象我们的每个 K 内核滑过输入区域,计算元素级乘法、求和,然后将输出值存储在一个二维激活图中,比如图 1 中的。
在将所有的 K 过滤器应用到输入体积之后,我们现在有了 K ,二维激活图。然后,我们沿着数组的深度维度堆叠我们的 K 激活图,以形成最终的输出体积(图 2 )。
因此,输出体积中的每一个条目都是一个神经元的输出,该神经元只“看”输入的一小部分。以这种方式,网络“学习”过滤器,当它们在输入体积中的给定空间位置处看到特定类型的特征时,过滤器被激活。在网络的较低层,当过滤器看到边缘状或角状区域时,它们可能会激活。
然后,在网络的更深层,过滤器可以在出现高级特征时激活,例如面部的部分、狗的爪子、汽车的引擎盖等。这种激活概念就好像这些神经元在看到输入图像中的特定模式时变得“兴奋”和“激活”。
将小滤波器与大(r)输入量进行卷积的概念在卷积神经网络中具有特殊的意义——具体来说,就是神经元的局部连通性和感受域。当处理图像时,将当前体积中的神经元连接到前一体积中的所有神经元通常是不切实际的——连接太多,权重太大,使得不可能在具有大空间维度的图像上训练深度网络。相反,当利用 CNN 时,我们选择将每个神经元仅连接到输入体积的一个局部区域——我们将这个局部区域的大小称为神经元的感受野(或简称为变量 F )。
为了明确这一点,让我们回到我们的 CIFAR-10 数据集,其中输入卷的输入大小为 32 × 32 × 3。因此,每个图像的宽度为 32 像素,高度为 32 像素,深度为 3(每个 RGB 通道一个像素)。如果我们的感受野大小为 3 × 3,那么CONV层中的每个神经元将连接到图像的 3 × 3 局部区域,总共 3 × 3 × 3 = 27 个权重(记住,滤波器的深度为 3,因为它们延伸通过输入图像的整个深度,在这种情况下,为 3 个通道)。
现在,让我们假设我们的输入体积的空间维度已经被减小到更小的尺寸,但是我们的深度现在更大了,这是由于在网络中使用了更多更深的过滤器,因此体积尺寸现在是 16 × 16 × 94。同样,如果我们假设感受野的大小为 3 × 3,那么CONV层中的每个神经元将总共有 3 个 × 3 × 94 = 846 个连接到输入体积。简单地说,感受野 F 是滤波器的 大小 ,产生一个 F×F 核,该核与输入体积卷积。
至此,我们已经解释了输入体积中神经元的连接性,但没有解释输出体积的排列或大小。有三个参数控制输出音量的大小:深度、步幅和补零大小,下面我们将逐一介绍。
深度
输出体积的深度控制连接到输入体积局部区域的CONV层中神经元(即过滤器)的数量。每个过滤器产生一个激活图,该激活图在存在定向边缘或斑点或颜色时“激活”。
对于给定的CONV层,激活图的深度将是 K ,或者简单地说是我们在当前层中学习的过滤器的数量。“查看”输入的相同( x,y )位置的一组过滤器被称为深度列。
步幅
考虑一下我们将卷积运算描述为将一个小矩阵“滑过”一个大矩阵,在每个坐标处停止,计算一个逐元素的乘法和求和,然后存储输出。这个描述类似于一个从从左到右和从上到下滑过图像的滑动窗口(【http://pyimg.co/0yizo】的)。
在上面卷积的上下文中,我们每次只采取一个像素的步长。在 CNN 的上下文中,可以应用相同的原理——对于每一步,我们在图像的局部区域周围创建一个新的深度列,其中我们将每个 K 滤波器与该区域进行卷积,并将输出存储在 3D 体积中。当创建我们的CONV层时,我们通常使用步长 S 或者 S = 1 或者 S = 2。
较小的步幅将导致感受野重叠和较大的输出量。相反,较大的步幅将导致较少的感受野重叠和较小的输出量。为了使卷积步幅的概念更具体,考虑表 1 ,其中我们有一个 5 × 5 输入图像(左)以及一个 3 × 3 拉普拉斯核(右)。
使用 S = 1,我们的内核从从左到右和从上到下滑动,一次一个像素,产生下面的输出(表 2 ,左)。然而,如果我们应用相同的操作,只是这次的步幅为 S = 2,我们一次跳过两个像素(沿 x 轴两个像素,沿 y 轴两个像素),产生较小的输出音量(右)。
因此,我们可以看到卷积层如何通过简单地改变核的步幅来减少输入体积的空间维度。卷积图层和池化图层是减少空间输入大小的主要方法。
补零
当应用卷积时,我们需要“填充”图像的边界,以保持原始图像大小——CNN 内部的过滤器也是如此。使用零填充,我们可以沿着边界“填充”我们的输入,以便我们的输出音量大小与我们的输入音量大小相匹配。我们应用的填充量由参数 P 控制。
当我们开始研究在彼此之上应用多个过滤器的深度 CNN 架构时,这种技术尤其关键。为了可视化零填充,再次参考表 1 ,其中我们将 3 × 3 拉普拉斯核应用于步长为 S = 1 的 5 × 5 输入图像。
我们可以在表 3 ( 左)中看到,由于卷积运算的性质,输出音量如何比输入音量 (3 × 3)小。如果我们改为设置 P = 1,我们可以用零(右)填充我们的输入音量,以创建 7 × 7 的音量,然后应用卷积运算,得到与原始输入音量大小 5 × 5 ( 下)匹配的输出音量大小。
如果没有零填充,输入量的空间维度会下降得太快,我们将无法训练深层网络(因为输入量太小,无法从中学习任何有用的模式)。
将所有这些参数放在一起,我们可以计算输出音量的大小,作为输入音量大小( W ,假设输入图像是正方形的,它们几乎总是正方形),感受野大小 F ,步幅 S ,以及零填充量 P 的函数。为了构建一个有效的CONV层,我们需要确保下面的等式是一个整数:
(1)((W-F+2P)/S)+1
如果不是整数,则步幅设置不正确,并且神经元不能平铺以使它们以对称的方式适合输入体积。
作为一个例子,考虑 AlexNet 架构的第一层,它赢得了 2012 年 ImageNet 分类挑战赛,并对当前应用于图像分类的深度学习热潮做出了巨大贡献。在他们的论文中, [Krizhevsky 等人(2012)](http://papers.nips.cc/paper/4824-imagenet-classification-with-deepconvolutional- neural-networks.pdf) 根据图 3 记录了他们的 CNN 架构。
注意第一层是如何宣称输入图像尺寸为 224×224像素的。然而,如果我们使用 11 个 × 11 个过滤器、4 个步幅并且没有填充来应用上面的等式,这不可能是正确的:
(2)((224-11+2(0))/4)+1 = 54。25****
这当然不是一个整数。
对于刚刚开始学习深度学习和 CNN 的新手读者来说,这样一篇开创性论文中的这个小错误已经导致了无数困惑和沮丧的错误。不知道为什么会出现这种打字错误,但很可能 Krizhevsky 等人使用了 227 × 227 张输入图像,因为:
(3)((227-11+2(0))/4)+1 = 55
像这样的错误比你想象的更常见,所以当从出版物中实现 CNN 时,一定要亲自检查参数,而不是简单地假设列出的参数是正确的。由于 CNN 中的大量参数,在记录架构时很容易犯印刷错误(我自己也犯过很多次)。
总而言之,CONV层以与卡帕西相同的优雅方式:
-
接受大小为W[input]×H[input]×D[input]的输入量(输入大小一般为方形,所以常见的有W[input]=H[input])。
-
需要四个参数:
- 滤镜数量 K (控制输出量的深度)。
- 感受野大小 F (用于卷积的 K 核的大小,并且早期总是平方,产生 F×F 核)。
- 步幅 S 。
- 补零量 P 。
-
然后
CONV层的输出为 W [输出] ×H [输出] ×D [输出] ,其中:- W [输出]=((W[输入]—F+2P)/S)+1
- H [输出]=((H[输入]—F+2P)/S)+1
- D [输出]=K**
激活层
在 CNN 的每一个CONV层之后,我们应用一个非线性激活函数,比如 ReLU,eLU,或者任何其他的泄漏 ReLU 变体。在网络图中,我们通常将激活层表示为RELU,因为 ReLU 激活是最常用的,我们也可以简单地表示为ACT——在这两种情况下,我们都清楚地表明激活功能应用于网络架构内部。
激活层在技术上不是“层”(由于在激活层内部不学习参数/权重的事实),并且有时从网络架构图中省略,因为假设激活紧接着卷积。
在这种情况下,出版物的作者将在他们论文的某个地方的每个CONV层后提到他们正在使用的激活函数。例如,考虑以下网络架构:INPUT => CONV => RELU => FC。
为了使这个图更简洁,我们可以简单地删除RELU组件,因为它假设激活总是遵循卷积:INPUT => CONV => FC。我个人不喜欢这样,选择明确将激活层包含在网络图中,以明确何时和我在网络中应用什么激活功能。
激活层接受大小为W[input]×H[input]×D[input]的输入量,然后应用给定的激活函数(图 4 )。由于激活函数是以元素方式应用的,所以激活层的输出总是与输入维度相同, W [输入] = W [输出] , H [输入] = H [输出] , D [输入] = D
汇集层
有两种方法可以减小输入体积的大小——步长为 > 1 的CONV层(我们已经见过)和POOL层。在 CNN 架构中,通常在连续的CONV层之间插入POOL层:
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC
POOL层的主要功能是逐渐减小输入体积的空间尺寸(即宽度和高度)。这样做可以让我们减少网络中的参数和计算量——池化也有助于我们控制过度拟合。
POOL层使用最大值或平均值功能独立地对输入的每个深度切片进行操作。最大池通常在 CNN 架构的中间完成,以减少空间大小,而平均池通常用作网络的最后一层(例如,GoogLeNet、SqueezeNet、ResNet),我们希望完全避免使用FC层。最常见的POOL层类型是 max pooling,尽管这种趋势正在随着更奇特的微架构的引入而改变。
通常我们将使用 2 × 2 的池大小,尽管在网络架构的早期,使用更大输入图像( > 200 像素)的更深 CNN 可能使用 3 × 3 的池大小。我们通常也将步幅设置为 S = 1 或 S = 2。图 5 (很大程度上受 Karpathy 等人的启发)给出了一个应用最大池的示例,池大小为 2 × 2,步长为 S = 1。请注意,对于每 2 个 × 2 块,我们只保留最大值,单步执行(像滑动窗口一样),并再次应用该操作,从而产生 3 个 × 3 的输出音量大小。
我们可以通过增加步幅来进一步减小输出音量——这里我们将 S = 2 应用于相同的输入(图 5 ,底部)。对于输入中的每 2 个 × 2 块,我们只保留最大值,然后采取两个像素的步长,再次应用运算。这种池允许我们将宽度和高度减少一半,有效地丢弃了前一层中 75%的激活。
总之,POOL层接受大小为 W [输入] ×H [输入] ×D [输入] 的输入量。它们需要两个参数:
- 感受野大小 F (也称为“池大小”)。
- 步幅 S 。
应用POOL操作产生大小为 W [输出] ×H [输出] ×D [输出] 的输出体积,其中:
- W [输出]=((W[输入]—F)/S)+1
- H [输出]=((H[输入]—F)/S)+1
- D [输出]=D[输入]**
在实践中,我们倾向于看到两种类型的最大池变化:
- Type #1: F = 3 ,S = 2,称为重叠池,通常应用于空间维度较大的图像/输入体。
- Type #2: F = 2 ,S = 2,称为非重叠池。这是最常见的池类型,适用于空间尺寸较小的图像。
对于接受较小输入图像(在 32-64 像素范围内)的网络架构,您也可能会看到 F = 2 ,S = 1。
去潭州还是 CONV?
在他们的 2014 年论文中, 力求简单:全卷积网,Springenberg 等人 建议完全丢弃POOL层,而简单地依靠具有较大跨距的CONV层来处理体积的空间维度的下采样。他们的工作表明,这种方法在各种数据集上工作得非常好,包括 CIFAR-10(小图像,低类别数)和 ImageNet(大输入图像,1000 个类别)。这种趋势随着 ResNet 架构 而延续,该架构也使用CONV层进行下采样。
越来越常见的是,不在网络架构中间使用POOL层,而如果要避免使用FC层,只有*在网络末端使用平均池。也许在未来,卷积神经网络中不会有池层,但与此同时,我们必须研究它们,了解它们的工作原理,并将它们应用到我们自己的架构中。
完全连接的层
FC层中的神经元完全连接到前一层中的所有激活,这是前馈神经网络的标准。FC层是总是放置在网络的末端(即,我们不应用CONV层,然后是FC层,接着是另一个CONV层)。
在应用 softmax 分类器之前,通常使用一个或两个FC层,如下(简化)架构所示:
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC => FC
这里,我们在(隐含的)softmax 分类器之前应用两个完全连接的层,该分类器将计算每个类的最终输出概率。
批量归一化
由 Ioffe 和 Szegedy 在他们 2015 年的论文中首次介绍,批量标准化:通过减少内部协变量移位 加速深度网络训练,顾名思义,批量标准化层(或简称为BN)用于在给定输入量传递到网络的下一层之前对其激活进行标准化。
如果我们考虑
to be our mini-batch of activations, then we can compute the normalized  via the following equation:
via the following equation:
(4) 
在训练期间,我们计算每个小批量 β 的[β] 和 σ [β] ,其中:
(5) ^{2}")
我们设置 ε 等于一个小的正值,比如 1e-7,以避免被零除。应用该等式意味着离开批量归一化层的激活将具有近似为零的平均值和单位方差(即,以零为中心)。
在测试时间,我们将小批量和 σ [β] 替换为训练过程中计算的[【β】]和 σ [β] 的移动平均值。这确保了我们可以通过我们的网络传递图像,并且仍然获得准确的预测,而不会受到来自在训练时通过网络传递的最终小批量的 [β] 和 σ [β] 的偏差。
在减少训练一个神经网络所需的历元数方面,批量标准化已经被证明是非常有效的。批量规范化还有助于“稳定”训练,允许更大范围的学习速率和规范化强度。使用批量规范化当然不会减轻调整这些参数的需要,但是它将通过使学习率和规范化不那么不稳定并且更容易调整来使你的生活更容易。在网络中使用批量标准化时,您还会注意到更低的最终损耗和更稳定的损耗曲线。
批量归一化的最大缺点是,由于每批统计数据和归一化的计算,它实际上会将训练网络所需的时间减少 2-3 倍(即使您需要更少的历元来获得合理的精度)。
也就是说,我建议在的几乎所有情况下都使用批处理规范化,因为它确实会产生显著的差异。对我们的网络架构应用批量标准化可以帮助我们防止过度拟合,并且与没有批量标准化的相同网络架构相比,允许我们在更少的时期内获得显著更高的分类准确度。
那么,批量归一化图层去哪里了呢?
你可能已经注意到,在我关于批处理规范化的讨论中,我完全忽略了在网络架构中放置批处理规范化层的位置。根据 Ioffe 和 Szegedy 的原始论文,他们将批处理规范化(BN ) 放在激活之前:
我们通过归一化 x = 吴 + b. ,在非线性之前立即添加 BN 变换
使用这种方案,利用批处理规范化的网络体系结构将如下所示:
INPUT => CONV => BN => RELU ...
然而,从统计学的角度来看,这种批处理规范化的观点没有意义。在这种情况下,BN层对来自CONV层的特征分布进行标准化。这些特征中的一些可以是负的,其中它们将被诸如 ReLU 的非线性激活函数箝位(即,设置为零)。
如果我们在激活之前对进行归一化,我们实际上是在归一化中包含了负值。然后,我们以零为中心的特征通过 ReLU,在 ReLU 中,我们删除任何小于零的激活(包括在归一化之前可能不是负值的特征),这种层排序完全违背了首先应用批量归一化的目的。
相反,如果我们将批量归一化放在ReLU 之后,我们将归一化正值特征,而不会使它们在统计上偏向那些本来不会到达下一个CONV层的特征。事实上,Keras 的创建者和维护者 Franç ois Chollet 证实了这一点,他指出BN应该在激活之后出现:
我可以保证 Christian [Szegedy,来自 BN 论文]最近写的代码在 BN 之前应用 relu。尽管如此,它仍然偶尔成为争论的话题。
目前还不清楚为什么 Ioffe 和 Szegedy 在他们的论文中建议在激活之前放置BN层,但进一步的实验 以及来自其他深度学习研究人员 的轶事证据证实,在非线性激活之后放置批量归一化层几乎在所有情况下都会产生更高的准确性和更低的损失。
将激活后的BN放置在网络架构中,看起来像这样:
INPUT => CONV => RELU => BN ...
我可以确认,在我用 CNN 进行的几乎所有实验中,将BN放在RELU之后会产生稍高的精确度和较低的损耗。也就是说,请注意单词“几乎”——有极少数情况下,在激活前放置BN效果更好,这意味着您应该默认在激活后放置BN,但可能希望专门(最多)进行一次实验,在激活前放置BN并记录结果。
在运行了一些这样的实验后,你会很快意识到激活后的BN表现得更好,并且你的网络有更多重要的参数需要调整以获得更高的分类精度。
辍学
我们要讨论的最后一种层类型是辍学。退出实际上是正则化的一种形式,旨在通过提高测试精度来帮助防止过度拟合,这可能是以训练精度为代价的。对于我们训练集中的每个小批量,丢弃层以概率 p 随机断开网络架构中前一层到下一层的输入。
图 6 形象化了这个概念,我们以概率 p = 0 随机断开连接。 5 给定小批量的两个FC层之间的连接。同样,请注意这个小批量的一半连接是如何被切断的。在为小批量计算了向前和向后传递之后,我们重新连接丢弃的连接,然后对另一组要丢弃的连接进行采样。
我们应用 dropout 的原因是通过在训练时显式改变网络架构来减少过拟合。随机丢弃连接确保网络中没有单个节点在面对给定模式时负责“激活”。相反,dropout 确保了有多个冗余节点在出现类似输入时会被激活——这反过来帮助我们的模型推广。
最常见的是放置 p = 0 的辍学层。 5 在架构的 FC层之间,其中最后的FC层被假定为我们的 softmax 分类器:
... CONV => RELU => POOL => FC => DO => FC => DO => FC
然而,我们也可以应用具有较小概率的退出(即, p = 0 )。10—0。 25)在网络的早期层中也是如此(通常在下采样操作之后,通过最大池或卷积)。
通用架构和培训模式
正如我们所见,卷积神经网络由四个主要层组成:CONV、POOL、RELU和FC。将这些层按照特定的模式堆叠在一起,就产生了一个 CNN 架构。
CONV和FC层(以及BN层)是网络中唯一实际学习参数的层,其他层只是负责执行给定的操作。激活层,(ACT)如RELU和 dropout 在技术上不是层,但经常包含在 CNN 架构图中,以使操作顺序明确明确——我们将采用相同的约定。
图层模式
到目前为止,CNN 架构最常见的形式是堆叠几个CONV和RELU层,在它们之后是一个POOL操作。我们重复这个顺序,直到体积的宽度和高度变小,此时我们应用一个或多个FC层。因此,我们可以使用以下模式推导出最常见的 CNN 架构:
INPUT => [[CONV => RELU]*N => POOL?]*M => [FC => RELU]*K => FC
这里的*操作符表示一个或多个操作,而?表示可选操作。
每次重复的常见选择包括:
- 0<=<= 3
- M > = 0
- 0<=K<= 2
下面,我们可以看到遵循这种模式的 CNN 架构的一些例子:
INPUT => FCINPUT => [CONV => RELU => POOL] * 2 => FC => RELU => FCINPUT => [CONV => RELU => CONV => RELU => POOL] * 3 => [FC => RELU] * 2 => FC
下面是一个非常浅的 CNN 的例子,只有一个CONV层( N = M = K = 0):
INPUT => CONV => RELU => FC
下面是一个类似于 [AlexNet 的](http://papers.nips.cc/paper/4824-imagenet-classification-with-deepconvolutional- neural-networks.pdf) CNN 架构的例子,它有多个CONV => RELU => POOL层集,后面是FC层:
INPUT => [CONV => RELU => POOL] * 2 => [CONV => RELU] * 3 => POOL =>
[FC => RELU => DO] * 2 => SOFTMAX
对于更深层次的网络架构,例如 [VGGNet](http://arxiv.org/ abs/1409.1556) ,我们将在每个POOL层之前堆叠两个(或更多)层:
INPUT => [CONV => RELU] * 2 => POOL => [CONV => RELU] * 2 => POOL =>
[CONV => RELU] * 3 => POOL => [CONV => RELU] * 3 => POOL =>
[FC => RELU => DO] * 2 => SOFTMAX
一般来说,当我们(1)有大量标记的训练数据并且(2)分类问题足够具有挑战性时,我们应用更深的网络架构。在应用POOL层之前堆叠多个CONV层允许CONV层在破坏性汇集操作执行之前开发更复杂的特征。
有更多的“外来”网络架构偏离了这些模式,反过来也创造了自己的模式。一些架构完全移除了POOL操作,依靠CONV层对体积进行下采样,然后,在网络的末端,应用平均池而不是FC层来获得 softmax 分类器的输入。
GoogLeNet、ResNet 和 SqueezeNet ( 何等人、赛格迪等人、伊恩多拉等人)等网络架构就是这种模式的典型例子,它们展示了移除FC层如何减少参数并加快训练时间。
这些类型的网络架构还跨通道维度“堆叠”和连接过滤器:GoogLeNet 应用 1 个 × 1、3 个 × 3 和 5 个 × 5 过滤器,然后跨通道维度将它们连接在一起,以学习多级特征。同样,这些架构被认为是更“奇特”的,被认为是先进的技术。
经验法则
在构建自己的 CNN 时,我将回顾一些常见的经验法则。首先,呈现给输入层的图像应该是正方形。使用平方输入允许我们利用线性代数优化库。常见的输入层大小包括 32×32、64×64、96×96、224×224、227×227 和 229×229(为方便标注,省略了通道数)。
其次,在应用第一个CONV操作之后,输入层也应该是可被两个倍数整除的。你可以通过调整过滤器的大小和步幅来做到这一点。“除以 2 规则”使我们的网络中的空间输入能够通过POOL操作以有效的方式方便地进行下采样。
一般来说,你的CONV图层应该使用较小的滤镜尺寸,比如 3 × 3 和 5 × 5。微型 1 × 1 过滤器用于学习本地特性,但仅在更高级的网络架构中使用。更大的过滤器尺寸,例如 7 × 7 和 11 × 11,可以用作网络中的第CONV层(为了减小空间输入尺寸,假设您的图像足够大于>200×200 像素);然而,在这个最初的CONV层之后,过滤器的尺寸应该会急剧下降,否则你会过快地减少体积的空间尺寸。
*对于CONV图层,您通常还会使用步幅为 S = 1 的步幅,至少对于较小的空间输入量(接受较大输入量的网络在第一个CONV图层中使用步幅 S > = 2 的步幅,以帮助减少空间维度)。使用 S = 1 的步幅使我们的CONV层能够学习滤镜,而POOL层负责下采样。但是,请记住,并不是所有的网络体系结构都遵循这种模式,有些体系结构完全跳过最大池,依靠 T4 来减少卷的大小。
我个人的偏好是将零填充应用到我的CONV层,以确保输出维度大小与输入维度大小相匹配——这个规则的唯一例外是,如果我想要故意通过卷积减少空间维度。当将多个CONV层堆叠在彼此之上时应用零填充也已经证明在实践中增加了分类精度。像 Keras 这样的库可以自动为您计算零填充,使得构建 CNN 架构更加容易。
第二个个人建议是使用POOL层(而不是CONV层)来减少输入的空间维度,至少在你更有经验构建自己的 CNN 架构之前。一旦达到这一点,您应该开始尝试使用CONV层来减少空间输入大小,并尝试从您的架构中删除最大池层。
最常见的是,你会看到最大池应用于 2 × 2 感受野大小和 S = 2 的步幅。在网络架构的早期,你可能还会看到一个 3 × 3 感受域,以帮助减小图像尺寸。看到感受野大于 3 是非常罕见的,因为这些操作对它们的输入是非常有害的。
批量标准化是一个昂贵的操作,它会使训练 CNN 的时间增加一倍(T2)或三倍(T4);不过,我推荐在 中使用BN几乎所有的情况 。虽然 BN 确实降低了训练时间,但它也倾向于“稳定”训练,从而更容易调整其他超参数(当然,也有一些例外)。
我还将批处理规范化放在激活之后,这在深度学习社区中已经变得司空见惯,尽管它违背了最初的 Ioffe 和 Szegedy paper 。
将BN插入到上面的通用层架构中,它们变成:
INPUT => CONV => RELU => BN => FCINPUT => [CONV => RELU => BN => POOL] * 2 => FC => RELU => BN => FCINPUT => [CONV => RELU => BN => CONV => RELU => BN => POOL] * 3 => [FC RELU => BN] * 2 => FC
您没有在 softmax 分类器之前应用批量标准化,因为在这一点上,我们假设我们的网络已经在架构的早期学习了它的区别特征。
Dropout ( DO)通常应用于FC层之间,丢失概率为 50% —您应该考虑在您构建的几乎每个架构中应用 Dropout。虽然并不总是执行,但我也喜欢在POOL和CONV层之间包含脱落层(概率很小,10-25%)。由于CONV层的局部连通性,这里的辍学效果不太好,但我经常发现它有助于对抗过度拟合。
记住这些经验法则,您将能够减少构建 CNN 架构时的麻烦,因为您的CONV层将保持输入大小,而POOL层负责减少卷的空间维度,最终导致FC层和最终的输出分类。
一旦你掌握了这种构建卷积神经网络的“传统”方法,你就应该开始探索将最大汇集运算完全排除在之外,并且仅使用的层来降低空间维度,最终导致平均汇集层而不是FC层。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
OpenCV 和 Python 的卷积
原文:https://pyimagesearch.com/2016/07/25/convolutions-with-opencv-and-python/
我将通过问一系列问题来开始今天的博文,这些问题将在本教程的后面部分讨论:
- 什么是图像卷积?
- 他们做什么?
- 为什么我们要使用它们?
- 我们如何应用它们?
- 而卷积在深度学习中起到什么作用?

“卷积”这个词听起来像是一个奇特而复杂的术语,但事实并非如此。事实上,如果你以前曾经使用过计算机视觉、图像处理或 OpenCV,无论你是否意识到,你都已经应用过卷积、应用过!
曾经应用过模糊或者平滑吗?是的,这是一个卷积。
边缘检测呢?没错,卷积。
有没有打开 Photoshop 或者 GIMP 来锐化图像?你猜对了——卷积。
卷积是计算机视觉和图像处理中最关键、最基本的构建模块之一。但这个词本身往往会吓跑人们——事实上,从表面上看,这个词甚至似乎有负面的含义。
相信我,回旋一点也不可怕。它们其实很容易理解。
实际上,一个(image) 卷积就是两个矩阵按元素相乘,然后求和。
说真的。就是这样。你刚刚学了什么是卷积:
- 取两个矩阵(都有相同的维数)。
- 将它们逐个元素相乘(即,不是的点积,只是一个简单的乘法)。
- 将元素加在一起。
要了解更多关于卷积的知识,我们为什么使用它们,如何应用它们,以及它们在深度学习中发挥的 整体作用+图像分类 ,一定要继续阅读这篇帖子。
OpenCV 和 Python 的卷积
可以这样想——图像只是一个多维矩阵。我们的图像有一个宽度(列数)和一个高度(行数),就像一个矩阵。
但与你在小学时可能接触过的传统矩阵不同,图像也有深度(T1)——图像中 T2 通道的数量(T3)。对于标准的 RGB 图像,我们有一个深度为 3 的通道,分别对应红色、绿色和蓝色通道的和。
有了这些知识,我们可以将图像想象成一个 大矩阵 和内核或卷积矩阵作为一个 小矩阵 ,用于模糊、锐化、边缘检测和其他图像处理功能。
本质上,这个小内核位于大图像的顶部,从左到右和从上到下滑动,在原始图像的每个 (x,y)-坐标处应用数学运算(即卷积)。
手工定义内核来获得各种图像处理功能是很正常的。事实上,你可能已经熟悉模糊(平均平滑,高斯平滑,中值平滑等)。)、边缘检测(拉普拉斯、索贝尔、沙尔、普鲁伊特等。),以及锐化— 所有这些操作都是手工定义内核的形式,是专门设计的来执行特定的功能。
这就提出了一个问题,有没有办法让自动学习这些类型的过滤器?***甚至使用这些滤镜进行图像分类和物体检测?***
**当然有。
但是在我们到达那里之前,我们需要多理解一些内核和卷积。
核心
同样,让我们把一个图像想象成一个 大矩阵 ,一个内核想象成 小矩阵 (至少相对于原始的“大矩阵”图像而言):
如上图所示,我们沿着原始图像从左到右和从上到下滑动内核。
在原始图像的每个 (x,y)-坐标处,我们停下来检查位于图像核的 中心 的像素邻域。然后我们取这个像素邻域,用内核对它们进行卷积,并获得一个输出值。然后,该输出值存储在输出图像中与内核中心相同的 (x,y)-坐标处。
如果这听起来令人困惑,不要担心,我们将在这篇博文的“理解图像卷积”部分回顾一个例子。
但是在我们深入一个例子之前,让我们先来看看内核是什么样子的:
上面我们定义了一个正方形的 3 x 3 内核(猜猜这个内核是做什么用的?)
内核可以是任意大小的 M x N 像素,前提是两个 M 和 N 都是 奇数。
注意:你通常看到的大多数内核实际上是 N×N 的方阵。
我们使用一个奇数的内核大小来确保在图像的中心有一个有效的整数 (x,y)-坐标:
在左边,我们有一个3×3矩阵。矩阵的中心显然位于 x=1,y=1 ,这里矩阵的左上角作为原点,我们的坐标是零索引的。
但是在右边的上,我们有一个2×2矩阵。这个矩阵的中心将位于 x=0.5,y=0.5 。但是我们知道,没有应用插值,就没有像素位置 (0.5,0.5)——我们的像素坐标必须是整数!这就是为什么我们使用奇数内核大小的原因——以确保在内核的中心有一个有效的 (x,y) 坐标。
*### 理解图像卷积
现在我们已经讨论了内核的基础知识,让我们来谈谈一个叫做卷积的数学术语。
在图像处理中,卷积需要三个分量:
- 输入图像。
- 我们将应用于输入图像的核矩阵。
- 输出图像,用于存储与内核卷积的输入图像的输出。
卷积本身其实很容易。我们需要做的就是:
- 从原始图像中选择一个 (x,y)-坐标。
- 将内核的中心放在这个 (x,y) 坐标上。
- 对输入图像区域和内核进行逐元素乘法运算,然后将这些乘法运算的值相加为单个值。这些乘法的总和被称为内核输出。
- 使用相同的 (x,y)-来自步骤#1 的坐标,但是这次,将内核输出存储在与输出图像相同的 (x,y)-位置。
下面你可以找到一个卷积(数学上表示为 ""* 运算符)图像的 3 x 3 区域的例子,其中 3 x 3 内核用于模糊:
因此,
在应用这个卷积之后,我们将把位于输出图像 O 的坐标 (i,j) 处的像素设置为 O_i,j = 126。
这就是全部了!
卷积是内核和内核覆盖的输入图像的邻域之间的元素矩阵乘法的总和。
用 OpenCV 和 Python 实现卷积
讨论内核和卷积很有趣——但是现在让我们继续看一些实际的代码,以确保您理解内核和卷积是如何实现的。这个源代码也将帮助你理解如何应用图像卷积。
打开一个新文件,命名为convolutions.py,让我们开始工作:
# import the necessary packages
from skimage.exposure import rescale_intensity
import numpy as np
import argparse
import cv2
我们从第 2-5 行的开始,导入我们需要的 Python 包。你应该已经在你的系统上安装了 NumPy 和 OpenCV,但是你可能没有安装 scikit-image 。要安装 scikit-image,只需使用pip:
$ pip install -U scikit-image
接下来,我们可以开始定义我们的自定义convolve方法:
def convolve(image, kernel):
# grab the spatial dimensions of the image, along with
# the spatial dimensions of the kernel
(iH, iW) = image.shape[:2]
(kH, kW) = kernel.shape[:2]
# allocate memory for the output image, taking care to
# "pad" the borders of the input image so the spatial
# size (i.e., width and height) are not reduced
pad = (kW - 1) // 2
image = cv2.copyMakeBorder(image, pad, pad, pad, pad,
cv2.BORDER_REPLICATE)
output = np.zeros((iH, iW), dtype="float32")
convolve函数需要两个参数:我们希望与kernel卷积的(灰度)image。
给定我们的image和kernel(我们假设它们是 NumPy 数组),然后我们确定每个(第 10 行和第 11 行)的空间维度(即宽度和高度)。
在我们继续之前,重要的是要理解在图像上“滑动”卷积矩阵、应用卷积、然后存储输出的过程实际上会减少我们输出图像的空间维度。
这是为什么呢?
回想一下,我们将计算“集中”在中心 (x,y)-内核当前所在的输入图像的坐标。这意味着对于落在图像边缘的像素来说,没有所谓的“中心”像素。空间维度的减少只是对图像应用卷积的副作用。有时这种效果是理想的,有时不是,这完全取决于你的应用。
然而,在大多数情况下,我们希望我们的输出图像具有与我们的输入图像相同的尺寸。为了确保这一点,我们应用了(第 16-19 行)。在这里,我们只是沿着图像的边界复制像素,这样输出图像将匹配输入图像的尺寸。
还存在其他填充方法,包括零填充(用零填充边界——在构建卷积神经网络时非常常见)和环绕(通过检查图像的另一端来确定边界像素)。在大多数情况下,您会看到复制或零填充。
我们现在准备将实际卷积应用于我们的图像:
# loop over the input image, "sliding" the kernel across
# each (x, y)-coordinate from left-to-right and top to
# bottom
for y in np.arange(pad, iH + pad):
for x in np.arange(pad, iW + pad):
# extract the ROI of the image by extracting the
# *center* region of the current (x, y)-coordinates
# dimensions
roi = image[y - pad:y + pad + 1, x - pad:x + pad + 1]
# perform the actual convolution by taking the
# element-wise multiplicate between the ROI and
# the kernel, then summing the matrix
k = (roi * kernel).sum()
# store the convolved value in the output (x,y)-
# coordinate of the output image
output[y - pad, x - pad] = k
第 24 行和第 25 行在我们的image上循环,从左到右和从上到下一次“滑动”内核一个像素。
第 29 行使用 NumPy 数组切片从image中提取感兴趣区域(ROI)。roi将以image的当前 (x,y) 坐标为中心。roi也将和我们的kernel一样大,这对下一步至关重要。
通过在roi和kernel之间进行逐元素乘法,接着对矩阵中的条目求和,在行 34 上执行卷积。
输出值k然后被存储在output数组中相同的 (x,y)-坐标(相对于输入图像)。
我们现在可以完成我们的convolve方法了:
# rescale the output image to be in the range [0, 255]
output = rescale_intensity(output, in_range=(0, 255))
output = (output * 255).astype("uint8")
# return the output image
return output
当处理图像时,我们通常处理落在范围【0,255】内的像素值。然而,当应用卷积时,我们可以很容易地获得在这个范围之外的值。
为了将我们的output图像带回到【0,255】范围内,我们应用了 scikit-image 的rescale_intensity函数( Line 41 )。我们还在第 42 行将我们的图像转换回无符号的 8 位整数数据类型(以前,output图像是浮点类型,以便处理范围【0,255】之外的像素值)。
最后,output图像返回到线 45 上的调用函数。
现在我们已经定义了我们的convolve函数,让我们继续脚本的驱动程序部分。我们程序的这一部分将处理命令行参数的解析,定义一系列我们将应用于图像的内核,然后显示输出结果:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
# construct average blurring kernels used to smooth an image
smallBlur = np.ones((7, 7), dtype="float") * (1.0 / (7 * 7))
largeBlur = np.ones((21, 21), dtype="float") * (1.0 / (21 * 21))
# construct a sharpening filter
sharpen = np.array((
[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]), dtype="int")
第 48-51 行处理解析我们的命令行参数。这里我们只需要一个参数,--image,它是我们输入路径的路径。
然后我们继续到第 54 行和第 55 行,它们定义了一个用于模糊/平滑图像的 T2 7×7 内核和 T4 21×21 内核。内核越大,图像越模糊。检查这个内核,您可以看到将内核应用到 ROI 的输出就是输入区域的平均。
我们在线 58-61 上定义了一个锐化内核*,用来增强图像的线条结构和其他细节。详细解释这些内核超出了本教程的范围,所以如果你有兴趣学习更多关于内核构造的知识,我建议从这里开始,然后在 Setosa.io 上使用优秀的内核可视化工具。
让我们再定义几个内核:
# construct the Laplacian kernel used to detect edge-like
# regions of an image
laplacian = np.array((
[0, 1, 0],
[1, -4, 1],
[0, 1, 0]), dtype="int")
# construct the Sobel x-axis kernel
sobelX = np.array((
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]), dtype="int")
# construct the Sobel y-axis kernel
sobelY = np.array((
[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]), dtype="int")
第 65-68 行定义了一个拉普拉斯算子,其可以用作边缘检测的一种形式。
注:拉普拉斯算子对于检测图像中的模糊也非常有用。
最后,我们将在第 71-80 行的上定义两个索贝尔滤波器。第一个(线 71-74** )用于检测图像梯度中的垂直变化。类似地,行 77-80 构造了一个用于检测渐变中水平变化 的滤波器。**
给定所有这些内核,我们将它们集合成一组元组,称为“内核库”:
# construct the kernel bank, a list of kernels we're going
# to apply using both our custom `convole` function and
# OpenCV's `filter2D` function
kernelBank = (
("small_blur", smallBlur),
("large_blur", largeBlur),
("sharpen", sharpen),
("laplacian", laplacian),
("sobel_x", sobelX),
("sobel_y", sobelY)
)
最后,我们准备将我们的kernelBank应用到我们的--input图像:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# loop over the kernels
for (kernelName, kernel) in kernelBank:
# apply the kernel to the grayscale image using both
# our custom `convole` function and OpenCV's `filter2D`
# function
print("[INFO] applying {} kernel".format(kernelName))
convoleOutput = convolve(gray, kernel)
opencvOutput = cv2.filter2D(gray, -1, kernel)
# show the output images
cv2.imshow("original", gray)
cv2.imshow("{} - convole".format(kernelName), convoleOutput)
cv2.imshow("{} - opencv".format(kernelName), opencvOutput)
cv2.waitKey(0)
cv2.destroyAllWindows()
第 95 行和第 96 行从磁盘加载我们的图像,并将其转换为灰度。卷积运算符当然可以应用于 RGB(或其他多通道图像),但为了本文的简单起见,我们将只对灰度图像应用滤镜。
我们开始在第 99 行的kernelBank中循环我们的内核集,然后通过调用我们之前定义的自定义convolve方法,将当前的kernel应用到第行 104** 的gray图像。**
作为健全性检查,我们也调用cv2.filter2D,它也将我们的kernel应用到gray图像。cv2.filter2D函数是我们的convolve函数的一个更加优化的版本。我在这篇博文中包含了convolve的实现,主要是为了让你更好地理解卷积是如何工作的。
最后,行 108-112 向我们的屏幕显示输出图像。
OpenCV 和 Python 的卷积示例
今天的例子图片来自我几周前在康涅狄格州南诺沃克我最喜欢的酒吧拍摄的一张照片。在这张图片中,你会看到一杯我最喜欢的啤酒(Smuttynose Findest Kind IPA)和三个 3D 打印的口袋妖怪(不幸的是,现在已经关门了):

Figure 6: The example image we are going to apply our convolutions to.
要运行我们的脚本,只需发出以下命令:
$ python convolutions.py --image 3d_pokemon.png
然后你会看到将我们的smallBlur内核应用到输入图像的结果:

Figure 7: Applying a small blur convolution with our “convolve” function and then validating it against the results of OpenCV’s “cv2.filter2D” function.
左边的,是我们最初的图像。然后在中心我们得到了来自convolve函数的结果。而在右边的,则是来自cv2.filter2D的结果。如结果所示,我们的输出与cv2.filter2D匹配,这表明我们的convolve功能工作正常。此外,由于平滑内核,我们的原始图像现在显得“模糊”和“平滑”。
接下来,让我们应用一个更大的模糊:

Figure 8: As we convolve our image with a larger smoothing kernel, our image becomes more blurred.
比较图 7 和图 8 ,注意当平均内核的大小增加时,输出图像中的模糊量也增加。
我们也可以提升我们的形象:

Figure 9: Using a sharpening kernel enhances edge-like structures and other details in our image.
让我们使用拉普拉斯算子来计算边:

Figure 10: Applying the Laplacian operator via convolution with OpenCV and Python.
使用 Sobel 算子查找垂直边:

Figure 11: Utilizing the Sobel-x kernel to find vertical images.
并使用 Sobel 找到水平边缘:

Figure 12: Finding horizontal gradients in an image using the Sobel-y operator and convolutions.
卷积在深度学习中的作用
正如你从这篇博客文章中收集到的,我们必须手动定义我们的每个内核来应用各种操作,比如平滑、锐化和边缘检测。
这一切都很好,但是如果有一种方法可以让学习这些过滤器呢?有没有可能定义一种机器学习算法,可以看图像,最终学习这些类型的算子?
事实上,有——这些类型的算法是神经网络的一个子类型,称为卷积神经网络(CNN)。通过应用卷积滤波器、非线性激活函数、池化和反向传播,CNN 能够学习能够在网络的较低层中检测边缘和斑点状结构的滤波器——然后使用边缘和结构作为构建块,最终检测较高层的对象(例如,脸、猫、狗、杯子等)。)在网络的更深层。
CNN 是如何做到这一点的?
我会展示给你看——但是要等到我们介绍了足够多的基础知识之后,再看另外几篇博文。
摘要
在今天的博文中,我们讨论了图像内核和卷积。如果我们把图像想象成一个大矩阵,那么图像内核就是位于图像顶部的一个小矩阵。
然后这个内核从左到右和从上到下滑动,计算输入图像和内核之间的元素乘法之和——我们把这个值称为内核输出。然后将内核输出存储在与输入图像相同的 (x,y)-坐标处的输出图像中(在考虑任何填充以确保输出图像与输入图像具有相同的尺寸之后)。
鉴于我们新发现的卷积知识,我们定义了一个 OpenCV 和 Python 函数来将一系列内核应用于图像。这些运算符允许我们模糊图像、锐化图像并检测边缘。
最后,我们简要讨论了内核/卷积在深度学习中扮演的角色,特别是卷积神经网络,以及这些过滤器如何能够自动学习而不是需要手动首先定义它们。
在下周的博文中,我将向您展示如何使用 Python 从头开始训练您的第一个T2 卷积神经网络— 请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在博文发布时得到通知!********
使用 Tesseract 和 Python 校正文本方向
原文:https://pyimagesearch.com/2022/01/31/correcting-text-orientation-with-tesseract-and-python/
任何 OCR 系统的一个重要组成部分是图像预处理——你呈现给 OCR 引擎的输入图像质量越高,你的 OCR 输出就越好。要想在 OCR 中取得成功,你需要回顾一下可以说是最重要的预处理步骤:文本定位。
要学习如何使用 Tesseract 和 Python 进行文本定位, 继续阅读。
使用 Tesseract 和 Python 校正文本方向
文本方向是指图像中一段文本的旋转角度。如果文本被显著旋转,给定的单词、句子或段落对 OCR 引擎来说将看起来像乱码。OCR 引擎是智能的,但像人类一样,它们没有被训练成颠倒阅读!
因此,为 OCR 准备图像数据的第一个关键步骤是检测文本方向(如果有),然后更正文本方向。从那里,您可以将校正后的图像呈现给您的 OCR 引擎(并理想地获得更高的 OCR 准确性)。
学习目标
在本教程中,您将学习:
- 方向和脚本检测(OSD)的概念
- 如何用 Tesseract 检测文本脚本(即书写系统)
- 如何使用 Tesseract 检测文本方向
- 如何用 OpenCV 自动校正文本方向
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
什么是定向和脚本检测?
在我们使用 Tesseract 自动检测和纠正文本方向之前,我们首先需要讨论一下方向和脚本检测(OSD)的概念。在自动检测和 OCR 文本时,Tesseract 有几种不同的模式可供您使用。其中一些模式对输入图像执行全面的 OCR,而其他模式输出元数据,如文本信息、方向等。(即您的 OSD 模式)。Tesseract 的 OSD 模式将为您提供两个输出值:
- 文本方向:输入图像中文本的估计旋转角度(以度为单位)。
- 脚本:图像中文本的预测“书写系统”。
图 2 显示了一个改变文本方向的例子。当在 OSD 模式下,Tesseract 将检测这些方向,并告诉我们如何纠正方向。
书写系统是一种交流信息的视觉方法,但不同于语音,书写系统还包括“存储”和“知识转移”的概念
当我们落笔时,我们使用的字符是书写系统的一部分。这些字符可以被我们和其他人阅读,从而从作者那里传递知识。此外,这种知识“储存”在纸上,这意味着如果我们死了,留在纸上的知识可以传授给其他人,他们可以阅读我们的手稿/书写系统。
图 2 还提供了各种文字和书写系统的例子,包括拉丁语(英语和其他语言中使用的文字)和 Abjad(其他语言中的希伯来语文字)。当置于 OSD 模式时,Tesseract 会自动检测输入图像中文本的书写系统。
如果你对脚本/书写系统的概念不熟悉,我强烈推荐阅读维基百科关于这个主题的优秀文章。这是一本很好的读物,它涵盖了书写系统的历史以及它们是如何演变的。
使用 Tesseract 检测和纠正文本方向
现在我们已经了解了 OSD 的基础知识,让我们继续使用 Tesseract 检测和纠正文本方向。我们将从快速回顾我们的项目目录结构开始。从那以后,我将向您展示如何实现文本方向校正。我们将讨论我们的结果来结束本教程。
项目结构
让我们深入了解一下这个项目的目录结构:
|-- images
| |-- normal.png
| |-- rotated_180.png
| |-- rotated_90_clockwise.png
| |-- rotated_90_counter_clockwise.png
| |-- rotated_90_counter_clockwise_hebrew.png
|-- detect_orientation.py
检测和纠正文本方向的所有代码都包含在detect_orientation.py Python 脚本中,并在不到 35 行代码中实现,包括注释。我们将使用项目文件夹中包含的一组images/来测试代码。
实现我们的文本定位和校正脚本
让我们开始用 Tesseract 和 OpenCV 实现我们的文本方向修正器。
打开一个新文件,将其命名为detect_orientation.py,并插入以下代码:
# import the necessary packages
from pytesseract import Output
import pytesseract
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
args = vars(ap.parse_args())
一开始您可能没有意识到的一个导入是 PyTesseract 的Output类(【https://github.com/madmaze/pytesseract】的)。这个类简单地指定了四种数据类型,包括我们将利用的DICT。
我们唯一的命令行参数是要进行 OCR 的输入--image。现在让我们加载输入:
# load the input image, convert it from BGR to RGB channel ordering,
# and use Tesseract to determine the text orientation
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pytesseract.image_to_osd(rgb, output_type=Output.DICT)
# display the orientation information
print("[INFO] detected orientation: {}".format(
results["orientation"]))
print("[INFO] rotate by {} degrees to correct".format(
results["rotate"]))
print("[INFO] detected script: {}".format(results["script"]))
第 16 行和第 17 行加载我们的输入--image并交换颜色通道,以便它与 Tesseract 兼容。
从那里,我们将方向和脚本检测(OSD) 应用到rgb图像,同时指定我们的output_type=Output.DICT ( 第 18 行)。然后我们在终端显示方向和脚本信息(包含在results字典中),包括:
- 当前的方向
- 将图像旋转多少度以校正其方向
- 检测到的脚本类型,如拉丁文或阿拉伯文
根据这些信息,接下来,我们将更正文本方向:
# rotate the image to correct the orientation
rotated = imutils.rotate_bound(image, angle=results["rotate"])
# show the original image and output image after orientation
# correction
cv2.imshow("Original", image)
cv2.imshow("Output", rotated)
cv2.waitKey(0)
使用我的 imutils rotate_bound方法(【http://pyimg.co/vebvn】T2),我们旋转图像,确保整个图像在结果中保持完全可见(第 28 行)。如果我们使用 OpenCV 的通用cv2.rotate方法,图像的边角就会被剪掉。最后,我们显示原始图像和旋转图像,直到按下一个键(第 32-34 行)。
文本方向和校正结果
我们现在准备应用文本 OSD!打开终端并执行以下命令:
$ python detect_orientation.py --image images/normal.png
[INFO] detected orientation: 0
[INFO] rotate by 0 degrees to correct
[INFO] detected script: Latin
图 3 显示了我们的脚本和方向检测的结果。注意,输入图像已经而不是旋转,意味着方向是 0 。不需要旋转校正。然后,该脚本被检测为“拉丁文”
让我们试试另一张图片,这张图片带有旋转的文字:
$ python detect_orientation.py --image images/rotated_90_clockwise.png
[INFO] detected orientation: 90
[INFO] rotate by 270 degrees to correct
[INFO] detected script: Latin
图 4 显示了包含旋转文本的原始输入图像。在 OSD 模式下使用 Tesseract,我们可以检测到输入图像中的文本方向为 90 —我们可以通过将图像旋转 270 (即—90)来纠正这一方向。同样,检测到的脚本是拉丁文。
*我们将用最后一个非拉丁语文本的例子来结束本教程:
$ python detect_orientation.py \
--image images/rotated_90_counter_clockwise_hebrew.png
[INFO] detected orientation: 270
[INFO] rotate by 90 degrees to correct
[INFO] detected script: Hebrew
图 5 显示了我们输入的文本图像。然后,我们检测该脚本(希伯来语),并通过将文本旋转 90来校正其方向。
正如你所看到的,宇宙魔方使文本 OSD 变得简单!
总结
在本教程中,您学习了如何使用 Tesseract 的方向和脚本检测(OSD)模式执行自动文本方向检测和校正。
OSD 模式为我们提供图像中文本的元数据,包括估计的文本方向和脚本/书写系统检测。文本方向是指图像中文本的角度(以度为单位)。当执行 OCR 时,我们可以通过校正文本方向来获得更高的准确性。另一方面,文字检测指的是文本的书写系统,可以是拉丁语、汉字、阿拉伯语、希伯来语等。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
用 OpenCV 和 Python 统计一个视频的总帧数

今天的博客文章是关于使用 OpenCV 和 Python 处理视频文件的两部分系列文章的一部分。
本系列的第一部分将关注 PyImageSearch 读者 Alex 发来的一个问题。
亚历克斯问道:
我需要用 OpenCV 计算一个视频文件的总帧数。我发现做到这一点的唯一方法是单独循环视频文件中的每一帧,并递增一个计数器。有更快的方法吗?
问得好,亚历克斯。
请放心,你不是第一个问我这个问题的人。
在这篇博文的剩余部分,我将向你展示如何定义一个函数,它可以快速确定一个视频文件中的总帧数。
*下周我们将使用这个函数来帮助我们完成一个有趣的可视化任务,我将演示如何创建“电影条形码”。为了生成这些电影条形码,我们首先需要知道在我们的输入电影文件中有多少帧。
要了解更多关于 OpenCV 和 Python 快速高效的帧计数,请继续阅读。
用 OpenCV 和 Python 统计一个视频的总帧数
使用 OpenCV 和 Python 有两种方法可以确定视频文件中的总帧数:
- 方法#1: 利用 OpenCV 的内置属性,我们可以快速、高效地访问视频文件的元信息,并返回总帧数。
- 方法#2: 这种缓慢、低效的技术需要我们手动循环每一帧,并为我们读取的每一帧递增一个计数器。
*方法#1 显然是理想的。
我们所需要做的就是打开一个指向视频文件的指针,告诉 OpenCV 我们对哪个元属性感兴趣,并获得返回值。
没有手动循环帧。
没有浪费 CPU 周期解码帧。
…但是,我相信你已经意识到这里面有一个圈套。
这里的问题是,基于你的 OpenCV 版本和安装的视频编解码器,方法#1 是错误的。
你会发现有些情况下,视频指针上的.get和.set方法中的超过一半根本不起作用。在这种情况下,我们不可避免地要回到方法 2。
那么,有没有办法把这些方法的两个封装成一个函数呢?
你打赌有。
我已经在 imutils 库中实现了 count_frames 函数,但是为了确保您理解幕后发生的事情,我们今天将在这里回顾整个函数。
用 OpenCV 和 Python 计算帧数的简单方法
使用 Python 在 OpenCV 中计数视频帧的第一种方法非常快——它只是使用 OpenCV 提供的内置属性来访问视频文件并读取视频的元信息。
现在让我们来看看这个函数是如何在 imutils 中实现的:
# import the necessary packages
from ..convenience import is_cv3
import cv2
def count_frames(path, override=False):
# grab a pointer to the video file and initialize the total
# number of frames read
video = cv2.VideoCapture(path)
total = 0
# if the override flag is passed in, revert to the manual
# method of counting frames
if override:
total = count_frames_manual(video)
首先,我们在第 2 行和第 3 行导入必要的 Python 包。我们将需要is_cv3函数来检查我们正在使用哪个版本的 OpenCV,以及用于实际 OpenCV 绑定的cv2。
我们在第 5 条线上的定义count_frames函数。此方法需要一个参数,后跟第二个可选参数:
- 这是我们的视频文件在磁盘上的路径。
override:一个布尔标志,用于确定我们是否应该跳过方法#1,直接进入较慢(但保证准确/无错误)的方法#2。
我们调用行 8 上的cv2.VideoCapture来获得指向实际视频文件的指针,然后初始化视频中的帧数total。
然后我们在第 13 行做一个检查,看看我们是否应该override。如果是这样,我们调用count_frames_manual(我们将在下一节定义它)。
否则,让我们看看方法#1 实际上是如何实现的:
# otherwise, let's try the fast way first
else:
# lets try to determine the number of frames in a video
# via video properties; this method can be very buggy
# and might throw an error based on your OpenCV version
# or may fail entirely based on your which video codecs
# you have installed
try:
# check if we are using OpenCV 3
if is_cv3():
total = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
# otherwise, we are using OpenCV 2.4
else:
total = int(video.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))
# uh-oh, we got an error -- revert to counting manually
except:
total = count_frames_manual(video)
# release the video file pointer
video.release()
# return the total number of frames in the video
return total
为了通过 OpenCV 提供的 API 来确定视频文件中的帧数,我们需要利用所谓的**属性,或者 OpenCV 所谓的CAP_PROP——任何时候你看到一个以CAP_PROP_*开头的常数,你都应该知道它与视频处理有关。
*在 OpenCV 3 中,帧数属性名为cv2.CAP_PROP_FRAME_COUNT,而在 OpenCV 2.4 中,该属性名为cv2.cv.CV_CAP_PROP_FRAME_COUNT。
理想情况下,将各自的属性名传递给video指针的.get方法将允许我们获得视频中的总帧数(第 25-30 行)。
但是,根据您的特定 OpenCV 安装和视频编解码器,在某些情况下这种方法会失败。
如果是这种情况,我们已经用一个try/except块包装了我们的关键代码段。如果出现异常,我们只需恢复手动计数帧数(第 33 行和第 34 行)。
最后,我们释放视频文件指针(行 37 )并将总帧数返回给调用函数(行 40 )。
用 OpenCV 和 Python 计算帧数的慢方法
我们已经看到了在视频中计算帧数的快速有效的方法——现在让我们来看看称为count_frames_manual的较慢的方法。
# import the necessary packages
from ..convenience import is_cv3
import cv2
def count_frames(path, override=False):
# grab a pointer to the video file and initialize the total
# number of frames read
video = cv2.VideoCapture(path)
total = 0
# if the override flag is passed in, revert to the manual
# method of counting frames
if override:
total = count_frames_manual(video)
# otherwise, let's try the fast way first
else:
# lets try to determine the number of frames in a video
# via video properties; this method can be very buggy
# and might throw an error based on your OpenCV version
# or may fail entirely based on your which video codecs
# you have installed
try:
# check if we are using OpenCV 3
if is_cv3():
total = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
# otherwise, we are using OpenCV 2.4
else:
total = int(video.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))
# uh-oh, we got an error -- revert to counting manually
except:
total = count_frames_manual(video)
# release the video file pointer
video.release()
# return the total number of frames in the video
return total
def count_frames_manual(video):
# initialize the total number of frames read
total = 0
# loop over the frames of the video
while True:
# grab the current frame
(grabbed, frame) = video.read()
# check to see if we have reached the end of the
# video
if not grabbed:
break
# increment the total number of frames read
total += 1
# return the total number of frames in the video file
return total
正如我们所见,count_frames_manual只需要一个参数,video,我们假设它是一个由cv2.VideoCapture实例化的指针。
然后,我们初始化从video文件中读取的总帧数,循环遍历这些帧,直到我们到达视频的末尾,并在此过程中递增total计数器。
然后将total返回给调用函数。
值得一提的是,这种方法完全准确无误。如果您确实得到一个错误,它几乎肯定与您的视频编解码器的问题或视频文件的无效路径有关。
使用该函数时,也可能会返回总共零帧。当这种情况发生时,99%的可能性是:
- 您为
cv2.VideoCapture提供了无效的路径。 - 您没有安装正确的视频编解码器,因此 OpenCV 无法读取该文件。如果是这种情况,您需要安装合适的视频编解码器,然后重新编译和安装 OpenCV。
用 OpenCV 计算视频文件中的帧数
让我们继续使用我们的count_frames方法进行测试。
首先,确保您已经安装了 imutils 库:
$ pip install imutils
否则,如果您已经安装了imutils,您应该更新到最新版本( > v0.3.9 ):
$ pip install --upgrade imutils
从这里,让我们创建名为frame_counter.py的驱动程序脚本:
# import the necessary packages
from imutils.video import count_frames
import argparse
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
ap.add_argument("-o", "--override", type=int, default=-1,
help="whether to force manual frame count")
args = vars(ap.parse_args())
我们从导入所需的 Python 包并解析命令行参数开始。我们需要一个开关,然后是第二个可选开关:
--video:我们输入视频文件的路径。--override:是否强制手动帧数。默认情况下,我们将尝试使用更快的方法#1。
然后我们调用count_frames并将结果显示在屏幕上:
# count the total number of frames in the video file
override = False if args["override"] < 0 else True
total = count_frames(args["video"], override=override)
# display the frame count to the terminal
print("[INFO] {:,} total frames read from {}".format(total,
args["video"][args["video"].rfind(os.path.sep) + 1:]))
为了测试这个 Python 脚本,我决定使用我最喜欢的电影侏罗纪公园的预告片:
https://www.youtube.com/embed/lc0UehYemQA?feature=oembed***
新冠肺炎:具有 OpenCV、Keras/TensorFlow 和深度学习的人脸面具检测器
在本教程中,您将学习如何使用 OpenCV、Keras/TensorFlow 和深度学习来训练新冠肺炎面具检测器。
上个月,我写了一篇关于使用深度学习在 X 射线图像中检测新冠肺炎的博文。
读者真的很喜欢从该教程的及时、实际应用中学习,所以今天我们将看看计算机视觉的另一个与 COVID 相关的应用,这是一个关于使用 OpenCV 和 Keras/TensorFlow 检测口罩的应用。
我创作这篇教程的灵感来自于:
- 收到无数来自 PyImageSearch 读者的请求,要求我写这样一篇博文
- 看到其他人实现他们自己的解决方案(我最喜欢的是般若班达里的,我们将从今天开始构建)
如果部署正确,我们今天在这里建造的新冠肺炎面具探测器有可能用于帮助确保你和他人的安全(但我将把这留给医疗专业人员来决定,实施和在野外分发)。
要了解如何使用 OpenCV、Keras/TensorFlow 和深度学习创建新冠肺炎面具检测器,请继续阅读!
新冠肺炎:具有 OpenCV、Keras/TensorFlow 和深度学习的人脸面具检测器
在本教程中,我们将讨论如何在我们的两阶段新冠肺炎面具检测器中使用计算机视觉,详细说明如何实现我们的计算机视觉和深度学习流水线。
从那里,我们将审查数据集,我们将使用训练我们的自定义面具检测器。
然后,我将向您展示如何使用 Keras 和 TensorFlow 实现一个 Python 脚本,在我们的数据集上训练一个人脸遮罩检测器。
我们将使用这个 Python 脚本来训练一个面具检测器,并检查结果。
鉴于训练有素的新冠肺炎面具检测器,我们将继续实现两个额外的 Python 脚本用于:
- 检测图像中的新冠肺炎面具
- 检测实时视频流中的面具
我们将通过查看应用我们的面罩检测器的结果来结束这篇文章。
我还将提供一些进一步改进的额外建议。
两相新冠肺炎面罩检测器
为了训练一个定制的人脸面具检测器,我们需要将我们的项目分成两个不同的阶段,每个阶段都有各自的子步骤(如上面的图 1 所示):
- 训练:在这里,我们将重点关注从磁盘加载我们的人脸面具检测数据集,在该数据集上训练模型(使用 Keras/TensorFlow),然后将人脸面具检测器序列化到磁盘
- 部署:一旦训练好了面具检测器,我们就可以继续加载面具检测器,执行面部检测,然后将每个面部分类为
with_mask或without_mask
我们将在本教程的剩余部分详细回顾这些阶段中的每一个和相关联的子集,但同时,让我们看看将用于训练我们的新冠肺炎面具检测器的数据集。
我们的新冠肺炎面具检测数据集
我们今天在这里使用的数据集是由 PyImageSearch 阅读器 Prajna Bhandary 创建的。
该数据集由属于两类的1376 幅图像组成:
with_mask: 690 张图片without_mask: 686 张图片
我们的目标是训练一个定制的深度学习模型来检测一个人是不是戴着面具的或者不是。
注:为了方便起见,我将般若创建的数据集包含在本教程的“下载”*部分。*
我们的面罩数据集是如何创建的?
般若,像我一样,一直对世界的现状感到沮丧和压抑——每天都有成千上万的人死去,而对我们许多人来说,我们能做的(如果有的话)很少。
为了帮助她保持斗志,般若决定通过应用计算机视觉和深度学习来分散自己的注意力,以解决一个现实世界的问题:
- 最好的情况是——她可以用她的项目去帮助别人
- 最坏的情况——这给了她一个急需的精神解脱
不管怎样,这都是双赢!
作为程序员、开发人员和计算机视觉/深度学习从业者,我们可以都从般若的书中吸取一页——让你的技能成为你的分心和避风港。
为了创建这个数据集,般若有一个巧妙的解决方案:
- 拍摄正常的人脸图像
- 然后创建一个定制的计算机视觉 Python 脚本来给它们添加面具,从而创建一个人造的(但仍然适用于现实世界)数据集
一旦你把面部标志应用到问题上,这个方法实际上比听起来要容易得多。
面部标志允许我们自动推断面部结构的位置,包括:
- 眼睛
- 眉毛
- 鼻子
- 口
- 下颌的轮廓
为了使用面部标志来建立戴着面罩的面部数据集,我们需要首先从戴着面罩的人而不是的图像开始:
从那里,我们应用面部检测来计算图像中面部的边界框位置:
一旦我们知道人脸在图像中的位置,我们就可以提取人脸感兴趣区域(ROI):
从那里,我们应用面部标志,允许我们定位眼睛,鼻子,嘴等。:
接下来,我们需要一个面具的图像(背景透明),如下图所示:
通过使用面部标志(即沿着下巴和鼻子的点)计算将放置面具的,该面具将自动应用到面部。
然后调整面具的大小并旋转,将其放在脸上:
然后,我们可以对所有输入图像重复这一过程,从而创建我们的人工人脸面具数据集:
但是,使用这种方法人为创建数据集时,有一点需要注意!
如果您使用一组图像来创建一个戴着面具的人的人工数据集,您不能在您的训练集中“重用”没有面具的图像——您仍然需要收集在人工生成过程中而不是使用的非人脸面具图像!
如果您将用于生成人脸遮罩样本的原始图像作为非人脸遮罩样本包括在内,您的模型将变得严重偏颇,并且无法很好地进行概括。不惜一切代价,通过花时间收集没有面具的面孔的新例子来避免这种情况。
介绍如何使用面部标志将面具应用到脸上超出了本教程的范围,但如果你想了解更多,我建议:
- 参考般若的 GitHub 库
- 在 PyImageSearch 博客上阅读本教程,在那里我讨论了如何使用面部标志自动将太阳镜应用到脸上
我的太阳镜帖子中的相同原理适用于构建人工人脸面具数据集——使用面部标志来推断面部结构,旋转和调整面具的大小,然后将其应用于图像。
项目结构
一旦您从本文的 【下载】 部分获取文件,您将看到以下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── with_mask [690 entries]
│ └── without_mask [686 entries]
├── examples
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── detect_mask_image.py
├── detect_mask_video.py
├── mask_detector.model
├── plot.png
└── train_mask_detector.py
5 directories, 10 files
train_mask_detector.py:接受我们的输入数据集,并对其进行微调,以创建我们的mask_detector.model。还会生成包含精度/损耗曲线的训练历史plot.pngdetect_mask_image.py:在静态图像中执行人脸遮罩检测- 这个脚本使用你的网络摄像头,对视频流中的每一帧进行面具检测
在接下来的两个部分中,我们将训练我们的面罩检测器。
使用 Keras 和 TensorFlow 实现我们的新冠肺炎面罩检测器训练脚本
现在我们已经回顾了我们的面具数据集,让我们学习如何使用 Keras 和 TensorFlow 来训练一个分类器来自动检测一个人是否戴着面具。
为了完成这项任务,我们将微调 MobileNet V2 架构,这是一种高效的架构,可应用于计算能力有限的嵌入式设备(例如、树莓派、谷歌珊瑚、英伟达 Jetson Nano 等。).
注:如果你的兴趣是嵌入式计算机视觉,一定要看看我的 树莓 Pi for Computer Vision book 该书涵盖了使用计算有限的设备进行计算机视觉和深度学习。
将我们的面罩检测器部署到嵌入式设备可以降低制造这种面罩检测系统的成本,因此我们选择使用这种架构。
我们开始吧!
打开目录结构中的train_mask_detector.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
我们的训练脚本的导入对您来说可能看起来有些吓人,要么是因为有太多的导入,要么是因为您对深度学习不熟悉。如果你是新手,我会推荐你在继续之前阅读我的 Keras 教程和 T2 微调教程。
我们的一套tensorflow.keras进口允许:
- 数据扩充
- 加载 MobilNetV2 分类器(我们将使用预先训练的 ImageNet 权重来微调该模型)
- 构建新的全连接(FC)磁头
- 预处理
- 加载图像数据
要安装必要的软件以便您可以使用这些导入,请确保遵循我的任一 Tensorflow 2.0+安装指南:
让我们继续解析一些从终端启动脚本所需的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to output face mask detector model")
args = vars(ap.parse_args())
我们的命令行参数包括:
--dataset:面和带遮罩的面的输入数据集的路径--plot:输出训练历史图的路径,将使用matplotlib生成--model:生成的序列化人脸面具分类模型的路径
我喜欢在一个地方定义我的深度学习超参数:
# initialize the initial learning rate, number of epochs to train for,
# and batch size
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the input image (224x224) and preprocess it
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
image = preprocess_input(image)
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)
在这个街区,我们是:
- 抓取数据集中的所有
imagePaths(行 44 ) - 初始化
data和labels列表(第 45 和 46 行 - 循环
imagePaths并加载+预处理图像(第 49-60 行)。预处理步骤包括调整大小为 224×224 像素,转换为数组格式,以及将输入图像中的像素亮度缩放到范围 [-1,1] (通过preprocess_input便利函数) - 将预处理后的
image和关联的label分别追加到data和labels列表中(第 59 行和第 60 行 - 确保我们的训练数据是 NumPy 数组格式(行 63 和 64 )
上面几行代码假设您的整个数据集足够小,可以放入内存。如果你的数据集大于你可用的内存,我建议使用 HDF5,这是我在 用 Python 进行计算机视觉的深度学习 (从业者捆绑包第 9 章和第 10 章)中介绍的策略。
我们的数据准备工作还没有完成。接下来,我们将对我们的labels进行编码,对我们的数据集进行分区,并为数据扩充做准备:
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator(
rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
第 67-69 行 one-hot 编码我们的类标签,这意味着我们的数据将采用以下格式:
$ python train_mask_detector.py --dataset dataset
[INFO] loading images...
-> (trainX, testX, trainY, testY) = train_test_split(data, labels,
(Pdb) labels[500:]
array([[1., 0.],
[1., 0.],
[1., 0.],
...,
[0., 1.],
[0., 1.],
[0., 1.]], dtype=float32)
(Pdb)
# load the MobileNetV2 network, ensuring the head FC layer sets are
# left off
baseModel = MobileNetV2(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers:
layer.trainable = False
微调设置分为三个步骤:
- 用预先训练好的 ImageNet 权重加载 MobileNet,留下网络头(行 88 和 89
- 构建一个新的 FC 头,并将其附加到基座上以代替旧的头(第 93-102 行)
- 冻结网络的基本层(行 106 和 107 )。这些基本层的权重在反向传播过程中不会更新,而头层权重将被调整。
微调是一种策略,我几乎总是推荐这种策略来建立基线模型,同时节省大量时间。要了解更多关于理论、目的和策略的信息,请参考我的微调博文和 用 Python 进行计算机视觉的深度学习 (从业者捆绑第五章)。
准备好数据和用于微调的模型架构后,我们现在准备编译和训练我们的面罩检测器网络:
# compile our model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
H = model.fit(
aug.flow(trainX, trainY, batch_size=BS),
steps_per_epoch=len(trainX) // BS,
validation_data=(testX, testY),
validation_steps=len(testX) // BS,
epochs=EPOCHS)
训练完成后,我们将在测试集上评估结果模型:
# make predictions on the testing set
print("[INFO] evaluating network...")
predIdxs = model.predict(testX, batch_size=BS)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testY.argmax(axis=1), predIdxs,
target_names=lb.classes_))
# serialize the model to disk
print("[INFO] saving mask detector model...")
model.save(args["model"], save_format="h5")
我们的最后一步是绘制精度和损耗曲线:
# plot the training loss and accuracy
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
一旦我们的绘图准备就绪,第 152 行使用--plot文件路径将数字保存到磁盘。
用 Keras/TensorFlow 训练新冠肺炎口罩检测器
我们现在准备使用 Keras、TensorFlow 和深度学习来训练我们的面罩检测器。
确保您已经使用本教程的 【下载】 部分下载源代码和面罩数据集。
从那里,打开一个终端,并执行以下命令:
$ python train_mask_detector.py --dataset dataset
[INFO] loading images...
[INFO] compiling model...
[INFO] training head...
Train for 34 steps, validate on 276 samples
Epoch 1/20
34/34 [==============================] - 30s 885ms/step - loss: 0.6431 - accuracy: 0.6676 - val_loss: 0.3696 - val_accuracy: 0.8242
Epoch 2/20
34/34 [==============================] - 29s 853ms/step - loss: 0.3507 - accuracy: 0.8567 - val_loss: 0.1964 - val_accuracy: 0.9375
Epoch 3/20
34/34 [==============================] - 27s 800ms/step - loss: 0.2792 - accuracy: 0.8820 - val_loss: 0.1383 - val_accuracy: 0.9531
Epoch 4/20
34/34 [==============================] - 28s 814ms/step - loss: 0.2196 - accuracy: 0.9148 - val_loss: 0.1306 - val_accuracy: 0.9492
Epoch 5/20
34/34 [==============================] - 27s 792ms/step - loss: 0.2006 - accuracy: 0.9213 - val_loss: 0.0863 - val_accuracy: 0.9688
...
Epoch 16/20
34/34 [==============================] - 27s 801ms/step - loss: 0.0767 - accuracy: 0.9766 - val_loss: 0.0291 - val_accuracy: 0.9922
Epoch 17/20
34/34 [==============================] - 27s 795ms/step - loss: 0.1042 - accuracy: 0.9616 - val_loss: 0.0243 - val_accuracy: 1.0000
Epoch 18/20
34/34 [==============================] - 27s 796ms/step - loss: 0.0804 - accuracy: 0.9672 - val_loss: 0.0244 - val_accuracy: 0.9961
Epoch 19/20
34/34 [==============================] - 27s 793ms/step - loss: 0.0836 - accuracy: 0.9710 - val_loss: 0.0440 - val_accuracy: 0.9883
Epoch 20/20
34/34 [==============================] - 28s 838ms/step - loss: 0.0717 - accuracy: 0.9710 - val_loss: 0.0270 - val_accuracy: 0.9922
[INFO] evaluating network...
precision recall f1-score support
with_mask 0.99 1.00 0.99 138
without_mask 1.00 0.99 0.99 138
accuracy 0.99 276
macro avg 0.99 0.99 0.99 276
weighted avg 0.99 0.99 0.99 276
如你所见,我们在测试集上获得了 ~99%的准确率。
查看图 10 ,我们可以看到几乎没有过度拟合的迹象,验证损失低于培训损失(我在这篇博文中讨论了的这一现象)。
鉴于这些结果,我们希望我们的模型能够很好地推广到我们的训练和测试集之外的图像。
用 OpenCV 实现我们的新冠肺炎人脸面具检测器
既然我们的面罩检测器已经过培训,让我们来学习如何:
- 从磁盘加载输入图像
- 检测图像中的人脸
- 应用我们的面罩检测器将面部分类为
with_mask或without_mask
打开目录结构中的detect_mask_image.py文件,让我们开始吧:
# import the necessary packages
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import cv2
import os
我们的驱动程序脚本需要三个 TensorFlow/Keras 导入来(1)加载我们的 MaskNet 模型和(2)预处理输入图像。
显示和图像操作需要 OpenCV。
下一步是解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to trained face mask detector model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们的四个命令行参数包括:
--image:包含用于推断的面部的输入图像的路径--face:人脸检测器模型目录的路径(我们需要在分类之前定位人脸)--model:我们之前在本教程中训练的面罩检测器模型的路径--confidence:可选的概率阈值可以设置为覆盖 50%来过滤弱的人脸检测
接下来,我们将加载我们的人脸检测器和人脸面具分类器模型:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNet(prototxtPath, weightsPath)
# load the face mask detector model from disk
print("[INFO] loading face mask detector model...")
model = load_model(args["model"])
现在我们的深度学习模型已经在内存中,我们的下一步是加载和预处理输入图像:
# load the input image from disk, clone it, and grab the image spatial
# dimensions
image = cv2.imread(args["image"])
orig = image.copy()
(h, w) = image.shape[:2]
# construct a blob from the image
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
print("[INFO] computing face detections...")
net.setInput(blob)
detections = net.forward()
在从磁盘加载我们的--image(第 37 行)时,我们制作一个副本并获取帧尺寸,用于将来的缩放和显示目的(第 38 和 39 行)。
预处理由 OpenCV 的 blobFromImage 函数 ( 第 42 行和第 43 行)处理。如参数所示,我们将尺寸调整为 300×300 像素,并执行均值减法。
行 47 和 48 然后执行面部检测以定位在图像中的位置所有的面部。
一旦我们知道了每张脸的预测位置,我们将确保在提取人脸之前它们满足--confidence阈值:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# ensure the bounding boxes fall within the dimensions of
# the frame
(startX, startY) = (max(0, startX), max(0, startY))
(endX, endY) = (min(w - 1, endX), min(h - 1, endY))
接下来,我们将通过我们的 MaskNet 模型运行面部 ROI:
# extract the face ROI, convert it from BGR to RGB channel
# ordering, resize it to 224x224, and preprocess it
face = image[startY:endY, startX:endX]
face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)
face = cv2.resize(face, (224, 224))
face = img_to_array(face)
face = preprocess_input(face)
face = np.expand_dims(face, axis=0)
# pass the face through the model to determine if the face
# has a mask or not
(mask, withoutMask) = model.predict(face)[0]
在这一部分,我们:
- 通过 NumPy 切片提取
faceROI(第 71 行 - 像我们在培训期间一样预处理 ROI(第 72-76 行)
- 进行掩膜检测,预测
with_mask或without_mask( 行 80 )
从这里,我们将注释和显示结果!
# determine the class label and color we'll use to draw
# the bounding box and text
label = "Mask" if mask > withoutMask else "No Mask"
color = (0, 255, 0) if label == "Mask" else (0, 0, 255)
# include the probability in the label
label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100)
# display the label and bounding box rectangle on the output
# frame
cv2.putText(image, label, (startX, startY - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)
cv2.rectangle(image, (startX, startY), (endX, endY), color, 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
用 OpenCV 实现图像中的新冠肺炎人脸检测
让我们把我们的新冠肺炎面罩探测器投入使用吧!
确保您已经使用本教程的 “下载” 部分下载了源代码、示例图像和预训练的面罩检测器。
从那里,打开一个终端,并执行以下命令:
$ python detect_mask_image.py --image examples/example_01.png
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] computing face detections...
正如你所看到的,我们的面罩检测器正确地将这张图像标记为Mask。
让我们尝试另一个图像,这是一个戴着面具的人而不是:
$ python detect_mask_image.py --image examples/example_02.png
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] computing face detections...
我们的面罩探测器已经正确预测了No Mask。
让我们尝试最后一张图片:
$ python detect_mask_image.py --image examples/example_03.png
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] computing face detections...
这里发生了什么?
为什么我们能够检测到背景中两位男士的脸,并且正确地为他们分类戴面具/不戴面具,但是我们不能检测到前景中的女人?
我将在本教程后面的“进一步改进的建议”部分讨论这个问题的原因,,但是要点是我们太依赖我们的两阶段过程。
请记住,为了对一个人是否戴着面具进行分类,我们首先需要执行人脸检测— 如果没有找到人脸(这就是本图中发生的情况),则不能应用面具检测器!
我们无法检测前景中的人脸的原因是:
- 它被面具遮住了
- 用于训练人脸检测器的数据集不包含戴口罩的人的示例图像
因此,如果人脸的大部分被遮挡,我们的人脸检测器将很可能无法检测到人脸。
在本教程的“进一步改进的建议”部分,我再次更详细地讨论了这个问题,包括如何提高我们的掩模检测器的精度。
用 OpenCV 实现实时视频流中的新冠肺炎人脸检测器
在这一点上,我们知道我们可以将人脸面具检测应用于静态图像— 但是实时视频流呢?
我们的新冠肺炎面罩检测器能够实时运行吗?
让我们找出答案。
打开目录结构中的detect_mask_video.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
import os
这个脚本的算法是相同的,但它是以这样一种方式拼凑起来的,以允许处理您的网络摄像头流的每一帧。
def detect_and_predict_mask(frame, faceNet, maskNet):
# grab the dimensions of the frame and then construct a blob
# from it
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
faceNet.setInput(blob)
detections = faceNet.forward()
# initialize our list of faces, their corresponding locations,
# and the list of predictions from our face mask network
faces = []
locs = []
preds = []
通过在这里定义这个方便的函数,我们的帧处理循环在后面会更容易阅读。
此功能检测人脸,然后将我们的人脸遮罩分类器应用于每个人脸感兴趣区域。这样一个函数合并了我们的代码——如果您愿意,它甚至可以被移动到一个单独的 Python 文件中。
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# ensure the bounding boxes fall within the dimensions of
# the frame
(startX, startY) = (max(0, startX), max(0, startY))
(endX, endY) = (min(w - 1, endX), min(h - 1, endY))
在循环内部,我们过滤掉弱检测(行 34-38 )并提取边界框,同时确保边界框坐标不会落在图像的边界之外(行 41-47 )。
接下来,我们将面部 ROI 添加到两个相应的列表中:
# extract the face ROI, convert it from BGR to RGB channel
# ordering, resize it to 224x224, and preprocess it
face = frame[startY:endY, startX:endX]
face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)
face = cv2.resize(face, (224, 224))
face = img_to_array(face)
face = preprocess_input(face)
# add the face and bounding boxes to their respective
# lists
faces.append(face)
locs.append((startX, startY, endX, endY))
# only make a predictions if at least one face was detected
if len(faces) > 0:
# for faster inference we'll make batch predictions on *all*
# faces at the same time rather than one-by-one predictions
# in the above `for` loop
faces = np.array(faces, dtype="float32")
preds = maskNet.predict(faces, batch_size=32)
# return a 2-tuple of the face locations and their corresponding
# locations
return (locs, preds)
第 72 行向调用者返回我们的面部边界框位置和相应的遮罩/非遮罩预测。
接下来,我们将定义我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to trained face mask detector model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们的命令行参数包括:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
faceNet = cv2.dnn.readNet(prototxtPath, weightsPath)
# load the face mask detector model from disk
print("[INFO] loading face mask detector model...")
maskNet = load_model(args["model"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
这里我们已经初始化了我们的:
- 人脸检测器
- 新冠肺炎面罩检测器
- 网络摄像头视频流
让我们继续循环流中的帧:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# detect faces in the frame and determine if they are wearing a
# face mask or not
(locs, preds) = detect_and_predict_mask(frame, faceNet, maskNet)
我们开始在行 103 的帧上循环。在里面,我们从流中抓取frame并resize它(第 106 和 107 行)。
从那里,我们使用我们的便利工具;111 线检测并预测人们是否戴着口罩。
让我们后处理(即,注释)新冠肺炎面罩检测结果:
# loop over the detected face locations and their corresponding
# locations
for (box, pred) in zip(locs, preds):
# unpack the bounding box and predictions
(startX, startY, endX, endY) = box
(mask, withoutMask) = pred
# determine the class label and color we'll use to draw
# the bounding box and text
label = "Mask" if mask > withoutMask else "No Mask"
color = (0, 255, 0) if label == "Mask" else (0, 0, 255)
# include the probability in the label
label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100)
# display the label and bounding box rectangle on the output
# frame
cv2.putText(frame, label, (startX, startY - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)
cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)
在我们对预测结果的循环中(从行 115 开始),我们:
- 解包面部边界框并屏蔽/不屏蔽预测(行 117 和 118
- 确定
label和color( 线 122-126 ) - 注释
label和面部边界框(第 130-132 行
最后,我们显示结果并执行清理:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
在frame显示之后,我们捕获key按压。如果用户按下q(退出),我们break退出循环并执行内务处理。
使用 Python、OpenCV 和 TensorFlow/Keras 的深度学习实现您的实时人脸面具检测器非常棒!
用 OpenCV 实时检测新冠肺炎面具
要查看我们的实时新冠肺炎面罩检测器,请确保使用本教程的 【下载】 部分下载源代码和预先训练的面罩检测器模型。
然后,您可以使用以下命令在实时视频流中启动遮罩检测器:
$ python detect_mask_video.py
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] starting video stream...
在这里,你可以看到我们的面罩检测器能够实时运行(并且在其预测中也是正确的)。
改进建议
从上面的结果部分可以看出,我们的面罩检测器运行良好,尽管:
- 训练数据有限
- 人工生成的
with_mask类(参见“我们的面罩数据集是如何创建的?”上节)。
为了进一步改进我们的面具检测模型,你应该收集戴面具的人的真实图像(而不是人工生成的图像)。
虽然我们的人工数据集在这种情况下工作得很好,但没有什么可以替代真实的东西。
其次,你还应该收集面部图像,这些图像可能会“迷惑”我们的分类器,使其认为这个人戴着面具,而实际上他们并没有戴面具 —潜在的例子包括裹在脸上的衬衫、蒙在嘴上的大手帕等。
所有这些都是可能被我们的面罩检测器误认为面罩的例子。
最后,你应该考虑训练一个专用的两类物体检测器,而不是一个简单的图像分类器。
我们目前检测一个人是否戴着口罩的方法是一个两步过程:
- 步骤#1: 执行面部检测
- 步骤#2: 将我们的面具检测器应用到每张脸上
这种方法的问题是,根据定义,面具遮住了脸的一部分。如果足够多的人脸被遮挡,则无法检测到人脸,因此,人脸遮罩检测器将不会被应用。
首先,对象检测器将能够自然地检测戴着面具的人,否则由于太多的面部被遮挡,面部检测器不可能检测到戴着面具的人。
其次,这种方法将我们的计算机视觉管道减少到一个步骤——而不是应用人脸检测和然后我们的人脸面具检测器模型,我们需要做的只是应用对象检测器,在网络的单次前向传递中为我们提供人物with_mask和without_mask的边界框。
这种方法不仅计算效率更高,而且更加“优雅”和端到端。
摘要
在本教程中,您学习了如何使用 OpenCV、Keras/TensorFlow 和深度学习来创建新冠肺炎面具检测器。
为了创建我们的面具检测器,我们训练了一个两类模型,一类是戴面具的人和不戴面具的人。
我们在我们的屏蔽/无屏蔽数据集上微调了 MobileNetV2,并获得了一个准确率为 ~99%的分类器。
然后,我们将这个人脸面具分类器应用到图像和实时视频流中,方法是:
- 检测图像/视频中的人脸
- 提取每一张人脸
- 应用我们的面罩分类器
我们的面具检测器是准确的,而且由于我们使用了 MobileNetV2 架构,它也是计算高效的,使得它更容易部署到嵌入式系统(树莓派、谷歌珊瑚、英伟达等)。).
我希望你喜欢这个教程!
更新:【2022 年 12 月,更新链接和文字。
要下载这篇文章的源代码(包括预先训练的新冠肺炎面罩检测器模型),只需在下面的表格中输入您的电子邮件地址!
用 Python 和 OpenCV 创建人脸检测 API(只需 5 分钟)
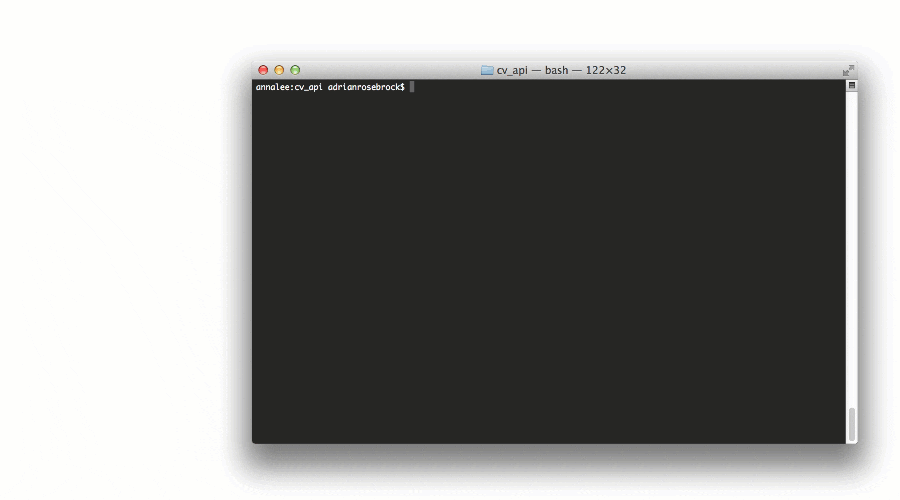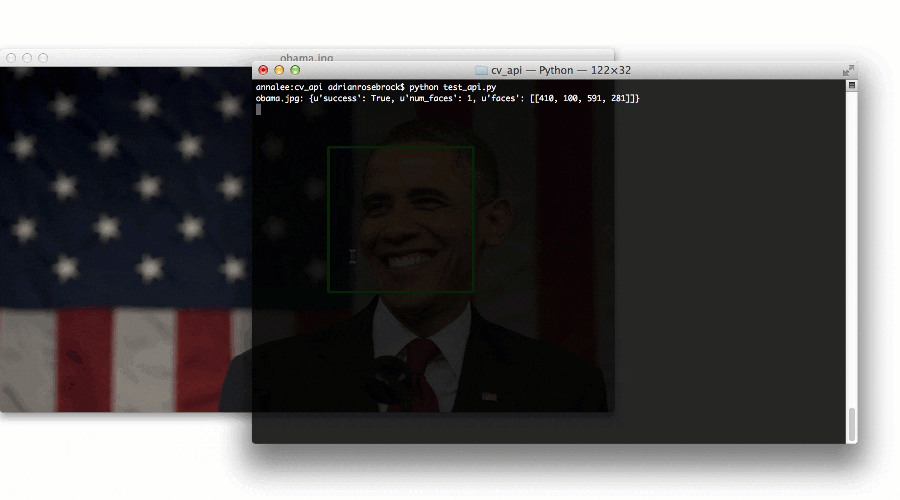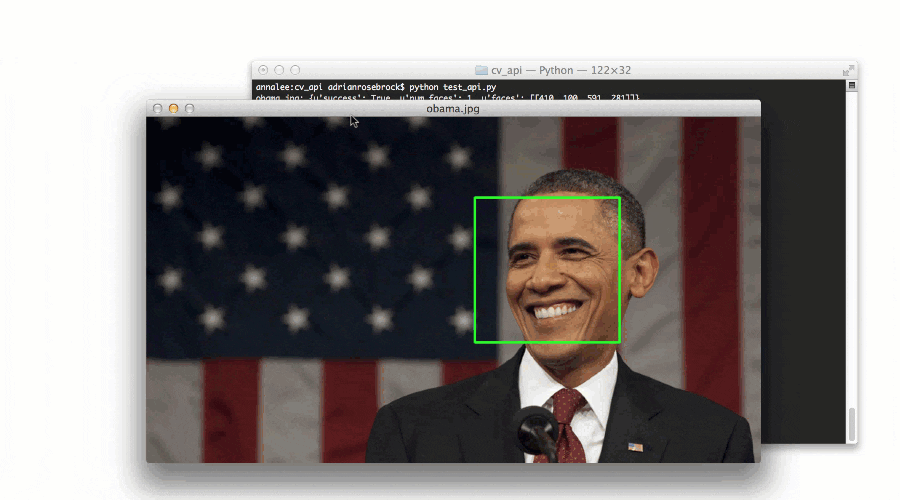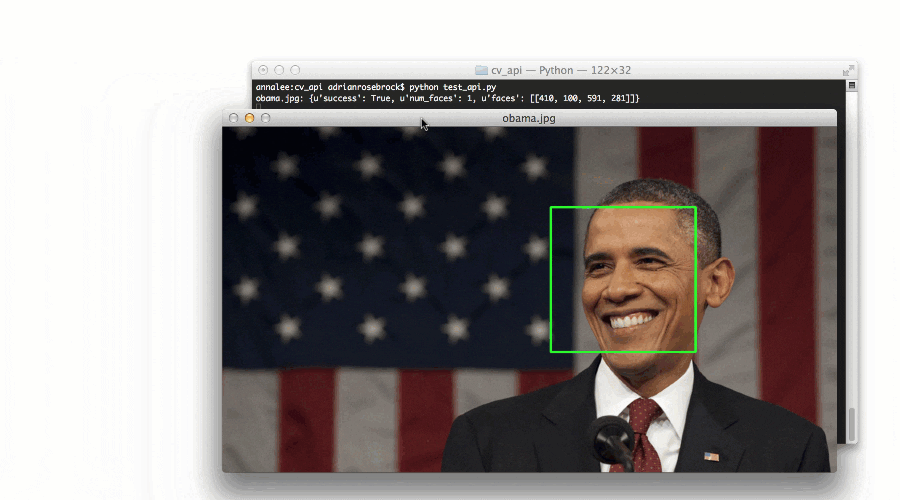
所以你刚刚建立了你的第一个了不起的计算机视觉应用程序。
也许它可以检测图像中的人脸。或者你的应用程序可以识别照片中的处方药。或者,也许你的计算机视觉应用程序可以识别畅销书的封面,同时显示最新的读者评论和最便宜的在线购买网站。
所以大问题是… 你如何把你的计算机视觉 app 包装成一个易于使用的 web API?
随着越来越多的服务走向云,您的用户、客户和开发伙伴可能希望有一个易于使用的 web API(可能是 JSON 格式)。
创建一个计算机视觉 web API 实际上没有你想象的那么难——我甚至可以说,使用一个 Python web 框架,如 Django 或 Flask ,将你的应用程序包装在一个可消费的 API 中,是一件令人难以置信的简单事情。
就我个人而言,我是姜戈的超级粉丝。过去我和姜戈一起做了大量的工作,我喜欢其中的每一分钟。虽然对于这样一个小的示例项目来说有点大材小用(尤其是与 Flask 这样的微框架相比),但我仍然认为这是一个极好的选择。当然,您可以随意将这个实现移植到最适合您个人需求和偏好的框架中。
无论如何,在本教程的其余部分,我将演示如何创建自己的人脸检测 API 在 只有 5 分钟!
作为本文最后的奖励,我将让您先睹为快下周即将发布的内容——免费的 PyImageSearch web API。
设置你的定时器——准备好。设置。走!
OpenCV 和 Python 版本:
为了运行这个例子,你需要 Python 2.7 和 OpenCV 2.4.X 。
用 Python 和 OpenCV 创建人脸检测 API(只需 5 分钟)
在关于在你的 Raspberry Pi 2/B+ 上安装 OpenCV 的一步一步的教程上获得了大量令人敬畏的读者反馈后,我决定对本教程采取同样的方法——我已经创建了 8 个简单的、一口大小的步骤来建立和运行你自己的人脸检测 API。
这里的目标是,如果您要运行下面每个步骤中出现的命令,并将代码片段复制并粘贴到适当的 Django 项目文件中,那么您的人脸检测 API 将在 5 分钟内在您的本地系统上启动并运行。
然而,我将从假设您已经安装了 OpenCV 开始。如果没有,那么您需要在继续之前安装它(这将打破这篇文章的 5 分钟目标)。
免责声明:在读完博士之前,我曾经做过很多 web 应用开发的。但是在过去的三年里,我的注意力完全集中在计算机视觉、科学和研究方面。如果我的 Django 代码不完美,我会第一个道歉。然而,也要意识到本教程的目的并不是使用所有最新的 Django 花里胡哨的东西来构建一个“防弹”API。相反,它旨在简单明了地演示如何轻松地将计算机视觉应用程序(特别是人脸检测器)转化为 web API。
步骤 1:设置您的环境
第一步是安装并运行我们的开发环境。我们只需要三个必需的包:
$ pip install numpy django requests
我们需要 NumPy ,因为 OpenCV 将图像表示为多维 NumPy 数组。从技术上讲,如果你已经安装了 OpenCV,NumPy 应该已经安装了。
django包显然包含了 Django web 框架。
我们还将包括使用请求包来使与我们的 web API 的接口更加容易。
步骤 2:创建我们的 Django 项目
既然安装了先决条件,让我们设置 Django 项目:
$ django-admin startproject cv_api
$ cd cv_api
这些命令创建了一个新的 Django 项目,命名为cv_api。
cv_api目录现在包含了运行 Django 项目所需的所有代码和配置——这些代码是自动生成的,包括基本的数据库配置、基于项目的选项和应用程序设置。它还包括运行内置 web 服务器进行测试的能力(我们将在本教程的后面讨论)。
下面是我们新项目的目录结构:
|--- cv_api
| |--- cv_api
| |--- __init__.py
| |--- settings.py
| |--- urls.py
| |--- wsgi.py
| |--- manage.py
在我们继续之前,让我们简单地讨论一下 Django 项目的结构。
Django 项目由多个应用组成。Django 框架的核心范例之一是,每个应用在任何项目中都应该是可重用的(理论上是这样的)——因此,我们(通常)不会将任何特定于应用的代码放在cv_api目录中。相反,我们在cv_api项目中显式地创建单独的“应用程序”。
记住这一点,让我们创建一个名为face_detector的新应用程序,它将包含我们构建人脸检测 API 的代码:
$ python manage.py startapp face_detector
注意我们现在在cv_api目录中有一个face_detector目录。同样,Django 已经为我们的face_detector应用程序自动生成了一些样板代码和配置,我们可以看到下面的内容:
|--- cv_api
| |--- cv_api
| |--- __init__.py
| |--- settings.py
| |--- urls.py
| |--- wsgi.py
| |--- face_detector
| |--- __init__.py
| |--- admin.py
| |--- migrations
| |--- models.py
| |--- tests.py
| |--- views.py
| |--- manage.py
现在我们的 Django 项目已经设置好了,我们可以开始编码了。
步骤 3:我的个人计算机视觉 API 模板
这一步是我们的计算机视觉项目实际“包装”的地方,也是我们将要插入面部检测代码的地方。
Django 框架是一种模型-视图-模板 (MVT)框架,类似于模型-视图-控制器,其中“视图”可以被认为是一种网页。在视图中,您放置了与模型交互的所有必要代码,比如从数据库中提取数据,并对其进行处理。视图还负责在将模板发送给用户之前填充模板。
在我们的例子中,我们需要的只是框架的视图部分。我们不会与数据库进行交互,因此模型与我们无关。我们将把 API 的结果作为 JSON 对象发送给最终用户,因此我们不需要模板来呈现任何 HTML。
同样,我们的 API 只是接受来自 URL/流的图像,对其进行处理,并返回一个 JSON 响应。
步骤 3a:构建 Python + OpenCV API 时我的个人样板模板
在我们深入代码执行实际的人脸检测之前,我想与您分享我在构建 Python + OpenCV 时的个人样板模板。当您构建自己的计算机视觉 API 时,可以使用此代码作为起点。
# import the necessary packages
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
import numpy as np
import urllib
import json
import cv2
@csrf_exempt
def detect(request):
# initialize the data dictionary to be returned by the request
data = {"success": False}
# check to see if this is a post request
if request.method == "POST":
# check to see if an image was uploaded
if request.FILES.get("image", None) is not None:
# grab the uploaded image
image = _grab_image(stream=request.FILES["image"])
# otherwise, assume that a URL was passed in
else:
# grab the URL from the request
url = request.POST.get("url", None)
# if the URL is None, then return an error
if url is None:
data["error"] = "No URL provided."
return JsonResponse(data)
# load the image and convert
image = _grab_image(url=url)
### START WRAPPING OF COMPUTER VISION APP
# Insert code here to process the image and update
# the `data` dictionary with your results
### END WRAPPING OF COMPUTER VISION APP
# update the data dictionary
data["success"] = True
# return a JSON response
return JsonResponse(data)
def _grab_image(path=None, stream=None, url=None):
# if the path is not None, then load the image from disk
if path is not None:
image = cv2.imread(path)
# otherwise, the image does not reside on disk
else:
# if the URL is not None, then download the image
if url is not None:
resp = urllib.urlopen(url)
data = resp.read()
# if the stream is not None, then the image has been uploaded
elif stream is not None:
data = stream.read()
# convert the image to a NumPy array and then read it into
# OpenCV format
image = np.asarray(bytearray(data), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
# return the image
return image
这个样板 API 代码定义了两个函数:detect,这是我们的实际视图,和_grab_image,这是一个很好的小函数,用于将图像从磁盘、URL 或流中读入 OpenCV 格式。从代码组织和可重用性的角度来看,您可能希望将_grab_image函数放在一个“utilities”模块中,该模块在整个 Django 项目中是全局可访问的。但是为了完整起见,我在views.py文件中包含了_grab_image函数——至于您想在哪里存储这个函数,我将由个人决定。
我们的大部分时间应该花在检查detect方法上。实际上,您可以随意调用这个方法,但是您可能希望这个名称与函数要实现的目标相关。在人脸检测的背景下,在face_detection Django 应用中将主 API 端点命名为detect似乎是合适的。
detect方法接受一个参数,一个request,它是一个 Django 对象,包含与 web 请求密切相关的属性。
在实际视图中,我喜欢定义一个data字典。这个字典表示所有将被 JSON 化并返回给用户的数据。最起码,这本字典应该包括一个成功/失败标志。
从那里,我们需要处理实际的request,并确定图像是如何发送到我们的 API 的。
如果我们的图像是通过多部分表单数据上传的,我们可以简单地直接处理数据流并将其读入 OpenCV 格式(第 17-19 行)。
否则,我们将假设不是上传原始图像,而是将指向图像的 URL 传递到我们的 API 中。在这种情况下,我们将从 URL 读取图像并转换成 OpenCV 格式(第 22-32 行)。
第 34-37 行是你实际“包装”你的计算机视觉应用的地方。在这里,您可以插入任何与处理、操作、分类等相关的代码。你的形象。您还需要用任何与图像处理结果相关的信息来更新您的data字典。
最后,在所有的图像处理完成后,我们在第 43 行的上向用户发送一个data的 JSON 响应。
步骤 4:将人脸检测器插入我的模板 API
既然我们已经检查了 Python + OpenCV web API 的样板代码,让我们把它插入人脸检测器。打开cv_api/face_detector/views.py文件并插入以下代码:
# import the necessary packages
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
import numpy as np
import urllib
import json
import cv2
import os
# define the path to the face detector
FACE_DETECTOR_PATH = "{base_path}/cascades/haarcascade_frontalface_default.xml".format(
base_path=os.path.abspath(os.path.dirname(__file__)))
@csrf_exempt
def detect(request):
# initialize the data dictionary to be returned by the request
data = {"success": False}
# check to see if this is a post request
if request.method == "POST":
# check to see if an image was uploaded
if request.FILES.get("image", None) is not None:
# grab the uploaded image
image = _grab_image(stream=request.FILES["image"])
# otherwise, assume that a URL was passed in
else:
# grab the URL from the request
url = request.POST.get("url", None)
# if the URL is None, then return an error
if url is None:
data["error"] = "No URL provided."
return JsonResponse(data)
# load the image and convert
image = _grab_image(url=url)
# convert the image to grayscale, load the face cascade detector,
# and detect faces in the image
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
detector = cv2.CascadeClassifier(FACE_DETECTOR_PATH)
rects = detector.detectMultiScale(image, scaleFactor=1.1, minNeighbors=5,
minSize=(30, 30), flags=cv2.cv.CV_HAAR_SCALE_IMAGE)
# construct a list of bounding boxes from the detection
rects = [(int(x), int(y), int(x + w), int(y + h)) for (x, y, w, h) in rects]
# update the data dictionary with the faces detected
data.update({"num_faces": len(rects), "faces": rects, "success": True})
# return a JSON response
return JsonResponse(data)
def _grab_image(path=None, stream=None, url=None):
# if the path is not None, then load the image from disk
if path is not None:
image = cv2.imread(path)
# otherwise, the image does not reside on disk
else:
# if the URL is not None, then download the image
if url is not None:
resp = urllib.urlopen(url)
data = resp.read()
# if the stream is not None, then the image has been uploaded
elif stream is not None:
data = stream.read()
# convert the image to a NumPy array and then read it into
# OpenCV format
image = np.asarray(bytearray(data), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
# return the image
return image
如您所见,除了标准的样板 OpenCV API 模板,我们没有插入太多代码。
您会注意到的第一件事是,我正在定义FACE_DETECTOR_PATH ( 第 11 行和第 12 行),它只是预训练的 OpenCV 人脸检测器所在的路径——在本例中,我已经将预训练的人脸检测器包含在了face_detector/cascades应用程序中。
真正的人脸检测魔术发生在第 41-44 行的处。
现在我们已经有了 OpenCV 格式的图像(无论它是通过多部分表单编码数据还是通过 URL 上传的),我们开始将输入图像转换为灰度。我们丢弃任何颜色信息,因为颜色对人脸检测准确性增加很少。
从那里,我们在线 42 上加载我们的面部detector,为我们预先训练的面部检测器提供路径。既然我们的人脸检测器已经加载,我们可以应用detectMultiScale方法来检测实际的人脸。
我不打算对detectMultiScale的参数进行详尽的回顾,因为我在我的书《实用 Python 和 OpenCV +案例研究、中对它们进行了深入的讨论,但是这里重要的一点是,这些参数影响速度、效率和图像中人脸的误报检测率。
detectMultiScale函数返回边界框列表,或者简单地返回图像中人脸的 (x,y) 坐标、宽度和高度。给定这个边界框列表,我们将它们打包到我们的data字典中,并在的第 47-53 行将它们发送给用户。
不算太坏,对吧?
如您所见,大部分代码仍然与计算机视觉 API 样板相关——人脸的实际检测只需要几行代码。
步骤 5:更新 URL 以包含 API 的端点
但是在我们可以访问我们的人脸检测 API 之前,我们首先需要更新项目 URL 以包含我们的人脸检测端点。
只需打开cv_api/cv_api/urls.py文件,并将其更新为包含一个指向我们的人脸检测视图的 URL 端点:
from django.conf.urls import patterns, include, url
from django.contrib import admin
urlpatterns = patterns('',
# Examples:
url(r'^face_detection/detect/$', 'face_detector.views.detect'),
# url(r'^$', 'cv_api.views.home', name='home'),
# url(r'^blog/', include('blog.urls')),
url(r'^admin/', include(admin.site.urls)),
)
步骤 6:运行 Django 测试服务器
好了,现在我们准备好测试我们的面部检测 API 了!
只需使用您的终端导航回cv_api项目根目录并启动测试服务器:
$ python manage.py runserver
我们的网络服务器现在在http://localhost:8000可用
如果你打开你的网络浏览器并指向http://localhost:8000/face_detection/detect/,你应该会看到来自我们的人脸检测 API 的 JSON 响应:
Figure 1: Navigating our browser to the face detection API endpoint.
显然,由于我们没有上传图像到我们的 API,我们得到了一个 JSON 响应{success: false},这意味着在(不存在的)图像中检测不到人脸。
步骤 7:通过 cURL 测试人脸检测 API
在我们做任何疯狂的事情之前,让我们用 cURL 测试一下我们的人脸检测。我们首先将巴拉克·奥巴马的这张图片的 URL(https://pyimagesearch . com/WP-content/uploads/2015/05/Obama . jpg)传递到我们的面部检测 API 中:

Figure 2: Passing the URL of this Barack Obama image into our face detector API.
让我们构造一个命令,通过 cURL 与我们的人脸检测 API 进行交互:
$ curl -X POST 'http://localhost:8000/face_detection/detect/' -d 'url=https://pyimagesearch.com/wp-content/uploads/2015/05/obama.jpg' ; echo ""
{"num_faces": 1, "success": true, "faces": [[410, 100, 591, 281]]}
果然,基于输出,我们能够检测到奥巴马的脸(虽然我们还不能可视化的边界框,我们将在下面的部分)。
让我们试试另一张图片,这次是通过文件上传,而不是通过网址:

Figure 3: A picture of myself outside Horseshoe Bend, AZ. Will the face detector API be able to detect my face in the image?
同样,我们需要构造 cURL 命令,假设上述文件的名称是adrian.jpg:
$ curl -X POST -F image=@adrian.jpg 'http://localhost:8000/face_detection/detect/' ; echo ""
{"num_faces": 1, "success": true, "faces": [[180, 114, 222, 156]]}
根据 JSON 的响应,我们确实要检测图像中的人脸。
步骤 8:编写一些 Python 代码来与人脸检测 API 进行交互
使用 cURL 测试我们的人脸检测 API 非常简单——但是让我们编写一些实际的 Python 代码,这些代码可以上传和与发送到我们 API 的图像进行交互。通过这种方式,我们实际上可以接收 JSON 响应并绘制图像中人脸周围的边界框。
打开一个新文件,将其命名为test_api.py,并包含以下代码:
# import the necessary packages
import requests
import cv2
# define the URL to our face detection API
url = "http://localhost:8000/face_detection/detect/"
# use our face detection API to find faces in images via image URL
image = cv2.imread("obama.jpg")
payload = {"url": "https://pyimagesearch.com/wp-content/uploads/2015/05/obama.jpg"}
r = requests.post(url, data=payload).json()
print "obama.jpg: {}".format(r)
# loop over the faces and draw them on the image
for (startX, startY, endX, endY) in r["faces"]:
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
# show the output image
cv2.imshow("obama.jpg", image)
cv2.waitKey(0)
# load our image and now use the face detection API to find faces in
# images by uploading an image directly
image = cv2.imread("adrian.jpg")
payload = {"image": open("adrian.jpg", "rb")}
r = requests.post(url, files=payload).json()
print "adrian.jpg: {}".format(r)
# loop over the faces and draw them on the image
for (startX, startY, endX, endY) in r["faces"]:
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
# show the output image
cv2.imshow("adrian.jpg", image)
cv2.waitKey(0)
我们将从导入requests包开始,以处理从我们的 API 发送和接收数据。我们还将为 OpenCV 绑定导入cv2。
从那里,行 6-20 处理通过 URL 将图像上传到我们的人脸检测 API。
我们所需要做的就是定义一个包含一个url键的payload字典,对应的值就是上面巴拉克·奥巴马的图片 URL。然后,我们将这个有效负载字典发送到人脸检测端点(第 6-11 行),在这里,我们的 API 用图像中检测到的人脸数量以及人脸的边界框进行响应。最后,我们将边界框画在实际的图像上(第 15-20 行)。
我们还将从磁盘上传一张图像到我们的面部检测 API,在第 24-35 行。就像通过 URL 上传图像一样,从磁盘上传图像也很简单——我们只需要在调用requests.post时指定files参数,而不是data参数。
要查看我们的脚本运行情况,只需执行以下命令:
$ python test_api.py
首先,我们将看到围绕奥巴马的脸绘制的边界框的图像:
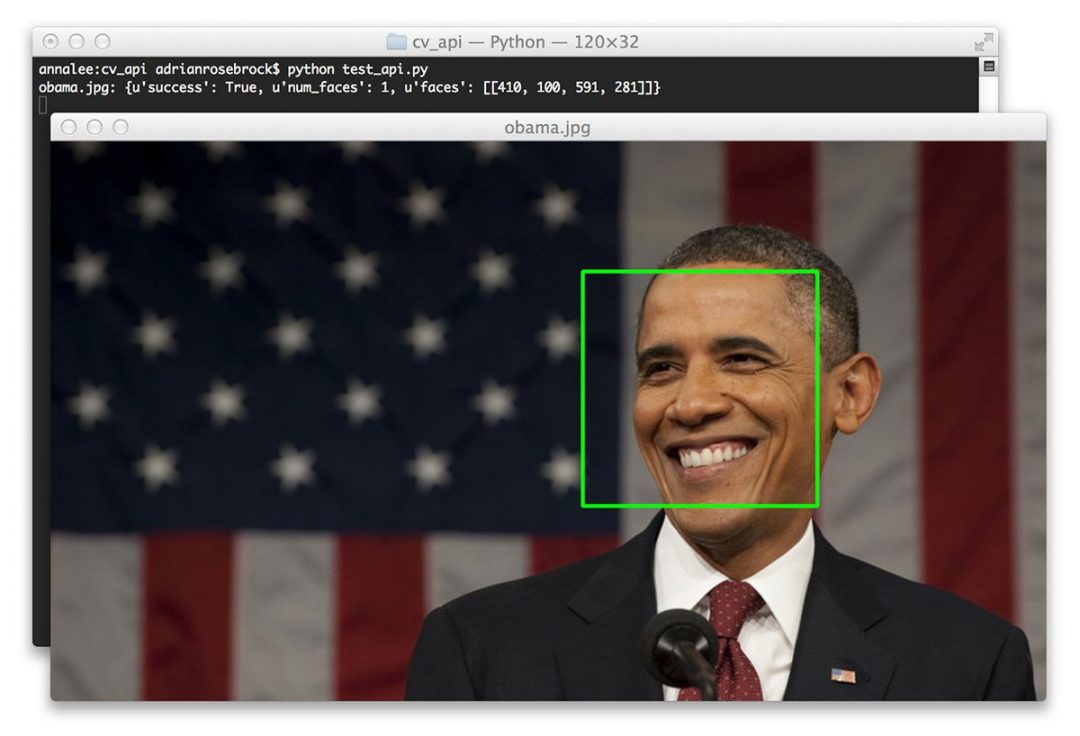
Figure 4: Taking the JSON response from our face detection API and drawing the bounding box around Obama’s face.
接着是成功的检测和包围我的脸的包围盒:

Figure 5: Uploading an image from disk to our face detection API — once again, we are able to detect the face and draw the bounding box surrounding it.
显然,我们的人脸检测 API 正在工作!我们能够通过图像文件上传和图像 URL 来利用它。
我的图像中没有检测到人脸。怎么回事?
如果你下载了这篇文章的代码,并用你自己的图像试了一下,你可能会遇到在你的图像中检测不到人脸的情况——即使人脸清晰可见。
那么是什么原因呢?
虽然哈尔级联相当快,并且可以获得相当好的精度,但是它们有两个突出的缺点。
第一个是参数调整——你需要调整detectMultiScale的参数来获得对许多图像的检测恰到好处的。这可能是一种真正的痛苦,尤其是如果您希望批量处理许多图像,并且无法直观地检查每个人脸检测的输出。
哈尔级联的第二个缺点是,它们非常容易出现假阳性,这意味着当实际上没有任何人脸时,却检测到了人脸!同样,这个问题可以通过根据具体情况调整detectMultiScale的参数来解决。
事实上,哈尔·卡斯卡德和维奥拉·琼斯探测器虽然有效,但已经在计算机视觉史上走完了它们的旅程。对于高度精确的对象检测器,我们现在依赖于 HOG +线性支持向量机和基于深度学习的方法,特别是卷积神经网络。
尽管如此,很难击败哈尔瀑布的纯速度,即使它们的准确性和假阳性率有点低于标准,至少与今天的最先进的技术相比。
额外收获:人脸检测 API 的一个实例
想试试人脸检测 API 吗?没问题。
我已经有一个面部检测 API 实例开始运行。您可以在此处找到人脸检测 API 端点:
http://api.pyimagesearch.com/face_detection/detect/
这是另一个在图像中检测人脸的例子。只是这次我们使用的是实时 API 端点:
$ curl -X POST 'http://api.pyimagesearch.com/face_detection/detect/' -d 'url=https://pyimagesearch.com/wp-content/uploads/2015/05/obama.jpg' ; echo ""
{"num_faces": 1, "success": true, "faces": [[410, 100, 591, 281]]}
所以给定网址http://api.pyimagesearch.com,我打赌你能猜到下周的公告是什么…但是我会把剩下的留到下周一。
摘要
在这篇博文中,我们学习了如何将我们的计算机视觉应用程序包装成一个易于使用和消费的 JSON web API。我们利用 Django web 框架来构建我们的 API,但是我们可以使用任何其他 Python web 框架,比如 Flask——这实际上取决于您的个人偏好以及您希望您的 API 有多简单或高级。
我还分享了我的个人样板 API 代码,你可以用它来包装你自己的计算机视觉应用程序,并使它们适合网络。
最后,我先睹为快下周的大发布——(免费)PyImageSearch API。
那么,下一步是什么?

如果你喜欢这篇博文,并且想了解更多关于计算机视觉和 OpenCV 的知识,我肯定会推荐你看一下我的书,《实用 Python 和 OpenCV +案例研究 》。
在我的书中,你将继续学习所有关于图像和视频中的人脸检测(包括我在这篇文章前面提到的detectMultiScale参数的解释);跟踪视频中的物体;识别手写数字,甚至如何在智能手机的快照中识别图书封面。
如果你对这些话题感兴趣, 一定要看看 并考虑抓取一个免费的样本章节。
用 OpenCV 创建 gif
原文:https://pyimagesearch.com/2018/11/05/creating-gifs-with-opencv/
在本教程中,您将学习如何使用 OpenCV、Python 和 ImageMagick 创建动画 gif。
然后,您将结合所有这些技术,用 OpenCV 构建一个热图生成器!
我们都需要不时开怀大笑。也许从迷因中找到 LOLs 是最好的方法。
我最喜欢的一些空前的迷因包括:
- 科米蛙的“但那不关我的事”
- 暴躁猫
- 严重失败
- 好人格雷格
但对我个人来说,这些模因都比不上“处理它”模因(本文顶部有一个例子),通常:
- 用来回应或反驳某人不同意你做的/说的事情
- 比如在你离开的时候戴上太阳镜,让他们自己“处理”
几年前,我看到一篇轻松的博文,作者是一个我现在不记得的人,他讲述了如何用计算机视觉生成这些迷因。上周,我在任何地方都找不到这个教程,所以,作为一个博客作者、计算机视觉专家和迷因鉴赏家,我决定创建自己的教程!(顺便说一句,如果你碰巧知道这个想法的原始来源,请告诉我,以便我可以信任作者更新:我刚刚发现我想到的原始文章来自柯克·凯撒的博客, MakeArtWithPython )。
使用 OpenCV 与 It 热图生成器建立交易可以教会我们许多在实践中使用的有价值的技术,包括:
- 如何进行基于深度学习的人脸检测
- 如何使用 dlib 库应用面部标志检测并提取眼睛区域
- 如何取这两个区域并计算两眼之间的旋转角度
- 最后,如何用 OpenCV 生成动画 gif(在 ImageMagick 的帮助下)
今天的教程旨在变得有趣、愉快和有娱乐性——同时教会你在现实世界中使用的有价值的计算机视觉技能。
要学习如何用 OpenCV 生成 gif 和 memes,继续阅读!
用 OpenCV 创建 gif
在今天的博文中,我们将使用 OpenCV、dlib 和 ImageMagick 工具箱创建动画 gif。
在教程的第一部分,我们将讨论这个项目的先决条件和依赖项,包括如何正确配置您的开发环境。
从这里我们将回顾 OpenCV GIF 创建器的项目/目录结构。
一旦我们理解了项目结构,我们将回顾(1)我们的配置文件,和(2)我们负责用 OpenCV 创建 gif 的 Python 脚本。
最后,我们将通过为流行的“处理它”模因构建一个热图生成器来看看我们的 OpenCV GIF 创建器的结果。
先决条件和依赖项

Figure 1: To create GIFs with OpenCV we’ll be taking advantage of OpenCV, dlib, and ImageMagick.
OpenCV 和 dlib
OpenCV 将用于人脸检测和基本的图像处理。如果您的系统上没有安装 OpenCV,请务必遵循我的 OpenCV 安装指南。
Dlib 将用于检测面部标志,使我们能够找到一张脸的两只眼睛,并降低它们上面的太阳镜。你可以用这个指南来安装 dlib。
图像魔术
如果你不熟悉 ImageMagick ,你应该熟悉。ImageMagick 是一个基于跨平台命令行的工具,提供了相当多的图像处理功能。
想用一个命令把 PNG/JPG 文件转换成 PDF 文件吗?没问题。
有多张图像想转换成 PDF 幻灯片?那很简单。
你需要画多边形、线条和其他形状吗?去吧。
如何在一个命令中批量调整颜色或调整整个图像数据集的空间尺寸?为此编写多行 Python 代码来使用 OpenCV 是没有意义的。
使用 ImageMagick,我们也可以通过一组输入图像生成 GIF 图像。
要在 Ubuntu(或 Raspbian)上安装 ImageMagick,只需使用 apt:
$ sudo apt-get install imagemagick
或者,如果你在 macOS 上,你可以使用自制软件:
$ brew install imagemagick
imutils
我的许多博客文章和书籍/课程内容都利用了我的图像处理便利功能包 imutils 。您可以使用 pip 在您的系统或虚拟环境中安装 imutils:
$ pip install imutils
项目结构
Figure 2: Our OpenCV GIF generator project structure consists of two directories, a config file, and a single Python script.
我们的项目有两个目录:
images/:我们的例子输入我们希望为其创建动画“处理它”GIF 的图像。我提供了一些我的照片,但你可以随意添加自己的照片。assets/:该文件夹包含我们的人脸检测器、面部标志检测器和所有图像+关联的遮罩。我们将用这些资产在输入图像上叠加“太阳镜”和“处理它”文本。
由于可配置参数的数量,我决定创建一个 JSON 配置文件(1)使编辑参数更容易,以及(2)需要更少的命令行参数。这个项目需要的所有配置参数都包含在config.json中。
今天我们将复习config.json和create_gif.py。
在今天教程的 【下载】 部分,你可以破解整个项目!
用 OpenCV 生成 gif
让我们开始实现我们的 OpenCV GIF 生成器吧!
理解我们的 JSON 配置文件
我们将首先从 JSON 配置文件开始,然后进入 Python 脚本。
继续打开一个名为config.json的新文件,然后插入以下键/值对:
{
"face_detector_prototxt": "assets/deploy.prototxt",
"face_detector_weights": "assets/res10_300x300_ssd_iter_140000.caffemodel",
"landmark_predictor": "assets/shape_predictor_68_face_landmarks.dat",
第 2 行和第 3 行是 OpenCV 的深度学习人脸检测器模型文件。
第 4 行是到 dlib 的面部标志预测器的路径。
现在我们有了一些图像文件路径:
"sunglasses": "assets/sunglasses.png",
"sunglasses_mask": "assets/sunglasses_mask.png",
"deal_with_it": "assets/deal_with_it.png",
"deal_with_it_mask": "assets/deal_with_it_mask.png",
第 5-8 行分别是我们与 It 打交道的途径太阳镜、文字和两者相关的面具——如下图所示。
首先是我们精美的太阳镜和面具:

Figure 3: Do you dislike pixelated sunglasses? Deal with it.

Figure 4: Are you wondering WTH this sunglasses mask is for? Deal with it — or just read the rest of the blog post for the answer.
而现在我们的【对付它】文字和蒙版:

Figure 5: Do you loathe Helvetica Neue Condensed? Deal with it.

Figure 6: This mask will allow for a border. Oh, I’m guessing you don’t want a border around your text. Deal with it.
我们需要蒙版来覆盖照片上相应的图像,这个过程我会在今天的教程中向你展示。
现在让我们为热图生成器设置一些参数:
"min_confidence": 0.5,
"steps": 20,
"delay": 5,
"final_delay": 250,
"loop": 0,
"temp_dir": "temp"
}
以下是每个参数的定义:
min_confidence:正面人脸检测所需的最小概率。steps:我们将为输出 GIF 生成的帧数。每“一步”都会将太阳镜从镜架顶部向目标(即眼睛)移动更远。delay:每帧之间百分之一秒的延迟数。final_delay:最后一帧的百分之一秒延迟(在这种情况下很有用,因为我们希望“处理它”文本比其余帧更长时间可见)。loop:GIF 是否循环(零值表示 GIF 将永远循环,否则提供一个正整数表示 GIF 允许循环的次数)。temp_dir:临时输出目录,在构建最终的 GIF 图像之前,每个帧都将存储在这个目录中。
迷因、gif 和 OpenCV
现在我们已经创建了 JSON 配置文件,让我们进入实际的代码。
打开一个新文件,将其命名为create_gif.py,并插入以下代码:
# import the necessary packages
from imutils import face_utils
from imutils import paths
import numpy as np
import argparse
import imutils
import shutil
import json
import dlib
import cv2
import sys
import os
在第 2-12 行,我们导入必要的包。值得注意的是,我们将使用 imutils、dlib 和 OpenCV。要安装这些依赖项,请参见上面的“先决条件和依赖项”部分。
现在我们的脚本已经有了我们需要的包,让我们定义overlay_image函数:
def overlay_image(bg, fg, fgMask, coords):
# grab the foreground spatial dimensions (width and height),
# then unpack the coordinates tuple (i.e., where in the image
# the foreground will be placed)
(sH, sW) = fg.shape[:2]
(x, y) = coords
# the overlay should be the same width and height as the input
# image and be totally blank *except* for the foreground which
# we add to the overlay via array slicing
overlay = np.zeros(bg.shape, dtype="uint8")
overlay[y:y + sH, x:x + sW] = fg
# the alpha channel, which controls *where* and *how much*
# transparency a given region has, should also be the same
# width and height as our input image, but will contain only
# our foreground mask
alpha = np.zeros(bg.shape[:2], dtype="uint8")
alpha[y:y + sH, x:x + sW] = fgMask
alpha = np.dstack([alpha] * 3)
# perform alpha blending to merge the foreground, background,
# and alpha channel together
output = alpha_blend(overlay, bg, alpha)
# return the output image
return output
overlay_image功能在位置coords(即 (x,y)-坐标)将前景图像(fg)叠加在背景图像(bg)之上,允许通过前景蒙版fgMask实现 alpha 透明。
为了复习 OpenCV 的基础知识,比如使用遮罩,请务必阅读一下本教程。
为了完成叠加过程,我们需要应用阿尔法混合:
def alpha_blend(fg, bg, alpha):
# convert the foreground, background, and alpha layers from
# unsigned 8-bit integers to floats, making sure to scale the
# alpha layer to the range [0, 1]
fg = fg.astype("float")
bg = bg.astype("float")
alpha = alpha.astype("float") / 255
# perform alpha blending
fg = cv2.multiply(alpha, fg)
bg = cv2.multiply(1 - alpha, bg)
# add the foreground and background to obtain the final output
# image
output = cv2.add(fg, bg)
# return the output image
return output.astype("uint8")
alpha 混合的实现在 LearnOpenCV 博客中也有介绍。
本质上,我们将在【0,1】(第 46-48 行)的范围内将前景、背景和 alpha 层转换为浮动。然后我们将执行实际的阿尔法混合(第 51 行和第 52 行)。最后,我们将添加前景和背景,以获得我们的输出,然后返回到调用函数(第 56-59 行)。
让我们也创建一个助手函数,它将使我们能够使用 ImageMagick 和convert命令从一组图像路径生成 GIF:
def create_gif(inputPath, outputPath, delay, finalDelay, loop):
# grab all image paths in the input directory
imagePaths = sorted(list(paths.list_images(inputPath)))
# remove the last image path in the list
lastPath = imagePaths[-1]
imagePaths = imagePaths[:-1]
# construct the image magick 'convert' command that will be used
# generate our output GIF, giving a larger delay to the final
# frame (if so desired)
cmd = "convert -delay {} {} -delay {} {} -loop {} {}".format(
delay, " ".join(imagePaths), finalDelay, lastPath, loop,
outputPath)
os.system(cmd)
create_gif函数获取一组图像,并在必要时利用帧和循环之间的指定延迟将它们组合成 GIF 动画。所有这些都由 ImageMagick 处理——我们只是用一个动态处理不同参数的函数来包装命令行convert命令。
要查看convert命令的可用命令行参数,请参考文档。从文档中可以看出,convert内置了很多功能!
具体来说,在此功能中,我们:
- 抢
imagePaths( 第 63 行)。 - 抓取最后一个图像路径,因为它将有单独的延迟(行 66 )。
- 重新分配
imagePaths以排除最后一个图像路径(第 67 行)。 - 用命令行参数组装命令字符串,然后指示操作系统执行
convert来创建 GIF ( 第 72-75 行)。
让我们构造我们自己的脚本的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--config", required=True,
help="path to configuration file")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-o", "--output", required=True,
help="path to output GIF")
args = vars(ap.parse_args())
我们有三个在运行时处理的命令行参数:
--config:我们的 JSON 配置文件的路径。我们在上一节中回顾了配置文件。--image:我们输入图像的路径。我们将用这个图像创建我们的动画(即找到脸+添加太阳镜,然后添加“处理它”文本)。--output:我们输出 GIF 的目标路径。
当您在命令行/终端中执行脚本时,这些参数都是必需的。
让我们加载配置文件以及我们的太阳镜+相关面具:
# load the JSON configuration file and the "Deal With It" sunglasses
# and associated mask
config = json.loads(open(args["config"]).read())
sg = cv2.imread(config["sunglasses"])
sgMask = cv2.imread(config["sunglasses_mask"])
# delete any existing temporary directory (if it exists) and then
# create a new, empty directory where we'll store each individual
# frame in the GIF
shutil.rmtree(config["temp_dir"], ignore_errors=True)
os.makedirs(config["temp_dir"])
在这里,我们在第 89 行的上加载配置文件(从这里开始可以像 Python 字典一样访问它)。然后,我们加载太阳镜图像和太阳镜面具(行 90 和 91** )。**
如果有先前运行脚本的任何残余,我们从磁盘中删除临时目录,然后重新创建一个空的临时目录(行 96 和 97 )。临时文件夹将保存 GIF 中的每个单独的帧。
现在让我们将 OpenCV 的深度学习人脸检测器加载到内存中:
# load our OpenCV face detector and dlib facial landmark predictor
print("[INFO] loading models...")
detector = cv2.dnn.readNetFromCaffe(config["face_detector_prototxt"],
config["face_detector_weights"])
predictor = dlib.shape_predictor(config["landmark_predictor"])
为了加载 OpenCV 的深度学习人脸检测器,我们调用cv2.dnn.readNetFromCaffe ( 第 101 行和第 102 行)。dnn模块只能在 OpenCV 3.3 或更高版本中访问。人脸检测器将使我们能够检测图像中是否存在人脸:

Figure 7: The OpenCV DNN face detector finds faces in images.
然后,在第 103 行,我们加载 dlib 的面部标志预测器。另一方面,面部标志预测器将使我们能够定位面部的结构,例如眼睛、眉毛、鼻子、嘴和下颌线:

Figure 8: Shown on my face are overlays of the facial landmarks detected by dlib.
在这个脚本的后面,我们将只提取眼睛区域。
继续,让我们来看看这张脸:
# load the input image and construct an input blob from the image
image = cv2.imread(args["image"])
(H, W) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
# pass the blob through the network and obtain the detections
print("[INFO] computing object detections...")
detector.setInput(blob)
detections = detector.forward()
# we'll assume there is only one face we'll be applying the "Deal
# With It" sunglasses to so let's find the detection with the largest
# probability
i = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence < config["min_confidence"]:
print("[INFO] no reliable faces found")
sys.exit(0)
在这一部分中,我们:
- 负载输入
image( 线 106 )。 - 构建一个
blob发送通过人脸检测器的神经网络(行 108 和 109 )。你可以在这篇博文中了解 OpenCV 的blobFromImage是如何工作的。 - 执行面部检测(行 113 和 114 )。
- 确定具有最大概率的面部检测,并对照置信度阈值进行检查(第 119-124 行)。如果不满足标准,我们简单地退出脚本(第 125 行)。否则,我们将继续下去。
让我们提取面部并计算面部标志:
# compute the (x, y)-coordinates of the bounding box for the face
box = detections[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
# construct a dlib rectangle object from our bounding box coordinates
# and then determine the facial landmarks for the face region
rect = dlib.rectangle(int(startX), int(startY), int(endX), int(endY))
shape = predictor(image, rect)
shape = face_utils.shape_to_np(shape)
# grab the indexes of the facial landmarks for the left and right
# eye, respectively, then extract (x, y)-coordinates for each eye
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
leftEyePts = shape[lStart:lEnd]
rightEyePts = shape[rStart:rEnd]
为了提取面部并找到面部标志,我们:
- 提取脸部的边界框坐标(行 128 和 129 )。
- 构造一个 dlib
rectangle对象(行 133 )和应用面部标志定位 ( 行 134 和 135 )。 - 分别为
leftEyePts和rightEyePts(行 139-142 )提取【T2(x,y)】-坐标。
给定眼睛的坐标,我们可以计算出需要放置太阳镜的位置和位置😗*
# compute the center of mass for each eye
leftEyeCenter = leftEyePts.mean(axis=0).astype("int")
rightEyeCenter = rightEyePts.mean(axis=0).astype("int")
# compute the angle between the eye centroids
dY = rightEyeCenter[1] - leftEyeCenter[1]
dX = rightEyeCenter[0] - leftEyeCenter[0]
angle = np.degrees(np.arctan2(dY, dX)) - 180
# rotate the sunglasses image by our computed angle, ensuring the
# sunglasses will align with how the head is tilted
sg = imutils.rotate_bound(sg, angle)
# the sunglasses shouldn't be the *entire* width of the face and
# ideally should just cover the eyes -- here we'll do a quick
# approximation and use 90% of the face width for the sunglasses
# width
sgW = int((endX - startX) * 0.9)
sg = imutils.resize(sg, width=sgW)
# our sunglasses contain transparency (the bottom parts, underneath
# the lenses and nose) so in order to achieve that transparency in
# the output image we need a mask which we'll use in conjunction with
# alpha blending to obtain the desired result -- here we're binarizing
# our mask and performing the same image processing operations as
# above
sgMask = cv2.cvtColor(sgMask, cv2.COLOR_BGR2GRAY)
sgMask = cv2.threshold(sgMask, 0, 255, cv2.THRESH_BINARY)[1]
sgMask = imutils.rotate_bound(sgMask, angle)
sgMask = imutils.resize(sgMask, width=sgW, inter=cv2.INTER_NEAREST)
首先,我们计算每只眼睛的中心,然后计算眼睛质心之间的角度(行 145-151 ),就像我们正在执行面部对齐。
从那里我们可以旋转(行 155 )和调整(行 161 和 162 )太阳镜的大小。注意,我们正在使用 rotate_bound 函数。我们在这里使用rotate_bound而不仅仅是rotate来确保 OpenCV 不会在仿射变换后裁剪掉图像中不可见的部分。
我们应用于太阳镜本身的相同操作需要应用于面具。但是首先,我们需要将蒙版转换成灰度并将其二值化(行 170 和 171 ),因为蒙版总是二值化。然后我们继续旋转和调整面具的大小,就像我们在第 172 和 173 行对太阳镜所做的那样。
注意: 注意,我们在调整蒙版大小时使用的是最近邻插值。这是因为我们的掩码应该只有两个值(0 和 255)。其他插值方法可能更美观悦目,但实际上对我们的面具有害。你可以在这里阅读更多关于最近邻插值的内容。
剩下的三个代码块将创建我们的 GIF 框架:
# our sunglasses will drop down from the top of the frame so let's
# define N equally spaced steps between the top of the frame and the
# desired end location
steps = np.linspace(0, rightEyeCenter[1], config["steps"],
dtype="int")
# start looping over the steps
for (i, y) in enumerate(steps):
# compute our translation values to move the sunglasses both
# slighty to the left and slightly up -- the reason why we are
# doing this is so the sunglasses don't *start* directly at
# the center of our eye, translation helps us shift the
# sunglasses to adequately cover our entire eyes (otherwise
# what good are sunglasses!)
shiftX = int(sg.shape[1] * 0.25)
shiftY = int(sg.shape[0] * 0.35)
y = max(0, y - shiftY)
# add the sunglasses to the image
output = overlay_image(image, sg, sgMask,
(rightEyeCenter[0] - shiftX, y))
我们的太阳镜会从图像的顶部掉下来。每一帧依次显示太阳镜逐渐靠近脸部,直到遮住眼睛。使用我们的 JSON 配置变量"steps"(steps的数量),让我们生成均匀间隔的y-值,以将太阳镜放置在每个相应的框架上。这是在第 178 行和第 179 行上处理的,在那里我们毫不费力地利用了 NumPy 的linspace函数。
给定steps,我们将迭代它们(它们只是 y 值)来计算太阳镜的平移。
瞥一眼第 189 行和第 190 行,你可能会想,“WTH?”
参考我的代码文档对前面几行的注释,我简单地解释说,我们确保太阳镜覆盖每只眼睛,而不仅仅是到达眼睛中心的点。我确定了百分比值,以根据经验计算第 189 和 190 行上的 x -shift 和 y -shift。第 191 行用于确保我们没有负值。
利用我们的overlay_image函数,我们在行 194 和 195 上生成我们的output帧。
我们的最终输出帧是一个特例,因为它是“处理它”文本,我们将通过另一个遮罩操作在该帧上绘制:
# if this is the final step then we need to add the "DEAL WITH
# IT" text to the bottom of the frame
if i == len(steps) - 1:
# load both the "DEAL WITH IT" image and mask from disk,
# ensuring we threshold the mask as we did for the sunglasses
dwi = cv2.imread(config["deal_with_it"])
dwiMask = cv2.imread(config["deal_with_it_mask"])
dwiMask = cv2.cvtColor(dwiMask, cv2.COLOR_BGR2GRAY)
dwiMask = cv2.threshold(dwiMask, 0, 255,
cv2.THRESH_BINARY)[1]
# resize both the text image and mask to be 80% the width of
# the output image
oW = int(W * 0.8)
dwi = imutils.resize(dwi, width=oW)
dwiMask = imutils.resize(dwiMask, width=oW,
inter=cv2.INTER_NEAREST)
# compute the coordinates of where the text will go on the
# output image and then add the text to the image
oX = int(W * 0.1)
oY = int(H * 0.8)
output = overlay_image(output, dwi, dwiMask, (oX, oY))
如果我们在最后一步(第 199 行),我们需要覆盖我们的“处理它”图像(图 5)——这又是一个特例。
这里的“文本”实际上是另一个“图像”。
我选择使用图像,因为 OpenCV 的字体渲染能力非常有限,此外,我想给文本添加阴影和边框,这也是 OpenCV 做不到的。
上述代码块的其余部分加载图像和遮罩,然后继续执行 alpha 混合,以生成最终的帧输出。
现在我们只需要将每一帧输出到磁盘,然后创建我们的 GIF:
# write the output image to our temporary directory
p = os.path.sep.join([config["temp_dir"], "{}.jpg".format(
str(i).zfill(8))])
cv2.imwrite(p, output)
# now that all of our frames have been written to disk we can finally
# create our output GIF image
print("[INFO] creating GIF...")
create_gif(config["temp_dir"], args["output"], config["delay"],
config["final_delay"], config["loop"])
# cleanup by deleting our temporary directory
print("[INFO] cleaning up...")
shutil.rmtree(config["temp_dir"], ignore_errors=True)
在第 222-224 行上,我们将循环的output帧写入磁盘。
一旦所有的帧都生成了,我们调用我们的create_gif函数来生成 GIF 动画文件(第 229 和 230 行)。记住,create_gif函数是一个包装器,它将参数传递给 ImageMagick 的convert命令行工具。
最后,我们通过删除临时输出目录+单个图像文件来进行清理。
OpenCV GIF 结果
现在是有趣的部分——让我们看看我们的热图生成器创造了什么!
确保你使用这篇博客文章的 “下载” 部分来下载源代码、示例图像和深度学习模型。从那里,打开您的终端并执行以下命令:
$ python create_gif.py --config config.json --image images/adrian.jpg \
--output adrian_out.gif
[INFO] loading models...
[INFO] computing object detections...
[INFO] creating GIF...
[INFO] cleaning up...

Figure 9: Generating GIFs with OpenCV and ImageMagick is easy with today’s Python script.
在这里,您可以看到用 OpenCV 和 ImageMagick 创建的 GIF,显示:
- 我的脸被正确地检测到了。
- 我的眼睛已经被定位,它们的中心也被计算出来了。
- 太阳镜正好垂到我的脸上。
你们中的许多人都知道我是一个《侏罗纪公园》的超级书呆子,经常在我的书、课程和教程中提到《T2》和《侏罗纪公园》。
不喜欢侏罗纪公园?
好吧,这是我的回应:
$ python create_gif.py --config config.json --image images/adrian_jp.jpg \
--output adrian_jp_out.gif
[INFO] loading models...
[INFO] computing object detections...
[INFO] creating GIF...
[INFO] cleaning up...

Figure 10: A GIF made with OpenCV of me at the recent Jurassic Park: Fallen Kingdom movie showing.
这是我在《侏罗纪公园:堕落王国》的开幕式上,展示我的特殊的侏罗纪公园衬衫、品脱玻璃杯和收藏版书。
有趣的故事:
五六年前,我现在的妻子和我参观了佛罗里达州奥兰多华特·迪士尼世界的 EPCOT 中心。
我们决定去旅行,远离康涅狄格州的严冬——我们迫切需要阳光。
不幸的是,我们在佛罗里达的整个时间都在下雨,天气几乎没有超过 50 华氏度。
Trisha 在 Epcot 的“加拿大花园”外面给我拍了以下照片——她说我看起来像吸血鬼,皮肤苍白,穿着深色衣服,戴着兜帽,与我身后郁郁葱葱的花园形成鲜明对比:
$ python create_gif.py --config config.json --image images/vampire.jpg \
--output vampire_out.gif
[INFO] loading models...
[INFO] computing object detections...
[INFO] creating GIF...
[INFO] cleaning up...

Figure 11: You can create a “Deal with it” GIF or another type of GIF using OpenCV and Python.
Trisha 决定当晚晚些时候在社交媒体上发布这张照片——我被留下来处理这件事。
对于那些参加 PyImageConf 2018 的人(阅读这里的摘要),你知道我总是一个笑话。这里有一个有趣的笑话:
问:公鸡为什么要过马路?
$ python create_gif.py --config config.json --image images/rooster.jpg \
--output rooster_out.gif
[INFO] loading models...
[INFO] computing object detections...
[INFO] creating GIF...
[INFO] cleaning up...

Figure 12: Even in low contrast, my face is detected and my sunglasses are put on by OpenCV, making for an excellent “Deal With It” meme/GIF.
我不会告诉你答案的——面对现实吧。
最后,我们用一个好心的 meme 来总结一下今天用 OpenCV 制作 gif 的教程。
大约六年前,我和爸爸收养了一只名叫杰玛的家庭猎犬。
在这里你可以看到小小的杰玛小狗坐在我的肩膀上:
$ python create_gif.py --config config.json --image images/pupper.jpg \
--output pupper_out.gif
[INFO] loading models...
[INFO] computing object detections...
[INFO] creating GIF...
[INFO] cleaning up...

Figure 13: Jemma is adorable. Don’t think so? Then “Deal With It!” This GIF was made with OpenCV and Python.
不觉得她是只可爱的小狗吗?处理好它。
是否遇到了 AttributeError?
不要担心!
如果您看到以下错误:
$ python create_gif.py --config config.json --image images/adrian.jpg \
--output adrian_out.gif
...
Traceback (most recent call last):
File "create_gif.py", line 142, in <module>
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
AttributeError: module 'imutils.face_utils' has no attribute 'FACIAL_LANDMARKS_IDXS'
然后你只需要升级 imutils 包:
$ pip install --upgrade imutils
Collecting imutils
...
Successfully installed imutils-0.5.1
你会问为什么?
默认情况下imutils.face_utils将使用 dlib 内置的 68 点标志检测器(这篇博文也是如此)。还有一个更快的 dlib 五点地标探测器,现在也可以与 imutils 一起工作。我最近更新了 imutils 以支持这两者(这就是你可能会看到错误的原因)。
摘要
在今天的教程中,您学习了如何使用 OpenCV 创建 gif。
为了保持帖子的轻松和有趣,我们学会了如何使用 OpenCV 来生成“处理它”的 gif,这是一种流行的模因(也是我个人最喜欢的),几乎在每个社交媒体网站上都可以找到。
为了构建我们的热图生成器,我们以多种实用的方式利用了计算机视觉和深度学习,包括:
- 人脸检测
- 面部标志预测
- 提取面部区域(在这种情况下,是眼睛)
- 计算两眼之间的角度,这是面部对齐的一个要求
- 通过阿尔法混合生成透明覆盖
最后,我们使用生成的图像集,然后使用 OpenCV 和 ImageMagick 创建了一个动画 GIF。
我希望你喜欢今天用 OpenCV 创建 GIF 的教程!
如果你喜欢它,请留下评论让我知道。
如果你不喜欢这个教程,不管怎样,解决它😉
要下载今天帖子的源代码,并在 PyImageSearch 上发布未来教程时得到通知,*只需在下表中输入您的电子邮件地址!***
用 OpenCV 和 Python 实现信用卡 OCR
原文:https://pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/
今天的博文是我们最近关于光学字符识别(OCR)和计算机视觉系列的延续。
在之前的博客文章中,我们学习了如何安装 Tesseract 二进制文件并将其用于 OCR 。然后,我们学习了如何使用基本的图像处理技术来清理图像,以提高 Tesseract OCR 的输出。
然而,正如我在这些之前的帖子中多次提到的,Tesseract 不应该被视为能够获得高精度的光学字符识别的通用现成解决方案。
在某些情况下,它会工作得很好,而在其他情况下,它会悲惨地失败。
这种用例的一个很好的例子是信用卡识别,给定一个输入图像,
我们希望:
- 检测图像中信用卡的位置。
- 将与信用卡上的十六位数字相关的四组四位数字本地化。
- 应用 OCR 来识别信用卡上的十六位数字。
- 识别信用卡的类型(如 Visa、MasterCard、American Express 等。).
在这些情况下,Tesseract 库无法正确识别数字(这可能是因为 Tesseract 没有接受过信用卡示例字体的训练)。因此,我们需要设计自己的 OCR 信用卡定制解决方案。
在今天的博文中,我将展示我们如何使用模板匹配作为一种 OCR 形式来帮助我们创建一个解决方案,以自动识别信用卡并从图像中提取相关的信用卡数字。
要了解更多关于在 OpenCV 和 Python 中使用 OCR 模板匹配的信息,请继续阅读。
用 OpenCV 和 Python 实现信用卡 OCR
今天的博文分为三部分。
在第一部分中,我们将讨论 OCR-A 字体,这是一种专门为帮助光学字符识别算法而创建的字体。
然后我们将设计一个计算机视觉和图像处理算法,它可以:
- 定位信用卡上的四组四位数。
- 提取这四个分组中的每一个,然后分别对十六个数字进行分段。
- 使用模板匹配和 OCR-A 字体识别十六位信用卡数字中的每一位。
最后,我们将看一些将我们的信用卡 OCR 算法应用于实际图像的例子。
OCR 字体
OCR-A 字体是在 20 世纪 60 年代末设计的,以便(1)当时的 OCR 算法和(2)人类可以容易地识别字符。该字体得到包括 ANSI 和 ISO 等标准组织的支持。
尽管现代 OCR 系统不需要 OCR-A 等特殊字体,但它仍广泛用于身份证、报表和信用卡。
事实上,有相当多的字体是专门为 OCR 设计的,包括 OCR-B 和 MICR E-13B。
虽然现在你可能不会经常写纸质支票,但下次你写的时候,你会看到底部使用的 MICR E-13B 字体包含了你的路由和账号。MICR 代表磁性墨水字符识别代码。磁性传感器、照相机和扫描仪都会定期读取你的支票。
以上每种字体都有一个共同点——它们都是为方便 OCR 而设计的。
在本教程中,我们将为 OCR 制作一个模板匹配系统——一种常见于信用卡/借记卡正面的字体。
使用 OpenCV 通过模板匹配进行 OCR
在本节中,我们将使用 Python + OpenCV 实现我们的模板匹配算法,以自动识别信用卡数字。
为了实现这一点,我们需要应用一些图像处理操作,包括阈值处理、计算梯度幅度表示、形态学操作和轮廓提取。这些技术已经在其他博客文章中使用过,用于检测图像中的条形码和识别护照图像中的机器可读区域。
因为将会有许多图像处理操作被应用来帮助我们检测和提取信用卡数字,所以我已经包括了输入图像通过我们的图像处理管道时的许多中间截图。
这些额外的截图将让您更加深入地了解我们如何能够将基本的图像处理技术链接在一起,以构建计算机视觉项目的解决方案。
让我们开始吧。
打开一个新文件,命名为ocr_template_match.py,然后我们开始工作:
# import the necessary packages
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
行 1- 6 处理这个脚本的导入包。如果你的机器上还没有安装 OpenCV 和 imutils ,你将需要安装它们。模板匹配在 OpenCV 中已经存在一段时间了,所以您的版本(v2.4,v3。*,等等。)可能会起作用。
要安装/升级imutils,只需使用pip:
$ pip install --upgrade imutils
注意:如果你正在使用 Python 虚拟环境(正如我所有的 OpenCV 安装教程所做的),确保你首先使用workon命令访问你的虚拟环境,然后安装/升级imutils 。
现在我们已经安装并导入了包,我们可以解析我们的命令行参数了:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-r", "--reference", required=True,
help="path to reference OCR-A image")
args = vars(ap.parse_args())
在的第 8-14 行我们建立了一个参数解析器,添加两个参数,解析它们,存储为变量args。
两个必需的命令行参数是:
--image:要进行 OCR 的图像的路径。--reference:参考 OCR-A 图像的路径。该图像包含 OCR-A 字体中的数字 0-9,从而允许我们稍后在管道中执行模板匹配。
接下来,让我们定义信用卡类型:
# define a dictionary that maps the first digit of a credit card
# number to the credit card type
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MasterCard",
"6": "Discover Card"
}
信用卡类型,如美国运通卡、维萨卡等。,可以通过检查 16 位信用卡号的第一位来识别。在第 16-23 行我们定义了一个字典FIRST_NUMBER,它将第一个数字映射到相应的信用卡类型。
让我们通过加载参考 OCR-A 图像来开始我们的图像处理管道:
# load the reference OCR-A image from disk, convert it to grayscale,
# and threshold it, such that the digits appear as *white* on a
# *black* background
# and invert it, such that the digits appear as *white* on a *black*
ref = cv2.imread(args["reference"])
ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
首先,我们加载reference OCR-A 图像(第 29 行),然后将其转换为灰度(第 30 行)并对其进行阈值处理+反转(第 31 行)。在每个操作中,我们存储或覆盖我们的参考图像ref。

Figure 4: The OCR-A font for the digits 0-9. We will be using this font along with template matching to OCR credit card digits in images.
图 4 显示了这些步骤的结果。
现在让我们在 OCR 上定位轮廓——字体图像:
# find contours in the OCR-A image (i.e,. the outlines of the digits)
# sort them from left to right, and initialize a dictionary to map
# digit name to the ROI
refCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
refCnts = imutils.grab_contours(refCnts)
refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]
digits = {}
在的第 36 行和第 37 行中,我们找到了ref图像中的轮廓。然后,由于 OpenCV 2.4、3 和 4 版本存储返回轮廓信息的方式不同,我们检查版本并对第行第 38 处的refCnts进行适当的更改。
接下来,我们从左到右对轮廓进行排序,并初始化一个字典digits,它将数字名称映射到感兴趣的区域(第 39 和 40 行)。
此时,我们应遍历轮廓,提取 ROI,并将其与相应的数字相关联:
# loop over the OCR-A reference contours
for (i, c) in enumerate(refCnts):
# compute the bounding box for the digit, extract it, and resize
# it to a fixed size
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
# update the digits dictionary, mapping the digit name to the ROI
digits[i] = roi
在第 43 行,我们循环参考图像轮廓。在循环中,i保存数字名称/数字,c保存轮廓。
我们在每个轮廓周围计算一个边界框,c,(第 46 行)存储 (x,y)——矩形的坐标和宽度/高度。
在第 47 行上,我们使用边界矩形参数从ref(参考图像)中提取roi。该 ROI 包含数字。我们将第 48 行的每个 ROI 调整为 57×88 像素的固定大小。我们需要确保每个数字都被调整到固定的大小,以便在本教程的后面应用数字识别的模板匹配。
我们将每个数字 0-9(字典键)与第 51 行的每个roi图像(字典值)相关联。
此时,我们已经完成了从参考图像中提取数字,并将它们与相应的数字名称相关联。
我们的下一个目标是分离出输入--image中的 16 位信用卡号码。我们需要找到并隔离这些数字,然后才能启动模板匹配来识别每个数字。这些图像处理步骤相当有趣和有见地,尤其是如果你以前从未开发过图像处理管道,一定要密切关注。
让我们继续初始化几个结构化内核:
# initialize a rectangular (wider than it is tall) and square
# structuring kernel
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
你可以把内核想象成一个小矩阵,我们在图像上滑动它来进行(卷积)操作,例如模糊、锐化、边缘检测或其他图像处理操作。
在第 55 行和第 56 行上,我们构造了两个这样的内核——一个是矩形的,一个是正方形的。我们将使用矩形的用于礼帽形态操作符,方形的用于闭合操作。我们将很快看到这些技术的实际应用。
现在让我们准备要进行 OCR 的图像:
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=300)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
在第 59 行中,我们加载了保存信用卡照片的命令行参数image。然后,我们将它调整为width=300、,保持纵横比 ( 第 60 行),接着将其转换为灰度(第 61 行)。
让我们看看我们的输入图像:

Figure 5: The example input credit card image that we will be OCR’ing in the rest of this tutorial.
接下来是我们的调整大小和灰度操作:

Figure 6: Converting the image to grayscale is a requirement prior to applying the rest of our image processing pipeline.
现在,我们的图像是灰度的,大小是一致的,让我们执行一个形态学操作:
# apply a tophat (whitehat) morphological operator to find light
# regions against a dark background (i.e., the credit card numbers)
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
使用我们的rectKernel和gray图像,我们执行一个礼帽形态学操作,将结果存储为tophat ( 第 65 行)。
正如您在下图中看到的,礼帽操作在深色背景(即信用卡号码)下显示出浅色区域:

Figure 7: Applying a tophat operations reveals light regions (i.e., the credit card digits) against a dark background.
给定我们的tophat图像,让我们计算沿着 x 方向的梯度:
# compute the Scharr gradient of the tophat image, then scale
# the rest back into the range [0, 255]
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0,
ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
我们分离数字的下一步是计算tophat图像在 x 方向的沙尔梯度。我们在第 69 行和第 70 行完成这个计算,将结果存储为gradX。
在计算了gradX数组中每个元素的绝对值之后,我们采取一些步骤将这些值缩放到范围 [0-255] (因为图像当前是浮点数据类型)。为此,我们计算gradX ( 行 72 )的minVal和maxVal,然后是行 73 所示的缩放等式(即最小/最大归一化)。最后一步是将gradX转换为uint8,其范围为【0-255】(行 74 )。
结果如下图所示:

Figure 8: Computing the Scharr gradient magnitude representation of the image reveals vertical changes in the gradient.
让我们继续改进我们的信用卡数字查找算法:
# apply a closing operation using the rectangular kernel to help
# cloes gaps in between credit card number digits, then apply
# Otsu's thresholding method to binarize the image
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# apply a second closing operation to the binary image, again
# to help close gaps between credit card number regions
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
为了缩小间隙,我们在线 79 上进行关闭操作。注意,我们再次使用了rectKernel。随后,我们对gradX图像执行 Otsu 和二进制阈值处理(行 80 和 81 ),随后是另一个关闭操作(行 85 )。这些步骤的结果如下所示:

Figure 9: Thresholding our gradient magnitude representation reveals candidate regions” for the credit card numbers we are going to OCR.
接下来,让我们找到轮廓并初始化数字分组位置列表。
# find contours in the thresholded image, then initialize the
# list of digit locations
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
locs = []
在第 89-91 行中,我们找到轮廓并把它们存储在一个列表中,cnts。然后,我们初始化一个列表来保存行 92 上的数字组位置。
现在让我们循环遍历轮廓,同时根据每个轮廓的纵横比进行过滤,这样我们就可以从信用卡的其他不相关区域中删除数字组位置:
# loop over the contours
for (i, c) in enumerate(cnts):
# compute the bounding box of the contour, then use the
# bounding box coordinates to derive the aspect ratio
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# since credit cards used a fixed size fonts with 4 groups
# of 4 digits, we can prune potential contours based on the
# aspect ratio
if ar > 2.5 and ar < 4.0:
# contours can further be pruned on minimum/maximum width
# and height
if (w > 40 and w < 55) and (h > 10 and h < 20):
# append the bounding box region of the digits group
# to our locations list
locs.append((x, y, w, h))
在第 95 行,我们以和参考图像相同的方式循环遍历轮廓。在计算了每个轮廓的外接矩形之后,c ( 第 98 行),我们通过将宽度除以高度(第 99 行)来计算纵横比,ar。
使用纵横比,我们分析每个轮廓的形状。如果ar在 2.5 和 4.0 之间(宽大于高),以及w在 40 和 55 像素之间,而h在 10 和 20 像素之间,我们将边界矩形参数以一个方便的元组追加到locs ( 第 101-110 行)。
注意:这些长宽比以及最小宽度和高度的值是在我的输入信用卡图像集上通过实验找到的。您可能需要为自己的应用程序更改这些值。
下图显示了我们找到的分组——出于演示目的,我让 OpenCV 在每个分组周围绘制了一个边界框:

Figure 10: Highlighting the four groups of four digits (sixteen overall) on a credit card.
接下来,我们将从左到右对分组进行排序,并为信用卡数字初始化一个列表:
# sort the digit locations from left-to-right, then initialize the
# list of classified digits
locs = sorted(locs, key=lambda x:x[0])
output = []
在行 114 上,我们根据 x- 值对locs进行排序,因此它们将从左到右排序。
我们初始化一个列表output,它将在行 115 中保存图像的信用卡号。
现在我们知道了每组四位数的位置,让我们遍历这四个已排序的分组并确定其中的位数。
这个循环相当长,分为三个代码块,这是第一个代码块:
# loop over the 4 groupings of 4 digits
for (i, (gX, gY, gW, gH)) in enumerate(locs):
# initialize the list of group digits
groupOutput = []
# extract the group ROI of 4 digits from the grayscale image,
# then apply thresholding to segment the digits from the
# background of the credit card
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# detect the contours of each individual digit in the group,
# then sort the digit contours from left to right
digitCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
digitCnts = imutils.grab_contours(digitCnts)
digitCnts = contours.sort_contours(digitCnts,
method="left-to-right")[0]
在该循环的第一个块中,我们在每侧提取并填充该组 5 个像素(行 125 ),应用阈值处理(行 126 和 127 ),并查找和排序轮廓(行 129-135 )。详情一定要参考代码。
下面显示的是已提取的单个组:
Figure 11: An example of extracting a single group of digits from the input credit card for OCR.
让我们用一个嵌套循环继续这个循环,进行模板匹配和相似性得分提取:
# loop over the digit contours
for c in digitCnts:
# compute the bounding box of the individual digit, extract
# the digit, and resize it to have the same fixed size as
# the reference OCR-A images
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
# initialize a list of template matching scores
scores = []
# loop over the reference digit name and digit ROI
for (digit, digitROI) in digits.items():
# apply correlation-based template matching, take the
# score, and update the scores list
result = cv2.matchTemplate(roi, digitROI,
cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# the classification for the digit ROI will be the reference
# digit name with the *largest* template matching score
groupOutput.append(str(np.argmax(scores)))
使用cv2.boundingRect我们获得提取包含每个数字的 ROI 所需的参数(行 142 和 143 )。为了使模板匹配具有一定程度的准确性,我们将第 144 行上的roi调整为与我们的参考 OCR-A 字体数字图像(57×88 像素)相同的大小。
我们在行 147 上初始化一个scores列表。请将此视为我们的置信度得分——它越高,就越有可能是正确的模板。
现在,让我们循环(第三个嵌套循环)每个参考数字并执行模板匹配。这是为这个脚本所做的繁重工作。
OpenCV 有一个方便的函数叫做cv2.matchTemplate,在这个函数中你提供两个图像:一个是模板,另一个是输入图像。对这两幅图像应用cv2.matchTemplate的目的是确定它们有多相似。
在这种情况下,我们提供参考图像digitROI和来自包含候选数字的信用卡的roi。使用这两幅图像,我们调用模板匹配函数并存储result ( 行 153 和 154 )。
接下来,我们从result ( 第 155 行)中提取score,并将其添加到我们的scores列表中(第 156 行)。这就完成了最内层的循环。
使用分数(0-9 的每个数字一个),我们取最大分数——最大分数应该是我们正确识别的数字。我们在第 160 行找到得分最高的数字,通过np.argmax抓取具体指标。这个索引的整数名称表示基于与每个模板的比较的最可能的数字(同样,记住索引已经预先排序为 0-9)。
最后,让我们在每组周围画一个矩形,并以红色文本查看图像上的信用卡号:
# draw the digit classifications around the group
cv2.rectangle(image, (gX - 5, gY - 5),
(gX + gW + 5, gY + gH + 5), (0, 0, 255), 2)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
# update the output digits list
output.extend(groupOutput)
对于这个循环的第三个也是最后一个块,我们在组周围画一个 5 像素的填充矩形(行 163 和 164 ),然后在屏幕上画文本(行 165 和 166 )。
最后一步是将数字附加到输出列表中。Pythonic 式的方法是使用extend函数,将 iterable 对象(本例中是一个列表)的每个元素附加到列表的末尾。
为了查看脚本的执行情况,让我们将结果输出到终端,并在屏幕上显示我们的图像。
# display the output credit card information to the screen
print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))
print("Credit Card #: {}".format("".join(output)))
cv2.imshow("Image", image)
cv2.waitKey(0)
线 172 将信用卡类型打印到控制台,然后在随后的线 173 上打印信用卡号。
在最后一行,我们在屏幕上显示图像,并在退出脚本前等待任何键被按下行 174 和 175 。
花一点时间祝贺自己——你坚持到了最后。概括地说,这个脚本:
- 在字典中存储信用卡类型。
- 拍摄参考图像并提取数字。
- 将数字模板存储在字典中。
- 本地化四个信用卡号码组,每个组包含四个数字(总共 16 个数字)。
- 提取要“匹配”的数字。
- 对每个数字执行模板匹配,将每个 ROI 与每个数字模板 0-9 进行比较,同时存储每个尝试匹配的分数。
- 找到每个候选数字的最高分,并构建一个名为
output的列表,其中包含信用卡号。 - 将信用卡号和信用卡类型输出到我们的终端,并将输出图像显示到我们的屏幕上。
现在是时候看看脚本的运行情况并检查我们的结果了。
信用卡 OCR 结果
既然我们已经编写了信用卡 OCR 系统的代码,让我们试一试。
在这个例子中,我们显然不能使用真实的信用卡号码,所以我使用 Google 收集了一些信用卡的示例图片。这些信用卡显然是伪造的,并且仅用于演示目的。
然而,你可以在这篇博文中应用同样的技术来识别真实信用卡上的数字。
要查看我们的信用卡 OCR 系统的运行情况,请打开一个终端并执行以下命令:
$ python ocr_template_match.py --reference ocr_a_reference.png \
--image images/credit_card_05.png
Credit Card Type: MasterCard
Credit Card #: 5476767898765432
我们的第一张结果图,100%正确:
Figure 12: Applying template matching with OpenCV and Python to OCR the digits on a credit card.
请注意,我们是如何通过检查信用卡号的第一个数字来正确地将信用卡标记为 MasterCard 的。
让我们尝试第二个图像,这一次是签证:
$ python ocr_template_match.py --reference ocr_a_reference.png \
--image images/credit_card_01.png
Credit Card Type: Visa
Credit Card #: 4000123456789010
Figure 13: A second example of OCR’ing digits using Python and OpenCV.
再一次,我们能够使用模板匹配正确地识别信用卡。
再来一张图片,这次来自宾夕法尼亚州的一家信用合作社 PSECU:
$ python ocr_template_match.py --reference ocr_a_reference.png \
--image images/credit_card_02.png
Credit Card Type: Visa
Credit Card #: 4020340002345678
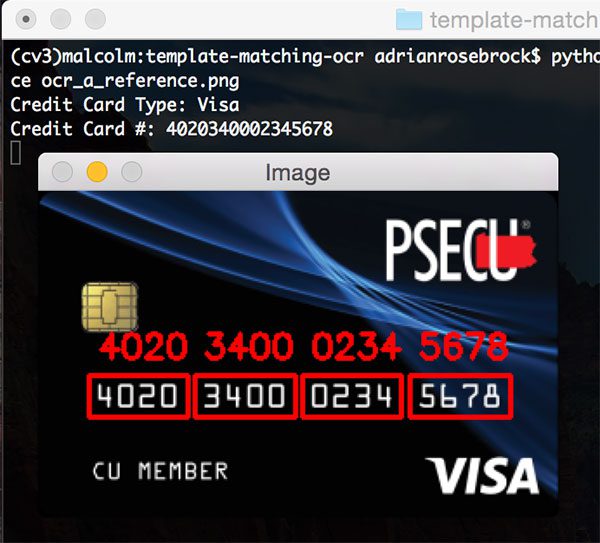
Figure 14: Our system is correctly able to find the digits on the credit card, then apply template matching to recognize them.
我们的 OCR 模板匹配算法可以正确识别 16 位数字中的每一位。假设 16 位数字中的每一位都被正确识别,我们也可以将信用卡标记为 Visa。
这是另一张万事达卡的示例图片,这张图片来自《床、浴室和其他》:
$ python ocr_template_match.py --reference ocr_a_reference.png \
--image images/credit_card_03.png
Credit Card Type: MasterCard
Credit Card #: 5412751234567890

Figure 15: Regardless of credit card design and type, we can still detect the digits and recognize them using template matching.
我们的模板匹配 OCR 算法在这里没有问题!
作为我们的最后一个例子,让我们使用另一种签证:
$ python ocr_template_match.py --reference ocr_a_reference.png \
--image images/credit_card_04.png
Credit Card Type: Visa
Credit Card #: 4000123456789010
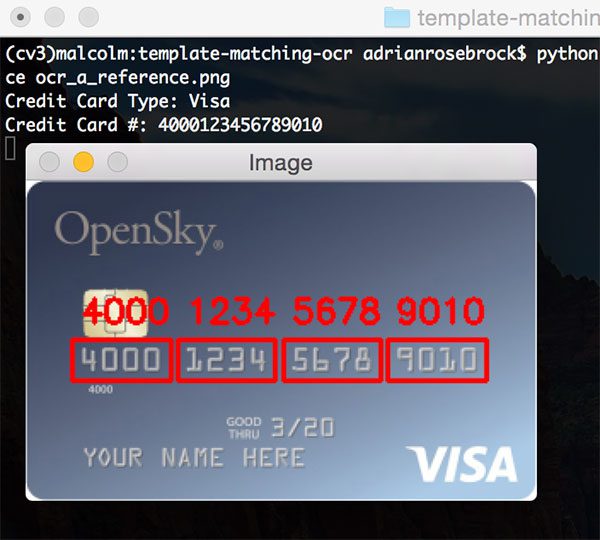
Figure 16: A final example of applying OCR with Python and OpenCV.
在这篇博文的每个例子中,我们使用 OpenCV 和 Python 的模板匹配 OCR 脚本 100%正确地识别了 16 位数字中的每一位。
再者,模板匹配也是比较数字时非常快速的方法。
不幸的是,我们无法将我们的 OCR 图像应用到真实的信用卡图像上,因此这无疑提出了一个问题,即这种方法在真实的图像上是否可靠。鉴于照明条件、视角和其他一般噪声的变化,我们可能需要采取一种更加面向机器学习的方法。
不管怎样,至少对于这些示例图像,我们能够成功地将模板匹配应用为一种 OCR 形式。
摘要
在本教程中,我们学习了如何通过 OpenCV 和 Python 使用模板匹配来执行光学字符识别(OCR)。
具体来说,我们应用我们的模板匹配 OCR 方法来识别信用卡的类型以及 16 个信用卡数字。
为此,我们将图像处理流程分为 4 个步骤:
- 通过各种图像处理技术,包括形态学操作、阈值处理和轮廓提取,检测信用卡上的四组四个数字。
- 从四个分组中提取每个单独的数字,得到需要分类的 16 个数字。
- 通过与 OCR-A 字体进行比较,将模板匹配应用于每个数字,以获得我们的数字分类。
- 检查信用卡号的第一个数字以确定发行公司。
在评估了我们的信用卡 OCR 系统之后,我们发现,如果发卡的信用卡公司使用 OCR-A 字体来表示数字,那么它是 100%准确的。
为了扩展这个应用程序,您可能希望在野外收集信用卡的真实图像,并潜在地训练一个机器学习模型(通过标准的特征提取或训练或卷积神经网络),以进一步提高该系统的准确性。
我希望你喜欢这篇关于使用 OpenCV 和 Python 通过模板匹配进行 OCR 的博文。
为了在 PyImageSearch 上发布未来教程时得到通知,请务必在下表中输入您的电子邮件地址!
使用 OpenCV 裁剪图像
原文:https://pyimagesearch.com/2021/01/19/crop-image-with-opencv/
在本教程中,您将学习如何使用 OpenCV 裁剪图像。

顾名思义,裁剪是选择和提取感兴趣区域(或简称 ROI)的行为,是图像中我们感兴趣的部分。
例如,在人脸检测应用程序中,我们可能希望从图像中裁剪出人脸。如果我们正在开发一个 Python 脚本来识别图像中的狗,我们可能希望在找到狗后从图像中裁剪掉它。
我们已经在教程中使用了裁剪, 使用 OpenCV ,获取和设置像素,但是为了更加完整,我们将再次回顾它。
要学习如何用 OpenCV 裁剪图像,继续阅读。
使用 OpenCV 的裁剪图像
在本教程的第一部分,我们将讨论如何将 OpenCV 图像表示为 NumPy 数组。因为每个图像都是一个 NumPy 数组,所以我们可以利用 NumPy 数组切片来裁剪图像。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后我将演示用 OpenCV 裁剪图像是多么简单!
了解使用 OpenCV 和 NumPy 数组切片进行图像裁剪
当我们裁剪图像时,我们希望删除图像中我们不感兴趣的外部部分。我们通常将这一过程称为选择我们的感兴趣区域,或者更简单地说,我们的 ROI。
我们可以通过使用 NumPy 数组切片来实现图像裁剪。
让我们首先用范围从【0,24】:的值初始化一个 NumPy 列表
>>> import numpy as np
>>> I = np.arange(0, 25)
>>> I
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24])
>>>
现在让我们把这个 1D 列表重塑成一个 2D 矩阵,假设它是一个图像:
>>> I = I.reshape((5, 5))
>>> I
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
>>>
现在,假设我要提取从 x = 0 、 y = 0 开始,到 x = 2 、 y = 3 结束的“像素”。使用以下代码可以实现这一点:
>>> I[0:3, 0:2]
array([[ 0, 1],
[ 5, 6],
[10, 11]])
>>>
注意我们是如何提取了三行( y = 3 )和两列( x = 2 )。
现在,让我们提取从 x = 1 、 y = 3 开始到 x = 5 和 y = 5 结束的像素:
>>> I[3:5, 1:5]
array([[16, 17, 18, 19],
[21, 22, 23, 24]])
>>>
这个结果提供了图像的最后两行,减去第一列。
你注意到这里的模式了吗?
将 NumPy 数组切片应用于图像时,我们使用以下语法提取 ROI:
roi = image[startY:endY, startX:endX]
startY:endY切片提供图像中我们的行(因为y-轴是我们的行数),而startX:endX提供我们的列(因为x-轴是列数)。现在花一点时间说服你自己,上面的陈述是正确的。
但是如果你有点困惑,需要更多的说服力,不要担心!在本指南的后面,我将向您展示一些代码示例,使 OpenCV 的图像裁剪更加清晰和具体。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们使用 OpenCV 实现图像裁剪之前,让我们先回顾一下我们的项目目录结构。
首先使用本指南的 “下载” 部分访问源代码和示例图像:
$ tree . --dirsfirst
.
├── adrian.png
└── opencv_crop.py
0 directories, 2 files
今天我们只回顾一个 Python 脚本opencv_crop.py,它将从磁盘加载输入的adrian.png图像,然后使用 NumPy 数组切片从图像中裁剪出脸部和身体。
用 OpenCV 实现图像裁剪
我们现在准备用 OpenCV 实现图像裁剪。
打开项目目录结构中的opencv_crop.py文件,插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
我们只需要一个命令行参数--image,它是我们希望裁剪的输入图像的路径。对于这个例子,我们将默认把--image切换到项目目录中的adrian.png文件。
接下来,让我们从磁盘加载我们的映像:
# load the input image and display it to our screen
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# cropping an image with OpenCV is accomplished via simple NumPy
# array slices in startY:endY, startX:endX order -- here we are
# cropping the face from the image (these coordinates were
# determined using photo editing software such as Photoshop,
# GIMP, Paint, etc.)
face = image[85:250, 85:220]
cv2.imshow("Face", face)
cv2.waitKey(0)
第 12 和 13 行加载我们的原件image,然后显示在我们的屏幕上:
我们的目标是使用简单的裁剪方法从这个区域中提取出我的脸和身体。
我们通常会应用物体检测技术来检测图像中我的脸和身体。然而,由于我们仍然处于 OpenCV 教育课程的相对早期,我们将使用我们的先验图像知识和手动提供身体和面部所在的 NumPy 数组切片。
同样,我们当然可以使用对象检测方法从图像中自动检测和提取人脸,但是暂时让事情简单一些。
*我们用一行代码从图像中提取我的脸(第 20 行)。
我们提供 NumPy 数组切片来提取图像的矩形区域,从 (85,85) 开始,到 (220,250) 结束。
我们为作物提供指数的顺序可能看起来违反直觉;但是,请记住 OpenCV 将图像表示为 NumPy 数组,首先是高度(行数),其次是宽度(列数)。
为了执行我们的裁剪,NumPy 需要四个索引:
- 起始 y : 起始 y 坐标。在这种情况下,我们从 y = 85 开始。
- 终点y终点 y 坐标。我们将在 y = 250 时结束收割。
- 起始 x : 起始 x 切片坐标。我们在 x = 85 开始裁剪。
- 结束xT3:结束x-切片的轴坐标。我们的切片结束于 x = 220 。
我们可以看到下面裁剪我的脸的结果:
同样,我们可以从图像中裁剪出我的身体:
# apply another image crop, this time extracting the body
body = image[90:450, 0:290]
cv2.imshow("Body", body)
cv2.waitKey(0)
裁剪我的身体是通过从原始图像的坐标 (0,90) 开始裁剪到 (290,450) 结束。
下面你可以看到 OpenCV 的裁剪输出:
虽然简单,裁剪是一个极其重要的技能,我们将在整个系列中使用。如果你仍然对裁剪感到不安,现在一定要花时间练习,磨练你的技能。从现在开始,裁剪将是一个假设的技能,你需要理解!
OpenCV 图像裁剪结果
要使用 OpenCV 裁剪图像,请确保您已经进入本教程的 【下载】 部分,以访问源代码和示例图像。
从那里,打开一个 shell 并执行以下命令:
$ python opencv_crop.py
您的裁剪输出应该与我在上一节中的输出相匹配。
总结
在本教程中,您学习了如何使用 OpenCV 裁剪图像。因为 OpenCV 将图像表示为 NumPy 数组,所以裁剪就像将裁剪的开始和结束范围作为 NumPy 数组切片一样简单。
你需要做的就是记住下面的语法:
cropped = image[startY:endY, startX:endX]
只要记住提供起始和结束 (x,y)-坐标的顺序,用 OpenCV 裁剪图像就是轻而易举的事情!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
CycleGAN:不成对的图像到图像的翻译(第 1 部分)
原文:https://pyimagesearch.com/2022/09/12/cyclegan-unpaired-image-to-image-translation-part-1/
目录
【cycle gan:不成对图像到图像的翻译(第一部分)
在本教程中,您将了解图像到图像的转换,以及在我们有不成对的图像数据的情况下如何实现它。此外,我们将了解 CycleGAN(非成对图像翻译的最著名成果之一)是如何工作的,并深入探讨它用于在不需要成对图像数据的情况下将图像从一个域无缝翻译到另一个域的机制。
具体来说,我们将在本教程中详细讨论以下内容。
- 不成对意象翻译的范式
- CycleGAN(不成对图像翻译最成功的方法之一)背后的思想和直觉
- CycleGAN 使用的损失函数背后的细节和直觉,尤其是循环一致性损失
- 关于用于不成对图像翻译的 CycleGAN 的流水线和训练过程的细节
本课是关于 GANs 301 的三部分系列的第一部分:
- 【cycle gan:不成对图像到图像的翻译(上) (本教程)
- CycleGAN:不成对的图像到图像翻译(第二部分)
- CycleGAN:不成对的图像到图像翻译(第三部分)
在本系列的第一部分(本教程),我们将了解 CycleGAN 背后的思想,并理解它用于执行图像翻译的机制。此外,我们将理解循环一致性的概念,它允许 CycleGAN 在不需要成对数据的情况下执行图像转换。
接下来,在本系列的第 2 部分中,我们将开始使用 TensorFlow 和 Keras 实现 CycleGAN 模型,并深入研究模型架构和苹果到橙子数据集的细节,我们将使用它来完成不成对图像翻译任务。
最后,在最后一部分,我们将研究训练细节并生成图像,以查看我们的实时 CycleGAN 模型的运行情况。
要了解 CycleGAN 如何从不成对的图像执行图像到图像的翻译, 继续阅读。
【cycle gan:不成对图像到图像的翻译(第一部分)
简介
高质量图像生成过程中的一个关键点是 2014 年生成性对抗网络的出现。在之前的教程中,我们已经看到了 GAN 如何从任意分布中生成图像。此外,在的另一个教程中,我们已经看到了如何转变 GANs 的训练范式,并生成适合实际应用的高分辨率图像。
这主要是可能的,由于优雅的对抗训练范式,形成了甘训练的基础。值得注意的是,通过将其公式化为生成器和鉴别器之间的竞争,潜在的基于 2 个玩家的对抗范例可以用于匹配任意分布。
这就提出了一个问题,如此强大的 GAN 框架是否可以不仅仅用于图像生成。在我们之前的教程中,我们详细探讨了如何重新利用这些网络将图像从一个领域转换到另一个领域:这是一项名为图像转换的任务。
然而,pix-to-pix 模型依赖于两个域中成对数据的存在,必须在这两个域上执行图像转换。图 1 显示了成对和不成对数据的示例。
这产生了瓶颈并阻碍了在实际情况中的利用,在实际情况中,由于可用性、实际可行性限制或高注释成本,这种定制的成对图像数据集可能不存在。因此,人们很自然地会问,我们是否还能在不需要成对图像的情况下利用 GANs 的能力进行图像翻译。
不成对图像翻译
CycleGAN 模型标志着解决不成对图像到图像转换问题的第一个也是最优雅的解决方案之一。代替使用需要在数据集图像中一对一映射的传统监督范例,它提出使用循环一致性损失来实现来自不成对数据集的图像翻译。
形式上,给定源域 X 和目标域 Y ,CycleGAN 旨在学习映射 G : X → Y ,使得 G ( X )是图像从域 X 到域 Y 的转换。此外,它还旨在学习反向映射F:Y→X,使得 F ( Y )是图像从域 Y 到域 X 的平移。图 2 显示了 CycleGAN 组件的概述。
例如,这可能意味着将斑马图像翻译成相应的马图像(改变类语义),将风格差异从夏季视图转移到冬季视图,或者预测图像场景的分割遮罩,如图图 3 所示。
但是,值得注意的是,对抗性损失仅确保分布级别的对应性。因此,它可以确保属于来自域 A 的图像分布的图像被转换成来自域 b 的图像分布的图像。它不保证样本级别的图像的一致性。
让我们通过一个例子来理解这一点,在这个例子中,我们想把斑马(域 A)翻译成马(域 B)。如图图 4 所示,我们看到第一张是属于斑马图像分布的图像,第二张和第三张是属于马图像分布的图像。
然而,注意,只有第二图像是第一图像的对应样本,而第三图像(即使来自域 B 的图像)不是第一图像的对应样本。应用对抗性损失可以确保翻译图像属于来自域 B 的图像的分布,但不能保证我们在域 B 中得到精确的对应样本。
在 pix-to-pix 的情况下,将域 A 中的图像转换成域 B 中的相应图像是很容易的,因为我们有来自两个域的成对样本。因此,简单的监督损失,如发生器输出的平均绝对误差和域 B 中的地面实况图像,足以确保域 A 中图像的平移产生域 B 中的相应图像。
然而,由于我们在不成对图像翻译的任务中无法访问相应的成对样本,因此我们无法使用监督损失,这使得难以确保两个域中样本级别的对应性。
为了解决这个问题,CycleGAN 框架提出使用循环一致性丢失,我们将在后面详细讨论。循环一致性损失确保了所学习的两个函数是彼此的反函数。因为对具有逆的函数的要求是它们必须是双射的(即,一对一和到上),所以在不成对的图像平移的情况下,它隐含地确保了样本水平上的一对一对应。
CycleGAN 管道和训练
现在我们已经理解了 CycleGAN 背后的直觉,让我们更深入地探究它执行不成对图像翻译的机制。
因为我们将在后面的教程中使用苹果到橙子数据集来实现,所以让我们考虑这样一种情况:我们必须将域 A(即苹果)中的图像 x 转换为域 B(即橙子)中的图像 y 。
图 5 显示了一个 CycleGAN 的整体管道。
首先,我们从域 A 中取出图像 x ,它属于描绘苹果(顶端)的图像分布。这个图像通过生成器 G (如图所示),它试图输出一个属于域 b 中图像分布的图像
鉴别器 D 是一个对手,它对生成器 G 生成的样本(即y′)和来自域 B 的实际样本(即 y )进行区分。使用对抗训练范例来针对该对手训练生成器。这允许生成器在输出端生成属于域 B 的分布的图像(即橙子)。
类似地,我们从域 B 获取一个图像 y ,它属于描绘橙子的图像分布(底部)。这个图像通过一个生成器 F (如图所示),它试图输出一个属于域 a 中图像分布的图像
鉴别器 D 是一个对手,它对生成器 F 生成的样本(即x′)和来自域 A 的实际样本(即 x )进行区分。使用对抗训练范例来针对该对手训练生成器。这允许生成器在输出端生成属于域 A 的分布的图像(即苹果)。
最后,我们注意到,除了两个对抗性损失之外,我们还有前向和后向循环一致性损失。这确保了:
- 对于来自域 A 的每个图像 x ,图像平移周期应该能够将 x 带回原始图像
- 对于来自域 B 的每个图像 y ,图像平移周期应该能够将 y 带回原始图像
损失公式化
最后,为了完成我们对训练过程的理解,让我们看一下 CysleGAN 在训练期间使用的损失函数的数学公式。
如前所述,CycleGAN 基本上使用两种损失函数(即对抗性损失和循环一致性损失)。现在让我们来看看这些损失的公式。
对抗性损失的数学公式由等式 1** 定义。
这里,生成器试图生成看起来属于来自域 B 的图像分布的图像。另一方面,对手或鉴别者试图区分生成器的输出(即, G ( x ))和来自域 B 的真实样本(即, Y )。
因此,在每次训练迭代中:
- 鉴别器被更新以使损耗最大化(发电机被冻结)
- 更新发生器以最小化损耗(鉴频器冻结)
遵循对抗性训练范例,最终,生成器从域 B 的分布中学习并能够生成图像(其与原始样本 y 不可区分)。
类似地,如前所述,对于从域 Y 到域 X 的反向映射,施加了另一个不利损失。这里,生成器 F 试图生成类似于域 A 的分布的图像。此外,鉴别器 D [X] 试图区分生成器的输出(即 F ( x ))和来自域 A 的真实样本(即 X )。
周期一致性
正如我们前面所看到的,对抗性损失只能确保分布水平的一致性。然而,为了确保在执行图像转换时生成相应的样本,CycleGAN 在样本级利用循环一致性损失。
如等式 4 所示,循环一致性损失由两项组成:
- 正向循环一致性
- 反向循环一致性
具体来说,第一项确保当域 A(比如说 x )中的样本通过生成器 G (从域 A 转换到 B)然后通过生成器 F (当它将其转换回域 A)时,输出为 F ( G ( x ))与原始输入样本 x. ( x →)相同
x).
类似地,第二项确保当域 B(比如说 y )中的样本通过发生器 F (从域 B 转换到域 A)然后通过发生器 G (将其转换回域 B)时,输出为 G ( F ( x ))与原始输入样本 y 相同。(y→F(y)→G(F(y)
y).
换句话说,这两个术语都旨在学习函数 F ()和 G ()使得它们互为逆函数。因此,循环一致性损失确保了来自域 A 的样本 x 和来自域 b 的样本 y 之间在样本水平上的对应性
汇总
在本教程中,我们学习了图像转换的任务,以及当两个域中的成对输入图像不可用时如何实现。
具体来说,我们详细讨论了 CycleGAN 背后的思想,并理解了循环一致性的范例,这允许 CycleGAN 无缝地从不配对数据执行图像转换。
此外,我们讨论了 CycleGAN 在训练中使用的各种损失,并了解了它们的数学公式以及它们在不成对图像翻译任务中所起的作用。
最后,我们讨论了 CycleGAN 的端到端流水线,以解码来自不成对数据的图像翻译过程。
引用信息
Chandhok,s .“cycle gan:不成对的图像到图像的翻译(第一部分), PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/7vh0s
@incollection{Chandhok_2022_CycleGAN,
author = {Shivam Chandhok},
title = {{CycleGAN}: Unpaired Image-to-Image Translation (Part 1)},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/7vh0s},
}
Keras 和深度学习的循环学习率
原文:https://pyimagesearch.com/2019/07/29/cyclical-learning-rates-with-keras-and-deep-learning/
在本教程中,您将学习如何使用循环学习率(CLR)和 Keras 来训练您自己的神经网络。使用循环学习率,您可以大大减少调整和找到模型的最佳学习率所需的实验次数。
今天是我们关于调整深度神经网络学习速率的三部分系列的第二部分:
- Part #1: Keras 学习进度和衰变 (上周的帖子)
- Part #2: 循环学习率与 Keras 和深度学习 (今日帖)
- 第三部分: 自动寻找最佳学习率(下周帖子)
上周,我们讨论了学习速率表的概念,以及我们如何根据设定的函数(即线性、多项式或阶跃下降)随时间衰减和降低我们的学习速率。
然而,基本学习率计划有两个问题:
- 我们不知道最优的初始学习率是多少。
- 单调地降低我们的学习率可能会导致我们的网络陷入“停滞”状态。
循环学习率采取了不同的方法。使用 clr,我们现在可以:
- 定义一个 最小学习率
- 定义一个 最大学习率
- 允许学习率在两个界限之间循环振荡
实际上,使用循环学习率会导致更快的收敛和更少的实验/超参数更新。
当我们将 CLRs 与下周的自动寻找最佳学习率的技术结合起来时,你可能再也不需要调整你的学习率了!(或者至少运行少得多的实验来调整它们)。
要了解如何使用 Keras 的循环学习率,继续阅读!
Keras 和深度学习的循环学习率
2020-06-11 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将讨论循环学习率,包括:
- 什么是循环学习率?
- 为什么要使用循环学习率?
- 我们如何在 Keras 中使用循环学习率?
在此基础上,我们将实现 CLRs,并在 CIFAR-10 数据集上训练一个 GoogLeNet 变体— 我甚至会指出如何在您自己的定制数据集上使用循环学习率。
最后,我们将回顾我们的实验结果,您将直接看到 CLRs 如何减少您需要执行的学习率试验次数,以找到最佳学习率范围。
什么是循环学习率?
Figure 1: Cyclical learning rates oscillate back and forth between two bounds when training, slowly increasing the learning rate after every batch update. To implement cyclical learning rates with Keras, you simply need a callback.
正如我们在上周的文章中讨论的那样,我们可以定义学习率计划,在每个时期后单调地降低我们的学习率。
随着时间的推移,通过降低我们的学习率,我们可以允许我们的模型(理想地)下降到损失景观的较低区域。
在实践中;然而,单调递减的学习速率存在一些问题:
- 首先,我们的模型和优化器仍然对我们最初选择的学习速率敏感。
- 第二,我们不知道初始学习速率应该是多少 —我们可能需要进行 10 秒到 100 秒的实验,只是为了找到我们的初始学习速率。
- 最后,当降低学习率时,不能保证我们的模型会下降到低损失区域。
为了解决这些问题,NRL 的 Leslie Smith 在他 2015 年的论文 中引入了循环学习率用于训练神经网络 的循环学习率。
现在,我们不再单调递减我们的学习速率,而是:
- 定义我们学习率(称为“base _ lr”)的下限。
- 定义学习率的上限(称为“max _ lr”)。
- 训练时允许学习率在这两个界限之间来回振荡,在每批更新后缓慢增加和减少学习率。
在图 1 中可以看到一个循环学习率的例子。
注意我们的学习速度是如何遵循一个三角形模式的。第一,学习率很小。然后,随着时间的推移,学习率继续增长,直到达到最大值。然后学习率下降回到基础值。这种循环模式贯穿整个训练。
为什么要使用循环学习率?
Figure 2: Monotonically decreasing learning rates could lead to a model that is stuck in saddle points or a local minima. By oscillating learning rates cyclically, we have more freedom in our initial learning rate, can break out of saddle points and local minima, and reduce learning rate tuning experimentation. (image source)
如上所述,循环学习率使我们的学习率在下限和上限之间来回振荡。
所以,为什么要费这么大劲呢?
为什么不像我们一直做的那样,单调地降低我们的学习速度呢?
第一个原因是,我们的网络可能会陷入鞍点或局部最小值、中,并且低学习率可能不足以突破该区域并下降到损失较低的损失区域。
其次,我们的模型和优化器可能对我们的初始学习率选择非常敏感。如果我们在学习速率上做了一个糟糕的初始选择,我们的模型可能会从一开始就停滞不前。
相反,我们可以使用循环学习率在上限和下限之间摆动我们的学习率,使我们能够:
- 在最初的学习速度选择上有更多的自由。
- 突破鞍点和局部极小值。
在实践中,使用 CLRs 导致更少的学习率调整实验,以及与穷举超参数调整几乎相同的精度。
我们如何使用循环学习率?
Figure 3: Brad Kenstler’s implementation of deep learning Cyclical Learning Rates for Keras includes three modes — “triangular”, “triangular2”, and “exp_range”. Cyclical learning rates seek to handle training issues when your learning rate is too high or too low shown in this figure. (image source)
我们将使用 Brad Kenstler 对 Keras 的循环学习率的实现。
为了使用这个实现,我们需要首先定义几个值:
- 批量:在训练期间网络的单次向前和向后传递中使用的训练样本的数量。
- 批次/迭代:每个时期的权重更新次数(即,总训练样本数除以批次大小)。
- 循环:我们的学习率从下界到上界,再到下界,再下降回到下界所需要的迭代次数。
- 步长:半个周期的迭代次数。CLRs 的创造者 Leslie Smith 推荐 step_size 应该是
(2-8) * training_iterations_in_epoch。在实践中,我发现步长为 4 或 8 在大多数情况下都很有效。
定义了这些术语后,让我们看看它们是如何一起定义循环学习率策略的。
“三角”政策
Figure 4: The “triangular” policy mode for deep learning cyclical learning rates with Keras.
“三角”循环学习率政策是一个简单的三角循环。
我们的学习率从基础值开始,然后开始增加。
我们在周期的中途达到最大学习率值(即步长,或半个周期中的迭代次数)。一旦达到最大学习率,我们就将学习率降低回基础值。同样,需要半个周期才能回到基础学习率。
整个过程重复(即循环)直到训练结束。
“三角 2”政策
Figure 5: The deep learning cyclical learning rate “triangular2” policy mode is similar to “triangular” but cuts the max learning rate bound in half after every cycle.
“triangular 2”CLR 策略类似于标准的“triangular”策略,但在每个周期后,它会将我们的最大学习速率限制减半。
这里的论点是我们得到了两个世界的最好的东西:
我们可以调整我们的学习速度来突破鞍点/局部最小值…
…同时降低我们的学习速度,使我们能够下降到损失范围的较低损失区域。
此外,随着时间的推移降低我们的最大学习速度有助于稳定我们的训练。采用“三角形”策略的后期可能会在损失和准确性方面表现出较大的跳跃——“三角形 2”策略将有助于稳定这些跳跃。
“exp_range”策略
Figure 6: The “exp_range” cyclical learning rate policy undergoes exponential decay for the max learning rate bound while still exhibiting the “triangular” policy characteristics.
“exp_range”循环学习率策略类似于“triangular2”策略,但是,顾名思义,它遵循指数衰减,从而对最大学习率的下降速率进行更精细的控制。
注意:在实践中,我不使用“exp_range”策略——“triangular”和“triangular2”策略在绝大多数项目中已经足够了。
如何在我的系统上安装循环学习率?
我们正在使用的循环学习率实现不是 pip 可安装的。
相反,您可以:
- 使用 “下载” 部分获取本教程的文件和相关代码/数据。
- 从 GitHub repo(上面的链接)下载
clr_callback.py文件,并将其插入到您的项目中。
从那里,让我们继续使用循环学习率来训练我们的第一个 CNN。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
继续从keras-cyclical-learning-rates/目录中运行tree命令来打印我们的项目结构:
$ tree --dirsfirst
.
├── output
│ ├── triangular2_clr_plot.png
│ ├── triangular2_training_plot.png
│ ├── triangular_clr_plot.png
│ └── triangular_training_plot.png
├── pyimagesearch
│ ├── __init__.py
│ ├── clr_callback.py
│ ├── config.py
│ └── minigooglenet.py
└── train_cifar10.py
2 directories, 9 files
output/目录将包含我们的 CLR 和精度/损耗图。
pyimagesearch模块包含我们的循环学习率回调类、MiniGoogLeNet CNN 和配置文件:
clr_callback.py文件包含循环学习率回调,它将在每次批量更新结束时自动更新我们的学习率。minigooglenet.py文件保存了MiniGoogLeNetCNN,我们将使用 CIFAR-10 数据对其进行训练。我们今天不回顾 MiniGoogLeNet 请参考 用 Python 进行计算机视觉的深度学习 来了解这个 CNN 架构的更多信息。- 我们的
config.py只是一个包含配置变量的 Python 文件——我们将在下一节回顾它。
我们的训练脚本train_cifar10.py,使用 CIFAR-10 数据集训练 MiniGoogLeNet。培训脚本利用了我们的 CLR 回调和配置。
我们的配置文件
在实现我们的培训脚本之前,让我们先来回顾一下我们的配置文件:
# import the necessary packages
import os
# initialize the list of class label names
CLASSES = ["airplane", "automobile", "bird", "cat", "deer", "dog",
"frog", "horse", "ship", "truck"]
我们将在配置中使用os模块,这样我们就可以直接构造与操作系统无关的路径( Line 2 )。
从那里,我们的 CIFAR-10 CLASSES被定义(第 5 行和第 6 行)。
让我们定义我们的循环学习率参数:
# define the minimum learning rate, maximum learning rate, batch size,
# step size, CLR method, and number of epochs
MIN_LR = 1e-7
MAX_LR = 1e-2
BATCH_SIZE = 64
STEP_SIZE = 8
CLR_METHOD = "triangular"
NUM_EPOCHS = 96
MIN_LR和MAX_LR分别定义我们的基本学习率和最大学习率(第 10 行和第 11 行)。我知道这些学习率在按照我已经用 Python 为计算机视觉的 深度学习 运行的实验训练 MiniGoogLeNet 时会很好地工作——下周我将向你展示如何自动找到这些值。
BATCH_SIZE ( 第 12 行)是每次批量更新的训练样本数。
然后我们有了STEP_SIZE,它是半个周期中批量更新的次数(第 13 行)。
CLR_METHOD控制着我们的周期性学习率政策(第 14 行)。这里我们使用的是”triangular”策略,正如上一节所讨论的。
我们可以通过下式计算给定历元数中的完整 CLR 周期数:
NUM_CLR_CYCLES = NUM_EPOCHS / STEP_SIZE / 2
比如用NUM_EPOCHS = 96和STEP_SIZE = 8,总共会有 6 个完整周期:96 / 8 / 2 = 6。
最后,我们定义输出绘图路径/文件名:
# define the path to the output training history plot and cyclical
# learning rate plot
TRAINING_PLOT_PATH = os.path.sep.join(["output", "training_plot.png"])
CLR_PLOT_PATH = os.path.sep.join(["output", "clr_plot.png"])
我们将绘制一个训练历史准确性/损失图以及一个循环学习率图。您可以在第 19 行和第 20 行指定图形的路径+文件名。
实施我们的循环学习率培训脚本
定义好配置后,我们可以继续实施我们的培训脚本。
打开train_cifar10.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minigooglenet import MiniGoogLeNet
from pyimagesearch.clr_callback import CyclicLR
from pyimagesearch import config
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
2-15 线进口我们需要的包装。最值得注意的是我们的CyclicLR(来自clr_callback文件)是通过行 7 导入的。matplotlib后端被设置在行 3 上,这样我们的图可以在训练过程结束时被写入磁盘。
接下来,让我们加载我们的 CIFAR-10 数据:
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
# apply mean subtraction to the data
mean = np.mean(trainX, axis=0)
trainX -= mean
testX -= mean
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
第 20-22 行加载 CIFAR-10 图像数据集。数据被预先分成训练集和测试集。
从那里,我们计算mean并应用均值减法(第 25-27 行)。均值减法是一种归一化/缩放技术,可提高模型精度。更多详情请参考 用 Python 进行计算机视觉深度学习的练习者捆绑**。
然后标签被二进制化(第 30-32 行)。
接下来,我们初始化我们的数据扩充对象(第 35-37 行)。数据扩充通过在训练过程中从数据集生成随机变异的图像来提高模型的泛化能力。我在《用 Python 进行计算机视觉的深度学习》 和两篇博客文章【如何使用 Keras fit 和 fit _ generator【实用教程】* 和Keras imagedata generator 和数据增强 )中深入讨论了数据增强。***
让我们初始化(1)我们的模型,以及(2)我们的周期性学习率回调:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=config.MIN_LR, momentum=0.9)
model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# initialize the cyclical learning rate callback
print("[INFO] using '{}' method".format(config.CLR_METHOD))
clr = CyclicLR(
mode=config.CLR_METHOD,
base_lr=config.MIN_LR,
max_lr=config.MAX_LR,
step_size= config.STEP_SIZE * (trainX.shape[0] // config.BATCH_SIZE))
我们的model用随机梯度下降(SGD)优化和"categorical_crossentropy"损失(第 41-44 行)初始化。如果数据集中只有两个类,一定要设置loss="binary_crossentropy"。
接下来,我们通过线路 48-52** 初始化循环学习率回调**。CLR 参数被提供给构造函数。现在是在“我们如何使用循环学习率?”顶部回顾它们的好时机上一节。Leslie Smith 建议将其设置为每个时期批量更新次数的倍数。
现在让我们使用 CLR 来训练和评估我们的模型:
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
callbacks=[clr],
verbose=1)
# evaluate the network and show a classification report
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=config.BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=config.CLASSES))
2020-06-11 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
56-62 行使用clr回调和数据增强启动培训。
然后行 66-68 在测试集上评估网络并打印一个classification_report。
最后,我们将生成两个图:
# plot the training loss and accuracy
N = np.arange(0, config.NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.TRAINING_PLOT_PATH)
# plot the learning rate history
N = np.arange(0, len(clr.history["lr"]))
plt.figure()
plt.plot(N, clr.history["lr"])
plt.title("Cyclical Learning Rate (CLR)")
plt.xlabel("Training Iterations")
plt.ylabel("Learning Rate")
plt.savefig(config.CLR_PLOT_PATH)
2020-06-11 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
生成了两个图:
- 训练准确性/损失历史(第 71-82 行)。标准的情节格式包括在我的大部分教程和我的深度学习书的每个实验中。
- 学习率历史(第 86-91 行)。这个图将帮助我们直观地验证我们的学习速度是根据我们的意图振荡的。
以循环学习率进行培训
我们现在准备使用 Keras 的循环学习率来训练我们的 CNN!
确保你已经使用了这篇文章的 “下载” 部分来下载源代码——从那里,打开一个终端并执行以下命令:
$ python train_cifar10.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] using 'triangular' method
[INFO] training network...
Epoch 1/96
781/781 [==============================] - 21s 27ms/step - loss: 1.9768 - accuracy: 0.2762 - val_loss: 1.6559 - val_accuracy: 0.4040
Epoch 2/96
781/781 [==============================] - 20s 26ms/step - loss: 1.4149 - accuracy: 0.4827 - val_loss: 1.5753 - val_accuracy: 0.4895
Epoch 3/96
781/781 [==============================] - 20s 26ms/step - loss: 1.1499 - accuracy: 0.5902 - val_loss: 1.6790 - val_accuracy: 0.5242
Epoch 4/96
781/781 [==============================] - 20s 26ms/step - loss: 0.9762 - accuracy: 0.6563 - val_loss: 1.1674 - val_accuracy: 0.6079
Epoch 5/96
781/781 [==============================] - 20s 26ms/step - loss: 0.8552 - accuracy: 0.7057 - val_loss: 1.1270 - val_accuracy: 0.6545
...
Epoch 92/96
781/781 [==============================] - 20s 25ms/step - loss: 0.0625 - accuracy: 0.9790 - val_loss: 0.4958 - val_accuracy: 0.8852
Epoch 93/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0472 - accuracy: 0.9842 - val_loss: 0.3810 - val_accuracy: 0.9059
Epoch 94/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0377 - accuracy: 0.9882 - val_loss: 0.3733 - val_accuracy: 0.9092
Epoch 95/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0323 - accuracy: 0.9901 - val_loss: 0.3609 - val_accuracy: 0.9124
Epoch 96/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0277 - accuracy: 0.9919 - val_loss: 0.3516 - val_accuracy: 0.9146
[INFO] evaluating network...
precision recall f1-score support
airplane 0.91 0.94 0.92 1000
automobile 0.95 0.96 0.96 1000
bird 0.89 0.89 0.89 1000
cat 0.83 0.82 0.83 1000
deer 0.91 0.91 0.91 1000
dog 0.88 0.85 0.86 1000
frog 0.92 0.95 0.93 1000
horse 0.95 0.93 0.94 1000
ship 0.96 0.95 0.95 1000
truck 0.95 0.95 0.95 1000
accuracy 0.91 10000
macro avg 0.91 0.91 0.91 10000
weighted avg 0.91 0.91 0.91 10000
如您所见,通过使用“三角形”CLR 策略,我们在 CIFAR-10 测试集上获得了 91%的准确率。
下图显示了学习率图,演示了它如何循环地从学习率下限开始,在半个周期时增加到最大值,然后再次降低到下限,从而完成循环:
Figure 7: Our first experiment of deep learning cyclical learning rates with Keras uses the “triangular” policy.
检查我们的培训历史,您可以看到学习率的周期性行为:
Figure 8: Our first experiment training history plot shows the effects of the “triangular” policy on the accuracy/loss curves.
请注意训练准确性和验证准确性中的“波浪”——波浪的底部是我们的基础学习率,波浪的顶部是学习率的上限,波浪的底部,就在下一个开始之前,是较低的学习率。
只是为了好玩,回到config.py文件的第 14 行,将CLR_METHOD从”triangular”更新为”triangular2”:
# define the minimum learning rate, maximum learning rate, batch size,
# step size, CLR method, and number of epochs
MIN_LR = 1e-7
MAX_LR = 1e-2
BATCH_SIZE = 64
STEP_SIZE = 8
CLR_METHOD = "triangular2"
NUM_EPOCHS = 96
从那里,训练网络:
$ python train_cifar10.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] using 'triangular2' method
[INFO] training network...
Epoch 1/96
781/781 [==============================] - 21s 26ms/step - loss: 1.9612 - accuracy: 0.2816 - val_loss: 1.8604 - val_accuracy: 0.3650
Epoch 2/96
781/781 [==============================] - 20s 26ms/step - loss: 1.4167 - accuracy: 0.4832 - val_loss: 1.5907 - val_accuracy: 0.4916
Epoch 3/96
781/781 [==============================] - 21s 26ms/step - loss: 1.1566 - accuracy: 0.5889 - val_loss: 1.2650 - val_accuracy: 0.5667
Epoch 4/96
781/781 [==============================] - 20s 26ms/step - loss: 0.9837 - accuracy: 0.6547 - val_loss: 1.1343 - val_accuracy: 0.6207
Epoch 5/96
781/781 [==============================] - 20s 26ms/step - loss: 0.8690 - accuracy: 0.6940 - val_loss: 1.1572 - val_accuracy: 0.6128
...
Epoch 92/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0711 - accuracy: 0.9765 - val_loss: 0.3636 - val_accuracy: 0.9021
Epoch 93/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0699 - accuracy: 0.9775 - val_loss: 0.3693 - val_accuracy: 0.8995
Epoch 94/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0702 - accuracy: 0.9773 - val_loss: 0.3660 - val_accuracy: 0.9013
Epoch 95/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0682 - accuracy: 0.9782 - val_loss: 0.3644 - val_accuracy: 0.9005
Epoch 96/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0661 - accuracy: 0.9789 - val_loss: 0.3649 - val_accuracy: 0.9007
[INFO] evaluating network...
precision recall f1-score support
airplane 0.90 0.91 0.91 1000
automobile 0.95 0.97 0.96 1000
bird 0.85 0.86 0.86 1000
cat 0.83 0.79 0.81 1000
deer 0.90 0.88 0.89 1000
dog 0.84 0.84 0.84 1000
frog 0.90 0.94 0.92 1000
horse 0.94 0.93 0.93 1000
ship 0.96 0.94 0.95 1000
truck 0.94 0.95 0.94 1000
accuracy 0.90 10000
macro avg 0.90 0.90 0.90 10000
weighted avg 0.90 0.90 0.90 10000
这一次,我们获得了 90%的准确率,比使用“三角”策略略低。
我们的学习率图直观地显示了我们的学习率是如何循环更新的:
Figure 9: Our second experiment uses the “triangular2” cyclical learning rate policy mode. The actual learning rates throughout training are shown in the plot.
请注意,在每个完整周期后,最大学习率减半。由于我们的最大学习率在每个周期后都在下降,因此我们在训练和验证准确性方面的“波动”将变得不那么明显:
Figure 10: Our second experiment training history plot shows the effects of the “triangular2” policy on the accuracy/loss curves.
虽然“三角”周期学习率策略获得了稍好的准确性,但它也表现出大得多的波动,并且具有更大的过度拟合风险。
相比之下,“三角 2”策略虽然不太准确,但在训练中更稳定。
当你用循环学习率进行自己的实验时,我建议你测试两个策略,并选择一个平衡了准确性和稳定性的策略(即,具有较小过度拟合风险的稳定训练)。
在下周的教程中,我将向你展示如何用循环学习率自动定义你的最小和最大学习率界限。
摘要
在本教程中,您学习了如何对 Keras 使用循环学习率(clr)。
与单调降低我们学习速率的标准学习速率衰减时间表不同,CLRs:
- 定义一个 最小学习率
- 定义一个 最大学习率
- 允许学习率在两个界限之间循环振荡
循环学习率通常导致更快的收敛和更少的实验和超参数调整。
但是还有一个问题…
我们怎么知道学习率的最优上下界是?
这是一个很好的问题——我将在下周的帖子中回答这个问题,我将向你展示如何自动找到最佳学习率值。
**我希望你喜欢今天的帖子!
要下载这篇文章的源代码(并在 PyImageSearch 上发布以后的教程时得到通知),*只需在下面的表格中输入您的电子邮件地址。***
使用 tf.data 和 TensorFlow 进行数据扩充
原文:https://pyimagesearch.com/2021/06/28/data-augmentation-with-tf-data-and-tensorflow/
在本教程中,您将学习使用 Keras 和 TensorFlow 将数据扩充合并到您的tf.data管道中的两种方法。
本教程是我们关于tf.data模块的三部分系列中的一部分:
- 温柔介绍 TF . data
- 带有 tf.data 和 TensorFlow 的数据管道
- 用 tf.data 进行数据扩充(今天的教程)
在这个系列中,我们已经发现了tf.data模块对于构建数据处理管道是多么的快速和高效。一旦建成,这些管道可以训练你的神经网络比使用标准方法快得多。
然而,我们还没有讨论的一个问题是:
我们如何在 tf.data 管道中应用数据增强?
数据扩充是训练神经网络的一个重要方面,这些神经网络将部署在现实世界的场景中。通过应用数据扩充,我们可以提高我们的模型的能力,使其能够对未经训练的数据进行更好、更准确的预测。
TensorFlow 为我们提供了两种方法,我们可以使用这两种方法将数据增强应用于我们的tf.data管道:
- 使用
Sequential类和preprocessing模块构建一系列数据扩充操作,类似于 Keras 的ImageDataGenerator类 - 应用
tf.image功能手动创建数据扩充程序
第一种方法要简单得多,也更省力。第二种方法稍微复杂一些(通常是因为您需要阅读 TensorFlow 文档来找到您需要的确切函数),但是允许对数据扩充过程进行更细粒度的控制。
在本教程中,你将学习如何使用和tf.data两种数据扩充程序。
继续阅读,了解如何使用tf.data、、、进行数据扩充。
使用 tf.data 和 TensorFlow 进行数据扩充
在本教程的第一部分中,我们将分解两种方法,您可以使用这两种方法通过tf.data处理管道进行数据扩充。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
今天我们将回顾两个 Python 脚本:
- 第一个脚本将向您展示如何使用层应用数据扩充,而另一个脚本将使用 TensorFlow 操作演示数据扩充
- 我们的第二个脚本将使用数据增强和
tf.data管道来训练一个深度神经网络
我们将讨论我们的结果来结束本教程。
用 tf.data 和 TensorFlow 进行数据扩充的两种方法
本节介绍了使用 TensorFlow 和tf.data模块应用图像数据增强的两种方法。
使用层和“顺序”类的数据扩充
通过使用 TensorFlow 的preprocessing模块和Sequential类,将数据扩充合并到tf.data管道中是最容易实现的。
我们通常称这种方法为 【层数据扩充】 ,因为我们用于数据扩充的Sequential类与我们用于实现顺序神经网络(例如 LeNet、VGGNet、AlexNet)的 类 相同。
这个方法最好通过代码来解释:
trainAug = Sequential([
preprocessing.Rescaling(scale=1.0 / 255),
preprocessing.RandomFlip("horizontal_and_vertical"),
preprocessing.RandomZoom(
height_factor=(-0.05, -0.15),
width_factor=(-0.05, -0.15)),
preprocessing.RandomRotation(0.3)
])
在这里,您可以看到我们正在构建一系列数据增强操作,包括:
- 随机水平和垂直翻转
- 随机缩放
- 随机旋转
然后,我们可以通过以下方式将数据扩充纳入我们的tf.data管道:
trainDS = tf.data.Dataset.from_tensor_slices((trainX, trainLabels))
trainDS = (
trainDS
.shuffle(BATCH_SIZE * 100)
.batch(BATCH_SIZE)
.map(lambda x, y: (trainAug(x), y),
num_parallel_calls=tf.data.AUTOTUNE)
.prefetch(tf.data.AUTOTUNE)
)
注意我们如何使用map函数在每一个输入图像上调用我们的trainAug管道。
在用tf.data应用数据增强时,我真的很喜欢这种方法。它非常容易使用,来自 Keras 的深度学习实践者会喜欢它与 Keras 的ImageDataGenerator类有多么相似。
另外,这些层还可以操作内部的一个模型架构本身。如果你使用的是 GPU,这意味着 GPU 可以应用数据增强,而不是你的 CPU!请注意,当使用只在您的 CPU 上运行的本地 TensorFlow 操作构建数据扩充时,这不是而不是的情况。
*### 使用张量流运算的数据增强
我们可用于将数据扩充应用于tf.data管道的第二种方法是应用张量流运算,包括以下两种:
- 图像处理功能内置于
tf.image模块内的tensor flow 库中 - 任何你想自己实现的自定义操作(使用 OpenCV、scikit-image、PIL/Pillow 等库。)
这种方法稍微复杂一点,因为它需要您手动实现数据扩充管道(相对于使用preprocessing模块中的类),但是好处是您获得了更细粒度的控制(当然您可以实现任何您想要的定制操作)。
要使用 TensorFlow 操作应用数据扩充,我们首先需要定义一个接受输入图像的函数,然后应用我们的操作:
def augment_using_ops(images, labels):
images = tf.image.random_flip_left_right(images)
images = tf.image.random_flip_up_down(images)
images = tf.image.rot90(images)
return (images, labels)
在这里,你可以看到我们是:
- 随机水平翻转我们的图像
- 随机垂直翻转图像
- 应用随机的 90 度旋转
然后,将增强的图像返回给调用函数。
我们可以将这个数据扩充例程合并到我们的tf.data管道中,如下所示:
ds = tf.data.Dataset.from_tensor_slices(imagePaths)
ds = (ds
.shuffle(len(imagePaths), seed=42)
.map(load_images, num_parallel_calls=AUTOTUNE)
.cache()
.batch(BATCH_SIZE)
.map(augment_using_ops, num_parallel_calls=AUTOTUNE)
.prefetch(tf.data.AUTOTUNE)
)
如您所见,这种数据扩充方法要求您对 TensorFlow 文档有更深入的了解,特别是tf.image模块,因为 TensorFlow 在那里实现其图像处理功能。
我应该对 tf.data 使用哪种数据扩充方法?
对于大多数深度学习实践者来说,使用层和Sequential类来应用数据增强将会比 绰绰有余。
TensorFlow 的preprocessing模块实现了您日常所需的绝大多数数据增强操作。
此外,Sequential类结合preprocessing模块更容易使用——熟悉 Keras 的ImageDataGenerator的深度学习实践者使用这种方法会感觉很舒服。
也就是说,如果您想要对您的数据扩充管道进行更细致的控制,或者如果您需要实施定制的数据扩充程序,您应该使用 TensorFlow 操作方法来应用数据扩充。
这个方法需要更多的代码和 TensorFlow 文档知识(特别是tf.image中的函数),但是如果你需要对你的数据扩充过程进行细粒度控制,你就不能打败这个方法。
*### 配置您的开发环境
这篇关于 tf.keras 数据扩充的教程利用了 keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都有助于在一个方便的 Python 虚拟环境中为您的系统配置这篇博客文章所需的所有软件。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
我们的示例数据集
动物数据集中的图像属于三个不同的类别:狗、猫和熊猫,如图 4 中的所示,每个类别有 1000 张示例图像。
狗和猫的图像是从 Kaggle 狗对猫挑战赛中采集的,而熊猫的图像是从 ImageNet 数据集中采集的。
我们的目标是训练一个卷积神经网络,可以正确识别这些物种中的每一个。
注: 更多使用 Animals 数据集的例子,参考我的 k-NN 教程 和我的Keras 入门教程 。
项目结构
在我们使用tf.data应用数据扩充之前,让我们首先检查我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索我们的 Python 脚本和示例数据集:
$ tree . --dirsfirst --filelimit 10
.
├── dataset
│ └── animals
│ ├── cats [1000 entries exceeds filelimit, not opening dir]
│ ├── dogs [1000 entries exceeds filelimit, not opening dir]
│ └── panda [1000 entries exceeds filelimit, not opening dir]
├── data_aug_layers.png
├── data_aug_ops.png
├── load_and_visualize.py
├── no_data_aug.png
├── train_with_sequential_aug.py
└── training_plot.png
5 directories, 6 files
在dataset/animals目录中,我们有一个示例图像数据集,我们将对其应用数据扩充(我们在上一节中回顾了这个数据集)。
然后我们有两个 Python 脚本要实现:
load_and_visualize.py:演示了如何使用(1)Sequential类和preprocessing模块以及(2) TensorFlow 操作来应用数据扩充。两种数据扩充程序的结果都将显示在我们的屏幕上,因此我们可以直观地验证该过程正在工作。train_with_sequential_aug.py:使用数据扩充和tf.data管道训练一个简单的 CNN。
运行这些脚本将产生以下输出:
data_aug_layers.png:应用层和Sequential类的数据扩充的输出data_aug_ops.png:内置 TensorFlow 运算应用数据增强的输出可视化no_data_aug.png:未应用数据增强的示例图像training_plot.png:我们的培训和验证损失/准确性的图表
审查完我们的项目目录后,我们现在可以开始深入研究实现了!
用 tf.data 和 TensorFlow 实现数据扩充
我们今天将在这里实现的第一个脚本将向您展示如何:
- 使用“层”和
Sequential类执行数据扩充 - 使用内置张量流运算应用数据增强
- 或者,简单地说而不是应用数据扩充
使用tf.data,您将熟悉各种可用的数据扩充选项。然后,在本教程的后面,您将学习如何使用tf.data和数据增强来训练 CNN。
但是我们先走后跑吧。
打开项目目录结构中的load_and_visualize.py文件,让我们开始工作:
# import the necessary packages
from tensorflow.keras.layers.experimental import preprocessing
from tensorflow.data import AUTOTUNE
from imutils import paths
import matplotlib.pyplot as plt
import tensorflow as tf
import argparse
import os
第 2-8 行导入我们需要的 Python 包。最重要的是,注意来自layers.experimental 的preprocessing模块——preprocessing模块提供了我们使用 TensorFlow 的Sequential类执行数据扩充所需的函数。
虽然这个模块被称为experimental,但它已经在 TensorFlow API 中存在了近一年,所以可以肯定地说,这个模块绝不是“实验性的”(我想 TensorFlow 开发人员会在未来的某个时候重命名这个子模块)。
接下来,我们有我们的load_images函数:
def load_images(imagePath):
# read the image from disk, decode it, convert the data type to
# floating point, and resize it
image = tf.io.read_file(imagePath)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.image.resize(image, (156, 156))
# parse the class label from the file path
label = tf.strings.split(imagePath, os.path.sep)[-2]
# return the image and the label
return (image, label)
与本系列前面的教程一样,该函数负责:
- 从磁盘加载我们的输入图像并预处理它(第 13-16 行)
- 从文件路径中提取类标签(行 19 )
- 将
image和label返回到调用函数(第 22 行
请注意,我们使用 TensorFlow 函数而不是 OpenCV 和 Python 函数来执行这些操作——我们使用 TensorFlow 函数,因此 TensorFlow 可以最大限度地优化我们的tf.data管道。
我们的下一个函数augment_using_layers,负责获取Sequential(使用preprocessing操作构建)的一个实例,然后应用它生成一组增强图像:
def augment_using_layers(images, labels, aug):
# pass a batch of images through our data augmentation pipeline
# and return the augmented images
images = aug(images)
# return the image and the label
return (images, labels)
我们的augment_using_layers函数接受三个必需的参数:
- 数据批内的输入
images - 对应的类
labels - 我们的数据扩充(
aug)对象,假设它是Sequential的一个实例
通过aug对象传递我们的输入images会导致随机扰动应用到图像上(第 27 行)。我们将在这个脚本的后面学习如何构造这个aug对象。
然后将增加的images和相应的labels返回给调用函数。
我们的最后一个函数augment_using_ops,使用tf.image模块中内置的 TensorFlow 函数应用数据扩充:
def augment_using_ops(images, labels):
# randomly flip the images horizontally, randomly flip the images
# vertically, and rotate the images by 90 degrees in the counter
# clockwise direction
images = tf.image.random_flip_left_right(images)
images = tf.image.random_flip_up_down(images)
images = tf.image.rot90(images)
# return the image and the label
return (images, labels)
这个函数接受我们的数据批次images和labels。从这里开始,它适用于:
- 随机水平翻转
- 随机垂直翻转
- 90 度旋转(这实际上不是随机操作,而是与其他操作结合在一起,看起来像是随机操作)
同样,请注意,我们正在使用内置的 TensorFlow 函数构建这个数据扩充管道— 与使用augment_using_layers函数中的Sequential类和层方法相比,这种方法有什么优势?
虽然前者实现起来要简单得多,但后者给了您对数据扩充管道更多的控制权。
根据您的数据扩充过程的先进程度,在preprocessing模块中可能没有实现您的管道。当这种情况发生时,您可以使用 TensorFlow 函数、OpenCV 方法和 NumPy 函数调用来实现您自己的定制方法。
从本质上来说,使用操作来应用数据扩充可以为您提供最细粒度的控制……但这也需要大量的工作,因为您需要(1)在 TensorFlow、OpenCV 或 NumPy 中找到适当的函数调用,或者(2)您需要手工实现这些方法。
现在我们已经实现了这两个函数,我们将看看如何使用它们来应用数据扩充。
让我们从解析命令行参数开始:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input images dataset")
ap.add_argument("-a", "--augment", type=bool, default=False,
help="flag indicating whether or not augmentation will be applied")
ap.add_argument("-t", "--type", choices=["layers", "ops"],
help="method to be used to perform data augmentation")
args = vars(ap.parse_args())
我们有一个命令行参数,后跟两个可选参数:
--dataset:我们要应用数据增强的图像的输入目录的路径--augment:一个布尔值,表示我们是否要对图像的输入目录应用数据扩充--type:我们将应用的数据增强类型(或者是layers或者是ops)
现在让我们为数据扩充准备我们的tf.data管道:
# set the batch size
BATCH_SIZE = 8
# grabs all image paths
imagePaths = list(paths.list_images(args["dataset"]))
# build our dataset and data input pipeline
print("[INFO] loading the dataset...")
ds = tf.data.Dataset.from_tensor_slices(imagePaths)
ds = (ds
.shuffle(len(imagePaths), seed=42)
.map(load_images, num_parallel_calls=AUTOTUNE)
.cache()
.batch(BATCH_SIZE)
)
第 54 行设置我们的批量大小,而第 57 行获取我们的--dataset目录中所有输入图像的路径。
然后,我们开始在线 61-67 上建设tf.data管道,包括:
- 打乱我们的图像
- 在
imagePaths列表中的每个输入图像上调用load_images - 缓存结果
- 设置我们的批量
接下来,让我们检查是否应该应用数据扩充:
# check if we should apply data augmentation
if args["augment"]:
# check if we will be using layers to perform data augmentation
if args["type"] == "layers":
# initialize our sequential data augmentation pipeline
aug = tf.keras.Sequential([
preprocessing.RandomFlip("horizontal_and_vertical"),
preprocessing.RandomZoom(
height_factor=(-0.05, -0.15),
width_factor=(-0.05, -0.15)),
preprocessing.RandomRotation(0.3)
])
# add data augmentation to our data input pipeline
ds = (ds
.map(lambda x, y: augment_using_layers(x, y, aug),
num_parallel_calls=AUTOTUNE)
)
# otherwise, we will be using TensorFlow image operations to
# perform data augmentation
else:
# add data augmentation to our data input pipeline
ds = (ds
.map(augment_using_ops, num_parallel_calls=AUTOTUNE)
)
第 70 行检查我们的--augment命令行参数是否表明我们是否应该应用数据扩充。
提供检查通道,第 72 行检查我们是否应用了层/顺序数据扩充。
使用preprocessing模块和Sequential类应用数据扩充在行 74-80 完成。顾名思义Sequential,你可以看到我们正在应用随机水平/垂直翻转、随机缩放和随机旋转,一次一个,一个操作后面跟着下一个(因此得名“顺序”)。
如果您以前使用过 Keras 和 TensorFlow,那么您会知道Sequential类也用于构建简单的神经网络,其中一个操作进入下一个操作。类似地,我们可以使用Sequential类构建一个数据扩充管道,其中一个扩充函数调用的输出是下一个的输入。
Keras 的ImageDataGenerator功能的用户在这里会有宾至如归的感觉,因为使用preprocessing和Sequential应用数据增强非常相似。
然后我们将我们的aug对象添加到行 83-86 上的tf.data管道中。注意我们如何将map函数与lambda函数一起使用,需要两个参数:
x:输入图像y:图像的类别标签
然后,augment_using_layers函数应用实际的数据扩充。
否则,第 90-94 行处理我们使用张量流运算执行数据扩充时的情况。我们需要做的就是更新tf.data管道,为每批数据调用augment_using_ops。
现在,让我们最终确定我们的tf.data渠道:
# complete our data input pipeline
ds = (ds
.prefetch(AUTOTUNE)
)
# grab a batch of data from our dataset
batch = next(iter(ds))
用AUTOTONE参数调用prefetch优化了我们整个tf.data管道。
然后,我们使用我们的数据管道在行 102 上生成数据batch(如果设置了--augment命令行参数,则可能应用了数据扩充)。
这里的最后一步是可视化我们的输出:
# initialize a figure
print("[INFO] visualizing the first batch of the dataset...")
title = "With data augmentation {}".format(
"applied ({})".format(args["type"]) if args["augment"] else \
"not applied")
fig = plt.figure(figsize=(BATCH_SIZE, BATCH_SIZE))
fig.suptitle(title)
# loop over the batch size
for i in range(0, BATCH_SIZE):
# grab the image and label from the batch
(image, label) = (batch[0][i], batch[1][i])
# create a subplot and plot the image and label
ax = plt.subplot(2, 4, i + 1)
plt.imshow(image.numpy())
plt.title(label.numpy().decode("UTF-8"))
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
第 106-110 行初始化一个 matplotlib 图形来显示我们的输出结果。
然后我们循环遍历batch ( 行 113 )内的每个图像/类标签,并继续:
- 提取图像和标签
- 在图上显示图像
- 将类别标签添加到图中
由此产生的图然后显示在我们的屏幕上。
用 tf.data 结果进行数据扩充
我们现在已经准备好用tf.data来可视化应用数据扩充的输出!
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从那里,执行以下命令:
$ python load_and_visualize.py --dataset dataset/animals
[INFO] loading the dataset...
[INFO] visualizing the first batch of the dataset...
如你所见,我们在这里执行了无数据扩充——我们只是在屏幕上加载一组示例图像并显示它们。这个输出作为我们的基线,我们可以将接下来的两个输出进行比较。
现在,让我们使用“层”方法(即preprocessing模块和Sequential类)来应用数据扩充。
$ python load_and_visualize.py --dataset dataset/animals \
--aug 1 --type layers
[INFO] loading the dataset...
[INFO] visualizing the first batch of the dataset...
请注意我们是如何成功地将数据扩充应用于输入图像的——每个输入图像都被随机翻转、缩放和旋转。
最后,让我们检查用于数据扩充的 TensorFlow 操作方法的输出(即手动定义管道函数) :
$ python load_and_visualize.py --dataset dataset/animals \
--aug 1 --type ops
[INFO] loading the dataset...
[INFO] visualizing the first batch of the dataset...
我们的输出非常类似于图 5,从而证明我们已经能够成功地将数据增强整合到我们的tf.data管道中。
使用 tf.data 实施我们的数据扩充培训脚本
在上一节中,我们学习了如何使用tf.data构建数据扩充管道;然而,我们没有使用我们的管道训练神经网络。本节将解决这个问题。
本教程结束时,您将能够开始将数据扩充应用到您自己的tf.data管道中。
在您的项目目录结构中打开train_with_sequential.py脚本,让我们开始工作:
# import the necessary packages
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras import Sequential
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers.experimental import preprocessing
import matplotlib.pyplot as plt
import tensorflow as tf
import argparse
第 2-11 行导入我们需要的 Python 包。我们将使用Sequential类来:
- 建立一个简单、浅显的 CNN
- 用
preprocessing模块构建我们的数据扩充管道
然后,我们将在 CIFAR-10 数据集上训练我们的 CNN,应用数据增强。
接下来,我们有命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="training_plot.png",
help="path to output training history plot")
args = vars(ap.parse_args())
确实只有一个参数是--plot,它是我们输出训练历史图的路径。
接下来,我们继续设置超参数并加载 CIFAR-10 数据集。
# define training hyperparameters
BATCH_SIZE = 64
EPOCHS = 50
# load the CIFAR-10 dataset
print("[INFO] loading training data...")
((trainX, trainLabels), (textX, testLabels)) = cifar10.load_data()
现在我们已经准备好建立我们的数据扩充程序:
# initialize our sequential data augmentation pipeline for training
trainAug = Sequential([
preprocessing.Rescaling(scale=1.0 / 255),
preprocessing.RandomFlip("horizontal_and_vertical"),
preprocessing.RandomZoom(
height_factor=(-0.05, -0.15),
width_factor=(-0.05, -0.15)),
preprocessing.RandomRotation(0.3)
])
# initialize a second data augmentation pipeline for testing (this
# one will only do pixel intensity rescaling
testAug = Sequential([
preprocessing.Rescaling(scale=1.0 / 255)
])
第 28-35 行初始化我们的trainAug序列,包括:
- 将我们的像素强度从范围【0,255】重新调整到【0,1】
- 执行随机水平和垂直翻转
- 随机缩放
- 应用随机旋转
除了Rescaling之外,所有这些操作都是随机的,它只是我们构建到Sequential管道中的一个基本预处理操作。
然后我们在第 39-41 行的中定义我们的testAug过程。我们在这里执行的唯一操作是我们的【0,1】像素强度缩放。我们 必须 在这里使用Rescaling类,因为我们的训练数据也被重新调整到范围【0,1】——否则在训练我们的网络时会导致错误的输出。
处理好预处理和增强初始化后,让我们为我们的训练和测试数据构建一个tf.data管道:
# prepare the training data pipeline (notice how the augmentation
# layers have been mapped)
trainDS = tf.data.Dataset.from_tensor_slices((trainX, trainLabels))
trainDS = (
trainDS
.shuffle(BATCH_SIZE * 100)
.batch(BATCH_SIZE)
.map(lambda x, y: (trainAug(x), y),
num_parallel_calls=tf.data.AUTOTUNE)
.prefetch(tf.data.AUTOTUNE)
)
# create our testing data pipeline (notice this time that we are
# *not* apply data augmentation)
testDS = tf.data.Dataset.from_tensor_slices((textX, testLabels))
testDS = (
testDS
.batch(BATCH_SIZE)
.map(lambda x, y: (testAug(x), y),
num_parallel_calls=tf.data.AUTOTUNE)
.prefetch(tf.data.AUTOTUNE)
)
第 45-53 行构建我们的训练数据集,包括洗牌、创建批处理和应用trainAug函数。
第 57-64 行对我们的测试集执行类似的操作,除了两个例外:
- 我们不需要打乱数据进行评估
- 我们的
testAug对象只有执行重新缩放,而没有随机扰动
现在让我们实现一个基本的 CNN:
# initialize the model as a super basic CNN with only a single CONV
# and RELU layer, followed by a FC and soft-max classifier
print("[INFO] initializing model...")
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=(32, 32, 3)))
model.add(Activation("relu"))
model.add(Flatten())
model.add(Dense(10))
model.add(Activation("softmax"))
这个 CNN 非常简单,仅由一个 CONV 层、一个 RELU 激活层、一个 FC 层和我们的 softmax 分类器组成。
然后我们继续使用我们的tf.data管道训练我们的 CNN:
# compile the model
print("[INFO] compiling model...")
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd", metrics=["accuracy"])
# train the model
print("[INFO] training model...")
H = model.fit(
trainDS,
validation_data=testDS,
epochs=EPOCHS)
# show the accuracy on the testing set
(loss, accuracy) = model.evaluate(testDS)
print("[INFO] accuracy: {:.2f}%".format(accuracy * 100))
一个简单的调用model.fit通过我们的trainDS和testDS使用我们的tf.data管道训练我们的模型,并应用数据增强。
训练完成后,我们在测试集上评估模型的性能。
我们的最终任务是生成一个训练历史图:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.plot(H.history["accuracy"], label="train_acc")
plt.plot(H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
然后将结果图保存到磁盘上通过--plot命令行参数提供的文件路径中。
数据扩充和 tf.data 的训练结果
我们现在准备通过tf.data管道使用数据增强来训练一个深度神经网络。
请务必访问本教程的 “下载” 部分来检索源代码。
从那里,您可以执行培训脚本:
$ python train_with_sequential_aug.py
[INFO] loading training data...
[INFO] initializing model...
[INFO] compiling model...
[INFO] training model...
Epoch 1/50
782/782 [==============================] - 12s 12ms/step - loss: 2.1271 - accuracy: 0.2212 - val_loss: 2.0173 - val_accuracy: 0.2626
Epoch 2/50
782/782 [==============================] - 10s 13ms/step - loss: 1.9319 - accuracy: 0.3154 - val_loss: 1.9148 - val_accuracy: 0.3104
Epoch 3/50
782/782 [==============================] - 10s 13ms/step - loss: 1.8720 - accuracy: 0.3338 - val_loss: 1.8430 - val_accuracy: 0.3403
Epoch 4/50
782/782 [==============================] - 10s 13ms/step - loss: 1.8333 - accuracy: 0.3515 - val_loss: 1.8326 - val_accuracy: 0.3483
Epoch 5/50
782/782 [==============================] - 10s 13ms/step - loss: 1.8064 - accuracy: 0.3554 - val_loss: 1.9409 - val_accuracy: 0.3246
...
Epoch 45/50
782/782 [==============================] - 10s 13ms/step - loss: 1.5882 - accuracy: 0.4379 - val_loss: 1.7483 - val_accuracy: 0.3860
Epoch 46/50
782/782 [==============================] - 10s 13ms/step - loss: 1.5800 - accuracy: 0.4380 - val_loss: 1.6637 - val_accuracy: 0.4110
Epoch 47/50
782/782 [==============================] - 10s 13ms/step - loss: 1.5851 - accuracy: 0.4357 - val_loss: 1.7648 - val_accuracy: 0.3834
Epoch 48/50
782/782 [==============================] - 10s 13ms/step - loss: 1.5823 - accuracy: 0.4371 - val_loss: 1.7195 - val_accuracy: 0.4054
Epoch 49/50
782/782 [==============================] - 10s 13ms/step - loss: 1.5812 - accuracy: 0.4388 - val_loss: 1.6914 - val_accuracy: 0.4045
Epoch 50/50
782/782 [==============================] - 10s 13ms/step - loss: 1.5785 - accuracy: 0.4381 - val_loss: 1.7291 - val_accuracy: 0.3937
157/157 [==============================] - 0s 2ms/step - loss: 1.7291 - accuracy: 0.3937
[INFO] accuracy: 39.37%
由于我们的非常浅的神经网络(只有一个 CONV 层,后面跟着一个 FC 层),我们在测试集上只获得了 39%的准确率——准确率是 而不是 这是我们输出的重要收获。
相反,这里的关键要点是,我们已经能够成功地将数据增强应用到我们的培训渠道中。你可以在中替换任何你想要的神经网络架构,我们的tf.data管道将自动将数据增强整合到其中。
作为对你的一个练习,我建议换掉我们超级简单的 CNN,尝试用诸如 LeNet 、 MiniVGGNet 或 ResNet 之类的架构来代替它。无论您选择哪种架构,我们的tf.data管道都将能够应用数据扩充,而无需您添加任何额外的代码(更重要的是,这个数据管道将比依赖旧的ImageDataGenerator类高效得多)。
总结
在本教程中,您学习了如何使用tf.data和 TensorFlow 执行数据扩充。
使用tf.data应用数据扩充有两种方法:
- 使用
preprocessing模块和Sequential类进行数据扩充 - 在
tf.image模块中使用 TensorFlow 操作进行数据扩充(以及您想要使用 OpenCV、scikit-image 等实现的任何其他自定义图像处理例程。)
对于大多数深度学习实践者来说,第一种方法就足够了。最流行的数据扩充操作是已经在preprocessing模块中实现的。
类似地,使用Sequential类是在彼此之上应用一系列数据扩充操作的自然方式。Keras 的ImageDataGenerator类用户使用这种方法会有宾至如归的感觉。
第二种方法主要针对那些需要对其数据增强管道进行更细粒度控制的深度学习实践者。这种方法允许你利用tf.image中的图像处理功能以及你想使用的任何其他计算机视觉/图像处理库,包括 OpenCV、scikit-image、PIL/Pillow 等。
本质上,只要你能把你的图像作为一个 NumPy 数组处理,并作为一个张量返回,第二种方法对你来说是公平的。
注: 如果只使用原生张量流运算,可以避免中间的 NumPy 数组表示,直接对张量流张量进行运算,这样会导致更快的增强。
也就是说,从第一种方法开始——preprocessing模块和Sequential类是一种非常自然、易于使用的方法,用于通过tf.data应用数据扩充。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 tf.data 和 TensorFlow 的数据管道
原文:https://pyimagesearch.com/2021/06/21/data-pipelines-with-tf-data-and-tensorflow/
在本教程中,您将学习如何使用tf.data和 TensorFlow 实现快速、高效的数据管道来训练神经网络。
本教程是我们关于tf.data模块的三部分系列的第二部分:
- 温柔介绍 tf.data (上周教程)
- 带有 tf.data 和 TensorFlow 的数据管道(本帖)
- 用 tf.data 进行数据扩充(下周教程)
上周,我们主要关注了 Keras 的ImageDataGenerator类与 TensorFlow v2 的tf.data类的基准测试— 如我们的结果所示,tf.data的图像数据效率提高了约 38 倍。
但是,该教程没有解决以下问题:
- 如何使用 TensorFlow 函数有效地加载图像?
- 如何使用 TensorFlow 函数从文件路径中解析类标签?
- 什么是
@tf.function装饰器,它如何用于数据加载和预处理? - 我如何初始化三个独立的
tf.data管道,一个用于训练,一个用于验证,一个用于测试? - 最重要的是,我如何使用
tf.data管道训练神经网络?
今天我们就在这里回答这些问题。
要学习如何使用tf.data模块、 来训练一个神经网络,只需继续阅读。
带有 tf.data 和 TensorFlow 的数据管道
在本教程的第一部分,我们将讨论tf.data管道的效率,以及我们是否应该使用tf.data而不是 Keras 的经典ImageDataGenerator函数。
然后,我们将配置我们的开发环境,查看我们的项目目录结构,并讨论我们将在本教程中使用的图像数据集。
从那里我们可以实现我们的 Python 脚本,包括在磁盘上组织数据集的方法,初始化我们的tf.data管道,然后最终使用管道作为我们的数据生成器训练 CNN。
我们将通过比较我们的tf.data流水线速度和ImageDataGenerator来总结本指南,并确定哪一个获得了更快的吞吐率。
用 TensorFlow 构建数据管道,tf.data 和 ImageDataGenerator 哪个更好?
就像计算机科学中的许多复杂问题一样,这个问题的答案是“视情况而定”
ImageDataGenerator类有很好的文档记录,易于使用,并且直接嵌入在 Keras API 中(如果你有兴趣的话,我有一个关于使用 ImageDataGenerator 进行数据扩充的教程)。
另一方面,tf.data模块是一个较新的实现,旨在将 PyTorch 式的数据加载和处理引入 TensorFlow 库。
当使用tf.data 创建数据管道时 是否需要更多的工作,所获得的加速是值得的。
正如我上周在演示的,使用tf.data可以使数据生成速度提高大约 38 倍。如果你需要纯粹的速度,并且愿意多写 20-30 行代码(取决于你想达到的高级程度),那么花额外的前期时间来实现tf.data流水线是非常值得的。
配置您的开发环境
这篇关于 tf.keras 数据管道的教程利用了 keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都有助于在一个方便的 Python 虚拟环境中为您的系统配置这篇博客文章所需的所有软件。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
乳腺癌组织学数据集
我们在今天的帖子中使用的数据集是浸润性导管癌(IDC),这是所有乳腺癌中最常见的一种。长期使用 PyImageSearch 的读者会认识到,我们在使用 Keras 和深度学习教程的 乳腺癌分类中使用了这个数据集。
我们今天将在这里使用相同的数据集,以便我们可以比较ImageDataGenerator和tf.data的数据处理速度,从而我们可以确定哪种方法是用于训练深度神经网络的更快、更有效的数据管道。
该数据集最初是由 Janowczyk 和 Madabhushi 和 Roa 等人策划的,但在 Kaggle 的网站上可以在公共领域获得。
总共有 277,524 个图像,每个图像都是 50×50 像素,属于两类:
- 198,738 例阴性病例(即无乳腺癌)
- 78786 个阳性病例(即表明在该贴片中发现了乳腺癌)
显然,类数据中存在不平衡,负数据点的数量是正数据点的两倍多,因此我们需要做一些类加权来处理这种偏差。
图 3 显示了正面和负面样本的例子——我们的目标是训练一个深度学习模型,能够辨别这两个类别之间的差异。
注意: 在继续之前,我 强烈建议阅读我之前的乳腺癌分类教程——这不仅会让你更深入地回顾数据集,还会帮助你更好地理解/欣赏ImageDataGenerator管道和我们的tf.data管道之间的差异和字幕。**
*### 项目结构
首先,请务必访问本教程的 “下载” 部分以检索源代码。
从那里,解压缩归档文件:
$ cd path/to/downloaded/zip
$ unzip tfdata-piplines.zip
现在您已经提取了文件,是时候将数据集放入目录结构中了。
继续创建以下目录:
$ cd tfdata-pipelines
$ mkdir datasets
$ mkdir datasets/orig
然后,前往 Kaggle 的网站并登录。在那里,您可以单击以下链接将数据集下载到项目文件夹中:
点击这里从 Kaggle 下载数据
注: 你需要在 Kaggle 的网站上创建一个账户(如果你还没有账户的话)来下载数据集。
请务必保存。tfdata-pipelines/datasets/orig folder中的 zip 文件。
现在回到您的终端,导航到您刚刚创建的目录,并解压缩数据:
$ cd path/to/tfdata-pipelines/datasets/orig
$ unzip archive.zip -x "IDC_regular_ps50_idx5/*"
从那里,让我们回到项目目录,并使用 tree 命令来检查我们的项目结构:
$ tree . --dirsfirst --filelimit 10
.
├── datasets
│ └── orig
│ ├── 10253
│ │ ├── 0
│ │ └── 1
│ ├── 10254
│ │ ├── 0
│ │ └── 1
│ ├── 10255
│ │ ├── 0
│ │ └── 1
...[omitting similar folders]
│ ├── 9381
│ │ ├── 0
│ │ └── 1
│ ├── 9382
│ │ ├── 0
│ │ └── 1
│ ├── 9383
│ │ ├── 0
│ │ └── 1
│ └── 7415_10564_bundle_archive.zip
├── build_dataset.py
├── plot.png
└── train_model.py
2 directories, 6 files
datasets目录,更具体地说,datasets/orig文件夹包含我们的原始组织病理学图像,我们将在这些图像上训练我们的 CNN。
在pyimagesearch模块中,我们有一个配置文件(用于存储重要的训练参数),以及我们将要训练的 CNN,CancerNet。
build_dataset.py将重组datasets/orig的目录结构,这样我们就可以进行适当的训练、验证和测试分割。
然后,train_model.py脚本将使用tf.data在我们的数据集上训练CancerNet。
创建我们的配置文件
在我们可以在磁盘上组织数据集并使用tf.data管道训练我们的模型之前,我们首先需要实现一个 Python 配置文件来存储重要的变量。这个配置文件在很大程度上是基于我以前的教程 乳腺癌分类与 Keras 和深度学习 所以我强烈建议你阅读该教程,如果你还没有。
否则,打开pyimagesearch模块中的config.py文件并插入以下代码:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = os.path.join("datasets", "orig")
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = os.path.join("datasets", "idc")
首先,我们将路径设置为从 Kaggle ( 第 5 行)下载的原始输入目录。
在创建训练、测试和验证分割后,我们指定BASE_PATH存储图像文件的位置(第 9 行)。
使用BASE_PATH集合,我们可以分别定义我们的输出训练、验证和测试目录:
# derive the training, validation, and testing directories
TRAIN_PATH = os.path.sep.join([BASE_PATH, "training"])
VAL_PATH = os.path.sep.join([BASE_PATH, "validation"])
TEST_PATH = os.path.sep.join([BASE_PATH, "testing"])
以下是我们的数据分割信息:
# define the amount of data that will be used training
TRAIN_SPLIT = 0.8
# the amount of validation data will be a percentage of the
# *training* data
VAL_SPLIT = 0.1
# define input image spatial dimensions
IMAGE_SIZE = (48, 48)
我们将 80%的数据用于训练,20%用于测试。我们还将使用 10%的数据进行验证,这 10%将来自分配给培训的 80%份额。
此外,我们指出所有输入图像都将被调整大小,使其空间尺寸为 48×48。
最后,我们有几个重要的培训参数:
# initialize our number of epochs, early stopping patience, initial
# learning rate, and batch size
NUM_EPOCHS = 40
EARLY_STOPPING_PATIENCE = 5
INIT_LR = 1e-2
BS = 128
我们将允许我们的网络总共训练40个时期,但是如果在5个时期之后验证损失没有减少,我们将终止训练过程。
然后,我们定义我们的初始学习率和每批的大小。
在磁盘上实现我们的数据集管理器
我们的乳腺癌图像数据集包含近 20 万幅图像,每幅图像都是 50 × 50 像素。如果我们试图一次将整个数据集存储在内存中,我们将需要将近 6GB 的 RAM。
大多数深度学习钻机可以轻松处理这么多数据;然而,一些笔记本电脑或台式机可能没有足够的内存,此外,本教程的全部目的是演示如何为驻留在磁盘上的数据创建有效的tf.data管道,所以让我们假设您的机器不能将整个数据集放入 RAM。
但是在我们能够构建我们的tf.data管道之前,我们首先需要实现build_dataset.py,它将获取我们的原始输入数据集并创建训练、测试和验证分割。
打开build_dataset.py脚本,让我们开始工作:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import random
import shutil
import os
# grab the paths to all input images in the original input directory
# and shuffle them
imagePaths = list(paths.list_images(config.ORIG_INPUT_DATASET))
random.seed(42)
random.shuffle(imagePaths)
# compute the training and testing split
i = int(len(imagePaths) * config.TRAIN_SPLIT)
trainPaths = imagePaths[:i]
testPaths = imagePaths[i:]
# we'll be using part of the training data for validation
i = int(len(trainPaths) * config.VAL_SPLIT)
valPaths = trainPaths[:i]
trainPaths = trainPaths[i:]
# define the datasets that we'll be building
datasets = [
("training", trainPaths, config.TRAIN_PATH),
("validation", valPaths, config.VAL_PATH),
("testing", testPaths, config.TEST_PATH)
]
我们从在第 2-6 行导入我们需要的包开始。我们需要刚刚在上一节中实现的config脚本。paths模块允许我们获取数据集中所有图像的路径。random模块将被用来改变我们的图像路径。最后,shutil和os将用于将图像文件复制到它们的最终位置。
第 10-12 行抓取我们ORIG_INPUT_DATASET中的所有imagePaths,然后按随机顺序洗牌。
使用我们的TRAIN_SPLIT和VAL_SPLIT参数,我们然后创建我们的训练、测试和验证分割(第 15-22 行)。
第 25-29 行创建一个名为datasets的列表。datasets中的每个条目由三个元素组成:
- 拆分的名称
- 与拆分相关联的图像路径
- 该分割中的图像将存储到的目录的路径
我们现在可以循环我们的datasets:
# loop over the datasets
for (dType, imagePaths, baseOutput) in datasets:
# show which data split we are creating
print("[INFO] building '{}' split".format(dType))
# if the output base output directory does not exist, create it
if not os.path.exists(baseOutput):
print("[INFO] 'creating {}' directory".format(baseOutput))
os.makedirs(baseOutput)
# loop over the input image paths
for inputPath in imagePaths:
# extract the filename of the input image and extract the
# class label ("0" for "negative" and "1" for "positive")
filename = inputPath.split(os.path.sep)[-1]
label = filename[-5:-4]
# build the path to the label directory
labelPath = os.path.sep.join([baseOutput, label])
# if the label output directory does not exist, create it
if not os.path.exists(labelPath):
print("[INFO] 'creating {}' directory".format(labelPath))
os.makedirs(labelPath)
# construct the path to the destination image and then copy
# the image itself
p = os.path.sep.join([labelPath, filename])
shutil.copy2(inputPath, p)
在我们的for循环中,我们:
- 如果基础输出目录不存在,则创建它(第 37-39 行)
- 在当前分割(行 42 )中循环
imagePaths - 提取图像
filename和类label( 第 45 和 46 行) - 构建输出标签目录的路径(第 49 行)
- 如果
labelPath不存在,则创建它(第 52-54 行) - 将原始图像复制到最终的
{split_name}/{label_name}子目录中
我们现在准备在磁盘上组织我们的数据集。
组织我们的图像数据集
现在我们已经完成了数据拆分器的实现,让我们在数据集上运行它。
确保你们俩:
- 转到本教程的 “下载” 部分检索源代码
- 从 Kaggle 下载乳腺组织病理学图像数据集
从那里,我们可以在磁盘上组织我们的数据集:
$ python build_dataset.py
[INFO] building 'training' split
[INFO] 'creating datasets/idc/training' directory
[INFO] 'creating datasets/idc/training/0' directory
[INFO] 'creating datasets/idc/training/1' directory
[INFO] building 'validation' split
[INFO] 'creating datasets/idc/validation' directory
[INFO] 'creating datasets/idc/validation/0' directory
[INFO] 'creating datasets/idc/validation/1' directory
[INFO] building 'testing' split
[INFO] 'creating datasets/idc/testing' directory
[INFO] 'creating datasets/idc/testing/0' directory
现在让我们来看看datasets/idc子目录:
$ tree --dirsfirst --filelimit 10
.
├── datasets
│ ├── idc
│ │ ├── training
│ │ │ ├── 0 [143065 entries]
│ │ │ └── 1 [56753 entries]
│ │ ├── validation
│ │ | ├── 0 [15962 entries]
│ │ | └── 1 [6239 entries]
│ │ └── testing
│ │ ├── 0 [39711 entries]
│ │ └── 1 [15794 entries]
│ └── orig [280 entries]
请注意我们是如何计算我们的培训、验证和测试分割的。
使用 tf.data 和 TensorFlow 数据管道实施我们的培训脚本
准备好学习如何使用tf.data管道训练卷积神经网络了吗?
你当然是!(不然你也不会在这里了吧?)
打开项目目录结构中的train_model.py文件,让我们开始工作:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.cancernet import CancerNet
from pyimagesearch import config
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adagrad
from tensorflow.keras.utils import to_categorical
from tensorflow.data import AUTOTUNE
from imutils import paths
import matplotlib.pyplot as plt
import tensorflow as tf
import argparse
import os
第 2 行和第 3 行导入matplotlib,设置后台,以便在后台保存数字。
第 6-16 行导入我们所需的其余包,值得注意的包括:
CancerNet:我们将培训 CNN 的实施。我没有在这篇文章中介绍 CancerNet 的实现,因为我在之前的教程中已经广泛介绍过了, 使用 Keras 的乳腺癌分类和深度学习 。config:我们的配置文件Adagrad:我们将用来训练CancerNet的优化器AUTOTUNE: TensorFlow 的自动调整功能
因为我们正在构建一个tf.data管道来处理磁盘上的图像,所以我们需要定义一个函数来:
- 从磁盘加载我们的图像
- 从文件路径中解析类标签
- 将图像和标签返回给调用函数
如果你读了上周关于 的教程,一个关于使用 TensorFlow 的 tf.data 的温和介绍(如果你还没有,你现在应该停下来阅读那个指南),那么下面的load_images函数应该看起来很熟悉:
def load_images(imagePath):
# read the image from disk, decode it, convert the data type to
# floating point, and resize it
image = tf.io.read_file(imagePath)
image = tf.image.decode_png(image, channels=3)
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.image.resize(image, config.IMAGE_SIZE)
# parse the class label from the file path
label = tf.strings.split(imagePath, os.path.sep)[-2]
label = tf.strings.to_number(label, tf.int32)
# return the image and the label
return (image, label)
load_images函数需要一个参数imagePath,它是我们想要加载的输入图像的路径。然后,我们继续:
- 从磁盘加载输入图像
- 将其解码为无损 PNG 图像
- 将其从无符号 8 位整数数据类型转换为 float32
- 将图像大小调整为 48 × 48 像素
类似地,我们通过分割文件路径分隔符并提取适当的子目录名(存储类标签)来解析来自imagePath的类标签。
然后将image和label返回到调用函数。
注意: 注意,我们没有使用 OpenCV 来加载我们的图像,而是使用 NumPy 来改变数据类型,或者内置 Python 函数来提取类标签, 我们改为使用 TensorFlow 函数。这是故意的! 尽可能使用 TensorFlow 的功能,让 TensorFlow 更好地优化数据管道。
接下来,让我们定义一个将执行简单数据扩充的函数:
@tf.function
def augment(image, label):
# perform random horizontal and vertical flips
image = tf.image.random_flip_up_down(image)
image = tf.image.random_flip_left_right(image)
# return the image and the label
return (image, label)
augment函数需要两个参数——我们的输入image和类label。
我们随机执行水平和垂直翻转(第 36 行和第 37 行),其结果返回给调用函数。
注意@tf.function函数装饰器。这个装饰器告诉 TensorFlow 使用我们的 Python 函数,并将其转换成 TensorFlow 可调用的图。图形转换允许 TensorFlow 对其进行优化,并使其更快——由于我们正在建立一个数据管道,速度是我们希望优化的。
现在让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们有一个单独的(可选的)参数,--plot,它是显示我们的损失和准确性的训练图的路径。
# grab all the training, validation, and testing dataset image paths
trainPaths = list(paths.list_images(config.TRAIN_PATH))
valPaths = list(paths.list_images(config.VAL_PATH))
testPaths = list(paths.list_images(config.TEST_PATH))
# calculate the total number of training images in each class and
# initialize a dictionary to store the class weights
trainLabels = [int(p.split(os.path.sep)[-2]) for p in trainPaths]
trainLabels = to_categorical(trainLabels)
classTotals = trainLabels.sum(axis=0)
classWeight = {}
# loop over all classes and calculate the class weight
for i in range(0, len(classTotals)):
classWeight[i] = classTotals.max() / classTotals[i]
第 49-51 行分别获取我们的训练、测试和验证目录中所有图像的路径。
然后,我们提取训练类标签,对它们进行一次性编码,并计算每个标签在分割中出现的次数(第 55-57 行)。我们执行该操作,因为我们知道在我们的数据集中存在严重的类别不平衡(参见上面的“乳腺癌组织学数据集”部分以获得关于类别不平衡的更多信息)。
第 61 行和第 62 行通过计算类别权重来说明类别不平衡,该权重将允许代表不足的标签在训练过程的权重更新阶段具有“更多权重”。
接下来,让我们定义我们的培训tf.data渠道:
# build the training dataset and data input pipeline
trainDS = tf.data.Dataset.from_tensor_slices(trainPaths)
trainDS = (trainDS
.shuffle(len(trainPaths))
.map(load_images, num_parallel_calls=AUTOTUNE)
.map(augment, num_parallel_calls=AUTOTUNE)
.cache()
.batch(config.BS)
.prefetch(AUTOTUNE)
)
我们首先使用from_tensor_slices函数(第 65 行)创建一个tf.data.Dataset的实例。
tf.data管道本身由以下步骤组成:
- 混洗训练集中的所有图像路径
- 将图像载入缓冲区
- 对加载的图像执行数据扩充
- 缓存结果以供后续更快的读取
- 创建一批数据
- 允许
prefetch在后台优化程序
注: 如果你想知道更多关于如何构建tf.data管道的细节,请看我之前的教程 一个用 TensorFlow 对 tf.data 的温和介绍。
以类似的方式,我们可以构建我们的验证和测试tf.data管道:
# build the validation dataset and data input pipeline
valDS = tf.data.Dataset.from_tensor_slices(valPaths)
valDS = (valDS
.map(load_images, num_parallel_calls=AUTOTUNE)
.cache()
.batch(config.BS)
.prefetch(AUTOTUNE)
)
# build the testing dataset and data input pipeline
testDS = tf.data.Dataset.from_tensor_slices(testPaths)
testDS = (testDS
.map(load_images, num_parallel_calls=AUTOTUNE)
.cache()
.batch(config.BS)
.prefetch(AUTOTUNE)
)
76-82 线建立我们的验证管道。请注意,我们在这里没有调用shuffle或augment,这是因为:
- 验证数据不需要被打乱
- 数据扩充不适用于验证数据
我们仍然使用prefetch,因为这允许我们在每个时期结束时优化评估例程。
类似地,我们在第 85-91 行的上创建我们的测试tf.data管道。
如果不考虑数据集初始化,我们会实例化我们的网络架构:
# initialize our CancerNet model and compile it
model = CancerNet.build(width=48, height=48, depth=3,
classes=1)
opt = Adagrad(lr=config.INIT_LR,
decay=config.INIT_LR / config.NUM_EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
第 94 和 95 行初始化我们的CancerNet模型。我们在这里提供classes=1,尽管这是一个两类问题,因为我们在CancerNet中有一个 sigmoid 激活函数作为我们的最终层——sigmoid 激活将自然地处理这个两类问题。
然后,我们初始化优化器,并使用二进制交叉熵损失编译模型。
从那里,培训可以开始:
# initialize an early stopping callback to prevent the model from
# overfitting
es = EarlyStopping(
monitor="val_loss",
patience=config.EARLY_STOPPING_PATIENCE,
restore_best_weights=True)
# fit the model
H = model.fit(
x=trainDS,
validation_data=valDS,
class_weight=classWeight,
epochs=config.NUM_EPOCHS,
callbacks=[es],
verbose=1)
# evaluate the model on test set
(_, acc) = model.evaluate(testDS)
print("[INFO] test accuracy: {:.2f}%...".format(acc * 100))
第 103-106 行初始化我们的EarlyStopping标准。如果验证损失在总共EARLY_STOPPING_PATIENCE个时期后没有下降,那么我们将停止训练过程并保存我们的 CPU/GPU 周期。
在行 109-115 上调用model.fit开始训练过程。
如果你以前曾经用 Keras/TensorFlow 训练过一个模型,那么这个函数调用应该看起来很熟悉,但是请注意,为了利用tf.data,我们需要做的就是通过我们的训练和测试tf.data管道对象— ,真的很容易!
第 118 和 119 行在测试集上评估我们的模型。
最后一步是绘制我们的训练历史:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.plot(H.history["accuracy"], label="train_acc")
plt.plot(H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
然后将结果图保存到磁盘。
TensorFlow 和 tf.data 管道结果
我们现在准备使用我们定制的tf.data管道来训练一个卷积神经网络。
首先访问本教程的 【下载】 部分来检索源代码。从那里,您可以启动train_model.py脚本:
$ python train_model.py
1562/1562 [==============================] - 39s 23ms/step - loss: 0.6887 - accuracy: 0.7842 - val_loss: 0.4085 - val_accuracy: 0.8357
Epoch 2/40
1562/1562 [==============================] - 30s 19ms/step - loss: 0.5556 - accuracy: 0.8317 - val_loss: 0.5096 - val_accuracy: 0.7744
Epoch 3/40
1562/1562 [==============================] - 30s 19ms/step - loss: 0.5384 - accuracy: 0.8378 - val_loss: 0.5246 - val_accuracy: 0.7727
Epoch 4/40
1562/1562 [==============================] - 30s 19ms/step - loss: 0.5296 - accuracy: 0.8412 - val_loss: 0.5035 - val_accuracy: 0.7819
Epoch 5/40
1562/1562 [==============================] - 30s 19ms/step - loss: 0.5227 - accuracy: 0.8431 - val_loss: 0.5045 - val_accuracy: 0.7856
Epoch 6/40
1562/1562 [==============================] - 30s 19ms/step - loss: 0.5177 - accuracy: 0.8451 - val_loss: 0.4866 - val_accuracy: 0.7937
434/434 [==============================] - 5s 12ms/step - loss: 0.4184 - accuracy: 0.8333
[INFO] test accuracy: 83.33%...
正如你所看到的,我们在检测输入图像中的乳腺癌时获得了大约 83%的准确率。但是更有趣的是查看每个历元的速度——注意,使用tf.data会导致历元花费大约 30 秒来完成。
现在让我们将 epoch speed 与我们关于乳腺癌分类的原始教程进行比较,该教程利用了ImageDataGenerator功能:
$ python train_model.py
Found 199818 images belonging to 2 classes.
Found 22201 images belonging to 2 classes.
Found 55505 images belonging to 2 classes.
Epoch 1/40
6244/6244 [==============================] - 142s 23ms/step - loss: 0.5954 - accuracy: 0.8211 - val_loss: 0.5407 - val_accuracy: 0.7796
Epoch 2/40
6244/6244 [==============================] - 135s 22ms/step - loss: 0.5520 - accuracy: 0.8333 - val_loss: 0.4786 - val_accuracy: 0.8097
Epoch 3/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5423 - accuracy: 0.8358 - val_loss: 0.4532 - val_accuracy: 0.8202
...
Epoch 38/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5248 - accuracy: 0.8408 - val_loss: 0.4269 - val_accuracy: 0.8300
Epoch 39/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5254 - accuracy: 0.8415 - val_loss: 0.4199 - val_accuracy: 0.8318
Epoch 40/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5244 - accuracy: 0.8422 - val_loss: 0.4219 - val_accuracy: 0.8314
使用ImageDataGenerator作为我们的数据管道导致需要大约 133 秒来完成的时期。
数字说明了一切——通过用tf.data、、替换我们的ImageDataGenerator呼叫,我们获得了大约 4.4 倍的加速!
如果你愿意做一些额外的工作来编写一个定制的tf.data管道,那么性能的提升是非常值得的。
总结
在本教程中,您学习了如何使用 TensorFlow 和tf.data模块实现自定义数据管道来训练深度神经网络。
在训练我们的网络时,当使用tf.data而不是ImageDataGenerator时,我们获得了4.4 倍的加速比。
缺点是它要求我们编写额外的代码,包括实现两个自定义函数:
- 一个用来加载我们的图像数据,然后解析类标签
- 另一个执行一些基本的数据扩充
说到数据扩充,下周我们将学习一些更高级的技术,在tf.data管道内执行数据扩充——请继续收听该教程,您不会想错过它的。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
深度梦境:可视化谷歌网络的每一层
原文:https://pyimagesearch.com/2015/08/03/deep-dream-visualizing-every-layer-of-googlenet/
几周前我介绍了 bat-country ,这是我实现的一个轻量级、可扩展、易于使用的 Python 包,用于深度做梦和灵感。
图书馆的接收效果非常好,所以我决定做一个后续的帖子会很有趣——但与其像在 Twitter #deepdream stream 上那样生成一些真正迷幻的图像,我认为使用 bat-country 来可视化 GoogLeNet 的每一层会更有吸引力。
用 Python 可视化 GoogLeNet 的每一层
下面是我加载图像的 Python 脚本,循环遍历网络的每一层,然后将每个输出图像写入文件:
# import the necessary packages
from __future__ import print_function
from batcountry import BatCountry
from PIL import Image
import numpy as np
import argparse
import warnings
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-b", "--base-model", required=True, help="base model path")
ap.add_argument("-i", "--image", help="path to image file")
ap.add_argument("-o", "--output", help="path to output directory")
args = ap.parse_args()
# filter warnings, initialize bat country, and grab the layer names of
# the CNN
warnings.filterwarnings("ignore")
bc = BatCountry(args.base_model)
layers = bc.layers()
# extract the filename and extension of the input image
filename = args.image[args.image.rfind("/") + 1:]
(filename, ext) = filename.split(".")
# loop over the layers
for (i, layer) in enumerate(layers):
# perform visualizing using the current layer
print("[INFO] processing layer `{}` {}/{}".format(layer, i + 1, len(layers)))
try:
# pass the image through the network
image = bc.dream(np.float32(Image.open(args.image)), end=layer,
verbose=False)
# draw the layer name on the image
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
cv2.putText(image, layer, (5, image.shape[0] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, (0, 255, 0), 2)
# construct the output path and write the image to file
p = "{}/{}_{}.{}".format(args.output, filename, str(i + 1).zfill(4), ext)
cv2.imwrite(p, image)
except KeyError, e:
# the current layer can not be used
print("[ERROR] cannot use layer `{}`".format(layer))
# perform housekeeping
bc.cleanup()
这个脚本需要三个命令行参数:我们的 Caffe 模型所在的--base-model目录,我们的输入路径--image,以及最后的--output目录,我们的图像在通过网络后将存储在这个目录中。
正如你也会看到的,我使用了一个try/except块来捕捉任何不能用于可视化的层。
下面是我输入网络的图像:

Figure 1: The iconic input image of Dr. Grant and the T-Rex from Jurassic Park.
然后,我使用以下命令执行 Python 脚本:
$ python visualize_layers.py \
--base-model $CAFFE_ROOT/caffe/models/bvlc_googlenet \
--image images/jp.jpg --output output/jp
可视化过程将会开始。我在一个启用了 GPU 支持的 Amazon EC2 g2.2xlarge 实例上生成了我的结果,因此脚本在 30 分钟内完成。
下面可以看到一张 所有图层可视化 的. gif:
Figure 2: Visualizing every layer of GoogLeNet using bat-country.
的。gif 文件相当大,有 9.6 MB,所以给它几秒钟加载时间,尤其是如果你的网速很慢的话。
同时,这里有一些我最喜欢的图层:

Figure 3: This is my far my favorite one of the bunch. The lower layers of the network reflect edge-like regions in the input image.

Figure 4: The inception_3a/3×3 layer also products a nice effect.

Figure 5: The same goes for the inception_3b/3x3_reduce layer.

Figure 6: This one I found amusing — it seems that Dr. Grant has developed a severe case of dog-ass.

Figure 7: Eventually, our Dr. Grant and T-Rex have morphed into something else entirely.
摘要
这篇博文是一个快速的“只是为了好玩”的教程,介绍如何使用蝙蝠国图书馆可视化 CNN 的每一层。它还很好地演示了如何使用bat-country库。
如果你还没有机会玩转深度梦境或幻觉,那么一定要读一读 bat-country 上的原始帖子——我想你会发现它很有趣,令人愉快。
下周见!
用 Python 和 nolearn 在亚马逊 EC2 GPU 上进行深度学习
原文:https://pyimagesearch.com/2014/10/13/deep-learning-amazon-ec2-gpu-python-nolearn/
![]() 上周我写了一篇文章,详细介绍了我在 MacBook Pro 上使用 CUDAMat、Deep Belief Networks 和 Python 的体验。
上周我写了一篇文章,详细介绍了我在 MacBook Pro 上使用 CUDAMat、Deep Belief Networks 和 Python 的体验。
这篇文章相当长,并且有很多截图来记录我的经历。
但它的要旨是这样的:即使在安装了 NVIDIA Cuda SDK 并配置了 CUDAMat 之后,我的 CPU 在训练我的深度信念网络(由 nolearn 实现)的速度比我的 GPU 还要快。你可以想象,我被留在那里挠头。
然而,自从这个帖子上周发布以来,我得到了大量有价值的反馈。
有人告诉我,我的网络不够大,无法完全实现 GPU 加速。我还被告知我应该使用 Theano 而不是 nolearn ,因为他们的 GPU 支持更先进。甚至有人建议我应该探索 CUDAMat 的一些编译时选项。最后,我被告知我不应该使用我的 MacBook Pro 的 GPU 。
所有这些都是很好的反馈,对我帮助很大——但我并不满意。
在阅读了 Markus Beissinger 关于在 Amazon EC2 GPU 实例上安装 Theano 的精彩帖子后,我决定亲自尝试一下。
但我没有使用 Theano,而是想使用 no learn——主要是想看看我能否在亚马逊云上重现我的 MacBook Pro 遇到的问题。如果我可以复制我的结果,那么我可以得出结论,问题在于 nolearn 库,而不是我的 MacBook Pro 的 GPU。
所以,无论如何,就像上一篇文章一样,这篇文章充满了截图,因为我记录了我通过设置 Amazon EC2 GPU 实例来使用 Python 和 nolearn 训练深度信仰网络的方法。
使用 Python 和 nolearn 在 Amazon EC2 GPU 上进行深度学习
如果您还不知道,Amazon 提供了一个 EC2 实例,它提供了对 GPU 的访问以进行计算。
这个实例的名称是 g2.2xlarge ,成本大约是每小时 0.65 美元。然而,正如 Markus 指出的,通过使用 Spot 实例,你可以将这一成本降低到大约每小时 0.07 美元(当然,前提是你可以处理计算中的中断)。
受 Markus 帖子的启发,我决定建一个自己的 g 2.2x 大操场,找点乐子。
如果你一直关注这篇文章,我会假设你已经有了一个 Amazon AWS 帐户,并且可以设置一个 EC2 实例:
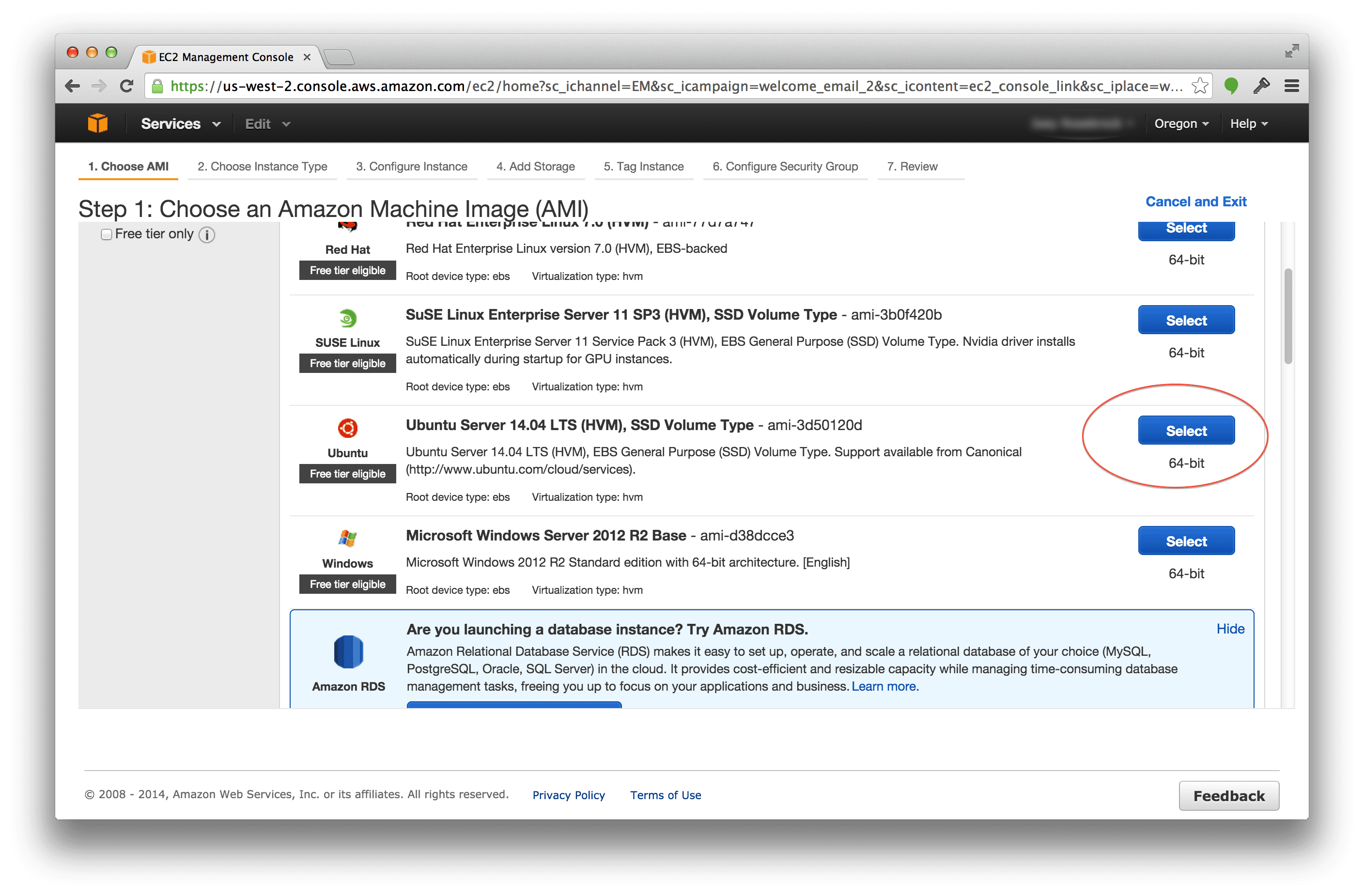
您需要做的第一件事是为您的实例选择一个操作系统。我选择了 Ubuntu 14.04 LTS (64 位)(ami-3d50120d)。
从那里,您需要选择您需要的实例。Amazon 提供了许多不同层次的实例,每一层都面向您希望执行的计算类型。您有非常适合 web 服务器的通用实例,有适合处理大量数据的高内存服务器,还有可以提高吞吐量的高 CPU 可用性。
在我们的例子中,我们对利用 GPU 感兴趣:
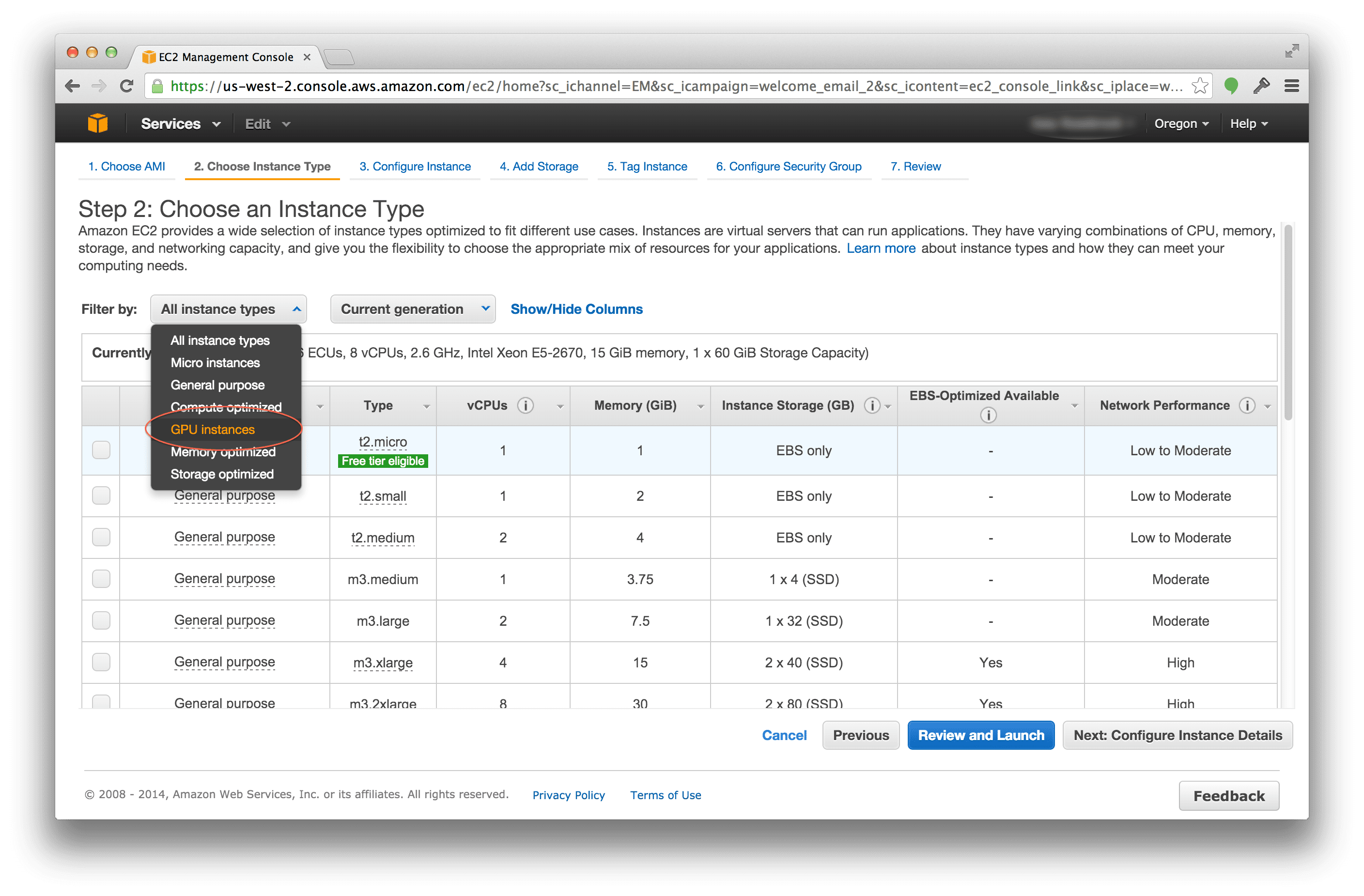
一定要选择“GPU 实例”,只过滤 Amazon 提供的可用 GPU 实例。
您的下一个屏幕应该如下所示:
 这里我要选择 g2.2xlarge 实例。需要注意的是,这个实例 不是免费的 ,如果你启动它 你将被收费 。
这里我要选择 g2.2xlarge 实例。需要注意的是,这个实例 不是免费的 ,如果你启动它 你将被收费 。
启动并运行 g2.2xlarge 实例的下一步是配置您的安全组以防止外部访问:
点击“启动”按钮,等待您的实例启动。
系统会提示您下载您的密钥对,这样您就可以 SSH 到您的服务器。下载密钥对并将其存储在安全的位置:

等待几分钟,让您的实例启动。
一旦它打开了,你就可以嘘它了。您的 SSH 命令应该如下所示:
$ ssh -i EC2KeyPair.pem ubuntu@<your instance ip address>
如果一切顺利,您现在应该登录到您的 g2.2xlarge 实例。下面是我的实例的一个例子:
 到目前为止这是一个极其无痛的过程。幸运的是,在接下来的教程中,它仍然没有痛苦。
到目前为止这是一个极其无痛的过程。幸运的是,在接下来的教程中,它仍然没有痛苦。
为了让您的系统准备好使用 GPU,您需要安装一些包和库。下面我只是简单地重现了马库斯的步骤,并加入了一些我自己的:
更新默认包:
$ sudo apt-get update
安装任何 Ubuntu 更新:
$ sudo apt-get -y dist-upgrade
安装依赖项:
$ sudo apt-get install -y gcc g++ gfortran build-essential git wget linux-image-generic libopenblas-dev python-dev python-pip python-nose python-numpy python-scipy
安装 LAPACK:
$ sudo apt-get install -y liblapack-dev
安装 BLAS:
$ sudo apt-get install -y libblas-dev
获取最新版本的 CUDA 工具包:
$ wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/cuda-repo-ubuntu1404_6.5-14_amd64.deb
解包工具包:
$ sudo dpkg -i cuda-repo-ubuntu1404_6.5-14_amd64.deb
添加 CUDA 工具包:
$ sudo apt-get update
安装 CUDA 工具包:
$ sudo apt-get install -y cuda
更新你的 PATH :
$ echo "export PATH=/usr/local/cuda-6.5/bin:$PATH" >> .bashrc
$ echo "export LD_LIBRARY_PATH=/usr/local/cuda-6.5/lib64:$LD_LIBRARY_PATH" >> .bashrc
$ source ~/.bashrc
安装 virtualenv 和 virtualenvwrapper:
$ pip install virtualenv virtualenvwrapper
配置 virtualenv 和 virtualenvwrapper:
$ mkdir ~/.virtualenvs
$ export WORKON_HOME=~/.virtualenvs
$ echo ". /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
$ source ~/.bashrc
打造你的深度学习环境:
$ mkvirtualenv deeplearning
安装 Python 包:
$ pip install numpy scipy scikit-learn nolearn
编译 CUDAMat:
$ git clone https://github.com/cudamat/cudamat
$ cd cudamat
$ make
我知道。看起来有很多步骤。但老实说,这并不坏,而且我花的时间不超过 10 分钟。
作为一项健康检查,我决定运行deviceQuery来确保我的 GPU 正在被拾取:
果然是!
所以现在让我们来训练一个深度的信念网络。打开一个新文件,将其命名为dbn.py,并添加以下代码:
# import the necessary packages
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn import datasets
from nolearn.dbn import DBN
import numpy as np
# grab the MNIST dataset (if this is the first time you are running
# this script, this make take a minute -- the 55mb MNIST digit dataset
# will be downloaded)
print "[X] downloading data..."
dataset = datasets.fetch_mldata("MNIST Original")
# scale the data to the range [0, 1] and then construct the training
# and testing splits
(trainX, testX, trainY, testY) = train_test_split(
dataset.data / 255.0, dataset.target.astype("int0"), test_size = 0.33)
# train the Deep Belief Network with 784 input units (the flattened,
# 28x28 grayscale image), 800 hidden units in the 1st hidden layer,
# 800 hidden nodes in the 2nd hidden layer, and 10 output units (one
# for each possible output classification, which are the digits 1-10)
dbn = DBN(
[trainX.shape[1], 800, 800, 10],
learn_rates = 0.3,
learn_rate_decays = 0.9,
epochs = 10,
verbose = 1)
dbn.fit(trainX, trainY)
# compute the predictions for the test data and show a classification
# report
preds = dbn.predict(testX)
print classification_report(testY, preds)
注意第 12 行。这一行将用于手写数字识别的 MNIST 数据集下载并缓存到您的 EC2 实例中。对这个函数的后续调用会快得多(因为您不必再次下载数据)。我提到这一点是因为如果您正在监控您的训练时间,并且您还没有缓存 MNIST 数据集,您将得到不可靠的结果。
我在深度信念网络上的前一篇文章使用了一个非常小的 DBN——一个 784 个输入的输入层,一个 300 个节点的隐藏层,和一个 10 个节点的输出层,每个节点对应一个可能的数字 1-9。
我注意到,在更大的网络得到训练之前,GPU 训练相对于 CPU 训练的加速并没有完全实现。
因此,我不是训练一个小网络,而是训练一个大得多的网络(但与我们今天看到的最先进的网络相比仍然“小”)。
这次我将使用 784 个输入的输入层,800 个节点的隐藏层,800 个节点的第二个隐藏层,最后是 10 个节点的输出层。我将允许我的网络训练 10 个纪元。
当我在我的 CPU 上训练我的深度信念网络时,我得到了以下结果:
(deeplearning)ubuntu@ip-xxx:~/deep-belief-network-gpu$ time python dbn.py
gnumpy: failed to import cudamat. Using npmat instead. No GPU will be used.
[X] downloading data...
[DBN] fitting X.shape=(46900, 784)
[DBN] layers [784, 800, 800, 10]
[DBN] Fine-tune...
100%
Epoch 1:
loss 0.554249416375
err 0.139429644809
(0:00:25)
100%
Epoch 2:
loss 0.285018297291
err 0.071956113388
(0:00:25)
100%
Epoch 3:
loss 0.216535961656
err 0.0562884221311
(0:00:25)
100%
Epoch 4:
loss 0.1733764816
err 0.0465975068306
(0:00:25)
100%
Epoch 5:
loss 0.145248167361
err 0.0397242144809
(0:00:25)
100%
Epoch 6:
loss 0.118301114211
err 0.0330430327869
(0:00:24)
100%
Epoch 7:
loss 0.0983925512707
err 0.0277279713115
(0:00:24)
100%
Epoch 8:
loss 0.0761229886239
err 0.0223702185792
(0:00:24)
100%
Epoch 9:
loss 0.0661320222977
err 0.0195099043716
(0:00:24)
100%
Epoch 10:
loss 0.0540665843727
err 0.0165215163934
(0:00:24)
precision recall f1-score support
0 0.99 0.98 0.99 2274
1 0.98 0.99 0.99 2587
2 0.97 0.96 0.97 2408
3 0.96 0.95 0.96 2337
4 0.95 0.97 0.96 2220
5 0.97 0.95 0.96 2132
6 0.96 0.99 0.97 2204
7 0.97 0.98 0.98 2382
8 0.96 0.96 0.96 2271
9 0.96 0.95 0.96 2285
avg / total 0.97 0.97 0.97 23100
real 4m48.487s
user 9m51.390s
sys 28m24.093s
差不多 5 分钟在 CPU 上进行训练和评估——这是一个很好的起点。
现在,为了训练深度信念网络,我将我编译的cudamat目录移动到与dbn.py相同的目录中。或者,您可以将cudamat目录添加到您的PATH中。
(deeplearning)ubuntu@ip-xxx:~/deep-belief-network-gpu$ time python dbn.py[X] downloading data...
[DBN] fitting X.shape=(46900, 784)
[DBN] layers [784, 800, 800, 10]
gnumpy: failed to use gpu_lock. Using board #0 without knowing whether it is in use or not.
[DBN] Fine-tune...
100%
Epoch 1:
loss 0.37499609756
err 0.102971311475
(0:00:08)
100%
Epoch 2:
loss 0.223706473163
err 0.0572703210383
(0:00:08)
100%
Epoch 3:
loss 0.176561286027
err 0.0470671106557
(0:00:08)
100%
Epoch 4:
loss 0.131326457655
err 0.036031420765
(0:00:08)
100%
Epoch 5:
loss 0.095808146489
err 0.0266606898907
(0:00:08)
100%
Epoch 6:
loss 0.075324679088
err 0.0217511953552
(0:00:08)
100%
Epoch 7:
loss 0.0538377553038
err 0.0162653688525
(0:00:08)
100%
Epoch 8:
loss 0.0431808142149
err 0.0129567964481
(0:00:08)
100%
Epoch 9:
loss 0.0353603169236
err 0.010843579235
(0:00:08)
100%
Epoch 10:
loss 0.0275717724744
err 0.00823941256831
(0:00:08)
precision recall f1-score support
0 0.99 0.98 0.98 2223
1 0.99 0.99 0.99 2639
2 0.96 0.98 0.97 2285
3 0.97 0.97 0.97 2354
4 0.99 0.97 0.98 2234
5 0.98 0.97 0.97 2085
6 0.98 0.99 0.99 2248
7 0.99 0.97 0.98 2467
8 0.97 0.97 0.97 2217
9 0.96 0.97 0.96 2348
avg / total 0.98 0.98 0.98 23100
real 2m20.350s
user 2m5.786s
sys 0m15.155s
在 g2.2xlarge GPU 上进行训练,我能够将训练和评估时间从 4 分 48 秒缩短到 2 分 20 秒。
这是一个巨大的进步。当然比我在 MacBook Pro 上得到的结果要好。
此外,随着网络规模的增加,GPU 和 CPU 训练时间之间的差异将变得更加显著。
摘要
受 Markus Beissinger 关于使用 Theano 安装用于深度学习的 Amazon EC2 g 2.2x 大型实例的帖子的启发,我决定对 nolearn Python 包做同样的事情。
此外,在我试图在我的 MacBook Pro 的 GPU 上训练一个深度信念网络并获得糟糕的结果后,这篇文章也算是一种“救赎”。
总的来说,我发现以下几点很重要:
- 你的 GPU 很重要。很多。大多数笔记本电脑中包含的 GPU 针对能效进行了优化,但不一定针对计算效率。
- 更重要的是: 你的人际网络的规模很重要。如果您的网络不够大,您不会注意到 CPU 和 GPU 之间的训练时间有显著的改善。
- 将数据传输到 GPU 会产生开销。如果传输的数据量太小,那么 CPU 的运行效率会更高(因为你会把所有的时间都浪费在传输上,而不是计算上)。
- 亚马逊的 g2.2xlarge 实例非常有趣。这确实需要钱(用一下午的快乐换取不到一杯咖啡,这是显而易见的),但如果你不想花这笔钱购买一个专门用于深度学习的新系统,这是非常值得的。
基于 Keras 的深度学习和医学图像分析
原文:https://pyimagesearch.com/2018/12/03/deep-learning-and-medical-image-analysis-with-keras/

在本教程中,您将学习如何应用深度学习来执行医学图像分析。具体来说,您将发现如何使用 Keras 深度学习库来自动分析用于疟疾测试的医学图像。
这样的深度学习+医学影像系统可以帮助减少疟疾每年造成的 40 万+死亡。
今天的教程受到了两个来源的启发。第一条来自 PyImageSearch 的读者 Kali,她在两周前写道:
嗨,阿德里安,非常感谢你的教程。在我研究深度学习的时候,他们帮助了我。
我生活在非洲的一个疾病多发地区,尤其是疟疾。我希望能够应用计算机视觉来帮助减少疟疾的爆发。
有医学影像方面的教程吗?如果你能写一本,我会非常感激。你的知识可以帮助我,也可以帮助我帮助别人。
在我看到 Kali 的电子邮件后不久,我偶然发现了 Johnson Thomas 博士的一篇非常有趣的文章,他是一位执业内分泌学家,他提供了一个很好的基准,总结了美国国家卫生研究院(NIH)使用深度学习建立自动疟疾分类系统的工作。
约翰逊将 NIH 的方法(准确率约为 95.9%)与他在同一疟疾数据集上亲自训练的两个模型(准确率分别为 94.23%和 97.1%)进行了比较。
这让我开始思考——我该如何为深度学习和医学图像分析做出贡献?我如何帮助抗击疟疾?我怎样才能帮助像 Kali 这样的读者开始医学图像分析呢?
为了让这个项目更加有趣,我决定尽量减少我要写的自定义代码的数量。
在疾病爆发时,时间是至关重要的——如果我们能够利用预先训练的模型或现有的代码,那就太棒了。我们将能够更快地帮助在该领域工作的医生和临床医生。
因此,我决定:
- 利用我已经为我的书 创建的模型和代码示例,用 Python 进行计算机视觉的深度学习。
- 并演示如何将这些知识轻松应用到自己的项目中(包括深度学习和医学成像)。
今天超过 75%的代码直接来自我的书,只做了一些修改,使我们能够快速训练一个深度学习模型,能够以(1)训练时间和(2)模型大小的分之一复制 NIH 的工作。
要了解如何将深度学习应用于医学图像分析(更不用说,帮助对抗疟疾流行),继续阅读。
基于 Keras 的深度学习和医学图像分析
2020-06-16 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将讨论如何将深度学习和医学成像应用于疟疾流行。
从那里,我们将探索我们的疟疾数据库,该数据库包含分为两类的血液涂片图像:疟疾的阳性或疟疾的阴性。
探索完数据库后,我们将简要回顾一下今天项目的目录结构。
然后,我们将在我们的医学图像上训练一个深度学习模型,以预测给定患者的血液涂片是否对疟疾呈阳性。
最后,我们将回顾我们的结果。
深度学习、医学成像和疟疾流行
Figure 1: A world map of areas currently affected by malaria (source).
疟疾是一种传染病,每年导致超过 40 万人死亡。
疟疾在世界上的一些地区是真正的地方病,这意味着这种疾病在这些地区很常见。
在世界的其他地区,疟疾是一种流行病——它在该地区广泛传播,但还没有达到地方病的程度。
然而,在世界其他地区,即使有,也很少发现疟疾。
那么,是什么让世界上一些地区更容易感染疟疾,而另一些地区却完全没有疟疾呢?
有许多因素使一个地区易受传染病爆发的影响。我们将主要成分介绍如下。
贫困水平

Figure 2: There is a correlation between areas of poverty and areas affected by malaria.
在评估传染病爆发的风险时,我们通常会检查人口中有多少人处于或低于贫困线。
贫困程度越高,传染病的风险就越高,尽管一些研究人员会说相反的话——疟疾导致贫困。
无论我们都同意的原因是什么,这两者之间都有关联。
获得适当的医疗保健
Figure 3: Areas lacking access to proper and modern healthcare can be affected by infectious disease.
世界上低于贫困线的地区很可能无法获得适当的医疗保健。
如果没有良好的医疗保健、适当的治疗以及必要的隔离,传染病会迅速传播。
战争与政府

Figure 4: Areas of the world experiencing war have higher poverty levels and lower access to proper healthcare; thus, infectious disease outbreaks are common in these areas ([source](http://www.newindianexpress.com/world/2017/ mar/15/european-union-unveils-reconstruction-plan-for-war-torn-syria-1581395.html)).
这个地区饱受战争蹂躏吗?
政府腐败吗?
一个国家的各个州或地区之间有内讧吗?
不足为奇的是,世界上一个地区,要么有腐败的政府,要么正在经历内战,也将有更高的贫困水平和更低的医疗保障。
此外,腐败的政府不可能在大规模疫情爆发时提供紧急医疗救治或发布适当的隔离令。
疾病传播媒介
Figure 5: Disease vectors such as mosquitos can carry infectious diseases like malaria.
病媒是携带疾病并将其传播给其他生物的媒介。蚊子因携带疟疾而臭名昭著。
一旦被感染,人也可以成为带菌者,通过输血、器官移植、共用针头/注射器等传播疟疾。
此外,全球气候变暖让蚊子大量繁殖,进一步传播疾病。
如果没有适当的医疗保健,这些传染病可能会导致地方病。
我们如何检测疟疾?

Figure 6: Two methods of testing for malaria include (1) blood smears, and (2) antigen testing (i.e. rapid tests). These are the two common means of testing for malaria that are most often discussed and used (source).
我想以我不是临床医生也不是传染病专家来开始这一部分。
我将尽我所能提供一个极其简短的疟疾检测回顾。
如果你想更详细地了解疟疾是如何被检测和诊断的,请参考卡洛斯·阿蒂科·阿里扎的精彩文章。
检测疟疾的方法有很多,但我最常读到的两种方法包括:
- 血涂片
- 抗原测试(即快速测试
血液涂片过程可以在上面的图 6 中看到:
- 首先,从病人身上抽取血液样本,然后放在载玻片上。
- 样本被一种对比剂染色,以帮助突出红细胞中的疟原虫
- 然后,临床医生在显微镜下检查载玻片,手动计数被感染的红细胞数量。
根据世卫组织官方的疟原虫计数协议,临床医生可能需要手动计数多达 5,000 个细胞,这是一个极其繁琐和耗时的过程。
为了帮助在实地更快地进行疟疾检测,科学家和研究人员开发了用于快速诊断检测的抗原检测(RDT)。
用于疟疾检测的 RDT 设备示例如下:
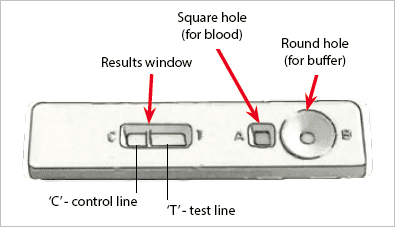
Figure 7: An antigen test classified as Rapid Diagnosis Testing (RDT) involves a small device that allows a blood sample and buffer to be added. The device performs the test and provides the results. These devices are fast to report a result, but they are also significantly less accurate (source).
在这里,您可以看到一个小装置,可以添加血样和缓冲液。
在内部,设备执行测试并提供结果。
虽然 RDT 比细胞计数快得多,但它们的准确性也差得多。
因此,理想的解决方案需要将 RDT 的速度与显微镜的精度结合起来。
注:非常感谢 Carlos Atico Ariza 博士的精彩文章。请参考他的文章,了解更多关于他如何实现机器学习来创建疟疾英雄的信息,这是一个用于筛查和诊断疟疾的开源 web 应用程序。
NIH 提出的深度学习解决方案
2018 年,Rajaraman 等人发表了一篇题为 的论文,将预训练的卷积神经网络作为特征提取器,用于改进薄血涂片图像中的寄生虫检测 。
在他们的工作中,Rajaraman 等人利用了六个预训练的卷积神经网络,包括:
- AlexNet
- VGG-16
- ResNet-50
- Xception
- DenseNet-121
- 他们创造的定制模型
特征提取和随后的训练花了 24 小时多一点,获得了令人印象深刻的 95.9%的准确率。
这里的问题是使用的模型数量— 效率低下。
想象一下,作为一名身处偏远地区的现场工作人员,拥有一台预装了这些疟疾分类模型的设备。
这样的模型必须是某种组合:
- 电池供电的
- 需要电源(即插在墙上)
- 连接到云(需要互联网连接)
让我们进一步分解这个问题:
- 在世界上偏远、贫困的地区,可能无法找到可靠的电源 —电池供电会更好,只要有电就可以充电。
- 但是,如果你使用电池供电的设备,你的计算能力会更低——尝试运行所有六种型号会更快地耗尽你的电池。
- 所以,如果电池寿命是一个问题,我们应该利用云——但如果你使用云,你依赖于一个可靠的互联网连接,你可能有也可能没有。
很明显,我强调了每一项的最坏情况。你当然可以运用一点工程技术,创建一个智能手机应用程序,如果互联网连接可用,它会将医学图像推送到云端,然后退回到使用手机上本地存储的模型,但我想你明白我的意思。
总的来说,最好是:
- 获得与 NIH 相同的准确度
- 一个更小,计算效率更高的模型
- 可以轻松部署到边缘和物联网(IoT)设备
在今天余下的教程中,我将向你展示如何做到这一点。
我们的疟疾数据库
Figure 8: A subset of the Malaria Dataset provided by the National Institute of Health (NIH). We will use this dataset to develop a deep learning medical imaging classification model with Python, OpenCV, and Keras.
我们将在今天的深度学习和医学图像分析教程中使用的疟疾数据集与 Rajaraman 等人在 2018 年的出版物中使用的数据集完全相同。
数据集本身可以在NIH 官方网页上找到:

Figure 9: The National Institute of Health (NIH) has made their Malaria Dataset available to the public on their website.
如果您按照教程进行操作,您会想要将cell_images.zip文件下载到您的本地机器上。
该数据集由 27,588 幅图像组成,属于两个独立的类别:
- 寄生:暗示该地区有疟疾。
- 未感染:表示该地区没有疟疾的迹象。
每个类别的图像数量平均分布,每个相应类别有 13,794 个图像。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
一定要抢到 【下载】 的帖子。没有包括数据集,但是本节中的说明也将向您展示如何下载它。
首先,更改目录并解压缩文件:
$ cd /path/where/you/downloaded/the/files
$ unzip dl-medical-imaging.zip
然后将目录切换到项目文件夹中,并在其中创建一个malaria/目录+ cd:
$ cd dl-medical-imaging
$ mkdir malaria
$ cd malaria
接下来,下载数据集(到您当前应该“在”的dl-medical-imaging/malaria/目录中):
$ wget https://ceb.nlm.nih.gov/proj/malaria/cell_images.zip
$ unzip cell_images.zip
如果您没有tree包,您将需要它:
$ sudo apt-get install tree # for Ubuntu
$ brew install tree # for macOS
现在让我们切换回父目录:
$ cd ..
最后,现在让我们使用 tree 命令来检查我们的项目结构:
$ tree --dirsfirst --filelimit 10
.
├── malaria
│ ├── cell_images.zip
│ └── cell_images
│ │ ├── Parasitized [13780 entries]
│ │ └── Uninfected [13780 entries]
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── resnet.py
├── build_dataset.py
├── train_model.py
└── plot.png
5 directories, 7 files
NIH 疟疾数据集位于malaria/文件夹中。里面的东西已经被解压了。用于培训和测试的cell_images/分为Parasitized/或Uninfected/。
pyimagesearch模块就是pyimagesearch/目录。经常有人问我如何 pip-install pyimagesearch。不可以!它简单地包含在博文 【下载】 中。今天的pyimagesearch模块包括:
config.py:配置文件。我选择直接使用 Python,而不是 YAML/JSON/XML/等等。阅读下一节,在我们查看配置文件时找出原因。resnet.py:这个文件包含了用 Python 进行计算机视觉深度学习的 中包含的精确 ResNet 模型类。在我的深度学习一书中,我演示了如何复制 2015 年 ResNet 学术出版物中的 ResNet 模型,何等人的 用于图像识别的深度残差学习;我还展示了如何在 CIFAR-10 、Tiny ImageNet 和 ImageNet 上训练 ResNet,向您介绍我的每个实验以及我更改了哪些参数及其原因。
今天我们将回顾两个 Python 脚本:
- 这个文件将把我们的疟疾细胞图像数据集分割成训练集、验证集和测试集。
- 在这个脚本中,我们将使用 Keras 和我们的 ResNet 模型来训练一个疟疾分类器。
但是首先,让我们从查看两个脚本都需要的配置文件开始!
我们的配置文件
当从事更大的深度学习项目时,我喜欢创建一个config.py文件来存储我所有的常量变量。
我也可以使用 JSON、YAML 或等效文件,但是能够将 Python 代码直接引入到您的配置中也不错。
现在让我们回顾一下config.py文件:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = "malaria/cell_images"
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = "malaria"
# derive the training, validation, and testing directories
TRAIN_PATH = os.path.sep.join([BASE_PATH, "training"])
VAL_PATH = os.path.sep.join([BASE_PATH, "validation"])
TEST_PATH = os.path.sep.join([BASE_PATH, "testing"])
# define the amount of data that will be used training
TRAIN_SPLIT = 0.8
# the amount of validation data will be a percentage of the
# *training* data
VAL_SPLIT = 0.1
让我们简要回顾一下配置,我们:
- 定义细胞图像原始数据集的路径(第 5 行)。
- 设置我们的数据集基本路径(第 9 行)。
- 建立输出训练、验证和测试目录的路径(第 12-14 行)。
build_dataset.py文件将负责在您的文件系统中创建路径。 - 定义我们的培训/测试划分,其中 80%的数据用于培训,其余 20%用于测试(第 17 行)。
- 设置我们的验证分割,其中 80%用于培训,我们将拿出 10%用于验证(第 21 行)。
现在让我们建立我们的数据集!
构建我们的深度学习+医学图像数据集
我们的疟疾数据集没有用于训练、验证和测试的预分割数据,因此我们需要自己执行分割。
为了创建我们的数据分割,我们将使用build_dataset.py脚本—该脚本将:
- 获取所有示例图像的路径,并随机洗牌。
- 将映像路径分为培训、验证和测试。
- 在
malaria/目录下新建三个子目录,分别是training/、validation/和testing/。 - 自动将图像复制到相应的目录中。
要查看数据分割过程是如何执行的,打开build_dataset.py并插入以下代码:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import random
import shutil
import os
# grab the paths to all input images in the original input directory
# and shuffle them
imagePaths = list(paths.list_images(config.ORIG_INPUT_DATASET))
random.seed(42)
random.shuffle(imagePaths)
我们的包装是在2-6 线进口的。请注意,我们正在从pyimagesearch导入config,从imutils导入paths。
在第行第 10-12 行,来自疟疾数据集的图像被抓取并混洗。
现在,让我们拆分数据:
# compute the training and testing split
i = int(len(imagePaths) * config.TRAIN_SPLIT)
trainPaths = imagePaths[:i]
testPaths = imagePaths[i:]
# we'll be using part of the training data for validation
i = int(len(trainPaths) * config.VAL_SPLIT)
valPaths = trainPaths[:i]
trainPaths = trainPaths[i:]
上面代码块中的行计算训练和测试拆分。
首先,我们计算列车/测试分流的指标(15 号线)。然后使用索引和一点数组切片,我们将数据分成trainPaths和testPaths ( 第 16 行和第 17 行)。
同样,我们从trainPaths ( 第 20 行)计算训练/验证分割的指数。然后我们把图像路径分成valPaths和trainPaths ( 第 21 行和第 22 行)。是的,trainPaths被重新分配,因为正如我在上一节中所述,“…在这 80%的培训中,我们将拿出 10%用于验证”。
现在,我们已经将图像路径组织到各自的分割中,让我们定义将要构建的数据集:
# define the datasets that we'll be building
datasets = [
("training", trainPaths, config.TRAIN_PATH),
("validation", valPaths, config.VAL_PATH),
("testing", testPaths, config.TEST_PATH)
]
在这里,我创建了一个三元组列表(称为datasets),包含:
- 拆分的名称
- 分割的图像路径
- 拆分的输出目录的路径
有了这些信息,我们可以开始循环每个datasets:
# loop over the datasets
for (dType, imagePaths, baseOutput) in datasets:
# show which data split we are creating
print("[INFO] building '{}' split".format(dType))
# if the output base output directory does not exist, create it
if not os.path.exists(baseOutput):
print("[INFO] 'creating {}' directory".format(baseOutput))
os.makedirs(baseOutput)
# loop over the input image paths
for inputPath in imagePaths:
# extract the filename of the input image along with its
# corresponding class label
filename = inputPath.split(os.path.sep)[-1]
label = inputPath.split(os.path.sep)[-2]
# build the path to the label directory
labelPath = os.path.sep.join([baseOutput, label])
# if the label output directory does not exist, create it
if not os.path.exists(labelPath):
print("[INFO] 'creating {}' directory".format(labelPath))
os.makedirs(labelPath)
# construct the path to the destination image and then copy
# the image itself
p = os.path.sep.join([labelPath, filename])
shutil.copy2(inputPath, p)
在第 32 行上,我们开始遍历数据集类型、图像路径和输出目录。
如果输出目录不存在,我们创建它(第 37-39 行)。
然后我们从第行第 42 开始遍历路径本身。在循环中,我们:
- 提取
filename+label( 第 45 行和第 46 行)。 - 如有必要,创建子目录(第 49-54 行)。
- 将实际图像文件本身复制到子目录中(第 58 行和第 59 行)。
为了构建您的疟疾数据集,请确保您已经(1)使用本指南的 【下载】 部分下载了源代码+项目结构,并且(2)已经从 NIH 的网站正确下载了cell_images.zip文件。
从那里,打开一个终端并执行以下命令:
$ python build_dataset.py
[INFO] building 'training' split
[INFO] 'creating malaria/training' directory
[INFO] 'creating malaria/training/Uninfected' directory
[INFO] 'creating malaria/training/Parasitized' directory
[INFO] building 'validation' split
[INFO] 'creating malaria/validation' directory
[INFO] 'creating malaria/validation/Uninfected' directory
[INFO] 'creating malaria/validation/Parasitized' directory
[INFO] building 'testing' split
[INFO] 'creating malaria/testing' directory
[INFO] 'creating malaria/testing/Uninfected' directory
[INFO] 'creating malaria/testing/Parasitized' directory
脚本本身应该只需要几秒钟就可以创建目录和复制映像,即使是在一台功率适中的机器上。
检查build_dataset.py的输出,您可以看到我们的数据分割已经成功创建。
让我们再看一下我们的项目结构,只是为了好玩:
$ tree --dirsfirst --filelimit 10
.
├── malaria
│ ├── cell_images
│ │ ├── Parasitized [13780 entries]
│ │ └── Uninfected [13780 entries]
│ ├── testing
│ │ ├── Parasitized [2726 entries]
│ │ └── Uninfected [2786 entries]
│ ├── training
│ │ ├── Parasitized [9955 entries]
│ │ └── Uninfected [9887 entries]
│ ├── validation
│ │ ├── Parasitized [1098 entries]
│ │ └── Uninfected [1106 entries]
│ └── cell_images.zip
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── resnet.py
├── build_dataset.py
├── train_model.py
└── plot.png
15 directories, 9 files
请注意,新目录已经在malaria/文件夹中创建,图像已经复制到其中。
训练用于医学图像分析的深度学习模型
现在,我们已经创建了我们的数据拆分,让我们继续为医学图像分析训练我们的深度学习模型。
正如我在本教程前面提到的,我的目标是尽可能多地重用我的书《用 Python 进行计算机视觉的深度学习中章节的代码。事实上, 以上的代码 的 75%+都是直接来自文本和代码示例。
*对于医学图像分析来说,时间是至关重要的,因此我们越依赖可靠、稳定的代码就越好。
正如我们将看到的,我们将能够使用这个代码获得 97%的准确率。
让我们开始吧。
打开train_model.py脚本并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers import SGD
from pyimagesearch.resnet import ResNet
from pyimagesearch import config
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
既然您遵循了我在“安装必要的软件”部分的指示,那么您应该准备好使用行 2-15 上的导入。
我们使用keras来训练我们的医学图像深度学习模型,使用sklearn来打印classification_report,从我们的数据集中抓取paths,使用numpy进行数值处理,使用argparse进行命令行参数解析。
棘手的是matplotlib。因为我们要将我们的绘图保存到磁盘上(在我的例子中,是在一台无头机器上),我们需要使用"Agg"后端(行 3 )。
第 9 行导入我的ResNet架构实现。
我们不会在本教程中涉及 ResNet 架构,但如果你有兴趣了解更多,请务必参考官方 ResNet 出版物以及 使用 Python 进行计算机视觉的深度学习 ,在那里我详细回顾了 ResNet。
我们有一个单独的命令行参数,它在的第 18-21 行、--plot被解析。默认情况下,我们的绘图将放在当前工作目录中,并命名为plot.png。或者,当您执行程序时,可以在命令行提供不同的文件名/路径。
现在让我们设置我们的训练参数,并定义我们的学习率衰减函数:
# define the total number of epochs to train for along with the
# initial learning rate and batch size
NUM_EPOCHS = 50
INIT_LR = 1e-1
BS = 32
def poly_decay(epoch):
# initialize the maximum number of epochs, base learning rate,
# and power of the polynomial
maxEpochs = NUM_EPOCHS
baseLR = INIT_LR
power = 1.0
# compute the new learning rate based on polynomial decay
alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power
# return the new learning rate
return alpha
在第 25-26 行上,我们定义了时期数、初始学习率和批量大小。
我发现针对NUM_EPOCHS = 50(训练迭代)的训练效果很好。对于大多数系统(CPU)来说,BS = 32(批处理大小)已经足够了,但是如果您使用 GPU,您可以将该值增加到 64 或更高。我们的INIT_LR = 1e-1(初始学习率)会根据poly_decay函数衰减。
我们的poly_dcay功能在第 29-40 行中定义。这个函数将帮助我们在每个时期后衰减我们的学习率。我们正在设置power = 1.0,它有效地将我们的多项式衰减变成了线性衰减。魔术发生在线 37 上的衰减方程中,其结果返回到线 40 上。
接下来,我们来看看训练集、验证集和测试集中图像路径的数量:
# determine the total number of image paths in training, validation,
# and testing directories
totalTrain = len(list(paths.list_images(config.TRAIN_PATH)))
totalVal = len(list(paths.list_images(config.VAL_PATH)))
totalTest = len(list(paths.list_images(config.TEST_PATH)))
我们将需要这些量值来确定验证/测试过程中每个时期的总步骤数。
让我们应用数据扩充(我几乎总是为每个深度学习数据集推荐这个过程):
# initialize the training training data augmentation object
trainAug = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=20,
zoom_range=0.05,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
horizontal_flip=True,
fill_mode="nearest")
# initialize the validation (and testing) data augmentation object
valAug = ImageDataGenerator(rescale=1 / 255.0)
在第 49-57 行上,我们初始化我们的ImageDataGenerator,它将被用于通过随机移动、翻译和翻转每个训练样本来应用数据扩充。我在使用 Python 进行计算机视觉深度学习的 的实践者包中介绍了数据增强的概念。
验证图像数据生成器将而不是执行任何数据扩充( 行 60 )。相反,它会简单地将我们的像素值重新调整到范围【0,1】,就像我们对训练生成器所做的那样。请注意,我们将使用valAug进行验证和测试。
让我们初始化我们的训练、验证和测试生成器:
# initialize the training generator
trainGen = trainAug.flow_from_directory(
config.TRAIN_PATH,
class_mode="categorical",
target_size=(64, 64),
color_mode="rgb",
shuffle=True,
batch_size=BS)
# initialize the validation generator
valGen = valAug.flow_from_directory(
config.VAL_PATH,
class_mode="categorical",
target_size=(64, 64),
color_mode="rgb",
shuffle=False,
batch_size=BS)
# initialize the testing generator
testGen = valAug.flow_from_directory(
config.TEST_PATH,
class_mode="categorical",
target_size=(64, 64),
color_mode="rgb",
shuffle=False,
batch_size=BS)
在这个块中,我们创建了用于从输入目录加载图像的 Keras 生成器。
flow_from_directory功能假设:
- 数据分割有一个基本输入目录。
- 在基本输入目录中,有 N 个子目录,每个子目录对应一个类标签。
请务必查看 Keras 预处理文档以及我们提供给上面每个生成器的参数。值得注意的是,我们:
- 将
class_mode设置为等于categorical,以确保 Keras 对类标签执行一键编码。 - 将所有图像的大小调整为
64 x 64像素。 - 设置我们的
color_mode到"rgb"频道排序。 - 仅为训练发生器打乱图像路径。
- 使用批量大小
BS = 32。
让我们初始化ResNet并编译模型:
# initialize our ResNet model and compile it
model = ResNet.build(64, 64, 3, 2, (3, 4, 6),
(64, 128, 256, 512), reg=0.0005)
opt = SGD(lr=INIT_LR, momentum=0.9)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
在第 90 行上,我们初始化 ResNet:
- 图像为
64 x 64 x 3(3 通道 RGB 图像)。 - 我们总共有
2门课。 - ResNet 将使用
(64, 128, 256, 512)CONV 层执行(3, 4, 6)堆叠,这意味着:- 在减少空间维度之前,ResNet 中的第一个 CONV 图层将有
64个总过滤器。 - 然后我们会堆叠
3组剩余模块。每个残差模块中的三个 CONV 层将分别学习 32、32 和128CONV 滤波器。然后我们降低空间维度。
- 在减少空间维度之前,ResNet 中的第一个 CONV 图层将有
- 接下来,我们堆叠 4 组剩余模块,其中三个 CONV 层中的每一个都将 64、64 和
256过滤。同样,空间维度也随之减少 - 最后,我们堆叠 6 组残差模块,其中每个 CONV 层学习 128、128 和
512滤波器。在执行平均汇集和应用 softmax 分类器之前,最后一次降低空间维度。
同样,如果您有兴趣了解 ResNet 的更多信息,包括如何从头开始实现它,请参考使用 Python 进行计算机视觉深度学习的。
*第 92 行用默认初始学习1e-1和动量项0.9初始化 SGD 优化器。
第 93 行和第 94 行使用binary_crossentropy作为我们的损失函数来编译实际的模型(因为我们正在执行二元 2 类分类)。对于两个以上的类,我们将使用categorical_crossentropy。
我们现在准备训练我们的模型:
# define our set of callbacks and fit the model
callbacks = [LearningRateScheduler(poly_decay)]
H = model.fit(
x=trainGen,
steps_per_epoch=totalTrain // BS,
validation_data=valGen,
validation_steps=totalVal // BS,
epochs=NUM_EPOCHS,
callbacks=callbacks)
2020-06-16 更新: 以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移(在下一个代码块中)。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
在第 97 行的上,我们创建了我们的callbacks集合。回调在每个时期结束时执行。在我们的例子中,我们应用我们的基于多项式衰减的学习速率调度器在每个时期后衰减我们的学习速率。
我们在第 98-104 行上的model.fit调用指示我们的脚本开始我们的训练过程。
trainGen生成器将自动(1)从磁盘加载我们的图像,( 2)从图像路径解析类标签。
同样,valGen将做同样的过程,只针对验证数据。
让我们评估一下测试数据集的结果:
# reset the testing generator and then use our trained model to
# make predictions on the data
print("[INFO] evaluating network...")
testGen.reset()
predIdxs = model.predict(x=testGen, steps=(totalTest // BS) + 1)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testGen.classes, predIdxs,
target_names=testGen.class_indices.keys()))
现在模型已经训练好了,我们可以在测试集上进行评估。
第 109 行在技术上可以删除,但无论何时使用 Keras 数据发生器,您都应该养成在评估前重置它的习惯。
为了评估我们的模型,我们将对测试数据进行预测,并随后为测试集中的每个图像找到具有最大概率的标签(行 110-114 )。
然后我们将print我们的classification_report在终端中以可读的格式(第 117 行和第 118 行)。
最后,我们将绘制我们的训练数据:
# plot the training loss and accuracy
N = NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-16 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
第 121-131 行生成用于训练和验证的准确度/损失图。
为了将我们的绘图保存到磁盘,我们调用.savefig ( 第 132 行)。
医学图像分析结果
现在,我们已经编写了我们的训练脚本,让我们继续为医学图像分析训练我们的 Keras 深度学习模型。
如果您还没有,请确保您(1)使用今天教程的 【下载】 部分获取源代码+项目结构,并且(2)从官方 NIH 疟疾数据集页面下载cell_images.zip文件。我建议遵循我上面的项目结构。
在那里,您可以使用以下命令开始训练:
$ python train_model.py
Found 19842 images belonging to 2 classes.
Found 2204 images belonging to 2 classes.
Found 5512 images belonging to 2 classes.
Epoch 1/50
620/620 [==============================] - 29s 47ms/step - loss: 1.5878 - accuracy: 0.5893 - val_loss: 1.4247 - val_accuracy: 0.6075 - lr: 0.1000
Epoch 2/50
620/620 [==============================] - 24s 39ms/step - loss: 1.1723 - accuracy: 0.7534 - val_loss: 0.7597 - val_accuracy: 0.9334 - lr: 0.0980
Epoch 3/50
620/620 [==============================] - 24s 38ms/step - loss: 0.6843 - accuracy: 0.9387 - val_loss: 0.6271 - val_accuracy: 0.9430 - lr: 0.0960
...
Epoch 48/50
620/620 [==============================] - 24s 39ms/step - loss: 0.1354 - accuracy: 0.9691 - val_loss: 0.1791 - val_accuracy: 0.9508 - lr: 0.0060
Epoch 49/50
620/620 [==============================] - 24s 39ms/step - loss: 0.1414 - accuracy: 0.9669 - val_loss: 0.1487 - val_accuracy: 0.9660 - lr: 0.0040
Epoch 50/50
620/620 [==============================] - 24s 38ms/step - loss: 0.1383 - accuracy: 0.9683 - val_loss: 0.1474 - val_accuracy: 0.9642 - lr: 0.0020
[INFO] evaluating network...
precision recall f1-score support
Parasitized 0.97 0.95 0.96 2786
Uninfected 0.95 0.97 0.96 2726
accuracy 0.96 5512
macro avg 0.96 0.96 0.96 5512
weighted avg 0.96 0.96 0.96 5512
Figure 10: Our malaria classifier model training/testing accuracy and loss plot shows that we’ve achieved high accuracy and low loss. The model isn’t exhibiting signs of over/underfitting. This deep learning medical imaging “malaria classifier” model was created with ResNet architecture using Keras/TensorFlow.
这里我们可以看到我们的模型总共被训练了 50 个时期。
在一个 Titan X GPU 上,每个纪元大约需要 65 秒。
总的来说,整个训练过程只花了54 分钟 ( 明显比 NIH 的方法 24 小时的训练过程快)。在第 50 个纪元结束时,我们在训练、 验证、和测试数据上获得了 96%的准确度。
使用我们今天在这里培训的基于 ResNet 的模型进行医学图像分析有很多好处。
首先,我们的模型是一个完整的端到端疟疾分类系统。
与 NIH 的方法不同,NIH 的方法利用了(1)从多个模型中提取特征和(2)分类的多步骤过程,相反,我们可以仅利用单个紧凑模型并获得可比较的结果。
说到紧凑性,我们的序列化模型文件只有 17.7MB 。量化模型中的权重本身将允许我们获得一个模型 < 10MB (或者甚至更小,取决于量化方法),如果有的话,精确度只有轻微的降低。
我们的方法在两个方面也更快。
首先,与 NIH 的方法相比,训练我们的模型需要更少的时间。
我们的模型只花了 54 分钟来训练,而 NIH 的模型花了大约 24 小时。
第二,我们的模型在(1)前向传递推理时间和(2)明显更少的参数和存储器/硬件需求方面更快。
考虑到 NIH 的方法需要预先训练的网络来进行特征提取。
每个模型都接受输入图像空间尺寸在 224×244、227×227 和 299×299 像素范围内的输入图像。
我们的模型只需要 64×64 的输入图像,并且获得了几乎相同的精度。
尽管如此,我已经而不是进行了全面的准确性、敏感性和特异性测试,但根据我们的结果,我们可以看到,我们正在创建一个自动疟疾分类器,它不仅更准确,而且明显更小,需要更少的处理能力。
我的希望是,你将使用今天关于深度学习和医学成像分析的教程中的知识,并将其应用于自己的医学成像问题。
摘要
在今天的博文中,你学习了如何将深度学习应用于医学图像分析;特别是疟疾预测。
疟疾是一种传染病,通常通过蚊子传播。鉴于蚊子的快速繁殖周期,疟疾在世界一些地区已经成为真正的地方病,而在另一些地区则成为流行病。总之,每年有 40 多万人死于疟疾。
NIH 开发了一种移动应用程序,当与智能手机上的特殊显微镜附件镜头结合时,现场临床医生可以自动预测接受血液涂片检查的患者的疟疾风险因素。NIH 的模型结合了六个独立的最先进的深度学习模型,花了大约 24 小时进行训练。
总的来说,他们获得了 ~95.9%的准确率。
使用今天的教程中讨论的模型,ResNet 的一个较小的变体,其模型大小仅为 17.7MB ,我们能够在仅 54 分钟内获得 96%的准确性。
此外,今天教程中使用的 75%以上的代码来自我的书 用 Python 进行计算机视觉的深度学习 。
只需很少的努力就可以从书中获得代码示例和技术,然后将其应用于一个定制的医学图像分析问题。
在疾病爆发期间,时间是至关重要的,能够利用现有的代码和模型可以减少工程师/培训时间,确保模型更快地投入使用,并最终帮助医生和临床医生更好地治疗患者(最好还能挽救生命)。
我希望你喜欢今天关于医学图像分析深度学习的帖子!
要下载今天帖子的源代码,并在以后的帖子在 PyImageSearch 上发布时得到通知,*只需在下面的表格中输入您的电子邮件地址!***
深度学习、水培和医用大麻
原文:https://pyimagesearch.com/2018/10/15/deep-learning-hydroponics-and-medical-marijuana/

在今天的博文中,我们将调查一个将深度学习应用于水培的实际使用案例,这是一种使用富含矿物质的水溶剂营养液在无土栽培中种植植物的方法。
具体来说,你将学习如何使用 Keras 训练一个卷积神经网络(CNN)来自动对根部健康状况进行分类,而不必实际接触植物。
本教程的实际实验设计是由 Darrah 等人在他们 2017 年的论文中提出的:水培作物植物的实时根系监测:新图像分析系统的概念证明。
这样的系统可以提高现有水培农场的产量,使农场的运营更加高效和可持续。当然,水培法的成功应用对医用大麻产业有着巨大的影响。
虽然可能会有争议,而且我很清楚我会收到一些关于这篇博文的愤怒/不安的电子邮件,但我还是决定发布今天的教程。
对于作为学生、研究人员和工程师的我们来说,看到深度学习如何能够和如何在现实世界中应用的实际例子是重要的、有用的和 高度教育性的 。
此外,今天的教程不是旨在讨论大麻的合法性、道德性或使用——这是而不是一个分享“合法化”或反毒品运动的平台,或者只是讨论大麻的娱乐性使用。互联网上已经有足够多的网站可以这样做,如果你觉得有必要进行这样的讨论,请这样做,只是要明白 PyImageSearch 不是那个平台。
我还想敦促您记住,我们都是这里的研究人员、学生和开发人员,最重要的是,我们都是来学习实际的、真实的例子的。文明一点,不管你是否同意水培的一些下游影响。
说了这么多,要了解更多关于深度学习如何应用于水培法(是的,医用大麻),继续阅读!
深度学习、水培和医用大麻
2020-06-15 更新:此博文现已兼容 TensorFlow 2+!
在今天博客文章的前半部分,我们将简要讨论水培农场的概念,它们与大麻的关系,以及深度学习如何将它们两者结合起来。
在此基础上,我们将使用 Keras 实现一个卷积神经网络,自动对水培系统中生长的植物的根部健康状况进行分类,而无需物理接触或干扰植物。
最后,我们将回顾我们的实验结果。
什么是水培?

Figure 1: Hydroponic farming is useful to grow and yield more plants within confined spaces. Read the rest of this case study to find out how Keras + deep learning can be used to spot hydroponic root system problem areas.
水培是一个庞大的产业,2016 年估计市值212.035 亿美元(是的,百万)。从 2018 年到 2023 年,该市场预计将以每年 6.5%的复合年增长率(CAGR)增长。欧洲和亚洲预计也将以相似的速度增长(所有统计数据来源)。
**水培法本身是水培法的一个分支,水培法是在不利用土壤的情况下种植植物的过程,而不是使用富含矿物质的溶液。
使用水培法,植物可以在根部接触到矿物质溶液的情况下生长。
如果你自动将“水培”与“大麻”联系起来,请记住,水培农业已经得到了主要政府和组织的认可和使用,包括美国、美国宇航局、欧洲,甚至传说中的巴比伦空中花园。
一个很好的例子是国际空间站(ISS)——我们已经在 ISS 进行了多年的水培实验,包括种植蔬菜。
水培是一门自巴比伦人和阿兹特克人以来就存在的科学,并在现代继续使用——所以在你翘起鼻子之前,请记住这是真正的科学,一门远比计算机视觉和深度学习更古老的科学。
那么,为什么要为水培耕作费心呢?
营养土仍然非常珍贵,尤其是由于不负责任或过度耕种土地、疾病、战争、森林砍伐和不断变化的环境等等。
水培农场允许我们在传统土壤农场无法种植的较小区域种植水果和蔬菜。
如果你想考虑一个更大的图景,如果我们要殖民火星,水培法无疑会被利用。
水培和医用大麻有什么关系?

Figure 2: Despite the controversy over the legalization of marijuana in some states in the US, marijuana is often grown via hydroponic means and makes for a great use case of plant root health analysis. Deep learning, by means of the Keras library, is used in this blog post to classify “hairy” (good) vs “non-hairy” (poor) root systems in hydroponics.
如果你读了前一节关于什么是水培法以及我们为什么使用这种方法,水培法被广泛应用于大麻产业就不足为奇了,甚至在美国合法化立法(在一些州)之前。
我不会对水培法和医用大麻进行详尽的回顾(为此,你可以参考这篇文章),但要点是:
- 在大麻合法化之前(在美国的一些州),种植者希望保持他们的植物秘密和安全——室内水培有助于解决这个问题。
- 医用大麻的规则在美国是新的,在某些情况下,唯一允许的种植方法是水培。
- 水培种植有助于保护我们宝贵的土壤,这可能需要几十年或更长时间才能自然补充。
根据 Brightfield Group 的报告,2017 年,大麻市场的价值为77 亿美元,随着其他国家和州的合法化,复合年增长率高达60%——这使得 2021 年的市场估值达到 314 亿美元(来源)。
水培和大麻有很多钱,在一个高风险、高回报的行业,这个行业本质上依赖于(1)立法和(2)技术,深度学习找到了另一种应用。
深度学习、计算机视觉、水培是如何交叉的?

Figure 3: PyImageSearch reader, Timothy Darrah’s research lab for analyzing plant root health in a hydroponics growing configuration is pictured with his permission. His project inspired this deep learning blog post.
回到 2017 年,PyImageSearch 的读者 Timothy Darrah 是田纳西州立大学的一名本科生,他向我提出了一个有趣的问题——他需要设计一种算法来自动对植物根部进行分类,而又不能以任何方式接触或干扰植物。
特别是,达拉正在研究柳枝稷植物,一种北美草原草的主要品种。
注: Darrah 等人的工作发表在一篇名为水培作物植物的实时根系监测:一种新图像分析系统的概念证明的论文中。达拉慷慨地让我主持他的论文给你看。
该项目的总体目标是开发一个自动化根系生长分析系统,该系统能够准确测量根系,然后检测任何生长问题:
Figure 4: An automated root growth analysis system concept. We’re demonstrating the concept of deep learning as a tool to help classify the roots in a hydroponic system.
特别是,根需要分为两类:
- “多毛”的根
- “无毛”根
根的“毛”越多,根就能更好地吸收养分。
根的“毛越少”,它能吸收的营养就越少,这可能会导致植物饥饿和死亡。
为了这个项目,蒂莫西和马赫什·顾然(一名博士生)以及他们的顾问·额尔德米尔博士和·周博士一起开发了一个系统,可以在不干扰植物本身的情况下自动捕捉根部图像。
他们的实验设置的示例图像可以在本节顶部的图 3 中看到。
从那时起,他们需要应用计算机视觉将牙根分为两类(并最终分为多类以检测其他牙根病变)。
唯一的问题是如何解决图像分类问题?
注:在 2017 年 4 月蒂莫西给我发邮件要求尝试一种算法后,蒂莫西和团队的其他成员解决了他们最初的问题。我建议本地二进制模式为他们工作;然而,为了本教程,我们也将探索如何利用深度学习。
我们的图像数据集

Figure 5: Our deep learning dataset for hydroponics root analysis.
我们的 1,524 个根图像数据集包括:
- 长毛: 748 张图片(左)
- 无毛: 776 张图片(右)
每个类别的示例图像子集可以在上面的图 4 中看到。
原始图像以 1920×1080 像素的较高分辨率拍摄;然而,为了这篇博文,为了方便起见(也为了节省空间/带宽),我将它们的大小调整为 256×256 像素。
调整大小由以下人员执行:
- 将高度调整为 256 像素
- 然后选取中间的 256 像素裁剪
由于图像的中心总是包含大量的根毛(或者缺少根毛),这种调整大小和裁剪的方法非常有效。
Darrah 等人也慷慨地允许我们将这些图像用于我们自己的教育(但是你不能将它们用于商业目的)。
在本教程的剩余部分,您将学习如何训练一个深度学习网络来自动分类这些根物种类。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
要直接在你的终端查看项目结构,首先,抓取这篇文章的 【下载】 ,解压存档。
然后导航到项目目录,使用tree命令检查内容:
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── hairy_root [748 images]
│ └── non_hairy_root [776 images]
├── pyimagesearch
│ ├── __init__.py
│ └── simplenet.py
├── train_network.py
└── plot.png
4 directories, 4 files
我们的dataset/目录由hairy_root/和non_hairy_root/图像组成。
pyimagesearch/ 目录是包含 simplenet.py 的 Python 模块。SimpleNet架构是我为根健康分类设计的 Keras 深度学习架构。我们今天将回顾这一架构。
然后我们将使用train_network.py训练我们的网络,产生plot.png,我们的训练图。我们将一行一行地浏览培训脚本,以便您了解它是如何工作的。
我们开始吧!
利用深度学习对根部健康进行分类
既然我们已经了解了(1)水培法和(2)我们正在处理的数据集,我们可以开始了。
实现我们的卷积神经网络
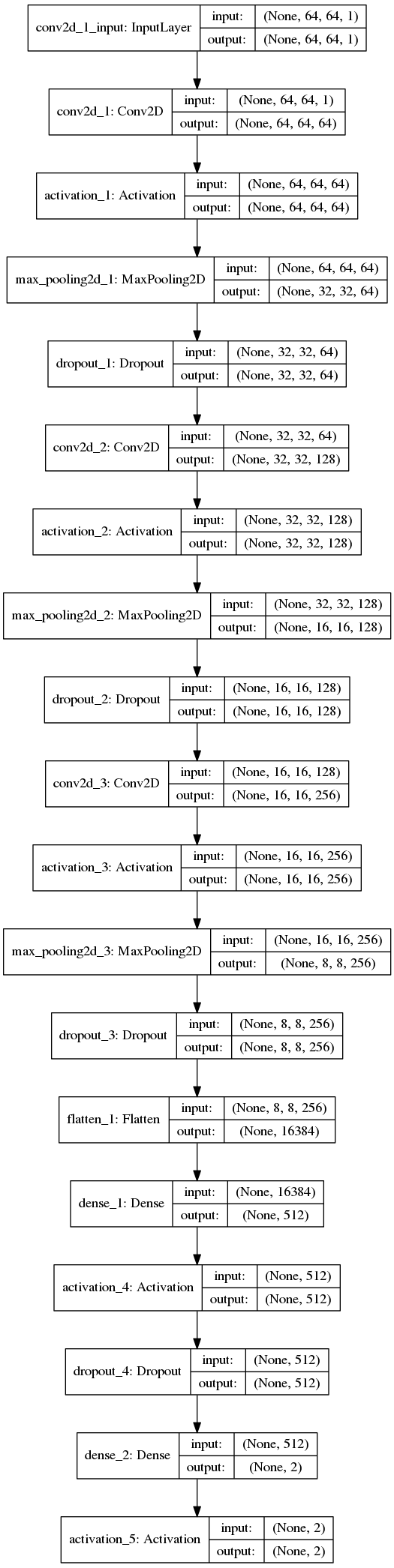
Figure 6: Our deep learning Convolutional Neural Network (CNN) is based on the concepts of AlexNet and OverFeat. Keras will be utilized to build the network and train the model. We will apply this CNN to hydroponics root analysis where marijuana growers might take notice as hydroponics accounts for a segment of their agriculture industry.
我们今天要实现的网络大致基于 AlexNet 和over feet中介绍的概念。
我们的网络将从卷积过滤器开始,其过滤器尺寸更大,用于快速降低卷的空间维度。从那里,我们将应用两个 CONV 层用于学习 3×3 过滤器。点击此处查看完整的网络架构图。
打开simplenet.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
我们从从keras导入必要的图层类型开始我们的脚本。向下滚动以查看每个正在使用的。
我们也进口 keras。后端将允许我们在定义SimpleNet类和build方法的下一个块中动态处理不同的输入形状:
class SimpleNet:
@staticmethod
def build(width, height, depth, classes, reg):
# initialize the model along with the input shape to be
# "channels last"
model = Sequential()
inputShape = (height, width, depth)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
SimpleNet类定义从行第 11 开始。
我们唯一的方法build在第 13 行中定义。
该功能的第一步是初始化一个Sequential模型(行 16 )。
然后我们指定我们的inputShape,其中输入图像被假定为 64×64 像素大小 ( 第 17 行)。
大多数人将使用 TensorFlow 作为后端,假设"channels_last"最后一次订购。如果你正在使用 Theano 或另一个"channels_first"后端,那么inputShape在行 20 和 21 被修改。
让我们开始向我们的网络添加层:
# first set of CONV => RELU => POOL layers
model.add(Conv2D(64, (11, 11), input_shape=inputShape,
padding="same", kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# second set of CONV => RELU => POOL layers
model.add(Conv2D(128, (5, 5), padding="same",
kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# third (and final) CONV => RELU => POOL layers
model.add(Conv2D(256, (3, 3), padding="same",
kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
第一个CONV => RELU => POOL层块(第 24-28 行)使用较大的过滤器尺寸来(1)帮助检测较大的毛发组(或缺少毛发),随后(2)快速减小体积的空间维度。
我们在网络中越深入,每个 CONV 层学习的过滤器越多(第 31-42 行)。
标准整流线性单位(RELU)激活是利用整个。在我的深度学习书籍中讨论了替代和权衡。
池图层的主要功能是逐渐减小图层输入量的空间大小(即宽度和高度)。您通常会在 CNN 中看到连续 CONV 层之间的池层,如本例所示。
在上面的每个模块中,我们去掉了 25%的节点(断开随机神经元),以努力引入正则化并帮助网络更好地泛化。这种方法被证明可以减少过度拟合,提高准确性,并允许我们的网络更好地推广不熟悉的图像。
我们的最后一个FC => RELU块以 softmax 分类器结束:
# first and only set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
全连接层(Dense)常见于 CNN 的末尾。这次我们采用 50%的退学率。
我们的 softmax 分类器被应用于我们的最后一个全连接层,其具有对应于我们的两个classes : (1) non_hairy_root和(2) hairy_root的 2 个输出。
最后,我们返回构建的模型。
实现驱动程序脚本
现在我们已经实现了SimpleNet,让我们创建负责训练我们网络的驱动脚本。
打开train_network.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.simplenet import SimpleNet
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
from imutils import build_montages
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import os
我们的驱动脚本有许多重要的导入。让我们回顾一下:
matplotlib:Python 的事实上的绘图包。我们将绘制一段时间内的训练准确性/损失数据。- 我们在前面的章节中定义了 CNN 的架构。
- scikit-learn 包有一个方便的标签编码器。我们将执行“一次性”编码——稍后会详细介绍。
- 我们将把我们的训练数据分割成一定比例的图像用于训练,剩余的图像用于测试。分割数据在机器学习中很常见,无论你使用什么工具,你都会发现类似的功能。
classification_report:允许我们在终端上以可读格式方便地打印统计数据。- 我们将要使用的学习优化器。另一个选择是新加坡元。
- l2 正则化器结合到损失函数中,允许我们在优化期间惩罚层参数或层活动。这将防止过度拟合,并允许我们的网络推广。
build_montages:我们将在一帧的图像蒙太奇中看到我们努力工作的成果。这来自我的 imutils 包。paths:同样来自 imutils,这个函数将从一个输入目录中提取所有图像路径(递归)。argparse:解析命令行参数——我们接下来将回顾这一点。cv2:别忘了 OpenCV!我们将使用 OpenCV 进行预处理以及可视化/显示。os:我不是 Windows 迷,在 PyImageSearch 上我也不正式支持 Windows,但是我们将使用os.path.sep来适应 Windows 和 Linux/Mac 路径分隔符。
那是一口。你在 CV 和 DL 领域工作的越多,你就会越熟悉这些和其他的包和模块。
让我们利用其中的一个。我们将使用argparse来解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-e", "--epochs", type=int, default=100,
help="# of epochs to train our network for")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我的博客的读者倾向于熟悉这几行代码,但是我总是为新手解释它们。argparse工具将解析在终端中输入的带有命令行参数的命令字符串。如果你是第一次来这里或者你以前从未使用过命令行参数,请务必阅读我在 Python、argparse 和命令行参数 上的帖子。
我们的驱动程序脚本有三个命令行参数:
- 这是我们图像数据集的路径。这个论点是必需的,因为我们需要数据进行训练。
- 你可以尝试不同迭代次数的训练。我发现
100已经足够了,所以它是默认的。 - 如果你想为你的绘图指定一个路径+文件名,你可以使用这个参数。默认情况下,您的绘图将被命名为
"plot.png"并保存在当前工作目录中。每次你以更好的性能为目标进行实验时,你都应该记下 DL 参数,并给你的图命名,这样你就能记住它对应于哪个实验。
现在我们已经解析了我们的命令行参数,让我们加载+预处理我们的图像数据并解析标签:
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the image, convert it to grayscale, and resize it to be a
# fixed 64x64 pixels, ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (64, 64))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
在第 34 行的处,我们创建了数据集中所有imagePaths的列表。然后,我们继续初始化一个地方来保存内存中的data以及相应的labels ( 第 35 行和第 36 行)。
给定我们的imagePaths,我们继续在行 39 上循环它们。
循环的第一步是提取第 41 行上的类标签。让我们看看这在 Python Shell 中是如何工作的:
$ python
>>> from imutils import paths
>>> import os
>>> imagePaths = list(paths.list_images("dataset"))
>>> imagePath = imagePaths[0]
>>> imagePath
'dataset/hairy_root/100_a.jpg'
>>> imagePath.split(os.path.sep)
['dataset', 'hairy_root', '100_a.jpg']
>>> imagePath.split(os.path.sep)[-2]
'hairy_root'
>>>
请注意,通过使用imagePath.split并提供拆分字符(操作系统路径分隔符 Unix 上的“/”和 Windows 上的“\”),该函数如何生成一个文件夹/文件名称(字符串)列表,这些名称沿着目录树向下排列(第 8 行和第 9 行)。我们获取倒数第二个索引,即类标签,在本例中是'hairy_root' ( 第 10 行和第 11 行)。
然后我们继续加载image并预处理它(第 45-47 行)。灰度(单通道)是我们识别毛状根和非毛状根所需要的。我们的网络设计需要 64×64 像素的图像。
最后,我们将image添加到data,将label添加到labels ( 第 50 行和第 51 行)。
接下来,我们将重塑数据并对标签进行编码:
# convert the data into a NumPy array, then preprocess it by scaling
# all pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
# reshape the data matrix so that it explicity includes a channel
# dimension
data = data.reshape((data.shape[0], data.shape[1], data.shape[2], 1))
# encode the labels (which are currently strings) as integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# transform the labels into vectors in the range [0, classes],
# generating a vector for each label, where the index of the label
# is set to '1' and all other entries are set to '0' -- this process
# is called "one-hot encoding"
labels = to_categorical(labels, 2)
# partition the data into training and testing splits using 60% of
# the data for training and the remaining 40% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.40, stratify=labels, random_state=42)
数据在行 55-59 上被整形。在这个过程中,我们从一个列表转换成一个 NumPy 的浮点数组,这个数组被缩放成【0,1】。即使我们只有一个灰度通道,我们也增加了通道尺寸。这个额外的维度是我们 CNN 所期待的。
然后我们在第 62-69 行对我们的标签进行编码。我们使用“一热编码”,这意味着我们有一个向量,其中在任何给定的时间只有一个元素(类)是“热的”。回顾我最近的 Keras 教程中一个应用于 3 个类的数据集的例子来理解这个概念。
现在是数据的拆分。我保留了 60%的数据用于训练,40%用于测试(第 73 行和第 74 行)。
让我们编译我们的模型:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = Adam(lr=1e-4, decay=1e-4 / args["epochs"])
model = SimpleNet.build(width=64, height=64, depth=1,
classes=len(le.classes_), reg=l2(0.0002))
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
我们用学习率1e-4和学习率衰减(第 78 行)初始化Adam优化器。
注:Adam 的默认学习速率是1e-3,但是我通过实验发现使用1e-3太高了——网络无法获得任何“牵引力”,无法学习。使用1e-4作为初始学习速率允许网络开始学习。这向你展示了理解深度学习的参数和基础是多么重要。拿一本我的书《用 Python 进行计算机视觉的深度学习》,看看我在调整这些参数时的最佳实践、技巧和建议。**
**我还包含了少量的正则化,以帮助防止过度拟合,并确保网络泛化。这种正则化显示在第 79 行和第 80 行上,在这里我们build我们的模型,同时指定我们的维度、编码标签以及正则化强度。
我们在81 号线和 82 号线展示我们的模型。因为我们的网络只有两个类,所以我们使用"binary_crossentropy"。如果你有> 2 个类,你会想要使用"categorical_crossentropy"。
接下来是培训,然后是评估:
# train the network
print("[INFO] training network for {} epochs...".format(
args["epochs"]))
H = model.fit(x=trainX, y=trainY, validation_data=(testX, testY),
batch_size=32, epochs=args["epochs"], verbose=1)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=le.classes_))
培训,也称为“试模”,在87 线和 88 线开始。我已经设置了32的批量。
然后我们评估网络并在终端中打印一个classification_report(第 92-94 行)。
接下来,我们使用 matplotlib 生成一个训练图:
# plot the training loss and accuracy
N = args["epochs"]
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-15 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
以上是在使用 Keras 和深度学习时制作训练图的一个很好的参考配方。该代码在整个训练期间(x轴)在同一曲线图( y 轴)上绘制损失和准确度。
我们调用savefig将绘图图像导出到磁盘(第 108 行)。
最后,让我们可视化输出:
# randomly select a few testing images and then initialize the output
# set of images
idxs = np.arange(0, testY.shape[0])
idxs = np.random.choice(idxs, size=(25,), replace=False)
images = []
# loop over the testing indexes
for i in idxs:
# grab the current testing image and classify it
image = np.expand_dims(testX[i], axis=0)
preds = model.predict(image)
j = preds.argmax(axis=1)[0]
label = le.classes_[j]
# rescale the image into the range [0, 255] and then resize it so
# we can more easily visualize it
output = (image[0] * 255).astype("uint8")
output = np.dstack([output] * 3)
output = cv2.resize(output, (128, 128))
# draw the colored class label on the output image and add it to
# the set of output images
color = (0, 0, 255) if "non" in label else (0, 255, 0)
cv2.putText(output, label, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
color, 2)
images.append(output)
# create a montage using 128x128 "tiles" with 5 rows and 5 columns
montage = build_montages(images, (128, 128), (5, 5))[0]
# show the output montage
cv2.imshow("Output", montage)
cv2.waitKey(0)
每当你测试一个机器学习或深度学习模型时,你不应该只依赖统计数据来证明模型正在工作。您还应该在测试图像上可视化您的结果。有时我会编写一个单独的脚本来加载任意图像并分类+显示它。鉴于这些图像都是相似的,我选择制作一个图像蒙太奇,这样我们就可以直观地检查我们的模型是否表现良好。
做到这一点的步骤包括:
- 随机选择一些测试图像指标进行可视化(112 行和 113 行)。还要初始化一个列表来保存
images( 第 114 行)。 - 从第行第 117 开始循环随机图像
idxs:- 加载并分类图像(第 119-122 行)。我们获取最高预测的索引,并将该索引提供给我们的标签编码器,以生成一个
label。 - 重新缩放/调整图像大小以便可视化(第 126-128 行)。
- 在输出图像上绘制
label文本(第 132-134 行)。发根(好的)会有green字体,非发根(坏的)会有红色。 - 将输出图像添加到我们的图像列表中,以便我们稍后可以构建一个蒙太奇( Line 135 )。
- 加载并分类图像(第 119-122 行)。我们获取最高预测的索引,并将该索引提供给我们的标签编码器,以生成一个
- 构建结果的蒙太奇(第 138 行)。用 OpenCV 学习构建 蒙太奇。
最后,我们显示结果,直到在最后两行上按下一个键。
根健康分类结果
要了解我们的根健康深度神经网络的表现,请务必使用本文的 【下载】 部分下载源代码和数据集。
从那里,打开一个终端,导航到您下载并提取代码的位置,然后执行以下命令:
$ python train_network.py --dataset dataset
Using TensorFlow backend.
[INFO] loading images...
[INFO] compiling model...
[INFO] training network for 100 epochs...
Epoch 1/100
29/29 [==============================] - 1s 23ms/step - loss: 0.9461 - accuracy: 0.4956 - val_loss: 0.9262 - val_accuracy: 0.5098
Epoch 2/100
29/29 [==============================] - 0s 14ms/step - loss: 0.9149 - accuracy: 0.5470 - val_loss: 0.9097 - val_accuracy: 0.4902
Epoch 3/100
29/29 [==============================] - 0s 15ms/step - loss: 0.9045 - accuracy: 0.5208 - val_loss: 0.8931 - val_accuracy: 0.5098
...
Epoch 98/100
29/29 [==============================] - 0s 13ms/step - loss: 0.1081 - accuracy: 0.9891 - val_loss: 0.1360 - val_accuracy: 0.9770
Epoch 99/100
29/29 [==============================] - 0s 13ms/step - loss: 0.2083 - accuracy: 0.9551 - val_loss: 0.1358 - val_accuracy: 0.9852
Epoch 100/100
29/29 [==============================] - 0s 16ms/step - loss: 0.2043 - accuracy: 0.9420 - val_loss: 0.1648 - val_accuracy: 0.9541
[INFO] evaluating network...
precision recall f1-score support
hairy_root 1.00 0.91 0.95 299
non_hairy_root 0.92 1.00 0.96 311
accuracy 0.95 610
macro avg 0.96 0.95 0.95 610
weighted avg 0.96 0.95 0.95 610
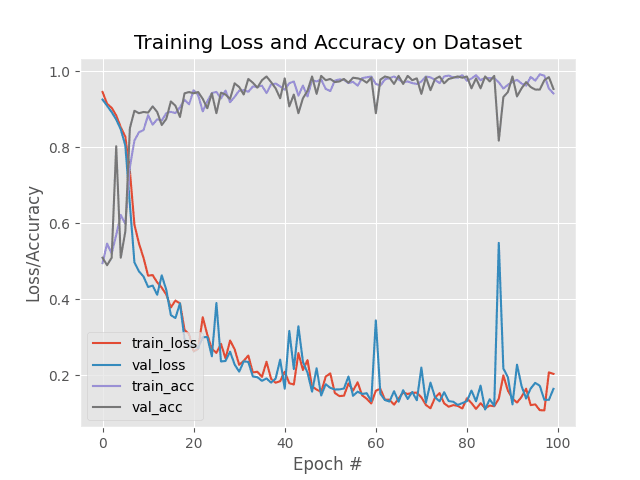
Figure 7: Our deep learning training plot contains accuracy and loss curves for our hydroponics plant root health case study. The CNN was trained with Keras and the plot was generated with Matplotlib.
如我们所见,我们的网络获得了 95%的分类准确率,并且如我们的图所示,没有过拟合。
**此外,我们可以检查我们的结果蒙太奇,这再次表明我们的网络正在准确地分类每个根类型:
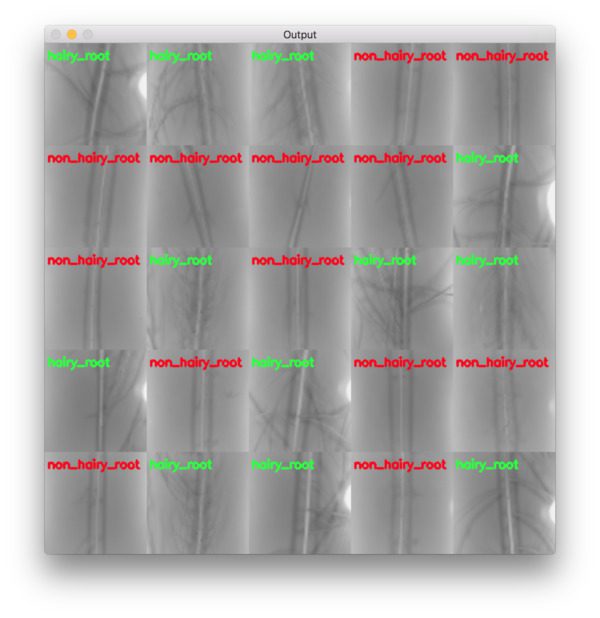
Figure 8: A montage of our hydroponic root classification system results. Keras + deep learning was utilized to build a “hairy_root” vs “non_hairy_root” classifier. Training images were provided by Darrah et al.’s research.
使用这样的技术,深度学习研究人员、从业者和工程师可以帮助解决现实世界的问题。
摘要
在今天的博客文章中,我们探索了深度学习的一个现实世界应用:自动分类水培农场中的植物根系健康,特别是如何在大规模增长的(不是双关语)医用大麻行业中利用这样一个系统。
为了对根部健康状况进行分类,我们用 Keras 和 Python 训练了一个卷积神经网络,将根部标记为“有毛”或“无毛”。
根上的毛越多,就越容易吸收营养。根上的毛发越少,吸收养分就越困难,这可能会导致植物死亡和作物损失。
使用今天帖子中详细介绍的方法,我们能够以超过 95%的准确率对根健康进行分类。
**有关水培和计算机视觉如何交叉的更多信息,请参考 Darrah 等人的 2017 年出版物。
我希望你喜欢今天关于将深度学习应用于现实世界应用的博文。
要下载这篇博文的源代码(并注册 PyImageSearch 时事通讯),*只需在下面的表格中输入您的电子邮件地址!*********
基于 OpenCV 的树莓 Pi 深度学习
原文:https://pyimagesearch.com/2017/10/02/deep-learning-on-the-raspberry-pi-with-opencv/
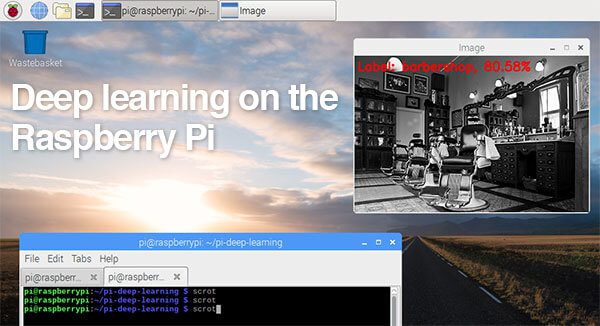
我收到了许多来自 PyImageSearch 读者的电子邮件,他们对在他们的 Raspberry Pi 中执行深度学习感兴趣。大多数问题都是这样的:
嗨,阿德里安,谢谢你所有关于深度学习的教程。你真的让深度学习变得简单易懂了。我有一个问题:我能在树莓派上做深度学习吗?有哪些步骤?
几乎总是,我有相同的回答:
这个问题真的取决于你所说的“做”是什么意思。你永远不应该在树莓派上训练神经网络——它的功能太弱了。你最好在你的笔记本电脑、台式机甚至 GPU(如果你有的话)上训练网络。
也就是说,你可以在 Raspberry Pi 上部署高效的浅层神经网络,并使用它们对输入图像进行分类。
我再次强调这一点:
你 不应该 在树莓 Pi 上训练神经网络(除非你用 Pi 来做类似于神经网络的【你好,世界】——但我仍然认为你的笔记本电脑/台式机更合适)。
有了树莓派就没有足够的内存了。
处理器太慢了。
总的来说,它并不适合繁重的计算过程。
相反,你应该首先在你的笔记本电脑、台式机或深度学习环境中 训练 你的网络。
一旦网络被训练好,你就可以 部署 神经网络到你的树莓派。
在这篇博文的剩余部分,我将演示我们如何使用 Raspberry Pi 和预先训练的深度学习神经网络来对输入图像进行分类。
基于 OpenCV 的树莓 Pi 深度学习
当使用 Raspberry Pi 进行深度学习时,我们有两个主要的陷阱:
- 内存受限(树莓 Pi 3 上只有 1GB)。
- 处理器速度有限。
这使得使用更大、更深的神经网络几乎是不可能的。
相反,我们需要使用内存/处理空间更小、计算效率更高的网络,比如 MobileNet 和 SqueezeNet。这些网络更适合树莓派;然而,你需要相应地设定你的期望——你不应该期待极快的速度。
在本教程中,我们将特别使用 SqueezeNet。
什么是 SqueezeNet?

Figure 1: The “fire” module in SqueezeNet, consisting of a “squeeze” and an “expand” (Iandola et al., 2016).
SqueezeNet 最早是由 Iandola 等人在他们 2016 年的论文 中提出的,SqueezeNet: AlexNet 级别的精度,参数少 50 倍,< 0.5MB 模型大小 。
光是这篇论文的标题就应该能引起你的兴趣。
ResNet 等最新架构的模型大小超过 100MB。VGGNet 超过 550MB。AlexNet 位于这个大小范围的中间,模型大小约为 250MB。
事实上,用于图像分类的较小的卷积神经网络之一是大约 25-50MB 的 GoogLeNet(取决于实现了哪个版本的架构)。
真正的问题是: 我们能变小吗?
正如 Iandola 等人的工作所展示的,答案是:是的,我们可以通过应用一种新的用法来减小模型的大小,这种用法是 1×1 和 3×3 卷积,并且没有完全连接的层。最终结果是一个权重为 4.9MB 的模型,可以通过模型处理(也称为“权重修剪”和“稀疏化模型”)进一步减少到< 0.5MB。
在本教程的剩余部分,我将演示 SqueezeNet 如何在大约 GoogLeNet 一半的时间内对图像进行分类,这使得它成为在您的 Raspberry Pi 上应用深度学习的合理选择。
有兴趣了解更多关于 SqueezeNet 的信息吗?

Figure 2: Deep Learning for Computer Vision with Python book
如果你有兴趣了解更多关于 SqueezeNet 的知识,我会鼓励你看看我的新书,《用 Python 进行计算机视觉的深度学习》。
*在 ImageNet 包中,我:
- 解释 SqueezeNet 架构的内部工作原理。
- 演示如何手工实现 SqueezeNet。
- 在具有挑战性的 ImageNet 数据集上从头开始训练 SqueezeNet,并复制 Iandola 等人的原始结果。
继续前进并看一看 —当我说这是你能在网上找到的最完整的深度学习+计算机视觉教育时,我想你会同意我的观点。
在树莓派上运行深度神经网络
这篇博文的源代码很大程度上是基于我之前的帖子, 用 OpenCV 进行深度学习。
我仍然会在这里完整地回顾这段代码;然而,我想让你参考一下上一篇文章中完整详尽的评论。
首先,创建一个名为pi_deep_learning.py的新文件,并插入以下源代码:
# import the necessary packages
import numpy as np
import argparse
import time
import cv2
第 2-5 行简单导入我们需要的包。
从那里,我们需要解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-l", "--labels", required=True,
help="path to ImageNet labels (i.e., syn-sets)")
args = vars(ap.parse_args())
如第 9-16 行所示,我们有四个必需的命令行参数:
--image:输入图像的路径。--prototxt:Caffe proto txt 文件的路径,该文件本质上是一个遵循类似 JSON 结构的纯文本配置文件。我在我的 PyImageSearch 大师课程中讲述了 Caffe 项目的剖析。--model:通往预训 Caffe 模式的道路。如上所述,您可能希望在比 Raspberry Pi 更强大的硬件上训练您的模型——但是,我们可以在 Pi 上利用一个小的、预先存在的模型。--labels:类标签的路径,在本例中是 ImageNet“syn-sets”标签。
接下来,我们将从磁盘加载类标签和输入图像:
# load the class labels from disk
rows = open(args["labels"]).read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
# load the input image from disk
image = cv2.imread(args["image"])
请打开这篇文章的 【下载】 部分的synset_words.txt。您将看到每行/每列都有一个 ID 和与之相关联的类标签(用逗号分隔)。
第 20 行和第 21 行简单地逐行读入标签文件(rows)并提取第一个相关的类标签。结果是一个包含我们的类标签的classes列表。
然后,我们利用 OpenCV 在第 24 行加载图像。
现在,我们将利用 OpenCV 3.3 的深度神经网络(DNN)模块将image转换为blob,并从磁盘加载模型:
# our CNN requires fixed spatial dimensions for our input image(s)
# so we need to ensure it is resized to 227x227 pixels while
# performing mean subtraction (104, 117, 123) to normalize the input;
# after executing this command our "blob" now has the shape:
# (1, 3, 227, 227)
blob = cv2.dnn.blobFromImage(image, 1, (227, 227), (104, 117, 123))
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
请务必记下我们在上面第 31 行的中调用cv2.dnn.blobFromImage之前的注释。
输入到卷积神经网络的宽度和高度图像尺寸的常见选择包括 32 × 32、64 × 64、224 × 224、227 × 227、256 × 256 和 299 × 299。在我们的例子中,我们将图像预处理(标准化)为 227 x 227 的尺寸(这是 SqueezeNet 训练的图像尺寸),并执行称为均值减法的缩放技术。我在我的书中讨论了这些步骤的重要性。
注意:当使用 SqueezeNet 和 GoogLeNet 时,你会想要使用 224 x 224 的 blob 大小来与 prototxt 定义保持一致。
然后,我们通过利用我们的prototxt和model文件路径引用,在行 35 上从磁盘加载网络。
如果你在上面错过了,这里值得注意的是,我们正在加载一个预训练的模型。训练步骤已经在一台更强大的机器上执行了,不在这篇博文的讨论范围之内(但是在 PyImageSearch 大师和用 Python 进行计算机视觉深度学习 中有详细介绍)。
现在,我们准备通过网络传递图像,并查看预测:
# set the blob as input to the network and perform a forward-pass to
# obtain our output classification
net.setInput(blob)
start = time.time()
preds = net.forward()
end = time.time()
print("[INFO] classification took {:.5} seconds".format(end - start))
# sort the indexes of the probabilities in descending order (higher
# probabilitiy first) and grab the top-5 predictions
preds = preds.reshape((1, len(classes)))
idxs = np.argsort(preds[0])[::-1][:5]
为了对查询blob进行分类,我们通过网络将其向前传递(第 39-42 行),并打印出对输入图像进行分类所花费的时间(第 43 行)。
然后我们可以将概率从最高到最低排序(第 47 行),同时抓住前五位predictions ( 第 48 行)。
剩余的行(1)在图像上绘制最高预测类标签和相应的概率,(2)将前五个结果和概率打印到终端,以及(3)将图像显示到屏幕:
# loop over the top-5 predictions and display them
for (i, idx) in enumerate(idxs):
# draw the top prediction on the input image
if i == 0:
text = "Label: {}, {:.2f}%".format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# display the predicted label + associated probability to the
# console
print("[INFO] {}. label: {}, probability: {:.5}".format(i + 1,
classes[idx], preds[0][idx]))
# display the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
我们在图像顶部绘制顶部预测和概率(行 53-57 ),并在终端显示前 5 个预测+概率(行 61 和 62 )。
最后,我们在屏幕上显示输出图像(第 65 行和第 66 行)。如果你使用 SSH 来连接你的 Raspberry Pi,只有当你在 SSH 连接到你的 Pi 时为 X11 转发提供了-X标志,这才会起作用。
要查看使用 OpenCV 和 Python 在 Raspberry Pi 上应用深度学习的结果,请继续下一节。
树莓 Pi 和深度学习结果
我们将根据两个预训练的深度神经网络对我们的 Raspberry Pi 进行深度学习基准测试:
- 谷歌网
- 斯奎泽尼
正如我们将看到的,SqueezeNet 比 GoogLeNet 小得多(分别为 5MB 和 25MB ),这将使我们能够在 Raspberry Pi 上更快地对图像进行分类。
要在 Raspberry Pi 上运行预先训练好的卷积神经网络,请使用这篇博文的 【下载】 部分下载源代码+预先训练好的神经网络+示例图像。
从这里开始,让我们首先根据这个输入图像对 GoogLeNet 进行基准测试:

Figure 3: A “barbershop” is correctly classified by both GoogLeNet and Squeezenet using deep learning and OpenCV.
从输出中我们可以看到,GoogLeNet 在 1.7 秒内正确地将图像分类为“理发店:
$ python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt \
--model models/bvlc_googlenet.caffemodel --labels synset_words.txt \
--image images/barbershop.png
[INFO] loading model...
[INFO] classification took 1.7304 seconds
[INFO] 1\. label: barbershop, probability: 0.70508
[INFO] 2\. label: barber chair, probability: 0.29491
[INFO] 3\. label: restaurant, probability: 2.9732e-06
[INFO] 4\. label: desk, probability: 2.06e-06
[INFO] 5\. label: rocking chair, probability: 1.7565e-06
让我们试试 SqueezeNet:
$ python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \
--model models/squeezenet_v1.0.caffemodel --labels synset_words.txt \
--image images/barbershop.png
[INFO] loading model...
[INFO] classification took 0.92073 seconds
[INFO] 1\. label: barbershop, probability: 0.80578
[INFO] 2\. label: barber chair, probability: 0.15124
[INFO] 3\. label: half track, probability: 0.0052873
[INFO] 4\. label: restaurant, probability: 0.0040124
[INFO] 5\. label: desktop computer, probability: 0.0033352
SqueezeNet 也正确地将图像分类为【理发店】 …
……但只用了 0.9 秒!
正如我们所见,SqueezeNet 明显比 GoogLeNet 快——这一点极其重要,因为我们正在将深度学习应用于资源受限的 Raspberry Pi。
让我们用 SqueezeNet 试试另一个例子:
$ python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \
--model models/squeezenet_v1.0.caffemodel --labels synset_words.txt \
--image images/cobra.png
[INFO] loading model...
[INFO] classification took 0.91687 seconds
[INFO] 1\. label: Indian cobra, probability: 0.47972
[INFO] 2\. label: leatherback turtle, probability: 0.16858
[INFO] 3\. label: water snake, probability: 0.10558
[INFO] 4\. label: common iguana, probability: 0.059227
[INFO] 5\. label: sea snake, probability: 0.046393

Figure 4: SqueezeNet correctly classifies an image of a cobra using deep learning and OpenCV on the Raspberry Pi.
然而,尽管 SqueezeNet 速度明显更快,但不如 GoogLeNet 准确:
$ python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \
--model models/squeezenet_v1.0.caffemodel --labels synset_words.txt \
--image images/jellyfish.png
[INFO] loading model...
[INFO] classification took 0.92117 seconds
[INFO] 1\. label: bubble, probability: 0.59491
[INFO] 2\. label: jellyfish, probability: 0.23758
[INFO] 3\. label: Petri dish, probability: 0.13345
[INFO] 4\. label: lemon, probability: 0.012629
[INFO] 5\. label: dough, probability: 0.0025394
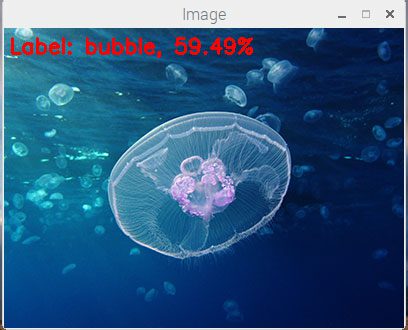
Figure 5: A jellyfish is incorrectly classified by SqueezNet as a bubble.
这里我们看到 SqueezeNet 预测的顶部是“泡沫”。虽然该图像可能看起来像气泡一样,但它实际上是一只“水母”(这是 SqueezeNet 的第二个预测)。
另一方面,GoogLeNet 正确地将“水母”报告为第一预测(牺牲了处理时间):
$ python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt \
--model models/bvlc_googlenet.caffemodel --labels synset_words.txt \
--image images/jellyfish.png
[INFO] loading model...
[INFO] classification took 1.7824 seconds
[INFO] 1\. label: jellyfish, probability: 0.53186
[INFO] 2\. label: bubble, probability: 0.33562
[INFO] 3\. label: tray, probability: 0.050089
[INFO] 4\. label: shower cap, probability: 0.022811
[INFO] 5\. label: Petri dish, probability: 0.013176
摘要
今天,我们学习了如何使用 Python 和 OpenCV 在 Raspberry Pi 上应用深度学习。
一般来说,您应该:
- 永远不要用你的树莓派来训练神经网络。
- 只用你的树莓派部署一个预先训练好的深度学习网络。
Raspberry Pi 没有足够的内存或 CPU 能力来从头训练这些类型的深度、复杂的神经网络。
事实上,Raspberry Pi 几乎没有足够的处理能力来运行它们——我们将在下周的博客文章中发现,对于视频处理应用程序,你将很难获得合理的每秒帧数。
如果你对低成本硬件上的嵌入式深度学习感兴趣,我会考虑看看优化的设备,如 NVIDIA 的 Jetson TX1 和 TX2。这些板旨在 GPU 上执行神经网络,并提供实时(或尽可能接近实时)分类速度。
在下周的博客文章中,我将讨论如何在 Raspberry Pi 上优化 OpenCV,以获得超过 100%的性能增益,用于使用深度学习的对象检测。
要在这篇博文发表时得到通知,只需在下面的表格中输入您的电子邮件地址!***
深度学习:OpenCV 的 blobFromImage 如何工作
原文:https://pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/
今天的博文受到了许多 PyImageSearch 读者的启发,他们对之前的深度学习教程发表了评论,希望了解 OpenCV 的blobFromImage函数到底在做什么。
你看,为了从深度神经网络获得(正确的)预测,你首先需要预处理你的数据。
在深度学习和图像分类的背景下,这些预处理任务通常涉及:
- 均值减法
- 按某个因子缩放
OpenCV 的新深度神经网络(dnn)模块包含两个功能,可用于预处理图像,并通过预训练的深度学习模型为分类做准备。
在今天的博文中,我们将剖析 OpenCV 的cv2.dnn.blobFromImage和cv2.dnn.blobFromImages预处理函数,并理解它们是如何工作的。
要了解更多关于通过 OpenCV 进行深度学习的图像预处理,继续阅读。
深度学习:OpenCV 的 blobFromImage 如何工作
OpenCV 提供了两个功能来促进深度学习分类的图像预处理:
cv2.dnn.blobFromImagecv2.dnn.blobFromImages
这两个功能执行
- 均值减法
- 缩放比例
- 以及可选的频道交换
在本教程的剩余部分,我们将:
- 探索均值减法和缩放
- 检查每个深度学习预处理函数的函数签名
- 详细研究这些方法
- 最后,将 OpenCV 的深度学习功能应用于一组输入图像
让我们开始吧。
深度学习和均值减法

Figure 1: A visual representation of mean subtraction where the RGB mean (center) has been calculated from a dataset of images and subtracted from the original image (left) resulting in the output image (right).
在我们深入解释 OpenCV 的深度学习预处理功能之前,我们首先需要了解均值减法。均值减法用于帮助应对数据集中输入图像的光照变化。因此,我们可以将均值减法视为一种用于帮助我们的卷积神经网络的技术。
在我们开始训练我们的深度神经网络之前,我们首先计算红色、绿色和蓝色通道的训练集中所有图像的平均像素强度。
这意味着我们最终有三个变量:

,  , and
, and 
通常,结果值是一个三元组,分别由红色、绿色和蓝色通道的平均值组成。
例如,ImageNet 训练集的平均值为 R=103.93 、 G=116.77 和 B=123.68 (如果您以前使用过 ImageNet 上预先训练的网络,您可能已经遇到过这些值)。
然而,在某些情况下,平均红色、绿色和蓝色值可能是按通道方式计算的,而不是按像素方式计算的,从而产生一个 MxN 矩阵。在这种情况下,在训练/测试期间,从输入图像中减去每个通道的 MxN 矩阵。
这两种方法都是均值减法的完美有效形式;然而,我们倾向于看到更经常使用的逐像素版本,尤其是对于更大的数据集。
当我们准备好通过我们的网络传递图像时(无论是为了训练还是测试,我们减去的平均值、
, from each input channel of the input image:



我们可能还有一个比例因子、
, which adds in a normalization:
 / \sigma")
 / \sigma")
 / \sigma")
的值
may be the standard deviation across the training set (thereby turning the preprocessing step into a standard score/z-score). However,may also be manually set (versus calculated) to scale the input image space into a particular range — it really depends on the architecture, how the network was trained, and the techniques the implementing author is familiar with.
需要注意的是并非所有深度学习架构都执行均值减法和缩放!在预处理图像之前,请务必阅读您正在使用的深度神经网络的相关出版物/文档。
正如你将在深度学习的旅程中发现的,一些架构只执行均值减法(从而设置
). Other architectures perform both mean subtraction and scaling. Even other architectures choose to perform no mean subtraction or scaling. Always check the relevant publication you are implementing/using to verify the techniques the author is using.
均值减法、缩放和归一化在使用 Python 的计算机视觉深度学习中有更详细的介绍。
OpenCV 的 blobFromImage 和 blobFromImages 函数
让我们从参考官方 OpenCV 文档开始:
[blobFromImage]从图像创建 4 维 blob。可选地调整大小和从中心裁剪
image,减去mean值,通过scalefactor缩放值,交换蓝色和红色通道。
非正式地说,斑点仅仅是具有相同空间尺寸(即,宽度和高度)、相同深度(通道数量)的图像的(潜在集合),它们都已经以相同的方式进行了预处理。
cv2.dnn.blobFromImage和cv2.dnn.blobFromImages功能几乎相同。
让我们从检查下面的cv2.dnn.blobFromImage函数签名开始:
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size, mean, swapRB=True)
我在下面提供了对每个参数的讨论:
image:这是我们要预处理的输入图像,然后通过我们的深度神经网络进行分类。- 在我们执行了均值减法后,我们可以选择用一些因子来缩放我们的图像。该值默认为“1.0”(即无缩放),但我们也可以提供另一个值。同样需要注意的是,
scalefactor应该是 ,因为我们实际上是将输入通道(减去平均值后)乘以
,因为我们实际上是将输入通道(减去平均值后)乘以scalefactor。 size:这里我们提供卷积神经网络期望的空间大小。对于大多数当前最先进的神经网络来说,这要么是 224×224 , 227×227 ,要么是 299×299 。- 这些是我们的平均减法值。它们可以是 RGB 平均值的三元组,或者它们可以是单个值,在这种情况下,从图像的每个通道中减去所提供的值。如果你正在执行均值减法,确保你以
( R,G,B)'的顺序提供三元组,尤其是在使用默认行为swapRB=True`的时候。 swapRB: OpenCV 假设图像是 BGR 通道顺序;然而,“平均值”假定我们使用 RGB 顺序。为了解决这种差异,我们可以通过将该值设置为“真”来交换image中的 R 和 B 通道。默认情况下,OpenCV 为我们执行这种通道交换。
 ,因为我们实际上是将输入通道(减去平均值后)乘以
,因为我们实际上是将输入通道(减去平均值后)乘以cv2.dnn.blobFromImage函数返回一个blob,这是经过均值相减、归一化和通道交换后的输入图像。
cv2.dnn.blobFromImages功能完全相同:
blob = cv2.dnn.blobFromImages(images, scalefactor=1.0, size, mean, swapRB=True)
唯一的例外是我们可以传入多个图像,使我们能够批量处理一组images。
如果您正在处理多个图像/帧,请确保使用cv2.dnn.blobFromImages函数,因为它的函数调用开销较少,您可以更快地批量处理图像/帧。
利用 OpenCV 的 blobFromImage 功能进行深度学习
既然我们已经研究了blobFromImage和blobFromImages函数,让我们将它们应用于一些示例图像,然后将它们通过卷积神经网络进行分类。
作为先决条件,你至少需要 OpenCV 版本 3 . 3 . 0。NumPy 是 OpenCV 的 Python 绑定的依赖项, imutils 是我在 GitHub 和 Python 包索引中提供的便利函数包。
*如果你还没有安装 OpenCV,你会想在这里跟随最新的可用教程,并且在你克隆/下载opencv和opencv_contrib的时候一定要指定 OpenCV 3.3.0 或更高版本。
imutils 软件包可以通过pip安装:
$ pip install imutils
假设您的图像处理环境已经准备就绪,让我们打开一个新文件,将其命名为blob_from_images.py,并插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import cv2
# load the class labels from disk
rows = open("synset_words.txt").read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
# load our serialized model from disk
net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt",
"bvlc_googlenet.caffemodel")
# grab the paths to the input images
imagePaths = sorted(list(paths.list_images("images/")))
首先我们导入imutils、numpy、cv2 ( 第 2-4 行)。
然后我们读取synset_words.txt(ImageNet 类标签)并提取classes(我们的类标签),在的第 7 行和第 8 行。
为了从磁盘加载我们的模型模型,我们使用 DNN 函数cv2.dnn.readNetFromCaffe,并指定bvlc_googlenet.prototxt作为文件名参数,指定bvlc_googlenet.caffemodel作为实际的模型文件(第 11 行和第 12 行)。
注意:你可以使用本教程底部的“下载”*部分获取预训练的卷积神经网络、类标签文本文件、源代码和示例图像。*
最后,我们在行 15 上获取输入图像的路径。如果您使用的是 Windows,您应该在此处更改路径分隔符,以确保您可以正确加载图像路径。
接下来,我们将从磁盘加载图像,并使用blobFromImage对它们进行预处理:
# (1) load the first image from disk, (2) pre-process it by resizing
# it to 224x224 pixels, and (3) construct a blob that can be passed
# through the pre-trained network
image = cv2.imread(imagePaths[0])
resized = cv2.resize(image, (224, 224))
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
print("First Blob: {}".format(blob.shape))
在这个块中,我们首先加载image ( 第 20 行),然后将其调整为 224×224 ( 第 21 行),这是 GoogLeNet 所需的输入图像尺寸。
现在我们到了这篇文章的关键。
在第 22 行上,我们调用cv2.dnn.blobFromImage,如前一节所述,它将创建一个 4 维的blob用于我们的神经网络。
让我们打印出我们的blob的形状,这样我们可以稍后在终端中分析它(第 23 行)。
接下来,我们将通过 GoogLeNet 发送blob:
# set the input to the pre-trained deep learning network and obtain
# the output predicted probabilities for each of the 1,000 ImageNet
# classes
net.setInput(blob)
preds = net.forward()
# sort the probabilities (in descending) order, grab the index of the
# top predicted label, and draw it on the input image
idx = np.argsort(preds[0])[::-1][0]
text = "Label: {}, {:.2f}%".format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
如果你熟悉这个博客上最近的深度学习帖子,上面的几行应该看起来很熟悉。
我们通过网络(第 28 行和第 29 行)输入blob,并获取预测值preds。
然后,我们将最有把握的预测排在列表的前面,并生成一个标签文本显示在图像上。标签文本由分类标签和顶部预测的预测百分比值组成(第 34 行和第 35 行)。
从那里,我们在image ( 第 36 行和第 37 行)的顶部写下标签text,然后在屏幕上显示image,并在继续前进(第 40 行和第 41 行)之前等待按键。
现在该使用blobFromImage函数的复数形式了。
这里我们将做(几乎)同样的事情,除了我们将创建并填充一个列表images,然后将该列表作为参数传递给blobFromImages:
# initialize the list of images we'll be passing through the network
images = []
# loop over the input images (excluding the first one since we
# already classified it), pre-process each image, and update the
# `images` list
for p in imagePaths[1:]:
image = cv2.imread(p)
image = cv2.resize(image, (224, 224))
images.append(image)
# convert the images list into an OpenCV-compatible blob
blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))
print("Second Blob: {}".format(blob.shape))
首先我们初始化我们的images列表(第 44 行),然后,使用imagePaths,我们读取、调整并将image追加到列表中(第 49-52 行)。
使用列表切片,我们已经省略了第 49 行上imagePaths的第一幅图像。
从那里,我们将images作为第一个参数传递到cv2.dnn.blobFromImages的行 55 上。cv2.dnn.blobFromImages的所有其他参数与上面的cv2.dnn.blobFromImage相同。
为了以后的分析,我们在第 56 行的上打印blob.shape。
接下来,我们将通过 GoogLeNet 传递blob,并在每张图片的顶部写入类别标签和预测:
# set the input to our pre-trained network and obtain the output
# class label predictions
net.setInput(blob)
preds = net.forward()
# loop over the input images
for (i, p) in enumerate(imagePaths[1:]):
# load the image from disk
image = cv2.imread(p)
# find the top class label from the `preds` list and draw it on
# the image
idx = np.argsort(preds[i])[::-1][0]
text = "Label: {}, {:.2f}%".format(classes[idx],
preds[i][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# display the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
剩下的代码基本上和上面的一样,只有我们的for循环现在处理每个imagePaths的循环(同样,省略第一个,因为我们已经对它进行了分类)。
就是这样!让我们在下一节看看这个脚本的运行情况。
OpenCV blobfromImage 和 blobFromImages 结果
现在我们到了有趣的部分。
继续使用这篇博文的 【下载】 部分下载源代码、示例图像和预先训练好的神经网络。您将需要额外的文件来执行代码。
从那里,启动一个终端并运行以下命令:
$ python blob_from_images.py
第一个终端输出是关于在我们应用cv2.dnn.blobFromImage函数的images文件夹中找到的第一幅图像:
First Blob: (1, 3, 224, 224)
生成的啤酒杯图像显示在屏幕上:
Figure 2: An enticing beer has been labeled and recognized with high confidence by GoogLeNet. The blob dimensions resulting from blobFromImage are displayed in the terminal.
那满满的啤酒杯让我口渴。但在我享受啤酒之前,我会解释为什么这个斑点的形状是(1, 3, 224, 224)。
结果元组具有以下格式:
(num_images=1, num_channels=3, width=224, height=224)
因为我们只处理了个图像,所以我们的blob中只有个条目。BGR 频道的频道计数是三。最后 224×224 是我们输入图像的空间宽度和高度。
接下来,让我们从剩余的四个输入图像中构建一个blob。
第二个斑点的形状是:
Second Blob: (4, 3, 224, 224)
因为这个斑点包含 4 个图像,所以num_images=4。其余维度与第一个单一图像 blob 相同。
我在下面附上了正确分类的图片样本:

Figure 3: My keyboard has been correctly identified by GoogLeNet with a prediction confidence of 81%.

Figure 4: I tested the pre-trained network on my computer monitor as well. Here we can see the input image is correctly classified using our Convolutional Neural Network.

Figure 5: A NASA space shuttle is recognized with a prediction value of over 99% by our deep neural network.
摘要
在今天的教程中,我们检查了 OpenCV 的blobFromImage和blobFromImages深度学习功能。
这些方法用于通过预训练的深度学习模型为分类准备输入图像。
blobFromImage和blobFromImages都执行均值减法和缩放。我们也可以根据通道顺序交换图像的红色和蓝色通道。几乎所有最先进的深度学习模型都执行均值减法和缩放——这里的好处是 OpenCV 使这些预处理任务变得非常简单。
如果你有兴趣更详细地研究深度学习,一定要看看我的新书, 用 Python 进行计算机视觉的深度学习 。
在这本书里,你会发现:
- 超级实用的演练展示了实际、真实世界图像分类问题、挑战和竞赛的解决方案。
- 详细、彻底的实验(使用高度文档化的代码)使您能够重现最先进的结果。
- 我最喜欢的“最佳实践”提高网络准确率。光是这些技巧就能为你节省足够的时间来支付这本书的多次费用。
- ..还有更多!
听起来不错吧?
否则,请务必在下表中输入您的电子邮件地址,以便在 PyImageSearch 博客上发布未来的深度学习教程时得到通知。
下周见!*
使用 Keras、Redis、Flask 和 Apache 在生产中进行深度学习
原文:https://pyimagesearch.com/2018/02/05/deep-learning-production-keras-redis-flask-apache/
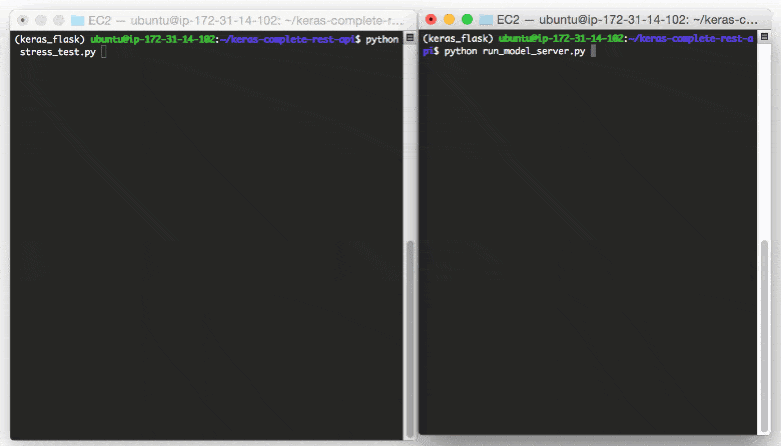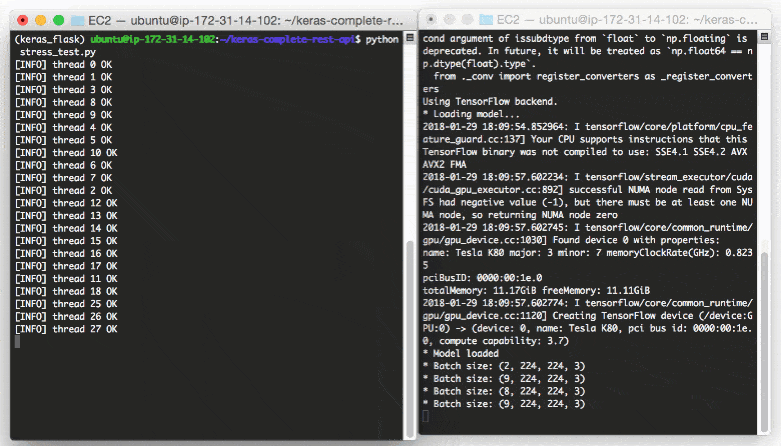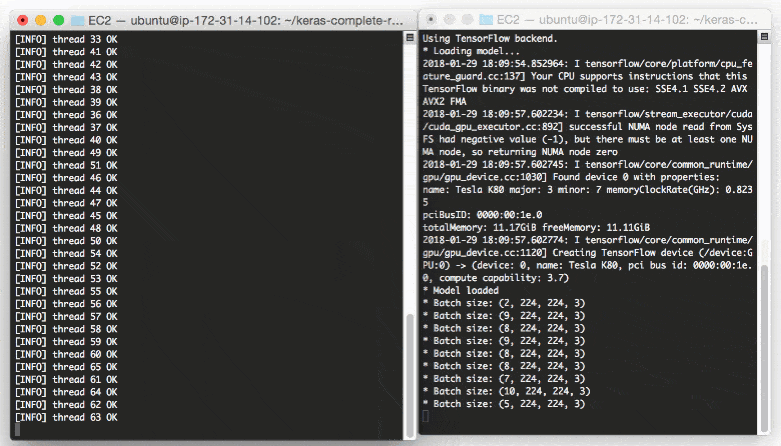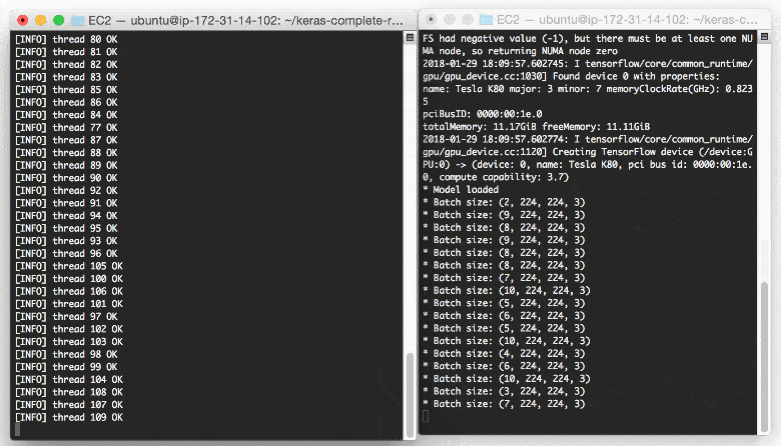
将深度学习模型交付给生产是一项重要的任务。
如果你不相信我,花一秒钟看看亚马逊、谷歌、微软等“科技巨头”。— 几乎所有的都提供了一些方法,将你的机器学习/深度学习模型运送到云中进行生产。
使用模型部署服务是完全可以接受的……但是如果您想拥有整个流程并且不依赖外部服务,该怎么办?
这种情况比你想象的更常见。考虑:
- 不能将敏感数据移出网络的内部项目
- 指定整个基础结构必须位于公司内部的项目
- 需要私有云的政府组织
- 处于“秘密模式”的初创公司,需要在内部对其服务/应用进行压力测试
在这些情况下,你会如何将你的深度学习模型投入生产,也许最重要的是,同时使它可扩展?
今天的帖子是我们关于构建深度学习模型服务器 REST API 的三部分系列的最后一章:
- 第一部分 ( 发布在 Keras.io 官方博客上!)是一个简单的 Keras +深度学习 REST API,用于单线程使用,没有并发请求。如果这是你第一次构建深度学习 web 服务器,或者如果你正在做一个家庭/业余爱好项目,这种方法非常适合。
- 在第二部分中,我们展示了如何利用 Redis 以及消息排队/消息代理范例高效地批量处理传入的推理请求(但是在服务器线程上有一个小警告,可能会导致问题)。
- 在本系列的最后一部分,我将向您展示如何解决这些服务器线程问题,进一步扩展我们的方法,提供基准,并演示如何使用 Keras、Redis、Flask 和 Apache 在生产中高效扩展深度学习。
正如我们的压力测试结果将展示的那样,我们的单个 GPU 机器可以轻松处理 500 个并发请求(每个请求之间的延迟为 0.05 秒),而无需担心— 这种性能还会继续扩展。
要了解如何使用 Keras、Redis、Flask 和 Apache 将自己的深度学习模型交付到生产中,继续阅读。
使用 Keras、Redis、Flask 和 Apache 在生产中进行深度学习
2020-06-16 更新:此博文现已兼容 TensorFlow 2+!
https://www.youtube.com/embed/1uoHYcMZ7nc?feature=oembed
你的深度学习+ Python Ubuntu 虚拟机
原文:https://pyimagesearch.com/2017/09/22/deep-learning-python-ubuntu-virtual-machine/

当谈到使用深度学习+ Python 时,我强烈推荐使用 Linux 环境。
深度学习工具可以更容易地配置和安装在 Linux 上,允许您快速开发和运行神经网络。
当然,配置自己的深度学习+ Python + Linux 开发环境可能是一项非常繁琐的任务,尤其是如果您是 Linux 新手,是命令行/终端的初学者,或者是手动编译和安装包的新手。
为了帮助你快速启动你的深度学习+ Python 教育,我已经创建了一个 Ubuntu 虚拟机 ,其中包含了你成功所需的所有深度学习库(包括 Keras 、 TensorFlow 、 scikit-learn 、 scikit-image 、 OpenCV 和其他) 预配置的 和
*这个虚拟机是我的书的所有三个捆绑包的一部分, 用 Python 进行计算机视觉的深度学习 。购买副本后,您将能够下载虚拟机并立即开始深度学习。
在本教程的剩余部分,我将向您展示:
- 如何下载并安装用于管理、创建和导入虚拟机的 VirtualBox 。
- 如何导入预先配置好的 Ubuntu 虚拟机进行深度学习?
- 如何访问虚拟机上预装的深度学习库。
让我们开始吧。
你的深度学习+ Python 虚拟机
您使用 Python 购买的用于计算机视觉的 深度学习包含一个预配置的用于深度学习的 Ubuntu 虚拟机。在接下来的部分,我将向你展示导入你的 Ubuntu 深度学习虚拟机是多么的容易。
本教程分为三个部分,以便于消化和理解:
- 下载并安装 VirtualBox。
- 下载并导入您预先配置的 Ubuntu 深度学习虚拟机。
- 访问深度学习虚拟机内部的 Python 开发环境。
步骤 1:下载并安装 VirtualBox
第一步是下载 VirtualBox ,一个管理虚拟机的免费开源平台。
VirtualBox 会在MAC OSLinuxWindows上运行。
我们称运行在你的 主机 上的物理硬件 VirtualBox。将要导入到 VirtualBox 中的虚拟机是 来宾机 。
要安装 VirtualBox,首先访问下载页面,然后为您的操作系统选择合适的二进制文件:

Figure 1: VirtualBox downloads.
从这里开始,按照提供的说明在您的系统上安装软件——在这个示例中,我将使用 macOS,但是同样,这些说明也适用于 Linux 和 Windows:

Figure 2: Installing VirtualBox on macOS
第二步:下载你的深度学习虚拟机
现在已经安装了 VirtualBox,您需要下载与您购买的使用 Python : 的 计算机视觉深度学习相关的预配置 Ubuntu 虚拟机

Figure 3: Downloading the pre-configured Ubuntu deep learning virtual machine.
该文件大约为 4GB,因此根据您的互联网连接,下载需要一些时间才能完成。
一旦你下载了VirtualMachine.zip文件,解压它,你会发现一个名为DL4CV Ubuntu VM.ova的文件。我已将此文件放在我的桌面上:

Figure 4: The DL4CV Ubuntu VM.ova file.
这是您将导入到 VirtualBox 管理器中的实际文件。
第三步:将深度学习虚拟机导入 VirtualBox
继续打开 VirtualBox 管理器。
从那里选择File => Import Appliance...:

Figure 5: Importing the pre-configured Ubuntu deep learning virtual machine.
对话框打开后,您需要导航到DL4CV Ubuntu VM.ova文件在磁盘上的位置:

Figure 6: Selecting the pre-configured Ubuntu deep learning virtual machine.
最后,您可以点击“导入”,允许虚拟机导入:

Figure 7: Importing the Ubuntu deep learning virtual machine may take 3-4 minutes depending on your system.
整个导入过程应该只需要几分钟。
第四步:启动深度学习虚拟机
既然深度学习虚拟机已经导入,我们需要启动它。
从 VirtualBox 管理器中选择窗口左侧窗格中的“DL4CV Ubuntu VM”,然后点击“开始”:

Figure 8: Booting the pre-configured Ubuntu deep learning virtual machine.
虚拟机启动后,您可以使用以下凭据登录:
- 用户名:
pyimagesearch - 密码:
deeplearning

Figure 9: Logging into the deep learning virtual machine.
步骤#5:访问深度学习 Python 虚拟环境
登录虚拟机后的下一步是启动终端:

Figure 10: Launching a terminal window.
从那里,执行workon dl4cv来访问 Python +深度学习开发环境:

Figure 11: Accessing the dl4cv deep learning + Python development environment.
注意,现在我的提示前面有了文本(dl4cv),这意味着我在dl4cv Python 虚拟环境中。
您可以运行pip freeze来查看所有安装的 Python 库。
我在下面附上了一个截图,演示了如何从 Python shell 导入 Keras、TensorFlow 和 OpenCV:
Figure 12: Importing Keras, TensorFlow, and OpenCV into our deep learning Python virtual environment.
步骤#6:(可选)在虚拟机上安装来宾附件
您可能希望执行的一个可选步骤是在您的机器上安装 VirtualBox Guest Additions 。
客人附加服务包允许您:
- 从虚拟机复制并粘贴到您的主机(反之亦然)
- 在虚拟机和主机之间共享文件夹
- 调整屏幕分辨率
- 等等。
您可以通过从屏幕顶部的 VirtualBox 菜单中选择Devices => Install Guest Additions...来安装来宾附件。
在虚拟机上使用 Python 执行来自计算机视觉深度学习的代码
有多种方法可以从您的虚拟机访问使用 Python 的计算机视觉深度学习源代码+数据集。
到目前为止最简单的方法 就是直接打开 Firefox 下载。从“你的购买”页面压缩存档在购买了你的用 Python 进行计算机视觉深度学习的副本之后。我建议将收据邮件转发给你自己,这样你就可以通过 Firefox 登录到你的收件箱,然后下载代码+数据集。
您还可以使用您最喜欢的 SFTP/FTP 客户端将代码从您的主机传输到虚拟机。
当然,当你阅读这本书时,你可以使用内置的文本编辑器在 Ubuntu 虚拟机中手工编写代码。
使用深度学习虚拟机的提示
当使用 Ubuntu VirtualBox 虚拟机进行深度学习时,我建议如下:
- 使用 Sublime Text 作为轻量级代码编辑器。Sublime Text 是我最喜欢的 Linux 代码编辑器。它简单、易于使用,并且非常轻量级,非常适合虚拟机。
- 使用 PyCharm 作为一个成熟的 IDE。说到 Python IDEs,很难打败 PyCharm。我个人不喜欢在虚拟机中使用 PyCharm,因为它非常消耗资源。一旦安装完毕,您还需要配置 PyCharm 来使用
dl4cvPython 环境。
故障排除和常见问题
在这一节中,我将详细解答关于预先配置的 Ubuntu 深度学习虚拟机的常见问题。
我如何启动我的深度学习虚拟机?
一旦你的虚拟机被导入,选择 VirtualBox 软件左侧的“DL4CV Ubuntu 虚拟机”,然后点击“开始”按钮。然后,您的虚拟机将启动。
Ubuntu 深度学习虚拟机的用户名和密码是什么?
用户名是pyimagesearch,密码是deeplearning。
用户名和密码对我无效。
为 Ubuntu 虚拟机选择的键盘布局是标准的 英文布局 。如果您使用的键盘不是英语,请为您的特定语言添加键盘布局。
为此,首先打开系统设置应用程序,选择“键盘”。从那里,点击面板底部的“文本输入”按钮:

Figure 13: Selecting “Text Entry” in the deep learning virtual image.
最后,点击“+”图标,选择你的键盘布局,点击“添加”:

Figure 14: Updating the keyboard layout in the Ubuntu virtual machine.
您可能需要重新启动系统才能使这些更改生效。
如何运行访问深度学习库的 Python 脚本?
使用 Python 的计算机视觉深度学习虚拟机使用 Python 虚拟环境来帮助组织 Python 模块,并将它们与 Python 的系统安装分开。
要访问虚拟环境,只需在 shell 中执行workon dl4cv。从那里你可以访问深度学习/计算机视觉库,如 TensorFlow、Keras、OpenCV、scikit-learn、scikit-image 等。
如何从 Ubuntu 虚拟机访问我的 GPU?
简而言之,你不能从虚拟机访问你的 GPU。
虚拟机将您的硬件抽象化,并在您的主机和客户机器之间创建一个人工屏障。外围设备,如您的 GPU、USB 端口等。虚拟机无法访问物理计算机上的。
如果你想使用你的 GPU 进行深度学习,我建议你配置你的原生开发环境。
我收到一条与“VT-x/AMD-V 硬件加速不适用于您的系统”相关的错误消息。我该怎么办?
如果您收到类似如下的错误消息:

Figure 13: Resolving “VT-x/AMD-V hardware acceleration is not available for your system” errors.
那么您可能需要检查您的 BIOS 并确保虚拟化已启用。如果您使用的是 Windows,您可能还需要禁用 Hyper-V 模式。
要解决该问题:
- 从 Windows 控制面板禁用 Hyper-V 模式(如果使用 Windows 操作系统)。看一下这个问题的答案,这和你遇到的问题是一样的。禁用 Hyper-V 在不同的 Windows 版本上是不同的,但是根据上面问题的答案,您应该能够找到您的解决方案。也就是说,你也要确保完成下面的第 2 步。
- 检查你的 BIOS。下次启动系统时,进入 BIOS 并确保虚拟化已启用(通常在某种“高级设置”下)。如果未启用虚拟化,则虚拟机将无法启动。
摘要
在今天的教程中,我演示了:
- 如何下载和安装用于管理虚拟机的软件 VirtualBox。
- 如何导入并启动你的 Ubuntu 深度学习虚拟机?
- Ubuntu 启动后如何访问深度学习开发环境?
所有购买我的书, 使用 Python 的计算机视觉深度学习 ,都包括我预先配置的虚拟机的副本。
这个虚拟机是迄今为止使用 Python 编程语言启动和运行深度学习和计算机视觉的最快方式。
如果你想更多地了解我的新书(并自己拿一本), 点击这里 。*
利用 OpenCV 进行深度学习
原文:https://pyimagesearch.com/2017/08/21/deep-learning-with-opencv/
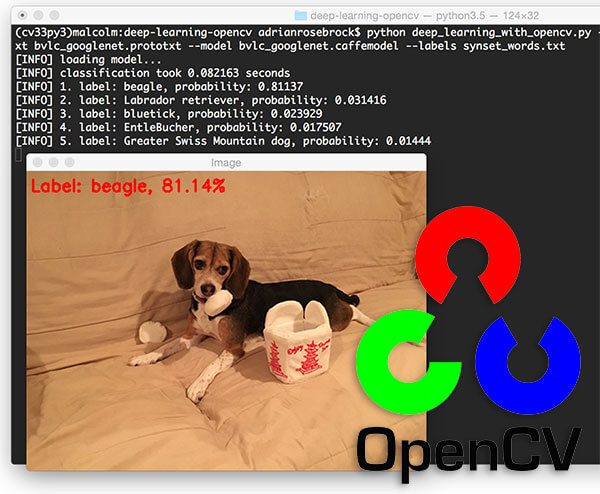
两周前 OpenCV 3.3 正式发布,带来了高度改进的深度学习(dnn)模块。这个模块现在支持很多深度学习框架,包括 Caffe、TensorFlow、Torch/PyTorch。
此外,这个用于使用预训练深度学习模型的 API 与兼容c++ API 和 Python 绑定,使非常简单能够:
- 从磁盘加载模型。
- 预处理输入图像。
- 通过网络传递图像并获得输出分类。
虽然我们不能使用 OpenCV 训练深度学习模型(我们也不应该),但这个确实允许我们使用专用的深度学习库/工具训练我们的模型,然后在我们的 OpenCV 脚本中直接有效地使用它们。
在这篇博文的剩余部分,我将演示如何在 ImageNet 数据集上使用预训练的深度学习网络并将其应用于输入图像的基础知识。
想了解更多关于 OpenCV 深度学习的知识,继续阅读。
利用 OpenCV 进行深度学习
在这篇文章的第一部分,我们将讨论 OpenCV 3.3 版本和经过彻底改革的dnn模块。
然后我们将编写一个 Python 脚本,该脚本将使用 OpenCV 和 GoogleLeNet(在 ImageNet 上进行了预训练)来对图像进行分类。
最后,我们将探索分类的结果。
OpenCV 3.3 内部的深度学习
OpenCV 的 dnn 模块从 3.1 版开始就是opencv_contrib资源库的一部分。现在在 OpenCV 3.3 中,它被包含在主资源库中。
你为什么要在乎?
深度学习是机器学习的一个快速发展的领域,如果你已经在计算机视觉/图像处理领域工作(或者正在加速),这是一个值得探索的重要领域。
借助 OpenCV 3.3,我们可以利用带有流行深度学习框架的预训练网络。事实上,它们是经过预训练的,这意味着我们不需要花很多时间来训练网络——相反,我们可以完成一个正向传递,并利用输出在我们的应用中做出决策。
OpenCV 不是(也不打算)成为训练网络的工具——已经有很好的框架可以用于这个目的。由于网络(如 CNN)可以用作分类器,因此 OpenCV 有一个深度学习模块是合乎逻辑的,我们可以在 OpenCV 生态系统中轻松利用它。
与 OpenCV 3.3 兼容的流行网络架构包括:
- GoogleLeNet(在这篇博文中使用)
- AlexNet
- 斯奎泽尼
- VGGNet(以及相关的风味)
- ResNet
该模块的发行说明可在 OpenCV 资源库页面上获得。
本模块的主要贡献者 Aleksandr Rybnikov 对本模块有着雄心勃勃的计划,因此请务必保持关注并阅读他的发行说明(俄语版,因此如果俄语不是您的母语,请确保您的浏览器启用了谷歌翻译)。
我认为dnn模块将对 OpenCV 社区产生重大影响,所以让我们把这个消息传出去。
用 OpenCV 3.3 配置您的机器
安装 OpenCV 3.3 等同于安装其他版本。可以使用相同的安装教程—只要确保下载并使用正确的版本。
只需遵循这些针对 MacOS 或 Ubuntu 的说明,同时确保使用 OpenCV 3.3 的 opencv 和 opencv_contrib 版本。如果你选择了 MacOS + homebrew 安装指令,确保使用--HEAD开关(在提到的其他开关中)来获得 OpenCV 的最新版本。
如果你正在使用虚拟环境(强烈推荐),你可以很容易地安装 OpenCV 3.3 和以前的版本。按照与您的系统相对应的教程,创建一个全新的虚拟环境(并适当地命名它)。
OpenCV 深度学习功能和框架
OpenCV 3.3 支持 Caffe 、 TensorFlow 和 Torch / PyTorch 框架。
目前还不支持 Keras (因为 Keras 实际上是 TensorFlow 和 Theano 等后端的包装器),尽管鉴于深度学习库的流行,我认为 Keras 得到直接支持只是时间问题。
使用 OpenCV 3.3,我们可以使用dnn中的以下函数从磁盘加载图像:
cv2.dnn.blobFromImagecv2.dnn.blobFromImages
我们可以通过“创建”方法直接从各种框架中导入模型:
cv2.dnn.createCaffeImportercv2.dnn.createTensorFlowImportercv2.dnn.createTorchImporter
尽管我认为简单地使用“读取”方法并直接从磁盘加载序列化模型更容易:
cv2.dnn.readNetFromCaffecv2.dnn.readNetFromTensorFlowcv2.dnn.readNetFromTorchcv2.dnn.readhTorchBlob
一旦我们从磁盘加载了一个模型,就可以使用`. forward '方法向前传播我们的图像并获得实际的分类。
为了了解所有这些 OpenCV 深度学习部分是如何组合在一起的,让我们进入下一部分。
使用深度学习和 OpenCV 对图像进行分类
在这一节中,我们将创建一个 Python 脚本,该脚本可以使用 Caffe 框架,使用 OpenCV 和 GoogLeNet(在 ImageNet 上进行了预训练)对输入图像进行分类。
Szegedy 等人在他们 2014 年的论文 中介绍了 GoogLeNet 架构(在小说《微架构》之后,现在被称为“Inception”)。
OpenCV 3.3 还支持其他架构,包括 AlexNet、ResNet 和 SqueezeNet——我们将在未来的博客文章中研究这些用于 OpenCV 深度学习的架构。
与此同时,让我们学习如何加载一个预先训练好的 Caffe 模型,并使用它通过 OpenCV 对图像进行分类。
首先,打开一个新文件,将其命名为deep_learning_with_opencv.py,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import time
import cv2
在第 2-5 行,我们导入我们需要的包。
然后我们解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-l", "--labels", required=True,
help="path to ImageNet labels (i.e., syn-sets)")
args = vars(ap.parse_args())
在第 8 行上,我们创建了一个参数解析器,然后建立了四个必需的命令行参数(第 9-16 行):
--image:输入图像的路径。--prototxt:Caffe“deploy”proto txt 文件的路径。--model:预训练的 Caffe 模型(即网络权重本身)。--labels:ImageNet 标签的路径(即“syn-sets”)。
现在我们已经建立了我们的参数,我们解析它们并将它们存储在变量args中,以便于以后访问。
让我们加载输入图像和类标签:
# load the input image from disk
image = cv2.imread(args["image"])
# load the class labels from disk
rows = open(args["labels"]).read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
在第 20 行,我们通过cv2.imread从磁盘加载image。
让我们仔细看看我们在第 23 行和第 24 行加载的类标签数据:
n01440764 tench, Tinca tinca
n01443537 goldfish, Carassius auratus
n01484850 great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
n01491361 tiger shark, Galeocerdo cuvieri
n01494475 hammerhead, hammerhead shark
n01496331 electric ray, crampfish, numbfish, torpedo
n01498041 stingray
...
正如您所看到的,我们有一个惟一的标识符,后跟一个空格、一些类标签和一个换行符。使用 Python 逐行解析这个文件简单而高效。
首先,我们将类标签rows从磁盘加载到一个列表中。为此,我们去除了每行开头和结尾的空白,同时使用新行(“\n”)作为行分隔符(第 23 行)。结果是 id 和标签的列表:
['n01440764 tench, Tinca tinca', 'n01443537 goldfish, Carassius auratus',
'n01484850 great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias',
'n01491361 tiger shark, Galeocerdo cuvieri',
'n01494475 hammerhead, hammerhead shark',
'n01496331 electric ray, crampfish, numbfish, torpedo',
'n01498041 stingray', ...]
第二,我们使用 list comprehension 从rows中提取相关的类标签,方法是查找 ID 后面的空格(’),然后用逗号(,’)分隔类标签。结果只是一个类标签列表:
['tench', 'goldfish', 'great white shark', 'tiger shark',
'hammerhead', 'electric ray', 'stingray', ...]
现在我们已经处理好了标签,让我们深入研究 OpenCV 3.3 的dnn模块:
# our CNN requires fixed spatial dimensions for our input image(s)
# so we need to ensure it is resized to 224x224 pixels while
# performing mean subtraction (104, 117, 123) to normalize the input;
# after executing this command our "blob" now has the shape:
# (1, 3, 224, 224)
blob = cv2.dnn.blobFromImage(image, 1, (224, 224), (104, 117, 123))
注意上面块中的注释,我们使用cv2.dnn.blobFromImage执行均值减法来归一化输入图像,这导致已知的斑点形状(行 31 )。
然后,我们从磁盘加载我们的模型:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
既然我们已经选择使用 Caffe,我们就利用cv2.dnn.readNetFromCaffe从磁盘加载我们的 Caffe 模型定义prototxt和预先训练的model(第 35 行)。
如果您熟悉 Caffe,您会发现prototxt文件是一个纯文本配置,遵循类似 JSON 的结构——我建议您从文本编辑器的 “下载” 部分打开bvlc_googlenet.prototxt来检查它。
注意:如果你不熟悉配置 Caffe CNNs,那么这是一个考虑 PyImageSearch 大师课程的好时机——在课程中,你将深入了解使用深度网络进行计算机视觉和图像分类。
现在,让我们以blob作为输入,通过网络完成一次正向传递:
# set the blob as input to the network and perform a forward-pass to
# obtain our output classification
net.setInput(blob)
start = time.time()
preds = net.forward()
end = time.time()
print("[INFO] classification took {:.5} seconds".format(end - start))
在这一步需要注意的是,我们不是在训练一个 CNN——相反,我们是在利用一个预先训练好的网络。因此,我们只是通过网络传递斑点(即正向传播)以获得结果(没有反向传播)。
首先,我们指定blob作为我们的输入(第 39 行)。其次,我们制作一个start时间戳( Line 40 ),然后通过网络传递我们的输入图像并存储预测。最后,我们设置了一个end时间戳( Line 42 ),这样我们就可以计算差值并打印运行时间( L ine 43 )。
最后,我们来确定输入图像的前五个预测:
# sort the indexes of the probabilities in descending order (higher
# probabilitiy first) and grab the top-5 predictions
idxs = np.argsort(preds[0])[::-1][:5]
使用 NumPy,我们可以很容易地排序并提取第 47 行上的前五个预测。
接下来,我们将显示排名前五的类别预测:
# loop over the top-5 predictions and display them
for (i, idx) in enumerate(idxs):
# draw the top prediction on the input image
if i == 0:
text = "Label: {}, {:.2f}%".format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# display the predicted label + associated probability to the
# console
print("[INFO] {}. label: {}, probability: {:.5}".format(i + 1,
classes[idx], preds[0][idx]))
# display the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
该循环的思想是(1)在图像本身上绘制顶部预测标签,以及(2)将相关的类别标签概率打印到终端。
最后,我们将图像显示到屏幕上(行 64 ),并在退出(行 65 )之前等待用户按键。
深度学习和 OpenCV 分类结果
既然我们已经通过 OpenCV 实现了利用深度学习的 Python 脚本,那么让我们继续将它应用于一些示例图像。
确保你使用这篇博文的 【下载】 部分下载源代码+预先训练好的 GoogLeNet 架构+示例图片。
从那里,打开一个终端并执行以下命令:
$ python deep_learning_with_opencv.py --image images/jemma.png
--prototxt bvlc_googlenet.prototxt \
--model bvlc_googlenet.caffemodel --labels synset_words.txt
[INFO] loading model...
[INFO] classification took 0.075035 seconds
[INFO] 1\. label: beagle, probability: 0.81137
[INFO] 2\. label: Labrador retriever, probability: 0.031416
[INFO] 3\. label: bluetick, probability: 0.023929
[INFO] 4\. label: EntleBucher, probability: 0.017507
[INFO] 5\. label: Greater Swiss Mountain dog, probability: 0.01444
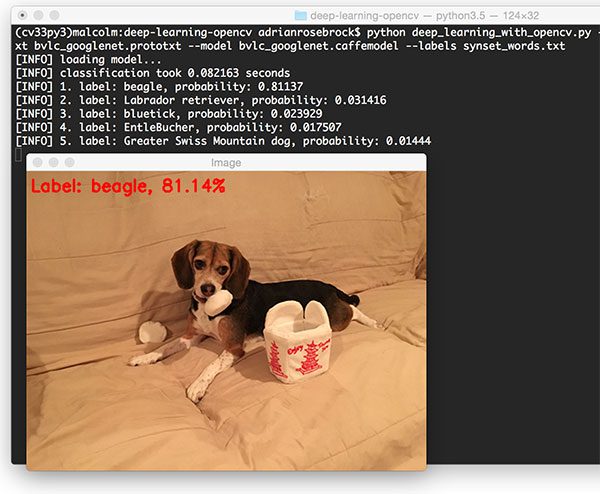
Figure 1: Using OpenCV and deep learning to predict the class label for an input image.
在上面的例子中,我们有 Jemma,家庭小猎犬。使用 OpenCV 和 GoogLeNet,我们已经正确地将这张图片分类为 【小猎犬】 。
此外,检查前 5 名的结果,我们可以看到其他的预测也是相关的,它们都是与比格犬有相似外貌的狗。
看一下时间,我们还看到向前传递花费了不到 1 秒,即使我们正在使用我们的 CPU。
请记住,前向传递比后向传递快得多,因为我们不需要计算梯度和通过网络的反向传播。
让我们使用 OpenCV 和深度学习对另一幅图像进行分类:
$ python deep_learning_with_opencv.py --image images/traffic_light.png
--prototxt bvlc_googlenet.prototxt \
--model bvlc_googlenet.caffemodel --labels synset_words.txt
[INFO] loading model...
[INFO] classification took 0.080521 seconds
[INFO] 1\. label: traffic light, probability: 1.0
[INFO] 2\. label: pole, probability: 4.9961e-07
[INFO] 3\. label: spotlight, probability: 3.4974e-08
[INFO] 4\. label: street sign, probability: 3.3623e-08
[INFO] 5\. label: loudspeaker, probability: 2.0235e-08
Figure 2: OpenCV and deep learning is used to correctly label this image as “traffic light”.
OpenCV 和 GoogLeNet 以 100%的把握正确地将这张图片标注为 【红绿灯】 。
在这个例子中我们有一个 【秃鹰】 :
$ python deep_learning_with_opencv.py --image images/eagle.png
--prototxt bvlc_googlenet.prototxt \
--model bvlc_googlenet.caffemodel --labels synset_words.txt
[INFO] loading model...
[INFO] classification took 0.087207 seconds
[INFO] 1\. label: bald eagle, probability: 0.96768
[INFO] 2\. label: kite, probability: 0.031964
[INFO] 3\. label: vulture, probability: 0.00023595
[INFO] 4\. label: albatross, probability: 6.3653e-05
[INFO] 5\. label: black grouse, probability: 1.6147e-05

Figure 3: The “deep neural network” (dnn) module inside OpenCV 3.3 can be used to classify images using pre-trained models.
我们再次能够正确地对输入图像进行分类。
我们最后的例子是一个【自动售货机】:
$ python deep_learning_with_opencv.py --image images/vending_machine.png
--prototxt bvlc_googlenet.prototxt \
--model bvlc_googlenet.caffemodel --labels synset_words.txt
[INFO] loading model...
[INFO] classification took 0.099602 seconds
[INFO] 1\. label: vending machine, probability: 0.99269
[INFO] 2\. label: cash machine, probability: 0.0023691
[INFO] 3\. label: pay-phone, probability: 0.00097005
[INFO] 4\. label: ashcan, probability: 0.00092097
[INFO] 5\. label: mailbox, probability: 0.00061188
Figure 4: Since our GoogLeNet model is pre-trained on ImageNet, we can classify each of the 1,000 labels inside the dataset using OpenCV + deep learning.
OpenCV +深度学习再一次正确地对图像进行了分类。
摘要
在今天的博文中,我们学习了如何使用 OpenCV 进行深度学习。
随着 OpenCV 3.3 的发布,深度神经网络(dnn)库得到了实质性的改革,允许我们通过 Caffe、TensorFlow 和 Torch/PyTorch 框架加载预训练的网络,然后使用它们对输入图像进行分类。
鉴于这个框架如此受欢迎,我想 Keras 的支持也将很快到来。这可能是一个不简单的实现,因为 Keras 本身可以支持多个数值计算后端。
在接下来的几周里,我们将:
- 深入研究
dnn模块,以及如何在我们的 Python + OpenCV 脚本中使用它。 - 了解如何修改 Caffe
.prototxt文件以兼容 OpenCV。 - 了解我们如何使用 OpenCV 将深度学习应用于 Raspberry Pi。
这是一个不容错过的系列博客文章,所以在你离开之前,请确保在下面的表格中输入你的电子邮件地址,以便在这些文章发布时得到通知!***
利用 Keras 和 TensorFlow 防御恶意图像攻击
在本教程中,您将学习如何使用 Keras 和 TensorFlow 防御恶意图像攻击。
到目前为止,您已经学习了如何使用三种不同的方法生成对立的图像:
使用对立的图像,我们可以欺骗我们的卷积神经网络(CNN)做出不正确的预测。虽然,根据人类的眼睛,敌对的图像可能看起来与它们的原始副本一样*,但是它们包含小的干扰,导致我们的 CNN 做出非常不正确的预测。
正如我在本教程中讨论的,将未设防的模型部署到野外会有巨大的后果。
例如,想象一下部署到自动驾驶汽车上的深度神经网络。邪恶的用户可以生成敌对的图像,打印它们,然后将它们应用于道路、标志、立交桥等。,这将导致模型认为有行人、汽车或障碍物,而实际上没有!结果可能是灾难性的,包括车祸、受伤和生命损失。
鉴于敌对图像带来的风险,这就提出了一个问题:
我们能做些什么来抵御这些攻击呢?
我们将在关于对抗性图像防御的两部分系列中讨论这个问题:
- 使用 Keras 和 TensorFlow 防御恶意图像攻击(今天的教程)
- 训练 CNN 时混合正常图像和敌对图像(下周指南)
对抗性的形象辩护不是闹着玩的。如果您正在将模型部署到现实世界中,那么请确保您有适当的程序来防御恶意攻击。
通过遵循这些教程,你可以训练你的 CNN 做出正确的预测,即使他们面对的是敌对的图像。
要了解如何训练 CNN 抵御 Keras 和 TensorFlow 的对抗性攻击,继续阅读。
使用 Keras 和 TensorFlow 防御恶意图像攻击
在本教程的第一部分,我们将讨论作为“军备竞赛”的对立图像的概念,以及我们可以做些什么来抵御它们。
然后,我们将讨论两种方法,我们可以用来抵御敌对的形象。我们今天实现第一个方法,下周实现第二个方法。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们要回顾几个 Python 脚本,包括:
- 我们的 CNN 架构
- 使用 FGSM 生成对抗图像的功能
- 一个数据生成器功能,用于生成批对立的图像,这样我们就可以对它们进行微调
- 一个将所有片段放在一起的训练脚本在 MNIST 数据集上训练我们的模型,生成敌对的图像,然后对 CNN 进行微调以提高准确性
我们开始吧!
对立的图像是一场“军备竞赛”,我们需要防范它们
防御敌对攻击已经并将继续是一个活跃的研究领域。没有“灵丹妙药”的方法可以让你的模型在对抗攻击时变得健壮。
相反,你应该重新定义你对对抗性攻击的想法——这不像是“灵丹妙药”程序的和,而更像是一场军备竞赛。
在美苏冷战期间,两国都投入了巨额资金和无数时间进行研发:
- 制造强大的武器
- 同时创造系统来防御这些武器
对于核武器棋盘上的每一步棋,都有同等的防御企图。
我们一直看到这种类型的军备竞赛:
一家公司在业内创造新产品,而另一家公司创造自己的版本。本田和丰田就是一个很好的例子。当本田在 1986 年推出他们的高端豪华车版本讴歌时,丰田在 1989 年推出了他们的豪华车版本雷克萨斯作为反击。
另一个例子来自反病毒软件,它可以持续防御新的攻击。当一种新的计算机病毒进入数字世界时,反病毒公司会迅速向其软件发布补丁,以检测和删除这些病毒。
不管我们喜欢与否,我们生活在一个不断升级的世界里。对于每一个动作,都有一个相等的反作用力。这不仅仅是物理,这是世界的方式。
假设我们的计算机视觉和深度学习模型存在于真空中,缺乏操纵,这是不明智的。它们可以(也确实)被操纵。
就像我们的计算机可以感染黑客开发的病毒一样,我们的神经网络也容易受到各种类型的攻击,最常见的是敌对攻击。
好消息是我们可以抵御这些攻击。
你如何抵御对抗性的形象攻击?
防御敌对攻击的最简单方法之一是在这些类型的图像上训练你的模型。
例如,如果我们担心邪恶的用户将 FGSM 攻击应用于我们的模型,那么我们可以通过在我们自己的 FSGM 图像上训练他们来“接种”我们的神经网络。
典型地,这种类型的对抗性接种通过以下任一方式应用:
- 在给定数据集上训练我们的模型,生成一组对立图像,然后在对立图像上微调模型
- 生成混合批次的原始训练图像和对抗图像,随后在这些混合批次上微调我们的神经网络
第一种方法更简单,需要更少的计算(因为我们只需要生成一组对立的图像)。不利的一面是,这种方法往往不够稳健,因为我们只是在训练结束时对对立例子的模型进行微调。
第二种方法要复杂得多并且需要明显更多的计算。我们需要使用该模型为每批生成敌对图像,其中网络被训练。
第二种方法的好处是,该模型往往更鲁棒,因为它在训练期间的每一次批量更新中都看到了原始训练图像和对抗图像。
此外,模型本身*用于在每批期间生成对抗图像。随着模型越来越善于愚弄自己,它可以从错误中学习,从而产生一个可以更好地抵御对抗性攻击的模型。
今天我们将讨论第一种方法。下周我们将实现更高级的方法。
对抗性图像防御的问题和考虑事项
前面提到的两种对抗性图像防御方法都依赖于:
- 用于生成对立示例的模型架构和权重
- 用于生成它们的优化器
如果我们简单地用一个不同的模型(可能是一个更复杂的模型)创建一个敌对的形象,这些训练方案可能不能很好地推广。
此外,如果我们只在对抗性图像上训练而不是,那么这个模型在常规图像上可能表现不好。这种现象通常被称为灾难性遗忘,在对抗性防御的背景下,意味着模型已经“忘记”了真实图像的样子。
为了缓解这个问题,我们首先生成一组对立的图像,将它们与常规训练集混合,然后最终训练模型(我们将在下周的博客文章中进行)。
配置您的开发环境
这篇关于防御恶意图像攻击的教程使用了 Keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们深入任何代码之前,让我们首先回顾一下我们的项目目录结构。
请务必访问本指南的 “下载” 部分以检索源代码:
$ tree . --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── datagen.py
│ ├── fgsm.py
│ └── simplecnn.py
└── train_adversarial_defense.py
1 directory, 5 files
在pyimagesearch模块中,您会发现三个文件:
datagen.py:实现一次批量生成对抗图像的功能。我们将使用这个函数来训练和评估我们的 CNN 对抗防御的准确性。fgsm.py:执行快速梯度符号法(FGSM) 生成对抗图像。- 我们的 CNN 架构,我们将对其进行训练和评估,以进行图像攻击防御。
最后,train_adversarial_defense.py将所有这些部分粘合在一起,并展示:
- 如何训练我们的 CNN 架构
- 如何评价 CNN 对我们的测试集
- 如何使用我们训练有素的 CNN 生成一批图像对手
- 如何评价我们 CNN 对图像对手的准确性
- 如何微调我们的 CNN 形象对手
- 如何重新评价 CNN 对双方最初的训练设置和形象的敌对
在本指南结束时,你将对训练 CNN 进行基本的图像对手防御有一个很好的理解。
我们简单的 CNN 架构
我们将训练一个基本的 CNN 架构,并用它来演示对抗性图像防御。
虽然我今天在这里介绍了这个模型的实现,但我在上周关于快速梯度符号方法的教程中详细介绍了这个架构,所以如果你需要更全面的复习,我建议你参考那里。
打开您的pyimagesearch模块中的simplecnn.py文件,您会发现以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
我们文件的顶部由我们的 Keras 和 TensorFlow 导入组成。
然后我们定义SimpleCNN架构。
class SimpleCNN:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# first CONV => RELU => BN layer set
model.add(Conv2D(32, (3, 3), strides=(2, 2), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
# second CONV => RELU => BN layer set
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
正如你所看到的,这是一个基本的 CNN 模型,包括两组CONV => RELU => BN图层,后跟一个 softmax 图层头。softmax 分类器将返回给定输入图像的类别标签概率分布。
同样,你应该参考上周的教程获得更详细的解释。
用于生成对抗图像的 FGSM 技术
我们将使用快速梯度符号方法(FGSM)来生成对抗图像。上周我们讨论了这种技术,但是为了完整起见,我今天在这里加入了代码。
如果您在pyimagesearch模块中打开fgsm.py文件,您会发现以下代码:
# import the necessary packages
from tensorflow.keras.losses import MSE
import tensorflow as tf
def generate_image_adversary(model, image, label, eps=2 / 255.0):
# cast the image
image = tf.cast(image, tf.float32)
# record our gradients
with tf.GradientTape() as tape:
# explicitly indicate that our image should be tacked for
# gradient updates
tape.watch(image)
# use our model to make predictions on the input image and
# then compute the loss
pred = model(image)
loss = MSE(label, pred)
# calculate the gradients of loss with respect to the image, then
# compute the sign of the gradient
gradient = tape.gradient(loss, image)
signedGrad = tf.sign(gradient)
# construct the image adversary
adversary = (image + (signedGrad * eps)).numpy()
# return the image adversary to the calling function
return adversary
本质上,该函数跟踪图像的梯度,对其进行预测,计算损失,然后使用梯度的符号来更新输入图像的像素强度,例如:
- 这张照片最终被我们的 CNN 错误分类了
- 然而图像看起来与原始图像完全相同(根据人眼的观察)
参考上周关于快速梯度符号方法的教程,了解更多关于该技术如何工作及其实现的细节。
实现自定义数据生成器,用于在训练 期间生成对抗图像
*今天我们这里最重要的函数是generate_adverserial_batch方法。该函数是一个自定义数据生成器,我们将在培训中使用。
在高层次上,该功能:
- 接受一组训练图像
- 从我们的训练图像中随机抽取一批大小为 N 的样本
- 将
generate_image_adversary函数应用于它们,以创建我们的形象对手 - 为我们的训练循环产生一批图像对手,从而允许我们的模型从图像对手那里学习模式,并理想地防御它们
现在让我们来看看我们的定制数据生成器。在我们的项目目录结构中打开datagen.py文件,并插入以下代码:
# import the necessary packages
from .fgsm import generate_image_adversary
import numpy as np
def generate_adversarial_batch(model, total, images, labels, dims,
eps=0.01):
# unpack the image dimensions into convenience variables
(h, w, c) = dims
我们从导入我们需要的包开始。注意,我们通过前面实现的generate_image_adversary函数来使用 FGSM 实现。
我们的generate_adversarial_batch函数需要几个参数,包括:
model:我们要忽悠的 CNN(即我们正在训练的模型)。total:我们要生成的一批对抗性图像的大小。- 我们将从中取样的图像集(通常是训练集或测试集)。
labels:对应于images的分类标签dims:我们输入的空间维度images。eps:当应用快速梯度符号方法时,用于控制像素强度更新幅度的小ε因子。
第 8 行将我们的dims解包成高度(h)、宽度(w)和通道数量(c),这样我们就可以很容易地在剩下的函数中引用它们。
现在让我们构建数据生成器本身:
# we're constructing a data generator here so we need to loop
# indefinitely
while True:
# initialize our perturbed images and labels
perturbImages = []
perturbLabels = []
# randomly sample indexes (without replacement) from the
# input data
idxs = np.random.choice(range(0, len(images)), size=total,
replace=False)
第 12 行开始一个循环,该循环将无限期继续,直到训练完成。
然后我们初始化两个列表,perturbImages(存储稍后在这个while循环中生成的一批对立图像)和perturbLabels(存储图像的原始类标签)。
19 号线和 20 号线随机抽取一套我们的images。
我们现在可以循环这些随机选择的图像的索引:
# loop over the indexes
for i in idxs:
# grab the current image and label
image = images[i]
label = labels[i]
# generate an adversarial image
adversary = generate_image_adversary(model,
image.reshape(1, h, w, c), label, eps=eps)
# update our perturbed images and labels lists
perturbImages.append(adversary.reshape(h, w, c))
perturbLabels.append(label)
# yield the perturbed images and labels
yield (np.array(perturbImages), np.array(perturbLabels))
25、26 线抢电流image和label。
然后我们应用我们的generate_image_adversary函数使用 FGSM 创建图像对手(第 29 行和第 30 行)。
随着adversary的生成,我们分别更新了我们的perturbImages和perturbLabels列表。
我们的数据生成器通过为训练过程产生我们的对立图像和标签的二元组来完成。
该功能可以概括为:
- 接受一组输入图像
- 随机选择其中的一个子集
- 为子集生成镜像对手
- 让形象对手回到训练过程中,这样我们的 CNN 可以从他们身上学习模式
假设我们用原始训练图像和对抗图像来训练 CNN。在这种情况下,我们的 CNN 可以在两个集合上做出正确的预测,从而使我们的模型对对抗性攻击更加健壮。
正常图像的训练,对抗图像的微调
实现了所有的助手函数后,让我们继续创建训练脚本来防御敌对图像。
打开项目结构中的train_adverserial_defense.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.simplecnn import SimpleCNN
from pyimagesearch.datagen import generate_adversarial_batch
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import numpy as np
第 2-7 行导入我们需要的 Python 包。注意,我们正在导入我们的SimpleCNN架构和generate_adverserial_batch函数,这是我们刚刚实现的。
然后,我们继续加载 MNIST 数据集并对其进行预处理:
# load MNIST dataset and scale the pixel values to the range [0, 1]
print("[INFO] loading MNIST dataset...")
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX / 255.0
testX = testX / 255.0
# add a channel dimension to the images
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
# one-hot encode our labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
加载 MNIST 数据集后,我们可以编译模型并在训练集上对其进行训练:
# initialize our optimizer and model
print("[INFO] compiling model...")
opt = Adam(lr=1e-3)
model = SimpleCNN.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the simple CNN on MNIST
print("[INFO] training network...")
model.fit(trainX, trainY,
validation_data=(testX, testY),
batch_size=64,
epochs=20,
verbose=1)
下一步是在测试集上评估模型:
# make predictions on the testing set for the model trained on
# non-adversarial images
(loss, acc) = model.evaluate(x=testX, y=testY, verbose=0)
print("[INFO] normal testing images:")
print("[INFO] loss: {:.4f}, acc: {:.4f}\n".format(loss, acc))
# generate a set of adversarial from our test set
print("[INFO] generating adversarial examples with FGSM...\n")
(advX, advY) = next(generate_adversarial_batch(model, len(testX),
testX, testY, (28, 28, 1), eps=0.1))
# re-evaluate the model on the adversarial images
(loss, acc) = model.evaluate(x=advX, y=advY, verbose=0)
print("[INFO] adversarial testing images:")
print("[INFO] loss: {:.4f}, acc: {:.4f}\n".format(loss, acc))
第 40-42 行利用我们训练过的 CNN 对测试集进行预测。然后,我们在终端上显示精确度和损耗。
现在,让我们看看我们的模型在敌对图像上的表现。
第 46 行和第 47 行生成一组敌对的图像,而第 50-52 行 重新评估我们训练有素的 CNN 对这些敌对的例子。正如我们将在下一节中看到的,我们的预测准确度在敌对图像上直线下降。
这就提出了一个问题:
我们如何抵御这些敌对的攻击?
一个基本的解决方案是在对立图像上微调我们的模型:
# lower the learning rate and re-compile the model (such that we can
# fine-tune it on the adversarial images)
print("[INFO] re-compiling model...")
opt = Adam(lr=1e-4)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# fine-tune our CNN on the adversarial images
print("[INFO] fine-tuning network on adversarial examples...")
model.fit(advX, advY,
batch_size=64,
epochs=10,
verbose=1)
第 57-59 行降低优化器的学习率,然后重新编译模型。
然后我们在对立的例子上微调我们的模型(第 63-66 行)。
最后,我们将进行最后一组评估:
# now that our model is fine-tuned we should evaluate it on the test
# set (i.e., non-adversarial) again to see if performance has degraded
(loss, acc) = model.evaluate(x=testX, y=testY, verbose=0)
print("")
print("[INFO] normal testing images *after* fine-tuning:")
print("[INFO] loss: {:.4f}, acc: {:.4f}\n".format(loss, acc))
# do a final evaluation of the model on the adversarial images
(loss, acc) = model.evaluate(x=advX, y=advY, verbose=0)
print("[INFO] adversarial images *after* fine-tuning:")
print("[INFO] loss: {:.4f}, acc: {:.4f}".format(loss, acc))
在微调之后,我们需要重新评估我们的模型在原始测试集(第 70-73 行)和我们的对抗示例(第 76-78 行)上的准确性。
正如我们将在下一节中看到的,在这些对立的例子上微调我们的 CNN 允许我们的模型对原始图像和通过对立技术生成的图像做出正确的预测!
*### 对抗性图像防御结果
我们现在已经准备好训练我们的 CNN 来抵御敌对的图像攻击!
首先访问本指南的 “下载” 部分以检索源代码。从那里,打开一个终端并执行以下命令:
$ time python train_adversarial_defense.py
[INFO] loading MNIST dataset...
[INFO] compiling model...
[INFO] training network...
Epoch 1/20
938/938 [==============================] - 12s 13ms/step - loss: 0.1973 - accuracy: 0.9402 - val_loss: 0.0589 - val_accuracy: 0.9809
Epoch 2/20
938/938 [==============================] - 12s 12ms/step - loss: 0.0781 - accuracy: 0.9762 - val_loss: 0.0453 - val_accuracy: 0.9838
Epoch 3/20
938/938 [==============================] - 12s 13ms/step - loss: 0.0599 - accuracy: 0.9814 - val_loss: 0.0410 - val_accuracy: 0.9868
...
Epoch 18/20
938/938 [==============================] - 11s 12ms/step - loss: 0.0103 - accuracy: 0.9963 - val_loss: 0.0476 - val_accuracy: 0.9883
Epoch 19/20
938/938 [==============================] - 11s 12ms/step - loss: 0.0091 - accuracy: 0.9967 - val_loss: 0.0420 - val_accuracy: 0.9889
Epoch 20/20
938/938 [==============================] - 11s 12ms/step - loss: 0.0087 - accuracy: 0.9970 - val_loss: 0.0443 - val_accuracy: 0.9892
[INFO] normal testing images:
[INFO] loss: 0.0443, acc: 0.9892
在这里,你可以看到我们已经在 MNIST 数据集上训练了 20 个时期的 CNN。我们在训练集上获得了 99.70%的准确率,在测试集上获得了 98.92%的准确率,这意味着我们的 CNN 在数字预测方面做得很好。
然而,当我们生成一组 10,000 张敌对图像并要求 CNN 对它们进行分类时,这种“高精度”模型是可悲的不充分和不准确:
[INFO] generating adversarial examples with FGSM...
[INFO] adversarial testing images:
[INFO] loss: 17.2824, acc: 0.0170
如你所见,我们的准确度从最初的98.92%直线下降到 1.7%。
显然,我们的 CNN 在敌对形象上完全失败了。
也就是说,希望并没有消失!现在让我们对 CNN 的 10,000 张敌对图片进行微调:
[INFO] re-compiling model...
[INFO] fine-tuning network on adversarial examples...
Epoch 1/10
157/157 [==============================] - 2s 12ms/step - loss: 8.0170 - accuracy: 0.2455
Epoch 2/10
157/157 [==============================] - 2s 11ms/step - loss: 1.9634 - accuracy: 0.7082
Epoch 3/10
157/157 [==============================] - 2s 11ms/step - loss: 0.7707 - accuracy: 0.8612
...
Epoch 8/10
157/157 [==============================] - 2s 11ms/step - loss: 0.1186 - accuracy: 0.9701
Epoch 9/10
157/157 [==============================] - 2s 12ms/step - loss: 0.0894 - accuracy: 0.9780
Epoch 10/10
157/157 [==============================] - 2s 12ms/step - loss: 0.0717 - accuracy: 0.9817
我们现在获得
98% accuracy on the adversarial images after fine-tuning.
现在让我们回过头来,重新评估 CNN 关于原始测试集和我们的对抗图像:
[INFO] normal testing images *after* fine-tuning:
[INFO] loss: 0.0594, acc: 0.9844
[INFO] adversarial images *after* fine-tuning:
[INFO] loss: 0.0366, acc: 0.9906
real 5m12.753s
user 12m42.125s
sys 10m0.498s
最初,我们的 CNN 在我们的测试集上获得了 98.92%的准确率。由设定的测试精度下降
0.5%, but the good news is that we’re now hitting 99% accuracy when classifying our adversarial images, thereby implying that:
- 我们的模型可以对来自 MNIST 数据集的原始的、未受干扰的图像做出正确的预测。
- 我们还可以对生成的敌对图像做出准确的预测(意味着我们已经成功地抵御了它们)。
我们还能如何抵御敌对攻击?
在对抗性图像上微调模型只是抵御对抗性攻击的一种方式。
一种更好的方式是在训练过程 中将对抗性的图像与原始图像混合并融合。
其结果是一个更强大的模型,能够抵御对抗性攻击,因为该模型在每一批中都生成自己的对抗性图像,从而不断改进自己,而不是依赖于训练后的一轮微调。
我们将在下周的教程中讨论这种“混合批次对抗训练法”。
演职员表和参考资料
FGSM 和数据生成器的实现受到了塞巴斯蒂安·蒂勒关于对抗性攻击和防御的优秀文章的启发。非常感谢 Sebastian 分享他的知识。
总结
在本教程中,您学习了如何使用 Keras 和 TensorFlow 来防御恶意图像攻击。
我们的对抗性形象辩护通过以下方式发挥作用:
- 在我们的数据集上训练 CNN
- 使用所训练的模型生成一组对立图像
- 在对立图像上微调我们的模型
结果是一个模型,它既:
- 在原始测试图像上精确
- 也能够正确地分类对立的图像
对抗性图像防御的微调方法本质上是最基本的对抗性防御。下周,您将学习一种更高级的方法,该方法合并了大量动态生成的对立图像,允许模型从每个时期“愚弄”它的对立示例中学习。
如果你喜欢这个指南,你肯定不想错过下周的教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****
使用 Keras、TensorFlow 和深度学习对自动编码器进行降噪
原文:https://pyimagesearch.com/2020/02/24/denoising-autoencoders-with-keras-tensorflow-and-deep-learning/
在本教程中,您将学习如何使用自动编码器通过 Keras、TensorFlow 和深度学习对图像进行降噪。
今天的教程是关于自动编码器应用的三部分系列的第二部分:
- 带 Keras、TensorFlow、深度学习的自动编码器 (上周教程)
- 使用 Keras、TensorFlow 和深度学习对自动编码器进行降噪(今天的教程)
- 利用 Keras、TensorFlow 和深度学习进行异常检测(下周教程)
上周,您学习了自动编码器的基础知识,包括如何使用 Keras 和 TensorFlow 训练您的第一个自动编码器——然而,由于我们需要打下基础,该教程的实际应用不可否认地有点有限。
今天,我们将深入了解自动编码器如何用于去噪 ,也称为“降噪”,即从信号中去除噪声的过程。
这里的术语“噪声”可以是:
- 由有故障或质量差的图像传感器产生
- 亮度或颜色的随机变化
- 量化噪声
- JPEG 压缩导致的伪像
- 图像扫描仪或阈值后处理产生的图像扰动
- 尝试执行 OCR 时纸张质量差(起皱和折叠)
从图像处理和计算机视觉的角度来看,你应该认为噪音是任何可以被真正好的T2 预处理过滤器去除的东西。
我们的目标是训练一个自动编码器来执行这样的预处理——我们称这样的模型为去噪自动编码器。
要了解如何使用 Keras 和 TensorFlow 训练去噪自动编码器,继续阅读!
使用 Keras、TensorFlow 和深度学习对自动编码器进行降噪
在本教程的第一部分,我们将讨论什么是去噪自动编码器,以及为什么我们可能要使用它们。
从那以后,我将向您展示如何使用 Keras 和 TensorFlow 实现和训练一个去噪自动编码器。
我们将通过检查去噪自动编码器的结果来结束本教程。
什么是去噪自动编码器,我们为什么要使用它们?
去噪自动编码器是简单自动编码器的扩展。然而,值得注意的是去噪自动编码器是而不是最初的意思是自动去噪图像。
相反,发明去噪自动编码器程序是为了帮助:
- 自动编码器的隐藏层学习更健壮的过滤器
- 降低自动编码器过拟合的风险
- 防止自动编码器学习简单的识别功能
在文森特等人 2008 年的 ICML 论文中, 使用去噪自动编码器 提取和合成鲁棒特征,作者发现他们可以通过故意将噪声引入信号来提高其内部层(即潜在空间表示)的鲁棒性。
噪声被随机地(即,随机地)添加到输入数据中,然后自动编码器被训练以恢复原始的、未受干扰的信号。
从图像处理的角度来看,我们可以训练自动编码器来为我们执行自动图像预处理。
一个很好的例子就是预处理图像来提高光学字符识别(OCR)算法的准确性。如果你以前曾经应用过 OCR,你应该知道一点点错误类型的噪声(例如。打印机墨水污迹、扫描期间图像质量差等等。)T4 会对你的 OCR 方法的性能造成显著影响吗?使用去噪自动编码器,我们可以自动预处理图像,提高质量,并因此增加下游 OCR 算法的准确性。
如果你有兴趣了解更多关于去噪自动编码器的知识,我强烈建议你阅读这篇文章,以及本吉奥和德拉鲁的论文,证明和归纳对比差异,T2 和 T4。
关于为 OCR 相关预处理去噪自动编码器的更多信息,请看 Kaggle 上的这个数据集。
配置您的开发环境
为了跟随今天关于自动编码器的教程,你应该使用 TensorFlow 2.0。我有两个 TF 2.0 的安装教程和相关的包,可以帮助您的开发系统跟上速度:
- 如何在 UbuntuT3 上安装 tensor flow 2.0【Ubuntu 18.04 OS;CPU 和可选的 NVIDIA GPU)
- 如何在 macOS 上安装 tensor flow 2.0(Catalina 和 Mojave OSes)
请注意: PyImageSearch 不支持 Windows — 参考我们的 FAQ 。
项目结构
去拿吧。zip 来自今天教程的 【下载】 部分。从那里,拉开拉链。
您将看到以下项目布局:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── convautoencoder.py
├── output.png
├── plot.png
└── train_denoising_autoencoder.py
1 directory, 5 files
pyimagesearch模块包含了ConvAutoencoder类。我们在之前的教程中复习了这个类;然而,我们今天将再次简要地浏览一遍。
今天教程的核心是在train_denoising_autoencoder.py Python 训练脚本中。该脚本与之前的教程有一个主要不同之处:
我们将特意使用以0.5为中心的随机正态分布为我们的 MNIST 训练图像添加噪声,标准差为0.5。
将噪声添加到我们的训练数据的目的是使我们的自动编码器能够有效地从输入图像中去除噪声(即,去噪)。
用 Keras 和 TensorFlow 实现去噪自动编码器
我们今天要实现的去噪自动编码器与我们在上周的自动编码器基础教程中实现的基本相同。
为了完整起见,我们今天将在这里回顾模型架构,但是请确保您参考了上周的指南以了解更多细节。
也就是说,打开项目结构中的convautoencoder.py文件,并插入以下代码:
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
import numpy as np
class ConvAutoencoder:
@staticmethod
def build(width, height, depth, filters=(32, 64), latentDim=16):
# initialize the input shape to be "channels last" along with
# the channels dimension itself
# channels dimension itself
inputShape = (height, width, depth)
chanDim = -1
# define the input to the encoder
inputs = Input(shape=inputShape)
x = inputs
进口包括tf.keras和 NumPy。
我们的ConvAutoencoder类包含一个静态方法build,它接受五个参数:
width:输入图像的宽度,单位为像素height:输入图像的高度,单位为像素depth:输入体积的通道数(即深度)filters:包含用于卷积运算的过滤器集合的元组。默认情况下,如果调用者没有提供这个参数,我们将添加两组带有32和64过滤器的CONV => RELU => BNlatentDim:我们的全连通(Dense)潜在向量中的神经元数量。默认情况下,如果该参数未被传递,则该值被设置为16
从那里,我们初始化inputShape并定义编码器的Input(第 25 和 26 行)。
让我们开始构建编码器的滤波器:
# loop over the number of filters
for f in filters:
# apply a CONV => RELU => BN operation
x = Conv2D(f, (3, 3), strides=2, padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# flatten the network and then construct our latent vector
volumeSize = K.int_shape(x)
x = Flatten()(x)
latent = Dense(latentDim)(x)
# build the encoder model
encoder = Model(inputs, latent, name="encoder")
使用 Keras 的函数式 API,我们继续循环多个filters并添加我们的CONV => RELU => BN层集合(第 29-33 行)。
然后我们拉平网络并构建我们的潜在向量(第 36-38 行)。潜在空间表示是我们数据的压缩形式。
从那里,我们构建自动编码器的encoder部分(第 41 行)。
接下来,我们将使用我们的潜在空间表示来重建原始输入图像。
# start building the decoder model which will accept the
# output of the encoder as its inputs
latentInputs = Input(shape=(latentDim,))
x = Dense(np.prod(volumeSize[1:]))(latentInputs)
x = Reshape((volumeSize[1], volumeSize[2], volumeSize[3]))(x)
# loop over our number of filters again, but this time in
# reverse order
for f in filters[::-1]:
# apply a CONV_TRANSPOSE => RELU => BN operation
x = Conv2DTranspose(f, (3, 3), strides=2,
padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# apply a single CONV_TRANSPOSE layer used to recover the
# original depth of the image
x = Conv2DTranspose(depth, (3, 3), padding="same")(x)
outputs = Activation("sigmoid")(x)
# build the decoder model
decoder = Model(latentInputs, outputs, name="decoder")
# our autoencoder is the encoder + decoder
autoencoder = Model(inputs, decoder(encoder(inputs)),
name="autoencoder")
# return a 3-tuple of the encoder, decoder, and autoencoder
return (encoder, decoder, autoencoder)
这里,我们采用潜在输入,并使用全连接层将其重塑为 3D 体积(即图像数据)。
我们再次循环我们的过滤器,但是以相反的顺序,应用CONV_TRANSPOSE => RELU => BN层,其中CONV_TRANSPOSE层的目的是增加体积大小。
最后,我们建立了解码器模型并构建了自动编码器。记住,自动编码器的概念——上周讨论过——由编码器和解码器组件组成。
实现去噪自动编码器训练脚本
现在,让我们来实现用于以下目的的培训脚本:
- 向 MNIST 数据集添加随机噪声
- 在噪声数据集上训练去噪自动编码器
- 从噪声中自动恢复原始数字
我的实现遵循 Francois Chollet 在官方 Keras 博客上自己的去噪自动编码器的实现——我在这里的主要贡献是更详细地介绍实现本身。
打开train_denoising_autoencoder.py文件,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.convautoencoder import ConvAutoencoder
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--samples", type=int, default=8,
help="# number of samples to visualize when decoding")
ap.add_argument("-o", "--output", type=str, default="output.png",
help="path to output visualization file")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
在线 2-12 我们处理我们的进口。我们将使用matplotlib的"Agg"后端,这样我们可以将我们的训练图导出到磁盘。我们在上一节中实现的自定义ConvAutoencoder类包含自动编码器架构本身。模仿 Chollet 的例子,我们也将使用 Adam 优化器。
我们的脚本接受三个可选的命令行参数:
--samples:可视化输出样本数。默认情况下,该值设置为8。--output:输出可视化图像的路径。默认情况下,我们将我们的可视化命名为output.png。--plot:matplotlib 输出图的路径。如果终端中未提供该参数,则分配默认值plot.png。
接下来,我们初始化超参数并预处理我们的 MNIST 数据集:
# initialize the number of epochs to train for and batch size
EPOCHS = 25
BS = 32
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, _), (testX, _)) = mnist.load_data()
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
我们的训练周期将是25,我们将使用32的批量。
我们继续抓取 MNIST 数据集(第 30 行),而第 34-37 行 (1)向数据集中的每个图像添加通道维度,以及(2)将像素强度缩放到范围【0,1】。
此时,我们将偏离上周的教程:
# sample noise from a random normal distribution centered at 0.5 (since
# our images lie in the range [0, 1]) and a standard deviation of 0.5
trainNoise = np.random.normal(loc=0.5, scale=0.5, size=trainX.shape)
testNoise = np.random.normal(loc=0.5, scale=0.5, size=testX.shape)
trainXNoisy = np.clip(trainX + trainNoise, 0, 1)
testXNoisy = np.clip(testX + testNoise, 0, 1)
为了将随机噪声添加到 MNIST 数字中,我们使用 NumPy 的随机正态分布,以0.5为中心,标准差为0.5 ( 第 41-44 行)。
下图显示了添加噪声前(左)和添加噪声后(右)的图像:
Figure 2: Prior to training a denoising autoencoder on MNIST with Keras, TensorFlow, and Deep Learning, we take input images (left) and deliberately add noise to them (right).
正如你所看到的,我们的图像非常糟糕——从噪声中恢复原始数字需要一个强大的模型。
幸运的是,我们的去噪自动编码器将胜任这项任务:
# construct our convolutional autoencoder
print("[INFO] building autoencoder...")
(encoder, decoder, autoencoder) = ConvAutoencoder.build(28, 28, 1)
opt = Adam(lr=1e-3)
autoencoder.compile(loss="mse", optimizer=opt)
# train the convolutional autoencoder
H = autoencoder.fit(
trainXNoisy, trainX,
validation_data=(testXNoisy, testX),
epochs=EPOCHS,
batch_size=BS)
# construct a plot that plots and saves the training history
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
第 48 行构建我们的去噪自动编码器,传递必要的参数。使用初始学习速率为1e-3的Adam优化器,我们继续用均方差loss ( 第 49 行和第 50 行)编译自动编码器。
通过线 53-57 启动培训。使用训练历史数据,H,行 60-69 绘制损失,将结果数字保存到磁盘。
让我们编写一个快速循环来帮助我们可视化去噪自动编码器的结果:
# use the convolutional autoencoder to make predictions on the
# testing images, then initialize our list of output images
print("[INFO] making predictions...")
decoded = autoencoder.predict(testXNoisy)
outputs = None
# loop over our number of output samples
for i in range(0, args["samples"]):
# grab the original image and reconstructed image
original = (testXNoisy[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# save the outputs image to disk
cv2.imwrite(args["output"], outputs)
我们继续使用我们训练过的自动编码器从测试集中的图像中去除噪声( Line 74 )。
然后我们抓取 N --samples值的original和重建数据,并放在一起形成一个可视化蒙太奇(第 78-93 行)。第 96 行将可视化图形写入磁盘进行检查。
用 Keras 和 TensorFlow 训练去噪自动编码器
为了训练你的去噪自动编码器,确保你使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端并执行以下命令:
$ python train_denoising_autoencoder.py --output output_denoising.png \
--plot plot_denoising.png
[INFO] loading MNIST dataset...
[INFO] building autoencoder...
Train on 60000 samples, validate on 10000 samples
Epoch 1/25
60000/60000 [==============================] - 85s 1ms/sample - loss: 0.0285 - val_loss: 0.0191
Epoch 2/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0187 - val_loss: 0.0211
Epoch 3/25
60000/60000 [==============================] - 84s 1ms/sample - loss: 0.0177 - val_loss: 0.0174
Epoch 4/25
60000/60000 [==============================] - 84s 1ms/sample - loss: 0.0171 - val_loss: 0.0170
Epoch 5/25
60000/60000 [==============================] - 83s 1ms/sample - loss: 0.0167 - val_loss: 0.0177
...
Epoch 21/25
60000/60000 [==============================] - 67s 1ms/sample - loss: 0.0146 - val_loss: 0.0161
Epoch 22/25
60000/60000 [==============================] - 67s 1ms/sample - loss: 0.0145 - val_loss: 0.0164
Epoch 23/25
60000/60000 [==============================] - 67s 1ms/sample - loss: 0.0145 - val_loss: 0.0158
Epoch 24/25
60000/60000 [==============================] - 67s 1ms/sample - loss: 0.0144 - val_loss: 0.0155
Epoch 25/25
60000/60000 [==============================] - 66s 1ms/sample - loss: 0.0144 - val_loss: 0.0157
[INFO] making predictions...

Figure 3: Example results from training a deep learning denoising autoencoder with Keras and Tensorflow on the MNIST benchmarking dataset. Inside our training script, we added random noise with NumPy to the MNIST images.
在我的配备 3 GHz 英特尔至强 W 处理器的 iMac Pro 上训练降噪自动编码器花费了 ~32.20 分钟。
如图 3 所示,我们的训练过程稳定,没有过度适应的迹象。
去噪自动编码器结果
我们的去噪自动编码器已经被成功训练,但是它在去除我们添加到 MNIST 数据集的噪声时表现如何呢?
要回答这个问题,请看一下图 4:

Figure 4: The results of removing noise from MNIST images using a denoising autoencoder trained with Keras, TensorFlow, and Deep Learning.
在左侧我们有添加了噪声的原始 MNIST 数字,而在右侧我们有去噪自动编码器的输出— 我们可以清楚地看到去噪自动编码器能够在去除噪声的同时从图像中恢复原始信号(即数字)。
更先进的去噪自动编码器可用于自动预处理图像,以提高 OCR 准确度。
摘要
在本教程中,您了解了去噪自动编码器,顾名思义,它是用于从信号中去除噪声的模型。
在计算机视觉的背景下,去噪自动编码器可以被视为非常强大的过滤器,可以用于自动预处理。例如,去噪自动编码器可用于自动预处理图像,提高 OCR 算法的质量,从而提高 OCR 准确度。
为了演示去噪自动编码器的运行,我们向 MNIST 数据集添加了噪声,从而大大降低了图像质量,以至于任何模型都难以正确分类图像中的数字。使用我们的去噪自动编码器,我们能够从图像中去除噪声,恢复原始信号(即数字)。
在下周的教程中,您将了解自动编码器的另一个实际应用——异常和异常值检测。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
从用于深度学习的数据集中检测并移除重复图像
在本教程中,您将学习如何从深度学习的数据集中检测和删除重复图像。
在过去的几周里,我一直在和 Victor Gevers 合作一个项目,他是 GDI 受人尊敬的道德黑客。该组织以负责任地披露数据泄露和报告安全漏洞而闻名。
我不能进入项目的细节(还不能),但其中一项任务要求我训练一个定制的深度神经网络来检测图像中的特定模式。
我所使用的数据集是由多个来源的图像组合而成的。我知道数据集中会有重复的图像——因此我需要一种方法来检测和从我的数据集中移除这些重复的图像。
当我在做这个项目时,我碰巧收到了一封来自 Dahlia 的电子邮件,她是一名大学生,也有一个关于图像重复以及如何处理它们的问题:
嗨,阿德里安,我的名字是大丽花。我是一名本科生,正在进行最后一年的毕业设计,任务是通过抓取谷歌图片、必应等建立一个图像数据集。然后在数据集上训练深度神经网络。
我的教授告诉我在构建数据集时要小心,说我需要移除重复的图像。
这引起了我的一些怀疑:
为什么数据集中的重复图像是一个问题?其次,我如何检测图像副本?
试图手动这样做听起来像是一个容易出错的过程。我不想犯任何错误。
有什么办法可以让我自动从我的图像数据集中检测并删除重复的图像吗?
谢谢你。
*大丽花问了一些很棒的问题。
数据集中存在重复影像会产生问题,原因有两个:
- 它将偏差引入到你的数据集中,给你的深度神经网络额外的机会来学习模式特定的到副本
- 这损害了你的模型对超出其训练范围的新图像进行概括的能力
虽然我们经常假设数据集中的数据点是独立且同分布的,但在处理真实世界的数据集时,这种情况很少(如果有的话)发生。当训练卷积神经网络时,我们通常希望在训练模型之前移除那些重复的图像。
其次,试图手动检测数据集中的重复图像是极其耗时且容易出错的——它也不能扩展到大型图像数据集。因此,我们需要一种方法来自动检测并从我们的深度学习数据集中删除重复的图像。**
***这样的方法可能吗?
的确如此——我将在今天教程的剩余部分讲述这一点。
要了解如何从深度学习数据集中检测和删除重复图像,继续阅读!
从用于深度学习的数据集中检测并移除重复图像
在本教程的第一部分中,您将了解为什么在您尝试在数据基础上训练深度神经网络之前,通常需要从数据集中检测和移除重复图像。
从那里,我们将回顾我创建的示例数据集,以便我们可以练习检测数据集中的重复图像。
然后,我们将使用一种叫做图像散列的方法来实现我们的图像重复检测器。
最后,我们将回顾我们的工作结果,并:
- 执行模拟运行,以验证我们的图像重复检测器工作正常
- 再次运行我们的重复检测器,这一次从数据集中删除实际的重复项
在训练深度神经网络时,为什么要费心从数据集中删除重复的图像?
如果您曾经尝试过手动构建自己的影像数据集,那么您知道很有可能(如果不是不可避免的话)您的数据集中会有重复的影像。
通常,由于以下原因,您最终会在数据集中得到重复的图像:
- 从多个来源抓取图像(例如,Google、Bing 等。)
- 组合现有数据集(例如将 ImageNet 与 Sun397 和室内场景相结合)
发生这种情况时,您需要一种方法来:
- 检测数据集中有重复的图像
- 删除重复项
但这也引出了一个问题— 为什么一开始就要费心去关心副本呢?
监督机器学习方法的通常假设是:
- 数据点是独立的
- 它们是同分布的
- 训练和测试数据是从同一个分布中抽取的
问题是这些假设在实践中很少(如果有的话)成立。
你真正需要害怕的是你的模型的概括能力。
如果您的数据集中包含多个相同的图像,您的神经网络将被允许在每个时期多次从该图像中查看和学习模式。
你的网络可能会变得偏向那些重复图像中的模式,使得它不太可能推广到新的图像。
偏见和归纳能力在机器学习中是一件大事——当处理“理想”数据集时,它们可能很难克服。
花些时间从影像数据集中移除重复项,以免意外引入偏差或损害模型的概化能力。
我们的示例重复图像数据集
为了帮助我们学习如何从深度学习数据集中检测和删除重复的图像,我基于斯坦福狗数据集创建了一个我们可以使用的“练习”数据集。
这个数据集由 20,580 张狗品种的图片组成,包括比格犬、纽芬兰犬和博美犬等等。
为了创建我们的复制图像数据集,我:
- 下载了斯坦福狗的数据集
- 我会复制三个图像样本
- 将这三个图像中的每一个总共复制了 N 次
- 然后进一步随机取样斯坦福狗数据集,直到我总共获得了 1000 张图像
下图显示了每个图像的副本数量:
我们的目标是创建一个 Python 脚本,它可以在训练深度学习模型之前检测并删除这些重复。
项目结构
我已经在本教程的 “下载” 部分包含了复制的图像数据集和代码。
一旦您提取了.zip,您将看到下面的目录结构:
$ tree --dirsfirst --filelimit 10
.
├── dataset [1000 entries]
└── detect_and_remove.py
1 directory, 1 file
如您所见,我们的项目结构非常简单。我们有 1000 张图片(包括重复的)。此外,我们还有我们的detect_and_remove.py Python 脚本,它是今天教程的基础。
实现我们的图像重复检测器
我们现在准备实施我们的图像重复检测器。
打开项目目录中的detect_and_remove.py脚本,让我们开始工作:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import cv2
import os
我们脚本的导入包括来自 imutils 的我的paths实现,因此我们可以获取我们数据集中所有图像的文件路径,NumPy 用于图像堆叠,OpenCV 用于图像 I/O、操作和显示。os和argparse都是 Python 内置的。
如果你的机器上没有安装 OpenCV 或 imutils,我建议你遵循我的 pip 安装 opencv 指南,它会告诉你如何安装两者。
本教程的主要组件是dhash函数:
def dhash(image, hashSize=8):
# convert the image to grayscale and resize the grayscale image,
# adding a single column (width) so we can compute the horizontal
# gradient
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, (hashSize + 1, hashSize))
# compute the (relative) horizontal gradient between adjacent
# column pixels
diff = resized[:, 1:] > resized[:, :-1]
# convert the difference image to a hash and return it
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
- 将图像转换为单通道灰度图像(第 12 行)
- 根据
hashSize( 第 13 行)调整图像大小。该算法要求图像的宽度恰好比高度多1列,如维度元组所示。 - 计算相邻列像素之间的相对水平梯度(行 17 )。这就是现在众所周知的“差异图像”
- 应用我们的散列计算并返回结果(第 20 行)。
我已经在之前的文章的中介绍过图像哈希技术。特别是,你应该阅读我的使用 OpenCV 和 Python 进行图像哈希的指南,来理解使用我的dhash函数进行图像哈希的概念。
定义好散列函数后,我们现在准备好定义和解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-r", "--remove", type=int, default=-1,
help="whether or not duplicates should be removed (i.e., dry run)")
args = vars(ap.parse_args())
我们的脚本处理两个命令行参数,您可以通过终端或命令提示符传递这两个参数:
--dataset:输入数据集的路径,其中包含您希望从数据集中删除的重复项--remove
我们现在准备开始计算哈希值:
# grab the paths to all images in our input dataset directory and
# then initialize our hashes dictionary
print("[INFO] computing image hashes...")
imagePaths = list(paths.list_images(args["dataset"]))
hashes = {}
# loop over our image paths
for imagePath in imagePaths:
# load the input image and compute the hash
image = cv2.imread(imagePath)
h = dhash(image)
# grab all image paths with that hash, add the current image
# path to it, and store the list back in the hashes dictionary
p = hashes.get(h, [])
p.append(imagePath)
hashes[h] = p
- 加载图像(第 39 行)
- 使用
dhash便利函数(第 40 行)计算散列值h - 抓取所有图像路径,
p,用相同的 hash,h( 第 44 行)。 - 将最新的
imagePath追加到p( 第 45 行)。此时,p代表我们的一组重复图像(即,具有相同散列值的图像) - 将所有这些重复项添加到我们的
hashes字典中(第 46 行)
{
...
7054210665732718398: ['dataset/00000005.jpg', 'dataset/00000071.jpg', 'dataset/00000869.jpg'],
8687501631902372966: ['dataset/00000011.jpg'],
1321903443018050217: ['dataset/00000777.jpg'],
...
}
请注意第一个散列关键字示例如何具有三个关联的图像路径(表示重复),而接下来的两个散列关键字只有一个路径条目(表示没有重复)。
此时,计算完所有的散列后,我们需要循环遍历散列并处理重复项:
# loop over the image hashes
for (h, hashedPaths) in hashes.items():
# check to see if there is more than one image with the same hash
if len(hashedPaths) > 1:
# check to see if this is a dry run
if args["remove"] <= 0:
# initialize a montage to store all images with the same
# hash
montage = None
# loop over all image paths with the same hash
for p in hashedPaths:
# load the input image and resize it to a fixed width
# and heightG
image = cv2.imread(p)
image = cv2.resize(image, (150, 150))
# if our montage is None, initialize it
if montage is None:
montage = image
# otherwise, horizontally stack the images
else:
montage = np.hstack([montage, image])
# show the montage for the hash
print("[INFO] hash: {}".format(h))
cv2.imshow("Montage", montage)
cv2.waitKey(0)
如果不是,我们忽略这个散列并继续检查下一个散列。
另一方面,如果事实上有两个或更多的hashedPaths,它们就是重复的!
因此,我们启动一个if / else块来检查这是否是一次“预演”;如果--remove标志不是正值,我们将进行一次试运行(第 53 行)。
预演意味着我们还没有准备好删除副本。相反,我们只是想让检查,看看是否存在任何重复项。
# otherwise, we'll be removing the duplicate images
else:
# loop over all image paths with the same hash *except*
# for the first image in the list (since we want to keep
# one, and only one, of the duplicate images)
for p in hashedPaths[1:]:
os.remove(p)
在这种情况下,我们实际上是从我们的系统中删除重复的图像。
在这个场景中,除了列表中的第一个图像的之外,我们简单地循环所有具有相同散列值的图像路径——我们希望保留一个,并且只保留一个示例图像,而删除所有其他相同的图像。
伟大的工作实现自己的重复图像检测和删除系统。
为我们的深度学习数据集运行图像重复检测器
让我们把我们的图像重复检测工作。
首先确保您已经使用了本教程的 【下载】 部分来下载源代码和示例数据集。
从那里,打开一个终端,执行以下命令来验证在我们的dataset/目录中有 1,000 个图像:
$ ls -l dataset/*.jpg | wc -l
1000
现在,让我们执行一次预演,这将允许我们可视化数据集中的重复项:
$ python detect_and_remove.py --dataset dataset
[INFO] computing image hashes...
[INFO] hash: 7054210665732718398
[INFO] hash: 15443501585133582635
[INFO] hash: 13344784005636363614
下图显示了我们脚本的输出,表明我们已经能够成功地找到重复项,如上面的“我们的示例重复图像数据集”部分所述。
为了从我们的系统中真正删除重复项,我们需要再次执行detect_and_remove.py,这次提供--remove 1命令行参数:
$ python detect_and_remove.py --dataset dataset --remove 1
[INFO] computing image hashes...
我们可以通过计算dataset目录中 JPEG 图像的数量来验证重复图像是否已被删除:
$ ls -l dataset/*.jpg | wc -l
993
最初dataset中有 1000 张图片,现在有 993 张,暗示我们去掉了 7 张重复的图片。
在这一点上,你可以继续在这个数据集上训练一个深度神经网络。
如何创建自己的影像数据集?
我为今天的教程创建了一个示例数据集,它包含在 【下载】 中,以便您可以立即开始学习重复数据删除的概念。
但是,您可能想知道:
“首先,我如何创建数据集?”
创建数据集没有“一刀切”的方法。相反,你需要考虑这个问题并围绕它设计你的数据收集。
您可能会确定需要自动化和摄像机来收集数据。或者您可能决定需要合并现有的数据集来节省大量时间。
让我们首先考虑以人脸应用为目的的数据集。如果您想创建一个自定义的人脸数据集,您可以使用三种方法中的任何一种:
- 通过 OpenCV 和网络摄像头注册人脸
- 以编程方式下载人脸图像
- 手动采集人脸图像
从那里,你可以应用面部应用,包括面部识别、面部标志等。
但是如果你想利用互联网和现有的搜索引擎或抓取工具呢?有希望吗?
事实上是有的。我写了三个教程来帮助你入门。
使用这些博客帖子来帮助创建您的数据集,请记住图像所有者的版权。一般来说,你只能出于教育目的使用受版权保护的图片。出于商业目的,您需要联系每个图像的所有者以获得许可。
在网上收集图片几乎总会导致重复——一定要快速检查。创建数据集后,请按照今天的重复数据删除教程计算哈希值并自动删除重复项。
回想一下从机器学习和深度学习数据集中删除重复项的两个重要原因:
- 你的数据集中的重复图像将偏差引入到你的数据集中,给你的深度神经网络额外的机会来学习重复图像的特定模式。
- 此外,副本会影响您的模型将归纳为超出其训练范围的新图像的能力。
从那里,您可以在新形成的数据集上训练您自己的深度学习模型,并部署它!
摘要
在本教程中,您学习了如何从深度学习数据集中检测和移除重复图像。
通常,您会希望从数据集中移除重复的图像,以确保每个数据点(即图像)仅表示一次-如果数据集中有多个相同的图像,您的卷积神经网络可能会学习偏向这些图像,从而使您的模型不太可能推广到新图像。
*为了帮助防止这种类型的偏差,我们使用一种叫做图像哈希的方法实现了我们的重复检测器。
图像哈希的工作原理是:
- 检查图像的内容
- 构造散列值(即整数),该散列值仅基于图像的内容唯一地量化输入图像的
使用我们的散列函数,我们可以:
- 循环浏览我们图像数据集中的所有图像
- 为每个图像计算图像哈希
- 检查“哈希冲突”,这意味着如果两个图像有相同的哈希,它们一定是重复的
- 从我们的数据集中删除重复的图像
使用本教程中介绍的技术,您可以从自己的数据集中检测并删除重复的图像——从那里,您将能够在新删除重复数据的数据集上训练一个深度神经网络!
我希望你喜欢这个教程。
要下载这篇文章的源代码和示例数据集(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
使用 dlib、OpenCV 和 Python 检测眼睛、鼻子、嘴唇和下巴
原文:https://pyimagesearch.com/2017/04/10/detect-eyes-nose-lips-jaw-dlib-opencv-python/
今天的博客文章是我们当前关于面部标志检测及其在计算机视觉和图像处理中的应用系列的第三部分。

两周前,我演示了如何安装 dlib 库,我们用它来检测面部标志。
然后,上周我讨论了如何使用 dlib 来实际地 检测图像中的面部标志。
今天,我们将采取下一步,使用我们检测到的面部标志来帮助我们标记和提取面部区域,包括:
- 口
- 右眉
- 左眉毛
- 右眼
- 左眼
- 鼻子
- 颌
要了解如何使用 dlib、OpenCV 和 Python 分别提取这些人脸区域,继续阅读。
使用 dlib、OpenCV 和 Python 检测眼睛、鼻子、嘴唇和下巴
今天的博文将首先讨论与面部标志相关的 (x,y)-坐标,以及如何将这些面部标志映射到面部的特定区域。
然后,我们将编写一些代码,用于提取面部区域的每一个。
我们将通过在一些示例图像上演示我们的方法的结果来结束这篇博文。
在这篇博文结束时,你将对如何通过面部标志(自动)提取面部区域有一个深刻的理解,并将能够将这一知识应用到你自己的应用中。
面部区域的面部标志索引
dlib 内部实现的面部标志检测器产生 68 个 (x,y)-坐标,映射到特定的面部结构。这 68 个点映射是通过在标记的 iBUG 300-W 数据集上训练形状预测器而获得的。
下面我们可以看到这 68 个坐标中的每一个都映射到了什么:

Figure 1: Visualizing each of the 68 facial coordinate points from the iBUG 300-W dataset (higher resolution).
检查图像,我们可以看到面部区域可以通过简单的 Python 索引来访问(假设使用 Python 零索引,因为上面的图像是一个索引):
- 通过【48,68】可以进入口。
- 右眉通穴【17、22】。
- 左眉经穴【22、27】。
- 右眼使用【36,42】。
- 左眼与【42,48】。
- 鼻使用【27,35】。
- 并且通过【0,17】夹爪。
这些映射编码在 imutils 库的 face_utils 内的FACIAL_LANDMARKS_IDXS字典中:
# define a dictionary that maps the indexes of the facial
# landmarks to specific face regions
FACIAL_LANDMARKS_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 35)),
("jaw", (0, 17))
])
使用这个字典,我们可以很容易地将索引提取到面部标志数组中,并通过提供一个字符串作为关键字来提取各种面部特征。
用 OpenCV 和 Python 可视化面部标志
稍微困难一点的任务是可视化这些面部标志中的每一个,并将结果叠加在输入图像上。
为此,我们需要已经包含在 imutils 库中的visualize_facial_landmarks函数:
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# create two copies of the input image -- one for the
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# if the colors list is None, initialize it with a unique
# color for each facial landmark region
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
我们的visualize_facial_landmarks函数需要两个参数,后跟两个可选参数,每个参数详述如下:
- 我们将要在其上绘制面部标志可视化的图像。
shape:NumPy 数组,包含映射到各个面部部位的 68 个面部标志坐标。colors:用于对每个面部标志区域进行颜色编码的 BGR 元组列表。alpha:用于控制原始图像上叠加的不透明度的参数。
第 45 行和第 46 行创建了我们输入图像的两个副本——我们需要这些副本,以便在输出图像上绘制一个半透明的覆盖图。
第 50 行检查colors列表是否为None,如果是,用预设的 BGR 元组列表初始化(记住,OpenCV 是按 BGR 顺序而不是 RGB 顺序存储颜色/像素强度的)。
我们现在准备通过面部标志来可视化每个单独的面部区域:
# loop over the facial landmark regions individually
for (i, name) in enumerate(FACIAL_LANDMARKS_IDXS.keys()):
# grab the (x, y)-coordinates associated with the
# face landmark
(j, k) = FACIAL_LANDMARKS_IDXS[name]
pts = shape[j:k]
# check if are supposed to draw the jawline
if name == "jaw":
# since the jawline is a non-enclosed facial region,
# just draw lines between the (x, y)-coordinates
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# otherwise, compute the convex hull of the facial
# landmark coordinates points and display it
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
在第 56 行上,我们遍历了FACIAL_LANDMARKS_IDXS字典中的每个条目。
对于这些区域中的每一个,我们提取给定面部部分的索引,并从shape NumPy 数组中获取 (x,y) 坐标。
第 63-69 行检查我们是否在画爪,如果是,我们简单地循环各个点,画一条连接爪点的线。
否则,行 73-75 处理计算点的凸包并在覆盖图上绘制凸包。
最后一步是通过cv2.addWeighted函数创建一个透明叠加:
# apply the transparent overlay
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
# return the output image
return output
将visualize_facial_landmarks应用到图像和相关的面部标志后,输出将类似于下图:

Figure 2: A visualization of each facial landmark region overlaid on the original image.
为了学习如何将所有的部分粘在一起(并提取每个面部区域),让我们继续下一部分。
使用 dlib、OpenCV 和 Python 提取人脸部分
在继续学习本教程之前,请确保您已经:
从那里,打开一个新文件,将其命名为detect_face_parts.py,并插入以下代码:
# import the necessary packages
from imutils import face_utils
import numpy as np
import argparse
import imutils
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale image
rects = detector(gray, 1)
本例中的第一个代码块与我们之前的教程中的代码块相同。
我们只是:
- 导入我们需要的 Python 包(第 2-7 行)。
- 解析我们的命令行参数(第 10-15 行)。
- 实例化 dlib 的基于 HOG 的人脸检测器并加载面部标志预测器(第 19 行和第 20 行)。
- 加载并预处理我们的输入图像(第 23-25 行)。
- 检测输入图像中的人脸(第 28 行)。
同样,要想更全面、更详细地了解这个代码块,请参阅上周关于使用 dlib、OpenCV 和 Python 进行面部标志检测的博客文章。
既然我们已经在图像中检测到面部,我们可以单独循环每个面部 ROI:
# loop over the face detections
for (i, rect) in enumerate(rects):
# determine the facial landmarks for the face region, then
# convert the landmark (x, y)-coordinates to a NumPy array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the face parts individually
for (name, (i, j)) in face_utils.FACIAL_LANDMARKS_IDXS.items():
# clone the original image so we can draw on it, then
# display the name of the face part on the image
clone = image.copy()
cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# loop over the subset of facial landmarks, drawing the
# specific face part
for (x, y) in shape[i:j]:
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
对于每个面部区域,我们确定 ROI 的面部标志,并将 68 个点转换成一个 NumPy 数组(行 34 和 35 )。
然后,对于每一个面部部分,我们在第 38 行的处循环。
我们在线 42 和 43 上画出面部区域的名称/标签,然后在线 47 和 48 上画出每个单独的面部标志作为圆圈。
为了实际地提取每个面部区域,我们只需要计算与特定区域相关联的 (x,y) 坐标的边界框,并使用 NumPy 数组切片来提取它:
# extract the ROI of the face region as a separate image
(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))
roi = image[y:y + h, x:x + w]
roi = imutils.resize(roi, width=250, inter=cv2.INTER_CUBIC)
# show the particular face part
cv2.imshow("ROI", roi)
cv2.imshow("Image", clone)
cv2.waitKey(0)
# visualize all facial landmarks with a transparent overlay
output = face_utils.visualize_facial_landmarks(image, shape)
cv2.imshow("Image", output)
cv2.waitKey(0)
通过cv2.boundingRect在行 51 处理计算区域的包围盒。
使用 NumPy 数组切片,我们可以提取第 52 行上的 ROI。
然后这个 ROI 被调整到 250 像素的宽度,这样我们可以更好地可视化它( Line 53 )。
第 56-58 行向我们的屏幕显示个人面部区域。
第 61-63 行然后应用visualize_facial_landmarks函数为每个面部部分创建一个透明叠加。
面零件标注结果
既然我们的例子已经编写好了,让我们来看看一些结果。
请务必使用本指南的 【下载】 部分下载源代码+示例图像+ dlib 面部标志预测器模型。
在那里,您可以使用以下命令来可视化结果:
$ python detect_face_parts.py --shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_01.jpg
注意我的嘴是如何首先被检测到的:

Figure 3: Extracting the mouth region via facial landmarks.
接着是我的右眉:

Figure 4: Determining the right eyebrow of an image using facial landmarks and dlib.
然后是左眉:

Figure 5: The dlib library can extract facial regions from an image.
接下来是右眼:

Figure 6: Extracting the right eye of a face using facial landmarks, dlib, OpenCV, and Python.
连同左眼:
*
Figure 7: Extracting the left eye of a face using facial landmarks, dlib, OpenCV, and Python.
最后是下颌线:

Figure 8: Automatically determining the jawline of a face with facial landmarks.
正如你所看到的,下颚线的边界框是 m 整张脸。
这张图像的最后一个可视化效果是我们的透明覆盖图,每个面部标志区域都用不同的颜色突出显示:
Figure 9: A transparent overlay that displays the individual facial regions extracted via the image with facial landmarks.
让我们试试另一个例子:
$ python detect_face_parts.py --shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_02.jpg
这次我创建了一个输出的 GIF 动画:

Figure 10: Extracting facial landmark regions with computer vision.
最后一个例子也是如此:
$ python detect_face_parts.py --shape-predictor shape_predictor_68_face_landmarks.dat \
--image images/example_03.jpg

Figure 11: Automatically labeling eyes, eyebrows, nose, mouth, and jaw using facial landmarks.
摘要
在这篇博文中,我演示了如何使用面部标志检测来检测图像中的各种面部结构。
具体来说,我们学习了如何检测和提取:
- 口
- 右眉
- 左眉毛
- 右眼
- 左眼
- 鼻子
- 下颌的轮廓
这是使用 dlib 预先训练的面部标志检测器以及一点 OpenCV 和 Python 的魔力完成的。
此时,您可能对面部标志的准确性印象深刻——使用面部标志有明显的优势,特别是对于面部对齐、面部交换和提取各种面部结构。
…但最大的问题是:
"面部标志检测可以实时运行吗?"
为了找到答案,你需要继续关注下周的博客文章。
为了在下周发布关于实时面部标志检测的博文时得到通知,请务必在下表中输入您的电子邮件地址!
到时候见。*
用 Tesseract 和 Python 检测和识别数字
原文:https://pyimagesearch.com/2021/08/30/detecting-and-ocring-digits-with-tesseract-and-python/
在之前的教程中,我们实现了第一个 OCR 项目。我们看到,Tesseract 在一些图像上工作得很好,但在其他例子中却完全没有意义。成为一名成功的 OCR 从业者的一部分是了解当您看到 Tesseract 的这种乱码、无意义的输出时,这意味着(1)您的图像预处理技术和(2)您的 Tesseract OCR 选项是不正确的。
要学习如何用宇宙魔方和 Python 检测和 OCR 数字,只要坚持读下去。**
用宇宙魔方和 Python 检测和识别数字
宇宙魔方是一种工具,就像任何其他软件包一样。就像一个数据科学家不能简单地将数百万条客户购买记录导入 Microsoft Excel 并期望 Excel 自动识别购买模式,期望 Tesseract 找出你需要的东西并自动正确地输出它是不现实的。
*相反,如果您了解如何为手头的任务正确配置 Tesseract 会有所帮助。例如,假设你的任务是创建一个计算机视觉应用程序来自动 OCR 名片上的电话号码。
你将如何着手建设这样一个项目?你会尝试对整张名片进行 OCR,然后结合使用正则表达式和后处理模式识别来解析出数字吗?
或者,您会后退一步,检查宇宙魔方 OCR 引擎本身— 是否可以将宇宙魔方仅告知OCR 位数?
*原来是有的。这就是我们将在本教程中讨论的内容。
学习目标
在本教程中,您将:
- 获得从输入图像中识别数字的实践经验
- 扩展我们以前的 OCR 脚本来处理数字识别
- 了解如何将 Tesseract 配置为仅支持 OCR 数字
- 通过
pytesseract库将这个配置传递给 Tesseract
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
用魔方进行数字检测和识别
在本教程的第一部分,我们将回顾数字检测和识别,包括现实世界中我们可能希望仅 OCR 数字的问题。
从那里,我们将回顾我们的项目目录结构,我将向您展示如何使用 Tesseract 执行数字检测和识别。我们将以回顾我们的数字 OCR 结果来结束本教程。
什么是数字检测和识别?
顾名思义,数字识别是仅识别数字,有意忽略其他字符的过程。数字识别经常应用于现实世界的 OCR 项目(可以在图 2 中看到其蒙太奇),包括:
- 从名片中提取信息
- 构建智能水监控阅读器
- 银行支票和信用卡 OCR
我们的目标是“消除非数字字符的干扰”。我们将改为“激光输入”数字。幸运的是,一旦我们为 Tesseract 提供了正确的参数,完成这个数字识别任务就相对容易了。
项目结构
让我们回顾一下该项目的目录结构:
|-- apple_support.png
|-- ocr_digits.py
我们的项目由一个测试图像(apple_support.png)和我们的ocr_digits.py Python 脚本组成。该脚本接受图像和可选的“仅数字”设置,并相应地报告 OCR 结果。
使用 Tesseract 和 OpenCV 对数字进行 OCR 识别
我们现在已经准备好用宇宙魔方来识别数字了。打开一个新文件,将其命名为ocr_digits.py,并插入以下代码:
# import the necessary packages
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-d", "--digits", type=int, default=1,
help="whether or not *digits only* OCR will be performed")
args = vars(ap.parse_args())
如您所见,我们将 PyTesseract 包与 OpenCV 结合使用。处理完导入后,我们解析两个命令行参数:
--image:要进行 OCR 的图像的路径--digits:一个标志,指示我们是否应该仅 OCR 位的(通过default,该选项被设置为一个True布尔)
让我们继续加载我们的图像并执行 OCR:
# load the input image, convert it from BGR to RGB channel ordering,
# and initialize our Tesseract OCR options as an empty string
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
options = ""
# check to see if *digit only* OCR should be performed, and if so,
# update our Tesseract OCR options
if args["digits"] > 0:
options = "outputbase digits"
# OCR the input image using Tesseract
text = pytesseract.image_to_string(rgb, config=options)
print(text)
Tesseract 需要 RGB 颜色通道排序来执行 OCR。第 16 和 17 行加载输入--image并相应地交换颜色通道。
然后我们建立我们的宇宙魔方options ( 第 18–23 行)。使用选项配置 Tesseract 允许对 Tesseract 执行 OCR 的方法进行更细粒度的控制。
目前,我们的options或者是空的(第 18 行或者是outputbase digits,表示我们将在输入图像上仅 OCR 数字(第 22 行和第 23 行)。
从那里,我们使用image_to_string函数调用,同时传递我们的rgb图像和我们的配置options ( 第 26 行)。请注意,如果--digits命令行参数布尔值为True,我们将使用config参数并包括仅数字设置。
最后,我们在终端中显示 OCR text结果(第 27 行)。让我们看看这些结果是否符合我们的期望。
数字 OCR 结果
我们现在已经准备好用宇宙魔方来识别数字了。
打开终端并执行以下命令:
$ python ocr_digits.py --image apple_support.png
1-800-275-2273
作为对我们的ocr_digits.py脚本的输入,我们提供了一个类似名片的样本图像,其中包含文本“苹果支持”,以及相应的电话号码(图 3 )。我们的脚本可以正确地识别电话号码,将其显示到我们的终端上,同时忽略“Apple Support”文本。
通过命令行或通过image_to_string函数使用 Tesseract 的一个问题是,很难准确调试tessera CT 如何得到最终输出。
一旦我们获得更多使用 Tesseract OCR 引擎的经验,我们将把注意力转向视觉调试,并最终通过置信度/概率分数过滤掉无关字符。目前,请注意我们提供给 Tesseract 的选项和配置,以实现我们的目标(即数字识别)。
如果您想 OCR 所有字符(不仅限于数字),您可以将--digits命令行参数设置为任意值 ≤0:
$ python ocr_digits.py --image apple_support.png --digits 0
a
Apple Support
1-800-275-2273
请注意“Apple Support”文本现在是如何与电话号码一起包含在 OCR 输出中的。可是那个【a】在输出什么呢?这是从哪里来的?
输出中的“a”是将苹果 logo顶端的叶子混淆为字母(图 4 )。
总结
在本教程中,您学习了如何将 Tesseract 和pytesseract配置为仅 OCR 的数字。然后,我们使用 Python 脚本来处理数字的 OCR 识别。
你会想要密切注意我们提供给宇宙魔方的config和options。通常,能否成功地将 OCR 应用到一个 Tesseract 项目取决于提供正确的配置集。
在我们的下一个教程中,我们将通过学习如何将一组自定义字符列入白名单和黑名单来继续探索 Tesseract 选项。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
用 OpenCV 和 Python 检测 ArUco 标记
原文:https://pyimagesearch.com/2020/12/21/detecting-aruco-markers-with-opencv-and-python/
在本教程中,您将学习如何使用 OpenCV 和 Python 检测图像和实时视频流中的 ArUco 标记。
这篇博文是我们关于 ArUco 标记和基准的三部分系列的第二部分:
- 用 OpenCV 和 Python 生成 ArUco 标记 (上周帖子)
- 使用 OpenCV 检测图像和视频中的 ArUco 标记(今天的教程)
- 使用 OpenCV 自动确定 ArUco 标记类型(下周发布)
上周我们学习了:
- 什么是阿鲁科字典
- 如何选择适合我们任务的 ArUco 字典
- 如何使用 OpenCV 生成 ArUco 标记
- 如何使用在线工具创建 ArUco 标记
今天我们将学习如何使用 OpenCV 实际检测 ArUco 标记。
要了解如何使用 OpenCV 检测图像和实时视频中的 ArUco 标记,请继续阅读。
用 OpenCV 和 Python 检测 ArUco 标记
从这里,我们将回顾我们的项目目录结构,并实现两个 Python 脚本:
- 一个 Python 脚本来检测图像中的 ArUco 标记
- 和另一个 Python 脚本来检测实时视频流中的 ArUco 标记
我们将用对我们结果的讨论来结束这篇关于使用 OpenCV 进行 ArUco 标记检测的教程。
OpenCV ArUCo 标记检测
正如我在上周的教程中所讨论的,OpenCV 库带有内置的 ArUco 支持,既支持生成 ArUco 标记,也支持检测它们。
了解" cv2 . aruco . detect markers "函数
我们可以用 3-4 行代码定义一个 ArUco 标记检测程序:
arucoDict = cv2.aruco.Dictionary_get(cv2.aruco.DICT_6X6_50)
arucoParams = cv2.aruco.DetectorParameters_create()
(corners, ids, rejected) = cv2.aruco.detectMarkers(image, arucoDict,
parameters=arucoParams)
配置您的开发环境
为了生成和检测 ArUco 标记,您需要安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助配置 OpenCV 4.3+的开发环境,我强烈推荐阅读我的 pip 安装 opencv 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们学习如何检测图像中的 ArUco 标签之前,让我们先回顾一下我们的项目目录结构,这样您就可以很好地了解我们的项目是如何组织的,以及我们将使用哪些 Python 脚本。
首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,我们可以检查项目目录:
$ tree . --dirsfirst
.
├── images
│ ├── example_01.png
│ └── example_02.png
├── detect_aruco_image.py
└── detect_aruco_video.py
2 directories, 9 files
回顾了我们的项目目录结构后,我们可以继续用 OpenCV 实现 ArUco 标签检测了!
使用 OpenCV 在图像中检测 ArUco 标记
准备好学习如何使用 OpenCV 检测图像中的 ArUco 标签了吗?
打开项目目录中的detect_aruco_image.py 文件,让我们开始工作:
# import the necessary packages
import argparse
import imutils
import cv2
import sys
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image containing ArUCo tag")
ap.add_argument("-t", "--type", type=str,
default="DICT_ARUCO_ORIGINAL",
help="type of ArUCo tag to detect")
args = vars(ap.parse_args())
因此,您必须绝对确定用于生成ArUco 标签的类型与您用于检测阶段的类型相同。
注:不知道你输入图片中的标签是用什么 ArUco 字典生成的?别担心,我会掩护你的。下周我将向你展示我个人收藏的一个 Python 脚本,当我不能识别一个给定的 ArUco 标签是什么类型时,我就使用它。这个脚本自动识别*ArUco 标签类型。请继续关注下周的教程,在那里我将详细回顾它。*
接下来是我们的ARUCO_DICT ,它列举了 OpenCV 支持的每个 ArUco 标签类型:
# define names of each possible ArUco tag OpenCV supports
ARUCO_DICT = {
"DICT_4X4_50": cv2.aruco.DICT_4X4_50,
"DICT_4X4_100": cv2.aruco.DICT_4X4_100,
"DICT_4X4_250": cv2.aruco.DICT_4X4_250,
"DICT_4X4_1000": cv2.aruco.DICT_4X4_1000,
"DICT_5X5_50": cv2.aruco.DICT_5X5_50,
"DICT_5X5_100": cv2.aruco.DICT_5X5_100,
"DICT_5X5_250": cv2.aruco.DICT_5X5_250,
"DICT_5X5_1000": cv2.aruco.DICT_5X5_1000,
"DICT_6X6_50": cv2.aruco.DICT_6X6_50,
"DICT_6X6_100": cv2.aruco.DICT_6X6_100,
"DICT_6X6_250": cv2.aruco.DICT_6X6_250,
"DICT_6X6_1000": cv2.aruco.DICT_6X6_1000,
"DICT_7X7_50": cv2.aruco.DICT_7X7_50,
"DICT_7X7_100": cv2.aruco.DICT_7X7_100,
"DICT_7X7_250": cv2.aruco.DICT_7X7_250,
"DICT_7X7_1000": cv2.aruco.DICT_7X7_1000,
"DICT_ARUCO_ORIGINAL": cv2.aruco.DICT_ARUCO_ORIGINAL,
"DICT_APRILTAG_16h5": cv2.aruco.DICT_APRILTAG_16h5,
"DICT_APRILTAG_25h9": cv2.aruco.DICT_APRILTAG_25h9,
"DICT_APRILTAG_36h10": cv2.aruco.DICT_APRILTAG_36h10,
"DICT_APRILTAG_36h11": cv2.aruco.DICT_APRILTAG_36h11
}
这个字典的键是一个人类可读的字符串(即 ArUco 标签类型的名称)。然后这个键映射到值,这是 OpenCV 对于 ArUco 标签类型的唯一标识符。
使用这个字典,我们可以获取输入的--type命令行参数,通过ARUCO_DICT传递它,然后获得 ArUco 标签类型的唯一标识符。
以下 Python shell 块显示了如何执行查找操作的简单示例:
>>> print(args)
{'type': 'DICT_5X5_100'}
>>> arucoType = ARUCO_DICT[args["type"]]
>>> print(arucoType)
5
>>> 5 == cv2.aruco.DICT_5X5_100
True
>>>
我介绍了 ArUco 字典的类型,包括它们的命名约定,在我之前的教程中, 使用 OpenCV 和 Python 生成 ArUco 标记。
如果你想了解更多关于阿鲁科字典的信息,请参考那里;否则,简单理解一下,这个字典列出了 OpenCV 可以检测到的所有可能的 ArUco 标签。
接下来,让我们继续从磁盘加载输入图像:
# load the input image from disk and resize it
print("[INFO] loading image...")
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
# verify that the supplied ArUCo tag exists and is supported by
# OpenCV
if ARUCO_DICT.get(args["type"], None) is None:
print("[INFO] ArUCo tag of '{}' is not supported".format(
args["type"]))
sys.exit(0)
# load the ArUCo dictionary, grab the ArUCo parameters, and detect
# the markers
print("[INFO] detecting '{}' tags...".format(args["type"]))
arucoDict = cv2.aruco.Dictionary_get(ARUCO_DICT[args["type"]])
arucoParams = cv2.aruco.DetectorParameters_create()
(corners, ids, rejected) = cv2.aruco.detectMarkers(image, arucoDict,
parameters=arucoParams)
# verify *at least* one ArUco marker was detected
if len(corners) > 0:
# flatten the ArUco IDs list
ids = ids.flatten()
# loop over the detected ArUCo corners
for (markerCorner, markerID) in zip(corners, ids):
# extract the marker corners (which are always returned in
# top-left, top-right, bottom-right, and bottom-left order)
corners = markerCorner.reshape((4, 2))
(topLeft, topRight, bottomRight, bottomLeft) = corners
# convert each of the (x, y)-coordinate pairs to integers
topRight = (int(topRight[0]), int(topRight[1]))
bottomRight = (int(bottomRight[0]), int(bottomRight[1]))
bottomLeft = (int(bottomLeft[0]), int(bottomLeft[1]))
topLeft = (int(topLeft[0]), int(topLeft[1]))
# draw the bounding box of the ArUCo detection
cv2.line(image, topLeft, topRight, (0, 255, 0), 2)
cv2.line(image, topRight, bottomRight, (0, 255, 0), 2)
cv2.line(image, bottomRight, bottomLeft, (0, 255, 0), 2)
cv2.line(image, bottomLeft, topLeft, (0, 255, 0), 2)
# compute and draw the center (x, y)-coordinates of the ArUco
# marker
cX = int((topLeft[0] + bottomRight[0]) / 2.0)
cY = int((topLeft[1] + bottomRight[1]) / 2.0)
cv2.circle(image, (cX, cY), 4, (0, 0, 255), -1)
# draw the ArUco marker ID on the image
cv2.putText(image, str(markerID),
(topLeft[0], topLeft[1] - 15), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 255, 0), 2)
print("[INFO] ArUco marker ID: {}".format(markerID))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
最终的输出可视化显示在我们屏幕的第 98 和 99 行。
OpenCV ArUco 标记检测结果
让我们使用 OpenCV ArUco 检测器吧!
使用本教程的 “下载” 部分下载源代码和示例图像。
从那里,您可以执行以下命令:
$ python detect_aruco_image.py --image images/example_01.png --type DICT_5X5_100
[INFO] loading image...
[INFO] detecting 'DICT_5X5_100' tags...
[INFO] ArUco marker ID: 42
[INFO] ArUco marker ID: 24
[INFO] ArUco marker ID: 70
[INFO] ArUco marker ID: 66
[INFO] ArUco marker ID: 87
这张图片包含了我们在上周的博客文章中生成的 ArUco 标记。我把五个单独的 ArUco 标记中的每一个都放在一张图片中进行了剪辑。
如图 3 所示,我们已经能够正确地检测出每个 ArUco 标记并提取它们的 id。
让我们尝试一个不同的图像,这个图像包含 ArUco 标记而不是我们生成的:
$ python detect_aruco_image.py --image images/example_02.png --type DICT_ARUCO_ORIGINAL
[INFO] loading image...
[INFO] detecting 'DICT_ARUCO_ORIGINAL' tags...
[INFO] ArUco marker ID: 241
[INFO] ArUco marker ID: 1007
[INFO] ArUco marker ID: 1001
[INFO] ArUco marker ID: 923
图 4 显示了我们的 OpenCV ArUco 检测器的结果。正如你所看到的,我已经在我的 Pantone 配色卡上检测到了四个 ArUco 标记(我们将在接下来的一些教程中使用它,所以习惯于看到它)。
查看上面脚本的命令行参数,您可能会想知道:
“嗨,阿德里安,你怎么知道用
DICT_ARUCO_ORIGINAL而不用其他阿鲁科字典呢?”
简短的回答是,我没有 …至少最初没有。
实际上,我有一个“秘密武器”。我已经编写了一个 Python 脚本,它可以自动推断 ArUco 标记类型,即使我不知道图像中的标记是什么类型。
下周我会和你分享这个剧本,所以请留意它。
使用 OpenCV 检测实时视频流中的 ArUco 标记
在上一节中,我们学习了如何检测图像中的 ArUco 标记…
…但是有可能在实时视频流中检测出阿鲁科标记吗?
答案是是的,绝对是——我将在这一节向你展示如何做到这一点。
打开项目目录结构中的detect_aruco_video.py文件,让我们开始工作:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import imutils
import time
import cv2
import sys
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--type", type=str,
default="DICT_ARUCO_ORIGINAL",
help="type of ArUCo tag to detect")
args = vars(ap.parse_args())
# define names of each possible ArUco tag OpenCV supports
ARUCO_DICT = {
"DICT_4X4_50": cv2.aruco.DICT_4X4_50,
"DICT_4X4_100": cv2.aruco.DICT_4X4_100,
"DICT_4X4_250": cv2.aruco.DICT_4X4_250,
"DICT_4X4_1000": cv2.aruco.DICT_4X4_1000,
"DICT_5X5_50": cv2.aruco.DICT_5X5_50,
"DICT_5X5_100": cv2.aruco.DICT_5X5_100,
"DICT_5X5_250": cv2.aruco.DICT_5X5_250,
"DICT_5X5_1000": cv2.aruco.DICT_5X5_1000,
"DICT_6X6_50": cv2.aruco.DICT_6X6_50,
"DICT_6X6_100": cv2.aruco.DICT_6X6_100,
"DICT_6X6_250": cv2.aruco.DICT_6X6_250,
"DICT_6X6_1000": cv2.aruco.DICT_6X6_1000,
"DICT_7X7_50": cv2.aruco.DICT_7X7_50,
"DICT_7X7_100": cv2.aruco.DICT_7X7_100,
"DICT_7X7_250": cv2.aruco.DICT_7X7_250,
"DICT_7X7_1000": cv2.aruco.DICT_7X7_1000,
"DICT_ARUCO_ORIGINAL": cv2.aruco.DICT_ARUCO_ORIGINAL,
"DICT_APRILTAG_16h5": cv2.aruco.DICT_APRILTAG_16h5,
"DICT_APRILTAG_25h9": cv2.aruco.DICT_APRILTAG_25h9,
"DICT_APRILTAG_36h10": cv2.aruco.DICT_APRILTAG_36h10,
"DICT_APRILTAG_36h11": cv2.aruco.DICT_APRILTAG_36h11
}
请参考上面的“使用 OpenCV 在图像中检测 ArUco 标记”一节,了解此代码块的更多详细信息。
我们现在可以加载我们的 ArUco 字典:
# verify that the supplied ArUCo tag exists and is supported by
# OpenCV
if ARUCO_DICT.get(args["type"], None) is None:
print("[INFO] ArUCo tag of '{}' is not supported".format(
args["type"]))
sys.exit(0)
# load the ArUCo dictionary and grab the ArUCo parameters
print("[INFO] detecting '{}' tags...".format(args["type"]))
arucoDict = cv2.aruco.Dictionary_get(ARUCO_DICT[args["type"]])
arucoParams = cv2.aruco.DetectorParameters_create()
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 1000 pixels
frame = vs.read()
frame = imutils.resize(frame, width=1000)
# detect ArUco markers in the input frame
(corners, ids, rejected) = cv2.aruco.detectMarkers(frame,
arucoDict, parameters=arucoParams)
# verify *at least* one ArUco marker was detected
if len(corners) > 0:
# flatten the ArUco IDs list
ids = ids.flatten()
# loop over the detected ArUCo corners
for (markerCorner, markerID) in zip(corners, ids):
# extract the marker corners (which are always returned
# in top-left, top-right, bottom-right, and bottom-left
# order)
corners = markerCorner.reshape((4, 2))
(topLeft, topRight, bottomRight, bottomLeft) = corners
# convert each of the (x, y)-coordinate pairs to integers
topRight = (int(topRight[0]), int(topRight[1]))
bottomRight = (int(bottomRight[0]), int(bottomRight[1]))
bottomLeft = (int(bottomLeft[0]), int(bottomLeft[1]))
topLeft = (int(topLeft[0]), int(topLeft[1]))
# draw the bounding box of the ArUCo detection
cv2.line(frame, topLeft, topRight, (0, 255, 0), 2)
cv2.line(frame, topRight, bottomRight, (0, 255, 0), 2)
cv2.line(frame, bottomRight, bottomLeft, (0, 255, 0), 2)
cv2.line(frame, bottomLeft, topLeft, (0, 255, 0), 2)
# compute and draw the center (x, y)-coordinates of the
# ArUco marker
cX = int((topLeft[0] + bottomRight[0]) / 2.0)
cY = int((topLeft[1] + bottomRight[1]) / 2.0)
cv2.circle(frame, (cX, cY), 4, (0, 0, 255), -1)
# draw the ArUco marker ID on the frame
cv2.putText(frame, str(markerID),
(topLeft[0], topLeft[1] - 15),
cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 255, 0), 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
OpenCV ArUco 视频检测结果
准备好将 ArUco 检测应用于实时视频流了吗?
首先使用本教程的 【下载】 部分下载源代码和示例图像。
在那里,打开一个 shell,并执行以下命令:
$ python detect_aruco_video.py
如你所见,我很容易在实时视频中检测到阿鲁科标记。
总结
在本教程中,您学习了如何使用 OpenCV 和 Python 检测图像和实时视频流中的 ArUco 标记。
使用 OpenCV 检测 ArUco 标记分为三个步骤:
- 设置你正在使用的 ArUco 字典。
- 定义 ArUco 检测器的参数(通常默认选项就足够了)。
- 使用 OpenCV 的
cv2.aruco.detectMarkers功能应用 ArUco 检测器。
OpenCV 的 ArUco 标记是极快的,正如我们的结果所示,能够实时检测 ArUco 标记。
在您自己的计算机视觉管道中使用 ArUco 标记时,请随意使用此代码作为起点。
然而,假设你正在开发一个计算机视觉项目来自动检测图像中的 ArUco 标记,但是你不知道正在使用什么类型的标记,因此,你不能显式地设置 ArUco 标记字典——那么你会怎么做?
如果你不知道正在使用的标记类型,如何检测 ArUco 标记?
我将在下周的博客文章中回答这个问题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
用 Python 和 OpenCV 检测图像中的条形码
原文:https://pyimagesearch.com/2014/11/24/detecting-barcodes-images-python-opencv/

更新:这篇帖子的介绍可能看起来有点“扎眼”。出于某些背景,在写这篇文章之前,我刚刚看完了南方公园黑色星期五集,所以我肯定有一些关于僵尸购物者、黑色星期五混乱和权力的游戏的灵感。
黑色星期五要来了。
成群愤怒的购物者。中西部的中年妇女蜂拥而至,她们的牙齿掉光了,在当地的沃尔玛,最新一季的《权力的游戏》打了 75 折。
他们会在感恩节午夜在沃尔玛门口排队。他们会聚集起来,用手和头敲打锁着的门,直到他们的身体血肉模糊,就像 28 天后的僵尸一样。但他们渴望的不是人肉,而是琐碎的消费食物。他们关于打折和销售的呐喊将会响彻云霄。他们雷鸣般的脚步声会在大平原上引起地震。
当然,媒体不会帮忙——他们会大肆渲染每一个细节。从冻伤的家庭在酷寒中整夜露营,到愤怒的讨价还价的猎人开门时践踏的小老太太,类似于《侏罗纪公园》中的加利米穆斯踩踏事件。所有这一切仅仅是因为她想为她 9 岁的小孙子 Timmy 购买最新的 Halo 游戏,他的父母去年这个时候去世了。在沃尔玛。在黑色星期五期间。
我不得不问,这些混乱和混乱值得吗?
地狱。号
这个黑色星期五,我将(安全地)在笔记本电脑屏幕后购物,可能会喝一杯咖啡,吃一把泰诺,来缓解前一天晚上的宿醉。
但是,如果你决定冒险进入现实世界,勇敢面对捡便宜货的人, 你会想先下载这篇博文的源代码……
想象一下,你会觉得自己有多傻,排队等着结账,只是为了扫描最新一季《权力的游戏》的条形码,却发现 Target 只便宜了 5 美元?
在这篇博文的剩余部分,我将向你展示如何只使用 Python 和 OpenCV 来检测图像中的条形码。
使用 Python 和 OpenCV 检测图像中的条形码
这篇博文的目的是演示使用计算机视觉和图像处理技术实现条形码检测的基本方法。我的算法实现最初松散地基于这个 StackOverflow 问题。我检查了代码,并对原始算法进行了一些更新和改进。
值得注意的是,这种算法并不适用于所有的条形码,但它会给你一个基本的直觉,告诉你应该应用什么类型的技术。
对于本例,我们将检测下图中的条形码:

Figure 1: Example image containing a barcode that we want to detect.
让我们开始写一些代码。打开一个新文件,命名为detect_barcode.py,让我们开始编码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True,
help = "path to the image file")
args = vars(ap.parse_args())
我们要做的第一件事是导入我们需要的包。我们将利用 NumPy 进行数值处理,利用argparse解析命令行参数,利用cv2进行 OpenCV 绑定。
然后我们将设置我们的命令行参数。这里我们只需要一个开关,--image,它是包含我们想要检测的条形码的图像的路径。
现在,是时候进行一些实际的图像处理了:
# load the image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# compute the Scharr gradient magnitude representation of the images
# in both the x and y direction using OpenCV 2.4
ddepth = cv2.cv.CV_32F if imutils.is_cv2() else cv2.CV_32F
gradX = cv2.Sobel(gray, ddepth=ddepth, dx=1, dy=0, ksize=-1)
gradY = cv2.Sobel(gray, ddepth=ddepth, dx=0, dy=1, ksize=-1)
# subtract the y-gradient from the x-gradient
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
在第 14 行和第 15 行上,我们从磁盘上加载image并将其转换成灰度。
然后,我们使用 Scharr 算子(使用ksize = -1指定)在行 19-21 上构建灰度图像在水平和垂直方向上的梯度幅度表示。
从那里,我们从第 24 和 25 行上的x-Scharr 算子的梯度中减去 Scharr 算子的y-梯度。通过执行这种减法,我们得到了具有高水平梯度和低垂直梯度的图像区域。
我们上面的原始图像看起来像:
Figure 2: The gradient representation of our barcode image.
注意我们的梯度操作是如何检测到图像的条形码区域的。接下来的步骤是滤除图像中的噪声,只关注条形码区域。
# blur and threshold the image
blurred = cv2.blur(gradient, (9, 9))
(_, thresh) = cv2.threshold(blurred, 225, 255, cv2.THRESH_BINARY)
我们要做的第一件事是使用一个 9 x 9 内核将第 28 行的平均模糊应用到渐变图像上。这将有助于消除图像的梯度表示中的高频噪声。
然后我们将对第 29 行上的模糊图像进行阈值处理。渐变图像中不大于 225 的任何像素都被设置为 0(黑色)。否则,像素设置为 255(白色)。
模糊和阈值处理的输出如下所示:
Figure 3: Thresholding the gradient image to obtain a rough approximation to the rectangular barcode region.
然而,正如您在上面的阈值图像中看到的,条形码的垂直条之间有间隙。为了填补这些空白,并使我们的算法更容易检测条形码的“斑点”状区域,我们需要执行一些基本的形态学操作:
# construct a closing kernel and apply it to the thresholded image
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 7))
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
我们将从使用第 32 行的第行的cv2.getStructuringElement构建一个矩形内核开始。这个内核的宽度大于高度,因此允许我们闭合条形码的垂直条纹之间的间隙。
然后,我们对第 33 行执行我们的形态学操作,将我们的内核应用于我们的阈值图像,从而试图闭合条之间的间隙。
现在,您可以看到,与上面的阈值图像相比,这些间隙更加紧密:
Figure 4: Applying closing morphological operations to close the gap between barcode stripes.
当然,现在我们在图像中有小斑点,它们不是实际条形码的一部分,但可能会干扰我们的轮廓检测。
让我们继续尝试移除这些小斑点:
# perform a series of erosions and dilations
closed = cv2.erode(closed, None, iterations = 4)
closed = cv2.dilate(closed, None, iterations = 4)
我们在这里所做的就是执行 4 次腐蚀迭代,然后是 4 次膨胀迭代。侵蚀将“侵蚀”图像中的白色像素,从而移除小斑点,而膨胀将“扩张”剩余的白色像素,并使白色区域重新生长出来。
假如这些小斑点在侵蚀过程中被去除,它们将不会在扩张过程中再次出现。
经过一系列腐蚀和扩张后,您可以看到小斑点已被成功移除,剩下的是条形码区域:
Figure 5: Removing small, irrelevant blobs by applying a series of erosions and dilations.
最后,让我们找到图像条形码区域的轮廓:
# find the contours in the thresholded image, then sort the contours
# by their area, keeping only the largest one
cnts = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(rect) if imutils.is_cv2() else cv2.boxPoints(rect)
box = np.int0(box)
# draw a bounding box arounded the detected barcode and display the
# image
cv2.drawContours(image, [box], -1, (0, 255, 0), 3)
cv2.imshow("Image", image)
cv2.waitKey(0)
幸运的是,这是最简单的部分。在行 41-44 上,我们简单地找到图像中的最大轮廓,如果我们正确地完成了图像处理步骤,该轮廓应该对应于条形码区域。
然后我们确定第 47-49 行上最大轮廓的最小边界框,最后在第 53-55 行上显示检测到的条形码。
如下图所示,我们已成功检测到条形码:

Figure 6: Successfully detecting the barcode in our example image.
在下一部分,我们将尝试更多的图片。
成功的条形码检测
要了解这些结果,请使用本文底部的表格下载这篇博文的源代码和附带的图片。
努力运行这一部分的代码?看看我的命令行参数博文。
获得代码和图像后,打开终端并执行以下命令:
$ python detect_barcode.py --image images/barcode_02.jpg

Figure 7: Using OpenCV to detect a barcode in an image.
检测那罐椰子油上的条形码没问题!
让我们尝试另一个图像:
$ python detect_barcode.py --image images/barcode_03.jpg

Figure 8: Using computer vision to detect a barcode in an image.
我们也能在那张图片中找到条形码!
食品已经够多了,那么书上的条形码呢:
$ python detect_barcode.py --image images/barcode_04.jpg

Figure 9: Detecting a barcode on a book using Python and OpenCV.
再说一遍,没问题!
包裹上的追踪代码怎么样?
$ python detect_barcode.py --image images/barcode_05.jpg

Figure 10: Detecting the barcode on a package using computer vision and image processing.
同样,我们的算法能够成功检测条形码。
最后,让我们再看一张图片,这是我最喜欢的面酱,饶自制的伏特加酱:
$ python detect_barcode.py --image images/barcode_06.jpg

Figure 11: Barcode detection is easy using Python and OpenCV!
我们又一次检测到了条形码!
摘要
在这篇博文中,我们回顾了使用计算机视觉技术检测图像中条形码的必要步骤。我们使用 Python 编程语言和 OpenCV 库实现了我们的算法。
该算法的一般概要是:
- 计算在 x 和 y 方向上的沙尔梯度幅度表示。
- 从 x 梯度中减去 y 梯度,以显示条形码区域。
- 模糊和阈值的图像。
- 对阈值化图像应用关闭内核。
- 进行一系列的扩张和侵蚀。
- 找到图像中最大的轮廓,现在大概就是条形码。
重要的是要注意,由于这种方法对图像的梯度表示进行了假设,因此只适用于水平条形码。
如果您想要实现更强大的条形码检测算法,您需要考虑图像的方向,或者更好的是,应用机器学习技术,如 Haar 级联或 HOG +线性 SVM 来“扫描”图像中的条形码区域。
用 OpenCV 检测图像中的猫
原文:https://pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/

(source)
您知道 OpenCV 可以检测图像中的猫脸… 开箱即用 没有额外功能吗?
我也没有。
我不得不亲自检查一下…并做一些调查工作,看看这个 cat 检测器如何在我没有注意到的情况下偷偷溜进 OpenCV 库(就像一只猫溜进一个空的谷物盒,等待被发现)。
在这篇博文的剩余部分,我将演示如何使用 OpenCV 的 cat 检测器来检测图像中的猫脸。同样的技术也可以应用于视频流。
用 OpenCV 检测图像中的猫
如果你看一下 OpenCV 储存库,特别是在 haarcascades 目录中(OpenCV 在那里存储了所有预先训练的 Haar 分类器,以检测各种对象、身体部位等。),您会注意到两个文件:
haarcascade_frontalcatface.xmlhaarcascade_frontalcatface_extended.xml
这两种哈尔级联都可以用来检测图像中的“猫脸”。事实上,我使用了这些非常相同的级联来生成这篇博文顶部的示例图像。
做了一点调查工作,我发现 cascades 是由传奇人物 Joseph Howse 训练并贡献给 OpenCV 库的,他撰写了许多关于计算机视觉的教程、书籍和演讲。
在这篇博文的剩余部分,我将向你展示如何利用 Howse 的 Haar 级联来检测图像中的猫。
Cat 检测代码
让我们开始使用 OpenCV 检测图像中的猫。打开一个新文件,将其命名为cat_detector.py,并插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-c", "--cascade",
default="haarcascade_frontalcatface.xml",
help="path to cat detector haar cascade")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-12 行解析我们的命令行参数。这里我们只需要一个参数,输入--image,我们想用 OpenCV 检测猫的脸。
我们也可以(可选地)通过--cascade开关为我们的 Haar 级联提供一条路径。我们将默认这个路径为haarcascade_frontalcatface.xml,并假设您在的同一个目录中有haarcascade_frontalcatface.xml文件作为您的cat_detector.py脚本。
注意:我在这篇博文的“下载”部分方便地包含了代码、cat 检测器 Haar cascade 和本教程中使用的示例图像。如果您是使用 Python + OpenCV(或 Haar cascades)的新手,我建议您下载提供的。zip 文件,以便更容易理解。
接下来,让我们检测输入图像中的猫:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# load the cat detector Haar cascade, then detect cat faces
# in the input image
detector = cv2.CascadeClassifier(args["cascade"])
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
minNeighbors=10, minSize=(75, 75))
在第行第 15 和 16 行,我们从磁盘加载输入图像,并将其转换为灰度(这是将图像传递给 Haar 级联分类器之前的一个常规预处理步骤,尽管并不严格要求)。
第 20 行从磁盘加载我们的 Haar cascade(在本例中是 cat 检测器)并实例化cv2.CascadeClassifier对象。
通过调用detector对象的detectMultiScale方法,在的第 21 行和第 22 行上用 OpenCV 检测图像中的猫脸。我们向detectMultiScale方法传递四个参数,包括:
- 我们的图像,
gray,我们想要检测其中的猫脸。 - 检测猫脸时使用的图像金字塔中的
scaleFactor。较大的比例因子会提高检测器的速度,但会损害我们的真阳性检测精度。相反,较小的比例会减慢检测过程,但会增加真阳性检测。然而,这种较小的规模也会增加假阳性检测率。更多信息见这篇博文的 【关于哈尔喀特的笔记】 部分。 minNeighbors参数控制给定区域中被视为“猫脸”区域的最小检测边界框数量。该参数对于删除误报检测非常有帮助。- 最后,
minSize参数是不言自明的。该值确保每个检测到的边界框至少为宽 x 高像素(在本例中为 75 x 75 )。
detectMultiScale函数返回一个 4 元组列表rects。这些元组包含每个检测到的猫脸的 (x,y)-坐标和宽度和高度。
最后,让我们画一个矩形包围图像中的每只猫的脸:
# loop over the cat faces and draw a rectangle surrounding each
for (i, (x, y, w, h)) in enumerate(rects):
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
# show the detected cat faces
cv2.imshow("Cat Faces", image)
cv2.waitKey(0)
给定我们的边界框(即rects),我们在行的第 25 上逐个遍历它们。
然后我们在第 26 行的处画一个矩形包围每个猫的脸,而第 27 和 28 行的显示一个整数,计算图像中猫的数量。
最后,行 31 和 32 将输出图像显示到我们的屏幕上。
Cat 检测结果
为了测试我们的 OpenCV cat 检测器,请务必使用本文底部的 【下载】 部分下载源代码到本教程。
然后,解压缩归档文件后,您应该有以下三个文件/目录:
- 我们的 Python + OpenCV 脚本用来检测图像中的猫。
haarcascade_frontalcatface.xml:猫探测器哈尔梯级。 出于兼容性考虑,请使用提供的 Haar 级联,而不是 OpenCV 的 GitHub 库中的那个。images:我们将对其应用 cat detector cascade 的测试图像目录。
从那里,执行以下命令:
$ python cat_detector.py --image images/cat_01.jpg

Figure 1: Detecting a cat face in an image, even with parts of the cat occluded (source).
请注意,我们已经能够检测到图像中的猫脸,即使它身体的其他部分被遮挡。
让我们尝试另一个图像:
python cat_detector.py --image images/cat_02.jpg

Figure 2: A second example of detecting a cat in an image with OpenCV, this time the cat face is slightly different
这只猫的脸明显不同于另一只,因为它正在“喵”叫。在任一情况下,cat 检测器级联都能够正确地找到图像中的猫脸。
这张图片也是如此:
$ python cat_detector.py --image images/cat_03.jpg

Figure 3: Cat detection with OpenCV and Python
我们的最后一个例子演示了使用 OpenCV 和 Python 在一幅图像中检测多只猫:
$ python cat_detector.py --image images/cat_04.jpg
Figure 4: Detecting multiple cats in the same image with OpenCV (source).
请注意,Haar cascade 可能会以您不喜欢的顺序返回边界框。在这种情况下,中间的猫实际上被标记为第三只猫。您可以通过根据边界框的 (x,y)-坐标对边界框进行排序来解决这个“问题”,以获得一致的排序。
关于准确性的快速注释
值得注意的是,在.xml文件的注释部分,Joseph Howe 详细描述了猫探测器 Haar cascades 可以在实际存在人脸的地方报告猫脸。
在这种情况下,他建议同时执行人脸检测和猫检测,然后丢弃任何与人脸边界框重叠的猫边界框。
*### 关于哈尔瀑布的一个注记
保罗·维奥拉(Paul Viola)和迈克尔·琼斯(Michael Jones)于 2001 年首次发表了 使用简单特征的增强级联进行快速物体检测,这项原创工作已经成为计算机视觉领域被引用最多的论文之一。
该算法能够检测图像中的对象,而不管它们的位置和比例。也许最有趣的是,探测器可以在现代硬件上实时运行。
在他们的论文中,Viola 和 Jones 专注于训练一个人脸检测器;然而,该框架也可以用于训练任意“对象”的检测器,例如汽车、香蕉、路标等。
问题?
哈尔级联最大的问题是获得正确的detectMultiScale参数,特别是scaleFactor和minNeighbors。您很容易遇到需要逐个图像地调整这些参数的和的情况,这在使用对象检测器时非常不理想。
scaleFactor变量控制你的图像金字塔,用于检测图像中不同比例的物体。如果你的scaleFactor太大,那么你只会评估图像金字塔的几层,可能会导致你错过金字塔各层之间尺度的物体。
另一方面,如果您将scaleFactor设置得太低,那么您将评估许多金字塔层。这将有助于你检测图像中的更多对象,但它(1)使检测过程更慢,(2) 大大增加了假阳性检测率,这是 Haar cascades 众所周知的。
为了记住这一点,我们经常应用 梯度方向直方图+线性 SVM 检测 来代替。
HOG +线性 SVM 框架参数通常更容易调整——最棒的是,HOG +线性 SVM 享有小得多的假阳性检测率。唯一的缺点是更难让 HOG +线性 SVM 实时运行。
摘要
在这篇博文中,我们学习了如何使用 OpenCV 附带的默认 Haar 级联来检测图像中的猫。这些哈尔级联由 Joseph Howse 训练并贡献给 OpenCV 项目,最初是由 Kendrick Tan 在本文中引起我的注意。
虽然哈尔级联非常有用,但我们经常使用 HOG +线性 SVM,因为它更容易调整检测器参数,更重要的是,我们可以享受到低得多的假阳性检测率。
在 PyImageSearch 大师课程中,我详细介绍了如何构建定制的 HOG +线性 SVM 物体检测器来识别图像中的各种物体,包括汽车、路标和更多的 。
无论如何,我希望你喜欢这篇博文!
在你离开之前,请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在新的博客文章发表时得到通知。*
利用 OpenCV 和 Hough 圆检测图像中的圆
原文:https://pyimagesearch.com/2014/07/21/detecting-circles-images-using-opencv-hough-circles/

几天前,我收到了一封来自 PyImageSearch 读者的邮件,询问关于圆检测的问题。要点见下文:
嘿阿德里安,
喜欢你的博客。我看到了你关于检测图像中的矩形/正方形的帖子,但是我想知道,你如何使用 OpenCV 检测图像中的圆形?
谢了。
问得好。
您可能已经发现,使用 OpenCV 检测图像中的圆形比检测其他具有尖锐边缘的形状要困难得多。
但是不用担心!
在这篇博文中,我将向你展示如何使用 OpenCV 利用cv2.HoughCircles函数来检测图像中的圆形。
要学习如何用 OpenCV 检测圆,继续阅读!
cv2。霍夫圆函数
为了检测图像中的圆圈,您需要使用cv2.HoughCircles功能。这肯定不是最容易使用的功能,但只要稍加解释,我想你就会掌握它的窍门。
看看下面的函数签名:
cv2.HoughCircles(image, method, dp, minDist)
image: 8 位,单通道图像。如果使用彩色图像,请先转换为灰度图像。method: 定义检测图像中圆圈的方法。目前唯一实现的方法是cv2.HOUGH_GRADIENT,对应于袁等人的论文。dp: 该参数是累加器分辨率与图像分辨率的反比(详见 Yuen 等)。实际上,dp越大,累加器数组就越小。minDist: 被检测圆的圆心 (x,y) 坐标间的最小距离。如果minDist太小,可能会(错误地)检测到与原始圆在同一邻域的多个圆。如果minDist太大,那么一些圆圈可能根本检测不到。param1:Yuen 等人方法中用于处理边缘检测的梯度值。param2: 为cv2.HOUGH_GRADIENT方法的累加器阈值。阈值越小,检测到的圆越多(包括假圆)。阈值越大,可能返回的圆就越多。minRadius: 半径的最小尺寸(像素)。maxRadius: 半径的最大值(以像素为单位)。
如果这个方法看起来很复杂,不要担心。其实也不算太差。
但是我要说的是——准备好从一个图像到另一个图像调整参数值。minDist参数对于正确使用尤其重要。没有一个最佳的minDist值,您可能会错过一些圆,或者您可能会检测到许多错误的圆。
利用 OpenCV 和 Hough 圆检测图像中的圆
准备好应用cv2.HoughCircles功能来检测图像中的圆形了吗?
太好了。让我们跳到一些代码中:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的必要包。我们将利用 NumPy 进行数值处理,argparse用于解析命令行参数,而cv2用于 OpenCV 绑定。
然后,在第 7-9 行我们解析我们的命令行参数。我们只需要一个开关,--image,它是我们想要检测圆圈的图像的路径。
让我们继续加载图像:
# load the image, clone it for output, and then convert it to grayscale
image = cv2.imread(args["image"])
output = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
我们在第 12 行处从磁盘上下载我们的图像,并在第 13 行处创建它的副本,这样我们就可以在不破坏原始图像的情况下绘制我们检测到的圆。
正如我们将看到的,cv2.HoughCircles功能需要一个 8 位的单通道图像,所以我们将在第 14 行上从 RGB 颜色空间转换为灰度。
好了,该检测圆圈了:
# detect circles in the image
circles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT, 1.2, 100)
# ensure at least some circles were found
if circles is not None:
# convert the (x, y) coordinates and radius of the circles to integers
circles = np.round(circles[0, :]).astype("int")
# loop over the (x, y) coordinates and radius of the circles
for (x, y, r) in circles:
# draw the circle in the output image, then draw a rectangle
# corresponding to the center of the circle
cv2.circle(output, (x, y), r, (0, 255, 0), 4)
cv2.rectangle(output, (x - 5, y - 5), (x + 5, y + 5), (0, 128, 255), -1)
# show the output image
cv2.imshow("output", np.hstack([image, output]))
cv2.waitKey(0)
圆的检测由线 17 上的cv2.HoughCircles功能处理。我们传入想要检测圆的图像作为第一个参数,圆检测方法作为第二个参数(目前,cv2.cv.HOUGH_GRADIENT方法是 OpenCV 支持的唯一圆检测方法,并且在一段时间内很可能是唯一的方法),累加器值 1.5 作为第三个参数,最后是 100 像素的minDist。
对第 20 行进行检查,以确保在图像中至少找到一个圆。
然后,第 22 行处理将我们的圆从浮点 (x,y) 坐标转换成整数,允许我们在输出图像上绘制它们。
从那里,我们开始在中心 (x,y) 坐标和线 25 上的圆的半径上循环。
我们使用cv2.circle函数在线 28 上绘制实际检测到的圆,然后在线 29 上的圆的中心绘制一个矩形。
最后,行 32 和 33 显示我们的输出图像。
现在你有了——使用 OpenCV 检测图像中的圆。
但是让我们来看看一些结果。
启动一个 shell,并执行以下命令:
$ python detect_circles.py --image images/simple.png
我们从简单的东西开始,检测黑色背景上的红色圆圈:

Figure 1: Detecting a simple circle in an image using OpenCV.
还不错!我们的 Python 脚本检测到了红色的圆圈,用绿色勾勒出它的轮廓,然后在它的中心放置一个橙色的正方形。
让我们转到别的事情上来:
$ python detect_circles.py --image images/soda.png
Figure 2: Detecting the top of a soda can using circle detection with OpenCV.
同样,我们的 Python 脚本能够检测罐子的圆形区域。
现在,让我们来试试 8 圈问题。
在这个问题中,我们有一个大圆,接着是七个大圆。
由于这是一个比之前小得多的图像(我们正在检测多个圆圈),我将调整minDist为 75 像素而不是 100 像素。
Figure 3: Notice how cv2.HoughCircles failed to detect the inner-most circle.
嗯。现在看来,我们遇到了一个问题。
cv2.HoughCircles功能只能检测到圆圈中的七个,而不是所有的八个,忽略了中心的一个。
为什么会这样?
这是由于minDist参数。大外圆的中心 (x,y) 坐标与中心内圆相同,因此中心内圆被丢弃。
不幸的是,除非我们将minDist做得不合理的小,并因此产生许多“错误的”圆检测,否则没有办法解决这个问题。
摘要
在这篇博文中,我展示了如何使用 OpenCV 中的cv2.HoughCircles函数来检测图像中的圆形。
与检测图像中的正方形或矩形不同,检测圆形要困难得多,因为我们无法回答轮廓中大约有多少个点。
为了帮助我们检测图像中的圆形,OpenCV 提供了cv2.HoughCircles函数。
虽然cv2.HoughCircles方法初看起来可能很复杂,但我认为最重要的参数是minDist,或者检测圆的中心 (x,y) 坐标之间的最小距离。
如果将minDist设置得太小,最终可能会出现许多错误检测到的圆圈。另一方面,如果minDist太大,那么你可能会错过一些圆。设置这个参数肯定需要一些微调。
有问题吗?
你有关于 OpenCV 和 Python 的问题吗?给我发个信息就行了。我会尽我所能在这个博客上回答这个问题。
利用 Keras、TensorFlow 和深度学习检测 X 射线图像中的新冠肺炎

In this tutorial, you will learn how to automatically detect COVID-19 in a hand-created X-ray image dataset using Keras, TensorFlow, and Deep Learning.
像现在世界上大多数人一样,我真的很担心新冠肺炎。我发现自己不断地分析自己的健康状况,想知道自己是否/何时会感染。
我越担心它,它就越变成一场合法症状与疑病症相结合的痛苦心理游戏:
- 我今天早上醒来觉得有点疼,就倒下了。
- 当我从床上爬起来时,我注意到我在流鼻涕(尽管现在报道流鼻涕是而不是新冠肺炎的症状)。
- 当我去洗手间拿纸巾的时候,我也在咳嗽。
起初,我并没有把它放在心上 — 我对花粉过敏,而且由于美国东海岸的温暖天气,今年的春天来得很早。我的过敏症可能只是发作了。
但是我的症状一整天都没有改善。
实际上,我正坐在这里,嘴里含着温度计,写着这个教程。低头一看,我看到它的读数是华氏 99.4 度。
我的体温比大多数人都要低,通常在华氏 97.4 度左右。任何高于 99 F 的对我来说都是低烧。
咳嗽低烧?可能是新冠肺炎……也可能只是我过敏。
不经过测试是不可能知道的,而从人类的本能层面来看,“不知道”正是这种情况如此可怕的原因。
作为人类,没有什么比未知更可怕的了。
尽管我焦虑不安,但我试图用理性来消除它们。我 30 出头,身材很好,免疫系统很强。我会隔离自己(以防万一),好好休息,度过难关 — 从我自己个人健康的角度来看,新冠肺炎并不会吓到我(至少我一直这么告诉自己)。
也就是说,我很担心我的年长亲戚,包括任何已经患有疾病的人,或者那些在疗养院或医院的人。他们很脆弱,看着他们因为新冠肺炎而离开真的是毁灭性的。
我没有无所事事,也没有让任何困扰我的事情让我沮丧(无论是过敏、新冠肺炎还是我自己的个人焦虑),我决定做我最擅长的事情 — 通过 专注于整个 CV/DL 社区,编写代码,进行实验,并教育其他人如何在实际的现实世界应用中使用计算机视觉和深度学习。
说实话,这是我写过的最科学的文章。事实上,远非如此。所使用的方法和数据集将而不是值得出版。但是对于那些需要感觉自己在做一些事情来帮助别人的人来说,它们是一个起点。
我关心你,也关心这个社区。我想尽我所能帮助——这篇博客是我在精神上处理困难时期的一种方式,,同时帮助处于类似情况的其他人。
我希望你也这样认为。
在今天的教程中,您将学习如何:
- 对新冠肺炎病毒检测呈阳性的患者的 X 射线图像的开源数据集进行采样
- 来自健康患者的“正常”(即未感染)X 射线图像样本
- 通过我们创建的数据集,训练 CNN 自动检测 X 射线图像中的新冠肺炎
- 从教育的角度评估结果
免责声明:我已经暗示过这一点,但我将在这里明确地说出来。本文中使用的方法和技术仅用于教育目的。这不是科学严谨的研究,也不会发表在杂志上。这篇文章是为那些对(1)计算机视觉/深度学习感兴趣,并希望通过实用的动手方法学习,以及(2)受当前事件启发的读者写的。我恳请你如此对待它。
要了解如何使用 Keras、TensorFlow 和深度学习来检测 X 射线图像中的新冠肺炎,请继续阅读!
利用 Keras、TensorFlow 和深度学习检测 X 射线图像中的新冠肺炎
在本教程的第一部分,我们将讨论如何在病人的胸部 x 光片中检测出新冠肺炎。
从那里,我们将回顾我们的新冠肺炎胸部 x 光数据集。
然后,我将向您展示如何使用 Keras 和 TensorFlow 来训练深度学习模型,以预测我们图像数据集中的新冠肺炎。
放弃
这篇关于自动新冠肺炎检测的博文仅用于教育目的。它不是 T2 想要的可靠、高度精确的新冠肺炎诊断系统,也没有经过专业或学术审查。
我的目标只是启发你,让你看到学习计算机视觉/深度学习,然后将这些知识应用到医学领域,可以对世界产生巨大影响。
简单来说:你不需要医学学位就可以在医学领域产生影响 — 深度学习实践者与医生和医疗专业人士密切合作,可以解决复杂的问题,拯救生命,让世界变得更美好。
我希望这篇教程能启发你这样做。
但尽管如此,研究人员、期刊管理者和同行评审系统正被质量可疑的新冠肺炎预测模型所淹没。请不要从这篇文章中提取代码/模型并提交给期刊或开放科学——你只会增加噪音。
此外,如果你打算利用这篇文章(或你在网上找到的任何其他新冠肺炎文章)进行研究,确保你参考了关于报告预测模型的 TRIPOD 指南。
正如你可能意识到的,应用于医学领域的人工智能会产生非常真实的后果。如果您是医学专家,或者与医学专家有密切联系,请仅发布或部署此类模型。
如何在 x 光图像中发现新冠肺炎?
Figure 1: Example of an X-ray image taken from a patient with a positive test for COVID-19. Using X-ray images we can train a machine learning classifier to detect COVID-19 using Keras and TensorFlow.
新冠肺炎测试目前很难获得————数量根本不够而且生产速度也不够快,这引起了恐慌。
当出现恐慌时,就会有邪恶的人伺机利用他人,即在在社交媒体平台和聊天应用程序上找到受害者后出售假冒的新冠肺炎检测试剂盒。
鉴于新冠肺炎检测试剂盒有限,我们需要依靠其他诊断方法。
出于本教程的目的,我想探索 X 射线图像,因为医生经常使用 X 射线和 CT 扫描来诊断肺炎、肺部炎症、脓肿和/或肿大的淋巴结。
由于新冠肺炎攻击我们呼吸道的上皮细胞,我们可以使用 X 射线来分析患者肺部的健康状况。
鉴于几乎所有的医院都有 X 射线成像设备,使用 X 射线来检测新冠肺炎病毒而不需要专用的检测工具是可能的。
一个缺点是 X 射线分析需要放射学专家,并且花费大量时间——当世界各地的人们生病时,这些时间是宝贵的。因此,需要开发一种自动化分析系统来节省医疗专业人员的宝贵时间。
注: 有更新的出版物提出 CT 扫描更适合诊断新冠肺炎,但我们在本教程中所要做的只是一个 X 射线图像数据集。第二,我不是医学专家,我认为除了专用的检测试剂盒之外,还有其他更可靠的方法可以让医生和医学专家检测新冠肺炎病毒。
我们的新冠肺炎患者 X 射线图像数据集
Figure 2: CoronaVirus (COVID-19) chest X-ray image data. On the left we have positive (i.e., infected) X-ray images, whereas on the right we have negative samples. These images are used to train a deep learning model with TensorFlow and Keras to automatically predict whether a patient has COVID-19 (i.e., coronavirus).
我们将在本教程中使用的新冠肺炎 X 射线图像数据集由蒙特利尔大学的博士后 Joseph Cohen 博士管理。
一周前,科恩博士开始收集新冠肺炎病例的 x 光图像,并在 GitHub repo 之后的中发表。
在回购中,你会发现新冠肺炎病例的例子,以及中东呼吸综合征,非典和急性呼吸窘迫综合征。
为了创建本教程的新冠肺炎 X 射线图像数据集,我:
- 解析了在科恩博士的知识库中找到的
metadata.csv文件。 - 选择所有符合以下条件的行:
- 新冠肺炎阳性(即忽略 MERS、SARS 和 ARDS 病例)。
- 肺的后前(PA)视图。我使用 PA 视图,据我所知,这是用于我的“健康”案例的视图,如下所述;然而,我确信如果我说错了(我很可能是错的,这只是一个例子),医学专家将会澄清并纠正我。
总共,这给我留下了 25 张阳性新冠肺炎病例的 x 光照片。
下一步是采集健康的患者的 x 光图像样本。
为此,我使用了 Kaggle 的胸部 x 光图像(肺炎)数据集,并从健康患者 ( 图 2 ,右)中采样了的 25 张 x 光图像。Kaggle 的胸部 X 射线数据集有许多问题,即噪音/错误的标签,但它是这种概念验证新冠肺炎探测器的一个足够好的起点。
在收集了我的数据集之后,我剩下了总共 50 张图像,其中 25 张是新冠肺炎阳性 x 光图像,25 张是健康患者 x 光图像。
我已经在本教程的“下载”部分包含了我的样本数据集,所以您不必重新创建它。
此外,我还在下载中包含了用于生成数据集的 Python 脚本,但这些脚本不在本文讨论范围之内,因此不在本教程中讨论。
项目结构
继续从本教程的 “下载” 部分获取今天的代码和数据。从那里,提取文件,您将看到以下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── covid [25 entries]
│ └── normal [25 entries]
├── build_covid_dataset.py
├── sample_kaggle_dataset.py
├── train_covid19.py
├── plot.png
└── covid19.model
3 directories, 5 files
我们的冠状病毒(新冠肺炎)胸部 x 光数据在dataset/目录中,我们的两类数据被分为covid/和normal/。
我的两个数据集构建脚本都提供了;但是,我们今天不会复习它们。
相反,我们将回顾训练我们的新冠肺炎探测器的train_covid19.py脚本。
让我们开始工作吧!
使用 Keras 和 TensorFlow 实现我们的新冠肺炎培训脚本
现在,我们已经查看了我们的图像数据集以及我们项目的相应目录结构,让我们继续微调卷积神经网络,以使用 Keras、TensorFlow 和深度学习自动诊断新冠肺炎。
打开目录结构中的train_covid19.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import os
该脚本通过选择tensorflow.keras导入来利用 TensorFlow 2.0 和 Keras 深度学习库。
此外,我们使用 scikit-learn 、事实上的 Python 库用于机器学习、 matplotlib 用于绘图,以及 OpenCV 用于加载和预处理数据集中的图像。
要了解如何安装 TensorFlow 2.0(包括相关的 scikit-learn、OpenCV 和 matplotlib 库),只需遵循我的 Ubuntu 或 macOS 指南。
导入完成后,接下来我们将解析命令行参数并初始化超参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
ap.add_argument("-m", "--model", type=str, default="covid19.model",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
# initialize the initial learning rate, number of epochs to train for,
# and batch size
INIT_LR = 1e-3
EPOCHS = 25
BS = 8
我们的三个命令行参数 ( 第 24-31 行)包括:
--dataset:胸部 x 光图像输入数据集的路径。--plot:输出训练历史图的可选路径。默认情况下,该图被命名为plot.png,除非命令行另有规定。--model:我们输出新冠肺炎模型的可选路径;默认情况下,它将被命名为covid19.model。
从那里,我们初始化我们的初始学习率、训练时期数和批量超参数(第 35-37 行)。
我们现在准备加载和预处理 X 射线数据:
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the image, swap color channels, and resize it to be a fixed
# 224x224 pixels while ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
# convert the data and labels to NumPy arrays while scaling the pixel
# intensities to the range [0, 1]
data = np.array(data) / 255.0
labels = np.array(labels)
为了加载我们的数据,我们在--dataset目录中获取图像的所有路径(行 42 )。然后,对于每个imagePath,我们:
- 从路径(行 49 )中提取类
label(或者covid或者normal)。 - 加载
image,并通过转换为 RGB 通道排序对其进行预处理,并将其调整为 224×224 像素,以便为我们的卷积神经网络做好准备( 行 53-55 )。 - 更新我们的
data和labels列表分别( 第 58 行和第 59 行 )。
然后,我们将像素强度缩放到范围【0,1】,并将我们的data和labels转换为 NumPy 数组格式(第 63 行和第 64 行)。
接下来,我们将对labels进行一次性编码,并创建我们的培训/测试分割:
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.20, stratify=labels, random_state=42)
# initialize the training data augmentation object
trainAug = ImageDataGenerator(
rotation_range=15,
fill_mode="nearest")
labels的一次性编码发生在的第 67-69 行,这意味着我们的数据将采用以下格式:
[[0\. 1.]
[0\. 1.]
[0\. 1.]
...
[1\. 0.]
[1\. 0.]
[1\. 0.]]
每个编码标签由两个元素的数组组成,其中一个元素是“热”(即1)而不是“非”(即0)。
第 73 行和第 74 行然后构建我们的数据分割,保留 80%的数据用于训练,20%用于测试。
为了确保我们的模型一般化,我们通过将随机图像旋转设置为顺时针或逆时针 15 度来执行数据扩充。
第 77-79 行初始化数据扩充生成器对象。
从这里,我们将初始化我们的 VGGNet 模型,并为微调设置它:
# load the VGG16 network, ensuring the head FC layer sets are left
# off
baseModel = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(4, 4))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(64, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers:
layer.trainable = False
第 83 行和第 84 行用 ImageNet 上预先训练的权重实例化 VGG16 网络,去掉了 FC 层头。
从那里,我们构建一个新的全连接层头,它由POOL => FC = SOFTMAX层(行 88-93 )组成,并将其附加到 VGG16 ( 行 97 )的顶部。
然后我们冻结 VGG16 的CONV权重,这样只有层头会被训练(第 101-102 行);这就完成了我们的微调设置。
我们现在准备编译和训练我们的新冠肺炎(冠状病毒)深度学习模型:
# compile our model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
H = model.fit_generator(
trainAug.flow(trainX, trainY, batch_size=BS),
steps_per_epoch=len(trainX) // BS,
validation_data=(testX, testY),
validation_steps=len(testX) // BS,
epochs=EPOCHS)
第 106-108 行用学习速率衰减和Adam优化器编译网络。鉴于这是一个 2 类问题,我们使用"binary_crossentropy"损失而不是分类交叉熵。
为了启动我们的新冠肺炎神经网络训练过程,我们调用了 Keras 的 fit_generator 方法,,同时通过我们的数据增强对象(第 112-117 行)传入我们的胸部 X 射线数据。
接下来,我们将评估我们的模型:
# make predictions on the testing set
print("[INFO] evaluating network...")
predIdxs = model.predict(testX, batch_size=BS)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testY.argmax(axis=1), predIdxs,
target_names=lb.classes_))
为了进行评估,我们首先对测试集进行预测,并获取预测指数(第 121-125 行)。
然后,我们使用 scikit-learn 的助手实用程序生成并打印一份分类报告(第 128 行和第 129 行)。
接下来,我们将为进一步的统计评估计算混淆矩阵:
# compute the confusion matrix and and use it to derive the raw
# accuracy, sensitivity, and specificity
cm = confusion_matrix(testY.argmax(axis=1), predIdxs)
total = sum(sum(cm))
acc = (cm[0, 0] + cm[1, 1]) / total
sensitivity = cm[0, 0] / (cm[0, 0] + cm[0, 1])
specificity = cm[1, 1] / (cm[1, 0] + cm[1, 1])
# show the confusion matrix, accuracy, sensitivity, and specificity
print(cm)
print("acc: {:.4f}".format(acc))
print("sensitivity: {:.4f}".format(sensitivity))
print("specificity: {:.4f}".format(specificity))
在这里我们:
- 生成混淆矩阵(行 133 )
- 使用混淆矩阵得出准确性、敏感性和特异性(第 135-137 行),并打印这些指标(第 141-143 行)
然后,我们绘制我们的训练准确度/损失历史以供检查,将该图输出到图像文件:
# plot the training loss and accuracy
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on COVID-19 Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
最后,我们将我们的tf.keras新冠肺炎分类器模型序列化到磁盘:
# serialize the model to disk
print("[INFO] saving COVID-19 detector model...")
model.save(args["model"], save_format="h5")
用 Keras 和 TensorFlow 训练我们的新冠肺炎检测器
随着我们的train_covid19.py脚本的实现,我们现在准备训练我们的自动新冠肺炎检测器。
确保使用本教程的 “下载” 部分下载源代码、新冠肺炎 X 射线数据集和预训练模型。
从那里,打开一个终端并执行以下命令来训练新冠肺炎检测器:
$ python train_covid19.py --dataset dataset
[INFO] loading images...
[INFO] compiling model...
[INFO] training head...
Epoch 1/25
5/5 [==============================] - 20s 4s/step - loss: 0.7169 - accuracy: 0.6000 - val_loss: 0.6590 - val_accuracy: 0.5000
Epoch 2/25
5/5 [==============================] - 0s 86ms/step - loss: 0.8088 - accuracy: 0.4250 - val_loss: 0.6112 - val_accuracy: 0.9000
Epoch 3/25
5/5 [==============================] - 0s 99ms/step - loss: 0.6809 - accuracy: 0.5500 - val_loss: 0.6054 - val_accuracy: 0.5000
Epoch 4/25
5/5 [==============================] - 1s 100ms/step - loss: 0.6723 - accuracy: 0.6000 - val_loss: 0.5771 - val_accuracy: 0.6000
...
Epoch 22/25
5/5 [==============================] - 0s 99ms/step - loss: 0.3271 - accuracy: 0.9250 - val_loss: 0.2902 - val_accuracy: 0.9000
Epoch 23/25
5/5 [==============================] - 0s 99ms/step - loss: 0.3634 - accuracy: 0.9250 - val_loss: 0.2690 - val_accuracy: 0.9000
Epoch 24/25
5/5 [==============================] - 27s 5s/step - loss: 0.3175 - accuracy: 0.9250 - val_loss: 0.2395 - val_accuracy: 0.9000
Epoch 25/25
5/5 [==============================] - 1s 101ms/step - loss: 0.3655 - accuracy: 0.8250 - val_loss: 0.2522 - val_accuracy: 0.9000
[INFO] evaluating network...
precision recall f1-score support
covid 0.83 1.00 0.91 5
normal 1.00 0.80 0.89 5
accuracy 0.90 10
macro avg 0.92 0.90 0.90 10
weighted avg 0.92 0.90 0.90 10
[[5 0]
[1 4]]
acc: 0.9000
sensitivity: 1.0000
specificity: 0.8000
[INFO] saving COVID-19 detector model...
根据 X 射线图像结果进行自动新冠肺炎诊断
免责声明:以下章节不主张,也不打算“解决”,新冠肺炎检测。它是根据本教程的上下文和结果编写的。这是初露头角的计算机视觉和深度学习从业者的一个例子,这样他们就可以了解各种指标,包括原始准确性、灵敏度和特异性(以及我们在医疗应用中必须考虑的权衡)。再次声明,本节/教程并没有宣称*可以解决新冠肺炎检测。*
正如您从上面的结果中看到的,我们的自动新冠肺炎检测器在我们的样本数据集上获得了 ~90-92%的准确率,该数据集仅基于X 射线图像 — 没有其他数据,包括地理位置、人口密度等。用来训练这个模型。
*我们还获得了 100%的灵敏度和 80%的特异性,这意味着:
- 在患有新冠肺炎(即,真阳性)的患者中,我们可以使用我们的模型 100%准确地将他们识别为“新冠肺炎阳性”。
- 在没有新冠肺炎(即,真阴性)的患者中,使用我们的模型,我们只能在 80%的时间内将他们准确识别为“新冠肺炎阴性”。
正如我们的训练历史图所示,尽管的训练数据非常有限,但我们的网络并没有过度拟合:
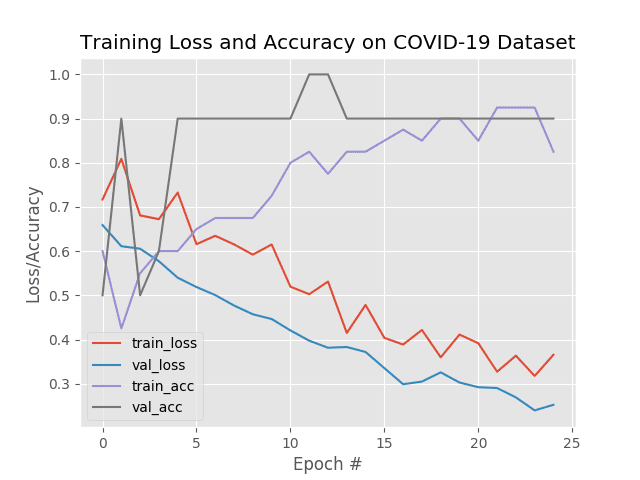
Figure 3: This deep learning training history plot showing accuracy and loss curves demonstrates that our model is not overfitting despite limited COVID-19 X-ray training data used in our Keras/TensorFlow model.
能够以 100%的准确率准确检测新冠肺炎是很棒的;然而,我们的真实阴性率有点涉及 — 我们不想把某人归类为、【新冠肺炎阴性】、,当他们是、【新冠肺炎阳性】。
事实上,我们想做的最后一件事是告诉病人他们是新冠肺炎阴性,然后让他们回家并感染他们的家人和朋友;从而进一步传播疾病。
我们还希望对我们的假阳性率——非常小心。我们不想错误地将某人归类为【新冠肺炎阳性】,将他们与其他新冠肺炎阳性患者隔离,然后感染一个实际上从未感染过病毒的人。
在医疗应用方面,平衡灵敏度和特异性是非常具有挑战性的,,,尤其是像新冠肺炎这样可以快速传播的传染病。
谈到医学计算机视觉和深度学习,我们必须时刻注意这样一个事实,即我们的预测模型可能会产生非常真实的后果——*一次漏诊可能会导致生命损失。
同样,收集这些结果只是为了教育目的。这篇文章和附带的结果是而非旨在成为一篇期刊文章,也不符合关于报告预测模型的 TRIPOD 指南。如果你对此感兴趣,我建议你参考这些指南以获取更多信息。
局限性、改进和未来工作

Figure 4: Currently, artificial intelligence (AI) experts and deep learning practitioners are suffering from a lack of quality COVID-19 data to effectively train automatic image-based detection systems. (image source)
本教程中讨论的方法的最大限制之一是数据。
我们根本没有足够(可靠)的数据来训练新冠肺炎探测器。
医院已经不堪新冠肺炎病例的数量,考虑到患者的权利和保密性,及时收集高质量的医学图像数据集变得更加困难。
我想象在接下来的 12-18 个月里,我们会有更多高质量的新冠肺炎图像数据集;但目前我们只能凑合着用现有的。
鉴于我有限的时间和资源,我已经尽我所能(鉴于我目前的精神状态和身体健康状况)为我的读者整理了一份教程,这些读者有兴趣将计算机视觉和深度学习应用于新冠肺炎疫情;然而,我必须提醒你,我是受过训练的医学专家,而不是 T2。
对于部署在现场的新冠肺炎探测器,它必须经过训练有素的医疗专业人员的严格测试,并与专业的深度学习实践者携手合作。今天这里介绍的方法当然是而不是这样的方法,并且仅仅是为了教育的目的。
此外,我们需要关心模型实际上在“学习”什么。
正如我在上周的 Grad-CAM 教程的中所讨论的,我们的模型可能正在学习与新冠肺炎不相关的模式,而只是两个数据分割之间的变化(即,阳性与阴性新冠肺炎诊断)。
需要训练有素的医疗专业人员和严格的测试来验证我们的新冠肺炎检测器得出的结果。
最后,未来(更好)的新冠肺炎探测器将是多模态的。
目前,我们仅使用的图像数据(即 X 射线) — 更好的自动新冠肺炎检测器应利用多种数据源,而不仅限于的图像,包括患者生命体征、人口密度、地理位置等。图像数据本身通常不足以满足这些类型的应用。
出于这些原因,我必须再次强调,本教程仅用于教育目的—它不是打算成为一个强大的新冠肺炎探测器。
如果你认为你自己或你所爱的人患有新冠肺炎病毒,你应该遵循由疾病控制中心(CDC) 、世界卫生组织(世卫组织)或当地国家、州或司法管辖区制定的协议。
我希望你喜欢这个教程,并发现它的教育意义。我也希望这篇教程可以作为任何对将计算机视觉和深度学习应用于自动新冠肺炎检测感兴趣的人的起点。
下一步是什么?
我通常会通过推荐我的一本书/课程来结束我的博客帖子,以便您可以了解更多关于将计算机视觉和深度学习应用到您自己的项目中的信息。出于对冠状病毒严重性的尊重,我不打算这么做——此时此地不合适。
相反,我要说的是,我们现在正处于人生中一个非常可怕的时期。
像所有季节一样,它将会过去,但我们需要蹲下身子,为寒冷的冬天做准备——最糟糕的情况可能还没有到来。
坦率地说,我感到难以置信的沮丧和孤立。我明白了:
- 股票市场暴跌。
- 封锁边境的国家。
- 大型体育赛事被取消。
- 一些世界上最受欢迎的乐队推迟了他们的巡演。
- 在当地,我最喜欢的餐馆和咖啡店都关门了。
以上都是宏观层面的— 但是微观层面的呢?
作为个体的我们又如何呢?
太容易陷入全球统计数据中。
我们看到的数字是 6000 人死亡,160000 例确诊病例(由于缺乏新冠肺炎检测试剂盒,一些人选择自我隔离,因此可能会多几个数量级)。
当我们用这些术语思考时,我们就看不到自己和我们所爱的人。我们需要日复一日地对待事情。我们需要在个人层面上考虑我们自己的心理健康和理智。我们需要可以撤退的安全空间。
当我 5 年前开始 PyImageSearch 时,我知道这将是一个安全的空间。我为 PyImageSearch 后来的发展树立了榜样,直到今天我依然如此。为此,我不允许任何形式的骚扰,包括但不限于种族主义、性别歧视、仇外心理、精英主义、欺凌等。
PyImageSearch 社区很特别。这里的人尊重他人——如果他们不尊重,我就把他们赶走。
当我跑 PyImageConf 2018 时,我最喜欢的善良、接受和利他的人性表现之一出现了——与会者被会议的友好和热情所淹没。
软件工程师 Dave Snowdon 和 PyImageConf 与会者说:
毫无疑问,PyImageConf 是我参加过的最友好、最受欢迎的会议。技术含量也很高!很荣幸见到一些人,并向他们学习,他们贡献了自己的时间来构建我们工作(和娱乐)所依赖的工具。
工程学博士、弗吉尼亚联邦大学教授大卫斯通分享了以下内容:
感谢您整理 PyImageConf。我也同意这是我参加过的最友好的会议。
我为什么要说这些?
因为我知道你现在可能很害怕。
我知道你可能已经穷途末路了(相信我,我也是)。
最重要的是,因为我想让 PyImageSearch 成为你的安全空间。
- 你可能是一个学期提前结束后从学校回家的学生,对你的教育被搁置感到失望。
- 你可能是一名开发人员,在你的工作场所在可预见的未来关上大门后,你完全迷失了。
- 你可能是一名研究人员,因为无法继续你的实验和撰写那篇小说论文而感到沮丧。
- 你可能是一位家长,试图兼顾两个孩子和一个强制性的“在家工作”的要求,但没有成功。
或者,你可能像我一样——只是试图通过学习一项新技能、算法或技术来度过一天。
我收到了许多来自 PyImageSearch 读者的电子邮件,他们想利用这段时间研究计算机视觉和深度学习,而不是在家里发疯。
我尊重这一点,也想提供帮助,在某种程度上,我认为尽我所能提供帮助是我的道德义务:
- 首先,你可以在 PyImageSearch 博客上学习超过 350 个免费教程。美国东部时间每周一上午 10 点,我会发布一个新的教程。
- 我已经在我的 【入门】 页面上对这些教程进行了分类、交叉引用和编译。
- 在【入门】页面上最受欢迎的话题包括 【深度学习】【人脸应用】 。
所有这些指南都是 100%免费的。用它们来学习和借鉴。
也就是说,许多读者也要求我出售我的书和课程。起初,我对此有点犹豫——我最不想做的事情是让人们认为我在以某种方式利用冠状病毒来“赚钱”。
但事实是,作为一个小企业主,不仅要对我自己和我的家人负责,还要对我队友的生活和家人负责,有时会令人恐惧和不知所措——人们的生活,包括小企业,将被这种病毒摧毁。
为此,就像:
- 乐队和表演者正在提供打折的“仅在线”表演
- 餐馆提供送货上门服务
- 健身教练在网上提供培训课程
…我会照着做。
从明天开始,我将在 PyImageSearch 上销售图书。这次销售不是的盈利目的,当然也不是计划好的(我整个周末都在生病,试图把这些放在一起)。
相反,这是为了帮助像我这样的人(也许就像你 T2 一样),他们在混乱中努力寻找自己的安全空间。让我自己和 PyImageSearch 成为你的退路。
我通常每年只进行一次大拍卖(黑色星期五),但考虑到有多少人要求,我相信这是我需要为那些想利用这段时间学习和/或从世界其他地方转移注意力的人做的事情。
随意加入或不加入。完全没问题。我们都以自己的方式处理这些艰难的时刻。
但是,如果你需要休息,如果你需要一个避风港,如果你需要通过教育撤退——我会在这里。
谢谢,注意安全。
摘要
在本教程中,您学习了如何使用 Keras、TensorFlow 和深度学习在 X 射线图像数据集上训练自动新冠肺炎检测器。
(目前)还没有高质量的、经过同行评审的新冠肺炎影像数据集,所以我们不得不利用现有的资料,即 Joseph Cohen 的 GitHub repo 的开源 X 射线影像:
- 我们从 Cohen 的数据集中采样了 25 幅图像,仅取新冠肺炎阳性病例的后前(PA)视图。
- 然后我们使用 Kaggle 的胸部 x 光图像(肺炎)数据集对 25 个健康患者的图像进行采样。
在那里,我们使用 Keras 和 TensorFlow 来训练新冠肺炎检测器,该检测器能够在我们的测试集上获得 90-92%的准确性,具有 100%的灵敏度和 80%的特异性(给定我们有限的数据集)。
请记住,本教程中涉及的新冠肺炎探测器仅用于 教育目的(参考我在本教程顶部的“免责声明”)。 我的目标是激励深度学习的实践者,比如你自己,并睁开眼睛看看深度学习和计算机视觉如何能够对世界产生大影响。
我希望你喜欢这篇博文。
要下载这篇文章的源代码(包括预先训练的新冠肺炎诊断模型),*只需在下面的表格中输入您的电子邮件地址!***
用 OpenCV、scikit-image 和 Python 检测低对比度图像
在本教程中,您将学习如何使用 OpenCV 和 scikit-image 检测低对比度图像。
每当我给渴望学习的学生讲授计算机视觉和图像处理的基础知识时,我教的第件事之一就是:
“为在受控光照条件下拍摄的图像编写代码,比在没有保证的动态条件下容易得多。
如果你能够控制环境,最重要的是,当你捕捉图像时,能够控制光线,那么编写处理图像的代码就越容易。
在受控的照明条件下,您可以对参数进行硬编码,包括:
- 模糊量
- 边缘检测界限
- 阈值限制
- 等等。
本质上,受控条件允许你利用你对环境的先验知识,然后编写代码来处理特定的环境,而不是试图处理每一个边缘情况或条件。
当然,控制你的环境和照明条件并不总是可能的…
…那你会怎么做?
你尝试过编码一个超级复杂的图像处理管道来处理每一个边缘情况吗?
嗯……你可以这么做——可能会浪费几周或几个月的时间,而且仍然可能无法捕捉到所有的边缘情况。
或者,当低质量图像,特别是低对比度图像出现在您的管道中时,您可以改为检测。
如果检测到低对比度图像,您可以丢弃图像或提醒用户在更好的照明条件下捕捉图像。
这样做将使您更容易开发图像处理管道(并减少您的麻烦)。
要了解如何使用 OpenCV 和 scikit-image 检测低对比度图像,请继续阅读。
使用 OpenCV、scikit-image 和 Python 检测低对比度图像
在本教程的第一部分,我们将讨论什么是低对比度图像,它们给计算机视觉/图像处理从业者带来的问题,以及我们如何以编程方式检测这些图像。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
回顾了我们的项目结构后,我们将继续编写两个 Python 脚本:
- 一种用于检测静态图像中的低对比度
- 另一个用于检测实时视频流中的低对比度帧
我们将讨论我们的结果来结束我们的教程。
低对比度图像/帧会产生什么问题?我们怎样才能发现它们?
低对比度图像的亮区和暗区差别很小,很难看出物体的边界和场景的背景从哪里开始。
在图 1 (左图)中显示了一个低对比度图像的示例。 这里你可以看到一个背景上的颜色匹配/校正卡。由于照明条件差(即光线不足),卡片相对于背景的边界没有被很好地定义-就其本身而言,边缘检测算法,如 Canny 边缘检测器,可能难以检测卡片的边界,尤其是如果 Canny 边缘检测器参数是硬编码的。
图 1 (右) 显示“正常对比度”的示例图像。由于更好的照明条件,我们在这张图像中有更多的细节。请注意,颜色匹配卡的白色与背景形成了充分的对比——对于图像处理管道来说,更容易检测颜色匹配卡的边缘(与右侧的图像相比)。**
每当你处理计算机视觉或图像处理问题时,总是从捕捉图像/帧的环境开始。 你越能控制和保证光线条件,就越容易一次你就有时间编写代码来处理场景。
然而,有时你无法控制照明条件和你硬编码到管道中的任何参数(例如模糊尺寸、阈值限制、Canny 边缘检测参数等。)可能导致不正确/不可用的输出。
当这种情况不可避免地发生时,不要放弃。并且当然不会开始进入编码复杂图像处理管道的兔子洞去处理每一个边缘情况。
相反,利用低对比度图像检测。
使用低对比度图像检测,您可以以编程方式检测不足以用于图像处理管道的图像。
在本教程的剩余部分,您将学习如何检测静态场景和实时视频流中的低对比度图像。
我们将丢弃低对比度和不适合我们管道的图像/帧,同时只保留我们知道会产生有用结果的图像/帧。
本指南结束时,您将对低对比度图像检测有一个很好的了解,并且能够将其应用到您自己的项目中,从而使您自己的管道更容易开发,在生产中更稳定。
配置您的开发环境
为了检测低对比度图像,您需要安装 OpenCV 库以及 scikit-image 。
幸运的是,这两个都是 pip 可安装的:
$ pip install opencv-contrib-python
$ pip install scikit-image
如果您需要帮助配置 OpenCV 和 scikit-image 的开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们深入了解本指南之前,让我们花点时间来检查一下我们的项目目录结构。
首先使用本教程的 “下载” 部分下载源代码、示例图像和示例视频:
$ tree . --dirsfirst
.
├── examples
│ ├── 01.jpg
│ ├── 02.jpg
│ └── 03.jpg
├── detect_low_contrast_image.py
├── detect_low_contrast_video.py
└── example_video.mp4
1 directory, 6 files
我们今天要复习两个 Python 脚本:
detect_low_contrast_image.py:对静态图像(即examples目录下的图像)进行低对比度检测detect_low_contrast_video.py:对实时视频流(本例中为example_video.mp4)进行低对比度检测
当然,如果你认为合适的话,你可以用你自己的图像和视频文件/流来代替。
用 OpenCV 实现低对比度图像检测
让我们学习如何使用 OpenCV 和 scikit-image 检测低对比度图像!
打开项目目录结构中的detect_low_contrast_image.py文件,并插入以下代码。
# import the necessary packages
from skimage.exposure import is_low_contrast
from imutils.paths import list_images
import argparse
import imutils
import cv2
我们从第 2-6 行的开始,导入我们需要的 Python 包。
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of images")
ap.add_argument("-t", "--thresh", type=float, default=0.35,
help="threshold for low contrast")
args = vars(ap.parse_args())
我们有两个命令行参数,第一个是必需的,第二个是可选的:
--input:驻留在磁盘上的输入图像的路径--thresh:低对比度的阈值
我已经将--thresh参数设置为默认值0.35,这意味着“当亮度范围小于其数据类型全部范围的一小部分时” ( 官方 scikit-image 文档),图像将被视为低对比度。
本质上,这意味着如果亮度范围的 35%以下占据了数据类型的全部范围,则图像被认为是低对比度的。
为了使这成为一个具体的例子,考虑 OpenCV 中的图像由一个无符号的 8 位整数表示,该整数的取值范围为 [0,255】。如果像素强度分布占据的小于该【0,255】范围的 35%,则图像被视为低对比度。
# grab the paths to the input images
imagePaths = sorted(list(list_images(args["input"])))
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the input image from disk, resize it, and convert it to
# grayscale
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
image = cv2.imread(imagePath)
image = imutils.resize(image, width=450)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# blur the image slightly and perform edge detection
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 30, 150)
# initialize the text and color to indicate that the input image
# is *not* low contrast
text = "Low contrast: No"
color = (0, 255, 0)
- 从磁盘加载
image - 将其宽度调整为 450 像素
- 将图像转换为灰度
从那里,我们应用模糊(以减少高频噪声),然后应用 Canny 边缘检测器(行 30 和 31 )来检测输入图像中的边缘。
# check to see if the image is low contrast
if is_low_contrast(gray, fraction_threshold=args["thresh"]):
# update the text and color
text = "Low contrast: Yes"
color = (0, 0, 255)
# otherwise, the image is *not* low contrast, so we can continue
# processing it
else:
# find contours in the edge map and find the largest one,
# which we'll assume is the outline of our color correction
# card
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
# draw the largest contour on the image
cv2.drawContours(image, [c], -1, (0, 255, 0), 2)
# draw the text on the output image
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
color, 2)
# show the output image and edge map
cv2.imshow("Image", image)
cv2.imshow("Edge", edged)
cv2.waitKey(0)
否则,图像是而不是低对比度,所以我们可以继续我们的图像处理流水线(第 46-56 行)。在这个代码块中,我们:
- 在我们的边缘地图中寻找轮廓
- 在我们的
cnts列表中找到最大的轮廓(我们假设它将是我们在输入图像中的卡片) - 在图像上画出卡片的轮廓
最后,我们在image上绘制text,并在屏幕上显示image和边缘图。
低对比度图像检测结果
现在让我们将低对比度图像检测应用于我们自己的图像!
首先使用本教程的 【下载】 部分下载源代码和示例图像:
$ python detect_low_contrast_image.py --input examples
[INFO] processing image 1/3
[INFO] processing image 2/3
[INFO] processing image 3/3
我们这里的第一个图像被标记为“低对比度”。如你所见,将 Canny 边缘检测器应用于低对比度图像导致我们无法检测图像中的卡片轮廓。
如果我们试图进一步处理这个图像并检测卡片本身,我们最终会检测到其他轮廓。相反,通过应用低对比度检测,我们可以简单地忽略图像。
我们的第二个图像具有足够的对比度,因此,我们能够精确地计算边缘图并提取与卡片轮廓相关联的轮廓:
我们的最终图像也被标记为具有足够的对比度:
我们再次能够计算边缘图,执行轮廓检测,并提取与卡的轮廓相关联的轮廓。
在实时视频流中实现低对比度帧检测
在本节中,您将学习如何使用 OpenCV 和 Python 在实时视频流中实现低对比度帧检测。
打开项目目录结构中的detect_low_contrast_video.py文件,让我们开始工作:
# import the necessary packages
from skimage.exposure import is_low_contrast
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, default="",
help="optional path to video file")
ap.add_argument("-t", "--thresh", type=float, default=0.35,
help="threshold for low contrast")
args = vars(ap.parse_args())
# grab a pointer to the input video stream
print("[INFO] accessing video stream...")
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
# loop over frames from the video stream
while True:
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we've reached the end of
# the video stream so exit the script
if not grabbed:
print("[INFO] no frame read from stream - exiting")
break
# resize the frame, convert it to grayscale, blur it, and then
# perform edge detection
frame = imutils.resize(frame, width=450)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 30, 150)
# initialize the text and color to indicate that the current
# frame is *not* low contrast
text = "Low contrast: No"
color = (0, 255, 0)
第 18 行实例化了一个指向我们视频流的指针。默认情况下,我们将使用网络摄像头;但是,如果你是一个视频文件,你可以提供--input命令行参数。
然后,我们在第 21 行的视频流中循环播放帧。在循环内部,我们:
- 阅读下一篇
frame - 检测我们是否到达了视频流的末尾,如果是,则从循环中
break - 预处理帧,将其转换为灰度,模糊,并应用 Canny 边缘检测器
# check to see if the frame is low contrast, and if so, update
# the text and color
if is_low_contrast(gray, fraction_threshold=args["thresh"]):
text = "Low contrast: Yes"
color = (0, 0, 255)
# otherwise, the frame is *not* low contrast, so we can continue
# processing it
else:
# find contours in the edge map and find the largest one,
# which we'll assume is the outline of our color correction
# card
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
# draw the largest contour on the frame
cv2.drawContours(frame, [c], -1, (0, 255, 0), 2)
# draw the text on the output frame
cv2.putText(frame, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
color, 2)
# stack the output frame and edge map next to each other
output = np.dstack([edged] * 3)
output = np.hstack([frame, output])
# show the output to our screen
cv2.imshow("Output", output)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
实时检测低对比度帧
我们现在可以检测实时视频流中的低对比度图像了!
使用本教程的 “下载” 部分下载源代码、示例图像和示例视频文件。
从那里,打开一个终端,并执行以下命令:
$ python detect_low_contrast_video.py --input example_video.mp4
[INFO] accessing video stream...
[INFO] no frame read from stream - exiting
正如我们的输出所示,我们的低对比度帧检测器能够检测低对比度帧,防止它们进入我们图像处理管道的其余部分。
相反,具有足够对比度的图像被允许继续。然后,我们对这些帧中的每一帧应用边缘检测,计算轮廓,并提取与颜色校正卡相关联的轮廓/轮廓。
您可以以同样的方式在视频流中使用低对比度检测。
总结
在本教程中,您学习了如何检测静态场景和实时视频流中的低对比度图像。我们使用 OpenCV 库和 scikit-image 包来开发我们的低对比度图像检测器。
虽然简单,但当用于计算机视觉和图像处理流水线时,这种方法会非常有效。
使用这种方法最简单的方法之一是向用户提供反馈。如果用户为您的应用程序提供了一个低对比度的图像,提醒他们并要求他们提供一个高质量的图像。
采用这种方法允许您对用于捕获图像的环境进行“保证”,这些图像最终会呈现给您的管道。此外,它有助于用户理解你的应用程序只能在特定的场景中使用,并且需要确保它们符合你的标准。
这里的要点是不要让你的图像处理管道过于复杂。当你可以保证光照条件和环境时,编写 OpenCV 代码就变得容易得多——尽你所能尝试执行这些标准。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
检测护照图像中的机器可读区域
原文:https://pyimagesearch.com/2015/11/30/detecting-machine-readable-zones-in-passport-images/

没有 图片搜索大师 的成员汉斯·布恩,今天的博客是不可能的。汉斯正在进行一个计算机视觉项目,以自动检测护照图像中的机器可读区域(MRZs)—很像上图中检测到的区域。
护照或旅行卡上的 MRZ 地区分为两类:第一类和第三类。类型 1 MRZs 是三行,每行包含 30 个字符。类型 3 MRZ 只有两行,但每行包含 44 个字符。在任一情况下,MRZ 对给定公民的识别信息进行编码,包括护照类型、护照 ID、签发国、姓名、国籍、有效期等。
在 PyImageSearch 大师课程中,Hans 向我展示了他在这个项目上的进展,我立即产生了兴趣。我一直想将计算机视觉算法应用于护照图像(主要只是为了好玩),但缺乏这样做的数据集。鉴于护照包含的个人识别信息,我显然不能就此主题写博客,也不能分享我用来开发算法的图像。
幸运的是,Hans 同意分享一些他可以接触到的护照样本图片,我抓住机会玩这些图片。
现在,在我们深入讨论之前,重要的是要注意,这些护照不是“真实的”,因为它们可以与真实的人联系起来。但它们是用假名字、假地址等伪造的真护照。供开发人员使用。
你可能会认为,为了检测护照上的 MRZ 地区,你需要一点机器学习,也许使用线性 SVM +猪框架来构建一个“MRZ 检测器”——,但这将是多余的。
相反,我们可以仅使用基本图像处理技术来执行 MRZ 检测,例如阈值处理、形态操作和轮廓属性。在这篇博文的剩余部分,我将详述我自己对如何应用这些方法来检测护照的 MRZ 地区的看法。
*## 检测护照图像中的机器可读区域
让我们着手开始这个项目吧。打开一个新文件,将其命名为detect_mrz.py,并插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True, help="path to images directory")
args = vars(ap.parse_args())
# initialize a rectangular and square structuring kernel
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 5))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 21))
2-6 线进口我们必要的包装。我假设您已经安装了 OpenCV。你还需要 imutils ,我的便利函数集合,让 OpenCV 的基本图像处理操作更容易。您可以使用pip安装imutils:
$ pip install --upgrade imutils
从那里,第 9-11 行处理解析我们的命令行参数。这里我们只需要一个开关--images,它是包含我们要处理的护照图像的目录的路径。
最后,行 14 和 15 初始化两个内核,我们稍后将在应用形态操作,特别是关闭操作时使用它们。目前,只需注意第一个内核是矩形的,宽度大约比高度大 3x。第二个内核是方形的。这些内核将允许我们填补 MRZ 字符之间的空白和 MRZ 线之间的空白。
既然我们的命令行参数已经被解析,我们就可以开始遍历数据集中的每个图像并处理它们了:
# loop over the input image paths
for imagePath in paths.list_images(args["images"]):
# load the image, resize it, and convert it to grayscale
image = cv2.imread(imagePath)
image = imutils.resize(image, height=600)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# smooth the image using a 3x3 Gaussian, then apply the blackhat
# morphological operator to find dark regions on a light background
gray = cv2.GaussianBlur(gray, (3, 3), 0)
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKernel)
第 20 行和第 21 行从磁盘加载我们的原始图像,并将其调整到最大高度 600 像素。您可以在下面看到原始图像的示例:

Figure 1: Our original passport image that we are trying to detect the MRZ in.
在行 26 上应用高斯模糊以减少高频噪声。然后我们对第 27 行的模糊的灰度图像应用黑帽形态学操作。
blackhat 操作器用于在浅色背景(即护照本身的背景)下显示深色区域(即 MRZ 文本)。由于护照文本在浅色背景下总是黑色的(至少对于这个数据集来说),所以 blackhat 操作是合适的。下面您可以看到应用 blackhat 运算符的输出:

Figure 2: Applying the blackhat morphological operator reveals the black MRZ text against the light passport background.
MRZ 检测的下一步是使用 Scharr 算子计算 blackhat 图像的梯度幅度表示:
# compute the Scharr gradient of the blackhat image and scale the
# result into the range [0, 255]
gradX = cv2.Sobel(blackhat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal))).astype("uint8")
这里我们计算沿着 blackhat 图像的 x 轴的 Scharr 梯度,揭示图像的区域,这些区域不仅相对于亮背景是暗的,而且包含梯度中的垂直变化,例如 MRZ 文本区域。然后,我们使用最小/最大缩放将该梯度图像缩放回范围【0,255】:

Figure 3: Applying Scharr operator to our blackhat image reveals regions that contain strong vertical changes in gradient.
虽然我们为什么应用这一步骤还不完全清楚,但我可以说它对减少 MRZ 检测的假阳性非常有帮助。没有它,我们可能会意外地将护照上的修饰或设计区域标记为 MRZ。我将把这作为一个练习留给您,以验证计算 blackhat 图像的梯度可以提高 MRZ 检测精度。
下一步是尝试检测 MRZ 的实际线:
# apply a closing operation using the rectangular kernel to close
# gaps in between letters -- then apply Otsu's thresholding method
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(gradX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
首先,我们使用矩形内核应用一个关闭操作。这种闭合操作意在闭合 MRZ 字符之间的间隙。然后,我们使用大津法应用阈值处理来自动对图像进行阈值处理:

Figure 4: Applying a closing operation using a rectangular kernel (that is wider than it is tall) to close gaps in between the MRZ characters
从上图中我们可以看到,每条 MRZ 线都出现在我们的阈值图上。
下一步是闭合实际线条之间的间隙,给我们一个对应于 MRZ 的大矩形区域:
# perform another closing operation, this time using the square
# kernel to close gaps between lines of the MRZ, then perform a
# series of erosions to break apart connected components
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
thresh = cv2.erode(thresh, None, iterations=4)
这里我们执行另一个关闭操作,这一次使用我们的方形内核。这个内核用于闭合 MRZ 各条线之间的间隙,给我们一个与 MRZ 相对应的大区域。然后进行一系列腐蚀,以分开在闭合操作中可能已经连接的连接部件。这些侵蚀也有助于去除与 MRZ 无关的小斑点。

Figure 5: A second closing operation is performed, this time using a square kernel to close the gaps in between individual MRZ lines.
对于一些护照扫描,护照的边界可能在关闭过程中附着在 MRZ 地区。为了解决这个问题,我们将图像的 5%左右边框设置为零(即黑色):
# during thresholding, it's possible that border pixels were
# included in the thresholding, so let's set 5% of the left and
# right borders to zero
p = int(image.shape[1] * 0.05)
thresh[:, 0:p] = 0
thresh[:, image.shape[1] - p:] = 0
你可以在下面看到我们移除边框的输出。

Figure 6: Setting 5% of the left and right border pixels to zero, ensuring that the MRZ region is not attached to the scanned margin of the passport.
与上面的图 5 相比,您现在可以看到边框被移除了。
最后一步是在我们的阈值图像中找到轮廓,并使用轮廓属性来识别 MRZ:
# find contours in the thresholded image and sort them by their
# size
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# loop over the contours
for c in cnts:
# compute the bounding box of the contour and use the contour to
# compute the aspect ratio and coverage ratio of the bounding box
# width to the width of the image
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
crWidth = w / float(gray.shape[1])
# check to see if the aspect ratio and coverage width are within
# acceptable criteria
if ar > 5 and crWidth > 0.75:
# pad the bounding box since we applied erosions and now need
# to re-grow it
pX = int((x + w) * 0.03)
pY = int((y + h) * 0.03)
(x, y) = (x - pX, y - pY)
(w, h) = (w + (pX * 2), h + (pY * 2))
# extract the ROI from the image and draw a bounding box
# surrounding the MRZ
roi = image[y:y + h, x:x + w].copy()
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
break
# show the output images
cv2.imshow("Image", image)
cv2.imshow("ROI", roi)
cv2.waitKey(0)
在行 56-58 上,我们计算阈值图像的轮廓(即轮廓)。然后我们取出这些轮廓,并根据它们在行 59 上的大小降序排列(暗示着最大的轮廓是列表中的第第一个)。
在第 62 行,我们开始循环我们的轮廓排序列表。对于这些轮廓中的每一个,我们将计算边界框(线 66** )并使用它来计算两个属性:纵横比和覆盖率。纵横比就是边界框的宽度除以高度。覆盖率是边界框的宽度除以实际图像的宽度。**
使用这两个属性,我们可以在第 72 行上做一个检查,看看我们是否在检查 MRZ 地区。MRZ 是长方形的,宽度远大于高度。MRZ 还应该覆盖输入图像的至少 75%。
假设这两种情况成立,行 75-84 使用边界框的 (x,y)-坐标来提取 MRZ 并在我们的输入图像上绘制边界框。
最后,第 87-89 行显示了我们的结果。
结果
要查看我们的 MRZ 检测器的运行情况,只需执行以下命令:
$ python detect_mrz.py --images examples
下面你可以看到一个成功的 MRZ 探测的例子,MRZ 用绿色标出:
Figure 7: On the left, we have our input image. And on the right, we have the MRZ region that has been successfully detected.
下面是使用 Python 和 OpenCV 检测 passport 图像中的机器可读区域的另一个示例:

Figure 8: Applying MRZ detection to a scanned passport.
MRZ 地区是在图像的顶部还是底部并不重要。通过应用形态学操作、提取轮廓和计算轮廓属性,我们能够毫无问题地提取 MRZ。
下图也是如此:

Figure 9: Detecting machine-readable zones in images using computer vision.
让我们试试另一个图像:

Figure 10: Again, we are able to detect the MRZ in the passport scan using basic image processing techniques.
到目前为止,我们只看到了包含三条线的 1 型 mrz。然而,我们的方法同样适用于只包含两行的类型 3 MRZs:

Figure 11: Detecting the MRZ in a Type 3 passport image using Python and OpenCV.
这是另一个检测 3 型 MRZ 的例子:

Figure 12: Applying computer vision and image processing to detect machine-readable zones in images.
摘要
在这篇博文中,我们学习了如何仅使用基本的图像处理技术来检测护照扫描中的机器可读区域(mrz ),即:
- 阈值处理。
- 渐变。
- 形态学操作(具体来说,闭合和腐蚀)。
- 轮廓属性。
这些操作虽然简单,但允许我们检测图像中的 MRZ 区域,而不必依赖更高级的特征提取和机器学习方法,如线性 SVM + HOG 进行对象检测。
记住,当面对具有挑战性的计算机视觉问题— 时,要时刻考虑问题和你的假设! 正如这篇博文所展示的,你可能会惊讶于串联使用基本的图像处理功能可以完成什么。
再次感谢 图片搜索大师 成员汉斯·布恩,他为我们提供了这些护照图片样本!谢谢汉斯!*
用 Python 和 OpenCV 检测图像中的多个亮点

今天的博客是我几年前做的一个关于寻找图像中最亮的地方的教程的后续。
我之前的教程假设图像中只有一个亮点需要检测…
…但是如果有多个亮点呢?
如果你想检测一幅图像中的多个亮点,代码会稍微复杂一点,但不会太复杂。不过不用担心:我会详细解释每个步骤。
要了解如何检测图像中的多个亮点,请继续阅读。
用 Python 和 OpenCV 检测图像中的多个亮点
通常,当我在 PyImageSearch 博客上做基于代码的教程时,我会遵循一个非常标准的模板:
- 解释问题是什么以及我们将如何解决它。
- 提供解决项目的代码。
- 演示执行代码的结果。
这个模板对于 95%的 PyImageSearch 博客文章都很有效,但是对于这个,我将把模板压缩到一个步骤中。
我觉得检测图像中最亮区域的问题是不言自明的,所以我不需要用一整节来详细说明这个问题。
我还认为,解释每个代码块,紧接着是显示执行相应代码块的输出的,会帮助你更好地理解发生了什么。
也就是说,看看下面的图片:

Figure 1: The example image that we are detecting multiple bright objects in using computer vision and image processing techniques (source image).
在这张图片中,我们有五个灯泡。
我们的目标是检测出图像中的这五个灯泡,并给它们贴上独特的标签。
首先,打开一个新文件,命名为detect_bright_spots.py。从那里,插入以下代码:
# import the necessary packages
from imutils import contours
from skimage import measure
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the image file")
args = vars(ap.parse_args())
第 2-7 行进口我们所需的 Python 包。在本教程中,我们将使用 scikit-image ,所以如果您的系统上还没有安装它,请确保按照这些安装说明进行操作。
我们还将使用 imutils ,这是我的一组便利函数,用来使应用图像处理操作更容易。
如果您的系统上还没有安装imutils,您可以使用pip为您安装:
$ pip install --upgrade imutils
从那里,第 10-13 行解析我们的命令行参数。这里我们只需要一个开关--image,它是我们输入图像的路径。
要开始检测图像中最亮的区域,我们首先需要从磁盘加载图像,然后将其转换为灰度,并对其进行平滑(即模糊)以减少高频噪声:
# load the image, convert it to grayscale, and blur it
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (11, 11), 0)
这些操作的输出如下所示:

Figure 2: Converting our image to grayscale and blurring it.
注意我们的image现在是如何(1)灰度和(2)模糊的。
为了显示模糊图像中最亮的区域,我们需要应用阈值处理:
# threshold the image to reveal light regions in the
# blurred image
thresh = cv2.threshold(blurred, 200, 255, cv2.THRESH_BINARY)[1]
该操作取任意像素值 p > = 200 并将其设置为 255 (白色)。像素值 < 200 被设置为 0 (黑色)。
阈值处理后,我们剩下以下图像:

Figure 3: Applying thresholding to reveal the brighter regions of the image.
注意图像的明亮区域现在都是白色的,而图像的其余部分被设置为黑色的。
然而,这个图像中有一点噪声(即小斑点),所以让我们通过执行一系列腐蚀和膨胀来清理它:
# perform a series of erosions and dilations to remove
# any small blobs of noise from the thresholded image
thresh = cv2.erode(thresh, None, iterations=2)
thresh = cv2.dilate(thresh, None, iterations=4)
应用这些操作后,你可以看到我们的thresh图像更加“干净”,尽管我们仍然有一些想要排除的残留斑点(我们将在下一步处理):

Figure 4: Utilizing a series of erosions and dilations to help “clean up” the thresholded image by removing small blobs and then regrowing the remaining regions.
该项目的关键步骤是标记上图中的每个区域;然而,即使在应用了腐蚀和膨胀之后,我们仍然想要过滤掉任何残留的“噪声”区域。
一个很好的方法是执行连接组件分析:
# perform a connected component analysis on the thresholded
# image, then initialize a mask to store only the "large"
# components
labels = measure.label(thresh, neighbors=8, background=0)
mask = np.zeros(thresh.shape, dtype="uint8")
# loop over the unique components
for label in np.unique(labels):
# if this is the background label, ignore it
if label == 0:
continue
# otherwise, construct the label mask and count the
# number of pixels
labelMask = np.zeros(thresh.shape, dtype="uint8")
labelMask[labels == label] = 255
numPixels = cv2.countNonZero(labelMask)
# if the number of pixels in the component is sufficiently
# large, then add it to our mask of "large blobs"
if numPixels > 300:
mask = cv2.add(mask, labelMask)
第 32 行使用 scikit-image 库执行实际的连接组件分析。从measure.label返回的labels变量与我们的thresh图像具有完全相同的尺寸——唯一的区别是labels为thresh中的每个斑点存储一个 唯一整数 。
然后我们初始化第 33 行上的mask来只存储大的斑点。
在的第 36 行,我们开始循环每个独特的labels。如果label是零,那么我们知道我们正在检查背景区域,可以安全地忽略它(第 38 和 39 行)。
否则,我们为第 43 行和第 44 行上的构造一个掩码当前的label。
我在下面提供了一个 GIF 动画,它可视化了每个label的labelMask的构造。使用此动画帮助您理解如何访问和显示各个组件:

Figure 5: A visual animation of applying a connected-component analysis to our thresholded image.
第 45 行然后计算labelMask中非零像素的数量。如果numPixels超过预定义的阈值(在这种情况下,总共有 300 个像素),那么我们认为该斑点“足够大”,并将其添加到我们的mask。
输出mask如下所示:

Figure 6: After applying a connected-component analysis we are left with only the larger blobs in the image (which are also bright).
请注意小斑点是如何被过滤掉的,只有大斑点被保留下来。
最后一步是在我们的图像上绘制标记的斑点:
# find the contours in the mask, then sort them from left to
# right
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = contours.sort_contours(cnts)[0]
# loop over the contours
for (i, c) in enumerate(cnts):
# draw the bright spot on the image
(x, y, w, h) = cv2.boundingRect(c)
((cX, cY), radius) = cv2.minEnclosingCircle(c)
cv2.circle(image, (int(cX), int(cY)), int(radius),
(0, 0, 255), 3)
cv2.putText(image, "#{}".format(i + 1), (x, y - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
首先,我们需要检测mask图像中的轮廓,然后从左到右对它们进行排序(第 54-57 行)。
一旦我们的轮廓被排序,我们就可以逐个循环了( Line 60 )。
对于这些轮廓中的每一个,我们将计算最小封闭圆 ( 线 63 ),它代表明亮区域包含的区域。
然后,我们对该区域进行唯一标记,并将其绘制在我们的image ( 第 64-67 行)上。
最后,行 70 和 71 显示我们的输出结果。
为了可视化灯泡图像的输出,请务必使用本教程底部的 【下载】 部分将源代码+示例图像下载到这篇博文中。
从那里,只需执行以下命令:
$ python detect_bright_spots.py --image images/lights_01.png
然后,您应该会看到以下输出图像:
Figure 7: Detecting multiple bright regions in an image with Python and OpenCV.
请注意,每一个灯泡都有独特的标签,上面画了一个圆圈来包围每个单独的明亮区域。
您可以通过执行以下命令来可视化第二个示例:
$ python detect_bright_spots.py --image images/lights_02.png

Figure 8: A second example of detecting multiple bright regions using computer vision and image processing techniques.
这次输入图像里有多个灯泡!然而,即使图像中有许多明亮的区域,我们的方法仍然能够正确地(并且唯一地)标记它们中的每一个。
摘要
在这篇博文中,我扩展了之前关于检测图像中最亮点的教程来处理 T2 的多个明亮区域。我能够通过应用阈值来揭示图像中最亮的区域来完成这个任务。
这里的关键是阈值步骤——如果您的thresh图非常嘈杂,并且无法使用轮廓属性或连通分量分析进行过滤,那么您将无法定位图像中的每个明亮区域。
因此,您应该通过应用各种阈值处理技术(简单阈值处理、Otsu 阈值处理、自适应阈值处理,甚至可能是 GrabCut)来评估您的输入图像,并可视化您的结果。
这一步应该在之前执行,你甚至都懒得应用连通分量分析或轮廓过滤。
如果你能合理地将图像中较亮的区域与较暗的无关区域分割开来,那么这篇博文中概述的方法应该非常适合你。
无论如何,我希望你喜欢这篇博文!
在您离开之前,请务必在下表中输入您的电子邮件地址,以便在 PyImageSearch 博客上发布未来教程时得到通知。
利用 Keras 和深度学习检测自然灾害
原文:https://pyimagesearch.com/2019/11/11/detecting-natural-disasters-with-keras-and-deep-learning/
在本教程中,您将学习如何使用 Keras、计算机视觉和深度学习自动检测自然灾害(地震、洪水、野火、气旋/飓风),准确率高达95%。
我记得我第一次经历自然灾害的时候——我只是一个幼儿园的孩子,不超过 6-7 岁。
课间休息时,我们在户外玩攀登架,像小孩子一样像野生动物一样跑来跑去。
天气预报说有雨。天气多云。而且非常潮湿。
我妈妈给了我一件外套让我在外面穿,但我又热又不舒服——潮湿的天气让棉/涤纶混纺面料粘在了我的皮肤上。这件外套,就像我周围的空气一样,令人窒息。
突然间,天空从“正常的雨云”变成了不祥的绿色。
课间休息的班长把手伸进她的口袋,抓起她的哨子,吹了一声,表示我们该停止野生动物的古怪行为,到里面去上学了。
课间休息后,我们通常会围着老师的桌子坐成一圈,进行展示和讲解。
但这次不是。
我们立即被冲进走廊,并被告知用手捂住头部——一场龙卷风刚刚在我们学校附近登陆。
一想到龙卷风就足以吓到一个孩子。
而是去实际体验一次?
那完全是另外一回事。
风急剧加大,愤怒的暴风雨咆哮着,用树枝、岩石和任何没有绑好的松散碎片斥责我们的学校。
整个折磨不会超过 5-10 分钟,但感觉像是可怕的永恒。
结果证明我们一直都是安全的。龙卷风登陆后,它开始穿过玉米地,从我们学校离开,而不是从 T2 到 T3。
我们很幸运。
有趣的是,小时候的经历,尤其是那些让你害怕的经历,会在你长大后塑造你。
活动结束几天后,我妈妈带我去了当地的图书馆。我挑选了所有我能找到的关于龙卷风和飓风的书。尽管当时我只有基本的阅读水平,但我还是狼吞虎咽地阅读了它们,专心研究这些照片,直到我能在脑海中重现它们——想象置身于其中一场风暴中会是什么样子。
后来,在研究生院,我经历了具有历史意义的 2012 年 6 月 29 日的飓风 derecho,持续风速超过 60 英里/小时,阵风超过 100 英里/小时,撞倒了电线和大树。
那场风暴造成 29 人死亡,数百人受伤,并导致美国东海岸部分地区停电超过 6 天,这在现代美国是前所未有的。
自然灾害是无法预防的,但是它们是可以被探测到的,给人们宝贵的时间逃到安全的地方。
在本教程中,您将了解我们如何使用计算机视觉和深度学习来帮助检测自然灾害。
要了解如何用 Keras、计算机视觉和深度学习来检测自然灾害,继续阅读!
利用 Keras 和深度学习检测自然灾害
在本教程的第一部分,我们将讨论如何使用计算机视觉和深度学习算法来自动检测图像和视频流中的自然灾害。
接下来,我们将回顾我们的自然灾害数据集,它由四个类组成:
- 旋风/飓风
- 地震
- 洪水
- 野火
然后,我们将设计一组实验,这些实验将:
- 帮助我们在数据集上微调 VGG16(在 ImageNet 上进行了预训练)。
- 找到最佳的学习速度。
- 训练我们的模型,获得 > 95%的准确率!
我们开始吧!
计算机视觉和深度学习如何检测自然灾害?

Figure 1: We can detect natural disasters with Keras and Deep Learning using a dataset of natural disaster images. (image source)
自然灾害无法预防,但却可以被发现。
在世界各地,我们使用传感器来监测自然灾害:
- 地震传感器(地震仪)和振动传感器(地震仪)用于监测地震(和下游海啸)。
- 雷达图用于探测龙卷风的标志性“钩状回波”(即从雷达回波延伸出来的一个钩子)。
- 洪水传感器用于测量湿度水平,而水位传感器用于监控河流、小溪等的水位。
- 野火传感器仍处于初级阶段,但有望探测到微量的烟和火。
这些传感器中的每一个都是高度专业化的来完成手头的任务——及早发现自然灾害,向人们发出警报,并让他们到达安全地带。
使用计算机视觉,我们可以增强现有的传感器,从而提高自然灾害探测器的准确性,最重要的是,让人们采取预防措施,保持安全,防止/减少因这些灾害而发生的伤亡人数。
我们的自然灾害图像数据集

Figure 2: A dataset of natural disaster images. We’ll use this dataset to train a natural disaster detector with Keras and Deep Learning.
我们今天在这里使用的数据集是由 PyImageSearch 阅读器 Gautam Kumar 策划的。
高塔姆使用谷歌图片收集了总共4428 张图片,它们属于四个不同的类别:
- 气旋/飓风: 928 张图片
- 地震:1350
- 洪水:1073 人
- 野火:1077 人
然后,他训练了一个卷积神经网络来识别每一个自然灾害案例。
高塔姆在他的 LinkedIn 个人资料上分享了他的工作,吸引了许多深度学习从业者的注意(包括我自己)。我问他是否愿意(1)与 PyImageSearch 社区共享他的数据集,以及(2)允许我使用该数据集编写一个教程。高塔姆同意了,于是我们就有了今天!
我再次衷心感谢高塔姆的辛勤工作和贡献——如果有机会,一定要感谢他!
下载自然灾害数据集
Figure 3: Gautam Kumar’s dataset for detecting natural disasters with Keras and deep learning.
您可以使用此链接通过 Google Drive 下载原始自然灾害数据集。
下载归档文件后,您应该将其解压缩并检查内容:
$ tree --dirsfirst --filelimit 10 Cyclone_Wildfire_Flood_Earthquake_Database
Cyclone_Wildfire_Flood_Earthquake_Database
├── Cyclone [928 entries]
├── Earthquake [1350 entries]
├── Flood [1073 entries]
├── Wildfire [1077 entries]
└── readme.txt
4 directories, 1 file
在这里,您可以看到每个自然灾害都有自己的目录,每个类的示例都位于各自的父目录中。
项目结构
使用tree命令,让我们通过本教程的 【下载】 部分查看今天的项目:
$ tree --dirsfirst --filelimit 10
.
├── Cyclone_Wildfire_Flood_Earthquake_Database
│ ├── Cyclone [928 entries]
│ ├── Earthquake [1350 entries]
│ ├── Flood [1073 entries]
│ ├── Wildfire [1077 entries]
│ └── readme.txt
├── output
│ ├── natural_disaster.model
│ │ ├── assets
│ │ ├── variables
│ │ │ ├── variables.data-00000-of-00002
│ │ │ ├── variables.data-00001-of-00002
│ │ │ └── variables.index
│ │ └── saved_model.pb
│ ├── clr_plot.png
│ ├── lrfind_plot.png
│ └── training_plot.png
├── pyimagesearch
│ ├── __init__.py
│ ├── clr_callback.py
│ ├── config.py
│ └── learningratefinder.py
├── videos
│ ├── floods_101_nat_geo.mp4
│ ├── fort_mcmurray_wildfire.mp4
│ ├── hurricane_lorenzo.mp4
│ ├── san_andreas.mp4
│ └── terrific_natural_disasters_compilation.mp4
├── Cyclone_Wildfire_Flood_Earthquake_Database.zip
├── train.py
└── predict.py
11 directories, 20 files
我们的项目包含:
- 自然灾害数据集。参考前面两节。
- 一个目录,我们的模型和绘图将存储在这里。我的实验结果包括在内。
- 我们的
pyimagesearch模块包含我们的循环学习率 Keras 回调,一个配置文件,和 Keras 学习率查找器。 - 选择
videos/用于测试视频分类预测脚本。 - 我们的训练脚本,
train.py。该脚本将对在 ImageNet 数据集上预训练的 VGG16 模型执行微调。 - 我们的视频分类预测脚本
predict.py,执行滚动平均预测,实时对视频进行分类。
我们的配置文件
我们的项目将跨越多个 Python 文件,因此为了保持代码整洁有序(并确保我们没有大量命令行参数),让我们创建一个配置文件来存储所有重要的路径和变量。
打开pyimagesearch模块中的config.py文件,插入以下代码:
# import the necessary packages
import os
# initialize the path to the input directory containing our dataset
# of images
DATASET_PATH = "Cyclone_Wildfire_Flood_Earthquake_Database"
# initialize the class labels in the dataset
CLASSES = ["Cyclone", "Earthquake", "Flood", "Wildfire"]
os模块导入允许我们直接在这个配置文件中构建与操作系统无关的路径(第 2 行)。
第 6 行指定了自然灾害数据集的根路径。
第 7 行提供了类标签的名称(即数据集中子目录的名称)。
让我们定义数据集分割:
# define the size of the training, validation (which comes from the
# train split), and testing splits, respectively
TRAIN_SPLIT = 0.75
VAL_SPLIT = 0.1
TEST_SPLIT = 0.25
第 13-15 行包含我们的培训、测试和验证分割尺寸。请注意,验证分割是训练分割的 10%(而不是所有数据的 10%)。
接下来,我们将定义我们的培训参数:
# define the minimum learning rate, maximum learning rate, batch size,
# step size, CLR method, and number of epochs
MIN_LR = 1e-6
MAX_LR = 1e-4
BATCH_SIZE = 32
STEP_SIZE = 8
CLR_METHOD = "triangular"
NUM_EPOCHS = 48
第 19 行和第 20 行包含循环学习率 (CLR)的最小和最大学习率。我们将在下面的“找到我们的初始学习率”部分学习如何设置这些学习率值。
第 21-24 行定义批量大小、步长、CLR 方法和训练时期数。
在这里,我们将定义输出路径:
# set the path to the serialized model after training
MODEL_PATH = os.path.sep.join(["output", "natural_disaster.model"])
# define the path to the output learning rate finder plot, training
# history plot and cyclical learning rate plot
LRFIND_PLOT_PATH = os.path.sep.join(["output", "lrfind_plot.png"])
TRAINING_PLOT_PATH = os.path.sep.join(["output", "training_plot.png"])
CLR_PLOT_PATH = os.path.sep.join(["output", "clr_plot.png"])
第 27-33 行定义了以下输出路径:
- 训练后的序列化模型
- 学习率探测器图
- 训练历史图
- CLR plot
使用 Keras 实现我们的培训脚本
我们的培训程序将包括两个步骤:
- 步骤#1: 使用我们的学习率查找器来查找最佳学习率,以在我们的数据集上微调我们的 VGG16 CNN。
- 步骤#2: 结合循环学习率(CLR)使用我们的最优学习率来获得高精度模型。
我们的train.py文件将处理这两个步骤。
继续在您最喜欢的代码编辑器中打开train.py,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.learningratefinder import LearningRateFinder
from pyimagesearch.clr_callback import CyclicLR
from pyimagesearch import config
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import pickle
import cv2
import sys
import os
第 2-27 行导入必要的包,包括:
matplotlib:用于绘图(使用"Agg"后端,以便将绘图图像保存到磁盘)。tensorflow:导入包括我们的VGG16CNN,数据扩充,图层类型,和SGD优化器。scikit-learn:导入包括标签二进制化器、数据集分割功能、评估报告工具。LearningRateFinder:我们的 Keras 学习率查找器类。CyclicLR:波动学习率的 Keras 回调,称为周期性学习率。clr 导致更快的收敛,并且通常需要更少的超参数更新实验。config:我们在上一节中回顾的自定义配置设置。paths:包含在目录树中列出图像路径的功能。cv2: OpenCV,用于预处理和显示。
让我们解析命令行参数并获取我们的图像路径:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--lr-find", type=int, default=0,
help="whether or not to find optimal learning rate")
args = vars(ap.parse_args())
# grab the paths to all images in our dataset directory and initialize
# our lists of images and class labels
print("[INFO] loading images...")
imagePaths = list(paths.list_images(config.DATASET_PATH))
data = []
labels = []
回想一下,我们大部分的设定都在config.py里。有一个例外。--lr-find命令行参数告诉我们的脚本是否找到最优的学习率(第 30-33 行)。
第 38 行获取数据集中所有图像的路径。
然后我们初始化两个同步列表来保存我们的图像data和labels ( 第 39 行和第 40 行)。
现在让我们填充data和labels列表:
# loop over the image paths
for imagePath in imagePaths:
# extract the class label
label = imagePath.split(os.path.sep)[-2]
# load the image, convert it to RGB channel ordering, and resize
# it to be a fixed 224x224 pixels, ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
# convert the data and labels to NumPy arrays
print("[INFO] processing data...")
data = np.array(data, dtype="float32")
labels = np.array(labels)
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
第 43-55 行在imagePaths上循环,同时:
- 从路径中提取类
label(第 45 行)。 - 加载并预处理
image( 第 49-51 行)。对于 VGG16,图像被转换为 RGB 通道排序,并被调整为 224×224 。 - 将预处理后的
image添加到data列表中(第 54 行)。 - 将
label添加到labels列表中(行 55 )。
第 59 行通过将data转换为"float32"数据类型 NumPy 数组来执行最后的预处理步骤。
类似地,行 60 将labels转换成一个数组,这样行 63 和 64 可以执行一键编码。
从这里开始,我们将对数据进行分区,并设置数据扩充:
# partition the data into training and testing splits
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=config.TEST_SPLIT, random_state=42)
# take the validation split from the training split
(trainX, valX, trainY, valY) = train_test_split(trainX, trainY,
test_size=config.VAL_SPLIT, random_state=84)
# initialize the training data augmentation object
aug = ImageDataGenerator(
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
第 67-72 行构建培训、测试和验证分割。
第 75-82 行实例化我们的数据扩充对象。在我的以前的帖子中以及在的 的实践者包中阅读更多关于使用 Python 进行计算机视觉深度学习的信息。
此时,我们将设置 VGG16 模型以进行微调:
# load the VGG16 network, ensuring the head FC layer sets are left
# off
baseModel = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(512, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(len(config.CLASSES), activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers:
layer.trainable = False
# compile our model (this needs to be done after our setting our
# layers to being non-trainable
print("[INFO] compiling model...")
opt = SGD(lr=config.MIN_LR, momentum=0.9)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
第 86 行和第 87 行使用预先训练的 ImageNet 权重加载VGG16(但没有全连接层头)。
第 91-95 行创建一个新的全连接层头,随后是第 99 行,它将新的 FC 层添加到 VGG16 的主体。
第 103 行和第 104 行将 VGG16 的主体标记为不可训练——我们将只训练(即微调)FC 层头部。
第 109-111 行然后compile我们的随机梯度下降(SGD)优化器模型和我们指定的最小学习率。
第一次运行脚本时,您应该设置--lr-find命令行参数,以使用 Keras 学习率查找器来确定最佳学习率。让我们看看它是如何工作的:
# check to see if we are attempting to find an optimal learning rate
# before training for the full number of epochs
if args["lr_find"] > 0:
# initialize the learning rate finder and then train with learning
# rates ranging from 1e-10 to 1e+1
print("[INFO] finding learning rate...")
lrf = LearningRateFinder(model)
lrf.find(
aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
1e-10, 1e+1,
stepsPerEpoch=np.ceil((trainX.shape[0] / float(config.BATCH_SIZE))),
epochs=20,
batchSize=config.BATCH_SIZE)
# plot the loss for the various learning rates and save the
# resulting plot to disk
lrf.plot_loss()
plt.savefig(config.LRFIND_PLOT_PATH)
# gracefully exit the script so we can adjust our learning rates
# in the config and then train the network for our full set of
# epochs
print("[INFO] learning rate finder complete")
print("[INFO] examine plot and adjust learning rates before training")
sys.exit(0)
第 115 行检查我们是否应该尝试找到最佳学习率。假设如此,我们:
- 初始化
LearningRateFinder( 第 119 行)。 - 以
1e-10的学习率开始训练,并以指数方式增加,直到我们达到1e+1( 第 120-125 行)。 - 绘制损失与学习率的关系图,并保存结果数字(第 129 和 130 行)。
- 优雅地
exit打印一条消息后的脚本,该消息指示用户检查学习率查找器图(第 135-137 行)。
在这段代码执行之后,我们现在需要:
- 步骤#1: 检查生成的绘图。
- 步骤#2: 分别用我们的
MIN_LR和MAX_LR更新config.py。 - 步骤#3: 在我们的完整数据集上训练网络。
假设我们已经完成了步骤#1 和#2 ,现在让我们处理步骤#3 ,其中我们的最小和最大学习率已经在配置中找到并更新。
在这种情况下,是时候初始化我们的循环学习率类并开始训练了:
# otherwise, we have already defined a learning rate space to train
# over, so compute the step size and initialize the cyclic learning
# rate method
stepSize = config.STEP_SIZE * (trainX.shape[0] // config.BATCH_SIZE)
clr = CyclicLR(
mode=config.CLR_METHOD,
base_lr=config.MIN_LR,
max_lr=config.MAX_LR,
step_size=stepSize)
# train the network
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
validation_data=(valX, valY),
steps_per_epoch=trainX.shape[0] // config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
callbacks=[clr],
verbose=1)
第 142-147 行初始化我们的CyclicLR。
第 151-157 行然后使用.fit_generator 和我们的aug数据增强对象以及我们的clr回调来训练我们的model 。
培训完成后,我们开始评估并保存我们的model:
# evaluate the network and show a classification report
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=config.BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=config.CLASSES))
# serialize the model to disk
print("[INFO] serializing network to '{}'...".format(config.MODEL_PATH))
model.save(config.MODEL_PATH)
第 161 行对我们的测试集进行预测。这些预测被传递到行 162 和 163 ,它们打印一个分类报告摘要。
第 167 行将微调后的模型序列化保存到磁盘。
最后,让我们绘制我们的培训历史和 CLR 历史:
# construct a plot that plots and saves the training history
N = np.arange(0, config.NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.TRAINING_PLOT_PATH)
# plot the learning rate history
N = np.arange(0, len(clr.history["lr"]))
plt.figure()
plt.plot(N, clr.history["lr"])
plt.title("Cyclical Learning Rate (CLR)")
plt.xlabel("Training Iterations")
plt.ylabel("Learning Rate")
plt.savefig(config.CLR_PLOT_PATH)
第 170-181 行生成我们训练历史的图表,并将图表保存到磁盘。
注:在 TensorFlow 2.0 中,历史字典键由acc变为accuracy,val_acc变为val_accuracy。尤其令人困惑的是,现在“准确性”被拼写出来了,而“有效性”却没有。根据您的 TensorFlow 版本,请特别注意这一细微差别。
第 184-190 行绘制我们的循环学习率历史,并将数字保存到磁盘。
找到我们的初始学习率
在我们尝试微调我们的模型以识别自然灾害之前,让我们首先使用我们的学习率查找器来找到一组最优的学习率范围。使用这个最佳学习率范围,我们将能够应用循环学习率来提高我们的模型精度。
确保你两者都有:
- 使用本教程的 【下载】 部分下载源代码。
- 使用上面的“下载自然灾害数据集”部分下载数据集。
从那里,打开一个终端并执行以下命令:
$ python train.py --lr-find 1
[INFO] loading images...
[INFO] processing data...
[INFO] compiling model...
[INFO] finding learning rate...
Epoch 1/20
94/94 [==============================] - 29s 314ms/step - loss: 9.7411 - accuracy: 0.2664
Epoch 2/20
94/94 [==============================] - 28s 295ms/step - loss: 9.5912 - accuracy: 0.2701
Epoch 3/20
94/94 [==============================] - 27s 291ms/step - loss: 9.4601 - accuracy: 0.2731
...
Epoch 12/20
94/94 [==============================] - 27s 290ms/step - loss: 2.7111 - accuracy: 0.7764
Epoch 13/20
94/94 [==============================] - 27s 286ms/step - loss: 5.9785 - accuracy: 0.6084
Epoch 14/20
47/94 [==============>...............] - ETA: 13s - loss: 10.8441 - accuracy: 0.3261
[INFO] learning rate finder complete
[INFO] examine plot and adjust learning rates before training
假设train.py脚本已正确退出,那么现在您的输出目录中应该有一个名为lrfind_plot.png的文件。
现在花点时间来看看这张图片:
Figure 4: Using a Keras Learning Rate Finder to find the optimal learning rates to fine tune our CNN on our natural disaster dataset. We will use the dataset to train a model for detecting natural disasters with the Keras deep learning framework.
检查该图,您可以看到我们的模型最初在1e-6左右开始学习并获得牵引力。
我们的损失继续下降,直到大约1e-4时又开始上升,这是过度拟合的明显迹象。
因此,我们的最佳学习率范围是1e-6到1e-4。
更新我们的学习率
既然我们已经知道了我们的最佳学习率,让我们回到我们的config.py文件并相应地更新它们:
# define the minimum learning rate, maximum learning rate, batch size,
# step size, CLR method, and number of epochs
MIN_LR = 1e-6
MAX_LR = 1e-4
BATCH_SIZE = 32
STEP_SIZE = 8
CLR_METHOD = "triangular"
NUM_EPOCHS = 48
请注意我们配置文件的第 19 行和第 20 行(高亮显示)上的MIN_LR和MAX_LR学习率值是最新更新的。这些值是通过检查我们的 Keras Learning Rate Finder 图找到的。
用 Keras 训练自然灾害检测模型
我们现在可以微调我们的模型来识别自然灾害!
执行以下命令,该命令将在整个时期内训练我们的网络:
$ python train.py
[INFO] loading images...
[INFO] processing data...
[INFO] compiling model...
[INFO] training network...
Epoch 1/48
93/93 [==============================] - 32s 343ms/step - loss: 8.5819 - accuracy: 0.3254 - val_loss: 2.5915 - val_accuracy: 0.6829
Epoch 2/48
93/93 [==============================] - 30s 320ms/step - loss: 4.2144 - accuracy: 0.6194 - val_loss: 1.2390 - val_accuracy: 0.8573
Epoch 3/48
93/93 [==============================] - 29s 316ms/step - loss: 2.5044 - accuracy: 0.7605 - val_loss: 1.0052 - val_accuracy: 0.8862
Epoch 4/48
93/93 [==============================] - 30s 322ms/step - loss: 2.0702 - accuracy: 0.8011 - val_loss: 0.9150 - val_accuracy: 0.9070
Epoch 5/48
93/93 [==============================] - 29s 313ms/step - loss: 1.5996 - accuracy: 0.8366 - val_loss: 0.7397 - val_accuracy: 0.9268
...
Epoch 44/48
93/93 [==============================] - 28s 304ms/step - loss: 0.2180 - accuracy: 0.9275 - val_loss: 0.2608 - val_accuracy: 0.9476
Epoch 45/48
93/93 [==============================] - 29s 315ms/step - loss: 0.2521 - accuracy: 0.9178 - val_loss: 0.2693 - val_accuracy: 0.9449
Epoch 46/48
93/93 [==============================] - 29s 312ms/step - loss: 0.2330 - accuracy: 0.9284 - val_loss: 0.2687 - val_accuracy: 0.9467
Epoch 47/48
93/93 [==============================] - 29s 310ms/step - loss: 0.2120 - accuracy: 0.9322 - val_loss: 0.2646 - val_accuracy: 0.9476
Epoch 48/48
93/93 [==============================] - 29s 311ms/step - loss: 0.2237 - accuracy: 0.9318 - val_loss: 0.2664 - val_accuracy: 0.9485
[INFO] evaluating network...
precision recall f1-score support
Cyclone 0.99 0.97 0.98 205
Earthquake 0.96 0.93 0.95 362
Flood 0.90 0.94 0.92 267
Wildfire 0.96 0.97 0.96 273
accuracy 0.95 1107
macro avg 0.95 0.95 0.95 1107
weighted avg 0.95 0.95 0.95 1107
[INFO] serializing network to 'output/natural_disaster.model'...
这里您可以看到,在测试集中识别自然灾害时,我们获得了 95%的准确率。
检查我们的训练图,我们可以看到我们的验证损失跟随着我们的训练损失,这意味着在我们的数据集本身内几乎没有过度拟合:
Figure 5: Training history accuracy/loss curves for creating a natural disaster classifier using Keras and deep learning.
最后,我们有我们的学习率图,它显示了我们的 CLR 回调分别在我们的MIN_LR和MAX_LR之间振荡学习率:
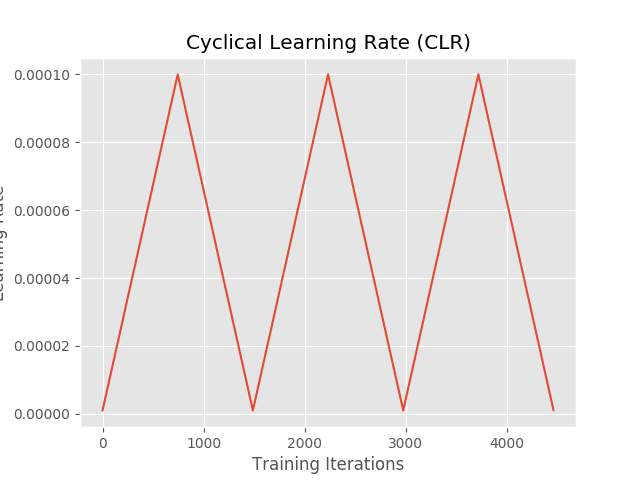
Figure 6: Cyclical learning rates are used with Keras and deep learning for detecting natural disasters.
实施我们的自然灾害预测脚本
现在我们的模型已经训练好了,让我们看看如何使用它对它从未见过的图像/视频进行预测,从而为自动自然灾害检测系统铺平道路。
为了创建这个脚本,我们将利用视频 的 时间特性,特别是假设视频中的 后续帧将具有相似的语义内容。
通过执行滚动预测准确性,我们将能够“平滑”预测并避免“预测闪烁”。
我已经在我的 视频分类与 Keras 和深度学习 文章中深入介绍了这个近乎相同的脚本。请务必参考那篇文章,了解完整的背景和更详细的代码解释。
为了完成自然灾害视频分类让我们来看看predict.py:
# import the necessary packages
from tensorflow.keras.models import load_model
from pyimagesearch import config
from collections import deque
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to our input video")
ap.add_argument("-o", "--output", required=True,
help="path to our output video")
ap.add_argument("-s", "--size", type=int, default=128,
help="size of queue for averaging")
ap.add_argument("-d", "--display", type=int, default=-1,
help="whether or not output frame should be displayed to screen")
args = vars(ap.parse_args())
2-7 线装载必要的包和模块。特别是,我们将使用 Python 的collections模块中的deque来辅助我们的滚动平均算法。
第 10-19 行 解析命令行参数,包括我们输入/输出视频的路径,我们滚动平均队列的大小,以及我们是否会在视频生成时在屏幕上显示输出帧。
让我们继续加载我们的自然灾害分类模型,并初始化我们的队列+视频流:
# load the trained model from disk
print("[INFO] loading model and label binarizer...")
model = load_model(config.MODEL_PATH)
# initialize the predictions queue
Q = deque(maxlen=args["size"])
# initialize the video stream, pointer to output video file, and
# frame dimensions
print("[INFO] processing video...")
vs = cv2.VideoCapture(args["input"])
writer = None
(W, H) = (None, None)
随着我们的model、Q和vs准备就绪,我们将开始循环播放帧:
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# if the frame dimensions are empty, grab them
if W is None or H is None:
(H, W) = frame.shape[:2]
# clone the output frame, then convert it from BGR to RGB
# ordering and resize the frame to a fixed 224x224
output = frame.copy()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (224, 224))
frame = frame.astype("float32")
第 38-47 行抓取一个frame并存储其尺寸。
第 51-54 行为了output的目的复制我们的frame,然后对其进行分类预处理。预处理步骤是,和必须,与我们为训练执行的步骤相同。
现在让我们在框架上做一个自然灾害预测:
# make predictions on the frame and then update the predictions
# queue
preds = model.predict(np.expand_dims(frame, axis=0))[0]
Q.append(preds)
# perform prediction averaging over the current history of
# previous predictions
results = np.array(Q).mean(axis=0)
i = np.argmax(results)
label = config.CLASSES[i]
第 58 行和第 59 行执行推理并将预测添加到我们的队列中。
第 63 行执行Q中可用预测的滚动平均预测。
第 64 行和第 65 行然后提取最高概率类标签,以便我们可以注释我们的帧:
# draw the activity on the output frame
text = "activity: {}".format(label)
cv2.putText(output, text, (35, 50), cv2.FONT_HERSHEY_SIMPLEX,
1.25, (0, 255, 0), 5)
# check if the video writer is None
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(W, H), True)
# write the output frame to disk
writer.write(output)
# check to see if we should display the output frame to our
# screen
if args["display"] > 0:
# show the output image
cv2.imshow("Output", output)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# release the file pointers
print("[INFO] cleaning up...")
writer.release()
vs.release()
第 68-70 行在output画面的角落标注自然灾害活动。
第 73-80 行处理将output帧写入视频文件。
如果--display标志被置位,行 84-91 向屏幕显示该帧并捕捉按键。
否则,处理继续,直到完成,此时循环结束,我们执行清除(行 95 和 96 )。
用 Keras 预测自然灾害
出于本教程的目的,我通过 YouTube 下载了自然灾害视频示例——具体视频在下面的“Credits”部分列出。您可以使用自己的示例视频,也可以通过演职员表下载视频。
无论哪种方式,请确保您已经使用本教程的 “下载” 部分下载了源代码和预先训练好的自然灾害预测模型。
下载后,您可以使用以下命令启动predict.py脚本:
$ python predict.py --input videos/terrific_natural_disasters_compilation.mp4 \
--output output/natural_disasters_output.avi
[INFO] processing video...
[INFO] cleaning up...
在这里你可以看到我们的模型的一个样本结果,正确地将这个视频剪辑分类为“洪水”:

Figure 7: Natural disaster “flood” classification with Keras and Deep Learning.
下面的例子来自 2016 年麦克默里堡野火:

Figure 8: Detecting “wildfires” and other natural disasters with Keras, deep learning, and computer vision.
出于好玩,我随后尝试将自然灾害探测器应用到电影圣安地列斯(2015) :

Figure 9: Detecting “earthquake” damage with Keras, deep learning, and Python.
请注意我们的模型如何能够正确地将视频剪辑标记为(过度戏剧化的)地震。
您可以在下面找到完整的演示视频:
https://www.youtube.com/embed/MjK_jGmYkps?feature=oembed
用 OpenCV、计算机视觉和螺旋波试验检测帕金森病

在本教程中,您将学习如何使用 OpenCV 和机器学习在手绘的螺旋和波浪图像中自动检测帕金森病。
今天的教程灵感来自 PyImageSearch 阅读器,若奥·保罗·福拉多,一个来自巴西的博士生。
Joao 感兴趣的是利用计算机视觉和机器学习,基于几何图形(即螺旋和符号波)自动检测和预测帕金森病。
虽然我对帕金森病很熟悉,但我没有听说过几何绘画测试——一点点研究让我看到了 2017 年的一篇论文, 使用绘制螺旋 的速度和笔压的综合指数来区分帕金森病的不同阶段,作者是扎姆等人。
研究人员发现,在帕金森病患者中绘画速度较慢,笔压较低——这在帕金森病更严重/更严重的患者中尤其明显。
帕金森氏症的症状之一是肌肉颤抖和僵硬,使其更难画出平滑的螺旋和波浪。
Joao 假设,有可能仅用图画而不用测量笔在纸上的速度和压力来检测帕金森氏病。
降低对跟踪笔速度和压力的要求:
- 执行测试时不需要额外的硬件。
- 让自动检测帕金森氏症变得更加容易。
Joao 和他的顾问亲切地允许我访问他们收集的数据集,这些数据集包括由(1)帕金森病患者和(2)健康参与者绘制的螺旋和波浪。
我看了看数据集,考虑了我们的选择。
最初,Joao 想将深度学习应用到项目中,但经过考虑,我仔细解释说,深度学习虽然强大,并不总是适合这项工作的工具!例如,你不会想用锤子敲螺丝。
相反,你看着你的工具箱,仔细考虑你的选择,并抓住正确的工具。
我向 Joao 解释了这一点,然后展示了我们如何使用标准的计算机视觉和机器学习算法,以 83.33%的准确率预测图像中的帕金森氏症。
学习如何应用计算机视觉和 OpenCV 基于几何图形检测帕金森,继续阅读!
用 OpenCV、计算机视觉和螺旋波测试检测帕金森病
在本教程的第一部分,我们将简要讨论帕金森病,包括几何图形如何用于检测和预测帕金森病。
然后,我们将检查从患有帕金森症的患者(T0)和没有帕金森症的患者(T3)那里收集的数据集。
在查看数据集之后,我将介绍如何使用 HOG 图像描述符来量化输入图像,然后我们如何在提取的特征之上训练随机森林分类器。
我们将通过检查我们的结果来结束。
什么是帕金森病?
Figure 1: Patients with Parkinson’s disease have nervous system issues. Symptoms include movement issues such as tremors and rigidity. In this blog post, we’ll use OpenCV and machine learning to detect Parkinson’s disease from hand drawings consisting of spirals and waves.
帕金森病是一种影响运动的神经系统疾病。这种疾病是进行性的,分为五个不同的阶段(来源)。
- 第一阶段:通常不会影响日常生活的轻微症状,包括仅身体一侧的震颤和运动问题。
- 第二阶段:症状继续恶化,震颤和僵硬现在影响到身体的两侧。日常任务变得富有挑战性。
- 阶段 3: 失去平衡和运动,跌倒变得频繁和常见。患者仍然能够(通常)独立生活。
- 第四阶段:症状变得严重且拘束。患者无法独自生活,需要他人帮助进行日常活动。
- 第五阶段:可能无法行走或站立。病人很可能被束缚在轮椅上,甚至会产生幻觉。
虽然帕金森病无法治愈,早期检测加上适当的药物治疗可以显著地改善症状和生活质量,使其成为计算机视觉和机器学习从业者探索的重要课题。
画出螺旋和波浪来检测帕金森病
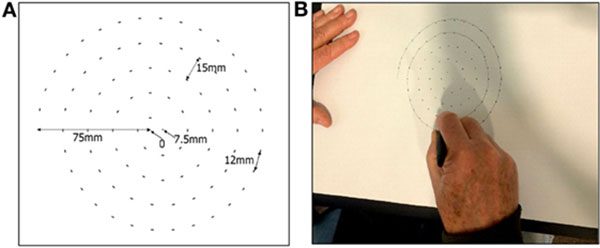
Figure 2: A 2017 study by Zham et al. concluded that it is possible to detect Parkinson’s by asking the patient to draw a spiral while tracking the speed of pen movement and pressure. No image processing was conducted in this study. (image source)
Zham 等人在 2017 年进行的一项研究发现,通过让患者画一个螺旋然后跟踪,可以检测出帕金森氏症:
- 绘图速度
- 笔压
研究人员发现,在帕金森病患者中绘画速度较慢,笔压较低——这在帕金森病更严重/更严重的患者中尤其明显。
我们将利用这样一个事实,即两种最常见的帕金森氏症症状包括震颤和肌肉僵硬,它们直接影响手绘螺旋和波浪的视觉外观。
视觉外观的变化将使我们能够训练一种计算机视觉+机器学习算法来自动检测帕金森病。
螺旋和波浪数据集
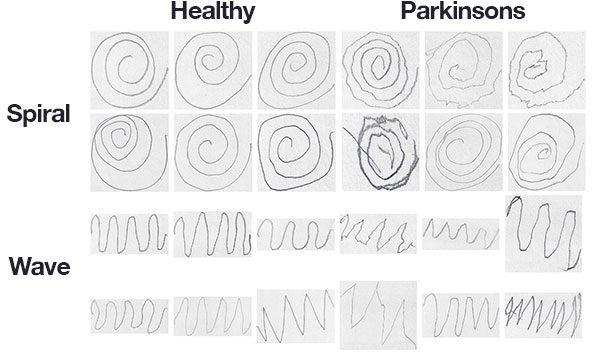
Figure 3: Today’s Parkinson’s image dataset is curated by Andrade and Folado from the NIATS of Federal University of Uberlândia. We will use Python and OpenCV to train a model for automatically classifying Parkinson’s from similar spiral/wave drawings.
我们今天在这里使用的数据集是由 Uberlândia 联邦大学 niats 的 Adriano de Oliveira Andrade 和 Joao Paulo Folado 策划的。
数据集本身由 204 幅图像组成,并预先分为训练集和测试集,包括:
- 螺旋: 102 张图像,72 次训练,30 次测试
- 波: 102 张图像,72 次训练,30 次测试
上面的图 3 显示了每个图纸和相应类别的示例。
虽然对一个人来说,在这些画中对帕金森和健康进行分类是具有挑战性的,如果不是不可能的话,但其他人在视觉外观上表现出明显的偏差——我们的目标是量化这些画的视觉外观,然后训练一个机器学习模型来对它们进行分类。
为今天的项目准备计算环境
今天的环境很容易在您的系统上启动和运行。
您将需要以下软件:
- OpenCV
- NumPy
- Scikit-learn
- Scikit-image
- imutils
每个包都可以用 Python 的包管理器 pip 安装。
但是在你深入 pip 之前,阅读这篇教程来设置你的虚拟环境并安装 OpenCV 和 pip 。
下面您可以找到配置开发环境所需的命令。
$ workon cv # insert your virtual environment name such as `cv`
$ pip install opencv-contrib-python # see the tutorial linked above
$ pip install scikit-learn
$ pip install scikit-image
$ pip install imutils
项目结构
继续并抓取今天的 【下载】 与今天的帖子相关联。的。zip 文件包含螺旋和波浪数据集以及一个 Python 脚本。
您可以在终端中使用tree命令来检查文件和文件夹的结构:
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── spiral
│ │ ├── testing
│ │ │ ├── healthy [15 entries]
│ │ │ └── parkinson [15 entries]
│ │ └── training
│ │ ├── healthy [36 entries]
│ │ └── parkinson [36 entries]
│ └── wave
│ ├── testing
│ │ ├── healthy [15 entries]
│ │ └── parkinson [15 entries]
│ └── training
│ ├── healthy [36 entries]
│ └── parkinson [36 entries]
└── detect_parkinsons.py
15 directories, 1 file
我们的dataset/首先被分解成spiral/和wave/。这些文件夹中的每一个都被进一步分成testing/和training/。最后,我们的图像保存在healthy/或parkinson/文件夹中。
今天我们将回顾一个 Python 脚本:detect_parkinsons.py。这个脚本将读取所有的图像,提取特征,并训练一个机器学习模型。最后,结果将显示在一个蒙太奇。
实施帕金森检测器脚本
为了实现我们的帕金森检测器,你可能会试图用深度学习和卷积神经网络(CNN)来解决这个问题——不过这种方法有一个问题。
开始,我们没有太多的训练数据,只有 72 张图片用于训练。当面临缺乏跟踪数据时,我们通常采用数据扩充——但在这种情况下数据扩充也是有问题的。
你需要非常小心,因为数据增强的不当使用可能会使健康患者的画看起来像帕金森患者的画(反之亦然)。
更重要的是,有效地将计算机视觉应用到问题中就是将正确的工具带到工作中——例如,你不会用螺丝刀敲钉子。
仅仅因为你可能知道如何将深度学习应用于一个问题,并不一定意味着深度学习“总是”该问题的最佳选择。
在本例中,我将向您展示在训练数据量有限的情况下,梯度方向直方图(HOG)图像描述符和随机森林分类器如何表现良好。
打开一个新文件,将其命名为detect_parkinsons.py,并插入以下代码:
# import the necessary packages
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix
from skimage import feature
from imutils import build_montages
from imutils import paths
import numpy as np
import argparse
import cv2
import os
我们从第 2-11 行的开始:
- 我们将大量使用 scikit-learn,这在前三个导入中显而易见:
- 我们使用的分类器是
RandomForestClassifier。 - 我们将使用一个
LabelEncoder把标签编码成整数。 - 一个
confusion_matrix将被建立,以便我们可以获得原始的准确性、敏感性和特异性。
- 我们使用的分类器是
- 定向梯度直方图(HOG)将来自 scikit-image 的
feature导入。 - 来自
imutils的两个模块将投入使用:- 我们将
build_montages进行可视化。 - 我们的
paths导入将帮助我们提取数据集中每个图像的文件路径。
- 我们将
- NumPy 将帮助我们计算统计数据并获取随机指数。
argparse导入将允许我们解析命令行参数。- OpenCV (
cv2)将用于读取、处理和显示图像。 - 我们的程序将通过
os模块适应 Unix 和 Windows 文件路径。
让我们用 HOG 方法定义一个量化波形/螺旋image的函数:
def quantify_image(image):
# compute the histogram of oriented gradients feature vector for
# the input image
features = feature.hog(image, orientations=9,
pixels_per_cell=(10, 10), cells_per_block=(2, 2),
transform_sqrt=True, block_norm="L1")
# return the feature vector
return features
我们将使用quantify_image函数从每个输入图像中提取特征。
首先由 Dalal 和 Triggs 在他们的 CVPR 2005 年论文中介绍,HOG 将用于量化我们的图像。
HOG 是一个结构描述符*,它将捕获并量化输入图像中局部梯度的变化。HOG 自然能够量化螺旋和波的方向是如何变化的。
此外,如果这些画有更多的“晃动”,HOG 将能够捕捉到,就像我们可能从一个帕金森氏症患者那里期待的那样。
HOG 的另一个应用是这个 PyImageSearch Gurus 样本课程。关于feature.hog参数的完整解释,请务必参考示例课程。
得到的特征是 12,996 维的特征向量(数字列表),量化波或螺旋。我们将在数据集中所有图像的特征之上训练一个随机森林分类器。
接下来,让我们加载数据并提取特征:
def load_split(path):
# grab the list of images in the input directory, then initialize
# the list of data (i.e., images) and class labels
imagePaths = list(paths.list_images(path))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the input image, convert it to grayscale, and resize
# it to 200x200 pixels, ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (200, 200))
# threshold the image such that the drawing appears as white
# on a black background
image = cv2.threshold(image, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
# quantify the image
features = quantify_image(image)
# update the data and labels lists, respectively
data.append(features)
labels.append(label)
# return the data and labels
return (np.array(data), np.array(labels))
load_split函数的目标是接受数据集path并返回所有特征data和相关类labels。让我们一步一步地分解它:
- 该函数被定义为在行 23 上接受数据集的
path(波形或螺旋)。 - 从那里我们获取输入
imagePaths,利用 imutils ( 第 26 行)。 data和labels列表都被初始化(行 27 和 28 )。- 从那里开始,我们循环所有从第 31 行开始的
imagePaths:- 每个
label都是从路径中提取的(行 33 )。 - 每个
image都被加载和预处理(第 37-44 行)。阈值处理步骤从输入图像中分割出图画,使图画在黑色背景上呈现为白色前景。 - 通过我们的
quantify_image函数(第 47 行)提取特征。 features和label分别被追加到data和labels列表中(第 50-51 行)。
- 每个
- 最后
data和labels被转换成 NumPy 数组,并在一个元组中方便地返回(第 54 行)。
让我们继续解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-t", "--trials", type=int, default=5,
help="# of trials to run")
args = vars(ap.parse_args())
我们的脚本处理两个命令行参数:
--dataset:输入数据集的路径(波浪或螺旋)。--trials:要运行的试验次数(默认情况下我们运行5试验)。
为了准备培训,我们将进行初始化:
# define the path to the training and testing directories
trainingPath = os.path.sep.join([args["dataset"], "training"])
testingPath = os.path.sep.join([args["dataset"], "testing"])
# loading the training and testing data
print("[INFO] loading data...")
(trainX, trainY) = load_split(trainingPath)
(testX, testY) = load_split(testingPath)
# encode the labels as integers
le = LabelEncoder()
trainY = le.fit_transform(trainY)
testY = le.transform(testY)
# initialize our trials dictionary
trials = {}
在这里,我们正在构建训练和测试输入目录的路径(行 65 和 66 )。
从那里,我们通过将每个路径传递到load_split ( 第 70 行和第 71 行)来加载我们的训练和测试分割。
我们的trials字典在第 79 行被初始化(回想一下,默认情况下我们将运行5试验)。
让我们现在开始试验:
# loop over the number of trials to run
for i in range(0, args["trials"]):
# train the model
print("[INFO] training model {} of {}...".format(i + 1,
args["trials"]))
model = RandomForestClassifier(n_estimators=100)
model.fit(trainX, trainY)
# make predictions on the testing data and initialize a dictionary
# to store our computed metrics
predictions = model.predict(testX)
metrics = {}
# compute the confusion matrix and and use it to derive the raw
# accuracy, sensitivity, and specificity
cm = confusion_matrix(testY, predictions).flatten()
(tn, fp, fn, tp) = cm
metrics["acc"] = (tp + tn) / float(cm.sum())
metrics["sensitivity"] = tp / float(tp + fn)
metrics["specificity"] = tn / float(tn + fp)
# loop over the metrics
for (k, v) in metrics.items():
# update the trials dictionary with the list of values for
# the current metric
l = trials.get(k, [])
l.append(v)
trials[k] = l
在第 82 行的上,我们循环每个试验。在每次试验中,我们:
- 初始化我们的随机森林分类器并训练模型(第 86 和 87 行)。关于随机森林的更多信息,包括它们如何在计算机视觉环境中使用,请务必参考 PyImageSearch 大师 。
- 在测试数据上做
predictions(行 91 )。 - 计算准确性、敏感性和特异性
metrics( 第 96-100 行)。 - 更新我们的
trials字典(第 103-108 行)。
循环查看我们的每个指标,我们将打印统计信息:
# loop over our metrics
for metric in ("acc", "sensitivity", "specificity"):
# grab the list of values for the current metric, then compute
# the mean and standard deviation
values = trials[metric]
mean = np.mean(values)
std = np.std(values)
# show the computed metrics for the statistic
print(metric)
print("=" * len(metric))
print("u={:.4f}, o={:.4f}".format(mean, std))
print("")
在第 111 行的上,我们循环遍历每个metric。
然后我们继续从trials ( 线 114 )中抓取values。
使用values,计算每个指标的平均值和标准偏差(第 115 和 116 行)。
从那里,统计数据显示在终端中。
现在是视觉盛宴——我们将创建一个蒙太奇,以便我们可以直观地分享我们的工作:
# randomly select a few images and then initialize the output images
# for the montage
testingPaths = list(paths.list_images(testingPath))
idxs = np.arange(0, len(testingPaths))
idxs = np.random.choice(idxs, size=(25,), replace=False)
images = []
# loop over the testing samples
for i in idxs:
# load the testing image, clone it, and resize it
image = cv2.imread(testingPaths[i])
output = image.copy()
output = cv2.resize(output, (128, 128))
# pre-process the image in the same manner we did earlier
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (200, 200))
image = cv2.threshold(image, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
首先,我们从测试集中随机抽取图像样本(第 126-128 行)。
我们的images列表将保存每个波浪或螺旋图像以及通过 OpenCV 绘图函数添加的注释(第 129 行)。
我们继续循环第 132 行上的随机图像索引。
在循环内部,每个图像以与训练期间相同的方式处理(行 134-142 )。
接下来,我们将使用新的 HOG +基于随机森林的分类器自动对图像进行分类,并添加颜色编码注释:
# quantify the image and make predictions based on the extracted
# features using the last trained Random Forest
features = quantify_image(image)
preds = model.predict([features])
label = le.inverse_transform(preds)[0]
# draw the colored class label on the output image and add it to
# the set of output images
color = (0, 255, 0) if label == "healthy" else (0, 0, 255)
cv2.putText(output, label, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
color, 2)
images.append(output)
# create a montage using 128x128 "tiles" with 5 rows and 5 columns
montage = build_montages(images, (128, 128), (5, 5))[0]
# show the output montage
cv2.imshow("Output", montage)
cv2.waitKey(0)
每个image用猪features ( 线 146 )量化。
然后通过这些features到model.predict ( 行 147 和 148 )对图像进行分类。
等级标签用颜色**green**表示【健康】和**red**否则(线 152 )。标签绘制在图像的左上角(行 153 和 154 )。
每个output图像然后被添加到一个images列表中(第 155 行),这样我们就可以开发一个montage ( 第 158 行)。你可以了解更多关于用 OpenCV 创建 蒙太奇。
然后通过线 161 显示montage,直到按下一个键。
训练帕金森检测器模型

Figure 4: Using Python, OpenCV, and machine learning (Random Forests), we have classified Parkinson’s patients using their hand-drawn spirals with 83.33% accuracy.
让我们来测试一下我们的帕金森病检测器吧!
使用本教程的 “下载” 部分下载源代码和数据集。
从那里,导航到您下载的位置。zip 文件,将其解压缩,然后执行下面的命令来训练我们的“wave”模型:
$ python detect_parkinsons.py --dataset dataset/wave
[INFO] loading data...
[INFO] training model 1 of 5...
[INFO] training model 2 of 5...
[INFO] training model 3 of 5...
[INFO] training model 4 of 5...
[INFO] training model 5 of 5...
acc
===
u=0.7133, o=0.0452
sensitivity
===========
u=0.6933, o=0.0998
specificity
===========
u=0.7333, o=0.0730
检查我们的输出,你会看到我们在测试集上获得了 71.33%的分类准确率,灵敏度 69.33% (真阳性率),特异性73.33%(真阴性率)。
很重要的一点是,我们要衡量灵敏度和特异性,因为:
- 灵敏度测量也被预测为阳性的真阳性。
- 特异性测量也被预测为阴性的真阴性。
机器学习模型,尤其是医疗领域的机器学习模型,在平衡真阳性和真阴性时需要格外小心:
- 我们不想把某人归类为【非帕金森】,而事实上他们是帕金森阳性。
- 同样,我们不想将某人归类为【帕金森阳性】,而事实上他们并没有患病。
现在让我们在“螺旋”图上训练我们的模型:
$ python detect_parkinsons.py --dataset dataset/spiral
[INFO] loading data...
[INFO] training model 1 of 5...
[INFO] training model 2 of 5...
[INFO] training model 3 of 5...
[INFO] training model 4 of 5...
[INFO] training model 5 of 5...
acc
===
u=0.8333, o=0.0298
sensitivity
===========
u=0.7600, o=0.0533
specificity
===========
u=0.9067, o=0.0327
这次我们在测试集上达到了 83.33%的准确率,其中的敏感度为 76.00% ,而的特异度为 90.67%。
查看标准差,我们还可以看到更少的显著更少的方差和更紧凑的分布。
当自动检测手绘中的帕金森氏症时,至少当利用这个特定的数据集时,“螺旋”图似乎更加有用和信息丰富。
摘要
在本教程中,您学习了如何使用 OpenCV 和计算机视觉在几何图形(特别是螺旋和波浪)中检测帕金森病。我们利用梯度方向直方图图像描述符来量化每个输入图像。
在从输入图像中提取特征之后,我们用森林中总共 100 棵决策树来训练随机森林分类器,获得:
- 83.33%精度对于螺旋
- 71.33%准确度对于波
有趣的是,在螺旋数据集上训练的随机森林获得了 76.00%的灵敏度,这意味着该模型能够在近 76%的时间内预测到真正的阳性(即“是的,该患者患有帕金森症”)。
本教程是计算机视觉如何应用于医学领域的又一个例子(点击此处获取更多关于 PyImageSearch 的医学教程)。
我希望您喜欢它,并发现它有助于您进行自己的研究或构建自己的医学计算机视觉应用。
要下载这篇文章的源代码,并在 PyImageSearch 上发布以后的教程时得到通知,只需在下面的表格中输入您的电子邮件地址!***
用 OpenCV 和 Python 确定 ArUco 标记类型
原文:https://pyimagesearch.com/2020/12/28/determining-aruco-marker-type-with-opencv-and-python/
在本教程中,您将学习如何使用 OpenCV 和 Python 自动确定 ArUco 标记类型/字典。
今天的教程是我们关于 ArUco 标记生成和检测的三部分系列的最后一部分:
- 用 OpenCV 和 Python 生成 ArUco 标记 (两周前的教程)
- 用 OpenCV 检测图像和视频中的阿鲁科标记(上周的帖子)
- 用 OpenCV 和 Python 自动确定 ArUco 标记类型(今日教程)
到目前为止,在这个系列中,我们已经学习了如何生成和检测 ArUco 标记;然而,这些方法依赖于这样一个事实,即我们已经知道使用了什么类型的 ArUco 字典来生成标记。
这就提出了一个问题:
如果你不知道用来生成标记的阿鲁科字典会怎么样?
如果不知道使用的 ArUco 字典,你将无法在你的图像/视频中发现它们。
当这种情况发生时,你需要一种能够自动确定图像中 ArUco 标记类型的方法——这正是我今天将向你展示的方法。
要了解如何使用 OpenCV 自动确定 ArUco 标记类型/字典,继续阅读。
使用 OpenCV 和 Python 确定 ArUco 标记类型
在本教程的第一部分,您将了解各种 ArUco 标记和 AprilTags。
从那里,您将实现一个 Python 脚本,它可以自动检测图像或视频流中是否存在任何类型的 ArUco 字典,从而允许您可靠地检测 ArUco 标记,即使您不知道是用什么 ArUco 字典生成它们!
然后,我们将回顾我们的工作成果,并讨论接下来的步骤(提示:我们将从下周开始做一些增强现实)。
ArUco 和 AprilTag 标记的类型
两周前我们学习了如何生成阿鲁科标记,然后上周我们学习了如何 在图像和视频中检测它们 — 但是如果我们还不知道我们正在使用的阿鲁科字典会怎么样呢?
当你开发一个计算机视觉应用程序,而你没有自己生成 ArUco 标记时,就会出现这种情况。相反,这些标记可能是由另一个人或组织生成的(或者,你可能只需要一个通用算法来检测图像或视频流中的任何阿鲁科类型)。
当这样的情况出现时,你需要能够自动推断出 ArUco 字典的类型。
在撰写本文时,OpenCV 文库可以检测 21 种不同类型的 AruCo/AprilTag 标记。
以下代码片段显示了分配给每种类型的标记字典的唯一变量标识符:
# define names of each possible ArUco tag OpenCV supports
ARUCO_DICT = {
"DICT_4X4_50": cv2.aruco.DICT_4X4_50,
"DICT_4X4_100": cv2.aruco.DICT_4X4_100,
"DICT_4X4_250": cv2.aruco.DICT_4X4_250,
"DICT_4X4_1000": cv2.aruco.DICT_4X4_1000,
"DICT_5X5_50": cv2.aruco.DICT_5X5_50,
"DICT_5X5_100": cv2.aruco.DICT_5X5_100,
"DICT_5X5_250": cv2.aruco.DICT_5X5_250,
"DICT_5X5_1000": cv2.aruco.DICT_5X5_1000,
"DICT_6X6_50": cv2.aruco.DICT_6X6_50,
"DICT_6X6_100": cv2.aruco.DICT_6X6_100,
"DICT_6X6_250": cv2.aruco.DICT_6X6_250,
"DICT_6X6_1000": cv2.aruco.DICT_6X6_1000,
"DICT_7X7_50": cv2.aruco.DICT_7X7_50,
"DICT_7X7_100": cv2.aruco.DICT_7X7_100,
"DICT_7X7_250": cv2.aruco.DICT_7X7_250,
"DICT_7X7_1000": cv2.aruco.DICT_7X7_1000,
"DICT_ARUCO_ORIGINAL": cv2.aruco.DICT_ARUCO_ORIGINAL,
"DICT_APRILTAG_16h5": cv2.aruco.DICT_APRILTAG_16h5,
"DICT_APRILTAG_25h9": cv2.aruco.DICT_APRILTAG_25h9,
"DICT_APRILTAG_36h10": cv2.aruco.DICT_APRILTAG_36h10,
"DICT_APRILTAG_36h11": cv2.aruco.DICT_APRILTAG_36h11
}
在本教程的剩余部分,您将学习如何自动检查输入图像中是否存在这些 ArUco 类型。
要了解更多关于这些 ArUco 类型的信息,请参考这篇文章。
配置您的开发环境
为了生成和检测 ArUco 标记,您需要安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 opencv 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,让我们检查我们项目的目录结构:
$ tree . --dirsfirst
.
├── images
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
└── guess_aruco_type.py
1 directory, 4 files
当您的任务是在图像/视频流中查找 ArUco 标签,但不确定使用什么 ArUco 字典来生成这些标签时,这样的脚本非常有用。
实施我们的 ArUco/AprilTag 标记类型标识符
我们将为我们的自动 AruCo/AprilTag 类型标识符实现的方法有点像黑客,但我的感觉是,黑客只是一个在实践中有效的启发式。
有时抛弃优雅,取而代之的是得到该死的解决方案是可以的——这个脚本就是这种情况的一个例子。
打开项目目录结构中的guess_aruco_type.py 文件,插入以下代码:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image containing ArUCo tag")
args = vars(ap.parse_args())
我们在第 2-4 行导入我们需要的命令行参数,然后解析我们的命令行参数。
# define names of each possible ArUco tag OpenCV supports
ARUCO_DICT = {
"DICT_4X4_50": cv2.aruco.DICT_4X4_50,
"DICT_4X4_100": cv2.aruco.DICT_4X4_100,
"DICT_4X4_250": cv2.aruco.DICT_4X4_250,
"DICT_4X4_1000": cv2.aruco.DICT_4X4_1000,
"DICT_5X5_50": cv2.aruco.DICT_5X5_50,
"DICT_5X5_100": cv2.aruco.DICT_5X5_100,
"DICT_5X5_250": cv2.aruco.DICT_5X5_250,
"DICT_5X5_1000": cv2.aruco.DICT_5X5_1000,
"DICT_6X6_50": cv2.aruco.DICT_6X6_50,
"DICT_6X6_100": cv2.aruco.DICT_6X6_100,
"DICT_6X6_250": cv2.aruco.DICT_6X6_250,
"DICT_6X6_1000": cv2.aruco.DICT_6X6_1000,
"DICT_7X7_50": cv2.aruco.DICT_7X7_50,
"DICT_7X7_100": cv2.aruco.DICT_7X7_100,
"DICT_7X7_250": cv2.aruco.DICT_7X7_250,
"DICT_7X7_1000": cv2.aruco.DICT_7X7_1000,
"DICT_ARUCO_ORIGINAL": cv2.aruco.DICT_ARUCO_ORIGINAL,
"DICT_APRILTAG_16h5": cv2.aruco.DICT_APRILTAG_16h5,
"DICT_APRILTAG_25h9": cv2.aruco.DICT_APRILTAG_25h9,
"DICT_APRILTAG_36h10": cv2.aruco.DICT_APRILTAG_36h10,
"DICT_APRILTAG_36h11": cv2.aruco.DICT_APRILTAG_36h11
}
我在之前的教程 中介绍了 ArUco 字典的类型,包括它们的命名约定,使用 OpenCV 和 Python 生成 ArUco 标记。
如果你想了解更多关于 ArUco 字典的信息,请参考那里;否则,简单理解一下,这个字典列出了 OpenCV 可以检测到的所有可能的 ArUco 标签。
我们将彻底遍历这个字典,为每个条目加载 ArUco 检测器,然后将检测器应用到我们的输入图像。
如果我们找到了特定的标记类型,那么我们就知道 ArUco 标记存在于图像中。
说到这里,我们现在来实现这个逻辑:
# load the input image from disk and resize it
print("[INFO] loading image...")
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
# loop over the types of ArUco dictionaries
for (arucoName, arucoDict) in ARUCO_DICT.items():
# load the ArUCo dictionary, grab the ArUCo parameters, and
# attempt to detect the markers for the current dictionary
arucoDict = cv2.aruco.Dictionary_get(arucoDict)
arucoParams = cv2.aruco.DetectorParameters_create()
(corners, ids, rejected) = cv2.aruco.detectMarkers(
image, arucoDict, parameters=arucoParams)
# if at least one ArUco marker was detected display the ArUco
# name to our terminal
if len(corners) > 0:
print("[INFO] detected {} markers for '{}'".format(
len(corners), arucoName))
在这种情况下,我们将在图像中找到的标签数量以及 ArUco 字典的名称记录到我们的终端,这样我们就可以在运行脚本后进一步调查。
如我所说,这个脚本没有多少“优雅”——它是一个彻头彻尾的黑客。但是没关系。有时候,你所需要的只是一个好的黑客来解除你的障碍,让你继续你的项目。
ArUco 标记类型识别结果
让我们使用 ArUco 标记类型标识符吧!
确保使用本教程的 【下载】 部分下载源代码和示例图片到本文。
从那里,弹出打开一个终端,并执行以下命令:
$ python guess_aruco_type.py --image images/example_01.png
[INFO] loading image...
[INFO] detected 2 markers for 'DICT_5X5_50'
[INFO] detected 5 markers for 'DICT_5X5_100'
[INFO] detected 5 markers for 'DICT_5X5_250'
[INFO] detected 5 markers for 'DICT_5X5_1000'
该图像包含五个 ArUco 图像示例(我们在 ArUco 标记的本系列第 1 部分中生成)。
ArUco 标记属于 5×5 类,id 分别高达 50、100、250 或 1000。这些结果意味着:
- 我们知道一个事实这些是 5×5 标记。
- 我们知道在这个图像中检测到的标记的 id 为 < 50。
- 但是,如果在其他图像中有更多的标记,我们可能会遇到值为 > 50 的 ArUco 5×5 标记。
- 如果我们使用的只是这张图片,那么假设
DICT_5X5_50是安全的,但是如果我们有更多的图片,继续调查并找到最小的 ArUco 字典,将所有唯一的 id 放入其中。
让我们尝试另一个示例图像:
$ python guess_aruco_type.py --image images/example_02.png
[INFO] loading image...
[INFO] detected 1 markers for 'DICT_4X4_50'
[INFO] detected 1 markers for 'DICT_4X4_100'
[INFO] detected 1 markers for 'DICT_4X4_250'
[INFO] detected 1 markers for 'DICT_4X4_1000'
[INFO] detected 4 markers for 'DICT_ARUCO_ORIGINAL'
这里你可以看到一个包含 Pantone 颜色匹配卡的示例图像。 OpenCV(错误地)认为这些标记可能属于 4×4 类,但是如果你放大示例图像,你会发现这不是真的,因为这些实际上是 6×6 标记,标记周围有一点额外的填充。
$ python guess_aruco_type.py --image images/example_03.png
[INFO] loading image...
[INFO] detected 3 markers for 'DICT_APRILTAG_36h11'
在这里,OpenCV 可以推断出我们最有可能看到的是 AprilTags。
我希望你喜欢这一系列关于 ArUco 标记和 AprilTags 的教程!
在接下来的几周里,我们将开始研究 ArUco 标记的实际应用,包括如何将它们融入我们自己的计算机视觉和图像处理管道。
总结
在本教程中,您学习了如何自动确定 ArUco 标记类型, 即使您不知道最初使用的是什么 ArUco 字典!
我们的方法有点麻烦,因为它要求我们遍历所有可能的 ArUco 字典,然后尝试在输入图像中检测特定的 ArUco 字典。
也就是说,我们的黑客技术有效,所以很难反驳。
请记住,“黑客”没有任何问题。正如我喜欢说的,hack 只是一种有效的启发式方法。
从下周开始,你将看到应用 ArUco 检测的真实世界示例,包括增强现实。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
用 OpenCV 确定对象颜色
原文:https://pyimagesearch.com/2016/02/15/determining-object-color-with-opencv/

这是我们关于形状检测和分析的三部分系列的最后一篇文章。
之前,我们学习了如何:
今天我们将对图像中的物体进行 形状检测 和 颜色标注 。
在这一点上,我们理解图像的区域可以由颜色直方图和基本颜色通道统计来表征,例如平均值和标准偏差。
但是,虽然我们可以计算这些不同的统计数据,但它们无法给我们一个实际的标签,如“红色”、“绿色”、“蓝色”或“黑色”,来标记包含特定颜色的区域。
……或者他们能?
在这篇博文中,我将详细介绍我们如何利用 Lab*颜色空间以及欧几里德距离,使用 Python 和 OpenCV 来标记、标注和确定图像中对象的颜色。
用 OpenCV 确定对象颜色
在深入研究任何代码之前,让我们简要回顾一下我们的项目结构:
|--- pyimagesearch
| |--- __init__.py
| |--- colorlabeler.py
| |--- shapedetector.py
|--- detect_color.py
|--- example_shapes.png
注意我们是如何重用我们之前的博客文章中的shapedetector.py和ShapeDetector类的。我们还将创建一个新文件,colorlabeler.py,它将被用来标记带有颜色的文本标签的图像区域。
最后,detect_color.py驱动脚本将被用来把所有的部分粘在一起。
在继续阅读本文之前,请确保您的系统上安装了 imutils Python 包:
$ pip install imutils
在本课的剩余部分,我们将使用这个库中的各种函数。
标记图像中的颜色
该项目的第一步是创建一个 Python 类,该类可用于用相关颜色标记图像中的形状。
为此,让我们在colorlabeler.py文件中定义一个名为ColorLabeler的类:
# import the necessary packages
from scipy.spatial import distance as dist
from collections import OrderedDict
import numpy as np
import cv2
class ColorLabeler:
def __init__(self):
# initialize the colors dictionary, containing the color
# name as the key and the RGB tuple as the value
colors = OrderedDict({
"red": (255, 0, 0),
"green": (0, 255, 0),
"blue": (0, 0, 255)})
# allocate memory for the L*a*b* image, then initialize
# the color names list
self.lab = np.zeros((len(colors), 1, 3), dtype="uint8")
self.colorNames = []
# loop over the colors dictionary
for (i, (name, rgb)) in enumerate(colors.items()):
# update the L*a*b* array and the color names list
self.lab[i] = rgb
self.colorNames.append(name)
# convert the L*a*b* array from the RGB color space
# to L*a*b*
self.lab = cv2.cvtColor(self.lab, cv2.COLOR_RGB2LAB)
第 2-5 行导入我们需要的 Python 包,而第 7 行定义了ColorLabeler类。
然后我们进入第 8 行的构造函数。首先,我们需要初始化一个颜色字典(第 11-14 行),它指定了颜色名称(字典的键)到 RGB 元组(字典的值)的映射。
从那里,我们为 NumPy 数组分配内存来存储这些颜色,然后初始化颜色名称列表(行 18 和 19 )。
下一步是遍历colors字典,然后分别更新 NumPy 数组和colorNames列表(第 22-25 行)。
最后,我们将 NumPy“图像”从 RGB 颜色空间转换到 Lab*颜色空间。
那么,为什么我们使用 Lab*颜色空间,而不是 RGB 或 HSV?
好吧,为了真正地将图像区域标记为包含某种颜色,我们将计算我们的已知颜色(即lab数组)的数据集和特定图像区域的平均值之间的欧几里德距离。
将选择最小化欧几里德距离的已知颜色作为颜色标识。
与 HSV 和 RGB 颜色空间不同,Lab颜色之间的欧几里德距离具有实际的感知意义*——因此我们将在本文的剩余部分使用它。
下一步是定义label方法:
def label(self, image, c):
# construct a mask for the contour, then compute the
# average L*a*b* value for the masked region
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1)
mask = cv2.erode(mask, None, iterations=2)
mean = cv2.mean(image, mask=mask)[:3]
# initialize the minimum distance found thus far
minDist = (np.inf, None)
# loop over the known L*a*b* color values
for (i, row) in enumerate(self.lab):
# compute the distance between the current L*a*b*
# color value and the mean of the image
d = dist.euclidean(row[0], mean)
# if the distance is smaller than the current distance,
# then update the bookkeeping variable
if d < minDist[0]:
minDist = (d, i)
# return the name of the color with the smallest distance
return self.colorNames[minDist[1]]
label方法需要两个参数:Lab* image包含我们想要计算颜色通道统计的形状,后面是c,我们感兴趣的image的轮廓区域。
第 34 行和第 35 行为轮廓区域构造了一个遮罩,我们可以在下面看到一个例子:
Figure 1: (Right) The original image. (Left) The mask image for the blue pentagon at the bottom of the image, indicating that we will only perform computations in the “white” region of the image, ignoring the black background.
注意如何将mask的前景区域设置为白色,而背景设置为黑色。我们将只在图像的蒙版(白色)区域进行计算。
我们还稍微腐蚀了一下蒙版,以确保只为蒙版区域计算统计数据和而不意外地包括背景(例如,由于原始图像中形状的不完美分割)。
第 37 行仅针对masked 区域计算image的 L、a和b通道中每一个的平均值(即平均值)。
最后,第 43-51 行**处理lab数组每行的循环,计算每个已知颜色和平均颜色之间的欧几里德距离,然后返回欧几里德距离最小的颜色的名称。
定义颜色标记和形状检测过程
现在我们已经定义了我们的ColorLabeler,让我们创建detect_color.py驱动脚本。在这个脚本中,我们将组合和上周的ShapeDetector类以及今天帖子中的ColorLabeler。
让我们开始吧:
# import the necessary packages
from pyimagesearch.shapedetector import ShapeDetector
from pyimagesearch.colorlabeler import ColorLabeler
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
第 2-6 行导入我们需要的 Python 包——注意我们是如何导入我们的ShapeDetector和ColorLabeler的。
第 9-12 行然后解析我们的命令行参数。像本系列的其他两篇文章一样,我们只需要一个参数:我们想要处理的图像在磁盘上的路径。
接下来,我们可以加载图像并处理它:
# load the image and resize it to a smaller factor so that
# the shapes can be approximated better
image = cv2.imread(args["image"])
resized = imutils.resize(image, width=300)
ratio = image.shape[0] / float(resized.shape[0])
# blur the resized image slightly, then convert it to both
# grayscale and the L*a*b* color spaces
blurred = cv2.GaussianBlur(resized, (5, 5), 0)
gray = cv2.cvtColor(blurred, cv2.COLOR_BGR2GRAY)
lab = cv2.cvtColor(blurred, cv2.COLOR_BGR2LAB)
thresh = cv2.threshold(gray, 60, 255, cv2.THRESH_BINARY)[1]
# find contours in the thresholded image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# initialize the shape detector and color labeler
sd = ShapeDetector()
cl = ColorLabeler()
第 16-18 行处理从磁盘加载图像,然后创建它的resized版本,跟踪原始高度到调整后高度的ratio。我们调整图像的大小,以便我们的轮廓近似对于形状识别更精确。此外,图像越小,需要处理的数据就越少,因此我们的代码会执行得更快。
第 22-25 行将高斯平滑应用于调整后的图像,转换为灰度和 Lab*,最后进行阈值处理以显示图像中的形状:
Figure 2: Thresholding is applied to segment the background from the foreground shapes.
我们在第 29-30 行的上找到形状的轮廓(即轮廓),根据我们的 OpenCV 版本注意获取cnts 的适当元组值。
我们现在准备检测图像中每个物体的形状和颜色:
# loop over the contours
for c in cnts:
# compute the center of the contour
M = cv2.moments(c)
cX = int((M["m10"] / M["m00"]) * ratio)
cY = int((M["m01"] / M["m00"]) * ratio)
# detect the shape of the contour and label the color
shape = sd.detect(c)
color = cl.label(lab, c)
# multiply the contour (x, y)-coordinates by the resize ratio,
# then draw the contours and the name of the shape and labeled
# color on the image
c = c.astype("float")
c *= ratio
c = c.astype("int")
text = "{} {}".format(color, shape)
cv2.drawContours(image, [c], -1, (0, 255, 0), 2)
cv2.putText(image, text, (cX, cY),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
我们开始在第 38 行的上循环每个轮廓,同时第 40-42 行的计算形状的中心。
使用轮廓,我们可以检测物体的shape,随后确定其在线 45 和 46 上的color。
最后,第 51-57 行处理绘制当前形状的轮廓,随后是输出图像上的颜色+文本标签。
第 60 和 61 行将结果显示到我们的屏幕上。
彩色标签结果
要运行我们的 shape detector + color labeler,只需使用本教程底部的表单将源代码下载到 post 并执行以下命令:
$ python detect_color.py --image example_shapes.png
Figure 3: Detecting the shape and labeling the color of objects in an image.
正如你从上面的 GIF 中看到的,每个物体都被正确地识别出了形状和颜色。
限制
使用这篇文章中介绍的方法来标记颜色的一个主要缺点是,由于光照条件以及各种色调和饱和度,颜色很少看起来像纯红色、绿色、蓝色等。
您通常可以使用 Lab*颜色空间和欧几里德距离来识别小颜色集,但是对于较大的调色板,根据图像的复杂性,此方法可能会返回不正确的结果。
那么,也就是说,我们怎样才能更可靠地标记图像中的颜色呢?
也许有一种方法可以让你了解真实世界中的颜色“看起来”是什么样的。
*确实有。
这正是我将在未来的博客文章中讨论的内容。
摘要
今天是我们关于形状检测和分析的三部分系列的最后一篇文章。
我们开始学习如何使用 OpenCV 计算轮廓的中心。上周我们学习了如何利用轮廓逼近检测图像中的形状。最后,今天我们把我们的形状检测算法和一个颜色标签结合起来,用来给形状加上一个特定的颜色名称。
虽然这种方法适用于半受控照明条件下的小颜色集,但它可能不适用于受控程度较低的环境中的较大调色板。正如我在这篇文章的“局限性”部分所暗示的,实际上有一种方法可以让我们“了解”真实世界中的颜色“看起来”是什么样的。我将把对这种方法的讨论留到以后的博客文章中。
那么,你对这一系列博文有什么看法?一定要在评论区让我知道。
请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在新帖子发布时得到通知!***
如何显示 Matplotlib RGB 图像
原文:https://pyimagesearch.com/2014/11/03/display-matplotlib-rgb-image/

所以我们知道 matplotlib 在生成图形和数字方面非常棒。
但是如果我们想要显示一个简单的 RGB 图像呢?我们能用 matplotlib 做到吗?
当然啦!
这篇博客文章将向你展示如何用几行代码显示 Matplotlib RGB 图像……同时也澄清了你在一起使用 OpenCV 和 Matplotlib 时可能遇到的任何警告。
教程:如何显示 Matplotlib RGB 图像
好吧,我们别浪费时间了。让我们跳到一些代码中:
>>> import matplotlib.pyplot as plt
>>> import matplotlib.image as mpimg
>>> image = mpimg.imread("chelsea-the-cat.png")
>>> plt.imshow(image)
>>> plt.show()
我们要做的第一件事是导入我们的matplotlib包。然后我们将导入matplotlib的image子包,为了方便起见,将其别名为mpimg。这个子程序包处理 matplotlib 的图像操作。
对imread方法的简单调用将我们的图像作为一个多维 NumPy 数组加载(每个数组分别对应一个红色、绿色和蓝色组件),然后imshow将我们的图像显示到我们的屏幕上。
我们可以在下面看到我们的图像:

Figure 1: Displaying a Matplotlib RGB image (note how the axes are labeled).
这是一个好的开始,但是去掉编号的轴怎么样呢?
plt.axis("off")
plt.imshow(image)
plt.show()
通过调用plt.axis("off"),我们可以移除编号轴。
执行我们的代码,我们最终会得到:

Figure 2: Displaying a Matplotlib RGB image, this time, turning off our axes.
没什么!您现在可以看到编号的轴已经消失了。
OpenCV 警告
但是当然,我们在这个博客上经常使用 OpenCV。
因此,让我们使用 OpenCV 加载一个图像,并用 matplotlib 显示它:
import cv2
image = cv2.imread("chelsea-the-cat.png")
plt.axis("off")
plt.imshow(image)
plt.show()
同样,代码很简单。
但是结果并不像预期的那样:

Figure 3: Loading an image with OpenCV and displaying it with matplotlib.
啊哦。这可不好。
我们图像的颜色明显不对!
这是为什么呢?
答案在于对 OpenCV 的警告。
OpenCV 将 RGB 图像表示为多维 NumPy 数组… 但是顺序相反!
这意味着图像实际上是以 BGR 顺序而不是 RGB 来表示的!
不过有一个简单的解决方法。
我们需要做的就是将图像从 BGR 转换成 RGB:
plt.axis("off")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
运行我们的脚本,我们可以看到我们的图像颜色现在是正确的:

Figure 4: When using OpenCV and displaying an image using matplotlib, be sure to call cv2.cvtColor first.
如我所说,显示 matplotlib RGB 图像没什么!
摘要
在这篇博文中,我展示了如何显示 matplotlib RGB 图像。
我们利用matplotlib、pyplot和mpimg来加载和显示我们的图像。
要删除图形的轴,调用plt.axis("off")。
只要记住,如果你使用 OpenCV,你的图像是以 BGR 顺序存储的,而不是 RGB!
只要你记住这一点,你就不会有任何问题!
用 OpenCV 和 Tkinter 显示视频提要
原文:https://pyimagesearch.com/2016/05/30/displaying-a-video-feed-with-opencv-and-tkinter/

我在上周的博客文章中说过,今天我会在这里再说一遍——无论怎么想象,我都不是 GUI 开发人员。
我想我对 GUI 开发的厌恶可以追溯到高中早期,那时我正在自学 Java 具体来说,如何编写 Java 小程序(还记得什么是该死的噩梦小程序吗?)利用javax和摆动。
那是我一生中的黑暗时期。
我经常生病,错过了很多学校。
有许多家庭问题正在发生。
我还没有从青少年成长为成年人,陷入青春期的痛苦之中——一个笨拙的十几岁的男孩,沉醉于冷漠,同时缺乏任何方向或目标。
在我(早期)编程生涯的那一点上,我转向 Java 和 GUI 开发,作为逃避的最后努力,就像海洛因成瘾者转向勺子和针寻求几分钟的缓解,只是为了在最初的兴奋消退后世界又会崩溃。
你看,我发现开发 GUI 应用程序很有趣。这是上瘾。它完全背离了大家太熟悉的命令行界面。
但是这种“乐趣”是有代价的。
冗长的代码块来完成哪怕是微小的简单任务。奇怪的编译错误。通宵达旦地试图解决比赛状况、回拨地狱和线程噩梦,即使是一个有经验的女裁缝也无法解开。
从那以后,我总是(在精神上)将 GUI 开发与痛苦、艰难的时期联系起来。这是一扇我从… 到现在都没有打开过的门。
在这篇博文中,我将直面我麻烦的过去,写一点代码用 OpenCV 和 Tkinter 显示一个视频提要。最终,这个 GUI 应用程序将允许我们创建一个类似“照片亭”的东西,让我们通过点击一个按钮就可以将视频流中的帧保存到磁盘上。
你会发现,我有点儿失败了,但是我想和你分享我的经验——希望更多有经验的 GUI 开发者能给我指出正确的方向。
用 OpenCV 和 Tkinter 显示视频提要
我假设你已经阅读了上周关于使用 OpenCV 和 Tkinter 的博文。在本教程中,我详细介绍了 Tkinter 是什么 , 如何安装它,以及如何编写一个简单的 Tkinter GUI 应用程序,它可以显示通过 OpenCV 加载的图像。
今天,我们将在上周帖子中获得的知识的基础上,并结合一些在早期博客帖子中讨论的特殊技术,具体来说,如何以高效、线程化的方式访问视频流。
注意:我认为我对利用线程流的渴望最终导致了这个应用程序的问题。正如我从其他来源读到的, Tkinter 没有用线程放置尼斯。
模仿照片亭应用程序
正如我们在上周的文章中所做的,让我们从创建应用程序的模型开始。下面你可以看到我们的 GUI 应用程序的主屏幕:

Figure 1: A mockup of our Photo Both Application. This GUI will contain two elements: an image panel where the frames of our live video stream will be displayed, followed by a button, that allows us to save the current frame to disk.
该屏幕有两个元素。最下面的第一张,是我们的 快照! 按钮。每次点击该按钮,从视频流中读取的当前帧将被存储在磁盘上。
第二个元素位于第一个元素的正上方,是视频流本身的一个实时显示。
我们的目标是编写 Python + OpenCV + Tkinter 代码来连续轮询视频流中的帧,更新实时显示,然后在单击快照按钮时处理将当前帧写入文件。
创建照片亭应用程序
现在我们已经创建了项目的模型,让我们继续并开始编码 GUI。打开一个新文件,将其命名为photoboothapp.py,并插入以下代码:
# import the necessary packages
from __future__ import print_function
from PIL import Image
from PIL import ImageTk
import Tkinter as tki
import threading
import datetime
import imutils
import cv2
import os
第 2-10 行处理导入我们需要的 Python 包。我们需要Image类的PIL,这是ImageTk和Label类在 Tkinter GUI 中显示图像/帧所需要的。
我们还需要 Python 的threading包来产生一个线程(独立于 Tkinter 的mainloop),用于处理视频流中新帧的轮询。
datetime模块将用于为我们保存到磁盘的每一帧构建一个人类可读的时间戳文件名。
最后,我们将需要 imutils ,我的便利函数集合用来使 OpenCV 工作更容易。如果您的系统上还没有安装imutils,让pip为您安装软件包:
$ pip install imutils
让我们继续我们的PhotoBoothApp类的定义:
class PhotoBoothApp:
def __init__(self, vs, outputPath):
# store the video stream object and output path, then initialize
# the most recently read frame, thread for reading frames, and
# the thread stop event
self.vs = vs
self.outputPath = outputPath
self.frame = None
self.thread = None
self.stopEvent = None
# initialize the root window and image panel
self.root = tki.Tk()
self.panel = None
第 13 行定义了我们的PhotoBoothApp类的构造函数。这个构造函数需要两个参数— vs,它是一个VideoStream的实例化,和outputPath,我们想要存储我们捕获的快照的路径。
第 17 行和第 18 行存储我们的视频流对象和输出路径,而第 19-21 行对最近读取的frame、用于控制我们的视频轮询循环的thread和用于指示何时应该停止帧池线程的stopEvent``thread.Event对象执行一系列初始化。
然后我们初始化root Tkinter 窗口和用于在 GUI 中显示我们的框架的面板(第 24 行和第 25 行)。
我们继续下面的构造函数的定义:
# create a button, that when pressed, will take the current
# frame and save it to file
btn = tki.Button(self.root, text="Snapshot!",
command=self.takeSnapshot)
btn.pack(side="bottom", fill="both", expand="yes", padx=10,
pady=10)
# start a thread that constantly pools the video sensor for
# the most recently read frame
self.stopEvent = threading.Event()
self.thread = threading.Thread(target=self.videoLoop, args=())
self.thread.start()
# set a callback to handle when the window is closed
self.root.wm_title("PyImageSearch PhotoBooth")
self.root.wm_protocol("WM_DELETE_WINDOW", self.onClose)
第 29-32 行创建我们的 快照! 按钮,单击该按钮将调用takeSnapshot方法(我们将在本例中稍后定义)。
为了从我们的视频流中连续轮询帧并更新 GUI 中的panel,我们需要生成一个单独的线程来监控我们的视频传感器并获取最近读取的帧(第 36-38 行)。
最后,我们设置了一个回调函数来处理窗口关闭时的情况,这样我们就可以执行清理操作,并且(理想情况下)停止视频轮询线程并释放所有资源(不幸的是,这在实践中并没有像我预期的那样工作)。
接下来,让我们定义videoLoop函数,顾名思义,它监视视频流中的新帧:
def videoLoop(self):
# DISCLAIMER:
# I'm not a GUI developer, nor do I even pretend to be. This
# try/except statement is a pretty ugly hack to get around
# a RunTime error that Tkinter throws due to threading
try:
# keep looping over frames until we are instructed to stop
while not self.stopEvent.is_set():
# grab the frame from the video stream and resize it to
# have a maximum width of 300 pixels
self.frame = self.vs.read()
self.frame = imutils.resize(self.frame, width=300)
# OpenCV represents images in BGR order; however PIL
# represents images in RGB order, so we need to swap
# the channels, then convert to PIL and ImageTk format
image = cv2.cvtColor(self.frame, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = ImageTk.PhotoImage(image)
# if the panel is not None, we need to initialize it
if self.panel is None:
self.panel = tki.Label(image=image)
self.panel.image = image
self.panel.pack(side="left", padx=10, pady=10)
# otherwise, simply update the panel
else:
self.panel.configure(image=image)
self.panel.image = image
except RuntimeError, e:
print("[INFO] caught a RuntimeError")
正如我在这篇博文的开头所说——我不是 GUI 开发人员,我对 Tkinter 也没有什么经验。为了避开 Tkinter 抛出的RunTime异常(可能是由于线程),我求助于真正的丑陋的try/except黑客来捕捉RunTime错误。我试图解决这个 bug,但在几个小时没有任何进展后,我最终放弃了,求助于这个黑客。
第 51 行开始一个循环,用于从我们的视频传感器读取帧。这个循环将继续,直到stopEvent被设置,指示线程应该返回到它的父线程。
第 54 行和第 55 行从我们的视频流中读取frame,并使用imutils库调整其大小。
我们现在需要对我们的图像进行一些格式化。首先,OpenCV 以 BGR 顺序表示图像;然而,PIL 希望图像以 RGB 顺序存储。为了解决这个问题,我们需要通过调用cv2.cvtColor来交换频道。从那里,我们将frame转换成 PIL/枕头格式,然后是ImageTk格式。在 Tkinter 窗口中显示图像时需要ImageTk格式。
如果我们的panel没有初始化,第 65-68 行通过创建Label来处理实例化它。我们特别注意第 67 行的来存储对image的引用,确保 Python 的垃圾收集例程不会在image显示在我们的屏幕上之前回收它。
否则,如果panel已经被初始化,我们简单地用第 71-73 行上最近的image来更新它。
现在,让我们来看看takeSnapshot回调:
def takeSnapshot(self):
# grab the current timestamp and use it to construct the
# output path
ts = datetime.datetime.now()
filename = "{}.jpg".format(ts.strftime("%Y-%m-%d_%H-%M-%S"))
p = os.path.sep.join((self.outputPath, filename))
# save the file
cv2.imwrite(p, self.frame.copy())
print("[INFO] saved {}".format(filename))
当“快照!”点击按钮,调用takeSnapshot函数。第 81-83 行基于当前时间戳为frame生成一个文件名。
然后我们通过调用cv2.imwrite将frame保存到磁盘的行 86 上。
最后,我们可以定义我们的最后一个方法,onClose:
def onClose(self):
# set the stop event, cleanup the camera, and allow the rest of
# the quit process to continue
print("[INFO] closing...")
self.stopEvent.set()
self.vs.stop()
self.root.quit()
当我们点击 GUI 中的“X”关闭应用程序时,这个函数被调用。首先,我们设置stopEvent,这样我们的无限videoLoop就停止了,线程返回。然后我们清理视频流指针,让root应用程序完成关闭。
构建照相亭驱动程序
创建 Photo Booth 的最后一步是构建驱动程序脚本,用于初始化VideoStream和PhotoBoothApp。为了创建驱动程序脚本,我将下面的代码添加到一个名为photo_booth.py的文件中:
# import the necessary packages
from __future__ import print_function
from pyimagesearch.photoboothapp import PhotoBoothApp
from imutils.video import VideoStream
import argparse
import time
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory to store snapshots")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# start the app
pba = PhotoBoothApp(vs, args["output"])
pba.root.mainloop()
第 9-14 行处理解析我们脚本的命令行参数。第一个命令行参数--output,是 必需的 。--output开关只是我们想要存储输出快照的路径。
然后我们有--picamera,一个 可选的 开关,用于指示是否应该使用树莓派相机模块。默认情况下,这个值将是 -1 ,表示应该使用我们的内置/USB 网络摄像头。如果我们想使用 Pi 摄像机,我们可以指定一个值 > 0 。在这篇博文中,你可以了解更多关于这个参数的信息,以及如何结合VideoStream类使用它。
第 18 和 19 行初始化我们的VideoStream并允许摄像机传感器预热。
最后,线 22 和 23 线启动PhotoBoothApp。
经营我们的照相亭
要运行我们的 photo booth 应用程序,请确保您已经安装了必要的库和包(详见之前的博文)。确保系统配置正确后,执行以下命令:
$ python photo_booth.py --output output
摄像头传感器预热后,您应该会看到以下显示:

Figure 2: Once our app launches, you should see the live stream of the camera displayed in the Tkinter window.
注意我们的 GUI 是如何包含来自网络摄像头的实时流以及用于触发快照的按钮的。
点击快照按钮后,我可以看到我的output目录中包含了我刚刚拍摄的照片:

Figure 3: Whenever I click the “Snapshot!” button, the current frame is saved to my local disk.
下面我放了一个短片来演示 Photo Booth 应用程序:
https://www.youtube.com/embed/CMwin1SFb-I?feature=oembed
用 OpenCV 绘图
原文:https://pyimagesearch.com/2021/01/27/drawing-with-opencv/
在本教程中,你将学习如何使用 OpenCV 的基本绘图功能。您将学习如何使用 OpenCV 来绘制:
- 线
- 长方形
- 环

您还将学习如何使用 OpenCV 在图像和用 NumPy 初始化的空白/空数组上绘图。
学习如何使用 OpenCV 的基本绘图功能, 继续阅读。
用 OpenCV 绘图
在本教程的第一部分,我们将简要回顾 OpenCV 的绘图功能。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
完成审查后,我们将继续实现两个 Python 脚本:
basic_drawing.pyimage_drawing.py
这些脚本将帮助您理解如何使用 OpenCV 执行基本的绘图功能。
本指南结束时,您将了解如何使用 OpenCV 绘制直线、圆和矩形。
OpenCV 中的绘图功能
OpenCV 有许多绘图函数,您可以使用它们来绘制各种形状,包括不规则形状的多边形,但是您将看到的三个最常见的 OpenCV 绘图函数是:
cv2.line:在图像上画一条线,从指定的 (x,y) 坐标开始,到另一个 (x,y) 坐标结束cv2.circle:在由中心 (x,y) 坐标和提供的半径指定的图像上画一个圆cv2.rectangle:在由左上角和右下角指定的图像上绘制一个矩形 (x,y)-坐标
今天我们将讨论这三个绘图功能。
但是,值得注意的是,还有更高级的 OpenCV 绘图函数,包括:
cv2.ellipse:在图像上画一个椭圆cv2.polylines:绘制一组 (x,y) 坐标指定的多边形轮廓cv2.fillPoly:绘制多边形,但不是绘制轮廓,而是填充多边形cv2.arrowedLine:画一个箭头,从起点 (x,y) 坐标指向终点 (x,y) 坐标
这些 OpenCV 绘图函数不太常用,但仍然值得注意。我们偶尔会在 PyImageSearch 博客上使用它们。
配置您的开发环境
为了遵循本指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你的系统启动并运行。
在配置开发环境时遇到了问题?

Figure 1: Having trouble configuring your development environment? Want access to pre-configured Jupyter Notebooks running on Google Colab? Be sure to join PyImageSearch Plus — your system will be up and running with this tutorial in a matter of minutes.
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从查看 OpenCV 绘图项目的项目目录结构开始:
$ tree . --dirsfirst
.
├── adrian.png
├── basic_drawing.py
└── image_drawing.py
0 directories, 3 files
我们今天要复习两个 Python 脚本:
- 初始化一个空的 NumPy 数组,并利用 OpenCV 绘制线条、圆形和矩形
image_drawing.py:从磁盘加载adrian.png,然后在图像上绘制(而不是空的/空白的 NumPy 数组画布)。
我们现在准备开始了!
用 OpenCV 实现基本绘图功能
在我们绘制实际图像之前,让我们首先学习如何初始化一个空的 NumPy 数组/图像并在其上绘制。
打开项目目录结构中的basic_drawing.py文件,让我们开始工作。
# import the necessary packages
import numpy as np
import cv2
# initialize our canvas as a 300x300 pixel image with 3 channels
# (Red, Green, and Blue) with a black background
canvas = np.zeros((300, 300, 3), dtype="uint8")
第 2 行和第 3 行导入我们将要使用的包。
作为一种快捷方式,我们将为numpy创建一个别名为np。您将在所有利用 NumPy 的 PyImageSearch 教程中看到这种约定(事实上,您在 Python 社区中也会经常看到这种约定!)
我们还将导入cv2,因此我们可以访问 OpenCV 库。
初始化我们的图像是在线 7 上处理的。我们使用np.zeros方法构造一个 300 行 300 列的 NumPy 数组,得到一个 300 x 300 像素的图像。我们还为 3 个通道分配空间——红色、绿色和蓝色各一个。顾名思义,np.zeros方法用初始值零填充数组中的每个元素。
其次,需要注意的是np.zeros方法的第二个参数:数据类型dtype。
因为我们用范围【0,255】内的像素来表示我们的图像,所以我们必须使用 8 位无符号整数,或uint8。我们可以使用许多其他的数据类型(常见的包括 32 位整数和 32 位和 64 位浮点数),但是对于本课中的大多数例子,我们将主要使用uint8。
现在我们已经初始化了画布,我们可以开始绘制了:
# draw a green line from the top-left corner of our canvas to the
# bottom-right
green = (0, 255, 0)
cv2.line(canvas, (0, 0), (300, 300), green)
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
# draw a 3 pixel thick red line from the top-right corner to the
# bottom-left
red = (0, 0, 255)
cv2.line(canvas, (300, 0), (0, 300), red, 3)
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
我们在第 11 行做的第一件事是定义一个用于表示颜色“绿色”的元组然后,我们从图像左上角的点 (0,0)(T4)到图像右下角的点 (300,300) (在第 12 行处)画一条绿线。****
为了画线,我们使用了cv2.line方法:
- 这个方法的第一个参数是我们将要绘制的图像。在这种情况下,是我们的
canvas。 - 第二个参数是该行的起点。我们选择从图像左上角的开始我们的行,在点 (0,0)——同样,记住 Python 语言是零索引的。
- 我们还需要为该行提供一个终点(第三个参数)。我们定义我们的终点为 (300,300) ,图像右下角的。**
- 最后一个参数是我们的线的颜色(在本例中是绿色)。第 13 和 14 行显示我们的图像,然后等待按键(见图 2 )。
**
Figure 2: Drawing lines with OpenCV.
如你所见,使用cv2.line函数非常简单!但是在cv2.line方法中还有一个重要的参数需要考虑:厚度。
在第 18-21 行,我们将红色定义为一个元组(同样是 BGR 格式,而不是 RGB 格式)。然后我们从图像右上角的到左下角的画一条红线。该方法的最后一个参数控制线条的粗细——我们决定将粗细设为 3 个像素。我们再次显示我们的图像并等待按键:**

Figure 3: Drawing multiple lines with OpenCV.
画一条线很简单。现在我们可以继续画矩形了。查看下面的代码了解更多细节:
# draw a green 50x50 pixel square, starting at 10x10 and ending at 60x60
cv2.rectangle(canvas, (10, 10), (60, 60), green)
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
# draw another rectangle, this one red with 5 pixel thickness
cv2.rectangle(canvas, (50, 200), (200, 225), red, 5)
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
# draw a final rectangle (blue and filled in )
blue = (255, 0, 0)
cv2.rectangle(canvas, (200, 50), (225, 125), blue, -1)
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
在的第 24 行,我们使用了cv2.rectangle的方法。这个方法的签名与上面的cv2.line方法相同,但是无论如何让我们研究一下每个参数:
- 第一个参数是我们要在其上绘制矩形的图像。我们想利用我们的
canvas,所以我们把它传递到方法中。 - 第二个参数是我们矩形的起始位置 (x,y)—这里,我们从点 (10,10) 开始矩形。
- 然后,我们必须为矩形提供一个结束点 (x,y) 。我们决定在 (60,60) 处结束我们的矩形,定义一个 50 x 50 像素的区域(花一秒钟让自己相信最终的矩形是 50 x 50 )。
- 最后,最后一个参数是我们要绘制的矩形的颜色。这里,我们画一个绿色的长方形。
正如我们可以控制线条的粗细一样,我们也可以控制矩形的粗细。第 29 行提供了厚度参数。这里,我们画一个 5 像素厚的红色矩形,从点 (50,200) 开始,到 (200,225)结束。
至此,我们只画出了一个长方形的轮廓。我们如何画一个“完全填充”的矩形?
简单。我们只是为厚度参数传递了一个负值。
演示了如何绘制一个纯色的矩形。我们画一个蓝色的矩形,从 (200,50) 开始,到 (225,125) 结束。通过指定-1(或者使用cv2.FILLED关键字)作为厚度,我们的矩形被绘制为纯蓝色。
图 4 显示绘制我们的线条和矩形的完整输出:

Figure 4: Using OpenCV to draw lines and rectangles.
如您所见,输出与我们的代码相匹配。我们可以从左上角到右下角画一条绿线,然后从右上角到左下角画一条粗红线。
我们还能够画出一个绿色矩形 T1,一个稍微 T2 粗一点的红色矩形 T3,以及一个完全填充的蓝色矩形 T4。
这很好,但是圆圈呢?
怎样才能用 OpenCV 画圆?
画圆和画矩形一样简单,但函数参数略有不同:
# re-initialize our canvas as an empty array, then compute the
# center (x, y)-coordinates of the canvas
canvas = np.zeros((300, 300, 3), dtype="uint8")
(centerX, centerY) = (canvas.shape[1] // 2, canvas.shape[0] // 2)
white = (255, 255, 255)
# loop over increasing radii, from 25 pixels to 150 pixels in 25
# pixel increments
for r in range(0, 175, 25):
# draw a white circle with the current radius size
cv2.circle(canvas, (centerX, centerY), r, white)
# show our work of art
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
在第 41 行,我们将画布重新初始化为空白:

Figure 5: Re-initializing our canvas as a blank image.
第 42 行计算两个变量:centerX和centerY。这两个变量代表图像中心的 (x,y)-坐标。
我们通过检查 NumPy 数组的形状来计算中心,然后除以 2:
- 图像的高度可以在
canvas.shape[0](行数)中找到 - 宽度在
canvas.shape[1](列数)中找到
最后,行 43 定义了一个白色像素(即,红色、绿色和蓝色分量的每一个的桶都是“满的”)。
现在,让我们画一些圆圈!
在第 45 行,我们循环了几个半径值,从0开始,到150结束,每一步增加25。range功能是独占;因此,我们指定停止值为175而不是150。
要亲自演示这一点,请打开 Python shell,并执行以下代码:
$ python
>>> list(range(0, 175, 25))
[0, 25, 50, 75, 100, 125, 150]
注意range的输出如何在150停止,并且不包括175。
第 49 行处理圆的实际绘制:
- 第一个参数是我们的
canvas,我们想要在上面画圆的图像。 - 然后我们需要提供一个点,我们将围绕这个点画一个圆。我们传入一个元组
(centerX, centerY),这样我们的圆就会以图像的中心为中心。 - 第三个参数是我们想要画的圆的半径
r。 - 最后,我们传入圆圈的颜色:在本例中,是白色。
第 52 行和第 53 行然后显示我们的图像并等待按键:

Figure 6: Drawing a bullseye with OpenCV.
查看图 6 ,你会看到我们已经画了一个简单的靶心!图像正中心的“点”是以半径 0 绘制的。较大的圆是从我们的for循环中以不断增加的半径尺寸画出的。
不算太坏。但是我们还能做什么呢?
让我们画一些抽象画:
# re-initialize our canvas once again
canvas = np.zeros((300, 300, 3), dtype="uint8")
# let's draw 25 random circles
for i in range(0, 25):
# randomly generate a radius size between 5 and 200, generate a
# random color, and then pick a random point on our canvas where
# the circle will be drawn
radius = np.random.randint(5, high=200)
color = np.random.randint(0, high=256, size=(3,)).tolist()
pt = np.random.randint(0, high=300, size=(2,))
# draw our random circle on the canvas
cv2.circle(canvas, tuple(pt), radius, color, -1)
# display our masterpiece to our screen
cv2.imshow("Canvas", canvas)
cv2.waitKey(0)
我们的代码从第 59 行的开始,有更多的循环。这一次,我们不是在我们的半径大小上循环——相反,我们将绘制25随机圆,通过np.random.randint函数利用 NumPy 的随机数功能。
要画一个随机的圆,我们需要生成三个值:圆的radius、圆的color和pt —将要画圆的地方的 (x,y)—坐标。
我们在第 63 行的上生成一个【5,200】范围内的radius值。这个值控制我们的圆有多大。
在第 64 行,我们随机生成一个color。我们知道,RGB 像素的颜色由范围【0,255】内的三个值组成。为了得到三个随机整数而不是一个整数,我们传递关键字参数size=(3,),指示 NumPy 返回一个包含三个数字的列表。
最后,我们需要一个 (x,y)-中心点来画我们的圆。我们将再次使用 NumPy 的np.random.randint函数在【0,300】范围内生成一个点。
然后在第 68 行上画出我们的圆,使用我们随机生成的radius、color和pt。注意我们是如何使用厚度-1的,所以我们的圆被绘制成纯色,而不仅仅是轮廓。
第 71 行和第 72 行展示了我们的杰作,你可以在图 7 中看到:

Figure 7: Drawing multiple circles with OpenCV.
注意每个圆在画布上有不同的大小、颜色和位置。
OpenCV 基本绘图结果
要执行我们的基本绘图脚本,请确保访问 “下载” 部分以检索源代码和示例图像。
从那里,您可以执行以下命令:
$ python basic_drawing.py
您的输出应该与前一部分的输出相同。
使用 OpenCV 在图像上绘图
到目前为止,我们只探索了在空白画布上绘制形状。但是如果我们想在一个现有的图像上画形状呢?
原来,在现有图像上绘制形状的代码是 完全相同的 就好像我们在 NumPy 生成的空白画布上绘图一样。
为了演示这一点,让我们看一些代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
我们只需要一个参数--image,它是我们在磁盘上的输入图像的路径。默认情况下,我们将--image命令行参数设置为指向项目目录结构中的adrian.png图像。
# load the input image from disk
image = cv2.imread(args["image"])
# draw a circle around my face, two filled in circles covering my
# eyes, and a rectangle over top of my mouth
cv2.circle(image, (168, 188), 90, (0, 0, 255), 2)
cv2.circle(image, (150, 164), 10, (0, 0, 255), -1)
cv2.circle(image, (192, 174), 10, (0, 0, 255), -1)
cv2.rectangle(image, (134, 200), (186, 218), (0, 0, 255), -1)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
第 12 行从磁盘加载我们的--image。从那里,我们继续:
- 在我的头(线 16 )周围画一个空的圆(不是填充)
- 画两个填充的圆圈遮住我的眼睛(第 17 行和第 18 行
- 在我的嘴上画一个矩形
我们的最终输出image,然后显示在我们的屏幕上。
OpenCV 图像绘制结果
让我们看看如何使用 OpenCV 在图像上绘制,而不是使用 NumPy 生成的“空白画布”。
首先访问本指南的 “下载” 部分,检索源代码和示例图像。
然后,您可以执行以下命令:
$ python image_drawing.py

Figure 8: Drawing shapes on an image with OpenCV.
在这里,你可以看到我们在我的脸周围画了一个圆形,在我的眼睛上画了两个圆形,在我的嘴巴上画了一个矩形。
事实上,在从磁盘加载的图像和空白数字数组上绘制形状没有区别。只要我们的图像/画布可以表示为一个 NumPy 数组,OpenCV 也会在其上绘制。**
总结
在本教程中,您学习了如何使用 OpenCV 绘图。具体来说,您学习了如何使用 OpenCV 来绘制:
- 线
- 环
- 长方形
使用cv2.line功能绘制线条。我们用 OpenCV 的cv2.circle函数画圆,用cv2.rectangle方法画矩形。
OpenCV 中还存在其他绘图功能。但是,这些是您最常使用的功能。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!**
利用 OpenCV 进行睡意检测
原文:https://pyimagesearch.com/2017/05/08/drowsiness-detection-opencv/
https://www.youtube.com/embed/Q23K7G1gJgY?feature=oembed
使用 Keras 调谐器和 TensorFlow 轻松调整超参数
原文:https://pyimagesearch.com/2021/06/07/easy-hyperparameter-tuning-with-keras-tuner-and-tensorflow/
在本教程中,您将学习如何使用 Keras Tuner 软件包通过 Keras 和 TensorFlow 轻松进行超参数调谐。
本教程是我们关于超参数调优的四部分系列的第四部分:
- 使用 scikit-learn 和 Python 进行超参数调优的介绍(本系列的第一篇教程)
- 【网格搜索超参数调优】用 scikit-learn(GridSearchCV)(教程来自两周前)
- 用 scikit-learn、Keras 和 TensorFlow 进行深度学习的超参数调优(上周的帖子)
- 使用 Keras 调谐器和 TensorFlow 轻松调整超参数(今天的帖子)
上周我们学习了如何使用 scikit-learn 与 Keras 和 TensorFlow 进行交互,以执行随机交叉验证的超参数搜索。
然而,还有更先进的超参数调整算法,包括贝叶斯超参数优化和超带,这是对传统随机超参数搜索的适应和改进。
贝叶斯优化和 Hyperband 都在 keras 调谐器包中实现。正如我们将看到的,在您自己的深度学习脚本中使用 Keras Tuner 就像单个导入和单个类实例化一样简单——从那里开始,它就像训练您的神经网络一样简单!
除了易于使用,你会发现 Keras 调谐器:
- 集成到您现有的深度学习培训管道中,只需最少的代码更改
- 实现新的超参数调整算法
- 可以用最少的努力提高准确性
要了解如何使用 Keras Tuner 调整超参数, 继续阅读。
使用 Keras 调谐器和 TensorFlow 轻松调谐超参数
在本教程的第一部分,我们将讨论 Keras Tuner 包,包括它如何帮助用最少的代码自动调整模型的超参数。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
我们今天要回顾几个 Python 脚本,包括:
- 我们的配置文件
- 模型架构定义(我们将调整超参数,包括 CONV 层中的过滤器数量、学习速率等。)
- 绘制我们训练历史的实用程序
- 一个驱动程序脚本,它将所有部分粘合在一起,并允许我们测试各种超参数优化算法,包括贝叶斯优化、超波段和传统的随机搜索
我们将讨论我们的结果来结束本教程。
什么是 Keras Tuner,它如何帮助我们自动调整超参数?
上周,您学习了如何使用 scikit-learn 的超参数搜索功能来调整基本前馈神经网络的超参数(包括批量大小、要训练的时期数、学习速率和给定层中的节点数)。
虽然这种方法工作得很好(并且给了我们一个很好的准确性提升),但是代码并不一定“漂亮”
更重要的是,它使我们不容易调整模型架构的“内部”参数(例如,CONV 层中过滤器的数量、步幅大小、池的大小、辍学率等。).
像 keras tuner 这样的库使得以一种有机的方式将超参数优化实现到我们的训练脚本中变得非常简单:
- 当我们实现我们的模型架构时,我们定义我们想要为给定的参数搜索什么范围(例如,我们的第一 CONV 层中的过滤器的数量,第二 CONV 层中的过滤器的数量,等等)。)
- 然后我们定义一个
Hyperband、RandomSearch或BayesianOptimization的实例 - keras tuner 包负责剩下的工作,运行多次试验,直到我们收敛到最佳的超参数集
这听起来可能很复杂,但是一旦你深入研究了代码,这就很容易了。
此外,如果您有兴趣了解更多关于 Hyperband 算法的信息,请务必阅读李等人的 2018 年出版物, Hyperband:一种基于 Bandit 的超参数优化新方法 。
要了解关于贝叶斯超参数优化的更多信息,请参考多伦多大学教授兼研究员罗杰·格罗斯的幻灯片。
配置您的开发环境
要遵循本指南,您需要安装 TensorFlow、OpenCV、scikit-learn 和 Keras Tuner。
所有这些软件包都是 pip 可安装的:
$ pip install tensorflow # use "tensorflow-gpu" if you have a GPU
$ pip install opencv-contrib-python
$ pip install scikit-learn
$ pip install keras-tuner
此外,这两个指南提供了在您的计算机上安装 Keras 和 TensorFlow 的更多详细信息、帮助和提示:
这两个教程都有助于在一个方便的 Python 虚拟环境中为您的系统配置这篇博客文章所需的所有软件。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们可以使用 Keras Tuner 来调优我们的 Keras/TensorFlow 模型的超参数之前,让我们首先回顾一下我们的项目目录结构。
通过访问本教程的 【下载】 部分来检索源代码。
从那里,您将看到以下目录结构:
$ tree . --dirsfirst --filelimit 10
.
├── output
│ ├── bayesian [12 entries exceeds filelimit, not opening dir]
│ ├── hyperband [79 entries exceeds filelimit, not opening dir]
│ └── random [12 entries exceeds filelimit, not opening dir]
│ ├── bayesian_plot.png
│ ├── hyperband_plot.png
│ └── random_plot.png
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ ├── model.py
│ └── utils.py
└── train.py
2 directories, 8 files
在pyimagesearch模块中,我们有三个 Python 脚本:
config.py:包含重要的配置选项,例如输出路径目录、输入图像尺寸以及数据集中唯一类标签的数量model.py:包含build_model函数,负责实例化我们模型架构的一个实例;该函数设置将要调整的超参数以及每个超参数的适当取值范围utils.py:实现save_plot,一个助手/便利函数,生成训练历史图
train.py脚本使用pyimagesearch模块中的每个实现来执行三种类型的超参数搜索:
- 超波段
- 随意
- 贝叶斯优化
每个实验的结果都保存在output目录中。为每个实验使用专用输出目录的主要好处是,您可以启动、停止和恢复超参数调整实验。这一点尤其重要,因为超参数调整可能需要相当长的时间。
创建我们的配置文件
在使用 Keras Tuner 优化超参数之前,我们首先需要创建一个配置文件来存储重要的变量。
打开项目目录结构中的config.py文件,插入以下代码:
# define the path to our output directory
OUTPUT_PATH = "output"
# initialize the input shape and number of classes
INPUT_SHAPE = (28, 28, 1)
NUM_CLASSES = 10
第 2 行定义了我们的输出目录路径(即存储训练历史图和超参数调整实验日志的位置)。
在这里,我们定义了数据集中图像的输入空间维度以及唯一类标签的总数(第 5 行和第 6 行)。
下面我们定义我们的训练变量:
# define the total number of epochs to train, batch size, and the
# early stopping patience
EPOCHS = 50
BS = 32
EARLY_STOPPING_PATIENCE = 5
对于每个实验,我们将允许我们的模型训练最大的50个时期。我们将在每个实验中使用批量32。
对于没有显示有希望迹象的短路实验,我们定义了一个早期停止耐心5,这意味着如果我们的精度在5个时期后没有提高,我们将终止训练过程,并继续进行下一组超参数。
调整超参数是一个计算量非常大的过程。如果我们可以通过取消表现不佳的实验来减少需要进行的实验数量,我们就可以节省大量的时间。
实现我们的绘图助手功能
在为我们的模型找到最佳超参数后,我们将希望在这些超参数上训练模型,并绘制我们的训练历史(包括训练集和验证集的损失和准确性)。
为了简化这个过程,我们可以在utils.py文件中定义一个save_plot助手函数。
现在打开这个文件,让我们来看看:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary package
import matplotlib.pyplot as plt
def save_plot(H, path):
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.plot(H.history["accuracy"], label="train_acc")
plt.plot(H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(path)
save_plot函数需要我们传入两个变量:通过调用model.fit获得的训练历史H和输出图的path。
然后,我们绘制训练损失、验证损失、训练准确度和验证准确度。
结果图保存到输出path。
创建我们的 CNN
可以说,本教程最重要的部分是定义我们的 CNN 架构,也就是说,因为这是我们设置想要调谐的超参数的地方。
打开pyimagesearch模块内的model.py文件,让我们看看发生了什么:
# import the necessary packages
from . import config
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
2-11 行导入我们需要的包。请注意我们是如何导入我们在本指南前面创建的config文件的。
如果您以前使用 Keras 和 TensorFlow 创建过 CNN,那么这些导入的其余部分对您来说应该很熟悉。如果没有,建议你看我的 Keras 教程,连同我的书 用 Python 进行计算机视觉的深度学习 。
现在让我们构建我们的模型:
def build_model(hp):
# initialize the model along with the input shape and channel
# dimension
model = Sequential()
inputShape = config.INPUT_SHAPE
chanDim = -1
# first CONV => RELU => POOL layer set
model.add(Conv2D(
hp.Int("conv_1", min_value=32, max_value=96, step=32),
(3, 3), padding="same", input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
build_model函数接受单个对象hp,这是我们从 Keras Tuner 得到的超参数调整对象。在本教程的后面,我们将在我们的驱动脚本train.py中创建hp。
第 16-18 行初始化我们的model,获取我们数据集中输入图像的空间维度,并设置通道排序(假设“通道最后”)。
从那里,行 21-26 定义了我们的第一个 conv =>=>池层集,最重要的一行是行 22。
这里,我们定义了第一个要搜索的超参数——conv 层中过滤器的数量。
由于 CONV 层中滤镜的数量是一个整数,我们使用hp.Int创建一个整数超参数对象。
超参数被命名为conv_1,可以接受范围【32,96】内的值,步长为32。这意味着conv_1的有效值是32, 64, 96。
我们的超参数调谐器将自动为这个 CONV 层选择最大化精度的最佳值。
同样,我们对第二个 CONV => RELU = >池层集做同样的事情:
# second CONV => RELU => POOL layer set
model.add(Conv2D(
hp.Int("conv_2", min_value=64, max_value=128, step=32),
(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
对于我们的第二个 CONV 层,我们允许在【64,128】范围内学习更多的过滤器。步长为32,这意味着我们将测试64, 96, 128的值。
我们将对完全连接的节点数量做类似的事情:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(hp.Int("dense_units", min_value=256,
max_value=768, step=256)))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(config.NUM_CLASSES))
model.add(Activation("softmax"))
第 38 行和第 39 行定义了我们的 FC 层。我们希望调整这一层中的节点数量。我们指定最少256和最多768个节点,允许一步256。
我们的下一个代码块使用了hp.Choice函数:
# initialize the learning rate choices and optimizer
lr = hp.Choice("learning_rate",
values=[1e-1, 1e-2, 1e-3])
opt = Adam(learning_rate=lr)
# compile the model
model.compile(optimizer=opt, loss="categorical_crossentropy",
metrics=["accuracy"])
# return the model
return model
对于我们的学习率,我们希望看到1e-1、1e-2和1e-3中哪一个表现最好。使用hp.Choice将允许我们的超参数调谐器选择最佳学习率。
最后,我们编译模型并将其返回给调用函数。
使用 Keras 调谐器实现超参数调谐
让我们把所有的部分放在一起,学习如何使用 Keras Tuner 库来调整 Keras/TensorFlow 超参数。
打开项目目录结构中的train.py文件,让我们开始吧:
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.model import build_model
from pyimagesearch import utils
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import backend as K
from sklearn.metrics import classification_report
import kerastuner as kt
import numpy as np
import argparse
import cv2
第 2-13 行导入我们需要的 Python 包。值得注意的进口包括:
config:我们的配置文件build_model:接受一个超参数调整对象,该对象选择各种值来测试 CONV 滤波器、FC 节点和学习率——生成的模型被构建并返回给调用函数utils:用于绘制我们的训练历史EarlyStopping:一个 Keras/TensorFlow 回调,用于缩短运行不佳的超参数调整实验fashion_mnist:我们将在时尚 MNIST 数据集上训练我们的模特kerastuner:用于实现超参数调谐的 Keras 调谐器包
接下来是我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--tuner", required=True, type=str,
choices=["hyperband", "random", "bayesian"],
help="type of hyperparameter tuner we'll be using")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
我们有两个命令行参数要解析:
- 我们将使用的超参数优化器的类型
- 输出训练历史图的路径
在那里,从磁盘加载时尚 MNIST 数据集:
# load the Fashion MNIST dataset
print("[INFO] loading Fashion MNIST...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# add a channel dimension to the dataset
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# one-hot encode the training and testing labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
# initialize the label names
labelNames = ["top", "trouser", "pullover", "dress", "coat",
"sandal", "shirt", "sneaker", "bag", "ankle boot"]
第 26 行装载时装 MNIST,预分割成训练和测试集。
然后,我们向数据集添加一个通道维度(行 29 和 30 ),将像素强度从范围【0,255】缩放到【0,1】(行 33 和 34 ),然后对标签进行一次性编码(行 37 和 38 )。
正如在这个脚本的导入部分提到的,我们将使用EarlyStopping来缩短运行不佳的超参数试验:
# initialize an early stopping callback to prevent the model from
# overfitting/spending too much time training with minimal gains
es = EarlyStopping(
monitor="val_loss",
patience=config.EARLY_STOPPING_PATIENCE,
restore_best_weights=True)
我们会监控验证损失。如果验证损失在EARLY_STOPPING_PATIENCE总时期后未能显著改善,那么我们将终止试验并继续下一个试验。
请记住,调整超参数是一个极其计算量巨大的过程,因此,如果我们能够取消表现不佳的试验,我们就可以节省大量时间。
下一步是初始化我们的超参数优化器:
# check if we will be using the hyperband tuner
if args["tuner"] == "hyperband":
# instantiate the hyperband tuner object
print("[INFO] instantiating a hyperband tuner object...")
tuner = kt.Hyperband(
build_model,
objective="val_accuracy",
max_epochs=config.EPOCHS,
factor=3,
seed=42,
directory=config.OUTPUT_PATH,
project_name=args["tuner"])
第 52-62 行处理我们是否希望使用 Hyperband 调谐器。Hyperband 调谐器是随机搜索与“自适应资源分配和提前停止”的结合它实质上是李等人的论文, Hyperband:一种新的基于 Bandit 的超参数优化方法的实现。
如果我们提供一个值random作为我们的--tuner命令行参数,那么我们将使用一个基本的随机超参数搜索:
# check if we will be using the random search tuner
elif args["tuner"] == "random":
# instantiate the random search tuner object
print("[INFO] instantiating a random search tuner object...")
tuner = kt.RandomSearch(
build_model,
objective="val_accuracy",
max_trials=10,
seed=42,
directory=config.OUTPUT_PATH,
project_name=args["tuner"])
否则,我们将假设我们正在使用贝叶斯优化:
# otherwise, we will be using the bayesian optimization tuner
else:
# instantiate the bayesian optimization tuner object
print("[INFO] instantiating a bayesian optimization tuner object...")
tuner = kt.BayesianOptimization(
build_model,
objective="val_accuracy",
max_trials=10,
seed=42,
directory=config.OUTPUT_PATH,
project_name=args["tuner"])
一旦我们的超参数调谐器被实例化,我们可以搜索空间:
# perform the hyperparameter search
print("[INFO] performing hyperparameter search...")
tuner.search(
x=trainX, y=trainY,
validation_data=(testX, testY),
batch_size=config.BS,
callbacks=[es],
epochs=config.EPOCHS
)
# grab the best hyperparameters
bestHP = tuner.get_best_hyperparameters(num_trials=1)[0]
print("[INFO] optimal number of filters in conv_1 layer: {}".format(
bestHP.get("conv_1")))
print("[INFO] optimal number of filters in conv_2 layer: {}".format(
bestHP.get("conv_2")))
print("[INFO] optimal number of units in dense layer: {}".format(
bestHP.get("dense_units")))
print("[INFO] optimal learning rate: {:.4f}".format(
bestHP.get("learning_rate")))
第 90-96 行开始超参数调整过程。
调谐过程完成后,我们获得最佳超参数(行 99 )并在终端上显示最佳:
- 第一个 CONV 图层中的滤镜数量
- 第二 CONV 层中的过滤器数量
- 全连接层中的节点数
- 最佳学习率
一旦我们有了最好的超参数,我们需要基于它们实例化一个新的model:
# build the best model and train it
print("[INFO] training the best model...")
model = tuner.hypermodel.build(bestHP)
H = model.fit(x=trainX, y=trainY,
validation_data=(testX, testY), batch_size=config.BS,
epochs=config.EPOCHS, callbacks=[es], verbose=1)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# generate the training loss/accuracy plot
utils.save_plot(H, args["plot"])
第 111 行负责用我们最好的超参数建立模型。
在行 112-114 上对model.fit的调用在最佳超参数上训练我们的模型。
训练完成后,我们对测试集进行全面评估(第 118-120 行)。
最后,使用我们的save_plot实用函数将生成的训练历史图保存到磁盘。
超波段超参数调谐
让我们看看应用 Keras 调谐器的超波段优化器的结果。
通过访问本教程的 【下载】 部分来检索源代码。
从那里,打开一个终端并执行以下命令:
$ time python train.py --tuner hyperband --plot output/hyperband_plot.png
[INFO] loading Fashion MNIST...
[INFO] instantiating a hyperband tuner object..."
[INFO] performing hyperparameter search...
Search: Running Trial #1
Hyperparameter |Value |Best Value So Far
conv_1 |96 |?
conv_2 |96 |?
dense_units |512 |?
learning_rate |0.1 |?
Epoch 1/2
1875/1875 [==============================] - 119s 63ms/step - loss: 3.2580 - accuracy: 0.6568 - val_loss: 3.9679 - val_accuracy: 0.7852
Epoch 2/2
1875/1875 [==============================] - 79s 42ms/step - loss: 3.5280 - accuracy: 0.7710 - val_loss: 2.5392 - val_accuracy: 0.8167
Trial 1 Complete [00h 03m 18s]
val_accuracy: 0.8166999816894531
Best val_accuracy So Far: 0.8285999894142151
Total elapsed time: 00h 03m 18s
Keras 调谐器包通过运行几个“试验”来工作在这里,我们可以看到,在第一次试验中,我们将对第一个 CONV 层使用96过滤器,对第二个 CONV 层使用96过滤器,对全连接层使用总共512个节点,学习速率为0.1。
随着我们试验的结束,Best Value So Far栏将会更新,以反映找到的最佳超参数。
但是,请注意,我们仅针对总共两个时期训练该模型——这是由于我们的EarlyStopping停止标准。如果我们的验证准确性没有提高一定的量,我们将缩短训练过程,以避免花费太多时间探索不会显著提高我们准确性的超参数。
由此可见,在第一次试验结束时,我们坐在 的准确率为 82%。
现在让我们跳到最后的审判:
Search: Running Trial #76
Hyperparameter |Value |Best Value So Far
conv_1 |32 |64
conv_2 |64 |128
dense_units |768 |512
learning_rate |0.01 |0.001
Epoch 1/17
1875/1875 [==============================] - 41s 22ms/step - loss: 0.8586 - accuracy: 0.7624 - val_loss: 0.4307 - val_accuracy: 0.8587
...
Epoch 17/17
1875/1875 [==============================] - 40s 21ms/step - loss: 0.2248 - accuracy: 0.9220 - val_loss: 0.3391 - val_accuracy: 0.9089
Trial 76 Complete [00h 11m 29s]
val_accuracy: 0.9146000146865845
Best val_accuracy So Far: 0.9289000034332275
Total elapsed time: 06h 34m 56s
目前发现的最好的验证准确率是92%。
Hyperband 完成运行后,我们会看到终端上显示的最佳参数:
[INFO] optimal number of filters in conv_1 layer: 64
[INFO] optimal number of filters in conv_2 layer: 128
[INFO] optimal number of units in dense layer: 512
[INFO] optimal learning rate: 0.0010
对于我们的第一个 CONV 层,我们看到64过滤器是最好的。网络中的下一个 CONV 层喜欢128层——这并不是一个完全令人惊讶的发现。通常,随着我们深入 CNN,随着体积大小的空间维度减少,过滤器的数量增加。
AlexNet、VGGNet、ResNet 和几乎所有其他流行的 CNN 架构都有这种类型的模式。
最终的 FC 层有512个节点,而我们的最优学习速率是1e-3。
现在让我们用这些超参数来训练 CNN:
[INFO] training the best model...
Epoch 1/50
1875/1875 [==============================] - 69s 36ms/step - loss: 0.5655 - accuracy: 0.8089 - val_loss: 0.3147 - val_accuracy: 0.8873
...
Epoch 11/50
1875/1875 [==============================] - 67s 36ms/step - loss: 0.1163 - accuracy: 0.9578 - val_loss: 0.3201 - val_accuracy: 0.9088
[INFO] evaluating network...
precision recall f1-score support
top 0.83 0.92 0.87 1000
trouser 0.99 0.99 0.99 1000
pullover 0.83 0.92 0.87 1000
dress 0.93 0.93 0.93 1000
coat 0.90 0.83 0.87 1000
sandal 0.99 0.98 0.99 1000
shirt 0.82 0.70 0.76 1000
sneaker 0.94 0.99 0.96 1000
bag 0.99 0.98 0.99 1000
ankle boot 0.99 0.95 0.97 1000
accuracy 0.92 10000
macro avg 0.92 0.92 0.92 10000
weighted avg 0.92 0.92 0.92 10000
real 407m28.169s
user 2617m43.104s
sys 51m46.604s
在我们最好的超参数上训练 50 个时期后,我们在我们的验证集上获得了 92%的准确度。
在我的 3 GHz 英特尔至强 W 处理器上,总的超参数搜索和训练时间为
6.7 hours. Using a GPU would reduce the training time considerably.
随机搜索超参数调谐
现在让我们来看一个普通的随机搜索。
同样,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
在那里,您可以执行以下命令:
$ time python train.py --tuner random --plot output/random_plot.png
[INFO] loading Fashion MNIST...
[INFO] instantiating a random search tuner object...
[INFO] performing hyperparameter search...
Search: Running Trial #1
Hyperparameter |Value |Best Value So Far
conv_1 |64 |?
conv_2 |64 |?
dense_units |512 |?
learning_rate |0.01 |?
Epoch 1/50
1875/1875 [==============================] - 51s 27ms/step - loss: 0.7210 - accuracy: 0.7758 - val_loss: 0.4748 - val_accuracy: 0.8668
...
Epoch 14/50
1875/1875 [==============================] - 49s 26ms/step - loss: 0.2180 - accuracy: 0.9254 - val_loss: 0.3021 - val_accuracy: 0.9037
Trial 1 Complete [00h 12m 08s]
val_accuracy: 0.9139999747276306
Best val_accuracy So Far: 0.9139999747276306
Total elapsed time: 00h 12m 08s
在第一次试验结束时,我们获得了
91% accuracy on our validation set with 64 filters for the first CONV layer, 64 filters for the second CONV layer, a total of 512 nodes in the FC layer, and a learning rate of 1e-2.
到第 10 次试验时,我们的准确率有所提高,但没有使用 Hyperband 时的进步大:
Search: Running Trial #10
Hyperparameter |Value |Best Value So Far
conv_1 |96 |96
conv_2 |64 |64
dense_units |512 |512
learning_rate |0.1 |0.001
Epoch 1/50
1875/1875 [==============================] - 64s 34ms/step - loss: 3.8573 - accuracy: 0.6515 - val_loss: 1.3178 - val_accuracy: 0.7907
...
Epoch 6/50
1875/1875 [==============================] - 63s 34ms/step - loss: 4.2424 - accuracy: 0.8176 - val_loss: 622.4448 - val_accuracy: 0.8295
Trial 10 Complete [00h 06m 20s]
val_accuracy: 0.8640999794006348
Total elapsed time: 01h 47m 02s
Best val_accuracy So Far: 0.9240000247955322
Total elapsed time: 01h 47m 02s
我们现在到了
92% accuracy. Still, the good news is that we’ve only spent 1h47m exploring the hyperparameter space (as opposed to 6h30m from the Hyperband trials).
下面我们可以看到随机搜索找到的最佳超参数:
[INFO] optimal number of filters in conv_1 layer: 96
[INFO] optimal number of filters in conv_2 layer: 64
[INFO] optimal number of units in dense layer: 512
[INFO] optimal learning rate: 0.0010
我们随机搜索的输出与超波段调谐的输出略有不同。第一层 CONV 有96滤镜,第二层有64 (Hyperband 分别有64和128)。
也就是说,随机搜索和 Hyperband 都同意 FC 层中的512节点和1e-3的学习速率。
经过培训后,我们达到了与 Hyperband 大致相同的验证准确度:
[INFO] training the best model...
Epoch 1/50
1875/1875 [==============================] - 64s 34ms/step - loss: 0.5682 - accuracy: 0.8157 - val_loss: 0.3227 - val_accuracy: 0.8861
...
Epoch 13/50
1875/1875 [==============================] - 63s 34ms/step - loss: 0.1066 - accuracy: 0.9611 - val_loss: 0.2636 - val_accuracy: 0.9251
[INFO] evaluating network...
precision recall f1-score support
top 0.85 0.91 0.88 1000
trouser 0.99 0.98 0.99 1000
pullover 0.88 0.89 0.88 1000
dress 0.94 0.90 0.92 1000
coat 0.82 0.93 0.87 1000
sandal 0.97 0.99 0.98 1000
shirt 0.82 0.69 0.75 1000
sneaker 0.96 0.95 0.96 1000
bag 0.99 0.99 0.99 1000
ankle boot 0.97 0.96 0.97 1000
accuracy 0.92 10000
macro avg 0.92 0.92 0.92 10000
weighted avg 0.92 0.92 0.92 10000
real 120m52.354s
user 771m17.324s
sys 15m10.248s
虽然 92%的准确率与 Hyperband 基本相同,一次随机搜索将我们的超参数搜索时间缩短了 3 倍,这本身就是一个 巨大的 改进。
使用贝叶斯优化的超参数调整
让我们看看贝叶斯优化性能如何与超波段和随机搜索进行比较。
请务必访问本教程的 “下载” 部分来检索源代码。
从这里开始,让我们尝试一下贝叶斯超参数优化:
$ time python train.py --tuner bayesian --plot output/bayesian_plot.png
[INFO] loading Fashion MNIST...
[INFO] instantiating a bayesian optimization tuner object...
[INFO] performing hyperparameter search...
Search: Running Trial #1
Hyperparameter |Value |Best Value So Far
conv_1 |64 |?
conv_2 |64 |?
dense_units |512 |?
learning_rate |0.01 |?
Epoch 1/50
1875/1875 [==============================] - 143s 76ms/step - loss: 0.7434 - accuracy: 0.7723 - val_loss: 0.5290 - val_accuracy: 0.8095
...
Epoch 12/50
1875/1875 [==============================] - 50s 27ms/step - loss: 0.2210 - accuracy: 0.9223 - val_loss: 0.4138 - val_accuracy: 0.8693
Trial 1 Complete [00h 11m 45s]
val_accuracy: 0.9136999845504761
Best val_accuracy So Far: 0.9136999845504761
Total elapsed time: 00h 11m 45s
在我们的第一次试验中,我们击中了
91% accuracy.
在最后的试验中,我们略微提高了精确度:
Search: Running Trial #10
Hyperparameter |Value |Best Value So Far
conv_1 |64 |32
conv_2 |96 |96
dense_units |768 |768
learning_rate |0.001 |0.001
Epoch 1/50
1875/1875 [==============================] - 64s 34ms/step - loss: 0.5743 - accuracy: 0.8140 - val_loss: 0.3341 - val_accuracy: 0.8791
...
Epoch 16/50
1875/1875 [==============================] - 62s 33ms/step - loss: 0.0757 - accuracy: 0.9721 - val_loss: 0.3104 - val_accuracy: 0.9211
Trial 10 Complete [00h 16m 41s]
val_accuracy: 0.9251999855041504
Best val_accuracy So Far: 0.9283000230789185
Total elapsed time: 01h 47m 01s
我们现在获得
92% accuracy.
通过贝叶斯优化找到的最佳超参数如下:
[INFO] optimal number of filters in conv_1 layer: 32
[INFO] optimal number of filters in conv_2 layer: 96
[INFO] optimal number of units in dense layer: 768
[INFO] optimal learning rate: 0.0010
以下列表对超参数进行了细分:
- 我们的第一个 CONV 层有
32个节点(相对于超波段的64和随机的96) - 第二 CONV 层有
96个节点(超波段选择128和随机搜索64 - 完全连接的层有
768个节点(超波段和随机搜索都选择了512 - 我们的学习率是
1e-3(这三个超参数优化器都同意)
现在让我们在这些超参数上训练我们的网络:
[INFO] training the best model...
Epoch 1/50
1875/1875 [==============================] - 49s 26ms/step - loss: 0.5764 - accuracy: 0.8164 - val_loss: 0.3823 - val_accuracy: 0.8779
...
Epoch 14/50
1875/1875 [==============================] - 47s 25ms/step - loss: 0.0915 - accuracy: 0.9665 - val_loss: 0.2669 - val_accuracy: 0.9214
[INFO] evaluating network...
precision recall f1-score support
top 0.82 0.93 0.87 1000
trouser 1.00 0.99 0.99 1000
pullover 0.86 0.92 0.89 1000
dress 0.93 0.91 0.92 1000
coat 0.90 0.86 0.88 1000
sandal 0.99 0.99 0.99 1000
shirt 0.81 0.72 0.77 1000
sneaker 0.96 0.98 0.97 1000
bag 0.99 0.98 0.99 1000
ankle boot 0.98 0.96 0.97 1000
accuracy 0.92 10000
macro avg 0.93 0.92 0.92 10000
weighted avg 0.93 0.92 0.92 10000
real 118m11.916s
user 740m56.388s
sys 18m2.676s
这里的精确度有所提高。我们现在处于 93%的准确率使用贝叶斯优化(超波段和随机搜索都有报道
92% accuracy).
我们如何解释这些结果?
现在让我们花点时间来讨论这些结果。既然贝叶斯优化返回了最高的精度,这是否意味着您应该总是使用贝叶斯超参数优化?
不,不一定。
相反,我建议对每个超参数优化器进行一些试验,这样您就可以了解跨几种算法的超参数的“一致程度”。如果所有三个超参数调谐器都报告了相似的超参数,那么你可以有理由相信你找到了最佳的。
说到这里,下表列出了每个优化器的超参数结果:
虽然在 CONV 滤波器的数量和 FC 节点的数量上有一些分歧, 三者都同意 1e-3 是最佳学习速率。
这告诉我们什么?
假设其他超参数有变化,但所有三个优化器的学习率是相同的,我们可以得出结论,学习率对准确性有最大的影响。其他参数没有简单地获得正确的学习率重要。
总结
在本教程中,您学习了如何使用 Keras Tuner 和 TensorFlow 轻松调整神经网络超参数。
Keras Tuner 软件包通过以下方式使您的模型超参数的调整变得非常简单:
- 只需要一次进口
- 允许您在您的模型架构中定义值和范围
- 直接与 Keras 和 TensorFlow 接口
- 实施最先进的超参数优化器
*当训练你自己的神经网络时,我建议你至少花一些时间来调整你的超参数,因为你很可能能够在精度上从 1-2%的提升(低端)到 25%的提升(高端)。同样,这取决于你项目的具体情况。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!**
增强型超分辨率生成对抗网络
目录
**上周我们学习了超分辨率甘斯。他们在实现超分辨率图像的更好清晰度方面做得非常好。但是,在超分辨率领域,甘斯的路走到尽头了吗?
深度学习的一个共同主题是,成长永不停止。因此,我们转向增强的超分辨率 gan。顾名思义,它对原来的 SRGAN 架构进行了许多更新,极大地提高了性能和可视化。
在本教程中,您将学习如何使用 tensorflow 实现 ESRGAN。
本课是关于 GANs 201 的 4 部分系列中的第 2 部分:
要了解如何实现 ESRGAN ,请继续阅读。*
前言
GANs 同时训练两个神经网络:鉴别器和生成器。生成器创建假图像,而鉴别器判断它们是真的还是假的。
SRGANs 将这一思想应用于图像超分辨率领域。发生器产生超分辨率图像,鉴别器判断真假。
增强型超分辨率甘斯
建立在 SRGANs 领导的基础上,ESRGAN 的主要目标是引入模型修改,从而提高训练效率并降低复杂性。
SRGANs 的简要概述:
- 将低分辨率图像作为输入提供给生成器,并将超分辨率图像作为输出。
- 将这些预测通过鉴别器,得到真实或虚假的品牌。
- 使用 VGG 网添加感知损失(像素方面)来增加我们预测的假图像的清晰度。
但是 ESRGANs 带来了哪些更新呢?
首先,发电机采取了一些主要措施来确保性能的提高:
-
删除批量标准化层:对 SRGAN 架构的简要回顾将显示批量标准化层在整个生成器架构中被广泛使用。由于提高了性能和降低了计算复杂性,ESRGANs 完全放弃了 BN 层的使用。
-
Residual in Residual Dense Block:标准残差块的升级,这种特殊的结构允许一个块中的所有层输出传递给后续层,如图图 1 所示。这里的直觉是,模型可以访问许多可供选择的特性,并确定其相关性。此外,ESRGAN 使用残差缩放来缩小残差输出,以防止不稳定。
-
对于鉴频器,主要增加的是相对论损耗。它估计真实图像比假预测图像更真实的概率。自然地,将它作为损失函数加入使得模型能够克服相对论损失。
-
感知损失有一点改变,使损失基于激活功能之前而不是激活功能之后的特征,如上周 SRGAN 论文所示。
-
总损失现在是 GAN 损失、感知损失以及地面真实高分辨率和预测图像之间的像素距离的组合。
这些添加有助于显著改善结果。在我们的实现中,我们忠实于论文,并对传统的 SRGAN 进行了这些更新,以提高超分辨率结果。
ESRGAN 背后的核心理念不仅是提高结果,而且使流程更加高效。因此,本文并没有全面谴责批量规范化的使用。尽管如此,它指出,刮 BN 层的使用将有利于我们的特定任务,即使在最小的像素的相似性是必要的。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── create_tfrecords.py
├── inference.py
├── outputs
├── pyimagesearch
│ ├── config.py
│ ├── data_preprocess.py
│ ├── __init__.py
│ ├── losses.py
│ ├── esrgan.py
│ ├── esrgan_training.py
│ ├── utils.py
│ └── vgg.py
└── train_esrgan.py
2 directories, 11 files
在pyimagesearch目录中,我们有:
config.py:包含完整项目的端到端配置管道。data_preprocess.py:包含有助于数据处理的功能。__init__.py:使目录像 python 包一样运行。losses.py:初始化训练 ESRGAN 所需的损耗。esrgan.py:包含 ESRGAN 架构。esrgan_training.py:包含运行 ESRGAN 训练的训练类。utils.py:包含附加实用程序vgg.py:初始化用于感知损失计算的 VGG 模型。
在根目录中,我们有:
create_tfrecords.py:从我们将使用的数据集创建TFRecords。inference.py:使用训练好的模型进行推理。train_srgan.py:使用esrgan.py和esrgan_training.py脚本执行 ESRGAN 训练。
配置先决条件
位于pyimagesearch目录中的config.py脚本包含了整个项目所需的几个参数和路径。将配置变量分开是一个很好的编码实践。为此,让我们转向config.py剧本。
# import the necessary packages
import os
# name of the TFDS dataset we will be using
DATASET = "div2k/bicubic_x4"
# define the shard size and batch size
SHARD_SIZE = 256
TRAIN_BATCH_SIZE = 64
INFER_BATCH_SIZE = 8
# dataset specs
HR_SHAPE = [96, 96, 3]
LR_SHAPE = [24, 24, 3]
SCALING_FACTOR = 4
我们首先在第 5 行引用我们项目的数据集。
TFRecords的SHARD_SIZE定义在线 8 上。随后是第 9 行和第 10 行上的TRAIN_BATCH_SIZE和INFER_BATCH_SIZE定义。
我们的高分辨率输出图像将具有尺寸96 x 96 x 3,而我们的输入低分辨率图像将具有尺寸24 x 24 x 3 ( 行 13 和 14 )。相应地,在线 15 上SCALING_FACTOR被设置为4。
# GAN model specs
FEATURE_MAPS = 64
RESIDUAL_BLOCKS = 16
LEAKY_ALPHA = 0.2
DISC_BLOCKS = 4
RESIDUAL_SCALAR = 0.2
# training specs
PRETRAIN_LR = 1e-4
FINETUNE_LR = 3e-5
PRETRAIN_EPOCHS = 1500
FINETUNE_EPOCHS = 1000
STEPS_PER_EPOCH = 10
# define the path to the dataset
BASE_DATA_PATH = "dataset"
DIV2K_PATH = os.path.join(BASE_DATA_PATH, "div2k")
正如我们对 SRGAN 所做的那样,该架构由剩余网络组成。首先,我们设置在Conv2D层使用的滤镜数量(第 18 行)。在第 19 行上,我们定义了剩余块的数量。我们的ReLU功能的alpha参数设置在第 20 行的上。
鉴别器架构将基于DISC_BLOCKS ( 第 21 行)的值实现自动化。现在,我们为RESIDUAL_SCALAR定义一个值,这将有助于我们将剩余块输出缩放到各个级别,并保持训练过程稳定(第 22 行)。
现在,重复一下我们的 SRGAN 参数(学习率、时期等。)在第 25-29 行完成。我们将对我们的 GAN 进行预训练,然后对其进行全面训练以进行比较。出于这个原因,我们为预训练的 GAN 和完全训练的 GAN 定义了学习率和时期。
设置BASE_DATA_PATH来定义存储数据集的。DIV2K_PATH引用了DIV2K数据集(第 32 和 33 行)。 div2k 数据集非常适合辅助图像超分辨率研究,因为它包含各种高分辨率图像。
# define the path to the tfrecords for GPU training
GPU_BASE_TFR_PATH = "tfrecord"
GPU_DIV2K_TFR_TRAIN_PATH = os.path.join(GPU_BASE_TFR_PATH, "train")
GPU_DIV2K_TFR_TEST_PATH = os.path.join(GPU_BASE_TFR_PATH, "test")
# define the path to the tfrecords for TPU training
TPU_BASE_TFR_PATH = "gs://<PATH_TO_GCS_BUCKET>/tfrecord"
TPU_DIV2K_TFR_TRAIN_PATH = os.path.join(TPU_BASE_TFR_PATH, "train")
TPU_DIV2K_TFR_TEST_PATH = os.path.join(TPU_BASE_TFR_PATH, "test")
# path to our base output directory
BASE_OUTPUT_PATH = "outputs"
# GPU training ESRGAN model paths
GPU_PRETRAINED_GENERATOR_MODEL = os.path.join(BASE_OUTPUT_PATH,
"models", "pretrained_generator")
GPU_GENERATOR_MODEL = os.path.join(BASE_OUTPUT_PATH, "models",
"generator")
# TPU training ESRGAN model paths
TPU_OUTPUT_PATH = "gs://<PATH_TO_GCS_BUCKET>/outputs"
TPU_PRETRAINED_GENERATOR_MODEL = os.path.join(TPU_OUTPUT_PATH,
"models", "pretrained_generator")
TPU_GENERATOR_MODEL = os.path.join(TPU_OUTPUT_PATH, "models",
"generator")
# define the path to the inferred images and to the grid image
BASE_IMAGE_PATH = os.path.join(BASE_OUTPUT_PATH, "images")
GRID_IMAGE_PATH = os.path.join(BASE_OUTPUT_PATH, "grid.png")
因此,为了比较训练效率,我们将在 TPU 和 GPU 上训练 GAN。为此,我们必须为 GPU 训练和 TPU 训练分别创建引用数据和输出的路径。
在的第 36-38 行,我们为 GPU 训练定义了TFRecords。在第 41-43 行,我们为 TPU 训练定义了TFRecords。
现在,我们在线 46 上定义基本输出路径。接下来是经过 GPU 训练的 ESRGAN 发电机模型的参考路径(第 49-52 行)。我们对 TPU 培训的 ESRGAN 发电机模型做同样的事情(线 55-59 )。
完成所有设置后,剩下的唯一任务是引用推断图像的路径(行 62 和 63 )。
实现数据处理实用程序
训练 GANs 需要大量的计算能力和数据。为了确保我们有足够的数据,我们将采用几种数据扩充技术。让我们看看位于pyimagesearch目录中的data_preprocess.py脚本中的那些。
# import the necessary packages
from tensorflow.io import FixedLenFeature
from tensorflow.io import parse_single_example
from tensorflow.io import parse_tensor
from tensorflow.image import flip_left_right
from tensorflow.image import rot90
import tensorflow as tf
# define AUTOTUNE object
AUTO = tf.data.AUTOTUNE
def random_crop(lrImage, hrImage, hrCropSize=96, scale=4):
# calculate the low resolution image crop size and image shape
lrCropSize = hrCropSize // scale
lrImageShape = tf.shape(lrImage)[:2]
# calculate the low resolution image width and height offsets
lrW = tf.random.uniform(shape=(),
maxval=lrImageShape[1] - lrCropSize + 1, dtype=tf.int32)
lrH = tf.random.uniform(shape=(),
maxval=lrImageShape[0] - lrCropSize + 1, dtype=tf.int32)
# calculate the high resolution image width and height
hrW = lrW * scale
hrH = lrH * scale
# crop the low and high resolution images
lrImageCropped = tf.slice(lrImage, [lrH, lrW, 0],
[(lrCropSize), (lrCropSize), 3])
hrImageCropped = tf.slice(hrImage, [hrH, hrW, 0],
[(hrCropSize), (hrCropSize), 3])
# return the cropped low and high resolution images
return (lrImageCropped, hrImageCropped)
考虑到我们将在这个项目中使用的 TensorFlow 包装器的数量,为空间优化定义一个tf.data.AUTOTUNE对象是一个好主意。
我们定义的第一个数据增强函数是random_crop ( 第 12 行)。它接受以下参数:
lrImage:低分辨率图像。hrImage:高分辨率图像。hrCropSize:用于低分辨率裁剪计算的高分辨率裁剪尺寸。scale:我们用来计算低分辨率裁剪的因子。
然后计算左右宽度和高度偏移(第 18-21 行)。
为了计算相应的高分辨率值,我们简单地将低分辨率值乘以比例因子(行 24 和 25 )。
使用这些值,我们裁剪出低分辨率图像及其对应的高分辨率图像,并返回它们(第 28-34 行)
def get_center_crop(lrImage, hrImage, hrCropSize=96, scale=4):
# calculate the low resolution image crop size and image shape
lrCropSize = hrCropSize // scale
lrImageShape = tf.shape(lrImage)[:2]
# calculate the low resolution image width and height
lrW = lrImageShape[1] // 2
lrH = lrImageShape[0] // 2
# calculate the high resolution image width and height
hrW = lrW * scale
hrH = lrH * scale
# crop the low and high resolution images
lrImageCropped = tf.slice(lrImage, [lrH - (lrCropSize // 2),
lrW - (lrCropSize // 2), 0], [lrCropSize, lrCropSize, 3])
hrImageCropped = tf.slice(hrImage, [hrH - (hrCropSize // 2),
hrW - (hrCropSize // 2), 0], [hrCropSize, hrCropSize, 3])
# return the cropped low and high resolution images
return (lrImageCropped, hrImageCropped)
数据扩充实用程序中的下一行是get_center_crop ( 第 36 行),它接受以下参数:
lrImage:低分辨率图像。hrImage:高分辨率图像。hrCropSize:用于低分辨率裁剪计算的高分辨率裁剪尺寸。scale:我们用来计算低分辨率裁剪的因子。
就像我们为之前的函数创建裁剪大小值一样,我们在第 38 行和第 39 行得到 lr 裁剪大小值和图像形状。
现在,要获得中心像素坐标,我们只需将低分辨率形状除以2 ( 第 42 行和第 43 行)。
为了获得相应的高分辨率中心点,将 lr 中心点乘以比例因子(第 46 和 47 行)。
def random_flip(lrImage, hrImage):
# calculate a random chance for flip
flipProb = tf.random.uniform(shape=(), maxval=1)
(lrImage, hrImage) = tf.cond(flipProb < 0.5,
lambda: (lrImage, hrImage),
lambda: (flip_left_right(lrImage), flip_left_right(hrImage)))
# return the randomly flipped low and high resolution images
return (lrImage, hrImage)
我们有random_flip功能来翻转行 58 上的图像。它接受低分辨率和高分辨率图像作为其参数。
基于使用tf.random.uniform的翻转概率值,我们翻转我们的图像并返回它们(第 60-66 行)。
def random_rotate(lrImage, hrImage):
# randomly generate the number of 90 degree rotations
n = tf.random.uniform(shape=(), maxval=4, dtype=tf.int32)
# rotate the low and high resolution images
lrImage = rot90(lrImage, n)
hrImage = rot90(hrImage, n)
# return the randomly rotated images
return (lrImage, hrImage)
在行 68 上,我们有另一个数据扩充函数叫做random_rotate,它接受低分辨率图像和高分辨率图像作为它的参数。
变量n生成一个值,这个值稍后将帮助应用于我们的图像集的旋转量(第 70-77 行)。
def read_train_example(example):
# get the feature template and parse a single image according to
# the feature template
feature = {
"lr": FixedLenFeature([], tf.string),
"hr": FixedLenFeature([], tf.string),
}
example = parse_single_example(example, feature)
# parse the low and high resolution images
lrImage = parse_tensor(example["lr"], out_type=tf.uint8)
hrImage = parse_tensor(example["hr"], out_type=tf.uint8)
# perform data augmentation
(lrImage, hrImage) = random_crop(lrImage, hrImage)
(lrImage, hrImage) = random_flip(lrImage, hrImage)
(lrImage, hrImage) = random_rotate(lrImage, hrImage)
# reshape the low and high resolution images
lrImage = tf.reshape(lrImage, (24, 24, 3))
hrImage = tf.reshape(hrImage, (96, 96, 3))
# return the low and high resolution images
return (lrImage, hrImage)
数据扩充功能完成后,我们可以转到第 79 行上的图像读取功能read_train_example。该函数在单个图像集(低分辨率和相应的高分辨率图像)中运行
在第行第 82-90 行,我们创建一个 lr,hr 特征模板,并基于它解析示例集。
现在,我们在 lr-hr 集合上应用数据扩充函数(第 93-95 行)。然后,我们将 lr-hr 图像重塑回它们需要的尺寸(第 98-102 行)。
def read_test_example(example):
# get the feature template and parse a single image according to
# the feature template
feature = {
"lr": FixedLenFeature([], tf.string),
"hr": FixedLenFeature([], tf.string),
}
example = parse_single_example(example, feature)
# parse the low and high resolution images
lrImage = parse_tensor(example["lr"], out_type=tf.uint8)
hrImage = parse_tensor(example["hr"], out_type=tf.uint8)
# center crop both low and high resolution image
(lrImage, hrImage) = get_center_crop(lrImage, hrImage)
# reshape the low and high resolution images
lrImage = tf.reshape(lrImage, (24, 24, 3))
hrImage = tf.reshape(hrImage, (96, 96, 3))
# return the low and high resolution images
return (lrImage, hrImage)
我们为推断图像创建一个类似于read_train_example的函数,称为read_test_example,它接受一个 lr-hr 图像集(行 104 )。除了数据扩充过程(第 107-125 行)之外,重复前面函数中所做的一切。
def load_dataset(filenames, batchSize, train=False):
# get the TFRecords from the filenames
dataset = tf.data.TFRecordDataset(filenames,
num_parallel_reads=AUTO)
# check if this is the training dataset
if train:
# read the training examples
dataset = dataset.map(read_train_example,
num_parallel_calls=AUTO)
# otherwise, we are working with the test dataset
else:
# read the test examples
dataset = dataset.map(read_test_example,
num_parallel_calls=AUTO)
# batch and prefetch the data
dataset = (dataset
.shuffle(batchSize)
.batch(batchSize)
.repeat()
.prefetch(AUTO)
)
# return the dataset
return dataset
现在,总结一下,我们在行 127 上有了load_dataset函数。它接受文件名、批量大小和一个布尔变量,指示模式是训练还是推理。
在第 129 行和第 130 行上,我们从提供的文件名中得到TFRecords。如果模式设置为 train,我们将read_train_example函数映射到数据集。这样,它里面的所有条目都通过read_train_example函数传递(第 133-136 行)。
如果模式是推理,我们将read_test_example函数移至数据集(第 138-141 行)。
随着我们的数据集的创建,它现在被批处理、混洗并设置为自动预取(第 144-152 行)。
实现 ESRGAN 架构
我们的下一个目的地是位于pyimagesearch目录中的esrgan.py脚本。该脚本包含完整的 ESRGAN 架构。我们已经讨论了 ESRGAN 带来的变化,现在让我们一个一个地来看一下。
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import GlobalAvgPool2D
from tensorflow.keras.layers.experimental.preprocessing import Rescaling
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Add
from tensorflow.nn import depth_to_space
from tensorflow.keras import Model
from tensorflow.keras import Input
class ESRGAN(object):
@staticmethod
def generator(scalingFactor, featureMaps, residualBlocks,
leakyAlpha, residualScalar):
# initialize the input layer
inputs = Input((None, None, 3))
xIn = Rescaling(scale=1.0/255, offset=0.0)(inputs)
# pass the input through CONV => LeakyReLU block
xIn = Conv2D(featureMaps, 9, padding="same")(xIn)
xIn = LeakyReLU(leakyAlpha)(xIn)
为了简化工作流程,最好将 ESRGAN 定义为类模板(第 14 行)。
首先,我们算出发电机。第 16 行上的函数generator作为我们的生成器定义,并接受以下参数:
scalingFactor:输出图像缩放的决定因素。featureMaps:卷积滤波器的数量。residualBlocks:添加到架构中的剩余块数。leakyAlpha:决定我们漏ReLU函数阈值的因子residualScalar:保持残差块的输出成比例的值,使得训练稳定。
输入被初始化,像素被缩放到0和1的范围(第 19 行和第 20 行)。
处理后的输入然后通过一个Conv2D层,接着是一个LeakyReLU激活功能(行 23 和 24 )。这些层的参数已经在config.py中定义过了。
# construct the residual in residual block
x = Conv2D(featureMaps, 3, padding="same")(xIn)
x1 = LeakyReLU(leakyAlpha)(x)
x1 = Add()([xIn, x1])
x = Conv2D(featureMaps, 3, padding="same")(x1)
x2 = LeakyReLU(leakyAlpha)(x)
x2 = Add()([x1, x2])
x = Conv2D(featureMaps, 3, padding="same")(x2)
x3 = LeakyReLU(leakyAlpha)(x)
x3 = Add()([x2, x3])
x = Conv2D(featureMaps, 3, padding="same")(x3)
x4 = LeakyReLU(leakyAlpha)(x)
x4 = Add()([x3, x4])
x4 = Conv2D(featureMaps, 3, padding="same")(x4)
xSkip = Add()([xIn, x4])
# scale the residual outputs with a scalar between [0,1]
xSkip = Lambda(lambda x: x * residualScalar)(xSkip)
正如我们之前提到的,ESRGAN 在残差块中使用残差。因此,接下来定义基块。
我们开始添加一个Conv2D和一个LeakyReLU层。由于块的性质,这种层组合的输出x1然后被添加到初始输入x。这被重复三次,在连接初始输入xIn和块输出x4 ( 行 27-40 )的跳跃连接之前添加最后的Conv2D层。
现在,这和原来的论文有点偏离,所有的层都是相互连接的。互连的目的是确保模型在每一步都可以访问前面的特征。基于我们今天使用的任务和数据集,我们的方法足以给出我们想要的结果。
添加跳过连接后,使用线 43 上的residualScalar变量缩放输出。
# create a number of residual in residual blocks
for blockId in range(residualBlocks-1):
x = Conv2D(featureMaps, 3, padding="same")(xSkip)
x1 = LeakyReLU(leakyAlpha)(x)
x1 = Add()([xSkip, x1])
x = Conv2D(featureMaps, 3, padding="same")(x1)
x2 = LeakyReLU(leakyAlpha)(x)
x2 = Add()([x1, x2])
x = Conv2D(featureMaps, 3, padding="same")(x2)
x3 = LeakyReLU(leakyAlpha)(x)
x3 = Add()([x2, x3])
x = Conv2D(featureMaps, 3, padding="same")(x3)
x4 = LeakyReLU(leakyAlpha)(x)
x4 = Add()([x3, x4])
x4 = Conv2D(featureMaps, 3, padding="same")(x4)
xSkip = Add()([xSkip, x4])
xSkip = Lambda(lambda x: x * residualScalar)(xSkip)
现在,块重复是使用for循环的自动化。根据指定的剩余块数量,将添加块层(第 46-61 行)。
# process the residual output with a conv kernel
x = Conv2D(featureMaps, 3, padding="same")(xSkip)
x = Add()([xIn, x])
# upscale the image with pixel shuffle
x = Conv2D(featureMaps * (scalingFactor // 2), 3,
padding="same")(x)
x = tf.nn.depth_to_space(x, 2)
x = LeakyReLU(leakyAlpha)(x)
# upscale the image with pixel shuffle
x = Conv2D(featureMaps, 3, padding="same")(x)
x = tf.nn.depth_to_space(x, 2)
x = LeakyReLU(leakyAlpha)(x)
# get the output layer
x = Conv2D(3, 9, padding="same", activation="tanh")(x)
output = Rescaling(scale=127.5, offset=127.5)(x)
# create the generator model
generator = Model(inputs, output)
# return the generator model
return generator
最终的剩余输出在行 64 和 65 上加上另一个Conv2D层。
现在,升级过程在线 68 开始,这里scalingFactor变量开始起作用。随后是depth_to_space效用函数,通过相应地均匀减小通道尺寸来增加featureMaps的高度和宽度(行 70 )。添加一个LeakyReLU激活功能来完成这个特定的层组合(行 71 )。
在行 73-76 上重复相同的一组层。输出层是通过将featureMaps传递给另一个Conv2D层来实现的。注意这个卷积层有一个tanh激活函数,它将你的输入缩放到-1和1的范围。
因此,像素被重新调整到 0 到 255 的范围内。(第 79 行和第 80 行)。
随着线 83 上发电机的初始化,我们的 ESRGAN 发电机侧要求完成。
@staticmethod
def discriminator(featureMaps, leakyAlpha, discBlocks):
# initialize the input layer and process it with conv kernel
inputs = Input((None, None, 3))
x = Rescaling(scale=1.0/127.5, offset=-1)(inputs)
x = Conv2D(featureMaps, 3, padding="same")(x)
x = LeakyReLU(leakyAlpha)(x)
# pass the output from previous layer through a CONV => BN =>
# LeakyReLU block
x = Conv2D(featureMaps, 3, padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(leakyAlpha)(x)
正如我们所知,鉴别器的目标是接受图像作为输入,并输出一个单一的值,它表示图像是真的还是假的。
第 89 行上的discriminator函数由以下参数定义:
featureMaps:图层Conv2D的滤镜数量。leakyAlpha:激活功能LeakyReLU所需的参数。discBlocks:我们在架构中需要的鉴别器块的数量。
鉴频器的输入被初始化,像素被缩放到-1和1的范围(行 91 和 92 )。
该架构从一个Conv2D层开始,接着是一个LeakyReLU激活层(行 93 和 94 )。
尽管我们已经为生成器放弃了批处理规范化层,但我们将把它们用于鉴别器。下一组图层是一个Conv → BN → LeakyReLU的组合(第 98-100 行)。
# create a downsample conv kernel config
downConvConf = {
"strides": 2,
"padding": "same",
}
# create a number of discriminator blocks
for i in range(1, discBlocks):
# first CONV => BN => LeakyReLU block
x = Conv2D(featureMaps * (2 ** i), 3, **downConvConf)(x)
x = BatchNormalization()(x)
x = LeakyReLU(leakyAlpha)(x)
# second CONV => BN => LeakyReLU block
x = Conv2D(featureMaps * (2 ** i), 3, padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(leakyAlpha)(x)
在第行第 103-106 行,我们创建一个下采样卷积模板配置。然后在线 109-118 上的自动鉴别器模块中使用。
# process the feature maps with global average pooling
x = GlobalAvgPool2D()(x)
x = LeakyReLU(leakyAlpha)(x)
# final FC layer with sigmoid activation function
x = Dense(1, activation="sigmoid")(x)
# create the discriminator model
discriminator = Model(inputs, x)
# return the discriminator model
return discriminator
特征地图然后通过GlobalAvgPool2D层和另一个LeakyReLU激活层,之后最终的密集层给出我们的输出(第 121-125 行)。
鉴别器对象被初始化并在行 128-131 返回,鉴别器功能结束。
为 ESRGAN 建立训练管道
架构完成后,是时候转到位于pyimagesearch目录中的esrgan_training.py脚本了。
# import the necessary packages
from tensorflow.keras import Model
from tensorflow import concat
from tensorflow import zeros
from tensorflow import ones
from tensorflow import GradientTape
from tensorflow.keras.activations import sigmoid
from tensorflow.math import reduce_mean
import tensorflow as tf
class ESRGANTraining(Model):
def __init__(self, generator, discriminator, vgg, batchSize):
# initialize the generator, discriminator, vgg model, and
# the global batch size
super().__init__()
self.generator = generator
self.discriminator = discriminator
self.vgg = vgg
self.batchSize = batchSize
为了使事情变得更简单,完整的培训模块被打包在第 11 行上定义的类中。
自然地,第一个函数变成了__init__,它接受发生器模型、鉴别器模型、VGG 模型和批量规格(第 12 行)。
在这个函数中,我们为参数创建相应的类变量(第 16-19 行)。这些变量将在后面用于类函数。
def compile(self, gOptimizer, dOptimizer, bceLoss, mseLoss):
super().compile()
# initialize the optimizers for the generator
# and discriminator
self.gOptimizer = gOptimizer
self.dOptimizer = dOptimizer
# initialize the loss functions
self.bceLoss = bceLoss
self.mseLoss = mseLoss
第 21 行上的compile函数接收生成器和鉴别器优化器、二元交叉熵损失函数和均方损失函数。
该函数初始化发生器和鉴别器的优化器和损失函数(第 25-30 行)。
def train_step(self, images):
# grab the low and high resolution images
(lrImages, hrImages) = images
lrImages = tf.cast(lrImages, tf.float32)
hrImages = tf.cast(hrImages, tf.float32)
# generate super resolution images
srImages = self.generator(lrImages)
# combine them with real images
combinedImages = concat([srImages, hrImages], axis=0)
# assemble labels discriminating real from fake images where
# label 0 is for predicted images and 1 is for original high
# resolution images
labels = concat(
[zeros((self.batchSize, 1)), ones((self.batchSize, 1))],
axis=0)
现在是我们定义培训程序的时候了。这在行 32 上定义的函数train_step中完成。这个函数接受图像作为它的参数。
我们将图像集解包成相应的低分辨率和高分辨率图像,并将它们转换成float32数据类型(第 34-36 行)。
在行 39 处,我们从生成器中得到一批假的超分辨率图像。这些与真实的超分辨率图像连接,并且相应地创建标签(行 47-49 )。
# train the discriminator with relativistic error
with GradientTape() as tape:
# get the raw predictions and divide them into
# raw fake and raw real predictions
rawPreds = self.discriminator(combinedImages)
rawFake = rawPreds[:self.batchSize]
rawReal = rawPreds[self.batchSize:]
# process the relative raw error and pass it through the
# sigmoid activation function
predFake = sigmoid(rawFake - reduce_mean(rawReal))
predReal = sigmoid(rawReal - reduce_mean(rawFake))
# concat the predictions and calculate the discriminator
# loss
predictions = concat([predFake, predReal], axis=0)
dLoss = self.bceLoss(labels, predictions)
# compute the gradients
grads = tape.gradient(dLoss,
self.discriminator.trainable_variables)
# optimize the discriminator weights according to the
# gradients computed
self.dOptimizer.apply_gradients(
zip(grads, self.discriminator.trainable_variables)
)
# generate misleading labels
misleadingLabels = ones((self.batchSize, 1))
首先,我们将定义鉴别器训练。开始一个GradientTape,我们从我们的鉴别器得到对组合图像集的预测(第 52-55 行)。我们从这些预测中分离出假图像预测和真实图像预测,并得到两者的相对论误差。然后这些值通过一个 sigmoid 函数得到我们的最终输出值(第 56-62 行)。
预测再次被连接,并且通过使预测通过二元交叉熵损失来计算鉴别器损失(行 66 和 67 )。
利用损失值,计算梯度,并相应地改变鉴别器权重(第 70-77 行)。
鉴别器训练结束后,我们现在生成生成器训练所需的误导标签(第 80 行)。
# train the generator (note that we should *not* update
# the weights of the discriminator)
with GradientTape() as tape:
# generate fake images
fakeImages = self.generator(lrImages)
# calculate predictions
rawPreds = self.discriminator(fakeImages)
realPreds = self.discriminator(hrImages)
relativisticPreds = rawPreds - reduce_mean(realPreds)
predictions = sigmoid(relativisticPreds)
# compute the discriminator predictions on the fake images
# todo: try with logits
#gLoss = self.bceLoss(misleadingLabels, predictions)
gLoss = self.bceLoss(misleadingLabels, predictions)
# compute the pixel loss
pixelLoss = self.mseLoss(hrImages, fakeImages)
# compute the normalized vgg outputs
srVGG = tf.keras.applications.vgg19.preprocess_input(
fakeImages)
srVGG = self.vgg(srVGG) / 12.75
hrVGG = tf.keras.applications.vgg19.preprocess_input(
hrImages)
hrVGG = self.vgg(hrVGG) / 12.75
# compute the perceptual loss
percLoss = self.mseLoss(hrVGG, srVGG)
# compute the total GAN loss
gTotalLoss = 5e-3 * gLoss + percLoss + 1e-2 * pixelLoss
# compute the gradients
grads = tape.gradient(gTotalLoss,
self.generator.trainable_variables)
# optimize the generator weights according to the gradients
# calculated
self.gOptimizer.apply_gradients(zip(grads,
self.generator.trainable_variables)
)
# return the generator and discriminator losses
return {"dLoss": dLoss, "gTotalLoss": gTotalLoss,
"gLoss": gLoss, "percLoss": percLoss, "pixelLoss": pixelLoss}
我们再次为生成器初始化一个GradientTape,并使用生成器生成假的超分辨率图像(第 84-86 行)。
计算伪超分辨率图像和真实超分辨率图像的预测,并计算相对论误差(行 89-92 )。
预测被馈送到二进制交叉熵损失函数,同时使用均方误差损失函数计算像素损失(行 97-100 )。
接下来,我们计算 VGG 输出和感知损失(行 103-111 )。有了所有可用的损耗值,我们使用行 114 上的等式计算 GAN 总损耗。
计算并应用发电机梯度(第 117-128 行)。
创建效用函数辅助甘训练
我们使用了一些实用程序脚本来帮助我们的培训。第一个是保存我们在训练中使用的损失的脚本。为此,让我们转到pyimagesearch目录中的losses.py脚本。
# import necessary packages
from tensorflow.keras.losses import MeanSquaredError
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.losses import Reduction
from tensorflow import reduce_mean
class Losses:
def __init__(self, numReplicas):
self.numReplicas = numReplicas
def bce_loss(self, real, pred):
# compute binary cross entropy loss without reduction
BCE = BinaryCrossentropy(reduction=Reduction.NONE)
loss = BCE(real, pred)
# compute reduced mean over the entire batch
loss = reduce_mean(loss) * (1\. / self.numReplicas)
# return reduced bce loss
return
__init__函数定义了后续损失函数中使用的批量大小(第 8 行和第 9 行)。
损失被打包到第 7 行的一个类中。我们定义的第一个损失是线 11** 上的二元交叉熵损失。它接受真实标签和预测标签。**
二进制交叉熵损失对象定义在行 13 ,损失计算在行 14 。然后在整批中调整损耗(第 17 行)。
def mse_loss(self, real, pred):
# compute mean squared error loss without reduction
MSE = MeanSquaredError(reduction=Reduction.NONE)
loss = MSE(real, pred)
# compute reduced mean over the entire batch
loss = reduce_mean(loss) * (1\. / self.numReplicas)
# return reduced mse loss
return loss
下一个损失是在行 22 上定义的均方误差函数。一个均方误差损失对象被初始化,随后是整个批次的损失计算(第 24-28 行)。
我们的losses.py脚本到此结束。我们接下来进入utils.py脚本,它将帮助我们更好地评估 GAN 生成的图像。为此,接下来让我们进入utils.py剧本。
# import the necessary packages
from . import config
from matplotlib.pyplot import subplots
from matplotlib.pyplot import savefig
from matplotlib.pyplot import title
from matplotlib.pyplot import xticks
from matplotlib.pyplot import yticks
from matplotlib.pyplot import show
from tensorflow.keras.preprocessing.image import array_to_img
from mpl_toolkits.axes_grid1.inset_locator import zoomed_inset_axes
from mpl_toolkits.axes_grid1.inset_locator import mark_inset
import os
# the following code snippet has been taken from:
# https://keras.io/examples/vision/super_resolution_sub_pixel
def zoom_into_images(image, imageTitle):
# create a new figure with a default 111 subplot.
(fig, ax) = subplots()
im = ax.imshow(array_to_img(image[::-1]), origin="lower")
title(imageTitle)
# zoom-factor: 2.0, location: upper-left
axins = zoomed_inset_axes(ax, 2, loc=2)
axins.imshow(array_to_img(image[::-1]), origin="lower")
# specify the limits.
(x1, x2, y1, y2) = 20, 40, 20, 40
# apply the x-limits.
axins.set_xlim(x1, x2)
# apply the y-limits.
axins.set_ylim(y1, y2)
# remove the xticks and yticks
yticks(visible=False)
xticks(visible=False)
# make the line.
mark_inset(ax, axins, loc1=1, loc2=3, fc="none", ec="blue")
# build the image path and save it to disk
imagePath = os.path.join(config.BASE_IMAGE_PATH,
f"{imageTitle}.png")
savefig(imagePath)
# show the image
show()
这个脚本在第 16 行的处包含一个名为zoom_into_images的函数,它接受图像和图像标题作为参数。
首先定义支线剧情,绘制图像(第 18 行和第 19 行)。在第 21-24 行,我们放大图像的左上区域,并再次绘制该部分。
该图的界限设置在第 27-31 行的上。现在,我们移除 x 轴和 y 轴上的记号,并在原始绘图上插入线条(第 34-38 行)。
绘制完图像后,我们保存图像并结束该功能(第 41-43 行)。
我们最后的实用程序脚本是vgg.py脚本,它初始化了我们感知损失的 VGG 模型。
# import the necessary packages
from tensorflow.keras.applications import VGG19
from tensorflow.keras import Model
class VGG:
@staticmethod
def build():
# initialize the pre-trained VGG19 model
vgg = VGG19(input_shape=(None, None, 3), weights="imagenet",
include_top=False)
# slicing the VGG19 model till layer #20
model = Model(vgg.input, vgg.layers[20].output)
# return the sliced VGG19 model
return model
我们在5 号线为 VGG 模型创建一个类。该函数包含一个名为build的单一函数,它简单地初始化一个预训练的 VGG-19 架构,并返回一个切片到第 20 层的 VGG 模型(第 7-16 行)。这就结束了vgg.py脚本。
训练 ESR gan
现在我们所有的积木都准备好了。我们只需要按照正确的顺序来执行它们,以便进行适当的 GAN 训练。为了实现这一点,我们进入train_esrgan.py脚本。
# USAGE
# python train_esrgan.py --device gpu
# python train_esrgan.py --device tpu
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch.data_preprocess import load_dataset
from pyimagesearch.esrgan_training import ESRGANTraining
from pyimagesearch.esrgan import ESRGAN
from pyimagesearch.losses import Losses
from pyimagesearch.vgg import VGG
from pyimagesearch import config
from tensorflow import distribute
from tensorflow.config import experimental_connect_to_cluster
from tensorflow.tpu.experimental import initialize_tpu_system
from tensorflow.keras.optimizers import Adam
from tensorflow.io.gfile import glob
import argparse
import sys
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("--device", required=True, default="gpu",
choices=["gpu", "tpu"], type=str,
help="device to use for training (gpu or tpu)")
args = vars(ap.parse_args())
这里的第一个任务是定义一个参数解析器,以便用户可以选择是使用 TPU 还是 GPU 来完成 GAN 训练(第 26-30 行)。正如我们已经提到的,我们已经使用 TPU 和 GPU 训练了 GAN 来评估效率。
# check if we are using TPU, if so, initialize the TPU strategy
if args["device"] == "tpu":
# initialize the TPUs
tpu = distribute.cluster_resolver.TPUClusterResolver()
experimental_connect_to_cluster(tpu)
initialize_tpu_system(tpu)
strategy = distribute.TPUStrategy(tpu)
# ensure the user has entered a valid gcs bucket path
if config.TPU_BASE_TFR_PATH == "gs://<PATH_TO_GCS_BUCKET>/tfrecord":
print("[INFO] not a valid GCS Bucket path...")
sys.exit(0)
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for TPU training
tfrTrainPath = config.TPU_DIV2K_TFR_TRAIN_PATH
pretrainedGenPath = config.TPU_PRETRAINED_GENERATOR_MODEL
genPath = config.TPU_GENERATOR_MODEL
# otherwise, we are using multi/single GPU so initialize the mirrored
# strategy
elif args["device"] == "gpu":
# define the multi-gpu strategy
strategy = distribute.MirroredStrategy()
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for GPU training
tfrTrainPath = config.GPU_DIV2K_TFR_TRAIN_PATH
pretrainedGenPath = config.GPU_PRETRAINED_GENERATOR_MODEL
genPath = config.GPU_GENERATOR_MODEL
# else, invalid argument was provided as input
else:
# exit the program
print("[INFO] please enter a valid device argument...")
sys.exit(0)
# display the number of accelerators
print(f"[INFO] number of accelerators: {strategy.num_replicas_in_sync}...")
根据设备选择,我们必须初始化策略。首先,我们探索 TPU 选择的案例(第 33 行)。
为了恰当地利用 TPU 的能力,我们初始化了一个TPUClusterResolver来有效地利用资源。接下来,TPU 策略被初始化(第 35-43 行)。
定义了到 TPU 训练数据、预训练发生器和完全训练发生器的TFRecords路径(第 47-49 行)。
现在探讨第二种设备选择,即 GPU。对于 GPU,使用 GPU 镜像策略(第 55 行),并定义 GPU 特定的TFRecords路径、预训练的生成器路径和完全训练的生成器路径(第 59-61 行)。
如果给出了任何其他选择,脚本会自己退出(第 64-67 行)。
# grab train TFRecord filenames
print("[INFO] grabbing the train TFRecords...")
trainTfr = glob(tfrTrainPath +"/*.tfrec")
# build the div2k datasets from the TFRecords
print("[INFO] creating train and test dataset...")
trainDs = load_dataset(filenames=trainTfr, train=True,
batchSize=config.TRAIN_BATCH_SIZE * strategy.num_replicas_in_sync)
# call the strategy scope context manager
with strategy.scope():
# initialize our losses class object
losses = Losses(numReplicas=strategy.num_replicas_in_sync)
# initialize the generator, and compile it with Adam optimizer and
# MSE loss
generator = ESRGAN.generator(
scalingFactor=config.SCALING_FACTOR,
featureMaps=config.FEATURE_MAPS,
residualBlocks=config.RESIDUAL_BLOCKS,
leakyAlpha=config.LEAKY_ALPHA,
residualScalar=config.RESIDUAL_SCALAR)
generator.compile(optimizer=Adam(learning_rate=config.PRETRAIN_LR),
loss=losses.mse_loss)
# pretraining the generator
print("[INFO] pretraining ESRGAN generator ...")
generator.fit(trainDs, epochs=config.PRETRAIN_EPOCHS,
steps_per_epoch=config.STEPS_PER_EPOCH)
我们获取TFRecords文件,然后使用load_dataset函数(第 74-79 行)创建一个训练数据集。
首先,我们将初始化预训练的生成器。为此,我们首先调用策略范围上下文管理器来初始化第 82-95 行上的损失和生成器。接着在线 99 和 100 上训练发电机。
# check whether output model directory exists, if it doesn't, then
# create it
if args["device"] == "gpu" and not os.path.exists(config.BASE_OUTPUT_PATH):
os.makedirs(config.BASE_OUTPUT_PATH)
# save the pretrained generator
print("[INFO] saving the pretrained generator...")
generator.save(pretrainedGenPath)
# call the strategy scope context manager
with strategy.scope():
# initialize our losses class object
losses = Losses(numReplicas=strategy.num_replicas_in_sync)
# initialize the vgg network (for perceptual loss) and discriminator
# network
vgg = VGG.build()
discriminator = ESRGAN.discriminator(
featureMaps=config.FEATURE_MAPS,
leakyAlpha=config.LEAKY_ALPHA,
discBlocks=config.DISC_BLOCKS)
# build the ESRGAN model and compile it
esrgan = ESRGANTraining(
generator=generator,
discriminator=discriminator,
vgg=vgg,
batchSize=config.TRAIN_BATCH_SIZE)
esrgan.compile(
dOptimizer=Adam(learning_rate=config.FINETUNE_LR),
gOptimizer=Adam(learning_rate=config.FINETUNE_LR),
bceLoss=losses.bce_loss,
mseLoss=losses.mse_loss,
)
# train the ESRGAN model
print("[INFO] training ESRGAN...")
esrgan.fit(trainDs, epochs=config.FINETUNE_EPOCHS,
steps_per_epoch=config.STEPS_PER_EPOCH)
# save the ESRGAN generator
print("[INFO] saving ESRGAN generator to {}..."
.format(genPath))
esrgan.generator.save(genPath)
如果设备被设置为 GPU,基本输出模型目录被初始化(如果还没有完成的话)(行 104 和 105 )。预训练的发电机然后被保存到指定的路径(行 109 )。
现在我们来看看训练有素的 ESRGAN。我们再次初始化策略范围上下文管理器,并初始化一个 loss 对象(行 112-114 )。
感知损失所需的 VGG 模型被初始化,随后是 ESRGAN ( 行 118-129 )。然后用所需的优化器和损耗编译 es rgan(第 130-135 行)。
这里的最后一步是用训练数据拟合 ESRGAN,并让它训练(行 139 和 140 )。
一旦完成,被训练的重量被保存在线 145 上的预定路径中。
为 ESRGAN 构建推理脚本
随着我们的 ESRGAN 培训的完成,我们现在可以评估我们的 ESRGAN 在结果方面表现如何。为此,让我们看看位于核心目录中的inference.py脚本。
# USAGE
# python inference.py --device gpu
# python inference.py --device tpu
# import the necessary packages
from pyimagesearch.data_preprocess import load_dataset
from pyimagesearch.utils import zoom_into_images
from pyimagesearch import config
from tensorflow import distribute
from tensorflow.config import experimental_connect_to_cluster
from tensorflow.tpu.experimental import initialize_tpu_system
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.io.gfile import glob
from matplotlib.pyplot import subplots
import argparse
import sys
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("--device", required=True, default="gpu",
choices=["gpu", "tpu"], type=str,
help="device to use for training (gpu or tpu)")
args = vars(ap.parse_args())
根据我们用于训练的设备,我们需要提供相同的设备来初始化模型并相应地加载所需的权重。为此,我们构建了一个参数解析器,它接受用户的设备选择(第 21-25 行)。
# check if we are using TPU, if so, initialize the strategy
# accordingly
if args["device"] == "tpu":
tpu = distribute.cluster_resolver.TPUClusterResolver()
experimental_connect_to_cluster(tpu)
initialize_tpu_system(tpu)
strategy = distribute.TPUStrategy(tpu)
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for TPU training
tfrTestPath = config.TPU_DIV2K_TFR_TEST_PATH
pretrainedGenPath = config.TPU_PRETRAINED_GENERATOR_MODEL
genPath = config.TPU_GENERATOR_MODEL
# otherwise, we are using multi/single GPU so initialize the mirrored
# strategy
elif args["device"] == "gpu":
# define the multi-gpu strategy
strategy = distribute.MirroredStrategy()
# set the train TFRecords, pretrained generator, and final
# generator model paths to be used for GPU training
tfrTestPath = config.GPU_DIV2K_TFR_TEST_PATH
pretrainedGenPath = config.GPU_PRETRAINED_GENERATOR_MODEL
genPath = config.GPU_GENERATOR_MODEL
# else, invalid argument was provided as input
else:
# exit the program
print("[INFO] please enter a valid device argument...")
sys.exit(0)
根据用户输入的选择,我们必须建立处理数据的策略。
第一个设备选择(TPU)是通过初始化TPUClusterResolver、策略和特定于 TPU 的输出路径来探索的,其方式与我们为训练脚本所做的相同(第 29-33 行)。
对于第二个选择(GPU),我们重复与训练脚本相同的过程(第 43-51 行)。
如果给出了任何其他输入,脚本会自行退出(第 54-57 行)。
# get the dataset
print("[INFO] loading the test dataset...")
testTfr = glob(tfrTestPath + "/*.tfrec")
testDs = load_dataset(testTfr, config.INFER_BATCH_SIZE, train=False)
# get the first batch of testing images
(lrImage, hrImage) = next(iter(testDs))
# call the strategy scope context manager
with strategy.scope():
# load the ESRGAN trained models
print("[INFO] loading the pre-trained and fully trained ESRGAN model...")
esrganPreGen = load_model(pretrainedGenPath, compile=False)
esrganGen = load_model(genPath, compile=False)
# predict using ESRGAN
print("[INFO] making predictions with pre-trained and fully trained ESRGAN model...")
esrganPreGenPred = esrganPreGen.predict(lrImage)
esrganGenPred = esrganGen.predict(lrImage)
出于测试目的,我们在行 62 上创建一个测试数据集。使用next(iter()),我们可以抓取一批图像集,我们在行 65 上将其解包。
接下来,预训练的 GAN 和完全训练的 ESRGAN 被初始化并加载到线 71 和 72 上。然后低分辨率图像通过这些 gan 进行预测(线 76 和 77 )。
# plot the respective predictions
print("[INFO] plotting the ESRGAN predictions...")
(fig, axes) = subplots(nrows=config.INFER_BATCH_SIZE, ncols=4,
figsize=(50, 50))
# plot the predicted images from low res to high res
for (ax, lowRes, esrPreIm, esrGanIm, highRes) in zip(axes, lrImage,
esrganPreGenPred, esrganGenPred, hrImage):
# plot the low resolution image
ax[0].imshow(array_to_img(lowRes))
ax[0].set_title("Low Resolution Image")
# plot the pretrained ESRGAN image
ax[1].imshow(array_to_img(esrPreIm))
ax[1].set_title("ESRGAN Pretrained")
# plot the ESRGAN image
ax[2].imshow(array_to_img(esrGanIm))
ax[2].set_title("ESRGAN")
# plot the high resolution image
ax[3].imshow(array_to_img(highRes))
ax[3].set_title("High Resolution Image")
# check whether output image directory exists, if it doesn't, then
# create it
if not os.path.exists(config.BASE_IMAGE_PATH):
os.makedirs(config.BASE_IMAGE_PATH)
# serialize the results to disk
print("[INFO] saving the ESRGAN predictions to disk...")
fig.savefig(config.GRID_IMAGE_PATH)
# plot the zoomed in images
zoom_into_images(esrganPreGenPred[0], "ESRGAN Pretrained")
zoom_into_images(esrganGenPred[0], "ESRGAN")
为了可视化我们的结果,在第 81 行和第 82 行初始化子情节。然后,我们对批处理进行循环,并绘制低分辨率图像、预训练 GAN 输出、ESRGAN 输出和实际高分辨率图像进行比较(第 85-101 行)。
的可视化效果
**图 3 和图 4 分别向我们展示了预训练的 ESRGAN 和完全训练的 ESRGAN 的最终预测图像。
这两个模型的输出在视觉上是无法区分的。然而,结果比上周的 SRGAN 输出要好,即使 ESRGAN 被训练的时期更少。
放大的补丁显示了 ESRGAN 实现的像素化信息的复杂清晰度,证明用于 SRGAN 增强的增强配方工作得相当好。
汇总
根据他们的结果,SRGANs 已经给人留下了深刻的印象。它优于现有的几种超分辨率算法。在其基础上,提出增强配方是整个深度学习社区非常赞赏的事情。
这些添加是经过深思熟虑的,结果一目了然。我们的 ESRGAN 取得了很大的成绩,尽管被训练了很少的时代。这非常符合 ESRGAN 优先关注效率的动机。
GANs 一直给我们留下深刻的印象,直到今天,新的域名都在使用 GANs。但是在今天的项目中,我们讨论了可以用来改善最终结果的方法。
引用信息
Chakraborty,D. “增强的超分辨率生成对抗网络(ESRGAN), PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki 编辑。,2022 年,【https://pyimg.co/jt2cb
@incollection{Chakraborty_2022_ESRGAN,
author = {Devjyoti Chakraborty},
title = {Enhanced Super-Resolution Generative Adversarial Networks {(ESRGAN)}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/jt2cb},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!*********


 浙公网安备 33010602011771号
浙公网安备 33010602011771号