PyImgSearch-博客中文翻译-七-
PyImgSearch 博客中文翻译(七)
Keras 保存并加载您的深度学习模型
原文:https://pyimagesearch.com/2018/12/10/keras-save-and-load-your-deep-learning-models/

在本教程中,您将学习如何保存和加载 Keras 深度学习模型。
这篇博客的灵感来自于 PyImageSearch 的读者梅森,他上周发邮件问:
阿德里安,我一直在看你的博客和你的深度学习教程。谢谢他们。
但是我有一个问题:
训练结束后,如何保存你的 Keras 模型?
一旦你保存了它,你如何再次加载它,这样你就可以分类新的图像?
我知道这是一个基本的问题,但我不知道如何保存和加载我的 Keras 模型。
梅森问了一个很好的问题— 实际上,这个问题并不像他(甚至你)认为的那样是一个“基本”的概念。
从表面上看,保存 Keras 模型就像调用model.save和load_model函数一样简单。但是实际上要考虑的不仅仅是的加载和保存模型功能!
什么是更重要的,并且有时被新的深度学习实践者忽略的,是预处理阶段——你用于训练和验证的预处理步骤必须与加载你的模型和分类新图像时的训练步骤相同。
在今天剩余的课程中,我们将探索:
- 如何正确保存和加载你的 Keras 深度学习模型?
- 加载模型后预处理图像的正确步骤。
要了解如何用 Keras 保存和加载你的深度学习模型,继续阅读!
keras–保存并加载您的深度学习模型
2020-06-03 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将简要回顾(1)我们将在其上训练 Keras 模型的示例数据集,以及(2)我们的项目目录结构。在这里,我将向您展示如何:
- 用 Keras 训练深度学习模型
- 将 Keras 模型序列化并保存到磁盘
- 从磁盘加载保存的 Keras 模型
- 使用保存的 Keras 模型对新图像数据进行预测
让我们开始吧!
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
我们的示例数据集
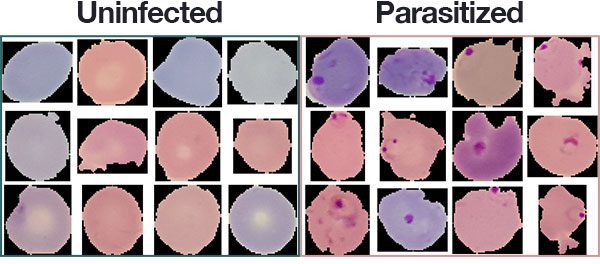
Figure 1: A subset of the Malaria Dataset provided by the National Institute of Health (NIH). We will use this dataset to develop a deep learning medical imaging classification model saved to disk with Python, OpenCV, and Keras.
我们将在今天的教程中使用的数据集是我们在上周的 深度学习和 Keras 医学图像分析博文中涉及的疟疾检测和分类数据集的子集。
原始数据集由 27,588 幅图像组成,分为两类:
- 寄生:暗示图像包含疟疾
- 未感染:表示图像中没有疟疾的迹象
由于本教程的目标不是医学图像分析,而是如何保存和加载您的 Keras 模型,我已经将数据集采样到 100 张图像。
我减少了数据集的大小,主要是因为:
- 您应该能够在您的 CPU 上运行这个示例(如果您不拥有/没有访问 GPU 的权限)。
- 我们的目标是教授保存和加载 Keras 模型的基本概念,而不是训练一个最先进的疟疾检测器。
- 正因为如此,最好使用较小的示例数据集
如果你想阅读我关于如何利用完整数据集构建(接近)最先进的疟疾分类器的完整博客文章,请务必参考这篇博客文章。
项目结构
一定要抓住今天的 【下载】 由精简的数据集、ResNet 模型和 Python 脚本组成。
解压缩文件后,您将看到以下目录结构:
$ tree --filelimit 10 --dirsfirst
.
├── malaria
│ ├── testing
│ │ ├── Parasitized [50 entries]
│ │ └── Uninfected [50 entries]
│ ├── training
│ │ ├── Parasitized [175 entries]
│ │ └── Uninfected [185 entries]
│ └── validation
│ ├── Parasitized [18 entries]
│ └── Uninfected [22 entries]
├── pyimagesearch
│ ├── __init__.py
│ └── resnet.py
├── save_model.py
└── load_model.py
11 directories, 4 files
我们的项目由根目录中的两个文件夹组成:
- 我们精简的疟疾数据集。它通过上周的“构建数据集”脚本被组织成训练集、验证集和测试集。
pyimagesearch/:下载包中包含的一个包,其中包含了我们的 ResNet 模型类。
今天,我们还将回顾两个 Python 脚本:
- 一个演示脚本,它将在我们的 Keras 模型被训练后保存到磁盘上。
load_model.py:我们的脚本从磁盘加载保存的模型,并对一小部分测试图像进行分类。
通过查看这些文件,你会很快看到 Keras 使保存和加载深度学习模型文件变得多么容易。
使用 Keras 和 TensorFlow 保存模型

Figure 2: The steps for training and saving a Keras deep learning model to disk.
在从磁盘加载 Keras 模型之前,我们首先需要:
- 训练 Keras 模型
- 保存 Keras 模型
我们将要回顾的脚本将涵盖这两个概念。
请打开您的save_model.py文件,让我们开始吧:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from pyimagesearch.resnet import ResNet
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
我们从第 2-14 行开始,导入所需的包。
在第 3 行的上,指定了"Agg" matplotlib 后端,因为我们将把我们的绘图保存到磁盘上(除了我们的模型之外)。
我们的ResNet CNN 是在8 号线导入的。为了使用这个 CNN,一定要抢今天博文的 【下载】 。
使用argparse导入,让解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path dataset of input images")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained model")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们的脚本要求在终端中为命令字符串提供三个参数:
--dataset:我们数据集的路径。我们正在使用上周在 T2 建立的疟疾数据集的子集。--model:您需要指定训练输出模型的路径(即 Keras 模型将要保存的位置)。这是我们今天所讲内容的关键。--plot:训练地块的路径。默认情况下,该图形将被命名为plot.png。
这些代码行不需要修改。同样,您需要在终端中输入参数的值,让argparse完成剩下的工作。如果你不熟悉命令行参数的概念,请看这篇文章。
让我们初始化我们的训练变量和路径:
# initialize the number of training epochs and batch size
NUM_EPOCHS = 25
BS = 32
# derive the path to the directories containing the training,
# validation, and testing splits, respectively
TRAIN_PATH = os.path.sep.join([args["dataset"], "training"])
VAL_PATH = os.path.sep.join([args["dataset"], "validation"])
TEST_PATH = os.path.sep.join([args["dataset"], "testing"])
# determine the total number of image paths in training, validation,
# and testing directories
totalTrain = len(list(paths.list_images(TRAIN_PATH)))
totalVal = len(list(paths.list_images(VAL_PATH)))
totalTest = len(list(paths.list_images(TEST_PATH)))
我们将以32的批量训练25个时期。
上周,我们将 NIH 疟疾数据集分为三组,并为每组创建了相应的目录:
- 培养
- 确认
- 测试
如果你想知道数据分割过程是如何工作的,一定要回顾一下教程中的build_dataset.py脚本。今天,我已经将得到的数据集进行了分割(并且为了这篇博文的目的,已经变得非常小)。
图像路径建立在行 32-34 上,每次分割的图像数量在行 38-40 上抓取。
让我们初始化我们的数据扩充对象:
# initialize the training training data augmentation object
trainAug = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=20,
zoom_range=0.05,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
horizontal_flip=True,
fill_mode="nearest")
# initialize the validation (and testing) data augmentation object
valAug = ImageDataGenerator(rescale=1 / 255.0)
数据扩充是通过随机修改从数据集生成新图像的过程。它产生了一个更好的深度学习模型,我几乎总是推荐它(这对小数据集尤其重要)。
数据增强在我的 Keras 教程 博文中有简要介绍。要全面了解数据增强,请务必阅读我的深度学习书籍, 用 Python 进行计算机视觉的深度学习 。
注意:valAug对象只是执行缩放——实际上没有执行任何放大。我们将使用这个对象两次:一次用于验证重缩放,一次用于测试重缩放。
既然已经创建了训练和验证增强对象,让我们初始化生成器:
# initialize the training generator
trainGen = trainAug.flow_from_directory(
TRAIN_PATH,
class_mode="categorical",
target_size=(64, 64),
color_mode="rgb",
shuffle=True,
batch_size=32)
# initialize the validation generator
valGen = valAug.flow_from_directory(
VAL_PATH,
class_mode="categorical",
target_size=(64, 64),
color_mode="rgb",
shuffle=False,
batch_size=BS)
# initialize the testing generator
testGen = valAug.flow_from_directory(
TEST_PATH,
class_mode="categorical",
target_size=(64, 64),
color_mode="rgb",
shuffle=False,
batch_size=BS)
上面的三个生成器实际上根据我们的增强对象和这里给出的参数在训练/验证/测试期间按需产生图像。
现在我们将构建、编译和训练我们的模型。我们还将评估我们的模型并打印一份分类报告:
# initialize our Keras implementation of ResNet model and compile it
model = ResNet.build(64, 64, 3, 2, (2, 2, 3),
(32, 64, 128, 256), reg=0.0005)
opt = SGD(lr=1e-1, momentum=0.9, decay=1e-1 / NUM_EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train our Keras model
H = model.fit(
x=trainGen,
steps_per_epoch=totalTrain // BS,
validation_data=valGen,
validation_steps=totalVal // BS,
epochs=NUM_EPOCHS)
# reset the testing generator and then use our trained model to
# make predictions on the data
print("[INFO] evaluating network...")
testGen.reset()
predIdxs = model.predict(x=testGen, steps=(totalTest // BS) + 1)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testGen.classes, predIdxs,
target_names=testGen.class_indices.keys()))
2020-06-03 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit 生成器以及数据扩充的文章。
在上面的代码块中,我们:
- 初始化我们在第 84-88 行上
ResNet的实现(来自 用 Python 进行计算机视觉的深度学习 )。注意我们是如何指定"binary_crossentropy"的,因为我们的模型有两个类。如果你正在使用> 2 类,你应该把它改成"categorical_crossentropy"。 - 在扩充的疟疾数据集上训练 ResNet
model(第 91-96 行)。 - 对测试集进行预测(行 102 ),并提取每个预测的最高概率等级指数(行 106 )。
- 在我们的终端显示一个
classification_report(行 109-110 )。
现在我们的模型已经训练好了,让我们将我们的 Keras 模型保存到磁盘:
# save the network to disk
print("[INFO] serializing network to '{}'...".format(args["model"]))
model.save(args["model"], save_format="h5")
为了将我们的 Keras 模型保存到磁盘,我们只需调用model ( 第 114 行)上的.save。
2020-06-03 更新:注意,对于 TensorFlow 2.0+我们建议明确设置save_format="h5" (HDF5 格式)。
简单吧?
是的,这是一个简单的函数调用,但之前的辛勤工作使这一过程成为可能。
在我们的下一个脚本中,我们将能够从磁盘加载模型并进行预测。
让我们绘制训练结果并保存训练图:
# plot the training loss and accuracy
N = NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-03 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
至此,我们的脚本完成了。让我们继续训练我们的 Keras 模型吧!
为了在我们的示例数据集上训练您的 Keras 模型,请确保您使用了博文的 【下载】 部分来下载源代码和图像本身。
从那里,打开一个终端并执行以下命令:
$ python save_model.py --dataset malaria --model saved_model.model
Found 360 images belonging to 2 classes.
Found 40 images belonging to 2 classes.
Found 100 images belonging to 2 classes.
Epoch 1/25
11/11 [==============================] - 10s 880ms/step - loss: 0.9204 - accuracy: 0.5686 - val_loss: 7.0116 - val_accuracy: 0.5625
Epoch 2/25
11/11 [==============================] - 7s 624ms/step - loss: 0.8821 - accuracy: 0.5899 - val_loss: 1.4123 - val_accuracy: 0.4375
Epoch 3/25
11/11 [==============================] - 7s 624ms/step - loss: 0.9426 - accuracy: 0.5878 - val_loss: 0.8156 - val_accuracy: 0.6562
...
Epoch 23/25
11/11 [==============================] - 7s 664ms/step - loss: 0.3372 - accuracy: 0.9659 - val_loss: 0.2396 - val_accuracy: 0.9688
Epoch 24/25
11/11 [==============================] - 7s 622ms/step - loss: 0.3035 - accuracy: 0.9514 - val_loss: 0.3389 - val_accuracy: 0.9375
Epoch 25/25
11/11 [==============================] - 7s 624ms/step - loss: 0.2934 - accuracy: 0.9543 - val_loss: 0.2876 - val_accuracy: 0.9375
[INFO] evaluating network...
precision recall f1-score support
Parasitized 0.98 1.00 0.99 50
Uninfected 1.00 0.98 0.99 50
accuracy 0.99 100
macro avg 0.99 0.99 0.99 100
weighted avg 0.99 0.99 0.99 100
[INFO] serializing network to 'saved_model.model'...
请注意命令行参数。我已经指定了疟疾数据集目录的路径(--dataset malaria)和目标模型的路径(--model saved_model.model)。这些命令行参数是该脚本运行的关键。你可以给你的模型起任何你喜欢的名字,而不用修改一行代码!
这里你可以看到我们的模型在测试集上获得了 ~99%的准确率。
在我的 CPU 上,每个时期占用了 ~7 秒。在我的 GPU 上,每个纪元需要 ~1 秒。请记住,训练比上周更快,因为由于我减少了今天的数据集,我们在每个时期通过网络推送的数据更少。
培训后,您可以列出目录的内容,并查看保存的 Keras 模型:
$ ls -l
total 5216
-rw-r--r--@ 1 adrian staff 2415 Nov 28 10:09 load_model.py
drwxr-xr-x@ 5 adrian staff 160 Nov 28 08:12 malaria
-rw-r--r--@ 1 adrian staff 38345 Nov 28 10:13 plot.png
drwxr-xr-x@ 6 adrian staff 192 Nov 28 08:12 pyimagesearch
-rw-r--r--@ 1 adrian staff 4114 Nov 28 10:09 save_model.py
-rw-r--r--@ 1 adrian staff 2614136 Nov 28 10:13 saved_model.model
Figure 3: Our Keras model is now residing on disk. Saving Keras models is quite easy via the Keras API.
saved_model.model文件是您实际保存的 Keras 模型。
在下一节中,您将学习如何从磁盘加载保存的 Keras 模型。
使用 Keras 和 TensorFlow 加载模型
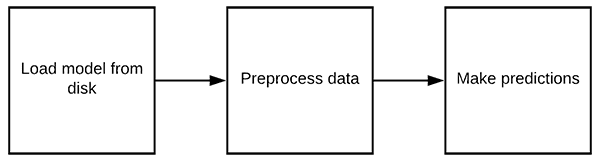
Figure 4: The process of loading a Keras model from disk and putting it to use to make predictions. Don’t forget to preprocess your data in the same manner as during training!
既然我们已经学会了如何将 Keras 模型保存到磁盘,下一步就是加载 Keras 模型,这样我们就可以用它来进行分类。打开您的load_model.py脚本,让我们开始吧:
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from imutils import build_montages
from imutils import paths
import numpy as np
import argparse
import random
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to out input directory of images")
ap.add_argument("-m", "--model", required=True,
help="path to pre-trained model")
args = vars(ap.parse_args())
我们在2-10 号线进口我们需要的包装。最值得注意的是,我们需要load_model来从磁盘加载我们的模型并投入使用。
我们的两个命令行参数在第 12-17 行上解析:
--images:我们想用来做预测的图像的路径。--model:我们之前刚刚保存的模型的路径。
同样,这些线不需要改变。当您在终端中输入命令时,您将为--images和--model提供值。
下一步是从磁盘加载我们的 Keras 模型:
# load the pre-trained network
print("[INFO] loading pre-trained network...")
model = load_model(args["model"])
在第 21 行,为了加载我们的 Keras model,我们调用load_model,提供模型本身的路径(包含在我们解析的args字典中)。
给定model,我们现在可以用它进行预测。但是首先我们需要一些图片和一个地方来放置我们的结果:
# grab all image paths in the input directory and randomly sample them
imagePaths = list(paths.list_images(args["images"]))
random.shuffle(imagePaths)
imagePaths = imagePaths[:16]
# initialize our list of results
results = []
在第 24-26 行,我们随机选择测试图像路径。
第 29 行初始化一个空列表来保存results。
让我们循环一遍我们的每个imagePaths:
# loop over our sampled image paths
for p in imagePaths:
# load our original input image
orig = cv2.imread(p)
# pre-process our image by converting it from BGR to RGB channel
# ordering (since our Keras mdoel was trained on RGB ordering),
# resize it to 64x64 pixels, and then scale the pixel intensities
# to the range [0, 1]
image = cv2.cvtColor(orig, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (64, 64))
image = image.astype("float") / 255.0
在第 32 行的上,我们开始循环我们的imagePaths。
我们从从磁盘加载我们的图像(第 34 行)并预处理它(第 40-42 行)开始循环。这些预处理步骤应该与我们的训练脚本中的 相同 。正如你所看到的,我们已经将图像从 BGR 转换为 RGB 通道排序,调整为 64×64 像素,并缩放到范围【0,1】。
我看到新的深度学习实践者犯的一个常见错误是未能以与训练图像相同的方式预处理新图像。
继续,让我们对循环的每次迭代进行预测:
# order channel dimensions (channels-first or channels-last)
# depending on our Keras backend, then add a batch dimension to
# the image
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
# make predictions on the input image
pred = model.predict(image)
pred = pred.argmax(axis=1)[0]
# an index of zero is the 'parasitized' label while an index of
# one is the 'uninfected' label
label = "Parasitized" if pred == 0 else "Uninfected"
color = (0, 0, 255) if pred == 0 else (0, 255, 0)
# resize our original input (so we can better visualize it) and
# then draw the label on the image
orig = cv2.resize(orig, (128, 128))
cv2.putText(orig, label, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
color, 2)
# add the output image to our list of results
results.append(orig)
在这一部分中,我们:
- 处理渠道订购(行 47 )。TensorFlow 后端默认为
"channels_first",但是不要忘记 Keras 也支持其他后端。 - 通过向卷添加一个维度来创建一个要通过网络发送的批处理( Line 48 )。我们只是一次通过网络发送一幅图像,但是额外的维度是至关重要的。
- 将图像通过 ResNet
model( 第 51 行),获得一个预测。我们在行 52 上取最大预测值的索引(或者是"Parasitized"或者是"Uninfected")。 - 然后我们创建一个彩色标签,并在原始图像上绘制它(第 56-63 行)。
- 最后,我们将带注释的
orig图像添加到results中。
为了可视化我们的结果,让我们创建一个蒙太奇,并显示在屏幕上:
# create a montage using 128x128 "tiles" with 4 rows and 4 columns
montage = build_montages(results, (128, 128), (4, 4))[0]
# show the output montage
cv2.imshow("Results", montage)
cv2.waitKey(0)
一个montage的成果建立在线 69 上。我们的montage是一个 4×4 的图像网格,以容纳我们之前获取的 16 个随机测试图像。在我的博客文章 用 OpenCV 蒙太奇中了解这个函数是如何工作的。
将显示montage,直到按下任何键(行 72 和 73 )。
要查看我们的脚本,请确保使用教程的 “下载” 部分下载源代码和图像数据集。
从那里,打开一个终端并执行以下命令:
$ python load_model.py --images malaria/testing --model saved_model.model
Using TensorFlow backend.
[INFO] loading pre-trained network...
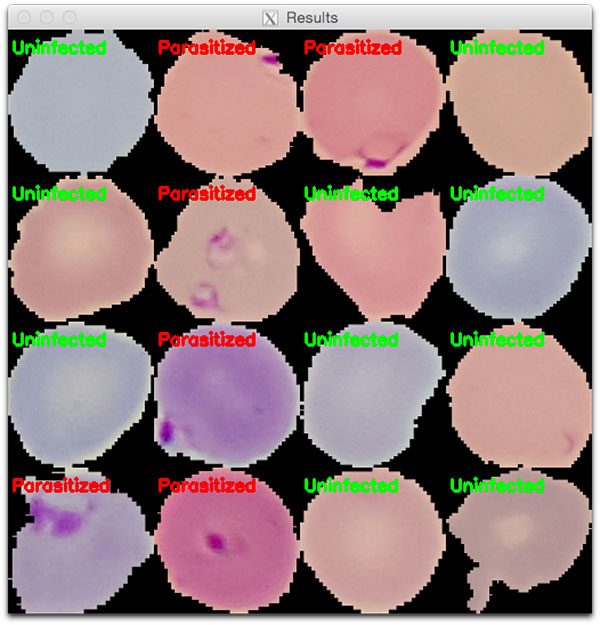
Figure 5: A montage of cells either “Parasitized” or “Uninfected” with Malaria. In today’s blog post we saved a ResNet deep learning model to disk and then loaded it with a separate script to make these predictions.
在这里,您可以看到我们有:
- 通过命令行参数提供我们的测试图像(
--images malaria/testing)以及已经驻留在磁盘上的模型(--model saved_model.model)的路径 - 从磁盘加载我们的 Keras 模型
- 预处理我们的输入图像
- 对每个示例图像进行分类
- 构建了我们分类的输出可视化(图 5 )
这个过程之所以成为可能,是因为我们能够在训练脚本中从磁盘保存我们的 Keras 模型,然后在一个单独的脚本中从磁盘加载 Keras 模型。
摘要
在今天的教程中,您学习了:
- 如何在数据集上训练 Keras 模型
- 如何将 Keras 模型序列化并保存到磁盘
- 如何从单独的 Python 脚本加载保存的 Keras 模型
- 如何使用载入的 Keras 模型对新的输入图像进行分类
在训练、保存和加载您自己的 Keras 模型时,您可以使用今天教程中介绍的 Python 脚本作为模板。
我希望你喜欢今天的博文!
要下载今天教程的源代码,并在未来的博客文章在 PyImageSearch 上发表时得到通知,只需在下面的表格中输入您的电子邮件地址!
Keras:开始、停止和恢复训练
原文:https://pyimagesearch.com/2019/09/23/keras-starting-stopping-and-resuming-training/

在本教程中,您将学习如何使用 Keras 来训练神经网络,停止训练,更新您的学习率,然后使用新的学习率从您停止的地方继续训练。使用这种方法,您可以提高精确度,同时减少模型损失。
今天的教程是受我从张敏的 PyImageSearch 读者那里收到的一个问题的启发。
张敏写道:
嗨,阿德里安,感谢你的图片搜索博客。我有两个问题:
首先,我正在进行我的毕业设计,我的大学允许我在他们的 GPU 机器上共享时间。问题是,我只能以两个小时为增量访问 GPU 机器——在我的两个小时结束后,我会自动从 GPU 启动。如何保存我的训练进度,安全地停止训练,然后从我停止的地方继续训练?
其次,我最初的实验并不顺利。我的模型很快跳到 80%以上的准确率,但之后又停留了 50 个纪元。我还能做些什么来提高我的模型准确性?我的导师说我应该考虑调整学习率,但我不确定该怎么做。
谢谢艾利安。
学习如何开始、停止和恢复训练深度学习模型是一项需要掌握的超级重要的技能——在你深度学习从业者职业生涯的某个时候,你会遇到类似张敏的情况:
- 您在 GPU 实例上的时间有限(这可能发生在 Google Colab 或使用 Amazon EC2 的更便宜的 spot 实例时)。
- 您的 SSH 连接中断,并且您忘记使用终端多路复用器来保存您的会话(例如
screen或tmux)。 - 你的深度学习平台会锁定并强制关闭。
想象一下,花整整一周的时间来训练一个最先进的深度神经网络… 结果你的模型却因为断电而丢失了!
幸运的是,有一个解决方案,但是当这些情况发生时,你需要知道如何:
- 获取在培训期间保存/序列化到磁盘的快照模型。
- 将模型加载到内存中。
- 从你停止的地方继续训练。
其次,开始、停止、恢复训练是手动调整学习率时的标准做法:
- 开始训练您的模型,直到损失/准确性达到稳定水平
- 每隔 N 个时期(通常是 N={1,5,10} )给你的模型拍快照
- 停止训练,通常通过
ctrl + c强制退出 - 打开你的代码编辑器,调整你的学习速度(通常降低一个数量级)
- 回到您的终端,重新启动训练脚本,从最后一个
模型权重快照开始
使用这种ctrl + c训练方法,你可以提高你的模型准确性,同时降低损失,得到更准确的模型。
调整学习速率的能力是任何一个深度学习实践者都需要掌握的关键技能,所以现在就花时间去学习和练习吧!
学习如何开始、停止和恢复 Keras 训练,继续阅读!
Keras:开始、停止和恢复训练
2020-06-05 更新:此博文现已兼容 TensorFlow 2+!
在这篇博文的第一部分,我们将讨论为什么我们想要开始、停止和恢复深度学习模型的训练。
我们还将讨论停止训练以降低你的学习率如何能够提高你的模型准确性(以及为什么学习率计划/衰减可能是不够的)。
在这里,我们将实现一个 Python 脚本来处理 Keras 的启动、停止和恢复训练。
然后,我将向您介绍整个培训过程,包括:
- 开始初始培训脚本
- 监控损失/准确性
- 注意损失/准确性何时趋于平稳
- 停止训练
- 降低你的学习速度
- 用新的、降低的学习率从你停止的地方继续训练
使用这种训练方法,您通常能够提高模型的准确性。
让我们开始吧!
为什么我们需要开始、停止和恢复训练?
您可能需要开始、停止和恢复深度学习模型的训练有许多原因,但两个主要原因包括:
- 您的训练课程被终止,训练停止(由于停电、GPU 课程超时等原因。).
- 需要调整你的学习率来提高模型精度(通常通过降低学习率一个数量级)。
第二点尤其重要——如果你回过头去阅读开创性的 AlexNet、SqueezeNet、ResNet 等。你会发现论文的作者都说了一些类似的话:
我们开始用 SGD 优化器训练我们的模型,初始学习率为 1e-1。我们分别在第 30 和第 50 个时期将学习速度降低了一个数量级。
为什么下降学习率如此重要?它如何能导致一个更精确的模型?
为了探究这个问题,看一下下面在 CIFAR-10 数据集上训练的 ResNet-18 的图:
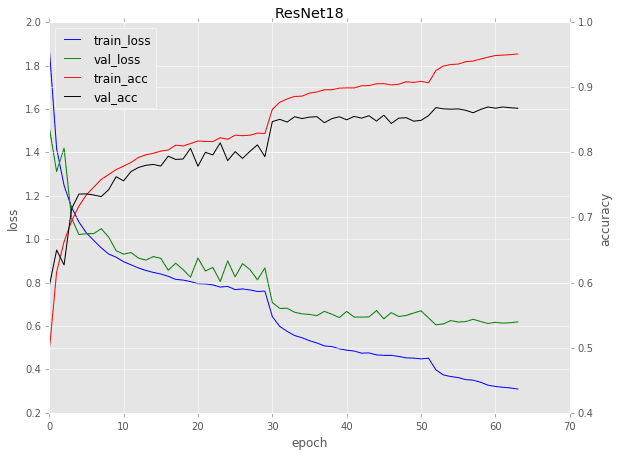
Figure 1: Training ResNet-18 on the CIFAR-10 dataset. The characteristic drops in loss and increases in accuracy are evident of learning rate changes. Here, (1) training was stopped on epochs 30 and 50, (2) the learning rate was lowered, and (3) training was resumed. (image source)
请注意,对于时段 1-29,在训练网络时会遇到一条相当“标准”的曲线:
- 损失开始时非常高,但随后迅速下降
- 准确度开始时非常低,但随后迅速上升
- 最终损失和准确性趋于平稳
但是在第 30 纪元前后发生了什么呢?
为什么亏损下降得这么厉害?为什么准确度会提高这么多?
出现这种行为的原因是因为:
- 训练被停止
- 学习率降低了一个数量级
- 然后训练恢复
同样的情况也发生在第 50 纪元——再次,训练停止,学习率降低,然后训练重新开始。
每次我们都会遇到一个典型的损失下降,然后精度略有增加。
随着学习率变小,学习率降低的影响越来越小的影响。
最终,我们遇到了两个问题:
- 学习率变得非常小,这又使得权重更新非常小,因此模型不能取得任何有意义的进展。
- 由于学习率低,我们开始过度适应。该模型下降到损失范围中的较低损失区域,过度适合训练数据,而不能推广到验证数据。
在上面图 1 中的时期 50 之后,过拟合行为是明显的。
注意验证损失是如何稳定下来的,甚至开始有所上升。与此同时,培训损失持续下降,这是过度适应的明显迹象。
降低你的学习率是在训练期间提高你的模型的准确性的一个很好的方法,只要意识到存在(1)一个收益递减点,以及(2)如果训练没有得到适当的监控,有可能过度拟合。
为什么不使用学习率调度器或衰减?

Figure 2: Learning rate schedulers are great for some training applications; however, starting/stopping Keras training typically leads to more control over your deep learning model.
你可能想知道“为什么不使用一个学习率计划程序?”
我们可以使用许多学习率计划程序,包括:
如果目标是通过降低学习率来提高模型的准确性,那么为什么不仅仅依靠那些各自的时间表和课程呢?
问得好。
问题是你可能没有好主意:
- 要训练的大概历元数
- 什么是合适的初始学习率
- clr 使用什么学习率范围
此外,使用我所谓的ctrl + c培训的一个好处是它给你对你的模型更精细的控制。
能够在特定的时间手动停止你的训练,调整你的学习率,然后从你停止的地方继续训练(用新的学习率),这是大多数学习率计划者不允许你做的。
一旦你用ctrl + c训练进行了一些实验,你就会对你的超参数应该是什么有一个好主意——当这发生时,然后你开始结合硬编码的学习率时间表来进一步提高你的准确性。
最后,请记住,几乎所有在 ImageNet 上接受培训的 CNN 开创性论文都使用了一种方法来开始/停止/恢复培训。
仅仅因为其他方法存在并不能使它们天生更好——作为深度学习实践者,你需要学习如何使用ctrl + c训练以及学习速率调度(不要严格依赖后者)。
如果你有兴趣了解更多关于ctrl + c训练的信息,以及我在训练你自己的模型时的技巧、建议和最佳实践,一定要参考我的书, 用 Python 进行计算机视觉的深度学习 。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
让我们回顾一下我们的项目结构:
$ tree --dirsfirst
.
├── output
│ ├── checkpoints
│ └── resnet_fashion_mnist.png
├── pyimagesearch
│ ├── callbacks
│ │ ├── __init__.py
│ │ ├── epochcheckpoint.py
│ │ └── trainingmonitor.py
│ ├── nn
│ │ ├── __init__.py
│ │ └── resnet.py
│ └── __init__.py
└── train.py
5 directories, 8 files
今天我们将回顾我们的训练脚本train.py。这个脚本在 ResNet 上训练时尚 MNIST 。
这个训练脚本的关键是它使用了两个“回调”,epochcheckpoint.py和trainingmonitor.py。我在使用 Python 的计算机视觉深度学习中详细回顾了这些回调——今天没有涉及它们,但我鼓励你回顾代码。
*这两个回调允许我们(1)在每个第 N 个时期结束时保存我们的模型,以便我们可以根据需要恢复训练,以及(2)在每个时期结束时输出我们的训练图,确保我们可以轻松地监控我们的模型是否有过度拟合的迹象。
模型在output/checkpoints/目录中进行检查点检查(即保存)。
2020-06-05 更新:本教程的output/文件夹中不再有附带的 JSON 文件。对于 TensorFlow 2+,这是不必要的,而且会引入一个错误。
训练图在每个时期结束时被覆盖为resnet_fashion_mnist.png。我们将密切关注训练情节,以决定何时停止训练。
实施培训脚本
让我们开始实现我们的 Python 脚本,该脚本将用于启动、停止和恢复 Keras 的训练。
本指南是为中级从业者编写的,尽管它教授的是一项基本技能。如果你是 Keras 或深度学习的新手,或者也许你只是需要温习一下基础知识,一定要先看看我的 Keras 教程。
打开一个新文件,将其命名为train.py,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.callbacks.epochcheckpoint import EpochCheckpoint
from pyimagesearch.callbacks.trainingmonitor import TrainingMonitor
from pyimagesearch.nn.resnet import ResNet
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import load_model
import tensorflow.keras.backend as K
import numpy as np
import argparse
import cv2
import sys
import os
第 2-19 行导入我们需要的包,即我们的EpochCheckpoint和TrainingMonitor回调。我们还导入我们的fashion_mnist数据集和ResNet CNN。tensorflow.keras.backend as K将允许我们检索和设置我们的学习速度。
现在让我们继续解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--checkpoints", required=True,
help="path to output checkpoint directory")
ap.add_argument("-m", "--model", type=str,
help="path to *specific* model checkpoint to load")
ap.add_argument("-s", "--start-epoch", type=int, default=0,
help="epoch to restart training at")
args = vars(ap.parse_args())
我们的命令行参数包括:
--checkpoints:输出检查点目录的路径。--model:恢复训练时加载的可选路径到 特定 模型检查点。--start-epoch:如果恢复训练,可以提供可选的开始时间。默认情况下,训练在时期0开始。
让我们继续加载我们的数据集:
# grab the Fashion MNIST dataset (if this is your first time running
# this the dataset will be automatically downloaded)
print("[INFO] loading Fashion MNIST...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# Fashion MNIST images are 28x28 but the network we will be training
# is expecting 32x32 images
trainX = np.array([cv2.resize(x, (32, 32)) for x in trainX])
testX = np.array([cv2.resize(x, (32, 32)) for x in testX])
# scale data to the range of [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# reshape the data matrices to include a channel dimension (required
# for training)
trainX = trainX.reshape((trainX.shape[0], 32, 32, 1))
testX = testX.reshape((testX.shape[0], 32, 32, 1))
34 线装载时尚 MNIST 。
第 38-48 行然后预处理数据,包括(1)调整大小到 32×32 , (2)缩放像素强度到范围【0,1】,( 3)增加通道尺寸。
从这里,我们将(1)二进制化我们的标签,以及(2)初始化我们的数据扩充对象:
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
现在来看看加载模型检查点的代码:
# if there is no specific model checkpoint supplied, then initialize
# the network (ResNet-56) and compile the model
if args["model"] is None:
print("[INFO] compiling model...")
opt = SGD(lr=1e-1)
model = ResNet.build(32, 32, 1, 10, (9, 9, 9),
(64, 64, 128, 256), reg=0.0001)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# otherwise, we're using a checkpoint model
else:
# load the checkpoint from disk
print("[INFO] loading {}...".format(args["model"]))
model = load_model(args["model"])
# update the learning rate
print("[INFO] old learning rate: {}".format(
K.get_value(model.optimizer.lr)))
K.set_value(model.optimizer.lr, 1e-2)
print("[INFO] new learning rate: {}".format(
K.get_value(model.optimizer.lr)))
如果没有提供模型检查点,那么我们需要初始化模型(第 62-68 行)。注意,我们在第 64 行的上指定初始学习速率为1e-1。
否则,行 71-81 加载模型检查点(即先前通过ctrl + c停止的模型)并更新学习率。第 79 行将成为你编辑的那一行,只要你想 更新学习率。
接下来,我们将构造我们的回调:
# build the path to the training plot and training history
plotPath = os.path.sep.join(["output", "resnet_fashion_mnist.png"])
jsonPath = os.path.sep.join(["output", "resnet_fashion_mnist.json"])
# construct the set of callbacks
callbacks = [
EpochCheckpoint(args["checkpoints"], every=5,
startAt=args["start_epoch"]),
TrainingMonitor(plotPath,
jsonPath=jsonPath,
startAt=args["start_epoch"])]
第 84 行和第 85 行指定了我们的 plot 和 JSON 路径。
第 88-93 行构造两个callbacks,将它们直接放入一个列表中:
- 这个回调函数负责保存我们的模型,因为它当前处于每个时期的末尾。这样,如果我们通过
ctrl + c(或者不可预见的电源故障)停止训练,我们不会丢失我们机器的工作——对于在巨大数据集上训练复杂模型来说,这确实可以节省您几天的时间。 TrainingMonitor:将我们的训练精度/损失信息保存为 PNG 图像 plot 和 JSON 字典的回调。我们将能够在任何时候打开我们的训练图来查看我们的训练进度——对作为从业者的您来说是有价值的信息,尤其是对于多日训练过程。
同样,请自行查看epochcheckpoint.py和trainingmonitor.py以了解详细信息和/或您是否需要添加功能。我在 用 Python 对计算机视觉进行深度学习里面详细介绍了这些回调。
最后,我们有了开始、停止和恢复训练所需的一切。这最后一块实际上开始或恢复训练:
# train the network
print("[INFO] training network...")
model.fit(
x=aug.flow(trainX, trainY, batch_size=128),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // 128,
epochs=80,
callbacks=callbacks,
verbose=1)
2020-06-05 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移(本例中未使用)。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
我们对.fit的调用适合/训练我们的model使用和我们的回调(第 97-103 行)。请务必查看我的关于 Keras 拟合方法的教程以获得关于如何使用.fit函数训练我们的模型的更多细节。
我想提醒您注意epochs参数(第 101 行 ) — 当您调整学习速率时,您通常也会想要更新纪元。通常情况下,你应该高估历元的数量,你将在接下来的三节中看到。
关于开始、停止和恢复训练的更详细的解释(以及我的EpochCheckpoint和TrainingMonitor类的实现),请务必参考使用 Python 进行计算机视觉深度学习的 。
阶段# 1:1e-1 的 40 个历元
确保你已经使用了这篇博文的 【下载】 部分来下载本教程的源代码。
从那里,打开一个终端并执行以下命令:
$ python train.py --checkpoints output/checkpoints
[INFO] loading Fashion MNIST...
[INFO] compiling model...
[INFO] training network...
Epoch 1/40
468/468 [==============================] - 46s 99ms/step - loss: 1.2367 - accuracy: 0.7153 - val_loss: 1.0503 - val_accuracy: 0.7712
Epoch 2/40
468/468 [==============================] - 46s 99ms/step - loss: 0.8753 - accuracy: 0.8427 - val_loss: 0.8914 - val_accuracy: 0.8356
Epoch 3/40
468/468 [==============================] - 45s 97ms/step - loss: 0.7974 - accuracy: 0.8683 - val_loss: 0.8175 - val_accuracy: 0.8636
Epoch 4/40
468/468 [==============================] - 46s 98ms/step - loss: 0.7490 - accuracy: 0.8850 - val_loss: 0.7533 - val_accuracy: 0.8855
Epoch 5/40
468/468 [==============================] - 46s 98ms/step - loss: 0.7232 - accuracy: 0.8922 - val_loss: 0.8021 - val_accuracy: 0.8587
...
Epoch 36/40
468/468 [==============================] - 44s 94ms/step - loss: 0.4111 - accuracy: 0.9466 - val_loss: 0.4719 - val_accuracy: 0.9265
Epoch 37/40
468/468 [==============================] - 44s 94ms/step - loss: 0.4052 - accuracy: 0.9483 - val_loss: 0.4499 - val_accuracy: 0.9343
Epoch 38/40
468/468 [==============================] - 44s 94ms/step - loss: 0.4009 - accuracy: 0.9485 - val_loss: 0.4664 - val_accuracy: 0.9270
Epoch 39/40
468/468 [==============================] - 44s 94ms/step - loss: 0.3951 - accuracy: 0.9495 - val_loss: 0.4685 - val_accuracy: 0.9277
Epoch 40/40
468/468 [==============================] - 44s 95ms/step - loss: 0.3895 - accuracy: 0.9497 - val_loss: 0.4672 - val_accuracy: 0.9254
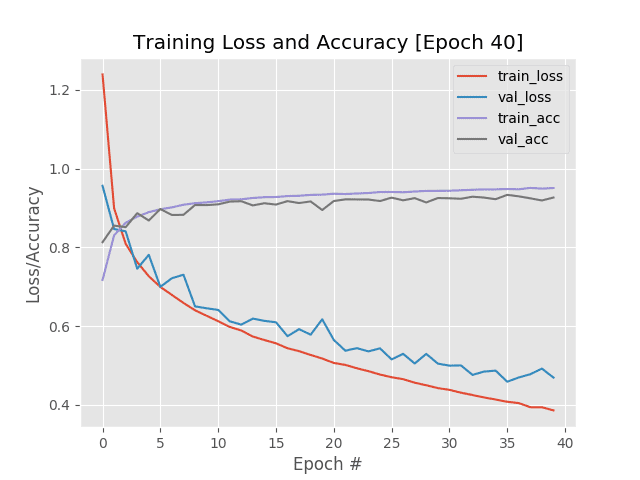
Figure 3: Phase 1 of training ResNet on the Fashion MNIST dataset with a learning rate of 1e-1 for 40 epochs before we stop via ctrl + c, adjust the learning rate, and resume Keras training.
在这里,我已经开始使用 SGD 优化器和 1e-1 的初始学习率在时尚 MNIST 数据集上训练 ResNet。
在每个时期后,我在图 3 中的损失/准确度图会更新,使我能够实时监控训练。
过了第 20 个纪元,我们可以看到训练和验证损失开始出现分歧,到了第 40 个纪元,我决定ctrl + c退出train.py脚本。
阶段 2:1e-2 的 10 个时期
下一步是更新两者:
- 我的学习速度
- 要训练的纪元数
对于学习率,标准的做法是将其降低一个数量级。
回到train.py的行 64 我们可以看到我的初始学习率是1e-1:
# if there is no specific model checkpoint supplied, then initialize
# the network (ResNet-56) and compile the model
if args["model"] is None:
print("[INFO] compiling model...")
opt = SGD(lr=1e-1)
model = ResNet.build(32, 32, 1, 10, (9, 9, 9),
(64, 64, 128, 256), reg=0.0001)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
我现在将把我的学习率更新为第 79 行的上的1e-2:
# otherwise, we're using a checkpoint model
else:
# load the checkpoint from disk
print("[INFO] loading {}...".format(args["model"]))
model = load_model(args["model"])
# update the learning rate
print("[INFO] old learning rate: {}".format(
K.get_value(model.optimizer.lr)))
K.set_value(model.optimizer.lr, 1e-2)
print("[INFO] new learning rate: {}".format(
K.get_value(model.optimizer.lr)))
那么,为什么我更新的是行 79 而不是行 64 ?
原因在于if/else声明。
else语句处理我们何时需要从磁盘加载特定于的检查点——一旦我们有了检查点,我们将恢复训练,因此需要在else块中更新学习率。
其次,我也在线 101 更新我的epochs。最初,epochs值是80:
# train the network
print("[INFO] training network...")
model.fit(
x=aug.flow(trainX, trainY, batch_size=128),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // 128,
epochs=80,
callbacks=callbacks,
verbose=1)
我决定将训练的纪元数量减少到40个纪元:
# train the network
print("[INFO] training network...")
model.fit(
x=aug.flow(trainX, trainY, batch_size=128),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // 128,
epochs=40,
callbacks=callbacks,
verbose=1)
通常情况下,你会将epochs值设置为比你认为的实际值大得多的。
这样做的原因是因为我们使用EpochCheckpoint类来保存每 5 个时期的模型快照——如果在任何时候我们认为我们对训练进度不满意,我们可以直接ctrl + c退出脚本并返回到之前的快照。
因此,训练更长时间没有坏处,因为我们总是可以从先前的模型重量文件中恢复训练。
在更新了我的学习速度和训练的次数之后,我执行了下面的命令:
$ python train.py --checkpoints output/checkpoints \
--model output/checkpoints/epoch_40.hdf5 --start-epoch 40
[INFO] loading Fashion MNIST...
[INFO] loading output/checkpoints/epoch_40.hdf5...
[INFO] old learning rate: 0.10000000149011612
[INFO] new learning rate: 0.009999999776482582
[INFO] training network...
Epoch 1/10
468/468 [==============================] - 45s 97ms/step - loss: 0.3606 - accuracy: 0.9599 - val_loss: 0.4173 - val_accuracy: 0.9412
Epoch 2/10
468/468 [==============================] - 44s 94ms/step - loss: 0.3509 - accuracy: 0.9637 - val_loss: 0.4171 - val_accuracy: 0.9416
Epoch 3/10
468/468 [==============================] - 44s 94ms/step - loss: 0.3484 - accuracy: 0.9647 - val_loss: 0.4144 - val_accuracy: 0.9424
Epoch 4/10
468/468 [==============================] - 44s 94ms/step - loss: 0.3454 - accuracy: 0.9657 - val_loss: 0.4151 - val_accuracy: 0.9412
Epoch 5/10
468/468 [==============================] - 46s 98ms/step - loss: 0.3426 - accuracy: 0.9667 - val_loss: 0.4159 - val_accuracy: 0.9416
Epoch 6/10
468/468 [==============================] - 45s 96ms/step - loss: 0.3406 - accuracy: 0.9663 - val_loss: 0.4160 - val_accuracy: 0.9417
Epoch 7/10
468/468 [==============================] - 45s 96ms/step - loss: 0.3409 - accuracy: 0.9663 - val_loss: 0.4150 - val_accuracy: 0.9418
Epoch 8/10
468/468 [==============================] - 44s 94ms/step - loss: 0.3362 - accuracy: 0.9687 - val_loss: 0.4159 - val_accuracy: 0.9428
Epoch 9/10
468/468 [==============================] - 44s 95ms/step - loss: 0.3341 - accuracy: 0.9686 - val_loss: 0.4175 - val_accuracy: 0.9406
Epoch 10/10
468/468 [==============================] - 44s 95ms/step - loss: 0.3336 - accuracy: 0.9687 - val_loss: 0.4164 - val_accuracy: 0.9420
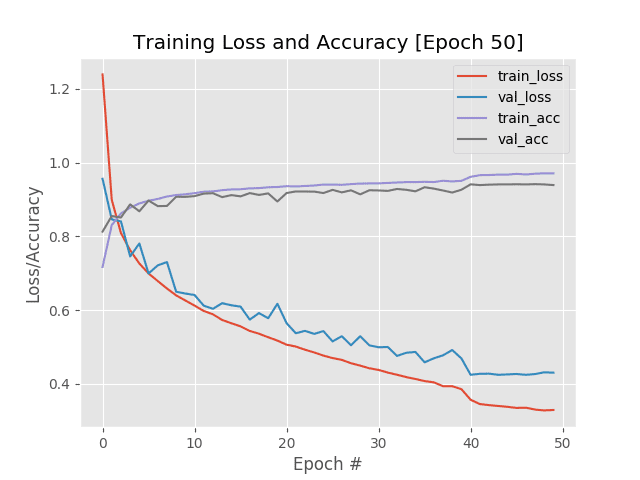
Figure 4: Phase 2 of Keras start/stop/resume training. The learning rate is dropped from 1e-1 to 1e-2 as is evident in the plot at epoch 40. I continued training for 10 more epochs until I noticed validation metrics plateauing at which point I stopped training via ctrl + c again.
请注意我们是如何将学习率从1e-1更新到1e-2然后继续训练的。
我们立即看到训练/验证损失的下降以及训练/验证准确性的增加。
这里的问题是,我们的验证指标已经稳定下来——如果不冒过度拟合的风险,可能不会有更多的收益。正因为如此,在再次脱离剧本之前,我只允许训练再持续 10 个纪元。
阶段# 3:1e-3 的 5 个时期
在培训的最后阶段,我决定:
- 将我的学习率从
1e-2降低到1e-3。 - 允许训练继续进行(但要知道,考虑到过度适应的风险,我可能只会训练几个时期)。
在更新了我的学习率之后,我执行了以下命令:
$ python train.py --checkpoints output/checkpoints \
--model output/checkpoints/epoch_50.hdf5 --start-epoch 50
[INFO] loading Fashion MNIST...
[INFO] loading output/checkpoints/epoch_50.hdf5...
[INFO] old learning rate: 0.009999999776482582
[INFO] new learning rate: 0.0010000000474974513
[INFO] training network...
Epoch 1/5
468/468 [==============================] - 45s 97ms/step - loss: 0.3302 - accuracy: 0.9696 - val_loss: 0.4155 - val_accuracy: 0.9414
Epoch 2/5
468/468 [==============================] - 44s 94ms/step - loss: 0.3297 - accuracy: 0.9703 - val_loss: 0.4160 - val_accuracy: 0.9411
Epoch 3/5
468/468 [==============================] - 44s 94ms/step - loss: 0.3302 - accuracy: 0.9694 - val_loss: 0.4157 - val_accuracy: 0.9415
Epoch 4/5
468/468 [==============================] - 44s 94ms/step - loss: 0.3282 - accuracy: 0.9708 - val_loss: 0.4143 - val_accuracy: 0.9421
Epoch 5/5
468/468 [==============================] - 44s 95ms/step - loss: 0.3305 - accuracy: 0.9694 - val_loss: 0.4152 - val_accuracy: 0.9414

Figure 5: Upon resuming Keras training for phase 3, I only let the network train for 5 epochs because there is not significant learning progress being made. Using a start/stop/resume training approach with Keras, we have achieved 94.14% validation accuracy.
此时,学习率变得如此之小,以至于相应的权重更新也非常小,这意味着模型不能学习更多。
在杀死脚本之前,我只允许训练持续 5 个纪元。然而,查看我的最终指标,你可以看到我们获得了 96.94%的训练准确率和 94.14%的验证准确率。
我们能够通过使用我们的开始、停止和恢复训练方法达到这个结果。
在这一点上,我们可以继续调整我们的学习率,利用学习率调度器,应用循环学习率,或者尝试一个全新的模型架构。
摘要
在本教程中,您学习了如何使用 Keras 和深度学习来开始、停止和恢复训练。
学习如何从培训中断的地方恢复是一项非常有价值的技能,原因有二:
- 它确保如果你的训练脚本崩溃,你可以从最近的模型检查点重新开始。
- 它使您能够调整您的学习速率并提高您的模型准确性。
当训练您自己的定制神经网络时,您需要监控您的损失和准确性——一旦您开始看到验证损失/准确性平台,请尝试终止训练脚本,将您的学习率降低一个数量级,然后恢复训练。
你会经常发现这种训练方法可以产生更高精度的模型。
不过,要警惕过度拟合!
降低你的学习率能使你的模型下降到亏损的较低区域;但是,不能保证这些较低的损失区域仍然会通用化!
你可能只能降低 1-3 次学习率,在此之前:
- 学习率变得太小,使得相应的权重更新太小,并且阻止模型进一步学习。
- 验证损失停滞或爆炸,而训练损失继续下降(暗示模型过度拟合)。
如果出现这些情况,并且您的模型仍然不令人满意,您应该考虑调整模型的其他超参数,包括正则化强度、丢失等。您可能还想探索其他的模型架构。
关于我在自定义数据集上训练自己的神经网络时的更多技巧、建议和最佳实践,请务必参考使用 Python 的计算机视觉深度学习,其中我深入介绍了我的最佳实践。
要下载本教程的源代码(并在未来教程发布在 PyImageSearch 博客上时得到通知),只需在下表中输入您的电子邮件地址!*
Keras 教程:如何入门 Keras、深度学习和 Python

在这篇 Keras 教程中,你会发现开始学习深度学习和 Python 是多么容易。您将使用 Keras 深度学习库在自定义图像数据集上训练您的第一个神经网络,并从那里实现您的第一个卷积神经网络(CNN)。
这个指南的灵感来自于 PyImageSearch 的读者 Igor,他几周前给我发了一封电子邮件,问我:
嗨,阿德里安,谢谢你的图片搜索博客。我注意到,我遇到的几乎所有关于 Keras 和影像分类的“入门”指南都使用了内置于 Keras 中的 MNIST 或 CIFAR-10 数据集。我只需调用其中一个函数,数据就会自动加载。
但是我如何在 Keras 上使用我自己的图像数据集呢?
我必须采取什么步骤?
Igor 有一个很好的观点——你遇到的大多数 Keras 教程都会尝试使用 MNIST(手写识别)或 CIFAR-10(基本对象识别)等图像分类数据集来教你基本的库。
这些图像数据集是计算机视觉和深度学习文献中的标准基准,当然,它们绝对会让你开始使用 Keras…
…但是它们不一定实用,因为它们没有教你如何使用驻留在磁盘上的自己的映像集。相反,您只是调用助手函数来加载预编译的数据集。
我对 Keras 入门教程有不同的看法。
我不会教你如何利用这些预编译的数据集,而是教你如何使用自定义数据集——训练你的第一个神经网络和卷积神经网络,因为让我们面对现实吧,你的目标是将深度学习应用于你的自己的数据集,而不是内置在 Keras 中的数据集,对吗?
要了解如何开始使用 Keras、深度学习和 Python,继续阅读!
Keras 教程:如何入门 Keras、深度学习和 Python
2020-05-13 更新:此博文现已兼容 TensorFlow 2+!
今天的 Keras 教程是为从业者设计的——它旨在成为从业者应用深度学习的方法。
这意味着我们将在实践中学习。
我们会弄脏自己的手。
写一些 Keras 代码。
然后在我们定制的数据集上训练我们的网络。
本教程是而不是旨在深入探究深度学习的相关理论。
如果你有兴趣在 odepth 学习深度学习,包括(1)动手实现和(2)理论讨论,我建议你看看我的书, 用 Python 进行计算机视觉的深度学习 。
将要涵盖的内容概述
用 Keras 训练你的第一个简单的神经网络并不需要很多代码,但我们会慢慢开始,一步一步来,确保你理解如何在你自己的自定义数据集上训练网络的过程。
我们今天将讨论的步骤包括:
- 在系统上安装 Keras 和其他依赖项
- 从磁盘加载数据
- 创建您的培训和测试拆分
- 定义您的 Keras 模型架构
- 编译您的 Keras 模型
- 根据训练数据训练模型
- 根据测试数据评估您的模型
- 使用训练好的 Keras 模型进行预测
我还包括了一个关于训练你的第一个卷积神经网络的附加部分。
这可能看起来像很多步骤,但我向你保证,一旦我们开始进入示例,你会看到这些示例是线性的,有直观的意义,并会帮助你理解用 Keras 训练神经网络的基础。
我们的示例数据集

Figure 1: In this Keras tutorial, we won’t be using CIFAR-10 or MNIST for our dataset. Instead, I’ll show you how you can organize your own dataset of images and train a neural network using deep learning with Keras.
你遇到的大多数 Keras 图像分类教程都会利用 MNIST 或 CIFAR-10 — 我在这里不打算这么做。
首先,MNIST 和 CIFAR-10 并不是非常令人兴奋的例子。
这些教程实际上并没有涵盖如何使用您自己的自定义影像数据集。相反,他们简单地调用内置的 Keras 实用程序,这些实用程序神奇地将 MNIST 和 CIFAR-10 数据集作为 NumPy 数组返回。其实你的训练和测试拆分早就给你预拆分好了!
其次,如果你想使用自己的自定义数据集,你真的不知道从哪里开始。你会发现自己抓耳挠腮,问出这样的问题:
- 那些助手函数从哪里加载数据?
- 我在磁盘上的数据集应该是什么格式?
- 如何将数据集加载到内存中?
- 我需要执行哪些预处理步骤?
实话实说吧——你研究 Keras 和深度学习的目标不是与这些预先烘焙的数据集一起工作。
相反,您希望使用自己的自定义数据集。
你所遇到的那些介绍性的 Keras 教程只能带你到这里。
这就是为什么,在这个 Keras 教程中,我们将使用一个名为“动物数据集”的自定义数据集,这是我为我的书创建的, 用 Python 进行计算机视觉的深度学习 :

Figure 2: In this Keras tutorial we’ll use an example animals dataset straight from my deep learning book. The dataset consists of dogs, cats, and pandas.
该数据集的目的是将图像正确分类为包含以下内容之一:
- 猫
- 狗
- 熊猫
动物数据集仅包含 3000 张图像,旨在成为一个介绍性数据集,我们可以使用我们的 CPU 或 GPU 快速训练一个深度学习模型(并仍然获得合理的准确性)。
此外,使用这个自定义数据集使您能够理解:
- 应该如何在磁盘上组织数据集
- 如何从磁盘加载图像和类别标签
- 如何将您的数据划分为训练和测试部分
- 如何根据训练数据训练您的第一个 Keras 神经网络
- 如何根据测试数据评估您的模型
- 您如何在全新的数据上重用您的训练模型,并且在您的训练和测试分割之外
按照 Keras 教程中的步骤,你可以用我的动物数据集替换你选择的任何数据集,前提是你使用了下面详述的项目/目录结构。
需要数据?如果你需要从互联网上搜集图片来创建一个数据集,看看如何去做用必应图片搜索的简单方法,或者用谷歌图片的稍微复杂一点的方法。
项目结构
有许多文件与此项目相关联。从 “下载” 部分抓取 zip 文件,然后使用tree命令在您的终端中显示项目结构(我已经为tree提供了两个命令行参数标志,以使输出美观整洁):
$ tree --dirsfirst --filelimit 10
.
├── animals
│ ├── cats [1000 entries exceeds filelimit, not opening dir]
│ ├── dogs [1000 entries exceeds filelimit, not opening dir]
│ └── panda [1000 entries exceeds filelimit, not opening dir]
├── images
│ ├── cat.jpg
│ ├── dog.jpg
│ └── panda.jpg
├── output
│ ├── simple_nn.model
│ ├── simple_nn_lb.pickle
│ ├── simple_nn_plot.png
│ ├── smallvggnet.model
│ ├── smallvggnet_lb.pickle
│ └── smallvggnet_plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── smallvggnet.py
├── predict.py
├── train_simple_nn.py
└── train_vgg.py
7 directories, 14 files
如前所述,今天我们将使用动物数据集。注意animals在项目树中是如何组织的。在animals/里面,有三个类别目录:cats/、dogs/、panda/。这些目录中的每一个都有 1,000 张属于各自类别的图像。
如果你使用你自己的数据集,就用同样的方式组织它!理想情况下,每节课至少要收集 1000 张图片。这并不总是可能的,但是你至少应该有职业平衡。一个类别文件夹中的图像过多会导致模型偏差。
接下来是images/目录。该目录包含三个用于测试目的的图像,我们将使用它们来演示如何(1)从磁盘加载一个训练好的模型,然后(2)对一个输入图像进行分类,该图像是我们原始数据集的而不是部分。
output/文件夹包含训练生成的三种文件:
.model:训练后生成一个序列化的 Keras 模型文件,可以在以后的推理脚本中使用。.pickle:序列化标签二进制文件。这个文件包含一个包含类名的对象。它伴随着一个模型文件。.png:我总是将我的训练/验证图放在输出文件夹中,因为它是训练过程的输出。
pyimagesearch/目录是一个模块。与我收到的许多问题相反,pyimagesearch是 而不是 一个可安装 pip 的包。相反,它位于项目文件夹中,其中包含的类可以导入到您的脚本中。它在本 Keras 教程的 “下载” 部分提供。
今天我们将复习四个。py 文件:
- 在博文的前半部分,我们将训练一个简单的模型。训练脚本是
train_simple_nn.py。 - 我们将使用
train_vgg.py脚本继续培训SmallVGGNet。 smallvggnet.py文件包含我们的SmallVGGNet类,一个卷积神经网络。- 除非我们可以部署它,否则序列化模型有什么用?在
predict.py中,我已经为您提供了样本代码来加载一个序列化的模型+标签文件,并对一幅图像做出推断。预测脚本只有在我们成功训练了具有合理精确度的模型之后才有用。运行此脚本来测试数据集中不包含的图像总是很有用的。
配置您的开发环境

Figure 3: We’ll use Keras with the TensorFlow backend in this introduction to Keras for deep learning blog post.
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
2.从磁盘加载数据

Figure 4: Step #2 of our Keras tutorial involves loading images from disk into memory.
现在 Keras 已经安装在我们的系统上,我们可以开始使用 Keras 实现我们的第一个简单的神经网络训练脚本。我们稍后将实现一个成熟的卷积神经网络,但让我们从简单的开始,一步一步来。
打开train_simple_nn.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
第 2-19 行导入我们需要的包。如您所见,这个脚本利用了相当多的工具。让我们回顾一下重要的问题:
- 这是 Python 的绘图包。也就是说,它确实有其细微之处,如果你对此有困难,请参考这篇博文。在第 3 行,我们指示
matplotlib使用"Agg"后端,使我们能够将绘图保存到磁盘上——这是您的第一个细微差别! - scikit-learn 库将帮助我们将标签二进制化,分割数据用于训练/测试,并在我们的终端中生成训练报告。
tensorflow.keras:您正在阅读本教程以了解 Keras——它是我们进入 TensorFlow 和其他深度学习后端的高级前端。- 我的便利功能包。我们将使用
paths模块来生成用于训练的图像文件路径列表。 numpy: NumPy 是用 Python 进行数值处理的。这是另一个首选产品包。如果您安装了 OpenCV for Python 和 scikit-learn,那么您将拥有 NumPy,因为它是一个依赖项。cv2:这是 OpenCV。在这一点上,即使您可能使用 OpenCV 3 或更高版本,这也是一个传统和需求。- …剩余的导入被构建到您的 Python 安装中!
咻!这已经很多了,但是在我们浏览这些脚本时,对每个导入的用途有一个好的了解将有助于您的理解。
让我们用 argparse 解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
当我们执行脚本时,我们的脚本将动态处理通过命令行提供的附加信息。附加信息采用命令行参数的形式。argparse模块内置于 Python 中,将处理解析您在命令字符串中提供的信息。如需更多解释,参见这篇博文。
我们有四个命令行参数要解析:
- 磁盘上图像数据集的路径。
- 我们的模型将被序列化并输出到磁盘。此参数包含输出模型文件的路径。
--label-bin:数据集标签被序列化到磁盘上,以便在其他脚本中调用。这是输出标签二进制文件的路径。--plot:输出训练图图像文件的路径。我们将查看该图,检查数据是否过度拟合/拟合不足。
有了数据集信息,让我们加载图像和类标签:
# initialize the data and labels
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# loop over the input images
for imagePath in imagePaths:
# load the image, resize the image to be 32x32 pixels (ignoring
# aspect ratio), flatten the image into 32x32x3=3072 pixel image
# into a list, and store the image in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (32, 32)).flatten()
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
在这里我们:
- 为我们的
data和labels( 第 35 行和第 36 行)初始化列表。这些将成为 NumPy 数组。 - 抓住
imagePaths,随机洗牌(第 39-41 行)。在我们对它们进行排序和排序之前,paths.list_images函数会很方便地在我们的--dataset目录中找到所有输入图像的所有路径。我设置了一个seed,这样随机重新排序是可重复的。 - 开始循环我们数据集中的所有
imagePaths(行 44 )。
对于每个imagePath,我们继续:
- 将
image载入存储器(第 48 行)。 - 调整
image到32x32像素的大小(忽略纵横比)以及flatten图像(第 49 行)。因为这个神经网络 需要 这些维度,所以 对resize我们的图像是至关重要的。每个神经网络都需要不同的维度,所以要意识到这一点。拉平数据使我们能够轻松地将原始像素强度传递给输入层神经元。稍后您将看到,对于 VGGNet,我们将卷传递到网络,因为它是卷积卷。请记住,这个例子只是一个简单的非卷积网络——我们将在本文后面看到一个更高级的例子。 - 将调整后的图像附加到
data( 第 50 行)。 - 从路径中提取图像的类
label(第 54 行)并将其添加到labels列表中(第 55 行)。labels列表包含对应于数据列表中每个图像的类别。
现在,我们可以一下子将数组操作应用于数据和标签:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
在行 58 上,我们将像素强度从范围【0,255】缩放到【0,1】(一个常见的预处理步骤)。
我们还将labels列表转换成一个 NumPy 数组(第 59 行)。
3.构建您的培训和测试划分

Figure 5: Before fitting a deep learning or machine learning model you must split your data into training and testing sets. Scikit-learn is employed in this blog post to split our data.
既然我们已经从磁盘加载了图像数据,接下来我们需要构建我们的训练和测试分割:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
通常将一定比例的数据用于训练,将较小比例的数据用于测试。scikit-learn 提供了一个方便的train_test_split函数,它将为我们拆分数据。
trainX和testX组成图像数据本身,而trainY和testY组成标签。
我们的类标签目前表示为字符串;然而,Keras 将假设两者:
- 标签被编码为整数
- 此外,对这些标签执行一键编码,使得每个标签被表示为一个向量而不是一个整数
为了完成这种编码,我们可以使用 scikit-learn 中的LabelBinarizer类:
# convert the labels from integers to vectors (for 2-class, binary
# classification you should use Keras' to_categorical function
# instead as the scikit-learn's LabelBinarizer will not return a
# vector)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
在第 70 行的上,我们初始化了LabelBinarizer对象。
对fit_transform的调用在trainY中找到所有唯一的类标签,然后将它们转换成独热编码标签。
对testY上的.transform的调用只执行一次性编码步骤——唯一的一组可能的类标签已经由对.fit_transform的调用决定了。
这里有一个例子:
[1, 0, 0] # corresponds to cats
[0, 1, 0] # corresponds to dogs
[0, 0, 1] # corresponds to panda
请注意,只有一个数组元素是“热”的,这就是为什么我们称之为“一热”编码。
4.定义您的 Keras 模型架构
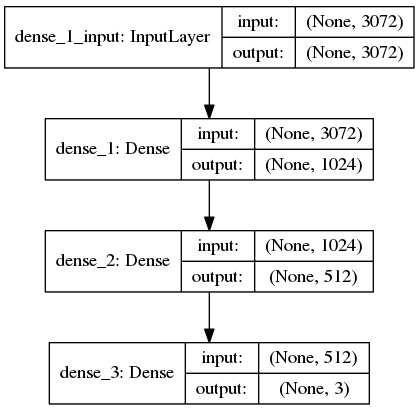
Figure 6: Our simple neural network is created using Keras in this deep learning tutorial.
下一步是使用 Keras 定义我们的神经网络架构。这里我们将使用一个具有一个输入层、两个隐藏层和一个输出层的网络:
# define the 3072-1024-512-3 architecture using Keras
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="sigmoid"))
model.add(Dense(512, activation="sigmoid"))
model.add(Dense(len(lb.classes_), activation="softmax"))
由于我们的模型非常简单,我们继续在这个脚本中定义它(通常我喜欢在一个单独的文件中为模型架构创建一个单独的类)。
输入层和第一隐藏层定义在线 76 上。将具有3072的input_shape,因为在展平的输入图像中有32x32x3=3072个像素。第一个隐藏层将有1024个节点。
第二个隐藏层将有512个节点(行 77 )。
最后,最终输出层中的节点数(第 78 行)将是可能的类标签数——在这种情况下,输出层将有三个节点,每个节点对应一个类标签(分别是、、、和、【熊猫】、)。
5.编译您的 Keras 模型
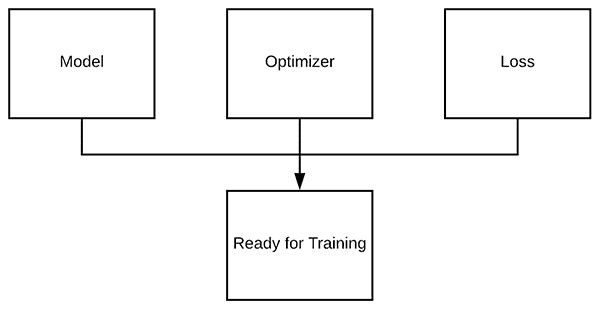
Figure 7: Step #5 of our Keras tutorial requires that we compile our model with an optimizer and loss function.
一旦我们定义了我们的神经网络架构,下一步就是“编译”它:
# initialize our initial learning rate and # of epochs to train for
INIT_LR = 0.01
EPOCHS = 80
# compile the model using SGD as our optimizer and categorical
# cross-entropy loss (you'll want to use binary_crossentropy
# for 2-class classification)
print("[INFO] training network...")
opt = SGD(lr=INIT_LR)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
首先,我们初始化我们的学习率和训练的总时期数(行 81 和 82 )。
然后,我们使用随机梯度下降(SGD)优化器将"categorical_crossentropy"作为loss函数来compile我们的模型。
分类交叉熵被用作几乎所有被训练来执行分类的网络的损失。唯一的例外是 2 级分类,这里只有两个可能的级标签。在这种情况下,你可能想用"binary_crossentropy"替换"categorical_crossentropy"。
6.使您的 Keras 模型符合数据

Figure 8: In Step #6 of this Keras tutorial, we train a deep learning model using our training data and compiled model.
现在我们的 Keras 模型已经编译好了,我们可以根据我们的训练数据来“拟合”(即训练)它:
# train the neural network
H = model.fit(x=trainX, y=trainY, validation_data=(testX, testY),
epochs=EPOCHS, batch_size=32)
除了batch_size,我们已经讨论了所有的输入。batch_size控制通过网络的每组数据的大小。更大的 GPU 将能够适应更大的批量。我建议从32或64开始,然后从那里往上走。
7.评估您的 Keras 模型

Figure 9: After we fit our model, we can use our testing data to make predictions and generate a classification report.
我们已经训练了我们的实际模型,但现在我们需要根据我们的测试数据来评估它。
我们对测试数据进行评估是很重要的,这样我们就可以获得一个无偏(或尽可能接近无偏)的表示,来说明我们的模型在使用从未训练过的数据时表现如何。
为了评估我们的 Keras 模型,我们可以结合使用模型的.predict方法和来自 scikit-learn 的classification_report:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy (Simple NN)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
2020-05-13 更新:为了使这个绘图片段与 TensorFlow 2+兼容,H.history 字典键被更新以完全拼出“准确性”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
运行此脚本时,您会注意到我们的 Keras 神经网络将开始训练,一旦训练完成,我们将在测试集上评估网络:
$ python train_simple_nn.py --dataset animals --model output/simple_nn.model \
--label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Using TensorFlow backend.
[INFO] loading images...
[INFO] training network...
Train on 2250 samples, validate on 750 samples
Epoch 1/80
2250/2250 [==============================] - 1s 311us/sample - loss: 1.1041 - accuracy: 0.3516 - val_loss: 1.1578 - val_accuracy: 0.3707
Epoch 2/80
2250/2250 [==============================] - 0s 183us/sample - loss: 1.0877 - accuracy: 0.3738 - val_loss: 1.0766 - val_accuracy: 0.3813
Epoch 3/80
2250/2250 [==============================] - 0s 181us/sample - loss: 1.0707 - accuracy: 0.4240 - val_loss: 1.0693 - val_accuracy: 0.3533
...
Epoch 78/80
2250/2250 [==============================] - 0s 184us/sample - loss: 0.7688 - accuracy: 0.6160 - val_loss: 0.8696 - val_accuracy: 0.5880
Epoch 79/80
2250/2250 [==============================] - 0s 181us/sample - loss: 0.7675 - accuracy: 0.6200 - val_loss: 1.0294 - val_accuracy: 0.5107
Epoch 80/80
2250/2250 [==============================] - 0s 181us/sample - loss: 0.7687 - accuracy: 0.6164 - val_loss: 0.8361 - val_accuracy: 0.6120
[INFO] evaluating network...
precision recall f1-score support
cats 0.57 0.59 0.58 236
dogs 0.55 0.31 0.39 236
panda 0.66 0.89 0.76 278
accuracy 0.61 750
macro avg 0.59 0.60 0.58 750
weighted avg 0.60 0.61 0.59 750
[INFO] serializing network and label binarizer...
这个网络很小,当与一个小数据集结合时,在我的 CPU 上每个时期只需要 2 秒钟。
这里你可以看到我们的网络获得了 60%的准确率。
由于我们有 1/3 的机会随机选择给定图像的正确标签,我们知道我们的网络实际上已经学习了可以用来区分这三类图像的模式。
我们还保存了我们的一个情节:
- 培训损失
- 验证损失
- 训练准确性
- 验证准确性
…确保我们能够轻松发现结果中的过度拟合或欠拟合。
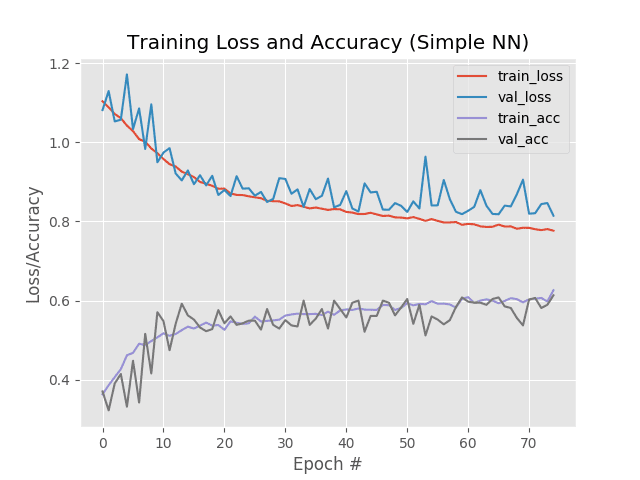
Figure 10: Our simple neural network training script (created with Keras) generates an accuracy/loss plot to help us spot under/overfitting.
查看我们的图,我们看到少量的过度拟合开始出现在大约 45 个时期之后,此时我们的训练和验证损失开始发散,并出现明显的缺口。
最后,我们可以将模型保存到磁盘上,这样我们就可以在以后重用它,而不必重新训练它:
# save the model and label binarizer to disk
print("[INFO] serializing network and label binarizer...")
model.save(args["model"], save_format="h5")
f = open(args["label_bin"], "wb")
f.write(pickle.dumps(lb))
f.close()
8.使用 Keras 模型对新数据进行预测
在这一点上,我们的模型已经被训练好了——但是如果我们想在我们的网络已经被训练好的之后对图像进行预测呢?
那我们该怎么办?
我们如何从磁盘加载模型?
如何加载一幅图像,然后进行预处理进行分类?
在predict.py脚本中,我将向您展示如何操作,因此打开它并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import load_model
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image we are going to classify")
ap.add_argument("-m", "--model", required=True,
help="path to trained Keras model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to label binarizer")
ap.add_argument("-w", "--width", type=int, default=28,
help="target spatial dimension width")
ap.add_argument("-e", "--height", type=int, default=28,
help="target spatial dimension height")
ap.add_argument("-f", "--flatten", type=int, default=-1,
help="whether or not we should flatten the image")
args = vars(ap.parse_args())
首先,我们将导入我们需要的包和模块。
每当您编写脚本从磁盘加载 Keras 模型时,您都需要从tensorflow.keras.models显式导入load_model。OpenCV 将用于注释和显示。pickle模块将用于加载我们的标签二进制化器。
接下来,让我们解析我们的命令行参数:
--image:我们输入图像的路径。--model:我们经过训练和序列化的 Keras 模型路径。--label-bin:序列化标签二进制化器路径。--width:CNN 的输入形状的宽度。记住——你不能在这里随便指定任何东西。您需要指定模型的设计宽度。--height:输入 CNN 的图像的高度。指定的高度还必须与网络的输入形状相匹配。- 我们是否应该使图像变平。默认情况下,我们不会展平图像。如果需要展平图像,应该为此参数传递一个
1。
接下来,让我们加载图像并根据命令行参数调整其大小:
# load the input image and resize it to the target spatial dimensions
image = cv2.imread(args["image"])
output = image.copy()
image = cv2.resize(image, (args["width"], args["height"]))
# scale the pixel values to [0, 1]
image = image.astype("float") / 255.0
然后我们会flatten图片如果需要的话:
# check to see if we should flatten the image and add a batch
# dimension
if args["flatten"] > 0:
image = image.flatten()
image = image.reshape((1, image.shape[0]))
# otherwise, we must be working with a CNN -- don't flatten the
# image, simply add the batch dimension
else:
image = image.reshape((1, image.shape[0], image.shape[1],
image.shape[2]))
展平标准全连接网络的图像非常简单(第 33-35 行)。
在 CNN 的情况下,我们也添加了批处理维度,但是我们没有展平图像(第 39-41 行)。下一节将介绍一个 CNN 的例子。
从那里,让我们将模型+标签二进制化器加载到内存中,并进行预测:
# load the model and label binarizer
print("[INFO] loading network and label binarizer...")
model = load_model(args["model"])
lb = pickle.loads(open(args["label_bin"], "rb").read())
# make a prediction on the image
preds = model.predict(image)
# find the class label index with the largest corresponding
# probability
i = preds.argmax(axis=1)[0]
label = lb.classes_[i]
我们的模型和标签二进制化器通过线 45 和 46 加载。
我们可以通过调用model.predict ( 第 49 行)对输入image进行预测。
preds数组是什么样子的?
(Pdb) preds
array([[5.4622066e-01, 4.5377851e-01, 7.7963534e-07]], dtype=float32)
2D 数组包含(1)批中图像的索引(这里只有一个索引,因为只有一个图像被传入神经网络进行分类)和(2)对应于每个类标签的百分比,如在我的 Python 调试器中查询变量所示:
- 猫:54.6%
- 狗:45.4%
- 熊猫:约 0%
换句话说,我们的网络“认为”它看到了、【猫】、,而且它肯定“知道”它没有看到、【熊猫】、。
第 53 行找到最大值的指标(第 0 个“猫”指标)。
并且行 54 从标签二进制化器中提取【猫】字符串标签。
简单对吗?
现在让我们显示结果:
# draw the class label + probability on the output image
text = "{}: {:.2f}%".format(label, preds[0][i] * 100)
cv2.putText(output, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(0, 0, 255), 2)
# show the output image
cv2.imshow("Image", output)
cv2.waitKey(0)
我们在第 57 行的上格式化我们的text字符串。这包括label和百分比格式的预测值。
然后我们将text放在output图像上(第 58 行和第 59 行)。
最后,我们在屏幕上显示输出图像,并等待直到用户按下第 62 行和第 63 行上的任意键(观察 Homer Simpson 试图定位“任意”键)。
我们的预测脚本相当简单。
一旦您使用本教程的 【下载】 部分下载了代码,您就可以打开一个终端,尝试在自定义映像上运行我们训练有素的网络:
$ python predict.py --image images/cat.jpg --model output/simple_nn.model \
--label-bin output/simple_nn_lb.pickle --width 32 --height 32 --flatten 1
Using TensorFlow backend.
[INFO] loading network and label binarizer...
确保从相对于脚本的文件夹中复制/粘贴或键入了整个命令(包括命令行参数)。如果你在命令行参数上有问题,请阅读一下这篇博文。

Figure 11: A cat is correctly classified with a simple neural network in our Keras tutorial.
这里可以看到,我们简单的 Keras 神经网络已经以 55.87%的概率将输入图像分类为“猫”,尽管猫的脸被一片面包部分遮挡。
9.额外收获:用 Keras 训练你的第一个卷积神经网络
诚然,使用标准的前馈神经网络对图像进行分类并不是一个明智的选择。
相反,我们应该利用卷积神经网络(CNN ),它旨在对图像的原始像素强度进行操作,并学习可用于高精度分类图像的鉴别过滤器。
我们今天将在这里讨论的模型是 VGGNet 的一个较小的变体,我将其命名为“SmallVGGNet”。
类似 VGGNet 的模型有两个共同的特征:
- 仅使用 3×3 卷积
- 在应用破坏性池操作之前,卷积层在网络体系结构中更深地堆叠在彼此之上
现在让我们开始实现 SmallVGGNet。
打开smallvggnet.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
从2-10线的进口可以看出,SmallVGGNet所需的一切都来自keras。我鼓励你在 Keras 文档和我的深度学习书籍中熟悉每一个。
然后我们开始定义我们的SmallVGGNet类和build方法:
class SmallVGGNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们的类在行 12 定义,唯一的build方法在行 14 定义。
build需要四个参数:输入图像的width、height输入图像的高度、depth和classes的数量。
depth也可以认为是通道的数量。我们的图像在 RGB 颜色空间中,所以当我们调用build方法时,我们将传递3的depth。
首先,我们初始化一个Sequential模型(第 17 行)。
然后,我们确定通道排序。Keras 支持"channels_last"(即 TensorFlow)和"channels_first"(即 Theano)排序。第 18-25 行允许我们的模型支持任何类型的后端。
现在,让我们给网络添加一些层:
# CONV => RELU => POOL layer set
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
我们的第一个CONV => RELU => POOL层是由这个模块添加的。
我们的第一个CONV层有32个大小为3x3的滤镜。
我们指定第一层的inputShape非常重要,因为所有后续层的尺寸将使用涓滴法计算。
我们将在该网络架构中使用 ReLU(整流线性单元)激活功能。有许多激活方法,我鼓励你熟悉一下 使用 Python 进行计算机视觉的深度学习 中的流行方法,其中讨论了利弊和权衡。
还应用了批处理规范化、最大池化和丢弃。
批量标准化用于在将给定输入体积传递到网络中的下一层之前对其激活进行标准化。已经证明它在减少训练 CNN 所需的纪元数量以及稳定训练本身方面非常有效。
池图层的主要功能是逐渐减小图层输入量的空间大小(即宽度和高度)。在 CNN 架构中,通常在连续的 CONV 层之间插入池层。
辍学是一个不容忽视的有趣概念。为了使网络更强大,我们可以应用 dropout,即在层间断开随机神经元的过程。这个过程被证明可以减少过度拟合,提高准确性,并允许我们的网络更好地推广不熟悉的图像。如参数所示,在每次训练迭代期间,25%的节点连接在层之间随机断开(丢弃)。
注意:如果你是深度学习的新手,这可能对你来说听起来像是一种不同的语言。就像学习一门新的口语一样,它需要时间、学习和练习。如果你渴望学习深度学习的语言,为什么不抓住我评价很高的书,用 Python 进行计算机视觉的深度学习?我保证我会在书中分解这些概念,并通过实际例子来强化它们。
继续前进,我们到达下一个(CONV => RELU) * 2 => POOL层:
# (CONV => RELU) * 2 => POOL layer set
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
注意,我们的滤波器维数保持不变(3x3,这对于类 VGG 网络是常见的);但是,我们将学习的过滤器总数从 32 个增加到 64 个。
接下来是一个(CONV => RELU => POOL) * 3图层组:
# (CONV => RELU) * 3 => POOL layer set
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
再一次,注意所有的 CONV 层是如何学习3x3过滤器的,但是 CONV 层学习的过滤器总数从 64 增加到了 128。随着你进入 CNN 越深(并且随着你的输入音量变得越来越小),增加所学习的过滤器的总数是常见的做法。
最后,我们有一组FC => RELU层:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
在 Keras 中,完全连接的层由Dense表示。最后一层与三个输出完全连接(因为我们的数据集中有三个classes)。softmax层返回每个标签的分类概率。
现在SmallVGGNet已经实现了,让我们编写驱动脚本,它将被用来在我们的动物数据集上训练它。
这里的大部分代码与前面的例子相似,但是我将:
- 检查整个脚本的完整性
- 并指出过程中的任何差异
打开train_vgg.py脚本,让我们开始吧:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.smallvggnet import SmallVGGNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
导入与我们之前的培训脚本相同,但有两个例外:
- 这次我们通过
from pyimagesearch.smallvggnet import SmallVGGNet导入SmallVGGNet,而不是from keras.models import Sequential。稍微向上滚动可以看到 SmallVGGNet 实现。 - 我们将用
ImageDataGenerator来扩充我们的数据。数据扩充几乎总是被推荐,并且导致更好地概括的模型。数据扩充包括向现有训练数据添加应用随机旋转、移位、剪切和缩放。你不会看到一堆新的。巴新和。jpg 文件—它是在脚本执行时动态完成的。
在这一点上,您应该认识到其他的导入。如果没有,请参考上方的列表。
让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
我们有四个命令行参数要解析:
- 磁盘上图像数据集的路径。这可以是到
animals/或另一个以相同方式组织的数据集的路径。 - 我们的模型将被序列化并输出到磁盘。此参数包含输出模型文件的路径。确保相应地命名您的模型,这样您就不会覆盖任何以前训练过的模型(例如简单的神经网络模型)。
--label-bin:数据集标签被序列化到磁盘上,以便在其他脚本中调用。这是输出标签二进制文件的路径。--plot:输出训练图图像文件的路径。我们将查看该图,检查数据是否过度拟合/拟合不足。每次使用参数更改训练模型时,都应该在命令行中指定不同的绘图文件名,以便在笔记本或注释文件中拥有与训练注释相对应的绘图历史记录。本教程使深度学习看起来很容易,但请记住,在我决定在这个脚本中与您分享所有参数之前,我经历了几次迭代训练。
让我们加载并预处理我们的数据:
# initialize the data and labels
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# loop over the input images
for imagePath in imagePaths:
# load the image, resize it to 64x64 pixels (the required input
# spatial dimensions of SmallVGGNet), and store the image in the
# data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (64, 64))
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
正如在简单的神经网络脚本中一样,这里我们:
- 为我们的
data和labels( 第 35 行和第 36 行)初始化列表。 - 抓住
imagePaths并随机shuffle它们(第 39-41 行)。在我们对它们进行排序和shuffle之前,paths.list_images函数将方便地找到我们的输入数据集目录中的所有图像。 - 开始循环我们数据集中的所有
imagePaths(行 44 )。
当我们循环每个imagePath时,我们继续:
- 将
image载入存储器(第 48 行)。 - 将图像调整到
64x64,需要输入SmallVGGNet( 第 49 行)的空间尺寸。一个关键的区别是,我们 不是 为神经网络展平我们的数据,因为它是卷积的。 - 将调整后的
image追加到data( 第 50 行)。 - 从
imagePath中提取图像的类label,并将其添加到labels列表中(第 54 行和第 55 行)。
在第 58 行的上,我们以阵列形式从范围【0,255】到【0,1】缩放像素强度。
我们还将labels列表转换成 NumPy 数组格式(第 59 行)。
然后,我们将分割数据,并将标签二进制化:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
# convert the labels from integers to vectors (for 2-class, binary
# classification you should use Keras' to_categorical function
# instead as the scikit-learn's LabelBinarizer will not return a
# vector)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
我们对数据进行 75/25 的训练和测试分割(行 63 和 64 )。我鼓励你尝试的一个实验是将训练分成 80/20,看看结果是否有显著变化。
标签二进制化发生在行 70-72 上。这允许一键编码,并在脚本的后面将我们的标签二进制化器序列化为 pickle 文件。
现在是数据扩充:
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
# initialize our VGG-like Convolutional Neural Network
model = SmallVGGNet.build(width=64, height=64, depth=3,
classes=len(lb.classes_))
在第行第 75-77 行,我们初始化我们的图像数据生成器来执行图像增强。
图像增强允许我们通过随机旋转、移动、剪切、缩放和翻转,从现有的训练数据中构建“附加的”训练数据。
数据扩充通常是实现以下目标的关键步骤:
- 避免过度拟合
- 确保您的模型能够很好地概括
我建议您总是执行数据扩充,除非您有明确的理由不这样做。
为了构建我们的SmallVGGNet,我们简单地调用SmallVGGNet.build,同时传递必要的参数(第 80 行和第 81 行)。
让我们编译和训练我们的模型:
# initialize our initial learning rate, # of epochs to train for,
# and batch size
INIT_LR = 0.01
EPOCHS = 75
BS = 32
# initialize the model and optimizer (you'll want to use
# binary_crossentropy for 2-class classification)
print("[INFO] training network...")
opt = SGD(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
H = model.fit(x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
首先,我们建立我们的学习率、时期数和批量大小(第 85-87 行)。
然后我们初始化我们的随机梯度下降(SGD)优化器(第 92 行)。
我们现在准备编译和训练我们的模型(第 93-99 行)。我们的model.fit调用处理训练和动态数据增强。我们必须将训练数据作为第一个参数传递给生成器。生成器将根据我们之前所做的设置生成批量的增强训练数据。
2020-05-13 更新:以前,TensorFlow/Keras 需要使用一种叫做fit_generator的方法来完成数据扩充。现在,fit方法也可以处理数据扩充,使代码更加一致。请务必查看我关于 fit 和 fit 生成器以及数据扩充的文章。
最后,我们将评估我们的模型,绘制损耗/精度曲线,并保存模型:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy (SmallVGGNet)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
# save the model and label binarizer to disk
print("[INFO] serializing network and label binarizer...")
model.save(args["model"], save_format="h5")
f = open(args["label_bin"], "wb")
f.write(pickle.dumps(lb))
f.close()
我们对测试集进行预测,然后使用 scikit-learn 计算并打印我们的classification_report ( 第 103-105 行)。
Matplotlib 用于绘制损耗/精度曲线— 行 108-118 展示了我的典型绘图设置。第 119 行将图形保存到磁盘。
2020-05-13 更新:为了使这个绘图片段与 TensorFlow 2+兼容,H.history 字典键被更新以完全拼出“准确性”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
最后,我们将我们的模型和标签二进制化器保存到磁盘(第 123-126 行)。
让我们继续训练我们的模型。
确保你已经使用了这篇博文的 【下载】 部分来下载源代码和示例数据集。
从那里,打开一个终端并执行以下命令:
$ python train_vgg.py --dataset animals --model output/smallvggnet.model \
--label-bin output/smallvggnet_lb.pickle \
--plot output/smallvggnet_plot.png
Using TensorFlow backend.
[INFO] loading images...
[INFO] training network...
Train for 70 steps, validate on 750 samples
Epoch 1/75
70/70 [==============================] - 13s 179ms/step - loss: 1.4178 - accuracy: 0.5081 - val_loss: 1.7470 - val_accuracy: 0.3147
Epoch 2/75
70/70 [==============================] - 12s 166ms/step - loss: 0.9799 - accuracy: 0.6001 - val_loss: 1.6043 - val_accuracy: 0.3253
Epoch 3/75
70/70 [==============================] - 12s 166ms/step - loss: 0.9156 - accuracy: 0.5920 - val_loss: 1.7941 - val_accuracy: 0.3320
...
Epoch 73/75
70/70 [==============================] - 12s 166ms/step - loss: 0.3791 - accuracy: 0.8318 - val_loss: 0.6827 - val_accuracy: 0.7453
Epoch 74/75
70/70 [==============================] - 12s 167ms/step - loss: 0.3823 - accuracy: 0.8255 - val_loss: 0.8157 - val_accuracy: 0.7320
Epoch 75/75
70/70 [==============================] - 12s 166ms/step - loss: 0.3693 - accuracy: 0.8408 - val_loss: 0.5902 - val_accuracy: 0.7547
[INFO] evaluating network...
precision recall f1-score support
cats 0.66 0.73 0.69 236
dogs 0.66 0.62 0.64 236
panda 0.93 0.89 0.91 278
accuracy 0.75 750
macro avg 0.75 0.75 0.75 750
weighted avg 0.76 0.75 0.76 750
[INFO] serializing network and label binarizer...
粘贴命令时,请确保您拥有所有命令行参数,以避免“用法”错误。如果您不熟悉命令行参数,请确保在继续之前阅读了它们。
在 CPU 上进行训练需要一些时间——75 个纪元中的每一个都需要一分钟以上。训练将持续一个多小时。
GPU 将在几分钟内完成这个过程,因为每个历元只需要 2 秒,正如演示的那样!
让我们来看看在output/目录中得到的训练图:

Figure 12: Our deep learning with Keras accuracy/loss plot demonstrates that we have obtained 76% accuracy on our animals data with our SmallVGGNet model.
正如我们的结果所展示的,你可以看到我们使用卷积神经网络在我们的动物数据集上实现了 76%的准确率,显著高于使用标准全连接网络的之前 60% 的准确率。
我们还可以将新培训的 Keras CNN 应用于示例图像:
$ python predict.py --image images/panda.jpg --model output/smallvggnet.model \
--label-bin output/smallvggnet_lb.pickle --width 64 --height 64
Using TensorFlow backend.
[INFO] loading network and label binarizer...

Figure 13: Our deep learning with Keras tutorial has demonstrated how we can confidently recognize pandas in images.
我们的 CNN 非常有信心这是一只“熊猫”。我也是,但我只是希望他不要再盯着我看了!
让我们试试可爱的小猎犬:
$ python predict.py --image images/dog.jpg --model output/smallvggnet.model \
--label-bin output/smallvggnet_lb.pickle --width 64 --height 64
Using TensorFlow backend.
[INFO] loading network and label binarizer...

Figure 14: A beagle is recognized as a dog using Keras, TensorFlow, and Python. Our Keras tutorial has introduced the basics for deep learning, but has just scratched the surface of the field.
几只比格犬是我家庭和童年的一部分。我很高兴我在网上找到的这张小猎犬图片被认出是一只狗!
我可以用类似的 CNN 在我的电脑上找到我的小猎犬的照片。
事实上,在 Google Photos 中,如果你在搜索框中键入“dog ”,你的照片库中的狗的照片将会被返回——我非常确定 CNN 已经被用于该图像搜索引擎功能。图像搜索引擎并不是 CNN 的唯一用例——我敢打赌,你的大脑已经开始想出各种各样的想法来应用深度学习。
摘要
在今天的教程中,您学习了如何开始使用 Keras、深度学习和 Python。
具体来说,您学习了使用 Keras 和您自己的自定义数据集的七个关键步骤:
- 如何从磁盘加载数据
- 如何创建您的培训和测试拆分
- 如何定义你的 Keras 模型架构
- 如何编译和准备您的 Keras 模型
- 如何根据训练数据训练模型
- 如何根据测试数据评估您的模型
- 如何使用训练好的 Keras 模型进行预测
从那里,您还学习了如何实现卷积神经网络,使您能够获得比标准全连接网络更高的准确性。
如果你有任何关于 Keras 的问题,一定要留下你的评论,我会尽力回答。
为了在 PyImageSearch 上发布未来的 Keras 和深度学习帖子时得到通知,请务必在下表中输入您的电子邮件地址!
keras vs tensor flow——哪个更好,我该学哪个?

我的项目应该使用 Keras vs. TensorFlow 吗?TensorFlow 和 Keras 哪个更好?我该不该投入时间学习 TensorFlow?还是 Keras?
以上是我在整个收件箱、社交媒体,甚至是与深度学习研究人员、实践者和工程师的面对面对话中听到的所有问题的例子。
我甚至收到了与我的书《用 Python 进行计算机视觉的深度学习相关的问题,读者们问我为什么“只”讨论 Keras——tensor flow 呢?
*很不幸。
因为这是一个错误的问题。
截至2017 年年中,Keras 实际上已经完全采用并整合到 TensorFlow 中。TensorFlow + Keras 集成意味着您可以:
- 使用 Keras 的易用界面定义您的模型
- 如果您需要(1)特定的 TensorFlow 功能或(2)需要实现 Keras 不支持但 TensorFlow 支持的自定义功能,请进入 TensorFlow。
简而言之:
您可以将 TensorFlow 代码直接插入到您的 Keras 模型或训练管道中!
不要误解我。我并不是说,对于某些应用程序,您不需要了解一点 TensorFlow 如果您正在进行新颖的研究并需要定制实现,这一点尤其正确。我只是说如果你在转动轮子:
- 刚开始研究深度学习…
- 试图决定下一个项目使用哪个库…
- 想知道 Keras 或 TensorFlow 是否“更好”…
…那么是时候给这些轮子一些牵引力了。
别担心,开始吧。我的建议是使用 Keras 启动,然后进入 TensorFlow,获得您可能需要的任何特定功能。
在今天的帖子中,我将向您展示如何训练(1)一个使用严格 Keras 的神经网络和(2)一个使用 Keras + TensorFlow 集成(具有自定义功能)直接内置到 TensorFlow 库中的模型。
要了解更多关于 Keras vs. Tensorflow 的信息,请继续阅读!
keras vs tensor flow——哪个更好,我该学哪个?
在今天教程的剩余部分,我将继续讨论 Keras 与 TensorFlow 的争论,以及这个问题为什么是错误的。
从那里,我们将使用标准的keras模块和内置在 TensorFlow 中的tf.keras模块实现一个卷积神经网络(CNN)。
我们将在一个示例数据集上训练这些 CNN,然后检查结果——正如你将发现的那样,Keras 和 TensorFlow 和谐地生活在一起。
也许最重要的是,你将了解为什么 Keras 与 TensorFlow 的争论不再有意义。
如果你问的是“Keras vs. TensorFlow”,那你就问错问题了

Figure 1: “Should I use Keras or Tensorflow?”
问你是否应该使用 Keras 或 TensorFlow 是一个错误的问题——事实上,这个问题甚至不再有意义。尽管 TensorFlow 宣布 Keras 将被集成到官方 TensorFlow 版本中已经一年多了,但我仍然对深度学习从业者的数量感到惊讶,他们不知道他们可以通过tf.keras子模块访问 Keras。
更重要的是,Keras + TensorFlow 集成是无缝的,允许您将原始 TensorFlow 代码直接放入 Keras 模型中。
在 TensorFlow 中使用 Keras 可以让您两全其美:
- 您可以使用 Keras 提供的简单、直观的 API 来创建您的模型。
- Keras API 本身类似于 scikit-learn 的 API,可以说是机器学习 API 的“黄金标准”。
- Keras API 是模块化的、Pythonic 式的,并且非常容易使用。
- 当你需要一个自定义的层实现,一个更复杂的损失函数等。,您可以进入 TensorFlow,让代码自动与您的 Keras 模型集成。
在前几年,深度学习研究人员、实践者和工程师经常必须做出选择:
- 我应该选择易于使用,但可能难以定制的 Keras 库吗?
- 或者,我是利用更难的【TensorFlow API,编写更多数量级的代码,更不用说使用不太容易理解的 API 了?
幸运的是,我们不用再做选择了。
如果你发现自己处于这样一种情况:问“我应该使用 Keras 还是 TensorFlow?”,退一步说——你问错问题了——你可以两者兼得。
Keras 通过“tf.keras”模块内置到 TensorFlow 中
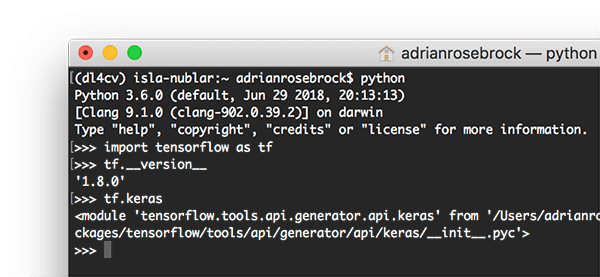
Figure 3: As you can see, by importing TensorFlow (as tf) and subsequently calling tf.keras, I’ve demonstrated in a Python shell that Keras is actually part of TensorFlow.
将 Keras 包含在tf.keras中允许您使用标准 Keras 包,采用以下简单的前馈神经网络:
# import the necessary packages
from keras.models import Sequential
from keras.layers.core import Dense
import tensorflow as tf
# define the 3072-1024-512-3 architecture using Keras
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="sigmoid"))
model.add(Dense(512, activation="sigmoid"))
model.add(Dense(10, activation="softmax"))
然后使用 TensorFlow 的tf.keras子模块实现相同的网络:
# define the 3072-1024-512-3 architecture using tf.keras
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(1024, input_shape=(3072,),
activation="sigmoid"))
model.add(tf.keras.layers.Dense(512, activation="sigmoid"))
model.add(tf.keras.layers.Dense(10, activation="softmax"))
这是不是意味着你有可以用tf.keras?标准的 Keras 包现在过时了吗?不,当然不是。
作为一个库,Keras 仍将独立于 TensorFlow 运行和,因此两者在未来可能会有分歧;然而,鉴于谷歌官方支持 Keras 和 TensorFlow,这种分歧似乎极不可能。**
**重点是:
如果你习惯使用纯 Keras 编写代码,那就去做吧,并坚持做下去。
但是如果您发现自己在 TensorFlow 中工作,您应该开始利用 Keras API:
- 它内置在 TensorFlow 中
- 它更容易使用
- 当您需要纯 TensorFlow 来实现特定的特性或功能时,它可以直接放入您的 Keras 模型中。
不再有 Keras 对 TensorFlow 的争论——你可以两者兼得,两全其美。
我们的示例数据集

Figure 4: The CIFAR-10 dataset has 10 classes and is used for today’s demonstration (image credit).
为了简单起见,我们将在 CIFAR-10 数据集上训练两个独立的卷积神经网络(CNN ),使用:
- Keras with a TensorFlow backend
- 里面的喀喇斯子模
tf.keras
我还将展示如何在实际的 Keras 模型中包含定制的 TensorFlow 代码。
CIFAR-10 数据集本身由 10 个独立的类组成,包含 50,000 幅训练图像和 10,000 幅测试图像。样品如图 4 中的所示。
我们的项目结构
我们今天的项目结构可以在终端中用tree命令查看:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── minivggnetkeras.py
│ └── minivggnettf.py
├── plot_keras.png
├── plot_tf.png
├── train_network_keras.py
└── train_network_tf.py
1 directory, 7 files
与这篇博文相关的下载中包含了pyimagesearch模块。它是不 pip-installable,但是包含在 【下载】 中。让我们回顾一下模块中的两个重要 Python 文件:
minivggnetkeras.py:这是我们严格的 Keras 对MiniVGGNet的实现,基于VGGNet的深度学习模型。minivggnettf.py:这是我们MiniVGGNet的 TensorFlow + Keras (即tf.keras)实现。
项目文件夹的根目录包含两个 Python 文件:
- 这是我们将使用 strict Keras 实现的第一个培训脚本。
train_network_tf.py:训练脚本的 TensorFlow + Keras 版本基本相同;我们将逐步介绍它,同时强调不同之处。
每个脚本还将生成各自的训练准确度/损失图:
plot_keras.pngplot_tf.png
正如你从目录结构中看到的,我们今天将展示 Keras 和 TensorFlow(使用tf.keras模块)的MiniVGGNet的实现+训练。
用 Keras 训练网络

Figure 5: The MiniVGGNet CNN network architecture implemented using Keras.
训练我们的网络的第一步是在 Keras 中实现网络架构本身。
我假设你已经熟悉用 Keras 训练神经网络的基础知识——如果你不熟悉,请参考这篇介绍性文章。
打开minivggnetkeras.py文件并插入以下代码:
# import the necessary packages
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras.layers import Flatten
from keras.layers import Input
from keras.models import Model
我们从构建模型所需的大量 Keras 导入开始。
从那里,我们定义了我们的MiniVGGNetKeras类:
class MiniVGGNetKeras:
@staticmethod
def build(width, height, depth, classes):
# initialize the input shape and channel dimension, assuming
# TensorFlow/channels-last ordering
inputShape = (height, width, depth)
chanDim = -1
# define the model input
inputs = Input(shape=inputShape)
我们在行 12 上定义build方法,定义我们的inputShape和input。我们将假设“信道最后”排序,这就是为什么depth是inputShape元组中的最后一个值。
让我们开始定义卷积神经网络的主体:
# first (CONV => RELU) * 2 => POOL layer set
x = Conv2D(32, (3, 3), padding="same")(inputs)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Conv2D(32, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
# second (CONV => RELU) * 2 => POOL layer set
x = Conv2D(64, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Conv2D(64, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
检查代码块,您会注意到我们在应用池层以减少卷的空间维度之前,堆叠了一系列卷积、ReLU 激活和批量标准化层。辍学也适用于减少过度拟合。
对于图层类型和术语的简要回顾,请务必查看我以前的 Keras 教程。而为了深入学习,你应该拿起一本我的深度学习书, 用 Python 进行计算机视觉的深度学习 。
让我们将全连接(FC)层添加到网络中:
# first (and only) set of FC => RELU layers
x = Flatten()(x)
x = Dense(512)(x)
x = Activation("relu")(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
# softmax classifier
x = Dense(classes)(x)
x = Activation("softmax")(x)
# create the model
model = Model(inputs, x, name="minivggnet_keras")
# return the constructed network architecture
return model
我们的 FC 和 Softmax 分类器被附加到网络上。然后我们定义神经网络model和return给调用函数。
现在我们已经在 Keras 中实现了 CNN,让我们创建将用于训练它的驱动脚本。
打开train_network_keras.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minivggnetkeras import MiniVGGNetKeras
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot_keras.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们在线 2-13 上import我们需要的包裹。
请注意以下事项:
- 在第 3 行的上,Matplotlib 的后端被设置为
"Agg",这样我们可以将我们的训练图保存为图像文件。 - 在第 6 行的上,我们导入了
MiniVGGNetKeras类。 - 我们使用 scikit-learn 的
LabelBinarizer进行“一次性”编码,使用它的classification_report打印分类精度统计数据(第 7 行和第 8 行)。 - 我们的数据集在行 10 方便的导入。如果你想学习如何使用自定义数据集,我建议你参考之前的 Keras 教程或这篇展示如何使用 Keras 的文章。
我们唯一的命令行参数(我们的输出--plot路径)在的第 16-19 行被解析。
让我们加载 CIFAR-10 并对标签进行编码:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
split = cifar10.load_data()
((trainX, trainY), (testX, testY)) = split
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
我们在行 24 和 25 上加载和提取我们的训练和测试分割,并在行 26 和 27 上将数据转换为浮点+比例。
我们对标签进行编码,并在第 30-36 行的上初始化实际的labelNames。
接下来,我们来训练模型:
# initialize the initial learning rate, total number of epochs to
# train for, and batch size
INIT_LR = 0.01
EPOCHS = 30
BS = 32
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model = MiniVGGNetKeras.build(width=32, height=32, depth=3,
classes=len(labelNames))
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network for {} epochs...".format(EPOCHS))
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=BS, epochs=EPOCHS, verbose=1)
设定训练参数和优化方法(第 40-46 行)。
然后我们用我们的MiniVGGNetKeras.build方法初始化我们的model和compile(T3)它(第 47-50 行)。
随后,我们开始训练程序(行 54 和 55 )。
让我们评估网络并生成一个图:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, EPOCHS), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, EPOCHS), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, EPOCHS), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, EPOCHS), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
在这里,我们根据数据的测试分割来评估网络,并生成一个classification_report。最后,我们组装并导出我们的图。
注意:通常,我会在这里序列化并导出我们的模型,以便它可以在图像或视频处理脚本中使用,但我们今天不打算这么做,因为这超出了本教程的范围。
要运行我们的脚本,请确保使用博客文章的 【下载】 部分下载源代码。
从那里,打开一个终端并执行以下命令:
$ python train_network_keras.py
Using TensorFlow backend.
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network for 30 epochs...
Train on 50000 samples, validate on 10000 samples
Epoch 1/30
50000/50000 [==============================] - 328s 7ms/step - loss: 1.7652 - acc: 0.4183 - val_loss: 1.2965 - val_acc: 0.5326
Epoch 2/30
50000/50000 [==============================] - 325s 6ms/step - loss: 1.2549 - acc: 0.5524 - val_loss: 1.1068 - val_acc: 0.6036
Epoch 3/30
50000/50000 [==============================] - 324s 6ms/step - loss: 1.1191 - acc: 0.6030 - val_loss: 0.9818 - val_acc: 0.6509
...
Epoch 28/30
50000/50000 [==============================] - 337s 7ms/step - loss: 0.7673 - acc: 0.7315 - val_loss: 0.7307 - val_acc: 0.7422
Epoch 29/30
50000/50000 [==============================] - 330s 7ms/step - loss: 0.7594 - acc: 0.7346 - val_loss: 0.7284 - val_acc: 0.7447
Epoch 30/30
50000/50000 [==============================] - 324s 6ms/step - loss: 0.7568 - acc: 0.7359 - val_loss: 0.7244 - val_acc: 0.7432
[INFO] evaluating network...
precision recall f1-score support
airplane 0.81 0.73 0.77 1000
automobile 0.92 0.80 0.85 1000
bird 0.68 0.56 0.61 1000
cat 0.56 0.55 0.56 1000
deer 0.64 0.77 0.70 1000
dog 0.69 0.64 0.66 1000
frog 0.72 0.88 0.79 1000
horse 0.88 0.72 0.79 1000
ship 0.80 0.90 0.85 1000
truck 0.78 0.89 0.83 1000
avg / total 0.75 0.74 0.74 10000
在我的 CPU 上,每个时期需要 5 分多一点的时间来完成。
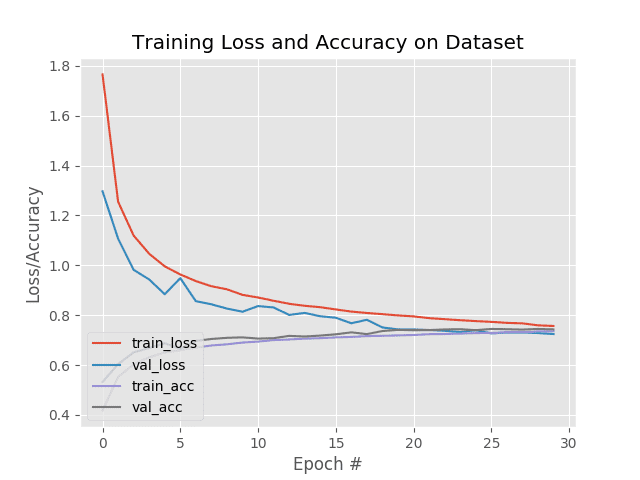
Figure 6: The accuracy/loss training curves are plotted with Matplotlib. This network was trained with Keras.
正如我们从终端输出中看到的,我们在测试集上获得了 75%的准确率——当然不是最先进的;但是,这远远好于随机猜测(1/10)。
**对于一个小网络来说,我们的准确率其实已经相当不错了!
正如我们的输出图在图 6 中所示,没有发生过拟合。
用 TensorFlow 和tf.keras训练网络

Figure 7: The MiniVGGNet CNN architecture built with tf.keras (a module which is built into TensorFlow) is identical to the model that we built with Keras directly. They are one and the same with the exception of the activation function which I have changed for demonstration purposes.
现在,我们已经使用 Keras 库实现并训练了一个简单的 CNN,让我们学习如何:
- 使用 TensorFlow 的
tf.keras实现相同的网络架构 - 在我们的 Keras 模型中包含一个张量流激活函数,它是而不是在 Keras 中实现的。
首先,打开minivggnettf.py文件,我们将实现我们的 TensorFlow 版本的MiniVGGNet:
# import the necessary packages
import tensorflow as tf
class MiniVGGNetTF:
@staticmethod
def build(width, height, depth, classes):
# initialize the input shape and channel dimension, assuming
# TensorFlow/channels-last ordering
inputShape = (height, width, depth)
chanDim = -1
# define the model input
inputs = tf.keras.layers.Input(shape=inputShape)
# first (CONV => RELU) * 2 => POOL layer set
x = tf.keras.layers.Conv2D(32, (3, 3), padding="same")(inputs)
x = tf.keras.layers.Activation("relu")(x)
x = tf.keras.layers.BatchNormalization(axis=chanDim)(x)
x = tf.keras.layers.Conv2D(32, (3, 3), padding="same")(x)
x = tf.keras.layers.Lambda(lambda t: tf.nn.crelu(x))(x)
x = tf.keras.layers.BatchNormalization(axis=chanDim)(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = tf.keras.layers.Dropout(0.25)(x)
# second (CONV => RELU) * 2 => POOL layer set
x = tf.keras.layers.Conv2D(64, (3, 3), padding="same")(x)
x = tf.keras.layers.Lambda(lambda t: tf.nn.crelu(x))(x)
x = tf.keras.layers.BatchNormalization(axis=chanDim)(x)
x = tf.keras.layers.Conv2D(64, (3, 3), padding="same")(x)
x = tf.keras.layers.Lambda(lambda t: tf.nn.crelu(x))(x)
x = tf.keras.layers.BatchNormalization(axis=chanDim)(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = tf.keras.layers.Dropout(0.25)(x)
# first (and only) set of FC => RELU layers
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(512)(x)
x = tf.keras.layers.Lambda(lambda t: tf.nn.crelu(x))(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(0.5)(x)
# softmax classifier
x = tf.keras.layers.Dense(classes)(x)
x = tf.keras.layers.Activation("softmax")(x)
# create the model
model = tf.keras.models.Model(inputs, x, name="minivggnet_tf")
# return the constructed network architecture
return model
在这个文件中,请注意,导入被替换为一行(行 2 )。tf.keras子模块包含我们可以直接调用的所有 Keras 功能。
我想提醒大家注意一下Lambda层,它们用于插入一个自定义激活函数、CRELU(级联 ReLUs),基于尚等人的论文、【通过级联整流线性单元 理解和改进卷积神经网络。这些行用黄色突出显示。
CRELUs 是在 Keras 中实现的而不是 ,而是在 TensorFlow 中实现的——通过使用 TensorFlow 和tf.keras,我们只需一行代码就可以将 CRELUs 添加到我们的 Keras 模型中。
注:CRELU 有两个输出,一个正 RELU 和一个负 ReLU 串联在一起。对于正的 x 值,CRELU 将返回[x,0],而对于负的 x 值,CRELU 将返回[0,x]。有关更多信息,请参考尚等人的出版物。
下一步是实现我们的 TensorFlow + Keras 驱动脚本来训练MiniVGGNetTF。
打开train_network_tf.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minivggnettf import MiniVGGNetTF
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot_tf.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
split = tf.keras.datasets.cifar10.load_data()
((trainX, trainY), (testX, testY)) = split
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
我们的进口货物在2-12 号线处理。与我们的 Keras 训练脚本相比,唯一的变化包括导入MiniVGGNetTF类和导入tensorflow as tf而不是 Keras。
我们的命令行参数在第 15-18 行的处被解析。
然后,我们像以前一样将数据加载到第 23 行上。
其余的行是相同的——提取训练/测试分割并编码我们的标签。
让我们训练我们的模型:
# initialize the initial learning rate, total number of epochs to
# train for, and batch size
INIT_LR = 0.01
EPOCHS = 30
BS = 32
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = tf.keras.optimizers.SGD(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model = MiniVGGNetTF.build(width=32, height=32, depth=3,
classes=len(labelNames))
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network for {} epochs...".format(EPOCHS))
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=BS, epochs=EPOCHS, verbose=1)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, EPOCHS), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, EPOCHS), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, EPOCHS), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, EPOCHS), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
在第行第 39-54 行进行的培训过程是相同的,除了那些用黄色突出显示的,这里只注意到微小的变化。
从那里我们评估并绘制数据(第 58-73 行)。
如您所见,我们已经实现了完全相同的培训过程,只是现在我们使用了tf.keras。
要运行这个脚本,请确保您使用博文的 【下载】 部分来获取代码。
从那里,打开一个终端并执行以下命令:
$ python train_network_tf.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network for 30 epochs...
Train on 50000 samples, validate on 10000 samples
Epoch 1/30
50000/50000 [==============================] - 457s 9ms/step - loss: 1.7024 - acc: 0.4369 - val_loss: 1.3181 - val_acc: 0.5253
Epoch 2/30
50000/50000 [==============================] - 441s 9ms/step - loss: 1.1981 - acc: 0.5761 - val_loss: 1.1025 - val_acc: 0.6072
Epoch 3/30
50000/50000 [==============================] - 441s 9ms/step - loss: 1.0506 - acc: 0.6317 - val_loss: 1.0647 - val_acc: 0.6227
...
Epoch 28/30
50000/50000 [==============================] - 367s 7ms/step - loss: 0.6798 - acc: 0.7611 - val_loss: 0.7161 - val_acc: 0.7479
Epoch 29/30
50000/50000 [==============================] - 364s 7ms/step - loss: 0.6732 - acc: 0.7639 - val_loss: 0.6969 - val_acc: 0.7544
Epoch 30/30
50000/50000 [==============================] - 366s 7ms/step - loss: 0.6743 - acc: 0.7641 - val_loss: 0.6973 - val_acc: 0.7550
[INFO] evaluating network...
precision recall f1-score support
airplane 0.86 0.69 0.76 1000
automobile 0.93 0.79 0.85 1000
bird 0.75 0.59 0.66 1000
cat 0.59 0.55 0.57 1000
deer 0.65 0.78 0.71 1000
dog 0.70 0.66 0.68 1000
frog 0.67 0.93 0.78 1000
horse 0.90 0.75 0.82 1000
ship 0.81 0.91 0.86 1000
truck 0.80 0.89 0.84 1000
avg / total 0.76 0.76 0.75 10000
训练完成后,您会看到一个类似于下图的训练图:
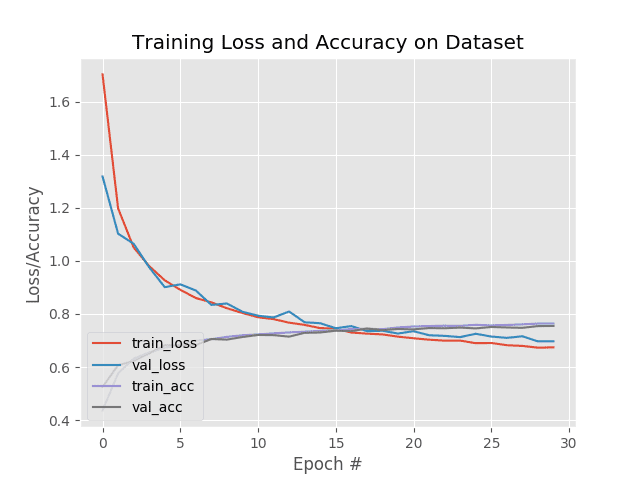
Figure 8: The deep learning training plot shows our accuracy and loss curves. The CNN was trained with the Keras module which is built into TensorFlow.
通过将 CRELU 换成 RELU 激活函数,我们获得了 76%的准确度;然而,这 1%的增加可能是由于网络中权重的随机初始化——需要进一步的交叉验证实验来证明 CRELU 确实对准确性的增加负责。
然而,原始精度是而不是这一节的重要方面。
相反,请关注我们如何在 Keras 模型的内替换标准 Keras 激活函数的 TensorFlow 激活函数!
您可以使用自己的自定义激活函数、损失/成本函数或层实现来做同样的事情。
摘要
在今天的博文中,我们讨论了围绕 Keras 与 TensorFlow 的问题,包括:
- 我的项目应该使用 Keras vs. TensorFlow 吗?
- Is TensorFlow or Keras better?
- 我该不该投入时间学习 TensorFlow?还是 Keras?
最终,我们发现试图在 Keras 和 TensorFlow 之间做出决定变得越来越无关紧要。
Keras 库已经通过tf.keras模块直接集成到 TensorFlow 中。
本质上,您可以使用易于使用的 Keras API 对您的模型和训练过程进行编码,然后使用 pure TensorFlow 对模型或训练过程进行自定义实现!
如果你正在努力尝试开始深度学习,试图为你的下一个项目在 Keras 和 TensorFlow 之间做出决定,或者只是想知道 Keras 和 TensorFlow 是否“更好”… 那么是时候寻求一些动力了。
我给你的建议很简单:
- 刚入门。
- 在您的 Python 项目中键入
import keras或import tensorflow as tf(这样您就可以访问tf.keras),然后开始工作。 - TensorFlow 可以直接集成到您的模型或培训流程中,因此无需比较特性、功能或易用性—tensor flow 和 Keras 的所有都可供您在项目中使用。
我希望你喜欢今天的博文!
如果你对计算机视觉和深度学习入门感兴趣,我建议你看一下我的书, 用 Python 进行计算机视觉的深度学习 。在书中,我利用 Keras 和 TensorFlow 来教你应用于计算机视觉应用的深度学习。
如果您想下载今天教程的源代码(并在以后的博客文章在 PyImageSearch 上发表时得到通知),只需在下面的表格中输入您的电子邮件地址!*******
keras vs . TF . keras:tensor flow 2.0 有什么不同?
原文:https://pyimagesearch.com/2019/10/21/keras-vs-tf-keras-whats-the-difference-in-tensorflow-2-0/

在本教程中,您将发现 Keras 和tf.keras之间的区别,包括 TensorFlow 2.0 中的新功能。
今天的教程是从上周二我收到的一封来自 PyImageSearch 读者 Jeremiah 的电子邮件中得到启发的。
耶利米问道:
你好 Adrian,我看到前几天发布了 TensorFlow 2.0。
TensorFlow 开发者似乎正在推广 Keras,或者更确切地说, 一种叫做 tf.keras, 的东西,作为 TensorFlow 2.0 的推荐高级 API。
但是我以为 Keras 是它自己的独立包装?
当我训练我自己的网络时,我对应该使用“哪个 Keras 包”感到困惑。
其次,tensor flow 2.0 值得升级到吗?
我在深度学习博客圈中看到了一些讨论 TensorFlow 2.0 的教程,但由于对 Keras、
tf.keras和 TensorFlow 2.0 的所有困惑,我不知道从哪里开始。你能解释一下这个地区吗?
很好的问题,耶利米。
以防你没听说,期待已久的 TensorFlow 2.0 于 9 月 30 日正式发布。
虽然这肯定是一个值得庆祝的时刻,但许多深度学习实践者,如 Jeremiah,都在挠头:
- TensorFlow 2.0 版本对我这个 Keras 用户来说意味着什么?
- 我应该用
keras包来训练我自己的神经网络吗? - 或者我应该使用 TensorFlow 2.0 中的
tf.keras子模块? - 作为一个 Keras 用户,我应该关心 TensorFlow 2.0 的哪些特性?
从 TensorFlow 1.x 到 TensorFlow 2.0 的过渡将会有点艰难,至少在开始时是这样,但是有了正确的理解,您将能够轻松地完成迁移。
在本教程的其余部分,我将讨论 Keras、tf.keras和 TensorFlow 2.0 版本之间的相似之处,包括你应该关心的特性。
要了解 Keras、tf.keras 和 TensorFlow 2.0 的区别, 继续阅读!
keras vs . TF . keras:tensor flow 2.0 有什么不同?
在本教程的第一部分,我们将讨论 Keras 和 TensorFlow 之间交织的历史,包括它们的共同普及如何相互促进,相互成长和培育,引领我们到达今天的位置。
然后我会讨论为什么你应该用tf.keras做所有你未来的深度学习项目和实验。
接下来,我将讨论“计算后端”的概念,以及TensorFlow 的流行如何使其成为 Keras 最流行的后端,为 Keras 集成到 tensor flow 的tf.keras子模块铺平道路。
最后,我们将讨论作为 Keras 用户应该关注的一些最受欢迎的 TensorFlow 2.0 功能,包括:
- 会话和急切执行
- 自动微分
- 模型和层子类化
- 更好的多 GPU/分布式培训支持
TensorFlow 2.0 包含一个完整的生态系统,由 TensorFlow Lite(用于移动和嵌入式设备)和 tensor flow Extended for development production 机器学习管道(用于部署生产模型)组成。
我们开始吧!
Keras 和张量流之间的交织关系
Figure 1: Keras and TensorFlow have a complicated history together. Read this section for the Cliff’s Notes of their love affair. With TensorFlow 2.0, you should be using tf.keras rather than the separate Keras package.
了解 Keras 和 TensorFlow 之间复杂、交织的关系,就像听两个高中恋人开始约会、分手、最终找到共同道路的爱情故事——很长,很详细,在某些时候甚至是矛盾的。
我们不再为你回忆完整的爱情故事,而是回顾故事的片断:
- Keras 最初是由谷歌人工智能开发人员/研究人员 Francois Chollet 创建和开发的。
- Francois 在 2015 年 3 月 27 日提交并发布了第一版 Keras 到他的 GitHub。
- 最初,弗朗索瓦开发 Keras 是为了方便自己的研究和实验。
- 然而,随着深度学习普及的爆发,许多开发人员、程序员和机器学习从业者因其易于使用的 API 而涌向 Keras。
- 当时,没有太多的深度学习库可用——流行的包括 Torch、Theano 和 Caffe。
- 这些库的问题在于,它就像试图编写汇编/C++来执行您的实验一样——乏味、耗时且低效。
- 另一方面,Keras 非常容易使用,使得研究人员和开发人员能够更快地重复他们的实验。
- 为了训练你自己定制的神经网络, Keras 需要一个 后端。
- A 后端 是一个计算引擎 —它构建网络图/拓扑,运行优化器,并执行实际的数字运算。
- 为了理解后端的概念,考虑从头开始构建一个网站。这里你可以使用 PHP 编程语言和 SQL 数据库。您的 SQL 数据库是您的后端。您可以使用 MySQL、PostgreSQL 或 SQL Server 作为您的数据库;然而,用于与数据库交互的 PHP 代码不会改变(当然,前提是您使用某种抽象数据库层的 MVC 范式)。本质上,PHP 并不关心使用的是什么数据库,只要它遵守 PHP 的规则。
- Keras 也是如此。你可以把后端想象成你的数据库,把 Keras 想象成你用来访问数据库的编程语言。您可以换入任何您喜欢的后端,只要它遵守某些规则,您的代码就不必更改。
- 因此,你可以将 Keras 视为一组抽象,使其更容易执行深度学习 ( 边注:虽然 Keras 一直支持快速原型制作,但对研究人员来说不够灵活。这在 TensorFlow 2.0 中有所改变,本文稍后将详细介绍)。
- 最初,Keras 的默认后端是 Theano ,直到 v1.1.0 都是默认的
- 与此同时,谷歌发布了 TensorFlow,一个用于机器学习和训练神经网络的符号数学库。
- Keras 开始支持 TensorFlow 作为后端,慢慢地,但确实地,TensorFlow 成为最受欢迎的后端,导致 TensorFlow 成为从 Keras v1.1.0. 版本开始的 默认后端
*** 一旦 TensorFlow 成为 Keras 的默认后端,根据定义,TensorFlow 和 Keras 的使用量一起增长 —没有 TensorFlow 就不可能有 Keras,如果你在系统上安装了 Keras,你也在安装 tensor flow。
* 类似地,TensorFlow 用户越来越喜欢高级 Keras API 的简单性。* TensorFlow v 1 . 10 . 0 中引入了tf.keras子模块,将 Keras 直接集成到 tensor flow 包本身内的第一步。
* tf.keras包是/曾经是与keras包分开的,你将通过 pip(即pip install keras)安装该包。
* 最初的keras包没有包含在tensorflow中,以确保兼容性,这样它们可以有机地开发。* 然而,现在这种情况正在改变——当谷歌在 2019 年 6 月宣布 TensorFlow 2.0 时,他们宣布 Keras 现在是 TensorFlow 的官方高级 API,用于快速轻松的模型设计和训练。* 随着 Keras 2.3.0 的发布,Francois 声明:
* 这是 Keras 的第一个版本,它使keras包与tf.keras同步
* Keras 的最终版本将支持多个后端(即,Theano、CNTK 等。).
* 最重要的是,未来所有深度学习实践者都应该将他们的代码切换到 TensorFlow 2.0 和tf.keras包。
* 最初的keras包仍然会得到错误修复,但是继续向前,**你应该使用tf.keras。****
**正如你所知道的,Keras 和 TensorFlow 之间的历史是漫长的,复杂的,交织在一起的。
但作为一名 Keras 用户,最重要的一点是,您应该在未来的项目中使用 TensorFlow 2.0 和tf.keras。
开始在所有未来项目中使用tf.keras

Figure 2: What’s the difference between Keras and tf.keras in TensorFlow 2.0?
2019 年 9 月 17 日 Keras v2.3.0 正式发布 —在发布中 Francois Chollet(Keras 的创建者和主要维护者)表示:
Keras v2.3.0 是第一个发布的 Keras,它使
keras与tf.keras同步这将是最后一个支持 TensorFlow 之外的后端和的主要版本(例如,Theano、CNTK 等)。)
最重要的是,深度学习实践者应该开始转向 TensorFlow 2.0 和
tf.keras包
对于您的大多数项目来说,这很简单,只需将您的import行从:
from keras... import ...
给import加上tensorflow的前缀:
from tensorflow.keras... import ...
如果你正在使用定制的训练循环或者使用Sessions,那么你将不得不更新你的代码来使用新的GradientTape特性,但是总的来说,更新你的代码是相当容易的。
为了帮助你(自动)将代码从keras更新到tf.keras,谷歌发布了一个名为tf_upgrade_v2的脚本,顾名思义,它会分析你的代码并报告哪些行需要更新——该脚本甚至可以为你执行升级过程。
您可以参考此处,了解更多关于自动将您的代码更新到 TensorFlow 2.0 的信息。
Keras 的计算“后端”

Figure 3: What computational backends does Keras support? What does it mean to use Keras directly in TensorFlow via tf.keras?
正如我在本文前面提到的,Keras 依赖于计算后端的概念。
计算后端在构建模型图、数值计算等方面执行所有的“繁重”工作。
Keras 然后作为抽象坐在这个计算引擎之上,让深度学习开发者/实践者更容易实现和训练他们的模型。
最初,Keras 支持 Theano 作为其首选的计算后端——后来它支持其他后端,包括 CNTK 和 mxnet ,仅举几例。
然而,最流行的后端, , 是 TensorFlow,它最终成为 Keras 的 默认 计算后端。
随着越来越多的 TensorFlow 用户开始使用 Keras 的易用高级 API,TensorFlow 开发人员不得不认真考虑将 Keras 项目纳入 TensorFlow 中一个名为tf.keras的独立模块。
TensorFlow v1.10 是 TensorFlow 第一个在tf.keras中包含keras分支的版本。
现在 TensorFlow 2.0 发布了keras和tf.keras都同步**,暗示keras和tf.keras仍然是单独的项目;然而,开发者应该开始使用tf.keras向前发展,因为keras包将只支持错误修复。**
*引用 Keras 的创建者和维护者 Francois Chollet 的话:
这也是多后端 Keras 的最后一个主要版本。展望未来,我们建议用户考虑在 TensorFlow 2.0 中将他们的 Keras 代码切换到
tf.keras。它实现了相同的 Keras 2.3.0 API(因此切换应该像更改 Keras 导入语句一样容易),但它对 TensorFlow 用户有许多优势,例如支持急切执行、分发、TPU 训练,以及低级 TensorFlow 和高级概念(如
Layer和Model)之间通常更好的集成。也比较好保养。
如果你同时是 Keras 和 TensorFlow 用户,你应该考虑将你的代码切换到 TensorFlow 2.0 和tf.keras。
TensorFlow 2.0 中的会话和急切执行

Figure 4: Eager execution is a more Pythonic way of working dynamic computational graphs. TensorFlow 2.0 supports eager execution (as does PyTorch). You can take advantage of eager execution and sessions with TensorFlow 2.0 and tf.keras. (image source)
在tf.keras中使用 Keras API 的 TensorFlow 1.10+用户将熟悉如何创建一个Session来训练他们的模型:
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
model.fit(X_train, y_train, validation_data=(X_valid, y_valid),
epochs=10, batch_size=64)
创建Session对象并要求提前构建整个模型图有点麻烦,因此 TensorFlow 2.0 引入了急切执行的概念,从而将代码简化为:
model.fit(X_train, y_train, validation_data=(X_valid, y_valid),
epochs=10, batch_size=64)
急切执行的好处是不需要构建整个模型图。
取而代之的是,立即对操作进行评估,这使得开始构建您的模型(以及调试它们)变得更加容易。
*关于急切执行的更多细节,包括如何在 TensorFlow 2.0 中使用它,请参考本文。
如果你想比较急切执行和会话,以及它对训练模型速度的影响,请参考本页。
使用 TensorFlow 2.0 自动微分和梯度胶带

Figure 5: How is TensorFlow 2.0 better at handling custom layers or loss functions? The answer lies in automatic differentiation and GradientTape. (image source)
如果您是一名需要实现自定义图层或损失函数的研究人员,您可能不喜欢 TensorFlow 1.x(当然喜欢)。
TensorFlow 1.x 的定制实现至少可以说是笨拙的——还有很多需要改进的地方。
随着 TensorFlow 2.0 的发布,这种情况开始改变——现在更容易实现自己的自定义损失。
变得更容易的一种方法是通过自动微分和GradientTape实现。
为了利用GradientTape,我们需要做的就是实现我们的模型架构:
# Define our model architecture
model = tf.keras.Sequential([
tf.keras.layers.Dropout(rate=0.2, input_shape=X.shape[1:]),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
定义我们的损失函数和优化器:
# Define loss and optimizer
loss_func = tf.keras.losses.BinaryCrossentropy()
optimizer = tf.keras.optimizers.Adam()
创建负责执行单个批量更新的函数:
def train_loop(features, labels):
# Define the GradientTape context
with tf.GradientTape() as tape:
# Get the probabilities
predictions = model(features)
# Calculate the loss
loss = loss_func(labels, predictions)
# Get the gradients
gradients = tape.gradient(loss, model.trainable_variables)
# Update the weights
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
然后训练模型:
# Train the model
def train_model():
start = time.time()
for epoch in range(10):
for step, (x, y) in enumerate(dataset):
loss = train_loop(x, y)
print('Epoch %d: last batch loss = %.4f' % (epoch, float(loss)))
print("It took {} seconds".format(time.time() - start))
# Initiate training
train_model()
这个GradientTape魔法在幕后为我们处理差异,使得更容易处理自定义损失和层。
说到定制层和模型实现,请务必参考下一节。
TensorFlow 2.0 中的模型和图层子类化
TensorFlow 2.0 和tf.keras为我们提供了三种独立的方法来实现我们自己的定制模型:
- 连续的
- 功能
- 子类
顺序范式和函数范式在 Keras 中已经存在了很长一段时间,但是子类化特性对于许多深度学习实践者来说仍然是未知的。
我将在下周就这三种方法做一个专门的教程,但是现在,让我们来看看如何使用(1) TensorFlow 2.0,(2) tf.keras,和(3)模型子类化特性实现一个基于开创性 LeNet 架构的简单 CNN:
class LeNet(tf.keras.Model):
def __init__(self):
super(LeNet, self).__init__()
self.conv2d_1 = tf.keras.layers.Conv2D(filters=6,
kernel_size=(3, 3), activation='relu',
input_shape=(32,32,1))
self.average_pool = tf.keras.layers.AveragePooling2D()
self.conv2d_2 = tf.keras.layers.Conv2D(filters=16,
kernel_size=(3, 3), activation='relu')
self.flatten = tf.keras.layers.Flatten()
self.fc_1 = tf.keras.layers.Dense(120, activation='relu')
self.fc_2 = tf.keras.layers.Dense(84, activation='relu')
self.out = tf.keras.layers.Dense(10, activation='softmax')
def call(self, input):
x = self.conv2d_1(input)
x = self.average_pool(x)
x = self.conv2d_2(x)
x = self.average_pool(x)
x = self.flatten(x)
x = self.fc_2(self.fc_1(x))
return self.out(x)
lenet = LeNet()
注意LeNet类是Model的子类。
LeNet的构造器(即init)定义了模型中的每一层。
然后,call方法执行向前传递,使您能够定制您认为合适的向前传递。
使用模型子类化的好处是您的模型:
- 变得完全可定制。
- 使您能够实现和利用自己的自定义丢失实现。
由于您的架构继承了Model类,您仍然可以调用像.fit()、.compile()和.evaluate()这样的方法,从而保持易于使用(并且熟悉)的 Keras API。
如果你有兴趣了解更多关于 LeNet 的知识,你可以参考上一篇文章。
TensorFlow 2.0 引入了更好的多 GPU 和分布式训练支持

Figure 6: Is TenorFlow 2.0 better with multiple GPU training? Yes, with the single worker MirroredStrategy. (image source)
TensorFlow 2.0 和tf.keras通过他们的MirroredStrategy 提供了更好的多 GPU 和分布式训练。
引用 TensorFlow 2.0 文档,“MirroredStrategy支持一台机器上多个 GPU 的同步分布式训练”。
如果你想使用多台机器(每台机器可能有多个 GPU),你应该看看MultiWorkerMirroredStrategy 。
或者,如果你正在使用谷歌的云进行培训,查看一下TPUStrategy 。
不过现在,让我们假设你在一台拥有多个 GPU的单机上,你想确保你所有的 GPU 都用于训练。
您可以通过首先创建您的MirroredStrategy:
strategy = tf.distribute.MirroredStrategy()
print ('Number of devices: {}'.format(strategy.num_replicas_in_sync))
然后您需要声明您的模型架构,并在strategy的范围内编译它:
# Call the distribution scope context manager
with strategy.scope():
# Define a model to fit the above data
model = tf.keras.Sequential([
tf.keras.layers.Dropout(rate=0.2, input_shape=X.shape[1:]),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
# Compile the model
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
在那里,您可以调用.fit来训练模型:
# Train the model
model.fit(X, y, epochs=5)
如果您的机器有多个 GPU,TensorFlow 将为您处理多 GPU 培训。
TensorFlow 2.0 是一个生态系统,包括 TF 2.0、TF Lite、TFX、量化、部署
Figure 7: What is new in the TensorFlow 2.0 ecosystem? Should I use Keras separately or should I use tf.keras?
TensorFlow 2.0 不仅仅是一个计算引擎和一个用于训练神经网络的深度学习库— 远不止如此。
借助 TensorFlow Lite (TF Lite),我们可以训练、优化和量化模型,这些模型旨在运行在资源受限的设备上,如智能手机和其他嵌入式设备(如 Raspberry Pi、Google Coral 等)。).
或者,如果您需要将您的模型部署到生产中,您可以使用 TensorFlow Extended (TFX),这是一个用于模型部署的端到端平台。
一旦你的研究和实验完成,你就可以利用 TFX 为生产准备模型,并使用谷歌的生态系统扩展你的模型。
借助 TensorFlow 2.0,我们真正开始看到研究、实验、模型准备/量化和生产部署之间更好、更高效的桥梁。
我对 TensorFlow 2.0 的发布以及它将对深度学习社区产生的影响感到非常兴奋。
学分
这篇文章中的所有代码示例都来自于 TensorFlow 2.0 的官方示例。请务必参考 Francois Chollet 提供的完整代码示例了解更多详情。
此外,一定要看看 Sayak Paul 的 TensorFlow 2.0 的十个重要更新,这篇文章激发了今天的博文。
摘要
在本教程中,您了解了 Keras、tf.keras和 TensorFlow 2.0。
第一个重要的收获是,使用keras包的深度学习实践者应该开始使用 TensorFlow 2.0 内的tf.keras。
您不仅会享受到 TensorFlow 2.0 增加的速度和优化,还会收到新的功能更新——最新发布的keras包(v2.3.0)将是最后一个支持多后端和功能更新的版本。向前看,keras包将只接受错误修复。
你应该认真考虑在你未来的项目中迁移到tf.keras和 TensorFlow 2.0。
第二点是,TensorFlow 2.0 比 GPU 加速的深度学习库更加T2。
您不仅能够使用 TensorFlow 2.0 和tf.keras来训练您自己的模型,而且您现在可以:
- 使用 TensorFlow Lite (TF Lite)将这些模型用于移动/嵌入式部署。
- 使用 TensorFlow Extended (TF Extended)将模型部署到生产中。
从我的角度来看,我已经已经开始将我最初的keras代码移植到tf.keras。我建议你也开始这样做。
我希望你喜欢今天的教程——我很快会带着新的 TensorFlow 2.0 和tf.keras教程回来。
当未来的教程在 PyImageSearch 上发布时会得到通知(并收到我的关于计算机视觉、深度学习和 OpenCV 的 17 页免费资源指南 PDF),只需在下面的表格中输入您的电子邮件地址!****
使用 Keras、TensorFlow 和深度学习进行标签平滑
原文:https://pyimagesearch.com/2019/12/30/label-smoothing-with-keras-tensorflow-and-deep-learning/

在本教程中,您将学习使用 Keras、TensorFlow 和深度学习实现标注平滑的两种方法。
当训练你自己的定制深度神经网络时,有两个关键问题你应该不断地问自己:
- 我是否让过度适应我的训练数据?
- 我的模型会将推广到我的训练和测试分割之外的数据吗?
正则化方法用于帮助克服过度拟合,并帮助我们的模型泛化。正则化方法的例子包括丢弃、L2 权重衰减、数据扩充等。
然而,还有另一个我们还没有讨论的正则化技术—标签平滑。
标签平滑:
- 将“硬”类别标签分配转换为“软”标签分配。
- 对标签本身直接操作。
** 实现起来非常简单。* 可以产生一个更好的模型。*
*在本教程的剩余部分,我将向您展示如何实现标签平滑,并在训练您自己的自定义神经网络时使用它。
要了解更多关于使用 Keras 和 TensorFlow 进行标签平滑的信息,请继续阅读!
使用 Keras、TensorFlow 和深度学习进行标签平滑
在本教程的第一部分,我将解决三个问题:
- 什么是标签平滑?
- 为什么我们要应用标签平滑?
- 标签平滑如何改进我们的输出模型?
在这里,我将向您展示使用 Keras 和 TensorFlow 实现标注平滑的两种方法:
- 通过显式更新你的标签列表来平滑标签
- 使用损失函数进行标签平滑
**然后,我们将使用这两种方法训练我们自己的定制模型,并检查结果。
什么是标注平滑,我们为什么要使用它?
当执行图像分类任务时,我们通常认为标签是硬的二进制分配。
例如,让我们考虑来自 MNIST 数据集的以下图像:

Figure 1: Label smoothing with Keras, TensorFlow, and Deep Learning is a regularization technique with a goal of enabling your model to generalize to new data better.
这个数字显然是一个“7”,如果我们写出这个数据点的独热编码标签向量,它将看起来像下面这样:
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0]
注意我们在这里是如何执行硬标签赋值的:向量中的所有条目都是 0 ,除了第 8 个索引(对应于数字 7)的是一个1。
硬标签分配对我们来说是很自然的,并映射到我们的大脑希望如何有效地将信息分类并存储在标签和包装整齐的盒子中。
例如,我们会看着图 1 并说类似这样的话:
“我确定那是一个 7。我要给它贴上 7 的标签,把它放进‘7’的盒子里。”
说下面的话会觉得尴尬和不直观:
“嗯,我肯定那是一个 7。但即使我 100%确定这是一个 7,我还是会把这 7 的 90%放在“7”框中,然后把剩下的 10%分到所有的框中,这样我的大脑就不会过度适应“7”的样子。”
如果我们将软标签分配应用到上面的独热编码向量,它现在看起来像这样:
[0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.91 0.01 0.01]
注意如何对值列表求和等于1,就像在原始的独热编码向量中一样。
这种类型的标签分配称为软标签分配。
与类别标签为二元的硬标签分配不同(即一个类别为正,所有其他类别为负),软标签分配允许:
- 概率最大的正类
- 而所有其他类别的概率非常小
那么,为什么要大费周章呢?
答案是,我们不希望我们的模型对其预测过于自信。
通过应用标签平滑,我们可以降低模型的可信度,并防止它陷入过度拟合发生的损失景观的深裂缝中。
对于标签平滑的数学讨论,我推荐阅读毛蕾的文章。
此外,请务必阅读 Müller 等人 2019 年的论文 标签平滑何时有帮助?同贺在艾尔讯 s 卷积神经网络图像分类小窍门 标签平滑详细研究。
在本教程的剩余部分,我将向您展示如何使用 Keras 和 TensorFlow 实现标签平滑。
项目结构
继续从今天教程的 【下载】 部分获取今天的文件。
一旦您提取了文件,您可以使用如图所示的tree命令来查看项目结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── learning_rate_schedulers.py
│ └── minigooglenet.py
├── label_smoothing_func.py
├── label_smoothing_loss.py
├── plot_func.png
└── plot_loss.png
1 directory, 7 files
在pyimagesearch模块中,您会发现两个文件:
learning_rate_schedulers.py:一定要参考之前的 PyImageSearch 教程 Keras 学习率调度器和衰减 。- 迷你谷歌网是我们将利用的 CNN 架构。关于模型架构的更多细节,一定要参考我的书, 用 Python 进行计算机视觉的深度学习 。
我们今天将不讨论上述实现,而是将重点放在我们的两种标签平滑方法上:
- 方法#1 通过显式更新
label_smoothing_func.py中的标签列表来使用标签平滑。 - 方法#2 包括使用
label_smoothing_loss.py中的张量流/Keras 损失函数进行标签平滑。
方法 1:通过显式更新标注列表来平滑标注
我们将看到的第一个标签平滑实现在一次性编码后直接修改我们的标签——我们需要做的就是实现一个简单的定制函数。
让我们开始吧。
打开项目结构中的label_smoothing_func.py文件,插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.learning_rate_schedulers import PolynomialDecay
from pyimagesearch.minigooglenet import MiniGoogLeNet
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-16 行导入我们的包、模块、类和函数。特别是,我们将使用 scikit-learn LabelBinarizer ( 第 9 行)。
方法#1 的核心在于smooth_labels函数:
def smooth_labels(labels, factor=0.1):
# smooth the labels
labels *= (1 - factor)
labels += (factor / labels.shape[1])
# returned the smoothed labels
return labels
第 18 行定义了smooth_labels功能。该函数接受两个参数:
labels:包含数据集中所有数据点的的独热编码标签。factor:可选的“平滑因子”默认设置为 10%。
smooth_labels函数的其余部分是,最好用一个两步示例来解释。
首先,让我们假设下面的独热编码向量被提供给我们的函数:
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0]
注意我们在这里有一个硬标签分配——真正的类标签是1而所有其他的都是 0。
第 20 行将我们的1硬分配标签减去供应的factor数量。使用factor=0.1,在线 20 上的操作产生以下向量:
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.9, 0.0, 0.0]
注意1.0的硬赋值是如何被降到0.9的。
下一步是对向量中的其余类别标签应用非常小的置信度。
我们通过用factor除以可能的类标签总数来完成这个任务。在我们的例子中,有10个可能的类标签,因此当factor=0.1时,我们有0.1 / 10 = 0.01——那个值被加到我们在行 21 的向量上,结果是:
[0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.91 0.01 0.01]
注意这里的“不正确的”类有非常小的可信度。这看起来不多,但在实践中,它可以帮助我们的模型避免过拟合。
最后,第 24 行将平滑后的标签返回给调用函数。
注:smooth_labels函数部分来自程维的文章,其中他们讨论了用卷积神经网络进行图像分类的技巧*论文。如果您对文章中的实现感兴趣,请务必阅读这篇文章。*
让我们继续实施:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--smoothing", type=float, default=0.1,
help="amount of label smoothing to be applied")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
我们的两个命令行参数包括:
--smoothing:平滑factor(参考上面的smooth_labels函数和例子)。--plot:输出绘图文件的路径。
让我们准备好超参数和数据:
# define the total number of epochs to train for, initial learning
# rate, and batch size
NUM_EPOCHS = 70
INIT_LR = 5e-3
BATCH_SIZE = 64
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer", "dog",
"frog", "horse", "ship", "truck"]
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
# apply mean subtraction to the data
mean = np.mean(trainX, axis=0)
trainX -= mean
testX -= mean
第 36-38 行初始化三个训练超参数,包括要训练的总时期数、初始学习率和批量大小。
第 41 和 42 行然后为 CIFAR-10 数据集初始化我们的类labelNames。
第 47-49 行处理加载 CIFAR-10 数据集。
均值减法(Mean subtraction)是一种标准化形式,包含在使用 Python 的 计算机视觉深度学习的实践者包中,通过行 52-54 应用于数据。
让我们通过方法#1 应用标签平滑:
# convert the labels from integers to vectors, converting the data
# type to floats so we can apply label smoothing
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
trainY = trainY.astype("float")
testY = testY.astype("float")
# apply label smoothing to the *training labels only*
print("[INFO] smoothing amount: {}".format(args["smoothing"]))
print("[INFO] before smoothing: {}".format(trainY[0]))
trainY = smooth_labels(trainY, args["smoothing"])
print("[INFO] after smoothing: {}".format(trainY[0]))
第 58-62 行对标签进行一次性编码,并将其转换为浮点数。
第 67 行使用我们的smooth_labels函数应用标签平滑。
在这里,我们将准备数据扩充和我们的学习率调度程序:
# construct the image generator for data augmentation
aug = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
fill_mode="nearest")
# construct the learning rate scheduler callback
schedule = PolynomialDecay(maxEpochs=NUM_EPOCHS, initAlpha=INIT_LR,
power=1.0)
callbacks = [LearningRateScheduler(schedule)]
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9)
model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BATCH_SIZE,
epochs=NUM_EPOCHS,
callbacks=callbacks,
verbose=1)
第 71-75 行实例化我们的数据扩充对象。
第 78-80 行通过将在每个时期开始时执行的回调来初始化学习率衰减。要了解如何创建自己的定制 Keras 回调,请务必参考使用 Python 进行计算机视觉深度学习的 的入门包。
然后我们编译并训练我们的模型(第 84-97 行)。
一旦模型完全训练完毕,我们将继续生成分类报告和训练历史图:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# construct a plot that plots and saves the training history
N = np.arange(0, NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
方法 2:使用张量流/Keras 损失函数进行标注平滑
我们实现标签平滑的第二种方法直接利用 Keras/TensorFlow 的CategoricalCrossentropy类。
这里的好处是,我们不需要实现任何定制函数——标签平滑可以在用label_smoothing参数实例化CategoricalCrossentropy类时动态应用,如下所示:
CategoricalCrossentropy(label_smoothing=0.1)
同样,这里的好处是我们不需要任何定制的实现。
缺点是我们无法访问原始标签列表,如果您在监控培训过程时需要它来计算您自己的自定义指标,这将是一个问题。
说了这么多,让我们学习如何利用CategoricalCrossentropy进行标签平滑。
我们的实现与前一部分的非常相似,但有一些例外——我将一路指出不同之处。要详细查看我们的培训脚本,请参考上一节。
打开目录结构中的label_smoothing_loss.py文件,我们将开始:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.learning_rate_schedulers import PolynomialDecay
from pyimagesearch.minigooglenet import MiniGoogLeNet
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--smoothing", type=float, default=0.1,
help="amount of label smoothing to be applied")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
第 2-17 行处理我们的进口。最值得注意的10 号线进口CategoricalCrossentropy。
我们的--smoothing和--plot命令行参数与方法#1 中的相同。
我们的下一个代码块与方法#1 几乎相同,除了最后一部分:
# define the total number of epochs to train for initial learning
# rate, and batch size
NUM_EPOCHS = 2
INIT_LR = 5e-3
BATCH_SIZE = 64
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer", "dog",
"frog", "horse", "ship", "truck"]
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
# apply mean subtraction to the data
mean = np.mean(trainX, axis=0)
trainX -= mean
testX -= mean
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
在这里我们:
- 初始化训练超参数(第 29-31 行)。
- 初始化我们的 CIFAR-10 类名(第 34 和 35 行)。
- 加载 CIFAR-10 数据(第 40-42 行)。
- 应用平均减法(第 45-47 行)。
这些步骤中的每一步都与方法#1 相同。
第 50-52 行与我们之前的方法相比,一次性编码标签带有警告。CategoricalCrossentropy类会为我们处理标签平滑,所以不需要像我们之前做的那样直接修改trainY和testY列表。
让我们实例化我们的数据扩充和学习率调度回调:
# construct the image generator for data augmentation
aug = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
fill_mode="nearest")
# construct the learning rate scheduler callback
schedule = PolynomialDecay(maxEpochs=NUM_EPOCHS, initAlpha=INIT_LR,
power=1.0)
callbacks = [LearningRateScheduler(schedule)]
从那里我们将用标签平滑参数 初始化我们的损失
# initialize the optimizer and loss
print("[INFO] smoothing amount: {}".format(args["smoothing"]))
opt = SGD(lr=INIT_LR, momentum=0.9)
loss = CategoricalCrossentropy(label_smoothing=args["smoothing"])
print("[INFO] compiling model...")
model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss=loss, optimizer=opt, metrics=["accuracy"])
第 84 和 85 行初始化我们的优化器和损失函数。
方法#2 的核心在带有标签平滑的损失方法中:注意我们如何将label_smoothing参数传递给CategoricalCrossentropy类。这个类将自动为我们应用标签平滑。
然后我们编译这个模型,传入带有标签平滑的loss。
最后,我们将训练我们的模型,评估它,并绘制训练历史:
# train the network
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BATCH_SIZE,
epochs=NUM_EPOCHS,
callbacks=callbacks,
verbose=1)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# construct a plot that plots and saves the training history
N = np.arange(0, NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
标注平滑结果
既然我们已经实现了我们的标签平滑脚本,让我们把它们投入工作。
首先使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端,执行以下命令,使用我们的自定义smooth_labels函数应用标签平滑:
$ python label_smoothing_func.py --smoothing 0.1
[INFO] loading CIFAR-10 data...
[INFO] smoothing amount: 0.1
[INFO] before smoothing: [0\. 0\. 0\. 0\. 0\. 0\. 1\. 0\. 0\. 0.]
[INFO] after smoothing: [0.01 0.01 0.01 0.01 0.01 0.01 0.91 0.01 0.01 0.01]
[INFO] compiling model...
[INFO] training network...
Epoch 1/70
781/781 [==============================] - 115s 147ms/step - loss: 1.6987 - accuracy: 0.4482 - val_loss: 1.2606 - val_accuracy: 0.5488
Epoch 2/70
781/781 [==============================] - 98s 125ms/step - loss: 1.3924 - accuracy: 0.6066 - val_loss: 1.4393 - val_accuracy: 0.5419
Epoch 3/70
781/781 [==============================] - 96s 123ms/step - loss: 1.2696 - accuracy: 0.6680 - val_loss: 1.0286 - val_accuracy: 0.6458
Epoch 4/70
781/781 [==============================] - 96s 123ms/step - loss: 1.1806 - accuracy: 0.7133 - val_loss: 0.8514 - val_accuracy: 0.7185
Epoch 5/70
781/781 [==============================] - 95s 122ms/step - loss: 1.1209 - accuracy: 0.7440 - val_loss: 0.8533 - val_accuracy: 0.7155
...
Epoch 66/70
781/781 [==============================] - 94s 120ms/step - loss: 0.6262 - accuracy: 0.9765 - val_loss: 0.3728 - val_accuracy: 0.8910
Epoch 67/70
781/781 [==============================] - 94s 120ms/step - loss: 0.6267 - accuracy: 0.9756 - val_loss: 0.3806 - val_accuracy: 0.8924
Epoch 68/70
781/781 [==============================] - 95s 121ms/step - loss: 0.6245 - accuracy: 0.9775 - val_loss: 0.3659 - val_accuracy: 0.8943
Epoch 69/70
781/781 [==============================] - 94s 120ms/step - loss: 0.6245 - accuracy: 0.9773 - val_loss: 0.3657 - val_accuracy: 0.8936
Epoch 70/70
781/781 [==============================] - 94s 120ms/step - loss: 0.6234 - accuracy: 0.9778 - val_loss: 0.3649 - val_accuracy: 0.8938
[INFO] evaluating network...
precision recall f1-score support
airplane 0.91 0.90 0.90 1000
automobile 0.94 0.97 0.95 1000
bird 0.84 0.86 0.85 1000
cat 0.80 0.78 0.79 1000
deer 0.90 0.87 0.89 1000
dog 0.86 0.82 0.84 1000
frog 0.88 0.95 0.91 1000
horse 0.94 0.92 0.93 1000
ship 0.94 0.94 0.94 1000
truck 0.93 0.94 0.94 1000
accuracy 0.89 10000
macro avg 0.89 0.89 0.89 10000
weighted avg 0.89 0.89 0.89 10000
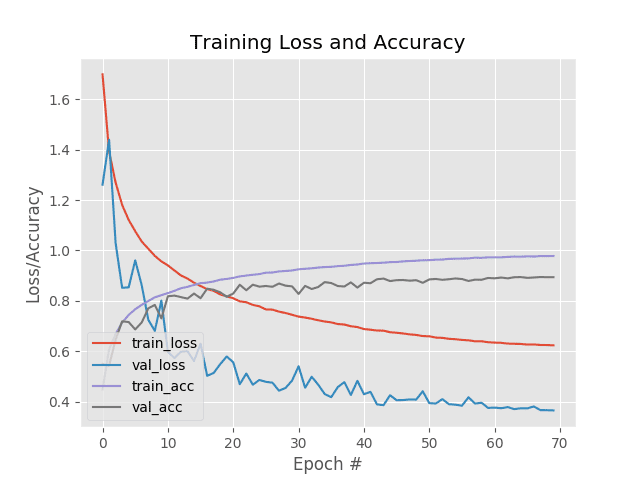
Figure 2: The results of training using our Method #1 of Label smoothing with Keras, TensorFlow, and Deep Learning.
这里你可以看到我们在测试集上获得了 ~89%的准确率。
但是真正有趣的要研究的是 ****图二中我们的训练历史情节。
请注意:
- 验证损失 明显低于培训损失 。
- 然而训练精度比验证精度好。
这是非常奇怪的行为——通常,较低的损耗与较高的精度*相关。
验证损失低于训练损失,而训练精度又高于验证精度,这怎么可能呢?
答案在于标签平滑— 请记住,我们只是平滑了训练标签。验证标签没有磨平。
因此,您可以认为训练标签中有额外的“噪音”。
在训练我们的深度神经网络时应用正则化的最终目标是减少过度拟合和增加我们模型的泛化能力。
通常,我们通过在训练期间牺牲训练损失/准确性来实现这一目标,希望获得更好的可概括模型——这正是我们在这里看到的行为。
接下来,让我们在执行标签平滑时使用 Keras/TensorFlow 的CategoricalCrossentropy类:
$ python label_smoothing_loss.py --smoothing 0.1
[INFO] loading CIFAR-10 data...
[INFO] smoothing amount: 0.1
[INFO] compiling model...
[INFO] training network...
Epoch 1/70
781/781 [==============================] - 101s 130ms/step - loss: 1.6945 - accuracy: 0.4531 - val_loss: 1.4349 - val_accuracy: 0.5795
Epoch 2/70
781/781 [==============================] - 99s 127ms/step - loss: 1.3799 - accuracy: 0.6143 - val_loss: 1.3300 - val_accuracy: 0.6396
Epoch 3/70
781/781 [==============================] - 99s 126ms/step - loss: 1.2594 - accuracy: 0.6748 - val_loss: 1.3536 - val_accuracy: 0.6543
Epoch 4/70
781/781 [==============================] - 99s 126ms/step - loss: 1.1760 - accuracy: 0.7136 - val_loss: 1.2995 - val_accuracy: 0.6633
Epoch 5/70
781/781 [==============================] - 99s 127ms/step - loss: 1.1214 - accuracy: 0.7428 - val_loss: 1.1175 - val_accuracy: 0.7488
...
Epoch 66/70
781/781 [==============================] - 97s 125ms/step - loss: 0.6296 - accuracy: 0.9762 - val_loss: 0.7729 - val_accuracy: 0.8984
Epoch 67/70
781/781 [==============================] - 131s 168ms/step - loss: 0.6303 - accuracy: 0.9753 - val_loss: 0.7757 - val_accuracy: 0.8986
Epoch 68/70
781/781 [==============================] - 98s 125ms/step - loss: 0.6278 - accuracy: 0.9765 - val_loss: 0.7711 - val_accuracy: 0.9001
Epoch 69/70
781/781 [==============================] - 97s 124ms/step - loss: 0.6273 - accuracy: 0.9764 - val_loss: 0.7722 - val_accuracy: 0.9007
Epoch 70/70
781/781 [==============================] - 98s 126ms/step - loss: 0.6256 - accuracy: 0.9781 - val_loss: 0.7712 - val_accuracy: 0.9012
[INFO] evaluating network...
precision recall f1-score support
airplane 0.90 0.93 0.91 1000
automobile 0.94 0.97 0.96 1000
bird 0.88 0.85 0.87 1000
cat 0.83 0.78 0.81 1000
deer 0.90 0.88 0.89 1000
dog 0.87 0.84 0.85 1000
frog 0.88 0.96 0.92 1000
horse 0.93 0.92 0.92 1000
ship 0.95 0.95 0.95 1000
truck 0.94 0.94 0.94 1000
accuracy 0.90 10000
macro avg 0.90 0.90 0.90 10000
weighted avg 0.90 0.90 0.90 10000

Figure 3: The results of training using our Method #2 of Label smoothing with Keras, TensorFlow, and Deep Learning.
在这里,我们获得了大约 90%的准确度,但这并不意味着CategoricalCrossentropy方法比smooth_labels技术“更好”——对于所有意图和目的来说,这些结果是“相等的”,如果结果是多次运行的平均值,将显示遵循相同的分布。
图 3 显示了基于损失的标签平滑方法的训练历史。
请再次注意,我们的验证损失低于我们的训练损失,但我们的训练精度高于我们的验证精度-这在使用标注平滑时完全是正常行为,因此不要大惊小怪。
何时应该应用标注平滑?
我建议在您的模型难以泛化和/或模型过度适应训练集时应用标注平滑。
当这些情况发生时,我们需要应用正则化技术。然而,标注平滑只是正则化的一种类型。其他类型的正规化包括:
- 拒绝传统社会的人
- L1、L2 等。重量衰减
- 数据扩充
- 减少模型容量
您可以混合搭配这些方法,以防止过度拟合,并提高模型的泛化能力。
摘要
在本教程中,您学习了使用 Keras、TensorFlow 和深度学习应用标注平滑的两种方法:
- 方法#1: 通过使用自定义标签解析功能更新标签列表来平滑标签
- 方法#2: 使用 TensorFlow/Keras 中的损失函数进行标签平滑
您可以将标签平滑视为一种形式的正则化,它可以提高您的模型对测试数据进行概括的能力,但可能会以训练集的精度为代价—通常这种权衡是非常值得的。
在下列情况下,我通常会推荐标注平滑的方法#1:
- 你的整个数据集适合内存,你可以在一次函数调用中平滑所有标签。
- 你需要直接访问你的标签变量。
否则,方法#2 往往更容易使用,因为(1)它直接嵌入到 Keras/TensorFlow 中,并且(2)不需要任何手动实现的函数。
无论您选择哪种方法,它们都做同样的事情— 平滑您的标签,从而尝试提高您的模型的泛化能力。
我希望你喜欢这个教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
用 OpenCV 和 Python 标记超像素色彩
原文:https://pyimagesearch.com/2017/06/26/labeling-superpixel-colorfulness-opencv-python/
 在我们上一篇关于计算图像色彩度的帖子发表后,PyImageSearch 的读者 Stephan 在教程上留下了一条评论,询问是否有一种方法可以计算图像(而不是整个图像)的特定区域的色彩度。
在我们上一篇关于计算图像色彩度的帖子发表后,PyImageSearch 的读者 Stephan 在教程上留下了一条评论,询问是否有一种方法可以计算图像(而不是整个图像)的特定区域的色彩度。
解决这个问题有多种方法。第一种可能是应用一个滑动窗口在图像上循环,并计算每个 ROI 的色彩分数。如果需要在多个尺度上计算特定区域的色彩,甚至可以应用图像金字塔。
然而,更好的方法是使用超像素。通过分割算法提取超像素,该算法基于像素的局部颜色/纹理将像素分组为(非矩形)区域。在流行的 SLIC 超像素算法的情况下,基于 Lab*颜色空间中的本地版本的 k-means 聚类算法对图像区域进行分组。
鉴于超像素将为我们提供比滑动窗口更自然的输入图像分割,我们可以通过以下方式计算图像中特定区域的色彩:
- 对输入图像应用超像素分割。
- 分别在每个超像素上循环,并计算它们各自的色彩分数。
- 维护包含每个超像素的色彩分数的掩模。
基于这个遮罩,我们可以看到图像中最丰富多彩的区域。色彩丰富的图像区域将具有较大的色彩度量分数,而色彩不丰富的区域将具有较小的值。
要了解更多关于超像素和计算图像色彩的信息,请继续阅读。
用 OpenCV 和 Python 标记超像素色彩
在这篇博文的第一部分,我们将学习如何应用 SLIC 算法从输入图像中提取超像素。阿坎塔等人在 2010 年发表的原始文章【SLIC super pixels】详细介绍了该方法和技术。在这篇的博客文章中,我们还简要介绍了 SLIC 超像素,以方便那些想要更简洁地了解该算法的读者。
给定这些超像素,我们将逐个循环并计算它们的色彩分数,注意计算特定区域的色彩度量,而不是整个图像的色彩度量(正如我们在之前的帖子中所做的)。
在我们实现脚本之后,我们将把超像素+图像色彩的组合应用到一组输入图像上。
使用超像素进行分割
让我们从在您最喜欢的编辑器或 IDE 中打开一个新文件开始,将其命名为colorful_regions.py,并插入以下代码:
# import the necessary packages
from skimage.exposure import rescale_intensity
from skimage.segmentation import slic
from skimage.util import img_as_float
from skimage import io
import numpy as np
import argparse
import cv2
第一个行 1-8 处理我们的导入——如你所见,我们在本教程中大量使用了几个 scikit-image 函数。
slic函数将用于计算超像素(sci kit-图像文档)。
接下来,我们将定义我们的色彩度度量函数,从上一篇文章开始,我们对它做了一个小的修改:
def segment_colorfulness(image, mask):
# split the image into its respective RGB components, then mask
# each of the individual RGB channels so we can compute
# statistics only for the masked region
(B, G, R) = cv2.split(image.astype("float"))
R = np.ma.masked_array(R, mask=mask)
G = np.ma.masked_array(B, mask=mask)
B = np.ma.masked_array(B, mask=mask)
# compute rg = R - G
rg = np.absolute(R - G)
# compute yb = 0.5 * (R + G) - B
yb = np.absolute(0.5 * (R + G) - B)
# compute the mean and standard deviation of both `rg` and `yb`,
# then combine them
stdRoot = np.sqrt((rg.std() ** 2) + (yb.std() ** 2))
meanRoot = np.sqrt((rg.mean() ** 2) + (yb.mean() ** 2))
# derive the "colorfulness" metric and return it
return stdRoot + (0.3 * meanRoot)
第 10-31 行表示我们的色彩度量函数,该函数已经被适配成计算图像的特定区域的色彩。
该区域可以是任何形状,因为我们利用了 NumPy 掩码数组——只有掩码的像素部分将被包括在计算中。
对于特定image的指定mask区域,segment_colorfulness功能执行以下任务:
- 将图像分割成 RGB 分量通道(第 14 行)。
- 使用
mask(针对每个通道)屏蔽image,以便只在指定的区域进行着色——在这种情况下,该区域将是我们的超像素(第 15-17 行)。 - 使用
R和G组件计算rg( 第 20 行)。 - 使用 RGB 分量计算
yb( 行 23 )。 - 计算
rg和yb的平均值和标准偏差,同时合并它们(第 27 行和第 28 行)。 - 对指标进行最终计算,并将其返回( Line 31 )给调用函数。
既然已经定义了关键的 colorfulness 函数,下一步就是解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-s", "--segments", type=int, default=100,
help="# of superpixels")
args = vars(ap.parse_args())
在第 34-39 行中,我们利用argparse来定义两个参数:
--image:我们输入图像的路径。--segments:超像素数量。 SLIC 超像素论文展示了将图像分解成不同数量超像素的例子。这个参数很有意思(因为它控制着你生成的超像素的粒度水平);然而,我们将与一个default=100一起工作。该值越小,超像素越少越大,从而使算法运行得更快。段的数量越大,分段就越精细,但是 SLIC 将花费更长的时间来运行(由于需要计算更多的聚类)。
现在是时候将图像加载到内存中,为我们的可视化分配空间,并计算 SLIC 超像素分割:
# load the image in OpenCV format so we can draw on it later, then
# allocate memory for the superpixel colorfulness visualization
orig = cv2.imread(args["image"])
vis = np.zeros(orig.shape[:2], dtype="float")
# load the image and apply SLIC superpixel segmentation to it via
# scikit-image
image = io.imread(args["image"])
segments = slic(img_as_float(image), n_segments=args["segments"],
slic_zero=True)
在的第 43 行,我们将命令行参数--image作为orig (OpenCV 格式)加载到内存中。
按照这个步骤,我们为可视化图像vis分配与原始输入图像具有相同形状(宽度和高度)的内存。
接下来,我们将命令行参数--image作为image加载到内存中,这次是 scikit-image 格式。我们在这里使用 scikit-image 的io.imread的原因是因为 OpenCV 以 BGR 顺序加载图像,而不是 RGB 格式(scikit-image 就是这样)。假设我们的图像是 RGB 格式,在超像素生成过程中,slic函数会将我们的输入image转换到 Lab颜色空间。*
因此我们有两个选择:
- 用 OpenCV 加载图像,克隆它,然后交换通道的顺序。
- 只需使用 scikit-image 加载原始图像的副本。
这两种方法都是有效的,并且会产生相同的输出。
超像素是通过调用slic来计算的,其中我们指定了image、n_segments和slic_zero开关。指定slic_zero=True表明我们想要使用 SLIC 的零参数版本,这是对原始算法的扩展,不需要我们手动调整算法的参数。对于脚本的其余部分,我们将超像素称为segments。
现在让我们计算每个超像素的色彩:
# loop over each of the unique superpixels
for v in np.unique(segments):
# construct a mask for the segment so we can compute image
# statistics for *only* the masked region
mask = np.ones(image.shape[:2])
mask[segments == v] = 0
# compute the superpixel colorfulness, then update the
# visualization array
C = segment_colorfulness(orig, mask)
vis[segments == v] = C
我们从循环第 52 条线上的每一个segments开始。
线 56 和 57 负责为当前超像素构建一个mask。mask将与我们的输入图像具有相同的宽度和高度,并将(最初)填充一个 1 的数组(第 56 行)。
请记住,当使用 NumPy 掩码数组时,如果相应的mask值被设置为零(意味着像素未被掩码),则数组中的给定条目仅包含在计算中。如果mask中的值是一个,那么该值被假定为屏蔽并因此被忽略。
这里我们最初将所有像素设置为屏蔽,然后仅将当前超像素的像素部分设置为未屏蔽 ( 第 57 行)。
使用我们的orig图像和我们的mask作为segment_colorfulness的参数,我们可以计算C,这是超像素的色彩(线 61 )。
然后,我们用值C ( 行 62 )更新我们的可视化数组vis。
至此,我们已经回答了 PyImageSearch 读者 Stephan 的问题——我们已经计算了图像不同区域的色彩。
自然,我们希望看到我们的结果,所以让我们继续为输入图像中最/最不鲜艳的区域构建一个透明的叠加可视化:
# scale the visualization image from an unrestricted floating point
# to unsigned 8-bit integer array so we can use it with OpenCV and
# display it to our screen
vis = rescale_intensity(vis, out_range=(0, 255)).astype("uint8")
# overlay the superpixel colorfulness visualization on the original
# image
alpha = 0.6
overlay = np.dstack([vis] * 3)
output = orig.copy()
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
由于vis目前是浮点数组,所以有必要将其重新缩放为典型的 8 位无符号整数【0-255】数组。这很重要,这样我们就可以用 OpenCV 在屏幕上显示输出图像。我们通过使用行 67 上的rescale_intensity函数(来自skimage.exposure)来实现这一点。
现在我们将在原始图像上叠加超像素色彩可视化。我们已经讨论过透明叠加和cv2.addWeighted(以及相关参数),所以请参考这篇博文了解更多关于透明叠加是如何构建的细节。
最后,让我们在屏幕上显示图像,并结束这个脚本:
# show the output images
cv2.imshow("Input", orig)
cv2.imshow("Visualization", vis)
cv2.imshow("Output", output)
cv2.waitKey(0)
我们将使用cv2.imshow在屏幕上显示三幅图像,包括:
orig:我们的输入图像。vis:我们的可视化图像(即,每个超像素区域的色彩水平)。output:我们的输出图像。
超像素和色彩度量结果
让我们看看 Python 脚本的运行情况——打开一个终端,workon您的虚拟环境(如果您正在使用的话)(强烈推荐),并输入以下命令:
$ python colorful_regions.py --image images/example_01.jpg

Figure 1: Computing a region-based colorfulness score using superpixel segmentation.
在左边你可以看到原始输入图像,一张我自己探索羚羊峡谷的照片,可以说是美国最美丽的狭槽峡谷。在这里,我们可以看到由于从上方过滤进来的光线而产生的颜色混合。
在中间的中,我们对 100 个超像素中的每一个进行了计算可视化。该可视化中的深色区域指的是色彩较淡的区域,而浅色区域表示色彩较浓的。
在这里,我们可以看到最不鲜艳的区域在峡谷壁的周围,最靠近相机——这是光线最少的地方。
输入图像中色彩最丰富的区域是光线直接到达峡谷内部的地方,像烛光一样照亮了部分墙壁。
最后,在右侧我们的原始输入图像上覆盖了色彩可视化效果——该图像使我们能够更容易地识别图像中色彩最丰富/最不丰富的区域。
下面这张照片是我在波士顿的照片,站在标志性的 Citgo 标志前俯瞰肯莫尔广场:
$ python colorful_regions.py --image images/example_02.jpg
Figure 2: Using superpixels, we can first segment our image, and then compute a colorfulness score for each region.
在这里,我们可以看到图像中色彩最淡的区域位于底部,阴影遮挡了人行道的大部分。更丰富多彩的地区可以发现对标志和天空本身。
最后,这里有一张来自彩虹点的照片,彩虹点是布莱斯峡谷的最高海拔:
$ python colorful_regions.py --image images/example_03.jpg

Figure 3: Labeling individual superpixels in an image based on how “colorful” each region is.
请注意,我的黑色连帽衫和短裤是图像中最不鲜艳的区域,而照片中央的天空和树叶是最鲜艳的区域。
摘要
在今天的博文中,我们学习了如何使用 SLIC 分割算法来计算输入图像的超像素。
然后,我们访问每个单独的超像素,并应用我们的色彩度量。
每个区域的色彩分数被组合成一个遮罩,显示出输入图像的色彩最丰富的和色彩最不丰富的区域。
有了这种计算,我们能够以两种方式可视化每个区域的色彩:
- 通过检查原始的
vis面具。 - 创建一个透明的覆盖图,将
vis放在原始图像的上面。
在实践中,我们可以使用这种技术来设定蒙版的阈值,只提取最/最不鲜艳的区域。
为了在 PyImageSearch 上发布未来教程时得到通知,请务必在下表中输入您的电子邮件地址!
使用 Tesseract 和 Python 进行语言翻译和 OCR
原文:https://pyimagesearch.com/2021/09/20/language-translation-and-ocr-with-tesseract-and-python/
鉴于我们可以检测出文字的书写系统,这就提出了一个问题:
是否可以使用 OCR 和 Tesseract 将文本从一种语言翻译成另一种语言?
*要学习如何使用宇宙魔方和 Python 翻译语言, 继续阅读。
使用 Tesseract 和 Python 进行语言翻译和 OCR
简短的回答是是的,这是可能的——但是我们需要textblob库的一点帮助,这是一个流行的用于文本处理的 Python 包( TextBlob:简化的文本处理)。本教程结束时,您将自动将 OCR 文本从一种语言翻译成另一种语言。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
学习目标
在本教程中,您将:
- 了解如何使用
TextBlobPython 包翻译文本 - 实现一个 Python 脚本,对文本进行 ocr,然后进行翻译
- 查看文本翻译的结果
OCR 和语言翻译
在本教程的第一部分,我们将简要讨论textblob包以及如何用它来翻译文本。从那里,我们将回顾我们的项目目录结构,并实现我们的 OCR 和文本翻译 Python 脚本。我们将讨论我们的 OCR 和文本翻译结果来结束本教程。
用 TextBlob 将文本翻译成不同的语言
为了将文本从一种语言翻译成另一种语言,我们将使用textblob Python 包(https://textblob.readthedocs.io/en/dev/)。如果您遵循了早期教程中的开发环境配置说明,那么您应该已经在系统上安装了textblob。如果没有,可以用pip安装:
$ pip install textblob
一旦安装了textblob,您应该运行以下命令来下载textblob用来自动分析文本的自然语言工具包(NLTK)语料库:
$ python -m textblob.download_corpora
接下来,您应该通过打开 Python shell 来熟悉这个库:
$ python
>>> from textblob import TextBlob
>>>
注意我们是如何导入TextBlob类的——这个类使我们能够自动分析一段文本的标签、名词短语,是的,甚至是语言翻译。一旦实例化,我们可以调用TextBlob类的translate()方法并执行自动文本翻译。现在让我们使用TextBlob来做这件事:UTF8ipxm
>>> text = u"おはようございます。"
>>> tb = TextBlob(text)
>>> translated = tb.translate(to="en")
>>> print(translated)
Good morning.
>>>
请注意我是如何成功地将日语短语“早上好”翻译成英语的。
项目结构
让我们首先回顾一下本教程的项目目录结构:
|-- comic.png
|-- ocr_translate.py
我们的项目包括一个有趣的卡通形象,我用一个叫做 Explosm 的漫画工具制作的。我们基于textblob的 OCR 翻译器包含在ocr_translate.py脚本中。
实施我们的 OCR 和语言翻译脚本
我们现在准备实现我们的 Python 脚本,它将自动 OCR 文本并将其翻译成我们选择的语言。在我们的项目目录结构中打开ocr_translate.py,并插入下面的代码:
# import the necessary packages
from textblob import TextBlob
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-l", "--lang", type=str, default="es",
help="language to translate OCR'd text to (default is Spanish)")
args = vars(ap.parse_args())
我们从导入开始,其中TextBlob是这个脚本中最值得注意的。从那里,我们深入到我们的命令行参数解析过程。我们有两个命令行参数:
--image:要进行 OCR 识别和翻译的输入图像的路径--lang:将 OCR 文本翻译成的语言—默认情况下,是西班牙语(es)
使用pytesseract,我们将对输入图像进行 OCR:
# load the input image and convert it from BGR to RGB channel
# ordering
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# use Tesseract to OCR the image, then replace newline characters
# with a single space
text = pytesseract.image_to_string(rgb)
text = text.replace("\n", " ")
# show the original OCR'd text
print("ORIGINAL")
print("========")
print(text)
print("")
在加载并将我们的--image转换为 RGB 格式后(第 17 行和第 18 行),我们通过pytesseract ( 第 22 行)通过 Tesseract 引擎发送它。我们的textblob包不知道如何处理text中出现的换行符,所以我们用空格replace它们(第 23 行)。
在打印出我们最初的 OCR'd text之后,我们将继续进行将字符串翻译成我们想要的语言:
# translate the text to a different language
tb = TextBlob(text)
translated = tb.translate(to=args["lang"])
# show the translated text
print("TRANSLATED")
print("==========")
print(translated)
第 32 行构造一个TextBlob对象,将原来的text传递给构造函数。从那里,第 33 行将tb翻译成我们想要的--lang。最后,我们在终端中打印出translated结果(第 36-38 行)。
这就是全部了。请记住翻译引擎的复杂性。引擎盖下的TextBlob引擎类似于谷歌翻译之类的服务,尽管功能可能没那么强大。当谷歌翻译在 2000 年代中期问世时,它远没有今天这么完美和准确。有些人可能会认为谷歌翻译是黄金标准。根据您的 OCR 翻译需求,如果您发现textblob不适合您,您可以调用 Google Translate REST API。
OCR 语言翻译结果
我们现在准备用 Tesseract 对输入图像进行 OCR,然后用textblob翻译文本。为了测试我们的自动 OCR 和翻译脚本,打开一个终端并执行图 2 ( 右)所示的命令。在这里,我们的输入图像在左边的 T5 处,包含了英文感叹号,T7,“你告诉我学习 OCR 会很容易!”这张图片是使用 Explosm 漫画生成器生成的。正如我们的终端输出所示,我们成功地将文本翻译成了西班牙语、德语和阿拉伯语(一种从右向左的语言)。
一旦你使用了textblob包,文本的 OCR 识别和翻译就变得非常容易!
总结
在本教程中,您学习了如何使用 Tesseract、Python 和textblob库自动 OCR 和翻译文本。使用textblob,翻译文本就像调用一个函数一样简单。
在我们的下一个教程中,您将学习如何使用 Tesseract 来自动OCR 非英语语言,包括非拉丁语书写系统(例如,阿拉伯语、汉语等)。).
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
了解如何(通过智能手机)快速识别酒瓶。
原文:https://pyimagesearch.com/2015/02/10/learn-identify-wine-bottles-snap-smartphone/

我们正在接近 PyImageSearch 大师 Kickstarter — 的结尾,我们刚刚实现了我们的第二个目标!
这意味着我们将在 PyImageSearch 大师计算机视觉课程中学习所有关于手势识别的知识!
无论如何,在过去的几天里,我一直在拜访家人。令人惊讶的是,我多么想念一顿美味的家常饭——坐下来吃一顿家庭晚餐就是要有一些关心和爱。
当我和我的母亲在餐桌旁坐下时,我的父亲把手伸到我们的酒架上,拉下一瓶红酒,慢慢地打开瓶盖,倒了一点到我的杯子里品尝。
检查葡萄酒的时候,我把酒杯斜放在一边,这样我就可以对照我的白色餐巾检查颜色:桃花心木,略带砖色。
然后,我摇晃了几秒钟,给葡萄酒充气,让单宁变得醇厚,然后用鼻子深呼吸三次,再用嘴深呼吸一次
我只有一个词来形容这款酒:
辉煌。
就在我第一次品尝葡萄酒的时候,PyImageSearch 大师们的下一个目标给了我如此大的打击,以至于我差点像卡通人物一样把美味的葡萄酒吐到房间的另一边:
关于构建识别酒瓶的应用程序的完整操作指南和教程。

Figure 1: Learn how to use computer vision, image processing, and machine learning to automatically recognize wine labels.
比如你听说过 Vivino 葡萄酒扫描 app 吗?
基本上,它是一个移动应用程序,允许你拍一张酒瓶的照片,然后立即识别它,查看评级,甚至购买一瓶!
如果我们达到了第三阶段的目标,我们将在第一阶段(学习如何将计算机视觉融入移动应用)的基础上,构建我们自己版本的 Vivino。**
**在本指南的最后,你将拥有一个功能齐全的葡萄酒鉴定应用程序,你可以在闲暇时使用它——甚至可以提交到应用程序商店!
你觉得怎么样?
你想从前到后构建一个完整的移动计算机视觉应用吗?或许还能在应用商店赚几美元?
对我来说,这听起来是一项不错的投资——但我会让你来判断。
在 PyImageSearch 大师 Kickstarter 的大门关闭之前,还有不到 72 小时。而一旦大门关闭, 它们直到八月才会重新开放!
*如果您还没有参加课程(或者想要提升您的奖励,以便我们能够达到第三个延伸目标),请使用此链接:
再次感谢你们让这次活动如此成功。我非常感谢你和你的支持——我迫不及待地想在 PyImageSearch 大师课程中见到你!***
LeNet——Python 中的卷积神经网络
原文:https://pyimagesearch.com/2016/08/01/lenet-convolutional-neural-network-in-python/

在今天的博文中,我们将使用 Python 和 Keras 深度学习包来实现我们的第一个卷积神经网络(CNN)——LeNet——。
LeNet 架构由 LeCun 等人在其 1998 年的论文 中首次提出,基于梯度的学习应用于文档识别。顾名思义,作者实现的 LeNet 主要用于文档中的 OCR 和字符识别。
LeNet 架构简单和小(就内存占用而言),使其非常适合教授 CNN的基础知识——它甚至可以在 CPU 上运行(如果你的系统没有合适的 GPU),使其成为一个伟大的“第一 CNN”。
然而,如果你确实有 GPU 支持,并且可以通过 Keras 访问你的 GPU,你将享受到极快的训练时间(大约每历元 3-10 秒,取决于你的 GPU)。
在这篇文章的剩余部分,我将展示如何使用 Python 和 Keras 实现 LeNet 卷积神经网络架构。
在那里,我将向您展示如何在 MNIST 数据集上训练 LeNet 进行数字识别。
要了解如何训练你的第一个卷积神经网络,请继续阅读。
LeNet——Python 中的卷积神经网络
本教程将主要面向代码和,意在帮助你尝试深度学习和卷积神经网络。出于这个目的,我不会花太多时间讨论激活功能、池层或密集/全连接层——在未来的 PyImageSearch 博客上将会有大量的教程,将会详细介绍*每一种层类型/概念。*****
同样,本教程是你第一个端到端的例子,在这里你可以训练一个真实的 CNN(并看到它的运行)。我们将在这一系列文章的后面讨论激活函数、池层和全连接层的血淋淋的细节(尽管你应该已经知道卷积运算如何工作的基础知识);但与此同时,只要跟着学习,享受这堂课,并且学习如何用 Python 和 Keras 实现你的第一个卷积神经网络。
MNIST 数据集

Figure 1: MNIST digit recognition dataset.
你可能已经看过 MNIST 数据集了,无论是在 PyImageSearch 博客上,还是在你研究的其他地方。无论是哪种情况,我都会继续快速查看数据集,以确保您确切地知道我们正在处理什么数据。
*MNIST 数据集可以说是计算机视觉和机器学习文献中研究得最充分、理解得最透彻的数据集,这使它成为您在深度学习之旅中使用的优秀“第一个数据集”。
注意:正如我们将发现的,在这个数据集上用最少的训练时间,甚至在 CPU 上,获得> 98%的分类准确率也是相当容易的。
这个数据集的目标是对手写数字 0-9 进行分类。我们总共得到 70,000 张图片,其中(通常)60,000 张图片用于训练,10,000 张用于评估;但是,我们可以根据自己的需要自由分割这些数据。常见的拆分包括标准的 60,000/10,000、75%/25%和 66.6%/33.3%。在博文的后面,我将使用 2/3 的数据进行训练,1/3 的数据进行测试。
每个数字被表示为一个 28 x 28 灰度图像(来自 MNIST 数据集的例子可以在上图中看到)。这些灰度像素强度是无符号整数,像素值在【0,255】范围内。所有数字被放置在黑色背景上,其中浅色前景(即数字本身)为白色和各种灰色阴影。
值得注意的是,许多库(如 scikit-learn )都有内置的帮助器方法来下载 MNIST 数据集,将其缓存到本地磁盘,然后加载它。这些辅助方法通常将每个图像表示为一个 784-d 向量。
数字 784 从何而来?
简单。只不过是把 展平了28×28 = 784的图像。
为了从 784-d 向量中恢复我们的原始图像,我们简单地将数组整形为一个 28 x 28 图像。
在这篇博文的上下文中,我们的目标是训练 LeNet,使我们在测试集上最大化准确性。
LeNet 架构

Figure 2: The LeNet architecture consists of two sets of convolutional, activation, and pooling layers, followed by a fully-connected layer, activation, another fully-connected, and finally a softmax classifier
LeNet 架构是卷积神经网络的优秀“第一架构”(特别是在 MNIST 数据集(一种用于手写数字识别的图像数据集)上训练时)。
LeNet 很小,很容易理解——但也足够大,可以提供有趣的结果。此外,LeNet + MNIST 的组合能够在 CPU 上运行,这使得初学者可以轻松地迈出深度学习和卷积神经网络的第一步。
在许多方面,LeNet + MNIST 是图像分类深度学习的“你好,世界”。
LeNet 架构由以下几层组成:
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC => RELU => FC
我现在不解释每层卷积滤波器的数量、滤波器本身的大小以及全连接节点的数量,而是将这个讨论留到我们的博客文章的 “用 Python 和 Keras 实现 LeNet”部分,在那里源代码将作为解释的辅助。
同时,让我们看看我们的项目结构——我们将在未来的 PyImageSearch 博客文章中多次重用这个结构。
注:原 LeNet 架构使用TANH激活函数而非RELU。我们在这里使用RELU的原因是因为它有许多好的、令人满意的属性(我将在以后的博客文章中讨论这些属性),所以它往往会给出更好的分类精度。如果你在 LeNet 上遇到任何其他的讨论,你可能会看到他们用TANH来代替——同样,只是要记住一些事情。
我们的 CNN 项目结构
在我们深入任何代码之前,让我们首先回顾一下我们的项目结构:
|--- output
|--- pyimagesearch
| |--- __init__.py
| |--- cnn
| | |--- __init__.py
| | |--- networks
| | | |--- __init__.py
| | | |--- lenet.py
|--- lenet_mnist.py
为了保持我们的代码有条理,我们将定义一个名为pyimagesearch的包。在pyimagesearch模块中,我们将创建一个cnn子模块——这是我们存储卷积神经网络实现以及任何与 CNN 相关的辅助工具的地方。
看一看cnn内部,你会看到networks子模块:这是网络实现本身将被存储的地方。顾名思义,lenet.py文件将定义一个名为LeNet的类,这是我们在 Python + Keras 中实际的 LeNet 实现。
lenet_mnist.py脚本将是我们的驱动程序,用于实例化 LeNet 网络架构、训练模型(或加载模型,如果我们的网络是预训练的),然后在 MNIST 数据集上评估网络性能。
最后,output目录将在我们的LeNet模型被训练后存储它,允许我们在对lenet_mnist.py 的后续调用中对数字进行分类,而不必重新训练网络。
在过去的一年里,我个人一直在使用这种项目结构(或与之非常相似的项目结构)。我发现它组织良好,易于扩展——随着我们向这个库中添加更多的网络架构和助手功能,这一点将在未来的博客文章中变得更加明显。
用 Python 和 Keras 实现 LeNet
首先,我假设您的系统上已经安装了 Keras 、 scikit-learn 和 OpenCV (可选地,启用 GPU 支持)。如果您没有, 请参考这篇博文 来帮助您正确配置您的系统。
否则,打开lenet.py文件并插入以下代码:
# import the necessary packages
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras import backend as K
class LeNet:
@staticmethod
def build(numChannels, imgRows, imgCols, numClasses,
activation="relu", weightsPath=None):
# initialize the model
model = Sequential()
inputShape = (imgRows, imgCols, numChannels)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (numChannels, imgRows, imgCols)
第 2-8 行处理从keras库中导入所需的函数/类。
在第 10 行的上定义了LeNet类,然后在第 12 行的上定义了build方法。每当我定义一个新的网络架构时,我总是将它放在自己的类中(主要是为了命名空间和组织的目的),然后创建一个静态的 T2 函数。
顾名思义,build方法接受任何提供的参数,至少包括:
- 我们输入图像的宽度。
- 我们输入图像的高度。
- 我们输入图像的深度(即通道数)。
- 以及我们数据集中的类的数量(即类标签的唯一数量)。
我通常还会包含一个weightsPath,它可以用来加载一个预先训练好的模型。给定这些参数,build函数负责构建网络架构。
说到构建 LeNet 架构,第 15 行实例化了一个Sequential类,我们将用它来构建网络。
然后,我们处理第 16-20 行上的“通道最后”或“通道优先”张量。Tensorflow 默认为“通道最后”。
既然模型已经初始化,我们可以开始向它添加层:
# define the first set of CONV => ACTIVATION => POOL layers
model.add(Conv2D(20, 5, padding="same",
input_shape=inputShape))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
在第 23-26 行我们创建了第一组CONV => RELU => POOL图层组。
我们的CONV层将学习 20 个卷积滤波器,其中每个滤波器的大小为5×5。该值的输入尺寸与我们的输入图像具有相同的宽度、高度和深度,在本例中为 MNIST 数据集,因此我们将使用具有单通道深度(灰度)的 28 x 28 输入。
然后,我们将应用 ReLU 激活函数,然后在 x 和 y 两个方向上应用 2 x 2 max-pooling,步幅为 2(想象一个2x 2滑动窗口“滑过”激活体积,取每个区域的最大值操作,同时在水平和垂直方向上取 2 个像素的步长)。
注意: 本教程主要是基于代码的,旨在让您第一次接触实现卷积神经网络——在以后的博客文章中,我将深入更多关于卷积层、激活函数和最大池层的细节。与此同时,只需尝试遵循代码即可。
我们现在准备应用我们的第二套CONV => RELU => POOL层:
# define the second set of CONV => ACTIVATION => POOL layers
model.add(Conv2D(50, 5, padding="same"))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
这一次我们将学习 50 个卷积滤波器,而不是像前一层设置中的 20 个卷积滤波器。
常见的是,在网络的更深层,学习到的CONV过滤器的数量增加。
接下来,我们来看 LeNet 架构的全连接层(通常称为“密集”层):
# define the first FC => ACTIVATION layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation(activation))
# define the second FC layer
model.add(Dense(numClasses))
# lastly, define the soft-max classifier
model.add(Activation("softmax"))
在第 34 行的上,我们取前面MaxPooling2D层的输出,将展平成一个向量,允许我们应用密集/完全连接的层。如果您以前有过神经网络方面的经验,那么您会知道密集/全连接层是网络中的“标准”类型层,其中前一层中的每个节点都连接到下一层中的每个节点(因此有了术语“全连接”)。
我们的全连接层将包含 500 个单元( Line 35 ),我们通过另一个非线性 ReLU 激活。
第 39 行是非常重要的,虽然它很容易被忽略——这一行定义了另一个Dense类,但是接受一个可变的(即非硬编码的)大小。这个大小是由变量classes表示的类标签 的数量。在 MNIST 数据集的情况下,我们有 10 个类(我们试图学习识别的 10 个数字中的每一个都有一个类)。
最后,我们应用一个 softmax 分类器(多项式逻辑回归),它将返回一个概率列表(T0),10 个类别标签中的每一个都有一个(第 42 行)。具有最大概率的类别标签将被选择作为来自网络的最终分类。
我们的最后一个代码块处理加载一个预先存在的weightsPath(如果这样的文件存在)并将构建的模型返回给调用函数:
# if a weights path is supplied (inicating that the model was
# pre-trained), then load the weights
if weightsPath is not None:
model.load_weights(weightsPath)
# return the constructed network architecture
return model
创建 LeNet 驱动程序脚本
现在我们已经使用 Python + Keras 实现了 LeNet 卷积神经网络架构,是时候定义lenet_mnist.py驱动程序脚本了,它将处理:
- 加载 MNIST 数据集。
- 将 MNIST 划分为训练和测试两部分。
- 加载和编译 LeNet 架构。
- 训练网络。
- 可选地将序列化的网络权重保存到磁盘,以便可以重复使用(无需重新训练网络)。
- 显示网络输出的可视示例,以证明我们的实现确实工作正常。
打开您的lenet_mnist.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch.cnn.networks.lenet import LeNet
from sklearn.model_selection import train_test_split
from keras.datasets import mnist
from keras.optimizers import SGD
from keras.utils import np_utils
from keras import backend as K
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--save-model", type=int, default=-1,
help="(optional) whether or not model should be saved to disk")
ap.add_argument("-l", "--load-model", type=int, default=-1,
help="(optional) whether or not pre-trained model should be loaded")
ap.add_argument("-w", "--weights", type=str,
help="(optional) path to weights file")
args = vars(ap.parse_args())
第 2-10 行处理导入我们需要的 Python 包。注意我们是如何从cnn和pyimagesearch的networks子模块中导入我们的LeNet类的。
注意: 如果你正在关注这篇博文并打算执行代码, 请 使用本文底部的“下载”部分。为了保持这篇文章的简洁,我省略了__init__.py更新,这些更新可能会让新的 Python 开发者感到困惑。
从那里,行 13-20 解析三个可选的命令行参数,下面详细介绍了每个参数:
--save-model:一个指示变量,用于指定在训练 LeNet 之后,我们是否应该保存我们的模型到磁盘。--load-model:另一个指示变量,这次指定我们是否应该从磁盘中加载一个预先训练好的模型。--weights:在提供了--save-model的情况下,--weights-path应该指向我们要保存序列化模型的地方。在提供了--load-model的情况下,--weights应该指向预先存在的权重文件在我们系统中的位置。
我们现在准备加载 MNIST 数据集,并将其划分为训练和测试部分:
# grab the MNIST dataset (if this is your first time running this
# script, the download may take a minute -- the 55MB MNIST dataset
# will be downloaded)
print("[INFO] downloading MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# if we are using "channels first" ordering, then reshape the
# design matrix such that the matrix is:
# num_samples x depth x rows x columns
if K.image_data_format() == "channels_first":
trainData = trainData.reshape((trainData.shape[0], 1, 28, 28))
testData = testData.reshape((testData.shape[0], 1, 28, 28))
# otherwise, we are using "channels last" ordering, so the design
# matrix shape should be: num_samples x rows x columns x depth
else:
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
第 26 行从磁盘加载 MNIST 数据集。如果这是您第一次使用"MNIST Original"字符串调用fetch_mldata函数,那么需要下载 MNIST 数据集。MNIST 数据集是一个 55MB 的文件,因此根据您的互联网连接,下载可能需要几秒到几分钟的时间。
第 31-39 行处理“通道优先”或“通道最后”实施的整形数据。例如,TensorFlow 支持“通道最后”排序。
最后,行 42-43 执行训练和测试分割,使用 2/3 的数据进行训练,剩余的 1/3 用于测试。我们还将图像从范围【0,255】缩小到【0,1.0】,这是一种常见的缩放技术。
下一步是处理我们的标签,以便它们可以用于分类交叉熵损失函数:
# transform the training and testing labels into vectors in the
# range [0, classes] -- this generates a vector for each label,
# where the index of the label is set to `1` and all other entries
# to `0`; in the case of MNIST, there are 10 class labels
trainLabels = np_utils.to_categorical(trainLabels, 10)
testLabels = np_utils.to_categorical(testLabels, 10)
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(numChannels=1, imgRows=28, imgCols=28,
numClasses=10,
weightsPath=args["weights"] if args["load_model"] > 0 else None)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
第 49 行和第 50 行处理我们的训练和测试标签(即,MNIST 数据集中每幅图像的“地面真相”标签)。
由于我们正在使用分类交叉熵损失函数,我们需要应用to_categorical函数,将我们的标签从整数转换为向量,其中每个向量的范围从[0, classes]开始。该函数为的每个类标签生成一个向量,其中正确标签的索引被设置为 1 ,所有其他条目被设置为 0。
在 MNIST 数据集的情况下,我们有 10 个类标签,因此每个标签现在被表示为一个 10-d 向量。例如,考虑培训标签“3”。在应用了to_categorical函数后,我们的向量现在看起来像这样:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
注意向量中的所有条目都是零,除了现在被设置为 1 的第三个索引的。
我们将使用随机梯度下降(SGD) 来训练我们的网络,学习速率为0.01 ( 第 54 行)。分类交叉熵将用作我们的损失函数,这是处理具有两个以上类别标签的数据集时的一个相当标准的选择。然后我们的模型被编译并加载到内存的第 55-59 行上。
我们现在准备好构建我们的LeNet架构,可选地从磁盘加载任何预训练的权重,然后训练我们的网络:
# only train and evaluate the model if we *are not* loading a
# pre-existing model
if args["load_model"] < 0:
print("[INFO] training...")
model.fit(trainData, trainLabels, batch_size=128, epochs=20,
verbose=1)
# show the accuracy on the testing set
print("[INFO] evaluating...")
(loss, accuracy) = model.evaluate(testData, testLabels,
batch_size=128, verbose=1)
print("[INFO] accuracy: {:.2f}%".format(accuracy * 100))
在--load-model 没有供给的情况下,我们需要训练我们的网络(63 线)。
训练我们的网络是通过调用实例化的model ( 第 65 和 66 行)的.fit方法来完成的。我们将允许我们的网络训练 20 个时期(表示我们的网络将“看到”每个训练示例总共 20 次,以学习每个数字类别的区分过滤器)。
然后,我们根据测试数据(第 70-72 行)评估我们的网络,并将结果显示到我们的终端上。
接下来,我们检查是否应该将网络权重序列化到文件中,这样我们就可以运行lenet_mnist.py脚本后续的,而不必从头开始重新训练网络:
# check to see if the model should be saved to file
if args["save_model"] > 0:
print("[INFO] dumping weights to file...")
model.save_weights(args["weights"], overwrite=True)
我们的最后一个代码块处理从我们的测试集中随机选择几个数字,然后将它们通过我们训练过的 LeNet 网络进行分类:
# randomly select a few testing digits
for i in np.random.choice(np.arange(0, len(testLabels)), size=(10,)):
# classify the digit
probs = model.predict(testData[np.newaxis, i])
prediction = probs.argmax(axis=1)
# extract the image from the testData if using "channels_first"
# ordering
if K.image_data_format() == "channels_first":
image = (testData[i][0] * 255).astype("uint8")
# otherwise we are using "channels_last" ordering
else:
image = (testData[i] * 255).astype("uint8")
# merge the channels into one image
image = cv2.merge([image] * 3)
# resize the image from a 28 x 28 image to a 96 x 96 image so we
# can better see it
image = cv2.resize(image, (96, 96), interpolation=cv2.INTER_LINEAR)
# show the image and prediction
cv2.putText(image, str(prediction[0]), (5, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2)
print("[INFO] Predicted: {}, Actual: {}".format(prediction[0],
np.argmax(testLabels[i])))
cv2.imshow("Digit", image)
cv2.waitKey(0)
对于每个随机选择的数字,我们使用 LeNet 模型对图像进行分类(第 82 行)。
我们网络的实际prediction是通过寻找最大概率 的类标签的索引得到的。记住,我们的网络将通过 softmax 函数返回一组概率,每个类别标签一个——因此网络的实际“预测”是具有最大概率的类别标签。
第 87-103 行处理将 28 x 28 图像调整到 96 x 96 像素,这样我们可以更好地可视化它,然后在image上绘制prediction。
最后,行 104-107 将结果显示到我们的屏幕上。
用 Python 和 Keras 训练 LeNet
为了在 MNIST 数据集上训练 LeNet,请确保您已经使用本教程底部的 【下载】 表单下载了源代码。这个.zip文件包含了我在本教程中详述的所有代码——此外,这些代码被组织在我在上面详述的相同的项目结构中,其中确保将在您的系统上正确运行(假设您已经正确配置了您的环境)。
下载完.zip代码档案后,您可以通过执行以下命令在 MNIST 上训练 LeNet:
$ python lenet_mnist.py --save-model 1 --weights output/lenet_weights.hdf5
我在下面包括了我的机器的输出:
Figure 3: Training LeNet on the MNIST dataset on my Titan X takes approximately 3 seconds per epoch. After 20 epochs, LeNet is reaching 98.90% classification accuracy on the training data and 98.49% accuracy on the testing data.
在我的 Titan X GPU 上,每个历元大约需要 3 秒钟,允许整个训练过程在大约 60 秒内完成。
仅经过 20 个历元,LeNet 在 MNIST 数据集— 上的分类准确率就达到了98.49%【一点也不差,计算时间仅 60 秒!
**注: 如果你在我们的 CPU 而不是 GPU 上执行lenet_mnist.py脚本,预计每历元时间会跳到 70-90 秒。仍然有可能在你的 CPU 上训练 LeNet,只是需要多花一点时间。
使用 Python 和 Keras 评估 LeNet
下面,我提供了一些来自我们 LeNet + MNIST 实施的示例评估图片:

Figure 4: Applying LeNet to classify a digit from the MNIST dataset.
在上图中,我们能够正确地将数字分类为“6”。
在这张图片中,LeNet 正确地将数字识别为“2”:

Figure 5: Implementing LeNet in Python and Keras.
下图是一个很好的例子,说明了 CNN 过滤器学习卷积过滤器的强大、辨别性质:这个 "6" 非常扭曲,在数字的圆形区域之间几乎没有间隙,但 LeNet 仍然能够正确地对数字进行分类:

Figure 6: Correctly classifying a particularly hard to read digit with LeNet and Convolutional Neural Networks.
这是另一张图片,这次对严重倾斜的 "1" 进行分类:

Figure 7: Even skewed digits are correctly classified using Convolutional Neural Networks.
最后,最后一个例子展示了 LeNet 模型对一个“2”的分类:

Figure 8: A final example of classifying digits using LeNet and Deep Learning.
运行序列化的 LeNet 模型
在我们的lenet_mnist.py脚本完成第一次执行后(假设您提供了--save-model和--weights,您现在应该在您的output目录中有一个lenet_weights.hdf5文件。
我们可以加载这些权重,并使用它们来对数字进行分类,而不是在后续的lenet_mnist.py运行中重新训练我们的网络。
要加载我们预先训练的 LeNet 模型,只需执行以下命令:
$ python lenet_mnist.py --load-model 1 --weights output/lenet_weights.hdf5
我在下面添加了一个 LeNet 的 GIF 动画,用于正确分类手写数字:

Figure 9: An example animation of LeNet correctly classifying digits.
摘要
在今天的博客文章中,我展示了如何使用 Python 编程语言和 Keras 库实现 LeNet 架构以进行深度学习。
LeNet 架构是一个很棒的“你好,世界”网络,可以让你接触深度学习和卷积神经网络。网络本身很简单,占用的内存很少,当应用于 MNIST 数据集时,可以在 CPU 或 GPU 上运行,这使它成为实验和学习的理想选择,尤其是如果你是深度学习的新手。
本教程主要关注代码,正因为如此,我需要跳过对重要的卷积神经网络概念的详细回顾,例如激活层、池层和密集/全连接层(否则这篇文章可能会很容易长 5 倍)。
*在未来的博客文章中,我将详细回顾这些层类型的每一个层类型——同时,简单地熟悉代码并尝试自己执行它。如果你觉得真的很大胆,试着调整每个卷积层的滤波器数量和滤波器尺寸,看看会发生什么!
无论如何,我希望你喜欢这篇博文——我将来肯定会做更多关于深度学习和图像分类的帖子。
但是在你离开之前,请务必在下面的表格中输入你的电子邮件地址,以便在未来 PyImageSearch 博客文章发表时得到通知——你不想错过它们!******
LeNet:识别手写数字
原文:https://pyimagesearch.com/2021/05/22/lenet-recognizing-handwritten-digits/
LeNet 架构是深度学习社区中的一项开创性工作,由 LeCun 等人在其 1998 年的论文基于梯度的学习应用于文档识别 中首次介绍。正如论文名所示,作者实现 LeNet 的动机主要是为了光学字符识别(OCR)。
LeNet 架构简单和小(就内存占用而言),使其成为教授 CNN 基础知识的完美。
在本教程中,我们将试图重复类似于 LeCun 在 1998 年论文中的实验。我们将从回顾 LeNet 架构开始,然后使用 Keras 实现网络。最后,我们将在 MNIST 数据集上评估 LeNet 的手写数字识别性能。
要了解更多 LeNet 架构, 继续阅读。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
LeNet 架构
LeNet 架构(图 2 )是第一个优秀的“真实世界”网络。这个网络很小,很容易理解——但是足够大,可以提供有趣的结果。
此外,LeNet + MNIST 的组合能够轻松地在 CPU 上运行,使初学者能够轻松地迈出深度学习和 CNN 的第一步。在许多方面,LeNet + MNIST 是应用于图像分类的深度学习的“你好,世界”。LeNet 架构由以下层组成,使用来自 卷积神经网络(CNN)的CONV => ACT => POOL模式和 层类型:
INPUT => CONV => TANH => POOL => CONV => TANH => POOL =>
FC => TANH => FC
注意 LeNet 架构如何使用 tanh 激活函数,而不是更流行的 ReLU 。早在 1998 年,ReLU 还没有在深度学习的背景下使用——更常见的是使用 tanh 或 sigmoid 作为激活函数。当今天实现 LeNet 时,用RELU替换TANH是很常见的。
表 1 总结了 LeNet 架构的参数。我们的输入层采用 28 行、28 列的输入图像,深度(即 MNIST 数据集中图像的尺寸)采用单通道(灰度)。然后我们学习 20 个滤镜,每个滤镜都是 5 × 5。CONV层之后是 ReLU 激活,然后是最大池,大小为 2 × 2,步幅为 2 × 2。
该架构的下一个模块遵循相同的模式,这次学习 50 个 5×5过滤器。随着实际空间输入维度减少,通常会看到网络更深层的CONV层的数量增加。
然后我们有两个FC层。第一个FC包含 500 个隐藏节点,随后是一个 ReLU 激活。最后的FC层控制输出类标签的数量(0-9;一个用于可能的十个数字中的每一个)。最后,我们应用 softmax 激活来获得类别概率。
实现 LeNet
给定表 1 ,我们现在准备使用 Keras 库实现开创性的 LeNet 架构。首先在pyimagesearch.nn.conv子模块中添加一个名为lenet.py的新文件——这个文件将存储我们实际的 LeNet 实现:
--- pyimagesearch
| |--- __init__.py
| |--- nn
| | |--- __init__.py
...
| | |--- conv
| | | |--- __init__.py
| | | |--- lenet.py
| | | |--- shallownet.py
从那里,打开lenet.py,我们可以开始编码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
第 2-8 行处理导入我们需要的 Python 包。这些导入与之前的教程中的 ShallowNet 实现完全相同,并且在使用 Keras 构建(几乎)任何 CNN 时,形成了必需导入的基本集合。
然后我们定义下面LeNet的build方法,用于实际构建网络架构:
class LeNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model
model = Sequential()
inputShape = (height, width, depth)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
构建方法需要四个参数:
- 输入图像的宽度。
- 输入图像的高度。
- 图像的通道数(深度)。
- 分类任务中的编号类别标签。
在行 14 上初始化Sequential类,顺序网络的构建块一层接一层地顺序堆叠。然后我们初始化inputShape,就像使用“信道最后”排序一样。在我们的 Keras 配置被设置为使用“通道优先”排序的情况下,我们更新第 18 行和第 19 行上的inputShape。
第一组CONV => RELU => POOL层定义如下:
# first set of CONV => RELU => POOL layers
model.add(Conv2D(20, (5, 5), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
我们的CONV层将学习 20 个过滤器,每个大小为 5 × 5。然后,我们应用一个 ReLU 激活函数,之后是一个 2 × 2 池,步长为 2 × 2,从而将输入卷大小减少了 75%。
然后应用另一组CONV => RELU => POOL层,这次学习 50 个过滤器而不是 20 个:
# second set of CONV => RELU => POOL layers
model.add(Conv2D(50, (5, 5), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
然后可以展平输入体积,并且可以应用具有 500 个节点的完全连接的层:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation("relu"))
接着是最终的 softmax 分类器:
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
现在我们已经编写了 LeNet 架构,我们可以继续将其应用于 MNIST 数据集。
MNIST 的莱内特
我们的下一步是创建一个驱动程序脚本,它负责:
- 从磁盘加载 MNIST 数据集。
- 实例化 LeNet 架构。
- 培训 LeNet。
- 评估网络性能。
为了在 MNIST 上训练和评估 LeNet,创建一个名为lenet_mnist.py的新文件,我们可以开始了:
# import the necessary packages
from pyimagesearch.nn.conv import LeNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import mnist
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
此时,我们的 Python 导入应该开始感觉非常标准,出现了一个明显的模式。在绝大多数机器学习的情况下,我们必须导入:
- 一个我们要训练的网络架构。
- 一个优化器来训练网络(在这种情况下,SGD)。
- 一组便利函数,用于构造给定数据集的训练和测试拆分。
- 计算分类报告的功能,这样我们就可以评估我们的分类器的性能。
同样,几乎所有的例子都将遵循这种导入模式,除此之外还有一些额外的类来帮助完成某些任务(比如预处理图像)。MNIST 数据集已经过预处理,因此我们可以通过以下函数调用进行加载:
# grab the MNIST dataset (if this is your first time using this
# dataset then the 11MB download may take a minute)
print("[INFO] accessing MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
第 14 行从磁盘加载 MNIST 数据集。如果这是您第一次调用mnist.load_data()函数,那么需要从 Keras 数据集存储库中下载 MNIST 数据集。MNIST 数据集被序列化为一个 11MB 的文件,因此根据您的互联网连接,下载可能需要几秒到几分钟的时间。
需要注意的是,data中的每个 MNIST 样本都由一个 28×28灰度图像的 784-d 矢量(即原始像素亮度)表示。因此,我们需要根据我们使用的是“信道优先”还是“信道最后”排序来重塑data矩阵:
# if we are using "channels first" ordering, then reshape the
# design matrix such that the matrix is:
# num_samples x depth x rows x columns
if K.image_data_format() == "channels_first":
trainData = trainData.reshape((trainData.shape[0], 1, 28, 28))
testData = testData.reshape((testData.shape[0], 1, 28, 28))
# otherwise, we are using "channels last" ordering, so the design
# matrix shape should be: num_samples x rows x columns x depth
else:
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
如果我们正在执行“通道优先”排序(第 20 行和第 21 行),那么data矩阵被重新整形,使得样本数是矩阵中的第一个条目,单个通道是第二个条目,随后是行数和列数(分别为 28 和 28)。否则,我们假设我们使用“信道最后”排序,在这种情况下,矩阵首先被重新整形为样本数、行数、列数,最后是信道数(第 26 和 27 行)。
既然我们的数据矩阵已经成形,我们可以将图像像素强度调整到范围[0, 1]:
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
# convert the labels from integers to vectors
le = LabelBinarizer()
trainLabels = le.fit_transform(trainLabels)
testLabels = le.transform(testLabels)
我们还将我们的类标签编码为一个热点向量,而不是单个整数值。例如,如果给定样本的类别标签是3,那么对标签进行一键编码的输出将是:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
注意向量中的所有条目都是零,除了第四个索引的现在被设置为 1(记住数字0是第一个索引,因此为什么第三个是第四个索引)。现在的舞台是在 MNIST 训练 LeNet:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainData, trainLabels,
validation_data=(testData, testLabels), batch_size=128,
epochs=20, verbose=1)
第 40 行用学习率0.01初始化我们的SGD优化器。LeNet本身在第 41 行被实例化,表明我们数据集中的所有输入图像都将是28像素宽,28像素高,深度为1。假设 MNIST 数据集中有 10 个类(每个数字对应一个类,0-9),我们设置classes=10。
第 42 行和第 43 行使用交叉熵损失作为我们的损失函数来编译模型。47-49 线使用128的小批量在 MNIST 训练 LeNet 总共20个时期。
最后,我们可以评估我们网络的性能,并在下面的最终代码块中绘制损耗和精度随时间的变化图:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testData, batch_size=128)
print(classification_report(testLabels.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in le.classes_]))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 20), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 20), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 20), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 20), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
我之前在一个 的前一课 中提到过这个事实,当评估 ShallowNet 时,但是要确保你理解当model.predict被调用时 Line 53 在做什么。对于testX中的每个样本,构建 128 个批量,然后通过网络进行分类。在所有测试数据点被分类后,返回predictions变量。
predictions变量实际上是一个形状为(len(testX), 10)的 NumPy 数组,表示我们现在有 10 个概率与testX中每个数据点的每个类标签相关联。取第 54-56 行的classification_report中的predictions.argmax(axis=1),找到概率最大的标签的索引(即最终输出分类)。给定来自网络的最终分类,我们可以将我们的预测类别标签与基础事实标签进行比较。
要执行我们的脚本,只需发出以下命令:
$ python lenet_mnist.py
然后,应该从磁盘下载和/或加载 MNIST 数据集,并开始训练:
[INFO] accessing MNIST...
[INFO] compiling model...
[INFO] training network...
Train on 52500 samples, validate on 17500 samples
Epoch 1/20
3s - loss: 1.0970 - acc: 0.6976 - val_loss: 0.5348 - val_acc: 0.8228
...
Epoch 20/20
3s - loss: 0.0411 - acc: 0.9877 - val_loss: 0.0576 - val_acc: 0.9837
[INFO] evaluating network...
precision recall f1-score support
0 0.99 0.99 0.99 1677
1 0.99 0.99 0.99 1935
2 0.99 0.98 0.99 1767
3 0.99 0.97 0.98 1766
4 1.00 0.98 0.99 1691
5 0.99 0.98 0.98 1653
6 0.99 0.99 0.99 1754
7 0.98 0.99 0.99 1846
8 0.94 0.99 0.97 1702
9 0.98 0.98 0.98 1709
avg / total 0.98 0.98 0.98 17500
使用我的 Titan X GPU,我获得了三秒的时间。使用仅仅CPU,每个纪元的秒数跃升至 30 秒。训练完成后,我们可以看到 LeNet 获得了 98% 的分类精度,比使用标准前馈神经网络时的92%有了巨大的提高。
此外,在图 3 的中查看我们的损耗和精度随时间的变化曲线,可以看出我们的网络表现良好。仅仅过了五个纪元,已经达到了 ≈ 96%的分类准确率。由于我们的学习率保持不变且不衰减,训练和验证数据的损失继续下降,只有少数轻微的“峰值”。在第二十个纪元结束时,我们的测试集达到了 98%的准确率。
这张展示 MNIST LeNet 的损失和准确性的图可以说是我们正在寻找的典型的图:训练和验证损失和准确性(几乎)完全相互模拟,没有过度拟合的迹象。正如我们将看到的,通常很难获得这种表现如此良好的训练图,这表明我们的网络正在学习底层模式而没有过度拟合。
还有一个问题是,MNIST 数据集经过了大量预处理,不能代表我们在现实世界中会遇到的图像分类问题。研究人员倾向于使用 MNIST 数据集作为基准来评估新的分类算法。如果他们的方法不能获得 > 95%的分类准确率,那么要么是(1)算法的逻辑有缺陷,要么是(2)实现本身有缺陷。
尽管如此,将 LeNet 应用于 MNIST 是一种很好的方式,可以让你首次尝试将深度学习应用于图像分类问题,并模仿 LeCun 等人论文的结果。
总结
在本教程中,我们探索了 LeNet 架构,该架构由 LeCun 等人在其 1998 年的论文基于梯度的学习应用于文档识别 中介绍。LeNet 是深度学习文献中的一项开创性工作——它彻底展示了如何训练神经网络以端到端的方式识别图像中的对象(即,不需要进行特征提取,网络能够从图像本身学习模式)。
尽管 LeNet 具有开创性,但以今天的标准来看,它仍被认为是一个“肤浅”的网络。只有四个可训练层(两个CONV层和两个FC层),LeNet 的深度与当前最先进的架构如 VGG (16 和 19 层)和 ResNet (100+层)的深度相比相形见绌。
在我们的下一个教程 中,我们将讨论 VGGNet 架构的一个变种,我称之为“迷你 VGGNet”这种架构的变体使用了与 Simonyan 和 Zisserman 的工作完全相同的指导原则,但降低了深度,允许我们在更小的数据集上训练网络。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 OpenCV 和 ImageZMQ 通过网络进行实时视频流传输
原文:https://pyimagesearch.com/2019/04/15/live-video-streaming-over-network-with-opencv-and-imagezmq/

在今天的教程中,您将学习如何使用 OpenCV 通过网络传输实时视频。具体来说,您将学习如何实现 Python + OpenCV 脚本来从摄像机捕获视频帧并将其传输到服务器。
大约每周,我都会收到一篇博客帖子的评论或电子邮件中的一个问题,大概是这样的:
你好,Adrian,我正在做一个项目,我需要使用 OpenCV 将帧从客户端摄像头传输到服务器进行处理。我应该使用 IP 摄像头吗?树莓派有用吗?RTSP 流媒体怎么样?你试过用 FFMPEG 或者 GStreamer 吗?你建议我如何处理这个问题?
这是一个很好的问题——如果你曾经尝试过用 OpenCV 进行视频直播,你就会知道有很多不同的选择。
你可以走 IP 摄像头路线。但 IP 摄像头可能是一个痛苦的工作。一些 IP 摄像机甚至不允许你访问 RTSP(实时流协议)流。其他 IP 摄像头根本无法与 OpenCV 的cv2.VideoCapture功能配合使用。IP 相机可能太贵了,超出了你的预算。
在这些情况下,你只能使用标准的网络摄像头— 问题就变成了, 你如何使用 OpenCV 从网络摄像头传输帧?
使用 FFMPEG 或 GStreamer 绝对是一个选择。但是这两者都是工作中的痛苦。
今天我将向大家展示我的首选解决方案,使用消息传递库,具体来说就是 ZMQ 和 ImageZMQ,后者是由 PyImageConf 2018 演讲者 Jeff Bass 开发的。Jeff 为 ImageZMQ 投入了大量的工作,他的努力确实得到了体现。
正如你将看到的,OpenCV 视频流的这种方法不仅可靠而且非常容易使用,只需要几行代码。
要了解如何使用 OpenCV 执行实时网络视频流,请继续阅读!
使用 OpenCV 和 ImageZMQ 通过网络进行实时视频流传输
https://www.youtube.com/embed/tvzWNh094V0?feature=oembed
用 OpenCV 进行活性检测
原文:https://pyimagesearch.com/2019/03/11/liveness-detection-with-opencv/

在本教程中,您将学习如何使用 OpenCV 执行活性检测。您将创建一个能够在人脸识别系统中识别假脸并执行反人脸欺骗的活体检测器。
在过去的一年里,我创作了许多人脸识别教程,包括:
然而,我在电子邮件和面部识别帖子的评论部分被问到的一个常见问题是:
我如何辨别真实的和假的面孔?
想想如果一个邪恶的用户试图故意绕过你的面部识别系统会发生什么。
这样的用户可以尝试拿起另一个人的照片。也许他们甚至在他们的智能手机上有一张照片或视频,他们可以举到负责执行面部识别的相机(比如在这篇文章顶部的图片中)。
在这种情况下,面对摄像头的人脸完全有可能被正确识别…但最终会导致未经授权的用户绕过您的人脸识别系统!
你将如何辨别这些“假”和“真/合法”的面孔?如何将反面部欺骗算法应用到面部识别应用程序中?
答案是将 活性检测 应用于 OpenCV,这正是我今天要讨论的内容。
要了解如何将 OpenCV 的活性检测融入您自己的人脸识别系统,请继续阅读!
用 OpenCV 进行活性检测
2020-06-11 更新:此博文现已兼容 TensorFlow 2+!
https://www.youtube.com/embed/MPedzm6uOMA?feature=oembed
从磁盘加载经过训练的 Keras/TensorFlow 模型
原文:https://pyimagesearch.com/2021/05/22/load-a-trained-keras-tensorflow-model-from-disk/
既然我们已经训练了模型并序列化了它,我们需要从磁盘加载它。作为模型序列化的一个实际应用,我将演示如何对动物数据集中的张图片进行分类,然后将分类后的图片显示在屏幕上。
要了解如何从磁盘加载经过训练的 Keras/TensFlow 模型,继续阅读。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
从磁盘加载经过训练的 Keras/TensorFlow 模型
打开一个新的文件,命名为shallownet_load.py,我们来动手做:
# import the necessary packages
from pyimagesearch.preprocessing import ImageToArrayPreprocessor
from pyimagesearch.preprocessing import SimplePreprocessor
from pyimagesearch.datasets import SimpleDatasetLoader
from tensorflow.keras.models import load_model
from imutils import paths
import numpy as np
import argparse
import cv2
我们从导入所需的 Python 包开始。第 2-4 行导入用于构建我们的标准管道的类,该管道将图像的大小调整为固定大小,将其转换为 Keras 兼容的数组,然后使用这些预处理程序将整个图像数据集加载到内存中。
用于从磁盘加载我们训练好的模型的实际函数是第 5 行的上的load_model。该函数负责接受到我们训练好的网络(HDF5 文件)的路径,解码 HDF5 文件内的权重和优化器,并在我们的架构内设置权重,以便我们可以(1)继续训练或(2)使用网络对新图像进行分类。
我们还将在第 9 行导入 OpenCV 绑定,这样我们就可以在图像上绘制分类标签,并将它们显示在屏幕上。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to pre-trained model")
args = vars(ap.parse_args())
# initialize the class labels
classLabels = ["cat", "dog", "panda"]
就像在shallownet_save.py中一样,我们需要两个命令行参数:
--dataset:包含我们想要分类的图像的目录的路径(在这个例子中,是动物数据集)。--model:磁盘上序列化的训练好的网络的路径。
然后,第 20 行初始化动物数据集的类标签列表。
我们的下一个代码块处理从动物数据集中随机采样十个图像路径进行分类:
# grab the list of images in the dataset then randomly sample
# indexes into the image paths list
print("[INFO] sampling images...")
imagePaths = np.array(list(paths.list_images(args["dataset"])))
idxs = np.random.randint(0, len(imagePaths), size=(10,))
imagePaths = imagePaths[idxs]
这十个图像中的每一个都需要预处理,所以让我们初始化我们的预处理器,并从磁盘加载这十个图像:
# initialize the image preprocessors
sp = SimplePreprocessor(32, 32)
iap = ImageToArrayPreprocessor()
# load the dataset from disk then scale the raw pixel intensities
# to the range [0, 1]
sdl = SimpleDatasetLoader(preprocessors=[sp, iap])
(data, labels) = sdl.load(imagePaths)
data = data.astype("float") / 255.0
请注意我们是如何以与训练中预处理图像完全相同的方式预处理图像的。不执行此程序会导致不正确的分类,因为网络将呈现其无法识别的模式。始终特别注意确保您的测试图像以与您的训练图像相同的方式进行预处理。
接下来,让我们从磁盘加载保存的网络:
# load the pre-trained network
print("[INFO] loading pre-trained network...")
model = load_model(args["model"])
加载我们的序列化网络就像调用load_model并提供驻留在磁盘上的模型的 HDF5 文件的路径一样简单。
一旦加载了模型,我们就可以对我们的 10 幅图像进行预测:
# make predictions on the images
print("[INFO] predicting...")
preds = model.predict(data, batch_size=32).argmax(axis=1)
请记住,model的.predict方法将为data中的每个图像返回一个概率列表——分别为每个类别标签返回一个概率。在axis=1上取argmax为每幅图像找到具有最大概率的类别标签的索引。
现在我们有了我们的预测,让我们来想象一下结果:
# loop over the sample images
for (i, imagePath) in enumerate(imagePaths):
# load the example image, draw the prediction, and display it
# to our screen
image = cv2.imread(imagePath)
cv2.putText(image, "Label: {}".format(classLabels[preds[i]]),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
在第行第 48 处,我们开始循环十个随机采样的图像路径。对于每个图像,我们从磁盘中加载它(第 51 行),并在图像本身上绘制分类标签预测(第 52 行和第 53 行)。然后输出图像通过第 54 和 55 行显示在我们的屏幕上。
要尝试一下shallownet_load.py,请执行以下命令:
$ python shallownet_load.py --dataset ../datasets/animals \
--model shallownet_weights.hdf5
[INFO] sampling images...
[INFO] loading pre-trained network...
[INFO] predicting...
根据输出,您可以看到我们的图像已被采样,预训练的浅网权重已从磁盘加载,浅网已对我们的图像进行了预测。我在图 2 中包含了一个来自图像本身上绘制的浅水网的预测样本。
请记住,ShallowNet 在动物数据集上获得了 ≈ 70%的分类准确率,这意味着近三分之一的示例图像将被错误分类。此外,根据早期教程中的中的classification_report,我们知道网络仍然在努力坚持区分狗和猫。随着我们继续将深度学习应用于计算机视觉分类任务,我们将研究帮助我们提高分类准确性的方法。
总结
在本教程中,我们学习了如何:
- 训练一个网络。
- 将网络权重和优化器状态序列化到磁盘。
- 加载训练好的网络,对图像进行分类。
在单独的教程、中,我们将发现如何在每个时期的之后将模型的权重保存到磁盘,从而允许我们“检查”我们的网络并选择性能最佳的网络。在实际训练过程中保存模型权重也使我们能够从一个特定点重新开始训练,如果我们的网络开始出现过度拟合的迹象。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 Python 和 OpenCV 的本地二进制模式
原文:https://pyimagesearch.com/2015/12/07/local-binary-patterns-with-python-opencv/

好吧。我就直说了。 今天是我 27 岁的生日。
小时候,我总是对自己的生日感到超级兴奋。离能开车又近了一年。去看 R 级电影。或者买酒。
但现在作为一个成年人,我并不太在乎我的生日——我想这只是对时间流逝的又一个提醒,以及它是如何无法停止的。老实对你说,我想我对在短短几年内进入“大 3-0”有点紧张。
为了重新点燃一些“小孩子的兴奋”,我想用今天的帖子做一些特别的事情。由于今天既是星期一(当新的 PyImageSearch 博客帖子发布的时候)又是我的生日(这两个事件直到 2020 年才会再次重合),我决定整理一个关于 图像纹理和模式识别的非常棒的教程 。
在这篇博文的剩余部分,我将向你展示如何使用局部二元模式图像描述符(以及一点机器学习)来自动分类和识别图像中的纹理和模式(例如包装纸、蛋糕糖衣或蜡烛的纹理/模式)。
请继续阅读,了解更多关于局部二进制模式以及它们如何用于纹理分类的信息。
图片搜索大师
这篇关于纹理和模式识别的博文大部分是基于 PyImageSearch 大师课程 里面的局部二进制模式课。
虽然 PyImageSearch 大师们的课程比本教程更详细地介绍了,但我仍然想让你领略一下 PyImageSearch 大师们——我的计算机视觉巨著——为你准备了什么。
**如果你喜欢这个教程,有超过 29 课跨越 324 页涵盖图像描述符(猪,哈拉里克,泽尼克等)。)、关键点检测器(FAST、DoG、GFTT 等。),以及局部不变描述符(SIFT,SURF,RootSIFT 等)。),课程里面。
在撰写本文时,PyImageSearch 大师课程还涵盖了额外的 166 节课和1291 页,包括计算机视觉主题,如人脸识别、深度学习、自动车牌识别和训练您自己的定制物体检测器,仅举几例。
如果您对此感兴趣, 请务必看一看,并考虑报名参加下一次公开招生!
什么是局部二进制模式?
局部二进制模式,或简称为 LBPs,是一种因 Ojala 等人的工作而流行的纹理描述符,他们在 2002 年的论文 【多分辨率灰度和具有局部二进制模式的旋转不变纹理分类 (尽管 LBPs 的概念早在 1993 年就被引入)。
与基于灰度共生矩阵计算纹理的全局表示的 Haralick 纹理特征不同,LBPs 计算纹理的局部表示。这种局部表示是通过将每个像素与其周围的相邻像素进行比较而构建的。
构造 LBP 纹理描述符的第一步是将图像转换成灰度。对于灰度图像中的每个像素,我们选择围绕中心像素的大小为 r 的邻域。然后为该中心像素计算 LBP 值,并将其存储在与输入图像具有相同宽度和高度的输出 2D 阵列中。
例如,让我们看看原始的 LBP 描述符,它对固定的 3 x 3 像素邻域进行操作,就像这样:
Figure 1: The first step in constructing a LBP is to take the 8 pixel neighborhood surrounding a center pixel and threshold it to construct a set of 8 binary digits.
在上图中,我们选取中心像素(以红色突出显示)并将其与其邻域的 8 个像素进行阈值比较。如果中心像素的亮度大于或等于其邻居的亮度,那么我们将该值设置为1;否则,我们将其设置为 0 。有了 8 个周围像素,我们总共有 2 个^ 8 = 256 个可能的 LBP 码组合。
从那里,我们需要计算中心像素的 LBP 值。我们可以从任何相邻像素开始,顺时针或逆时针工作,但我们的排序必须保持一致用于我们图像中的所有像素和我们数据集中的所有图像。给定一个 3 x 3 的邻域,我们就有 8 个邻居需要进行二元测试。二进制测试的结果存储在一个 8 位数组中,然后我们将其转换为十进制,如下所示:

Figure 2: Taking the 8-bit binary neighborhood of the center pixel and converting it into a decimal representation. (Thanks to Bikramjot of Hanzra Tech for the inspiration on this visualization!)
在这个例子中,我们从右上角开始,顺时针地累积二进制字符串。然后,我们可以将这个二进制字符串转换为十进制,得到值 23。
*该值存储在输出 LBP 2D 数组中,我们可以如下图所示:
Figure 3: The calculated LBP value is then stored in an output array with the same width and height as the original image.
然后,对输入图像中的每个像素重复这个阈值处理、累积二进制串以及将输出十进制值存储在 LBP 阵列中的过程。
以下是一个计算和可视化完整 LBP 2D 阵列的示例:

Figure 4: An example of computing the LBP representation (right) from the original input image (left).
最后一步是计算输出 LBP 阵列的直方图。由于一个 3 x 3 邻域具有 2 ^ 8 = 256 个可能的模式,因此我们的 LBP 2D 阵列具有 0 的最小值和 255 的最大值,允许我们构建 LBP 代码的 256-bin 直方图作为我们的最终特征向量:
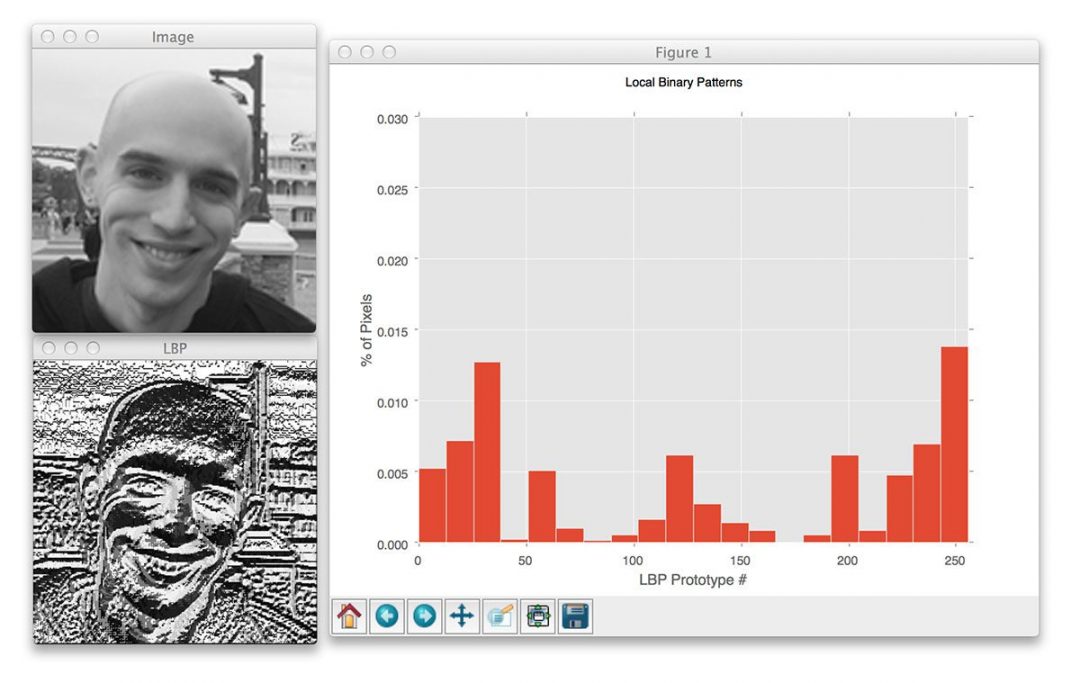
Figure 5: Finally, we can compute a histogram that tabulates the number of times each LBP pattern occurs. We can treat this histogram as our feature vector.
这种原始 LBP 实现的一个主要好处是,我们可以捕获图像中非常细粒度的细节。然而,能够在如此小的尺度下捕捉细节也是算法的最大缺点——我们无法捕捉不同尺度下的细节,只能捕捉固定的 3 x 3 尺度!
为了解决这个问题,Ojala 等人提出了对原始 LBP 实现的扩展,以处理可变的邻域大小。为了说明可变的邻域大小,引入了两个参数:
- 要考虑的圆形对称邻域中的点数 p (从而消除对方形邻域的依赖)。
- 圆的半径 r ,这允许我们考虑不同的尺度。
以下是这些参数的可视化:
Figure 6: Three neighborhood examples with varying p and r used to construct Local Binary Patterns.
最后,重要的是我们要考虑 LBP 一致性 的概念。如果一个 LBP 最多有两个 0-1 或 1-0 转换,则认为它是均匀的。例如,模式00001000 (2 个转变)和10000000 (1 个转变)都被认为是统一模式,因为它们最多包含两个 0-1 和 1-0 转变。另一方面,图案01010010是而不是被认为是统一图案,因为它有六个 0-1 或 1-0 转换。
**局部二进制模式中统一原型的数量完全取决于点的数量 p 。随着 p 值的增加,直方图的维数也会增加。请参考 Ojala 等人的原始论文,以获得关于基于该值导出图案和均匀图案的数量的完整解释。然而,暂时简单地记住,给定 LBP 中的点数 p ,存在 p + 1 统一模式。因此,直方图的最终维度是 p + 2 ,其中添加的条目列出了 不一致 的所有模式。
那么为什么统一的 LBP 模式如此有趣呢?简而言之:它们增加了额外的旋转和灰度不变性,因此它们通常在从图像中提取 LBP 特征向量时使用。
使用 Python 和 OpenCV 的本地二进制模式
本地二进制模式实现可以在 scikit-image 和 mahotas 包中找到。OpenCV 也实现了 LBP,但是严格地说是在人脸识别的环境中——底层的 LBP 提取器不公开用于原始 LBP 直方图计算。
总的来说,我推荐使用 LBP 的 scikit-image 实现,因为它们提供了对您想要生成的 LBP 直方图类型的更多控制。此外,scikit-image 实现还包括改进旋转和灰度不变性的 LBP 的变体。
在我们开始从图像中提取局部二进制模式并使用它们进行分类之前,我们首先需要创建一个纹理数据集。为了形成这个数据集,今天早些时候,我在我的公寓里走了一圈,收集了 20 张不同纹理和图案的照片,包括一张区域地毯:

Figure 7: Example images of the area rug texture and pattern.
请注意地毯图片是如何进行几何设计的。
我还收集了一些地毯的例子:

Figure 8: Four examples of the carpet texture.
请注意地毯是如何具有粗糙纹理的独特图案的。
然后我拍了几张桌子上的键盘的照片:

Figure 9: Example images of my keyboard.
请注意,键盘几乎没有纹理,但它确实展示了白色按键和其间银色金属间距的可重复模式。
最后,我收集了最后几个包装纸的例子(因为毕竟是我的生日):

Figure 10: Our final texture we are going to classify — wrapping paper.
包装纸具有非常光滑的纹理,但也展示了独特的模式。
给定这个由区域地毯、地毯、键盘和包装纸组成的数据集,我们的目标是从这些图像中提取局部二进制模式,并应用机器学习对这些纹理图像进行自动识别和分类。
让我们通过为我们的项目定义目录结构来开始演示:
$ tree --dirsfirst -L 3
.
├── images
│ ├── testing
│ │ ├── area_rug.png
│ │ ├── carpet.png
│ │ ├── keyboard.png
│ │ └── wrapping_paper.png
│ └── training
│ ├── area_rug [4 entries]
│ ├── carpet [4 entries]
│ ├── keyboard [4 entries]
│ └── wrapping_paper [4 entries]
├── pyimagesearch
│ ├── __init__.py
│ └── localbinarypatterns.py
└── recognize.py
8 directories, 7 files
images/目录包含我们的testing/和training/图像。
我们将创建一个pyimagesearch模块来组织我们的代码。在pyimagesearch模块中,我们将创建localbinarypatterns.py,顾名思义,这里将存储我们的本地二进制模式实现。
说到本地二进制模式,现在让我们继续创建描述符类:
# import the necessary packages
from skimage import feature
import numpy as np
class LocalBinaryPatterns:
def __init__(self, numPoints, radius):
# store the number of points and radius
self.numPoints = numPoints
self.radius = radius
def describe(self, image, eps=1e-7):
# compute the Local Binary Pattern representation
# of the image, and then use the LBP representation
# to build the histogram of patterns
lbp = feature.local_binary_pattern(image, self.numPoints,
self.radius, method="uniform")
(hist, _) = np.histogram(lbp.ravel(),
bins=np.arange(0, self.numPoints + 3),
range=(0, self.numPoints + 2))
# normalize the histogram
hist = hist.astype("float")
hist /= (hist.sum() + eps)
# return the histogram of Local Binary Patterns
return hist
我们从导入 scikit-image 的feature子模块开始,它包含本地二进制模式描述符的实现。
第 5 行为我们的LocalBinaryPatterns类定义了构造函数。正如上一节提到的,我们知道 LBPs 需要两个参数:围绕中心像素的图案的半径,以及沿着外半径的点数。我们将把这两个值存储在第 8 行和第 9 行上。
从那里,我们在第 11 行的上定义我们的describe方法,它接受一个必需的参数——我们想要从中提取 LBP 的图像。
使用我们提供的半径和点数,在行 15 和 16 处理实际的 LBP 计算。uniform方法表明我们正在计算 LBPs 的旋转和灰度不变形式。
然而,由local_binary_patterns函数返回的lbp变量不能直接用作特征向量。相反,lbp是一个 2D 数组,其宽度和高度与我们的输入图像相同——lbp中的每个值的范围从 [0,numPoints + 2] ,每个可能的 numPoints + 1 可能的旋转不变原型的值(有关更多信息,请参见本文顶部对均匀模式的讨论)以及所有不均匀模式的额外维度,总共产生个 numPoints
因此,为了构建实际的特征向量,我们需要调用np.histogram,它计算每个 LBP 原型出现的次数。返回的直方图是 numPoints + 2 维的,每个原型的整数计数。然后,我们获取这个直方图并对其进行归一化,使其总和为 1 ,然后将其返回给调用函数。
既然已经定义了我们的LocalBinaryPatterns描述符,让我们看看如何用它来识别纹理和图案。创建一个名为recognize.py的新文件,让我们开始编码:
# import the necessary packages
from pyimagesearch.localbinarypatterns import LocalBinaryPatterns
from sklearn.svm import LinearSVC
from imutils import paths
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--training", required=True,
help="path to the training images")
ap.add_argument("-e", "--testing", required=True,
help="path to the tesitng images")
args = vars(ap.parse_args())
# initialize the local binary patterns descriptor along with
# the data and label lists
desc = LocalBinaryPatterns(24, 8)
data = []
labels = []
我们从的第 2-7 行开始,导入必要的命令行参数。注意我们是如何从上面定义的pyimagesearch子模块导入LocalBinaryPatterns描述符的。
从那里,第 10-15 行处理解析我们的命令行参数。这里我们只需要两个开关:到--training数据的路径和到--testing数据的路径。
在本例中,我们将纹理分为两组:每组 4 个图像的训练组(每组 4 个图像=总共 16 个图像),以及每组 1 个图像的测试组(每组 4 个图像 x 每组 1 个图像= 4 个图像)。16 幅图像的训练集将用于“训练”我们的分类器,然后我们将在 4 幅图像的测试集上评估性能。
在第 19 行上,我们使用 numPoints=24 和 radius=8 初始化我们的LocalBinaryPattern描述符。
为了存储 LBP 特征向量和与每个纹理类相关联的标签名称,我们将初始化两个列表:data存储特征向量,labels存储每个纹理的名称(第 20 行和第 21 行)。
现在是时候从我们的训练图像集中提取 LBP 特征了:
# loop over the training images
for imagePath in paths.list_images(args["training"]):
# load the image, convert it to grayscale, and describe it
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
hist = desc.describe(gray)
# extract the label from the image path, then update the
# label and data lists
labels.append(imagePath.split(os.path.sep)[-2])
data.append(hist)
# train a Linear SVM on the data
model = LinearSVC(C=100.0, random_state=42)
model.fit(data, labels)
我们开始在24 号线循环播放我们的训练图像。对于这些图像中的每一个,我们从磁盘加载它们,将它们转换成灰度,并提取局部二进制模式特征。然后从图像路径中提取标签(即纹理名称),并分别更新我们的labels和data列表。
一旦我们提取了我们的特征和标签,我们就可以在第 36 行和第 37 行上训练我们的线性支持向量机来学习各种纹理类别之间的差异。
一旦我们的线性 SVM 被训练,我们可以用它来分类后续的纹理图像:
# loop over the testing images
for imagePath in paths.list_images(args["testing"]):
# load the image, convert it to grayscale, describe it,
# and classify it
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
hist = desc.describe(gray)
prediction = model.predict(hist.reshape(1, -1))
# display the image and the prediction
cv2.putText(image, prediction[0], (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
1.0, (0, 0, 255), 3)
cv2.imshow("Image", image)
cv2.waitKey(0)
正如我们在第 24 行的训练图像上循环以收集数据来训练我们的分类器一样,我们现在在第 40 行的测试图像上循环以测试我们的分类器的性能和准确性。
同样,我们需要做的只是从磁盘加载我们的图像,将其转换为灰度,从灰度图像中提取局部二进制模式,然后将特征传递到我们的线性 SVM 进行分类(第 43-46 行)。
我想提醒您注意 46 号线上的hist.reshape(1, -1)。这将我们的直方图从 1D 阵列重塑为 2D 阵列,从而允许多个特征向量的潜力来运行预测。
第 49-52 行显示了我们屏幕的输出分类。
结果
让我们通过执行以下命令来尝试我们的纹理分类系统:
$ python recognize.py --training images/training --testing images/testing
这是我们分类的第一张输出图像:
Figure 11: Our Linear SVM + Local Binary Pattern combination is able to correctly classify the area rug pattern.
果然,图像被正确分类为“区域地毯”。
让我们试试另一个:

Figure 12: We are also able to recognize the carpet pattern.
我们的分类器再次正确地识别了图像的纹理/图案。
以下是正确标记键盘模式的示例:

Figure 13: Classifying the keyboard pattern is also easy for our method.
最后,我们还能够识别包装纸的纹理和图案:

Figure 14: Using Local Binary Patterns to classify the texture of an image.
虽然这个例子很小很简单,但它仍然能够证明,通过使用局部二进制模式特征和一点机器学习,我们能够正确地对图像的纹理和模式进行分类。
摘要
在这篇博文中,我们学习了如何从图像中提取局部二进制模式,并使用它们(以及一点机器学习)来执行 纹理和模式识别 。
如果你喜欢这篇博文,一定要看一看 PyImageSearch 大师课程 这一课的大部分内容都是从那里得来的。
在课程中,你会发现超过 166 节课涵盖1291页的计算机视觉主题,例如:
- 人脸识别。
- 深度学习。
- 自动车牌识别。
- 训练您自己的自定义对象检测器。
- 构建图像搜索引擎。
- …还有更多!
如果您对此感兴趣, 请务必看一看,并考虑报名参加下一次公开招生!
下周见!*****
长时间接触 OpenCV 和 Python
原文:https://pyimagesearch.com/2017/08/14/long-exposure-with-opencv-and-python/

我最喜欢的摄影技术之一是长时间曝光,这是一种创造照片的过程,可以展示时间流逝的效果,这是传统摄影所无法捕捉的。
当应用这种技术时,水变得如丝般光滑,夜空中的星星随着地球旋转留下光迹,汽车前灯/尾灯以单带连续运动照亮高速公路。
长时间曝光是一种华丽的技术,但是为了捕捉这些类型的镜头,你需要采取一种系统的方法:将你的相机安装在三脚架上,应用各种滤镜,计算曝光值,等等。更不用说,你需要是一个熟练的摄影师!
作为一名计算机视觉研究人员和开发人员,我知道很多关于处理图像的知识——但是让我们面对现实吧,我是一个糟糕的摄影师。
幸运的是,有一种方法可以通过应用图像/帧平均来模拟长曝光。通过在给定的时间段内平均从安装的相机捕获的图像,我们可以(实际上)模拟长时间曝光。
由于视频只是一系列图像,我们可以通过平均视频中的所有帧来轻松构建长曝光。结果是惊人的长曝光风格的图像,就像这篇博文顶部的那张。
要了解更多关于长时间曝光以及如何用 OpenCV 模拟效果的信息,继续阅读。
长时间接触 OpenCV 和 Python
这篇博文分为三个部分。
在这篇博文的第一部分,我们将讨论如何通过帧平均来模拟长时间曝光。
在此基础上,我们将编写 Python 和 OpenCV 代码,用于从输入视频中创建类似长曝光的效果。
最后,我们将把我们的代码应用到一些示例视频中,以创建华丽的长曝光图像。
通过图像/帧平均模拟长曝光
通过平均来模拟长时间曝光的想法并不是什么新想法。
事实上,如果你浏览流行的摄影网站,你会发现如何使用你的相机和三脚架手动创建这些类型的效果的教程(这种教程的一个很好的例子可以在这里找到)。
我们今天的目标是简单地实现这种方法,这样我们就可以使用 Python 和 OpenCV 从输入视频中自动创建类似长曝光的图像。给定一个输入视频,我们将所有帧平均在一起(平均加权)以创建长曝光效果。
注意:你也可以使用多张图像来创建这种长曝光效果,但由于视频只是一系列图像,所以使用视频来演示这种技术更容易。在将该技术应用于您自己的文件时,请记住这一点。
正如我们将看到的,代码本身非常简单,但当应用于使用三脚架捕捉的视频时,会产生美丽的效果,确保帧之间没有相机移动。
用 OpenCV 实现长曝光模拟
让我们首先打开一个名为long_exposure.py的新文件,并插入以下代码:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", required=True,
help="path to output 'long exposure'")
args = vars(ap.parse_args())
第 2-4 行处理我们的进口——你需要 imutils 和 OpenCV。
如果您的环境中还没有安装imutils,只需使用pip:
$ pip install --upgrade imutils
如果您还没有配置和安装 OpenCV,请前往我的 OpenCV 3 教程页面并选择适合您系统的指南。
我们在第 7-12 行解析我们的两个命令行参数:
--video:视频文件的路径。--output:输出“长曝光”文件的路径+文件名。
接下来,我们将执行一些初始化步骤:
# initialize the Red, Green, and Blue channel averages, along with
# the total number of frames read from the file
(rAvg, gAvg, bAvg) = (None, None, None)
total = 0
# open a pointer to the video file
print("[INFO] opening video file pointer...")
stream = cv2.VideoCapture(args["video"])
print("[INFO] computing frame averages (this will take awhile)...")
在行 16 上,我们初始化 RGB 通道平均值,稍后我们将把它合并到最终的长曝光图像中。
我们还对第 17 行上的总帧数进行初始化。
对于本教程,我们正在处理一个包含所有帧的视频文件,因此有必要打开一个指向第 21 行上的视频捕获stream的文件指针。
现在让我们开始计算平均值的循环:
# loop over frames from the video file stream
while True:
# grab the frame from the file stream
(grabbed, frame) = stream.read()
# if the frame was not grabbed, then we have reached the end of
# the sfile
if not grabbed:
break
# otherwise, split the frmae into its respective channels
(B, G, R) = cv2.split(frame.astype("float"))
在我们的循环中,我们将从stream ( 行 27 )中抓取帧,并将frame拆分到其各自的 BGR 通道(行 35 )。注意中间的退出条件——如果一帧是来自视频流的not grabbed,我们就在视频文件的末尾,我们将break退出循环(第 31 行和第 32 行)。
在循环的剩余部分,我们将执行运行平均值计算:
# if the frame averages are None, initialize them
if rAvg is None:
rAvg = R
bAvg = B
gAvg = G
# otherwise, compute the weighted average between the history of
# frames and the current frames
else:
rAvg = ((total * rAvg) + (1 * R)) / (total + 1.0)
gAvg = ((total * gAvg) + (1 * G)) / (total + 1.0)
bAvg = ((total * bAvg) + (1 * B)) / (total + 1.0)
# increment the total number of frames read thus far
total += 1
如果这是第一次迭代,我们将初始 RGB 平均值设置为在第 38-41 行上抓取的相应第一帧通道(只有在第一次循环时才需要这样做,因此有了if-语句)。
****否则,我们将计算第 45-48 行上每个通道的运行平均值。求平均值的计算非常简单,我们将总帧数乘以通道平均值,将各个通道相加,然后将结果除以浮点总帧数(我们在分母中的总数上加 1,因为这是一个新帧)。我们将计算结果存储在各自的 RGB 通道平均数组中。
最后,我们增加总帧数,从而保持我们的运行平均值(第 51 行)。
一旦我们循环了视频文件中的所有帧,我们就可以将(平均)通道合并到一个图像中,并将其写入磁盘:
# merge the RGB averages together and write the output image to disk
avg = cv2.merge([bAvg, gAvg, rAvg]).astype("uint8")
cv2.imwrite(args["output"], avg)
# do a bit of cleanup on the file pointer
stream.release()
在的第 54 行,我们利用了方便的cv2.merge函数,同时在一个列表中指定我们的每个通道平均值。由于这些数组包含浮点数(因为它们是所有帧的平均值,我们添加了astype("uint8")来将像素转换为范围 [0-255]内的整数。
我们使用命令行参数 path + filename 在随后的第 55行将avg映像写入磁盘。我们也可以通过cv2.imshow将图像显示到我们的屏幕上,但由于处理视频文件需要大量的 CPU 时间,我们将简单地将图像保存到磁盘,以防我们希望将其保存为桌面背景或在社交媒体上与我们的朋友分享。
这个脚本的最后一步是通过释放我们的视频流指针来执行清理( Line 58 )。
长时间曝光和 OpenCV 结果
让我们通过处理三个示例视频来看看我们的脚本是如何工作的。请注意,每个视频都是由安装在三脚架上的摄像机拍摄的,以确保稳定性。
注:我用来创作这些例子的视频不属于我,经原创作者许可;因此,我不能在这篇博文的源代码下载中包含它们。相反,如果你想复制我的结果,我提供了原始视频的链接。
我们的第一个例子是一个 15 秒长的视频,关于水冲过岩石——我在下面的视频中加入了一个样本:

Figure 1: Sample frames of river water rushing over rocks.
要创建我们的长曝光效果,只需执行以下命令:
$ time python long_exposure.py --video videos/river_01.mov --output river_01.png
[INFO] opening video file pointer...
[INFO] computing frame averages (this will take awhile)...
real 2m1.710s
user 0m50.959s
sys 0m40.207s

Figure 2: Long exposure of 15 seconds of river water rushing over rocks, constructed by averaging frames with Python and OpenCV.
请注意,由于平均过程,水已经混合成丝滑的形式。
让我们继续看第二个河流的例子,再一次,下面显示了一组蒙太奇画面:

Figure 3: Sample frames of another river.
以下命令用于生成长曝光图像:
$ time python long_exposure.py --video videos/river_02.mov --output river_02.png
[INFO] opening video file pointer...
[INFO] computing frame averages (this will take awhile)...
real 0m57.881s
user 0m27.207s
sys 0m21.792s

Figure 4: Long exposure of a second river which makes the water look silky smooth (created using OpenCV).
注意静止的岩石是如何保持不变的,但是湍急的水流被平均化为连续的一片,从而模仿了长时间曝光的效果。
这个最后的例子是我最喜欢的,因为水的颜色非常迷人,在水本身和森林之间形成了鲜明的对比:

Figure 5: Sample frames of a rushing river through a forest
当使用 OpenCV 生成长曝光时,它会给输出一种超现实、梦幻般的感觉:
$ time python long_exposure.py --video videos/river_03.mov --output river_03.png
[INFO] opening video file pointer...
[INFO] computing frame averages (this will take awhile)...
real 3m17.212s
user 1m11.826s
sys 0m56.707s

Figure 6: A dream-like long exposure of a river through a forest created using Python and OpenCV.
不同的输出可以通过定期从输入视频中采样帧来构建,而不是平均所有帧。这是留给你,读者,去实现的一个练习。
摘要
在今天的博文中,我们学习了如何使用 OpenCV 和图像处理技术模拟长曝光图像。
为了模拟长时间曝光,我们采用了帧平均法,即将一组图像平均在一起的过程。我们假设我们的输入图像/视频是使用安装的摄像机捕获的(否则产生的输出图像会失真)。
虽然这不是真正的“长时间曝光”,但效果(视觉上)非常相似。更重要的是,这使你可以在不需要(1)成为专业摄影师或(2)购买昂贵的相机、镜头和滤镜的情况下应用长曝光效果。
如果您喜欢今天的博文,请务必在下表中输入您的电子邮件地址,以便在未来教程发布时收到通知!****
长短期记忆网络
原文:https://pyimagesearch.com/2022/08/01/long-short-term-memory-networks/
https://www.youtube.com/embed/woyMFtaSqQs?feature=oembed
Python 中的机器学习
原文:https://pyimagesearch.com/2019/01/14/machine-learning-in-python/

挣扎着用 Python 入门机器学习?在这个循序渐进的实践教程中,您将学习如何使用 Python 对数值数据和图像数据执行机器学习。
当你读完这篇文章时,你将能够开始学习机器。
要在 Python 教育中启动您的机器学习,继续阅读!
Python 中的机器学习
在本教程中,您将学习如何在 Python 中对数值数据和图像数据执行机器学习。
您将学习如何操作流行的 Python 机器学习和深度学习库,包括我最喜欢的两个库:
- scikit-learn
- Keras
具体来说,您将学习如何:
- 检查你的问题
- 准备您的数据(原始数据、特征提取、特征工程等)。)
- 抽查一组算法
- 检查您的结果
- 对最有效的算法加倍下注
使用这种技术,你将能够开始学习机器和 Python!
在这个过程中,你会发现流行的机器学习算法,你也可以在自己的项目中使用,包括:
- k-最近邻
- 朴素贝叶斯
- 逻辑回归
- 支持向量机
- 决策树
- 随机森林
- 感觉
- 多层前馈神经网络
- 卷积神经网络
这种实践经验将会给你将 Python 中的机器学习应用到你自己的项目中所需的知识(和信心)。
安装所需的 Python 机器学习库
在我们开始学习本教程之前,你首先需要确保你的系统是为机器学习而配置的。今天的代码需要以下库:
- NumPy: 用 Python 进行数值处理。
- PIL: 一个简单的图像处理库。
- scikit-learn: 包含了我们今天要讨论的机器学习算法(我们需要 0.20 以上的版本,这就是为什么你会看到下面的
--upgrade标志)。 - Keras 和 TensorFlow: 用于深度学习。TensorFlow 的 CPU 版本对于今天的例子来说很好。
- 虽然我们在这篇博文中没有使用 OpenCV, imutils 依赖于它(下一个项目符号)。正因为如此,你可以简单地使用 pip 来安装 OpenCV ,只是要记住你不会有 OpenCV 的完整安装,你也不能定制它。
- imutils: 我的个人图像处理/计算机视觉便捷功能包
这些都可以通过 pip 安装在您的环境中(推荐虚拟环境):
$ pip install numpy
$ pip install pillow
$ pip install --upgrade scikit-learn
$ pip install tensorflow # or tensorflow-gpu
$ pip install keras
$ pip install opencv-contrib-python
$ pip install --upgrade imutils
资料组
为了帮助您获得在 Python 中执行机器学习的经验,我们将使用两个独立的数据集。
第一个,虹膜数据集,是机器学习实践者的“你好,世界!”(可能是你在学习如何编程时编写的第一批软件之一)。
第二个数据集, 3-scenes,是我整理的一个示例图像数据集—该数据集将帮助您获得处理图像数据的经验,最重要的是,了解什么技术最适合数值/分类数据集与图像数据集。
让我们继续深入了解这些数据集。
虹膜数据集
Figure 1: The Iris dataset is a numerical dataset describing Iris flowers. It captures measurements of their sepal and petal length/width. Using these measurements we can attempt to predict flower species with Python and machine learning. (source)
Iris 数据集可以说是最简单的机器学习数据集之一——它通常用于帮助教授程序员和工程师机器学习和模式识别的基础知识。
我们称这个数据集为“鸢尾数据集”,因为它捕捉了三种鸢尾花的属性:
- 丝状虹膜
- 杂色鸢尾
- 北美鸢尾
每种花卉都通过四个数字属性进行量化,所有属性都以厘米为单位:
- 萼片长度
- 萼片宽度
- 花瓣长度
- 花瓣宽度
我们的目标是训练一个机器学习模型,从测得的属性中正确预测花种。
值得注意的是,其中一个类与其他两个类是线性可分的——后者是而不是彼此线性可分的。
为了正确地对这些花卉种类进行分类,我们需要一个非线性模型。
在现实世界中使用 Python 执行机器学习时,需要非线性模型是非常常见的——本教程的其余部分将帮助您获得这种经验,并为在自己的数据集上执行机器学习做好更充分的准备。
3 场景图像数据集

Figure 2: The 3-scenes dataset consists of pictures of coastlines, forests, and highways. We’ll use Python to train machine learning and deep learning models.
我们将用于训练机器学习模型的第二个数据集称为 3 场景数据集,包括 3 个场景的 948 幅图像:
- 海岸(360°图像)
- 森林(328 张图片)
- 高速公路(260 张图片)
3 场景数据集是通过对 Oliva 和 Torralba 在 2001 年的论文 中的 8 场景数据集进行采样而创建的,该论文对场景的形状进行建模:空间包络 的整体表示。
我们的目标将是用 Python 训练机器学习和深度学习模型,以正确识别这些场景中的每一个。
我已经在本教程的 “下载” 部分包含了 3 场景数据集。在继续之前,请确保将 dataset +代码下载到这篇博文中。
在 Python 中执行机器学习的步骤
Figure 3: Creating a machine learning model with Python is a process that should be approached systematically with an engineering mindset. These five steps are repeatable and will yield quality machine learning and deep learning models.
每当你在 Python 中执行机器学习时,我建议从一个简单的 5 步过程开始:
- 检查你的问题
- 准备您的数据(原始数据、特征提取、特征工程等)。)
- 抽查一组算法
- 检查您的结果
- 对最有效的算法加倍下注
这个管道会随着你的机器学习经验的增长而演变,但对于初学者来说,这是我推荐入门的机器学习过程。
首先,我们必须检查问题。
问问你自己:
- 我在处理什么类型的数据?数值?绝对的?图像?
- 我的模型的最终目标是什么?
- 我将如何定义和衡量“准确性”?
- 鉴于我目前对机器学习的了解,我知道有什么算法可以很好地解决这类问题吗?
特别是最后一个问题,非常关键 —你在 Python 中应用机器学习越多,你获得的经验就越多。
基于你以前的经验,你可能已经知道一个运行良好的算法。
从那里开始,你需要准备你的数据。
通常这一步包括从磁盘加载数据,检查数据,并决定是否需要执行特征提取或特征工程。
特征提取是应用算法以某种方式量化数据的过程。
例如,在处理图像时,我们可能希望计算直方图来总结图像中像素强度的分布,这样,我们就可以表征图像的颜色。
另一方面,特征工程是将原始输入数据转换成更好地代表潜在问题的表示的过程。
特征工程是一种更高级的技术,我建议你在已经有了一些机器学习和 Python 的经验后再去探索。
接下来,你会想要抽查一组算法。
我所说的抽查是什么意思?
只需将一组机器学习算法应用于数据集即可!
你可能会想把下面的机器学习算法放进你的工具箱里:
- 线性模型(例如逻辑回归、线性 SVM),
- 一些非线性模型(例如 RBF 支持向量机,SGD 分类器),
- 一些基于树和集合的模型(例如决策树、随机森林)。
- 一些神经网络,如果适用的话(多层感知器,卷积神经网络)
尝试为问题带来一套强大的机器学习模型——你的目标是通过识别哪些机器学习算法在问题上表现良好,哪些表现不佳,来获得关于你的问题/项目的经验。
一旦你定义了你的模型,训练它们并评估结果。
哪些机器学习模型效果很好?哪些车型表现不佳?
利用你的结果,在表现良好的机器学习模型上加倍努力,同时放弃表现不佳的模型。
随着时间的推移,你将开始看到在多个实验和项目中出现的模式。
你将开始发展一种“第六感”,知道什么机器学习算法在什么情况下表现良好。
例如,您可能会发现随机森林在应用于具有许多实值特性的项目时工作得非常好。
另一方面,您可能会注意到,逻辑回归可以很好地处理稀疏的高维空间。
你甚至会发现卷积神经网络非常适合图像分类(事实也确实如此)。
在这里用你的知识来补充传统的机器学习教育— 用 Python 学习机器学习最好的方法就是简单地卷起袖子,把手弄脏!
一个基于实践经验(辅以一些超级基础理论)的机器学习教育,会带你在机器学习的旅途上走得很远!
让我们把手弄脏吧!
既然我们已经讨论了机器学习的基础知识,包括在 Python 中执行机器学习所需的步骤,那就让我们动手吧。
在下一节中,我们将简要回顾一下本教程的目录和项目结构。
注意:我建议您使用本教程的“下载”*部分来下载源代码和示例数据,这样您就可以轻松地跟随了。*
一旦我们回顾了机器学习项目的目录结构,我们将实现两个 Python 脚本:
- 第一个脚本将用于在 数字数据 (即虹膜数据集)上训练机器学习算法
- 第二个 Python 脚本将用于在 图像数据 (即,3 场景数据集)上训练机器学习
作为奖励,我们将实现另外两个 Python 脚本,每个脚本都专用于神经网络和深度学习:
- 我们将从实现 Python 脚本开始,该脚本将在 Iris 数据集上训练神经网络
- 其次,您将学习如何在 3 场景数据集上训练您的第一个卷积神经网络
让我们首先回顾一下我们的项目结构。
我们的机器学习项目结构
一定要抓取与这篇博文相关的 【下载】 。
在那里,您可以解压缩归档文件并检查内容:
$ tree --dirsfirst --filelimit 10
.
├── 3scenes
│ ├── coast [360 entries]
│ ├── forest [328 entries]
│ └── highway [260 entries]
├── classify_iris.py
├── classify_images.py
├── nn_iris.py
└── basic_cnn.py
4 directories, 4 files
虹膜数据集内置于 scikit-learn 中。然而,3 场景数据集却不是。我已经将它包含在3scenes/目录中,正如你所看到的,有三个图像子目录(类)。
我们今天将回顾四个 Python 机器学习脚本:
classify_iris.py:加载 Iris 数据集,通过简单的命令行参数开关,可以应用七种机器学习算法中的任意一种。classify_images.py:收集我们的图像数据集(3 个场景)并应用 7 种 Python 机器学习算法中的任何一种nn_iris.py:将简单的多层神经网络应用于虹膜数据集basic_cnn.py:建立卷积神经网络(CNN)并使用 3 场景数据集训练模型
实现数值数据的 Python 机器学习
Figure 4: Over time, many statistical machine learning approaches have been developed. You can use this map from the scikit-learn team as a guide for the most popular methods. Expand.
我们要实现的第一个脚本是classify_iris.py —这个脚本将用于在 Iris 数据集上抽查机器学习算法。
一旦实现,我们将能够使用classify_iris.py在 Iris 数据集上运行一套机器学习算法,查看结果,并决定哪个算法最适合该项目。
让我们开始吧——打开classify_iris.py文件并插入以下代码:
# import the necessary packages
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import load_iris
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="knn",
help="type of python machine learning model to use")
args = vars(ap.parse_args())
第 2-12 行导入我们需要的包,具体是:
- 我们的 Python 机器学习方法来自 scikit-learn ( 第 2-8 行)
- 一种数据集分割方法,用于将我们的数据分成训练和测试子集(第 9 行)
- scikit-learn 的分类报告实用程序,它将打印我们的机器学习结果的摘要(第 10 行)
- 我们的虹膜数据集,内置于 scikit-learn ( Line 11 )
- 一个用于命令行参数解析的工具叫做
argparse( 第 12 行)
使用argparse,让我们解析第 15-18 行上的单个命令行参数标志--model。--model开关允许我们从以下任何型号中进行选择:
# define the dictionary of models our script can use, where the key
# to the dictionary is the name of the model (supplied via command
# line argument) and the value is the model itself
models = {
"knn": KNeighborsClassifier(n_neighbors=1),
"naive_bayes": GaussianNB(),
"logit": LogisticRegression(solver="lbfgs", multi_class="auto"),
"svm": SVC(kernel="rbf", gamma="auto"),
"decision_tree": DecisionTreeClassifier(),
"random_forest": RandomForestClassifier(n_estimators=100),
"mlp": MLPClassifier()
}
第 23-31 行的models字典定义了我们将要抽查的模型套件(我们将在稍后的文章中回顾这些算法的结果):
- k-最近邻
- 朴素贝叶斯
- 逻辑回归
- 支持向量机
- 决策树
- 随机森林
- 感觉
按键可以通过--model开关直接输入终端。这里有一个例子:
$ python classify_irs.py --model knn
从那里,KNeighborClassifier将被自动加载。这方便地允许我们在单个 Python 脚本中一次一个地按需调用 7 个机器学习模型中的任何一个(不需要编辑代码)!
接下来,让我们加载并拆分数据:
# load the Iris dataset and perform a training and testing split,
# using 75% of the data for training and 25% for evaluation
print("[INFO] loading data...")
dataset = load_iris()
(trainX, testX, trainY, testY) = train_test_split(dataset.data,
dataset.target, random_state=3, test_size=0.25)
我们的数据集很容易用专用的load_iris方法在第 36 行加载。一旦数据在内存中,我们继续调用train_test_split将数据分成 75%用于训练,25%用于测试(第 37 和 38 行)。
最后一步是训练和评估我们的模型:
# train the model
print("[INFO] using '{}' model".format(args["model"]))
model = models[args["model"]]
model.fit(trainX, trainY)
# make predictions on our data and show a classification report
print("[INFO] evaluating...")
predictions = model.predict(testX)
print(classification_report(testY, predictions,
target_names=dataset.target_names))
42 线和 43 线训练 Python 机器学习model(也称“拟合模型”,故名.fit)。
从那里,我们评估测试装置上的model(线 47 )然后print a classification_report到我们的终端(线 48 和 49 )。
实现图像的 Python 机器学习
Figure 5: A linear classifier example for implementing Python machine learning for image classification (Inspired by Karpathy’s example in the CS231n course).
下面的脚本classify_images.py用于仅在 3 场景图像数据集上训练上述相同的一套机器学习算法。
它与我们之前的 Iris 数据集分类脚本非常相似,因此请确保在学习过程中对两者进行比较。
现在让我们实现这个脚本:
# import the necessary packages
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from PIL import Image
from imutils import paths
import numpy as np
import argparse
import os
首先,我们在第 2-16 行导入必要的包。看起来很多,但是你会从之前的脚本中认出其中的大部分。该脚本的其他导入包括:
LabelEncoder将用于将文本标签转换成数字(第 9 行)。- 一个叫 PIL/枕头的基本图像处理工具( Line 12 )。
- 我的便捷模块,
paths,用于从磁盘中轻松抓取图像路径(第 13 行)。这包含在我个人的 imutils 包中,我已经发布给 GitHub 和 PyPi 。 - NumPy 将用于数值计算(第 14 行)。
- Python 内置的
os模块(第 16 行)。我们将使用它来容纳不同操作系统之间的路径分隔符。
在接下来的代码行中,您将看到每个导入是如何使用的。
接下来让我们定义一个名为extract_color_stats的函数:
def extract_color_stats(image):
# split the input image into its respective RGB color channels
# and then create a feature vector with 6 values: the mean and
# standard deviation for each of the 3 channels, respectively
(R, G, B) = image.split()
features = [np.mean(R), np.mean(G), np.mean(B), np.std(R),
np.std(G), np.std(B)]
# return our set of features
return features
大多数机器学习算法在原始像素数据上的表现非常差。相反,我们执行特征提取来表征图像的内容。
这里,我们试图通过提取图像中每个颜色通道的平均值和标准偏差来量化图像的颜色。
给定图像的三个通道(红色、绿色和蓝色),以及每个通道的两个特征(平均值和标准偏差),我们有 3 x 2 = 6 个总特征来量化图像。我们通过连接这些值来形成特征向量。
事实上,正是的extract_color_stats函数正在做的事情:
- 我们从第 22 条线上的
image分割出三个颜色通道。 - 然后在第 23 和 24 行上构建特征向量,您可以看到我们使用 NumPy 来计算每个通道的平均值和标准偏差
我们将使用这个函数来计算数据集中每个图像的特征向量。
让我们继续解析两个命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, default="3scenes",
help="path to directory containing the '3scenes' dataset")
ap.add_argument("-m", "--model", type=str, default="knn",
help="type of python machine learning model to use")
args = vars(ap.parse_args())
前面的脚本只有一个参数,而这个脚本有两个命令行参数:
--dataset:驻留在磁盘上的 3 场景数据集的路径。--model:要采用的 Python 机器学习模型。
同样,我们有七个机器学习模型可供选择,带有--model参数:
# define the dictionary of models our script can use, where the key
# to the dictionary is the name of the model (supplied via command
# line argument) and the value is the model itself
models = {
"knn": KNeighborsClassifier(n_neighbors=1),
"naive_bayes": GaussianNB(),
"logit": LogisticRegression(solver="lbfgs", multi_class="auto"),
"svm": SVC(kernel="linear"),
"decision_tree": DecisionTreeClassifier(),
"random_forest": RandomForestClassifier(n_estimators=100),
"mlp": MLPClassifier()
}
定义完models字典后,我们需要继续将图像加载到内存中:
# grab all image paths in the input dataset directory, initialize our
# list of extracted features and corresponding labels
print("[INFO] extracting image features...")
imagePaths = paths.list_images(args["dataset"])
data = []
labels = []
# loop over our input images
for imagePath in imagePaths:
# load the input image from disk, compute color channel
# statistics, and then update our data list
image = Image.open(imagePath)
features = extract_color_stats(image)
data.append(features)
# extract the class label from the file path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
我们的imagePaths是在线 53 上提取的。这只是路径本身的列表,我们将很快加载每个实际的图像。
我定义了两个列表,data和labels ( 第 54 行和第 55 行)。列表data将保存我们的图像特征向量和对应的类labels。知道每个图像的标签允许我们训练我们的机器学习模型来自动预测我们的测试图像的类别标签。
线 58-68 在imagePaths上形成一个环,以便:
- 加载每个
image( 行 61 )。 - 使用之前定义的函数(第 62 行)从
image提取一个颜色统计特征向量(每个通道的平均值和标准偏差)。 - 然后在第 63 行的上,特征向量被添加到我们的
data列表中。 - 最后,从路径中提取出类
label,并附加到相应的labels列表中(第 67 行和第 68 行)。
现在,让我们编码我们的labels并构造我们的数据分割:
# encode the labels, converting them from strings to integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# perform a training and testing split, using 75% of the data for
# training and 25% for evaluation
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25)
使用LabelEncoder ( 第 71 行和第 72 行)将我们的文本labels转换成表示标签的整数:
(pdb) labels = le.fit_transform(labels)
(pdb) set(labels)
{0, 1, 2}
正如在我们的虹膜分类脚本中,我们将数据分成 75%用于训练,25%用于测试(第 76 行和第 77 行)。
最后,我们可以训练和评估我们的模型:
# train the model
print("[INFO] using '{}' model".format(args["model"]))
model = models[args["model"]]
model.fit(trainX, trainY)
# make predictions on our data and show a classification report
print("[INFO] evaluating...")
predictions = model.predict(testX)
print(classification_report(testY, predictions,
target_names=le.classes_))
这些行几乎与虹膜分类脚本相同。我们正在调整(训练)我们的model并评估它(第 81-86 行)。一个classification_report被打印在终端中,以便我们可以分析结果(第 87 行和第 88 行)。
说到结果,现在我们已经完成了classify_irs.py和classify_images.py的实现,让我们使用 7 种 Python 机器学习算法中的每一种来测试它们。
k-最近邻
Figure 6: The k-Nearest Neighbor (k-NN) method is one of the simplest machine learning algorithms.
k-最近邻分类器是迄今为止最简单的图像分类算法。
事实上,它是如此简单,以至于它实际上并没有“学习”任何东西。相反,该算法依赖于特征向量之间的距离。简单来说,k-NN 算法通过在 k 最接近的例子中找到最常见的类来对未知数据点进行分类。
第 k 个最接近的数据点中的每个数据点进行投票,票数最高的类别获胜!
或者,说白了:“告诉我你的邻居是谁,我就知道你是谁。”
例如,在上面的图 6 中,我们看到了三组花卉:
- 黛丝
- 短裤
- 向日葵
我们已经根据花瓣的亮度(颜色)和花瓣的大小绘制了每一幅花的图像(这是一个任意的例子,所以请原谅我的不正式)。
我们可以清楚地看到图像是一朵向日葵,但是如果我们的新图像与一朵三色堇和两朵向日葵的距离相等,k-NN 会怎么想?
嗯,k-NN 将检查三个最近的邻居( k=3 ),因为向日葵有两票,三色紫罗兰有一票,所以向日葵类将被选中。
要将 k-NN 投入使用,请确保您已经使用了本教程的“下载”部分来下载源代码和示例数据集。
从那里,打开一个终端并执行以下命令:
$ python classify_iris.py
[INFO] loading data...
[INFO] using 'knn' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.92 0.92 0.92 12
virginica 0.91 0.91 0.91 11
micro avg 0.95 0.95 0.95 38
macro avg 0.94 0.94 0.94 38
这里你可以看到 k-NN 在 Iris 数据集上获得了 95%的准确率,这是一个不错的开始!
让我们来看看我们的 3 场景数据集:
python classify_images.py --model knn
[INFO] extracting image features...
[INFO] using 'knn' model
[INFO] evaluating...
precision recall f1-score support
coast 0.84 0.68 0.75 105
forest 0.78 0.77 0.77 78
highway 0.56 0.78 0.65 54
micro avg 0.73 0.73 0.73 237
macro avg 0.72 0.74 0.72 237
weighted avg 0.75 0.73 0.73 237
在 3 场景数据集上,k-NN 算法获得了 75%的准确率。
特别是,k-NN 正在努力识别“高速公路”类(约 56%的准确率)。
在本教程的剩余部分,我们将探索提高图像分类精度的方法。
关于 k-最近邻算法如何工作的更多信息,请务必参考这篇文章。
朴素贝叶斯
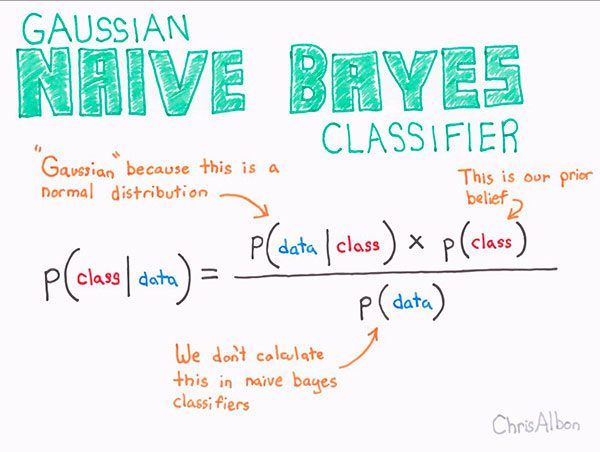
Figure 7: The Naïve Bayes machine learning algorithm is based upon Bayes’ theorem (source).
在 k-NN 之后,朴素贝叶斯通常是从业者将研究的第一个真正的机器学习算法。
该算法本身自 20 世纪 50 年代以来就已经存在,并经常用于为未来的实验获取基线(特别是在与文本检索相关的领域)。
朴素贝叶斯算法由于贝叶斯定理而成为可能(图 7 )。
本质上,朴素贝叶斯将分类表述为一种预期概率。
给定我们的输入数据, D ,我们寻求计算给定类别的概率, C 。
形式上,这变成了 P(C | D) 。
为了实际计算概率,我们计算图 7 的分子(忽略分母)。
该表达式可以解释为:
- 计算给定类的输入数据的概率(例如。给定的花是具有 4.9 厘米萼片长度的鸢尾的概率)
- 然后乘以我们在整个数据群体中遇到该类的概率(例如甚至首先遇到鸢尾 Setosa 类的概率)
让我们继续将朴素贝叶斯算法应用于虹膜数据集:
$ python classify_iris.py --model naive_bayes
[INFO] loading data...
[INFO] using 'naive_bayes' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.92 0.96 12
virginica 0.92 1.00 0.96 11
micro avg 0.97 0.97 0.97 38
macro avg 0.97 0.97 0.97 38
weighted avg 0.98 0.97 0.97 38
我们现在达到了 98%的准确率,比 k-NN 算法有了显著的提高!
现在,让我们将朴素贝叶斯应用于 3 场景数据集进行图像分类:
$ python classify_images.py --model naive_bayes
[INFO] extracting image features...
[INFO] using 'naive_bayes' model
[INFO] evaluating...
precision recall f1-score support
coast 0.69 0.40 0.50 88
forest 0.68 0.82 0.74 84
highway 0.61 0.78 0.68 65
micro avg 0.65 0.65 0.65 237
macro avg 0.66 0.67 0.64 237
weighted avg 0.66 0.65 0.64 237
啊哦!
看起来我们在这里只获得了 66%的准确率。
这是否意味着 k-NN 比朴素贝叶斯更好,我们应该总是使用 k-NN 进行图像分类?
没那么快。
我们在这里可以说的是,对于这个特定项目和这个特定的提取特征集,k-NN 机器学习算法优于朴素贝叶斯。
我们不能说 k-NN 比朴素贝叶斯好,我们应该总是用 k-NN 代替。
认为一种机器学习算法总是比另一种更好是我看到许多新的机器学习从业者陷入的一个陷阱——不要犯这个错误。
有关朴素贝叶斯机器学习算法的更多信息,请务必参考这篇优秀文章。
逻辑回归
图 8: 逻辑回归是一种基于逻辑函数始终在【0,1】范围内的机器学习算法。类似于线性回归,但是基于不同的函数,每个机器学习和 Python 爱好者都需要知道逻辑回归(来源)。
我们要探索的下一个机器学习算法是逻辑回归。
逻辑回归是一种监督分类算法,通常用于预测类别标签的概率(逻辑回归算法的输出总是在【0,1】范围内)。
逻辑回归在机器学习中被大量使用,并且是任何机器学习从业者在其 Python 工具箱中需要逻辑回归的算法。
让我们将逻辑回归应用于 Iris 数据集:
$ python classify_iris.py --model logit
[INFO] loading data...
[INFO] using 'logit' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.92 0.96 12
virginica 0.92 1.00 0.96 11
micro avg 0.97 0.97 0.97 38
macro avg 0.97 0.97 0.97 38
weighted avg 0.98 0.97 0.97 38
在这里我们能够获得 98%的分类准确率!
此外,请注意,Setosa 和 Versicolor 类的分类 100%正确!
现在让我们将逻辑回归应用于图像分类的任务:
$ python classify_images.py --model logit
[INFO] extracting image features...
[INFO] using 'logit' model
[INFO] evaluating...
precision recall f1-score support
coast 0.67 0.67 0.67 92
forest 0.79 0.82 0.80 82
highway 0.61 0.57 0.59 63
micro avg 0.70 0.70 0.70 237
macro avg 0.69 0.69 0.69 237
weighted avg 0.69 0.70 0.69 237
逻辑回归在这里的表现略好于朴素贝叶斯,获得了 69%的准确率,但是为了击败 k-NN,我们需要一个更强大的 Python 机器学习算法。
支持向量机
Figure 9: Python machine learning practitioners will often apply Support Vector Machines (SVMs) to their problems. SVMs are based on the concept of a hyperplane and the perpendicular distance to it as shown in 2-dimensions (the hyperplane concept applies to higher dimensions as well).
支持向量机(SVM)是非常强大的机器学习算法,能够通过内核技巧学习非线性数据集上的分离超平面。
如果一组数据点在一个 N 维空间中不是线性可分的,我们可以将它们投影到一个更高维度——也许在这个更高维度的空间中,数据点是线性可分的。
支持向量机的问题是,调整 SVM 上的旋钮以使其正常工作可能是一件痛苦的事情,尤其是对于新的 Python 机器学习实践者来说。
使用支持向量机时,通常需要对数据集进行多次实验来确定:
- 适当的核类型(线性、多项式、径向基函数等。)
- 内核函数的任何参数(例如多项式的次数)
如果一开始,你的 SVM 没有获得合理的精度,你会想回去调整内核和相关参数——调整 SVM 的这些旋钮对于获得一个好的机器学习模型至关重要。也就是说,让我们将 SVM 应用于虹膜数据集:
$ python classify_iris.py --model svm
[INFO] loading data...
[INFO] using 'svm' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.92 0.96 12
virginica 0.92 1.00 0.96 11
micro avg 0.97 0.97 0.97 38
macro avg 0.97 0.97 0.97 38
weighted avg 0.98 0.97 0.97 38
就像逻辑回归一样,我们的 SVM 获得了 98%的准确率 —为了在 SVM 的虹膜数据集上获得 100%的准确率,我们需要进一步调整内核的参数。
让我们将 SVM 应用于 3 场景数据集:
$ python classify_images.py --model svm
[INFO] extracting image features...
[INFO] using 'svm' model
[INFO] evaluating...
precision recall f1-score support
coast 0.84 0.76 0.80 92
forest 0.86 0.93 0.89 84
highway 0.78 0.80 0.79 61
micro avg 0.83 0.83 0.83 237
macro avg 0.83 0.83 0.83 237
哇,83%的准确率!
这是迄今为止我们看到的最好的精确度!
显然,如果调整得当,支持向量机非常适合非线性可分数据集。
决策树
Figure 10: The concept of Decision Trees for machine learning classification can easily be explained with this figure. Given a feature vector and “set of questions” the bottom leaf represents the class. As you can see we’ll either “Go to the movies” or “Go to the beach”. There are two leaves for “Go to the movies” (nearly all complex decision trees will have multiple paths to arrive at the same conclusion with some shortcutting others).
决策树背后的基本思想是将分类分解成关于我们的特征向量中每个条目的一组选择。
我们从树根开始,然后向下进行到树叶,在树叶中进行实际的分类。
与许多机器学习算法不同,例如可能表现为“黑盒”学习算法(其中做出决策的路线可能很难解释和理解),决策树可以非常直观——我们实际上可以可视化并且解释树正在做出的选择,然后遵循适当的路径进行分类。
例如,让我们假设我们要去海滩度假。我们在假期的第一天早上醒来,查看天气预报——阳光明媚,华氏 90 度。
这就给我们留下了一个决定:“我们今天应该做什么?去海边?还是看电影?”
潜意识里,我们可能会通过构建自己的决策树来解决问题(图 10 )。
首先,我们需要知道外面是不是晴天。
快速查看一下我们智能手机上的天气应用程序,证实天气确实晴朗。
然后,我们沿着 Sunny=Yes 分支,到达下一个决策点——室外温度是否高于 70 度?
同样,在检查天气应用程序后,我们可以确认今天室外温度将超过 70 度。
沿着 > 70=Yes 分支,我们找到了一片树叶,最终决定——看起来我们要去海滩了!
在内部,决策树检查我们的输入数据,并使用 CART 或 ID3 等算法寻找最佳的可能节点/值进行分割。然后自动为我们建立树,我们能够做出预测。
让我们继续将决策树算法应用于 Iris 数据集:
$ python classify_iris.py --model decision_tree
[INFO] loading data...
[INFO] using 'decision_tree' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.92 0.92 0.92 12
virginica 0.91 0.91 0.91 11
micro avg 0.95 0.95 0.95 38
macro avg 0.94 0.94 0.94 38
weighted avg 0.95 0.95 0.95 38
我们的决策树能够获得 95%的准确率。
我们的图像分类项目呢?
$ python classify_images.py --model decision_tree
[INFO] extracting image features...
[INFO] using 'decision_tree' model
[INFO] evaluating...
precision recall f1-score support
coast 0.71 0.74 0.72 85
forest 0.76 0.80 0.78 83
highway 0.77 0.68 0.72 69
micro avg 0.74 0.74 0.74 237
macro avg 0.75 0.74 0.74 237
weighted avg 0.74 0.74 0.74 237
在这里,我们获得了 74%的准确率(T1),这不是最好的,但肯定也不是最差的。
随机森林
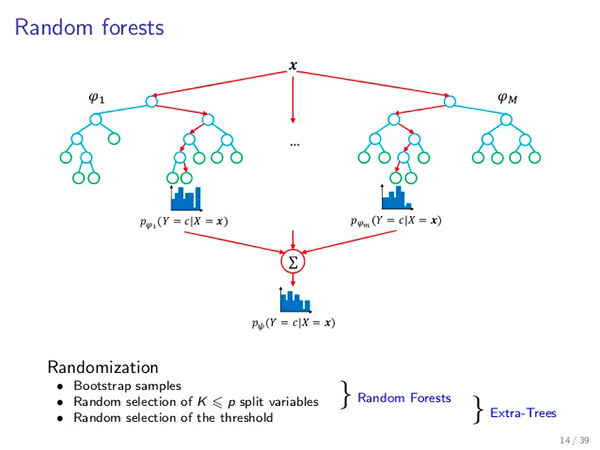
Figure 11: A Random Forest is a collection of decision trees. This machine learning method injects a level of “randomness” into the algorithm via bootstrapping and random node splits. The final classification result is calculated by tabulation/voting. Random Forests tend to be more accurate than decision trees. (source)
因为森林是树的集合,所以随机森林是决策树的集合。
然而,顾名思义,随机森林注入了决策树中不存在的“随机性”——这种随机性应用于算法中的两个点。
- 自举 —随机森林分类器在来自原始训练数据的自举样本上训练每个单独的决策树。从本质上来说,自举就是用替换共 D 次。自举用于提高我们的机器学习算法的准确性,同时降低过拟合的风险。
- 节点分裂中的随机性 —对于随机森林训练的每个决策树,随机森林将仅给予决策树可能特征的部分。
在实践中,通过为每棵树引导训练样本来将随机性注入到随机森林分类器中,随后仅允许特征的子集用于每棵树,通常会产生更准确的分类器。
在预测时,查询每个决策树,然后元随机森林算法将最终结果制成表格。
让我们在 Iris 数据集上尝试我们的随机森林:
$ python classify_iris.py --model random_forest
[INFO] loading data...
[INFO] using 'random_forest' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.83 0.91 12
virginica 0.85 1.00 0.92 11
micro avg 0.95 0.95 0.95 38
macro avg 0.95 0.94 0.94 38
weighted avg 0.96 0.95 0.95 38
正如我们所看到的,我们的随机森林获得了 96%的准确率,比只使用一个决策树要好一些。
但是对于图像分类呢?
随机森林适合我们的 3 场景数据集吗?
$ python classify_images.py --model random_forest
[INFO] extracting image features...
[INFO] using 'random_forest' model
[INFO] evaluating...
precision recall f1-score support
coast 0.80 0.83 0.81 84
forest 0.92 0.84 0.88 90
highway 0.77 0.81 0.79 63
micro avg 0.83 0.83 0.83 237
macro avg 0.83 0.83 0.83 237
weighted avg 0.84 0.83 0.83 237
使用一个随机森林,我们能够获得 84%的准确率,比使用 T2 决策树好了整整 10%。
一般来说,如果你发现决策树很适合你的机器学习和 Python 项目,你可能也想试试随机森林!
神经网络
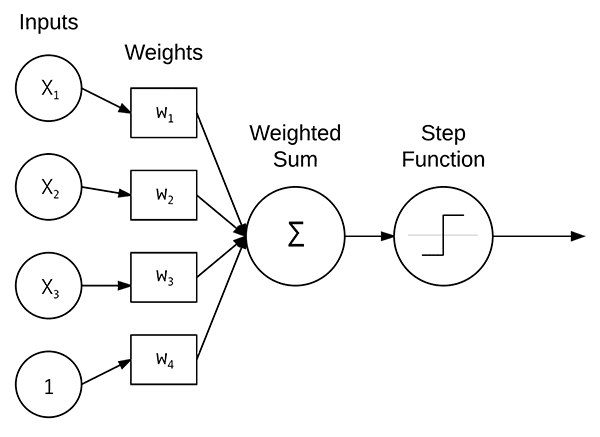
Figure 12: Neural Networks are machine learning algorithms which are inspired by how the brains work. The Perceptron, a linear model, accepts a set of weights, computes the weighted sum, and then applies a step function to determine the class label.
最常见的神经网络模型之一是感知器,一种用于分类的线性模型。
感知器接受一组输入,获取输入和权重之间的点积,计算加权和,然后应用阶跃函数来确定输出类别标签。
我们通常不使用原始的感知器公式,因为我们现在有更先进的机器学习和深度学习模型。此外,由于反向传播算法的出现,我们可以训练多层感知器(MLP)。
结合非线性激活函数,MLPs 也可以求解非线性可分离数据集。
让我们使用 Python 和 scikit-learn 将多层感知器机器学习算法应用于我们的虹膜数据集:
$ python classify_iris.py --model mlp
[INFO] loading data...
[INFO] using 'mlp' model
[INFO] evaluating...
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.92 0.96 12
virginica 0.92 1.00 0.96 11
micro avg 0.97 0.97 0.97 38
macro avg 0.97 0.97 0.97 38
weighted avg 0.98 0.97 0.97 38
我们的 MLP 在这里表现很好,获得了 98%的分类准确率。
让我们继续使用 MLP 进行图像分类:
$ python classify_images.py --model mlp
[INFO] extracting image features...
[INFO] using 'mlp' model
[INFO] evaluating...
precision recall f1-score support
coast 0.72 0.91 0.80 86
forest 0.92 0.89 0.90 79
highway 0.79 0.58 0.67 72
micro avg 0.80 0.80 0.80 237
macro avg 0.81 0.79 0.79 237
weighted avg 0.81 0.80 0.80 237
MLP 在这里达到了 81%的准确率——考虑到模型的简单性,这已经相当不错了!
深度学习和深度神经网络

Figure 13: Python is arguably the most popular language for Deep Learning, a subfield of machine learning. Deep Learning consists of neural networks with many hidden layers. The process of backpropagation tunes the weights iteratively as data is passed through the network. (source)
如果你对机器学习和 Python 感兴趣,那么你可能也遇到过术语深度学习。
深度学习到底是什么?
它与标准的机器学习有何不同?
好吧,首先,理解深度学习是机器学习的一个子领域是非常重要的,而机器学习又是更大的人工智能(AI)领域的一个子领域。
术语“深度学习”来自于训练具有许多隐藏层的神经网络。
事实上,在 20 世纪 90 年代,训练具有两个以上隐藏层的神经网络是非常具有挑战性的,原因是(解释杰夫·辛顿):
- 我们标记的数据集太小了
- 我们的计算机太慢了
- 无法在训练前正确初始化我们的神经网络权重
- 使用错误类型的非线性函数
现在情况不同了。我们现在有:
- 更快的计算机
- 高度优化的硬件(即 GPU)
- 大型标注数据集
- 更好地理解权重初始化
- 卓越的激活功能
所有这些都在正确的时间达到了高潮,产生了深度学习的最新化身。
很有可能,如果你正在阅读这个关于机器学习的教程,那么你很可能也对深度学习感兴趣!
为了获得一些关于神经网络的经验,让我们用 Python 和 Keras 实现一个。
打开nn_iris.py并插入以下代码:
# import the necessary packages
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import load_iris
# load the Iris dataset and perform a training and testing split,
# using 75% of the data for training and 25% for evaluation
print("[INFO] loading data...")
dataset = load_iris()
(trainX, testX, trainY, testY) = train_test_split(dataset.data,
dataset.target, test_size=0.25)
# encode the labels as 1-hot vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
让我们导入我们的包。
我们的 Keras 导入用于创建和训练我们简单的神经网络(第 2-4 行)。至此,您应该认识到 scikit-learn 导入(第 5-8 行)。
我们将继续加载+分割我们的数据,并在第 13-20 行一次性编码我们的标签。一个独热编码向量由二进制元素组成,其中一个是“热”的,例如在我们的三个花类中的[0, 0, 1]或[1, 0, 0]。
现在让我们建立我们的神经网络:
# define the 4-3-3-3 architecture using Keras
model = Sequential()
model.add(Dense(3, input_shape=(4,), activation="sigmoid"))
model.add(Dense(3, activation="sigmoid"))
model.add(Dense(3, activation="softmax"))
我们的神经网络由使用 sigmoid 激活的两个完全连接的层组成。
最后一层有一个“softmax 分类器”,这基本上意味着它为我们的每个类都有一个输出,并且输出是概率百分比。
让我们继续训练和评估我们的model:
# train the model using SGD
print("[INFO] training network...")
opt = SGD(lr=0.1, momentum=0.9, decay=0.1 / 250)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=250, batch_size=16)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=16)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=dataset.target_names))
我们的model在线 30-32 编制,然后在线 33 和 34 开始培训。
正如我们前面的两个脚本一样,我们希望通过评估我们的网络来检查性能。这是通过对我们的测试数据进行预测,然后打印一份分类报告来完成的(第 38-40 行)。
在这短短的 40 行代码中,隐藏着许多东西。对于神经网络基础知识的深入演练,请参考使用 Python 进行计算机视觉深度学习的入门包或 PyImageSearch 大师课程。
*我们到了关键时刻— 我们的神经网络在虹膜数据集上会有怎样的表现?
$ python nn_iris.py
Using TensorFlow backend.
[INFO] loading data...
[INFO] training network...
Train on 112 samples, validate on 38 samples
Epoch 1/250
2019-01-04 10:28:19.104933: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA
112/112 [==============================] - 0s 2ms/step - loss: 1.1454 - acc: 0.3214 - val_loss: 1.1867 - val_acc: 0.2368
Epoch 2/250
112/112 [==============================] - 0s 48us/step - loss: 1.0828 - acc: 0.3929 - val_loss: 1.2132 - val_acc: 0.5000
Epoch 3/250
112/112 [==============================] - 0s 47us/step - loss: 1.0491 - acc: 0.5268 - val_loss: 1.0593 - val_acc: 0.4737
...
Epoch 248/250
112/112 [==============================] - 0s 46us/step - loss: 0.1319 - acc: 0.9554 - val_loss: 0.0407 - val_acc: 1.0000
Epoch 249/250
112/112 [==============================] - 0s 46us/step - loss: 0.1024 - acc: 0.9643 - val_loss: 0.1595 - val_acc: 0.8947
Epoch 250/250
112/112 [==============================] - 0s 47us/step - loss: 0.0795 - acc: 0.9821 - val_loss: 0.0335 - val_acc: 1.0000
[INFO] evaluating network...
precision recall f1-score support
setosa 1.00 1.00 1.00 9
versicolor 1.00 1.00 1.00 10
virginica 1.00 1.00 1.00 19
avg / total 1.00 1.00 1.00 38
哇,太完美了!我们达到了 100%的准确率!
这个神经网络是我们应用的第一个Python 机器学习算法,它能够在虹膜数据集上达到 100%的准确率。
我们的神经网络在这里表现良好的原因是因为我们利用了:
- 多个隐藏层
- 非线性激活函数(即,sigmoid 激活函数)
鉴于我们的神经网络在虹膜数据集上表现如此之好,我们应该假设在图像数据集上也有类似的准确性,对吗?嗯,我们实际上有一个锦囊妙计——为了在图像数据集上获得更高的精确度,我们可以使用一种特殊类型的神经网络,称为卷积神经网络。
卷积神经网络
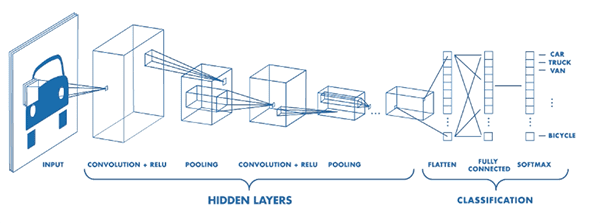
Figure 14: Deep learning Convolutional Neural Networks (CNNs) operate directly on the pixel intensities of an input image alleviating the need to perform feature extraction. Layers of the CNN are stacked and patterns are learned automatically. (source)
卷积神经网络,简称 CNN,是一种特殊类型的神经网络,非常适合图像理解任务。与大多数机器学习算法不同,CNN 直接对我们输入图像的像素强度操作——不需要执行特征提取!
在内部,CNN 中的每个卷积层都在学习一组滤波器。这些滤波器与我们的输入图像进行卷积,并且模式被自动学习。我们也可以堆叠这些卷积运算,就像神经网络中的任何其他层一样。
让我们继续学习如何实现一个简单的 CNN,并将其应用于基本的图像分类。
打开basic_cnn.py脚本并插入以下代码:
# import the necessary packages
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.optimizers import Adam
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from PIL import Image
from imutils import paths
import numpy as np
import argparse
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, default="3scenes",
help="path to directory containing the '3scenes' dataset")
args = vars(ap.parse_args())
为了用 Python 和 Keras 为机器学习构建一个卷积神经网络,我们需要在第 2-8 行的上添加五个 Keras 导入。
这一次,我们正在导入卷积层类型,最大池操作,不同的激活函数,以及扁平化的能力。此外,我们使用的是Adam优化器,而不是我们在前面的简单神经网络脚本中使用的 SGD。
至此,您应该已经熟悉了 scikit-learn 和其他导入的名称。
这个脚本只有一个命令行参数--dataset。它再次表示磁盘上 3-scenes 目录的路径。
现在让我们加载数据:
# grab all image paths in the input dataset directory, then initialize
# our list of images and corresponding class labels
print("[INFO] loading images...")
imagePaths = paths.list_images(args["dataset"])
data = []
labels = []
# loop over our input images
for imagePath in imagePaths:
# load the input image from disk, resize it to 32x32 pixels, scale
# the pixel intensities to the range [0, 1], and then update our
# images list
image = Image.open(imagePath)
image = np.array(image.resize((32, 32))) / 255.0
data.append(image)
# extract the class label from the file path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
类似于我们的classify_images.py脚本,我们将继续获取我们的imagePaths并构建我们的数据和标签列表。
这次有一点你不能忽视:
我们正在对原始像素本身而不是颜色统计特征向量进行操作。花时间再次回顾classify_images.py,并将其与basic_cnn.py的台词进行比较。
为了对原始像素强度进行操作,我们继续将每个图像的大小调整为 32×32 ,并通过除以行 36 和 37 上的255.0(像素的最大值)缩放到范围【0,1】。然后我们将调整大小和缩放后的image添加到data列表中(第 38 行)。
让我们一次性编码我们的标签,并拆分我们的培训/测试数据:
# encode the labels, converting them from strings to integers
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
# perform a training and testing split, using 75% of the data for
# training and 25% for evaluation
(trainX, testX, trainY, testY) = train_test_split(np.array(data),
np.array(labels), test_size=0.25)
然后用 Keras 建立我们的图像分类 CNN:
# define our Convolutional Neural Network architecture
model = Sequential()
model.add(Conv2D(8, (3, 3), padding="same", input_shape=(32, 32, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(16, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(3))
model.add(Activation("softmax"))
在第 55-67 行上,演示一个基本的 CNN 架构。具体细节现在并不重要,但是如果你很好奇,你应该:
- 阅读我的 Keras 教程,它会让你跟上 Keras 的步伐
- 通读我的书 用 Python 进行计算机视觉的深度学习 ,里面有超级实用的演练和动手教程
- 浏览我在 Keras Conv2D 参数上的博客文章,包括每个参数的作用以及何时使用该特定参数
让我们继续训练和评估我们的 CNN 模型:
# train the model using the Adam optimizer
print("[INFO] training network...")
opt = Adam(lr=1e-3, decay=1e-3 / 50)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=50, batch_size=32)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
我们的模型的训练和评估类似于我们之前的脚本。
让我们试试 CNN,好吗?
$ python basic_cnn.py
Using TensorFlow backend.
[INFO] loading images...
[INFO] training network...
Train on 711 samples, validate on 237 samples
Epoch 1/50
711/711 [==============================] - 0s 629us/step - loss: 1.0647 - acc: 0.4726 - val_loss: 0.9920 - val_acc: 0.5359
Epoch 2/50
711/711 [==============================] - 0s 313us/step - loss: 0.9200 - acc: 0.6188 - val_loss: 0.7778 - val_acc: 0.6624
Epoch 3/50
711/711 [==============================] - 0s 308us/step - loss: 0.6775 - acc: 0.7229 - val_loss: 0.5310 - val_acc: 0.7553
...
Epoch 48/50
711/711 [==============================] - 0s 307us/step - loss: 0.0627 - acc: 0.9887 - val_loss: 0.2426 - val_acc: 0.9283
Epoch 49/50
711/711 [==============================] - 0s 310us/step - loss: 0.0608 - acc: 0.9873 - val_loss: 0.2236 - val_acc: 0.9325
Epoch 50/50
711/711 [==============================] - 0s 307us/step - loss: 0.0587 - acc: 0.9887 - val_loss: 0.2525 - val_acc: 0.9114
[INFO] evaluating network...
precision recall f1-score support
coast 0.85 0.96 0.90 85
forest 0.99 0.94 0.97 88
highway 0.91 0.80 0.85 64
avg / total 0.92 0.91 0.91 237
使用机器学习和我们的 CNN,我们能够获得 92%的准确率,远远好于我们在本教程中尝试的任何先前的机器学习算法!
显然,CNN 非常适合解决图像理解问题。
我们的 Python +机器学习结果意味着什么?
从表面上看,你可能会想看看这篇文章的结果,并得出如下结论:
- “逻辑回归在图像分类上表现不佳,我不应该使用逻辑回归。”
- k-NN 在图像分类方面做得相当好,我将一直使用 k-NN
对这些类型的结论要小心,并记住我在本文前面详述的 5 步机器学习过程:
- 检查你的问题
- 准备您的数据(原始数据、特征提取、特征工程等)。)
- 抽查一组算法
- 检查您的结果
- 对最有效的算法加倍下注
你遇到的每一个问题在某种程度上都是不同的。
随着时间的推移,通过大量的实践和经验,你将获得一种“第六感”,知道什么样的机器学习算法在给定的情况下会工作得很好。
然而,在你达到这一点之前,你需要开始应用各种机器学习算法,检查什么有效,并在显示潜力的算法上加倍努力。
没有两个问题是相同的,在某些情况下,一个你曾经认为“差”的机器学习算法实际上会表现得很好!
摘要
在本教程中,您学习了如何开始学习机器学习和 Python。
具体来说,你学习了如何训练总共九种不同的机器学习算法:
- k-最近邻
- 朴素贝叶斯
- 逻辑回归
- 支持向量机
- 决策树
- 随机森林
- 感觉
- 多层前馈神经网络
- 卷积神经网络
然后,我们将我们的机器学习算法应用于两个不同的领域:
- 通过 Iris 数据集进行数值数据分类
- 基于 3 场景数据集的图像分类
我建议你使用本教程中的 Python 代码和相关的机器学习算法作为你自己项目的起点。
最后,请记住我们用 Python 处理机器学习问题的五个步骤(您甚至可能希望打印出这些步骤并放在身边):
- 检查你的问题
- 准备您的数据(原始数据、特征提取、特征工程等)。)
- 抽查一组算法
- 检查您的结果
- 对最有效的算法加倍下注
通过使用今天帖子中的代码,你将能够开始使用 Python 进行机器学习——享受它,如果你想继续你的机器学习之旅,请务必查看 PyImageSearch 大师课程 ,以及我的书 使用 Python 进行计算机视觉的深度学习 ,其中我详细介绍了机器学习、深度学习和计算机视觉。
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址。*
使用 Python、TensorFlow 和 Keras 进行深度学习的 macOS
原文:https://pyimagesearch.com/2017/09/29/macos-for-deep-learning-with-python-tensorflow-and-keras/

在今天的教程中,我将演示如何使用 Python、TensorFlow 和 Keras 为深度学习配置 macOS 系统。
本教程是为深度学习配置开发环境系列的最后一部分。我创建了这些教程来配合我的新书, 用 Python 进行计算机视觉的深度学习;然而,不管你是否买了我的书,你都可以使用这些说明来配置你的系统。
如果你在错误的页面(或者你没有 macOS),看看这个系列的其他深度学习开发环境教程:
- 你的深度学习+ Python Ubuntu 虚拟机
- 用 Python 预配置亚马逊 AWS 深度学习 AMI
- 用 Python 为深度学习配置 Ubuntu(仅限 CPU)
** 用 Python 设置 Ubuntu 16.04 + CUDA + GPU 进行深度学习* 使用 Python、TensorFlow 和 Keras 进行深度学习的 macOS(本文)*
要了解如何用 Python 配置 macOS 进行深度学习和计算机视觉,继续阅读。*
使用 Python、TensorFlow 和 Keras 进行深度学习的 macOS
随着你适应深度学习领域,你会想要进行许多实验来磨练你的技能,甚至解决现实世界的问题。
你会发现初学者捆绑包中的大部分章节和实践者捆绑包中的一半章节的实验可以在你的 CPU 上执行。 ImageNet 捆绑包的读者将需要一台 GPU 机器来执行更高级的实验。
我绝对不建议在你的笔记本电脑上处理大型数据集和深度神经网络,但就像我说的,对于小型实验来说,这很好。
今天,我将带您了解配置 Mac 进行深度学习的步骤。
首先,我们将安装 Xcode 和 Homebrew(一个包管理器)。在那里,我们将创建一个名为dl4cv的虚拟环境,并将 OpenCV、TensorFlow 和 Keras 安装到该环境中。
让我们开始吧。
步骤 1:安装 Xcode
首先,你需要从苹果应用商店获得 Xcode 并安装它。别担心,它是 100%免费的。
Figure 1: Selecting Xcode from the Apple App Store.
从那里,打开一个终端并执行以下命令来接受开发人员许可证:
$ sudo xcodebuild -license
下一步是安装苹果命令行工具:
$ sudo xcode-select --install
Figure 2: Accepting the Xcode license.
第二步:安装自制软件
家酿(也称为 brew),是 macOS 的软件包管理器。您的系统中可能已经有了它,但是如果没有,您将需要执行本节中的操作。
首先,我们将通过复制并粘贴整个命令到您的终端来安装 Homebrew:
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
接下来,我们将更新我们的包定义:
$ brew update
随后使用nano终端编辑器更新您的~/.bash_profile(任何其他编辑器也应该这样做):
$ nano ~/.bash_profile
将以下几行添加到文件中:
# Homebrew
export PATH=/usr/local/bin:$PATH
Figure 3: Changing ~/.bash_profile to accommodate Homebrew.
接下来,只需重新加载您的~/.bash_profile(当一个新的终端打开时,这将自动发生):
$ source ~/.bash_profile
现在 Brew 已经准备好了,让我们安装 Python 3。
步骤 3:安装 macOS 版的 Homebrew Python 3
这一步其实很容易,但是我想先理清一些可能的困惑。
macOS 自带 Python 安装;然而,我们将使用 Brew 安装一个非系统 Python。虽然你可以使用你的系统 Python,但实际上是 极力劝阻 。因此,不要跳过这一步,这对您的成功安装非常重要。
要用 Homebrew 安装 Python 3,只需执行以下命令:
$ brew install python3
在继续之前,您需要验证您的 Python 3 安装是自制的,而不是 macOS 系统的:
$ which python3
/usr/local/bin/python3
$ which pip3
/usr/local/bin/pip3
确保在每个路径中都看到“local”。如果您没有看到这个输出,那么您没有使用 Homebrew 的 Python 3 安装。
Figure 4: Executing which python3 and which pip3 to ensure that you are using the Homebrew version of each rather than the system version.
假设您的 Python 3 安装工作正常,让我们继续进行步骤#4 。
步骤 4:创建您的 Python 虚拟环境
正如我在本网站的其他安装指南中所述,虚拟环境绝对是使用 Python 时的必由之路,使您能够在沙盒环境中适应不同的版本。
换句话说,你不太可能去做一些让人头疼的事情。如果您搞乱了一个环境,您可以简单地删除该环境并重新构建它。
$ pip3 install virtualenv virtualenvwrapper
从那里,我们将再次更新我们的~/.bash_profile:
$ nano ~/.bash_profile
我们将在文件中添加以下几行:
# virtualenv and virtualenvwrapper
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
Figure 5: The bottom of our ~/.bash_profile should contain these lines for virtualenv and virtualenvwrapper.
然后重新加载文件:
$ source ~/.bash_profile
创建“dl4cv”环境
这个dl4cv环境将包含我们所有的软件,用于执行与我的书相关的实验。您可以随意命名这个环境,但是从现在开始,我们将把它称为dl4cv。
要使用 Python 3 创建 dl4cv 环境,只需输入以下命令:
$ mkvirtualenv dl4cv -p python3
在 Python 3 和支持脚本被安装到新环境中之后,您实际上应该已经在环境的中了。这在 bash 提示符的开头用“(dl4cv)”表示,如下图所示:
Figure 6: The (dl4cv) in the bash prompt signifies that we are working inside the dl4cv virtual environment. If you don’t see this, then execute workon dl4cv to activate the environment.
如果您没有看到修改后的 bash 提示符,那么您可以随时输入以下命令来随时进入环境:
$ workon dl4cv
OpenCV 需要的唯一 Python 依赖项是 NumPy,我们可以在下面安装它:
$ pip install numpy
这就是创建虚拟环境和安装 NumPy 的全部内容。让我们继续步骤#5 。
步骤 5:使用自制软件安装 OpenCV 先决条件
需要安装以下工具来进行编译、映像 I/O 和优化:
$ brew install cmake pkg-config wget
$ brew install jpeg libpng libtiff openexr
$ brew install eigen tbb
安装完这些包之后,我们就可以安装 OpenCV 了。
步骤 6:编译并安装 OpenCV
首先,让我们下载源代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/3.3.0.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/3.3.0.zip
然后打开档案:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
接下来用 CMake 配置构建(非常重要的是,您要完全复制 CMake 命令,就像它在这里出现的那样,注意复制并越过整个命令;我建议点击下面工具栏中的 " < = > " 按钮展开整个命令)😗***
$ cd ~/opencv-3.3.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.3.0/modules \
-D PYTHON3_LIBRARY=`python -c 'import subprocess ; import sys ; s = subprocess.check_output("python-config --configdir", shell=True).decode("utf-8").strip() ; (M, m) = sys.version_info[:2] ; print("{}/libpython{}.{}.dylib".format(s, M, m))'` \
-D PYTHON3_INCLUDE_DIR=`python -c 'import distutils.sysconfig as s; print(s.get_python_inc())'` \
-D PYTHON3_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_python3=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D BUILD_EXAMPLES=ON ..
注意:对于上面的 CMake 命令,我花了相当多的时间来创建、测试和重构它。我相信,如果你完全按照它显示的那样使用它,它会节省你的时间和挫折。确保点击上面代码块工具栏中的“< = >”按钮,展开代码块。这将使你能够复制并粘贴整个命令。**
您的输出应该类似于下面的屏幕截图,确保使用了正确的 Python 3 二进制/库和 NumPy 版本:
Figure 7: The OpenCV CMake output that ensures the correct Python 3 and NumPy will be used for compiling.
然后我们准备执行编译编译 OpenCV:
$ make -j4
注:上面的数字“4”表示我们有 4 个内核/处理器用于编译。如果您有不同数量的处理器,您可以更新-j开关。对于只有一个内核/处理器,只需使用make命令(如果构建失败或停滞,在重试之前,从构建目录输入make clean)。
从那里您可以安装 OpenCV:
$ sudo make install
安装后,有必要将cv2.so文件符号链接到dl4cv虚拟环境中:
$ cd ~/.virtualenvs/dl4cv/lib/python3.6/site-packages/
$ ln -s /usr/local/lib/python3.6/site-packages/cv2.cpython-36m-darwin.so cv2.so
$ cd ~
最后,我们可以测试安装:
$ python
>>> import cv2
>>> cv2.__version__
'3.3.0'
Figure 8: OpenCV 3.3 has been installed and linked as is shown by the successful import and display of the version.
如果您的输出正确地显示了您安装的 OpenCV 版本,那么您就可以继续进行步骤#7 了,我们将在那里安装 Keras 深度学习库。
Step #7: Install Keras
在开始这一步之前,确保您已经激活了dl4cv virtualenv。如果您不在该环境中,只需执行:
$ workon dl4cv
然后,使用pip,安装所需的 Python 计算机视觉、图像处理和机器学习库:
$ pip install scipy pillow
$ pip install imutils h5py requests progressbar2
$ pip install scikit-learn scikit-image
接下来安装 matplotlib 并更新渲染后端:
$ pip install matplotlib
$ touch ~/.matplotlib/matplotlibrc
$ echo "backend: TkAgg" >> ~/.matplotlib/matplotlibrc
然后,安装 TensorFlow:
$ pip install tensorflow
其次是 keras:
$ pip install keras
要验证 Keras 是否正确安装,我们可以导入它并检查错误:
$ python
>>> import keras
Using TensorFlow backend.
>>>
Keras 应该被正确导入,同时声明 TensorFlow 被用作后端。

Figure 9: Keras is successfully installed into the dl4cv virtual environment.
此时,您可以熟悉一下~/.keras/keras.json文件:
{
"image_data_format": "channels_last",
"backend": "tensorflow",
"epsilon": 1e-07,
"floatx": "float32"
}
确保image_data_format设置为channels_last并且backend设置为tensorflow。
恭喜恭喜! 你现在可以出发了。如果您在安装过程中没有打开啤酒或咖啡,现在是时候了。也是时候找个舒服的地方读读 用 Python 做计算机视觉的深度学习 。
摘要
在今天的帖子中,我们为计算机视觉和深度学习配置了我们的 macOS 盒子。软件的主要部分包括 Python 3、OpenCV、TensorFlow 和 Keras,并附有依赖项和安装/编译工具。
正如您所看到的,利用自制软件、pip 和 virtualenv + virtualenvwrapper 使安装变得相当容易。我花了相当多的时间来创建和测试 CMake 命令,它应该很容易在您的计算机上运行。一定要试一试。
如果您在此过程中遇到任何问题,请在下面的表格中留下您的评论。
如果你想很好地利用你新配置的 macOS 深度学习环境,我强烈建议你看看我的新书, 用 Python 进行计算机视觉的深度学习 。
不管你是深度学习的新手还是已经是经验丰富的实践者,这本书都有内容可以帮助你掌握深度学习——看这里。*****
macOS:安装 OpenCV 3 和 Python 2.7
原文:https://pyimagesearch.com/2016/11/28/macos-install-opencv-3-and-python-2-7/

我承认:在 macOS Sierra 上编译和安装 OpenCV 3 比我想象的要困难得多,即使对于一生中在数百台机器上编译过 OpenCV 的人来说也是如此。**
*如果你试图使用我以前的教程中的一个在你新升级的 Mac (Sierra 或更高版本)上安装 OpenCV,你可能会遇到一些错误,特别是关于QTKit.h头文件。
甚至如果您能够解决 QTKit 问题,您可能会遇到更多的问题,试图让您的 CMake 命令配置正确。
为了帮助解决在 macOS Sierra(或更高版本)上安装带有 Python 绑定的 OpenCV 时的任何问题、难题或困惑,我决定创建两个超详细教程:
- 第一篇教程讲述了如何在 macOS 上安装带有 Python 2.7 绑定的 OpenCV 3。
- 我的第二篇教程将在下周发布,届时我将演示如何在 macOS 上安装带有 Python 3.5 绑定的 OpenCV 3。
我决定将这些教程分成两篇独立的博文,因为它们相当冗长。
此外,调整您的 CMake 命令以使其完全正确可能有点困难,特别是如果您是从源代码编译 OpenCV 的新手,所以我想花时间设计一个简单的方法来帮助读者将 OpenCV 安装在 macOS 上。
要了解如何在 macOS 系统上安装 OpenCV 和 Python 2.7 绑定,继续阅读。
macOS:安装 OpenCV 3 和 Python 2.7
这篇博文的第一部分详细介绍了为什么我要创建一个新的教程,在 Mac 操作系统上安装 OpenCV 3 和 Python 绑定。特别是,我解释了您可能遇到的一个常见错误——来自现在已被否决的 QTKit 库的QTKit.h头问题。
从那里,我提供了如何在 macOS Sierra 系统或更高版本上安装 OpenCV 3 + Python 2.7 的详细说明。
避免 QTKit/QTKit.h 文件未找到错误
在 Mac OSX 环境中,QTKit (QuickTime Kit) Objective-C 框架用于操作、读取和写入媒体。在 OSX 版本 10.9 (Mavericks)中,QTKit 被弃用( source )。
然而,直到发布了 macOS Sierra,QTKit 的大部分内容才被移除,取而代之的是 QTKit 的继任者 AVFoundation 。AVFoundation 是在 iOS 和 macOS 中处理视听媒体的新框架。
当在 Mac 系统上编译 OpenCV 时,这产生了一个大问题——Qt kit 头在系统上找不到,并且应该存在。
因此,如果你试图在你的 Mac 上使用我以前的教程编译 OpenCV,你的编译可能会失败,你最终会得到一个类似下面的错误信息:
fatal error:
'QTKit/QTKit.h' file not found
#import <QTKit/QTKit.h>
^ 1 error generated. make[2]: *** [modules/videoio/CMakeFiles/opencv_videoio.dir/src/cap_qtkit.mm.o]
Error 1 make[1]: ***
[modules/videoio/CMakeFiles/opencv_videoio.dir/all] Error 2 make: ***
[all] Error 2
更有问题的是,OpenCV v3.0 和 3.1 的标记版本都不包含对这个问题的修复。
也就是说,对 OpenCV GitHub repo 的最新提交确实解决了这个问题;然而,一个新的带标签的 3.2 版本还没有发布。
也就是说,我很高兴地报告,通过使用 OpenCV 的 GitHub 的最新提交,我们可以在 macOS Sierra 和更高版本上安装 OpenCV。
诀窍在于,我们需要使用回购的HEAD,而不是带标签的释放。
一旦 OpenCV 3.2 发布,我敢肯定 QKit 到 AVFoundation 的迁移将包括在内,但在此之前,如果你想在运行 Sierra 或更高版本的 macOS 系统上安装 OpenCV 3,你需要避免使用标记版本,而是编译并安装 OpenCV 3 的开发版本。
如何检查我的 Mac 操作系统版本?
要检查您的 Mac OS 版本,请在菜单中点击屏幕左上角的苹果图标,然后选择“关于这台 Mac”。
然后会弹出一个窗口,如下所示:

Figure 1: Checking your OS version on Mac. My machine is currently running macOS Sierra (10.12).
如果您运行的是 macOS Sierra 或更高版本,您可以使用本教程来帮助您安装 OpenCV 3 和 Python 2.7 绑定。
如果你用的是老版本的 Mac 操作系统(Mavericks,Yosemite 等。),请参考我的以前的教程。
步骤 1:安装 Xcode
在我们考虑编译 OpenCV 之前,我们首先需要安装 Xcode,这是一套完整的 Mac 操作系统软件开发工具。
注册一个苹果开发者账户
在下载 Xcode 之前,你需要注册苹果开发者计划(免费)。如果你有一个现有的 Apple ID(即你用来登录 iTunes 的 ID ),这就更容易了。简单提供一些基本信息如姓名、地址等。你就一切就绪了。
从那里,最简单的下载 Xcode 的方法是通过 App Store。在搜索栏中搜索“Xcode”,选中后点击“Get”按钮:

Figure 2: Selecting Xcode from the Apple App Store.
Xcode 将开始下载和安装。在我的机器上,下载和安装过程大约需要 30 分钟。
接受苹果开发者许可
假设这是你第一次安装或使用 Xcode,你需要接受开发者许可(否则,你可以跳过这一步)。我更喜欢尽可能使用终端。您可以使用以下命令来接受 Apple Developer 许可证:
$ sudo xcodebuild -license
滚动到许可证的底部并接受它。
安装 Apple 命令行工具
最后,我们需要安装命令行工具。这些工具包括 make、GCC、clang 等包。这是绝对必需的一步,所以确保你安装了命令行工具:
$ sudo xcode-select --install
输入上面的命令后,会弹出一个窗口,确认您要安装命令行工具:

Figure 3: Installing the Apple Command Line Tools on macOS.
点击“安装”,苹果命令行工具将被下载并安装到您的系统上。这应该不到 5 分钟。
第二步:安装自制软件
我们现在准备安装家酿,一个 macOS 的包管理器。对于基于 Ubuntu 和 Debian 的系统,可以把 Homebrew 想象成类似于的 apt-get 。
安装家酿很简单。只需将家酿网站“安装家酿”部分下的命令复制并粘贴到您的终端中(确保您复制并粘贴了整个命令):
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
一旦安装了 Homebrew,您应该更新它以确保下载了最新的软件包定义:
$ brew update
最后一步是更新我们的~/.bash_profile文件。该文件可能已经存在于您的系统中,也可能不存在。无论哪种情况,用您最喜欢的文本编辑器打开它(在这种情况下,我将使用nano):
$ nano ~/.bash_profile
并在文件底部插入以下几行(如果~/.bash_profile不存在,文件将是空的,因此只需插入以下几行):
# Homebrew
export PATH=/usr/local/bin:$PATH
上面的代码片段更新了您的PATH变量,以便在搜索您的系统路径之前沿着 Homebrew 路径查找二进制文件/库。
更新文件后,保存并退出编辑器。我在下面附上了我的~/.bash_profile截图:

Figure 4: Updating my .bash_profile file to include Homebrew.
然后,您应该使用source命令来确保对您的~/.bash_profile文件的更改被手动重新加载:
$ source ~/.bash_profile
该命令只需执行一次。每当你登录,打开一个新的终端,等等。,你的.bash_profile将会自动为你加载和获取。
步骤 3:为 Python 2.7 和 macOS 设置自制程序
一般来说,你不会想把 Python 系统作为你的主要解释器来开发。这被认为是不好的形式。Python 的系统版本应该(在理想世界中)只服务于一个目的——支持系统操作。
相反,你会希望安装你自己的 Python 版本,该版本独立于系统版本。通过自制软件安装 Python 非常简单:
$ brew install python
注:本教程讲述了如何在 macOS 上用 Python 2.7 绑定安装 OpenCV 3。下周我将讨论 OpenCV 3 与 Python 3 的绑定——如果你想在 macOS 上使用 OpenCV 的 Python 3 ,请参考下周的博客文章。
安装命令完成后,我们只需运行以下命令来完成 Python 安装:
$ brew linkapps python
为了确认我们使用的是 Python 的自制版本,而不是 Python 的系统版本,您应该使用which命令:
$ which python
/usr/local/bin/python
重要:一定要检查which命令的输出!如果你看到了/usr/local/bin/python,那么你正在正确地使用 Python 的 Hombrew 版本。
然而,如果输出是/usr/bin/python,那么你就没有正确地使用 Python 的系统版本。如果是这种情况,您应该确保:
- 自制软件安装无误。
brew install python命令成功完成。- 您已经正确更新了您的
~/.bash_profile文件,并使用source重新加载了更改。这基本上可以归结为确保你的~/.bash_profile看起来像我上面图 4 中的。
步骤 4:安装 virtualenv、virtualenvwrapper 和 NumPy
我们现在准备安装三个 Python 包: virtualenv 和 virtualenvwrapper ,以及 NumPy,用于数值处理。
安装 virtualenv 和 virtualenvwrapper
virtualenv和virtualenvwrapper包允许我们为我们正在进行的每个项目创建单独的、独立的 Python 环境。我之前已经多次提到 Python 虚拟环境,所以我不会重复已经说过的内容。相反,如果你不熟悉 Python 虚拟环境,它们是如何工作的,以及我们为什么使用它们,请参考这篇博文的前半部分。在 RealPython.com 博客的上也有一个很好的教程,深入探究 Python 虚拟环境。
要安装virtualenv和virtualenvwrapper,只需使用pip:
$ pip install virtualenv virtualenvwrapper
安装完这些包后,我们需要再次更新我们的~/.bash_profile文件:
# Virtualenv/VirtualenvWrapper
source /usr/local/bin/virtualenvwrapper.sh
更新后,您的~/.bash_profile应该与我的类似:

Figure 5: Update your .bash_profile file to include virtualenv/virtualenvwrapper.
保存并退出您的文本编辑器,然后使用source命令刷新您的环境:
$ source ~/.bash_profile
同样,该命令只需执行一次。每当你打开一个新的终端,你的.bash_profile文件的内容将会自动加载。
创建您的 Python 虚拟环境
假设以上命令没有错误地完成,我们现在可以使用mkvirtualenv命令来创建我们的 Python 虚拟环境。我们将这个 Python 虚拟环境命名为cv:
$ mkvirtualenv cv
该命令将创建一个 Python 环境,该环境独立于系统上所有其他 Python 环境的(意味着该环境有自己单独的site-packages目录,等等)。).这是我们在编译和安装 OpenCV 时将使用的虚拟环境。
*mkvirtualenv命令只需要执行一次。如果您需要再次访问这个虚拟环境,只需使用workon命令:
$ workon cv
要验证您是否在cv虚拟环境中,只需检查您的命令行——如果您在提示符前看到文本(cv),那么您 在cv虚拟环境中就是 :

Figure 6: Make sure you see the “(cv)” text on your prompt, indicating that you are in the cv virtual environment.
否则,如果你 没有 看到cv文本,那么你 在cv虚拟环境中就不是 :

Figure 7: If you do not see the “(cv)” text on your prompt, then you are not in the cv virtual environment and you need to run the “workon” command to resolve this issue before continuing.
要访问cv虚拟环境,只需使用上面提到的workon命令。
安装 NumPy
最后一步是安装 Python 的科学计算包 NumPy 。
确保您处于cv虚拟环境中(否则 NumPy 将被安装到系统版本的 Python 中,而不是cv环境中),然后使用pip安装 NumPy:
$ pip install numpy
步骤 5:使用自制软件安装 OpenCV 先决条件
OpenCV 需要一些先决条件,所有这些都可以使用自制软件轻松安装。
其中一些包与用于实际构建和编译 OpenCV 的工具相关,而其他包用于图像 I/O 操作(即,加载各种图像文件格式,如 JPEG、PNG、TIFF 等)。)
要在 macOS 上安装 OpenCV 所需的先决条件,只需执行以下命令:
$ brew install cmake pkg-config
$ brew install jpeg libpng libtiff openexr
$ brew install eigen tbb
步骤 6:从 GitHub 下载 OpenCV 3 源代码
正如我在本教程开头提到的,我们需要从最近的提交中编译 OpenCV,而不是一个带标签的发布。这就需要我们下载 OpenCV GitHub repo :
$ cd ~
$ git clone https://github.com/opencv/opencv
连同 opencv_contrib repo :
$ git clone https://github.com/opencv/opencv_contrib
步骤 7:在 macOS 上通过 CMake 配置 OpenCV 3 和 Python 2.7
在这一节中,我将详细介绍如何使用 CMake 在 macOS Sierra build 上配置 OpenCV 3 + Python 2.7。
首先,我演示如何通过创建build目录来设置您的构建。
然后,我提供了一个您可以使用的 CMake 构建模板。该模板要求您填写两个值——到您的libpython2.7.dylib文件的路径和到您的Python.h头的路径。
我会帮你找到并确定这两条路径的正确值。
最后,我提供了一个完整的 CMake 命令的示例。但是,请注意,该命令是专门针对我的机器的。由于指定的路径不同,您的 CMake 命令可能略有不同。请阅读本节的其余部分以了解更多详细信息。
设置构件
为了用 Python 2.7 支持 macOS 编译 OpenCV 3,我们需要首先设置构建。这相当于将目录更改为opencv并创建一个build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
适用于 macOS 的 OpenCV 3 + Python 2.7 CMake 模板
为了让编译安装过程更简单,我构造了以下模板 OpenCV 3 + Python 2.7 CMake 模板:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON2_LIBRARY=YYY \
-D PYTHON2_INCLUDE_DIR=ZZZ \
-D PYTHON2_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=ON \
-D BUILD_opencv_python3=OFF \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D BUILD_EXAMPLES=ON ..
看着这个模板,我想向你指出几件事:
- 这表明我们想要为 OpenCV 3 安装构建 Python 2.7 绑定。
BUILD_opencv_python3=OFF:由于我们正在编译 Python 2.7 绑定,我们需要明确声明我们不需要 Python 3 绑定。不包括这两个开关会导致 CMake 配置过程中出现问题。PYTHON2_LIBRARY=YYY:这是 第一个 值,需要你自己填写。您需要用您的libpython2.7.dylib文件的路径替换YYY(我将在下一节中帮助您找到它)。PYTHON2_INCLUDE_DIR:这是 第二个 值,您需要填写。您需要用到您的Python.h头的路径替换ZZZ(同样,我将帮助您确定这个路径)。
确定您的 Python 2.7 库和包含目录
让我们从配置您的PYTHON2_LIBRARY值开始。这个开关应该指向我们的libpython2.7.dylib文件。你可以在/usr/local/Cellar/python/的多个嵌套子目录中找到这个文件。要找到libpython2.7.dylib文件的准确的路径,只需使用ls命令和通配符星号:
$ ls /usr/local/Cellar/python/2.7.*/Frameworks/Python.framework/Versions/2.7/lib/python2.7/config/libpython2.7.dylib
/usr/local/Cellar/python/2.7.12_2/Frameworks/Python.framework/Versions/2.7/lib/python2.7/config/libpython2.7.dylib
请注意这个命令的输出— 这是您的libpython2.7.dylib文件的完整路径,将替换上面 CMake 模板中的YYY。
接下来,我们来确定PYTHON2_INCLUDE_DIR。该路径应该指向用于生成实际 OpenCV + Python 2.7 绑定的Python.h头。
同样,我们将使用相同的ls和通配符技巧来确定正确的路径:
$ ls -d /usr/local/Cellar/python/2.7.*/Frameworks/Python.framework/Versions/2.7/include/python2.7/
/usr/local/Cellar/python/2.7.12_2/Frameworks/Python.framework/Versions/2.7/include/python2.7/
ls -d命令的输出是我们到Python.h头的完整路径。 该值将替换 CMake 模板中的ZZZ。
填写 CMake 模板
现在您已经确定了PYTHON2_LIBRARY和PYTHON2_INCLUDE_DIR的值,您需要用这些值更新 CMake 命令。
在我的特定机器上, full CMake 命令如下所示:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON2_LIBRARY=/usr/local/Cellar/python/2.7.12_2/Frameworks/Python.framework/Versions/2.7/lib/python2.7/config/libpython2.7.dylib \
-D PYTHON2_INCLUDE_DIR=/usr/local/Cellar/python/2.7.12_2/Frameworks/Python.framework/Versions/2.7/include/python2.7/ \
-D PYTHON2_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=ON \
-D BUILD_opencv_python3=OFF \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D BUILD_EXAMPLES=ON ..
但是,请不要复制和粘贴我的 CMake 命令——确保您已经使用了上面的说明来正确地确定您的PYTHON2_LIBRARY和PYTHON2_INCLUDE_DIR值。
一旦你填写了这些值,执行你的cmake命令,你的 OpenCV 3 + Python 2.7 构建将被配置。
例如,看看我的配置输出的Python 2部分:

Figure 8: Ensuring that Python 2.7 will be used when compiling OpenCV 3 for macOS.
您需要确保:
Interpreter指向您的cv虚拟环境中的 Python 二进制文件。Libraries指向你的libpython2.7.dylib文件。- 正在使用的
numpy版本是您在cv虚拟环境中安装的版本。
步骤 8:在 macOS 上编译并安装 OpenCV
假设您的cmake命令正确退出并且您的Python 2部分正确配置,您现在可以编译 OpenCV:
$ make -j4
-j开关控制编译 OpenCV 的并行进程数量。我们通常将它设置为机器上可用的内核/处理器数量。由于我在四核系统上,所以我使用-j4。
OpenCV 可能需要一段时间来编译(30-90 分钟),这取决于机器的速度。成功的编译将以 100%的完成结束:

Figure 9: Successfully compiling OpenCV 3 from source with Python 2.7 bindings on macOS.
假设 OpenCV 编译无误,您现在可以在 macOS 系统上安装它了:
$ sudo make install
步骤 9: Sym-link 你的 OpenCV 3 + Python 2.7 绑定
运行完make install之后,您应该会在/usr/local/lib/python2.7/site-packages中看到一个名为cv2.so的文件:
$ cd /usr/local/lib/python2.7/site-packages/
$ ls -l cv2.so
-rwxr-xr-x 1 root admin 3694564 Nov 15 09:20 cv2.so
cv2.so文件是 OpenCV 3 + Python 2.7 绑定的实际集合。
然而,我们需要将这些绑定符号链接到我们的cv虚拟环境中。这可以使用以下命令来完成:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
$ cd ~
步骤 10:在 macOS 上测试 OpenCV 安装
要验证您在 macOS 上安装的 OpenCV 3 + Python 2.7 是否正常工作:
- 打开一个新的终端。
- 执行
workon命令来访问cvPython 虚拟环境。 - 尝试导入 Python + OpenCV 绑定。
以下是测试安装过程的具体步骤:
$ workon cv
$ python
Python 2.7.12 (default, Oct 11 2016, 05:20:59)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.38)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.1.0-dev'
>>>
注:记下cv2.__version__中的-dev。这表明我们使用的是 OpenCV 的开发版本,而不是带标签的版本。一旦 OpenCV 3.2 发布,这些指令可以被更新,只需下载一个带标签版本的. zip 文件,而不必克隆整个存储库。
我还在下面附上了一个利用这些相同步骤的截图。如您所见,我可以在 macOS Sierra 上从 Python 2.7 shell 访问我的 OpenCV 3 绑定:

Figure 10: Ensuring that I can successfully import my OpenCV 3 + Python 2.7 bindings on macOS.
恭喜你,你已经在 macOS 系统上安装了带 Python 2.7 绑定的 OpenCV 3!
那么,下一步是什么?
恭喜你。你现在在 macOS 系统上有了一个全新的 OpenCV 安装——我敢肯定你只是渴望利用你的安装来构建一些很棒的计算机视觉应用程序…
…但我也愿意打赌你刚刚开始学习计算机视觉和 OpenCV ,可能会对到底从哪里开始感到有点困惑和不知所措。
就我个人而言,我是以身作则的忠实粉丝,所以好的第一步是找点乐子,读读这篇关于在图像/视频中发现猫的博文。本教程旨在非常实用,演示如何(快速)构建一个 Python + OpenCV 应用程序来检测图像中猫的存在。
如果你真的对提升你的计算机视觉技能感兴趣,你绝对应该看看我的书《实用 Python 和 OpenCV +案例研究》。我的书不仅涵盖了计算机视觉和图像处理的基础知识,还教你如何解决现实世界的计算机视觉问题包括 图像和视频流中的人脸检测视频中的物体跟踪手写识别 。

因此,让我们在 macOS 系统上充分利用 OpenCV 3 新安装程序。
摘要
在这篇博文中,我演示了如何在 macOS Sierra 和更高版本上安装 OpenCV 3 和 Python 2.7 绑定。
下周我将有第二个教程,这一个涵盖了在 macOS 上 OpenCV 3 与 Python 3.5 的绑定。
更多其他操作系统上的 OpenCV 安装教程(如 Ubuntu、Raspbian 等。),请参考本页,我在这里提供了额外的链接和资源。
但是在你走之前
如果您有兴趣了解更多关于 OpenCV、计算机视觉和图像处理的知识,请务必在下面的表格中输入您的电子邮件地址,以便在新的博客帖子和教程发布时收到通知!**
macOS:安装 OpenCV 3 和 Python 3.5
原文:https://pyimagesearch.com/2016/12/05/macos-install-opencv-3-and-python-3-5/

上周我报道了如何在 macOS Sierra 和更高版本上安装 OpenCV 3 和 Python 2.7 绑定。
在今天的教程中,我们将学习如何在 macOS 上安装带有 Python 3.5 绑定的 OpenCV 3。
我决定将这些安装教程分成两个独立的指南,以使它们组织有序,易于理解。
要了解如何在 macOS 系统上安装 OpenCV 3 和 Python 3.5 绑定,继续阅读。
macOS:安装 OpenCV 3 和 Python 3.5
正如我在这篇文章的介绍中提到的,我上周花了时间讲述如何在 macOS 上安装 OpenCV 3 和 Python 2.7 绑定。
上周的教程和今天的教程中的许多步骤非常相似(在某些情况下是相同的),所以我试图删减每个步骤的一些解释以减少冗余。如果你发现任何步骤令人困惑或麻烦,我建议参考 OpenCV 3 + Python 2.7 教程,在那里我提供了更多的见解。
例外情况是“第 7 步:在 macOS 上通过 CMake 配置 OpenCV 3 和 Python 3.5”,其中我提供了一个关于如何配置 OpenCV 版本的 非常全面的演练 。您应该格外注意这一步,以确保您的 OpenCV 构建已经正确配置。
说了这么多,让我们继续在 macOS 上安装 OpenCV 3 和 Python 3.5 绑定。
步骤 1:安装 Xcode
在我们的系统上编译 OpenCV 之前,我们首先需要安装 Xcode,这是苹果公司为 Mac 操作系统提供的一套软件开发工具。
下载 Xcode 最简单的方法是打开桌面上的 App Store 应用,在搜索栏中搜索“Xcode”,然后点击“获取”按钮:
Figure 1: Downloading and installing Xcode on macOS.
安装 Xcode 后,你需要打开一个终端,确保你已经接受了开发者许可:
$ sudo xcodebuild -license
我们还需要安装苹果命令行工具。这些工具包括 GCC、make、clang 等程序和库。您可以使用以下命令来安装 Apple 命令行工具:
$ sudo xcode-select --install
执行上述命令时,将弹出一个确认窗口,要求您确认安装:
Figure 2: Installing the Apple Command Line Tools on macOS.
点击“安装”按钮继续。实际安装过程应该不到 5 分钟即可完成。
第二步:安装自制软件
下一步是安装 Homebrew ,一个 macOS 的包管理器。你可以把家酿看作是 macOS 上基于 Ubuntu/Debian 的 apt-get 。
安装 Homebrew 本身超级简单,只需复制并粘贴下面的整个命令:
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
一旦安装了 Homebrew,您应该运行以下命令来确保软件包定义是最新的:
$ brew update
我们现在需要更新我们的~/.bash_profile文件(或者创建它,如果它不存在的话)。使用您最喜欢的文本编辑器打开文件(在本例中我使用的是nano):
$ nano ~/.bash_profile
然后将以下几行添加到文件中:
# Homebrew
export PATH=/usr/local/bin:$PATH
这个export命令简单地更新了PATH变量,在查询系统路径之前,沿着自制程序路径寻找二进制文件/库。
我在下面附上了我的~/.bash_profile的截图作为参考:
Figure 3: Updating my .bash_profile file to include Homebrew.
更新.bash_profile文件后,保存并退出编辑器,然后使用source确保对.bash_profile的更改被手动重新加载:
$ source ~/.bash_profile
该命令只需要执行一次。每当你打开一个新的终端,你的.bash_profile将会自动为你source。
**### 步骤 3:为 Python 3.5 和 macOS 设置自制程序
将 Python 系统作为您的主要解释器来开发被认为是不好的形式。Python 的系统版本应该只服务于一个目的——支持系统例程和操作。还有一个事实是 macOS 没有自带 Python 3。
相反,你应该安装你自己的 Python 版本,该版本独立于系统安装。使用自制软件,我们可以使用以下命令安装 Python 3:
$ brew install python3
注:确保你没有忘记“python3”中的“3”。以上命令将在您的系统上安装 Python 3.5。然而,如果你去掉“3 ”,你将最终安装 Python 2.7。
作为健全性检查,重要的是确认你使用的是 Python 3 的自制版本,而不是 Python 3 的系统版本。要做到这一点,只需使用which命令:
$ which python3
/usr/local/bin/python3
重要提示:仔细检查这个输出。如果你看到/usr/local/bin/python3,那么你就是正确的使用自制版本的 Python* 。然而,如果输出是/usr/bin/python3,那么你就是错误地使用了系统版本的 Python 。*
*如果您发现自己使用的是 Python 的系统版本,而不是自制版本,您应该:
- 确保自制软件安装无误。
- 检查
brew install python3是否成功完成。 - 您已经正确更新了您的
~/.bash_profile,并使用source重新加载了更改。这基本上可以归结为确保你的~/.bash_profile看起来像我上面图 3 中的。
步骤 4:安装 Python 虚拟环境和 NumPy
到目前为止,我们已经取得了很大进展。我们已经通过自制程序安装了 Python 3 的非系统版本。然而,我们不能就此止步。让我们安装 virtualenv 和 virtualenvwrapper ,这样我们就可以为我们正在进行的每个项目创建独立的 Python 环境——这被认为是用 Python 编程语言开发软件的最佳实践。
我已经在以前的博客文章中令人作呕地讨论过 Python 虚拟环境,所以如果你对它们如何工作以及我们为什么使用它们感到好奇,请参考这篇博客文章的前半部分。我也强烈推荐通读RealPython.com 博客上的这篇精彩教程,它深入探究了 Python 虚拟环境。
*#### 安装 virtualenv 和 virtualenvwrapper
使用pip可以轻松安装virtualenv和virtualenvwrapper:
$ pip install virtualenv virtualenvwrapper
安装完这些软件包后,我们需要再次更新我们的~/.bash_profile:
$ nano ~/.bash_profile
打开后,将下列行追加到文件中:
# Virtualenv/VirtualenvWrapper
source /usr/local/bin/virtualenvwrapper.sh
更新后,您的~/.bash_profile应该与我的相似:
Figure 4: Updating your .bash_profile file to include virtualenv/virtualenvwrapper.
更新您的.bash_profile后,保存它,退出,然后再次source它:
$ source ~/.bash_profile
我将重申这个命令只需要执行一次。每次你打开一个新的终端窗口,这个文件就会自动为你生成。
**#### 创建您的 Python 3 虚拟环境
我们现在可以使用mkvirtualenv命令创建一个名为cv的 Python 3 虚拟环境:
$ mkvirtualenv cv -p python3
-p python3开关确保创建 Python 3 虚拟环境,而不是 Python 2.7 虚拟环境。
同样,上面的命令将创建一个名为cv的 Python 环境,它独立于系统上所有其他 Python 环境的。这个环境将有自己的site-packages目录,等等。,允许您避免跨项目的任何类型的库版本问题。
mkvirtualenv命令只需要执行一次。在创建了之后,要访问cv Python 虚拟环境,只需使用workon命令:*
$ workon cv
要验证您是否在cv虚拟环境中,只需检查您的命令行。如果你看到提示前面的文字(cv),那么你就是 在cv虚拟环境中的 :
Figure 5: Make sure you see the “(cv)” text on your prompt, indicating that you are in the cv virtual environment.
否则,如果你 没有 看到cv文本,那么你 在cv虚拟环境中就不是 :
Figure 6: If you do not see the “(cv)” text on your prompt, then you are not in the cv virtual environment and you need to run the “workon” command to resolve this issue before continuing.
如果你发现自己处于这种情况,你需要做的就是利用上面提到的workon命令。
安装 NumPy
OpenCV 需要的唯一基于 Python 的先决条件是一个科学计算包 NumPy 。
要将 NumPy 安装到我们的cv虚拟环境中,请确保您处于cv环境中(否则 NumPy 将被安装到系统的版本的 Python 中),然后利用pip来处理实际安装:
$ pip install numpy
步骤 5:使用自制软件安装 OpenCV 先决条件
OpenCV 要求在我们编译它之前安装一些先决条件。这些软件包与(1)用于构建和编译的工具,(2)用于图像 I/O 操作的库(即,从磁盘加载各种图像文件格式,如 JPEG、PNG、TIFF 等)相关。)或(3)优化库。
要在 macOS 上安装 OpenCV 的这些必备组件,请执行以下命令:
$ brew install cmake pkg-config
$ brew install jpeg libpng libtiff openexr
$ brew install eigen tbb
步骤 6:从 GitHub 下载 OpenCV 3 源代码
正如我在上周的教程中所详述的,macOS 上的 OpenCV 3 需要通过对 GitHub 的最新提交来编译,而不是实际的标记版本(即 3.0、3.1 等。).这是因为 OpenCV 的当前标记版本没有提供对 QTKit vs. AVFoundation 错误的修复(请参见上周的博客文章以获得对此的详细讨论)。
首先,我们需要下载 OpenCV GitHub repo :
$ cd ~
$ git clone https://github.com/opencv/opencv
后面是 opencv_contrib repo :
$ git clone https://github.com/opencv/opencv_contrib
步骤 7:在 macOS 上通过 CMake 配置 OpenCV 和 Python 3.5
教程的这一部分是最具挑战性的部分,也是你最想关注的部分。
首先,我将演示如何通过创建一个build目录来设置您的构建。
然后我提供了一个 CMake 模板,您可以使用它在 macOS 上开始编译 OpenCV 3 和 Python 3.5 绑定。该模板要求您填写两个值:
- 您的
libpython3.5.dylib文件的路径。 - Python 3.5 的
Python.h头的路径。
我会帮你找到并确定这些路径的正确值。
最后,我提供一个完整的 CMake 命令作为例子。请注意,is 命令是专用于我的机器。由于指定的路径不同,您的 CMake 命令可能略有不同。请阅读本节的其余部分了解详细信息。
设置构件
为了用 Python 3.5 绑定为 macOS 编译 OpenCV,我们首先需要设置构建。这相当于更改目录并创建一个build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
用于 macOS 的 OpenCV 3 + Python 3.5 CMake 模板
下一部分,我们配置我们的实际构建,变得有点棘手。为了使这个过程更容易,我构建了下面的 OpenCV 3 + Python 3.5 CMake 模板:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON3_LIBRARY=YYY \
-D PYTHON3_INCLUDE_DIR=ZZZ \
-D PYTHON3_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_python3=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D BUILD_EXAMPLES=ON ..
看着这个模板,我想向你指出几件事:
BUILD_opencv_python2=OFF:这个开关表示我们不想构建 Python 2.7 绑定。这需要在 CMake 命令中明确声明。当我们实际运行 CMake 时,不这样做可能会导致问题。BUILD_opencv_python3=ON:我们希望 OpenCV 3 + Python 3.5 绑定能够建立起来。此指令向 CMake 表明应该构建 Python 3.5 绑定,而不是 Python 2.7。PYTHON3_LIBRARY=YYY:这是 第一个 值,需要自己填写。您需要用您的libpython3.5.dylib文件的路径替换YYY。在下一节中,我将帮助您找到这个值的路径。PYTHON3_INCLUDE_DIR=ZZZ:这是您需要填写的 秒 值。您需要用到您的Python.h头的路径替换ZZZ。再说一遍,我会帮你确定这条路。
确定您的 Python 3.5 库和包含目录
我们将从配置您的PYTHON3_LIBRARY值开始。这个开关应该指向您的libpython3.5.dylib文件。该文件位于/usr/local/Cellar/python的多个嵌套子目录中。要找到libpython3.5.dylib文件的确切路径,只需使用带有通配符的ls命令(自动制表符结束也可以):
$ ls /usr/local/Cellar/python3/3.*/Frameworks/Python.framework/Versions/3.5/lib/python3.5/config-3.5m/libpython3.5.dylib
/usr/local/Cellar/python3/3.5.2_3/Frameworks/Python.framework/Versions/3.5/lib/python3.5/config-3.5m/libpython3.5.dylib
请注意这个命令的输出— 这是您的libpython3.5.dylib文件的完整路径,将替换上面 CMake 模板中的YYY。
让我们继续确定PYTHON3_INCLUDE_DIR变量。这个路径应该指向用于生成实际 OpenCV 3 + Python 3.5 绑定的 Python 3.5 的Python.h头文件。
同样,我们将使用相同的ls和通配符技巧来确定正确的路径:
$ ls -d /usr/local/Cellar/python3/3.*/Frameworks/Python.framework/Versions/3.5/include/python3.5m/
/usr/local/Cellar/python3/3.5.2_3/Frameworks/Python.framework/Versions/3.5/include/python3.5m/
ls -d命令的输出是我们到Python.h头的完整路径。 该值将替换 CMake 模板中的ZZZ。
填写 CMake 模板
现在我们已经确定了PYTHON3_LIBRARY和PYTHON3_INCLUDE_DIR的值,我们需要更新 CMake 命令来反映这些路径。
在我的机器上,配置我的 OpenCV 3 + Python 3.5 版本的 full CMake 命令如下所示:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON3_LIBRARY=/usr/local/Cellar/python3/3.5.2_3/Frameworks/Python.framework/Versions/3.5/lib/python3.5/config-3.5m/libpython3.5.dylib \
-D PYTHON3_INCLUDE_DIR=/usr/local/Cellar/python3/3.5.2_3/Frameworks/Python.framework/Versions/3.5/include/python3.5m/ \
-D PYTHON3_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_python3=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D BUILD_EXAMPLES=ON ..
但是,请不要复制和粘贴我的 CMake 命令——确保您已经使用了上面的说明来正确地确定您的PYTHON3_LIBRARY和PYTHON3_INCLUDE_DIR值。
一旦您填写了这些值,执行您的cmake命令,您的 OpenCV 3 + Python 3.5 构建将被配置。
例如,看看我的配置中的Python 3部分的输出:

Figure 7: Ensuring that Python 3.5 will be used when compiling OpenCV 3 for macOS.
特别是,您需要确保:
Interpreter指向您的cv虚拟环境中的 Python 二进制文件。Libraries指向你的libpython3.5.dylib文件。- 正在使用的
numpy版本是您在cv虚拟环境中安装的版本。
步骤 8:在 macOS 上编译并安装 OpenCV 3
在研究了您的cmake命令并确保它没有错误地退出(并且Python 3部分被正确配置)之后,您现在可以编译 OpenCV:
$ make -j4
在这种情况下,我提供了-j4来使用我机器上的所有四个内核编译 OpenCV。您可以根据您拥有的处理器/内核数量来调整该值。
OpenCV 可能需要一段时间来编译,大约 30-90 分钟,这取决于您的系统规格。我会考虑在编译的时候出去散散步。
成功的编译将以 100%的完成结束:
Figure 8: Successfully compiling OpenCV 3 from source with Python 3.5 bindings on macOS.
假设 OpenCV 编译无误,您现在可以在 macOS 系统上安装它了:
$ sudo make install
步骤 9:重命名并符号化链接你的 OpenCV 3 + Python 3.5 绑定
运行sudo make install之后,您的 OpenCV 3 + Python 3.5 绑定应该位于/usr/local/lib/python3.5/site-packages中。您可以使用ls命令来验证这一点:
$ cd /usr/local/lib/python3.5/site-packages/
$ ls -l *.so
-rwxr-xr-x 1 root admin 3694564 Nov 15 11:28 cv2.cpython-35m-darwin.so
自从 OpenCV 3 发布以来,我一直对这种行为感到困惑,但出于某种原因,当编译 OpenCV 并启用 Python 3 支持时,输出cv2.so绑定的名称不同。实际的文件名会根据您的系统架构而有所不同,但是它看起来应该类似于cv2.cpython-35m-darwin.so。
同样,我不知道为什么会发生这种情况,但这很容易解决。我们需要做的就是将文件重命名为cv2.so:
$ cd /usr/local/lib/python3.5/site-packages/
$ mv cv2.cpython-35m-darwin.so cv2.so
$ cd ~
将cv2.cpython-35m-darwin.so重命名为cv2.so后,我们需要将 OpenCV 绑定符号链接到 Python 3.5 的cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2.so cv2.so
$ cd ~
步骤 10:验证你的 OpenCV 3 在 macOS 上的安装
要验证您在 macOS 上安装的 OpenCV 3 + Python 3.5 是否正常工作,您应该:
- 打开一个新的终端。
- 执行
workon命令来访问cvPython 虚拟环境。 - 尝试导入 Python + OpenCV 绑定。
以下是您可以用来测试安装的具体步骤:
$ workon cv
$ python
Python 3.5.2 (default, Oct 11 2016, 04:59:56)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.38)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'3.1.0-dev'
>>>
注:记下cv2.__version__中的-dev。这表明我们使用的是 OpenCV 的开发版本,而不是带标签的版本。一旦 OpenCV 3.2 发布,这些指令可以被更新,只需下载一个带标签版本的. zip 文件,而不必克隆整个存储库。
我还在下面附上了一个利用这些相同步骤的截图。如您所见,我可以从 Python 3.5 shell 访问我的 OpenCV 3 绑定:

Figure 9: Ensuring that I have successfully installed my OpenCV 3 + Python 3.5 bindings on macOS.
恭喜你,你已经在 macOS 系统上安装了带 Python 3.5 绑定的 OpenCV!
那么,下一步是什么?
恭喜你。你现在在 macOS 系统上有了一个全新的 OpenCV 安装——我敢肯定你只是渴望利用你的安装来构建一些很棒的计算机视觉应用程序…
…但我也愿意打赌你刚刚开始学习计算机视觉和 OpenCV ,可能会对到底从哪里开始感到有点困惑和不知所措。
就我个人而言,我是以身作则的忠实粉丝,所以好的第一步是找点乐子,读读这篇关于在图像/视频中发现猫的博文。本教程旨在非常实用,演示如何(快速)构建一个 Python + OpenCV 应用程序来检测图像中猫的存在。
如果你真的对提升你的计算机视觉技能感兴趣,你绝对应该看看我的书《实用 Python 和 OpenCV +案例研究》。我的书不仅涵盖了计算机视觉和图像处理的基础知识,还教你如何解决现实世界的计算机视觉问题包括 图像和视频流中的人脸检测视频中的物体跟踪手写识别 。
因此,让我们在 macOS 系统上充分利用 OpenCV 3 新安装程序
摘要
在本教程中,您学习了如何在 macOS Sierra 上编译和安装 OpenCV 3 和 Python 3.5 绑定。
为此,我们使用 CMake 实用程序手工配置和编译 OpenCV 3。虽然这不完全是最“有趣”的体验,但它确实给了我们对安装的完全和总的控制。
如果你正在寻找一种更简单的方式将 OpenCV 安装到你的 Mac 系统上,请不要忘记关注下周的博客文章,在这篇文章中,我将演示如何只用自制软件在 macOS 上安装 OpenCV。
为了在这篇博文发布时得到通知,请在下面的表格中输入您的电子邮件地址,我会在教程发布时通知您。*******
macOS Mojave:安装 TensorFlow 和 Keras 进行深度学习
原文:https://pyimagesearch.com/2019/01/30/macos-mojave-install-tensorflow-and-keras-for-deep-learning/

在本教程中,您将了解如何为深度学习配置 macOS Mojave。
在您完成本教程后,您的 macOS Mojave 系统将准备好(1)使用 Keras 和 TensorFlow 进行深度学习,以及(2)使用 Python 进行计算机视觉的 深度学习。
自从 2018 年 9 月 Mojave OS 正式发布以来,关于配置 Mojave 的教程已经在我的博客上出现了很长时间。
这个操作系统从一开始就被问题所困扰,所以我决定推迟。实际上,我仍然在我的机器上运行 High Sierra,但是在整理了这个指南之后,我有信心向 PyImageSearch 的读者推荐 Mojave。
苹果已经修复了大部分的 bug,但是正如你将在本指南中看到的,Homebrew(一个非官方的 macOS 软件包管理器)并没有让一切变得特别容易。
如果你已经准备好全新安装 macOS Mojave,并准备好迎接今天的挑战,让我们开始为深度学习配置你的系统。
今天同时发布的还有我的 带可选 GPU 支持的 Ubuntu 18.04 深度学习配置指南。一定要去看看!
要了解如何用 Python 配置 macOS 进行深度学习和计算机视觉,继续阅读。
macOS Mojave:安装 TensorFlow 和 Keras 进行深度学习
在本教程中,我们将回顾为深度学习配置 Mojave 的七个步骤。
在 步骤#3 中,我们将做一些自制公式功夫来安装 Python 3.6 。
你看,家酿现在默认安装 Python 3.7。
这对我们深度学习社区提出了挑战,因为 Tensorflow 尚未正式支持 Python 3.7。
TensorFlow 团队肯定在致力于 Python 3.7 支持——但如果你运行的是 macOS Mojave,你可能不想闲着,等到 Python 3.7 支持正式发布。
如果你遇到了这个难题,那么我的安装指南就是为你准备的。
我们开始吧!
步骤 1:安装和配置 Xcode
首先,你需要从苹果应用商店获得 Xcode 并安装它。别担心,它是 100%免费的。
Figure 1: Download Xcode for macOS Mojave prior to setting up your system for deep learning.
从 App Store 下载并安装 Xcode 后,打开终端并执行以下命令接受开发者许可:
$ sudo xcodebuild -license
按下“输入”然后用“空格”键滚动到底部,然后输入“同意”。
下一步是安装苹果命令行工具:
$ sudo xcode-select --install
这将启动一个窗口,您需要按下“安装”。从那里,您将不得不接受另一个协议(这次是一个按钮)。最后,会出现一个下载进度窗口,您需要等待几分钟。
步骤 2:在 macOS Mojave 上安装自制软件
家酿(也称为 brew),是 macOS 的软件包管理器。您的系统上可能已经安装了它,但是如果您没有,您将希望按照本节中的命令来安装它。
首先,我们将通过复制并粘贴整个命令到您的终端来安装 Homebrew:
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
接下来,我们将更新我们的包定义:
$ brew update
随后使用nano终端编辑器更新您的~/.bash_profile(任何其他编辑器也应该这样做):
$ nano ~/.bash_profile
将以下几行添加到文件中:
# Homebrew
export PATH=/usr/local/bin:$PATH
Figure 2: Editing the ~/.bash_profile to ensure that Homebrew is set up with your PATH. We will use Homebrew to install some of the tools on macOS Mojave for deep learning.
保存并关闭,按“ctrl+o”(保存),然后按“回车”保存文件名,最后按“ctrl+x”(退出)。
让我们重新加载我们的个人资料:
$ source ~/.bash_profile
现在 Brew 已经准备好了,让我们安装 Python 3.6。
步骤 3:在 macOS Mojave 上将 Python 3.7 降级到 Python 3.6
我对家酿啤酒又爱又恨。我喜欢它的便利性以及志愿者团队支持如此多软件的方式。他们做得非常好。他们总是在游戏中支持最新的软件。
Mojave 的问题是默认情况下 Homebrew 会安装 Python 3.7,但是 TensorFlow(目前)还不支持 3.7。
因此,我们需要做一些功夫来让 Python 3.6 安装在 Mojave 上。
如果你尝试直接安装 Python 3.6,你会遇到这个问题:
Figure 3: The sphinx-doc + Python 3.7 circular dependency causes issues with installing Python 3.6 on macOS Mojave.
问题是sphinx-doc依赖 Python 3.7,Python 3.6.5 依赖sphinx-doc依赖 Python 3.7。
阅读这句话可能会让你头疼,但是我想你已经明白了我们有一个循环依赖的问题。
注:以下步骤对我有效,我在 Mojave 的两个新实例上测试了两次。如果你知道安装 Python 3.6 的改进方法,请在评论中告诉我和社区。
让我们采取措施来解决循环依赖问题。
首先,安装 Python(这将安装 Python 3.7,我们稍后将降级它):
$ brew install python3
现在我们需要移除循环依赖。
让我们继续编辑sphinx-doc的自制公式,因为这就是问题所在:
$ nano /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/Formula/sphinx-doc.rb
现在向下滚动并删除 Python 依赖项,方法是在它前面放置一个#来注释掉它:
Figure 4: Removing the sphinx-doc dependency on Python 3.7. This will ultimately allow us to install Python 3.6 on macOS Mojave for deep learning.
一旦添加了#来注释掉这一行,继续保存+退出。
从那里,只需重新安装 sphinx-doc:
$ brew reinstall sphinx-doc
现在是时候安装 Python 3.6.5 了。
第一步是解除 Python 的链接:
$ brew unlink python
从那里我们可以安装 Python 3.6:
$ brew install https://raw.githubusercontent.com/Homebrew/homebrew-core/f2a764ef944b1080be64bd88dca9a1d80130c558/Formula/python.rb
在这里,您应该通过查询版本来检查正在使用的 Python:
$ which python3
/usr/local/bin/python3
$ python3 --version
Python 3.6.5
检查第一个命令的输出,确保看到 /usr/和bin/python3之间的local/ 。
正如我们的输出所示,我们现在使用的是 Python 3.6.5!
步骤 4:在 macOS Mojave 上安装用于 OpenCV 的 brew 包
需要安装以下工具来进行编译、映像 I/O 和优化:
$ brew install cmake pkg-config wget
$ brew install jpeg libpng libtiff openexr
$ brew install eigen tbb hdf5
安装完这些包之后,我们就可以创建 Python 虚拟环境了。
步骤 5:在 macOS Mojave 中创建您的 Python 虚拟环境
正如我在本网站的其他安装指南中所述,虚拟环境绝对是使用 Python 时的必由之路,使您能够在沙盒环境中适应不同的版本。
如果您搞乱了一个环境,您可以简单地删除该环境并重新构建它,而不会影响其他 Python 虚拟环境。
$ pip3 install virtualenv virtualenvwrapper
从那里,我们将再次更新我们的~/.bash_profile:
$ nano ~/.bash_profile
我们将在文件中添加以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /usr/local/bin/virtualenvwrapper.sh

Figure 5: Editing the ~/.bash_profile again, this time to accommodate virtualenv and virtualenvwrapper tools for Python virtual environments.
然后重新加载配置文件:
$ source ~/.bash_profile
检查终端输出中的任何错误。如果virtualenvwrapper和 Python 3.6 配合得很好,你应该准备好创建一个新的虚拟环境。
在 macOS Mojave 上创建dl4cv虚拟环境
dl4cv环境将容纳 TensorFlow、Keras、OpenCV 和所有其他与我的深度学习书相关的 Python 包。当然,您可以随意命名这个环境,但是从现在开始,我们将把它称为dl4cv。
要使用 Python 3 创建dl4cv环境,只需输入以下命令:
$ mkvirtualenv dl4cv -p python3
在 Python 3 和支持脚本被安装到新环境中之后,您实际上应该已经在环境的中了。这在 bash 提示符的开头用(dl4cv)表示,如下图所示:
Figure 6: The workon command allows us to activate a Python virtual environment of our choice. In this case, I’m activating the dl4cv environment on macOS Mojave for deep learning.
如果您没有看到修改后的 bash 提示符,那么您可以随时输入以下命令来随时进入环境:
$ workon dl4cv
为了安全起见,让我们检查一下我们的环境使用的是哪种 Python,并再次查询版本:
$ workon dl4cv
$ which python
/Users/admin/.virtualenvs/dl4cv/bin/python
$ python --version
Python 3.6.5
请注意,python 可执行文件位于我们的虚拟环境dl4cv中的~/.virtualenvs/dl4cv/bin/。另外在这里三重检查你使用的是 Python 3.6.5。
当您确定使用 Python 3.6.5 正确配置了虚拟环境后,就可以安全地继续将软件安装到环境中了。
让我们继续步骤#6 。
步骤 6:在 macOS Mojave 上安装 OpenCV
为了与我的深度学习书籍兼容,我们有两种安装 OpenCV 的选项。
第一种方法( 步骤#6a )是通过使用 Python 包索引中可用的预编译二进制文件(pip 从中提取)。缺点是的维护者选择了不把专利算法编译成二进制。
第二个选项( 步骤#6b )是从源码编译 OpenCV。这种方法允许完全控制编译,包括优化和专利算法(“非免费”)。
如果你是初学者,受时间限制,或者如果你知道你不需要专利算法 (DL4CV 不需要增加的功能),我建议你选择第一个选项。第一个选项只需要 5 分钟。
高级用户应该选择第二个选项,同时留出大约 40 到 60 分钟的编译时间。
步骤 6a:用 pip 安装 OpenCV
确保您在dl4cv环境中工作,然后输入带有包名的pip install命令,如下所示:
$ workon dl4cv
$ pip install opencv-contrib-python
注意: 如果你需要一个特定的版本你可以使用下面的语法:pip install opencv-contrib-python==3.4.4。
恭喜你。您现在已经安装了 OpenCV。
从这里你可以跳到第 7 步的 。
步骤 6b:编译并安装 OpenCV
如果您执行了 步骤#6a ,您应该跳过此选项,转到 步骤#7 。
让我们从源代码编译 OpenCV。
OpenCV 需要的唯一 Python 依赖项是 NumPy,我们可以通过以下方式安装它:
$ workon dl4cv
$ pip install numpy
首先,让我们下载源代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/3.4.4.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/3.4.4.zip
注: 如果你想使用不同版本的 OpenCV,你可以用4.0.0.zip或更高版本替换3.4.4.zip。只要确保opencv和opencv_contrib下载都是针对 相同的 版本!
**接下来打开归档文件:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
并重命名目录:
$ mv opencv-3.4.4 opencv
$ mv opencv_contrib-3.4.4 opencv_contrib
注意: 将命令中的文件夹名替换为您的 OpenCV 版本对应的文件夹名。
为了准备我们的编译过程,我们使用 CMake。
复制 CMake 命令 与此处出现的 是非常重要的,注意复制并越过整个命令;我建议点击下面工具栏中的<>按钮展开整个命令:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D PYTHON3_LIBRARY=`python -c 'import subprocess ; import sys ; s = subprocess.check_output("python-config --configdir", shell=True).decode("utf-8").strip() ; (M, m) = sys.version_info[:2] ; print("{}/libpython{}.{}.dylib".format(s, M, m))'` \
-D PYTHON3_INCLUDE_DIR=`python -c 'import distutils.sysconfig as s; print(s.get_python_inc())'` \
-D PYTHON3_EXECUTABLE=$VIRTUAL_ENV/bin/python \
-D BUILD_opencv_python2=OFF \
-D BUILD_opencv_python3=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D BUILD_EXAMPLES=ON ..
注意:对于上面的 CMake 命令,我花了相当多的时间来创建、测试和重构它。我相信,如果你完全按照它显示的那样使用它,它会节省你的时间和挫折。确保点击上面代码块工具栏中的< >按钮,展开代码块。这将使你能够复制并粘贴整个命令。**
运行 CMake 需要 2-5 分钟。
您应该始终检查 CMake 输出中的错误,并确保您的编译设置符合预期。
您的输出应该类似于下面的截图,确保使用了正确的 Python 3 二进制/库和 NumPy 版本,并且“非自由算法”处于打开状态:
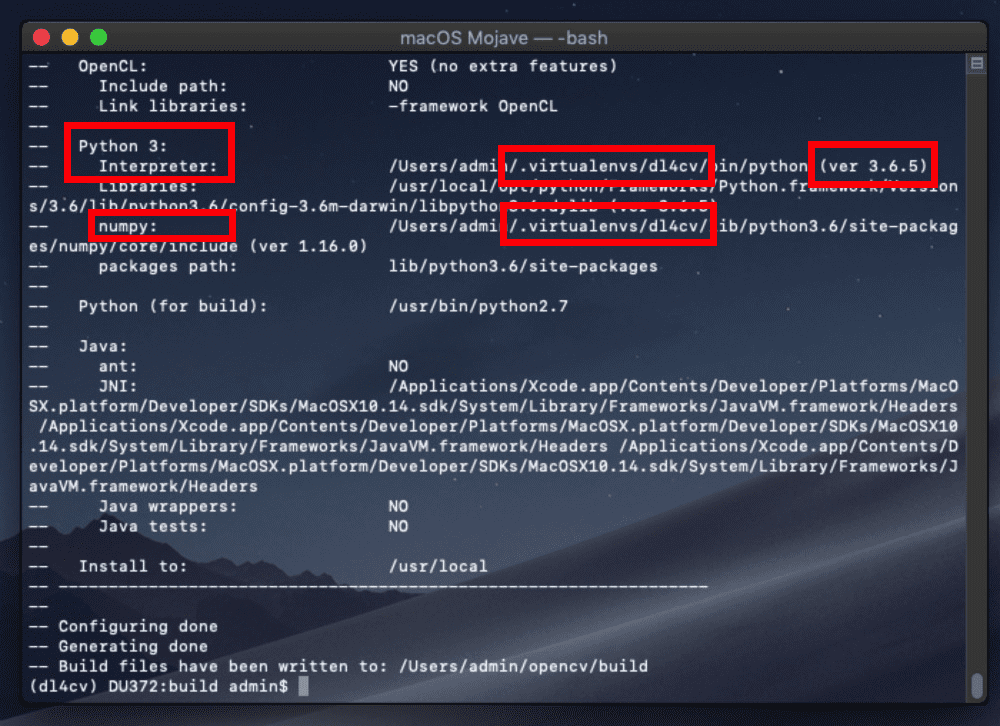
Figure 7: Inspecting OpenCV CMake output prior to installing deep learning frameworks on macOS.
Figure 8: Ensuring that the OpenCV patented (“non-free”) algorithms are installed.
如果您的 OpenCV 的 CMake 输出与我的匹配,那么我们就可以实际编译 OpenCV 了:
$ make -j4
注意:大多数 macOS 机器至少会有 4 个核心/CPU。您可以(也应该)根据您系统的处理规范用一个数字来编辑上面的标志,以加快编译过程。
Figure 9: OpenCV compilation is complete on macOS Mojave.
从那里您可以安装 OpenCV:
$ sudo make install
安装后,有必要将cv2.so文件符号链接到dl4cv虚拟环境中。
我们需要做的是创建一个从 OpenCV 安装位置到虚拟环境本身的链接。这就是所谓的符号链接。
现在让我们继续处理这个问题,首先获取.so文件的名称:
$ cd /usr/local/python/cv2/python-3.6
$ ls
cv2.cpython-36m-darwin.so
现在让我们重命名.so文件:
$ sudo mv cv2.cpython-36m-darwin.so cv2.opencv3.4.4.so
$ cd ~/.virtualenvs/dl4cv/lib/python3.6/site-packages
$ ln -s /usr/local/python/cv2/python-3.6/cv2.opencv3.4.4.so cv2.so
注意:如果您的系统中安装了多个 OpenCV 版本,您可以使用相同的命名约定和符号链接方法。
最后,我们可以测试安装:
$ cd ~
$ python
>>> import cv2
>>> cv2.__version__
'3.4.4'
如果您的输出正确地显示了您安装的 OpenCV 版本,那么您就可以继续进行步骤#7 了,我们将在那里安装 Keras 深度学习库。
步骤 7:在 macOS Mojave 上安装 TensorFlow 和 Keras
在开始这一步之前,确保您已经激活了dl4cv虚拟环境。如果您不在该环境中,只需执行:
$ workon dl4cv
然后,使用pip,安装所需的 Python 计算机视觉、图像处理和机器学习库:
$ pip install scipy pillow
$ pip install imutils h5py requests progressbar2
$ pip install scikit-learn scikit-image
接下来,安装 matplotlib 并更新渲染后端:
$ pip install matplotlib
$ mkdir ~/.matplotlib
$ touch ~/.matplotlib/matplotlibrc
$ echo "backend: TkAgg" >> ~/.matplotlib/matplotlibrc
如果你曾经遇到过绘图不出现的问题,请务必阅读关于在 OSX 上使用 Matplotlib 的指南。
然后,安装张量流:
$ pip install tensorflow
其次是 Keras :
$ pip install keras
要验证 Keras 是否正确安装,我们可以导入它并检查错误:
$ workon dl4cv
$ python
>>> import keras
Using TensorFlow backend.
>>>
Keras 应该被正确导入,同时声明 TensorFlow 被用作后端。
此时,您可以熟悉一下~/.keras/keras.json文件:
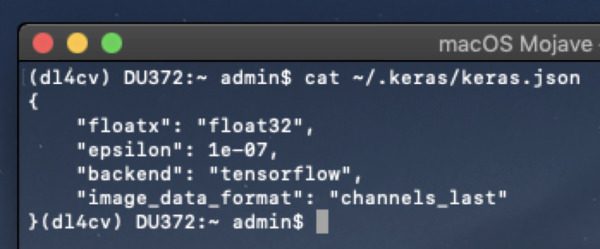
Figure 10: The Keras configuration file allows you to set the backend as well as other settings.
确保image_data_format设置为channels_last并且backend设置为tensorflow。
预配置环境
恭喜恭喜! 你已经成功配置了你的 macOS Mojave 台式机/笔记本电脑进行深度学习!
你现在已经准备好了。如果你在安装过程中没有喝过茶或咖啡,现在是时候了。也是时候找个舒服的地方读读 用 Python 进行计算机视觉的深度学习了。
您在配置 Mojave 深度学习系统时遇到过任何问题吗?
如果您在这个过程中遇到了困难,我鼓励您重新阅读说明并尝试调试。如果你还在挣扎,你可以在 DL4CV 伴侣网站问题跟踪者(在你的书的前面有一个注册链接)或者通过联系我来寻求帮助。
我还想借此机会向您介绍一下您的图书附带的预配置实例:
- DL4CV VirtualBox VM 是预先配置好的,随时可以与 Ubuntu 18.04 和所有其他必要的深度学习包/库一起使用。这个虚拟机能够在一个叫做 VirtualBox 的工具中,在你的 macOS 操作系统之上独立运行。它将帮助你通过初学者和实践者包中几乎所有的实验。对于 ImageNet 捆绑包,GPU 是必需的,而这个虚拟机不支持 GPU。
- 我的用于 AWS 云的 DL4CV 亚马逊机器映像对互联网免费开放——不需要购买(当然,除了 AWS 收费)。在云中开始使用 GPU 只需要大约 4-6 分钟。以不到一杯咖啡的价格,您可以使用一个 GPU 实例一两个小时,这刚好够完成 DL4CV 中一些(肯定不是全部)更高级的课程。预先配置了以下环境:
dl4cv、mxnet、tfod_api、mask_rcnn、retinanet。
Azure 用户应该考虑 Azure DSVM。你可以点击阅读我对微软 Azure DSVM 的评论。2017 年 DL4CV 第一个版本中的所有代码都是使用微软的 DSVM 进行测试的。DSVM 需要额外的配置来支持 DL4CV 的附加包章节,但是除此之外,你不会发现自己安装了很多工具。如果 Azure 是你首选的云提供商,我鼓励你继续使用 Azure,利用 DSVM 所提供的优势。
摘要
在今天的帖子中,我们为计算机视觉和深度学习配置了我们的 macOS Mojave box。软件的主要部分包括 Python 3.6、OpenCV、TensorFlow 和 Keras,并附有依赖项和安装/编译工具。
TensorFlow 尚未正式支持 Python 3.7,所以你应该不惜一切代价避免使用它(暂时)。
相反,我们学会了如何在 macOS Mojave 上从 Python 3.7 降级到 Python 3.6,并将所有软件放入一个名为dl4cv的 Python 3.6 虚拟环境中。
如果你想很好地利用你新配置的 macOS 深度学习环境,我强烈建议你看看我的新书, 用 Python 进行计算机视觉的深度学习 。
不管你是深度学习的新手还是已经是经验丰富的实践者,这本书都有内容可以帮助你掌握深度学习——看这里。
为了在 PyImageSearch 上发布未来的博客文章时得到通知(并获取我的 17 页深度学习和计算机视觉资源指南 PDF),只需在下面的表格中输入您的电子邮件地址!****
用 OpenCV 屏蔽 R-CNN
原文:https://pyimagesearch.com/2018/11/19/mask-r-cnn-with-opencv/

在本教程中,您将学习如何在 OpenCV 中使用 Mask R-CNN。
使用 Mask R-CNN,您可以为图像中的每个对象自动分割和构建像素级遮罩。我们将对图像和视频流应用 Mask R-CNN。
在上周的博客文章中,你学习了如何使用 YOLO 物体探测器来探测图像中物体的存在。物体检测器,如 YOLO、快速 R-CNN 和单次检测器(SSD),产生四组 (x,y)-坐标,代表图像中物体的边界框。
获得对象的边界框是一个好的开始,但是边界框本身并没有告诉我们任何关于(1)哪些像素属于前景对象和(2)哪些像素属于背景的信息。
这就引出了一个问题:
有没有可能为我们图像中的每个物体生成一个遮罩,从而让我们能够从背景中分割出前景物体?
这样的方法可能吗?
答案是肯定的 —我们只需要使用 Mask R-CNN 架构执行实例分割。
要了解如何通过 OpenCV 将 Mask R-CNN 应用于图像和视频流,请继续阅读!
用 OpenCV 屏蔽 R-CNN
在本教程的第一部分,我们将讨论图像分类、、、实例分割、和语义分割的区别。
从这里,我们将简要回顾一下 Mask R-CNN 架构及其与更快的 R-CNN 的连接。
然后,我将向您展示如何使用 OpenCV 将 Mask R-CNN 应用于图像和视频流。
我们开始吧!
实例分割与语义分割
Figure 1: Image classification (top-left), object detection (top-right), semantic segmentation (bottom-left), and instance segmentation (bottom-right). We’ll be performing instance segmentation with Mask R-CNN in this tutorial. (source)
解释传统的图像分类、对象检测、语义分割和实例分割之间的差异最好通过视觉来完成。
当执行传统的图像分类时,我们的目标是预测一组标签来表征输入图像的内容(左上)。
**物体检测 建立在图像分类的基础上,但这一次允许我们定位图像中的每个物体。该图像现在的特征是:
- 边界框 (x,y)-每个对象的坐标
- 每个边界框的相关联的类标签
语义切分 的例子见左下。语义分割算法要求我们将输入图像中的每个像素与类别标签(包括背景的类别标签)相关联。
密切关注我们的语义分割可视化——注意每个对象实际上是如何分割的,但每个“立方体”对象都有相同的颜色。
虽然语义分割算法能够标记图像中的每个对象,但是它们不能区分同一类别的两个对象。
如果同一类的两个对象彼此部分遮挡,这种行为尤其成问题——我们不知道一个对象的边界在哪里结束,下一个对象的边界在哪里开始,如两个紫色立方体所示,我们无法分辨一个立方体在哪里开始,另一个在哪里结束。
另一方面, 实例分割 算法为图像中的每个对象计算逐像素掩码,即使对象具有相同的类别标签(右下角)。在这里,你可以看到每个立方体都有自己独特的颜色,这意味着我们的实例分割算法不仅定位了每个单独的立方体,还预测了它们的边界。
我们将在本教程中讨论的 Mask R-CNN 架构是一个 实例分割 算法的例子。
什么是 Mask R-CNN?
Mask R-CNN 算法是何等人在他们 2017 年的论文 中介绍的 Mask R-CNN 。
Mask R-CNN 建立在之前的R-CNN(2013)Fast R-CNN(2015)Fast R-CNN(2015)的物体检测工作之上,全部由 Girshick 等人完成。
为了理解 Mask R-CNN,让我们简单回顾一下 R-CNN 的变体,从最初的 R-CNN 开始:
Figure 2: The original R-CNN architecture (source: Girshick et al,. 2013)
最初的 R-CNN 算法有四个步骤:
- 步骤#1: 向网络输入图像。
- 步骤#2: 使用诸如选择性搜索的算法提取区域提议(即,图像中可能包含对象的区域)。
- 步骤#3: 使用迁移学习,特别是特征提取,使用预训练的 CNN 计算每个提议(实际上是 ROI)的特征。
- 步骤#4: 利用支持向量机(SVM)使用提取的特征对每个提议进行分类。
这种方法有效的原因是由于 CNN 学习到的健壮的、有区别的特征。
然而,R-CNN 方法的问题是它非常慢。此外,我们实际上并没有通过深度神经网络来学习定位,我们只是有效地构建了一个更先进的 HOG +线性 SVM 检测器。
为了改进最初的 R-CNN,Girshick 等人发表了快速 R-CNN 算法:

Figure 3: The Fast R-CNN architecture (source: Girshick et al., 2015).
类似于原始的 R-CNN,Fast R-CNN 仍然利用选择性搜索来获得区域提议;然而,论文的新颖贡献在于感兴趣区域(ROI)汇集模块。
ROI 池的工作原理是从特征图中提取一个固定大小的窗口,并使用这些特征来获得最终的类标签和边界框。这里的主要好处是网络现在可以有效地进行端到端训练:
- 我们输入一幅图像和相关的地面实况包围盒
- 提取特征图
- 应用 ROI 合并并获得 ROI 特征向量
- 最后,使用两组完全连接的层来获得(1)分类标签预测和(2)每个提议的边界框位置。
虽然网络现在是端到端可训练的,但是由于依赖于选择性搜索,在推断(即,预测)时性能显著受损。
为了让 R-CNN 架构更快我们需要将地区提案直接整合到 R-CNN 中:
*
Figure 4: The Faster R-CNN architecture (source: Girshick et al., 2015)
Girshick 等人的fast R-CNN论文引入了区域提议网络(RPN) ,将区域提议直接烘焙到架构中,减轻了对选择性搜索算法的需求。
总的来说,更快的 R-CNN 架构能够以大约 7-10 FPS 的速度运行,这是向通过深度学习实现实时对象检测迈出的一大步。
Mask R-CNN 算法建立在更快的 R-CNN 架构之上,有两个主要贡献:
- 用更精确的 ROI 对齐模块替换 ROI 汇集模块
- 从 ROI 对齐模块中插入一个附加分支
这个额外的分支接受 ROI Align 的输出,然后将其馈入两个 CONV 层。
CONV 图层的输出是蒙版本身。
我们可以在下图中直观地看到 Mask R-CNN 架构:
Figure 5: The Mask R-CNN work by He et al. replaces the ROI Polling module with a more accurate ROI Align module. The output of the ROI module is then fed into two CONV layers. The output of the CONV layers is the mask itself.
注意从 ROI Align 模块出来的两个 CONV 层的分支——这是我们实际生成蒙版的地方。
正如我们所知,更快的 R-CNN/Mask R-CNN 架构利用区域提议网络(RPN)来生成图像的区域,这些区域可能包含对象。
这些区域中的每一个都基于它们的“客观性分数”(即,给定区域可能潜在地包含对象的可能性)来排名,然后保留前 N 个最有把握的客观性区域。
在最初的更快的 R-CNN 出版物中,Girshick 等人设置N = 2000,但是在实践中,我们可以使用小得多的 N,例如 N={10,100,200,300} ,并且仍然获得良好的结果。
何等人在他们的出版物中设置 N=300 ,这也是我们在这里使用的值。
300 个选定 ROI 中的每一个都经过网络的三个平行分支:
- 标签预测
- 包围盒预测
- 掩模预测
上面的图 5 显示了这些分支。
在预测期间,300 个感兴趣区域中的每一个都经过非最大值抑制并保留前 100 个检测框,从而得到100×L×15×15的 4D 张量,其中 L 是数据集中的类标签的数量,15×15是每个 L 掩码的大小。
我们今天在这里使用的 Mask R-CNN 是在 COCO 数据集上训练的,该数据集有 L=90 个类,因此从 Mask R CNN 的 Mask 模块得到的卷大小是 100 x 90 x 15 x 15。
为了直观显示屏蔽 R-CNN 过程,请看下图:

Figure 6: A visualization of Mask R-CNN producing a 15 x 15 mask, the mask resized to the original dimensions of the image, and then finally overlaying the mask on the original image. (source: Deep Learning for Computer Vision with Python, ImageNet Bundle)
在这里,您可以看到,我们从输入图像开始,并通过我们的 Mask R-CNN 网络进行馈送,以获得我们的 Mask 预测。
预测的遮罩只有 15 x 15 像素,因此我们将遮罩的尺寸调整回原始输入图像尺寸。
最后,调整大小后的遮罩可以覆盖在原始输入图像上。关于 Mask R-CNN 如何工作的更详细的讨论,请参考:
- 原 面罩 R-CNN 由何等人出版。
- 我的书, 用 Python 进行计算机视觉的深度学习 ,其中我更详细地讨论了 Mask R-cns,包括如何在自己的数据上从头开始训练自己的 Mask R-cns。
项目结构
我们今天的项目由两个脚本组成,但是还有其他几个重要的文件。
我按照以下方式组织了项目(如直接在终端中输出的tree命令所示):
$ tree
.
├── mask-rcnn-coco
│ ├── colors.txt
│ ├── frozen_inference_graph.pb
│ ├── mask_rcnn_inception_v2_coco_2018_01_28.pbtxt
│ └── object_detection_classes_coco.txt
├── images
│ ├── example_01.jpg
│ ├── example_02.jpg
│ └── example_03.jpg
├── videos
│ ├──
├── output
│ ├──
├── mask_rcnn.py
└── mask_rcnn_video.py
4 directories, 9 files
我们的项目包括四个目录:
mask-rcnn-coco/:屏蔽 R-CNN 模型文件。有四个文件:frozen_inference_graph.pb:屏蔽 R-CNN 模型权重。权重是在 COCO 数据集上预先训练的。mask_rcnn_inception_v2_coco_2018_01_28.pbtxt:面罩 R-CNN 型号配置。如果你想在你自己的标注数据上建立+训练你自己的模型,参考 用 Python 进行计算机视觉的深度学习。- 这个文本文件中列出了所有 90 个类,每行一个。在文本编辑器中打开它,看看我们的模型可以识别哪些对象。
- 这个文本文件包含六种颜色,随机分配给图像中的物体。
images/:我在 【下载】 中提供了三张测试图片。请随意添加您自己的图片进行测试。- 这是一个空目录。我实际上用我从 YouTube 上搜集的大视频进行了测试(演职员表在下面,就在“总结”部分的上面)。与其提供一个很大的 zip 文件,我建议你在 YouTube 上找几个视频下载并测试。或者用手机拍些视频,然后回到电脑前使用!
output/:另一个空目录,将保存已处理的视频(假设您设置了命令行参数标志以输出到该目录)。
我们今天将复习两个剧本:
- 这个脚本将执行实例分割,并对图像应用一个遮罩,这样您就可以看到 R-CNN 认为一个对象所在的遮罩的像素位置。
mask_rcnn_video.py:这个视频处理脚本使用相同的遮罩 R-CNN,并将模型应用于视频文件的每一帧。然后,脚本将输出帧写回磁盘上的视频文件。
OpenCV 和屏蔽图像中的 R-CNN
既然我们已经回顾了 Mask R-CNN 是如何工作的,那么让我们用一些 Python 代码来体验一下。
在我们开始之前,确保您的 Python 环境安装了 OpenCV 3.4.2/3.4.3 或更高版本。可以跟着我的一个 OpenCV 安装教程升级/安装 OpenCV。如果你想在 5 分钟或更短的时间内启动并运行,你可以考虑用 pip 安装 OpenCV。如果您有一些其他需求,您可能希望从源代码编译 OpenCV。
确保你已经使用这篇博文的 【下载】 部分下载了源代码、训练好的 Mask R-CNN 和示例图片。
从那里,打开mask_rcnn.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import random
import time
import cv2
import os
首先,我们将在第 2-7 行中导入我们需要的包。值得注意的是,我们正在导入 NumPy 和 OpenCV。大多数 Python 安装都附带了其他东西。
从那里,我们将解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-m", "--mask-rcnn", required=True,
help="base path to mask-rcnn directory")
ap.add_argument("-v", "--visualize", type=int, default=0,
help="whether or not we are going to visualize each instance")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="minimum threshold for pixel-wise mask segmentation")
args = vars(ap.parse_args())
我们的脚本要求命令行参数标志和参数在运行时在我们的终端中传递。我们的参数在第 10-21 行被解析,其中下面的前两个是必需的,其余的是可选的:
--image:我们输入图像的路径。--mask-rnn:屏蔽 R-CNN 文件的基路径。--visualize(可选):正值表示我们希望在屏幕上直观地看到我们是如何提取被屏蔽的区域的。无论哪种方式,我们都将在屏幕上显示最终输出。--confidence(可选):您可以覆盖0.5的概率值,用于过滤弱检测。- (可选):我们将为图像中的每个物体创建一个二元遮罩,这个阈值将帮助我们过滤掉弱遮罩预测。我发现缺省值
0.3工作得很好。
现在我们的命令行参数存储在args字典中,让我们加载标签和颜色:
# load the COCO class labels our Mask R-CNN was trained on
labelsPath = os.path.sep.join([args["mask_rcnn"],
"object_detection_classes_coco.txt"])
LABELS = open(labelsPath).read().strip().split("\n")
# load the set of colors that will be used when visualizing a given
# instance segmentation
colorsPath = os.path.sep.join([args["mask_rcnn"], "colors.txt"])
COLORS = open(colorsPath).read().strip().split("\n")
COLORS = [np.array(c.split(",")).astype("int") for c in COLORS]
COLORS = np.array(COLORS, dtype="uint8")
第 24-26 行加载 COCO 对象类LABELS。今天的面具 R-CNN 能够识别 90 类,包括人,车辆,标志,动物,日常用品,运动装备,厨房用品,食物,等等!我鼓励您查看object_detection_classes_coco.txt来了解可用的课程。
从那里,我们从 path 加载COLORS,执行几个数组转换操作(第 30-33 行)。
让我们加载我们的模型:
# derive the paths to the Mask R-CNN weights and model configuration
weightsPath = os.path.sep.join([args["mask_rcnn"],
"frozen_inference_graph.pb"])
configPath = os.path.sep.join([args["mask_rcnn"],
"mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"])
# load our Mask R-CNN trained on the COCO dataset (90 classes)
# from disk
print("[INFO] loading Mask R-CNN from disk...")
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)
首先,我们构建我们的权重和配置路径(第 36-39 行),然后通过这些路径加载模型(第 44 行)。
在下一个模块中,我们将通过 Mask R-CNN 神经网络加载并传递一幅图像:
# load our input image and grab its spatial dimensions
image = cv2.imread(args["image"])
(H, W) = image.shape[:2]
# construct a blob from the input image and then perform a forward
# pass of the Mask R-CNN, giving us (1) the bounding box coordinates
# of the objects in the image along with (2) the pixel-wise segmentation
# for each specific object
blob = cv2.dnn.blobFromImage(image, swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
(boxes, masks) = net.forward(["detection_out_final", "detection_masks"])
end = time.time()
# show timing information and volume information on Mask R-CNN
print("[INFO] Mask R-CNN took {:.6f} seconds".format(end - start))
print("[INFO] boxes shape: {}".format(boxes.shape))
print("[INFO] masks shape: {}".format(masks.shape))
在这里我们:
- 加载输入
image并提取尺寸用于稍后的缩放目的(第 47 和 48 行)。 - 通过
cv2.dnn.blobFromImage( 线 54 )构建一个blob。你可以在我的之前的教程中了解为什么以及如何使用这个功能。 - 在收集时间戳(第 55-58 行)的同时,执行
blob到net的正向传递。结果包含在两个重要的变量中:boxes和masks。
既然我们已经在图像上执行了掩膜 R-CNN 的正向传递,我们将想要过滤+可视化我们的结果。这正是下一个 for 循环要完成的任务。它很长,所以我把它分成五个代码块,从这里开始:
# loop over the number of detected objects
for i in range(0, boxes.shape[2]):
# extract the class ID of the detection along with the confidence
# (i.e., probability) associated with the prediction
classID = int(boxes[0, 0, i, 1])
confidence = boxes[0, 0, i, 2]
# filter out weak predictions by ensuring the detected probability
# is greater than the minimum probability
if confidence > args["confidence"]:
# clone our original image so we can draw on it
clone = image.copy()
# scale the bounding box coordinates back relative to the
# size of the image and then compute the width and the height
# of the bounding box
box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
boxW = endX - startX
boxH = endY - startY
在这个模块中,我们开始我们的过滤/可视化循环(行 66 )。
我们继续提取特定检测对象的classID和confidence(行 69 和 70 )。
从那里,我们通过比较confidence和命令行参数confidence的值来过滤弱预测,确保我们超过它(第 74 行)。
假设是这样的话,我们将继续制作图像的clone(第 76 行)。我们以后会需要这张图片。
然后我们缩放我们对象的边界框并计算框的尺寸(行 81-84 )。
图像分割要求我们找到物体所在的所有像素。因此,我们将在对象的顶部放置一个透明的覆盖层,以观察我们的算法执行得有多好。为了做到这一点,我们将计算一个掩码:
# extract the pixel-wise segmentation for the object, resize
# the mask such that it's the same dimensions of the bounding
# box, and then finally threshold to create a *binary* mask
mask = masks[i, classID]
mask = cv2.resize(mask, (boxW, boxH),
interpolation=cv2.INTER_NEAREST)
mask = (mask > args["threshold"])
# extract the ROI of the image
roi = clone[startY:endY, startX:endX]
在第 89-91 行,我们提取对象的像素分割,并将其调整到原始图像尺寸。最后,我们对mask进行阈值处理,使其成为二进制数组/图像(第 92 行)。
我们还提取目标所在的感兴趣区域(行 95 )。
在帖子后面的图 8 中可以看到mask和roi。
为了方便起见,如果通过命令行参数设置了--visualize标志,则下一个块实现了对mask、roi和分段instance的可视化:
# check to see if are going to visualize how to extract the
# masked region itself
if args["visualize"] > 0:
# convert the mask from a boolean to an integer mask with
# to values: 0 or 255, then apply the mask
visMask = (mask * 255).astype("uint8")
instance = cv2.bitwise_and(roi, roi, mask=visMask)
# show the extracted ROI, the mask, along with the
# segmented instance
cv2.imshow("ROI", roi)
cv2.imshow("Mask", visMask)
cv2.imshow("Segmented", instance)
在这一部分中,我们:
- 查看我们是否应该可视化 ROI、遮罩和分段实例(第 99 行)。
- 将我们的遮罩从布尔值转换为整数,其中值“0”表示背景,“255”表示前景(第 102 行)。
- 执行逐位屏蔽,仅可视化实例本身(第 103 行)。
- 显示所有三幅图像(第 107-109 行)。
同样,只有通过可选的命令行参数设置了--visualize标志,这些可视化图像才会显示(默认情况下,这些图像不会显示)。
现在让我们继续视觉化:
# now, extract *only* the masked region of the ROI by passing
# in the boolean mask array as our slice condition
roi = roi[mask]
# randomly select a color that will be used to visualize this
# particular instance segmentation then create a transparent
# overlay by blending the randomly selected color with the ROI
color = random.choice(COLORS)
blended = ((0.4 * color) + (0.6 * roi)).astype("uint8")
# store the blended ROI in the original image
clone[startY:endY, startX:endX][mask] = blended
第 113 行通过传递布尔掩模阵列作为切片条件,仅提取ROI 的掩模区域。
然后我们将随机选择六个COLORS中的一个来应用我们的透明覆盖在物体上(第 118 行)。
随后,我们将我们的蒙版区域与roi ( 第 119 行)混合,然后将这个blended区域放到clone图像中(第 122 行)。
最后,我们将在图像上绘制矩形和文本类标签+置信度值,并显示结果!
# draw the bounding box of the instance on the image
color = [int(c) for c in color]
cv2.rectangle(clone, (startX, startY), (endX, endY), color, 2)
# draw the predicted label and associated probability of the
# instance segmentation on the image
text = "{}: {:.4f}".format(LABELS[classID], confidence)
cv2.putText(clone, text, (startX, startY - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# show the output image
cv2.imshow("Output", clone)
cv2.waitKey(0)
最后,我们:
- 在对象周围画一个彩色边框(第 125 行和第 126 行)。
- 构建我们的类标签+置信度
text,并在边界框上方绘制text(第 130-132 行)。 - 显示图像,直到按下任意键(行 135 和 136 )。
让我们试试我们的面具 R-CNN 代码吧!
确保您已经使用教程的 【下载】 部分下载了源代码、经过训练的掩码 R-CNN 和示例图像。从那里,打开您的终端并执行以下命令:
$ python mask_rcnn.py --mask-rcnn mask-rcnn-coco --image images/example_01.jpg
[INFO] loading Mask R-CNN from disk...
[INFO] Mask R-CNN took 0.761193 seconds
[INFO] boxes shape: (1, 1, 3, 7)
[INFO] masks shape: (100, 90, 15, 15)

Figure 7: A Mask R-CNN applied to a scene of cars. Python and OpenCV were used to generate the masks.
在上面的图像中,你可以看到我们的掩模 R-CNN 不仅对图像中的每辆汽车进行了定位,而且,还构建了一个像素掩模,允许我们从图像中分割出每辆汽车。
如果我们运行相同的命令,这次提供--visualize标志,我们也可以可视化 ROI、遮罩和实例:
Figure 8: Using the --visualize flag, we can view the ROI, mask, and segmentmentation intermediate steps for our Mask R-CNN pipeline built with Python and OpenCV.
让我们尝试另一个示例图像:
$ python mask_rcnn.py --mask-rcnn mask-rcnn-coco --image images/example_02.jpg \
--confidence 0.6
[INFO] loading Mask R-CNN from disk...
[INFO] Mask R-CNN took 0.676008 seconds
[INFO] boxes shape: (1, 1, 8, 7)
[INFO] masks shape: (100, 90, 15, 15)

Figure 9: Using Python and OpenCV, we can perform instance segmentation using a Mask R-CNN.
我们的掩模 R-CNN 已经从图像中正确地检测和分割了两个人,一只狗,一匹马和一辆卡车。
在我们继续在视频中使用屏蔽 R-CNN 之前,这里是最后一个例子:
$ python mask_rcnn.py --mask-rcnn mask-rcnn-coco --image images/example_03.jpg
[INFO] loading Mask R-CNN from disk...
[INFO] Mask R-CNN took 0.680739 seconds
[INFO] boxes shape: (1, 1, 3, 7)
[INFO] masks shape: (100, 90, 15, 15)
Figure 10: Here you can see me feeding a treat to the family beagle, Jemma. The pixel-wise map of each object identified is masked and transparently overlaid on the objects. This image was generated with OpenCV and Python using a pre-trained Mask R-CNN model.
在这张照片中,你可以看到一张我和 Jemma 的合照。
我们的面具 R-CNN 有能力检测和定位我,Jemma,和椅子。
视频流中的 OpenCV 和 Mask R-CNN
既然我们已经了解了如何将掩模 R-CNN 应用于图像,那么让我们来探索如何将它们应用于视频。
打开mask_rcnn_video.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import time
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", required=True,
help="path to output video file")
ap.add_argument("-m", "--mask-rcnn", required=True,
help="base path to mask-rcnn directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="minimum threshold for pixel-wise mask segmentation")
args = vars(ap.parse_args())
首先,我们导入必要的包并解析命令行参数。
有两个新的命令行参数(取代了前面脚本中的--image):
--input:我们输入视频的路径。--output:我们输出视频的路径(因为我们将把结果以视频文件的形式写入磁盘)。
现在让我们加载我们的类LABELS、COLORS,并屏蔽 R-CNN 神经net:
# load the COCO class labels our Mask R-CNN was trained on
labelsPath = os.path.sep.join([args["mask_rcnn"],
"object_detection_classes_coco.txt"])
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the Mask R-CNN weights and model configuration
weightsPath = os.path.sep.join([args["mask_rcnn"],
"frozen_inference_graph.pb"])
configPath = os.path.sep.join([args["mask_rcnn"],
"mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"])
# load our Mask R-CNN trained on the COCO dataset (90 classes)
# from disk
print("[INFO] loading Mask R-CNN from disk...")
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)
我们的LABELS和COLORS装在24-31 线上。
在加载我们的 R-CNN 神经net ( 第 34-42 行)之前,我们从那里定义我们的weightsPath和configPath。
现在让我们初始化我们的视频流和视频编写器:
# initialize the video stream and pointer to output video file
vs = cv2.VideoCapture(args["input"])
writer = None
# try to determine the total number of frames in the video file
try:
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
else cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
print("[INFO] {} total frames in video".format(total))
# an error occurred while trying to determine the total
# number of frames in the video file
except:
print("[INFO] could not determine # of frames in video")
total = -1
我们的视频流(vs)和视频writer在线 45 和 46 上初始化。
我们试图确定视频文件中的帧数并显示total ( 第 49-53 行)。如果我们不成功,我们将捕获异常并打印一条状态消息,同时将total设置为-1 ( 第 57-59 行)。我们将使用这个值来估计处理一个完整的视频文件需要多长时间。
让我们开始我们的帧处理循环:
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# construct a blob from the input frame and then perform a
# forward pass of the Mask R-CNN, giving us (1) the bounding box
# coordinates of the objects in the image along with (2) the
# pixel-wise segmentation for each specific object
blob = cv2.dnn.blobFromImage(frame, swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
(boxes, masks) = net.forward(["detection_out_final",
"detection_masks"])
end = time.time()
我们通过定义一个无限的while循环并捕获第一个frame ( 第 62-64 行)来开始对帧进行循环。该循环将处理视频直到完成,这由第 68 和 69 行上的退出条件处理。
然后,我们从该帧构建一个blob,并通过神经net传递它,同时获取经过的时间,这样我们就可以计算完成的估计时间(第 75-80 行)。结果包含在boxes和masks中。
现在让我们开始循环检测到的对象:
# loop over the number of detected objects
for i in range(0, boxes.shape[2]):
# extract the class ID of the detection along with the
# confidence (i.e., probability) associated with the
# prediction
classID = int(boxes[0, 0, i, 1])
confidence = boxes[0, 0, i, 2]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > args["confidence"]:
# scale the bounding box coordinates back relative to the
# size of the frame and then compute the width and the
# height of the bounding box
(H, W) = frame.shape[:2]
box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
boxW = endX - startX
boxH = endY - startY
# extract the pixel-wise segmentation for the object,
# resize the mask such that it's the same dimensions of
# the bounding box, and then finally threshold to create
# a *binary* mask
mask = masks[i, classID]
mask = cv2.resize(mask, (boxW, boxH),
interpolation=cv2.INTER_NEAREST)
mask = (mask > args["threshold"])
# extract the ROI of the image but *only* extracted the
# masked region of the ROI
roi = frame[startY:endY, startX:endX][mask]
首先,我们过滤掉具有低置信度值的弱检测。然后我们确定包围盒坐标并获得mask和roi。
现在让我们绘制对象的透明覆盖图、边框和标签+置信度:
# grab the color used to visualize this particular class,
# then create a transparent overlay by blending the color
# with the ROI
color = COLORS[classID]
blended = ((0.4 * color) + (0.6 * roi)).astype("uint8")
# store the blended ROI in the original frame
frame[startY:endY, startX:endX][mask] = blended
# draw the bounding box of the instance on the frame
color = [int(c) for c in color]
cv2.rectangle(frame, (startX, startY), (endX, endY),
color, 2)
# draw the predicted label and associated probability of
# the instance segmentation on the frame
text = "{}: {:.4f}".format(LABELS[classID], confidence)
cv2.putText(frame, text, (startX, startY - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
在这里,我们用颜色blended了我们的roi并在原始frame中store了它,有效地创建了一个彩色透明叠加(第 118-122 行)。
然后我们在对象周围画一个rectangle,并在上面显示类标签+confidence(第 125-133 行)。
最后,让我们写入视频文件并清理:
# check if the video writer is None
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
# some information on processing single frame
if total > 0:
elap = (end - start)
print("[INFO] single frame took {:.4f} seconds".format(elap))
print("[INFO] estimated total time to finish: {:.4f}".format(
elap * total))
# write the output frame to disk
writer.write(frame)
# release the file pointers
print("[INFO] cleaning up...")
writer.release()
vs.release()
在循环的第一次迭代中,我们的视频writer被初始化。
在终端的行 143-147 上打印出处理所需时间的估计值。
我们循环的最后一个操作是通过我们的writer对象( Line 150 )将帧write到磁盘。
你会注意到我没有在屏幕上显示每一帧。显示操作是耗时的,当脚本完成处理时,你可以用任何媒体播放器来观看输出视频。
注:此外,OpenCV 的dnn模块不支持 NVIDIA GPUs。目前只支持有限数量的 GPU,主要是英特尔 GPU。NVIDIA GPU 支持即将推出,但目前我们无法轻松使用带有 OpenCVdnn模块的 GPU。
最后,我们发布视频输入和输出文件指针(行 154 和 155 )。
现在我们已经为视频流编写了 Mask R-CNN + OpenCV 脚本,让我们来试试吧!
确保使用本教程的 【下载】 部分下载源代码并屏蔽 R-CNN 模型。
然后你需要用你的智能手机或其他录制设备来收集你自己的视频。或者,你可以像我一样从 YouTube 上下载视频。
注:我是故意不把今天下载的视频包括进来,因为它们相当大(400MB+)。如果你选择使用和我一样的视频,演职员表和链接在这一部分的底部。**
**从那里,打开一个终端并执行以下命令:
$ python mask_rcnn_video.py --input videos/cats_and_dogs.mp4 \
--output output/cats_and_dogs_output.avi --mask-rcnn mask-rcnn-coco
[INFO] loading Mask R-CNN from disk...
[INFO] 19312 total frames in video
[INFO] single frame took 0.8585 seconds
[INFO] estimated total time to finish: 16579.2047

Figure 11: Mask R-CNN applied to video with Python and OpenCV.
https://www.youtube.com/embed/T_GXkW0BUyA?feature=oembed*****
使用 COCO 评估器的平均精度(mAP)
原文:https://pyimagesearch.com/2022/05/02/mean-average-precision-map-using-the-coco-evaluator/
使用 COCO 评估器 平均精度(mAP)
在本教程中,您将学习对象检测中的平均精度(mAP ),并使用 COCO 评估器评估 YOLO 对象检测模型。
这是我们关于 YOLO 天体探测器的 7 集系列的第 4 课:
- YOLO 家族简介
- 了解一个实时物体检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的物体探测器(YOLOv2)
- 平均精度(地图)使用 COCO 评估器 (今日教程)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
- 【yolov 4】
- 在自定义数据集上训练 YOLOv5 物体检测器
我们将在本帖中讨论这些关键话题:
- 什么是精度和召回率?
- 精确召回曲线
- 并集上的交集
- 平均精度
- 平均精度
- 浏览使用 COCO 评估器评估 YOLO 对象检测模型的代码实现
在我们开始之前,您是否熟悉物体探测器的工作原理,尤其是像 YOLO 这样的单级探测器?
如果没有,一定要看看我们以前的帖子,YOLO 家族介绍和了解实时物体检测网络:你只看一次(YOLOv1) ,对单级物体检测一般如何工作有一个高层次的直觉。单级目标检测器将目标检测视为简单的回归问题。例如,馈送到网络的输入图像直接输出类别概率和边界框坐标。
这些模型跳过区域提议阶段,也称为区域提议网络,它通常是两阶段对象检测器的一部分,是图像中可能包含对象的区域。
要了解什么是对象检测中的 mAP 以及如何使用 COCO 评估器评估对象检测模型, 继续阅读。
使用 COCO 评估器 平均精度(mAP)
在解决一个涉及机器学习和深度学习的问题时,我们通常会有各种模型可供选择;例如,在图像分类中,可以选择 VGG16 或 ResNet50。每一种都有其独特之处,并会根据数据集或目标平台等各种因素表现不同。为了通过客观地比较我们用例的模型来最终决定最佳模型,我们需要有一个合适的评估度量。
在训练集上对模型进行训练或微调之后,将根据它在验证和测试数据上的表现来判断它的好坏或准确性。各种评估度量或统计可以评估深度学习模型,但是使用哪个度量取决于特定的问题陈述和应用。
在图像分类问题中用于评估的最常见的度量是精度、召回、混淆矩阵、 PR 曲线等。而在图像分割中,使用的是联合平均交集,又名 mIoU 。
然而,如果我们解决房间里的大象,用于对象检测问题的最常见的度量选择是平均精度(又名图)。
因为在对象检测中,目标不仅是正确地分类图像中的对象,而且还要找到它在图像中的位置,所以我们不能简单地使用像精度和召回这样的图像分类度量。
因此,目标检测评估标准需要考虑目标的类别和位置,这就是 mAP 发挥作用的地方。而要理解图,就要理解 IoU 、精度、召回、精度——召回曲线。所以,让我们开始深入研究吧!
配置您的开发环境
要遵循本指南,您需要在系统上安装 Pycocotools 库。对于额外的图像处理目的,您将使用 OpenCV、Sklearn 来计算精度和召回、Matplotlib 来绘制图形,以及其他一些库。
幸运的是,下面所有的库都是 pip 安装的!
$ pip install pycocotools==2.0.4
$ pip install matplotlib==3.2.2
$ pip install opencv==4.1.2
$ pip install progressbar==3.38.0
$ pip install sklearn==1.0.2
以上是本指南所需的环境配置!
但是,您还需要在您的系统上安装 Darknet 框架,以便使用 YOLOv4 运行推理。为此,我们强烈建议你去看看 AlexeyAB 的 Darknet 知识库。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们进入各种关键主题的理论和实现之前,让我们看一下项目结构。
一旦我们下载了我们的项目目录,它应该看起来像这样:
$ tree .
.
├── darknet
├── data
│ ├── dog.jpg
│ ├── label2idx.pkl
│ └── yolo_90_class_map.pkl
├── eval_iou.py
├── eval_map.py
├── main.py
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ ├── utils_iou.py
│ ├── utils_map.py
│ └── utils_precision_recall.py
└── results
├── COCO_Val_mAP.png
├── dog_iou.png
└── pr_curve.png
36 directories, 2135 files
请注意,我们没有显示darknet目录,因为它有很多文件,并且很难将所有文件作为目录结构的一部分。
父目录有 3 个 python 脚本和 4 个文件夹。
-
这是驱动程序脚本,是我们实验的入口点。基于从用户接收的命令行输入,它将执行三个实验之一(IoU、精度-召回曲线或 COCO 评估器)。
-
eval_iou.py:python 脚本有compute_iou()方法。它是从主服务器调用的。它以imagePath为参数,调用两个方法:第一个是计算 IoU,第二个是在屏幕上显示输出。 -
eval_map.py:加载地面实况标注文件,调用run_inference()方法生成预测,然后计算 mAP 并在终端上显示结果。
接下来,让我们进入pyimagesearch目录!在其中,我们将找到 5 个 python 脚本:
__init__.py:这将使 Python 把pyimagesearch目录当作一个模块config.py:该脚本包含各种超参数预设,并定义数据路径utils_iou.py:这个脚本实现了 IoU 方法和 plot 方法utils_map.py:这个脚本包含一个image_detection方法,它对每个图像进行推理,还有一些加载 pickle 文件和修改边界框坐标的方法。它还有run_inference()方法,该方法迭代每个图像调用image_detection(),并以 JSON 格式存储预测- 这个脚本有一堆计算精度的方法,超过不同阈值的召回,以及一个绘制精度召回曲线的方法
接下来,我们有data目录,它包含:
- 我们将在其上运行 IoU 实验的示例图像
- 存储对象类别相关信息的 Pickle 文件
- 我们将在这个目录中下载 YOLOv4 重量
- 最后,我们还将在这里下载 MS COCO 验证图像和地面实况注释
最后,我们有results目录,其中包含:
COCO_Val_mAP.png:COCO 验证数据集上的 YOLOv4 映射结果dog_iou.png:狗图像上的样本 IoU 输出pr_curve.png:精度-召回曲线图
【交集超过并集(借据)
并集上的交集,也称为 Jaccard 索引,测量真实边界框和预测边界框之间的重叠。它是基础真值框与预测边界框的交集和并集之间的比率。地面真实边界框是测试集中指定的手工标记边界框,其中是我们对象的图像,预测的边界框来自模型。
只要我们有这两个(基础事实和预测)边界框,我们就可以在并集上应用交集。
图 2 是真实边界框与预测边界框的可视化示例。目标是计算这两个边界框之间的交集。
在图 2 中,我们可以看到物体检测器已经检测到图像中存在停车标志。预测的包围盒以红色绘制,而地面真实(即手绘)包围盒以绿色绘制。
如图 3 所示,并集上的交集就像用并集的面积除以边界框之间的重叠面积一样简单。
从图 3 可以看出,交集超过并集就是一个简单的比值。在分子中,我们计算了预测边界框和地面真实边界框之间的重叠区域。
分母是并集的区域或由预测边界框和实际边界框包围的区域。
IoU 分数被归一化(因为分母是联盟区 ) ,范围从 0.0 到 1.0。此处,0.0 表示预测边界框和实际边界框之间没有重叠,而 1.0 是最佳值,意味着预测边界框与实际边界框完全重叠。
交集超过联合分数 > 0.5 通常被认为是“好的”预测。
我们为什么要用借条?
假设你在职业生涯中执行过任何以前的机器学习,特别是分类。在这种情况下,您可能会习惯于预测类别标签,其中您的模型输出一个标签,该标签要么是正确的要么是不正确的。
这种类型的二进制分类使得计算精度简单明了;然而,对于物体检测来说就没那么简单了。
实际上,不可能我们预测的边界框的 (x,y)-坐标将精确匹配**(x,y)-真实边界框的坐标。
由于我们的模型的不同参数(图像金字塔比例、滑动窗口大小、特征提取方法等)。),预测边界框和真实边界框之间的完全和完全匹配是不现实的。
正因为如此,我们需要定义一个评估标准,即奖励预测的边界框与地面真相严重重叠(不是 100%)。
图 4 显示了优差交集对联合分数的示例;每个案例中展示的借据分数只是出于直觉的目的,可能并不精确。
如您所见,与地面实况边界框重叠严重的预测边界框比重叠较少的预测边界框得分更高。这使得交集/并集成为评估自定义对象检测器的优秀指标。
我们并不关心 (x,y)-坐标的精确匹配,但是我们希望确保我们预测的边界框尽可能地匹配——并集上的交集可以考虑这一点。
很快,您将会看到 IoU 的概念和魔力如何使对象检测模型中的 mAP 指标受益。
在深入 IoU 的实现、精确召回曲线和评估 YOLOv4 object detector 之前,让我们设置路径和超参数。为此,我们将进入模块config.py。我们项目中的大多数其他脚本将调用这个模块并使用它的预置。
# import the necessary packages
from glob import glob
YOLO_CONFIG = "darknet/cfg/yolov4.cfg"
YOLO_WEIGHTS = "data/yolov4.weights"
COCO_DATA = "darknet/cfg/coco.data"
YOLO_NETWORK_WIDTH = 608
YOLO_NETWORK_HEIGHT = 608
LABEL2IDX = "data/label2idx.pkl"
YOLO_90CLASS_MAP = "data/yolo_90_class_map.pkl"
IMAGES_PATH = glob("data/val2017/*")
COCO_GT_ANNOTATION = "data/annotations/instances_val2017.json"
COCO_VAL_PRED = "data/COCO_Val_Predictions.json"
CONF_THRESHOLD = 0.25
IOU_GT = [90, 80, 250, 450]
IOU_PRED = [100, 100, 220, 400]
IOU_RESULT = "results/dog_iou.png"
PR_RESULT = "results/pr_curve.png"
GROUND_TRUTH_PR = ["dog", "cat", "cat", "dog", "cat", "cat", "dog",
"dog", "cat", "dog", "dog", "dog", "dog", "cat", "cat", "dog"]
PREDICTION_PR = [0.7, 0.3, 0.5, 0.6, 0.3, 0.35, 0.55, 0.2, 0.4, 0.3,
0.7, 0.5, 0.8, 0.2, 0.9, 0.4]
在上面几行代码中,我们首先导入glob模块(在第 2 行上),该模块用于获取第 14 行上列出的所有图像路径。
从第 4-6 行,我们定义了 YOLOv4 模型重量和配置文件以及 COCO 数据文件。然后我们定义 YOLOv4 模型输入宽度和高度(即608)。
然后,在第 11 行和第 12 行,我们定义了 pickle 文件路径。COCO 地面实况注释和预测 JSON 文件路径在第 16 行和第 17 行中声明。YOLOv4 置信阈值在线 19 上指定,其被设置为0.25。
在行 21-24 上,IoU 地面实况和预测框坐标与 IoU 结果路径一起定义。
最后,从第 25-30 行,定义了精度-召回曲线实验相关参数。
用 Python 编码欠条
既然我们已经理解了什么是并上交集以及为什么我们使用它来评估对象检测模型,那么让我们继续在utils_iou.py脚本中实现它。请注意,我们没有运行对象检测器来获得 IoU 示例的预测边界框坐标;我们假设预测的坐标。对于地面真实坐标,我们手动注释了图像。
# import the necessary packages
from matplotlib import pyplot as plt
import cv2
def intersection_over_union(gt, pred):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(gt[0], pred[0])
yA = max(gt[1], pred[1])
xB = min(gt[2], pred[2])
yB = min(gt[3], pred[3])
# if there is no overlap between predicted and ground-truth box
if xB < xA or yB < yA:
return 0.0
# compute the area of intersection rectangle
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# compute the area of both the prediction and ground-truth
# rectangles
boxAArea = (gt[2] - gt[0] + 1) * (gt[3] - gt[1] + 1)
boxBArea = (pred[2] - pred[0] + 1) * (pred[3] - pred[1] + 1)
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the intersection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
我们从行 2 和 3 中的必要导入开始。
在第 5 行上,我们定义了intersection_over_union方法,它需要两个参数:gt和pred被假定为我们的地面实况和预测边界框(实际的顺序你提供给intersection_over_union这两个参数并不重要)。
然后,从行 7-10 中,我们确定相交矩形的 (x,y)-坐标,然后用于计算行 17 上的相交面积。
在第 13 行和第 14 行上,我们执行了一个健全性检查,如果预测的和真实边界框之间有零重叠,那么我们返回零。
inter_Area变量代表交集并集公式中的分子。
为了计算分母(即联合面积,我们首先需要导出预测边界框和地面真实边界框的面积(第 21 行和第 22 行)。
注: 由于我们是在一个“像素坐标空间”中计算矩形的面积,所以我们必须在每个方向上加上1。第一个像素将从 0 开始直到(高/宽
- in the pixel space. For example, if an image has a width of 1920, the pixels would start from
0and go till1919, which would result in an incorrect area. Hence, we add1to the intersection and union areas calculation.
然后可以在第 27 行上通过将交集面积除以两个边界框的并集面积来计算交集,注意从分母中减去交集面积(否则,交集面积将被计算两次)。
最后,将 Union score 上的交集返回给第 30 行上的调用函数。
def plt_imshow(title, image, path):
# convert the image frame BGR to RGB color space and display it
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.title(title)
plt.grid(False)
plt.axis("off")
plt.imsave(path, image)
plt.show()
从第 32-40 行,我们定义了接受两个参数的plt_imshow方法:图的标题和要显示的图像。它使用plt.show()方法显示输出图像。由于matplotlib绘图功能期望图像在 RGB 颜色空间中,我们在第 34 行将图像从 BGR 转换为 RGB。
一旦我们写好了计算并集交集的方法,是时候将所有东西包装在一个compute_iou方法中了,在这个方法中,我们将传递用于计算借据的imagePath,所以让我们进入eval_iou.py脚本。
# import the necessary packages
from pyimagesearch.utils_iou import intersection_over_union
from pyimagesearch.utils_iou import plt_imshow
from pyimagesearch import config
import cv2
def compute_iou(imagePath):
# load the image
image = cv2.imread(imagePath)
# define the top-left and bottom-right coordinates of ground-truth
# and prediction
groundTruth = [90, 80, 250, 450]
prediction = [100, 100, 220, 400]
# draw the ground-truth bounding box along with the predicted
# bounding box
cv2.rectangle(image, tuple(groundTruth[:2]),
tuple(groundTruth[2:]), (0, 255, 0), 2)
cv2.rectangle(image, tuple(prediction[:2]),
tuple(prediction[2:]), (0, 0, 255), 2)
# compute the intersection over union and display it
iou = intersection_over_union(groundTruth, prediction)
cv2.putText(image, "IoU: {:.4f}".format(iou), (10, 34),
cv2.FONT_HERSHEY_SIMPLEX, 1.4, (0, 255, 0), 3)
# show the output image
plt_imshow("Image", image, config.IOU_RESULT)
在第 9 行上,我们从磁盘加载image,然后绘制绿色的真实边界框(第 18 和 19 行),接着是红色的预测边界框(第 20 和 21 行)。
通过传入我们在第 13 行和第 14 行定义的地面实况和预测边界框坐标,在第 24 行计算联合度量上的交集。
然后,我们在图像上写入交集值(第 25 行和第 26 行),最后,输出图像显示在我们的屏幕上(第 29 行)。
在图 5 中,我们可以看到联合分数上的交集是0.6098,这表明真实值(绿色)和预测值(红色)边界框之间有明显的重叠。
精确和召回
本节将讨论精确度、召回率和精确度-召回率曲线。既然你们是在物体探测系列中,我确信你们中的大多数人会更早地研究图像分类问题,并且已经熟悉精度、召回和混淆矩阵,不会对这些技术术语感到陌生。
然而,让我们回顾一下这些术语。
假设处理一个二元分类问题,其中每个输入样本被分配到两个类别中的一个,即 1(正)和 0(负)。例如,这两个类别标签可以是垃圾邮件或非垃圾邮件、恶性或良性(医学成像-癌症分类问题)、简单的猫或狗分类器等。
我们举个例子更详细的了解一下。假设我们有一个数据集,里面有十张猫和其他动物的图片。我们需要对给定的输入样本进行分类。这意味着这是一个二元分类问题。
这里我们有数据的ground-truth标签:
[cat, cat, others, cat, others, others, cat, cat, cat, others]
这些类别标签目前是人类可读的形式;但是,该模型期望地面实况为数字或整数。因此,当输入到模型中时,模型会为每个类别返回一个分数。例如,给定数据集中的十幅图像,模型的预测将为:
[0.8, 0.1, 0.5, 0.9, 0.28, 0.35, 0.7, 0.4, 0.2, 0.68]
现在我们有了每个样本的模型预测;对于二元分类问题,我们可以使用阈值将这些预测分数转换为类别标签。阈值是一个超参数,你可以在这里进行实验。暂且假设阈值为0.5,也就是说如果模型预测大于等于 0.5,那么样本属于一个cat(正)类;否则,就是others(否定)类。
使用阈值将预测转换为类标注后,预测的标注将如下所示:
prediction: [cat, others, cat, cat, others, others, cat, others, others, cat]
如果我们比较实际标签和预测标签,我们可以看到模型在阈值0.5下做出了五个正确和五个不正确的预测,改变阈值会改变结果。
直接将实际情况与预测进行比较是没问题的,但是如果我们需要对模型的性能进行更深入的分析呢?
例如,给定一只猫的图像,模型有多少次预测它是一只猫,或者把它误分类为其他?类似地,对于其他类图像,模型正确预测为其他和错误分类为猫的次数。
基于上述示例,让我们定义四个新术语:
- 真阳性(TP): 模型正确预测阳性输入样本(即
cat)为阳性的次数。 - 假阳性(FP): 模型错误地将阴性样本(即
others)预测为阳性的次数。 - 真阴性(TN): 模型正确预测阴性样本(即
others)为阴性的次数。 - 假阴性(FN): 模型错误地将实际输入(即
cat)预测为阴性的次数。
以上四个术语帮助我们提取关于模型性能的更深层次的信息。最后,让我们把它们放在一起,以获得精度和召回率。
它是正确分类的阳性样本与分类为阳性(不正确和正确)的样本总数之间的比率。简而言之,精度回答了当模型猜测时猜测有多准确的问题,或者它测量了模型在将样本分类为阳性时的精度/准确性。
在 Precision 中,由于在计算中存在假阳性,焦点也集中在被错误分类为阳性的阴性样本上。举个例子,
- 没有癌症迹象的患者被预测为癌症或
- 图像的一个补片被检测为一个人,而该补片中没有人
精度可以计算为

其中
are the total predicted objects.
为了提高精度,分子需要更高(简单的数学)。当模型正确地将阳性样本预测为阳性(即,最大化真阳性),并且同时将更少(不正确)的阴性样本预测为阳性(即,最小化假阳性)时,精度会更高。
当模型将许多阴性样本预测为阳性或较少正确的阳性分类时,精度会较低。这会增加分母,降低精度。
现在,让我们用几行 Python 代码来计算精度。
import sklearn.metrics
ground_truth = ["cat", "cat", "others", "cat", "others", "others","cat", "cat", "cat", "others" ]
prediction = ["cat", "others", "cat", "cat", "others", "others","cat", "others", "others", "cat"]
precision = sklearn.metrics.precision_score(ground_truth, prediction, pos_label="cat")
print(precision)
在上面几行代码中,我们使用sklearn.metrics方法来计算上面为了理解二进制分类问题所举的cat和others例子的精度。
相对简单,从第 3 行和第 4 行开始,我们在一个列表中定义ground_truth和prediction。然后将它们传递给线 6 上sklearn的precision_score方法。我们还给出一个pos_label参数,让您指定哪个类应该被视为精度计算的positive。
回忆
它是正确分类的阳性样本与实际阳性样本总数之间的比率。回忆你的模型是否每次都猜到了它应该猜到的答案。召回率越高,检测到的阳性样本越多。

其中
are the total ground-truth objects.
正如我们所了解的,精度确实考虑了如何对阴性样本进行分类;然而,召回率与负样本如何分类无关,只关心正样本如何分类。这意味着即使所有的阴性样本都被归类为阳性,召回仍然是完美的1.0。
当所有阳性样本都被归类为阳性时,召回率为1.0或 100%。另一方面,如果阳性样本被归类为阴性,召回率会很低;例如,假设一幅图像中有五辆汽车,但只有四辆被检测到,那么假阴性就是一辆。
import sklearn.metrics
ground_truth = ["cat", "cat", "others", "cat", "others", "others","cat", "cat", "cat", "others"]
prediction = ["cat", "others", "cat", "cat", "others", "others", "cat", "others", "others", "cat"]
recall = sklearn.metrics.recall_score(ground_truth, prediction, pos_label="cat")
print(recall)
与 Precision 类似,我们只需将第 6 行上的sklearn.metrics.precision_score改为sklearn.metrics.recall_score就可以计算召回率。
检测上下文中的 TP、FP、TN、FN
我们学习了精确度和召回率,为了计算它们,我们需要计算真阳性、真阴性、假阳性和假阴性。我们还了解了并集上的交集,以及它如何帮助评估对象检测模型的定位误差。那么,让我们了解一下目标检测环境中的精度和召回率,以及 IoU 和置信度得分如何发挥作用。
置信度得分反映了该框包含对象的可能性(客观性得分)和边界框的准确性。但是,如果该单元中不存在任何对象,置信度得分应该为零。
真阳性
只有在满足以下两个条件时,由模型进行的检测才被认为是真阳性:
- 预测的边界框的置信度得分应该大于置信度阈值(超参数),这将表明我们已经找到了我们正在寻找的对象。
- 预测边界框和地面实况边界框之间的 IoU 应该大于 IoU 阈值。
而以上两个条件的意思是,不仅检测到物体,而且是在正确的位置检测到物体。图 6 显示了 IoU 为0.81且置信度为0.7的真阳性检测。
假阳性
检测被认为是假阳性:
- 如果模型检测到具有高置信度得分的对象,但是它不存在(没有地面事实),则 IoU 将等于零。
- 另一种情况可能是 IoU 小于 IoU 阈值。
- 如果所提议的边界框与地面真相完全对齐,但是所提议的框的类别标签不正确。
真负
这通常是不需要的,主要是因为它不是精度和召回计算的一部分。
当置信度得分小于置信度阈值,并且 IoU(预测框和实际框)小于 IoU 阈值时,检测结果为真阴性。在物体检测中,可能有很多真正的底片,因为背景比物体本身覆盖了更多的图像区域。
假阴性
如果有一个物体存在,但模型不能检测到它,那么这是一个假阴性。
精确召回曲线
根据上一节的学习,我们现在知道,如果模型同时具有高精度和高召回率,那么它会正确地预测样本为阳性,并预测大多数阳性样本(不会遗漏样本或预测它们为阴性)。但是,如果模型具有高精度和低召回率,它准确地预测样本为阳性但只有少数阳性样本(更多的假阴性)。
现在我们知道了精确度和召回率的重要性,并且我们的最终目标是获得精确度和召回率的最高分,让我们看看如何在同一个图表上绘制它们。
精确召回值的绘制被称为精确召回曲线,它描述了基于不同阈值的两者之间的权衡。精度-召回曲线有助于选择最佳阈值,使精度和召回率最大化。
让我们用一个猫和狗的二元分类例子来理解精确召回曲线。在utils_precision_recall.py中,我们将编写compute_precision_recall方法,该方法将在一个向量中采用实际向量和预测向量以及 10 个阈值。最后,返回 10 个阈值中每个阈值的精度和召回率。这也将有助于绘制精确召回曲线。
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import sklearn.metrics
import numpy as np
def compute_precision_recall(yTrue, predScores, thresholds):
precisions = []
recalls = []
# loop over each threshold from 0.2 to 0.65
for threshold in thresholds:
# yPred is dog if prediction score greater than threshold
# else cat if prediction score less than threshold
yPred = [
"dog" if score >= threshold else "cat"
for score in predScores
]
# compute precision and recall for each threshold
precision = sklearn.metrics.precision_score(y_true=yTrue,
y_pred=yPred, pos_label="dog")
recall = sklearn.metrics.recall_score(y_true=yTrue,
y_pred=yPred, pos_label="dog")
# append precision and recall for each threshold to
# precisions and recalls list
precisions.append(np.round(precision, 3))
recalls.append(np.round(recall, 3))
# return them to calling function
return precisions, recalls
在第 7 行的上,我们定义了compute_precision_recall函数,它将基本事实标签、预测分数和阈值列表作为参数。
然后,我们迭代通过行 12 上的每个阈值,通过检查预测分数(或概率)是否大于或等于阈值将概率转换为类别标签,我们将dog标签赋值为 else cat。
从第 21-24 行,我们计算给定阈值和预测的精确度和召回率。然后我们将 precision 和 recall 四舍五入到三个小数位,并将它们添加到第 28 行和第 29 行的列表的precisions和recalls中。
最后,我们将precisions和recalls返回给行 32 上的调用函数。
def pr_compute():
# define thresholds from 0.2 to 0.65 with step size of 0.05
thresholds = np.arange(start=0.2, stop=0.7, step=0.05)
# call the compute_precision_recall function
precisions, recalls = compute_precision_recall(
yTrue=config.GROUND_TRUTH_PR, predScores=config.PREDICTION_PR,
thresholds=thresholds,
)
# return the precisions and recalls
return (precisions, recalls)
在的第 36 行,我们使用np.arange定义阈值,这创建了一个向量,其值从0.2到0.65,步长为0.05。
从的第 39-42 行,我们通过传入ground_truth、prediction和thresholds数组来调用compute_precision_recall方法。
def plot_pr_curve(precisions, recalls, path):
# plots the precision recall values for each threshold
# and save the graph to disk
plt.plot(recalls, precisions, linewidth=4, color="red")
plt.xlabel("Recall", fontsize=12, fontweight='bold')
plt.ylabel("Precision", fontsize=12, fontweight='bold')
plt.title("Precision-Recall Curve", fontsize=15, fontweight="bold")
plt.savefig(path)
plt.show()
在上面几行代码中,我们创建了一个plot_pr_curve方法,帮助我们在 2D 图上绘制precisions和recalls列表,其中precision在 x 轴上,recall在 y 轴上。请注意,在 0.6 之后,随着回忆的增加,精确度开始下降。
我们有我们的精度-召回曲线,但是我们如何知道在哪个阈值下模型表现最好(即,高精度和召回)?
为了找出最佳的精确度和召回率,我们使用 F1-score 通过取它们的调和平均值将精确度和召回率结合成一个单一的度量。较高的 F1 分数意味着精确度和召回率较高,而较低的 F1 分数意味着精确度和召回率之间的高度不平衡(或者较低的精确度和召回率)。
}")
f1_score = np.divide(2 * (np.array(precisions) * np.array(recalls)), (np.array(precisions) + np.array(recalls)))
print(f1_score)
array([0.71959027, 0.69536849, 0.69536849, 0.69986987, 0.73694181, 0.70606916, 0.70606916, 0.66687977, 0.57106109, 0.46121884])
在行 1 上,我们通过传递从上面得到的precisions和recalls列表来计算f1_score。从输出中,我们可以观察到最高的f1_score是索引 5 处的0.7369。
现在,让我们使用最高的f1_score来获得平衡精确度和召回率的最佳阈值。
precision = precisions[np.argmax(f1_score)]
recall = recalls[np.argmax(f1_score)]
best_threshold = np.round(thresholds[np.argmax(f1_score)], 1)
print(precision, recall, best_threshold)
(0.7, 0.778, 0.4)
从第 7-9 行,我们通过将f1_score传递给np.argmax函数来计算精度、召回率和最佳阈值,以获得f1_score数组中的最大值索引。
最后,我们可以得出结论,平衡精确度和召回率的最佳阈值是0.4。另一种方式是期望我们的模型在0.4阈值达到最佳精度和召回率。
物体探测竞赛数据集
【Pascal VOC 2012】
PASCAL 视觉对象类 2012 (VOC2012)是一个在现实场景中从各种视觉对象类中识别对象的挑战。这是一个监督学习的挑战,其中提供了标记的地面真相图像。该数据集有 20 个对象类,如人、鸟、猫、狗、自行车、汽车、椅子、沙发、电视、瓶子等。
PASCAL VOC 的历史可以追溯到 2005 年,当时数据集只包含四个类:自行车、汽车、摩托车和人。它总共有 1578 幅图像,包含 2209 个带注释的对象。
图 10 显示了 20 个班级的样本图片,正如我们所看到的,第一排倒数第二张图片中有几把椅子。
VOC2012 数据集由 11,530 幅图像和 27,450 个带训练/值分割的感兴趣区域(ROI)注释对象组成。27,450 ROI 指的是整个数据集中的边界框,因为每个图像可以有多个对象或 ROI。因此,与图像相比,ROI 超过 2 倍。
可可女士
微软通用对象上下文 (MS COCO)是 2014 年在使用新颖用户界面的广泛众包的帮助下推出的大规模对象检测、分割和字幕数据集。该数据集包含 80 个对象类别的图像,在 328k 图像中有 250 万个标记实例。
图 11 显示了 COCO 数据集中标记有实例分割的示例图像。
COCO 还有一个优秀的用户界面来浏览数据集中的图像。例如,您可以从 80 个类别中选择缩略图;它会将它们作为标签放在搜索栏中,当你搜索时,它会显示数据集中带有那些标签(类)的所有图像,如图图 12 所示。
此外,当显示结果图像时,所有类别(多于搜索的类别)被显示为缩略图。您可以通过进一步单击这些缩略图来查看与这些类相关的分段掩码,从而对其进行调整。
物体检测的精确召回曲线
与分类相比,精确-召回曲线在评估对象检测模型的性能方面具有相同甚至更大的重要性。当我们改变置信度阈值(一个盒子包含一个对象的概率)时,如果精度和召回不受影响,则对象检测器被认为是好的。此外,准确率不会随着召回率的增加而降低。
具有高精度和高召回率的理想对象检测器将具有零假阳性(仅检测相关对象)和零假阴性(不遗漏相关对象或预测所有地面真实对象)。
现在,让我们借助一个例子来理解精确度和召回率是如何变化的。对于这个例子和随后的例子,我们将使用 Rafael Padilla 的对象检测指标 GitHub 知识库 ,它提供了关于精确召回和平均精确的例子的极好的总结。
考虑图 13 中所示的例子;七幅图像由 15 个 ROI 或真实边界框(显示为绿色)和 24 个 ROI 建议或预测边界框(显示为红色)组成。每个预测的边界框都有一个与之相关联的置信度得分。
现在让我们将所有这七个图像数据转移到表 1 中,该表有四列:图像名称、检测、每个检测的置信度得分以及真阳性(TP)或假阳性(FP)。对于这个例子,假设
.
对于Image 1,我们有三个检测:A、B和C,它们分别有各自的置信度得分88%、70%和80%,以及这些检测是 TP 还是 FP。如果我们观察Image 1,我们可以看到检测A是一个 FP。这是因为它与 GT 的重叠明显较少,尽管可信度很高。记住,我们在对象检测的上下文中讨论了 TP/FP。检测B似乎与 GT 匹配得很好,因此它被标记为 TP,而检测C也是 FP,因为该提议中没有 GT。因此,我们得到了其余六幅图像的 TP 和 FP。
我们获得了数据集(七幅图像)的所有 TP/FP,但是我们需要计算整个数据集上累积的 TP/FP,以得出精确-召回曲线。因此,我们首先根据从最高到最低的置信度对上面的表行进行排列,由此我们得到一个新的表 2 。
表 2 还有五列:TP/FP 被分成两个单独的列,累计 TP、累计 FP、Precision 和 Recall。为了计算精度和召回率,我们使用前面讨论过的公式。
让我们将表 2 分解为以下步骤:
- 我们将 TP 和 FP 分成两列,对于每个建议的 ROI,我们在它们各自的列中指定 1 和 0。例如,在
Image 5中,检测R是一个 TP,所以我们在第一行的 TP 列中指定 1,而在同一个图像中,检测Q是一个 FP,所以我们在第 18 行的 FP 列中设置 1。对于所有提议的 ROI,遵循相同的想法。 - 一旦我们完成了所有建议 ROI 的 TP 和 FP,我们将进入以下两列:
Acc TP和Acc FP。计算它们非常简单。对于第一行,Acc TP将与 TP 相同(即 1)。对于第二行,它将保持不变,因为 TP 为 0。对于第三行,它将是 2,因为 TP 是 1(到目前为止,两个 TP:第一行和第三行)。类似地,我们将计算所有行的Acc TP,直到我们到达末尾。 - 然后,我们将对
Acc FP列进行同样的练习,并根据前一个Acc FP和当前行 FP 的值填充所有行。 - 现在我们有了
Acc TP和Acc FP,计算精度和召回率就很简单了。对于每个建议的 ROI,我们将使用Acc TP和Acc FP来计算精度,并使用Acc TP作为分子,GT 的数量作为分母(TP+FN)来计算召回。 - 对于第一行,精度会是
 ,无非就是
,无非就是1;对于第二行,会是 ,也就是
,也就是0.5,我们会对所有行进行计算。同样,我们可以计算召回率;例如,对于最后一行,它将是 (即
(即0.466)。
 ,无非就是
,无非就是 ,也就是
,也就是 (即
(即很好,现在我们有了所有建议感兴趣区域的精度和召回值,我们可以绘制精度与召回的关系图,如图图 14 所示。
从上图中我们可以看到,我们的精度-召回曲线在左上角以绿色显示了所有具有最高置信度得分R的建议感兴趣区域,在右下角以红色显示了具有最低置信度得分的检测。
现在我们已经有了精确召回率(PR)曲线,下一步是计算 PR 曲线下的面积(即平均精确率(AP))。然而,在计算 AP 之前,我们需要消除锯齿形模式(即上图中的噪声),因为精度和召回率一直在上升和下降。
计算平均精度
如上所述,平均精度(AP)找到了精度-召回曲线下的区域;我们可以使用 PASCAL VOC 挑战赛中介绍的 11 点插值技术从 PR 曲线计算平均精度。
让我们看看如何将这一技术应用于 PR 曲线,并得出平均精度。
11 点插补
11 点插值计算![[0, 0.1, 0.2, \dots, 1]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/6e27beb19e8bf70034196c98e5334f7f.png "[0, 0.1, 0.2, \dots, 1]") 召回级别的精度
召回级别的精度
(i.e., 11 equally spaced recall levels), and then averages them out. Mathematically it can be expressed as:
}")
")
其中")
is the measured precision at recall  .
.
由于精度和召回率在0和1之间,AP 也落在0和1之间。因此,在计算 AP 之前,我们需要从 PR 曲线中平滑掉之字形图案。
在每个召回级别,我们将每个精度值替换为该召回级别右侧的最大精度值,如图图 16 所示。
所以蓝线变成了红线,曲线会单调递减,而不是之字形。因此,计算出的 AP 值将更不容易受到排序中的微小变化的影响。在数学上,我们用任何召回的最大精度≥ ȓ 替换召回 ȓ 的精度值。
一旦我们有了这个图表,我们就可以将从0到1.0的召回值分成 11 个 0.1 的相等间隔,从而得到图 17 。
现在让我们根据下面的 11 点插值图计算 AP:
")
")


注: 据原研究者介绍,内插精度/召回曲线的意图是为了减少因实例排序的细微变化而导致的精度/召回曲线中“摆动”的影响。
【地图平均精度】
我们可以通过简单地取所有 AP 类的平均值来计算 mAP。例如,在 PASCAL VOC 数据集中,我们可以为 20 个类别中的每一个计算 AP,然后对所有 20 个 AP 类进行平均,以获得平均精度。
表 3 显示了 PASCAL VOC 数据集上各种检测器(如 SSD300 和 SSD512)的图,以及 20 类中每一类的 AP。每个类上的 AP 提供了对对象检测器的更细粒度的评估,因为它告诉我们检测器在哪些类上表现良好,在哪些类上表现不佳。
使用 COCO 评估器 评估 YOLOv4 模型
这最后一节将学习使用 COCO 评估器评估对象检测模型的性能。我们将使用在 MS COCO 数据集上训练的 YOLOv4 对象检测器,它在 Tesla Volta100 GPU 上以∼65 FPS 的实时速度实现了 MS COCO 数据集的 43.5% AP (65.7% AP50)。
我们将在 2017 年 MS COCO 验证数据集上评估 YOLOv4 模型,该数据集包含 5000 张不同大小的图像,并采用 COCO 格式的地面实况。
COCO 地图评估员
COCO 评估器现在是计算物体探测器地图的黄金标准。大多数研究论文使用过去几年的 COCO 评估为 COCO 数据集提供了基准。主要有两个原因。首先,数据集比 VOC 数据集丰富得多。其次,COCO 评估对检测模型进行了更深入的分析,从而提供了完整的结果。
正如在 PASCAL VOC 评估中所了解到的,如果满足以下条件,则建议的 ROI 被认为是真正的正值
with the ground truth. Since there is only one threshold, hence, a detection that very closely aligns ( ) with the ground truth would be considered similar to the one with
) with the ground truth would be considered similar to the one with  .
.
使用单一 IoU 阈值来评估我们的检测模型可能不是一个好主意,因为单一阈值可能会导致评估指标出现偏差。还有,可以对模特宽大。因此,COCO mAP 评估器以步长 0.05 (AP@[0.5:0.05:0.95])对 10 个 IoU 阈值上的 80 个类的 mAP 进行平均。
值得注意的是,与 PASCAL VOC 不同,COCO 评估器使用 101 点插值 AP(即,它计算 101 个召回级别[0:0.01:1]的精度值)。
图 18 显示了 COCO 评价器为我们提供的物体检测评价的变化,我们也将在教程的下一节学习计算。
上图显示 COCO 评价者可以通过多种方式报告 AP,即 AP@[0.5:0.05:0.95],AP@0.5,AP@0.75,AP 跨三个尺度(小、中、大)。
如果您的用例要求您检测大量小物体,那么您可能希望最大化 ,那么跨三个尺度的 AP 会非常有益
,那么跨三个尺度的 AP 会非常有益
.
图 19 展示了 JSON 格式中地面真相的 COCO 格式。它有一个可选的info字段,其中包含一些关于数据发布年份、版本和与数据集相关的 URL 的信息。
然后,image字段包含图像的元数据,如width、height、file_name等。
由于 COCO 数据集不仅用于对象检测任务,还用于分割、图像字幕和关键点检测,因此每个任务的注释会有所不同。让我们看看annotations格式对于物体检测是什么样子的。
图 20 显示了物体检测annotation和categories字段。annotation字段有image_id,这对于所有 ROI 都是一样的,category_id是类 id,area是边界框的区域(
), bbox – top-left corner coordinates, width, and height of the bounding box.
最后,categories字段将包含类别数据(即类别 id、类别名称(汽车、人))和超级类别。因此,例如,汽车和自行车将具有相同的超级类别(即车辆)。
但我们不必将数据集地面实况转换为上述 COCO 格式,因为 COCO Val2017 数据集已经是所需的格式。
这是关于基本事实的格式,但是让我们看看 COCO 中的预测格式是什么样子的。
在图 21 中我们可以看到,预测格式相当简单;我们有image_id:图像名称,category_id:类别 id,bbox:左上角坐标,边界框的宽度和高度,score:预测的置信度。
现在我们已经完全理解了基本事实和预测 COCO 格式,让我们直接进入代码并计算 YOLOv4 模型的平均精度。
注: 我们将使用来自 AlexeyAB 的 Darknet 资源库的 YOLOv4,在 Google Colab 中配置它是小菜一碟。
配置先决条件
对于今天的任务,我们将使用 MS COCO Val 2017 数据集。我们创建了这个数据集,用于对象检测、分割和图像字幕。它在验证集中包含 5000 个图像。
在继续执行代码之前,请确保您已经配置了 Darknet 框架,并下载了 YOLOv4 权重和 MSCOCO Val 2017 图像和标签。
如果您使用的是非 Linux 系统,您可以在这里获得数据集。这将启动压缩数据集的下载。然后,将这个 zip 文件的内容解压到项目的data目录中。
如果您使用的是 Linux 系统,只需按照以下说明操作即可:
$ cd data
$ wget http://images.cocodataset.org/zips/val2017.zip
$ unzip val2017.zip
$ wget -c http://images.cocodataset.org/annotations/annotations_trainval2017.zip
$ unzip annotations_trainval2017.zip
$ wget https://github.com/AlexeyAB/darknet/releases/download/yolov4/yolov4.weights
$ cd ../
在行 1 上,我们首先将目录更改为data,然后在行 2 和 3 上,我们下载并解压缩val2017图像。然后,我们下载并解压缩第 4 行和第 5 行中的基本事实注释。最后,在第 6 行,我们下载了YOLOv4权重文件。
为了计算平均精度,我们打开utils_map.py脚本,它有几个非常重要的方法来检测对象:将边界框转换为所需的格式,加载 pickle 文件,在图像目录上运行推理,最后以 JSON 格式存储它们的预测。
# import the necessary packages
from pyimagesearch import config
from progressbar import progressbar
from darknet import darknet
import pickle
import json
import cv2
import os
def image_detection(imagePath, network, classNames, thresh):
# image_detection takes the image as an input and returns
# the detections to the calling function
width = darknet.network_width(network)
height = darknet.network_height(network)
# create an empty darknetImage of shape [608, 608, 3]
darknetImage = darknet.make_image(width, height, 3)
# read the image from imagePath, convert from BGR->RGB
# resize the image as per YOLOv4 network input size
image = cv2.imread(imagePath)
imageRGB = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
imageResized = cv2.resize(imageRGB, (width, height),
interpolation=cv2.INTER_LINEAR)
darknet.copy_image_from_bytes(darknetImage, imageResized.tobytes())
# detections include the class labels, bounding box coordinates, and
# confidence score for all the proposed ROIs in the image
detections = darknet.detect_image(network, classNames, darknetImage,
thresh=thresh)
darknet.free_image(darknetImage)
# return the detections and image shape to the calling function
return (detections, image.shape)
我们定义的第一个方法是image_detection。顾名思义,它将图像作为输入,并将检测结果返回给调用函数(第 10-35 行)。
检测包括图像中所有建议 ROI 的类别标签、边界框坐标和置信度得分。我们还返回原始图像形状,因为我们稍后需要它来缩放预测的边界框坐标。
从第 13-17 行,我们定义了从yolov4.cfg文件中得到的网络输入宽度和高度,并创建了一个形状为[608, 608, 3]的空darknetImage。
然后从第 21-24 行开始,我们从路径中读取图像,将图像转换到 RGB 颜色空间,因为 OpenCV 以 BGR 格式读取图像,并根据网络宽度和高度调整图像大小。
接下来,我们将图像的内容复制到空的darknetImage中,最后调用带有几个参数的detect_image方法,如network、classNames、darknetImage和thresh。然后,它返回detections,其中包含建议的边界框坐标、类别标签和每个建议 ROI 的置信度得分。
最后,我们将detections和image.shape返回给行 35 上的调用函数。
def bbox2points(bbox, img_shape):
#from bounding box yolo format centerx, centery, w, h
#to corner points top-left and bottom right
(x, y, w, h) = bbox
# compute scale ratio dividing by 608
hRatio = img_shape[0] / config.YOLO_NETWORK_HEIGHT
wRatio = img_shape[1] / config.YOLO_NETWORK_WIDTH
xMin = int(round(x - (w / 2)))
yMin = int(round(y - (h / 2)))
# scale them as per the original image size
return (xMin * wRatio, yMin * hRatio, w * wRatio, h * hRatio)
从第 37-49 行,我们定义了接受bbox坐标和img_shape的bbox2points方法:输入到模型的输入图像的形状。
YOLOv4 模型在![[c_{x}, c_{y}, w, h]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/739f9617bd3194a12344c345e36f7bae.png "[c_{x}, c_{y}, w, h]") 中输出边界框预测
中输出边界框预测
format where  and
and  are the center coordinates of the bounding box,
are the center coordinates of the bounding box,  and
and  are the width and height of the bounding box. These coordinates are normalized per network input size (i.e.,
are the width and height of the bounding box. These coordinates are normalized per network input size (i.e., 608) since we use the YOLOv4 model with 608 input resolution.
然而,我们需要将边界框预测转换成![[\text{left}_{x}, \text{top}_{y}, w, h]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/c941c2f590535f02559dcdfcff653707.png "[\text{left}_{x}, \text{top}_{y}, w, h]")
format and also scale them as per the original image size. We do this so that the bbox prediction format matches the ground-truth bbox format.
我们通过将原始图像尺寸除以网络输入尺寸") 来计算第 43 行和第 44 行的缩放比例
来计算第 43 行和第 44 行的缩放比例
. Then we calculate the top-left coordinates: xmin and ymin and finally return the scaled top-left, width, and height of the bounding box to the calling function.
def load_yolo_cls_idx(path):
# load pickle files: COCO 'class_id' to the
# class_name list and the COCO 0-90 class ids list
with open(path, "rb") as f:
out = pickle.load(f)
return out
load_yolo_cls_idx函数是一个将 COCO class_id加载到class_name列表和 COCO 0-90 类 id 列表的实用函数。我们需要将 COCO 0-80 类 id 映射到 0-90 类 id,因为 COCO Val2017 地面实况category_id的范围是从 0 到 90。
def run_inference(imagePaths, network, class_names,
label2idx, yolo_cls_90, conf_thresh, pred_file):
results = []
# loop over all the images
for path in progressbar(imagePaths):
# pass the imagePath, network, class names and confidence
# threshold to image_detection method that returns detections
# and original image shape
detections, imgShape = image_detection(
path, network, class_names, thresh=conf_thresh
)
# extract imageID
imageId = int(os.path.splitext(os.path.basename(path))[0])
# loop over all the proposed ROIs
for cls, conf, box in detections:
(x, y, w, h) = bbox2points(box, imgShape)
label = [key for key, value in label2idx.items()
if value == cls][0]
label = yolo_cls_90[label]
# append result for each ROI as per COCO prediction
# in a dictionary format
results.append({"image_id": imageId,
"category_id": label,
"bbox": [x, y, w, h],
"score": float(conf)})
# save the results on disk in a JSON format
with open(pred_file, "w") as f:
json.dump(results, f, indent=4)
run_inference方法是最神奇的地方:
- 迭代图像以调用
image_detection进行检测 - 从路径的尾部获取
imageId - 在建议的检测上循环
- 用
bbox2points方法转换提议的包围盒坐标 - 然后提取标签 id 并将其转换为 0-90 的类别索引
- 将所有需要的信息添加到一个
results列表中 - 最后,以 JSON 格式创建和转储结果
现在大部分工作已经在前面的脚本中完成了,我们定义了eval_map.py脚本,它是从磁盘加载YOLOv4模型并调用utils_map.py脚本中所需方法的主驱动程序脚本。最后,它使用COCOevalAPI 在 COCO Val 2017 数据集上计算YOLOv4探测器的地图。
# import the necessary packages
from pyimagesearch.utils_map import run_inference
from pyimagesearch.utils_map import load_yolo_cls_idx
from pyimagesearch import config
from pycocotools.cocoeval import COCOeval
from pycocotools.coco import COCO
from darknet import darknet
def compute_map():
# use the COCO class to load and read the ground-truth annotations
cocoAnnotation = COCO(annotation_file=config.COCO_GT_ANNOTATION)
# call the darknet.load_network method, which loads the YOLOv4
# network based on the configuration, weights, and data file
(network, classNames, _) = darknet.load_network(
config.YOLO_CONFIG,
config.COCO_DATA,
config.YOLO_WEIGHTS,
)
label2Idx = load_yolo_cls_idx(config.LABEL2IDX)
yoloCls90 = load_yolo_cls_idx(config.YOLO_90CLASS_MAP)
# call the run_inference function to generate prediction JSON file
run_inference(config.IMAGES_PATH, network, classNames, label2Idx,
yoloCls90, config.CONF_THRESHOLD, config.COCO_VAL_PRED)
在第 11 行,我们使用COCO类来加载和读取基本事实注释。
从的第 15-19 行,我们调用darknet.load_network方法,该方法根据配置、权重和数据文件加载 YOLOv4 网络。例如,如果配置文件的宽度和高度设置为 512,它将相应地创建模型。它还会返回类名。
然后我们在的第 21 行和第 22 行加载label2Idx字典和yoloCls90地图列表。
现在我们已经定义了image_paths列表、创建了网络、加载了类名和其他帮助文件,我们可以通过将这些作为参数传递来调用第 25 行和第 26 行上的run_inference函数。一旦函数执行完成,就会创建一个COCO_Val_Prediction.json文件,样本预测 JSON 如图图 22 所示。
# load detection JSON file from the disk
cocovalPrediction = cocoAnnotation.loadRes(config.COCO_VAL_PRED)
# initialize the COCOeval object by passing the coco object with
# ground truth annotations, coco object with detection results
cocoEval = COCOeval(cocoAnnotation, cocovalPrediction, "bbox")
# run evaluation for each image, accumulates per image results
# display the summary metrics of the evaluation
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
在第 29 行的上,我们加载了由run_inference()方法生成的预测注释文件。
然后,在第 33 行上,我们通过传递带有基本事实注释的 coco 对象(instances_val2017.json)和带有检测结果的 coco 对象(COCO_Val_Predictions.json)来初始化COCOeval对象。第三个参数很有趣;IoUType为分割评估的segm,为关键点检测评估的keypoints。但是,我们需要评估一个对象检测模型,所以我们通过bbox。
最后,从第 37-39 行,我们依次调用三个函数:
cocoEval.evaluate对每张图像进行评估cocoEval.accumulate累积每幅图像的结果cocoEval.summarize显示评估的汇总指标
真相大白的时刻终于到来了!YOLOv4 模型在 COCO Val 2017 数据集上实现了 65.8mAP@0.5 IoU 和 45.8mAP@[0.5:0.95]平均 IoU(图 23) 。完成run_inference方法总共花费了 267 秒,这意味着 YOLOv4 模型在特斯拉 T4 上实现了超过 19 FPS 的速度;然而,这个数字在 Google Colab 上可能会有所不同。
汇总
恭喜你走到这一步!我们希望你通过本教程学到了很多东西,所以让我们快速总结一下我们学到的东西。
- 我们从讨论 IoU 的概念开始,为什么要使用 IoU,并学习了用 Python 计算 IoU。
- 然后,我们从分类的角度讨论了精确度和召回率,这有助于我们通过示例从对象检测上下文中理解真阳性、假阳性和假阴性。
- 接下来,我们讨论了两个最流行的对象检测数据集,PASCAL VOC 和 MS COCO,它们也设计了使用 11 点和 101 点插值计算 mAP 的方法。
- 然后,我们讨论了对象检测的精度-召回曲线,并借助一个示例学习了使用 11 点插值技术计算平均精度。
- 最后,我们学习了如何使用 Python 中的 COCO 评估器在 MS COCO Val2017 数据集上评估 YOLOv4 模型。
引用信息
Sharma,A. “使用 COCO 评估器的平均精度(mAP)”PyImageSearch,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/nwoka
@incollection{Sharma_2022_mAP,
author = {Aditya Sharma},
title = {Mean Average Precision {(mAP)} Using the {COCO} Evaluator},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/nwoka},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
用 OpenCV 测量图像中物体间的距离
原文:https://pyimagesearch.com/2016/04/04/measuring-distance-between-objects-in-an-image-with-opencv/

We have now reached the final installment in our three part series on measuring the size of objects in an image and computing the distance between objects.
两周前,我们通过学习如何使用 Python 和 OpenCV 以顺时针方式(正确地)排序坐标,开始了这一轮教程。然后,上周,我们讨论了如何使用参照物测量图像中物体的大小。
这个参考对象应该有两个重要的属性,包括:
- 我们知道尺寸(以英寸、毫米等为单位。)的对象。
- 它可以在我们的图像中容易识别(基于位置或外观)。
给定这样一个参考物体,我们可以用它来计算我们图像中物体的大小。
今天,我们将结合本系列之前博文中使用的技术,使用这些方法来计算物体之间的 距离。
继续阅读了解……
用 OpenCV 测量图像中物体间的距离
计算物体之间的距离与计算图像中物体的大小非常相似——都是从参考物体开始的。
正如我们在之前的博客文章中所详述的,我们的引用对象应该有两个重要的属性:
- 性质#1: 我们知道物体的尺寸以某种可测量的单位(如英寸、毫米等)表示。).
- 属性#2: 我们可以很容易地找到并识别我们图像中的参照物。
正如我们上周所做的,我们将使用一个美国硬币作为我们的参考对象,其宽度为 0.955 英寸(满足属性#1)。
我们还将确保我们的四分之一始终是图像中最左边的对象,从而满足属性#2:

Figure 1: We’ll identify our reference object based on location, hence we’ll always ensure our quarter is the left-most object in the image.
我们在这张图片中的目标是(1)找到四分之一,然后(2)使用四分之一的尺寸来测量四分之一和所有其他物体之间的距离。
定义我们的参照物并计算距离
让我们开始这个例子。打开一个新文件,将其命名为distance_between.py,并插入以下代码:
# import the necessary packages
from scipy.spatial import distance as dist
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
def midpoint(ptA, ptB):
return ((ptA[0] + ptB[0]) * 0.5, (ptA[1] + ptB[1]) * 0.5)
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-w", "--width", type=float, required=True,
help="width of the left-most object in the image (in inches)")
args = vars(ap.parse_args())
我们这里的代码与上周几乎相同。我们从在第 2-8 行导入我们需要的 Python 包开始。如果你还没有安装 imutils 包,现在停止安装它:
$ pip install imutils
否则,您应该升级到最新版本(0.3.6在撰写本文时),这样您就有了更新的订单积分函数:
$ pip install --upgrade imutils
第 14-19 行解析我们的命令行参数。这里我们需要两个开关:--image,它是包含我们想要测量的对象的输入图像的路径,以及--width,我们的参考对象的宽度(以英寸为单位)。
接下来,我们需要预处理我们的图像:
# load the image, convert it to grayscale, and blur it slightly
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# perform edge detection, then perform a dilation + erosion to
# close gaps in between object edges
edged = cv2.Canny(gray, 50, 100)
edged = cv2.dilate(edged, None, iterations=1)
edged = cv2.erode(edged, None, iterations=1)
# find contours in the edge map
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# sort the contours from left-to-right and, then initialize the
# distance colors and reference object
(cnts, _) = contours.sort_contours(cnts)
colors = ((0, 0, 255), (240, 0, 159), (0, 165, 255), (255, 255, 0),
(255, 0, 255))
refObj = None
第 22-24 行从磁盘加载我们的图像,将其转换为灰度,然后使用具有 7 x 7 内核的高斯滤镜将其模糊。
一旦我们的图像变得模糊,我们应用 Canny 边缘检测器来检测图像中的边缘——然后执行膨胀+腐蚀来闭合边缘图中的任何间隙(第 28-30 行)。
调用cv2.findContours检测边缘图中物体的轮廓(第 33-35 行),而第 39 行从左到右对我们的轮廓进行排序。由于我们知道我们的 US quarter(即参考对象)将始终是图像中最左边的对象,从左到右对轮廓进行排序确保了对应于参考对象的轮廓将始终是cnts列表中第个条目。
然后我们初始化一个用于绘制距离的列表colors以及refObj变量,它将存储我们的边界框、质心和参考对象的每公制像素值。
# loop over the contours individually
for c in cnts:
# if the contour is not sufficiently large, ignore it
if cv2.contourArea(c) < 100:
continue
# compute the rotated bounding box of the contour
box = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box)
box = np.array(box, dtype="int")
# order the points in the contour such that they appear
# in top-left, top-right, bottom-right, and bottom-left
# order, then draw the outline of the rotated bounding
# box
box = perspective.order_points(box)
# compute the center of the bounding box
cX = np.average(box[:, 0])
cY = np.average(box[:, 1])
在第 45 行的处,我们开始遍历cnts列表中的每个轮廓。如果轮廓不够大(第 47 和 48 行,我们忽略它。
否则,第 51-53 行计算当前对象的旋转边界框(OpenCV 2.4 使用cv2.cv.BoxPoints,OpenCV 3 使用cv2.boxPoints)。
对第 59 行上的order_points的调用重新排列了边界框 (x,y)——以左上、右上、右下和左下的顺序排列坐标,正如我们将看到的,这在我们计算对象角之间的距离时很重要。
第 62 行和第 63 行通过在 x 和 y 两个方向上取边界框的平均值,计算旋转后的边界框的中心 (x,y) 坐标。
下一步是校准我们的refObj:
# if this is the first contour we are examining (i.e.,
# the left-most contour), we presume this is the
# reference object
if refObj is None:
# unpack the ordered bounding box, then compute the
# midpoint between the top-left and top-right points,
# followed by the midpoint between the top-right and
# bottom-right
(tl, tr, br, bl) = box
(tlblX, tlblY) = midpoint(tl, bl)
(trbrX, trbrY) = midpoint(tr, br)
# compute the Euclidean distance between the midpoints,
# then construct the reference object
D = dist.euclidean((tlblX, tlblY), (trbrX, trbrY))
refObj = (box, (cX, cY), D / args["width"])
continue
如果我们的refObj是None ( 第 68 行),那么我们需要初始化它。
我们首先解包(有序的)旋转边界框坐标,并分别计算左上和左下之间的中点以及右上和右下的点(行 73-75 )。
从那里,我们计算点之间的欧几里德距离,给出我们的“每度量像素”,允许我们确定多少像素适合--width英寸。
注:参见上周的帖子中关于“像素/度量”变量的更详细的讨论。
最后,我们将refObj实例化为一个三元组,包括:
- 对应于旋转的边界框参考对象的排序坐标。
- 参考对象的质心。
- 我们将用来确定物体之间距离的每米像素比率。
我们的下一个代码块处理围绕我们的参考对象和我们当前正在检查的对象绘制轮廓,然后构造refCoords和objCoords,使得(1)边界框坐标和(2)质心的 (x,y) 坐标包含在相同的数组中:
# draw the contours on the image
orig = image.copy()
cv2.drawContours(orig, [box.astype("int")], -1, (0, 255, 0), 2)
cv2.drawContours(orig, [refObj[0].astype("int")], -1, (0, 255, 0), 2)
# stack the reference coordinates and the object coordinates
# to include the object center
refCoords = np.vstack([refObj[0], refObj[1]])
objCoords = np.vstack([box, (cX, cY)])
我们现在准备计算图像中各个角和物体质心之间的距离:
# loop over the original points
for ((xA, yA), (xB, yB), color) in zip(refCoords, objCoords, colors):
# draw circles corresponding to the current points and
# connect them with a line
cv2.circle(orig, (int(xA), int(yA)), 5, color, -1)
cv2.circle(orig, (int(xB), int(yB)), 5, color, -1)
cv2.line(orig, (int(xA), int(yA)), (int(xB), int(yB)),
color, 2)
# compute the Euclidean distance between the coordinates,
# and then convert the distance in pixels to distance in
# units
D = dist.euclidean((xA, yA), (xB, yB)) / refObj[2]
(mX, mY) = midpoint((xA, yA), (xB, yB))
cv2.putText(orig, "{:.1f}in".format(D), (int(mX), int(mY - 10)),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, color, 2)
# show the output image
cv2.imshow("Image", orig)
cv2.waitKey(0)
在第 94 行的上,我们开始循环成对的 (x,y)-坐标,这些坐标对应于我们的参考对象和感兴趣对象。
然后我们画一个圆代表 (x,y)-我们正在计算的当前点之间的距离的坐标,并画一条线连接这些点(线 97-110 )。
从那里,行 105 计算参考位置和目标位置之间的欧几里德距离,接着将该距离除以“每度量像素”,给出两个目标之间以英寸为单位的最终距离。然后计算出的距离被绘制在我们的图像上(第 106-108 行)。
注:对左上、右上、右下、左下和质心坐标进行距离计算,总共进行五次距离比较。
最后,行 111 和 112 将输出图像显示到我们的屏幕上。
距离测量结果
为了尝试一下我们的距离测量脚本,请使用本教程底部的“下载”表单下载源代码和相应的图片。解压缩.zip文件,将目录切换到distance_between.py脚本,然后执行以下命令:
$ python distance_between.py --image images/example_01.png --width 0.955
下面是演示我们脚本输出的 GIF 动画:
Figure 2: Computing the distance between objects in an image with OpenCV.
在每种情况下,我们的脚本都匹配左上角的(红色)、右上角的(紫色)、右下角的(橙色)、左下角的(蓝绿色)和质心(粉色)坐标,然后计算参考对象和当前对象之间的距离(以英寸为单位)。
请注意图像中的两个四分之一是如何完美地相互平行的,这意味着所有五个控制点之间的距离是 6.1 英寸。
下面是第二个例子,这次计算我们的参考对象和一组药丸之间的距离:
$ python distance_between.py --image images/example_02.png --width 0.955

Figure 3: Computing the distance between pills using OpenCV.
这个例子可以用作药丸分类机器人的输入,该机器人自动取出一组药丸,并根据它们的大小和与药丸容器的距离来组织它们。
我们的最后一个例子计算了我们的参考对象(一张 3.5 英寸 x 2 英寸的名片)和一套 7 英寸的黑胶唱片以及一个信封之间的距离:
$ python distance_between.py --image images/example_03.png --width 3.5

Figure 4: A final example of computing the distance between objects using OpenCV and computer vision.
正如你所看到的,在每一种情况下,我们都成功地计算出了图像中物体之间的距离(以实际的、可测量的单位)。
摘要
在测量物体尺寸系列的第三部分也是最后一部分中,我们学习了如何在一幅图像中拍摄两个不同的物体,并以实际可测量单位(如英寸、毫米等)计算它们之间的距离。).
正如我们在上周的帖子中发现的那样,在我们能够(1)计算一个对象的大小或(2)测量两个对象之间的距离之前,我们首先需要计算“每度量像素”比率,用于确定有多少像素“适合”给定的测量单位。
一旦我们有了这个比率,计算物体之间的距离就变得非常简单了。
无论如何,我希望你喜欢这一系列的博文!如果你对未来的系列有任何建议,请在给我留言上留下评论。
在您离开之前,请务必在下表中输入您的电子邮件地址,注册订阅 PyImageSearch 时事通讯!【T2
用 OpenCV 测量图像中物体的尺寸
原文:https://pyimagesearch.com/2016/03/28/measuring-size-of-objects-in-an-image-with-opencv/
最后更新于 2021 年 7 月 8 日。
测量图像中一个(或多个)物体的尺寸已经成为在 PyImageSearch 博客上被大量请求的教程—把这个帖子放到网上并与你分享感觉很棒。
今天的帖子是关于测量图像中物体尺寸和计算物体间距离的三部分系列文章的第二部分。
上周,我们学习了一项重要的技术:如何可靠地按左上、右上、右下和左下排列一组旋转的边界框坐标。
今天我们将利用这项技术来帮助我们计算图像中物体的大小。一定要阅读整篇文章,看看是怎么做的!
- 【2021 年 7 月更新:增加了如何通过使用棋盘执行适当的摄像机校准来提高物体尺寸测量精度的章节。
用 OpenCV 测量图像中物体的尺寸
测量图像中物体的大小类似于计算我们的相机到物体的距离——在这两种情况下,我们都需要定义一个比率来测量每个给定度量的像素数量。
我称之为“像素/度量”比率,我在下一节中有更正式的定义。
“像素/度量”比率
为了确定图像中物体的大小,我们首先需要使用参考物体执行“校准”(不要与内在/外在校准混淆)。我们的引用对象应该有两个重要的属性:
- 属性#1: 我们要知道这个物体的尺寸(以宽度或高度表示),以的可测单位(如毫米、英寸等)表示。).
- 属性#2: 我们应该能够很容易地在图像中找到这个参考对象,要么基于对象的位置(比如参考对象总是被放在图像的左上角),要么通过外观(比如是一种独特的颜色或形状,与图像中的所有其他对象都不同)。无论哪种情况,我们的引用应该是以某种方式唯一可识别的。
在本例中,我们将使用美国地区作为我们的参考对象,在所有示例中,确保它始终是我们图像中最左侧的对象:
通过确保四分之一是最左边的对象,我们可以从左到右对我们的对象轮廓进行排序,获取四分之一(它将始终是排序列表中的第一个轮廓),并使用它来定义我们的 pixels_per_metric ,我们将其定义为:
pixels _ per _ metric = object _ width/know _ width
一个美国硬币的已知宽度为 0.955 英寸。现在,假设我们的 object_width (以像素为单位)被计算为 150 像素宽(基于其相关的边界框)。
因此, pixels_per_metric 为:
pixels _ per _ metric = 150 px/0.955 in = 157 px
因此意味着在我们的图像中每 0.955 英寸大约有 157 个像素。利用这个比率,我们可以计算出图像中物体的大小。
用计算机视觉测量物体的尺寸
既然我们已经了解了“像素/度量”比率,我们就可以实现用于测量图像中对象大小的 Python 驱动程序脚本了。
打开一个新文件,将其命名为object_size.py,并插入以下代码:
# import the necessary packages
from scipy.spatial import distance as dist
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
def midpoint(ptA, ptB):
return ((ptA[0] + ptB[0]) * 0.5, (ptA[1] + ptB[1]) * 0.5)
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-w", "--width", type=float, required=True,
help="width of the left-most object in the image (in inches)")
args = vars(ap.parse_args())
第 2-8 行导入我们需要的 Python 包。在本例中,我们将大量使用 imutils 包,因此如果您还没有安装它,请确保在继续之前安装它:
$ pip install imutils
否则,如果你确实安装了imutils,确保你有最新的版本,也就是本文撰写时的0.3.6:
$ pip install --upgrade imutils
第 10 行和第 11 行定义了一个叫做midpoint的辅助方法,顾名思义,这个方法用于计算两组 (x,y)-坐标之间的中点。
然后我们在第 14-19 行解析命令行参数。我们需要两个参数,--image,它是包含我们想要测量的对象的输入图像的路径,和--width,它是我们的参考对象的宽度(以英寸为单位),假定是我们的--image中最左边的对象。
我们现在可以加载图像并对其进行预处理:
# load the image, convert it to grayscale, and blur it slightly
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# perform edge detection, then perform a dilation + erosion to
# close gaps in between object edges
edged = cv2.Canny(gray, 50, 100)
edged = cv2.dilate(edged, None, iterations=1)
edged = cv2.erode(edged, None, iterations=1)
# find contours in the edge map
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# sort the contours from left-to-right and initialize the
# 'pixels per metric' calibration variable
(cnts, _) = contours.sort_contours(cnts)
pixelsPerMetric = None
第 22-24 行从磁盘加载我们的图像,将其转换为灰度,然后使用高斯滤波器平滑。然后,我们执行边缘检测以及膨胀+腐蚀来闭合边缘图中边缘之间的任何缝隙(第 28-30 行)。
第 33-35 行找到与我们的边缘图中的物体相对应的轮廓(即轮廓)。
然后这些轮廓在第 39 行的上从左到右排序(允许我们提取我们的参考对象)。我们还在线 40** 上初始化我们的pixelsPerMetric值。**
下一步是检查每个轮廓:
# loop over the contours individually
for c in cnts:
# if the contour is not sufficiently large, ignore it
if cv2.contourArea(c) < 100:
continue
# compute the rotated bounding box of the contour
orig = image.copy()
box = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box)
box = np.array(box, dtype="int")
# order the points in the contour such that they appear
# in top-left, top-right, bottom-right, and bottom-left
# order, then draw the outline of the rotated bounding
# box
box = perspective.order_points(box)
cv2.drawContours(orig, [box.astype("int")], -1, (0, 255, 0), 2)
# loop over the original points and draw them
for (x, y) in box:
cv2.circle(orig, (int(x), int(y)), 5, (0, 0, 255), -1)
在第行第 43 处,我们开始循环每个单独的轮廓。如果轮廓不够大,我们丢弃该区域,假定它是边缘检测过程遗留的噪声(第 45 和 46 行)。
假设轮廓区域足够大,我们在行 50-52 上计算图像的旋转边界框,特别注意使用 OpenCV 2.4 的cv2.cv.BoxPoints函数和 OpenCV 3 的cv2.boxPoints方法。
然后,我们按照左上、右上、右下和左下的顺序排列旋转后的边界坐标box,,正如上周的博文 ( 第 58 行)中所讨论的。
最后,行 59-63 在绿色中画出物体的轮廓,随后在中画出包围盒矩形的顶点为红色小圆圈。
现在我们已经有了边界框,我们可以计算一系列的中点:
# unpack the ordered bounding box, then compute the midpoint
# between the top-left and top-right coordinates, followed by
# the midpoint between bottom-left and bottom-right coordinates
(tl, tr, br, bl) = box
(tltrX, tltrY) = midpoint(tl, tr)
(blbrX, blbrY) = midpoint(bl, br)
# compute the midpoint between the top-left and top-right points,
# followed by the midpoint between the top-righ and bottom-right
(tlblX, tlblY) = midpoint(tl, bl)
(trbrX, trbrY) = midpoint(tr, br)
# draw the midpoints on the image
cv2.circle(orig, (int(tltrX), int(tltrY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(blbrX), int(blbrY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(tlblX), int(tlblY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(trbrX), int(trbrY)), 5, (255, 0, 0), -1)
# draw lines between the midpoints
cv2.line(orig, (int(tltrX), int(tltrY)), (int(blbrX), int(blbrY)),
(255, 0, 255), 2)
cv2.line(orig, (int(tlblX), int(tlblY)), (int(trbrX), int(trbrY)),
(255, 0, 255), 2)
第 68-70 行打开我们的有序边界框,然后计算左上和右上点之间的中点,接着是右下点之间的中点。
我们还将分别计算左上+左下和右上+右下的中点(行 74 和 75 )。
线 78-81 在我们的image上画出蓝色中点,然后用紫色线连接中点。
接下来,我们需要通过研究我们的引用对象来初始化我们的pixelsPerMetric变量:
# compute the Euclidean distance between the midpoints
dA = dist.euclidean((tltrX, tltrY), (blbrX, blbrY))
dB = dist.euclidean((tlblX, tlblY), (trbrX, trbrY))
# if the pixels per metric has not been initialized, then
# compute it as the ratio of pixels to supplied metric
# (in this case, inches)
if pixelsPerMetric is None:
pixelsPerMetric = dB / args["width"]
首先,我们计算我们的中点集合之间的欧几里德距离(线 90 和 91 )。dA变量将包含高度距离(以像素为单位),而dB将保存我们的宽度距离。
然后我们检查第 96 行的,看看我们的pixelsPerMetric变量是否已经初始化,如果还没有,我们用dB除以我们提供的--width,从而得到我们每英寸的(近似)像素。
既然已经定义了我们的pixelsPerMetric变量,我们可以测量图像中对象的大小:
# compute the size of the object
dimA = dA / pixelsPerMetric
dimB = dB / pixelsPerMetric
# draw the object sizes on the image
cv2.putText(orig, "{:.1f}in".format(dimA),
(int(tltrX - 15), int(tltrY - 10)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (255, 255, 255), 2)
cv2.putText(orig, "{:.1f}in".format(dimB),
(int(trbrX + 10), int(trbrY)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (255, 255, 255), 2)
# show the output image
cv2.imshow("Image", orig)
cv2.waitKey(0)
第 100 行和第 101 行通过将各自的欧几里德距离除以pixelsPerMetric值来计算对象的尺寸( 英寸 )(参见上面的“像素/度量”部分,了解为什么这个比率有效)。
第 104-109 行在我们的image上绘制物体的尺寸,而第 112 和 113 行显示输出结果。
物体尺寸测量结果
要测试我们的object_size.py脚本,只需发出以下命令:
$ python object_size.py --image images/example_01.png --width 0.955
您的输出应该如下所示:

Figure 2: Measuring the size of objects in an image using OpenCV, Python, and computer vision + image processing techniques.
正如你所看到的,我们已经成功地计算了我们的图像中每个对象的大小——我们的名片被正确地报告为3.5 英寸 x 2 英寸。同样,我们的镍被准确地描述为0.8 英寸 x 0.8in 英寸。
然而,并不是所有的结果都是完美的。
据报道,Game Boy 墨盒的尺寸略有不同(尽管它们的尺寸相同)。两个四分之一的高度也相差0.1 英寸。
那么这是为什么呢?为什么物体测量不是 100%准确?
原因有两个:
- 首先,我匆忙用我的 iPhone 拍了这张照片。这个角度肯定不是一个完美的 90 度“俯视”(像鸟瞰一样)的角度。如果没有一个完美的 90 度视角(或尽可能接近它),对象的尺寸可能会出现扭曲。
- 第二,我没有使用相机的内部和外部参数来校准我的 iPhone。如果不确定这些参数,照片可能会出现径向和切向镜头失真。执行额外的校准步骤来找到这些参数可以“消除”我们的图像失真,并导致更好的对象大小近似(但我将失真校正的讨论作为未来博客帖子的主题)。
与此同时,在拍摄物体照片时,努力获得尽可能接近 90 度的视角——这将有助于提高物体尺寸估计的准确性。
也就是说,让我们看看测量物体尺寸的第二个例子,这次是测量药丸的尺寸:
$ python object_size.py --image images/example_02.png --width 0.955

Figure 3: Measuring the size of pills in an image with OpenCV.
在美国的 20,000 多种处方药中,近 50%是圆形和/或白色的,因此,如果我们能够根据它们的尺寸来筛选药丸,我们就有更好的机会来准确识别药物。
最后,我们还有最后一个例子,这次使用一张3.5 英寸 x 2 英寸的名片来测量两个乙烯基 EPs 和一个信封的大小:
$ python object_size.py --image images/example_03.png --width 3.5
同样,结果不是很完美,但这是由于(1)视角和(2)镜头失真,如上所述。
通过适当的摄像机校准提高物体尺寸测量精度
在测量图像中物体的尺寸之前,我们首先需要校准我们的系统。在这篇文章中,我们使用了一个简单的“像素/度量”技术。
然而,通过计算外部和内部参数来执行适当的摄像机校准,可以获得更好的精度:
- 外部参数是用于将物体从世界坐标系转换到摄像机坐标系的旋转和平移矩阵
- 内在参数是内部相机参数,如焦距,将信息转换成像素
具体来说,我们对内在参数感兴趣。但是我们如何去获得它们呢?
最常见的方法是使用 OpenCV 执行棋盘式摄像机校准。这样做将会消除影响输出图像的径向失真和切向失真,从而影响图像中对象的输出测量。
这里有一些资源可以帮助您开始进行相机校准:
摘要
在这篇博文中,我们学习了如何使用 Python 和 OpenCV 测量图像中对象的大小。
就像在我们的教程中测量从相机到物体的距离一样,我们需要确定我们的“每米像素”比率,它描述了可以“适合”给定的英寸、毫米、米等数量的像素数量。
为了计算这个比率,我们需要一个具有两个重要属性的参考对象:
- 属性#1: 参照物应具有已知的尺寸(如宽度或高度),以可测量单位(英寸、毫米等)表示。).
- 属性#2: 无论是从物体的位置还是从其外观来看,参照物都应该是容易找到的。
*假设这两个属性都能满足,你就可以利用你的参考对象来校准你的 pixels_per_metric 变量,并由此计算图像中其他对象的大小。
在我们的下一篇博客文章中,我们将进一步讨论这个例子,并学习如何计算图像中 物体之间的距离 。
请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在下一篇博文发布时得到通知— 您不会想错过它的!【T2*
MiniVGGNet:深入 CNN
原文:https://pyimagesearch.com/2021/05/22/minivggnet-going-deeper-with-cnns/
在我们之前的教程 中,我们讨论了 LeNet,这是深度学习和计算机视觉文献中的一个开创性的卷积神经网络。VGGNet(有时简称为 VGG)是由 Simonyan 和 Zisserman 在他们 2014 年的论文中首次提出的,用于大规模图像识别的超深度学习卷积神经网络 。他们工作的主要贡献是证明了具有非常小(3 × 3)过滤器的架构可以被训练到越来越高的深度(16-19 层),并在具有挑战性的 ImageNet 分类挑战中获得最先进的分类。
要学习如何实现 VGGNet,继续阅读。
MiniVGGNet:深入 CNN
以前,深度学习文献中的网络架构使用多种过滤器尺寸:
CNN 的第一层通常包括介于 7 × 7 ( Krizhevsky、Sutskever 和 Hinton,2012 )和 11 × 11 ( Sermanet 等人,2013 )之间的滤波器大小。从那里开始,过滤器尺寸逐渐减小到 5 × 5。最后,只有网络的最深层使用了 3 个×3 个过滤器。
VGGNet 的独特之处在于它在整个架构中使用了 3 个内核×3 个内核。可以说,这些小内核的使用帮助 VGGNet 将推广到网络最初训练之外的分类问题。
任何时候你看到一个完全由 3 个 × 3 个过滤器组成的网络架构,你可以放心,它的灵感来自 VGGNet。回顾 VGGNet 的整个 16 和 19 层变体对于这个卷积神经网络的介绍来说太超前了。**
相反,我们将回顾 VGG 网络家族,并定义 CNN 必须展现出什么样的特征才能融入这个家族。在此基础上,我们将实现一个名为 MiniVGGNet 的较小版本的 VGGNet,它可以很容易地在您的系统上进行训练。这个实现还将演示如何使用两个重要的层— 批处理规范化 (BN)和丢失。
VGG 网络家族
卷积神经网络的 VGG 家族可以由两个关键部分来表征:
- 网络中的所有
CONV层仅使用33×3 过滤器。 - 在应用
POOL操作之前,堆叠多个CONV => RELU层集(其中连续CONV => RELU层的数量通常增加越深越多)。
在本教程中,我们将讨论 VGGNet 架构的一种变体,我称之为“MiniVGGNet ”,因为该网络比它的老大哥要浅得多。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
(迷你)VGGNet 架构
在 ShallowNet 和 LeNet 中,我们应用了一系列的CONV => RELU => POOL层。然而,在 VGGNet 中,我们在应用单个POOL层之前堆叠多个 CONV => RELU层。这样做允许网络在通过POOL操作对空间输入大小进行下采样之前,从CONV层中学习更多丰富的特征。
总体来说,MiniVGGNet 由两组的CONV => RELU => CONV => RELU => POOL层组成,后面是一组FC => RELU => FC => SOFTMAX层。前两个CONV层将学习 32 个滤镜,每个大小为 3×3。接下来的两个CONV层将学习 64 个滤镜,同样,每个大小为 3 × 3。我们的POOL层将以 2 × 2 的步幅在 2 × 2 的窗口上执行最大池化。我们还将在激活后插入批量标准化层,以及在POOL和FC层后插入丢弃层(DO)。
网络架构本身详见表 1 ,其中初始输入图像大小假设为 32 × 32 × 3。
同样,请注意批量归一化和丢弃层是如何根据我在卷积神经网络(CNN)和层类型中的“经验法则】包含在网络架构中的。应用批量标准化将有助于减少过度拟合的影响,并提高我们在 CIFAR-10 上的分类准确性。
实现 MiniVGGNet
根据表 1 中对 MiniVGGNet 的描述,我们现在可以使用 Keras 实现网络架构。首先,在pyimagesearch.nn.conv子模块中添加一个名为minivggnet.py的新文件——这是我们编写 MiniVGGNet 实现的地方:
--- pyimagesearch
| |--- __init__.py
| |--- nn
| | |--- __init__.py
...
| | |--- conv
| | | |--- __init__.py
| | | |--- lenet.py
| | | |--- minivggnet.py
| | | |--- shallownet.py
创建完minivggnet.py文件后,在您最喜欢的代码编辑器中打开它,然后我们开始工作:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
第 2-10 行从 Keras 库中导入我们需要的类。这些导入中的大部分你已经见过了,但我想让你注意一下BatchNormalization ( 第 3 行)和Dropout ( 第 8 行)——这些类将使我们能够对我们的网络架构应用批量标准化和丢弃。
就像我们对 ShallowNet 和 LeNet 的实现一样,我们将定义一个build方法,可以调用它来使用提供的width、height、depth和数量classes来构建架构:
class MiniVGGNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
第 17 行实例化了Sequential类,Keras 中顺序神经网络的构建块。然后我们初始化inputShape,假设我们正在使用信道最后的排序(第 18 行)。
第 19 行引入了一个我们之前没见过的变量chanDim,通道维度的指标。批量归一化在通道上操作,因此为了应用 BN,我们需要知道在哪一个轴上归一化。设置chanDim = -1意味着通道维度的索引在输入形状中最后(即通道最后排序)。但是,如果我们使用通道优先排序(第 23-25 行),我们需要更新inputShape并设置chanDim = 1,因为通道维度现在是输入形状中的第一个条目。
MiniVGGNet 的第一层块定义如下:
# first CONV => RELU => CONV => RELU => POOL layer set
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
在这里,我们可以看到我们的架构由(CONV => RELU => BN) * 2 => POOL => DO组成。第 28 行定义了一个有 32 个滤镜的CONV层,每个滤镜有一个 3 × 3 的滤镜大小。然后我们应用一个 ReLU 激活(第 30 行),它立即被输入到一个BatchNormalization层(第 31 行)来使激活归零。
然而,我们没有应用一个POOL层来减少我们输入的空间维度,而是应用另一组CONV => RELU => BN——这允许我们的网络学习更丰富的特征,这是训练更深层次 CNN 时的常见做法。
在线 35 上,我们用的是尺寸为 2 × 2 的MaxPooling2D。由于我们没有显式设置步幅,Keras 隐式假设我们的步幅等于最大池大小(即 2 × 2)。
然后,我们将Dropout应用于第 36 行,概率为 p = 0 。 25,暗示来自POOL层的一个节点在训练时会以 25%的概率随机断开与下一层的连接。我们应用辍学来帮助减少过度拟合的影响。你可以在单独的一课中读到更多关于辍学的内容。然后,我们将第二层块添加到下面的 MiniVGGNet 中:
# second CONV => RELU => CONV => RELU => POOL layer set
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
上面的代码遵循与上面完全相同的模式;然而,现在我们正在学习两组 64 个过滤器(每组尺寸为 3 × 3),而不是 32 个过滤器。同样,随着空间输入尺寸在网络中更深处减小,通常增加滤波器的数量。
接下来是我们的第一组(也是唯一一组)图层:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
我们的FC层有512个节点,后面是 ReLU 激活和 BN。我们还将在这里应用辍学,将概率增加到 50% —通常您会看到辍学与 p = 0 。 5 应用于FC层间。
最后,我们应用 softmax 分类器,并将网络架构返回给调用函数:
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
现在我们已经实现了 MiniVGGNet 架构,让我们继续将它应用于 CIFAR-10。
cifar-10上的 minivggnet
我们将遵循类似的模式训练 MiniVGGNet,就像我们在之前的教程 中为 LeNet 所做的那样,只是这次使用的是 CIFAR-10 数据集:
- 从磁盘加载 CIFAR-10 数据集。
- 实例化 MiniVGGNet 架构。
- 使用训练数据训练 MiniVGGNet。
- 使用测试数据评估网络性能。
要创建驱动程序脚本来训练 MiniVGGNet,请打开一个新文件,将其命名为minivggnet_cifar10.py,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from pyimagesearch.nn.conv import MiniVGGNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2 行导入了matplotlib库,我们稍后将使用它来绘制我们的精度和损耗。我们需要将matplotlib后端设置为Agg,以指示创建一个非交互,它将被简单地保存到磁盘。取决于你默认的matplotlib后端是什么和你是否正在远程访问你的深度学习机器(例如,通过 SSH),X11 会话可能会超时。如果发生这种情况,matplotlib会在试图显示你的身材时出错。相反,我们可以简单地将背景设置为Agg,并在完成网络训练后将图形写入磁盘。
第 9-13 行导入我们需要的 Python 包的剩余部分,所有这些你以前都见过——例外的是第 8 行的MiniVGGNet,,我们之前已经实现了。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
该脚本只需要一个命令行参数--output,即输出训练和损耗图的路径。
我们现在可以加载 CIFAR-10 数据集(预分割为训练和测试数据),将像素缩放到范围[0, 1],然后一次性编码标签:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
让我们编译我们的模型并开始训练 MiniVGGNet:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=64, epochs=40, verbose=1)
我们将使用 SGD 作为我们的优化器,学习率为 α = 0 。 01 和 γ = 0 的动量项。 9。设置nestrov=True表示我们希望将 Nestrov 加速梯度应用于 SGD 优化器。
我们还没有见过的一个优化器术语是decay参数。这个论点是用来随着时间慢慢降低学习率的。衰减学习率有助于减少过拟合并获得更高的分类精度——学习率越小,权重更新就越小。decay的一个常见设置是将初始学习率除以总时期数——在这种情况下,我们将用 0.01 的初始学习率训练我们的网络总共 40 个时期,因此为decay = 0.01 / 40。
训练完成后,我们可以评估网络并显示一份格式良好的分类报告:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=64)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
将我们的损耗和精度图保存到磁盘:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 40), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
在评估 MinIVGGNet 时,我进行了两个实验:
- 一个与批量归一化。
- 一个没有批量归一化。
让我们来看看这些结果,比较应用批处理规范化时网络性能是如何提高的。
批量归一化
要在 CIFAR-10 数据集上训练 MiniVGGNet,只需执行以下命令:
$ python minivggnet_cifar10.py --output output/cifar10_minivggnet_with_bn.png
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/40
23s - loss: 1.6001 - acc: 0.4691 - val_loss: 1.3851 - val_acc: 0.5234
Epoch 2/40
23s - loss: 1.1237 - acc: 0.6079 - val_loss: 1.1925 - val_acc: 0.6139
Epoch 3/40
23s - loss: 0.9680 - acc: 0.6610 - val_loss: 0.8761 - val_acc: 0.6909
...
Epoch 40/40
23s - loss: 0.2557 - acc: 0.9087 - val_loss: 0.5634 - val_acc: 0.8236
[INFO] evaluating network...
precision recall f1-score support
airplane 0.88 0.81 0.85 1000
automobile 0.93 0.89 0.91 1000
bird 0.83 0.68 0.75 1000
cat 0.69 0.65 0.67 1000
deer 0.74 0.85 0.79 1000
dog 0.72 0.77 0.74 1000
frog 0.85 0.89 0.87 1000
horse 0.85 0.87 0.86 1000
ship 0.89 0.91 0.90 1000
truck 0.88 0.91 0.90 1000
avg / total 0.83 0.82 0.82 10000
在我的 GPU 上,纪元相当快,23 秒。在我的 CPU 上,纪元要长得多,达到 171 秒。
训练完成后,我们可以看到 MiniVGGNet 在 CIFAR-10 数据集上通过批量归一化获得了 83% 的分类准确率——这一结果大大高于在 单独教程 中应用 ShallowNet 时的 60%准确率。因此,我们看到了更深层次的网络架构如何能够学习更丰富、更有区别的特征。
无批量归一化
回到minivggnet.py实现并注释掉所有 BatchNormalization层,就像这样:
# first CONV => RELU => CONV => RELU => POOL layer set
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
#model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
#model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
一旦您注释掉了网络中的所有BatchNormalization层,请在 CIFAR-10 上重新训练 MiniVGGNet:
$ python minivggnet_cifar10.py \
--output output/cifar10_minivggnet_without_bn.png
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/40
13s - loss: 1.8055 - acc: 0.3426 - val_loss: 1.4872 - val_acc: 0.4573
Epoch 2/40
13s - loss: 1.4133 - acc: 0.4872 - val_loss: 1.3246 - val_acc: 0.5224
Epoch 3/40
13s - loss: 1.2162 - acc: 0.5628 - val_loss: 1.0807 - val_acc: 0.6139
...
Epoch 40/40
13s - loss: 0.2780 - acc: 0.8996 - val_loss: 0.6466 - val_acc: 0.7955
[INFO] evaluating network...
precision recall f1-score support
airplane 0.83 0.80 0.82 1000
automobile 0.90 0.89 0.90 1000
bird 0.75 0.69 0.71 1000
cat 0.64 0.57 0.61 1000
deer 0.75 0.81 0.78 1000
dog 0.69 0.72 0.70 1000
frog 0.81 0.88 0.85 1000
horse 0.85 0.83 0.84 1000
ship 0.90 0.88 0.89 1000
truck 0.84 0.89 0.86 1000
avg / total 0.79 0.80 0.79 10000
您将注意到的第一件事是,您的网络在没有批量标准化的情况下训练更快(13s 比 23s,减少了 43%)。然而,一旦网络完成训练,你会注意到一个较低的分类准确率 79% 。
当我们在图 2 中并排绘制 MiniVGGNet 与批量归一化(左)和与批量归一化(右)时,我们可以看到批量归一化对训练过程的积极影响:
注意没有批量归一化的 MiniVGGNet 的损失如何开始增加超过第 30 个时期,表明网络对训练数据过度拟合。我们还可以清楚地看到,到第 25 个纪元时,验证精度已经相当饱和。
另一方面,带有批处理规范化的 MiniVGGNet 实现更加稳定。虽然损失和准确性在 35 年后开始持平,但我们没有过度拟合得那么糟糕——这是我建议对您自己的网络架构应用批量标准化的众多原因之一。
总结
在本教程中,我们讨论了卷积神经网络的 VGG 家族。CNN 可以被认为是 VGG 网络,如果:
- 它仅使用3×3 过滤器,而不考虑网络深度。
- 在单个
POOL操作的之前应用了多个CONV => RELU层,随着网络深度的增加,有时会有更多的CONV => RELU层堆叠在彼此之上。
然后我们实现了一个受 VGG 启发的网络,恰当地命名为MiniVGGNet。这个网络架构由两组(CONV => RELU) * 2) => POOL层和一组FC => RELU => FC => SOFTMAX层组成。我们还在每次激活后应用了批量标准化,并在每个池和完全连接层后应用了丢弃。为了评估 MiniVGGNet,我们使用了 CIFAR-10 数据集。
我们之前在 CIFAR-10 上最好的准确率只有 60%来自浅网( 早前教程 )。然而,使用 MiniVGGNet 我们能够将精确度一直提高到 83% 。
最后,我们检查了批处理规范化在深度学习和 CNN中扮演的角色,使用批处理规范化,MiniVGGNet 达到了 83%的分类准确率——但没有批处理规范化的,准确率下降到 79%(我们也开始看到过度拟合的迹象)。
因此,这里的要点是:
- 批量标准化可以导致更快、更稳定的收敛和更高的精度。
- 然而,这种优势是以训练时间为代价的——批量标准化将需要更多的“墙时间”来训练网络,尽管网络将在更少的时期内获得更高的精度。
也就是说,额外的培训时间往往超过了负面影响,我强烈鼓励您对自己的网络架构应用批量规范化。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
训练细胞神经网络时混合正常图像和敌对图像
原文:https://pyimagesearch.com/2021/03/15/mixing-normal-images-and-adversarial-images-when-training-cnns/
在本教程中,您将学习如何在训练过程中生成(1)正常图像和(2)敌对图像的图像批次。这样做可以提高您的模型的概括能力和防御敌对攻击的能力。
上周,我们学习了一个简单的方法来抵御敌对攻击。这种方法是一个简单的三步过程:
- 在你的原始训练集上训练 CNN
- 从测试集(或等价的抵制集)中生成对立的例子
- 微调 CNN 上的对抗性例子
这种方法效果很好,但可以通过改变训练过程来大大改善。
我们可以改变批量生成过程本身,而不是在一组对立的例子上微调网络。
当我们训练神经网络时,我们是在批量数据中进行的。每批都是训练数据的子集,通常大小为 2 的幂(8、16、32、64、128 等。).对于每一批,我们执行网络的正向传递,计算损耗,执行反向传播,然后更新网络的权重。这是基本上任何神经网络的标准训练协议。
我们可以通过以下方式修改此标准培训程序,以纳入对抗性示例:
- 初始化我们的神经网络
- 选择总共 N 个训练实例
- 使用该模型和类似于 FGSM 的方法来生成总共 N 个对抗示例
- 将两组组合,形成一批尺寸 Nx2
- 在对立示例和原始训练样本上训练模型
这种方法的好处是模型可以自我学习。
每次批量更新后,模型都有两个因素的改进。首先,模型已经在训练数据中理想地学习了更多的辨别模式。第二,模型已经学会了抵御模型本身产生的对抗性例子。
在整个训练过程中(几十到几百个时期,有几万到几十万次批量更新),模型自然地学会了防御敌对攻击。
这种方法比基本的微调方法更复杂,但好处远远大于坏处。
学习如何在训练中混合正常图像和对立图像,以提高模型的鲁棒性,继续阅读。
训练 CNN 时混合正常图像和敌对图像
在本教程的第一部分,我们将学习如何在训练过程中混合正常图像和敌对图像。
从那里,我们将配置我们的开发环境,然后检查我们的项目目录结构。
我们今天要实现几个 Python 脚本,包括:
- 我们的 CNN 架构
- 对抗图像生成器
- 一个数据生成器,它(1)对训练数据点进行采样,以及(2)动态生成对立的示例
- 一份将所有内容整合在一起的培训脚本
我们将通过在混合敌对图像生成过程中训练我们的模型来结束本教程,然后讨论结果。
我们开始吧!
如何在训练中混合正常图像和敌对图像?
将训练图像与敌对图像混合在一起可以得到最好的视觉解释。我们从神经网络架构和训练集开始:
普通训练过程的工作方式是从训练集中抽取一批数据,然后训练模型:
然而,我们想要合并对抗性训练,所以我们需要一个单独的过程,它使用模型来生成对抗性的例子:
现在,在我们的训练过程中,我们对训练集进行采样并生成对立的例子,然后训练网络:
训练过程稍微复杂一点,因为我们从训练集和中取样,动态生成对立的例子。不过,好处是该模型可以:
- 从原始训练集中学习模式
- 从对立的例子中学习句型
由于该模型现在已经在对立的例子上被训练,所以当呈现对立的图像时,它将更健壮并且概括得更好。
配置您的开发环境
这篇关于防御恶意图像攻击的教程使用了 Keras 和 TensorFlow。如果你打算遵循这个教程,我建议你花时间配置你的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从回顾我们的项目目录结构开始本教程。
使用本指南的 “下载” 部分检索源代码。然后,您将看到以下目录:
$ tree . --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── datagen.py
│ ├── fgsm.py
│ └── simplecnn.py
└── train_mixed_adversarial_defense.py
1 directory, 5 files
我们的目录结构基本上与上周关于用 Keras 和 TensorFlow 防御对抗性图像攻击的教程 相同。主要区别在于:
- 我们在我们的
datagen.py文件中添加了一个新函数,来处理同时混合训练图像和动态生成的敌对图像。 - 我们的驱动程序训练脚本
train_mixed_adversarial_defense.py,有一些额外的附加功能来处理混合训练。
如果你还没有,我强烈建议你阅读本系列的前两个教程:
*他们被认为是 必读 才继续!
我们的基本 CNN
我们的 CNN 架构可以在项目结构的simplecnn.py文件中找到。在我们的快速梯度符号方法教程中,我已经详细回顾了这个模型定义,所以我将把对代码的完整解释留给那个指南。
也就是说,我在下面列出了SimpleCNN的完整实现供您查看:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
第 2-8 行导入我们需要的 Python 包。
然后我们可以创建SimpleCNN架构:
class SimpleCNN:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# first CONV => RELU => BN layer set
model.add(Conv2D(32, (3, 3), strides=(2, 2), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
# second CONV => RELU => BN layer set
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
这种架构的突出之处包括:
- 第一套
CONV => RELU => BN图层。CONV层学习总共 32 个 3×3 滤波器,用 2×2 步进卷积减少体积大小。 - 第二套
CONV => RELU => BN图层。同上,但这次CONV层学习 64 个滤镜。 - 一组密集/完全连接的层。其输出是我们的 softmax 分类器,用于返回每个类别标签的概率。
使用 FGSM 生成对抗图像
我们使用快速梯度符号方法(FGSM)来生成图像对手。我们已经在本系列的前面中详细介绍了这个实现,所以你可以在那里查阅完整的代码回顾。
也就是说,如果你打开项目目录结构中的fgsm.py文件,你会发现下面的代码:
# import the necessary packages
from tensorflow.keras.losses import MSE
import tensorflow as tf
def generate_image_adversary(model, image, label, eps=2 / 255.0):
# cast the image
image = tf.cast(image, tf.float32)
# record our gradients
with tf.GradientTape() as tape:
# explicitly indicate that our image should be tacked for
# gradient updates
tape.watch(image)
# use our model to make predictions on the input image and
# then compute the loss
pred = model(image)
loss = MSE(label, pred)
# calculate the gradients of loss with respect to the image, then
# compute the sign of the gradient
gradient = tape.gradient(loss, image)
signedGrad = tf.sign(gradient)
# construct the image adversary
adversary = (image + (signedGrad * eps)).numpy()
# return the image adversary to the calling function
return adversary
概括地说,这段代码是:
- 接受一个我们想要“愚弄”做出错误预测的
model - 获取
model并使用它对输入image进行预测 - 基于地面实况类
label计算模型的loss - 计算损失相对于图像的梯度
- 获取梯度的符号(或者
-1、0、1),然后使用带符号的梯度来创建图像对手
最终结果将是一个输出图像,看起来与原始图像在视觉上相同,但是 CNN 将会错误地分类。
同样,你可以参考我们的 FGSM 指南来详细查看代码。
更新我们的数据生成器,在运行中混合正常图像和敌对图像
在本节中,我们将实现两个功能:
generate_adversarial_batch:使用我们的 FGSM 实现生成总共 N 张敌对图像。generate_mixed_adverserial_batch:生成一批 N 张图像,一半是正常图像,另一半是敌对图像。
我们在上周的教程 中实现了第一种方法,用 Keras 和 TensorFlow 防御对抗性图像攻击。第二个函数是全新的,是本教程独有的。
让我们从数据批处理生成器开始吧。在我们的项目结构中打开datagen.py文件,并插入以下代码:
# import the necessary packages
from .fgsm import generate_image_adversary
from sklearn.utils import shuffle
import numpy as np
2-4 号线处理我们所需的进口。
我们正在从我们的fgsm模块导入generate_image_adversary,这样我们就可以生成镜像对手。
导入shuffle函数以将图像和标签混洗在一起。
下面是我们的generate_adversarial_batch函数的定义,我们在上周实现了:
def generate_adversarial_batch(model, total, images, labels, dims,
eps=0.01):
# unpack the image dimensions into convenience variables
(h, w, c) = dims
# we're constructing a data generator here so we need to loop
# indefinitely
while True:
# initialize our perturbed images and labels
perturbImages = []
perturbLabels = []
# randomly sample indexes (without replacement) from the
# input data
idxs = np.random.choice(range(0, len(images)), size=total,
replace=False)
# loop over the indexes
for i in idxs:
# grab the current image and label
image = images[i]
label = labels[i]
# generate an adversarial image
adversary = generate_image_adversary(model,
image.reshape(1, h, w, c), label, eps=eps)
# update our perturbed images and labels lists
perturbImages.append(adversary.reshape(h, w, c))
perturbLabels.append(label)
# yield the perturbed images and labels
yield (np.array(perturbImages), np.array(perturbLabels))
由于我们在之前的帖子中详细讨论了该函数,所以我将推迟对该函数的完整讨论,但在高级别上,您可以看到该函数:
- 从我们的输入
images集(通常是我们的训练集或测试集)中随机抽取 N 个图像(total) - 然后,我们使用 FGSM 从我们随机采样的图像中生成对立的例子
- 该函数通过将对立的图像和标签返回给调用函数来完成
这里最重要的一点是generate_adversarial_batch方法只返回和对立的图像。
然而,这个帖子的目标是包含正常图像和敌对图像的混合训练。因此,我们需要实现第二个助手函数:
def generate_mixed_adverserial_batch(model, total, images, labels,
dims, eps=0.01, split=0.5):
# unpack the image dimensions into convenience variables
(h, w, c) = dims
# compute the total number of training images to keep along with
# the number of adversarial images to generate
totalNormal = int(total * split)
totalAdv = int(total * (1 - split))
顾名思义,generate_mixed_adverserial_batch创造了一个混合了和正常形象和敌对形象的作品。
此方法有几个参数,包括:
- 我们正在训练和使用 CNN 来生成敌对的图像
total:我们每批需要的图像总数images:输入图像集(通常是我们的训练或测试分割)labels:对应的属于images的分类标签dims:输入图像的空间尺寸eps:用于生成对抗图像的小ε值split:正常图像与对抗图像的百分比;在这里,我们做的是五五分成
从那里,我们将dims元组分解成我们的高度、宽度和通道数(第 43 行)。
我们还基于我们的split ( 第 47 行和第 48 行)导出训练图像的总数和对抗图像的数量。
现在让我们深入了解数据生成器本身:
# we're constructing a data generator so we need to loop
# indefinitely
while True:
# randomly sample indexes (without replacement) from the
# input data and then use those indexes to sample our normal
# images and labels
idxs = np.random.choice(range(0, len(images)),
size=totalNormal, replace=False)
mixedImages = images[idxs]
mixedLabels = labels[idxs]
# again, randomly sample indexes from the input data, this
# time to construct our adversarial images
idxs = np.random.choice(range(0, len(images)), size=totalAdv,
replace=False)
第 52 行开始一个无限循环,一直持续到训练过程完成。
然后,我们从我们的输入集中随机抽取总共totalNormal幅图像(第 56-59 行)。
接下来,行 63 和 64 执行第二轮随机采样,这次是为了对抗图像生成。
我们现在可以循环这些idxs:
# loop over the indexes
for i in idxs:
# grab the current image and label, then use that data to
# generate the adversarial example
image = images[i]
label = labels[i]
adversary = generate_image_adversary(model,
image.reshape(1, h, w, c), label, eps=eps)
# update the mixed images and labels lists
mixedImages = np.vstack([mixedImages, adversary])
mixedLabels = np.vstack([mixedLabels, label])
# shuffle the images and labels together
(mixedImages, mixedLabels) = shuffle(mixedImages, mixedLabels)
# yield the mixed images and labels to the calling function
yield (mixedImages, mixedLabels)
对于每个图像索引i,我们:
- 抓取当前
image和label( 线 70 和 71 ) - 通过 FGSM 生成对抗图像(行 72 和 73 )
- 用我们的敌对形象和标签更新我们的
mixedImages和mixedLabels列表(第 76 行和第 77 行
80 线联合洗牌我们的mixedImages和mixedLabels。我们执行这种混洗操作是因为正常图像和敌对图像被顺序地加在一起,这意味着正常图像出现在列表的前面,而敌对图像出现在列表的后面。洗牌确保我们的数据样本在整个批次中随机分布。
然后,将混洗后的一批数据交给调用函数。
创建我们的混合图像和对抗图像训练脚本
实现了所有的助手函数后,我们就可以创建我们的训练脚本了。
打开项目结构中的train_mixed_adverserial_defense.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.simplecnn import SimpleCNN
from pyimagesearch.datagen import generate_mixed_adverserial_batch
from pyimagesearch.datagen import generate_adversarial_batch
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import numpy as np
第 2-8 行导入我们需要的 Python 包。请注意我们的定制实施,包括:
- 我们将要训练的 CNN 架构。
generate_mixed_adverserial_batch:批量生成正常图像和对抗图像generate_adversarial_batch:生成一批专属的敌对图像
*我们将在 MNIST 数据集上训练SimpleCNN,现在让我们加载并预处理它:
# load MNIST dataset and scale the pixel values to the range [0, 1]
print("[INFO] loading MNIST dataset...")
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX / 255.0
testX = testX / 255.0
# add a channel dimension to the images
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
# one-hot encode our labels
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
第 12 行从磁盘加载 MNIST 数字数据集。然后,我们通过以下方式对其进行预处理:
- 将像素强度从范围【0,255】缩放到【0,1】
- 向数据添加批次维度
- 一键编码标签
我们现在可以编译我们的模型了:
# initialize our optimizer and model
print("[INFO] compiling model...")
opt = Adam(lr=1e-3)
model = SimpleCNN.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the simple CNN on MNIST
print("[INFO] training network...")
model.fit(trainX, trainY,
validation_data=(testX, testY),
batch_size=64,
epochs=20,
verbose=1)
第 26-29 行编译我们的模型。然后,我们根据我们的trainX和trainY数据在的第 33-37 行上训练它。
培训后,下一步是评估模型:
# make predictions on the testing set for the model trained on
# non-adversarial images
(loss, acc) = model.evaluate(x=testX, y=testY, verbose=0)
print("[INFO] normal testing images:")
print("[INFO] loss: {:.4f}, acc: {:.4f}\n".format(loss, acc))
# generate a set of adversarial from our test set (so we can evaluate
# our model performance *before* and *after* mixed adversarial
# training)
print("[INFO] generating adversarial examples with FGSM...\n")
(advX, advY) = next(generate_adversarial_batch(model, len(testX),
testX, testY, (28, 28, 1), eps=0.1))
# re-evaluate the model on the adversarial images
(loss, acc) = model.evaluate(x=advX, y=advY, verbose=0)
print("[INFO] adversarial testing images:")
print("[INFO] loss: {:.4f}, acc: {:.4f}\n".format(loss, acc))
第 41-43 行根据我们的测试数据评估模型。
然后我们在第 49 行和第 50 行的上生成一组专有的敌对图像。
然后,我们的模型被重新评估,这一次是在对抗性图像上(第 53-55 行)。
正如我们将在下一节中看到的,我们的模型将在原始测试数据上表现良好,但在敌对图像上准确性将骤降。
为了帮助防御敌对攻击,我们可以在由正常图像和敌对示例组成的数据批次上微调模型。
下面的代码块完成了这项任务:
# lower the learning rate and re-compile the model (such that we can
# fine-tune it on the mixed batches of normal images and dynamically
# generated adversarial images)
print("[INFO] re-compiling model...")
opt = Adam(lr=1e-4)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# initialize our data generator to create data batches containing
# a mix of both *normal* images and *adversarial* images
print("[INFO] creating mixed data generator...")
dataGen = generate_mixed_adverserial_batch(model, 64,
trainX, trainY, (28, 28, 1), eps=0.1, split=0.5)
# fine-tune our CNN on the adversarial images
print("[INFO] fine-tuning network on dynamic mixed data...")
model.fit(
dataGen,
steps_per_epoch=len(trainX) // 64,
epochs=10,
verbose=1)
第 61-63 行降低我们的学习速度,然后重新编译我们的模型。
从那里,我们创建我们的数据生成器(第 68 行和第 69 行)。在这里,我们告诉我们的数据生成器使用我们的model来生成数据批次(每批中有64个数据点),从我们的训练数据中采样,对于正常图像和敌对图像,以 50/50 的比例进行分割。
通过我们的dataGen到model.fit允许我们的 CNN 在这些混合批次上接受训练。
让我们进行最后一轮评估:
# now that our model is fine-tuned we should evaluate it on the test
# set (i.e., non-adversarial) again to see if performance has degraded
(loss, acc) = model.evaluate(x=testX, y=testY, verbose=0)
print("")
print("[INFO] normal testing images *after* fine-tuning:")
print("[INFO] loss: {:.4f}, acc: {:.4f}\n".format(loss, acc))
# do a final evaluation of the model on the adversarial images
(loss, acc) = model.evaluate(x=advX, y=advY, verbose=0)
print("[INFO] adversarial images *after* fine-tuning:")
print("[INFO] loss: {:.4f}, acc: {:.4f}".format(loss, acc))
第 81-84 行在对混合批次进行微调后,在我们的原始测试集上评估我们的 CNN。
然后,我们再一次评估 CNN 对我们的原始敌对图像(第 87-89 行)。
理想情况下,我们将看到的是我们的正常图像和敌对图像之间的平衡准确性,从而使我们的模型更加健壮,能够抵御敌对攻击。
在正常图像和敌对图像上训练我们的 CNN
我们现在准备在正常训练图像和动态生成的敌对图像上训练我们的 CNN。
通过访问本教程的 【下载】 部分来检索源代码。
从那里,打开一个终端并执行以下命令:
$ time python train_mixed_adversarial_defense.py
[INFO] loading MNIST dataset...
[INFO] compiling model...
[INFO] training network...
Epoch 1/20
938/938 [==============================] - 6s 6ms/step - loss: 0.2043 - accuracy: 0.9377 - val_loss: 0.0615 - val_accuracy: 0.9805
Epoch 2/20
938/938 [==============================] - 6s 6ms/step - loss: 0.0782 - accuracy: 0.9764 - val_loss: 0.0470 - val_accuracy: 0.9846
Epoch 3/20
938/938 [==============================] - 6s 6ms/step - loss: 0.0597 - accuracy: 0.9810 - val_loss: 0.0493 - val_accuracy: 0.9828
...
Epoch 18/20
938/938 [==============================] - 6s 6ms/step - loss: 0.0102 - accuracy: 0.9965 - val_loss: 0.0478 - val_accuracy: 0.9889
Epoch 19/20
938/938 [==============================] - 6s 6ms/step - loss: 0.0116 - accuracy: 0.9961 - val_loss: 0.0359 - val_accuracy: 0.9915
Epoch 20/20
938/938 [==============================] - 6s 6ms/step - loss: 0.0105 - accuracy: 0.9967 - val_loss: 0.0477 - val_accuracy: 0.9891
[INFO] normal testing images:
[INFO] loss: 0.0477, acc: 0.9891
上面,你可以看到在正常 MNIST 训练集上训练我们 CNN 的输出。这里,我们在训练集上获得了 99.67% 的准确率,在测试集上获得了 98.91% 的准确率。
现在,让我们看看当我们用快速梯度符号方法生成一组对立图像时会发生什么:
[INFO] generating adversarial examples with FGSM...
[INFO] adversarial testing images:
[INFO] loss: 14.0658, acc: 0.0188
我们的准确度从 98.91%的准确度下降到 1.88%的准确度。显然,我们的模型不能很好地处理对立的例子。
我们现在要做的是降低学习率,重新编译模型,然后使用数据生成器进行微调,数据生成器包括和原始训练图像和动态生成的对抗图像:
[INFO] re-compiling model...
[INFO] creating mixed data generator...
[INFO] fine-tuning network on dynamic mixed data...
Epoch 1/10
937/937 [==============================] - 162s 173ms/step - loss: 1.5721 - accuracy: 0.7653
Epoch 2/10
937/937 [==============================] - 146s 156ms/step - loss: 0.4189 - accuracy: 0.8875
Epoch 3/10
937/937 [==============================] - 146s 156ms/step - loss: 0.2861 - accuracy: 0.9154
...
Epoch 8/10
937/937 [==============================] - 146s 155ms/step - loss: 0.1423 - accuracy: 0.9541
Epoch 9/10
937/937 [==============================] - 145s 155ms/step - loss: 0.1307 - accuracy: 0.9580
Epoch 10/10
937/937 [==============================] - 146s 155ms/step - loss: 0.1234 - accuracy: 0.9604
使用这种方法,我们获得了 96.04%的准确率。
当我们将其应用于最终测试图像时,我们会得出以下结论:
[INFO] normal testing images *after* fine-tuning:
[INFO] loss: 0.0315, acc: 0.9906
[INFO] adversarial images *after* fine-tuning:
[INFO] loss: 0.1190, acc: 0.9641
real 27m17.243s
user 43m1.057s
sys 14m43.389s
在使用动态数据生成过程对我们的模型进行微调之后,我们在原始测试图像上获得了 99.06% 的准确性(高于上周方法的 98.44%)。
我们的对抗性图像准确率为 96.41%,比上周的 99%有所下降,但这在这种情况下是有意义的——请记住,我们不是在上微调模型,而是像上周一样在上微调对抗性示例。相反,我们允许模型“反复愚弄自己”,并从它产生的对立例子中学习。
通过仅在对立示例(没有任何原始训练样本)的上再次微调,可以潜在地获得进一步的准确性。尽管如此,我还是把它作为一个练习留给读者去探索。
演职员表和参考资料
FGSM 和数据生成器的实现受到了塞巴斯蒂安·蒂勒关于对抗性攻击和防御的优秀文章的启发。非常感谢 Sebastian 分享他的知识。
总结
在本教程中,您学习了如何修改 CNN 的训练过程来生成图像批,包括:
- 正常训练图像
- CNN 产生的对立例子
这种方法不同于我们上周学过的方法,在那种方法中,我们简单地对一个对立图像的样本微调 CNN。
今天的方法的好处是,CNN 可以通过以下方式更好地抵御敌对的例子:
- 从原始训练示例中学习模式
- 从即时生成的敌对图像中学习模式
由于模型可以在每批训练的期间生成自己的对抗实例,它可以不断地自我学习。
总的来说,我认为你会发现这种方法在训练你自己的模型抵御对抗性攻击时更有益。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
使用 OpenCV 的蒙太奇
原文:https://pyimagesearch.com/2017/05/29/montages-with-opencv/

今天这篇博文的灵感来自于我从 PyImageSearch 阅读器 Brian 那里收到的一封邮件。
布莱恩问道:
嗨阿德里安,
我真的很喜欢 PyImageSearch 博客。几天前我发现了你的网站,从那以后我就迷上了你的教程。
我按照你的教程构建了一个图片搜索引擎,但是我不想一个接一个地显示结果图片(就像你做的那样),我想以蒙太奇的方式显示前 20 个结果。
OpenCV 有办法吗?
谢谢,
布赖恩
问得好,布莱恩,谢谢你的提问。
运行 PyImageSearch 博客我最喜欢的一个方面是能够和你,读者聊天,发现你正在做的项目。
特别令人兴奋的是当我可以把问题或评论转化成博客帖子时——这样整个 PyImageSearch 社区都能从答案中受益。
*今天我们将学习如何使用 OpenCV 和 imutils 包来构建图像蒙太奇。非常感谢凯尔·豪恩斯洛为 imutils 贡献了build_montages功能。
要了解更多关于用 OpenCV 构建图像蒙太奇的信息,继续阅读。
使用 OpenCV 的蒙太奇
今天的博文有四个主要部分。
在第一部分中,我们将学习如何从驻留在磁盘上的图像数据集构建图像路径列表。
从那里,我们将使用build_montages函数来获取这个图像列表并创建实际的蒙太奇。
接下来,我们将在屏幕上显示蒙太奇。
最后,我将提供一个通过 OpenCV 使用蒙太奇显示图像的例子。
要下载这篇博文的源代码+示例图片,请务必使用下面的 “下载” 部分。
用 OpenCV 创建蒙太奇
首先,打开一个新文件,将其命名为montage_example.py,并插入以下代码:
# import the necessary packages
from imutils import build_montages
from imutils import paths
import argparse
import random
import cv2
第 2-6 行导入我们需要的 Python 包。注意build_montages是如何从 imutils 包中导入的。
如果您的系统上没有安装imutils(在撰写本文时, v0.4.3 ,那么请确保您通过pip安装/升级它:
$ pip install --upgrade imutils
注意:如果你正在使用 Python 虚拟环境(正如我所有的 OpenCV 安装教程所做的那样),确保你首先使用workon命令访问你的虚拟环境,然后使用安装/升级imutils。**
从那里,我们可以解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to input directory of images")
ap.add_argument("-s", "--sample", type=int, default=21,
help="# of images to sample")
args = vars(ap.parse_args())
我们的脚本需要一个命令行参数,后跟第二个可选参数,每个参数的详细信息如下:
--images:你的目录的路径,包含你想要建立一个蒙太奇的图像。--samples:一个可选的命令行参数,指定要采样的图像数量(我们将该值默认为21总图像数)。
接下来,我们可以使用--images路径随机选择一些输入图像:
# grab the paths to the images, then randomly select a sample of
# them
imagePaths = list(paths.list_images(args["images"]))
random.shuffle(imagePaths)
imagePaths = imagePaths[:args["sample"]]
为了获得--images目录中所有图像路径的列表,我们调用了list_images函数(第 18 行)。
出于这个练习的目的,我们随机打乱了行 19 上的图像路径,然后从这些图像中抽取一个样本显示到我们的屏幕上(行 20 )。这次采样返回的一组imagePaths将用于构建我们的蒙太奇。
对于你自己的应用程序来说,你可能不需要去随机选择一组图像路径——你已经有了自己的图像路径。
在 Brian 最初问题的上下文中,他希望显示他的图像搜索引擎的结果。
因此,结果包含他的图像路径。
再次提醒,请记住我们只是在演示如何用 OpenCV 构建一个蒙太奇——你实际上如何使用这个例子是完全由你决定的。
给定我们的imagePaths,我们准备建立蒙太奇:
# initialize the list of images
images = []
# loop over the list of image paths
for imagePath in imagePaths:
# load the image and update the list of images
image = cv2.imread(imagePath)
images.append(image)
# construct the montages for the images
montages = build_montages(images, (128, 196), (7, 3))
在第 23 行的上,我们初始化了我们的images列表。
然后我们遍历第 26-29 行上的imagePaths,从磁盘加载每个image,然后将image添加到我们的images列表中。
为了实际构建蒙太奇,我们调用了第 32 行上的build_montages函数——这是所有繁重工作完成的地方。如果你对build_montages方法的内部以及幕后发生的事情感到好奇,一定要查看 GitHub 上的源代码实现。
build_montages函数需要三个参数:
image_list:该参数是通过 OpenCV 加载的图像列表。在我们的例子中,我们提供建立在行 26-29 上的images列表。image_shape:包含蒙太奇中每个图像的宽度和高度的元组。这里我们指出蒙太奇中的所有图像将被调整到 129 x 196 。将蒙太奇中的每个图像调整到一个固定的大小是一个需求,这样我们可以在结果 NumPy 数组中适当地分配内存。 注意:蒙太奇中的空白区域会用黑色像素填充。montage_shape:一个第二元组,这个元组指定蒙太奇中的行数和列数。这里我们指出我们的蒙太奇将有 7 列(7 幅图像宽)和 3 行(3 幅图像高)。
方法返回一个 NumPy 数组格式的蒙太奇图像列表。
如果images列表中的多于montage_shape所能容纳的图像,会为多余的images创建一个新的蒙太奇。重复这个过程,直到所有的images都被添加到一个剪辑画面中。此过程等同于在多个页面上显示搜索结果。
我们的最后一个代码块处理向屏幕显示montages:
# loop over the montages and display each of them
for montage in montages:
cv2.imshow("Montage", montage)
cv2.waitKey(0)
在第 35 行的上,我们循环遍历每一个montages(同样,类似于在一个页面上显示 N 个(假的)“搜索结果”)。
第 36 行和第 37 行然后在我们的屏幕上显示当前的montage。cv2.waitKey调用暂停我们脚本的执行,直到我们选择当前活动的窗口并按下键盘上的任意键。这将导致for回路前进。
一旦我们到达montages列表的末尾,脚本就退出。
显示蒙太奇
大约两年前,我参与了一个计算机视觉项目,需要我建立一个简单的图像时尚搜索引擎。为了做到这一点,我构建了一个简单的网络爬虫来抓取Nordstrom.com并下载所有的产品图片和相关的元数据。
在演示build_montages函数时,我们今天将使用这个数据的一个小样本。
一旦您使用下面的 【下载】 部分下载了源代码+示例图像,您可以执行以下命令来查看结果:
$ python montage_example.py --images nordstrom_sample
执行该脚本后,您应该会看到类似如下的输出:

Figure 1: Building a montage with OpenCV and Python.
注:你在蒙太奇中看到的确切的图像将与我的有所不同,因为我们是从输入目录中随机抽样。
正如我们在上面的图 1 中看到的,我们有三行,每行包含七幅图像。蒙太奇中的每个图像都被调整为固定的 128 x 196 像素大小。
根据 Brian 在这篇博文顶部提出的问题,这个蒙太奇可能是他的图像搜索引擎算法的搜索结果。
作为第二个例子,让我们增加--sample,这样我们创建多个蒙太奇,因为所有的图像都不适合三行七列的格式:
$ python montage_example.py --images nordstrom_sample --sample 33
因为 3 x 7 = 21 ,我们知道采样 33 个图像不可能适合 21 个图像的蒙太奇。
幸运的是,build_montages功能意识到有太多的图像不适合一个单一的蒙太奇,因此创建了两个蒙太奇。
下面可以看到第一个蒙太奇,蒙太奇中的所有 21 个空间都被占用:

Figure 2: The first montage generated with OpenCV is completely filled.
第二个蒙太奇包含了第一个蒙太奇无法容纳的剩余 12 个图像:

Figure 3: The second montage displays images that could not fit in the first montage.
注意蒙太奇中的空白空间是如何被黑色像素填充的。
摘要
在今天的博文中,我演示了如何用 OpenCV 和 Python 构建一个蒙太奇来可视化一组图像。这是一个方便的工具,你可以在你自己的图像处理项目中使用,比如在这篇博文顶部详细介绍的 Brian 的图像搜索引擎项目中。
我还想花一点时间,对为 imutils 包贡献了build_montages功能的凯尔·豪恩斯洛大声欢呼——再次感谢凯尔!
在下周的博文中,我将展示如何在一个实际的应用程序中使用蒙太奇功能,在这个应用程序中,我们根据图像的“丰富多彩”程度对数据集中的图像进行排序。
为了在下一篇博文发布时得到通知,请务必在下表中输入您的电子邮件地址。*
使用 Keras、TensorFlow 和深度学习的多类对象检测和包围盒回归
在本教程中,您将学习如何通过 Keras 和 TensorFlow 深度学习库使用边界框回归来训练自定义多类对象检测器。
上周的教程涵盖了如何使用包围盒回归训练单类物体检测器。今天,我们将扩展我们的包围盒回归方法来处理多个类。
为了用 Keras 和 TensorFlow 从头开始创建一个多类对象检测器,我们需要修改我们架构的网络头。操作顺序如下:
- 步骤#1: 取 VGG16(预先在 ImageNet 上训练好的)取下全连接(FC)层头
- 步骤#2: 构造一个带有两个分支的新 FC 层头:
- 分支#1: 一系列 FC 层,以具有(1)四个神经元的层结束,对应于预测边界框的左上和右下 (x,y)-( 2)sigmoid 激活函数,使得每四个神经元的输出位于范围【0,1】内。这个分支负责包围盒的预测。
- 分支#2: 另一个 FC 层系列,但这一个在最后有一个 softmax 分类器。这个分支负责类标签的预测。
- 步骤#3: 将新的 FC 层头(带有两个分支)放在 VGG16 主体的顶部
- 步骤#4: 微调整个网络以进行端到端对象检测
结果将是一个卷积神经网络在您自己的自定义数据集上训练/微调,用于对象检测!
让我们开始吧。
要了解如何使用 Keras/TensorFlow 通过包围盒回归来训练自定义多类对象检测器,继续阅读。
使用 Keras、TensorFlow 和深度学习进行多类对象检测和包围盒回归
在本教程的第一部分,我们将简要讨论单类对象检测和多类对象检测之间的区别。
然后,我们将回顾我们将在其上训练多类对象检测器的数据集,以及我们项目的目录结构。
从这里,我们将实现两个 Python 脚本:
- 一个是加载数据集,构建模型架构,然后训练多类对象检测器
- 第二个脚本将从磁盘加载我们训练过的对象检测器,然后使用它对测试图像进行预测
这是一个更高级的教程,我认为以下教程是本指南的先决条件和必读材料:
- Keras,回归,CNN
- Keras:多输出多损耗
- 用 Keras 和深度学习进行微调
- R-CNN 物体检测用 Keras、TensorFlow、深度学习
- 物体检测:使用 Keras、TensorFlow、深度学习的包围盒回归 (上周教程)
在继续之前,请务必阅读上述教程。
多类物体检测与单类物体检测有何不同?
多类对象检测,顾名思义,意味着我们试图(1)检测输入图像中的处的对象,以及(2)预测检测到的对象是什么。
例如,下面的图 1 显示我们正在尝试检测属于【飞机】**【人脸】或【摩托车】类别的对象:
另一方面,单类对象检测是多类对象检测的简化形式,因为我们已经知道对象是什么(因为根据定义只有一个类,在这种情况下是“飞机”),只需检测对象在输入图像中的位置就足够了:
与仅需要回归层头来预测边界框的单类对象检测器不同,多类对象检测器需要具有个分支的全连接层头:
- 分支#1: 一个回归层集合,就像在单类对象检测情况下一样
- 分支#2: 一个附加层集,这个层集带有一个 softmax 分类器,用于预测类标签
一起使用,我们的多类物体检测器的单次向前通过将导致:
- 图像中对象的预测边界框坐标
- 图像中对象的预测类别标签
今天,我将向您展示如何使用包围盒回归来训练您自己的自定义多类对象检测器。
我们的多类对象检测和包围盒回归数据集
我们今天在这里使用的示例数据集是 CALTECH-101 数据集的子集,可用于训练对象检测模型。
具体来说,我们将使用以下类:
- 飞机: 800 张图片
- 脸: 435 张图片
- 摩托车: 798 张图片
总的来说,我们的数据集由 2033 个图像和它们相应的边界框 (x,y)-坐标组成。在这一部分的顶部,我已经在图 3 中包含了每个职业的可视化。
我们的目标是训练一个能够准确预测输入图像中的飞机、人脸和摩托车的包围盒坐标的物体检测器。
注意:没有必要从加州理工学院 101 的网站上下载完整的数据集。在与本教程相关的下载中,我包含了我们的样本数据集,包括一个边界框的 CSV 文件。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
这样说来,你是:
- 时间紧迫?
- 在雇主管理锁定的笔记本电脑上学习?
- 想要跳过与包管理器、bash/ZSH 概要文件和虚拟环境的争论吗?
- 准备好运行代码了吗(并尽情体验它)?
那今天就加入 PyImageSearch 加吧!在你的浏览器——无需安装 中获取运行在谷歌的 Colab 生态系统上的 PyImageSearch 教程 Jupyter 笔记本。
最棒的是,这些笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
去拿吧。本教程的 【下载】 部分的 zip 文件。在里面,您将找到数据子集以及我们的项目文件:
$ tree --dirsfirst --filelimit 20
.
├── dataset
│ ├── annotations
│ │ ├── airplane.csv
│ │ ├── face.csv
│ │ └── motorcycle.csv
│ └── images
│ ├── airplane [800 entries]
│ ├── face [435 entries]
│ └── motorcycle [798 entries]
├── output
│ ├── plots
│ │ ├── accs.png
│ │ └── losses.png
│ ├── detector.h5
│ ├── lb.pickle
│ └── test_paths.txt
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── predict.py
└── train.py
9 directories, 12 files
$ head -n 10 face.csv
image_0001.jpg,251,15,444,300,face
image_0002.jpg,106,31,296,310,face
image_0003.jpg,207,17,385,279,face
image_0004.jpg,102,55,303,328,face
image_0005.jpg,246,30,446,312,face
image_0006.jpg,248,22,440,298,face
image_0007.jpg,173,25,365,302,face
image_0008.jpg,227,47,429,333,face
image_0009.jpg,116,27,299,303,face
image_0010.jpg,121,34,314,302,face
如您所见,每行包含六个元素:
- 文件名
- 起始x-坐标
- 开始 y 坐标
- 终点x-坐标
- 终点y-坐标
- 类别标签
detector.h5文件是我们训练的多类包围盒回归器。- 然后我们有了
lb.pickle,一个序列化的标签二进制化器,我们用它一次性编码类标签,然后将预测的类标签转换为人类可读的字符串。 - 最后,
test_paths.txt文件包含我们测试图像的文件名。
我们有三个 Python 脚本:
config.py:配置设置和变量文件。train.py:我们的训练脚本,它将从磁盘加载我们的图像和注释,为边界框回归修改 VGG16 架构,为对象检测微调修改后的架构,最后用我们的序列化模型、训练历史图和测试图像文件名填充output/目录。predict.py:使用我们训练过的物体检测器进行推理。这个脚本将加载我们的序列化模型和标签编码器,遍历我们的测试图像,然后对每个图像应用对象检测。
让我们从实现配置文件开始。
创建我们的配置文件
在实现我们的训练脚本之前,让我们首先定义一个简单的配置文件来存储重要的变量(即输出文件路径和模型训练超参数)——这个配置文件将在我们的两个 Python 脚本中使用。
打开pyimagesearch模块中的config.py文件,让我们看看里面有什么:
# import the necessary packages
import os
# define the base path to the input dataset and then use it to derive
# the path to the input images and annotation CSV files
BASE_PATH = "dataset"
IMAGES_PATH = os.path.sep.join([BASE_PATH, "images"])
ANNOTS_PATH = os.path.sep.join([BASE_PATH, "annotations"])
Python 的os模块( Line 2 )允许我们在配置文件中构建动态路径。我们的前两条路径源自BASE_PATH ( 线 6 ):
IMAGES_PATH:加州理工学院 101 图像子集的路径ANNOTS_PATH:包含 CSV 格式的包围盒标注的文件夹路径
接下来,我们有四个与输出文件相关联的路径:
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the output model, label binarizer, plots output
# directory, and testing image paths
MODEL_PATH = os.path.sep.join([BASE_OUTPUT, "detector.h5"])
LB_PATH = os.path.sep.join([BASE_OUTPUT, "lb.pickle"])
PLOTS_PATH = os.path.sep.join([BASE_OUTPUT, "plots"])
TEST_PATHS = os.path.sep.join([BASE_OUTPUT, "test_paths.txt"])
最后,让我们定义我们的标准深度学习超参数:
# initialize our initial learning rate, number of epochs to train
# for, and the batch size
INIT_LR = 1e-4
NUM_EPOCHS = 20
BATCH_SIZE = 32
我们的学习速度、训练次数和批量大小是通过实验确定的。这些参数存在于我们方便的配置文件中,这样当您在这里时,您可以根据自己的需要以及任何输入/输出文件路径轻松地对它们进行调整。
使用 Keras 和 TensorFlow 实现我们的多类对象检测器训练脚本
实现了配置文件后,现在让我们继续创建训练脚本,该脚本用于使用边界框回归来训练多类对象检测器。
打开项目目录中的train.py文件,插入以下代码:
# import the necessary packages
from pyimagesearch import config
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import pickle
import cv2
import os
既然我们的包、文件和方法已经导入,让我们初始化几个列表:
# initialize the list of data (images), class labels, target bounding
# box coordinates, and image paths
print("[INFO] loading dataset...")
data = []
labels = []
bboxes = []
imagePaths = []
第 25-28 行初始化与我们的数据相关的四个空列表;这些列表将很快包括:
data:图像labels:类别标签bboxes:目标包围盒 (x,y)-坐标imagePaths:驻留在磁盘上的图像的文件路径
现在我们的列表已经初始化,在接下来的三个代码块中,我们将准备数据并填充这些列表,以便它们可以作为多类边界框回归训练的输入:
# loop over all CSV files in the annotations directory
for csvPath in paths.list_files(config.ANNOTS_PATH, validExts=(".csv")):
# load the contents of the current CSV annotations file
rows = open(csvPath).read().strip().split("\n")
# loop over the rows
for row in rows:
# break the row into the filename, bounding box coordinates,
# and class label
row = row.split(",")
(filename, startX, startY, endX, endY, label) = row
$ head -n 5 dataset/annotations/*.csv
==> dataset/annotations/airplane.csv <==
image_0001.jpg,49,30,349,137,airplane
image_0002.jpg,59,35,342,153,airplane
image_0003.jpg,47,36,331,135,airplane
image_0004.jpg,47,24,342,141,airplane
image_0005.jpg,48,18,339,146,airplane
==> dataset/annotations/face.csv <==
image_0001.jpg,251,15,444,300,face
image_0002.jpg,106,31,296,310,face
image_0003.jpg,207,17,385,279,face
image_0004.jpg,102,55,303,328,face
image_0005.jpg,246,30,446,312,face
==> dataset/annotations/motorcycle.csv <==
image_0001.jpg,31,19,233,141,motorcycle
image_0002.jpg,32,15,232,142,motorcycle
image_0003.jpg,30,20,234,143,motorcycle
image_0004.jpg,30,15,231,132,motorcycle
image_0005.jpg,31,19,232,145,motorcycle
在我们的循环中,我们对逗号分隔的row ( 第 39 行和第 40 行)进行解包,给出 CSV 中特定行的filename、 (x,y)-坐标和类label。
接下来让我们使用这些值:
# derive the path to the input image, load the image (in
# OpenCV format), and grab its dimensions
imagePath = os.path.sep.join([config.IMAGES_PATH, label,
filename])
image = cv2.imread(imagePath)
(h, w) = image.shape[:2]
# scale the bounding box coordinates relative to the spatial
# dimensions of the input image
startX = float(startX) / w
startY = float(startY) / h
endX = float(endX) / w
endY = float(endY) / h
最后,让我们加载图像并进行预处理:
# load the image and preprocess it
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
# update our list of data, class labels, bounding boxes, and
# image paths
data.append(image)
labels.append(label)
bboxes.append((startX, startY, endX, endY))
imagePaths.append(imagePath)
尽管我们的数据准备循环已经完成,但我们仍有一些预处理任务要处理:
# convert the data, class labels, bounding boxes, and image paths to
# NumPy arrays, scaling the input pixel intensities from the range
# [0, 255] to [0, 1]
data = np.array(data, dtype="float32") / 255.0
labels = np.array(labels)
bboxes = np.array(bboxes, dtype="float32")
imagePaths = np.array(imagePaths)
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
# only there are only two labels in the dataset, then we need to use
# Keras/TensorFlow's utility function as well
if len(lb.classes_) == 2:
labels = to_categorical(labels)
如果你对一键编码不熟悉,请参考我的 Keras 教程:如何入门 Keras、深度学习和 Python 或我的书 用 Python 进行计算机视觉的深度学习 中的解释和例子。
让我们继续划分我们的数据分割:
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
split = train_test_split(data, labels, bboxes, imagePaths,
test_size=0.20, random_state=42)
# unpack the data split
(trainImages, testImages) = split[:2]
(trainLabels, testLabels) = split[2:4]
(trainBBoxes, testBBoxes) = split[4:6]
(trainPaths, testPaths) = split[6:]
# write the testing image paths to disk so that we can use then
# when evaluating/testing our object detector
print("[INFO] saving testing image paths...")
f = open(config.TEST_PATHS, "w")
f.write("\n".join(testPaths))
f.close()
使用 scikit-learn 的实用程序,我们将数据分成 80%用于训练,20%用于测试(第 86 行和第 87 行)。split数据通过列表切片经由行 90-93 被进一步解包。
出于评估目的,我们将在预测脚本中使用我们的测试图像路径,所以现在是将它们以文本文件形式导出到磁盘的好时机(第 98-100 行)。
唷!这就是数据准备——正如你所看到的,为深度学习准备图像数据集可能是乏味的,但如果我们想成为成功的计算机视觉和深度学习实践者,这是没有办法的。
现在到了换挡到准备我们的多输出(二分支)模型用于多类包围盒回归的时候了。 当我们建造模型时,我们将为微调做准备。我的建议是在单独的窗口打开上周的教程,这样你就可以并排看到单类和多类包围盒回归的区别。
事不宜迟,让我们准备我们的模型:
# load the VGG16 network, ensuring the head FC layers are left off
vgg = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# freeze all VGG layers so they will *not* be updated during the
# training process
vgg.trainable = False
# flatten the max-pooling output of VGG
flatten = vgg.output
flatten = Flatten()(flatten)
第 103 行和第 104 行用在 ImageNet 数据集上预先训练的权重加载 VGG16 网络。我们省略了全连接的层头(include_top=False),因为我们将构建一个新的层头,负责多输出预测(即,类标签和边界框位置)。
行 108 冻结 VGG16 网络的主体,这样在微调过程中权重将而不是被更新。
然后我们展平网络的输出,这样我们就可以构建我们的新层 had,并将其添加到网络主体中(行 111 和 112 )。
说到构建新的层头,让我们现在就做:
# construct a fully-connected layer header to output the predicted
# bounding box coordinates
bboxHead = Dense(128, activation="relu")(flatten)
bboxHead = Dense(64, activation="relu")(bboxHead)
bboxHead = Dense(32, activation="relu")(bboxHead)
bboxHead = Dense(4, activation="sigmoid",
name="bounding_box")(bboxHead)
# construct a second fully-connected layer head, this one to predict
# the class label
softmaxHead = Dense(512, activation="relu")(flatten)
softmaxHead = Dropout(0.5)(softmaxHead)
softmaxHead = Dense(512, activation="relu")(softmaxHead)
softmaxHead = Dropout(0.5)(softmaxHead)
softmaxHead = Dense(len(lb.classes_), activation="softmax",
name="class_label")(softmaxHead)
# put together our model which accept an input image and then output
# bounding box coordinates and a class label
model = Model(
inputs=vgg.input,
outputs=(bboxHead, softmaxHead))
利用 TensorFlow/Keras 的功能 API 、我们构建了两个全新的分支。
- 对应于预测边界框的左上角和右上角的 (x,y) 坐标的
4神经元。 - 然后,我们使用一个
sigmoid函数来确保我们的输出预测值在范围【0,1】内(因为我们在数据预处理步骤中将目标/地面真实边界框坐标缩放到这个范围)。
新的两个分支图层头的可视化如下所示:
请注意图层头是如何附加到 VGG16 的主体上,然后分裂成类别标签预测的分支(左)以及边界框 (x,y)-坐标预测(右)。
如果你之前从未创建过多输出神经网络,我建议你看看我的教程 Keras:多输出多损失。
下一步是定义我们的损失并编译模型:
# define a dictionary to set the loss methods -- categorical
# cross-entropy for the class label head and mean absolute error
# for the bounding box head
losses = {
"class_label": "categorical_crossentropy",
"bounding_box": "mean_squared_error",
}
# define a dictionary that specifies the weights per loss (both the
# class label and bounding box outputs will receive equal weight)
lossWeights = {
"class_label": 1.0,
"bounding_box": 1.0
}
# initialize the optimizer, compile the model, and show the model
# summary
opt = Adam(lr=config.INIT_LR)
model.compile(loss=losses, optimizer=opt, metrics=["accuracy"], loss_weights=lossWeights)
print(model.summary())
第 140 行定义了一个字典来存储我们的损失方法。我们将使用分类交叉熵作为我们的类标签分支,使用均方误差作为我们的包围盒回归头。
优化器初始化后,我们编译模型并在终端上显示模型架构的摘要(第 155 行和第 156 行)——我们将在本教程稍后执行train.py脚本时查看模型摘要的输出。
接下来,我们需要再定义两个字典:
# construct a dictionary for our target training outputs
trainTargets = {
"class_label": trainLabels,
"bounding_box": trainBBoxes
}
# construct a second dictionary, this one for our target testing
# outputs
testTargets = {
"class_label": testLabels,
"bounding_box": testBBoxes
}
我们现在准备训练我们的多类包围盒回归器:
# train the network for bounding box regression and class label
# prediction
print("[INFO] training model...")
H = model.fit(
trainImages, trainTargets,
validation_data=(testImages, testTargets),
batch_size=config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
verbose=1)
# serialize the model to disk
print("[INFO] saving object detector model...")
model.save(config.MODEL_PATH, save_format="h5")
# serialize the label binarizer to disk
print("[INFO] saving label binarizer...")
f = open(config.LB_PATH, "wb")
f.write(pickle.dumps(lb))
f.close()
我们将LabelBinarizer序列化,以便在运行我们的predict.py脚本时,我们可以将预测的类标签转换回人类可读的字符串。
现在让我们构建一个图来可视化我们的总损失、类别标签损失(分类交叉熵)和边界框回归损失(均方误差)。
# plot the total loss, label loss, and bounding box loss
lossNames = ["loss", "class_label_loss", "bounding_box_loss"]
N = np.arange(0, config.NUM_EPOCHS)
plt.style.use("ggplot")
(fig, ax) = plt.subplots(3, 1, figsize=(13, 13))
# loop over the loss names
for (i, l) in enumerate(lossNames):
# plot the loss for both the training and validation data
title = "Loss for {}".format(l) if l != "loss" else "Total loss"
ax[i].set_title(title)
ax[i].set_xlabel("Epoch #")
ax[i].set_ylabel("Loss")
ax[i].plot(N, H.history[l], label=l)
ax[i].plot(N, H.history["val_" + l], label="val_" + l)
ax[i].legend()
# save the losses figure and create a new figure for the accuracies
plt.tight_layout()
plotPath = os.path.sep.join([config.PLOTS_PATH, "losses.png"])
plt.savefig(plotPath)
plt.close()
第 193 行定义了我们每笔损失的名称。然后我们构建一个有三行的图,每一行代表各自的损失(第 195 行)。
第 198 行在每个损失名称上循环。对于每个损失,我们绘制训练和验证损失结果(第 200-206 行)。
一旦我们构建了损失图,我们就构建了输出损失文件的路径,然后将它保存到磁盘上(第 209-212 行)。
最后一步是规划我们的培训和验证准确性:
# create a new figure for the accuracies
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["class_label_accuracy"],
label="class_label_train_acc")
plt.plot(N, H.history["val_class_label_accuracy"],
label="val_class_label_acc")
plt.title("Class Label Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Accuracy")
plt.legend(loc="lower left")
# save the accuracies plot
plotPath = os.path.sep.join([config.PLOTS_PATH, "accs.png"])
plt.savefig(plotPath)
第 215-224 行描绘了我们的训练和训练期间验证数据的准确性。然后我们在的第 227 和 228 行将这个精度图序列化到磁盘上。
为包围盒回归训练我们的多类对象检测器
我们现在准备使用 Keras 和 TensorFlow 来训练我们的多类对象检测器。
首先使用本教程的 【下载】 部分下载源代码和数据集。
从那里,打开一个终端,并执行以下命令:
$ python train.py
[INFO] loading dataset...
[INFO] saving testing image paths...
Model: "model"
_____________________________________________________
Layer (type) Output Shape
=====================================================
input_1 (InputLayer) [(None, 224, 224, 3)
_____________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64)
_____________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64)
_____________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64)
_____________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128
_____________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128
_____________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128)
_____________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256)
_____________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256)
_____________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256)
_____________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256)
_____________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512)
_____________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512)
_____________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512)
_____________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512)
_____________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512)
_____________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512)
_____________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512)
_____________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512)
_____________________________________________________
flatten (Flatten) (None, 25088)
_____________________________________________________
dense_3 (Dense) (None, 512)
_____________________________________________________
dense (Dense) (None, 128)
_____________________________________________________
dropout (Dropout) (None, 512)
_____________________________________________________
dense_1 (Dense) (None, 64)
_____________________________________________________
dense_4 (Dense) (None, 512)
_____________________________________________________
dense_2 (Dense) (None, 32)
_____________________________________________________
dropout_1 (Dropout) (None, 512)
_____________________________________________________
bounding_box (Dense) (None, 4)
_____________________________________________________
class_label (Dense) (None, 3)
=====================================================
Total params: 31,046,311
Trainable params: 16,331,623
Non-trainable params: 14,714,688
_____________________________________________________
在这里,我们从磁盘加载数据集,然后构建我们的模型架构。
注意,我们的架构在层头中有两个分支——第一个分支预测包围盒坐标,第二个分支预测被检测对象的类标签(见上面的图 4 )。
随着我们的数据集加载和模型的构建,让我们训练用于多类对象检测的网络:
[INFO] training model...
Epoch 1/20
51/51 [==============================] - 255s 5s/step - loss: 0.0526 - bounding_box_loss: 0.0078 - class_label_loss: 0.0448 - bounding_box_accuracy: 0.7703 - class_label_accuracy: 0.9070 - val_loss: 0.0016 - val_bounding_box_loss: 0.0014 - val_class_label_loss: 2.4737e-04 - val_bounding_box_accuracy: 0.8793 - val_class_label_accuracy: 1.0000
Epoch 2/20
51/51 [==============================] - 232s 5s/step - loss: 0.0039 - bounding_box_loss: 0.0012 - class_label_loss: 0.0027 - bounding_box_accuracy: 0.8744 - class_label_accuracy: 0.9945 - val_loss: 0.0011 - val_bounding_box_loss: 9.5491e-04 - val_class_label_loss: 1.2260e-04 - val_bounding_box_accuracy: 0.8744 - val_class_label_accuracy: 1.0000
Epoch 3/20
51/51 [==============================] - 231s 5s/step - loss: 0.0023 - bounding_box_loss: 8.5802e-04 - class_label_loss: 0.0014 - bounding_box_accuracy: 0.8855 - class_label_accuracy: 0.9982 - val_loss: 0.0010 - val_bounding_box_loss: 8.6327e-04 - val_class_label_loss: 1.8589e-04 - val_bounding_box_accuracy: 0.8399 - val_class_label_accuracy: 1.0000
...
Epoch 18/20
51/51 [==============================] - 231s 5s/step - loss: 9.5600e-05 - bounding_box_loss: 8.2406e-05 - class_label_loss: 1.3194e-05 - bounding_box_accuracy: 0.9544 - class_label_accuracy: 1.0000 - val_loss: 6.7465e-04 - val_bounding_box_loss: 6.7077e-04 - val_class_label_loss: 3.8862e-06 - val_bounding_box_accuracy: 0.8941 - val_class_label_accuracy: 1.0000
Epoch 19/20
51/51 [==============================] - 231s 5s/step - loss: 1.0237e-04 - bounding_box_loss: 7.7677e-05 - class_label_loss: 2.4690e-05 - bounding_box_accuracy: 0.9520 - class_label_accuracy: 1.0000 - val_loss: 6.7227e-04 - val_bounding_box_loss: 6.6690e-04 - val_class_label_loss: 5.3710e-06 - val_bounding_box_accuracy: 0.8966 - val_class_label_accuracy: 1.0000
Epoch 20/20
51/51 [==============================] - 231s 5s/step - loss: 1.2749e-04 - bounding_box_loss: 7.3415e-05 - class_label_loss: 5.4076e-05 - bounding_box_accuracy: 0.9587 - class_label_accuracy: 1.0000 - val_loss: 7.2055e-04 - val_bounding_box_loss: 6.6672e-04 - val_class_label_loss: 5.3830e-05 - val_bounding_box_accuracy: 0.8941 - val_class_label_accuracy: 1.0000
[INFO] saving object detector model...
[INFO] saving label binarizer...
由于培训过程的输出非常冗长,所以很难直观地解析它,所以我提供了一些图表来帮助可视化正在发生的事情。
我们的第一个图是我们的类标签精度:
这里我们可以看到,我们的对象检测器以 100%的准确率正确地对训练和测试集中检测到的对象的标签进行分类。
下一个图可视化了我们的三个损失成分:类别标签损失、 边界框损失、和总损失(类别标签和边界框损失的组合):
我们的总损失一开始很高,但是到大约第三个时期,训练和验证损失几乎相同。
到了第五个纪元,它们基本上是相同的。
经过第十(10)个时期,我们的训练损失开始低于我们的验证损失——我们可能开始过度拟合,这从边界框损失(底部)可以明显看出,这表明验证损失没有训练损失下降得多。
培训完成后,您的output目录中应该有以下文件:
$ ls output/
detector.h5 lb.pickle plots test_paths.txt
用 Keras 和 TensorFlow 实现对象检测预测脚本
我们的多类对象检测器现在已经被训练并序列化到磁盘,但我们仍然需要一种方法来获取这个模型,并使用它在输入图像上实际做出预测——我们的predict.py文件会处理这些。
# import the necessary packages
from pyimagesearch import config
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.models import load_model
import numpy as np
import mimetypes
import argparse
import imutils
import pickle
import cv2
import os
现在让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input image/text file of image paths")
args = vars(ap.parse_args())
# determine the input file type, but assume that we're working with
# single input image
filetype = mimetypes.guess_type(args["input"])[0]
imagePaths = [args["input"]]
# if the file type is a text file, then we need to process *multiple*
# images
if "text/plain" == filetype:
# load the image paths in our testing file
imagePaths = open(args["input"]).read().strip().split("\n")
- 默认:我们的
imagePaths由来自--input( 第 23 行)的一条单独的图像路径组成。 - 文本文件:如果行 27 上的文本
filetype的条件/检查符合True,那么我们 覆盖 并从--input文本文件(行 29 )中的所有filenames(每行一个)填充我们的imagePaths。
现在让我们从磁盘加载我们的序列化多类边界框回归器和LabelBinarizer:
# load our object detector and label binarizer from disk
print("[INFO] loading object detector...")
model = load_model(config.MODEL_PATH)
lb = pickle.loads(open(config.LB_PATH, "rb").read())
# loop over the images that we'll be testing using our bounding box
# regression model
for imagePath in imagePaths:
# load the input image (in Keras format) from disk and preprocess
# it, scaling the pixel intensities to the range [0, 1]
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image) / 255.0
image = np.expand_dims(image, axis=0)
# predict the bounding box of the object along with the class
# label
(boxPreds, labelPreds) = model.predict(image)
(startX, startY, endX, endY) = boxPreds[0]
# determine the class label with the largest predicted
# probability
i = np.argmax(labelPreds, axis=1)
label = lb.classes_[i][0]
第 38 行在所有图像路径上循环。第 41-43 行通过以下方式对每幅图像进行预处理:
-
从磁盘加载输入图像,将其调整为 224×224 像素
-
将其转换为 NumPy 数组,并将像素亮度缩放到范围【0,1】
-
向图像添加批次维度
-
边界框预测(
boxPreds) -
和类标签预测(
labelPreds)
我们提取第 48 行上的边界框坐标。
第 52 行确定对应概率最大的类标签,而第 53 行使用这个索引值从我们的LabelBinarizer中提取人类可读的类标签串。
最后一步是将边界框坐标缩放回图像的原始空间尺寸,然后注释我们的输出:
# load the input image (in OpenCV format), resize it such that it
# fits on our screen, and grab its dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
# scale the predicted bounding box coordinates based on the image
# dimensions
startX = int(startX * w)
startY = int(startY * h)
endX = int(endX * w)
endY = int(endY * h)
# draw the predicted bounding box and class label on the image
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(image, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (0, 255, 0), 2)
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
第 57 行和第 58 行从磁盘加载我们的输入图像,然后将其调整到 600 像素的宽度(因此保证图像适合我们的屏幕)。
在调整图像大小后,我们在第 59 行获取它的空间尺寸(即宽度和高度)。
请记住,我们的边界框回归模型返回范围为【0,1】的边界框坐标,但是我们的图像分别具有范围为【0,w和【0,h】的空间维度。
因此,我们需要根据图像的空间尺寸缩放预测的边界框坐标——我们在的第 63-66 行完成。
最后,我们通过绘制预测的边界框及其相应的类标签来注释我们的输出图像(行 69-73 )。
该输出图像随后显示在我们的屏幕上(行 76 和 77 )。按一个键循环循环,一个接一个地显示结果,直到所有的测试图像都用完。
实现我们的predict.py脚本干得漂亮!让我们在下一节中让它发挥作用。
使用包围盒回归检测多类对象
我们现在准备测试我们的多类对象检测器!
确保您已经使用本教程的 “下载” 部分下载了源代码、示例图像和预训练模型。
从那里,打开一个终端,并执行以下命令:
$ python predict.py --input datasimg/face/image_0131.jpg
[INFO] loading object detector...
在这里,我们传入了一张“脸”的示例图像——我们的多类对象检测器已经正确地检测到了这张脸,并对它进行了标记。
让我们试试另一张图片,这张是“摩托车”:
$ python predict.py --input datasimg/motorcycle/image_0026.jpg
[INFO] loading object detector...
我们的多类对象检测器再次表现良好,正确地定位和标记图像中的摩托车。
这是最后一个例子,这是一架“飞机”:
$ python predict.py --input datasimg/airplane/image_0002.jpg
[INFO] loading object detector...
同样,我们的对象检测器的输出是正确的。
您还可以通过更新--input命令行参数来预测output/test_images.txt中的测试图像:
$ python predict.py --input output/test_paths.txt
[INFO] loading object detector...
在上面的图 10 中可以看到输出的剪辑,注意我们的物体探测器能够:
- 检测目标在输入图像中的位置
- 正确标注被检测对象是什么
您可以使用本教程中讨论的代码和方法作为起点,使用边界框回归和 Keras/TensorFlow 训练您自己的自定义多类对象检测器。
局限与不足
本教程中使用的对象检测体系结构和训练过程的最大限制之一是,该模型只能预测一组边界框和类别标签。
如果图像中有个多个物体,那么只会预测最有把握的一个。
这是一个完全不同的问题,我们将在以后的教程中讨论。
总结
在本教程中,您学习了如何使用边界框回归和 Keras/TensorFlow 深度学习库来训练自定义多类对象检测器。
单类对象检测器只需要一个回归层头来预测边界框。另一方面,多类对象检测器需要具有两个分支的全连接层头。**
第一个分支是回归层集,就像在单类对象检测架构中一样。第二个分支由 softmax 分类器组成,该分类器用于预测检测到的边界框的类别标签。
一起使用,我们的多类物体检测器的单次向前通过将导致:
- 图像中对象的预测边界框坐标
- 图像中对象的预测类别标签
我希望这篇教程能让你更好地理解边界框回归对于单对象和多对象用例的工作原理。请随意使用本指南作为训练您自己的自定义对象检测器的起点。
如果你需要额外的帮助来训练你自己的自定义对象检测器,一定要参考我的书 用 Python 进行计算机视觉的深度学习 ,在那里我详细讨论了对象检测。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
多级 SVM 损耗
原文:https://pyimagesearch.com/2016/09/05/multi-class-svm-loss/

几周前,我们讨论了 线性分类和参数化学习 的概念。这种类型的学习允许我们获取一组输入数据和类标签,并实际学习一个函数,该函数通过简单地定义一组参数并对它们进行优化,将输入映射到输出预测。
我们的线性分类教程主要关注评分函数的概念,以及如何使用它将输入数据映射到类标签。但是为了实际“学习”从输入数据到类标签的映射,我们需要讨论两个重要的概念:
- 损失函数
- 优化方法
在今天和下周的博客文章中,我们将讨论两个损失函数,这是在应用机器学习、神经网络和深度学习算法时常见的:
- 多级 SVM 损耗
- 交叉熵(用于 Softmax 分类器/多项式逻辑回归)
要了解更多关于你的第一个损失函数,多级 SVM 损失,请继续阅读。
多级 SVM 损耗
在最基本的层面上,损失函数仅用于量化给定预测器在对数据集中的输入数据点进行分类时的好坏程度。
损失越小,我们的分类器在建模输入数据和输出类标签之间的关系时就越好(尽管有一点我们可以过度拟合我们的模型——当训练数据建模太接近并且我们的模型失去概括能力时就会发生这种情况)。
相反,我们的损失越大,就需要做更多的工作来提高分类精度。在参数化学习方面,这涉及到调整参数,如我们的权重矩阵 W 或偏置向量 b 以提高分类精度。确切地说我们如何着手更新这些参数是一个优化问题,我们将在这一系列教程的后面讨论这个问题。
多类 SVM 损失背后的数学
通读完Python 线性分类教程后,你会注意到我们使用了线性支持向量机(SVM) 作为我们的分类器选择。
之前的教程关注于评分函数的概念,它将我们的特征向量映射到类别标签,作为数字分数。顾名思义,线性 SVM 应用简单的线性映射:
 = Wx_{i} + b")
现在我们有了这个评分/映射函数 f ,我们需要确定这个函数在进行预测时有多“好”或“坏”(给定权重矩阵 W 和偏差向量 b )。
为此,我们需要一个损失函数。我们现在就开始定义吧。
基于我们的之前的线性分类教程,我们知道我们有一个特征向量矩阵x——这些特征向量可以是提取的颜色直方图、定向梯度特征的直方图,甚至是原始像素强度。
不管我们选择如何量化我们的图像,关键是我们有一个从图像数据集中提取的特征矩阵 x 。然后我们可以通过语法 访问与给定图像相关的特征
访问与给定图像相关的特征
, which will yield the i-th feature vector inside x.
类似地,我们也有一个向量 y ,它包含每个 x 的类标签。这些 y 值是我们的基本事实标签,也是我们希望我们的评分函数能够正确预测的。就像我们可以通过访问给定的特征向量一样
, we can access the i-th class label via  .
.
为了简单起见,让我们将我们的评分函数缩写为 s :
")
这意味着我们可以通过第 i 个数据点得到第 j 级的预测分数:
_{j}")
.
使用这种语法,我们可以把所有这些放在一起,得到 铰链损失函数:
")
注意:我现在特意跳过正则化参数。一旦我们更好地理解损失函数,我们将在以后的文章中回到正则化。
那么上面的等式到底在做什么呢?
很高兴你问了。
本质上,铰链损失函数是对所有不正确类别 (  )求和
)求和
) and comparing the output of our scoring function s returned for the j-th class label (the incorrect class) and the -th class (the correct class).
我们应用 max 运算将值箝位到0——这样做很重要,这样我们就不会最终累加负值。
给定的
is classified correctly when the loss  (I’ll provide a numerical example of this in the following section).
(I’ll provide a numerical example of this in the following section).
- 为了得到整个训练集 的损失,我们简单地取每个个体
 的平均值
的平均值 

你可能遇到的另一个相关的常见损耗函数是 平方铰链损耗:
^{2}")
平方项通过对输出求平方来更严重地惩罚我们的损失。这导致了损失的二次增长,而不是线性增长。
至于您应该使用哪个损失函数,这完全取决于您的数据集。通常会看到标准铰链损失函数被更频繁地使用,但在一些数据集上,方差平方可能会获得更好的精度— 总的来说,这是一个超参数,您应该交叉验证。
一个多类 SVM 损失的例子
现在,我们已经了解了铰链损耗和平方铰链损耗背后的数学原理,让我们来看一个实际例子。
我们将再次假设我们正在使用 Kaggle Dogs vs. Cats 数据集,顾名思义,该数据集旨在对给定图像是否包含狗或猫进行分类。
该数据集中只有两个可能的类标签,因此这是一个 2 类问题,可以使用标准的二进制 SVM 损失函数来解决。也就是说,让我们仍然应用多类 SVM 损失,这样我们就可以有一个如何应用它的工作示例。从这里开始,我将扩展这个例子来处理一个 3 类问题。
首先,请看下图,其中我包含了来自狗与猫数据集的两个类的两个训练示例:

Figure 1: Let’s apply hinge loss to the images in this figure.
给定一些(任意的)权重矩阵 W 和偏差向量 b ,输出得分 = Wx + b")
are displayed in the body of the matrix. The larger the scores are, the more confident our scoring function is regarding the prediction.
让我们从计算损失 开始
开始
for the “dog” class. Given a two class problem, this is trivially easy:
>>> max(0, 1.33 - 4.26 + 1)
0
>>>
注意“dog”的损失如何为零——这意味着 dog 类被正确预测。对上面的图 1 的快速调查证明了这一点:“狗”的得分大于“猫”的得分。
同样,我们可以对第二张图片做同样的操作,这张图片包含一只猫:
>>> max(0, 3.76 - (-1.2) + 1)
5.96
>>>
在这种情况下,我们的损失函数大于零,说明我们的预测不正确。
然后,我们通过取平均值获得两幅示例图像的总损失:
>>> (0 + 5.96) / 2
2.98
>>
这对于 2 类问题来说很简单,但是对于 3 类问题呢?过程是否变得更加复杂?
事实上,并没有——我们的求和只是扩大了一点。你可以在下面找到一个 3 类问题的例子,我添加了第三个类“马”:

Figure 2: An example of applying hinge loss to a 3-class image classification problem.
让我们再次计算狗类的损失:
>>> max(0, 1.49 - (-0.39) + 1) + max(0, 4.21 - (-0.39) + 1)
8.48
>>>
请注意,我们的求和已经扩展到包括两项——预测的狗分数和猫和马分数之差。
*同样,我们可以计算 cat 类的损失:
>>> max(0, -4.61 - 3.28 + 1) + max(0, 1.46 - 3.28 + 1)
0
>>>
最后是马类的损失:
>>> max(0, 1.03 - (-2.27) + 1) + max(0, -2.37 - (-2.27) + 1)
5.199999999999999
>>>
因此,总损失为:
>>> (8.48 + 0.0 + 5.2) / 3
4.56
>>>
如你所见,同样的一般原则也适用——只要记住,随着类别数量的增加,你的总和也会增加。
小测验:根据上面三个等级的损失,哪一个被正确分类?
我需要手动实现多级 SVM 损耗吗?
如果你愿意,你可以手工实现铰链损耗和平方铰链损耗——但这主要是为了教学目的。
你会看到几乎任何机器学习/深度学习库中都实现了铰链损耗和平方铰链损耗,包括 scikit-learn、Keras、Caffe 等。
摘要
今天我讨论了多级 SVM 损失的概念。给定一个评分函数(将输入数据映射到输出类别标签),我们的损失函数可用于量化我们的评分函数在预测数据集中的正确类别标签方面有多“好”或“差”。
损失越小,我们的预测就越准确(但我们也有“过度拟合”的风险,即我们对输入数据到类别标签的映射建模过于紧密)。
相反,损失越大,我们的预测就越不准确,因此我们需要进一步优化我们的 W 和 b 参数——但是一旦我们更好地理解损失函数,我们将把优化方法留给未来的帖子。
在理解了“损失”的概念以及它如何应用于机器学习和深度学习算法之后,我们接着看两个特定的损失函数:
- 铰链损耗
- 平方铰链损耗
一般来说,你会更经常地看到铰链损失——但仍然值得尝试调整分类器的超参数,以确定哪个损失函数在特定数据集上提供更好的准确性。
下周我将回来讨论第二个损失函数——交叉熵——以及它与多项式逻辑回归的关系。如果你以前有过机器学习或深度学习的经验,你可能会更好地了解这个函数作为 Softmax 分类器。
如果你对应用深度学习和卷积神经网络感兴趣,那么你不会想错过这个即将到来的帖子——你会发现,soft max 分类器是深度学习中最常用的模型/损失函数。
要在下一篇博文发表时得到通知,只需在下面的表格中输入您的电子邮件地址。下周见!*
多栏表格 OCR
原文:https://pyimagesearch.com/2022/02/28/multi-column-table-ocr/
在本教程中,您将:
- 发现一种将行和列关联在一起的技术
- 了解如何检测图像中的文本/数据表
- 从图像中提取检测到的表格
- 对表格中的文本进行 OCR
- 应用层次凝聚聚类(HAC)来关联行和列
- 从 OCR 数据中构建一个熊猫
本教程是关于使用 Python 进行 OCR 的 4 部分系列的第一部分:
- 多栏表格 OCR (本教程)
- OpenCV 快速傅立叶变换(FFT)用于图像和视频流中的模糊检测
- 对视频流进行光学字符识别
- 使用 OpenCV 和 GPU 提高文本检测速度
学习如何 OCR 多栏表格, 继续阅读。
多栏表格 OCR
也许光学字符识别(OCR)更具挑战性的应用之一是如何成功地 OCR 多列数据(例如,电子表格、表格等)。).
从表面上看,对表格进行 OCR 似乎是一个更容易的问题,对吗?然而,考虑到文档有一个保证结构,难道我们不应该利用这个先验知识,然后对表中的每一列进行 OCR 吗?
大多数情况下,是的,会是这样。但不幸的是,我们有几个问题要解决:
- Tesseract 不太擅长多列 OCR,尤其是如果你的图像有噪声。
- 您可能需要先检测图像中的表格,然后才能对其进行 OCR。
- 你的 OCR 引擎(宇宙魔方,基于云的,等等。)可以正确地对文本进行 OCR,但是不能将文本关联到列/行中。
因此,尽管对多列数据进行 OCR 可能看起来是一项简单的任务,但它要困难得多,因为我们可能需要负责将文本关联到列和行中——正如您将看到的,这确实是我们实现中最复杂的部分。
好消息是,虽然对多列数据进行 OCR 肯定比其他 OCR 任务要求更高,但只要您将正确的算法和技术引入项目,这并不是一个“难题”。
在本教程中,您将学习一些 OCR 多列数据的提示和技巧,最重要的是,将文本的行/列关联在一起。
对多列数据进行光学字符识别
在本教程的第一部分,我们将讨论我们的多列 OCR 算法的基本过程。这就是对多列数据进行 OCR 的精确算法。这是一个很好的起点,我们建议您在需要对表格进行 OCR 时使用它。
从那里,我们将回顾我们项目的目录结构。我们还将安装本教程所需的任何额外的 Python 包。
在我们的开发环境完全配置好之后,我们可以继续我们的实现了。我们将在这里花大部分时间讲述多列 OCR 算法的细节和内部工作原理。
我们将通过将我们的 Python 实现应用于以下各项来结束本课:
- 检测图像中的文本表格
- 提取表格
- 对表格进行 OCR
- 从表中构建一个 Pandas
DataFrame来处理它,查询它,等等。
我们的多列 OCR 算法
我们的多列 OCR 算法是一个多步骤的过程。首先,我们需要接受一个包含表格、电子表格等的输入图像。(图、 1 、左)。给定这个图像,然后我们需要提取表格本身(右)。
一旦我们有了表格,我们就可以应用 OCR 和文本本地化来为文本边界框生成 (x,y)-坐标。获得这些包围盒坐标是至关重要的。
为了将多列文本关联在一起,我们需要根据它们的起始 x 坐标对文本进行分组。
为什么开始 x 坐标?嗯,记住表格、电子表格等的结构。每一列的文本将具有几乎相同的起始x-坐标,因为它们属于相同的列(现在花一点时间来说服自己该陈述是正确的)。
因此,我们可以利用这些知识,然后用近似相同的 x 坐标将文本分组。
但是问题仍然存在,我们如何进行实际的分组?
答案是使用一种叫做层次凝聚聚类(HAC)的特殊聚类算法。如果你以前上过数据科学、机器学习或文本挖掘课程,那么你可能以前遇到过 HAC。
对 HAC 算法的全面回顾超出了本教程的范围。然而,总的想法是我们采用“自下而上”的方法,从我们的初始数据点(即文本边界框的 x 坐标)开始,作为单独的集群,每个集群仅包含一个观察值。
然后,我们计算坐标之间的距离,并开始以距离 < T 对观测值进行分组,其中 T 是预定义的阈值。
在 HAC 的每次迭代中,我们选择具有最小距离的两个聚类并将它们合并,同样,假设满足距离阈值要求。
我们继续聚类,直到不能形成其他聚类,通常是因为没有两个聚类落在我们的阈值要求内。
在多列 OCR 的情况下,将 HAC 应用于x-坐标值会产生具有相同或接近相同的x-坐标的聚类。由于我们假设属于同一列的文本将具有相似/接近相同的 x 坐标,我们可以将列关联在一起。
虽然这种多列 OCR 技术看起来很复杂,但它很简单,尤其是,因为我们将能够利用 scikit-learn 库中的 AgglomerativeClustering实现。
也就是说,如果您有兴趣了解更多关于机器学习和数据科学技术的知识,手动实现聚集聚类是一个很好的练习。在我的职业生涯中,我曾经不得不实施 HAC 3-4 次,主要是在我上大学的时候。
如果你想了解更多关于 HAC 的知识,我推荐 Cory Maklin 的 scikit-learn 文档和优秀文章。
对于更具理论性和数学动机的凝聚聚类处理,包括一般的聚类算法,我强烈推荐 Witten 等人的 【数据挖掘:实用的机器学习工具和技术】(2011)。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
接下来,让我们回顾一下我们的项目目录结构:
|-- michael_jordan_stats.png
|-- multi_column_ocr.py
|-- results.csv
正如您所看到的,我们的项目目录结构非常简单——但是不要让这种简单性欺骗了您!
我们的multi_column_ocr.py脚本将接受输入图像michael_jordan_stats.png,检测数据表,提取它,然后通过 OCR 将它与行/列关联起来。
作为参考,我们的示例图像是迈克尔·乔丹棒球卡(图 3 )的扫描图,当时他在父亲去世后暂停篮球一年去打棒球。
我们的 Python 脚本可以对表格进行 OCR,解析出他的统计数据,然后将它们作为经过 OCR 处理的文本输出为 CSV 文件(results.csv)。
安装所需的软件包
我们的 Python 脚本将向我们的终端显示一个格式良好的 OCR 文本表。我们仍然需要利用 tabulate Python 包来生成这个格式化的表格。
您可以使用以下命令安装tabulate:
$ workon your_env_name # optional
$ pip install tabulate
如果您正在使用 Python 虚拟环境,不要忘记在安装tabulate之前使用workon命令(或等效命令)访问您的虚拟环境(否则,您的import命令将失败)。
同样,tabulate包仅用于显示目的,和不会影响我们实际的多列 OCR 算法。如果你不想安装tabulate,那也没关系。您只需要在我们的 Python 脚本中注释掉利用它的 2-3 行代码。
实现多列 OCR
我们现在准备实现多列 OCR!打开项目目录结构中的multi_column_ocr.py文件,让我们开始工作:
# import the necessary packages
from sklearn.cluster import AgglomerativeClustering
from pytesseract import Output
from tabulate import tabulate
import pandas as pd
import numpy as np
import pytesseract
import argparse
import imutils
import cv2
我们从导入所需的 Python 包开始。我们有几个以前没有(或者至少不经常)使用过的包,所以让我们回顾一下重要的包。
首先,我们有来自 scikit-learn 的AgglomerativeClustering实现。正如我前面所讨论的,我们将使用 HAC 将文本聚集成列。这个实现将允许我们这样做。
在执行 OCR 之后,tabulate包将允许我们在终端上打印一个格式良好的数据表。这个包是可选的,所以如果您不想安装它,只需在我们的实现中稍后注释掉import行和行 178 。
然后我们有了pandas库,这在数据科学家中很常见。在本课中,我们将使用pandas,因为它能够轻松地构建和管理表格数据。
其余的导入对您来说应该很熟悉,因为我们在整个课程中多次使用过它们。
让我们继续我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-o", "--output", required=True,
help="path to output CSV file")
ap.add_argument("-c", "--min-conf", type=int, default=0,
help="minimum confidence value to filter weak text detection")
ap.add_argument("-d", "--dist-thresh", type=float, default=25.0,
help="distance threshold cutoff for clustering")
ap.add_argument("-s", "--min-size", type=int, default=2,
help="minimum cluster size (i.e., # of entries in column)")
args = vars(ap.parse_args())
如你所见,我们有几个命令行参数。让我们逐一讨论一下:
--image:包含表格、电子表格等的输入图像的路径。,我们想要检测和 OCR--output:包含我们提取的列数据的输出 CSV 文件的路径--min-conf:用于过滤弱文本检测--dist-thresh:应用 HAC 时的距离阈值截止(以像素为单位);您可能需要为影像和数据集调整该值--min-size:一个簇中被认为是一列的最小数据点数
这里最重要的命令行参数是--dist-thresh和--min-size。
当应用 HAC 时,我们需要使用距离阈值截止。如果您允许聚类无限期地继续,HAC 将在每次迭代中继续聚类,直到您最终得到一个包含所有数据点的聚类。
相反,当没有两个聚类的距离小于阈值时,应用距离阈值来停止聚类过程。
出于您的目的,您需要检查您正在处理的图像数据。如果你的表格数据在每行之间有大量的空白,那么你可能需要增加--dist-thresh(图 4 ,左)。
否则,如果每行之间的空白减少,--dist-thresh会相应地减少(图 4 ,右*)。
正确设置--dist-thresh是最重要的要对多列数据进行光学字符识别,一定要尝试不同的值。
--min-size命令行参数也很重要。在我们的聚类算法的每次迭代中,HAC 将检查两个聚类,每个聚类可能包含多个数据点或仅仅一个单个数据点。如果两个簇之间的距离小于--dist-thresh,HAC 将合并它们。
然而,总会有异常值,远离表格的文本片段,或者只是图像中的噪声。如果 Tesseract 检测到该文本,那么 HAC 将尝试对其进行聚类。但是有没有一种方法可以防止这些集群出现在我们的结果中呢?
一种简单的方法是在 HAC 完成后检查给定集群中文本数据点的数量。
在这种情况下,我们设置了--min-size=2,这意味着如果一个聚类中有≤2个数据点,我们会将其视为异常值并忽略它。你可能需要为你的应用程序调整这个变量,但是我建议首先调整--dist-thresh。
考虑到我们的命令行参数,让我们开始我们的图像处理管道:
# set a seed for our random number generator
np.random.seed(42)
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
第 27 行设置我们的伪随机数发生器的种子。我们这样做是为了为我们检测到的每一列文本生成颜色(这对可视化很有用)。
然后,我们从磁盘加载输入数据--image,并将其转换为灰度。
我们的下一个代码块检测我们的image中的大块文本,采用与我们的教程 OCR 识别护照 : 相似的过程
# initialize a rectangular kernel that is ~5x wider than it is tall,
# then smooth the image using a 3x3 Gaussian blur and then apply a
# blackhat morphological operator to find dark regions on a light
# background
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (51, 11))
gray = cv2.GaussianBlur(gray, (3, 3), 0)
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, kernel)
# compute the Scharr gradient of the blackhat image and scale the
# result into the range [0, 255]
grad = cv2.Sobel(blackhat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
grad = np.absolute(grad)
(minVal, maxVal) = (np.min(grad), np.max(grad))
grad = (grad - minVal) / (maxVal - minVal)
grad = (grad * 255).astype("uint8")
# apply a closing operation using the rectangular kernel to close
# gaps in between characters, apply Otsu's thresholding method, and
# finally a dilation operation to enlarge foreground regions
grad = cv2.morphologyEx(grad, cv2.MORPH_CLOSE, kernel)
thresh = cv2.threshold(grad, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
thresh = cv2.dilate(thresh, None, iterations=3)
cv2.imshow("Thresh", thresh)
首先,我们构建一个大的矩形内核,它的宽度比高度大(第 37 行)。然后,我们对图像应用小的高斯模糊,并计算 blackhat 输出,显示亮背景上的暗区域(即亮背景上的暗文本)。
下一步是计算 blackhat 图像的梯度幅度表示,并将输出图像缩放回范围[0, 255] ( 第 43-47 行)。
我们现在可以应用一个关闭操作(线 52 )。我们在这里使用我们的大矩形kernel来缩小表格中文本行之间的间隙。
我们通过对图像进行阈值处理并应用一系列扩张来放大前景区域来完成流水线。
图 5 显示该预处理流水线的输出。在左边,我们有我们的原始输入图像。这张图片是迈克尔·乔丹棒球卡的背面(当他离开 NBA 一年去打棒球的时候)。由于他们没有乔丹的任何棒球数据,他们在卡片的背面包括了他的篮球数据,尽管这是一张棒球卡(我知道这很奇怪,这也是为什么他的棒球卡是收藏家的物品)。
我们的目标是 OCR 他的“完整 NBA 记录”表。如果你看一下图 5 (右),你可以看到这个桌子是一个大的矩形斑点。
我们的下一个代码块处理检测和提取这个表:
# find contours in the thresholded image and grab the largest one,
# which we will assume is the stats table
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
tableCnt = max(cnts, key=cv2.contourArea)
# compute the bounding box coordinates of the stats table and extract
# the table from the input image
(x, y, w, h) = cv2.boundingRect(tableCnt)
table = image[y:y + h, x:x + w]
# show the original input image and extracted table to our screen
cv2.imshow("Input", image)
cv2.imshow("Table", table)
首先,我们检测阈值图像中的所有轮廓(行 60-62 )。然后我们根据轮廓的面积找到一个最大的轮廓(线 63 )。
我们假设最大的轮廓是我们的桌子,我们可以从图 5 (右图)中验证,事实确实如此。但是,您可能需要更新轮廓处理,以使用其他方法为您的项目找到表格。这里介绍的方法当然不是万能的解决方案。
给定对应于表格的轮廓tableCnt,我们计算其边界框并提取table本身(行 67 和 68 )。
提取的table然后通过线 72 ( 图 6 )显示到我们的屏幕上。
现在我们有了统计数据table,让我们对其进行 OCR:
# set the PSM mode to detect sparse text, and then localize text in
# the table
options = "--psm 6"
results = pytesseract.image_to_data(
cv2.cvtColor(table, cv2.COLOR_BGR2RGB),
config=options,
output_type=Output.DICT)
# initialize a list to store the (x, y)-coordinates of the detected
# text along with the OCR'd text itself
coords = []
ocrText = []
第 76-80 行使用 Tesseract 来计算table中每段文本的边界框位置。
此外,注意我们在这里是如何使用--psm 6的,原因是当文本是单个统一的文本块时,这种特殊的页面分割模式工作得很好。
大多数数据表和将是统一的。他们将利用几乎相同的字体和字体大小。
如果--psm 6对你不太管用,你应该试试教程中涉及的其他 PSM 模式,tesserac Page Segmentation Modes(PSMs)讲解:如何提高你的 OCR 准确率 。具体来说,我建议看一下关于检测稀疏文本的--psm 11——这种模式也适用于表格数据。
**在应用 OCR 文本检测之后,我们初始化两个列表:coords和ocrText。coords列表将存储文本边界框的 (x,y)-坐标,而ocrText将存储实际的 OCR 文本本身。
让我们继续循环我们的每个文本检测:
# loop over each of the individual text localizations
for i in range(0, len(results["text"])):
# extract the bounding box coordinates of the text region from
# the current result
x = results["left"][i]
y = results["top"][i]
w = results["width"][i]
h = results["height"][i]
# extract the OCR text itself along with the confidence of the
# text localization
text = results["text"][i]
conf = int(results["conf"][i])
# filter out weak confidence text localizations
if conf > args["min_conf"]:
# update our text bounding box coordinates and OCR'd text,
# respectively
coords.append((x, y, w, h))
ocrText.append(text)
行 91-94 从检测到的文本区域提取边界框坐标,而行 98 和 99 提取 OCR 处理的文本本身,以及文本检测的置信度。
第 102 行过滤掉弱文本检测。如果conf小于我们的--min-conf,我们忽略文本检测。否则,我们分别更新我们的coords和ocrText列表。
我们现在可以进入项目的集群阶段:
# extract all x-coordinates from the text bounding boxes, setting the
# y-coordinate value to zero
xCoords = [(c[0], 0) for c in coords]
# apply hierarchical agglomerative clustering to the coordinates
clustering = AgglomerativeClustering(
n_clusters=None,
affinity="manhattan",
linkage="complete",
distance_threshold=args["dist_thresh"])
clustering.fit(xCoords)
# initialize our list of sorted clusters
sortedClusters = []
第 110 行从文本边界框中提取所有的 x 坐标。注意我们是如何在这里形成一个合适的 (x,y)- 坐标元组,但是为每个条目设置y = 0 。为什么y 设置为0?
答案是双重的:
- 首先,为了应用 HAC,我们需要一组输入向量(也称为“特征向量”)。我们的输入向量必须至少是二维的,所以我们添加了一个包含值
0的平凡维度。 - 其次,我们对 y 坐标值不感兴趣。我们只想聚集在 x 坐标位置上。具有相似的 x 坐标的文本片段很可能是表格中某一列的一部分。
从那里,行 113-118 应用层次凝聚聚类。我们将n_clusters设置为None,因为我们不知道我们想要生成多少个集群——相反,我们希望 HAC 自然地形成集群,并继续使用我们的distance_ threshold来创建集群。一旦没有两个聚类的距离小于--dist-thresh,我们就停止聚类处理。
另外,请注意,我们在这里使用的是曼哈顿距离函数。为什么不是其他的距离函数(例如欧几里德距离函数)?
虽然你可以(也应该)尝试我们的距离度量标准,但曼哈顿似乎是一个合适的选择。我们想要非常严格地要求 x 坐标彼此靠近。但是,我还是建议你尝试其他的距离方法。
关于 scikit-learn 的AgglomerativeClustering实现的更多细节,包括对参数和自变量的全面回顾,请务必参考 scikit-learn 关于方法的文档。
现在我们的聚类已经完成,让我们遍历每个独特的聚类:
# loop over all clusters
for l in np.unique(clustering.labels_):
# extract the indexes for the coordinates belonging to the
# current cluster
idxs = np.where(clustering.labels_ == l)[0]
# verify that the cluster is sufficiently large
if len(idxs) > args["min_size"]:
# compute the average x-coordinate value of the cluster and
# update our clusters list with the current label and the
# average x-coordinate
avg = np.average([coords[i][0] for i in idxs])
sortedClusters.append((l, avg))
# sort the clusters by their average x-coordinate and initialize our
# data frame
sortedClusters.sort(key=lambda x: x[1])
df = pd.DataFrame()
第 124 行循环遍历所有唯一的集群标签。然后,我们使用 NumPy 来查找当前标签为l ( 第 127 行)的所有数据点的索引,从而暗示它们都属于同一个集群。
第 130 行然后验证当前的集群中有超过--min-size个项目。
然后,我们计算集群内的 x 坐标的平均值,并用包含当前标签l和平均 x 坐标值的二元组更新我们的sortedClusters列表。
第 139 行根据我们的平均 x 坐标对我们的sortedClusters列表进行排序。我们执行这个排序操作,使得我们的集群在页面上从左到右排序。
最后,我们初始化一个空的DataFrame来存储我们的多列 OCR 结果。
现在让我们循环遍历排序后的集群:
# loop over the clusters again, this time in sorted order
for (l, _) in sortedClusters:
# extract the indexes for the coordinates belonging to the
# current cluster
idxs = np.where(clustering.labels_ == l)[0]
# extract the y-coordinates from the elements in the current
# cluster, then sort them from top-to-bottom
yCoords = [coords[i][1] for i in idxs]
sortedIdxs = idxs[np.argsort(yCoords)]
# generate a random color for the cluster
color = np.random.randint(0, 255, size=(3,), dtype="int")
color = [int(c) for c in color]
第 143 行在我们的sortedClusters列表中的标签上循环。然后,我们找到属于当前聚类标签l的所有数据点的索引(idxs)。
使用这些索引,我们从集群中的所有文本片段中提取出 y- 坐标,并从到 ( 第 150 行和第 151 行)对它们进行排序。
我们还为当前列初始化了一个随机的color(这样我们就可以可视化哪些文本属于哪一列)。
现在,让我们遍历该列中的每一段文本:
# loop over the sorted indexes
for i in sortedIdxs:
# extract the text bounding box coordinates and draw the
# bounding box surrounding the current element
(x, y, w, h) = coords[i]
cv2.rectangle(table, (x, y), (x + w, y + h), color, 2)
# extract the OCR'd text for the current column, then construct
# a data frame for the data where the first entry in our column
# serves as the header
cols = [ocrText[i].strip() for i in sortedIdxs]
currentDF = pd.DataFrame({cols[0]: cols[1:]})
# concatenate *original* data frame with the *current* data
# frame (we do this to handle columns that may have a varying
# number of rows)
df = pd.concat([df, currentDF], axis=1)
对于每个sortedIdx,我们抓取边界框 (x,y)——文本块的坐标,并将其绘制在我们的table ( 第 158-162 行)上。
然后我们抓取当前集群中所有的ocrText片段,从到 ( 第 167 行)排序。这些文本代表表格中的一个唯一列(cols)。
既然我们已经提取了当前列,我们为它创建一个单独的DataFrame,假设列中的第一个条目是标题,其余的是数据(第 168 行)。
最后,我们将原始数据帧df与新数据帧currentDF ( 第 173 行)连接起来。我们执行这个连接操作来处理某些列比其他列有更多行的情况(自然地,由于表的设计,或者由于 Tesseract OCR 引擎在一行中缺少一段文本)。
至此,我们的表格 OCR 过程已经完成,我们只需要将表格保存到磁盘:
# replace NaN values with an empty string and then show a nicely
# formatted version of our multi-column OCR'd text
df.fillna("", inplace=True)
print(tabulate(df, headers="keys", tablefmt="psql"))
# write our table to disk as a CSV file
print("[INFO] saving CSV file to disk...")
df.to_csv(args["output"], index=False)
# show the output image after performing multi-column OCR
cv2.imshow("Output", image)
cv2.waitKey(0)
如果一些列比其他列有更多的条目,那么空条目将被填充一个“非数字”(NaN)值。我们在第 177 行的中用一个空字符串替换所有的NaN值。
第 178 行向我们的终端显示了一个格式良好的表格,表明我们已经成功地对多列数据进行了 OCR。
然后,我们将数据帧作为 CSV 文件保存到磁盘的第182 行。
最后,我们在屏幕的第 185 行显示输出图像。
多列 OCR 结果
我们现在可以看到我们的多列 OCR 脚本了!
打开终端并执行以下命令:
$ python multi_column_ocr.py --image michael_jordan_stats.png --output results.csv
+----+---------+---------+-----+---------+-------+-------+-------+-------+-------+--------+
| | Year | CLUB | G | FG% | REB | AST | STL | BLK | PTS | AVG. |
|----+---------+---------+-----+---------+-------+-------+-------+-------+-------+--------|
| 0 | 1984-85 | CHICAGO | 82 | 515 | 534 | 481 | 196 | 69 | 2313 | 282 |
| 1 | 1985-86 | CHICAGO | 18 | 0.457 | 64 | 53 | ar | A | 408 | 227 |
| 2 | 1986-87 | CHICAGO | 82 | 482 | 430 | 377 | 236 | 125 | 3041 | 37.1 |
| 3 | 1987-88 | CHICAGO | 82 | 535 | 449 | 485 | 259 | 131 | 2868 | 35 |
| 4 | 1988-89 | CHICAGO | 81 | 538 | 652 | 650 | 234 | 65 | 2633 | 325 |
| 5 | 1989-90 | CHICAGO | 82 | 526 | 565 | 519 | 227 | 54 | 2763 | 33.6 |
| 6 | TOTALS | | 427 | 516 | 2694 | 2565 | 1189 | 465 | 14016 | 328 |
+----+---------+---------+-----+---------+-------+-------+-------+-------+-------+--------+
[INFO] saving CSV file to disk...
图 7 (上)显示提取的表格。然后,我们应用层次凝聚聚类(HAC)对表格进行 OCR,得到底部的图。
注意我们是如何对文本列进行颜色编码的。具有相同边框颜色的文本属于相同列,表明我们的 HAC 方法成功地将文本列关联在一起。
我们的 OCR 表的文本版本可以在上面的终端输出中看到。我们的 OCR 结果在很大程度上是非常准确的,但也有一些值得注意的问题。
首先,字段 goal percentage ( FG%)除了一行之外都缺少小数点,可能是因为图像的分辨率太低,Tesseract 无法成功检测小数点。幸运的是,这很容易解决——使用基本的字符串解析/正则表达式来插入小数点或,只需将字符串转换为float数据类型。然后会自动添加小数点。
同样的问题可以在每场比赛的平均分数(AVG.)栏中找到——小数点又不见了。
不过,这个问题有点难以解决。如果我们简单地转换成一个float,文本282将会被错误地解析为0.282。相反,我们能做的是:
- 检查绳子的长度
- 如果字符串有四个字符,那么已经添加了小数点,所以不需要做进一步的工作
- 否则,字符串有三个字符,所以在第二个和第三个字符之间插入一个小数点
任何时候,你都可以利用任何关于手头 OCR 任务的先验知识,这样你就有了更容易的 T2 时间。在这种情况下,我们的领域知识告诉我们哪些列应该有小数点,因此我们可以利用文本后处理试探法来进一步改进我们的 OCR 结果,即使 Tesseract 的性能没有达到最佳。
我们的 OCR 结果的最大问题可以在STL和BLK列中找到,这里的 OCR 结果完全不正确。我们对此无能为力,因为这是宇宙魔方结果的问题,是而不是我们的列分组算法。
由于本教程重点关注多列数据的 OCR 处理特别是,最重要的是,驱动多列数据的算法,我们在这里不打算花太多时间关注对 Tesseract 选项和配置的改进。
在我们的 Python 脚本被执行之后,我们有一个输出results.csv文件,其中包含我们的表,该表作为 CSV 文件被序列化到磁盘上。我们来看看它的内容:
$ cat results.csv
Year,CLUB,G,FG%,REB,AST,STL,BLK,PTS,AVG.
1984-85,CHICAGO,82,515,534,481,196,69,2313,282
1985-86,CHICAGO,18,.457,64,53,ar,A,408,227
1986-87,CHICAGO,82,482,430,377,236,125,3041,37.1
1987-88,CHICAGO,82,535,449,485,259,131,2868,35.0
1988-89,CHICAGO,81,538,652,650,234,65,2633,325
1989-90,CHICAGO,82,526,565,519,227,54,2763,33.6
TOTALS,,427,516,2694,2565,1189,465,14016,328
如您所见,我们的 OCR 表已经作为 CSV 文件写入磁盘。您可以获取这个 CSV 文件,并使用数据挖掘技术对其进行处理。
总结
在本教程中,您学习了如何使用 Tesseract OCR 引擎和分层凝聚聚类(HAC)对多列数据进行 OCR。
我们的多列 OCR 算法的工作原理是:
- 使用梯度和形态学操作检测输入图像中的文本表格
- 提取检测到的表
- 使用 Tesseract(或等效物)定位表格中的文本并提取边界框 (x,y)-表格中文本的坐标
- 将 HAC 应用于具有最大距离阈值截止的桌子的 x 坐标上的聚类
本质上,我们在这里所做的是用坐标 x 将文本本地化分组,这些坐标或者是相同或者是彼此非常接近。
这种方法为什么有效?
好吧,考虑电子表格、表格或任何其他具有多列的文档的结构。在这种情况下,每列中的数据将具有几乎相同的起始x-坐标,因为它们属于相同的列。因此,我们可以利用这些知识,然后用近似相同的 x 坐标将文本分组。
虽然这种方法很简单,但在实践中效果很好。
引用信息
罗斯布鲁克,A. “多栏表格 OCR”, PyImageSearch ,2022,【https://pyimg.co/h18s2】T4
@article{Rosebrock_2022_MCT_OCR,
author = {Adrian Rosebrock},
title = {Multi-Column Table {OCR}},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimg.co/h18s2},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****
基于 Keras 的多标签分类
原文:https://pyimagesearch.com/2018/05/07/multi-label-classification-with-keras/

今天这篇关于 Keras 多标签分类的博客文章是从上周我收到的一封电子邮件中得到的启发,这封邮件来自瑞士的 PyImageSearch 阅读器。
Switaj 写道:
嗨,Adrian,感谢你的 PyImageSearch 博客和每周分享你的知识。
我正在建立一个图像时尚搜索引擎,需要帮助。
使用我的应用程序,用户将上传他们喜欢的衣服的照片(例如。衬衫,连衣裙,裤子,鞋子),我的系统将返回类似的项目,并包括他们在线购买衣服的链接。
问题是我需要训练一个分类器来将这些项目分成不同的类别:
- 服装类型:衬衫、连衣裙、裤子、鞋子等。
- 颜色:红色、蓝色、绿色、黑色等。
- 质地/外观:棉、毛、丝、花呢等。
我已经为这三个类别中的每一个训练了三个独立的 CNN,它们工作得非常好。
有没有办法把三个 CNN 合并成一个网络?或者至少训练单个网络来完成所有三个分类任务?
我不想在一系列 if/else 代码中单独应用它们,这些代码根据先前分类的输出使用不同的网络。
谢谢你的帮助。
Switaj 提出了一个很好的问题:
Keras 深度神经网络有可能返回多个预测吗?
如果是,是如何做到的?
要了解如何使用 Keras 执行多标签分类,继续阅读。
基于 Keras 的多标签分类
2020-06-12 更新:此博文现已兼容 TensorFlow 2+!
今天这篇关于多标签分类的博文分为四个部分。
在第一部分,我将讨论我们的多标签分类数据集(以及如何快速构建自己的数据集)。
从那里,我们将简要讨论SmallerVGGNet,我们将实现和用于多标签分类的 Keras 神经网络架构。
然后,我们将使用我们的多标签分类数据集来训练我们的SmallerVGGNet实现。
最后,我们将通过在示例图像上测试我们的网络来结束今天的博客文章,并讨论何时多标签分类是合适的,包括一些需要注意的警告。
我们的多标签分类数据集

Figure 1: A montage of a multi-class deep learning dataset. We’ll be using Keras to train a multi-label classifier to predict both the color and the type of clothing.
我们将在今天的 Keras 多标签分类教程中使用的数据集旨在模拟 Switaj 在这篇文章顶部提出的问题(尽管为了这篇博客文章的缘故做了一些简化)。
我们的数据集由跨越六个类别的2167幅图像组成,包括:
- 黑色牛仔裤(344 张图片)
- 蓝色连衣裙(386 张图片)
- 蓝色牛仔裤(356 张图片)
- 蓝色衬衫(369 张图片)
- 红色连衣裙(380 张图片)
- 红色衬衫(332 张图片)
我们卷积神经网络的目标将是预测颜色和服装类型。
我按照我之前的教程 如何(快速)建立深度学习图像数据集 创建了这个数据集。
下载图像并手动删除六个类别中每个类别的不相关图像的整个过程大约需要 30 分钟。
当试图建立自己的深度学习图像数据集时,请确保遵循上面链接的教程——它将为你建立自己的数据集提供一个巨大的跳跃。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
多标签分类项目结构
继续访问这篇博客文章的 【下载】 部分,获取代码和文件。解压缩 zip 文件后,您将看到以下目录结构:
├── classify.py
├── dataset
│ ├── black_jeans [344 entries
│ ├── blue_dress [386 entries]
│ ├── blue_jeans [356 entries]
│ ├── blue_shirt [369 entries]
│ ├── red_dress [380 entries]
│ └── red_shirt [332 entries]
├── examples
│ ├── example_01.jpg
│ ├── example_02.jpg
│ ├── example_03.jpg
│ ├── example_04.jpg
│ ├── example_05.jpg
│ ├── example_06.jpg
│ └── example_07.jpg
├── fashion.model
├── mlb.pickle
├── plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── smallervggnet.py
├── search_bing_api.py
└── train.py
在压缩包的根目录下,你会看到 6 个文件和 3 个目录。
我们正在处理的重要文件(按照本文中出现的大致顺序)包括:
search_bing_api.py:这个脚本使我们能够快速构建我们的深度学习图像数据集。您不需要运行这个脚本,因为图像数据集已经包含在 zip 存档中。为了完整起见,我只是包含了这个脚本。train.py:一旦我们获得了数据,我们将使用train.py脚本来训练我们的分类器。fashion.model:我们的train.py脚本将把我们的 Keras 模型序列化到磁盘上。我们将在classify.py脚本的后面使用这个模型。mlb.pickle:由train.py创建的 scikit-learnMultiLabelBinarizerpickle 文件——该文件以一种方便的序列化数据结构保存我们的类名。plot.png:训练脚本将生成一个plot.png图像文件。如果您在自己的数据集上进行训练,您会想要检查该文件的准确性/损失和过度拟合。- 为了测试我们的分类器,我写了
classify.py。在将模型部署到其他地方之前,你应该总是在本地测试你的分类器(比如部署到 iPhone 深度学习应用或者部署到 Raspberry Pi 深度学习项目)。
今天项目中的三个目录是:
- 这个目录保存了我们的图像数据集。每个类都有各自的子目录。我们这样做是为了(1)保持我们的数据集有组织,( 2)便于从给定的图像路径中提取类标签名称。
- 这是我们的模块,包含我们的 Keras 神经网络。因为这是一个模块,所以它包含一个正确格式化的
__init__.py。另一个文件smallervggnet.py包含了组装神经网络本身的代码。 examples:该目录中有七个示例图像。我们将使用classify.py对每个示例图像执行带有 Keras 的多标签分类。
如果这看起来很多,不要担心!我们将按照我展示的大致顺序来回顾这些文件。
我们的用于多标签分类的 Keras 网络架构
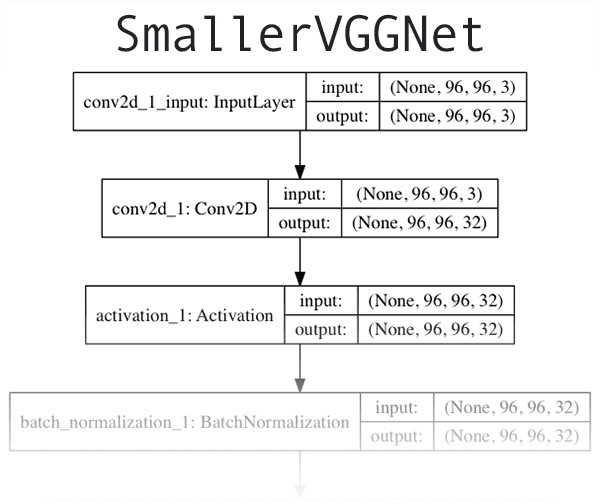
Figure 2: A VGGNet-like network that I’ve dubbed “SmallerVGGNet” will be used for training a multi-label deep learning classifier with Keras.
本教程我们使用的 CNN 架构是SmallerVGGNet,它的老大哥VGGNet的简化版。VGGNet模型是由 Simonyan 和 Zisserman 在他们 2014 年的论文 中首次提出的,用于大规模图像识别的超深度卷积网络 。
出于完整性考虑,我们将在本指南中实现SmallerVGGNet;然而,我将把对架构/代码的任何冗长解释推迟到我的 上一篇文章——如果你对架构有任何问题或者只是想了解更多细节,请参考它。如果你正在寻找设计自己的模型,你会想要拿起我的书的副本, 用 Python 进行计算机视觉的深度学习。
确保你已经使用了这篇博文底部的 【下载】 部分来获取源代码+示例图片。从那里,打开pyimagesearch模块中的smallervggnet.py文件,继续执行:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
在第 2-10 行,我们导入相关的 Keras 模块,并从那里创建我们的SmallerVGGNet类:
class SmallerVGGNet:
@staticmethod
def build(width, height, depth, classes, finalAct="softmax"):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们的类定义在行 12 。然后我们在行 14 上定义build函数,负责组装卷积神经网络。
build方法需要四个参数— width、height、depth和classes。depth指定输入图像中通道的数量,而classes是类别/类的数量(整数)(不是类标签本身)。我们将在训练脚本中使用这些参数来实例化带有96 x 96 x 3输入体积的模型。
可选参数finalAct(默认值为"softmax")将在网络架构的末端 使用 。将此值从 softmax 更改为 sigmoid 将使我们能够使用 Keras 执行多标签分类。
请记住,此行为与我们在上一篇文章中最初实现的SmallerVGGNet不同——我们在这里添加它是为了控制我们是执行简单分类还是多类分类。
从那里,我们进入build的主体,初始化model ( 第 17 行)并在第 18 行和第 19 行上默认为"channels_last"架构(在第 23-25 行*上有一个方便的支持"channels_first"架构的后端开关)。
让我们构建第一个CONV => RELU => POOL模块:
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
我们的CONV层有带3 x 3内核和RELU激活的32过滤器(整流线性单元)。我们应用批量标准化、最大池化和 25%的退出率。
掉线是从当前层到下一层随机断开节点的过程。这种随机断开的过程自然有助于网络减少过拟合,因为层中没有一个单独的节点负责预测某个类、对象、边或角。
从那里我们有两组(CONV => RELU) * 2 => POOL模块:
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
请注意这个代码块中过滤器、内核和池大小的数量,它们一起工作,逐渐减小空间大小,但增加深度。
这些块后面是我们唯一的一组FC => RELU层:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation(finalAct))
# return the constructed network architecture
return model
完全连接的层被放置在网络的末端(由行 57 和 63 上的Dense指定)。
第 64 行对于我们的多标签分类来说是 重要的—finalAct决定了我们是将"softmax"激活用于单标签分类,还是将"sigmoid"激活用于今天的多标签分类。参见本剧本第 14 行、train.py的smallervggnet.py和第 95 行。
为多标签分类实现我们的 Keras 模型
现在我们已经实现了SmallerVGGNet,让我们创建train.py,我们将使用这个脚本来训练我们的 Keras 网络进行多标签分类。
我敦促你回顾一下今天的train.py剧本所基于的 之前的 。事实上,您可能希望在屏幕上并排查看它们,以了解不同之处并阅读完整的解释。相比之下,今天的回顾将是简洁的。
打开train.py并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.model_selection import train_test_split
from pyimagesearch.smallervggnet import SmallerVGGNet
import matplotlib.pyplot as plt
from imutils import paths
import tensorflow as tf
import numpy as np
import argparse
import random
import pickle
import cv2
import os
在第 2-20 行中,我们导入了这个脚本所需的包和模块。第 3 行指定了一个 matplotlib 后端,这样我们可以在后台保存我们的图形。
我将假设此时您已经安装了 Keras、scikit-learn、matpolotlib、imutils 和 OpenCV。请务必参考上面的“配置您的开发环境”部分。
现在,( a)您的环境已经准备好,( b)您已经导入了包,让我们解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset (i.e., directory of images)")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
脚本的命令行参数就像函数的参数——如果你不理解这个类比,那么你需要仔细阅读命令行参数。
我们今天使用四个命令行参数(第 23-32 行):
--dataset:我们数据集的路径。--model:我们输出序列化 Keras 模型的路径。--labelbin:我们输出多标签二值化器对象的路径。--plot:训练损失和精度输出图的路径。
请务必根据需要参考之前的帖子来解释这些论点。
让我们继续初始化一些在我们的培训过程中起关键作用的重要变量:
# initialize the number of epochs to train for, initial learning rate,
# batch size, and image dimensions
EPOCHS = 30
INIT_LR = 1e-3
BS = 32
IMAGE_DIMS = (96, 96, 3)
# disable eager execution
tf.compat.v1.disable_eager_execution()
第 36-39 行上的这些变量定义如下:
- 我们的网络将训练 75 次
EPOCHS,以便通过反向传播的增量改进来学习模式。 - 我们正在建立一个初始学习率
1e-3(Adam 优化器的默认值)。 - 批量大小为
32。如果你使用的是 GPU,你应该根据你的 GPU 能力来调整这个值,但是我发现32的批量大小很适合这个项目。 - 如上所述,我们的图像是
96 x 96并且包含3通道。
关于超参数的更多信息在上一篇文章中提供。
第 42 行禁用 TensorFlow 的急切执行模式。我们发现,在我们的 2020-06-12 更新 期间,这是必要的,以实现与本文最初发布日期相同的准确性。
接下来的两个代码块处理训练数据的加载和预处理:
# grab the image paths and randomly shuffle them
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# initialize the data and labels
data = []
labels = []
这里我们抓取imagePaths并随机洗牌,然后初始化data和labels列表。
接下来,我们将遍历imagePaths,预处理图像数据,并提取多类标签。
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
image = img_to_array(image)
data.append(image)
# extract set of class labels from the image path and update the
# labels list
l = label = imagePath.split(os.path.sep)[-2].split("_")
labels.append(l)
首先,我们将每幅图像加载到内存中(第 57 行)。然后,我们在行 58 和 59 上执行预处理(深度学习流水线的重要步骤)。我们把image追加到data ( 行 60 )。
第 64 行和第 65 行处理将图像路径分割成多个标签,用于我们的多标签分类任务。在行 64 被执行后,一个 2 元素列表被创建,然后被添加到行 65 的标签列表中。这里有一个在终端中分解的例子,这样您可以看到在多标签解析期间发生了什么:
$ python
>>> import os
>>> labels = []
>>> imagePath = "dataset/red_dress/long_dress_from_macys_red.png"
>>> l = label = imagePath.split(os.path.sep)[-2].split("_")
>>> l
['red', 'dress']
>>> labels.append(l)
>>>
>>> imagePath = "dataset/blue_jeans/stylish_blue_jeans_from_your_favorite_store.png"
>>> l = label = imagePath.split(os.path.sep)[-2].split("_")
>>> labels.append(l)
>>>
>>> imagePath = "dataset/red_shirt/red_shirt_from_target.png"
>>> l = label = imagePath.split(os.path.sep)[-2].split("_")
>>> labels.append(l)
>>>
>>> labels
[['red', 'dress'], ['blue', 'jeans'], ['red', 'shirt']]
如您所见,labels列表是一个“列表列表”——labels的每个元素是一个 2 元素列表。每个列表的两个标签是基于输入图像的文件路径构建的。
我们还没有完成预处理:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
print("[INFO] data matrix: {} images ({:.2f}MB)".format(
len(imagePaths), data.nbytes / (1024 * 1000.0)))
我们的data列表包含存储为 NumPy 数组的图像。在一行代码中,我们将列表转换为 NumPy 数组,并将像素亮度缩放到范围[0, 1]。
我们也将标签转换成 NumPy 数组。
从那里,让我们将标签二进制化—下面的块是本周多类分类概念的 关键 :
# binarize the labels using scikit-learn's special multi-label
# binarizer implementation
print("[INFO] class labels:")
mlb = MultiLabelBinarizer()
labels = mlb.fit_transform(labels)
# loop over each of the possible class labels and show them
for (i, label) in enumerate(mlb.classes_):
print("{}. {}".format(i + 1, label))
为了将我们的标签二进制化用于多类分类,我们需要利用 scikit-learn 库的 MultiLabelBinarizer 类。你不能使用标准LabelBinarizer级进行多级分类。第 76 行和第 77 行将我们人类可读的标签拟合并转换成一个向量,该向量对图像中存在的类别进行编码。
下面的例子展示了MultiLabelBinarizer如何将一个("red", "dress")元组转换成一个总共有六个类别的向量:
$ python
>>> from sklearn.preprocessing import MultiLabelBinarizer
>>> labels = [
... ("blue", "jeans"),
... ("blue", "dress"),
... ("red", "dress"),
... ("red", "shirt"),
... ("blue", "shirt"),
... ("black", "jeans")
... ]
>>> mlb = MultiLabelBinarizer()
>>> mlb.fit(labels)
MultiLabelBinarizer(classes=None, sparse_output=False)
>>> mlb.classes_
array(['black', 'blue', 'dress', 'jeans', 'red', 'shirt'], dtype=object)
>>> mlb.transform([("red", "dress")])
array([[0, 0, 1, 0, 1, 0]])
一键编码将分类标签从单个整数转换为向量。相同的概念适用于第 16 行和第 17 行,除了这是双热编码的情况。
注意在 Python shell 的第 17 行(不要与train.py的代码块混淆)的上,两个分类标签是“热的”(由数组中的“1”表示),表示每个标签的存在。在这种情况下,“连衣裙”和“红色”在数组中是热的(第 14-17 行)。所有其他标签的值为“0”。
让我们构建培训和测试拆分,并初始化数据增强器:
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.2, random_state=42)
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=25, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
分割数据用于训练和测试在机器学习实践中很常见——我将 80%的图像分配给训练数据,20%分配给测试数据。这由 scikit-learn 在行 85 和 86 上处理。
我们的数据增强器对象在第 89-91 行初始化。数据扩充是一种最佳实践,如果您每个班处理的图像少于 1,000 张,那么很可能是“必须的”。
接下来,让我们构建模型并初始化 Adam 优化器:
# initialize the model using a sigmoid activation as the final layer
# in the network so we can perform multi-label classification
print("[INFO] compiling model...")
model = SmallerVGGNet.build(
width=IMAGE_DIMS[1], height=IMAGE_DIMS[0],
depth=IMAGE_DIMS[2], classes=len(mlb.classes_),
finalAct="sigmoid")
# initialize the optimizer (SGD is sufficient)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
在第 96-99 行中,我们构建了我们的SmallerVGGNet模型,注意到finalAct="sigmoid"参数表明我们将执行多标签分类。
在那里,我们将编译模型并开始培训(这可能需要一段时间,具体取决于您的硬件):
# compile the model using binary cross-entropy rather than
# categorical cross-entropy -- this may seem counterintuitive for
# multi-label classification, but keep in mind that the goal here
# is to treat each output label as an independent Bernoulli
# distribution
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
2020-06-12 更新: 以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
在第行的第 109 和 110 行,我们使用二元交叉熵而不是分类交叉熵来编译模型。
对于多标签分类来说,这似乎是违反直觉的;然而,我们的目标是将每个输出标签视为一个独立的伯努利分布(T1)和 T2,我们希望独立地惩罚每个输出节点(T3)。
从那里,我们用我们的数据扩充生成器启动训练过程(行 114-118 )。
训练完成后,我们可以将模型和标签二进制化器保存到磁盘:
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
# save the multi-label binarizer to disk
print("[INFO] serializing label binarizer...")
f = open(args["labelbin"], "wb")
f.write(pickle.dumps(mlb))
f.close()
2020-06-12 更新:注意,对于 TensorFlow 2.0+我们建议明确设置save_format="h5" (HDF5 格式)。
在此基础上,我们绘制精度和损耗图:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
N = EPOCHS
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="upper left")
plt.savefig(args["plot"])
2020-06-12 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
在行 131-141 上绘制了训练和验证的准确度+损失。该图在行 142 保存为图像文件。
在我看来,训练剧情和模型本身一样重要。在我满意地在博客上与你分享之前,我通常会经历几次反复的训练和观看情节。
我喜欢在这个迭代过程中将图保存到磁盘,原因有两个:(1)我在一个无头服务器上,不想依赖 X-forwarding,以及(2)我不想忘记保存图(即使我正在使用 X-forwarding 或者如果我在一个有图形桌面的机器上)。
回想一下,我们在上面的脚本的第 3 行处修改了 matplotlib 后端,以便于保存到磁盘。
训练用于多标签分类的 Keras 网络
不要忘记使用本文的 【下载】 部分下载代码、数据集和预先训练好的模型(以防万一你不想自己训练模型)。
如果你想自己训练模型,打开一个终端。从那里,导航到项目目录,并执行以下命令:
$ python train.py --dataset dataset --model fashion.model \
--labelbin mlb.pickle
Using TensorFlow backend.
[INFO] loading images...
[INFO] data matrix: 2165 images (467.64MB)
[INFO] class labels:
1\. black
2\. blue
3\. dress
4\. jeans
5\. red
6\. shirt
[INFO] compiling model...
[INFO] training network...
Epoch 1/30
54/54 [==============================] - 2s 35ms/step - loss: 0.3184 - accuracy: 0.8774 - val_loss: 1.1824 - val_accuracy: 0.6251
Epoch 2/30
54/54 [==============================] - 2s 37ms/step - loss: 0.1881 - accuracy: 0.9427 - val_loss: 1.4268 - val_accuracy: 0.6255
Epoch 3/30
54/54 [==============================] - 2s 38ms/step - loss: 0.1551 - accuracy: 0.9471 - val_loss: 1.0533 - val_accuracy: 0.6305
...
Epoch 28/30
54/54 [==============================] - 2s 41ms/step - loss: 0.0656 - accuracy: 0.9763 - val_loss: 0.1137 - val_accuracy: 0.9773
Epoch 29/30
54/54 [==============================] - 2s 40ms/step - loss: 0.0801 - accuracy: 0.9751 - val_loss: 0.0916 - val_accuracy: 0.9715
Epoch 30/30
54/54 [==============================] - 2s 37ms/step - loss: 0.0636 - accuracy: 0.9770 - val_loss: 0.0500 - val_accuracy: 0.9823
[INFO] serializing network...
[INFO] serializing label binarizer...
如您所见,我们对网络进行了 30 个纪元的训练,实现了:
- 训练集上的多标签分类准确率为 97.70%
- 测试集上的多标签分类准确率为 98.23%
训练图如图 3: 所示
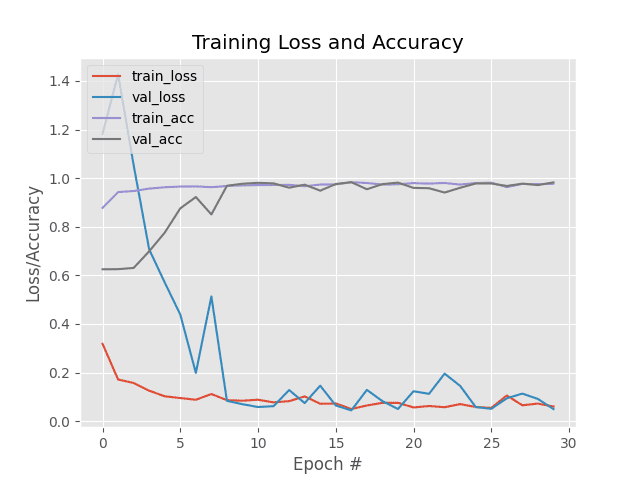
Figure 3: Our Keras deep learning multi-label classification accuracy/loss graph on the training and validation data.
将 Keras 多标签分类应用于新图像
现在我们的多标签分类 Keras 模型已经训练好了,让我们将它应用于测试集之外的图像。
这个脚本与我的 上一篇 中的classify.py脚本非常相似——一定要注意多标签的区别。
准备就绪后,在项目目录中打开创建一个名为classify.py的新文件,并插入以下代码(或者跟随 “下载” 中包含的文件):
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
在第 2-9 行我们import了这个脚本的必要包。值得注意的是,我们将在这个脚本中使用 Keras 和 OpenCV。
然后我们继续解析第 12-19 行上的三个必需的命令行参数。
从那里,我们加载并预处理输入图像:
# load the image
image = cv2.imread(args["image"])
output = imutils.resize(image, width=400)
# pre-process the image for classification
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
我们小心地以与预处理训练数据相同的方式对图像进行预处理。
接下来,我们加载模型+多标签二值化器,对图像进行分类:
# load the trained convolutional neural network and the multi-label
# binarizer
print("[INFO] loading network...")
model = load_model(args["model"])
mlb = pickle.loads(open(args["labelbin"], "rb").read())
# classify the input image then find the indexes of the two class
# labels with the *largest* probability
print("[INFO] classifying image...")
proba = model.predict(image)[0]
idxs = np.argsort(proba)[::-1][:2]
我们将model和多标签二进制化器从磁盘加载到内存的行 34 和 35 。
从那里,我们对(预处理的)输入image ( 第 40 行)进行分类,并通过以下方式提取最高的两个类别标签索引(第 41 行):
- 按关联概率降序排列数组索引
- 抓取前两个类标签索引,这两个类标签索引因此是我们网络中的前 2 个预测
如果愿意,您可以修改这段代码来返回更多的类标签。我还建议设定概率阈值,只返回置信度为 > N% 的标签。
在此基础上,我们将准备分类标签+相关联的置信度值,以便叠加在输出图像上:
# loop over the indexes of the high confidence class labels
for (i, j) in enumerate(idxs):
# build the label and draw the label on the image
label = "{}: {:.2f}%".format(mlb.classes_[j], proba[j] * 100)
cv2.putText(output, label, (10, (i * 30) + 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# show the probabilities for each of the individual labels
for (label, p) in zip(mlb.classes_, proba):
print("{}: {:.2f}%".format(label, p * 100))
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
行 44-48 上的循环在output图像上画出前两个多标签预测和相应的置信度值。
类似地,行 51 和 52 上的循环打印终端中的所有预测。这对于调试非常有用。
最后,我们在屏幕上显示output图像(第 55 行和第 56 行)。
Keras 多标签分类结果
让我们使用命令行参数让classify.py工作。您不需要修改上面讨论的代码来通过 CNN 传递新的图像。简单地在你的终端中使用命令行参数,如下所示。
让我们尝试一幅红色连衣裙的图像—注意运行时处理的三个命令行参数:
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_01.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 0.00%
blue: 3.58%
dress: 95.14%
jeans: 0.00%
red: 100.00%
shirt: 64.02%

Figure 4: The image of a red dress has correctly been classified as “red” and “dress” by our Keras multi-label classification deep learning script.
成功!注意这两个类(“红色”和“礼服”)是如何被标记为高置信度的。
现在让我们试试一条蓝色的裙子:
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_02.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 0.03%
blue: 99.98%
dress: 98.50%
jeans: 0.23%
red: 0.00%
shirt: 0.74%

Figure 5: The “blue” and “dress” class labels are correctly applied in our second test of our Keras multi-label image classification project.
对我们的分类员来说,一件蓝色的连衣裙是没有竞争力的。我们有了一个良好的开端,所以让我们尝试一个红色衬衫的图像:
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_03.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 0.00%
blue: 0.69%
dress: 0.00%
jeans: 0.00%
red: 100.00%
shirt: 100.00%

Figure 6: With 100% confidence, our deep learning multi-label classification script has correctly classified this red shirt.
红衫军的结果很有希望。
一件蓝色的衬衫怎么样?
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_04.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 0.00%
blue: 99.99%
dress: 22.59%
jeans: 0.08%
red: 0.00%
shirt: 82.82%

Figure 7: Deep learning + multi-label + Keras classification of a blue shirt is correctly calculated.
我们的模型非常确信它看到了蓝色,但稍微不太确信它遇到了衬衫。话虽如此,这还是一个正确的多标签分类!
让我们看看是否可以用蓝色牛仔裤欺骗我们的多标签分类器:
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_05.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 0.00%
blue: 100.00%
dress: 0.01%
jeans: 99.99%
red: 0.00%
shirt: 0.00%

Figure 8: This deep learning multi-label classification result proves that blue jeans can be correctly classified as both “blue” and “jeans”.
让我们试试黑色牛仔裤:
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_06.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 100.00%
blue: 0.00%
dress: 0.01%
jeans: 100.00%
red: 0.00%
shirt: 0.00%

Figure 9: Both labels, “jeans” and “black” are correct in this Keras multi-label classification deep learning experiment.
我不能 100%确定这些是牛仔牛仔裤(对我来说它们看起来更像打底裤/jeggings),但我们的多标签分类器是!
让我们试试最后一个黑色礼服的例子。虽然我们的网络已经学会预测“黑色牛仔裤”**“蓝色牛仔裤”以及“蓝色连衣裙”和“红色连衣裙”,但它能用来对一件“黑色连衣裙”进行分类吗?
$ python classify.py --model fashion.model --labelbin mlb.pickle \
--image examples/example_07.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
black: 91.28%
blue: 7.70%
dress: 5.48%
jeans: 71.87%
red: 0.00%
shirt: 5.92%

Figure 10: What happened here? Our multi-class labels are incorrect. Color is marked as “black” but the classifier had a higher confidence that this was an image of “jeans” than a “dress”. The reason is that our neural network never saw this combination in its training data. See the “Summary” below for further explanation.
哦,不——大错特错!我们的分类器报告说模特穿的是黑色牛仔裤,而实际上她穿的是黑色裙子。
这里发生了什么?
为什么我们的多类预测不正确?要找出原因,请查看下面的摘要。
摘要
在今天的博文中,您学习了如何使用 Keras 执行多标签分类。
使用 Keras 执行多标签分类非常简单,包括两个主要步骤:
- 将网络末端的 softmax 激活替换为 sigmoid 激活
- 将分类交叉熵换成二进制交叉熵作为你的损失函数
从那里你可以像平常一样训练你的网络。
应用上述过程的最终结果是一个多类分类器。
你可以使用你的 Keras 多类分类器来预测多个标签,只需一个单个向前传递。
但是,有一个难点你需要考虑:
您需要您想要预测的类别的每个组合的训练数据。
就像神经网络无法预测它从未训练过的类一样,您的神经网络也无法预测它从未见过的组合的多个类标签。这种行为的原因是由于网络内部神经元的激活。
如果您的网络是根据(1)黑色裤子和(2)红色衬衫的示例训练的,现在您想要预测“红色裤子”(在您的数据集中没有“红色裤子”图像),负责检测“红色”和“裤子”的神经元将会触发,但是由于网络在数据/激活到达完全连接的层之前从未见过这种数据/激活的组合,因此您的输出预测很可能是不正确的(即,您可能会遇到“红色”或
同样,你的网络不能正确地对它从未在上训练过的数据做出预测(你也不应该期望它这样做)。在为多标签分类训练自己的 Keras 网络时,请记住这一点。
我希望你喜欢这篇文章!
要在 PyImageSearch 上发布帖子时得到通知,只需在下表中输入您的电子邮件地址!***
基于 dlib 的多目标跟踪
原文:https://pyimagesearch.com/2018/10/29/multi-object-tracking-with-dlib/

在本教程中,您将学习如何使用 dlib 库有效地跟踪实时视频中的多个对象。
到目前为止,在这个关于对象跟踪的系列中,我们已经学习了如何:
- 用 OpenCV 追踪单个物体
- 利用 OpenCV 追踪多个物体
- 用 dlib 进行单个物体跟踪
- 跟踪并统计进入商店的人数
我们当然可以用 dlib 跟踪多个物体;然而,为了获得可能的最佳性能,我们需要利用多处理,并将对象跟踪器分布在我们处理器的多个内核上。
正确利用多处理技术使我们的 dlib 多目标跟踪每秒帧数(FPS)吞吐率提高了 45%以上!
要了解如何使用 dlib 跟踪多个对象,继续阅读!
基于 dlib 的多目标跟踪
在本指南的第一部分,我将演示如何实现一个简单、简单的 dlib 多对象跟踪脚本。这个程序将跟踪视频中的多个对象;然而,我们会注意到脚本运行得有点慢。
为了提高我们的 FPS 吞吐率,我将向您展示一个更快、更高效的 dlib 多对象跟踪器实现。
最后,我将讨论一些改进和建议,您可以用它们来增强我们的多对象跟踪实现。
项目结构
首先,请确保使用本教程的 “下载” 部分下载源代码和示例视频。
从那里,您可以使用tree命令来查看我们的项目结构:
$ tree
.
├── mobilenet_ssd
│ ├── MobileNetSSD_deploy.caffemodel
│ └── MobileNetSSD_deploy.prototxt
├── multi_object_tracking_slow.py
├── multi_object_tracking_fast.py
├── race.mp4
├── race_output_slow.avi
└── race_output_fast.avi
1 directory, 7 files
目录包含我们的 MobileNet + SSD Caffe 模型文件,允许我们检测人(以及其他对象)。
今天我们将回顾两个 Python 脚本:
- dlib 多目标跟踪的简单“天真”方法。
- 利用多重处理的先进、快速的方法。
剩下的三个文件是视频。我们有原始的race.mp4视频和两个处理过的输出视频。
“天真”的 dlib 多目标跟踪实现
我们今天要讨论的第一个 dlib 多目标跟踪实现是“天真的”,因为它将:
- 利用一个简单的跟踪对象列表。
- 仅使用我们处理器的一个内核,按顺序更新每个跟踪器。
对于一些目标跟踪任务,这种实现将多于足够的;然而,为了优化我们的 FPS 吞吐率,我们应该将对象跟踪器分布在多个进程中。
在这一节中,我们将从简单的实现开始,然后在下一节中讨论更快的方法。
首先,打开multi_object_tracking_slow.py脚本并插入以下代码:
# import the necessary packages
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import dlib
import cv2
我们从在第 2-7 行导入必要的包和模块开始。最重要的是,我们将使用 dlib 和 OpenCV。我们还将使用我的 imutils 便利功能包中的一些功能,例如每秒帧数计数器。
要安装 dlib,请遵循本指南。我也有一些 OpenCV 安装教程(甚至是最新的 OpenCV 4!).你甚至可以尝试最快的方法通过 pip 在你的系统上安装 OpenCV。
要安装imutils,只需在终端中使用 pip:
$ pip install --upgrade imutils
现在我们(a)已经安装了软件,并且(b)已经在脚本中放置了相关的导入语句,让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", type=str,
help="path to optional output video file")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
如果你不熟悉终端和命令行参数,请阅读这篇文章。
我们的脚本在运行时处理以下命令行参数:
--prototxt:Caffe“deploy”proto txt 文件的路径。--model:伴随 prototxt 的模型文件的路径。--video:输入视频文件的路径。我们将在这段视频中使用 dlib 进行多目标跟踪。--output:输出视频文件的可选路径。如果未指定路径,则不会将视频输出到磁盘。我建议输出到。avi 或. mp4 文件。--confidence:对象检测置信度阈值0.2的可选覆盖。该值表示从对象检测器过滤弱检测的最小概率。
让我们定义该模型支持的CLASSES列表,并从磁盘加载我们的模型:
# initialize the list of class labels MobileNet SSD was trained to
# detect
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
MobileNet SSD 预训练 Caffe 模型支持 20 个类和 1 个后台类。CLASSES以列表形式定义在行 25-28 上。
注意: 如果您正在使用“下载”中提供的 Caffe 模型,请不要修改这个列表或类对象的排序。类似地,如果您碰巧装载了一个不同的模型,您将需要在这里定义模型支持的类(顺序很重要)。如果你对我们的物体探测器是如何工作的感到好奇,一定要参考这篇文章。
对于今天的竞走例子,我们只关心"person"职业,但是你可以很容易地修改下面的第 95 行(将在本文后面讨论)来跟踪替代职业。
在第 32 行上,我们加载了我们预先训练好的对象检测器模型。我们将使用我们预先训练的 SSD 来检测视频中对象的存在。在那里,我们将创建一个 dlib 对象跟踪器来跟踪每个检测到的对象。
我们还需要执行一些初始化:
# initialize the video stream and output video writer
print("[INFO] starting video stream...")
vs = cv2.VideoCapture(args["video"])
writer = None
# initialize the list of object trackers and corresponding class
# labels
trackers = []
labels = []
# start the frames per second throughput estimator
fps = FPS().start()
在第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第 36 行第
随后,在线 37 上,我们的视频writer被初始化为None。在即将到来的while循环中,我们将更多地与视频writer合作。
现在让我们初始化第 41 和 42 行上的trackers和labels列表。
最后,我们在第 45 行启动每秒帧数计数器。
我们已经准备好开始处理我们的视频:
# loop over frames from the video file stream
while True:
# grab the next frame from the video file
(grabbed, frame) = vs.read()
# check to see if we have reached the end of the video file
if frame is None:
break
# resize the frame for faster processing and then convert the
# frame from BGR to RGB ordering (dlib needs RGB ordering)
frame = imutils.resize(frame, width=600)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# if we are supposed to be writing a video to disk, initialize
# the writer
if args["output"] is not None and writer is None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
在第 48 行的上,我们开始在帧上循环,其中第 50 行的实际上抓取了frame本身。
在第行第 53 和 54 行进行快速检查,看看我们是否已经到达视频文件的末尾,是否需要停止循环。
预处理发生在线 58 和 59 上。首先,frame被调整到600像素宽,保持纵横比。然后,frame转换为rgb颜色通道排序,以兼容 dlib(OpenCV 默认为 BGR,dlib 默认为 RGB)。
从那里我们在第 63-66 行的上实例化视频writer(如果需要的话)。要了解更多关于用 OpenCV 将视频写入磁盘的信息,请查看我之前的博文。
让我们开始物体探测阶段:
# if there are no object trackers we first need to detect objects
# and then create a tracker for each object
if len(trackers) == 0:
# grab the frame dimensions and convert the frame to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 0.007843, (w, h), 127.5)
# pass the blob through the network and obtain the detections
# and predictions
net.setInput(blob)
detections = net.forward()
为了执行对象跟踪,我们必须首先执行对象检测,或者:
- 手动,通过停止视频流并手动选择每个对象的边界框。
- 程序化,使用经过训练的物体检测器检测物体的存在(这就是我们在这里做的)。
如果没有物体追踪器( Line 70 ),那么我们知道我们还没有执行物体检测。
我们创建一个blob并通过 SSD 网络来检测线 72-78 上的对象。要了解cv2.blobFromImage功能,请务必参考我在本文中撰写的。
接下来,我们继续循环检测以找到属于"person"类的对象,因为我们的输入视频是一场人类竞走:
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated
# with the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by requiring a minimum
# confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# detections list
idx = int(detections[0, 0, i, 1])
label = CLASSES[idx]
# if the class label is not a person, ignore it
if CLASSES[idx] != "person":
continue
我们开始在行 81 上循环检测,在此我们:
- 过滤掉弱检测(行 88 )。
- 确保每个检测都是一个
"person"( 行 91-96 )。当然,您可以删除这行代码,或者根据自己的过滤需要对其进行定制。
现在我们已经在帧中定位了每个"person",让我们实例化我们的跟踪器并绘制我们的初始边界框+类标签:
# compute the (x, y)-coordinates of the bounding box
# for the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# construct a dlib rectangle object from the bounding
# box coordinates and start the correlation tracker
t = dlib.correlation_tracker()
rect = dlib.rectangle(startX, startY, endX, endY)
t.start_track(rgb, rect)
# update our set of trackers and corresponding class
# labels
labels.append(label)
trackers.append(t)
# grab the corresponding class label for the detection
# and draw the bounding box
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, label, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
为了开始跟踪对象,我们:
- 计算每个检测到的对象的边界
box(行 100 和 101 )。 - 实例化边界框坐标并将其传递给跟踪器 ( 第 105-107 行)。边界框在这里尤其重要。我们需要为边界框创建一个
dlib.rectangle并将其传递给start_track方法。从那里,dlib 可以开始跟踪该对象。 - 最后,我们用个人追踪器(行 112 )填充
trackers列表。
因此,在下一个代码块中,我们将处理已经建立跟踪器的情况,我们只需要更新位置。
在初始检测步骤中,我们还需要执行另外两项任务:
- 将类别标签附加到
labels列表中(第 111 行)。如果你在追踪多种类型的物体(比如"dog"+"person",你可能想知道每个物体的类型是什么。 - 在对象周围绘制每个边界框
rectangle并在对象上方分类label(第 116-119 行)。
如果我们的检测列表的长度大于零,我们知道我们处于对象跟踪阶段:
# otherwise, we've already performed detection so let's track
# multiple objects
else:
# loop over each of the trackers
for (t, l) in zip(trackers, labels):
# update the tracker and grab the position of the tracked
# object
t.update(rgb)
pos = t.get_position()
# unpack the position object
startX = int(pos.left())
startY = int(pos.top())
endX = int(pos.right())
endY = int(pos.bottom())
# draw the bounding box from the correlation object tracker
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, l, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
在物体跟踪阶段,我们循环所有trackers和行 125 上对应的labels。
然后我们进行到update每个物体位置(第 128-129 行)。为了更新位置,我们简单地传递rgb图像。
提取包围盒坐标后,我们可以为每个被跟踪的对象绘制一个包围盒rectangle和label(第 138-141 行)。
帧处理循环中的其余步骤包括写入输出视频(如有必要)并显示结果:
# check to see if we should write the frame to disk
if writer is not None:
writer.write(frame)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
在这里我们:
- 如有必要,将
frame写入视频(第 144 和 145 行)。 - 显示输出帧并捕捉按键(第 148 和 149 行)。如果按下
"q"键(“退出”),我们break退出循环。 - 最后,我们更新每秒帧数信息,用于基准测试(第 156 行)。
剩下的步骤是在终端中打印 FPS 吞吐量信息并释放指针:
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# check to see if we need to release the video writer pointer
if writer is not None:
writer.release()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.release()
为了结束,我们的fps统计数据被收集和打印(第 159-161 行),视频writer被发布(第 164 和 165 行),我们关闭所有窗口+发布视频流。
让我们来评估准确性和性能。
要跟随并运行这个脚本,请确保使用这篇博文的 “下载” 部分下载源代码+示例视频。
从那里,打开一个终端并执行以下命令:
$ python multi_object_tracking_slow.py --prototxt mobilenet_ssd/MobileNetSSD_deploy.prototxt \
--model mobilenet_ssd/MobileNetSSD_deploy.caffemodel \
--video race.mp4 --output race_output_slow.avi
[INFO] loading model...
[INFO] starting video stream...
[INFO] elapsed time: 24.51
[INFO] approx. FPS: 13.87
看来我们的多目标追踪器起作用了!
但是如你所见,我们只获得了 ~13 FPS 。
对于某些应用来说,这种 FPS 吞吐率可能已经足够了——然而,如果你需要更快的 FPS,我建议你看看下面的 T2 更高效的 dlib 多目标跟踪器。
其次,要明白跟踪精度并不完美。参考下面“改进和建议”部分的第三个建议,以及阅读我关于 dlib 对象跟踪的第一篇文章了解更多信息。
快速、高效的 dlib 多目标跟踪实现
如果您运行上一节中的 dlib 多对象跟踪脚本,同时打开系统的活动监视器,您会注意到处理器中只有个内核被利用。
为了加速我们的对象跟踪管道,我们可以利用 Python 的多处理模块,类似于线程模块,但是用于产生进程而不是线程。
利用进程使我们的操作系统能够执行更好的进程调度,将进程映射到我们机器上的特定处理器核心(大多数现代操作系统能够以并行方式高效地调度使用大量 CPU 的进程)。
如果你是 Python 多重处理模块的新手,我建议你阅读 Sebastian Raschka 的这篇精彩介绍。
否则,打开mutli_object_tracking_fast.py并插入以下代码:
# import the necessary packages
from imutils.video import FPS
import multiprocessing
import numpy as np
import argparse
import imutils
import dlib
import cv2
我们的包装是在2-8 线进口的。我们正在导入线 3 上的multiprocessing库。
我们将使用 Python Process类来生成一个新的进程——每个新进程都独立于原始进程。
*为了生成这个流程,我们需要提供一个 Python 可以调用的函数,然后 Python 将获取并创建一个全新的流程+执行它:
def start_tracker(box, label, rgb, inputQueue, outputQueue):
# construct a dlib rectangle object from the bounding box
# coordinates and then start the correlation tracker
t = dlib.correlation_tracker()
rect = dlib.rectangle(box[0], box[1], box[2], box[3])
t.start_track(rgb, rect)
start_tracker的前三个参数包括:
- 我们将要跟踪的物体的边界框坐标,可能是由某种物体探测器返回的,不管是手动的还是编程的。
label:物体的人类可读标签。- 一张 RGB 排序的图像,我们将用它来启动初始的 dlib 对象跟踪器。
请记住 Python 多重处理的工作方式——Python 将调用这个函数,然后创建一个全新的解释器来执行其中的代码。因此,每个start_tracker衍生的进程将独立于其父进程。为了与 Python 驱动脚本通信,我们需要利用管道或队列。这两种类型的对象都是线程/进程安全的,使用锁和信号量来实现。
本质上,我们正在创建一个简单的生产者/消费者关系:
- 我们的父进程将产生新帧,并将它们添加到特定对象跟踪器的队列中。
- 然后,子进程将使用帧,应用对象跟踪,然后返回更新后的边界框坐标。
我决定在这篇文章中使用Queue对象;然而,请记住,如果您愿意,您可以使用一个Pipe——一定要参考 Python 多处理文档,以获得关于这些对象的更多细节。
现在让我们开始一个无限循环,它将在这个过程中运行:
# loop indefinitely -- this function will be called as a daemon
# process so we don't need to worry about joining it
while True:
# attempt to grab the next frame from the input queue
rgb = inputQueue.get()
# if there was an entry in our queue, process it
if rgb is not None:
# update the tracker and grab the position of the tracked
# object
t.update(rgb)
pos = t.get_position()
# unpack the position object
startX = int(pos.left())
startY = int(pos.top())
endX = int(pos.right())
endY = int(pos.bottom())
# add the label + bounding box coordinates to the output
# queue
outputQueue.put((label, (startX, startY, endX, endY)))
我们在这里无限循环——这个函数将作为守护进程调用,所以我们不需要担心加入它。
首先,我们将尝试从第 21 行的上的inputQueue抓取一个新的帧。
如果帧不是空的,我们将抓取帧,然后update对象跟踪器,允许我们获得更新的边界框坐标(第 24-34 行)。
最后,我们将label和边界框写到outputQueue中,这样父进程就可以在我们脚本的主循环中使用它们(第 38 行)。
回到父进程,我们将解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", type=str,
help="path to optional output video file")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
这个脚本的命令行参数与我们较慢的非多处理脚本完全相同。如果你需要复习这些论点,只需点击这里。此外,如果你不熟悉 argparse 和命令行参数,请阅读我的帖子。
让我们初始化输入和输出队列:
# initialize our lists of queues -- both input queue and output queue
# for *every* object that we will be tracking
inputQueues = []
outputQueues = []
这些队列将保存我们正在跟踪的对象。每个产生的进程将需要两个Queue对象:
- 一个用来读取输入帧的
- 另一个用来写入结果
下一个代码块与我们之前的脚本相同:
# initialize the list of class labels MobileNet SSD was trained to
# detect
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# initialize the video stream and output video writer
print("[INFO] starting video stream...")
vs = cv2.VideoCapture(args["video"])
writer = None
# start the frames per second throughput estimator
fps = FPS().start()
我们定义模型的CLASSES并加载模型本身(第 61-68 行)。请记住,这些CLASSES是静态的——我们的 MobileNet SSD 支持这些类,并且只支持这些类。如果你想检测+跟踪其他物体,你需要找到另一个预训练的模型或训练一个。此外,这个列表的顺序很重要!除非你喜欢混乱,否则不要改变列表的顺序!如果你想进一步了解物体探测器是如何工作的,我还建议你阅读本教程。
我们初始化我们的视频流对象,并将我们的视频writer对象设置为None ( 第 72 行和第 73 行)。
我们的每秒帧数计算器在第 76 行被实例化并启动。
现在让我们开始循环视频流中的帧:
# loop over frames from the video file stream
while True:
# grab the next frame from the video file
(grabbed, frame) = vs.read()
# check to see if we have reached the end of the video file
if frame is None:
break
# resize the frame for faster processing and then convert the
# frame from BGR to RGB ordering (dlib needs RGB ordering)
frame = imutils.resize(frame, width=600)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# if we are supposed to be writing a video to disk, initialize
# the writer
if args["output"] is not None and writer is None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
上面的代码块再次与前面脚本中的代码块相同。确保根据需要参考上述中的。
现在让我们来处理没有inputQueues的情况:
# if our list of queues is empty then we know we have yet to
# create our first object tracker
if len(inputQueues) == 0:
# grab the frame dimensions and convert the frame to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 0.007843, (w, h), 127.5)
# pass the blob through the network and obtain the detections
# and predictions
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated
# with the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by requiring a minimum
# confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# detections list
idx = int(detections[0, 0, i, 1])
label = CLASSES[idx]
# if the class label is not a person, ignore it
if CLASSES[idx] != "person":
continue
如果没有inputQueues ( 线 101 ),那么我们知道我们需要在对象跟踪之前应用对象检测。
我们在行 103-109 上应用对象检测,然后继续循环行 112 上的结果。我们获取我们的confidence值,并过滤掉行 115-119 上的弱detections。
如果我们的confidence满足由我们的命令行参数建立的阈值,我们考虑检测,但是我们通过类label进一步过滤它。在这种情况下,我们只寻找"person"对象(第 122-127 行)。
假设我们已经找到了一个"person",我们将创建队列并生成跟踪流程:
# compute the (x, y)-coordinates of the bounding box
# for the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
bb = (startX, startY, endX, endY)
# create two brand new input and output queues,
# respectively
iq = multiprocessing.Queue()
oq = multiprocessing.Queue()
inputQueues.append(iq)
outputQueues.append(oq)
# spawn a daemon process for a new object tracker
p = multiprocessing.Process(
target=start_tracker,
args=(bb, label, rgb, iq, oq))
p.daemon = True
p.start()
# grab the corresponding class label for the detection
# and draw the bounding box
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, label, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
我们首先计算第 131-133 行上的边界框坐标。
从那里我们创建两个新队列,iq和oq ( 行 137 和 138 ),分别将它们追加到inputQueues和outputQueues(行 139 和 140 )。
从那里我们产生一个新的start_tracker进程,传递边界框、label、rgb图像和iq + oq ( 第 143-147 行)。不要忘记在这里阅读更多关于多重处理的内容。
我们还画出被检测物体的包围盒rectangle和类label ( 第 151-154 行)。
否则,我们已经执行了对象检测,因此我们需要将每个 dlib 对象跟踪器应用于该帧:
# otherwise, we've already performed detection so let's track
# multiple objects
else:
# loop over each of our input ques and add the input RGB
# frame to it, enabling us to update each of the respective
# object trackers running in separate processes
for iq in inputQueues:
iq.put(rgb)
# loop over each of the output queues
for oq in outputQueues:
# grab the updated bounding box coordinates for the
# object -- the .get method is a blocking operation so
# this will pause our execution until the respective
# process finishes the tracking update
(label, (startX, startY, endX, endY)) = oq.get()
# draw the bounding box from the correlation object
# tracker
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, label, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
循环遍历每个inputQueues,我们给它们添加rgb图像(第 162 和 163 行)。
然后我们循环遍历每个outputQueues ( 行 166 ),从每个独立的对象跟踪器(行 171 )获得边界框坐标。最后,我们在第 175-178 行的上画出边界框+关联的类label。
让我们完成循环和脚本:
# check to see if we should write the frame to disk
if writer is not None:
writer.write(frame)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# check to see if we need to release the video writer pointer
if writer is not None:
writer.release()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.release()
如果需要的话,我们将帧写入输出视频,并将frame显示到屏幕上(第 181-185 行)。
如果按下"q"键,我们“退出”,退出循环(第 186-190 行)。
如果我们继续处理帧,我们的fps计算器在行 193 上更新,然后我们再次从while循环的开始开始处理。
否则,我们处理完帧,显示 FPS 吞吐量信息+释放指针并关闭窗口。
要执行这个脚本,请确保您使用帖子的 【下载】 部分下载源代码+示例视频。
从那里,打开一个终端并执行以下命令:
$ python multi_object_tracking_fast.py --prototxt mobilenet_ssd/MobileNetSSD_deploy.prototxt \
--model mobilenet_ssd/MobileNetSSD_deploy.caffemodel \
--video race.mp4 --output race_output_fast.avi
[INFO] loading model...
[INFO] starting video stream...
[INFO] elapsed time: 14.01
[INFO] approx. FPS: 24.26
https://www.youtube.com/embed/8PvvsPbSkUs?feature=oembed*
基于 Python 和 OpenCV 的多尺度模板匹配
原文:https://pyimagesearch.com/2015/01/26/multi-scale-template-matching-using-python-opencv/
过去的这个周末,我患了流感,病得很重。除了躺在我的沙发上,从咖啡杯里啜饮鸡肉面条汤,以及玩《使命召唤》的马拉松游戏之外,我什么也没做。

老实说,自从我花了一个周末坚持不懈地玩《使命召唤》以来,已经有年了。上网玩无休止的死亡之战和统治之战让我想起了大学室友和我在大学期间通宵玩游戏的美好回忆。
https://www.youtube.com/embed/MfdKh0HEOBs?feature=oembed
使用 PyTorch 的多任务学习和消防栓
原文:https://pyimagesearch.com/2022/08/17/multi-task-learning-and-hydranets-with-pytorch/
目录
【多任务学习与绣球与 PyTorch
今天,我们将学习多任务学习和消防栓。这是一种深度学习技术,我在 2020 年中期向 653 人发送的电子邮件中首次介绍了这种技术。
对这封邮件的回应非常热烈(来自世界各地的工程师告诉我,他们很喜欢它,并希望将其应用到他们的公司)我不得不在我的课程目录中创建一个完整的 HydraNet 部分。你可以通过访问https://www.thinkautonomous.ai/
了解更多信息不仅这项技术是深度学习领域的新和令人兴奋,而且它也是许多计算机视觉工程师能够接触到的。我怀疑,在未来几年,它甚至可能成为深度学习课程中的必修课。
今天,我们要学习多任务学习的基本原理,为了开始这篇文章,下面是我第一次了解它的故事:
几年前我研究了特斯拉的自动驾驶仪,以写一篇文章。通过他们的会议、文章以及在 LinkedIn 上关注工程师,我学到了很多东西。但在某些时候,我偶然发现了一个词:
"消防栓"
绣球网?有意思,这是什么?
我做了一些调查,了解到特斯拉没有使用 10 或 20 个型号。尽管有 20 多个任务要解决,他们只用了一个(至少,这是背后的主要思想)。
他们有一个模型可以解决他们正在处理的所有可能的任务,例如:
- 目标检测
- 道路曲线估计
- 深度估计
- 三维重建
- 视频分析
- 目标跟踪
- 等等…
在我们开始“如何做”之前,我想让你看看消防栓能做什么。
这是在 NVIDIA GPU 上以 3 种不同配置运行的 2 个计算机视觉模型的基准测试。
- 在第一个配置中,我们正在运行一个语义分割模型。
- 在第二种配置上,我们将 叠加 一个单目深度估计模型。
- 在第三种配置中,我们正在建造一个能够同时完成这两项任务的消防栓。
现在,看看结果(见表 1 ):
语义分割在第一列中以 29 FPS 运行,并使用 70%的 GPU。但是一旦我们添加深度估计,GPU 就变得满满的。
**这发生在几年前,当时我正在研究自主航天飞机。我训练了一个 YOLOv3 模型来检测障碍物,需要增加更多的任务,比如车道线估计。
突然我的 GPU 就满了,车也跑不动了。
因此,在第三列中,您会注意到HydraNet 节省了 GPU 的使用,同时保持了相对较高的 FPS。
因为这不是平行进行的:
我们正在这样做:
这是特斯拉使用的同一种架构;正如你注意到的,它很强大。
一个身体,几个脑袋。
这就是特斯拉正在做的事情,我提到的那篇文章可以在这里找到。
在本课中,我们将看到一个多任务学习项目的简单版本:
解决一个多任务学习项目
现在你已经熟悉了消防栓,我们将有一个简短的教程来教你如何使用 PyTorch 的消防栓。
为此,我们将使用 UTK 人脸数据集。这是一个分类数据集,其中每个图像有 3 个标签:
- 性别(男性或女性)
- 种族(白人、黑人、亚洲人、印度人、其他)
- 年龄(连续数字)
因此,我们的消防栓将有 3 个头,每个头负责一项任务。有趣的是,这些不会是相同的头:预测年龄是一个回归任务,但预测性别是一个二元分类任务和预测种族是一个多类分类任务。
这意味着将有几个损失函数需要处理。
使用 PyTorch,我们将创建这个确切的项目。为此,我们将:
- 用 PyTorch 创建一个多任务数据加载
- 创建一个多任务网络
- 训练模型并运行结果
使用 PyTorch,我们总是从一个数据集开始,我们将它封装在一个 PyTorch 数据加载器中并提供给一个模型。
数据加载器是我们的第一步。
用 PyTorch 创建多任务数据加载器
在本教程中,我将假设你熟悉 PyTorch 。你对数据集和数据加载器了如指掌,看到__dunders__不会吓到你。
想法是这样的:我们的数据将被提供给一个转换成 PyTorch 数据加载器的 dataset 类。
在图像上:
- 我们收集数据,就像任何深度学习项目一样
- 我们将这些数据发送到一个自定义数据集类,并创建一个训练和测试数据集
- 我们将这两个数据集封装到两个 PyTorch 数据加载器中
- 训练时,我们使用这些数据加载器
数据
首先是数据。
数据集是一组图像,图像的名称给出了标签。比如图像UTKFace/100_****0__0****_ 20170112213500903 . jpg . chip . jpg可以解释如下:
- UTKFace/ 是前缀
- 100 是年龄
- 0 是性别 (0:男,1:女)
- 0 是种族 (0:白人,1:黑人,2:亚洲人,3:印度人,4:其他)
- 剩下的就是日期和扩展名(jpg)
数据集
数据集类必须实现 3 个函数:
def __init__(self):定义数据集元素的函数(如输入和标签)def __len__(self):返回元素个数的函数def __getitem__(self):从数据集中返回一个项目的函数
现在,这里是每个功能是如何实现的。
INIT
def __init__(self, image_paths):
# Define the Transforms
self.transform = transforms.Compose([transforms.Resize((32, 32)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# Set Inputs and Labels
self.image_paths = image_paths
self.images = []
self.ages = []
self.genders = []
self.races = []
for path in image_paths:
filename = path[8:].split("_")
if len(filename)==4:
self.images.append(path)
self.ages.append(int(filename[0]))
self.genders.append(int(filename[1]))
self.races.append(int(filename[2]))
在init函数中,我们定义了变换(数据扩充、转换为张量等。)运营。
然后,我们检查图像路径并获取元素(例如,100、0和0),并将它们添加到标签列表中。
一旦我们调用了__init__函数,我们应该有 4 个列表定义(图片、种族、性别、年龄)。
LEN
这个函数只返回图像的数量。
def __len__(self):
return len(self.images)
如果不使用它,就不能对每个数据集图像运行训练循环。您需要len函数,因为len()不支持定制类;它可以处理列表、数组等。,但不是自定义元素。所以你需要重新定义它。
获取 _ 物品
这个函数将完成您在__init__中定义的所有工作(例如,加载一个图像,调用转换,并获得标签)。此外,这个函数的目的是返回给定索引的数据集的特定元素。
def __getitem__(self, index):
# Load an Image
img = Image.open(self.images[index]).convert('RGB')
# Transform it
img = self.transform(img)
# Get the Labels
age = self.ages[index]
gender = self.genders[index]
race = self.races[index]
# Return the sample of the dataset
sample = {'image':img, 'age': age, 'gender': gender, 'race':race}
return sample
注意: 在这个例子中,我们把它作为一个字典返回,但是你也可以返回 4 个元素(毕竟这是 Python!)
数据加载器
最后,我们可以通过调用以下函数获得一个数据加载器:
train_dataloader = DataLoader(UTKFace(train_dataset), shuffle=True, batch_size=BATCH_SIZE)
val_dataloader = DataLoader(UTKFace(valid_dataset), shuffle=False, batch_size=BATCH_SIZE)
模型定义
一旦我们有了数据加载器,我们就可以用 PyTorch 定义和训练我们的模型。
我们可以从零开始,但是如果你上过一些深度学习课程,你就会知道我们通常更喜欢使用迁移学习。这就是为什么我们将从一个预训练的模型开始,我们将转换它,使它符合我们的问题。
我们将使用的主干可以是任何东西(例如,ResNet、MobileNet、Inception 等。).
重要的是网络的尽头! 我们想改变预训练模型的最后一层,就像迁移学习一样,使它适应我们的问题。
在这种情况下,有两种处理方式:
- 由于我们的情况非常简单,我们可以改变最后一层并添加 7 个神经元: 1 个用于性别(二进制分类需要一个神经元),5 个用于种族(对于 5 个类),1 个用于年龄(一个回归需要一个神经元)
- 或者,我们可以制作头部,每个头部有几层。
在第一种情况下,我们会有这样简单的东西:
self.net = models.resnet18(pretrained=True)
self.net.fc = nn.Linear(model.fc.in_features, 7)
- 在线 1 ,我们从 PyTorch 下载
resnet18模型。 - 在的第二行,注意我们使用了
model.fc。我们下载的预训练 ResNet 的最后一层称为“FC ”,表示完全连接。我们通过改变神经元的数量来修改这一层。如果你有一个不同的模型,fc可以被命名为别的什么。
在第二种情况下,我们制作头部。为此,我们在现有 FC 层之上构建了一系列层。
我们将定义:
fc1:作为年龄的全连接层- 对两性来说
- 为了比赛
下面是代码版本:
class HydraNet(nn.Module):
def __init__(self):
super().__init__()
self.net = models.resnet18(pretrained=True)
self.n_features = self.net.fc.in_features
self.net.fc = nn.Identity()
self.net.fc1 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 1))]))
self.net.fc2 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 1))]))
self.net.fc3 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 5))]))
def forward(self, x):
age_head = self.net.fc1(self.net(x))
gender_head = self.net.fc2(self.net(x))
race_head = self.net.fc3(self.net(x))
return age_head, gender_head, race_head
在init()函数中,我们定义了序列模型,它是层的序列。
如果我们只考虑年龄:
self.net.fc1 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 1))]))
我们用一个大小为(n_features, n_features)的线性层创建一个字典(我们没有必要这样做,但这是命名层的好习惯),然后是一个 ReLU 激活和另一个大小为(n_features, 1)的线性层。
那么,在网络中:
age_head = self.net.fc1(self.net(x))
我们的输入通过模型,然后通过fc1。
然后,我们对另外两个头重复这一过程。同样,forward 函数返回 3 个头,但这一次,它也可以返回一个由 3 组成的字典(就像 dataset 类一样)。
接下来,我们需要定义损失函数并训练我们的模型。
训练:损失功能
我们将从损失函数开始。在多任务学习中,你仍然有一个损失。不同的是,这个损失结合了你所有的其他损失。
我们可以有一些简单的东西:
 😗***年龄损失,是一种回归损失。例如,均方误差或负对数似然。
😗***年龄损失,是一种回归损失。例如,均方误差或负对数似然。 😗***种族损失,是一种多等级分类损失。在我们的例子中,它是交叉熵!****
😗***种族损失,是一种多等级分类损失。在我们的例子中,它是交叉熵!**** :性别损失,是二进制分类损失。在我们的例子中,二元交叉熵。********
:性别损失,是二进制分类损失。在我们的例子中,二元交叉熵。********
 😗***种族损失,是一种多等级分类损失。在我们的例子中,它是交叉熵!****
😗***种族损失,是一种多等级分类损失。在我们的例子中,它是交叉熵!**** :性别损失,是二进制分类损失。在我们的例子中,二元交叉熵。********
:性别损失,是二进制分类损失。在我们的例子中,二元交叉熵。**************每种损失都有其独特之处。在性别的情况下,我们希望在最后一层应用 sigmoid 激活;但是在比赛的情况下,我们想要应用一个 softmax。
现在,这里是它可能会失败的地方:
考虑到我们必须预测一个时代。如果我们的预测是 50,但实际年龄是 30,我们就损失了 20。如果我们使用均方差,我们的损失就变成了(20 = 400)。
如果我们加上性别的分类损失,它将是一个介于 0 和 1 之间的数字。
如果我们把两者相加,我们最终会发现损失只受年龄误差的影响;我们的损失不在同一个规模上。
一种简单的方法是在损失前增加系数,并使总损失具有平衡值:
更好的方法是将我们的年龄损失从均方误差改为
Loss:
20 的误差将保持在 20,我们可以把它带回正常范围。
最后是训练循环。
训练循环
我们现在准备用 PyTorch 训练我们的模型!
代码将是最少的“使它工作”,只是为了培训。
net = resnet34(pretrained=True)
model = HydraNet(net).to(device=device)
race_loss = nn.CrossEntropyLoss() # Includes Softmax
gender_loss = nn.BCELoss() # Doesn't include Softmax
age_loss = nn.L1Loss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.09)
Sig = nn.Sigmoid()
所有这些都是我们工作的前奏。我们定义一个模型,然后:
- 竞争损失是交叉熵损失
- 性别损失是二元交叉熵损失
- 年龄损失是
 损失
损失
需要注意的是,对于二进制分类,我们将使用不包括 softmax 的二进制交叉熵。相反,我们将使用更适合这种特殊情况的s 形。
最后,循环:
for epoch in range(n_epochs):
model.train()
total_training_loss = 0
for i, data in enumerate(train_dataloader):
inputs = data["image"].to(device=device)
age_label = data["age"].to(device=device)
gender_label = data["gender"].to(device=device)
race_label = data["race"].to(device=device)
optimizer.zero_grad()
age_output, gender_output, race_output = model(inputs)
loss_1 = race_loss(race_output, race_label)
loss_2 = gender_loss(sig(gender_output), gender_label.unsqueeze(1).float())
loss_3 = age_loss(age_output, age_label.unsqueeze(1).float())
loss = loss_1 + loss_2 + loss_3
loss.backward()
optimizer.step()
total_training_loss += loss
验证也是如此。
该模型将训练多个时期,并且损失将被优化。
一旦模型被训练,我们就可以用它来进行推理,并预测我们对任何输入人脸的 3 个值!
结论
多任务学习是深度学习中最有前途的技术之一。许多研究人员认为这是人工智能的未来。
它解决了一个重要的速度和内存问题(堆叠 20 个模型对您的 RAM 和 GPU 没有好处),并且在训练几个任务时有大量的好处。例如,在计算机视觉领域,研究人员指出,共同训练特定任务比不训练它们更有优势。就像学打网球一样,让你非常擅长乒乓球!
如果你想应用这些概念,我推荐 PyImageSearch 大学,里面有计算机视觉的 HydraNets 课程。
事实上,我们比这走得更远,并将其应用于自动驾驶汽车的语义分割和深度估计。
这是你将要做的事情的预览:
报名: PyImageSearch 大学
这篇文章是由 Think Autonomous 的 Jérémy Cohen 撰写的。杰瑞米一直在通过他的日常电子邮件和在线课程,教数千名工程师如何在自动驾驶汽车或高级计算机视觉等前沿领域工作。你可以订阅杰瑞米的邮件,并在 https://www.thinkautonomous.ai/py 的阅读。
引用信息
科恩,J. “使用 PyTorch 的多任务学习和消防栓”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot 和 R. Raha 编辑。,2022 年,【https://pyimg.co/hdkl7
@incollection{Cohen_2022_HydraNets,
author = {Jeremy Cohen},
title = {Multi-Task Learning and HydraNets with PyTorch},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Ritwik Raha}, year = {2022},
note = {https://pyimg.co/hdkl7},
}
用 OpenCV 进行多模板匹配
原文:https://pyimagesearch.com/2021/03/29/multi-template-matching-with-opencv/
在本教程中,您将学习如何使用 OpenCV 执行多模板匹配。
上周您发现了如何利用 OpenCV 和cv2.matchTemplate函数进行基本的模板匹配。这种方法的问题是它只能检测输入图像中模板的一个实例—你不能执行多目标检测!
我们只能检测到一个物体,因为我们使用了cv2.minMaxLoc函数来寻找具有最大归一化相关分数的单一位置。
为了执行多对象模板匹配,我们需要做的是:
- 像平常一样应用
cv2.matchTemplate功能 - 找出模板匹配结果矩阵大于预设阈值分数的所有 (x,y)-坐标
- 提取所有这些区域
- 对它们应用非最大值抑制
应用以上四个步骤后,我们将能够在输入图像中检测多个模板。
要学习如何用 OpenCV 进行多模板匹配,继续阅读。
OpenCV 多模板匹配
在本教程的第一部分,我们将讨论基本模板匹配的问题,以及如何使用一些基本的计算机视觉和图像处理技术将其扩展到多模板匹配。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
从那里,我们将使用 OpenCV 实现多模板匹配。
我们将讨论我们的结果来结束本教程。
基本模板匹配的问题
正如我们在上周的教程中看到的,应用基本模板匹配只会导致一个特定模板的实例被匹配,如图图 1 所示。
我们的输入图像包含方块 8。虽然我们的模板包含钻石符号,但我们希望检测输入图像中的所有钻石。
然而,当使用基本模板匹配时,多目标检测根本不可能。
解决方案是从cv2.matchTemplate函数中过滤结果矩阵,然后应用非最大值抑制。
如何用 OpenCV 匹配 多个 模板?
为了使用 OpenCV 和cv2.matchTemplate检测多个对象/模板,我们需要过滤由cv2.matchTemplate生成的result矩阵,如下所示:
result = cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED)
(yCoords, xCoords) = np.where(result >= args["threshold"])
调用cv2.matchTemplate会产生一个具有以下空间维度的result矩阵:
- 宽度:
image.shape[1] - template.shape[1] + 1 - 身高:
image.shape[0] - template.shape[0] + 1
然后,我们应用np.where函数来寻找归一化相关系数大于预设阈值的所有 (x,y)——坐标——这个阈值步骤允许我们执行多模板匹配!
最后一步,我们将在本教程稍后介绍,是应用非最大值抑制来过滤由np.where过滤生成的重叠边界框。
应用这些步骤后,我们的输出图像将如下所示:
请注意,我们已经检测到(几乎)输入图像中的所有钻石。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们花点时间来检查一下我们的项目目录结构。请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
解压代码档案后,您会发现以下目录:
$ tree . --dirsfirst
.
├── images
│ ├── 8_diamonds.png
│ └── diamonds_template.png
└── multi_template_matching.py
1 directory, 5 files
我们今天只回顾一个 Python 脚本multi_template_matching.py,它将使用我们的images目录中的输入图像执行多模板匹配。
用 OpenCV 实现多模板匹配
上周我们学习了如何执行模板匹配。这种方法的问题在于,当模板的多次出现在输入图像中时失败——模板匹配将仅报告一个匹配的模板(即,具有最大相关分数的模板)。
我们将要讨论的 Python 脚本multi_template_matching.py,将扩展我们的基本模板匹配方法,并允许我们匹配多个模板。
让我们开始吧:
# import the necessary pages
from imutils.object_detection import non_max_suppression
import numpy as np
import argparse
import cv2
第 2-5 行导入我们需要的 Python 包。最重要的是,我们需要本教程中的non_max_suppression函数,它执行非最大值抑制 (NMS)。
应用多模板匹配将导致在我们的输入图像中对的每个物体进行多次检测。我们可以通过应用 NMS 来抑制弱的重叠边界框,从而解决这一问题。
从那里,我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image where we'll apply template matching")
ap.add_argument("-t", "--template", type=str, required=True,
help="path to template image")
ap.add_argument("-b", "--threshold", type=float, default=0.8,
help="threshold for multi-template matching")
args = vars(ap.parse_args())
我们有三个参数要解析,其中两个是必需的,第三个是可选的:
--image:我们将应用多模板匹配的输入图像的路径。--template:模板图像的路径(即我们想要检测的物体的例子)。--threshold:用于 NMS 的阈值——范围【0.8,0.95】内的值通常效果最佳。
接下来,让我们从磁盘加载我们的image和template:
# load the input image and template image from disk, then grab the
# template image spatial dimensions
print("[INFO] loading images...")
image = cv2.imread(args["image"])
template = cv2.imread(args["template"])
(tH, tW) = template.shape[:2]
# display the image and template to our screen
cv2.imshow("Image", image)
cv2.imshow("Template", template)
线 20 和 21 从磁盘加载我们的image和template。我们在第 22 行上获取模板的空间维度,这样我们就可以用它们轻松地导出匹配对象的边界框坐标。
第 25 行和第 26 行将我们的image和template显示到我们的屏幕上。
下一步是执行模板匹配,就像我们上周做的一样:
# convert both the image and template to grayscale
imageGray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
templateGray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
# perform template matching
print("[INFO] performing template matching...")
result = cv2.matchTemplate(imageGray, templateGray,
cv2.TM_CCOEFF_NORMED)
第 29 和 30 行将我们的输入图像转换成灰度,而第 34 和 35 行执行模板匹配。
如果我们希望只检测模板的一个实例,我们可以简单地调用cv2.minMaxLoc来找到具有最大归一化相关系数的 (x,y)-坐标。
然而,由于我们想要检测多个物体,我们需要过滤我们的result矩阵并找到 所有的 (x,y)-分数大于我们的--threshold的坐标:
# find all locations in the result map where the matched value is
# greater than the threshold, then clone our original image so we
# can draw on it
(yCoords, xCoords) = np.where(result >= args["threshold"])
clone = image.copy()
print("[INFO] {} matched locations *before* NMS".format(len(yCoords)))
# loop over our starting (x, y)-coordinates
for (x, y) in zip(xCoords, yCoords):
# draw the bounding box on the image
cv2.rectangle(clone, (x, y), (x + tW, y + tH),
(255, 0, 0), 3)
# show our output image *before* applying non-maxima suppression
cv2.imshow("Before NMS", clone)
cv2.waitKey(0)
第 40 行使用np.where来查找所有 (x,y)-相关分数大于我们的--threshold命令行参数的坐标。
第 42 行显示在应用 NMS 之前匹配位置的总数。
从那里,我们循环所有匹配的 (x,y)-坐标,并在屏幕上绘制它们的边界框(第 45-48 行)。
如果我们在这里结束我们的实现,我们将会有一个问题——对np.where的调用将会返回 (x,y) 的所有位置的,这些坐标都在我们的阈值之上。
很有可能多个位置指向同一个物体。如果发生这种情况,我们基本上会多次报告同一个对象,这是我们不惜一切代价想要避免的。
*解决方案是应用非最大值抑制:
# initialize our list of rectangles
rects = []
# loop over the starting (x, y)-coordinates again
for (x, y) in zip(xCoords, yCoords):
# update our list of rectangles
rects.append((x, y, x + tW, y + tH))
# apply non-maxima suppression to the rectangles
pick = non_max_suppression(np.array(rects))
print("[INFO] {} matched locations *after* NMS".format(len(pick)))
# loop over the final bounding boxes
for (startX, startY, endX, endY) in pick:
# draw the bounding box on the image
cv2.rectangle(image, (startX, startY), (endX, endY),
(255, 0, 0), 3)
# show the output image
cv2.imshow("After NMS", image)
cv2.waitKey(0)
第 55 行开始初始化我们的边界框列表rects。然后我们循环所有的 (x,y)-坐标,计算它们各自的边界框,然后更新rects列表。
在行 63 上应用非最大值抑制,抑制具有较低分数的重叠边界框,本质上将多个重叠检测压缩成单个检测。
最后,行 67-70 在我们最终的边界框上循环,并在我们的输出image上绘制它们。
多模板匹配结果
我们现在准备用 OpenCV 应用多模板匹配!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python multi_template_matching.py --image images/8_diamonds.png \
--template images/diamonds_template.png
[INFO] loading images...
[INFO] performing template matching...
[INFO] 601 matched locations *before* NMS
[INFO] 8 matched locations *after* NMS
图 4 显示我们的diamonds_template.png (左)8_diamonds.png图像(右)。我们的目标是检测右图像中的所有菱形符号。
在应用了cv2.matchTemplate函数之后,我们过滤得到的矩阵,找到归一化相关系数大于我们的--threshold参数的 (x,y)- 坐标。
这个过程产生总共 601 个匹配的对象,,我们在下面可视化:
查看图 5 ,以及我们的终端输出,您可能会惊讶地发现我们有 601 个匹配的区域— 这怎么可能?!方块 8 的牌上只有 8 颗方块(如果你用8数字本身来计算额外的方块,那就是 10 颗)——但那肯定加起来不到 601 个匹配!
这个现象是我在我的非极大值抑制教程中讨论的。对象检测算法类似于“热图”一个滑动窗口越靠近图像中的一个物体,热图就变得“越来越热”。
然后,当我们使用np.where调用过滤这个热图时,我们最终得到了所有高于给定阈值的位置。记住np.where函数不知道一幅图像中有多少物体——它只是告诉你哪里有可能的物体。
这里的解决方案很简单,几乎所有的对象检测算法(包括基于高级深度学习的算法)都使用非极大值抑制(NMS)。
使用 NMS,我们检查相关系数得分,并抑制那些(1)重叠和(2)得分低于其周围邻居的得分。
应用 NMS 产生菱形符号的 8 个匹配位置:
卡片角上的【8】数字旁边的小钻石呢?为什么那些没有被检测出来?
这又回到了模板匹配的主要限制之一:
当您想要检测的对象在比例、旋转和视角方面开始不同时,模板匹配将会失败。
由于钻石的尺寸比我们的模板小,标准的模板匹配程序将无法检测出它们。
当这种情况发生时,你可以依靠多尺度模板匹配。或者,您可能需要考虑训练一个可以自然处理这些类型变化的对象检测器,例如大多数基于深度学习的对象检测器(例如,更快的 R-CNN、SSDs、YOLO 等)。).
演职员表和参考资料
我要感谢在线教师关于模板匹配的精彩文章——我不能因为用扑克牌来演示模板匹配的想法而居功。这是他们的想法,而且是一个很好的想法。感谢他们想出了这个例子,我无耻地用在这里,谢谢。
此外,u/fireball_73 从 Reddit 帖子中获得了方块 8 的图像。
总结
在本教程中,您学习了如何使用 OpenCV 执行多模板匹配。
与只能检测输入图像中模板的单个实例的基本模板匹配不同,多模板匹配允许我们检测模板的多个实例。
应用多对象模板匹配是一个四步过程:
- 像平常一样应用
cv2.matchTemplate功能 - 找出模板匹配结果矩阵大于预设阈值分数的所有 (x,y)-坐标
- 提取所有这些区域
- 对它们应用非最大值抑制
虽然这种方法可以处理多对象模板匹配,但它仍然容易受到模板匹配的其他限制—如果对象的比例、旋转或视角发生变化,模板匹配可能会失败。
你也许可以利用多尺度模板匹配(不同于多模板匹配)。不过,如果你到了那一步,你可能会想看看更先进的对象检测方法,如猪+线性 SVM,更快的 R-CNN,固态硬盘和 YOLO。
无论如何,模板匹配是超级快速、高效且易于实现的。因此,在执行模板匹配时,作为“第一步”是值得的(只是要事先意识到限制)。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
使用 Raspberry Pi 和 OpenCV 的多个摄像头
原文:https://pyimagesearch.com/2016/01/18/multiple-cameras-with-the-raspberry-pi-and-opencv/
我将保持今天帖子的简介简短,因为我认为这个帖子的标题和上面的 GIF 动画说明了一切。
在这篇文章中,我将演示如何将多个摄像机连接到你的树莓 Pi……上,并使用一个 Python 脚本访问所有这些摄像机。
无论您的设置是否包括:
- 多个 USB 网络摄像头。
- 或者 Raspberry Pi 摄像头模块+额外的 USB 摄像头…
…这篇文章中详细介绍的代码将允许您访问您的所有视频流— ,并对每个视频流执行运动检测!
最重要的是,我们使用 Raspberry Pi 和 OpenCV 实现的多摄像头访问能够在实时运行(或接近实时,取决于您连接的摄像头数量),非常适合创建您自己的多摄像头家庭监控系统。
继续阅读,了解更多。
使用 Raspberry Pi 和 OpenCV 的多个摄像头
当构建 Raspberry Pi 设置以利用多个摄像机时,您有两种选择:
- 只需使用多个 USB 网络摄像头。
- 或者使用一个 Raspberry Pi 摄像头模块和至少一个 USB 网络摄像头。
Raspberry Pi 板只有一个摄像头端口,所以你将无法使用多个 Raspberry Pi 摄像头板(除非你想对你的 Pi 进行一些大范围的黑客攻击)。所以为了给你的 Pi 连接多个摄像头,你需要利用至少一个(如果不是更多的话)USB 摄像头。
也就是说,为了构建我自己的多摄像头 Raspberry Pi 设置,我最终使用了:
- 树莓 Pi 摄像头模块 + 摄像头外壳(可选)。我们可以使用
picameraPython 包或者(最好)在之前的博客文章中定义的线程化VideoStream类与相机交互。 - 一个罗技 C920 网络摄像头,即插即用,兼容树莓派。我们可以使用 OpenCV 内置的
cv2.VideoCapture函数或者本课中的VideoStream类来访问这个相机。
您可以在下面看到我的设置示例:

Figure 1: My multiple camera Raspberry Pi setup.
在这里,我们可以看到我的树莓 Pi 2,以及树莓 Pi 相机模块(位于 Pi 2 的顶部)和我的罗技 C920 网络摄像头。
Raspberry Pi 摄像头模块指向我的公寓大门,以监控任何进出的人,而 USB 网络摄像头指向厨房,观察任何可能正在进行的活动:

Figure 2: The Raspberry Pi camera module and USB camera are both hooked up to my Raspberry Pi, but are monitoring different areas of the room.
忽略 USB 摄像头上的绝缘胶带和纸板——这是之前的一个实验,应该(希望)很快会在 PyImageSearch 博客上发表。
最后,您可以在下图中看到向我的 Raspberry Pi 显示的两个视频源的示例:
Figure 3: An example screenshot of monitoring both video feeds from the multiple camera Raspberry Pi setup.
在这篇博文的剩余部分,我们将定义一个简单的运动检测类,它可以检测一个人/物体是否在给定摄像机的视野内移动。然后,我们将编写一个 Python 驱动程序脚本,实例化我们的两个视频流,并在两个视频流中执行运动检测。
正如我们将看到的,通过使用线程化的视频流捕获类(其中每个摄像机一个线程专用于执行 I/O 操作,允许主程序线程继续畅通无阻),我们可以轻松地让我们的运动检测器在树莓 Pi 2 上为多个摄像机运行实时。
让我们从定义简单的运动检测器类开始。
定义我们的简单运动检测器
在本节中,我们将构建一个简单的 Python 类,该类可用于检测给定摄像机视野中的运动。
为了提高效率,这个类将假设一次只有个对象在摄像机视图中移动——在未来的博客文章中,我们将研究更高级的运动检测和背景减除方法来跟踪多个对象。
事实上,我们在上一课中已经(部分)回顾了这种运动检测方法,使用 Raspberry Pi、Python、OpenCV 和 Dropbox 进行家庭监控和运动检测,我们现在将这种实现正式化为一个可重用的类,而不仅仅是内联代码。
让我们从打开一个新文件开始,将其命名为basicmotiondetector.py,并添加以下代码:
# import the necessary packages
import imutils
import cv2
class BasicMotionDetector:
def __init__(self, accumWeight=0.5, deltaThresh=5, minArea=5000):
# determine the OpenCV version, followed by storing the
# the frame accumulation weight, the fixed threshold for
# the delta image, and finally the minimum area required
# for "motion" to be reported
self.isv2 = imutils.is_cv2()
self.accumWeight = accumWeight
self.deltaThresh = deltaThresh
self.minArea = minArea
# initialize the average image for motion detection
self.avg = None
第 6 行定义了我们的BasicMotionDetector类的构造函数。构造函数接受三个可选的关键字参数,包括:
accumWeight:当前帧与前一组帧进行加权平均所用的浮点值。更大的accumWeight将导致背景模型具有更少的“记忆”,并且很快“忘记”先前帧的样子。如果你不希望在短时间内有大量的运动,使用高值的accumWeight是很有用的。相反,accumWeight的值越小,背景模型的权重就越大,这样就可以在前景中检测到更大的变化。在这个例子中,我们将使用默认值0.5,请记住,这是一个您应该考虑使用的可调参数。
**deltaThresh:在计算当前帧和背景模型之间的差异后,我们需要应用阈值来找到帧中包含运动的区域——这个deltaThresh值用于阈值。较小的deltaThresh值将检测到更多的运动,而较大的值将检测到较少的运动。* 应用阈值处理后,我们将得到一个二进制图像,从中提取轮廓。为了处理噪声并忽略小的运动区域,我们可以使用minArea参数。任何带有> minArea的区域都被标注为“运动”;否则,它将被忽略。*
*最后,第 17 行初始化avg,这仅仅是BasicMotionDetector已经看到的先前帧的运行加权平均。
让我们继续我们的update方法:
def update(self, image):
# initialize the list of locations containing motion
locs = []
# if the average image is None, initialize it
if self.avg is None:
self.avg = image.astype("float")
return locs
# otherwise, accumulate the weighted average between
# the current frame and the previous frames, then compute
# the pixel-wise differences between the current frame
# and running average
cv2.accumulateWeighted(image, self.avg, self.accumWeight)
frameDelta = cv2.absdiff(image, cv2.convertScaleAbs(self.avg)
update函数只需要一个参数——我们想要检测运动的图像。
第 21 行初始化locs,对应图像中运动位置的轮廓列表。然而,如果avg没有被初始化(第 24-26 行),我们将avg设置为当前帧并从该方法返回。
否则,avg已经被初始化,所以我们使用提供给构造器的accumWeight值(第 32 行)来累加先前帧和当前帧之间的移动加权平均值。取当前帧和移动平均值之间的绝对值差,得到图像中包含运动的区域——我们称之为我们的增量图像。
然而,为了实际上检测我们的 delta 图像中包含运动的区域,我们首先需要应用阈值和轮廓检测:
# threshold the delta image and apply a series of dilations
# to help fill in holes
thresh = cv2.threshold(frameDelta, self.deltaThresh, 255,
cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
# find contours in the thresholded image, taking care to
# use the appropriate version of OpenCV
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# loop over the contours
for c in cnts:
# only add the contour to the locations list if it
# exceeds the minimum area
if cv2.contourArea(c) > self.minArea:
locs.append(c)
# return the set of locations
return locs
使用提供的值deltaThresh调用cv2.threshold允许我们将 delta 图像二值化,然后我们在(第 37-45 行)中找到轮廓。
注意: 检查第 43-45 行时要特别小心。正如我们所知,cv2.findContours方法返回签名在 OpenCV 2.4、3 和 4 之间发生了变化。这个代码块允许我们在 OpenCV 2.4,3,& 4 中使用cv2.findContours,而无需更改一行代码(或者担心版本问题)。
最后,第 48-52 行在检测到的轮廓上循环,检查它们的面积是否大于提供的minArea,如果是,更新locs列表。
然后,包含运动的轮廓列表返回到行 55 上的调用方法。
注:再次,关于运动检测算法的更详细回顾,请参见 家庭监控教程 。
在 Raspberry Pi 上访问多个摄像头
既然已经定义了我们的BasicMotionDetector类,我们现在准备创建multi_cam_motion.py驱动程序脚本来访问带有树莓 Pi 的 多个 摄像机,并对每个视频流应用运动检测。
让我们开始定义我们的驱动程序脚本:
# import the necessary packages
from __future__ import print_function
from pyimagesearch.basicmotiondetector import BasicMotionDetector
from imutils.video import VideoStream
import numpy as np
import datetime
import imutils
import time
import cv2
# initialize the video streams and allow them to warmup
print("[INFO] starting cameras...")
webcam = VideoStream(src=0).start()
picam = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# initialize the two motion detectors, along with the total
# number of frames read
camMotion = BasicMotionDetector()
piMotion = BasicMotionDetector()
total = 0
我们从第 2-9 行的开始,导入我们需要的 Python 包。请注意,出于组织的目的,我们是如何将BasicMotionDetector类放在pyimagesearch模块中的。我们还导入了VideoStream,我们的线程视频流类能够访问树莓 Pi 摄像头模块和内置/USB 网络摄像头。
VideoStream类是 imutils 包的一部分,所以如果您还没有安装它,只需执行以下命令:
$ pip install imutils
第 13 行初始化我们的 USB 摄像头 VideoStream类而第 14 行初始化我们的 树莓派摄像头模块 VideoStream类(通过指定usePiCamera=True)。
如果您不想使用 Raspberry Pi 摄像头模块,而是想利用两个 USB 摄像头,只需将的第 13 行和第 14 行更改为:
webcam1 = VideoStream(src=0).start()
webcam2 = VideoStream(src=1).start()
其中src参数控制机器上摄像机的索引。还要注意的是,在这个脚本的剩余部分中,你必须分别用webcam1和webcam2替换webcam和picam。
最后,第 19 行和第 20 行实例化了两个BasicMotionDetector,一个用于 USB 摄像机,另一个用于覆盆子 Pi 摄像机模块。
我们现在准备在两个视频源中执行运动检测:
# loop over frames from the video streams
while True:
# initialize the list of frames that have been processed
frames = []
# loop over the frames and their respective motion detectors
for (stream, motion) in zip((webcam, picam), (camMotion, piMotion)):
# read the next frame from the video stream and resize
# it to have a maximum width of 400 pixels
frame = stream.read()
frame = imutils.resize(frame, width=400)
# convert the frame to grayscale, blur it slightly, update
# the motion detector
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
locs = motion.update(gray)
# we should allow the motion detector to "run" for a bit
# and accumulate a set of frames to form a nice average
if total < 32:
frames.append(frame)
continue
在第 24 行上,我们开始了一个无限循环,用于不断轮询来自我们(两个)相机传感器的帧。我们在第 26 行的上初始化一个这样的frames列表。
然后,行 29 定义了一个for循环,分别在每个视频流和运动检测器上循环。我们使用stream从我们的相机传感器读取一个frame,然后调整帧的大小,使其宽度固定为 400 像素。
通过将帧转换为灰度并应用高斯平滑操作来减少高频噪声,对行 37 和 38 执行进一步的预处理。最后,经过处理的帧被传送到我们的motion检测器,在那里进行实际的运动检测(第 39 行)。
然而,重要的是让我们的运动检测器“运行”一会儿,以便它可以获得我们背景“看起来”的准确运行平均值。在应用任何运动检测(第 43-45 行)之前,我们将允许 32 帧用于平均背景计算。
在我们允许 32 帧被传递到我们的BasicMotionDetector之后,我们可以检查是否检测到任何运动:
# otherwise, check to see if motion was detected
if len(locs) > 0:
# initialize the minimum and maximum (x, y)-coordinates,
# respectively
(minX, minY) = (np.inf, np.inf)
(maxX, maxY) = (-np.inf, -np.inf)
# loop over the locations of motion and accumulate the
# minimum and maximum locations of the bounding boxes
for l in locs:
(x, y, w, h) = cv2.boundingRect(l)
(minX, maxX) = (min(minX, x), max(maxX, x + w))
(minY, maxY) = (min(minY, y), max(maxY, y + h))
# draw the bounding box
cv2.rectangle(frame, (minX, minY), (maxX, maxY),
(0, 0, 255), 3)
# update the frames list
frames.append(frame)
第 48 行检查当前视频stream的frame中是否检测到运动。
假设检测到运动,我们初始化最小和最大 (x,y)-与轮廓相关的坐标(即locs)。然后我们逐个循环这些轮廓,并使用它们来确定包含所有轮廓的(行 51-59 )的最小边界框。
然后围绕第 62 和 63 行上的运动区域绘制边界框,接着是在第 66 行上更新的frames列表。
同样,这篇博文中详细描述的代码假设在给定的帧中,一次只有个物体/人在移动,因此这种方法将获得预期的结果。然而,如果有多个移动物体,那么我们将需要使用更先进的背景减除和跟踪方法 PyImageSearch 上的未来博客帖子将涵盖如何执行多物体跟踪。
最后一步是在屏幕上显示我们的frames:
# increment the total number of frames read and grab the
# current timestamp
total += 1
timestamp = datetime.datetime.now()
ts = timestamp.strftime("%A %d %B %Y %I:%M:%S%p")
# loop over the frames a second time
for (frame, name) in zip(frames, ("Webcam", "Picamera")):
# draw the timestamp on the frame and display it
cv2.putText(frame, ts, (10, frame.shape[0] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)
cv2.imshow(name, frame)
# check to see if a key was pressed
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
print("[INFO] cleaning up...")
cv2.destroyAllWindows()
webcam.stop()
picam.stop()
Liens 70-72 递增total处理的帧数,随后抓取并格式化当前时间戳。
然后,我们在第 75 条的线上循环我们已经处理过的每一个frames,并将它们显示在我们的屏幕上。
最后,行 82-86 检查q键是否被按下,表示我们应该从读帧循环中脱离。第 89-92 行然后执行一点清理。
多摄像头树莓派上的运动检测
要查看我们在 Raspberry Pi 上运行的多摄像机运动检测器,只需执行以下命令:
$ python multi_cam_motion.py
我在下面的 GIF 中包含了一系列“高亮帧”,展示了我们的多摄像头运动检测器的运行情况:
Figure 4: An example of applying motion detection to multiple cameras using the Raspberry Pi, OpenCV, and Python.
请注意我是如何从厨房开始,打开橱柜,伸手拿杯子,然后走向水槽将杯子装满水的——这一系列的动作和运动被第一个摄像头检测到。
最后,在退出第二个摄像头的帧视图之前,我去垃圾桶扔纸巾。
下面是使用 Raspberry Pi 访问多个摄像机的完整视频演示:
https://www.youtube.com/embed/ssJnIiQWkDQ?feature=oembed*
OpenCV 和 Python 的多重处理
原文:https://pyimagesearch.com/2019/09/09/multiprocessing-with-opencv-and-python/

在本教程中,您将学习如何使用 OpenCV 和 Python 的多重处理来执行特征提取。您将了解如何使用 OpenCV 的多处理功能来并行处理系统总线上的特征提取,包括计算机上的所有处理器和内核。
今天的教程是受 PyImageSearch 阅读器 Abigail 的启发。
阿比盖尔写道:
嗨,阿德里安,我刚刚读了你的关于 OpenCV 图像哈希的教程,非常喜欢。
我正在尝试将图像哈希应用到我在大学的研究项目中。
他们为我提供了大约 750 万张图片的数据集。我用你的代码来执行图像哈希,但是处理整个数据集需要很长时间。
我能做些什么来加速这个过程吗?
阿比盖尔问了一个很好的问题。
她所指的图像哈希帖子是单线程的,这意味着只使用了处理器的一个内核— 如果我们改用多线程/进程,我们就可以显著加快哈希过程。
但是我们实际上如何利用 OpenCV 和 Python 的多重处理呢?
我将在本教程的剩余部分向您展示。
要了解如何在 OpenCV 和 Python 中使用多重处理,继续阅读。
OpenCV 和 Python 的多重处理
在本教程的第一部分,我们将讨论单线程与多线程应用程序,包括为什么我们可能选择使用 OpenCV 的多处理来加快给定数据集的处理。
我还将讨论为什么立即转向大数据算法、工具和范例(如 Hadoop 和 MapReduce)是错误的决定— 相反,你应该首先跨系统总线并行化。
从这里,我们将实现我们的 Python 和 OpenCV 多处理函数,以方便快捷地处理大型数据集。
最后,我们将把所有部分放在一起,比较处理数据集需要多长时间:
- 只有一个单核处理器
- 并将负载分布在处理器的所有核心上
我们开始吧!
为什么要使用多重处理来处理图像数据集?
您已经实现的绝大多数项目和应用程序(很可能)都是单线程的。
当您启动 Python 项目时,python二进制文件会启动一个 Python 解释器(即“Python 进程”)。
实际的 Python 进程本身如何分配给 CPU 内核取决于操作系统如何处理(1)进程调度和(2)分配系统和用户线程。
有整本书致力于多进程、操作系统以及进程如何被调度、分配、移除、删除等。通过操作系统;然而,为了简单起见,我们假设:
- 我们启动我们的 Python 脚本。
- 操作系统将 Python 程序分配给处理器的单个内核。
- 然后,操作系统允许 Python 脚本在处理器内核上运行,直到完成。
这一切都很好,但是我们只利用了我们真正处理能力的一小部分。
要了解我们是如何利用处理器的,请看下图:

Figure 1: Multiprocessing with OpenCV and Python. By default, Python scripts use a single process. This 3GHz Intel Xeon W processor is being underutilized.
此图旨在展示我的 iMac Pro 上的 3 GHz 英特尔至强 W 处理器— 请注意该处理器总共有 20 个内核。
现在,让我们假设我们启动了 Python 脚本。操作系统会将进程分配给这些内核中的一个:
Figure 2: Without multiprocessing, your OpenCV program may not be efficiently using all cores or processors available on your machine.
Python 脚本将运行至完成。
但是你看到这里的问题了吗?
我们只使用了真正处理能力的 5%!
因此,为了加速我们的 Python 脚本,我们可以利用多重处理。在引擎盖下,Python 的multiprocessing包为处理器的每个内核旋转出一个新的python进程。每个python进程都是独立的,与其他进程分开(也就是说,没有共享的变量、内存等等。).
然后,我们将数据集处理工作负载的一部分分配给每个单独的python流程:
Figure 3: By multiprocessing with OpenCV, we can harness the full capability of our processor. In this case, an Intel Xeon 3GHz processor has 20 cores available and each core can be running an independent Python process.
注意每个进程是如何被分配数据集的一小部分的。
每个进程独立地咀嚼分配给它的数据集的子集,直到整个数据集被处理。
现在,我们不再只使用处理器的一个内核,而是使用所有内核!
注意:记住,这个例子有点简化。操作系统将管理进程分配,因为在您的系统上运行的不仅仅是您的 Python 脚本,还有更多进程。一些内核可能负责多个 Python 进程,其他内核不负责 Python 进程,而其余内核负责 OS/系统例程。
为什么不用 Hadoop、MapReduce 等大数据工具呢?
当尝试并行处理大型数据集时,您的第一想法是应用大数据工具、算法和范例,如 Hadoop 和 MapReduce — ,但这将是一个很大的错误。
处理大型数据集的黄金法则是:
- 首先通过系统总线并行化。
- 如果性能/吞吐量不够,那么,并且只有在之后,开始跨多台机器(包括 Hadoop、MapReduce 等)进行并行化。).
我认为计算机科学家犯的最大的多重处理错误是立即投入大数据工具。
不要那样做。
相反,将数据集处理分散到您的系统总线上,首先是。
如果您没有在系统总线上获得您想要的吞吐速度,那么只有才应该考虑跨多台机器并行化并引入大数据工具。
如果您发现自己需要 Hadoop/MapReduce,报名参加 PyImageSearch 大师课程,了解使用 Hadoop 的流 API 进行高吞吐量 Python + OpenCV 图像处理!
我们的示例数据集

Figure 4: The CALTECH-101 dataset consists of 101 object categories. Will generate image hashes using OpenCV, Python, and multiprocessing for all images in the dataset.
我们将在多重处理和 OpenCV 示例中使用的数据集是 CALTECH-101 ,这是我们在构建图像哈希搜索引擎时使用的数据集。
该数据集由 9,144 幅图像组成。
我们将使用多重处理将图像哈希提取分散到处理器的所有内核中。
你可以从他们的官方网页下载加州理工学院-101 数据集,或者你可以使用下面的wget命令:
$ wget http://www.vision.caltech.edu/Image_Datasets/Caltech101/101_ObjectCategories.tar.gz
$ tar xvzf 101_ObjectCategories.tar.gz
项目结构
让我们检查一下我们的项目结构:
$ tree --dirsfirst --filelimit 10
.
├── pyimagesearch
│ ├── __init__.py
│ └── parallel_hashing.py
├── 101_ObjectCategories [9,144 images]
├── temp_output
└── extract.py
在pyimagesearch模块中是我们的parallel_hashing.py助手脚本。这个脚本包含了我们的散列函数、分块函数和我们的process_images工具。
101_ObjectCatories/目录包含来自 CALTECH-101 的图像的 101 个子目录(通过上一节下载)。
许多中间文件将临时存储在temp_output/文件夹中。
我们多重处理的核心在于extract.py。这个脚本包括我们的预多处理开销、跨系统总线的并行化和后多处理开销。
我们的多重处理辅助功能
在我们利用 OpenCV 的多重处理来加速数据集处理之前,让我们首先实现一组用于促进多重处理的辅助工具。
打开目录结构中的parallel_hashing.py文件,插入以下代码:
# import the necessary packages
import numpy as np
import pickle
import cv2
def dhash(image, hashSize=8):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# resize the input image, adding a single column (width) so we
# can compute the horizontal gradient
resized = cv2.resize(gray, (hashSize + 1, hashSize))
# compute the (relative) horizontal gradient between adjacent
# column pixels
diff = resized[:, 1:] > resized[:, :-1]
# convert the difference image to a hash
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
我们从导入 NumPy、OpenCV 和pickle ( 第 2-5 行)开始。
从那里,我们定义我们的差分散列函数,dhash。图像哈希算法有很多种,但最流行的一种叫做 差分哈希 ,它包括四个步骤:
- 步骤#1: 将输入图像转换成灰度(第 8 行)。
- 步骤#2: 将图像调整到固定尺寸, N + 1 x N ,忽略长宽比。通常我们设置 N=8 或 N=16 。我们使用 N + 1 作为行数,这样我们可以计算图像中相邻像素(行 12 )之间的差异(因此为“差异散列】)。
- 第三步:计算差值。如果我们设置 N=8 ,那么每行有 9 个像素,每列有 8 个像素。然后我们可以计算相邻列像素之间的差异,产生 8 差异。 8 个行的 8 个差值(即 8×8 )产生 64 个值(行 16 )。
- 第四步:最后,我们可以建立散列。在实践中,我们实际需要执行的只是一个比较列的“大于”运算,产生二进制值。这些 64 二进制值被压缩成一个整数,形成我们的最终散列(第 19 行)。
通常,图像哈希算法用于在大型数据集中找到个近似重复的图像。
要全面了解差异散列法,请务必阅读以下两篇博文:
- 用 VP-Trees 和 OpenCV 构建图像哈希搜索引擎
- 用 OpenCV 和 Python 哈希图像
接下来,我们来看看convert_hash函数:
def convert_hash(h):
# convert the hash to NumPy's 64-bit float and then back to
# Python's built in int
return int(np.array(h, dtype="float64"))
当我第一次为图像哈希搜索引擎教程编写代码时,我发现 VP-Tree 实现在内部将点转换为 NumPy 64 位浮点。那没问题;然而,散列必须是整数,如果我们将它们转换成 64 位浮点数,它们就变成了不可散列的数据类型。为了克服 VP-Tree 实现的限制,我想到了convert_hash hack:
- 我们接受一个输入散列,
h。 - 该散列然后被转换成 NumPy 64 位浮点数。
- 然后将 NumPy 浮点数转换回 Python 内置的整数数据类型。
这种方法确保了哈希在整个哈希、索引和搜索过程中得到一致的表示。
为了利用多处理,我们首先需要将数据集分成大小相等的 N 个块(每个处理器内核一个块)。
现在让我们定义我们的chunk生成器:
def chunk(l, n):
# loop over the list in n-sized chunks
for i in range(0, len(l), n):
# yield the current n-sized chunk to the calling function
yield l[i: i + n]
chunk发生器接受两个参数:
l:元素列表(本例中为文件路径)。n:要生成的 N 大小的块的数量。
在函数内部,我们将列表l和yield N 大小的块循环到调用函数。
我们终于到了多处理实现的主力——process_images函数:
def process_images(payload):
# display the process ID for debugging and initialize the hashes
# dictionary
print("[INFO] starting process {}".format(payload["id"]))
hashes = {}
# loop over the image paths
for imagePath in payload["input_paths"]:
# load the input image, compute the hash, and conver it
image = cv2.imread(imagePath)
h = dhash(image)
h = convert_hash(h)
# update the hashes dictionary
l = hashes.get(h, [])
l.append(imagePath)
hashes[h] = l
# serialize the hashes dictionary to disk using the supplied
# output path
print("[INFO] process {} serializing hashes".format(payload["id"]))
f = open(payload["output_path"], "wb")
f.write(pickle.dumps(hashes))
f.close()
在单独的 extract.py脚本中,我们将使用 Python 的multiprocessing库启动一个专用的 Python 进程,将其分配给处理器的特定内核,然后在该特定内核上运行process_images函数。
process_images函数是这样工作的:
- 它接受一个
payload作为输入(行 32 )。假设payload是一个 Python 字典,但实际上可以是任何数据类型,只要我们可以对它进行 pickle 和 unpickle。 - 初始化
hashes字典(第 36 行)。 - 在
payload( 第 39 行 ) 的输入图像路径上循环。在循环中,我们加载每个图像,提取散列,并更新hashes字典(第 41-48 行)。 - 最后,我们将
hashes作为.pickle文件写入磁盘(第 53-55 行)。
为了这篇博文的目的,我们正在利用多重处理来促进输入数据集的更快图像散列;但是, 你应该使用这个函数作为模板来对你自己的数据集进行处理。
你应该很容易在关键点检测/局部不变特征提取、颜色通道统计、局部二进制模式等方面进行切换。在那里,你可以根据自己的需要修改这个函数。
实现 OpenCV 和多重处理脚本
既然我们的实用程序方法已经实现,让我们创建多处理驱动程序脚本。
该脚本将负责:
- 获取输入数据集中的所有图像路径。
- 将图像路径分成大小相等的 N 个块(其中 N 是我们希望使用的进程总数)。
- 使用
multiprocessing、Pool和map调用处理器每个内核上的process_images函数。 - 从每个独立的过程中获取结果,然后将它们组合起来。
如果你需要复习 Python 的多处理模块,一定要查阅文档。
让我们看看如何实现 OpenCV 和多重处理脚本。打开extract.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch.parallel_hashing import process_images
from pyimagesearch.parallel_hashing import chunk
from multiprocessing import Pool
from multiprocessing import cpu_count
from imutils import paths
import numpy as np
import argparse
import pickle
import os
第 2-10 行导入我们的包、模块和函数:
- 从我们的定制
parallel_hashing文件中,我们导入了我们的process_images和chunk函数。 - 为了适应并行处理,我们将使用 python
multiprocessing模块。具体来说,我们导入Pool(构建一个处理池)和cpu_count(如果没有提供--procs命令行参数,则获取可用 CPUs 内核的数量)。
我们所有的多重处理设置代码必须在主线程中执行:
# check to see if this is the main thread of execution
if __name__ == "__main__":
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True, type=str,
help="path to input directory of images")
ap.add_argument("-o", "--output", required=True, type=str,
help="path to output directory to store intermediate files")
ap.add_argument("-a", "--hashes", required=True, type=str,
help="path to output hashes dictionary")
ap.add_argument("-p", "--procs", type=int, default=-1,
help="# of processes to spin up")
args = vars(ap.parse_args())
第 13 行确保我们在执行的主线程中。这有助于防止多重处理错误,尤其是在 Windows 操作系统上。
第 15-24 行解析四个命令行参数:
--images:输入图像目录的路径。--output:存放中间文件的输出目录路径。--hashes:输出哈希字典的路径。泡菜格式。--procs:为多重处理启动的进程数。
随着我们的命令行参数被解析并准备就绪,现在我们将(1)确定要启动的并发进程的数量,以及(2)准备我们的映像路径(有点预多处理开销):
# determine the number of concurrent processes to launch when
# distributing the load across the system, then create the list
# of process IDs
procs = args["procs"] if args["procs"] > 0 else cpu_count()
procIDs = list(range(0, procs))
# grab the paths to the input images, then determine the number
# of images each process will handle
print("[INFO] grabbing image paths...")
allImagePaths = sorted(list(paths.list_images(args["images"])))
numImagesPerProc = len(allImagePaths) / float(procs)
numImagesPerProc = int(np.ceil(numImagesPerProc))
# chunk the image paths into N (approximately) equal sets, one
# set of image paths for each individual process
chunkedPaths = list(chunk(allImagePaths, numImagesPerProc))
第 29 行决定了我们将要启动的并发进程的总数,而第 30 行给每个进程分配一个 ID 号。默认情况下,我们将利用系统上的所有 CPUs 内核。
第 35 行获取数据集中输入图像的路径。
第 36 行和第 37 行通过将图像路径数除以进程数并取上限来确定每个进程的图像总数,以确保我们从此处开始使用整数值。
第 41 行利用我们的chunk函数创建一个由 N 个大小相等的图像路径组成的列表。我们将把每个块映射到一个独立的进程。
让我们准备好分配给每个进程的payloads(我们最后的预多处理开销):
# initialize the list of payloads
payloads = []
# loop over the set chunked image paths
for (i, imagePaths) in enumerate(chunkedPaths):
# construct the path to the output intermediary file for the
# current process
outputPath = os.path.sep.join([args["output"],
"proc_{}.pickle".format(i)])
# construct a dictionary of data for the payload, then add it
# to the payloads list
data = {
"id": i,
"input_paths": imagePaths,
"output_path": outputPath
}
payloads.append(data)
第 44 行初始化payloads列表。每个有效载荷将由data组成,包括:
- 一个 ID
- 输入路径列表
- 到中间文件的输出路径
第 47 行在我们的分块图像路径上开始一个循环。在循环内部,我们指定中间输出文件路径(它将存储该特定图像路径块的相应图像散列),同时在文件名中小心地用进程 ID 命名它(第 50 行和第 51 行)。
为了完成这个循环,我们append我们的data——一个由(1) ID、i、(2)输入imagePaths和(3) outputPath ( 第 55-60 行)组成的字典。
下一个块是我们在系统总线上分配数据集处理的地方:
# construct and launch the processing pool
print("[INFO] launching pool using {} processes...".format(procs))
pool = Pool(processes=procs)
pool.map(process_images, payloads)
# close the pool and wait for all processes to finish
print("[INFO] waiting for processes to finish...")
pool.close()
pool.join()
print("[INFO] multiprocessing complete")
Pool类在处理器的每个内核上创建 Python 进程/解释器(第 64 行)。
调用map获取payloads列表,然后在每个核上调用process_images,将payloads分配给每个核(行 65 )。
然后我们将关闭接受新任务的pool,并等待多重处理完成(第 69 行和第 70 行)。
最后一步(后多处理开销)是获取我们的中间散列并构建最终的组合散列。
# initialize our *combined* hashes dictionary (i.e., will combine
# the results of each pickled/serialized dictionary into a
# *single* dictionary
print("[INFO] combining hashes...")
hashes = {}
# loop over all pickle files in the output directory
for p in paths.list_files(args["output"], validExts=(".pickle"),):
# load the contents of the dictionary
data = pickle.loads(open(p, "rb").read())
# loop over the hashes and image paths in the dictionary
for (tempH, tempPaths) in data.items():
# grab all image paths with the current hash, add in the
# image paths for the current pickle file, and then
# update our hashes dictionary
imagePaths = hashes.get(tempH, [])
imagePaths.extend(tempPaths)
hashes[tempH] = imagePaths
# serialize the hashes dictionary to disk
print("[INFO] serializing hashes...")
f = open(args["hashes"], "wb")
f.write(pickle.dumps(hashes))
f.close()
第 77 行初始化散列字典来保存我们将从每个中间文件中填充的组合散列。
第 80-91 行填充组合散列字典。为此,我们循环所有中间的.pickle文件(即,每个进程一个.pickle文件)。在循环内部,我们(1)从数据中读取散列和相关的imagePaths,以及(2)更新hashes字典。
最后,第 94-97 行将hashes序列化为磁盘。我们可以使用序列化的哈希来构建一个 VP-Tree,并在这个时候在一个单独的脚本中搜索接近重复的图像。
***注意:**您可以更新代码从系统中删除临时.pickle文件;然而,我把它作为实现决策留给了读者。
OpenCV 和多重处理结果
让我们来测试一下 OpenCV 和多重处理方法。确保您已经:
- 使用本教程的 【下载】 部分下载源代码。
- 使用上面的“我们的示例数据集”部分中的说明下载了 CALTECH-101 数据集。
首先,让我们测试仅使用单核处理我们的 9,144 张图像数据集需要多长时间
$ time python extract.py --images 101_ObjectCategories --output temp_output \
--hashes hashes.pickle --procs 1
[INFO] grabbing image paths...
[INFO] launching pool using 1 processes...
[INFO] starting process 0
[INFO] process 0 serializing hashes
[INFO] waiting for processes to finish...
[INFO] multiprocessing complete
[INFO] combining hashes...
[INFO] serializing hashes...
real 0m9.576s
user 0m7.857s
sys 0m1.489s
仅使用单个进程(我们处理器的单核)需要 9.576 秒来处理整个图像数据集。
现在,让我们尝试使用所有的 20 个进程(可以映射到我的处理器的所有 20 个内核):
$ time python extract.py --images ~/Desktop/101_ObjectCategories \
--output temp_output --hashes hashes.pickle
[INFO] grabbing image paths...
[INFO] launching pool using 20 processes...
[INFO] starting process 0
[INFO] starting process 1
[INFO] starting process 2
[INFO] starting process 3
[INFO] starting process 4
[INFO] starting process 5
[INFO] starting process 6
[INFO] starting process 7
[INFO] starting process 8
[INFO] starting process 9
[INFO] starting process 10
[INFO] starting process 11
[INFO] starting process 12
[INFO] starting process 13
[INFO] starting process 14
[INFO] starting process 15
[INFO] starting process 16
[INFO] starting process 17
[INFO] starting process 18
[INFO] starting process 19
[INFO] process 3 serializing hashes
[INFO] process 4 serializing hashes
[INFO] process 6 serializing hashes
[INFO] process 8 serializing hashes
[INFO] process 5 serializing hashes
[INFO] process 19 serializing hashes
[INFO] process 11 serializing hashes
[INFO] process 10 serializing hashes
[INFO] process 16 serializing hashes
[INFO] process 14 serializing hashes
[INFO] process 15 serializing hashes
[INFO] process 18 serializing hashes
[INFO] process 7 serializing hashes
[INFO] process 17 serializing hashes
[INFO] process 12 serializing hashes
[INFO] process 9 serializing hashes
[INFO] process 13 serializing hashes
[INFO] process 2 serializing hashes
[INFO] process 1 serializing hashes
[INFO] process 0 serializing hashes
[INFO] waiting for processes to finish...
[INFO] multiprocessing complete
[INFO] combining hashes...
[INFO] serializing hashes...
real 0m1.508s
user 0m12.785s
sys 0m1.361s
通过在我的处理器的所有 20 个内核上分配图像哈希负载,我能够将处理数据集的时间从 9.576 秒减少到 1.508 秒,减少了 535%以上!
但是等等,如果我们用了 20 个核,那么总处理时间不应该约为 9.576 / 20 = 0.4788 秒吗?
嗯,不完全是,有几个原因:
- 首先,我们正在执行大量的I/O 操作。每个
cv2.imread调用都会导致 I/O 开销。哈希算法本身也非常简单。如果我们的算法真的是 CPU 受限的,而不是 I/O 受限的,那么加速系数会更高。 - 其次,多重处理不是一个“免费”的操作。在 Python 级别和操作系统级别都有开销函数调用,这使得我们看不到真正的 20 倍加速。
所有的计算机视觉和 OpenCV 算法都可以用多处理并行吗?
简而言之,答案是否定的,不是所有的算法都可以并行处理并分配给处理器的所有内核,有些算法本质上就是单线程的。
此外,您不能使用multiprocessing库来加速已编译的 OpenCV 例程,如cv2.GaussianBlur、cv2.Canny或cv2.dnn包中的任何深度神经网络例程。
这些例程以及所有其他的cv2.*函数都是预编译的 C/C++函数——Python 的multiprocessing库对它们没有任何影响。
相反,如果你对如何加速这些功能感兴趣,一定要看看 OpenCL 、线程构建模块(TBB) 、 NEON 和 VFPv3 。
此外,如果你正在使用 Raspberry Pi,你应该阅读这篇关于如何优化 OpenCV 安装的教程。
我还在我的书中加入了额外的 OpenCV 优化, 计算机视觉的树莓 Pi。
摘要
在本教程中,您学习了如何在 OpenCV 和 Python 中利用多处理。
具体来说,我们学习了如何使用 Python 的内置multiprocessing库以及Pool和map方法,在所有处理器和处理器的所有内核之间并行化和分布处理。
最终结果是在处理我们的图像数据集的时间上大幅加速了 535%。
我们通过索引一个图像数据集来检验 OpenCV 的多重处理,以构建一个图像哈希搜索引擎;然而,您可以修改/实现您自己的process_images函数来包含您自己的功能。
我个人的建议是,在构建自己的多处理和 OpenCV 应用程序时,使用process_images函数作为模板。
我希望你喜欢这个教程!
如果你想在未来看到更多的多重处理和 OpenCV 优化教程,请在下面留下评论,让我知道。
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!*
我的深度学习 Kickstarter 将于美国东部时间 1 月 18 日星期三上午 10 点上线
今天我有一些令人兴奋的消息要分享!
我的用 Python 进行计算机视觉深度学习的Kickstarter 活动将在正好一周美国东部时间 1 月 18 日周三上午 10 点开始。**
*
这本书只有一个目标——帮助像你一样的开发者、研究人员和学生成为图像识别和分类深度学习的专家。
无论这是你第一次使用机器学习和神经、网络还是你已经是一个经验丰富的深度学习实践者、使用 Python 进行计算机视觉的深度学习是从零开始设计的,以帮助你达到专家状态。
在这本书里,你会发现:
- 超级实用的演练展示了实际、真实世界图像分类问题、挑战和竞赛的解决方案。
- 实践教程(有大量代码)不仅向你展示了计算机视觉深度学习背后的算法,还展示了它们的实现。
- 一本正经的教学风格,保证能打破所有障碍,帮助你掌握图像理解和视觉识别的深度学习。
作为提醒,在接下来的 7 天里,我会再发布一些你不想错过的公告,包括:
1 月 12 日星期四:
Kickstarter 活动的预览,包括你将在书中发现的内容的演示视频。
1 月 13 日星期五:
用 Python 进行计算机视觉深度学习的目录。这本书是广泛的,涵盖了深度学习的基础知识,一直到在海量 ImageNet 数据集上训练大规模网络。你不会想错过这个列表的!
1 月 16 日星期一:
Kickstarter 奖励的完整列表(包括早鸟折扣 ) 这样你就可以提前计划在 Kickstarter 启动时你想要的奖励。
我不会公开发布这份名单——这份奖励名单仅面向 PyImageSearch 简讯的 PyImageSearch 读者。
1 月 17 日星期二:
请记住,这本书已经得到了很多的关注,所以在 18 日星期三 Kickstarter 活动启动时,将有多人排队等待每个奖励等级。为了确保你得到你想要的奖励,我将分享你可以用来确保你排在第一位的技巧和诀窍。
再说一次,我也不会公开发布这个。确保你注册了 PyImageSearch 简讯来接收这些提示和技巧,以确保你在队伍的最前面。
1 月 18 日星期三:
Kickstarter 活动链接,你可以用它来领取你的Python 计算机视觉深度学习副本。
要在这些公告发布时收到通知, 请务必注册 Kickstarter 通知列表!*
我的 Kickstarter 将于美国东部时间 1 月 14 日星期三上午 10 点上线
原文:https://pyimagesearch.com/2015/01/07/my-kickstarter-will-go-live-wednesday-january-14th-10am/
哦,伙计,我今天有一些令人兴奋的消息要分享:
我的视频搜索大师 Kickstarter】将在一周后于美国东部时间 1 月 14 日(星期三)上午 10 点在推出。****
如果你还没有听说过 PyImageSearch 大师,这里有一个快速的 4 点分解:
- 关于 OpenCV 和计算机视觉的可操作的、真实世界的 6-8 个月课程。本课程将使用 Python 和 OpenCV(以及其他一些库)来讲授。每个月都会发布一套新的课程。
- 一个由志趣相投的开发者、程序员和学生组成的社区,他们渴望学习计算机视觉并提升他们的 OpenCV 技能。
- 云中的 IPython 笔记本开发环境。我们研究的一切和我们从事的所有项目都将在云中完成,并通过您的浏览器完成。没有东西可以下载,也没有东西可以安装。
- 直接找我。每天我都会收到 100 封电子邮件,而且数量每周都在增加。PyImageSearch 大师论坛和 Q & A 将会是我的新家,也是你保证能接触到我的地方。
作为提醒,在接下来的 7 天里,我会再发布一些你不想错过的公告,包括:
1 月 8 日星期四:
Kickstarter 活动的预览,包括 PyImageSearch 大师们的演示视频。
1 月 9 日星期五:
我们将在 PyImageSearch 大师中讨论的主题分类。从人脸识别,到自动车牌检测、深度学习、和树莓派项目,有太多令人敬畏的计算机视觉主题我们将要涉及。你不会想错过这个列表的!
1 月 12 日星期一:
Kickstarter 奖励的完整列表,这样你就可以提前计划你想要的奖励。
1 月 14 日星期三:
Kickstarter 活动链接,你可以用它来认领你的 PyImageSearch 大师名额和获得你的 Kickstarter 奖励。
要在这些公告发布时收到通知, 请务必注册 Kickstarter 通知列表!
随着 1 月 14 日的临近,请务必查看您的收件箱!
我的 OCR with OpenCV、Tesseract 和 Python IndieGoGo 活动将于美国东部时间 8 月 19 日星期三上午 10 点上线
今天要分享的大新闻!
我非常激动地宣布,我的 OCR with Tesseract、OpenCV 和 Python IndieGoGo 活动将于一周后美国东部时间 8 月 19 日星期三上午 10 点在启动。** ( 注:此战役已经结束。但是你仍然可以在这里预购我的新书 OCR with Tesseract、OpenCV 和 Python 和。)**

那么,我为什么要写一本关于 OCR 的书呢?
- 尽管深度学习取得了诸多进步,但 OCR 仍然极具挑战性。
- 像 Tesseract 这样的工具很麻烦,很难使用,并且很少提供教程或文档
- 更不用说,将 OCR 和 Tesseract 集成到您自己的 OpenCV 项目中会让您拔头发(我应该知道,我是秃头)。
我的新书揭开了 OCR 的神秘面纱,让你能够成功地和自信地将 OCR 应用到你的工作、学校项目和研究中。
书中会涉及哪些内容?

我的新 OCR 书:
- 介绍宇宙魔方 OCR 引擎
- 向您展示如何调整 Tersseract 的所有旋钮和刻度盘来提高 OCR 准确度
- 教你如何在自己的项目中集成 Tesseract 和 OpenCV
- 提供从头开始训练自定义 OCR 模型的章节
- 利用深度学习在您自己的自定义数据集上创建 OCR 模型
- 向您展示如何使用基于云的 OCR APIs,例如 Amazon Rekognition、微软认知服务和 Google Vision API
此外,我还提供了一些案例研究,内容涉及:
- 构建 OpenCV 数独求解器
- 对发票、简历等表格文件进行光学字符识别。
- 创建收据扫描仪
- 用 OCR 建立自动牌照/号码牌(ANPR)系统
- 如何对视频流应用 OCR
- 如何用你的 GPU 提高 OCR 速度
- 从头开始训练一个立方体模型
- 如何使用 Keras 和 TensorFlow 训练自定义 OCR 模型
- … 还有更多!
竣工证明

这本书将包括一个完成证书选项。成功完成书中每一课的测验和作业后,您将获得一份结业证书,您可以将它放在您的 LinkedIn 个人资料、简历等中。
为什么选择 IndieGoGo?以前的活动不是用 Kickstarter 吗?
长期使用 PyImageSearch 的读者会注意到,我过去发起过三次众筹活动(一次是为 PyImageSearch 大师课程,一次是为 用 Python 进行计算机视觉深度学习,另一次是为 计算机视觉 树莓 Pi)。这三个项目都是通过 Kickstarter(一个流行的众筹平台)推出的。
这就提出了一个问题— 为什么要使用 IndieGoGo 而不是 Kickstarter?
有两个原因:
首先,Kickstarter 平台漏洞百出。在过去的四年里,我已经向 Kickstarter 报告了许多使用他们平台的错误。这些错误从未被修复。坦率地说,我已经开始对 Kickstarter 失去一点信心了。
但更重要的是,Kickstarter 让提供多重折扣和交易变得令人困惑。当我在 Kickstarter 上为计算机视觉的 Raspberry Pi 开展活动的时候,反馈中最大的一点就是结账过程令人困惑。
IndieGoGo 有一个更加直观、简单的结账流程,允许您:
- 以独家预发布价格获取您的 OpenCV、Tesseract 和 PythonOCR 副本
- 另外,以折扣价购买我的其他书籍和课程(如果您愿意)
我的目标是让你尽可能容易地利用这些交易和折扣——当我测试 IndieGoGo 平台时,这是显而易见的。
我害怕失败。
回到 2015 年 2 月,我发起了我的第一次 Kickstarter 众筹活动。这一活动是为了 PyImageSearch 大师课程,该课程现在已经成为学习计算机视觉、深度学习和 OpenCV 的最佳在线课程。
但是让我告诉你,【Kickstarter 活动几乎从未启动过。
没有人知道这一点,但回到 2014 年 11 月,我工作的初创公司失去了我们的资金。我们与马里兰州有政府合同,当州选举导致州长易手时,当选州长立即取消了我们的合同。
我刚从研究生院毕业,手里拿着博士文凭,却已经失业了!
我当时正处于人生的关键时刻;我可以出去,找一份新工作,继续走同样的路 … 或者,我可以想办法让 PyImageSearch 成为我的全职工作。
我选择了后者。
我背靠着墙,蹲下身子,我知道这将是一场生死之战。
我知道打击即将来临。我感觉就像洛奇·巴尔博亚在和阿波罗·奎迪战斗……但是如果我能承受这一拳,我就能成功。
但是让我告诉你,一拳还是一拳——而且很痛。
账单堆积如山。我刚刚和我的女朋友同居(几年后,她成了我的妻子)。我正面临困境。我举起手套保护我的头,但是我被一次又一次的身体打击。如果我的手倒下了,我知道我出局了——我不能一拳打在头上。
在 PyImageSearch Kickstarter 活动之前,我非常紧张。在它发射前的四个晚上,我几乎没有睡觉。
我紧张又焦虑。我的左眼在抽搐。我不断有灾难性的“如果”想法:
- 如果我付不起账单怎么办?
- 如果我破产了怎么办?
- 我刚和我爱的女孩同居——如果她因为这个职业决定失败而离开我怎么办?
我没有意识到,但我现在知道的是,不管 PyImageSearch Gurus 课程是否成功,我仍然会在第二天早上醒来。生活还会继续。
- 如果成功了,太好了! 我早就明确了全职运行 PyImageSearch 的敲门砖。
- 如果失败了,至少我学到了一些东西。 是的,在接下来的 6-12 个月里,随着我找到一份新工作并偿还债务,生活会变得更加艰难,但实际上,那时我只有 24 岁。我有足够的时间从那次打击中恢复过来。
我经常看到开发人员、学生和研究人员说服自己而不是去学习一项新技能,因为他们害怕失败。
我从六年前的 Kickstarter 活动中学到了一些东西——对我来说最大的失败是而不是启动它。
如果我屈服于对失败的恐惧,在最后一刻退出,那么 PyImageSearch 大师课程就不会存在。
如果这个课程不存在,那么很有可能 PyImageSearch 也不会存在。该课程的成功吸引了大量的学生和资金,使 PyImageSearch 发展到今天的水平。
在我看来,唯一真正的失败是没有在身体上、精神上和教育上投资自己。
- 投资你的身体,它是你唯一拥有的。它需要持续 70 年以上。经常锻炼,健康饮食,多喝水。学会减少(或消除)酒精和咖啡因的摄入。每晚保证 8 小时睡眠。
- 投资于你的头脑,保持它的敏锐。睡前冥想,早上第一件事。利用每日感恩日记。当你伤害了别人的感情时,放下你的自我并道歉(即使你知道你是对的和有道理的)。最重要的是,赞美你生命中对你最重要的人。把他们放在一个基座上,让他们觉得自己是被需要的、特别的、了不起的。
- 投资于你的教育,这能让你保持年轻。对神经可塑性(即你的大脑修改连接和自我重组的能力)的研究表明,通过教育进行刺激有助于降低痴呆症、阿尔茨海默病和其他大脑退化疾病的风险。即使你年纪大了,退休了,你仍然需要学习来保持大脑年轻!如果你还年轻,就没有理由不投资自己和教育——这不仅对你的职业很重要,对你的长期健康也很重要。
下一步是什么?

OCR 是计算机视觉和深度学习中最具挑战性的子领域之一。虽然 OCR 是一个简单、直观的概念,但它仍有待“完全解决”。没有现成的 OCR 包是 100%准确的,并且在每种用例/情况下都能工作。
我的书将教你如何成功地和自信地将 OCR 应用到你自己的工作、项目和研究中。我保证。请考虑加入我,以独家折扣价购买我的新书。
点击下面的按钮领取您的预购副本:
我的计算机视觉 Kickstarter 版树莓 Pi 将于美国东部时间 4 月 10 日周三上午 10 点上线。
我今天有重大消息要分享!
我非常兴奋地宣布,我的用于计算机视觉的 树莓 PiKickstarter 活动将于一周后美国东部时间 4 月 10 日星期三上午 10 点在发布。****

计算机视觉、深度学习和物联网(IoT) 是计算机科学中发展最快的三个行业和学科——在我的新书中,你将学习如何使用 Raspberry Pi 将这三个结合起来。
无论这是你第一次使用树莓 Pi,还是你是一个多年来一直使用 Pi 的业余爱好者, 用于计算机视觉的树莓 Pi将使你能够“看到”Pi。
在这本书里面我们将重点介绍:
- Raspberry Pi 上的计算机视觉入门
- Pi 上的计算机视觉和物联网项目
- 伺服系统、PID 和用计算机视觉控制 Pi
- 人类活动、家庭监控和面部应用
- 树莓派上的深度学习
- 借助 Movidius NCS 和 OpenVINO 工具包实现快速、高效的深度学习
- 树莓派上的自动驾驶汽车应用
- 使用 RPi 执行计算机视觉和深度学习时的提示、建议和最佳实践
我也有关于 NVIDIA Jetson Nano 和 Google Coral 的章节。
作为提醒,在接下来的 7 天里,我会再发布一些你不想错过的公告,包括:
2019 年 4 月 4 日星期四
Kickstarter 活动的预览,包括一个演示视频,展示你将在书中发现的内容。
2019 年 4 月 5 日星期五
目录为 为计算机视觉树莓派。 这本书是实用和动手,给你把 CV 和 DL 带到嵌入式设备需要的知识。你不想错过这个章节列表!
2019 年 4 月 8 日星期一
Kickstarter 奖励的完整列表(包括早鸟折扣和销售)。 当 Kickstarter 启动时,你可以使用这个列表提前计划你想要的奖励等级。
2019 年 4 月 9 日星期二
请记住,这本书已经得到了很多的关注,所以当 Kickstarter 在美国东部时间 4 月 10 日星期三上午 10 点发布时,将有多人排队等待每个奖励等级。为了帮助确保你得到你想要的奖励等级,我将分享我的提示和建议,你可以用它们来确保你是第一个。
2019 年 4 月 10 日星期三
我会通过电子邮件向您发送 Kickstarter 活动链接,您可以使用该链接申领您的简历 RPi 副本,以及额外的折扣和销售!
为了在这些公告发布时得到通知, 请务必注册参加Raspberry Pi for Computer VisionKickstarter 通知列表!
我对微软深度学习数据科学虚拟机(DSVM)的评论
原文:https://pyimagesearch.com/2018/03/21/my-review-of-microsofts-deep-learning-virtual-machine/

Image credit: OnMSFT
在过去的几个月里,我一直在使用微软的 Ubuntu 深度学习和数据科学虚拟机(DSVM)来完成我在 PyImageSearch 的几个项目。
起初,我有点犹豫(甚至有点抗拒)尝试一下——我已经有了一个预配置的亚马逊 AWS 深度学习 AMI ,它(1)我经常使用,( 2)对任何希望在自己的项目中使用它的 PyImageSearch 读者都是公开可用的。
虽然我不是亚马逊 AWS 用户界面的粉丝,但多年来我已经习惯了它。我想在它笨拙的复杂性中有一种“熟悉感”。
但是我听说了关于 Ubuntu DSVM 的 如此好的事情,所以我决定测试一下。
我被深深打动了。
界面更容易使用。表演很棒。价格很合理。
…而且,使用 Python 的计算机视觉深度学习的所有代码都在上面运行,没有任何改动,这也没有什么坏处。
微软甚至慷慨地允许我在他们的机器学习博客上发表一系列客座博文,分享我在使用、测试和评估机器学习时的经历:
微软非常认真地将自己打造成深度学习、机器学习和数据科学的“首选”云环境。他们 DSVM 产品的质量表明了这一点。
在今天特别版博文的剩余部分,我将分享我对 DSVM 的想法,甚至演示如何启动您的第一个实例,并在其上运行您的第一个深度学习示例。
了解更多微软深度学习虚拟机(以及它是否适合你),继续阅读!
微软深度学习虚拟机综述
当我第一次评估微软的数据科学和深度学习虚拟机(DSVM)时,我用 Python 和 在 DSVM 上运行了所有来自 计算机视觉深度学习的代码示例 。
手动运行每个示例并检查输出的过程有点乏味,但这也是将 DSVM 放入振铃器并评估它的一个很好的方法:
- 初学者用法(即刚入门深度学习)
- 从业者使用,在这里你要建立深度学习模型,需要快速评估表现
- 研究用途,在大型图像数据集上训练深度神经网络。
使用 Python 进行计算机视觉深度学习的代码库完美地补充了这个测试。
Starter Bundle 里面的代码是为了帮助你迈出图像分类、深度学习和卷积神经网络(CNN)的第一步。
如果代码在 DSVM 上运行顺利,那么我肯定会推荐给正在寻找预配置深度学习环境的初学者。
实践者包中的章节+附带代码涵盖了更高级的技术(迁移学习、微调 GANs 等)。这些是深度学习实践者或工程师将在日常工作中应用的技术。
如果 DSVM 处理了这些例子,那么我知道我可以把它推荐给深度学习的从业者。
最后, ImageNet 捆绑包内的代码需要 GPU 马力(越多越好)和 I/O 性能。在这个包里,我演示了如何复制最先进的出版物(例如。ResNet、SqueezeNet 等。)在海量图像数据集上,如 120 万图像 ImageNet 数据集。
如果 DSVM 可以处理复制最先进论文的结果,那么我知道我可以向研究人员推荐 DSVM。
在这篇博文的前半部分,我将总结我在这些测试中的经历。
在那里,我将向您展示如何在微软云中启动您的第一个深度学习实例,然后在 DSVM 中运行您的第一个深度学习代码示例。
全面的深度学习库
Figure 1: The Microsoft Azure Data Science Virtual Machine comes with all packages shown pre-installed and pre-configured for your immediate use.
微软的深度学习虚拟机运行在他们的 Azure 云中。
它在技术上可以运行 Windows 或 Linux,但对于几乎所有的深度学习项目,我会建议你使用他们的 Ubuntu DSVM 实例(除非你有特定的理由使用 Windows)。
安装在 DSVM 上的包的列表非常全面——你可以在这里找到完整的列表。我在下面列出了最著名的深度学习和计算机视觉包(特别是对 PyImageSearch 的读者),让你知道这个列表有多全面:
- TensorFlow
- Keras
- mxnet
- Caffe/Caffe2
- Torch/PyTorch
- OpenCV
- Jupyter
- CUDA 和 cuDNN
- python3
DSVM 团队每隔几个月发布一个新的、更新的 DSVM,并预先配置和安装最新的软件包。这是一个 巨大的 的证明,不仅证明了 DSVM 团队保持这个实例无缝运行(保持 DSVM 没有包冲突肯定是一个痛苦的过程,但它对最终用户是完全透明的),也证明了微软希望让用户也享受体验的愿望。
GPU 呢?
DSVM 可以在纯 CPU 和 GPU 实例中运行。
对于我下面运行的大多数实验和测试,我使用了一个带有标准 NVIDIA K80 GPU 的 Ubuntu GPU 实例。
此外,微软允许我访问他们刚刚发布的 NVIDIA V100 庞然大物,我用它进行了一些额外的快速抽查(见下面的结果— 真快!)
对于所有的初学者捆绑包和实践者捆绑包实验,我选择测试微软的 Jupyter 笔记本。
这个过程非常简单。
我在浏览器中复制并粘贴了 Jupyter 笔记本服务器的 URL,启动了一个新的笔记本,几分钟后我就可以运行书中的例子了。
对于 ImageNet 捆绑包实验,我使用 SSH 来复制最先进的论文的结果,这需要几天的训练时间,我个人认为这不是 Jupyter 笔记本的正确用法。
便于深度学习初学者使用
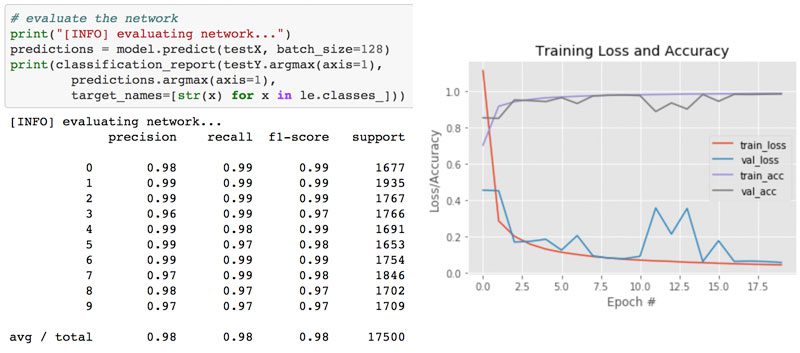
Figure 2: Training the LeNet architecture on the MNIST dataset. This combination is often referred to as the “hello world” example of Deep Learning.
在我在微软博客上的第一篇客座博文中,我在 MNIST 手写数字数据集上训练了一个简单的卷积神经网络(LeNet)。在 MNIST 上训练 LeNet 可能是研究深度学习的初学者的第一次“真正”实验。
模型和数据集都很简单,训练也可以在 CPU 或 GPU 上进行。
我用 Python(Starter Bundle)从计算机视觉的 深度学习的第 14 章中取出代码,并在微软 DSVM 上的 Jupyter 笔记本(你可以在这里找到)中执行。
其结果可以在上面的图 2 中看到。
经过 20 个时期的训练,我能够获得 98%的分类准确率。
使用 Python 进行计算机视觉深度学习的的初学者包中的所有其他代码示例也运行顺利。
能够在 Azure DSVM 上通过 Jupyter 笔记本在浏览器中运行代码(没有额外的配置)是一种很好的体验,我相信刚接触深度学习的用户会喜欢并欣赏这种体验。
对深度学习从业者实用有用
Figure 3: Taking 2nd place on the Kaggle Leaderboard for the dogs vs. cats challenge is a breeze with the Microsoft Azure DSVM (pre-configured) using code from Deep Learning for Computer Vision with Python.
我在微软博客上的第二篇文章是面向从业者的。
深度学习实践者使用的一种常见技术是应用迁移学习,特别是特征提取,以快速训练模型并获得高精度。
为了演示如何将 DSVM 用于寻求快速训练模型和评估不同超参数的从业者,我:
- 在 Kaggle Dogs vs. Cats 数据集上使用预训练的 ResNet 模型进行特征提取。
- 对提取的特征应用具有网格搜索超参数的逻辑回归分类器。
- 获得了能够在比赛中夺取第二名的最终模型。
我还想在 25 分钟内完成所有这些。
最终的结果是一个模型能够以仅仅 22 分钟的计算 滑入第二名(如图图 3 所示)。
你可以在这篇文章中找到关于我如何完成这项任务的完整文章,包括 Jupyter 笔记本+代码。
但是它能更快地完成吗?
在我在 NVIDIA K80 上运行了 Kaggle Dogs vs. Cats 实验之后,微软允许我访问他们刚刚发布的 NVIDIA V100 GPUs。
我以前从未使用过 NVIDIA V100,所以看到结果我真的很兴奋。
我被震撼了。
NVIDIA K80 花了 22 分钟完成流水线,而 NVIDIA V100 只用了 5 分钟就完成了任务——这比 340 提高了一大截!
我相信深度学习实践者将从在 V100 和 K80 上运行他们的实验中获得很多价值,但你也需要证明价格是合理的(见下文)。
强大到足以进行最先进的深度学习研究
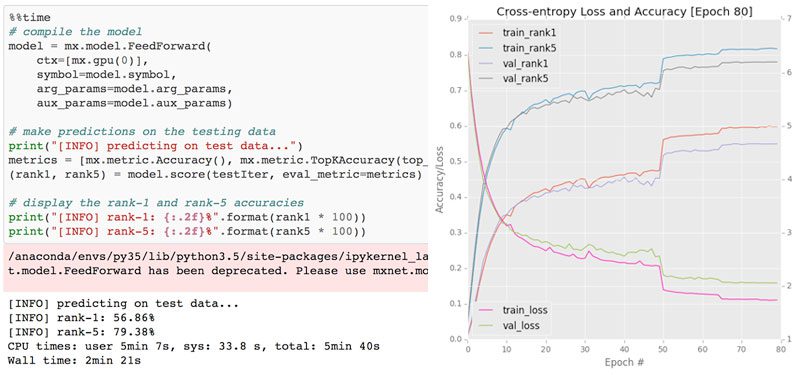
Figure 4: The Microsoft Azure DSVM handles training SqueezeNet on the ImageNet dataset easily.
DSVM 非常适合深度学习的初学者和实践者——但是从事最先进工作的研究人员呢?DSVM 对他们还有用吗?
为了评价这个问题,我:
- 将整个 ImageNet 数据集下载到虚拟机
- 从第九章 ImageNet 捆绑包的 用 Python 进行计算机视觉的深度学习 中取出代码,在那里我演示了如何在 ImageNet 上训练 SqueezeNet
我选择 SqueezeNet 有几个原因:
- 我有一台本地机器已经在 ImageNet 上为一个单独的项目训练了 SqueezeNet,这使我能够很容易地比较结果。
- SqueezeNet 是我个人最喜欢的架构之一。
- 得到的模型大小(小于 5MB,无量化)更容易用于生产环境,其中模型需要部署在资源受限的网络或设备上。
我在 NVIDIA K80 上总共训练了 80 个纪元的 SqueezeNet。SGD 用于以 1e-2 的初始学习速率训练网络(我发现 Iandola 等人推荐的 4e-2 对于稳定训练来说太大了)。在第 50、65 和 75 个时期,学习率分别下降了一个数量级。
在 K80 上,每个历元大约需要 140 分钟,所以整个训练时间为 ~1 周。
根据使用的 GPU 数量,使用多个 GPU 可以轻松地将培训时间减少到 1-3 天。
训练完成后,我在 50,000 个图像测试集上进行评估(我从训练集中取样,因此我不必将结果提交给 ImageNet 评估服务器)。
总的来说,我获得了 58.86% rank-1 和 79.38% rank-5 的准确率。这些结果与 Iandola 等人报道的结果一致。
关于 SqueezeNet + ImageNet 的完整文章可以在微软博客上找到。
使用 NVIDIA V100 进行难以置信的快速训练
在我使用 NVIDIA K80 在 ImageNet 上训练 SqueezeNet 之后,我使用单个 V100 GPU 重复了这个实验。
训练中的加速令人难以置信。
与 K80 相比(每个周期约 140 分钟),V100 在 28 分钟 内完成了一个周期,一个巨大的 加速超过 400%!
我能够在 36 个多小时内训练 SqueezeNet 并复制我之前实验的结果。
深度学习研究人员应该认真考虑 DSVM,特别是如果你不想拥有和维护实际的硬件。
但是价格呢?
Figure 5: GPU compute pricing comparison for various deep learning + GPU providers.
在亚马逊的 EC2 上,对于一个 p2.xlarge 实例,你将支付 0.90 美元/小时(1x K80)、7.20 美元/小时(8x K80)或 14.40 美元/小时(16x K80)。每 K80 每小时 0.90 美元。
在微软 Azure 上,价格完全相同,分别为 0.90 美元/小时(1x K80)、1.80 美元/小时(2x K80)和 3.60 美元/小时(4x K80)。每 K80 小时的费用也是 0.90 美元。
亚马逊已经准备好了 V100 机器,定价为 3.06 美元/小时(1x V100)、12.24 美元/小时(4x V100)、24.48 美元/小时(8x V100)。准备在亚马逊 EC2 上为每 V100 花费 3.06 美元/小时。
Azure 上最近发布的 V100 实例的价格极具竞争力,分别为 3.06 美元/小时(1 个 V100)、6.12 美元/小时(2 个 V100)、12.24 美元/小时(4 个 V100)。这也是每 V100 每小时 3.06 美元。
微软提供 Azure Batch AI 定价,类似于亚马逊的现货定价,使你有可能在实例上获得更好的交易。
除非我们也看看谷歌、Paperspace 和 Floydhub,否则这不会是一个完整(和公平)的价格比较。
谷歌收费 0.45 美元/小时(1x K80),0.90 美元(2x K80),1.80 美元/小时(4x K80),3.60 美元/小时(8x K80)。这显然是 K80 的最佳定价模式,价格是 MS/EC2 的一半。据我所知,谷歌没有 V100 机器。相反,他们提供自己的品种,TPU,价格为 6.50 美元/小时/TPU。
Paperspace 收费 2.30 美元/小时(1x V100 ),他们有 API 端点。
Floydhub 的定价是 4.20 美元/小时(1x V100),但他们提供了一些很棒的团队协作解决方案。
说到可靠性,EC2 和 Azure 是最突出的。当你考虑到 Azure 的易用性(与 EC2 相比)时,就越来越难以证明长期坚持使用亚马逊是正确的。
如果你有兴趣尝试一下 Azure 云,微软也提供了 免费试用积分;然而,试用不能用于 GPU 机器(我知道,这是个败笔,但 GPU 实例很珍贵)。
在微软云中启动第一个深度学习实例
启动 DSVM 实例非常简单——本节将是启动 DSVM 实例的快速入门指南。
对于高级配置,您需要参考文档(因为我将主要选择默认选项)。
此外,你可能想考虑注册微软的免费 Azure 试用版 ,这样你就可以测试他们的 Azure 云,而无需花费你的资金
注:微软的试用不能用于 GPU 机器。我知道,这是令人失望的,但 GPU 实例是一个巨大的溢价。
我们开始吧!
第一步:在【portal.azure.com】创建用户账号或登录。
第二步:点击左上角的“创建资源”。
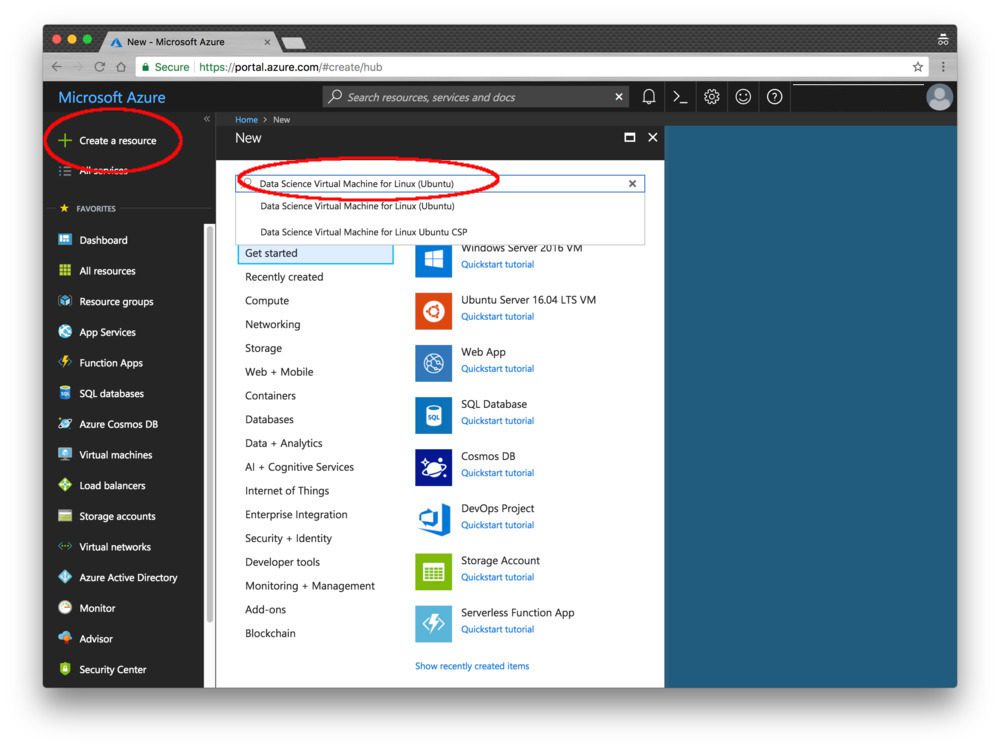
Figure 6: Microsoft Azure “Create Resource” screen.
第三步:在搜索框中输入“Data Science Virtual Machine for Linux”,它会根据您的输入自动完成。选择第一个 Ubuntu 选项。
第四步:配置基本设置:创建一个名字(没有空格或特殊字符)。选择 HDD (不要选择 SSD)。我选择使用一个简单的密码,而不是一个密钥文件,但这取决于你。在【订阅】下,查看您是否有可用的免费积分。您需要创建一个“资源组”——我使用了现有的“rg1”。

Figure 7: Microsoft Azure resource “Basic Settings”.
第五步:选择一个地区,然后选择你的 VM。我选择了可用的 K80 实例(NC65_V3)。如果向下滚动(NC6S_V3),V100 实例也可用。我的一个抱怨是我不理解命名惯例。我希望它们能像跑车一样命名,或者至少像 2x K80 机器的“K80-2”那样命名,但它们是以虚拟 CPU 的数量命名的,当我们对 GPU 感兴趣时,这有点令人困惑。

Figure 8: The Microsoft Azure DSVM will run on a K80 GPU and V100 GPU.
第 6 步:查看总结页面并同意合同:
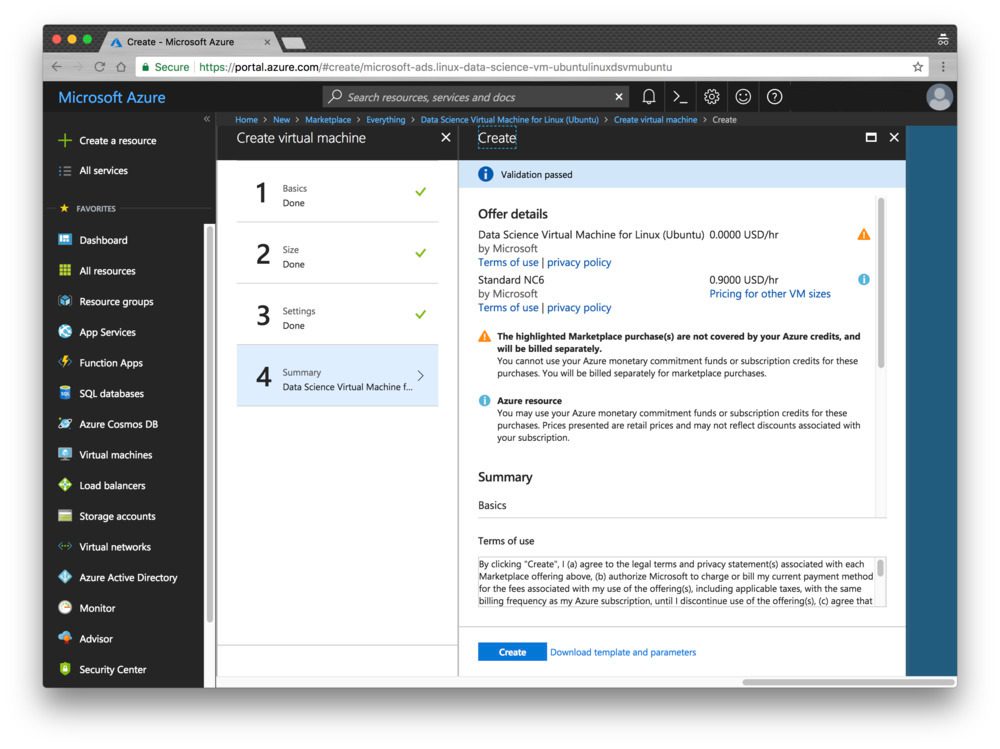
Figure 9: The summary page allows you to review and agree to the contract.
第 7 步 : 等待系统部署完成——当您的系统准备就绪时,您会看到一个方便的通知。
第八步:点击“所有资源”。您将在这里看到您所支付的一切:
Figure 10: The Azure “All Resources” page shows my DSVM and associated services.
如果您选择虚拟机,那么您将看到关于您的机器的信息(在一个新的选项卡中打开下面的屏幕截图,以便您可以看到包含 IP 地址等的图像的更高分辨率版本。):
Figure 11: The “Resource Overview” page allows for you to see your instance’s
步骤 9: 通过 SSH 和/或 Jupyter 连接。
无论您使用的是密钥文件还是密码,单击 connect 选项都会为您提供 SSH 的连接详细信息:
不幸的是,没有显示到 Jupyter 的便捷链接。要访问 Jupyter,您需要:
- 在浏览器中打开一个新标签
- 导航到
https://yourAzureDsvmPublicIP:8000(“http”后面的“s”很重要)。请确保在 URL 中填入您的公共 IP。
在深度学习虚拟机上运行代码
现在,让我们运行我在 Jupyter 的第一篇微软帖子中的 LeNet + MNIST 的例子。
这是一个两步过程:
第一步: SSH 入机(见上一节第九步)。
将目录更改为~/notebooks目录。
克隆回购:$ git clone https://github.com/jrosebr1/microsoft-dsvm.git
第二步:在浏览器中启动 Jupyter(参见上一节中的第九步)。
点击microsoft-dsvm目录。
打开相应的.ipynb文件(pyimagesearch-training-your-first-cnn.ipynb)。
在运行笔记本之前,我想向您介绍一个小技巧。
这不是强制性的,但是如果您在 DSVM 中使用多台笔记本电脑,这可以减少一些麻烦。
这种伎俩的动机是这样的:如果你执行一个笔记本,但让它“运行”,内核仍然有一个 GPU 锁。无论何时运行不同的笔记本,您都会看到诸如“资源耗尽”之类的错误。
快速解决方法是将下面两行 放在笔记本最底部的自己的单元格 中:
%%javascript
Jupyter.notebook.session.delete();
现在,当你执行完笔记本中的所有单元格,笔记本会优雅地关闭自己的内核。这样你就不必记得手动关闭它。
从那里,你可以点击第一个单元格内的某处,然后点击“单元格>运行全部”。 这将运行笔记本中的所有单元,并在 MNIST 上训练 LeNet。从那里,您可以在浏览器中查看输出,并获得类似于下面的结果:

Figure 12: Training LeNet on MNIST in the Microsoft Azure cloud and the Data Science Virtual Machine (DSVM).
我喜欢在完成后或修改后开始新的运行前清除所有输出。你可以从“内核>重启&清除输出菜单中选择。
摘要
在今天的博文中,我回顾并讨论了我个人对微软的数据科学和深度学习虚拟机(DSVM)的体验。
我还演示了如何启动您的第一个 DSVM 实例,并在其上运行您的第一个深度学习示例。
我将第一个承认,在尝试 DSVM 时我有点犹豫,但我很高兴我这样做了。
我对 DSVM 进行的每一项测试,从初学者的使用到复制最先进论文的结果,它都处理得很轻松。
当我能够使用微软新的 NVIDIA V100 GPU 实例时,我的实验飞了,看到 NVIDIA K80 实例的加速比高达% 400。
****如果你在市场上寻找一个基于深度学习云的 GPU 实例,我会鼓励你尝试一下微软的 DSVM——体验非常棒,微软的支持非常好,DSVM 本身功能强大但易于使用。
此外,微软和 DSVM 团队将赞助 PyImageConf 2018 ,这是 PyImageSearch 自己的计算机视觉和深度学习会议。

在会议期间,PyImageConf 与会者将有 免费访问 DSVM GPU 实例,允许您:
- 接着是讲座和研讨会
- 训练他们自己的模型
- 最好向演讲者学习
了解更多关于 PyImageConf 2018, 只需点击这里 。
我希望在那里见到你!****
我最喜欢的 9 个 Python 深度学习库
原文:https://pyimagesearch.com/2016/06/27/my-top-9-favorite-python-deep-learning-libraries/

所以你对深度学习和卷积神经网络感兴趣。但是你从哪里开始呢?你使用哪个图书馆?有太多了!
在这篇博文中,我详细介绍了我最喜欢的9 个 Python 深度学习库。
这个列表绝对不是 详尽的,它只是我在计算机视觉职业生涯中使用过的库的列表,并且在某个时候发现特别有用。
其中一些库我用得比其他的多——具体来说就是 Keras 、 mxnet 和 sklearn-theano 。
其他的,我用间接,比如 Theano 和 TensorFlow (像 Keras 、 deepy 和 Blocks 都是在这些库的基础上构建的)。
甚至还有一些,我只用于非常具体的任务(比如诺勒和他们的深度信念网络实现)。
这篇博文的目标是向您介绍这些库。我鼓励你仔细阅读每一个,以决定哪一个最适合你的特殊情况。
我最喜欢的 9 个 Python 深度学习库
再次重申,这个列表绝不是穷举。此外,由于我是一名计算机视觉研究人员,并且活跃在该领域,这些库中的许多都非常关注卷积神经网络(CNN)。
我把这个深度学习库的列表组织成了三个部分。
第一部分详细介绍了您可能已经熟悉的流行库。对于其中的每一个库,我都提供了一个非常一般的、高层次的概述。然后我详述了我对每个库的一些好恶,以及一些适当的用例。
第二部分深入到我个人最喜欢的深度学习库,我经常使用(提示:Keras、mxnet 和 sklearn-theano)。
***最后,我提供了一个“额外奖励”部分,用于我(1)很长时间没有使用,但仍然认为您可能会发现有用的库,或者(2)我还没有尝试过,但看起来很有趣的库。
让我们开始吧!
首先:
1.咖啡
提到“深度学习库”而不提到 Caffe 几乎是不可能的。事实上,既然你现在正在阅读深度学习图书馆,我敢打赌你已经听说过 Caffe。
那么,咖啡到底是什么?
Caffe 是由伯克利视觉和学习中心(BVLC)开发的深度学习框架。它是模块化的。速度极快。它被学术界和工业界用于尖端应用。
事实上,如果你浏览最近的深度学习出版物(也提供源代码),你将更有可能在它们相关的 GitHub 存储库中找到 Caffe 模型。
虽然 Caffe 本身不是 Python 库,但它确实提供了到 Python 编程语言的绑定。当在野外实际部署我们的网络时,我们通常会使用这些绑定。
我把 Caffe 列入这个列表的原因是因为它几乎在所有地方都被使用。您在一个名为.prototxt配置文件的类似 JSON 的纯文本文件中定义您的模型架构和求解器方法。Caffe 二进制文件获取这些.prototxt文件并训练你的网络。在 Caffe 完成训练后,您可以使用您的网络,通过 Caffe 二进制文件对新图像进行分类,或者更好的是,通过 Python 或 MATLAB APIs。
虽然我喜欢 Caffe 的性能(它在 K40 GPU 上每天可以处理6000 万张图像*,但我不像 Keras 或 mxnet 那样喜欢它。
主要原因是在.prototxt文件中构建一个架构会变得非常单调乏味。更重要的是,用 Caffe 调优超参数不能通过编程!由于这两个原因,我倾向于使用允许我在基于 Python 的 API 中实现端到端网络(包括交叉验证和超参数调优)的库。
2.theno
我先说 Theano 很美。 没有 Theano,我们就不会有接近我们今天所做的深度学习库(特别是 Python)的数量。同样,如果没有 NumPy,我们就不会有 SciPy、scikit-learn 和 scikit-image,这同样适用于深度学习的 no 和更高级别的抽象。
最核心的是,Theano 是一个 Python 库,用于定义、优化和评估涉及多维数组的数学表达式。Theano 通过与 NumPy 的紧密集成和对 GPU 的透明使用实现了这一点。
虽然你可以在 ano 中建立深度学习网络,但我倾向于认为 ano 是神经网络的 T2 积木,就像 NumPy 是科学计算的积木一样。事实上,我在这篇博文中提到的大多数库都包装了 ano 以使其更加方便和易于访问。
不要误解我,我喜欢用 ano 写代码,我只是不喜欢用 ano 写代码。
虽然不是完美的比较,但在 Theano 中构建卷积神经网络就像用原生 Python 编写一个自定义的支持向量机(SVM ),只需要少量的 NumPy。
你能做到吗?
当然,绝对的。
值得你花费时间和精力吗?
呃,也许吧。这要看你想去多低级/你的应用要求。
就我个人而言,我更愿意使用像 Keras 这样的库,它将 Theano 封装到一个更加用户友好的 API 中,就像 scikit-learn 使机器学习算法更容易工作一样。
3. TensorFlow
类似于 Theano, TensorFlow 是一个使用数据流图进行数值计算的开源库(这就是神经网络的全部)。该库最初是由谷歌机器智能研究组织谷歌大脑团队的研究人员开发的,此后一直是开源的,可供公众使用。
TensorFlow 的一个主要优势(与 Theano 相比)是分布式计算,特别是在多 GPU之间(尽管这是 Theano 正在努力的方向)。
除了替换掉 Keras 后端以使用 TensorFlow(而不是 Theano),我对 TensorFlow 库没有太多经验。然而,在接下来的几个月里,我预计这种情况会有所改变。
4.千层面
Lasagne 是一个轻量级库,用于在 Theano 中构建和训练网络。这里的关键术语是轻量级——它不像 Keras 那样是一个沉重的包装。虽然这导致你的代码更加冗长,但它确实让你摆脱了任何束缚,同时仍然给你基于 ano 的模块化构建块。
简而言之:千层面的功能是作为茶餐厅的低级编程和 Keras 的高级抽象之间的中间媒介。
我的首选:
5. Keras
如果我必须选择一个最喜欢的深度学习 Python 库,我很难在 Keras 和 mxnet 之间做出选择——但最终,我认为 Keras 可能会胜出。
真的,对于 Keras 的好我说不尽。
Keras 是一个极简的模块化神经网络库,可以使用the ano 或 TensorFlow 作为后端。Keras 背后的主要动机是,你应该能够快速试验,并尽快从 想法 到 结果 。**
**在喀拉斯构建网络感觉简单和自然。它包括优化器(Adam,RMSProp),规范化(BatchNorm)和激活层(PReLU,eLU,LeakyReLU)的一些最新的算法。
Keras 还非常关注卷积神经网络,这是我非常感兴趣的东西。不管这是有意还是无意, 我认为从计算机视觉的角度来看,这是非常有价值的。
更重要的是,您可以轻松地构建基于序列的网络(其中输入在网络中线性流动)和基于图的网络(其中输入可以“跳过”某些层,只在以后连接)。这使得实现更复杂的网络架构,如 GoogLeNet 和 SqueezeNet 更加容易。
我对 Keras 的唯一问题是,它不支持并行训练网络的多 GPU 环境。这对你来说可能是也可能不是一个交易破坏者。
如果我想尽可能快地训练一个网络,那么我可能会使用 mxnet。但是如果我正在调优超参数,我可能会用 Keras 设置四个独立的实验(在我的每一个 Titan X GPUs 上运行)并评估结果。
6. mxnet
我第二喜欢的深度学习 Python 库(再次强调训练图像分类网络),无疑是 mxnet。虽然在 mxnet 中建立一个网络可能需要更多的代码,但是它确实给了你大量的语言绑定(C++、Python、R、JavaScript 等等。)
mxnet 库确实为分布式计算大放异彩,允许你跨多个 CPU/GPU 机器,甚至在 AWS、Azure 和 YARN 集群中训练你的网络。
同样,在 mxnet 中启动并运行一个实验需要更多的代码(与 Keras 相比),但是如果你希望 在多个 GPU 或系统 中分配训练,我会使用 mxnet。
7.硬化-theano
有些时候你不需要训练一个端到端的卷积神经网络。相反,你需要把 CNN 当作一个特征提取器。这是特别有用的在你没有足够的数据从头开始训练一个完整的 CNN 的情况下。相反,只需通过流行的预训练架构(如 OverFeat、AlexNet、VGGNet 或 GoogLeNet)传递您的输入图像,并从 FC 层(或您决定使用的任何层)提取特征。
简而言之,这正是 sklearn-theano 允许你做的事情。你不能用它从零开始训练一个模型——但是把网络当作特征提取器是奇妙的。在评估某个特定问题是否适合深度学习时,我倾向于把这个库作为我的第一站。
8.无学习
我已经在 PyImageSearch 博客上使用过几次 nolearn,主要是当在我的 MacBook Pro 上执行一些初始 GPU 实验和在亚马逊 EC2 GPU 实例上执行深度学习的时候。
虽然 Keras 将 Theano 和 TensorFlow 打包成一个更加用户友好的 API,但 nolearn 做了同样的事情——只针对千层面。此外,nolearn 中的所有代码都与 scikit-learn 兼容,这在我的书中是一个巨大的好处。
我个人不使用 nolearn 构建卷积神经网络(CNN),尽管你当然可以(我更喜欢 Keras 和 mxnet 构建 CNN)——我主要使用 nolearn 构建深度信念网络(DBNs)。
9.位数
好吧,你抓到我了。
DIGITS 不是真正的深度学习库(虽然它是用 Python 写的)。DIGITS(深度学习 GPU 训练系统)实际上是一个用于在 Caffe 中训练深度学习模型的 web 应用(虽然我认为你可以破解源代码以与 Caffe 以外的后端一起工作,但这听起来像一个噩梦)。
如果你以前曾经使用过 Caffe,那么你应该知道定义你的.prototxt文件,生成你的图像数据集,运行你的网络,以及照看你的网络培训都是通过你的终端进行的,这是非常乏味的。DIGITS 旨在通过允许你在浏览器中完成(大部分)这些任务来解决这个问题。
此外,用户界面非常出色,为您的模型训练提供有价值的统计数据和图表。我还喜欢你可以很容易地为各种输入可视化网络的激活层。最后,如果您想要测试某个特定图像,您可以将该图像上传到您的 DIGITS 服务器,或者输入该图像的 URL,您的 Caffe 模型将自动对该图像进行分类,并在您的浏览器中显示结果。相当整洁!
奖金:
10.块
老实说,我以前从未使用过 Blocks,尽管我确实想尝试一下(因此我把它包括在这个列表中)。像这个列表中的许多其他库一样,Blocks 构建在 ano 之上,公开了一个更加用户友好的 API。
11.深度
如果让你猜 deepy 使用哪个库,你会猜是什么?
没错,就是 Theano。
我记得不久前用过 deepy(在第一次提交的时候),但是我已经有 6-8 个月没碰它了。我计划在以后的博客中再试一次。
12.派拉恩 2
出于历史原因,我觉得必须将 pylearn2 包括在这个列表中,尽管我不再积极使用它。Pylearn2 不仅仅是一个通用的机器学习库(在 it 方面类似于 scikit-learn),还包括深度学习算法的实现。
我对 pylearn2 最大的担心是(在撰写本文时),它没有一个活跃的开发者。正因为如此,我不太愿意推荐 pylearn2,而推荐 Keras 和 mxnet 等维护性更强、更活跃的库。
13.深度学习 4j
这应该是一个基于 Python 的列表,但我想我会在这里包括 Deeplearning4j,主要是出于我对他们所做的事情的巨大尊重——为 JVM 构建一个开源的分布式深度学习库。
如果你在企业中工作,你可能有一个地下室,里面都是用于 Hadoop 和 MapReduce 的服务器。也许你还在用这些机器。也许你不是。
但是如果你可以用这些相同的机器来应用深度学习会怎么样呢?
事实证明你可以——你只需要深度学习。
摘要
在这篇博文中,我回顾了一些我最喜欢的深度学习和卷积神经网络库。这个列表绝不是详尽的,而且肯定偏向于专注于计算机视觉和卷积神经网络的深度学习库。
综上所述,我确实认为,如果你刚刚开始进入深度学习领域,并正在寻找一个可供尝试的库,这是一个很好的列表。
在我个人看来,我觉得很难打败mxnet。Keras 库位于 Theano 和 TensorFlow 等计算强国之上,允许您用非常少的几行 Python 代码构建深度学习架构。
虽然用 mxnet 构建和训练一个网络可能需要更多的代码,但是你可以获得在多个 GPU之间轻松有效地分配训练的能力。如果你在一个多 GPU 系统/环境中,并且想要充分利用这个环境,那么一定要试试 mxnet。
在你去之前,一定要使用下面的表格注册 PyImageSearch 时事通讯,以便在新的深度学习帖子发布时得到通知(未来几个月将会有很多帖子!)******
我最喜欢的 9 个构建图像搜索引擎的 Python 库
八年前,当我第一次对计算机视觉和图像搜索引擎感兴趣时,我不知道从哪里开始。我不知道使用哪种语言,不知道安装哪些库,我找到的库也不知道如何使用。我希望有一个像这样的列表,详细列出用于图像处理、计算机视觉和图像搜索引擎的最佳库。
这份清单绝不是完整的或详尽的。这只是我最喜欢的 Python 库,我每天都用它来做计算机视觉和图像搜索引擎。如果你认为我漏掉了一个重要的,请在评论中给我留言或者给我发电子邮件。
对于新手:
1. NumPy
NumPy 是 Python 编程语言的一个库,它提供了对大型多维数组的支持。为什么这很重要?使用 NumPy,我们可以将图像表示为多维数组。例如,假设我们从 Google 下载了我们最喜欢的暴躁猫图片,现在我们想用 NumPy 把它表示成一个数组。这幅图像是 RGB 颜色空间中的 452×589 像素,其中每个像素由三个分量组成:红色值、绿色值和蓝色值。每个像素值 p 在范围 0 < = p < = 255 内。这样我们就有了一个 452×589 像素的矩阵。使用 NumPy,我们可以方便地将该图像存储在一个 (452,593,3) 数组中,该数组有 452 行、593 列和 3 个值,每个值对应 RGB 颜色空间中的一个像素。将图像表示为 NumPy 数组不仅计算和资源效率高,而且许多其他图像处理和机器学习库也使用 NumPy 数组表示。此外,通过使用 NumPy 内置的高级数学函数,我们可以快速地对图像进行数值分析。
2.轨道轨道
与 NumPy 齐头并进,我们还有 SciPy。SciPy 增加了对科学和技术计算的进一步支持。我最喜欢的 SciPy 子包之一是空间包,它包含了大量的距离函数和 kd-tree 实现。为什么距离函数很重要?当我们“描述”一幅图像时,我们执行特征提取。通常在特征提取之后,图像由一个向量(一列数字)来表示。为了比较两幅图像,我们依赖于距离函数,例如欧几里德距离。为了比较两个任意的特征向量,我们简单地计算它们的特征向量之间的距离。在欧几里德距离的情况下,距离越小,两幅图像越“相似”。
3. matpotlib
简单来说,matplotlib 就是一个绘图库。如果你以前用过 MATLAB,你可能会觉得在 matplotlib 环境中很舒服。当分析图像时,我们将利用 matplotlib,无论是绘制搜索系统的整体准确性还是简单地查看图像本身,matplotlib 都是您工具箱中的一个伟大工具。
4. PIL 和枕头
我并不反对 PIL 或枕头,不要误会我,他们非常擅长做什么:简单的图像操作,如调整大小,旋转等。总的来说,我只是觉得语法笨拙。也就是说,许多非科学的 Python 项目使用了 PIL 或 Pillow。例如,Python web 框架 Django 使用 PIL 来表示数据库中的图像字段。如果你需要做一些快速和肮脏的图像操作,PIL 和 Pillow 有他们的位置,但是如果你认真学习图像处理、计算机视觉和图像搜索引擎,我会高度推荐你花时间玩 OpenCV 和 SimpleCV。
我的首选:
5. OpenCV
如果 NumPy 的主要目标是大型、高效、多维数组表示,那么,到目前为止,OpenCV 的主要目标是实时图像处理。这个库从 1999 年就存在了,但是直到 2009 年的 2.0 版本我们才看到令人难以置信的 NumPy 支持。库本身是用 C/C++编写的,但是 Python 绑定是在运行安装程序时提供的。OpenCV 无疑是我最喜欢的计算机视觉库,但它确实有一个学习曲线。准备好花大量的时间学习库的复杂性和浏览文档(现在已经增加了 NumPy 支持,这已经变得非常好了)。如果您仍然在测试计算机视觉 waters,您可能想要查看下面提到的 SimpleCV 库,它的学习曲线要小得多。
6. SimpleCV
SimpleCV 的目标是让你尽快涉足图像处理和计算机视觉。他们在这方面做得很好。学习曲线比 OpenCV 小得多,正如他们的标语所说,“让计算机视觉变得简单”。也就是说,因为学习曲线更短,所以您无法接触到 OpenCV 提供的许多原始的、强大的技术。如果你只是在试水,一定要试试这个库。然而,作为一个公平的警告,我在这个博客中超过 95%的代码示例将使用 OpenCV。不过不要担心,我对文档绝对一丝不苟,我会为您提供完整而简洁的代码解释。
7.穆罕默德
Mahotas 就像 OpenCV 和 SimpleCV 一样,依赖于 NumPy 数组。在 Mahotas 中实现的许多功能可以在 OpenCV 和/或 SimpleCV 中找到,但在某些情况下,Mahotas 接口更容易使用,尤其是当涉及到他们的特性包时。
8. scikit-learn
好吧,我明白了,Scikit-learn 不是一个图像处理或计算机视觉库——它是一个机器学习库。也就是说,如果没有某种机器学习,你就不可能拥有先进的计算机视觉技术,无论是聚类、矢量量化、分类模型等等。Scikit-learn 还包括一些图像特征提取功能。
9.统计数据
我实话实说。我从来没用过 ilastik。但是通过我在计算机视觉会议上的经历,我遇到了相当多这样做的人,所以我觉得有必要把它放在这个列表中。Ilastik 主要用于图像分割和分类,特别面向科学界。

奖金:
我不能在九点就停下来。这里是我一直在使用的另外三个额外的库。
10.过程
从图像中提取特征本质上是一项可并行化的任务。通过使用多处理库,可以减少从整个数据集中提取要素所需的时间。我最喜欢的是 process,因为我需要它的简单性质,但是你可以使用你最喜欢的。
11. h5py
h5py 库是 Python 中存储大型数值数据集的事实上的标准。最精彩的部分?它支持 NumPy 数组。因此,如果您有一个表示为 NumPy 数组的大型数据集,并且它不适合内存,或者如果您希望高效、持久地存储 NumPy 数组,那么 h5py 是一个不错的选择。我最喜欢的技术之一是将我提取的特征存储在 h5py 数据集中,然后应用 scikit-learn 的 MiniBatchKMeans 对这些特征进行聚类。整个数据集不必一次全部从磁盘上加载,内存占用也非常小,即使对于成千上万的特征向量也是如此。
12. scikit-image
在这篇博文的初稿上,我完全忘记了 scikit-image。我真傻。无论如何,scikit-image 很棒,但是你必须知道你在做什么来有效地使用这个库——我不是指“有一个陡峭的学习曲线”类型的方式。学习曲线实际上相当低,尤其是如果你查看他们的画廊。scikit-image 中包含的算法(我认为)更接近计算机视觉的最先进水平。在 scikit-image 中可以找到来自学术论文的新算法,但是为了(有效地)使用这些算法,您需要在计算机视觉领域有一些严谨和理解。如果你已经有一些计算机视觉和图像处理的经验,一定要看看 scikit-image;否则,我会继续使用 OpenCV 和 SimpleCV。
总之:
NumPy 为您提供了一种将图像表示为多维数组的方法。许多其他图像处理、计算机视觉和机器学习库都使用 NumPy,因此安装它(和 SciPy)非常重要。虽然 PIL 和 Pillow 非常适合简单的图像处理任务,但如果你认真测试计算机视觉水域,你的时间最好花在玩 SimpleCV 上。一旦你确信计算机视觉很棒,安装 OpenCV 并重新学习你在 SimpleCV 中所做的。我将在博客中展示的 95%以上的代码都是 OpenCV。最后安装 scikit-learn 和 h5py。你现在还不需要它们。但是一旦我向你展示了他们的能力,你就会爱上他们。
使用 TensorFlow 和 Keras 的 Bahdanau 注意力的神经机器翻译
目录
神经机器翻译用 Bahdanau 的注意力使用 TensorFlow 和 Keras
想象一下明天是你的考试,而你还没有学完很多章节。你停顿了一会儿,然后采取了更聪明的选择,让优先于。你关注那些(根据你的说法)比其他章节更有分量的章节。
我们不建议在学期的最后一天进行优先排序,但是嘿,我们都这么做了!除非你对哪些章节更有分量的评估完全错了,否则你已经得到了超出你所能得到的分数,如果你涵盖了所有章节的话。
将注意力的这种类比延伸一点,今天,我们将这种机制应用于神经机器翻译的任务。
在本教程中,您将学习如何将 Bahdanau 的注意力应用于神经机器翻译任务。
本课是关于 NLP 103 的两部分系列的第一部分:
- 神经机器翻译用 Bahdanau 的注意力使用 TensorFlow 和 Keras (本教程)
- 使用 TensorFlow 和 Keras 进行 Luong 注意力的神经机器翻译
要学习如何将 Bahdanau 的注意力应用到神经机器翻译任务中, 只要坚持阅读。
神经机器翻译用 Bahdanau 的注意力使用 TensorFlow 和 Keras
在之前的博客文章中,我们讨论了神经机器翻译背后的数学直觉。我们请求您查看博客帖子,以获得关于该任务的深入知识。
在本教程中,我们将借助注意力解决从源语言(英语)翻译到目标语言(法语)的问题。在本教程中训练的模型的帮助下,我们还为翻译任务构建了一个交互式演示。
简介
我们经常被谷歌翻译震惊。深度学习模型可以从任何语言翻译成任何其他语言。你可能已经猜到了,这是一个神经机器翻译模型。
神经机器翻译模型有一个编码器和一个解码器。编码器将源句子编码成丰富的表示形式。解码器接受编码的表示,并将其解码成目标语言。
Bahdanau 等人在他们的学术论文《通过联合学习对齐和翻译的神经机器翻译》中提出,每次在解码器中解码一个单词时,都要构建编码器表示。
这种动态表示将取决于输入句子的部分t与当前解码的单词最相关。我们关注输入句子的最相关部分,以解码目标句子。
*在本教程中,我们不仅解释了注意力的概念,还在 TensorFlow 和 Keras 中建立了一个模型。我们今天的任务是有一个从英语翻译成法语的模型。
配置您的开发环境
要遵循这个指南,您需要在系统上安装tensorflow和tensorflow-text。
幸运的是,TensorFlow 可以在 pip 上安装:
$ pip install tensorflow==2.8.0
$ pip install tensorflow-text==2.8.0
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
├── download.sh
├── inference.py
├── output
│ └── loss.png
├── pyimagesearch
│ ├── config.py
│ ├── dataset.py
│ ├── __init__.py
│ ├── loss.py
│ ├── models.py
│ ├── schedule.py
│ └── translator.py
├── requirements.txt
└── train.py
在pyimagesearch目录中,我们有:
config.py:任务的配置文件。dataset.py:数据集管道的实用程序。loss.py:保存训练模型所需损失的代码片段。models.py:翻译模型的编码器和解码器。schedule.py:培训管道的学习率调度程序。- 训练和推理模型。
在核心目录中,我们有四个脚本:
download.sh:下载训练数据的 shell 脚本。requirements.txt:本教程需要的 python 包。train.py:训练模型的脚本。inference.py:推理脚本。
RNN 编解码器
在神经机器翻译中,我们有一个编码器和一个解码器。编码器构建源句子的丰富表示,而解码器解码编码表示并产生目标句子。
由于源句子和目标句子是序列数据,我们可以从可信的序列模型中获得帮助。要获得顺序建模的初级知识,请关注我们之前的博文。
虽然编码器构建的信息非常有用,但它没有捕获源句子的一些非常重要的方面。利用静态和固定编码器表示,我们受到对每个解码单词使用源句子的相同含义的约束。
在下一节中,我们将讨论编码器、解码器和注意模块。注意力模块将在解码时帮助从源句子中收集重要信息。*
学习对齐和平移
编码器
递归神经网络采用当前输入
and the previous hidden state  to model the present hidden state
to model the present hidden state  . This forms a recurrence chain, which helps RNNs to model sequential data.
. This forms a recurrence chain, which helps RNNs to model sequential data.
对于编码器,作者提出了一种双向 RNN。这样 RNN 将提供两套隐藏状态,正向
and the backward  hidden states. The authors suggest that concatenating the two states gives a richer and better representation
hidden states. The authors suggest that concatenating the two states gives a richer and better representation ![h_{t}=[\overrightarrow{h_{t}}; \overleftarrow{h_{t}}]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/fd7f6a86f90e4de85d92b7cd8610d738.png "h_{t}=[\overrightarrow{h_{t}}; \overleftarrow{h_{t}}]") .
.
解码器
无注意:解码器使用递归神经网络将编码后的表示解码成目标句子。
最后编码的隐藏状态
theoretically contains information of the entire source sentence. The decoder is fed with the previous decoder hidden state, the previous decoded word, and the last encoded hidden state.
下面的等式是条件概率,需要将最大化,以便解码器正确翻译。
 \ = \ \text{RNN}(y_{i-1},s_{i-1},c)")
其中
is the hidden state for the decoder and  the context vector which is the last encoder hidden state .
the context vector which is the last encoder hidden state .
有注意力的情况下:有注意力和没有注意力的唯一区别在于上下文向量
. With attention in place, the decoder receives a newly built context vector for each step. Each context vector depends on the relevant information from which the source sentence is attended.
条件概率的等式现在变为如下。
 \ = \ \text{RNN}\left(y_{i-1},s_{i-1},\boxed{c_{i}}\right)")
我们有来自编码器 的整个隐藏状态集(称为注释)
的整个隐藏状态集(称为注释)
. We need a mechanism to evaluate the importance of each annotation for a decoded word. We can either formulate this behavior by hard-coded equations or let another model figure this out. Turns out, being of the lazy kind, we delegate the entire workload to another model. This model is our attention module.
注意力层将一个元组作为输入。元组由注释组成
and the previously decoded hidden state  . This provides a set of unnormalized importance maps. Intuitively this provides the answer to the question, “How important is for
. This provides a set of unnormalized importance maps. Intuitively this provides the answer to the question, “How important is for  ?”
?”
了解到神经网络在定义明确的分布方面表现出色,我们对非标准化重要性应用 softmax,以获得定义明确的重要性正态分布,如图图 2 所示。
未标准化的重要性称为能量矩阵。
")
标准化的重要性是注意力权重。
}}{\sum\limits_{k=1}^{T_{x}}\exp{(e_{ik})}}")
现在我们已经有了注意力权重,我们需要逐点将权重与注释相乘,以获得重要的注释,同时丢弃不重要的注释。然后,我们对加权的标注求和,以获得单个特征丰富的向量。

我们为解码器的每一步构建上下文向量,并关注特定的注释,如图图 3 所示。
代码预排
配置先决条件
在我们开始实现之前,让我们检查一下项目的配置管道。为此,我们将转到位于pyimagesearch目录中的config.py脚本。
# define the data file name
DATA_FNAME = "fra.txt"
# define the batch size
BATCH_SIZE = 512
# define the vocab size for the source and the target
# text vectorization layers
SOURCE_VOCAB_SIZE = 15_000
TARGET_VOCAB_SIZE = 15_000
# define the encoder configurations
ENCODER_EMBEDDING_DIM = 512
ENCODER_UNITS = 512
# define the attention configuration
ATTENTION_UNITS = 512
# define the decoder configurations
DECODER_EMBEDDING_DIM = 512
DECODER_UNITS = 1024
# define the training configurations
EPOCHS = 100
LR_START = 1e-4
LR_MAX = 1e-3
WARMUP_PERCENT = 0.15
# define the patience for early stopping
PATIENCE = 10
# define the output path
OUTPUT_PATH = "output"
在第 2 行的上,我们有引用我们将在项目中使用的数据集的数据文件名。该数据集具有输入的英语句子及其对应的法语翻译句子。
我们数据的批量在第 5 行的中定义。接下来是定义源和目标词汇表的大小(第 9 行和第 10 行)。您可以根据自己的喜好自由调整,以获得不同的结果。
我们架构的编码器模型将使用它自己的源语言嵌入空间。我们已经在第 13 行定义了嵌入空间的维数,接着是第 14 行的编码器隐藏状态维数。
在行 17 上,定义了使用的注意单位的数量。
定义解码器配置,类似于行 20 和 21 上的编码器配置。
在行 24-27 中定义了训练超参数,即时期的数量和学习率的规格。由于我们将使用提前停止回调,耐心设置在线 30 。
配置管道的最后一步是为我们的结果设置输出路径(第 33 行)。
配置数据集
如前所述,我们需要一个包含源语言-目标语言句子对的数据集。为了配置和预处理这样的数据集,我们准备了位于pyimagesearch目录中的dataset.py脚本。
# import the necessary packages
import tensorflow_text as tf_text
import tensorflow as tf
import random
# define a module level autotune
_AUTO = tf.data.AUTOTUNE
def load_data(fname):
# open the file with utf-8 encoding
with open(fname, "r", encoding="utf-8") as textFile:
# the source and the target sentence is demarcated with tab
# iterate over each line and split the sentences to get
# the individual source and target sentence pairs
lines = textFile.readlines()
pairs = [line.split("\t")[:-1] for line in lines]
# randomly shuffle the pairs
random.shuffle(pairs)
# collect the source sentences and target sentences into
# respective lists
source = [src for src, _ in pairs]
target = [trgt for _, trgt in pairs]
# return the list of source and target sentences
return (source, target)
我们从定义线 7 上的有效训练的AUTOTUNE常数开始。
这个脚本中的第一个函数是load_data ( 第 9 行),它接受文件名作为参数。我们使用open功能读取带有utf-8编码的数据集文件(第 11 行)。
我们循环遍历文本文件中的每一行(行 15 ),并基于每个源和目标对由制表符(行 16 )分隔的前提来创建对。
为了减少偏差,我们在第 19 行随机洗牌。我们将拆分后的源语句和目标语句存储到相应的变量中并返回它们(第 23-27 行)。
def splitting_dataset(source, target):
# calculate the training and validation size
trainSize = int(len(source) * 0.8)
valSize = int(len(source) * 0.1)
# split the inputs into train, val, and test
(trainSource, trainTarget) = (source[: trainSize],
target[: trainSize])
(valSource, valTarget) = (source[trainSize : trainSize + valSize],
target[trainSize : trainSize + valSize])
(testSource, testTarget) = (source[trainSize + valSize :],
target[trainSize + valSize :])
# return the splits
return (
(trainSource, trainTarget),
(valSource, valTarget),
(testSource, testTarget),
)
在第 29 行的上,我们有splitting_dataset函数,它接收源句子和目标句子。下一步是计算训练数据集和验证数据集的大小(第 31 行和第 32 行)。使用这些值,我们将源句子和目标句子分成训练集、测试集和验证集(第 35-47 行)。
def make_dataset(splits, batchSize, train=False):
# build a TensorFlow dataset from the input and target
(source, target) = splits
dataset = tf.data.Dataset.from_tensor_slices((source, target))
# check if this is the training dataset, if so, shuffle, batch,
# and prefetch it
if train:
dataset = (
dataset
.shuffle(dataset.cardinality().numpy())
.batch(batchSize)
.prefetch(_AUTO)
)
# otherwise, just batch the dataset
else:
dataset = (
dataset
.batch(batchSize)
.prefetch(_AUTO)
)
# return the dataset
return dataset
在第 49 行的上,我们有一个make_dataset函数,它接受以下参数:
splits:三个(训练、测试和 val)数据集分割之一。batchSize:我们希望数据集拥有的批量大小。train:bool 变量,表示所讨论的数据集是否是训练数据集。
我们从当前分割中分离出源句子和目标句子(行 51 ),并使用行 52 上的tf.data.Dataset.from_tensor_slices构建 TensorFlow 数据集。
在的第 56-62 行,我们有一个 if 语句来检查train bool 是否被设置为 true。如果满足条件,我们将对数据集进行洗牌、批处理和预取。else条件是针对测试和验证集的,在这里我们只批处理和预取数据集(第 65-73 行)。
def tf_lower_and_split_punct(text):
# split accented characters
text = tf_text.normalize_utf8(text, "NFKD")
text = tf.strings.lower(text)
# keep space, a to z, and selected punctuations
text = tf.strings.regex_replace(text, "[^ a-z.?!,]", "")
# add spaces around punctuation
text = tf.strings.regex_replace(text, "[.?!,]", r" \0 ")
# strip whitespace and add [START] and [END] tokens
text = tf.strings.strip(text)
text = tf.strings.join(["[START]", text, "[END]"], separator=" ")
# return the processed text
return text
最后一个数据实用函数是tf_lower_and_split_punct,它接受任何一个句子作为参数(第 75 行)。我们首先将句子规范化并将其转换成小写(第 77 行和第 78 行)。
在的第 81-84 行,我们去掉了句子中不必要的标点和字符。在第 87 行的中,句子前的空格被删除,随后在句子中添加了start和end标记。这些标记帮助模型理解何时开始或结束一个序列。
建造巴赫丹瑙 NMT 模型
随着我们的数据集实用程序脚本的完成,现在的重点是神经机器翻译模型本身。为此,我们将跳转到pyimagesearch目录中的models.py脚本。
# import the necessary packages
from tensorflow.keras.layers import AdditiveAttention
from tensorflow.keras.layers import Bidirectional
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import Layer
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import GRU
from tensorflow.keras import Sequential
import tensorflow as tf
class Encoder(Layer):
def __init__(self, sourceVocabSize, embeddingDim, encUnits,
**kwargs):
super().__init__(**kwargs)
# initialize the source vocab size, embedding dimensions, and
# the encoder units
self.sourceVocabSize = sourceVocabSize
self.embeddingDim = embeddingDim
self.encUnits = encUnits
def build(self, inputShape):
# the embedding layer converts token IDs to embedding vectors
self.embedding = Embedding(
input_dim=self.sourceVocabSize,
output_dim=self.embeddingDim,
mask_zero=True,
)
# the GRU layer processes the embedding vectors sequentially
self.gru = Bidirectional(
GRU(
units=self.encUnits,
# return the sequence and the state
return_sequences=True,
return_state=True,
recurrent_initializer="glorot_uniform",
)
)
编码器模型、注意机制和解码器模型被打包到单独的类中,以便于访问和使用。我们从11线的Encoder班开始。__init__函数(第 12 行)接受以下参数:
sourceVocabSize:定义源词汇大小。embeddingDim:定义源词汇的嵌入空间大小。encUnits:定义编码器隐藏层尺寸。
该函数的唯一目的是使用self功能创建自变量的类变量(第 17-19 行)。
build函数接受输入形状(tf自定义层在函数调用中需要此参数,但不强制在函数内部使用)作为其参数(第 21 行)。该函数首先创建一个嵌入层(第 23-27 行),然后是GRU层,它将依次处理嵌入向量(第 30-38 行)。隐藏层尺寸在提供给GRU层的units参数的__init__函数中设置。
def get_config(self):
# return the configuration of the encoder layer
return {
"inputVocabSize": self.inputVocabSize,
"embeddingDim": self.embeddingDim,
"encUnits": self.encUnits,
}
def call(self, sourceTokens, state=None):
# pass the source tokens through the embedding layer to get
# source vectors
sourceVectors = self.embedding(sourceTokens)
# create the masks for the source tokens
sourceMask = self.embedding.compute_mask(sourceTokens)
# pass the source vectors through the GRU layer
(encOutput, encFwdState, encBckState) = self.gru(
inputs=sourceVectors,
initial_state=state,
mask=sourceMask
)
# return the encoder output, encoder state, and the
# source mask
return (encOutput, encFwdState, encBckState, sourceMask)
在的第 40 行,我们有get_config函数,它简单地返回类变量,如inputVocabSize、embeddingDim和encUnits ( 的第 42-46 行)。
行 48 上的call函数接收以下令牌:
sourceTokens:输入输出的句子标记。state:单元格GRU的初始状态。
call功能只是作为embedding和GRU层的使用中心。我们首先通过嵌入层传递令牌以获得嵌入向量,然后我们为源令牌创建掩码(第 51-54 行)。屏蔽有助于使我们的GRU只关注标记而忽略填充。
嵌入向量然后通过GRU层,并且获得由编码器输出、编码器前向状态和编码器后向状态(双向)组成的前向传递(行 57-61 )。
class BahdanauAttention(Layer):
def __init__(self, attnUnits, **kwargs):
super().__init__(**kwargs)
# initialize the attention units
self.attnUnits = attnUnits
def build(self, inputShape):
# the dense layers projects the query and the value
self.denseEncoderAnnotation = Dense(
units=self.attnUnits,
use_bias=False,
)
self.denseDecoderAnnotation = Dense(
units=self.attnUnits,
use_bias=False,
)
# build the additive attention layer
self.attention = AdditiveAttention()
如前所述,Bahdanau 注意块被打包成一个单独的类( Line 67 )。在第 68 行的上,__init__函数接受关注单位的数量作为其参数,并为其创建一个类变量(行第 71** )。**
在build函数(第 73 行)中,编码器和解码器注释的密集层以及附加注意层被初始化(第 75-85 行)。
def get_config(self):
# return the configuration of the layer
return {
"attnUnits": self.attnUnits,
}
def call(self, hiddenStateEnc, hiddenStateDec, mask):
# grab the source and target mask
sourceMask = mask[0]
targetMask = mask[1]
# pass the query and value through the dense layer
encoderAnnotation = self.denseEncoderAnnotation(hiddenStateEnc)
decoderAnnotation = self.denseDecoderAnnotation(hiddenStateDec)
# apply attention to align the representations
(contextVector, attentionWeights) = self.attention(
inputs=[decoderAnnotation, hiddenStateEnc, encoderAnnotation],
mask=[targetMask, sourceMask],
return_attention_scores=True
)
# return the context vector and the attention weights
return (contextVector, attentionWeights)
这个类的get_config函数返回关注单元的数量(第 87-91 行)。
在第 93 行的上,我们定义了call函数,它接受以下参数:
hiddenStateEnc:编码器隐藏状态hiddenStateDec:解码器隐藏状态mask:源和目标矢量蒙版
首先,我们通过先前在build函数中创建的密集层传递各自的隐藏状态(第 99 行和第 100 行)。使用这些注释,我们简单地将它们传递给关注层,同时指定目标和输入掩码(第 103-107 行)。
该函数返回从关注层获得的上下文向量和关注权重(行 110 )。
class Decoder(Layer):
def __init__(self, targetVocabSize, embeddingDim, decUnits, **kwargs):
super().__init__(**kwargs)
# initialize the target vocab size, embedding dimension, and
# the decoder units
self.targetVocabSize = targetVocabSize
self.embeddingDim = embeddingDim
self.decUnits = decUnits
def get_config(self):
# return the configuration of the layer
return {
"targetVocabSize": self.targetVocabSize,
"embeddingDim": self.embeddingDim,
"decUnits": self.decUnits,
}
编码器和注意力层完成后,我们继续到解码器。和前两个一样,我们将解码器打包成一个单独的类( Line 112 )。
像encoder类的__init__函数一样,decoder__init__接受:
targetVocabSize:目标语言词汇量。embeddingDim:用于目标词汇的嵌入空间的嵌入维度大小。decUnits:解码器隐藏层尺寸大小。
这个函数简单地创建了上述参数的类变量(第 117-119 行)。
在的第 121 行,我们有get_config函数,它返回先前在__init__函数中创建的类变量。
def build(self, inputShape):
# build the embedding layer which converts token IDs to
# embedding vectors
self.embedding = Embedding(
input_dim=self.targetVocabSize,
output_dim=self.embeddingDim,
mask_zero=True,
)
# build the GRU layer which processes the embedding vectors
# in a sequential manner
self.gru = GRU(
units=self.decUnits,
return_sequences=True,
return_state=True,
recurrent_initializer="glorot_uniform"
)
# build the attention layer
self.attention = BahdanauAttention(self.decUnits)
# build the final output layer
self.fwdNeuralNet = Sequential([
Dense(
units=self.decUnits,
activation="tanh",
use_bias=False,
),
Dense(
units=self.targetVocabSize,
),
])
正如我们在这个脚本中遇到的前面的build函数一样,inputShape参数需要包含在函数调用中(第 129 行)。类似于encoder,我们将首先构建嵌入空间,然后是GRU层(行 132-145 )。这里额外增加的是BahdanauAttention层以及我们输出的最终前馈神经网络(第 148-160 行)。
def call(self, inputs, state=None):
# grab the target tokens, encoder output, and source mask
targetTokens = inputs[0]
encOutput = inputs[1]
sourceMask = inputs[2]
# get the target vectors by passing the target tokens through
# the embedding layer and create the target masks
targetVectors = self.embedding(targetTokens)
targetMask = self.embedding.compute_mask(targetTokens)
# process one step with the GRU
(decOutput, decState) = self.gru(inputs=targetVectors,
initial_state=state, mask=targetMask)
# use the GRU output as the query for the attention over the
# encoder output
(contextVector, attentionWeights) = self.attention(
hiddenStateEnc=encOutput,
hiddenStateDec=decOutput,
mask=[sourceMask, targetMask],
)
# concatenate the context vector and output of GRU layer
contextAndGruOutput = tf.concat(
[contextVector, decOutput], axis=-1)
# generate final logit predictions
logits = self.fwdNeuralNet(contextAndGruOutput)
# return the predicted logits, attention weights, and the
# decoder state
return (logits, attentionWeights, decState)
现在是时候在第 162 行的函数中依次使用所有初始化的层和变量了。该函数接受以下参数:
inputs:包含目标令牌、encoder输出和源令牌掩码。state:指定解码层的初始状态。
首先,我们通过将目标记号传递通过为decoder ( 行 170 )定义的嵌入层来获得目标记号向量。目标令牌掩码的计算与我们在encoder ( 第 171 行)中对源令牌所做的完全一样。
在行 174 和 175 上,我们通过将向量传递到decoderGRU层并获得输出和状态变量来处理一个步骤。
然后使用第行第 179-183 上的attention层计算注意力权重和上下文向量。
上下文向量和GRUdecoder输出然后被连接,并且使用前馈神经网络计算最终的 logits 预测(行 186-190 )。
为我们的模型建立损失函数
我们的模型输入序列使用了大量的掩蔽。为此,我们需要确保我们的损失函数也是适当的。让我们转到pyimagesearch目录中的loss.py脚本。
# import the necessary packages
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.losses import Loss
import tensorflow as tf
class MaskedLoss(Loss):
def __init__(self):
# initialize the name of the loss and the loss function
self.name = "masked_loss"
self.loss = SparseCategoricalCrossentropy(from_logits=True,
reduction="none")
def __call__(self, yTrue, yPred):
# calculate the loss for each item in the batch
loss = self.loss(yTrue, yPred)
# mask off the losses on padding
mask = tf.cast(yTrue != 0, tf.float32)
loss *= mask
# return the total loss
return tf.reduce_sum(loss)
损失被打包成一个名为MaskedLoss的类放在行 6 上。 __init__函数创建类变量name和loss,它们分别被设置为masked_loss和稀疏分类交叉熵(第 9 行和第 10 行)。对于后者,我们简单的从tensorflow本身导入损耗。
在第 13 行,我们有__call__函数,它接受标签和预测。首先,我们使用行 15 上的稀疏分类交叉熵损失来计算损失。
考虑到我们的序列中的填充,我们通过创建一个简单的条件变量mask来掩盖填充的损失,该变量只考虑不为 0 的序列标记,并用它乘以我们的损失(第 19 行)。这样,我们就抵消了填充对损失的影响。
最后,损失以reduce_sum格式返回(第 22 行)。
用调度器优化我们的训练
为了确保我们的培训效率达到最高,我们创建了schedule.py脚本。
# import the necessary packages
from tensorflow.keras.optimizers.schedules import LearningRateSchedule
import tensorflow as tf
import numpy as np
class WarmUpCosine(LearningRateSchedule):
def __init__(self, lrStart, lrMax, warmupSteps, totalSteps):
super().__init__()
self.lrStart = lrStart
self.lrMax = lrMax
self.warmupSteps = warmupSteps
self.totalSteps = totalSteps
self.pi = tf.constant(np.pi)
我们将使用动态学习率,为此我们在第 6 行的中创建了一个类。
__init__函数接受以下参数:
lrStart:我们学习率的起始值lrMax:最大学习率值warmupSteps:动态 LR 计算所需的“预热”步骤数totalSteps:总步数
在这个函数中,创建了这些参数的类变量,以及一个pi变量(第 9-13 行)。
def __call__(self, step):
# check whether the total number of steps is larger than the
# warmup steps. If not, then throw a value error
if self.totalSteps < self.warmupSteps:
raise ValueError(
f"Total number of steps {self.totalSteps} must be"
+ f"larger or equal to warmup steps {self.warmupSteps}."
)
# a graph that increases to 1 from the initial step to the
# warmup step, later decays to -1 at the final step mark
cosAnnealedLr = tf.cos(
self.pi
* (tf.cast(step, tf.float32) - self.warmupSteps)
/ tf.cast(self.totalSteps - self.warmupSteps, tf.float32)
)
# shift the learning rate and scale it
learningRate = 0.5 * self.lrMax * (1 + cosAnnealedLr)
接下来,我们有了__call__函数,它将step数字作为它的参数(第 15 行)。
在第 18-22 行中,我们检查步数是否大于预热步数,如果是后者,则抛出错误。
接下来,我们建立一个图表,该图表最初增加到1,但后来衰减到-1,从而保持我们的 LR 值动态(第 26-33 行)。
# check whether warmup steps is more than 0.
if self.warmupSteps > 0:
# throw a value error is max lr is smaller than start lr
if self.lrMax < self.lrStart:
raise ValueError(
f"lr_start {self.lrStart} must be smaller or"
+ f"equal to lr_max {self.lrMax}."
)
# calculate the slope of the warmup line and build the
# warmup rate
slope = (self.lrMax - self.lrStart) / self.warmupSteps
warmupRate = slope * tf.cast(step, tf.float32) + self.lrStart
# when the current step is lesser that warmup steps, get
# the line graph, when the current step is greater than
# the warmup steps, get the scaled cos graph.
learning_rate = tf.where(
step < self.warmupSteps, warmupRate, learningRate
)
# return the lr schedule
return tf.where(
step > self.totalSteps, 0.0, learningRate,
name="learning_rate",
)
在第 36 行的上,我们检查warmupSteps是否大于 0。如果是,我们进一步检查最大学习速率是否小于在行 38** 开始学习。如果返回 true,我们将引发一个值错误。**
接下来,在线 46 和 47 上,我们计算暖机线的斜率并建立暖机率。
在第 52-54 行上,我们通过检查当前步长是否小于预热步长来计算学习率。如果是这样,我们就得到了线图。如果当前步长更大,我们会得到缩放的余弦图。
最后,在第 57-60 行,我们返回学习率时间表。
列车翻译员
# import the necessary packages
from tensorflow.keras.layers import StringLookup
from tensorflow import keras
import tensorflow as tf
import numpy as np
我们从导入必要的包开始(第 2-5 行)。
class TrainTranslator(keras.Model):
def __init__(self, encoder, decoder, sourceTextProcessor,
targetTextProcessor, **kwargs):
super().__init__(**kwargs)
# initialize the encoder, decoder, source text processor,
# and the target text processor
self.encoder = encoder
self.decoder = decoder
self.sourceTextProcessor = sourceTextProcessor
self.targetTextProcessor = targetTextProcessor
我们在第 7 行上创建了一个名为TrainTranslator的类,它包含了所有的功能,这些功能将有助于用model.fit() API 训练我们的编码器、注意模块和解码器。
在__init__函数中,我们初始化编码器、解码器、源文本处理器和目标文本处理器(第 13-16 行)。
def _preprocess(self, sourceText, targetText):
# convert the text to token IDs
sourceTokens = self.sourceTextProcessor(sourceText)
targetTokens = self.targetTextProcessor(targetText)
# return the source and target token IDs
return (sourceTokens, targetTokens)
接下来,我们有_preprocess函数(第 18 行),它将源文本和目标文本作为输入。它将第 20 行和第 21 行上的文本转换为源文本和目标文本的令牌 id,然后在第 24 行上返回它们。
def _calculate_loss(self, sourceTokens, targetTokens):
# encode the input text token IDs
(encOutput, encFwdState, encBckState, sourceMask) = self.encoder(
sourceTokens=sourceTokens
)
# initialize the decoder's state to the encoder's final state
decState = tf.concat([encFwdState, encBckState], axis=-1)
(logits, attentionWeights, decState) = self.decoder(
inputs=[targetTokens[:, :-1], encOutput, sourceMask],
state=decState,
)
# calculate the batch loss
yTrue = targetTokens[:, 1:]
yPred = logits
batchLoss = self.loss(yTrue=yTrue, yPred=yPred)
# return the batch loss
return batchLoss
在第 26 行的上,我们定义了_calculate_loss函数,它接受源和目标令牌。我们通过第 28 行上的编码器传递源令牌。编码器输出以下内容:
encOutput:编码器输出encFwdState:编码器正向隐藏状态encBckState:编码器反向隐藏状态sourceMask:源的掩码标记
在第行第 33 处,我们按照作者在论文中的建议,将前向和后向隐藏状态连接起来。接下来,在的第 35-38 行,我们传递目标令牌(偏移 1)、编码器输出和源掩码作为解码器的输入,级联的编码器隐藏状态作为解码器的初始状态。然后,解码器输出逻辑、注意力权重和解码器状态。
在第 41-43 行上,我们使用目标令牌和检索到的逻辑来计算批次损失,然后在第 46 行上返回。
@tf.function(
input_signature=[[
tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])
]])
def train_step(self, inputs):
# grab the source and the target text from the inputs
(sourceText, targetText) = inputs
# pre-process the text into token IDs
(sourceTokens, targetTokens) = self._preprocess(
sourceText=sourceText,
targetText=targetText
)
# use gradient tape to track the gradients
with tf.GradientTape() as tape:
# calculate the batch loss
loss = self._calculate_loss(
sourceTokens=sourceTokens,
targetTokens=targetTokens,
)
# normalize the loss
averageLoss = (
loss / tf.reduce_sum(
tf.cast((targetTokens != 0), tf.float32)
)
)
# apply an optimization step on all the trainable variables
variables = self.trainable_variables
gradients = tape.gradient(averageLoss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# return the batch loss
return {"batch_loss": averageLoss}
我们定义火车步骤(第 53 行),在第 49-52 行指定函数的输入签名。稍后,当我们使用tf.module为这个模型提供推理服务时,将需要输入签名。
在第 55 行的上,我们从输入中获取源文本和目标文本。接下来,在的第 58-61 行,我们将文本预处理成令牌 id。第 64-69 行在计算损耗时,用梯度带跟踪梯度。
最后,在第 72-76 行上,我们将损失标准化。然后,我们对所有可训练变量应用优化步骤(第 79-81 行),并在第 84 行返回归一化损失。
@tf.function(
input_signature=[[
tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])
]])
def test_step(self, inputs):
# grab the source and the target text from the inputs
(sourceText, targetText) = inputs
# pre-process the text into token IDs
(sourceTokens, targetTokens) = self._preprocess(
sourceText=sourceText,
targetText=targetText
)
# calculate the batch loss
loss = self._calculate_loss(
sourceTokens=sourceTokens,
targetTokens=targetTokens,
)
# normalize the loss
averageLoss = (
loss / tf.reduce_sum(
tf.cast((targetTokens != 0), tf.float32)
)
)
# return the batch loss
return {"batch_loss": averageLoss}
在行 91 上,我们创建了测试步骤函数,它接受输入。我们还在行 87-90 上指定测试步骤的输入签名(如同在训练步骤中所做的那样)。
接下来,在行 9 6 -99 上,我们将文本标记预处理成标记 id。然后,我们计算第行第 10 行第 2 -105 行的批次损失,并归一化第行第 108-112 行的损失。最后,我们返回第 115 行的归一化损失。
译者
class Translator(tf.Module):
def __init__(self, encoder, decoder, sourceTextProcessor,
targetTextProcessor):
# initialize the encoder, decoder, source text processor, and
# target text processor
self.encoder = encoder
self.decoder = decoder
self.sourceTextProcessor = sourceTextProcessor
self.targetTextProcessor = targetTextProcessor
# initialize index to string layer
self.stringFromIndex = StringLookup(
vocabulary=targetTextProcessor.get_vocabulary(),
mask_token="",
invert=True
)
# initialize string to index layer
indexFromString = StringLookup(
vocabulary=targetTextProcessor.get_vocabulary(),
mask_token="",
)
# generate IDs for mask tokens
tokenMaskIds = indexFromString(["", "[UNK]", "[START]"]).numpy()
tokenMask = np.zeros(
[indexFromString.vocabulary_size()],
dtype=np.bool
)
tokenMask[np.array(tokenMaskIds)] = True
# initialize the token mask, start token, and end token
self.tokenMask = tokenMask
self.startToken = indexFromString(tf.constant("[START]"))
self.endToken = indexFromString(tf.constant("[END]"))
我们创建了一个名为Translator的类,它包含了使用我们训练过的编码器和解码器进行推理所需的所有实用函数。
在__init__功能内(行 118 ):
- 我们初始化编码器、解码器、源文本处理器和目标文本处理器(行 122-125 )
- 在的第 128-132 行,我们初始化
stringFromIndex层进行字符串查找。 - 我们初始化
indexFromString层(第 135-138 行)。这一层将令牌索引转换回字符串格式。 - 使用行 141-146 上的
indexFromString层生成屏蔽令牌的 id。 - 初始化令牌掩码、开始令牌和结束令牌(行 149-151 )。
def tokens_to_text(self, resultTokens):
# decode the token from index to string
resultTextTokens = self.stringFromIndex(resultTokens)
# format the result text into a human readable format
resultText = tf.strings.reduce_join(inputs=resultTextTokens,
axis=1, separator=" ")
resultText = tf.strings.strip(resultText)
# return the result text
return resultText
在的第 153-163 行,我们创建了tokens_to_text函数,它使用stringFromIndex层将令牌从索引解码回字符串格式。
def sample(self, logits, temperature):
# reshape the token mask
tokenMask = self.tokenMask[tf.newaxis, tf.newaxis, :]
# set the logits for all masked tokens to -inf, so they are
# never chosen
logits = tf.where(
condition=self.tokenMask,
x=-np.inf,
y=logits
)
# check if the temperature is set to 0
if temperature == 0.0:
# select the index for the maximum probability element
newTokens = tf.argmax(logits, axis=-1)
# otherwise, we have set the temperature
else:
# sample the index for the element using categorical
# probability distribution
logits = tf.squeeze(logits, axis=1)
newTokens = tf.random.categorical(logits / temperature,
num_samples=1
)
# return the new tokens
return newTokens
接下来,在第 165-192 行,我们创建了sample函数。在第 167 行上,我们对tokenMask进行整形,然后在第 171-175 行上,我们将这些屏蔽令牌的 logits 设置为-inf。这样做是为了跳过被屏蔽的令牌。
在行 178 上,我们检查temperature参数是否设置为零。如果是,那么我们选择行 180 上最大概率元素的索引。如果不是,我们在第 186-189 行使用分类概率分布对元素的索引进行采样。
最后,我们在行 192 返回newTokens。
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string,
shape=[None])])
def translate(self, sourceText, maxLength=50, returnAttention=True,
temperature=1.0):
# grab the batch size
batchSize = tf.shape(sourceText)[0]
# encode the source text to source tokens and pass them
# through the encoder
sourceTokens = self.sourceTextProcessor(sourceText)
(encOutput, encFwdState, encBckState, sourceMask) = self.encoder(
sourceTokens=sourceTokens
)
在第 196 行上,我们创建了translate函数,它接受sourceText、maxLength、returnAttention和temperature。我们还在第 194 行和第 195 行指定了函数的输入签名。
首先,我们从第 199 行的向量中提取batchSize。接下来,在的第 203-206 行,我们将源文本编码成标记,并通过编码器传递它们。
# initialize the decoder state and the new tokens
decState = tf.concat([encFwdState, encBckState], axis=-1)
newTokens = tf.fill([batchSize, 1], self.startToken)
# initialize the result token, attention, and done tensor
# arrays
resultTokens = tf.TensorArray(tf.int64, size=1,
dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1,
dynamic_size=True)
done = tf.zeros([batchSize, 1], dtype=tf.bool)
# loop over the maximum sentence length
for i in tf.range(maxLength):
# pass the encoded tokens through the decoder
(logits, attentionWeights, decState) = self.decoder(
inputs=[newTokens, encOutput, sourceMask],
state=decState,
)
# store the attention weights and sample the new tokens
attention = attention.write(i, attentionWeights)
newTokens = self.sample(logits, temperature)
# if the new token is the end token then set the done
# flag
done = done | (newTokens == self.endToken)
# replace the end token with the padding
newTokens = tf.where(done, tf.constant(0, dtype=tf.int64),
newTokens)
# store the new tokens in the result
resultTokens = resultTokens.write(i, newTokens)
# end the loop once done
if tf.reduce_all(done):
break
# convert the list of generated token IDs to a list of strings
resultTokens = resultTokens.stack()
resultTokens = tf.squeeze(resultTokens, -1)
resultTokens = tf.transpose(resultTokens, [1, 0])
resultText = self.tokens_to_text(resultTokens)
# check if we have to return the attention weights
if returnAttention:
# format the attention weights
attentionStack = attention.stack()
attentionStack = tf.squeeze(attentionStack, 2)
attentionStack = tf.transpose(attentionStack, [1, 0, 2])
# return the text result and attention weights
return {"text": resultText, "attention": attentionStack}
# otherwise, we will just be returning the result text
else:
return {"text": resultText}
我们初始化解码器状态和newTokens ( 行 209 和 210 )。我们还分别初始化第 214、216 和 218 行上的resultTokens、attention向量和done向量。
从第 221 行开始,我们循环最大句子长度。我们首先通过第 223-226 行上的解码器传递编码的令牌。接下来,我们将注意力权重存储在注意力向量中,并在行 229 和 230** 上采样newTokens。**
如果新令牌是结束令牌,那么我们将第 234 行上的done标志设置为零。我们将newTokens存储在线 241 上的resultTokens向量中。一旦整个迭代完成,我们就在 L 行 244 和 245 上跳出循环。
在第 248-251 行,我们使用tokens_to_text层将所有生成的令牌 id 列表转换回字符串。
在行 254 上,我们检查是否必须返回注意力权重,如果是,我们用行 261 上的resultText返回它们。
如果没有,我们将只在行 265 返回resultText。
训练
创建完所有的块后,我们最终从train.py开始。
# USAGE
# python train.py
# set random seed for reproducibility
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.schedule import WarmUpCosine
from pyimagesearch.dataset import load_data
from pyimagesearch.dataset import splitting_dataset
from pyimagesearch.dataset import make_dataset
from pyimagesearch.dataset import tf_lower_and_split_punct
from pyimagesearch.models import Encoder
from pyimagesearch.models import Decoder
from pyimagesearch.translator import TrainTranslator
from pyimagesearch.translator import Translator
from pyimagesearch.loss import MaskedLoss
from tensorflow.keras.layers import TextVectorization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import numpy as np
import os
# load data from disk
print(f"[INFO] loading data from {config.DATA_FNAME}...")
(source, target) = load_data(fname=config.DATA_FNAME)
# split the data into training, validation, and test set
(train, val, test) = splitting_dataset(source=source, target=target)
# build the TensorFlow data datasets of the respective data splits
print("[INFO] building TensorFlow Data input pipeline...")
trainDs = make_dataset(splits=train, batchSize=config.BATCH_SIZE,
train=True)
valDs = make_dataset(splits=val, batchSize=config.BATCH_SIZE,
train=False)
testDs = make_dataset(splits=test, batchSize=config.BATCH_SIZE,
train=False)
我们在第 5-26 行导入所有必需的包。接下来,在的第 29 行和第 30 行,我们从磁盘加载数据,并在的第 33 行将数据分成训练、验证和测试数据集。
我们分别在行 37、39 和 41 、上创建每个的张量流数据集。
# create source text processing layer and adapt on the training
# source sentences
print("[INFO] performing text vectorization...")
sourceTextProcessor = TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=config.SOURCE_VOCAB_SIZE
)
sourceTextProcessor.adapt(train[0])
# create target text processing layer and adapt on the training
# target sentences
targetTextProcessor = TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=config.TARGET_VOCAB_SIZE
)
targetTextProcessor.adapt(train[1])
接下来,我们创建源文本处理层,并将其应用于第 47-51 行的训练源句子。在的第 55-59 行,我们对目标句子做同样的处理。
# build the encoder and the decoder
print("[INFO] building the encoder and decoder models...")
encoder = Encoder(
sourceVocabSize=config.SOURCE_VOCAB_SIZE,
embeddingDim=config.ENCODER_EMBEDDING_DIM,
encUnits=config.ENCODER_UNITS
)
decoder = Decoder(
targetVocabSize=config.TARGET_VOCAB_SIZE,
embeddingDim=config.DECODER_EMBEDDING_DIM,
decUnits=config.DECODER_UNITS,
)
# build the trainer module
print("[INFO] build the translator trainer model...")
translatorTrainer = TrainTranslator(
encoder=encoder,
decoder=decoder,
sourceTextProcessor=sourceTextProcessor,
targetTextProcessor=targetTextProcessor,
)
在第行第 63-67 行,我们使用 vocab 大小、嵌入维度和编码器单元构建编码器模型。类似地,我们用相应的配置在线 68-7 2 上建立解码器模型。
最后,我们初始化名为TrainTranslator ( 第 76 行)的训练器模块。我们通过编码器、解码器、源和目标文本处理器在第 77-81 行上构建它。
# get the total number of steps for training.
totalSteps = int(trainDs.cardinality() * config.EPOCHS)
# calculate the number of steps for warmup.
warmupEpochPercentage = config.WARMUP_PERCENT
warmupSteps = int(totalSteps * warmupEpochPercentage)
# Initialize the warmupcosine schedule.
scheduledLrs = WarmUpCosine(
lrStart=config.LR_START,
lrMax=config.LR_MAX,
warmupSteps=warmupSteps,
totalSteps=totalSteps,
)
# configure the loss and optimizer
print("[INFO] compile the translator trainer model...")
translatorTrainer.compile(
optimizer=Adam(learning_rate=scheduledLrs),
loss=MaskedLoss(),
)
# build the early stopping callback
earlyStoppingCallback = EarlyStopping(
monitor="val_batch_loss",
patience=config.PATIENCE,
restore_best_weights=True,
)
接下来,我们为训练定义一些重要的参数和配置。在第 84 行上,我们得到训练的总步数。在第 87 行和第 88 行,我们计算暖机百分比和暖机步骤。在第 91-96 行,我们定义了热身余弦时间表。
我们在行 100-103 上编译translatorTrainer模型,使用Adam作为优化器,使用MaskedLoss作为损失度量。
接下来,我们用我们在第 106-110 行上配置的耐心来构建提前停止回调。
# train the model
print("[INFO] training the translator model...")
history = translatorTrainer.fit(
trainDs,
validation_data=valDs,
epochs=config.EPOCHS,
callbacks=[earlyStoppingCallback],
)
# save the loss plot
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
plt.plot(history.history["batch_loss"], label="batch_loss")
plt.plot(history.history["val_batch_loss"], label="val_batch_loss")
plt.xlabel("EPOCHS")
plt.ylabel("LOSS")
plt.title("Loss Plots")
plt.legend()
plt.savefig(f"{config.OUTPUT_PATH}/loss.png")
# build the translator module
print("[INFO] build the inference translator model...")
translator = Translator(
encoder=translatorTrainer.encoder,
decoder=translatorTrainer.decoder,
sourceTextProcessor=sourceTextProcessor,
targetTextProcessor=targetTextProcessor,
)
# save the model
print("[INFO] serialize the inference translator to disk...")
tf.saved_model.save(
obj=translator,
export_dir="translator",
signatures={"serving_default": translator.translate}
)
在第 113-119 行上,我们用数据、时期和回调来调用 fit API。我们检查与时期相关的损失图,并将该图保存到磁盘的第 122-130 行。
在的第 134-139 行上,我们构建了用于推理的Translator模型,然后在的第 143-14 行 7 上序列化并保存模型到磁盘。我们将使用这个序列化模型进行推理。
推论
训练完成后,我们终于可以转到我们的推理脚本,看看我们的模型作为翻译器表现如何。
# USAGE
# python inference.py -s "input sentence"
# import the necessary packages
import tensorflow_text as tf_text
import tensorflow as tf
import argparse
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--sentence", required=True,
help="input english sentence")
args = vars(ap.parse_args())
# convert the input english sentence to a constant tensor
sourceText = tf.constant([args["sentence"]])
# load the translator model from disk
print("[INFO] loading the translator model from disk...")
translator = tf.saved_model.load("translator")
# perform inference and display the result
print("[INFO] translating english sentence to french...")
result = translator.translate(sourceText)
translatedText = result["text"][0].numpy().decode()
print("[INFO] english sentence: {}".format(args["sentence"]))
print("[INFO] french translation: {}".format(translatedText))
在inference.py脚本的第 5-7 行,我们导入必要的包。在的第 10-13 行,我们构建了解析源句子所需的参数解析器。
我们先把源英语句子转换成第 16 行的常数张量。接下来,我们在的第 20 行从磁盘加载序列化的翻译器。
我们使用加载的翻译器对第 24 行的源文本执行神经机器翻译,然后在第 26 行和第 27 行的上显示结果。
你可以试试拥抱的表情?更好地理解推理任务的空间:
汇总
这是我们第一次讨论注意力并将其用于神经机器翻译的教程。在接下来的教程中,我们将学习如何利用 Luong 的注意力来改进这个架构,然后如何利用和的注意力来设计机器翻译的架构。
本教程背后的思想和方法非常简单。然而,它们是最先进的深度学习架构(如变形金刚)的基础。
因此,正如图灵教授在图 4 中询问我们所有人的那样,“你们注意了吗?”
引用信息
A. R. Gosthipaty 和 R. Raha。“使用 TensorFlow 和 Keras 的 Bahdanau 注意力的神经机器翻译”, PyImageSearch ,P. Chugh,S. Huot,K. Kidriavsteva,A. Thanki,eds .,2022 年,【https://pyimg.co/kf8ma
@incollection{ARG-RR_2022_Bahdanau,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Neural Machine Translation with {Bahdanau's} Attention Using TensorFlow and Keras},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/kf8ma},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****


 浙公网安备 33010602011771号
浙公网安备 33010602011771号