PyImgSearch-博客中文翻译-六-
PyImgSearch 博客中文翻译(六)
在 Raspberry Pi 4 和 Raspbian Buster 上安装 OpenCV 4
原文:https://pyimagesearch.com/2019/09/16/install-opencv-4-on-raspberry-pi-4-and-raspbian-buster/

在本教程中,您将学习如何在 Raspberry Pi 4 和 Raspbian Buster 上安装 OpenCV 4。
您将通过以下两种方式学习如何在 Raspbian Buster 上安装 OpenCV 4:
- 简单的管道安装方法(几分钟内即可完成)
- 从源代码编译(这将花费更长的时间,但将让您访问 OpenCV 的完整、优化安装)
要了解更多关于在 Raspberry Pi 4 和 Raspbian Buster 上安装 OpenCV 4 的信息,请继续阅读。
2019-11-21 更新: 由于使用 pip 安装方法与 OpenCV 的兼容性问题,本博客发布了一个更新。一定要在搜索“2019-11-21 更新”时通过ctrl + f找到更新。
在 Raspberry Pi 4 和 Raspbian Buster 上安装 OpenCV 4
在本教程中,我们将通过五个简单易行的步骤在 Raspbian Buster 上安装和测试 OpenCV 4。
如果你以前曾经从头编译过 OpenCV,你就会知道这个过程是特别耗时的,如果你错过了一个关键步骤,或者如果你是 Linux 和 Bash 的新手,甚至会痛苦地挫败。
2018 年第四季度,在树莓 Pi 上安装 OpenCV 的新方法(即 pip 安装)得以实现,这要归功于以下人员的辛勤工作:
- Olli-PE kka Heini soo—PyPi 上 opencv-contrib-python 包的维护者
- Ben Nuttall —来自 Raspberry Pi 社区运营的piwheels.org,一个为 Raspberry Pi 提供 ARM wheels(即预编译的二进制包)的 Python 包库
- 达夫·琼斯—
picameraPython 模块的创建者
通过 pip 安装 OpenCV 比以往更加容易。事实上,您可以在不到 10 分钟的时间内启动并运行(步骤# 1–步骤#4a )。
但是有什么问题呢?
使用 pip 安装 OpenCV 很棒,但是对于一些项目(包括许多关于 PyImageSearch.com 和我的书/课程中的教育项目)你可能想要 OpenCV 的完整安装(pip 安装不会给你)。
不要担心,我会在下面的步骤 4b 中为您介绍——您将从头开始学习使用 CMake 和 Make 在 BusterOS 上编译 OpenCV 4。
让我们开始吧!
在我们开始之前:拿起你的 Raspberry Pi 4 和 flash BusterOS 到你的 microSD
让我们回顾一下本教程的硬件要求:
- 树莓 Pi: 本教程假设你使用的是 树莓 Pi 4B 1GB、2GB 或 4GB 硬件。
- 操作系统:这些指令 只适用于 Raspbian BusterT5。
- 32GB microSD: 我推荐优质的 SanDisk 32GB 98Mb/s 卡。这里有一个在亚马逊上的例子(不过你可以在你最喜欢的在线经销商上购买)。
- microSD 适配器:你需要购买一个 microSD 转 USB 适配器,这样你就可以从你的笔记本电脑上闪存存储卡。
如果你还没有树莓 Pi 4,我强烈推荐 CanaKits ( 在亚马逊有售)以及直接通过 Canakit 的网站购买。他们的大多数套件都带有 Raspberry Pi、电源适配器、microSD、microSD 适配器、散热器等等!

Figure 1: Hardware for installing OpenCV 4 on your Raspberry Pi 4 running Raspbian Buster.
一旦你准备好了硬件,你就需要刷新 Raspbian Buster 操作系统的副本到 microSD 卡。
- 前往【BusterOS 官方下载页面 ( 图 2 ),开始下载。我推荐“Raspbian Buster 带桌面和推荐软件”。
- 下载 Balena Etcher —用于刷新存储卡的软件。它适用于所有主流操作系统。
- 使用 Etcher 将 BusterOS 闪存到您的存储卡中(图 3 )。
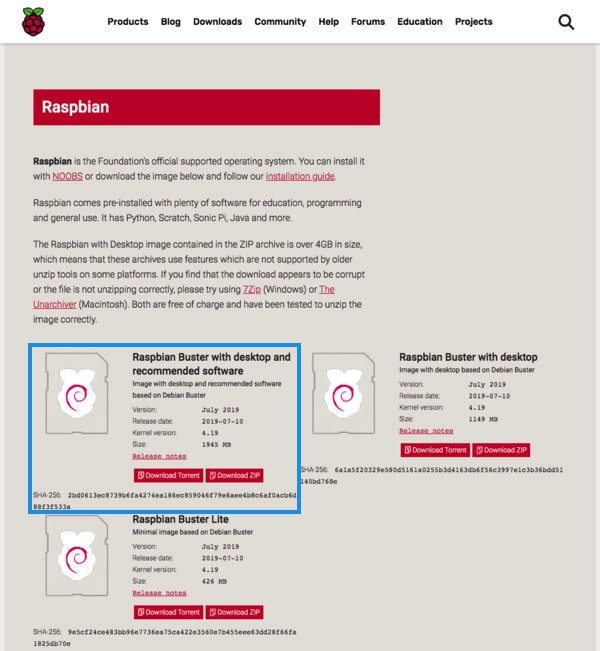
Figure 2: Download Raspbian Buster for your Raspberry Pi and OpenCV 4.
下载了拉斯扁克星后。img 文件,您可以使用 Etcher 将其闪存到您的 micro-SD 卡中:
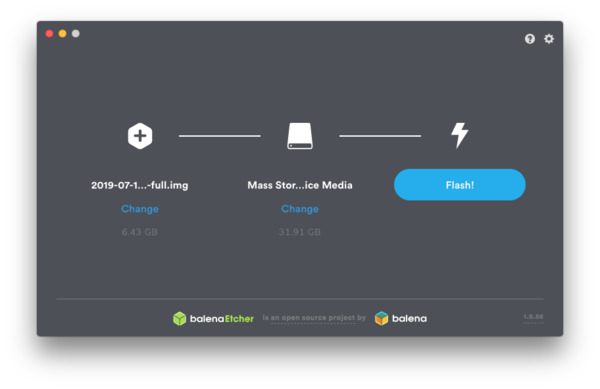
Figure 3: Flash Raspbian Buster with Etcher. We will use BusterOS to install OpenCV 4 on our Raspberry Pi 4.
几分钟后,刷新过程应该完成——将 micro-SD 卡插入您的 Raspberry Pi 4,然后启动。
从这里开始,您可以继续本指南中其余的 OpenCV 安装步骤。
步骤 1:扩展文件系统并回收空间
在本教程的剩余部分,我将做以下假设:
- 您正在使用一个全新安装的 Raspbian Buster (参见上一节了解如何将 Buster 刷新到您的 microSD)。
- 您已经熟悉了命令行和 Unix 环境。
- 您与您的 Pi 建立了一个 SSH 或 VNC 连接。或者,你可以使用键盘+鼠标+屏幕。
继续把你的 microSD 插入到你的 Raspberry Pi 中,用一个附加的屏幕启动它。
启动后,配置您的 WiFi/以太网设置以连接到互联网(您需要互联网连接来下载和安装 OpenCV 所需的软件包)。
在那里,你可以像我一样使用 SSH,或者打开一个终端。
第一步是运行并扩展您的文件系统:
$ sudo raspi-config
然后选择【7 高级选项】 菜单项:
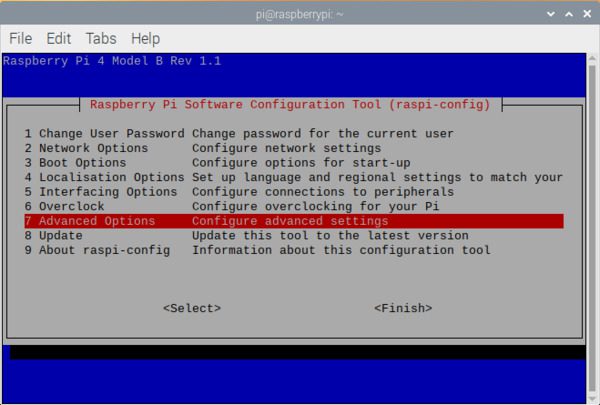
Figure 4: The raspi-config configuration screen for Raspbian Buster. Select 7 Advanced Options so that we can expand our filesystem.
依次选择【A1 扩展文件系统】 :
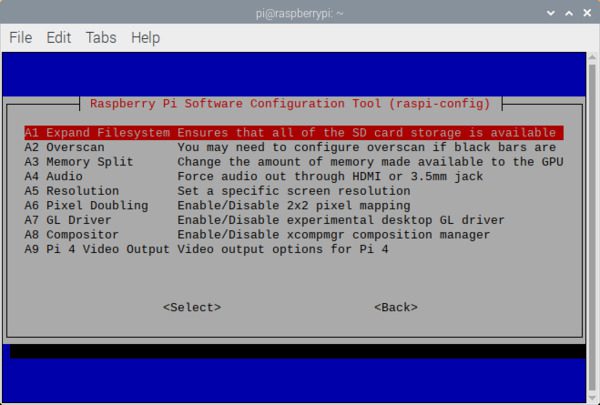
Figure 5: The A1 Expand Filesystem menu item allows you to expand the filesystem on your microSD card containing the Raspberry Pi Buster operating system. Then we can proceed to install OpenCV 4.
一旦出现提示,您应该选择第一个选项,【A1 扩展文件系统】 ,点击键盘上的enter,向下箭头到<【完成】>按钮,然后重新启动您的 Pi——您可能会被提示重新启动,但如果不是,您可以执行:
$ sudo reboot
重新启动后,您的文件系统应该已经扩展到包括 micro-SD 卡上的所有可用空间。您可以通过执行df -h并检查输出来验证磁盘是否已经扩展:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 29G 5.3G 23G 20% /
devtmpfs 1.8G 0 1.8G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 8.6M 1.9G 1% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mmcblk0p1 253M 40M 213M 16% /boot
tmpfs 386M 0 386M 0% /run/user/1000
如您所见,我的 Raspbian 文件系统已经扩展到包括所有 32GB 的 micro-SD 卡。
然而,即使我的文件系统扩展了,我也已经使用了 32GB 卡的 15%。
虽然这不是必需的,但我建议删除 Wolfram Engine 和 LibreOffice,以便在您的 Raspberry Pi 上回收大约 1GB 的空间:
$ sudo apt-get purge wolfram-engine
$ sudo apt-get purge libreoffice*
$ sudo apt-get clean
$ sudo apt-get autoremove
步骤 2:安装依赖项
以下命令将更新和升级任何现有的包,然后安装 OpenCV 的依赖项、I/O 库和优化包:
第一步是更新和升级任何现有的软件包:
$ sudo apt-get update && sudo apt-get upgrade
然后我们需要安装一些开发工具,包括 CMake ,它帮助我们配置 OpenCV 构建过程:
$ sudo apt-get install build-essential cmake pkg-config
接下来,我们需要安装一些图像 I/O 包,允许我们从磁盘加载各种图像文件格式。这种文件格式的例子包括 JPEG、PNG、TIFF 等。:
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng-dev
就像我们需要图像 I/O 包一样,我们也需要视频 I/O 包。这些库允许我们从磁盘读取各种视频文件格式,并直接处理视频流:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
OpenCV 库附带了一个名为highgui的子模块,用于在屏幕上显示图像和构建基本的 GUI。为了编译highgui模块,我们需要安装 GTK 开发库和先决条件:
$ sudo apt-get install libfontconfig1-dev libcairo2-dev
$ sudo apt-get install libgdk-pixbuf2.0-dev libpango1.0-dev
$ sudo apt-get install libgtk2.0-dev libgtk-3-dev
OpenCV 内部的许多操作(即矩阵操作)可以通过安装一些额外的依赖项来进一步优化:
$ sudo apt-get install libatlas-base-dev gfortran
这些优化库对于资源受限的设备来说尤其重要,比如 Raspberry Pi。
以下先决条件是针对步骤 4a 的,它们当然也不会对步骤 4b 造成伤害。它们适用于 HDF5 数据集和 Qt GUIs:
$ sudo apt-get install libhdf5-dev libhdf5-serial-dev libhdf5-103
$ sudo apt-get install libqtgui4 libqtwebkit4 libqt4-test python3-pyqt5
最后,让我们安装 Python 3 头文件,这样我们就可以用 Python 绑定来编译 OpenCV:
$ sudo apt-get install python3-dev
如果您使用的是全新安装的操作系统,那么 Python 的这些版本可能已经是最新版本了(您会看到一条终端消息说明这一点)。
步骤 3:创建您的 Python 虚拟环境并安装 NumPy
我们将使用 Python 虚拟环境,这是使用 Python 时的最佳实践。
Python 虚拟环境是您系统上的一个隔离的开发/测试/生产环境——它与其他环境完全隔离。最重要的是,您可以使用 pip (Python 的包管理器)管理虚拟环境中的 Python 包。
当然,也有管理虚拟环境和包的替代方法(即 Anaconda/conda)。我已经使用/尝试了所有这些工具,但最终选定 pip、 virtualenv 和 virtualenvwrapper 作为我安装在所有系统上的首选工具。如果你使用和我一样的工具,你会得到我最好的支持。
您可以使用以下命令安装 pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo python3 get-pip.py
$ sudo rm -rf ~/.cache/pip
现在让我们安装virtualenv和virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper
一旦virtualenv和virtualenvwrapper都安装好了,打开你的~/.bashrc文件:
$ nano ~/.bashrc
…并将以下几行附加到文件的底部:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
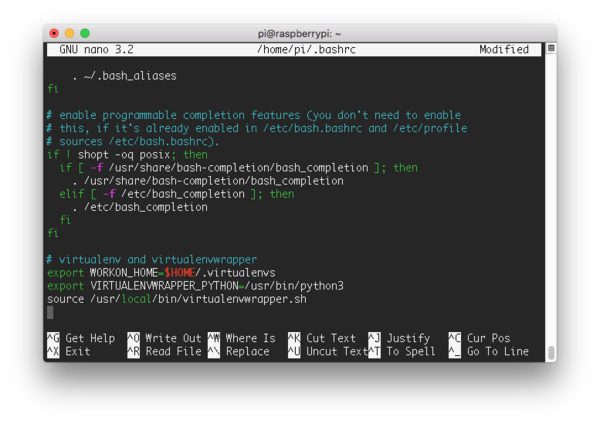
Figure 6: Using the nano editor to update ~/.bashrc with virtualenvwrapper settings.
通过ctrl + x、y、enter保存并退出。
从那里,重新加载您的~/.bashrc文件,将更改应用到您当前的 bash 会话:
$ source ~/.bashrc
接下来,创建您的 Python 3 虚拟环境:
$ mkvirtualenv cv -p python3
这里我们使用 Python 3 创建了一个名为cv的 Python 虚拟环境。展望未来,我推荐 Python 3 和 OpenCV 4+。
注意: Python 2.7 将于 2020 年 1 月 1 日到达生命的尽头,所以我不*推荐使用 Python 2.7。*
您可以随意命名虚拟环境,但是我在 PyImageSearch 上使用cv作为标准命名约定。
如果你的 RPi 上有一个 Raspberry Pi 相机模块,你现在也应该安装 PiCamera API :
$ pip install "picamera[array]"
步骤#4(a 或 b):决定你想要 1 分钟的快速安装还是 2 小时的完整安装
从这里开始,您需要决定安装的其余部分。有两个选择。
- 步骤#4a: pip 安装 OpenCV 4: 如果你决定 pip 安装 OpenCV,你将在几秒钟内完成。这是迄今为止安装 OpenCV 最快、最简单的方法。这是我向 90%的人推荐的方法——尤其是初学者。在此步骤之后,您将跳到* 步骤#5 来测试您的安装。*
*** 步骤#4b:从源代码编译 OpenCV 4:这个方法给你 OpenCV 4 的完全安装。根据您的 Raspberry Pi 中的处理器,这将需要 2-4 个小时。**
**如上所述,我强烈建议您使用 pip 说明。它们速度更快,可以为你 90%的项目工作。此外,专利算法只能用于教育目的(专利算法也有很多很好的替代品)。
步骤 4a: pip 安装 OpenCV 4
在几秒钟内,你可以将 OpenCV 安装到虚拟环境中:
$ pip install opencv-contrib-python==4.1.0.25
2019-11-21 更新:读者反映,通过 pip 安装的 OpenCV 4 的某些版本在树莓 Pi 上无法正常工作。如果您没有使用上面代码块中提到的 OpenCV 的特定版本,当您从 Python 中执行import cv2时,您可能会遇到一个“”未定义的符号:_ _ atomic _ fetch _ add 8”“*,表示libatomic错误。*
如果你观察终端输出,你会看到安装的是 OpenCV 3.4 而不是 OpenCV 4?
怎么回事?
在撰写本文时,PiWheels 还没有用 Raspbian Buster 的预编译 OpenCV 4 二进制文件进行更新。PiWheels 通常会稍微落后于 OpenCV 的最新版本,这可能是为了确保主要 Raspbian 版本之间的兼容性。一旦 OpenCV 4 为 PiWheels 发布,我将更新这一部分。
这就是事情的全部。您现在可以跳到步骤#5 来测试您的安装。
步骤 4b:从源代码编译 OpenCV 4
此选项安装 OpenCV 的完整安装,包括专利(“非自由”)算法。
注意:如果您遵循了步骤 4a,请不要遵循步骤 4b。
让我们继续下载 OpenCV 源代码,包括 opencv 和 opencv_contrib 库,然后解包:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.1.1.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.1.1.zip
$ unzip opencv.zip
$ unzip opencv_contrib.zip
$ mv opencv-4.1.1 opencv
$ mv opencv_contrib-4.1.1 opencv_contrib
对于这篇博文,我们将使用 OpenCV 4 . 1 . 1;但是,随着 OpenCV 新版本的发布,您可以更新相应的版本号。
增加您的交换空间
在你开始编译之前,你必须 增加你的交换空间 。增加交换空间将使你能够用树莓派的全部四个核心 编译 OpenCV(而不会因为内存耗尽而导致编译挂起)。
继续打开您的/etc/dphys-swapfile文件:
$ sudo nano /etc/dphys-swapfile
…然后编辑CONF_SWAPSIZE变量:
# set size to absolute value, leaving empty (default) then uses computed value
# you most likely don't want this, unless you have an special disk situation
# CONF_SWAPSIZE=100
CONF_SWAPSIZE=2048
注意,我将交换空间从 100MB 增加到了 2048MB 。这对于在 Raspbian Buster 上用多核编译 OpenCV 至关重要。
2019-11-21 更新:我们的测试表明,在 OpenCV 编译时,2048MB 的交换对于防止锁定是最有效的。
通过ctrl + x、y、enter保存并退出。
如果你不增加 SWAP,你的 Pi 很可能会在编译过程中挂起。
从那里,重新启动交换服务:
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
注意:增加交换空间是烧坏你的 Raspberry Pi microSD 卡的好方法。基于闪存的存储可以执行的写入次数有限,直到卡基本上无法再容纳 1 和 0。我们只会在短时间内启用大规模互换,所以这没什么大不了的。无论如何,一定要在安装 OpenCV + Python 后备份你的.img文件,以防你的卡意外提前死亡。你可以在本页的阅读更多关于大容量交换损坏存储卡的信息。
在 Raspbian Buster 上编译并安装 OpenCV 4
我们现在准备在 Raspberry Pi 4 上编译和安装完整的、优化的 OpenCV 库。
使用workon命令确保您处于cv虚拟环境中:
$ workon cv
然后,将 NumPy(一个 OpenCV 依赖项)安装到 Python 虚拟环境中:
$ pip install numpy
并从那里配置您的构建:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D ENABLE_NEON=ON \
-D ENABLE_VFPV3=ON \
-D BUILD_TESTS=OFF \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D CMAKE_SHARED_LINKER_FLAGS=-latomic \
-D BUILD_EXAMPLES=OFF ..
我想提请大家注意四个 CMake 标志:
- (1) 霓虹灯和 (2) VFPv3 优化标志已启用。这几行代码可以确保你在 Raspberry Pi 上为 ARM 处理器编译出最快、最优化的 OpenCV(第 7 行和第 8 行)。
- 注:树莓 Pi Zero W** 硬件不兼容 NEON 或 VFPv3。如果你正在编译一个 Raspberry Pi Zero W. ,一定要删除第 7 行和第 8 行
- (3) 专利“非自由”算法给你 OpenCV 的完整安装(第 11 行)。
- 并且通过深入 OpenCV 的源代码,确定了我们需要 (4)
-latomic共享链接器标志(第 12 行)。
现在我想花一点时间让大家意识到初学者的一个常见陷阱:
- 在上面的端子板中,您将目录更改为
~/opencv/。 - 然后在其中创建一个
build/目录,并在其中更改目录。 - 如果您试图在不在
~/opencv/build目录中的情况下执行 CMake,CMake 将会失败。试着运行pwd看看在运行cmake之前你在哪个工作目录。
在为编译准备和配置 OpenCV 时,cmake命令将需要大约 3-5 分钟的时间来运行。
当 CMake 完成时,一定要检查 Python 3 部分下 CMake 的输出:
请注意Interpreter、Libraries、numpy和packages路径变量是如何正确设置的。这些都是指我们的cv虚拟环境。
现在继续操作,向上滚动以确保“非自由算法”被设置为已安装:
如你所见,OpenCV 4 的“非自由算法”将被编译+安装。
现在我们已经为 OpenCV 4 编译做好了准备,是时候使用所有四个内核启动编译过程了:
$ make -j4
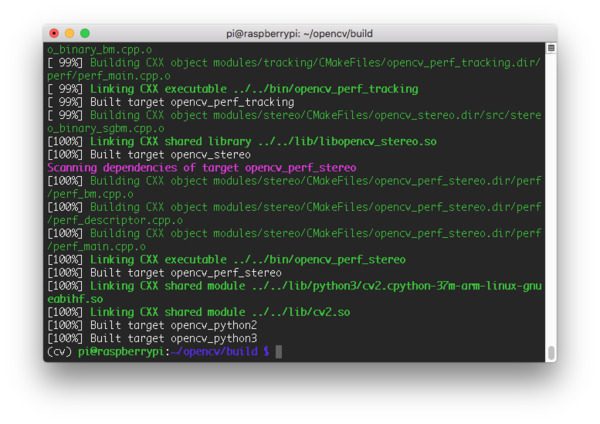
Figure 9: We used Make to compile OpenCV 4 on a Raspberry Pi 4 running Raspbian Buster.
运行make可能需要 1-4 个小时,这取决于你的 Raspberry Pi 硬件(本教程与 Raspberry Pi 3B、3B+和 4 兼容)。在撰写本文时,Raspberry Pi 4 是最快的。
假设 OpenCV 编译没有错误(如我上面的截图所示),您可以在您的 Raspberry Pi 上安装您的 OpenCV 优化版本:
$ sudo make install
$ sudo ldconfig
重置您的交换
别忘了回去 给你的/etc/dphys-swapfile文件还有:
- 将
CONF_SWAPSIZE重置为 100MB。 - 重新启动交换服务。
Sym-link 你的 OpenCV 4 在树莓 Pi 上
符号链接是一种从一个目录指向系统中其他位置的文件或文件夹的方式。对于这一子步骤,我们将把cv2.so绑定符号链接到您的cv虚拟环境中。
让我们继续创建我们的符号链接。确保对以下所有路径使用“tab-completion”(而不是盲目复制这些命令):
$ cd /usr/local/lib/python3.7/site-packages/cv2/python-3.7
$ sudo mv cv2.cpython-37m-arm-linux-gnueabihf.so cv2.so
$ cd ~/.virtualenvs/cv/lib/python3.7/site-packages/
$ ln -s /usr/local/lib/python3.7/site-packages/cv2/python-3.7/cv2.so cv2.so
请记住,确切的路径可能会改变,您应该使用“tab-completion”。
步骤 5:测试 OpenCV 4 Raspberry Pi BusterOS 安装
作为快速检查,访问cv虚拟环境,启动 Python shell,并尝试导入 OpenCV 库:
$ cd ~
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'4.1.1'
>>>
恭喜你!您刚刚在您的 Raspberry Pi 上安装了 OpenCV 4。
如果你正在寻找一些有趣的项目来使用 OpenCV 4,一定要看看我的 Raspberry Pi 档案。
常见问题(FAQ)
问:当我遇到与libatomic.so相关的"undefined symbol: __atomic_fetch_add8"错误时,我该怎么办?
答:自 OpenCV 4.1.1(大约在 2019 年 11 月的时间框架内)以来,pip 安装一直给读者带来麻烦。确保安装版本4.1.0.25:
$ pip install opencv-contrib-python==4.1.0.25
下一步是什么?

准备好让您的 Raspberry Pi 和 OpenCV 安装工作了吗?
我全新的书, 计算机视觉的树莓派 ,有超过 40 个嵌入式计算机视觉和物联网(IoT)应用的计算机视觉和深度学习项目。你可以利用书中的项目来解决你的家庭、商业甚至是客户的问题。每个项目都强调:
- 做中学
- 卷起你的袖子
- 在代码和实现中动手
- 使用 Raspberry Pi 构建实际的、真实的项目
几个突出显示的项目包括:
- 日间和夜间野生动物监测
- 交通计数和车速检测
- 资源受限设备上的深度学习分类、对象检测和实例分割
- 手势识别
- 基本机器人导航
- 安全应用
- 课堂出勤率
- 还有更多!
这本书还涵盖了使用谷歌 Coral 和英特尔 Movidius NCS 协处理器以及英伟达 Jetson Nano 主板的深度学习。
如果你对研究计算机视觉和嵌入式设备上的深度学习感兴趣, 你不会找到比这本书更好的书了!
Pick up your copy of Raspberry Pi for Computer Vision today!
摘要
在今天的教程中,您学习了如何通过两种方法在运行 Raspbian Buster 操作系统的 Raspberry Pi 4 上安装 OpenCV 4:
- 简单的 pip 安装(快速简单)
- 从源代码编译(花费更长时间,但是给你完整的 OpenCV 安装/优化)
安装 OpenCV 4 的 pip 方法是迄今为止安装 OpenCV 最简单的方法(也是我为 90%的项目推荐的方法)。这对初学者来说也是非常棒的。
如果您需要 OpenCV 的完整安装,您必须从源代码编译。从源代码编译可以确保您拥有完整的安装,包括带有专利(“非免费”)算法的“contrib”模块。
虽然从源代码编译既(1)更复杂,又(2)更耗时,但这是目前访问 OpenCV 所有特性的唯一方法。
我希望你喜欢今天的教程!
如果你准备好让你的 RPi 和 OpenCV 安装工作,一定要看看我的书, 用于计算机视觉的树莓 Pi——在这本书里,你将学习如何在树莓 Pi、Google Coral、Movidius NCS 和 NVIDIA Jetson Nano 上构建实用的、真实世界的计算机视觉和深度学习应用。
当未来的教程在 PyImageSearch 博客上发布时会得到通知(并下载我的免费 17 页简历和 DL 资源指南 PDF),*只需在下面的表格中输入您的电子邮件地址!***
在你的树莓 Pi 上安装 OpenCV 4
原文:https://pyimagesearch.com/2018/09/26/install-opencv-4-on-your-raspberry-pi/

今天我将向您展示如何在您的 Raspberry Pi 上编译和安装 OpenCV 4。
OpenCV 4 于 2018 年 11 月 20 日正式发布。
这篇博文随后于 11 月 28 日更新,以适应安装的变化(之前这些说明链接到 alpha 版本源代码)。
也可以 pip 安装 OpenCV!然而,截至此次更新,PyPi 不包含可通过 pip 安装的预编译 OpenCV 4 二进制文件。
因此,如果你想要 OpenCV 4,那么你需要从源代码编译。
要了解如何在您的树莓 Pi 上安装 OpenCV 4,只需遵循本教程!
在你的树莓 Pi 上安装 OpenCV 4
在这篇博文中,我们将在你的树莓 Pi 上安装 OpenCV 4。OpenCV 4 的目标是减少膨胀,增加优化,并更新深度学习模块。
注: 我的博客上有很多安装指南。开始之前,请务必查看我的 OpenCV 安装指南 页面上的可用安装教程。
首先,我们将涵盖本教程附带的假设。
从这里开始,我们将通过 7 个步骤在您的 Raspberry Pi 上编译和安装 OpenCV 4。从源代码编译允许我们完全控制编译和构建。它还允许我们获取最新的代码——这是 pip 和 apt-get 所不提供的。
最后,我们将通过一个有趣的项目来测试我们在 Raspberry Pi 上安装的 OpenCV 4。
让我们开始吧。
假设
在本教程中,我将假设您已经拥有一个 树莓 Pi 3 B 或更新的 树莓 Pi 3 B+ 与Raspbian Stretch installed。
如果你还没有 Raspbian Stretch 操作系统,你需要升级你的操作系统来利用 Raspbian Stretch 的新特性。
要将你的树莓 Pi 3 升级到 Raspbian Stretch,你可以在这里下载,然后按照这些升级说明(或者这些是针对 NOOBS 路线的,这是推荐给初学者的)。通过 torrent 客户端下载前一个指令大约需要 10 分钟,使用 Etcher 或其他工具刷新 SD 卡大约需要 10 分钟。此时,您可以通电并继续下一部分。
假设您的操作系统是最新的,您将需要以下之一来完成本文的剩余部分:
- 物理访问您的 Raspberry Pi 3,以便您可以打开终端并执行命令
- 通过 SSH 或 VNC 远程访问。
我将通过 SSH 完成本教程的大部分内容,但是只要您可以访问终端,您就可以轻松地跟着做。
宋承宪不会吗? 如果您在网络上看到您的 Pi,但无法对其进行 ssh,您可能需要启用 SSH。这可以通过 Raspberry Pi 桌面首选项菜单(你需要一根 HDMI 线和一个键盘/鼠标)或从 Pi 的命令行运行sudo service ssh start来轻松完成。
更改设置并重新启动后,您可以使用本地主机地址直接在 Pi 上测试 SSH。打开一个终端,输入ssh pi@127.0.0.1看看它是否工作。要从另一台计算机进行 SSH,您需要 Pi 的 IP 地址——您可以通过查看路由器的客户端页面或在 Pi 上运行ifconfig来找到它。
键盘布局给你带来困扰? 进入 Raspberry Pi 桌面首选项菜单,更改你的键盘布局。我使用标准的美国键盘布局,但是你会想要选择一个适合你的。
步骤 1:在您的 Raspberry Pi 上扩展文件系统
要启动 OpenCV 4 party,启动您的 Raspberry Pi 并打开一个 SSH 连接(或者使用带有键盘+鼠标的 Raspbian 桌面并启动一个终端)。
你用的是全新的 Raspbian Stretch 吗?
如果是这样的话,你应该做的第一件事就是扩展你的文件系统,在你的 micro-SD 卡上包含所有可用空间:
$ sudo raspi-config
然后选择【高级选项】菜单项:
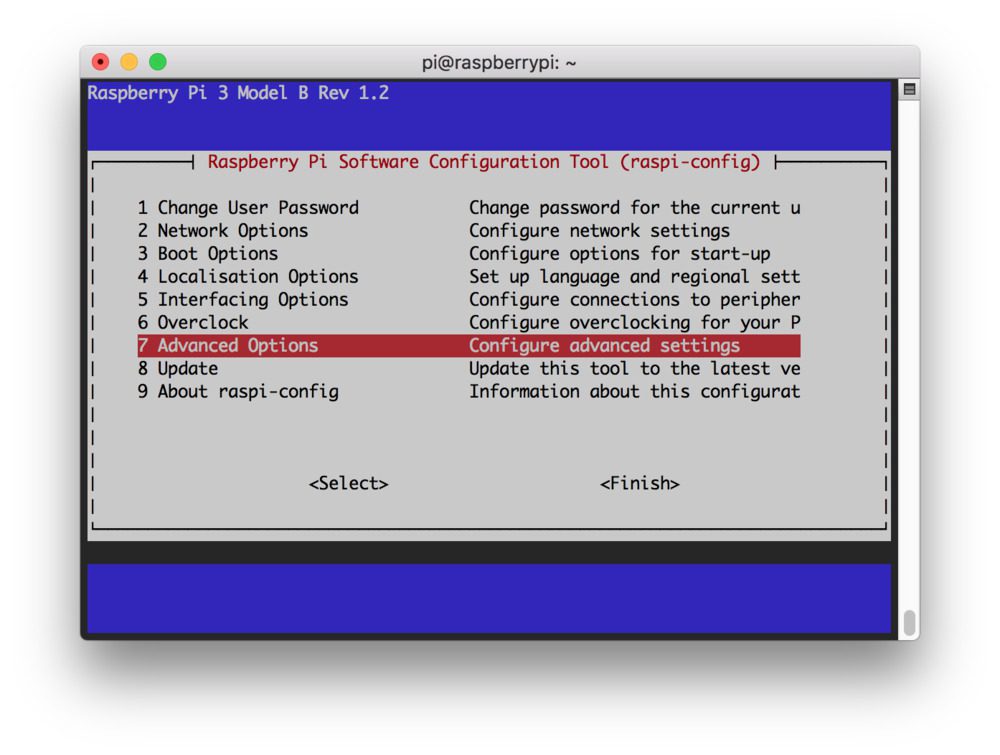
Figure 1: Selecting the “Advanced Options” from the raspi-config menu to expand the Raspbian file system on your Raspberry Pi is important before installing OpenCV 4. Next we’ll actually expand the filesystem.
接着选择“扩展文件系统”:
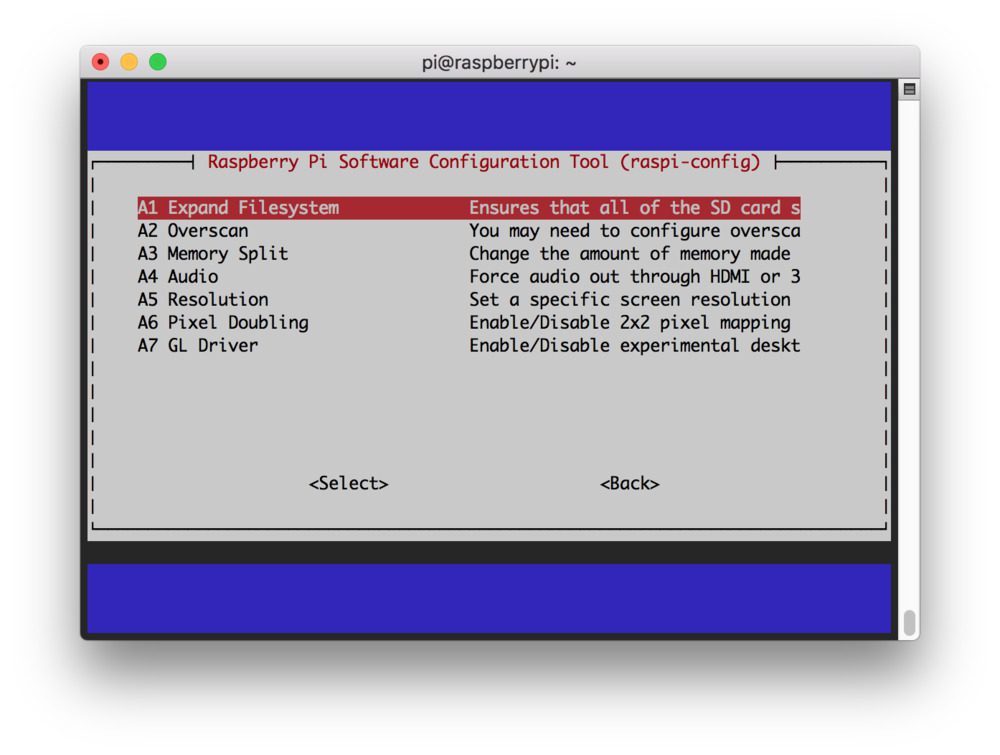
Figure 2: The Raspberry Pi “Expand Filesystem” menu allows us to take advantage of our entire flash memory card. This will give us space necessary to install OpenCV 4 and other packages.
一旦出现提示,你应该选择第一个选项,“A1。展开文件系统" , 点击键盘上的回车键 ,向下箭头到 " <完成> " 按钮,然后重新启动您的 Pi——可能会提示您重新启动,但如果不是,您可以执行:
$ sudo reboot
重新启动后,您的文件系统应该已经扩展到包括 micro-SD 卡上的所有可用空间。您可以通过执行df -h并检查输出来验证磁盘是否已经扩展:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 30G 4.2G 24G 15% /
devtmpfs 434M 0 434M 0% /dev
tmpfs 438M 0 438M 0% /dev/shm
tmpfs 438M 12M 427M 3% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 438M 0 438M 0% /sys/fs/cgroup
/dev/mmcblk0p1 42M 21M 21M 51% /boot
tmpfs 88M 0 88M 0% /run/user/1000
如您所见,我的 Raspbian 文件系统已经扩展到包括所有 32GB 的 micro-SD 卡。
然而,即使我的文件系统扩展了,我也已经使用了 32GB 卡的 15%。
如果您使用的是 8GB 卡,您可能会使用将近 50%的可用空间,因此一个简单的方法是删除 LibreOffice 和 Wolfram engine,以释放 Pi 上的一些空间:
$ sudo apt-get purge wolfram-engine
$ sudo apt-get purge libreoffice*
$ sudo apt-get clean
$ sudo apt-get autoremove
移除 Wolfram 引擎和 LibreOffice 后,您可以回收近 1GB 的空间!
步骤 2:在你的 Raspberry Pi 上安装 OpenCV 4 依赖项
从那里,让我们更新我们的系统:
$ sudo apt-get update && sudo apt-get upgrade
然后让我们安装开发工具,包括 CMake :
$ sudo apt-get install build-essential cmake unzip pkg-config
接下来,让我们安装一系列图像和视频库——这些库对于能够处理图像和视频文件至关重要:
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
从那里,让我们安装 GTK,我们的 GUI 后端:
$ sudo apt-get install libgtk-3-dev
现在让我们安装一个可以减少讨厌的 GTK 警告的包:
$ sudo apt-get install libcanberra-gtk*
星号会抓住手臂特定的 GTK。
然后安装两个包含 OpenCV 数值优化的包:
$ sudo apt-get install libatlas-base-dev gfortran
最后,让我们安装 Python 3 开发头:
$ sudo apt-get install python3-dev
一旦安装了所有这些先决条件,您就可以进入下一步。
步骤 3:为你的树莓 Pi 下载 OpenCV 4
我们的下一步是下载 OpenCV。
让我们导航到我们的主文件夹,下载 opencv 和 T2 的 opencv_contrib。contrib repo 包含我们在 PyImageSearch 博客上经常使用的额外模块和函数。你应该也在安装 OpenCV 库和附加的 contrib 模块。
当你准备好了,就跟着下载opencv和opencv_contrib代码:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.0.0.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.0.0.zip
从那里,让我们解压缩档案:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
我也喜欢重命名目录:
$ mv opencv-4.0.0 opencv
$ mv opencv_contrib-4.0.0 opencv_contrib
如果您跳过重命名目录,不要忘记更新 CMake 路径。
既然opencv和opencv_contrib已经下载并准备好了,让我们设置我们的环境。
步骤 4:为 OpenCV 4 配置 Python 3 虚拟环境
让我们抓取并安装 pip,一个 Python 包管理器。
要安装 pip,只需在终端中输入以下内容:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
利用虚拟环境进行 Python 开发
如果你不熟悉虚拟环境,请花点时间看看 RealPython 上的这篇文章,或者读一下 PyImageSearch 上的这篇博文的前半部分。
虚拟环境将允许您在系统上独立运行不同版本的 Python 软件。今天我们将只设置一个环境,但是您可以轻松地为每个项目设置一个环境。
现在让我们继续安装virtualenv和virtualenvwrapper——它们支持 Python 虚拟环境:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
为了完成这些工具的安装,我们需要更新我们的~/.profile文件(类似于.bashrc或.bash_profile)。
使用终端文本编辑器,如vi / vim或nano,将下列行添加到您的~/.profile中:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
或者,您可以通过 bash 命令直接附加这些行:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.profile
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.profile
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.profile
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.profile
接下来,获取~/.profile文件:
$ source ~/.profile
创建一个虚拟环境来存放 OpenCV 4 和其他包
现在,您可以在 Raspberry Pi 上创建 OpenCV 4 + Python 3 虚拟环境了:
$ mkvirtualenv cv -p python3
这一行简单地创建了一个名为cv的 Python 3 虚拟环境。
你可以(也应该)随心所欲地命名你的环境——我喜欢让它们简洁明了,同时提供足够的信息,以便我记住它们的用途。例如,我喜欢这样命名我的环境:
py3cv4py3cv3py2cv2- 等等。
让我们通过使用workon命令来验证我们是否处于cv环境中:
$ workon cv

Figure 3: The workon command is part of the virtualenvwrapper package and allows us to easily activate virtual environments. Here I’m activating the cv environment which we’ll install OpenCV 4 into on our Raspberry Pi.
安装 NumPy
我们将安装的第一个 Python 包和唯一的 OpenCV 先决条件是 NumPy:
$ pip install numpy
我们现在可以准备 OpenCV 4 在我们的 Raspberry Pi 上进行编译。
步骤 5:为你的树莓 Pi 创建并编译 OpenCV 4
对于这一步,我们将使用 CMake 设置我们的编译,然后运行make来实际编译 OpenCV。这是今天博文最耗时的一步。
导航回 OpenCV repo 并创建+输入一个build目录:
$ cd ~/opencv
$ mkdir build
$ cd build
为 OpenCV 4 运行 CMake
现在让我们运行 CMake 来配置 OpenCV 4 版本:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D ENABLE_NEON=ON \
-D ENABLE_VFPV3=ON \
-D BUILD_TESTS=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D BUILD_EXAMPLES=OFF ..
更新 2018-11-27: 注意-D OPENCV_ENABLE_NONFREE=ON旗。用 OpenCV 4 设置这个标志可以确保你可以访问 SIFT/SURF 和其他专利算法。
确保更新上述命令以使用正确的OPENCV_EXTRA_MODULES_PATH路径。如果你完全按照这个教程来做,你应该不需要更新路径。
一旦 CMake 完成,检查输出是很重要的。您的输出应该类似于下面的内容:
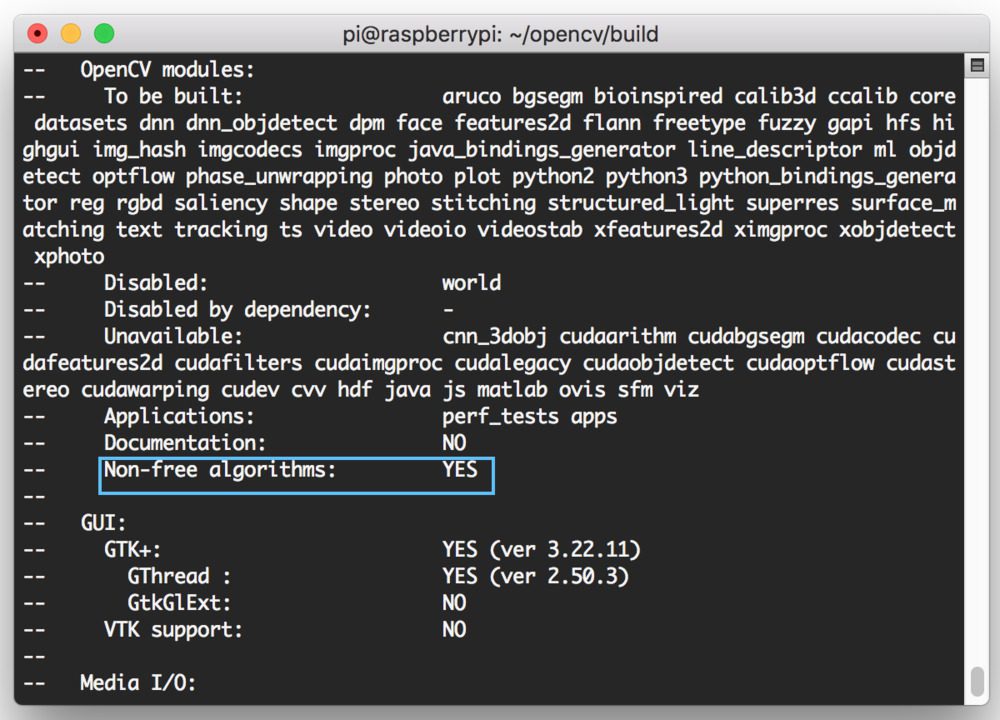
Figure 4: Ensure that “Non-free algorithms” is set to “YES”. This will allow you to use patented algorithms such as SIFT/SURF for educational purposes.
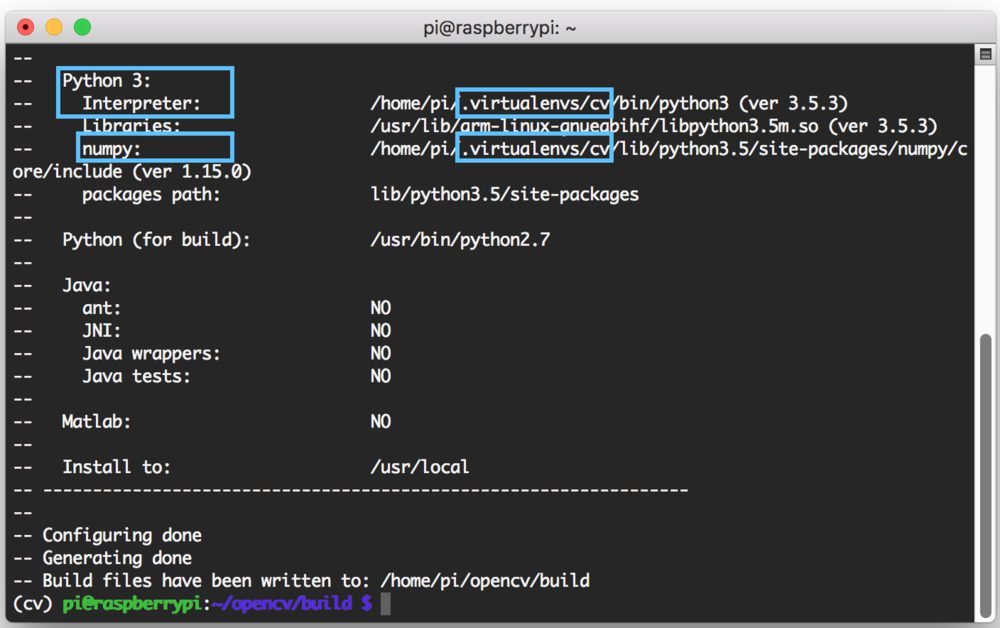
Figure 5: The CMake command allows us to generate build files for compiling OpenCV 4 on the Raspberry Pi. Since we’re using virtual environments, you should inspect the output to make sure that the compile will use the proper interpreter and NumPy.
现在花一点时间来确保Interpreter指向正确的 Python 3 二进制文件。还要检查numpy是否指向我们的 NumPy 包,该包安装在虚拟环境的中。
增加树莓派的互换
在你开始编译之前,我建议 增加你的交换空间 。这将使你能够用树莓派的 所有四个内核 编译 OpenCV,而不会因为内存耗尽而导致编译挂起。
打开您的/etc/dphys-swapfile文件:
$ sudo nano /etc/dphys-swapfile
…然后编辑CONF_SWAPSIZE变量:
# set size to absolute value, leaving empty (default) then uses computed value
# you most likely don't want this, unless you have an special disk situation
# CONF_SWAPSIZE=100
CONF_SWAPSIZE=2048
请注意,我正在将交换空间从 100MB 增加到 2048MB。
如果你不执行这个步骤,你的 Pi 很可能会挂起。
从那里,重新启动交换服务:
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
注意:增加交换空间是烧坏你的 Raspberry Pi microSD 卡的好方法。基于闪存的存储可以执行的写入次数有限,直到卡基本上无法再容纳 1 和 0。我们只会在短时间内启用大规模互换,所以这没什么大不了的。无论如何,一定要在安装 OpenCV + Python 后备份你的.img文件,以防你的卡意外提前死亡。你可以在本页的阅读更多关于大容量交换损坏存储卡的信息。
编译 OpenCV 4
现在我们准备编译 OpenCV 4:
$ make -j4
注意:在上面的make命令中,-j4参数指定我有 4 个内核进行编译。如果你有编译错误或者你的 Raspberry Pi 挂起/冻结*你可以不使用-j4开关来消除竞争条件。*
在这里,您可以看到 OpenCV 4 编译时没有任何错误:
Figure 6: I’ve compiled OpenCV 4 on my Raspberry Pi successfully (the make command has reached 100%). So now I’ll issue the sudo make install command.
接下来,让我们用另外两个命令安装 OpenCV 4:
$ sudo make install
$ sudo ldconfig
别忘了回去 给你的/etc/dphys-swapfile文件还有:
- 将
CONF_SWAPSIZE重置为 100MB。 - 重新启动交换服务。
步骤 6:将 OpenCV 4 链接到 Python 3 虚拟环境中
让我们创建一个从系统site-packages目录中的 OpenCV 安装到我们的虚拟环境的符号链接:
$ cd ~/.virtualenvs/cv/lib/python3.5/site-packages/
$ ln -s /usr/local/python/cv2/python-3.5/cv2.cpython-35m-arm-linux-gnueabihf.so cv2.so
$ cd ~
我再怎么强调这一步也不为过——这一步非常关键。 如果你不创建一个符号链接,你将无法在你的脚本中导入 OpenCV。此外,确保上述命令中的路径和文件名对于您的 Raspberry Pi 是正确的。我建议 tab 补全。
步骤 7:在您的 Raspberry Pi 上测试您的 OpenCV 4 安装
让我们做一个快速的健全性测试,看看 OpenCV 4 是否准备好了。
打开终端并执行以下操作:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'4.0.0'
>>> exit()
第一个命令激活我们的虚拟环境。然后我们运行与环境相关的 Python 解释器。
如果你看到你已经安装了 4.0.0 版本,那么你现在全副武装,危险+准备执行计算机视觉和图像处理。
一个 Raspberry Pi + OpenCV 4 项目,让您的双脚沾湿
不久前,我正努力通过评论、电子邮件和 Twitter/脸书/LinkedIn 回复 PyImageSearch 的读者。我会尽可能多地回复收到的问题和评论。
当时是下午 4:30,我在“流畅”状态下不停地敲击键盘。
但是当我打字的时候,我的大脑中触发了我口渴的感觉。非常渴。
所以我离开键盘,去冰箱拿了瓶美味的啤酒?。
WTF?
我所有的啤酒都不见了!
谁偷了我的啤酒?!
我拿了些水,回到电脑前。我关闭了所有的信件窗口,启动了代码编辑器/IDE ( 我喜欢 PyCharm )。
我又开始敲键盘,喝点水。
我在建造什么?
我用我的树莓皮制作了一个安全摄像头,它将捕捉人们离开/进入我的公寓和打开/关闭我的冰箱。下次我会抓住那个偷我啤酒的混蛋!

Figure 7: Examples of the Raspberry Pi home surveillance system detecting motion in video frames and uploading them to my personal Dropbox account.
如果你想学习如何用你的树莓 Pi 和 OpenCV 4 构建一个安全摄像头,那么我建议你阅读 原创博文 。
该项目相对简单,将完成以下工作:
- 通过背景减法检测运动。
- 将入侵者和其他动作的图像上传到 Dropbox,以便您可以稍后查看事件。所有的图片都有时间标记,这样你就能知道什么时候有人在你的 Raspberry Pi 安全摄像头里。
或者,如果您很聪明,并且想要立即获取代码,那么在将 Dropbox API 密钥粘贴到配置文件中之后,您可以很快启动并运行。
要下载这个项目,请滚动到这篇博文的 “下载” 部分并填写表格。
您可以将 zip 文件下载到您的~/Downloads文件夹,然后启动一个终端:
$ cd ~/Downloads
$ scp pi-home-surveillance.zip pi@192.168.1.119:~ # replace IP with your Pi's IP
$ ssh pi@192.168.1.119 # replace with your Pi's IP
一旦建立了 SSH 连接,让我们安装几个包,即 Dropbox API:
$ workon cv
$ pip install dropbox
$ pip install imutils
$ pip install "picamera[array]"
从那里,解压缩文件并更改工作目录:
$ cd ~
$ unzip pi-home-surveillance.zip
$ cd pi-home-surveillance
您将看到如下所示的目录结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── tempimage.py
├── conf.json
└── pi_surveillance.py
1 directory, 6 files
在您能够部署项目之前,您需要编辑配置文件conf.json。让我们使用nano文本编辑器(或者vim / emacs)在我们的终端中快速检查一下:
$ nano conf.json
您将看到一个如下所示的 JSON 字典:
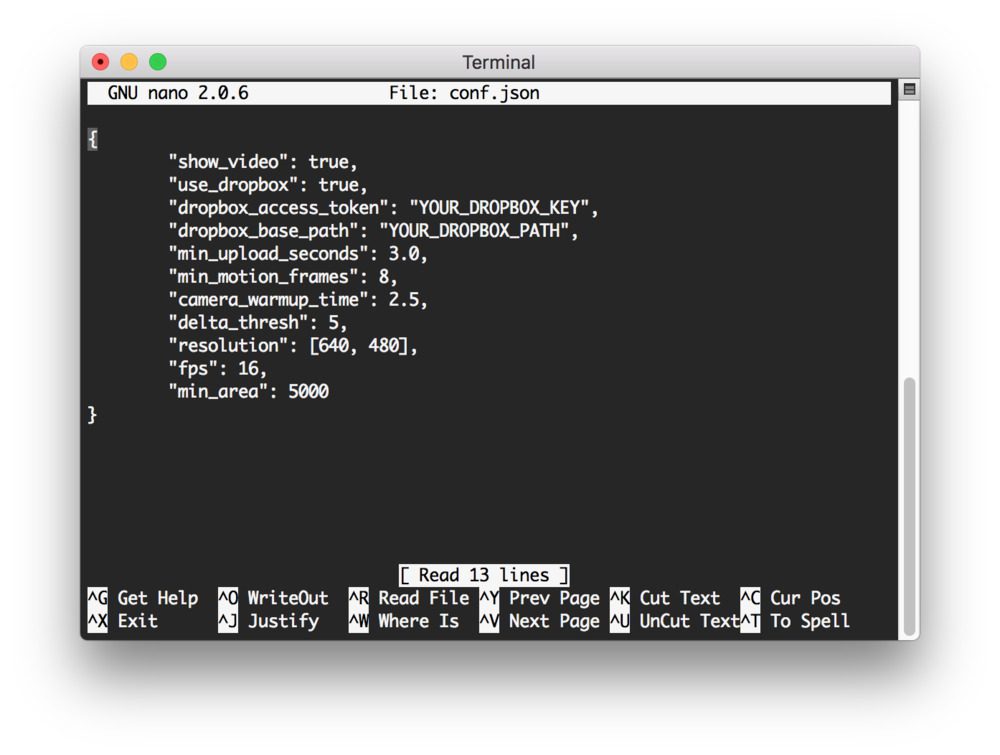
Figure 8: The Raspberry Pi security camera configuration file. An API key must be pasted in, and a base path must be configured. For headless mode, “show_video” should be set to “false”.
此时,使用 API 键和路径编辑配置文件很重要。要找到您的 API 密钥,您可以在应用创建页面上创建一个应用。一旦你创建了一个应用,API 密匙可以在应用控制台上的应用页面的 OAuth 部分下生成(只需点击“生成”按钮并将密匙复制/粘贴到配置文件中)。该路径必须是收存箱文件结构中的有效路径。
注意: 不要和任何人分享你的 API 密匙,除非你信任他们!
为了测试,你可以离开"show_video": true并连接一个 HDMI 屏幕+键盘/鼠标到你的 Pi。最终,您会希望将值设置为false,并让您的 Pi 无头运行,只需连接几根电缆,这样您就可以将它隐藏在不显眼的地方。
项目开始工作后,您可以在 web 浏览器中监控 Dropbox 文件夹(您可能需要刷新以检查图像),或者如果您正在将文件夹同步到您的笔记本电脑/台式机,您可以在那里监控该文件夹。
我强烈推荐你也阅读整个博文。
祝您使用 Raspberry Pi 和 OpenCV 4 愉快!
故障排除和常见问题(FAQ)
在你的 Raspberry Pi 上安装 OpenCV 4 遇到错误了吗?
先不要把这个小玩意儿扔到房间的另一头。第一次在您的 Raspberry Pi 上安装 OpenCV 可能会非常令人沮丧,我最不希望您做的事情就是在此结束学习过程。
如果你真的卡住了,别忘了的 快速入门捆绑包 的 实用 Python 和 OpenCV +案例分析 自带树莓派镜像,已经预配置好,随时可用。包括 RPi 3B/3B+和 RPi Zero W 的图像。这些图片可以帮你省下几个小时和几天的时间(是的,我花了大约 6 天来设置 RPi Zero W)。
如果你下定决心要自己解决这个问题,我整理了一个简短的常见问题(FAQ)列表,我建议你熟悉它们。
问:如何将操作系统闪存到我的 Raspberry Pi 存储卡上?
**A. 我推荐你:
- 拿个 16GB 或者 32GB 的内存卡。
- Flash Raspbian 用蚀刻机对卡片进行拉伸。Etcher 受所有 3 个主要操作系统的支持。
- 将卡片插入你的树莓派,从这篇博文中的“假设”和“第一步”开始。
Q. 我能用 Python 2.7 吗?
A. 我不推荐使用 Python 2.7,因为它正迅速接近生命的尽头。Python 3 是现在的标准。但是如果你坚持…
以下是如何开始使用 Python 2.7 的方法:
$ sudo apt-get install python2.7 python2.7-dev
然后,在您在步骤#4 中创建您的虚拟环境之前,首先安装 pip for Python 2.7:
$ sudo python2.7 get-pip.py
同样在步骤#4 中:当您创建虚拟环境时,只需使用相关的 Python 版本标志:
$ mkvirtualenv cv -p python2.7
从那以后,一切都应该是一样的。
问 我能不能就 pip 安装 OpenCV 4?
A. 未来,是的。目前你需要从源代码编译,直到 piwheels 有 OpenCV 4 二进制文件可用。
Q. 为什么我不能直接 apt-get 安装 OpenCV?
A. 不惜一切代价避免这个【解决方案】即使它可能有效。首先,这种方法可能暂时不会安装 OpenCV 4。其次,apt-get 不适合虚拟环境,而且您无法控制编译和构建。
*q .mkvirtualenv和workon命令产生“命令未找到错误”。我不确定下一步该做什么。
A. 你会看到这个错误消息的原因有很多,都来自于步骤#4:
- 首先,确保你已经使用
pip软件包管理器正确安装了virtualenv和virtualenvwrapper。通过运行pip freeze进行验证,确保在已安装包列表中看到virtualenv和virtualenvwrapper。 - 您的
~/.profile文件可能有错误。查看您的~/.profile文件的内容,查看正确的export和source命令是否存在(检查步骤#4 中应该附加到~/.profile的命令)。 - 你可能忘记了你的 T1。确保编辑完
source ~/.profile后运行它,以确保你可以访问mkvirtualenv和workon命令。
问 当我打开一个新的终端,注销,或者重启我的树莓派,我无法执行mkvirtualenv或者workon命令。
A. 如果你在 Raspbian 桌面上,很可能会出现这种情况。由于某种原因,当您启动终端时加载的默认概要文件并不包含~/.profile文件。请参考上一个问题的 #2 。通过 SSH,你可能不会碰到这种情况。
Q. 当我尝试导入 OpenCV 时,遇到了这个消息:Import Error: No module named cv2。
发生这种情况有几个原因,不幸的是,很难诊断。我推荐以下建议来帮助诊断和解决错误:
**1. 使用workon cv命令确保您的cv虚拟环境处于活动状态。如果这个命令给你一个错误,然后验证virtualenv和virtualenvwrapper是否正确安装。
2. 尝试在您的cv虚拟环境中研究site-packages目录的内容。根据您的 Python 版本,您可以在~/.virtualenvs/cv/lib/python3.5/site-packages/中找到site-packages目录。确保(1)在site-packages目录中有一个cv2符号链接目录,并且(2)它被正确地符号链接。
3. 务必分别检查位于/usr/local/python/的 Python 的系统安装的site-packages(甚至dist-packages)目录。理想情况下,您应该在那里有一个cv2目录。
4. 作为最后一招,检查 OpenCV 构建的build/lib目录。那里的应该是那里的cv2目录(如果cmake和make都执行无误)。如果cv2目录存在,手动将其复制到/usr/local/python中,然后链接。因此,将文件保存到虚拟环境的目录中。
问: 为什么我会遇到“非自由模块”没有被安装的消息?如何获取 OpenCV 非自由模块?
答:OpenCV 4 中新增,必须设置一个特殊的 CMake 标志来获取非自由模块。参考上面的步骤 5 ,注意 CMake 命令中的标志。
摘要
今天我们在树莓 Pi 上安装了 OpenCV 4。
从源代码编译是最重要的,这样我们就可以获得 OpenCV 4,因为还不可能通过 pip 安装 OpenCV 4。
然后,我们测试了我们的安装,并部署了一个 Raspberry Pi 作为安全摄像头。这个安全摄像头将通过背景减法检测运动,并将入侵者的照片上传到 Dropbox。你可以在这里阅读完整的 Raspberry Pi +家庭监控帖子。
要及时了解 PyImageSearch,*请务必在下面的表格中留下您的电子邮件!******
在你的 Raspberry Pi 2 和 B+上安装 OpenCV 和 Python
原文:https://pyimagesearch.com/2015/02/23/install-opencv-and-python-on-your-raspberry-pi-2-and-b/

我的树莓派 2 昨天刚寄到,伙计,这浆果真甜。
这款小巧的个人电脑配备了 900mhz 四核处理器和 1gb 内存,性能强劲。举个例子,Raspberry Pi 2 比我高中计算机实验室的大多数台式机都要快。
无论如何,自从 Raspberry Pi 2 发布以来,我收到了很多请求,要求我提供 OpenCV 和 Python 的详细安装说明。
所以,如果你想让 OpenCV 和 Python 在你的 Raspberry Pi 上运行,不用再犹豫了!
在这篇博文的其余部分,我提供了树莓 Pi 2 和树莓 Pi B+的详细安装说明。
我还为每个步骤提供了安装时间。其中一些步骤需要大量的处理时间。例如,在 Raspberry Pi 2 上编译 OpenCV 库大约需要 2.8 小时,而在 Raspberry Pi B+上需要 9.5 小时,因此请相应地计划您的安装。
最后,值得一提的是,我们将在 PyImageSearch 大师计算机视觉课程中使用 Raspberry Pi。我们的项目将包括家庭监控应用,如检测运动和跟踪房间里的人。
这里有一个快速的例子,当我在我的公寓里走来走去的时候,我可以通过手机来检测运动和跟踪自己:

在你的 Raspberry Pi 2 和 B+上安装 OpenCV 和 Python
更新:您现在正在阅读的教程涵盖了如何在Raspbian wheesy上安装带有 Python 2.7 和 Python 3 绑定的 OpenCV 3。Raspbian Jessie 现在已经取代了 Raspbian Wheezy,如果这是你第一次阅读本教程,那么你很可能正在使用 Raspbian Jessie。请使用以下更新的指南来帮助您在您的 Raspberry Pi 上安装 OpenCV + Python。
我将假设您已经开箱并安装了您的 Raspberry Pi 2 或 Raspberry Pi B+。如果你还没有树莓派,我绝对建议你挑一个。它们超级便宜,玩起来很有趣。
就我个人而言,我更喜欢多花一点钱,从 Canakit 购买——他们的运输既快速又可靠,加上他们完整的现成包真的很好。
无论如何,让我们进入 OpenCV 和 Python 安装说明。
步骤 0:
同样,我将假设您刚刚取消了 Raspberry Pi 2/B+的装箱。打开终端,我们将从更新和升级已安装的软件包开始,然后更新 Raspberry Pi 固件:
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo rpi-update
第一步:
安装所需的开发工具和软件包:
$ sudo apt-get install build-essential cmake pkg-config
build-essential和pkg-config可能都已经安装了,但是万一它们没有安装,请确保将它们包含在您的apt-get命令中。
计时:
树莓派 B+: < 2 分钟
树莓派 2: < 40 秒
第二步:
安装必要的映像 I/O 包。这些软件包允许您加载各种图像文件格式,如 JPEG、PNG、TIFF 等。
$ sudo apt-get install libjpeg8-dev libtiff4-dev libjasper-dev libpng12-dev
计时:
树莓派 B+: < 5 分钟
树莓派 2: < 30 秒
第三步:
安装 GTK 开发库。该库用于构建图形用户界面(GUI ),并且是 OpenCV 的highgui库所必需的,OpenCV 允许您在屏幕上查看图像:
$ sudo apt-get install libgtk2.0-dev
计时:
树莓派 B+: < 10 分钟
树莓派 2: < 3 分钟
第四步:
安装必要的视频 I/O 包。这些包用于使用 OpenCV 加载视频文件:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
计时:
树莓派 B+: < 5 分钟
树莓派 2: < 30 秒
第五步:
安装用于优化 OpenCV 中各种操作的库:
$ sudo apt-get install libatlas-base-dev gfortran
计时:
树莓派 B+: < 2 分钟
树莓派 2: < 30 秒
第六步:
安装pip:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
计时:
树莓派 B+: < 2 分钟
树莓派 2: < 30 秒
第七步:
安装virtualenv和virtualenvwrapper:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip
然后,更新您的~/.profile文件以包含以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
重新加载您的.profile文件:
$ source ~/.profile
创建您的计算机视觉虚拟环境:
$ mkvirtualenv cv
计时:
树莓派 B+: < 2 分钟
树莓派 2: < 2 分钟
第八步:
现在我们可以安装 Python 2.7 开发工具了:
$ sudo apt-get install python2.7-dev
注:是的,我们要用 Python 2.7。OpenCV 2.4.X 尚不支持 Python 3,OpenCV 3.0 仍处于测试阶段。目前还不清楚 OpenCV 3.0 的 Python 绑定何时会完成,所以我建议暂时坚持使用 OpenCV 2.4.X。
我们还需要安装 NumPy,因为 OpenCV Python 绑定将图像表示为多维 NumPy 数组:
$ pip install numpy
计时:
树莓派 B+: < 45 分钟
树莓派 2: < 15 分钟
第九步:
下载 OpenCV 并解压:
$ wget -O opencv-2.4.10.zip http://sourceforge.net/projects/opencvlibrary/files/opencv-unix/2.4.10/opencv-2.4.10.zip/download
$ unzip opencv-2.4.10.zip
$ cd opencv-2.4.10
设置版本:
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D BUILD_NEW_PYTHON_SUPPORT=ON -D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON -D BUILD_EXAMPLES=ON ..
计时:
树莓派 B+: < 3 分钟
树莓派 2: < 1.5 分钟
编译 OpenCV:
$ make
重要:确保你在cv虚拟环境中,这样 OpenCV 是针对虚拟环境 Python 和 NumPy 编译的。否则,OpenCV 将针对系统 Python 和 NumPy 进行编译,这可能会导致问题。
计时:
树莓派 B+: < 9.5 小时
树莓派 2: < 2.8 小时
最后,我们可以安装 OpenCV:
$ sudo make install
$ sudo ldconfig
计时:
树莓派 B+: < 3 分钟
树莓派 2: < 1 分钟
第十步:
如果您已经阅读了本指南,OpenCV 现在应该安装在/usr/local/lib/python2.7/site-packages中
但是为了在我们的cv虚拟环境中使用 OpenCV,我们首先需要将 OpenCV 符号链接到我们的site-packages目录中:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
$ ln -s /usr/local/lib/python2.7/site-packages/cv.py cv.py
第十一步:
最后,我们可以测试一下 OpenCV 和 Python 的安装:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'2.4.10'
OpenCV 和 Python 现已成功安装在您的 Raspberry Pi 上!
下面是一个例子,我 ssh'ing(带 X11 转发)到我的 Raspberry Pi,然后加载并显示一个图像:
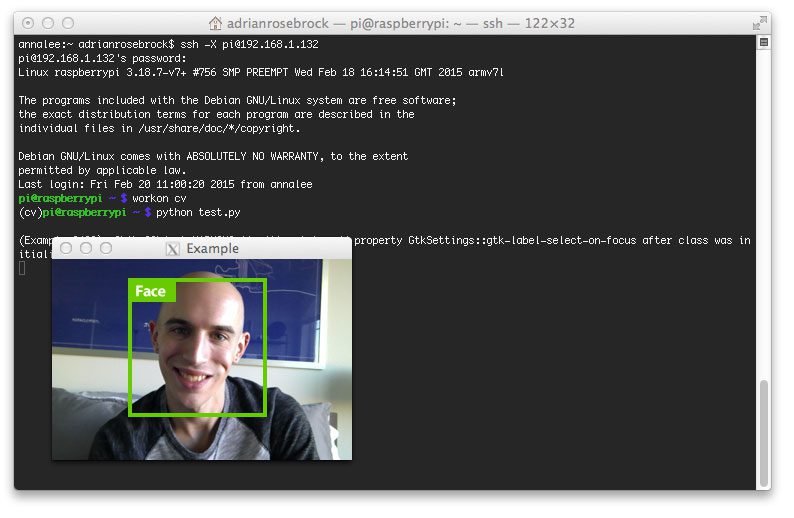
摘要
在这篇博文中,我详细介绍了如何在您的 Raspberry Pi 2 或 Raspberry Pi B+上安装 OpenCV 和 Python。还提供了每个安装步骤的时间,以便您可以相应地计划安装。
随着 Raspberry Pi(以及 Raspbian/NOOBS)的发展,安装说明可能会改变。如果您在安装说明中遇到任何边缘情况或变化,请随时让我知道。虽然我不能保证我能回复每一封邮件,但是我认为在 Raspberry Pi 系统上建立 OpenCV 和 Python 的方法列表是很好的。
在未来的博客文章中,我们将探索如何利用树莓 Pi 的相机插件。
在那之前,看一看 PyImageSearch 大师计算机视觉课程。我们将在课程中的几个项目中使用 Raspberry Pi,包括构建一个可以检测室内运动和人员的家庭监控应用程序。
用自制软件在 OSX 上安装 boost 和 boost-python
原文:https://pyimagesearch.com/2015/04/27/installing-boost-and-boost-python-on-osx-with-homebrew/

我真的真的希望有人觉得这个资源有用。在过去的几个月里,我浪费了大量的时间(被动地)试图通过自制软件将 boost 和 boost-python 安装到我的 OSX 机器上,这简直是折磨人。
别误会,我喜欢自制。如果你在一台 OSX 机器上,而没有使用自制软件,那么我建议你停止阅读这篇文章,现在就安装它。
无论如何,就像我说的,我希望这篇文章能为其他人节省一些时间和麻烦。虽然这篇文章并不完全是专门针对计算机视觉的,但是如果你正在使用 Python 和 OpenCV 开发基于计算机视觉的应用程序,它仍然非常有意义。
Spotify 的用于近似最近邻搜索的等软件包在基于内容的图像检索(CBIR)/图像搜索引擎领域有直接应用。
【2015 年 5 月 4 日更新: 埃里克·伯恩哈德森发布了一个更新,消除了对 Boost 和 Boost 的依赖。Python 免于烦扰。你现在可以简单地使用 pip: pip install annoy安装 angry,而不需要任何额外的依赖。
像 dlib 这样的库提供了 Python 绑定,因此您可以从 Python shell 中利用 dlib 的能力。
aroy 和 dlib 只是需要使用 boost 的包的两个例子(如果需要 python 绑定,还需要 boost-python)。
无论如何,让我们开始这个教程吧——我已经浪费了足够多的时间来解决这个问题,我也不想浪费你的时间!
什么是自制?
家酿是“OSX 缺失的包装经理”。它使得安装和管理默认苹果安装的软件包而不是变得轻而易举,就像 Debian apt-get一样。
注意:将家酿和 apt-get 进行比较并不完全公平,但是如果这是你第一次听说家酿,这种比较就足够了。
什么是 boost 和 boost-python?
Boost 是一个经过同行评审的(也就是非常高质量的)C++库的集合,它可以帮助程序员和开发人员避免重复劳动。Boost 提供了线性代数、多线程、基本图像处理和单元测试等实现。
同样,这些图书馆是同行评审的,质量非常高。大量的 C++应用程序,尤其是在科学领域,都以某种方式依赖于 Boost 库。
我们还有 boost-python ,它提供了 C++和 python 编程语言之间的互操作性。
这为什么有用?
好吧,假设你正在实现一个近似最近邻算法(就像 Spotify 的 asury)并且你想提供纯粹的、普通的 Python 支持。
然而,您希望从库中榨出最后一点内存和 CPU 性能,所以您决定在 C++中实现性能关键部分。
为此,您可以使用 boost 在 C++中编写这些关键任务,然后使用 boost-python 与 Python 编程语言进行交互。
事实上,这正是骚扰包所做的。虽然这个包是 pip 可安装的,但是它需要 boost 和 boost-python 才能被编译和安装。
用自制软件在 OSX 上安装 boost 和 boost-python
现在我们已经有了一些基本的术语,让我们继续安装我们的软件包。
步骤 1:安装自制软件
安装家酿不能更容易。
只需进入 Homebrew 主页,将以下代码复制并粘贴到您的终端中:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
注: 这篇博文写于 2015 年 1 月。一定要访问家酿主页,使用家酿社区提供的最新安装脚本。
第二步:更新自制软件
现在您已经安装了 Homebrew,您需要更新它并获取最新的包(即“formula”)定义。这些公式只是关于如何安装给定库或包的简单说明。
要更新 Homebrew,只需:
$ brew update
步骤 3:安装 Python
用系统 Python 作为你的主要解释器是不好的形式。如果你打算使用 virtualenv ,这一点尤其正确。
在我们继续之前,让我们通过 brew 安装 Python:
$ brew install python
步骤 4:安装 boost
到目前为止一切顺利。但是现在是时候安装 boost 了。
这是你真正需要开始注意的地方。
要安装 boost,请执行以下命令:
$ brew install boost --with-python
你看到那面旗了吗?
是的,别忘了——这很重要。
在我的例子中,我认为已经安装了 boost-python,给出了--with-python标志。
显然事实并非如此。您还需要显式安装 boost-python。否则,当您试图从 Python 内部调用一个期望找到 boost 绑定的包时,就会出现可怕的 segfault 错误。
此外,在 boost 下载、编译和安装时,您可能想出去散散步。这是一个很大的图书馆,如果你热衷于优化你工作日的时间(像我一样),那么我强烈建议你转换环境,做一些其他的工作。
步骤 5:安装 boost-python
既然已经安装了 boost,我们也可以安装 boost-python 了:
$ brew install boost-python
boost-python 包的安装速度应该比 boost 快得多,但是您可能还是想为自己泡一杯咖啡,尤其是如果您的系统很慢的话。
步骤 6:确认安装了 boost 和 boost-python
确保安装了 boost 和 boost-python:
$ brew list | grep 'boost'
boost
boost-python
从我的终端输出可以看到,boost 和 boost-python 都已经成功安装(当然前提是你没有从上面的步骤中得到任何错误)。
已经在用 Python + virtualenv 了?继续读。
哦,你以为我们结束了?
我也是。天哪,那是个错误。
因为你猜怎么着?如果你已经安装了 Python 并且正在使用 virtualenv (在我的例子中是 virtualenvwrapper ),你还有一些工作要做。
注意:如果你还没有使用virtualenv和virtualenvwrapper来管理你的 Python 包,这是你应该认真考虑的事情。相信我,这让你的生活变得简单多了。
新虚拟环境:
如果你正在创建一个新的虚拟环境,你就可以开始了。不需要额外的工作,一切都将顺利开箱。
现有虚拟设备:
那么让我告诉你一些你已经知道的事情:当我们构建一个虚拟环境时,我们的 Python 可执行文件,连同相关的库、includes 和 site-packages 被克隆并隔离到它们自己的独立环境中。
让我告诉你一些你可能不知道的事情:如果你在编译和安装 boost 和 boost-python 之前已经有了你的 virtualenv 设置(像我一样),那么你将不能访问你的 boost 绑定。
那么解决这个问题的最好方法是什么呢?
老实说,我不确定什么是【最佳】方式。一定有比我提议的更好的方法。但是我是这样解决这个问题的:
- 为我的 virtualenv 生成了一个
requirements.txt - 停用并删除了我的虚拟
- 再造了我的虚拟人生
- 那件事就此了结吧
执行完这些步骤后,您的新 virtualenv 将拥有 boost-python 绑定。希望你不会像我一样浪费太多时间。
一个恼人例子
现在我们已经安装了 boost 和 boost-python,让我们使用骚扰包对它们进行测试。
【2015 年 5 月 4 日更新:正如我在这篇文章的顶部提到的,埃里克·伯恩哈德森发布了一个更新,消除了对 Boost 和 Boost 的依赖。Python 免于烦扰。你现在可以简单地安装恼人的使用画中画没有一个有助推或助推。Python 已安装。
让我们从使用 virtualenvwrapper 创建 virtualenv 开始:
$ mkvirtualenv annoy
...
$ pip install numpy annoy
...
现在我们的包已经安装好了,让我们用 128-D 创建 1,000 个随机向量。我们将把这些向量传递给 Annoy,并使用 10 棵树构造我们的嵌入:
>>> import numpy as np
>>> M = np.random.normal(size=(1000, 128))
>>> from annoy import AnnoyIndex
>>> ann = AnnoyIndex(128)
>>> for (i, row) in enumerate(M):
... ann.add_item(i, row.tolist())
...
>>> ann.build(10)
现在我们的嵌入已经创建好了,让我们找到列表中第一个向量的 10 个(近似)最近的邻居:
>>> ann.get_nns_by_item(0, 10)
[0, 75, 934, 148, 506, 915, 392, 849, 602, 95]
我们还可以找到不属于索引的最近邻居:
>>> ann.get_nns_by_vector(np.random.normal(size=(128,)).tolist(), 10)
[176, 594, 742, 215, 478, 903, 516, 413, 484, 480]
那么,如果您试图在没有安装 boost 和 boost-python 的情况下执行这段代码,会发生什么情况呢?
您的代码会在get_nns_by_item和get_nns_by_vector函数中出现 segfault。如果您使用的是 dlib ,那么您会在导入过程中出现 segfault。一定要牢记在心。如果你在运行这些函数的时候出现了问题,那么你的 boost 和 boost-python 安装就有问题了。
摘要
在这篇博文中,我回顾了如何使用自制软件在 OSX 上安装 boost 和 boost-python 。
就我个人而言,我在几个月的时间里被动地处理这个问题,浪费了大量的时间——这篇文章的目的是(希望)帮助你节省时间,避免任何痛苦和挫折。
如果你知道一个更好的方法来解决这个问题,请在评论中告诉我,或者发邮件给我!
为深度学习安装 Keras
原文:https://pyimagesearch.com/2016/07/18/installing-keras-for-deep-learning/
这篇博文的目的是演示如何安装用于深度学习的 Keras 库。安装程序将显示如何安装 Keras:
- 借助 GPU 支持,您可以利用您的 GPU、CUDA 工具包、cuDNN 等。,用于更快的网络训练。
- 没有 GPU 的支持,所以即使你没有一个用于训练神经网络的 GPU,你仍然可以跟着做。
先说 Keras 是我的最爱深度学习 Python 库。这是一个极简的模块化神经网络库,可以使用tensor flow 或 Theano 作为后端。
此外,Keras 背后的主要动机真的引起了我的共鸣:你应该能够超快地实验——尽可能快地从想法到结果。****
来自一个混合了学术界和企业家的世界,快速迭代的能力非常有价值,尤其是在深度学习领域,训练一个单一模型可能需要几天到几周的时间。*
在接下来的 PyImageSearch 博客文章中,我将会大量使用 Keras,所以请确保您按照本教程在您的机器上安装 Keras!
*## 为深度学习安装 Keras
我将假设您已经关注了这一系列关于设置深度学习开发环境的博文:
我将使用我在以前的教程中使用的运行 Ubuntu 16.04 的 Amazon EC2 p2.xlarge 实例——也可以随意使用你一直使用的同一台机器。
总的来说,安装 Keras 是一个 4 步的过程,其中三步是可选的。
可选的第一步是你是否愿意使用 Python 虚拟环境— 我建议你使用,但是这个决定完全取决于你。
第二个可选步骤是你是否想使用 GPU 来加速训练你的神经网络——这显然取决于你是否拥有一个兼容 CUDA 的 GPU。Keras 库可以很好地在 CPU 上运行,但如果你真的想训练深度神经网络,你会想得到一个 GPU 安装设置。
最后一个可选步骤是,您是否希望在您的 Python 虚拟环境中有 OpenCV 绑定以及 Keras 安装。如果你这样做了,你会想要注意步骤#4 。
说了这么多,让我们开始吧!
步骤 1:创建一个单独的 Python 虚拟环境(可选)
如果你一直在关注这一系列的帖子,那么你已经知道我喜欢使用 Python 虚拟环境。当我们开始与各种深度学习库(Keras、mxnet、TensorFlow 等)合作时,利用虚拟环境尤其重要。)和版本问题很容易发生(特别是围绕 TensorFlow 使用哪个版本)。
由于与冲突库版本相关的问题,我建议为基于 Keras 的项目专门创建一个虚拟环境:
$ mkvirtualenv keras -p python3
这将创建一个名为keras的 Python 虚拟环境。任何时候您想要访问这个虚拟环境,只需使用workon命令,后跟虚拟环境的名称:
$ workon <virtual env name>
在这种情况下,我们可以通过执行以下命令来访问keras虚拟环境:
$ workon keras
Step #2: Install Keras
安装 Keras 是一件轻而易举的事情,它可以为我们完成所有的艰苦工作。首先,我们需要安装一些依赖项:
$ pip install numpy scipy
$ pip install scikit-learn
$ pip install pillow
$ pip install h5py
我们还需要安装张量流。您当然可以使用pip来安装 TensorFlow:
$ pip install tensorflow
已经安装 CUDA 和 cuDNN 的 GPU 用户可以安装带 pip 的 TensorFlow 的 GPU 版本:
$ pip install tensorflow-gpu
从那里,我们也可以使用pip来安装 Keras:
$ pip install keras
Keras 完成安装后,您可以通过打开一个终端,访问keras虚拟环境,然后导入库来验证安装(参见步骤#3 中如何操作的示例)。
步骤 OpenCV 中的符号链接(可选)
如果您想从keras虚拟环境中访问 OpenCV 绑定,您需要将cv2.so文件符号链接到keras的site-packages目录中:
$ ls /usr/local/lib/python3.6/site-packages/
cv2.cpython-36m-x86_64-linux-gnu.so
$ cd /usr/local/lib/python3.6/site-packages/
$ mv cv2.cpython-36m-x86_64-linux-gnu.so cv2.so
$ cd ~/.virtualenvs/keras/lib/python3.6/site-packages/
$ ln -s /usr/local/lib/python3.6/site-packages/cv2.so cv2.so
$ cd ~
正如我在上周的教程中所详述的,编译安装 OpenCV 后,我的cv2.so绑定在/usr/local/lib/python3.6/site-packages/cv2.cpython-36m-x86_64-linux-gnu.so中被发现。根据您在自己的系统上安装 OpenCV 的方式,您的cv2.so绑定可能位于不同的位置。如果您不记得您的cv2.so绑定在哪里,或者如果您不再有您的 CMake 输出(哪个指示了绑定将被存储在哪里),您可以使用find实用程序来帮助定位它们:
$ cd /
$ sudo find . -name '*cv2*.so*'
./usr/local/lib/python3.6/site-packages/cv2.cpython-36m-x86_64-linux-gnu.so
./home/adrian/.virtualenvs/cv/lib/python3.6/site-packages/cv2.so
同样,这是一个完全可选的步骤,如果您想从keras虚拟环境访问 OpenCV,只需完成。
步骤 4:测试安装
要验证 Keras 是否已经安装,请访问keras虚拟环境,打开一个 Python shell,并导入它:
$ workon keras
$ python
>>> import keras
>>>
下面是我自己的 EC2 实例的截图:
Figure 1: Installing the Keras Python library for deep learning.
请注意,正在使用 TensorFlow 后端。
还要注意正在使用的 GPU,在本例中是安装在 Amazon EC2 p2.xlarge 实例上的 K80。关于我如何安装 CUDA 工具包和 cuDNN 的更多信息,请看这篇博文。
可选地,如果您执行了步骤#3 ,并且想要测试您的 OpenCV sym-link,也尝试将您的 OpenCV 绑定导入到keras虚拟环境中:
Figure 2: Importing OpenCV and Keras together for deep learning with Python.
至此,您应该能够将 Keras 和 OpenCV 导入到同一个 Python 虚拟环境中。花一点时间祝贺你自己——你现在已经有了开始构建深度神经网络的所有构建模块!
摘要
在今天的博文中,我演示了如何安装深度学习的 Keras Python 包。
在未来的 PyImageSearch 博客帖子中,我们将广泛使用 Keras 库,所以我强烈建议您在您的机器上安装 Keras,即使它只是 CPU 版本——这将使您能够在未来的深度学习 PyImageSearch 教程中跟随。
下周,我们将通过研究卷积,它们是什么,它们如何工作,,以及你如何在你的计算机视觉应用中使用它们*(无论你是否意识到这一点),在我们的深度学习之旅中迈出另一步。
请务必使用下面的表格注册 PyImageSearch 时事通讯——你一定不想错过即将发布的关于 convolutions 的帖子!*****
使用 TensorFlow 后端安装 Keras
原文:https://pyimagesearch.com/2016/11/14/installing-keras-with-tensorflow-backend/

几个月前,我演示了如何用 T2 后端安装 Keras 深度学习库。
在今天的博文中,我提供了详细的分步说明,使用最初由谷歌大脑团队的研究人员和工程师开发的 TensorFlow 后端安装 Keras。
我还将(可选地)演示如何将 OpenCV 集成到这个设置中,以实现成熟的计算机视觉+深度学习开发环境。
要了解更多,就继续阅读。
使用 TensorFlow 后端安装 Keras
这篇博文的第一部分提供了对 Keras 后端的简短讨论,以及为什么我们应该(或不应该)关心我们正在使用的后端。
在那里,我提供了详细的说明,您可以使用 TensorFlow 后端在自己的系统上安装机器学习的 Keras。
TensorFlow?Theano?谁在乎呢。
在讨论开始时,有一点很重要,那就是 Keras 只是一个更复杂的数值计算引擎的包装器,比如 TensorFlow 和 Theano 。
Keras 抽象掉了构建深度神经网络的大部分复杂性,给我们留下了一个非常简单、漂亮、易于使用的界面来快速构建、测试和部署深度学习架构。
说到 Keras,你有两个后端引擎选择——要么是 TensorFlow 要么是the no。Theano 比 TensorFlow 更老,最初是为 Keras 选择后端时唯一的选择。
那么,为什么你可能想在不同的后端使用 TensorFlow(比如不再开发的 Theano)?
简而言之,TensorFlow 极其灵活,允许您将网络计算部署到多个 CPU、GPU、服务器,甚至移动系统,而无需更改一行代码。
这使得 TensorFlow 成为以架构不可知的方式训练分布式深度学习网络的绝佳选择,这是 ano(目前)不提供的。
老实说,我在 TensorFlow 发布(甚至有传言称其存在)之前很久就开始使用 Keras——那是在 Theano 是后端唯一可能的选择的时候。
我还没有太多的考虑 Theano 或 TensorFlow 是否应该成为我的“目标”后端。我需要它的时候,它工作得很好,所以为什么要换呢?
当我在 Twitter 上运行最近的民意调查,询问我的粉丝在使用 Keras 时他们更喜欢哪个后端时,我的眼睛开始睁开了:

Figure 1: I polled my Twitter followers (@pyimagesearch) to determine whether they preferred using Theano or TensorFlow as their Keras backend.
67%的受访者表示他们正在使用 TensorFlow 作为后端。老实说,我很惊讶。作为 Keras 的长期用户,我怎么可能是少数呢?
这 67%的受访者可能会动摇,因为 TensorFlow 现在是安装 Keras 时的默认后端…或者可能是因为我的许多追随者发现 TensorFlow 是一个更好、更有效的后端(并使用更多 TensorFlow 特定功能)。
不管确切的推理是什么,有一件事你不能否认: TensorFlow 会一直存在。
如果你需要进一步的证明,你需要做的就是看一看来自 Fran ois Chollet(Keras 的创建者和维护者)的这个深度学习 GitHub 活动分析:

Figure 2: TensorFlow tops the charts as the deep learning library with most GitHub activity. Keras follows at #2 with Theano all the way at #9.
正如我们所看到的,TensorFlow 遥遥领先于排行榜第一名,而 Theano 排名第九。
虽然 Keras 让我们切换后端变得很简单(我们需要做的只是安装各自的后端并编辑一个简单的 JSON 配置文件),但我们仍然需要注意趋势告诉我们的东西:tensor flow 将在(不久的)未来继续成为首选的 Keras 后端。
更新 2018-06-04:the ano 不再被积极开发(公告 2017-09-29) 而且如你所料,TensorFlow 现在是默认的。
步骤 1:设置 Python 虚拟环境
如果你曾经读过我以前的任何教程(无论是 OpenCV,CUDA,Keras 等。)你可能已经意识到,我是使用 Python 虚拟环境的《T2》的超级粉丝。
当在深度学习生态系统中工作时,我特别推荐 Python 虚拟环境。许多基于 Python 的深度学习库需要各种依赖的不同版本。
例如,如果你想一起使用 Keras + Theano,你需要最新版本的 Theano(例如,他们最新的 GitHub commit,并不总是发布在 PyPI 上的版本)。
但是,如果您想尝试 scikit-theano 之类的库,您需要一个与 Keras 不兼容的早期版本的 theano。
当您开始添加其他 Python 库时,依赖版本问题只会变得更加复杂,特别是深度学习库(如 TensorFlow),这些库本质上是不稳定的(因为深度学习是一个快速发展的领域,每天都有更新和新功能被推送到网上)。
解决办法?
使用 Python 虚拟环境。
我不会大谈 Python 虚拟环境的好处(,因为我已经在这篇博文的前半部分中谈过了),但是要点是,通过使用 Python 虚拟环境,你可以为你的项目的每个创建一个单独的、隔离的 Python 环境,确保每个 Python 环境相互独立。这样做可以让你完全避免版本依赖问题。
我将假设您的系统上已经安装了 virtualenv 和 virtualenvwrapper (如果没有,两者都是 pip 可安装的,只需要对您的 shell 配置进行小的更新;请点击上面的链接了解更多信息)。
安装 virtualenv 和 virtualenvwrapper 后,让我们为基于 Keras + TensorFlow 的项目专门创建一个 Python 3 虚拟环境和:
$ mkvirtualenv keras_tf -p python3
我将这个虚拟环境命名为keras_tf为 Keras + TensorFlow (我也有一个虚拟环境命名为keras_th为 Keras + Theano )。
每当您需要访问给定的 Python 虚拟环境时,只需使用workon命令:
$ workon <virtual_env_name>
在这种特殊情况下,我们可以使用以下方式访问keras_tf虚拟环境:
$ workon keras_tf
同样,虽然这是一个可选的步骤,但我真的鼓励你花时间正确地设置你的开发环境,如果你甚至是远程认真地使用 Python 编程语言进行深度学习研究、实验或开发的话——虽然这是更多的前期工作,从长远来看,你会感谢我的。
Step #2: Install TensorFlow
安装 TensorFlow 非常简单,因为pip将为我们完成所有繁重的工作:
$ pip install --upgrade tensorflow
下面你可以看到 TensorFlow 正在下载安装的截图:

Figure 3: Installing TensorFlow for deep learning via pip into my Python virtual environment.
假设您的 TensorFlow 安装已正确退出,您现在可以通过打开 Python shell 并尝试导入tensorflow包来测试安装:
$ python
>>> import tensorflow
>>>
Step #3: Install Keras
安装 Keras 甚至比安装 TensorFlow 更容易。
首先,让我们安装一些 Python 依赖项:
$ pip install numpy scipy
$ pip install scikit-learn
$ pip install pillow
$ pip install h5py
其次是安装keras本身:
$ pip install keras
就是这样!Keras 现已安装在您的系统上!
步骤 4:验证您的 keras.json 文件配置正确
在我们深入之前,我们应该检查一下我们的keras.json配置文件的内容。你可以在~/.keras/keras.json中找到这个文件。
用你最喜欢的文本编辑器打开它,看看里面的内容。默认值应该如下所示:
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
具体来说,您需要确保将image_data_format设置为"channels_last"(表示使用 TensorFlow 图像维度排序,而不是将"channels_first"设置为“无”)。
你还需要确保backend被正确地设置为tensorflow(而不是theano)。同样,默认的 Keras 配置应该满足这两个要求,但仔细检查一下也无妨。
对配置文件进行任何必要的更新(如果有),然后退出编辑器。
关于image_data_format的快速说明
你可能想知道image_data_format到底控制什么。
使用 TensorFlow,图像被表示为具有形状(高度、宽度、深度)的 NumPy 数组,其中深度是图像中通道的数量。
但是,如果您使用的是 Theano,图像将被假定为用(深度、高度、宽度)表示。
这种细微差别是使用 Keras 时 许多令人头疼的 的来源(以及许多寻找这些特定配置的if声明)。
如果您在使用 Keras 时得到奇怪的结果(或与给定张量的形状相关的错误消息),您应该:
- 检查你的后端。
- 确保您的映像维度排序与后端相匹配。
找不到您的 keras.json 文件?
在大多数系统中,直到你打开 Python shell 并直接导入keras包本身,才会创建keras.json文件(以及相关的子目录)。
如果您发现~/.keras/keras.json文件在您的系统上不存在,只需打开一个 shell,(可选地)访问您的 Python 虚拟环境(如果您正在使用虚拟环境),然后导入 Keras:
$ workon keras_tf
$ python
>>> import keras
>>> quit()
从那里,您应该看到您的keras.json文件现在存在于您的本地磁盘上。
如果您在导入keras时发现任何错误,请返回到本节的顶部,确保您的keras.json配置文件已经正确更新。
步骤 OpenCV 中的符号链接(可选)
这一步完全是可选的,但是如果您的系统上安装了 OpenCV,并且想要从 Python 虚拟环境中访问 OpenCV 绑定,您首先需要将cv2.so文件符号链接到您的环境的site-packages目录。
为此,首先要找到您的cv2.so绑定在系统中的位置:
$ cd /
$ sudo find . -name '*cv2.so*'
./Users/adrianrosebrock/.virtualenvs/cv/lib/python3.6/site-packages/cv2.so
./Users/adrianrosebrock/.virtualenvs/gurus/lib/python3.6/site-packages/cv2.so
./Users/adrianrosebrock/.virtualenvs/keras_th/lib/python3.6/site-packages/cv2.so
./usr/local/lib/python3.6/site-packages/cv2.so
如果您从源代码构建 OpenCV(除非您指定了一个定制的 OpenCV 安装目录),您将需要寻找 OpenCV 的全局安装,它通常在/usr/local/lib目录中。
注意:我的find命令返回的其他cv2.so文件只是简单的符号链接回/usr/local/lib中原来的cv2.so文件。
从那里,将目录更改为 Python 虚拟环境的site-packages目录(在本例中是keras_tf环境)并创建 sym-link:
$ cd ~/.virtualenvs/keras_tf/lib/python3.6/site-packages/
$ ln -s /usr/local/lib/python3.6/site-packages/cv2.so cv2.so
$ cd ~
同样,这一步完全是可选的,只有当您想从keras_tf虚拟环境中访问 OpenCV 时才需要这样做。
步骤 6:测试 Keras + TensorFlow 安装
要验证 Keras + TensorFlow 是否已经安装,只需使用workon命令访问keras_tf环境,打开一个 Python shell,并导入keras:
(keras_tf) ~ $ python
Python 3.6.4 (default, Mar 27 2018, 15:31:37)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import keras
Using TensorFlow backend.
>>>
具体来说,您可以在导入 Keras 时看到文本Using TensorFlow backend显示——这成功地证明了 Keras 已经安装了 TensorFlow 后端。
如果您执行了可选的步骤#5 并且想要测试您的 OpenCV sym-link,也尝试导入您的 OpenCV 绑定:
(keras_tf) ~ $ python
Python 3.6.4 (default, Mar 27 2018, 15:31:37)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import keras
Using TensorFlow backend.
>>> import cv2
>>>
如果你得到一个关于 OpenCV 找不到的错误信息,那么你需要仔细检查你的符号链接,确保它指向一个有效的文件。
摘要
在今天的博文中,我演示了如何使用 TensorFlow 后端安装 Keras 深度学习库。
在为 Keras 选择后端时,你需要考虑几个方面。
第一个是流行度,因此是一个给定的库在未来继续被更新和支持的概率。在这种情况下,TensorFlow 轻而易举地赢得了胜利——它是目前世界上最受欢迎的用于机器学习和深度学习的数值计算引擎。
其次,你需要考虑给定库的功能。虽然 Theano 与 TensorFlow 一样易于使用(就 Keras 后端而言),但 TensorFlow 允许更不受架构限制的部署。通过使用 TensorFlow,无需更改一行代码,就可以跨 CPU、GPU 和其他设备训练分布式深度学习网络。
自从 2017 年 9 月 Theano 开发正式停止后,我就全面转投 TensorFlow,不回头了。
如果你喜欢这个安装教程,并发现它很有帮助,一定要在评论中留下你的笔记!
如果您希望在 PyImageSearch 博客上发布新博文时收到电子邮件更新,请在下表中输入您的电子邮件地址。
在您的 Raspberry Pi 2 上为 Python 2.7 和 Python 3+安装 OpenCV 3.0

老实说,我喜欢 Raspberry Pi 用于计算机视觉教学——它可能是向程序员、开发人员和学生展示计算机视觉世界的最佳教学工具之一。
对于业余爱好者和车库黑客来说,这是非常棒的,因为你可以在一个便宜但超级有趣的硬件上学习。这对的企业和产品来说太棒了,因为他们可以在价格合理且可靠的硬件上部署计算机视觉算法。树莓派在研究和学术界也很流行。考虑到它的成本损失,我们现在可以使用大量的 Raspberry Pis 来进行大规模的分布式计算机视觉研究项目。
鉴于这些好处和对各种领域的适用性,我的关于在你的 Raspberry Pi 2 和 B+ 上安装 OpenCV 和 Python 的教程仍然是 PyImageSearch 博客上最受欢迎的帖子之一也就不足为奇了。
但是今天,这种情况将会改变——因为我认为 这篇博文 将会超过它的前任,成为 PyImageSearch 博客上最受欢迎的文章。
你看,我们将向前迈出一步,学习如何在你的树莓 Pi 上安装(刚刚发布的) OpenCV 3.0 库forbothPython 2.7和 Python 3+ 。
没错。在本分步指南结束时,你将在你的 Raspberry Pi 2 上安装全新的 OpenCV 3.0 库,以及 Python 2.7+ 或 Python 3+ 绑定。这绝对是一个激动人心的教程——到目前为止,OpenCV 只支持 Python 2.7。但是现在有了 OpenCV 3.0 版本,我们终于可以在我们的项目中利用 Python 3+。
正如你在 PyImageSearch 博客的其他地方看到的,能够在树莓 Pi 上利用 OpenCV 已经导致了真正伟大的项目,例如使用 Python + OpenCV + Dropbox +树莓 Pi 2:
因此,如果你对构建这样的基于计算机视觉的项目感兴趣,那么请跟我来,我们将很快在你的 Raspberry Pi 2 上安装带有 Python 绑定的 OpenCV 3.0。
在您的 Raspberry Pi 2 上安装适用于 Python 2.7+和 Python 3+的 OpenCV 3.0
更新:您现在正在阅读的教程涵盖了如何在Raspbian wheesy上安装带有 Python 2.7 和 Python 3 绑定的 OpenCV 3。Raspbian Jessie 现在已经取代了 Raspbian Wheezy,如果这是你第一次阅读本教程,那么你很可能正在使用 Raspbian Jessie。请使用以下更新的指南来帮助您在您的 Raspberry Pi 上安装 OpenCV + Python。
这篇博客文章的其余部分将详细介绍如何在你的 Raspberry Pi 2 上为 Python 2.7 和 Python 3+ 安装 OpenCV 3.0。这些安装说明也可以用于 B+,但是我强烈推荐使用 Pi 2 运行 OpenCV 应用程序——增加的速度和内存使 Pi 2 更适合计算机视觉。
为了保持本教程的简洁和有条理,我将 OpenCV 3.0 的安装过程分成了四个部分:
- 第 1 部分:通过安装所需的包和库来配置您的 Raspberry Pi。不管你使用的是 Python 2.7 还是 Python 3+,我们都需要采取一些步骤来为 OpenCV 3.0 准备我们的 Raspberry Pi——这些步骤主要是调用
apt-get,然后安装所需的包和库。 - 第二节:用 Python 2.7+支持编译 OpenCV 3.0。如果您想在您的 Raspberry Pi 上安装 OpenCV 3.0 和 Python 2.7+绑定,那么这是您想去的地方。完成本部分后,跳过第 3 部分,直接进入第 4 部分。
- 第三节:用 Python 3+支持编译 OpenCV 3.0。类似地,如果您想在您的 Pi 2 上安装 OpenCV 3.0 和 Python 3+绑定,那么请完成第 1 部分并直接跳到第 3 部分。
- 第 4 部分:验证您的 OpenCV 3.0 安装。在您的 Raspberry Pi 2 上安装了支持 Python 的 OpenCV 3.0 之后,您会想要确认它是否确实正确安装并按预期运行。本节将向您展示如何验证您的 OpenCV 3.0 安装,并确保它正常工作。
Python 2.7+还是 Python 3+?
在我们开始之前,花点时间考虑一下您将使用哪个版本的 Python。你准备用 Python 2.7 绑定编译 OpenCV 3.0 吗? 还是准备编译 OpenCV 3.0 Python 3 绑定?
每个都有优点和缺点,但是选择取决于你自己。如果您经常使用 Python 3 并且对它很熟悉,那么继续使用 Python 3 绑定进行编译。然而,如果你做了大量的科学 Python 开发,你可能想要坚持使用 Python 2.7(至少目前是这样)。虽然像 NumPy 、 Scipy 和 scikit-learn 这样的软件包确实增加了科学社区中 Python 3+的采用率,但是仍然有许多科学软件包仍然需要 Python 2.7——因此,如果您使用 Python 3,然后意识到您日常使用的许多软件包只支持 Python 2.7,您可以很容易地将自己归类。
如果有疑问,我通常建议科学开发人员使用 Python 2.7,因为它确保了使用更大的科学软件包的能力,并允许您使用遗留代码进行实验。然而,这种情况正在迅速改变——所以继续使用你最熟悉的 Python 版本吧!
第 1 部分:通过安装所需的包和库来配置您的 Raspberry Pi
让我们通过更新我们的 Raspberry Pi 来开始这个 OpenCV 3.0 安装教程:
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo rpi-update
计时: 9m 5s
现在,我们可以安装从源代码构建 OpenCV 所需的开发人员工具:
$ sudo apt-get install build-essential git cmake pkg-config
计时: 43s
以及用于从磁盘加载各种图像格式的安装包:
$ sudo apt-get install libjpeg8-dev libtiff4-dev libjasper-dev libpng12-dev
计时:27 秒
让我们安装一些视频 I/O 包:
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
计时:26 秒
安装 GTK,它处理 OpenCV 的 GUI 操作:
$ sudo apt-get install libgtk2.0-dev
计时: 2m 20s
我们还可以通过安装这些包来优化 OpenCV 中的各种功能(如矩阵运算):
$ sudo apt-get install libatlas-base-dev gfortran
计时:46 秒
至此,我们已经安装了所有的先决条件,所以让我们从 GitHub 下载 OpenCV 库并检查3.0.0版本:
$ cd ~
$ git clone https://github.com/Itseez/opencv.git
$ cd opencv
$ git checkout 3.0.0
计时:8 米 34 秒
更新(2016 年 1 月 3 日):你可以用任何当前版本替换3.0.0版本(现在是3.1.0)。请务必查看 OpenCV.org的最新发布信息。
对于 OpenCV 3.0 的完整安装,也要抓取 opencv_contrib repo:
$ cd ~
$ git clone https://github.com/Itseez/opencv_contrib.git
$ cd opencv_contrib
$ git checkout 3.0.0
计时:1 分 7 秒
同样,确保你为opencv_contrib检查的 版本与你为上面的opencv检查的 版本相同,否则你可能会遇到编译错误。
现在我们正处在一个十字路口,一种选择你自己(OpenCV)的冒险!
你可以按照第 2 节用 Python 2.7+绑定编译 OpenCV 3.0。或者你可以前往第 3 节并安装带有 Python 3+绑定的 OpenCV 3.0。选择权在你——但要明智地选择!一旦你做出了选择,以后改变主意就不那么容易了。
注:两个版本的 Python 当然都可以安装 OpenCV 3.0(其实也不是太难),但不在本教程讨论范围之内;我一定会在以后的文章中介绍这种技术。
第 2 节:用 Python 2.7+支持编译 OpenCV 3.0
安装 Python 2.7 头文件,以便我们可以编译 OpenCV 3.0 绑定:
$ sudo apt-get install python2.7-dev
计时:1 分 20 秒
安装pip,兼容 Python 2.7 的 Python 包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
计时:33 秒
正如我们在最初的教程中在你的 Raspberry Pi 上安装 OpenCV 2.4.X 一样,我们将利用 virtualenv 和 virtualenvwrapper ,它们允许我们为每个 Python 项目创建单独的 Python 环境。在安装 OpenCV 和 Python 绑定时,安装virtualenv和virtualenvwrapper肯定是而不是的需求;然而, 是标准的 Python 开发实践 , 我强烈推荐 ,本教程的其余部分将假设您正在使用它们!
安装virtualenv和virtualenvwrapper就像使用pip命令一样简单:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip
计时:17 秒
接下来,我们需要更新我们的~/.profile文件,方法是在您最喜欢的编辑器中打开它,并在文件的底部添加以下几行。
# virtualenv and virtualenvwrapper
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python2.7
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
而如果你的~/.profile文件不存在, 创建它 。
现在您的~/.profile文件已经更新了,您需要重新加载它,以便更改生效。强制重新加载。profile,可以:注销,重新登录;关闭您的终端并打开一个新的终端;或者最简单的解决方法是使用source命令:
$ source ~/.profile
是时候创建cv3虚拟环境了,我们将在这里进行计算机视觉工作:
$ mkvirtualenv cv3
计时:19 秒
如果您需要访问cv3虚拟环境(例如在您注销或重启您的 Pi 后),只需source您的~/.profile file (to ensure it has been loaded) and use the 工作站 command:
$ workon cv3
您的 shell 将被更新为只使用cv3虚拟环境中的包。
接下来,我们需要的唯一 Python 依赖项是 NumPy,所以确保您在cv3虚拟环境中并安装 NumPy:
$ pip install numpy
计时 13 分 47 秒
虽然不太可能,但自从我们使用sudo命令安装pip以来,我已经看到过.cache目录给出“权限被拒绝”错误的例子。如果您遇到这种情况,只需删除.cache/pip目录并重新安装 NumPy:
$ sudo rm -rf ~/.cache/pip/
$ pip install numpy
太棒了,我们有进步了!现在,您应该已经在cv3虚拟环境中的 Raspberry Pi 上安装了 NumPy,如下所示:
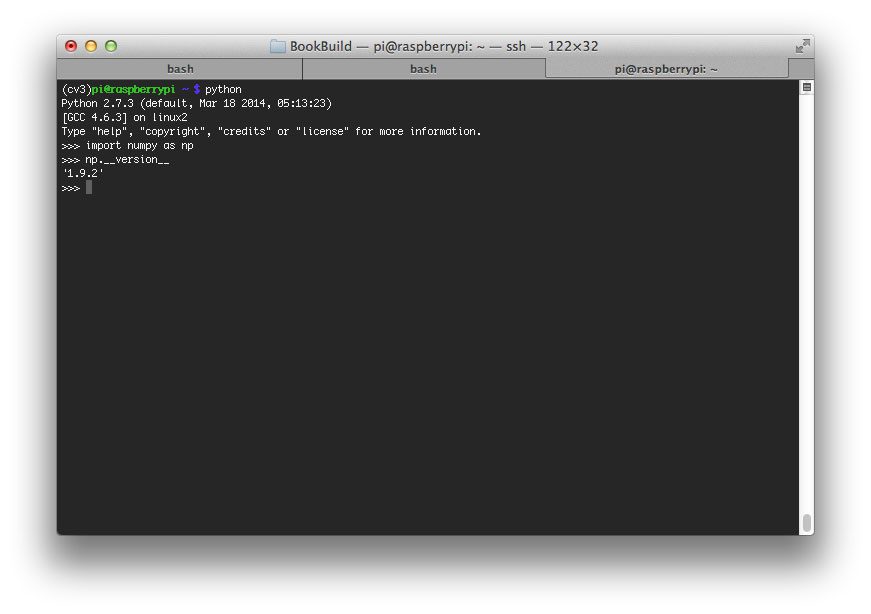
Figure 1: NumPy has been successfully installed into our virtual environment for Python 2.7+.
注意: 执行所有这些步骤可能会很耗时,所以注销/重启并稍后回来完成安装是完全正常的。但是,如果您已经注销或重启了您的 Pi ,那么您需要返回到您的cv3虚拟环境,然后再继续本指南。否则,OpenCV 3.0 将无法正确编译和安装,并且您可能会遇到导入错误。
所以我再说一遍,在你运行任何其他命令之前,你要确保你是在cv3虚拟环境中:
$ workon cv3
一旦您进入cv3虚拟环境,您就可以使用cmake来设置构建:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D BUILD_EXAMPLES=ON ..
更新(2016 年 1 月 3 日):为了构建 OpenCV 3.1.0,需要在cmake命令中设置-D INSTALL_C_EXAMPLES=OFF(而不是ON)。OpenCV v3.1.0 CMake 构建脚本中有一个错误,如果您打开此开关,可能会导致错误。一旦您将此开关设置为 off,CMake 应该会顺利运行。
CMake 将运行大约 30 秒,在它完成后(假设没有错误),您将需要检查输出,尤其是 Python 2 部分:
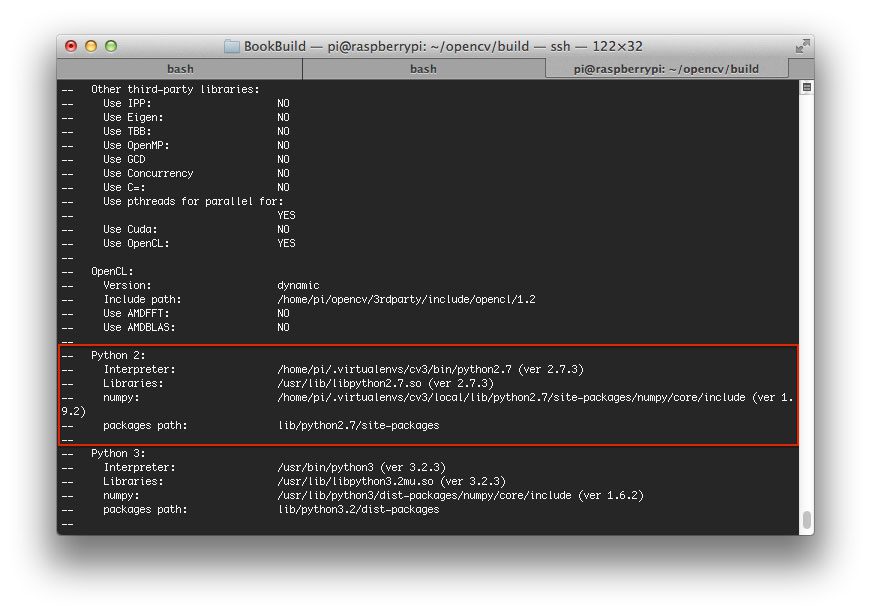
Figure 2: The output of CMake looks good — OpenCV 3.0 will compile with Python 2.7 bindings using the Python interpreter and NumPy package associated with our virtual environment.
这里的关键是确保 CMake 已经获得了 Python 2.7 解释器和与cv3虚拟环境相关联的numpy包。
其次,请务必查看 packages path 配置——这是 OpenCV 3.0 绑定将被编译和存储的目录路径。从上面的输出中,我们可以看到我的 OpenCV 绑定将存储在/usr/local/lib/python2.7/site-packages中
现在剩下的就是编译 OpenCV 3.0 了:
$ make -j4
其中 4 对应于我们的 Raspberry Pi 2 上的 4 个内核。
计时:65 米 33 秒
假设 OpenCV 已经编译成功,现在您可以将它安装到您的 Raspberry Pi 上:
$ sudo make install
$ sudo ldconfig
至此,OpenCV 3.0 已经安装在您的 Raspberry Pi 2 上了——只差一步了。
还记得我上面提到的packages path吗?
花点时间研究一下这个目录的内容,在我的例子中是/usr/local/lib/python2.7/site-packages/:
Figure 3: Our Python 2.7+ bindings for OpenCV 3.0 have been successfully installed on our system. The last step is to sym-link the cv2.so file into our virtual environment.
您应该会看到一个名为cv2.so的文件,这是我们实际的 Python 绑定。我们需要采取的最后一步是将cv2.so文件符号链接到我们的cv3环境的site-packages目录中:
$ cd ~/.virtualenvs/cv3/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
这就是你想要的!您刚刚在您的 Raspberry Pi 上编译并安装了 OpenCV 3.0 和 Python 2.7 绑定!
继续第 4 节以验证您的 OpenCV 3.0 安装是否正常工作。
第 3 节:用 Python 3+支持编译 OpenCV 3.0
首先:安装 Python 3 头文件,这样我们就可以编译 OpenCV 3.0 绑定:
$ sudo apt-get install python3-dev
计时:54 秒
安装pip,确保它与 Python 3 兼容(注意我执行的是python3而不仅仅是python):
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
计时:28 秒
就像原创教程中关于在你的树莓 Pi 2 上安装 OpenCV 2.4.X 一样,我们要利用 virtualenv 和 virtualenvwrapper 。同样,这不是在您的系统上安装 OpenCV 3.0 的必要条件,但是我强烈推荐您使用这些包来管理您的 Python 环境。此外,本教程的其余部分将假设您正在使用virtualenv和virtualenvwrapper。
使用pip3命令安装virtualenv和virtualenvwrapper:
$ sudo pip3 install virtualenv virtualenvwrapper
计时:17 秒
既然virtualenv和virtualenvwrapper已经安装在我们的系统上,我们需要更新每次启动终端时加载的~/.profile文件。在您最喜欢的文本编辑器中打开您的~/.profile文件(如果它不存在创建它,并添加以下几行:
# virtualenv and virtualenvwrapper
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
为了使对我们的~/.profile文件的更改生效,您可以(1)注销并重新登录,(2)关闭您当前的终端并打开一个新的终端,或者(3)简单地使用source命令:
$ source ~/.profile
让我们创建我们的cv虚拟环境,OpenCV 将在其中编译和访问:
$ mkvirtualenv cv
计时:19 秒
注意: 我把 Python 2.7+和 Python 3+的安装指令聚集在同一个树莓派上,所以我不能对每个安装使用相同的虚拟环境名。在这种情况下,cv3虚拟环境指的是我的 Python 2.7 环境,cv虚拟环境指的是我的 Python 3+环境。您可以随意命名这些环境,我只是想澄清一下,希望能消除任何困惑。
这个命令将创建你的cv虚拟环境,它完全独立于Python 安装系统。如果您需要访问这个虚拟环境,只需使用workon命令:
$ workon cv
你会被丢进你的cv虚拟环境。
无论如何,我们需要的唯一 Python 依赖项是 NumPy,所以确保您在cv虚拟环境中并安装 NumPy:
$ pip install numpy
计时 13 分 47 秒
如果由于某种原因,你的.cache目录给你一个权限被拒绝的错误,只需删除它并重新安装 NumPy,否则你可以跳过这一步:
$ sudo rm -rf ~/.cache/pip/
$ pip install numpy
此时,您应该有了一个很好的 NumPy 的全新安装,如下所示:
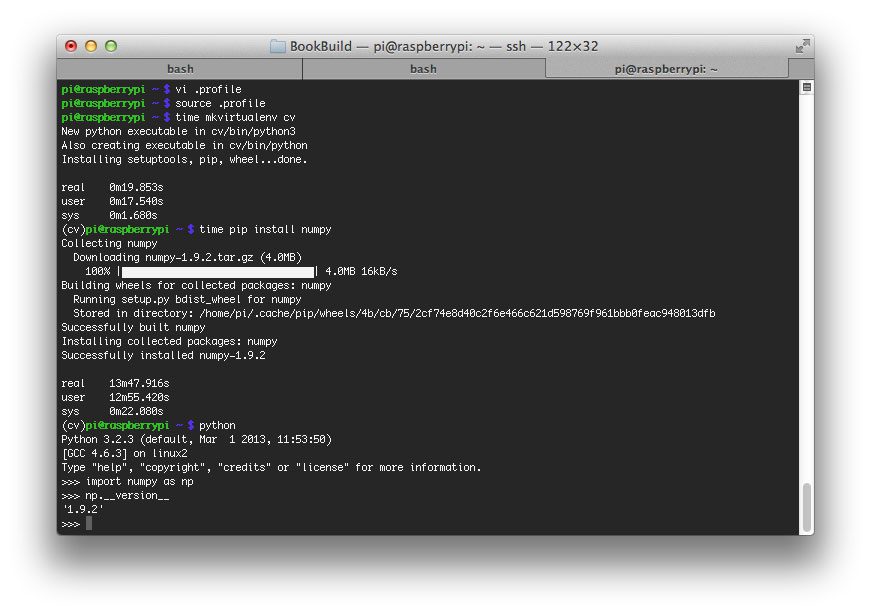
Figure 4: NumPy has been successfully installed for Python 3+ in the cv virtual environment.
好了,这需要一段时间,但是我们终于准备好在你的 Raspberry Pi 上用 Python 3+绑定编译 OpenCV 3.0 了。
需要注意的是,如果你已经注销了**或者重启了,那么在编译 OpenCV 3.0 之前,你需要回到你的cv虚拟环境中。如果你不这样做,OpenCV 3.0 将无法正确编译和安装,当你试图导入 OpenCV 并得到可怕的ImportError: No module named cv2错误时,你将会感到困惑。
同样,在运行本节*中的任何其他命令之前,您需要确保您处于cv虚拟环境中:
$ workon cv
在您进入cv虚拟环境后,我们可以设置我们的构建:
$ cd ~/opencv
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D BUILD_EXAMPLES=ON ..
更新(2016 年 1 月 3 日):为了构建 OpenCV 3.1.0,需要在cmake命令中设置-D INSTALL_C_EXAMPLES=OFF(而不是ON)。OpenCV v3.1.0 CMake 构建脚本中有一个错误,如果您打开此开关,可能会导致错误。一旦您将此开关设置为 off,CMake 应该会顺利运行。
在 CMake 运行之后,花一点时间检查 Make 配置的输出,密切注意 Python 3 部分:
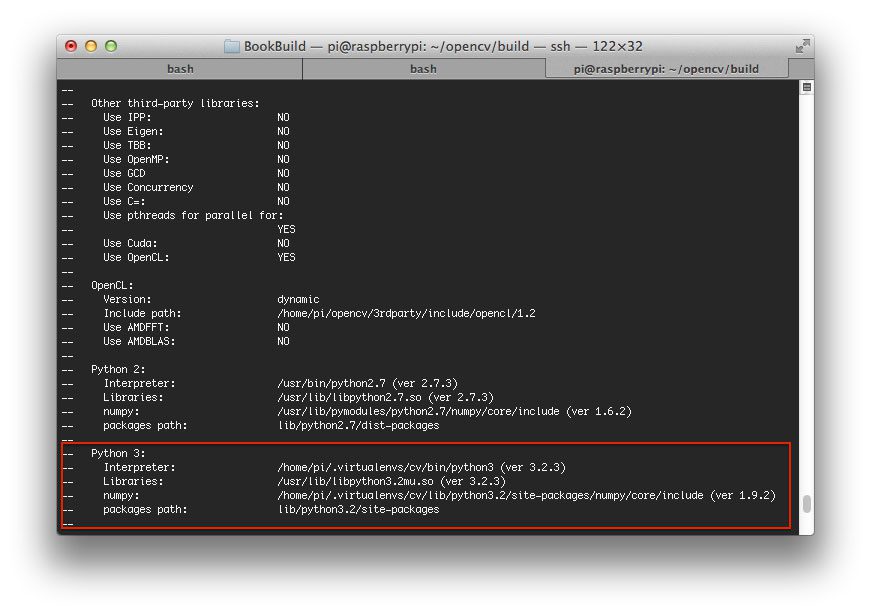
Figure 5: Definitely take the time to ensure that CMake has found the correct Python 3+ interpreter before continuing on to compile OpenCV 3.0.
具体来说,您需要确保 CMake 已经获得了您的 Python 3 解释器!
由于我们正在用 Python 3 绑定来编译 OpenCV 3.0,我将检查 Python 3 部分并确保我的Interpreter和numpy路径指向我的cv虚拟环境。正如你从上面所看到的,它们确实如此。
另外,要特别注意packages path 配置——这是到 OpenCV 3.0 绑定将被编译和存储的目录的路径。在运行了make命令之后(下面将详细描述),您将在这个目录中检查您的 OpenCV 3.0 绑定。在这种情况下,我的packages path是lib/python3.2/site-packages,所以我将检查/usr/local/lib/python3.2/site-packages中我编译的输出文件。
现在剩下的就是编译 OpenCV 3.0 了:
$ make -j4
其中 4 对应于我们的 Raspberry Pi 2 上的 4 个内核。使用多个内核将极大地加速编译时间,将它从的 2.8 小时降低到的 1 小时多一点!
计时:65 米 33 秒
假设 OpenCV 已经编译成功,现在您可以将它安装到您的 Raspberry Pi 上:
$ sudo make install
$ sudo ldconfig
计时:39 秒
至此 OpenCV 3.0 已经安装在我们的树莓 Pi 上了!
然而,我们还没有完全完成。
还记得我上面提到的packages path吗?
让我们列出该目录的内容,看看 OpenCV 绑定是否在其中:
$ ls -l /usr/local/lib/python3.2/site-packages
total 1416
-rw-r--r-- 1 root staff 1447637 Jun 22 18:26 cv2.cpython-32mu.so
这里我们可以看到有一个名为cv2.cpython-32mu.so的文件,这是我们实际的 Python 绑定。
然而,为了在我们的cv虚拟环境中使用 OpenCV 3.0,我们首先需要将 OpenCV 二进制文件符号链接到cv环境的site-packages目录中:
$ cd ~/.virtualenvs/cv/lib/python3.2/site-packages/
$ ln -s /usr/local/lib/python3.2/site-packages/cv2.cpython-32mu.so cv2.so
因此,现在当您列出与我们的cv虚拟环境相关联的site-packages目录的内容时,您将看到我们的 OpenCV 3.0 绑定(cv2.so文件):
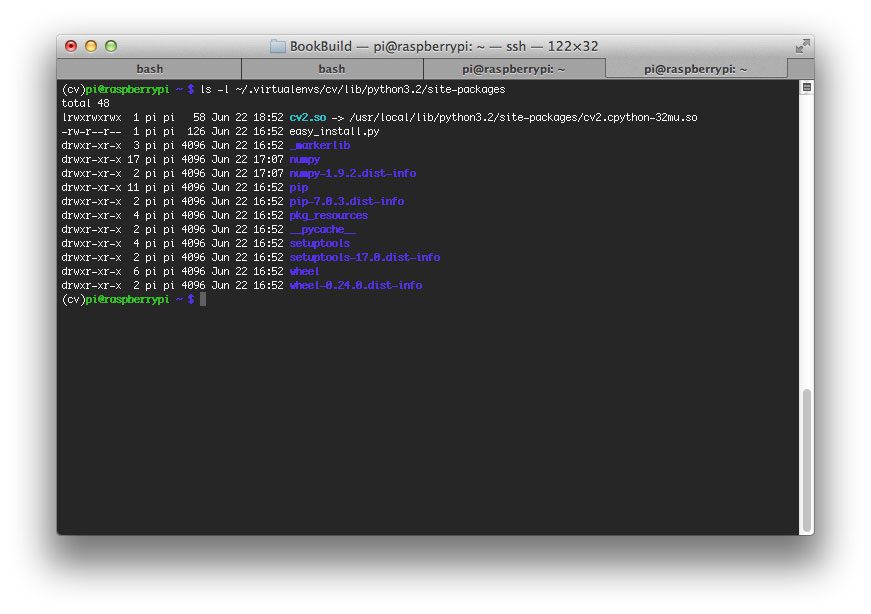
Figure 6: A good validation step to take is to list the contents of the site-packages directory for the cv virtual environment. You should see your cv2.so file sym-linked into the directory.
这就是你想要的!支持 Python 3+的 OpenCV 3.0 现已成功安装在您的系统上!
第 4 节:验证您的 OpenCV 3.0 安装
在我们结束本教程之前,让我们确保 OpenCV 绑定已经正确安装。打开一个终端,进入cv虚拟环境(或者cv3,如果你遵循 Python 2.7+安装步骤),启动你的 Python shell 导入 OpenCV:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.0.0'
果然,我们可以看到 OpenCV 3.0 和 Python 3+支持已经安装在我的 Raspberry Pi 上:
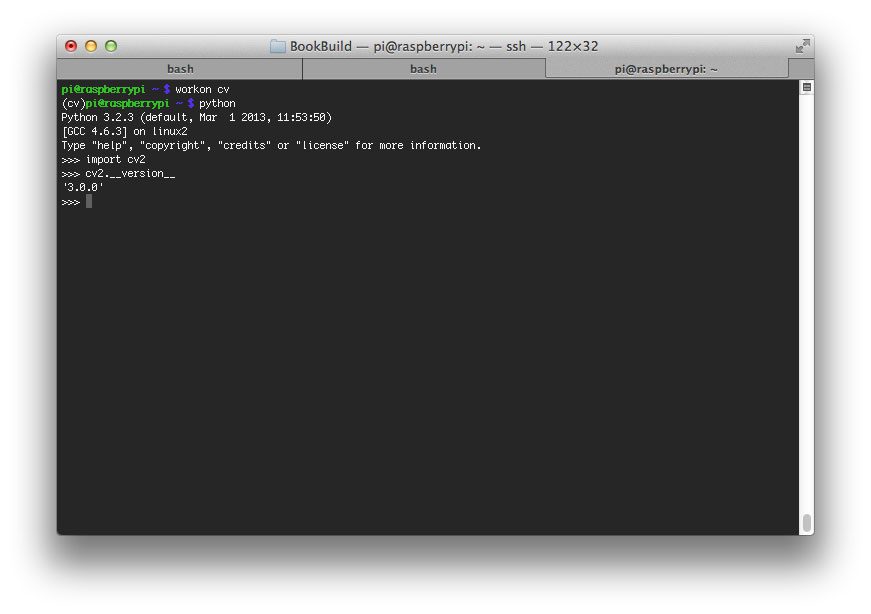
Figure 7: Success! OpenCV 3.0 with Python bindings has been successfully installed on our Raspberry Pi 2!
摘要
在这篇博客文章中,我详细介绍了如何在您的 Raspberry Pi 2 上安装 OpenCV 3.0 以及 Python 2.7+和 Python 3+绑定。还提供了每个安装步骤的时间,以便您可以相应地计划安装。请记住,如果您在设置了virtualenv和virtualenvwrapper之后注销或重启您的 Pi,您将需要执行workon命令来重新访问您的计算机视觉虚拟环境,然后继续我详述的步骤。如果你不这样做,你很容易发现自己处于可怕的ImportError: No module named cv2错误的境地。
随着 Raspberry Pi 和 Raspbian/NOOBS 操作系统的发展,我们的安装说明也将随之发展。如果您遇到任何边缘情况,请随时让我知道,这样我就可以随时更新这些安装说明。
当然,在未来的博客帖子中,我们将使用 OpenCV 3.0 和 Raspberry Pi 做一些真正令人惊叹的项目,所以请考虑在下面的表格中输入您的电子邮件地址,以便在这些帖子发布时得到通知!***
在 Windows 上安装 OpenCV
原文:https://pyimagesearch.com/2022/04/25/installing-opencv-on-windows/
在本教程中,您将学习如何在 Windows 上安装 OpenCV。这包括使用预构建的二进制文件进行安装的完整指南。
完成这篇博文后,你就可以自己在 Windows 机器上安装 OpenCV 了。你也可以选择最适合你的方法。
要了解如何在 Windows 上安装 OpenCV,继续阅读。
在 Windows 上安装 OpenCV
大家好,欢迎来到今天的教程。如果你在这里,我假设你必须有一台 Windows 电脑,或者需要使用一台计算机视觉。首先,让我向你保证你可能产生了怀疑。
是的,在 Windows 机器上练习深度学习和计算机视觉是可能的。我们 PyImageSearch 是民主化学习的坚定信仰者。
你不需要一台昂贵的笔记本电脑来开始使用 OpenCV。
在本教程中,我们将指导您通过各种方法在 Windows 计算机上安装 OpenCV。
使用 Pip 安装 OpenCV
使用 pip 安装 OpenCV Python 相当容易。然而,在我们开始之前,有一些事情需要记住。
- 这是一个为 Python 预先构建的 CPU 专用 OpenCV 包。如果您使用的是 GPU 驱动的计算机,则无法遵循这些步骤。
- 这些是用于安装 OpenCV 的非官方预构建包。它们不是由 OpenCV.org 团队发布的官方 OpenCV 包。
- 在开始之前,有必要在您的 Windows 机器上安装 Python 和 pip。如果您没有安装 Python,请从这里下载并安装最新版本。
完成所有免责声明和先决条件后,让我们开始安装。这里有四个 OpenCV 包,它们可以通过 pip 安装在 PyPI 存储库上:
- opencv-python:这个库包含正好是 OpenCV 库的主要模块。如果你是 PyImageSearch 阅读器,你不会想安装这个包。
- opencv-contrib-python:opencv-contrib-python 库包含了主模块和贡献模块。这是我们建议您安装的库,因为它包含了所有 OpenCV 功能。
- opencv-python-headless:与 opencv-python 相同,但没有 GUI 功能。对无头系统有用。
- opencv-contrib-python-headless:与 opencv-contrib-python 相同,但没有 GUI 功能。对无头系统有用。
你不想同时安装 opencv-python 和 opencv-contrib-python。挑一个吧。
第一步:确保你已经安装了 python 和 pip。Pip 版本 19.3 是支持的最低版本。这意味着需要版本高于 19.3 的 pip。
要检查 pip 版本,打开您的命令提示符并键入:
$ pip -V
这将让您知道您正在使用的 pip 版本。要将 pip 升级到最新版本类型:
$ pip install --upgrade pip
第二步(可选):创建一个虚拟环境,在那里安装 OpenCV。用 Python 创建虚拟环境是一个非常好的实践,我们强烈推荐它。你可以开发多个项目,而不用担心你的库会互相碰撞。这可以通过virtualenv和virtualenvwrapper以及 Anaconda 来实现。在本教程中,我们将使用virtualenv和virtualenvwrapper。
$ pip install virtualenv virtualenvwrapper
$ pip install virtualenvwrapper-win
您将看到一些设置了virtualenvwrapper的终端输出。您现在可以访问新的终端命令:
- 用
mkvirtualenv创造一个环境。 - 用
workon激活环境(或切换到不同的环境)。 - 使用
deactivate停用环境。 - 用
rmvirtualenv删除一个环境。
阅读文档以熟悉命令。
接下来,创建一个名为cv(您可以随意命名)的虚拟环境来安装 OpenCV。
$ mkvirtualenv cv -p python3
使用以下选项切换到此环境:
$ workon cv
第三步:万事俱备,我们终于开始在你的 Windows 系统上安装 OpenCV 了。
$ pip install opencv-contrib-python
要检查 OpenCV 是否安装正确,请打开一个新的命令提示符,并使用以下命令输入 Python shell:
$ python
>> import cv2
>> print(cv2.__version__)
仅此而已。OpenCV 已成功安装在您的 windows 计算机上。您已经准备好开始您的计算机视觉之旅。
我们建议您浏览一下我们关于 OpenCV 基础的教程,以熟悉这个主题。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
汇总
在本教程中,我们学习了如何从预构建的二进制文件中安装 OpenCV。我们还学习了要安装哪个包,以及如何创建一个虚拟环境来处理这个包。出于使用 Python 学习计算机视觉的所有目的,我们强烈建议使用预构建的二进制文件安装 opencv-contrib-python。
如果你想开始你的计算机视觉开发之旅,请查看我们在 OpenCV 上的教程。
快乐学习🙂
参考文献
- PyImageSearch: Pip 安装 OpenCV 指南
- Adam Hacks: 在 Windows 上安装 OpenCV
- PyPi: Pip 安装 OpenCV
引用信息
Raha,R. “在 Windows 上安装 OpenCV”, PyImageSearch ,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,A. Thanki,2022,https://pyimg.co/b3q05
@incollection{Raha_2022_Installing-OpenCV-Windows,
author = {Ritwik Raha},
title = {Installing {OpenCV} on {W}indows},
Booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/b3q05},
}
在您的 Raspberry Pi Zero 上安装 OpenCV
原文:https://pyimagesearch.com/2015/12/14/installing-opencv-on-your-raspberry-pi-zero/

在这篇博文中,我将演示如何在树莓 Pi Zero 上安装 OpenCV 3。
由于我已经在 多篇、之前的博文 中介绍了如何在树莓 Pi 上安装 OpenCV,所以我将把这篇博文放在较短的一边,只详述启动和运行 OpenCV 所必需的相关命令。关于如何在你的 Pi 上安装 OpenCV 3 的更详细的讨论(以及一个 22 分钟的视频安装指南,请参考这篇文章。
我还将在本安装指南中做出以下假设:
- 您使用的是 Raspberry Pi 零硬件 (因此每个命令提供的时间将匹配)。
- 你有 Raspbian 杰西 安装在你的圆周率为零。
- 你要用 Python 2.7 绑定 安装 OpenCV v3.0 (对于 Python 3 的支持,见本帖)。
同样,我已经介绍了如何在多种 Raspberry Pi 平台和 Raspbian 风格平台上安装 OpenCV——本教程的主要目标是在您的 Pi Zero 上安装并运行 OpenCV,这样您就可以开始学习计算机视觉、图像处理和 OpenCV 库。
在您的 Raspberry Pi Zero 上安装 OpenCV
如果你还没有看过树莓派 Zero(T1 ),这是一款非常酷的硬件。它包含一个单核 1GHz ARM 处理器。512 兆内存。它比信用卡还小。
但最精彩的部分呢?
只要 5 美元!
虽然 Pi Zero 对于高级视频处理来说不够快,但它仍然是一个很好的工具,可以用来学习计算机视觉和 OpenCV 的基础知识。
步骤#1:扩展文件系统
如果你使用的是全新安装的 Raspbian Jessie,那么你要做的第一件事就是确保你的文件系统已经扩展到包括你的 micro-SD 卡上的所有可用空间:
$ sudo raspi-config
选择第一个选项 "1。展开文件系统",向下箭头指向"完成",并重启您的 Pi:
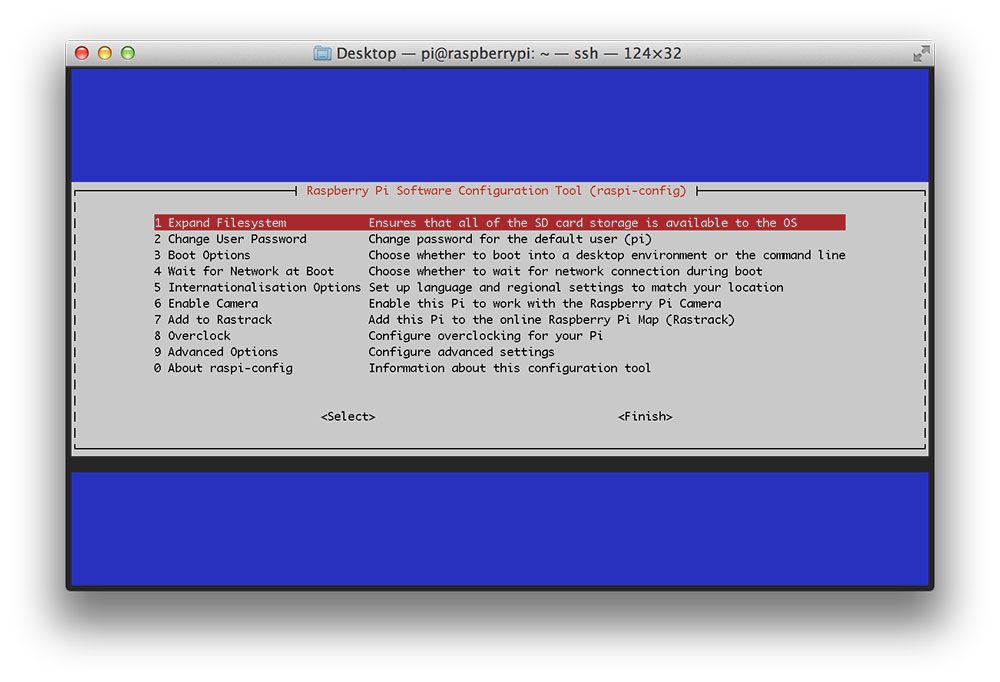
Figure 1: Expanding the filesystem on your Raspberry Pi Zero.
重新启动后,您的文件系统将被扩展到包括 micro-SD 卡上的所有可用空间。
步骤 2:安装依赖项
我已经在以前的帖子中讨论了这些依赖项,所以我将只提供一个简短的描述,命令本身,以及执行每个命令 所花费的 时间,这样你就可以相应地计划你的 OpenCV 安装(仅 OpenCV 的编译就需要 9 个多小时)。
首先,我们需要更新和升级我们现有的软件包:
$ sudo apt-get update
$ sudo apt-get upgrade
计时:2 分 29 秒
安装我们的开发工具:
$ sudo apt-get install build-essential cmake pkg-config
计时:49 秒
让我们获取映像 I/O 包并安装它们:
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng12-dev
计时:36s
以及一些视频 I/O 包(尽管您不太可能使用 Raspberry Pi Zero 进行大量视频处理):
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
计时:36s
我们需要为 OpenCV 的 GUI 界面安装 GTK 开发库:
$ sudo apt-get install libgtk2.0-dev
计时:2 分 57 秒
让我们来看看 OpenCV 利用的几个例行优化包:
$ sudo apt-get install libatlas-base-dev gfortran
计时:52s
最后,让我们安装 Python 2.7 头文件,以便 wen 可以编译我们的 OpenCV + Python 绑定:
$ sudo apt-get install python2.7-dev
计时:55s
注意:在这篇文章中,我将只讲述如何安装 OpenCV 3 和 Python 2.7 绑定。如果你想用 Python 3 绑定安装 OpenCV 3,请参考这篇文章。
步骤 3:获取 OpenCV 源代码
至此,我们所有的依赖项都已安装完毕,所以让我们从 GitHub 获取 OpenCV 的3.0.0版本并将其拉下来:
$ cd ~
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.0.0.zip
$ unzip opencv.zip
计时:1 米 58 秒
让我们也抓住 opencv_contrib 库:
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.0.0.zip
$ unzip opencv_contrib.zip
计时:1 米 5 秒
如果你想访问 SIFT 和 SURF ,获取opencv_contrib repo 尤为重要,这两个功能已经从 OpenCV 的默认安装中移除。
现在opencv.zip和opencv_contrib.zip已经展开,让我们删除它们以节省空间:
$ rm opencv.zip opencv_contrib.zip
步骤 4:设置 Python
为 OpenCV 构建设置 Python 的第一步是安装pip,这是一个 Python 包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
计时:49 秒
让我们也安装virtualenv和virtualenvwarpper,允许我们为未来的每个项目创建单独的、隔离的 Python 环境:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip
计时:30 秒
注:我在 PyImageSearch 博客上多次讨论过virtualenv和virtualenvwrapper。如果这是你第一次使用它们,我建议参考这篇关于在 Raspbian Jessie 上安装 OpenCV 3 的博文。
要完成virtualenv和virtualenvwrapper的安装,请打开您的~./profile:
$ nano ~/.profile
并将以下几行附加到文件的底部:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
现在,source你的~/.profile文件重新载入修改:
$ source ~/.profile
让我们创建一个新的 Python 虚拟环境,适当地命名为cv:
$ mkvirtualenv cv
计时:31 秒
构建 Python + OpenCV 绑定的唯一要求是安装了 NumPy ,所以让我们使用pip来为我们安装 NumPy:
$ pip install numpy
计时:35 米 4 秒
第 5 步:为 Raspberry Pi Zero 编译并安装 OpenCV
我们现在准备编译和安装 OpenCV。使用workon命令确保您处于cv虚拟环境中:
$ workon cv
然后使用 CMake 设置构建:
$ cd ~/opencv-3.0.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D INSTALL_C_EXAMPLES=ON \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.0.0/modules \
-D BUILD_EXAMPLES=ON ..
计时:4 分 29 秒
既然构建已经完成,运行make开始编译过程(这需要一段时间,所以您可能想让它运行一整夜):
$ make
计时:9 小时 42 分钟
假设 OpenCV 编译无误,您可以使用以下命令将其安装在您的 Raspberry Pi Zero 上:
$ sudo make install
$ sudo ldconfig
计时:2 米 31 秒
第 6 步:完成安装
如果您没有错误地完成了步骤#5 ,您的 OpenCV 绑定现在应该安装在/usr/local/lib/python2.7/site-packages:
$ ls -l /usr/local/lib/python2.7/site-packages
total 1640
-rw-r--r-- 1 root staff 1677024 Dec 2 08:34 cv2.so
我们现在需要做的就是将cv2.so文件(这是我们实际的 Python + OpenCV 绑定)符号链接到cv虚拟环境的site-packages目录中:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
步骤 7:验证您的 OpenCV 安装
现在剩下要做的就是验证 OpenCV 已经正确安装在您的 Raspberry Pi Zero 上。
每当您想要使用 OpenCV 时,首先确保您处于cv虚拟环境中:
$ workon cv
从那里,您可以启动 Python shell 并导入 OpenCV 绑定:
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.0.0'
>>>
或者可以执行导入 OpenCV 的 Python 脚本。
一旦安装了 OpenCV,您就可以删除opencv-3.0.0和opencv_contrib-3.0.0目录,在您的文件系统上释放一些空间:
$ rm -rf opencv-3.0.0 opencv_contrib-3.0.0
但是在运行这个命令之前要小心!在清空这些目录之前,确保 OpenCV 已经正确安装在您的系统上,否则您将不得不重新开始(漫长的,9 个多小时)编译!
解决纷争
如果你在 Raspberry Pi Zero 上安装 OpenCV 3 时遇到任何错误,我建议你咨询一下 的 故障排除 部分,这篇文章 详细介绍了每个安装步骤。
这篇文章还包括一个完整的 22 分钟的视频,其中我演示了如何运行每个命令来完美地将 OpenCV 3 安装到您的树莓 Pi 上:

Figure 2: Getting OpenCV up and running on your Raspberry Pi.
摘要
这篇文章详细介绍了如何在你的 Raspberry Pi Zero 上安装 OpenCV 3。这篇博客文章的目的是提供准确的时间安排,当您计划在 Pi Zero 上安装 OpenCV 时可以使用。
为了启动并运行 OpenCV,我做了以下假设:
- 你正在运行 Raspbian 杰西 在你的树莓派零。
- 你正在安装OpenCV v3T3。
- 你想在 OpenCV 绑定中使用 Python 2.7 。
如果您想将 Python 3+ 与您的 OpenCV 绑定一起使用,请参考这篇文章,在这篇文章中,我详细阐述了每个步骤,提供了更详细的信息,并包括一个 22 分钟的视频,带您一步一步地在您的 Raspberry Pi 上安装 OpenCV 3。
正在为 OCR 安装宇宙魔方
原文:https://pyimagesearch.com/2017/07/03/installing-tesseract-for-ocr/

今天的博客文章是关于安装和使用用于光学字符识别(OCR)的宇宙魔方库的两部分系列文章的第一部分。
OCR 是将键入的、手写的或印刷的文本转换成机器编码的文本的自动过程,我们可以通过字符串变量来访问和操作这些文本。
本系列的第一部分将着重于在您的机器上安装和配置 Tesseract,然后利用tesseract命令对输入图像应用 OCR。
在下周的博客文章中,我们将发现如何使用 Python“绑定”到宇宙魔方库,从 Python 脚本中直接调用宇宙魔方。
要了解更多关于宇宙魔方以及它如何用于 OCR 的信息,继续阅读。*
正在为 OCR 安装宇宙魔方
宇宙魔方最初是由惠普公司在 20 世纪 80 年代开发的,于 2005 年开源。后来,在 2006 年,谷歌采纳了该项目,并一直是赞助商。
宇宙魔方软件适用于许多自然语言,从英语(最初)到旁遮普语到意第绪语。自 2015 年更新以来,它现在支持超过 100 种书面语言,并有代码,因此它也可以很容易地在其他语言上进行培训。
最初是 C 程序,1998 年移植到 C++上。该软件是无头的,可以通过命令行执行。它不附带 GUI,但是有几个其他软件包包装 Tesseract 来提供 GUI 界面。
要阅读更多关于宇宙魔方的内容,请访问项目页面并阅读维基百科文章。
在这篇博文中,我们将:
- 在我们的系统上安装宇宙魔方。
- 验证宇宙魔方安装是否正常工作。
- 在一些样本输入图像上尝试 Tesseract OCR。
完成本教程后,你将掌握在自己的图像上运行宇宙魔方的知识。
步骤 1:安装宇宙魔方
为了使用宇宙魔方库,我们首先需要在我们的系统上安装它。
对于 macOS 用户 ,我们将使用自制软件来安装宇宙魔方:
$ brew install tesseract

Figure 1: Installing Tesseract OCR on macOS.
如果您使用的是 Ubuntu 操作系统 ,只需使用apt-get安装 Tesseract OCR:
$ sudo apt-get install tesseract-ocr

Figure 2: Installing Tesseract OCR on Ubuntu.
对于 窗口 ,请查阅宇宙魔方文档,因为 PyImageSearch 不支持或不推荐计算机视觉开发的窗口。
步骤#2:验证已经安装了 Tesseract
要验证 Tesseract 是否已成功安装在您的计算机上,请执行以下命令:
$ tesseract -v
tesseract 3.05.00
leptonica-1.74.1
libjpeg 8d : libpng 1.6.29 : libtiff 4.0.7 : zlib 1.2.8

Figure 3: Validating that Tesseract has been successfully installed on my machine.
您应该会看到打印到屏幕上的 Tesseract 版本,以及与 Tesseract 兼容的图像文件格式库列表。
如果您得到的是错误消息:
-bash: tesseract: command not found
那么宇宙魔方没有正确安装在你的系统上。回到 步骤#1 并检查错误。此外,您可能需要更新您的PATH变量(仅适用于高级用户)。
步骤 3:测试 Tesseract OCR
为了让宇宙魔方 OCR 获得合理的结果,您需要提供经过干净预处理的图像。
**当使用宇宙魔方时,我建议:
- 使用尽可能高的分辨率和 DPI 作为输入图像。
- 应用阈值将文本从背景中分割出来。
- 确保前景尽可能清晰地从背景中分割出来(即,没有像素化或字符变形)。
- 对输入图像应用文本倾斜校正以确保文本正确对齐。
偏离这些建议会导致不正确的 OCR 结果,我们将在本教程的后面部分了解这一点。
现在,让我们将 OCR 应用于下图:

Figure 4: An example image we are going to apply OCR to using Tesseract.
只需在终端中输入以下命令:
$ tesseract tesseract_inputs/example_01.png stdout
Warning in pixReadMemPng: work-around: writing to a temp file
Testing Tesseract OCR
正确!宇宙魔方正确识别,“测试宇宙魔方 OCR”,并在终端打印出来。
接下来,让我们试试这张图片:

Figure 5: A second example image to apply Optical Character Recognition to using Tesseract.
在您的终端中输入以下内容,注意更改后的输入文件名:
$ tesseract tesseract_inputs/example_02.png stdout
Warning in pixReadMemPng: work-around: writing to a temp file
PyImageSearch
Figure 6: Tesseract is able to correctly OCR our image.
成功!宇宙魔方正确地识别了图像中的文本“PyImageSearch”。
现在,让我们尝试 OCR 识别数字而不是字母字符:

Figure 7: Using Tesseract to OCR digits in images.
本例使用命令行digits开关来仅报告数字:
$ tesseract tesseract_inputs/example_03.png stdout digits
Warning in pixReadMemPng: work-around: writing to a temp file
650 3428
宇宙魔方再一次正确地识别了我们的字符串(在这种情况下只有数字)。
在这三种情况下,Tesseract 都能够正确地 OCR 我们所有的图像——你甚至可能认为 Tesseract 是所有 OCR 用例的正确工具。
然而,正如我们将在下一节中发现的,宇宙魔方有许多限制。
OCR 的宇宙魔方的限制
几周前,我在做一个识别信用卡上 16 位数字的项目。
我可以很容易地编写 Python 代码来本地化四组 4 位数中的每一组。
以下是一个 4 位数感兴趣区域的示例:

Figure 8: Localizing a 4-digit grouping of characters on a credit card.
然而,当我尝试将 Tesseract 应用于下图时,结果并不令人满意:

Figure 9: Trying to apply Tesseract to “noisy” images.
$ tesseract tesseract_inputs/example_04.png stdout digits
Warning in pixReadMemPng: work-around: writing to a temp file
5513
注意宇宙魔方是如何报告5513的,但是图像清楚地显示了5678。
不幸的是,这是宇宙魔方局限性的一个很好的例子。虽然我们已经将前景文本从背景中分割出来,但是文本的像素化性质“混淆”了宇宙魔方。也有可能宇宙魔方没有被训练成类似信用卡的字体。
Tesseract 最适合构建文档处理管道,在这种管道中,图像被扫描进来,进行预处理,然后需要应用光学字符识别。
我们应该注意到,Tesseract 是而不是OCR 的现成解决方案,可以在所有(甚至大多数)图像处理和计算机视觉应用程序中工作。
为了实现这一点,你需要应用特征提取技术、机器学习和深度学习。
摘要
今天我们学习了如何在我们的机器上安装和配置 Tesseract,这是将 Tesseract 用于 OCR 的两部分系列的第一部分。然后,我们使用tesseract二进制文件对输入图像进行 OCR。
然而,我们发现,除非我们的图像被干净地分割,否则立方体将给出糟糕的结果。在“嘈杂”的输入图像的情况下,我们可能会通过训练一个定制的机器学习模型来识别我们特定的用例中的字符,从而获得更好的准确性。
宇宙魔方最适合高分辨率输入的情况,其中前景文本 从背景中干净地分割 。
下周我们将学习如何通过 Python 代码访问宇宙魔方,敬请关注。
为了在下一篇关于宇宙魔方的博文发布时得到通知,请务必在下面的表格中输入您的电子邮件地址!***
在系统上安装 Tesseract、PyTesseract 和 Python OCR 包
在本教程中,我们将配置我们的 OCR 开发环境。一旦您的机器配置完毕,我们将开始编写执行 OCR 的 Python 代码,为您开发自己的 OCR 应用程序铺平道路。
要了解如何配置你的开发环境, 继续阅读。
学习目标
在本教程中,您将:
- 了解如何在您的计算机上安装 Tesseract OCR 引擎
- 了解如何创建 Python 虚拟环境(Python 开发中的最佳实践)
- 安装运行本教程中的示例所需的必要 Python 包(并开发您自己的 OCR 项目)
OCR 开发环境配置
在本教程的第一部分,您将学习如何在您的系统上安装 Tesseract OCR 引擎。从这里,您将学习如何创建一个 Python 虚拟环境,然后安装 OpenCV、PyTesseract 和 OCR、计算机视觉和深度学习所需的所有其他必要的 Python 库。
安装说明注释
宇宙魔方 OCR 引擎已经存在了 30 多年。Tesseract OCR 的安装说明相当稳定。因此,我已经包括了这些步骤。
也就是说,让我们在您的系统上安装 Tesseract OCR 引擎!
安装宇宙魔方
在本教程中,你将学习如何在你的机器上安装宇宙魔方。
在 macOS 上安装宇宙魔方
如果您使用家酿包管理器,在 macOS 上安装 Tesseract OCR 引擎相当简单。
如果您的系统上尚未安装 Homebrew,请使用上面的链接进行安装。
从那里,你需要做的就是使用brew命令来安装宇宙魔方:
$ brew install tesseract
如果上面的命令没有出现错误,那么您现在应该已经在 macOS 机器上安装了 Tesseract。
在 Ubuntu 上安装宇宙魔方
在 Ubuntu 18.04 上安装 Tesseract 很容易——我们需要做的就是利用apt-get:
$ sudo apt install tesseract-ocr
apt-get包管理器将自动安装宇宙魔方所需的任何必备库或包。
在 Windows 上安装宇宙魔方
请注意,PyImageSearch 团队和我并不正式支持 Windows,除了使用我们预配置的 Jupyter/Colab 笔记本的客户,这些客户可以在 PyImageSearch 大学找到。这些笔记本电脑可以在所有环境下运行,包括 macOS、Linux 和 Windows。
相反,我们建议使用基于 Unix 的机器,如 Linux/Ubuntu 或 macOS ,这两种机器都更适合开发计算机视觉、深度学习和 OCR 项目。
也就是说,如果你想在 Windows 上安装宇宙魔方,我们建议你遵循官方的 Windows 安装说明,这些说明是由宇宙魔方团队提供的。
验证您的宇宙魔方安装
假设您能够在您的操作系统上安装 Tesseract,您可以使用tesseract命令验证 Tesseract 是否已安装:
$ tesseract -v
tesseract 4.1.1
leptonica-1.79.0
libgif 5.2.1 : libjpeg 9d : libpng 1.6.37 : libtiff 4.1.0 : zlib 1.2.11 : libwebp 1.1.0 : libopenjp2 2.3.1
Found AVX2
Found AVX
Found FMA
Found SSE
您的输出应该与我的相似。
为 OCR 创建 Python 虚拟环境
Python 虚拟环境是 Python 开发的最佳实践,我们建议使用它们来获得更可靠的开发环境。
在我们的pip Install OpenCV教程中可以找到为 Python 虚拟环境安装必要的包,以及创建您的第一个 Python 虚拟环境。我们建议您按照该教程创建您的第一个 Python 虚拟环境。
*### 安装 OpenCV 和 PyTesseract】
既然您已经创建了 Python 虚拟环境并做好了准备,我们可以安装 OpenCV 和 PyTesseract,这是与 Tesseract OCR 引擎接口的 Python 包。
这两者都可以使用以下命令进行安装:
$ workon <name_of_your_env> # required if using virtual envs
$ pip install numpy opencv-contrib-python
$ pip install pytesseract
接下来,我们将安装 OCR、计算机视觉、深度学习和机器学习所需的其他 Python 包。
安装其他计算机视觉、深度学习和机器学习库
现在让我们安装一些其他支持计算机视觉和机器学习/深度学习的软件包,我们将在本教程的剩余部分中用到它们:
$ pip install pillow scipy
$ pip install scikit-learn scikit-image
$ pip install imutils matplotlib
$ pip install requests beautifulsoup4
$ pip install h5py tensorflow textblob
总结
在本教程中,您学习了如何在您的计算机上安装 Tesseract OCR 引擎。您还学习了如何安装执行 OCR、计算机视觉和图像处理所需的 Python 包。
现在您的开发环境已经配置好了,我们将在下一个教程中编写 OCR 代码!*
利用 OpenCV 进行实例分割
原文:https://pyimagesearch.com/2018/11/26/instance-segmentation-with-opencv/

在本教程中,您将学习如何使用 OpenCV、Python 和深度学习来执行实例分割。
早在 9 月份,我看到微软在他们的 Office 365 平台上发布了一个非常棒的功能——进行视频电话会议的能力,模糊背景,让你的同事只能看到你(而看不到你身后的任何东西)。
这篇文章顶部的 GIF 展示了一个类似的特性,这是我为了今天的教程而实现的。
无论你是在酒店房间接电话,还是在丑陋不堪的办公楼里工作,或者只是不想清理家庭办公室,电话会议模糊功能都可以让与会者专注于你(而不是背景中的混乱)。
对于在家工作并希望保护家庭成员隐私的人来说,这样的功能会特别有帮助(T2)。
想象一下,您的工作站可以清楚地看到您的厨房,您不会希望您的同事看到您的孩子吃晚饭或做作业吧!相反,只需打开模糊功能,一切就搞定了。
为了构建这样一个功能,微软利用了计算机视觉、深度学习,最值得注意的是, 实例分割。
我们在上周的博客文章中介绍了 Mask R-CNN 的实例分割,今天我们将采用我们的 Mask R-CNN 实现,并使用它来构建一个类似 Microsoft Office 365 的视频模糊功能。
要了解如何使用 OpenCV 执行实例分割,继续阅读!
利用 OpenCV 进行实例分割
https://www.youtube.com/embed/puSN8Dg-bdI?feature=oembed
用于对象检测的并集交集(IoU)
原文:https://pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
最后更新于 2022 年 4 月 30 日
目录
并集上的交集(IoU)用于评估对象检测的性能,方法是将基础真实边界框与预测边界框进行比较,IoU 是本教程的主题。
今天这篇博文的灵感来自我收到的一封电子邮件,来自罗切斯特大学的学生杰森。
Jason 有兴趣在他的最后一年项目中使用 HOG +线性 SVM 框架构建一个定制的物体检测器。他非常了解构建目标探测器所需的步骤— ,但他不确定一旦训练完成,如何评估他的探测器 的准确性。
他的教授提到他应该用 交集超过并集【IoU】的方法来进行评估,但杰森不确定如何实施。
我通过电子邮件帮助 Jason 解决了问题:
- 描述什么是并集上的交集。
- 解释为什么我们使用并集上的交集来评估对象检测器。
- 向他提供一些来自我个人库的示例 Python 代码,以在边界框上执行交集并运算。
我的电子邮件真的帮助杰森完成了他最后一年的项目,我相信他会顺利通过。
考虑到这一点,我决定把我对 Jason 的回应变成一篇真正的博文,希望对你也有帮助。
要了解如何使用交集超过并集评估指标来评估您自己的自定义对象检测器,请继续阅读。
- 【2021 年 7 月更新:添加了关于 Union 实现的替代交集的部分,包括在训练深度神经网络对象检测器时可用作损失函数的 IoU 方法。
- 更新 2022 年 4 月:增加了 TOC,并把帖子链接到一个新的交集 over Union 教程。
- 【2022 年 12 月更新:删除了数据集的链接,因为该数据集不再公开,并刷新了内容。
用于物体检测的并集上的交集
在这篇博文的剩余部分,我将解释什么是联合评估指标的交集,以及为什么我们使用它。
我还将提供 Union 上交集的 Python 实现,您可以在评估自己的自定义对象检测器时使用它。
最后,我们将查看将交集运算评估指标应用于一组地面实况和预测边界框的一些实际结果。
什么是交集大于并集?
并集上的交集是一种评估度量,用于测量特定数据集上的对象检测器的准确性。我们经常在物体检测挑战中看到这种评估指标,例如广受欢迎的 PASCAL VOC 挑战。
你通常会发现用于评估 HOG +线性 SVM 物体检测器和卷积神经网络检测器(R-CNN,fast R-CNN,YOLO 等)性能的交集。);然而,请记住,用于生成预测的实际算法并不重要。
并集上的交集仅仅是一个评估度量。任何提供预测边界框作为输出的算法都可以使用 IoU 进行评估。
更正式地说,为了将交集应用于并集来评估(任意)对象检测器,我们需要:
- 地面真实边界框(即来自测试集的手动标记边界框,其指定了我们的对象在图像中的位置)。
- 来自我们模型的预测边界框。
只要我们有这两组边界框,我们就可以在并集上应用交集。
下面,我提供了一个真实边界框与预测边界框的可视化示例:
在上图中,我们可以看到我们的对象检测器已经检测到图像中存在停车标志。
预测的包围盒以红色绘制,而地面真实(即手绘)包围盒以绿色绘制。
因此,计算并集上的交集可以通过以下方式确定:
检查这个等式,你可以看到交集除以并集仅仅是一个比率。
在分子中,我们计算在预测边界框和地面真实边界框之间的重叠区域的 。
分母是联合 的 区域,或者更简单地说,由和预测边界框和真实边界框包围的区域。**
将重叠面积除以并集面积,得到我们的最终分数— 并集上的交集。
你从哪里得到这些真实的例子?
在我们走得太远之前,您可能想知道地面真相的例子从何而来。我之前提到过这些图像是“手动标记的”,但这到底是什么意思呢?
你看,在训练自己的物体检测器(比如 HOG +线性 SVM 方法)的时候,你需要一个数据集。该数据集应(至少)分为两组:
- 一个训练集用于训练你的物体探测器。
- 一个测试装置,用于评估您的物体探测器。
您可能还有一个验证集,用于调整您的模型的超参数。
训练和测试集将包括:
- 真实的图像本身。
- 与图像中的对象相关联的边界框。边界框就是图像中物体的 (x,y)-坐标。
训练集和测试集的边界框由手工标注,因此我们称之为“地面真相”。
您的目标是获取训练图像+包围盒,构造一个对象检测器,然后在测试集上评估其性能。
超过联合分数 > 0.5 的交集通常被认为是“好的”预测。
为什么我们使用交集而不是并集?
如果你以前在职业生涯中执行过任何机器学习,特别是分类,你可能会习惯于预测类别标签,其中你的模型输出单个标签,要么是正确的要么是不正确的。
这种类型的二进制分类使得计算精度简单明了;然而,对于对象检测来说,这并不简单。
在所有现实中,极不可能我们预测的边界框的 (x,y)-坐标将会 精确地匹配(x,y)-地面真实边界框的坐标。
由于我们的模型的不同参数(图像金字塔比例、滑动窗口大小、特征提取方法等)。),预测边界框和真实边界框之间的完全和完全匹配是不现实的。
正因为如此,我们需要定义一个评估标准,让奖励预测的边界框与实际情况有很大的重叠:
在上图中,我已经包括了优、劣交集的例子。
如您所见,与地面实况边界框重叠严重的预测边界框比重叠较少的预测边界框得分更高。这使得交集/并集成为评估自定义对象检测器的优秀指标。
我们并不关心 (x,y)-坐标的精确匹配,但是我们确实想要确保我们预测的边界框尽可能地匹配——并集上的交集能够考虑到这一点。
在 Python 中实现 Union 上的交集
既然我们已经理解了什么是并上交集以及为什么我们使用它来评估对象检测模型,那么让我们继续用 Python 来实现它。
不过,在我们开始编写任何代码之前,我想提供我们将使用的五个示例图像:
这些图像是 CALTECH-101 数据集的一部分,用于图像分类和物体检测。
该数据集是公开可用的,但截至 2022 年 12 月,它不再公开。
在 PyImageSearch 大师课程 中,我演示了如何使用 HOG +线性 SVM 框架训练一个自定义对象检测器来检测图像中汽车的存在。
我从下面的自定义对象检测器中提供了真实边界框(绿色)和预测边界框(红色)的可视化效果:
给定这些边界框,我们的任务是定义联合上的交集度量,该度量可用于评估我们的预测有多“好(或坏)”。
也就是说,打开一个新文件,命名为intersection_over_union.py,让我们开始编码:
# import the necessary packages
from collections import namedtuple
import numpy as np
import cv2
# define the `Detection` object
Detection = namedtuple("Detection", ["image_path", "gt", "pred"])
我们从导入所需的 Python 包开始。然后我们定义一个Detection对象,它将存储三个属性:
image_path:驻留在磁盘上的输入图像的路径。gt:地面真实包围盒。- 从我们的模型预测的边界框。
正如我们将在这个例子的后面看到的,我已经从我们各自的五个图像中获得了预测的边界框,并将它们硬编码到这个脚本中,以保持这个例子的简短和简洁。
对于 HOG +线性 SVM 物体检测框架的完整回顾,请参考这篇博文。如果你有兴趣学习更多关于从头开始训练你自己的定制物体探测器的知识,一定要看看的 PyImageSearch 大师课程。
让我们继续定义bb_intersection_over_union函数,顾名思义,它负责计算两个边界框之间的交集:
def bb_intersection_over_union(boxA, boxB):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# compute the area of intersection rectangle
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# compute the area of both the prediction and ground-truth
# rectangles
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the interesection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
这个方法需要两个参数:boxA和boxB,它们被假定为我们的地面实况和预测边界框(这些参数被提供给bb_intersection_over_union的实际顺序并不重要)。
第 11-14 行确定了 (x,y)-相交矩形的坐标,然后我们用它来计算相交的面积(第 17 行)。
现在,interArea变量代表交集并集计算中的分子。
为了计算分母,我们首先需要导出预测边界框和真实边界框的面积(行 21 和 22 )。
然后可以在第 27 行上通过将交集面积除以两个边界框的并集面积来计算交集,注意从分母中减去交集面积(否则交集面积将被加倍计算)。
最后,将 Union score 上的交集返回给第 30 行上的调用函数。
既然我们的联合交集方法已经完成,我们需要为我们的五个示例图像定义地面实况和预测边界框坐标:
# define the list of example detections
examples = [
Detection("image_0002.jpg", [39, 63, 203, 112], [54, 66, 198, 114]),
Detection("image_0016.jpg", [49, 75, 203, 125], [42, 78, 186, 126]),
Detection("image_0075.jpg", [31, 69, 201, 125], [18, 63, 235, 135]),
Detection("image_0090.jpg", [50, 72, 197, 121], [54, 72, 198, 120]),
Detection("image_0120.jpg", [35, 51, 196, 110], [36, 60, 180, 108])]
正如我上面提到的,为了保持这个例子简短,我从我的 HOG +线性 SVM 检测器中手动获得了预测的边界框坐标。这些预测的边界框(和相应的真实边界框)然后被硬编码到这个脚本中。
关于我如何训练这个精确物体探测器的更多信息,请参考 PyImageSearch 大师课程。
我们现在准备评估我们的预测:
# loop over the example detections
for detection in examples:
# load the image
image = cv2.imread(detection.image_path)
# draw the ground-truth bounding box along with the predicted
# bounding box
cv2.rectangle(image, tuple(detection.gt[:2]),
tuple(detection.gt[2:]), (0, 255, 0), 2)
cv2.rectangle(image, tuple(detection.pred[:2]),
tuple(detection.pred[2:]), (0, 0, 255), 2)
# compute the intersection over union and display it
iou = bb_intersection_over_union(detection.gt, detection.pred)
cv2.putText(image, "IoU: {:.4f}".format(iou), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
print("{}: {:.4f}".format(detection.image_path, iou))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
在的第 41 行,我们开始循环遍历我们的每个examples(它们是Detection对象)。
对于它们中的每一个,我们在行 43 上从磁盘加载各自的image,然后绘制绿色的真实边界框(行 47 和 48 ),接着是红色的预测边界框(行 49 和 50 )。
通过传入地面实况和预测边界框,在行 53 上计算联合度量上的实际交集。
然后,我们在控制台后面的image上写交集并值。
最后,输出图像通过第 59 和 60 行显示在我们的屏幕上。
用并集上的交集将预测检测与实际情况进行比较
要查看联合度量的交集,请确保您已经使用本教程底部的 “下载” 部分下载了源代码+示例图片到这篇博客文章中。
解压缩归档文件后,执行以下命令:
$ python intersection_over_union.py
我们的第一个示例图像在联合分数上有一个交集 0.7980 ,表明两个边界框之间有明显的重叠:
下图也是如此,其交集超过联合分数 0.7899 :
请注意实际边界框(绿色)比预测边界框(红色)宽。这是因为我们的对象检测器是使用 HOG +线性 SVM 框架定义的,这要求我们指定固定大小的滑动窗口(更不用说图像金字塔比例和 HOG 参数本身)。
真实边界框自然会与预测的边界框具有稍微不同的纵横比,但是如果联合分数的交集是 > 0.5 也没关系——正如我们所看到的,这仍然是一个很好的预测。
下一个示例演示了一个稍微“不太好”的预测,其中我们的预测边界框比地面实况边界框“紧密”得多:
其原因是因为我们的 HOG +线性 SVM 检测器可能无法在图像金字塔的较低层“找到”汽车,而是在图像小得多的金字塔顶部附近发射。
以下示例是一个非常好的检测,交集超过联合分数 0.9472 :
请注意预测的边界框是如何与真实边界框几乎完美重叠的。
下面是计算并集交集的最后一个例子:
【Union 实现上的可选交集
本教程提供了 IoU 的 Python 和 NumPy 实现。但是,对于您的特定应用程序和项目,IoU 的其他实现可能更好。
例如,如果你正在使用 TensorFlow、Keras 或 PyTorch 等流行的库/框架训练深度学习模型,那么使用你的深度学习框架实现 IoU应该会提高算法的速度。
下面的列表提供了我建议的交集/并集的替代实现,包括在训练深度神经网络对象检测器时可以用作损失/度量函数的实现:
- TensorFlow 的 MeanIoU 函数,其计算对象检测结果样本的并集上的平均交集。
- TensorFlow 的 GIoULoss 损失度量,最早由 Rezatofighi 等人在 的《并集上的广义交集:包围盒回归的一个度量和一个损失 中引入,就像你训练一个神经网络使均方误差、交叉熵等最小化一样。这种方法充当插入替换损失函数,潜在地导致更高的对象检测精度。
- IoU 的 PyTorch 实现(我没有测试或使用过),但似乎对 PyTorch 社区有所帮助。
- 我们有一个很棒的使用 COCO 评估器的平均精度(mAP)教程,将带您了解如何使用交集/并集来评估 YOLO 性能。了解平均精度(mAP)的理论概念,并使用黄金标准 COCO 评估器评估 YOLOv4 检测器。
当然,您可以随时将我的 IoU Python/NumPy 实现转换成您自己的库、语言等。
黑客快乐!
总结
在这篇博文中,我讨论了用于评估对象检测器的 Union 上的交集度量。该指标可用于评估任何物体检测器,前提是(1)模型为图像中的物体生成预测的 (x,y)-坐标【即边界框】,以及(2)您拥有数据集的真实边界框。
通常,您会看到该指标用于评估 HOG +线性 SVM 和基于 CNN 的物体检测器。
要了解更多关于训练你自己的自定义对象检测器的信息,请参考这篇关于 HOG +线性 SVM 框架的博客文章,以及 PyImageSearch 大师课程 ,在那里我演示了如何从头开始实现自定义对象检测器。如果你想深入研究,可以考虑通过我们的免费课程学习计算机视觉。
最后,在你离开之前,请务必在下面的表格中输入你的电子邮件地址,以便在将来发布 PyImageSearch 博客文章时得到通知——你不会想错过它们的!
大卫·奥斯汀访谈:在 Kaggle 最受欢迎的图像分类比赛中获得第一名和 25,000 美元奖金

在今天的博文中,我采访了大卫·奥斯丁,他和他的队友王为民一起在卡格尔冰山分类挑战赛中获得了 第一名(以及 25,000 美元)。
David 和 Weimin 的获奖解决方案实际上可用于让船只在危险水域中更安全地航行,从而减少对船只和货物的损坏,最重要的是,减少事故、伤害和死亡。
根据 Kaggle 的说法,冰山图像分类挑战:
- 是他们遇到过的最受欢迎的图像分类挑战(以参赛队伍来衡量)
- 并且是的第七届最受欢迎的比赛(跨越所有挑战类型:图像、文本等。)
*比赛结束后不久,大卫给我发来了以下信息:
你好,阿德里安,我是一名 PyImageSearch 大师的成员,你所有书籍的消费者,将于 8 月参加 PyImageConf,并且总体上是一名欣赏你教学的学生。
我只是想与您分享一个成功的故事,因为我刚刚在挪威国家石油公司冰山分类器 Kaggle 竞赛中获得了 3,343 个团队中的第一名(25,000 美元第一名奖金)。
我的许多深度学习和简历知识都是通过您的培训获得的,我从您那里学到的一些具体技术也用在了我的获奖解决方案中(特别是阈值和迷你谷歌网络)。只想说声谢谢,让你知道你的影响很大。
谢谢!大卫
大卫的个人信息对我来说真的很重要,说实话,这让我有点激动。
作为一名教师和教育者,世界上没有比看到读者更好的感觉了:
- 从你的博客文章、书籍和课程中获取你所教授的东西的价值
- 用他们的知识丰富自己的生活,改善他人的生活
在今天的帖子中,我将采访大卫并讨论:
- 冰山图像分类的挑战是什么……为什么它很重要
- David 和 Weimin 在其获奖作品中使用的方法、算法和技术
- 挑战中最困难的方面是什么(以及他们是如何克服的)
- 他对任何想参加追逐赛的人的建议是
我非常为大卫和为民高兴——他们值得所有的祝贺和热烈的掌声。
和我一起接受采访,探索大卫和他的队友伟民是如何赢得 Kaggle 最受欢迎的图像分类比赛的。
大卫·奥斯汀访谈:在 Kaggle 最受欢迎的比赛中获得第一名和 25,000 美元

Figure 1: The goal of the Kaggle Iceberg Classifier challenge is to build an image classifier that classifies input regions of a satellite image as either “iceberg” or “ship” (source).
阿德里安:嗨,大卫!谢谢你同意接受这次采访。祝贺您在 Kaggle 冰山分类器更换中获得第一名,干得好!
大卫:谢谢阿德里安,很高兴与你交谈。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
大卫:在过去的两年里,我对深度学习的兴趣一直在稳步增长,因为我看到人们如何使用它来从他们处理的数据中获得令人难以置信的洞察力。我对深度学习的积极研究和实际应用都感兴趣,所以我发现参加 Kaggle 比赛是保持技能敏锐和尝试新技术的好地方。
Adrian: 你参赛前在计算机视觉和机器学习/深度学习方面的背景如何?你参加过以前的 Kaggle 比赛吗?
David: 我第一次接触机器学习可以追溯到大约 10 年前,当时我刚开始学习梯度增强树和随机森林,并将它们应用于分类类型问题。在过去的几年里,我开始更广泛地关注深度学习和计算机视觉。
不到一年前,我开始在业余时间参加 Kaggle 比赛,以此来提高我的技能,这是我的第三次图像分类比赛。

Figure 2: An example of how an iceberg looks. The goal of the Kaggle competition was to recognize such icebergs from satellite imagery (source).
阿德里安:你能告诉我更多关于冰山分类器挑战的事情吗?是什么激励你参加比赛?
当然,冰山分类挑战是一个二进制图像分类问题,参与者被要求对船只和通过卫星图像收集的冰山进行分类。在能源勘探领域,能够识别和避免漂流冰山等威胁尤为重要。
该数据集有几个有趣的方面,这使得它成为一个有趣的挑战。
首先,数据集相对较小,训练集中只有 1604 幅图像,因此从硬件角度来看,进入的障碍相当低,但使用有限的数据集的难度很高。
其次,在观看图像时,对人眼来说,许多图像看起来类似于电视屏幕上“下雪”的样子,只是一堆椒盐噪声,在视觉上根本看不清哪些图像是船只,哪些是冰山:

Figure 3: It’s extremely difficult for the human eye to accurately determine if an input region is an “iceberg” or a “ship” (source).
因此,事实上,人类很难准确预测分类,我认为这将是一个很好的测试,看看计算机视觉和深度学习能做什么。

Figure 4: David and Weimin winning solution involved using an ensemble of CNN architectures.
阿德里安:让我们来谈一点技术问题。你能告诉我们一些你在获奖作品中使用的方法、算法和技术吗?
大卫:嗯,总体方法与大多数典型的计算机视觉问题非常相似,因为我们花了相当多的时间预先理解数据。
我最喜欢的早期技术之一是使用无监督学习方法来识别数据中的自然模式,并使用该学习来确定采取什么样的深度学习方法。
在这种情况下,标准的 KNN 算法能够识别出帮助定义我们的模型架构的关键信号。从那时起,我们使用了一个非常广泛的 CNN 架构,它由 100 多个定制的 CNN 和 VGG 式架构组成,然后使用贪婪混合和两级堆叠以及其他图像功能来组合这些模型的结果。
这听起来可能是一个非常复杂的方法,但请记住,这里的目标函数是最小化对数损失误差,在这种情况下,我们只添加了模型,因为它们减少了对数损失而没有过度拟合,所以这是集合许多较弱学习者的力量的另一个很好的例子。
我们结束了第二次训练许多相同的 CNN,但只使用了我们在过程开始时从无监督学习中识别的数据子集,因为这也给了我们性能的改善。

Figure 5: The most difficult aspect of the Kaggle Iceberg challenge for David and his teammate was avoiding overfitting.
Adrian: 这次挑战对你来说最困难的方面是什么,为什么?
大卫:挑战中最困难的部分是确认我们没有过度适应。
图像分类问题的数据集规模相对较小,因此我们总是担心过度拟合可能是一个问题。出于这个原因,我们确保我们所有的模型都使用 4 重交叉验证,这增加了计算成本,但降低了过度拟合的风险。特别是当你处理像对数损失这样的无情损失函数时,你必须时刻警惕过度拟合。
阿德里安:训练你的模特花了多长时间?
David: 即使我们选择使用大量的 CNN,即使在整套模型上使用 4 重交叉验证,培训也只需要 1-2 天。没有交叉验证的单个模型在某些情况下可以训练几分钟。
阿德里安:如果让你选择你在比赛中运用的最重要的技术或技巧,你会选择什么?
David: 毫无疑问,最重要的一步是前期探索性分析,以便更好地理解数据集。
结果发现,除了图像数据之外,还有一个非常重要的信号,有助于消除数据中的大量噪声。
在我看来,任何 CV 或深度学习问题中最容易被忽视的步骤之一是理解数据并利用这些知识做出最佳设计选择所需的前期工作。
随着算法变得越来越容易获得和导入,经常会出现在没有真正理解这些算法是否适合工作,或者是否有工作应该在培训之前或之后完成以适当地处理数据的情况下,就匆忙地向问题“扔算法”的情况。

Figure 6: David used TensorFlow, Keras, and xgboost in the winning Kaggle submission.
阿德里安:你有哪些工具和库可供选择?
大卫:我个人认为 Tensorflow 和 Keras 是最有用的,所以当处理深度学习问题时,我倾向于坚持使用它们。
对于堆叠和提升,我使用 xgboost ,这也是因为熟悉和它的已证实的结果。
在这个比赛中我使用了我的dl4cv virtualenv(一个在 内部使用的 Python 虚拟环境,用 Python 进行计算机视觉的深度学习)并在其中加入了 xgboost。
阿德里安:你会给第一次想参加 Kaggle 比赛的人什么建议?
David:ka ggle 竞赛的一大优点是竞赛的社区性质。
有一个非常丰富的讨论论坛,如果参与者选择这样做,他们可以分享他们的代码。当你试图学习一般方法以及将代码应用于特定问题的方法时,这真的是非常宝贵的。
当我开始我的第一次比赛时,我花了几个小时阅读论坛和其他高质量的代码,发现这是最好的学习方法之一。
Adrian:PyImageSearch 大师课程和 用 Python 进行计算机视觉深度学习 的书是如何让你为 Kaggle 比赛做准备的?
与参加 Kaggle 竞赛非常相似,PyImageSearch Gurus 是一门边做边学的格式化课程。
对我来说,没有什么能像实际解决问题和遵循高质量的解决方案和代码一样让你为解决问题做好准备,我最欣赏 PyImageSearch 材料的一点是它通过生产级代码带你了解实际解决方案的方式。
我还认为,真正学习和理解深度学习架构的最佳方式之一是阅读一篇论文,然后尝试实现它。
这一策略在整个 ImageNet 捆绑包书中得到了实际实施,而且这一策略也可用于修改和调整架构,就像我们在本次竞赛中所做的那样。
我还从从业者捆绑包书中了解到了 MiniGoogleNet,这是我以前没有遇到过的,并且是在这次比赛中表现良好的一个模型。
Adrian: 你会向其他试图学习计算机视觉+深度学习的开发者、研究人员和学生推荐 PyImageSearch Gurus 或用 Python 进行计算机视觉的深度学习吗?
大卫:绝对是。我会向任何希望在 CV 和深度学习方面建立强大基础的人推荐它,因为你不仅要学习原理,还要学习如何使用最流行和最新的工具和软件将你的知识快速应用到现实世界的问题中。
阿德里安:接下来是什么?
大卫:嗯,我有一大堆项目要做,所以我会忙上一段时间。还有几个其他的 Kaggle 比赛,看起来真的很有趣,所以我也很有可能会参加这些比赛。
Adrian: 如果一个 PyImageSearch 的读者想聊天,和你联系的最佳地点是哪里?
大卫:联系我的最好方式是我的 LinkedIn 个人资料。你也可以在 LinkedIn 上与王为民联系。如果你想亲自聊天,我还将参加 8 月举行的 2018 年 PyImageConf。
你呢?你准备好追随大卫的脚步了吗?

你准备好开始你的计算机视觉+深度学习掌握之旅并跟随大卫·奥斯汀的脚步了吗?
David 是一名长期的 PyImageSearch 读者,他已经阅读了以下两种材料:
- PyImageSearch 大师课程 ,深入治疗计算机视觉和图像处理
- 计算机视觉深度学习用 Python ,当今最全面的计算机视觉+深度学习书籍
我不能保证你会像大卫一样赢得 Kaggle 比赛,但我可以保证这是当今掌握计算机视觉和深度学习的两个最佳资源。
引用亚马逊机器人公司高级系统工程师斯蒂芬·卡尔达拉的话:
我对您创建的[PyImageSearch Gurus]内容非常满意。我会很容易地将其评为大学“硕士项目”水平。更有条理。
和广受欢迎的《机器学习很有趣》一书的作者亚当·盖特基一起!博客系列:
我强烈推荐用 Python 抢一本《计算机视觉深度学习》。它涉及了很多细节,并有大量详细的例子。这是我迄今为止看到的唯一一本既涉及事物如何工作,又涉及如何在现实世界中实际使用它们来解决难题的书。看看吧!
试试 课程 和 书籍 吧——我会在你身边帮助你一步步走下去。
摘要
在今天的博文中,我采访了大卫·奥斯丁,他和他的队友王为民在卡格尔的冰山分类挑战赛中获得了第一名(以及 25000 美元)。
大卫和魏民的辛勤工作将有助于确保通过冰山易发水域的旅行更加安全,危险性更低。
我为大卫和伟民感到无比的高兴和骄傲。请和我一起,在这篇博文的评论区祝贺他们。*
OpenCV、计算机视觉和 scikit 异常检测简介-学习

在本教程中,您将学习如何使用 OpenCV、计算机视觉和 scikit-learn 机器学习库在图像数据集中执行异常/新奇检测。
想象一下,你刚从大学毕业,获得了计算机科学学位。你的研究重点是计算机视觉和机器学习。
你离开学校后的第一份工作是在美国国家公园部。
你的任务?
建立一个能够自动识别公园里的花卉品种的计算机视觉系统。这样的系统可以用来检测可能对公园整体生态系统有害的入侵植物物种。
你马上意识到计算机视觉可以用来识别花卉种类。
但首先你需要:
- 收集公园内各花卉品种的示例图像(即建立数据集)。
- 量化图像数据集,训练机器学习模型识别物种。
- 发现异常/异常植物物种,通过这种方式,受过训练的植物学家可以检查植物,并确定它是否对公园的环境有害。
第 1 步和第 2 步相当简单,但是第 3 步就难多了。
你应该如何训练一个机器学习模型来自动检测给定的输入图像是否在公园植物外观的“正态分布”之外?
答案在于一类特殊的机器学习算法,包括异常值检测和新奇/异常检测。
在本教程的剩余部分,您将了解这些算法之间的区别,以及如何使用它们来发现您自己的影像数据集中的异常值和异常值。
要了解如何在图像数据集中执行异常/新奇检测,继续阅读!
OpenCV、计算机视觉和 scikit 异常检测简介-学习
在本教程的第一部分,我们将讨论自然发生的标准事件和异常事件之间的区别。
我们还将讨论为什么机器学习算法很难检测到这些类型的事件。
在这里,我们将回顾本教程的示例数据集。
然后,我将向您展示如何:
- 从磁盘加载我们的输入图像。
- 量化它们。
- 训练用于在我们的量化图像上进行异常检测的机器学习模型。
- 从那里,我们将能够检测新输入图像中的异常值/异常。
我们开始吧!
什么是异常值和异常值?为什么它们很难被发现?

Figure 1: Scikit-learn’s definition of an outlier is an important concept for anomaly detection with OpenCV and computer vision (image source).
异常被定义为偏离标准、很少发生、不遵循“模式”其余部分的事件。
异常情况的例子包括:
- 由世界事件引起的股票市场的大幅下跌和上涨
- 工厂里/传送带上的次品
- 实验室中被污染的样本
如果你想一个钟形曲线,异常存在于尾部的远端。
Figure 2: Anomalies exist at either side of a bell curve. In this tutorial we will conduct anomaly detection with OpenCV, computer vision, and scikit-learn (image source).
这些事件会发生,但发生的概率非常小。
从机器学习的角度来看,这使得检测异常变得困难——根据定义,我们有许多“标准”事件的例子,很少有“异常”事件的例子。
因此,我们的数据集中有一个大规模偏斜。
当我们想要检测的异常可能只发生 1%、0.1%或 0.0001%的时候,倾向于以最佳方式处理平衡数据集的机器学习算法应该如何工作?
幸运的是,机器学习研究人员已经研究了这种类型的问题,并设计了处理这项任务的算法。
异常检测算法
Figure 3: To detect anomalies in time-series data, be on the lookout for spikes as shown. We will use scikit-learn, computer vision, and OpenCV to detect anomalies in this tutorial (image source).
异常检测算法可以分为两个子类:
- 异常值检测:我们的输入数据集包含标准事件和异常事件的例子。这些算法试图拟合标准事件最集中的训练数据区域,忽略并因此隔离异常事件。这种算法通常以无人监管的方式(即没有标签)进行训练。在应用其他机器学习技术之前,我们有时会使用这些方法来帮助清理和预处理数据集。
** 新奇检测:与包括标准和异常事件的例子的离群点检测不同,新奇检测算法在训练时间内只有标准事件数据点(即没有异常事件)。在训练过程中,我们为这些算法提供了标准事件的标记示例(监督学习)。在测试/预测时,新异检测算法必须检测输入数据点何时是异常值。*
*离群点检测是无监督学习的一种形式。在这里,我们提供了示例数据点的整个数据集,并要求算法将它们分组为内点(标准数据点)和外点(异常)。
新奇检测是监督学习的一种形式,但我们只有标准数据点的标签——由新奇检测算法来预测给定数据点在测试时是内部还是外部。
在这篇博文的剩余部分,我们将重点关注作为异常检测形式的新奇检测。
用于异常检测的隔离林
Figure 4: A technique called “Isolation Forests” based on Liu et al.’s 2012 paper is used to conduct anomaly detection with OpenCV, computer vision, and scikit-learn (image source).
我们将使用隔离森林来执行异常检测,基于刘等人 2012 年的论文,基于隔离的异常检测。
隔离林是一种集成算法,由多个决策树组成,用于将输入数据集划分为不同的内联体组。
正如上面的图 4 所示,隔离森林接受一个输入数据集(白点,然后围绕它们建立一个流形。
在测试时,隔离林可以确定输入点是否落在流形内(标准事件;绿点或高密度区域外(异常事件;红点。
回顾隔离林如何构建分区树的集合超出了本文的范围,因此请务必参考刘等人的论文以了解更多细节。
配置您的异常检测开发环境
为了跟随今天的教程,你需要一个安装了以下软件包的 Python 3 虚拟环境 :
幸运的是,这些包都是 pip 可安装的,但是有一些先决条件(包括 Python 虚拟环境)。请务必遵循以下指南,首先使用 OpenCV 设置您的虚拟环境: pip 安装 opencv
一旦 Python 3 虚拟环境准备就绪,pip 安装命令包括:
$ workon <env-name>
$ pip install numpy
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install scikit-learn
注意:根据 pip install opencv 安装指南安装virtualenv和virtualenvwrapper后,workon命令变为可用。
项目结构
确保使用教程的 “下载” 部分获取今天帖子的源代码和示例图片。在您将。您将看到以下项目结构:
$ tree --dirsfirst
.
├── examples
│ ├── coast_osun52.jpg
│ ├── forest_cdmc290.jpg
│ └── highway_a836030.jpg
├── forest
│ ├── forest_bost100.jpg
│ ├── forest_bost101.jpg
│ ├── forest_bost102.jpg
│ ├── forest_bost103.jpg
│ ├── forest_bost98.jpg
│ ├── forest_cdmc458.jpg
│ ├── forest_for119.jpg
│ ├── forest_for121.jpg
│ ├── forest_for127.jpg
│ ├── forest_for130.jpg
│ ├── forest_for136.jpg
│ ├── forest_for137.jpg
│ ├── forest_for142.jpg
│ ├── forest_for143.jpg
│ ├── forest_for146.jpg
│ └── forest_for157.jpg
├── pyimagesearch
│ ├── __init__.py
│ └── features.py
├── anomaly_detector.model
├── test_anomaly_detector.py
└── train_anomaly_detector.py
3 directories, 24 files
我们的项目由forest/图像和example/测试图像组成。我们的异常探测器将尝试确定这三个例子中的任何一个与这组森林图像相比是否是异常。
在pyimagesearch模块中有一个名为features.py的文件。这个脚本包含两个函数,负责从磁盘加载我们的图像数据集,并计算每个图像的颜色直方图特征。
我们将分两个阶段运行我们的系统— (1)培训,和(2)测试。
首先,train_anomaly_detector.py脚本计算特征并训练用于异常检测的隔离森林机器学习模型,将结果序列化为anomaly_detector.model。
然后我们将开发test_anomaly_detector.py,它接受一个示例图像并确定它是否是一个异常。
我们的示例图像数据集

Figure 5: We will use a subset of the 8Scenes dataset to detect anomalies among pictures of forests using scikit-learn, OpenCV, and computer vision.
本教程的示例数据集包括 16 幅森林图像(每一幅都显示在上面的 图 5 中)。
这些示例图像是 Oliva 和 Torralba 的论文 中的 8 个场景数据集的子集,该论文对场景的形状进行建模:空间包络 的整体表示。
我们将获取这个数据集,并在此基础上训练一个异常检测算法。
当呈现新的输入图像时,我们的异常检测算法将返回两个值之一:
- 是的,那是一片森林
-1: “不,看起来不像森林。肯定是离群值。”
因此,您可以将该模型视为“森林”与“非森林”检测器。
该模型是在森林图像上训练的,现在必须决定新的输入图像是否符合“森林流形”或者是否确实是异常/异常值。
为了评估我们的异常检测算法,我们有 3 个测试图像:

Figure 6: Three testing images are included in today’s Python + computer vision anomaly detection project.
正如你所看到的,这些图像中只有一个是森林,另外两个分别是高速公路和海滩的例子。
如果我们的异常检测管道工作正常,我们的模型应该为森林图像返回1 (inlier),为两个非森林图像返回-1。
实现我们的特征提取和数据集加载器辅助函数
Figure 7: Color histograms characterize the color distribution of an image. Color will be the basis of our anomaly detection introduction using OpenCV, computer vision, and scikit-learn.
在我们可以训练机器学习模型来检测异常和异常值之前,我们必须首先定义一个过程来量化和表征我们输入图像的内容。
为了完成这项任务,我们将使用颜色直方图。
颜色直方图是表征图像颜色分布的简单而有效的方法。
由于我们在这里的任务是描述森林和非森林图像的特征,我们可以假设森林图像比非森林图像包含更多的绿色阴影。
让我们看看如何使用 OpenCV 实现颜色直方图提取。
打开pyimagesearch模块中的features.py文件,插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import cv2
def quantify_image(image, bins=(4, 6, 3)):
# compute a 3D color histogram over the image and normalize it
hist = cv2.calcHist([image], [0, 1, 2], None, bins,
[0, 180, 0, 256, 0, 256])
hist = cv2.normalize(hist, hist).flatten()
# return the histogram
return hist
2-4 线导入我们的套餐。我们将使用我的imutils包中的paths来列出输入目录中的所有图像。OpenCV 将用于计算和归一化直方图。NumPy 用于数组操作。
既然导入已经处理好了,让我们定义一下quantify_image函数。该函数接受两个参数:
image:OpenCV 加载的图像。bins:绘制直方图时,x-轴充当我们的“仓”在这种情况下,我们的default指定了4色调箱、6饱和度箱和3值箱。这里有一个简单的例子——如果我们只使用 2 个(等间距)面元,那么我们将计算一个像素在范围【0,128】或【128,255】内的次数。然后在 y 轴上绘制合并到 x 轴值的像素数。
注:要了解包括 HSV、RGB、Lab 和灰度在内的直方图和色彩空间的更多信息,请务必参考实用 Python 和 OpenCV 和 PyImageSearch 大师。
第 8-10 行计算颜色直方图并归一化。归一化允许我们计算百分比,而不是原始频率计数,在一些图像比其他图像大或小的情况下有所帮助。
第 13 行将归一化直方图返回给调用者。
我们的下一个函数处理:
- 接受包含图像数据集的目录的路径。
- 在图像路径上循环,同时使用我们的
quantify_image方法量化它们。
现在让我们来看看这个方法:
def load_dataset(datasetPath, bins):
# grab the paths to all images in our dataset directory, then
# initialize our lists of images
imagePaths = list(paths.list_images(datasetPath))
data = []
# loop over the image paths
for imagePath in imagePaths:
# load the image and convert it to the HSV color space
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# quantify the image and update the data list
features = quantify_image(image, bins)
data.append(features)
# return our data list as a NumPy array
return np.array(data)
我们的load_dataset函数接受两个参数:
- 到我们的图像数据集的路径。
bins:颜色直方图的箱数。参考上面的解释。容器被传递给quantify_image功能。
第 18 行抓取datasetPath中的所有图像路径。
第 19 行初始化一个列表来保存我们的特性data。
从那里,线 22 开始在imagePaths上循环。在循环中,我们加载一幅图像,并将其转换到 HSV 颜色空间(第 24 行和第 25 行)。然后我们量化image,并将结果features添加到data列表中(第 28 行和第 29 行)。
最后, Line 32 将我们的data列表作为 NumPy 数组返回给调用者。
使用 scikit-learn 实施我们的异常检测培训脚本
实现了助手函数后,我们现在可以继续训练异常检测模型。
正如本教程前面提到的,我们将使用隔离森林来帮助确定异常/新奇数据点。
打开train_anomaly_detector.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.features import load_dataset
from sklearn.ensemble import IsolationForest
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output anomaly detection model")
args = vars(ap.parse_args())
2-6 号线处理我们的进口。这个脚本使用了我们定制的load_dataset函数和 scikit-learn 的隔离森林实现。我们将把生成的模型序列化为 pickle 文件。
第 8-13 行解析我们的命令行参数包括:
- 到我们的图像数据集的路径。
--model:输出异常检测模型的路径。
此时,我们已经准备好加载数据集并训练我们的隔离森林模型:
# load and quantify our image dataset
print("[INFO] preparing dataset...")
data = load_dataset(args["dataset"], bins=(3, 3, 3))
# train the anomaly detection model
print("[INFO] fitting anomaly detection model...")
model = IsolationForest(n_estimators=100, contamination=0.01,
random_state=42)
model.fit(data)
第 17 行加载并量化图像数据集。
第 21 行和第 22 行用以下参数初始化我们的IsolationForest模型:
n_estimators:集合中基本估计量(即树)的数量。contamination:数据集中离群点的比例。random_state:再现性的随机数发生器种子值。可以使用任意整数;42常用于机器学习领域,因为它与书中的一个笑话、银河系漫游指南T5 有关。
确保参考 scikit-learn 文档中隔离林的其他可选参数。
第 23 行在直方图data顶部训练异常检测器。
既然我们的模型已经定型,剩下的几行将异常检测器序列化到磁盘上的 pickle 文件中:
# serialize the anomaly detection model to disk
f = open(args["model"], "wb")
f.write(pickle.dumps(model))
f.close()
训练我们的异常探测器
既然我们已经实现了我们的异常检测训练脚本,让我们把它投入工作。
首先确保您已经使用了本教程的 【下载】 部分来下载源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python train_anomaly_detector.py --dataset forest --model anomaly_detector.model
[INFO] preparing dataset...
[INFO] fitting anomaly detection model...
要验证异常检测器是否已序列化到磁盘,请检查工作项目目录的内容:
$ ls *.model
anomaly_detector.model
创建异常检测器测试脚本
在这一点上,我们已经训练了我们的异常检测模型— ,但是我们如何使用实际的来检测新数据点中的异常?
要回答这个问题,让我们看看test_anomaly_detector.py脚本。
在高层次上,这个脚本:
- 加载上一步训练的异常检测模型。
- 加载、预处理和量化查询图像。
- 使用我们的异常检测器进行预测,以确定查询图像是内部图像还是外部图像(即异常)。
- 显示结果。
继续打开test_anomaly_detector.py并插入以下代码:
# import the necessary packages
from pyimagesearch.features import quantify_image
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained anomaly detection model")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
2-5 号线办理我们的进口业务。注意,我们导入自定义的quantify_image函数来计算输入图像的特征。我们还导入pickle来加载我们的异常检测模型。OpenCV 将用于加载、预处理和显示图像。
我们的脚本需要两个命令行参数:
--model:驻留在磁盘上的序列化异常检测器。--image:输入图像的路径(即我们的查询)。
让我们加载我们的异常检测器并量化我们的输入图像:
# load the anomaly detection model
print("[INFO] loading anomaly detection model...")
model = pickle.loads(open(args["model"], "rb").read())
# load the input image, convert it to the HSV color space, and
# quantify the image in the *same manner* as we did during training
image = cv2.imread(args["image"])
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
features = quantify_image(hsv, bins=(3, 3, 3))
17 号线装载我们预先训练的异常探测器。
第 21-23 行加载、预处理和量化我们的输入image。我们的预处理步骤必须与我们的训练脚本相同(即从 BGR 转换到 HSV 色彩空间)。
此时,我们准备好进行异常预测并显示结果:
# use the anomaly detector model and extracted features to determine
# if the example image is an anomaly or not
preds = model.predict([features])[0]
label = "anomaly" if preds == -1 else "normal"
color = (0, 0, 255) if preds == -1 else (0, 255, 0)
# draw the predicted label text on the original image
cv2.putText(image, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, color, 2)
# display the image
cv2.imshow("Output", image)
cv2.waitKey(0)
第 27 行对输入图像features进行预测。我们的异常检测模型将为“正常”数据点返回1,为“异常”数据点返回-1。
第 28 行给我们的预测分配一个"anomaly"或"normal"标签。
第 32-37 行然后在查询图像上标注label并显示在屏幕上,直到按下任何键。
使用计算机视觉和 scikit-learn 检测图像数据集中的异常
要查看我们的异常检测模型,请确保您已使用本教程的 【下载】 部分下载源代码、示例图像数据集和预训练模型。
在那里,您可以使用以下命令来测试异常检测器:
$ python test_anomaly_detector.py --model anomaly_detector.model \
--image examples/forest_cdmc290.jpg
[INFO] loading anomaly detection model...

Figure 8: This image is clearly not an anomaly as it is a green forest. Our intro to anomaly detection method with computer vision and Python has passed the first test.
这里你可以看到我们的异常检测器已经正确地将森林标记为内层。
现在让我们来看看这个模型如何处理一幅公路的图像,它当然不是森林:
$ python test_anomaly_detector.py --model anomaly_detector.model \
--image examples/highway_a836030.jpg
[INFO] loading anomaly detection model...

Figure 9: A highway is an anomaly compared to our set of forest images and has been marked as such in the top-left corner. This tutorial presents an intro to anomaly detection with OpenCV, computer vision, and scikit-learn.
我们的异常检测器正确地将该图像标记为异常值/异常值。
作为最后的测试,让我们向异常探测器提供一个海滩/海岸的图像:
$ python test_anomaly_detector.py --model anomaly_detector.model \
--image examples/coast_osun52.jpg
[INFO] loading anomaly detection model...
Figure 10: A coastal landscape is marked as an anomaly against a set of forest images using Python, OpenCV, scikit-learn, and computer vision anomaly detection techniques.
我们的异常检测器再次正确地将图像识别为异常值/异常。
摘要
在本教程中,您学习了如何使用计算机视觉和 scikit-learn 机器学习库在图像数据集中执行异常和异常值检测。
为了执行异常检测,我们:
- 收集了森林图像的示例图像数据集。
- 使用颜色直方图和 OpenCV 库量化图像数据集。
- 根据我们的量化图像训练了一个隔离森林。
- 使用隔离林检测图像异常值和异常。
除了隔离森林,您还应该研究单类支持向量机、椭圆包络和局部异常因子算法,因为它们也可以用于异常值/异常检测。
但是深度学习呢?
深度学习也可以用来执行异常检测吗?
我将在以后的教程中回答这个问题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
生成对抗网络简介
原文:https://pyimagesearch.com/2021/09/13/intro-to-generative-adversarial-networks-gans/
这篇文章涵盖了高层次的生成对抗网络(GAN)的直觉,各种 GAN 变体,以及解决现实世界问题的应用。
这是 GAN 教程系列的第一篇文章:
- 生成对抗网络(GANs)简介(本帖)
- 入门:DCGAN for Fashion-MNIST
- GAN 训练挑战:针对彩色图像的 DCGAN
【GANs 如何工作
GANs 是一种生成模型,它观察许多样本分布,生成更多相同分布的样本。其他生成模型包括变分自动编码器()和自回归模型。
氮化镓架构
在基本的 GAN 架构中有两个网络:发生器模型和鉴别器模型。GANs 得名于单词“对抗性的”,因为这两个网络同时接受训练并相互竞争,就像在国际象棋这样的零和游戏中一样。
生成器模型生成新图像。生成器的目标是生成看起来如此真实的图像,以至于骗过鉴别器。在用于图像合成的最简单 GAN 架构中,输入通常是随机噪声,输出是生成的图像。
鉴别器只是一个你应该已经熟悉的二值图像分类器。它的工作是分类一幅图像是真是假。
注: 在更复杂的 GANs 中,我们可以用图像或文本作为鉴别器的条件,用于图像到图像的翻译或文本到图像的生成。
将所有这些放在一起,下面是一个基本的 GAN 架构的样子:生成器生成假图像;我们将真实图像(训练数据集)和伪图像分批次输入鉴别器。鉴别器然后判断一幅图像是真的还是假的。
训练甘斯
极大极小游戏:G 对 D
大多数深度学习模型(例如,图像分类)都基于优化:找到成本函数的低值。gan 是不同的,因为两个网络:生成器和鉴别器,每个都有自己的成本和相反的目标:
- 生成器试图欺骗鉴别者,让他们认为假图像是真的
- 鉴别器试图正确地分类真实和伪造的图像
下面的最小最大游戏数学函数说明了训练中的这种对抗性动态。如果你不理解数学,不要太担心,我会在未来的 DCGAN 帖子中对 G 损失和 D 损失进行编码时进行更详细的解释。
发生器和鉴别器在训练期间都随着时间而改进。生成器在产生类似训练数据的图像方面变得越来越好,而鉴别器在区分真假图像方面变得越来越好。
训练 GANs 是为了在游戏中找到一个平衡当:
- 生成器生成的数据看起来几乎与训练数据相同。
- 鉴别器不再能够区分伪图像和真实图像。
艺术家与批评家
模仿杰作是学习艺术的一个好方法——“艺术家如何在世界知名的博物馆里临摹杰作”作为一个模仿杰作的人类艺术家,我会找到我喜欢的艺术品作为灵感,并尽可能多地复制它:轮廓、颜色、构图和笔触,等等。然后一位评论家看了看复制品,告诉我它是否像真正的杰作。
GANs 培训与此过程类似。我们可以把生成者想象成艺术家,把鉴别者想象成批评家。请注意人类艺术家和机器(GANs)艺术家之间的类比差异:生成器无法访问或看到它试图复制的杰作。相反,它只依靠鉴别器的反馈来改善它生成的图像。
评估指标
好的 GAN 模型应该具有好的图像质量——例如,不模糊并且类似于训练图像;以及多样性:生成了各种各样的图像,这些图像近似于训练数据集的分布。
**要评估 GAN 模型,您可以在训练期间直观地检查生成的图像,或者通过生成器模型进行推断。如果您想对您的 GANs 进行定量评估,这里有两个流行的评估指标:
- Inception Score,捕获生成图像的 质量 和 多样性
- 弗雷歇初始距离比较真实图像和虚假图像,而不仅仅是孤立地评估生成的图像
GAN 变体
自 Ian Goodfellow 等人在 2014 年发表最初的 GANs 论文以来,出现了许多 GAN 变体。它们倾向于相互建立,要么解决特定的培训问题,要么创建新的 GANs 架构,以便更好地控制 GANs 或获得更好的图像。
以下是一些具有突破性的变体,为未来 GAN 的发展奠定了基础。这绝不是所有 GAN 变体的完整列表。
DCGAN (深度卷积生成对抗网络的无监督表示学习)是第一个在其网络架构中使用卷积神经网络(CNN)的 GAN 提案。今天的大多数 GAN 变体多少都是基于 DCGAN 的。因此,DCGAN 很可能是你的第一个 GAN 教程,学习 GAN 的“Hello-World”。
WGAN(wasser stein GAN)和 WGAN-GP (被创建来解决 GAN 训练挑战,例如模式崩溃——当生成器重复产生相同的图像或(训练图像的)一个小的子集。WGAN-GP 通过使用梯度惩罚而不是训练稳定性的权重削减来改进 WGAN。
cGAN (条件生成对抗网)首先引入了基于条件生成图像的概念,条件可以是图像类标签、图像或文本,如在更复杂的 GANs 中。 Pix2Pix 和 CycleGAN 都是条件 GAN,使用图像作为图像到图像转换的条件。
pix 2 pixhd利用条件 GANs 进行高分辨率图像合成和语义操纵】理清多种输入条件的影响,如论文示例中所述:为服装设计控制生成的服装图像的颜色、纹理和形状。此外,它还可以生成逼真的 2k 高分辨率图像。
****萨根 (自我注意生成对抗网络)提高图像合成质量:通过将自我注意模块(来自 NLP 模型的概念)应用于 CNN,使用来自所有特征位置的线索生成细节。谷歌 DeepMind 扩大了 SAGAN 的规模,以制造 BigGAN。
BigGAN (高保真自然图像合成的大规模 GAN 训练)可以创建高分辨率和高保真的图像。
ProGAN、StyleGAN 和 StyleGAN2 都能创建高分辨率图像。
ProGAN (为提高质量、稳定性和变化性而进行的 GANs 渐进增长)使网络渐进增长。
NVIDIA Research 推出的 StyleGAN (一种基于风格的生成式对抗网络生成器架构),使用带有自适应实例规范化(AdaIN)的 ProGAN plus 图像风格转移,能够控制生成图像的风格。
【StyleGAN 2】(StyleGAN 的图像质量分析与改进)在原始 StyleGAN 的基础上,在归一化、渐进生长和正则化技术等方面进行了多项改进。
氮化镓应用
gan 用途广泛,可用于多种应用。
图像合成
图像合成可能很有趣,并提供实际用途,如机器学习(ML)培训中的图像增强或帮助创建艺术品和设计资产。
GANs 可以用来创造在之前从未存在过的图像,这也许是 GANs 最出名的地方。他们可以创造看不见的新面孔,猫的形象和艺术品,等等。我在下面附上了几张高保真图片,它们是我从 StyleGAN2 支持的网站上生成的。去这些链接,自己实验,看看你从实验中得到了什么图像。
Zalando Research 使用 GANs 生成基于颜色、形状和纹理的时装设计(解开 GANs 中的多个条件输入)。
脸书研究公司的 Fashion++超越了创造时尚的范畴,提出了改变时尚的建议:“什么是时尚?”
GANs 还可以帮助训练强化剂。比如英伟达的 GameGAN 模拟游戏环境。
图像到图像的翻译
图像到图像转换是一项计算机视觉任务,它将输入图像转换到另一个领域(例如,颜色或风格),同时保留原始图像内容。这也许是在艺术和设计中使用 GANs 的最重要的任务之一。
Pix2Pix (使用条件对抗网络的图像到图像翻译)是一个条件 GAN,它可能是最著名的图像到图像翻译 GAN。然而,Pix2Pix 的一个主要缺点是它需要成对的训练图像数据集。
CycleGAN 基于 Pix2Pix 构建,只需要不成对的图像,在现实世界中更容易获得。它可以把苹果的图像转换成橘子,把白天转换成黑夜,把马转换成斑马……好的。这些可能不是真实世界的用例;从那时起,艺术和设计领域出现了许多其他的图像到图像的 GANs。
现在你可以把自己的自拍翻译成漫画、绘画、漫画,或者任何你能想象到的其他风格。例如,我可以使用白盒卡通将我的自拍变成卡通版本:
彩色化不仅可以应用于黑白照片,还可以应用于艺术作品或设计资产。在艺术品制作或 UI/UX 设计过程中,我们从轮廓开始,然后着色。自动上色有助于为艺术家和设计师提供灵感。
文本到图像
我们已经看到了 GANs 的很多图像到图像的翻译例子。我们还可以使用单词作为条件来生成图像,这比使用类别标签作为条件要灵活和直观得多。
近年来,自然语言处理和计算机视觉的结合已经成为一个热门的研究领域。这里有几个例子: StyleCLIP 和驯服高分辨率图像合成的变形金刚。
超越影像
GANs 不仅可以用于图像,还可以用于音乐和视频。比如 Magenta 项目的 GANSynth 会做音乐。这里有一个有趣的视频动作转移的例子,叫做“现在每个人都跳舞”( YouTube | Paper )。我一直喜欢看这个迷人的视频,专业舞者的舞步被转移到业余舞者身上。
https://www.youtube.com/embed/PCBTZh41Ris?feature=oembed******
PyTorch 简介:使用 PyTorch 训练您的第一个神经网络
在本教程中,您将学习如何使用 PyTorch 深度学习库来训练您的第一个神经网络。
本教程是 PyTorch 深度学习基础知识五部分系列的第二部分:
- py torch 是什么?
- PyTorch 简介:使用 PyTorch 训练你的第一个神经网络(今天的教程)
- PyTorch:训练你的第一个卷积神经网络(下周教程)
- 使用预训练网络的 PyTorch 图像分类
- 使用预训练网络的 PyTorch 对象检测
本指南结束时,您将学会:
- 如何用 PyTorch 定义一个基本的神经网络架构
- 如何定义你的损失函数和优化器
- 如何正确地调零你的梯度,执行反向传播,并更新你的模型参数 —大多数刚接触 PyTorch 的深度学习实践者都会在这一步犯错误
要学习如何用 PyTorch 训练你的第一个神经网络, 继续阅读。
PyTorch 简介:使用 py torch 训练你的第一个神经网络
在本指南中,您将熟悉 PyTorch 中的常见程序,包括:
- 定义您的神经网络架构
- 初始化优化器和损失函数
- 循环你的训练次数
- 在每个时期内循环数据批次
- 对当前一批数据进行预测和计算损失
- 归零你的梯度
- 执行反向传播
- 告诉优化器更新网络的梯度
- 告诉 PyTorch 用 GPU 训练你的网络(当然,如果你的机器上有 GPU 的话)
我们将首先回顾我们的项目目录结构,然后配置我们的开发环境。
从这里,我们将实现两个 Python 脚本:
- 第一个脚本将是我们简单的前馈神经网络架构,用 Python 和 PyTorch 库实现
- 然后,第二个脚本将加载我们的示例数据集,并演示如何训练我们刚刚使用 PyTorch 实现的网络架构
随着我们的两个 Python 脚本的实现,我们将继续训练我们的网络。我们将讨论我们的结果来结束本教程。
我们开始吧!
配置您的开发环境
要遵循本指南,您需要在系统上安装 PyTorch 深度学习库和 scikit-machine 学习包。
幸运的是,PyTorch 和 scikit-learn 都非常容易使用 pip 安装:
$ pip install torch torchvision
$ pip install scikit-image
如果您需要帮助配置 PyTorch 的开发环境,我强烈推荐您 阅读 PyTorch 文档——py torch 的文档非常全面,可以让您快速上手并运行。
**### 在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
要跟随本教程,请务必访问本指南的 “下载” 部分以检索源代码。
然后,您将看到下面的目录结构。
$ tree . --dirsfirst
.
├── pyimagesearch
│ └── mlp.py
└── train.py
1 directory, 2 files
文件将存储我们的基本多层感知器(MLP)的实现。
然后我们将实现train.py,它将用于在一个示例数据集上训练我们的 MLP。
用 PyTorch 实现我们的神经网络
您现在已经准备好用 PyTorch 实现您的第一个神经网络了!
这个网络是一个非常简单的前馈神经网络,称为多层感知器(MLP) (意味着它有一个或多个隐藏层)。在下周的教程中,您将学习如何构建更高级的神经网络架构。
要开始构建我们的 PyTorch 神经网络,打开项目目录结构的pyimagesearch模块中的mlp.py文件,让我们开始工作:
# import the necessary packages
from collections import OrderedDict
import torch.nn as nn
def get_training_model(inFeatures=4, hiddenDim=8, nbClasses=3):
# construct a shallow, sequential neural network
mlpModel = nn.Sequential(OrderedDict([
("hidden_layer_1", nn.Linear(inFeatures, hiddenDim)),
("activation_1", nn.ReLU()),
("output_layer", nn.Linear(hiddenDim, nbClasses))
]))
# return the sequential model
return mlpModel
第 2 行和第 3 行导入我们需要的 Python 包:
OrderedDict:一个字典对象,记住对象被添加的顺序——我们使用这个有序字典为网络中的每一层提供人类可读的名称- PyTorch 的神经网络实现
然后我们定义了接受三个参数的get_training_model函数( Line 5 ):
- 神经网络的输入节点数
- 网络隐藏层中的节点数
- 输出节点的数量(即输出预测的维度)
根据提供的默认值,您可以看到我们正在构建一个 4-8-3 神经网络,这意味着输入层有 4 个节点,隐藏层有 8 个节点,神经网络的输出将由 3 个值组成。
然后,通过首先初始化一个nn.Sequential对象(非常类似于 Keras/TensorFlow 的Sequential类),在第 7-11 行上构建实际的神经网络架构。
在Sequential类中,我们构建了一个OrderedDict,其中字典中的每个条目都包含两个值:
- 一个包含人类可读的层名称的字符串(当使用 PyTorch 调试神经网络架构时,这个名称非常有用)
- PyTorch 层定义本身
Linear类是我们的全连接层定义,这意味着该层中的每个输入连接到每个输出。Linear类接受两个必需的参数:
- 层的输入的数量
- 输出的数量
在线 8 上,我们定义了hidden_layer_1,它由一个接受inFeatures (4)输入然后产生hiddenDim (8)输出的全连接层组成。
从那里,我们应用一个 ReLU 激活函数(第 9 行),接着是另一个Linear层,作为我们的输出(第 10 行)。
注意,第二个Linear定义包含与之前的 Linear层输出相同的数量的输入——这不是偶然的!前一层的输出尺寸必须匹配下一层的输入尺寸,否则 PyTorch 将出错(然后您将有一个相当繁琐的任务,自己调试层尺寸)。
PyTorch 在这方面没有宽容(相对于 Keras/TensorFlow),所以在指定你的图层尺寸时要格外小心。
然后,将生成的 PyTorch 神经网络返回给调用函数。
创建我们的 PyTorch 培训脚本
随着我们的神经网络架构的实现,我们可以继续使用 PyTorch 来训练模型。
为了完成这项任务,我们需要实施一个培训脚本,该脚本:
- 创建我们的神经网络架构的一个实例
- 构建我们的数据集
- 确定我们是否在 GPU 上训练我们的模型
- 定义一个训练循环(我们脚本中最难的部分)
打开train.py,让我们开始吧:
# import the necessary packages
from pyimagesearch import mlp
from torch.optim import SGD
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
import torch.nn as nn
import torch
第 2-7 行导入我们需要的 Python 包,包括:
- 我们对多层感知器架构的定义,在 PyTorch 中实现
SGD:我们将用来训练我们的模型的随机梯度下降优化器make_blobs:建立示例数据的合成数据集train_test_split:将我们的数据集分成训练和测试部分nn: PyTorch 的神经网络功能torch:基地 PyTorch 图书馆
当训练一个神经网络时,我们通过批数据来完成(正如你之前所学的)。下面的函数next_batch为我们的训练循环产生这样的批次:
def next_batch(inputs, targets, batchSize):
# loop over the dataset
for i in range(0, inputs.shape[0], batchSize):
# yield a tuple of the current batched data and labels
yield (inputs[i:i + batchSize], targets[i:i + batchSize])
next_batch函数接受三个参数:
inputs:我们对神经网络的输入数据targets:我们的目标输出值(即,我们希望我们的神经网络准确预测的值)batchSize:数据批量的大小
然后我们在batchSize块中循环输入数据(第 11 行),并将它们交给调用函数(第 13 行)。
接下来,我们要处理一些重要的初始化:
# specify our batch size, number of epochs, and learning rate
BATCH_SIZE = 64
EPOCHS = 10
LR = 1e-2
# determine the device we will be using for training
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print("[INFO] training using {}...".format(DEVICE))
当使用 PyTorch 训练我们的神经网络时,我们将使用 64 的批量大小,训练 10 个时期,并使用 1e-2 的学习速率(第 16-18 行)。
我们将我们的训练设备(CPU 或 GPU)设置在第 21 行。GPU 当然会加快训练速度,但是在这个例子中不是必需的。
接下来,我们需要一个示例数据集来训练我们的神经网络。在本系列的下一篇教程中,我们将学习如何从磁盘加载图像并对图像数据训练神经网络,但现在,让我们使用 scikit-learn 的 make_blobs 函数为我们创建一个合成数据集:
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
第 27 行和第 28 行构建我们的数据集,包括:
- 三级标签(
centers=3) - 神经网络的四个总特征/输入(
n_features=4) - 总共 1000 个数据点(
n_samples=1000)
从本质上来说,make_blobs函数正在生成聚集数据点的高斯斑点。对于 2D 数据,make_blobs函数将创建如下所示的数据:
注意这里有三组数据。我们在做同样的事情,但是我们有四维而不是二维(这意味着我们不容易想象它)。
一旦我们的数据生成,我们应用train_test_split函数(第 32 行和第 33 行)来创建我们的训练分割,85%用于训练,15%用于评估。
从那里,训练和测试数据从 NumPy 数组转换为 PyTorch 张量,然后转换为浮点数据类型(第 34-37 行)。
现在让我们实例化我们的 PyTorch 神经网络架构:
# initialize our model and display its architecture
mlp = mlp.get_training_model().to(DEVICE)
print(mlp)
# initialize optimizer and loss function
opt = SGD(mlp.parameters(), lr=LR)
lossFunc = nn.CrossEntropyLoss()
第 40 行初始化我们的 MLP,并将其推送到我们用于训练的任何东西DEVICE(CPU 或 GPU)。
第 44 行定义了我们的 SGD 优化器,它接受两个参数:
- 通过简单调用
mlp.parameters()获得的 MLP 模型参数 - 学习率
最后,我们初始化我们的分类交叉熵损失函数,这是使用 > 2 类执行分类时使用的标准损失方法。
我们现在到达最重要的代码块,训练循环。与 Keras/TensorFlow 允许你简单地调用model.fit来训练你的模型不同,PyTorch 要求你手工实现你的训练循环。
手动实现训练循环有好处也有坏处。
一方面,你可以对训练过程进行完全的控制,这使得实现定制训练循环变得更加容易。
但另一方面,手工实现训练循环需要更多的代码,最糟糕的是,这更容易搬起石头砸自己的脚(这对初露头角的深度学习实践者来说尤其如此)。
我的建议:你会想要多次阅读对以下代码块*的解释,以便你理解训练循环的复杂性。您将 尤其是 想要密切关注我们如何将梯度归零,执行反向传播,然后更新模型参数— 如果不按照正确的顺序执行,将会导致错误的结果!*
*让我们回顾一下我们的培训循环:
# create a template to summarize current training progress
trainTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
# loop through the epochs
for epoch in range(0, EPOCHS):
# initialize tracker variables and set our model to trainable
print("[INFO] epoch: {}...".format(epoch + 1))
trainLoss = 0
trainAcc = 0
samples = 0
mlp.train()
# loop over the current batch of data
for (batchX, batchY) in next_batch(trainX, trainY, BATCH_SIZE):
# flash data to the current device, run it through our
# model, and calculate loss
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# zero the gradients accumulated from the previous steps,
# perform backpropagation, and update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# update training loss, accuracy, and the number of samples
# visited
trainLoss += loss.item() * batchY.size(0)
trainAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current training batch
trainTemplate = "epoch: {} train loss: {:.3f} train accuracy: {:.3f}"
print(trainTemplate.format(epoch + 1, (trainLoss / samples),
(trainAcc / samples)))
第 48 行初始化trainTemplate,这是一个字符串,允许我们方便地显示纪元编号,以及每一步的损失和精度。
然后我们在第 51 行上循环我们想要的训练时期数。紧接着在这个for循环里面我们:
- 显示纪元编号,这对调试很有用(行 53 )
- 初始化我们的训练损失和精确度(第 54 行和第 55 行)
- 初始化训练循环当前迭代中使用的数据点总数(行 56 )
- 将 PyTorch 模型置于训练模式(第 57 行)
调用 PyTorch 模型的train()方法需要在反向传播过程中更新模型参数。
在我们的下一个代码块中,您将看到我们将模型置于eval()模式,这样我们就可以在测试集上评估损失和准确性。如果我们忘记在下一个训练循环的顶部调用train(),那么我们的模型参数将不会被更新。
外部的for循环(第 51 行)在我们的历元数上循环。第 60 行然后开始一个内部for循环,遍历训练集中的每一批。几乎你用 PyTorch 编写的每一个训练程序都将包含一个外循环(在一定数量的时期内)和一个内循环(在数据批次内)。
在内部循环(即批处理循环)中,我们继续:
- 将
batchX和batchY数据移动到我们的 CPU 或 GPU(取决于我们的DEVICE) - 通过神经系统传递
batchX数据,并对其进行预测 - 使用我们的损失函数,通过将输出
predictions与我们的地面实况类标签进行比较来计算我们的损失
现在我们已经有了loss,我们可以更新我们的模型参数了— 这是 PyTorch 训练程序中最重要的一步,也是大多数初学者经常出错的一步。
为了更新我们模型的参数,我们必须按照指定的的确切顺序调用行 69-71 :
opt.zero_grad():将模型前一批次/步骤累积的梯度归零loss.backward():执行反向传播opt.step():基于反向传播的结果更新我们的神经网络中的权重
再次强调,你 必须 应用归零渐变,执行一个向后的过程,然后按照我已经指出的 的确切顺序 更新模型参数。
正如我提到的,PyTorch 让你对你的训练循环有很多的控制……但它也让很容易搬起石头砸自己的脚。每一个深度学习实践者,无论是深度学习领域的新手还是经验丰富的专家,都曾经搞砸过这些步骤。
最常见的错误是忘记将梯度归零。如果您不将梯度归零,那么您将在多个批次和多个时期累积梯度。这将打乱你的反向传播,并导致错误的体重更新。
说真的,别把这些步骤搞砸了。把它们写在便利贴上,如果需要的话,可以把它们放在你的显示器上。
在我们将权重更新到我们的模型后,我们在第 75-77 行上计算我们的训练损失、训练精度和检查的样本数量(即,批中数据点的数量)。
然后我们应用我们的trainTemplate来显示我们的纪元编号、训练损失和训练精度。请注意我们如何将损失和准确度除以批次中的样本总数,以获得平均值。
此时,我们已经在一个时期的所有数据点上训练了我们的 PyTorch 模型——现在我们需要在我们的测试集上评估它:
# initialize tracker variables for testing, then set our model to
# evaluation mode
testLoss = 0
testAcc = 0
samples = 0
mlp.eval()
# initialize a no-gradient context
with torch.no_grad():
# loop over the current batch of test data
for (batchX, batchY) in next_batch(testX, testY, BATCH_SIZE):
# flash the data to the current device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# run data through our model and calculate loss
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current test batch
testTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
print(testTemplate.format(epoch + 1, (testLoss / samples),
(testAcc / samples)))
print("")
类似于我们如何初始化我们的训练损失、训练精度和一批中的样本数量,我们在第 86-88 行对我们的测试集做同样的事情。这里,我们初始化变量来存储我们的测试损失、测试精度和测试集中的样本数。
我们还将我们的模型放入第 89 行的eval()模型中。我们被要求在我们需要计算测试或验证集的损失/精确度时,将我们的模型置于评估模式。
但是eval()模式实际上做什么呢? 您将评估模式视为关闭特定图层功能的开关,例如停止应用丢弃,或允许应用批量归一化的累积状态。
其次,你通常将eval()与torch.no_grad()上下文结合使用,意味着在评估模式下关闭(第 92 行)。
从那里,我们循环测试集中的所有批次(第 94 行),类似于我们在前面的代码块中循环训练批次的方式。
对于每一批(行 96 ),我们使用我们的模型进行预测,然后计算损耗(行 99 和 100 )。
然后我们更新我们的testLoss、testAcc和数量samples ( 行 104-106 )。
最后,我们在我们的终端(行 109-112 )上显示我们的纪元编号、测试损失和测试精度。
总的来说,我们训练循环的评估部分是 与训练部分非常相似的 ,没有微小的 但是非常显著的 变化:
- 我们使用
eval()将模型置于评估模式 - 我们使用
torch.no_grad()上下文来确保不执行毕业计算
从那里,我们可以使用我们的模型进行预测,并计算测试集的准确性/损失。
PyTorch 培训结果
我们现在准备用 PyTorch 训练我们的神经网络!
请务必访问本教程的 “下载” 部分来检索源代码。
要启动 PyTorch 培训流程,只需执行train.py脚本:
$ python train.py
[INFO] training on cuda...
[INFO] preparing data...
Sequential(
(hidden_layer_1): Linear(in_features=4, out_features=8, bias=True)
(activation_1): ReLU()
(output_layer): Linear(in_features=8, out_features=3, bias=True)
)
[INFO] training in epoch: 1...
epoch: 1 train loss: 0.971 train accuracy: 0.580
epoch: 1 test loss: 0.737 test accuracy: 0.827
[INFO] training in epoch: 2...
epoch: 2 train loss: 0.644 train accuracy: 0.861
epoch: 2 test loss: 0.590 test accuracy: 0.893
[INFO] training in epoch: 3...
epoch: 3 train loss: 0.511 train accuracy: 0.916
epoch: 3 test loss: 0.495 test accuracy: 0.900
[INFO] training in epoch: 4...
epoch: 4 train loss: 0.425 train accuracy: 0.941
epoch: 4 test loss: 0.423 test accuracy: 0.933
[INFO] training in epoch: 5...
epoch: 5 train loss: 0.359 train accuracy: 0.961
epoch: 5 test loss: 0.364 test accuracy: 0.953
[INFO] training in epoch: 6...
epoch: 6 train loss: 0.302 train accuracy: 0.975
epoch: 6 test loss: 0.310 test accuracy: 0.960
[INFO] training in epoch: 7...
epoch: 7 train loss: 0.252 train accuracy: 0.984
epoch: 7 test loss: 0.259 test accuracy: 0.967
[INFO] training in epoch: 8...
epoch: 8 train loss: 0.209 train accuracy: 0.987
epoch: 8 test loss: 0.215 test accuracy: 0.980
[INFO] training in epoch: 9...
epoch: 9 train loss: 0.174 train accuracy: 0.988
epoch: 9 test loss: 0.180 test accuracy: 0.980
[INFO] training in epoch: 10...
epoch: 10 train loss: 0.147 train accuracy: 0.991
epoch: 10 test loss: 0.153 test accuracy: 0.980
我们的前几行输出显示了简单的 4-8-3 MLP 架构,这意味着有四个输入到神经网络,一个隐藏层有八个节点,最后一个输出层有三个节点。
然后我们训练我们的网络总共十个纪元。在训练过程结束时,我们在训练集上获得了 99.1%的准确率,在测试集上获得了 98%的准确率。
因此,我们可以得出结论,我们的神经网络在做出准确预测方面做得很好。
恭喜你用 PyTorch 训练了你的第一个神经网络!
如何在我自己的自定义数据集上训练 PyTorch 模型?
本教程向您展示了如何在 scikit-learn 的make_blobs函数生成的示例数据集上训练 PyTorch 神经网络。
虽然这是学习 PyTorch 基础知识的一个很好的例子,但是从真实场景的角度来看,它并不十分有趣。
下周,您将学习如何在手写字符数据集上训练 PyTorch 模型,它有许多实际应用,包括手写识别、OCR、等等!
敬请关注下周的教程,了解更多关于 PyTorch 和图像分类的知识。
总结
在本教程中,您学习了如何使用 PyTorch 深度学习库训练您的第一个神经网络。这个例子很简单,但是展示了 PyTorch 框架的基本原理。
我认为 PyTorch 库的深度学习实践者最大的错误是忘记和/或混淆了以下步骤:
- 将先前步骤的梯度归零(
opt.zero_grad()) - 执行反向传播(
loss.backward()) - 更新模型参数(
opt.step())
不按照这个顺序执行这些步骤*在使用 PyTorch 时肯定会搬起石头砸自己的脚,更糟糕的是,如果你混淆了这些步骤,PyTorch 不会报错, 所以你可能甚至不知道自己打中了自己!*
PyTorch 库超级强大,*但是你需要习惯这样一个事实:用 PyTorch 训练神经网络就像卸下你自行车的训练轮——如果你混淆了重要的步骤,没有安全网可以抓住你(不像 Keras/TensorFlow,它允许你将整个训练过程封装到一个单独的model.fit调用中)。
这并不是说 Keras/TensorFlow 比 PyTorch“更好”,这只是你需要知道的两个深度学习库之间的差异。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
PyTorch 分布式培训简介
原文:https://pyimagesearch.com/2021/10/18/introduction-to-distributed-training-in-pytorch/
在本教程中,您将学习使用 PyTorch 进行分布式培训的基础知识。
这是计算机视觉和深度学习从业者中级 PyTorch 技术 3 部分教程的最后一课:
- py torch中的图像数据加载器(第一课)
- py torch:Transfer 学习与图像分类 (上周教程)
- py torch 分布式培训简介(今天的课程)
当我第一次了解 PyTorch 时,我对它相当冷漠。作为一个在深度学习期间一直使用 TensorFlow 的人,我还没有准备好离开 TensorFlow 创造的舒适区,尝试一些新的东西。
由于命运的安排,由于一些不可避免的情况,我不得不最终潜入 PyTorch。虽然说实话,我的开始很艰难。已经习惯于躲在 TensorFlow 的抽象后面,PyTorch 的冗长本质提醒了我为什么离开 Java 而选择 Python。
然而,过了一会儿,PyTorch 的美丽开始显露出来。它之所以更冗长,是因为它让你对自己的行为有更多的控制。PyTorch 让您对自己的每一步都有更明确的把握,给您更多的自由。也许 Java 也有同样的意图,但我永远不会知道,因为那艘船已经起航了!
分布式训练为您提供了几种方法来利用您拥有的每一点计算能力,并使您的模型训练更加有效。PyTorch 的一个显著特点是它支持分布式训练。
今天我们就来学习一下数据并行包,可以实现单机,多 GPU 并行。完成本教程后,读者将会:
- 清晰理解 PyTorch 的数据并行性
- 一种实现数据并行的设想
- 在遍历 PyTorch 的冗长代码时,对自己的目标有一个清晰的认识
学习如何在 PyTorch 中使用数据并行训练, 继续阅读即可。
py torch 分布式培训简介
py torch 的数据并行训练是什么?
想象一下,有一台配有 4 个 RTX 2060 图形处理器的计算机。你被赋予了一项任务,你必须处理几千兆字节的数据。小菜一碟,对吧?如果你没有办法将所有的计算能力结合在一起会怎么样?这将是非常令人沮丧的,就像我们有 10 亿美元,但每个月只能花 5 美元一样!
如果我们没有办法一起使用我们所有的资源,那将是不理想的。谢天谢地, PyTorch 有我们撑腰!图 1 展示了 PyTorch 如何以简单而高效的方式在单个系统中利用多个 GPU。
这被称为数据并行训练,在这里你使用一个带有多个 GPU 的主机系统来提高效率,同时处理大量的数据。
这个过程非常简单。一旦调用了nn.DataParallel,就会在每个 GPU 上创建单独的模型实例。然后,数据被分成相等的部分,每个模型实例一个。最后,每个实例创建自己的渐变,然后在所有可用的实例中进行平均和反向传播。
事不宜迟,让我们直接进入代码,看看分布式培训是如何运行的!
配置您的开发环境
要遵循这个指南,首先需要在系统中安装 PyTorch。要访问 PyTorch 自己的视觉计算模型,您还需要在您的系统中安装 Torchvision。我们也在使用imutils包进行数据处理。最后,我们将使用matplotlib来绘制我们的结果!
幸运的是,上面提到的所有包都是 pip-installable!
$ pip install torch
$ pip install torchvision
$ pip install imutils
$ pip install matplotlib
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在进入项目之前,让我们回顾一下项目结构。
$ tree -d .
.
├── distributed_inference.py
├── output
│ ├── food_classifier.pth
│ └── model_training.png
├── prepare_dataset.py
├── pyimagesearch
│ ├── config.py
│ ├── create_dataloaders.py
│ └── food_classifier.py
├── results.png
└── train_distributed.py
2 directories, 9 files
首先也是最重要的,是pyimagesearch目录。它包含:
config.py:包含在整个项目中使用的几个重要参数和路径- 包含一个函数,可以帮助我们加载、处理和操作数据集
food_classifier.py:驻留在这个脚本中的主模型架构
我们将使用的其他脚本在父目录中。它们是:
train_distributed.py:定义数据流程,训练我们的模型distributed_inference.py:将用于评估我们训练好的模型的个别测试数据
最后,我们有我们的output文件夹,它将存放所有其他脚本产生的所有结果(图、模型)。
配置先决条件
为了开始我们的实现,让我们从config.py开始,这个脚本将包含端到端训练和推理管道的配置。这些值将在整个项目中使用。
# import the necessary packages
import torch
import os
# define path to the original dataset
DATA_PATH = "Food-11"
# define base path to store our modified dataset
BASE_PATH = "dataset"
# define paths to separate train, validation, and test splits
TRAIN = os.path.join(BASE_PATH, "training")
VAL = os.path.join(BASE_PATH, "validation")
TEST = os.path.join(BASE_PATH, "evaluation")
我们定义了一个到原始数据集的路径(行 6 )和一个基本路径(行 9 )来存储修改后的数据集。在第 12-14 行上,我们使用os.path.join函数为修改后的数据集定义了单独的训练、验证和测试路径。
# initialize the list of class label names
CLASSES = ["Bread", "Dairy_product", "Dessert", "Egg", "Fried_food",
"Meat", "Noodles/Pasta", "Rice", "Seafood", "Soup",
"Vegetable/Fruit"]
# specify ImageNet mean and standard deviation and image size
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
IMAGE_SIZE = 224
在第 17-19 行,我们定义了我们的目标类。我们正在选择 11 个类,我们的数据集将被分组到这些类中。在第 22-24 行上,我们为我们的 ImageNet 输入指定平均值、标准偏差和图像大小值。请注意,平均值和标准偏差各有 3 个值。每个值分别代表通道方向、高度方向、和宽度方向的平均值和标准偏差。图像尺寸被设置为224 × 224 以匹配 ImageNet 模型的可接受的通用输入尺寸。
# set the device to be used for training and evaluation
DEVICE = torch.device("cuda")
# specify training hyperparameters
LOCAL_BATCH_SIZE = 128
PRED_BATCH_SIZE = 4
EPOCHS = 20
LR = 0.0001
# define paths to store training plot and trained model
PLOT_PATH = os.path.join("output", "model_training.png")
MODEL_PATH = os.path.join("output", "food_classifier.pth")
由于今天的任务涉及演示用于训练的多个图形处理单元,我们将设置torch.device到cuda ( 第 27 行)。cuda是 NVIDIA 开发的一个巧妙的应用编程接口(API),使CUDA(Compute Unified Device Architecture)的 GPU 被允许用于通用处理。此外,由于 GPU 比 CPU 拥有更多的带宽和内核,因此它们在训练机器学习模型方面速度更快。
在的第 30-33 行,我们设置了几个超参数,如LOCAL_BATCH_SIZE(训练期间的批量)、PRED_BATCH_SIZE(推断期间的批量)、时期和学习率。然后,在第 36 行和第 37 行,我们定义路径来存储我们的训练图和训练模型。前者将评估它相对于模型度量的表现,而后者将被调用到推理模块。
对于我们的下一个任务,我们将进入create_dataloaders.py脚本。
# import the necessary packages
from . import config
from torch.utils.data import DataLoader
from torchvision import datasets
import os
def get_dataloader(rootDir, transforms, bs, shuffle=True):
# create a dataset and use it to create a data loader
ds = datasets.ImageFolder(root=rootDir,
transform=transforms)
loader = DataLoader(ds, batch_size=bs, shuffle=shuffle,
num_workers=os.cpu_count(),
pin_memory=True if config.DEVICE == "cuda" else False)
# return a tuple of the dataset and the data loader
return (ds, loader)
在第 7 行的上,我们定义了一个名为get_dataloader的函数,它将根目录、PyTorch 的转换实例和批处理大小作为外部参数。
在的第 9 行和第 10 行,我们使用torchvision.datasets.ImageFolder来映射给定目录中的所有条目,以拥有__getitem__和__len__方法。这些方法在这里有非常重要的作用。
首先,它们有助于在从索引到数据样本的类似地图的结构中表示数据集。
其次,新映射的数据集现在可以通过一个torch.utils.data.DataLoader实例(第 11-13 行)传递,它可以并行加载多个数据样本。
最后,我们返回数据集和DataLoader实例(第 16 行)。
为分布式训练准备数据集
对于今天的教程,我们使用的是 Food-11 数据集。如果你想快速下载 Food-11 数据集,请参考 Adrian 关于使用 Keras 创建的微调模型的这篇精彩博文!
尽管数据集已经有了一个训练、测试和验证分割,但我们将以一种更易于理解的方式来组织它。
在其原始形式中,数据集的格式如图图 3 所示:
每个文件名的格式都是class_index_imageNumber.jpg。例如,文件0_10.jpg指的是属于Bread标签的图像。来自所有类别的图像被分组在一起。在我们的自定义数据集中,我们将按标签排列图像,并将它们放在各自带有标签名称的文件夹中。因此,在数据准备之后,我们的数据集结构将看起来像图 4 :
每个标签式文件夹将包含属于这些标签的相应图像。这样做是因为许多现代框架和函数在处理输入时更喜欢这样的文件夹结构。
所以,让我们跳进我们的prepare_dataset.py脚本,并编码出来!
# USAGE
# python prepare_dataset.py
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import shutil
import os
def copy_images(rootDir, destiDir):
# get a list of the all the images present in the directory
imagePaths = list(paths.list_images(rootDir))
print(f"[INFO] total images found: {len(imagePaths)}...")
我们首先定义一个函数copy_images ( 第 10 行),它有两个参数:图像所在的根目录和自定义数据集将被复制到的目标目录。然后,在的第 12 行,我们使用paths.list_images函数生成根目录中所有图像的列表。这将在以后复制文件时使用。
# loop over the image paths
for imagePath in imagePaths:
# extract class label from the filename
filename = imagePath.split(os.path.sep)[-1]
label = config.CLASSES[int(filename.split("_")[0])].strip()
# construct the path to the output directory
dirPath = os.path.sep.join([destiDir, label])
# if the output directory does not exist, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
# construct the path to the output image file and copy it
p = os.path.sep.join([dirPath, filename])
shutil.copy2(imagePath, p)
我们开始遍历第 16 行的图像列表。首先,我们通过分隔前面的路径名(第 18 行)挑出文件的确切名称,然后我们通过filename.split("_")[0])识别文件的标签,并将其作为索引馈送给config.CLASSES。在第一次循环中,该函数创建目录路径(第 25 行和第 26 行)。最后,我们构建当前图像的路径,并使用 shutil 包将图像复制到目标路径。
# calculate the total number of images in the destination
# directory and print it
currentTotal = list(paths.list_images(destiDir))
print(f"[INFO] total images copied to {destiDir}: "
f"{len(currentTotal)}...")
# copy over the images to their respective directories
print("[INFO] copying images...")
copy_images(os.path.join(config.DATA_PATH, "training"), config.TRAIN)
copy_images(os.path.join(config.DATA_PATH, "validation"), config.VAL)
copy_images(os.path.join(config.DATA_PATH, "evaluation"), config.TEST)
我们对第 34 行和第 35 行进行健全性检查,看看是否所有的文件都被复制了。这就结束了copy_images功能。我们调用行 40-42 上的函数,并创建我们修改后的训练、测试、和验证数据集!
创建 PyTorch 分类器
既然我们的数据集创建已经完成,是时候进入food_classifier.py脚本并定义我们的分类器了。
# import the necessary packages
from torch.cuda.amp import autocast
from torch import nn
class FoodClassifier(nn.Module):
def __init__(self, baseModel, numClasses):
super(FoodClassifier, self).__init__()
# initialize the base model and the classification layer
self.baseModel = baseModel
self.classifier = nn.Linear(baseModel.classifier.in_features,
numClasses)
# set the classifier of our base model to produce outputs
# from the last convolution block
self.baseModel.classifier = nn.Identity()
我们首先定义我们的自定义nn.Module类(第 5 行)。这通常是在架构更复杂时完成的,在定义我们的模型时允许更大的灵活性。在类内部,我们的第一项工作是定义__init__函数来初始化对象的状态。
第 7 行上的super方法将允许访问基类的方法。然后,在第行第 10 行,我们将基本模型初始化为构造函数(__init__)中传递的baseModel参数。然后我们创建一个单独的分类输出层(第 11 行),带有 11 个输出,每个输出代表我们之前定义的一个类。最后,由于我们使用了自己的分类层,我们用nn.Identity替换了baseModel的内置分类层,这只是一个占位符层。因此,baseModel的内置分类器将正好反映其分类层之前的卷积模块的输出。
# we decorate the *forward()* method with *autocast()* to enable
# mixed-precision training in a distributed manner
@autocast()
def forward(self, x):
# pass the inputs through the base model and then obtain the
# classifier outputs
features = self.baseModel(x)
logits = self.classifier(features)
# return the classifier outputs
return logits
在第 21 行上,我们定义了自定义模型的forward()道次,但在此之前,我们用@autocast()修饰模型。这个 decorator 函数在训练期间支持混合精度,由于数据类型的智能分配,这实质上使您的训练更快。我已经把链接到了 TensorFlow 的一个博客,里面详细解释了混合精度。最后,在第 24 行和第 25 行上,我们获得baseModel输出,并将其通过自定义classifier层以获得最终输出。
使用分布式训练来训练 PyTorch 分类器
我们的下一个目的地是train_distributed.py,在那里我们将进行模型训练,并学习如何使用多个 GPU!
# USAGE
# python train_distributed.py
# import the necessary packages
from pyimagesearch.food_classifier import FoodClassifier
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from sklearn.metrics import classification_report
from torchvision.models import densenet121
from torchvision import transforms
from tqdm import tqdm
from torch import nn
from torch import optim
import matplotlib.pyplot as plt
import numpy as np
import torch
import time
# determine the number of GPUs we have
NUM_GPU = torch.cuda.device_count()
print(f"[INFO] number of GPUs found: {NUM_GPU}...")
# determine the batch size based on the number of GPUs
BATCH_SIZE = config.LOCAL_BATCH_SIZE * NUM_GPU
print(f"[INFO] using a batch size of {BATCH_SIZE}...")
torch.cuda.device_count()函数(第 20 行)将列出我们系统中兼容 CUDA 的 GPU 数量。这将用于确定我们的全局批量大小(行 24 ),即config.LOCAL_BATCH_SIZE * NUM_GPU。这是因为如果我们的全局批量大小是B ,并且我们有N 兼容 CUDA 的 GPU,那么每个 GPU 都会处理批量大小B/N的数据。例如,对于全局批量12 和2 兼容 CUDA 的 GPU,每个 GPU 都会评估批量6 的数据。
# define augmentation pipelines
trainTansform = transforms.Compose([
transforms.RandomResizedCrop(config.IMAGE_SIZE),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(90),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
testTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
# create data loaders
(trainDS, trainLoader) = create_dataloaders.get_dataloader(config.TRAIN,
transforms=trainTansform, bs=BATCH_SIZE)
(valDS, valLoader) = create_dataloaders.get_dataloader(config.VAL,
transforms=testTransform, bs=BATCH_SIZE, shuffle=False)
(testDS, testLoader) = create_dataloaders.get_dataloader(config.TEST,
transforms=testTransform, bs=BATCH_SIZE, shuffle=False)
接下来,我们使用 PyTorch 的一个非常方便的函数,称为torchvision.transforms。它不仅有助于构建复杂的转换管道,而且还赋予我们对选择使用的转换的许多控制权。
注意第 28-34 行,我们为我们的训练集图像使用了几个数据增强,如RandomHorizontalFlip、RandomRotation等。我们还使用此函数将均值和标准差归一化值添加到我们的数据集。
我们再次使用torchvision.transforms进行测试转换(第 35-39 行,但是我们没有添加额外的扩充。相反,我们通过在create_dataloaders脚本中创建的get_dataloader函数传递这些实例,并分别获得训练、验证和测试数据集和数据加载器(第 42-47 行)。
# load up the DenseNet121 model
baseModel = densenet121(pretrained=True)
# loop over the modules of the model and if the module is batch norm,
# set it to non-trainable
for module, param in zip(baseModel.modules(), baseModel.parameters()):
if isinstance(module, nn.BatchNorm2d):
param.requires_grad = False
# initialize our custom model and flash it to the current device
model = FoodClassifier(baseModel, len(trainDS.classes))
model = model.to(config.DEVICE)
我们选择densenet121作为我们的基础模型来覆盖我们模型架构的大部分( Line 50 )。然后我们在densenet121层上循环,并将batch_norm层设置为不可训练(行 54-56 )。这样做是为了避免由于批次大小不同而导致的批次标准化不稳定的问题。一旦完成,我们将densenet121发送给FoodClassifier类,并初始化我们的定制模型( Line 59 )。最后,我们将模型加载到我们的设备上(第 60 行)。
# if we have more than one GPU then parallelize the model
if NUM_GPU > 1:
model = nn.DataParallel(model)
# initialize loss function, optimizer, and gradient scaler
lossFunc = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=config.LR * NUM_GPU)
scaler = torch.cuda.amp.GradScaler(enabled=True)
# initialize a learning-rate (LR) scheduler to decay the it by a factor
# of 0.1 after every 10 epochs
lrScheduler = optim.lr_scheduler.StepLR(opt, step_size=10, gamma=0.1)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // BATCH_SIZE
valSteps = len(valDS) // BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "train_acc": [], "val_loss": [],
"val_acc": []}
首先,我们使用一个条件语句来检查我们的系统是否适合 PyTorch 数据并行(行 63 和 64 )。如果条件为真,我们通过nn.DataParallel模块传递我们的模型,并将我们的模型并行化。然后,在第 67-69 行,我们定义我们的损失函数,优化器,并创建一个 PyTorch 渐变缩放器实例。梯度缩放器是一个非常有用的工具,有助于将混合精度引入梯度计算。然后,我们初始化一个学习率调度器,使其每 10 个历元衰减一个因子的值(行 73 )。
在第 76 行和第 77 行,我们为训练和验证批次计算每个时期的步骤。第 80行和第 81 行的H变量将是我们的训练历史字典,包含训练损失、训练精度、验证损失和验证精度等值。
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.EPOCHS)):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (x, y) in trainLoader:
with torch.cuda.amp.autocast(enabled=True):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFunc(pred, y)
# calculate the gradients
scaler.scale(loss).backward()
scaler.step(opt)
scaler.update()
opt.zero_grad()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss.item()
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# update our LR scheduler
lrScheduler.step()
为了评估我们的模型训练的速度有多快,我们对训练过程进行计时( Line 85 )。为了开始我们的模型训练,我们开始在第 87 行循环我们的纪元。我们首先将 PyTorch 定制模型设置为训练模式(第 89 行),并初始化训练和验证损失以及正确预测(第 92-98 行)。
然后,我们使用 train dataloader ( Line 101 )循环我们的训练集。一旦进入训练集循环,我们首先启用混合精度(行 102 )并将输入(数据和标签)加载到 CUDA 设备(行 104 )。最后,在第 107 行和第 108 行,我们让我们的模型执行向前传递,并使用我们的损失函数计算损失。
scaler.scale(loss).backward函数自动为我们计算梯度(第 111 行),然后我们将其插入模型权重并更新模型(第 111-113 行)。最后,我们在完成一遍后使用opt.zero_grad重置梯度,因为backward函数不断累积梯度(我们每次只需要逐步梯度)。
第 118-120 行更新我们的损失并校正预测值,同时在一次完整的训练通过后更新我们的 LR 调度器(第 123 行)。
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (x, y) in valLoader:
with torch.cuda.amp.autocast(enabled=True):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation
# loss
pred = model(x)
totalValLoss += lossFunc(pred, y).item()
# calculate the number of correct predictions
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(valDS)
在我们的评估过程中,我们将使用torch.no_grad关闭 PyTorch 的自动渐变,并将我们的模型切换到评估模式(第 126-128 行)。然后,在训练步骤中,我们循环验证数据加载器,并在将数据加载到我们的 CUDA 设备之前启用混合精度(第 131-134 行)。接下来,我们获得验证数据集的预测,并更新验证损失值(第 138 和 139 行)。
一旦脱离循环,我们计算训练和验证损失和预测的分批平均值(行 146-151 )。
# update our training history
H["train_loss"].append(avgTrainLoss)
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss)
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
在我们的纪元循环结束之前,我们将所有损失和预测值记录到我们的历史字典H ( 第 154-157 行)中。
一旦在循环之外,我们使用行 167 上的time.time()函数记录时间,看看我们的模型执行得有多快。
# evaluate the network
print("[INFO] evaluating network...")
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# initialize a list to store our predictions
preds = []
# loop over the test set
for (x, _) in testLoader:
# send the input to the device
x = x.to(config.DEVICE)
# make the predictions and add them to the list
pred = model(x)
preds.extend(pred.argmax(axis=1).cpu().numpy())
# generate a classification report
print(classification_report(testDS.targets, preds,
target_names=testDS.classes))
现在是时候在测试数据上测试我们新训练的模型了。再次关闭自动梯度计算,我们将模型设置为评估模式(第 173-175 行)。
接下来,我们在行 178 上初始化一个名为preds的空列表,它将存储测试数据的模型预测。最后,我们遵循同样的程序,将数据加载到我们的设备中,获得批量测试数据的预测,并将值存储在preds列表中(第 181-187 行)。
在几个方便的工具中,scikit-learnclassification_report为我们提供了评估我们的模型的工具,其中classification_report提供了我们的模型给出的预测的完整的分类概述(第 190 和 191 行)。
[INFO] evaluating network...
precision recall f1-score support
Bread 0.92 0.88 0.90 368
Dairy_product 0.87 0.84 0.86 148
Dessert 0.87 0.92 0.89 500
Egg 0.94 0.92 0.93 335
Fried_food 0.95 0.91 0.93 287
Meat 0.93 0.95 0.94 432
Noodles 0.97 0.99 0.98 147
Rice 0.99 0.95 0.97 96
Seafood 0.95 0.93 0.94 303
Soup 0.96 0.98 0.97 500
Vegetable 0.96 0.97 0.96 231
accuracy 0.93 3347
macro avg 0.94 0.93 0.93 3347
weighted avg 0.93 0.93 0.93 3347
我们的模型的完整分类报告应该是这样的,让我们对我们的模型比其他模型预测得更好/更差的类别有一个全面的了解。
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
# serialize the model state to disk
torch.save(model.module.state_dict(), config.MODEL_PATH)
我们训练脚本的最后一步是绘制模型历史字典中的值(行 194-204 ),并将模型状态保存在我们预定义的路径中(行 207 )。
使用 PyTorch 进行分布式训练
在执行训练脚本之前,我们需要运行prepare_dataset.py脚本。
$ python prepare_dataset.py
[INFO] copying images...
[INFO] total images found: 9866...
[INFO] total images copied to dataset/training: 9866...
[INFO] total images found: 3430...
[INFO] total images copied to dataset/validation: 3430...
[INFO] total images found: 3347...
[INFO] total images copied to dataset/evaluation: 3347...
一旦这个脚本运行完毕,我们就可以继续执行train_distributed.py脚本了。
$ python train_distributed.py
[INFO] number of GPUs found: 4...
[INFO] using a batch size of 512...
[INFO] training the network...
0%| | 0/20 [00:00<?, ?it/s][INFO] EPOCH: 1/20
Train loss: 1.267870, Train accuracy: 0.6176
Val loss: 0.838317, Val accuracy: 0.7586
5%|███▏ | 1/20 [00:37<11:47, 37.22s/it][INFO] EPOCH: 2/20
Train loss: 0.669389, Train accuracy: 0.7974
Val loss: 0.580541, Val accuracy: 0.8394
10%|██████▍ | 2/20 [01:03<09:16, 30.91s/it][INFO] EPOCH: 3/20
Train loss: 0.545763, Train accuracy: 0.8305
Val loss: 0.516144, Val accuracy: 0.8580
15%|█████████▌ | 3/20 [01:30<08:14, 29.10s/it][INFO] EPOCH: 4/20
Train loss: 0.472342, Train accuracy: 0.8547
Val loss: 0.482138, Val accuracy: 0.8682
...
85%|█████████████████████████████████████████████████████▌ | 17/20 [07:40<01:19, 26.50s/it][INFO] EPOCH: 18/20
Train loss: 0.226185, Train accuracy: 0.9338
Val loss: 0.323659, Val accuracy: 0.9099
90%|████████████████████████████████████████████████████████▋ | 18/20 [08:06<00:52, 26.32s/it][INFO] EPOCH: 19/20
Train loss: 0.227704, Train accuracy: 0.9331
Val loss: 0.313711, Val accuracy: 0.9140
95%|███████████████████████████████████████████████████████████▊ | 19/20 [08:33<00:26, 26.46s/it][INFO] EPOCH: 20/20
Train loss: 0.228238, Train accuracy: 0.9332
Val loss: 0.318986, Val accuracy: 0.9105
100%|███████████████████████████████████████████████████████████████| 20/20 [09:00<00:00, 27.02s/it]
[INFO] total time taken to train the model: 540.37s
经过 20 个时期后,平均训练精度达到了 0.9332 ,而验证精度达到了值得称赞的 0.9105 。让我们先来看看图 5 中的度量图!
通过观察整个过程中训练和验证指标的发展,我们可以有把握地说,我们的模型没有过度拟合。
数据分布式训练推理
虽然我们已经在测试集上评估了模型,但是我们将创建一个单独的脚本distributed_inference.py,其中我们将逐个单独评估测试图像,而不是一次评估一整批。
# USAGE
# python distributed_inference.py
# import the necessary packages
from pyimagesearch.food_classifier import FoodClassifier
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from torchvision import models
from torchvision import transforms
import matplotlib.pyplot as plt
from torch import nn
import torch
# determine the number of GPUs we have
NUM_GPU = torch.cuda.device_count()
print(f"[INFO] number of GPUs found: {NUM_GPU}...")
# determine the batch size based on the number of GPUs
BATCH_SIZE = config.PRED_BATCH_SIZE * NUM_GPU
print(f"[INFO] using a batch size of {BATCH_SIZE}...")
# define augmentation pipeline
testTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
在初始化迭代器之前,我们设置了这些脚本的初始需求。这些包括设置由 CUDA GPUs 数量决定的批量大小(第 15-19 行)和为我们的测试数据集初始化一个torchvision.transforms实例(第 23-27 行)。
# calculate the inverse mean and standard deviation
invMean = [-m/s for (m, s) in zip(config.MEAN, config.STD)]
invStd = [1/s for s in config.STD]
# define our denormalization transform
deNormalize = transforms.Normalize(mean=invMean, std=invStd)
# create test data loader
(testDS, testLoader) = create_dataloaders.get_dataloader(config.TEST,
transforms=testTransform, bs=BATCH_SIZE, shuffle=True)
# load up the DenseNet121 model
baseModel = models.densenet121(pretrained=True)
# initialize our food classifier
model = FoodClassifier(baseModel, len(testDS.classes))
# load the model state
model.load_state_dict(torch.load(config.MODEL_PATH))
理解我们为什么计算第 30 和 31 行的反均值和反标准差值很重要。这是因为我们的torchvision.transforms实例在数据集被插入模型之前对其进行了规范化。所以,为了把图像变回原来的形式,我们要预先计算这些值。我们很快就会看到这些是如何使用的!
用这些值,我们创建一个torchvision.transforms.Normalize实例供以后使用(第 34 行)。接下来,我们在第 37 和 38 行的上使用create_dataloaders方法创建我们的测试数据集和数据加载器。
注意,我们已经在train_distributed.py中保存了训练好的模型状态。接下来,我们将像在训练脚本中一样初始化模型(第 41-44 行),并使用model.load_state_dict函数将训练好的模型权重插入到初始化的模型(第 47 行)。
# if we have more than one GPU then parallelize the model
if NUM_GPU > 1:
model = nn.DataParallel(model)
# move the model to the device and set it in evaluation mode
model.to(config.DEVICE)
model.eval()
# grab a batch of test data
batch = next(iter(testLoader))
(images, labels) = (batch[0], batch[1])
# initialize a figure
fig = plt.figure("Results", figsize=(10, 10 * NUM_GPU))
我们使用nn.DataParallel重复并行化模型,并将模型设置为评估模式(第 50-55 行)。因为我们将处理单个数据点,所以我们不需要遍历整个测试数据集。相反,我们将使用next(iter(loader)) ( 第 58 行和第 59 行)抓取一批测试数据。您可以运行此功能(直到发生器用完批次)来随机化批次选择。
# switch off autograd
with torch.no_grad():
# send the images to the device
images = images.to(config.DEVICE)
# make the predictions
preds = model(images)
# loop over all the batch
for i in range(0, BATCH_SIZE):
# initialize a subplot
ax = plt.subplot(BATCH_SIZE, 1, i + 1)
# grab the image, de-normalize it, scale the raw pixel
# intensities to the range [0, 255], and change the channel
# ordering from channels first to channels last
image = images[i]
image = deNormalize(image).cpu().numpy()
image = (image * 255).astype("uint8")
image = image.transpose((1, 2, 0))
# grab the ground truth label
idx = labels[i].cpu().numpy()
gtLabel = testDS.classes[idx]
# grab the predicted label
pred = preds[i].argmax().cpu().numpy()
predLabel = testDS.classes[pred]
# add the results and image to the plot
info = "Ground Truth: {}, Predicted: {}".format(gtLabel,
predLabel)
plt.imshow(image)
plt.title(info)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
同样,由于我们不打算改变模型的权重,我们关闭了自动渐变功能( Line 65 ),并将测试图像刷新到我们的设备中。最后,在第 70 行,我们直接对批量图像进行模型预测。
在批处理的图像中循环,我们选择单个图像,反规格化它们,放大它们的值并改变它们的尺寸顺序(第 80-83 行)。如果我们显示图像,改变尺寸是必要的,因为 PyTorch 选择将其模块设计为接受通道优先输入。也就是说,我们刚从torchvision.transforms出来的图像现在是Channels * Height * Width。为了显示它,我们必须以Height * Width * Channels的形式重新排列维度。
我们使用图像的单独标签,通过使用testDS.classes ( 第 86 行和第 87 行)来获得类的名称。接下来,我们得到单个图像的预测类别(第 90 行和第 91 行)。最后,我们比较单个图像的真实和预测标签(行 94-98 )。
这就结束了我们的数据并行训练的推理脚本!
数据并行训练模型的 PyTorch 可视化
让我们看看我们的推理脚本distributed_inference.py绘制的一些结果。
由于我们已经在推理脚本中采用了 4 个的批次大小,我们的绘图将显示当前批次的图片。
发送给我们的推理脚本的那批数据包含:牡蛎壳的图像(图 6 )、薯条的图像(图 7 )、包含肉的图像(图 8 )和巧克力蛋糕的图像(图 9 )。
这里我们看到 3 个预测是正确的,共 4 个。这一点,加上我们完整的测试集分数,告诉我们使用 PyTorch 的数据并行非常有效!
总结
在今天的教程中,我们领略了 PyTorch 的大量分布式训练程序。就内部工作而言,nn.DataParallel可能不是其他分布式培训程序中最有效或最快的,但它肯定是一个很好的起点!它很容易理解,只需要一行代码就可以实现。正如我之前提到的,其他过程需要更多的代码,但是它们是为了更有效地处理事情而创建的。
nn.DataParallel的一些非常明显的问题是:
- 创建整个模型实例本身的冗余
- 当模型变得太大而不适合时无法工作
- 当可用的 GPU 不同时,无法自适应地调整训练
尤其是在处理大型架构时,模型并行是首选,在这种情况下,您可以在 GPU 之间划分模型层。
也就是说,如果你的系统中有多个 GPU,那么使用nn.DataParallel充分利用你的系统所能提供的每一点计算能力。
我希望本教程对你有足够的帮助,为你从整体上掌握分布式培训的好奇心铺平道路!
引用信息
Chakraborty,d .“py torch 分布式培训简介”, PyImageSearch ,2021,https://PyImageSearch . com/2021/10/18/Introduction-to-Distributed-Training-in-py torch/
@article{Chakraborty_2021_Distributed, author = {Devjyoti Chakraborty}, title = {Introduction to Distributed Training in {PyTorch}}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/10/18/introduction-to-distributed-training-in-pytorch/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 scikit-learn 和 Python 调整超参数简介
在本教程中,您将学习如何使用 scikit-learn 和 Python 调优机器学习模型超参数。
本教程是关于超参数调整的四部分系列的第一部分:
- 介绍使用 scikit-learn 和 Python 进行超参数调优(今天的帖子)
- 用 scikit-learn ( GridSearchCV)进行网格搜索超参数调优(下周的帖子)
- 使用 scikit-learn、Keras 和 TensorFlow 进行深度学习的超参数调整(两周后的教程)
- 使用 Keras 调谐器和 TensorFlow 实现简单的超参数调谐(本系列的最后一篇文章)
调整您的超参数是 获得高精度模型的绝对关键 。许多机器学习模型都有各种旋钮、转盘和参数可供您设置。
一个非常低精度的模型和一个高精度的模型之间的区别有时就像调整正确的刻度盘一样简单。本教程将向你展示如何调整你的机器学习模型上的转盘,以提高你的准确性。
具体来说,我们将通过以下方式介绍超参数调整的基础:
- 获得基线和无超参数调优,我们有一个要改进的基准
- 在一组超参数上进行彻底的网格搜索
- 利用随机搜索从超参数空间采样
我们将使用 Python 和 scikit-learn 实现每个方法,训练我们的模型,并评估结果。
在本教程结束时,您将对如何在您自己的项目中实际使用超参数调整来提高模型精度有很深的理解。
学习如何用 scikit-learn 和 Python 调优超参数, 继续阅读。
介绍使用 scikit-learn 和 Python 进行超参数调整
在本教程中,您将学习如何使用 scikit-learn 和 Python 调优模型超参数。
我们将从讨论什么是超参数调整以及为什么它如此重要开始本教程。
从那里,我们将配置您的开发环境并检查项目目录结构。
然后我们将实现三个 Python 脚本:
- 一个是用 no 超参数调整来训练模型(这样我们可以获得一个基线)
- 一种是利用一种叫做“网格搜索”的算法来彻底检查超参数的所有组合——这种方法可以保证对超参数值进行全面扫描,但是非常慢
- 最后一种方法使用“随机搜索”,从分布中对各种超参数进行采样(不保证覆盖所有超参数值,但实际上通常与网格搜索一样准确,并且运行速度比快得多)
最后,我们将以对结果的讨论来结束我们的教程。
什么是超参数调整,为什么它很重要?
你以前试过用老式的 AM/FM 收音机吗?你知道,模拟收音机有旋钮和转盘,你可以移动它们来选择电台,调节均衡器等等。,像是在图一?
这些收音机可能是过去的遗物,但如果你以前用过,你就会知道让电台选择器“恰到好处”是多么重要如果你让电台选择器位于两个频率之间,你会得到两个不同电台的音频相互渗透。噪音刺耳,几乎无法理解。
类似地,机器学习模型有各种各样你可以调整的旋钮和转盘:
- 神经网络具有学习速率和正则化强度
- 卷积神经网络有几层,每个卷积层的滤波器数量,全连接层中的节点数量等。
- 决策树具有节点分裂标准(基尼指数、信息增益等。)
- 随机森林具有森林中的树木总数,以及特征空间采样百分比
- 支持向量机(SVMs)具有核类型(线性、多项式、径向基函数(RBF)等)。)以及针对特定内核需要调整的任何参数
支持向量机是 臭名昭著的 因为需要显著的超参数调整, 尤其是 如果你使用的是非线性内核。您不仅需要为您的数据选择正确的内核类型,而且还需要调整与内核相关的任何旋钮和刻度盘— 一个错误的选择,您的准确性就会直线下降。
Scikit-learn:使用网格搜索和随机搜索进行超参数调整
scikit-learn 最常用的两种超参数方法是网格搜索和随机搜索。这两种算法背后的总体思路是:
- 定义一组要优化的超参数
- 将这些超参数用于网格搜索或随机搜索
- 然后,这些算法自动检查超参数搜索空间,并试图找到最大化精度的最佳值
也就是说,网格搜索和随机搜索本质上是超参数调整的不同技术。图 2 显示了这两种超参数搜索算法:
在图 2 中,我们有一个 2D 网格,第一个超参数的值沿 x 轴绘制,第二个超参数的值沿 y- 轴绘制。白色突出显示的椭圆形是和这两个超参数的最佳值。我们的目标是使用我们的超参数调整算法来定位这个区域。
图 2 ( 左)可视化网格搜索:
- 我们首先定义一组所有的超参数和我们想要研究的相关值
- 网格搜索然后检查这些超参数的 所有组合
- 对于超参数的每个可能组合,我们在它们上面训练一个模型
- 然后返回与最高精度相关的超参数
网格搜索保证检查所有可能的超参数组合。问题是超参数越多,组合的数量就越多 呈指数增长!
由于要检查的组合太多,网格搜索往往会运行得非常慢。
为了帮助加速这个过程,我们可以使用一个随机搜索 ( 图 2 ,右)。
通过随机搜索,我们可以:
- 定义我们要搜索的超参数
- 为每个超参数设置值的下限和上限(如果是连续变量)或超参数可以采用的可能值(如果是分类变量)
- 随机搜索然后从这些分布中随机采样总共 N 次,在每组超参数上训练一个模型
- 然后返回与最高精度模型相关的超参数
虽然根据定义,随机搜索不是像网格搜索那样的穷举搜索,但随机搜索的好处是它的 比 快得多,并且通常获得与网格搜索一样高的准确性。
这是为什么呢?
网格搜索既然如此详尽,难道不应该获得最高的精确度吗?
不一定。
在调整超参数时,并不是只有 一个 【黄金数值组】能给你最高的精度。取而代之的是一个 分布——每个超参数都有 范围 来获得最佳精度。如果您落在该范围/分布内,您仍将享受相同的高精度,而不需要使用网格搜索彻底调整您的超参数。
配置您的开发环境
为了遵循这个指南,您需要在您的系统上安装 scikit-learn 机器库和 Pandas 数据科学库。
幸运的是,这两个包都是 pip 可安装的:
$ pip install scikit-learn
$ pip install pandas
如果您在配置开发环境时遇到问题,您应该参考下一节。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
我们的示例数据集
我们今天要使用的数据集是来自 UCI 机器学习库的鲍鱼。
鲍鱼是海洋生物学家经常研究的海洋蜗牛。具体来说,海洋生物学家对蜗牛的年龄感兴趣。
问题是确定鲍鱼的年龄是一项耗时、乏味的任务,需要生物学家:
- 将鲍鱼壳切开
- 弄脏它
- 用显微镜数一数染色贝壳上的年轮数量(就像测量树上的年轮一样)
是的,就像听起来一样无聊。
然而,使用更容易收集的值,有可能预测海洋蜗牛的年龄。
鲍鱼数据集包括七个值:
- 外壳的长度
- 壳的直径
- 外壳的高度
- 重量(鲍鱼的总重量)
- 去壳重量(鲍鱼肉的重量)
- 内脏重量
- 外壳重量
给定这七个值,我们的目标是训练一个机器学习模型来预测鲍鱼的年龄。正如我们将看到的,根据我们的机器学习模型调整超参数可以提高准确性。
项目结构
让我们从回顾我们的项目目录结构开始。
请务必访问本教程的 “下载” 部分来检索源代码。
然后,您将看到以下文件:
$ tree . --dirsfirst
.
├── pyimagesearch
│ └── config.py
├── abalone_train.csv
├── train_svr.py
├── train_svr_grid.py
└── train_svr_random.py
1 directory, 5 files
abalone_train.csv文件包含来自 UCI 机器学习库的鲍鱼数据集(不需要从 UCI 下载 CSV 文件,因为我已经在与教程相关的下载中包含了 CSV 文件)。
鲍鱼数据集包含 3,320 行,每行 8 列(7 列用于特征,包括壳长、直径等。)和最后一列年龄(这是我们试图预测的目标值)。
为了评估超参数调整的影响,我们将实现三个 Python 脚本:
train_svr.py:通过训练支持向量回归(SVR)在鲍鱼数据集上建立基线,其中没有超参数调整。train_svr_grid.py:利用网格搜索进行超参数调谐。train_svr_random.py:对超参数值的分布进行随机超参数搜索。
pyimagesearch模块中的config.py文件实现了我们在三个驱动程序脚本中使用的重要配置变量,包括输入 CSV 数据集的路径和列名。
创建我们的配置文件
在我们能够实现任何训练脚本之前,让我们首先回顾一下我们的配置文件。
打开pyimagesearch模块中的config.py文件,您会发现如下代码:
# specify the path of our dataset
CSV_PATH = "abalone_train.csv"
# specify the column names of our dataframe
COLS = ["Length", "Diameter", "Height", "Whole weight",
"Shucked weight", "Viscera weight", "Shell weight", "Age"]
在第 2 行,上,我们初始化CSV_PATH以指向驻留在磁盘上的鲍鱼 CSV 文件。
第 5 行和第 6 行定义 CSV 文件中八列的名称。我们需要训练脚本中的列名来从磁盘加载并解析它。
这就是我们的配置文件!让我们继续实施我们的培训脚本。
实施基本培训脚本
我们的第一个训练脚本train_svr.py,将通过执行无超参数调整来建立基线精度。一旦我们有了这个基线,我们将尝试通过应用超参数调整算法来改进它。
但是现在,让我们建立我们的基线。
打开项目目录中的train_svr.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch import config
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
import pandas as pd
第 2-6 行导入我们需要的 Python 包,包括:
config:我们在上一节中实现的配置文件StandardScaler:一种数据预处理技术,执行标准缩放(也称为z-统计世界中的分数),通过减去特定列值的平均值除以标准偏差来缩放每个数据观察值train_test_split:构建训练和测试分割SVR: scikit-learn 实现了一个用于回归的支持向量机pandas:用于从磁盘加载我们的 CSV 文件并解析数据
说到这里,现在让我们从磁盘加载我们的鲍鱼 CSV 文件:
# load the dataset, separate the features and labels, and perform a
# training and testing split using 85% of the data for training and
# 15% for evaluation
print("[INFO] loading data...")
dataset = pd.read_csv(config.CSV_PATH, names=config.COLS)
dataX = dataset[dataset.columns[:-1]]
dataY = dataset[dataset.columns[-1]]
(trainX, testX, trainY, testY) = train_test_split(dataX,
dataY, random_state=3, test_size=0.15)
第 12 行从磁盘读取我们的 CSV 文件。注意我们如何将列的CSV_PATH传递给磁盘上的文件。
从那里,我们需要提取我们的特征向量(即,壳的长度,直径,高度等。)和我们希望预测的目标值(年龄)— 第 13 行和第 14 行通过简单的数组切片为我们实现了这一点。
一旦我们的数据被加载和解析,我们在第 15 行和第 16 行构建一个训练和测试分割,使用 85%的数据用于训练,15%用于测试。
加载数据后,我们现在需要对其进行预处理:
# standardize the feature values by computing the mean, subtracting
# the mean from the data points, and then dividing by the standard
# deviation
scaler = StandardScaler()
trainX = scaler.fit_transform(trainX)
testX = scaler.transform(testX)
第 21 行实例化了我们的StandardScaler的一个实例。然后,我们计算训练数据中所有列值的平均值和标准偏差,然后对它们进行缩放(第 22 行)。
第 23 行使用在训练集上计算的平均值和标准偏差来缩放我们的测试数据。
现在剩下的就是训练 SVR:
# train the model with *no* hyperparameter tuning
print("[INFO] training our support vector regression model")
model = SVR()
model.fit(trainX, trainY)
# evaluate our model using R^2-score (1.0 is the best value)
print("[INFO] evaluating...")
print("R2: {:.2f}".format(model.score(testX, testY)))
第 27 行实例化了我们用于回归的支持向量机。请记住,我们在这里使用回归是因为我们试图预测一个实值输出,鲍鱼的**年龄 。**
****第 28 行**然后使用我们的trainX(特征向量)和trainY(要预测的目标年龄)训练模型。
一旦我们的模型被训练,我们就使用决定系数在第 32 行对其进行评估。
决定系数通常在分析回归模型的输出时使用。本质上,它衡量的是因变量和自变量之间“可解释的差异”的数量。
该系数将具有在范围 [0,1],内的值,其中 0 意味着我们不能正确预测目标输出,而值 1 意味着我们可以准确无误地预测输出。
有关决定系数的更多信息,请务必参考本页中的。
采集我们的基线结果( 否 超参数调优)
在我们将超参数调整到我们的 SVM 之前,我们首先需要获得一个没有超参数调整的基线。这样做将为我们提供一个可以改进的基线/基准。
首先访问本教程的 “下载” 部分,检索源代码和示例数据集。
然后,您可以执行train_svr.py脚本:
$ time python train_svr.py
[INFO] loading data...
[INFO] training our support vector regression model
[INFO] evaluating...
R2: 0.55
real 0m1.386s
user 0m1.928s
sys 0m1.040s
这里我们得到一个决定值系数0.55,这意味着基于 X (我们的七个特征值),在 Y (海洋蜗牛的年龄)中 55%的方差是可预测的。
我们的目标是使用超参数调整来超越这个值。
用网格搜索调整超参数
现在我们已经建立了一个基线分数,让我们看看是否可以使用 scikit-learn 的超参数调优来击败它。
我们将从实施网格搜索开始。在本指南的后面,您还将学习如何使用随机搜索进行超参数调整。
打开项目目录结构中的train_svr_grid.py文件,我们将使用 scikit-learn 实现网格搜索:
# import the necessary packages
from pyimagesearch import config
from sklearn.model_selection import RepeatedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.model_selection import train_test_split
import pandas as pd
第 2-8 行导入我们需要的 Python 包。这些导入与我们之前的train_svr.py脚本相同,但是增加了两项:
GridSearchCV: scikit-learn 的网格搜索超参数调整算法的实现RepeatedKFold:在每次迭代中使用不同的随机化,总共执行k-折叠交叉验证 N 次
执行 k- 折叠交叉验证允许我们“提高机器学习模型的估计性能” ( 来源)并且通常在执行超参数调整时使用。
在优化超参数时,您需要做的最后一件事是对一组随机数据进行长时间的实验,获得高精度,然后发现高精度是由于数据本身的随机异常造成的。利用交叉验证有助于防止这种情况发生。
我们现在可以从磁盘加载 CSV 文件并对其进行预处理:
# load the dataset, separate the features and labels, and perform a
# training and testing split using 85% of the data for training and
# 15% for evaluation
print("[INFO] loading data...")
dataset = pd.read_csv(config.CSV_PATH, names=config.COLS)
dataX = dataset[dataset.columns[:-1]]
dataY = dataset[dataset.columns[-1]]
(trainX, testX, trainY, testY) = train_test_split(dataX,
dataY, random_state=3, test_size=0.15)
# standardize the feature values by computing the mean, subtracting
# the mean from the data points, and then dividing by the standard
# deviation
scaler = StandardScaler()
trainX = scaler.fit_transform(trainX)
testX = scaler.transform(testX)
上面的“实现一个基本的训练脚本”一节已经介绍了这个代码,所以如果你需要关于这个代码做什么的更多细节,可以参考那里。
接下来,我们可以初始化我们的回归模型和超参数搜索空间:
# initialize model and define the space of the hyperparameters to
# perform the grid-search over
model = SVR()
kernel = ["linear", "rbf", "sigmoid", "poly"]
tolerance = [1e-3, 1e-4, 1e-5, 1e-6]
C = [1, 1.5, 2, 2.5, 3]
grid = dict(kernel=kernel, tol=tolerance, C=C)
第 29 行初始化我们的支持向量机回归(SVR)模型。SVR 有几个要优化的超参数,包括:
kernel:将数据投影到高维空间时使用的核的类型,在高维空间中数据理想地变成线性可分的tolerance:停止标准的公差C:SVR 的“严格性”(即,在拟合数据时允许 SVR 在多大程度上出错)
第 30-32 行定义了每个超参数的值,而第 33 行创建了一个超参数字典。
我们的目标是搜索这些超参数,并找到kernel、tolerance和C的最佳值。
说到这里,让我们现在进行网格搜索:
# initialize a cross-validation fold and perform a grid-search to
# tune the hyperparameters
print("[INFO] grid searching over the hyperparameters...")
cvFold = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
gridSearch = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1,
cv=cvFold, scoring="neg_mean_squared_error")
searchResults = gridSearch.fit(trainX, trainY)
# extract the best model and evaluate it
print("[INFO] evaluating...")
bestModel = searchResults.best_estimator_
print("R2: {:.2f}".format(bestModel.score(testX, testY)))
第 38 行创建我们的交叉验证折叠,表明我们将生成10个折叠,然后重复整个过程总共3次(通常,您会看到范围【3,10】内的折叠和重复值)。
第 39 行和第 40 行实例化我们的GridSearchCV对象。让我们来分析一下每个论点:
estimator:我们试图优化的模型(例如,我们的 SVR 将预测鲍鱼的年龄)param_grid:超参数搜索空间n_jobs:处理器上用于运行并行作业的内核数量。值-1意味着所有的核心/处理器都将被使用,从而加速网格搜索过程。- 我们试图优化的损失函数;在这种情况下,我们试图降低我们的均方误差(MSE),这意味着越低的均方误差,越好我们的模型在预测鲍鱼的年龄
第 41 行开始网格搜索。
在网格搜索运行之后,我们获得搜索期间找到的bestModel(第 45 行),然后计算决定系数,这将告诉我们我们的模型做得有多好(第 46 行)。
网格搜索超参数调谐结果
让我们来测试一下网格搜索超参数调优方法。
请务必访问本教程的 “下载” 部分,以检索源代码和示例数据集。
从那里,您可以执行以下命令:
$ time python train_svr_grid.py
[INFO] loading data...
[INFO] grid searching over the hyperparameters...
[INFO] evaluating...
R2: 0.56
real 4m34.825s
user 35m47.816s
sys 0m37.268s
以前,没有超参数调谐产生一个确定值系数0.55。
使用网格搜索,我们已经将该值提高到了0.56,这意味着我们调整后的模型在预测蜗牛年龄方面做得更好。
然而,获得这种精度是以速度为代价的:
- 在没有超参数调整的情况下,仅用了 1.3 秒来训练我们的原始模型
- 彻底的网格搜索花了 4m34s
- 增长了 18,166%
而且更糟糕的是,你要调优的超参数越多,可能的值组合数量爆炸——对于现实世界的数据集和问题来说,那就是不可行的。**
**解决方案是利用随机搜索来调整您的超参数。
用随机搜索调整超参数
我们最后的实验将使用随机超参数搜索进行探索。
打开train_svr_random.py文件,我们将开始:
# import the necessary packages
from pyimagesearch import config
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import RepeatedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.model_selection import train_test_split
from scipy.stats import loguniform
import pandas as pd
第 2-9 行导入我们需要的 Python 包。这些导入与我们之前的两个脚本几乎相同,最显著的区别是RandomizedSearchCV,scikit-learn 的随机超参数搜索的实现。
导入工作完成后,我们可以从磁盘加载鲍鱼 CSV 文件,然后使用StandardScaler对其进行预处理:
# load the dataset, separate the features and labels, and perform a
# training and testing split using 85% of the data for training and
# 15% for evaluation
print("[INFO] loading data...")
dataset = pd.read_csv(config.CSV_PATH, names=config.COLS)
dataX = dataset[dataset.columns[:-1]]
dataY = dataset[dataset.columns[-1]]
(trainX, testX, trainY, testY) = train_test_split(dataX,
dataY, random_state=3, test_size=0.15)
# standardize the feature values by computing the mean, subtracting
# the mean from the data points, and then dividing by the standard
# deviation
scaler = StandardScaler()
trainX = scaler.fit_transform(trainX)
testX = scaler.transform(testX)
接下来,我们初始化我们的 SVR 模型,然后定义超参数的搜索空间:
# initialize model and define the space of the hyperparameters to
# perform the randomized-search over
model = SVR()
kernel = ["linear", "rbf", "sigmoid", "poly"]
tolerance = loguniform(1e-6, 1e-3)
C = [1, 1.5, 2, 2.5, 3]
grid = dict(kernel=kernel, tol=tolerance, C=C)
在那里,我们可以使用随机搜索来调整超参数:
# initialize a cross-validation fold and perform a randomized-search
# to tune the hyperparameters
print("[INFO] grid searching over the hyperparameters...")
cvFold = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
randomSearch = RandomizedSearchCV(estimator=model, n_jobs=-1,
cv=cvFold, param_distributions=grid,
scoring="neg_mean_squared_error")
searchResults = randomSearch.fit(trainX, trainY)
# extract the best model and evaluate it
print("[INFO] evaluating...")
bestModel = searchResults.best_estimator_
print("R2: {:.2f}".format(bestModel.score(testX, testY)))
第 40-42 行实例化我们的RandomizedSearchCV对象,类似于我们如何创建我们的GridSearchCV调谐器。
从那里,行 43 在我们的超参数空间上运行随机搜索。
最后,第 47 行和第 48 行获取在超参数空间中找到的最佳模型,并在我们的测试集上对其进行评估。
随机超参数搜索结果
我们现在可以看到我们的随机超参数搜索是如何执行的。
访问本教程的 “下载” 部分来检索源代码和鲍鱼数据集。
然后,您可以执行train_svr_random.py脚本。
$ time python train_svr_random.py
[INFO] loading data...
[INFO] grid searching over the hyperparameters...
[INFO] evaluating...
R2: 0.56
real 0m36.771s
user 4m36.760s
sys 0m6.132s
这里,我们获得一个确定值系数0.56(与我们的网格搜索相同);但是随机搜索只用了 36 秒而不是网格搜索,网格搜索用了 4m34s。
只要有可能,我建议您使用随机搜索而不是网格搜索来进行超参数调整。您通常会在很短的时间内获得类似的准确度。
总结
在本教程中,您学习了使用 scikit-learn 和 Python 进行超参数调优的基础知识。
我们通过以下方式研究了超参数调谐:
- 使用无超参数调优在我们的数据集上获得基线精度—这个值成为我们要打破的分数
- 利用彻底的网格搜索
- 应用随机搜索
网格搜索和随机搜索都超过了原始基线,但随机搜索的时间减少了 86%。
我建议在调整超参数时使用随机搜索,因为节省的时间本身就使它在机器学习项目中更加实用和有用。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!*****
红外视觉介绍:近红外与中远红外图像
目录
红外视觉介绍:近中远红外图像
在本教程中,您将学习红外成像的基础知识,包括:
- 什么是红外图像:近红外与中远红外
- 红外摄像机的类型
- 它们有什么用处
本教程是关于红外视觉基础知识的 4 部分系列中的第一部分:
- 红外视觉入门:近中远红外图像 (今日教程)
- 热视觉:使用 Python 和 OpenCV 从图像中测量第一个温度
- 热视觉:使用 Python 和 OpenCV 的发热探测器(初始项目)
- 热视觉:用 PyTorch 和 YOLOv5 探测夜间物体(真实项目)
本课结束时,你将知道什么是红外图像,它们的技术,以及它们现在的用途。
什么是红外图像?近红外图像
在开始处理这种奇怪的图像之前,我们应该了解它们来自哪里。
我们都熟悉常见的数字彩色可视图片(图 1 、左),因为我们每年都会用智能手机、平板电脑和数码相机生成数百张甚至数千张图片。


Figure 1: Left: Color visible-light image. Right: Color near-infrared-light image.
数码相机内部的传感器不仅能够捕捉可见光或辐射,还能够捕捉来自太阳和人造聚光灯的近红外光。
然而,我们的眼睛无法感知红外辐射,所以我们看到了我们周围的世界,如图图 1 ( 左)所示。
为了复制我们眼睛的工作方式,数码相机通常在传感器和镜头之间包含一个近红外阻挡滤光玻璃。由于这个原因,传感器只捕捉可见光,就像我们的眼睛一样。
在少数不包括这个滤镜的情况下,我们有一个近红外相机,它可以拍摄像图 1 ( 右)中所示的照片,同时还可以捕捉可见光。
所以是的,你可能在想的是可能的!如果你从相机上取下玻璃滤镜,你会得到一个惊人的可见光和近红外捕捉设备!
免责声明: PyImageSearch 如果你对程序没有信心,不建议你遵循这个流程。对设备的不正确操作可能会导致相机损坏。
图 2 显示了不带近红外阻挡滤光片的单色或黑白(BW)普通摄像机的响应。
通过查看图 3 中所示的电磁光谱,我们了解到可见光的波长从 380 纳米的紫色到 750 纳米的红色,近红外辐射从大约 760 到 1500 纳米。
我们说过,如果没有近红外阻挡滤光片,我们常见的可见光数码相机就变成了近红外和可见光相机,如图图 3 所示(这种相机光谱响应的最高光吸收发生在可见光部分,在 400 到 750 nm 之间)。
但是,如果我们想在红外辐射中使用不同的波长(即中红外和远红外或长红外),会发生什么呢?
答案是,我们需要一种不同的技术,称为热红外成像。
中远红外图像:热红外成像
再次查看图 3 ,我们可以识别大约 1500 nm 到 100 万 nm 之间的中波和长波/远红外。
这些热像或者红外中远红外像是什么样子的?
图 4 ( 左)展示了用小型热感相机拍摄的中远距或热感图片图 4 ( 右)。

Figure 4: Left: Thermal image example. Right: Small thermal camera (source).
红外摄像机类型
正如我们已经看到的,根据当前的技术,有两种类型的红外图像:
- 近红外光谱
- 中远红外(MIR,FIR)
近红外或夜视摄像头
众所周知,普通的彩色或单色可见光相机可以很容易地转换成近红外和可见光相机。
捕获的近红外辐射让我们在黑暗中也能看见!
这也是我们通常称之为夜视摄像头的原因。
它们通常包括单色或黑白传感器,图 5 ( 顶部)。这项技术需要外部人工聚光灯来照亮拍摄的夜景。为此,如图图 5 ( 下图所示的夜间监控摄像头,包括一个环绕镜头的 LED 红外线灯环。


Figure 5: Top: Security surveillance camera. Bottom: Security surveillance camera (source), night scene.
在下一节中,除了安全监控,我们将看到这项技术更有趣的应用。
中远红外或热感摄像机
这种成像需要一种不同的技术,称为热感相机。
为什么热感相机,你可能会疑惑。
这项技术可以让我们通过获得温度分布图来测量任何场景的温度,如图图 6 所示!


Figure 6: Measuring a BBQ temperature distribution with a thermal camera. Left: visible color image. Right: thermal image.
是的,这就是捕捉中远红外辐射的“魔力”。
最终得到的图像是灰度格式,用不同的调色板着色,让我们可以实时测量和显示每个像素的温度,我们将在下一篇教程的中发现这一点。
就像近红外相机一样,这项技术使我们有可能在黑暗中看到东西。更重要的是,我们不需要外部人工聚光灯/手电筒来照亮夜景。
是的,再次,中远红外“魔法”!
它们对近红外或夜视摄像机有什么用
夜视摄像头通常用作监控摄像头。
但是它们还有什么用呢?
最常见的用途是:
- 面部和虹膜生物识别
- 动物研究监督
- 打猎
生物识别是一项需求量很大的技术,已经完全融入到我们的日常生活中。例如,这些摄像头可以在我们的智能手机中找到,用于虹膜或面部识别。因此,我们可以在银行交易中验证我们的身份,或者在夜间、低质量的照明条件下,甚至在戴着太阳镜的情况下解锁我们的设备。
动物研究是这项技术的另一个巧妙应用。图 7 ( 左下方)让我们了解到分布在特定野生区域的几个这样的设备是如何为生物学家研究人员提供可靠的信息的,例如,关于山猫活动的信息。



Figure 7: Common uses of near-infrared cameras. Top-left: Iris biometric recognition (source). Top-right: Facial biometric recognition (source). Bottom-left: Animal research surveillance (source), bobcat activity tracking. Bottom-right: Hunting, deer detection (source).
同样的,猎人可以探测并跟踪目标鹿的行动。
中远红外或热感摄像机
在本教程的最后一点,我们将学习热感相机的常见用途。
需要指出的是,它是一种比近红外相机更昂贵的技术。
然而,尽管成本较高,但热感相机受益于不需要限制工作距离的人工聚光灯。
为了利用其温度测量能力,这些摄像机用于以下用途:
- 野火探测
- 配电板和电子设备监管
- 新冠肺炎温度访问控制
不幸的是,我们的星球每年遭受数百次野火。为了对抗这个问题,嵌入无人机的热感摄像机可以帮助灭火,我们可以从图 8 ( 左上)中提取。



Figure 8: Common uses of middle-far-infrared cameras. Top-left: Fire areas detection (source). Top-right: Electric panel heat distribution (source). Bottom-left: Electronic PCB temperature map for efficient design (source). Bottom-right: COVID-19 temperature access control (source).
在工业中,热像仪非常有助于获得分布加热图,以在设计过程中优化电气和电子设备或预防故障。
它们还可用于防止和检测液体泄漏和水分问题。
最后但同样重要的是,由于新冠肺炎,热感摄像机可以控制接入点的温度。
汇总
在本教程中,我们学习了什么是红外图像,以及近红外(NIR)和中远红外(MIR 和 FIR)图像之间的区别,认识了支持它们的不同技术。我们还发现了这些特殊相机的常见用途,我们将在接下来的课程中探讨将它们与人工智能结合的最佳方式。
在下一个教程中,我们将进入热成像。你将学会从这些特殊的图像中测量你的第一个温度,以将这一令人敬畏的技术应用到你的项目中。
那里见!
引用信息
Garcia-Martin,R. “红外视觉简介:近中远红外图像”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/oj6kb
@incollection{Garcia-Martin_2022_Intro-Infrared-Vision,
author = {Raul Garcia-Martin},
title = {Introduction to Infrared Vision: Near vs. Mid-Far Infrared Images},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/oj6kb},
}
自然语言处理(NLP)简介
原文:https://pyimagesearch.com/2022/06/27/introduction-to-natural-language-processing-nlp/
目录
-
自然语言处理的开端
自然语言处理入门
**很多时候,人脑的聪明是理所当然的。每天,我们都要处理无数的信息,这些信息都属于不同的领域。
我们用眼睛看事物。我们把看到的物体分成不同的组。我们在工作中应用数学公式。甚至我们的交流模式也需要大脑处理信息。
所有这些任务都在不到一秒钟的时间内完成。人工智能的最终目标一直是再造大脑。但是现在,我们受到了一些限制,比如计算能力和数据。
制造能同时完成多项任务的机器极其困难。因此,我们将问题分类,并将其主要分为计算机视觉和自然语言处理。
我们已经变得擅长用图像数据制作模型。图像有肉眼可见的潜在模式,在它们的核心,图像是矩阵。数字的模式现在是可以识别的,特别是通过卷积神经网络的进步。
但是当我们进入自然语言处理(NLP)领域时会发生什么呢?你如何让计算机理解语言、语义、语法等背后的逻辑。?
本教程标志着我们的 NLP 系列的开始。在本教程中,您将了解 NLP 的历史演变。
本课是关于 NLP 101 的 4 部分系列的第 1 部分:
- 【自然语言处理入门】 (今日教程)
- 单词袋(BoW)模型简介
- Word2Vec:自然语言处理中的嵌入研究
- 【BagofWords 和 Word2Vec 的比较
要了解自然语言处理的历史, 只要保持阅读。
自然语言处理入门
自然语言处理
由于图像的核心是矩阵,卷积滤波器可以很容易地帮助我们检测图像的特征。语言就不一样了。CV 技术最多只能教会一个模型从图像中识别字母。
即使这样也导致了用 26 个标签进行训练,总的来说,这是一个非常糟糕的方法,因为我们根本没有抓住语言的本质。那我们在这里做什么?我们如何解开语言之谜(图 1 )?
先来个大剧透;我们目前正处于语言模型的时代,如 GPT-3(生成式预训练转换器 3)和 BERT(来自转换器的双向编码器表示)。这些模型遵循完美的语法和语义,能够与我们进行对话。
但这一切是从哪里开始的?
让我们通过历史来简单了解一下 NLP。
前言
人类创造了语言作为交流的媒介,以便更有效地分享信息。我们足够聪明去创造复杂的范式作为语言的基础。纵观历史,语言经历了广泛的变化,但通过语言分享信息的本质却保持不变。
当我们听到苹果这个词时,一个新鲜的红色椭圆形水果的形象就会浮现在我们的脑海中。我们可以立即将这个词与我们脑海中的形象联系起来。我们所看到的,我们所触摸到的,以及我们所感觉到的。我们复杂的神经系统对这些刺激做出反应,我们的大脑帮助我们将这些感觉归类为固定的词语。
但在这里,我们面对的是一台计算机,它只能理解 a 0或1是什么。我们的规则和范例不适用于计算机。那么,我们如何向计算机解释像语言这样复杂的东西呢?
在此之前,重要的是要明白我们对语言的理解并不像今天这样敏锐。作为一门科学,语言是语言学的主题。因此,自然语言处理成为语言学本身的一个子集。
所以让我们稍微绕一下语言学本身是如何发展成今天这个样子的。
自然语言处理的雏形
语言学本身就是对人类语言的科学研究。这意味着它采取了一种彻底的、有条理的、客观的、准确的对语言各个方面进行检查的方法。不用说,NLP 中的很多基础都和语言学有直接的联系。
现在你可能会问这和我们今天的旅程有什么关系。答案在于一个人的故事,他现在被认为是 20 世纪语言学之父,弗迪南·德·索绪尔。
在 20 世纪的第一个十年,德·索绪尔在日内瓦大学教授一门课程,这门课程采用了一种将语言描述为系统的方法。
一位著名的俄罗斯语言学家 Vladimir Plungyan 后来指出,
语言学中的“索绪尔革命”的本质是,语言被规定不被视为事实的混乱总和,而是被视为一座大厦,其中所有元素都相互联系( source )。
对德·索绪尔来说,语言中的声学声音代表了一种随语境变化的概念。
他的遗作《语言学概论》将他的结构主义语言观推向了语言学的中心。
将语言视为一个系统的结构主义方法是我们可以在现代 NLP 技术中普遍看到的。根据德索绪尔和他的学生的观点,答案在于将语言视为一个系统,在这个系统中,你可以将各种元素相互关联,从而通过因果关系识别语境。
我们的下一站是 20 世纪 50 年代,当时艾伦·图灵发表了他著名的“计算机械和智能”文章,现在被称为图灵测试。该测试确定计算机程序在有独立人类法官在场的实时对话中模仿人类的能力(图 3 )。
虽然这个测试有几个限制,但是仍然使用这个测试启发的几个检查。最值得注意的是,当浏览互联网时,CAPTCHA(区分计算机和人类的完全自动化的公共图灵测试)不时弹出。
图灵测试通常被称为“模仿游戏”,因为该测试旨在观察机器是否能模仿人类。原文章《计算机械与智能》,问“机器能思考吗?”这里出现的一个大问题是模仿是否等同于独立思考的能力。
1957 年,诺姆·乔姆斯基的“句法结构”采用了基于规则的方法,但仍然成功地彻底改变了 NLP 世界。然而,这个时代也有自己的问题,尤其是计算的复杂性。
在此之后,出现了一些发明,但计算复杂性带来的令人震惊的问题似乎阻碍了任何重大进展。
那么,在研究人员慢慢获得足够的计算能力之后,会发生什么呢?
自然语言处理找到了自己的立足点
一旦对复杂的硬编码规则的依赖减轻,使用决策树等早期机器学习算法就可以获得出色的结果。然而,这一突破是由完全不同的原因造成的。
20 世纪 80 年代统计计算的兴起也进入了 NLP 领域。这些模型的基础仅仅在于为输入要素分配加权值的能力。因此,这意味着输入将总是决定模型所采取的决策,而不是基于复杂的范例。
基于统计的 NLP 的一个最简单的例子是 n-grams,其中使用了马尔可夫模型的概念(当前状态仅依赖于前一状态)。这里,想法是在上下文中识别单词对其相邻单词的解释。
推动 NLP 世界向前发展的最成功的概念之一是递归神经网络(RNNs) ( 图 4 )。
RNNs 背后的想法既巧妙又简单。我们有一个递归单元,输入x1通过它传递。递归单元给我们一个输出y1和一个隐藏状态h1,它携带来自x1的信息。
RNN 的输入是代表单词序列的符号序列。这对于所有输入重复进行,因此,来自先前状态的信息总是被保留。当然,rnn 并不完美,被更强的算法(例如 LSTMs 和 GRUs)所取代。
这些概念使用了 RNNs 背后相同的总体思想,但是引入了一些额外的效率机制。LSTM(长短期记忆)细胞有三个路径或门:输入、输出和遗忘门。LSTMs 试图解决长期依赖性问题,它可以将输入与其之前的长序列相关联。
然而,LSTMs 带来了复杂性的问题。门控递归单元(GRUs)通过减少门的数量和降低 LSTMs 的复杂性来解决这个问题。
让我们花一点时间来欣赏这些算法出现在 20 世纪 90 年代末和 21 世纪初的事实,当时计算能力仍然是一个问题。因此,让我们看看我们在强大的计算能力下取得的成就。
NLP 的崛起
在我们进一步讨论之前,让我们先看一下计算机如何理解语言。计算机可以创建一个矩阵,其中的列表示上下文,在该矩阵中对行中的单词进行评估(表 1 )。
|
| 活着 | 财富 | 性别 |
| 男人 | one | -1 | -1 |
| 女王 | one | one | one |
| 框 | -1 | Zero | Zero |
| 表 1: 嵌入。 |
既然我们不能把单词的意思填鸭式地输入计算机,为什么不创造一个我们可以表达单词的有限范围呢?
这里,单词Man在Alive列下具有值1,在Wealth列下具有值-1,在Gender列下具有值-1。同样,我们在Alive、Wealth和Gender下有值为1、1和1的单词Queen。
注意Gender和Wealth列是如何为这两个单词取极坐标值的。如果这就是我们如何向计算机解释Man是穷的,而Queen是富的,或者Man是男的,而Queen是女的呢?
所以我们尝试在有限的 N 维空间中“表示”每个单词。该模型基于每个单词在每个 N 维中的权重来理解每个单词。这种表示学习方法在 2003 年首次出现,自 2010 年以来在 NLP 领域得到了广泛应用。
2013 年发表了word2vec系列论文。它使用了表征学习(嵌入)的概念,通过在 N 维空间中表达单词,根据定义,作为存在于该空间中的向量(图 5 )。
根据输入语料库的好坏,适当的训练将显示,当在可见空间中表达时,具有相似上下文的单词最终会在一起,如图 5 所示。根据数据的好坏和一个词在相似上下文中的使用频率,它的含义取决于它的相邻词。
这个概念又一次打开了 NLP 的世界,直到今天,嵌入在所有后续的研究中都扮演着重要的角色。Word2Vec 值得注意的精神追随者是 FastText 系列论文,该系列论文引入了子词的概念来进一步增强模型。
2017 年,注意力的概念出现了,它使一个模型专注于每个输入单词与每个输出单词的相关性。令人困惑的变形金刚概念是基于一种被称为自我关注的注意力变体。
变形金刚已经产生了足够强大的模型,甚至可以轻松击败图灵测试。这本身就证明了我们在教会计算机如何理解语言的过程中已经走了多远。
最近,当经过任务训练的 GPT-3 模型出现在网络上时,GPT-3 模型引起了巨大的轰动。这些模型可以完美地与任何人进行对话,这也成为了娱乐的主题,因为针对不同的任务对它们进行微调会产生非常有趣的结果。
看看变形金刚对语言的把握有多好(图 6 )。
GPT-尼奥 1.3B 是 EleutherAI 的 GPT-3 复制模型,它提供了几个起始标记,为我们提供了一小段输出,最大限度地尊重了句法和语义规则。
NLP 一度被认为过于昂贵,其研究被严重叫停。我们缺乏计算能力和获取数据的能力。现在我们有了可以和我们保持对话的模型,甚至不会怀疑我们在和非人类对话。
然而,如果你想知道 GPT-尼奥名字中的 1.3B 代表什么,那就是模型中参数的数量。这充分说明了当今最先进的(SOTA)语言模型所拥有的计算复杂性。
汇总
对 NLP 历史的简要回顾表明,研究工作在很久以前就开始了。研究人员利用我们在语言学上对人类语言的理解所奠定的基础,并对如何推进 NLP 有了正确的想法。
然而,技术的局限性成了最大的障碍,在某一点上,这一领域的研究几乎停滞不前。但是技术只朝一个方向发展,那就是前进。技术的发展为 NLP 研究人员提供了足够的计算能力,拓宽了他们的视野。
我们正处于语言模型帮助创造虚拟助手的阶段,这些助手可以与我们交谈,帮助我们完成任务,等等。想象一下,世界已经发展到一个地步,盲人可以要求虚拟助手描述一幅图像,而且它可以完美地做到这一点。
但是这种进步是以苛刻的计算能力要求为代价的,最重要的是,要访问成吨成吨的数据。语言是这样一个话题,像我们在图像中所做的那样应用增强技术根本不能帮助我们。因此,接下来的研究集中在如何减少这些庞大的需求。
即便如此,NLP 多年来的发展还是值得称赞的。这些概念既巧妙又直观。本系列的下一篇博客将更详细地关注现代 NLP 概念。
引用信息
Chakraborty,D. “自然语言处理(NLP)导论”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki 编辑。,2022 年,【https://pyimg.co/60xld
@incollection{Chakraborty_2022_NLP,
author = {Devjyoti Chakraborty},
title = {Introduction to Natural Language Processing {(NLP)}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/60xld},
}
神经网络导论
原文:https://pyimagesearch.com/2021/05/06/introduction-to-neural-networks/
我们将深入研究神经网络的基础。我们将从讨论人工神经网络开始,以及它们是如何受到我们自己身体中现实生活的生物神经网络的启发。从那里,我们将回顾经典的感知器算法和它在神经网络历史中扮演的角色。
在感知器的基础上,我们还将研究现代神经学习的基石反向传播算法——没有反向传播,我们将无法有效地训练我们的网络。我们还将从头开始用 Python 实现反向传播,确保我们理解这个重要的算法。
当然,现代神经网络库如 Keras 已经内置了(高度优化的)反向传播算法。每次我们希望训练神经网络时,手动实现反向传播就像每次我们处理通用编程问题时,从头开始编码链表或哈希表数据结构一样——不仅不现实,而且浪费我们的时间和资源。为了简化这个过程,我将演示如何使用 Keras 库创建标准的前馈神经网络。
最后,我们将讨论构建任何神经网络时需要的四个要素。
神经网络基础知识
在使用卷积神经网络之前,我们首先需要了解神经网络的基础知识。我们将回顾:
人工神经网络及其与生物学的关系。开创性的感知器算法。
反向传播算法及其如何用于有效训练多层神经网络。
如何使用 Keras 库训练神经网络。
当你完成时,你将对神经网络有深刻的理解,并能够继续学习更高级的卷积神经网络。
神经网络简介
神经网络是深度学习系统的构建模块。为了在深度学习方面取得成功,我们需要从回顾神经网络的基础知识开始,包括架构、节点、类型,以及用于“教导”我们的网络的算法。
我们将从神经网络及其背后的动机的高级概述开始,包括它们与人类大脑中生物学的关系。从那里我们将讨论最常见的架构类型,前馈神经网络。我们还将简要讨论神经学习的概念,以及它将如何与我们用来训练神经网络的算法相关联。
什么是神经网络?
许多涉及智能、模式识别和物体探测的任务极难 自动化,然而似乎可以由动物和小孩轻松自然地完成。例如,你家的狗是如何认出你这个主人,而不是一个完全陌生的人?一个小孩子如何学会辨别校车和公交巴士的区别?我们自己的大脑是如何每天下意识地执行复杂的模式识别任务,而我们却没有注意到呢?
答案就在我们自己的身体里。我们每个人都包含一个现实生活中的生物神经网络,它与我们的神经系统相连——这个网络由大量相互连接的神经元(神经细胞)组成。
【神经】一词是【神经元】**【网络】的形容词形式,表示一种图形状结构;因此,“人工神经网络”是一个试图模仿(或者至少是受其启发)我们神经系统中的神经连接的计算系统。人工神经网络也被称为【神经网络】或【人工神经系统】通常缩写人工神经网络,称之为“ANN”或简称为“NN”——我将使用这两个缩写。
对于一个被认为是神经网络的系统,它必须包含一个带标签的有向图结构,其中图中的每个节点执行一些简单的计算。从图论中,我们知道有向图由一组节点(即顶点)和一组将节点对链接在一起的连接(即边)组成。在图 1 中,我们可以看到这样一个 NN 图的例子。
每个节点执行一个简单的计算。然后,每个连接将一个信号(即计算的输出)从一个节点传送到另一个节点,由一个权重标记,指示信号被放大或减弱的程度。一些连接具有放大信号的大的、正权重,表明在进行分类时信号非常重要。其他的具有负权重,减弱信号的强度,从而指定节点的输出在最终分类中不太重要。如果这样一个系统由一个带有连接权重的图结构(如图 1 所示)组成,并且连接权重可以使用学习算法修改,那么我们称之为人工神经网络。
与生物学的关系
我们的大脑由大约 100 亿个神经元组成,每个神经元都与大约 10,000 个其他神经元相连。神经元的细胞体被称为胞体,在这里输入(树突)和输出(轴突)将胞体与其他胞体连接起来(图 2 )。
每个神经元在其树突处接收来自其他神经元的电化学输入。如果这些电输入足够强大,可以激活神经元,那么被激活的神经元就会沿着其轴突传递信号,并将其传递给其他神经元的树突。这些附着的神经元也可能会放电,从而继续传递信息。
这里的关键要点是,神经元触发是一个二元运算 — 神经元要么触发,要么不触发 。开火没有不同的“等级”。简而言之,神经元只有在体细胞接收到的总信号超过给定阈值时才会激活。
然而,请记住,人工神经网络只是受到我们对大脑及其工作方式的了解的启发。深度学习的目标是而不是模仿我们的大脑如何运作,而是获取我们理解的片段,并允许我们在自己的工作中绘制类似的类比。最终,我们对神经科学和大脑的深层功能了解不足,无法正确模拟大脑的工作方式——相反,我们带着我们的灵感继续前进。
人工模型
让我们先来看看一个基本的神经网络,它对图 3 中的输入进行简单的加权求和。值 x [1] 、x [2] 和 x [3] 是我们 NN 的输入,通常对应于我们设计矩阵中的单行(即数据点)。常数值 1 是我们的偏差,假设它嵌入到设计矩阵中。我们可以认为这些输入是神经网络的输入特征向量。
在实践中,这些输入可以是用于以系统的、预定义的方式量化图像内容的向量(例如,颜色直方图、方向梯度直方图、局部二元模式等)。).在深度学习的背景下,这些输入是图像本身的原始像素强度。
每个 x 通过权重向量 W 连接到一个神经元,权重向量由 w [1] ,w [2] ,…,w [n] 组成,这意味着对于每个输入 x 我们也有一个关联的权重 w 。
最后,图 3 右边的输出节点取加权和,应用一个激活函数 f (用于确定神经元是否“触发”),输出一个值。用数学方法表示输出,您通常会遇到以下三种形式:
• f(w[1]x[1] +w[2]x[2] + ··· +w[n]x[n])
• f(∑[i=1 -> n]w[i]x[i])
• Or simply, f(net), where net = ∑ni=1wixi
不管输出值是如何表示的,请理解我们只是简单地取输入的加权和,然后应用激活函数 f 。
激活功能
最简单的激活函数是感知器算法使用的“阶跃函数”。
 \begin{cases} 1 & \textit{if net} > 0 \ 0 & \textit{otherwise} \end{cases}")
从上面的等式可以看出,这是一个非常简单的阈值函数。如果加权求和∑[i=1 -> n]w[i]x[i]>0,我们输出 1,否则,我们输出 0。
沿着x-轴绘制输入值,沿着 y 轴绘制 f ( net )的输出,我们可以看到为什么这个激活函数得到它的名字(图 4 ,左上)。当 net 小于或等于零时 f 的输出始终为零。如果 net 大于零,那么 f 将返回一。因此,这个功能看起来像一个楼梯台阶,与你每天上下的楼梯没有什么不同。
然而,虽然直观且易于使用,但阶跃函数是不可微的,这在应用梯度下降和训练我们的网络时会导致问题。
相反,在神经网络文献的历史中使用的更常见的激活函数是 sigmoid 函数(图 4 ,右上),其遵循以下等式:
【①
**sigmoid 函数是比简单阶跃函数更好的学习选择,因为它:
- 在任何地方都是连续且可微的。
- 关于 y 轴对称。
- 渐近地接近其饱和值。
这里的主要优点是 sigmoid 函数的平滑性使得设计学习算法更容易。然而,sigmoid 函数有两个大问题:
- sigmoid 的输出不以零为中心。
- 饱和的神经元基本上消除了梯度,因为梯度的增量将非常小。
双曲正切,或 tanh (具有类似于 s 形的形状)也大量用作激活函数,直到 20 世纪 90 年代后期(图 4 、中左):tanh 的公式如下:
(2)f(z)=tanh(z)=(e(z)e(—z))/(e(z)*+*e(—z))
**tanh 函数以零为中心,但当神经元饱和时,梯度仍然会消失。
我们现在知道激活函数有比 sigmoid 和 tanh 函数更好的选择。具体来说,哈恩洛瑟等人的工作在其 2000 年的论文中,数字选择和模拟放大共存于一个受皮层启发的硅电路 中,介绍了整流线性单元(ReLU) ,定义为:
(3)f(x)=max(0,x )
由于绘制时的外观,ReLUs 也被称为“斜坡函数”(图 4 、中右)。请注意,对于负输入,函数为零,但对于正值,函数线性增加。ReLU 函数是不饱和的,而且计算效率极高。
根据经验,在几乎所有的应用中,ReLU 激活函数的表现都优于 sigmoid 函数和 T2 函数。结合 Hahnloser 和 Seung 在他们 2003 年的后续论文 对称阈值线性网络 中的允许和禁止集的工作,发现 ReLU 激活函数比以前的激活函数家族具有更强的生物学动机,包括更完整的数学证明。
截至 2015 年,ReLU 是深度学习中使用的最流行的激活函数 (LeCun,Bengio,and Hinton,2015) 。然而,当我们的值为零时,问题就出现了——梯度不能取。
ReLUs 的一个变体,称为泄漏 ReLUs (Maas、Hannun 和 Ng,2013) 当装置不工作时,允许一个小的非零梯度:
 = \begin{cases} \textit{net} & \textit{if net} >= 0 \ \alpha \times \textit{net} & \textit{otherwise} \end{cases}")
在图 4 ( 左下方中绘制该函数,我们可以看到该函数确实允许取负值,不像传统的 ReLUs 将函数输出“箝位”在零。
参数 ReLUs,或简称为 PReLUs(何,张,任,孙,2015 ) ,建立在泄漏 ReLUs 的基础上,并允许在逐个激活的基础上学习参数 α ,这意味着网络中的每个节点都可以学习与其他节点不同的“泄漏系数”。
最后,我们还有 Clevert 等人在他们 2015 年的论文中介绍的指数线性单元(ELUs)* 通过指数线性单元(ELUs)* 进行快速准确的深度学习:
 = \begin{cases} \textit{net} & \textit{if net} >= 0 \ \alpha \times (\textit{exp}(\textit{net}) - 1) & \textit{otherwise} \end{cases}")
α 的值是恒定的,并且是在网络架构被实例化时设置的——这不像在 PReLUs 中学习 α 。 α 的典型值为 α = 1 。 0。图 4 ( 右下)可视化 ELU 激活功能。
通过 Clevert 等人的工作(以及我自己的轶事实验),ELUs 往往比 ReLUs 获得更高的分类精度。eLU 的性能很少比标准的 ReLU 函数差。
我使用哪个激活功能?
鉴于深度学习的最新化身的流行,激活功能也出现了相关的爆炸。由于激活功能的选择数量,现代(ReLU,漏 ReLU,eLU 等。)和“古典”的(step、sigmoid、、tanh 等。),选择一个合适的激活函数可能看起来是一项艰巨的,甚至是压倒性的任务。
然而,在几乎所有情况下,我建议从 ReLU 开始,以获得基线准确性(正如在深度学习文献中发表的大多数论文一样)。从那里你可以试着把你的标准 ReLU 换成一个泄漏的 ReLU 变体。
我个人的偏好是从一个 ReLU 开始,调整我的网络和优化器参数(架构,学习率,正则化强度等。),并注意准确性。一旦我对准确度相当满意,我就换上 ELU,并经常注意到分类准确度提高了 1-5 %,这取决于数据集。同样,这只是我的轶事建议。你应该运行你自己的实验并记录你的发现,但是作为一般的经验法则,从一个正常的 ReLU 开始并调整你的网络中的其他参数——然后换入一些更“奇特”的 ReLU 变体。
前馈网络架构
虽然有许多不同的神经网络架构,但最常见的架构是f前馈网络,如图图 5 所示。
在这种类型的架构中,从层 i 中的节点到层 i +1 中的节点之间的连接只允许(因此有了术语前馈)。不允许向后或层间连接。当前馈网络包括反馈连接(反馈到输入的输出连接)时,它们被称为递归神经网络。
我们专注于前馈神经网络,因为它们是应用于计算机视觉的现代深度学习的基石。卷积神经网络只是前馈神经网络的一个特例。
为了描述一个前馈网络,我们通常使用一个整数序列来快速简洁地表示每层中的节点数。例如图 5 中的网络是一个 3-2-3-2 前馈网络:
层 0 包含 3 个输入,我们的x**I[值。这些可以是图像的原始像素强度或从图像中提取的特征向量。]
层 1 和 2 是隐藏层,分别包含 2 和 3 个节点。
第 3 层是输出层或可见层 —在那里我们从我们的网络获得整体输出分类。输出层通常具有与类标签一样多的节点;每个潜在输出一个节点。例如,如果我们要建立一个神经网络来分类手写数字,我们的输出层将由 10 个节点组成,每个节点对应一个数字 0-9 。
神经学习
神经学习指的是修改网络中节点之间的权重和连接的方法。从生物学上来说,我们根据 Hebb 的原则来定义学习:
当细胞 A 的轴突足够靠近以激发细胞 B,并且重复或持续地激发它时,在一个或两个细胞中发生一些生长过程或代谢变化,使得作为激发 B 的细胞之一的 A 的效率增加。
就人工神经网络而言,这一原则意味着,当输入相同时,输出相似的节点之间的连接强度应该增加。我们称之为相关性学习,因为神经元之间的连接强度最终代表了输出之间的相关性。
神经网络是用来做什么的?
神经网络可用于监督、非监督和半监督学习任务,当然,前提是使用适当的架构。神经网络的常见应用包括分类、回归、聚类、矢量量化、模式关联和函数逼近等。
事实上,对于机器学习的几乎每个方面,神经网络都以某种形式被应用。我们将使用神经网络进行计算机视觉和图像分类。
神经网络基础知识概述
今天,我们回顾了人工神经网络的基础知识。我们从检查人工神经网络背后的生物动机开始,然后学习我们如何能够用数学方法定义一个模拟神经元激活的函数(即激活函数)。
基于神经元的这个模型,我们能够定义一个网络的架构,该网络由(最低限度的)输入层和输出层组成。一些网络架构可能在输入层和输出层之间包含多个隐藏层。最后,每层可以有一个或多个节点。输入层中的节点不包含激活函数(它们是我们图像的单个像素强度被输入的“地方”);然而,隐藏层和输出层中的节点包含一个激活函数。
我们还回顾了三个流行的激活函数: sigmoid 、 tanh 和 ReLU (及其变体)。
传统上,sigmoid 和 tanh 函数被用于训练网络;然而,自从哈恩洛瑟等人 2000 年的论文以来,ReLU 函数被更多地使用。
2015 年,ReLU 是到目前为止深度学习架构中使用的最流行的激活函数 (LeCun,Bengio,和 Hinton,2015) 。基于 ReLU 的成功,我们还有泄漏 ReLU,一种 ReLU 的变体,它通过允许函数取负值来改善网络性能。leaky ReLU 系列函数由标准 Leaky ReLU 变体、PReLUs 和 eLUs 组成。
最后,值得注意的是,尽管我们严格地在图像分类的背景下关注深度学习,但神经网络已经以某种方式用于几乎所有的机器学习领域。****
OpenCV AI Kit (OAK)简介
原文:https://pyimagesearch.com/2022/11/28/introduction-to-opencv-ai-kit-oak/
目录
OpenCV AI Kit 介绍(橡树)
我们非常兴奋能够在 Luxonis OpenCV AI Kit (OAK)上开始新的系列,这是一款独一无二的嵌入式视觉硬件。OAK 是部署计算机视觉和深度学习解决方案的一站式解决方案,因为它在一个硬币大小的设备中内置了多个摄像头和神经网络推理加速器。它由英特尔 Movidius Myriad X 视觉处理单元(VPU)提供支持,用于神经网络推理。
在今天的教程中,我们将向您介绍 OAK 硬件系列,并讨论它的功能和众多可以在 OAK 上运行的应用程序。此外,讨论具有立体深度的 OAK 如何同时运行高级神经网络并提供深度信息,使其成为市场上独一无二的嵌入式硬件。简而言之,我们想让您对 OAK 设备有一个全面的了解,并展示其真正的潜力。
本课是关于橡树 101 的 4 部分系列中的第一部分:
- OpenC 简介VAI Kit(橡树) (今日教程)
- 橡树 101:第二部
- 橡树 101:第三部
- 橡树 101:第四部
要了解 OAK-D 在计算机视觉和空间人工智能方面提供了什么,以及为什么它是市场上对爱好者和企业来说最好的嵌入式视觉硬件之一, 请继续阅读。
OpenCV AI Kit 简介(橡树)
简介
为了庆祝 OpenCV 库成立 20 周年, Luxonis 与 OpenCV.org 官方组织合作创建了 OpenCV AI Kit,这是一个麻省理工学院许可的开源软件 API,以及无数基于 X 的嵌入式板/相机。
2020 年 7 月,Luxonis 和 OpenCV 组织发起了一项 Kickstarter 活动来资助这些奇妙的嵌入式人工智能板的创建。这场运动获得了巨大的成功;它从 6500 多名 Kickstarter 支持者那里筹集了大约 130 万美元的资金,有可能使它成为众筹史上最成功的嵌入式主板之一!
当他们第一次通过 Kickstarter 公开他们的产品时,OAK 由 OAK API 软件套件组成,支持 Python 和 OpenCV,允许对设备和两种不同类型的硬件进行编程:
- OAK-1: 标准的 OpenCV AI 板(如图图 1 ( 左)),可以进行神经网络推理、物体检测、物体跟踪、特征检测、基本的图像处理操作。
- OAK-D:OAK-1 中的一切,但带有立体深度相机,3D 对象定位,并在 3D 空间中跟踪对象。OAK-D(如图图 1 ( 右)是一款旗舰产品,可以同时运行高级神经网络并提供物体深度信息。
除了 OAK-1 和 OAK-D 型号共享的 4K/30FPS 12MP 摄像头之外,OAK-D 还利用两个单目摄像头提供空间人工智能。OAK-1 和 OAK-D 非常容易使用,使用 DepthAI API 更是如此。相信我们,如果你是一名研究人员、业余爱好者或专业人士,你不会失望的,因为 OAK 允许任何人充分利用它的力量。
在推出 OAK-1 和 OAK-D 一年后,2021 年 9 月,Luxonis 带着 OpenCV 发起了第二次 Kickstarter 战役,这次是 OAK 的变种 OAK-D Lite(如图图 2 )。顾名思义,它的重量和外形尺寸更小,但空间 AI 功能与 OAK-D 相同。此外,虽然 OAK-1 和 OAK-D 的价格分别为 99 美元和 149 美元,但 OAK-D Lite 的价格甚至低于 OAK-1(即仅 89 美元)。
为了降低成本和缩小尺寸,OAK-D Lite 采用了分辨率更低的单目摄像头,并取消了 IMU(惯性测量单元)的使用,因为它们价格昂贵且很少使用。有了许多这样的变化,OAK-D Lite 需要更少的功率,你可以用一个在 5V 电源下提供 900 毫安的 USB-C 来旋转它。
OAK 变体的列表不仅限于 OAK-1、OAK-D 和 OAK-D Lite。尽管如此,Luxonis 提供了更多的变体,它面向几乎所有的细分市场,如开发人员、研究人员和企业,用于生产级部署。
然而,所有的 OAK 模块都有许多标准功能,包括神经网络推理、计算机视觉方法(对象跟踪、特征跟踪、裁剪、Warp/Dewarp)、板载 Python 脚本、部署深度学习模型的 OpenVINO 兼容性(如图图 3 )。
橡木五金
到目前为止,我们已经讨论了 OAK 硬件家族中的 OAK-1 和 OAK-D,我们还讨论了 OAK 的一个变体(即 OAK-D Lite)。在本节中,我们将深入探讨除 OAK-1、OAK-D 和 OAK-D Lite 之外的所有 Luxonis 产品,因为它们将其所有硬件产品分为三类:系列、变体和连接性,如图图 4 所示。
如上图所示,OAK 系列模块提供了三种类型的硬件;所有这些都有相同的板载 Myriad X VPU 用于神经网络推理,并提供一组标准功能,在图 3 中讨论。
如果您想了解更多关于英特尔 Myriad X VPU 的信息,请查看本产品文档。
橡树-1
它附带一个 12MP RGB 摄像头,支持基于 USB 的连接和以太网供电(PoE)连接。Myriad X VPU 芯片允许它每秒执行 4 万亿次板载运算,保持主机(计算机)空闲。由于该设备具有 12 MP 摄像头和板载神经推理芯片,通信通过板载 2.1 Gbps MIPI 接口进行,速度超快。因此,总体推断速度是标准设置(通过 USB 连接到计算机的神经计算棒 2)的六倍以上,其中主机处理视频流。图 5 显示了通过 USB 连接到笔记本电脑的 NCS2。
以下是在 OAK-1 viz-a-viz NCS2 上运行对象检测网络(MobileNet-SSD)时获得的数字,主机为 Raspberry Pi:
- OAK-1 + Raspberry Pi: 50+FPS,0% RPi CPU 利用率
- NCS2 + Raspberry Pi: 8FPS,225% RPi CPU 利用率
奥克-D
像 OAK-1 一样,OAK-D 模块配备了 12 MP RGB 彩色摄像头,并支持 USB 和 PoE 连接。除了 RGB 摄像头,它还有一对灰度立体摄像头,有助于执行深度感知。所有三个机载相机都实现了立体和 RGB 视觉,直接传输到 OAK System on Module (SoM)进行深度感知和人工智能推理。
引起我们注意的一个有趣的事实是左、右灰度立体相机之间的距离是 7.5 厘米,类似于两只眼睛瞳孔中心之间的距离。这种距离估计适用于大多数应用。最小可感知距离为 20 厘米,最大可感知距离为 35 米。
限制
OAK-D 中的立体摄像机基线为 7.5 厘米,在图 6 的中表示为BL。灰度立体摄像机对具有 89.5°的视野(FOV),由于两个摄像机相距 7.5 厘米,它们将具有特定的盲点区域。两个摄像头中只有一个能看到这个盲点区域。
由于我们需要从视差计算深度(深度与视差成反比),这需要像素重叠,因此存在盲点。例如,在左单声道相机的左侧和右单声道相机的右侧的区域,其中深度不能被计算,因为它仅被两个相机中的一个看到。因此在图 6 中,该区域标有B (即无法计算深度的条带宽度)。
奥克-FFC
如图 7 所示,OAK FFC 模块化产品系列面向需要灵活硬件设置的开发人员和从业人员,而标准 OAK-D 并不适合他们的应用。它们更适合需要自定义安装、自定义基线(左右摄像机之间的距离)或自定义摄像机方向的应用。模块化允许您将立体摄像机放置在不同的基线上,不像 OAK-D 那样设置为 7.5 厘米。
俗话说,“没有值得拥有的东西是容易的”,这意味着这种灵活性带来了一个挑战,你需要弄清楚如何以及在哪里安装摄像机,一旦安装完毕,你需要执行立体校准。当然,OAK-D 已经为你做好了所有的基础工作,所以记住这些 OAK-FFC 模块不像 OAK-1、OAK-D、OAK-D Lite 等那样是“即插即用”的,这一点很重要。因此,简而言之,你需要成为处理这些模块化设备的专家,或者有一些设置定制硬件的经验,以利用奥克-FFC 的力量。
橡树 USB 硬件产品
通过 Kickstarter 活动首次推向市场的 OAK 模块是带有 USB 连接的 OAK,这也是最受欢迎的模块。OAK-1、OAK-D 和 OAK-D Lite 已经解决了两年多的实际问题。USB 连接非常适合开发——它易于使用,允许高达 10Gbps 的吞吐量。
OAK 的最新版本,如 OAK-D Pro,具有主动立体和夜视功能,使其成为市场上更有前景的边缘设备。通常很难找到支持夜视的摄像机,更不用说在这种情况下运行神经网络推理了。然而,有什么比将所有这些能力都烘焙到一个设备中更好的呢?该设备可以感知弱光环境,然后对这些帧进行神经网络推理(如图图 9 )。
橡坡硬件产品
OAK PoE 模块与 USB 模块非常相似,但它们没有 USB 连接,而是具有 PoE 连接。PoE 电缆的覆盖范围比 USB 大得多。另一个关键区别是,它们还具有板载闪存,因此您可以在独立模式下运行管道。这意味着您不需要将 OAK 连接到主机,OAK PoE 可以无主机或在边缘运行推理。
PoE 设备具有 IP67 等级的外壳,这意味着它具有防水和防尘功能。
橡树开发者套件
OAK developer kit 是 Luxonis 提供的所有变体中我们最喜欢的。简单来说,开发者套件就像在一个紧凑的解决方案中结合了 Raspberry Pi(或任何像 Nvidia 的 Jetson Nano 这样的微处理器)和 OAK-D。微处理器充当 OAK-D 的主机,使其完全独立。
图 11 显示了三种型号:OAK-D-CM3、OAK-D-CM4 和 OAK-D CM4 PoE。最新的计算模块 4 变体集成了 Raspberry Pi 计算模块 4(无线、4 GB RAM)及其所有接口(USB、以太网、3.5 mm 音频等。).此外,Raspberry Pi 操作系统也闪存到 32 GB eMMC 存储中。最后,为了连接、配置、构建管道并与 OAK 设备通信,它有一个 DepthAI Python 接口。
橡树模块对比
表 1 显示了所有 OAK 变体,以及每种变体提供的特性和功能。从下表中可以看出,所有的 OAK 型号都支持 AI 和 CV 功能,因为所有的模块都配有至少一个摄像头和无数的 X 芯片。此外,除 OAK-1 变体之外的所有设备都支持空间数据(即深度感知)。
所有基于 PoE 连接的 OAK 型号也具有 IP67 等级,如下表所示。此外,OAK-D Pro USB 和 PoE 具有主动立体和夜视支持,使计算机视觉更上一层楼。
回想一下,带有 PoE 的 OAK 具有板载闪存,因此它可以在没有主机的情况下运行。类似地,那些有 Raspberry Pi 计算模块的已经有了主机。因此,PoE 和 CM 版本都支持独立模式。此外,CM 模块有一个协处理器(即 Raspberry Pi CM 4)。
橡树上的应用
在这一节中,我们将讨论一些可以在 OAK-1 上开箱即用的应用程序,而有些应用程序需要 OAK-D。
图像分类器 On-Device
图像分类对于计算机视觉来说就像是深度学习的“hello world”。像大多数边缘设备一样,您也可以在 OAK 设备上高效地运行图像分类模型。图 12 显示了运行 Efficientnet-b0 变体的示例,该变体将动物分类为 Ibex(山羊)的概率为 34.46%。这个 Efficientnet 分类器是在 1000 类 ImageNet 数据集上训练的,可以在 DepthAI API 中动态加载。
人脸检测
图 13 展示了基于 libfacedetection 实现的 OAK 设备上的人脸检测应用演示。它检测图像中的人脸和五个面部标志:一双眼睛、鼻尖和嘴角点。检测器在 OAK 设备上达到 40 FPS。
人脸面具检测
图 14 显示了一个面具/无面具检测器,它使用 MobileNet SSD v2 对象检测模型来检测人们是否戴着面具。从下面的 gif 可以看出,模型做得相当不错。当然,这是在 OAK-D 上运行的。你可以在这里阅读更多关于这个的内容。
人数统计
对象计数是一个两步过程,包括检测对象,然后在对象跟踪器的帮助下计数唯一出现的对象。图 15 显示了对向左和向右行走的人进行计数的演示。它的灵感来自于 PyImageSearch 博客文章 OpenCV 人物计数器。当您需要计算进出商场或百货公司的人数时,人数计算非常有用。参考 GitHub 库来了解更多关于 OAK 的物体追踪。
年龄和性别识别
图 16 显示了在 OAK-D 上使用 DepthAI 库运行两阶段推理的一个很好的例子。它首先检测给定帧中的人脸,裁剪它们,然后将这些人脸发送到年龄-性别分类模型。面部检测和年龄性别模型可在英特尔目录内的 OpenVINO 的 GitHub 存储库中获得。你也可以参考这个官方 OpenVINO 文档进行预训练的车型。
凝视估计
凝视估计是一个有点复杂但有趣的例子。根据一个人的整张脸,它可以预测这个人看向哪里。如图图 17 所示,两个注视向量基于人的眼球运动而移动。
这个例子显示了在 OAK 上运行更复杂的应用程序的能力,这些应用程序涉及运行不是 1 个而是 4-5 个不同的神经网络模型。像前面的例子是两阶段推理流水线一样,凝视估计是使用 DepthAI 的三阶段推理(3 阶段,2 并行)。你可以在 luxonis 库上了解更多信息。
另一个简单的例子是在 OAK 设备上运行预训练的人脸检测神经网络,从给定的图像中提取感兴趣的人脸区域。然后在主机上使用标准的 OpenCV 方法来模糊人脸区域。图 18 中的所示的端到端应用实时运行。**

Figure 18: Automate Face-Blurring.
人体骨骼姿态估计
图 19 显示了一个在 OAK 设备上使用 Gen2 Pipeline Builder 的人体姿势估计网络示例。这是一个多人 2D 姿态估计网络(基于 OpenPose 方法)。该网络检测图像中每个人的姿势:由关键点和它们之间的连接组成的身体骨架。例如,姿势可以包含 18 个关键点,如耳朵、眼睛、鼻子、脖子、肩膀、肘部等。您可以使用blobconverter模块加载现成的人体姿势估计模型,该模块有助于将 OpenVINO 转换为 MyriadX blob 格式。
三维物体检测
具有深度的对象检测需要 OAK-D;它不能在 OAK-1 设备上工作,下面两个例子也需要 OAK-D。
简单来说,3D 对象检测是关于在物理空间而不是像素空间(2D)中找到对象的位置/坐标。因此,当实时测量或与物理世界互动时,它是有用的。图 20 显示了一个融合了立体深度的神经推理示例,其中 DepthAI 使用空间信息扩展了 SSD 和 YOLO 等 2D 物体检测器,为其提供 3D 环境。
因此,在下图中,MobileNet 检测对象,并将对象检测与深度图融合,以提供它看到的对象的空间坐标(XYZ ):人、监视器、盆栽植物、瓶子和椅子。如果你仔细注意,瓶子的z 比人小,显示器的z 最大。而z 是物体离相机的距离。
3D 地标定位
3D 手标志检测器与前面的例子非常相似。使用常规相机,该网络返回所有 21 个手部标志(手指中所有关节的轮廓)的 2D (XY)坐标。然后,使用与立体深度融合的神经推理的相同概念,将这 21 个手标志转换为物理空间中的 3D 点,如图 21 所示。该应用在 OAK-D 上实现了大约 20 FPS。

Figure 21: Hand Landmark Detection with Depth.
语义切分带深度
像图像分类、对象检测和关键点检测一样,您也可以在 OAK-D 上运行语义分割。图 22 展示了一个使用 DepthAI API 以 27 FPS 运行 DeepLabv3+的示例。它基于语义分割模型输出进一步裁剪深度图像。第一个窗口是语义分割输出,第二个是基于语义分割输出的裁剪的深度图,第三个是深度图。

Figure 22: Person Semantic Segmentation with Depth Image Cropping.
汇总
在本教程中,我们向您介绍了 OAK 硬件系列,并讨论了它的功能以及可以在 OAK 设备上运行的众多应用。
具体来说,我们详细讨论了 Luxonis 的两款旗舰产品,即 OAK-1 和 OAK-D,以及它们如何借助 Kickstarter 活动获得市场的牵引力。我们还讨论了 OAK-D 的局限性。
我们进一步研究了 Luxonis 硬件产品,讨论了 OAK-FFC、OAK USB 产品、OAK PoE 硬件、开发套件和 OAK 完整模块。
最后,我们讨论了可以在 OAK 硬件上运行的各种计算机视觉应用程序。
引用信息
Sharma,a .“OpenCV AI Kit(OAK)简介”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha,A. Thanki 编辑。,2022 年,【https://pyimg.co/dus4w
@incollection{Sharma_2022_OAK1,
author = {Aditya Sharma},
title = {Introduction to {OpenCV AI} Kit {(OAK)}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/dus4w},
}
用 Keras 和张量流介绍递归神经网络
https://www.youtube.com/embed/lAIA7l0_cf8?feature=oembed
TFRecords 简介
原文:https://pyimagesearch.com/2022/08/08/introduction-to-tfrecords/
目录
TF records 简介
在本教程中,您将了解 TensorFlow 的 TFRecords。
要了解如何使用 TensorFlow 的 TFRecords 格式, 继续阅读。
TF records 简介
简介
本教程的目标是作为一个一站式的目的地,让你了解关于 TFRecords 的一切。我们有目的地组织教程,使你对主题有更深的理解。它是为初学者设计的,我们希望你有没有关于这个主题的知识。
因此,没有任何进一步的拖延,让我们直接进入我们的教程。
配置您的开发环境
要遵循本指南,您需要在系统上安装 TensorFlow 和 TensorFlow 数据集库。
幸运的是,两者都是 pip 可安装的:
$ pip install tensorflow
$ pip install tensorflow-datasets
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
.
├── create_tfrecords.py
├── example_tf_record.py
├── pyimagesearch
│ ├── advance_config.py
│ ├── config.py
│ ├── __init__.py
│ └── utils.py
├── serialization.py
└── single_tf_record.py
1 directory, 8 files
在pyimagesearch目录中,我们有:
utils.py:从磁盘加载和保存图像的实用程序。config.py:单数据 tfrecord 示例的配置文件。advance_config.py:div2k数据集示例的配置文件。
在核心目录中,我们有四个脚本:
single_tf_record.py:处理单个二进制记录的脚本,展示了如何将它保存为 TFRecord 格式。serialization.py:解释数据序列化重要性的脚本。example_tf_record.py:保存和加载单幅图像为 TFRecord 的脚本。create_tfrecords.py:保存和加载整个div2k数据集的脚本。
什么是 TFRecords?
TFRecord 是用于存储二进制记录序列的自定义 TensorFlow 格式。TFRecords 针对 TensorFlow 进行了高度优化,因此具有以下优势:
- 数据存储的有效形式
- 与其他类型的格式相比,读取速度更快
TFRecords 最重要的一个用例是当我们使用 TPU 训练一个模型时。TPU 超级强大,但要求与之交互的数据远程存储(通常,我们使用 Google 云存储),这就是 TFRecords 的用武之地。当在 TPU 上训练模型时,我们以 TFRecord 格式远程存储数据集,因为这使得有效地保存数据和更容易地加载数据。
在这篇博文中,您将了解从如何构建基本 TF record 到用于训练 SRGAN 和 e SRGAN 模型的高级 TF record 的所有内容,这些内容将在以下博文中介绍:
- https://pyimagesearch . com/2022/06/06/super-resolution-generative-adversarial-networks-srgan/
- https://pyimagesearch . com/2022/06/13/enhanced-super-resolution-generative-adversarial-networks-ESR gan/
在我们开始之前,我们想提一下,这篇博客文章的灵感很大程度上来自于 Ryan Holbrook 关于 TFRecords 基础知识的 Kaggle 笔记本和 T2 tensor flow 关于 TFRecords 的指南。
建立自己的 TFRecords
建立 TFRecord
先说简单的。我们将创建二进制记录(字节字符串),然后使用 API 将它们保存到 TFRecord 中。这将使我们了解如何将大型数据集保存到 TFRecords 中。
# USAGE
# python single_tf_record.py
# import the necessary packages
from pyimagesearch import config
from tensorflow.io import TFRecordWriter
from tensorflow.data import TFRecordDataset
# build a byte-string that will be our binary record
record = "12345"
binaryRecord = record.encode()
# print the original data and the encoded data
print(f"Original data: {record}")
print(f"Encoded data: {binaryRecord}")
# use the with context to initialize the record writer
with TFRecordWriter(config.TFRECORD_SINGLE_FNAME) as recordWriter:
# write the binary record into the TFRecord
recordWriter.write(binaryRecord)
# open the TFRecord file
with open(config.TFRECORD_SINGLE_FNAME, "rb") as filePointer:
# print the binary record from the TFRecord
print(f"Data from the TFRecord: {filePointer.read()}")
# build a dataset from the TFRecord and iterate over it to read
# the data in the decoded format
dataset = TFRecordDataset(config.TFRECORD_SINGLE_FNAME)
for element in dataset:
# fetch the string from the binary record and then decode it
element = element.numpy().decode()
# print the decoded data
print(f"Decoded data: {element}")
在第 5-7 行,我们导入我们需要的包。
让我们初始化想要存储为 TFRecord 的数据。在的第 10 行,我们构建了一个名为record的变量,用字符串"12345"初始化。接下来,在的第 11 行,我们将这个字符串编码成一个字节串。
这一点特别重要,因为 TFRecords 只能存储二进制记录,而字节串就是这样。
行 14 和 15 打印原始的和编码的字符串,以显示两者的区别。当我们查看脚本的输出时,我们将能够注意到差异。
第 18-20 行初始化一个TFRecordWriter。我们可以使用write() API 任意多次,只要我们想将二进制记录写入 TFRecord。注意TFRecordWriter是如何使用with上下文的。
在第 23-25 行上,我们打开 TFRecord 文件并检查其数据。
第 29 行对我们特别有用,因为我们现在可以从任何 TFRecord 构建一个tf.data.Dataset。
一旦我们有了数据集,我们就可以遍历它,按照我们自己的意愿使用数据。
你可以参考tf.data上的这篇博文来温习一些基础知识。
让我们看看这个脚本的输出。
$ python single_tf_record.py
Original data: 12345
Encoded data: b'12345'
Data from the TFRecord: b'\x05\x00\x00\x00\x00\x00\x00\x00\xea\xb2\x04>12345z\x1c\xed\xe8'
Decoded data: 12345
请注意以下事项:
- 原始数据和解码数据应该是相同的。
- 编码的数据只是原始数据的字节串。
- TFRecord 中的数据是序列化的二进制记录。
序列化
那么,什么是序列化二进制记录呢?
我们知道 TFRecords 存储一系列二进制记录。因此,我们首先需要学习如何将数据转换成二进制表示。稍后我们将在此基础上建立我们的直觉。
TensorFlow 有两个公共 API,负责在二进制记录中编码和解码数据。这两个公共 API 分别来自 tf.io.serialize_tensor 和 tf.io.parse_tensor 。
让我们用这个例子来弄脏我们的手。
# USAGE
# python serialization.py
# import the necessary packages
import tensorflow as tf
from tensorflow.io import serialize_tensor, parse_tensor
# build the original data
originalData = tf.constant(
value=[1, 2, 3, 4],
dtype=tf.dtypes.uint8
)
# serialize the data into binary records
serializedData = serialize_tensor(originalData)
# read the serialized data into the original format
parsedData = parse_tensor(
serializedData,
out_type=tf.dtypes.uint8
)
# print the original, encoded, and the decoded data
print(f"Original Data: {originalData}\n")
print(f"Encoded Data: {serializedData}\n")
print(f"Decoded Data: {parsedData}\n")
行 5 和 6 包含代码运行所需的导入。我们正在导入我们的盟友 TensorFlow 和两个用于序列化和反序列化的公共 API。
在第 9-12 行上,我们构建了一个tf.constant,它将作为我们的原始数据。该数据属于数据类型tf.dtypes.uint8。原始数据的数据类型很重要,因为在我们对二进制记录进行反序列化(解码)时需要用到它。
在的第 15 行,我们将originalData序列化为字节串(二进制表示)。
在的第 18-21 行,我们将serializedData反序列化为原始格式。注意我们需要如何使用参数out_type指定输出格式。这里我们提供与原始数据相同的数据类型(tf.dtypes.uint8)。
第 2 行 第 4 行 -第 26 行是帮助我们可视化流程的打印语句。我们来看看输出。
$ python serialization.py
Original Data: [1 2 3 4]
Encoded Data: b'\x08\x04\x12\x04\x12\x02\x08\x04"\x04\x01\x02\x03\x04'
Decoded Data: [1 2 3 4]
从输出中可以明显看出,原始数据被序列化为一系列字节字符串,然后反序列化为原始数据。
TF records from structuredtf.data:让我们稍微回顾一下我们刚刚讲过的内容。
我们知道二进制记录是如何存储在 TFRecord 中的;我们还讨论了将任何数据解析成二进制记录。现在,我们将深入研究将结构化数据集转换为 TFRecords 的过程。
在这一步中,我们将需要到目前为止我们已经讨论过的所有先决条件。
在我们处理整个数据集之前,让我们首先尝试理解如何处理数据集的单个实例。
数据集(结构化数据集)由单个实例组成。这些实例可以认为是一个 Example 。让我们把一个图像和类名对看作一个Example。这个例子由两个单独的 Feature 合称为 Features 。其中一个Feature是图像,另一个是类名。
从 TFRecords 上的 TensorFlow 官方指南中,如图图 2 所示,我们可以看到tf.train.Feature可以接受的不同数据类型。
这意味着该特性需要被序列化为上述列表中的一个,然后被打包成一个特性。
让我们通过下面的例子来看看如何做到这一点。
# import the necessary packages
import tensorflow as tf
from pyimagesearch import config
from tensorflow.io import read_file
from tensorflow.image import decode_image, convert_image_dtype, resize
import matplotlib.pyplot as plt
import os
def load_image(pathToImage):
# read the image from the path and decode the image
image = read_file(pathToImage)
image = decode_image(image, channels=3)
# convert the image data type and resize it
image = convert_image_dtype(image, tf.dtypes.float32)
image = resize(image, (16, 16))
# return the processed image
return image
def save_image(image, saveImagePath, title=None):
# show the image
plt.imshow(image)
# check if title is provided, if so, add the title to the plot
if title:
plt.title(title)
# turn off the axis and save the plot to disk
plt.axis("off")
plt.savefig(saveImagePath)
在这个例子中,我们同时做很多事情。首先,让我们查看一下utils.py文件,了解一下预处理步骤。
在2-7 行,我们导入必要的包。接下来,我们在第 9-19 行的上定义我们的load_image函数,它从磁盘读取一个图像,将其转换为 32 位浮点格式,将图像大小调整为 16×16,然后返回。
接下来,我们在第 21-31 行的上定义我们的save_image函数,它将图像和输出图像路径作为输入。在第 23 行上,我们显示图像,然后在第 26 行和第 27 行上设置情节标题。最后,我们将图像保存到磁盘的第 30 行和第 31 行。
现在让我们看看如何从磁盘加载一个原始图像,并将其序列化为 TFRecord 格式。然后,我们将看到如何加载序列化的 TFRecord 并反序列化图像。
# USAGE
# python example_tf_record.py
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
from tensorflow.keras.utils import get_file
from tensorflow.io import serialize_tensor
from tensorflow.io import parse_example
from tensorflow.io import parse_tensor
from tensorflow.io import TFRecordWriter
from tensorflow.io import FixedLenFeature
from tensorflow.train import BytesList
from tensorflow.train import Example
from tensorflow.train import Features
from tensorflow.train import Feature
from tensorflow.data import TFRecordDataset
import tensorflow as tf
import os
从行 5 -19 ,我们导入所有需要的包。
# a single instance of structured data will consist of an image and its
# corresponding class name
imagePath = get_file(
config.IMAGE_FNAME,
config.IMAGE_URL,
)
image = utils.load_image(pathToImage=imagePath)
class_name = config.IMAGE_CLASS
# check to see if the output folder exists, if not, build the output
# folder
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# save the resized image
utils.save_image(image=image, saveImagePath=config.RESIZED_IMAGE_PATH)
# build the image and the class name feature
imageFeature = Feature(
bytes_list=BytesList(value=[
# notice how we serialize the image
serialize_tensor(image).numpy(),
])
)
classNameFeature = Feature(
bytes_list=BytesList(value=[
class_name.encode(),
])
)
# wrap the image and class feature with a features dictionary and then
# wrap the features into an example
features = Features(feature={
"image": imageFeature,
"class_name": classNameFeature,
})
example = Example(features=features)
在的第 23-26 行,我们从一个特定的 url 下载一个图像,并将图像保存到磁盘。接下来,在的第 27 行,我们使用load_image函数从磁盘加载图像作为tf.Tensor。最后,第 28 行指定了图像的类名。
图像和类名将作为我们的单个实例数据。我们现在需要将它们序列化并保存为单独的Feature。第 39-49 行负责序列化过程,并将图像和类名包装为Feature。
现在我们有了自己的个体Feature,我们需要将它包装成一个名为Features的集合。第 53-56 行构建一个Features,由一个Feature的字典组成。最后,第 57 行通过将Features包装成一个Example结束了我们的旅程。
# serialize the entire example
serializedExample = example.SerializeToString()
# write the serialized example into a TFRecord
with TFRecordWriter(config.TFRECORD_EXAMPLE_FNAME) as recordWriter:
recordWriter.write(serializedExample)
# build the feature schema and the TFRecord dataset
featureSchema = {
"image": FixedLenFeature([], dtype=tf.string),
"class_name": FixedLenFeature([], dtype=tf.string),
}
dataset = TFRecordDataset(config.TFRECORD_EXAMPLE_FNAME)
# iterate over the dataset
for element in dataset:
# get the serialized example and parse it with the feature schema
element = parse_example(element, featureSchema)
# grab the serialized class name and the image
className = element["class_name"].numpy().decode()
image = parse_tensor(
element["image"].numpy(),
out_type=tf.dtypes.float32
)
# save the de-serialized image along with the class name
utils.save_image(
image=image,
saveImagePath=config.DESERIALIZED_IMAGE_PATH,
title=className
)
在第 60 行上,我们可以使用SerializeToString函数直接序列化Example。接下来,我们从第 63 行和第 64 行的上的序列化示例中直接构建 TFRecord。
现在我们在第 67-70 行的处构建一个特征示意图。该示意图将用于解析每个示例。
如前所述,使用 TFRecords 构建tf.data.Dataset非常简单。在第 71 行,我们使用简单的 API TFRecordDataset构建数据集。
在第 74-90 行上,我们迭代数据集。第 76 行用于解析数据集的每个元素。请注意,我们在这里是如何使用特征原理图来解析示例的。在的第 79-83 行,我们获取了类名和图像的反序列化状态。最后,我们将图像保存到磁盘的第 86-90 行中。
高级 TFRecord 生成
现在让我们看看如何生成高级 TFRecords。在本节中,我们将使用tfds(代表tensorflow_datasets,即用型数据集的集合)加载 div2k 数据集,对其进行预处理,然后将预处理后的数据集序列化为 TFRecords。
# USAGE
# python create_tfrecords.py
# import the necessary packages
from pyimagesearch import config
from tensorflow.io import serialize_tensor
from tensorflow.io import TFRecordWriter
from tensorflow.train import BytesList
from tensorflow.train import Feature
from tensorflow.train import Features
from tensorflow.train import Example
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# define AUTOTUNE object
AUTO = tf.data.AUTOTUNE
从第 5-14 行,我们导入所有必需的包,包括我们的配置文件、tensorflow 数据集集合,以及将数据集序列化为 TFrecords 所需的其他 TensorFlow 子模块。在第 17 行的上,我们定义了tf.data.AUTOTUNE用于优化目的。
def pre_process(element):
# grab the low and high resolution images
lrImage = element["lr"]
hrImage = element["hr"]
# convert the low and high resolution images from tensor to
# serialized TensorProto proto
lrByte = serialize_tensor(lrImage)
hrByte = serialize_tensor(hrImage)
# return the low and high resolution proto objects
return (lrByte, hrByte)
在的第 19-30 行,我们定义了我们的pre_process函数,它接受一个由低分辨率和高分辨率图像组成的元素作为输入。在第 21 和 22 行,我们抓取低分辨率和高分辨率图像。在第 26 行和第 27 行,我们将低分辨率和高分辨率图像从 tensors 转换为序列化 TensorProto 类型。最后,在第 30 行,我们返回低分辨率和高分辨率图像。
def create_dataset(dataDir, split, shardSize):
# load the dataset, save it to disk, and preprocess it
ds = tfds.load(config.DATASET, split=split, data_dir=dataDir)
ds = (ds
.map(pre_process, num_parallel_calls=AUTO)
.batch(shardSize)
)
# return the dataset
return ds
在的第 32-41 行,我们定义了我们的create_dataset函数,它将存储数据集、数据集分割和碎片大小的目录路径作为输入。在第 34 行,我们加载 div2k 数据集并将其存储在磁盘上。在第 35-38 行,我们预处理数据集和批量大小。最后,在第 41 行,我们返回 TensorFlow 数据集对象。
def create_serialized_example(lrByte, hrByte):
# create low and high resolution image byte list
lrBytesList = BytesList(value=[lrByte])
hrBytesList = BytesList(value=[hrByte])
# build low and high resolution image feature from the byte list
lrFeature = Feature(bytes_list=lrBytesList)
hrFeature = Feature(bytes_list=hrBytesList)
# build a low and high resolution image feature map
featureMap = {
"lr": lrFeature,
"hr": hrFeature,
}
# build a collection of features, followed by building example
# from features, and serializing the example
features = Features(feature=featureMap)
example = Example(features=features)
serializedExample = example.SerializeToString()
# return the serialized example
return serializedExample
在的第 43-65 行,我们定义了我们的create_serialized_example函数,它以字节形式接受低分辨率和高分辨率图像作为输入。在第 45 和 46 行,我们创建了低分辨率和高分辨率图像字节列表对象。在第 49-56 行上,我们从字节列表构建低分辨率和高分辨率图像特征,并从低分辨率和高分辨率图像特征构建后续图像特征图。在第 60-62 行,我们从特征映射中构建一个特征集合,然后从特征中构建一个例子并序列化这个例子。最后,在第 65 行上,我们返回序列化的例子。
def prepare_tfrecords(dataset, outputDir, name, printEvery=50):
# check whether output directory exists
if not os.path.exists(outputDir):
os.makedirs(outputDir)
# loop over the dataset and create TFRecords
for (index, images) in enumerate(dataset):
# get the shard size and build the filename
shardSize = images[0].numpy().shape[0]
tfrecName = f"{index:02d}-{shardSize}.tfrec"
filename = outputDir + f"/{name}-" + tfrecName
# write to the tfrecords
with TFRecordWriter(filename) as outFile:
# write shard size serialized examples to each TFRecord
for i in range(shardSize):
serializedExample = create_serialized_example(
images[0].numpy()[i], images[1].numpy()[i])
outFile.write(serializedExample)
# print the progress to the user
if index % printEvery == 0:
print("[INFO] wrote file {} containing {} records..."
.format(filename, shardSize))
在第 67-90 行上,我们定义了prepare_tfrecords函数,它主要以 TensorFlow 数据集和输出目录路径作为输入。在第 69 行和第 70 行,我们检查输出目录是否存在,如果不存在,我们就创建它。在第 73 行,我们开始遍历数据集,抓取索引和图像。在第 75-77 行上,我们设置了分片大小、输出 TFRecord 名称和输出 TFrecord 的路径。在第 80-90 行,我们打开一个空的 TFRecord,并开始向其中写入序列化的示例。
# create training and validation dataset of the div2k images
print("[INFO] creating div2k training and testing dataset...")
trainDs = create_dataset(dataDir=config.DIV2K_PATH, split="train",
shardSize=config.SHARD_SIZE)
testDs = create_dataset(dataDir=config.DIV2K_PATH, split="validation",
shardSize=config.SHARD_SIZE)
# create training and testing TFRecords and write them to disk
print("[INFO] preparing and writing div2k TFRecords to disk...")
prepare_tfrecords(dataset=trainDs, name="train",
outputDir=config.GPU_DIV2K_TFR_TRAIN_PATH)
prepare_tfrecords(dataset=testDs, name="test",
outputDir=config.GPU_DIV2K_TFR_TEST_PATH)
在第 93-97 行,我们创建了 div2k 训练和测试 TensorFlow 数据集。从第 100-104 行,我们开始调用prepare_tfrecords函数来创建将保存在磁盘上的训练和测试 TFRecords。
汇总
在本教程中,您学习了什么是 TFRecords,以及如何使用 TensorFlow 生成 TFRecords 来训练深度神经网络。
我们首先从 TFRecords 的基础知识开始,学习如何使用它们来序列化数据。接下来,我们学习了如何使用 TFRecords 预处理和序列化像 div2k 这样的大型数据集。
TFRecord 格式的两个主要优点是,它帮助我们高效地存储数据集,并且我们获得了比从磁盘读取原始数据更快的 I/O 速度。
当我们用 TPU 训练深度神经网络时,TFRecords 是极其有益的。如果你对此感兴趣,那么一定要看看 SRGAN 和 ESRGAN 教程,它们涵盖了如何使用张量处理单元(TPU)和图形处理单元(GPU)来训练深度神经网络。
参考
对我们有帮助的所有教程列表:
- https://www . ka ggle . com/code/ryanholbrook/TF records-basics/notebook
- https://www.tensorflow.org/tutorials/load_data/tfrecord
引用信息
A. R. Gosthipaty 和 A. Thanki。“TF records 简介”, PyImageSearch ,D. Chakraborty,P. Chugh,S. Huot,K. Kidriavsteva,R. Raha 编辑。,2022 年,【https://pyimg.co/s5p1b
@incollection{ARG-AT_2022_TFRecords,
author = {Aritra Roy Gosthipaty and Abhishek Thanki},
title = {Introduction to TFRecords},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/s5p1b},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!*
单词袋(BoW)模型简介
原文:https://pyimagesearch.com/2022/07/04/introduction-to-the-bag-of-words-bow-model/
目录
介绍词袋(BoW)模型
基于文本数据创建统计模型总是比基于图像数据建模更复杂。图像数据包含可检测的模式,这可以帮助模型识别它们。文本数据中的模式更复杂,使用传统方法需要更多的计算。
上周,我们简单回顾了一下自然语言处理(NLP)的历史。今天,我们将学习计算机语言数据建模中最先使用的技术之一,单词袋(BoW)。
在本教程中,您将了解单词袋模型以及如何实现它。
本课是关于 NLP 101 的四部分系列的第二部分:
*要学习如何 实现词汇袋模型 , 就继续阅读吧。
介绍词袋(BoW)模型
弓型简介
单词袋模型是一种从文本数据中提取特征的简单方法。这个想法是将每个句子表示为一个单词包,不考虑语法和范例。句子中单词的出现为模型定义了句子的含义。
这可以被认为是表征学习的延伸,你在一个 N 维空间中表征句子。对于每一句话,模型将为每个维度分配一个权重。这将成为模型的句子标识。
让我们更深入地了解它的含义。看一下图一。
我们有两句话:“我有一只狗”和“你有一只猫。”首先,我们获取当前词汇表中的所有单词,并创建一个表示矩阵,其中每一列都对应一个单词,如图 1 所示。
我们的句子总共有 8 个单词,但是因为我们有 2 个单词(have、a)重复,所以总词汇量变成了 6。现在我们有 6 列代表词汇表中的每个单词。
现在,每个句子都表示为词汇表中所有单词的组合。例如,“我有一只狗”在词汇表中有 6 个单词中的 4 个,因此我们将打开现有单词的位,关闭句子中不存在的单词的位。
因此,如果 vocab 矩阵列按照I、have、a、dog、you和cat的顺序排列,那么第一句话(“我有一只狗”)表示变成1,1,1,1,0,0,而第二句话(“你有一只猫”)表示变成0,1,1,0,1,1。
这些表征成为让一个模型理解不同句子本质的关键。我们确实忽略了语法,但是因为这些句子是相对于完整的词汇来看的,所以每个句子都有独特的标记化表示,这有助于它们从其他句子中脱颖而出。
例如,第一个句子会很突出,因为它打开了dog和I位,而第二个句子打开了cat和you位。表示中的这些小变化有助于我们使用单词袋方法对文本数据建模。
这里,我们用逐位方法解释了 BoW。BoW 还可以配置为存储单词的出现频率,以便在模型训练期间进行额外的强化。
鞠躬的利弊
马上,我们看到了这种方法的一个主要问题。如果我们的输入数据很大,那就意味着词汇量也会增加。这反过来又使我们的表示矩阵变得更大,计算变得非常复杂。
另一个计算噩梦是在我们的矩阵(即稀疏矩阵)中包含许多 0。稀疏矩阵包含的信息较少,会浪费大量内存。
单词袋最大的缺点是完全不会学习语法和语义。表示矩阵中的标记化表示定义了一个句子,只有单词在句子中的出现/不出现才能将其与其他单词区分开来。
从更好的方面来看,单词袋方法以一种显著的方式强调了表征学习的好处。它简单直观的方法至少帮助我们解释了单词的组合对计算机意味着什么。
当然,这就给词汇袋的应用带来了问题。首先,这是向更复杂的表示学习示例(如 Word2Vec 和 Glove)迈出的一大步。由于它也呼应了“一键编码”表示的概念,词袋主要用于文本文档的特征生成。
既然我们已经掌握了单词袋的概念,那就让我们来实施它吧!
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install tensorflow
$ pip install numpy
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── pyimagesearch
│ ├── bow.py
│ ├── config.py
│ ├── data_processing.py
│ ├── __init__.py
│ ├── model.py
│ └── tensorflow_wrapper.py
└── train.py
1 directory, 7 files
在pyimagesearch目录中,我们有:
- 将单词袋技术应用到句子中。
config.py:包含项目的配置管道。data_processing.py:容纳数据处理实用程序。__init__.py:将pyimagesearch目录变成 python 包。model.py:包含一个小型的神经网络架构。tensorflow_wrapper.py:包含用tensorflow工具包装的单词包方法。
在父目录中,我们有:
- 包含单词袋方法的训练脚本。
配置先决条件
在pyimagesearch目录中,我们有一个名为config.py的脚本,它包含了这个项目的配置管道。
# define the data to be used
dataDict = {
"sentence":[
"Avengers is a great movie.",
"I love Avengers it is great.",
"Avengers is a bad movie.",
"I hate Avengers.",
"I didnt like the Avengers movie.",
"I think Avengers is a bad movie.",
"I love the movie.",
"I think it is great."
],
"sentiment":[
"good",
"good",
"bad",
"bad",
"bad",
"bad",
"good",
"good"
]
}
# define a list of stopwords
stopWrds = ["is", "a", "i", "it"]
# define model training parameters
epochs = 30
batchSize = 10
# define number of dense units
denseUnits = 50
我们将使用 NumPy 和 TensorFlow 实现单词包,以比较这两种方法。在的第 2-23 行,我们有dataDict,一个包含我们输入数据的字典,这些数据被分成句子和它们相应的标签。
在第 26 行的上,我们定义了一个停用词列表,由于 BoW 方法不关心语法和语义,我们将从数据中省略它。每个句子的独特单词越多,就越容易与其他句子区分开来。
在第 29-33 行上,我们为 TensorFlow 模型定义了一些参数,如历元数、批量大小以及要添加到我们的小型神经网络中的密集单元数。配置管道到此结束。
处理我们的数据为弓近
作为深度学习的从业者,你我大概都忽略了,把日常项目中的很多东西想当然了。我们几乎在每个处理任务中都使用 TensorFlow/PyTorch 包装器,却忘记了是什么让这些包装器如此重要。
对于我们今天的项目,我们将自己编写一些预处理包装器。为此,让我们进入data_processing.py脚本。
# import the necessary packages
import re
def preprocess(sentDf, stopWords, key="sentence"):
# loop over all the sentences
for num in range(len(sentDf[key])):
# lowercase the string and remove punctuation
sentence = sentDf[key][num]
sentence = re.sub(
r"[^a-zA-Z0-9]", " ", sentence.lower()
).split()
# define a list for processed words
newWords = list()
# loop over the words in each sentence and filter out the
# stopwords
for word in sentence:
if word not in stopWords:
# append word if not a stopword
newWords.append(word)
# replace sentence with the list of new words
sentDf[key][num] = newWords
# return the preprocessed data
return sentDf
在第 4 行的上,我们有第一个帮助函数preprocess,它接受以下参数:
sentDf:输入数据帧。stopWords:要从数据中省略的单词列表。key:进入输入数据帧相关部分的键。
我们循环遍历数据帧中所有可用的句子(第 6-27 行),将单词小写,去掉标点符号,并省略停用词。
def prepare_tokenizer(df, sentKey="sentence", outputKey="sentiment"):
# counters for tokenizer indices
wordCounter = 0
labelCounter = 0
# create placeholder dictionaries for tokenizer
textDict = dict()
labelDict = dict()
# loop over the sentences
for entry in df[sentKey]:
# loop over each word and
# check if encountered before
for word in entry:
if word not in textDict.keys():
textDict[word] = wordCounter
# update word counter if new
# word is encountered
wordCounter += 1
# repeat same process for labels
for label in df[outputKey]:
if label not in labelDict.keys():
labelDict[label] = labelCounter
labelCounter += 1
# return the dictionaries
return (textDict, labelDict)
这个脚本中的第二个函数是prepare_tokenizer ( 第 29 行),它接受以下参数:
df:我们将从中创建我们的标记器的数据帧。sentKey:从数据框中进入句子的键。outputKey:从数据框中访问标签的键。
首先,我们为第 31 行和第 32 行的索引创建计数器。在的第 35 行和第 36 行,我们为分词器创建字典。
接下来,我们开始循环句子(第 39 行),并将单词添加到我们的字典中。如果我们遇到一个我们已经见过的单词,我们忽略它。如果这个单词是新遇到的,它将被添加到词典中(第 42-48 行)。
我们对标签应用相同的过程(第 51-54 行),结束prepare_tokenizer脚本。
建立文字袋功能
现在,我们将进入bow.py脚本,看看我们计算单词包的自定义函数。
def calculate_bag_of_words(text, sentence):
# create a dictionary for frequency check
freqDict = dict.fromkeys(text, 0)
# loop over the words in sentences
for word in sentence:
# update word frequency
freqDict[word]=sentence.count(word)
# return dictionary
return freqDict
函数calculate_bag_of_words接受词汇和句子作为它的参数(第 1 行)。接下来,我们在第三行创建一个字典来检查和存储单词的出现。
循环一个句子中的每个单词(第 6 行),我们计算一个特定单词出现的次数并返回它(第 8-11 行)。
张量流缠绕:另类
到目前为止,我们已经看到了自己创建所有预处理功能是什么样子。如果你觉得太复杂,我们也将向你展示如何使用 TensorFlow 进行同样的过程。让我们进入tensorflow_wrapper.py。
# import the necessary packages
from tensorflow.keras.preprocessing.text import Tokenizer
def tensorflow_wrap(df):
# create the tokenizer for sentences
tokenizerSentence = Tokenizer()
# create the tokenizer for labels
tokenizerLabel = Tokenizer()
# fit the tokenizer on the documents
tokenizerSentence.fit_on_texts(df["sentence"])
# fit the tokenizer on the labels
tokenizerLabel.fit_on_texts(df["sentiment"])
# create vectors using tensorflow
encodedData = tokenizerSentence.texts_to_matrix(
texts=df["sentence"], mode="count")
# add label column
labels = df["sentiment"]
# correct label vectors
for i in range(len(labels)):
labels[i] = tokenizerLabel.word_index[labels[i]] - 1
# return data and labels
return (encodedData[:, 1:], labels.astype("float32"))
在脚本内部,我们有tensorflow_wrap ( 第 4 行)函数,它接受数据帧作为参数。
在的第 6-9 行,我们分别为句子和标签初始化分词器。通过简单地使用fit_on_texts函数,我们已经完成了句子和标签的标记器的创建(第 12-15 行)。
使用另一个名为texts_to_matrix的函数来创建我们的编码,我们得到了经过处理的句子的矢量化格式(第 18 行和第 19 行)。
在第 22-26 行上,我们创建标签,然后在第 29 行上返回编码和标签。
#import the necessary packages
import pyimagesearch.config as config
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
def build_shallow_net():
# define the model
model = Sequential()
model.add(Dense(config.denseUnits, input_dim=10, activation="relu"))
model.add(Dense(config.denseUnits, activation="relu"))
model.add(Dense(1, activation="sigmoid"))
# compile the keras model
model.compile(loss="binary_crossentropy", optimizer="adam",
metrics=["accuracy"]
)
# return model
return model
在第 6 行的上,我们定义了build_shallow_net函数,它初始化了一个浅层神经网络。
网络从一个dense层开始,其中输入数设置为 10。这是因为我们的文本语料库经过处理后的词汇量是 10。接下来是两个致密层,最后是乙状结肠激活的输出层(第 8-11 行)。
在第 14 行和第 15 行,我们用binary_crossentropy损失、adam优化器和accuracy作为度量来编译模型。
这样,我们的模型就可以使用了。
训练弓模型
现在是时候结合我们所有的模块,训练单词袋模型方法了。让我们进入train.py脚本。
# USAGE
# python train.py
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.model import build_shallow_net
from pyimagesearch.bow import calculate_bag_of_words
from pyimagesearch.data_processing import preprocess
from pyimagesearch.data_processing import prepare_tokenizer
from pyimagesearch.tensorflow_wrapper import tensorflow_wrap
import pandas as pd
# convert the input data dictionary to a pandas data frame
df = pd.DataFrame.from_dict(config.dataDict)
# preprocess the data frame and create data dictionaries
preprocessedDf = preprocess(sentDf=df, stopWords=config.stopWrds)
(textDict, labelDict) = prepare_tokenizer(df)
# create an empty list for vectors
freqList = list()
# build vectors from the sentences
for sentence in df["sentence"]:
# create entries for each sentence and update the vector list
entryFreq = calculate_bag_of_words(text=textDict,
sentence=sentence)
freqList.append(entryFreq)
在第 14 行,我们将config.py中定义的输入数据字典转换成数据帧。然后使用data_processing.py创建的preprocess函数处理数据帧(行 17 )。随后在行 18 上创建记号赋予器。
我们生成一个空列表来存储在行 21 出现的单词。循环每个句子,使用位于bow.py ( 第 24-28 行)的calculate_bag_of_words函数计算单词的频率。
# create an empty data frame for the vectors
finalDf = pd.DataFrame()
# loop over the vectors and concat them
for vector in freqList:
vector = pd.DataFrame([vector])
finalDf = pd.concat([finalDf, vector], ignore_index=True)
# add label column to the final data frame
finalDf["label"] = df["sentiment"]
# convert label into corresponding vector
for i in range(len(finalDf["label"])):
finalDf["label"][i] = labelDict[finalDf["label"][i]]
# initialize the vanilla model
shallowModel = build_shallow_net()
print("[Info] Compiling model...")
# fit the Keras model on the dataset
shallowModel.fit(
finalDf.iloc[:,0:10],
finalDf.iloc[:,10].astype("float32"),
epochs=config.epochs,
batch_size=config.batchSize
)
在行 31 上创建一个空数据帧来存储矢量化输入。freqList中的每个向量被添加到第 34-36 行的空数据帧中。
标签被添加到第 39 行的数据帧中。但是由于标签仍然是字符串格式,我们在的第 42 行和第 43 行将它们转换成矢量格式。
用于训练的普通模型在行 46 上初始化,我们继续在行 50-55 上拟合训练数据和标签。因为我们已经将标签列添加到数据帧中,所以我们可以使用iloc功能来分离数据和标签(0:10用于数据,10用于标签)。
# create dataset using TensorFlow
trainX, trainY = tensorflow_wrap(df)
# initialize the new model for tf wrapped data
tensorflowModel = build_shallow_net()
print("[Info] Compiling model with tensorflow wrapped data...")
# fit the keras model on the tensorflow dataset
tensorflowModel.fit(
trainX,
trainY,
epochs=config.epochs,
batch_size=config.batchSize
)
现在我们进入tensorflow包装的数据。仅仅一行代码(第 58 行)就让我们得到了trainX(数据)和trainY(标签)。数据被放入名为tensorflowModel ( 第 61-70 行)的不同模型中。
了解培训指标
需要记住的重要一点是,我们的数据集非常小,结果应该被认为是不确定的。然而,让我们来看看我们的训练精度。
[INFO] Compiling model...
Epoch 1/30
1/1 [==============================] - 0s 495ms/step - loss: 0.7262 - accuracy: 0.5000
Epoch 2/30
1/1 [==============================] - 0s 10ms/step - loss: 0.7153 - accuracy: 0.5000
Epoch 3/30
1/1 [==============================] - 0s 10ms/step - loss: 0.7046 - accuracy: 0.5000
...
Epoch 27/30
1/1 [==============================] - 0s 7ms/step - loss: 0.4756 - accuracy: 1.0000
Epoch 28/30
1/1 [==============================] - 0s 5ms/step - loss: 0.4664 - accuracy: 1.0000
Epoch 29/30
1/1 [==============================] - 0s 10ms/step - loss: 0.4571 - accuracy: 1.0000
Epoch 30/30
1/1 [==============================] - 0s 5ms/step - loss: 0.4480 - accuracy: 1.0000
我们的普通模型在30th时期达到了100%的精度,这是给定数据集的大小所期望的。
<keras.callbacks.History at 0x7f7bc5b5a110>
[Info] Compiling Model with Tensorflow wrapped data...
1/30
1/1 [==============================] - 1s 875ms/step - loss: 0.6842 - accuracy: 0.5000
Epoch 2/30
1/1 [==============================] - 0s 14ms/step - loss: 0.6750 - accuracy: 0.5000
Epoch 3/30
1/1 [==============================] - 0s 7ms/step - loss: 0.6660 - accuracy: 0.5000
...
Epoch 27/30
1/1 [==============================] - 0s 9ms/step - loss: 0.4730 - accuracy: 0.8750
Epoch 28/30
1/1 [==============================] - 0s 12ms/step - loss: 0.4646 - accuracy: 0.8750
Epoch 29/30
1/1 [==============================] - 0s 12ms/step - loss: 0.4561 - accuracy: 0.8750
Epoch 30/30
1/1 [==============================] - 0s 9ms/step - loss: 0.4475 - accuracy: 0.8750
<keras.callbacks.History at 0x7f7bc594c710>
由于数据集较小,数据包装模型在其最后一个时期似乎也达到了相当高的精度。
很明显,这两个模型都必须过度拟合。然而,要注意的重要一点是,当涉及到文本数据时,我们很可能希望我们的模型过度拟合训练数据以获得最佳结果。
如果您想知道为什么我们希望我们的模型过度拟合,那是因为当涉及到文本数据时,您的训练文本数据成为您的不容置疑的戒律。假设一个特定的单词在不同的句子中出现了多次。尽管如此,对于类似的上下文,您肯定希望您的模型能够理解并适应它,这样这个词的意思对模型来说就变得很清楚了。
正如我前面提到的,文本数据与图像数据有很大的不同。我们在进行过度拟合语句时考虑的一个假设是,训练数据将覆盖出现在不同上下文中的单词的几乎所有实例。
汇总
今天我们学习了单词袋(BoW),这是自然语言处理(NLP)中表征学习的一个很好的介绍。我们本质上是按照一定的模式,将我们的数据重新打包成标记组。这些有助于模型对句子的意思有一个基本的理解。
自然语言处理的 BoW 方法在考虑上下文和含义的能力方面是有限的。自然,将句子表示为词汇出现在处理多义词和同音异义词时是无效的。
它无法解释句法依赖性和非标准文本,这表明 BoW 不是一个强大的算法。但是在 NLP 发展的背景下,这种技术开启了表征学习的许多后续推动,因此成为 NLP 历史的关键部分。
引用信息
Chakraborty,D. “单词袋(BoW)模型介绍”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/oa2kt
@incollection{Chakraborty_2022_BoW,
author = {Devjyoti Chakraborty},
title = {Introduction to the Bag-of-Words {(BoW)} Model},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/oa2kt},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
YOLO 家族简介
原文:https://pyimagesearch.com/2022/04/04/introduction-to-the-yolo-family/
YOLO 家族简介
目标检测是计算机视觉中最重要的课题之一。大多数计算机视觉问题涉及检测视觉对象类别,如行人、汽车、公共汽车、人脸等。这是一个不仅限于学术界的领域,在视频监控、医疗保健、车载传感和自动驾驶等领域也有潜在的真实世界商业用例。
很多用例,尤其是自动驾驶,需要很高的精度和实时推理速度。因此,选择一款既能满足速度要求又能满足精度要求的物体检测器变得至关重要。YOLO(你只看一次)是一个单级对象检测器,介绍了实现两个目标(即,速度和准确性)。今天,我们将介绍 YOLO 家族,包括所有的 YOLO 变种(例如,YOLOv1,YOLOv2,…,YOLOX,YOLOR)。
从一开始,对象检测领域就有了很大的发展,最先进的体系结构在各种测试数据集上得到了很好的推广。但是为了理解这些当前最好的架构背后的魔力,有必要知道这一切是如何开始的,以及我们在 YOLO 家族中已经达到了什么程度。
在对象检测中有三类算法:
- 基于传统的计算机视觉
- 基于两阶段深度学习的算法
- 第三种是基于单阶段深度学习的算法
今天,我们将讨论 YOLO 对象检测家族,它属于单阶段深度学习算法。
我们相信这是一篇独一无二的博客文章,在一篇文章中涵盖了所有 YOLO 版本,将帮助您深入了解每个版本,并可能帮助您为您的项目选择最佳的 YOLO 版本。
这节课是我们关于 YOLO 天体探测器的 7 部分系列的第一节课:
- (今日教程)
- 了解一个实时物体检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的物体探测器(YOLOv2)
- 使用 COCO 评估器 平均精度(mAP)
- 用 Darknet-53 和多尺度预测的增量改进(YOLOv3)
- 【yolov 4】
- 在自定义数据集上训练 YOLOv5 物体检测器
要了解 YOLO 家族是如何进化的,每一个变种在检测图像中的物体方面都不同于前一个版本,并且比前一个版本更好,继续阅读。*
物体探测简介
回忆在图像分类中,目标是回答“图像中存在什么?”其中模型试图通过给图像分配特定的标签来理解整个图像。
通常,我们处理图像分类中只存在一个对象的情况。如图图 1 所示,我们有一个圣诞老人,还有几个物体,但主要物体是圣诞老人,有 98%的概率被正确分类。太好了。在像这样的特定情况下,当一幅图像描绘一个单一的物体时,分类足以回答我们的问题。
然而,在许多情况下,我们无法用单个标签说出图像中的内容,图像分类不足以帮助回答这个问题。例如,考虑图 2 ,其中模型检测三个对象:两个人和一个棒球手套,不仅如此,它还识别每个对象的位置。这被称为对象检测。
物体检测的另一个关键用例是自动车牌识别,如图图 3 所示。现在问你自己一个问题,如果你不知道车牌的位置,你如何识别车牌上的字母和数字?当然,首先,你需要用物体检测器识别车牌的位置,然后应用第二种算法来识别数字。
对象检测包括分类和定位任务,用于分析图像中可能存在多个对象的更真实的情况。因此,目标检测是一个两步过程;第一步是找到物体的位置。
第二步是将这些边界框分类成不同的类别,因为这种对象检测会遇到与图像分类相关的所有问题。此外,它还有本地化和执行速度的挑战。
挑战
-
拥挤或杂乱场景:图像中过多的物体(图 4 )使其变得极其拥挤。这给对象检测模型带来了各种挑战,如遮挡可能很大,对象可能很小,以及比例可能不一致。
-
类内方差:对象检测的另一个主要挑战是正确检测同一类的对象,这可能具有高方差。比如图五所示,狗的品种有六种,而且都有不同的大小、颜色、皮毛长度、耳朵等。,所以检测这些同类的物体可能具有挑战性。
-
类别不平衡:这是一个影响几乎所有模态的挑战,无论是图像、文本还是时间序列;更具体地说,在图像领域,图像分类非常困难,对象检测也不例外。我们称之为物体检测中的前景-背景类不平衡,如图图 6 所示。
为了理解类别不平衡如何在对象检测中造成问题,考虑包含很少主要对象的图像。图像的其余部分用背景填充。因此,该模型将查看图像(数据集)中的许多区域,其中大多数区域将被认为是负面的。由于这些负面因素,模型学不到任何有用的信息,并且会淹没模型的整个训练。
许多其他挑战与对象检测相关,如遮挡、变形、视点变化、光照条件,以及实时检测的基本速度(许多工业应用中需要)。
物体探测的历史
目标检测是计算机视觉中最关键和最具挑战性的问题之一,在过去的十年中,它的发展创造了历史。然而,这一领域的进展是显著的;每年,研究界都会实现一个新的最先进的基准。当然,如果没有深度神经网络的力量和 NVIDIA GPUs 的大规模计算,这一切都不可能实现。
在物体检测的历史中,有两个截然不同的时代:
- 传统的计算机视觉方法一直持续到 2010 年,
- 从 2012 年开始,当 AlexNet(一种图像分类网络)赢得 ImageNet 视觉识别挑战赛时,卷积神经网络的新时代开始了。
这两个时代之间的区别在图 7 中也很明显,该图显示了物体检测的路线图,从 2004 年的Viola–Jones探测器到 2019 年的 EfficientDet 。值得一提的是,基于深度学习的检测方法进一步分为两级检测器和单级检测器。
大多数传统的对象检测算法,如 Viola–Jones、梯度方向直方图(HOG)和可变形部分模型(DPM ),都依赖于从图像中提取手工特征,如边缘、角、梯度和经典的机器学习算法。例如,第一个对象检测器 Viola–Jones 仅设计用于检测人的正面,而在侧面和上下面部上表现不佳。
然后,2012 年迎来了一个新时代。一场彻底改变了计算机视觉游戏的革命,当一种深度卷积神经网络(CNN)架构 AlexNet 因需要改善 ImageNet challenge 的结果而诞生时,在 2012 ImageNet LSVRC-2012 challenge 上实现了相当高的准确度,其准确度为 84.7% ,而第二名的准确度为 73.8%。
那么,这些最先进的图像分类架构开始被用作对象检测管道中的特征提取器只是时间问题。这两个问题是相互关联的,它们依赖于学习健壮的高级特征。因此, Girschick 等人(2014) 展示了我们如何使用卷积特征进行对象检测,引入了 R-CNN(将 CNN 应用于区域提议)。从那时起,物体检测开始以前所未有的速度发展。
如图图 7 所示,深度学习检测方法可以分为两个阶段;第一种称为两阶段检测算法,在多个阶段进行预测,包括像 RCNN,Fast-RCNN Faster-RCNN 等网络。
第二类探测器称为单级探测器,如 SSD ,YOLO,EfficientDet 等。
在图 8 中,你可以看到所有的 YOLO 物体检测算法以及它们是如何进化的,从 2016 年 YOLOv1 在 Pascal VOC (20 类)数据集上获得 63.4mAP 到 2021 年 YOLOR 在更具挑战性的 MS COCO 数据集(80 类)上获得 73.3 mAP。这就是学术界的魅力所在。凭借持续的努力和应变能力,YOLO 天体探测已经取得了长足的进步!
什么是单级物体探测器?
单级对象检测器是一类单级对象检测架构。他们将目标检测视为简单的回归问题。例如,馈送到网络的输入图像直接输出类别概率和边界框坐标。
这些模型跳过区域提议阶段,也称为区域提议网络,它通常是两阶段对象检测器的一部分,是图像中可能包含对象的区域。
图 9 显示了单级和两级探测器的工作流程。在单阶段中,我们直接在特征图上应用检测头,而在两阶段中,我们首先在特征图上应用区域建议网络。
然后,这些区域被进一步传递到第二阶段,对每个区域进行预测。fast-RCNN 和 Mask-RCNN 是一些最流行的两阶段对象检测器。
虽然两级检测器被认为比单级对象检测器更准确,但是它们涉及多级时推理速度较慢。另一方面,单级检测器比两级检测器快得多。
yolov 1
2016 年,Joseph Redmon 等人在 CVPR 会议上发布了第一款单级物体探测器 You Only Look Once: Unified,Real-Time Object Detection 。
YOLO (你只看一次)是物体探测领域的突破,因为它是第一个将探测视为回归问题的单级物体探测器方法。检测架构仅查看图像一次,以预测对象的位置及其类别标签。
与两阶段检测器方法(快速 RCNN,更快 RCNN)不同,YOLOv1 没有建议生成器和细化阶段;它使用一个单一的神经网络,从一个完整的图像中预测类别概率和边界框坐标。因为检测管道本质上是一个网络,所以它可以被端到端地优化;可以把它想象成一个图像分类网络。
由于该网络旨在以类似于图像分类的端到端方式进行训练,因此该架构速度极快,并且基本 YOLO 模型在 Titan X GPU 上以 45 FPS(每秒帧数)的速度预测图像。作者还提出了一种更轻便的 YOLO 版本,称为快速 YOLO,具有更少的以 155 FPS 处理图像的层。是不是很神奇?
YOLO 实现了 63.4 mAP (均值平均精度),如表 1 所示,是其他实时探测器的两倍多,让它更加特别。我们可以看到,在平均精度(接近 2 倍)和 FPS 方面,YOLO 和快速 YOLO 都远远超过 DPM 的实时对象检测器变体。
YOLO 的概括能力在来自互联网的艺术作品和自然图像上进行了测试。此外,它大大优于可变形部分模型(DPM)和基于区域的卷积神经网络(RCNN)等检测方法。
在我们接下来的第 2 课中,我们将深入探讨 YOLOv1,所以一定要去看看!
约洛夫 2
雷德蒙和法尔哈迪(2017)在 CVPR 会议上发表了 YOLO9000:更好、更快、更强的论文。作者在本文中提出了两种最先进的 YOLO 变种:YOLOv2 和 YOLO9000 两者完全相同,但训练策略不同。
YOLOv2 在检测数据集上接受训练,如 Pascal VOC 和 MS COCO 。同时,YOLO9000 被设计成通过在 MS COCO 和 ImageNet 数据集上联合训练来预测 9000 多种不同的物体类别。
改进的 YOLOv2 模型使用了各种新技术,在速度和准确性方面都优于 Faster-RCNN 和 SSD 等最先进的方法。一种这样的技术是多尺度训练,它允许网络在不同的输入规模下进行预测,从而允许在速度和准确性之间进行权衡。
在 416×416 输入分辨率下,YOLOv2 在 VOC 2007 数据集上实现了 76.8 mAP ,在 Titan X GPU 上实现了 67 FPS 。在 544×544 输入的同一数据集上,YOLOv2 获得了 78.6 mAP 和 40 FPS 。
图 10 显示了 YOLOv2 在 Titan X GPU 上不同分辨率下的基准测试,以及其他检测架构,如更快的 R-CNN、YOLOv1、SSD。我们可以观察到,几乎所有的 YOLOv2 变体在速度或准确性方面都优于其他检测框架,并且在 YOLOv2 中可以观察到准确性(mAP)和 FPS 之间的明显权衡。
关于 YOLOv2 的详细回顾,请关注我们即将到来的第 3 课。
约洛夫 3
雷德蒙和法尔哈迪(2018)发表了关于 arXiv 的 YOLOv3:增量改进论文。作者对网络架构做了许多设计上的修改,并采用了 YOLOv1 的大部分其他技术,尤其是 YOLOv2。
本文介绍了一种新的网络体系结构 Darknet-53。Darknet-53 是一个比以前大得多的网络,并且更加精确和快速。它在各种图像分辨率下进行训练,如 320×320、416×416。在 320×320 分辨率下,YOLOv3 在 Titan X GPU 上实现了 28.2 mAP 以 45 FPS 运行,精度与单镜头探测器(SSD321)一样,但速度快 3 倍(如图图 11 )。
在接下来的第 5 课中,我们将彻底分解 YOLOv3。
约洛夫 4
YOLOv4 是许多实验和研究的产物,结合了各种提高卷积神经网络准确性和速度的小型新技术。
本文对不同的 GPU 架构进行了广泛的实验,结果显示 YOLOv4 在速度和准确性方面优于所有其他对象检测网络架构。
2020 年,Bochkovskiy 等人(著名 GitHub 知识库:Darknet 的作者)在 arXiv 上发表了 YOLOv4:物体检测的最佳速度和精度论文。我们可以从图 12 中观察到,在性能相当的情况下,YOLOv4 的运行速度是 EfficientDet 的两倍,它将 YOLOv3 的 mAP 和 FPS 提高了 10%和 12%。
卷积神经网络(CNN)的性能很大程度上取决于我们使用和组合的特征。例如,某些功能仅适用于特定的模型、问题陈述和数据集。但是批量规范化和残差连接等功能适用于大多数模型、任务和数据集。因此,这些特征可以被称为普遍性的。
Bochkovskiy 等人利用这一想法并假设一些通用特征,包括
- 加权剩余连接(WRC)
- 跨级部分连接(CSP)
- 交叉小批量归一化(CmBN)
- 自我对抗训练
- Mish 激活
- 镶嵌数据增强
- 丢弃块正则化
- CIoU 损失
上述功能相结合,实现了最先进的结果:在特斯拉 V100 GPU 上以 65 FPS 的实时速度在 MS COCO 数据集上实现了 43.5%的 mAP (65.7% mAP50)。
YOLOv4 模型结合了上述和更多的特征,形成了用于改进模型训练的“赠品包”和用于改进物体检测器精度的“特殊包”。
我们将在即将到来的第 6 课中用代码全面介绍 YOLOv4。
约洛夫 5
2020 年,YOLOv4 发布后,短短两个月内, Ultralytics 的创始人兼首席执行官 Glenn Jocher 在 GitHub 上发布了 YOLOv5 的开源实现。YOLOv5 提供了一系列在 MS COCO 数据集上预先训练的对象检测架构。紧接着发布了 EfficientDet 和 YOLOv4。这是唯一一个没有研究论文的 YOLO 天体探测器,最初导致了一些争议;然而,很快,这种想法被打破了,因为它的能力破坏了噪音。
今天,YOLOv5 是官方最先进的模型之一,拥有巨大的支持,并且在生产中更容易使用。最好的部分是 YOLOv5 是在 PyTorch 中本地实现的,消除了 Darknet 框架的限制(基于 C 编程语言,而不是从生产环境的角度构建的)。Darknet 框架已经随着时间的推移而发展,是一个很好的研究框架,可以使用 TensorRT 进行训练、微调和推理;所有这些都可以通过 Darknet 实现。然而,它有一个较小的社区,因此,支持较少。
PyTorch 中 YOLO 的这一巨大变化使得开发人员更容易修改架构并直接导出到许多部署环境中。别忘了,YOLOv5 是火炬中心展示区的官方最先进车型之一。
正如您在下面的 shell 块中所看到的,您可以用 YOLOv5 和 PyTorch Hub 在仅仅五行代码中运行一个推理。是不是很神奇?
$ import torch
$ model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l
$ img = 'https://ultralytics.cimg/zidane.jpg' # or file, Path, PIL, OpenCV
$ results = model(img)
$ results.print() # or .show(), .save()
在发布的时候,YOLOv5 是所有已知的 YOLO 实现中最先进的。自从 YOLOv5 发布以来,这个库一直非常活跃,自从 YOLOv5-v1.0 发布以来,已经有超过 90 个贡献者。
从开发的角度来看,YOLOv5 存储库提供了大量的功能,使得在各种目标平台上训练、调整、测试和部署变得更加容易。他们提供的一些现成教程包括:
- 自定义数据集训练
- 多 GPU 训练
- 在tensort、CoreML、ONNX 和 TFLite 上导出训练好的 YOLOv5 模型
- 修剪 YOLOv5 架构
- 使用 TensorRT 部署
此外,他们还开发了一款名为 iDetection 的 iOS 应用,提供了 YOLOv5 的四种变体。我们在 iPhone 13 Pro 上测试了该应用,结果令人印象深刻;该模型以接近 30FPS 的速度运行检测。
与 YOLOv4 相同,YOLO v5 使用跨级部分连接,主干是 Darknet-53,路径聚合网络是瓶颈。主要改进包括新的镶嵌数据增强(来自 YOLOv3 PyTorch 实现)和自动学习边界框锚点。
镶嵌数据增强
镶嵌数据增强的想法最初由 Glenn Jocher 在 YOLOv3 PyTorch 实现中使用,现在用于 YOLOv5。镶嵌增强将四幅训练图像按照特定的比例拼接成一幅图像,如图图 13 所示。马赛克增强对流行的 COCO 对象检测基准特别有用,有助于模型学习解决众所周知的“小对象问题”——小对象不如较大对象检测得准确。
使用镶嵌数据增强的好处在于
- 网络在一个图像中看到更多的上下文信息,甚至在它们的正常上下文之外。
- 允许模型学习如何在比通常更小的尺度上识别对象。
- 批量标准化将减少 4 倍,因为它将在每层计算 4 个不同图像的激活统计数据。这将减少在训练期间对大的小批量的需求。
量化基准
在表 2 中,我们展示了 Volta 100 GPU 上 640×640 图像分辨率的 MS COCO 验证数据集上五个 YOLOv5 变体的性能(mAP)和速度(FPS)基准。所有五个模型都是在 MS COCO 训练数据集上训练的。型号性能指标评测从 YOLOv5n 开始按升序显示(即,具有最小型号尺寸的 nano 变体到最大型号 YOLOv5x)。
考虑 YOLOv5l 它实现了 10.1ms(或 100 FPS)的推理速度,批量大小= 1,在 0.5 IOU 时的 mAP 为 67.2。相比之下,V100 上 608 分辨率的 YOLOv4 在 0.5 IOU 下用 65.7 mAP 实现了 62 FPS 的推理速度。YOLOv5 是这里的明显赢家,因为它提供了最好的性能,甚至比 YOLOv4 更快。
YOLOv5 纳米释放
2021 年 10 月,YOLOv5-v6.0 发布,整合了许多新功能和错误修复(来自 73 名贡献者的 465 条 PRs),带来了架构调整,并重点介绍了新的 P5 和 P6 Nano 型号:YOLOv5n 和 YOLOv5n6。Nano 型号的参数比以前的型号少~75%,从 7.5M 到 1.9M,小到足以在移动设备和 CPU 上运行(如图图 14 所示)。从下图中还可以明显看出,YOLOv5 的性能远远优于 EfficientDet。此外,即使是最小的 YOLOv5 变体(即 YOLOv5n6)也能比 EfficientDet 更快地达到相当的精度。
约洛夫 5n 与约洛夫 4 相比——微小的
由于 YOLOv5n 是 YOLOv5 最小的变体,我们将其与 YOLOv4-Tiny 进行比较,YOLOv4-Tiny 也是 yolov 4 型号中最轻的变体。图 15 显示 YOLOv5 nano 变体在训练时间和准确性方面明显优于 YOLOv4-Tiny。
PP-YOLO
到目前为止,我们已经在两个不同的框架中看到了 YOLO,即 Darknet 和 PyTorch 然而,还有第三个实现 YOLO 的框架叫做 PaddlePaddle framework,因此得名 PP-YOLO 。PaddlePaddle 是百度编写的深度学习框架,拥有海量的计算机视觉和自然语言处理模型知识库。
YOLOv4 发布还不到四个月,2020 年 8 月,百度 ( 龙等)的研究人员发表了《PP-YOLO:物体检测器的有效实现》。与 YOLOv4 类似,PP-YOLO 物体探测器也是基于 YOLOv3 架构构建的。
PP-YOLO 是 PaddleDetection 的一部分,这是一个基于 PaddlePaddle 框架的端到端对象检测开发套件(如图图 16** 所示)。它提供了大量的对象检测架构、主干、数据增强技术、组件(如 losses、特征金字塔网络等)。)可以组合成不同的配置来设计最佳的对象检测网络。
简而言之,它提供了图像处理功能,如对象检测、实例分割、多对象跟踪、关键点检测,从而以更快、更好的方式简化了这些模型的构建、训练、优化和部署中的对象检测过程。
现在让我们回到 PP-YOLO 论文。
PP-YOLO 论文的目标不是发布一个新颖的对象检测模型,而是一个具有相对平衡的有效性和效率的对象检测器,可以直接应用于实际应用场景。这个目标与 PaddleDetection 开发套件的动机产生了共鸣。因此,新奇的是证明这些技巧和技术的组合更好地平衡了有效性和效率,并提供了一个消融研究每一步对探测器有多大帮助。
与 YOLOv4 类似,本文还尝试结合现有的各种技巧,在不增加模型参数和 FLOPs 数量的情况下,尽可能提高检测器的精度,并保证检测器的速度几乎不变。然而,与 YOLOv4 不同,这篇论文没有探索不同的主干网络(Darknet-53,ResNext50)和数据增强方法,也没有使用神经架构搜索(NAS)来搜索模型超参数。
PP-YOLO 表演
通过结合所有的技巧和技术,当在批量= 1 的 Volta 100 GPU 上测试时,PP-YOLO 实现了 45.2%的 mAP 和 72.9 FPS 的推理速度(如图图 17 所示),标志着有效性和效率之间的更好平衡,超过了著名的最先进的检测器,如 EfficientDet、YOLOv4 和 RetinaNet。
PP-YOLO 建筑
单级检测模型通常由主干、检测颈和检测头组成。PP-YOLO 的架构(如图图 18 所示)与 YOLOv3 和 YOLO4 检测模型非常相似。
PP-YOLO 检测器分为三个部分:
-
主干:物体检测器的主干是一个完全卷积的网络,有助于从图像中提取特征图。它在精神上类似于预先训练的图像分类模型。提议的模型使用 ResNet50-vd-dcn 作为主干,而不是使用 Darknet-53 架构(在 YOLOv3 和 YOLOv4 中)。
在提出的主干模型中,3×3 卷积层在架构的最后一级被可变形卷积代替。ResNet50-vd 的参数数和 FLOPs 数比 Darknet-53 少得多。这有助于实现比 YOLOv3 略高的 39.1 的 mAP。
-
检测瓶颈:特征金字塔网络(FPN)通过特征地图之间的横向连接创建特征金字塔。如果你仔细观察下图,来自 C3、C4 和 C5 阶段的特征地图作为输入被馈送到 FPN 模块。
-
检测头:检测头是物体检测流水线的最后一部分,预测物体的包围盒(定位)和分类。PP-YOLO 的头部与 YOLOv3 的头部相同。预测最终输出使用 3×3 卷积层,然后是 1×1 卷积层。
最终输出的输出通道为
") ,其中
,其中 为类数(MS COCO 数据集为 80),3 为每个网格的锚点数。对于每个锚点,前 K 个通道是预测类别概率,四个通道是边界框坐标预测,一个通道是客观分数预测。
为类数(MS COCO 数据集为 80),3 为每个网格的锚点数。对于每个锚点,前 K 个通道是预测类别概率,四个通道是边界框坐标预测,一个通道是客观分数预测。
") ,其中
,其中 为类数(MS COCO 数据集为 80),3 为每个网格的锚点数。对于每个锚点,前 K 个通道是预测类别概率,四个通道是边界框坐标预测,一个通道是客观分数预测。
为类数(MS COCO 数据集为 80),3 为每个网格的锚点数。对于每个锚点,前 K 个通道是预测类别概率,四个通道是边界框坐标预测,一个通道是客观分数预测。在上面的 PP-YOLO 架构中,菱形注入点表示坐标-conv 层,紫色三角形表示拖放块,红色星形标记表示空间金字塔池。
选择招数和技巧
如果您还记得,我们讨论过本文结合了各种技巧和技术来设计有效且高效的对象检测网络;现在,我们将简要介绍每一项。这些技巧都是已经存在的,来自不同的论文。
- 更大的批量:利用更大的批量有助于稳定训练,并让模型产生更好的结果。批次大小从 64 个更改为 192 个,相应地,学习率和培训计划也将更新。
- 指数移动平均:作者声称,使用训练参数的移动平均在推断过程中产生了更好的结果。
- DropBlock 正则化:这是一种类似于用于防止过拟合的 drop 正则化的技术。然而,在丢弃块正则化中,丢弃的特征点不再随机分布,而是组合成块,并且丢弃整个块。因此,这是一种结构性缺失,其中来自特征图相邻区域的神经元被一起丢弃,如图图 19 所示。
在 PP-YOLO 中,DropBlock 仅应用于检测头(即 FPN),因为将其添加到主干会降低模型的性能。
- 交集超过并集(IoU)损耗:增加了一个额外的损耗(即 IoU 损耗)来训练模型,而 YOLOv3 中使用了现有的 L1 损耗,大部分 YOLO 架构都没有替换。增加了一个额外的分支来计算 IoU 损失。这是因为 mAP 评估指标强烈依赖于 IoU。
- IoU Aware: 由于在最终检测置信度中不考虑定位精度,所以增加了 IoU 预测分支来测量定位精度。而在推断期间,预测的 IoU 分数乘以分类概率和客观性分数来预测最终的检测置信度。
- 矩阵非最大值抑制(NMS): 软 NMS 版本的并行实现比传统 NMS 使用得更快,并且不会带来任何效率损失。软 NMS 按顺序工作,不能并行实现。
- 空间金字塔池(SPP)层:yolov 4 中实现的 SPP 层也应用于 PP-YOLO,但仅应用于顶部要素地图。添加 SPP 会增加 2%的模型参数和 1%的 FLOPS,但这会让模型增加特征的感受域。
- 更好的预训练模型:使用 ImageNet 上分类精度更好的预训练模型,检测性能更好。提取的 ResNet50-vd 模型被用作预训练模型。
结果
在前面对 PP-YOLO 的介绍中,我们了解到 PP-YOLO 的运行速度比 YOLOv4 更快,平均精度得分从 43.5%提高到 45.2%。PP-YOLO 的详细性能如表 3 所示。
Long et al. (2020) 在 Volta 100 GPU 上比较了有无 TensorRT 的模型(以加快推断速度)。从表中,我们可以得出结论,与 YOLOv4 相比,MS COCO 数据集上的 mAP 得分从 43.5%增加到 45.2%,FPS 从 62 增加到 72.9(不含 TensorRT)。
该表还显示了具有其他图像分辨率的 PP-YOLO,与其他最先进的检测器相比,PP-YOLO 在速度和准确性的平衡方面确实具有优势。
消融研究
作者进行的烧蚀研究显示了技巧和技术如何影响模型的参数和性能。在表 4 中,PP-YOLO 从表示为 B 的第二行开始,其中检测器使用 ResNet50 作为具有可变形卷积的主干。当您移动到下一行 C 时,技巧被添加到先前的模型架构中,并且贯穿始终。参数和触发器的性能增益和增加显示在相应的列中。
我们强烈建议您查看论文了解更多细节。
【约洛夫 4】
王等(2021) 在会议上发表了题为“Scaled-YOLOv4: Scaling 跨级局部网络”的论文。这篇论文到目前为止已经收集了 190 多篇引用!有了 Scaled-YOLOv4,作者通过有效地扩展网络的设计和规模,推动了 YOLOv4 模型的发展,超过了今年早些时候由谷歌研究大脑团队发布的先前最先进的 EfficientDet 。
PyTorch 框架中 Scaled-YOLOv4 的实现可以在这里找到。
所提出的基于跨阶段部分方法的检测网络可以向上和向下扩展,在速度和准确性的两端都超过了以前的小型和大型对象检测模型的基准。此外,网络扩展方法修改了网络的深度、宽度、分辨率和结构。
图 20 显示了缩放的 YOLOv4-large 模型在 Tesla V100 GPU 上以 16 FPS 的速度对 MS COCO 数据集实现了 55.5%的 AP (73.4% AP50)。
另一方面,名为 Scaled-YOLOv4-tiny 的较轻版本在 RTX 2080Ti GPU 上以 443 FPS 的速度实现了 22.0% AP (42.0% AP50),同时使用 TensorRT(具有半精度 FP-16)优化(批量大小= 4)。
图 20 显示,与其他最先进的检测器相比,Scaled-YOLOv4 获得了最佳结果。
什么是模型缩放?
卷积神经网络架构可以在三个维度上扩展:深度、宽度和分辨率。网络的深度对应于网络的层数。宽度与卷积层中滤波器或信道的数量相关。最后,分辨率就是输入图像的高度和宽度。
图 21 给出了跨这三个维度的模型缩放的更直观的理解,其中(a)是基线网络示例;(b)-(d)是仅增加网络宽度、深度或分辨率的一个维度的传统缩放;以及(e)是提出的(在效率上)复合缩放方法,其以固定的比率均匀地缩放所有三个维度。
传统的模型缩放方法是改变一个模型的深度,即增加更多的卷积层数。例如,Simonyan 等人设计的 VGGNet 在不同阶段堆叠了额外的卷积层,并使用这一概念设计了 VGG-16 和 VGG-19 架构。
以下方法通常遵循相同的模型缩放方法。首先是由何等(2015) 提出的 ResNet 架构,使用深度缩放来构造非常深的网络,如 ResNet-50、ResNet-101,这种架构允许网络学习更复杂的特征,但遭受消失梯度问题。后来, Zagoruyko 和 Komodakis (2017) 想到了网络的宽度,他们改变了卷积层的核的数量来实现缩放,于是,wide ResNet (WRN),同时保持了相同的精度。尽管 WRN 的参数比 ResNet 多,但推理速度却快得多。
然后近年来,复合缩放使用复合系数统一缩放卷积神经网络架构的深度/宽度/分辨率的所有维度。与任意缩放这些因素的传统实践不同,复合缩放方法使用一组固定的缩放系数统一缩放网络宽度、深度和分辨率。
而这也是 scaled-YOLOv4 试图做的事情,即使用最优网络缩放技术来实现 YOLOv4-CSP -> P5 -> P6 -> P7 检测网络。
约洛夫 4 对约洛夫 4 的改进
- Scaled-YOLOv4 使用最佳网络扩展技术来实现 YOLOv4-CSP -> P5 -> P6 -> P7 网络。
- 修改了宽度和高度的激活,允许更快的网络训练。
- 改进的网络架构:主干优化和颈部(路径聚合网络)使用 CSP 连接和 Mish 激活。
- 在训练期间使用指数移动平均线(EMA)。
- 对于网络的每个分辨率,训练一个单独的网络,而在 YOLOv4 中,在多个分辨率上训练单个网络。
约洛夫 4 设计
CSP 化的 yolov 4
YOLOv4 是为通用 GPU 上的实时对象检测而设计的。在缩放 YOLOv4 中,YOLOv4 根据 YOLOv4-CSP 进行了重新设计,以获得最佳的速度/精度平衡。
王等(2021) 在论文中经常提到,他们将物体检测网络的某个给定部分“CSP 化”。这里的 CSP-ize 意味着应用跨级部分网络论文中提出的概念。CSP 是一种构建卷积神经网络的新方法,它减少了各种 CNN 网络的计算量:高达 50%(对于 FLOPs 中的暗网主干)。
在 CSP 连接中:
- 一半的输出信号沿着主路径,这有助于利用大的感受野产生更多的语义信息。
- 信号中枢的另一半通过一个小的感受野帮助保留更多的空间信息。
图 22 显示了一个 CSP 连接的例子。左边是标准网络,右边是 CSP 网络。
缩放 yolov 4-微型模型
YOLOv4-tiny 模型与缩放的 YOLOv4 模型有不同的考虑,因为在 edge 上,各种约束开始起作用,如内存带宽和内存访问。对于 YOLOv4-tiny 的浅层 CNN,作者期待 OSANet 在小深度的有利计算复杂性。
表 5 显示了 YOLOv4-tiny 与其他微小物体探测器的性能对比。同样,与其他微型型号相比,YOLOv4-tiny 实现了最佳性能。
表 6 显示了 YOLOv4-tiny 在不同嵌入式 GPU 上测试的结果,包括 Xavier AGX、Xavier NX、Jetson TX2、Jetson NANO。如果采用 FP16 和 batch size = 4 来测试 Xavier AGX 和 Xavier NX ,帧率可以分别达到 290 FPS 和 118 FPS 。
另外,如果一个人使用 TensorRT FP16 在通用 GPU RTX 2080ti 上运行 YOLOv4-tiny,当批量分别等于 1 和 4 时,各自的帧率可以达到 773 FPS 和 1774 FPS ,速度极快。
YOLOv4-tiny 无论使用哪种设备都能实现实时性能。
缩放 YOLOv4-CSP 型号
为了检测大图像中的大物体,作者发现增加 CNN 主干和颈部的深度和级数是必不可少的(据报道,增加宽度几乎没有影响)。这允许他们首先扩大输入大小和级数,并根据实时推理速度要求动态调整宽度和深度。除了这些比例因子之外,作者还在论文中改变了他们的模型体系结构的配置。
YOLOv4-large 是为云 GPU 设计的;主要目的是实现物体检测的高精度。此外,开发了一个完全 CSP 化的型号 YOLOv4-P5,并将其放大到 YOLOv4-P6 和 YOLOv4-P7,如图图 23 所示。
当宽度缩放因子等于 1 时,YOLOv4-P6 可以在视频上达到 30 FPS 的实时性能。当宽度缩放因子等于 1.25 时,YOLOv4-P7 可以在视频上实现 16 FPS 的实时性能。
数据扩充
YOLOv4 中的数据增强是 YOLOv4 令人印象深刻的性能的关键贡献之一。在 Scaled-YOLOv4 中,作者首先在一个较少扩充的数据集上进行训练,然后在训练结束时打开扩充进行微调。他们还使用“测试时间扩充”,将几个扩充应用于测试集。然后,对这些测试增强的预测进行平均,以进一步提高其非实时结果。
总之,作者表明基于 CSP 方法的 YOLOv4 对象检测神经网络可向上和向下扩展,并适用于小型和大型网络;因此,他们称之为缩放 YOLOv4。此外,建议的模型(YOLOv4-large)在测试开发 MS COCO 数据集上实现了 56.0% AP 的最高精度,通过使用 TensorRT-FP16,小模型 YOLOv4-tiny RTX 2080Ti 实现了极高的速度 1774 FPS,以及其他 YOLOv4 模型的最佳速度和精度。
到目前为止,我们已经覆盖了七个 YOLO 物体探测器,我们可以说,对于物体探测来说,2020 年是迄今为止最好的一年,对 YOLO 家族来说更是如此。我们了解到,YOLOv4、YOLOv5、PP-YOLO 和 Scaled-YOLOv4 相继达到了物体检测的最新水平。
现在让我们继续下一个 YOLO 探测器,看看 2021 年会发生什么!
PP-yolov 2
2021 年,百度发布了 PP-YOLO 的第二个版本,名为 PP-YOLOv2:黄兴等人的实用对象检测器,发表在 arXiv 上,实现了对象检测领域的新高度。
从该论文的标题中,人们可以很容易地推断出该论文背后的动机是开发一种目标检测器,该检测器实现良好的准确性并以更快的速度执行推理。因此,这是一种实用的物体检测器。此外,由于本文是之前工作(即 PP-YOLO)的后续,作者希望开发一种在有效性和效率之间达到完美平衡的检测器,为了实现这一点,采用了类似的组合技巧和技术,重点是消融研究。
通过结合多种有效的改进,PP-YOLOv2 显著提高了性能(即在 MS COCO2017 测试集上从 45.9%的 mAP 提高到 49.5%的 mAP)。再者,在速度上,PP-YOLOv2 在 640×640 图像分辨率下运行在 68.9FPS,如图图 24 所示。此外,PPYOLOv2 还引入了两种不同的主干架构:ResNet-50 和 ResNet-101,这与 PPYOLOv1 不同,ppyolov 1 只发布了 ResNet-50 主干。
在 TensorRT 引擎的支持下,on half-precision (FP16,批处理大小= 1)进一步将 PP-YOLOv2-ResNet50 推理速度提高到 106.5 FPS,超过了 YOLOv4-CSP 和 YOLOv5l 等其他最先进的对象检测器,模型参数数量大致相同。
当检测器的主干从 ResNet50 更换为 ResNet101 时,PP-YOLOv2 在 MS COCO2017 测试集上实现了 50.3%的 mAP,实现了与 YOLOv5x 相似的性能,在速度上大幅领先 YOLOv5x 近 16%。
所以现在你知道如果你的老板让你处理一个涉及物体检测的问题,你需要选择哪个检测器。当然,如果 KPI 要以快得多的速度取得好的业绩,答案会是 PP-YOLOv2:)!
重访 PP-YOLO
到目前为止,我们知道 PP-YOLOv2 建立在 PP-YOLO 论文的研究进展基础上,该论文是 PP-YOLOv2 的基线模型。
PP-YOLO 是 YOLOv3 的增强版本,其中骨架被来自 Darknet-53 的 ResNet50-vd 取代。通过利用总共 10 个技巧进行严格的消融研究,实现了许多其他改进,例如
- 丢弃块正则化
- 可变形卷积
- CoordConv
- 空间金字塔池
- 欠条损失和分支
- 网格灵敏度
- 矩阵 NMS
- 更好的图像预处理模型
选择细化的
- 路径聚合网络(PAN): 为了检测不同尺度的对象,作者在对象检测网络的颈部使用 PAN。在 PP-YOLO 中,特征金字塔网络被用来构建自底向上的路径。与 YOLOv4 类似,在 PP-YOLOv2 中,作者遵循 PAN 的设计来聚合自顶向下的信息。
- Mish 激活函数:Mish 激活函数用于检测网络的颈部;因为 PP-YOLOv2 使用预训练的参数,因为它在 ImageNet 分类数据集上具有稳健的 82.4% top-1 准确度。在 YOLOv4 和 YOLOv5 等各种实际物体探测器的主干中,它被证明是有效的。
- 更大的输入尺寸:检测更小的物体通常是一项挑战,随着图像在网络中穿行,小尺寸物体的信息会丢失。因此,在 PP-YOLOv2 中,输入尺寸增加,从而扩大了对象的面积。因此,性能将会提高。最大输入大小 608 增加到 768。因为,较大的输入分辨率会占用更多的内存,因此,批量大小会从每 GPU 24 张图像减少到每 GPU 12 张图像,并在不同的输入大小上均匀绘制
[320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768]。 - 欠条感知分支:在 PP-YOLO 中,欠条感知损失以软权重格式计算,与初衷不符。因此,在 PP-YOLOv2 中,软标签格式可以更好地调整 PP-YOLO 损失函数,并使其更加了解边界框之间的重叠。
表 7 显示了在 Volta 100 GPU 上对 MS COCO mini 验证分割推断进行改进的消融研究。表中, A 指基线 PP-YOLO 模型。然后在 B 中,潘和米什加入到 A 中,对 2 地图进行了大幅提升;虽然 B 比 A 慢,但是精度的跃升还是值得的。
YOLOv4 和 YOLOv5 在 640 图像分辨率上进行评估,PP-YOLOv2 的输入大小增加到 640,用于训练和评估,以便进行公平的比较(如 C 所示)。
在推断时间没有减少的情况下,可以看到在 D (更大的输入大小)和 E (IoU 感知分支)中增加的 mAP 增益,这是一个好现象。
有关 PP-YOLOv2 与其他最先进的物体探测器的速度和精度比较的更多详细信息,请查看他们关于 arXiv 的论文中的表 2。
YOLOX
2021 年,Ge 等人在 arXiv 上发表了名为YOLOX:2021 年超越 YOLO 系列的技术报告。到目前为止,我们知道的唯一无锚 YOLO 物体探测器是 YOLOv1,但 YOLOX 也以无锚方式探测物体。此外,它还实施其他先进的检测技术,如解耦头,利用稳健的数据增强技术,以及领先的标签分配策略 SimOTA 来实现最先进的结果。
YOLOX 使用单个 YOLOX-L 模型在串流感知挑战赛(与 CVPR 2021 联合举办的自动驾驶研讨会)中获得第一名。
如图图 25 (右)所示,YOLOX-Nano 仅用 0.91M 的参数,在 MS COCO 数据集上取得了 25.3%的 AP,超过NanoDet1.8%的 AP。对 YOLOv3 添加各种修改将 COCO 上的准确率从 44.3%提高到 47.3%。
YOLOX-L 在 Tesla V100 上以 68.9 FPS 的速度在 COCO 上实现了 50.0%的 AP,参数与 YOLOv4- CSP、YOLOv5-L 大致相同,超过 yolo V5-L 1.8%的 AP。
YOLOX】在 PyTorch 框架中实现,设计时考虑了开发人员和研究人员的实际使用。因此,YOLOX deploy 版本也可以在 ONNX、TensorRT 和 OpenVino 框架中使用。
在过去的两年中,目标检测学术界的重大进展集中在无锚点检测器、高级标签分配策略和端到端(无 NMS)检测器上。然而,这些技术还没有一个被应用于 YOLO 目标检测体系结构,包括最近的模型:YOLOv4、YOLOv5 和 PP-YOLO。它们中的大多数仍然是基于锚的检测器,具有用于训练的手工分配规则。这就是出版 YOLOX 的动机!
YOLOX-darknet 53
选择具有 Darknet-53 骨架的 YOLOv3 作为基线。然后,对基本模型进行了一系列改进。
从基线到最终的 YOLOX 模型,训练设置基本相似。在批量为 128 的 MS COCO train2017 数据集上对所有模型进行了 300 个时期的训练。输入大小从 448 到 832 以 32 步均匀绘制。在单个 Tesla Volta 100 GPU 上使用 FP16 精度(半精度)和批量= 1 测量 FPS 和延迟。
——约洛夫 3——基线
它使用 DarkNet-53 主干和一个称为 YOLOv3-SPP 的 SPP 层。与最初的实现相比,一些培训策略被修改,例如
- 指数移动平均权重更新
- 余弦学习率计划
- 分类和目标处的 BCE 损失
- 回归分支的 IoU 损失
通过这些改进,YOLOv3 基线在 MS COCO 验证集上获得了 38.5%的 AP,如表 8 所示。所有模型都在 Tesla V100 上以 640×640 分辨率测试,FP16 精度,批量= 1。下表中的延迟和 FPS 是在没有后处理的情况下测量的。
解耦头
图 26 显示了 YOLOv3 至 YOLOv5 型号中使用的耦合头(顶部)和 YOLOX 中的分离头(底部)。这里的头是指不同尺度下的输出预测。例如,在耦合头中,我们有一个预测张量}")
(the detailed explanation is shown in the below figure). And the problem with this way is that usually, we have the classification and localization tasks in the same head during the training, which often compete with each other during the training. As a result, the model struggles to classify and localize each object in the image correctly.
因此,在 YOLOX 中使用了用于分类和定位的解耦头,如图图 26 ( 底部)所示。对于 FPN 特征的每个级别,首先,应用 1×1 conv 层以将特征通道减少到 256 个。然后增加两个 3×3 conv 层的并行分支,分别用于分类和定位任务。最后,一个额外的 IoU 分支被添加到本地化分支。
如图图 27 所示,去耦头允许 YOLOX 模型比耦合头收敛得更快。此外,在 x 轴上,我们可以观察到去耦头的 COCO AP 分数如何比 YOLOv3 头提高得更快。
强数据增强
添加了类似于 YOLOv4 的镶嵌和混合数据增强技术,以提高 YOLOX 的性能。Mosaic 是由 ultralytics-YOLOv3 提出的一种高效增强策略。
使用上述两种增强技术,作者发现在 ImageNet 数据集上预先训练主干并没有更多好处,所以他们从头开始训练模型。
无锚检测
为了开发高速物体探测器,YOLOX 采用了无锚机制,减少了设计参数的数量,因为现在我们不必再处理锚盒,这大大增加了预测的数量。因此,对于预测头中的每个位置或网格,我们现在只有一个预测,而不是预测三个不同锚盒的输出。每个对象的中心位置被视为正样本,并且有预定义的缩放范围。
简单来说,在无锚检测中,对每个网格的预测从 3 个减少到 1 个,它直接预测 4 个值,即网格左上角和预测框的高度和宽度方面的两个偏移量。
通过这种方法,检波器的网络参数和 GFLOPs 降低,检波器速度更快,甚至性能提高到 42.9% AP,如表 8 所示。
多重阳性
为了与 YOLOv3 的分配规则保持一致,无锚点版本只为每个对象选择一个正样本(中心位置),而忽略其他高质量的预测。然而,优化那些高质量的预测也可能带来有益的梯度,这可能会缓解训练过程中正/负采样的极端不平衡。在 YOLOX 中,中心 3×3 区域被指定为阳性,在 FCOS 论文中也被称为“中心采样”。结果,探测器的性能提高到 45.0% AP,如表 2 所示。
其他骨干
修改了 CSPNet 中的 yolov 5
为了进行公平的比较,YOLOX 用 YOLOv5 的改良 CSP v5 主干以及路斯激活和 PAN 头替换了 Darknet-53 主干。通过利用其缩放规则,产生了 YOLOX-S、YOLOX-M、YOLOX-L 和 YOLOX-X 模型。
表 9 显示了 YOLOv5 型号和 YOLOX 生产的型号之间的比较。所有 YOLOX 变体都显示出一致的改善,AP 提高了 3.0%至 1.0%,使用分离式磁头仅略微增加了时间。以下模型在 Tesla Volta 100 GPU 上以 640×640 图像分辨率、FP16 精度(半精度)和批量= 1 进行了测试。
微小和纳米探测器
我们对比了 YOLOX 和 YOLOv5 的型号,分别是小号、中号、大号和超大号(更多参数)。作者更进一步,缩小了 YOLOX 模型,使其参数低于 YOLOX-S 变体,从而生产出 YOLOX-Tiny 和 YOLOX-Nano。YOLOX-Nano 是专门为移动设备设计的。为了构造该模型,采用了深度方向卷积,结果得到了只有 0.91M 参数和 1.08G FLOPs 的模型。
如表 10 所示,YOLOX-Tiny 与 YOLOv4-Tiny、PPYOLO-Tiny 对比。同样,YOLOX 在比同类产品更小的模型尺寸下表现良好。
汇总
恭喜你走到这一步。如果你能轻松地跟上,甚至多花一点努力,那就做得很好!所以让我们快速总结一下:
- 我们从介绍对象检测开始教程:对象检测如何不同于图像分类,检测中的挑战,以及什么是单级和两级对象检测器。
- 随后,我们向您介绍了第一款名为 YOLOv1 的单级检波器。
- 然后我们简要介绍了 YOLOv2、YOLOv3 和 YOLOv4。
- 接下来,我们讨论了 Ultralytics 开发的 YOLOv5,这是继 YOLOv4 之后 PyTorch 中实现的第一个 YOLO 模型。
- 然后是百度在 PaddlePaddle 框架中实现的 PP-YOLO,它显示了优于 YOLOv4 和 EfficientDet 的有希望的结果。
- 然后讨论了 YOLOv4 的扩展,称为 Scaled-YOLOv4,基于跨阶段部分方法放大和缩小,在速度和准确性方面击败了以前的小型和大型对象检测模型(如 EfficientDet、YOLOv4 和 PP-YOLO)的基准。
- 然后我们讨论了 PP-YOLO 的第二个版本,称为 PP-YOLOv2,它对 PP-YOLO 进行了各种改进,从而显著提高了 MS COCO2017 测试集上的性能(即从 45.9% mAP 到 49.5% mAP)。
- 然后,我们讨论了 YOLOX,这是继 YOLOv1 之后的一种无锚点对象检测网络。YOLOX 在 CVPR 研讨会上赢得了流式感知挑战赛的第一名,在准确性和速度方面都超过了 YOLOv5 large 和 nano 模型。
参考文献
- https://alexeyab 84 . medium . com/scaled-yolo-v4-is-the-best-neural-network-for-object-detection-on-ms-coco-dataset-39 DFA 22 fa 982
- https://blog.roboflow.com/scaled-yolov4-tops-efficientdet/
引用信息
夏尔马,a .【YOLO 家族简介】 PyImageSearch ,d .查克拉博蒂,p .丘格,A. R .戈斯蒂帕蒂,s .霍特,k .基德里亚夫斯特瓦,r .拉哈,A. Thanki 合编。,2022 年,https://pyimg.co/dgbvi
@incollection{Sharma_2022_YOLO_Intro,
author = {Aditya Sharma},
title = {Introduction to the {YOLO} Family},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/dgbvi},
}
被修正的亚当真的比亚当更好吗?
原文:https://pyimagesearch.com/2019/10/07/is-rectified-adam-actually-better-than-adam/

修正的 Adam (RAdam)优化器真的比标准的 Adam 优化器更好吗?根据我的 24 次实验,答案是否定的,通常不会(但也有你确实想用它代替 Adam 的情况)。
在刘等人 2018 年的论文关于自适应学习率的方差和超越中,作者声称修正后的 Adam 可以得到:
- 更高的准确性(或至少与 Adam 相比具有相同的准确性)
- 并且在比标准 Adam 更少的时期内
作者在三个不同的数据集上测试了他们的假设,包括一个 NLP 数据集和两个计算机视觉数据集(ImageNet 和 CIFAR-10)。
在每个案例中,修正的 Adam 优于标准的 Adam… ,但是未能优于标准的随机梯度下降(SGD)!
修正的 Adam 优化器有一些强有力的理论依据——但作为深度学习实践者,你需要的不仅仅是理论——你需要看到经验结果应用于各种数据集。
也许更重要的是,您还需要获得操作/驱动优化器(或一小部分优化器)的精通水平的经验。
今天是我们关于修正 Adam 优化器的两部分系列的第二部分:
- 用 Keras 修正了 Adam (RAdam)优化器(上周帖子)
- 被矫正的亚当真的比亚当更好吗(今天的教程)
如果您还没有,请继续阅读第一部分,以确保您很好地理解了 Adam 优化器是如何工作的。
从那里,阅读今天的帖子,以帮助您了解如何设计、编码和运行用于比较深度学习优化器的实验。
要学习如何比较修正亚当和标准亚当,继续阅读!
被修正的亚当真的比亚当更好吗?
在本教程的第一部分,我们将简要讨论修正的 Adam 优化器,包括它是如何工作的,以及为什么它对我们这些深度学习实践者来说是有趣的。
从那里,我将指导你设计和规划我们的一组实验,以比较校正的 Adam 和 Adam — 你也可以使用这一部分来学习如何设计自己的深度学习实验。
然后我们将回顾这篇文章的项目结构,包括手工实现我们的培训和评估脚本。
最后,我们将运行我们的实验,收集结果,并最终决定是否比亚当更好?
什么是修正的 Adam 优化器?
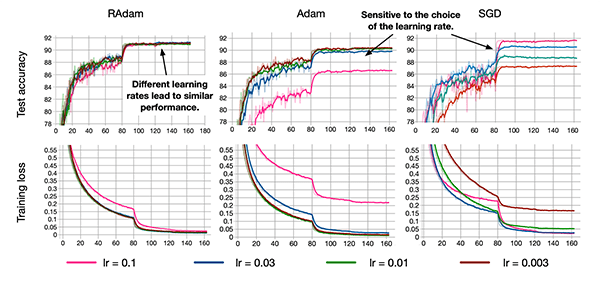
Figure 1: The Rectified Adam (RAdam) deep learning optimizer. Is it better than the standard Adam optimizer? (image source: Figure 6 from Liu et al.)
修正的 Adam 优化器是刘等人在他们 2019 年的论文 中提出的关于自适应学习率的方差和超越 。在他们的论文中,他们讨论了他们对 Adam 优化器的更新,称为整流 Adam ,如何能够:
- 获得一个精度更高/更通用的深度神经网络。
- 在个更少的时期内完成训练。
他们的工作也有一些强有力的理论依据。他们发现自适应学习率优化器(如 Adam)既:
- 在最初的几批更新中努力归纳
- 有非常高的方差
刘等人对该问题进行了详细研究,发现该问题可以通过以下方法进行纠正(因此命名为“已纠正的 Adam ”):
- 用低初始收益率进行热身。
- 简单地关闭前几组输入训练批次的动量项。
作者评估了他们在一个 NLP 数据集和两个图像分类数据集上的实验,发现他们的修正 Adam 实现优于标准 Adam(但是和优化器都没有优于标准 SGD)。
今天我们将继续刘等人的实验,并在 24 个单独的实验中比较校正 Adam 和标准 Adam。
关于 Adam 优化器如何工作的更多细节,请务必查看我之前的博客文章。
计划我们的实验

Figure 2: We will plan our set of experiments to evaluate the performance of the Rectified Adam (RAdam) optimizer using Keras.
为了比较 Adam 和整流 Adam,我们将训练三个卷积神经网络(CNN),包括:
- ResNet
- 谷歌网
- MiniVGGNet
这些 CNN 的实现直接来自我的书, 用 Python 进行计算机视觉的深度学习 。
这些网络将在四个数据集上进行训练:
- 梦妮丝
- 时尚 MNIST
- CIFAR-10
- 西发尔-100
对于数据集和 CNN 架构的每个组合,我们将应用两个优化器:
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
- 整流器 adam
取所有可能的组合,我们最终得到3×4×2 = 24个单独的训练实验。
我们将分别运行这些实验,收集结果,然后解释它们,以确定哪个优化器确实更好。
每当你计划你自己的实验时,确保你花时间写出你打算应用它们的模型架构、优化器和数据集的列表。此外,您可能希望列出您认为重要且值得调整的超参数(例如,学习率、L2 重量衰减强度等)。).
考虑到我们计划进行的 24 个实验,自动化数据收集阶段是最有意义的。从那里,我们将能够在计算进行的同时处理其他任务(通常需要几天的计算时间)。在完成我们 24 个实验的数据收集后,我们将能够坐下来分析图和分类报告,以便在我们的 CNN、数据集和优化器上评估 RAdam。
如何设计自己的深度学习实验

Figure 3: Designing your own deep learning experiments, requires thought and planning. Consider your typical deep learning workflow and design your initial set of experiments such that a thorough preliminary investigation can be conducted using automation. Planning for automated evaluation now will save you time (and money) down the line.
通常,我的实验设计工作流程是这样的:
- 选择 2-3 个我认为适合特定数据集的模型架构(即 ResNet、VGGNet 等)。).
- 决定我是要从零开始训练还是执行 转移学习 。
- 使用我的 学习率查找器 为 SGD 优化器找到一个可接受的初始学习率。
- 使用 SGD 和Keras 的标准衰变时间表 T5 在我的数据集上训练模型。****
- 查看我的训练结果,选择表现最好的架构,开始调整我的超参数,包括模型容量、正则化强度、重新访问初始学习率、应用循环学习率,并潜在地探索其他优化器。
你会注意到我在最初的实验中倾向于使用 SGD,而不是 Adam、RMSprop 等。
这是为什么呢?
要回答这个问题,你需要阅读下面的“你需要获得操作这三个优化器的大师级经验”部分。
注:关于我在设计和运行自己的实验时的更多建议、提示和最佳实践,请务必参考我的书,用 Python 进行计算机视觉的深度学习。
然而,在本教程的上下文中,我们试图将我们的结果与刘等人的工作进行比较。
因此,我们需要修正模型架构、从头开始的训练、学习率和优化器— 我们的实验设计现在变成:
- 分别在 MNIST、时尚 MNIST、CIFAR-10 和 CIFAR-100 上训练 ResNet、GoogLeNet 和 MiniVGGNet。
- 从头开始训练所有网络。
- 使用 Adam/修正 Adam (1e-3)的初始默认学习率。
- 利用 Adam 和修正的 Adam 优化器进行培训。
- 由于这些是一次性的实验,我们不会对调整超参数进行详尽的探讨(如果您想了解如何调整超参数的详细信息,可以参考 使用 Python 的计算机视觉深度学习 )。
在这一点上,我们已经激励并计划了我们的一组实验——现在让我们学习如何实现我们的培训和评估脚本。
项目结构
继续抓取 【下载】 ,然后用tree命令检查项目目录:
$ tree --dirsfirst --filelimit 10
.
├── output [48 entries]
├── plots [12 entries]
├── pyimagesearch
│ ├── __init__.py
│ ├── minigooglenet.py
│ ├── minivggnet.py
│ └── resnet.py
├── combinations.py
├── experiments.sh
├── plot.py
└── train.py
3 directories, 68 files
我们的项目包含两个输出目录:
output/:保存我们按实验组织的分类报告.txt文件。此外,每个实验都有一个.pickle文件,包含序列化的训练历史数据(用于绘图)。plots/:对于每个 CNN/数据集组合,输出一个堆叠的精度/损失曲线图,以便我们可以方便地比较 Adam 和 RAdam 优化器。
pyimagesearch模块包含三个用 Keras 构建的卷积神经网络(CNN)架构。这些 CNN 实现直接来自于 用 Python 进行计算机视觉深度学习 。
在今天的教程中,我们将回顾三个 Python 脚本:
train.py:我们的训练脚本通过命令行参数接受 CNN 架构、数据集和优化器,并开始相应地拟合模型。这个脚本将通过experiments.shbash 脚本为我们的 24 个实验中的每个实验自动调用。我们的训练脚本生成两种类型的输出文件:.txt:sci kit-learn 标准格式的分类报告打印件。.pickle:序列化的训练历史,以便以后可以调用用于绘图目的。
- 这个脚本计算我们将训练模型和收集数据的所有实验组合。执行这个脚本的结果是一个名为
experiments.sh的 bash/shell 脚本。 plot.py:直接从output/*.pickle文件使用 matplotlib 绘制 Adam/RAdam 的精度/损耗曲线。
实施培训脚本
我们的培训脚本将负责接受:
- 给定的模型架构
- 数据集
- 优化器
然后,脚本将使用指定的优化器,在提供的数据集上处理指定模型的训练。
我们将使用这个脚本来运行 24 个实验中的每一个。
现在让我们继续执行train.py脚本:
# import the necessary packages
from pyimagesearch.minigooglenet import MiniGoogLeNet
from pyimagesearch.minivggnet import MiniVGGNet
from pyimagesearch.resnet import ResNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras_radam import RAdam
from keras.datasets import fashion_mnist
from keras.datasets import cifar100
from keras.datasets import cifar10
from keras.datasets import mnist
import numpy as np
import argparse
import pickle
import cv2
导入包括我们的三个 CNN 架构、四个数据集和两个优化器(Adam和RAdam)。
让我们解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--history", required=True,
help="path to output training history file")
ap.add_argument("-r", "--report", required=True,
help="path to output classification report file")
ap.add_argument("-d", "--dataset", type=str, default="mnist",
choices=["mnist", "fashion_mnist", "cifar10", "cifar100"],
help="dataset name")
ap.add_argument("-m", "--model", type=str, default="resnet",
choices=["resnet", "googlenet", "minivggnet"],
help="type of model architecture")
ap.add_argument("-o", "--optimizer", type=str, default="adam",
choices=["adam", "radam"],
help="type of optmizer")
args = vars(ap.parse_args())
我们的命令行参数包括:
--history:输出训练历史.pickle文件的路径。--report:输出分类报告.txt文件的路径。--dataset:训练我们模型的数据集可以是第 26 行中列出的任何一个choices。--model:深度学习模型架构必须是29 线上的choices之一。--optimizer:我们的adam或radam深度学习优化方法。
通过终端提供命令行参数后,我们的训练脚本会动态设置并启动实验。输出文件根据实验的参数命名。
在这里,我们将设置两个常数,并初始化数据集的默认通道数:
# initialize the batch size and number of epochs to train
BATCH_SIZE = 128
NUM_EPOCHS = 60
# initialize the number of channels in the dataset
numChans = 1
如果我们的--dataset是 MNIST 或时尚 MNIST,我们将以下列方式加载数据集:
# check if we are using either the MNIST or Fashion MNIST dataset
if args["dataset"] in ("mnist", "fashion_mnist"):
# check if we are using MNIST
if args["dataset"] == "mnist":
# initialize the label names for the MNIST dataset
labelNames = [str(i) for i in range(0, 10)]
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, trainY), (testX, testY)) = mnist.load_data()
# otherwise, are are using Fashion MNIST
else:
# initialize the label names for the Fashion MNIST dataset
labelNames = ["top", "trouser", "pullover", "dress", "coat",
"sandal", "shirt", "sneaker", "bag", "ankle boot"]
# load the Fashion MNIST dataset
print("[INFO] loading Fashion MNIST dataset...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# MNIST dataset images are 28x28 but the networks we will be
# training expect 32x32 images
trainX = np.array([cv2.resize(x, (32, 32)) for x in trainX])
testX = np.array([cv2.resize(x, (32, 32)) for x in testX])
# reshape the data matrices to include a channel dimension which
# is required for training)
trainX = trainX.reshape((trainX.shape[0], 32, 32, 1))
testX = testX.reshape((testX.shape[0], 32, 32, 1))
请记住,MNIST 图像是 28×28 ,但我们的架构需要 32×32 图像。因此,行 66 和行 67 是数据集中的所有图像。第 71 行和第 72 行然后添加批次维度。
否则,我们需要加载一个 CIFAR 变量--dataset:
# otherwise, we must be using a variant of CIFAR
else:
# update the number of channels in the images
numChans = 3
# check if we are using CIFAR-10
if args["dataset"] == "cifar10":
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat",
"deer", "dog", "frog", "horse", "ship", "truck"]
# load the CIFAR-10 dataset
print("[INFO] loading CIFAR-10 dataset...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
# otherwise, we are using CIFAR-100
else:
# initialize the label names for the CIFAR-100 dataset
labelNames = ["apple", "aquarium_fish", "baby", "bear",
"beaver", "bed", "bee", "beetle", "bicycle", "bottle",
"bowl", "boy", "bridge", "bus", "butterfly", "camel",
"can", "castle", "caterpillar", "cattle", "chair",
"chimpanzee", "clock", "cloud", "cockroach", "couch",
"crab", "crocodile", "cup", "dinosaur", "dolphin",
"elephant", "flatfish", "forest", "fox", "girl",
"hamster", "house", "kangaroo", "keyboard", "lamp",
"lawn_mower", "leopard", "lion", "lizard", "lobster",
"man", "maple_tree", "motorcycle", "mountain", "mouse",
"mushroom", "oak_tree", "orange", "orchid", "otter",
"palm_tree", "pear", "pickup_truck", "pine_tree", "plain",
"plate", "poppy", "porcupine", "possum", "rabbit",
"raccoon", "ray", "road", "rocket", "rose", "sea", "seal",
"shark", "shrew", "skunk", "skyscraper", "snail", "snake",
"spider", "squirrel", "streetcar", "sunflower",
"sweet_pepper", "table", "tank", "telephone", "television",
"tiger", "tractor", "train", "trout", "tulip", "turtle",
"wardrobe", "whale", "willow_tree", "wolf", "woman", "worm"]
# load the CIFAR-100 dataset
print("[INFO] loading CIFAR-100 dataset...")
((trainX, trainY), (testX, testY)) = cifar100.load_data()
CIFAR 数据集包含 3 通道彩色图像(第 77 行)。这些数据集已经由 32×32 的图像组成(不需要调整大小)。
从这里开始,我们将扩展我们的数据并确定类的总数:
# scale the data to the range [0, 1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
# determine the total number of unique classes in the dataset
numClasses = len(np.unique(trainY))
print("[INFO] {} classes in dataset".format(numClasses))
随后初始化本实验的深度学习优化器:
# check if we are using Adam
if args["optimizer"] == "adam":
# initialize the Adam optimizer
print("[INFO] using Adam optimizer")
opt = Adam(lr=1e-3)
# otherwise, we are using Rectified Adam
else:
# initialize the Rectified Adam optimizer
print("[INFO] using Rectified Adam optimizer")
opt = RAdam(total_steps=5000, warmup_proportion=0.1, min_lr=1e-5)
根据--optimizer命令行参数开关初始化Adam或RAdam。
然后,根据--model命令行参数构建我们的model:
# check if we are using the ResNet architecture
if args["model"] == "resnet":
# utilize the ResNet architecture
print("[INFO] initializing ResNet...")
model = ResNet.build(32, 32, numChans, numClasses, (9, 9, 9),
(64, 64, 128, 256), reg=0.0005)
# check if we are using Tiny GoogLeNet
elif args["model"] == "googlenet":
# utilize the MiniGoogLeNet architecture
print("[INFO] initializing MiniGoogLeNet...")
model = MiniGoogLeNet.build(width=32, height=32, depth=numChans,
classes=numClasses)
# otherwise, we must be using MiniVGGNet
else:
# utilize the MiniVGGNet architecture
print("[INFO] initializing MiniVGGNet...")
model = MiniVGGNet.build(width=32, height=32, depth=numChans,
classes=numClasses)
一旦构建了 ResNet、GoogLeNet 或 MiniVGGNet,我们将二进制化我们的标签并构建我们的数据扩充对象:
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=18, zoom_range=0.15,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
horizontal_flip=True, fill_mode="nearest")
然后编译我们的模型并训练网络:
# compile the model and train the network
print("[INFO] training network...")
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // BATCH_SIZE,
epochs=NUM_EPOCHS,
verbose=1)
然后,我们评估经过训练的模型,并将训练历史转储到磁盘:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BATCH_SIZE)
report = classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames)
# serialize the training history to disk
print("[INFO] serializing training history...")
f = open(args["history"], "wb")
f.write(pickle.dumps(H.history))
f.close()
# save the classification report to disk
print("[INFO] saving classification report...")
f = open(args["report"], "w")
f.write(report)
f.close()
每个实验将包含一个分类报告.txt文件以及一个序列化的训练历史.pickle文件。
分类报告将被手动检查,而训练历史文件稍后将通过plot.py内的操作打开,训练历史将被解析并最终绘制。
正如您所了解的,创建一个动态设置实验的训练脚本非常简单。
创建我们的实验组合
在这一点上,我们有我们的训练脚本,它可以接受(1)模型架构,(2)数据集,和(3)优化器,然后使用各自的组合来拟合模型。
也就是说,我们要手动运行每个单独的命令吗?
不,这不仅是一项乏味的任务,还容易出现人为错误。
相反,让我们创建一个 Python 脚本来为我们想要运行的每个实验生成一个包含命令的 shell 脚本。
打开combinations.py文件并插入以下代码:
# import the necessary packages
import argparse
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output output directory")
ap.add_argument("-s", "--script", required=True,
help="path to output shell script")
args = vars(ap.parse_args())
我们的脚本需要两个命令行参数:
--output:存储训练文件的输出目录的路径。--script:输出 shell 脚本的路径,它将包含我们所有的训练脚本命令和命令行参数组合。
让我们打开一个新文件进行写入:
# open the output shell script for writing, then write the header
f = open(args["script"], "w")
f.write("#!/bin/sh\n\n")
# initialize the list of datasets, models, and optimizers
datasets = ["mnist", "fashion_mnist", "cifar10", "cifar100"]
models = ["resnet", "googlenet", "minivggnet"]
optimizers = ["adam", "radam"]
第 14 行打开一个 shell 脚本文件写。随后,第 15 行写“shebang”表示这个 shell 脚本是可执行的。
第 18-20 行然后列出我们的datasets、models、optimizers。
我们将在嵌套循环中从这些列表中形成所有可能的实验组合:
# loop over all combinations of datasets, models, and optimizers
for dataset in datasets:
for model in models:
for opt in optimizers:
# build the path to the output training log file
histFilename = "{}_{}_{}.pickle".format(model, opt, dataset)
historyPath = os.path.sep.join([args["output"],
histFilename])
# build the path to the output report log file
reportFilename = "{}_{}_{}.txt".format(model, opt, dataset)
reportPath = os.path.sep.join([args["output"],
reportFilename])
# construct the command that will be executed to launch
# the experiment
cmd = ("python train.py --history {} --report {} "
"--dataset {} --model {} --optimizer {}").format(
historyPath, reportPath, dataset, model, opt)
# write the command to disk
f.write("{}\n".format(cmd))
# close the shell script file
f.close()
在循环内部,我们:
- 构建我们的历史文件路径(第 27-29 行)。
- 组装我们的报告文件路径(第 32-34 行)。
- 按照当前循环迭代的组合连接每个命令,并将其写入 shell 文件(第 38-43 行)。
最后,我们关闭 shell 脚本文件。
注意:我假设您正在使用一台 Unix 机器来运行这些实验。如果您使用的是 Windows,您应该(1)更新这个脚本来生成一个批处理文件,或者(2)为每个实验手动执行train.py命令。请注意,我不支持 PyImageSearch 博客上的 Windows ,所以你需要自己基于这个脚本来实现它。
生成实验外壳脚本
继续使用本教程的 【下载】 部分将源代码下载到指南中。
从那里,打开一个终端并执行combinations.py脚本:
$ python combinations.py --output output --script experiments.sh
脚本执行后,您的工作目录中应该有一个名为experiments.sh的文件——该文件包含我们将运行的 24 个单独的实验,以比较 Adam 和修正的 Adam。
现在就开始调查experiments.sh:
#!/bin/sh
python train.py --history output/resnet_adam_mnist.pickle --report output/resnet_adam_mnist.txt --dataset mnist --model resnet --optimizer adam
python train.py --history output/resnet_radam_mnist.pickle --report output/resnet_radam_mnist.txt --dataset mnist --model resnet --optimizer radam
python train.py --history output/googlenet_adam_mnist.pickle --report output/googlenet_adam_mnist.txt --dataset mnist --model googlenet --optimizer adam
python train.py --history output/googlenet_radam_mnist.pickle --report output/googlenet_radam_mnist.txt --dataset mnist --model googlenet --optimizer radam
python train.py --history output/minivggnet_adam_mnist.pickle --report output/minivggnet_adam_mnist.txt --dataset mnist --model minivggnet --optimizer adam
python train.py --history output/minivggnet_radam_mnist.pickle --report output/minivggnet_radam_mnist.txt --dataset mnist --model minivggnet --optimizer radam
python train.py --history output/resnet_adam_fashion_mnist.pickle --report output/resnet_adam_fashion_mnist.txt --dataset fashion_mnist --model resnet --optimizer adam
python train.py --history output/resnet_radam_fashion_mnist.pickle --report output/resnet_radam_fashion_mnist.txt --dataset fashion_mnist --model resnet --optimizer radam
python train.py --history output/googlenet_adam_fashion_mnist.pickle --report output/googlenet_adam_fashion_mnist.txt --dataset fashion_mnist --model googlenet --optimizer adam
python train.py --history output/googlenet_radam_fashion_mnist.pickle --report output/googlenet_radam_fashion_mnist.txt --dataset fashion_mnist --model googlenet --optimizer radam
python train.py --history output/minivggnet_adam_fashion_mnist.pickle --report output/minivggnet_adam_fashion_mnist.txt --dataset fashion_mnist --model minivggnet --optimizer adam
python train.py --history output/minivggnet_radam_fashion_mnist.pickle --report output/minivggnet_radam_fashion_mnist.txt --dataset fashion_mnist --model minivggnet --optimizer radam
python train.py --history output/resnet_adam_cifar10.pickle --report output/resnet_adam_cifar10.txt --dataset cifar10 --model resnet --optimizer adam
python train.py --history output/resnet_radam_cifar10.pickle --report output/resnet_radam_cifar10.txt --dataset cifar10 --model resnet --optimizer radam
python train.py --history output/googlenet_adam_cifar10.pickle --report output/googlenet_adam_cifar10.txt --dataset cifar10 --model googlenet --optimizer adam
python train.py --history output/googlenet_radam_cifar10.pickle --report output/googlenet_radam_cifar10.txt --dataset cifar10 --model googlenet --optimizer radam
python train.py --history output/minivggnet_adam_cifar10.pickle --report output/minivggnet_adam_cifar10.txt --dataset cifar10 --model minivggnet --optimizer adam
python train.py --history output/minivggnet_radam_cifar10.pickle --report output/minivggnet_radam_cifar10.txt --dataset cifar10 --model minivggnet --optimizer radam
python train.py --history output/resnet_adam_cifar100.pickle --report output/resnet_adam_cifar100.txt --dataset cifar100 --model resnet --optimizer adam
python train.py --history output/resnet_radam_cifar100.pickle --report output/resnet_radam_cifar100.txt --dataset cifar100 --model resnet --optimizer radam
python train.py --history output/googlenet_adam_cifar100.pickle --report output/googlenet_adam_cifar100.txt --dataset cifar100 --model googlenet --optimizer adam
python train.py --history output/googlenet_radam_cifar100.pickle --report output/googlenet_radam_cifar100.txt --dataset cifar100 --model googlenet --optimizer radam
python train.py --history output/minivggnet_adam_cifar100.pickle --report output/minivggnet_adam_cifar100.txt --dataset cifar100 --model minivggnet --optimizer adam
python train.py --history output/minivggnet_radam_cifar100.pickle --report output/minivggnet_radam_cifar100.txt --dataset cifar100 --model minivggnet --optimizer radam
注意:务必使用水平滚动条查看experiments.sh脚本的全部内容。为了更好地显示,我故意不换行。你也可以参考下面的图 4—我建议点击图像放大+检查*它。*
Figure 4: The output of our combinations.py file is a shell script listing the training script commands to run in succession. Click image to enlarge.
注意模型架构、数据集和优化器的 24 种可能组合中的每一种都有一个train.py调用。此外,行 1 上的“shebang”表示这个 shell 脚本是可执行的。
运行我们的实验
下一步是实际执行这些实验。
我用 NVIDIA K80 GPU 在一个亚马逊 EC2 实例上执行了 shell 脚本。运行所有实验大约需要 48 小时。
要自己启动实验,只需运行以下命令:
$ ./experiments.sh
脚本运行完成后,您的output/目录中应该会充满.pickle和.txt文件:
$ ls -l output/
googlenet_adam_cifar10.pickle
googlenet_adam_cifar10.txt
googlenet_adam_cifar100.pickle
googlenet_adam_cifar100.txt
...
resnet_radam_fashion_mnist.pickle
resnet_radam_fashion_mnist.txt
resnet_radam_mnist.pickle
resnet_radam_mnist.txt
.txt文件包含 scikit-learn 的classification_report输出,这是一个人类可读的输出,告诉我们我们的模型执行得有多好。
.pickle文件包含模型的训练历史。在下一节中,我们将使用这个.pickle文件来绘制 Adam 和修正 Adam 的性能。
实施我们的 Adam 与修正的 Adam 绘图脚本
我们最终的 Python 脚本plot.py将用于绘制 Adam 与修正 Adam 的性能对比图,为我们提供在特定数据集上训练的给定模型架构的清晰可视化效果。
绘图文件打开每个 Adam/RAdam .pickle文件对,并生成相应的绘图。
打开plot.py并插入以下代码:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
import argparse
import pickle
import os
def plot_history(adamHist, rAdamHist, accTitle, lossTitle):
# determine the total number of epochs used for training, then
# initialize the figure
N = np.arange(0, len(adamHist["loss"]))
plt.style.use("ggplot")
(fig, axs) = plt.subplots(2, 1, figsize=(7, 9))
# plot the accuracy for Adam vs. Rectified Adam
axs[0].plot(N, adamHist["acc"], label="adam_train_acc")
axs[0].plot(N, adamHist["val_acc"], label="adam_val_acc")
axs[0].plot(N, rAdamHist["acc"], label="radam_train_acc")
axs[0].plot(N, rAdamHist["val_acc"], label="radam_val_acc")
axs[0].set_title(accTitle)
axs[0].set_xlabel("Epoch #")
axs[0].set_ylabel("Accuracy")
axs[0].legend(loc="lower right")
# plot the loss for Adam vs. Rectified Adam
axs[1].plot(N, adamHist["loss"], label="adam_train_loss")
axs[1].plot(N, adamHist["val_loss"], label="adam_val_loss")
axs[1].plot(N, rAdamHist["loss"], label="radam_train_loss")
axs[1].plot(N, rAdamHist["val_loss"], label="radam_val_loss")
axs[1].set_title(lossTitle)
axs[1].set_xlabel("Epoch #")
axs[1].set_ylabel("Loss")
axs[1].legend(loc="upper right")
# update the layout of the plot
plt.tight_layout()
第 2-6 行处理进口,即matplotlib.pyplot模块。
plot_history函数负责通过子图功能生成两个堆叠图:
- 训练/验证 准确度 曲线(第 16-23 行)。
- 训练/验证 损失 曲线(第 26-33 行)。
Adam 和修正的 Adam 训练历史曲线均由作为参数传递给函数的adamHist和rAdamHist数据生成。
注意:如果您使用 TensorFlow 2.0(即tf.keras)来运行此代码,您需要将所有出现的acc和val_acc分别更改为accuracy和val_accuracy,因为 TensorFlow 2.0 对精确度名称进行了重大更改。
让我们来处理解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of Keras training history files")
ap.add_argument("-p", "--plots", required=True,
help="path to output directory of training plots")
args = vars(ap.parse_args())
# initialize the list of datasets and models
datasets = ["mnist", "fashion_mnist", "cifar10", "cifar100"]
models = ["resnet", "googlenet", "minivggnet"]
我们的命令行参数包括:
--input:要解析生成图的训练历史文件的输入目录路径。--plots:我们将储存图形的输出路径。
第 47 和 48 行列出了我们的datasets和models。我们将遍历数据集和模型的组合来生成我们的图:
# loop over all combinations of datasets and models
for dataset in datasets:
for model in models:
# construct the path to the Adam output training history files
adamFilename = "{}_{}_{}.pickle".format(model, "adam",
dataset)
adamPath = os.path.sep.join([args["input"], adamFilename])
# construct the path to the Rectified Adam output training
# history files
rAdamFilename = "{}_{}_{}.pickle".format(model, "radam",
dataset)
rAdamPath = os.path.sep.join([args["input"], rAdamFilename])
# load the training history files for Adam and Rectified Adam,
# respectively
adamHist = pickle.loads(open(adamPath, "rb").read())
rAdamHist = pickle.loads(open(rAdamPath, "rb").read())
# plot the accuracy/loss for the current dataset, comparing
# Adam vs. Rectified Adam
accTitle = "Adam vs. RAdam for '{}' on '{}' (Accuracy)".format(
model, dataset)
lossTitle = "Adam vs. RAdam for '{}' on '{}' (Loss)".format(
model, dataset)
plot_history(adamHist, rAdamHist, accTitle, lossTitle)
# construct the path to the output plot
plotFilename = "{}_{}.png".format(model, dataset)
plotPath = os.path.sep.join([args["plots"], plotFilename])
# save the plot and clear it
plt.savefig(plotPath)
plt.clf()
在嵌套的datasets / models循环中,我们:
- 构造 Adam 并修正 Adam 的文件路径(第 54-62 行)。
- 加载序列化的培训历史(行 66 和 67 )。
- 使用我们的
plot_history函数生成图表(第 71-75 行)。 - 将数字导出到磁盘(第 78-83 行)。
绘制 Adam vs .修正 Adam
我们现在准备运行plot.py脚本。
同样,确保你已经使用了本教程的 【下载】 部分来下载源代码。
从那里,执行以下命令:
$ python plot.py --input output --plots plots
然后,您可以检查plots/目录,并确保它已经填充了培训历史数据:
$ ls -l plots/
googlenet_cifar10.png
googlenet_cifar100.png
googlenet_fashion_mnist.png
googlenet_mnist.png
minivggnet_cifar10.png
minivggnet_cifar100.png
minivggnet_fashion_mnist.png
minivggnet_mnist.png
resnet_cifar10.png
resnet_cifar100.png
resnet_fashion_mnist.png
resnet_mnist.png
在下一部分,我们将回顾我们的实验结果。
亚当 vs .修正亚当与 MNIST 的实验

Figure 5: Montage of samples from the MNIST digit dataset.
我们的第一组实验将在 MNIST 数据集上比较 Adam 与修正的 Adam,这是一个用于手写数字识别的标准基准图像分类数据集。
mnst–minivvnet
Figure 6: Which is better — Adam or RAdam optimizer using MiniVGGNet on the MNIST dataset?
当在 MNIST 数据集上训练 MiniVGGNet 时,我们的第一个实验比较了 Adam 和修正的 Adam。
下面是 Adam 优化器的输出分类报告:
precision recall f1-score support
0 0.99 1.00 1.00 980
1 0.99 1.00 0.99 1135
2 0.98 0.96 0.97 1032
3 1.00 1.00 1.00 1010
4 0.99 1.00 0.99 982
5 0.97 0.98 0.98 892
6 0.98 0.98 0.98 958
7 0.99 0.99 0.99 1028
8 0.99 0.99 0.99 974
9 1.00 0.99 0.99 1009
micro avg 0.99 0.99 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
以及修正的 Adam 优化器的分类报告:
precision recall f1-score support
0 0.99 1.00 0.99 980
1 1.00 0.99 1.00 1135
2 0.97 0.97 0.97 1032
3 0.99 0.99 0.99 1010
4 0.99 0.99 0.99 982
5 0.98 0.97 0.97 892
6 0.98 0.98 0.98 958
7 0.99 0.99 0.99 1028
8 0.99 0.99 0.99 974
9 0.99 0.99 0.99 1009
micro avg 0.99 0.99 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
如你所见,我们在两个 T2 实验中都获得了 99%的准确率。
查看图 6 ,您可以观察到与整流 Adam 相关的预热时间:
损耗开始时非常高,精度非常低
预热完成后,经过修正的 Adam 优化器会赶上 Adam
有趣的是,与经过整流的 Adam 相比, Adam 获得了更低的损耗——我们实际上会看到这一趋势在我们运行的其余实验中继续(我将解释为什么也会发生这种情况)。
mnst–Google net
Figure 7: Which deep learning optimizer is actually better — Rectified Adam or Adam? This plot is from my experiment notebook while testing RAdam and Adam using GoogLeNet on the MNIST dataset.
下一个实验将 Adam 与在 MNIST 数据集上训练的 GoogLeNet 的修正 Adam 进行比较。
下面是 Adam 优化器的输出:
precision recall f1-score support
0 1.00 1.00 1.00 980
1 1.00 0.99 1.00 1135
2 0.96 0.99 0.97 1032
3 0.99 1.00 0.99 1010
4 0.99 0.99 0.99 982
5 0.99 0.96 0.98 892
6 0.98 0.99 0.98 958
7 0.99 0.99 0.99 1028
8 1.00 1.00 1.00 974
9 1.00 0.98 0.99 1009
micro avg 0.99 0.99 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
以及经过修正的 Adam 优化器的输出:
precision recall f1-score support
0 1.00 1.00 1.00 980
1 1.00 0.99 1.00 1135
2 0.98 0.98 0.98 1032
3 1.00 0.99 1.00 1010
4 1.00 0.99 1.00 982
5 0.97 0.99 0.98 892
6 0.99 0.98 0.99 958
7 0.99 1.00 0.99 1028
8 0.99 1.00 1.00 974
9 1.00 0.99 1.00 1009
micro avg 0.99 0.99 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
同样,两个优化器都获得了 99%的准确度。
这一次,两个训练/验证图在准确性和损失方面几乎相同。
MNIST-雷斯内特
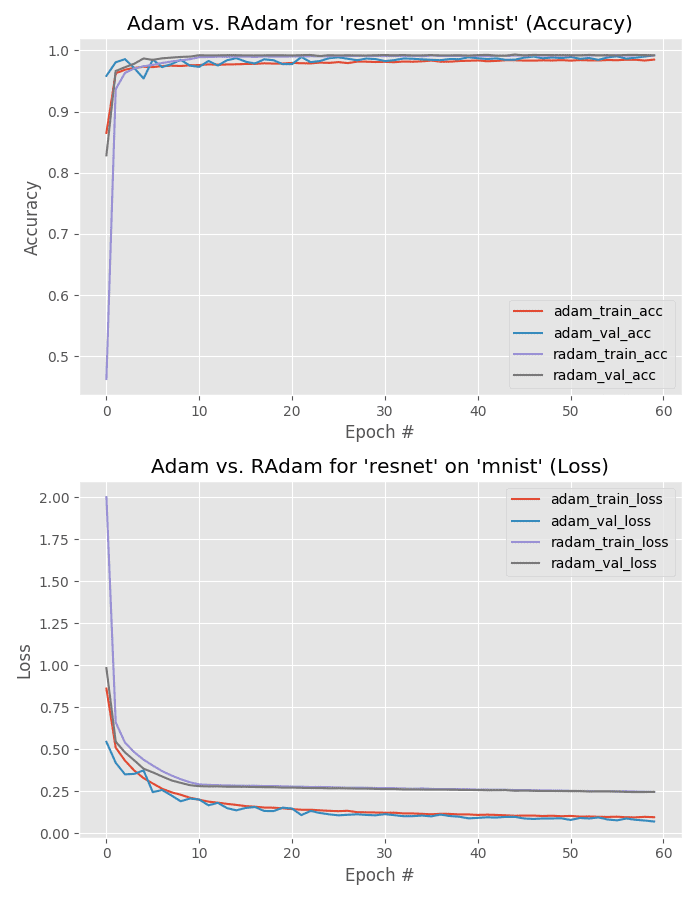
Figure 8: Training accuracy/loss plot for ResNet on the MNIST dataset using both the RAdam (Rectified Adam) and Adam deep learning optimizers with Keras.
我们最后的 MNIST 实验比较了使用 Adam 和修正 Adam 的训练 ResNet。
鉴于 MNIST 不是一个非常具有挑战性的数据集,我们为 Adam 优化器获得了 99%的准确率
precision recall f1-score support
0 1.00 1.00 1.00 980
1 1.00 0.99 1.00 1135
2 0.98 0.98 0.98 1032
3 0.99 1.00 1.00 1010
4 0.99 1.00 0.99 982
5 0.99 0.98 0.98 892
6 0.98 0.99 0.99 958
7 0.99 1.00 0.99 1028
8 0.99 1.00 1.00 974
9 1.00 0.98 0.99 1009
micro avg 0.99 0.99 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
以及整改后的 Adam 优化器:
precision recall f1-score support
0 1.00 1.00 1.00 980
1 1.00 1.00 1.00 1135
2 0.97 0.98 0.98 1032
3 1.00 1.00 1.00 1010
4 0.99 1.00 1.00 982
5 0.99 0.97 0.98 892
6 0.99 0.98 0.99 958
7 0.99 1.00 0.99 1028
8 1.00 1.00 1.00 974
9 1.00 0.99 1.00 1009
micro avg 0.99 0.99 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
但是看看图 8——注意 Adam 如何获得比整流 Adam 低得多的损耗。
这不一定是一件坏事,因为它可能意味着修正的亚当正在获得一个更通用的模型;然而,测试集上的性能是相同的,所以我们需要在 MNIST 之外的上测试图像(这超出了本文的范围)。
亚当 vs .纠正亚当实验与时尚 MNIST

Figure 9: The Fashion MNIST dataset was created by e-commerce company, Zalando, as a drop-in replacement for MNIST Digits. It is a great dataset to practice/experiment with when using Keras for deep learning. (image source)
我们的下一组实验在时尚 MNIST 数据集上评估了 Adam 与修正的 Adam,这是标准 MNIST 数据集的替代物。
你可以在这里阅读更多关于时尚 MNIST 的信息。
时尚梦游者 minivggnet
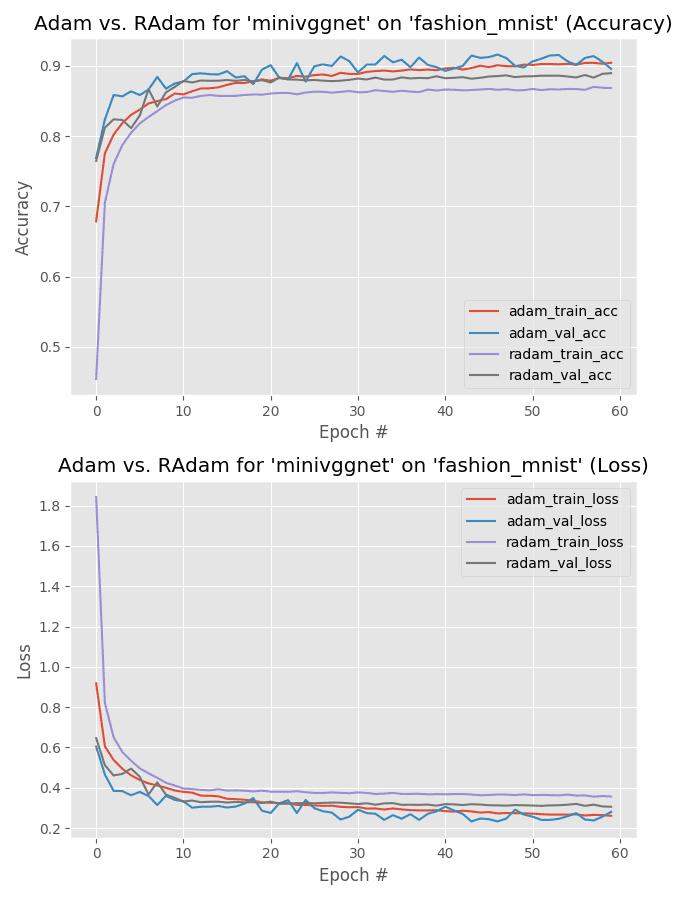
Figure 10: Testing optimizers with deep learning, including new ones such as RAdam, requires multiple experiments. Shown in this figure is the MiniVGGNet CNN trained on the Fashion MNIST dataset with both Adam and RAdam optimizers.
我们的第一个实验评估了在时尚 MNIST 数据集上训练的 MiniVGGNet 架构。
下面你可以找到使用 Adam 优化器的训练输出:
precision recall f1-score support
top 0.95 0.71 0.81 1000
trouser 0.99 0.99 0.99 1000
pullover 0.94 0.76 0.84 1000
dress 0.96 0.80 0.87 1000
coat 0.84 0.90 0.87 1000
sandal 0.98 0.98 0.98 1000
shirt 0.59 0.91 0.71 1000
sneaker 0.96 0.97 0.96 1000
bag 0.98 0.99 0.99 1000
ankle boot 0.97 0.97 0.97 1000
micro avg 0.90 0.90 0.90 10000
macro avg 0.92 0.90 0.90 10000
weighted avg 0.92 0.90 0.90 10000
以及整改后的 Adam 优化器:
precision recall f1-score support
top 0.85 0.85 0.85 1000
trouser 1.00 0.97 0.99 1000
pullover 0.89 0.84 0.87 1000
dress 0.93 0.81 0.87 1000
coat 0.85 0.80 0.82 1000
sandal 0.99 0.95 0.97 1000
shirt 0.62 0.77 0.69 1000
sneaker 0.92 0.96 0.94 1000
bag 0.96 0.99 0.97 1000
ankle boot 0.97 0.95 0.96 1000
micro avg 0.89 0.89 0.89 10000
macro avg 0.90 0.89 0.89 10000
weighted avg 0.90 0.89 0.89 10000
请注意,Adam 优化器优于修正的 Adam,与修正的 Adam 的 90%准确度相比,获得了 92%的准确度。
此外,看一下图 10 中的训练图——训练非常稳定,验证损失低于训练损失。
随着 Adam 更积极的训练,我们可能会进一步提高我们的准确性。
时尚 MNIST——谷歌网

Figure 11: Is either RAdam or Adam a better deep learning optimizer using GoogLeNet? Using the Fashion MNIST dataset with Adam shows signs of overfitting past epoch 30. RAdam appears more stable in this experiment.
我们现在使用 Adam 和 Rectified Adam 来评估在时尚 MNIST 上训练的 GoogLeNet。
下面是来自 Adam 优化器的分类报告:
precision recall f1-score support
top 0.84 0.89 0.86 1000
trouser 1.00 0.99 0.99 1000
pullover 0.87 0.94 0.90 1000
dress 0.95 0.88 0.91 1000
coat 0.95 0.85 0.89 1000
sandal 0.98 0.99 0.98 1000
shirt 0.79 0.82 0.81 1000
sneaker 0.99 0.90 0.94 1000
bag 0.98 0.99 0.99 1000
ankle boot 0.91 0.99 0.95 1000
micro avg 0.92 0.92 0.92 10000
macro avg 0.93 0.92 0.92 10000
weighted avg 0.93 0.92 0.92 10000
以及来自整流 Adam 优化器的输出:
precision recall f1-score support
top 0.91 0.83 0.87 1000
trouser 0.99 0.99 0.99 1000
pullover 0.94 0.85 0.89 1000
dress 0.96 0.86 0.90 1000
coat 0.90 0.91 0.90 1000
sandal 0.98 0.98 0.98 1000
shirt 0.70 0.88 0.78 1000
sneaker 0.97 0.96 0.96 1000
bag 0.98 0.99 0.99 1000
ankle boot 0.97 0.97 0.97 1000
micro avg 0.92 0.92 0.92 10000
macro avg 0.93 0.92 0.92 10000
weighted avg 0.93 0.92 0.92 10000
这次两个优化器都获得了 93%的准确率,但更有趣的是看一看图 11 中的训练历史情节。
在这里,我们可以看到,对于 Adam 优化器,训练损失在超过第 30 个时期后开始偏离——随着我们继续训练,这种偏离越来越大。在这一点上,我们应该开始关注使用 Adam 的过度拟合。
另一方面,经过调整的 Adam 的表现稳定,没有过度拟合的迹象。
在这个特定的实验中,很明显,经过修正的 Adam 推广得更好,如果我们希望将这个模型部署到生产环境中,那么经过修正的 Adam 优化器版本将是最佳选择。
时尚 MNIST-ResNet
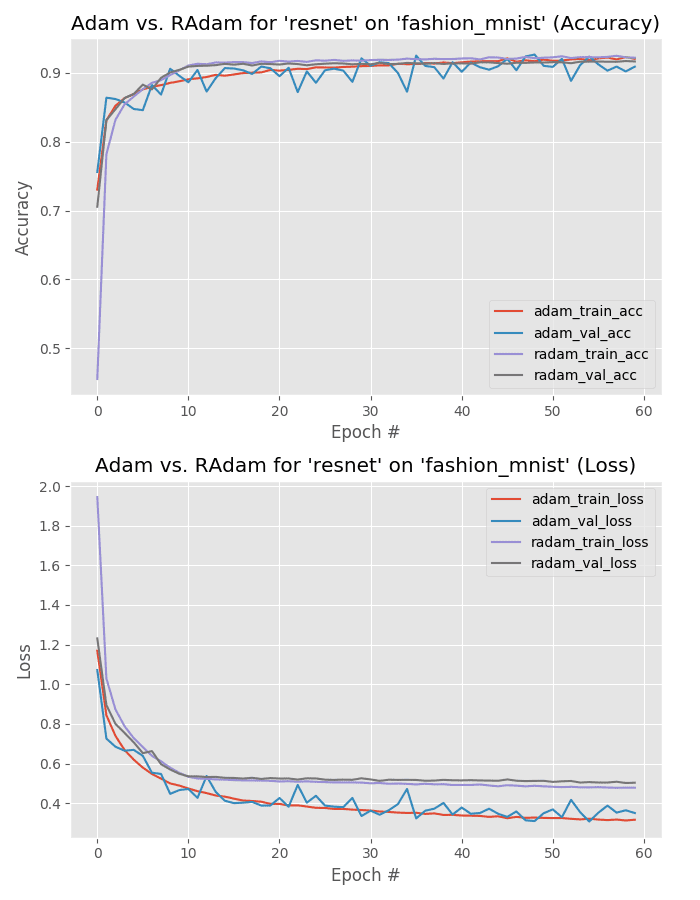
Figure 12: Which deep learning optimizer is better — Adam or Rectified Adam (RAdam) — using the ResNet CNN on the Fashion MNIST dataset?
我们最后的实验比较了 Adam 与使用 ResNet 在时尚 MNIST 数据集上训练的修正 Adam 优化器。
下面是 Adam 优化器的输出:
precision recall f1-score support
top 0.89 0.83 0.86 1000
trouser 0.99 0.99 0.99 1000
pullover 0.84 0.93 0.88 1000
dress 0.94 0.83 0.88 1000
coat 0.93 0.85 0.89 1000
sandal 0.99 0.92 0.95 1000
shirt 0.71 0.85 0.78 1000
sneaker 0.88 0.99 0.93 1000
bag 1.00 0.98 0.99 1000
ankle boot 0.98 0.93 0.95 1000
micro avg 0.91 0.91 0.91 10000
macro avg 0.92 0.91 0.91 10000
weighted avg 0.92 0.91 0.91 10000
下面是经过修正的 Adam 优化器的输出:
precision recall f1-score support
top 0.88 0.86 0.87 1000
trouser 0.99 0.99 0.99 1000
pullover 0.91 0.87 0.89 1000
dress 0.96 0.83 0.89 1000
coat 0.86 0.92 0.89 1000
sandal 0.98 0.98 0.98 1000
shirt 0.72 0.80 0.75 1000
sneaker 0.95 0.96 0.96 1000
bag 0.98 0.99 0.99 1000
ankle boot 0.97 0.96 0.96 1000
micro avg 0.92 0.92 0.92 10000
macro avg 0.92 0.92 0.92 10000
weighted avg 0.92 0.92 0.92 10000
两个模型都获得了 92%的准确度,但是请看一下图 12 中的训练历史图。
您可以观察到 Adam optimizer 导致更低的损失和,验证损失遵循训练曲线。
经修正的 Adam 损耗可以说更稳定,波动更少(与标准 Adam 相比)。
在这个实验中,到底哪一个“更好”将取决于该模型对训练、验证和测试集之外的图像的推广程度。
这里需要进一步的实验来标记获胜者,但我的直觉告诉我,它纠正了 Adam,因为(1)测试集上的准确性是相同的,以及(2)更低的损失不一定意味着更好的泛化(在某些情况下,这意味着模型可能不能很好地泛化)——但同时,训练/验证损失对于 Adam 来说几乎是相同的。没有进一步的实验,很难做出判断。
利用 CIFAR-10 进行的 Adam 对比校正 Adam 实验

Figure 13: The CIFAR-10 benchmarking dataset has 10 classes. We will use it for Rectified Adam experimentation to evaluate if RAdam or Adam is the better choice (image source).
在这些实验中,我们将使用 MiniVGGNet、GoogLeNet 和 ResNet 比较 Adam 与修正 Adam 的性能,所有这些都是在 CIFAR-10 数据集上训练的。
cifar-10 mini vvnet

Figure 14: Is the RAdam or Adam deep learning optimizer better using the MiniVGGNet CNN on the CIFAR-10 dataset?
我们的下一个实验通过在 CIFAR-10 数据集上训练 MiniVGGNet 来比较 Adam 和修正的 Adam。
下面是使用 Adam 优化器的训练输出:
precision recall f1-score support
airplane 0.90 0.79 0.84 1000
automobile 0.90 0.93 0.91 1000
bird 0.90 0.63 0.74 1000
cat 0.78 0.68 0.73 1000
deer 0.83 0.79 0.81 1000
dog 0.81 0.76 0.79 1000
frog 0.70 0.95 0.81 1000
horse 0.85 0.91 0.88 1000
ship 0.93 0.89 0.91 1000
truck 0.77 0.95 0.85 1000
micro avg 0.83 0.83 0.83 10000
macro avg 0.84 0.83 0.83 10000
weighted avg 0.84 0.83 0.83 10000
这是经过整流的 Adam: 的输出
precision recall f1-score support
airplane 0.84 0.72 0.78 1000
automobile 0.89 0.84 0.86 1000
bird 0.80 0.41 0.54 1000
cat 0.66 0.43 0.52 1000
deer 0.66 0.65 0.66 1000
dog 0.72 0.55 0.62 1000
frog 0.48 0.96 0.64 1000
horse 0.84 0.75 0.79 1000
ship 0.87 0.88 0.88 1000
truck 0.68 0.95 0.79 1000
micro avg 0.71 0.71 0.71 10000
macro avg 0.74 0.71 0.71 10000
weighted avg 0.74 0.71 0.71 10000
在这里,Adam 优化器( 84%的准确度)击败了经过修正的 Adam (74%的准确度)。
此外,对于大多数训练,验证损失低于训练损失,这意味着我们可以通过降低正则化强度和潜在增加模型容量来“更努力地训练”。
CIFAR-10–谷歌网络
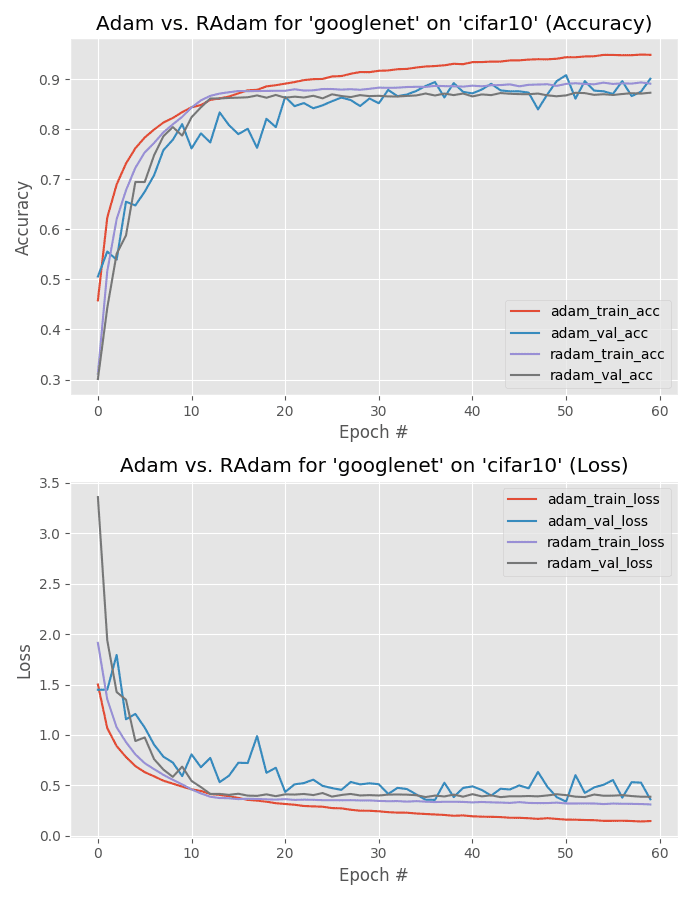
Figure 15: Which is a better deep learning optimizer with the GoogLeNet CNN? The training accuracy/loss plot shows results from using Adam and RAdam as part of automated deep learning experiment data collection.
接下来,让我们看看使用 Adam 和 Rectified Adam 在 CIFAR-10 上训练的 GoogLeNet。
下面是亚当的输出:
precision recall f1-score support
airplane 0.89 0.92 0.91 1000
automobile 0.92 0.97 0.94 1000
bird 0.90 0.87 0.88 1000
cat 0.79 0.86 0.82 1000
deer 0.92 0.85 0.89 1000
dog 0.92 0.81 0.86 1000
frog 0.87 0.96 0.91 1000
horse 0.95 0.91 0.93 1000
ship 0.96 0.92 0.94 1000
truck 0.90 0.94 0.92 1000
micro avg 0.90 0.90 0.90 10000
macro avg 0.90 0.90 0.90 10000
weighted avg 0.90 0.90 0.90 10000
这里是经过整流的 Adam 的输出:
precision recall f1-score support
airplane 0.88 0.88 0.88 1000
automobile 0.93 0.95 0.94 1000
bird 0.84 0.82 0.83 1000
cat 0.79 0.75 0.77 1000
deer 0.89 0.82 0.85 1000
dog 0.89 0.77 0.82 1000
frog 0.80 0.96 0.87 1000
horse 0.89 0.92 0.91 1000
ship 0.95 0.92 0.93 1000
truck 0.88 0.95 0.91 1000
micro avg 0.87 0.87 0.87 10000
macro avg 0.87 0.87 0.87 10000
weighted avg 0.87 0.87 0.87 10000
Adam 优化器获得了 90%的准确性,略微超过了修正 Adam 的 87%的准确性。
然而,图 15 讲述了一个有趣的故事——在过去的 20 年中,亚当的训练和验证损失之间存在很大的差异。
虽然 Adam 优化模型获得了更高的精度,但有过度拟合的迹象,因为验证损失在 30 个时期后基本上停滞不前。
将需要额外的实验来标记一个真正的赢家,但我想它会在一些额外的超参数调整后得到纠正。
CIFAR-10 – ResNet
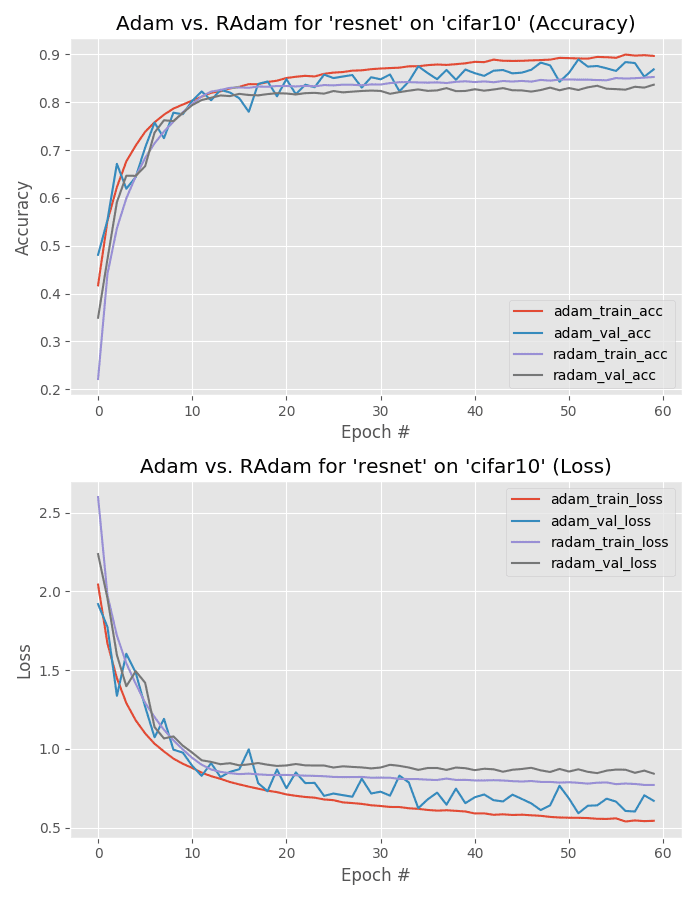
Figure 16: This Keras deep learning tutorial helps to answer the question: Is Rectified Adam or Adam the better deep learning optimizer? One of the 24 experiments uses the ResNet CNN and CIFAR-10 dataset.
接下来,让我们看看在 CIFAR-10 上使用 Adam 和 Rectified Adam 训练的 ResNet。
下面你可以找到标准的 Adam 优化器的输出:
precision recall f1-score support
airplane 0.80 0.92 0.86 1000
automobile 0.92 0.96 0.94 1000
bird 0.93 0.74 0.82 1000
cat 0.93 0.63 0.75 1000
deer 0.95 0.80 0.87 1000
dog 0.77 0.88 0.82 1000
frog 0.75 0.97 0.84 1000
horse 0.90 0.92 0.91 1000
ship 0.93 0.93 0.93 1000
truck 0.91 0.93 0.92 1000
micro avg 0.87 0.87 0.87 10000
macro avg 0.88 0.87 0.87 10000
weighted avg 0.88 0.87 0.87 10000
以及来自整流 Adam: 的输出
precision recall f1-score support
airplane 0.86 0.86 0.86 1000
automobile 0.89 0.95 0.92 1000
bird 0.85 0.72 0.78 1000
cat 0.78 0.66 0.71 1000
deer 0.83 0.81 0.82 1000
dog 0.82 0.70 0.76 1000
frog 0.72 0.95 0.82 1000
horse 0.86 0.90 0.87 1000
ship 0.94 0.90 0.92 1000
truck 0.84 0.93 0.88 1000
micro avg 0.84 0.84 0.84 10000
macro avg 0.84 0.84 0.83 10000
weighted avg 0.84 0.84 0.83 10000
亚当是这里的赢家,获得了 88%的准确率,而修正后的亚当只有 84%。
用 CIFAR-100 进行的 Adam 与修正的 Adam 实验

Figure 17: The CIFAR-100 classification dataset is the brother of CIFAR-10 and includes more classes of images. (image source)
CIFAR-100 数据集是 CIFAR-10 数据集的兄弟。顾名思义,CIFAR-100 包括 100 个类别标签,而 CIFAR-10 只有 10 个类别标签。
虽然在 CIFAR-100 中有更多的类标签,但实际上每个类的图像更少 (CIFAR-10 每个类有 6000 个图像,而 CIFAR-100 每个类只有 600 个图像)。
因此,CIFAR-100 是一个比 CIFAR-10 更具挑战性的数据集。
在本节中,我们将在 CIFAR-100 数据集上研究 Adam 与修正 Adam 的性能。
CIFAR-100 迷你 vvnet
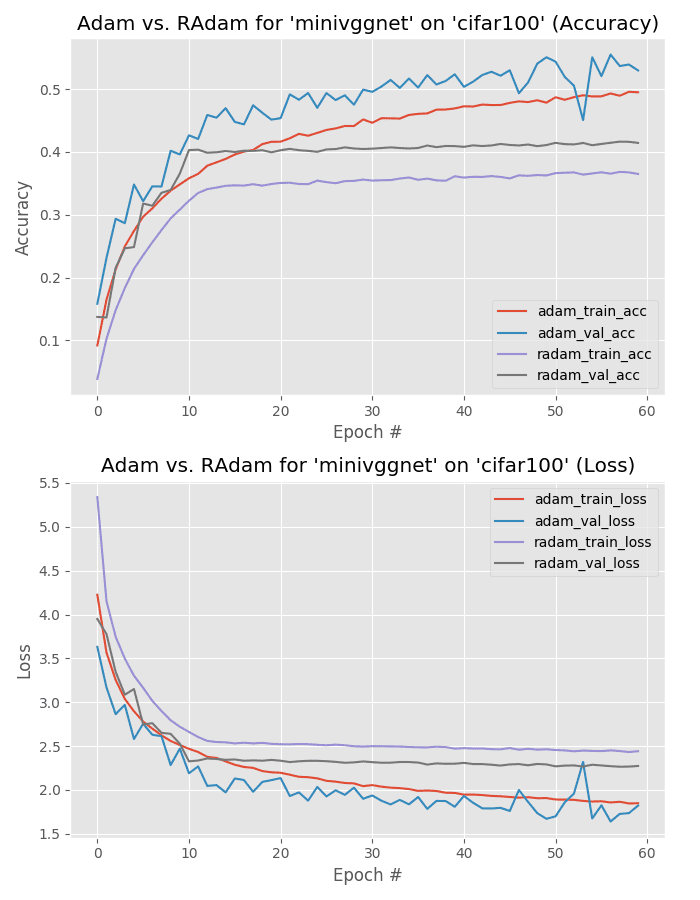
Figure 18: Will RAdam stand up to Adam as a preferable deep learning optimizer? How does Rectified Adam stack up to SGD? In this experiment (one of 24), we train MiniVGGNet on the CIFAR-100 dataset and analyze the results.
让我们将 Adam 和修正的 Adam 应用于在 CIFAR-100 上训练的 MiniVGGNet 架构。
下面是来自 Adam 优化器的输出:
precision recall f1-score support
apple 0.94 0.76 0.84 100
aquarium_fish 0.69 0.66 0.67 100
baby 0.56 0.45 0.50 100
bear 0.45 0.22 0.30 100
beaver 0.31 0.14 0.19 100
bed 0.48 0.59 0.53 100
bee 0.60 0.69 0.64 100
beetle 0.51 0.49 0.50 100
bicycle 0.50 0.65 0.57 100
bottle 0.74 0.63 0.68 100
bowl 0.51 0.38 0.44 100
boy 0.45 0.37 0.41 100
bridge 0.64 0.68 0.66 100
bus 0.42 0.57 0.49 100
butterfly 0.52 0.50 0.51 100
camel 0.61 0.33 0.43 100
can 0.44 0.68 0.54 100
castle 0.74 0.71 0.72 100
caterpillar 0.78 0.40 0.53 100
cattle 0.58 0.48 0.52 100
chair 0.72 0.80 0.76 100
chimpanzee 0.74 0.64 0.68 100
clock 0.39 0.62 0.48 100
cloud 0.88 0.46 0.61 100
cockroach 0.80 0.66 0.73 100
couch 0.56 0.27 0.36 100
crab 0.43 0.52 0.47 100
crocodile 0.34 0.32 0.33 100
cup 0.74 0.73 0.73 100
..."d" - "t" classes omitted for brevity
wardrobe 0.67 0.87 0.76 100
whale 0.67 0.58 0.62 100
willow_tree 0.52 0.44 0.48 100
wolf 0.40 0.48 0.44 100
woman 0.39 0.19 0.26 100
worm 0.66 0.56 0.61 100
micro avg 0.53 0.53 0.53 10000
macro avg 0.58 0.53 0.53 10000
weighted avg 0.58 0.53 0.53 10000
这是经过整流的 Adam: 的输出
precision recall f1-score support
apple 0.82 0.70 0.76 100
aquarium_fish 0.57 0.46 0.51 100
baby 0.55 0.26 0.35 100
bear 0.22 0.11 0.15 100
beaver 0.17 0.18 0.17 100
bed 0.47 0.37 0.42 100
bee 0.49 0.47 0.48 100
beetle 0.32 0.52 0.39 100
bicycle 0.36 0.64 0.46 100
bottle 0.74 0.40 0.52 100
bowl 0.47 0.29 0.36 100
boy 0.54 0.26 0.35 100
bridge 0.38 0.43 0.40 100
bus 0.34 0.35 0.34 100
butterfly 0.40 0.34 0.37 100
camel 0.37 0.19 0.25 100
can 0.57 0.45 0.50 100
castle 0.50 0.57 0.53 100
caterpillar 0.50 0.21 0.30 100
cattle 0.47 0.35 0.40 100
chair 0.54 0.72 0.62 100
chimpanzee 0.59 0.47 0.53 100
clock 0.29 0.37 0.33 100
cloud 0.77 0.60 0.67 100
cockroach 0.57 0.64 0.60 100
couch 0.42 0.18 0.25 100
crab 0.25 0.50 0.33 100
crocodile 0.30 0.28 0.29 100
cup 0.71 0.60 0.65 100
..."d" - "t" classes omitted for brevity
wardrobe 0.61 0.82 0.70 100
whale 0.57 0.39 0.46 100
willow_tree 0.36 0.27 0.31 100
wolf 0.32 0.39 0.35 100
woman 0.35 0.09 0.14 100
worm 0.62 0.32 0.42 100
micro avg 0.41 0.41 0.41 10000
macro avg 0.46 0.41 0.41 10000
weighted avg 0.46 0.41 0.41 10000
Adam 优化器是明显的赢家( 58%的准确度)超过了修正的 Adam (46%的准确度)。
就像在我们的 CIFAR-10 实验中一样,我们可以通过放松正则化和增加模型容量来进一步提高我们的模型性能。
CIFAR-100–谷歌网络
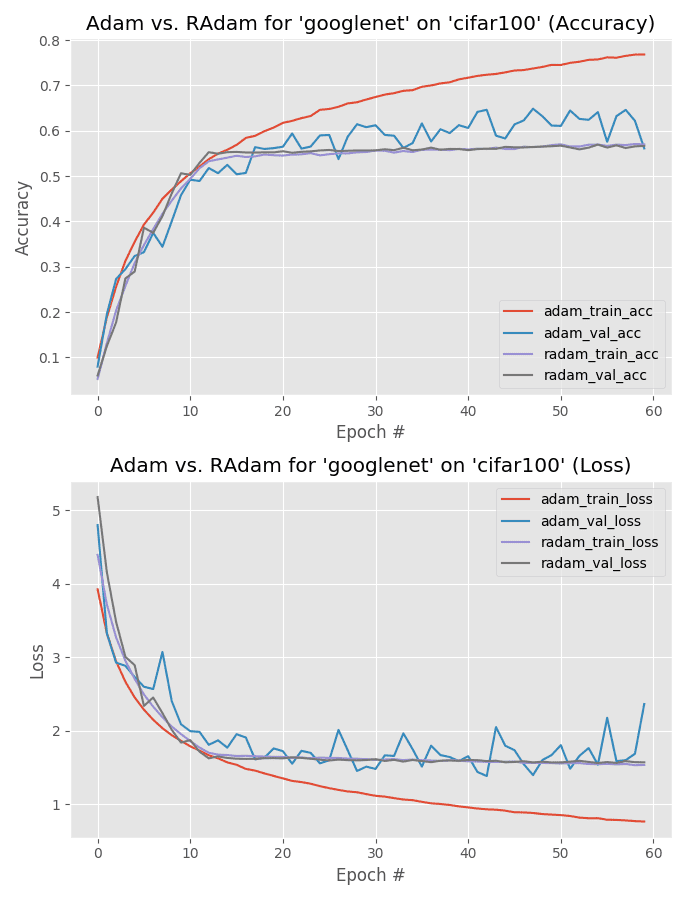
Figure 19: Adam vs. RAdam optimizer on the CIFAR-100 dataset using GoogLeNet.
现在让我们进行同样的实验,只是这次使用 GoogLeNet。
下面是来自 Adam 优化器的输出:
precision recall f1-score support
apple 0.95 0.80 0.87 100
aquarium_fish 0.88 0.66 0.75 100
baby 0.59 0.39 0.47 100
bear 0.47 0.28 0.35 100
beaver 0.20 0.53 0.29 100
bed 0.79 0.56 0.65 100
bee 0.78 0.69 0.73 100
beetle 0.56 0.58 0.57 100
bicycle 0.91 0.63 0.75 100
bottle 0.80 0.71 0.75 100
bowl 0.46 0.37 0.41 100
boy 0.49 0.47 0.48 100
bridge 0.80 0.61 0.69 100
bus 0.62 0.60 0.61 100
butterfly 0.34 0.64 0.44 100
camel 0.93 0.37 0.53 100
can 0.42 0.69 0.52 100
castle 0.94 0.50 0.65 100
caterpillar 0.28 0.77 0.41 100
cattle 0.56 0.55 0.55 100
chair 0.85 0.77 0.81 100
chimpanzee 0.95 0.58 0.72 100
clock 0.56 0.62 0.59 100
cloud 0.88 0.68 0.77 100
cockroach 0.82 0.74 0.78 100
couch 0.66 0.40 0.50 100
crab 0.40 0.72 0.52 100
crocodile 0.36 0.47 0.41 100
cup 0.65 0.68 0.66 100
..."d" - "t" classes omitted for brevity
wardrobe 0.86 0.82 0.84 100
whale 0.40 0.80 0.53 100
willow_tree 0.46 0.62 0.53 100
wolf 0.86 0.37 0.52 100
woman 0.56 0.31 0.40 100
worm 0.79 0.57 0.66 100
micro avg 0.56 0.56 0.56 10000
macro avg 0.66 0.56 0.57 10000
weighted avg 0.66 0.56 0.57 10000
这是经过整流的 Adam: 的输出
precision recall f1-score support
apple 0.93 0.76 0.84 100
aquarium_fish 0.72 0.77 0.74 100
baby 0.53 0.54 0.53 100
bear 0.47 0.26 0.34 100
beaver 0.26 0.22 0.24 100
bed 0.53 0.49 0.51 100
bee 0.52 0.62 0.56 100
beetle 0.50 0.55 0.52 100
bicycle 0.67 0.79 0.72 100
bottle 0.78 0.62 0.69 100
bowl 0.41 0.42 0.41 100
boy 0.45 0.41 0.43 100
bridge 0.59 0.72 0.65 100
bus 0.45 0.53 0.49 100
butterfly 0.27 0.58 0.37 100
camel 0.56 0.50 0.53 100
can 0.58 0.68 0.63 100
castle 0.81 0.73 0.77 100
caterpillar 0.51 0.52 0.51 100
cattle 0.56 0.59 0.58 100
chair 0.68 0.76 0.72 100
chimpanzee 0.83 0.73 0.78 100
clock 0.46 0.56 0.50 100
cloud 0.88 0.69 0.78 100
cockroach 0.79 0.68 0.73 100
couch 0.44 0.39 0.41 100
crab 0.46 0.47 0.46 100
crocodile 0.40 0.40 0.40 100
cup 0.76 0.62 0.68 100
..."d" - "t" classes omitted for brevity
wardrobe 0.76 0.87 0.81 100
whale 0.56 0.61 0.59 100
willow_tree 0.65 0.30 0.41 100
wolf 0.61 0.55 0.58 100
woman 0.39 0.30 0.34 100
worm 0.62 0.61 0.62 100
micro avg 0.57 0.57 0.57 10000
macro avg 0.59 0.57 0.57 10000
weighted avg 0.59 0.57 0.57 10000
Adam 优化器获得了 66%的准确率,比修正后的 Adam 的 59%要好。
然而,查看图 19 我们可以看到,来自 Adam 的验证损失非常不稳定——接近训练结束时,验证损失甚至开始增加,这是过度拟合的迹象。
CIFAR-100 – ResNet
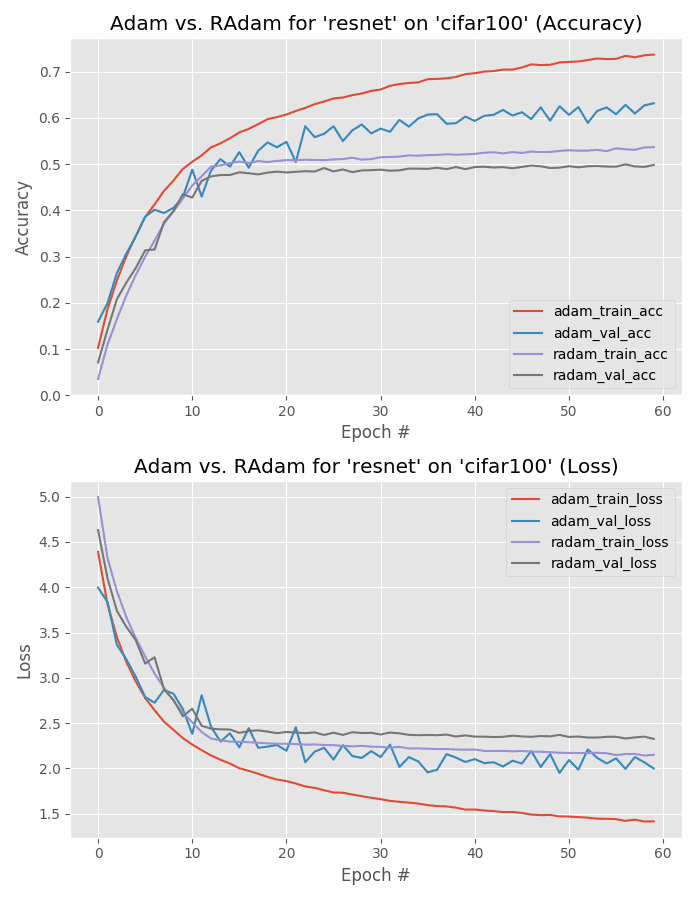
Figure 20: Training a ResNet model on the CIFAR-100 dataset using both RAdam and Adam for comparison. Which deep learning optimizer is actually better for this experiment?
下面我们可以在 CIFAR-100 数据集上使用 Adam 找到训练 ResNet 的输出:
precision recall f1-score support
apple 0.80 0.89 0.84 100
aquarium_fish 0.86 0.75 0.80 100
baby 0.75 0.40 0.52 100
bear 0.71 0.29 0.41 100
beaver 0.40 0.40 0.40 100
bed 0.91 0.59 0.72 100
bee 0.71 0.76 0.73 100
beetle 0.82 0.42 0.56 100
bicycle 0.54 0.89 0.67 100
bottle 0.93 0.62 0.74 100
bowl 0.75 0.36 0.49 100
boy 0.43 0.49 0.46 100
bridge 0.54 0.78 0.64 100
bus 0.68 0.48 0.56 100
butterfly 0.34 0.71 0.46 100
camel 0.72 0.68 0.70 100
can 0.69 0.60 0.64 100
castle 0.96 0.69 0.80 100
caterpillar 0.57 0.62 0.60 100
cattle 0.91 0.51 0.65 100
chair 0.79 0.82 0.80 100
chimpanzee 0.80 0.79 0.79 100
clock 0.41 0.86 0.55 100
cloud 0.89 0.74 0.81 100
cockroach 0.85 0.78 0.81 100
couch 0.73 0.44 0.55 100
crab 0.42 0.70 0.53 100
crocodile 0.47 0.55 0.51 100
cup 0.88 0.75 0.81 100
..."d" - "t" classes omitted for brevity
wardrobe 0.79 0.85 0.82 100
whale 0.58 0.75 0.65 100
willow_tree 0.71 0.37 0.49 100
wolf 0.79 0.64 0.71 100
woman 0.42 0.49 0.45 100
worm 0.48 0.80 0.60 100
micro avg 0.63 0.63 0.63 10000
macro avg 0.68 0.63 0.63 10000
weighted avg 0.68 0.63 0.63 10000
这里是经过整流的 Adam 的输出:
precision recall f1-score support
apple 0.86 0.72 0.78 100
aquarium_fish 0.56 0.62 0.59 100
baby 0.49 0.43 0.46 100
bear 0.36 0.20 0.26 100
beaver 0.27 0.17 0.21 100
bed 0.45 0.42 0.43 100
bee 0.54 0.61 0.57 100
beetle 0.47 0.55 0.51 100
bicycle 0.45 0.69 0.54 100
bottle 0.64 0.54 0.59 100
bowl 0.39 0.31 0.35 100
boy 0.43 0.35 0.38 100
bridge 0.52 0.67 0.59 100
bus 0.34 0.47 0.40 100
butterfly 0.33 0.39 0.36 100
camel 0.47 0.37 0.41 100
can 0.49 0.55 0.52 100
castle 0.76 0.67 0.71 100
caterpillar 0.43 0.43 0.43 100
cattle 0.56 0.45 0.50 100
chair 0.63 0.78 0.70 100
chimpanzee 0.70 0.71 0.71 100
clock 0.38 0.49 0.43 100
cloud 0.80 0.61 0.69 100
cockroach 0.73 0.72 0.73 100
couch 0.49 0.36 0.42 100
crab 0.27 0.45 0.34 100
crocodile 0.32 0.26 0.29 100
cup 0.63 0.49 0.55 100
..."d" - "t" classes omitted for brevity
wardrobe 0.68 0.84 0.75 100
whale 0.53 0.54 0.54 100
willow_tree 0.60 0.29 0.39 100
wolf 0.38 0.35 0.36 100
woman 0.33 0.29 0.31 100
worm 0.59 0.63 0.61 100
micro avg 0.50 0.50 0.50 10000
macro avg 0.51 0.50 0.49 10000
weighted avg 0.51 0.50 0.49 10000
Adam 优化器( 68%精度)在这里粉碎修正的 Adam (51%精度),但是我们需要小心过度拟合。正如图 20 所示,当使用 Adam 优化器时,训练和验证损失之间有很大的差异。
但另一方面,修正的亚当确实停滞在 20 世纪之后。
我倾向于使用 Adam 优化模型,因为它获得了更高的准确性;然而,我建议使用模型的 Adam 和修正 Adam 版本运行一些泛化测试。
我们能从这些实验中学到什么?
第一个收获来自于观察实验的训练图— 使用修正的 Adam 优化器可以导致更稳定的训练。
当使用修正的 Adam 进行培训时,我们看到验证损失的波动、峰值和下降明显减少(与标准 Adam 相比)。
此外,调整后的 Adam 验证损失更有可能跟随培训损失,在某些情况下几乎是准确的。
请记住,在训练你自己的定制神经网络时,原始精度并不代表一切——稳定性也很重要,因为它与泛化密切相关。
每当我训练一个定制的 CNN 时,我不仅要寻找高精度的模型,还要寻找稳定性。稳定性通常意味着模型很好地收敛,并且在理想情况下会很好地概括。
在这方面, Rectified Adam 兑现了刘等人论文中的承诺。
其次,你应该注意到,在的每一次实验中,Adam 获得的损耗都比经过整流的 Adam 低。
这种行为不一定是坏事——它可能暗示修正后的 Adam 泛化得更好,但在没有使用各自训练和测试集外的图像进行进一步实验的情况下,很难说。
再次提醒,请记住,更低的损失是而不是一定是更好的模型!当您遇到非常低的损失(尤其是接近零的损失)时,您的模型可能会过度拟合您的训练集。
你需要掌握操作这三个优化器的经验

Figure 21: Mastering deep learning optimizers is like driving a car. You know your car and you drive it well no matter the road condition. On the other hand, if you get in an unfamiliar car, something doesn’t feel right until you have a few hours cumulatively behind the wheel. Optimizers are no different. I suggest that SGD be your daily driver until you are comfortable trying alternatives. Then you can mix in RMSprop and Adam. Learn how to use them before jumping into the latest deep learning optimizer.
熟悉一个给定的优化算法类似于掌握如何驾驶一辆汽车— 你驾驶自己的车比别人的车更好,因为你花了太多时间驾驶它;你了解你的汽车及其复杂性。
通常,选择一个给定的优化器在数据集而不是上训练网络,是因为优化器本身更好,而是因为驱动者(即,你,深度学习实践者)更熟悉优化器,并且理解调整其各自参数背后的“艺术”。
作为一名深度学习实践者,你应该获得操作各种优化器的经验,但在我看来,你应该集中精力学习如何使用下面的三个优化器来训练网络:
- 签名于
- RMSprop
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
看到 SGD 包括在这个列表中,您可能会感到惊讶——难道 SGD 不是一个比较新的自适应方法(包括 Adam、Adagrad、Adadelta 等)更老、效率更低的优化器吗??
是的,绝对是。
但是事情是这样的——几乎每个最先进的计算机视觉模型都是用 SGD 训练的。
以 ImageNet 分类挑战为例:
- AlexNet (论文中没有提到,但是官方实现和 CaffeNet 都使用了 SGD)
- VGGNet(3.1 节,训练)
- ResNet (第 3.4 节,实现)
- SqueezeNet (文中没有提到,但是他们的 solver.prototxt 中使用了 SGD)
使用 SGD 来训练这些分类网络中的每一个。
现在让我们考虑在 COCO 数据集上训练的对象检测网络:
- 更快的 R-CNN (第 3.1.3 节,训练 RPN和第 3.2 节,共享 RPN 和快速 R-CNN 的特性,以及 Girshick 等人的 GitHub solver.prototxt )
- 单发探测器(第三节,实验结果
- RetinaNet (第 4.1 节,优化)
- YOLO(我在报纸上找不到它,但我相信约瑟夫·雷德蒙使用了新加坡元,如果我错了,请纠正我)
你猜对了——SGD 是用来训练他们所有人的。
是的,与年轻的对手相比,SGD 可能是“旧的,不性感的”优化器,但是事情是这样的,标准 SGD 只是工作。
这并不是说你不应该学习如何使用其他优化器,你绝对应该学习!
但是在你进入那个兔子洞之前,先获得一个 SGD 的掌握等级。从那里开始探索其他优化器——我通常推荐 RMSprop 和 Adam。
如果你发现 Adam 工作得很好,考虑用修正的 Adam 替换 Adam,看看你是否能在准确性上得到额外的提升(有点像用 eLUs 替换 ReLUs 通常能给你一点提升)。
一旦您理解了如何在各种数据集上使用这些优化器,请继续学习并探索其他优化器。
综上所述, 如果你是深度学习的新手,不要马上尝试跳入更“高级”的优化器——你只会在你的深度学习生涯中遇到麻烦。
摘要
在本教程中,我们研究了刘等人的观点,即修正的 Adam 优化器在以下方面优于标准 Adam 优化器:
- 更高的准确性(或至少与 Adam 相比具有相同的准确性)
- 并且在比标准 Adam 更少的时期内
为了评估这些说法,我们训练了三个 CNN 模型:
- ResNet
- 谷歌网
- MiniVGGNet
这些模型在四个数据集上进行训练:
- 梦妮丝
- 时尚 MNIST
- CIFAR-10
- 西发尔-100
使用两个优化器来训练模型架构和数据集的每个组合:
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
- 整流器 adam
总之,我们运行了 3 x 4 x 2 = 24 个不同的实验来比较标准 Adam 和修正 Adam。
结果呢?
在每一次实验中,与标准 Adam 相比,修正 Adam 要么表现得更差,要么获得相同的准确度。
也就是说,用修正的 Adam 训练的比标准的 Adam 更稳定,这可能意味着修正的 Adam 可以更好地概括(但需要额外的实验来验证这一说法)。
刘等人的热身研究可用于自适应学习率优化器,并可能有助于未来的研究人员在他们的工作基础上创造出甚至更好的优化器。
就目前而言,我个人的意见是,你最好还是坚持用标准的 Adam 来做你的初始实验。如果你发现 Adam 在你的实验中表现良好,代入修正后的 Adam,看看能否提高你的准确度。
如果您注意到 Adam 运行良好,您应该特别尝试使用修正的 Adam 优化器,但是您需要更好的泛化。
本指南的第二个要点是你应该掌握操作这三个优化器的经验:
- 签名于
- RMSprop
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
你应该特别是学习如何操作 SGD。
是的,与更新的自适应学习率方法相比,SGD“不那么性感”,但是几乎每一个计算机视觉最先进的架构都是用它来训练的。
先学学这三个优化器怎么操作。
一旦您很好地理解了它们是如何工作的,以及如何调整它们各自的超参数,然后继续其他优化器。
如果您需要帮助学习如何使用这些优化器和调整它们的超参数,请务必参考使用 Python 的计算机视觉深度学习,在那里我详细介绍了我的技巧、建议和最佳实践。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!**
是时候了。Python Kickstarter 的计算机视觉深度学习已经上线。

用 Python 进行计算机视觉的深度学习 Kickstarter 正式上线!
要支持 Kickstarter 活动,只需使用以下链接:
https://www . kickstarter . com/projects/adrianrosebrock/1866482244
记住,只有少数几个降价的早鸟名额——如果你想得到你的名额,你一定要现在就行动!
非常感谢你对我和 PyImageSearch 博客的支持。
我希望在另一边见到你。
我刚刚开源了我的个人 imutils 包:一系列 OpenCV 便利函数。
你知道什么是真正好的感觉吗?
为开源社区做贡献。
PyPI ,Python 包索引库是个奇妙的东西。它使得下载、安装和管理 Python 库和包变得轻而易举。
说了这么多, 我已经把自己的个人 imutils 包推上线了。在处理计算机视觉和图像处理问题时,我几乎每天都使用这个软件包。
这个包包括一系列 OpenCV +便利函数,执行基本任务,如平移、旋转、调整大小和骨架化。
在未来,我们将(很可能,取决于评论部分的反馈)对imutils包中的每个函数进行详细的代码审查,但是现在,看看这篇博文的其余部分,看看imutils中包含的功能,然后确保将它安装在您自己的系统上!
安装
这个包假设你已经安装了 NumPy 和 OpenCV (以及 matplotlib ,如果你打算使用opencv2matplotlib函数的话)。
要安装imutils库,只需发出以下命令:
$ pip install imutils
我的 imutils 包:一系列 OpenCV 便利函数
让我们来看看我们可以用imutils包做些什么。
翻译
平移是图像在 x 或 y 方向的移动。要在 OpenCV 中翻译图像,您需要提供 (x,y) -shift,表示为 (t [x] ,t [y] ) 来构造翻译矩阵 M :
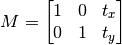
然后,您需要应用cv2.warpAffine函数。
不用手动构造平移矩阵 M 并调用cv2.warpAffine,只需调用imutils的translate函数即可。
示例:
# translate the image x=25 pixels to the right and y=75 pixels up
translated = imutils.translate(workspace, 25, -75)
输出:
旋转
在 OpenCV 中旋转图像是通过调用cv2.getRotationMatrix2D和cv2.warpAffine来完成的。还需要注意提供图像旋转点的 (x,y) 坐标。这些计算调用会很快累积起来,使您的代码变得庞大,可读性更差。imutils中的rotate功能有助于解决这个问题。
示例:
# loop over the angles to rotate the image
for angle in xrange(0, 360, 90):
# rotate the image and display it
rotated = imutils.rotate(bridge, angle=angle)
cv2.imshow("Angle=%d" % (angle), rotated)
输出:
调整大小
在 OpenCV 中调整图像大小是通过调用cv2.resize函数来完成的。但是,需要特别注意确保纵横比保持不变。imutils的这个resize函数维护纵横比并提供关键字参数width和height,因此图像可以调整到预期的宽度/高度,同时(1)维护纵横比和(2)确保图像的尺寸不必由开发人员显式计算。
另一个可选的关键字参数inter,也可以用来指定插值方法。
示例:
# loop over varying widths to resize the image to
for width in (400, 300, 200, 100):
# resize the image and display it
resized = imutils.resize(workspace, width=width)
cv2.imshow("Width=%dpx" % (width), resized)
输出:
骨骼化
骨架化是构建图像中对象的“拓扑骨架”的过程,其中对象被假定为黑色背景上的白色。OpenCV 没有提供显式构建框架的函数,但是提供了形态学和二进制函数来实现。
为了方便起见,可以使用imutils的skeletonize函数来构建图像的拓扑骨架。
第一个参数,size是结构化元素内核的大小。可选参数structuring可用于控制结构化元素——默认为cv2.MORPH_RECT,但可以是任何有效的结构化元素。
示例:
# skeletonize the image
gray = cv2.cvtColor(logo, cv2.COLOR_BGR2GRAY)
skeleton = imutils.skeletonize(gray, size=(3, 3))
cv2.imshow("Skeleton", skeleton)
输出:

使用 Matplotlib 显示
在 OpenCV 的 Python 绑定中,图像以 BGR 顺序表示为 NumPy 数组。这在使用cv2.imshow功能时工作良好。但是,如果您打算使用 Matplotlib,plt.imshow函数假定图像是 RGB 顺序的。一个简单的调用cv2.cvtColor将解决这个问题,或者您可以使用opencv2matplotlib便利功能。
示例:
# INCORRECT: show the image without converting color spaces
plt.figure("Incorrect")
plt.imshow(cactus)
# CORRECT: convert color spaces before using plt.imshow
plt.figure("Correct")
plt.imshow(imutils.opencv2matplotlib(cactus))
plt.show()
输出:
摘要
这就是你要的 imutils 软件包!
希望你安装一下,试一试。这肯定会使用 OpenCV 和 Python 执行简单的图像处理任务变得更加容易(并且代码更少)。
在接下来的几周里,我们将对每个功能进行代码审查,并讨论在引擎盖下发生了什么。
直到那时!
下载:
从 GitHub 获取 imutils 包。
用于图像分类的 k-NN 分类器
原文:https://pyimagesearch.com/2016/08/08/k-nn-classifier-for-image-classification/

现在我们已经在 LeNet 上的上周博客文章中领略了深度学习和卷积神经网络,我们将后退一步,开始更深入地研究图像分类背景下的机器学习。
首先,我们将回顾 k-最近邻(k-NN)分类器,可以说是最简单、最容易理解的机器学习算法。事实上,k-NN 是如此简单的,它根本不执行任何“学习”!
在这篇博文的剩余部分,我将详细说明 k-NN 分类器是如何工作的。然后,我们将 k-NN 应用于 Kaggle Dogs vs. Cats 数据集,这是来自微软的 Asirra 数据集的子集。
顾名思义,狗与猫数据集的目标是对给定图像是否包含一只狗或一只猫进行分类。我们将在未来的博客文章中大量使用这个数据集(原因我将在本教程稍后解释),所以请确保你现在花时间通读这篇文章并熟悉这个数据集。
*说了这么多, 让我们开始实现用于图像分类的 k-NN,以识别图像中的狗和猫!
用于图像分类的 k-NN 分类器
在上周第一次体验了卷积神经网络的之后,你可能会觉得我们今天讨论 k-NN 是在向倒退一大步。
怎么回事?
好吧,是这样的。
我曾经写过一篇关于摆脱深度学习潮流并获得一些观点的(有争议的)博文。尽管标题令人反感,但这篇文章的总主题围绕着机器学习历史的各种趋势,如神经网络(以及神经网络的研究如何在 70-80 年代几乎消亡)、支持向量机和集成方法。
当这些方法中的每一种被引入时,研究人员和从业者都配备了新的、强大的技术——实质上,他们得到了一把锤子,每个问题看起来都像一个钉子 ,而在现实中,他们需要的只是简单地转动几下菲利普头来解决特定的问题。
我有消息告诉你:深度学习也没什么不同。
去参加绝大多数流行的机器学习和计算机视觉会议,看看最近的出版物列表。最重要的主题是什么?
深度学习。
然后,跳上与计算机视觉和机器学习相关的大型 LinkedIn 群。很多人在问什么?
如何将深度学习应用于他们的数据集。
在那之后,去看看流行的计算机科学分支,比如 /r/machinelearning 。有哪些教程是最被一致看好的?
你猜对了:深度学习。
这是底线:
是的,我会在这个博客上教你关于深度学习和卷积神经网络的知识——但是你会明白深度学习只是一种工具,就像任何其他工具一样,使用它有一个正确的和错误的时间。
正因为如此,在我们走得太远之前,了解机器学习的基础知识对我们来说很重要。在接下来的几周里,我将讨论机器学习和神经网络的基础知识,最终建立深度学习(在这里你将能够更多地欣赏这些算法的内部工作方式)。
Kaggle 狗对猫数据集
狗对猫的数据集实际上是几年前的一个 Kaggle 挑战赛的一部分。这个挑战本身很简单:给定一张图片,预测它是包含一只狗还是一只猫:

Figure 1: Examples from the Kaggle Dogs vs. Cats dataset.
很简单,但是如果你了解图像分类,你就会明白:
- 视点变化
- 标度变化
- 变形
- 闭塞
- 背景杂斑
- 类内变异
这个问题比表面上看起来要困难得多。
通过简单的随机猜测,你应该可以达到 50%的准确率(因为只有两个类别标签)。一个机器学习算法将需要获得> 50%的准确性,以证明它事实上已经“学习”了一些东西(或在数据中发现了一个潜在的模式)。
就我个人而言,我喜欢狗与猫的挑战,尤其是教授深度学习的。
为什么?
数据集简单到足以让你晕头转向——只有两个类:【狗】或【猫】。
然而,数据集的大小很好,在训练数据中包含 25,000 张图像。这意味着你有足够的数据从头开始训练数据饥渴的卷积神经网络。
在未来的博客文章中,我们会大量使用这个数据集。为了您的方便,我实际上已经将它包含在这篇博文的 【下载】 部分,所以在您继续之前,请向下滚动以获取代码+数据。
项目结构
一旦你下载了这篇博文的归档文件,把它解压到一个方便的地方。从这里我们来看一下项目目录结构:
$ tree --filelimit 10
.
├── kaggle_dogs_vs_cats
│ └── train [25000 entries exceeds filelimit, not opening dir]
└── knn_classifier.py
2 directories, 1 file
Kaggle 数据集包含在kaggle_dogs_vs_cats/train目录中(它来自 Kaggle 网页上的train.zip)。
我们今天将回顾一个 Python 脚本— knn_classifier.py。该文件将加载数据集,建立并运行 K-NN 分类器,并打印出评估指标。
k-NN 分类器是如何工作的?
k 近邻分类器是到目前为止最简单的机器学习/图像分类算法。事实上,非常简单,它实际上并没有“学习”任何东西。
在内部,这种算法简单地依赖于特征向量之间的距离,很像构建一个图像搜索引擎——只是这一次,我们有了与每张图像相关联的标签,因此我们可以预测并返回该图像的实际类别。
简单来说,k-NN 算法通过在 k 个最接近的例子中找到个最常见的类来对未知数据点进行分类。*T5k最接近的例子中的每个数据点进行投票,得票最多的类别获胜!*
或者,说白了:“告诉我你的邻居是谁,我就知道你是谁”
为了形象化这一点,看一下下面的玩具示例,我沿着 x 轴绘制了动物的“蓬松度”,并在 y 轴绘制了它们皮毛的亮度:

Figure 2: Plotting the fluffiness of animals along the x-axis and the lightness of their coat on the y-axis.
这里我们可以看到有两类图像,每个类别中的每个数据点在一个 n- 维空间中相对紧密地组合在一起。我们的狗往往有深色的皮毛,不是很蓬松,而我们的猫有非常浅色的皮毛,非常蓬松。
这意味着红色圆圈中的两个数据点之间的距离比红色圆圈中的数据点和蓝色圆圈中的数据点之间的距离小得多。
为了应用 k-最近邻分类,我们需要定义一个距离度量或相似性函数。常见的选择包括欧几里德距离:

Figure 3: The Euclidean distance.
以及曼哈顿/城市街区距离:

Figure 4: The Manhattan/city block distance.
根据您的数据类型,可以使用其他距离度量/相似性函数(卡方距离通常用于分布[即直方图])。在今天的博文中,为了简单起见,我们将使用欧几里德距离来比较图像的相似性。
用 Python 实现 k-NN 图像分类
既然我们已经讨论了 k-NN 算法是什么,以及我们要将它应用到什么数据集,那么让我们编写一些代码来使用 k-NN 实际执行图像分类。
打开一个新文件,命名为knn_classifier.py,让我们开始编码:
# import the necessary packages
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
import os
我们从第 2-9 行开始,导入我们需要的 Python 包。如果你还没有安装 scikit-learn 库,那么你会希望按照这些说明现在就安装它。
注:此博文已更新为兼容未来scikit-learn==0.20其中sklearn.cross_validation已被sklearn.model_selection取代。
其次,我们将使用 imutils 库,这是我创建的一个包,用来存储常见的计算机视觉处理函数。如果您还没有安装imutils,您现在就想安装:
$ pip install imutils
接下来,我们将定义两种方法来获取输入图像并将其转换为特征向量,或者量化图像内容的数字列表。第一种方法如下图所示:
def image_to_feature_vector(image, size=(32, 32)):
# resize the image to a fixed size, then flatten the image into
# a list of raw pixel intensities
return cv2.resize(image, size).flatten()
image_to_feature_vector方法是一个非常简单的函数,它简单地获取一个输入image并将其调整为固定的宽度和高度(size),然后将 RGB 像素亮度展平为一个数字列表。
这意味着我们的输入image将被缩小到32×32像素,并且分别给每个红色、绿色和蓝色分量三个通道,我们的输出“特征向量”将是一列32×32×3 = 3072 个数字。
严格地说,image_to_feature_vector的输出不是真正的“特征向量”,因为我们倾向于将“特征”和“描述符”视为图像内容的抽象量化。
此外,利用原始像素强度作为机器学习算法的输入往往会产生很差的结果,即使是旋转、平移、视点、比例等的小变化。,能否显著影响图像本身(从而影响你的输出特征表示)。
注:正如我们将在后面的教程中发现的,卷积神经网络使用原始像素强度作为输入获得了惊人的结果——但这是因为它们在训练过程中学习了*一组强大的鉴别过滤器。*
然后我们定义第二个方法,这个方法叫做extract_color_histogram:
def extract_color_histogram(image, bins=(8, 8, 8)):
# extract a 3D color histogram from the HSV color space using
# the supplied number of `bins` per channel
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
hist = cv2.calcHist([hsv], [0, 1, 2], None, bins,
[0, 180, 0, 256, 0, 256])
# handle normalizing the histogram if we are using OpenCV 2.4.X
if imutils.is_cv2():
hist = cv2.normalize(hist)
# otherwise, perform "in place" normalization in OpenCV 3 (I
# personally hate the way this is done
else:
cv2.normalize(hist, hist)
# return the flattened histogram as the feature vector
return hist.flatten()
顾名思义,这个函数接受一个输入image并构建一个颜色直方图来描述图像的颜色分布。
首先,我们将第 19 行的image转换到 HSV 色彩空间。然后我们应用cv2.calcHist函数来计算image ( 行 20 和 21 )的 3D 颜色直方图。你可以在这篇文章中阅读更多关于计算颜色直方图的内容。您可能还会对将颜色直方图应用于图像搜索引擎以及如何比较颜色直方图的相似性感兴趣。
给定我们计算出的hist,然后我们将其规范化,注意使用基于 OpenCV 版本的适当的cv2.normalize函数签名(第 24-30 行)。
给定分别用于色调、饱和度和值通道的 8 个面元,我们的最终特征向量的大小为8×8×8 = 512,因此我们的图像由 512-d 特征向量表征。
接下来,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-k", "--neighbors", type=int, default=1,
help="# of nearest neighbors for classification")
ap.add_argument("-j", "--jobs", type=int, default=-1,
help="# of jobs for k-NN distance (-1 uses all available cores)")
args = vars(ap.parse_args())
我们只需要一个命令行参数,后面跟着两个可选参数,下面详细介绍了每个参数:
- 这是我们输入的 Kaggle 狗对猫数据集目录的路径。
--neighbors:这里我们可以提供给定数据点分类时考虑的最近邻的数量。我们将这个值默认为一个,这意味着图像将通过在一个n–维空间中找到其最近的邻居来分类,然后取最近图像的标签。在下周的帖子中,我将演示如何自动调优 k 以获得最佳精度。--jobs:找到给定图像的最近邻居需要我们计算从我们的输入图像到我们数据集中每隔一个图像的的距离。这显然是一个线性伸缩的 O(N) 运算。对于较大的数据集,这可能会变得非常慢。为了加速这个过程,我们可以将最近邻的计算分布在机器的多个处理器/内核上。将--jobs设置为-1可确保所有的处理器/内核都用于帮助加速分类过程。
注: 我们也可以通过利用专门的数据结构如 kd-trees 或近似最近邻算法如 FLANN 或ony来加速 k-NN 分类器。在实践中,这些算法可以将最近邻搜索减少到大约O(log N);然而,在这篇文章中,为了简单起见,我们将执行一个详尽的最近邻搜索。
我们现在准备好为特征提取准备我们的图像:
# grab the list of images that we'll be describing
print("[INFO] describing images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the raw pixel intensities matrix, the features matrix,
# and labels list
rawImages = []
features = []
labels = []
第 47 行从磁盘获取所有 25,000 个训练图像的路径。
然后我们初始化三个列表(行 51-53 )来存储原始图像像素强度( 3072-d 特征向量),另一个存储直方图特征( 512-d 特征向量),最后是类标签本身(或者是“狗”或者是“猫”)。
让我们继续从数据集中提取要素:
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# load the image and extract the class label (assuming that our
# path as the format: /path/to/dataset/{class}.{image_num}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-1].split(".")[0]
# extract raw pixel intensity "features", followed by a color
# histogram to characterize the color distribution of the pixels
# in the image
pixels = image_to_feature_vector(image)
hist = extract_color_histogram(image)
# update the raw images, features, and labels matricies,
# respectively
rawImages.append(pixels)
features.append(hist)
labels.append(label)
# show an update every 1,000 images
if i > 0 and i % 1000 == 0:
print("[INFO] processed {}/{}".format(i, len(imagePaths)))
我们开始在第 56 行的上循环我们的输入图像。每个图像从磁盘加载,并且从imagePath ( 行 59 和 60 )提取类别标签。
我们在第 65 和 66 行的上应用image_to_feature_vector和extract_color_histogram函数——这些函数用于从输入image中提取我们的特征向量。
给定我们的特性标签,然后我们更新第 70-72 行上的rawImages、features和labels列表。
最后,我们在终端上显示一个更新,通知我们每 1000 张图像的特征提取进度(行 75 和 76 )。
您可能会好奇我们的rawImages和features矩阵占用了多少内存——下面的代码块会在执行时告诉我们:
# show some information on the memory consumed by the raw images
# matrix and features matrix
rawImages = np.array(rawImages)
features = np.array(features)
labels = np.array(labels)
print("[INFO] pixels matrix: {:.2f}MB".format(
rawImages.nbytes / (1024 * 1000.0)))
print("[INFO] features matrix: {:.2f}MB".format(
features.nbytes / (1024 * 1000.0)))
我们首先将列表转换成 NumPy 数组。然后,我们使用 NumPy 数组的.nbytes属性来显示表示使用的内存兆字节数(大约 75MB 用于原始像素亮度,50MB 用于颜色直方图。这意味着我们可以轻松地将我们的特征存储在主存中。
接下来,我们需要将我们的数据分区分成两部分——一部分用于训练,另一部分用于测试:
# partition the data into training and testing splits, using 75%
# of the data for training and the remaining 25% for testing
(trainRI, testRI, trainRL, testRL) = train_test_split(
rawImages, labels, test_size=0.25, random_state=42)
(trainFeat, testFeat, trainLabels, testLabels) = train_test_split(
features, labels, test_size=0.25, random_state=42)
这里,我们将使用 75%的数据进行训练,剩下的 25%用于测试 k-NN 算法。
让我们将 k-NN 分类器应用于原始像素强度:
# train and evaluate a k-NN classifer on the raw pixel intensities
print("[INFO] evaluating raw pixel accuracy...")
model = KNeighborsClassifier(n_neighbors=args["neighbors"],
n_jobs=args["jobs"])
model.fit(trainRI, trainRL)
acc = model.score(testRI, testRL)
print("[INFO] raw pixel accuracy: {:.2f}%".format(acc * 100))
这里,我们使用提供的数量--neighbors和--jobs实例化来自 scikit-learn 库的KNeighborsClassifier对象。
然后,我们通过调用 99 线上的.fit来“训练”我们的模型,随后评估 100 线上的测试数据。
以类似的方式,我们也可以在直方图表示上训练和评估 k-NN 分类器:
# train and evaluate a k-NN classifer on the histogram
# representations
print("[INFO] evaluating histogram accuracy...")
model = KNeighborsClassifier(n_neighbors=args["neighbors"],
n_jobs=args["jobs"])
model.fit(trainFeat, trainLabels)
acc = model.score(testFeat, testLabels)
print("[INFO] histogram accuracy: {:.2f}%".format(acc * 100))
k-NN 图像分类结果
为了测试我们的 k-NN 图像分类器,确保你已经使用本教程底部的 【下载】 表单下载了这篇博文的源代码。
下载中包含了 Kaggle 狗与猫的数据集。
从那里,只需执行以下命令:
$ python knn_classifier.py --dataset kaggle_dogs_vs_cats
首先,您会看到我们的图像是通过image_to_feature_vector和extract_color_histogram函数描述和量化的:

Figure 5: Quantifying and extracting features from the Dogs vs. Cats dataset.
根据机器的速度,这个过程不会超过 1-3 分钟。
要素提取过程完成后,我们可以看到一些关于要素制图表达大小(MB)的信息:

Figure 6: Measuring the size of our feature matrices.
原始像素特征占用 75MB,而颜色直方图仅需要 50MB 的 RAM。
最后,对原始像素强度和颜色直方图训练和评估 k-NN 算法:

Figure 7: Evaluating our k-NN algorithm for image classification.
如上图所示,通过利用原始像素强度,我们能够达到 54.42%的准确度。另一方面,将 k-NN 应用于颜色直方图获得了稍好的 57.58%的准确度。
*在这两种情况下,我们能够获得超过 50%的准确性,表明原始像素强度和颜色直方图的图像都有一个潜在的模式。
然而,57%的准确率还有待提高。
正如你可能想象的那样,颜色直方图并不是区分狗和猫的最佳方式:
- 有棕色的狗。还有棕色的猫。
- 有黑狗。还有黑猫。
- 当然,狗和猫可以出现在相同的环境中(例如房子、公园、海滩等)。)其中背景颜色分布是相似的。
正因为如此,严格利用颜色来区分猫和狗并不是一个很好的选择——但这没关系。这篇博文的目的只是简单地介绍使用 k-NN 算法进行图像分类的概念。
我们可以很容易地应用方法来获得更高的精度。正如我们将看到的,利用卷积神经网络,我们可以达到> 95%的准确性,而不需要太多的努力——但是我将把它留到将来我们更好地理解图像分类时讨论。
现在想了解更多关于卷积神经网络的信息吗?
如果你喜欢这个关于图像分类的教程,你肯定会想看看 PyImageSearch 大师课程——今天最完整、全面的计算机视觉在线课程。
在课程里面,你会发现超过 168 课,涵盖2161+页的内容,关于深度学习、卷积神经网络、图像分类、、 F 、王牌识别、、以及更多。
要了解更多关于 PyImageSearch 大师课程的信息(并获取 10 节免费样课+课程大纲 ),只需点击下面的按钮:
Click here to learn more about PyImageSearch Gurus!
我们能做得更好吗?
你可能想知道,我们能比 57%的分类准确率做得更好吗?
你会注意到,在这个例子中我只使用了 k=1 ,这意味着在对每张图像进行分类时,只考虑了一个最近的邻居。如果我使用 k=3 或 k=5 ,结果会有什么变化?
那么距离度量的选择呢——曼哈顿/城市街区的距离会是更好的选择吗?
同时改变k和距离度量的值怎么样?**
**分类准确度会提高吗?变得更糟?保持不变?
事实是几乎所有的机器学习算法都需要一点调整来获得最佳结果。为了确定这些模型变量的最优值,我们应用了一个叫做超参数调整的过程,这正是下周博客文章的主题。
摘要
在这篇博文中,我们回顾了使用 k-NN 算法进行图像分类的基础知识。然后,我们将 k-NN 分类器应用于 Kaggle Dogs vs. Cats 数据集,以识别给定图像中包含的是狗还是猫。
仅利用输入图像的原始像素强度,我们获得了 54.42%的准确度。通过使用颜色直方图,我们获得了略好的 57.58%的准确率。由于这两个结果都大于 50%(我们应该期望简单地通过随机猜测获得 50%的准确性),我们可以确定在原始像素/颜色直方图中有一个潜在的模式,可以用来区分狗和猫(尽管 57%的准确性相当差)。
这就提出了一个问题:“使用 k-NN 有可能获得> 57%的分类准确率吗?如果有,怎么做?”
答案是 超参数调整——这正是我们将在下周的博客文章中涉及的内容。
请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在下一篇博文发布时得到通知!****
Keras 和卷积神经网络(CNN)
原文:https://pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/

Creating a Convolutional Neural Network using Keras to recognize a Bulbasaur stuffed Pokemon
今天的博客文章是关于构建完整的端到端图像分类+深度学习应用的三部分系列的第二部分:
- 第一部分: 如何(快速)建立深度学习图像数据集
- 第二部分: Keras 和卷积神经网络(今日邮报)
- 第三部分:在 iOS 上运行 Keras 模型(将于下周发布)
在今天的博文结束时,你将理解如何在你自己的定制数据集上实现、训练和评估卷积神经网络。
在下周的帖子中,我将展示如何使用经过训练的 Keras 模型,并通过几行代码将其部署到智能手机应用程序中!
为了让这个系列轻松有趣,我正在实现我童年的一个梦想建造一个 Pokedex。Pokedex 是一种存在于口袋妖怪世界的设备,口袋妖怪是一种流行的电视节目,视频游戏和交易卡系列(我过去是/现在仍然是一个超级口袋妖怪迷)。
如果你不熟悉口袋妖怪,你应该把 Pokedex 想象成一个智能手机应用程序,它可以识别口袋妖怪,即存在于口袋妖怪世界中的类似动物的生物。
你可以交换你自己的数据集,当然,我只是玩玩,享受一点童年的怀旧。
要了解如何在自己定制的数据集上用 Keras 和深度学习训练一个卷积神经网络,继续阅读。
Keras 和卷积神经网络
2020-05-13 更新:此博文现已兼容 TensorFlow 2+!
在上周的博客文章中,我们学习了如何快速构建深度学习图像数据集——我们使用了文章中介绍的过程和代码来收集、下载和组织磁盘上的图像。
现在我们已经下载并组织了我们的图像,下一步是在数据的基础上训练一个卷积神经网络(CNN)。
在今天的帖子中,我将向你展示如何使用 Keras 和深度学习来训练你的 CNN。本系列的最后一部分将于下周发布,将展示如何使用经过训练的 Keras 模型,只需几行代码就能将其部署到智能手机(尤其是 iPhone)上。
本系列的最终目标是帮助您构建一个功能齐全的深度学习应用程序——使用本系列作为灵感和起点,帮助您构建自己的深度学习应用程序。
让我们开始用 Keras 和深度学习来训练 CNN。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
我们的深度学习数据集

Figure 1: A montage of samples from our Pokemon deep learning dataset depicting each of the classes (i.e., Pokemon species). As we can see, the dataset is diverse, including illustrations, movie/TV show stills, action figures, toys, etc.
我们的深度学习数据集由 1,191 张口袋妖怪(存在于流行的电视节目、视频游戏和交易卡系列口袋妖怪世界中的类似动物的生物)的图像组成。
我们的目标是使用 Keras 和深度学习训练一个卷积神经网络,以 识别 和 对这些口袋妖怪的每一个进行分类 。
我们将认识的口袋妖怪包括:
在上面的图 1 中可以看到每个班级的训练图像剪辑。
如您所见,我们的培训图像包括以下内容:
- 电视节目和电影中的静止画面
- 交易卡
- 动作玩偶
- 玩具和 plus
- 粉丝提供的图纸和艺术效果图
这种训练图像的多样化组合将允许我们的 CNN 在一系列图像中识别我们的五个口袋妖怪类别— 正如我们将看到的,我们将能够获得 82%+ 的分类准确性!
卷积神经网络和 Keras 项目结构
今天的项目有几个移动部分,为了帮助我们理解项目,让我们先回顾一下项目的目录结构:
├── dataset
│ ├── bulbasaur [234 entries]
│ ├── charmander [238 entries]
│ ├── mewtwo [239 entries]
│ ├── pikachu [234 entries]
│ └── squirtle [223 entries]
├── examples [6 entries]
├── pyimagesearch
│ ├── __init__.py
│ └── smallervggnet.py
├── plot.png
├── lb.pickle
├── pokedex.model
├── classify.py
└── train.py
有 3 个目录:
dataset:包含五个类,每个类都有自己的子目录,以方便解析类标签。- 包含我们将用来测试 CNN 的图片。
pyimagesearch模块:包含我们的SmallerVGGNet模型类(我们将在本文稍后实现)。
和根目录中的 5 个文件:
plot.png:运行训练脚本后生成的我们的训练/测试准确度和损失图。lb.pickle:我们的LabelBinarizer序列化对象文件——它包含类名查找机制的类索引。pokedex.model:这是我们序列化的 Keras 卷积神经网络模型文件(即“权重文件”)。train.py:我们将使用这个脚本来训练我们的 Keras CNN,绘制准确度/损失,然后序列化 CNN 并将二进制化器标记到磁盘。- 我们的测试脚本。
我们的 Keras 和 CNN 架构
Figure 2: A VGGNet-like network that I’ve dubbed “SmallerVGGNet” will be used for training a deep learning classifier with Keras. You can find the full resolution version of this network architecture diagram here.
我们今天将利用的 CNN 架构是 VGGNet 网络的一个更小、更紧凑的变体,由 Simonyan 和 Zisserman 在他们 2014 年的论文 中介绍,用于大规模图像识别的超深度卷积网络 。
类似 VGGNet 的架构具有以下特征:
- 仅使用 3×3 的卷积层,以递增的深度相互堆叠
- 通过最大池化减少卷大小
- softmax 分类器之前网络末端的全连接图层
我假设您已经在系统上安装并配置了 Keras。如果没有,下面是我整理的几个深度学习开发环境配置教程的链接:
如果你想跳过配置你的深度学习环境,我会推荐使用以下云中预先配置的实例之一:
让我们继续实现SmallerVGGNet,我们的小版本 VGGNet。在pyimagesearch模块中创建一个名为smallervggnet.py的新文件,并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
首先我们导入我们的模块——注意它们都来自 Keras。在阅读使用 Python 进行计算机视觉的深度学习的整个过程中,这些都被广泛涵盖。
***注意:您还需要在pyimagesearch中创建一个__init__.py文件,这样 Python 就知道这个目录是一个模块。如果你不熟悉__init__.py文件或者它们是如何被用来创建模块的,不要担心,只需使用这篇博文末尾的“下载”**部分来下载我的目录结构、源代码和数据集+示例图像。
从那里,我们定义了我们的SmallerVGGNet类:
class SmallerVGGNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们的构建方法需要四个参数:
width:图像宽度尺寸。height:图像高度尺寸。depth:图像的深度——也称为通道数。classes:我们数据集中的类的数量(这将影响我们模型的最后一层)。我们在本帖中使用了 5 个口袋妖怪类别,但是不要忘记,如果你为每个物种下载了足够多的示例图片,你可以使用 807 个口袋妖怪物种!
注意: 我们将处理深度为3``96 x 96的输入图像(我们将在本文后面看到)。当我们解释输入量在网络中的空间维度时,请记住这一点。
由于我们使用 TensorFlow 后端,我们用“通道最后”数据排序来安排输入形状,但是如果您想使用“通道优先”(Theano,等等。)然后在行 23-25 上自动处理。
现在,让我们开始添加层到我们的模型:
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
上面是我们的第一个CONV => RELU => POOL区块。
卷积层有带3 x 3内核的32滤镜。我们使用RELU激活函数,然后进行批量标准化。
我们的POOL层使用一个3 x 3 POOL大小来快速将空间维度从96 x 96减少到32 x 32(我们将使用96 x 96 x 3输入图像来训练我们的网络,我们将在下一节中看到)。
从代码块中可以看出,我们还将在网络架构中利用 dropout。Dropout 通过随机断开从当前层到下一层的节点来工作。这种在训练批次期间随机断开的过程有助于自然地将冗余引入到模型中——层中没有单个节点负责预测某个类、对象、边或角。
在应用另一个POOL层之前,我们将添加(CONV => RELU) * 2层:
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
将多个CONV和RELU层堆叠在一起(在减少体积的空间维度之前)允许我们学习更丰富的特征集。
注意如何:
- 我们将过滤器的尺寸从
32增加到64。我们在网络中走得越深,我们体积的空间维度就越小,我们学习的过滤器就越多。 - 我们将 how max pooling size 从
3 x 3减少到2 x 2,以确保我们不会过快地减少空间维度。
在这个阶段再次执行退出。
再来补充一组(CONV => RELU) * 2 => POOL:
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
请注意,我们在这里将过滤器的大小增加到了128。执行 25%节点的丢弃以再次减少过度拟合。
最后,我们有一组FC => RELU层和一个 softmax 分类器:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
全连接层由Dense(1024)指定,带有整流线性单元激活和批量标准化。
丢弃是最后一次执行——这一次请注意,我们在训练期间丢弃了 50%的节点。通常,在我们的全连接层中使用 40-50%的压降,而在之前的层中使用低得多的压降,通常为 10-25%(如果有压降的话)。
我们使用 softmax 分类器来完善模型,该分类器将返回每个类别标签的预测概率。
在本节顶部的图 2 中可以看到SmallerVGGNet前几层网络架构的可视化。要查看我们的 Keras CNN 实现SmallerVGGNet的完整分辨率,请参考下面的链接。
实施我们的 CNN + Keras 培训脚本
现在SmallerVGGNet已经实现,我们可以使用 Keras 训练我们的卷积神经网络。
打开一个新文件,将其命名为train.py,并插入以下代码,我们将在其中导入所需的包和库:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from pyimagesearch.smallervggnet import SmallerVGGNet
import matplotlib.pyplot as plt
from imutils import paths
import numpy as np
import argparse
import random
import pickle
import cv2
import os
我们将使用"Agg" matplotlib 后端,以便数字可以保存在后台(行 3 )。
ImageDataGenerator类将用于数据扩充,这是一种用于获取数据集中现有图像并应用随机变换(旋转、剪切等)的技术。)来生成附加的训练数据。数据扩充有助于防止过度拟合。
第 7 行引入了Adam优化器,用于训练我们网络的优化器方法。
LabelBinarizer ( 第 9 行)是一个需要注意的重要类,这个类将使我们能够:
- 输入一组类标签(即,在我们的数据集中表示人类可读的类标签的字符串)。
- 将我们的类标签转换成一次性编码向量。
- 允许我们从我们的 Keras CNN 获取一个整数类标签预测,并将其转换回人类可读的标签。
在 PyImageSearch 博客上,我经常被问到如何将类标签字符串转换成整数,反之亦然。现在你知道解决方法是使用LabelBinarizer类。
train_test_split函数(第 10 行)将用于创建我们的训练和测试分割。还要注意我们在11 号线的SmallerVGGNet导入——这是我们在前一部分刚刚实现的 Keras CNN。
这个博客的读者熟悉我自己的 imutils 包。如果您没有安装/更新它,您可以通过以下方式安装:
$ pip install --upgrade imutils
如果您正在使用 Python 虚拟环境(正如我们通常在 PyImageSearch 博客上所做的),请确保在安装/升级imutils之前使用workon命令访问您的特定虚拟环境。
从那里,让我们解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset (i.e., directory of images)")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
对于我们的训练脚本,我们需要提供三个必需的命令行参数:
--dataset:输入数据集的路径。我们的数据集组织在一个dataset目录中,子目录代表每个类。每个子目录中有大约 250 个口袋妖怪图片。更多细节见本文顶部的项目目录结构。--model:输出模型的路径——这个训练脚本将训练模型并将其输出到磁盘。--labelbin:输出标签二进制化器的路径——很快您就会看到,我们将从数据集目录名中提取类标签并构建标签二进制化器。
我们还有一个可选参数,--plot。如果你不指定路径/文件名,那么一个plot.png文件将被放在当前的工作目录中。
你 不需要 修改第 22-31 行来提供新的文件路径。命令行参数在运行时处理。如果这对你没有意义,一定要看看我的命令行参数博文。
现在我们已经处理了命令行参数,让我们初始化一些重要的变量:
# initialize the number of epochs to train for, initial learning rate,
# batch size, and image dimensions
EPOCHS = 100
INIT_LR = 1e-3
BS = 32
IMAGE_DIMS = (96, 96, 3)
# initialize the data and labels
data = []
labels = []
# grab the image paths and randomly shuffle them
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
第 35-38 行初始化训练我们的 Keras CNN 时使用的重要变量:
- 我们将训练我们的网络的总次数(即,我们的网络“看到”每个训练示例并从中学习模式的次数)。
INIT_LR:初始学习率-1e-3 是 Adam 优化器的默认值,我们将使用该优化器来训练网络。- 我们会将一批批图像传入我们的网络进行训练。每个时期有多个批次。
BS值控制批量大小。 - 这里我们提供输入图像的空间维度。我们将要求我们的输入图像是带有
3通道的96 x 96像素(即 RGB)。我还会注意到,我们特别设计 SmallerVGGNet 时考虑到了96 x 96映像。
我们还初始化了两个列表— data和labels,它们将分别保存预处理后的图像和标签。
第 46-48 行抓取所有的图像路径并随机洗牌。
从这里开始,我们将循环遍历这些imagePaths:
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
image = img_to_array(image)
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
我们循环遍历第 51 行第行的imagePaths,然后加载图像(行第 53** )并调整其大小以适应我们的模型(行第 54 )。**
现在是时候更新我们的data和labels列表了。
我们调用 Keras img_to_array函数将图像转换成 Keras 兼容的数组(第 55 行),然后将图像附加到我们的列表data ( 第 56 行)。
对于我们的labels列表,我们从第 60 行的文件路径中提取出label,并将其(标签)附加到第 61 行的上。
那么,这个类标签解析过程为什么会起作用呢?
考虑这样一个事实,我们特意创建了我们数据集目录结构,使其具有以下格式:
dataset/{CLASS_LABEL}/{FILENAME}.jpg
使用第 60 行上的路径分隔符,我们可以将路径分成一个数组,然后获取列表中倒数第二个条目 class 标签。
如果这个过程让您感到困惑,我建议您打开 Python shell,通过在操作系统各自的路径分隔符上分割路径来探索示例imagePath。
让我们继续前进。下一个代码块中发生了一些事情—额外的预处理、二进制化标签和数据分区:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
print("[INFO] data matrix: {:.2f}MB".format(
data.nbytes / (1024 * 1000.0)))
# binarize the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.2, random_state=42)
这里我们首先将data数组转换为 NumPy 数组,然后将像素亮度缩放到范围[0, 1] ( 第 64 行)。我们还将第 65 行上的labels从列表转换为 NumPy 数组。打印一条信息消息,显示data矩阵的大小(MB)。
然后,我们利用 scikit-learn 的LabelBinarizer ( 第 70 行和第 71 行)将标签二进制化。
对于深度学习或任何机器学习来说,一种常见的做法是将训练和测试分开。这在第 75 行和第 76 行进行处理,我们创建了一个 80/20 的随机数据分割。
接下来,让我们创建我们的图像数据增强对象:
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=25, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
由于我们使用的数据点数量有限(每类少于 250 张图片),因此我们可以在训练过程中利用数据扩充来为我们的模型提供更多的图片(基于现有的图片)进行训练。
数据增强是每个深度学习从业者工具箱里都应该有的工具。我在用 Python 进行计算机视觉深度学习的 的从业者捆绑包中介绍了数据增强。
我们在第 79-81 行的上初始化我们的ImageDataGeneratoraug。
接下来,让我们编译模型并开始培训:
# initialize the model
print("[INFO] compiling model...")
model = SmallerVGGNet.build(width=IMAGE_DIMS[1], height=IMAGE_DIMS[0],
depth=IMAGE_DIMS[2], classes=len(lb.classes_))
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
在第 85 和 86 行,我们用96 x 96 x 3输入空间维度初始化我们的 Keras CNN 模型。当我经常收到这个问题时,我将再次声明这一点——SmallerVGGNet 被设计为接受96 x 96 x 3输入图像。如果您想要使用不同的空间维度,您可能需要:
- 对于较小的图像,减少网络的深度
- 为更大的图像增加网络的深度
不要盲目地编辑代码。首先考虑较大或较小图像的含义!
我们将使用学习率衰减的Adam优化器(第 87 行),然后使用分类交叉熵的compile我们的model,因为我们有> 2 个类(第 88 行和第 89 行)。
注意:对于仅有的两类你应该使用二进制交叉熵作为损失。
从那里,我们调用 Keras fit方法来训练网络(第 93-97 行)。耐心点——这可能需要一些时间,取决于您是使用 CPU 还是 GPU 进行训练。
2020-05-13 更新:以前,TensorFlow/Keras 需要使用一种叫做fit_generator的方法来完成数据扩充。现在,fit方法可以处理数据扩充,也可以产生更加一致的代码。请务必查看我关于 fit 和 fit 生成器以及数据扩充的文章。
一旦我们的 Keras CNN 完成训练,我们将希望保存(1)模型和(2)标签二值化器,因为当我们在训练/测试集之外的图像上测试网络时,我们需要从磁盘加载它们:
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
# save the label binarizer to disk
print("[INFO] serializing label binarizer...")
f = open(args["labelbin"], "wb")
f.write(pickle.dumps(lb))
f.close()
我们序列化了模型(第 101 行)和标签二进制化器(第 105-107 行),这样我们可以在后面的classify.py脚本中轻松使用它们。
标签二进制文件包含人类可读的类别标签字典的类别索引。这个对象确保我们不必在希望使用我们的 Keras CNN 的脚本中硬编码我们的类标签。
最后,我们可以绘制我们的训练和损失准确性:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
N = EPOCHS
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="upper left")
plt.savefig(args["plot"])
2020-05-13 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
我选择将我的绘图保存到磁盘( Line 121 )而不是显示它有两个原因:(1)我在云中的一个无头服务器上,(2)我想确保我不会忘记保存绘图。
用 Keras 训练我们的 CNN
现在我们准备训练我们的 Pokedex CNN。
请务必访问本帖的 【下载】 部分,以便下载代码+数据。
然后执行以下命令来训练模式;在确保正确提供命令行参数的同时:
$ python train.py --dataset dataset --model pokedex.model --labelbin lb.pickle
Using TensorFlow backend.
[INFO] loading images...
[INFO] data matrix: 252.07MB
[INFO] compiling model...
[INFO] training network...
Train for 29 steps, validate on 234 samples
Epoch 1/100
29/29 [==============================] - 7s 237ms/step - loss: 1.4218 - accuracy: 0.6271 - val_loss: 1.9534 - val_accuracy: 0.2436
Epoch 2/100
29/29 [==============================] - 6s 208ms/step - loss: 0.7470 - accuracy: 0.7703 - val_loss: 2.7184 - val_accuracy: 0.3632
Epoch 3/100
29/29 [==============================] - 6s 207ms/step - loss: 0.5928 - accuracy: 0.8080 - val_loss: 2.8207 - val_accuracy: 0.2436
...
29/29 [==============================] - 6s 208ms/step - loss: 0.2108 - accuracy: 0.9423 - val_loss: 1.7813 - val_accuracy: 0.8248
Epoch 98/100
29/29 [==============================] - 6s 208ms/step - loss: 0.1170 - accuracy: 0.9645 - val_loss: 2.2405 - val_accuracy: 0.7265
Epoch 99/100
29/29 [==============================] - 6s 208ms/step - loss: 0.0961 - accuracy: 0.9689 - val_loss: 1.2761 - val_accuracy: 0.8333
Epoch 100/100
29/29 [==============================] - 6s 207ms/step - loss: 0.0449 - accuracy: 0.9834 - val_loss: 1.1710 - val_accuracy: 0.8291
[INFO] serializing network...
[INFO] serializing label binarizer...
查看我们训练脚本的输出,我们看到我们的 Keras CNN 获得:
- 在训练集上的分类准确率为 98.34%
- 在测试集上准确率为 82.91%
训练损失/精度图如下:
Figure 3: Training and validation loss/accuracy plot for a Pokedex deep learning classifier trained with Keras.
正如您在图 3 中看到的,我对模型进行了 100 个历元的训练,并在有限的过拟合情况下实现了低损耗。有了额外的训练数据,我们也可以获得更高的准确度。
创建我们的 CNN 和 Keras 测试脚本
现在我们的 CNN 已经训练好了,我们需要实现一个脚本来对不属于我们训练或验证/测试集的图像进行分类。打开一个新文件,将其命名为classify.py,并插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
首先,我们导入必要的包(第 2-9 行)。
接下来,让我们解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
我们有三个必需的命令行参数需要解析:
--model:我们刚刚训练的模型的路径。--labelbin:标签二进制文件的路径。--image:我们输入的图像文件路径。
这些参数中的每一个都是在第 12-19 行上建立和解析的。请记住,您不需要修改这些行——在下一节中,我将向您展示如何使用运行时提供的命令行参数来运行程序。
接下来,我们将加载并预处理图像:
# load the image
image = cv2.imread(args["image"])
output = image.copy()
# pre-process the image for classification
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
这里我们加载输入image ( 第 22 行)并制作一个名为output的副本用于显示目的(第 23 行)。
然后我们以与训练完全相同的方式预处理image(第 26-29 行)。
从那里,让我们加载模型+标签二值化器,然后对图像进行分类:
# load the trained convolutional neural network and the label
# binarizer
print("[INFO] loading network...")
model = load_model(args["model"])
lb = pickle.loads(open(args["labelbin"], "rb").read())
# classify the input image
print("[INFO] classifying image...")
proba = model.predict(image)[0]
idx = np.argmax(proba)
label = lb.classes_[idx]
为了对图像进行分类,我们需要model和内存中的标签二值化器。我们在第 34 行和第 35 行都加载了。
随后,我们对image进行分类并创建label ( 第 39-41 行)。
剩余的代码块用于显示目的:
# we'll mark our prediction as "correct" of the input image filename
# contains the predicted label text (obviously this makes the
# assumption that you have named your testing image files this way)
filename = args["image"][args["image"].rfind(os.path.sep) + 1:]
correct = "correct" if filename.rfind(label) != -1 else "incorrect"
# build the label and draw the label on the image
label = "{}: {:.2f}% ({})".format(label, proba[idx] * 100, correct)
output = imutils.resize(output, width=400)
cv2.putText(output, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
# show the output image
print("[INFO] {}".format(label))
cv2.imshow("Output", output)
cv2.waitKey(0)
在第 46 和 47 行,我们从filename中提取口袋妖怪的名字,并将其与label进行比较。基于此,correct变量将是"correct"或"incorrect"。显然,这两行假设您的输入图像有一个包含真实标签的文件名。
在此基础上,我们采取以下步骤:
- 将概率百分比和
"correct"/"incorrect"文本附加到类label( 第 50 行)中。 - 调整
output图像的大小,使其适合我们的屏幕(第 51 行)。 - 在
output图像上绘制label文本(第 52 行和第 53 行)。 - 显示
output图像并等待按键退出(第 57 和 58 行)。
用我们的 CNN 和 Keras 分类图片
我们现在准备好运行classify.py脚本了!
确保你已经从这篇文章底部的 【下载】 部分抓取了代码+图片。
一旦你下载并解压了这个项目的根目录下的存档文件,从小火龙的图片开始。注意,为了运行脚本,我们提供了三个命令行参数:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/charmander_counter.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] charmander: 85.42% (correct)

Figure 4: Correctly classifying an input image using Keras and Convolutional Neural Networks.
现在让我们用忠诚而凶猛的妙蛙种子填充口袋妖怪来质疑我们的模型:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/bulbasaur_plush.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] bulbasaur: 99.61% (correct)

Figure 5: Again, our Keras deep learning image classifier is able to correctly classify the input image [image source]
让我们试试一个玩具动作人偶 Mewtwo (一个基因工程口袋妖怪):
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/mewtwo_toy.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] mewtwo: 81.52% (correct)

Figure 6: Using Keras, deep learning, and Python we are able to correctly classify the input image using our CNN. [image source]
如果 Pokedex 不能识别臭名昭著的皮卡丘,它会是什么样的例子呢:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/pikachu_toy.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] pikachu: 100.00% (correct)
Figure 7: Using our Keras model we can recognize the iconic Pikachu Pokemon. [image source]
让我们试试可爱的杰尼龟口袋妖怪:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/squirtle_plush.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] squirtle: 99.96% (correct)

Figure 8: Correctly classifying image data using Keras and a CNN. [image source]
最后但同样重要的是,让我们再次对我的火尾小火龙进行分类。这次他害羞了,被我的监视器遮住了一部分。
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/charmander_hidden.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] charmander: 98.78% (correct)

Figure 9: One final example of correctly classifying an input image using Keras and Convolutional Neural Networks (CNNs).
这些口袋妖怪都不是我的新口袋妖怪的对手。
目前,大约有 807 种不同种类的口袋妖怪。我们的分类器只在五个不同的口袋妖怪上训练过(为了简单起见)。
如果你想训练一个分类器来识别更大的口袋妖怪,你将需要每个职业 的额外训练图像。理想情况下,你的目标应该是每类 有500-1000 张你想识别的图像。
要获得训练图像,我建议你只需看看微软 Bing 的图像搜索 API 。这个 API 比我之前分享的谷歌图片搜索的版本更容易使用(但那也能工作)。
这种模式的局限性
这个模型的主要限制之一是训练数据量少。我测试了各种图像,有时分类是不正确的。当这种情况发生时,我更仔细地检查了输入图像+网络,发现图像中最主要的颜色会显著地影响分类。
例如,图像中大量的红色和橙色很可能会返回“小火龙”作为标签。类似地,图像中大量的黄色通常会导致一个“皮卡丘”标签。
这部分是由于我们的输入数据。口袋妖怪显然是虚构的,所以没有他们的实际“现实世界”的图像(除了动作人物和玩具 plushes)。
我们的大部分图片来自粉丝插图或电影/电视节目的剧照。此外,我们每个类只有有限的数据量(大约 225-250 张图片)。
理想情况下,当训练一个卷积神经网络时,我们每个类至少应该有 500-1000 个图像。在处理自己的数据时,请记住这一点。
我们可以把这个 Keras 深度学习模型作为 REST API 吗?
如果你想将这个模型(或任何其他深度学习模型)作为 REST API 运行,我写了三篇博文来帮助你开始:
- 搭建一个简单的 Keras +深度学习 REST API (Keras.io 客座博文)
- 一个可扩展的 Keras +深度学习 REST API
- 使用 Keras、Redis、Flask 和 Apache 在生产中进行深度学习
摘要
在今天的博文中,你学习了如何使用 Keras 深度学习库来训练卷积神经网络(CNN)。
我们的数据集是使用上周博文中讨论的程序收集的。
特别是,我们的数据集由 5 个独立的口袋妖怪(存在于流行的电视节目、视频游戏和交易卡系列口袋妖怪世界中的类似动物的生物)的 1,191 张图像组成。
使用我们的卷积神经网络和 Keras,我们能够获得 82%的准确度,考虑到(1)我们数据集的有限大小和(2)我们网络中的参数数量,这是相当可观的。
**在下周的博文中,我将展示我们如何做到:
- 以我们训练好的 Keras +卷积神经网络模型为例…
- 只需几行代码就能将其部署到智能手机上!
这将是一个伟大的职位,不要错过它!
要下载这篇文章的源代码(并在下周的《不能错过的文章》发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
Keras Conv2D 和卷积层
原文:https://pyimagesearch.com/2018/12/31/keras-conv2d-and-convolutional-layers/

在今天的教程中,我们将讨论 Keras Conv2D 类,包括在训练自己的卷积神经网络(CNN)时需要调整的最重要的参数。接下来,我们将使用 Keras Conv2D 类实现一个简单的 CNN。然后我们将在 CALTECH-101 数据集上训练和评估这个 CNN。
今天这篇文章的灵感来自于 PyImageSearch 的读者 Danny。
丹尼问道:
嗨,Adrian,我在理解 Keras 的 Conv2D 类的参数时遇到了一些问题。
哪些是重要的?
哪些应该保留默认值?
我对深度学习有点陌生,所以在创建自己的 CNN 时,我对如何选择参数值有点困惑。
Danny 提出了一个很好的问题 Keras 的 Conv2D 类有很多参数。如果你是计算机视觉和深度学习领域的新手,那么这个数字可能会有点令人难以招架。
在今天的教程中,我将讨论 Keras Conv2D 类的每一个参数,解释每一个参数,并举例说明何时何地需要设置特定值,使您能够:
- 快速确定是否需要对 Keras Conv2D 类使用特定参数
- 为该特定参数确定适当值
- 有效训练自己的卷积神经网络
总的来说,我的目标是帮助减少使用 Keras 的 Conv2D 类时的任何困惑、焦虑或挫折。阅读完本教程后,您将对 Keras Conv2D 参数有一个深入的了解。
要了解更多关于 Keras Conv2D 类和卷积层的信息,请继续阅读!
Keras Conv2D 和卷积层
2020-06-03 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将讨论 Keras Conv2D 类的参数。
接下来,我们将利用 Conv2D 类来实现一个简单的卷积神经网络。
然后,我们将采用我们的 CNN 实现,然后在 CALTECH-101 数据集上训练它。
最后,我们将评估网络并检查其性能。
让我们开始吧!
Keras Conv2D 类
Keras Conv2D 类构造函数具有以下签名:
tensorflow.keras.layers.Conv2D(filters, kernel_size, strides=(1, 1),
padding='valid', data_format=None, dilation_rate=(1, 1),
activation=None, use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None)
看起来有点势不可挡,对吧?
你究竟应该如何正确地设置这些值呢?
不要担心——让我们分别检查这些参数,让你不仅清楚地了解每个参数控制什么,还清楚地了解如何正确设置每个参数。
过滤
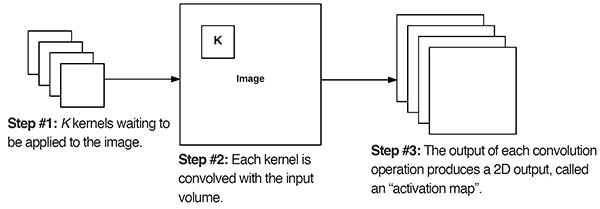
Figure 1: The Keras Conv2D parameter, filters determines the number of kernels to convolve with the input volume. Each of these operations produces a 2D activation map.
第一个必需的 Conv2D 参数是卷积层将学习的filters的编号。
网络架构中较早的层(即,更接近实际输入图像)学习较少的卷积滤波器,而网络中较深的层(即,更接近输出预测)将学习较多的滤波器。
中间的 Conv2D 层将比早期的 Conv2D 层学习更多的滤波器,但比更靠近输出的层学习更少的滤波器。让我们来看一个例子:
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
...
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
...
model.add(Conv2D(128, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
...
model.add(Activation("softmax"))
在第 1 行的上,我们总共学习了32个过滤器。然后使用最大池来减少输出体积的空间维度。
然后我们学习线 4 上的64滤波器。同样,最大池用于减少空间维度。
最终的 Conv2D 层学习128滤波器。
请注意,随着我们的输出空间音量减少,我们学习的滤波器数量增加——这是设计 CNN 架构的常见做法,我建议您也这样做。至于选择合适的filters数,我几乎总是推荐使用 2 的幂作为值。
您可能需要根据(1)数据集的复杂性和(2)神经网络的深度来调整确切的值,但我建议从早期的【32,64,128】范围内的过滤器开始,增加到更深层的【256,512,1024】。
同样,这些值的确切范围可能因人而异,但开始时要减少个过滤器,只在必要时增加数量。
内核大小
Figure 2: The Keras deep learning Conv2D parameter, filter_size, determines the dimensions of the kernel. Common dimensions include 1×1, 3×3, 5×5, and 7×7 which can be passed as (1, 1), (3, 3), (5, 5), or (7, 7) tuples.
您需要向 Keras Conv2D 类提供的第二个必需参数是kernel_size,它是一个 2 元组,指定 2D 卷积窗口的宽度和高度。
kernel_size也必须是一个奇整数。
kernel_size的典型值包括:(1, 1)、(3, 3)、(5, 5)、(7, 7)。很少看到内核大小大于 7×7 的。
那么,你什么时候使用它们呢?
如果您的输入图像大于 128×128 ,您可以选择使用内核大小> 3 来帮助(1)学习更大的空间过滤器和(2)帮助减少体积大小。
其他网络,如 VGGNet、exclusive在整个网络中使用(3, 3)过滤器。
更高级的架构,如 Inception、ResNet 和 SqueezeNet,设计整个微架构,它们是网络内部的【模块】,学习不同尺度的本地特征(即 1×1 、 3×3 和 5×5 ),然后组合输出。
一个很好的例子可以在下面的 Inception 模块中看到:
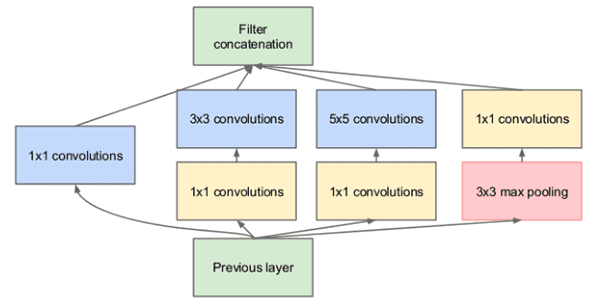
Figure 3: The Inception/GoogLeNet CNN architecture uses “micro-architecture” modules inside the network that learn local features at different scales (filter_size) and then combine the outputs.
ResNet 架构中的残差模块使用 1×1 和 3×3 过滤器作为一种降维形式,这有助于保持网络中的参数数量较少(或在给定网络深度的情况下尽可能少):
Figure 4: The ResNet “Residual module” uses 1×1 and 3×3 filters for dimensionality reduction. This helps keep the overall network smaller with fewer parameters.
那么,你应该如何选择你的filter_size?
首先,检查您的输入图像—它是否大于 128×128 ?
如果是这样,考虑使用一个 5×5 或 7×7 内核来学习更大的特性,然后快速降低空间维度——然后开始使用 3×3 内核:
model.add(Conv2D(32, (7, 7), activation="relu"))
...
model.add(Conv2D(32, (3, 3), activation="relu"))
如果你的图像小于 128×128 ,你可能要考虑坚持使用严格的 1×1 和 3×3 滤镜。
如果您打算使用 ResNet 或类似 Inception 的模块,您将希望手工实现相关的模块和架构。涵盖如何实现这些模块超出了本教程的范围,但如果你有兴趣了解更多关于它们的知识(包括如何手工编码),请参考我的书, 用 Python 进行计算机视觉的深度学习。
大步
strides参数是一个二元整数组,指定沿着输入体积的 x 和 y 轴的卷积的“步长”。
strides值默认为(1, 1),这意味着:
- 给定的卷积滤波器被应用于输入体积的当前位置
- 滤波器向右移动 1 个像素,再次将滤波器应用于输入体积
- 这个过程一直执行到我们到达体积的最右边界,在这里我们将滤波器向下移动一个像素,然后再从最左边开始
通常情况下,strides参数会保留默认的(1, 1)值;但是,您可能偶尔会将它增加到(2, 2),以帮助减少输出音量的大小(因为滤波器的步长更大)。
通常情况下,您会看到以 2×2 的步幅取代最大池:
model.add(Conv2D(128, (3, 3), strides=(1, 1), activation="relu"))
model.add(Conv2D(128, (3, 3), strides=(1, 1), activation="relu"))
model.add(Conv2D(128, (3, 3), strides=(2, 2), activation="relu"))
在这里,我们可以看到前两个 Conv2D 层的跨距为 1×1。最终的 Conv2D 层;但是,取代了最大池层,而是通过步长卷积减少了输出体积的空间维度。
2014 年,Springenber 等人发表了一篇题为 力求简单:全卷积网 的论文,该论文证明了在某些情况下,用步长卷积替换池层可以提高准确性。
受欢迎的 CNN ResNet 已经接受了这一发现——如果你曾经查看过 ResNet 实现(或自己实现)的源代码,你会看到 ResNet 基于步长卷积而不是最大池来减少剩余模块之间的空间维度。
填料

Figure 5: A 3×3 kernel applied to an image with padding. The Keras Conv2D padding parameter accepts either "valid" (no padding) or "same" (padding + preserving spatial dimensions). This animation was contributed to StackOverflow (source).
Keras Conv2D 类的padding参数可以取两个值之一:valid或same。
使用valid参数,输入体积不是零填充的,空间尺寸允许通过卷积的自然应用来减少。
下面的例子自然会减少我们体积的空间维度:
model.add(Conv2D(32, (3, 3), padding="valid"))
注:如果你需要帮助理解应用卷积时空间维度如何以及为什么会自然减少,请参见本教程的卷积基础知识。
如果您希望保留体积的空间维度,以使输出体积大小与输入体积大小相匹配,那么您可能希望为padding提供一个值same:
model.add(Conv2D(32, (3, 3), padding="same"))
虽然默认的 Keras Conv2D 值为valid,但我通常会将网络中大多数层的值设置为same,然后通过以下任一方式减小我的体积的空间维度:
- 最大池化
- 步进卷积
我建议您也使用类似的方法填充 Keras Conv2D 类。
数据格式
Figure 6: Keras, as a high-level framework, supports multiple deep learning backends. Thus, it includes support for both “channels last” and “channels first” channel ordering.
Conv2D 类中的数据格式值可以是channels_last或channels_first:
- Keras 的 TensorFlow 后端使用上次订购的渠道。
- Theano 后端使用通道优先排序。
出于两个原因,您通常不应该像 Keras 那样接触这个值:
- 您很可能使用 TensorFlow 后端来访问 Keras
- 如果没有,您可能已经更新了您的
~/.keras/keras.json配置文件来设置您的后端和相关的通道排序
我的建议是永远不要在 Conv2D 类中显式设置data_format,除非你有非常好的理由这样做。
膨胀率
Figure 7: The Keras deep learning Conv2D parameter, dilation_rate, accepts a 2-tuple of integers to control dilated convolution (source).
Conv2D 类的dilation_rate参数是一个 2 元组整数,控制膨胀卷积的膨胀率。扩张卷积是一种基本卷积,仅应用于具有确定间隙的输入体积,如上面的图 7 所示。
在以下情况下,可以使用扩张卷积:
- 您正在处理更高分辨率的图像,但精细的细节仍然很重要
- 您正在构建一个参数更少的网络
激活
Figure 8: Keras provides a number of common activation functions. The activation parameter to Conv2D is a matter of convenience and allows the activation function for use after convolution to be specified.
Conv2D 类的activation参数只是一个方便的参数,允许您提供一个字符串,指定在执行卷积后要应用的激活函数的名称。
在以下示例中,我们执行卷积,然后应用 ReLU 激活函数:
model.add(Conv2D(32, (3, 3), activation="relu"))
上面的代码相当于:
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
我的建议?
使用activation参数,如果它有助于保持您的代码更干净——这完全取决于您,不会对您的卷积神经网络的性能产生影响。
使用偏差
Conv2D 类的use_bias参数控制是否将偏置向量添加到卷积层。
通常情况下,您会希望将该值保留为True,尽管 ResNet 的一些实现将会省略 bias 参数。
我建议保持偏见,除非你有充分的理由不这样做。
内核初始化器和偏差初始化器
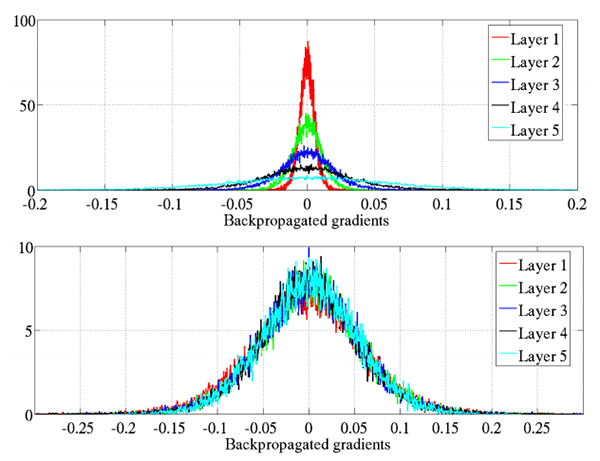
Figure 9: Keras offers a number of initializers for the Conv2D class. Initializers can be used to help train deeper neural networks more effectively.
在实际训练网络之前,kernel_initializer控制用于初始化 Conv2D 类中所有值的初始化方法。
类似地,bias_initializer控制训练开始前如何初始化偏置向量。
初始化器的完整列表可以在 Keras 文档中找到;然而,这里是我的建议:
- 不要管
bias_initialization——默认情况下,它会用零填充(你很少需要改变偏置初始化方法。 kernel_initializer默认为glorot_uniform, Xavier Glorot 统一初始化方法,这对于大多数任务来说非常好;然而,对于更深层次的神经网络,您可能希望使用he_normal( 和何等人的初始化),当您的网络有大量参数(即 VGGNet)时,它尤其适用。
在我实现的绝大多数 CNN 中,我要么使用glorot_uniform要么使用he_normal——我建议你也这样做,除非你有特定的理由使用不同的初始化器。
核正则化、偏差正则化和活动正则化
Figure 10: Regularization hyperparameters should be adjusted especially when working with large datasets and really deep networks. The kernel_regularizer parameter in particular is one that I adjust often to reduce overfitting and increase the ability for a model to generalize to unfamiliar images.
kernel_regularizer、bias_regularizer和activity_regularizer控制应用于 Conv2D 层的正则化方法的类型和数量。
应用正规化有助于您:
- 减少过度拟合的影响
- 提高你的模型的概括能力
当处理大型数据集和深度神经网络时,应用正则化通常是必须的。
*通常情况下,您会遇到应用 L1 或 L2 正则化的情况,如果我发现过度拟合的迹象,我会在我的网络上使用 L2 正则化:
from tensorflow.keras.regularizers import l2
...
model.add(Conv2D(32, (3, 3), activation="relu"),
kernel_regularizer=l2(0.0005))
您应用的正则化量是一个超参数,您需要针对自己的数据集进行调整,但我发现 0.0001-0.001 的值是一个很好的开始范围。
我建议不要管你的偏差正则化器 —正则化偏差通常对减少过度拟合影响很小。
我还建议将activity_regularizer保留为默认值(即没有活动调整)。
虽然权重正则化方法对权重本身 f(W) 进行操作,其中 f 是激活函数,而 W 是权重,但是活动正则化方法对输出、 f(O) 进行操作,其中 O 是层的输出。
除非有非常特殊的原因,否则最好不要使用这个参数。
内核约束和偏差约束
Keras Conv2D 类的最后两个参数是kernel_constraint和bias_constraint。
这些参数允许您对 Conv2D 层施加约束,包括非负性、单位归一化和最小-最大归一化。
您可以在 Keras 文档中看到支持的约束的完整列表。
同样,我建议不要考虑内核约束和偏差约束,除非您有特定的理由对 Conv2D 层施加约束。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
加州理工学院-101(子集)数据集

Figure 11: The CALTECH-101 dataset consists of 101 object categories with 40-80 images per class. The dataset for today’s blog post example consists of just 4 of those classes: faces, leopards, motorbikes, and airplanes (source).
CALTECH-101 数据集是 101 个对象类别的数据集,每个类别有 40 到 800 幅图像。
大多数图像每类大约有 50 个图像。
数据集的目标是训练一个能够预测目标类的模型。
在神经网络和深度学习重新兴起之前,最先进的准确率只有约 65%。
然而,通过使用卷积神经网络,有可能实现 90%以上的准确性(如何等人在 2014 年的论文中所展示的, 深度卷积网络中的空间金字塔池用于视觉识别 )。
今天,我们将实现一个简单而有效的 CNN,它能够在数据集的 4 类子集上实现 96%以上的准确率:
- 面孔: 436 张图片
- 豹子: 201 张图片
- 摩托车: 799 张图片
- 飞机: 801 张图片
我们使用数据集子集的原因是,即使您没有 GPU,您也可以轻松地按照这个示例从头开始训练网络。
同样,本教程的目的是而不是提供 CALTECH-101 的最新结果,而是教你如何使用 Keras 的 Conv2D 类实现和训练自定义卷积神经网络的基础知识。
下载数据集和源代码
有兴趣跟随今天的教程吗?如果是这样,您需要下载两者:
- 这篇帖子的源代码(使用了 【下载】 部分的帖子)
- 加州理工学院-101 数据集
下载完。源代码的 zip 文件,将其解压缩,然后将目录更改为keras-conv2d-example目录:
$ cd /path/to/keras-conv2d-example
从那里,使用下面的wget命令下载并解压缩 CALTECH-101 数据集:
$ wget http://www.vision.caltech.edu/Image_Datasets/Caltech101/101_ObjectCategories.tar.gz
$ tar -zxvf 101_ObjectCategories.tar.gz
现在我们已经下载了代码和数据集,我们可以继续检查项目结构。
项目结构
要查看我们的项目是如何组织的,只需使用tree命令:
$ tree --dirsfirst -L 2 -v
.
├── 101_ObjectCategories
...
│ ├── Faces [436 entries]
...
│ ├── Leopards [201 entries]
│ ├── Motorbikes [799 entries]
...
│ ├── airplanes [801 entries]
...
├── pyimagesearch
│ ├── __init__.py
│ └── stridednet.py
├── 101_ObjectCategories.tar.gz
├── train.py
└── plot.png
104 directories, 5 files
第一个目录101_ObjectCategories/是我们在上一节中提取的数据集。它包含 102 个文件夹,所以我为今天的博客文章删除了我们不关心的行。剩下的是前面讨论过的四个对象类别的子集。
pyimagesearch/模块不是 pip 可安装的。你必须使用 【下载】 来抓取文件。在模块内部,您会发现包含 StridedNet 类的stridendet.py。
除了stridednet.py,我们还将回顾根文件夹中的train.py。我们的训练脚本将利用 StridedNet 和我们的小型数据集来训练一个用于示例目的的模型。
训练脚本将生成一个训练历史图plot.png。
Keras Conv2D 示例

Figure 12: A deep learning CNN dubbed “StridedNet” serves as the example for today’s blog post about Keras Conv2D parameters. Click to expand.
现在,我们已经了解了(Keras Conv2D 类的工作方式,以及(2)我们将在其上训练网络的数据集,让我们继续实现我们将训练的卷积神经网络。
我们今天要用的 CNN,“StridedNet”,是我为了本教程的目的而编造的。
StridedNet 有三个重要特征:
- 它使用步长卷积而不是池化操作来减少卷大小
- 第一个 CONV 层使用 7×7 滤波器,但是网络中的所有其他层使用 3×3 滤波器(类似于 VGG)
- 使用 MSRA/何等人的正态分布算法来初始化网络中的所有权重
现在让我们继续实现 StridedNet。
打开一个新文件,将其命名为stridednet.py,并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
class StridedNet:
@staticmethod
def build(width, height, depth, classes, reg, init="he_normal"):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们所有的 Keras 模块都是在线 2-9 即Conv2D导入的。
我们的StridedNet类是在行 11 上用行 13 上的单个build方法定义的。
build方法接受六个参数:
width:以像素为单位的图像宽度。height:以像素为单位的图像高度。depth:图像的通道数。classes:模型需要预测的类别数。reg:正则化方法。init:内核初始化器。
width、height和depth参数影响输入体积形状。
对于"channels_last"排序,输入形状在depth最后的行 17 指定。
我们可以使用 Keras 后端来检查image_data_format,看看我们是否需要适应"channels_first"订购(第 22-24 行)。
让我们看看如何构建前三个 CONV 层:
# our first CONV layer will learn a total of 16 filters, each
# Of which are 7x7 -- we'll then apply 2x2 strides to reduce
# the spatial dimensions of the volume
model.add(Conv2D(16, (7, 7), strides=(2, 2), padding="valid",
kernel_initializer=init, kernel_regularizer=reg,
input_shape=inputShape))
# here we stack two CONV layers on top of each other where
# each layerswill learn a total of 32 (3x3) filters
model.add(Conv2D(32, (3, 3), padding="same",
kernel_initializer=init, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), strides=(2, 2), padding="same",
kernel_initializer=init, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Dropout(0.25))
每个Conv2D与model.add堆叠在网络上。
注意,对于第一个Conv2D层,我们已经明确指定了我们的inputShape,这样 CNN 架构就有了开始和构建的地方。然后,从这里开始,每次调用model.add时,前一层就作为下一层的输入。
考虑到前面讨论过的Conv2D的参数,你会注意到我们正在使用步长卷积来减少空间维度,而不是合并操作。
应用 ReLU 激活(参见图 8 )以及批量标准化和丢弃。
我几乎总是推荐批处理规范化,因为它有助于稳定训练并使超参数的调整更容易。也就是说,它可以让你的训练时间增加两倍或三倍。明智地使用它。
辍学的目的是帮助你的网络一般化,而不是过度拟合。来自当前层的的神经元,以概率 p ,将随机断开与下一层的神经元的连接,因此网络必须依赖现有的连接。我强烈建议利用辍学。**
让我们看看 StridedNet 的更多层:
# stack two more CONV layers, keeping the size of each filter
# as 3x3 but increasing to 64 total learned filters
model.add(Conv2D(64, (3, 3), padding="same",
kernel_initializer=init, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding="same",
kernel_initializer=init, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Dropout(0.25))
# increase the number of filters again, this time to 128
model.add(Conv2D(128, (3, 3), padding="same",
kernel_initializer=init, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), strides=(2, 2), padding="same",
kernel_initializer=init, kernel_regularizer=reg))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Dropout(0.25))
网络越深入,我们学到的过滤器就越多。
在大多数网络的末端,我们会添加一个全连接层:
# fully-connected layer
model.add(Flatten())
model.add(Dense(512, kernel_initializer=init))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
具有512节点的单个全连接层被附加到 CNN。
最后,一个"softmax"分类器被添加到网络中——这一层的输出是预测值本身。
那是一个包裹。
正如您所看到的,一旦您知道了参数的含义,Keras 的语法就非常简单了(Conv2D可能有相当多的参数)。
让我们来学习如何用一些数据写一个脚本来训练 StridedNet!
实施培训脚本
现在我们已经实现了我们的 CNN 架构,让我们创建用于训练网络的驱动程序脚本。
打开train.py文件并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.stridednet import StridedNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import os
我们在线 2-18 导入我们的模块和包。注意,我们没有在任何地方导入Conv2D。我们的 CNN 实现包含在stridednet.py中,我们的StridedNet导入处理它(行 6 )。
我们的matplotlib后端设置在行 3——这是必要的,这样我们可以将我们的绘图保存为图像文件,而不是在 GUI 中查看。
我们从第 7-9 行的上的sklearn导入功能:
LabelBinarizer:对我们的类标签进行“一次性”编码。- 用于分割我们的数据,这样我们就有了训练集和评估集。
- 我们将用它来打印评估的统计数据。
从keras开始,我们将使用:
ImageDataGenerator:用于数据扩充。关于 Keras 数据生成器的更多信息,请参见上周的博客文章。Adam:SGD 的替代优化器。- 我们将使用的正则化子。向上滚动阅读正则项。应用正则化可以减少过度拟合,有助于泛化。
我的 imutils paths模块将用于获取数据集中图像的路径。
我们将使用argparse在运行时处理命令行参数,OpenCV ( cv2)将用于从数据集中加载和预处理图像。
现在让我们继续解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-e", "--epochs", type=int, default=50,
help="# of epochs to train our network for")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们的脚本可以接受三个命令行参数:
--dataset:输入数据集的路径。--epochs:训练的历元数。到default,我们将为50时代而训练。--plot:我们的损失/精度图将被输出到磁盘。此参数包含文件路径。默认就是简单的"plot.png"。
让我们准备加载数据集:
# initialize the set of labels from the CALTECH-101 dataset we are
# going to train our network on
LABELS = set(["Faces", "Leopards", "Motorbikes", "airplanes"])
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
在实际加载数据集之前,我们将继续初始化:
- 我们将用于培训的标签。
imagePaths:数据集目录的图像路径列表。我们将很快根据从文件路径中解析的类标签过滤这些文件。- 一个保存我们的图像的列表,我们的网络将被训练。
labels:一个列表,用于保存与数据相对应的类标签。
让我们填充我们的data和labels列表:
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# if the label of the current image is not part of of the labels
# are interested in, then ignore the image
if label not in LABELS:
continue
# load the image and resize it to be a fixed 96x96 pixels,
# ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.resize(image, (96, 96))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
从第 42 行的开始,我们将循环所有的imagePaths。在循环中,我们:
- 从路径中提取
label(行 44 )。 - 仅过滤
LABELS集合中的类(第 48 行和第 49 行)。这两行使我们跳过任何分别属于面孔、豹子、摩托车或飞机类的label而不是,如行 32 所定义。 - 载和
resize我们的image(53 线和 54 线)。 - 最后,将
image和label添加到它们各自的列表中(行 57 和 58 )。
下一个模块中有四个动作:
# convert the data into a NumPy array, then preprocess it by scaling
# all pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator(rotation_range=20, zoom_range=0.15,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
horizontal_flip=True, fill_mode="nearest")
这些行动包括:
- 将
data转换成一个 NumPy 数组,每个image缩放到范围【0,1】(第 62 行)。 - 用我们的
LabelBinarizer( 第 65 行和第 66 行)将我们的labels二进制化为“一热编码”。这意味着我们的labels现在用数字表示,而“一个热点”的例子可能是:[0, 0, 0, 1]为“飞机”[0, 1, 0, 0]为“豹子”- 等等。
- 将我们的
data分成培训和测试(第 70 行和第 71 行)。 - 初始化我们的
ImageDataGenerator进行数据扩充(第 74-76 行)。你可以在这里了解更多。
现在我们准备编写代码来实际训练我们的模型:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = Adam(lr=1e-4, decay=1e-4 / args["epochs"])
model = StridedNet.build(width=96, height=96, depth=3,
classes=len(lb.classes_), reg=l2(0.0005))
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network for {} epochs...".format(
args["epochs"]))
H = model.fit(x=aug.flow(trainX, trainY, batch_size=32),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // 32,
epochs=args["epochs"])
2020-06-03 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit 生成器以及数据扩充的文章。
第 80-84 行准备我们的StridedNet model,用Adam优化器和学习率衰减、我们指定的输入形状、类的数量和l2正则化来构建它。
从那里开始,在第 89-91 行我们将使我们的模型符合数据。在这种情况下,“fit”意味着“train”,.fit意味着我们正在使用我们的数据增强图像数据生成器。
为了评估我们的模型,我们将使用testX数据并打印一个classification_report:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
2020-06-03 更新:每 TensorFlow 2.0+,我们不再使用.predict_generator方法;它被替换为.predict,并具有相同的函数签名(即,第一个参数可以是 Python 生成器对象)。
最后,我们将绘制我们的准确度/损失训练历史,并将其保存到磁盘:
# plot the training loss and accuracy
N = args["epochs"]
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-03 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
培训和评估我们的 Keras CNN
至此,我们已经准备好训练我们的网络了!
确保您已经使用今天教程的 【下载】 部分下载了源代码和示例图像。
在那里,打开一个终端,将目录切换到下载代码和 CALTECH-101 数据集的位置,然后执行以下命令:
$ python train.py --dataset 101_ObjectCategories
[INFO] loading images...
[INFO] compiling model...
[INFO] training network for 50 epochs...
Epoch 1/50
52/52 [==============================] - 2s 45ms/step - loss: 2.0399 - accuracy: 0.4963 - val_loss: 1.4532 - val_accuracy: 0.5671
Epoch 2/50
52/52 [==============================] - 2s 38ms/step - loss: 1.5679 - accuracy: 0.6748 - val_loss: 1.9899 - val_accuracy: 0.4651
Epoch 3/50
52/52 [==============================] - 2s 39ms/step - loss: 1.3503 - accuracy: 0.7284 - val_loss: 2.0150 - val_accuracy: 0.5510
...
Epoch 48/50
52/52 [==============================] - 2s 38ms/step - loss: 0.5473 - accuracy: 0.9689 - val_loss: 0.5118 - val_accuracy: 0.9857
Epoch 49/50
52/52 [==============================] - 2s 38ms/step - loss: 0.5734 - accuracy: 0.9555 - val_loss: 0.7230 - val_accuracy: 0.9410
Epoch 50/50
52/52 [==============================] - 2s 38ms/step - loss: 0.5697 - accuracy: 0.9653 - val_loss: 0.6236 - val_accuracy: 0.9517
[INFO] evaluating network...
precision recall f1-score support
Faces 0.97 0.99 0.98 109
Leopards 1.00 0.76 0.86 50
Motorbikes 0.91 1.00 0.95 200
airplanes 0.98 0.93 0.95 200
accuracy 0.95 559
macro avg 0.97 0.92 0.94 559
weighted avg 0.95 0.95 0.95 559
Figure 13: My accuracy/loss plot generated with Keras and matplotlib for training StridedNet, an example CNN to showcase Keras Conv2D parameters.
如您所见,我们的网络在测试集上以最小的过拟合获得了 ~95%的准确率 !
摘要
在今天的教程中,我们讨论了卷积层和 Keras Conv2D 类。
你现在知道了:
- 什么是最重要的参数是到 Keras Conv2D 类(
filters、kernel_size、strides、padding) - 这些参数的合适值是什么
- 如何使用 Keras Conv2D 类创建自己的卷积神经网络
- 如何训练 CNN 并在一个示例数据集上对其进行评估
我希望本教程对理解 Keras 的 Conv2D 类的参数有所帮助——如果有,请在评论部分留下评论。
如果您想下载这篇博文的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下表中输入您的电子邮件地址。*
Keras 和深度学习在树莓派上的应用
原文:https://pyimagesearch.com/2017/12/18/keras-deep-learning-raspberry-pi/

今天的博文是我曾经写过的一篇 PyImageSearch 教程中最有趣的。
**它包含了我们过去几周讨论的所有内容,包括:
- 深度学习
- 覆盆子馅饼
- 3D 圣诞树
- 参考 HBO 的硅谷“不是热狗”探测器
- 我打扮成圣诞老人!
为了与圣诞节和假期保持一致,我将演示如何采用深度学习模型(用 Keras 训练),然后将其部署到 Raspberry Pi。
但这不是任何机器学习模型…
这个图像分类器已经过专门训练来检测圣诞老人是否在我们的视频流中。
如果我们真的发现了圣诞老人…
好吧。我不会破坏这个惊喜(但它确实包括一棵 3D 圣诞树和一首欢快的曲子)。
享受教程。下载代码。用它来破解。
最重要的是,玩得开心!
Keras 和深度学习在树莓派上的应用
今天的博客文章是一个使用 Keras 在 Raspberry Pi 上运行深度神经网络的完整指南。
我把这个项目设计成一个而不是检测器,给你一个实际的实现(并且一路上有一些乐趣)。
在这篇博文的第一部分,我们将讨论什么是非圣诞老人探测器(以防你不熟悉 HBO 的硅谷【非热狗】探测器,它已经发展了一批狂热的追随者)。
然后,我们将通过安装 TensorFlow、Keras 和许多其他先决条件来配置我们的 Raspberry Pi 以进行深度学习。
一旦我们的 Raspberry Pi 配置为深度学习,我们将继续构建 Python 脚本,该脚本可以:
- 从磁盘加载我们的 Keras 模型
- 访问我们的 Raspberry Pi 摄像头模块/USB 网络摄像头
- 应用深度学习来检测圣诞老人是否在框架中
- 如果检测到圣诞老人,访问我们的 GPIO 引脚并播放音乐
这些是我最喜欢在 PyImageSearch 上写的博文类型,因为它们整合了我们讨论过的一系列技术,包括:
我们开始吧!
什么是非圣诞老人探测器?
我需要什么硬件?

Figure 2: The Not Santa detector setup includes the Raspberry Pi 3, speakers, 3D Christmas tree, and a webcam (not pictured). The Pi has LeNet implemented with Keras in a Python script in order to detect Santa.
为了准确地跟随本教程(没有修改),你需要:
- 一个树莓 Pi 3 (或者树莓 Pi 3 入门套装,我也强烈推荐)
- 一个 Raspberry Pi 摄像头模块或者一个 USB 摄像头。出于本教程的目的,我选择了罗技 C920 ,因为这是一款性价比很高的相机(与 Pi 相机上的短色带相比,USB 线给了你更多的工作空间)
- 树莓派的 3D 圣诞树(由瑞秋·瑞恩斯设计)
- 一套扬声器——我推荐 Pi Hut 的这些,Adafruit 的立体声扬声器,或者如果你正在寻找一些小的但仍然有冲击力的东西,你可以从亚马逊得到这个扬声器
当然,你不需要所有这些零件。
如果你只有一个 Raspberry Pi +摄像头模块/USB 摄像头,你就一切就绪了(但你必须修改代码,以便它不会试图访问 GPIO 引脚或通过扬声器播放音乐)。
你的设置看起来应该和我在上面的图 2 中的设置相似,我已经连接了我的扬声器、3D 圣诞树和网络摄像头(因为它不在摄像头下,所以没有显示)。
我还建议连接一个 HDMI 显示器+键盘来测试和调试你的脚本:

Figure 3: My deep learning setup includes the Raspberry Pi and components along with a keyboard, mouse, and small HDMI display. With this setup, we will surely catch Santa delivering presents in front of my tree.
在上图中,你可以看到我的树莓 Pi、HDMI、键盘和圣诞小动物朋友在我整理今天的教程时陪伴着我。
如何在树莓 Pi 上安装 TensorFlow 和 Keras?

Figure 4: We’re going to use Keras with the TensorFlow backend on the Raspberry Pi to implement a deep learning Not Santa detector.
上周,我们学习了如何使用 Keras 训练一个卷积神经网络来确定圣诞老人是否在输入图像中。
今天,我们将把预先训练好的模型部署到 Raspberry Pi 中。
正如我之前提到的,树莓派不适合训练神经网络(除了“玩具”的例子)。然而,树莓 Pi 可以用来部署一个神经网络,一旦它已经被训练好(当然,前提是该模型能够适合足够小的内存占用)。
我假设你已经在你的 Raspberry Pi 上安装了 OpenCV。
如果你还没有在你的 Raspberry Pi 上安装 OpenCV,从使用本教程开始吧,在本教程中,我演示了如何优化你的 Raspberry Pi + OpenCV 安装速度(导致 30%以上的性能提升)。
注意:本指南不适用于 Python 3 — 你需要使用 Python 2.7 。我将在本节稍后解释原因。现在花点时间用 Python 2.7 和 OpenCV 绑定来配置您的 Raspberry Pi。在 Raspberry Pi + OpenCV 安装指南的第 4 步中,确保使用-p python2开关创建一个虚拟环境。
从这里开始,我建议增加 Pi 上的交换空间。增加交换空间将使您能够使用 Raspberry Pi SD 卡获得额外的内存(当试图在内存有限的 Raspberry Pi 上编译和安装大型库时,这是一个关键步骤)。
要增加交换空间,打开/etc/dphys-swapfile,然后编辑CONF_SWAPSIZE变量:
# set size to absolute value, leaving empty (default) then uses computed value
# you most likely don't want this, unless you have a special disk situation
# CONF_SWAPSIZE=100
CONF_SWAPSIZE=1024
请注意,我将交换空间从 100MB 增加到了 1024MB。
从那里,重新启动交换服务:
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
注意:增加交换空间是烧坏你存储卡的一个好方法,所以当你完成后,一定要恢复这个改变并重启交换服务*。你可以在这里阅读更多关于大尺寸损坏存储卡的信息。*
既然您的交换空间已经增加了,让我们开始配置我们的开发环境。
首先,使用 Python 2.7 创建一个名为not_santa的 Python 虚拟环境(当我们使用 TensorFlow install 命令时,我将解释为什么使用 Python 2.7):
$ mkvirtualenv not_santa -p python2
注意这里的-p开关是如何指向python2的,这表明 Python 2.7 将用于虚拟环境。
如果你不熟悉 Python 虚拟环境,不知道它们是如何工作的,也不知道我们为什么使用它们,请参考这个指南来帮助你快速了解以及这个来自 RealPython 的优秀虚拟入门。
您还需要确保已经将您的cv2.so绑定符号链接到您的not_santa虚拟环境中(如果您还没有这样做):
$ cd ~/.virtualenvs/not_santa/lib/python2.7/site-packages
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
同样,确保你已经用 Python 2.7 绑定编译了 OpenCV。您还需要仔细检查您的cv2.so文件的路径,以防您的安装路径与我的略有不同。
如果您编译了 Python 3 + OpenCV 绑定,创建了 sym-link,然后试图import cv2到您的 Python shell 中,您将得到一个令人困惑的回溯,说导入失败。
重要提示:对于接下来的几个 pip 命令,请确保您处于not_santa环境中(或者您选择的 Python 环境),否则您将把这些包安装到您的 Raspberry Pi 的系统 Python 中。
要进入环境,只需在 bash 提示符下使用workon命令:
$ workon not_santa
从那里,您将在 bash 提示符的开头看到“(not_santa)”。
使用以下命令确保在not_santa环境中安装了 NumPy:
$ pip install numpy
由于我们将访问这个项目的 GPIO 引脚,我们需要安装两个 RPi。GPIO 和 gpiozero :
$ sudo pip install RPi.GPIO gpiozero
我们现在准备在您的树莓 Pi 上安装 TensorFlow。
问题是没有一个官方的(谷歌发布的)张量流分布。
我们可以在树莓派上跟随从零开始编译 TensorFlow 的漫长、艰难、痛苦的过程
或者我们可以使用 Sam Abrahams 创建的预编译二进制文件(发布在 GitHub )。
问题是只有两种预编译的 TensorFlow 二进制文件:
- 一个用于 Python 2.7
- 另一个用于 Python 3.4
Raspbian Stretch 发行版(在撰写本文时 Raspbian 操作系统的最新版本)随 Python 3.5 一起发布,因此我们有一个版本不匹配的问题。
为了避免 Python 3.4 和 Python 3.5 之间的任何问题,我决定继续安装 Python 2.7。
虽然我希望在本指南中使用 Python 3,但是安装过程会变得更加复杂(我可以轻松地写多篇关于在 Raspberry Pi 上安装 TensorFlow + Keras 的文章,但是由于安装不是本教程的主要重点,所以我决定让它更简单)。
让我们使用以下命令安装 TensorFlow for Python 2.7:
$ wget https://github.com/samjabrahams/tensorflow-on-raspberry-pi/releases/download/v1.1.0/tensorflow-1.1.0-cp27-none-linux_armv7l.whl
$ pip install tensorflow-1.1.0-cp27-none-linux_armv7l.whl
注意:你需要展开上面的代码块来复制完整的 URL。我建议你在复制命令之前按下< >按钮。
一旦 TensorFlow 编译并安装完毕(在我的 Raspberry Pi 上花了大约一个小时),你就需要安装 HDF5 和 h5py。这些库将允许我们从磁盘加载预先训练好的模型:
$ sudo apt-get install libhdf5-serial-dev
$ pip install h5py
我在没有运行time命令的情况下安装了 HDF5 + h5py,所以我不记得安装的确切时间了,但我相信大约是 30-45 分钟。
最后,让我们安装 Keras 和这个项目所需的其他先决条件:
$ pip install pillow imutils
$ pip install scipy --no-cache-dir
$ pip install keras==2.1.5
特别是 SciPy 的安装需要几个小时,所以请确保让安装运行一整夜/在你工作的时候。
很重要 你安装 Keras 2 . 1 . 5 版是为了兼容 TensorFlow 1.1.0。
为了测试您的配置,打开一个 Python shell(在not_santa环境中)并执行以下命令:
$ workon not_santa
$ python
>>> import h5py
>>> from gpiozero import LEDBoard
>>> from gpiozero.tools import random_values
>>> import cv2
>>> import imutils
>>> import keras
Using TesnsorFlow backend.
>>> print("OpenCV version: {}".format(cv2.__version__))
'OpenCV version: 3.3.1'
>>> print("Keras version: {}".format(keras.__version__))
'Keras version: 2.1.5'
>>> exit()
如果一切按计划进行,您应该会看到使用 TensorFlow 后端导入的 Keras。
正如上面的输出所示,您还应该仔细检查您的 OpenCV 绑定(cv2)是否也可以被导入。
最后, 不要忘记将您的交换空间 从 1024MB 减少到 100MB:
- 开放
/etc/dphys-swapfile。 - 将
CONF_SWAPSIZE重置为 100MB。 - 重启交换服务(正如我们在本文前面讨论的)。
正如上面提到的,将你的交换空间重新设置为 100MB 对于存储卡的寿命是很重要的。如果跳过这一步,您可能会遇到内存损坏问题,并缩短卡的使用寿命。
在树莓 Pi 上运行 Keras +深度学习模型

Figure 5: Running a deep learning model on the Raspberry Pi using Keras and Python.
我们现在准备使用 Keras、TensorFlow 和 Raspberry Pi 编写我们的 Not Santa 检测器。
同样,我将假设你有和我一样的硬件设置(即,3D 圣诞树和扬声器),所以如果你的设置不同,你需要破解下面的代码。
首先,打开一个新文件,将其命名为not_santa_detector.py,并插入以下代码:
# import the necessary packages
from keras.preprocessing.image import img_to_array
from keras.models import load_model
from gpiozero import LEDBoard
from gpiozero.tools import random_values
from imutils.video import VideoStream
from threading import Thread
import numpy as np
import imutils
import time
import cv2
import os
第 2-12 行处理我们的进口,特别是:
keras用于预处理输入帧以进行分类,并从磁盘加载我们预先训练好的模型。gpiozero用于访问 3D 圣诞树。imutils用于访问视频流(无论是 Raspberry Pi 摄像头模块还是 USB)。threading用于非阻塞操作,特别是当我们想要点亮圣诞树或播放音乐而不阻塞主线程执行时。
从那里,我们将定义一个函数来点亮我们的 3D 圣诞树:
def light_tree(tree, sleep=5):
# loop over all LEDs in the tree and randomly blink them with
# varying intensities
for led in tree:
led.source_delay = 0.1
led.source = random_values()
# sleep for a bit to let the tree show its Christmas spirit for
# santa clause
time.sleep(sleep)
# loop voer the LEDs again, this time turning them off
for led in tree:
led.source = None
led.value = 0
我们的light_tree函数接受一个tree参数(假设是一个LEDBoard对象)。
首先,我们循环遍历tree中的所有 led,随机点亮每一个 led 来创造一个“闪烁”的效果(第 17-19 行)。
我们让灯开一段时间来营造节日气氛(第 23 行),然后我们再次循环播放 led 灯,这一次关掉它们(第 26-28 行)。
打开 3D 圣诞树灯的示例如下所示:

Figure 6: The 3D Christmas tree for the Raspberry Pi. You can get yours from Pi Hut (photo credit: Pi Hut).
我们的下一个函数处理检测到圣诞老人时播放的音乐:
def play_christmas_music(p):
# construct the command to play the music, then execute the
# command
command = "aplay -q {}".format(p)
os.system(command)
在play_christmas_music函数中,我们对aplay命令进行系统调用,这使我们能够从命令行播放音乐文件。
使用os.system调用有点麻烦,但是通过纯 Python(使用 Pygame 之类的库)播放音频文件对这个项目来说是大材小用。
接下来,让我们对将要使用的配置进行硬编码:
# define the paths to the Not Santa Keras deep learning model and
# audio file
MODEL_PATH = "santa_not_santa.model"
AUDIO_PATH = "jolly_laugh.wav"
# initialize the total number of frames that *consecutively* contain
# santa along with threshold required to trigger the santa alarm
TOTAL_CONSEC = 0
TOTAL_THRESH = 20
# initialize is the santa alarm has been triggered
SANTA = False
第 38 行和第 39 行硬编码到我们预训练的 Keras 模型和音频文件的路径。一定要使用这篇博文的 【下载】 部分来抓取文件。
我们还初始化用于检测的参数,包括TOTAL_CONSEC和TOTAL_THRESH。这两个值分别代表包含圣诞老人的帧数和播放音乐并打开圣诞树的阈值(第 43 行和第 44 行)。
最后的初始化是SANTA = False,一个布尔(第 47 行)。我们将在稍后的脚本中使用SANTA变量作为状态标志来帮助我们的逻辑。
接下来,我们将加载预训练的 Keras 模型,并初始化我们的圣诞树:
# load the model
print("[INFO] loading model...")
model = load_model(MODEL_PATH)
# initialize the christmas tree
tree = LEDBoard(*range(2, 28), pwm=True)
Keras 允许我们将模型保存到磁盘上以备将来使用。上周,我们把不是圣诞老人的模型保存到磁盘上,本周我们将把它加载到我们的树莓派上。我们用 Keras load_model函数将模型加载到行 51 上。
我们的tree对象在行 54 被实例化。如图所示,tree是来自gpiozero包的一个LEDBoard对象。
现在我们将初始化我们的视频流:
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
要访问相机,我们将使用我的 imutils 包中的VideoStream(你可以在这里找到文档来进行视频流)在线 58 或 59 上。
重要提示:如果你想在这个项目中使用 PiCamera 模块(而不是 USB 摄像头),只需注释第 58 行,取消注释第 59 行*。*
我们sleep了短暂的 2 秒钟,这样我们的相机可以在我们开始循环画面之前预热一下( Line 60 ):
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
在第行第 63 处,我们开始在视频帧上循环,直到满足停止条件(在脚本的后面显示)。
首先,我们将通过调用vs.read ( 第 66 行)来获取一个frame。
然后我们调整frame到width=400,的大小,保持纵横比 ( 第 67 行)。在通过我们的神经网络模型发送之前,我们将对这个frame进行预处理。稍后,我们将在屏幕上显示这个框架以及一个文本标签。
从这里开始,我们对图像进行预处理,并通过我们的 Keras +深度学习模型进行预测:
# prepare the image to be classified by our deep learning network
image = cv2.resize(frame, (28, 28))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
# classify the input image and initialize the label and
# probability of the prediction
(notSanta, santa) = model.predict(image)[0]
label = "Not Santa"
proba = notSanta
第 70-73 行对image进行预处理,为分类做准备。要了解更多关于深度学习的预处理,请务必查看我最新著作的入门包, 用 Python 进行计算机视觉的深度学习 。
从那里,我们用我们的image作为参数查询model.predict。这将通过神经网络发送image,返回包含类别概率的元组(第 77 行)。
我们将label初始化为“不是圣诞老人”(我们稍后将重新访问label),并将概率proba初始化为第 78 行和第 79 行上notSanta的值。
让我们来看看圣诞老人是否在图片中:
# check to see if santa was detected using our convolutional
# neural network
if santa > notSanta:
# update the label and prediction probability
label = "Santa"
proba = santa
# increment the total number of consecutive frames that
# contain santa
TOTAL_CONSEC += 1
在第 83 行的上,我们检查santa的概率是否大于notSanta。如果是这种情况,我们继续更新label和proba,然后递增TOTAL_CONSEC ( 第 85-90 行)。
假设足够多的连续“圣诞老人”帧已经过去,我们需要触发圣诞老人警报:
# check to see if we should raise the santa alarm
if not SANTA and TOTAL_CONSEC >= TOTAL_THRESH:
# indicate that santa has been found
SANTA = True
# light up the christmas tree
treeThread = Thread(target=light_tree, args=(tree,))
treeThread.daemon = True
treeThread.start()
# play some christmas tunes
musicThread = Thread(target=play_christmas_music,
args=(AUDIO_PATH,))
musicThread.daemon = False
musicThread.start()
如果SANTA是False并且如果TOTAL_CONSEC达到TOTAL_THRESH阈值,我们有两个动作要执行:
- 创建并启动一个
treeThread来闪烁圣诞树灯(第 98-100 行)。 - 创建并启动一个
musicThread来在后台播放音乐(第 103-106 行)。
这些线程将在不停止脚本向前执行的情况下独立运行(即一个非阻塞操作)。
你还可以看到,在第 95 行上,我们将SANTA状态标志设置为True,这意味着我们已经在输入框中找到了圣诞老人。在下一次循环中,我们将像在第 93 行一样查看这个值。
否则(SANTA为True或TOTAL_THRESH未满足),我们将TOTAL_CONSEC重置为零,将SANTA重置为False:
# otherwise, reset the total number of consecutive frames and the
# santa alarm
else:
TOTAL_CONSEC = 0
SANTA = False
最后,我们在屏幕上显示带有生成的文本标签的框架:
# build the label and draw it on the frame
label = "{}: {:.2f}%".format(label, proba * 100)
frame = cv2.putText(frame, label, (10, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
print("[INFO] cleaning up...")
cv2.destroyAllWindows()
vs.stop()
概率值被附加到包含“圣诞老人”或“非圣诞老人”的label(行 115 )。
然后使用 OpenCV 的cv2.putText,我们可以在将帧显示到屏幕上之前,在帧的顶部写下标签(以圣诞主题的绿色)(第 116-120 行)。
我们的无限 while 循环的退出条件是在键盘上按下‘q’键(行 121-125 )。
如果循环的退出条件被满足,我们break在脚本退出之前对的第 129 行和第 130 行执行一些清理。
这就是全部了。回头看看我们一起回顾的 130 行——这个框架/模板也可以很容易地用于树莓 Pi 上的其他深度学习项目。
现在让我们抓住镜头里那个胖胖的,留着胡子的,快乐的男人!
深度学习+ Keras +树莓 Pi 结果
在上周的博客文章中,我们使用从网络上收集的股票图片测试了我们的而非圣诞老人深度学习模型。
但这一点都不好玩— 当然也不足以写这篇博文。
我一直想打扮成善良的圣尼古拉斯,所以上周我订购了一套便宜的圣诞老人服装:

Figure 7: Me, Adrian Rosebrock, dressed up as Santa. I’ll be personally testing our Not Santa detector, built using deep learning, Keras, Python, and and OpenCV.
我和真正的圣诞老人相差甚远,但这服装应该能达到目的。
然后,我把挂在树莓皮上的相机对准了公寓里的圣诞树:

Figure 8: My very own Christmas tree will serve as the background for testing our Not Santa detector deep learning model which has been deployed to the Raspberry Pi.
如果圣诞老人来给乖孩子分发礼物,我想通过闪烁 3D 圣诞树灯和播放一些圣诞歌曲来确保他感到受欢迎。
然后,我使用以下命令启动了 Not Santa 深度学习+ Keras 检测器:
$ python not_santa_detector.py
要跟进,请确保您使用下面的 【下载】 部分下载本指南中使用的源代码+预训练模型+音频文件。
一旦不是圣诞老人探测器启动并运行,我就开始行动:
Figure 9: Successfully detecting Santa in a video stream using deep learning, Python, Keras, and a Raspberry Pi.
每当检测到圣诞老人,3D 圣诞树就会亮起,音乐开始播放!(您听不到,因为这是一个示例 GIF 动画)。
要查看完整的 Not Santa 探测器(带声音),请看下面的视频:
https://www.youtube.com/embed/RdK-8pSQIP0?feature=oembed**
Keras:基于深度学习的大数据集特征提取
原文:https://pyimagesearch.com/2019/05/27/keras-feature-extraction-on-large-datasets-with-deep-learning/

在本教程中,您将了解如何使用 Keras 对太大而不适合内存的图像数据集进行特征提取。您将利用 ResNet-50(在 ImageNet 上进行了预训练)从大型图像数据集中提取特征,然后使用增量学习在提取的特征基础上训练分类器。
今天是我们关于 Keras 迁移学习的三部分系列的第二部分:
- Part 1: 用 Keras 转移学习和深度学习(上周教程)
- 第 2 部分: Keras:大型数据集上的特征提取(今天的帖子)
- 第三部分:用 Keras 和深度学习进行微调(下周教程)
上周我们讨论了如何使用 Keras 执行迁移学习——在该教程中,我们主要关注通过特征提取的 迁移学习。
使用这种方法,我们能够利用 CNN 来识别从未被训练过的类别!
这种方法的问题在于它假设我们提取的所有特征都可以放入内存——事实可能并非总是如此!
例如,假设我们有一个包含 50,000 幅图像的数据集,并希望利用 ResNet-50 网络通过 FC 层之前的最后一层进行特征提取,则输出体积的大小将为 7 x 7 x 2048 = 100,352-dim 。
如果我们有 50,000 个这样的 100,352 维特征向量(假设 32 位浮点),然后我们将需要总共 40.14GB 的 RAM 来在内存中存储整个特征向量集!
大多数人的机器中没有 40GB 以上的 RAM,因此在这些情况下,我们需要能够执行增量学习,并在 增量数据子集上训练我们的模型。
**今天剩余的教程将告诉你如何做到这一点。
要了解如何利用 Keras 在大型数据集上进行特征提取,请继续阅读!
Keras:基于深度学习的大数据集特征提取
2020-06-04 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将简要讨论将网络视为特征提取器的概念(这在上周的教程中有更详细的介绍)。
在此基础上,我们将研究提取的要素数据集过大而无法放入内存的情况,在这种情况下,我们需要对数据集应用增量学习。
接下来,我们将实现 Python 源代码,可用于:
- Keras 特征提取
- 随后对提取的特征进行增量学习
我们开始吧!
作为特征提取器的网络
![]()
Figure 1: Left: The original VGG16 network architecture that outputs probabilities for each of the 1,000 ImageNet class labels. Right: Removing the FC layers from VGG16 and instead returning the final POOL layer. This output will serve as our extracted features.
在执行深度学习特征提取时,我们将预先训练好的网络视为一个任意的特征提取器,允许输入图像向前传播,在预先指定的层停止,将该层的输出作为我们的特征。
这样做,我们仍然可以利用美国有线电视新闻网学到的强大的、有区别的特征。 我们也可以用它们来识别美国有线电视新闻网从未上过的课程!
通过深度学习进行特征提取的示例可以在本节顶部的图 1 中看到。
这里我们采用 VGG16 网络,允许图像向前传播到最终的 max-pooling 层(在完全连接的层之前),并提取该层的激活。
max-pooling 层的输出具有体积形状 7 x 7 x 512 ,我们将其展平为特征向量 21,055-dim 。
给定一个由 N 幅图像组成的数据集,我们可以对数据集中的所有图像重复特征提取过程,给我们留下总共N×21,055-dim 个特征向量。
鉴于这些特征,我们可以在这些特征上训练一个“标准”的机器学习模型(如逻辑回归或线性 SVM)。
注意:通过深度学习进行特征提取在 中有所涉及,更多细节在上周的帖子中——如果你对特征提取如何工作有任何问题,请参考它。
如果提取的特征太大,内存容纳不下怎么办?
通过深度学习进行特征提取是非常好的…
…但是当你提取的特征太大而不适合内存时会发生什么?
请记住,(的大多数实现,包括 scikit-learn)逻辑回归和支持向量机要求您的整个数据集可以一次性访问用于训练(即,整个数据集必须适合 RAM)。
那太好了,但是如果你有 50GB,100GB,甚至 1TB 的提取特征,你打算怎么办?
大部分人都接触不到这么大内存的机器。
那么,你会怎么做?
解决方案:渐进式学习(即“在线学习”)
Figure 2: The process of incremental learning plays a role in deep learning feature extraction on large datasets.
当你的整个数据集不适合内存时,你需要执行(有时称为“在线学习”)。
增量学习使你能够在被称为批次**的数据的小子集上训练你的模型。
使用增量学习,培训过程变成:
- 从数据集中加载一小批数据
- 在批次上训练模型
- 分批重复循环数据集,边走边训练,直到我们达到收敛
但是等等,这个过程听起来不是很熟悉吗?
应该的。
这正是我们如何训练神经网络的。
*神经网络是增量学习者的极好例子。
事实上,如果您查看 scikit-learn 文档,您会发现增量学习的分类模型要么是 NNs 本身,要么与 NNs 直接相关(即Perceptron和SGDClassifier)。
我们将使用 Keras 实现我们自己的神经网络,而不是使用 scikit-learn 的增量学习模型。
这个神经网络将在我们从 CNN 提取的特征之上被训练。
我们的培训流程现在变成了:
- 使用 CNN 从我们的图像数据集中提取所有特征。
- 在提取的特征之上训练一个简单的前馈神经网络。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
Food-5K 数据集
![]()
Figure 3: The Foods-5K dataset will be used for this example of deep learning feature extraction with Keras.
我们今天将在这里使用的数据集是 Food-5K 数据集 ,由瑞士联邦理工学院的多媒体信号处理小组(MSPG) 策划。
该数据集包含 5,000 幅图像,每幅图像属于以下两类之一:
- 食物
- 非食品
我们今天的目标是:
- 使用在 ImageNet 上预先训练的 ResNet-50,利用 Keras 特征提取从 Food-5K 数据集中提取特征。
- 在这些特征的基础上训练一个简单的神经网络来识别 CNN 从未被训练来识别的类别。
值得注意的是,整个 Food-5K 数据集,经过特征提取后,如果一次全部加载只会占用~2GB 的 RAM—这不是重点。
今天这篇文章的重点是向你展示如何使用增量学习来训练提取特征的模型。
这样,不管你是在处理 1GB 的数据还是 100GB 的数据,你都会知道在通过深度学习提取的特征之上训练模型的确切步骤。
下载 Food-5K 数据集
首先,确保你使用博文的 【下载】 部分获取了今天教程的源代码。
下载完源代码后,将目录更改为transfer-learning-keras:
$ unzip keras-feature-extraction.zip
$ cd keras-feature-extraction
根据我的经验,我发现下载 Food-5K 数据集有点不可靠。
因此,我更新了这篇教程,提供了一个链接,指向我托管的可下载的 Food-5K 数据集。使用以下链接可靠地下载数据集:
下载完数据集后,将它解压缩到项目文件夹中:
$ unzip Food-5k.zip
项目结构
继续并导航回根目录:
$ cd ..
从那里,我们能够用tree命令分析我们的项目结构:
$ tree --dirsfirst --filelimit 10
.
├── Food-5K
│ ├── evaluation [1000 entries]
│ ├── training [3000 entries]
│ └── validation [1000 entries]
├── dataset
├── output
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── build_dataset.py
├── extract_features.py
├── Food-5K.zip
└── train.py
8 directories, 6 files
config.py文件包含 Python 格式的配置设置。我们的其他 Python 脚本将利用配置。
使用我们的build_dataset.py脚本,我们将组织并输出Food-5K/目录的内容到数据集文件夹。
从那里,extract_features.py脚本将通过特征提取使用迁移学习来计算每个图像的特征向量。这些特征将输出到 CSV 文件。
build_dataset.py和extract_features.py都详细复习了上周;然而,我们今天将再次简要地浏览它们。
最后,我们来回顾一下train.py。在这个 Python 脚本中,我们将使用增量学习在提取的特征上训练一个简单的神经网络。这个脚本不同于上周的教程,我们将在这里集中精力。
我们的配置文件
让我们从查看存储配置的config.py文件开始,即图像输入数据集的路径以及提取特征的输出路径。
打开config.py文件并插入以下代码:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = "Food-5K"
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = "dataset"
# define the names of the training, testing, and validation
# directories
TRAIN = "training"
TEST = "evaluation"
VAL = "validation"
# initialize the list of class label names
CLASSES = ["non_food", "food"]
# set the batch size
BATCH_SIZE = 32
# initialize the label encoder file path and the output directory to
# where the extracted features (in CSV file format) will be stored
LE_PATH = os.path.sep.join(["output", "le.cpickle"])
BASE_CSV_PATH = "output"
花时间通读config.py脚本,注意注释。
大多数设置都与目录和文件路径有关,这些都在我们的其余脚本中使用。
关于配置的完整回顾,一定要参考上周的帖子。
构建影像数据集
每当我在数据集上执行机器学习(尤其是 Keras/deep learning)时,我都喜欢使用以下格式的数据集:
dataset_name/class_label/example_of_class_label.jpg
维护这个目录结构不仅使我们的数据集在磁盘上保持有序,而且和也使我们能够在本系列教程后面的微调中利用 Keras 的flow_from_directory函数。
由于 Food-5K 数据集提供了预先提供的数据分割,我们最终的目录结构将具有以下形式:
dataset_name/split_name/class_label/example_of_class_label.jpg
同样,这一步并不总是必要的,但是它是一个最佳实践(在我看来),并且我建议你也这样做。
至少它会给你编写 Python 代码来组织磁盘上的图像的经验。
现在让我们使用build_dataset.py文件来构建我们的目录结构:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import shutil
import os
# loop over the data splits
for split in (config.TRAIN, config.TEST, config.VAL):
# grab all image paths in the current split
print("[INFO] processing '{} split'...".format(split))
p = os.path.sep.join([config.ORIG_INPUT_DATASET, split])
imagePaths = list(paths.list_images(p))
# loop over the image paths
for imagePath in imagePaths:
# extract class label from the filename
filename = imagePath.split(os.path.sep)[-1]
label = config.CLASSES[int(filename.split("_")[0])]
# construct the path to the output directory
dirPath = os.path.sep.join([config.BASE_PATH, split, label])
# if the output directory does not exist, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
# construct the path to the output image file and copy it
p = os.path.sep.join([dirPath, filename])
shutil.copy2(imagePath, p)
在行 2-5 上导入我们的包之后,我们继续循环训练、测试和验证分割(行 8 )。
我们创建我们的 split + class 标签目录结构(如上所述),然后用 Food-5K 图像填充目录。结果是我们可以用来提取特征的有组织的数据。
让我们执行脚本并再次检查我们的目录结构。
您可以使用本教程的 “下载” 部分下载源代码——从那里,打开一个终端并执行以下命令:
$ python build_dataset.py
[INFO] processing 'training split'...
[INFO] processing 'evaluation split'...
[INFO] processing 'validation split'...
这样做之后,您将会看到以下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── Food-5K
│ ├── evaluation [1000 entries]
│ ├── training [3000 entries]
│ ├── validation [1000 entries]
│ └── Food-5K.zip
├── dataset
│ ├── evaluation
│ │ ├── food [500 entries]
│ │ └── non_food [500 entries]
│ ├── training
│ │ ├── food [1500 entries]
│ │ └── non_food [1500 entries]
│ └── validation
│ ├── food [500 entries]
│ └── non_food [500 entries]
├── output
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── build_dataset.py
├── extract_features.py
└── train.py
16 directories, 6 files
请注意,我们的数据集/目录现在已被填充。每个子目录的格式如下:
split_name/class_label
组织好数据后,我们就可以继续进行特征提取了。
使用 Keras 进行深度学习特征提取
现在我们已经为项目构建了数据集目录结构,我们可以:
- 使用 Keras 通过深度学习从数据集中的每个图像中提取特征。
- 以 CSV 格式将分类标签+提取的要素写入磁盘。
为了完成这些任务,我们需要实现extract_features.py文件。
上周的帖子中详细介绍了这个文件,所以为了完整起见,我们在这里只简要回顾一下这个脚本:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet50 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from pyimagesearch import config
from imutils import paths
import numpy as np
import pickle
import random
import os
# load the ResNet50 network and initialize the label encoder
print("[INFO] loading network...")
model = ResNet50(weights="imagenet", include_top=False)
le = None
# loop over the data splits
for split in (config.TRAIN, config.TEST, config.VAL):
# grab all image paths in the current split
print("[INFO] processing '{} split'...".format(split))
p = os.path.sep.join([config.BASE_PATH, split])
imagePaths = list(paths.list_images(p))
# randomly shuffle the image paths and then extract the class
# labels from the file paths
random.shuffle(imagePaths)
labels = [p.split(os.path.sep)[-2] for p in imagePaths]
# if the label encoder is None, create it
if le is None:
le = LabelEncoder()
le.fit(labels)
# open the output CSV file for writing
csvPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(split)])
csv = open(csvPath, "w")
在行 16 上,ResNet 被加载,但不包括头部。预先训练的 ImageNet 权重也被加载到网络中。使用这种预先训练的无头网络,通过迁移学习进行特征提取现在是可能的。
从那里,我们继续循环第 20 行上的数据分割。
在里面,我们为特定的split抓取所有的imagePaths,并安装我们的标签编码器(第 23-34 行)。
打开一个 CSV 文件进行写入(第 37-39 行),这样我们就可以将我们的类标签和提取的特征写入磁盘。
现在我们的初始化都设置好了,我们可以开始批量循环图像:
# loop over the images in batches
for (b, i) in enumerate(range(0, len(imagePaths), config.BATCH_SIZE)):
# extract the batch of images and labels, then initialize the
# list of actual images that will be passed through the network
# for feature extraction
print("[INFO] processing batch {}/{}".format(b + 1,
int(np.ceil(len(imagePaths) / float(config.BATCH_SIZE)))))
batchPaths = imagePaths[i:i + config.BATCH_SIZE]
batchLabels = le.transform(labels[i:i + config.BATCH_SIZE])
batchImages = []
# loop over the images and labels in the current batch
for imagePath in batchPaths:
# load the input image using the Keras helper utility
# while ensuring the image is resized to 224x224 pixels
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
# preprocess the image by (1) expanding the dimensions and
# (2) subtracting the mean RGB pixel intensity from the
# ImageNet dataset
image = np.expand_dims(image, axis=0)
image = preprocess_input(image)
# add the image to the batch
batchImages.append(image)
批次中的每个image被加载并预处理。从那里它被附加到batchImages。
我们现在将通过 ResNet 发送批处理以提取特征:
# pass the images through the network and use the outputs as
# our actual features, then reshape the features into a
# flattened volume
batchImages = np.vstack(batchImages)
features = model.predict(batchImages, batch_size=config.BATCH_SIZE)
features = features.reshape((features.shape[0], 7 * 7 * 2048))
# loop over the class labels and extracted features
for (label, vec) in zip(batchLabels, features):
# construct a row that exists of the class label and
# extracted features
vec = ",".join([str(v) for v in vec])
csv.write("{},{}\n".format(label, vec))
# close the CSV file
csv.close()
# serialize the label encoder to disk
f = open(config.LE_PATH, "wb")
f.write(pickle.dumps(le))
f.close()
批次的特征提取发生在线 72 上。使用 ResNet,我们的输出层的体积大小为 7 x 7 x 2,048 。将输出视为一个特征向量,我们简单地将其展平为一个列表7 x 7 x 2048 = 100352-dim(第 73 行)。
然后,该批特征向量被输出到 CSV 文件,每行的第一个条目是类label,其余的值组成特征vec。
我们将对每个分割中的所有批次重复这一过程,直到完成。最后,我们的标签编码器被转储到磁盘。
更详细的逐行回顾,请参考上周的教程。
要从我们的数据集中提取特征,请确保使用指南的 【下载】 部分下载本文的源代码。
从那里,打开一个终端并执行以下命令:
$ python extract_features.py
[INFO] loading network...
[INFO] processing 'training split'...
...
[INFO] processing batch 92/94
[INFO] processing batch 93/94
[INFO] processing batch 94/94
[INFO] processing 'evaluation split'...
...
[INFO] processing batch 30/32
[INFO] processing batch 31/32
[INFO] processing batch 32/32
[INFO] processing 'validation split'...
...
[INFO] processing batch 30/32
[INFO] processing batch 31/32
[INFO] processing batch 32/32
在 NVIDIA K80 GPU 上,整个特征提取过程花费了5 毫秒。
你也可以在 CPU 上运行extract_features.py ,但这会花费更长的时间。
特征提取完成后,您的输出目录中应该有三个 CSV 文件,分别对应于我们的每个数据分割:
$ ls -l output/
total 2655188
-rw-rw-r-- 1 ubuntu ubuntu 502570423 May 13 17:17 evaluation.csv
-rw-rw-r-- 1 ubuntu ubuntu 1508474926 May 13 17:16 training.csv
-rw-rw-r-- 1 ubuntu ubuntu 502285852 May 13 17:18 validation.csv
实施增量学习培训脚本
最后,我们现在准备利用增量学习通过对大型数据集进行特征提取来应用迁移学习。
我们在本节中实现的 Python 脚本将负责:
- 构造简单的前馈神经网络结构。
- 实现一个 CSV 数据生成器,用于向神经网络生成一批标签+特征向量。
- 使用数据生成器训练简单神经网络。
- 评估特征提取器。
打开train.py脚本,让我们开始吧:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from sklearn.metrics import classification_report
from pyimagesearch import config
import numpy as np
import pickle
import os
在2-10 行导入我们需要的包。我们最显著的导入是 TensorFlow/Keras' Sequential API,我们将使用它来构建一个简单的前馈神经网络。
几个月前,我写了一篇关于实现定制 Keras 数据生成器的教程,更具体地说,就是从 CSV 文件中产生数据,用 Keras 训练神经网络。
当时,我发现读者对使用这种生成器的实际应用有些困惑— today 就是这种实际应用的一个很好的例子。
再次请记住,我们假设提取的特征的整个 CSV 文件将而不是适合内存。因此,我们需要一个定制的 Keras 生成器来生成成批的标签和数据给网络,以便对其进行训练。
现在让我们实现生成器:
def csv_feature_generator(inputPath, bs, numClasses, mode="train"):
# open the input file for reading
f = open(inputPath, "r")
# loop indefinitely
while True:
# initialize our batch of data and labels
data = []
labels = []
# keep looping until we reach our batch size
while len(data) < bs:
# attempt to read the next row of the CSV file
row = f.readline()
我们的csv_feature_generator接受四个参数:
inputPath:包含提取特征的输入 CSV 文件的路径。bs:每个数据块的批量大小(或长度)。numClasses:一个整数值,表示我们的数据中类的数量。mode:我们是在培训还是在评估/测试。
在第 14 行,我们打开 CSV 文件进行读取。
从第 17 行的开始,我们无限循环,从初始化我们的数据和标签开始。(第 19 和 20 行)。
从那里开始,我们将循环直到长度data等于从行 23 开始的批量。
我们从读取 CSV 中的一行开始(第 25 行)。一旦我们有了行,我们将继续处理它:
# check to see if the row is empty, indicating we have
# reached the end of the file
if row == "":
# reset the file pointer to the beginning of the file
# and re-read the row
f.seek(0)
row = f.readline()
# if we are evaluating we should now break from our
# loop to ensure we don't continue to fill up the
# batch from samples at the beginning of the file
if mode == "eval":
break
# extract the class label and features from the row
row = row.strip().split(",")
label = row[0]
label = to_categorical(label, num_classes=numClasses)
features = np.array(row[1:], dtype="float")
# update the data and label lists
data.append(features)
labels.append(label)
# yield the batch to the calling function
yield (np.array(data), np.array(labels))
如果row为空,我们将从文件的开头重新开始(第 29-32 行)。如果我们处于评估模式,我们将从我们的循环中break,确保我们不会从文件的开始填充批处理(第 38 和 39 行)。
假设我们继续,从row ( 第 42-45 行)中提取label和features。
然后,我们将特征向量(features和label分别附加到data和labels列表,直到列表达到指定的批量大小(第 48 和 49 行)。
当批处理准备好时,行 52 产生作为元组的data和labels。Python 的yield关键字对于让我们的函数像生成器一样运行至关重要。
让我们继续—在训练模型之前,我们还有几个步骤:
# load the label encoder from disk
le = pickle.loads(open(config.LE_PATH, "rb").read())
# derive the paths to the training, validation, and testing CSV files
trainPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(config.TRAIN)])
valPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(config.VAL)])
testPath = os.path.sep.join([config.BASE_CSV_PATH,
"{}.csv".format(config.TEST)])
# determine the total number of images in the training and validation
# sets
totalTrain = sum([1 for l in open(trainPath)])
totalVal = sum([1 for l in open(valPath)])
# extract the testing labels from the CSV file and then determine the
# number of testing images
testLabels = [int(row.split(",")[0]) for row in open(testPath)]
totalTest = len(testLabels)
我们的标签编码器从磁盘的第 54 行加载。然后,我们得到训练、验证和测试 CSV 文件的路径(第 58-63 行)。
第 67 行和第 68 行处理对训练集和验证集中图像数量的计数。有了这些信息,我们将能够告诉.fit_generator函数每个时期有多少个batch_size步骤。
让我们为每个数据分割构建一个生成器:
# construct the training, validation, and testing generators
trainGen = csv_feature_generator(trainPath, config.BATCH_SIZE,
len(config.CLASSES), mode="train")
valGen = csv_feature_generator(valPath, config.BATCH_SIZE,
len(config.CLASSES), mode="eval")
testGen = csv_feature_generator(testPath, config.BATCH_SIZE,
len(config.CLASSES), mode="eval")
第 76-81 行初始化我们的 CSV 特征生成器。
我们现在准备建立一个简单的神经网络:
# define our simple neural network
model = Sequential()
model.add(Dense(256, input_shape=(7 * 7 * 2048,), activation="relu"))
model.add(Dense(16, activation="relu"))
model.add(Dense(len(config.CLASSES), activation="softmax"))
与上周的教程相反,我们使用了逻辑回归机器学习模型,今天我们将建立一个简单的神经网络进行分类。
第 84-87 行使用 Keras 定义了一个简单的100352-256-16-2前馈神经网络架构。
我是怎么得出两个隐藏层的256和16的值的?
一个好的经验法则是取层中先前节点数的平方根,然后找到最接近的 2 的幂。
在这种情况下,2 与100352最接近的幂就是256。256的平方根是16,因此给出了我们的架构定义。
让我们继续compile我们的model:
# compile the model
opt = SGD(lr=1e-3, momentum=0.9, decay=1e-3 / 25)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
我们compile我们的model使用随机梯度下降(SGD),初始学习速率为1e-3(它将在25时期衰减)。
我们在这里使用"binary_crossentropy"作为loss函数,因为我们只有两个类。 如果你有两个以上的职业,那么你应该使用"categorical_crossentropy"。
随着我们的model被编译,现在我们准备好训练和评估:
# train the network
print("[INFO] training simple network...")
H = model.fit(
x=trainGen,
steps_per_epoch=totalTrain // config.BATCH_SIZE,
validation_data=valGen,
validation_steps=totalVal // config.BATCH_SIZE,
epochs=25)
# make predictions on the testing images, finding the index of the
# label with the corresponding largest predicted probability, then
# show a nicely formatted classification report
print("[INFO] evaluating network...")
predIdxs = model.predict(x=testGen,
steps=(totalTest //config.BATCH_SIZE) + 1)
predIdxs = np.argmax(predIdxs, axis=1)
print(classification_report(testLabels, predIdxs,
target_names=le.classes_))
2020-06-04 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
第 96-101 行使用我们的训练和验证生成器(trainGen和valGen)适合我们的model。使用发电机和我们的model允许 增量学习 。
使用增量学习,我们不再需要一次将所有数据加载到内存中。相反,批量数据流经我们的网络,使得处理大规模数据集变得容易。
当然,CSV 数据并不能有效利用空间,速度也不快。在用 Python 进行计算机视觉深度学习的 里面,我教如何更高效地使用 HDF5 进行存储。
对模型的评估发生在行 107-109 上,其中testGen批量生成我们的特征向量。然后在终端打印一份分类报告(行 110 和 111 )。
Keras 特征提取结果
最后,我们准备在从 ResNet 提取的特征上训练我们的简单神经网络!
确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端并执行以下命令:
$ python train.py
Using TensorFlow backend.
[INFO] training simple network...
Epoch 1/25
93/93 [==============================] - 43s 462ms/step - loss: 0.0806 - accuracy: 0.9735 - val_loss: 0.0860 - val_accuracy: 0.9798
Epoch 2/25
93/93 [==============================] - 43s 461ms/step - loss: 0.0124 - accuracy: 0.9970 - val_loss: 0.0601 - val_accuracy: 0.9849
Epoch 3/25
93/93 [==============================] - 42s 451ms/step - loss: 7.9956e-04 - accuracy: 1.0000 - val_loss: 0.0636 - val_accuracy: 0.9859
Epoch 4/25
93/93 [==============================] - 42s 450ms/step - loss: 2.3326e-04 - accuracy: 1.0000 - val_loss: 0.0658 - val_accuracy: 0.9859
Epoch 5/25
93/93 [==============================] - 43s 459ms/step - loss: 1.4288e-04 - accuracy: 1.0000 - val_loss: 0.0653 - val_accuracy: 0.9859
...
Epoch 21/25
93/93 [==============================] - 42s 456ms/step - loss: 3.3550e-05 - accuracy: 1.0000 - val_loss: 0.0661 - val_accuracy: 0.9869
Epoch 22/25
93/93 [==============================] - 42s 453ms/step - loss: 3.1843e-05 - accuracy: 1.0000 - val_loss: 0.0663 - val_accuracy: 0.9869
Epoch 23/25
93/93 [==============================] - 42s 452ms/step - loss: 3.1020e-05 - accuracy: 1.0000 - val_loss: 0.0663 - val_accuracy: 0.9869
Epoch 24/25
93/93 [==============================] - 42s 452ms/step - loss: 2.9564e-05 - accuracy: 1.0000 - val_loss: 0.0664 - val_accuracy: 0.9869
Epoch 25/25
93/93 [==============================] - 42s 454ms/step - loss: 2.8628e-05 - accuracy: 1.0000 - val_loss: 0.0665 - val_accuracy: 0.9869
[INFO] evaluating network...
precision recall f1-score support
food 0.99 0.99 0.99 500
non_food 0.99 0.99 0.99 500
accuracy 0.99 1000
macro avg 0.99 0.99 0.99 1000
weighted avg 0.99 0.99 0.99 1000
在 NVIDIA K80 上的训练花费了大约 ~30m 。你也可以在 CPU 上训练,但是这将花费相当长的时间。
正如我们的输出所示,我们能够在 Food-5K 数据集上获得 ~99%的准确率,尽管 ResNet-50 从未接受过食品/非食品类的训练!
*正如你所看到的,迁移学习是一种非常强大的技术,使你能够从 CNN 中提取特征,并识别出他们没有被训练过的类。
在关于 Keras 和深度学习的迁移学习系列教程的后面,我将向您展示如何执行微调,这是另一种迁移学习方法。
有兴趣了解更多关于在线/增量学习的信息吗?

Figure 4: Creme is a library specifically tailored to incremental learning. The API is similar to that of scikit-learn’s which will make you feel at home while putting it to work on large datasets where incremental learning is required.
神经网络和深度学习是增量学习的一种形式——我们可以一次对一个样本或一批样本训练这样的网络。
然而,仅仅因为我们能够应用神经网络解决问题并不意味着我们应该。
相反,我们需要为工作带来合适的工具。仅仅因为你手里有一把锤子,并不意味着你会用它来敲螺丝。
增量学习算法包含一组用于以增量方式训练模型的技术。
当数据集太大而无法放入内存时,我们通常会利用增量学习。
然而,scikit-learn 库确实包含少量在线学习算法:
- 它没有把增量学习作为一等公民对待。
- 这些实现很难使用。
进入 Creme 库 —一个专门用于 creme ntal 学习 Python 的库。
我真的很喜欢我第一次使用 creme 的经历,并且发现 scikit-learn 启发的 API 非常容易使用。
点击这里阅读我的在线/增量学习与 Keras 和 Creme 的文章!
摘要
在本教程中,您学习了如何:
- 利用 Keras 进行深度学习特征提取。
- 对提取的特征执行增量学习。
利用增量学习使我们能够在太大而不适合内存的数据集上训练模型。
神经网络是增量学习者的一个很好的例子因为我们可以通过批量加载数据,确保整个网络不必一次装入 RAM。使用增量学习,我们能够获得 ~98%的准确率。
我建议在需要使用 Keras 对大型数据集进行特征提取时,使用这段代码作为模板。
我希望你喜欢这个教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!******
Keras 图像数据生成器和数据扩充
原文:https://pyimagesearch.com/2019/07/08/keras-imagedatagenerator-and-data-augmentation/

在今天的教程中,您将学习如何使用 Keras 的 ImageDataGenerator 类来执行数据扩充。我还将消除围绕什么是数据增强、我们为什么使用数据增强以及它做什么/不做什么的常见困惑。
知道我要写一篇关于数据扩充的教程,两个周末前我决定找点乐子,故意在我的 Twitter feed 上发布一个半恶作剧问题。
问题很简单— 数据增强能做以下哪些事情?
- 添加更多培训数据
- 替换培训数据
- 两者都有吗
- 我不知道
结果如下:

Figure 1: My @PyImageSearch twitter poll on the concept of Data Augmentation.
只有 5%的受访者“正确”回答了这个问题(至少如果你使用的是 Keras 的 ImageDataGenerator 类)。
同样,这是一个棘手的问题,因此这并不是一个公平的评估,但事情是这样的:
虽然单词“augment”的意思是使某物“更大”或“增加”某物(在本例中是数据),但 Keras ImageDataGenerator 类实际上是通过以下方式工作的:
- 接受一批用于训练的图像。
- 取这一批并对这一批中的每个图像应用一系列随机变换(包括随机旋转、调整大小、剪切等。).
- 用新的、随机转换的批次替换原始批次。
- 在这个随机转换的批次上训练 CNN(即原始数据本身是而不是用于训练)。
没错——Keras imagedata generator 类是而不是一个“加法”运算。它不是获取原始数据,对其进行随机转换,然后返回原始数据和转换后的数据。
相反,ImageDataGenerator 接受原始数据,对其进行随机转换,并只向返回新的转换后的数据。
但还记得我说过这是个棘手的问题吗?
从技术上来说,所有的答案都是正确的——但是你知道一个给定的数据增强定义是否正确的唯一方法是通过它的应用环境。
我将帮助您澄清一些关于数据扩充的困惑(并为您提供成功应用它所需的背景)。
在今天的剩余教程中,您将:
- 了解三种类型的数据扩充。
- 消除你对数据扩充的任何困惑。
- 了解如何使用 Keras 和
ImageDataGenerator类应用数据扩充。
要了解更多关于数据增强的信息,包括使用 Keras 的 ImageDataGenerator 类,请继续阅读!
Keras 图像数据生成器和数据扩充
2020-06-04 更新:此博文现已兼容 TensorFlow 2+!
我们将从讨论数据扩充和我们为什么使用它开始本教程。
然后,我将介绍在训练深度神经网络时您将看到的三种类型的数据增强:
- 通过数据扩充生成数据集和扩展数据(不太常见)
- 就地/动态数据扩充(最常见)
- 组合数据集生成和就地扩充
从那以后,我将教您如何使用 Keras 的ImageDataGenerator类将数据扩充应用到您自己的数据集(使用所有三种方法)。
什么是数据增强?
数据扩充包括一系列技术,用于通过应用随机抖动和扰动(但同时确保数据的类别标签不变)从原始样本生成“新”训练样本。
我们应用数据扩充的目标是提高模型的概化能力。
假设我们的网络不断看到输入数据的新的、稍微修改的版本,网络能够学习更健壮的特征。
在测试时,我们不应用数据扩充,而是简单地在未修改的测试数据上评估我们的训练网络——在大多数情况下,您会看到测试准确性的提高,也许是以训练准确性的轻微下降为代价。
一个简单的数据扩充示例

Figure 2: Left: A sample of 250 data points that follow a normal distribution exactly. Right: Adding a small amount of random “jitter” to the distribution. This type of data augmentation increases the generalizability of our networks.
让我们考虑均值和单位方差为零的正态分布的图 2 ( 左)。
在这些数据上训练一个机器学习模型可能会导致我们精确地模拟分布——然而,在现实世界的应用中,数据很少遵循这样一个漂亮、整洁的分布。
*相反,为了增加我们分类器的泛化能力,我们可以首先通过添加一些随机值 来随机抖动分布中的点
来随机抖动分布中的点
drawn from a random distribution (right).
我们的图仍然遵循一个近似的正态分布,但是它不像左边的那样是一个完美的 T2 分布。
根据这种修改的、扩充的数据训练的模型更有可能推广到不包括在训练集中的示例数据点。
计算机视觉和数据增强

Figure 3: In computer vision, data augmentation performs random manipulations on images. It is typically applied in three scenarios discussed in this blog post.
在计算机视觉的背景下,数据增强自然地有助于它自己。
例如,我们可以通过应用简单的几何变换从原始图像中获得增强数据,例如随机:
- 翻译
- 旋转
- 规模的变化
- 剪羊毛
- 水平(在某些情况下,垂直)翻转
对输入图像应用(少量)变换会略微改变其外观,但它不会改变类别标签——从而使数据增强成为应用于计算机视觉任务的非常自然、简单的方法。
三种类型的数据扩充
在计算机视觉应用的背景下应用深度学习时,您可能会遇到三种类型的数据增强。
数据扩充的确切定义是“正确的”,完全取决于你的项目/一组实验的背景。
花时间仔细阅读这一部分,因为我看到许多深度学习从业者混淆了数据增强做什么和不做什么。
*#### 类型 1:数据集生成和扩展现有数据集(不太常见)
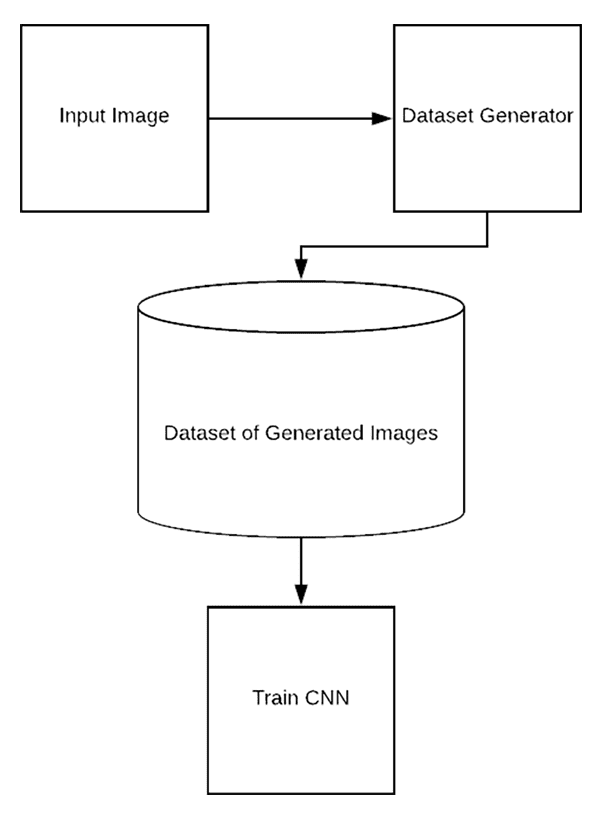
Figure 4: Type #1 of data augmentation consists of dataset generation/dataset expansion. This is a less common form of data augmentation.
第一种类型的数据扩充是我所说的数据集生成或数据集扩展。
正如你所知,机器学习模型,尤其是神经网络,可能需要相当多的训练数据— 但是如果你一开始就没有太多的训练数据,那该怎么办呢?
让我们来看看最简单的情况,您只有一张图像,并且您想要应用数据扩充来创建一个完整的图像数据集,所有这些都基于那一张图像。
要完成这项任务,您需要:
- 从磁盘加载原始输入图像。
- 通过一系列随机平移、旋转等随机变换原始图像。
- 将转换后的图像写回磁盘。
- 总共重复步骤 2 和 3N 次。
执行此过程后,您将拥有一个目录,其中包含随机转换的“新”图像,您可以使用这些图像进行训练,所有这些都基于单个输入图像。
当然,这是一个非常简单的例子。
你很可能有不止一张图片——你可能有 10 张或 100 张图片,现在你的目标是将这个较小的集合变成 1000 张图片用于训练。
在这些情况下,数据集扩展和数据集生成可能值得探索。
但是这种方法有一个问题——我们并没有增加模型的泛化能力。
是的,我们通过生成额外的示例增加了我们的训练数据,但所有这些示例都基于一个超小型数据集。
请记住,我们的神经网络的好坏取决于它接受训练的数据。
我们不能期望在少量数据上训练一个神经网络,然后期望它推广到它从未训练过并且从未见过的数据。
如果您发现自己正在认真考虑数据集生成和数据集扩展,您应该后退一步,转而花时间收集额外的数据或研究行为克隆的方法(然后应用下面的“组合数据集生成和就地增强”部分中涵盖的数据增强类型)。
类型 2:就地/动态数据扩充(最常见)
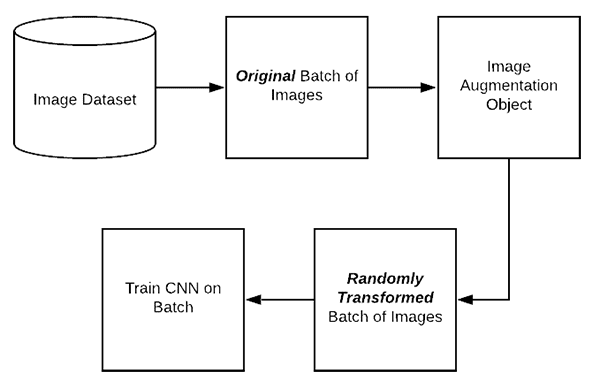
Figure 5: Type #2 of data augmentation consists of on-the-fly image batch manipulations. This is the most common form of data augmentation with Keras.
第二种类型的数据增强被称为就地数据增强或动态数据增强。这种类型的数据扩充是 Keras ' T0 '类实现的。
使用这种类型的数据增强,我们希望确保我们的网络在接受训练时,在每个时期都能看到我们数据的新变化。
图 5 展示了应用就地数据扩充的过程:
- 步骤#1: 一批输入图像被呈现给
ImageDataGenerator。 - 步骤# 2:
ImageDataGenerator通过一系列的随机平移、旋转等来变换批中的每个图像。 - 步骤#3: 然后将随机转换的批处理返回给调用函数。
我想提醒你注意两点:
ImageDataGenerator是而不是返回原始数据和转换后的数据— 该类只返回随机转换后的数据。- 我们称之为“就地”和“实时”数据增强,因为这种增强是在训练时间 完成的(即,我们不是提前/在训练之前生成这些例子)。
当我们的模型被训练时,我们可以把我们的ImageDataGenerator类想象成“截取”原始数据,随机转换它,然后返回给神经网络进行训练,而神经网络一直不知道数据被修改了!
我在 PyImageSearch 博客上写过以前的教程,读者认为 Keras 的 ImageDateGenerator 类是一个“加法运算”,类似于下图(不正确):
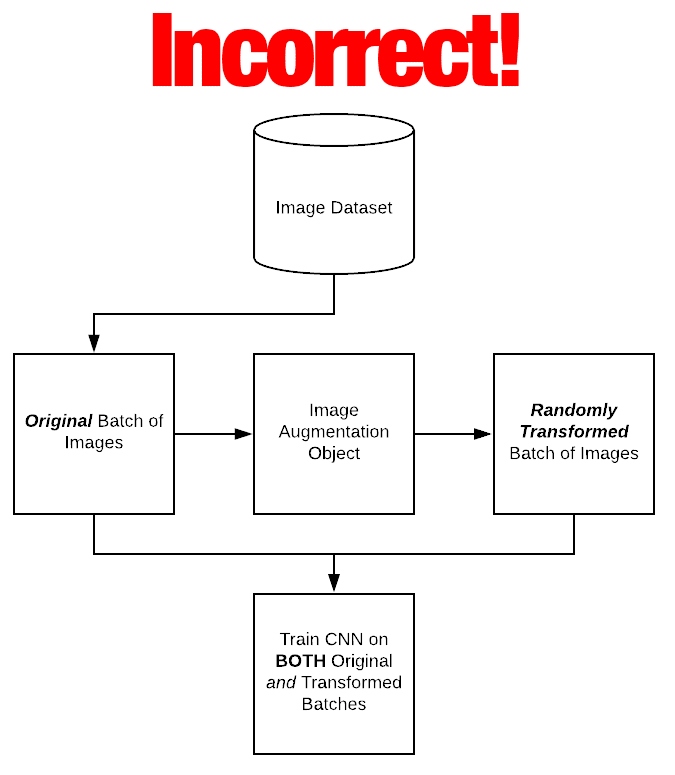
Figure 6: How Keras data augmentation does not work.
在上图中,ImageDataGenerator接受一批输入图像,随机转换该批图像,然后返回原始图像和修改后的数据— ,这是而不是KerasImageDataGenerator所做的。相反,ImageDataGenerator类将返回随机转换的数据。
当我向读者解释这个概念时,下一个问题通常是:
但是艾利安,原始的训练数据呢?为什么不用?原来的训练数据不是对训练还有用吗?
请记住,本节描述的数据增强技术的整点是为了确保网络在每个时期都能看到以前从未“见过”的“新”图像。
如果我们在每一批中包括原始训练数据和扩充数据,那么网络将多次“看到”原始训练数据,实际上违背了目的。其次,回想一下,数据扩充的总体目标是增加模型的可推广性。
为了实现这个目标,我们用随机转换的、扩充的数据“替换”训练数据。
在实践中,这导致模型在我们的验证/测试数据上表现更好,但在我们的训练数据上表现稍差(由于随机转换引起的数据变化)。
在本教程的后面,您将学习如何使用 Keras ImageDataGenerator类。
类型 3:结合数据集生成和就地扩充
最后一种数据扩充寻求将数据集生成和就地扩充结合起来——在执行行为克隆时,您可能会看到这种类型的数据扩充。
行为克隆的一个很好的例子可以在自动驾驶汽车应用中看到。
创建自动驾驶汽车数据集可能非常耗时且昂贵——解决这个问题的一个方法是使用视频游戏和汽车驾驶模拟器。
视频游戏图形已经变得如此栩栩如生,以至于现在可以将它们用作训练数据。
因此,您可以不驾驶实际的车辆,而是:
- 玩电子游戏
- 写一个玩电子游戏的程序
- 使用视频游戏的底层渲染引擎
…生成可用于训练的实际数据。
一旦获得了训练数据,您就可以返回并对通过模拟收集的数据应用类型 2 数据扩充(即就地/即时数据扩充)。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
在深入研究代码之前,让我们先回顾一下项目的目录结构:
$ tree --dirsfirst --filelimit 10
.
├── dogs_vs_cats_small
│ ├── cats [1000 entries]
│ └── dogs [1000 entries]
├── generated_dataset
│ ├── cats [100 entries]
│ └── dogs [100 entries]
├── pyimagesearch
│ ├── __init__.py
│ └── resnet.py
├── cat.jpg
├── dog.jpg
├── plot_dogs_vs_cats_no_aug.png
├── plot_dogs_vs_cats_with_aug.png
├── plot_generated_dataset.png
├── train.py
└── generate_images.py
7 directories, 9 files
首先,有两个数据集目录,不要混淆:
dogs_vs_cats_small/:流行的卡格狗对猫比赛数据集的子集。在我策划的子集中,只有 2,000 幅图像(每类 1,000 幅)(与挑战赛的 25,000 幅图像相反)。generated_dataset/:我们将使用父目录中的cat.jpg和dog.jpg图像创建这个生成的数据集。我们将利用数据扩充类型#1 来自动生成这个数据集,并用图像填充这个目录。
接下来,我们有我们的pyimagesearch模块,它包含我们的 ResNet CNN 分类器的实现。
今天,我们将回顾两个 Python 脚本:
train.py:用于训练类型#1 和类型#2 (如果用户愿意,还可以选择类型#3 )数据增强技术的模型。我们将执行三个训练实验,分别生成项目文件夹中的三个plot*.png文件。generate_images.py:用于使用类型#1 从单幅图像生成数据集。
我们开始吧。
实施我们的培训脚本
在本教程的剩余部分,我们将进行三个实验:
- 实验#1: 通过数据集扩展生成数据集,并在其上训练 CNN。
- 实验#2: 使用 Kaggle Dogs vs. Cats 数据集的子集,训练一个没有数据增强的 CNN 。
- 实验#3: 重复第二个实验,但是这次用数据增强。
所有这些实验都将使用相同的 Python 脚本来完成。
打开train.py脚本,让我们开始吧:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.resnet import ResNet
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import os
在2-18 行我们需要的包装是进口的。第 10 行是我们从 Keras 库的ImageDataGenerator导入——一个用于数据扩充的类。
让我们继续解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-a", "--augment", type=int, default=-1,
help="whether or not 'on the fly' data augmentation should be used")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们的脚本通过终端接受三个命令行参数:
--dataset:输入数据集的路径。--augment:是否应使用“即时”数据增强(参见上文类型#2 )。默认情况下,该方法是而不是执行的。--plot:输出训练历史图的路径。
让我们继续初始化超参数并加载我们的图像数据:
# initialize the initial learning rate, batch size, and number of
# epochs to train for
INIT_LR = 1e-1
BS = 8
EPOCHS = 50
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename, load the image, and
# resize it to be a fixed 64x64 pixels, ignoring aspect ratio
label = imagePath.split(os.path.sep)[-2]
image = cv2.imread(imagePath)
image = cv2.resize(image, (64, 64))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
在第 32-34 行的处初始化训练超参数,包括初始学习率、批量大小和训练的时期数。
从那里第 39-53 行抓取imagePaths,加载图像,并填充我们的data和labels列表。此时我们执行的唯一图像预处理是将每个图像的大小调整为 64×64 px。
接下来,让我们完成预处理,对标签进行编码,并对数据进行分区:
# convert the data into a NumPy array, then preprocess it by scaling
# all pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
# encode the labels (which are currently strings) as integers and then
# one-hot encode them
le = LabelEncoder()
labels = le.fit_transform(labels)
labels = to_categorical(labels, 2)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, random_state=42)
在第 57 行的上,我们将数据转换成一个 NumPy 数组,并将所有像素亮度缩放到范围 [0,1] 。这就完成了我们的预处理。
从那里我们执行我们的labels ( 第 61-63 行)的“一键编码”。这种对我们的labels进行编码的方法会产生一个如下所示的数组:
array([[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.]], dtype=float32)
对于这个数据样本,有两只猫([1., 0.])和五只狗([0., 1]),其中对应于图像的标签被标记为“热”。
从那里我们将data划分为训练和测试部分,标记 75%的数据用于训练,剩下的 25%用于测试(第 67 行和第 68 行)。
现在,我们准备好初始化我们的数据扩充对象:
# initialize an our data augmenter as an "empty" image data generator
aug = ImageDataGenerator()
第 71 行初始化我们的空数据扩充对象(即不执行任何扩充)。这是该脚本的默认操作。
让我们检查一下是否要用--augment命令行参数覆盖默认设置:
# check to see if we are applying "on the fly" data augmentation, and
# if so, re-instantiate the object
if args["augment"] > 0:
print("[INFO] performing 'on the fly' data augmentation")
aug = ImageDataGenerator(
rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
第 75 行检查我们是否正在执行数据扩充。如果是这样,我们用随机转换参数重新初始化数据扩充对象(第 77-84 行)。如参数所示,随机旋转、缩放、移动、剪切和翻转将在原地/动态数据扩充期间执行。
让我们编译和训练我们的模型:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9, decay=INIT_LR / EPOCHS)
model = ResNet.build(64, 64, 3, 2, (2, 3, 4),
(32, 64, 128, 256), reg=0.0001)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network for {} epochs...".format(EPOCHS))
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
2020-06-04 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。阅读完本教程后,请务必查看我的另一篇文章 fit 和 fit_generator 。
第 88-92 行使用随机梯度下降优化和学习率衰减构建我们的ResNet模型。对于这个 2 类问题,我们使用"binary_crossentropy"损失。如果你有两个以上的班级,一定要使用"categorial_crossentropy"。
第 96-100 行然后训练我们的模型。aug对象成批处理数据扩充(尽管请记住,只有在设置了--augment命令行参数的情况下,aug对象才会执行数据扩充)。
最后,我们将评估我们的模型,打印统计数据,并生成一个训练历史图:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX.astype("float32"), batch_size=BS)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=le.classes_))
# plot the training loss and accuracy
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-04 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
第 104 行为评估目的对测试集进行预测。通过线 105 和 106 打印分类报告。
从那里,行 109-120 生成并保存准确度/损失训练图。
使用数据扩充和 Keras 生成数据集/数据集扩展
在我们的第一个实验中,我们将使用 Keras 通过数据扩充来执行数据集扩展。
我们的数据集将包含 2 个类,最初,数据集通常每个类只包含 1 个图像:
- 猫: 1 张图片
- 狗: 1 图像
我们将利用 Type #1 数据扩充(参见上面的“Type # 1:Dataset generation and expanding a existing Dataset”部分)来生成一个新的数据集,每个类包含 100 幅图像:
- 猫: 100 张图片
- 狗: 100 张图片
同样,这意味着是一个示例——在现实世界的应用程序中,您会有 100 个示例图像,但我们在这里保持简单,以便您可以学习这个概念。
生成示例数据集

Figure 7: Data augmentation with Keras performs random manipulations on images.
在我们训练 CNN 之前,我们首先需要生成一个示例数据集。
从我们上面的“项目结构”部分,您知道我们在根目录中有两个示例图像:cat.jpg和dog.jpg。我们将使用这些示例图像为每个类生成 100 个新的训练图像(总共 200 个图像)。
要了解我们如何使用数据扩充来生成新的示例,请打开generate_images.py文件并按照以下步骤操作:
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
import numpy as np
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-o", "--output", required=True,
help="path to output directory to store augmentation examples")
ap.add_argument("-t", "--total", type=int, default=100,
help="# of training samples to generate")
args = vars(ap.parse_args())
2-6 线导入我们必要的包。我们的ImageDataGenerator在线 2 上导入,并将使用 Keras 处理我们的数据扩充。
从那里,我们将解析三个命令行参数:
--image:输入图像的路径。我们将生成此图像的额外随机变异版本。--output:存储数据扩充实例的输出目录路径。--total:要生成的样本图像的数量。
让我们继续加载我们的image和初始化我们的数据扩充对象:
# load the input image, convert it to a NumPy array, and then
# reshape it to have an extra dimension
print("[INFO] loading example image...")
image = load_img(args["image"])
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
# construct the image generator for data augmentation then
# initialize the total number of images generated thus far
aug = ImageDataGenerator(
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
total = 0
我们的image通过线路 21-23 加载并准备数据扩充。图像加载和处理是通过 Keras 功能处理的(即我们没有使用 OpenCV)。
从那里,我们初始化ImageDataGenerator对象。这个对象将有助于在我们的输入图像上执行随机旋转、缩放、移动、剪切和翻转。
接下来,我们将构建一个 Python 生成器,并让它工作,直到我们的所有图像都已生成:
# construct the actual Python generator
print("[INFO] generating images...")
imageGen = aug.flow(image, batch_size=1, save_to_dir=args["output"],
save_prefix="image", save_format="jpg")
# loop over examples from our image data augmentation generator
for image in imageGen:
# increment our counter
total += 1
# if we have reached the specified number of examples, break
# from the loop
if total == args["total"]:
break
我们将使用imageGen随机变换输入图像(第 39 行和第 40 行)。此生成器将图像存储为。jpg 文件到指定的输出目录包含在args["output"]内。
最后,我们将遍历来自图像数据生成器的示例,并对它们进行计数,直到我们达到所需的total数量的图像。
要运行generate_examples.py脚本,请确保您已经使用了教程的 【下载】 部分来下载源代码和示例图像。
从那里打开一个终端并执行以下命令:
$ python generate_images.py --image cat.jpg --output generated_dataset/cats
[INFO] loading example image...
[INFO] generating images...
检查generated_dataset/cats目录的输出,你现在会看到 100 张图片:
$ ls generated_dataset/cats/*.jpg | wc -l
100
现在让我们为“狗”类做同样的事情:
$ python generate_images.py --image dog.jpg --output generated_dataset/dogs
[INFO] loading example image...
[INFO] generating images...
现在检查狗的图像:
$ ls generated_dataset/dogs/*.jpg | wc -l
100
通过数据扩充生成数据集的可视化可以在本节顶部的图 6 中看到——注意我们是如何接受单个输入图像(我的图像——不是狗或猫的图像),然后从该单个图像中创建了 100 个新的训练示例(其中 48 个是可视化的)。
实验#1:数据集生成结果
我们现在准备进行我们的第一个实验:
$ python train.py --dataset generated_dataset --plot plot_generated_dataset.png
[INFO] loading images...
[INFO] compiling model...
[INFO] training network for 50 epochs...
Epoch 1/50
18/18 [==============================] - 1s 60ms/step - loss: 0.3191 - accuracy: 0.9220 - val_loss: 0.1986 - val_accuracy: 1.0000
Epoch 2/50
18/18 [==============================] - 0s 9ms/step - loss: 0.2276 - accuracy: 0.9858 - val_loss: 0.2044 - val_accuracy: 1.0000
Epoch 3/50
18/18 [==============================] - 0s 8ms/step - loss: 0.2839 - accuracy: 0.9574 - val_loss: 0.2046 - val_accuracy: 1.0000
...
Epoch 48/50
18/18 [==============================] - 0s 9ms/step - loss: 0.1770 - accuracy: 1.0000 - val_loss: 0.1768 - val_accuracy: 1.0000
Epoch 49/50
18/18 [==============================] - 0s 9ms/step - loss: 0.1767 - accuracy: 1.0000 - val_loss: 0.1763 - val_accuracy: 1.0000
Epoch 50/50
18/18 [==============================] - 0s 8ms/step - loss: 0.1767 - accuracy: 1.0000 - val_loss: 0.1758 - val_accuracy: 1.0000
[INFO] evaluating network...
precision recall f1-score support
cats 1.00 1.00 1.00 25
dogs 1.00 1.00 1.00 25
accuracy 1.00 50
macro avg 1.00 1.00 1.00 50
weighted avg 1.00 1.00 1.00 50
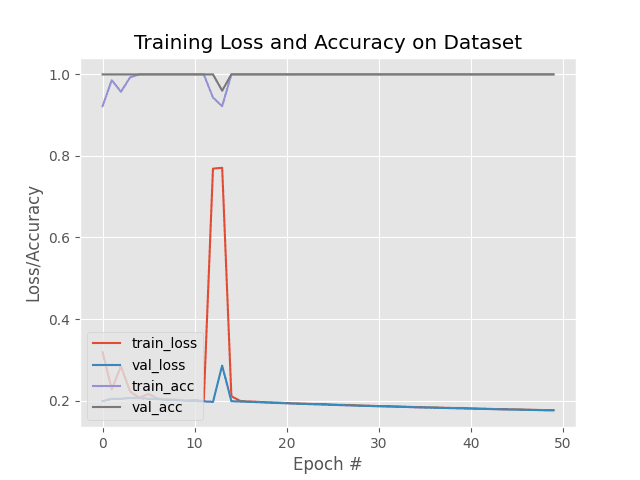
Figure 8: Data augmentation with Keras Experiment #1 training accuracy/loss results.
我们的结果表明,我们能够毫不费力地获得 100% 的准确性。
当然,这是一个微不足道的、人为的例子。实际上,你不会只拍摄一张单个图像,然后通过数据扩充建立一个由 100 或 1000 张图像组成的数据集。相反,您将拥有一个包含数百张图像的数据集,然后将数据集生成应用于该数据集,但同样,本节的目的是通过一个简单的示例进行演示,以便您能够理解该过程。
用就地数据扩充训练网络
更受欢迎的(基于图像的)数据增强形式被称为就地数据增强(参见本文的“类型#2:就地/动态数据增强”部分了解更多细节)。
在进行原位增强时,我们的 Keras ImageDataGenerator将:
- 接受一批输入图像。
- 随机转换输入批次。
- 将转换后的批次返回网络进行训练。
我们将通过两个实验来探索数据扩充如何减少过度拟合并提高我们的模型的泛化能力。
为了完成这项任务,我们将使用 Kaggle Dogs vs. Cats 数据集的一个子集:
- 猫:1000 张图片
- 狗:1000 张图片
然后,我们将从头开始,在这个数据集上训练 ResNet 的一个变体,有数据增强和没有数据增强。
实验 2:获得基线(没有数据扩充)
在我们的第一个实验中,我们不进行数据扩充:
$ python train.py --dataset dogs_vs_cats_small --plot plot_dogs_vs_cats_no_aug.png
[INFO] loading images...
[INFO] compiling model...
[INFO] training network for 50 epochs...
Epoch 1/50
187/187 [==============================] - 3s 13ms/step - loss: 1.0743 - accuracy: 0.5134 - val_loss: 0.9116 - val_accuracy: 0.5440
Epoch 2/50
187/187 [==============================] - 2s 9ms/step - loss: 0.9149 - accuracy: 0.5349 - val_loss: 0.9055 - val_accuracy: 0.4940
Epoch 3/50
187/187 [==============================] - 2s 9ms/step - loss: 0.9065 - accuracy: 0.5409 - val_loss: 0.8990 - val_accuracy: 0.5360
...
Epoch 48/50
187/187 [==============================] - 2s 9ms/step - loss: 0.2796 - accuracy: 0.9564 - val_loss: 1.4528 - val_accuracy: 0.6500
Epoch 49/50
187/187 [==============================] - 2s 10ms/step - loss: 0.2806 - accuracy: 0.9578 - val_loss: 1.4485 - val_accuracy: 0.6260
Epoch 50/50
187/187 [==============================] - 2s 9ms/step - loss: 0.2371 - accuracy: 0.9739 - val_loss: 1.5061 - val_accuracy: 0.6380
[INFO] evaluating network...
precision recall f1-score support
cats 0.61 0.70 0.65 243
dogs 0.67 0.58 0.62 257
accuracy 0.64 500
macro avg 0.64 0.64 0.64 500
weighted avg 0.64 0.64 0.64 500
查看原始分类报告,你会发现我们获得了 64%的准确率 — ,但是有一个问题!
看看与我们训练相关的情节:
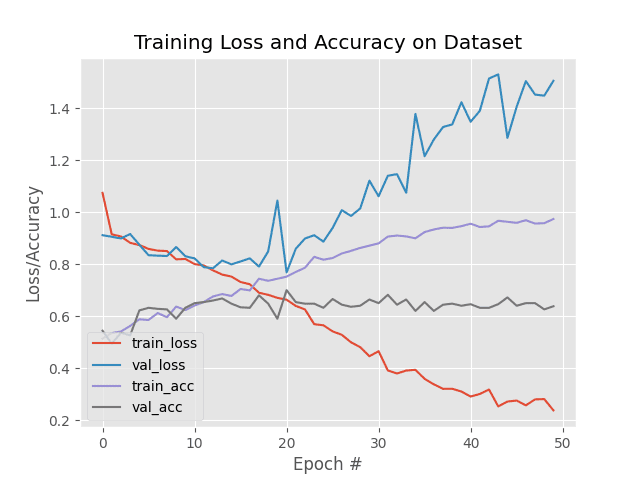
Figure 9: For Experiment #2 we did not perform data augmentation. The result is a plot with strong indications of overfitting.
出现了戏剧性的过度拟合—大约在第 15 代,我们看到我们的验证损失开始上升,而训练损失继续下降。到了第 20 个纪元,验证损失的上升尤其明显。
这种类型的行为表明过度拟合。
解决方案是(1)减少模型容量,和/或(2)执行正则化。
实验 3:改进我们的结果(通过数据扩充)
现在让我们研究一下数据扩充如何作为一种正则化形式:
[INFO] loading images...
[INFO] performing 'on the fly' data augmentation
[INFO] compiling model...
[INFO] training network for 50 epochs...
Epoch 1/50
187/187 [==============================] - 3s 14ms/step - loss: 1.1307 - accuracy: 0.4940 - val_loss: 0.9002 - val_accuracy: 0.4860
Epoch 2/50
187/187 [==============================] - 2s 8ms/step - loss: 0.9172 - accuracy: 0.5067 - val_loss: 0.8952 - val_accuracy: 0.6000
Epoch 3/50
187/187 [==============================] - 2s 8ms/step - loss: 0.8930 - accuracy: 0.5074 - val_loss: 0.8801 - val_accuracy: 0.5040
...
Epoch 48/50
187/187 [==============================] - 2s 8ms/step - loss: 0.7194 - accuracy: 0.6937 - val_loss: 0.7296 - val_accuracy: 0.7060
Epoch 49/50
187/187 [==============================] - 2s 8ms/step - loss: 0.7071 - accuracy: 0.6971 - val_loss: 0.7690 - val_accuracy: 0.6980
Epoch 50/50
187/187 [==============================] - 2s 9ms/step - loss: 0.6901 - accuracy: 0.7091 - val_loss: 0.7957 - val_accuracy: 0.6840
[INFO] evaluating network...
precision recall f1-score support
cats 0.72 0.56 0.63 243
dogs 0.66 0.80 0.72 257
accuracy 0.68 500
macro avg 0.69 0.68 0.68 500
weighted avg 0.69 0.68 0.68 500
我们现在达到了 69%的准确率,比之前的 64%有所提高。
但更重要的是,我们不再过度适应:

Figure 10: For Experiment #3, we performed data augmentation with Keras on batches of images in-place. Our training plot shows no signs of overfitting with this form of regularization.
请注意验证和训练损失是如何一起下降的,几乎没有差异。类似地,训练和验证拆分的分类准确性也在一起增长。
通过使用数据扩充,我们能够应对过度拟合!
几乎在所有情况下,除非你有很好的理由不这样做,否则你应该在训练自己的神经网络时进行数据扩充。
摘要
在本教程中,您了解了数据扩充以及如何通过 Keras 的 ImageDataGenerator 类应用数据扩充。
您还了解了三种类型的数据扩充,包括:
- 通过数据扩充进行数据集生成和数据扩展(不太常见)。
- 就地/动态数据增强(最常见)。
- 组合数据集生成器和就地扩充。
默认情况下, Keras' ImageDataGenerator类执行就地/动态数据扩充,这意味着该类:
- 接受一批用于训练的图像。
- 获取该批图像,并对该批图像中的每个图像应用一系列随机变换。
- 用随机转换的新批次替换原始批次
- 4.在这个随机转换的批次上训练 CNN(即原始数据本身是用于训练的而不是)。
话虽如此,我们实际上也可以将ImageDataGenerator类用于数据集生成/扩展——我们只需要在训练之前使用它来生成我们的数据集。
数据扩充的最后一种方法是就地扩充和数据集扩充相结合,这种方法很少使用。在这些情况下,您可能有一个小数据集,需要通过数据扩充生成额外的示例,然后在训练时进行额外的扩充/预处理。
我们通过对数据扩充进行大量实验来总结本指南,注意到数据扩充是一种正规化 的形式,使我们的网络能够更好地推广到我们的测试/验证集。
在我们的实验中验证了这种将数据扩充作为正则化的主张,我们发现:
- 在训练中不应用数据扩充导致过度拟合
- 而应用数据扩充允许平滑训练、没有过度拟合以及更高的精度/更低的损失
你应该在你所有的实验中应用数据扩充,除非你有一个很好的理由不这样做。
要了解更多关于数据增强的信息,包括我的最佳实践、技巧和建议,请务必看看我的书, 用 Python 进行计算机视觉的深度学习 。
我希望你喜欢今天的教程!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时接收电子邮件更新),*只需在下面的表格中输入您的电子邮件地址!***
Keras 学习率查找器
原文:https://pyimagesearch.com/2019/08/05/keras-learning-rate-finder/
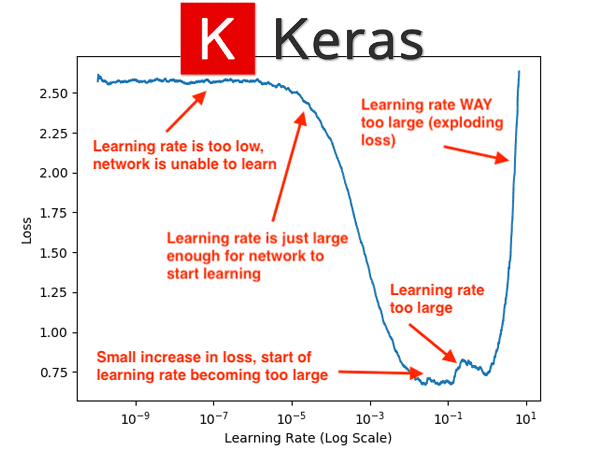
在本教程中,你将学习如何使用 Keras 自动找到学习率。本指南提供了 fast.ai 流行的“lr_find”方法的 Keras 实现。
今天是我们使用 Keras 的学习率计划、政策和衰退三部分系列的第三部分:
- Part #1: Keras 学习进度和衰减
- Part #2: 循环学习率与 Keras 和深度学习 (上周的帖子)
- Part #3: Keras 学习率查找器 (今日帖)
上周,我们讨论了循环学习率(clr)以及如何使用它们通过较少的实验和有限的超参数调整来获得高精度的模型。
CLR 方法允许我们的学习速率在下限和上限之间循环振荡;然而,问题仍然存在, 我们如何知道对于我们的学习率来说什么是好的选择?
今天我将回答这个问题。
当您完成本教程时,您将了解如何自动为您的神经网络找到最佳学习速率,为您节省 10 秒、100 秒甚至 1000 秒的计算时间运行实验来调整您的超参数。
要了解如何使用 Keras 找到最佳学习率,继续阅读!
Keras 学习率查找器
2020-06-11 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将简要讨论一个简单而优雅的算法,它可以用来自动为你的深度神经网络找到最佳学习速率。
从那以后,我将向您展示如何使用 Keras 深度学习框架来实现这种方法。
我们将学习率查找器实现应用于一个示例数据集,使我们能够获得最佳的学习率。
然后,我们将采用找到的学习率,并使用循环学习率策略来全面训练我们的网络。
如何为您的神经网络架构自动找到最佳学习速率
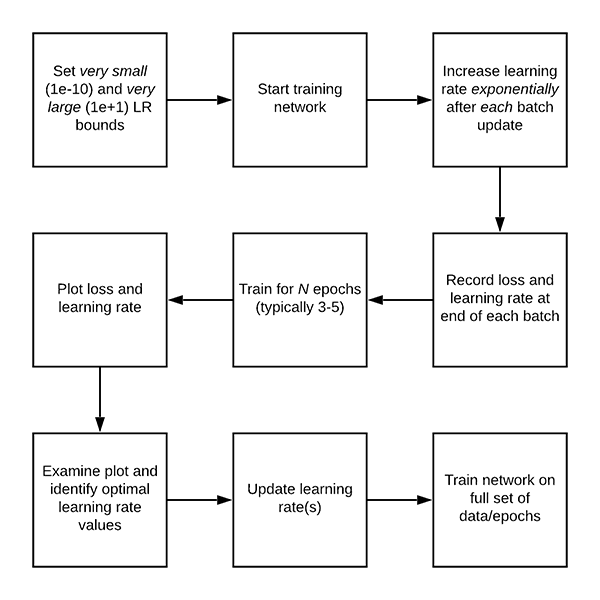
Figure 1: Deep learning requires tuning of hyperparameters such as the learning rate. Using a learning rate finder in Keras, we can automatically find a suitable min/max learning rate for cyclical learning rate scheduling and apply it with success to our experiments. This figure contains the basic algorithm for a learning rate finder.
在上周关于循环学习率(CLRs) 的教程中,我们讨论了 les lie Smith 2017 年的论文 用于训练神经网络 的循环学习率。
单从论文题目来看,史密斯博士对深度学习社区的明显贡献就是循环学习率算法。
然而,还有第二个贡献可以说比 CLRs 更重要— 自动发现学习率。 在这篇论文中,Smith 博士提出了一个简单而优雅的解决方案,告诉我们如何自动找到训练的最佳学习率。
注:虽然该算法是由 Smith 博士提出的,但直到 fast.ai 的 Jermey Howard 建议他的学生使用它时才得以推广。如果你是 fast.ai 用户,你可能还记得learn.lr_find函数——我们将使用 TensorFlow/Keras 实现一个类似的方法。
自动学习率查找算法是这样工作的:
- 步骤#1: 我们从定义学习率的上限和下限开始。下限应该非常小(1e-10),上限应该非常大(1e+1)。
- 在 1e-10 处,学习率对于我们的网络来说太小而无法学习,而在 1e+1 处,学习率太大,我们的模型将会过拟合。
- 这两个都没问题,其实也是我们希望看到的!
- 第二步:然后我们开始训练我们的网络,从下限开始。
- 每次批量更新后,我们都会成倍地提高学习速度。
- 我们还会在每次批量更新后记录损失。
- 步骤#3: 训练继续,因此学习率继续增加,直到达到最大学习率值。
- 通常,整个训练过程/学习率的增加只需要 1-5 个时期。
- 步骤#4: 训练完成后,我们绘制一个随时间变化的平滑损失图,使我们能够看到学习率同时为:
- 刚好足够减少损失
- 太大了,以至于损失开始增加。
下图(与帖子顶部的标题相同,但再次包含在这里,以便您可以轻松理解)使用 GoogLeNet 的变体(我们将在本教程的后面使用)可视化了 CIFAR-10 数据集上的学习率查找器算法的输出:
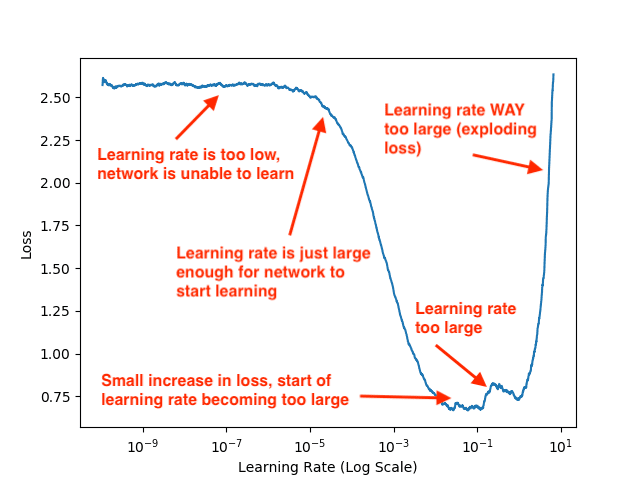
Figure 2: When inspecting a deep learning experiment, be sure to look at the loss landscape. This plot helps you identify when your learning rate is too low or too high.
在检查这个图的时候,请记住我们的学习率是在每批更新之后指数增长。在给定的一批完成后,我们增加下一批的学习率。
请注意,从 1e-10 到 1e-6,我们的损失基本上是平坦的— 学习率太小了,网络实际上无法学习任何东西。从大约 1e-5 开始,我们的损失开始下降— 这是我们的网络实际可以学习的最小学习速率。
当我们达到 1e-4 时,我们的网络学习速度非常快。在 1e-2 之后一点点,损耗有一个小的增加,但是大的增加直到 1e-1 才开始。
最后,到 1e+1 时,我们的损失急剧增加— 学习率对于我们的模型来说太高了,无法学习。
给定这个图,我可以直观地检查它,并挑选出我的 CLR 学习率的下限和上限:
- 下限: 1e-5
- 上限: 1e-2
如果您使用的是学习率计划/衰减策略,那么您将选择 1e-2 作为您的初始学习率,然后随着您的训练而降低。
然而,在本教程中,我们将使用一个循环学习率策略,所以我们需要的上下限。
但是,问题仍然存在:
我是如何生成学习率图的?
我将在本教程的后面回答这个问题。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
请点击今天帖子的 【下载】 ,其中除了我们的培训脚本之外,还包含上周的 CLR 实施和本周的学习率查找器。
然后,用tree命令检查项目布局:
$ tree --dirsfirst
.
├── output
│ ├── clr_plot.png
│ ├── lrfind_plot.png
│ └── training_plot.png
├── pyimagesearch
│ ├── __init__.py
│ ├── clr_callback.py
│ ├── config.py
│ ├── learningratefinder.py
│ └── minigooglenet.py
└── train.py
2 directories, 9 files
我们的output/目录包含三个图:
- 循环学习率图。
- 学习率查找器损失与学习率图。
- 我们的训练准确度/损失历史图。
pyimagesearch 模块包含三个类和一个配置:
clr_callback.py:包含作为 Keras 回调实现的CyclicLR类。learningratefinder.py:持有LearningRateFinder类——今天教程的重点。minigooglenet.py:有我们的 MiniGoogLeNet CNN 类。今天就不细说了。请参考 使用 Python 进行计算机视觉的深度学习 以深入了解 GoogLeNet 和 MiniGoogLeNet。config.py:保存配置参数/变量的 Python 文件。
在我们查看了config.py和learningratefinder.py文件后,我们将浏览一下train.py,我们的 Keras CNN 培训脚本。
实现我们的自动 Keras 学习率查找器
现在让我们定义一个名为LearningRateFinder的类,它封装了来自上面“如何为你的神经网络架构自动找到最佳学习速率”一节的算法逻辑。
我们的实现受到了来自 ktrain 库的LRFinder类的启发——我的主要贡献是对算法进行了一些调整,包括详细的文档和源代码的注释,使读者更容易理解算法的工作原理。
让我们开始吧——打开项目目录中的learningratefinder.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.callbacks import LambdaCallback
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
import tempfile
class LearningRateFinder:
def __init__(self, model, stopFactor=4, beta=0.98):
# store the model, stop factor, and beta value (for computing
# a smoothed, average loss)
self.model = model
self.stopFactor = stopFactor
self.beta = beta
# initialize our list of learning rates and losses,
# respectively
self.lrs = []
self.losses = []
# initialize our learning rate multiplier, average loss, best
# loss found thus far, current batch number, and weights file
self.lrMult = 1
self.avgLoss = 0
self.bestLoss = 1e9
self.batchNum = 0
self.weightsFile = None
包裹在2-6 号线进口。我们将使用一个LambdaCallback来指示我们的回调在每次批量更新结束时运行。我们将使用matplotlib来实现一个叫做plot_loss的方法,它绘制了损失与学习率的关系。
LearningRateFinder类的构造函数从第 9 行的开始。
首先,我们存储初始化的模型,stopFactor指示何时退出训练(如果我们的损失变得太大),以及beta值(用于平均/平滑我们的损失以便可视化)。
然后,我们初始化我们的学习率列表以及各个学习率的损失值(行 17 和 18 )。
我们继续执行一些初始化,包括:
lrMult:学习率倍增系数。avgLoss:一段时间内的平均损耗。bestLoss:我们在训练时发现的最好的损失。batchNum:当前批号更新。weightsFile:我们的初始模型权重的路径(这样我们可以在找到我们的学习率后重新加载权重,并在训练前将它们设置为初始值)。
reset方法是一个便利/帮助函数,用于从我们的构造函数中重置所有变量:
def reset(self):
# re-initialize all variables from our constructor
self.lrs = []
self.losses = []
self.lrMult = 1
self.avgLoss = 0
self.bestLoss = 1e9
self.batchNum = 0
self.weightsFile = None
使用我们的LearningRateFinder类时,必须能够同时处理以下两种情况:
- 可以放入内存的数据。
- (1)通过数据生成器加载,因此太大而不适合内存;或者(2)需要对其应用数据扩充/附加处理,因此使用生成器的数据。
如果整个数据集可以放入内存并且没有应用数据扩充,我们可以使用 Keras 的.fit方法来训练我们的模型。
但是,如果我们使用数据生成器,或者出于内存需求,或者因为我们正在应用数据扩充,我们需要使用 Keras' .fit函数,并将图像数据生成器对象作为训练的第一个参数。
注:你可以在本教程中读到.fit和.fit_generator 的区别。请注意,.fit_generator功能已被弃用,现在.fit可以增加数据。
is_data_generator函数可以确定我们的输入data是一个原始的 NumPy 数组还是我们正在使用一个数据生成器:
def is_data_iter(self, data):
# define the set of class types we will check for
iterClasses = ["NumpyArrayIterator", "DirectoryIterator",
"DataFrameIterator", "Iterator", "Sequence"]
# return whether our data is an iterator
return data.__class__.__name__ in iterClasses
这里我们检查输入数据类的名称是否属于第 41 行和第 42 行定义的数据迭代器类。
如果您正在使用自己的定制数据生成器,只需将其封装在一个类中,然后将您的类名添加到iterClasses列表中。
on_batch_end函数负责在每批完成后更新我们的学习率(即向前和向后传递):
def on_batch_end(self, batch, logs):
# grab the current learning rate and add log it to the list of
# learning rates that we've tried
lr = K.get_value(self.model.optimizer.lr)
self.lrs.append(lr)
# grab the loss at the end of this batch, increment the total
# number of batches processed, compute the average average
# loss, smooth it, and update the losses list with the
# smoothed value
l = logs["loss"]
self.batchNum += 1
self.avgLoss = (self.beta * self.avgLoss) + ((1 - self.beta) * l)
smooth = self.avgLoss / (1 - (self.beta ** self.batchNum))
self.losses.append(smooth)
# compute the maximum loss stopping factor value
stopLoss = self.stopFactor * self.bestLoss
# check to see whether the loss has grown too large
if self.batchNum > 1 and smooth > stopLoss:
# stop returning and return from the method
self.model.stop_training = True
return
# check to see if the best loss should be updated
if self.batchNum == 1 or smooth < self.bestLoss:
self.bestLoss = smooth
# increase the learning rate
lr *= self.lrMult
K.set_value(self.model.optimizer.lr, lr)
我们将使用这个方法作为 Keras 回调,因此我们需要确保我们的函数接受 Keras 期望看到的两个变量— batch和logs.
第 50 行和第 51 行从我们的优化器中获取当前的学习率,然后将其添加到我们的学习率列表中(lrs)。
第 57 行和第 58 行在批次结束时抓取损失,然后增加我们的批次号。
第 58-61 行计算平均损失,平滑它,然后用smooth平均值更新losses列表。
第 64 行计算我们的最大损失值,它是目前为止我们找到的stopFactor和bestLoss的函数。
如果我们的smoothLoss已经长得比stopLoss大,那么我们就停止训练(第 67-70 行)。
第 73 行和第 74 行检查是否找到了新的bestLoss,如果是,我们更新变量。
最后,行 77 增加我们的学习率,而行 78 设置下一批的学习率值。
我们的下一个方法find,负责自动找到我们训练的最优学习率。当我们准备好找到我们的学习率时,我们将从我们的驱动程序脚本中调用这个方法:
def find(self, trainData, startLR, endLR, epochs=None,
stepsPerEpoch=None, batchSize=32, sampleSize=2048,
verbose=1):
# reset our class-specific variables
self.reset()
# determine if we are using a data generator or not
useGen = self.is_data_iter(trainData)
# if we're using a generator and the steps per epoch is not
# supplied, raise an error
if useGen and stepsPerEpoch is None:
msg = "Using generator without supplying stepsPerEpoch"
raise Exception(msg)
# if we're not using a generator then our entire dataset must
# already be in memory
elif not useGen:
# grab the number of samples in the training data and
# then derive the number of steps per epoch
numSamples = len(trainData[0])
stepsPerEpoch = np.ceil(numSamples / float(batchSize))
# if no number of training epochs are supplied, compute the
# training epochs based on a default sample size
if epochs is None:
epochs = int(np.ceil(sampleSize / float(stepsPerEpoch)))
我们的find方法接受许多参数,包括:
trainData:我们的训练数据(数据的 NumPy 数组或者数据生成器)。startLR:初始,开始学习率。epochs:训练的时期数(如果没有提供值,我们将计算时期数)。stepsPerEpoch:每个历元的批量更新步骤总数。batchSize:我们优化器的批量大小。sampleSize:找到最佳学习率时使用的来自trainData的样本数。verbose:Keras '.fit方法的详细度设置。
第 84 行重置我们特定于类的变量,而第 87 行检查我们是否在使用数据迭代器或原始 NumPy 数组。
在我们使用数据生成器并且没有提供stepsPerEpoch变量的情况下,我们抛出一个异常,因为我们不可能从生成器中确定stepsPerEpoch(参见本教程了解为什么这是真的更多信息)。
否则,如果我们没有使用数据发生器,我们从trainData中获取numSamples,然后通过将数据点的数量除以我们的batchSize ( 第 97-101 行)来计算stepsPerEpoch的数量。
最后,如果没有提供时期的数量,我们通过将sampleSize除以stepsPerEpoch的数量来计算训练时期的数量。我个人的偏好是让周期数最终在 3-5 的范围内——足够长以获得可靠的结果,但又不会长到浪费我数小时的训练时间。
让我们转到自动学习率查找算法的核心:
# compute the total number of batch updates that will take
# place while we are attempting to find a good starting
# learning rate
numBatchUpdates = epochs * stepsPerEpoch
# derive the learning rate multiplier based on the ending
# learning rate, starting learning rate, and total number of
# batch updates
self.lrMult = (endLR / startLR) ** (1.0 / numBatchUpdates)
# create a temporary file path for the model weights and
# then save the weights (so we can reset the weights when we
# are done)
self.weightsFile = tempfile.mkstemp()[1]
self.model.save_weights(self.weightsFile)
# grab the *original* learning rate (so we can reset it
# later), and then set the *starting* learning rate
origLR = K.get_value(self.model.optimizer.lr)
K.set_value(self.model.optimizer.lr, startLR)
第 111 行计算当发现我们的学习率时将发生的批量更新的总数。
使用numBatchUpdates我们导出学习率倍增因子(lrMult),该因子用于指数增加我们的学习率(第 116 行)。
第 121 行和第 122 行创建了一个临时文件来存储我们的模型的初始权重。当我们的学习率查找器完成运行后,我们将恢复这些权重。
接下来,我们获取优化器的初始学习率(第 126 行),将其存储在origLR中,然后指示 Keras 为优化器设置初始学习率(startLR)。
让我们创建我们的LambdaCallback,它将在每次批处理完成时调用我们的on_batch_end方法:
# construct a callback that will be called at the end of each
# batch, enabling us to increase our learning rate as training
# progresses
callback = LambdaCallback(on_batch_end=lambda batch, logs:
self.on_batch_end(batch, logs))
# check to see if we are using a data iterator
if useGen:
self.model.fit(
x=trainData,
steps_per_epoch=stepsPerEpoch,
epochs=epochs,
verbose=verbose,
callbacks=[callback])
# otherwise, our entire training data is already in memory
else:
# train our model using Keras' fit method
self.model.fit(
x=trainData[0], y=trainData[1],
batch_size=batchSize,
epochs=epochs,
callbacks=[callback],
verbose=verbose)
# restore the original model weights and learning rate
self.model.load_weights(self.weightsFile)
K.set_value(self.model.optimizer.lr, origLR)
第 132 行和第 133 行构造了我们的callback——每当一个批处理完成时,就会调用on_batch_end方法来自动更新我们的学习速率。
如果我们使用数据生成器,我们将使用.fit_generator方法(第 136-142 行)来训练我们的模型。否则,我们的整个训练数据以 NumPy 数组的形式存在于内存中,所以我们可以使用.fit方法(第 145- 152 行)。
训练完成后,我们重置初始模型权重和学习率值(行 155 和 156 )。
我们的最后一种方法plot_loss,用于绘制我们的学习率和随时间的损失:
def plot_loss(self, skipBegin=10, skipEnd=1, title=""):
# grab the learning rate and losses values to plot
lrs = self.lrs[skipBegin:-skipEnd]
losses = self.losses[skipBegin:-skipEnd]
# plot the learning rate vs. loss
plt.plot(lrs, losses)
plt.xscale("log")
plt.xlabel("Learning Rate (Log Scale)")
plt.ylabel("Loss")
# if the title is not empty, add it to the plot
if title != "":
plt.title(title)
这种精确的方法生成了您在图 2 中看到的图。
稍后,在本教程的“使用 Keras 找到我们的最佳学习率”部分,您将发现如何使用我们刚刚实现的LearningRateFinder类来自动使用 Keras 找到最佳学习率。
我们的配置文件
在我们实现实际的训练脚本之前,让我们创建我们的配置。
打开config.py文件并插入以下代码:
# import the necessary packages
import os
# initialize the list of class label names
CLASSES = ["top", "trouser", "pullover", "dress", "coat",
"sandal", "shirt", "sneaker", "bag", "ankle boot"]
# define the minimum learning rate, maximum learning rate, batch size,
# step size, CLR method, and number of epochs
MIN_LR = 1e-5
MAX_LR = 1e-2
BATCH_SIZE = 64
STEP_SIZE = 8
CLR_METHOD = "triangular"
NUM_EPOCHS = 48
# define the path to the output learning rate finder plot, training
# history plot and cyclical learning rate plot
LRFIND_PLOT_PATH = os.path.sep.join(["output", "lrfind_plot.png"])
TRAINING_PLOT_PATH = os.path.sep.join(["output", "training_plot.png"])
CLR_PLOT_PATH = os.path.sep.join(["output", "clr_plot.png"])
我们将使用时尚 MNIST 作为这个项目的数据集。第 5 行和第 6 行为时尚 MNIST 数据集设置分类标签。
我们的循环学习率参数在第 10-15 行中指定。MIN_LR和MAX_LR将在下面的“用 Keras 找到我们的最佳学习率”一节中找到,但是为了完整起见,我们将它们包含在这里。如果需要复习这些参数,请参考上周的帖子。
我们将输出三种类型的图,路径通过行 19-21 指定。其中两个图将采用与上周相同的格式(培训和 CLR)。新类型是“学习率查找器”图。
实施我们的学习率查找器培训脚本
我们的学习率查找脚本将负责以下两个方面:
- 使用我们在本指南前面实现的
LearningRateFinder类自动找到我们的初始学习率 - 采用我们找到的学习率值,然后在整个数据集上训练网络。
让我们开始吧!
打开train.py文件并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.learningratefinder import LearningRateFinder
from pyimagesearch.minigooglenet import MiniGoogLeNet
from pyimagesearch.clr_callback import CyclicLR
from pyimagesearch import config
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import fashion_mnist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import sys
2-19 线导入我们需要的包。注意我们如何导入我们的LearningRateFinder以及我们的CyclicLR回调。我们将在fashion_mnist训练MiniGoogLeNet。要了解更多关于数据集的信息,请务必阅读《时尚 MNIST 与 Keras》和《深度学习》 。
让我们继续解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--lr-find", type=int, default=0,
help="whether or not to find optimal learning rate")
args = vars(ap.parse_args())
我们有一个单独的命令行参数,--lr-find,一个标志,指示是否找到最优的学习速率。
接下来,让我们准备数据:
# load the training and testing data
print("[INFO] loading Fashion MNIST data...")
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
# Fashion MNIST images are 28x28 but the network we will be training
# is expecting 32x32 images
trainX = np.array([cv2.resize(x, (32, 32)) for x in trainX])
testX = np.array([cv2.resize(x, (32, 32)) for x in testX])
# scale the pixel intensities to the range [0, 1]
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# reshape the data matrices to include a channel dimension (required
# for training)
trainX = trainX.reshape((trainX.shape[0], 32, 32, 1))
testX = testX.reshape((testX.shape[0], 32, 32, 1))
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
在这里我们:
- 加载时尚 MNIST 数据集(第 29 行)。
- 在第 33 行和第 34 行上,将每个图像从 28×28 图像调整为 32×32 图像(我们的网络期望的输入)。
- 将像素强度缩放到范围【0,1】(第 37 行和第 38 行)。
- 二进制化标签(第 46-48 行)。
- 构造我们的数据扩充对象(第 51-53 行)。在我的以前的帖子中以及在的 的实践者包中阅读更多关于使用 Python 进行计算机视觉深度学习的信息。
从这里,我们可以compile我们的model:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=config.MIN_LR, momentum=0.9)
model = MiniGoogLeNet.build(width=32, height=32, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
我们的model是用SGD(随机梯度下降)优化编译的。我们使用"categorical_crossentropy"损失,因为我们有 > 2 职业。如果您的数据集只有 2 个类,请务必使用"binary_crossentropy"。
下面的 if-then 块处理我们寻找最佳学习率时的情况:
# check to see if we are attempting to find an optimal learning rate
# before training for the full number of epochs
if args["lr_find"] > 0:
# initialize the learning rate finder and then train with learning
# rates ranging from 1e-10 to 1e+1
print("[INFO] finding learning rate...")
lrf = LearningRateFinder(model)
lrf.find(
aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
1e-10, 1e+1,
stepsPerEpoch=np.ceil((len(trainX) / float(config.BATCH_SIZE))),
batchSize=config.BATCH_SIZE)
# plot the loss for the various learning rates and save the
# resulting plot to disk
lrf.plot_loss()
plt.savefig(config.LRFIND_PLOT_PATH)
# gracefully exit the script so we can adjust our learning rates
# in the config and then train the network for our full set of
# epochs
print("[INFO] learning rate finder complete")
print("[INFO] examine plot and adjust learning rates before training")
sys.exit(0)
第 64 行检查我们是否应该尝试找到最佳学习率。假设如此,我们:
- 初始化
LearningRateFinder( 第 68 行)。 - 以
1e-10的学习率开始训练,并以指数方式增加,直到我们达到1e+1( 第 69-73 行)。 - 绘制损失与学习率的关系图,并保存结果数字(第 77 行和第 78 行)。
- 在向用户输出几条消息后,优雅地退出脚本(第 83-85 行)。
在这段代码执行之后,我们现在需要:
- 查看生成的图。
- 分别用我们的
MIN_LR和MAX_LR更新config.py。 - 在我们的完整数据集上训练网络。
假设我们已经完成了第 1 步和第 2 步,现在让我们处理第 3 步,我们的最小和最大学习率已经在配置中找到并更新了。在这种情况下,是时候初始化我们的循环学习率类并开始训练了:
# otherwise, we have already defined a learning rate space to train
# over, so compute the step size and initialize the cyclic learning
# rate method
stepSize = config.STEP_SIZE * (trainX.shape[0] // config.BATCH_SIZE)
clr = CyclicLR(
mode=config.CLR_METHOD,
base_lr=config.MIN_LR,
max_lr=config.MAX_LR,
step_size=stepSize)
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
callbacks=[clr],
verbose=1)
# evaluate the network and show a classification report
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=config.BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=config.CLASSES))
2020-06-11 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
我们的CyclicLR用配置文件中新设置的参数初始化(第 90-95 行)。
然后我们的model是使用.fit_generator 通过我们的aug数据增强对象和我们的clr回调(第 99-105 行)训练的。
训练完成后,我们继续在测试集上评估我们的网络( Line 109 )。终端打印出一个classification_report供我们检查。
最后,让我们绘制我们的培训历史和 CLR 历史:
# construct a plot that plots and saves the training history
N = np.arange(0, config.NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.TRAINING_PLOT_PATH)
# plot the learning rate history
N = np.arange(0, len(clr.history["lr"]))
plt.figure()
plt.plot(N, clr.history["lr"])
plt.title("Cyclical Learning Rate (CLR)")
plt.xlabel("Training Iterations")
plt.ylabel("Learning Rate")
plt.savefig(config.CLR_PLOT_PATH)
2020-06-11 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
为训练程序生成了两个图,以配合我们已经应该有的学习率查找器图:
- 训练准确度/损失历史(第 114-125 行)。标准的情节格式包含在我的大部分教程和我的深度学习书的每个实验中。
- 学习率历史(第 128-134 行)。该图将帮助我们直观地验证我们的学习率是根据我们的 CLR 意图而波动的。
使用 Keras 找到我们的最佳学习率
我们现在可以找到我们的最佳学习率了!
确保您已经使用本教程的 “下载” 部分下载了源代码——从那里,打开一个终端并执行以下命令:
$ python train.py --lr-find 1
[INFO] loading Fashion MNIST data...
[INFO] compiling model...
[INFO] finding learning rate...
Epoch 1/3
938/938 [==============================] - 23s 24ms/step - loss: 2.5839 - accuracy: 0.1072
Epoch 2/3
938/938 [==============================] - 21s 23ms/step - loss: 2.1177 - accuracy: 0.2587
Epoch 3/3
938/938 [==============================] - 21s 23ms/step - loss: 1.0178 - accuracy: 0.6591
[INFO] learning rate finder complete
[INFO] examine plot and adjust learning rates before training
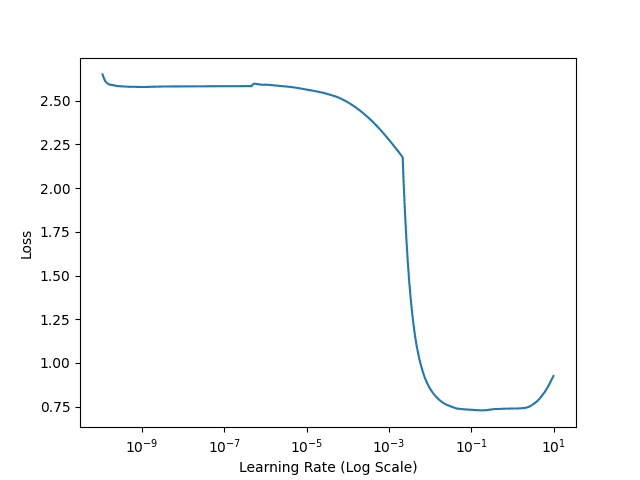
Figure 3: Analyzing a deep learning loss vs. learning rate plot to find an optimal learning rate for Keras.
--lr-find标志指示我们的脚本利用LearningRateFinder类将我们的学习速率从 1e-10 指数级提高到 1e+1。
在每次批量更新后,学习率增加,直到达到我们的最大学习率。
图 3 显示了我们的损失:
- 损耗停滞不前,没有从 1e-10 减少到大约 1e-6,这意味着学习率太小,我们的网络没有在学习。
- 在大约 1e-5 处,我们的损失开始减少,这意味着我们的学习速率刚好足够大,模型可以开始学习。
- 到 1e-3,损耗迅速下降,表明这是网络可以快速学习的“最佳点”。
- 就在 1e-1 之后,损失略有增加,这意味着我们的学习速率可能很快就会过大。
- 而到了 1e+1 的时候,我们的损失就开始爆发了(学习率远太大)。
基于这个图,我们应该选择 1e-5 作为我们的基本学习速率,选择 1e-2 作为我们的最大学习速率 —这些值表示学习速率足够小以使我们的网络开始学习,以及学习速率足够大以使我们的网络快速学习,但是不会大到以至于我们的损失爆炸。
如果您需要帮助分析图 3 ,请务必回头参考图 2 。
培训整个网络架构
如果还没有,回到我们的config.py文件,分别设置MIN_LR = 1e-5和MAX_LR = 1e-2:
# define the minimum learning rate, maximum learning rate, batch size,
# step size, CLR method, and number of epochs
MIN_LR = 1e-5
MAX_LR = 1e-2
BATCH_SIZE = 64
STEP_SIZE = 8
CLR_METHOD = "triangular"
NUM_EPOCHS = 48
从那里,执行以下命令:
$ python train.py
[INFO] loading Fashion MNIST data...
[INFO] compiling model...
[INFO] training network...
Epoch 1/48
937/937 [==============================] - 25s 27ms/step - loss: 1.2759 - accuracy: 0.5528 - val_loss: 0.7126 - val_accuracy: 0.7350
Epoch 2/48
937/937 [==============================] - 24s 26ms/step - loss: 0.5589 - accuracy: 0.7946 - val_loss: 0.5217 - val_accuracy: 0.8108
Epoch 3/48
937/937 [==============================] - 25s 26ms/step - loss: 0.4338 - accuracy: 0.8417 - val_loss: 0.5276 - val_accuracy: 0.8017
...
Epoch 46/48
937/937 [==============================] - 25s 26ms/step - loss: 0.0942 - accuracy: 0.9657 - val_loss: 0.1895 - val_accuracy: 0.9379
Epoch 47/48
937/937 [==============================] - 24s 26ms/step - loss: 0.0861 - accuracy: 0.9684 - val_loss: 0.1813 - val_accuracy: 0.9408
Epoch 48/48
937/937 [==============================] - 25s 26ms/step - loss: 0.0791 - accuracy: 0.9714 - val_loss: 0.1741 - val_accuracy: 0.9433
[INFO] evaluating network...
precision recall f1-score support
top 0.91 0.89 0.90 1000
trouser 0.99 0.99 0.99 1000
pullover 0.92 0.92 0.92 1000
dress 0.95 0.94 0.94 1000
coat 0.92 0.93 0.92 1000
sandal 0.99 0.99 0.99 1000
shirt 0.82 0.84 0.83 1000
sneaker 0.97 0.98 0.97 1000
bag 0.99 1.00 0.99 1000
ankle boot 0.98 0.97 0.97 1000
accuracy 0.94 10000
macro avg 0.94 0.94 0.94 10000
weighted avg 0.94 0.94 0.94 10000
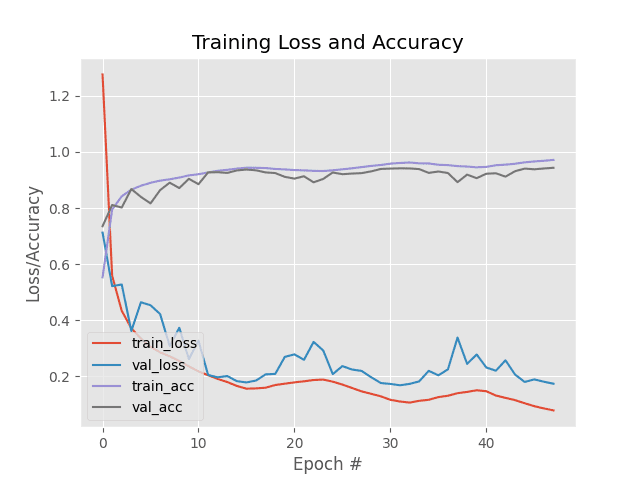
Figure 4: Our one and only experiment’s training accuracy/loss curves are plotted while using the min/max learning rate determined via our Keras learning rate finder method.
训练完成后,我们在时尚 MNIST 数据集上获得了 94%的准确率。
请记住,我们只运行了一个实验来调整我们模型的学习率。
我们的培训历史记录绘制在图 4 中。请注意三角循环学习率策略的特征“波浪”——随着学习率的增加和减少,我们的培训和验证损失会随着波浪上下波动。
说到周期性学习率政策,我们来看看学习率在培训期间是如何变化的:

Figure 5: A plot of our cyclical learning rate schedule using the “triangular” mode. The min/max learning rates were determined with a Keras learning rate finder.
这里,我们完成了三角策略的三个完整周期,从 1e-5 的初始学习速率开始,增加到 1e-2,然后再次降低回 1e-5。
结合使用循环学习率和我们的自动学习率查找器实现,我们能够仅在一次实验中获得高度准确的模型!
您可以在自己的项目中使用 clr 和自动学习率查找器的组合来帮助您快速有效地调整学习率。
摘要
在本教程中,您学习了如何使用 Keras 深度学习库创建自动学习率查找器。
这种自动学习率查找算法遵循了 Leslie Smith 博士在他们 2017 年的论文中提出的建议, 训练神经网络的循环学习率 (但这种方法本身并没有得到普及,直到 Jermey Howard 建议 fast.ai 用户使用它)。
本指南的主要贡献是提供了一个记录良好的 Keras 学习率查找工具,包括一个如何使用它的例子。
当使用 Keras 训练您自己的神经网络时,您可以使用这个学习率查找器实现,使您能够:
- 绕过 10 到 100 次调整你学习速度的实验。
- 用较少的努力获得高精度的模型。
确保在使用您自己的数据集和架构探索学习率时使用该实现。
我希望你喜欢我在关于用 Keras 寻找、调整和安排学习率的系列教程中的最后一篇文章!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
Keras 学习率时间表和衰减
原文:https://pyimagesearch.com/2019/07/22/keras-learning-rate-schedules-and-decay/
在本教程中,您将了解如何使用 Keras 学习速率计划和衰减。您将了解如何使用 Keras 的标准学习率衰减以及基于步长、线性和多项式的学习率计划。

在训练一个神经网络的时候,学习率往往是你要调优的最重要的超参数:
- 太小一个学习率,你的神经网络可能根本不会学习
- 过大的学习率,你可能会超越低损失区域(甚至从训练开始就超负荷)
当涉及到训练神经网络时,最大的回报(就准确性而言)将来自于选择正确的学习率和适当的学习率计划。
但是说起来容易做起来难。
为了帮助像你这样的深度学习实践者学习如何评估问题和选择合适的学习速率,我们将开始一系列关于学习速率计划、衰减和 Keras 超参数调整的教程。
到本系列结束时,您将会很好地理解如何恰当有效地将 Keras 的学习进度应用到您自己的深度学习项目中。
要了解如何使用 Keras 来学习速率表和衰减,只需继续阅读
Keras 学习率时间表和衰减
2020-06-11 更新:此博文现已兼容 TensorFlow 2+!
在本指南的第一部分,我们将讨论为什么在训练你自己的深度神经网络时,学习率是最重要的超参数。
然后我们将深入探讨为什么我们可能想要在训练中调整我们的学习速度。
接下来,我将向您展示如何使用 Keras 实施和利用许多学习率计划,包括:
- 大多数 Keras 优化器都内置了衰减时间表
- 基于步骤的学习率计划
- 线性学习率衰减
- 多项式学习速率表
然后,我们将使用这些学习率计划在 CIFAR-10 上执行大量实验,并评估哪一个执行得最好。
这几组实验将作为一个模板,你可以在探索自己的深度学习项目和选择合适的学习速率和学习速率时间表时使用。
为什么要调整我们的学习率和使用学习率计划?
要了解为什么学习速率表是一种值得应用的方法,有助于提高模型准确性并下降到较低损失的区域,请考虑几乎所有神经网络都使用的标准权重更新公式:

回想一下学习率,
, controls the “step” we make along the gradient. Larger values of imply that we are taking bigger steps. While smaller values of will make tiny steps. If is zero the network cannot make any steps at all (since the gradient multiplied by zero is zero).
你遇到的大多数初始学习率(但不是全部)通常在集合 中
中
.
然后,在不改变学习速率的情况下,对网络进行固定次数的训练。
这种方法在某些情况下可能很有效,但随着时间的推移,降低我们的学习速度通常是有益的。当训练我们的网络时,我们试图沿着我们的损失范围找到一些位置,在那里网络获得合理的准确性。不一定是全局极小值,甚至也不一定是局部极小值,但在实践中,简单地找到一个损失相当低的损失区域就“足够好”了。
如果我们一直保持较高的学习率,我们可能会越过这些低损失区域,因为我们将采取太大的步骤来下降到这些系列。
相反,我们能做的是降低我们的学习率,从而允许我们的网络采取更小的步骤 —这种降低的学习率使我们的网络能够下降到“更优”的损失领域,否则我们的学习率学习将会完全错过。
因此,我们可以将学习率计划的过程视为:
- 在训练过程的早期以较大的学习率找到一组合理的“好”重量。
- 稍后在该过程中调整这些权重,以使用较小的学习速率找到更优的权重。
我们将在本教程中讨论一些最流行的学习进度。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
一旦你抓取并提取了 【下载】 ,继续使用tree命令检查项目文件夹:
$ tree
.
├── output
│ ├── lr_linear_schedule.png
│ ├── lr_poly_schedule.png
│ ├── lr_step_schedule.png
│ ├── train_linear_schedule.png
│ ├── train_no_schedule.png
│ ├── train_poly_schedule.png
│ ├── train_standard_schedule.png
│ └── train_step_schedule.png
├── pyimagesearch
│ ├── __init__.py
│ ├── learning_rate_schedulers.py
│ └── resnet.py
└── train.py
2 directories, 12 files
我们的output/目录将包含学习率和训练历史图。结果部分包含的五个实验分别对应于文件名为train_*.png的五个图。
pyimagesearch模块包含我们的 ResNet CNN 和我们的learning_rate_schedulers.py。LearningRateDecay父类简单地包含了一个名为plot的方法,用于绘制我们每种类型的学习率衰减。还包括子类StepDecay和PolynomialDecay,它们在每个时期完成时计算学习率。这两个类都通过继承(一个面向对象的概念)包含了plot方法。
我们的训练脚本train.py将在 CIFAR-10 数据集上训练 ResNet。我们将在没有学习率衰减以及标准、线性、基于步长和多项式学习率衰减的情况下运行脚本。
Keras 的标准“衰变”时间表
Keras 库附带了一个基于时间的学习率调度器——它是通过优化器类的decay参数(如SGD、Adam等)来控制的。).
为了发现我们如何利用这种类型的学习率衰减,让我们看一个如何初始化 ResNet 体系结构和 SGD 优化器的示例:
# initialize our optimizer and model, then compile it
opt = SGD(lr=1e-2, momentum=0.9, decay=1e-2/epochs)
model = ResNet.build(32, 32, 3, 10, (9, 9, 9),
(64, 64, 128, 256), reg=0.0005)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
这里我们用初始学习率1e-2初始化我们的 SGD 优化器。然后,我们将我们的decay设置为学习率除以我们为其训练网络的总时期数(一个常见的经验法则)。
在内部,Keras 应用以下学习率时间表来调整每批更新后的学习率——这是一个误解,Keras 在每个时期后更新标准衰减。使用 Keras 提供的默认学习率调度程序时,请记住这一点。
更新公式如下:
以 CIFAR-10 数据集为例,我们总共有 50,000 个训练图像。
如果我们使用批量大小64,这意味着总共有
steps per epoch. Therefore, a total of 782 weight updates need to be applied before an epoch completes.
为了查看学习率进度计算的示例,让我们假设我们的初始学习率是
and our  (with the assumption that we are training for forty epochs).
(with the assumption that we are training for forty epochs).
在应用任何学习率计划之前,步骤 0 的学习率为:
} = 0.01")
在第一时段开始时,我们可以看到以下学习率:
} = 0.00836")
下面的图 1 继续计算 Keras 的标准学习率衰减
and a decay of  :
: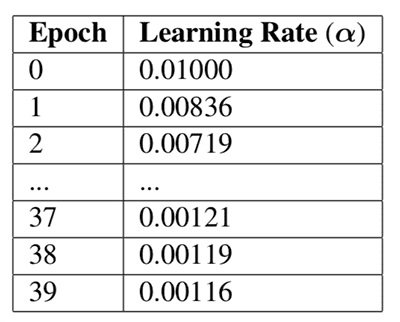
Figure 1: Keras’ standard learning rate decay table.
在这篇文章的“实施我们的培训脚本”和“Keras 学习率进度结果”部分,你将分别学习如何利用这种学习率衰减。
我们的学习率衰减类
在本教程的剩余部分,我们将实现我们自己的自定义学习率计划,然后在训练我们的神经网络时将它们与 Keras 合并。
为了保持我们的代码整洁,更不用说遵循面向对象编程的最佳实践,让我们首先定义一个基类LearningRateDecay,我们将为每个相应的学习率计划创建子类。
打开目录结构中的learning_rate_schedulers.py,插入以下代码:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
class LearningRateDecay:
def plot(self, epochs, title="Learning Rate Schedule"):
# compute the set of learning rates for each corresponding
# epoch
lrs = [self(i) for i in epochs]
# the learning rate schedule
plt.style.use("ggplot")
plt.figure()
plt.plot(epochs, lrs)
plt.title(title)
plt.xlabel("Epoch #")
plt.ylabel("Learning Rate")
我们实施的每一个学习进度计划都将有一个绘图功能,使我们能够可视化我们的学习进度。
有了我们的基本LearningRateSchedule类实现,让我们继续创建一个基于步骤的学习率计划。
使用 Keras 的基于步骤的学习率计划
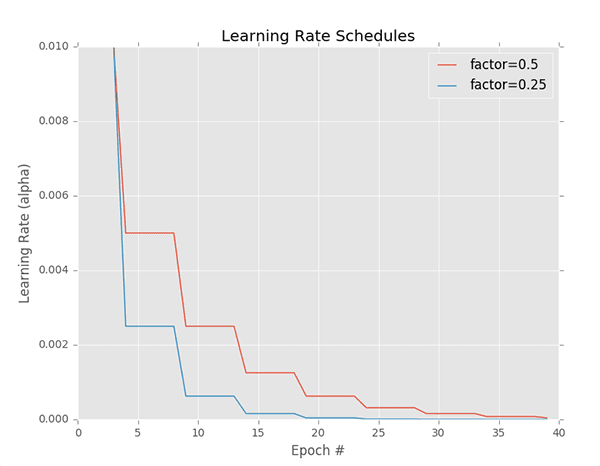
Figure 2: Keras learning rate step-based decay. The schedule in red is a decay factor of 0.5 and blue is a factor of 0.25.
一种流行的学习速率调度器是基于步长的衰减,在训练期间,我们在特定时期之后系统地降低学习速率。
阶跃衰减学习率调度器可以被视为一个分段函数,如图 2 中的所示——这里学习率在多个时期内保持不变,然后下降,再次保持不变,然后再次下降,以此类推。
当对我们的学习率应用步长衰减时,我们有两种选择:
- 定义一个方程来模拟我们希望实现的分段插入学习率。
- 使用我称之为
ctrl + c的方法来训练一个深度神经网络。在这里,我们以给定的学习速率训练一些时期,并最终注意到验证性能停滞/停止,然后ctrl + c停止脚本,调整我们的学习速率,并继续训练。
在这篇文章中,我们将主要关注基于等式的分段下降学习率调度。
ctrl + c方法稍微高级一点,通常应用于使用更深层次神经网络的更大数据集,其中获得合理模型所需的确切历元数是未知的。
如果您想了解更多关于ctrl + c方法的训练,请参考 用 Python 进行计算机视觉深度学习 。
当应用阶跃衰减时,我们经常在每个固定数量的时期之后,将我们的学习速率降低(1)一半或(2)一个数量级。例如,让我们假设我们的初始学习率是
.
在 10 个时期后,我们将学习速率降至
.
再过 10 个历元(即第 20 个总历元)后,
is dropped by a factor of 0.5 again, such that  , etc.
, etc.
事实上,这与图 2 ( 红线)中描述的学习率计划完全相同。
蓝线显示一个更积极的下降因子0.25。通过数学建模,我们可以将基于阶跃的衰减方程定义为:
 / D}")
其中
is the initial learning rate,  is the factor value controlling the rate in which the learning date drops, D is the “Drop every” epochs value, and E is the current epoch.
is the factor value controlling the rate in which the learning date drops, D is the “Drop every” epochs value, and E is the current epoch.
我们的因子越大
is, the slower the learning rate will decay.
反之,系数越小
, the faster the learning rate will decay.
说了这么多,现在让我们继续实现我们的StepDecay类。
返回到您的learning_rate_schedulers.py文件并插入以下代码:
class StepDecay(LearningRateDecay):
def __init__(self, initAlpha=0.01, factor=0.25, dropEvery=10):
# store the base initial learning rate, drop factor, and
# epochs to drop every
self.initAlpha = initAlpha
self.factor = factor
self.dropEvery = dropEvery
def __call__(self, epoch):
# compute the learning rate for the current epoch
exp = np.floor((1 + epoch) / self.dropEvery)
alpha = self.initAlpha * (self.factor ** exp)
# return the learning rate
return float(alpha)
第 20 行定义了我们的StepDecay类的构造函数。然后,我们存储初始学习速率(initAlpha)、丢弃因子和dropEvery历元值(第 23-25 行)。
__call__功能:
- 接受当前的
epoch号。 - 根据上面详述的基于步长的衰减公式计算学习率(第 29 行和第 30 行)。
- 返回当前时期的计算学习率(行 33 )。
在这篇文章的后面,你会看到如何使用这个学习进度计划。
Keras 中的线性和多项式学习率计划
我最喜欢的两个学习率时间表是线性学习率衰减和多项式学习率衰减。
使用这些方法,我们的学习率在固定数量的时期内衰减为零。
学习率衰减的速率基于多项式函数的参数。较小的多项式指数/幂将导致学习速率“更慢地”衰减,而较大的指数使学习速率“更快地”衰减。
方便的是,这两种方法都可以在一个类中实现:
class PolynomialDecay(LearningRateDecay):
def __init__(self, maxEpochs=100, initAlpha=0.01, power=1.0):
# store the maximum number of epochs, base learning rate,
# and power of the polynomial
self.maxEpochs = maxEpochs
self.initAlpha = initAlpha
self.power = power
def __call__(self, epoch):
# compute the new learning rate based on polynomial decay
decay = (1 - (epoch / float(self.maxEpochs))) ** self.power
alpha = self.initAlpha * decay
# return the new learning rate
return float(alpha)
第 36 行定义了我们的PolynomialDecay类的构造函数,它需要三个值:
- 我们将接受训练的总次数。
initAlpha:初始学习率。power:多项式的幂/指数。
注意,如果你设置power=1.0,那么你有一个线性学习率衰减。
行 45 和 46 计算当前时期的调整学习率,而行 49 返回新的学习率。
实施我们的培训脚本
现在,我们已经实现了一些不同的 Keras 学习率计划,让我们看看如何在实际的培训脚本中使用它们。
在编辑器中创建一个名为train.py file 的文件,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.learning_rate_schedulers import StepDecay
from pyimagesearch.learning_rate_schedulers import PolynomialDecay
from pyimagesearch.resnet import ResNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
第 2-16 行导入所需的包。第 3 行设置matplotlib后端,这样我们可以创建图像文件。我们最显著的进口产品包括:
StepDecay:我们的类,计算并绘制基于步长的学习率衰减。PolynomialDecay:我们写的计算基于多项式的学习率衰减的类。- 我们在 Keras 中实现的卷积神经网络。
- 一个 Keras 回调。我们将把我们的学习率
schedule传递给这个类,它将在每个时期结束时被调用作为回调来计算我们的学习率。
让我们继续,解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--schedule", type=str, default="",
help="learning rate schedule method")
ap.add_argument("-e", "--epochs", type=int, default=100,
help="# of epochs to train for")
ap.add_argument("-l", "--lr-plot", type=str, default="lr.png",
help="path to output learning rate plot")
ap.add_argument("-t", "--train-plot", type=str, default="training.png",
help="path to output training plot")
args = vars(ap.parse_args())
当通过终端调用脚本时,我们的脚本接受四个命令行参数中的任何一个:
--schedule:学习率进度法。有效选项包括“标准”、“步进”、“线性”、“多边形”。默认情况下,不会使用学习率计划。--epochs:训练的时期数(default=100)。--lr-plot:输出图的路径。我建议用更具描述性的路径+文件名来覆盖lr.png的default。--train-plot:输出精度/损耗训练历史图的路径。我再次建议一个描述性的路径+文件名,否则training.png将被default设置。
有了导入和命令行参数,现在是时候初始化我们的学习速率时间表:
# store the number of epochs to train for in a convenience variable,
# then initialize the list of callbacks and learning rate scheduler
# to be used
epochs = args["epochs"]
callbacks = []
schedule = None
# check to see if step-based learning rate decay should be used
if args["schedule"] == "step":
print("[INFO] using 'step-based' learning rate decay...")
schedule = StepDecay(initAlpha=1e-1, factor=0.25, dropEvery=15)
# check to see if linear learning rate decay should should be used
elif args["schedule"] == "linear":
print("[INFO] using 'linear' learning rate decay...")
schedule = PolynomialDecay(maxEpochs=epochs, initAlpha=1e-1, power=1)
# check to see if a polynomial learning rate decay should be used
elif args["schedule"] == "poly":
print("[INFO] using 'polynomial' learning rate decay...")
schedule = PolynomialDecay(maxEpochs=epochs, initAlpha=1e-1, power=5)
# if the learning rate schedule is not empty, add it to the list of
# callbacks
if schedule is not None:
callbacks = [LearningRateScheduler(schedule)]
第 33 行直接从命令行args变量设置我们要训练的epochs的数量。从那里我们将初始化我们的callbacks列表和学习率schedule ( 第 34 和 35 行)。
第 38-50 行如果args["schedule"]包含有效值,则选择学习率schedule:
"step":初始化StepDecay。"linear":用power=1初始化PolynomialDecay,表示将利用线性学习率衰减。- 将使用带有
power=5的"poly":PolynomialDecay。
在你复制了本教程中的实验结果后,一定要重温一下第 38-50 行,并插入你自己的附加elif语句,这样你就可以自己运行一些实验了!
第 54 行和第 55 行用调度初始化LearningRateScheduler,作为callbacks列表的单个回调部分。有一种情况是不会使用学习率衰减(即,如果执行脚本时没有覆盖--schedule命令行参数)。
让我们继续加载我们的数据:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
第 60 行加载我们的 CIFAR-10 数据。数据集已经方便地分成了训练集和测试集。
我们必须执行的唯一预处理是将数据缩放到范围【0,1】(行 61 和 62 )。
第 65-67 行将标签二进制化,然后第 70 和 71 行初始化我们的labelNames(即类)。不要添加或更改labelNames列表,因为列表的顺序和长度很重要。
让我们初始化decay参数:
# initialize the decay for the optimizer
decay = 0.0
# if we are using Keras' "standard" decay, then we need to set the
# decay parameter
if args["schedule"] == "standard":
print("[INFO] using 'keras standard' learning rate decay...")
decay = 1e-1 / epochs
# otherwise, no learning rate schedule is being used
elif schedule is None:
print("[INFO] no learning rate schedule being used")
第 74 行初始化我们的学习速率decay。
如果我们使用"standard"学习率衰减时间表,那么衰减被初始化为1e-1 / epochs ( 第 78-80 行)。
完成所有的初始化后,让我们继续编译并训练我们的ResNet模型:
# initialize our optimizer and model, then compile it
opt = SGD(lr=1e-1, momentum=0.9, decay=decay)
model = ResNet.build(32, 32, 3, 10, (9, 9, 9),
(64, 64, 128, 256), reg=0.0005)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
H = model.fit(x=trainX, y=trainY, validation_data=(testX, testY),
batch_size=128, epochs=epochs, callbacks=callbacks, verbose=1)
我们的随机梯度下降(SGD)优化器使用我们的decay在第 87 行初始化。
从那里,行 88 和 89 构建我们的ResNet CNN,输入形状为 32x32x3 和 10 个类。关于 ResNet 的深入复习,一定要参考第 10 章:ResNet of 用 Python 进行计算机视觉的深度学习 。
我们的model是用"categorical_crossentropy"的loss函数编译的,因为我们的数据集有 > 2 个类。如果你使用一个不同的只有 2 个类的数据集,一定要使用loss="binary_crossentropy"。
94、95 线踢我们的训练流程。注意,我们已经提供了callbacks作为参数。每个历元完成后会调用callbacks。其中包含的LearningRateScheduler将处理我们的学习率衰减(只要callbacks不是空列表)。
最后,让我们评估我们的网络并生成图表:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=128)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# plot the training loss and accuracy
N = np.arange(0, args["epochs"])
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["train_plot"])
# if the learning rate schedule is not empty, then save the learning
# rate plot
if schedule is not None:
schedule.plot(N)
plt.savefig(args["lr_plot"])
2020-06-11 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
第 99-101 行评估我们的网络,并将分类报告打印到我们的终端。
第 104-115 行生成并保存我们的训练历史图(准确度/损失曲线)。第 119-121 行生成学习率图表,如果适用。我们将在下一节中检查这些绘图可视化。
Keras 学习率计划结果
实施了(1)学习率计划和(2)培训脚本后,让我们进行一些实验,看看哪种学习率计划在给定的情况下表现最佳:
- 初始学习率为
1e-1 - 总共
100个时期的训练
实验#1:没有学习率衰减/进度
作为基线,让我们首先在 CIFAR-10 上训练我们的 ResNet 模型,没有学习率衰减或时间表:
$ python train.py --train-plot output/train_no_schedule.png
[INFO] loading CIFAR-10 data...
[INFO] no learning rate schedule being used
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.0893 - accuracy: 0.4525 - val_loss: 1.7665 - val_accuracy: 0.5566
Epoch 2/100
391/391 [==============================] - 34s 88ms/step - loss: 1.4742 - accuracy: 0.6599 - val_loss: 1.4228 - val_accuracy: 0.6673
Epoch 3/100
391/391 [==============================] - 33s 86ms/step - loss: 1.1942 - accuracy: 0.7456 - val_loss: 1.4430 - val_accuracy: 0.6697
...
Epoch 98/100
391/391 [==============================] - 33s 86ms/step - loss: 0.5259 - accuracy: 0.9554 - val_loss: 1.0222 - val_accuracy: 0.8232
Epoch 99/100
391/391 [==============================] - 34s 86ms/step - loss: 0.5176 - accuracy: 0.9570 - val_loss: 0.9845 - val_accuracy: 0.8386
Epoch 100/100
391/391 [==============================] - 34s 86ms/step - loss: 0.5328 - accuracy: 0.9516 - val_loss: 0.9788 - val_accuracy: 0.8414
[INFO] evaluating network...
precision recall f1-score support
airplane 0.84 0.88 0.86 1000
automobile 0.92 0.94 0.93 1000
bird 0.85 0.74 0.79 1000
cat 0.67 0.77 0.72 1000
deer 0.80 0.87 0.83 1000
dog 0.89 0.64 0.74 1000
frog 0.90 0.86 0.88 1000
horse 0.76 0.95 0.84 1000
ship 0.92 0.90 0.91 1000
truck 0.94 0.85 0.90 1000
accuracy 0.84 10000
macro avg 0.85 0.84 0.84 10000
weighted avg 0.85 0.84 0.84 10000
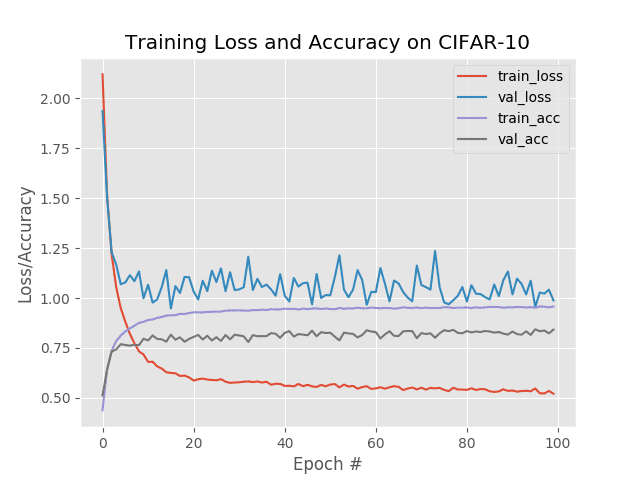
Figure 3: Our first experiment for training ResNet on CIFAR-10 does not have learning rate decay.
在这里,我们获得了 ~85%的准确度,但是正如我们所看到的,验证损失和准确度在第 15 个时期后停滞不前,并且在其余的 100 个时期内没有改善。
我们现在的目标是利用学习率计划来击败我们 85%的准确率(没有过度拟合)。
实验:#2: Keras 标准优化器学习率衰减
在我们的第二个实验中,我们将使用 Keras 的基于衰减的标准学习速率表:
$ python train.py --schedule standard --train-plot output/train_standard_schedule.png
[INFO] loading CIFAR-10 data...
[INFO] using 'keras standard' learning rate decay...
Epoch 1/100
391/391 [==============================] - 37s 95ms/step - loss: 2.0800 - accuracy: 0.4342 - val_loss: 1.8035 - val_accuracy: 0.5263
Epoch 2/100
391/391 [==============================] - 34s 87ms/step - loss: 1.5053 - accuracy: 0.6380 - val_loss: 1.4067 - val_accuracy: 0.6742
Epoch 3/100
391/391 [==============================] - 34s 86ms/step - loss: 1.2313 - accuracy: 0.7293 - val_loss: 1.3025 - val_accuracy: 0.7043
...
Epoch 98/100
391/391 [==============================] - 34s 87ms/step - loss: 0.1746 - accuracy: 1.0000 - val_loss: 0.9269 - val_accuracy: 0.8112
Epoch 99/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1741 - accuracy: 0.9999 - val_loss: 0.9301 - val_accuracy: 0.8123
Epoch 100/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1732 - accuracy: 1.0000 - val_loss: 0.9210 - val_accuracy: 0.8151
[INFO] evaluating network...
precision recall f1-score support
airplane 0.84 0.84 0.84 1000
automobile 0.89 0.92 0.91 1000
bird 0.72 0.76 0.74 1000
cat 0.67 0.65 0.66 1000
deer 0.78 0.78 0.78 1000
dog 0.75 0.73 0.74 1000
frog 0.85 0.85 0.85 1000
horse 0.87 0.83 0.85 1000
ship 0.89 0.92 0.90 1000
truck 0.88 0.88 0.88 1000
accuracy 0.82 10000
macro avg 0.81 0.82 0.81 10000
weighted avg 0.81 0.82 0.81 10000
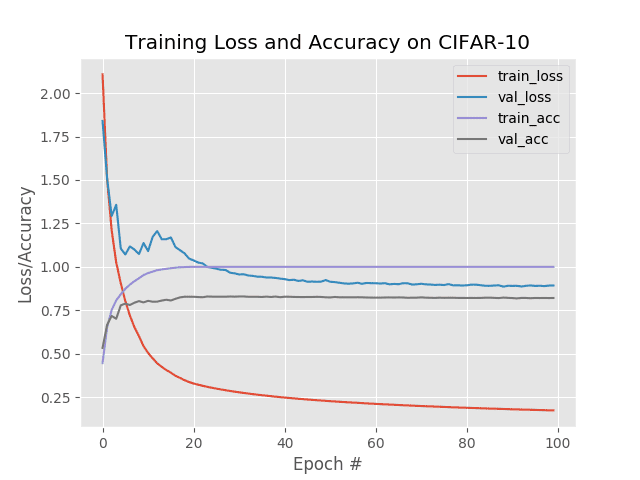
Figure 4: Our second learning rate decay schedule experiment uses Keras’ standard learning rate decay schedule.
这一次我们只获得了 81%的正确率,这表明,学习率衰减/时间安排将永远提高你的成绩,而不是 T2!你需要小心你使用的学习进度。
实验#3:基于步骤的学习率计划结果
让我们继续执行基于步骤的学习率计划,这将使我们的学习率每 15 个时期下降 0.25 倍:
$ python train.py --schedule step --lr-plot output/lr_step_schedule.png --train-plot output/train_step_schedule.png
[INFO] using 'step-based' learning rate decay...
[INFO] loading CIFAR-10 data...
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.1558 - accuracy: 0.4447 - val_loss: 1.7844 - val_accuracy: 0.5635 - lr: 0.1000
Epoch 2/100
391/391 [==============================] - 34s 86ms/step - loss: 1.5154 - accuracy: 0.6567 - val_loss: 1.5359 - val_accuracy: 0.6482 - lr: 0.1000
Epoch 3/100
391/391 [==============================] - 33s 86ms/step - loss: 1.2203 - accuracy: 0.7384 - val_loss: 1.3994 - val_accuracy: 0.6768 - lr: 0.1000
...
Epoch 98/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1821 - accuracy: 1.0000 - val_loss: 0.7240 - val_accuracy: 0.8679 - lr: 2.4414e-05
Epoch 99/100
391/391 [==============================] - 33s 85ms/step - loss: 0.1820 - accuracy: 1.0000 - val_loss: 0.7191 - val_accuracy: 0.8693 - lr: 2.4414e-05
Epoch 100/100
391/391 [==============================] - 33s 85ms/step - loss: 0.1821 - accuracy: 1.0000 - val_loss: 0.7220 - val_accuracy: 0.8680 - lr: 2.4414e-05
[INFO] evaluating network...
precision recall f1-score support
airplane 0.86 0.90 0.88 1000
automobile 0.94 0.94 0.94 1000
bird 0.83 0.80 0.81 1000
cat 0.74 0.74 0.74 1000
deer 0.84 0.84 0.84 1000
dog 0.83 0.79 0.81 1000
frog 0.88 0.91 0.89 1000
horse 0.93 0.90 0.91 1000
ship 0.91 0.94 0.92 1000
truck 0.92 0.92 0.92 1000
accuracy 0.87 10000
macro avg 0.87 0.87 0.87 10000
weighted avg 0.87 0.87 0.87 10000
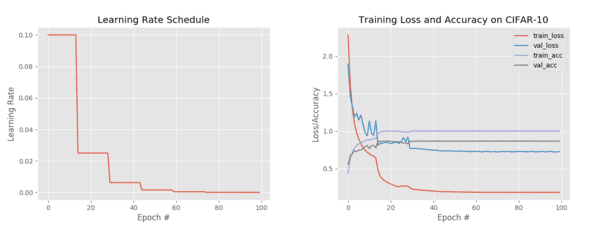
Figure 5: Experiment #3 demonstrates a step-based learning rate schedule (left). The training history accuracy/loss curves are shown on the right.
图 5 ( 左)可视化我们的学习率计划表。注意在每 15 个周期之后,我们的学习速度是如何下降的,产生了“阶梯”效应。
图 5 ( 右)展示了基于步骤的学习率计划的经典标志——您可以清楚地看到我们的:
- 培训/验证损失减少
- 培训/验证准确性提高
…当我们的学习速度下降时。
这在前两次下降(时期 15 和 30)中特别明显,之后下降变得不明显。
这种类型的急剧下降是正在使用的基于步长的学习率计划的典型标志——如果你在论文、出版物或其他教程中看到这种类型的训练行为,你几乎可以肯定他们使用了基于步长的衰减!
回到我们的精确度,我们现在达到了 87%的精确度,比我们第一次实验有所提高。
实验#4:线性学习率计划结果
让我们通过设置power=1.0来尝试使用 Keras 的线性学习率计划:
$ python train.py --schedule linear --lr-plot output/lr_linear_schedule.png --train-plot output/train_linear_schedule.png
[INFO] using 'linear' learning rate decay...
[INFO] loading CIFAR-10 data...
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.1397 - accuracy: 0.4394 - val_loss: 2.5532 - val_accuracy: 0.4208 - lr: 0.1000
Epoch 2/100
391/391 [==============================] - 34s 86ms/step - loss: 1.5470 - accuracy: 0.6350 - val_loss: 1.4195 - val_accuracy: 0.6732 - lr: 0.0990
Epoch 3/100
391/391 [==============================] - 33s 85ms/step - loss: 1.2511 - accuracy: 0.7252 - val_loss: 1.2352 - val_accuracy: 0.7238 - lr: 0.0980
...
Epoch 98/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1047 - accuracy: 1.0000 - val_loss: 0.6106 - val_accuracy: 0.8719 - lr: 0.0030
Epoch 99/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1043 - accuracy: 1.0000 - val_loss: 0.6091 - val_accuracy: 0.8718 - lr: 0.0020
Epoch 100/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1040 - accuracy: 1.0000 - val_loss: 0.6094 - val_accuracy: 0.8724 - lr: 0.0010
[INFO] evaluating network...
precision recall f1-score support
airplane 0.87 0.89 0.88 1000
automobile 0.93 0.95 0.94 1000
bird 0.83 0.81 0.82 1000
cat 0.74 0.75 0.75 1000
deer 0.88 0.84 0.86 1000
dog 0.82 0.79 0.80 1000
frog 0.90 0.93 0.91 1000
horse 0.92 0.91 0.91 1000
ship 0.93 0.94 0.93 1000
truck 0.92 0.92 0.92 1000
accuracy 0.87 10000
macro avg 0.87 0.87 0.87 10000
weighted avg 0.87 0.87 0.87 10000

Figure 6: Linear learning rate decay (left) applied to ResNet on CIFAR-10 over 100 epochs with Keras. The training accuracy/loss curve is displayed on the right.
图 6 ( 左)显示我们的学习率随着时间线性下降,而图 6 ( 右)可视化我们的培训历史。
我们现在看到训练和验证损失的急剧下降,特别是在大约 75 年以后;但是,请注意,我们的训练损失比验证损失下降得快得多——我们可能有过度拟合的风险。
无论如何,我们现在在我们的数据上获得了 87%的准确率,类似于实验 3 (基于步骤)。
实验#5:多项式学习率计划结果
作为最后一个实验,让我们通过设置power=5将多项式学习率调度应用于 Keras:
$ python train.py --schedule poly --lr-plot output/lr_poly_schedule.png --train-plot output/train_poly_schedule.png
[INFO] using 'polynomial' learning rate decay...
[INFO] loading CIFAR-10 data...
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.1474 - accuracy: 0.4376 - val_loss: 2.0406 - val_accuracy: 0.4850 - lr: 0.1000
Epoch 2/100
391/391 [==============================] - 34s 86ms/step - loss: 1.5195 - accuracy: 0.6429 - val_loss: 1.5406 - val_accuracy: 0.6380 - lr: 0.0951
Epoch 3/100
391/391 [==============================] - 34s 86ms/step - loss: 1.2210 - accuracy: 0.7337 - val_loss: 1.3527 - val_accuracy: 0.6878 - lr: 0.0904
...
Epoch 98/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1548 - accuracy: 1.0000 - val_loss: 0.6880 - val_accuracy: 0.8627 - lr: 2.4300e-09
Epoch 99/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1548 - accuracy: 1.0000 - val_loss: 0.6824 - val_accuracy: 0.8636 - lr: 3.2000e-10
Epoch 100/100
391/391 [==============================] - 33s 85ms/step - loss: 0.1549 - accuracy: 1.0000 - val_loss: 0.6883 - val_accuracy: 0.8651 - lr: 1.0000e-11
[INFO] evaluating network...
precision recall f1-score support
airplane 0.86 0.90 0.88 1000
automobile 0.93 0.94 0.93 1000
bird 0.84 0.78 0.81 1000
cat 0.75 0.72 0.73 1000
deer 0.87 0.85 0.86 1000
dog 0.78 0.82 0.80 1000
frog 0.87 0.90 0.88 1000
horse 0.91 0.89 0.90 1000
ship 0.93 0.94 0.93 1000
truck 0.91 0.92 0.91 1000
accuracy 0.87 10000
macro avg 0.86 0.87 0.86 10000
weighted avg 0.86 0.87 0.86 10000

Figure 7: Polynomial-based learning decay results using Keras.
图 7 ( 左)可视化了我们的学习率现在根据我们的多项式函数衰减的事实,而图 7 ( 右)绘制了我们的训练历史。
这一次我们获得了 86-87%的准确率。
学习率计划实验述评
我们最好的实验来自我们的第四个实验,在那里我们使用了线性学习率计划。
但是,这是否意味着我们应该总是使用线性学习率计划?
不,事实上,远非如此。
这里的关键要点是:
- 特定数据集(CIFAR-10)
- 特定神经网络架构(ResNet)
- 1e-2 的初始学习率
- 训练时期的数量(100)
线性学习率计划效果最好。
没有两个深度学习项目是相同的,因此您需要运行自己的一组实验,包括改变初始学习速率和总周期数,以确定合适的学习速率时间表(本教程的“总结”部分也包含了额外的注释)。
是否存在其他学习费率表?
还存在其他学习速率表,事实上,任何可以接受一个时期或批号作为输入并返回学习速率的数学函数都可以被认为是“学习速率表”。你可能会遇到的另外两种学习速率表包括 (1)指数学习速率衰减,以及 (2)周期学习速率。
我不经常使用指数衰减,因为我发现线性和多项式衰减已经足够了,但是如果您愿意,我们非常欢迎您创建LearningRateDecay类的子类并实现指数衰减。
另一方面,循环学习率非常强大——我们将在本系列后面的教程中讨论循环学习率。
我如何选择我的初始学习率?
你会注意到,在本教程中,我们没有改变我们的学习速率,我们将它保持在1e-2不变。
在进行您自己的实验时,您需要结合:
- 学习费率表…
- …学习速度不同
不要害怕混搭!
您想要探索的四个最重要的超参数包括:
- 初始学习率
- 训练时期的数量
- 学习率计划
- 正规化强度/数量(L2、辍学等。)
找到两者的适当平衡可能具有挑战性,但通过许多实验,您将能够找到一个导致高度精确的神经网络的配方。
如果你想了解更多关于我的学习率、学习率时间表和训练你自己的神经网络的技巧、建议和最佳实践,请参考我的书, 用 Python 进行计算机视觉的深度学习 。
摘要
在本教程中,您学习了如何利用 Keras 进行学习率衰减和学习率计划。
具体来说,您了解了如何使用 Keras 实施和利用许多学习率计划,包括:
- 大多数 Keras 优化器都内置了衰减时间表
- 基于步骤的学习率计划
- 线性学习率衰减
- 多项式学习速率表
在实现我们的学习率时间表后,我们在 CIFAR-10 数据集上的一组实验中评估了每个时间表。
我们的结果表明,对于初始学习速率1e-2,线性学习速率时间表,在100个时期内衰减,表现最好。
然而,这个并不意味着线性学习率计划将总是优于其他类型的计划。相反,这一切的意思是,对于这一点:
- 特定数据集(CIFAR-10)
- 特定神经网络架构(ResNet)
1e-2的初始学习率- 训练时期数(
100)
…线性学习率计划效果最好。
没有两个深度学习项目是相同的,因此你需要运行自己的一组实验, ,包括改变初始学习速率 ,以确定适当的学习速率计划。
我建议你保留一个实验日志,详细记录任何超参数选择和相关结果,这样你就可以参考它,并对看起来有希望的实验加倍下注。
不要期望你能够训练一个神经网络并“一劳永逸”——这很少发生。相反,你应该给自己设定一个预期,即你将进行许多实验,并在实验过程中调整超参数。机器学习、深度学习和人工智能作为一个整体是迭代的——你建立在你之前的结果之上。
在这一系列教程的后面,我还会告诉你如何选择你的初始学习速度。
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!
Keras Mask R-CNN

在本教程中,您将学习如何使用 Keras 和 Mask R-CNN 来执行实例分割(无论有无 GPU)。
使用掩码 R-CNN,我们可以同时执行这两项操作:
- 物体检测,给出图像中每个物体的 (x,y)-包围盒坐标。
- 实例分割,使我们能够为图像中的每个单独对象获得一个像素式掩模。
通过遮罩 R-CNN 进行实例分割的示例可以在本教程顶部的图像中看到——请注意,我们不仅拥有图像中对象的边界框,还拥有每个对象的像素遮罩,使我们能够分割每个单独的对象(这是对象检测本身无法提供的)。
实例分割和 Mask R-CNN 一起,推动了我们在计算机视觉中看到的“魔法”的一些最新进展,包括自动驾驶汽车、机器人等。
在本教程的剩余部分,您将学习如何将 Mask R-CNN 与 Keras 一起使用,包括如何在您自己的图像上执行实例分割。
想了解更多关于 Keras 和 Mask R-CNN 的信息,继续阅读!
Keras Mask R-CNN
在本教程的第一部分中,我们将简要回顾一下 Mask R-CNN 架构。从那里,我们将回顾我们这个项目的目录结构,然后在我们的系统上安装 Keras + Mask R-CNN。
然后我将向您展示如何使用 Python 实现 Mask R-CNN 和 Keras。
最后,我们将 Mask R-CNN 应用于我们自己的图像并检查结果。
我还将分享关于如何在您自己的自定义数据集上训练 Mask R-CNN 模型的资源。
面具 R-CNN 的历史
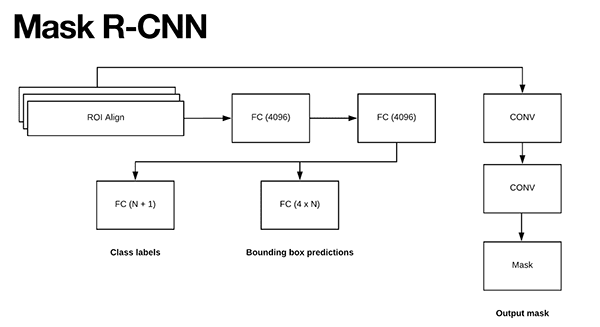
Figure 1: The Mask R-CNN architecture by He et al. enables object detection and pixel-wise instance segmentation. This blog post uses Keras to work with a Mask R-CNN model trained on the COCO dataset.
用于实例分割的掩模 R-CNN 模型已经从用于对象检测的三个在先架构中发展而来:
- R-CNN: 将输入图像呈现给网络,对图像进行选择性搜索,然后使用预训练的 CNN 将选择性搜索的输出区域用于特征提取和分类。
- Fast R-CNN: 仍然使用选择性搜索算法获取区域建议,但是增加了感兴趣区域(ROI)池模块。从特征映射中提取固定大小的窗口,并使用这些特征来获得最终的类标签和边界框。好处是网络现在是端到端可训练的。
- 更快的 R-CNN: 引入区域提议网络(RPN),将区域提议直接烘焙到架构中,减轻了对选择性搜索算法的需求。
Mask R-CNN 算法基于之前更快的 R-CNN,使网络不仅能够执行对象检测,还能够执行像素级实例分割!
我已经深入报道了 R-CNN 面具:
- “什么是面具 R-CNN?”段 用 OpenCV 屏蔽 R-CNN帖子。
- 我的书, 用 Python 进行计算机视觉的深度学习 。
请参考这些资源,了解关于该架构如何工作的更多详细信息,包括 ROI Align 模块以及它如何促进实例细分。
项目结构
继续使用今天博客文章的 【下载】 部分下载代码和预先训练好的模型。让我们检查一下我们的 Keras Mask R-CNN 项目结构:
$ tree --dirsfirst
.
├── images
│ ├── 30th_birthday.jpg
│ ├── couch.jpg
│ ├── page_az.jpg
│ └── ybor_city.jpg
├── coco_labels.txt
├── mask_rcnn_coco.h5
└── maskrcnn_predict.py
1 directory, 7 files
我们的项目包括一个测试目录和三个文件:
coco_labels.txt:由 81 个分类标签的逐行列表组成。第一个标签是“背景”类,所以通常我们说有 80 个类。mask_rcnn_coco.h5:我们的预训练掩模 R-CNN 模型权重文件,将从磁盘加载。maskrcnn_predict.py:Mask R-CNN 演示脚本加载标签和模型/权重。从那里,对通过命令行参数提供的测试图像进行推断。你可以用我们自己的图片或者 【下载】 包含的images/目录中的任何一张图片进行测试。
在我们回顾今天的脚本之前,我们将安装 Keras + Mask R-CNN,然后简单回顾一下 COCO 数据集。
安装 Keras 面罩 R-CNN
Keras + Mask R-CNN 安装过程用 pip、git 和setup.py直接引用。我建议您在今天项目的专用虚拟环境中安装这些包,这样就不会使系统的包树变得复杂。
首先,安装所需的 Python 包:
$ pip install numpy scipy
$ pip install pillow scikit-image matplotlib imutils
$ pip install "IPython[all]"
$ pip install tensorflow # or tensorflow-gpu
$ pip install keras h5py
如果您的机器上安装了 GPU、CUDA 和 cuDNN,请务必安装tensorflow-gpu。
从那里,继续安装 OpenCV,或者通过 pip 编译或者从源代码编译:
$ pip install opencv-contrib-python
接下来,我们将在 Keras 中安装掩码 R-CNN 的 Matterport 实现:
$ git clone https://github.com/matterport/Mask_RCNN.git
$ cd Mask_RCNN
$ python setup.py install
最后,在您的虚拟环境中启动一个 Python 解释器,以验证 Mask R-CNN + Keras 和 OpenCV 已经成功安装:
$ python
>>> import mrcnn
>>> import cv2
>>>
如果没有导入错误,那么您的环境现在已经为今天的博客文章做好了准备。
面具 R-CNN 和 COCO
我们今天将在这里使用的 Mask R-CNN 模型是在 COCO 数据集上预先训练的。
该数据集总共包括 80 个类(加上一个背景类),您可以从输入影像中检测和分割这些类(第一个类是背景类)。我已经在与这篇文章相关的 【下载】 中包含了名为coco_labels.txt的标签文件,但是为了方便起见,我在这里为您包含了它们:
在下一节中,我们将学习如何使用 Keras 和 Mask R-CNN 来检测和分割这些类别。
用 Keras 和 Python 实现屏蔽 R-CNN
让我们开始实现 Mask R-CNN 分段脚本。
打开maskrcnn_predict.py并插入以下代码:
# import the necessary packages
from mrcnn.config import Config
from mrcnn import model as modellib
from mrcnn import visualize
import numpy as np
import colorsys
import argparse
import imutils
import random
import cv2
import os
第 2-11 行导入我们需要的包。
mrcnn导入来自 Matterport 对 Mask R-CNN 的实现。从mrcnn开始,我们将使用Config为我们的配置创建一个自定义子类,modellib加载我们的模型,visualize绘制我们的遮罩。
让我们继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-w", "--weights", required=True,
help="path to Mask R-CNN model weights pre-trained on COCO")
ap.add_argument("-l", "--labels", required=True,
help="path to class labels file")
ap.add_argument("-i", "--image", required=True,
help="path to input image to apply Mask R-CNN to")
args = vars(ap.parse_args())
我们的脚本需要三个命令行参数:
--weights:COCO 上预训练的我们的 Mask R-CNN 模型权重之路。--labels:我们的 COCO 类标签文本文件的路径。--image:我们的输入图像路径。我们将对通过命令行提供的图像执行实例分割。
使用第二个参数,让我们继续为每个变量加载我们的CLASS_NAMES和COLORS:
# load the class label names from disk, one label per line
CLASS_NAMES = open(args["labels"]).read().strip().split("\n")
# generate random (but visually distinct) colors for each class label
# (thanks to Matterport Mask R-CNN for the method!)
hsv = [(i / len(CLASS_NAMES), 1, 1.0) for i in range(len(CLASS_NAMES))]
COLORS = list(map(lambda c: colorsys.hsv_to_rgb(*c), hsv))
random.seed(42)
random.shuffle(COLORS)
第 24 行将 COCO 类标签名称直接从文本文件加载到一个列表中。
从那里,行 28-31 为每个类标签生成随机的、不同的COLORS。方法来自 Matterport 的 Mask R-CNN 在 GitHub 上的实现。
让我们继续构建我们的SimpleConfig类:
class SimpleConfig(Config):
# give the configuration a recognizable name
NAME = "coco_inference"
# set the number of GPUs to use along with the number of images
# per GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# number of classes (we would normally add +1 for the background
# but the background class is *already* included in the class
# names)
NUM_CLASSES = len(CLASS_NAMES)
我们的SimpleConfig类继承自 Matterport 的 Mask R-CNN Config ( 第 33 行)。
配置给定一个NAME ( 行 35 )。
从那里我们设置了GPU_COUNT和IMAGES_PER_GPU(即批处理)。如果你安装了 GPU 和tensorflow-gpu,那么 Keras + Mask R-CNN 会自动使用你的 GPU。否则,将使用您的 CPU。
注:我在使用单个 Titan X GPU 的机器上执行了今天的实验,所以我设置了我的GPU_COUNT = 1。虽然我的 12GB GPU 在技术上可以一次处理多个图像(无论是在训练期间还是在预测期间,就像在这个脚本中一样),但我决定设置IMAGES_PER_GPU = 1,因为大多数读者不会有这么大内存的 GPU。如果您的 GPU 能够处理,请随意增加该值。
然后我们的NUM_CLASSES被设置为等于CLASS_NAMES列表的长度(第 45 行)。
接下来,我们将初始化我们的配置并加载我们的模型:
# initialize the inference configuration
config = SimpleConfig()
# initialize the Mask R-CNN model for inference and then load the
# weights
print("[INFO] loading Mask R-CNN model...")
model = modellib.MaskRCNN(mode="inference", config=config,
model_dir=os.getcwd())
model.load_weights(args["weights"], by_name=True)
第 48 行实例化我们的config。
然后,使用我们的config、行 53-55 加载我们在 COCO 数据集上预先训练的掩码 R-CNN model。
让我们继续执行实例分段:
# load the input image, convert it from BGR to RGB channel
# ordering, and resize the image
image = cv2.imread(args["image"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = imutils.resize(image, width=512)
# perform a forward pass of the network to obtain the results
print("[INFO] making predictions with Mask R-CNN...")
r = model.detect([image], verbose=1)[0]
第 59-61 行加载并预处理我们的image。我们的模型需要 RGB 格式的图像,所以我们使用cv2.cvtColor来交换颜色通道(相比之下,OpenCV 的默认 BGR 颜色通道排序)。
线 65 然后通过网络执行image的前向传递,以进行对象检测和像素式掩模预测。
剩下的两个代码块将处理结果,以便我们可以使用 OpenCV 可视化对象的边界框和遮罩:
# loop over of the detected object's bounding boxes and masks
for i in range(0, r["rois"].shape[0]):
# extract the class ID and mask for the current detection, then
# grab the color to visualize the mask (in BGR format)
classID = r["class_ids"][i]
mask = r["masks"][:, :, i]
color = COLORS[classID][::-1]
# visualize the pixel-wise mask of the object
image = visualize.apply_mask(image, mask, color, alpha=0.5)
为了可视化结果,我们开始循环对象检测(行 68 )。在循环内部,我们:
- 抓取唯一的
classID整数(第 71 行)。 - 提取当前检测的
mask(线 72 )。 - 确定用于
visualize屏蔽的color(线 73 )。 - 使用半透明
alpha通道在物体上应用/绘制我们预测的像素蒙版(第 76 行)。
从这里开始,我们将为图像中的每个对象绘制边界框和类标签+分数文本:
# convert the image back to BGR so we can use OpenCV's drawing
# functions
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# loop over the predicted scores and class labels
for i in range(0, len(r["scores"])):
# extract the bounding box information, class ID, label, predicted
# probability, and visualization color
(startY, startX, endY, endX) = r["rois"][i]
classID = r["class_ids"][i]
label = CLASS_NAMES[classID]
score = r["scores"][i]
color = [int(c) for c in np.array(COLORS[classID]) * 255]
# draw the bounding box, class label, and score of the object
cv2.rectangle(image, (startX, startY), (endX, endY), color, 2)
text = "{}: {:.3f}".format(label, score)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(image, text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX,
0.6, color, 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey()
第 80 行将我们的image转换回 BGR (OpenCV 的默认颜色通道排序)。
在第 83 行,我们开始遍历对象。在循环内部,我们:
- 提取包围盒坐标、
classID、label、score( 第 86-89 行)。 - 计算边界框和文本的
color(第 90 行)。 - 画出每个边界框(第 93 行)。
- 串接类别/概率
text( 第 94 行)然后画在image( 第 95-97 行)的顶部。
一旦该过程完成,产生的输出image显示在屏幕上,直到按下一个键(行 100-101 )。
屏蔽 R-CNN 和 Keras 结果
现在我们的 Mask R-CNN 脚本已经实现了,我们来试试吧。
确保您已经使用本教程的 【下载】 部分下载了源代码。
您需要了解命令行参数的概念来运行代码。如果您不熟悉,在尝试执行代码之前,请仔细阅读 argparse 和命令行参数。
准备就绪后,打开终端并执行以下命令:
$ python maskrcnn_predict.py --weights mask_rcnn_coco.h5 --labels coco_labels.txt \
--image images/30th_birthday.jpg
Using TensorFlow backend.
[INFO] loading Mask R-CNN model...
[INFO] making predictions with Mask R-CNN...
Processing 1 images
image shape: (682, 512, 3) min: 0.00000 max: 255.00000 uint8
molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 151.10000 float64
image_metas shape: (1, 93) min: 0.00000 max: 1024.00000 float64
anchors shape: (1, 261888, 4) min: -0.35390 max: 1.29134 float32

Figure 2: The Mask R-CNN model trained on COCO created a pixel-wise map of the Jurassic Park jeep (truck), my friend, and me while we celebrated my 30th birthday.
在我 30 岁生日的时候,我妻子找到了一个人,开着一辆仿《侏罗纪公园》吉普车带我们在费城转了一圈——这是我和我最好的朋友在自然科学院外面。
请注意,不仅为每个对象(即人和吉普车)生成了边界框,而且还生成了像素遮罩!
让我们试试另一个图像:
$ python maskrcnn_predict.py --weights mask_rcnn_coco.h5 --labels coco_labels.txt \
--image images/couch.jpg
Using TensorFlow backend.
[INFO] loading Mask R-CNN model...
[INFO] making predictions with Mask R-CNN...
Processing 1 images
image shape: (682, 512, 3) min: 0.00000 max: 255.00000 uint8
molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 151.10000 float64
image_metas shape: (1, 93) min: 0.00000 max: 1024.00000 float64
anchors shape: (1, 261888, 4) min: -0.35390 max: 1.29134 float32

Figure 3: My dog, Janie, has been segmented from the couch and chair using a Keras and Mask R-CNN deep learning model.
这是我的狗珍妮躺在沙发上的一张超级可爱的照片:
- 尽管沙发上的绝大部分看不见,R-CNN 的面具 T2 仍然能够给它贴上这样的标签。
- 掩模 R-CNN 能够正确地标记图像中的狗。
- 尽管我的咖啡杯几乎看不见,面具 R-CNN 也能给杯子贴上标签(如果你仔细看,你会发现我的咖啡杯是一个侏罗纪公园的杯子!)
Mask R-CNN 唯一不能正确标记的图像部分是沙发的背部,它误认为是椅子——仔细看图像,你可以看到 Mask R-CNN 是如何犯错误的(该区域看起来很像椅子,而不是沙发的一部分)。
下面是使用 Keras + Mask R-CNN 进行实例分割的另一个示例:
$ python maskrcnn_predict.py --weights mask_rcnn_coco.h5 --labels coco_labels.txt \
--image images/page_az.jpg
Using TensorFlow backend.
[INFO] loading Mask R-CNN model...
[INFO] making predictions with Mask R-CNN...
Processing 1 images
image shape: (682, 512, 3) min: 0.00000 max: 255.00000 uint8
molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 149.10000 float64
image_metas shape: (1, 93) min: 0.00000 max: 1024.00000 float64
anchors shape: (1, 261888, 4) min: -0.35390 max: 1.29134 float32

Figure 4: A Mask R-CNN segmented image (created with Keras, TensorFlow, and Matterport’s Mask R-CNN implementation). This picture is of me in Page, AZ.
几年前,我和妻子去了趟亚利桑那州的佩奇(这张照片是在马蹄弯外拍摄的)——你可以看到 R-CNN 的面具不仅探测到了我,还为我的身体构建了一个像素面具。
让我们将遮罩 R-CNN 应用于一个最终图像:
$ python maskrcnn_predict.py --weights mask_rcnn_coco.h5 --labels coco_labels.txt \
--image images/ybor_city.jpg
Using TensorFlow backend.
[INFO] loading Mask R-CNN model...
[INFO] making predictions with Mask R-CNN...
Processing 1 images
image shape: (688, 512, 3) min: 5.00000 max: 255.00000 uint8
molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 151.10000 float64
image_metas shape: (1, 93) min: 0.00000 max: 1024.00000 float64
anchors shape: (1, 261888, 4) min: -0.35390 max: 1.29134 float32

Figure 5: Keras + Mask R-CNN with Python of a picture from Ybor City.
在美国,我最喜欢参观的城市之一是 Ybor 市——这正是我喜欢这个地区的地方(也许是因为公鸡在这个城市受到保护,可以自由漫步)。
在这里你可以看到我和这样一只公鸡——注意我们每个人是如何被面具 R-CNN 正确标记和分割的。您还会注意到,Mask R-CNN 模型能够定位每辆单独的汽车和标记公共汽车!
Mask R-CNN 可以实时运行吗?
此时你可能想知道是否有可能实时运行 Keras + Mask R-CNN,对吗?
正如你从“面具 R-CNN 的历史?”上一节,Mask R-CNN 基于更快的 R-CNN 物体探测器。
更快的 R-CNN 是难以置信的计算开销,并且当你在对象检测之上添加实例分割时,模型只会变得计算开销更大,因此:
- 在 CPU 上,一个 Mask R-CNN 无法实时运行。
- 但是在 GPU 上, Mask R-CNN 最高可以达到 5-8 FPS。
如果你想半实时地运行 Mask R-CNN,你需要一个图形处理器。
摘要
在本教程中,您学习了如何使用 Keras + Mask R-CNN 来执行实例分割。
与对象检测不同,它只为您提供图像中对象的边界框 (x,y)-坐标,实例分割则更进一步, 为每个对象生成逐像素的遮罩 。
使用实例分割,我们实际上可以从图像中分割一个对象。
为了执行实例分割,我们使用了 Matterport Keras + Mask R-CNN 实现。
然后,我们创建了一个 Python 脚本:
- 为 Mask R-CNN 构造了一个配置类(有无 GPU 均可)。
- 已从磁盘加载 Keras + Mask R-CNN 架构
- 预处理我们的输入图像
- 图像中检测到的对象/遮罩
- 将结果可视化
如果您对如何进行感兴趣:
- 标注和注释您自己的自定义图像数据集
- 然后在你的标注数据集之上训练一个 Mask R-CNN 模型…
…然后你会想看看我的书, 用 Python 进行计算机视觉的深度学习 ,我在那里详细地掩盖了 R-CNN 和注释。
我希望你喜欢今天的帖子!
下载源代码(包括预先训练好的 Keras + Mask R- CNN 模型),只需在下面的表格中输入你的邮箱地址!当未来的教程在 PyImageSearch 上发布时,我会通知你的。
Keras:多重输入和混合数据
原文:https://pyimagesearch.com/2019/02/04/keras-multiple-inputs-and-mixed-data/
最后更新于 2021 年 7 月 8 日。
在本教程中,您将学习如何使用 Keras 处理多输入和混合数据。
您将学习如何定义一个能够接受多种输入的 Keras 架构,包括数字、分类和图像数据。然后,我们将在这种混合数据上训练单个端到端网络。
今天是我们关于 Keras 和回归的三部分系列的最后一部分:
- 带 Keras 的基本回归
- 为回归预测训练一个 Keras CNN
- Keras 的多输入和混合数据(今日邮报)
在这一系列的文章中,我们在房价预测的背景下探索了回归预测。
我们使用的房价数据集不仅包括 数字和分类数据,还包括 图像数据 —我们称多种类型的数据为 混合数据 ,因为我们的模型需要能够接受我们的多种输入(不属于同一类型)并对这些输入进行预测。
**在本教程的剩余部分,您将学习如何:
- 定义一个 Keras 模型,能够同时接受多个输入,包括数字、分类和图像数据。
- 在混合数据输入上训练端到端 Keras 模型。
- 使用多输入评估我们的模型。
要了解有关 Keras 的多输入和混合数据的更多信息,请继续阅读!
- 【2021 年 7 月更新:添加了与一次性编码分类数据相关的问题以及学习嵌入如何帮助解决该问题的章节,尤其是在多输入网络场景中工作时的。
Keras:多重输入和混合数据
2020-06-12 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将简要回顾一下混合数据和 T2 的概念,Keras 如何接受多个输入。
从那里,我们将审查我们的房价数据集和这个项目的目录结构。
接下来,我将向您展示如何:
- 从磁盘加载数值、分类和图像数据。
- 对数据进行预处理,这样我们就可以在此基础上训练一个网络。
- 准备混合数据,以便将其应用于多输入 Keras 网络。
一旦我们的数据准备好了,您将学习如何定义和训练一个多输入 Keras 模型,该模型在一个单一的端到端网络中接受多种类型的输入数据。
最后,我们将在我们的测试集上评估我们的多输入和混合数据模型,并将结果与我们在本系列中以前的文章进行比较。
什么是混合数据?
在机器学习中,混合数据是指具有多种类型的独立数据的概念。
例如,让我们假设我们是在一家医院工作的机器学习工程师,开发一个能够对病人的健康状况进行分类的系统。
对于给定的患者,我们会有多种类型的输入数据,包括:
- 数值/连续值,如年龄、心率、血压
- 分类值,包括性别和种族
- 图像数据,如任何核磁共振、x 光等。
所有这些值构成不同的数据类型;然而,我们的机器学习模型必须能够摄取这种“混合数据”,并对其进行(准确的)预测。
当处理多种数据形式时,您会在机器学习文献中看到术语“混合数据”。
开发能够处理混合数据的机器学习系统极具挑战性,因为每种数据类型可能需要单独的预处理步骤,包括缩放、归一化和特征工程。
处理混合数据仍然是一个非常开放的研究领域,并且通常在很大程度上依赖于特定的任务/最终目标。
在今天的教程中,我们将使用混合数据来帮助您了解与之相关的一些挑战。
Keras 如何接受多个输入?
Keras 能够通过其功能 API 处理多个输入(甚至多个输出)。
了解更多关于 使用 TensorFlow 2.0 创建 Keras 模型的 3 种方法(顺序、函数和模型子类化) 。
与顺序 API(您几乎肯定已经通过Sequential类使用过)相反,函数 API 可用于定义更复杂的非顺序模型,包括:
- 多输入模型
- 多输出模型
- 多输入多输出的模型
- 有向无环图
- 具有共享层的模型
例如,我们可以将简单的序列神经网络定义为:
model = Sequential()
model.add(Dense(8, input_shape=(10,), activation="relu"))
model.add(Dense(4, activation="relu"))
model.add(Dense(1, activation="linear"))
该网络是一个简单的前馈神经网络,有 10 个输入,第一个隐层有 8 个节点,第二个隐层有 4 个节点,最后一个输出层用于回归。
我们可以使用函数 API 定义样本神经网络:
inputs = Input(shape=(10,))
x = Dense(8, activation="relu")(inputs)
x = Dense(4, activation="relu")(x)
x = Dense(1, activation="linear")(x)
model = Model(inputs, x)
注意我们不再依赖于Sequential类。
要了解 Keras 函数 API 的强大功能,请考虑下面的代码,我们在其中创建了一个接受多个输入的模型:
# define two sets of inputs
inputA = Input(shape=(32,))
inputB = Input(shape=(128,))
# the first branch operates on the first input
x = Dense(8, activation="relu")(inputA)
x = Dense(4, activation="relu")(x)
x = Model(inputs=inputA, outputs=x)
# the second branch opreates on the second input
y = Dense(64, activation="relu")(inputB)
y = Dense(32, activation="relu")(y)
y = Dense(4, activation="relu")(y)
y = Model(inputs=inputB, outputs=y)
# combine the output of the two branches
combined = concatenate([x.output, y.output])
# apply a FC layer and then a regression prediction on the
# combined outputs
z = Dense(2, activation="relu")(combined)
z = Dense(1, activation="linear")(z)
# our model will accept the inputs of the two branches and
# then output a single value
model = Model(inputs=[x.input, y.input], outputs=z)
在这里,您可以看到我们为 Keras 神经网络定义了两个输入:
inputA: 32-diminputB: 128-dim
第 21-23 行使用 Keras 的功能 API 定义了一个简单的32-8-4网络。
类似地,行 26-29 定义了一个128-64-32-4网络。
然后将x和y的输出在线 32 上组合。x和y的输出都是四维的,所以一旦我们把它们连接起来,我们就有了一个 8 维的向量。
然后我们在第 36 行和第 37 行应用两个完全连接的层。第一层有 2 个节点,随后是 ReLU 激活,而第二层只有一个线性激活的节点(即我们的回归预测)。
构建多输入模型的最后一步是定义一个Model对象,它:
- 接受我们的两个
inputs - 将
outputs定义为最后一组 FC 层(即z)。
如果您要使用 Keras 来可视化模型架构,它将如下所示:
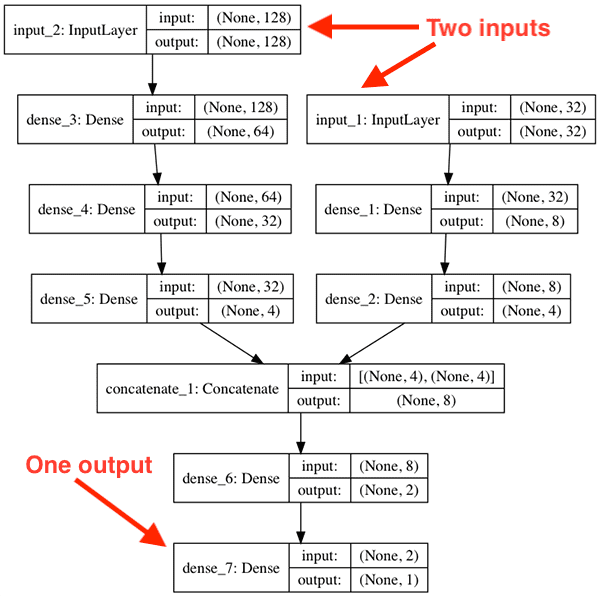
Figure 3: This model has two input branches that ultimately merge and produce one output. The Keras functional API allows for this type of architecture and others you can dream up.
注意我们的模型有两个不同的分支。
第一个分支接受我们的 128-d 输入,而第二个分支接受 32-d 输入。这些分支相互独立运行,直到它们被连接在一起。从那里,从网络输出单个值。
在本教程的剩余部分,您将学习如何使用 Keras 创建多个输入网络。
房价数据集

Figure 4: The House Prices dataset consists of both numerical/categorical data and image data. Using Keras, we’ll build a model supporting the multiple inputs and mixed data types. The result will be a Keras regression model which predicts the price/value of houses.
在这一系列帖子中,我们一直使用 Ahmed 和 Moustafa 2016 年论文中的房价数据集, 从视觉和文本特征进行房价估计 。
该数据集包括数据集中 535 个示例房屋中每个房屋的数字/分类数据以及图像数据。
数字和分类属性包括:
- 卧室数量
- 浴室数量
- 面积(即平方英尺)
- 邮政区码
也为每个房屋提供总共四幅图像:
- 卧室
- 浴室
- 厨房
- 房子的正面图
在本系列的第一篇文章中,您了解了如何在数字和分类数据上训练一个 Keras 回归网络。
然后,上周,你学习了如何用 Keras CNN 进行回归。
今天,我们将使用 Keras 处理多个输入和混合数据。
我们将接受数字/分类数据以及我们的图像数据到网络。
将定义网络的两个分支来处理每种类型的数据。这些分支将在最后合并,以获得我们最终的房价预测。
通过这种方式,我们将能够利用 Keras 来处理多个输入和混合数据。
获取房价数据集
要获取今天这篇文章的源代码,请使用 “下载” 部分。获得 zip 文件后,导航到下载该文件的位置,并将其解压缩:
$ cd path/to/zip
$ unzip keras-multi-input.zip
$ cd keras-multi-input
在那里,您可以通过以下方式下载房价数据集:
$ git clone https://github.com/emanhamed/Houses-dataset
房价数据集现在应该在keras-multi-input目录中,这是我们在这个项目中使用的目录。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
让我们看看今天的项目是如何组织的:
$ tree --dirsfirst --filelimit 10
.
├── Houses-dataset
│ ├── Houses\ Dataset [2141 entries]
│ └── README.md
├── pyimagesearch
│ ├── __init__.py
│ ├── datasets.py
│ └── models.py
└── mixed_training.py
3 directories, 5 files
Houses-dataset 文件夹包含我们在本系列中使用的房价数据集。当我们准备好运行mixed_training.py脚本时,您只需要提供一个路径作为数据集的命令行参数(我将在结果部分向您展示这是如何完成的)。
今天我们将回顾三个 Python 脚本:
pyimagesearch/datasets.py:处理数字/分类数据以及图像数据的加载和预处理。过去两周我们已经回顾了这个脚本,但今天我将再次向您演示。pyimagesearch/models.py:包含我们的多层感知器(MLP)和卷积神经网络(CNN)。这些组件是我们的多输入混合数据模型的输入分支。上周我们回顾了这个脚本,今天我们也将简要回顾一下。mixed_training.py:我们的训练脚本将使用pyimagesearch模块便利函数来加载+分割数据,并将两个分支连接到我们的网络+添加头。然后,它将训练和评估模型。
加载数值和分类数据
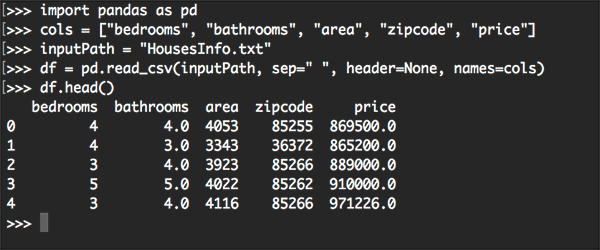
Figure 5: We use pandas, a Python package, to read CSV housing data.
我们在我们的 Keras regression post 中讨论了如何加载房价数据集的数值和分类数据,但是为了完整起见,我们今天将在这里回顾一下代码(不太详细)。
如果你想要代码的详细浏览,请务必参考之前的帖子。
打开datasets.py文件并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
import glob
import cv2
import os
def load_house_attributes(inputPath):
# initialize the list of column names in the CSV file and then
# load it using Pandas
cols = ["bedrooms", "bathrooms", "area", "zipcode", "price"]
df = pd.read_csv(inputPath, sep=" ", header=None, names=cols)
# determine (1) the unique zip codes and (2) the number of data
# points with each zip code
zipcodes = df["zipcode"].value_counts().keys().tolist()
counts = df["zipcode"].value_counts().tolist()
# loop over each of the unique zip codes and their corresponding
# count
for (zipcode, count) in zip(zipcodes, counts):
# the zip code counts for our housing dataset is *extremely*
# unbalanced (some only having 1 or 2 houses per zip code)
# so let's sanitize our data by removing any houses with less
# than 25 houses per zip code
if count < 25:
idxs = df[df["zipcode"] == zipcode].index
df.drop(idxs, inplace=True)
# return the data frame
return df
我们的进口在第 2-8 条线处理。
从那里我们在的第 10-33 行定义load_house_attributes函数。该函数通过第 13 行和第 14 行上的熊猫pd.read_csv以 CSV 文件的形式从房价数据集中读取数值/分类数据。
数据被过滤以适应不平衡。有些邮政编码仅由 1 或 2 个房屋代表,因此我们只需继续搜索邮政编码中房屋数量少于25的记录drop ( 第 23-30 行)。结果是以后会有一个更精确的模型。
现在让我们定义process_house_attributes函数:
def process_house_attributes(df, train, test):
# initialize the column names of the continuous data
continuous = ["bedrooms", "bathrooms", "area"]
# performin min-max scaling each continuous feature column to
# the range [0, 1]
cs = MinMaxScaler()
trainContinuous = cs.fit_transform(train[continuous])
testContinuous = cs.transform(test[continuous])
# one-hot encode the zip code categorical data (by definition of
# one-hot encoding, all output features are now in the range [0, 1])
zipBinarizer = LabelBinarizer().fit(df["zipcode"])
trainCategorical = zipBinarizer.transform(train["zipcode"])
testCategorical = zipBinarizer.transform(test["zipcode"])
# construct our training and testing data points by concatenating
# the categorical features with the continuous features
trainX = np.hstack([trainCategorical, trainContinuous])
testX = np.hstack([testCategorical, testContinuous])
# return the concatenated training and testing data
return (trainX, testX)
该功能通过 scikit-learn 的MinMaxScaler ( 第 41-43 行)将最小-最大缩放应用于连续特征。
然后,计算分类特征的一键编码,这次是通过 scikit-learn 的LabelBinarizer ( 第 47-49 行)。
然后连续和分类特征被连接并返回(第 53-57 行)。
请务必参考本系列中以前的文章,以了解我们在本节中讨论的两个函数的更多详细信息:
加载影像数据集

Figure 6: One branch of our model accepts a single image — a montage of four images from the home. Using the montage combined with the numerical/categorial data input to another branch, our model then uses regression to predict the value of the home with the Keras framework.
下一步是定义一个助手函数来加载我们的输入图像。再次打开datasets.py文件并插入以下代码:
def load_house_images(df, inputPath):
# initialize our images array (i.e., the house images themselves)
images = []
# loop over the indexes of the houses
for i in df.index.values:
# find the four images for the house and sort the file paths,
# ensuring the four are always in the *same order*
basePath = os.path.sep.join([inputPath, "{}_*".format(i + 1)])
housePaths = sorted(list(glob.glob(basePath)))
load_house_images功能有三个目标:
- 加载房价数据集中的所有照片。回想一下,我们每栋房子有四张照片(图 6 )。
- 从四张照片中生成一张单幅蒙太奇图像。蒙太奇将始终按照您在图中看到的方式排列。
- 将所有这些主蒙太奇添加到一个列表/数组中,并返回到调用函数。
从第 59 行的开始,我们定义了接受熊猫数据帧和数据集inputPath的函数。
从那里,我们继续:
- 初始化
images列表(行 61 )。我们将用我们创建的所有蒙太奇图像填充这个列表。 - 在我们的数据框中循环遍历房屋(行 64 )。在循环内部,我们:
- 获取当前房屋的四张照片的路径(行 67 和 68 )。
让我们在循环中不断进步:
# initialize our list of input images along with the output image
# after *combining* the four input images
inputImages = []
outputImage = np.zeros((64, 64, 3), dtype="uint8")
# loop over the input house paths
for housePath in housePaths:
# load the input image, resize it to be 32 32, and then
# update the list of input images
image = cv2.imread(housePath)
image = cv2.resize(image, (32, 32))
inputImages.append(image)
# tile the four input images in the output image such the first
# image goes in the top-right corner, the second image in the
# top-left corner, the third image in the bottom-right corner,
# and the final image in the bottom-left corner
outputImage[0:32, 0:32] = inputImages[0]
outputImage[0:32, 32:64] = inputImages[1]
outputImage[32:64, 32:64] = inputImages[2]
outputImage[32:64, 0:32] = inputImages[3]
# add the tiled image to our set of images the network will be
# trained on
images.append(outputImage)
# return our set of images
return np.array(images)
到目前为止,代码已经完成了上面讨论的第一个目标(为每个房子获取四个房子图像)。让我们总结一下load_house_images函数:
- 仍然在循环中,我们:
- 执行初始化(第 72 行和第 73 行)。我们的
inputImages将以列表形式包含每条记录的四张照片。我们的outputImage将是照片的蒙太奇(像图 6 )。 - 循环 4 张照片(第 76 行):
- 将每张照片加载、调整大小并附加到
inputImages( 第 79-81 行)。
- 将每张照片加载、调整大小并附加到
- 用以下方法为四个房屋图像(行 87-90 )创建拼贴(蒙太奇):
- 左上角的中的浴室图像。
- 右上角中的卧室图像。
- 右下中的正视图。
- 厨房在左下方。
- 将拼贴/蒙太奇
outputImage追加到images( 第 94 行)。
- 执行初始化(第 72 行和第 73 行)。我们的
- 跳出循环,我们将所有的
images以一个 NumPy 数组的形式return(行 97 )。
我们将拥有和我们训练的记录一样多的images(记住,我们在process_house_attributes函数中删除了一些记录)。
我们平铺的每个images将看起来像图 6 (当然没有覆盖的文本)。您可以看到其中的四张照片被安排在一个蒙太奇中(我使用了更大的图像尺寸,这样我们可以更好地可视化代码在做什么)。正如我们的数字和分类属性代表房子一样,这四张照片(平铺成一张图像)将代表房子的视觉美学。
如果您需要更详细地回顾这个过程,请务必参考上周的帖子。
定义我们的多层感知器(MLP)和卷积神经网络(CNN)

Figure 7: Our Keras multi-input + mixed data model has one branch that accepts the numerical/categorical data (left) and another branch that accepts image data in the form a 4-photo montage (right).
正如您到目前为止所收集的,我们不得不使用多个库仔细地处理我们的数据:Pandas、scikit-learn、OpenCV 和 NumPy。
此时,我们已经通过datasets.py组织并预处理了数据集的两种形态:
- 数字和分类数据
- 图像数据
我们用来实现这一点的技能是通过经验+实践、机器学习最佳实践以及这篇博文背后的一点点调试开发出来的。请不要忽视我们到目前为止使用数据按摩技巧所讨论的内容,因为这是我们项目成功的关键。
让我们换个话题,讨论我们将使用 Keras 的 functional API 构建的多输入和混合数据网络。
为了建立我们的多输入网络,我们需要两个分支:
- 第一个分支将是一个简单的多层感知器(MLP) ,用于处理分类/数字输入。
- 第二个分支将是一个卷积神经网络,对图像数据进行操作。
- 这些分支然后将连接在一起,形成最终的多输入 Keras 模型。
我们将在下一节中处理最终级联多输入模型的构建,我们当前的任务是定义这两个分支。
打开models.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
def create_mlp(dim, regress=False):
# define our MLP network
model = Sequential()
model.add(Dense(8, input_dim=dim, activation="relu"))
model.add(Dense(4, activation="relu"))
# check to see if the regression node should be added
if regress:
model.add(Dense(1, activation="linear"))
# return our model
return model
2-11 线处理我们的 Keras 进口。您将在这个脚本中看到每个导入的函数/类。
我们的分类/数字数据将由一个简单的多层感知器(MLP)处理。
MLP 由第 13-24 行上的create_mlp定义。
在本系列的第一篇文章中详细讨论过,MLP 依赖于 Keras Sequential API。我们的 MLP 非常简单:
- 带有 ReLU
activation( 线 16 )的全连接(Dense)输入层。 - 一个全连通的隐藏层,也有 ReLU
activation( Line 17 )。 - 最后,一个具有线性激活的可选回归输出(行 20 和 21 )。
虽然我们在第一篇文章中使用了 MLP 的回归输出,但它不会在这个多输入、混合数据网络中使用。您很快就会看到,我们将显式地设置regress=False,尽管它也是默认设置。回归实际上稍后将在整个多输入、混合数据网络(图 7的底部)的头部执行。
MLP 支路 在线路 24 返回。
回头参考图 7 ,我们现在已经建立了网络的左上角分支。
现在让我们定义一下我们网络的右上角的分支,CNN:
def create_cnn(width, height, depth, filters=(16, 32, 64), regress=False):
# initialize the input shape and channel dimension, assuming
# TensorFlow/channels-last ordering
inputShape = (height, width, depth)
chanDim = -1
# define the model input
inputs = Input(shape=inputShape)
# loop over the number of filters
for (i, f) in enumerate(filters):
# if this is the first CONV layer then set the input
# appropriately
if i == 0:
x = inputs
# CONV => RELU => BN => POOL
x = Conv2D(f, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
create_cnn函数处理图像数据并接受五个参数:
width:输入图像的宽度,单位为像素。height:输入图像有多少像素高。depth:我们输入图像的通道数。对于 RGB 彩色图像,它是三。- 一组逐渐变大的过滤器,这样我们的网络可以学习更多有区别的特征。
regress:一个布尔值,表示是否将一个全连接的线性激活层附加到 CNN 用于回归目的。
我们网络的inputShape定义在线 29 上。它假设 TensorFlow 后端的“最后频道”排序。
通过线 33 上的inputShape定义模型的Input。
从那里,我们开始循环过滤器,并创建一组CONV => RELU > BN => POOL 层。循环的每次迭代都会附加这些层。如果你不熟悉这些图层类型的更多信息,请务必查看第 11 章的入门包的 的【使用 Python 进行计算机视觉的深度学习】 。
让我们完成我们网络的 CNN 分支:
# flatten the volume, then FC => RELU => BN => DROPOUT
x = Flatten()(x)
x = Dense(16)(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Dropout(0.5)(x)
# apply another FC layer, this one to match the number of nodes
# coming out of the MLP
x = Dense(4)(x)
x = Activation("relu")(x)
# check to see if the regression node should be added
if regress:
x = Dense(1, activation="linear")(x)
# construct the CNN
model = Model(inputs, x)
# return the CNN
return model
我们Flatten下一层(第 49 行),然后添加一个带有BatchNormalization和Dropout ( 第 50-53 行)的全连接层。
应用另一个全连接层来匹配来自多层感知器的四个节点(行 57 和 58 )。匹配节点的数量不是必需的,但它有助于平衡分支。
在行 61 和 62 上,进行检查以查看是否应该附加回归节点;然后相应地添加它。同样,我们也不会在这个分支的末尾进行回归。回归将在多输入、混合数据网络的头部进行(图 7的最底部)。
最后,这个模型是由我们的inputs和我们组装在一起的所有图层x ( 第 65 行)构建而成的。
然后我们可以returnCNN分支 来调用函数( Line 68 )。
现在我们已经定义了多输入 Keras 模型的两个分支,让我们学习如何将它们结合起来!
*### 使用 Keras 的多输入
现在,我们已经准备好构建最终的 Keras 模型,它能够处理多个输入和混合数据。这是 分支聚集的地方,也是“魔法”最终发生的地方。训练也将发生在这个脚本中。
创建一个名为mixed_training.py的新文件,打开它,并插入以下代码:
# import the necessary packages
from pyimagesearch import datasets
from pyimagesearch import models
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import concatenate
import numpy as np
import argparse
import locale
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input dataset of house images")
args = vars(ap.parse_args())
首先处理我们的导入和命令行参数。
值得注意的进口包括:
datasets:我们的三个便利功能,用于加载/处理 CSV 数据和加载/预处理来自房屋数据集中的房屋照片。- 我们的 MLP 和 CNN 输入分支,将作为我们的多输入、混合数据。
- 一个 scikit-learn 函数来构造我们的训练/测试数据分割。
concatenate:一个特殊的 Keras 函数,它将接受多个输入。argparse:处理解析命令行参数。
在第 15-18 行、--dataset中,我们有一个命令行参数需要解析,这是下载房价数据集的路径。
让我们加载数值/分类数据和图像数据:
# construct the path to the input .txt file that contains information
# on each house in the dataset and then load the dataset
print("[INFO] loading house attributes...")
inputPath = os.path.sep.join([args["dataset"], "HousesInfo.txt"])
df = datasets.load_house_attributes(inputPath)
# load the house images and then scale the pixel intensities to the
# range [0, 1]
print("[INFO] loading house images...")
images = datasets.load_house_images(df, args["dataset"])
images = images / 255.0
在这里,我们将房价数据集加载为熊猫数据帧(第 23 行和第 24 行)。
然后我们已经加载了我们的images,并将它们缩放到范围【0,1】(第 29-30 行)。
如果您需要了解这些功能的作用,请务必查看上面的load_house_attributes和load_house_images功能。
既然我们的数据已经加载,我们将构建我们的培训/测试分割,调整价格,并处理房屋属性:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
print("[INFO] processing data...")
split = train_test_split(df, images, test_size=0.25, random_state=42)
(trainAttrX, testAttrX, trainImagesX, testImagesX) = split
# find the largest house price in the training set and use it to
# scale our house prices to the range [0, 1] (will lead to better
# training and convergence)
maxPrice = trainAttrX["price"].max()
trainY = trainAttrX["price"] / maxPrice
testY = testAttrX["price"] / maxPrice
# process the house attributes data by performing min-max scaling
# on continuous features, one-hot encoding on categorical features,
# and then finally concatenating them together
(trainAttrX, testAttrX) = datasets.process_house_attributes(df,
trainAttrX, testAttrX)
我们的培训和测试分割是在第 35 行和第 36 行上构建的。我们将 75%的数据用于训练,25%的数据用于测试。
从那里,我们从训练集中找到maxPrice(行 41 ,并相应地缩放训练和测试数据(行 42 和 43 )。使定价数据在范围【0,1】内会导致更好的训练和收敛。
最后,我们继续通过对连续特征执行最小-最大缩放和对分类特征执行一键编码来处理我们的房屋属性。process_house_attributes函数处理这些动作,并将连续和分类特征连接在一起,返回结果(第 48 和 49 行)。
准备好变魔术了吗?
好吧,我撒谎了。在下一个代码块中实际上没有任何“魔法”在进行!但是我们将concatenate我们网络的分支并完成我们的多输入 Keras 网络:
# create the MLP and CNN models
mlp = models.create_mlp(trainAttrX.shape[1], regress=False)
cnn = models.create_cnn(64, 64, 3, regress=False)
# create the input to our final set of layers as the *output* of both
# the MLP and CNN
combinedInput = concatenate([mlp.output, cnn.output])
# our final FC layer head will have two dense layers, the final one
# being our regression head
x = Dense(4, activation="relu")(combinedInput)
x = Dense(1, activation="linear")(x)
# our final model will accept categorical/numerical data on the MLP
# input and images on the CNN input, outputting a single value (the
# predicted price of the house)
model = Model(inputs=[mlp.input, cnn.input], outputs=x)
当您已经组织好代码和模型时,用 Keras 处理多个输入是非常容易的。
在第 52 和 53 行,我们创建了我们的mlp和cnn模型。请注意regress=False——我们的回归头稍后出现在行 62 。
然后我们将concatenate如行 57 所示的mlp.output和cnn.output。我称之为我们的combinedInput,因为它是网络其余部分的输入(来自图 3 这是两个分支汇合的concatenate_1)。
网络中最终层的combinedInput基于 MLP 和 CNN 分支的8-4-1 FC 层的输出(因为 2 个分支中的每一个都输出 4 维 FC 层,然后我们将它们连接起来以创建 8 维向量)。
我们在combinedInput ( 线 61 )上加上一个有四个神经元的全连接层。
然后我们加上我们的"linear" activation 回归头(第 62 行), ,其输出就是预测价格。
我们的Model是用两个分支的inputs作为我们的多输入,最后一组层x作为output ( 行 67 )。
让我们继续编译、训练和评估我们新成立的model:
# compile the model using mean absolute percentage error as our loss,
# implying that we seek to minimize the absolute percentage difference
# between our price *predictions* and the *actual prices*
opt = Adam(lr=1e-3, decay=1e-3 / 200)
model.compile(loss="mean_absolute_percentage_error", optimizer=opt)
# train the model
print("[INFO] training model...")
model.fit(
x=[trainAttrX, trainImagesX], y=trainY,
validation_data=([testAttrX, testImagesX], testY),
epochs=200, batch_size=8)
# make predictions on the testing data
print("[INFO] predicting house prices...")
preds = model.predict([testAttrX, testImagesX])
我们的model是用"mean_absolute_percentage_error" loss和一个Adam带学习率decay ( 第 72 行和第 73 行)的优化器编译的。
培训在线 77-80 开始。这就是所谓的拟合模型(也是所有权重通过反向传播过程进行调整的地方)。
在我们的测试数据上调用model.predict(第 84 行)允许我们获取评估我们模型的预测。现在让我们进行评估:
# compute the difference between the *predicted* house prices and the
# *actual* house prices, then compute the percentage difference and
# the absolute percentage difference
diff = preds.flatten() - testY
percentDiff = (diff / testY) * 100
absPercentDiff = np.abs(percentDiff)
# compute the mean and standard deviation of the absolute percentage
# difference
mean = np.mean(absPercentDiff)
std = np.std(absPercentDiff)
# finally, show some statistics on our model
locale.setlocale(locale.LC_ALL, "en_US.UTF-8")
print("[INFO] avg. house price: {}, std house price: {}".format(
locale.currency(df["price"].mean(), grouping=True),
locale.currency(df["price"].std(), grouping=True)))
print("[INFO] mean: {:.2f}%, std: {:.2f}%".format(mean, std))
为了评估我们的模型,我们计算了绝对百分比差异(第 89-91 行),并使用它来导出我们的最终指标(第 95 和 96 行)。
这些指标(价格平均值、价格标准偏差和绝对百分比差异的平均值+标准偏差)以适当的货币地区格式打印到终端(行 100-103 )。
多输入和混合数据结果

Figure 8: Real estate price prediction is a difficult task, but our Keras multi-input + mixed input regression model yields relatively good results on our limited House Prices dataset.
最后,我们准备在混合数据上训练我们的多输入网络!
确保你有:
- 根据本系列的第一篇教程配置您的开发环境。
- 使用本教程的 【下载】 部分下载源代码。
- 使用上述“获取房价数据集”一节中的说明下载房价数据集。
从那里,打开一个终端并执行以下命令开始训练网络:
$ python mixed_training.py --dataset Houses-dataset/Houses\ Dataset/
[INFO] loading house attributes...
[INFO] loading house images...
[INFO] processing data...
[INFO] training model...
Epoch 1/200
34/34 [==============================] - 0s 10ms/step - loss: 972.0082 - val_loss: 137.5819
Epoch 2/200
34/34 [==============================] - 0s 4ms/step - loss: 708.1639 - val_loss: 873.5765
Epoch 3/200
34/34 [==============================] - 0s 5ms/step - loss: 551.8876 - val_loss: 1078.9347
Epoch 4/200
34/34 [==============================] - 0s 3ms/step - loss: 347.1892 - val_loss: 888.7679
Epoch 5/200
34/34 [==============================] - 0s 4ms/step - loss: 258.7427 - val_loss: 986.9370
Epoch 6/200
34/34 [==============================] - 0s 3ms/step - loss: 217.5041 - val_loss: 665.0192
Epoch 7/200
34/34 [==============================] - 0s 3ms/step - loss: 175.1175 - val_loss: 435.5834
Epoch 8/200
34/34 [==============================] - 0s 5ms/step - loss: 156.7351 - val_loss: 465.2547
Epoch 9/200
34/34 [==============================] - 0s 4ms/step - loss: 133.5550 - val_loss: 718.9653
Epoch 10/200
34/34 [==============================] - 0s 3ms/step - loss: 115.4481 - val_loss: 880.0882
...
Epoch 191/200
34/34 [==============================] - 0s 4ms/step - loss: 23.4761 - val_loss: 23.4792
Epoch 192/200
34/34 [==============================] - 0s 5ms/step - loss: 21.5748 - val_loss: 22.8284
Epoch 193/200
34/34 [==============================] - 0s 3ms/step - loss: 21.7873 - val_loss: 23.2362
Epoch 194/200
34/34 [==============================] - 0s 6ms/step - loss: 22.2006 - val_loss: 24.4601
Epoch 195/200
34/34 [==============================] - 0s 3ms/step - loss: 22.1863 - val_loss: 23.8873
Epoch 196/200
34/34 [==============================] - 0s 4ms/step - loss: 23.6857 - val_loss: 1149.7415
Epoch 197/200
34/34 [==============================] - 0s 4ms/step - loss: 23.0267 - val_loss: 86.4044
Epoch 198/200
34/34 [==============================] - 0s 4ms/step - loss: 22.7724 - val_loss: 29.4979
Epoch 199/200
34/34 [==============================] - 0s 3ms/step - loss: 23.1597 - val_loss: 23.2382
Epoch 200/200
34/34 [==============================] - 0s 3ms/step - loss: 21.9746 - val_loss: 27.5241
[INFO] predicting house prices...
[INFO] avg. house price: $533,388.27, std house price: $493,403.08
[INFO] mean: 27.52%, std: 22.19%
我们的平均绝对百分比误差开始非常高,但在整个训练过程中不断下降。
在训练结束时,我们在我们的测试集上获得了 27.52% 的平均绝对百分比误差,这意味着,平均而言,我们的网络在其房价预测中将会有大约 26-27%的误差。
让我们将这个结果与我们之前的两篇系列文章进行比较:
- 用只是一个数值/分类数据上的 MLP:22.71%
- 利用仅仅是一个 CNN 上的图像数据: 56.91%
如您所见,通过处理混合数据
- 将我们的数字/分类数据与图像数据相结合
- 并在混合数据上训练多输入模型…
…产生了一个表现良好的模型,,但甚至不如更简单的 MLP 方法!
注:由于权重初始化的随机性,如果您运行实验的次数足够多,您可能会获得与[INFO] mean: 19.79%, std: 17.93%一样好的结果。
使用嵌入改进模型架构和准确性
在训练多输入网络之前,我们首先需要预处理数据,包括:
- 将最小-最大缩放应用于我们的连续特征
- 将一键编码应用于我们的分类特征
然而,有两个主要问题,一是对我们的分类值进行热编码:
- 高维度:如果有许多唯一的类别,那么输出的转换后的独热编码向量会变得难以管理。
- 没有“相似”类别的概念:在应用一键编码后,不能保证“相似”类别在**–维空间中比不相似的类别放置得更靠近。
*例如,假设我们正在尝试对水果的类别进行编码,包括:
- 史密斯奶奶苹果
- 甜脆苹果
- 香蕉
直觉告诉我们,在 N 维空间中,澳洲青苹苹果和甜脆苹果应该比香蕉住得更近;然而,一键编码不能保证这一点!
幸运的是,我们可以通过使用神经网络学习“嵌入”来克服这个问题。不要误解我的意思,学习嵌入比简单地使用一键编码更难;但是,模型的精度可以显著跃升,你就不用处理上面提到的两个问题了。
*这里有一些资源可以帮助你开始嵌入和深度学习:
摘要
在本教程中,您学习了如何定义能够接受多个输入的 Keras 网络。
您还学习了如何使用 Keras 处理混合数据。
为了实现这些目标,我们定义了一个多输入神经网络,它能够接受:
- 数据
- 分类数据
- 图像数据
在训练之前,数值数据被最小-最大缩放到范围【0,1】。我们的分类数据是一位热编码的(也确保产生的整数向量在【0,1】范围内)。
然后将数值和分类数据连接成一个单一的特征向量,形成 Keras 网络的第一个输入。
我们的图像数据也被缩放到范围【0,1】—该数据作为 Keras 网络的第二个输入。
该模型的一个分支包括严格完全连接的层(用于连接的数字和分类数据),而多输入模型的第二个分支本质上是一个小型卷积神经网络。
合并两个分支的输出,并定义单个输出(回归预测)。
通过这种方式,我们能够端到端地训练我们的多输入网络,其精度几乎与单独使用一个输入一样好。
我希望你喜欢今天的博文——如果你需要在自己的项目中处理多个输入和混合数据,一定要考虑使用本教程中的代码作为模板。
在那里,您可以根据自己的需要修改代码。
要下载源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下表中输入您的电子邮件地址!*******
Keras:多重输出和多重损失
原文:https://pyimagesearch.com/2018/06/04/keras-multiple-outputs-and-multiple-losses/

几周前,我们讨论了如何使用 Keras 和深度学习来执行多标签分类。
**今天我们要讨论一种更高级的技术叫做 多输出分类 。
那么,这两者有什么区别呢?你怎么能记住所有这些术语呢?
虽然这可能有点令人困惑,尤其是如果你是深度学习的新手,但这是我如何让他们保持清醒的方法:
- 在多标签分类中,你的网络在负责分类的网络末端只有一组全连通层(即“头”)。
- 但是在多输出分类中,你的网络至少分支两次(有时更多),在网络的末端创建多组全连接头——然后你的网络可以预测每个头的一组类别标签,使得学习不相交的标签组合成为可能。
你甚至可以将多标签分类和多输出分类结合起来,这样每个全连接头可以预测多个输出!
如果这开始让你头晕,不要担心——我设计了今天的教程来指导你使用 Keras 进行多输出分类。这实际上比听起来要容易得多。
也就是说,这是我们今天讨论的一种更高级的深度学习技术,所以如果你还没有阅读我关于 和 Keras 多标签分类的第一篇文章,请确保现在阅读。
在此基础上,您将准备用多个损失函数训练您的网络,并从网络获得多个输出。
要学习如何使用 TensorFlow 和 Keras 的多输出和多损失,继续阅读!
Keras:多重输出和多重损失
2020-06-12 更新:此博文现已兼容 TensorFlow 2+!

Figure 1: Using Keras we can perform multi-output classification where multiple sets of fully-connected heads make it possible to learn disjoint label combinations. This animation demonstrates several multi-output classification results.
在今天的博文中,我们将学习如何利用:
- 多重损失函数
- 多输出
…使用 TensorFlow/Keras 深度学习库。
正如本教程介绍中提到的,多标签和多输出预测是有区别的。
对于多标签分类,我们利用一个全连接头,可以预测多个类别标签。
但是对于多输出分类,我们有至少两个全连接的头——每个头负责执行特定的分类任务。
我们甚至可以将多输出分类与多标签分类相结合——在这种情况下,每个多输出头也将负责计算多个标签!
您的眼睛可能开始变得模糊,或者您可能开始感到头痛,因此,与其继续讨论多输出与多标签分类,不如让我们深入了解我们的项目。我相信这篇文章中的代码会帮助你巩固这个概念。
我们首先回顾一下将用于构建多输出 Keras 分类器的数据集。
在那里,我们将实现并训练我们的 Keras 架构 FashionNet,该架构将使用架构中的两个独立分支对服装/时尚商品进行分类:
- 一个分支负责给定输入图像的服装类型分类(例如、衬衫、连衣裙、牛仔裤、鞋子等。).
- 而二叉负责对服装的颜色进行分类(黑色、红色、蓝色等。).
最后,我们将使用训练好的网络对示例图像进行分类,并获得多输出分类。
让我们开始吧!
多输出深度学习数据集

Figure 2: Our multi-output classification dataset was created using the technique discussed in this post. Notice that our dataset doesn’t contain red/blue shoes or black dresses/shirts. Our multi-output classification with Keras method discussed in this blog post will still be able to make correct predictions for these combinations.
我们将在今天的 Keras 多输出分类教程中使用的数据集基于我们上一篇关于多标签分类的文章中的数据集,只有一个例外——我添加了一个包含 358 张“黑鞋”图像的文件夹。
总的来说,我们的数据集由跨越七种颜色+类别组合的2525 张图像组成,包括:
- 黑色牛仔裤(344 张图片)
- 黑色鞋子(358 张图片)
- 蓝色连衣裙(386 张图片)
- 蓝色牛仔裤(356 张图片)
- 蓝色衬衫(369 张图片)
- 红色连衣裙(380 张图片)
- 红色衬衫(332 张图片)
我使用我之前关于如何(快速)构建深度学习图像数据集 的教程中描述的方法创建了这个数据集。
为七种组合中的每一种下载图像并手动删除不相关图像的整个过程花费了大约 30 分钟。当建立自己的深度学习图像数据集时,确保你遵循上面链接的教程——它将为你建立自己的数据集提供一个巨大的跳跃。
我们今天的目标和上次几乎一样——预测颜色和服装类型……
…除了能够预测图像的服装类型和颜色之外,我们的网络没有在上训练过。
例如,给定以下“黑色礼服”的图像(同样,我们的网络将而不是被训练):

Figure 3: While images of “black dresses” are not included in today’s dataset, we’re still going to attempt to correctly classify them using multi-output classification with Keras and deep learning.
我们的目标将是正确地预测这个图像的“黑色”+“服装”。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
我们的 Keras +深度学习项目结构
要完成今天的代码演练以及在您自己的图像上训练和测试 FashionNet,请滚动到 “下载” 部分,并抓取与这篇博文相关的.zip。
从那里,unzip归档并改变目录(cd),如下所示。然后,利用tree命令,你可以有组织地查看文件和文件夹(双关语):
$ unzip multi-output-classification.zip
...
$ cd multi-output-classification
$ tree --filelimit 10 --dirsfirst
.
├── dataset
│ ├── black_jeans [344 entries]
│ ├── black_shoes [358 entries]
│ ├── blue_dress [386 entries]
│ ├── blue_jeans [356 entries]
│ ├── blue_shirt [369 entries]
│ ├── red_dress [380 entries]
│ └── red_shirt [332 entries]
├── examples
│ ├── black_dress.jpg
│ ├── black_jeans.jpg
│ ├── blue_shoes.jpg
│ ├── red_shirt.jpg
│ └── red_shoes.jpg
├── output
│ ├── fashion.model
│ ├── category_lb.pickle
│ ├── color_lb.pickle
│ ├── output_accs.png
│ └── output_losses.png
├── pyimagesearch
│ ├── __init__.py
│ └── fashionnet.py
├── train.py
└── classify.py
11 directories, 14 files
上面你可以找到我们的项目结构,但是在我们继续之前,让我们先回顾一下内容。
有 3 个值得注意的 Python 文件:
pyimagesearch/fashionnet.py:我们的多输出分类网络文件包含由三种方法组成的 FashionNet 架构类:build_category_branch、build_color_branch和build。我们将在下一节详细回顾这些方法。train.py:这个脚本将训练FashionNet模型,并在流程中生成输出文件夹中的所有文件。- 这个脚本加载我们训练好的网络,并使用多输出分类对示例图像进行分类。
我们还有 4 个顶级目录:
- 我们的时尚数据集是用他们的 API 从 Bing 图片搜索中搜集来的。我们在上一节中介绍了数据集。要像我一样创建自己的数据集,请参见 如何(快速)构建深度学习图像数据集 。
examples/:在这篇博文的最后一部分,我们有一些示例图片,将与我们的classify.py脚本一起使用。output/:我们的train.py脚本生成了一些输出文件:fashion.model:我们的系列化 Keras 车型。category_lb.pickle:sci kit-learn 为服装类别生成一个序列化的LabelBinarizer对象。这个文件可以通过我们的classify.py脚本加载(并召回标签)。color_lb.pickle:一个用于颜色的LabelBinarizer对象。output_accs.png:精度训练绘图图像。output_losses.png:损失训练图图像。
pyimagesearch/:这是一个包含FashionNet类的 Python 模块。
快速回顾我们的多输出 Keras 架构
为了使用 Keras 执行多输出预测,我们将实现一个名为 FashionNet 的特殊网络架构(这是我为了这篇博文而创建的)。
FashionNet 架构包含两个特殊组件,包括:
- 网络早期的一个分支,将网络分成两个“子网络”——一个负责服装类型分类,另一个负责颜色分类。
- 网络末端的两个(不相交的)全连接头,每个负责各自的分类职责。
在我们开始实现 FashionNet 之前,让我们来想象一下这些组件,首先是分支:

Figure 4: The top of our multi-output classification network coded in Keras. The clothing category branch can be seen on the left and the color branch on the right. Each branch has a fully-connected head.
在这张网络架构图中,您可以看到我们的网络接受一个96 x 96 x 3输入图像。
然后我们立即创建两个分支:
- 左边的分支负责将服装分类。
- 右边的分支负责对颜色进行分类。
每个分支执行其各自的卷积、激活、批处理规范化、汇集和删除操作,直到我们得到最终输出:
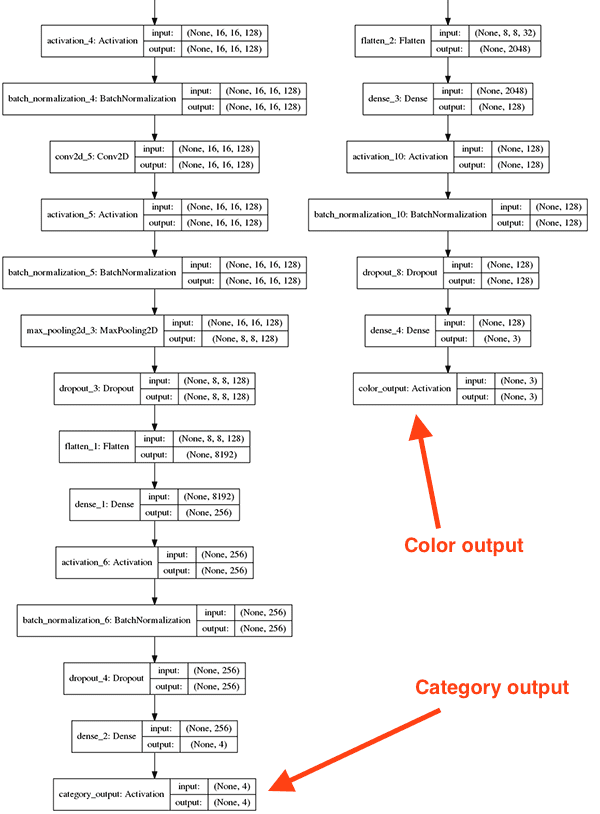
Figure 5: Our deep learning Keras multi-output classification network makes it possible to learn disjoint label combinations.
请注意,这些全连接(FC)头集看起来如何像我们在这篇博客上研究的其他架构的 FC 层——但现在它们有两个,每个负责其给定的分类任务。
网络右侧的分支明显比左侧的分支浅(没有那么深)。预测颜色远比预测服装类别容易,因此相比之下颜色分支较浅。
为了了解如何实现这样的架构,让我们继续下一部分。
实施我们的“时尚网”架构
Figure 6: The Keras deep learning library has all of the capability necessary to perform multi-output classification.
由于使用多个损失函数训练具有多个输出的网络是一种更高级的技术,我将假设您理解 CNN 的基础,而不是关注使多输出/多损失训练成为可能的元素。
如果你是深度学习和图像分类领域的新手,你应该考虑阅读我的书,《用 Python 进行计算机视觉的深度学习,以帮助你快速入门。
*在继续之前,请确保您已经从 “下载” 部分下载了文件和数据。
下载完成后,让我们打开fashionnet.py来回顾一下:
# import the necessary packages
from tensorflow.keras.models import Model
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
import tensorflow as tf
我们首先从 Keras 库中导入模块,然后导入 TensorFlow 本身。
由于我们的网络由两个子网络组成,我们将定义两个函数负责构建每个分支。
第一个build_category_branch,用于对 服装类型 进行分类,定义如下:
class FashionNet:
@staticmethod
def build_category_branch(inputs, numCategories,
finalAct="softmax", chanDim=-1):
# utilize a lambda layer to convert the 3 channel input to a
# grayscale representation
x = Lambda(lambda c: tf.image.rgb_to_grayscale(c))(inputs)
# CONV => RELU => POOL
x = Conv2D(32, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(3, 3))(x)
x = Dropout(0.25)(x)
build_category_branch功能在行 16 和 17 上定义,有三个值得注意的参数:
inputs:我们品类分支子网的输入量。numCategories:“连衣裙”、“鞋子”、“牛仔裤”、“衬衫”等类别的数量。finalAct:最终激活层类型,默认为 softmax 分类器。如果您正在执行多输出和多标签分类,您可能希望将此激活更改为 sigmoid。
请密切注意第 20 行,我们使用Lambda层将我们的图像从 RGB 转换为灰度。
为什么要这么做?
不管是红色、蓝色、绿色、黑色还是紫色,裙子就是裙子,对吗?
因此,我们决定扔掉任何颜色信息,而是专注于图像中实际的结构组件,确保我们的网络不会学习将特定颜色与服装类型关联起来。
注意: Lambdas 在 Python 3.5 和 Python 3.6 中的工作方式不同。我用 Python 3.5 训练了这个模型,所以如果你只是用 Python 3.6 运行classify.py脚本来测试带有示例图像的模型,你可能会遇到困难。如果你遇到与 Lambda 层相关的错误,我建议你要么(a)尝试 Python 3.5,要么(b)在 Python 3.6 上训练和分类。不需要修改代码。**
然后我们继续在第 23-27 行的上构建我们的CONV => RELU => POOL块。注意,我们使用的是 TensorFlow/Keras 的功能 API;我们需要功能 API 来创建我们的分支网络结构。
我们的第一个CONV层有带3 x 3内核的32滤镜和RELU激活(整流线性单元)。我们应用批量标准化、最大池化和 25%的退出率。
掉线是从当前层到下一层随机断开节点的过程。这种随机断开的过程自然有助于网络减少过拟合,因为层中没有一个单独的节点负责预测某个类、对象、边或角。
接下来是我们的两组(CONV => RELU) * 2 => POOL模块:
# (CONV => RELU) * 2 => POOL
x = Conv2D(64, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Conv2D(64, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
# (CONV => RELU) * 2 => POOL
x = Conv2D(128, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Conv2D(128, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
这个代码块中过滤器、内核和池大小的变化协同工作,逐渐减小空间大小,但增加深度。
让我们用一个FC => RELU层将它组合在一起:
# define a branch of output layers for the number of different
# clothing categories (i.e., shirts, jeans, dresses, etc.)
x = Flatten()(x)
x = Dense(256)(x)
x = Activation("relu")(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
x = Dense(numCategories)(x)
x = Activation(finalAct, name="category_output")(x)
# return the category prediction sub-network
return x
最后一个激活层是完全连接的,和我们的numCategories有相同数量的神经元/输出。
注意我们已经在行 57 上命名了我们的最终激活层"category_output"。这很重要,因为我们将在后面的train.py中通过名称引用该层。
让我们定义用于构建多输出分类网络的第二个函数。这一个被命名为build_color_branch,顾名思义,它负责对我们图像中的进行分类:
@staticmethod
def build_color_branch(inputs, numColors, finalAct="softmax",
chanDim=-1):
# CONV => RELU => POOL
x = Conv2D(16, (3, 3), padding="same")(inputs)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(3, 3))(x)
x = Dropout(0.25)(x)
# CONV => RELU => POOL
x = Conv2D(32, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
# CONV => RELU => POOL
x = Conv2D(32, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
我们对build_color_branch的参数基本上与build_category_branch相同。我们用numColors(不同于numCategories)来区分最后一层的激活次数。
这一次,我们不会应用一个Lambda灰度转换层,因为我们实际上关心的是颜色在网络的这个区域。如果我们转换成灰度,我们将失去所有的颜色信息!
网络的这一分支明显比服装类分支浅得多,因为手头的任务要简单得多。我们要求我们的子网络完成的只是对颜色进行分类——子网络不需要那么深。
就像我们的品类分支一样,我们还有第二个全连通的头。让我们构建FC => RELU块来完成:
# define a branch of output layers for the number of different
# colors (i.e., red, black, blue, etc.)
x = Flatten()(x)
x = Dense(128)(x)
x = Activation("relu")(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
x = Dense(numColors)(x)
x = Activation(finalAct, name="color_output")(x)
# return the color prediction sub-network
return x
为了区分颜色分支的最终激活层,我在第 94 行的处提供了name="color_output"关键字参数。我们将在培训脚本中引用该名称。
构建FashionNet的最后一步是将我们的两个分支放在一起,build最终架构:
@staticmethod
def build(width, height, numCategories, numColors,
finalAct="softmax"):
# initialize the input shape and channel dimension (this code
# assumes you are using TensorFlow which utilizes channels
# last ordering)
inputShape = (height, width, 3)
chanDim = -1
# construct both the "category" and "color" sub-networks
inputs = Input(shape=inputShape)
categoryBranch = FashionNet.build_category_branch(inputs,
numCategories, finalAct=finalAct, chanDim=chanDim)
colorBranch = FashionNet.build_color_branch(inputs,
numColors, finalAct=finalAct, chanDim=chanDim)
# create the model using our input (the batch of images) and
# two separate outputs -- one for the clothing category
# branch and another for the color branch, respectively
model = Model(
inputs=inputs,
outputs=[categoryBranch, colorBranch],
name="fashionnet")
# return the constructed network architecture
return model
我们的build函数定义在行 100 上,有 5 个自解释参数。
build函数假设我们使用 TensorFlow 和 channels last ordering。这在第 105 行的中很清楚,这里我们的inputShape元组是显式排序的(height, width, 3),其中 3 代表 RGB 通道。
如果你想使用 TensorFlow 之外的后端而不是,你需要修改代码:(1)为你的后端正确的通道排序和(2)实现一个自定义层来处理 RGB 到灰度的转换。
从那里,我们定义网络的两个分支(行 110-113 ,然后将它们放在一个Model ( 行 118-121 )。
关键是我们的分支有一个共同的输入 t,但是两个不同的输出(服装类型和颜色分类)。
实施多输出多损失训练脚本
现在我们已经实现了我们的FashionNet架构,让我们来训练它吧!
当你准备好了,打开train.py让我们开始吧:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from pyimagesearch.fashionnet import FashionNet
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
我们首先为脚本导入必要的包。
从那里我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset (i.e., directory of images)")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-l", "--categorybin", required=True,
help="path to output category label binarizer")
ap.add_argument("-c", "--colorbin", required=True,
help="path to output color label binarizer")
ap.add_argument("-p", "--plot", type=str, default="output",
help="base filename for generated plots")
args = vars(ap.parse_args())
我们将很快看到如何运行训练脚本。现在,只需要知道--dataset是数据集的输入文件路径,--model、--categorybin、--colorbin是三个输出文件路径。
或者,您可以使用--plot参数为生成的精度/损失图指定一个基本文件名。当我们在脚本中遇到这些命令行参数时,我会再次指出它们。如果第 21-32 行对你来说像希腊语,请看我的 argparse +命令行参数的博客文章。
现在,让我们建立四个重要的训练变量:
# initialize the number of epochs to train for, initial learning rate,
# batch size, and image dimensions
EPOCHS = 50
INIT_LR = 1e-3
BS = 32
IMAGE_DIMS = (96, 96, 3)
我们在第 36-39 行的上设置了以下变量:
EPOCHS:历元数设置为50。通过实验,我发现50时代产生了一个低损失的模型,并且没有过度适应训练集(或者尽我们所能不过度适应)。INIT_LR:我们的初始学习率设定为0.001。学习率控制着我们沿着梯度前进的“步伐”。较小的值表示较小的步长,较大的值表示较大的步长。我们很快就会看到,我们将使用 Adam 优化器,同时随着时间的推移逐渐降低学习率。BS:我们将以32的批量训练我们的网络。IMAGE_DIMS:所有输入的图像都将通过3通道(RGB)调整到96 x 96。我们正在用这些维度进行培训,我们的网络架构输入维度也反映了这些维度。当我们在后面的部分用示例图像测试我们的网络时,测试维度必须匹配训练维度。
我们的下一步是抓住我们的图像路径,并随机洗牌。我们还将初始化列表,分别保存图像本身以及服装类别和颜色:
# grab the image paths and randomly shuffle them
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# initialize the data, clothing category labels (i.e., shirts, jeans,
# dresses, etc.) along with the color labels (i.e., red, blue, etc.)
data = []
categoryLabels = []
colorLabels = []
随后,我们将循环遍历imagePaths,预处理,并填充data、categoryLabels和colorLabels列表:
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = img_to_array(image)
data.append(image)
# extract the clothing color and category from the path and
# update the respective lists
(color, cat) = imagePath.split(os.path.sep)[-2].split("_")
categoryLabels.append(cat)
colorLabels.append(color)
我们开始在线 54 上循环我们的imagePaths。
在循环内部,我们将图像加载到IMAGE_DIMS并调整其大小。我们还将我们的图像从 BGR 排序转换为 RGB。我们为什么要进行这种转换?回想一下我们在build_category_branch函数中的FashionNet类,我们在 Lambda 函数/层中使用了 TensorFlow 的rgb_to_grayscale转换。正因为如此,我们首先在第 58 行转换成 RGB,最终将预处理后的图像追加到data列表中。
接下来,仍然在循环内部,我们从当前图像所在的目录名中提取颜色和类别标签(第 64 行)。
要了解这一点,只需在您的终端中启动 Python,并提供一个示例imagePath进行实验,如下所示:
$ python
>>> import os
>>> imagePath = "dataset/red_dress/00000000.jpg"
>>> (color, cat) = imagePath.split(os.path.sep)[-2].split("_")
>>> color
'red'
>>> cat
'dress'
当然,您可以随意组织目录结构(但是您必须修改代码)。我最喜欢的两种方法包括(1)为每个标签使用子目录,或者(2)将所有的图像存储在一个目录中,然后创建一个 CSV 或 JSON 文件来将图像文件名映射到它们的标签。
让我们将这三个列表转换为 NumPy 数组,将标签二进制化,并将数据划分为训练和测试部分:
# scale the raw pixel intensities to the range [0, 1] and convert to
# a NumPy array
data = np.array(data, dtype="float") / 255.0
print("[INFO] data matrix: {} images ({:.2f}MB)".format(
len(imagePaths), data.nbytes / (1024 * 1000.0)))
# convert the label lists to NumPy arrays prior to binarization
categoryLabels = np.array(categoryLabels)
colorLabels = np.array(colorLabels)
# binarize both sets of labels
print("[INFO] binarizing labels...")
categoryLB = LabelBinarizer()
colorLB = LabelBinarizer()
categoryLabels = categoryLB.fit_transform(categoryLabels)
colorLabels = colorLB.fit_transform(colorLabels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
split = train_test_split(data, categoryLabels, colorLabels,
test_size=0.2, random_state=42)
(trainX, testX, trainCategoryY, testCategoryY,
trainColorY, testColorY) = split
我们最后的预处理步骤——转换成 NumPy 数组并将原始像素亮度缩放到[0, 1]——可以在第 70 行上一次性完成。
我们还将categoryLabels和colorLabels转换成 NumPy 数组(T4 第 75 行和第 76 行)。这是必要的,因为接下来我们将使用之前导入的 scikit-learn 的LabelBinarizer(第 80-83 行)对标签进行二值化。由于我们的网络有两个独立的分支,我们可以使用两个独立的标签二值化器——这不同于我们使用MultiLabelBinarizer(也来自 scikit-learn)的多标签分类。
接下来,我们在数据集上执行典型的 80%训练/20%测试分割(第 87-96 行)。
让我们建立网络,定义我们的独立损失,并编译我们的模型:
# initialize our FashionNet multi-output network
model = FashionNet.build(96, 96,
numCategories=len(categoryLB.classes_),
numColors=len(colorLB.classes_),
finalAct="softmax")
# define two dictionaries: one that specifies the loss method for
# each output of the network along with a second dictionary that
# specifies the weight per loss
losses = {
"category_output": "categorical_crossentropy",
"color_output": "categorical_crossentropy",
}
lossWeights = {"category_output": 1.0, "color_output": 1.0}
# initialize the optimizer and compile the model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(optimizer=opt, loss=losses, loss_weights=lossWeights,
metrics=["accuracy"])
在第 93-96 行,我们实例化了我们的多输出FashionNet模型。当我们在其中创建FashionNet类和build函数时,我们剖析了这些参数,所以一定要看看我们在这里实际提供的值。
接下来,我们需要为全连接头(行 101-104 )的每个定义两个 losses。
定义多个损失是通过使用每个分支激活层名称的字典来完成的— 这就是为什么我们在 FashionNet 实现中命名我们的输出层!每个损失将使用分类交叉熵,这是使用 > 2 类训练网络进行分类时使用的标准损失方法。
我们还在单独的字典中定义等于 lossWeights(同名键具有相等的值)在行 105 上。在您的特定应用中,您可能希望将一个损失看得比另一个更重。
既然我们已经实例化了我们的模型并创建了我们的losses + lossWeights字典,让我们用学习率衰减(行 109 )和compile我们的model ( 行 110 和 111 )初始化Adam优化器。
我们的下一个模块只是开始了训练过程:
# train the network to perform multi-output classification
H = model.fit(x=trainX,
y={"category_output": trainCategoryY, "color_output": trainColorY},
validation_data=(testX,
{"category_output": testCategoryY, "color_output": testColorY}),
epochs=EPOCHS,
verbose=1)
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
2020-06-12 更新:注意,对于 TensorFlow 2.0+我们建议明确设置save_format="h5" (HDF5 格式)。
回想一下的第 87-90 行,我们将数据分为训练(trainX)和测试(testX)。在第 114-119 行,我们在提供数据的同时启动训练过程。注意第 115 行,在这里我们将标签作为字典传递。第 116 行和第 117 行也是如此,我们为验证数据传入一个 2 元组。当使用 Keras 执行多输出分类时,以这种方式传递训练和验证标签是一个要求。我们需要指示 Keras 哪组目标标签对应于网络的哪一个输出分支。
使用我们的命令行参数(args["model"]),我们将序列化的模型保存到磁盘上以备将来调用。
我们还将做同样的事情,将我们的标签二进制化器保存为序列化的 pickle 文件:
# save the category binarizer to disk
print("[INFO] serializing category label binarizer...")
f = open(args["categorybin"], "wb")
f.write(pickle.dumps(categoryLB))
f.close()
# save the color binarizer to disk
print("[INFO] serializing color label binarizer...")
f = open(args["colorbin"], "wb")
f.write(pickle.dumps(colorLB))
f.close()
使用命令行参数路径(args["categorybin"]和args["colorbin"]),我们将两个标签二进制化器(categoryLB和colorLB)写入磁盘上的序列化 pickle 文件。
从这里开始,所有的工作都是在这个脚本中绘制结果:
# plot the total loss, category loss, and color loss
lossNames = ["loss", "category_output_loss", "color_output_loss"]
plt.style.use("ggplot")
(fig, ax) = plt.subplots(3, 1, figsize=(13, 13))
# loop over the loss names
for (i, l) in enumerate(lossNames):
# plot the loss for both the training and validation data
title = "Loss for {}".format(l) if l != "loss" else "Total loss"
ax[i].set_title(title)
ax[i].set_xlabel("Epoch #")
ax[i].set_ylabel("Loss")
ax[i].plot(np.arange(0, EPOCHS), H.history[l], label=l)
ax[i].plot(np.arange(0, EPOCHS), H.history["val_" + l],
label="val_" + l)
ax[i].legend()
# save the losses figure
plt.tight_layout()
plt.savefig("{}_losses.png".format(args["plot"]))
plt.close()
上述代码块负责在单独但堆叠的图上绘制每个损失函数的损失历史,包括:
- 全损
- 类别输出的损失
- 色彩输出的损失
同样,我们将在单独的图像文件中绘制精度:
# create a new figure for the accuracies
accuracyNames = ["category_output_accuracy", "color_output_accuracy"]
plt.style.use("ggplot")
(fig, ax) = plt.subplots(2, 1, figsize=(8, 8))
# loop over the accuracy names
for (i, l) in enumerate(accuracyNames):
# plot the loss for both the training and validation data
ax[i].set_title("Accuracy for {}".format(l))
ax[i].set_xlabel("Epoch #")
ax[i].set_ylabel("Accuracy")
ax[i].plot(np.arange(0, EPOCHS), H.history[l], label=l)
ax[i].plot(np.arange(0, EPOCHS), H.history["val_" + l],
label="val_" + l)
ax[i].legend()
# save the accuracies figure
plt.tight_layout()
plt.savefig("{}_accs.png".format(args["plot"]))
plt.close()
2020-06-12 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["category_output_accuracy"]和H.history["color_output_accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
我们的类别准确度和颜色准确度图最好分开查看,因此它们作为单独的图堆叠在一个图像中。
训练多输出/多损失 Keras 模型
一定要使用这篇博文的 【下载】 部分来抓取代码和数据集。
别忘了:我用 Python 3.7 来训练本教程下载中包含的网络。只要你保持一致(Python 3.5 以上),你就不会有 Lambda 实现不一致的问题。你甚至可以运行 Python 2.7(我没有测试过这个)。
打开终端。然后粘贴下面的命令开始训练过程(如果你没有 GPU,你也想喝一杯啤酒):
$ python train.py --dataset dataset --model output/fashion.model \
--categorybin output/category_lb.pickle --colorbin output/color_lb.pickle
Using TensorFlow backend.
[INFO] loading images...
[INFO] data matrix: 2521 images (544.54MB)
[INFO] loading images...
[INFO] data matrix: 2521 images (544.54MB)
[INFO] binarizing labels...
[INFO] compiling model...
Epoch 1/50
63/63 [==============================] - 1s 20ms/step - loss: 0.8523 - category_output_loss: 0.5301 - color_output_loss: 0.3222 - category_output_accuracy: 0.8264 - color_output_accuracy: 0.8780 - val_loss: 3.6909 - val_category_output_loss: 1.8052 - val_color_output_loss: 1.8857 - val_category_output_accuracy: 0.3188 - val_color_output_accuracy: 0.4416
Epoch 2/50
63/63 [==============================] - 1s 14ms/step - loss: 0.4367 - category_output_loss: 0.3092 - color_output_loss: 0.1276 - category_output_accuracy: 0.9033 - color_output_accuracy: 0.9519 - val_loss: 7.0533 - val_category_output_loss: 2.9279 - val_color_output_loss: 4.1254 - val_category_output_accuracy: 0.3188 - val_color_output_accuracy: 0.4416
Epoch 3/50
63/63 [==============================] - 1s 14ms/step - loss: 0.2892 - category_output_loss: 0.1952 - color_output_loss: 0.0940 - category_output_accuracy: 0.9350 - color_output_accuracy: 0.9653 - val_loss: 6.2512 - val_category_output_loss: 2.0540 - val_color_output_loss: 4.1972 - val_category_output_accuracy: 0.4020 - val_color_output_accuracy: 0.4416
...
Epoch 48/50
63/63 [==============================] - 1s 14ms/step - loss: 0.0189 - category_output_loss: 0.0106 - color_output_loss: 0.0083 - category_output_accuracy: 0.9960 - color_output_accuracy: 0.9970 - val_loss: 0.2625 - val_category_output_loss: 0.2250 - val_color_output_loss: 0.0376 - val_category_output_accuracy: 0.9564 - val_color_output_accuracy: 0.9861
Epoch 49/50
63/63 [==============================] - 1s 14ms/step - loss: 0.0190 - category_output_loss: 0.0041 - color_output_loss: 0.0148 - category_output_accuracy: 0.9985 - color_output_accuracy: 0.9950 - val_loss: 0.2333 - val_category_output_loss: 0.1927 - val_color_output_loss: 0.0406 - val_category_output_accuracy: 0.9604 - val_color_output_accuracy: 0.9881
Epoch 50/50
63/63 [==============================] - 1s 14ms/step - loss: 0.0188 - category_output_loss: 0.0046 - color_output_loss: 0.0142 - category_output_accuracy: 0.9990 - color_output_accuracy: 0.9960 - val_loss: 0.2140 - val_category_output_loss: 0.1719 - val_color_output_loss: 0.0421 - val_category_output_accuracy: 0.9624 - val_color_output_accuracy: 0.9861
[INFO] serializing network...
[INFO] serializing category label binarizer...
[INFO] serializing color label binarizer...
对于我们的类别输出,我们获得:
- 训练集上的准确率为 99.90%
- 测试集上的准确率为 96.24%
对于颜色输出,我们达到了:
- 训练集上的准确率为 99.60%
- 测试集上的准确率为 98.61%
下面你可以找到我们每次损失的曲线图:
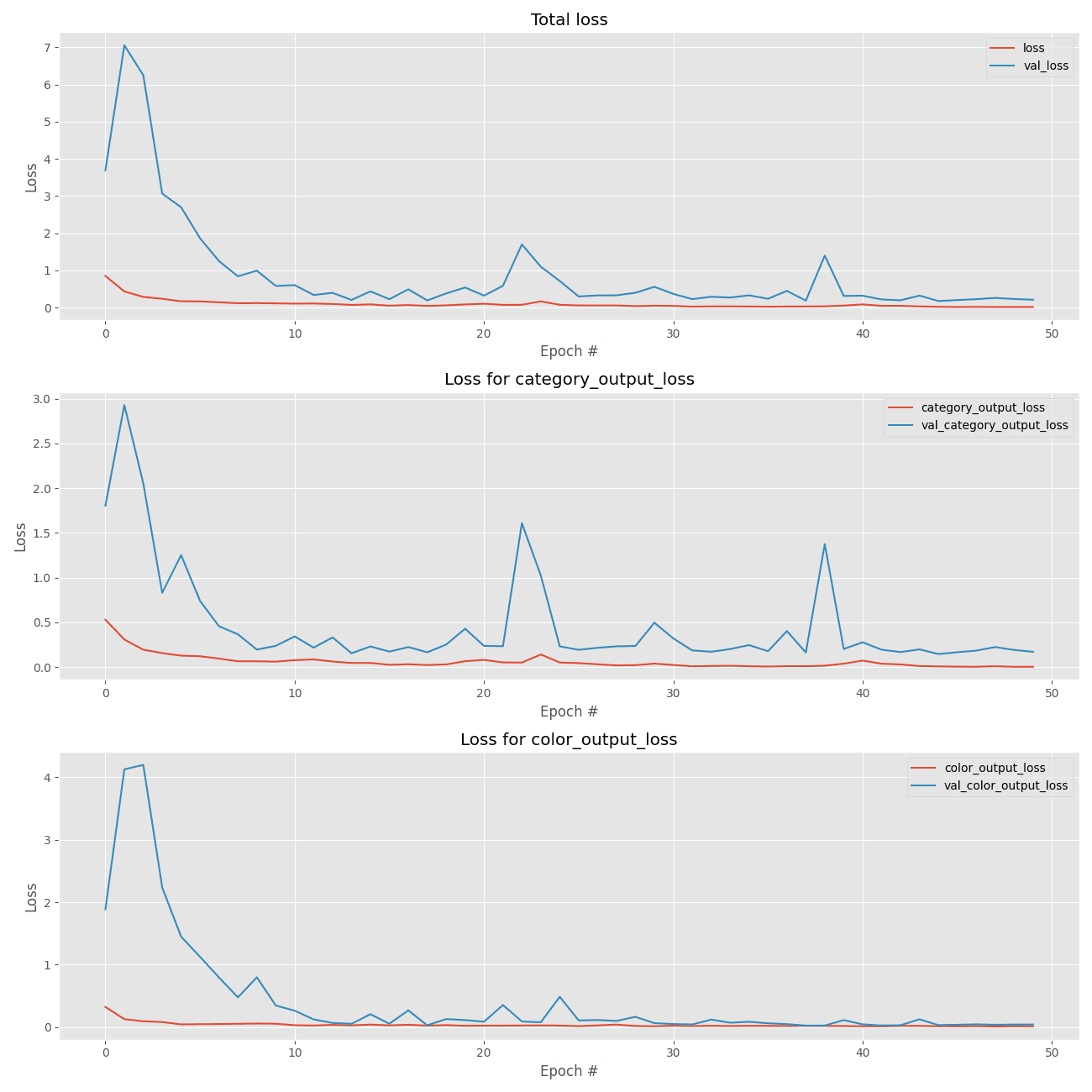
Figure 7: Our Keras deep learning multi-output classification training losses are plotted with matplotlib. Our total losses (top), clothing category losses (middle), and color losses (bottom) are plotted independently for analysis.
以及我们的多重精度:
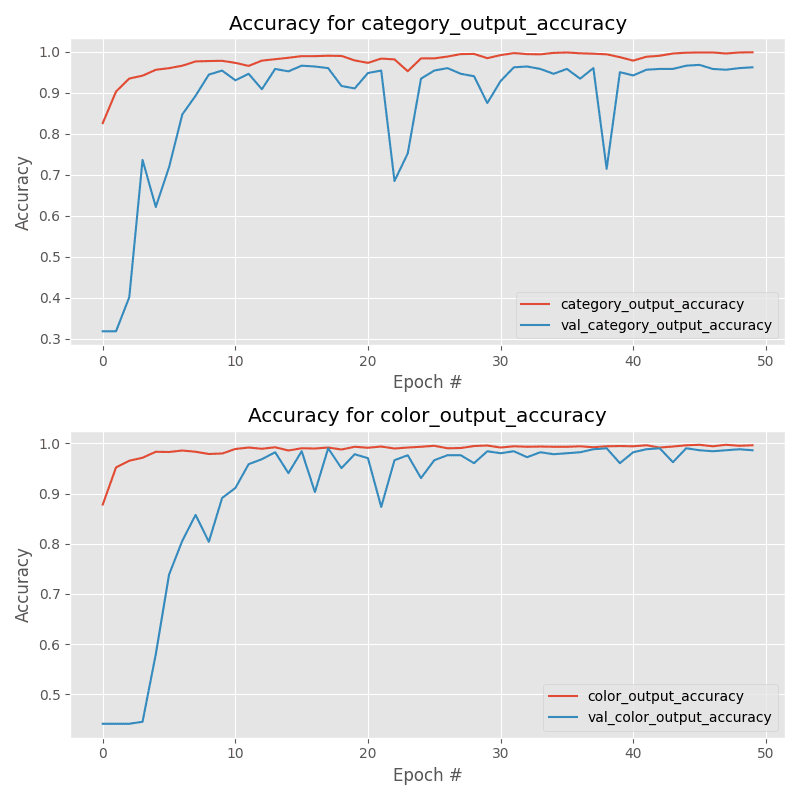
Figure 8: FashionNet, a multi-output classification network, is trained with Keras. In order to analyze the training it is best to show the accuracies in separate plots. Clothing category training accuracy plot (top). Color training accuracy plot (bottom).
通过应用数据增强(在我的书《用 Python 进行计算机视觉的深度学习 】中, 有所涉及),可能会获得进一步的准确性。
实现多输出分类脚本
现在我们已经训练了我们的网络,让我们学习如何将它应用于输入图像而不是我们训练集的部分。
打开classify.py并插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import tensorflow as tf
import numpy as np
import argparse
import imutils
import pickle
import cv2
首先,我们导入所需的包,然后解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--categorybin", required=True,
help="path to output category label binarizer")
ap.add_argument("-c", "--colorbin", required=True,
help="path to output color label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
我们有四个命令行参数,它们是在您的终端上运行这个脚本所必需的:
--model:我们刚刚训练的序列化模型文件的路径(我们之前脚本的输出)。--categorybin:类别标签二进制化器的路径(我们之前脚本的输出)。--colorbin:色标二值化器的路径(我们之前脚本的输出)。--image:我们的测试图像文件路径——该图像将来自我们的examples/目录。
在那里,我们加载图像并对其进行预处理:
# load the image
image = cv2.imread(args["image"])
output = imutils.resize(image, width=400)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# pre-process the image for classification
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
在我们运行推理之前,需要预处理我们的图像。在上面的块中,我们加载图像,为了输出的目的调整它的大小,并交换颜色通道(第 24-26 行),这样我们就可以在 FashionNet 的Lambda层中使用 TensorFlow 的 RGB 转灰度功能。然后,我们调整 RGB 图像的大小(从我们的训练脚本中调出IMAGE_DIMS,将其缩放为【0,1】,转换为 NumPy 数组,并为批处理添加一个维度(第 29-32 行)。
关键是预处理步骤遵循我们的训练脚本中采取的相同动作。
接下来,让我们加载我们的序列化模型和两个标签二进制化器:
# load the trained convolutional neural network from disk, followed
# by the category and color label binarizers, respectively
print("[INFO] loading network...")
model = load_model(args["model"], custom_objects={"tf": tf})
categoryLB = pickle.loads(open(args["categorybin"], "rb").read())
colorLB = pickle.loads(open(args["colorbin"], "rb").read())
使用第 37-39 行的上的四个命令行参数中的三个,我们加载model、categoryLB和colorLB。
现在,( 1)多输出 Keras 模型和(2)标签二值化器都在内存中,我们可以对图像进行分类:
# classify the input image using Keras' multi-output functionality
print("[INFO] classifying image...")
(categoryProba, colorProba) = model.predict(image)
# find indexes of both the category and color outputs with the
# largest probabilities, then determine the corresponding class
# labels
categoryIdx = categoryProba[0].argmax()
colorIdx = colorProba[0].argmax()
categoryLabel = categoryLB.classes_[categoryIdx]
colorLabel = colorLB.classes_[colorIdx]
我们在第 43 行上执行多输出分类,产生类别和颜色的概率(分别为categoryProba和colorProba)。
注意: 我没有包括 include 代码,因为它有点冗长,但是您可以通过检查输出张量的名称来确定 TensorFlow + Keras 模型返回多个输出的顺序。详见 StackOverflow 上的线程。
从那里,我们将提取类别和颜色的最高概率的索引(行 48 和 49 )。
使用高概率指数,我们可以提取类名(行 50 和 51 )。
这似乎有点太简单了,不是吗?但这就是使用 Keras 对新输入图像应用多输出分类的全部内容!
让我们展示结果来证明这一点:
# draw the category label and color label on the image
categoryText = "category: {} ({:.2f}%)".format(categoryLabel,
categoryProba[0][categoryIdx] * 100)
colorText = "color: {} ({:.2f}%)".format(colorLabel,
colorProba[0][colorIdx] * 100)
cv2.putText(output, categoryText, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
cv2.putText(output, colorText, (10, 55), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
# display the predictions to the terminal as well
print("[INFO] {}".format(categoryText))
print("[INFO] {}".format(colorText))
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
我们在我们的output图像上显示我们的结果(第 54-61 行)。如果我们遇到一件“红色连衣裙”,左上角的绿色文字看起来会像这样:
- 类别:服装(89.04%)
- 颜色:红色(95.07%)
相同的信息通过行 64 和 65 打印到终端,之后output图像显示在屏幕上(行 68 )。
使用 Keras 执行多输出分类
现在是有趣的部分了!
在这一部分中,我们将在examples目录中向我们的网络展示五幅图像,它们是而不是训练集的一部分。
有趣的是,我们的网络只经过专门训练,能够识别示例图像类别中的两个。这前两张图片(“黑色牛仔裤”和“红色衬衫”)应该特别容易让我们的网络正确地对类别和颜色进行分类。
剩下的三幅图像与我们的模型完全不同——我们没有用“红鞋”、“蓝鞋”或“黑裙子”进行训练,但我们将尝试多输出分类,看看会发生什么。
让我们从“黑色牛仔裤”开始——这应该很容易,因为在训练数据集中有大量类似的图像。确保像这样使用四个命令行参数:
$ python classify.py --model output/fashion.model \
--categorybin output/category_lb.pickle --colorbin output/color_lb.pickle \
--image examples/black_jeans.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] category: jeans (100.00%)
[INFO] color: black (97.04%)

Figure 9: Deep learning multi-label classification allows us to recognize disjoint label combinations such as clothing type and clothing color. Our network has correctly classified this image as both “jeans” and “black”.
正如所料,我们的网络正确地将图像分类为“牛仔裤”和“黑色”。
让我们试试“红衬衫”:
$ python classify.py --model fashion.model \
--categorybin output/category_lb.pickle --colorbin output/color_lb.pickle \
--image examples/red_shirt.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] category: shirt (100.00%)
[INFO] color: red (100.00%)

Figure 10: This image of a “red shirt” is a test image which is not in our deep learning image dataset. Our Keras multi-output network has; however, seen other red shirts. It easily classifies this image with both labels at 100% confidence.
对于两个类别标签都有 100%的置信度,我们的图像肯定包含“红色衬衫”。记住,我们的网络已经在训练过程中看到了其他“红衫军”的例子。
现在让我们退后一步。
看一下我们的数据集,回想一下,它以前从未见过“红色的鞋子”,但它见过“红色”以“连衣裙”和“衬衫”的形式出现,以及带有“黑色”颜色的“鞋子”。
是否可以区分这个不熟悉的测试图像包含的【鞋子】就是【红色】?
让我们来看看:
$ python classify.py --model fashion.model \
--categorybin output/category_lb.pickle --colorbin output/color_lb.pickle \
--image examples/red_shoes.jpgUsing TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] category: shoes (82.20%)
[INFO] color: red (99.99%)

Figure 11: Our deep learning multi-output classification network has never seen the combination of “red” and “shoes” before. During the training process, we did present “shoes” (albeit, “black” ones) and we did present “red” (both “shirts” and “dresses”). Amazingly, our network fires neurons resulting in the correct multi-output labels for this image of “red shoes”. Success!
答对了!
查看图像中的结果,我们成功了。
在展示不熟悉的多输出组合时,我们有了一个良好的开端。我们的网络设计+培训得到了回报,我们能够以很高的准确度识别“红鞋”。
我们还没有完成——让我们向我们的网络展示一张包含“黑色连衣裙”的图片。记住,之前在我们的 多标签分类教程中,同样的图像没有产生正确的结果。
我认为这一次我们很有可能成功,所以在您的终端中键入以下命令:
$ python classify.py --model fashion.model \
--categorybin output/category_lb.pickle --colorbin output/color_lb.pickle \
--image examples/black_dress.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] category: dress (98.80%)
[INFO] color: black (98.65%)
Figure 12: While images of “black dresses” are not included in today’s dataset, we’re still able to correctly classify them using multi-output classification with Keras and deep learning.
看看图片左上角的班级标签!
我们实现了对类别和颜色的正确分类,两者的报告置信度为 > 98% 准确度。我们已经完成了目标!
为了理智起见,我们再试试一个不熟悉的组合:“蓝鞋”。在您的终端中输入相同的命令,这次将参数--image改为examples/blue_shoes.jpg:
$ python classify.py --model fashion.model \
--categorybin output/category_lb.pickle --colorbin output/color_lb.pickle \
--image examples/blue_shoes.jpg
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] category: shoes (100.00%)
[INFO] color: blue (99.05%)

Figure 13: While multi-label classification may fail at unfamiliar label combinations, multi-output classification handles the task gracefully.
同样的交易得到了证实——我们的网络没有在“蓝色鞋子”图像上进行训练,但是我们能够通过使用我们的两个子网络以及多输出和多损失分类来正确地对它们进行分类。
摘要
在今天的博文中,我们学习了如何利用 Keras 深度学习库中的多个输出和多个损失函数。
为了完成这项任务,我们定义了一个称为 FashionNet 的 Keras 架构,用于时尚/服装分类。
FashionNet 架构包含两个分支:
- 一个分支负责给定输入图像的服装类型分类(例如、衬衫、连衣裙、牛仔裤、鞋子等。).
- 而第二叉负责对服装的颜色进行分类(黑色、红色、蓝色等。).
这种分支发生在网络的早期,本质上创建了两个“子网”,分别负责各自的分类任务,但都包含在同一个网络中。
最值得注意的是,多输出分类使我们能够解决我们之前关于多标签分类的帖子中的一个麻烦,其中:
- 我们在六个类别上训练我们的网络,包括:黑色牛仔裤、蓝色连衣裙、蓝色牛仔裤、蓝色衬衫、红色连衣裙和红色衬衫…
- …但是我们无法对“黑色礼服”进行分类,因为我们的网络之前从未见过这种数据组合!
通过创建两个完全连接的头部和相关的子网络(如有必要),我们可以训练一个头部对服装类型进行分类,另一个头部可以学习如何识别颜色——最终结果是一个可以对“黑色礼服”进行分类的网络,即使它从未在此类数据上进行过训练!
请记住,您应该始终尝试为您想要识别的每个类别提供示例训练数据— 深度神经网络虽然强大,但并不“神奇”!
你需要尽最大努力训练他们,这包括首先收集适当的训练数据。
我希望喜欢今天关于多输出分类的帖子!
要在 PyImageSearch 上发布帖子时得到通知,*只需在下表中输入您的电子邮件地址!******
Keras、回归和 CNN
原文:https://pyimagesearch.com/2019/01/28/keras-regression-and-cnns/
在本教程中,您将学习如何使用 Keras 训练卷积神经网络(CNN)进行回归预测。然后,您将训练 CNN 从一组图像中预测房价。
今天是我们关于 Keras 回归预测的三部分系列的第二部分:
- 第一部分: 带 Keras 的基本回归 —从分类和数字数据预测房价。
- 第二部分:用 Keras 和 CNN 回归——训练一个 CNN 从图像数据预测房价(今日教程)。
- 第三部分:将分类数据、数字数据和图像数据结合成一个单一的网络(下周的教程)。
今天的教程建立在上周的基本 Keras 回归示例的基础上,所以如果你还没有阅读它,请务必通读一遍,以便今天继续学习。
在本指南结束时,您不仅会对使用 Keras 训练 CNN 进行回归预测有很深的理解,而且还会有一个 Python 代码模板,您可以在自己的项目中遵循它。
要了解如何使用 Keras 训练 CNN 进行回归预测,继续阅读!
Keras、回归和 CNN
2020-06-15 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将讨论我们的房价数据集,它不仅包含数字/分类数据,还包含图像数据。接下来,我们将简要回顾一下我们的项目结构。
然后,我们将创建两个 Python 助手函数:
- 第一个将用于从磁盘加载我们的房价图像
- 第二种方法将用于构建我们的 Keras CNN 架构
最后,我们将实现我们的训练脚本,然后为回归预测训练一个 Keras CNN。
我们还将回顾我们的结果,并建议进一步的方法来提高我们的预测准确性。
我想再次重申,在继续之前,你应该阅读上周关于基本回归预测的教程——我们不仅要构建上周的概念,还要构建源代码。
正如你将在今天的剩余教程中发现的,用 CNN 和 Keras 执行回归很简单:
- 移除通常用于分类的全连接 softmax 分类器图层
- 取而代之的是一个全连接层,该层具有一个单节点(T1)和一个线性激活函数(T3)。
- 用连续值预测损失函数训练模型,如均方误差、平均绝对误差、平均绝对百分比误差等。
让我们开始吧!
预测房价…用图像?
我们在这一系列教程中使用的数据集是由 Ahmed 和 Moustafa 在他们 2016 年的论文中策划的, 根据视觉和文本特征进行房价估计 。
据我所知,这是第一个公开可用的数据集,既包括的数字/分类属性,也包括 的图像 。
**数字和分类属性包括:
- 卧室数量
- 浴室数量
- 面积(即平方英尺)
- 邮政区码
还提供了每个房屋的四幅图像:
- 卧室
- 浴室
- 厨房
- 房子的正面图
数据集中总共包括 535 所房屋,因此数据集中总共有 535 x 4 = 2,140 幅图像。
在数据清理期间,我们将把这个数字削减到 362 所房子(1,448 张图片)。
要下载房价数据集,你可以克隆 Ahmed 和 Moustafa 的 GitHub 库:
$ cd ~
$ git clone https://github.com/emanhamed/Houses-dataset
这条命令将下载数字/分类数据以及图像本身。
记下您在磁盘上的何处下载了存储库(我将它放在我的主文件夹中),因为在本教程的后面部分,您将需要通过命令行参数提供 repo 的路径。
有关房价数据集的更多信息,请参考上周的博文。
项目结构
让我们看看今天项目的结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── datasets.py
│ └── models.py
└── cnn_regression.py
1 directory, 4 files
我们将用附加的功能来更新上周教程中的datasets.py和models.py。
我们的训练脚本cnn_regression.py是本周全新的,它将利用前面提到的更新。
加载房价影像数据集
Figure 2: Our CNN accepts a single image — a montage of four images from the home. Using the montage, our CNN then uses regression to predict the value of the home with the Keras framework.
众所周知,我们的房价数据集包括与每栋房屋相关的四幅图像:
- 卧室
- 浴室
- 厨房
- 房子的正面图
但是我们如何利用这些图像来训练我们的 CNN 呢?
我们基本上有三种选择:
- 通过 CNN 一次传递一张图片,并使用房屋价格作为每张图片的目标值
** 利用带有 Keras 的多个输入,并有四个独立的类似 CNN 的分支,最终合并成一个输出* 创建一个蒙太奇,将所有四个图像组合/平铺成一个图像,然后通过 CNN 传送该蒙太奇*
*第一个选项是一个糟糕的选择 —我们将有多个目标价格相同的图片。
如果有的话,我们只是要结束“混淆”我们的有线电视新闻网,使网络无法学习如何将价格与输入图像相关联。
第二种选择也不是一个好主意——用四个独立的张量作为输入,网络在计算上会很浪费,并且更难训练。然后,每个分支都将拥有自己的一组 CONV 图层,这些图层最终需要合并成一个输出。
相反,我们应该选择第三个选项,我们将所有四个图像组合成一个单一图像,然后通过 CNN 传递该图像(如上面的图 2 所示)。
对于数据集中的每栋房屋,我们将创建一个相应的平铺图像,其中包括:
- 左上角的浴室图像
- 右上角的卧室图像
- 右下中的正视图
- 左下方的厨房
然后这个平铺的图像将通过 CNN,使用房价作为目标预测值。
这种方法的好处是我们:
- 允许 CNN 从房子的所有照片中学习,而不是试图一次一张地通过 CNN 传递房子的照片
- 使得 CNN 能够一次从所有房屋照片中学习区别滤波器(即,不会用具有相同目标预测值的不同图像“混淆”CNN)
为了了解如何为每栋房子平铺图像,让我们来看看datasets.py文件中的load_house_images函数:
def load_house_images(df, inputPath):
# initialize our images array (i.e., the house images themselves)
images = []
# loop over the indexes of the houses
for i in df.index.values:
# find the four images for the house and sort the file paths,
# ensuring the four are always in the *same order*
basePath = os.path.sep.join([inputPath, "{}_*".format(i + 1)])
housePaths = sorted(list(glob.glob(basePath)))
load_house_images函数接受两个参数:
df:房屋数据框。inputPath:我们的数据集路径。
使用这些参数,我们通过初始化一个images列表来继续,一旦被处理,该列表将被返回给调用函数。
从这里开始,我们在数据框中的索引上循环( Line 64 )。在循环中,我们:
- 构建
basePath到当前索引的四幅图像(第 67 行)。 - 使用
glob抓取四个图像路径(第 68 行)。
glob函数使用带有通配符的输入路径,然后查找所有匹配我们模式的输入路径。
在下一个代码块中,我们将填充一个包含四幅图像的列表:
# initialize our list of input images along with the output image
# after *combining* the four input images
inputImages = []
outputImage = np.zeros((64, 64, 3), dtype="uint8")
# loop over the input house paths
for housePath in housePaths:
# load the input image, resize it to be 32 32, and then
# update the list of input images
image = cv2.imread(housePath)
image = cv2.resize(image, (32, 32))
inputImages.append(image)
继续循环,我们继续:
- 初始化我们的
inputImages列表,并为我们的平铺图像outputImage( 第 72 行和第 73 行)分配内存。 - 在
housePaths( 第 76 行)上创建一个嵌套循环来加载每个image,调整大小为 32×32 ,并更新inputImages列表(第 79-81 行)。
从那里,我们将把四个图像拼接成一个蒙太奇,最终返回所有的蒙太奇:
# tile the four input images in the output image such the first
# image goes in the top-right corner, the second image in the
# top-left corner, the third image in the bottom-right corner,
# and the final image in the bottom-left corner
outputImage[0:32, 0:32] = inputImages[0]
outputImage[0:32, 32:64] = inputImages[1]
outputImage[32:64, 32:64] = inputImages[2]
outputImage[32:64, 0:32] = inputImages[3]
# add the tiled image to our set of images the network will be
# trained on
images.append(outputImage)
# return our set of images
return np.array(images)
为了结束循环,我们:
- 使用 NumPy 数组切片来平铺输入图像(行 87-90 )。
- 更新
images列表(第 94 行)。
一旦创建图块的过程完成,我们继续前进,将集合images返回给行 97 上的调用函数。
使用 Keras 实现用于回归的 CNN
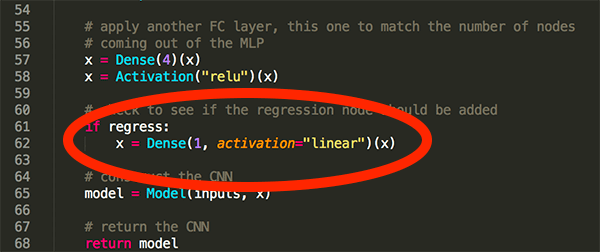
Figure 3: If we’re performing regression with a CNN, we’ll add a fully connected layer with linear activation.
让我们继续实现我们的 Keras CNN 进行回归预测。
打开models.py文件并插入以下代码:
def create_cnn(width, height, depth, filters=(16, 32, 64), regress=False):
# initialize the input shape and channel dimension, assuming
# TensorFlow/channels-last ordering
inputShape = (height, width, depth)
chanDim = -1
我们的create_cnn函数将返回我们的 CNN 模型,我们将在我们的训练脚本中编译和训练该模型。
create_cnn函数接受五个参数:
width:输入图像的宽度,单位为像素。height:输入图像有多少像素高。depth:图像的通道数。对于 RGB 图像,它是三。- 一组逐渐变大的过滤器,这样我们的网络可以学习更多有区别的特征。
regress:一个布尔值,表示是否将一个全连接的线性激活层附加到 CNN 用于回归目的。
我们网络的inputShape定义在线 29 上。它假设 TensorFlow 后端的“最后频道”排序。
让我们继续定义模型的输入,并开始创建我们的CONV => RELU > BN => POOL层集:
# define the model input
inputs = Input(shape=inputShape)
# loop over the number of filters
for (i, f) in enumerate(filters):
# if this is the first CONV layer then set the input
# appropriately
if i == 0:
x = inputs
# CONV => RELU => BN => POOL
x = Conv2D(f, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
我们的模型inputs定义在线 33 上。
从那里,在第 36 行的上,我们循环过滤并创建一组CONV => RELU > BN => POOL 层。循环的每次迭代都会附加这些层。请务必查看第 11 章的 Starter Bundle 的Deep Learning for Computer Vision with Python了解更多关于这些图层类型的信息。
让我们完成 CNN 的建设:
# flatten the volume, then FC => RELU => BN => DROPOUT
x = Flatten()(x)
x = Dense(16)(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Dropout(0.5)(x)
# apply another FC layer, this one to match the number of nodes
# coming out of the MLP
x = Dense(4)(x)
x = Activation("relu")(x)
# check to see if the regression node should be added
if regress:
x = Dense(1, activation="linear")(x)
# construct the CNN
model = Model(inputs, x)
# return the CNN
return model
我们Flatten下一层(第 49 行),然后添加一个带有BatchNormalization和Dropout ( 第 50-53 行)的全连接层。
应用另一个全连接层来匹配来自多层感知器的四个节点(行 57 和 58 )。
在行 61 和 62 上,进行检查以查看是否应该附加回归节点;然后相应地添加它。
最后,这个模型是由我们的inputs和我们组装在一起的所有图层x ( 第 65 行)构建而成的。
然后我们可以将model的return调用函数(第 68 行)。
实现回归训练脚本
现在,我们已经实现了数据集加载器实用函数以及 Keras CNN 回归,让我们继续创建训练脚本。
打开cnn_regression.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from pyimagesearch import datasets
from pyimagesearch import models
import numpy as np
import argparse
import locale
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input dataset of house images")
args = vars(ap.parse_args())
我们训练脚本的导入在第 2-9 行中处理。最值得注意的是,我们从datasets和models导入了我们的助手函数。locale计划将帮助我们格式化我们的货币。
在那里,我们使用 argparse : --dataset解析单个参数。这个标志和参数本身允许我们指定从终端到数据集的路径,而无需修改脚本。
现在让我们加载、预处理和分割我们的数据:
# construct the path to the input .txt file that contains information
# on each house in the dataset and then load the dataset
print("[INFO] loading house attributes...")
inputPath = os.path.sep.join([args["dataset"], "HousesInfo.txt"])
df = datasets.load_house_attributes(inputPath)
# load the house images and then scale the pixel intensities to the
# range [0, 1]
print("[INFO] loading house images...")
images = datasets.load_house_images(df, args["dataset"])
images = images / 255.0
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
split = train_test_split(df, images, test_size=0.25, random_state=42)
(trainAttrX, testAttrX, trainImagesX, testImagesX) = split
第 20 行上的inputPath包含 CSV 文件的路径,该文件包含数字和分类属性以及每栋房屋的目标价格。
我们的数据集是使用我们在上周的教程(第 21 行)中定义的load_house_attributes便利函数加载的。结果是一个 pandas 数据框df,包含数字/分类属性。
在本教程中没有使用实际的数字和分类属性,但是我们确实使用了数据框,以便使用我们在今天的博文中定义的便利函数加载第 26 行的中的images。
我们继续将图像的像素强度缩放到第 27 行上的【0,1】范围。
然后,我们的数据集训练和测试分割使用 scikit-learn 的便利的train_test_split函数(第 31 行和第 32 行)构建。
同样,我们今天不会使用数字/分类数据,只使用图像本身。本系列的第一部分(上周)和第三部分(下周)中使用了数字/分类数据。
现在,让我们调整定价数据并训练我们的模型:
# find the largest house price in the training set and use it to
# scale our house prices to the range [0, 1] (will lead to better
# training and convergence)
maxPrice = trainAttrX["price"].max()
trainY = trainAttrX["price"] / maxPrice
testY = testAttrX["price"] / maxPrice
# create our Convolutional Neural Network and then compile the model
# using mean absolute percentage error as our loss, implying that we
# seek to minimize the absolute percentage difference between our
# price *predictions* and the *actual prices*
model = models.create_cnn(64, 64, 3, regress=True)
opt = Adam(lr=1e-3, decay=1e-3 / 200)
model.compile(loss="mean_absolute_percentage_error", optimizer=opt)
# train the model
print("[INFO] training model...")
model.fit(x=trainImagesX, y=trainY,
validation_data=(testImagesX, testY),
epochs=200, batch_size=8)
这里我们有:
- 根据
maxPrice( 第 37-39 行)将房价缩放至【0,1】区间。执行这种缩放将导致更好的训练和更快的收敛。 - 使用
Adam优化器(第 45-47 行)创建并编译我们的模型。我们使用平均绝对百分比误差作为我们的损失函数,并且我们已经设置regress=True表示我们想要执行回归。 - 在培训过程中被踢出(第 51-53 行)。
现在让我们来评估结果!
# make predictions on the testing data
print("[INFO] predicting house prices...")
preds = model.predict(testImagesX)
# compute the difference between the *predicted* house prices and the
# *actual* house prices, then compute the percentage difference and
# the absolute percentage difference
diff = preds.flatten() - testY
percentDiff = (diff / testY) * 100
absPercentDiff = np.abs(percentDiff)
# compute the mean and standard deviation of the absolute percentage
# difference
mean = np.mean(absPercentDiff)
std = np.std(absPercentDiff)
# finally, show some statistics on our model
locale.setlocale(locale.LC_ALL, "en_US.UTF-8")
print("[INFO] avg. house price: {}, std house price: {}".format(
locale.currency(df["price"].mean(), grouping=True),
locale.currency(df["price"].std(), grouping=True)))
print("[INFO] mean: {:.2f}%, std: {:.2f}%".format(mean, std))
为了使用回归评估基于图像数据的房价模型,我们:
- 对测试数据进行预测(第 57 行)。
- 计算绝对百分比差异(第 62-64 行),并使用它来导出我们的最终指标(第 68 和 69 行)。
- 在我们的终端显示评估信息(第 73-76 行)。
那是一个包裹,但是…
不要被这个培训脚本的简洁所迷惑!
在引擎盖下有很多事情正在进行,我们的便利函数加载数据+创建 CNN 和调整所有神经元权重的训练过程。要温习卷积神经网络,请参考 的 Starter Bundle 用 Python 进行计算机视觉深度学习 。
训练我们的回归 CNN
准备好训练你的 Keras CNN 进行回归预测了吗?
确保你有:
- 根据上周的教程配置你的开发环境。
- 使用本教程的 【下载】 部分下载源代码。
- 使用“用图像预测房价?”中的说明下载房价数据集上一节。
从那里,打开一个终端并执行以下命令:
$ python cnn_regression.py --dataset ~/Houses-dataset/Houses\ Dataset/
[INFO] loading house attributes...
[INFO] loading house images...
[INFO] training model...
Epoch 1/200
34/34 [==============================] - 0s 9ms/step - loss: 1839.4242 - val_loss: 342.6158
Epoch 2/200
34/34 [==============================] - 0s 4ms/step - loss: 1117.5648 - val_loss: 143.6833
Epoch 3/200
34/34 [==============================] - 0s 3ms/step - loss: 682.3041 - val_loss: 188.1647
Epoch 4/200
34/34 [==============================] - 0s 3ms/step - loss: 642.8157 - val_loss: 228.8398
Epoch 5/200
34/34 [==============================] - 0s 3ms/step - loss: 565.1772 - val_loss: 740.4736
Epoch 6/200
34/34 [==============================] - 0s 3ms/step - loss: 460.3651 - val_loss: 1478.7289
Epoch 7/200
34/34 [==============================] - 0s 3ms/step - loss: 365.0139 - val_loss: 1918.3398
Epoch 8/200
34/34 [==============================] - 0s 3ms/step - loss: 368.6264 - val_loss: 2303.6936
Epoch 9/200
34/34 [==============================] - 0s 4ms/step - loss: 377.3214 - val_loss: 1325.1755
Epoch 10/200
34/34 [==============================] - 0s 3ms/step - loss: 266.5995 - val_loss: 1188.1686
...
Epoch 195/200
34/34 [==============================] - 0s 4ms/step - loss: 35.3417 - val_loss: 107.2347
Epoch 196/200
34/34 [==============================] - 0s 3ms/step - loss: 37.4725 - val_loss: 74.4848
Epoch 197/200
34/34 [==============================] - 0s 3ms/step - loss: 38.4116 - val_loss: 102.9308
Epoch 198/200
34/34 [==============================] - 0s 3ms/step - loss: 39.8636 - val_loss: 61.7900
Epoch 199/200
34/34 [==============================] - 0s 3ms/step - loss: 41.9374 - val_loss: 71.8057
Epoch 200/200
34/34 [==============================] - 0s 4ms/step - loss: 40.5261 - val_loss: 67.6559
[INFO] predicting house prices...
[INFO] avg. house price: $533,388.27, std house price: $493,403.08
[INFO] mean: 67.66%, std: 78.06%
我们的平均绝对百分比误差开始非常高,在第一个十代中为 300-2000 %;然而,当培训结束时,我们的培训损失要低得多,只有 40%。
然而,问题是我们显然吃得太多了。
虽然我们的培训损失为 40%,但我们的验证损失为 67.66% ,这意味着,平均而言,我们的网络对房价的预测将会降低约 68%。
怎样才能提高自己的预测准确率?
总的来说,我们的 CNN 得到的平均绝对误差为 67.66% ,这意味着,平均而言,我们的 CNN 对房价的预测将会比低 68%。
这是一个相当糟糕的结果,因为我们对数字和分类数据进行简单的 MLP 训练得到的平均绝对误差为 T2 的 22.71%,比 T4 的 67.66%好得多。
那么,这意味着什么呢?
这是否意味着 CNN 不适合回归任务,我们不应该使用它们进行回归?
事实上,不——完全不是那个意思。
相反,这意味着房子的内部并不一定与房子的价格相关。
例如,让我们假设在加利福尼亚州贝弗利山有一个价值 10,000,000 美元的超豪华名人住宅。
现在,让我们把同样的家搬到森林公园,这是底特律最糟糕的 T2 地区之一。
在这个社区,平均房价是 13,000 美元——你认为那个内部装饰华丽的名人豪宅还会值 10,000,000 美元吗?
当然不是。
房子的价格不仅仅是室内装潢。我们还必须考虑当地房地产市场本身的因素。
影响房价的因素有很多,但总的来说,T2 最重要的因素之一是当地本身。
因此,我们的 CNN 在房屋图像上的表现不如简单的 MLP 在数字和分类属性上的表现,这并不奇怪。
但这确实提出了一个问题:
- 是否有可能将我们的数字/分类数据与我们的图像数据结合起来,训练一个单一的端到端网络?
- 如果是这样,我们的房价预测精度会提高吗?
下周我会回答这个问题,敬请关注。
摘要
在今天的教程中,您学习了如何使用 Keras 训练卷积神经网络(CNN)进行回归预测。
实现用于回归预测的 CNN 很简单:
- 移除通常用于分类的全连接 softmax 分类器图层
- 取而代之的是具有单个节点的全连接层以及线性激活函数。
- 用均方误差、平均绝对误差、平均绝对百分比误差等连续值预测损失函数训练模型。
让这种方法如此强大的是,它意味着我们可以微调现有模型进行回归预测——只需移除旧的 FC + softmax 层,添加一个具有线性激活的单节点 FC 层,更新您的损失方法,然后开始训练!
如果你有兴趣了解更多关于迁移学习和预训练模型上的微调,请参考我的书, 用 Python 进行计算机视觉的深度学习 ,我在其中详细讨论了迁移学习和微调。
在下周的教程中,我将向您展示如何使用 Keras 处理混合数据,包括将分类、数字和图像数据组合成一个单一网络。
要下载这篇文章的源代码,并在下周文章发表时得到通知,请务必在下面的表格中输入您的电子邮件地址!***


 浙公网安备 33010602011771号
浙公网安备 33010602011771号