PyImgSearch-博客中文翻译-九-
PyImgSearch 博客中文翻译(九)
OpenCV 平滑和模糊
原文:https://pyimagesearch.com/2021/04/28/opencv-smoothing-and-blurring/
在本教程中,您将学习如何使用 OpenCV 进行平滑和模糊处理。
我们将涵盖以下模糊操作
- 简单模糊(
cv2.blur) - 加权高斯模糊(
cv2.GaussianBlur) - 中值滤波(
cv2.medianBlur) - 双侧模糊(
cv2.bilateralFilter)
在本教程结束时,你将能够自信地将 OpenCV 的模糊功能应用到你自己的图像中。
要学习如何用 OpenCV 执行平滑和模糊, 继续阅读。
OpenCV 平滑和模糊
我很确定我们都知道模糊是什么。从视觉上来说,这就是当你的相机拍摄一张失焦的照片时会发生的情况。图像中较清晰的区域会丢失细节。这里的目标是使用低通滤波器来减少图像中的噪声和细节。
实际上,这意味着图像中的每个像素都与其周围的像素亮度混合在一起。这种邻域像素的“混合”成为我们的模糊像素。
虽然这种效果在我们的照片中通常是不需要的,但实际上在执行图像处理任务时,非常有用。其实平滑模糊是计算机视觉和图像处理中最常见的预处理步骤之一。
*例如,我们可以看到在 PyImageSearch 博客上构建简单文档扫描仪时应用了模糊。当测量从一个物体到我们的相机的距离时,我们也应用平滑来帮助我们找到我们的标记。在这两个例子中,图像中较小的细节被平滑掉了,我们得到了图像更多的结构方面。
正如我们将在这一系列教程中看到的,如果图像首先被平滑或模糊,许多图像处理和计算机视觉功能,如阈值处理和边缘检测,会表现得更好。
为什么平滑和模糊是如此重要的预处理操作?
平滑和模糊是计算机视觉和图像处理中最重要的预处理步骤之一。通过在应用诸如边缘检测或阈值等技术之前平滑图像,我们能够减少高频内容的数量,例如噪声和边缘(即图像的“细节”)。
虽然这听起来可能有违直觉,但通过减少图像中的细节,我们可以更容易地找到我们感兴趣的对象。
此外,这使我们能够专注于图像中更大的结构对象。
在本课的剩余部分,我们将讨论您在自己的项目中经常使用的四个主要平滑和模糊选项:
- 简单平均模糊
- 高斯模糊
- 中值滤波
- 双边过滤
让我们开始吧。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们学习如何用 OpenCV 应用模糊之前,让我们先回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像:
$ tree . --dirsfirst
.
├── adrian.png
├── bilateral.py
└── blurring.py
0 directories, 3 files
我们的第一个脚本,blurring.py,将向您展示如何使用 OpenCV 将平均模糊、高斯模糊和中值模糊应用于图像(adrian.png)。
第二个 Python 脚本bilateral.py,将演示如何使用 OpenCV 对我们的输入图像应用双边模糊。
平均模糊度(cv2.blur )
我们要探索的第一个模糊方法是平均。
平均滤镜的功能与您想象的完全一样,即获取中心像素周围的像素区域,对所有这些像素进行平均,并用平均值替换中心像素。
通过取像素周围区域的平均值,我们对其进行平滑,并用其局部邻域的值替换它。这使我们能够简单地依靠平均值来减少噪声和细节层次。
还记得我们讨论过的内核和卷积吗?事实证明,我们不仅可以将内核用于边缘检测和梯度,还可以用于平均!
为了完成我们的平均模糊,我们实际上会用一个 来卷积我们的图像
来卷积我们的图像
normalized filter where both  and
and  are both odd integers.
are both odd integers.
对于输入图像中的每个像素,这个内核将从左到右、从上到下滑动。然后,位于内核中心的像素(因此我们必须使用奇数,否则就不会有真正的“中心”)被设置为周围所有其他像素的平均。
让我们继续定义一个
average kernel that can be used to blur the central pixel with a 3 pixel radius:
![K = \displaystyle\frac{1}{9} \left[\begin{tabular}{ccc}1 & 1 & 1\ 1 & 1 & 1\ 1 & 1 & 1\end{tabular}\right]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/cb7594f7d266ce0ae4b423d4c4a2d460.png "K = \displaystyle\frac{1}{9} \left[\begin{tabular}{ccc}1 & 1 & 1\ 1 & 1 & 1\ 1 & 1 & 1\end{tabular}\right]")
注意内核矩阵的每一项是如何被均匀加权的 — 我们给内核中的所有像素以相等的权重。另一种方法是给像素不同的权重,其中离中心像素越远的像素对平均值的贡献越小;我们将在本课的高斯模糊部分讨论这种平滑方法。
我们也可以定义一个
average kernel:
![K = \displaystyle\frac{1}{25} \left[\begin{tabular}{ccccc}1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\end{tabular}\right]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/6bf4d2f1ab05656e4f88bda32f62ea3c.png "K = \displaystyle\frac{1}{25} \left[\begin{tabular}{ccccc}1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\ 1 & 1 & 1 & 1 & 1\end{tabular}\right]")
这个内核考虑了更多的平均像素,并且会使图像比更加模糊
kernel since the kernel covers more area of the image.
因此,这给我们带来了一个重要的规则:随着内核大小的增加,图像模糊的程度也会增加。
简单地说:你的平滑内核越大,你的图像看起来就越模糊。
为了研究这个概念,让我们探索一些代码。打开项目目录结构中的blurring.py文件,让我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的包,而第 6-9 行解析我们的命令行参数。
我们只需要一个参数--image,它是我们希望对其应用平滑和模糊的磁盘上的输入图像的路径。默认情况下,我们将这个参数设置为adrian.png。
现在让我们从磁盘加载输入图像:
# load the image, display it to our screen, and initialize a list of
# kernel sizes (so we can evaluate the relationship between kernel
# size and amount of blurring)
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
kernelSizes = [(3, 3), (9, 9), (15, 15)]
# loop over the kernel sizes
for (kX, kY) in kernelSizes:
# apply an "average" blur to the image using the current kernel
# size
blurred = cv2.blur(image, (kX, kY))
cv2.imshow("Average ({}, {})".format(kX, kY), blurred)
cv2.waitKey(0)
第 14 行和第 15 行从磁盘加载我们的输入image并显示到我们的屏幕上。
然后,我们在第 16 行的上定义了一个kernelSizes列表——这些内核的大小逐渐增加,这样我们就可以直观地看到内核大小对输出图像的影响。
从那里,我们开始在第 19 行的上循环每个内核大小。
为了平均模糊图像,我们使用cv2.blur函数。这个函数需要两个参数:我们想要模糊的图像和内核的大小。
正如第 22-24 行所示,我们通过增加内核大小来模糊我们的图像。我们的内核变得越大,我们的图像就越模糊。
当您运行该脚本时,您将在应用cv2.blur函数后收到以下输出:
在左上角的上,我们有我们的原始输入图像。在右上角的,我们用对其进行了模糊处理**
*kernel. The image is only slightly more blurred at this point, and the only noticeable area of the blur is around the facial region. However, by the time we get to a kernel size of  and
and  , the image becomes practically unrecognizable.
, the image becomes practically unrecognizable.
同样,随着内核大小的增加,你的图像会变得越来越模糊。这很容易导致图像中重要结构物体的边缘丢失。在开发自己的计算机视觉应用时,选择合适的平滑量是非常关键的。
虽然平均平滑很容易理解,但它也对内核区域内的每个像素进行了平均加权——这样做很容易使我们的图像过度模糊,并错过重要的边缘。我们可以通过应用高斯模糊来解决这个问题。
高斯模糊(cv2。高斯布鲁)
接下来,我们将回顾高斯模糊。高斯模糊类似于平均模糊,但我们现在使用的不是简单的平均值,而是加权平均值,其中靠近中心像素的邻域像素对平均值的贡献更大。
顾名思义,高斯平滑用于去除近似遵循高斯分布的噪声。
最终结果是,我们的图像不那么模糊,但比使用上一节讨论的平均方法更“自然模糊”。此外,基于这种加权,与平均平滑相比,我们将能够在图像中保留更多的边缘。
就像平均模糊一样,高斯平滑也使用的内核
, where both and are odd integers.
然而,由于我们是根据像素与中心像素的距离来加权像素,所以我们需要一个等式来构造我们的内核。一个方向上的高斯函数的等式为:
 = \displaystyle\frac{1}{\displaystyle\sqrt{2\pi\sigma}}e^{-\frac{x^{2}}{2\sigma^{2}}}")
然后,将这个方程扩展到两个方向就变得很简单了,一个方向是 x 轴,另一个方向是 y 轴😗*
** = \displaystyle\frac{1}{2\pi\sigma}e^{-\frac{x^{2} + y^{2}}{2\sigma^{2}}}")
其中
and  are the respective distances to the horizontal and vertical center of the kernel and
are the respective distances to the horizontal and vertical center of the kernel and  is the standard deviation of the Gaussian kernel.
is the standard deviation of the Gaussian kernel.
同样,正如我们将在下面的代码中看到的,当我们的内核大小增加时,应用于输出图像的模糊量也会增加。然而,与简单的平均平滑相比,模糊会显得更加“自然”,并且会更好地保留图像中的边缘:
# close all windows to cleanup the screen
cv2.destroyAllWindows()
cv2.imshow("Original", image)
# loop over the kernel sizes again
for (kX, kY) in kernelSizes:
# apply a "Gaussian" blur to the image
blurred = cv2.GaussianBlur(image, (kX, kY), 0)
cv2.imshow("Gaussian ({}, {})".format(kX, kY), blurred)
cv2.waitKey(0)
第 27 行和第 28 行简单地关闭所有打开的窗口,显示我们的原始图像作为参考点。
通过使用cv2.GaussianBlur功能,实际的高斯模糊发生在线 31-35 上。该函数的第一个参数是我们想要模糊的图像。然后,类似于cv2.blur,我们提供一个元组来表示我们的内核大小。同样,我们从一个小的内核大小开始
and start to increase it.
最后一个参数是我们的
, the standard deviation of the Gaussian distribution. By setting this value to 0, we are instructing OpenCV to automatically compute based on our kernel size.
在大多数情况下,你会想让你的
be computed for you. But in the case you want to supply for yourself, I would suggest reading through the OpenCV documentation on cv2.GaussianBlur to ensure you understand the implications.
我们可以在图 3 中看到高斯模糊的输出:
与使用图 2 中的平均方法相比,我们的图像具有更少的模糊效果;然而,由于加权平均值的计算,模糊本身更自然,而不是允许核邻域中的所有像素具有相等的权重。
总的来说,我倾向于建议从简单的高斯模糊开始,并根据需要调整参数。虽然高斯模糊比简单的平均模糊稍慢(只慢很小一部分),但高斯模糊往往会产生更好的结果,尤其是在应用于自然图像时。
中值模糊(cv2.medianBlur )
传统上,中值模糊方法在去除椒盐噪声时最为有效。这种类型的噪音听起来就是这样:想象一下拍一张照片,把它放在你的餐桌上,并在上面撒上盐和胡椒。使用中值模糊法,你可以去除图像中的盐和胡椒。
当应用中值模糊时,我们首先定义我们的内核大小。然后,如同在平均模糊方法中一样,我们考虑大小为 的邻域中的所有像素
的邻域中的所有像素
where  is an odd integer.
is an odd integer.
请注意,与平均模糊和高斯模糊不同,它们的内核大小可以是矩形的,而中值的内核大小必须是 T2 的正方形。此外(与平均方法不同),我们不是用邻域的平均值替换中心像素,而是用邻域的中值替换中心像素。
中值模糊在去除图像中的椒盐噪声方面更有效的原因是,每个中心像素总是被图像中存在的像素强度所替换。由于中位数对异常值是稳健的,因此与其他统计方法(如平均值)相比,椒盐噪声对中位数的影响较小。
同样,诸如平均和高斯计算方法或加权方法用于邻域-该平均像素强度可能存在或可能不存在于邻域中。但是根据定义,中值像素必须存在于我们的邻域中。通过用中值而不是平均值替换我们的中心像素,我们可以大大减少噪声。
让我们现在应用我们的中间模糊:
# close all windows to cleanup the screen
cv2.destroyAllWindows()
cv2.imshow("Original", image)
# loop over the kernel sizes a final time
for k in (3, 9, 15):
# apply a "median" blur to the image
blurred = cv2.medianBlur(image, k)
cv2.imshow("Median {}".format(k), blurred)
cv2.waitKey(0)
应用中值模糊是通过调用cv2.medianBlur函数来完成的。这个方法有两个参数:我们想要模糊的图像和我们内核的大小。
在第 42 行的处,我们开始遍历(正方形)内核大小。我们从内核大小3开始,然后增加到9和15。
产生的中值模糊图像然后叠加并显示给我们,如图 4 所示:
请注意,我们不再像在平均和高斯模糊中那样创建“运动模糊”效果——相反,我们正在移除更多的细节和噪声。
例如,看看图片中我右边的岩石的颜色。随着我们内核大小的增加,岩石的细节和颜色变得不那么明显。当我们使用一个
kernel the rocks have lost almost all detail and look like a big “blob.”
对于图像中我的脸来说也是如此——随着内核大小的增加,我的脸迅速失去细节,实际上融合在一起。
中值模糊绝不是高斯平滑那样的“自然模糊”。然而,对于在非常不理想的条件下拍摄的受损图像或照片,在将图像传递给其他方法(如阈值处理和边缘检测)之前,中值模糊作为预处理步骤确实有所帮助。
双侧模糊(cv2 .双边过滤器)
我们要探索的最后一种方法是双边模糊。
到目前为止,我们模糊方法的目的是减少图像中的噪声和细节;然而,作为一个副作用,我们往往会失去图像的边缘。
为了在保持边缘的同时减少噪声,我们可以使用双边模糊。双边模糊通过引入两个高斯分布来实现这一点。
第一个高斯函数只考虑空间邻居。也就是说,在") 中出现在一起的像素
中出现在一起的像素
-coordinate space of the image. The second Gaussian then models the pixel intensity of the neighborhood, ensuring that only pixels with similar intensity are included in the actual computation of the blur.
直觉上,这是有道理的。如果相同(小)邻域中的像素具有相似的像素值,那么它们很可能表示相同的对象。但是,如果同一个邻域中的两个像素具有相反的值,那么我们可能会检查对象的边缘或边界,并且我们希望保留这个边缘。
总的来说,这种方法能够保留图像的边缘,同时还能减少噪声。这种方法最大的缺点是它比平均、高斯和中值模糊方法慢得多。
让我们深入研究一下双侧模糊的代码。打开项目目录结构中的bilateral.py文件,我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
同样,只需要一个参数--image,它是我们希望对其应用双边模糊的输入图像的路径。
现在让我们从磁盘加载我们的映像:
# load the image, display it to our screen, and construct a list of
# bilateral filtering parameters that we are going to explore
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
params = [(11, 21, 7), (11, 41, 21), (11, 61, 39)]
# loop over the diameter, sigma color, and sigma space
for (diameter, sigmaColor, sigmaSpace) in params:
# apply bilateral filtering to the image using the current set of
# parameters
blurred = cv2.bilateralFilter(image, diameter, sigmaColor, sigmaSpace)
# show the output image and associated parameters
title = "Blurred d={}, sc={}, ss={}".format(
diameter, sigmaColor, sigmaSpace)
cv2.imshow(title, blurred)
cv2.waitKey(0)
然后,我们在第 15 行的上定义一个模糊参数列表。这些参数对应于直径,
, and  of the bilateral filter, respectively.
of the bilateral filter, respectively.
从那里,我们在行 18 上循环这些参数集,并通过调用行 21 上的cv2.bilateralFilter来应用双边过滤。
最后,第 24-27 行将我们模糊的图像显示到屏幕上。
让我们花点时间回顾一下我们提供给cv2.bilateralFilter的参数。我们提供的第一个参数是我们想要模糊的图像。然后,我们需要定义像素邻域的直径——直径越大,模糊计算中包含的像素就越多。把这个参数想象成一个方形的内核大小。
第三个参数是我们的颜色标准偏差,记为
. A larger value for means that more colors in the neighborhood will be considered when computing the blur. If we let get too large in respect to the diameter, then we essentially have broken the assumption of bilateral filtering — that only pixels of similar color should contribute significantly to the blur.
最后,我们需要提供空间标准偏差,我们称之为
. A larger value of means that pixels farther out from the central pixel diameter will influence the blurring calculation.
当您执行这个脚本时,您将看到双边过滤的以下输出:
在左上角的上,我们有我们的原始输入图像。在右上角的,我们从直径为 开始**
开始**
*pixels,  , and
, and  .
.
我们的模糊效果还没有完全显现出来,但是如果你放大岩石,并与我们的原始图像进行比较,你会注意到大部分纹理已经消失了!这些岩石看起来光滑多了,就好像它们被年复一年的流水侵蚀和磨平了一样。然而,湖泊和岩石之间的边缘和边界清晰地保留了下来。
现在,看看左下方,我们增加了两个
and jointly. At this point we can really see the effects of bilateral filtering.
我黑色连帽衫上的纽扣几乎消失了,我皮肤上几乎所有的细节和皱纹都被去除了。然而与此同时,在我和图像背景之间仍然有一个清晰的界限。如果我们使用平均或高斯模糊,背景将与前景融合。
最后,我们有右下角的,我在这里增加了
*and yet again, just to demonstrate how powerful of a technique bilateral filtering is.
现在几乎所有的岩石、水、天空以及我的皮肤和连帽衫的细节和纹理都消失了。它也开始看起来好像图像中的颜色数量已经减少。
同样,这是一个夸张的例子,你可能不会对图像应用这么多模糊,但它确实展示了双边滤波对你的边缘的影响:显著平滑的细节和纹理,同时仍然保留边界和边缘。
所以你有它——模糊技术概述!如果还不完全清楚何时使用每种模糊或平滑方法,那也没关系。在这一系列的教程中,我们将基本上建立在这些模糊技术的基础上,你将会看到很多关于何时应用每种类型的模糊的例子。目前,试着消化这些材料,把模糊和平滑作为你工具箱中的另一个工具。
OpenCV 虚化结果
准备好运行平滑和模糊脚本了吗?
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
然后,您可以通过执行blurring.py脚本来应用基本的平滑和模糊:
$ python blurring.py
要查看双向模糊的输出,请运行以下命令:
$ python bilateral.py
这些脚本的输出应该与我上面提供的图像和图形相匹配。
总结
在本教程中,我们学习了如何使用 OpenCV 平滑和模糊图像。我们从讨论内核在平滑和模糊中的作用开始。
然后,我们回顾了在 OpenCV 中平滑图像的四种主要方法:
- 简单平均模糊
- 高斯模糊
- 中值滤波
- 双边过滤
简单平均法速度很快,但可能无法保留图像中的边缘。
应用高斯模糊可以更好地保留边缘,但比平均方法稍慢。
中值滤波器主要用于减少椒盐噪声,因为中值统计比平均值等其他统计方法更稳健,对异常值更不敏感。
最后,双边滤波器保留了边缘,但是比其他方法慢得多。双边滤波还拥有最多要调整的参数,要正确调整这些参数可能会很麻烦。
总的来说,我建议从简单的高斯模糊开始获得基线,然后从那里开始。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!******
OpenCV 社交距离检测器
原文:https://pyimagesearch.com/2020/06/01/opencv-social-distancing-detector/
在本教程中,您将学习如何使用 OpenCV、深度学习和计算机视觉来实现新冠肺炎社交距离探测器。
今天的教程是受 PyImageSearch 读者 Min-Jun 的启发,他发邮件问:
嗨,阿德里安,
我已经看到计算机视觉社区的一些人实现了“社交距离探测器”,但我不确定他们是如何工作的。
你会考虑就这个话题写一篇教程吗?
谢谢你。
Min-Jun 是正确的——我在社交媒体上看到过许多社交距离检测器的实现,我最喜欢的是来自 reddit 用户 danlapko 和 T2 Rohit Kumar Srivastava 的实现。
今天,我将为你提供一个你自己的社交距离探测器的起点。然后,您可以在认为合适的时候扩展它,以开发您自己的项目。
要了解如何用 OpenCV 实现社交距离检测器,请继续阅读。
OpenCV 社交距离检测器
在本教程的第一部分,我们将简要讨论什么是社交距离,以及如何使用 OpenCV 和深度学习来实现社交距离检测器。
然后,我们将回顾我们的项目目录结构,包括:
- 我们的配置文件用来保持我们的实现整洁
- 我们的
detect_people实用功能,使用 YOLO 物体检测器检测视频流中的人 - 我们的 Python 驱动程序脚本,它将所有部分粘合在一起,成为一个成熟的 OpenCV 社交距离检测器
我们将通过回顾结果来结束这篇文章,包括对局限性和未来改进的简短讨论。
什么是社交距离?
社会距离是一种用来控制传染病传播的方法。
顾名思义,社交距离意味着人们应该在身体上远离彼此,减少密切接触,从而减少传染病(如冠状病毒)的传播:
社交距离并不是一个新概念,可以追溯到五世纪(来源),甚至在《圣经》等宗教文献中也有提及:
那患了灾病的麻疯病人……他要独自居住;他的住处必在营外。—《利未记》13:46
社交距离可以说是防止疾病传播的最有效的非药物方法——根据定义,如果人们不在一起,他们就不能传播细菌。
将 OpenCV、计算机视觉和深度学习用于社交距离
我们可以使用 OpenCV、计算机视觉和深度学习来实现社交距离检测器。
构建社交距离检测器的步骤包括:
- 应用对象检测来检测视频流中的所有人(仅和人)(参见本教程关于构建 OpenCV 人物计数器)
- 计算所有检测到的人之间的成对距离
- 基于这些距离,检查任何两个人之间的距离是否小于 N 像素
为了获得最精确的结果,你应该通过内部/外部参数校准你的相机,这样你就可以将像素映射到可测单位。
一种更简单(但不太准确)的替代方法是应用三角形相似性校准(如本教程中的所述)。
这两种方法都可以用来将像素映射到可测量的单位。
最后,如果你不想/不能应用相机校准,你仍然可以利用社交距离探测器,但是你必须严格依赖像素距离,这不一定是准确的。
为了简单起见,我们的 OpenCV 社交距离检测器实现将依赖于像素距离——我将把它留给读者作为一个练习,以便您在认为合适的时候扩展实现。
项目结构
一定要从这篇博文的 【下载】 部分抓取代码。从那里,提取文件,并使用tree命令查看我们的项目是如何组织的:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── detection.py
│ └── social_distancing_config.py
├── yolo-coco
│ ├── coco.names
│ ├── yolov3.cfg
│ └── yolov3.weights
├── output.avi
├── pedestrians.mp4
└── social_distance_detector.py
2 directories, 9 files
让我们在下一节深入研究 Python 配置文件。
我们的配置文件
为了帮助保持代码整洁有序,我们将使用一个配置文件来存储重要的变量。
现在让我们来看看它们——打开pyimagesearch模块中的social_distancing_config.py文件,看一看:
# base path to YOLO directory
MODEL_PATH = "yolo-coco"
# initialize minimum probability to filter weak detections along with
# the threshold when applying non-maxima suppression
MIN_CONF = 0.3
NMS_THRESH = 0.3
这里,我们有到 YOLO 对象检测模型的路径(线 2 )。我们还定义了最小目标检测置信度和非极大值抑制阈值。
我们还要定义两个配置常数:
# boolean indicating if NVIDIA CUDA GPU should be used
USE_GPU = False
# define the minimum safe distance (in pixels) that two people can be
# from each other
MIN_DISTANCE = 50
第 10 行上的USE_GPU布尔值表示您的支持 NVIDIA CUDA 的 GPU 是否将用于加速推理(要求 OpenCV 的“dnn”模块安装有 NVIDIA GPU 支持)。
Line 14 定义了人们为了遵守社交距离协议而必须保持的最小距离(以像素为单位)。
用 OpenCV 检测图像和视频流中的人物
# import the necessary packages
from .social_distancing_config import NMS_THRESH
from .social_distancing_config import MIN_CONF
import numpy as np
import cv2
def detect_people(frame, net, ln, personIdx=0):
# grab the dimensions of the frame and initialize the list of
# results
(H, W) = frame.shape[:2]
results = []
# construct a blob from the input frame and then perform a forward
# pass of the YOLO object detector, giving us our bounding boxes
# and associated probabilities
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
net.setInput(blob)
layerOutputs = net.forward(ln)
# initialize our lists of detected bounding boxes, centroids, and
# confidences, respectively
boxes = []
centroids = []
confidences = []
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability)
# of the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# filter detections by (1) ensuring that the object
# detected was a person and (2) that the minimum
# confidence is met
if classID == personIdx and confidence > MIN_CONF:
# scale the bounding box coordinates back relative to
# the size of the image, keeping in mind that YOLO
# actually returns the center (x, y)-coordinates of
# the bounding box followed by the boxes' width and
# height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top
# and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates,
# centroids, and confidences
boxes.append([x, y, int(width), int(height)])
centroids.append((centerX, centerY))
confidences.append(float(confidence))
# apply non-maxima suppression to suppress weak, overlapping
# bounding boxes
idxs = cv2.dnn.NMSBoxes(boxes, confidences, MIN_CONF, NMS_THRESH)
# ensure at least one detection exists
if len(idxs) > 0:
# loop over the indexes we are keeping
for i in idxs.flatten():
# extract the bounding box coordinates
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# update our results list to consist of the person
# prediction probability, bounding box coordinates,
# and the centroid
r = (confidences[i], (x, y, x + w, y + h), centroids[i])
results.append(r)
# return the list of results
return results
利用 OpenCV 和深度学习实现社交距离检测器
# import the necessary packages
from pyimagesearch import social_distancing_config as config
from pyimagesearch.detection import detect_people
from scipy.spatial import distance as dist
import numpy as np
import argparse
import imutils
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, default="",
help="path to (optional) input video file")
ap.add_argument("-o", "--output", type=str, default="",
help="path to (optional) output video file")
ap.add_argument("-d", "--display", type=int, default=1,
help="whether or not output frame should be displayed")
args = vars(ap.parse_args())
# load the COCO class labels our YOLO model was trained on
labelsPath = os.path.sep.join([config.MODEL_PATH, "coco.names"])
LABELS = open(labelsPath).read().strip().split("\n")
# derive the paths to the YOLO weights and model configuration
weightsPath = os.path.sep.join([config.MODEL_PATH, "yolov3.weights"])
configPath = os.path.sep.join([config.MODEL_PATH, "yolov3.cfg"])
在这里,我们加载我们的 load COCO 标签(行 22 和 23 )以及定义我们的 YOLO 路径(行 26 和 27 )。
使用 YOLO 路径,现在我们可以将模型加载到内存中:
# load our YOLO object detector trained on COCO dataset (80 classes)
print("[INFO] loading YOLO from disk...")
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
# check if we are going to use GPU
if config.USE_GPU:
# set CUDA as the preferable backend and target
print("[INFO] setting preferable backend and target to CUDA...")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
# determine only the *output* layer names that we need from YOLO
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# initialize the video stream and pointer to output video file
print("[INFO] accessing video stream...")
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
writer = None
# loop over the frames from the video stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# resize the frame and then detect people (and only people) in it
frame = imutils.resize(frame, width=700)
results = detect_people(frame, net, ln,
personIdx=LABELS.index("person"))
# initialize the set of indexes that violate the minimum social
# distance
violate = set()
# ensure there are *at least* two people detections (required in
# order to compute our pairwise distance maps)
if len(results) >= 2:
# extract all centroids from the results and compute the
# Euclidean distances between all pairs of the centroids
centroids = np.array([r[2] for r in results])
D = dist.cdist(centroids, centroids, metric="euclidean")
# loop over the upper triangular of the distance matrix
for i in range(0, D.shape[0]):
for j in range(i + 1, D.shape[1]):
# check to see if the distance between any two
# centroid pairs is less than the configured number
# of pixels
if D[i, j] < config.MIN_DISTANCE:
# update our violation set with the indexes of
# the centroid pairs
violate.add(i)
violate.add(j)
如果我们不能可视化结果,我们的应用程序会有什么乐趣呢?
我说,一点也不好玩!因此,让我们用矩形、圆形和文本来注释我们的框架:
# loop over the results
for (i, (prob, bbox, centroid)) in enumerate(results):
# extract the bounding box and centroid coordinates, then
# initialize the color of the annotation
(startX, startY, endX, endY) = bbox
(cX, cY) = centroid
color = (0, 255, 0)
# if the index pair exists within the violation set, then
# update the color
if i in violate:
color = (0, 0, 255)
# draw (1) a bounding box around the person and (2) the
# centroid coordinates of the person,
cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)
cv2.circle(frame, (cX, cY), 5, color, 1)
# draw the total number of social distancing violations on the
# output frame
text = "Social Distancing Violations: {}".format(len(violate))
cv2.putText(frame, text, (10, frame.shape[0] - 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.85, (0, 0, 255), 3)
# check to see if the output frame should be displayed to our
# screen
if args["display"] > 0:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# if an output video file path has been supplied and the video
# writer has not been initialized, do so now
if args["output"] != "" and writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 25,
(frame.shape[1], frame.shape[0]), True)
# if the video writer is not None, write the frame to the output
# video file
if writer is not None:
writer.write(frame)
OpenCV 社交距离探测器结果
我们现在准备测试我们的 OpenCV 社交距离探测器。
确保使用本教程的 【下载】 部分下载源代码和示例演示视频。
从那里,打开一个终端,并执行以下命令:
$ time python social_distance_detector.py --input pedestrians.mp4 \
--output output.avi --display 0
[INFO] loading YOLO from disk...
[INFO] accessing video stream...
real 3m43.120s
user 23m20.616s
sys 0m25.824s
在这里,你可以看到我能够在我的 CPU 上用 3m43s 处理整个视频,正如结果所示,我们的社交距离检测器正在正确地标记违反社交距离规则的人。
当前实现的问题是速度。我们基于 CPU 的社交距离探测器正在获得 ~2.3 FPS ,这对于实时处理来说太慢了。
您可以通过以下方式获得更高的帧处理速率:( 1)利用支持 NVIDIA CUDA 的 GPU 😭 2)利用 NVIDIA GPU 支持编译/安装 OpenCV 的“dnn”模块。
如果你已经安装了 OpenCV 并支持 NVIDIA GPU,你需要做的就是在你的social_distancing_config.py文件中设置USE_GPU = True:
# boolean indicating if NVIDIA CUDA GPU should be used
USE_GPU = True
$ time python social_distance_detector.py --input pedestrians.mp4 \
--output output.avi --display 0
[INFO] loading YOLO from disk...
[INFO] setting preferable backend and target to CUDA...
[INFO] accessing video stream...
real 0m56.008s
user 1m15.772s
sys 0m7.036s
在这里,我们仅用 56 秒处理了整个视频,总计 ~9.38 FPS ,这是一个 307%的加速!
局限性和未来的改进
正如本教程前面已经提到的,我们的社交距离检测器没有利用适当的相机校准,这意味着我们不能(容易地)将像素距离映射到实际的可测量单位(即米、英尺等)。).
因此,改进社交距离探测器的第一步是利用适当的摄像机校准。
这样做将产生更好的结果,并使您能够计算实际的可测量单位(而不是像素)。
其次,你应该考虑应用自上而下的视角变换,正如这个实现所做的:
从那里,您可以将距离计算应用于行人的俯视图,从而获得更好的距离近似值。
我的第三个建议是改进人员检测流程。
OpenCV 的 YOLO 实现非常慢不是因为模型本身而是因为模型需要额外的后处理。
为了进一步加速流水线,可以考虑利用运行在 GPU 上的单次检测器(SSD)——这将大大提高帧吞吐率。
最后,我想提一下,你会在网上看到许多社交距离探测器的实现——我今天在这里介绍的一个应该被视为你可以建立的模板和起点。
如果您想了解更多关于使用计算机视觉实现社交距离检测器的信息,请查看以下资源:
- 自动社会距离测量
- 工作场所的社交距离
- Rohit Kumar Srivastava 的社交距离实现
- Venkatagiri Ramesh 的社交距离项目
- Mohan Morkel 的社交距离应用(我认为可能是基于 Venkatagiri Ramesh 的)
如果你已经实现了你自己的 OpenCV 社交距离项目,而我还没有链接到它,请接受我的道歉——现在有太多的实现让我无法跟踪。
摘要
在本教程中,您学习了如何使用 OpenCV、计算机视觉和深度学习来实现社交距离探测器。
我们的实施通过以下方式实现:
- 使用 YOLO 对象检测器检测视频流中的人
- 确定每个检测到的人的质心
- 计算所有质心之间的成对距离
- 检查是否有任何成对的距离相隔 < N 个像素,如果是,则表明这对人违反了社交距离规则
此外,通过使用支持 NVIDIA CUDA 的 GPU,以及在 NVIDIA GPU 支持下编译的 OpenCV 的dnn模块,我们的方法能够实时运行,使其可用作概念验证社交距离检测器。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV–将视频流传输到网络浏览器/HTML 页面
原文:https://pyimagesearch.com/2019/09/02/opencv-stream-video-to-web-browser-html-page/
最后更新于 2021 年 7 月 9 日。
在本教程中,您将学习如何使用 OpenCV 通过 Flask 和 Python 将视频从网络摄像头传输到 web 浏览器/HTML 页面。
你的车被偷过吗?
我的在周末被偷了。让我告诉你,我很生气。
我不能透露太多细节,因为这是一项正在进行的刑事调查,但我可以告诉你的是:
大约六个月前,我和妻子从康涅狄格州的诺沃克搬到了宾夕法尼亚州的费城。我有一辆车,不常开,但还是留着以备不时之需。
在我们附近很难找到停车位,所以我需要一个停车库。
我听说有一个车库,就注册了,并开始把车停在那里。
快进到刚刚过去的这个星期天。
我和妻子来到停车场取车。我们正准备去马里兰看望我的父母,吃些青蟹(马里兰以螃蟹闻名)。
我走向我的车,取下盖子。
我立刻被弄糊涂了——这不是我的车。
# $&@哪里是我的车?
短短几分钟后,我意识到了现实——我的车被偷了。
在过去的一周里,我关于即将出版的《计算机视觉的树莓派》 的工作被中断了——我一直在与停车场的所有者、费城警察局和我车上的 GPS 跟踪服务合作,以找出发生了什么。
在事情解决之前,我不能公开透露任何细节,但让我告诉你,有一大堆文件、警察报告、律师信和保险索赔需要我去处理。
我希望这个问题在下个月得到解决——我讨厌分心,尤其是让我远离我最喜欢做的事情的分心——教授计算机视觉和深度学习。
我成功地利用我的挫折激发了一篇新的与安全相关的计算机视觉博文。
在这篇文章中,我们将学习如何使用 Flask 和 OpenCV 将视频流式传输到网络浏览器。
您将能够在不到 5 分钟的时间内在 Raspberry Pi 上部署该系统:
- 只需安装所需的软件包/软件并启动脚本。
- 然后打开你的电脑/智能手机浏览器,导航到 URL/IP 地址观看视频(并确保你的东西没有被盗)。
没有什么比一点视频证据更能抓贼了。
当我继续和警察、保险等做文书工作的时候,你可以开始用树莓派相机武装自己,在你生活和工作的任何地方捕捉坏人。
要了解如何使用 OpenCV 和 Flask 将视频流式传输到网页浏览器 HTML 页面,请继续阅读!
- 【2021 年 7 月更新:新增两个章节。第一部分提供了使用 Django 作为 Flask web 框架的替代方案的建议。第二部分讨论使用 ImageZMQ 通过网络从多个摄像机源向单个中央服务器传输实时视频。
OpenCV–将视频流传输到网络浏览器/HTML 页面
在本教程中,我们将从讨论 Flask 开始,这是 Python 编程语言的一个微型 web 框架。
我们将学习运动检测的基本原理,以便将其应用到我们的项目中。我们将通过背景减法器来实现运动检测。
从那里,我们将结合 Flask 和 OpenCV,使我们能够:
- 从 RPi 摄像头模块或 USB 网络摄像头访问帧。
- 处理帧并应用任意算法(这里我们将使用背景减除/运动检测,但是你也可以应用图像分类、对象检测等。).
- 将结果流式传输到网页/网络浏览器。
此外,我们将要讨论的代码将能够支持多个客户端(即,多个人/网络浏览器/标签同时访问流),这是你在网上找到的绝大多数例子都无法处理的。
将所有这些部件放在一起,家庭监控系统就能够执行运动检测,然后将视频结果传输到您的网络浏览器。
我们开始吧!
Flask web 框架
在这一节中,我们将简要讨论 Flask web 框架以及如何在您的系统上安装它。
Flask 是一个流行的用 Python 编程语言编写的微型 web 框架。
与 Django 一起,Flask 是使用 Python 构建 web 应用程序时最常见的 web 框架之一。
然而,与 Django 不同,Flask 是非常轻量级的,这使得它非常容易构建基本的 web 应用程序。
正如我们将在本节中看到的,我们只需要少量代码来促进 Flask 的实时视频流——其余代码要么涉及(1) OpenCV 和访问我们的视频流,要么(2)确保我们的代码是线程安全的,可以处理多个客户端。
如果您需要在机器上安装 Flask,只需以下命令即可:
$ pip install flask
现在,继续安装 NumPy、OpenCV 和 imutils:
$ pip install numpy
$ pip install opencv-contrib-python
$ pip install imutils
注:如果你想完整安装 OpenCV,包括“非自由”(专利)算法,请务必从源代码编译 OpenCV。
项目结构
在我们继续之前,让我们看一下项目的目录结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── motion_detection
│ │ ├── __init__.py
│ │ └── singlemotiondetector.py
│ └── __init__.py
├── templates
│ └── index.html
└── webstreaming.py
3 directories, 5 files
为了执行背景减除和运动检测,我们将实现一个名为SingleMotionDetector的类——这个类将存在于pyimagesearch的motion_detection子模块中的singlemotiondetector.py文件中。
webstreaming.py文件将使用 OpenCV 访问我们的网络摄像头,通过SingleMotionDetector执行运动检测,然后通过 Flask web 框架将输出帧提供给我们的网络浏览器。
为了让我们的 web 浏览器有所显示,我们需要用 HTML 填充index.html的内容来提供视频提要。我们只需要插入一些基本的 HTML 标记——Flask 将为我们处理将视频流发送到我们的浏览器。
实现基本的运动检测器
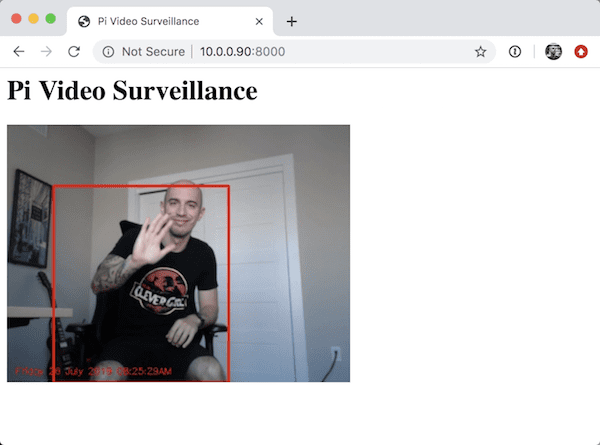
Figure 2: Video surveillance with Raspberry Pi, OpenCV, Flask and web streaming. By use of background subtraction for motion detection, we have detected motion where I am moving in my chair.
我们的运动检测器算法将通过 背景减法 的形式来检测运动。
大多数背景减除算法的工作原理是:
- 累加前 N 帧的加权平均值
- 取当前帧并将其从帧的加权平均值中减去
- 对减法的输出进行阈值处理,以突出像素值有显著差异的区域(“白色”用于前景,“黑色”用于背景)
- 应用诸如腐蚀和膨胀的基本图像处理技术来去除噪声
- 利用轮廓检测提取包含运动的区域
我们的运动检测实现将存在于singlemotiondetector.py中的SingleMotionDetector类中。
我们称之为“单个运动检测器”,因为算法本身只对寻找单个最大的运动区域感兴趣。
我们可以很容易地扩展这种方法来处理多个运动区域。
让我们继续实现运动检测器。
打开singlemotiondetector.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import imutils
import cv2
class SingleMotionDetector:
def __init__(self, accumWeight=0.5):
# store the accumulated weight factor
self.accumWeight = accumWeight
# initialize the background model
self.bg = None
2-4 号线处理我们所需的进口。
所有这些都是相当标准的,包括用于数字处理的 NumPy、imutils用于我们的便利函数,以及cv2用于我们的 OpenCV 绑定。
然后我们在的第 6 行定义我们的SingleMotionDetector类。该类接受一个可选参数accumWeight,它是用于我们的累计加权平均值的因子。
accumWeight越大,越小背景(bg)将在累加加权平均值时被考虑在内。
相反地,越小 accumWeight越大,越大背景bg在计算平均值时会被考虑。
均匀地设置背景和前景的accumWeight=0.5权重——我经常推荐这作为一个起点值(然后你可以根据你自己的实验来调整)。
接下来,让我们定义update方法,它将接受一个输入帧并计算加权平均值:
def update(self, image):
# if the background model is None, initialize it
if self.bg is None:
self.bg = image.copy().astype("float")
return
# update the background model by accumulating the weighted
# average
cv2.accumulateWeighted(image, self.bg, self.accumWeight)
在我们的bg帧是None(暗示update从未被调用过)的情况下,我们简单的存储bg帧(第 15-18 行)。
否则,我们计算输入frame、现有背景bg和我们相应的accumWeight因子之间的加权平均值。
给定我们的背景bg,我们现在可以通过detect方法应用运动检测:
def detect(self, image, tVal=25):
# compute the absolute difference between the background model
# and the image passed in, then threshold the delta image
delta = cv2.absdiff(self.bg.astype("uint8"), image)
thresh = cv2.threshold(delta, tVal, 255, cv2.THRESH_BINARY)[1]
# perform a series of erosions and dilations to remove small
# blobs
thresh = cv2.erode(thresh, None, iterations=2)
thresh = cv2.dilate(thresh, None, iterations=2)
detect方法需要一个参数和一个可选参数:
image:将应用运动检测的输入帧/图像。tVal:用于标记特定像素是否为“运动”的阈值。
给定我们的输入image,我们计算image和bg ( 第 27 行)之间的绝对差值。
任何具有差异> tVal的像素位置被设置为 255 (白色;前景),否则它们被设置为 0 (黑色;背景)(第 28 行)。
执行一系列腐蚀和扩张以去除噪声和小的局部运动区域,否则这些区域会被认为是假阳性的(可能是由于光的反射或快速变化)。
下一步是应用轮廓检测来提取任何运动区域:
# find contours in the thresholded image and initialize the
# minimum and maximum bounding box regions for motion
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
(minX, minY) = (np.inf, np.inf)
(maxX, maxY) = (-np.inf, -np.inf)
第 37-39 行在我们的thresh图像上执行轮廓检测。
然后,我们初始化两组簿记变量,以跟踪包含任何运动的位置(行 40 和 41 )。这些变量将形成“边界框”,它将告诉我们运动发生的位置。
最后一步是填充这些变量(当然,前提是帧中存在运动):
# if no contours were found, return None
if len(cnts) == 0:
return None
# otherwise, loop over the contours
for c in cnts:
# compute the bounding box of the contour and use it to
# update the minimum and maximum bounding box regions
(x, y, w, h) = cv2.boundingRect(c)
(minX, minY) = (min(minX, x), min(minY, y))
(maxX, maxY) = (max(maxX, x + w), max(maxY, y + h))
# otherwise, return a tuple of the thresholded image along
# with bounding box
return (thresh, (minX, minY, maxX, maxY))
在第 43-45 行上,我们检查轮廓列表是否为空。
如果是这样的话,那么在帧中没有发现运动,我们可以安全地忽略它。
否则,运动在帧中不存在,所以我们需要开始在轮廓上循环(线 48 )。
对于每个轮廓,我们计算边界框,然后更新我们的簿记变量(第 47-53 行),找到最小和最大 (x,y)-所有运动发生的坐标。
最后,我们将边界框的位置返回给调用函数。
结合 OpenCV 和 Flask

Figure 3: OpenCV and Flask (a Python micro web framework) make the perfect pair for web streaming and video surveillance projects involving the Raspberry Pi and similar hardware.
让我们继续将 OpenCV 和 Flask 结合起来,将视频流中的帧(在 Raspberry Pi 上运行)提供给 web 浏览器。
打开项目结构中的webstreaming.py文件,插入以下代码:
# import the necessary packages
from pyimagesearch.motion_detection import SingleMotionDetector
from imutils.video import VideoStream
from flask import Response
from flask import Flask
from flask import render_template
import threading
import argparse
import datetime
import imutils
import time
import cv2
第 2-12 行处理我们所需的进口:
- 第 2 行导入了我们上面实现的
SingleMotionDetector类。 VideoStream类( Line 3 )将使我们能够访问我们的 Raspberry Pi 相机模块或 USB 网络摄像头。- 第 4-6 行处理导入我们需要的 Flask 包——我们将使用这些包来渲染我们的
index.html模板并提供给客户。 - 第 7 行导入了
threading库,以确保我们可以支持并发性(即多个客户端、web 浏览器和标签同时存在)。
让我们继续执行一些初始化:
# initialize the output frame and a lock used to ensure thread-safe
# exchanges of the output frames (useful when multiple browsers/tabs
# are viewing the stream)
outputFrame = None
lock = threading.Lock()
# initialize a flask object
app = Flask(__name__)
# initialize the video stream and allow the camera sensor to
# warmup
#vs = VideoStream(usePiCamera=1).start()
vs = VideoStream(src=0).start()
time.sleep(2.0)
首先,我们在线 17 上初始化我们的outputFrame——这将是提供给客户端的帧(后期运动检测)。
然后我们在行 18 上创建一个lock,它将用于确保更新ouputFrame时的线程安全行为(即,确保一个线程不会在更新时试图读取帧)。
第 21 行初始化我们的烧瓶app本身,同时第 25-27 行访问我们的视频流:
- 如果您使用的是 USB 网络摄像头,您可以保留代码不变。
- 然而,如果你使用 RPi 相机模块,你应该 取消注释第 25 行和 注释掉第 26 行。
下一个函数index将呈现我们的index.html模板,并提供输出视频流:
@app.route("/")
def index():
# return the rendered template
return render_template("index.html")
这个函数非常简单——它所做的只是在我们的 HTML 文件上调用 Flask render_template。
我们将在下一节回顾index.html文件,所以在此之前,我们不会对文件内容进行进一步的讨论。
我们的下一个职能部门负责:
- 循环播放视频流中的帧
- 应用运动检测
- 在
outputFrame上绘制任何结果
此外,该函数必须以线程安全的方式执行所有这些操作,以确保支持并发性。
现在让我们来看看这个函数:
def detect_motion(frameCount):
# grab global references to the video stream, output frame, and
# lock variables
global vs, outputFrame, lock
# initialize the motion detector and the total number of frames
# read thus far
md = SingleMotionDetector(accumWeight=0.1)
total = 0
我们的detection_motion函数接受一个参数frameCount,这是在SingleMotionDetector类中构建背景bg所需的最少帧数:
- 如果我们没有至少
frameCount帧,我们将继续计算累计加权平均值。 - 一旦到达
frameCount,我们将开始执行背景减除。
第 37 行抓取对三个变量的全局引用:
vs:我们实例化的VideoStream对象outputFrame:将提供给客户的输出帧lock:更新outputFrame前必须获得的线程锁
第 41 行用值accumWeight=0.1初始化我们的SingleMotionDetector类,这意味着在计算加权平均值时bg值将被赋予更高的权重。
第 42 行然后初始化total到目前为止读取的帧数——我们需要确保已经读取了足够多的帧数来建立我们的背景模型。
从那里,我们将能够执行背景减法。
完成这些初始化后,我们现在可以开始循环摄像机中的帧:
# loop over frames from the video stream
while True:
# read the next frame from the video stream, resize it,
# convert the frame to grayscale, and blur it
frame = vs.read()
frame = imutils.resize(frame, width=400)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# grab the current timestamp and draw it on the frame
timestamp = datetime.datetime.now()
cv2.putText(frame, timestamp.strftime(
"%A %d %B %Y %I:%M:%S%p"), (10, frame.shape[0] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)
48 线从我们的摄像机读取下一个frame,而49-51 线执行预处理,包括:
- 调整大小,宽度为 400 像素(我们的输入帧越小,数据越少,因此我们的算法运行的越快)。
- 转换为灰度。
- 高斯模糊(减少噪声)。
然后,我们获取当前时间戳,并将其绘制在frame ( 第 54-57 行)上。
通过最后一项检查,我们可以执行运动检测:
# if the total number of frames has reached a sufficient
# number to construct a reasonable background model, then
# continue to process the frame
if total > frameCount:
# detect motion in the image
motion = md.detect(gray)
# check to see if motion was found in the frame
if motion is not None:
# unpack the tuple and draw the box surrounding the
# "motion area" on the output frame
(thresh, (minX, minY, maxX, maxY)) = motion
cv2.rectangle(frame, (minX, minY), (maxX, maxY),
(0, 0, 255), 2)
# update the background model and increment the total number
# of frames read thus far
md.update(gray)
total += 1
# acquire the lock, set the output frame, and release the
# lock
with lock:
outputFrame = frame.copy()
在第 62 行的上,我们确保我们已经读取了至少frameCount帧来构建我们的背景减除模型。
如果是这样,我们应用运动检测器的.detect运动,它返回一个变量motion。
如果motion是None,那么我们知道在当前的frame中没有发生运动。否则,如果motion是不是 None ( 行 67 ),那么我们需要在frame上画出运动区域的包围盒坐标。
第 76 行更新我们的运动检测背景模型,而第 77 行增加目前从摄像机读取的total帧数。
最后,行 81 获取支持线程并发所需的lock,行 82 设置outputFrame。
我们需要获得锁来确保outputFrame变量不会在我们试图更新它的时候被客户端读取。
我们的下一个函数generate,是一个 Python 生成器,用于将我们的outputFrame编码为 JPEG 数据——现在让我们来看看:
def generate():
# grab global references to the output frame and lock variables
global outputFrame, lock
# loop over frames from the output stream
while True:
# wait until the lock is acquired
with lock:
# check if the output frame is available, otherwise skip
# the iteration of the loop
if outputFrame is None:
continue
# encode the frame in JPEG format
(flag, encodedImage) = cv2.imencode(".jpg", outputFrame)
# ensure the frame was successfully encoded
if not flag:
continue
# yield the output frame in the byte format
yield(b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n' +
bytearray(encodedImage) + b'\r\n')
第 86 行抓取对我们的outputFrame和lock的全局引用,类似于detect_motion函数。
然后generate在第 89 行开始一个无限循环,一直持续到我们杀死这个脚本。
在循环内部,我们:
- 先获取
lock( 行 91 )。 - 确保
outputFrame不为空(第 94 行),如果一帧从摄像机传感器上掉落,可能会发生这种情况。 - 在行 98 上将
frame编码为 JPEG 图像——这里执行 JPEG 压缩是为了减少网络负载并确保帧的更快传输。 - 检查成功
flag是否失败(第 101 行和第 102 行),暗示 JPEG 压缩失败,我们应该忽略该帧。 - 最后,将编码的 JPEG 帧作为一个字节数组,供 web 浏览器使用。
这在少量的代码中做了大量的工作,所以一定要确保多次查看这个函数,以确保理解它是如何工作的。
下一个函数video_feed调用我们的generate函数:
@app.route("/video_feed")
def video_feed():
# return the response generated along with the specific media
# type (mime type)
return Response(generate(),
mimetype = "multipart/x-mixed-replace; boundary=frame")
注意这个函数是如何作为app.route签名的,就像上面的index函数一样。
app.route签名告诉 Flask 这个函数是一个 URL 端点,数据是从http://your_ip_address/video_feed提供的。
video_feed的输出是实时运动检测输出,通过generate函数编码为字节数组。您的 web 浏览器足够智能,可以接受这个字节数组,并将其作为实时提要显示在您的浏览器中。
我们的最后一个代码块处理解析命令行参数和启动 Flask 应用程序:
# check to see if this is the main thread of execution
if __name__ == '__main__':
# construct the argument parser and parse command line arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--ip", type=str, required=True,
help="ip address of the device")
ap.add_argument("-o", "--port", type=int, required=True,
help="ephemeral port number of the server (1024 to 65535)")
ap.add_argument("-f", "--frame-count", type=int, default=32,
help="# of frames used to construct the background model")
args = vars(ap.parse_args())
# start a thread that will perform motion detection
t = threading.Thread(target=detect_motion, args=(
args["frame_count"],))
t.daemon = True
t.start()
# start the flask app
app.run(host=args["ip"], port=args["port"], debug=True,
threaded=True, use_reloader=False)
# release the video stream pointer
vs.stop()
第 118-125 行处理解析我们的命令行参数。
这里我们需要三个参数,包括:
--ip:您从中启动webstream.py文件的系统的 IP 地址。--port:Flask 应用程序将运行的端口号(通常为该参数提供一个值8000)。--frame-count:在执行运动检测之前,用于累积和建立背景模型的帧数。默认情况下,我们使用32帧来构建背景模型。
第 128-131 行启动一个将用于执行运动检测的线程。
使用线程可以确保detect_motion功能可以在后台安全运行——它将不断运行并更新我们的outputFrame,这样我们就可以向我们的客户提供任何运动检测结果。
最后,第 134 和 135 行启动 Flask 应用程序本身。
HTML 页面结构
正如我们在webstreaming.py中看到的,我们正在渲染一个名为index.html的 HTML 模板。
模板本身由 Flask web 框架填充,然后提供给 web 浏览器。
然后,您的 web 浏览器获取生成的 HTML 并将其呈现在您的屏幕上。
让我们检查一下index.html文件的内容:
<html>
<head>
<title>Pi Video Surveillance</title>
</head>
<body>
<h1>Pi Video Surveillance</h1>
<img src="{{ url_for('video_feed') }}">
</body>
</html>
正如我们所看到的,这是超级基本的网页;然而,请密切注意第 7 行——注意我们是如何指示 Flask 动态呈现我们的video_feed路线的 URL 的。
由于video_feed函数负责从我们的网络摄像头提供帧,图像的src将自动填充我们的输出帧。
然后,我们的网络浏览器足够智能,可以正确地呈现网页并提供实时视频流。
将碎片拼在一起
既然我们已经编写了项目代码,就让我们来测试一下吧。
打开终端并执行以下命令:
$ python webstreaming.py --ip 0.0.0.0 --port 8000
* Serving Flask app "webstreaming" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://0.0.0.0:8000/ (Press CTRL+C to quit)
127.0.0.1 - - [26/Aug/2019 14:43:23] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [26/Aug/2019 14:43:23] "GET /video_feed HTTP/1.1" 200 -
127.0.0.1 - - [26/Aug/2019 14:43:24] "GET /favicon.ico HTTP/1.1" 404 -
正如你在视频中看到的,我从多个浏览器打开了与 Flask/OpenCV 服务器的连接,每个浏览器都有多个选项卡。我甚至拿出我的 iPhone,从那里打开了几个连接。服务器没有跳过一拍,继续用 Flask 和 OpenCV 可靠地提供帧。
使用 OpenCV 通过其他 web 框架流式传输视频
在本教程中,您学习了如何使用 Python 的 Flask web 框架将视频从网络摄像头流式传输到浏览器窗口。
Flask 可以说是最易于使用的轻量级 Python web 框架之一,虽然有许多其他的选择来用 Python 构建网站,但是你可能想要使用的另一个超级框架是 Django 。
在 Django 中构建网站肯定需要更多的代码,但它也包含了 Flask 没有的特性,这使得它成为大型制作网站的潜在更好选择。
我们今天没有讨论 Django,但是如果你有兴趣使用 Django 而不是 Flask,一定要看看 StackOverflow 上的这个帖子。
视频流的替代方法
如果你对 OpenCV 的其他视频流选项感兴趣,我的第一个建议是使用 ImageZMQ。
ImageZMQ 由 PyImageSearch 阅读器杰夫巴斯创建。该库旨在通过网络实时传输来自多个摄像机的视频帧。
不像 RTSP 或 GStreamer,这两者配置起来都很痛苦,ImageZMQ 非常容易使用,并且非常可靠,这要归功于底层的 ZMQ 消息传递库。
如果您需要一种可靠的方法来传输视频,可能来自多个来源, ImageZMQ 是我推荐的路线。
摘要
在本教程中,您学习了如何将帧从服务器传输到客户端 web 浏览器。使用这种网络流,我们能够构建一个基本的安全应用程序来监控我们房间的运动。
背景减除是计算机视觉中非常常用的方法。通常,这些算法计算效率高,适合资源受限的设备,如 Raspberry Pi。
在实现我们的背景减法器之后,我们将它与 Flask web 框架相结合,使我们能够:
- 从 RPi 摄像头模块/USB 网络摄像头访问帧。
- 对每一帧应用背景减除/运动检测。
- 将结果流式传输到网页/网络浏览器。
此外,我们的实现支持多个客户端、浏览器或标签——这是大多数其他实现中所没有的。
每当您需要将帧从设备传输到 web 浏览器时,一定要使用这段代码作为模板/起点。
要下载这篇文章的源代码,并在以后的文章在 PyImageSearch 上发表时得到通知,只需在下面的表格中输入您的电子邮件地址!
OpenCV 数独求解器和 OCR
原文:https://pyimagesearch.com/2020/08/10/opencv-sudoku-solver-and-ocr/
在本教程中,您将使用 OpenCV、深度学习和光学字符识别(OCR)创建一个自动数独解谜器。
我妻子是个超级数独迷。每次我们旅行,无论是从费城到奥尔巴尼的 45 分钟飞行,还是到加州的 6 小时洲际飞行,她总是带着一个数独谜题。
有趣的是,她更喜欢印刷的数独解谜书。她讨厌数码/智能手机应用程序版本,并拒绝玩它们。
我自己不是一个喜欢猜谜的人,但是有一次,我们坐在飞机上,我问:
如何知道你是否正确地解决了这个难题?书的后面有解决方案吗?还是你只是去做,希望它是正确的?
显然,这是一个愚蠢的问题,原因有二:
- 是的,那里的就是后面的一把解钥匙。你需要做的就是翻到书的背面,找到谜题号码,然后看到答案。
- 最重要的是,她不会猜错谜题。
然后她给我上了 20 分钟的课,告诉我她只能解决“4 级和 5 级难题”,接着是一堂关于“X 翼”和“Y 翼”技术的数独解谜课。我有计算机科学的博士学位,但所有这些我都不知道。
但对于那些没有像我一样嫁给数独大师的人来说,这确实提出了一个问题:
OpenCV 和 OCR 可以用来解决和检查数独谜题吗?
如果数独谜题制造商不需要在书的背面打印答案,而是提供一个应用程序让用户检查他们的谜题,打印机可以把节省下来的钱装进口袋,或者免费打印额外的谜题。
数独拼图公司赚了更多的钱,最终用户也很高兴。似乎是双赢。
从我的角度来看,如果我出版一本数独教程,也许我能重新赢得我妻子的好感。
要了解如何使用 OpenCV、深度学习和 OCR 构建自动数独解谜器,请继续阅读。
OpenCV 数独解算器和 OCR
在本教程的第一部分,我们将讨论使用 OpenCV、深度学习和光学字符识别(OCR)技术构建数独解谜器所需的步骤。
在那里,您将配置您的开发环境,并确保安装了正确的库和包。
在我们编写任何代码之前,我们将首先回顾我们的项目目录结构,确保您知道在本教程的整个过程中将创建、修改和使用什么文件。
然后我将向您展示如何实现SudokuNet,这是一个基本的卷积神经网络(CNN),将用于 OCR 数独拼图板上的数字。
然后,我们将使用 Keras 和 TensorFlow 训练该网络识别数字。
但是在我们真正能够检查和解决一个数独难题之前,我们首先需要定位数独板在图像中的位置——我们将实现助手函数和实用程序来帮助完成这项任务。
最后,我们将把所有的部分放在一起,实现我们完整的 OpenCV 数独解谜器。
如何用 OpenCV 和 OCR 解决数独难题
用 OpenCV 创建一个自动数独解谜程序需要 6 个步骤:
- 步骤#1: 向我们的系统提供包含数独谜题的输入图像。
- 步骤#2: 在输入图像中的处定位并提取棋盘。
- 步骤#3: 给定棋盘,定位数独棋盘的每个独立单元(大多数标准数独谜题是一个 9×9 网格,所以我们需要定位这些单元)。
- 步骤#4: 判断单元格中是否有数字,如果有,就进行 OCR。
- 步骤#5: 应用数独难题解算器/检验器算法来验证难题。
- 步骤#6: 向用户显示输出结果。
这些步骤中的大部分可以使用 OpenCV 以及基本的计算机视觉和图像处理操作来完成。
最大的例外是第 4 步,我们需要应用 OCR。
OCR 的应用可能有点棘手,但我们有很多选择:
- 使用 Tesseract OCR 引擎,这是开源 OCR 的事实上的标准
- 利用基于云的 OCR APIs,如微软认知服务、亚马逊 Rekognition 或谷歌视觉 API
- 训练我们自己的自定义 OCR 模型
所有这些都是完全有效的选择。然而,为了制作一个完整的端到端教程,我决定使用深度学习来训练我们自己的自定义数独 OCR 模型。
一定要系好安全带——这将是一次疯狂的旅行。
配置您的开发环境,使用 OpenCV 和 OCR 解决数独难题
要针对本教程配置您的系统,我建议您遵循以下任一教程来建立您的基准系统并创建一个虚拟环境:
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
一旦您的环境启动并运行,您将需要本教程的另一个包。你需要安装 py-sudoku ,我们将使用这个库来帮助我们解决数独难题:
$ pip install py-sudoku
项目结构
花点时间从本教程的 “下载” 部分抓取今天的文件。从那里,提取归档文件,并检查内容:
$ tree --dirsfirst
.
├── output
│ └── digit_classifier.h5
├── pyimagesearch
│ ├── models
│ │ ├── __init__.py
│ │ └── Sudokunet.py
│ ├── Sudoku
│ │ ├── __init__.py
│ │ └── puzzle.py
│ └── __init__.py
├── solve_sudoku_puzzle.py
├── sudoku_puzzle.jpg
└── train_digit_classifier.py
4 directories, 9 files
和所有 CNN 一样,SudokuNet 需要用数据来训练。我们的train_digit_classifier.py脚本将在 MNIST 数据集上训练一个数字 OCR 模型。
一旦 SudokuNet 训练成功,我们将部署它和我们的solve_sudoku_puzzle.py脚本来解决一个数独难题。
当你的系统工作时,你可以用这个应用给你的朋友留下深刻印象。或者更好的是,在飞机上愚弄他们,因为你解谜的速度可能比他们在你身后的座位上更快!别担心,我不会说出去的!
SudokuNet:在 Keras 和 TensorFlow 中实现的数字 OCR 模型
每一个数独谜题都以一个 NxN 网格开始(通常是 9×9 ),其中一些单元格是空白 而其他单元格已经包含一个数字。
目标是使用关于现有数字到的知识正确推断其他数字。
但是在我们可以用 OpenCV 解决数独难题之前,我们首先需要实现一个神经网络架构,它将处理数独难题板上的 OCR 数字——给定这些信息,解决实际的难题将变得微不足道。
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
class SudokuNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model
model = Sequential()
inputShape = (height, width, depth)
我们的SudokuNet类是在的第 10-12 行用一个静态方法(没有构造函数)定义的。build方法接受以下参数:
width:MNIST 数字的宽度(28像素)height:MNIST 数字的高度(28像素)depth:MNIST 数字图像通道(1灰度通道)classes:数字位数 0-9 (10位数)
# first set of CONV => RELU => POOL layers
model.add(Conv2D(32, (5, 5), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
# second set of CONV => RELU => POOL layers
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
# first set of FC => RELU layers
model.add(Flatten())
model.add(Dense(64))
model.add(Activation("relu"))
model.add(Dropout(0.5))
# second set of FC => RELU layers
model.add(Dense(64))
model.add(Activation("relu"))
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
如果您对 CNN 层和使用顺序 API 不熟悉,我建议您查看以下资源:
注意:作为题外话,我想在这里花点时间指出,例如,如果您正在构建一个 CNN 来分类 26 个大写英文字母加上 10 个数字(总共 36 个字符),那么您肯定需要一个更深层次的 CNN(超出了本教程的范围,本教程主要关注数字,因为它们适用于数独)。我在书中讲述了如何用 OpenCV、Tesseract 和 Python 在T4 数字和字母字符、 OCR 上训练网络。**
用 Keras 和 TensorFlow 实现我们的数独数字训练脚本
# import the necessary packages
from pyimagesearch.models import SudokuNet
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to output model after training")
args = vars(ap.parse_args())
我们从少量导入开始我们的训练脚本。最值得注意的是,我们正在导入SudokuNet(在上一节中讨论过)和mnist数据集。手写数字的 MNIST 数据集内置在 TensorFlow/Keras' datasets模块中,将根据需要缓存到您的机器上。
# initialize the initial learning rate, number of epochs to train
# for, and batch size
INIT_LR = 1e-3
EPOCHS = 10
BS = 128
# grab the MNIST dataset
print("[INFO] accessing MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# add a channel (i.e., grayscale) dimension to the digits
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
# convert the labels from integers to vectors
le = LabelBinarizer()
trainLabels = le.fit_transform(trainLabels)
testLabels = le.transform(testLabels)
您可以在第 17-19 行上配置训练超参数。通过实验,我已经确定了学习率、训练次数和批量的适当设置。
注:高级用户可能希望查看我的 Keras 学习率查找器教程,以帮助自动找到最佳学习率。
为了使用 MNIST 数字数据集,我们执行以下步骤:
- 将数据集加载到内存中(第 23 行)。这个数据集已经被分成训练和测试数据
- 给数字添加一个通道尺寸,表示它们是灰度级的(第 30 行和第 31 行)
- 将数据缩放到范围【0,1】(第 30 行和第 31 行)
- 一键编码标签(第 34-36 行)
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR)
model = SudokuNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
trainData, trainLabels,
validation_data=(testData, testLabels),
batch_size=BS,
epochs=EPOCHS,
verbose=1)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testData)
print(classification_report(
testLabels.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in le.classes_]))
# serialize the model to disk
print("[INFO] serializing digit model...")
model.save(args["model"], save_format="h5")
用 Keras 和 TensorFlow 训练我们的数独数字识别器
$ python train_digit_classifier.py --model output/digit_classifier.h5
[INFO] accessing MNIST...
[INFO] compiling model...
[INFO] training network...
[INFO] training network...
Epoch 1/10
469/469 [==============================] - 22s 47ms/step - loss: 0.7311 - accuracy: 0.7530 - val_loss: 0.0989 - val_accuracy: 0.9706
Epoch 2/10
469/469 [==============================] - 22s 47ms/step - loss: 0.2742 - accuracy: 0.9168 - val_loss: 0.0595 - val_accuracy: 0.9815
Epoch 3/10
469/469 [==============================] - 21s 44ms/step - loss: 0.2083 - accuracy: 0.9372 - val_loss: 0.0452 - val_accuracy: 0.9854
...
Epoch 8/10
469/469 [==============================] - 22s 48ms/step - loss: 0.1178 - accuracy: 0.9668 - val_loss: 0.0312 - val_accuracy: 0.9893
Epoch 9/10
469/469 [==============================] - 22s 47ms/step - loss: 0.1100 - accuracy: 0.9675 - val_loss: 0.0347 - val_accuracy: 0.9889
Epoch 10/10
469/469 [==============================] - 22s 47ms/step - loss: 0.1005 - accuracy: 0.9700 - val_loss: 0.0392 - val_accuracy: 0.9889
[INFO] evaluating network...
precision recall f1-score support
0 0.98 1.00 0.99 980
1 0.99 1.00 0.99 1135
2 0.99 0.98 0.99 1032
3 0.99 0.99 0.99 1010
4 0.99 0.99 0.99 982
5 0.98 0.99 0.98 892
6 0.99 0.98 0.99 958
7 0.98 1.00 0.99 1028
8 1.00 0.98 0.99 974
9 0.99 0.98 0.99 1009
accuracy 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
[INFO] serializing digit model...
$ ls -lh output
total 2824
-rw-r--r--@ 1 adrian staff 1.4M Jun 7 07:38 digit_classifier.h5
这个digit_classifier.h5文件包含我们的 Keras/TensorFlow 模型,我们将在本教程的后面使用它来识别数独板上的数字。
这个模型非常小,可以部署到一个 Raspberry Pi 甚至是一个移动设备,比如运行 CoreML 框架的 iPhone。
用 OpenCV 在图像中寻找数独拼图板
至此,我们有了一个可以识别图像中数字的模型;然而,如果数字识别器不能在图像中找到数独拼图板,它就没什么用了。
例如,假设我们向系统展示了以下数独拼图板:
我们如何在图像中找到真正的数独拼图板呢?
一旦我们找到了谜题,我们如何识别每一个单独的细胞?
为了让我们的生活更轻松,我们将实现两个助手工具:
find_puzzle:从输入图像中定位并提取数独拼图板extract_digit:检查数独拼图板上的每个单元格,并从单元格中提取数字(前提是有数字)
# import the necessary packages
from imutils.perspective import four_point_transform
from skimage.segmentation import clear_border
import numpy as np
import imutils
import cv2
def find_puzzle(image, debug=False):
# convert the image to grayscale and blur it slightly
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (7, 7), 3)
image:一张数独拼图的照片。debug:可选布尔值,表示是否显示中间步骤,以便您可以更好地可视化我们的计算机视觉管道中正在发生的事情。如果你遇到任何问题,我建议设置debug=True并使用你的计算机视觉知识来消除任何错误。
# apply adaptive thresholding and then invert the threshold map
thresh = cv2.adaptiveThreshold(blurred, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
thresh = cv2.bitwise_not(thresh)
# check to see if we are visualizing each step of the image
# processing pipeline (in this case, thresholding)
if debug:
cv2.imshow("Puzzle Thresh", thresh)
cv2.waitKey(0)
二进制自适应阈值操作允许我们将灰度像素锁定在【0,255】像素范围的两端。在这种情况下,我们都应用了二进制阈值,然后反转结果,如下面的图 5 所示:
# find contours in the thresholded image and sort them by size in
# descending order
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# initialize a contour that corresponds to the puzzle outline
puzzleCnt = None
# loop over the contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# if our approximated contour has four points, then we can
# assume we have found the outline of the puzzle
if len(approx) == 4:
puzzleCnt = approx
break
- 从线 35 开始循环所有轮廓
- 确定轮廓的周长(线 37 )
- 近似轮廓 ( 线 38 )
- 检查轮廓是否有四个顶点,如果有,标记为
puzzleCnt,并且break退出循环(第 42-44 行
有可能数独网格的轮廓没有找到。既然如此,我们来举个Exception:
# if the puzzle contour is empty then our script could not find
# the outline of the Sudoku puzzle so raise an error
if puzzleCnt is None:
raise Exception(("Could not find Sudoku puzzle outline. "
"Try debugging your thresholding and contour steps."))
# check to see if we are visualizing the outline of the detected
# Sudoku puzzle
if debug:
# draw the contour of the puzzle on the image and then display
# it to our screen for visualization/debugging purposes
output = image.copy()
cv2.drawContours(output, [puzzleCnt], -1, (0, 255, 0), 2)
cv2.imshow("Puzzle Outline", output)
cv2.waitKey(0)
有了拼图的轮廓(手指交叉),我们就可以对图像进行倾斜校正,从而获得拼图的俯视图:
# apply a four point perspective transform to both the original
# image and grayscale image to obtain a top-down bird's eye view
# of the puzzle
puzzle = four_point_transform(image, puzzleCnt.reshape(4, 2))
warped = four_point_transform(gray, puzzleCnt.reshape(4, 2))
# check to see if we are visualizing the perspective transform
if debug:
# show the output warped image (again, for debugging purposes)
cv2.imshow("Puzzle Transform", puzzle)
cv2.waitKey(0)
# return a 2-tuple of puzzle in both RGB and grayscale
return (puzzle, warped)
我们的find_puzzle返回签名由所有操作后的原始 RGB 图像和灰度图像的二元组组成,包括最终的四点透视变换。
到目前为止做得很好!
让我们继续朝着解决数独难题的方向前进。现在我们需要一种从数独谜题单元格中提取数字的方法,我们将在下一节中这样做。
用 OpenCV 从数独游戏中提取数字
在上一节中,您学习了如何使用 OpenCV 从图像中检测和提取数独拼图板。
本节将向您展示如何检查数独棋盘中的每个单元格,检测单元格中是否有数字,如果有,提取数字。
继续上一节我们停止的地方,让我们再次打开puzzle.py文件并开始工作:
def extract_digit(cell, debug=False):
# apply automatic thresholding to the cell and then clear any
# connected borders that touch the border of the cell
thresh = cv2.threshold(cell, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
thresh = clear_border(thresh)
# check to see if we are visualizing the cell thresholding step
if debug:
cv2.imshow("Cell Thresh", thresh)
cv2.waitKey(0)
在第 80-82 行上,我们的第一步是阈值化和清除任何接触单元格边界的前景像素(例如单元格分割线的任何线条标记)。该操作的结果可以通过线 85-87 显示。
让我们看看能否找到手指轮廓:
# find contours in the thresholded cell
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# if no contours were found than this is an empty cell
if len(cnts) == 0:
return None
# otherwise, find the largest contour in the cell and create a
# mask for the contour
c = max(cnts, key=cv2.contourArea)
mask = np.zeros(thresh.shape, dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1)
# compute the percentage of masked pixels relative to the total
# area of the image
(h, w) = thresh.shape
percentFilled = cv2.countNonZero(mask) / float(w * h)
# if less than 3% of the mask is filled then we are looking at
# noise and can safely ignore the contour
if percentFilled < 0.03:
return None
# apply the mask to the thresholded cell
digit = cv2.bitwise_and(thresh, thresh, mask=mask)
# check to see if we should visualize the masking step
if debug:
cv2.imshow("Digit", digit)
cv2.waitKey(0)
# return the digit to the calling function
return digit
伟大的工作实现数字提取管道!
实现我们的 OpenCV 数独解谜器
此时,我们配备了以下组件:
- 我们定制的数独网模型在 MNIST 数字数据集上训练,而驻留在准备使用的磁盘上
- 表示提取数独拼图板并应用透视变换
- 一个管道来提取数独谜题的单个单元格中的数字,或者忽略我们认为是噪音的数字
- 在我们的 Python 虚拟环境中安装了 py-sudoku 解谜器,这让我们不必手工设计算法,让我们可以专注于计算机视觉挑战
我们现在准备把每一部分放在一起构建一个 OpenCV 数独解算器!
打开solve_sudoku_puzzle.py文件,让我们完成数独求解器项目:
# import the necessary packages
from pyimagesearch.sudoku import extract_digit
from pyimagesearch.sudoku import find_puzzle
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from Sudoku import Sudoku
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained digit classifier")
ap.add_argument("-i", "--image", required=True,
help="path to input Sudoku puzzle image")
ap.add_argument("-d", "--debug", type=int, default=-1,
help="whether or not we are visualizing each step of the pipeline")
args = vars(ap.parse_args())
与几乎所有 Python 脚本一样,我们选择了一些导入来开始这个聚会。
既然我们现在配备了导入和我们的args字典,让我们从磁盘加载我们的(1)数字分类器model和(2)输入--image:
# load the digit classifier from disk
print("[INFO] loading digit classifier...")
model = load_model(args["model"])
# load the input image from disk and resize it
print("[INFO] processing image...")
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
从那里,我们将找到我们的难题,并准备分离其中的细胞:
# find the puzzle in the image and then
(puzzleImage, warped) = find_puzzle(image, debug=args["debug"] > 0)
# initialize our 9x9 Sudoku board
board = np.zeros((9, 9), dtype="int")
# a Sudoku puzzle is a 9x9 grid (81 individual cells), so we can
# infer the location of each cell by dividing the warped image
# into a 9x9 grid
stepX = warped.shape[1] // 9
stepY = warped.shape[0] // 9
# initialize a list to store the (x, y)-coordinates of each cell
# location
cellLocs = []
# loop over the grid locations
for y in range(0, 9):
# initialize the current list of cell locations
row = []
for x in range(0, 9):
# compute the starting and ending (x, y)-coordinates of the
# current cell
startX = x * stepX
startY = y * stepY
endX = (x + 1) * stepX
endY = (y + 1) * stepY
# add the (x, y)-coordinates to our cell locations list
row.append((startX, startY, endX, endY))
考虑到数独游戏中的每个单元格,我们以嵌套的方式循环行(第 48 行)和列(第 52 行)。
在里面,我们使用我们的步长值来确定开始和结束 (x,y)—当前单元格 ( 第 55-58 行)的坐标。
# crop the cell from the warped transform image and then
# extract the digit from the cell
cell = warped[startY:endY, startX:endX]
digit = extract_digit(cell, debug=args["debug"] > 0)
# verify that the digit is not empty
if digit is not None:
# resize the cell to 28x28 pixels and then prepare the
# cell for classification
roi = cv2.resize(digit, (28, 28))
roi = roi.astype("float") / 255.0
roi = img_to_array(roi)
roi = np.expand_dims(roi, axis=0)
# classify the digit and update the Sudoku board with the
# prediction
pred = model.predict(roi).argmax(axis=1)[0]
board[y, x] = pred
# add the row to our cell locations
cellLocs.append(row)
# construct a Sudoku puzzle from the board
print("[INFO] OCR'd Sudoku board:")
puzzle = Sudoku(3, 3, board=board.tolist())
puzzle.show()
# solve the Sudoku puzzle
print("[INFO] solving Sudoku puzzle...")
solution = puzzle.solve()
solution.show_full()
我们继续在终端上打印出解决的谜题( Line 93 )
当然,如果我们不能在拼图图片上看到答案,这个项目会有什么乐趣呢?让我们现在就开始吧:
# loop over the cell locations and board
for (cellRow, boardRow) in zip(cellLocs, solution.board):
# loop over individual cell in the row
for (box, digit) in zip(cellRow, boardRow):
# unpack the cell coordinates
startX, startY, endX, endY = box
# compute the coordinates of where the digit will be drawn
# on the output puzzle image
textX = int((endX - startX) * 0.33)
textY = int((endY - startY) * -0.2)
textX += startX
textY += endY
# draw the result digit on the Sudoku puzzle image
cv2.putText(puzzleImage, str(digit), (textX, textY),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 255), 2)
# show the output image
cv2.imshow("Sudoku Result", puzzleImage)
cv2.waitKey(0)
要用解决方案编号来诠释我们的形象,我们只需:
- 在单元位置和电路板上循环(第 96-98 行)
- 解包单元格坐标(第 100 行)
- 计算将要绘制文本注释的坐标(行 104-107 )
- 在我们的拼图板照片上画出每个输出数字(行 110 和 111 )
- 显示我们解决的数独难题图像(行 114 )直到按下任何键(行 115 )
干得好!
让我们在下一部分启动我们的项目。你会对你的努力工作印象深刻的!
OpenCV 数独解谜器 OCR 结果
我们现在准备好测试我们的 OpenV 数独解谜器了!
确保您使用本教程的 “下载” 部分下载源代码、经过训练的数字分类器和示例数独谜题图像。
从那里,打开一个终端,并执行以下命令:
$ python solve_sudoku_puzzle.py --model output/digit_classifier.h5 \
--image Sudoku_puzzle.jpg
[INFO] loading digit classifier...
[INFO] processing image...
[INFO] OCR'd Sudoku board:
+-------+-------+-------+
| 8 | 1 | 9 |
| 5 | 8 7 | 1 |
| 4 | 9 | 7 |
+-------+-------+-------+
| 6 | 7 1 | 2 |
| 5 8 | 6 | 1 7 |
| 1 | 5 2 | 9 |
+-------+-------+-------+
| 7 | 4 | 6 |
| 8 | 3 9 | 4 |
| 3 | 5 | 8 |
+-------+-------+-------+
[INFO] solving Sudoku puzzle...
---------------------------
9x9 (3x3) SUDOKU PUZZLE
Difficulty: SOLVED
---------------------------
+-------+-------+-------+
| 8 7 2 | 4 1 3 | 5 6 9 |
| 9 5 6 | 8 2 7 | 3 1 4 |
| 1 3 4 | 6 9 5 | 7 8 2 |
+-------+-------+-------+
| 4 6 9 | 7 3 1 | 8 2 5 |
| 5 2 8 | 9 6 4 | 1 3 7 |
| 7 1 3 | 5 8 2 | 4 9 6 |
+-------+-------+-------+
| 2 9 7 | 1 4 8 | 6 5 3 |
| 6 8 5 | 3 7 9 | 2 4 1 |
| 3 4 1 | 2 5 6 | 9 7 8 |
+-------+-------+-------+
如你所见,我们已经使用 OpenCV、OCR 和深度学习成功解决了数独难题!
现在,如果你是打赌型的,你可以挑战一个朋友或重要的人,看谁能在你的下一次跨大陆飞行中最快解决 10 个数独谜题!只是不要被抓到抓拍几张照片!
学分
本教程的灵感来自于 Aakash Jhawar 和他的数独解谜器的第一部分和第二部分的。
此外,你会注意到我使用了与 Aakash 做的相同的示例数独拼图板,不是出于懒惰,而是为了演示如何使用不同的计算机视觉和图像处理技术来解决相同的拼图。
我真的很喜欢 Aakash 的文章,并推荐 PyImageSearch 的读者也去看看(尤其是如果你想从头实现一个数独解算器,而不是使用py-sudoku库)。
总结
在本教程中,您学习了如何使用 OpenCV、深度学习和 OCR 实现数独解谜器。
为了在图像中找到并定位数独拼图板,我们利用了 OpenCV 和基本的图像处理技术,包括模糊、阈值处理和轮廓处理等。
为了真正 OCR 数独板上的数字,我们使用 Keras 和 TensorFlow 训练了一个自定义数字识别模型。
将数独板定位器与我们的数字 OCR 模型结合起来,让我们能够快速解决实际的数独难题。
如果你有兴趣了解更多关于 OCR 的知识,我正在用 OpenCV、Tesseract 和 Python 编写一本名为光学字符识别的新书。
要了解关于这本书的更多信息,并订购您自己的书(加上预发行折扣和附加内容),只需点击此处。
否则,要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
具有深度学习的 OpenCV 超分辨率
原文:https://pyimagesearch.com/2020/11/09/opencv-super-resolution-with-deep-learning/
在本教程中,您将学习如何使用 OpenCV 和深度学习在图像和实时视频流中执行超分辨率。
今天这篇博文的灵感来自于我收到的一封来自 PyImageSearch 阅读器 Hisham 的邮件:
"Hello Adrian, I have read your book on deep learning of computer vision written in Python, and I have browsed the super-resolution you achieved with Keras and TensorFlow. Very useful, thank you.
I wonder:
Is there a pre-trained super-resolution model compatible with the
dnnmodule of OpenCV?Can they work in real time?
If you have any suggestions, it will be a great help. "
你很幸运,希沙姆——这里有个超分辨率深度神经网络,它们都是:
- 预先训练(意味着你不必自己在数据集上训练他们)
- 与 OpenCV 兼容
然而 OpenCV 的超分辨率功能,其实是“隐藏”在一个名为 DnnSuperResImpl_create 的晦涩函数中的一个名为 dnn_superres 的子模块里。
这个函数需要一些解释才能使用,所以我决定写一个关于它的教程;这样每个人都可以学习如何使用 OpenCV 的超分辨率功能。
本教程结束时,你将能够使用 OpenCV 在图像和实时视频流中执行超分辨率处理!
要了解如何使用 OpenCV 进行基于深度学习的超分辨率,继续阅读。
具有深度学习的 OpenCV 超分辨率
在本教程的第一部分,我们将讨论:
- 什么是超分辨率
- 为什么我们不能使用简单的最近邻、线性或双三次插值来大幅提高图像的分辨率
- 专业化的深度学习架构如何帮助我们实时实现超分辨率
接下来,我将向您展示如何使用这两种方法实现 OpenCV 超分辨率:
- 形象
- 实时视频分辨率
我们将讨论我们的结果来结束本教程。
什么是超分辨率?
超分辨率包含一组用于增强、增加和上采样输入图像分辨率的算法和技术。更简单地说,取一幅输入图像,增加图像的宽度和高度,而质量下降最小(理想情况下为零)。
说起来容易做起来难。
任何曾经在 Photoshop 或 GIMP 中打开一个小图像,然后试图调整其大小的人都知道,输出的图像最终看起来像素化了。
那是因为 Photoshop,GIMP,Image Magick,OpenCV(通过cv2.resize函数)等。所有都使用经典的插值技术和算法(例如最近邻插值、线性插值、双三次插值)来增加图像分辨率。
这些函数的“工作”方式是,呈现一个输入图像,调整图像的大小,然后将调整后的图像返回给调用函数…
…然而,如果将空间维度、增加得太多,那么输出图像会出现像素化,会有伪像,总的来说,对人眼来说看起来“不美观”。
例如,让我们考虑下图:
在顶端我们有自己的原始图像。红色矩形中突出显示的区域是我们希望提取并提高分辨率的区域(即,在不降低图像补片质量的情况下,调整到更大的宽度和高度)。
在底部我们有应用双三次插值的输出,用于增加输入图像大小的标准插值方法(当需要增加输入图像的空间维度时,我们通常在cv2.resize中使用)。
然而,花一点时间来注意在应用双三次插值后,图像补丁是如何像素化、模糊和不可读的。
这就提出了一个问题:
有没有更好的方法在不降低质量的情况下提高图像的分辨率?
答案是肯定的——而且这也不是魔法。通过应用新颖的深度学习架构,我们能够生成没有这些伪像的高分辨率图像:
同样,在顶部我们有我们的原始输入图像。在中间我们在应用双三次插值后有低质量的尺寸调整。在底部我们有应用我们的超分辨率深度学习模型的输出。
区别就像白天和黑夜。输出的深度神经网络超分辨率模型是清晰的,易于阅读,并且显示出最小的调整大小伪像的迹象。
在本教程的剩余部分,我将揭开这个“魔术”,并向您展示如何使用 OpenCV 执行超分辨率!
OpenCV 超分辨率模型
在本教程中,我们将使用四个预先训练好的超分辨率模型。对模型架构、它们如何工作以及每个模型的培训过程的回顾超出了本指南的范围(因为我们只关注实现和)。
如果您想了解更多关于这些模型的信息,我在下面列出了它们的名称、实现和论文链接:
- EDSR: 单幅图像超分辨率增强深度残差网络 ( 实现 )
- ESPCN: 利用高效的亚像素卷积神经网络 ( 实现)实时单幅图像和视频超分辨率
- FSRCNN: 加速超分辨率卷积神经网络 ( 实现)
- LapSRN: 快速准确的图像超分辨率与深度拉普拉斯金字塔网络 ( 实现)
非常感谢来自 BleedAI 的 Taha Anwar 整理了他的关于 OpenCV 超分辨率的指南,其中收集了很多信息——这对创作这篇文章非常有帮助。
使用 OpenCV 为超分辨率配置您的开发环境
为了应用 OpenCV 超分辨率,您必须在您的系统上安装 OpenCV 4.3(或更高版本)。虽然在 OpenCV 4.1.2 中用 C++实现了dnn_superes模块,但是 Python 绑定直到 OpenCV 4.3 才实现。
幸运的是,OpenCV 4.3+是 pip 安装的:
$ pip install opencv-contrib-python
如果你需要帮助配置 OpenCV 4.3+的开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
配置您的开发环境有问题吗?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
配置好开发环境后,让我们继续检查我们的项目目录结构:
$ tree . --dirsfirst
.
├── examples
│ ├── adrian.png
│ ├── butterfly.png
│ ├── jurassic_park.png
│ └── zebra.png
├── models
│ ├── EDSR_x4.pb
│ ├── ESPCN_x4.pb
│ ├── FSRCNN_x3.pb
│ └── LapSRN_x8.pb
├── super_res_image.py
└── super_res_video.py
2 directories, 10 files
在这里,您可以看到我们今天要复习两个 Python 脚本:
super_res_image.py:对从磁盘加载的图像执行 OpenCV 超分辨率super_res_video.py:将 OpenCV 的超分辨率应用于实时视频流
我们将在本文后面详细介绍这两个 Python 脚本的实现。
从那里,我们有四个超分辨率模型:
EDSR_x4.pb:来自单幅图像超分辨率增强深度残差网络论文的模型— 将输入图像分辨率提高 4 倍ESPCN_x4.pb:来自的超分辨率模型,采用高效的亚像素卷积神经网络实现实时单幅图像和视频超分辨率——分辨率提升 4 倍FSRCNN_x3.pb:来自的模型加速超分辨率卷积神经网络——将图像分辨率提高 3 倍LapSRN_x8.pb:来自的超分辨率模型,深度拉普拉斯金字塔网络快速精确的图像超分辨率——将图像分辨率提高 8 倍
最后,examples目录包含我们将应用 OpenCV 超分辨率的示例输入图像。
用图像实现 OpenCV 超分辨率
我们现在准备在图像中实现 OpenCV 超分辨率!
打开项目目录结构中的super_res_image.py文件,让我们开始工作:
# import the necessary packages
import argparse
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to super resolution model")
ap.add_argument("-i", "--image", required=True,
help="path to input image we want to increase resolution of")
args = vars(ap.parse_args())
从那里,第 8-13 行解析我们的命令行参数。这里我们只需要两个命令行参数:
--model:输入 OpenCV 超分辨率模型的路径--image:我们要应用超分辨率的输入图像的路径
给定我们的超分辨率模型路径,我们现在需要提取模型名称和模型比例(即,我们将增加图像分辨率的因子):
# extract the model name and model scale from the file path
modelName = args["model"].split(os.path.sep)[-1].split("_")[0].lower()
modelScale = args["model"].split("_x")[-1]
modelScale = int(modelScale[:modelScale.find(".")])
第 16 行提取modelName,分别可以是EDSR、ESPCN、FSRCNN或LapSRN。modelName有是这些型号名称之一;否则,** dnn_superres 模块和 DnnSuperResImpl_create 功能将不起作用。**
**解析完模型名称和比例后,我们现在可以继续加载 OpenCV 超分辨率模型:
# initialize OpenCV's super resolution DNN object, load the super
# resolution model from disk, and set the model name and scale
print("[INFO] loading super resolution model: {}".format(
args["model"]))
print("[INFO] model name: {}".format(modelName))
print("[INFO] model scale: {}".format(modelScale))
sr = cv2.dnn_superres.DnnSuperResImpl_create()
sr.readModel(args["model"])
sr.setModel(modelName, modelScale)
我们首先实例化DnnSuperResImpl_create的一个实例,这是我们实际的超分辨率对象。
对readModel的调用从磁盘加载我们的 OpenCV 超分辨率模型。
然后我们必须明确地调用setModel到来设置modelName和modelScale。
*未能从磁盘读取模型或设置模型名称和比例将导致我们的超分辨率脚本出错或 segfaulting。
现在让我们用 OpenCV 执行超分辨率:
# load the input image from disk and display its spatial dimensions
image = cv2.imread(args["image"])
print("[INFO] w: {}, h: {}".format(image.shape[1], image.shape[0]))
# use the super resolution model to upscale the image, timing how
# long it takes
start = time.time()
upscaled = sr.upsample(image)
end = time.time()
print("[INFO] super resolution took {:.6f} seconds".format(
end - start))
# show the spatial dimensions of the super resolution image
print("[INFO] w: {}, h: {}".format(upscaled.shape[1],
upscaled.shape[0]))
第 31 和 32 行从磁盘加载我们的输入--image并显示原始的宽度和高度。
从那里,线 37 调用sr.upsample,提供原始输入image。upsample函数,顾名思义,执行 OpenCV 超分辨率模型的前向传递,返回upscaled图像。
我们小心地测量超分辨率过程需要多长时间,然后在我们的终端上显示升级图像的新宽度和高度。
为了比较,让我们应用标准的双三次插值并计算它需要多长时间:
# resize the image using standard bicubic interpolation
start = time.time()
bicubic = cv2.resize(image, (upscaled.shape[1], upscaled.shape[0]),
interpolation=cv2.INTER_CUBIC)
end = time.time()
print("[INFO] bicubic interpolation took {:.6f} seconds".format(
end - start))
双三次插值是用于提高图像分辨率的标准算法。这种方法在几乎个图像处理工具和库中实现,包括 Photoshop、GIMP、Image Magick、PIL/PIllow、OpenCV、Microsoft Word、Google Docs 等。— 如果一个软件需要处理图像,它很可能实现双三次插值。
最后,让我们在屏幕上显示输出结果:
# show the original input image, bicubic interpolation image, and
# super resolution deep learning output
cv2.imshow("Original", image)
cv2.imshow("Bicubic", bicubic)
cv2.imshow("Super Resolution", upscaled)
cv2.waitKey(0)
在这里,我们显示我们的原始输入image,调整后的图像bicubic,最后是我们的upscaled超分辨率图像。
我们将三个结果显示在屏幕上,这样我们可以很容易地比较结果。
OpenCV 超分辨率结果
首先,确保您已经使用本教程的 “下载” 部分下载了源代码、示例图像和预训练的超分辨率模型。
从那里,打开一个终端,并执行以下命令:
$ python super_res_image.py --model models/EDSR_x4.pb --image examples/adrian.png
[INFO] loading super resolution model: models/EDSR_x4.pb
[INFO] model name: edsr
[INFO] model scale: 4
[INFO] w: 100, h: 100
[INFO] super resolution took 1.183802 seconds
[INFO] w: 400, h: 400
[INFO] bicubic interpolation took 0.000565 seconds
在顶部我们有我们的原始输入图像。在中间我们应用了标准的双三次插值图像来增加图像的尺寸。最后,底部显示了 EDSR 超分辨率模型的输出(图像尺寸增加了 4 倍)。
如果你研究这两幅图像,你会发现超分辨率图像看起来“更平滑”特别是,看看我的前额区域。在双三次图像中,有很多像素化在进行— ,但是在超分辨率图像中,我的前额明显更平滑,像素化更少。
EDSR 超分辨率模式的缺点是速度有点慢。标准的双三次插值可以以每秒 > 1700 帧的速率将 100×100 像素的图像增加到 400×400 像素。
另一方面,EDSR 需要一秒以上的时间来执行相同的上采样。因此,EDSR 不适合实时超分辨率(至少在没有 GPU 的情况下不适合)。
注意:这里所有的计时都是用 3 GHz 英特尔至强 W 处理器收集的。一个 GPU 被而不是*使用。*
让我们试试另一张照片,这张是一只蝴蝶:
$ python super_res_image.py --model models/ESPCN_x4.pb --image examples/butterfly.png
[INFO] loading super resolution model: models/ESPCN_x4.pb
[INFO] model name: espcn
[INFO] model scale: 4
[INFO] w: 400, h: 240
[INFO] super resolution took 0.073628 seconds
[INFO] w: 1600, h: 960
[INFO] bicubic interpolation took 0.000833 seconds
同样,在顶部我们有我们的原始输入图像。在应用标准的双三次插值后,我们得到了中间的图像。在底部我们有应用 ESPCN 超分辨率模型的输出。
你可以看到这两个超分辨率模型之间的差异的最好方法是研究蝴蝶的翅膀。请注意双三次插值方法看起来更加嘈杂和扭曲,而 ESPCN 输出图像明显更加平滑。
这里的好消息是,ESPCN 模型的速度明显快于 T1,能够在 CPU 上以 13 FPS 的速率将 400x240px 的图像上采样为 1600x960px 的图像。
下一个示例应用 FSRCNN 超分辨率模型:
$ python super_res_image.py --model models/FSRCNN_x3.pb --image examples/jurassic_park.png
[INFO] loading super resolution model: models/FSRCNN_x3.pb
[INFO] model name: fsrcnn
[INFO] model scale: 3
[INFO] w: 350, h: 197
[INFO] super resolution took 0.082049 seconds
[INFO] w: 1050, h: 591
[INFO] bicubic interpolation took 0.001485 seconds
暂停一下,看看艾伦·格兰特的夹克(穿蓝色牛仔衬衫的那个人)。在双三次插值图像中,这件衬衫是颗粒状的。但是在 FSRCNN 输出中,封套要比 T1 平滑得多。
与 ESPCN 超分辨率模型类似,FSRCNN 仅用 0.08 秒对图像进行上采样(速率约为 12 FPS)。
最后,让我们看看 LapSRN 模型,它将输入图像分辨率提高了 8 倍:
$ python super_res_image.py --model models/LapSRN_x8.pb --image examples/zebra.png
[INFO] loading super resolution model: models/LapSRN_x8.pb
[INFO] model name: lapsrn
[INFO] model scale: 8
[INFO] w: 400, h: 267
[INFO] super resolution took 4.759974 seconds
[INFO] w: 3200, h: 2136
[INFO] bicubic interpolation took 0.008516 seconds
也许不出所料,这种型号是最慢的,需要 4.5 秒才能将 400x267px 输入的分辨率提高到 3200x2136px 的输出。鉴于我们将空间分辨率提高了 8 倍,这一时序结果是有意义的。
也就是说,LapSRN 超分辨率模型的输出非常棒。看双三次插值输出(中)和 LapSRN 输出(下)之间的斑马纹。斑马身上的条纹清晰分明,不像双三次输出。
用 OpenCV 实现实时超分辨率
我们已经看到超分辨率应用于单个图像——,但如何处理实时视频流呢?
有可能实时执行 OpenCV 超分辨率吗?
答案是肯定的,这绝对是可能的——这正是我们的super_res_video.py脚本所做的。
注:super_res_video.py的大部分脚本与我们的 super_res_image.py 脚本类似,所以我就不多花时间解释实时实现了。如果您需要更多的帮助来理解代码,请参考上一节“用图像实现 OpenCV 超分辨率”。
让我们开始吧:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import imutils
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to super resolution model")
args = vars(ap.parse_args())
第 2-7 行导入我们需要的 Python 包。除了我的 imutils 库和来自它的 VideoStream 实现之外,这些都与我们之前关于图像超分辨率的脚本几乎相同。
然后我们解析我们的命令行参数。只需要一个参数--model,它是我们的输入超分辨率模型的路径。
接下来,让我们提取模型名称和模型比例,然后从磁盘加载我们的 OpenCV 超分辨率模型:
# extract the model name and model scale from the file path
modelName = args["model"].split(os.path.sep)[-1].split("_")[0].lower()
modelScale = args["model"].split("_x")[-1]
modelScale = int(modelScale[:modelScale.find(".")])
# initialize OpenCV's super resolution DNN object, load the super
# resolution model from disk, and set the model name and scale
print("[INFO] loading super resolution model: {}".format(
args["model"]))
print("[INFO] model name: {}".format(modelName))
print("[INFO] model scale: {}".format(modelScale))
sr = cv2.dnn_superres.DnnSuperResImpl_create()
sr.readModel(args["model"])
sr.setModel(modelName, modelScale)
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
第 16-18 行从输入的--model文件路径中提取我们的modelName和modelScale。
使用这些信息,我们实例化我们的超分辨率(sr)对象,从磁盘加载模型,并设置模型名称和比例(第 26-28 行)。
然后我们初始化我们的VideoStream(这样我们可以从我们的网络摄像头读取帧)并允许摄像头传感器预热。
完成初始化后,我们现在可以从VideoStream开始循环遍历帧:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 300 pixels
frame = vs.read()
frame = imutils.resize(frame, width=300)
# upscale the frame using the super resolution model and then
# bicubic interpolation (so we can visually compare the two)
upscaled = sr.upsample(frame)
bicubic = cv2.resize(frame,
(upscaled.shape[1], upscaled.shape[0]),
interpolation=cv2.INTER_CUBIC)
第 36 行开始循环播放视频流中的帧。然后我们抓取下一个frame,调整它的宽度为 300 像素。
我们执行这个调整大小操作是为了可视化/示例的目的。回想一下,本教程的重点是用 OpenCV 应用超分辨率。因此,我们的示例应该显示如何获取低分辨率输入,然后生成高分辨率输出(这正是我们降低帧分辨率的原因)。
第 44 行使用我们的 OpenCV 分辨率模型调整输入frame的大小,得到upscaled图像。
第 45-47 行应用了基本的双三次插值,因此我们可以比较这两种方法。
我们的最后一个代码块将结果显示在屏幕上:
# show the original frame, bicubic interpolation frame, and super
# resolution frame
cv2.imshow("Original", frame)
cv2.imshow("Bicubic", bicubic)
cv2.imshow("Super Resolution", upscaled)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
这里我们显示原始的frame、bicubic插值输出,以及来自我们的超分辨率模型的upscaled输出。
我们继续处理并在屏幕上显示帧,直到点击 OpenCV 打开的窗口并按下q,导致 Python 脚本退出。
最后,我们通过关闭 OpenCV 打开的所有窗口并停止我们的视频流来执行一点清理。
实时 OpenCV 超分辨率结果
现在让我们在实时视频流中应用 OpenCV 超级分辨率!
确保您已经使用本教程的 “下载” 部分下载了源代码、示例图像和预训练模型。
从那里,您可以打开一个终端并执行以下命令:
$ python super_res_video.py --model models/FSRCNN_x3.pb
[INFO] loading super resolution model: models/FSRCNN_x3.pb
[INFO] model name: fsrcnn
[INFO] model scale: 3
[INFO] starting video stream...
在这里,您可以看到我能够在我的 CPU 上实时运行 FSRCNN 模型(不需要 GPU!).
此外,如果您将双三次插值的结果与超分辨率进行比较,您会发现超分辨率输出要干净得多。
建议
在一篇篇幅有限的博客文章中,很难展示超分辨率带给我们的所有微妙之处,因此我强烈建议下载代码/模型,并仔细研究输出。
摘要
在本教程中,您学习了如何在图像和实时视频流中实现 OpenCV 超分辨率。
诸如最近邻插值、线性插值和双三次插值之类的基本图像大小调整算法只能将输入图像的分辨率提高到一定程度,之后,图像质量会下降到图像看起来像素化的程度,并且一般来说,调整后的图像对人眼来说不美观。
深度学习超分辨率模型能够产生这些更高分辨率的图像,同时有助于防止这些像素化、伪像和令人不愉快的结果。
也就是说,你需要设定一个期望值,即不存在你在电视/电影中看到的神奇算法,它可以拍摄一张模糊的、缩略图大小的图像,并将其调整为海报,你可以打印出来并挂在墙上——这根本不可能。
也就是说,OpenCV 的超分辨率模块可以用于应用超分辨率。这是否适合您的管道是需要测试的:
- 首先尝试使用
cv2.resize和标准插值算法(以及调整大小需要多长时间)。 - 然后,运行相同的操作,但是换成 OpenCV 的超分辨率模块(同样,计时调整大小需要多长时间)。
比较输出和运行标准插值和 OpenCV 超分辨率花费的时间。从那里,选择在输出图像的质量和调整大小发生的时间之间达到最佳平衡的调整大小模式。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
OpenCV 模板匹配(cv2.matchTemplate)
原文:https://pyimagesearch.com/2021/03/22/opencv-template-matching-cv2-matchtemplate/
在本教程中,您将学习如何使用 OpenCV 和cv2.matchTemplate函数执行模板匹配。

除了轮廓过滤和处理,模板匹配可以说是物体检测的最简单形式之一:
- 实现起来很简单,只需要 2-3 行代码
- 模板匹配的计算效率很高
- 它不需要你执行阈值,边缘检测等。,以生成二进制图像(如轮廓检测和处理)
- 通过一个基本的扩展,模板匹配可以检测输入图像中相同/相似对象的多个实例(我们将在下周讨论)
当然,模板匹配并不完美。尽管有这些优点,但如果输入图像中存在变化因素,包括旋转、缩放、视角等变化,模板匹配很快就会失败。
如果您的输入图像包含这些类型的变化,您不应该使用模板匹配—利用专用的对象检测器,包括 HOG +线性 SVM、更快的 R-CNN、SSDs、YOLO 等。
但是在你知道旋转、缩放和视角不变的情况下,模板匹配可以创造奇迹。
要学习如何用 OpenCV 执行模板匹配, 继续阅读。
OpenCV 模板匹配(cv2.matchTemplate )
在本教程的第一部分,我们将讨论什么是模板匹配以及 OpenCV 如何通过cv2.matchTemplate函数实现模板匹配。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们将使用 OpenCV 实现模板匹配,将它应用于一些示例图像,并讨论它在哪里工作得好,什么时候不好,以及如何改进模板匹配结果。
什么是模板匹配?
模板匹配可以被视为对象检测的一种非常基本的形式。使用模板匹配,我们可以使用包含我们想要检测的对象的“模板”来检测输入图像中的对象。
本质上,这意味着我们需要两幅图像来应用模板匹配:
- 源图像:这是我们期望在其中找到与模板匹配的图像。
- 模板图像:我们在源图像中搜索的“对象补丁”。
为了在源图像中找到模板,我们将模板从左到右和从上到下滑过源图像:
在每个 (x,y)-位置,计算一个度量来表示匹配的“好”或“坏”程度。通常,我们使用归一化相关系数来确定两个块的像素强度有多“相似”:
有关相关系数的完整推导,包括 OpenCV 支持的所有其他模板匹配方法,请参考 OpenCV 文档。
对于 I 上的每个位置 T ,计算出的结果度量存储在我们的结果矩阵 R 中。源图像中的每个 (x,y)-坐标(对于模板图像也具有有效的宽度和高度)在结果矩阵 R 中包含一个条目:
在这里,我们可以看到覆盖在原始图像上的结果矩阵 R 。注意 R 是如何与原始模板的T5【而不是 大小相同的。这是因为整个模板必须适合要计算相关性的源图像。如果模板超出了源的边界,我们不计算相似性度量。
结果矩阵的亮位置 R 表示最佳匹配,其中暗区域表示源图像和模板图像之间的相关性很小。注意结果矩阵的最亮区域如何出现在咖啡杯的左上角。
尽管模板匹配应用起来极其简单并且计算效率高,但是有许多限制。如果有任何对象比例变化、旋转或视角,模板匹配很可能会失败。
几乎在所有情况下,您都希望确保您正在检测的模板与您希望在源代码中检测的对象几乎相同。即使外观上很小、很小的偏差也会显著影响模板匹配结果,并使其变得毫无用处。
OpenCV 的“cv2.matchTemplate”函数
我们可以使用 OpenCV 和cv2.matchTemplate函数应用模板匹配:
result = cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED)
在这里,您可以看到我们为cv2.matchTemplate函数提供了三个参数:
- 包含我们想要检测的对象的输入
image - 对象的
template(即我们希望在image中检测的内容) - 模板匹配方法
这里,我们使用归一化的相关系数,这是您通常想要使用的模板匹配方法,但是 OpenCV 也支持其他模板匹配方法。
来自cv2.matchTemplate的输出result是具有空间维度的矩阵:
- 宽度:
image.shape[1] - template.shape[1] + 1 - 身高:
image.shape[0] - template.shape[0] + 1
然后我们可以在result中找到具有最大相关系数的位置,它对应于最有可能找到模板的区域(在本教程的后面你将学习如何做)。
同样值得注意的是,如果您只想检测输入图像中特定区域内的对象,您可以提供一个遮罩,如下所示:
result = cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED, mask)
mask必须具有与template相同的空间维度和数据类型。对于输入image中你不想搜索的区域,应该将mask设置为零。对于您想要搜索的image区域,请确保mask具有相应的值255。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们深入之前,让我们回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
您的目录应该如下所示:
$ tree . --dirsfirst
.
├── images
│ ├── 8_diamonds.png
│ ├── coke_bottle.png
│ ├── coke_bottle_rotated.png
│ ├── coke_logo.png
│ └── diamonds_template.png
└── single_template_matching.py
1 directory, 6 files
我们今天要回顾一个 Python 脚本single_template_matching.py,它将使用 OpenCV 执行模板匹配。
在images目录中,我们有五个图像,我们将对它们应用模板匹配。我们将在教程的后面看到这些图像。
用 OpenCV 实现模板匹配
回顾了我们的项目目录结构后,让我们继续用 OpenCV 实现模板匹配。
打开目录结构中的single_template_matching.py文件,插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image where we'll apply template matching")
ap.add_argument("-t", "--template", type=str, required=True,
help="path to template image")
args = vars(ap.parse_args())
在第 2 行和第 3 行,我们导入我们需要的 Python 包。我们只需要用argparse解析命令行参数,用cv2绑定 OpenCV。
从那里,我们继续解析我们的命令行参数:
--image:我们将对其应用模板匹配的磁盘上的输入图像的路径(即,我们想要在其中检测对象的图像)。--template:我们希望在输入图像中找到其实例的示例模板图像。
接下来,让我们准备用于模板匹配的图像和模板:
# load the input image and template image from disk, then display
# them on our screen
print("[INFO] loading images...")
image = cv2.imread(args["image"])
template = cv2.imread(args["template"])
cv2.imshow("Image", image)
cv2.imshow("Template", template)
# convert both the image and template to grayscale
imageGray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
templateGray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
我们首先加载我们的image和template,然后在屏幕上显示它们。
模板匹配通常应用于灰度图像,因此第 22 行和第 23 行将图像转换为灰度图像。
接下来,需要做的就是调用cv2.matchTemplate:
# perform template matching
print("[INFO] performing template matching...")
result = cv2.matchTemplate(imageGray, templateGray,
cv2.TM_CCOEFF_NORMED)
(minVal, maxVal, minLoc, maxLoc) = cv2.minMaxLoc(result)
第 27 行和第 28 行通过cv2.matchTemplate功能执行模板匹配。我们向该函数传递三个必需的参数:
- 我们希望在其中找到对象的输入图像
- 我们要在输入图像中检测的对象的模板图像
- 模板匹配方法
通常情况下,归一化相关系数(cv2.TM_CCOEF_NORMED)在大多数情况下工作良好,,但是您可以参考 OpenCV 文档以获得关于其他模板匹配方法的更多细节。
一旦我们应用了cv2.matchTemplate,我们会收到一个具有以下空间维度的result矩阵:
- 宽度:
image.shape[1] - template.shape[1] + 1 - 身高:
image.shape[0] - template.shape[0] + 1
该result矩阵将具有一个大值(更接近于1),其中有更可能是一个模板匹配。类似地,result矩阵将具有小值(更接近于0),其中匹配的可能性更小。
为了找到具有最大值的位置,也就是最有可能匹配的位置,我们调用cv2.minMaxLoc ( 第 29 行),传入result矩阵。
一旦我们有了具有最大归一化相关系数(maxLoc)的位置的 (x,y) 坐标,我们就可以提取坐标并导出边界框坐标:
# determine the starting and ending (x, y)-coordinates of the
# bounding box
(startX, startY) = maxLoc
endX = startX + template.shape[1]
endY = startY + template.shape[0]
第 33 行从我们的maxLoc中提取起始 (x,y)-坐标,该坐标来源于前一代码块中的调用cv2.minMaxLoc。
使用startX和endX坐标,我们可以通过将模板的宽度和高度分别加到startX和endX坐标上,得到第 34 行和第 35 行上的endX和endY坐标。
最后一步是在image上绘制检测到的边界框:
# draw the bounding box on the image
cv2.rectangle(image, (startX, startY), (endX, endY), (255, 0, 0), 3)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
对第 38 行上的cv2.rectangle的调用在图像上绘制边界框。
第 41 和 42 行然后在我们的屏幕上显示我们的输出image。
OpenCV 模板匹配结果
我们现在准备用 OpenCV 应用模板匹配!
访问本教程的 “下载” 部分来检索源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python single_template_matching.py --image images/coke_bottle.png \
--template images/coke_logo.png
[INFO] loading images...
[INFO] performing template matching...
在这个例子中,我们有一个包含可口可乐瓶的输入图像:
我们的目标是检测图像中的可口可乐标志:
通过应用 OpenCV 和cv2.matchTemplate函数,我们可以正确定位在coke_bottle.png图像中的位置coke_logo.png图像是:
这种方法是可行的,因为coke_logo.png中的可口可乐标志与coke_bottle.png中的标志大小相同(就比例而言)。类似地,徽标以相同的视角观看,并且不旋转。
如果标识的规模不同或视角不同,这种方法就会失败。
例如,让我们试试这个示例图像,但这次我稍微旋转了可口可乐瓶子,并缩小了瓶子:
$ python single_template_matching.py \
--image images/coke_bottle_rotated.png \
--template images/coke_logo.png
[INFO] loading images...
[INFO] performing template matching...
请注意我们是如何进行假阳性检测的!我们没有发现可口可乐的标志,现在的规模和旋转是不同的。
这里的关键点在于模板匹配是对旋转、视角、比例的变化极其敏感。当这种情况发生时,你可能需要应用更先进的物体检测技术。
*在下面的示例中,我们正在处理一副牌,并试图检测方块 8 扑克牌上的“方块”符号:
$ python single_template_matching.py --image images/8_diamonds.png \
--template images/diamonds_template.png
[INFO] loading images...
[INFO] performing template matching...
在左边的,是我们的diamonds_template.png图像。我们使用 OpenCV 和cv2.matchTemplate函数找到所有的菱形符号(右) …
…但是这里发生了什么?
为什么没有检测出所有的钻石符号?
答案是,cv2.matchTemplate函数本身,无法检测多个对象!
不过,有一个解决方案——我将在下周的教程中介绍 OpenCV 的多模板匹配。
关于模板匹配的误报检测的说明
你会注意到,在我们旋转可口可乐标志的例子中,我们没有检测到可口可乐标志;然而,我们的代码仍然“报告”找到了徽标:
请记住,cv2.matchTemplate函数确实不知道是否正确找到了对象——它只是在输入图像上滑动模板图像,计算归一化的相关性分数,然后返回分数最大的位置。
模板匹配是“哑算法”的一个例子没有任何机器学习在进行,T2 也不知道输入图像中有什么。
要过滤掉误报检测,您应该获取maxVal并使用if语句过滤掉低于某个阈值的分数。
演职员表和参考资料
我要感谢在线教师关于模板匹配的精彩文章——我不能因为用扑克牌来演示模板匹配的想法而居功。这是他们的想法,而且是一个很好的想法。感谢他们想出了这个例子,我无耻地用在这里,谢谢。
此外,u/fireball_73 从 Reddit 帖子中获得了方块 8 的图像。
总结
在本教程中,您学习了如何使用 OpenCV 和cv2.matchTemplate函数执行模板匹配。
模板匹配是目标检测的一种基本形式。它非常快速有效,但缺点是当对象的旋转、缩放或视角发生变化时,它会失败——当这种情况发生时,你需要一种更高级的对象检测技术。
然而,假设您可以控制捕捉照片的环境中对象的比例或使其正常化。在这种情况下,您有可能摆脱模板匹配,并避免标记数据、训练对象检测器和调整其超参数的繁琐任务。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
OpenCV 文本检测(东方文本检测器)
原文:https://pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/
最后更新于 2021 年 7 月 7 日。
在本教程中,您将学习如何使用 OpenCV 使用 EAST 文本检测器检测自然场景图像中的文本。
OpenCV 的 EAST text detector 是一个深度学习模型,基于一种新颖的架构和训练模式。它能够(1)在 720p 图像上以 13 FPS 的速度近乎实时地运行,以及(2)获得最先进的文本检测精度。
在本教程的剩余部分,您将学习如何使用 OpenCV 的 EAST 检测器自动检测图像和视频流中的文本。
要了解如何使用 OpenCV 应用文本检测,请继续阅读!
- 【2021 年 7 月更新:增加了两个新部分,包括替代的 EAST 文本检测器实现,以及关于 EAST 模型本身的替代部分。
OpenCV 文本检测(东方文本检测器)
https://www.youtube.com/embed/NfiCmhLLxMA?feature=oembed
OpenCV 阈值(cv2.threshold)
原文:https://pyimagesearch.com/2021/04/28/opencv-thresholding-cv2-threshold/
在本教程中,您将学习如何使用 OpenCV 和cv2.threshold函数来应用基本阈值和 Otsu 阈值。
阈值分割是计算机视觉中最常见(也是最基本)的分割技术之一,它允许我们将图像的前景(即我们感兴趣的物体)与背景分开。
阈值有三种形式:
- 我们有简单的阈值处理,我们手动提供参数来分割图像——这在受控的照明条件下非常有效,我们可以确保图像的前景和背景之间的高对比度。
- 我们也有一些方法,比如试图更加动态化的 Otsu 阈值法和基于输入图像自动计算最佳阈值的。
- 最后,我们有自适应阈值,它不是试图使用单个值对图像全局进行阈值处理,而是将图像分成更小的块,并分别对这些块和分别进行阈值处理和。
*今天我们将讨论简单阈值和 Otsu 阈值。我们的下一个教程将详细介绍自适应阈值。
要了解如何使用 OpenCV 和cv2.threshold函数应用基本阈值和 Otsu 阈值,请继续阅读。
OpenCV 阈值处理(cv2.threshold )
在本教程的第一部分,我们将讨论阈值的概念,以及阈值如何帮助我们使用 OpenCV 分割图像。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我将向您展示使用 OpenCV 对图像进行阈值处理的两种方法:
- 基本阈值您必须手动提供阈值, T
- Otsu 的阈值,哪个自动决定阈值
作为一名计算机视觉从业者,理解这些方法是如何工作的非常重要。
让我们开始吧。
什么是阈值处理?
阈值处理是图像的二值化。一般来说,我们寻求将灰度图像转换成二进制图像,其中像素或者是 0 或者是 255 。
一个简单的阈值例子是选择一个阈值 T ,然后设置所有小于 T 到 0 的像素强度,以及所有大于 T 到 255 的像素值。这样,我们能够创建图像的二进制表示。
例如,看看下面的(灰度)PyImageSearch 徽标及其对应的阈值:
在左侧的上,我们有原始的 PyImageSearch 徽标,它已被转换为灰度。在右边,我们有 PyImageSearch 徽标的阈值化二进制表示。
为了构建这个阈值图像,我简单地设置我的阈值 T=225。这样,logo 中所有像素 p 其中 p < T 被设置为 255 ,所有像素 p > = T 被设置为 0 。
通过执行这个阈值处理,我已经能够从背景中分割出 PyImageSearch 徽标。
通常,我们使用阈值来聚焦图像中特别感兴趣的对象或区域。在下一课的示例中,我们将使用阈值处理来检测图像中的硬币,分割 OpenCV 徽标的片段,并将车牌字母和字符从车牌本身中分离出来。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们使用 OpenCV 和cv2.threshold函数应用阈值之前,我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
然后,您将看到以下目录结构:
$ tree . --dirsfirst
.
├── images
│ ├── coins01.png
│ ├── coins02.png
│ └── opencv_logo.png
├── otsu_thresholding.py
└── simple_thresholding.py
1 directory, 5 files
我们今天要复习两个 Python 脚本:
simple_thresholding.py:演示如何使用 OpenCV 应用阈值处理。在这里,我们手动设置阈值,这样我们就可以从背景中分割出前景。otsu_thresholding.py:应用 Otsu 阈值法,阈值参数自动设置。**
*Otsu 阈值技术的好处是,我们不必手动设置阈值截止,Otsu 的方法会自动为我们完成。
在images目录中有许多演示图像,我们将对它们应用这些阈值脚本。
用 OpenCV 实现简单的阈值处理
应用简单的阈值方法需要人工干预。我们必须指定一个阈值 T 。低于 T 的所有像素亮度被设置为 255 。并且所有大于 T 的像素亮度被设置为 0 。
我们也可以通过设置所有大于 T 到 255 的像素和所有小于 T 到 0 的像素强度来应用这种二进制化的逆过程。
让我们探索一些应用简单阈值方法的代码。打开项目目录结构中的simple_thresholding.py文件,插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
args = vars(ap.parse_args())
我们从第 2 行和第 3 行开始,导入我们需要的 Python 包。然后我们在的第 6-9 行解析我们的命令行参数。
只需要一个命令行参数--image,它是我们希望应用阈值的输入图像的路径。
完成导入和命令行参数之后,让我们继续从磁盘加载映像并对其进行预处理:
# load the image and display it
image = cv2.imread(args["image"])
cv2.imshow("Image", image)
# convert the image to grayscale and blur it slightly
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (7, 7), 0)
第 12 行和第 13 行从磁盘加载我们的输入image并显示在我们的屏幕上。
然后,我们通过以下两种方式对图像进行预处理:
- 将其转换为灰度
- 应用 7×7 高斯模糊
应用高斯模糊有助于移除图像中我们不关心的一些高频边缘,并允许我们获得更“干净”的分割。
现在,让我们继续应用实际的阈值:
# apply basic thresholding -- the first parameter is the image
# we want to threshold, the second value is is our threshold
# check; if a pixel value is greater than our threshold (in this
# case, 200), we set it to be *black, otherwise it is *white*
(T, threshInv) = cv2.threshold(blurred, 200, 255,
cv2.THRESH_BINARY_INV)
cv2.imshow("Threshold Binary Inverse", threshInv)
图像模糊后,我们使用cv2.threshold函数计算行 23 和 24 上的阈值图像。此方法需要四个参数。
第一个是我们希望设定阈值的灰度图像。我们首先提供我们的blurred图像。
然后,我们手动提供我们的 T 阈值。我们使用一个值 T=200 。
我们的第三个参数是阈值处理期间应用的输出值。任何大于 T 的像素亮度 p 被设置为零,任何小于 T 的像素亮度 p 被设置为输出值:
在我们的例子中,任何大于 200 的像素值被设置为 0 。任何小于 200 的值被设置为 255 。
最后,我们必须提供一个阈值方法。我们使用cv2.THRESH_BINARY_INV方法,表示小于 T 的像素值 p 被设置为输出值(第三个参数)。
然后,cv2.threshold函数返回一个由两个值组成的元组:第一个值是阈值。在简单阈值的情况下,这个值是微不足道的,因为我们首先手动提供了 T 的值。但是在 Otsu 阈值的情况下,动态地为我们计算出 T ,有这个值就很好了。第二个返回值是阈值图像本身。
但是,如果我们想执行反向操作,就像这样:
如果想要将大于 T 的所有像素 p 设置为输出值呢?这可能吗?
当然啦!有两种方法可以做到。第一种方法是简单地对输出阈值图像进行位非运算。但是这增加了一行额外的代码。
相反,我们可以给cv2.threshold函数提供一个不同的标志:
# using normal thresholding (rather than inverse thresholding)
(T, thresh) = cv2.threshold(blurred, 200, 255, cv2.THRESH_BINARY)
cv2.imshow("Threshold Binary", thresh)
在第 28 行的上,我们通过提供cv2.THRESH_BINARY来应用不同的阈值方法。
在大多数情况下,你通常希望被分割的物体在黑色背景上呈现为白色,因此使用cv2.THRESH_BINARY_INV。但是如果你想让你的对象在白色背景上显示为黑色,一定要提供cv2.THRESH_BINARY标志。
我们要执行的最后一项任务是显示图像中的前景对象,隐藏其他所有内容。还记得我们讨论过的图像遮罩吗?这在这里会派上用场:
# visualize only the masked regions in the image
masked = cv2.bitwise_and(image, image, mask=threshInv)
cv2.imshow("Output", masked)
cv2.waitKey(0)
在第 32 行,我们通过使用cv2.bitwise_and函数来执行屏蔽。我们提供我们的原始输入图像作为前两个参数,然后我们的反转阈值图像作为我们的遮罩。请记住,遮罩只考虑原始图像中遮罩大于零的像素。
简单阈值结果
准备好查看使用 OpenCV 应用基本阈值的结果了吗?
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从那里,您可以执行以下命令:
$ python simple_thresholding.py --image images/coins01.png
在左上角的,是我们的原始输入图像。在右上角的、我们有使用逆阈值分割的图像,硬币在黑背景上显示为白。
类似地,在左下方的上,我们翻转阈值方法,现在硬币在白色背景上显示为黑色。
最后,右下角的应用我们的位与阈值遮罩,我们只剩下图像中的硬币(没有背景)。
让我们试试硬币的第二个图像:
$ python simple_thresholding.py --image images/coins02.png
我们又一次成功地将图像的前景从背景中分割出来。
但是仔细看看,比较一下图 5 和图 6 的输出。你会注意到在图 5 中有一些硬币看起来有“洞”。这是因为阈值测试没有通过,因此我们不能在输出的阈值图像中包含硬币的那个区域。
然而,在图 6 中,你会注意到没有洞——表明分割(本质上)是完美的。
注: 实事求是地说,这不是问题。真正重要的是我们能够获得硬币的轮廓。可以使用 形态学操作 或轮廓方法来填充阈值硬币遮罩内的这些小间隙。
既然阈值处理在图 6 的中表现完美,为什么它在图 5 的中表现得不那么完美呢?
答案很简单:光照条件。
虽然很微妙,但这两张照片确实是在不同的光照条件下拍摄的。并且因为我们已经手动提供了阈值,所以不能保证在存在光照变化的情况下,该阈值 T 将从一个图像工作到下一个图像。
解决这个问题的一个方法是简单地为您想要阈值化的每个图像提供一个阈值 T 。但这是一个严重的问题,尤其是如果我们希望我们的系统是动态的 T2,并在各种光照条件下工作。
解决方案是使用 Otsu 法和自适应阈值法等方法来帮助我们获得更好的结果。
但是现在,让我们再看一个例子,在这个例子中,我们分割了 OpenCV 徽标的各个部分:
$ python simple_thresholding.py --image images/opencv_logo.png
请注意,我们已经能够从输入图像中分割出 OpenCV 徽标的半圆以及“OpenCV”文本本身。虽然这可能看起来不太有趣,但是能够将图像分割成小块是一项非常有价值的技能。当我们深入轮廓并使用它们来量化和识别图像中的不同对象时,这将变得更加明显。
但是现在,让我们继续讨论一些更高级的阈值技术,在这些技术中,我们不必手动提供值 T 。
使用 OpenCV 实现 Otsu 阈值处理
在前面关于简单阈值的部分中,我们需要手动提供阈值 T 。对于受控照明条件下的简单图像,我们硬编码该值可能是可行的。
*但是在我们没有任何关于照明条件的先验知识的真实世界条件下,我们实际上使用 Otsu 的方法自动计算出最佳值 T 。
Otsu 的方法假设我们的图像包含两类像素:背景和前景。
此外,Otsu 的方法假设我们的图像的像素强度的灰度直方图是 双峰 ,这简单地意味着直方图是 两个峰值。
例如,看看下面的处方药丸图像及其相关灰度直方图:
请注意直方图明显有两个峰值,第一个尖锐的峰值对应于图像的均匀背景色,而第二个峰值对应于药丸区域本身。
如果直方图的概念现在对你来说有点困惑,不要担心——我们将在我们的图像直方图博客文章中更详细地介绍它们。但目前只需理解直方图是一个简单的列表或一个像素值在图像中出现次数的“计数器”。
基于灰度直方图,Otsu 的方法然后计算最佳阈值 T ,使得背景和前景峰值之间的差异最小。
然而,Otsu 的方法不知道哪些像素属于前景,哪些像素属于背景,它只是试图最佳地分离直方图的峰值。
让我们来看看执行 Otsu 阈值处理的一些代码。打开项目目录结构中的otsu_thresholding.py文件,插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
这里我们只需要一个开关--image,它是我们希望应用 Otsu 阈值的输入图像的路径。
我们现在可以加载和预处理我们的图像:
# load the image and display it
image = cv2.imread(args["image"])
cv2.imshow("Image", image)
# convert the image to grayscale and blur it slightly
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (7, 7), 0)
第 12 行和第 13 行从磁盘加载我们的图像并显示在我们的屏幕上。
然后,我们应用预处理,将图像转换为灰度,并对其进行模糊处理,以减少高频噪声。
现在让我们应用 Otsu 的阈值算法:
# apply Otsu's automatic thresholding which automatically determines
# the best threshold value
(T, threshInv) = cv2.threshold(blurred, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
cv2.imshow("Threshold", threshInv)
print("[INFO] otsu's thresholding value: {}".format(T))
# visualize only the masked regions in the image
masked = cv2.bitwise_and(image, image, mask=threshInv)
cv2.imshow("Output", masked)
cv2.waitKey(0)
应用 Otsu 的方法是在第 21 和 22 行的上处理的,再次使用 OpenCV 的cv2.threshold函数。
我们首先传递我们想要阈值化的(模糊的)图像。但是看看第二个参数——这应该是我们的阈值 T 。
那么我们为什么要把它设置为零呢?
记住大津的方法是要 自动 为我们计算出 T 的最优值!从技术上讲,我们可以为这个参数指定我们想要的任何值;然而,我喜欢提供一个值0作为一种“无关紧要”的参数。
第三个参数是阈值的输出值,前提是给定的像素通过了阈值测试。
最后一个论点是我们需要特别注意的。之前,我们根据想要执行的阈值类型提供了值cv2.THRESH_BINARY或cv2.THRESH_BINARY_INV。
但是现在我们传入了第二个标志,它与前面的方法进行了逻辑“或”运算。注意这个方法是cv2.THRESH_OTSU,明显对应大津的阈值法。
cv2.threshold函数将再次为我们返回 2 个值的元组:阈值 T 和阈值图像本身。
在前面的部分中,返回的值 T 是多余的和不相关的——我们已经知道了这个值 T ,因为我们必须手动提供它。
但是现在我们使用 Otsu 的方法进行自动阈值处理,这个值 T 变得很有趣——我们不知道 T 的最佳值是多少,因此我们使用 Otsu 的方法来计算它。第 24 行打印出由 Otsu 方法确定的 T 的值。
最后,我们在屏幕的第 28 和 29 行显示输出的阈值图像。
Otsu 阈值结果
要查看 Otsu 方法的运行,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,您可以执行以下命令:
$ python otsu_thresholding.py --image images/coins01.png
[INFO] otsu's thresholding value: 191.0
很不错,对吧?我们甚至不需要提供我们的值T——Otsu 的方法自动为我们处理这个问题。我们仍然得到了一个很好的阈值图像作为输出。如果我们检查我们的终端,我们会看到 Otsu 的方法计算出了一个值 T=191 :
所以基于我们的输入图像, T 的最优值是191;因此,任何大于191的像素 p 被设置为0,任何小于191的像素被设置为255(因为我们在上面的“用 OpenCV 实现简单阈值处理”部分提供了详细的cv2.THRESH_BINARY_INV标志)。
在我们继续下一个例子之前,让我们花一点时间来讨论术语“最优”的含义由 Otsu 的方法返回的 T 的值在我们的图像的视觉研究中可能不是最优的——我们可以清楚地看到阈值图像的硬币中的一些间隙和洞。但是这个值是最佳的,因为假设灰度像素值的双模式分布,它尽可能好地分割前景和背景。
如果灰度图像不遵循双模态分布,那么 Otsu 的方法仍将运行,但它可能不会给出我们想要的结果。在这种情况下,我们将不得不尝试自适应阈值,这将在我们的下一个教程。
无论如何,让我们尝试第二个图像:
$ python otsu_thresholding.py --image images/coins02.png
[INFO] otsu's thresholding value: 180.0
再次注意,Otsu 的方法很好地将前景和背景分离开来。而这次大津的方法已经确定了 T 的最优值为180。任何大于180的像素值被设置为0,任何小于180的像素值被设置为255(同样,假设取反阈值)。
如你所见,Otsu 的方法可以为我们节省大量猜测和检查 T 最佳值的时间。然而,有一些主要的缺点。
第一个是 Otsu 的方法假设输入图像的灰度像素强度为双峰分布。如果不是这样,那么 Otsu 的方法可以返回低于标准的结果。
其次,Otsu 法是一种全局阈值法。在光照条件是半稳定的情况下,我们想要分割的对象与背景有足够的对比度,我们可能能够摆脱 Otsu 的方法。
但是当光照条件不均匀时——比如当图像的不同部分比其他部分被照亮得更多时,我们会遇到一些严重的问题。在这种情况下,我们需要依靠自适应阈值(我们将在下周讨论)
CV2 .阈值应用
在 cv2.threshold 的帮助下,您可以构建几个应用程序
- 图像分割应用程序,根据像素比较来分离对象。
- 背景去除,分离并去除前景和背景对象。
- 光学字符识别 (OCR),通过阈值处理提高对比度和 OCR 准确度。
- 创建一个二进制图像,在这里设定阈值,并将图像转换为每个像素为 0(黑色)或 255(白色)的二进制图像。
更新:
2022 年 12 月 30 日更新教程内容和链接。
总结
在这一课中,我们学习了所有关于阈值处理的知识:什么是阈值处理,我们为什么使用阈值处理,以及如何使用 OpenCV 和cv2.threshold函数来执行阈值处理。
我们从执行简单阈值开始,这需要我们手动提供一个值 T 来执行阈值。然而,我们很快意识到手动提供一个值 T 是非常繁琐的,需要我们硬编码这个值,这意味着这个方法不是在所有情况下都有效。
然后,我们继续使用 Otsu 的阈值方法,该方法会自动为我们计算 T 的最佳值,假设输入图像的灰度表示为双模态分布。
这里的问题是:( 1)我们的输入图像需要是双模态的,Otsu 的方法才能正确分割图像,以及(2) Otsu 的方法是一种全局阈值方法,这意味着我们至少需要对我们的照明条件进行一些适当的控制。
在我们的照明条件不理想的情况下,或者我们根本无法控制它们,我们需要自适应阈值(也称为局部阈值)。我们将在下一篇教程中讨论自适应阈值处理。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!****
OpenCV 跟踪对象运动
原文:https://pyimagesearch.com/2015/09/21/opencv-track-object-movement/

上周六,我陷入了对童年的怀念,所以我拿出了我的 PlayStation 1 和我的原版《最终幻想 7》。作为一个初中/高中早期的孩子,我花了 70 多个小时玩这个令人心碎、鼓舞人心、绝对经典的 RPG 游戏。
作为一个中学时代的孩子(那时我有更多的空闲时间),这个游戏几乎就像一张安全毯,一个最好的朋友,一个编码在 1 的和 0 的中的虚构世界,在那里我可以逃避,远离日常的青少年焦虑、不安和恐惧。
我在这个交替世界里花了太多时间,以至于我几乎完成了所有的支线任务。终极和红宝石武器?没问题。全斜线?完成了。圆形骑士?大师级别。
大概不用说,最终幻想 VII 是我有史以来最喜欢的 RPG——,感觉 绝对牛逼 再玩一次。
但几天前的一个晚上,当我坐在沙发上,一边喝着季节性的 Sam Adams 十月节,一边招待我的老朋友 Cloud、Tifa、Barret 和其他人时,我开始思考:“不仅有视频游戏在过去 10 年里发生了巨大的变化,而且 控制器也有 。”
想想吧。虽然有点噱头,但 Wii 遥控器是用户/游戏互动的一个重大范式转变。在 PlayStation 方面,我们有 PlayStation Move ,本质上是一个棒,带有(1)内部运动传感器,(2)和通过连接到 PlayStation 3 本身的网络摄像头的外部运动跟踪组件。当然,还有 XBox Kinect(现代计算机视觉最大的成功故事之一,尤其是游戏领域的*)不需要额外的遥控器或魔杖——使用立体摄像机和回归森林进行姿势分类,Kinect 允许 你成为控制器 。
本周的博客文章是上周关于用 OpenCV 跟踪 球的教程的延伸。我们不会学习如何构建下一代突破性的视频游戏控制器——但我会向你展示如何用 追踪图像中的物体移动 ,让你用 确定物体移动的方向:
https://www.youtube.com/embed/V9Hup-wImfA?feature=oembed*
OpenCV 教程:学习 OpenCV 的指南
原文:https://pyimagesearch.com/2018/07/19/opencv-tutorial-a-guide-to-learn-opencv/

无论您是有兴趣学习如何将面部识别应用于视频流,为图像分类建立一个完整的深度学习管道,还是只想修改您的 Raspberry Pi 并将图像识别添加到一个爱好项目中,您都需要在这个过程中学习 OpenCV。
事实是,学习 OpenCV 使用是相当具有挑战性的。文档很难浏览。这些教程很难理解,也不完整。甚至有些书读起来也有点乏味。
好消息是学习 OpenCV 不像以前那么难了。事实上,我甚至可以说学习 OpenCV 已经变得非常容易。
为了向您证明这一点(并帮助您学习 OpenCV),我整理了这本使用 Python 编程语言学习 OpenCV 库基础的完整指南。
让我们开始学习 OpenCV 和图像处理的基础知识。在今天的博文结束时,你会理解 OpenCV 的基本原理。
OpenCV 教程:学习 OpenCV 的指南
这个 OpenCV 教程是为刚刚开始学习基础知识的初学者准备的。在本指南中,您将学习使用 Python 的 OpenCV 库进行基本的图像处理操作。
在本教程结束时,你将完成一个完整的项目,使用轮廓来计算图像中的基本对象。
虽然本教程针对的是刚刚开始学习图像处理和 OpenCV 库的初学者,但我鼓励你即使有一点经验也要读一读。
OpenCV 基础知识的快速复习也将对您自己的项目有所帮助。
在系统上安装 OpenCV 和 imutils
今天的第一步是在您的系统上安装 OpenCV(如果您还没有安装的话)。
我维护了一个 OpenCV 安装教程 页面,其中包含了之前针对 Ubuntu、macOS 和 Raspberry Pi 的 OpenCV 安装指南的链接。
您应该访问该页面,找到并遵循适合您系统的指南。
一旦新的 OpenCV 开发环境设置好了,通过 pip 安装 imutils 包。我为图像处理社区创建并维护了imutils(GitHub 上的资源),它在我的博客上被大量使用。您应该在安装 OpenCV 的同一个环境中安装imutils——您将需要它来完成这篇博文,因为它将有助于基本的图像处理操作:
$ pip install imutils
注意: 如果你正在使用 Python 虚拟环境,不要忘记在安装imutils之前使用workon命令进入你的环境!
OpenCV 项目结构
在深入兔子洞之前,请务必从今天的博客文章的 【下载】 部分获取代码和图片。
从那里,导航到您下载的位置。压缩你的终端(cd)。然后我们可以unzip存档,将工作目录(cd)转到项目文件夹,并通过tree分析项目结构:
$ cd ~/Downloads
$ unzip opencv-tutorial.zip
$ cd opencv-tutorial
$ tree
.
├── jp.png
├── opencv_tutorial_01.py
├── opencv_tutorial_02.py
└── tetris_blocks.png
0 directories, 4 files
在本教程中,我们将创建两个 Python 脚本来帮助您学习 OpenCV 基础知识:
- 我们的第一个脚本,
opencv_tutorial_01.py将使用电影《侏罗纪公园》 (jp.png)中的一个图像来涵盖基本的图像处理操作。 - 从那里,
opencv_tutorial_02.py将向您展示如何使用这些图像处理构建块来创建 OpenCV 应用程序,以计算俄罗斯方块图像中的对象数量(tetris_blocks.png)。
加载和显示图像

Figure 1: Learning OpenCV basics with Python begins with loading and displaying an image — a simple process that requires only a few lines of code.
让我们首先在您最喜欢的文本编辑器或 IDE 中打开opencv_tutorial_01.py:
# import the necessary packages
import imutils
import cv2
# load the input image and show its dimensions, keeping in mind that
# images are represented as a multi-dimensional NumPy array with
# shape no. rows (height) x no. columns (width) x no. channels (depth)
image = cv2.imread("jp.png")
(h, w, d) = image.shape
print("width={}, height={}, depth={}".format(w, h, d))
# display the image to our screen -- we will need to click the window
# open by OpenCV and press a key on our keyboard to continue execution
cv2.imshow("Image", image)
cv2.waitKey(0)
在的第 2 行和第 3 行,我们导入了imutils和cv2。cv2包是 OpenCV,尽管嵌入了 2,但它实际上可以是 OpenCV 3(或者可能是 OpenCV 4,可能会在 2018 年晚些时候发布)。imutils套餐是我的一系列便民功能。
现在我们已经通过导入获得了所需的软件,让我们将一个映像从磁盘加载到内存中。
为了加载我们的侏罗纪公园图像(来自我最喜欢的电影之一),我们调用cv2.imread("jp.png")。正如你在第 8 行看到的,我们将结果赋给image。我们的image实际上只是一个 NumPy 数组。
在这个脚本的后面,我们将需要高度和宽度。所以在第 9 行的上,我调用image.shape来提取高度、宽度和深度。
高度在宽度之前,这可能看起来令人困惑,但请这样想:
- 我们用、行数 x 列数来描述矩阵
- 排数就是我们的高度
- 而列的数量就是我们的宽度
因此,表示为 NumPy 数组的图像的尺寸实际上表示为(高度、宽度、深度)。
深度是通道的数量——在我们的例子中是三个,因为我们使用 3 个颜色通道:蓝色、绿色和红色。
在行 10 显示的打印命令将把数值输出到终端:
width=600, height=322, depth=3
为了使用 OpenCV 在屏幕上显示图像,我们在第 14 行的上使用了cv2.imshow("Image", image)。下一行等待按键(第 15 行)。这一点很重要,否则我们的图像显示和消失的速度会比我们看到图像的速度更快。
注意: 你需要实际点击 OpenCV 打开的活动窗口,按下键盘上的一个键来推进脚本。OpenCV 不能监控你的终端输入,所以如果你在终端上按下一个键,OpenCV 不会注意到。同样,您需要单击屏幕上的活动 OpenCV 窗口,并按下键盘上的一个键。
访问单个像素
Figure 2: Top: grayscale gradient where brighter pixels are closer to 255 and darker pixels are closer to 0. Bottom: RGB venn diagram where brighter pixels are closer to the center.
首先,你可能会问:
什么是像素?
所有图像都由像素组成,像素是图像的原始构建块。图像由网格中的像素组成。640 x 480 的图像有 640 列(宽度)和 480 行(高度)。一幅图像中有640 * 480 = 307200个像素具有这些尺寸。
灰度图像中的每个像素都有一个代表灰度的值。在 OpenCV 中,有 256 种灰度——从 0 到 255。因此灰度图像将具有与每个像素相关联的灰度值。
彩色图像中的像素具有附加信息。随着您对图像处理的了解,您很快就会熟悉几种颜色空间。为了简单起见,让我们只考虑 RGB 颜色空间。
在 OpenCV 中,RGB(红、绿、蓝)色彩空间中的彩色图像有一个与每个像素相关联的三元组:(B, G, R)。
请注意,排序是 BGR,而不是 RGB。这是因为当 OpenCV 在许多年前首次被开发时,标准是 BGR 排序。多年来,标准现在已经变成了 RGB,但是 OpenCV 仍然保持这种“传统”的 BGR 排序,以确保没有现有的代码中断。
BGR 三元组中的每个值都有一个范围[0, 255]。OpenCV 中一个 RGB 图像的每个像素有多少种颜色的可能性?那很简单:256 * 256 * 256 = 16777216。
现在我们已经确切知道了像素是什么,让我们看看如何检索图像中单个像素的值:
# access the RGB pixel located at x=50, y=100, keepind in mind that
# OpenCV stores images in BGR order rather than RGB
(B, G, R) = image[100, 50]
print("R={}, G={}, B={}".format(R, G, B))
如前所示,我们的图像尺寸是width=600, height=322, depth=3。我们可以通过指定坐标来访问数组中的单个像素值,只要它们在最大宽度和高度范围内。
代码image[100, 50]从位于x=50和y=100的像素产生一个三元组的 BGR 值(再次提醒,记住高度是行的数量,而宽度是列的数量——现在花点时间让自己相信这是真的)。如上所述,OpenCV 以 BGR 顺序存储图像(例如,与 Matplotlib 不同)。看看提取第 19 行像素的颜色通道值有多简单。
生成的像素值显示在终端上,如下所示:
R=41, G=49, B=37
数组切片和裁剪
提取“感兴趣区域”是图像处理的一项重要技能。
比方说,你正在研究识别电影中的人脸。首先,你要运行一个人脸检测算法来找到你正在处理的所有帧中人脸的坐标。然后,您需要提取面部感兴趣区域,并保存或处理它们。定位《侏罗纪公园》中包含伊恩·马尔科姆博士的所有帧将是一个伟大的人脸识别迷你项目。
现在,让我们手动提取一个 ROI。这可以通过数组切片来实现。
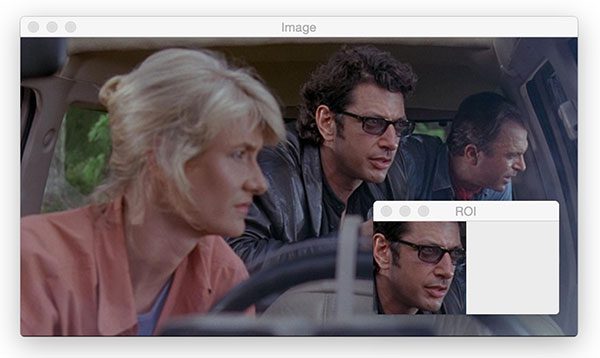
Figure 3: Array slicing with OpenCV allows us to extract a region of interest (ROI) easily.
# extract a 100x100 pixel square ROI (Region of Interest) from the
# input image starting at x=320,y=60 at ending at x=420,y=160
roi = image[60:160, 320:420]
cv2.imshow("ROI", roi)
cv2.waitKey(0)
数组切片显示在第 24 行,格式:image[startY:endY, startX:endX]。这段代码抓取了一个roi,然后我们将它显示在的第 25 行上。就像上次一样,我们显示直到一个键被按下( Line 26 )。
正如你在图 3 中看到的,我们已经提取了伊恩·马尔科姆博士的面部。在这个例子中,我实际上使用 Photoshop 预先确定了 (x,y)-坐标,但是如果你坚持使用我的博客,你可以自动检测和提取面部 ROI。
调整图像大小
调整图像大小很重要,原因有很多。首先,您可能想要调整大图像的大小以适合您的屏幕。图像处理在较小的图像上也更快,因为需要处理的像素更少。在深度学习的情况下,我们经常调整图像的大小,忽略长宽比,以便体积适合要求图像是正方形并具有一定维度的网络。
让我们将原始图像的大小调整为 200 x 200 像素:
# resize the image to 200x200px, ignoring aspect ratio
resized = cv2.resize(image, (200, 200))
cv2.imshow("Fixed Resizing", resized)
cv2.waitKey(0)
在第 29 行,我们已经调整了图像的大小,忽略了纵横比。图 4 ( 右)显示图像被调整了大小,但现在失真了,因为我们没有考虑宽高比。

Figure 4: Resizing an image with OpenCV and Python can be conducted with cv2.resize however aspect ratio is not preserved automatically.
让我们计算原始图像的长宽比,并使用它来调整图像的大小,以便它不会出现挤压和扭曲:
# fixed resizing and distort aspect ratio so let's resize the width
# to be 300px but compute the new height based on the aspect ratio
r = 300.0 / w
dim = (300, int(h * r))
resized = cv2.resize(image, dim)
cv2.imshow("Aspect Ratio Resize", resized)
cv2.waitKey(0)
回想一下这个脚本的第 9 行,我们在那里提取了图像的宽度和高度。
**假设我们想要将 600 像素宽的图像调整为 300 像素宽,同时保持宽高比不变。
在第 35 行的上,我们计算了新宽度与旧宽度的比值(恰好是 0.5)。
从那里,我们指定新图像的尺寸,dim。我们知道我们想要一个 300 像素宽的图像,但是我们必须使用比率通过将h乘以r来计算高度(分别是原始高度和我们的比率)。
将dim(我们的尺寸)输入到cv2.resize函数中,我们现在已经获得了一个名为resized的没有扭曲的新图像(第 37 行)。
为了检查我们的工作,我们使用第 38 行的代码显示图像:
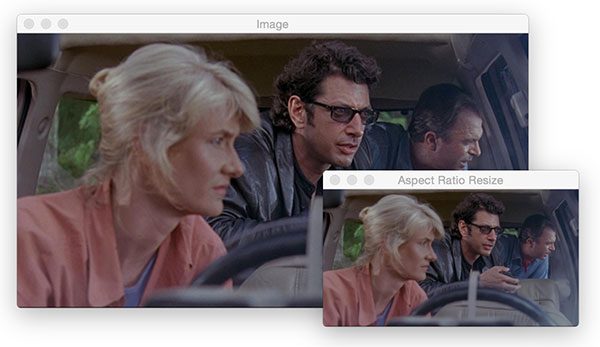
Figure 5: Resizing images while maintaining aspect ratio with OpenCV is a three-step process: (1) extract the image dimensions, (2) compute the aspect ratio, and (3) resize the image (cv2.resize) along one dimension and multiply the other dimension by the aspect ratio. See Figure 6 for an even easier method.
但是我们能不能让这个在调整大小时保持长宽比的过程变得更简单呢?
是啊!
每次我们想要调整图像大小时,计算长宽比都有点繁琐,所以我将代码包装在imutils中的一个函数中。
以下是你如何使用imutils.resize:
# manually computing the aspect ratio can be a pain so let's use the
# imutils library instead
resized = imutils.resize(image, width=300)
cv2.imshow("Imutils Resize", resized)
cv2.waitKey(0)
在一行代码中,我们保留了纵横比并调整了图像的大小。
简单吧?
你只需要提供你的目标width或者目标height作为关键字参数(第 43 行)。
结果如下:

Figure 6: If you’d like to maintain aspect ratio while resizing images with OpenCV and Python, simply use imutils.resize. Now your image won’t risk being “squished” as in Figure 4.
旋转图像
让我们为下一个例子旋转我们的侏罗纪公园图像:
# let's rotate an image 45 degrees clockwise using OpenCV by first
# computing the image center, then constructing the rotation matrix,
# and then finally applying the affine warp
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, -45, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("OpenCV Rotation", rotated)
cv2.waitKey(0)
围绕中心点旋转一幅图像需要我们先计算中心 (x,y)——图像的坐标(线 50 )。
注:我们用//进行整数数学运算(即无浮点值)。
从那里我们计算一个旋转矩阵,M ( 第 51 行)。-45意味着我们将顺时针旋转图像 45 度。回忆一下初中/高中几何课上关于单位圆的内容,你将能够提醒自己,正角是逆时针方向的,而负角是顺时针方向的。
从那里,我们使用第 52 行上的矩阵(有效地旋转它)扭曲图像。
旋转后的图像显示在线 52 的屏幕上,如图图 7 所示:
Figure 7: Rotating an image with OpenCV about the center point requires three steps: (1) compute the center point using the image width and height, (2) compute a rotation matrix with cv2.getRotationMatrix2D, and (3) use the rotation matrix to warp the image with cv2.warpAffine.
现在让我们使用imutils在一行代码中执行相同的操作:
# rotation can also be easily accomplished via imutils with less code
rotated = imutils.rotate(image, -45)
cv2.imshow("Imutils Rotation", rotated)
cv2.waitKey(0)
因为我不需要像调整图片大小那样旋转图片(相对来说),所以我觉得旋转的过程很难记住。因此,我在imutils中创建了一个函数来为我们处理它。在一行代码中,我可以完成顺时针旋转图像 45 度(第 57 行),如图图 8:

Figure 8: With imutils.rotate, we can rotate an image with OpenCV and Python conveniently with a single line of code.
此时你必须思考:
究竟为什么图像被剪切了?
事情是这样的,OpenCV 并不关心我们的图像在旋转后是否被裁剪掉了。我发现这很麻烦,所以这是我的imutils版本,它将保留整个图像。我称之为rotate_bound:
# OpenCV doesn't "care" if our rotated image is clipped after rotation
# so we can instead use another imutils convenience function to help
# us out
rotated = imutils.rotate_bound(image, 45)
cv2.imshow("Imutils Bound Rotation", rotated)
cv2.waitKey(0)
在rotate_bound的幕后发生了很多事情。如果你对第 64 条线上的方法是如何工作的感兴趣,一定要看看这篇博文。
结果如图 9 所示:

Figure 9: The rotate_bound function of imutils will prevent OpenCV from clipping the image during a rotation. See this blog post to learn how it works!
完美!整个图像都在框架中,并且顺时针正确旋转了 45 度。
平滑图像
在许多图像处理管道中,我们必须模糊图像以减少高频噪声,使我们的算法更容易检测和理解图像的实际内容,而不仅仅是会“混淆”我们算法的噪声。在 OpenCV 中模糊图像非常容易,有很多方法可以实现。
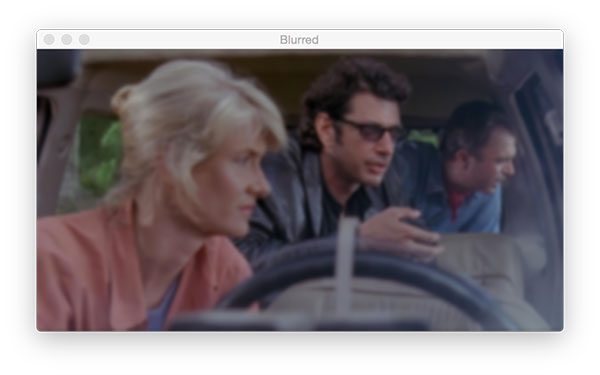
Figure 10: This image has undergone a Gaussian blur with an 11 x 11 kernel using OpenCV. Blurring is an important step of many image processing pipelines to reduce high-frequency noise.
我经常使用GaussianBlur功能:
# apply a Gaussian blur with a 11x11 kernel to the image to smooth it,
# useful when reducing high frequency noise
blurred = cv2.GaussianBlur(image, (11, 11), 0)
cv2.imshow("Blurred", blurred)
cv2.waitKey(0)
在第 70 行第 70 行第 71 行,我们用 11×11 的内核进行高斯模糊,结果如图 10(T3)中的所示。
更大的颗粒会产生更模糊的图像。更小的内核将创建更少的模糊图像。要阅读更多关于内核的内容,请参考这篇博客文章或 PyImageSearch 大师课程。
在图像上绘图
在这一节中,我们将在输入图像上绘制矩形、圆形和直线。我们还将在图像上覆盖文本。
在我们继续用 OpenCV 在图像上绘图之前,请注意图像上的绘图操作是就地执行的。因此,在每个代码块的开始,我们制作原始图像的副本,并将副本存储为output。然后我们继续就地绘制名为output的图像,这样我们就不会破坏我们的原始图像。
让我们围绕伊恩·马尔科姆的脸画一个矩形:
# draw a 2px thick red rectangle surrounding the face
output = image.copy()
cv2.rectangle(output, (320, 60), (420, 160), (0, 0, 255), 2)
cv2.imshow("Rectangle", output)
cv2.waitKey(0)
首先,出于刚才解释的原因,我们复制第 75 行上的图像。
然后我们继续画矩形。
在 OpenCV 中绘制矩形再简单不过了。使用预先计算的坐标,我已经向第 76 行的函数提供了以下参数:
img:要绘制的目标图像。我们正在利用output。- 左上角是我们的起始像素坐标。在我们的例子中,左上角是
(320, 60)。 pt2:结束像素——右下方。右下角的像素位于(420, 160)。color: BGR 元组。为了表示红色,我提供了(0 , 0, 255)。thickness:线条粗细(负值会形成实心矩形)。我已经提供了2的厚度。
因为我们使用的是 OpenCV 的函数而不是 NumPy 操作,所以我们可以按照 (x,y) 的顺序提供我们的坐标,而不是按照 (y,x) 的顺序,因为我们不直接操作或访问 NumPy 数组——OpenCV 会为我们处理这些。
这是我们在图 11 中的结果:
Figure 11: Drawing shapes with OpenCV and Python is an easy skill to pick up. In this image, I’ve drawn a red box using cv2.rectangle. I pre-determined the coordinates around the face for this example, but you could use a face detection method to automatically find the face coordinates.
现在让我们在艾丽·塞特勒的脸前面画一个蓝色的实心圆:
# draw a blue 20px (filled in) circle on the image centered at
# x=300,y=150
output = image.copy()
cv2.circle(output, (300, 150), 20, (255, 0, 0), -1)
cv2.imshow("Circle", output)
cv2.waitKey(0)
要画圆,需要向cv2.circle提供以下参数:
img:输出图像。center:我们圆的中心坐标。我提供的(300, 150)就在艾莉眼前。radius:以像素为单位的圆半径。我提供了一个20像素的值。color:圆形颜色。这一次,我选择了蓝色,这是由 BGR 元组(255, 0, 0)的 G + R 部分中的 B 和 0 表示的 255。thickness:线条粗细。因为我提供了一个负值(-1),所以圆是实心的/填充的。
下面是图 12 中的结果:
Figure 12: OpenCV’s cv2.circle method allows you to draw circles anywhere on an image. I’ve drawn a solid circle for this example as is denoted by the -1 line thickness parameter (positive values will make a circular outline with variable line thickness).
看起来艾莉对恐龙比对我的蓝点更感兴趣,所以我们继续吧!
接下来,我们将画一条红线。这条线穿过埃莉的头,经过她的眼睛,到达伊恩的手。
如果您仔细观察方法参数并将它们与矩形的参数进行比较,您会注意到它们是相同的:
# draw a 5px thick red line from x=60,y=20 to x=400,y=200
output = image.copy()
cv2.line(output, (60, 20), (400, 200), (0, 0, 255), 5)
cv2.imshow("Line", output)
cv2.waitKey(0)
就像在矩形中一样,我们提供两个点、一种颜色和一种线条粗细。OpenCV 的后端完成剩下的工作。
图 13 显示了来自代码块的行 89 的结果:
Figure 13: Similar to drawing rectangles and circles, drawing a line in OpenCV using cv2.line only requires a starting point, ending point, color, and thickness.
您经常会发现,出于显示目的,您希望在图像上覆盖文本。如果你在做人脸识别,你可能会想把这个人的名字画在他的脸上面。或者,如果你在计算机视觉事业上有所进步,你可以建立一个图像分类器或物体检测器。在这些情况下,您会发现您想要绘制包含类名和概率的文本。
让我们看看 OpenCV 的 putText 函数是如何工作的:
# draw green text on the image
output = image.copy()
cv2.putText(output, "OpenCV + Jurassic Park!!!", (10, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.imshow("Text", output)
cv2.waitKey(0)
OpenCV 的putText函数负责在图像上绘制文本。让我们来看看所需的参数:
img:输出图像。text:我们想要在图像上书写/绘制的文本字符串。pt:文字的起点。font:我经常用cv2.FONT_HERSHEY_SIMPLEX。可用的字体是这里列出的。scale:字体大小乘数。color:文字颜色。thickness:笔画的粗细,以像素为单位。
第 95 行和第 96 行的代码将绘制文本,*“OpenCV+侏罗纪公园!!!"图 14** 中的output图像上绿色的*😗*
Figure 14: Oftentimes, you’ll find that you want to display text on an image for visualization purposes. Using the cv2.putText code shown above you can practice overlaying text on an image with different colors, fonts, sizes, and/or locations.
运行第一个 OpenCV 教程 Python 脚本
在我的博客文章中,我通常会提供一个部分,详细说明如何在计算机上运行代码。在博文的这一点上,我做了如下假设:
- 你已经从这篇博文的 【下载】 部分下载了代码。
- 您已经解压缩了文件。
- 您已经在系统上安装了 OpenCV 和 imutils 库。
要执行我们的第一个脚本,打开一个终端或命令窗口,导航到文件或提取它们(如果需要)。
在那里,输入以下命令:
$ python opencv_tutorial_01.py
width=600, height=322, depth=3
R=41, G=49, B=37
该命令是 bash 提示符$字符之后的所有内容。只要在你的终端输入python opencv_tutorial_01.py,第一张图片就会出现。
要循环我们刚刚学习的每个步骤,请确保图像窗口处于活动状态,然后按任意键。
我们上面的第一对代码块告诉 Python 在终端中打印信息。如果您的终端可见,您将会看到显示的终端输出(行 2 和 3 )。
我还附上了一个 GIF 动画,展示了我们依次采取的所有图像处理步骤,一个接一个:

Figure 15: Output animation displaying the OpenCV fundamentals we learned from this first example Python script.
计数对象
现在我们将改变思路,开始编写与这篇博文相关的 【下载】 中的第二个脚本。
在接下来的几节中,我们将学习如何使用创建一个简单的 Python + OpenCV 脚本来计算下图中俄罗斯方块的数量:
Figure 16: If you’ve ever played Tetris (who hasn’t?), you’ll recognize these familiar shapes. In the 2nd half of this OpenCV fundamentals tutorial, we’re going to find and count the shape contours.
一路上我们会:
- 学习如何使用 OpenCV 将图像转换为灰度
- 执行边缘检测
- 设定灰度图像的阈值
- 查找、计数和绘制等高线
- 进行侵蚀和扩张
- 遮蔽图像
继续并关闭您下载的第一个脚本,打开opencv_tutorial_02.py开始第二个示例:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
在线 2-4 我们进口我们的包裹。这在每个 Python 脚本的开始都是必要的。对于第二个脚本,我导入了argparse——一个命令行参数解析包,它随 Python 的所有安装一起提供。
快速浏览一下第 7-10 行。这些行允许我们在运行时从终端向程序提供额外的信息。命令行参数在 PyImageSearch 博客和所有其他计算机科学领域中被大量使用。
我鼓励你在这篇文章中阅读它们: Python、argparse 和命令行参数。
我们有一个必需的命令行参数--image,在的第 8 行和第 9 行中有定义。
下面我们将学习如何使用所需的命令行参数运行脚本。现在,只要知道在脚本中遇到args["image"]的地方,我们指的是输入图像的路径。
将图像转换为灰度
# load the input image (whose path was supplied via command line
# argument) and display the image to our screen
image = cv2.imread(args["image"])
cv2.imshow("Image", image)
cv2.waitKey(0)
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Gray", gray)
cv2.waitKey(0)
我们在第 14 行将图像载入内存。cv2.imread函数的参数是包含在用"image"键args["image"]引用的args字典中的路径。
从那里,我们显示图像,直到我们遇到第一次按键(行 15 和 16 )。
我们将很快对图像进行阈值处理和边缘检测。因此,我们通过调用cv2.cvtColor并提供image和cv2.COLOR_BGR2GRAY标志,在行 19 上将图像转换成灰度。
我们再次显示图像并等待按键(行 20 和 21 )。
我们转换成灰度的结果显示在图 17 ( 底部)。
Figure 17: (top) Our Tetris image. (bottom) We’ve converted the image to grayscale — a step that comes before thresholding.
边缘检测
边缘检测对于寻找图像中对象的边界是有用的,它对于分割目的是有效的。
让我们执行边缘检测,看看这个过程是如何工作的:
# applying edge detection we can find the outlines of objects in
# images
edged = cv2.Canny(gray, 30, 150)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
使用流行的 Canny 算法(由 John F. Canny 于 1986 年开发),我们可以找到图像中的边缘。
我们为cv2.Canny函数提供三个参数:
img:图像gray。minVal:最小阈值,在我们的例子中是30。maxVal:最大阈值,在我们的例子中是150。aperture_size:索贝尔内核大小。默认情况下,该值为3,因此不会显示在行 25 上。
最小和最大阈值的不同值将返回不同的边缘图。
在下面的图 18 中,注意俄罗斯方块本身的边缘是如何显示的,以及组成俄罗斯方块的子方块:
Figure 18: To conduct edge detection with OpenCV, we make use of the Canny algorithm.
阈值处理
图像阈值化是图像处理流水线的重要中间步骤。阈值处理可以帮助我们去除图像中较亮或较暗的区域和轮廓。
我强烈建议您尝试阈值处理。我通过反复试验(以及经验)调整了下面的代码,使其适用于我们的示例:
# threshold the image by setting all pixel values less than 225
# to 255 (white; foreground) and all pixel values >= 225 to 255
# (black; background), thereby segmenting the image
thresh = cv2.threshold(gray, 225, 255, cv2.THRESH_BINARY_INV)[1]
cv2.imshow("Thresh", thresh)
cv2.waitKey(0)
在单行(行 32 )中我们是:
- 抓取
gray图像中大于 225 的所有像素,并设置为 0(黑色),对应于图像的背景 - 将小于 225 的像素值设置为 255(白色),对应于图像的前景(即俄罗斯方块本身)。
关于 cv2.threshold 函数的更多信息,包括阈值标志如何工作,请务必参考官方 OpenCV 文档。
用二进制图像从背景中分割前景是寻找轮廓的关键 (我们的下一步)。
Figure 19: Prior to finding contours, we threshold the grayscale image. We performed a binary inverse threshold so that the foreground shapes become white while the background becomes black.
注意在图 19 中,前景物体是白色的,背景是黑色的。
检测和绘制轮廓
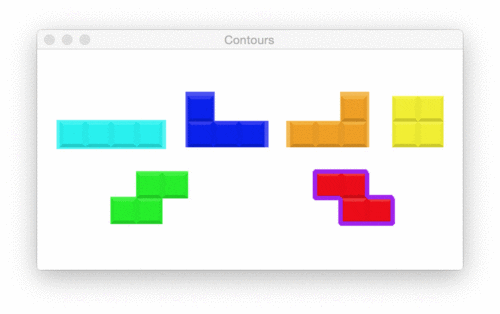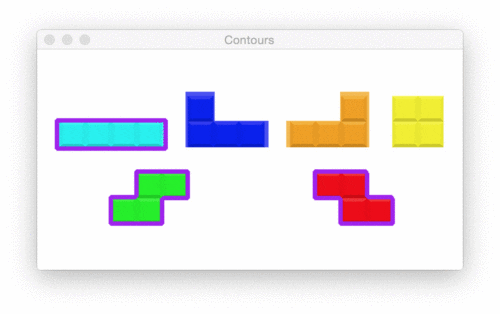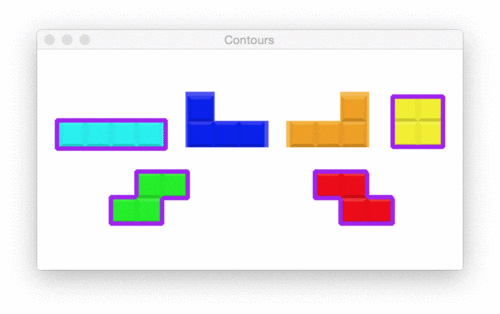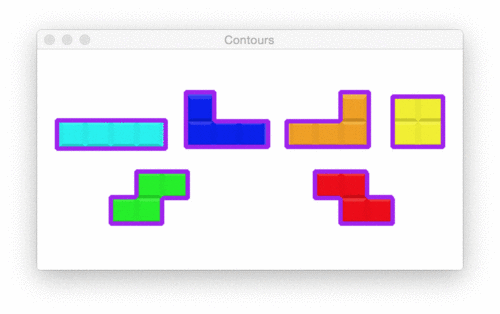
Figure 20: We’re working towards finding contour shapes with OpenCV and Python in this OpenCV Basics tutorial.
在图 20 动画中,我们有 6 个外形轮廓。让我们通过代码找到并画出它们的轮廓:
# find contours (i.e., outlines) of the foreground objects in the
# thresholded image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# loop over the contours
for c in cnts:
# draw each contour on the output image with a 3px thick purple
# outline, then display the output contours one at a time
cv2.drawContours(output, [c], -1, (240, 0, 159), 3)
cv2.imshow("Contours", output)
cv2.waitKey(0)
在的第 38 行和第 39 行,我们使用cv2.findContours来检测图像中的轮廓。请注意参数标志,但现在让我们保持简单——我们的算法是在thresh.copy()图像中找到所有前景(白色)像素。
第 40 行非常重要,因为cv2.findContours实现在 OpenCV 2.4、OpenCV 3 和 OpenCV 4 之间发生了变化。这条兼容性线出现在博客中涉及轮廓的地方。
我们在第行第 41 处复制原始图像,这样我们可以在随后的第行第 44-49 处绘制轮廓。
在的第 47 行,我们使用适当命名的cv2.drawContours从图像上的cnts列表中画出每个c。我选择了用元组(240, 0, 159)表示的紫色。
利用我们在这篇博文中所学的知识,让我们在图片上叠加一些文字:
# draw the total number of contours found in purple
text = "I found {} objects!".format(len(cnts))
cv2.putText(output, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(240, 0, 159), 2)
cv2.imshow("Contours", output)
cv2.waitKey(0)
第 52 行构建一个包含形状轮廓数量的text字符串。统计该图像中的对象总数就像检查轮廓列表的长度一样简单— len(cnts)。
结果如图 21 所示:

Figure 21: Counting contours with OpenCV is as easy as finding them and then calling len(cnts).
侵蚀和膨胀
腐蚀和膨胀通常用于减少二进制图像中的噪声(阈值处理的副作用)。
为了减小前景对象的尺寸,我们可以在给定迭代次数的情况下侵蚀掉像素:
# we apply erosions to reduce the size of foreground objects
mask = thresh.copy()
mask = cv2.erode(mask, None, iterations=5)
cv2.imshow("Eroded", mask)
cv2.waitKey(0)
在第 59 行我们复制了thresh图像,并将其命名为mask。
然后,利用cv2.erode,我们继续用 5 个iterations ( 线 60 )减少轮廓尺寸。
如图 22 所示,从俄罗斯方块轮廓生成的遮罩略小:
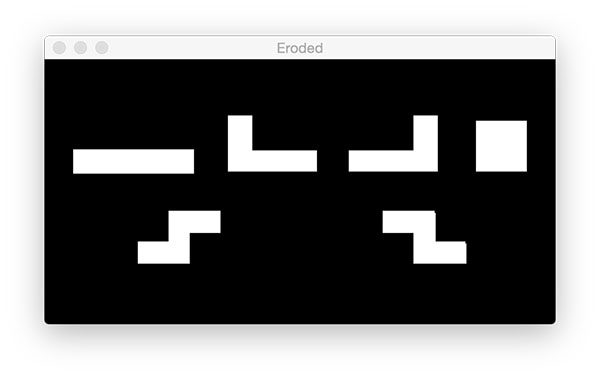
Figure 22: Using OpenCV we can erode contours, effectively making them smaller or causing them to disappear completely with sufficient iterations. This is typically useful for removing small blobs in mask image.
类似地,我们可以在蒙版中突出区域。要放大区域,只需使用cv2.dilate:
# similarly, dilations can increase the size of the ground objects
mask = thresh.copy()
mask = cv2.dilate(mask, None, iterations=5)
cv2.imshow("Dilated", mask)
cv2.waitKey(0)
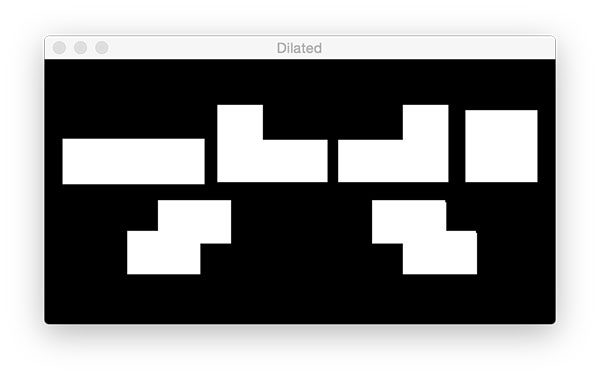
Figure 23: In an image processing pipeline if you ever have the need to connect nearby contours, you can apply dilation to the image. Shown in the figure is the result of dilating contours with five iterations, but not to the point of two contours becoming one.
屏蔽和位运算
蒙版允许我们“屏蔽掉”图像中我们不感兴趣的区域。我们称之为“遮罩”,因为它们会隐藏图像中我们不关心的区域。
如果我们使用图 18 中的阈值图像,并用原始图像遮盖它,我们会看到图 23** 😗*

Figure 24: When using the thresholded image as the mask in comparison to our original image, the colored regions reappear as the rest of the image is “masked out”. This is, of course, a simple example, but as you can imagine, masks are very powerful.
在图 24 中,背景现在是黑色的,我们的前景由彩色像素组成——任何被我们的mask图像掩盖的像素。
让我们来学习如何实现这一点:
# a typical operation we may want to apply is to take our mask and
# apply a bitwise AND to our input image, keeping only the masked
# regions
mask = thresh.copy()
output = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Output", output)
cv2.waitKey(0)
通过复制二进制thresh图像(第 73 行)来生成mask。
在那里,我们使用cv2.bitwise_and将两幅图像的像素按位进行 AND 运算。
结果就是上面的图 24 ,现在我们只显示/突出显示俄罗斯方块。
运行第二个 OpenCV 教程 Python 脚本
要运行第二个脚本,请确保您位于包含下载的源代码和 Python 脚本的文件夹中。从那里,我们将打开一个终端,提供脚本名称+ 命令行参数:
$ python opencv_tutorial_02.py --image tetris_blocks.png
参数标志是--image,图像参数本身是tetris_blocks.png——目录中相关文件的路径。
这个脚本没有终端输出。同样,要循环浏览图像,请确保您点击了一个图像窗口以激活它,从那里您可以按下一个键,它将被捕获以前进到脚本中的下一个waitKey(0)。当程序运行结束时,您的脚本将优雅地退出,您的终端中将出现一个新的 bash 提示行。
下面我在我们的示例脚本中加入了一个基本 OpenCV 图像处理步骤的 GIF 动画:

Figure 25: Learning OpenCV and the basics of computer vision by counting objects via contours.
摘要
在今天的博文中,您学习了使用 Python 编程语言进行图像处理和 OpenCV 的基础知识。
现在,您已经准备好开始使用这些图像处理操作作为“构建模块”,您可以将它们链接在一起,构建一个实际的计算机视觉应用程序——这类项目的一个很好的例子是我们通过计算轮廓创建的基本对象计数器。
希望这篇教程对你学习 OpenCV 有所帮助!
在 PyImageSearch 上发布 OpenCV 博客文章时,我们会通知您,*请在下面的表格中输入您的电子邮件地址!***
OpenCV 车辆检测、跟踪和速度估计
原文:https://pyimagesearch.com/2019/12/02/opencv-vehicle-detection-tracking-and-speed-estimation/
在本教程中,您将学习如何使用 OpenCV 和深度学习来检测视频流中的车辆,跟踪它们,并应用速度估计来检测移动车辆的 MPH/KPH。
本教程的灵感来自 PyImageSearch 的读者,他们给我发邮件询问速度估计计算机视觉解决方案。
当行人带着狗去散步,护送我们的孩子去学校,或者早上去我们的工作场所时,我们都经历过由粗心的司机驾驶的不安全、快速移动的车辆,这些车辆几乎将我们撞倒。
我们中的许多人生活在公寓楼或住宅区,无知的司机无视安全,飞驰而过,以太快的速度行驶。
我们感到几乎无能为力。这些司机完全无视限速、人行横道区、学校区和“儿童玩耍”的标志。当遇到减速带时,他们会加速,就好像他们在试图呼吸新鲜空气一样!
我们能做些什么吗?
不幸的是,在大多数情况下,答案是“不”——当我们走在我们居住的街区时,我们必须小心翼翼地保护自己和家人。
但是,如果我们能在行动中抓住这些鲁莽的社区恶棍,并向当地政府提供关于车辆、速度和时间的视频证据,会怎么样呢?
事实上,我们可以。
在本教程中,我们将构建一个 OpenCV 项目:
- 使用 MobileNet 固态硬盘和英特尔 Movidius 神经计算棒(NCS)检测视频中的车辆
- 追踪车辆
- 估计车辆的速度并将证据存储在云中(特别是存储在 Dropbox 文件夹中)。
一旦进入云端,你可以向你选择的任何人提供共享链接。我真诚地希望它能给你的邻居带来变化。
让我们乘坐自己的车,学习如何使用树莓派和英特尔 Movidius NCS 估算车速。
注:今天的教程其实是我新书中的一章,计算机视觉的树莓派。这本书向您展示了如何突破 Raspberry Pi 的极限来构建真实世界的计算机视觉、深度学习和 OpenCV 项目。如果你喜欢今天的教程,一定要拿起一本书。
OpenCV 车辆检测、跟踪和速度估计
在本教程中,我们将回顾 VASCAR 的概念,这是一种警方使用距离和时间戳来测量移动物体速度的方法。我们还将了解这是如何导致错误的人为因素,以及我们的方法如何纠正人为错误。
从那里,我们将设计我们的计算机视觉系统来收集汽车的时间戳以测量速度(以已知的距离)。通过消除人为因素,我们的系统将依赖于我们的物理知识和软件开发技能。
我们的系统依赖于对象检测和对象跟踪的组合来在不同的路点在视频流中找到汽车。我们将简要回顾这些概念,以便我们可以构建 OpenCV 速度估计驱动程序脚本。
最后,我们将部署和测试我们的系统。所有速度测量设备(包括雷达/激光雷达)都需要校准,我们的也不例外。我们将学习如何进行路测以及如何校准我们的系统。
什么是 VASCAR,如何用它来测量速度?

Figure 1: Vehicle Average Speed Computer and Recorder (VASCAR) devices allow police to measure speed without RADAR or LIDAR, both of which can be detected. We will use a VASCAR-esque approach with OpenCV to detect vehicles, track them, and estimate their speeds without relying on the human component.
视觉平均速度计算机和记录器(VASCAR)是一种计算车辆速度的方法——它不依赖于雷达或激光雷达,但它借用了那些首字母缩写词。相反,VASCAR 是一个简单的计时装置,依赖于以下等式:
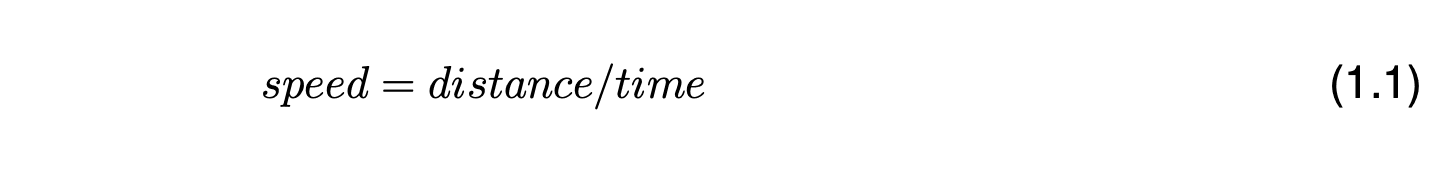
当雷达和激光雷达是非法的或者当他们不想被雷达/激光雷达检测器检测到时,警察使用 VASCAR。
为了利用 VASCAR 方法,警察必须知道道路上两个固定点之间的距离
- 当车辆通过第一个参考点时,他们按下按钮启动计时器。
- 当车辆通过第二点时,计时器停止。
速度是自动计算的,因为计算机已经知道根据等式 1.1 的距离。
VASCAR 测量的速度受到人为因素的严重限制。
例如,如果警察视力不好或反应时间不好怎么办
如果他们晚按按钮(第一参考点),然后早按按钮(第二参考点),那么计算出的速度会比实际速度快,因为时间分量更小。
如果警察给你开了一张罚单,上面写着 VASCAR,那么你很有可能在法庭上逃脱。你可以(也应该)与之抗争。准备好上面的等式 1.1 ,并解释人的因素有多重要。
我们的项目依赖于 VASCAR 方法,但有四个参考点。我们将平均所有四个点之间的速度,目的是更好地估计速度。我们的系统也依赖于距离和时间组件。
关于 VASCAR 的进一步阅读,请参考 VASCAR 维基百科文章。
配置您的 Raspberry Pi 4 + OpenVINO 环境

Figure 2: Configuring OpenVINO on your Raspberry Pi for detecting/tracking vehicles and measuring vehicle speed.
本教程需要 a Raspberry Pi 4B和 Movidius NCS2 (或者更高版本,一旦将来发布更快的版本)。更低的树莓 Pi 和 NCS 型号根本不够快。另一个选择是使用功能强大的笔记本电脑/台式机,而不使用 OpenVINO。
为这个项目配置您的 Raspberry Pi 4B + Intel Movidius NCS 无疑是一项挑战。
建议你(1)拿一个 树莓 Pi 的副本给计算机视觉 ,(2)把预配置的 收录闪一下。img 到你的 microSD。的。随书附赠的 img 价值连城。
对于那些固执的想要自己配置他们的 Raspberry Pi 4 + OpenVINO 的人来说,这里有一个简单的指南:
- 前往我的 BusterOS 安装指南并按照所有指示创建一个名为 cv 的环境。确保您使用 RPi 4B 型号(1GB、2GB 或 4GB)。
- 前往我的 OpenVINO 安装指南,创建第二个名为
openvino的环境。请务必下载最新的 OpenVINO,而不是旧版本。
在这一点上,你的 RPi 将有和一个普通的 OpenCV 环境以及一个 OpenVINO-OpenCV 环境。在本教程中,您将使用openvino环境。
现在,只需将您的 NCS2 插入蓝色 USB 3.0 端口(以获得最高速度),并按照教程的剩余部分进行操作。
注意事项:
- 某些版本的 OpenVINO 很难读取. mp4 视频。这是 PyImageSearch 已经向英特尔团队报告的一个已知 bug。我们预先配置的。img 包括一个修复程序— Abhishek Thanki 编辑了源代码,并从源代码编译了 OpenVINO。这篇博文已经够长了,所以我不能包含从源代码编译的说明。如果您遇到这个问题,请鼓励英特尔解决这个问题,或者(A)从源代码编译,或者(B)拿一份用于计算机视觉的Raspberry Pi并使用预配置的. img
- 如果我们发现其他注意事项,我们会添加到此列表中。
项目结构
让我们回顾一下我们的项目结构:
|-- config
| |-- config.json
|-- pyimagesearch
| |-- utils
| | |-- __init__.py
| | |-- conf.py
| |-- __init__.py
| |-- centroidtracker.py
| |-- trackableobject.py
|-- sample_data
| |-- cars.mp4
|-- output
| |-- log.csv
|-- MobileNetSSD_deploy.caffemodel
|-- MobileNetSSD_deploy.prototxt
|-- speed_estimation_dl_video.py
|-- speed_estimation_dl.py
我们的config.json文件保存了所有的项目设置——我们将在下一节回顾这些配置。在 里面用 Python 做计算机视觉的树莓 Pi,你会找到大部分章节的配置文件。您可以根据需要调整每个配置。这些以注释 JSON 或 Python 文件的形式出现。使用包json_minify,注释被解析出来,以便 JSON Python 模块可以将数据作为 Python 字典加载。
我们将在这个项目中同时利用CentroidTracker和TrackableObject类。质心跟踪器与爱好者捆绑包(第 19 和 20 章)和黑客捆绑包(第 13 章)中以前的人/车计数项目相同。另一方面,我们的可跟踪对象类包括我们将跟踪的附加属性,包括时间戳、位置和速度。
我的同事戴夫·霍夫曼(Dave Hoffman)家门前经过的车辆的视频剪辑样本也包括在内。
此视频用于演示目的;然而,请注意,您不应该依赖视频文件来获得准确的速度 —除了从文件中读取帧的速度之外,视频的 FPS 也会影响速度读数。
提供的视频非常有助于确保程序按预期运行,但同样,从视频文件中获取准确的速度读数是不太可能的— 要获得准确的读数,您应该使用实时视频流。
output/文件夹将存储一个日志文件log.csv,其中包括经过摄像机的车辆的时间戳和速度。
我们预先训练的 Caffe MobileNet SSD 对象检测器(用于检测车辆)文件包含在项目的根中。
包含一个测试脚本— speed_estimation_dl_video.py。除了使用预先录制的视频文件之外,它与实时脚本完全相同。请参考以下注释:
注意: OpenCV 无法根据真实帧率自动节流一个视频文件帧率。如果您使用speed_estimation_dl_video.py以及提供的cars.mp4测试文件,请记住报告的速度将是不准确的。为了获得准确的速度,你必须用一台摄像机设置完整的实验,并让真实的汽车驶过。请参考下一节“校准精度”,了解真实的现场演示,其中录制了现场系统运行的截屏。
驾驶员脚本speed_estimation_dl.py与实时视频流、物体检测器交互,并使用 VASCAR 方法计算车辆速度。这是我们在 中为计算机视觉 讲述的较长脚本之一。
速度估计配置文件
当我处理涉及许多可配置常量以及输入/输出文件和目录的项目时,我喜欢创建一个单独的配置文件。
在某些情况下,我使用 JSON,其他情况下使用 Python 文件。我们可以整天争论哪个更容易(JSON、YAML、XML 等等)。py 等。),但是对于大多数使用 Python 的计算机视觉项目【Raspberry Pi】中的项目,我们使用 Python 或 JSON 配置来代替冗长的命令行参数列表。
让我们回顾一下config.json,我们的 JSON 配置设置文件:
{
// maximum consecutive frames a given object is allowed to be
// marked as "disappeared" until we need to deregister the object
// from tracking
"max_disappear": 10,
// maximum distance between centroids to associate an object --
// if the distance is larger than this maximum distance we'll
// start to mark the object as "disappeared"
"max_distance": 175,
// number of frames to perform object tracking instead of object
// detection
"track_object": 4,
// minimum confidence
"confidence": 0.4,
// frame width in pixels
"frame_width": 400,
// dictionary holding the different speed estimation columns
"speed_estimation_zone": {"A": 120, "B": 160, "C": 200, "D": 240},
// real world distance in meters
"distance": 16,
// speed limit in mph
"speed_limit": 15,
“最大消失”和“最大距离”变量用于质心跟踪和对象关联:
- 当一个物体被标记为消失时,
"max_disappear"帧计数向我们的质心跟踪器发出信号(行 5 )。 "max_distance"值是以像素为单位的最大欧几里德距离,我们将为其关联对象质心(第 10 行)。如果质心超过这个距离,我们就标记这个物体消失了。
我们的"track_object"值代表执行物体跟踪而不是物体检测 ( 行 14 )的帧数。
对每一帧执行检测对于 RPi 来说计算量太大。相反,我们使用对象跟踪器来减轻 Pi 的负载。然后,我们将每隔 N 帧间歇地执行对象检测,以重新关联对象并改进我们的跟踪。
"confidence"值是 MobileNet SSD 对物体检测的概率阈值。检测物体(如汽车、卡车、公共汽车等。)不满足置信度阈值的被忽略(第 17 行)。
每个输入帧的尺寸将被调整到400的"frame_width"(第 20 行)。
如前所述,我们有四个速度估计区域。第 23 行保存了一个分隔区域的帧列(即y-像素)的字典。这些列显然依赖于"frame_width"。

Figure 3: The camera’s FOV is measured at the roadside carefully. Oftentimes calibration is required. Refer to the “Calibrating for Accuracy” section to learn about the calibration procedure for neighborhood speed estimation and vehicle tracking with OpenCV.
第 26 行是该配置中最重要的值。您必须在道路上从车架的一侧到另一侧实际测量"distance"。
如果你有助手帮忙,测量会容易些。让助手看着屏幕,告诉你什么时候站在画面的最边缘。把胶带放在地上。将录像带拉到画面的另一边,直到你的助手告诉你,他们在视频流的画面边缘看到了你。记下距离,单位为米——您的所有计算都将依赖于该值。
如图 3 所示,相对于我相机上的定位,汽车在画面中行驶的边缘之间有 49 英尺。49 英尺换算成米是 14.94 米。
那么为什么我们配置的线 26 反映的是"distance": 16?
该值已针对系统校准进行了调整。参见“校准精度”部分,了解如何测试和校准您的系统。其次,如果测量是在街道中心进行的(即离摄像机更远),距离会更长。戴夫·霍夫曼在街道旁边进行了测量,这样他就不会被车撞倒了。
我们这个例子中的speed_limit是 15 mph(29 线)。行驶速度低于此速度的车辆将不会被记录。超过这个速度的车辆将被记录。如果您需要记录所有速度,您可以将该值设置为 0。
其余的配置设置用于在我们的屏幕上显示帧,将文件上传到云(即 Dropbox),以及输出文件路径:
// flag indicating if the frame must be displayed
"display": true,
// path the object detection model
"model_path": "MobileNetSSD_deploy.caffemodel",
// path to the prototxt file of the object detection model
"prototxt_path": "MobileNetSSD_deploy.prototxt",
// flag used to check if dropbox is to be used and dropbox access
// token
"use_dropbox": false,
"dropbox_access_token": "YOUR_DROPBOX_APP_ACCESS_TOKEN",
// output directory and csv file name
"output_path": "output",
"csv_name": "log.csv"
}
如果你在第 32 行设置"display"为true,一个 OpenCV 窗口会显示在你的 Raspberry Pi 桌面上。
第 35-38 行指定了我们的 Caffe 对象检测模型和 prototxt 路径。
如果您选择"use_dropbox",那么您必须将行 42 上的值设置为true,并在行 43 上填写您的访问令牌。车辆通过摄像头的视频将被记录到 Dropbox。确保您有视频的配额!
第 46 和 47 行指定日志文件的"output_path"。
相机定位和常数
Figure 4: This OpenCV vehicle speed estimation project assumes the camera is aimed perpendicular to the road. Timestamps of a vehicle are collected at waypoints ABCD or DCBA. From there, our speed = distance / time equation is put to use to calculate 3 speeds among the 4 waypoints. Speeds are averaged together and converted to km/hr and miles/hr. As you can see, the distance measurement is different depending on where (edges or centerline) the tape is laid on the ground/road. We will account for this by calibrating our system in the “Calibrating for Accuracy” section.
图 4 显示了项目布局的俯视图。在戴夫·霍夫曼的房子里,RPi 和摄像机就放在他面向马路的窗户里。"distance"的测量是在 FOV 线远处的路边拍摄的。点 A、B、C、和 D 标记一帧中的列。它们应该在你的视频帧中等距分布(在配置中用"speed_estimation_zone"像素列表示)。
汽车以任一方向通过 FOV,而 MobileNet SSD 物体检测器结合物体跟踪器,有助于在点 ABCD (从左至右)或 DCBA (从右至左)获取时间戳。
质心跟踪器
![]()
Figure 5: Top-left: To build a simple object tracking algorithm using centroid tracking, the first step is to accept bounding box coordinates from an object detector and use them to compute centroids. Top-right: In the next input frame, three objects are now present. We need to compute the Euclidean distances between each pair of original centroids (circle) and new centroids (square). Bottom-left: Our simple centroid object tracking method has associated objects with minimized object distances. What do we do about the object in the bottom left though? Bottom-right: We have a new object that wasn’t matched with an existing object, so it is registered as object ID #3.
通过质心关联进行物体跟踪是一个我们已经在 PyImageSearch 上介绍过的概念,但是,让我们花点时间来回顾一下。
简单的对象跟踪算法依赖于保持对对象质心的跟踪。
通常一个物体跟踪器与一个效率较低的物体探测器携手工作。物体探测器负责定位物体。对象跟踪器负责通过分配和维护标识号(id)来跟踪哪个对象是哪个对象。
我们正在实现的这个对象跟踪算法被称为质心跟踪,因为它依赖于(1) 现有对象质心(即质心跟踪器之前已经看到的对象)和(2)视频中后续帧之间的新对象质心之间的欧几里德距离。质心跟踪算法是一个多步骤的过程。这五个步骤包括:
- 步骤#1: 接受边界框坐标并计算质心
- 步骤#2: 计算新边界框和现有对象之间的欧几里德距离
- 步骤#3: 更新 (x,y)-已有物体的坐标
- 步骤#4: 注册新对象
- 步骤#5: 注销旧对象
PyImageSearch 上的以下资源涵盖了CentroidTracker类:
- 用 OpenCV 进行简单的物体跟踪
- OpenCV 人物计数器
- 计算机视觉的覆盆子 :
- 创建一个人/脚步计数器—爱好者捆绑包第 19 章
- 建立一个交通计数器—爱好者捆绑包第二十章
- 构建一个邻居车辆速度监控器——黑客捆绑包第七章
- 使用 Movidius NCS 进行目标检测—黑客捆绑包第十三章
用 OpenCV 跟踪物体进行速度估计
为了跟踪和计算视频流中对象的速度,我们需要一种简单的方法来存储关于对象本身的信息,包括:
- 它的对象 ID。
- 它以前的质心(所以我们可以很容易地计算出物体移动的方向)。
- 对应于框架中四列中每一列的时间戳字典。
- x 的字典——物体的坐标位置。这些位置反映了记录时间戳的实际位置,因此可以精确计算速度。
- 最后一个布尔点作为一个标志,表示对象已经通过了帧中的最后一个路点(即列)。
- 以英里/小时和 KMPH 为单位的计算速度。我们计算两者,用户可以通过对驱动程序脚本的小修改来选择他/她更喜欢使用哪一个。
- 一个布尔值,表示速度是否已被估计(即计算)。
- 一个布尔值,表示速度是否已记录在
.csv日志文件中。 - 对象穿过 FOV 的方向(从左到右或从右到左)。
为了实现所有这些目标,我们可以定义一个TrackableObject的实例—打开trackableobject.py文件并插入以下代码:
# import the necessary packages
import numpy as np
class TrackableObject:
def __init__(self, objectID, centroid):
# store the object ID, then initialize a list of centroids
# using the current centroid
self.objectID = objectID
self.centroids = [centroid]
# initialize a dictionaries to store the timestamp and
# position of the object at various points
self.timestamp = {"A": 0, "B": 0, "C": 0, "D": 0}
self.position = {"A": None, "B": None, "C": None, "D": None}
self.lastPoint = False
# initialize the object speeds in MPH and KMPH
self.speedMPH = None
self.speedKMPH = None
# initialize two booleans, (1) used to indicate if the
# object's speed has already been estimated or not, and (2)
# used to indidicate if the object's speed has been logged or
# not
self.estimated = False
self.logged = False
# initialize the direction of the object
self.direction = None
TrackableObject构造函数接受一个objectID和一个centroid。centroids列表将包含一个对象的质心位置历史。
我们将有多个可跟踪对象——在帧中被跟踪的每辆汽车一个。每个对象将具有显示在第 8-29 行的属性(详见上文)
第 18 行和第 19 行以英里/小时和 KMPH 为单位保存速度。我们需要一个函数来计算速度,所以现在让我们定义这个函数:
def calculate_speed(self, estimatedSpeeds):
# calculate the speed in KMPH and MPH
self.speedKMPH = np.average(estimatedSpeeds)
MILES_PER_ONE_KILOMETER = 0.621371
self.speedMPH = self.speedKMPH * MILES_PER_ONE_KILOMETER
第 33 行将speedKMPH属性计算为四个点之间三个estimatedSpeeds的average(作为参数传递给函数)。
一公里有0.621371英里(34 线)。了解了这一点,第 35 行计算了speedMPH属性。
基于计算机视觉和 OpenCV 的速度估计

Figure 6: OpenCV vehicle detection, tracking, and speed estimation with the Raspberry Pi.
在我们开始编写我们的驱动程序脚本之前,让我们回顾一下我们的算法:
- 我们的速度公式是
speed = distance / time(方程式 1.1)。 - 我们有一个已知的常数
distance,是用路边的卷尺测量的。摄像机将垂直于距离测量面向没有障碍物阻挡的道路。 - 通过将距离常数除以以像素为单位的帧宽度来计算每像素米数(等式 1.2)。
- 以像素为单位的距离计算为质心经过区域的列时的差(等式 1.3)。然后计算特定区域的米距离(等式 1.4)。
- 当汽车穿过 FOV,经过视频帧的四个路点列时,将收集四个时间戳( t )。
- 四个时间戳中的三对将用于确定三个δt值。
- 我们将为每对时间戳和估计距离计算三个速度值(如等式 1.5 的分子所示)。
- 三个速度估计值将被平均为总速度(方程式 1.5)。
speed被转换并作为speedMPH或speedKMPH在TrackableObject类中可用。我们将以每小时英里数显示速度。如果您更喜欢记录和显示每小时公里数,则需要对脚本进行一些小的修改——请确保在学习本教程时阅读注释。
以下等式代表我们的算法:

既然我们已经理解了计算车辆速度的方法,并且我们已经定义了CentroidTracker和TrackableObject类,那么让我们开始我们的速度估计驱动程序脚本。
打开一个名为speed_estimation_dl.py的新文件,插入以下几行:
# import the necessary packages
from pyimagesearch.centroidtracker import CentroidTracker
from pyimagesearch.trackableobject import TrackableObject
from pyimagesearch.utils import Conf
from imutils.video import VideoStream
from imutils.io import TempFile
from imutils.video import FPS
from datetime import datetime
from threading import Thread
import numpy as np
import argparse
import dropbox
import imutils
import dlib
import time
import cv2
import os
第 2-17 行处理我们的导入,包括用于对象跟踪的CentroidTracker和TrackableObject。戴维斯·金的dlib中的相关跟踪器也是我们的对象跟踪方法的一部分。我们将使用dropbox API 将数据存储在云中一个单独的Thread中,这样就不会中断主线程的执行流程。
现在让我们实现upload_file函数:
def upload_file(tempFile, client, imageID):
# upload the image to Dropbox and cleanup the tempory image
print("[INFO] uploading {}...".format(imageID))
path = "/{}.jpg".format(imageID)
client.files_upload(open(tempFile.path, "rb").read(), path)
tempFile.cleanup()
我们的upload_file函数将在一个或多个单独的线程中运行。它接受tempFile对象、Dropbox client对象和imageID作为参数。使用这些参数,它构建一个path,然后将文件上传到 Dropbox ( 第 22 行和第 23 行)。从那里, Line 24 然后从本地存储中删除临时文件。
让我们继续加载我们的配置:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True,
help="Path to the input configuration file")
args = vars(ap.parse_args())
# load the configuration file
conf = Conf(args["conf"])
第 27-33 行解析--conf命令行参数并将配置内容加载到conf字典中。
然后,如果需要,我们将初始化预训练的 MobileNet SSD CLASSES和 Dropbox client:
# initialize the list of class labels MobileNet SSD was trained to
# detect
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
# check to see if the Dropbox should be used
if conf["use_dropbox"]:
# connect to dropbox and start the session authorization process
client = dropbox.Dropbox(conf["dropbox_access_token"])
print("[SUCCESS] dropbox account linked")
从那里,我们将加载我们的对象检测器并初始化我们的视频流:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(conf["prototxt_path"],
conf["model_path"])
net.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
# initialize the video stream and allow the camera sensor to warmup
print("[INFO] warming up camera...")
#vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# initialize the frame dimensions (we'll set them as soon as we read
# the first frame from the video)
H = None
W = None
第 50-52 行加载 MobileNet SSD net并将目标处理器设置为 Movidius NCS Myriad。
使用 Movidius NCS 协处理器( Line 52 )可确保我们的 FPS 足够高,能够进行精确的速度计算。换句话说,如果我们在帧捕获之间有延迟,我们的时间戳可能会变得不同步,并导致不准确的速度读数。如果您喜欢使用笔记本电脑/台式机进行处理(即没有 OpenVINO 和 Movidius NCS),请务必删除第 52 行。
第 57-63 行初始化 Raspberry Pi 视频流和帧尺寸。
我们还有一些初始化要处理:
# instantiate our centroid tracker, then initialize a list to store
# each of our dlib correlation trackers, followed by a dictionary to
# map each unique object ID to a TrackableObject
ct = CentroidTracker(maxDisappeared=conf["max_disappear"],
maxDistance=conf["max_distance"])
trackers = []
trackableObjects = {}
# keep the count of total number of frames
totalFrames = 0
# initialize the log file
logFile = None
# initialize the list of various points used to calculate the avg of
# the vehicle speed
points = [("A", "B"), ("B", "C"), ("C", "D")]
# start the frames per second throughput estimator
fps = FPS().start()
出于目标跟踪的目的,行 68-71 初始化我们的CentroidTracker、trackers列表和trackableObjects字典。
线 74 初始化一个totalFrames计数器,该计数器将在每次捕获一帧时递增。我们将使用该值来计算何时执行对象检测和对象跟踪。
我们的logFile对象将在稍后打开(第 77 行)。
我们的速度将基于我们框架中的 ABCD 列点。第 81 行初始化一个将被计算速度的points对列表。给定我们的四个点,我们可以计算三个估计速度,然后将它们平均。
第 84 行初始化我们的 FPS 计数器。
完成所有的初始化后,让我们开始在帧上循环:
# loop over the frames of the stream
while True:
# grab the next frame from the stream, store the current
# timestamp, and store the new date
frame = vs.read()
ts = datetime.now()
newDate = ts.strftime("%m-%d-%y")
# check if the frame is None, if so, break out of the loop
if frame is None:
break
# if the log file has not been created or opened
if logFile is None:
# build the log file path and create/open the log file
logPath = os.path.join(conf["output_path"], conf["csv_name"])
logFile = open(logPath, mode="a")
# set the file pointer to end of the file
pos = logFile.seek(0, os.SEEK_END)
# if we are using dropbox and this is a empty log file then
# write the column headings
if conf["use_dropbox"] and pos == 0:
logFile.write("Year,Month,Day,Time,Speed (in MPH),ImageID\n")
# otherwise, we are not using dropbox and this is a empty log
# file then write the column headings
elif pos == 0:
logFile.write("Year,Month,Day,Time (in MPH),Speed\n")
我们的帧处理循环从行 87 开始。我们首先获取一个frame并获取我们的第一个时间戳(第 90-92 行)。
第 99-115 行初始化我们的logFile和write列标题。注意,如果我们使用 Dropbox,CSV 中会出现一个额外的列——图像 ID。
注:如果您更喜欢以千米/小时记录速度,请务必更新行 110* 和行 115 上的 CSV 列标题。*
让我们预处理我们的frame并执行一些初始化:
# resize the frame
frame = imutils.resize(frame, width=conf["frame_width"])
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# if the frame dimensions are empty, set them
if W is None or H is None:
(H, W) = frame.shape[:2]
meterPerPixel = conf["distance"] / W
# initialize our list of bounding box rectangles returned by
# either (1) our object detector or (2) the correlation trackers
rects = []
第 118 行直接从配置文件中的"frame_width"值调整我们的框架到一个已知的宽度。
注意:如果您在配置中更改了"frame_width",请务必同时更新"speed_estimation_zone"列。
第 119 行为 dlib 的相关跟踪器将frame转换为 RGB 格式。
第 122-124 行初始化框架尺寸并计算meterPerPixel。每像素米值有助于计算四个点中的三个估计速度。
注意:如果您的镜头引入了失真(即广角镜头或鱼眼),您应该考虑通过内部/外部相机参数进行适当的相机校准,以便meterPerPixel值更加准确。校准将是未来 PyImageSearch 博客的主题。
第 128 行初始化一个空列表来保存由(1)我们的对象检测器或(2)相关跟踪器返回的边界框矩形。
此时,我们准备执行对象检测来更新我们的trackers:
# check to see if we should run a more computationally expensive
# object detection method to aid our tracker
if totalFrames % conf["track_object"] == 0:
# initialize our new set of object trackers
trackers = []
# convert the frame to a blob and pass the blob through the
# network and obtain the detections
blob = cv2.dnn.blobFromImage(frame, size=(300, 300),
ddepth=cv2.CV_8U)
net.setInput(blob, scalefactor=1.0/127.5, mean=[127.5,
127.5, 127.5])
detections = net.forward()
按照线 132 ,物体跟踪 willy 只发生在"track_object"的倍数上。仅每隔 N 帧执行对象检测减少了昂贵的推断操作。我们将尽可能执行对象跟踪以减少计算量。
第 134 行初始化我们的新对象列表trackers以更新精确的边界框矩形,以便相关跟踪可以稍后完成它的工作。
第 138-142 行使用 Movidius NCS 执行推理。
让我们遍历detections并更新我们的trackers:
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated
# with the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence`
# is greater than the minimum confidence
if confidence > conf["confidence"]:
# extract the index of the class label from the
# detections list
idx = int(detections[0, 0, i, 1])
# if the class label is not a car, ignore it
if CLASSES[idx] != "car":
continue
# compute the (x, y)-coordinates of the bounding box
# for the object
box = detections[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
# construct a dlib rectangle object from the bounding
# box coordinates and then start the dlib correlation
# tracker
tracker = dlib.correlation_tracker()
rect = dlib.rectangle(startX, startY, endX, endY)
tracker.start_track(rgb, rect)
# add the tracker to our list of trackers so we can
# utilize it during skip frames
trackers.append(tracker)
行 145 开始检测循环。
第 148-159 行根据"confidence"阈值和CLASSES类型过滤检测。我们只寻找使用我们预训练的 MobileNet 固态硬盘的“汽车”类。
第 163 和 164 行计算对象的边界框。
然后,我们初始化 dlib 关联tracker,并开始跟踪由我们的对象检测器找到的rectROI(行 169-171 )。第 175 行将tracker添加到我们的trackers列表中。
现在让我们来处理事件,我们将执行对象跟踪而不是对象检测:
# otherwise, we should utilize our object *trackers* rather than
# object *detectors* to obtain a higher frame processing
# throughput
else:
# loop over the trackers
for tracker in trackers:
# update the tracker and grab the updated position
tracker.update(rgb)
pos = tracker.get_position()
# unpack the position object
startX = int(pos.left())
startY = int(pos.top())
endX = int(pos.right())
endY = int(pos.bottom())
# add the bounding box coordinates to the rectangles list
rects.append((startX, startY, endX, endY))
# use the centroid tracker to associate the (1) old object
# centroids with (2) the newly computed object centroids
objects = ct.update(rects)
对象跟踪在我们的 RPi 上的计算量较小,所以大多数时候(即除了每隔 N "track_object"帧)我们将执行跟踪。
第 180-185 行循环显示可用的trackers和update每个对象的位置。
第 188-194 行将对象的边界框坐标添加到rects列表。
行 198 然后使用物体检测或物体跟踪 rects来更新CentroidTracker的objects。
现在让我们循环一遍objects,并逐步计算速度:
# loop over the tracked objects
for (objectID, centroid) in objects.items():
# check to see if a trackable object exists for the current
# object ID
to = trackableObjects.get(objectID, None)
# if there is no existing trackable object, create one
if to is None:
to = TrackableObject(objectID, centroid)
每个可跟踪对象都有一个关联的objectID。第 204-208 行如有必要,创建一个可跟踪对象(带 ID)。
从这里,我们将检查是否已经估计了这个可跟踪对象的速度:
# otherwise, if there is a trackable object and its speed has
# not yet been estimated then estimate it
elif not to.estimated:
# check if the direction of the object has been set, if
# not, calculate it, and set it
if to.direction is None:
y = [c[0] for c in to.centroids]
direction = centroid[0] - np.mean(y)
to.direction = direction
如果还没有估计出速度(行 212 ,那么我们首先需要确定物体运动的direction(行 215-218 )。
正值表示从左向右移动,负值表示从右向左移动。
知道方向是很重要的,这样我们就可以正确估计两点之间的速度。
有了direction,现在让我们收集我们的时间戳:
# if the direction is positive (indicating the object
# is moving from left to right)
if to.direction > 0:
# check to see if timestamp has been noted for
# point A
if to.timestamp["A"] == 0 :
# if the centroid's x-coordinate is greater than
# the corresponding point then set the timestamp
# as current timestamp and set the position as the
# centroid's x-coordinate
if centroid[0] > conf["speed_estimation_zone"]["A"]:
to.timestamp["A"] = ts
to.position["A"] = centroid[0]
# check to see if timestamp has been noted for
# point B
elif to.timestamp["B"] == 0:
# if the centroid's x-coordinate is greater than
# the corresponding point then set the timestamp
# as current timestamp and set the position as the
# centroid's x-coordinate
if centroid[0] > conf["speed_estimation_zone"]["B"]:
to.timestamp["B"] = ts
to.position["B"] = centroid[0]
# check to see if timestamp has been noted for
# point C
elif to.timestamp["C"] == 0:
# if the centroid's x-coordinate is greater than
# the corresponding point then set the timestamp
# as current timestamp and set the position as the
# centroid's x-coordinate
if centroid[0] > conf["speed_estimation_zone"]["C"]:
to.timestamp["C"] = ts
to.position["C"] = centroid[0]
# check to see if timestamp has been noted for
# point D
elif to.timestamp["D"] == 0:
# if the centroid's x-coordinate is greater than
# the corresponding point then set the timestamp
# as current timestamp, set the position as the
# centroid's x-coordinate, and set the last point
# flag as True
if centroid[0] > conf["speed_estimation_zone"]["D"]:
to.timestamp["D"] = ts
to.position["D"] = centroid[0]
to.lastPoint = True
第 222-267 行为我们的每一列 A、B、C、和 D 收集从从左到右移动的汽车的时间戳。
让我们检查列 A 的计算:
- 第 225 行检查是否为点 A 制作了时间戳,如果没有,我们将继续这样做。
- 行 230 检查当前 x 坐标
centroid是否大于列 A 。 - 如果是这样,行 231 和 232 记录了一个时间戳和
centroid的确切的x–position。 - 列 B、C、和 D 使用相同的方法收集时间戳和位置,只有一个例外。对于 D 列,
lastPoint标记为True。我们稍后将使用此标志来表示是时候执行速度公式计算了。
现在让我们对从右到左行驶的汽车(即direction < 0)执行相同的时间戳、位置和最后点更新:
# if the direction is negative (indicating the object
# is moving from right to left)
elif to.direction < 0:
# check to see if timestamp has been noted for
# point D
if to.timestamp["D"] == 0 :
# if the centroid's x-coordinate is lesser than
# the corresponding point then set the timestamp
# as current timestamp and set the position as the
# centroid's x-coordinate
if centroid[0] < conf["speed_estimation_zone"]["D"]:
to.timestamp["D"] = ts
to.position["D"] = centroid[0]
# check to see if timestamp has been noted for
# point C
elif to.timestamp["C"] == 0:
# if the centroid's x-coordinate is lesser than
# the corresponding point then set the timestamp
# as current timestamp and set the position as the
# centroid's x-coordinate
if centroid[0] < conf["speed_estimation_zone"]["C"]:
to.timestamp["C"] = ts
to.position["C"] = centroid[0]
# check to see if timestamp has been noted for
# point B
elif to.timestamp["B"] == 0:
# if the centroid's x-coordinate is lesser than
# the corresponding point then set the timestamp
# as current timestamp and set the position as the
# centroid's x-coordinate
if centroid[0] < conf["speed_estimation_zone"]["B"]:
to.timestamp["B"] = ts
to.position["B"] = centroid[0]
# check to see if timestamp has been noted for
# point A
elif to.timestamp["A"] == 0:
# if the centroid's x-coordinate is lesser than
# the corresponding point then set the timestamp
# as current timestamp, set the position as the
# centroid's x-coordinate, and set the last point
# flag as True
if centroid[0] < conf["speed_estimation_zone"]["A"]:
to.timestamp["A"] = ts
to.position["A"] = centroid[0]
to.lastPoint = True
第 271-316 行在汽车经过列 D、C、B、和 A 时获取它们的时间戳和位置(同样,用于从右到左跟踪)。对于 A 来说lastPoint被标记为True。
现在汽车的lastPoint是True,我们可以计算速度:
# check to see if the vehicle is past the last point and
# the vehicle's speed has not yet been estimated, if yes,
# then calculate the vehicle speed and log it if it's
# over the limit
if to.lastPoint and not to.estimated:
# initialize the list of estimated speeds
estimatedSpeeds = []
# loop over all the pairs of points and estimate the
# vehicle speed
for (i, j) in points:
# calculate the distance in pixels
d = to.position[j] - to.position[i]
distanceInPixels = abs(d)
# check if the distance in pixels is zero, if so,
# skip this iteration
if distanceInPixels == 0:
continue
# calculate the time in hours
t = to.timestamp[j] - to.timestamp[i]
timeInSeconds = abs(t.total_seconds())
timeInHours = timeInSeconds / (60 * 60)
# calculate distance in kilometers and append the
# calculated speed to the list
distanceInMeters = distanceInPixels * meterPerPixel
distanceInKM = distanceInMeters / 1000
estimatedSpeeds.append(distanceInKM / timeInHours)
# calculate the average speed
to.calculate_speed(estimatedSpeeds)
# set the object as estimated
to.estimated = True
print("[INFO] Speed of the vehicle that just passed"\
" is: {:.2f} MPH".format(to.speedMPH))
# store the trackable object in our dictionary
trackableObjects[objectID] = to
当可跟踪对象的(1)最后一点时间戳和位置已被记录,以及(2)速度尚未被估计时( Line 322 ),我们将继续估计速度。
第 324 行初始化一个列表来保存三个estimatedSpeeds。现在来算三个估计。
线 328 开始在我们的对对points上循环:
我们使用position值(第 330-331 行)来计算distanceInPixels。如果距离是 0,我们就跳过这一对(行 335 和 336 )。
接下来,我们以小时为单位计算两点之间经过的时间(第 339-341 行)。我们需要以小时为单位的时间,因为我们正在计算每小时的公里数和每小时的英里数。
然后,我们通过将像素距离乘以估计值meterPerPixel(第 345 行和第 346 行)来计算距离,单位为千米。回想一下meterPerPixel是基于(1)路边 FOV 的宽度和(2)车架的宽度。
速度通过等式 1.1-1.4 (时间上的距离)计算,并添加到estimatedSpeeds列表中。
第 350 行调用TrackableObject类方法calculate_speed,以英里/小时和公里/小时来平均我们的三个estimatedSpeeds(等式 1.5 )。
353 线标记速度为estimated。
354 线和 355 线然后print在终点站加速。
注意:如果您更喜欢以公里/小时为单位打印速度,请确保将字符串更新为 KMPH,并将格式变量更新为to.speedKMPH。
行 358 将可跟踪对象存储到trackableObjects字典中。
唷!在这个脚本中,最难的部分不在这里。让我们总结一下,首先在frame上标注质心和 id:
# draw both the ID of the object and the centroid of the
# object on the output frame
text = "ID {}".format(objectID)
cv2.putText(frame, text, (centroid[0] - 10, centroid[1] - 10)
, cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.circle(frame, (centroid[0], centroid[1]), 4,
(0, 255, 0), -1)
在行驶的汽车质心上画一个小点,旁边是 id 号。
接下来,我们将继续更新日志文件,并将车辆图像存储在 Dropbox 中:
# check if the object has not been logged
if not to.logged:
# check if the object's speed has been estimated and it
# is higher than the speed limit
if to.estimated and to.speedMPH > conf["speed_limit"]:
# set the current year, month, day, and time
year = ts.strftime("%Y")
month = ts.strftime("%m")
day = ts.strftime("%d")
time = ts.strftime("%H:%M:%S")
# check if dropbox is to be used to store the vehicle
# image
if conf["use_dropbox"]:
# initialize the image id, and the temporary file
imageID = ts.strftime("%H%M%S%f")
tempFile = TempFile()
cv2.imwrite(tempFile.path, frame)
# create a thread to upload the file to dropbox
# and start it
t = Thread(target=upload_file, args=(tempFile,
client, imageID,))
t.start()
# log the event in the log file
info = "{},{},{},{},{},{}\n".format(year, month,
day, time, to.speedMPH, imageID)
logFile.write(info)
# otherwise, we are not uploading vehicle images to
# dropbox
else:
# log the event in the log file
info = "{},{},{},{},{}\n".format(year, month,
day, time, to.speedMPH)
logFile.write(info)
# set the object has logged
to.logged = True
至少,每辆超过限速的车辆都将被记录在 CSV 文件中。可选地,Dropbox 将填充超速车辆的图像。
第 369-372 行检查可跟踪对象是否已被记录,速度是否被估计,以及汽车是否超速。
如果是这样的话行 374-477 从时间戳中提取year、month、day和time。
如果一个图像将被记录到 Dropbox 中,行 381-391 存储一个临时文件并产生一个线程将文件上传到 Dropbox。
使用一个单独的线程来进行可能很耗时的上传是至关重要的,这样我们的主线程就不会被阻塞,影响 FPS 和速度计算。文件名将是第 383 行上的imageID,这样,如果它与日志文件相关联,以后就可以很容易地找到它。
第 394-404 行将 CSV 数据写入logFile。如果使用 Dropbox,imageID是最后一个值。
注:如果你更喜欢记录公里每小时的速度,只需将行 395* 和行 403 上的to.speedMPH更新为to.speedKMPH。*
行 396 将可跟踪对象标记为logged。
让我们总结一下:
# if the *display* flag is set, then display the current frame
# to the screen and record if a user presses a key
if conf["display"]:
cv2.imshow("frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key is pressed, break from the loop
if key == ord("q"):
break
# increment the total number of frames processed thus far and
# then update the FPS counter
totalFrames += 1
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# check if the log file object exists, if it does, then close it
if logFile is not None:
logFile.close()
# close any open windows
cv2.destroyAllWindows()
# clean up
print("[INFO] cleaning up...")
vs.stop()
第 411-417 行显示带注释的frame并寻找q按键,在这种情况下我们将退出(break)。
线 421 和 422 增加totalFrames和update我们的 FPS 计数器。
当我们跳出帧处理循环时,我们执行内务处理,包括打印 FPS 统计数据、关闭我们的日志文件、销毁 GUI 窗口和停止我们的视频流(行 424-438 )
车速估计部署
现在我们的代码已经实现,我们将部署和测试我们的系统。
我强烈建议你进行一些受控的飞车追逐,并调整配置文件中的变量,直到你获得准确的速度读数。
在任何微调校准之前,我们将确保程序正常工作。在尝试运行应用程序之前,请确保您满足以下要求:
- 按照图 3 将您的摄像机垂直对准道路。
- 确保您的摄像机视线清晰,障碍物有限——我们的物体检测器必须能够在车辆穿过摄像机视野时在多个点检测到车辆(FOV)。
- 如果你的相机放置在远离马路的地方是最好的。汽车在道路上通过的点处的点 A 和 D 彼此离得越远,距离/时间的计算就越准确,并产生更准确的速度读数。如果你的相机靠近道路,广角镜头是一个选择,但你需要进行相机校准(未来的 PyImageSearch 博客主题)。
- 如果您使用 Dropbox 功能,请确保您的 RPi 有可靠的 WiFi、以太网甚至蜂窝连接。
- 确保您已经在配置文件中设置了所有常量。我们可以选择在下一节中微调常数。
假设您已经满足了每一个需求,那么现在就可以部署和运行您的程序了。首先,我们必须设置我们的环境。
预先配置的 Raspbian。img 用户 : 请按如下方式激活您的虚拟环境:
$ source ~/start_openvino.sh
使用该脚本可确保(1)激活虚拟环境,以及(2)加载英特尔的环境变量。
如果你自己安装了 open vino(也就是说,你没有使用我预先配置的 Raspbian。img): 请如下获取setupvars.sh脚本(根据您的脚本所在的位置调整命令):
$ workon <env_name>
$ source ~/openvino/inference_engine_vpu_arm/bin/setupvars.sh
注意:您可能已经根据 OpenVINO 安装说明在您的~/.bashrc文件中获取了环境。在这种情况下,当您启动终端或通过 SSH 连接时,会自动设置环境变量。也就是说,您仍然需要使用workon命令来激活您的虚拟环境。
同样,如果你用的是我预先配置的 Raspbian。img 带有 实用 Python 和 OpenCV +案例研究 (快速入门和硬拷贝)和/或 用于计算机视觉的树莓 Pi(所有捆绑包),然后~/start_openvino.sh将自动调用setupvars.sh脚本。
如果您不执行以下任何一个步骤,您将会遇到一个Illegal Instruction错误。
输入以下命令启动程序并开始记录速度:
$ python speed_estimation_dl.py --conf config/config.json
[INFO] loading model...
[INFO] warming up camera...
[INFO] Speed of the vehicle that just passed is: 26.08 MPH
[INFO] Speed of the vehicle that just passed is: 22.26 MPH
[INFO] Speed of the vehicle that just passed is: 17.91 MPH
[INFO] Speed of the vehicle that just passed is: 15.73 MPH
[INFO] Speed of the vehicle that just passed is: 41.39 MPH
[INFO] Speed of the vehicle that just passed is: 35.79 MPH
[INFO] Speed of the vehicle that just passed is: 24.10 MPH
[INFO] Speed of the vehicle that just passed is: 20.46 MPH
[INFO] Speed of the vehicle that just passed is: 16.02 MPH
Figure 7: OpenCV vehicle speed estimation deployment. Vehicle speeds are calculated after they leave the viewing frame. Speeds are logged to CSV and images are stored in Dropbox.
如图 7 和视频所示,我们的 OpenCV 系统正在测量双向行驶车辆的速度。在下一部分中,我们将执行路过测试,以确保我们的系统报告准确的速度。
注:视频经过后期处理,用于演示。请记住,在车辆通过车架后的之前,我们不知道车速。在视频中,车辆的速度显示为,而车辆在帧中,以便更好地可视化。**
注意: OpenCV 无法根据真实帧率自动节流一个视频文件帧率。如果您使用speed_estimation_dl_video.py以及提供的cars.mp4测试文件,请记住报告的速度将是不准确的。为了获得准确的速度,你必须用一台摄像机设置完整的实验,并让真实的汽车驶过。请参考下一节“校准精度”,了解真实的现场演示,其中录制了现场系统运行的截屏。要使用这个脚本,运行这个命令:python speed_estimation_dl_video.py --conf config/config.json --input sample_data/cars.mp4
当多辆汽车在某一给定时间通过框架时,速度会被不准确地报告。这可能发生在我们的质心跟踪器混淆质心的时候。这是我们算法的一个已知缺点。为了解决这个问题,作为读者的你需要进行额外的算法工程。一个建议是执行实例分割来精确分割每辆车。
学分:
- 演示视频的音频: BenSound
校准准确度
Figure 8: Neighborhood vehicle speed estimation and tracking with OpenCV drive test results.
你可能会发现该系统对经过的车辆速度的读数稍有不准确。暂时不要忽视这个项目。您可以调整配置文件,使其越来越接近准确的读数。
我们使用以下方法校准我们的系统,直到我们的读数准确无误:
- 开始录制 RPi 桌面的截屏,显示视频流和终端。该截屏应记录整个测试过程。
- 与此同时,在你驾驶的整个测试过程中,在你的智能手机上录制一段语音备忘录,同时说明你的驾驶速度。
- 由基于计算机视觉的 VASCAR 系统以预定速度双向驾驶。我们选择了 10 英里/小时、15 英里/小时、20 英里/小时和 25 英里/小时来比较我们的速度和 VASCAR 计算的速度。当你来回开车经过你的房子时,你的邻居可能会觉得你很奇怪,但是给他们一个美好的微笑吧!
- 将截屏与音频文件同步,以便可以播放。
- 回放带有同步音频文件的视频时,可以记下速度+/-差异。
- 根据这些信息,调整常数:
- (1)如果你的速度读数有点高,那么减小常数
"distance" - (2)相反,如果你的速度读数稍低,那么增加的
"distance"常数。
- (1)如果你的速度读数有点高,那么减小常数
- 冲洗,重复,直到你满意为止。别担心,在这个过程中你不会消耗太多的燃料。
PyImageSearch 的同事 Dave Hoffman 和 Abhishek Thanki 发现,Dave 需要将其距离常数从14.94 米 增加到16.00 米。
请务必参考以下最终测试视频,该视频对应于图 8中表格的时间戳和速度:
https://www.youtube.com/embed/V5Ns3QwEj-c?feature=oembed
OpenCV 视频增强现实
原文:https://pyimagesearch.com/2021/01/11/opencv-video-augmented-reality/
在本教程中,您将学习如何使用 OpenCV 在视频流中执行实时增强现实。
上周我们用 OpenCV 讲述了增强现实的基础知识;然而,该教程只专注于将增强现实应用于图像。
这就提出了一个问题:
“有没有可能用 OpenCV 在实时视频中进行实时增强现实?”
绝对是——本教程的其余部分将告诉你如何做。
要了解如何使用 OpenCV 执行实时增强现实,请继续阅读。
OpenCV:实时视频增强现实
在本教程的第一部分,您将了解 OpenCV 如何在实时视频流中促进增强现实。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们将回顾两个 Python 脚本:
- 第一个将包含一个助手函数
find_and_warp,它将接受输入图像,检测增强现实标记,然后将源图像扭曲到输入上。 - 第二个脚本将充当驱动程序脚本,并在实时视频流中使用我们的
find_and_warp函数。
我们将通过讨论我们的实时增强现实结果来结束本教程。
我们开始吧!
如何利用 OpenCV 将增强现实应用于实时视频流?
OpenCV 库存在的真正原因是为了促进实时图像处理。该库接受输入图像/帧,尽快处理它们,然后返回结果。
由于 OpenCV 适用于实时图像处理,我们也可以使用 OpenCV 来促进实时增强现实。
出于本教程的目的,我们将:
- 访问我们的视频流
- 检测每个输入帧中的 ArUco 标记
- 获取一个源图像,并应用透视变换将源输入映射到帧上,从而创建我们的增强现实输出!
为了让这个项目更加有趣,我们将利用两个视频流:
- 第一个视频流将充当我们进入真实世界的“眼睛”(即我们的摄像机所看到的)。
- 然后,我们将从第二个视频流中读取帧,然后将它们转换为第一个视频流。
本教程结束时,您将拥有一个实时运行的全功能 OpenCV 增强现实项目!
配置您的开发环境
为了使用 OpenCV 执行实时增强现实,您需要安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们可以用 OpenCV 实现实时增强现实之前,我们首先需要回顾一下我们的项目目录结构。
首先使用本教程的 【下载】 部分下载源代码和示例视频文件。
现在让我们看一下目录内容:
$ tree . --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── augmented_reality.py
├── videos
│ └── jp_trailer_short.mp4
├── markers.pdf
└── opencv_ar_video.py
2 directories, 4 files
如果你没有自己的配色卡,也不用担心!在我们的项目目录结构中,您会看到我已经包含了markers.pdf,它是我自己的 Pantone 颜色匹配卡的扫描件:
实现我们的标记检测器/增强现实实用功能
在我们使用 OpenCV 在实时视频流中实现增强现实之前,我们首先需要创建一个助手函数find_and_warp,顾名思义,它将:
- 接受输入图像和源图像
- 在输入图像上找到四个 ArUco 标签
- 构建并应用单应矩阵将源图像扭曲到输入表面
此外,我们将包括处理所有四个 ArUco 参考点未被检测到时的逻辑(以及如何确保我们的输出中没有闪烁/断续)。
打开我们项目目录结构的pyimagesearch模块中的augmented_reality.py 文件,让我们开始工作:
# import the necessary packages
import numpy as np
import cv2
# initialize our cached reference points
CACHED_REF_PTS = None
由于光照条件、视点或运动模糊的变化,有时我们的四个参考 ArUco 标记无法在给定的输入帧中检测到。
当这种情况发生时,我们有两种行动方案:
- 从输出为空的函数返回。这种方法的好处是简单且易于实施(逻辑上也很合理)。问题是,如果 ArUco 标签在帧#1 中被发现,在帧#2 中被错过,然后在帧#3 中再次被发现,那么它会产生“闪烁”效果。
- 退回到 ArUco 标记的先前已知位置。这是缓存方式。它减少了闪烁,有助于创建无缝的增强现实体验,但如果参考标记快速移动,则效果可能会显得有点“滞后”
您决定使用哪种方法完全取决于您,但我个人喜欢缓存方法,因为它为增强现实创造了更好的用户体验。
完成了导入和变量初始化之后,让我们继续关注我们的find_and_warp 函数。
def find_and_warp(frame, source, cornerIDs, arucoDict, arucoParams,
useCache=False):
# grab a reference to our cached reference points
global CACHED_REF_PTS
# grab the width and height of the frame and source image,
# respectively
(imgH, imgW) = frame.shape[:2]
(srcH, srcW) = source.shape[:2]
# detect AruCo markers in the input frame
(corners, ids, rejected) = cv2.aruco.detectMarkers(
frame, arucoDict, parameters=arucoParams)
# if we *did not* find our four ArUco markers, initialize an
# empty IDs list, otherwise flatten the ID list
ids = np.array([]) if len(corners) != 4 else ids.flatten()
# initialize our list of reference points
refPts = []
# loop over the IDs of the ArUco markers in top-left, top-right,
# bottom-right, and bottom-left order
for i in cornerIDs:
# grab the index of the corner with the current ID
j = np.squeeze(np.where(ids == i))
# if we receive an empty list instead of an integer index,
# then we could not find the marker with the current ID
if j.size == 0:
continue
# otherwise, append the corner (x, y)-coordinates to our list
# of reference points
corner = np.squeeze(corners[j])
refPts.append(corner)
否则,我们将拐角 (x,y)-坐标添加到我们的参考列表中(第 42 行和第 43 行)。
但是如果我们找不到所有的四个参考点会怎么样呢?接下来会发生什么?
下一个代码块解决了这个问题:
# check to see if we failed to find the four ArUco markers
if len(refPts) != 4:
# if we are allowed to use cached reference points, fall
# back on them
if useCache and CACHED_REF_PTS is not None:
refPts = CACHED_REF_PTS
# otherwise, we cannot use the cache and/or there are no
# previous cached reference points, so return early
else:
return None
# if we are allowed to use cached reference points, then update
# the cache with the current set
if useCache:
CACHED_REF_PTS = refPts
# unpack our ArUco reference points and use the reference points
# to define the *destination* transform matrix, making sure the
# points are specified in top-left, top-right, bottom-right, and
# bottom-left order
(refPtTL, refPtTR, refPtBR, refPtBL) = refPts
dstMat = [refPtTL[0], refPtTR[1], refPtBR[2], refPtBL[3]]
dstMat = np.array(dstMat)
# define the transform matrix for the *source* image in top-left,
# top-right, bottom-right, and bottom-left order
srcMat = np.array([[0, 0], [srcW, 0], [srcW, srcH], [0, srcH]])
# compute the homography matrix and then warp the source image to
# the destination based on the homography
(H, _) = cv2.findHomography(srcMat, dstMat)
warped = cv2.warpPerspective(source, H, (imgW, imgH))
上面的代码,以及这个函数的其余部分,基本上与上周的相同,所以我将把这些代码块的详细讨论推迟到前面的指南。
# construct a mask for the source image now that the perspective
# warp has taken place (we'll need this mask to copy the source
# image into the destination)
mask = np.zeros((imgH, imgW), dtype="uint8")
cv2.fillConvexPoly(mask, dstMat.astype("int32"), (255, 255, 255),
cv2.LINE_AA)
# this step is optional, but to give the source image a black
# border surrounding it when applied to the source image, you
# can apply a dilation operation
rect = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
mask = cv2.dilate(mask, rect, iterations=2)
# create a three channel version of the mask by stacking it
# depth-wise, such that we can copy the warped source image
# into the input image
maskScaled = mask.copy() / 255.0
maskScaled = np.dstack([maskScaled] * 3)
第 82-84 行为一个mask 分配内存,然后我们用白色填充前景,用黑色填充背景。
对第 89 和 90 行执行膨胀操作,以创建围绕源图像的黑色边框(可选,但出于美观目的看起来不错)。
然后,我们从范围【0,255】到【0,1】缩放我们的遮罩,然后在深度方向上堆叠它,得到一个 3 通道遮罩。
最后一步是使用mask将warped图像应用到输入表面:
# copy the warped source image into the input image by
# (1) multiplying the warped image and masked together,
# (2) then multiplying the original input image with the
# mask (giving more weight to the input where there
# *ARE NOT* masked pixels), and (3) adding the resulting
# multiplications together
warpedMultiplied = cv2.multiply(warped.astype("float"),
maskScaled)
imageMultiplied = cv2.multiply(frame.astype(float),
1.0 - maskScaled)
output = cv2.add(warpedMultiplied, imageMultiplied)
output = output.astype("uint8")
# return the output frame to the calling function
return output
行 104-109 将warped 图像复制到输出frame上,然后我们返回到行 112 上的调用函数。
有关实际单应矩阵构建、warp 变换和后处理任务的更多详细信息,请参考上周的指南。
创建我们的 OpenCV 视频增强现实驱动脚本
# import the necessary packages
from pyimagesearch.augmented_reality import find_and_warp
from imutils.video import VideoStream
from collections import deque
import argparse
import imutils
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, required=True,
help="path to input video file for augmented reality")
ap.add_argument("-c", "--cache", type=int, default=-1,
help="whether or not to use reference points cache")
args = vars(ap.parse_args())
# load the ArUCo dictionary and grab the ArUCo parameters
print("[INFO] initializing marker detector...")
arucoDict = cv2.aruco.Dictionary_get(cv2.aruco.DICT_ARUCO_ORIGINAL)
arucoParams = cv2.aruco.DetectorParameters_create()
# initialize the video file stream
print("[INFO] accessing video stream...")
vf = cv2.VideoCapture(args["input"])
# initialize a queue to maintain the next frame from the video stream
Q = deque(maxlen=128)
# we need to have a frame in our queue to start our augmented reality
# pipeline, so read the next frame from our video file source and add
# it to our queue
(grabbed, source) = vf.read()
Q.appendleft(source)
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# loop over the frames from the video stream
while len(Q) > 0:
# grab the frame from our video stream and resize it
frame = vs.read()
frame = imutils.resize(frame, width=600)
# attempt to find the ArUCo markers in the frame, and provided
# they are found, take the current source image and warp it onto
# input frame using our augmented reality technique
warped = find_and_warp(
frame, source,
cornerIDs=(923, 1001, 241, 1007),
arucoDict=arucoDict,
arucoParams=arucoParams,
useCache=args["cache"] > 0)
# if the warped frame is not None, then we know (1) we found the
# four ArUCo markers and (2) the perspective warp was successfully
# applied
if warped is not None:
# set the frame to the output augment reality frame and then
# grab the next video file frame from our queue
frame = warped
source = Q.popleft()
# for speed/efficiency, we can use a queue to keep the next video
# frame queue ready for us -- the trick is to ensure the queue is
# always (or nearly full)
if len(Q) != Q.maxlen:
# read the next frame from the video file stream
(grabbed, nextFrame) = vf.read()
# if the frame was read (meaning we are not at the end of the
# video file stream), add the frame to our queue
if grabbed:
Q.append(nextFrame)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
利用 OpenCV 实现实时视频流中的增强现实
准备好使用 OpenCV 在实时视频流中执行增强现实了吗?
首先使用本教程的 【下载】 部分下载源代码和示例视频。
从那里,打开一个终端,并执行以下命令:
$ python opencv_ar_video.py --input videos/jp_trailer_short.mp4
[INFO] initializing marker detector...
[INFO] accessing video stream...
[INFO] starting video stream...
正如您从我的输出中看到的,我们是:
- 从读取帧我的相机传感器以及侏罗纪公园驻留在磁盘上的预告片视频
- 检测卡上的 ArUco 标签
- 应用透视扭曲将视频帧从侏罗纪公园预告片转换到我的相机捕捉的真实世界环境中
此外,请注意,我们的增强现实应用程序是实时运行的!
但是,有一点问题…
注意在输出帧中出现了相当多的闪烁——为什么会这样?
原因是 ArUco 标记检测并不完全“稳定”在一些帧中,所有四个标记都被检测到,而在其他帧中,它们没有被检测到。
一个理想的解决方案是确保所有四个标记都被检测到,但这并不是在所有情况下都能保证。
相反,我们可以依靠参考点缓存:
$ python opencv_ar_video.py --input videos/jp_trailer_short.mp4 --cache 1
[INFO] initializing marker detector...
[INFO] accessing video stream...
[INFO] starting video stream...
使用参考点缓存,你现在可以看到我们的结果稍微好一点。当四个 ArUco 标记在当前帧中未被检测到时,我们退回到它们在先前帧中的位置,在那里四个标记都被检测到。
另一个潜在的解决方案是利用光流来帮助参考点跟踪(但这个主题超出了本教程的范围)。
总结
在本教程中,您学习了如何使用 OpenCV 执行实时增强现实。
使用 OpenCV,我们能够访问我们的网络摄像头,检测 ArUco 标签,然后将输入图像/帧转换到我们的场景中,,所有这些都是实时运行的!
然而,这种增强现实方法的最大缺点之一是它要求我们使用标记/基准,如 ArUco 标签、AprilTags 等。
有一个活跃的增强现实研究领域叫做无标记增强现实。
有了无标记增强现实,我们不需要事先知道真实世界的环境,比如有驻留在我们视频流中的特定标记或物体。
无标记增强现实带来了更加美丽、身临其境的体验;然而,大多数无标记增强现实系统需要平坦的纹理/区域才能工作。
此外,无标记增强现实需要明显更复杂和计算成本更高的算法。
我们将在 PyImageSearch 博客的未来一组教程中介绍无标记增强现实。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
带 Tkinter 的 OpenCV
原文:https://pyimagesearch.com/2016/05/23/opencv-with-tkinter/

我跟你说实话。
我不是一个优秀的图形用户界面开发者。
从来没有,将来也不会有。
我喜欢偶尔用 HTML + CSS 创建用户界面,或者编写一个 WordPress 插件使其更具美感——但是我从来不喜欢编写成熟的 GUI。
也就是说,我会尽我最大的努力来写你,PyImageSearch 的观众们想听到的东西。在过去的几个月里,我收到了一堆电子邮件,询问 Python GUI 库,使用哪些库,更具体地说, 如何将 OpenCV 与 Tkinter 集成,以在 Tkinter 面板中显示图像。
我通常会回答:
我不是 GUI 开发人员,所以相信我,你不会想听我的建议的。但是如果你想用 Python 来构建图形用户界面,那么看看 Qt 、 Tkinter 和 Kivy (如果你想构建移动/自然用户界面的话)。
尽管如此,我最终还是收到了足够多的关于 OpenCV + Tkinter 集成的邮件,这激起了我的兴趣和我必须试一试。
在接下来的两篇博文中,我将与 Tkinter 一起玩,开发一些简单的用户界面,并与您分享我的代码/经验。我之所以在这里强调在附近,是因为这些绝不是生产应用程序(很可能)不是 GUI 开发实践的好例子。
就像我说的,我不想假装是一个 GUI 开发者——我只是想和你分享我的经验。
将 OpenCV 与 Tkinter 一起使用
在本教程中,我们将使用 Tkinter Python 库构建一个简单的用户界面。这个用户界面将允许我们点击一个按钮,触发一个文件选择器对话框来从磁盘中选择一个文件。然后我们将使用 OpenCV 加载选中的图像,执行边缘检测,最后在 GUI 中显示原始图像和边缘图。
我已经包括了下面的第一个模型的粗略线框:

Figure 1: Our first screen contains only a button to load our image from disk.
当第一次加载时,我们的应用程序只包含一个允许我们从磁盘加载图像的按钮。
单击此按钮后,我们将被允许导航我们的文件系统并选择要处理的图像。然后我们将在 GUI 中显示原始图像和边缘图。

Figure 2: After selecting an image, we’ll display both the original image and edge map side-by-side in our GUI.
Tkinter 是什么?
如果你之前没听说过 Tkinter,Tkinter 是围绕 Tcl/Tk 的一个薄薄的面向对象层。使用 Tkinter 的一个好处是,在您的系统上安装了 Tkinter 之后,您可以运行任何利用 Tcl/Tk 的 Python GUI 应用程序。
在极少数情况下,我需要为 Python 开发一个 GUI 应用程序,我倾向于使用 Qt ,但是自从我上次使用 Tkinter 以来已经有 3-4 年了,我想我应该再试一次。
安装 Tkinter
我个人很难在我的 OSX 机器上正确安装和配置 Tkinter,所以我决定恢复使用 Ubuntu/Raspbian。
注:如果你有什么好的关于在 OSX 上安装 Tkinter 和 Tcl/Tk 的教程,请在这篇博文的评论区留下链接。
当我努力在 OSX 上安装 Tkinter 时,在 Ubuntu/Raspbian 上安装却轻而易举,只需要调用apt-get:
$ sudo apt-get install python-tk python3-tk python-imaging-tk
从那里,Tkinter 顺利安装。
您还应该确保安装了一个简单的基于 Python 的图像库 Pillow ,因为 Tkinter 将需要它来在我们的 GUI 中显示图像:
$ pip install Pillow
我通过启动 Python shell 并导入 PIL/Pillow、Tkinter 和我的 OpenCV 绑定来验证我的安装:
$ python
>>> import PIL
>>> import Tkinter
>>> import cv2
>>>
注意:我假设你的系统上已经安装了 OpenCV。如果你需要帮助配置、编译和安装 OpenCV,请查看这个页面,我在这里为各种系统编译了一个 OpenCV 安装说明列表。
编写我们的 OpenCV + Tkinter 应用程序
我们现在已经准备好编写简单的 GUI 应用程序了。打开一个新文件,将其命名为tkinter_test.py,并插入以下代码:
# import the necessary packages
from Tkinter import *
from PIL import Image
from PIL import ImageTk
import tkFileDialog
import cv2
def select_image():
# grab a reference to the image panels
global panelA, panelB
# open a file chooser dialog and allow the user to select an input
# image
path = tkFileDialog.askopenfilename()
第 2-6 行导入我们需要的 Python 包。我们将需要Tkinter来访问我们的 GUI 功能,以及来自 PIL/Pillow 的Image和ImageTk类来在我们的 GUI 中显示图像。tkFileDialog允许我们浏览文件系统并选择要处理的图像。最后,我们为 OpenCV 绑定导入cv2。
第 8 行定义了我们的select_image功能。在这个函数中,我们分别抓取一个全局引用到panelA和panelB。这些是我们的图片面板 。顾名思义,图像面板是用来拍摄图像,然后将其显示在我们的 GUI 中。
第一个面板panelA,是我们将从磁盘加载的原始图像,而第二个面板panelB,是我们将要计算的边缘图。
调用第 14 行上的tkFileDialog.askopenfilename会打开一个文件选择对话框,我们可以用它来导航我们的文件系统并选择我们选择的图像。
选择图像后,我们的程序继续:
# ensure a file path was selected
if len(path) > 0:
# load the image from disk, convert it to grayscale, and detect
# edges in it
image = cv2.imread(path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edged = cv2.Canny(gray, 50, 100)
# OpenCV represents images in BGR order; however PIL represents
# images in RGB order, so we need to swap the channels
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# convert the images to PIL format...
image = Image.fromarray(image)
edged = Image.fromarray(edged)
# ...and then to ImageTk format
image = ImageTk.PhotoImage(image)
edged = ImageTk.PhotoImage(edged)
第 17 行确保选择了一个文件,并且我们没有点击“取消”按钮。假设选择了path,我们从磁盘加载图像,将其转换为灰度,然后使用 Canny 边缘检测器检测边缘(第 20-22 行)。为了简单起见,我将阈值硬编码到 Canny 边缘检测器中,但是您也可以使用imutils包中的auto_canny函数来计算边缘图,而不需要提供任何参数。点击此处可了解更多关于 auto-canny 功能的信息。
为了在 Tkinter GUI 中显示我们的图像,我们首先需要更改格式。首先,OpenCV 以 BGR 顺序表示图像;然而,PIL/枕头以 RGB 顺序表示图像,因此我们需要反转通道的顺序(第 26 行)。
从那里,我们可以将image和edged从 OpenCV 格式转换成 PIL/枕头格式(第 29 行和第 30 行)。然后最终将 PIL/枕头图像转换为ImageTk格式(第 33 行和第 34 行)。
我们现在准备将图像添加到我们的 GUI 中:
# if the panels are None, initialize them
if panelA is None or panelB is None:
# the first panel will store our original image
panelA = Label(image=image)
panelA.image = image
panelA.pack(side="left", padx=10, pady=10)
# while the second panel will store the edge map
panelB = Label(image=edged)
panelB.image = edged
panelB.pack(side="right", padx=10, pady=10)
# otherwise, update the image panels
else:
# update the pannels
panelA.configure(image=image)
panelB.configure(image=edged)
panelA.image = image
panelB.image = edged
如果各个面板都是None,我们需要初始化它们(第 37-46 行)。首先,我们为每张图片创建一个Label实例。然后,我们把 特护 纳入panel.image = image。
为什么这如此重要?
防止 Python 的垃圾收集例程删除图像!
如果不存储这个引用,我们的图像将被删除,我们将无法在屏幕上显示它。
否则,我们可以假设我们的图像面板已经被初始化了(第 49-54 行)。在这种情况下,我们需要做的就是在每个面板上调用configure,然后更新对图像对象的引用。
最后一步是编写实际初始化、创建和启动 GUI 进程的代码:
# initialize the window toolkit along with the two image panels
root = Tk()
panelA = None
panelB = None
# create a button, then when pressed, will trigger a file chooser
# dialog and allow the user to select an input image; then add the
# button the GUI
btn = Button(root, text="Select an image", command=select_image)
btn.pack(side="bottom", fill="both", expand="yes", padx="10", pady="10")
# kick off the GUI
root.mainloop()
第 57 行初始化root Tkinter 窗口,而第 58 和 59 行初始化我们的两个图像面板。
然后我们创建一个按钮,并将其添加到 GUI 的第 64 行和第 65 行。当点击时,这个按钮将触发我们的文件选择器,允许我们浏览我们的文件系统并从磁盘中选择一个图像。
最后,行 68 开始 GUI 的实际主循环。
运行我们的 OpenCV + Tkinter GUI
要运行我们的 OpenCV + Tkinter 应用程序,只需执行以下命令:
$ python tkinter_test.py
首先,我们的 GUI 应该包含的只是我们单击以从磁盘中选择图像的按钮:

Figure 3: At startup, our GUI only contains a single button, that when clicked, will prompt us to select a file from disk.
单击该按钮后,我们会看到一个文件选择器:

Figure 4: The file chooser allows us to navigate our file system and select an image to process.
然后,我们可以导航到想要计算边缘的图像文件,并单击“打开”按钮:

Figure 5: We can select an image to process by first highlighting the image and then clicking the “Open” button.
在我们的图像被选中后,使用 OpenCV 计算边缘图,原始图像和边缘图都被添加到我们的 Tkinter GUI 中:
Figure 6: On the left, we have the original, unprocessed image. Then, on the right, we have the edge map.
当然,我们也可以对不同的图像重复这个过程:

Figure 7: Loading an image, computing edges using the Canny edge detector, and then displaying the result using Tkinter and OpenCV.
让我们做最后一个例子:

Figure 8: Displaying images in Tkinter using OpenCV.
摘要
在这篇博文中,我演示了如何构建一个非常简单的 GUI 应用程序,它集成了用于计算机视觉的 OpenCV 和用于使用 Python 编程语言开发 GUI 的 Tkinter 库。
我将是第个说我是而不是GUI 开发者的人,我也没有成为一名 GUI 开发者的打算。这段代码可能远非完美——这没关系。我只是想与你分享我的经验,希望它能帮助其他更投入、更高级的 GUI 开发人员学习如何将 OpenCV 与 Tkinter 集成。
尽管如此,下周我将在 OpenCV 和 Tkinter 上写第二篇博文, 这一次构建一个“Photo Booth”应用程序,它可以访问我们的网络摄像头,在我们的 GUI 上显示(实时)流,并且单击一个按钮就可以将流的快照保存到磁盘。
为了在这篇博文发表时得到通知,请务必在下面的表格中输入您的电子邮件地址!【T2
树莓 Pi 上的 OpenVINO、OpenCV 和 Movidius NCS
原文:https://pyimagesearch.com/2019/04/08/openvino-opencv-and-movidius-ncs-on-the-raspberry-pi/
在本教程中,您将了解如何利用 OpenCV 的 OpenVINO 工具包在 Raspberry Pi 上进行更快的深度学习推理。
Raspberry Pis 很棒——我喜欢高质量的硬件和围绕设备建立的支持社区。
也就是说,对于深度学习来说,当前的 Raspberry Pi 硬件天生就是资源受限的,你将很幸运地从大多数最先进的模型(尤其是对象检测和实例/语义分割)中获得超过几个 FPS(单独使用 RPi CPU)。
从我以前的帖子中我们知道,英特尔的 Movidius 神经计算棒允许通过插入 USB 插座的深度学习协处理器进行更快的推断:
自 2017 年以来,Movidius 团队一直在努力研究他们的无数处理器和消费级 USB 深度学习棒。
附带的 API 的第一个版本运行良好,展示了 Myriad 的强大功能,但仍有许多不足之处。
紧接着,Movidius APIv2 发布,受到 Movidius + Raspberry Pi 社区的欢迎。它比 APIv1 更容易/更可靠,但也存在一些问题。
但是现在,与 Movidius NCS、尤其是 OpenCV 的合作变得前所未有的容易。
了解 OpenVINO,这是一个英特尔硬件优化计算机视觉库,旨在取代 V1 和 V2 API。
英特尔转而使用 OpenVINO 软件支持 Movidius 硬件,这使得 Movidius 闪耀着金属般的蓝色光辉。
OpenVINO 使用起来非常简单——只需设置目标处理器(一个函数调用)并让 OpenVINO 优化的 OpenCV 处理剩下的事情。
但问题依然存在:
如何在树莓 Pi 上安装 OpenVINO?
今天我们将学习这一点,以及一个实用的对象检测演示(剧透警告:现在使用 Movidius 协处理器非常简单)。
更新 2020-04-06: 本教程有大量更新,以确保与 OpenVINO 4.2.0 的兼容性。
要了解如何在 Raspberry Pi 上安装 OpenVINO(并使用 Movidius 神经计算棒执行对象检测),只需遵循本教程!
树莓 Pi 上的 OpenVINO、OpenCV 和 Movidius NCS
在这篇博文中,我们将讨论三个主要话题。
- 首先,我们将了解什么是 OpenVINO,以及它是如何为树莓派带来一个非常受欢迎的范式转变。
- 然后我们将介绍如何在您的 Raspberry Pi 上安装 OpenCV 和 OpenVINO。
- 最后,我们将使用 OpenVINO、OpenCV 和 Movidius NCS 开发一个实时对象检测脚本。
注: 我的博客上有很多树莓派的安装指南,大部分与 Movidius 无关。开始之前,请务必查看我的 OpenCV 安装指南 页面上的可用安装教程,并选择最符合您需求的一个。
让我们开始吧。
什么是 OpenVINO?

Figure 1: The Intel OpenVINO toolkit optimizes your computer vision apps for Intel hardware such as the Movidius Neural Compute Stick. Real-time object detection with OpenVINO and OpenCV using Raspberry Pi and Movidius NCS sees a significant speedup. (source)
英特尔的 OpenVINO 是一个针对英特尔硬件产品组合优化计算的加速库。
OpenVINO 支持英特尔 CPU、GPU、FPGAs 和 vpu。
你所依赖的深度学习库,比如 TensorFlow、Caffe 和 mxnet,都是由 OpenVINO 支持的。
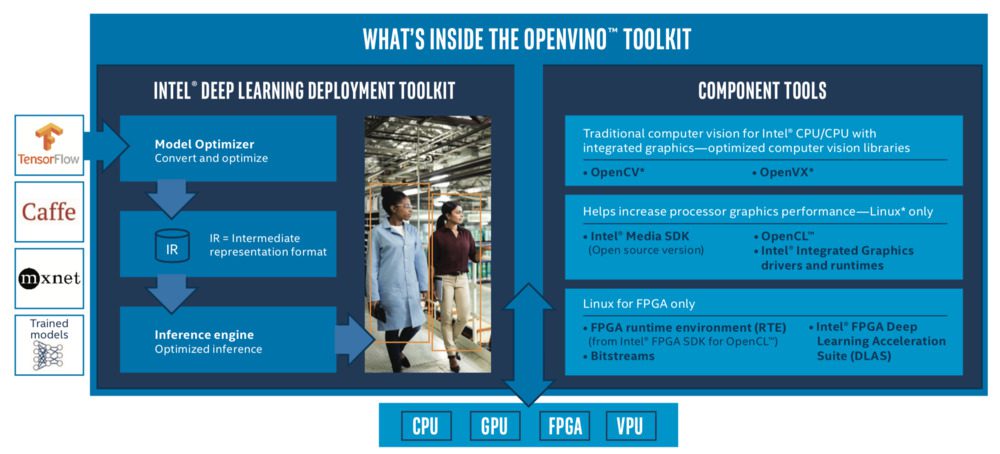
Figure 2: The Intel OpenVINO Toolkit supports intel CPUs, GPUs, FPGAs, and VPUs. TensorFlow, Caffe, mxnet, and OpenCV’s DNN module all are optimized and accelerated for Intel hardware. The Movidius line of vision processing units (VPUs) are supported by OpenVINO and pair well with the Raspberry Pi. (source: OpenVINO Product Brief)
英特尔甚至优化了 OpenCV 的 DNN 模块,以支持其深度学习硬件。
事实上,许多较新的智能相机使用英特尔的硬件和 OpenVINO 工具包。OpenVINO 是边缘计算和物联网的最佳选择——它使资源受限的设备(如 Raspberry Pi)能够与 Movidius 协处理器一起工作,以对现实世界应用有用的速度执行深度学习。
我们将在树莓 Pi 上安装 OpenVINO,这样它就可以在下一节中与 Movidius VPU(视觉处理单元)一起使用。
请务必阅读 OpenVINO 产品简介 PDF,了解更多信息。
在树莓 Pi 上安装 OpenVINO 的优化 OpenCV
在这一节中,我们将介绍在您的 Raspberry Pi 上安装 OpenCV 和 OpenVINO 所需的先决条件和所有步骤。
在开始之前,请务必通读这一节,以便熟悉所需的步骤。
我们开始吧。
硬件、假设和先决条件
在本教程中,我将假设您拥有以下硬件:
- 树莓 4B 或 3B+ (运行 Raspbian Buster)
- Movidius NCS 2 (或 Movidius NCS 1)
- 皮卡梅拉·V2(或 USB 网络摄像头)
- 32GB microSD 卡带 Raspbian 弹力刚闪
- HDMI 屏幕+键盘/鼠标(至少对于初始 WiFi 配置)
- 5V 电源(我推荐 2.5A 电源,因为 Movidius NCS 很耗电)
如果你没有新刻录的 Raspbian Stretch 的 microSD,你可以在这里下载。我建议完全安装:
Figure 3: Download Raspbian Buster for OpenVINO on your Raspberry Pi and Movidius NCS.
从那里,使用 balenaEtcher (或合适的替代物)来擦写卡片。【T2
准备好之后,将 microSD 卡插入您的 Raspberry Pi 并启动它。
输入您的 WiFi 凭据,并启用 SSH、VNC 和摄像头接口。
从这里开始,您将需要以下之一:
- 物理访问 您的 Raspberry Pi,以便您可以打开终端并执行命令
- 通过 SSH 或 VNC 远程访问
我将通过 SSH 完成本教程的大部分内容,但是只要您可以访问终端,您就可以轻松地跟着做。
宋承宪不会吗? 如果您在网络上看到您的 Pi,但无法对其进行 ssh,您可能需要启用 SSH。这可以通过 Raspberry Pi 桌面偏好菜单或使用raspi-config命令轻松完成。
更改设置并重新启动后,您可以使用本地主机地址直接在 Pi 上测试 SSH。
打开一个终端,输入ssh pi@127.0.0.1看看它是否工作。要从另一台计算机进行 SSH,您需要 Pi 的 IP 地址——您可以通过查看路由器的客户端页面或运行ifconfig来确定 Pi 本身的 IP 地址。
你的树莓 Pi 键盘布局给你带来问题了吗? 进入 Raspberry Pi 桌面首选项菜单,更改你的键盘布局。我使用标准的美国键盘布局,但是你会想要选择一个适合你的。
步骤 1:在您的 Raspberry Pi 上扩展文件系统
要启动 OpenVINO party,启动您的 Raspberry Pi 并打开一个 SSH 连接(或者使用带有键盘+鼠标的 Raspbian 桌面并启动一个终端)。
如果您刚刚刷新了 Raspbian Stretch,我总是建议您首先检查以确保您的文件系统正在使用 microSD 卡上的所有可用空间。
要检查您的磁盘空间使用情况,请在您的终端中执行df -h命令并检查输出:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 30G 4.2G 24G 15% /
devtmpfs 434M 0 434M 0% /dev
tmpfs 438M 0 438M 0% /dev/shm
tmpfs 438M 12M 427M 3% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 438M 0 438M 0% /sys/fs/cgroup
/dev/mmcblk0p1 42M 21M 21M 51% /boot
tmpfs 88M 0 88M 0% /run/user/1000
如您所见,我的 Raspbian 文件系统已经自动扩展到包括所有 32GB 的 micro-SD 卡。这表现在大小是 30GB(接近 32GB),而我有 24GB 可用(15%的使用率)。
如果你发现你没有使用你全部的存储卡容量,你可以在下面找到如何扩展文件系统的说明。
在您的终端中打开 Raspberry Pi 配置:
$ sudo raspi-config
然后选择【高级选项】菜单项:
Figure 4: Selecting the “Advanced Options” from the raspi-config menu to expand the Raspbian file system on your Raspberry Pi is important before installing OpenVINO and OpenCV. Next, we’ll actually expand the filesystem.
接着选择“扩展文件系统”:
Figure 5: The Raspberry Pi “Expand Filesystem” menu allows us to take advantage of our entire flash memory card. This will give us the space necessary to install OpenVINO, OpenCV, and other packages.
一旦出现提示,你应该选择第一个选项,“A1。展开文件系统" , 点击键盘上的回车键 ,向下箭头到<【完成】>按钮,然后重启你的 Pi——会提示你重启。或者,您可以从终端重新启动:
$ sudo reboot
确保再次运行df -h命令来检查您的文件系统是否被扩展。
第二步:回收你的树莓派的空间
在 Raspberry Pi 上获得更多空间的一个简单方法是删除 LibreOffice 和 Wolfram engine 来释放一些空间:
$ sudo apt-get purge wolfram-engine
$ sudo apt-get purge libreoffice*
$ sudo apt-get clean
$ sudo apt-get autoremove
移除 Wolfram 引擎和 LibreOffice 后,您可以回收近 1GB 的空间!
步骤 3:在你的 Raspberry Pi 上安装 OpenVINO + OpenCV 依赖项
这一步显示了我在每个 OpenCV 系统上安装的一些依赖项。虽然您很快就会看到 OpenVINO 已经编译好了,但我还是建议您继续安装这些包,以防您在以后的任何时候从头开始编译 OpenCV。
让我们更新我们的系统:
$ sudo apt-get update && sudo apt-get upgrade
然后安装开发者工具包括 CMake :
$ sudo apt-get install build-essential cmake unzip pkg-config
接下来,是时候安装一系列图像和视频库了——这些是能够处理图像和视频文件的关键:
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
从那里,让我们安装 GTK,我们的 GUI 后端:
$ sudo apt-get install libgtk-3-dev
现在让我们安装一个软件包,它可能有助于减少 GTK 警告:
$ sudo apt-get install libcanberra-gtk*
星号确保我们将抓住手臂特定的 GTK。这是必须的。
现在我们需要两个包含 OpenCV 数值优化的包:
$ sudo apt-get install libatlas-base-dev gfortran
最后,让我们安装 Python 3 开发头:
$ sudo apt-get install python3-dev
一旦安装了所有这些先决条件,您就可以进入下一步。
第四步:为你的树莓 Pi 下载并解压 OpenVINO

Figure 6: Download and install the OpenVINO toolkit for Raspberry Pi and Movidius computer vision apps (source: Intel’s OpenVINO Product Brief).
从现在开始,我们的安装说明主要基于英特尔的 Raspberry Pi OpenVINO 指南。有几个“陷阱”,这就是为什么我决定写一个指南。我们还将使用 PyImageSearch 读者所期望的虚拟环境。
我们的下一步是下载 OpenVINO。
让我们导航到我们的主文件夹并创建一个新目录
$ cd ~
从那里开始,通过wget获取 OpenVINO 工具包:
$ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.1/l_openvino_toolkit_runtime_raspbian_p_2020.1.023.tgz
更新 2020-04-06: 下载网址有变化;新的 URL 会反映出来。
一旦您成功下载了 OpenVINO toolkit,您可以使用以下命令对其进行解归档:
$ tar -xf l_openvino_toolkit_runtime_raspbian_p_2020.1.023.tgz
...
$ mv l_openvino_toolkit_runtime_raspbian_p_2020.1.023 openvino
步骤 5:在您的树莓 Pi 上配置 OpenVINO
让我们用nano来编辑我们的~/.bashrc。我们将添加一行代码,在您每次调用 Pi 终端时加载 OpenVINO 的setupvars.sh。继续打开文件:
$ nano ~/.bashrc
滚动到底部,添加以下几行:
# OpenVINO
source ~/openvino/bin/setupvars.sh
保存并退出 nano 文本编辑器。
然后,继续source您的~/.bashrc文件:
$ source ~/.bashrc
步骤 6:在 Raspberry Pi 上为你的 Movidius NCS 和 OpenVINO 配置 USB 规则
OpenVINO 要求我们设置自定义 USB 规则。这很简单,让我们开始吧。
首先,输入以下命令将当前用户添加到 Raspbian“users”组:
$ sudo usermod -a -G users "$(whoami)"
然后注销并重新登录。如果你在 SSH 上,你可以输入exit,然后重新建立你的 SSH 连接。通过sudo reboot now重启也是一个选项。
回到终端后,运行以下脚本来设置 USB 规则:
$ cd ~
$ sh openvino/install_dependencies/install_NCS_udev_rules.sh
步骤 7:在 Raspberry Pi 上创建一个 OpenVINO 虚拟环境
让我们抓取并安装 pip,一个 Python 包管理器。
要安装 pip,只需在终端中输入以下内容:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
我们将通过 OpenCV 和 OpenVINO 利用虚拟环境进行 Python 开发。
如果你不熟悉虚拟环境,请花点时间看看 RealPython 上的这篇文章,或者读一下 PyImageSearch 上的这篇博文的前半部分。
虚拟环境将允许您在自己的系统上运行独立的、隔离的 Python 环境。今天我们将只设置一个环境,但是您可以轻松地为每个项目设置一个环境。
现在让我们继续安装virtualenv和virtualenvwrapper——它们支持 Python 虚拟环境:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/get-pip.py ~/.cache/pip
为了完成这些工具的安装,我们需要再次更新我们的~/.bashrc:
$ nano ~/.bashrc
然后添加以下几行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
VIRTUALENVWRAPPER_ENV_BIN_DIR=bin
Figure 7: Our Raspberry Pi ~/.bashrc profile has been updated to accommodate OpenVINO and virtualenvwrapper. Now we’ll be able to create a virtual environment for Python packages.
或者,您可以通过 bash 命令直接附加这些行:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.bashrc
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bashrc
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.bashrc
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
$ echo "VIRTUALENVWRAPPER_ENV_BIN_DIR=bin" >> ~/.bashrc
接下来,获取~/.bashrc概要文件:
$ source ~/.bashrc
现在让我们创建一个虚拟环境来存放 OpenVINO、OpenCV 和相关的包:
$ mkvirtualenv openvino -p python3
这个命令简单地创建了一个名为openvino的 Python 3 虚拟环境。
你可以(也应该)随心所欲地命名你的环境——我喜欢让它们简洁明了,同时提供足够的信息,以便我记住它们的用途。
步骤 8:将软件包安装到您的 OpenVINO 环境中
让我们安装一些今天演示脚本所需的包
$ workon openvino
$ pip install numpy
$ pip install "picamera[array]"
$ pip install imutils
现在我们已经在openvino虚拟环境中安装了这些包,它们只在openvino环境中可用。这是您处理 OpenVINO 项目的隔离区域(我们在这里使用 Python 虚拟环境,所以我们不会冒险破坏您的 Python 系统安装)。
Caffe、TensorFlow 和 mxnet 的附加软件包可以使用 pip 通过 requirements.txt 文件安装。您可以在英特尔文档链接的处了解更多信息。这是今天教程要求的 不是 。
步骤 9:在你的 Raspberry Pi 上测试你的 OpenVINO 安装
在我们尝试 OpenVINO 示例之前,让我们做一个快速的健全性测试,看看 OpenCV 是否准备好了。
打开终端并执行以下操作:
$ workon openvino
$ source ~/openvino/bin/setupvars.sh
$ python
>>> import cv2
>>> cv2.__version__
'4.2.0-openvino'
>>> exit()
第一个命令激活我们的 OpenVINO 虚拟环境。第二个命令用 OpenVINO 设置 Movidius NCS,非常重要。从那里,我们在环境中启动 Python 3 二进制文件并导入 OpenCV。
OpenCV 的版本表明是 OpenVINO 优化安装!
推荐:创建一个 shell 脚本来启动 OpenVINO 环境
在这一节中,我们将创建一个 shell 脚本,就像我的 预配置和预安装的 Raspbian 上的脚本一样。imgT3。
打开一个名为start_openvino.sh的新文件,并将它放在您的~/目录中。插入以下几行:
#!/bin/bash
echo "Starting Python 3.7 with OpenCV-OpenVINO 4.2.0 bindings..."
source ~/openvino/bin/setupvars.sh
workon openvino
保存并关闭文件。
从现在开始,您可以用一个简单的命令来激活您的 OpenVINO 环境(与上一步中的两个命令相反:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.2.0 bindings...
基于 Raspberry Pi 和 OpenVINO 的实时目标检测
安装 OpenVINO 非常容易,甚至不需要编译 OpenCV。英特尔团队做得非常好!
现在让我们使用 OpenVINO 让 Movidius 神经计算棒工作。
为了便于比较,我们将运行带有的 MobileNet SSD 对象检测器和不带m ovidius 的来测试我们的 FPS。我们将这些值与之前使用 Movidius NCS APIv1 ( 我在 2018 年初写过的非 OpenVINO 方法)的结果进行比较。
我们开始吧!
项目结构
去抢今天博文的 【下载】 。
一旦解压了 zip 文件,就可以使用tree命令来检查项目目录:
$ tree
.
├── MobileNetSSD_deploy.caffemodel
├── MobileNetSSD_deploy.prototxt
├── openvino_real_time_object_detection.py
└── real_time_object_detection.py
0 directories, 3 files
我们的 MobileNet SSD 对象检测器文件包括。caffemodel 和. prototxt.txt 文件。这些都是经过预先训练的(我们今天不会训练 MobileNet SSD)。
我们将回顾一下openvino_real_time_object_detection.py脚本,并将其与最初的实时对象检测脚本(real_time_object_detection.py)进行比较。
利用 OpenVINO、Movidius NCS 和 Raspberry Pi 进行实时对象检测
为了通过 Movidius 在 Raspberry Pi 上展示 OpenVINO 的强大功能,我们将执行实时深度学习对象检测。
Movidius/Myriad 协处理器将执行实际的深度学习推理,减少 Pi 的 CPU 负载。
我们仍将使用 Raspberry Pi CPU 来处理结果,并告诉 Movidius 该做什么,但我们将深度学习推理保留给 Myriad,因为它的硬件已针对深度学习推理进行了优化和设计。
正如之前在中讨论的“什么是 OpenVINO?”部分,OpenVINO with OpenCV 允许我们在使用 OpenCV“DNN”模块时指定用于推理的处理器。
事实上,使用 Movidius NCS Myriad 处理器只需要一行代码(典型的)。
从那里开始,剩下的代码都是一样的!
在 PyImageSearch 博客上,我提供了所有 Python 脚本的详细介绍。
这是我决定偏离我的典型格式的少数帖子之一。
这个帖子首先是一个安装+配置的帖子。因此,我将跳过细节,而是通过突出显示插入到之前的博客文章(提供了所有细节)中的新代码行来展示 OpenVINO 的威力。
如果你想通过深度学习和 OpenCV 的 实时对象检测进入杂草中,请查看那个帖子,在那里我在仅用 100 行代码演示了使用 OpenCV 的 DNN 模块的概念。
今天,我们只添加一行执行计算的代码(和一个注释+空白行)。这就带来了新总到 103 行代码 没有使用之前复杂的 Movidius APIv1 ( 215 行代码)。
如果这是你第一次尝试 OpenVINO,我想你会和我一样惊讶和高兴,当我知道它有多简单的时候。
让我们来学习一下为了适应 OpenCV 和 Movidius 的 OpenVINO 的 API 所必须做的改变。
继续打开一个名为openvino_real_time_object_detection.py的文件,插入以下几行,密切注意的第 33-35 行(用黄色突出显示):
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
ap.add_argument("-u", "--movidius", type=bool, default=0,
help="boolean indicating if the Movidius should be used")
args = vars(ap.parse_args())
# initialize the list of class labels MobileNet SSD was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# specify the target device as the Myriad processor on the NCS
net.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
# initialize the video stream, allow the cammera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
fps = FPS().start()
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 0.007843, (300, 300), 127.5)
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# `detections`, then compute the (x, y)-coordinates of
# the bounding box for the object
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the prediction on the frame
label = "{}: {:.2f}%".format(CLASSES[idx],
confidence * 100)
cv2.rectangle(frame, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
第 33-35 行(以黄色突出显示)是新增的。但其中只有一句是有趣的。
在第 35 行,我们通过net.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)告诉 OpenCV 的 DNN 模块使用 Myriad 协处理器。
Myriad 处理器内置于 Movidius 神经计算棒中。如果你在一个嵌入了 Myriad 芯片的设备上运行 OpenVINO + OpenCV,你也可以使用同样的方法。
关于代码的详细解释,请务必参考本帖。
此外,请务必参考 2018 年初的这篇 Movidius APIv1 博文,在这篇博文中,我演示了使用 Movidius 和 Raspberry Pi 进行对象检测。令人难以置信的是,以前的 Movidius API 需要 215 行复杂得多的代码,而使用 OpenVINO 只需要 103 行简单得多的代码。
我认为这些行号差异在降低复杂性、时间和开发成本节约方面不言自明, 但是实际结果是什么呢? 奥本维诺和莫维奇的速度有多快?
让我们在下一节中找出答案。
OpenVINO 对象检测结果

Figure 8: Object detection with OpenVINO, OpenCV, and the Raspberry Pi.
要运行今天的脚本,首先,您需要获取与这篇文章相关的 【下载】 。
从那里,解压缩 zip 并导航到目录。
使用上面推荐的方法激活您的虚拟环境:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.2.0 bindings...
要使用 OpenVINO 执行对象检测,只需执行以下命令:
$ python openvino_real_time_object_detection.py
--prototxt MobileNetSSD_deploy.prototxt \
--model MobileNetSSD_deploy.caffemodel
[INFO] loading model...
[INFO] starting video stream...
[INFO] elasped time: 55.35
[INFO] approx. FPS: 8.31
如你所见,我们将在大约一分钟内达到 8.31FPS 。
我收集了使用 MobileNet SSD 的其他结果,如下表所示:

Figure 9: A benchmark comparison of the MobileNet SSD deep learning object detector using OpenVINO with the Movidius Neural Compute Stick.
OpenVINO 和 Movidius NCS 2 的速度非常快,是前几个版本的巨大加速。
令人惊讶的是,与仅使用 RPi 3B+ CPU(无 Movidius 协处理器)相比,结果提高了 8 倍以上。
最右边的两列(浅蓝色列 3 和 4)显示了 NCS1 和 NCS2 之间的 OpenVINO 比较。
请注意,第二栏的统计数据是 3B 的零售物价指数(不是 3B+)。它是在 2018 年 2 月使用以前的 API 和以前的 RPi 硬件拍摄的。
那么,下一步是什么?

Figure 10: Check out my new book, Raspberry Pi for Computer Vision to learn about computer vision and deep learning on embedded and internet of things (IoT) devices.
我写了一本新书,在资源受限的设备上最大化计算机视觉+深度学习的能力,比如 Raspberry Pi 单板计算机(SBC)。
在里面,您将使用我多年来在 Raspberry Pi、Intel Movidius NCS、Google Coral EdgeTPU、NVIDIA Jetson Nano 等计算机视觉领域积累的技术来学习和发展您的技能。
这本书涵盖了嵌入式计算机视觉和深度学习的 40 多个项目(包括 60 多个章节)。
一些突出的项目包括:
- 交通计数和车速检测
- 实时人脸识别
- 建立课堂考勤系统
- 自动手势识别
- 白天和夜间野生动物监测
- 安全应用
- 资源受限设备上的深度学习分类、物体检测、和人体姿态估计
- …还有更多!
作为奖励,包括的是 预配置的 Raspbian。img 文件 (针对树莓 Pi 4B/3B+/3B 和树莓 Pi Zero W)和 预配置的 Jetson Nano。img 文件 (针对 NVIDIA Jetson Nano A02/B01),这样您就可以跳过繁琐的安装问题,进入有趣的部分(代码和部署)。
如果你和我一样兴奋,请通过点击此处获取免费目录:
故障排除和常见问题(FAQ)
在你的 Raspberry Pi 上安装 OpenCV 和 OpenVINO 遇到错误了吗?
不要变得沮丧。
第一次在你的 Raspberry Pi 上安装这个软件时,你会感到非常沮丧。我最不希望你做的事就是放弃!
这里有一些常见的问题和答案——一定要阅读它们,看看它们是否适用于你。
问:如何将操作系统闪存到我的 Raspberry Pi 存储卡上?
**A. 我推荐你:
- 拿个 32GB 的内存卡。SanDisk 32GB 98MB/s microSD 卡的效果非常好,是我推荐的。
- Flash Raspbian 用蚀刻机对卡片进行拉伸。大多数主要操作系统都支持 Etcher。
- 将卡片插入你的树莓派,从这篇博文中的“假设”和“第一步”部分开始。
Q. 我能用 Python 2.7 吗?
A. Python 2.7 到达2020 年 1 月 1 日日落。我不建议使用它。
Q. 为什么我不能直接 apt-get 安装 OpenCV 并有 OpenVINO 支持?
A. 不惜一切代价避免这个【解决方案】即使它可能有效。首先,这种方法可能不会安装 OpenVINO,直到它更受欢迎。其次,apt-get 不适合虚拟环境,而且您无法控制编译和构建。
*q .mkvirtualenv和workon命令产生“命令未找到错误”。我不确定下一步该做什么。
A. 你会看到这个错误消息的原因有很多,都来自于步骤#4:
- 首先,确保你已经使用
pip软件包管理器正确安装了virtualenv和virtualenvwrapper。通过运行pip freeze进行验证,并确保您看到virtualenv和virtualenvwrapper都在已安装包列表中。 - 您的
~/.bashrc文件可能有错误。检查您的~/.bashrc文件的内容,查看正确的export和source命令是否存在(检查步骤#4 中应该附加到~/.bashrc的命令)。 - 你可能忘记了你的 T1。确保编辑完
source ~/.bashrc后运行它,以确保你可以访问mkvirtualenv和workon命令。
问 当我打开一个新的终端,注销,或者重启我的树莓派,我无法执行mkvirtualenv或者workon命令。
A. 如果你在 Raspbian 桌面上,很可能会出现这种情况。由于某种原因,当您启动终端时加载的默认概要文件并不包含~/.bashrc文件。请参考上一个问题的 #2 。通过 SSH,你可能不会碰到这种情况。
Q. 当我尝试导入 OpenCV 时,遇到了这个消息:Import Error: No module named cv2。
发生这种情况有几个原因,不幸的是,很难诊断。我推荐以下建议来帮助诊断和解决错误:
1. 使用workon openvino和source setupvars.sh命令确保您的openvino虚拟环境处于活动状态。如果这个命令给你一个错误,然后验证virtualenv和virtualenvwrapper是否正确安装。
2. 尝试在您的openvino虚拟环境中研究site-packages目录的内容。你可以在~/.virtualenvs/openvino/lib/python3.5/site-packages/中找到site-packages目录。确保(1)在site-packages目录中有一个cv2符号链接目录,并且(2)它被正确地符号链接。
3. 务必按照步骤#6** 中的演示对cv2*.so文件进行find。
问 如果我的问题没有列在这里怎么办?
A. 请在下方留言或发邮件给我。如果你在下面发表评论,请注意代码在评论表格中格式不好,我可能不得不通过电子邮件回复你。
寻找更多免费的 OpenVINO 内容?
我在 PyImageSearch 上有一些英特尔 Movidius / OpenVINO 博客文章供您欣赏。
摘要
今天,我们了解了英特尔的 OpenVINO 工具包,以及如何使用它来提高 Raspberry Pi 上的深度学习推理速度。
您还了解了如何在 Raspberry Pi 上安装 OpenVINO 工具包,包括 OpenCV 的 OpenVINO 优化版本。
然后,我们运行了一个简单的 MobileNet SSD 深度学习对象检测模型。只需要一行代码就可以将目标设备设置到 Movidius stick 上的 Myriad 处理器。
我们还展示了 Movidius NCS + OpenVINO 的速度相当快,显著地超过了 Raspberry Pi 的 CPU 上的对象检测速度。
如果你有兴趣了解更多关于如何在 Raspberry Pi 上构建真实世界的计算机视觉+深度学习项目,一定要看看我的新书,Raspberry Pi for Computer Vision。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中留下您的电子邮件!******
用 find_min_global 优化 dlib 形状预测精度
原文:https://pyimagesearch.com/2020/01/13/optimizing-dlib-shape-predictor-accuracy-with-find_min_global/

在本教程中,您将学习如何使用 dlib 的find_min_global函数来优化 dlib 的形状预测器的选项和超参数,从而生成更精确的模型。
几周前,我发表了一个关于使用 dlib 来训练定制形状预测器的两部分系列:
- 第一部分: 训练一个自定义的 dlib 形状预测器
- 第二部分: 调整 dlib 形状预测超参数以平衡速度、精度和模型大小
当我在社交媒体上发布第一篇帖子时,dlib 的创建者 Davis King 插话并建议我演示如何使用 dlib 的find_min_global函数来优化形状预测器超参数:
Figure 1: Dlib’s creator and maintainer, Davis King, suggested that I write content on optimizing dlib shape predictor accuracy with find_min_global.
我喜欢这个想法,并立即开始编写代码和收集结果。
今天,我很高兴分享关于训练 dlib 形状预测器和优化其超参数的奖励指南。
我希望你喜欢它!
要了解如何使用 dlib 的find_min_global函数来优化形状预测超参数,请继续阅读!
用find_min_global优化 dlib 形状预测精度
在本教程的第一部分,我们将讨论 dlib 的find_min_global函数,以及如何使用它来优化形状预测器的选项/超参数。
我们还将把find_min_global与标准网格搜索进行比较和对比。
接下来,我们将讨论本教程将使用的数据集,包括回顾项目的目录结构。
然后,我们将打开代码编辑器,通过实现三个 Python 脚本来动手实践,包括:
- 配置文件。
- 用于通过
find_min_global优化超参数的脚本。 - 一个脚本,用于获取通过
find_min_global找到的最佳超参数,然后使用这些值训练一个最佳形状预测器。
我们将用一个简短的讨论来结束这篇文章,讨论什么时候应该使用find_min_global而不是执行标准的网格超参数搜索。
我们开始吧!
dlib 的find_min_global函数是做什么的?我们如何使用它来调整形状预测选项?
视频来源: 一种值得使用的全局优化算法 作者:戴维斯·金
几周前,你学习了如何使用系统的网格搜索来调整 dlib 的形状预测器选项。
这种方法足够好,但问题是网格搜索不是一个真正的优化器!
相反,我们硬编码我们想要探索的超参数值,网格搜索计算这些值的所有可能组合,然后逐个探索它们。
网格搜索在计算上是浪费的,因为算法花费了宝贵的时间和 CPU 周期来探索超参数组合,这些组合将永远不会产生最佳可能结果。
如果我们可以迭代地调整我们的选项,确保每次迭代我们都在增量地改进我们的模型,这不是更有优势吗?
事实上,这正是 dlib find_min_global函数的作用!
dlib 库的创建者 Davis King记录了他与超参数调整算法的斗争,包括:
- 猜测和检查:专家使用他的直觉和以前的经验来手动设置超参数,运行算法,检查结果,然后使用结果来进行有根据的猜测,以确定下一组要探索的超参数将是什么。
- 网格搜索:硬编码你要测试的所有可能的超参数值,计算这些超参数的所有可能的组合,然后让计算机全部测试,一个一个测试。
- 随机搜索:对您想要探索的超参数的上限和下限/范围进行硬编码,然后允许计算机在这些范围内对超参数值进行随机采样。
- 贝叶斯优化:黑盒算法的全局优化策略。这种方法通常比原始算法本身需要调整更多的超参数。相比之下,你最好使用“猜测和检查”策略,或者通过网格搜索或随机搜索来解决问题。
- 具有良好初始猜测的局部优化:这种方法很好,但仅限于找到局部最优,不能保证它会找到全局最优。
最终,Davis 偶然发现了马尔赫比和瓦亚蒂斯 2017 年的论文,lip schitz 函数 的全局优化,然后他通过find_min_global函数将其实现到 dlib 库中。
与几乎不可能调整的贝叶斯方法和不能保证全局最优解的局部优化方法不同,马尔赫比和瓦亚蒂斯方法是无参数的和可证明是正确的,用于寻找一组最大化/最小化特定函数的值。
Davis 在博客文章的中写了大量关于最优化方法的文章——如果你对最优化方法背后的数学感兴趣,我建议你读一读。
iBUG-300W 数据集

Figure 2: The iBug 300-W face landmark dataset is used to train a custom dlib shape predictor. Using dlib’s find_min_global optimization method, we will optimize an eyes-only shape predictor.
为了找到最佳的 dlib 形状预测器超参数,我们将使用 iBUG 300-W 数据集,该数据集与我们之前关于形状预测器的两部分系列所使用的数据集相同。
iBUG 300-W 数据集非常适合于训练面部标志预测器来定位面部的各个结构,包括:
- 眉毛
- 眼睛
- 鼻子
- 口
- 下颌的轮廓
形状预测数据文件可能会变得非常大。为了解决这个问题,我们将训练我们的形状预测器来定位仅仅是眼睛 而不是所有的面部标志。你可以很容易地训练一个形状预测器只识别嘴,等等。
配置您的 dlib 开发环境
为了完成今天的教程,您需要一个安装了以下软件包的虚拟环境:
- dlib
- OpenCV
- imutils
- scikit-learn
幸运的是,这些包都是 pip 可安装的。也就是说,有一些先决条件(包括 Python 虚拟环境)。有关配置开发环境的更多信息,请务必遵循以下两个指南:
pip 安装命令包括:
$ workon <env-name>
$ pip install dlib
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install scikit-learn
一旦你按照我的 dlib 或 OpenCV 安装指南安装了virtualenv和virtualenvwrapper,那么workon命令就变得可用。
下载 iBUG-300W 数据集
要跟随本教程,您需要下载 iBUG 300-W 数据集(~1.7GB):
http://dlib . net/files/data/ibug _ 300 w _ large _ face _ landmark _ dataset . tar . gz
在下载数据集的同时,您还应该使用本教程的 “下载” 部分下载源代码。
您可以(1)使用上面的超链接,或者(2)使用wget下载数据集。让我们介绍这两种方法,这样你的项目就像我自己的项目一样有条理。
选项 1: 使用上面的超链接下载数据集,然后将 iBug 300-W 数据集放入与本教程下载相关的文件夹中,如下所示:
$ unzip tune-dlib-shape-predictor.zip
...
$ cd tune-dlib-shape-predictor
$ mv ~/Downloads/ibug_300W_large_face_landmark_dataset.tar.gz .
$ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz
...
选项 2: 不要点击上面的超链接,直接使用终端中的wget下载数据集:
$ unzip tune-dlib-shape-predictor.zip
...
$ cd tune-dlib-shape-predictor
$ wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
$ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz
...
现在您已经准备好跟随教程的其余部分了。
项目结构
请务必遵循上一节的内容,以便(1)下载今天的。从“Downloads”部分解压,(2)将 iBug 300-W 数据集下载到今天的项目中。
从那里,继续执行tree命令来查看我们的项目结构:
% tree --dirsfirst --filelimit 10
.
├── ibug_300W_large_face_landmark_dataset
│ ├── afw [1011 entries]
│ ├── helen
│ │ ├── testset [990 entries]
│ │ └── trainset [6000 entries]
│ ├── ibug [405 entries]
│ ├── lfpw
│ │ ├── testset [672 entries]
│ │ └── trainset [2433 entries]
│ ├── image_metadata_stylesheet.xsl
│ ├── labels_ibug_300W.xml
│ ├── labels_ibug_300W_test.xml
│ └── labels_ibug_300W_train.xml
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── best_predictor.dat
├── ibug_300W_large_face_landmark_dataset.tar.gz
├── parse_xml.py
├── predict_eyes.py
├── shape_predictor_tuner.py
└── train_best_predictor.py
10 directories, 11 files
如您所见,我们的数据集已经按照上一节中的说明提取到了ibug_300W_large_face_landmark_dataset/目录中。
我们的配置存放在pyimagesearch模块中。
我们的 Python 脚本包括:
parse_xml.py:首先,您需要从 iBug 300-W 数据集中准备并提取只看得见的地标,生成更小的 XML 文件。我们将在下一节回顾如何使用这个脚本,但是我们不会回顾脚本本身,因为它已经在之前的教程中介绍过了。shape_predictor_tuner.py:这个脚本利用 dlib 的find_min_global方法来寻找最佳的形状预测器。我们今天将详细讨论这个脚本。这个脚本将需要很长时间来执行(几天)。train_best_predictor.py:形状预测器调好后,我们将更新我们的形状预测器选项,并开始训练过程。predict_eys.py:加载序列化模型,寻找地标,并在实时视频流上标注。我们今天不会讨论这个脚本,因为我们已经在之前的中讨论过了。
我们开始吧!
准备 iBUG-300W 数据集

Figure 3: In this tutorial, we will optimize a custom dlib shape predictor’s accuracy with find_min_global.
正如之前在上面的“iBUG-300 w 数据集”部分提到的,我们将只在眼睛上训练我们的 dlib 形状预测器(即而不是眉毛、鼻子、嘴或下颌)。
为此,我们将首先从 iBUG 300-W 训练/测试 XML 文件中解析出我们不感兴趣的任何面部结构。
此时,请确保您已经:
- 使用本教程的 【下载】 部分下载源代码。
- 已使用上面的“下载 iBUG-300W 数据集”部分下载 iBUG-300W 数据集。
- 查看了“项目结构”部分,以便您熟悉文件和文件夹。
在你的目录结构中有一个名为parse_xml.py的脚本——这个脚本处理从 XML 文件中解析出仅仅是眼睛的位置。
我们在我之前的 训练自定义 dlib 形状预测器 教程中详细回顾了这个文件。我们不会再复习文件,所以一定要在本系列的第一篇教程中复习。
在继续本教程的其余部分之前,您需要执行以下命令来准备我们的“仅供参考”的培训和测试 XML 文件:
$ python parse_xml.py \
--input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml \
--output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml
[INFO] parsing data split XML file...
$ python parse_xml.py \
--input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test.xml \
--output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test_eyes.xml
[INFO] parsing data split XML file...
现在让我们验证培训/测试文件是否已经创建。您应该检查 iBUG-300W 根数据集目录中的labels_ibug_300W_train_eyes.xml和labels_ibug_300W_test_eyes.xml文件,如下所示:
$ cd ibug_300W_large_face_landmark_dataset
$ ls -lh *.xml
-rw-r--r--@ 1 adrian staff 21M Aug 16 2014 labels_ibug_300W.xml
-rw-r--r--@ 1 adrian staff 2.8M Aug 16 2014 labels_ibug_300W_test.xml
-rw-r--r-- 1 adrian staff 602K Dec 12 12:54 labels_ibug_300W_test_eyes.xml
-rw-r--r--@ 1 adrian staff 18M Aug 16 2014 labels_ibug_300W_train.xml
-rw-r--r-- 1 adrian staff 3.9M Dec 12 12:54 labels_ibug_300W_train_eyes.xml
$ cd ..
请注意,我们的*_eyes.xml文件被高亮显示。这些文件的文件大小比它们原始的、未经解析的副本小得多。
我们的配置文件
在我们可以使用find_min_global来调优我们的超参数之前,我们首先需要创建一个配置文件来存储我们所有的重要变量,确保我们可以跨多个 Python 脚本使用和访问它们。
打开pyimagesearch模块中的config.py文件(按照上面的项目结构)并插入以下代码:
# import the necessary packages
import os
# define the path to the training and testing XML files
TRAIN_PATH = os.path.join("ibug_300W_large_face_landmark_dataset",
"labels_ibug_300W_train_eyes.xml")
TEST_PATH = os.path.join("ibug_300W_large_face_landmark_dataset",
"labels_ibug_300W_test_eyes.xml")
os模块(第 2 行)允许我们的配置脚本加入文件路径。
第 5-8 行加入我们的培训和测试 XML 地标文件。
让我们定义我们的培训参数:
# define the path to the temporary model file
TEMP_MODEL_PATH = "temp.dat"
# define the number of threads/cores we'll be using when trianing our
# shape predictor models
PROCS = -1
# define the maximum number of trials we'll be performing when tuning
# our shape predictor hyperparameters
MAX_FUNC_CALLS = 100
在这里你会发现:
- 临时模型文件的路径(第 11 行)。
- 训练时使用的线程/内核数量(第 15 行)。值
-1表示您机器上的所有处理器内核都将被利用。 - 当试图优化我们的超参数时,
find_min_global将使用的函数调用的最大数量(第 19 行)。较小的值将使我们的调优脚本完成得更快,但可能会导致超参数“不太理想”。值越大,运行调优脚本的时间就越长,但可能会产生“更优”的超参数。
实施 dlib 形状预测器和find_min_global训练脚本
现在我们已经查看了我们的配置文件,我们可以继续使用find_min_global来调整我们的形状预测器超参数。
打开项目结构中的shape_predictor_tuner.py文件,插入以下代码:
# import the necessary packages
from pyimagesearch import config
from collections import OrderedDict
import multiprocessing
import dlib
import sys
import os
# determine the number of processes/threads to use
procs = multiprocessing.cpu_count()
procs = config.PROCS if config.PROCS > 0 else procs
2-7 线导入我们必需的包,即我们的config和dlib。我们将使用multiprocessing模块来获取我们系统拥有的 CPUs 内核数量(第 10 行和第 11 行)。一个OrderedDict将包含我们所有的 dlib 形状预测选项。
现在,让我们定义一个负责使用 dlib 调整形状预测器核心的函数:
def test_shape_predictor_params(treeDepth, nu, cascadeDepth,
featurePoolSize, numTestSplits, oversamplingAmount,
oversamplingTransJitter, padding, lambdaParam):
# grab the default options for dlib's shape predictor and then
# set the values based on our current hyperparameter values,
# casting to ints when appropriate
options = dlib.shape_predictor_training_options()
options.tree_depth = int(treeDepth)
options.nu = nu
options.cascade_depth = int(cascadeDepth)
options.feature_pool_size = int(featurePoolSize)
options.num_test_splits = int(numTestSplits)
options.oversampling_amount = int(oversamplingAmount)
options.oversampling_translation_jitter = oversamplingTransJitter
options.feature_pool_region_padding = padding
options.lambda_param = lambdaParam
# tell dlib to be verbose when training and utilize our supplied
# number of threads when training
options.be_verbose = True
options.num_threads = procs
test_shape_predictor_params功能:
- 接受一组输入超参数。
- 使用这些超参数训练 dlib 形状预测器。
- 计算测试集的预测损失/误差。
- 将错误返回给
find_min_global函数。 - 然后,
find_min_global函数将获取返回的误差,并使用它以迭代的方式调整迄今为止找到的最佳超参数。
如您所见,test_shape_predictor_params函数接受九个参数,,其中每个参数都是 dlib 形状预测超参数,我们将对其进行优化。
第 19-28 行从参数中设置超参数值(适当时转换为整数)。
第 32 行和第 33 行指示 dlib 输出详细信息,并利用提供的线程/进程数量进行训练。
让我们完成对test_shape_predictor_params函数的编码:
# display the current set of options to our terminal
print("[INFO] starting training...")
print(options)
sys.stdout.flush()
# train the model using the current set of hyperparameters
dlib.train_shape_predictor(config.TRAIN_PATH,
config.TEMP_MODEL_PATH, options)
# take the newly trained shape predictor model and evaluate it on
# both our training and testing set
trainingError = dlib.test_shape_predictor(config.TRAIN_PATH,
config.TEMP_MODEL_PATH)
testingError = dlib.test_shape_predictor(config.TEST_PATH,
config.TEMP_MODEL_PATH)
# display the training and testing errors for the current trial
print("[INFO] train error: {}".format(trainingError))
print("[INFO] test error: {}".format(testingError))
sys.stdout.flush()
# return the error on the testing set
return testingError
第 41 行和第 42 行使用当前超参数集训练 dlib 形状预测器。
从那里,行 46-49 在训练和测试集上评估新训练的形状预测器。
第 52-54 行在第 57 行将testingError返回给调用函数之前,打印当前试验的训练和测试错误。
让我们定义我们的形状预测超参数集:
# define the hyperparameters to dlib's shape predictor that we are
# going to explore/tune where the key to the dictionary is the
# hyperparameter name and the value is a 3-tuple consisting of the
# lower range, upper range, and is/is not integer boolean,
# respectively
params = OrderedDict([
("tree_depth", (2, 5, True)),
("nu", (0.001, 0.2, False)),
("cascade_depth", (4, 25, True)),
("feature_pool_size", (100, 1000, True)),
("num_test_splits", (20, 300, True)),
("oversampling_amount", (1, 40, True)),
("oversampling_translation_jitter", (0.0, 0.3, False)),
("feature_pool_region_padding", (-0.2, 0.2, False)),
("lambda_param", (0.01, 0.99, False))
])
OrderedDict中的每个值都是一个三元组,包括:
- 超参数值的下限。
- 超参数值的上限。
- 一个指示超参数是否为整数的布尔值。
对于超参数的完整回顾,请务必参考我之前的帖子。
从这里,我们将提取我们的上限和下限,以及超参数是否为整数:
# use our ordered dictionary to easily extract the lower and upper
# boundaries of the hyperparamter range, include whether or not the
# parameter is an integer or not
lower = [v[0] for (k, v) in params.items()]
upper = [v[1] for (k, v) in params.items()]
isint = [v[2] for (k, v) in params.items()]
第 79-81 行从我们的params字典中提取lower、upper和isint布尔。
现在我们已经设置好了,让我们用 dlib 的find_min_global方法来优化我们的形状预测器超参数
# utilize dlib to optimize our shape predictor hyperparameters
(bestParams, bestLoss) = dlib.find_min_global(
test_shape_predictor_params,
bound1=lower,
bound2=upper,
is_integer_variable=isint,
num_function_calls=config.MAX_FUNC_CALLS)
# display the optimal hyperparameters so we can reuse them in our
# training script
print("[INFO] optimal parameters: {}".format(bestParams))
print("[INFO] optimal error: {}".format(bestLoss))
# delete the temporary model file
os.remove(config.TEMP_MODEL_PATH)
第 84-89 行开始优化过程。
行 93 和 94 显示在行 97 删除临时模型文件之前的最佳参数。
用find_min_global调整形状预测器选项
要使用find_min_global将超参数调整到我们的 dlib 形状预测器,请确保:
- 使用本教程的 【下载】 章节下载源代码。
- 使用上面的“下载 iBUG-300W 数据集”部分下载 iBUG-300W 数据集。
- 在“准备 iBUG-300W 数据集”一节中为训练和测试 XML 文件执行了
parse_xml.py。
假设您已经完成了这三个步骤中的每一步,现在您可以执行shape_predictor_tune.py脚本:
$ time python shape_predictor_tune.py
[INFO] starting training...
shape_predictor_training_options(be_verbose=1, cascade_depth=15, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1005, oversampling_amount=21, oversampling_translation_jitter=0.15, feature_pool_size=550, lambda_param=0.5, num_test_splits=160, feature_pool_region_padding=0, random_seed=, num_threads=20, landmark_relative_padding_mode=1)
Training with cascade depth: 15
Training with tree depth: 4
Training with 500 trees per cascade level.
Training with nu: 0.1005
Training with random seed:
Training with oversampling amount: 21
Training with oversampling translation jitter: 0.15
Training with landmark_relative_padding_mode: 1
Training with feature pool size: 550
Training with feature pool region padding: 0
Training with 20 threads.
Training with lambda_param: 0.5
Training with 160 split tests.
Fitting trees...
Training complete
Training complete, saved predictor to file temp.dat
[INFO] train error: 5.518466441668642
[INFO] test error: 6.977162396336371
[INFO] optimal inputs: [4.0, 0.1005, 15.0, 550.0, 160.0, 21.0, 0.15, 0.0, 0.5]
[INFO] optimal output: 6.977162396336371
...
[INFO] starting training...
shape_predictor_training_options(be_verbose=1, cascade_depth=20, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1033, oversampling_amount=29, oversampling_translation_jitter=0, feature_pool_size=677, lambda_param=0.0250546, num_test_splits=295, feature_pool_region_padding=0.0974774, random_seed=, num_threads=20, landmark_relative_padding_mode=1)
Training with cascade depth: 20
Training with tree depth: 4
Training with 500 trees per cascade level.
Training with nu: 0.1033
Training with random seed:
Training with oversampling amount: 29
Training with oversampling translation jitter: 0
Training with landmark_relative_padding_mode: 1
Training with feature pool size: 677
Training with feature pool region padding: 0.0974774
Training with 20 threads.
Training with lambda_param: 0.0250546
Training with 295 split tests.
Fitting trees...
Training complete
Training complete, saved predictor to file temp.dat
[INFO] train error: 2.1037606164427904
[INFO] test error: 4.225682000183475
[INFO] optimal parameters: [4.0, 0.10329967171060293, 20.0, 677.0, 295.0, 29.0, 0.0, 0.09747738830224817, 0.025054553453757795]
[INFO] optimal error: 4.225682000183475
real 8047m24.389s
user 98916m15.646s
sys 464m33.139s
在我配有 20 个内核的 3 GHz 英特尔至强 W 处理器的 iMac Pro 上,总共运行 100 个MAX_TRIALS用了 ~8047m24s ,或者说 ~5.6 天。如果您没有功能强大的计算机,我建议您在功能强大的云实例上运行这个过程。
查看输出,您可以看到find_min_global函数找到了以下最佳形状预测超参数:
tree_depth: 4nu: 0.1033cascade_depth: 20feature_pool_size: 677num_test_splits: 295oversampling_amount: 29oversampling_translation_jitter: 0feature_pool_region_padding: 0.0975lambda_param: 0.0251
在下一节中,我们将获取这些值并更新我们的train_best_predictor.py脚本以包含它们。
使用find_min_global的结果更新我们的形状预测选项
此时,我们知道最佳可能的形状预测器超参数值,但是我们仍然需要使用这些值来训练我们的最终形状预测器。
要进行 make,打开train_best_predictor.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch import config
import multiprocessing
import argparse
import dlib
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path serialized dlib shape predictor model")
args = vars(ap.parse_args())
# determine the number of processes/threads to use
procs = multiprocessing.cpu_count()
procs = config.PROCS if config.PROCS > 0 else procs
# grab the default options for dlib's shape predictor
print("[INFO] setting shape predictor options...")
options = dlib.shape_predictor_training_options()
# update our hyperparameters
options.tree_depth = 4
options.nu = 0.1033
options.cascade_depth = 20
options.feature_pool_size = 677
options.num_test_splits = 295
options.oversampling_amount = 29
options.oversampling_translation_jitter = 0
options.feature_pool_region_padding = 0.0975
options.lambda_param = 0.0251
# tell the dlib shape predictor to be verbose and print out status
# messages our model trains
options.be_verbose = True
# number of threads/CPU cores to be used when training -- we default
# this value to the number of available cores on the system, but you
# can supply an integer value here if you would like
options.num_threads = procs
# log our training options to the terminal
print("[INFO] shape predictor options:")
print(options)
# train the shape predictor
print("[INFO] training shape predictor...")
dlib.train_shape_predictor(config.TRAIN_PATH, args["model"], options)
2-5 线导入我方config、multiprocessing、argparse、dlib。
从那里,我们使用从上一节找到的最佳值来设置形状预测器options ( 第 14-39 行)。
最后,线 47 训练输出模型。
关于这个脚本的更详细的回顾,请务必参考我之前的教程。
训练最终形状预测器
最后一步是执行我们的train_best_predictor.py文件,该文件将使用通过find_min_global找到的最佳超参数值来训练 dlib 形状预测器:
$ time python train_best_predictor.py --model best_predictor.dat
[INFO] setting shape predictor options...
[INFO] shape predictor options:
shape_predictor_training_options(be_verbose=1, cascade_depth=20, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1033, oversampling_amount=29, oversampling_translation_jitter=0, feature_pool_size=677, lambda_param=0.0251, num_test_splits=295, feature_pool_region_padding=0.0975, random_seed=, num_threads=20, landmark_relative_padding_mode=1)
[INFO] training shape predictor...
Training with cascade depth: 20
Training with tree depth: 4
Training with 500 trees per cascade level.
Training with nu: 0.1033
Training with random seed:
Training with oversampling amount: 29
Training with oversampling translation jitter: 0
Training with landmark_relative_padding_mode: 1
Training with feature pool size: 677
Training with feature pool region padding: 0.0975
Training with 20 threads.
Training with lambda_param: 0.0251
Training with 295 split tests.
Fitting trees...
Training complete
Training complete, saved predictor to file best_predictor.dat
real 111m46.444s
user 1492m29.777s
sys 5m39.150s
命令执行完毕后,您应该在本地目录结构中有一个名为best_predictor.dat的文件:
$ ls -lh *.dat
-rw-r--r--@ 1 adrian staff 24M Dec 22 12:02 best_predictor.dat
然后,您可以使用这个预测器,并使用predict_eyes.py脚本在实时视频中定位眼睛:
$ python predict_eyes.py --shape-predictor best_predictor.dat
[INFO] loading facial landmark predictor...
[INFO] camera sensor warming up...
什么时候应该使用 dlib 的find_min_global功能?
Figure 4: Using the find_min_global method to optimize a custom dlib shape predictor can take significant processing time. Be sure to review this section for general rules of thumb including guidance on when to use a Grid Search method to find a shape predictor model.
与盲目探索超参数集的标准网格搜索不同,find_min_global函数是真正的优化器,使其能够迭代探索超参数空间,选择最大化我们的准确性和最小化我们的损失/错误的选项。
然而,find_min_global的一个缺点是它不能以一种简单的方式与并行。
另一方面,标准网格搜索可以通过以下方式使并行:
- 将超参数的所有组合分成 N 个大小的块
- 然后在 M 个系统中分配每个块
这样做将导致比使用find_min_global更快的超参数空间探索。
缺点是您可能没有超参数的“真正”最佳选择,因为网格搜索只能探索您硬编码的值。
因此,我推荐以下经验法则:
如果你有 多台机器, 使用一个标准的网格搜索并在机器间分配工作。网格搜索完成后,取找到的最佳值,然后将它们作为 dlib 的find_min_global的输入,以找到您的最佳超参数。
如果你有一台单机,使用 dlib 的find_min_global,确保削减你想要探索的超参数范围。例如,如果你知道你想要一个小而快的模型,你应该限制tree_depth的范围上限,防止你的 ERTs 变得太深(因此更慢)。
虽然 dlib 的find_min_global功能非常强大,但它也可能缓慢,所以请确保您提前考虑并计划出哪些超参数对于您的应用程序来说是真正重要的。*
*你也应该阅读我以前的关于训练自定义 dlib 形状预测器的教程,详细了解每个超参数控制什么,以及如何使用它们来平衡速度、精度和模型大小。
使用这些建议,您将能够成功地调整和优化您的 dlib 形状预测器。
摘要
在本教程中,您学习了如何在训练自定义形状预测器时使用 dlib 的find_min_global函数来优化选项/超参数。
该功能非常易于使用,并使非常简单调整 dlib 形状预测器的超参数。
我还建议你使用我之前的教程,通过网格搜索调整 dlib 形状预测器选项——将网格搜索(使用多台机器)与find_min_global结合起来可以产生更好的形状预测器。
我希望你喜欢这篇博文!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
在树莓 Pi 上优化 OpenCV
原文:https://pyimagesearch.com/2017/10/09/optimizing-opencv-on-the-raspberry-pi/

本教程是为 高级 Raspberry Pi 用户 准备的,他们希望利用他们的 Pi 的最后一点性能来使用 OpenCV 进行计算机视觉和图像处理。
我会假设:
- 你已经完成了我之前的Raspberry Pi+OpenCV 安装教程(最好是多次)。
- 您已经熟悉了命令行和 Unix 环境。
由于这是一个高级指南,我将少做一些手把手的工作,而是专注于优化本身。如果你陷入困境或遇到错误,你需要参考我在 PyImageSearch 上提供的以前的教程。
当你完成本教程时,你的树莓 Pi 在执行 OpenCV 和 Python 脚本时将享受到 30%的速度提升。
要了解更多关于在您的 Raspberry Pi 上优化 OpenCV 的信息,请继续阅读。
在树莓 Pi 上优化 OpenCV
几周前,我演示了如何给你的树莓派部署一个深度神经网络。
结果是令人满意的,使用 GoogLeNet 对图像进行分类大约需要 1.7 秒,使用 SqueezeNet 大约需要 0.9 秒。
然而,我想知道我们是否能做得更好。
虽然我们不能在 Raspberry Pi 上 训练 神经网络,但我们可以 将 预先训练好的网络部署到我们的 Pi 上——前提是我们能够充分优化 Raspberry Pi(并且网络能够适合 Pi 硬件的有限内存)。
在本教程的剩余部分,我们将讨论在 OpenCV 安装过程中我们将利用的优化,然后完成七个安装步骤。
在我们优化的 OpenCV 编译器安装后,我们将运行一些快速测试来确定我们新的 OpenCV 安装是否比前一个更快。
我在这里的目标是证明优化实际上在树莓 Pi 3 上要快得多,你应该毫不犹豫地在你自己的项目中使用它们。
氖和 FVPV3
在我研究如何为 OpenCV 优化 Raspberry Pi 时,我看到了 Sagi Zeevi 的这篇优秀文章。
在教程中,Sagi 建议使用:
- 氖
- VFPV3
- 以及可选的线程构建模块(TBB)
我不是 TBB 的忠实粉丝,因为(1)性能增益很低,而且(2)安装在树莓派上很麻烦。
最划算的将是 NEON 和 VFPV3。
ARM NEON 是 ARM 处理器的优化架构扩展。它是由 ARM 工程师专门为更快的视频处理、图像处理、语音识别和机器学习而设计的。这种优化支持单指令多数据 (SIMD)(与 SISD、MISD、MIMD 相对),它描述了一种架构,其中流水线中的多个处理元件对多个数据点(硬件)执行操作,所有操作都用单个指令执行。
ARM 工程师还在我们的 Raspberry Pi 3 使用的芯片中内置了浮点优化功能 VFPV3 。此处链接的 ARM 页面描述了此优化中包含的功能,如可配置的舍入模式和可定制的默认非数字(NaN)行为。
这对我们来说意味着我们的神经网络可能会运行得更快,因为 Raspberry Pi 3 上的 ARM 处理器具有硬件优化,我们可以利用 4× ARM Cortex-A53,1.2GHz 处理器。
我想你会对结果印象深刻,所以让我们继续把你优化的 OpenCV 安装到 Raspberry Pi 上。
步骤#1:扩展文件系统并回收空间
在本教程的剩余部分,我将做以下假设:
- 你正在使用全新安装的拉斯比昂拉伸。
- 这不是你第一次使用 Python 虚拟环境在 Raspberry Pi 上安装 OpenCV。如果是的话,请使用我的介绍性 OpenCV 安装指南来体验一下。
- 您已经熟悉了命令行和 Unix 环境。
- 您知道如何调试 CMake 输出中的常见错误(找不到 Python 虚拟环境、缺少 Python 库等)。).
同样,本教程是一个高级指南,所以我将介绍这些命令,并且只提供相关的解释——总的来说,在执行这些命令之前,你应该知道它们是做什么的。
第一步是运行并扩展您的文件系统:
$ sudo raspi-config
然后重启你的 Raspberry Pi:
$ sudo reboot
从那里,删除 Wolfram Engine 和 LibreOffice,在您的 Raspberry Pi 上回收大约 1GB 的空间:
$ sudo apt-get purge wolfram-engine
$ sudo apt-get purge libreoffice*
$ sudo apt-get clean
$ sudo apt-get autoremove
步骤 2:安装依赖项
以下命令将更新和升级任何现有的包,然后安装 OpenCV 的依赖项、I/O 库和优化包:
$ sudo apt-get update && sudo apt-get upgrade
$ sudo apt-get install build-essential cmake pkg-config
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng12-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk2.0-dev libgtk-3-dev
$ sudo apt-get install libcanberra-gtk*
$ sudo apt-get install libatlas-base-dev gfortran
$ sudo apt-get install python2.7-dev python3-dev
整个过程大约需要 5 分钟。
注:我增加了libcanberra-gtk*这是抓住 GTK 手臂阻止 GTK 的特定警告(不是错误;警告)在 Raspberry Pi 上运行 Python + OpenCV 脚本时可能会遇到。
步骤 3:下载 OpenCV 源代码
接下来,下载 opencv 和 opencv_contrib 库的 OpenCV 源代码,然后解包:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/3.4.7.zip
$ unzip opencv.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/3.4.7.zip
$ unzip opencv_contrib.zip
注意:你需要点击上面代码块工具栏中的< = >按钮来获取 zip 存档的完整路径。
对于这篇博文,我们将使用 OpenCV 3 . 4 . 7;然而,随着 OpenCV 新版本的发布,您可以更新相应的版本号(注意:一些截图显示 3.3.0 是当时收集的可用的最高版本)。
步骤 4:创建您的 Python 虚拟环境并安装 NumPy
我们将使用 Python 虚拟环境,这是使用 Python 时的最佳实践。
您可以使用以下命令安装 pip、 virtualenv 和 virtualenvwrapper :
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo python3 get-pip.py
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip
一旦virtualenv和virtualenvwrapper都安装好了,打开你的~/.bashrc,使用你最喜欢的基于终端的文本编辑器,如vim、emacs或nano,将下面几行添加到文件的底部:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
从那里,重新加载您的~/.bashrc文件,将更改应用到您当前的 bash 会话:
$ source ~/.bashrc
每次在 Pi 中打开一个新的终端/SSH 时,您都需要运行source ~/.bashrc ,以确保您的系统变量设置正确(它还会在启动时加载该文件)。
接下来,创建 Python 3 虚拟环境:
$ mkvirtualenv cv -p python3
在这里,我使用 Python 3 创建了一个名为cv的 Python 虚拟环境(或者,您也可以通过将-p切换到python2来使用 Python 2.7)。
您可以随意命名虚拟环境,但是我在 PyImageSearch 上使用cv作为标准命名约定。
最后,将 NumPy 安装到 Python 虚拟环境中:
$ pip install numpy
步骤#5:编译并安装为 Raspberry Pi 优化的 OpenCV 库
我们现在准备编译和安装优化版的 Raspberry Pi。
使用workon命令确保您处于cv虚拟环境中:
$ workon cv
并从那里配置您的构建:
$ cd ~/opencv-3.4.7/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.4.7/modules \
-D ENABLE_NEON=ON \
-D ENABLE_VFPV3=ON \
-D BUILD_TESTS=OFF \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D CMAKE_SHARED_LINKER_FLAGS='-latomic' \
-D BUILD_EXAMPLES=OFF ..
注意 NEON 和 VFPV3 标志是如何使能的。这些线被突出显示。
此外,我强调了非自由算法标志(给你完整的安装)以及 OpenCV 3.4.7 需要的特殊链接标志。
如果您使用的是 Python 2.7,那么您的“Python 2”部分应该如下所示:
Figure 1: Running CMake to generate the build files for OpenCV 3.3. OpenCV will correctly be built with Python 2.7 and NumPy from our cv virtualenv.
否则,如果您正在为 Python 3 编译 OpenCV,请检查 CMake 的 "Python 3" 输出:
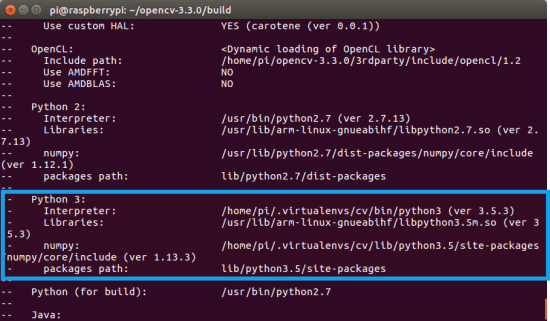
Figure 2: After running CMake, Python 3 + NumPy are correctly set from within our cv virtualenv on the Raspberry Pi.
请注意Interpreter、Libraries、numpy和packages path变量是如何正确设置的。
在你开始编译之前,我建议 增加你的交换空间 。这将使你能够用树莓派的 所有四个内核 编译 OpenCV,而不会因为内存耗尽而导致编译挂起。
打开您的/etc/dphys-swapfile文件,然后编辑CONF_SWAPSIZE变量:
# set size to absolute value, leaving empty (default) then uses computed value
# you most likely don't want this, unless you have an special disk situation
# CONF_SWAPSIZE=100
CONF_SWAPSIZE=1024
请注意,我将交换空间从 100MB 增加到了 1024MB。这是在 Raspbian Stretch 上编译多核 OpenCV 的秘方。
如果你不执行这个步骤,你的 Pi 很可能会挂起。
从那里,重新启动交换服务:
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
注意:增加交换空间是烧坏你的 Raspberry Pi microSD 卡的好方法。基于闪存的存储可以执行的写入次数有限,直到卡基本上无法再容纳 1 和 0。我们只会在短时间内启用大规模互换,所以这没什么大不了的。无论如何,一定要在安装 OpenCV + Python 后备份你的.img文件,以防你的卡意外提前死亡。你可以在本页的阅读更多关于大容量交换损坏存储卡的信息。
现在我们已经更新了交换空间大小,开始使用所有四个内核进行优化的 OpenCV 编译:
$ make -j4
Figure 3: Our optimized compile of OpenCV 3.3 for the Raspberry Pi 3 has been completed successfully.
假设 OpenCV 编译没有错误(如我上面的截图所示),您可以在您的 Raspberry Pi 上安装您的 OpenCV 优化版本:
$ sudo make install
$ sudo ldconfig
别忘了回去 给你的/etc/dphys-swapfile文件还有:
- 将
CONF_SWAPSIZE重置为 100MB。 - 重新启动交换服务。
第 6 步:在 Raspberry Pi 上完成安装你的优化的 OpenCV
如果您为 Python 3 编译了 OpenCV,那么您需要发出以下命令来将cv2.so绑定符号链接到您的cv虚拟环境中:
$ cd /usr/local/lib/python3.5/site-packages/
$ sudo mv cv2.cpython-35m-arm-linux-gnueabihf.so cv2.so
$ cd ~/.virtualenvs/cv/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2.so cv2.so
请记住,确切的路径需要根据您使用的是 Python 3.4、Python 3.5 还是 Python 3.6 等版本进行更新。
如果您转而编译了用于 Python 2.7 的 OpenCV,您可以使用这些命令将您的cv2.so文件符号链接到cv虚拟环境:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
步骤 7:测试您的优化的 OpenCV + Raspberry Pi 安装
作为快速检查,访问cv虚拟环境,启动 Python shell 并尝试导入 OpenCV 库:
$ source ~/.profile
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.4.7'
>>>
恭喜你!您刚刚在您的 Raspberry Pi 3 上安装了优化的 OpenCV 3.3。
那么,这些优化有多好呢?
阅读完本教程后,你可能会好奇这些 OpenCV + Raspberry Pi 优化有多好。
鉴于我们刚刚针对浮点运算进行了优化,一个很好的测试将是在 Raspberry Pi 上运行预先训练好的深度神经网络,类似于我们上周所做的。
继续使用这篇博文的 【下载】 部分来下载我们预先训练好的卷积神经网络+示例图像+分类脚本。
从那里,启动一个 shell 并执行以下命令:
$ python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt \
--model models/bvlc_googlenet.caffemodel --labels synset_words.txt \
--image images/barbershop.png
[INFO] loading model...
[INFO] classification took 0.87173 seconds
[INFO] 1\. label: barbershop, probability: 0.78055
[INFO] 2\. label: barber chair, probability: 0.2194
[INFO] 3\. label: rocking chair, probability: 3.4663e-05
[INFO] 4\. label: restaurant, probability: 3.7258e-06
[INFO] 5\. label: hair spray, probability: 1.4715e-06
Figure 4: Running an image of a “barbershop” through GoogLeNet on the Raspberry Pi 3 with an optimized install of OpenCV 3.3 achieves a 48.82% speedup.
在这里你可以看到 GoogLeNet 将我们的图像分类在 0.87 秒 ,比上周的 1.7 秒有了海量 48.82% 的提升。
让我们试试 SqueezeNet:
$ python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \
--model models/squeezenet_v1.0.caffemodel --labels synset_words.txt \
--image images/barbershop.png
[INFO] loading model...
[INFO] classification took 0.4777 seconds
[INFO] 1\. label: barbershop, probability: 0.80578
[INFO] 2\. label: barber chair, probability: 0.15124
[INFO] 3\. label: half track, probability: 0.0052872
[INFO] 4\. label: restaurant, probability: 0.0040124
[INFO] 5\. label: desktop computer, probability: 0.0033352
Figure 5: Squeezenet on the Raspberry Pi 3 also achieves performance gains using our optimized install of OpenCV 3.3.
在这里我们可以看到,SqueezeNet 在 0.47 秒内正确地对输入图像进行了分类,与上周的 0.9 秒(47.78%)相比又是一个巨大的进步。
根据我们的结果,很明显我们的 OpenCV 优化已经产生了显著的影响。
摘要
在今天的博文中,您了解了如何在 Raspberry Pi 上优化 OpenCV 安装。
这些优化来自于更新我们的 CMake 命令,以包括 NEON 和 VFPV3。当对 OpenCV 进行基准测试时,这导致 的速度提高了大约 30%。然而,当严格应用于 OpenCV 3 中的新dnn模块时,我们看到增加了超过 48% !
希望你喜欢这个教程,喜欢你优化的 OpenCV + Raspberry Pi!
但是在你走之前……
请务必在我的博客上查看其他 Raspberry Pi 帖子,并且 考虑在下面的表格中输入您的电子邮件地址,以便在未来深度学习/Raspberry Pi 帖子在 PyImageSearch 上发布时得到通知。**
用 Python 和 OpenCV 顺时针排序坐标
原文:https://pyimagesearch.com/2016/03/21/ordering-coordinates-clockwise-with-python-and-opencv/

Today we are going to kick-off a three part series on calculating the size of objects in images along with measuring the distances between them.
这些教程是 PyImageSearch 博客上最受欢迎的课程之一。我非常兴奋能让他们开始——,我相信你也是。
然而,在我们开始学习如何测量图像中物体的大小(更不用说它们之间的距离)之前,我们首先需要谈论一些事情…
一年多前,我在 PyImageSearch 博客上写了一篇我最喜欢的教程: 如何在短短 5 分钟内建立一个强大的移动文档扫描仪 。尽管这个教程已经有一年多的历史了,它的仍然是 PyImageSearch 上最受欢迎的博客帖子之一。
构建我们的移动文档扫描仪是基于我们能够 使用 OpenCV 应用 4 点 cv2.getPerspectiveTransform,使我们能够获得自上而下的文档鸟瞰图。
然而。我们的透视变换有一个致命的缺陷,这使得它不适合在生产环境中使用。
**你看,有这样的情况,把我们的四个点按左上、右上、右下、左下顺序排列的预处理步骤会返回不正确的结果!
要了解更多关于这种虫子的信息,以及如何消灭它,请继续阅读。
用 Python 和 OpenCV 顺时针排序坐标
这篇博文的目的有两个:
- 的主要目的是学习如何以左上、右上、右下和左下的顺序排列与旋转的边界框相关的 (x,y)-坐标。以这样的顺序组织边界框坐标是执行诸如透视变换或匹配对象的角(例如当我们计算对象之间的距离时)等操作的先决条件。
- 的第二个目的是解决 imutils 包的
order_points方法中一个微妙的、难以发现的错误。通过解决这个 bug,我们的order_points函数将不再容易受到削弱性 bug 的影响。
说了这么多,让我们从回顾最初的、有缺陷的按顺时针顺序排列边界框坐标的方法开始这篇博文。
原始的(有缺陷的)方法
在我们学习如何按照(1)顺时针顺序,更具体地说,(2)左上、右上、右下和左下顺序排列一组边界框坐标之前,我们应该先回顾一下原创 4 点 getPerspectiveTransform 博文中详细介绍的order_points方法。
我已经将(有缺陷的)order_points方法重命名为order_points_old,这样我们就可以比较我们原始的和更新的方法。首先,打开一个新文件,命名为order_coordinates.py:
# import the necessary packages
from __future__ import print_function
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
def order_points_old(pts):
# initialize a list of coordinates that will be ordered
# such that the first entry in the list is the top-left,
# the second entry is the top-right, the third is the
# bottom-right, and the fourth is the bottom-left
rect = np.zeros((4, 2), dtype="float32")
# the top-left point will have the smallest sum, whereas
# the bottom-right point will have the largest sum
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# now, compute the difference between the points, the
# top-right point will have the smallest difference,
# whereas the bottom-left will have the largest difference
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
# return the ordered coordinates
return rect
第 2-8 行处理导入我们需要的 Python 包。我们将在这篇博文的后面使用imutils包,所以如果你还没有安装它,一定要通过pip安装它:
$ pip install imutils
否则,如果你确实安装了imutils,你应该升级到最新版本(它有更新的order_points实现):
$ pip install --upgrade imutils
第 10 行定义了我们的order_points_old函数。这种方法只需要一个参数,即我们要按左上、右上、右下和左下顺序排列的一组点;虽然,正如我们将要看到的,这个方法有一些缺陷。
我们从第 15 行的开始,定义一个形状为(4, 2)的 NumPy 数组,它将用于存储我们的四个 (x,y) 坐标。
给定这些pts,我们将 x 和 y 值加在一起,然后找出最小和最大的和(第 19-21 行)。这些值分别给出了我们的左上和右下坐标。
然后我们取 x 和 y 值之间的差,其中右上点的差最小,左下点的距离最大(第 26-28 行)。
最后,行 31 将我们排序的 (x,y)-坐标返回给我们的调用函数。
说了这么多,你能发现我们逻辑中的漏洞吗?
我给你一个提示:
当两点之和或之差与 相同时会发生什么?
总之,悲剧。
如果和数组s或差数组diff具有相同的值,我们就有选择不正确索引的风险,这会对我们的排序产生级联效应。
选择错误的索引意味着我们从pts列表中选择了不正确的点。而如果我们从pts取了不正确的点,那么我们顺时针的左上、右上、右下、左下的排序就会被破坏。
那么,我们如何解决这个问题,并确保它不会发生?
为了处理这个问题,我们需要使用更合理的数学原理设计一个更好的order_points函数。这正是我们将在下一节讨论的内容。
用 OpenCV 和 Python 实现坐标顺时针排序的更好方法
既然我们已经看到了order_points函数的有缺陷的版本,让我们回顾一下更新的,正确的实现。
我们将要回顾的order_points函数的实现可以在 imutils 包中找到;具体来说,在 perspective.py 文件中。为了完整起见,我在这篇博文中包含了具体的实现:
# import the necessary packages
from scipy.spatial import distance as dist
import numpy as np
import cv2
def order_points(pts):
# sort the points based on their x-coordinates
xSorted = pts[np.argsort(pts[:, 0]), :]
# grab the left-most and right-most points from the sorted
# x-roodinate points
leftMost = xSorted[:2, :]
rightMost = xSorted[2:, :]
# now, sort the left-most coordinates according to their
# y-coordinates so we can grab the top-left and bottom-left
# points, respectively
leftMost = leftMost[np.argsort(leftMost[:, 1]), :]
(tl, bl) = leftMost
# now that we have the top-left coordinate, use it as an
# anchor to calculate the Euclidean distance between the
# top-left and right-most points; by the Pythagorean
# theorem, the point with the largest distance will be
# our bottom-right point
D = dist.cdist(tl[np.newaxis], rightMost, "euclidean")[0]
(br, tr) = rightMost[np.argsort(D)[::-1], :]
# return the coordinates in top-left, top-right,
# bottom-right, and bottom-left order
return np.array([tl, tr, br, bl], dtype="float32")
同样,我们从第 2-4 行开始,导入我们需要的 Python 包。然后我们在第 6 行上定义我们的order_points函数,它只需要一个参数——我们想要订购的pts的列表。
第 8 行然后根据它们的 x- 值对这些pts进行排序。给定排序后的xSorted列表,我们应用数组切片来抓取最左边的两个点和最右边的两个点(第 12 行和第 13 行)。
因此,leftMost点将对应于左上和左下点,而rightMost将是我们的右上和右下点— 关键是要弄清楚哪个是哪个。
幸运的是,这并不太具有挑战性。
如果我们根据它们的 y- 值对我们的leftMost点进行排序,我们可以分别导出左上角和左下角的点(第 18 行和第 19 行)。
然后,为了确定右下角和左下角的点,我们可以应用一点几何。
使用左上角的点作为锚点,我们可以应用勾股定理并计算左上角和rightMost点之间的欧几里得距离。根据三角形的定义,斜边是直角三角形的最大边。
因此,通过将左上角的点作为我们的锚点,右下角的点将具有最大的欧几里德距离,从而允许我们提取右下角和右上角的点(行 26 和 27 )。
最后,第 31 行返回一个 NumPy 数组,以左上、右上、右下和左下的顺序表示我们的有序边界框坐标。
测试我们的坐标排序实现
现在我们已经有了order_points的原版和更新版,让我们继续实现我们的order_coordinates.py脚本,并让他们都试试:
# import the necessary packages
from __future__ import print_function
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
def order_points_old(pts):
# initialize a list of coordinates that will be ordered
# such that the first entry in the list is the top-left,
# the second entry is the top-right, the third is the
# bottom-right, and the fourth is the bottom-left
rect = np.zeros((4, 2), dtype="float32")
# the top-left point will have the smallest sum, whereas
# the bottom-right point will have the largest sum
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# now, compute the difference between the points, the
# top-right point will have the smallest difference,
# whereas the bottom-left will have the largest difference
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
# return the ordered coordinates
return rect
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--new", type=int, default=-1,
help="whether or not the new order points should should be used")
args = vars(ap.parse_args())
# load our input image, convert it to grayscale, and blur it slightly
image = cv2.imread("example.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# perform edge detection, then perform a dilation + erosion to
# close gaps in between object edges
edged = cv2.Canny(gray, 50, 100)
edged = cv2.dilate(edged, None, iterations=1)
edged = cv2.erode(edged, None, iterations=1)
第 33-37 行处理解析我们的命令行参数。我们只需要一个参数--new,它用来表示是否应该使用新或原 order_points函数。我们将默认使用最初的实现。
从那里,我们从磁盘加载example.png,并通过将图像转换为灰度并用高斯滤波器平滑它来执行一点预处理。
我们继续通过应用 Canny 边缘检测器来处理我们的图像,然后通过膨胀+腐蚀来闭合边缘图中轮廓之间的任何间隙。
执行边缘检测过程后,我们的图像应该如下所示:

Figure 1: Computing the edge map of the input image.
如你所见,我们已经能够确定图像中物体的轮廓。
现在我们有了边缘图的轮廓,我们可以应用cv2.findContours函数来实际提取物体的轮廓:
# find contours in the edge map
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# sort the contours from left-to-right and initialize the bounding box
# point colors
(cnts, _) = contours.sort_contours(cnts)
colors = ((0, 0, 255), (240, 0, 159), (255, 0, 0), (255, 255, 0))
然后,我们从左到右对物体轮廓进行排序,这不是必需的,但是可以更容易地查看脚本的输出。
下一步是分别遍历每个轮廓:
# loop over the contours individually
for (i, c) in enumerate(cnts):
# if the contour is not sufficiently large, ignore it
if cv2.contourArea(c) < 100:
continue
# compute the rotated bounding box of the contour, then
# draw the contours
box = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box)
box = np.array(box, dtype="int")
cv2.drawContours(image, [box], -1, (0, 255, 0), 2)
# show the original coordinates
print("Object #{}:".format(i + 1))
print(box)
第 61 条线开始在我们的轮廓上循环。如果轮廓不够大(由于边缘检测过程中的“噪声”),我们丢弃轮廓区域(线 63 和 64 )。
否则,行 68-71 处理计算轮廓的旋转边界框(注意使用cv2.cv.BoxPoints[如果我们使用 OpenCV 2.4]或cv2.boxPoints[如果我们使用 OpenCV 3])并在image上绘制轮廓。
我们还将打印原始的旋转边界box,这样我们可以在排序坐标后比较结果。
我们现在准备按顺时针方向排列边界框坐标:
# order the points in the contour such that they appear
# in top-left, top-right, bottom-right, and bottom-left
# order, then draw the outline of the rotated bounding
# box
rect = order_points_old(box)
# check to see if the new method should be used for
# ordering the coordinates
if args["new"] > 0:
rect = perspective.order_points(box)
# show the re-ordered coordinates
print(rect.astype("int"))
print("")
第 81 行应用原始的(即有缺陷的)order_points_old函数按照左上、右上、右下、左下的顺序排列我们的包围盒坐标。
如果--new 1标志已经传递给我们的脚本,那么我们将应用我们的更新的 order_points函数(第 85 和 86 行)。
就像我们将原始边界框打印到我们的控制台一样,我们也将打印有序点,这样我们可以确保我们的功能正常工作。
最后,我们可以看到我们的结果:
# loop over the original points and draw them
for ((x, y), color) in zip(rect, colors):
cv2.circle(image, (int(x), int(y)), 5, color, -1)
# draw the object num at the top-left corner
cv2.putText(image, "Object #{}".format(i + 1),
(int(rect[0][0] - 15), int(rect[0][1] - 15)),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (255, 255, 255), 2)
# show the image
cv2.imshow("Image", image)
cv2.waitKey(0)
我们开始在线 93 上循环我们的(希望)有序坐标,并在我们的image上绘制它们。
根据colors列表,左上角应该是红色,右上角紫色,右下角蓝色,最后是左下角青色。
最后,第 97-103 行在我们的image上画出物体编号并显示输出结果。
要使用最初有缺陷的实现来执行我们的脚本,只需发出以下命令:
$ python order_coordinates.py

Figure 2: Arranging our rotated bounding box coordinates in top-left, top-right, bottom-right, and bottom-left order…but with a major flaw (take a look at Object #6).
正如我们所看到的,我们的输出是按照左上、右上、右下和左下排列的顺时针顺序排列的,除了对象#6!
注: 看看输出的圆圈——注意怎么没有蓝色的?
查看对象#6 的终端输出,我们可以看到原因:

Figure 3: Take a look at the bounding box coordinates for Object #6. And then see what happens what happens when we take their sum and differences.
对这些坐标求和,我们最终得到:
- 520 + 255 = 775
- 491 + 226 = 717
- 520 + 197 = 717
- 549 + 226 = 775
而这种差异给了我们:
- 520 – 255 = 265
- 491 – 226 = 265
- 520 – 197 = 323
- 549 – 226 = 323
正如你所看到的, 我们最终得到了重复的值!
由于有重复的值,argmin()和argmax()函数并不像我们期望的那样工作,给了我们一组不正确的“有序”坐标。
为了解决这个问题,我们可以使用 imutils 包中更新的order_points函数。我们可以通过发出以下命令来验证我们更新的函数是否正常工作:
$ python order_coordinates.py --new 1
这一次,我们所有的点都被正确排序,包括对象#6:
Figure 4: Correctly ordering coordinates clockwise with Python and OpenCV.
当利用透视变换(或任何其他需要有序坐标的项目)时,确保使用我们更新的实现!
摘要
在这篇博文中,我们开始了一个由三部分组成的系列,分别是计算图像中物体的尺寸和测量物体之间的距离。为了实现这些目标,我们需要对与每个对象的旋转边界框相关的 4 个点进行排序。
我们已经在之前的博客文章中实现了这样的功能;然而,正如我们所发现的,这个实现有一个致命的缺陷——在非常特殊的情况下,它会返回错误的坐标。
为了解决这个问题,我们定义了一个新的、更新的order_points函数,并把它放在 imutils 包中。这个实现确保了我们的点总是被正确排序。
既然我们可以以可靠的方式排序我们的 (x,y)-坐标,我们可以继续进行测量图像中物体的大小,这正是我将在我们的下一篇博客文章中讨论的。
请务必在下面的表格中输入您的电子邮件地址,注册 PyImageSearch 时事通讯— 您一定不想错过这一系列的帖子!【T2**
使用 Raspberry Pi 和 OpenCV 进行平移/倾斜人脸跟踪
原文:https://pyimagesearch.com/2019/04/01/pan-tilt-face-tracking-with-a-raspberry-pi-and-opencv/

在本教程中,您将学习如何使用 Raspberry Pi、Python 和计算机视觉来执行平移和倾斜对象跟踪。
我最喜欢的 Raspberry Pi 的一个特性是可以连接到 Pi 上的大量额外硬件。无论是摄像头、温度传感器、陀螺仪/加速度计,甚至是触摸传感器,围绕 Raspberry Pi 的社区让它几乎可以完成任何事情。
但是我最喜欢的树莓派的附件之一是云台相机。
使用两个伺服系统,这个附加组件使我们的相机能够同时从左到右和上下移动,允许我们检测和跟踪物体,即使它们会“超出画面”(如果一个物体接近传统相机的画面边界,就会发生这种情况)。
*今天我们将使用云台摄像机进行物体跟踪,更具体地说,是面部跟踪。
要了解如何使用树莓派和 OpenCV、 执行平移和倾斜跟踪,请继续阅读!
使用 Raspberry Pi 和 OpenCV 进行平移/倾斜人脸跟踪
在本教程的第一部分,我们将简要介绍什么是云台跟踪,以及如何使用伺服系统来完成。我们还将配置我们的 Raspberry Pi 系统,以便它可以与 PanTiltHAT 通信并使用摄像机。
从那里我们还将回顾 PID 控制器的概念,它是控制系统中常用的控制回路反馈机制。
然后,我们将实现我们的 PID 控制器,面部检测器+对象跟踪器,以及用于执行平移/倾斜跟踪的驱动程序脚本。
我还将介绍手动 PID 调节基础——一项基本技能。
让我们开始吧!
什么是平移/倾斜物体跟踪?

Figure 1: The Raspberry Pi pan-tilt servo HAT by Pimoroni.
平移和倾斜目标跟踪的目标是使摄像机保持在目标的中心。
通常这种跟踪是由两个伺服系统完成的。在我们的例子中,我们有一个伺服系统用于左右移动。我们有单独的伺服系统用于 上下倾斜。
我们的每个伺服系统和夹具本身都有 180 度的范围(有些系统的范围比这个更大)。
今天项目的硬件要求
您将需要以下硬件来复制今天的项目:
- 树莓派–我推荐 3B+或 3B,但其他型号也可以,只要它们有相同的插头引脚布局。
- 我推荐皮卡梅拉·V2
- 皮莫尔尼云台帽全套套件–皮莫尔尼套件是一款优质产品,它没有让我失望。安排大约 30 分钟的集合时间。我不推荐 SparkFun 套件,因为它需要焊接和额外的组装。
- 2.5A、5V 电源–如果您提供的电源低于 2.5A,您的 Pi 可能没有足够的电流使其复位。为什么?因为伺服系统把必要的电流带走了。获得一个电源,并将其专用于此项目硬件。
- HDMI 屏幕–当你四处走动时,在你的相机旁边放置一个 HDMI 屏幕将允许你进行可视化和调试,这对于手动调谐是必不可少的。不要尝试 X11 转发,它对于视频应用程序来说太慢了。如果你没有 HDMI 屏幕,VNC 是可能的,但我还没有找到一种简单的方法来启动 VNC,而不需要插入实际的屏幕。
- 键盘/鼠标——显而易见的原因。
为 PantiltHat 安装软件
对于今天的项目,您需要以下软件:
- OpenCV
- smbus
- 潘蒂尔特
- imutils
除了 smbus 的 之外,任何东西都可以通过 pip 轻松安装。让我们回顾一下这些步骤:
步骤#1: 创建一个虚拟环境并安装 OpenCV
前往我的 pip install opencv 博客帖子,你将学习如何在安装了 opencv 的 Python 虚拟环境中设置你的 Raspberry Pi。我把我的虚拟环境命名为py3cv4。
第二步:将smbus符号链接到您的py3cv4虚拟环境中
按照以下说明安装smbus:
$ cd ~/.virtualenvs/py3cv4/lib/python3.5/site-packages/
$ ln -s /usr/lib/python3/dist-packages/smbus.cpython-35m-arm-linux-gnueabihf.so smbus.so
步骤#3: 启用 i2c 接口和摄像头接口
启动 Raspbian 系统配置,打开 i2c 和摄像头接口(可能需要重启)。
$ sudo raspi-config
# enable the i2c and camera interfaces via the menu
步骤#4: 安装pantilthat、imutils和摄像头
使用 pip,继续安装剩余的工具:
$ workon py3cv4
$ pip install pantilthat
$ pip install imutils
$ pip install "picamera[array]"
从现在开始你应该都准备好了!
什么是 PID 控制器?
常见的反馈控制回路是所谓的 PID 或比例积分微分控制器。
PID 通常用于自动化,使得机械致动器可以快速准确地达到最佳值(由反馈传感器读取)。
它们被用于制造业、发电厂、机器人等等。
PID 控制器计算误差项(期望的设定点和传感器读数之间的差),并且具有补偿误差的目标。
PID 计算输出一个值,该值用作“过程”(机电过程,不是美国计算机科学/软件工程师认为的“计算机过程”)的输入。
传感器输出被称为“过程变量”,并作为等式的输入。在整个反馈环路中,定时被捕获,并被输入到等式中。
维基百科有一个很棒的 PID 控制器图:
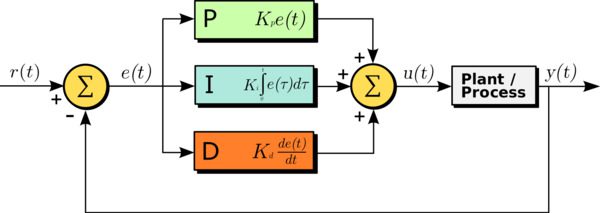
Figure 2: A Proportional Integral Derivative (PID) control loop will be used for each of our panning and tilting processes (image source).
注意输出是如何循环回到输入的。还要注意比例、积分和导数值是如何计算和求和的。
该数字可以用等式形式写成:
 = K_\text{p} e(t) + K_\text{i} \int_0^t e(t') ,dt' + K_\text{d} \frac{de(t)}{dt}")
我们来复习一下 P,I,和 D:
- P(比例):如果电流误差较大,则输出将按比例增大,从而导致显著校正。
- I(积分): 误差的历史值随时间积分。进行不太重要的校正以减少误差。如果消除了误差,这一项就不会增长。
- D(导数):这一项预见了的未来。实际上,这是一种阻尼方法。如果 P 或 I 将导致某个值超调(例如,伺服系统转过某个对象或方向盘转得太远),D 将在到达输出之前抑制该效果。
我需要学习更多关于 PIDs 的知识吗?哪里是最好的地方?
PID 是一个基本的控制理论概念。
有大量的资源。有些偏重数学,有些偏重概念。有些容易理解,有些不容易。
也就是说,作为一个软件程序员,你只需要知道如何实现一个和调优一个。即使你认为数学方程看起来很复杂,当你看到代码时,你将能够理解和理解。
如果你理解 PID 是如何工作的,那么它就更容易调优,但是只要你遵循本文后面演示的手动调优指南,你就不需要一直熟悉上面的等式。
只要记住:
- P–比例,存在(大修正)
- I–积分,“在过去”(历史)
- D–导数,阻尼(预测未来)
更多信息,维基百科 PID 控制器页面真的很棒,还链接到其他很棒的指南。
项目结构
一旦你抓取了今天的 【下载】 并提取它们,你会看到下面的目录结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── objcenter.py
│ └── pid.py
├── haarcascade_frontalface_default.xml
└── pan_tilt_tracking.py
1 directory, 5 files
今天我们将回顾三个 Python 文件:
objcenter.py:使用 Haar Cascade 人脸检测器计算人脸包围盒的中心。如果您愿意,您可以检测不同类型的对象,并将逻辑放在这个文件中。- 如上所述,这是我们的控制回路。我喜欢将 PID 保存在一个类中,这样我就可以根据需要创建新的
PID对象。今天我们有两个:(1)平移和(2)倾斜。 - 这是我们的平移/倾斜物体跟踪驱动脚本。它使用四个独立过程的多处理(其中两个用于平移和倾斜,一个用于寻找对象,一个用于以新的角度值驱动伺服系统)。
haarcascade_frontalface_default.xml是我们预先训练的 Haar Cascade 人脸检测器。Haar 与 Raspberry Pi 一起工作很好,因为它比 HOG 或深度学习需要更少的计算资源。
创建 PID 控制器
以下 PID 脚本基于乐儿机器人公司 GitBook 的例子以及维基百科伪代码。我添加了我自己的风格和格式,这是我的博客的读者(像你一样)所期望的。
继续打开pid.py。让我们回顾一下:
# import necessary packages
import time
class PID:
def __init__(self, kP=1, kI=0, kD=0):
# initialize gains
self.kP = kP
self.kI = kI
self.kD = kD
这个脚本实现了 PID 公式。基础数学很重。我们不需要导入高等数学库,但是我们需要导入第 2 行的中的time(我们唯一的导入)。
我们在第 4 行的上定义了一个名为PID的类。
PID类有三个方法:
__init__:构造者。initialize:初始化数值。这个逻辑可以在构造函数中,但是这样你就没有在任何时候重新初始化的便利选项了。update:这是进行计算的地方。
我们的构造函数在第 5-9 行的中定义,接受三个参数:kP、kI和kD。这些值是常量,在我们的驱动程序脚本中指定。在方法体中定义了三个相应的实例变量。
现在让我们回顾一下initialize:
def initialize(self):
# initialize the current and previous time
self.currTime = time.time()
self.prevTime = self.currTime
# initialize the previous error
self.prevError = 0
# initialize the term result variables
self.cP = 0
self.cI = 0
self.cD = 0
initialize方法在的第 13 行和第 14 行设置我们当前的时间戳和之前的时间戳(因此我们可以在update方法中计算时间增量)。
我们不言自明的先前误差项在第 17 行的中定义。
P、I 和 D 变量建立在行 20-22 上。
让我们转到 PID 类的核心——update方法:
def update(self, error, sleep=0.2):
# pause for a bit
time.sleep(sleep)
# grab the current time and calculate delta time
self.currTime = time.time()
deltaTime = self.currTime - self.prevTime
# delta error
deltaError = error - self.prevError
# proportional term
self.cP = error
# integral term
self.cI += error * deltaTime
# derivative term and prevent divide by zero
self.cD = (deltaError / deltaTime) if deltaTime > 0 else 0
# save previous time and error for the next update
self.prevtime = self.currTime
self.prevError = error
# sum the terms and return
return sum([
self.kP * self.cP,
self.kI * self.cI,
self.kD * self.cD])
我们的更新方法接受两个参数:以秒为单位的error值和sleep。
在update方法中,我们:
- 在线 26 上睡眠预定的时间,从而防止更新太快,以至于我们的伺服系统(或另一个致动器)不能足够快地响应。应该根据对机械、计算甚至通信协议限制的了解来明智地选择
sleep值。在没有先验知识的情况下,你应该尝试看起来最有效的方法。 - 计算
deltaTime( 第 30 行)。更新不会总是在同一时间到来(我们无法控制)。因此,我们计算前一次更新和现在(当前更新)之间的时间差。这将影响我们的cI和cD条款。 - 计算
deltaError( 第 33 行)提供的error和prevError之差。
然后我们计算我们的PID控制项:
cP:我们的比例项等于error项。cI:我们的积分项就是error乘以deltaTime。cD:我们的导数项是deltaError对deltaTime。被零除是有原因的。
最后,我们:
- 设置
prevTime和prevError( 线 45 和 46 )。我们将在下一次update中需要这些值。 - 返回计算项乘以常数项的总和(第 49-52 行)。
请记住,更新将以快节奏的循环方式进行。根据您的需要,您应该调整sleep参数(如前所述)。
实现面部检测器和对象中心跟踪器
![]()
Figure 3: Panning and tilting with a Raspberry Pi camera to keep the camera centered on a face.
我们的云台追踪器的目标是让摄像机以物体本身为中心。
为了实现这一目标,我们需要:
- 检测对象本身。
- 计算对象的中心 (x,y)-坐标。
让我们继续实现我们的ObjCenter类,它将实现这两个目标:
# import necessary packages
import imutils
import cv2
class ObjCenter:
def __init__(self, haarPath):
# load OpenCV's Haar cascade face detector
self.detector = cv2.CascadeClassifier(haarPath)
该脚本需要导入imutils和cv2。
我们的ObjCenter类定义在行第 5 上。
在第 6 行的上,构造函数接受一个参数 Haar Cascade 人脸检测器的路径。
我们用哈尔方法来寻找人脸。请记住,树莓派(即使是 3B+)是一个资源有限的设备。如果你选择使用较慢(但更准确)的 HOG 或 CNN,请记住,你会希望减慢 PID 计算,这样它们不会比你实际检测新的面部坐标更快。
注:您也可以选择使用 Movidius NCS 或谷歌珊瑚 TPU USB 加速器进行人脸检测。我们将在未来的教程/计算机视觉的Raspberry Pi书中涉及这个概念。
在线 8 上detector被初始化。
让我们定义update方法,该方法将找到一个面的中心 (x,y)- 坐标:
def update(self, frame, frameCenter):
# convert the frame to grayscale
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect all faces in the input frame
rects = self.detector.detectMultiScale(gray, scaleFactor=1.05,
minNeighbors=9, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
# check to see if a face was found
if len(rects) > 0:
# extract the bounding box coordinates of the face and
# use the coordinates to determine the center of the
# face
(x, y, w, h) = rects[0]
faceX = int(x + (w / 2.0))
faceY = int(y + (h / 2.0))
# return the center (x, y)-coordinates of the face
return ((faceX, faceY), rects[0])
# otherwise no faces were found, so return the center of the
# frame
return (frameCenter, None)
今天的项目有两个update方法,所以我在这里花点时间解释一下它们的区别:
- 我们之前回顾了
PIDupdate方法。该方法执行 PID 计算,以帮助计算伺服角度,从而将面部保持在相机视图的中心。 - 现在我们在复习
ObjCcenterupdate法。这个方法简单地找到一个面并返回它的中心坐标。
update方法(用于查找面部)在行 10 上定义,接受两个参数:
- 理想的包含一张脸的图像。
frameCenter:框架的中心坐标。
该帧在第 12 行转换为灰度。
从那里我们使用哈尔级联detectMultiScale方法执行面部检测。
在行 20-26 上,我们检查人脸是否已经被检测到,并从那里计算中心 (x,y)——人脸本身的坐标。
第 20-24 行做了一个重要的假设:我们假设在任何时候只有一个面在帧中,并且那个面可以被rects的第 0 个索引访问。
注:如果没有这个假设成立,将需要额外的逻辑来确定要跟踪哪个*。参见本帖的“树莓 Pi 对平移/倾斜人脸跟踪的改进”部分。在这里我描述了如何用 Haar 处理多个人脸检测。*
面的中心以及边界框坐标在第 29 行返回。为了显示的目的,我们将使用边界框坐标在面的周围画一个框。
否则,当没有发现人脸时,我们简单地返回帧的中心(这样伺服停止并且不做任何修正,直到再次发现人脸)。
我们的平移和倾斜驱动程序脚本
让我们把这些部分放在一起,实现我们的平移和倾斜驱动程序脚本!
打开pan_tilt_tracking.py文件并插入以下代码:
# import necessary packages
from multiprocessing import Manager
from multiprocessing import Process
from imutils.video import VideoStream
from pyimagesearch.objcenter import ObjCenter
from pyimagesearch.pid import PID
import pantilthat as pth
import argparse
import signal
import time
import sys
import cv2
# define the range for the motors
servoRange = (-90, 90)
在第 2-12 行我们导入必要的库。值得注意的是,我们将使用:
Process和Manager将帮助我们处理multiprocessing和共享变量。- 允许我们从相机中抓取画面。
ObjCenter将帮助我们定位帧中的对象,而PID将通过计算我们的伺服角度来帮助我们将对象保持在帧的中心。pantilthat是用于与树莓派皮莫尔尼云台帽接口的库。
我们在云台上的伺服范围为 180 度(-90 度到 90 度),如行 15 所定义。这些值应该反映出你的伺服系统的局限性。
我们来定义一个【ctrl+c】signal_handler:
# function to handle keyboard interrupt
def signal_handler(sig, frame):
# print a status message
print("[INFO] You pressed `ctrl + c`! Exiting...")
# disable the servos
pth.servo_enable(1, False)
pth.servo_enable(2, False)
# exit
sys.exit()
这个多重处理脚本可能很难退出。有很多方法可以实现它,但我决定采用一种signal_handler方法。
signal_handler是一个在后台运行的线程,将使用 Python 的signal模块调用它。它接受两个参数,sig和frame。sig就是信号本身(一般是“ctrl+c”)。frame是 不是视频帧 实际上是执行帧 。
我们需要在每个进程中启动signal_handler线程。
第 20 行打印状态信息。23 号线和 24 号线关闭我们的伺服系统。而第 27 行退出我们的节目。
您可能会把这个脚本作为一个整体来看,并且认为“如果我有四个进程,并且signal_handler正在其中的每一个中运行,那么这将会发生四次。”
你说的完全正确,但是这是一种简洁且易于理解的终止进程的方式,而不是在一秒钟内尽可能多地按下 "ctrl + c" 来尝试终止所有进程。想象一下,如果您有 10 个进程,并且试图用“ctrl+c”方法杀死它们。
现在我们知道了我们的流程将如何退出,让我们定义我们的第一个流程:
def obj_center(args, objX, objY, centerX, centerY):
# signal trap to handle keyboard interrupt
signal.signal(signal.SIGINT, signal_handler)
# start the video stream and wait for the camera to warm up
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# initialize the object center finder
obj = ObjCenter(args["cascade"])
# loop indefinitely
while True:
# grab the frame from the threaded video stream and flip it
# vertically (since our camera was upside down)
frame = vs.read()
frame = cv2.flip(frame, 0)
# calculate the center of the frame as this is where we will
# try to keep the object
(H, W) = frame.shape[:2]
centerX.value = W // 2
centerY.value = H // 2
# find the object's location
objectLoc = obj.update(frame, (centerX.value, centerY.value))
((objX.value, objY.value), rect) = objectLoc
# extract the bounding box and draw it
if rect is not None:
(x, y, w, h) = rect
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0),
2)
# display the frame to the screen
cv2.imshow("Pan-Tilt Face Tracking", frame)
cv2.waitKey(1)
我们的obj_center线程从第 29 行开始,接受五个变量:
- 我们的命令行参数字典(在我们的主线程中创建)。
objX和objY:物体的 (x,y)——坐标。我们会不断计算。centerX和centerY:框架的中心。
在第 31 条线上,我们开始了我们的signal_handler。
然后,在线 34 和 35 上,我们为PiCamera启动VideoStream,让它预热两秒钟。
我们的ObjCenter在第 38 行被实例化为obj。我们的级联路径被传递给构造函数。
从这里开始,我们的流程进入第 41 行的无限循环。摆脱循环的唯一方法是用户键入“ctrl+c”,因为你会注意到没有break命令。
我们的frame在线 44 和 45 上被抓取和翻转。我们必须flipT2,因为按照设计PiCamera在云台固定装置中是上下颠倒的。
第 49-51 行设置我们的框架宽度和高度,并计算框架的中心点。你会注意到我们使用.value来访问我们的中心点变量——这是在进程间共享数据的Manager方法所需要的。
为了计算我们的对象在哪里,我们将简单地调用obj上的update方法,同时传递视频frame。我们也传递中心坐标的原因是,如果没有看到 Haar 面,我们就让ObjCenter类返回框架中心。实际上,这使得 PID 误差 0,因此,伺服停止移动,并留在他们当前的位置,直到一个脸被发现。
注意:如果检测不到人脸,我选择返回画面中心。或者,您可能希望返回检测到人脸的最后位置的坐标。这是一个实施选择,我将留给你。
在第 55 行的上解析update的结果,在那里我们的对象坐标和边界框被赋值。
最后的步骤是在我们的脸周围画一个矩形(行 58-61 )并显示视频帧(行 64 和 65 )。
让我们定义下一个流程,pid_process:
def pid_process(output, p, i, d, objCoord, centerCoord):
# signal trap to handle keyboard interrupt
signal.signal(signal.SIGINT, signal_handler)
# create a PID and initialize it
p = PID(p.value, i.value, d.value)
p.initialize()
# loop indefinitely
while True:
# calculate the error
error = centerCoord.value - objCoord.value
# update the value
output.value = p.update(error)
我们的pid_process很简单,因为繁重的工作由PID级负责。这些过程中的两个将在任何给定时间运行(平移和倾斜)。如果你有一个复杂的机器人,你可能有更多的 PID 进程在运行。
该方法接受六个参数:
output:由我们的 PID 控制器计算出的伺服角度。这将是一个平移或倾斜角度。p、i、d:我们的 PID 常数。objCoord:这个值被传递给进程,以便进程可以跟踪对象的位置。对于平移,它是一个 x 坐标。同样,对于倾斜,它是一个 y 坐标。centerCoord:用来计算我们的error,这个值正好是画面的中心(或者是 x 或者是 y 取决于我们是平移还是倾斜)。
一定要追踪每个参数,直到在这个程序的主线程中进程开始的地方。
在 69 号线的上,我们开始了我们的特别节目signal_handler。
然后我们在第 72 行上实例化我们的 PID,传递 P、I 和 D 值。
随后,PID对象被初始化(第 73 行)。
现在,有趣的部分只出现在两行代码中:
- 计算第 78 行上的
error。例如,这可能是框架的y-中心减去对象的y-倾斜位置。 - 调用
update( 第 81 行),传递新的错误(如果需要,还有一个睡眠时间)。返回值是output.value。继续我们的例子,这将是以度为单位的倾斜角。
我们有另一个线程“监视”每个output.value来驱动伺服系统。
说到驱动我们的伺服系统,现在让我们实现一个伺服范围检查器和我们的伺服驱动器:
def in_range(val, start, end):
# determine the input value is in the supplied range
return (val >= start and val <= end)
def set_servos(pan, tlt):
# signal trap to handle keyboard interrupt
signal.signal(signal.SIGINT, signal_handler)
# loop indefinitely
while True:
# the pan and tilt angles are reversed
panAngle = -1 * pan.value
tiltAngle = -1 * tlt.value
# if the pan angle is within the range, pan
if in_range(panAngle, servoRange[0], servoRange[1]):
pth.pan(panAngle)
# if the tilt angle is within the range, tilt
if in_range(tiltAngle, servoRange[0], servoRange[1]):
pth.tilt(tiltAngle)
第 83-85 行定义了一个in_range方法来确定一个值是否在一个特定的范围内。
从那里,我们将用set_servos方法驱动我们的伺服系统到特定的平移和倾斜角度。
我们的set_servos方法将在另一个进程中运行。它接受pan和tlt值,并将观察这些值的更新。这些值本身通过我们的pid_process不断调整。
我们把我们的signal_handler建立在线 89 上。
从那里,我们将开始我们的无限循环,直到捕捉到一个信号:
- 我们的
panAngle和tltAngle值为负,以适应伺服系统和摄像机的方向(行 94 和 95 )。 - 然后,我们检查每个值,确保其在范围内,并将伺服驱动到新的角度(行 98-103 )。
那很容易。
现在让我们解析命令行参数:
# check to see if this is the main body of execution
if __name__ == "__main__":
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", type=str, required=True,
help="path to input Haar cascade for face detection")
args = vars(ap.parse_args())
执行主体从行 106 开始。
我们在第 108-111 行解析我们的命令行参数。我们只有一个——磁盘上的哈尔级联路径。
现在让我们使用进程安全变量并开始我们的进程:
# start a manager for managing process-safe variables
with Manager() as manager:
# enable the servos
pth.servo_enable(1, True)
pth.servo_enable(2, True)
# set integer values for the object center (x, y)-coordinates
centerX = manager.Value("i", 0)
centerY = manager.Value("i", 0)
# set integer values for the object's (x, y)-coordinates
objX = manager.Value("i", 0)
objY = manager.Value("i", 0)
# pan and tilt values will be managed by independed PIDs
pan = manager.Value("i", 0)
tlt = manager.Value("i", 0)
在Manager块中,建立了我们的过程安全变量。我们有相当多的。
首先,我们启用线 116 和 117 上的伺服系统。没有这些线,硬件就不行。
让我们看看我们的第一批过程安全变量:
- 帧中心坐标为整数(用
"i"表示),初始化为0( 第 120 行和第 121 行)。 - 物体中心坐标,也是整数,并初始化为
0( 第 124 行和第 125 行)。 - 我们的
pan和tlt角度(第 128 和 129 行)是整数,我已经设置为从中心开始指向一个面(角度为0度)。
现在我们将设置 P、I 和 D 常数:
# set PID values for panning
panP = manager.Value("f", 0.09)
panI = manager.Value("f", 0.08)
panD = manager.Value("f", 0.002)
# set PID values for tilting
tiltP = manager.Value("f", 0.11)
tiltI = manager.Value("f", 0.10)
tiltD = manager.Value("f", 0.002)
我们的平移和倾斜 PID 常量(过程安全)在行 132-139 上设置。这些是彩车。请务必查看下一节的 PID 调节,了解我们如何找到合适的值。为了从这个项目中获得最大的价值,我建议将每个设置为零,并遵循调优方法/过程(不要与计算机科学方法/过程混淆)。
所有流程安全变量准备就绪后,让我们启动流程:
# we have 4 independent processes
# 1\. objectCenter - finds/localizes the object
# 2\. panning - PID control loop determines panning angle
# 3\. tilting - PID control loop determines tilting angle
# 4\. setServos - drives the servos to proper angles based
# on PID feedback to keep object in center
processObjectCenter = Process(target=obj_center,
args=(args, objX, objY, centerX, centerY))
processPanning = Process(target=pid_process,
args=(pan, panP, panI, panD, objX, centerX))
processTilting = Process(target=pid_process,
args=(tlt, tiltP, tiltI, tiltD, objY, centerY))
processSetServos = Process(target=set_servos, args=(pan, tlt))
# start all 4 processes
processObjectCenter.start()
processPanning.start()
processTilting.start()
processSetServos.start()
# join all 4 processes
processObjectCenter.join()
processPanning.join()
processTilting.join()
processSetServos.join()
# disable the servos
pth.servo_enable(1, False)
pth.servo_enable(2, False)
每个过程在行 147-153 开始,传递所需的过程安全值。我们有四个流程:
- 在帧中找到对象的过程。在我们的例子中,它是一张脸。
- 用 PID 计算摇摄(左右)角度的过程。
- 用 PID 计算倾斜(上下)角度的过程。
- 驱动伺服系统的过程。
每个过程被启动,然后被加入(行 156-165 )。
当所有程序退出时,伺服系统被禁用(行 168 和 169 )。这也发生在signal_handler中以防万一。
独立调整平移和倾斜 PID,这是关键的一步
那是很大的工作量!
现在我们已经理解了代码,我们需要对两个独立的 PID(一个用于平移,一个用于倾斜)进行手动调谐。
调整 PID 可以确保我们的伺服系统平稳地跟踪物体(在我们的例子中,是一张脸)。
请务必参考 PID 维基百科文章中的手动调谐部分。
本文指导您按照这个过程来调整 PID:
- 将
kI和kD设置为零。 - 从零开始增加
kP直到输出振荡(即伺服来回或上下)。然后将该值设置为一半。 - 增加
kI,直到偏移被快速校正,知道值太高会导致不稳定。 - 增加
kD,直到负载扰动后输出快速稳定在所需的输出参考值(即,如果你快速移动你的脸)。过多的kD会导致过度的响应,使你的输出在需要的地方过冲。
我再怎么强调这一点也不为过:在调优时做一些小的改变。
让我们准备手动调整这些值。
即使您已经完成了前面的部分,也要确保使用本教程的 “下载” 部分来下载本指南的源代码。
使用 SCP 或其他方法将 zip 文件传输到您的 Raspberry Pi。在您的 Pi 上,解压文件。
我们将独立调整 PID,首先通过调整倾斜过程。
继续 注释掉驱动脚本中的平移过程:
# start all 4 processes
processObjectCenter.start()
#processPanning.start()
processTilting.start()
processSetServos.start()
# join all 4 processes
processObjectCenter.join()
#processPanning.join()
processTilting.join()
processSetServos.join()
从那里,打开一个终端并执行以下命令:
$ python pan_tilt_tracking.py --cascade haarcascade_frontalface_default.xml
您需要遵循上面的手动调谐指南来调谐倾斜过程。
在此过程中,您需要:
- 启动程序,上下移动面部,导致相机倾斜。我推荐做屈膝深蹲,直视镜头。
- 停止程序+根据调谐指南调整值。
- 重复直到你对结果(以及值)满意。它应该倾斜得很好,位移很小,脸的位置变化很大。一定要两个都测试。
此时,让我们切换到另一个 PID。这些值是相似的,但是也有必要对它们进行调整。
继续, 注释掉倾斜过程(完全调谐)。
从那里取消平移过程的注释:
# start all 4 processes
processObjectCenter.start()
processPanning.start()
#processTilting.start()
processSetServos.start()
# join all 4 processes
processObjectCenter.join()
processPanning.join()
#processTilting.join()
processSetServos.join()
再次执行以下命令:
$ python pan_tilt_tracking.py --cascade haarcascade_frontalface_default.xml
现在再次按照上述步骤调整平移过程。
利用 Raspberry Pi 和 OpenCV 进行云台跟踪
有了新调整的 PID 常数,让我们来测试一下我们的云台摄像机。
假设您遵循了上一节,确保两个过程(平移和倾斜)都已取消注释并准备就绪。
从那里,打开一个终端并执行以下命令:
$ python pan_tilt_tracking.py --cascade haarcascade_frontalface_default.xml
一旦脚本完成并运行,你就可以走到你的摄像机前了。
如果一切顺利,你应该看到你的脸被检测到和追踪到,类似于下面的 GIF:
Figure 4: Raspberry Pi pan tilt face tracking in action.
如你所见,云台摄像机很好地跟踪了我的脸。
使用 Raspberry Pi 改进平移/倾斜跟踪
有时相机会遇到一个假阳性脸,导致控制回路失控。不要被骗了!您的 PID 工作正常,但是您的计算机视觉环境用错误信息影响了系统。
我们选择 Haar 是因为它速度快,但是请记住 Haar 可能会导致假阳性:
- 哈尔没有猪那么准确。生猪是伟大的,但与哈尔相比是资源饥饿。
- 与深度学习人脸检测方法相比,Haar 远不准确。DL 方法太慢,不能在 Pi 上实时运行。如果你尝试使用它,平移和倾斜会很不平稳。
我的建议是你在一个新的环境中设置你的云台摄像机,看看这样是否能改善拍摄效果。例如,我们正在测试面部跟踪,我们发现由于地板、冰箱等的反射,它在厨房中工作得不好。然而,当我们将相机瞄准窗外,我站在外面时,跟踪效果显著提高,因为ObjCenter为面部提供了合法的值,因此我们的 PID 可以完成它的工作。
框架里有两张脸怎么办?
或者如果我是画面中唯一的一张脸,但总是有一个假阳性呢?
这是一个很棒的问题。一般来说,您可能只想跟踪一张脸,所以有很多选择:
- 使用置信度值,选择置信度最高的人脸。这是不可能使用默认的 Haar 检测器代码,因为它不报告置信度值。相反,让我们探索其他选择。
- 设法得到
rejectLevels和rejectWeightsT3。我从未尝试过,但以下链接可能会有所帮助: - 抓取最大的边界框 —简单易行。
- 选择最靠近框架中心的面部。由于相机试图保持面部最接近中心,我们可以计算所有质心边界框和中心 (x,y)-帧坐标之间的欧几里德距离。将选择最靠近质心的边界框。
摘要
在本教程中,您学习了如何使用 Raspberry Pi、OpenCV 和 Python 执行平移和倾斜跟踪。
为了完成这个任务,我们首先需要一个云台摄像机。
从那里我们实现了反馈控制回路中使用的 PID。
一旦我们有了 PID 控制器,我们就能够实现人脸检测器本身。
人脸检测器有一个目标——检测输入图像中的人脸,然后返回人脸边界框的中心 (x,y) 坐标,使我们能够将这些坐标传递到我们的平移和倾斜系统中。
从那里开始,伺服系统会将摄像机对准物体本身。
我希望你喜欢今天的教程!
要下载这篇文章的源代码,并在未来教程在 PyImageSearch、 上发布时得到通知,只需在下面的表格中输入您的电子邮件地址!*
行人检测 opencv
原文:https://pyimagesearch.com/2015/11/09/pedestrian-detection-opencv/

这些年来,我遇到了很多令人惊讶、令人振奋的人。帮助我读完研究生的博士导师。我的父亲总是在我小时候陪着我,现在也是。还有我的女朋友,她一直都很积极,乐于助人,支持我(即使我可能不配)。
我也遇到过一些令人沮丧、气馁的人。竭尽全力阻止我创业和为自己工作的家人。那些要么不喜欢我,要么不喜欢我的工作,并选择以公开的方式表达他们的鄙视的同事们。还有一些人在电子邮件、推特和其他网络渠道上说了一些令人沮丧的话。
我们都熟悉这些类型的人。然而,不管他们的态度如何(无论积极还是消极),我们都是由四种核碱基的相同遗传物质构成的:胞嘧啶、鸟嘌呤、腺嘌呤和胸腺嘧啶。
这些碱基对以这样一种方式组合在一起,使得我们的身体都具有相同的基本结构,而不管性别、种族或民族如何。**在最结构的层面上,我们都有一个头、两条胳膊、一个躯干和两条腿。**
我们可以使用计算机视觉来开发这种半刚性结构,并提取特征来量化人体。这些特征可以传递给机器学习模型,当经过训练时,这些模型可以用来在图像和视频流中 检测 和 跟踪 人类。这对于 行人检测 的任务特别有用,这也是我们今天博文要讨论的话题。
请继续阅读,了解如何使用 OpenCV 和 Python 来执行行人检测。
行人检测 opencv
您知道 OpenCV 有 内置方法 来执行行人检测吗?
OpenCV 附带了一个预训练的 HOG +线性 SVM 模型,可用于在图像和视频流中执行行人检测。如果你不熟悉梯度方向直方图和线性 SVM 方法,我建议你阅读这篇博客文章,我在这里讨论了 6 步框架 。
如果你已经熟悉这个过程(或者如果你只是想看一些关于如何使用 OpenCV 进行行人检测的代码),只需打开一个新文件,命名为detect.py,我们就会得到代码:
# import the necessary packages
from __future__ import print_function
from imutils.object_detection import non_max_suppression
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True, help="path to images directory")
args = vars(ap.parse_args())
# initialize the HOG descriptor/person detector
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
2-8 线从导入我们必要的包开始。我们将导入print_function以确保我们的代码兼容 Python 2.7 和 Python 3(该代码也适用于 OpenCV 2.4.X 和 OpenCV 3)。从那里,我们将从我的 imutils 包中导入non_max_suppression函数。
如果您的 没有 安装imutils,让pip为您安装:
$ pip install imutils
如果你 做 安装了imutils,你需要升级到最新版本( v0.3.1 ),其中包括non_max_suppression功能的实现,以及其他一些小的更新:
$ pip install --upgrade imutils
我已经在 PyImageSearch 博客上讨论过两次非极大值抑制,一次是在这篇介绍性文章中,另一次是在这篇关于实现更快的 NMS 算法的文章中。在任一情况下,非最大值抑制算法的要点是采用多个重叠的边界框,并将它们减少到只有一个边界框:

Figure 1: (Left) Multiple bounding boxes are falsely detected for the person in the image. (Right) Applying non-maxima suppression allows us to suppress overlapping bounding boxes, leaving us with the correct final detection.
这有助于减少最终对象检测器报告的误报数量。
第 11-13 行处理解析我们的命令行参数。这里我们只需要一个开关,--images,它是到包含我们将要对其执行行人检测的图像列表的目录的路径。
最后,16 号线和 17 号线初始化我们的行人探测器。首先,我们调用hog = cv2.HOGDescriptor()来初始化梯度方向直方图描述符。然后,我们调用setSVMDetector将支持向量机设置为预训练的行人检测器,通过cv2.HOGDescriptor_getDefaultPeopleDetector()函数加载。
此时,我们的 OpenCV 行人检测器已完全加载,我们只需将其应用于一些图像:
# loop over the image paths
for imagePath in paths.list_images(args["images"]):
# load the image and resize it to (1) reduce detection time
# and (2) improve detection accuracy
image = cv2.imread(imagePath)
image = imutils.resize(image, width=min(400, image.shape[1]))
orig = image.copy()
# detect people in the image
(rects, weights) = hog.detectMultiScale(image, winStride=(4, 4),
padding=(8, 8), scale=1.05)
# draw the original bounding boxes
for (x, y, w, h) in rects:
cv2.rectangle(orig, (x, y), (x + w, y + h), (0, 0, 255), 2)
# apply non-maxima suppression to the bounding boxes using a
# fairly large overlap threshold to try to maintain overlapping
# boxes that are still people
rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects])
pick = non_max_suppression(rects, probs=None, overlapThresh=0.65)
# draw the final bounding boxes
for (xA, yA, xB, yB) in pick:
cv2.rectangle(image, (xA, yA), (xB, yB), (0, 255, 0), 2)
# show some information on the number of bounding boxes
filename = imagePath[imagePath.rfind("/") + 1:]
print("[INFO] {}: {} original boxes, {} after suppression".format(
filename, len(rects), len(pick)))
# show the output images
cv2.imshow("Before NMS", orig)
cv2.imshow("After NMS", image)
cv2.waitKey(0)
在第 20 行我们开始循环浏览--images目录中的图像。这篇博文中的示例(以及本文源代码下载中包含的其他图片)是来自流行的 INRIA 个人数据集的样本(具体来说,来自 GRAZ-01 子集)。
从那里,第 23-25 行处理从磁盘上加载我们的图像,并调整它的最大宽度为 400 像素。我们试图减少图像尺寸的原因有两个:
- 减小图像尺寸确保需要评估图像金字塔中的更少的滑动窗口(即,从线性 SVM 中提取 HOG 特征,然后传递给线性),从而减少检测时间(并增加整体检测吞吐量)。
- 调整我们的图像大小也提高了我们的行人检测的整体准确性(即,更少的误报)。
通过调用hog描述符的detectMultiScale方法,第行第 28 行和第 29 行实际检测图像中的行人。detectMultiScale方法分别在 x 和 y 方向上构建具有scale=1.05和(4, 4)像素的滑动窗口步长的图像金字塔。
滑动窗口的大小固定在64×128 像素,如开创性的 Dalal 和 Triggs 论文 用于人体检测的定向梯度直方图所建议的。detectMultiScale函数返回一个二元组的rects,或边界框 (x,y)-图像中每个人的坐标,以及weights,SVM 为每个检测返回的置信度值。
较大的scale尺寸将评估图像金字塔中的较少的层,这可以使算法运行得更快。然而,使的比例过大(即图像金字塔中的层数较少)会导致无法检测到行人。类似地,使scale尺寸的过小会显著增加需要评估的图像金字塔层数。这不仅会造成计算上的浪费,还会显著增加行人检测器检测到的误报数量。也就是说,在执行行人检测时,scale是最重要的参数之一。我将在以后的博客文章中对detectMultiScale的每个参数进行更彻底的回顾。
第 32 行和第 33 行获取我们的初始边界框,并把它们画在我们的图像上。
然而,对于一些图像,你会注意到为每个人检测到了多个重叠的边界框(如上面的图 1 所示)。
在这种情况下,我们有两个选择。我们可以检测一个边界框是否完全包含在另一个内(作为 OpenCV 示例实现的一个)。或者我们可以应用非最大值抑制和抑制与重要阈值重叠的边界框——这正是第 38 行和第 39 行所做的。
注意: 如果你有兴趣了解更多关于 HOG 框架和非极大值抑制的知识,我会从阅读这篇关于 6 步框架的介绍文章开始。从那里,查看这篇关于简单非最大值抑制的文章,随后是一篇实现优化的 Malisiewicz 方法的更新文章。
在应用非最大值抑制后,我们在第 42 行和第 43 行的上绘制最终的边界框,在第 46-48 行的上显示图像的一些基本信息和边界框的数量,最后在第 51-53 行的上将我们的输出图像显示到我们的屏幕上。
图像中行人检测的结果
要查看我们的行人检测脚本的运行情况,只需发出以下命令:
$ python detect.py --images images
下面我提供了检测脚本的结果示例:

Figure 2: The first result of our pedestrian detection script.
这里我们发现一个人站在警车旁边。

Figure 3: Detecting a single person in the foreground and another person in the background.
在上面的例子中,我们可以看到在图像的前景中检测到一个男人,而在背景中检测到一个推着婴儿车的女人。
Figure 4: An example of why applying non-maxima suppression is important.
上图提供了一个例子,说明为什么应用非最大值抑制很重要。detectMultiScale函数错误地检测到两个边界框(以及正确的边界框),两者都与图像中的真人重叠。通过应用非最大值抑制,我们能够抑制无关的边界框,留给我们真正的检测

Figure 5: A second example demonstrating non-maxima suppression in action.
同样,我们看到检测到多个错误的边界框,但是通过应用 NMS,我们可以移除它们,给我们留下图像中的真实检测。

Figure 6: Detecting pedestrians in a shopping mall.
这里,我们正在检测购物中心的行人。请注意,有两个人正朝着远离摄像机的方向走去,而另一个人正朝着摄像机的方向走去。在这两种情况下,我们的 HOG 方法都能够检测到人。non_maxima_suppression函数中较大的overlapThresh确保边界框不被抑制,即使它们部分重叠。

Figure 7: Detecting people in a blurred image.
上图的结果让我特别惊讶。通常 HOG 描述符在存在运动模糊的情况下表现不佳,但是我们仍然能够检测出该图像中的行人。

Figure 8: Detecting pedestrians outdoors, walking along the street.
这是多个重叠边界框的另一个例子,但是由于更大的overlapThresh,它们被而不是抑制,留给我们正确的人物检测。

Figure 9: Detecting four members of a family.
上图展示了我们的 HOG + SVM 行人探测器的多功能性。我们不仅能探测到成年男性,还能探测到三个小孩。(注意,检测器不能发现躲在他[假定是]父亲后面的另一个孩子)。
Figure 10: Detecting a depiction of pedestrians.
我把这张图片放在最后只是因为我觉得它很有趣。我们清楚地看到一个路标,很可能是用来指示人行横道的。然而,我们的 HOG + SVM 检测器将此图像中的两个人标记为阳性分类!
摘要
在这篇博文中,我们学习了如何使用 OpenCV 库和 Python 编程语言来执行行人检测。
OpenCV 库实际上搭载了一个预先训练好的 HOG +线性 SVM 检测器基于 Dalal 和 Triggs 方法来自动检测图像中的行人。
虽然 HOG 方法比 Haar 方法更精确,但它仍然需要正确设置detectMultiScale的参数。在以后的博客文章中,我将回顾detectMultiScale的每个参数,详细说明如何调整它们,并描述准确性和性能之间的权衡。
无论如何,我希望你喜欢这篇文章!我计划在未来做更多的物体检测教程,所以如果你想在这些帖子发布时得到通知,请考虑使用下面的表格订阅时事通讯。
我还在 PyImageSearch 大师课程、、、中详细介绍了使用 HOG +线性 SVM 方法的物体检测,所以一定要看一看!
pip 安装 OpenCV
在本教程中,您将学习如何在 Ubuntu、macOS 和 Raspberry Pi 上 pip 安装 OpenCV。
在以前的 OpenCV 安装教程中,我推荐过从源代码编译;然而,在过去的一年里,通过 pip 安装 OpenCV 成为可能,pip 是 Python 自己的包管理器。
虽然从源代码安装可以让您最大程度地控制 OpenCV 配置,但这也是最困难和最耗时的。
如果你正在寻找在你的系统上安装 OpenCV 的最快的方法,你想使用 pip 来安装 OpenCV (但是在这个过程中有一些事情可能会使你出错,所以请确保你阅读了本指南的其余部分)。
2019-11-21 更新: 由于在运行 BusterOS 的 Raspberry Pi 4 上使用这种 pip 安装方式存在 OpenCV 的兼容性问题,已经对这篇博文发布了更新。一定要在搜索“2019-11-21 更新”时通过ctrl + f找到更新。
要了解如何在你的系统上 pip 安装 OpenCV,继续阅读。
pip 安装 OpenCV
在本教程的剩余部分,我将简要描述可以通过 Python 的包管理器 pip 安装的 OpenCV 包。
从那里,我将演示如何在 Ubuntu、macOS 和 Raspberry Pi 上 pip 安装 OpenCV。
最后,我将回顾一下使用 pip 安装 OpenCV 时可能会遇到的一些常见问题。
在我们开始之前,我想指出这个 OpenCV 安装方法的一个重要注意事项。
我们今天讨论的 OpenCV 的 PyPi/PiWheels 托管版本不包括“非自由”算法,例如 SIFT、SURF 和其他专利算法。如果你需要一个快速的环境,不需要运行包含非自由算法的程序,这是一个安装 OpenCV 的好方法——如果不是这样,你需要完成 OpenCV 的完整编译。
两个 pip OpenCV 包:opencv-python和opencv-contrib-python
在我们开始之前,我想提醒你,我今天来这里的方法是 非官方的预建的 OpenCV 包,可以通过 pip 安装——它们是而不是OpenCV.org发布的官方 OpenCV 包。
仅仅因为它们不是官方的软件包,并不意味着你应该对使用它们感到不舒服,但是对你来说重要的是要明白它们并没有得到 OpenCV.org 官方团队的直接认可和支持。
综上所述——在 PyPI 库上有四个 OpenCV 包可以通过 pip 安装:
- opencv-python : 这个库包含了 正好是 opencv 库的主要模块 。如果你是 PyImageSearch 阅读器,你不想安装这个包。
- opencv-contrib-python:OpenCV-contrib-python 库包含两个主模块以及 contrib 模块——这是我推荐您安装的库,因为它包含了所有 OpenCV 功能。
- opencv-python-headless:与 opencv-python 相同,但没有 GUI 功能。对无头系统有用。
- opencv-contrib-python-headless:与 opencv-contrib-python 相同,但没有 GUI 功能。对无头系统有用。
同样,在绝大多数情况下你会想在你的系统上安装opencv-contrib-python。
你 不要想把opencv-python和opencv-contrib-python都装——挑其中一个。
如何在 Ubuntu 上 pip 安装 OpenCV
在 Ubuntu 上用 pip 安装 OpenCV 有两种选择:
- 安装到您的系统中
site-packages - 安装到虚拟环境的
site-packages(首选)
首先,在 Ubuntu 上安装一些 OpenCV 依赖项
我们需要用 apt-get 包管理器刷新/升级预安装的包/库:
$ sudo apt-get update
$ sudo apt-get upgrade
然后安装两个必需的包:
$ sudo apt-get install python3-dev
$ sudo apt-get install libgl1-mesa-glx
接下来,安装 pip
如果您没有 pip,您需要先获得它:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
选项 A:用 pip 把 OpenCV 安装到你的 Ubuntu 系统上
我不推荐这种方法,除非您有不希望隔离、独立的 Python 环境的特殊用例。
让我们在我们的系统上安装 opencv-contrib-python:
$ sudo pip install opencv-contrib-python
几秒钟之内,OpenCV 就可以放入您系统的站点包中了!
选项 B:用 pip 将 Ubuntu 上的 OpenCV 安装到虚拟环境中
Python 虚拟环境有巨大的好处。
主要的好处是,您可以在您的系统上开发多个带有独立包的项目(许多都有版本依赖),而不必把您的系统搅浑。您还可以随时添加和删除虚拟环境。
简而言之:Python 虚拟环境是 Python 开发的最佳实践。很有可能,你应该赶时髦。
我选择的工具是virtualenv和virtualenvwrapper,但是您也可以选择其他工具,比如 venv 或 Anaconda(简称 conda)。
下面介绍如何安装virtualenv和virtualenvwrapper,它们都将驻留在您的 系统 site-packages中,并管理每个项目的 虚拟环境 站点包:
$ pip install virtualenv virtualenvwrapper
在我们继续之前,您首先需要在您的~/.bashrc个人资料中添加一些行。使用nano、vim或emacs打开文件,并将这些行附加到末尾:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.local/bin/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export VIRTUALENVWRAPPER_VIRTUALENV=$HOME/.local/bin/virtualenv
source $HOME/.local/bin/virtualenvwrapper.sh
保存文件。然后在您的终端中“搜索它”:
$ source ~/.bashrc
您将看到一些设置 virtualenvwrapper 的终端输出。您现在可以访问新的终端命令:
- 用
mkvirtualenv创造的环境。 - 用
workon激活一个环境(或切换到不同的环境)。 - 用
deactivate停用一个环境。 - 用
rmvirtualenv去掉一个环境。 - 务必阅读文件!
让我们为 OpenCV 创建一个 Python 3 虚拟环境,名为 CV:
$ mkvirtualenv cv -p python3
现在有了魔棒(pip),您可以在几秒钟内将 OpenCV 安装到您的新环境中:
$ pip install opencv-contrib-python
如何在 macOS 上 pip 安装 OpenCV
MacOS 的 pip 类似于 Ubuntu 安装 OpenCV。
同样,在带有 pip 的 macOS 上安装 OpenCV 有两种选择:
- 安装到您的系统中
site-packages - 安装到虚拟环境的
site-packages(首选)
安装 pip
如果您没有 pip,您需要先获得它:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
选项 A:使用 pip 将 OpenCV 安装到 macOS 系统中
不要这样。
为什么?我实际上建议你去选项 B 使用虚拟环境。
好吧,如果你坚持在你的 macOS 系统上安装,那么就像 pip 通过以下方式安装 OpenCV 一样简单:
$ sudo pip install opencv-contrib-python
几秒钟之内,OpenCV 就可以放入系统的站点包中了。
选项 B:使用 pip 将 macOS 上的 OpenCV 安装到虚拟环境中
就像用 pip 管理软件包一样轻而易举。
…在虚拟环境中,管理项目及其依赖关系轻而易举。
如果你对计算机视觉开发(或任何这方面的开发)很认真,你应该使用 Python 虚拟环境。
我不在乎你使用什么系统(是virtualenv、venv还是conda /Anaconda】,只要学会使用一个并坚持下去。
下面介绍如何安装 virtualenv 和 virtualenvwrapper,它们都将驻留在您的 系统 站点包中,并管理每个项目的 虚拟环境 站点包:
$ pip install virtualenv virtualenvwrapper
从那里,你需要添加下面几行到你的~/.bash_profile(注意 macOS 的文件名是.bash_profile,Ubuntu 的文件名是.bashrc。
使用nano、vim或emacs(大多数系统都有nano)打开文件:
$ nano ~/.bash_profile
…并将这几行附加到末尾:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
保存文件——如果您使用的是nano,快捷键会列在窗口底部。
然后在您的终端中“搜索它”:
$ source ~/.bash_profile
您将看到几行终端输出,表明 virtualenvwrapper 已经设置好了。您现在可以访问新的终端命令:
- 创建一个新的虚拟环境。
workon:激活/切换到虚拟环境。请记住,您可以拥有任意多的环境。- 跳出虚拟环境,你将与你的系统一起工作。
rmvirtualenv:删除虚拟环境。- 务必阅读文件!
让我们为 OpenCV 创建一个 Python 3 虚拟环境,名为 CV:
$ mkvirtualenv cv -p python3
现在,使用 pip,只需一眨眼的时间,您就可以在几秒钟内将 OpenCV 安装到您的新环境中:
$ pip install opencv-contrib-python
如何在树莓 Pi 上安装 OpenCV
在这篇文章的前面,我提到过安装 OpenCV 的一个缺点是你对编译本身没有任何控制——二进制文件是为你预先构建的,这虽然很好,但也意味着你不能包含任何额外的优化。
对于覆盆子酱,我们很幸运。
树莓派社区运营的piwheels.org的达夫·琼斯(picameraPython 模块的创建者)和本·纳托尔,一个为树莓派提供 ARM wheels(即预编译二进制包)的 Python 包仓库。
使用 PiWheels,您将能够在几秒钟内 pip 安装 OpenCV(对于其他需要很长时间编译的 Python 库也是如此,包括 NumPy、SciPy、scikit-learn 等。).
那么,如何指示 pip 命令使用 PiWheels 呢?
简短的回答是“没什么!”
如果您正在使用 Raspbian Stretch,您会很高兴地知道,pip 命令将在检查 PyPI 之前检查 PIWheels 的预编译二进制文件,从而使您的 Pi 节省大量 CPU 周期(以及大量安装时间)。
此外,当 Ben 和 Dave 为 PiWheels 编写 OpenCV 二进制文件时,他们问我应该使用哪些指令— ,我向他们推荐了针对 Raspberry Pi 的优化 OpenCV 安装程序 —这正是他们遵循的指令!
如果您最终使用 pip 在您的 Raspberry Pi 上安装 OpenCV,请放心,您使用的是优化版本。
让我们开始学习如何在我们的 Raspberry Pi 上安装 OpenCV。
在您的 Raspberry Pi 上安装先决条件
Raspberry Pi 要求您在开始之前安装几个系统包:
$ sudo apt-get install libhdf5-dev libhdf5-serial-dev libhdf5-103
$ sudo apt-get install libqtgui4 libqtwebkit4 libqt4-test python3-pyqt5
$ sudo apt-get install libatlas-base-dev
$ sudo apt-get install libjasper-dev
在你的树莓派上安装 pip
Python 包管理器“pip”可以通过 wget 获得:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
现在你有两个选择:
- 在您的 Raspberry Pi 上安装 OpenCV 到您的全局 Python
site-packages - 将 OpenCV 安装到您的 Raspberry Pi 上的虚拟环境中
选项 A:用 pip 将 OpenCV 安装到您的 Raspberry Pi 系统中
如果您希望能够在隔离环境中使用不同版本的 OpenCV,我不会推荐这个选项。
但是很多人部署他们的 Raspberry Pis 仅仅是为了一个目的/项目,并不需要虚拟环境。
也就是说,如果你后来改变主意,想要使用虚拟环境,那么清理起来会很混乱,所以我建议跳过这个选项,遵循选项 B 。
要在您的 Raspberry Pi 系统上 pip 安装 OpenCV,请确保像这样使用 sudo:
$ sudo pip install opencv-contrib-python==4.1.0.25
2019-11-21 更新:读者反映,通过 pip 安装的 OpenCV 4 的某些版本在树莓 Pi 上无法正常工作。如果您没有使用上面代码块中提到的 OpenCV 的特定版本,当您从 Python 中import cv2时,您可能会遇到**"undefined symbol: __atomic_fetch_add8"** for libatomic错误。
几秒钟之内,OpenCV 就可以和你已经安装的其他包一起放入你的 Raspberry Pi 的站点包中。
选项 B:在 Raspberry Pi 上用 pip 将 OpenCV 安装到虚拟环境中
如果您的 Raspberry Pi 有多种用途(或者如果您像我一样,一直在为博客帖子测试各种软件版本之间的代码兼容性),那么虚拟环境绝对是一个不错的选择。).
下面是如何安装 virtualenv 和 virtualenvwrapper,我用来完成它的工具:
$ pip install virtualenv virtualenvwrapper
然后,您需要在您的~/.bashrc中添加以下几行。使用nano、vim或emacs打开文件,并将这些行附加到末尾:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.local/bin/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export VIRTUALENVWRAPPER_VIRTUALENV=$HOME/.local/bin/virtualenv
source $HOME/.local/bin/virtualenvwrapper.sh
保存文件。然后在您的终端中“搜索它”:
$ source ~/.bashrc
将打印终端输出,指示 virtualenvwrapper 准备就绪。请务必检查它是否有错误。
您现在可以访问新的终端命令:
- 用
mkvirtualenv创造的环境。 - 用
workon激活一个环境(或切换到不同的环境)。 - 用
deactivate停用一个环境。 - 用
rmvirtualenv去掉一个环境。 - 务必阅读文件!
要创建一个 Python 3 虚拟环境,其中将包含 OpenCV 和您安装的其他包,只需使用 mkvirtualenv 和下面的命令:
$ mkvirtualenv cv -p python3
现在您有了一个名为cv的虚拟环境。您可以通过以下方式随时激活它:
$ workon cv
现在手腕一翻,你就可以 pip 安装 OpenCV 到cv:
$ pip install opencv-contrib-python==4.1.0.25
2019-11-21 更新:读者反映,通过 pip 安装的 OpenCV 4 的某些版本在树莓 Pi 上无法正常工作。如果您没有使用上面代码块中提到的 OpenCV 的特定版本,当您从 Python 中import cv2时,您可能会遇到**"undefined symbol: __atomic_fetch_add8"** for libatomic错误。
这就是 PiWheels 的全部内容!
我打赌你在用 PiCamera 作为你的成像传感器。您可以使用以下命令安装 Python 模块(注意引号):
$ pip install "picamera[array]"
测试 OpenCV 的 pip 安装
你知道 OpenCV 的 3.3+有一个可以运行深度学习模型的 DNN 模块吗?
您可能会感到惊讶,但是您的 OpenCV 版本现在可以开箱即用,几乎不需要额外的软件。
我们将使用 MobileNet 单镜头检测器在视频中执行对象检测。
以下是您需要首先安装的内容(假设有一个cv虚拟环境):
$ workon cv
$ pip install imutils
$ pip install "picamera[array]" # if you're using a Raspberry Pi
现在,打开一个 Python shell,仔细检查您是否准备好了所有软件:
$ workon cv
$ python
Python 3.6.3 (default, Oct 4 2017, 06:09:15)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.37)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'4.0.1'
>>> import imutils
>>>
树莓派将展示不同版本的 Python 3,这是意料之中的。
现在是下载代码的时候了。
一定要用这篇博文的 【下载】 部分下载源代码+预先训练好的 MobileNet SSD 神经网络。
从那里,执行以下命令:
$ python real_time_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel
[INFO] loading model...
[INFO] starting video stream...
[INFO] elapsed time: 55.07
[INFO] approx. FPS: 6.54
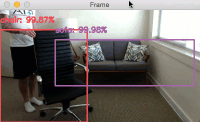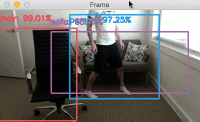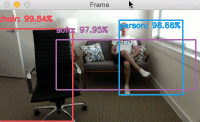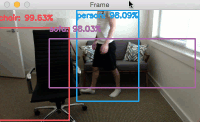
Figure 1: A short clip of Real-time object detection with deep learning and OpenCV
我用的是 Macbook Pro。在笔记本电脑上使用 CPU 时,6 FPS 的帧速率已经相当不错了。
树莓 pi 是资源受限的,因此我们可以利用一些技巧来制造高 FPS 的假象。如果你在 Raspberry Pi 上,执行以下命令:
$ python pi_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel
[INFO] loading model...
[INFO] starting process...
[INFO] starting video stream...
[INFO] elapsed time: 48.55
[INFO] approx. FPS: 27.83
https://www.youtube.com/embed/Ob_FrW7yuzw?feature=oembed
利用 TensorFlow、Keras 和深度学习实现像素混洗超分辨率
当图像的尺寸增加时(,)沿着宽度和高度,传统方法导致新的像素信息被创建,这经常降低图像质量,给出柔和且模糊的图像作为输出。值得庆幸的是,正如近年来的大多数话题一样,深度学习给了我们许多可行的解决方案来解决这个问题。
*在今天的博客中,我们将学习如何实现像素洗牌超分辨率,这是一个美丽的概念,让我们领略了深度学习对超分辨率领域的贡献。
该博客将涵盖:
- 利用 BSDS500 数据集
- 了解剩余密集块体系结构
- 实现像素洗牌
- 展示一系列预处理和后处理方法
- 训练我们自己的超分辨率模型
- 从模型结果中得出推论
- 根据标准指标评估结果
- 在模型上测试你自己的图像
在本教程结束时,你将对像素洗牌和这里显示的概念有一个清晰的理解。
您还可以定义自己的超分辨率架构,享受自定义图像带来的乐趣!如果这听起来很有趣,那就让我们开始吧。
要了解如何实现像素洗牌超分辨率, 继续阅读。
使用 TensorFlow、Keras 和深度学习的像素混合超分辨率
最近,NVIDIA 制造了一个名为 深度学习超级采样【DLSS】的发明。它使用深度学习将低分辨率图像提升到更高的分辨率,以适应高分辨率显示器的显示。问题是,放大的图像显示的质量类似于以更高的分辨率自然渲染图像的质量。
与此同时,大部分计算是在图像分辨率较低的情况下完成的。这有效地使计算机基础较弱的人能够享受游戏而不损害质量。那么,这是怎么发生的?
配置您的开发环境
要遵循本指南,您需要在系统上安装 TensorFlow 机器学习库。对于额外的图像处理目的,您将使用 Python 图像库(PIL)和 Imutils 库。
幸运的是,上面所有的库都是 pip 安装的!
$ pip install tensorflow
$ pip install pillow
$ pip install imutils
以上是本指南所需的环境配置!
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们开始实现像素洗牌超分辨率之前,让我们看看项目结构。
一旦我们下载了我们的项目目录,它应该看起来像这样:
$ tree .
.
├── generate_super_res.py
├── output
│ ├── super_res_model
│ │ ├── saved_model.pb
│ │ └── variables
│ │ ├── variables.data-00000-of-00001
│ │ └── variables.index
│ ├── training.png
│ └── visualizations
│ ├── 0_viz.png
│ ├── 1_viz.png
│ ├── 2_viz.png
│ ├── 3_viz.png
│ ├── 4_viz.png
│ ├── 5_viz.png
│ ├── 6_viz.png
│ ├── 7_viz.png
│ ├── 8_viz.png
│ └── 9_viz.png
├── pyimagesearch
│ ├── config.py
│ ├── data_utils.py
│ ├── __init__.py
│ └── subpixel_net.py
└── train.py
5 directories, 20 files
父目录有两个 python 脚本和两个文件夹。
generate_super_res.py:包含使用我们训练好的模型生成超分辨率图像的脚本。它还包含几个将用于图像预处理和后处理的函数。- python 脚本将调用我们定义的模型,训练它,并评估它的质量。它还包含我们将在模型中使用的定制度量函数。
接下来,让我们进入pyimagesearch目录!在其中,我们将找到 4 个 python 脚本:
__init__.py:这将使 python 把pyimagesearch目录当作一个模块config.py:该脚本包含各种超参数预设,并定义数据路径- 这个脚本将有助于在训练期间输入到我们的模型之前处理输入
subpixel_net.py:这个脚本包含了我们的超分辨率模型,它将被train.py脚本调用
最后,我们有一个output目录,其中包含:
super_res_model:我们训练好的模型将被存储的目录training.png:样本模型评估图visualizations:存储我们生成的所有超分辨率图像的目录。
什么是像素洗牌超分辨率?
超分辨率是一类技术的总称,其中添加了精确或接近精确的像素信息,以从其低分辨率形式构建高分辨率图像,同时保持其原始质量。
像素混洗超分辨率是一种上采样技术,其中图像超分辨率以一种相当巧妙的方法实现。特征地图是在它的 LR (低分辨率)空间中提取的(与在 HR (高分辨率)空间中完成的早期技术相反)。
然而,这种方法的亮点是一种新颖的高效亚像素卷积层,它学习一系列过滤器来将最终的 LR 特征映射放大到 HR 输出中。这种方法不仅取得了巨大的成功,而且降低了时间复杂度,因为大量的计算是在图像处于低分辨率状态时完成的。
我们还使用了剩余密集块 (RDBs),这是一种架构,主要关注保持在先前层提取的信息有效,同时计算当前层的输出。
配置先决条件
对于今天的任务,我们将使用 BSDS500 ,也称为伯克利分段数据集。该数据集是专门为图像分割领域提供帮助而创建的,包含 500 幅图像。
如果使用的是非 Linux 系统,可以在这里获取数据集(右键保存链接)。这将启动压缩数据集的下载。将这个 zip 文件的内容解压缩到项目的目录中。
如果您使用的是 Linux 系统,您可以简单地导航到项目的目录并执行以下命令:
$ wget http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/BSR/BSR_bsds500.tgz
$ tar xvf BSR_bsds500.tgz
在开始实现之前,让我们设置路径和超参数。为此,我们将进入模块config.py。我们项目中的大多数其他脚本将调用这个模块并使用它的预置。
# import the necessary packages
import os
# specify root path to the BSDS500 dataset
ROOT_PATH = os.path.join("BSR", "BSDS500", "data", "images")
# specify paths to the different splits of the dataset
TRAIN_SET = os.path.join(ROOT_PATH, "train")
VAL_SET = os.path.join(ROOT_PATH, "val")
TEST_SET = os.path.join(ROOT_PATH, "test")
首先,我们将把我们的ROOT_PATH设置为数据集,如第 5 行所示。从ROOT_PATH开始,我们分别定义我们的训练、验证和测试集路径(第 8-10 行)。为了方便起见, BSDS500 已经以数据集被分为训练集、验证集和测试集的方式进行了设置。
# specify the initial size of the images and downsampling factor
ORIG_SIZE = (300, 300)
DOWN_FACTOR = 3
# specify number of RDB blocks, batch size, number of epochs, and
# initial learning rate to train our model
RDB_LAYERS = 3
BATCH_SIZE = 8
EPOCHS = 100
LR = 1e-3
#define paths to serialize trained model, training history plot, and
# path to our inference visualizations
SUPER_RES_MODEL = os.path.join("output", "super_res_model")
TRAINING_PLOT = os.path.join("output", "training.png")
VISUALIZATION_PATH = os.path.join("output", "visualizations")
我们的下一步工作是设置一些重要的超参数:
ORIG_SIZE:将是我们图像的原始和目标形状(第 13 行)DOWN_FACTOR:确定我们将缩减原始图像的采样量(第 14 行)RDB_LAYERS:指定单个 RDB 内的卷积层数(第 18 行)
除此之外,我们还设置批量大小、时期、和学习速率 ( 第 19-21 行),并定义路径来序列化我们训练过的模型和历史图(第 25 和 26 行)。我们还创建了一个路径来保存将要创建的可视化效果( Line 27 )。
数据(图像)处理步骤
我们的下一步是创建一个处理图像处理任务的模块。为此,我们转到data_utils.py脚本。
# import the necessary packages
from . import config
import tensorflow as tf
def process_input(imagePath, downFactor=config.DOWN_FACTOR):
# determine size of the downsampled images
resizeShape = config.ORIG_SIZE[0] // downFactor
# load the original image from disk, decode it as a JPEG image,
# scale its pixel values to [0, 1] range, and resize the image
origImage = tf.io.read_file(imagePath)
origImage = tf.image.decode_jpeg(origImage, 3)
origImage = tf.image.convert_image_dtype(origImage, tf.float32)
origImage = tf.image.resize(origImage, config.ORIG_SIZE,
method="area")
根据我们的图像处理要求,我们编写了一个以imagePath和downFactor为参数的函数process_input ( Line 5 )。我们直接使用在config.py模块中设置的下采样因子。在第 7 行上,注意我们正在使用downFactor和原始图像尺寸来创建缩小尺寸所需的值。这一步的意义将在后面解释。
第 11-15 行包含基本的图像处理步骤,例如从指定的路径读取图像,将图像转换成必要的数据类型(本例中为Float32),以及根据我们之前在config.py模块中设置的大小调整图像大小。
# convert the color space from RGB to YUV and only keep the Y
# channel (which is our target variable)
origImageYUV = tf.image.rgb_to_yuv(origImage)
(target, _, _) = tf.split(origImageYUV, 3, axis=-1)
# resize the target to a lower resolution
downImage = tf.image.resize(target, [resizeShape, resizeShape],
method="area")
# clip the values of the input and target to [0, 1] range
target = tf.clip_by_value(target, 0.0, 1.0)
downImage = tf.clip_by_value(downImage, 0.0, 1.0)
# return a tuple of the downsampled image and original image
return (downImage, target)
接下来,我们做剩下的处理。在的第 19 和 20 行,我们使用tf.image.rgb_to_yuv函数将我们的图像从RGB转换成YUV格式,并分离出 Y 通道(因为它将是我们的目标变量)。在第 23 和 24 行上,我们使用tf.image.resize创建缩小的图像,最后,在第 27 和 28 行上,我们使用tf.clip_by_value功能,通过范围[0.0, 1.0]裁剪目标和缩小图像的值。
用剩余密集块(RDB)实现亚像素 CNN
在我们进入subpixel_net.py模块之前,让我们试着去理解剩余密集块背后的动机。
当我们第一次了解 CNN 时,关于它们的一个主要主题是,当我们从最初的层到后来的层时,CNN 的层提取简单的特征到越来越复杂/抽象/高级的特征。
RDB 打算尽可能地利用这一想法,用卷积层的密集连接网络提取尽可能多的层次特征。为了更好地理解这一点,让我们来看看 RDB。
图 2 显示了在一个 RDB 中,所有层都是相互连接的,以确保充分提取局部特征。每一层都从所有前面的层(通过连接)获得额外的输入,并将自己的特征映射传递给后面的层。
这样,也保留了网络的前馈性质。注意另一件重要的事情;来自先前层的输出与当前 RDB 内的所有本地连接有直接链接。最简单的含义是,来自前一层的信息将总是与当前状态一起可用,这使得我们的模型能够自适应地从各种特征中选择和区分优先级。这样,每一点信息都被保存了!
如果你听说过 ResNets 和 密集块*图 2 可能看起来很熟悉,因为 RDB 利用了这两个概念。*
*我们来看一下subpixel_net.py中剩余密集块的代码。
# import the necessary packages
from . import config
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
import tensorflow as tf
def rdb_block(inputs, numLayers):
# determine the number of channels present in the current input
# and initialize a list with the current inputs for concatenation
channels = inputs.get_shape()[-1]
storedOutputs = [inputs]
我们从rdb_block函数(第 9 行)开始,它接受一个层输入和块数作为参数。在的第 12 行和第 13 行,我们将通道的数量存储在一个变量中以备后用,同时创建一个列表storedOutputs,当遇到它们时,它将连接输出。
# iterate through the number of residual dense layers
for _ in range(numLayers):
# concatenate the previous outputs and pass it through a
# CONV layer, and append the output to the ongoing concatenation
localConcat = tf.concat(storedOutputs, axis=-1)
out = Conv2D(filters=channels, kernel_size=3, padding="same",
activation="relu",
kernel_initializer="Orthogonal")(localConcat)
storedOutputs.append(out)
这里,我们实现了 RDB 的内部结构。我们直接遍历 RDB 中的每个图层,并存储每个输出。在第 19 行上, localConcat充当到每个先前层的链接,如前所述。当我们遍历给定数量的层时,localConcat会遇到之前的每个输出,这些输出会在每次迭代结束时被追加到storedOutputs列表中(回显一个密集块)。在线 20-22 上,localConcat然后被送到Conv2D层。
# concatenate all the outputs, pass it through a pointwise
# convolutional layer, and add the outputs to initial inputs
finalConcat = tf.concat(storedOutputs, axis=-1)
finalOut = Conv2D(filters=inputs.get_shape()[-1], kernel_size=1,
padding="same", activation="relu",
kernel_initializer="Orthogonal")(finalConcat)
finalOut = Add()([finalOut, inputs])
# return the final output
return finalOut
在的第 27 行,我们将所有先前存储在storedOutputs中的输出连接起来,并为其分配一个新变量finalConcat。finalConcat然后被送入Conv2D层,这样就完成了 RDB 的内部结构。行 3 1 的最后一步是将我们的初始输入与我们的最终级联输出相加(回显剩余块)。这样,我们就完成了对剩余密集块的编码。可以对 RDB 中的图层数量进行实验,以了解结果是如何受到影响的。
接下来是我们的整体模型架构,在这里我们将实现像素混洗。
def get_subpixel_net(downsampleFactor=config.DOWN_FACTOR, channels=1,
rdbLayers=config.RDB_LAYERS):
# initialize an input layer
inputs = Input((None, None, 1))
# pass the inputs through a CONV => CONV block
x = Conv2D(64, 5, padding="same", activation="relu",
kernel_initializer="Orthogonal")(inputs)
x = Conv2D(64, 3, padding="same", activation="relu",
kernel_initializer="Orthogonal")(x)
# pass the outputs through an RDB => CONV => RDB block
x = rdb_block(x, numLayers=rdbLayers)
x = Conv2D(32, 3, padding="same", activation="relu",
kernel_initializer="Orthogonal")(x)
x = rdb_block(x, numLayers=rdbLayers)
我们从第 37 和 38 行的开始,定义get_subpixel_net的参数,这也是我们的模型函数。当rdbBlocks参数使用在config.py中设置的单个块中的层数时,在config.py中定义的下采样因子对于我们知道我们需要用什么因子来放大图像是必要的。我们还有参数channels,默认设置为1,因为我们已经将图像预处理为 YUV 格式并隔离了 Y 通道。
模型架构包括添加两个Conv2D层(行 43-46 ),之后我们调用前面定义的rdb_block函数(行 49 )。接着是另一个Conv2D层和一个 RDB 块(行 50-52 )。
我们代码的下一部分是奇迹发生的地方。在开始之前,让我们感谢 TensorFlow 的人们给了我们这么漂亮的效用函数tf.nn.depth_to_space。
根据其正式定义,它是一种将深度数据重新排列成空间数据块的功能。理解这一点是我们揭开像素错位之谜的关键。
当我们谈论深度时,我们指的是张量中的通道数量(用图像术语来说)。因此,如果我们有一个形状为2, 2, 12的张量,并且我们想要将depth_to_space应用于一个因子(也称为block_size)为2的张量,我们必须看到通道大小是如何除以block_size × block_size的。对于通道大小12,我们看到12/(2×2)给出了新的通道大小3。
但是,由于我们的通道大小减少到3,我们显然必须增加我们的高度和宽度维持张量的整体大小,因为我们没有丢失数据,只是重新排列它。这给了我们4, 4, 3的最终张量**形状。
这种现象就是我们所说的 像素洗牌 ,这里我们是重新排列 ") 的元素
的元素
to  \times (W*r) \times C") .
.
# pass the inputs through a final CONV layer such that the
# channels of the outputs can be spatially organized into
# the output resolution
x = Conv2D(channels * (downsampleFactor ** 2), 3, padding="same",
activation="relu", kernel_initializer="Orthogonal")(x)
outputs = tf.nn.depth_to_space(x, downsampleFactor)
# construct the final model and return it
model = Model(inputs, outputs)
return model
注意在第 57 行的上,Conv2D层的滤镜数量被设置为channels × downsampleFactor的平方。我们本质上是在实现
step before proceeding to use the tf.nn.depth_to_space (Line 59) function, where the tensor will be rearranged.
注意,即使这是我们的最终输出,tf.nn.depth_to_space是而不是模型的可学习参数。这意味着Conv2D层必须正确学习其放大滤波器,以便最终输出在反向传播期间产生最小的损耗。
训练像素混洗超分辨率模型
随着所有繁重工作的完成,留给我们的就是训练我们的模型,并在不同的图像上测试它。为此,让我们进入train.py模块。
在导入必要的包后,我们定义一个名为psnr的函数,它以一幅原始图像和一幅预测图像作为它的参数。我们的主要目的是通过比较原始图像和预测图像来计算峰值信噪比(PSNR) 。
# USAGE
# python train.py
# import the necessary packages
from pyimagesearch.data_utils import process_input
from pyimagesearch import config
from pyimagesearch import subpixel_net
from imutils import paths
import matplotlib.pyplot as plt
import tensorflow as tf
def psnr(orig, pred):
# cast the target images to integer
orig = orig * 255.0
orig = tf.cast(orig, tf.uint8)
orig = tf.clip_by_value(orig, 0, 255)
# cast the predicted images to integer
pred = pred * 255.0
pred = tf.cast(pred, tf.uint8)
pred = tf.clip_by_value(pred, 0, 255)
# return the psnr
return tf.image.psnr(orig, pred, max_val=255)
注意在第 14-16 行和第 19-21 行上,我们是如何将像素值从范围[0.0, 1.0]提升到[0, 255]的。为了便于计算,张量也被转换成整数。对于 PSNR 计算,我们使用tf.image.psnr函数(第 24 行)。顾名思义,比值越高,噪声值越低。psnr函数也将作为我们的模型度量。
我们的下一个任务是为训练和验证路径分配变量,并相应地创建我们的训练和验证数据集。
# define autotune flag for performance optimization
AUTO = tf.data.AUTOTUNE
# load the image paths from disk and initialize TensorFlow Dataset
# objects
print("[INFO] loading images from disk...")
trainPaths = list(paths.list_images(config.TRAIN_SET))
valPaths = list(paths.list_images(config.VAL_SET))
trainDS = tf.data.Dataset.from_tensor_slices(trainPaths)
valDS = tf.data.Dataset.from_tensor_slices(valPaths)
第 32 行和第 33 行上的paths.list_images函数为我们提供了所需目录中的所有可用图像,然后我们将这些图像作为列表传递给tf.data.Dataset.from_tensor_slices函数来初始化一个TensorFlow Dataset Object ( 第 34 行和第 35 行)。
接下来,我们创建训练和验证数据加载器,并编译我们的模型。
# prepare data loaders
print("[INFO] preparing data loaders...")
trainDS = trainDS.map(process_input,
num_parallel_calls=AUTO).batch(
config.BATCH_SIZE).prefetch(AUTO)
valDS = valDS.map(process_input,
num_parallel_calls=AUTO).batch(
config.BATCH_SIZE).prefetch(AUTO)
# initialize, compile, and train the model
print("[INFO] initializing and training model...")
model = subpixel_net.get_subpixel_net()
model.compile(optimizer="adam", loss="mse", metrics=psnr)
H = model.fit(trainDS, validation_data=valDS, epochs=config.EPOCHS)
在第 39-44 行,我们使用tf.data.Dataset.map函数将数据集元素映射到一个函数,并返回一个新的数据集。我们正在使用的函数是process_input,它是我们在data_utils模块中定义的。这样,我们训练和验证数据加载器就准备好了。
正如你在第 49 行看到的,我们使用psnr作为我们的模型度量,这意味着我们模型的目标将是最大化峰值信噪比。我们使用adam优化器,并选择mse(均方差)作为我们的损失函数。在第 50 行上,我们继续用数据加载器装配我们的模型。
# prepare training plot of the model and serialize it
plt.style.use("ggplot")
plt.figure()
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.plot(H.history["psnr"], label="train_psnr")
plt.plot(H.history["val_psnr"], label="val_psnr")
plt.title("Training Loss and PSNR")
plt.xlabel("Epoch #")
plt.ylabel("Loss/PSNR")
plt.legend(loc="lower left")
plt.savefig(config.TRAINING_PLOT)
# serialize the trained model
print("[INFO] serializing model...")
model.save(config.SUPER_RES_MODEL)
在第 53-63 行上,我们绘制了一些图表来评估我们的模型进展如何。我们的模型现在已经准备好了,我们将在一些测试图像上使用它,看看结果如何。所以,别忘了保存你的模型( Line 67 )!
培训结果和损失可视化
在执行文件train.py时,我们的模型得到训练。下面是该模型在历史上的培训历史,一旦您运行该模块,您将完全可以使用它。
$ python train.py
[INFO] loading images from disk...
[INFO] preparing data loaders...
[INFO] initializing and training model...
Epoch 1/100
25/25 [==============================] - 4s 65ms/step - loss: 0.0859 - psnr: 11.9725 - val_loss: 0.0105 - val_psnr: 18.9549
Epoch 2/100
25/25 [==============================] - 1s 42ms/step - loss: 0.0084 - psnr: 20.2418 - val_loss: 0.0064 - val_psnr: 20.6150
Epoch 3/100
25/25 [==============================] - 1s 42ms/step - loss: 0.0055 - psnr: 22.3704 - val_loss: 0.0043 - val_psnr: 22.2737
...
Epoch 98/100
25/25 [==============================] - 1s 42ms/step - loss: 0.0019 - psnr: 27.2354 - val_loss: 0.0021 - val_psnr: 26.2384
Epoch 99/100
25/25 [==============================] - 1s 42ms/step - loss: 0.0019 - psnr: 27.2533 - val_loss: 0.0021 - val_psnr: 25.9284
Epoch 100/100
25/25 [==============================] - 1s 42ms/step - loss: 0.0019 - psnr: 27.2359 - val_loss: 0.0021 - val_psnr: 25.9741
[INFO] serializing model...
因此,我们得到最终的验证损失为 0.0021 和验证 PSNR 得分 25.9741 。
图 3 显示了训练历史曲线,显示了不同时期的训练损失和 PSNR 分数。
像素混洗生成超分辨率图像
既然我们的模特培训结束了,那就来讨论几件事吧。我们模型的图表和分数表明,RDB 的使用并没有显著提高 PSNR 的统计数据。那么,我们的模型擅长于哪里呢?让我们测试一下,自己看看。
为了最终通过使用经过训练的具有 RDB 的亚像素 CNN 应用超分辨率来生成图像,让我们打开generate_super_res.py并开始编码。
# USAGE
# python generate_super_res.py
# import the necessary packages
from pyimagesearch import config
from PIL import Image
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.models import load_model
from imutils import paths
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
def psnr(orig, pred):
# cast the target images to integer
orig = orig * 255.0
orig = tf.cast(orig, tf.uint8)
orig = tf.clip_by_value(orig, 0, 255)
# cast the predicted images to integer
pred = pred * 255.0
pred = tf.cast(pred, tf.uint8)
pred = tf.clip_by_value(pred, 0, 255)
# return the psnr
return tf.image.psnr(orig, pred, max_val=255)
我们从第 15 行的开始,定义另一个函数psnr,它计算预测输出和原始图像的 PSNR 。如前所述,PSNR 越高,结果越好。
def load_image(imagePath):
# load image from disk and downsample it using the bicubic method
orig = load_img(imagePath)
downsampled = orig.resize((orig.size[0] // config.DOWN_FACTOR,
orig.size[1] // config.DOWN_FACTOR), Image.BICUBIC)
# return a tuple of the original and downsampled image
return (orig, downsampled)
在第 29 行,上,我们编写了一个辅助函数load_image,它将图像路径作为参数,并返回原始图像和缩减采样后的图像。注意在第 32 和 33 行的上,我们根据在config.py模块中定义的DOWN_FACTOR对图像进行下采样。这是非常重要的一步,因为我们模型的输出尺寸取决于此。
def get_y_channel(image):
# convert the image to YCbCr colorspace and then split it to get the
# individual channels
ycbcr = image.convert("YCbCr")
(y, cb, cr) = ycbcr.split()
# convert the y-channel to a numpy array, cast it to float, and
# scale its pixel range to [0, 1]
y = np.array(y)
y = y.astype("float32") / 255.0
# return a tuple of the individual channels
return (y, cb, cr)
接下来,我们定义一个名为get_y_channel的函数,它将 RGB 图像转换为其等效的 YCbCr 形式,以隔离 Y 通道。根据我们在整个博客中维护的东西,在通过我们的模型之前,我们将像素值缩放到范围[0.0, 1.0] ( Line 47 )。
def clip_numpy(image):
# cast image to integer, clip its pixel range to [0, 255]
image = tf.cast(image * 255.0, tf.uint8)
image = tf.clip_by_value(image, 0, 255).numpy()
# return the image
return image
第 52-58 行包含我们最后的辅助函数clip_numpy,它根据给定的范围裁剪图像的值。由于该函数是我们后处理步骤的一部分,我们将从[0.0, 1.0] ( 行 54 )再次将范围扩大到[0, 255],并剪裁任何超出给定边界(行 55 )的值。
def postprocess_image(y, cb, cr):
# do a bit of initial preprocessing, reshape it to match original
# size, and then convert it to a PIL Image
y = clip_numpy(y).squeeze()
y = y.reshape(y.shape[0], y.shape[1])
y = Image.fromarray(y, mode="L")
# resize the other channels of the image to match the original
# dimension
outputCB= cb.resize(y.size, Image.BICUBIC)
outputCR= cr.resize(y.size, Image.BICUBIC)
# merge the resized channels altogether and return it as a numpy
# array
final = Image.merge("YCbCr", (y, outputCB, outputCR)).convert("RGB")
return np.array(final)
在这里,让我提醒你,我们的模型只适用于 Y 通道,因此也将输出一个 Y 通道。第 60-75 行包含postprocess_image将我们的预测结果转换成 RGB 图像。
完成所有的效用函数后,我们终于可以继续生成一些超分辨率图像了。我们创建一个名为testPaths的变量,它将包含所有可用测试图像的路径。第二个变量currentTestPaths将在每次被调用时从可用的测试路径中随机选择 10 个值。我们还加载了之前保存的模型。
# load the test image paths from disk and select ten paths randomly
print("[INFO] loading test images...")
testPaths = list(paths.list_images(config.TEST_SET))
currentTestPaths = np.random.choice(testPaths, 10)
# load our super-resolution model from disk
print("[INFO] loading model...")
superResModel = load_model(config.SUPER_RES_MODEL,
custom_objects={"psnr" : psnr})
遍历currentTestPaths ( 第 80 行)中可用的测试图像路径,我们将图像通过我们的模型,并将预测与使用朴素双三次方法(用于放大图像的旧技术之一)调整大小的图像进行比较。
# iterate through our test image paths
print("[INFO] performing predictions...")
for (i, path) in enumerate(currentTestPaths):
# grab the original and the downsampled images from the
# current path
(orig, downsampled) = load_image(path)
# retrieve the individual channels of the current image and perform
# inference
(y, cb, cr) = get_y_channel(downsampled)
upscaledY = superResModel.predict(y[None, ...])[0]
# postprocess the output and apply the naive bicubic resizing to
# the downsampled image for comparison
finalOutput = postprocess_image(upscaledY, cb, cr)
naiveResizing = downsampled.resize(orig.size, Image.BICUBIC)
# visualize the results and save them to disk
path = os.path.join(config.VISUALIZATION_PATH, f"{i}_viz.png")
(fig, (ax1, ax2)) = plt.subplots(ncols=2, figsize=(12, 12))
ax1.imshow(naiveResizing)
ax2.imshow(finalOutput.astype("int"))
ax1.set_title("Naive Bicubic Resizing")
ax2.set_title("Super-res Model")
fig.savefig(path, dpi=300, bbox_inches="tight")
一旦进入循环,我们从第 92 行的开始,将当前迭代中的路径传递给load_image函数,然后用get_y_channel函数隔离 Y 通道。在行 97** 上,我们将隔离的 Y 通道传递给我们的超分辨率模型。注意格式是怎样的superResModel.predict(y)[0]。这是因为我们只需要模型输出的列表中第一个元素的值。我们通过postprocess_image函数传递预测的输出。**
我们已经完成了推理代码。在第行第 105 处,我们引用了为保存可视化效果而创建的目录。现在是时候浏览由106-111行生成的剧情了。
可视化生成的超分辨率图像
有了所有的代码,我们剩下要做的就是在 shell 脚本中运行python generate_super_res.py命令。
$ python generate_super_res.py
[INFO] loading test images...
[INFO] loading model...
[INFO] performing predictions...
如前所述,使用剩余密集块对 PSNR 属性没有任何显著影响。然而,通过对图像(图 4-7) 的可视化,我们看到它们在视觉质量上比简单的双三次方法优越。从这些可视化中可以得出一个微妙的结论; RDNs 很好地学习了层次特征,足以让图像升级到如此值得称赞的视觉质量。
总结
在本教程中,我们学习了一种方法来实现超分辨率的帮助下,一个有效的亚像素 CNN 拟合剩余密集块。在这个过程中,我们还遇到了几个在实现中使用的漂亮概念。
最后,我们观察到子像素 CNN 产生了与原始图像几乎相同质量的图像。鼓励读者修改参数(例如,RDB 内的层数)以查看结果是如何受到影响的。当你与全世界分享你的结果时,一定要标记 PyImageSearch(@ PyImageSearch)!
引用信息
Chakraborty,D. “使用 TensorFlow、Keras 和深度学习的像素混洗超分辨率”, PyImageSearch ,2021 年,https://PyImageSearch . com/2021/09/27/Pixel-shuffle-super-resolution-with-tensor flow-Keras-and-deep-learning/
@article{dev2021, author = {Devjyoti Chakraborty}, title = {Pixel Shuffle Super Resolution with {TensorFlow}, {K}eras, and Deep Learning}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/09/27/pixel-shuffle-super-resolution-with-tensorflow-keras-and-deep-learning/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
规划和撰写研究论文
原文:https://pyimagesearch.com/2022/04/13/planning-and-writing-a-research-paper/
策划并撰写研究论文
在本系列的前一课中,我们学习了为我们的研究课题构思解决方案和有效计划实验的方法。在构思和实验之后是下一个重要的步骤:计划和写一篇研究论文。写论文就像推销一个想法。你需要设定一个正确的基调,讲述一个着重于你的贡献和新鲜感的故事,同时,不要夸大任何东西。
它应该有适当的参考资料和背景,这样即使是在该领域没有多少专业知识的人也能掌握作品背后的主要思想。无论你的研究有多突破,如果你不清楚地、坦率地说明以上几点,你的论文都会被拒绝。
技术写作不像高中写散文和文章。我们经常假设审查者会发现它。但是正如吉姆·卡吉雅所说,“当你写论文的时候,最危险的错误就是假设审稿人会理解你论文的观点。经常听到有人抱怨说,审稿人不明白作者想说什么。
在这篇文章中,我想分享我在为一些顶级会议(如 CVPR 会议、ECCV 会议、WACV 会议、ICLR 会议、TPAMI 会议等)撰写和评审论文时学到的经验。).我希望这些教训能让写作过程变得更容易管理。图 1 概述了研究论文的要素。
在这个系列中,你将学习如何发表小说研究。
本课是关于如何发表小说研究的五部分系列的第三部分:
- 选择研究课题并阅读其文献
- 构思解决方案并规划实验
- **策划并撰写研究论文(本教程)
- 计划事情不顺利时的后续步骤
- 确保你的研究保持可见性和一般提示
**要学会如何策划和写一篇研究论文, 只要坚持读下去。
策划并撰写研究论文
在你开始写作之前,重要的是想象并决定文章的流程。这是在写作之前实现的最重要的工具之一。花几天时间创建它可以让你省去几个小时决定如何组织工作的麻烦。
图 2 显示了我在提交 ECCV 时使用的一个样本轮廓。首先为你的论文确定一个工作标题。不要把它留到最后。它不需要一开始就很花哨,但应该传达你在卖什么。接下来,列出所有重要的部分(引言、相关工作、方法论、实验、结论)、小节和段落,并简要提及它们的目标。章节和段落应该连接起来,为读者创造一个流畅的流程。这样做有助于你理解和想象作品的定位。一旦完成,你只需要遵循它,并详细阐述每一点。让我们详细地看一下这些部分的计划和编写。
第一节—简介
引言是一个至关重要的部分,它可以激励审稿人阅读论文的其余部分,而不是立即做出“拒绝”的决定。它应该清楚地陈述研究主题的相关性,你的方法背后的动机,以及主要的贡献。根据吉姆·卡吉雅的说法,你在引言中要做的是陈述你的解决方案的“含义”。即使对你来说显而易见,明确地拼写它可以避免误解和拒绝的风险。
通常,我会按照四到五段的结构来写引言,如下所示:
- Para 1: 研究什么问题?它如何与社区相关并引起社区的兴趣?为什么有挑战性?
- 在过去的几年里,文献中的方法和算法是如何发展的?使用了哪些不同类别的算法?现在的趋势是什么?
- 你的动力是什么?以前提出的解决方案有什么问题?你带来了什么新的想法?
- 你是如何处理这个问题的?与以前的方法相比,它有什么新颖之处?
- 第 5 段:投稿摘要(通常 3-4 个要点)。你的新鲜感是什么?你的方法在实验和分析中提供了什么改进和好处?
斯坦福信息实验室也为类似的五点介绍结构申请了专利:
- 什么问题?
- 为什么它有趣又重要?
- 为什么很难?(例如,为什么幼稚的方法会失败?)
- 为什么之前没有解决?(或者说,之前提出的解决方案有什么问题?我的有什么不同?)
- 我的方法和结果的关键组成部分是什么?此外,包括任何具体的限制。
然后是最后一段或一小节:“投稿摘要。”它应该以项目符号的形式列出主要的贡献,说明可以找到哪些部分。
介绍性的图表可以帮助你向评论者传达对你的作品的更广泛的理解。把它想象成一个缩略图,可以帮助你在视觉上记住你的作品。它使这一部分在视觉上吸引人,诱使评论者阅读你的论文。对于没有时间通读整篇文章的读者来说,介绍性的图表可以起到有益的作用。Maxwell Forbes 提供了一个优秀的教程来创建你论文的“图 1”。
写作时,记住不要过分夸大或夸大任何贡献或新奇。避免仅仅为了脱颖而出而过度批评他人的工作。记住新颖性是由评论者来评判的,而不是由你来宣称的。因此,不要每次提到你的方法时都声称它是“新颖的”。图 3 总结了如何写一篇强有力的引言。
第二节—相关工作
这一部分应该描述你的问题空间中的文献、最近的方法和趋势。您可以将该部分分成几个段落,每个段落描述一个独立的相关工作类别。记得提及最近的、最接近的、任何类似的或同时进行的工作,并通过清楚地解释你的工作中新颖或不同的方面(动机、想法、方法、应用或分析)来联系你的工作。尽可能多地引用论文,不要过度批评或对任何特定的工作做出不公正的评论。
一个有争议的问题是把相关的工作部分放在引言之后还是结论之前。两者都有利弊,你应该在下结论之前考虑清楚。
介绍后(最首选)
它有助于评审者清楚地理解作品的定位,以及它与之前的作品有何不同。然而,如果不知道该方法的技术细节,有时会变得很难联系起来。有一个介绍性的数字有助于在合理的程度上减轻这个问题。
结束前
评审者现在知道了你的方法的技术细节,并且能够更好地理解它在哪些方面不同于以前的努力。然而,有些人仍然想知道这项工作与之前的工作有什么不同。所以,无论何时采用这种风格,最好在引言中指出与重要相关作品的不同之处。
第三节——方法论
方法部分详细描述了你的方法,允许评审者评估工作的优点和缺点。当评论者读完这一部分的时候,他们可能已经部分地决定了是接受还是拒绝。他们会阅读论文的其余部分,寻找证据来支持他们的决定或改变他们的想法。因此,在本节结束时,技术贡献和方法应该非常清楚。
我遵循下面的结构和注释来帮助创建一个合适的流程,让读者在每一步都参与进来。
背景和准备工作
这一部分的目的是描述那些不是原创的,但却是理解这种方法所需要的材料。你不期望读者或评论者首先阅读重要的论文来理解你的方法。如前所述,每个部分本身应该是完整的。通过陈述你的研究问题的技术细节,使符号和术语非常清楚。解释假设,变量,培训和测试设置,基数,并简要介绍重要的相关工作。例如,
如果你的工作致力于深度神经网络的归因稳健性(例如,我的 ECCV 论文),那么定义归因稳健性(通过数学符号)以给读者设置适当的上下文是很重要的。如果它解决了问题设置(例如,领域一般化、少点学习或零点学习),解释训练和测试设置是至关重要的。
动机
接下来,开始陈述你的动机。在读者进入技术细节之前,它应该是清晰的和直接的。动机可以是理论上的,也可以是经验上的。无论如何,试着用证据、参考或玩具实验来支持它。
接近
选择一个独特的标题,而不是将这一小节命名为“方法”如果你的方法有一个“XYZ”的首字母缩略词,标题可以是“XYZ:建议的方法学”或“XYZ: <expanded form>”或“XYZ: <your novelty>”一些例子:
接下来,参考主要方法图,通过简要解释主要思想、组件(例如,特征提取器、分类器、辅助任务)和步骤(例如,预训练、训练、推理等)来概述您的方法。)涉及。这给了评审者一个预期的概念,以及每个组件/步骤是如何相互关联的。现在你可以详细解释你的每个组件/动作了。写作时,请记住以下几点:
- 每当你借用一些不新奇的东西(例如,损失函数、架构、数据扩充等)时,都要引用参考文献。).
- 与您的符号保持一致(例如,使用\mathbf{}表示向量,使用\hat{y}表示预测)。
- 尽量听起来笼统,尽可能避免具体的实现细节。
通过伪代码或算法提供该方法的总结来结束本节。背面的提供了关于如何用 LaTeX 编写算法的优秀的文档。
图 4 总结了如何写一个强有力的方法论部分。
第四、五节——实验与分析
你实验部分的陈述会显著影响评论者对你论文的印象。因此,让你的实验和发现在视觉上吸引人是很重要的。
实验设置
- 首先简要描述您将在实验中使用的数据集,并解释基线。
- 提及实施细节(例如,架构、超参数、库等)。)、评估协议和指标(FID、准确性、初始分数、精确度、召回率等)。).
- 使用参考资料强调您用于标准和评估方案的数据集与现有技术相同。
主要结果
- 参考并举例说明如何阅读你的表格和图表(解释行和列,标记 x 轴和 y 轴等)。)并总结你的发现。
- 记得回来回答假设和问题。
- 与其解释结果,不如试着描述你的见解。
- 如果你有任何基于实验结果的犹豫不决或悲观的答案,请坦率地给出明确的理由。
- 记住不要夸大和评论任何你的结果不明显的事情。
讨论和分析
或者,您可以有一个单独的“讨论和分析”子部分来讨论和提供额外的结果,以便清楚地理解该方法。你提供的消融和分析越多,评论者被打动的机会就越大。正如我们在上一篇中提到的,您可以包括像组件分析、对超参数的敏感性、t-SNE 图、注意力或显著性图、运行时间分析、各方面的可扩展性等研究。
除此之外,您还可以列出您的方法目前无法解决的范围、限制和问题。与其隐藏明显的局限性,不如列出它们并讨论可能的解决方案。即使你没有陈述,评论者通常也能识别出明显的限制;然后,他们会在这些局限性上批评你的工作。
此外,你可以陈述你的方法的可能应用,这些应用是你没有尝试过的,但却是可行的、有效的或简单明了的。
表格和图表
确保你的表格和数字清晰明了。有详细的标题描述使用的数据集、评估方案、缩写、运行次数和关键观察。不要忘记包括标准偏差,并突出显示最好的和第二好的结果。对于图表,确保文本、图例、轴标题和情节线异常大,以便读者不必每次都放大才能找到每个轴所代表的内容。****
*****图 5 提到了一些撰写研究论文成果部分的快速提示。
第六节——结论与未来工作
这一部分应该是一个简短的段落,以你的动机、主要观点、主要结果和更广泛的影响的总结开始。语气应该是结论性的,不要听起来像摘要或介绍。接下来可以简单提一下自己工作的局限性和未来的工作。作为未来的作品,可以提及自己正在积极从事或计划从事的后续工作。图 6 提到了有效研究论文结论的一些特征。
通用提示
图 7 展示了一些撰写成功研究论文的通用指南。这里有几个相同的提示。
引文
包括尽可能多的相关参考文献,因为这会给人一种作品被很好地研究过的印象。避免使用 arXiv 或任何其他非官方来源获取 BibTeX 条目。取而代之的是,把它们从会议、研讨会或期刊的正式记录中提取出来。仔细检查你的最终参考书目,确保每个条目看起来都是正确的。
附录或补充
包含额外的结果、分析、细节、证明、视频演示或匿名代码作为补充材料或附录通常是个好主意。他们不应该使用方法的改进版本(例如,在额外的参数调整或培训之后)或提交 PDF 的更新或修正版本获得结果。此外,它们不应包含理解贡献所必需的材料。
写作
这里有一些通用的写作技巧。
- 确保在提交之前进行拼写和语法检查。
- 表格和图表应该放在页面的顶部,除非足够小以适合流动或文本或环绕它。
- 不要为了增加引用的数量而添加引用。确保它们是相关的,并传达整体信息。
- 使用现在时态(例如,“我们提议”,“我们观察”),而不是过去时态(例如,“我们提议”,“我们观察”)。
- 利用 draw.io、MS Excel 和 MS PowerPoint 等工具创建专业外观的数字和图表。
议论文 vs .分析研究论文
科研论文大致可以分为两类:议论文和分析论文(图 8) 。一篇议论文支持它的论点,就像律师用证据来证明他们的观点。这种类型的论文旨在说服其读者采纳所提出的观点。
另一方面,分析性论文从多个来源对特定主题的不同观点进行分析。分析性研究论文的主要目的是提出一些不同的观点并得出合乎逻辑的结论。
从定义来看,很明显,我们到目前为止考虑的演示风格是辩论式的。如果你在写一篇分析性论文,你可以考虑采用不同的表达方式。
在这样的写作风格中,你的贡献应该包括你带来的结论和见解。分析性论文的文体与议论文的文体主要区别在于第三、四、五部分。你可以将第三、四、五部分合二为一,采用问答式、因果式、问题解决式或比较对比式。将该部分分成几个小节或段落,呈现不同的观点。
对于每一小节,从阐述目标、使用的方法和实验设置开始。参考结果,根据结果提出自己不偏不倚的想法和观点。你可以选择在结尾部分加入一些建议。这里有几个这样的分析论文的例子。
- Naseer 等人(2021) 遵循问答式,回答几个问题:视觉变形器对遮挡是否鲁棒?视觉转换器可以同时模拟形状和纹理特征吗?位置编码保留了全局图像上下文吗?
- Bhojanapalli 等人(2021) 通过对 ViT 模型的各种稳健性测量进行广泛研究,并将研究结果与 ResNet 基线进行比较,遵循比较对比风格。
汇总
计划和撰写研究论文是构思和实验之后的下一个重要步骤。
- 想象这张纸并创建一个简要描述每一节、小节和段落目标的大纲。选择一个传达作品主旨和定位的工作标题。
- 将引言分成四到五段,简要描述问题陈述及其重要性、局限性,以及之前工作、动机和方法中的差距。以一个贡献列表和一个介绍性的数字结束这一部分。
- 相关的工作应该描述你的问题领域的文献、最近的方法和趋势。尽可能多地引用相关论文,避免不合理的评论。事先决定这一部分应该紧接在引言之后还是结论之前。
- 花点时间在方法论部分来阐明你的技术贡献和新颖性。首先提供背景,然后是动机。接下来,通过插图、等式和玩具例子深入描述你的方法。尽量听起来笼统,避免具体的实现细节。以伪算法结束本节。
- 用视觉上吸引人的图表、图像和表格展示实验和分析部分。首先定义实验设置(数据集、评估、基线、指标等)。),总结您的结果,并描述您的见解。或者,有一个单独的讨论和分析部分/小节来讨论范围限制,并提供额外的结果或应用程序,以便清楚地理解该方法。
- 提供一个总结你的动机、主要想法、关键结果、更广泛的影响和可能的未来方向的结论。努力使所有的引用完整一致。包括额外的结果、分析、细节、证据、视频演示、作为补充材料的匿名代码或附录。
我希望这一课能帮助你计划和撰写你的研究论文。请继续关注下一课,当事情不顺利时,如何计划下一步。
引用信息
Mangla,P. “规划和撰写研究论文”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/qyafh
***@incollection{Mangla_2022_Planning,
author = {Puneet Mangla},
title = {Planning and Writing a Research Paper},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/qyafh},
}
当事情不顺利时,计划下一步
原文:https://pyimagesearch.com/2022/05/04/planning-next-steps-when-things-dont-work-out/
目录
计划下一步不顺心的事情
在本系列的前一课中,我们学习了如何计划和撰写研究论文。由于研究的本质,当事情似乎没有解决时,它会变得既令人兴奋又令人沮丧。尽管它的性质,总会有令人沮丧的时期,当你想退出,开始新的东西。
当进展缓慢,实验没有按计划进行,你开始对工作产生怀疑,或者工作被拒绝(可能是多次)时,你会感到沮丧。
不管原因是什么,重要的是要明白挫折是正常的,在研究中非常普遍。更重要的是妥善处理,不要让它影响你的自信心和数小时的研究工作。
这篇博文将讨论如何应对挫折,以及当事情不顺利时,如何计划下一步。
在这个系列中,你将学习如何发表小说研究。
本课是关于如何发表小说研究的 5 部分系列的第 4 部分:
- 选择研究课题并阅读其文献
- 构思解决方案并规划实验
- 策划并撰写研究论文
- (本教程)
- 确保你的研究保持可见性和一般提示
**要学会如何策划和写一篇研究论文, 只要坚持读下去。
计划下一步不顺心的事情
研究坎坷
研究和挫折相伴而生。在进行研究时,我们经常不知道我们到底在寻找什么,这可能会令人沮丧。正如阿尔伯特·爱因斯坦(图 1) 所说,“如果我们知道自己在做什么,那就不叫研究了吧?”因此,你应该重新激励自己,告诉自己当初为什么要从事这项研究,以及这些挫折在研究界是很常见的。
挫折可能是由几个原因引起的,在建设性地处理它们之前识别它们是很重要的。当你陷入对解决方案的思考或者实验长时间不按预期进行时,你会感到沮丧。这会让你怀疑你的研究是否会成功,以及你是否错过了其他更好的机会。
有时,一些局外人可能会批评你的工作,让你思考它是否有意义。你也可能开始意识到你没有花足够的时间和家人在一起,甚至在睡觉前和周末也在不停地思考你的研究。一旦你让自己平静下来,确定了原因,计划下一步。
制作研究日记
写研究日记(图 2 )提供了你已经尝试过的事情的总体情况,什么是可行的或不可行的,以及你还可以从文献中获得什么来启发和改进你的工作。整理所有重要的相关结果,想法,以及你到目前为止尝试过的实验。它可以是虚拟的,也可以是纸上的,取决于什么适合你的风格。
概述重要文献的动机、贡献和主要观点。提及你对如何通过这些作品改进和启发你的研究的想法。接下来,描述一下你目前为止尝试过的所有想法。写下它的新颖之处,并添加一个粗略的数字来说明你所做的实验的想法和结果。
参考这篇关于如何写研究日记的博客。
坚持你的研究
研究需要一种不期望任何利润的不同心态。因此,不要放弃你的研究而不给它一个公平的机会。坚持你的实验,相信你迟早会得到你期望的结果。如果你觉得自己被无限期地打击,那就开始读点别的吧。阅读最近的、令人兴奋的、但与你当前的研究无关的论文。这样做将有助于你暂时忘记这个项目,很可能会激发你的新想法。
继续讨论
与你的导师和顾问保持联系,定期讨论你的进步(图 3) 。你可以和他们分享你的研究日记,这样可以帮助他们追踪你的成就。他们可以通过建议你完成研究来正确地指导你,也许还会分享一些思考和开展研究的替代方法。
回顾
暂停思考和实验几天,回头看看你的实现,看看你是否可以做些不同的事情。仔细看看你的代码库,找出任何破坏你努力的愚蠢错误。
使用图表、注意力地图或损失图来可视化结果,并找出事情不顺利的根本原因。考虑如何通过实施、额外的损失函数或模块(如果已经确定)来减轻损失。
纸张退稿
每当我们在学术场所提交作品时,我们都抱着最好的希望。然而,由于学术场所的选择性,我们的论文将有更多的机会被拒绝。如图图 4 所示,学术场所(会议和期刊)通常有 20-25%的低接受率。据统计,大约需要 10-11 次重新提交才有 95%的机会被接受。因此,一个人应该明白拒绝是学术过程的一部分,如果他们被多次拒绝,不应该消极对待。
拒绝可能是残酷的、令人失望的,也是发人深省的,尤其是对年轻和新的研究人员来说。重要的是要记住,不要根据评论做出任何冲动的决定。例如,不要向项目主席抱怨糟糕的评论。既然已经做出了决定,除非出现笔误,否则你的投诉不会有任何影响(即使评论说接受,论文也会被拒绝)。
避免在网上发布评论。这样做会玷污你和你的合著者的名声。此外,在网上发表评论会侵犯评论的版权,因为他们不同意自己的话被公开。一些会议甚至有关于在网上发布评论的明确规定,这可能会危及你的研究生涯。
不要写愤怒的反驳来证明自己的观点,批评评论者。这只会让事情变得更糟,即使你是对的。感到失望并躲几天是完全合理的。相反,建议你慢慢来处理和治愈。当你完成后,重温你的工作,阅读评论,并开始如下行动。
了解拒绝原因
拒绝可能是因为
- 你的方法没有经过论证和适当的解释
- 结果微不足道
- 你的实验部分是薄弱的,因为你没有遵循标准的做法,或者可以做更多的实验
- 对评论家来说,这个想法听起来并不新颖
- 你的动机不明确
- 评论者有一个误解
- 这篇论文写得不好,表达也不好
为了有抱负的作者和读者的利益,图 5 回顾了拒绝的原因。
从评审者和区域主席的角度理解拒绝也很重要。在分配给区域主席的一堆文件中,有三分之一是明显被拒绝的。在整个系列中,可能有一两个写得很好(口头或重点),有很好的想法和结果。其余都是边界线。
在 75-80%拒绝率的情况下,问题是,“我如何拒绝边界论文?”区域座椅有两种类型的边界纸(图 6) 。
蟑螂:没有你能识别出来的破绽来杀纸。这篇论文写得很好。然而,审查还算可以,结果显示了逐步改善等。典型的普通海报纸。
六个脚趾的小狗:一张讨人喜欢的纸有很容易被指出的瑕疵。尽管这些缺点并不重要,但它让地区主席很容易拒绝。
阅读评论
通读综述和元综述,找出拒绝的主要和次要原因。主要问题通常包括实验不足、结果不显著、方法的原创性和新颖性有限等。,这是需要解决的问题。次要的评论可以包括写作、清晰度和陈述风格问题,这些问题可以在修改或重复论文时处理。
评论家有时会误解事情或故意提供不合理的评论来拒绝作品。因此,不要盲目相信所有的评论。而是透过文字来判断每个评论是合理的还是不合理的。
决定下一步向哪里提交
既然你已经了解了评论者是如何看待你的作品的,你应该开始寻找你认为修改过的作品有机会出现的其他地方。你需要寻找那些能给你足够时间修改论文并及时重新提交的备选方案。有四个可供选择的地方,你可以决定重新提交你的工作。
会议:会议提供了一种发布作品的快捷方式。他们会在 1-2 个月内为你提供即时反馈,还可能需要几个月的时间来决定你的论文。然而,由于时间的限制,复习可能会变得很慢。您可以查看助手列表来了解即将召开的会议,并决定下一次在哪里提交。考虑那些离截止日期很近的会议,这样你就不用等太久才能被接受。
日志:日志包括与评论者和编辑的持续对话,以改进你的工作。有像《自然》、《科学》、《TPAMI》和《IJCV》这样的期刊,它们被认为与像《CVPR》、《NeurIPS》等顶级会议一样具有竞争力。然而,它们的周转时间很长,整个过程(从提交到接受)长达两年。检查一下你的论文是否适合发表在期刊上。
通常情况下,复杂的论文、介绍理论模型的论文、文献综述的论文或者太长而不便于在会议上讨论的论文更适合发表在期刊上。有时,期刊会发布特别版,收录某些研究领域的投稿。与标准的期刊投稿相比,这些通常更快。
图 7 简单区分会议和期刊。
工作坊:工作坊接受率相对较高,适合新颖性有限或内容不够冗长的作品,以利用会议和期刊 8 至 10 页的限制。你可以在会议网站上浏览研讨会列表,并决定哪一个最适合你。
请注意,许多研讨会是档案,没有他们的程序。如果你想在《论文集》上发表你的作品,你可能会想寻找这些信息。
ArXiv: 如果你的作品找不到合适的场地,可以考虑上传到 ArXiv 这样的公共论坛上,寻找更好的替代品。它也可能适用于过时的作品,并且通过同行评审的可能性很小。
如何提高
这里有一些建议,可以帮助你在下次提交时改进工作。要点是仔细处理评审者的评论,以便在下一轮提交中可以避免它们。
获得额外的结果:评审者可能会建议进行额外的实验和分析,以便更好地评估作品。列出你需要进行的所有新实验和消融。试着把那些结果包含在主要的手稿中,而不是补充的(因为评论者经常跳过它)。如果由于篇幅限制而无法做到,则在补充部分添加结果,并在主稿中明确提及。这让评审者确信你做过这样的实验。
另一个要看的重要事情是,在持续时间(从第一次提交到第二次提交的时间)内,是否有新的作品发表。确保将您的方法与这些最新方法进行比较,或者在相关工作中讨论它们(如果不打算进行比较)。
邀请更多的合作者:有更多的合作者可以帮助你处理审稿人的意见,并相应地修改论文。
演示风格问题和误解:注意是否有任何误解会影响审核者的决定。在写反驳的同时,也不要完全责怪审稿人对作品的误解。相反,承认误解可能是因为你的写作和陈述风格。添加额外的视觉效果和文字来澄清它。对于演示风格的问题,确保你运行语法和拼写检查,并正确引用公式、表格和图表。
AJE 学者提供了一份修改和重新提交研究论文以供发表的清单。
汇总
因为研究的本质,会有事情不成功的时候。
如果你长时间陷入研究中,你可能会感到沮丧;如果工作被多次拒绝,你可能会流口水。合理的做法是把自己藏起来,慢慢恢复和处理。
有时,你会想放弃,但你不应该让这些负面情绪影响你的研究工作。因此,正确处理挫折和拒绝并计划好下一步是很重要的。
在计划下一步之前,重要的是找出你沮丧的原因。例如,当你陷入困境很长时间,并开始怀疑研究是否会成功时,挫折就会出现。
保持和维护研究日记可以为你提供一幅画面,什么进展顺利,你已经尝试了什么,还有什么可以做。你可以与你的合作者和顾问分享,这样他们可以定期跟踪你的进展,并在你遇到问题时提出解决问题的替代方法。
有时阅读最近的、令人兴奋的、但与你目前的研究无关的论文可以帮助你暂时忘记这个项目,并且很可能激发你的新想法。
论文退稿可能是严酷而发人深省的,尤其是对年轻的研究人员而言。然而,一个人应该明白拒绝是学术过程的一部分,如果他们被多次拒绝,不应该消极对待。不要向区域主席抱怨或者一时冲动在网上发布评论。让自己冷静下来,彻底检查一下评论,找出拒绝的主要和次要原因。
决定你可以提交作品的地点。你可以寻找即将到来的会议和研讨会,或者决定向期刊投稿。确保截止日期足够近,这样你就不必为接受而等待太久。如果你没有找到一个合适的地点,或者你的作品已经过时,很少有机会通过同行评审,可以考虑上传到 arXiv。
通过运行额外的实验,与最新的方法进行比较,澄清任何误解,解决任何演示和写作风格问题,来修改和改进您的工作。我希望这一课能帮助你在事情不顺利时计划下一步。敬请关注下一课,确保你的研究保持可见性和一般提示。
引用信息
Mangla,P. “当事情不顺利时规划下一步”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva,S. Huot 编辑。,2022 年,【https://pyimg.co/hvxgp
@incollection{Mangla_2022_Planning_Next_Steps,
author = {Puneet Mangla},
title = {Planning Next Steps When Things Don’t Work Out},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/hvxgp},
}
如何用 mxnet 绘制精度和损耗图
原文:https://pyimagesearch.com/2017/12/25/plot-accuracy-loss-mxnet/

当谈到在多个 GPU(更不用说多台机器)上进行高性能深度学习时,我倾向于使用 mxnet 库。
作为 Apache 孵化器的一部分,mxnet 是一个灵活、高效和可扩展的深度学习库( Amazon 甚至在他们自己的内部深度学习中使用它)。
在我的书《用 Python 进行计算机视觉深度学习的 的 ImageNet 捆绑包中,我们使用 mxnet 库来重现最先进的出版物的结果,并在大规模 ImageNet 数据集上训练深度神经网络,事实上的图像分类基准(由大约 120 万张图像组成)。
尽管 mxnet 具有可扩展性,但不幸的是,它缺少一些我们可能在 Keras、TensorFlow/TensorBoard 和其他深度学习库中找到的便利功能。
mxnet misses 的这些便利方法之一是绘制精度和随时间的损失。
mxnet 库将训练进度记录到您的终端或文件中,类似于 Caffe。
但是为了构建一个显示准确性和时间损失的图表,我们需要手动解析日志。
将来,我希望我们可以使用 mxnet 提供的回调方法来获取这些信息,但是我个人发现它们很难使用(特别是在利用多个 GPU 或多台机器时)。
相反,我建议您在使用 mxnet 构建准确性和损失图时解析原始日志文件。
在今天的博文中,我将展示如何解析 mxnet 的训练日志文件,然后绘制准确性和随时间的损失——要了解如何继续阅读、、、。
如何用 mxnet 绘制精度和损耗图
在今天的教程中,我们将使用 mxnet 库绘制精度和损耗。mxnet v.0.11 和 v0.12 之间的日志文件格式略有变化,因此我们将在这里讨论这两个版本。
特别是,我们将绘制:
- 培训损失
- 验证损失
- 训练 1 级准确度
- 验证等级-1 准确度
- 训练等级-5 准确度
- 验证等级-5 准确度
这六个指标通常是在 ImageNet 数据集上训练深度神经网络时测量的。
我们将解析的相关日志文件来自我们在 AlexNet inside 中的章节,使用 Python 进行计算机视觉的深度学习 ,我们在 ImageNet 数据集上训练开创性的 AlexNet 架构。
对我的书的免费样章感兴趣?免费目录+示例章节包括 ImageNet 捆绑包第 5 章“在 ImageNet 上培训 AlexNet”。在本页右下方的表格中输入您的电子邮件,获取免费章节。
当解析 mxnet 日志文件时,我们通常在磁盘上有一个或多个.log文件,如下所示:
(dl4cv) pyimagesearch@pyimagesearch-dl4cv:~/plot_log$ ls -al
total 108
drwxr-xr-x 2 pyimagesearch pyimagesearch 4096 Dec 25 15:46 .
drwxr-xr-x 23 pyimagesearch pyimagesearch 4096 Dec 25 16:48 ..
-rw-r--r-- 1 pyimagesearch pyimagesearch 3974 Dec 25 2017 plot_log.py
-rw-r--r-- 1 pyimagesearch pyimagesearch 60609 Dec 25 2017 training_0.log
-rw-r--r-- 1 pyimagesearch pyimagesearch 20303 Dec 25 2017 training_65.log
-rw-r--r-- 1 pyimagesearch pyimagesearch 12725 Dec 25 2017 training_85.log
这里您可以看到我有三个 mxnet 日志文件:
training_0.logtraining_65.logtraining_85.log
每个日志文件中的整数值是我开始训练我的深度神经网络时的。
**在大型数据集上训练深度卷积神经网络时,我们通常必须:
- 停止训练
- 降低学习率
- 恢复早期的训练
这个过程使我们能够打破局部最优,下降到较低损失的区域,并提高我们的分类精度。
根据上面文件名中的整数值,您可以看到 I:
- 从零纪元(第一个日志文件)开始训练
- 停止训练,降低学习率,并从纪元 65(第二个日志文件)开始恢复训练
- 再次停止训练,这一次是在第 85 个纪元,降低学习率,并恢复训练(第三个也是最后一个日志文件)
我们的目标是编写一个 Python 脚本,该脚本可以解析 mxnet 日志文件,并创建一个类似于下图的图,其中包括有关我们训练准确性的信息:
Figure 1: mxnet was used to train AlexNet on the ImageNet dataset. Using plot_logs.py we’ve parsed the log files in order to generate this plot utilizing matplotlib.
首先,让我们来看一个mxnet <= 0.11的 mxnet 培训日志格式的例子:
INFO:root:Epoch[73] Batch [500] Speed: 1694.57 samples/sec Train-accuracy=0.584035
INFO:root:Epoch[73] Batch [500] Speed: 1694.57 samples/sec Train-top_k_accuracy_5=0.816547
INFO:root:Epoch[73] Batch [500] Speed: 1694.57 samples/sec Train-cross-entropy=1.740517
INFO:root:Epoch[73] Batch [1000] Speed: 1688.18 samples/sec Train-accuracy=0.589742
INFO:root:Epoch[73] Batch [1000] Speed: 1688.18 samples/sec Train-top_k_accuracy_5=0.820633
INFO:root:Epoch[73] Batch [1000] Speed: 1688.18 samples/sec Train-cross-entropy=1.714734
INFO:root:Epoch[73] Resetting Data Iterator
INFO:root:Epoch[73] Time cost=728.322
INFO:root:Saved checkpoint to "imagenet/checkpoints/alexnet-0074.params"
INFO:root:Epoch[73] Validation-accuracy=0.559794
INFO:root:Epoch[73] Validation-top_k_accuracy_5=0.790751
INFO:root:Epoch[73] Validation-cross-entropy=1.914535
我们可以清楚地看到Epoch[*]文本中的纪元编号— 这将使提取纪元编号变得容易。
可以通过解析出以下值来提取所有验证信息,包括验证准确性、验证 top-k(即排名-5)和验证交叉熵:
Validation-accuracyValidation-top_k_accuracy_5Validation-cross-entropy
唯一棘手的提取是我们的训练集信息。
如果 mxnet 能像他们为验证所做的那样,在纪元结束时记录最终的训练精度和损失,那就太好了——但不幸的是,mxnet 没有这样做。
相反,mxnet 库基于“批处理”记录训练信息。在每N批(其中N是用户在训练期间提供的值)之后,mxnet 将训练准确度和损失记录到磁盘。
因此,如果我们提取以下各项的最终批次值:
Train-accuracyTrain-top_k_accuracyTrain-cross-entropy
…我们将能够获得给定时期的训练精度和损失的近似值。
你可以通过在训练过程中调整Speedometer回调,让你的训练精度和损耗更细粒度或者更不啰嗦。
让我们继续创建负责实际解析日志的plot_log.py文件。
打开一个新文件,将其命名为plot_log.py,并插入以下代码:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
import argparse
import re
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--network", required=True,
help="name of network")
ap.add_argument("-d", "--dataset", required=True,
help="name of dataset")
args = vars(ap.parse_args())
今天我们还将利用re,Python 的正则表达式解析器(第 5 行)。
我一直认为 Google 关于 Python 正则表达式的文档是最好的——如果你不熟悉 Python 中的正则表达式解析,一定要去看看。
另一个我最喜欢的网站是 Regex101.com。这个网站将允许你用最流行的编码语言测试你的正则表达式。我发现它对解析软件的开发非常有帮助。
现在我们已经准备好完成今天工作所需的工具,让我们解析一下第 8-13 行的命令行参数。
我们的plot_log.py脚本需要两个命令行参数:
--network:网络的名称。--dataset:数据集的名称。
我们将在脚本的后面引用这些args。
现在我们将创建一个logs列表:
# define the paths to the training logs
logs = [
(65, "training_0.log"), # lr=1e-2
(85, "training_65.log"), # lr=1e-3
(100, "training_85.log"), # lr=1e-4
]
考虑到logs列表作为命令行参数包含起来有点棘手,我在这里为这个示例脚本硬编码了**。当您绘制自己的日志时,您将需要编辑此列表。
**
一种替代方法是为每个实验创建一个 JSON(或等效的)配置文件,然后在执行plot_logs.py时从磁盘加载它。
正如您在第 16-20 行中看到的,我已经在一个元组列表中定义了日志文件路径以及它们对应的时期。
请务必阅读上面关于日志文件名的讨论。简而言之,文件名本身包含开始时期,元组的第一个元素包含结束时期。
对于这个例子,我们有三个日志文件,因为训练被停止两次以调整学习率。您可以根据自己的需要轻松地添加或删除列表中的内容。
从这里开始,我们将只执行一些紧凑列表初始化:
# initialize the list of train rank-1 and rank-5 accuracies, along
# with the training loss
(trainRank1, trainRank5, trainLoss) = ([], [], [])
# initialize the list of validation rank-1 and rank-5 accuracies,
# along with the validation loss
(valRank1, valRank5, valLoss) = ([], [], [])
第 24 行和第 28 行简单地以 Pythonic 的方式将变量初始化为空列表。我们将很快更新这些列表。
现在让我们遍历日志,开始正则表达式匹配:
# loop over the training logs
for (i, (endEpoch, p)) in enumerate(logs):
# load the contents of the log file, then initialize the batch
# lists for the training and validation data
rows = open(p).read().strip()
(bTrainRank1, bTrainRank5, bTrainLoss) = ([], [], [])
(bValRank1, bValRank5, bValLoss) = ([], [], [])
# grab the set of training epochs
epochs = set(re.findall(r'Epoch\[(\d+)\]', rows))
epochs = sorted([int(e) for e in epochs])
在第 31 行的上,我们开始循环遍历logs,我们的元组列表。
我们在第 34 行的上open和read一个日志文件,同时去掉不必要的空白。
训练和验证数据将存储在批处理列表中,所以我们继续初始化/设置这些列表为空(行 35 和 36 )。
注意:如果你没有注意到,让我在这里指出,我们已经初始化了 13 个列表。人们很容易对每个列表的目的感到困惑。十三也往往是一个不吉利的数字,所以让我们现在就把事情搞清楚。为了澄清,以b开头的 6 个列表是批列表——我们将成批地填充这些列表,然后将它们按元素追加(扩展)到在循环之前定义的相应的 6 个训练和验证列表。第 13 个列表logs很简单,因为它只是我们的纪元编号和日志文件路径。如果你是解析日志的新手或者在理解代码时有困难,确保你插入了print语句进行调试,并确保你理解了代码在做什么。
我们第一次使用re是在第 39 行。这里我们从日志文件的行中解析纪元编号。
正如我们在这篇文章的前面所知道的,日志文件包含Epoch[*],所以如果你仔细阅读,你会看到我们正在从括号中提取十进制数字\d+。请务必参考 Google Python 正则表达式文档来理解语法,或者继续阅读,在那里我将更详细地解释下一个正则表达式。
对这个正则表达式找到的epochs进行排序是在第 40 行的中完成的。
现在,我们将遍历列表中的每个时期,并提取+附加训练信息到相应的列表:
# loop over the epochs
for e in epochs:
# find all rank-1 accuracies, rank-5 accuracies, and loss
# values, then take the final entry in the list for each
s = r'Epoch\[' + str(e) + '\].*Train-accuracy=(.*)'
rank1 = re.findall(s, rows)[-1]
s = r'Epoch\[' + str(e) + '\].*Train-top_k_accuracy_5=(.*)'
rank5 = re.findall(s, rows)[-1]
s = r'Epoch\[' + str(e) + '\].*Train-cross-entropy=(.*)'
loss = re.findall(s, rows)[-1]
# update the batch training lists
bTrainRank1.append(float(rank1))
bTrainRank5.append(float(rank5))
bTrainLoss.append(float(loss))
在第 43 行上,我们开始循环所有的时期。
我们提取三个值:
- 我们排名第一的准确性。
- 这是我们 5 级的精确度。
Train-cross-entropy:这个值是我们的损失。
…为了干净利落地做到这一点,每次提取都跨越两行代码。
我将在第行的第 46 行和第 47 行的第行分解等级 1 的准确性提取—其他提取遵循相同的格式。
对于时段 3,批次 500,日志文件如下所示(从第 38 行的开始):
INFO:root:Epoch[3] Batch [500] Speed: 1692.63 samples/sec Train-accuracy=0.159705
INFO:root:Epoch[3] Batch [500] Speed: 1692.63 samples/sec Train-top_k_accuracy_5=0.352742
INFO:root:Epoch[3] Batch [500] Speed: 1692.63 samples/sec Train-cross-entropy=4.523639
等级 1 精度位于“=”之后的第 38 行的末端。
所以我们要寻找“Epoch[3]”+<any char(s)>+“Train-accuracy = "+<”rank-1 浮点值 > 。
首先,我们构建正则表达式格式字符串s。我们匹配(寻找)的内容大部分是拼写出来的,但是也有一些特殊的正则表达式格式字符混合在一起:
- 反斜杠(“\”)是转义字符。因为我们明确地寻找'['和']',所以我们在每个前面加了一个反斜杠。
- 的”。* "表示任何字符—在这种情况下,它位于格式字符串的中间,这意味着中间可能有任何字符。
- 关键字符是'('和')',它标记我们的提取。在这种情况下,我们提取的是行中“=”后面的字符。
然后,在我们构造了s之后,在下一行我们调用re.findall。使用我们的格式字符串,s和rows,re.findall函数找到所有匹配项并提取排名 1 的精确度。神奇!
旁注:我们只对最后一个值感兴趣,因此有了[-1]列表索引。
要查看这个 Python 正则表达式的运行情况,我们来看一个来自Regex101.com的截图(点击图片放大):
Figure 2: Using Regex101.com, we can easily work on Regular Expressions with Python.
我再次强烈推荐 Regex101 从正则表达式开始。它对于解析高级和复杂的字符串也非常有用(幸运的是我们的相对简单)。
接下来的两个表达式在第 48-51 行以同样的方式被解析。
我们已经成功提取了这些值,所以下一步是将这些值以浮点形式添加到它们各自的列表中的第 54-56 行上。
从那里,我们可以用同样的方式获取验证信息:
# extract the validation rank-1 and rank-5 accuracies for each
# epoch, followed by the loss
bValRank1 = re.findall(r'Validation-accuracy=(.*)', rows)
bValRank5 = re.findall(r'Validation-top_k_accuracy_5=(.*)', rows)
bValLoss = re.findall(r'Validation-cross-entropy=(.*)', rows)
# convert the validation rank-1, rank-5, and loss lists to floats
bValRank1 = [float(x) for x in bValRank1]
bValRank5 = [float(x) for x in bValRank5]
bValLoss = [float(x) for x in bValLoss]
我不会再重复复杂的正则表达式匹配了。因此,一定要研究上面的例子,并将其应用到第 60-63 行中,在这里我们提取验证等级 1、等级 5 和损失值。如果需要,将日志文件数据和正则表达式字符串插入 Regex101,如图图 2 所示。
和以前一样,我们将字符串转换成浮点型(这里是列表理解)并将列表附加到各自的批处理列表中(第 65-67 行)。
接下来,我们将计算出我们的数组切片,以便我们可以更新将用于绘图的列表:
# check to see if we are examining a log file other than the
# first one, and if so, use the number of the final epoch in
# the log file as our slice index
if i > 0 and endEpoch is not None:
trainEnd = endEpoch - logs[i - 1][0]
valEnd = endEpoch - logs[i - 1][0]
# otherwise, this is the first epoch so no subtraction needs
# to be done
else:
trainEnd = endEpoch
valEnd = endEpoch
这里需要设置trainEnd和valEnd。这些临时值将用于切片。
为此,我们检查当前正在解析哪个日志文件。我们知道哪个日志正在被解析,因为我们在开始循环时枚举了这些值。
如果我们碰巧检查的不是第一个日志,我们将使用日志文件中最后一个时期的时期号作为我们的片索引(第 72-74 行)。
否则,不需要发生减法,所以我们简单地将trainEnd和valEnd设置为endEpoch ( 第 78-80 行)。
最后但同样重要的是,我们需要更新培训和验证列表:
# update the training lists
trainRank1.extend(bTrainRank1[0:trainEnd])
trainRank5.extend(bTrainRank5[0:trainEnd])
trainLoss.extend(bTrainLoss[0:trainEnd])
# update the validation lists
valRank1.extend(bValRank1[0:valEnd])
valRank5.extend(bValRank5[0:valEnd])
valLoss.extend(bValLoss[0:valEnd])
使用来自循环每次迭代的批列表,我们将它们以元素的方式(这在 Python 中被称为扩展)添加到各自的训练列表(第 83-85 行)和验证列表(第 88-90 行)。
在我们遍历每个日志文件之后,我们有 6 个方便的列表可以绘制。
现在,我们的数据已经在这些有用的列表中进行了解析和组织,让我们继续使用 matplotlib 构建图表:
# plot the accuracies
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, len(trainRank1)), trainRank1,
label="train_rank1")
plt.plot(np.arange(0, len(trainRank5)), trainRank5,
label="train_rank5")
plt.plot(np.arange(0, len(valRank1)), valRank1,
label="val_rank1")
plt.plot(np.arange(0, len(valRank5)), valRank5,
label="val_rank5")
plt.title("{}: rank-1 and rank-5 accuracy on {}".format(
args["network"], args["dataset"]))
plt.xlabel("Epoch #")
plt.ylabel("Accuracy")
plt.legend(loc="lower right")
这里我们绘制了训练+验证的 1 级和 5 级精度。我们还从命令行参数中为我们的图指定了一个标题。
同样,让我们绘制训练+验证损失:
# plot the losses
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, len(trainLoss)), trainLoss,
label="train_loss")
plt.plot(np.arange(0, len(valLoss)), valLoss,
label="val_loss")
plt.title("{}: cross-entropy loss on {}".format(args["network"],
args["dataset"]))
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="upper right")
plt.show()
在 mxnet 0.12 和更高版本中,日志文件的格式略有变化。
主要区别是训练精度和损失现在显示在同一行。这里有一个来自第三纪元的例子,批次 500:
INFO:root:Epoch[3] Batch [500] Speed: 1997.40 samples/sec accuracy=0.013391 top_k_accuracy_5=0.048828 cross-entropy=6.878449
确保向右滚动以查看行 47 的全部输出。
感谢澳大利亚国立大学医学院的丹尼尔·邦纳博士,我们有了一个更新的剧本:
# loop over the epochs
for e in epochs:
# find all rank-1 accuracies, rank-5 accuracies, and loss
# values, then take the final entry in the list for each
s = r'Epoch\[' + str(e) + '\].*accuracy=([0]*\.?[0-9]+)'
rank1 = re.findall(s, rows)[-2]
s = r'Epoch\[' + str(e) + '\].*top_k_accuracy_5=([0]*\.?[0-9]+)'
rank5 = re.findall(s, rows)[-2]
s = r'Epoch\[' + str(e) + '\].*cross-entropy=([0-9]*\.?[0-9]+)'
loss = re.findall(s, rows)[-2]
# update the batch training lists
bTrainRank1.append(float(rank1))
bTrainRank5.append(float(rank5))
bTrainLoss.append(float(loss))
请务必查看下面的 “下载” 部分,在那里您可以下载这两个版本的脚本。
结果
我用 mxnet 框架在 ImageNet 数据集上训练了 Krizhevsky 等人的 AlexNet CNN,在我的书《用 Python 进行计算机视觉的 中有详细介绍。
一路上,我一边调整学习率,一边停止/开始训练过程。这个过程产生了前面提到的三个日志文件。
现在,通过一个命令,使用这篇博文中描述的方法,我已经解析了所有三个日志文件,并使用 matplotlib 生成了训练进度图:
$ python plot_log.py --network AlexNet --dataset ImageNet
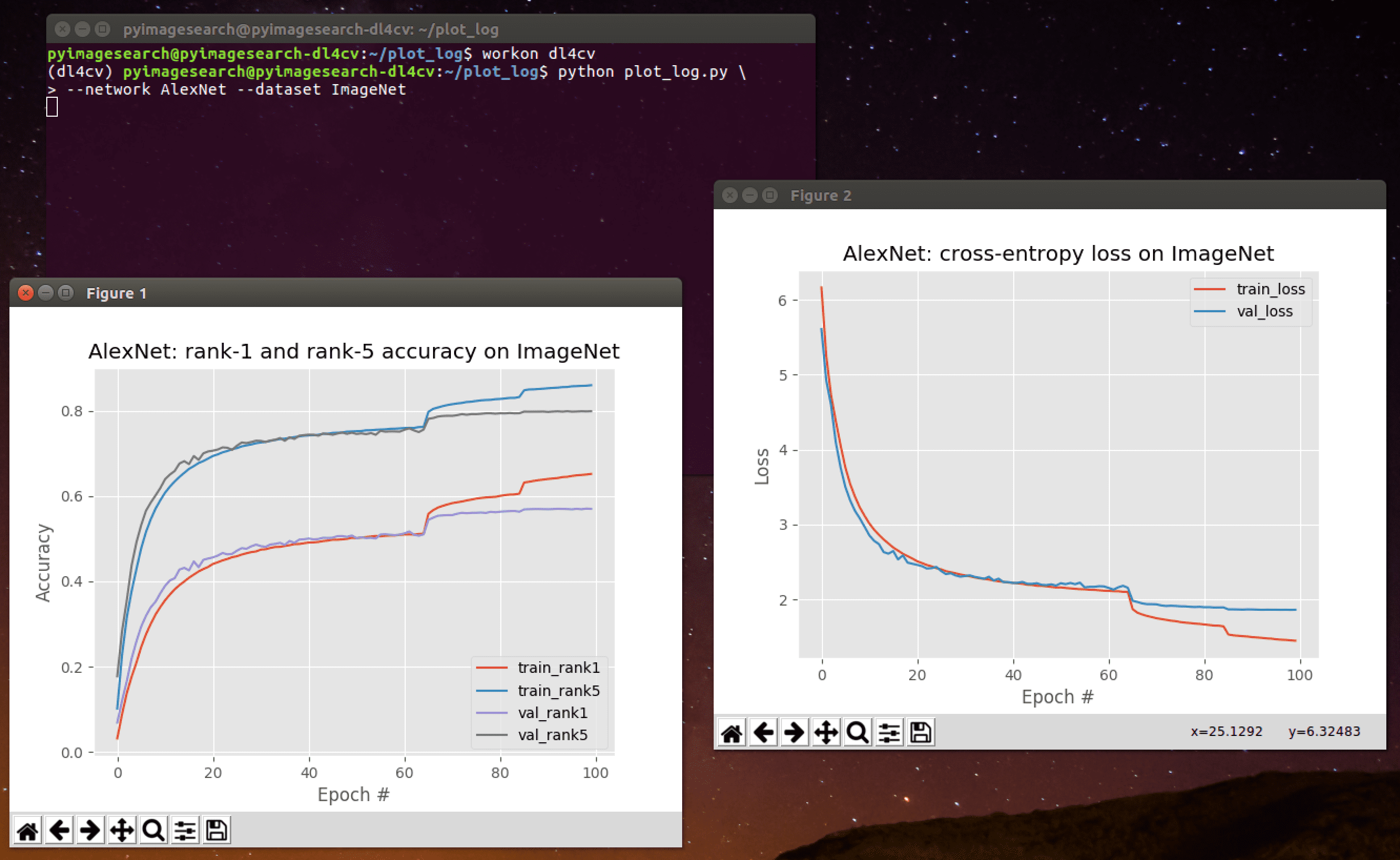
Figure 3: The plot_logs.py script has been used to plot data from mxnet training log files using Python and matplotlib.
摘要
在今天的博文中,我们学习了如何解析 mxnet 日志文件,提取训练和验证信息(包括损失和准确性),然后绘制这些信息。
解析 mxnet 日志可能有点乏味,所以我希望这篇博客文章中提供的代码可以帮助你。
如果你有兴趣学习如何使用 mxnet 库训练自己的卷积神经网络,一定要看看我的新书《用 Python 进行计算机视觉的深度学习》的 ImageNet 包。
否则,请务必在下面的表格中输入您的电子邮件地址,以便在以后的博客文章发布时得到通知!****
用 Python 预配置亚马逊 AWS 深度学习 AMI
原文:https://pyimagesearch.com/2017/09/20/pre-configured-amazon-aws-deep-learning-ami-with-python/

我的书 用 Python 进行计算机视觉的深度学习所附带的 Ubuntu VirtualBox 虚拟机,包含了你需要的所有必要的深度学习和计算机视觉库(比如 Keras、TensorFlow、scikit-learn、scikit-image、OpenCV 等。)预装。
然而,尽管深度学习虚拟机易于使用,但它也有许多缺点,包括:
- 比在本机上执行指令要慢得多。
- 无法访问您的 GPU(以及连接到主机的其他外围设备)。
虚拟机在便利性方面所拥有的东西,你最终会为其在性能方面所付出的代价——这对于初来乍到的读者来说是一个很好的选择,但是如果你希望能够 大幅提升速度 ,同时 仍然保持预先配置的环境 ,你应该考虑使用亚马逊网络服务(AWS)和我预先构建的深度学习亚马逊机器映像(AMI)。
使用本教程中概述的步骤,您将学习如何登录(或创建)您的 AWS 帐户,旋转一个新实例(带或不带GPU),并安装我预先配置的深度学习映像。这将使你能够享受预先构建的深度学习环境而不牺牲速度。
(2019-01-07)发布 DL4CV 的 v 2.1:AMI 2.1 版本发布有更多环境陪伴我的深度学习书的加成章节。
要了解如何使用我的深度学习 AMI,继续阅读。
用 Python 预配置亚马逊 AWS 深度学习 AMI
在本教程中,我将向您展示如何:
- 登录/创建您的 AWS 帐户。
- 启动我预配置的深度学习 AMI。
- 登录到服务器并执行您的代码。
- 完成后停止机器。
然而,在我们走得太远之前,我想提一下:
- 深度学习 AMI 是 基于 Linux 的 所以我建议对 Unix 环境、特别是命令行有一些基本的了解。
- AWS 不是免费的,需要按小时付费。时薪的多少取决于你选择的机器(无 GPU、一个 GPU、八个 GPU 等等。).不到 1 美元/小时,你就可以使用带有 GPU 的机器,这将大大加快深度神经网络的训练速度。你只为机器运行的时间付费。完成后,您可以关闭您的机器。
步骤 1:设置亚马逊网络服务(AWS)账户
为了启动我预先配置的深度学习,你首先需要一个亚马逊网络服务账户。
首先,进入亚马逊网络服务主页,点击“登录控制台”链接:

Figure 1: The Amazon Web Services homepage.
如果您已经有一个帐户,您可以使用您的电子邮件地址和密码登录。否则,您需要点击“创建新的 AWS 帐户”按钮并创建您的帐户:

Figure 2: Logging in to your Amazon Web services account.
我鼓励你使用现有的 Amazon.com 的登录,因为这将加快这个过程。
步骤 2:选择并启动深度学习 AWS 实例
现在,您已经准备好启动预配置的深度学习 AWS 实例。
首先,您应该将您的地区/区域设置为“美国西部(俄勒冈州)” 。我在俄勒冈地区创建了深度学习 AMI,所以你需要在这个地区找到它,启动它,并访问它:

Figure 3: Setting your AWS region to “US West (Oregon)”.
将您的地区设置为俄勒冈州后,单击“服务”选项卡,然后选择“EC2”(弹性云计算):

Figure 4: Accessing the Amazon EC2 dashboard.
在这里,您应该单击“启动实例”按钮:

Figure 5: Launching an Amazon AWS instance for deep learning.
然后选择“社区 ami”,搜索 “用 python-v2.1 深度学习计算机视觉-ami-089 c 8796 ad 90 c 7807”:
Figure 6: Searching for the Deep Learning for Computer Vision with Python AMI.
点击 AMI 旁边的“选择”。
现在可以选择实例类型了。亚马逊提供了大量虚拟服务器,用于运行各种各样的应用程序。这些实例具有不同数量的 CPU 能力、存储、网络容量或 GPU,因此您应该考虑:
- 你想推出什么类型的机器。
- 你特定的预算。
GPU 实例往往比标准 CPU 实例花费更多。然而,他们可以在很短的时间内训练深度神经网络。当您计算出在 CPU 上训练网络与在 GPU 上训练网络的平均时间时,您可能会意识到使用 GPU 实例将为您节省资金。
对于 CPU 实例,我建议您使用“计算优化” c4。* 实例。特别是, c4.xlarge 实例是一个很好的尝试。
如果你想使用 GPU,我强烈推荐“GPU 计算”实例。 p2.xlarge 实例有一个 NVIDIA K80 (12GB 内存)。
其中p 2.8x largesports8 GPU。而 p2.16xlarge 有 16 个 GPU。
我已经列出了以下每个实例的价格(在撰写本文时):
- C4 . xlarge:$ 0.199/小时
- p2 . x large:$ 0.90/小时
- p 2.8 x 大:$ 7.20/小时
- 2.16 倍大:$ 14.40/小时
如您所见,GPU 实例要贵得多;然而,你可以用成本的一小部分来训练网络,使它们成为一个更经济可行的选择。因此,如果这是你第一次使用 GPU 进行深度学习,我建议使用 p2.xlarge 实例。
在下面的示例截图中,您可以看到我选择了 p2.xlarge 实例:

Figure 7: Selecting the p2.xlarge instance for deep learning using the GPU.
(2019-01-07)DL4CV 2.1 版本: AWS 目前在【GPU 实例】*下有他们的 p2 实例,而不是“GPU 计算”。*
接下来,我可以单击“查看并启动”,然后单击“启动”来启动我的实例。
点击“Launch”后,系统会提示您选择您的密钥对或创建新的密钥对:

Figure 8: Selecting a key pair for our Elastic Cloud Compute instance.
如果您有一个现有的密钥对,您可以从下拉菜单中选择“选择一个现有的密钥对”。否则,您需要选择【创建新的密钥对】,然后下载密钥对。密钥对用于登录 AWS 实例。
在确认并接受来自 Amazon 的登录信息后,您的实例将开始启动。向下滚动到页面底部,然后单击“查看实例”。您的实例需要一分钟左右的时间才能启动。
一旦实例联机,您将看到实例的“实例状态”列被更改为“正在运行”。
选择它,您将能够查看实例的信息,包括 IP 地址:

Figure 9: Examining the IP address of my deep learning AWS instance.
这里可以看到我的 IP 地址是52.88.146.157。您的 IP 地址会有所不同。
启动一个终端,您就可以将 SSH 引入到您的 AWS 实例中:
$ ssh -i EC2KeyPair.pem ubuntu@52.88.146.157
您需要将上面的命令更新为:
- 使用您为密钥对创建的文件名。
- 使用实例的 IP 地址。
步骤 3:(仅 GPU 仅适用于 AMI 版本 1.0 和 1.2)重新安装 NVIDIA 深度学习驱动程序
(2019-01-07)发布 DL4CV 2.1:这一步是对于AMI 2.1 版本不需要。*既不需要更新驱动程序,也不需要重新启动。启动并运行。但是,请注意下面的nvidia-smi命令,因为它对验证驱动程序操作很有用。*
如果您选择了 GPU 实例,您将需要:
- 通过命令行重启您的 AMI
- 卸载 nvidia 驱动程序
这两个步骤的原因是因为从预先配置的 AMI 中启动的实例可能会以略有不同的内核重新启动,因此导致加载新的(默认)驱动程序,而不是 NVIDIA 驱动程序。
要避免这种情况,您可以:
- 重启你的系统现在,本质上是“锁定”当前内核,然后重新安装 NVIDA 驱动一次。
- 每次从 AWS admin 启动/重启实例时,请重新安装 NVIDIA 驱动程序。
这两种方法各有利弊,但我推荐第一种。
首先,通过命令行重新启动实例:
$ sudo reboot
您的 SSH 连接将在重启过程中终止。
一旦实例重新启动,重新 SSH 到实例,并重新安装 NVIDIA 内核驱动程序。幸运的是,这很容易,因为我已经将驱动程序文件包含在实例的主目录中。
如果您列出installers目录的内容,您会看到三个文件:
$ ls -l installers/
total 1435300
-rwxr-xr-x 1 root root 1292835953 Sep 6 14:03 cuda-linux64-rel-8.0.61-21551265.run
-rwxr-xr-x 1 root root 101033340 Sep 6 14:03 cuda-samples-linux-8.0.61-21551265.run
-rwxr-xr-x 1 root root 75869960 Sep 6 14:03 NVIDIA-Linux-x86_64-375.26.run
将目录更改为installers,然后执行以下命令:
$ cd installers
$ sudo ./NVIDIA-Linux-x86_64-375.26.run --silent
按照屏幕上的提示操作(包括覆盖任何现有的 NVIDIA 驱动程序文件),将会安装您的 NVIDIA 深度学习驱动程序。
您可以通过运行nvidia-smi命令来验证 NVIDIA 驱动程序是否安装成功:
$ nvidia-smi
Wed Sep 13 12:51:43 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 375.26 Driver Version: 375.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 0000:00:1E.0 Off | 0 |
| N/A 43C P0 59W / 149W | 0MiB / 11439MiB | 97% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
步骤 4:在 AWS 上访问深度学习 Python 虚拟环境
(2019-01-07)DL4CV 2.1 版本:AMI 2.1 版本有以下环境:dl4cv、mxnet、tfod_api、retinanet、mask_rcnn。确保您在与您正在学习的 DL4CV 书籍章节相对应的正确环境中工作。此外,请务必参考 DL4CV 配套网站,了解有关这些虚拟环境的更多信息。
您可以通过使用workon dl4cv命令访问 Python 虚拟虚拟环境来访问我们的深度学习和计算机视觉库:

Figure 10: Accessing the dl4cv Python virtual environment for deep learning.
注意,现在我的提示前面有了文本(dl4cv),这意味着我在dl4cv Python 虚拟环境中。
您可以运行pip freeze来查看所有安装的 Python 库。
我在下面附上了一个截图,演示了如何从 Python shell 导入 Keras、TensorFlow、mxnet 和 OpenCV:

Figure 11: Importing Keras, TensorFlow, mxnet, and OpenCV into our deep learning Python virtual environment.
如果您在导入 mxnet 时遇到错误,只需重新编译它:
$ cd ~/mxnet
$ make -j4 USE_OPENCV=1 USE_BLAS=openblas USE_CUDA=1 \
USE_CUDA_PATH=/usr/local/cuda USE_CUDNN=1
这是由于我在步骤#3 中提到的 NVIDIA 内核驱动程序问题。你只需要重新编译 mxnet 一次和,如果你在导入时收到一个错误。
使用 Python 的计算机视觉深度学习 的代码+数据集到 默认情况下是而不是包含在预先配置的 AMI 中(因为 AMI 是公开可用的,并且可以用于除了通过使用 Python 的计算机视觉深度学习读取之外的任务)。
要将您本地系统上的书中的代码上传到 AMI,我建议使用scp命令:
$ scp -i EC2KeyPair.pem ~/Desktop/sb_code.zip ubuntu@52.88.146.157:~
在这里,我指定:
- 使用 Python 代码+数据集的计算机视觉深度学习的
.zip文件路径。 - 我的亚马逊实例的 IP 地址。
从那里,.zip文件被上传到我的主目录。
然后,您可以解压缩归档文件并执行代码:
$ unzip sb_code.zip
$ cd sb_code/chapter12-first_cnn/
$ workon dl4cv
$ python shallownet_animals.py --dataset ../datasets/animals
Using TensorFlow backend.
[INFO] loading images...
...
Epoch 100/100
2250/2250 [==============================] - 0s - loss: 0.3429 - acc: 0.8800 - val_loss: 0.7278 - val_acc: 0.6720
[INFO] evaluating network...
precision recall f1-score support
cat 0.67 0.52 0.58 262
dog 0.59 0.64 0.62 249
panda 0.75 0.87 0.81 239
avg / total 0.67 0.67 0.67 750
步骤 5:停止深度学习 AWS 实例
一旦您完成了 AMI 的工作,请返回到 EC2 仪表板上的“Instances”菜单项,并选择您的实例。
选中实例后,单击“动作= >“实例状态= >“停止”:

Figure 12: Stopping my deep learning AWS instance.
这个过程将关闭你的深度学习实例(你将不再为此按小时付费)。
如果您想删除实例,您可以选择“终止”。删除一个实例会破坏您的所有数据,所以如果需要的话,请确保您已经将训练好的模型放回到您的笔记本电脑上。终止一个实例还会阻止您对该实例产生任何进一步的费用。
故障排除和常见问题
在这一部分中,我将详细解答关于预先配置的深度学习 AMI 的常见问题。
如何用深度学习 AMI 的 Python 执行计算机视觉深度学习的代码?
请参见上面的“在 AWS 上访问深度学习 Python 虚拟环境”部分。要点是您将通过scp命令上传代码的.zip到您的 AMI。下面是一个命令示例:
$ scp -i EC2KeyPair.pem path/to/code.zip ubuntu@your_aws_ip_address:~
我可以在深度学习 AMI 中使用 GUI/窗口管理器吗?
不,急性心肌梗塞只是晚期。我建议使用深度学习 AMI,如果你是:
- 熟悉 Unix 环境。
- 有使用终端的经验。
否则我会推荐用 Python 代替 计算机视觉深度学习的深度学习虚拟机部分。
AMI 可以使用 X11 转发。当您 SSH 到机器时,只需像这样提供-X标志:
$ ssh -X -i EC2KeyPair.pem ubuntu@52.88.146.157
如何使用 GPU 实例进行深度学习?
请参见上面的“步骤 2:选择并启动您的深度学习 AWS 实例”部分。当选择你的亚马逊 EC2 实例时,选择一个 p2。* (即“GPU 计算”或“GPU 实例”)实例。这些实例分别有一个、八个和十六个 GPU。
摘要
在今天的博客文章中,你学习了如何在亚马逊 Web 服务生态系统中使用我预先配置的 AMI 进行深度学习。
与预先配置的虚拟机相比,使用我的 AMI 的优势在于:
- 亚马逊网络服务和弹性云计算生态系统为您提供了大量系统供您选择,包括纯 CPU、单 GPU 和多 GPU。
- 你可以将你的深度学习环境扩展到多台机器。
- 您可以保留使用预先配置的深度学习环境的能力,但仍然可以通过专用硬件获得更快的速度。
缺点是 AWS:
- 需要花钱(通常是按小时收费)。
- 对于那些不熟悉 Unix 环境的人来说可能是令人畏惧的。
在你使用我的虚拟机体验了深度学习之后,我强烈建议你也尝试一下 AWS 你会发现额外的速度提升是值得的。
要了解更多,看看我的新书, 用 Python 进行计算机视觉的深度学习。
PyImageConf 2018:实用、动手的计算机视觉和深度学习会议

今天,我很高兴地宣布我在幕后工作了很长时间的一个活动的最终细节:
PyImageConf 2018:实用、动手的计算机视觉大会
想象一下,采用 PyImageSearch 博客的实用、动手教学风格…
并将其转化为现场的面对面会议。
听起来有趣吗?
请继续阅读,了解为什么您应该参加 PyImageConf。
会议在何时何地举行?
PyImageConf 2018 将于 8 月 26 日至 28 日在加利福尼亚州旧金山的凯悦酒店举行。
- 会谈将在凯悦酒店精致的艺术级宴会厅举行
- 研讨会和分组会议将利用酒店的专用工作空间
- 每天提供餐饮、坐下来吃午餐(给你足够的时间来建立关系网和社交)
- 还将包括晚间活动,包括演示、演示、社交和开放酒吧
谁将发言?

Figure 1: PyImageConf 2018 speakers include Adrian Rosebrock, François Chollet, Katherine Scott, Davis King, Satya Mallick, Joseph Howse, Adam Geitgey, Jeff Bass, and more.
PyImageConf 汇集了计算机视觉、深度学习和 OpenCV 教育领域的知名人士,为您提供最好的现场实践培训和讲座。
每个演讲者分别以他们的写作、教学、在线课程和对开源项目的贡献而闻名。
目前已有八位确认的演讲者和研讨会主持人,稍后还会有更多人加入:
- Fran ois Chollet:作者 Keras 深度学习库。谷歌深度学习和人工智能研究员。作品在 CVPR、日本、ICLR 等地出版。
- Katherine Scott:行星实验室的图像分析团队负责人。卫星图像分析专家。Tempo Automation 和 Sight Machine 的前联合创始人。《T4》的合著者。
- 戴维斯·金:作者 dlib 库。物体探测专家。十多年来,开源开发者和从业者一直在构建行业 CV 系统。
- Satya Mallick:learn openv的作者和创作者。人脸专家的计算机视觉。在 CV 和 ML 工作的企业家。
- 约瑟夫·豪斯:帕克特出版社出版的六部计算机视觉/OpenCV 书籍的作者。通过他的公司 Nummist Media 进行计算机视觉和咨询。增强现实、虚拟现实和红外计算机视觉系统方面的专家。
- 亚当·盖特吉:的作者机器学习很有趣!博客系列,领英学习,和 Lynda.com。喜欢用机器学习和计算机视觉来构建产品。
- Jeff Bass: Raspberry Pi 黑客,计算机视觉从业者,计量经济学精灵,35 年统计学经验。
- Adrian rose Brock:PyImageSearch.com 的作者和创造者, 实用 Python 和 OpenCV , PyImageSearch 大师 , 用 Python 进行计算机视觉的深度学习 。计算机视觉企业家。
谁应该参加?
您应该参加 PyImageConf,如果您:
- 是一名准备好驾驭计算机视觉和深度学习浪潮并开发新产品/应用的企业家
- 你是一名不确定你职业道路的学生,但准备探索计算机视觉、深度学习和人工智能吗
- 是一个计算机视觉爱好者,喜欢构建新的项目和工具
- 渴望向顶级计算机视觉和深度学习教育家学习
- 享受 PyImageSearch 的教学风格,想要个性化的现场培训
如果这听起来像你,请放心,这次会议将非常值得你投资的时间,资金和旅行。
会有多少张票?
PyImageConf 将是一个小型且私密的会议,最多可容纳 200 名与会者。
我特意将会议开得很小,以便您能够:
- 最好向演讲者和演示者学习
- 与计算机视觉和深度学习专家进行一对一的激光聚焦
- 更好地与你的同行和同事建立联系
一旦票卖完了,我不会(也不能)再加了。
门票多少钱?
门票价格:
- 745 美元给的 PyImageSearch 大师会员,他们也将获得门票的优先权
*** 845 美元面向早期读者和普通读者**
**这可能看起来很多,但请记住,您的 PyImageConf 票证包括:
- 整整两天的会谈、研讨会和培训
- 每天供应午餐
- 三场晚间活动(包括一个开放的酒吧)
大多数会议对这类活动的收费都超过 1500-2500 美元。
我的目标是尽可能地降低成本,同时确保我们的活动规模小且私密。
现在花时间检查一下你的工作、配偶、孩子、保姆等。指定你的资金去买一张票。
票什么时候开始出售?
门票将开始发售:
- 1 月 19 日星期五获取 PyImageSearch 大师和早鸟名单(大师成员将提前几小时收到购票链接)
- 1 月 26 日星期五全面发售
在这一点上,我不确定大减价开始时是否还有剩余的票。
如果您有兴趣参加 PyImageConf 并想要一张门票,请点击以下链接并加入早鸟名单:
不要错过购买 PyImageConf 门票的机会,点击此处报名参加早期投标列表。
试验性时间表
为了让你们感受到 PyImageConf 所付出的努力和思考,我在下面附上了一份(暂定的)讲座和研讨会时间表:
第一天:2018 年 8 月 26 日
- 下午 6:30-9:30:注册-现场注册将于下午 6:30 在凯悦酒店中庭开始
- 晚上 7:30-11:30:开业酒会、社交、酒吧
第二天:2018 年 8 月 27 日
- 上午 7:30-下午 5:30:PyImageConf 讲座-大宴会厅的大门将于上午 8 点打开
- 上午 7:30-11:00:迟到登记
- 上午 9:00:亚当·盖特基——生成性对抗网络(GANs)的应用
- 上午 10:00:萨提亚·马利克——计算机人脸视觉
- 上午 11:00:戴维斯·金——培训和改进您的物体探测器
- 中午 12:00-下午 1:30:在专用用餐区供应午餐
- 下午 1:30:杰夫·巴斯——树莓派和计算机视觉
- 下午 2:30:Joseph Howse——虚拟现实和增强现实
- 下午 3:30:凯瑟琳·斯科特——卫星图像分析
- 下午 4:30:弗朗索瓦·乔莱——深度学习
- 下午 5:30:Adrian rose Brock——启动计算机视觉或深度学习初创公司的实用可行步骤
- 晚上 8:30-11:30:网络、社交、酒吧
第三天:2018 年 8 月 28 日
- 上午 9:00-下午 4:30PyImageConf 研讨会
- 研讨会将包括:
- 实用深度学习和计算机视觉指南
- 用于面部识别和其他面部应用的计算机视觉
- 训练你自己的自定义物体探测器的完整指南(包括提示和技巧)
- 增强现实和虚拟现实与计算机视觉
- Raspberry Pi +计算机视觉项目
- …更多精彩即将到来!
- 上午 9:30-下午 12:00:研讨会第一部分
- 中午 12:00-下午 1:30:在专用用餐区供应午餐
- 下午 1:30-4:30:工作坊第二部分
- 下午 4:30-5:30:PyImageConf 总结
- 晚上 8:00-11:00:网络、社交、酒吧
正如你所看到的,我已经花了很多心思来组织这次会议,并确保它将成为今年最好的计算机视觉+深度学习教育会议。
听起来很棒,接下来我该做什么?
门票可能会很快销售一空…问问任何一个长期阅读 PyImageSearch 的读者,他们会告诉你像这样的特别活动/销售会多快销售一空:
- 几年前,我在 Kickstarter 上为 PyImageSearch 大师课程发起了一场活动——所有早期特价商品都在 30 分钟内销售一空。
- 2017 年 1 月,我发起了第二次 Kickstarter 活动,这一次是为了我的新书,用 Python 进行计算机视觉的深度学习——所有早鸟特价在不到 15 分钟内售罄。
- 去年 11 月,我向在黑色星期五购买我的书的前 30 名读者提供了免费的 NVIDA Jetson TX2s 和 Raspberry Pis 所有 30 本书都在 3 分钟多一点的时间内售罄。
我以前从未提供过像这样的现场、面对面的培训项目或会议,但鉴于只有200 张门票可用,我预计这些门票会很快售罄。
事实上,我不确定在 1 月 19 日周五的早鸟销售之后还会有任何票剩余(我不建议等到 1 月 26 日周五的大减价——你可能会错过票)。
如果您有兴趣参加 PyImageConf 并想要一张门票,请务必点击以下链接并加入早鸟名单:
这将是一个爆炸!我希望你能按时到达。**
PyImageConf 2018 概要
原文:https://pyimagesearch.com/2018/10/01/pyimageconf-2018-recap/

PyImageConf 2018,PyImageSearch 自己的计算机视觉和深度学习教育会议,于 8 月 26 日至 28 日在加利福尼亚州旧金山的 Regency Hyatt 举行。这是一次令人惊叹的会议,根据与会者的反馈,这是一次巨大的成功。
*今天,我想总结一下这次会议,分享一些亮点,也许最重要的是,讨论一下这次会议进展顺利的方面……以及需要改进的地方,如果将来有 PyImageConf,我会采取不同的做法。
虽然今天的博文在一定程度上是一个回顾,但它(本质上)也是一封写给未来自己的信,提醒我应该加倍努力什么以及我可以做得更好。
我将使用我在 PyImageConf 上使用的相同开场白来开始这个摘要,当我走上舞台,介绍我自己和 Jeff Nova (PyImageConf 的共同主持人)时,然后说了以下内容:
PyImageSearch 和现在的 PyImageConf,不是关于我的,而是关于你这个参与者和 PyImageSearch 的读者。这一切都是为了你。我可能是图片搜索的“代言人”,但你更重要。是你们成就了这个博客、书籍和课程,最重要的是,成就了这个社区。感谢你们来到这里,感谢你们使这一切成为可能,感谢你们给我特权和荣誉来教你们。
PyImageConf 2018 概要

Figure 1: PyImageConf 2018 took place August 26-28th in San Francisco, CA. The three day event included talks, workshops, and evening receptions every night.
PyImageConf 的想法始于三年前,坦率地说,这甚至不是我的主意。
旧金山 Colorhythm 的所有者、PyImageSearch 大师杰夫·诺瓦(Jeff Nova)找到我,问我是否有兴趣做一次现场教学活动(杰夫可以使用一个能容纳 50 名学生的大教室)。
当时,这不是我能做的事。
我没有时间也没有心理承受能力。我已经超负荷了。也许像所有好主意一样,我们让它搁置了几年。
然后,去年 8 月,我打电话给杰夫,问他是否仍有兴趣举办一场面对面的活动,但要扩大规模,让我们举办一场真正的会议。
我知道我需要 Jeff 来完成这项活动,当他说“是”时,我们启动了 PyImageConf 2018。
我的目标是让 PyImageConf 保持小巧、私密和易于操作。
本质上,我希望 PyImageConf 成为我一直想参加的计算机视觉和深度学习会议。
我想把会议开得小而私密,最多 200 名与会者。
我特意将会议开得很小,以便与会者能够:
- 向演讲者和演示者学习
- 与计算机视觉和深度学习领域的专家进行一对一的交流
- 与同行和同事建立更好的关系网
最终,我认为保持会议的小规模是绝对正确的决定。
PyImageConf 与会者 Douglas Jones 在会后调查中分享了以下内容:
向 Adrian 和所有辛勤工作的人们致以最诚挚的谢意,感谢他们举办了我参加过的最好的会议。这是一个非常小而私密的会议,在这里你可以和演讲者交谈并提问。小型会议的另一大好处是,你有更多机会认识同修,分享想法、秘诀和窍门。很容易遇到一个人,他面临着同样的绊脚石,可以帮助你,或者你有一些经验可以分享。如果你错过了这个 PyImageConf,对不起,你真的错过了什么。如果还有,千万不要错过!
安德鲁·贝克也有类似的观点:
英伟达 GTC 可以是一个压倒性的经验,由于它的规模。PyImageConf 提供了近距离的体验。演示者让他们自己对与会者可用。PyImageConf 提供了进入 CV 和 DL 世界的途径。
一旦 PyImageConf 的愿景形成,就该联系演讲者和研讨会主持人了。
我的目标是将计算机视觉、深度学习教育领域的大腕们聚集在一起,为与会者提供尽可能好的现场实践培训和讲座——哇,这些演讲者太棒了:
- Fran ois Chollet:作者 Keras 深度学习库。谷歌深度学习和人工智能研究员。作品在 CVPR、日本、ICLR 等地出版。
- Katherine Scott: 前行星实验室分析团队负责人。卫星图像分析专家。《T4》的合著者。
- 戴维斯·金:作者 dlib 库。物体探测专家。十多年来,开源开发者和从业者一直在构建行业 CV 系统。
- Satya Mallick:learn openv的作者和创作者。人脸专家的计算机视觉。在 CV 和 ML 工作的企业家。
- 约瑟夫·豪斯:帕克特出版社出版的六部计算机视觉/OpenCV 书籍的作者。通过他的公司 Nummist Media 进行计算机视觉和咨询。增强现实、虚拟现实和红外计算机视觉系统方面的专家。
- 亚当·盖特吉:的作者机器学习很有趣!博客系列,领英学习,和 Lynda.com。喜欢用机器学习和计算机视觉来构建产品。
- Jeff Bass: Raspberry Pi 黑客,计算机视觉从业者,计量经济学精灵,35 年统计学经验。
- Adrian rose Brock:PyImageSearch.com 的作者和创造者, 实用 Python 和 OpenCV , PyImageSearch 大师 , 用 Python 进行计算机视觉的深度学习 。计算机视觉企业家。
如果你在网上看到这些演讲者,请感谢他们为会议付出的时间和精力。没有它们,PyImageConf 是不可能的。
第一天——招待会

Figure 2: The PyImageConf 2018 reception, including an open bar and networking. Some attendees even brought their laptops to demo and share what they’ve created!
PyImageConf 2018 的第一天(或者说是晚上)是开幕酒会。
从下午 6:30 到 9:30,我们举办了一个长达三个小时的招待会,包括开放酒吧。
招待会的目的当然是欢迎与会者,但更重要的是,让与会者相互联系,建立关系。
我经常认为技术会议甚至学术会议缺少建立关系的方面——在许多方面,从长远来看,你与其他人建立的联系可能比技术内容更有价值。
一名研究生与雇主交谈,一名企业家与一名承包商交谈,或者一名研究人员与某个行业人士交谈,这些交谈都可能改变你的职业轨迹。永远不要忽视人际网络和与他人的联系。
PyImageConf 与会者 Mike Baum 分享了以下关于招待会的内容:
我认为你设立了晚间开放酒吧,所有的演讲者都出席并参与了非正式的讨论,这太棒了。我也喜欢晚上额外的时间和其他人交谈,了解他们在做什么,倾听他们的挑战,并为我的一些挑战收集想法。
对我个人来说,我真的很高兴能够面对面地与 PyImageSearch 的读者见面:

Figure 3: One of my favorite aspects of PyImageConf was being able to meet readers in person!
第一天也是演讲者晚宴。我,演讲者和研讨会主持人,以及他们的配偶在招待会完全开始前一起出去吃饭。
这真是一顿美妙的晚餐——与一些最聪明、最成功的计算机视觉和深度学习从业者、工程师和教育工作者围坐在一起是我真正珍惜的事情。没有这些演讲者,PyImageConf 是不可能的,所以如果你在网上看到他们,一定要感谢他们。
你可能还会惊讶地发现,我们的谈话并不总是围绕着 CV 和 DL!
虽然 CV 和 DL 可能让我们走到了一起,当然这也是我们在那个房间的原因,但我们也讨论了更多的个人问题,包括我们的生活,我们正在做什么,以及我们下一步希望做什么。
我知道我将永远记得的一次谈话是与我真正尊敬的演讲者杰夫·巴斯的谈话。
我认识杰夫有几年了。我们最初是通过 PyImageSearch Gurus 课程认识的。随着我对他的了解,我意识到他有着真正非凡的一生。他是一名飞行员,曾在越南服役,为安进公司工作多年,现在已经退休,正在建立自己的永久性农场。
这些年来,杰夫的故事和生活经历在很多方面帮助了我——这对我来说就是做人的真正意义——与一群有共同兴趣的人共处一室,但这种兴趣只是一个开始,它会给你带来巨大的帮助。
第二天——会谈

Figure 4: The grand ballroom at the Regency Hyatt was absolutely stunning. Here I am on Sunday, a few hours before the reception gets underway.
PyImageConf 的第二天,会谈在凯悦酒店的大宴会厅举行。
当我在前一天晚上看到舞厅时,我被震撼了——它非常漂亮,非常专业。
Adam Geitgey 以他关于使用深度学习的图像分割的演讲开始了会议,特别是 Mask R-CNN。

Figure 5: Adam Geitgey at PyImageConf 2018 giving his talk on Image Segmentation.
Adam 经历了整个语义分割管道,从分割如何不同于标准分类和对象检测开始,然后继续讨论如何注释您的训练数据,如何训练您的 Mask R-CNN,最后如何将其应用于您自己的图像。
亚当的讲话是会议的完美的开场,他的讲话也为会议的其余部分定下了基调——我们一起在那个舞厅里会学到很多东西。
Satya Mallick 的演讲计算机视觉:现实世界应用,讨论了他和他的团队使用计算机视觉算法处理和解决的实际应用。

Figure 6: Satya Mallick, author of the LearnOpenCV blog and owner of Big Vision LLC, giving his talk on Computer Vision and Real-World Applications at PyImageConf 2018.
最重要的是,萨提亚还讨论了一些他必须应用的特殊技巧来有效地解决这些问题。
戴维斯·金随后上台发表了他的演讲,训练和改进你的物体探测器。

Figure 7: There wasn’t an empty seat in the house for Davis King’s object detection talk at PyImageConf 2018.
Davis 回顾了整个对象检测管道,从基础开始(即滑动窗口、图像金字塔),逐步发展到 HOG +线性 SVM,最后是基于深度学习的对象检测器。
他的演讲不仅实用、信息丰富、有用,而且还很歇斯底里,包括许多有趣的妙语和来自实际计算机视觉项目的轶事。
然后我们停下来吃午饭,享受了一顿由凯悦酒店员工精心准备的美食。再一次,这是与会者相互交流和联系的绝佳时机。
午饭后,我们回到舞厅,杰夫·巴斯在那里讨论阴阳牧场:用多台树莓派和苹果机构建分布式计算机视觉管道。

Figure 8: Jeff Bass discussing computer vision on the Raspberry Pi at PyImageConf 2018, including how we can build distributed computer vision systems.
Jeff 正在他的土地上建造一个永久性农场,他利用树莓 Pi 和计算机视觉来监控农场,包括:
- 读取水表读数,优化用水
- 数蜜蜂、蝴蝶和其他授粉者
- 追踪郊狼、兔子、浣熊和其他动物
- 监控车库门、谷仓门以及大门是开着还是关着
- 跟踪日照时间、日照强度、云量等。
- 监控非摄像头传感器,如温度、湿度、太阳能电池板输出等
杰夫的演讲确实很特别——他不仅讨论了计算机视觉技术,还详细介绍了如何将所有的部分粘在一起!
他甚至创建了自己的 Python 库,以便有效地将树莓 Pi 中的图像/帧共享回中心。
从 Jeff 的演讲中学到的技术帮助与会者构建他们自己的真实世界计算机视觉应用。
约瑟夫·豪斯接着杰夫做了一个关于可视化无形事物的演讲。

Figure 9: Joe Howse discussed the concept of “invisible markers” and the role they can play in computer vision and augmented reality.
我喜欢乔的演讲。
在计算机视觉中,我们常常只关注可见光,但也有不可见光的形式。那么,如果我们可以利用只在特定波长下出现的隐形标记,会怎么样呢?我们能在此基础上构建增强现实应用吗?
答案是肯定的,在他的演讲中,Joe 向我们展示了如何构建这样一个应用程序的基础知识(包括一个实际的例子和演示)。
凯瑟琳·斯科特是下一个,她做了一个关于传感器> >相机以及计算机视觉如何不仅仅是推动像素的演讲。相反,计算机视觉是“分析光线以获得答案”的过程——在我们开始推动像素之前,我们需要考虑我们的图像是如何被捕捉的。

Figure 10: Katherine Scott challenged our assumptions that images must be 3-channel, 8-bit RGB data. Her PyImageConf 2018 talk was incredibly inspiring.
特别是,我们的世界针对 3 通道、8 位 RGB 数据进行了优化,但还有其他伪彩色技术可供探索。
凯特的演讲不仅提供了丰富的信息,也鼓舞了 T2。
Francois Chollet,可以说是一个不需要介绍的人,Keras 的创始人和谷歌的深度学习工程师,做了一个关于计算机视觉的 Xception 架构的演讲。

Figure 11: Francois Chollet, sharing technical details and the theory surrounding depthwise separable convolutions and their role in the Xception architecture.
特别是,Francois 的演讲集中在深度方向可分离卷积的概念,以及这种技术如何使他能够构想出异常神经网络架构,将剩余连接和深度方向可分离卷积结合起来。
这种架构受 Szegedy 等人的 Inception 架构的启发,优于 Inception 和其他架构,需要更少的参数和更少的训练步骤。
最后,我上台做了当天的最后一次演讲。
我的演讲题为 7 个教训——我对推出你的第一个计算机视觉或深度学习产品的建议。

Figure 12: Adrian Rosebrock delivering his PyImageConf 2018 talk, 7 lessons learned — My advice on launching your first computer vision or deep learning product.
在 PyImageSearch 博客上,我通常会教你一种特定的算法或技术,但在这次演讲中,我会教与会者如何让一切回到原点,特别是在你写一行代码或进行一次实验之前验证你的想法的重要性。
我分享了我多年来的经验,有好有坏,演讲结束后,与会者有了一个框架,他们可以在推出自己的想法或产品时应用。
第一天取得了巨大的成功,我真的要感谢各位演讲者在百忙之中抽出时间来促成这次会议——谢谢大家!
第 3 天—研讨会

Figure 13: It was a packed house for Davis King’s, creator of dlib, PyImageConf 2018 workshop.
第三天是研讨会日。举办了四次全天研讨会(上午 9 时至下午 5 时),包括:
- 用于面部识别和其他面部应用的计算机视觉 — Sayta Mallick
- 用于现实世界应用的先进计算机视觉技术
- 增强现实和计算机视觉虚拟现实 —约瑟夫·豪斯
- 用于物体检测的 DL 是如何完成的:实现和使用更快的 R-CNN — Alan Descoins 和 Augustín Azzinnari
每个研讨会都是满满当当的,每个研讨会都被设计成让你在笔记本电脑上学习、编写代码、应用特定的技术并获得结果。
本质上,我们的目标是将整个 PyImageSearch 教学体验带入一个现场的、面对面的研讨会。
与会者 Nicholas McKinney 特别喜欢他与 Satya 的研讨会:
我参加的研讨会非常注重实践,让我可以建立自己的计算机视觉实验室,使用记录良好的代码进行构建。
Giulio Giorcelli 也分享了他的经历:
PyImageConf 是一个由深度学习实践者为深度学习实践者举办的无废话、手把手的会议。我学到了很多新的东西,并用游戏中最优秀的人在他们自己的代码中使用的实用技术改进了我当前的工具箱。我带回家的新知识是无价的。
大卫斯通非常喜欢艾伦和奥古斯丁的快速 R-CNN 工作室:
我很兴奋能来,我没有失望。演讲者非常出色。我真的很喜欢“用更快的 R-CNN 进行物体检测”的研讨会,学到了很多东西。这是一个伟大的社区团体,也是我参加过的最友好的会议。
哪些进展顺利,哪些可以改进
本节的重点是强调会议的各个方面,包括未来 PyImageConf 可以改进的地方。
我不仅认为与你,PyImageSearch 的读者分享这些细节很重要,它们也是对我自己的笔记(以及对任何有兴趣在未来举行会议的人的笔记)。
涵盖了大量不同的主题(尤其是对于小型会议)
进展非常顺利的一个方面是话题的多样性。
PyImageConf 可能很小,但它有很大的冲击力。
亚当关于图像分割的演讲非常实用,为会议定下了基调——戴维斯的演讲也是如此。
Jeff Bass 的演讲探讨了我们如何将所有的碎片粘在一起,并解决现实世界中的实际问题。
Francois 对 Xception 架构以及我们如何在自己的应用程序中使用它进行了高度技术性的讨论。
Kat 的演讲非常鼓舞人心,让我们深入了解了计算机视觉不仅仅是 RGB 数据。
这种主题的多样性是一个巨大的成功,我要为此感谢发言者。
场地本身非常棒

Figure 14: It’s hard to argue with the incredibly professional, aesthetically pleasing atmosphere at the Regency Hyatt.
凯悦酒店是 PyImageConf 的绝佳场地。那里很漂亮,非常专业,他们提供的食物也很棒。我真的很享受在那里的时光,我知道与会者也一样。
招待会大受欢迎
PyImageConf 的每晚都有一个接待和开放酒吧,开放时间约为 2.5-3 小时。
正如我在这篇文章前面提到的,我坚信应该给与会者一个连接网络的机会。
这些联系往往比实际的讲座和研讨会本身更有价值。
我们的赞助商棒极了

Figure 15: PyImageConf 2018 was sponsored by Microsoft Azure, Clusterone, Colorhytm, and TryoLabs.
PyImageConf 的赞助商是:
微软甚至在云端提供了 GPU 实例供与会者使用。
与所有这些赞助商合作愉快。感谢您让 PyImageConf 成为可能!
在演讲者中更加强调种族和性别的多样性
对于未来的 PyImageConf,我想强调的一个方面是更多的种族和性别多样性——Satya 是唯一的非白人演讲者,Kat 是唯一的非男性演讲者。
当然,总共只有八位演讲者,但在未来,我将亲自确保有更多的种族和性别多样性。
PyImageConf 当然令人惊叹,我完全相信这组演讲者绝对适合这次会议,但我也知道,向前迈进,我有责任确保更多的多样性。这是我不能掉以轻心的事情,绝对是我愿意努力的领域。
也就是说,我们的与会者中确实有来自和的多样性。一些与会者从非洲、韩国、中国、日本、乌拉圭、印度和澳大利亚远道而来。
布莱恩·卡伦巴(Brian Karemba)从津巴布韦的哈拉雷远道而来,他对自己的旅行很满意:
PyImageConf2018 绝对是一次惊艳的体验!它不仅提供了一个独特的机会向该领域的大师学习,而且与简历专家、从业者和爱好者(像我一样)的交流和互动也是无价的。会场是一流的,会议的整体组织也是如此。向 Adrian、所有演讲者和与会者致敬,感谢他们让这次活动成为现实,并公开分享他们的知识、经验和见解。从哈拉雷到旧金山的 27 小时飞行非常值得!!期待 PyImageConf2019!?!
尤因·许在他的 PyImageConf 后调查中分享了以下内容:
从顾问、研究人员到教育工作者,PyImageConf 抓住了计算机视觉的本质。演讲者对他们正在展示的主题非常有热情,广泛的主题让我想知道接下来会发生什么。更重要的是,与会者的多样性给我留下了深刻的印象。从研究生,创业创新者,到真正的公司员工,每个人的背景和对计算机视觉的兴趣都给我留下了深刻的印象。这是一次真正的会议,将激励任何想了解计算机视觉的人。
看到这么多 PyImageSearch 的读者在同一个房间里,对我来说是一种屈辱的经历。PyImageSearch 社区是如此的强大和相互支持,有时候我开始感觉有点情绪失控(以一种好的方式)。
年龄多样性非常好
我认为我们确定的一个方面是演讲者和与会者的年龄差异——这是我永远不想改变的。
正如种族和性别多样性很重要一样,年龄多样性也很重要。我们都在不同的年龄经历不同的生活,我们都来自不同的行业。因此,我们在职业和个人方面都有不同的经历可以分享。我们插入的多样性越多,我们就越能相互学习。
杰夫·诺瓦是我能想到的最好的搭档主持人

Figure 16: Me (Adrian) with PyImageConf co-host, Jeff Nova. Jeff Nova owns Colorhythm, an image processing and retouching company. Look how amazing this photo looks after Colorhythm applied their magic!
杰夫·诺瓦确实是一个特别的人。
他是我的同事。一个朋友。在很多方面,他感觉就像是我从未有过的哥哥。
Jeff 共同主持 PyImageConf 并分担 MC 职责。没有他我不可能完成 PyImageConf。他总是在那里帮忙,伸出援手,确保会议顺利进行。
杰夫,如果你在读这封信,谢谢你。
有一个会议协调员是至关重要的

Figure 17: PyImageConf would not have been possible without Xander Castro, a truly excellent conference coordinator. Hysterically, we (totally accidentally) ended up matching during the final day of the conference!
我无法想象在没有会议协调员的情况下运行 PyImageConf。
有这么多的后勤工作要跟踪,有这么多的账单要付,有这么多的人要联系——如果我试图自己做这件事,我想我的光头上会重新长出头发,这样我就有东西可以拔了。
我过去参加过大约 6-7 次由史云光·卡斯特罗和他的公司 Startup Event Solutions 协调的会议,所有这些会议都是令人难以置信的执行得非常好,非常专业。
在一次会议上,就在午餐前,甚至有一个消防喷头爆炸,导致 40 年前的脏水(已经在管道中存放了几十年)倾泻而出,淹没了舞厅的整个角落。
史云光和他的团队忙得不可开交,午饭后他们为我们准备了一个新舞厅——会议从不错过任何一个节拍。
幸运的是,在 PyImageConf 上没有出现与洒水器相关的问题,但这只是向你展示了史云光在工作上有多出色。
拥有一个团队让这成为可能
在会议期间,大卫·麦克杜菲和大卫·霍夫曼,如果你以前给我发电子邮件的话,你们可能会有过互动,他们都在尽可能地提供帮助,无论是在登记台工作,拍照,还是在房间里为有问题的与会者安装麦克风。没有他们,我会觉得自己已经无路可走了。他们帮了大忙。
解决车间注册问题
PyImageConf 的门票在会议召开前一个月就销售一空,然后,在会议召开前一周,史云光和我发出了一份调查,让与会者报名参加一个特定的研讨会。
研讨会人数上限为 50 人,原因如下:
- 空间限制——每个房间最多能容纳 50 人
- 研讨会主持人的理智——超过 50 人在一个房间里对主持人来说太难保持跟踪了
研讨会注册以先到先得的方式进行,一些研讨会很快就满员了。
不可避免的是,在一些情况下,与会者想要参加X研讨会(他们的第一选择),但是已经满员了,所以他们需要参加Y研讨会(他们的第二选择)。
在未来,我想提供一个更好,更有效的车间注册过程,但不幸的是,它创造了一个有点“鸡和蛋”的情况。
一方面,当与会者购买 PyImageConf 的门票时,我们也可以让他们注册参加研讨会…
…但同时,这也极大地限制了车间主持人:
- 如果他们的工作坊改变了主题怎么办?
- 如果他们决定从研讨会中删除某个主题怎么办?
- 可以说最重要的是,对于一个研讨会主持人来说,提前 6 个月确定他们的研讨会细节是否现实?(那是反问句,答案是“不,不现实”)
对于这种情况,我还没有一个解决方案,因为它需要仔细的思考和冥想,但我确实想分享它,因为我相信必须有一个更好的解决方案。
为研讨会提供预配置的开发环境
对于实践工作,你显然需要一个适当配置的开发环境。
研讨会主持人在会前提供了有关如何配置开发环境的详细信息;然而,众所周知,配置您的开发环境有时并不简单。特别是在 Davis 的研讨会中,研讨会的前 30-60 分钟用于确保机器配置正确。
在未来,我相信这个问题可以通过提供预配置的开发环境来缓解,这也是我想在未来的 PyImageConf 中探索的。
车间使用多台显示器,这样人们可以看得更清楚
对于一些车间来说,如果人们坐在离教室前面较远的位置,就很难看到屏幕。
在与史云光交谈后,他建议在未来几年里,我们要么有(1)一个每个人都可以看到的大屏幕和/或(2)重复监视器,房间的每一侧各有两个,这样无论你坐在哪里,你都可以很容易地通过屏幕看到正在发生的事情。
史云光的解决方案是完美的,如果将来有 PyImageConf,我们无疑会利用它。
使用 Slack 进行会议交流是一个全面的胜利
我不是 Slack 的忠实粉丝——这是我日常使用的“必要的邪恶”之一,但我将说,利用 Slack 帮助与会者连接和联网是的一大胜利。
在#meetups 频道里,有晚餐、饮料,甚至是与锻炼有关的聚会。看到友谊和纽带在会议之外形成真是太酷了。
“最友好的会议”

Figure 15: PyImageConf — not only technical and rewarding to attend, but also one of the most friendly conferences around!
从 PyImageConf 与会者那里听到的一个共同主题是,这是他们参加过的最友好的会议之一。
事实上,在我发起的会后调查中,这个主题多次出现。一位与会者的以下回应对我来说意义非凡:
我很内向,很难交谈(听起来像陈词滥调哈哈),但每个人都很友好,很容易交谈,我在与其他与会者社交方面没有问题。午餐和网络招待会让这次会议成为一次很好的经历。
多年来,我是一个内向的人,我努力让自己变得与众不同。与人交往确实是我焦虑的来源,所以我能理解这位与会者的感受。在我看来,对他们来说,能够在社交环境中感到舒适并与他人建立关系网是 T2 的一大优势。
Thi Tran 还认为会议非常友好:
一次非常友好、组织良好、内容丰富的会议。我喜欢接触很多人,并向他们学习。实践研讨会是一个加分项。位置非常完美,可以看到海湾大桥的迷人景色和美味的食物。
戴夫·斯诺登也是如此:
毫无疑问,PyImageConf 2018 是我参加过的最友好、最受欢迎的会议。技术含量也很高!很荣幸见到一些人,并向他们学习,他们贡献了自己的时间来构建我们工作(和娱乐)所依赖的工具。
创造一个环境,让别人不仅能从这里学到东西,还能发现 T2 超级友好,这是一件值得骄傲的事情。
PyImageSearch 社区是一个友好、接纳和热情的社区,我永远也不想改变这一点?
我会主办 PyImageConf 2019 吗?
当我登上从旧金山飞回 CT 的飞机时,我发了以下微博:

Figure 16: Nearly every attendee who came up to me asked if I would do PyImageConf again next year. I would call that a success. Thank you all for making PyImageConf possible!
第二周,我发出了一份会后调查,以获得与会者的反馈。
其中一个问题是:
如果有 PyImageConf 2019,你会参加吗?
在参与调查的人中(约 50%),90%的与会者表示, “是的,我会参加 PyImageConf 2019”。
这是一个很大比例的参与者说他们明年会回来。史云光还证实,这是他见过的最高的数字之一——当然也是第一年会议的最高数字。
所以,就这样说:
会有 PyImageConf 2019 吗?
我现在还不打算做出任何承诺。主持 PyImageConf,虽然令人难以置信地值得,而且是我将永远记住的事情,但对我来说也是极其累人的。
我也是在 9 月 13 日(我结婚前大约一周)写这篇博客,所以我的大脑不一定在一个我可以预测到 2019 年的地方——我主要只是关注我即将成为的妻子。
在 2018 年剩下的时间里,我会花更多的时间来思考这个问题,但我会引用 PyImageSearch 读者 Douglas Jones 在询问 PyImageConf 2018 时的话作为结束:
我觉得你必须这么做。
我打开了 PyImageConf 和今天的博客,说没有你,PyImageSearch 阅读器,会议、博客书籍和课程是不可能的。你们都是这个家庭的一员,我很荣幸能和你们一起踏上这个旅程。*
PyImageSearch 大师:在我的课程中你将掌握的计算机视觉主题的大列表。

几天前 前我提到在1 月 14 日星期三我将启动一个 Kickstarter 来资助我的新项目——PyImageSearch Gurus:一个 课程、社区、 和 开发环境 致力于把你变成一个计算机视觉大师。
正如我所承诺的,这是 PyImageSearch 大师课程中包含的完整主题列表。如果你有一个主题的建议,就在这个帖子上留下评论或给我发消息,我会看看我们是否能做到!
计算机视觉和 OpenCV 基础知识
- 图像基础
- 加载、显示和保存图像
- 图画
- 图像处理
- 直方图
- 平滑和模糊
- 形态学运算
- 阈值处理
- 梯度和边缘检测
- 轮廓
自动车牌识别
- 准备您的培训数据
- 在图像中寻找车牌
- 训练您的分类器
- 分类车牌号码和数字
深度学习
- 深度学习基础介绍
- 案例研究:
- 深度信念网络
- 卷积神经网络
- …适用于各种数据集,例如
- 梦妮丝
- 西法尔
人脸识别
- 准备和预处理您的数据
- 特征脸
打造您自己的定制物体检测器
- 准备您的培训数据
- 选择图像描述符
- 滑动窗口技术
- 训练分类器
- 硬负开采
- 目标检测
基于内容的图像检索/图像搜索引擎
- 构建一个视觉单词包
- 码本构造
- 矢量量化
- 硬码字分配与软码字分配
- 搜索
- 倒排索引
- Tf-idf 加权
- 空间验证
标准图像分类
- 图像金字塔
- 选择合适的图像描述符
- 对各种数据集的评估,包括:
- 加州理工学院-101
- 鲜花 17
- …以及更多
用图像描述符描述图像
- 关键点(狗、哈里斯等。)
- 局部不变描述符(SIFT、SURF 等。)
- 方向梯度直方图
- 哈拉里克纹理
- 局部二元模式
- 泽尔尼克矩
- 胡瞬间
- …以及更多
计算机视觉案例研究
- 图像和照片中的人脸检测
- 眼球追踪
- 视频中的目标跟踪
- 手写识别
- 植物分类
- 车牌识别
- 在文档图像中查找文本区域
- 测量相机到图像中物体的距离
Hadoop +大数据
- 准备用于 HDFS 的图像
- Hadoop 和 MapReduce 简介
- 在 MapReduce 上运行计算机视觉作业
- 用于索引和检索的弹性搜索和累积
- 高通量人脸检测
- 高通量特征提取
所以你有它!PyImageSearch 大师们所涉及的主题的完整列表。我希望看完这份清单后,你会和我一样兴奋!
请记住,如果你看到一个你想让我介绍的话题不在列表上,只要给我发消息——这是你的课程,我想把它调到你想学的内容。
为了在 Kickstarter 奖励列表上线时得到通知, 请务必注册接收 PyImageSearch 大师的更新!
周一,我们将带着最终确定的 Kickstarter 奖励列表再见…
最终确定的 Kickstarter 奖励清单。
原文:https://pyimagesearch.com/2015/01/12/pyimagesearch-gurus-finalized-kickstarter-reward-list/
![]()
所以在过去的一周里,我已经宣布了 PyImageSearch 大师的 Kickstarter。我已经给了你一个独家预览。我甚至详细列出了 PyImageSearch 大师们的完整主题列表。
但是现在我有了更特别的东西…
今天,我非常兴奋与大家分享 Kickstarter 奖励等级。
这份奖励名单只对 PyImageSearch 博客读者开放,在 1 月 14 日美国东部时间上午 10 点Kickstarter 活动启动之前,不会在其他任何地方提供。
那为什么我现在要和你分享悬赏名单呢?当然是为了给你优势!
当 1 月 14 日 PyImageSearch 大师 Kickstarter 活动启动时,将有 100 名 PyImageSearch 读者(更不用说其他 Kickstarter 用户)阅读活动页面,并试图决定选择哪种奖励。
问题是 如果你等太久 才选择你想要的奖励等级, 你可能会错过!
你看,只有少数几个低价的早鸟名额&提前进入,所以如果你想得到你的名额,你一定要提前计划和快速行动!
但是因为你是一个忠实的 PyImageSearch 读者,我希望你提前拿到这个 Kickstarter 奖励列表,这样你就可以查看列表并决定你想要支持的奖励级别。现在决定将节省你周三的时间,并有助于确保你的位置被要求!
下面你可以找到 Kickstarter 奖励的完整分类。一定要提前计划,挑选出自己想要的奖励!请记住,其他 PyImageSearch 读者和 Kickstarter 用户也将试图获得这些位置!
Kickstarter 奖励
主要奖励是在或 大幅度折扣年度会员 获得 PyImageSearch 大师的 Kickstarter 专属早期访问通行证。请记住,本课程完全是自定进度的,因此您可以在闲暇时完成课程。但是,这些月费率和年费率仅适用于 Kickstarter 活动,在八月份 PyImageSearch Gurus 正式推出后将不再提供。
我还提供了我的书的独家印刷版本、实用 Python 和 OpenCV 、T3。此前,这本书只作为电子书存在。但是对于这个 Kickstarter 活动,我将制作实体副本,并且为每个副本单独编号并亲笔签名,只为你**。一定要看看这个奖励,我不确定我的书是否会再版!***
根据您选择的奖励等级,以下是 PyImageSearch 大师的访问时间表:
每月会员奖励
认捐 25 美元或以上:
早鸟特惠—成为 PyImageSearch Gurus +锁定 25 美元/月会员费率的第一波用户的一部分。有限(5 个中的 5 个左边)
认捐 35 美元或以上:
早期采用者——成为 PyImageSearch Gurus +锁定 35 美元/月会员费率的第二波用户的一部分。有限(10 个中的 10 个左边)
认捐 45 美元或以上:
第三波英雄——成为 PyImageSearch Gurus + lock 第三波用户的一部分,会员费为每月 45 美元。有限(20 个中的 20 个左边)
认捐 50 美元或以上:
早鸟特别版——我的书、实用 Python 和 OpenCV 的单独编号和亲笔签名的独家 Kickstarter 印刷 PyImageSearch Gurus 的第一波访问+以 25 美元/月的会员费率锁定有限(10 个中的 10 个剩余)
认捐 55 美元或以上:
前三波后,进入 PyImageSearch 大师+锁定会员费 55 美元/月。无限制
认捐 75 美元或以上:
我的书,实用 Python 和 OpenCV 的单独编号和亲笔签名的独家 Kickstarter 印刷 PyImageSearch Gurus 的第二波访问+每月 35 美元的会员费锁定。有限(15 个中的 15 个左边)
认捐 100 美元或以上:
我的书、实用 Python 和 OpenCV 的单独编号和亲笔签名的独家 Kickstarter 印刷 PyImageSearch Gurus 的第三波访问+每月 45 美元的会员费锁定。有限(20 个中的 20 个左边)
认捐 120 美元或以上:
我的书,实用的 Python 和 OpenCV 的单独编号和亲笔签名的独家 Kickstarter 印刷+前 3 波后进入 PyImageSearch 大师+锁定会员费 55 美元/月。无限制
年度会员奖励
认捐 250 美元或以上:
早鸟特惠 PyImageSearch 大师的 1 年使用权。成为第一波 inside +一个单独编号和手写签名的独家 Kickstarter 印刷我的书,实用 Python 和 OpenCV 的一部分。有限(3 个中的 3 个左边)
认捐 350 美元或以上:
PyImageSearch 大师的 1 年使用权。成为第二波 inside +一个单独编号和手写签名的独家 Kickstarter 印刷我的书,实用 Python 和 OpenCV 的一部分。有限(5 个中的 5 个左边)
认捐 400 美元或以上:
PyImageSearch 大师的 1 年使用权。成为第三波 inside +的一部分,一个单独编号和手写签名的独家 Kickstarter 印刷我的书,实用 Python 和 OpenCV。有限(8 个中的 8 个左边)
认捐 500 美元或以上:
PyImageSearch 大师的 1 年使用权。在前 3 波之后,可以访问 PyImageSearch Gurus,这是我的书、Practical Python 和 OpenCV 的单独编号和亲笔签名的独家 Kickstarter 印刷版本。无限制
点菜奖励
认捐 125 美元或以上:
点菜:给 PyImageSearch 大师们一个机会。一旦 PyImageSearch Gurus 启动,该奖励将使您能够访问您选择的一个模块。无限制
认捐 300 美元或以上:
单点 3 包:乘坐 PyImageSearch 大师兜风。一旦 PyImageSearch Gurus 启动,此奖励将让您获得三个您选择的模块。无限制
特殊奖励
认捐 1,000 美元或以上:
与我进行 60 分钟的 Skype 通话+ 2 年会员资格+第一波访问+亲笔签名的我的书。在通话中,我们可以讨论您自己的计算机视觉项目,或者谈论 PyImageSearch 以及您希望我在 PyImageSearch 大师中涉及的主题。有限(5 个中的 5 个左边)
认捐 2,500 美元或以上:
2 年会员+第一波访问+我的书的亲笔签名副本+在纽约地区与我共进晚餐。晚餐时,我们可以讨论你自己的计算机视觉项目或谈论 PyImageSearch 大师和你感兴趣的话题。有限(3 个中的 3 个左边)
正如你所看到的,尽早为项目提供资金会有很大的折扣,所以一定要在 Kickstarter 活动开始之前确定你想要的奖励级别!
记住,美国东部时间周三上午 10 点是个大日子!
别忘了,在大幅降价的提前获得的奖励数量非常有限,所以当你在周三启动 Kickstarter 时,你肯定想立即领取你的奖励!
明天我会在这个博客上发布一个 Kickstarter 的链接,但是如果你想在 Kickstarter 发布的那一刻收到电子邮件 ,就在这里注册吧!
我希望在 Kickstarter 支持者名单上看到你!*
PyImageSearch Kickstarter 大师们已经结束了……但是你仍然可以在队伍中占有一席之地。
原文:https://pyimagesearch.com/2015/02/15/pyimagesearch-gurus-kickstarter-can-still-claim-spot-line/

刚刚过去的这个周五 PyImageSearch 大师 Kickstarter 落下帷幕。该活动取得了巨大成功,有 253 名 T4 支持者加入进来。
看到来自你、PyImageSearch 的读者和 Kickstarter 的观众的支持,我感到非常惭愧。我感到非常幸运,能够每天醒来,做我喜欢的事情— 为您提供计算机视觉和 OpenCV 内容。
如果你错过了 PyImageSearch 大师 Kickstarter,但仍想在 8 月课程启动时申请你的位置, 只需使用此链接 。
一旦你排队认领了你的位置,你将收到独家预览、最终发布日期,以及更多关于的信息,一旦大门打开,PyImageSearch 大师们将优先访问。
你还在等什么?! 现在就去排队领取你的位置吧。
PyImageSearch 大师成员聚焦:Saideep Talari
原文:https://pyimagesearch.com/2017/06/12/pyimagesearch-gurus-member-spotlight-saideep-talari/

在今天的博文中,我采访了赛迪普·塔拉里,他是一名 PyImageSearch 大师的毕业生,最近被印度的一家初创公司聘为计算机视觉工程师。
赛义德·迪普的故事在我心中有着特殊的地位,因为它是如此难以置信地真诚、真诚、真挚。
你看,Saideep 来自一个收入很低的印度家庭。他们没有多少钱。事实上,在线教育(如 PyImageSearch Gurus 课程、Udacity 等。)被认为是“奢侈品”。
但这并没有阻止赛义德·迪普——他承担起学习计算机视觉的责任,不仅因为他觉得这是他的激情所在,也因为他想帮助他的家人。
事实上,Saideep 对学习计算机视觉的感觉是如此强烈,以至于他从自己的个人银行获得了教育贷款,以帮助补充 PyImageSearch 大师课程的费用。
Saideep 于 2016 年 8 月加入 PyImageSearch Gurus,随后于 2017 年 2 月毕业。我一直对他的奉献精神、T2 的职业道德和 T4 对掌握计算机视觉的承诺印象深刻。
早在 4 月份,我收到了 Saideep 的一封电子邮件,表达了他的快乐——他最近在印度的一家计算机视觉初创公司获得了一份工作,从事基于无人机的人工智能解决方案。
在面试过程中,公司给赛迪普布置了一项计算机视觉任务。他的解决方案令人印象深刻,以至于他们 立即雇佣了他 并让他加入公司,成为一名计算机视觉工程师。
*今天,我说:
- 拥有一份收入很高的工作。
- 能不能照顾他的家人赡养他们。
- 已经还清了他/他家人的所有债务。
- 目前正在做他喜欢的事情——从事计算机视觉工作。
更令人印象深刻的是,仅仅在六个月多一点的时间里,他就从计算机视觉学生变成了计算机视觉 T2 工程师。
老实说,这是我听过的最感人的计算机视觉成功故事之一,我为塞迪普和他的成就感到无比骄傲。
和我一起接受采访,了解 Saideep 如何通过研究计算机视觉改变了他的生活(和他家人的生活)。
PyImageSearch 大师成员聚焦:Saideep Talari
注:英语不是 Saideep 的第一语言,所以他友好地请我编辑他的语法和拼写,以使回答更具可读性。我做了很少的编辑(因为他的英语很容易理解),尽可能地保留了他的原文。再次感谢您接受我们的采访。
阿德里安:嗨,赛德普!谢谢你同意接受这次采访。通过 PyImageSearch 博客和图片搜索大师课程认识你是我的荣幸。
你好,阿德里安!很荣幸能接受像您这样伟大的计算机视觉研究者的采访!
阿德里安:你能告诉我们你最初是如何对计算机视觉感兴趣的吗?
Saideep: 这是一个很长的故事,但为了简单起见,我首先开始学习安全分析,这涉及到网络和 web 应用程序的渗透测试,但后来我通过数据分析和机器学习找到了我的兴趣。
驱使我从事计算机视觉的项目是当我试图创建一个破解验证码图片的机器人时。破解验证码涉及大量的图像处理和机器学习,所以这就是我如何从我的兴趣到安全分析开始我的计算机视觉之旅。
我试着在网上浏览资源,让自己接受计算机视觉方面的培训,但资源很少,我发现很多都不是很好解释。幸运的是,我在谷歌搜索上找到了你的[PyImageSearch]博客,并阅读了你发布的内容。
你的博客真的激励了我,提高了我学习计算机视觉的兴趣,因为现在我有了一个搜索计算机视觉问题的平台。
阿德里安:你在电子邮件中提到,你最近被一家印度初创公司聘为计算机视觉工程师。你能告诉我们这份工作的情况和面试过程吗?
Saideep: 耶!首先,非常感谢!如果我没有参加图片搜索大师课程,我就不会得到这份工作。是的,这是一家位于印度的早期创业公司,我们通过无人机处理空中情报。它有助于农业、矿业、太阳能工厂等。,通过为无人机提供人工智能和计算机视觉来解决他们的问题。
我和其他人一样申请了计算机视觉工程师的职位。我被分配了一个处理作物行检测和斑块识别的任务。

Figure 1: An example of detecting rows of crops in an image (source).
我花了 15 分钟才明白实际问题。我最初的计划是应用机器学习,但我发现它可以通过图像处理技术来实现。我尝试了我的方法,得到了有希望的结果。并非数据集中的每张图像都处于相同的光照条件下,但我记得您在 PyImageSearch 大师课上讲过如何处理不同的光照条件和不同的颜色通道。
我把问题反过来了。我没有检测空行,而是检测了包含树和其他东西的实际行,经过一些形态学运算,最终我得到了最有希望的解决方案。
从你在课程中的话语中我明白了一件事:
有时,巧妙使用图像处理技术可以节省大量时间,并避免更高级(和乏味)的算法。——阿德里安·罗斯布鲁克,图片搜索大师
后来我面试了使用深度学习、RCNNs 等优化方法的图像分割。我做得很好。
阿德里安:当你第一次给我发邮件,告诉我加入 PyImageSearch 大师课程时,我知道你最关心的问题之一是价格。你认为这个课程值得吗?
Saideep: 是的!最初我觉得价格很高。但在我参加课程的第一周之后,我相信即使 95 美元也非常便宜,因为你提供的内容是非常宝贵的。你不仅写下了教训,还写下了你的经历,这是任何金钱都无法衡量的。
坦率地说,这门课程比你收取的费用更有价值。我感觉到这一点,因为没有人能在地球上找到像这样从头开始的端到端的详尽课程。
Adrian: 你会向其他试图学习计算机视觉(并获得一份工作)的学生和开发者推荐 PyImageSearch Gurus 课程吗?
当然,肯定的。我已经向我的一些朋友推荐了 PyImageSearch 大师。从这门课开始非常好,因为它涵盖了广泛的现实生活问题。此外,学生们不必担心“练习”,因为你组织[课程]的方式推动人们获得尽可能多的实践经验。不仅如此,该课程还包括访问令人敬畏的社区[论坛]线程,在那里我们可以找到可以帮助我们解决计算机视觉问题的人。
如果一个人非常有激情,那么 PyImageSearch 大师对于获得计算机视觉领域的工作肯定是一个很大的肯定,因为这个领域非常复杂。你[和 PyImageSearch 大师课程]已经将复杂的事情分解为简单的,非常清晰易懂。
阿德里安:你还有什么想分享的吗?
Saideep: 我急切地等待你的 用 Python 进行计算机视觉深度学习 的书发布。我打算购买 ImageNet 套装。你真的把你所有的经历都放在了创作牛逼的内容上。
Adrian: 如果一个 PyImageSearch 的读者想聊天,在哪里和你联系最好?
Saideep: 请在 LinkedIn 或 GitHub 上联系我。
摘要
在今天的博文中,我采访了 Saideep Talari,他是一名 PyImageSearch 大师课程的毕业生,最近在印度的一家初创公司找到了一份计算机视觉工程师的工作。
通过这份工作,Saideep 现在能够供养和照顾他的家人。
这确实是我听过的最令人惊讶、最发自内心的计算机视觉成功故事之一,我为 Saideep 和他的成就感到骄傲。请和我一起在这篇博文的评论区祝贺他。
如果你想了解更多关于 PyImageSearch Gurus 的课程(并跟随 Saideep 的脚步), 只需点击这里 。*
PyImageSearch 大师成员聚焦:Tuomo Hiippala
原文:https://pyimagesearch.com/2016/03/14/pyimagesearch-gurus-member-spotlight-tuomo-hiippala/

Photo credit: Heta Koski / CSC
在今天的博文中,我采访了 PyImageSearch Gurus 的成员 Tuomo Hiippala,他最近获得了 28000 欧元(约合 30500 美元)的资助,用于研究计算机视觉如何用于研究视觉文化,包括社交媒体图像和照片档案。我们将讨论他在非常独特的研究领域,它融合了语言学和计算机视觉,以及 他的工作如何塑造现代视觉数据分析。
Tuomo 是 PyImageSearch 博客的长期读者,甚至是 PyImageSearch 大师 Kickstarter 活动的第一批支持者之一。很荣幸他今天来到这里,他是我在博客上采访的第一个人。从这次对托莫— 的采访中可以获得很多知识,尤其是计算机视觉如何应用于现实世界的问题。
理想情况下,我希望这种类型的聚焦和采访帖子在未来能够更频繁地出现在 PyImageSearch 博客上。虽然我试图每周发布新的技巧、窍门和教程,但真正重要的是你,读者,如何将这些知识应用到你自己的项目中。
如果 PyImageSearch 博客、 实用 Python 和 OpenCV ,或者 PyImageSearch 大师课程在你的计算机视觉之旅中对你有所帮助, 请在这篇博客上留下评论或者给我发消息 。就像我说的,我很乐意在未来做更多这样的采访帖子!
PyImageSearch 大师成员聚焦:Tuomo Hiippala
阿德里安: 嘿托莫!谢谢你同意接受采访。很高兴有你在 PyImageSearch 博客上。
托墨: 作为长期读者:荣幸之至!
阿德里安: 我们开始采访吧。你在哪里工作/你的工作是什么?
我现在是芬兰于韦斯屈莱大学应用语言研究中心的博士后研究员。至于我的背景,我获得了赫尔辛基大学的英语语言学博士学位,专业是语言学。不过,我是一种特殊的语言学家,因为我的兴趣远不止语言。
基本上,我研究语言是如何与其他交流方式互动的,比如照片、图表、信息图……等等。访问一个网站或拿起一份日报,很快就会让你意识到为什么一起研究所有这些不同的模式是有意义的。它们密切协调,并一直相互作用——这是交流的固有特征,但奇怪的是,这只是最近才真正受到不同领域研究人员的关注。
阿德里安: 你最初是如何对计算机视觉产生兴趣的?
我不得不检查我的笔记本:我在 2014 年德国法兰克福书展期间写下了一些东西…我依稀记得在交易会上检查了一些参展商,他们宣传自动文档管理解决方案。这是我真正想到这个主意的时候,尽管我显然已经熟悉了光学字符识别等技术,这些技术在 20 世纪 90 年代彻底改变了语言学,消除了手动输入的僵局。无论如何,那时我决定学习更多关于计算机视觉的知识,并顺便了解 Python。
阿德里安: 你如何在工作中使用计算机视觉?
我现在正在做几个项目:第一个是开发一个半自动的文档分析系统,它使用 OpenCV、Tesseract 和 NLTK 来检查文档图像,并将它们的特征标注到 XML 数据库中。商业 OCR 软件在这方面并不实用,因为它主要是提取内容。为了研究不同的交流模式是如何协同工作的,我们需要知道更多:内容、它在布局中的位置、逻辑组织和语义的相互关系——而这只能让我们对文档及其内部工作有一个最基本的了解。我希望明年夏天在柏林举行的计算语言学协会年会上展示我正在进行的工作!

Figure 1: Detecting text regions in images (outlined in green). Non-text regions are outlined in red.
我也在研究如何利用计算机视觉让研究人员更好地掌握大量的视觉数据。人文和社会科学的许多不同领域都与视觉传播有关——然而许多研究人员倾向于手工进行视觉分析,这实际上不允许他们认真处理通常在历史照片档案或 Instagram 等社交媒体服务中发现的大量数据。OpenCV 等开源库和其他使编程更易访问的工具有着巨大的潜力——IPython 是开发和共享此类工具的理想候选。这就是我想贡献的,专注于应用,把算法的开发留给计算机科学家。尽管如此,我还是努力学习算法!
阿德里安: 你提到你申请了助学金。你能多告诉我一些吗?
托莫: 确定!芬兰文化基金会刚刚授予我价值 28 000 欧元(约 35000 美元)的个人赠款,用于研究如何使用计算机视觉来研究视觉文化,如社交媒体图像和照片档案。我还在 2015 年从赫尔辛基市获得了 3500 欧元的资助,用于研究游览赫尔辛基的游客分享的照片,即他们如何看待这座城市,这是我的另一个长期研究兴趣。我目前正在等待旅游季节的开始,开始收集数据!
注:有兴趣了解更多拓跋研究?一定要把这两页看一遍:
- https://www.csc.fi/web/atcsc/-/humanisti-datailee
- http://www . inthefieldstories . net/a-humanist-take-on-scientific-computing/
阿德里安:PyImageSearch/PyImageSearch 大师们是如何帮助你获得资助的?
托莫: 我能说什么呢?博客和课程让我的工作受益匪浅:它为我开辟了一个全新的研究领域。虽然我只学了一年半的计算机视觉,但我已经有足够的信心在研究中应用这些技术。这显然对获得任何资金都是至关重要的。
阿德里安: 你会向其他试图学习计算机视觉的开发者和学生推荐 PyImageSearch 大师课程吗?
当然——我认为这个课程质量极高,物有所值——我想我是 Kickstarter 上第一批支持它的五个人之一!我发现特别吸引人的是课程材料写得非常好,并且以一种允许人们同时学习 Python 的方式呈现。它们很好地结合在一起,球场和周围的社区也是如此!
阿德里安: 你还有什么想分享的吗?
我当然会向任何人推荐学习计算机视觉(和机器学习),无论他们的专业或学术兴趣如何。我认为,PyImageSearch 大师课程中展示的各种项目很好地说明了计算机视觉在未来能够并将会有丰富的应用。最棒的是,由于 Python 和大量高质量的教程,这些技术中的大多数对于外行人来说都是可以理解的。只管潜进去,一定会有回报的!
Adrian: 如果一个 PyImageSearch 的读者想聊天,在哪里和你联系最好?
Tuomo: 你可以在 Twitter(【http://twitter.com/tuomo_h/)、LinkedIn(【https://fi.linkedin.com/in/tuomohiippala)和 GitHub(【https://github.com/thiippal)上找到我。随时联系!
摘要
在今天的帖子中,我采访了在于韦斯屈莱大学工作的 Tuomo Hiippala。他的研究融合了两个独特的研究领域:语言学和计算机视觉,他的工作重点是让研究人员更好地理解大量的视觉数据。
理想情况下,我很乐意在未来的博客文章中做更多的 PyImageSearch 读者采访和聚焦。如果 PyImageSearch 博客、 实用 Python 和 OpenCV 或者 PyImageSearch 大师课程在你的计算机视觉之旅中帮助了你, 请评论这篇文章或者给我发消息让我知道!
Python、argparse 和命令行参数
原文:https://pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/
今天,我们将讨论一项基本的开发人员、工程师和计算机科学家技能— 命令行参数。
具体来说,我们将讨论:
- 什么是命令行参数
- 为什么我们使用命令行参数
- 如何用 Python 解析命令行参数
命令行参数是您必须学会如何使用的基本技能,尤其是如果您试图应用更高级的计算机视觉、图像处理或深度学习概念。
如果你不熟悉命令行参数或者不知道如何使用它们,没关系! 但是你仍然需要花时间自学如何使用它们——这篇文章将帮助你做到这一点。
在今天的帖子结束时,你将对命令行参数,它们如何工作,以及如何使用它们有一个深刻的理解。
Python、argparse 和命令行参数
每天我都会收到 3-5 封来自 PyImageSearch 读者的邮件或评论,他们都在为命令行争论而挣扎。
事实上,就在我决定写这篇博文的一个小时前,我收到了 Arjun 的如下邮件:
嗨,阿德里安,我刚刚下载了你的深度学习人脸检测博文的源代码,但是当我执行它时,我得到了以下错误:
$ python detect_faces.py
用法:detect _ faces . py[-h]-I IMAGE-p proto txt-m MODEL[-c CONFIDENCE]
detect _ faces . py:错误:需要下列参数:-I/–IMAGE,-p/–proto txt,-m/–MODEL救命啊!
Arjun 并不是唯一一个在这个错误中挣扎的人。
许多其他读者在使用命令行参数时也会遇到类似的问题,但是诚实的事实是,几乎所有这些错误都可以通过花时间自学命令行参数来避免。
在今天这篇文章的剩余部分,你将了解到命令行参数比看起来容易使用得多(即使你以前从未使用过它们)。
你会发现你不需要修改一行代码就可以使用它们。在这篇文章的最后,你将能够像专家一样使用命令行参数。
让我们开始吧。
什么是命令行参数?
命令行参数是在运行时给程序/脚本的标志。它们包含我们程序的附加信息,以便它能够执行。
不是所有的程序都有命令行参数,因为不是所有的程序都需要它们。也就是说,在这个博客上,我们在 Python 脚本中大量使用了命令行参数,我甚至可以说这个博客上 98%的文章都使用了它们。
为什么我们使用命令行参数?
如上所述,命令行参数在运行时为程序提供了额外的信息。
这允许我们在不改变代码的情况下给我们的程序不同的输入。
您可以将命令行参数类比为函数参数。如果您知道在各种编程语言中函数是如何声明和调用的,那么当您发现如何使用命令行参数时,您会立即感到如鱼得水。
鉴于这是一个计算机视觉和图像处理博客,你将在这里看到的许多论点是图像路径或视频路径。
在深度学习的情况下,这个博客也是众所周知的,你会看到模型路径或纪元计数作为命令行参数。
在今天帖子的剩余部分,我们将通过两个脚本示例了解 Python argparse 包。
我还将展示 PyCharm 用户如何在不离开 PyCharm 的情况下运行脚本,如果他们愿意的话。
argparse Python 库
Figure 1: My terminal screen is used to run a Python script with command line arguments.
首先,让我们制作一个新的脚本,命名为simple_example.py:
# import the necessary packages
import argparse
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--name", required=True,
help="name of the user")
args = vars(ap.parse_args())
# display a friendly message to the user
print("Hi there {}, it's nice to meet you!".format(args["name"]))
首先,我们需要argparse包,所以我们在第 2 行导入它。
在的第 5 行,我们将ArgumentParser对象实例化为ap。
然后在的第 6 行和第 7 行我们添加了唯一的参数--name。我们必须指定简写 ( -n)和简写(--name)版本,其中任何一个标志都可以在命令行中使用。如required=True所示,这是一个必需的参数。
来自行 7 的help字符串将在终端中给出额外的信息,如果你需要的话。要查看命令用法帮助,您可以在终端中输入以下内容(直接在下面输出):
$ python simple_example.py --help
usage: simple_example.py [-h] -n NAME
optional arguments:
-h, --help show this help message and exit
-n NAME, --name NAME name of the user
请注意我是如何指定以下三项的:
- 可执行文件(
python) - 我们的 Python 脚本文件(
simple_example.py) - 和一个参数(
--help)以便打印用法。
脚本的第 8 行指示 Python 和argparse库解析命令行参数。我还调用对象上的vars将解析的命令行参数转换成 Python 字典,其中字典的键是命令行参数的名称,值是为命令行参数提供的字典的值。为了看到这一点,我建议在代码中插入一个print(args)语句。
虽然是可选的,但我更喜欢将 arguments 对象转换成字典,这样我就可以通过命令行或在 Jupyter 笔记本中执行脚本。当使用 Jupyter 笔记本时,我可以简单地删除解析代码的命令行参数,并插入一个名为args的带有任何硬编码值的字典。
现在你可能想知道:我如何从命令行参数 argument 中访问这个值?
这很简单,在脚本的第 11 行有一个例子。
在格式字符串中,我们指定args["name"]。您很快就会看到,我们将使用这个命令行参数动态地将我们的名字打印到屏幕上。
为了执行我们的simple_example.py脚本,我们需要采取以下步骤:
- 步骤 1: 从 【下载】 部分下载这篇博文的压缩文件到你选择的机器上的一个位置(为了简单起见,我建议是桌面)。
- 第二步:打开一个终端,把目录换到 zip 所在的位置。
- 第三步:拉开拉链。
- 第四步:再次改变目录,这次进入刚刚提取的新目录。
- 步骤 5: 使用
workon命令激活您的虚拟环境。例如:workon cv或workon py3cv4(取决于您的环境名称)。如果你用的是我的预配置的 Raspbian。img ,建议对 home 文件夹中的脚本使用source命令。例如:source ~/start_py3cv4.sh或source ~/start_openvino.sh。对于 OpenVINO 来说,使用source命令尤其重要,因为除了激活虚拟环境之外,它还会加载一些环境变量。 - 步骤 6: 执行程序(带命令行参数)并查看输出。
在这篇博客上,我在一个“shell”代码块中展示了命令及其参数。提示符开头的$是您的队列,表明这是一个终端命令,您应该在$字符后输入该命令,以及您喜欢的与所写内容相似或完全相同的参数。
我已经将本课的代码下载到桌面上的 PyImageSearch 目录中,以便于访问,从而完成了第步。
在那里,我输入了以下命令并生成了相应的输出:
$ cd ~/Desktop/PyImageSearch
$
$ unzip command-line-arguments.zip
...
$
$ cd command-line-arguments
$ pwd
/Users/adrianrosebrock/Desktop
$
$ python simple_example.py --name Adrian
Hi there Adrian, it's nice to meet you!
$
$ python simple_example.py --name Stephanie
Hi there Stephanie, it's nice to meet you!
$
$ python simple_example.py --name YourNameHere
Hi there YourNameHere, it's nice to meet you!
让我们在参考步骤 2-5 的同时,浏览一下我在上面的终端中演示的内容。
第二步:
我把目录换成了我下载本课压缩文件的地方(第一行)。
我按下行 2 上的 enter/return 按钮,使输出更容易阅读。这是可选的。
第三步:
我拉开了拉链。与本课相关的 zip 文件(第 3 行)。
第 4 行上的...表示解压缩过程有输出,但我没有在这里显示出来。注意,输出没有前面的$。
第四步:
接下来我需要将目录转换到我刚刚解压的文件夹中(第 6 行)。
为了确保我在我需要的地方,我在第 7 行打印我的工作目录,输出显示在第 8 行。
第五步:
我在第 10 行执行带参数的命令。我在--name标志后指定我的名字。只要我的名字没有空格,它就会正确地显示在输出中。
输出显示在行 11 上。注意脚本如何动态地显示我在命令中输入的名字。命令行参数非常强大,允许您在不更改一行代码的情况下用不同的输入测试您的程序。
第 13-17 行演示了两个额外的例子,我的脚本在没有修改代码的情况下将打印一个给定的名字。用你自己的名字或者你的仇人的名字来试试吧。
注意:如果我执行步骤 5* 而没有命令行参数(或者有不正确的参数),我将会看到如下所示的用法/错误信息。*
$ python simple_example.py
usage: simple_example.py [-h] -n NAME
simple_example.py: error: argument -n/--name is required
这个简单的例子帮助我们理解了命令行参数的概念;然而,打印一个包含我们名字的句子不是很有用。
在下一节中,我将提供一个使用命令行参数的更实际的例子
用 Python 解析命令行参数
Figure 2: Using the argparse Python package you can easily parse command line arguments in the terminal/command line.
在下一个例子中,我们将对任何给定的输入图像中的形状进行计数,同时对写入磁盘的输出图像进行注释。
我们将再次使用命令行参数来指定输入图像路径和输出图像路径。
对于这个解释来说,图像处理技术很简单——毕竟我们只是为了命令行参数的目的而举这个例子。
因此,让我们创建一个名为shape_counter.py的新文件,并开始编码:
Codeblock #1: Lines 1-20# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input image")
ap.add_argument("-o", "--output", required=True,
help="path to output image")
args = vars(ap.parse_args())
# load the input image from disk
image = cv2.imread(args["input"])
# convert the image to grayscale, blur it, and threshold it
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5,5), 0)
thresh = cv2.threshold(blurred, 60, 255, cv2.THRESH_BINARY)[1]
我们在第 2 行的上导入argparse——这是帮助我们解析和访问命令行参数的包。
然后,在第 7-12 行我们解析两个命令行参数。这几行代码可读性很强,你可以看到如何格式化一个参数。
我们以--input论证为例。
在的第 7 行,我们将ArgumentParser对象实例化为ap。
然后在第 8 行和第 9 行我们添加了我们的--input参数。我们必须指定速记和手写版本(-i和--input),其中任何一个标志都可以在命令行中使用。如required=True所示,这是一个必需的参数。正如我上面演示的那样,help字符串将在终端中给出额外的信息。
类似地,在第 10 行和第 11 行,我们指定了我们的--output参数,这也是必需的。
从那里,我们使用路径加载图像。记住,输入图像路径包含在args["input"]中,所以这是cv2.imread的参数。
简单吧?
其余几行是特定于图像处理的,所以如果您在没有任何 OpenCV 或图像处理技能的情况下登陆这个博客,您可能想要在档案中寻找关于这些概念的进一步解释。
在第行第 18-20 行,我们完成了三个操作:
- 将
image转换为灰度。 - 模糊灰度图像。
- 对
blurred图像进行阈值处理。
我们已经准备好寻找并画出形状轮廓:
# extract contours from the image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# loop over the contours and draw them on the input image
for c in cnts:
cv2.drawContours(image, [c], -1, (0, 0, 255), 2)
# display the total number of shapes on the image
text = "I found {} total shapes".format(len(cnts))
cv2.putText(image, text, (10, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 0, 255), 2)
# write the output image to disk
cv2.imwrite(args["output"], image)
在第 23-25 行中,我们在thresh图像中找到了形状轮廓。
从那里,我们在输入图像上绘制轮廓(行 28 和 29 )。
要了解更多关于轮廓的信息,请参见 使用 Python 和 OpenCV 在图像中查找形状和轮廓标签档案。我还在我的书 实用 Python 和 OpenCV +案例研究 中讨论轮廓和其他图像处理基础知识。
然后,我们组装并在图像上放置文本(第 32-34 行)。该文本包含形状的总数。
最后,我们使用我们的--output映像路径参数,通过cv2.imwrite ( 第 37 行)将映像写入磁盘。
让我们用两个参数来执行命令:
$ python shape_counter.py --input input_01.png --output output_01.png
如果检查您的工作目录,您会注意到现在出现了output_01.png图像:
Figure 3: Shapes have been counted with our Python + OpenCV script which takes in command line arguments.
让我们使用不同的参数再次执行该命令:
$ python shape_counter.py --input input_02.png --output output_02.png
同样,您会注意到在您的目录中有一个新的输出文件:output_02.png。
Figure 4: Three shapes have been detected with OpenCV and Python by simply changing the command line arguments.
现在,后退一步。从命令行参数的角度考虑我们做了什么。
我们在这里做的是使用的一个脚本和的不变,并为它提供不同的参数。--input参数包含输入图像的路径/文件名,同样的还有--output。
这个概念非常简单,我希望这已经阐明了如何使用命令行参数。在我们结束这篇文章之前,让我们来看看不要做什么。
如何而不是解析命令行参数
我不时会看到一些读者试图修改代码本身来接受命令行参数。
如何不解析命令行参数的一个很好的例子可以从上一节的第 6-12 行的命令行参数开始:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input image")
ap.add_argument("-o", "--output", required=True,
help="path to output image")
args = vars(ap.parse_args())
我见过读者错误地试图更新参数解析代码,以包含输入图像的实际路径:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "C:\example\input_image.png", required=True,
help="path to input image")
ap.add_argument("-o", "C:\example\output_image.png", required=True,
help="path to output image")
args = vars(ap.parse_args())
或者在列表沟工作中,尝试使用help参数来包含文件路径:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="/home/pi/my_input.png")
ap.add_argument("-o", "--output", required=True,
help="/home/pi/output_image.png")
args = vars(ap.parse_args())
记住 代码本身不需要更新。
花点时间打开您的终端,导航到您的代码所在的位置,然后执行脚本,确保提供命令行参数。
我想和你分享另一个“发现”。有时在这个博客上,我的命令行参数标志中有一个'-'(破折号),比如--features-db。当获取参数包含的值时,您需要使用一个' _ '(下划线),这有点令人困惑,也有点不安全。
这一点在 PyImageSearch 大师课程基于内容的图像检索模块的摘录中得到了证明:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True, help="Path to the directory of indexed images")
ap.add_argument("-f", "--features-db", required=True, help="Path to the features database")
ap.add_argument("-c", "--codebook", required=True, help="Path to the codebook")
ap.add_argument("-o", "--output", required=True, help="Path to output directory")
args = vars(ap.parse_args())
# load the codebook and open the features database
vocab = pickle.loads(open(args["codebook"], "rb").read())
featuresDB = h5py.File(args["features_db"], mode="r")
print("[INFO] starting distance computations...")
请注意突出显示的行,我已经将参数定义为--features-db(带破折号),但是我用args["features_db"](带下划线)引用它。这是因为argparse Python 库在解析过程中用下划线替换了破折号。
你能做到的!
如果你是一个终端新手,命令行参数可能需要一些练习或习惯,但是我对你有信心!
不要气馁。
慢慢来。
并且坚持练习。
不知不觉中,您已经掌握了命令行参数——现在就花时间投资于您的教育和这项宝贵的技能吧!
通过 IDE 设置命令行参数
我不时收到电子邮件和博客评论,询问如何在他们的 IDE 中运行 Python 脚本。
大约 90%的情况下,问题类似于:
嗨阿德里安,
救命啊!我无法运行代码。
如何用 PyCharm 运行你的博客文章中的代码?
PyCharm 和其他 ide 都是很棒的工具,具有丰富的特性。我喜欢 PyCharm,我每天都用它。
虽然可以在 IDE 中运行带有命令行参数的脚本,但我不建议这样做。
当你进行开发时,你真的需要熟悉命令行。实际上,使用终端比点击 IDE 的 GUI 并设置参数更节省时间。
为了服务社区,我提供了两个由大卫·霍夫曼拍摄的截屏视频,当我录制画外音来解释这些步骤时,你会听到我熟悉的声音。
第一步是通过 【下载】 部分获取本教程(或者本博客上的另一个教程)的代码。
正如您将在视频中看到的,David 将代码下载到了他桌面上的一个文件夹中。一旦您将下载内容放在方便的地方,请按播放并跟随:
https://www.youtube.com/embed/Byta5WkeNiA?feature=oembed
如何:Python 比较两幅图像
原文:https://pyimagesearch.com/2014/09/15/python-compare-two-images/
最后更新于 2021 年 7 月 1 日
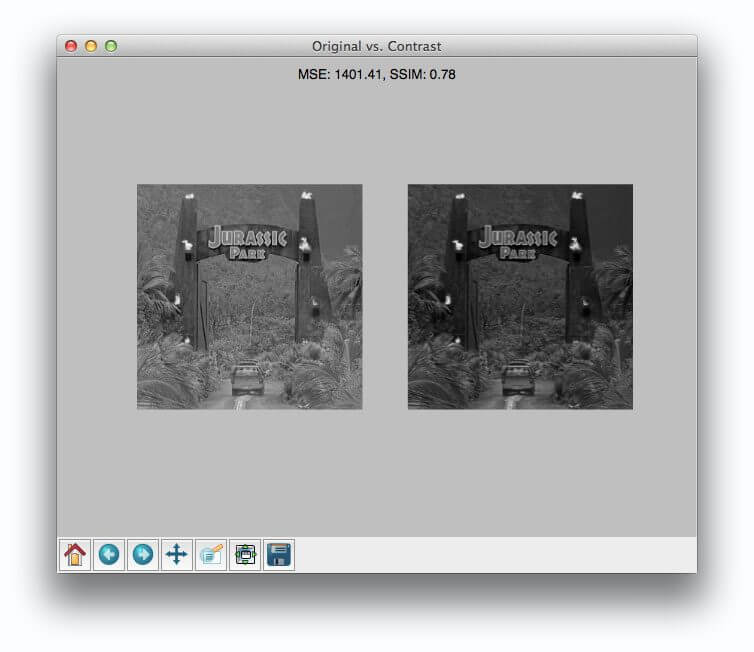
你能猜到我是一个集邮者吗?
开玩笑的。我没有。
但是让我们玩一个假装的小游戏。
让我们假设我们有一个巨大的邮票图像数据集。我们想要拍摄两张任意的邮票图像,并对它们进行比较,以确定它们是否相同,或者在某些方面是否接近相同。
一般来说,我们可以通过两种方式来实现这一点。
第一种方法是使用本地敏感散列,我将在以后的博客文章中介绍。
第二种方法是使用算法,如均方差(MSE)或结构相似性指数(SSIM)。
在这篇博文中,我将向你展示如何使用 Python 通过均方误差和结构相似性指数来比较两幅图像。
- 【2021 年 7 月更新:根据最新 API 更新,更新了 SSIM 从 scikit-image 的导入。添加了替代图像比较方法的部分,包括暹罗网络上的资源。
我们的示例数据集
让我们先来看看我们的示例数据集:
Figure 1: Our example image dataset. Left: The original image. Middle: The original image with contrast adjustments. Right: The original image with Photoshopped overlay.
在这里,你可以看到我们有三个图像:(左)我们来自侏罗纪公园的朋友的原始图像,他们的第一次(也是唯一一次)旅行,(中)应用了对比度调整的原始图像,(右),原始图像,上面通过 Photoshop 处理覆盖了侏罗纪公园的标志。
现在,我们很清楚左边和中间的图像彼此更“相似”——中间的图像就像第一个图像一样,只是它“更暗”。
但是我们会发现,“均方误差”实际上会说经过 PS 处理的图像比经过对比度调整的中间图像更接近原始图像。很奇怪,对吧?
均方误差与结构相似性度量
让我们来看看均方误差方程:
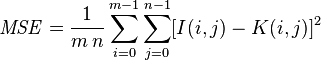
Equation 1: Mean Squared Error
虽然这个等式看起来很复杂,但我向你保证它并不复杂。
为了证明这一点,我将把这个等式转换成一个 Python 函数:
def mse(imageA, imageB):
# the 'Mean Squared Error' between the two images is the
# sum of the squared difference between the two images;
# NOTE: the two images must have the same dimension
err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)
err /= float(imageA.shape[0] * imageA.shape[1])
# return the MSE, the lower the error, the more "similar"
# the two images are
return err
这就是你要的——去掉注释后,只有四行 Python 代码的均方误差。
让我们把它拆开,看看发生了什么:
- 在第 7 行的上,我们定义了我们的
mse函数,它有两个参数:imageA和imageB(即我们想要比较相似性的图像)。 - 所有真正的工作都在线 11 上处理。首先,我们将图像从无符号的 8 位整数转换为浮点,这样我们就不会遇到任何模数运算“回绕”的问题。然后,我们通过减去像素强度来获得图像之间的差异。接下来,我们将这些差平方(因此意味着平方误差),最后将它们相加。
- 第 12 行处理均方误差的平均值。我们所做的就是将我们的平方和除以图像中的像素总数。
- 最后,我们将我们的 MSE 返回给调用者 one Line 16 。
MSE 实现起来非常简单——但是当使用它进行相似性分析时,我们可能会遇到问题。主要的一点是,像素强度之间的大距离不一定意味着图像的内容显著不同。在这篇文章的后面,我会提供一些证据来证明这个观点,但是同时,请相信我的话。
值得注意的是,MSE 值为 0 表示完全相似。大于 1 的值意味着相似性较低,并且将随着像素强度之间的平均差异的增加而继续增加。
为了弥补与图像比较的 MSE 相关的一些问题,我们有了由王等人开发的结构相似性指数:
Equation 2: Structural Similarity Index
SSIM 方法显然比 MSE 方法更复杂,但要点是 SSIM 试图模拟图像结构信息中的感知变化,而 MSE 实际上是估计感知误差。这两者之间有细微的差别,但结果是戏剧性的。
此外,等式 2 中的等式用于比较两个窗口(即小的子样本),而不是 MSE 中的整个图像。这样做产生了一种更健壮的方法,能够考虑图像结构的变化,而不仅仅是感知到的变化。
等式 2 的参数包括每个图像中的N×N窗口的 (x,y) 位置、在 x 和 y 方向上的像素强度的平均值、 x 和 y 方向上的强度的方差以及协方差。
与 MSE 不同,SSIM 值可以在-1 和 1 之间变化,其中 1 表示完全相似。
幸运的是,正如您将看到的,我们不必手动实现这个方法,因为 scikit-image 已经为我们准备好了一个实现。
让我们直接跳到代码中。
如何:使用 Python 比较两幅图像
# import the necessary packages
from skimage.metrics import structural_similarity as ssim
import matplotlib.pyplot as plt
import numpy as np
import cv2
我们首先导入我们需要的包——matplotlib用于绘图,NumPy 用于数值处理,而cv2用于 OpenCV 绑定。scikit-image 已经为我们实现了我们的结构相似性指数方法,所以我们将只使用他们的实现。
def mse(imageA, imageB):
# the 'Mean Squared Error' between the two images is the
# sum of the squared difference between the two images;
# NOTE: the two images must have the same dimension
err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)
err /= float(imageA.shape[0] * imageA.shape[1])
# return the MSE, the lower the error, the more "similar"
# the two images are
return err
def compare_images(imageA, imageB, title):
# compute the mean squared error and structural similarity
# index for the images
m = mse(imageA, imageB)
s = ssim(imageA, imageB)
# setup the figure
fig = plt.figure(title)
plt.suptitle("MSE: %.2f, SSIM: %.2f" % (m, s))
# show first image
ax = fig.add_subplot(1, 2, 1)
plt.imshow(imageA, cmap = plt.cm.gray)
plt.axis("off")
# show the second image
ax = fig.add_subplot(1, 2, 2)
plt.imshow(imageB, cmap = plt.cm.gray)
plt.axis("off")
# show the images
plt.show()
第 7-16 行定义了我们的mse方法,你已经很熟悉了。
然后我们在行的第 18 处定义compare_images函数,我们将用它来比较两幅使用 MSE 和 SSIM 的图像。mse函数有三个参数:imageA和imageB,这是我们要比较的两个图像,然后是我们图形的title。
然后,我们计算第 21 行和第 22 行上的两幅图像之间的 MSE 和 SSIM。
第 25-39 行处理一些简单的 matplotlib 绘图。我们只显示与我们正在比较的两幅图像相关的 MSE 和 SSIM。
# load the images -- the original, the original + contrast,
# and the original + photoshop
original = cv2.imread("images/jp_gates_original.png")
contrast = cv2.imread("images/jp_gates_contrast.png")
shopped = cv2.imread("images/jp_gates_photoshopped.png")
# convert the images to grayscale
original = cv2.cvtColor(original, cv2.COLOR_BGR2GRAY)
contrast = cv2.cvtColor(contrast, cv2.COLOR_BGR2GRAY)
shopped = cv2.cvtColor(shopped, cv2.COLOR_BGR2GRAY)
第 43-45 行处理使用 OpenCV 从磁盘加载我们的图像。我们将使用我们的原始图像(第 43 行)、对比度调整后的图像(第 44 行),以及叠加了《侏罗纪公园》标志的 Photoshopped 图像(第 45 行)。
然后我们在第 48-50 行将我们的图像转换成灰度。
# initialize the figure
fig = plt.figure("Images")
images = ("Original", original), ("Contrast", contrast), ("Photoshopped", shopped)
# loop over the images
for (i, (name, image)) in enumerate(images):
# show the image
ax = fig.add_subplot(1, 3, i + 1)
ax.set_title(name)
plt.imshow(image, cmap = plt.cm.gray)
plt.axis("off")
# show the figure
plt.show()
# compare the images
compare_images(original, original, "Original vs. Original")
compare_images(original, contrast, "Original vs. Contrast")
compare_images(original, shopped, "Original vs. Photoshopped")
现在我们的图像已经从磁盘上加载了,让我们来展示一下。在第 52-65 行上,我们简单地生成一个 matplotlib 图形,逐个循环我们的图像,并将它们添加到我们的绘图中。然后我们的情节在第 65 行显示给我们。
最后,我们可以使用第 68-70 行的函数来比较我们的图像。
我们可以通过发出以下命令来执行我们的脚本:
$ python compare.py
结果
一旦我们的脚本执行完毕,我们应该首先看到我们的测试用例——将原始图像与其自身进行比较:
Figure 2: Comparing the two original images together.
不足为奇的是,原始图像与自身完全相同,MSE 值为 0.0,SSIM 值为 1.0。请记住,随着 MSE 增加,图像的相似度降低,与 SSIM 相反,其中较小的值表示相似度降低。
现在,看一下对比原始图像和对比度调整后的图像:
Figure 3: Comparing the original and the contrast adjusted image.
在这种情况下,MSE 增加了,SSIM 减少了,这意味着图像不太相似。这确实是真的——调整对比度肯定会“损害”图像的表现。
但是事情并不有趣,直到我们将原始图像与 PS 过的覆盖图进行比较:
Figure 4: Comparing the original and Photoshopped overlay image.
将原始图像与 Photoshop 叠加图进行比较,得到的 MSE 为 1076,SSIM 为 0.69。
等一下。
1076 的 MSE 小于之前的 1401。但是很明显,PS 过的覆盖图与简单地调整对比度相比有很大的不同。但同样,这是我们在全局使用原始像素亮度时必须接受的限制。
另一方面,SSIM is 返回值 0.69,这确实小于将原始图像与对比度调整后的图像进行比较时获得的 0.78。
替代图像比较方法
MSE 和 SSIM 是传统的计算机视觉和图像处理方法来比较图像。当图像几乎完全对齐时,它们往往工作得最好(否则,像素位置和值不会匹配,从而失去相似性得分)。
当两幅图像在不同的视角、光照条件等条件下拍摄时,另一种可行的方法。,就是使用关键点检测器和局部不变描述符,包括 SIFT,SURF,ORB 等。本教程向您展示如何实现 RootSIFT ,它是流行的 SIFT 检测器和描述符的一个更精确的变体。
此外,我们可以利用基于深度学习的图像相似性方法,特别是暹罗网络。 暹罗网络是超级强大的模型,可以用很少的数据进行训练,计算出准确的图像相似度得分。
以下教程将向您介绍暹罗网络:
此外,暹罗网络在 PyImageSearch 大学中有详细介绍。
摘要
在这篇博文中,我向您展示了如何使用 Python 比较两幅图像。
为了进行比较,我们使用了均方误差(MSE)和结构相似性指数(SSIM)函数。
虽然 MSE 的计算速度要快得多,但它的主要缺点是:( 1)全局应用和(2)仅估计图像的感知误差。
另一方面,SSIM 虽然较慢,但能够通过比较图像的局部区域而不是全局来感知图像结构信息的变化。
那么应该用哪种方法呢?
看情况。
总的来说,SSIM 会给你更好的结果,但你会失去一点表现。
但在我看来,准确性的提高是非常值得的。
绝对要给 MSE 和 SSIM 一个机会,亲自看看!
基于预训练网络的 PyTorch 图像分类
原文:https://pyimagesearch.com/2021/07/26/pytorch-image-classification-with-pre-trained-networks/
在本教程中,您将学习如何使用 PyTorch 通过预训练的网络执行影像分类。利用这些网络,您只需几行代码就可以准确地对 1000 种常见的对象进行分类。
今天的教程是 PyTorch 基础知识五部分系列的第四部分:
- py torch 是什么?
- py torch 简介:用 PyTorch 训练你的第一个神经网络
- PyTorch:训练你的第一个卷积神经网络
- 使用预训练网络的 PyTorch 图像分类(今天的教程)
- 8 月 2 日:用预先训练好的网络进行 PyTorch 物体检测(下周的教程)
在本教程的其余部分中,您将获得使用 PyTorch 对输入图像进行分类的经验,这些输入图像使用创新的、最先进的图像分类网络,包括 VGG、Inception、DenseNet 和 ResNet。
学习如何用预先训练好的 PyTorch 网络进行图像分类, 继续阅读。
使用预训练网络的 PyTorch 图像分类
在本教程的第一部分,我们将讨论什么是预训练的图像分类网络,包括 PyTorch 库中内置的网络。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我将向您展示如何实现一个 Python 脚本,该脚本可以使用预先训练的 PyTorch 网络对输入图像进行准确分类。
我们将讨论我们的结果来结束本教程。
什么是预训练的图像分类网络?
说到图像分类,没有比 ImageNet 更出名的数据集/挑战了。ImageNet 的目标是将输入图像准确地分类到一组 1000 个常见的对象类别中,计算机视觉系统将在日常生活中“看到”这些类别。
大多数流行的深度学习框架,包括 PyTorch,Keras,TensorFlow,fast.ai 等,都包含了预先训练好的网络。这些是计算机视觉研究人员在 ImageNet 数据集上训练的高度准确、最先进的模型。
ImageNet 培训完成后,研究人员将他们的模型保存到磁盘上,然后免费发布给其他研究人员、学生和开发人员,供他们在自己的项目中学习和使用。
本教程将展示如何使用 PyTorch 通过以下先进的分类网络对输入图像进行分类:
- VGG16
- VGG19
- 开始
- DenseNet
- ResNet
我们开始吧!
配置您的开发环境
要遵循这个指南,您需要在系统上安装 PyTorch 和 OpenCV。
幸运的是,PyTorch 和 OpenCV 都非常容易使用 pip 安装:
$ pip install torch torchvision
$ pip install opencv-contrib-python
如果您需要帮助配置 PyTorch 的开发环境,我强烈推荐您 阅读 PyTorch 文档——py torch 的文档非常全面,可以让您快速上手并运行。
**如果你需要帮助安装 OpenCV,一定要参考我的 pip 安装 OpenCV 教程。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们用 PyTorch 实现图像分类之前,让我们先回顾一下我们的项目目录结构。
首先访问本指南的 “下载” 部分,检索源代码和示例图像。然后,您将看到下面的目录结构。
$ tree . --dirsfirst
.
├── images
│ ├── bmw.png
│ ├── boat.png
│ ├── clint_eastwood.jpg
│ ├── jemma.png
│ ├── office.png
│ ├── scotch.png
│ ├── soccer_ball.jpg
│ └── tv.png
├── pyimagesearch
│ └── config.py
├── classify_image.py
└── ilsvrc2012_wordnet_lemmas.txt
在pyimagesearch模块中,我们有一个单独的文件config.py。该文件存储重要的配置,例如:
- 我们的输入图像尺寸
- 均值相减和缩放的均值和标准差
- 无论我们是否使用 GPU 进行训练
- 人类可读的 ImageNet 类标签的路径(即
ilsvrc2012_wordnet_lemmas.txt)
我们的classify_image.py脚本将加载我们的config,然后使用 VGG16、VGG19、Inception、DenseNet 或 ResNet(取决于我们作为命令行参数提供的模型架构)对输入图像进行分类。
images目录包含了许多样本图像,我们将在其中应用这些图像分类网络。
创建我们的配置文件
在实现我们的图像分类驱动程序脚本之前,让我们首先创建一个配置文件来存储重要的配置。
打开pyimagesearch模块中的config.py文件,插入以下代码:
# import the necessary packages
import torch
# specify image dimension
IMAGE_SIZE = 224
# specify ImageNet mean and standard deviation
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
# determine the device we will be using for inference
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# specify path to the ImageNet labels
IN_LABELS = "ilsvrc2012_wordnet_lemmas.txt"
第 5 行定义了我们的输入图像空间维度,这意味着每幅图像在通过我们预先训练的 PyTorch 网络进行分类之前,将被调整到 224×224 像素。
注: 在 ImageNet 数据集上训练的大多数网络接受 224×224 或 227×227 的图像。一些网络,尤其是全卷积网络,可以接受更大的图像尺寸。
从那里,我们定义了我们的训练集的 RGB 像素强度的平均值和标准偏差(行 8 和 9 )。在将输入图像通过我们的网络进行分类之前,我们首先通过减去平均值,然后除以标准偏差来缩放图像像素强度,这种预处理对于在 ImageNet 等大型多样化图像数据集上训练的 CNN 来说是典型的。
从那里,行 12 指定我们是使用我们的 CPU 还是 GPU 进行训练,而行 15 定义 ImageNet 类标签的输入文本文件的路径。
如果在您喜欢的文本编辑器中打开该文件,您将看到以下内容:
tench, Tinca_tinca
goldfish, Carassius_auratus
...
bolete
ear, spike, capitulum
toilet_tissue, toilet_paper, bathroom_tissue
这个文本文件中的每一行都映射到我们的预训练 PyTorch 网络被训练来识别和分类的类标签的名称。
实现我们的图像分类脚本
有了我们的配置文件,让我们继续实现我们的主要驱动程序脚本,使用我们预先训练的 PyTorch 网络对输入图像进行分类。
打开项目目录结构中的classify_image.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch import config
from torchvision import models
import numpy as np
import argparse
import torch
import cv2
我们从第 2-7 行开始导入我们的 Python 包,包括:
config:我们在上一节中实现的配置文件- 包含 PyTorch 的预训练神经网络
numpy:数值数组处理torch:访问 PyTorch API- 我们的 OpenCV 绑定
考虑到我们的导入,让我们定义一个函数来接受输入图像并对其进行预处理:
def preprocess_image(image):
# swap the color channels from BGR to RGB, resize it, and scale
# the pixel values to [0, 1] range
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (config.IMAGE_SIZE, config.IMAGE_SIZE))
image = image.astype("float32") / 255.0
# subtract ImageNet mean, divide by ImageNet standard deviation,
# set "channels first" ordering, and add a batch dimension
image -= config.MEAN
image /= config.STD
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, 0)
# return the preprocessed image
return image
我们的 preprocess_image函数接受一个参数image,这是我们将要进行分类预处理的图像。
我们通过以下方式开始预处理操作:
- 从 BGR 到 RGB 通道排序的交换(我们这里使用的预训练网络利用 RGB 通道排序,而 OpenCV 默认使用 BGR 排序)
- 将我们的图像调整到固定尺寸(即 224×224 ),忽略纵横比
- 将我们的图像转换为浮点数据类型,然后将像素亮度缩放到范围【0,1】
从那里,我们执行第二组预处理操作:
- 减去平均值(行 18 )并除以标准偏差(行 19 )
- 将通道维度移动到数组(第 20 行)的前面,称为通道优先排序,是 PyTorch 期望的默认通道排序方式
- 向数组添加批次维度(第 21 行)
经过预处理的image然后被返回给调用函数。
接下来,让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-m", "--model", type=str, default="vgg16",
choices=["vgg16", "vgg19", "inception", "densenet", "resnet"],
help="name of pre-trained network to use")
args = vars(ap.parse_args())
我们有两个命令行参数要解析:
--image:我们希望分类的输入图像的路径- 我们将使用预先训练好的 CNN 模型对图像进行分类
现在让我们定义一个MODELS字典,它将--model命令行参数的名称映射到其对应的 PyTorch 函数:
# define a dictionary that maps model names to their classes
# inside torchvision
MODELS = {
"vgg16": models.vgg16(pretrained=True),
"vgg19": models.vgg19(pretrained=True),
"inception": models.inception_v3(pretrained=True),
"densenet": models.densenet121(pretrained=True),
"resnet": models.resnet50(pretrained=True)
}
# load our the network weights from disk, flash it to the current
# device, and set it to evaluation mode
print("[INFO] loading {}...".format(args["model"]))
model = MODELS[args["model"]].to(config.DEVICE)
model.eval()
第 37-43 行创建我们的MODELS字典:
- 字典的键是模型的可读名称,通过
--model命令行参数传递。 - 字典的值是相应的 PyTorch 函数,用于加载带有 ImageNet 上预先训练的权重的模型
通过 PyTorch,您将能够使用以下预训练模型对输入图像进行分类:
- VGG16
- VGG19
- 开始
- DenseNet
- ResNet
指定pretrained=True标志指示 PyTorch 不仅加载模型架构定义,而且还下载模型的预训练 ImageNet 权重。
Line 48 然后加载模型和预训练的权重(如果你之前从未下载过模型权重,它们会自动为你下载和缓存),然后将模型设置为在你的 CPU 或 GPU 上运行,这取决于你在配置文件中的DEVICE。
第 49 行将我们的model置于评估模式,指示 PyTorch 处理特殊层,如退出和批量标准化,这与训练期间处理它们的方式不同。在做出预测之前,将你的模型置于评估模式是至关重要的,所以别忘了这么做!
既然我们的模型已经加载,我们需要一个输入图像——现在让我们来处理它:
# load the image from disk, clone it (so we can draw on it later),
# and preprocess it
print("[INFO] loading image...")
image = cv2.imread(args["image"])
orig = image.copy()
image = preprocess_image(image)
# convert the preprocessed image to a torch tensor and flash it to
# the current device
image = torch.from_numpy(image)
image = image.to(config.DEVICE)
# load the preprocessed the ImageNet labels
print("[INFO] loading ImageNet labels...")
imagenetLabels = dict(enumerate(open(config.IN_LABELS)))
线 54 从磁盘加载我们的输入image。我们在第 55 行做了一份拷贝,这样我们就可以利用它来想象我们网络的最高预测。我们还利用第 56 行上的preprocess_image函数来执行尺寸调整和缩放。
第 60 行将我们的image从 NumPy 数组转换为 PyTorch 张量,而第 61 行将image移动到我们的设备(CPU 或 GPU)。
最后,行 65 从磁盘加载我们的输入 ImageNet 类标签。
我们现在准备使用我们的model对输入image进行预测:
# classify the image and extract the predictions
print("[INFO] classifying image with '{}'...".format(args["model"]))
logits = model(image)
probabilities = torch.nn.Softmax(dim=-1)(logits)
sortedProba = torch.argsort(probabilities, dim=-1, descending=True)
# loop over the predictions and display the rank-5 predictions and
# corresponding probabilities to our terminal
for (i, idx) in enumerate(sortedProba[0, :5]):
print("{}. {}: {:.2f}%".format
(i, imagenetLabels[idx.item()].strip(),
probabilities[0, idx.item()] * 100))
第 69 行执行我们网络的前向传递,产生网络的输出。
我们通过第 70 行上的Softmax函数传递这些,以获得model被训练的 1000 个可能的类标签中的每一个的预测概率。
第 71 行然后按照降序排列概率,在列表的前端概率较高。
然后,我们通过以下方式在第 75-78 行的终端上显示前 5 个预测类别标签和相应的概率:
- 循环前 5 个预测
- 使用我们的
imagenetLabels字典查找类标签的名称 - 显示预测的概率
我们的最终代码块在输出图像上绘制了 top-1(即顶部预测标签):
# draw the top prediction on the image and display the image to
# our screen
(label, prob) = (imagenetLabels[probabilities.argmax().item()],
probabilities.max().item())
cv2.putText(orig, "Label: {}, {:.2f}%".format(label.strip(), prob * 100),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
cv2.imshow("Classification", orig)
cv2.waitKey(0)
结果会显示在我们的屏幕上。
使用 PyTorch 结果的图像分类
我们现在准备用 PyTorch 应用图像分类!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
在那里,尝试使用以下命令对输入图像进行分类:
$ python classify_image.py --image images/boat.png
[INFO] loading vgg16...
[INFO] loading image...
[INFO] loading ImageNet labels...
[INFO] classifying image with 'vgg16'...
0\. wreck: 99.99%
1\. seashore, coast, seacoast, sea-coast: 0.01%
2\. pirate, pirate_ship: 0.00%
3\. breakwater, groin, groyne, mole, bulwark, seawall, jetty: 0.00%
4\. sea_lion: 0.00%
杰克·斯派洛船长似乎被困在了海滩上!果然,VGG16 网络能够以 99.99%的概率将输入图像正确分类为“沉船”(即沉船)。
有趣的是,“海滨”是模型的第二大预测——这个预测也很准确,因为船在沙滩上。
让我们尝试一个不同的图像,这次使用 DenseNet 模型:
$ python classify_image.py --image images/bmw.png --model densenet
[INFO] loading densenet...
[INFO] loading image...
[INFO] loading ImageNet labels...
[INFO] classifying image with 'densenet'...
0\. convertible: 96.61%
1\. sports_car, sport_car: 2.25%
2\. car_wheel: 0.45%
3\. beach_wagon, station_wagon, wagon, estate_car, beach_waggon, station_waggon, waggon: 0.22%
4\. racer, race_car, racing_car: 0.13%
来自 DenseNet 的顶级预测是“可转换的”,准确率为 96.61%。第二顶预测,“跑车”也准。
这张图片包含了 Jemma,我家的小猎犬:
$ python classify_image.py --image images/jemma.png --model resnet
[INFO] loading resnet...
[INFO] loading image...
[INFO] loading ImageNet labels...
[INFO] classifying image with 'resnet'...
0\. beagle: 95.98%
1\. bluetick: 1.46%
2\. Walker_hound, Walker_foxhound: 1.11%
3\. English_foxhound: 0.45%
4\. maraca: 0.25%
这里我们使用 ResNet 架构对输入图像进行分类。Jemma 是一只“小猎犬”(狗的一种),ResNet 以 95.98%的概率准确预测。
有趣的是,一只“蓝蜱”、“步行猎犬”和“英国猎狐犬”都是属于“猎犬”家族的狗——所有这些都是模型的合理预测。
让我们看看最后一个例子:
$ python classify_image.py --image images/soccer_ball.jpg --model inception
[INFO] loading inception...
[INFO] loading image...
[INFO] loading ImageNet labels...
[INFO] classifying image with 'inception'...
0\. soccer_ball: 100.00%
1\. volleyball: 0.00%
2\. sea_urchin: 0.00%
3\. rugby_ball: 0.00%
4\. silky_terrier, Sydney_silky: 0.00%
我们的初始模型以 100%的概率正确地将输入图像分类为“足球”。
图像分类允许我们给输入图像分配一个或多个标签;然而,它没有告诉我们任何关于物体在图像中的位置的信息。
为了确定给定对象在输入图像中的位置,我们需要应用对象检测:
就像我们有用于图像分类的预训练网络一样,我们也有用于对象检测的预训练网络。下周您将学习如何使用 PyTorch 通过专门的对象检测网络来检测图像中的对象。
总结
在本教程中,您学习了如何使用 PyTorch 执行影像分类。具体来说,我们利用了流行的预培训网络架构,包括:
- VGG16
- VGG19
- 开始
- DenseNet
- ResNet
这些模型是由负责发明和提出上面列出的新颖架构的研究人员训练的。训练完成后,这些研究人员将模型权重保存到磁盘上,然后发布给其他研究人员、学生和开发人员,供他们在自己的项目中学习和使用。
虽然模型可以免费使用,但请确保您检查了与它们相关的任何条款/条件,因为一些模型在商业应用中不能免费使用(通常人工智能领域的企业家通过训练模型本身而不是使用原作者提供的预训练权重来绕过这一限制)。
请继续关注下周的博文,在那里您将学习如何使用 PyTorch 执行对象检测。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用预训练网络的 PyTorch 对象检测
原文:https://pyimagesearch.com/2021/08/02/pytorch-object-detection-with-pre-trained-networks/
在本教程中,您将学习如何使用 PyTorch 通过预训练的网络执行对象检测。利用预先训练的对象检测网络,您可以检测和识别您的计算机视觉应用程序将在日常生活中“看到”的 90 个常见对象。
今天的教程是 PyTorch 基础知识五部分系列的最后一部分:
- py torch 是什么?
- py torch 简介:使用 PyTorch 训练你的第一个神经网络
- PyTorch:训练你的第一个卷积神经网络
- 【py torch】用预先训练好的网络进行图像分类
- PyTorch 物体检测,带有预训练网络(今天的教程)
在本教程的其余部分,您将获得使用 PyTorch 检测输入图像中的对象的经验,使用开创性的、最先进的图像分类网络,包括使用 ResNet 的更快 R-CNN、使用 MobileNet 的更快 R-CNN 和 RetinaNet。
要学习如何用预先训练好的 PyTorch 网络进行物体检测, 继续阅读。
使用预训练网络的 PyTorch 对象检测
在本教程的第一部分,我们将讨论什么是预训练的对象检测网络,包括 PyTorch 库中内置了什么对象检测网络。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
今天我们将回顾两个 Python 脚本。第一个将在图像中执行对象检测,而第二个将向您展示如何在视频流中执行实时对象检测(将需要 GPU 来获得实时性能)。
最后,我们将讨论我们的结果来结束本教程。
什么是预训练的物体检测网络?
正如 ImageNet challenge 倾向于成为图像分类的事实上的标准一样, COCO 数据集(上下文中的常见对象)倾向于成为对象检测基准的标准。
这个数据集包括你在日常生活中会看到的 90 多种常见物品。计算机视觉和深度学习研究人员在 COCO 数据集上开发、训练和评估最先进的对象检测网络。
大多数研究人员还将预训练的权重发布到他们的模型中,以便计算机视觉从业者可以轻松地将对象检测纳入他们自己的项目中。
本教程将展示如何使用 PyTorch 通过以下先进的分类网络来执行对象检测:
- 具有 ResNet50 主干的更快的 R-CNN(更准确,但更慢)
- 使用 MobileNet v3 主干的更快的 R-CNN(更快,但不太准确)
- 具有 ResNet50 主干的 RetinaNet(速度和准确性之间的良好平衡)
准备好了吗?让我们开始吧。
配置您的开发环境
要遵循这个指南,您需要在系统上安装 PyTorch 和 OpenCV。
幸运的是,PyTorch 和 OpenCV 都非常容易使用 pip 安装:
$ pip install torch torchvision
$ pip install opencv-contrib-python
如果您需要帮助配置 PyTorch 的开发环境,我强烈推荐您 阅读 PyTorch 文档——py torch 的文档非常全面,可以让您快速上手并运行。
**如果你需要帮助安装 OpenCV,一定要参考我的 pip 安装 OpenCV 教程。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们开始审查任何源代码之前,让我们首先审查我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
然后,您将看到以下目录结构:
$ tree . --dirsfirst
.
├── images
│ ├── example_01.jpg
│ ├── example_02.jpg
│ ├── example_03.jpg
│ ├── example_04.jpg
│ ├── example_05.jpg
│ └── example_06.jpg
├── coco_classes.pickle
├── detect_image.py
└── detect_realtime.py
1 directory, 9 files
在images目录中,您会发现许多我们将应用对象检测的示例图像。
coco_classes.pickle文件包含我们的 PyTorch 预训练对象检测网络被训练的类别标签的名称。
然后,我们要回顾两个 Python 脚本:
detect_image.py:在静态图像中用 PyTorch 进行物体检测detect_realtime.py:将 PyTorch 对象检测应用于实时视频流
实现我们的 PyTorch 对象检测脚本
在本节中,您将学习如何使用预先训练的 PyTorch 网络执行对象检测。
打开detect_image.py脚本并插入以下代码:
# import the necessary packages
from torchvision.models import detection
import numpy as np
import argparse
import pickle
import torch
import cv2
第 2-7 行导入我们需要的 Python 包。最重要的进口是来自torchvision.models的detection。detection模块包含 PyTorch 预先训练的物体探测器。
让我们继续解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to the input image")
ap.add_argument("-m", "--model", type=str, default="frcnn-resnet",
choices=["frcnn-resnet", "frcnn-mobilenet", "retinanet"],
help="name of the object detection model")
ap.add_argument("-l", "--labels", type=str, default="coco_classes.pickle",
help="path to file containing list of categories in COCO dataset")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
这里有许多命令行参数,包括:
--image:我们想要应用对象检测的输入图像的路径- 我们将使用的 PyTorch 对象检测器的类型(更快的 R-CNN + ResNet,更快的 R-CNN + MobileNet,或 RetinaNet + ResNet)
--labels:COCO 标签文件的路径,包含人类可读的类标签--confidence:过滤弱检测的最小预测概率
这里,我们有一些重要的初始化:
# set the device we will be using to run the model
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the list of categories in the COCO dataset and then generate a
# set of bounding box colors for each class
CLASSES = pickle.loads(open(args["labels"], "rb").read())
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
第 23 行设置我们将用于推理的device(CPU 或 GPU)。
然后,我们从磁盘加载我们的类标签(行 27 ),并为每个唯一标签初始化一个随机颜色(行 28 )。我们将在输出图像上绘制预测边界框和标签时使用这些颜色。
接下来,我们定义一个MODELS字典来将给定对象检测器的名称映射到其对应的 PyTorch 函数:
# initialize a dictionary containing model name and its corresponding
# torchvision function call
MODELS = {
"frcnn-resnet": detection.fasterrcnn_resnet50_fpn,
"frcnn-mobilenet": detection.fasterrcnn_mobilenet_v3_large_320_fpn,
"retinanet": detection.retinanet_resnet50_fpn
}
# load the model and set it to evaluation mode
model = MODELS[args["model"]](pretrained=True, progress=True,
num_classes=len(CLASSES), pretrained_backbone=True).to(DEVICE)
model.eval()
PyTorch 为我们提供了三种对象检测模型:
- 具有 ResNet50 主干的更快的 R-CNN(更准确,但更慢)
- 使用 MobileNet v3 主干的更快的 R-CNN(更快,但不太准确)
- 具有 ResNet50 主干的 RetinaNet(速度和准确性之间的良好平衡)
然后,我们从磁盘加载model并将它发送到行 39 和 40 上的适当的DEVICE。我们传入许多关键参数,包括:
pretrained:告诉 PyTorch 在 COCO 数据集上加载带有预训练权重的模型架构progress=True:如果模型尚未下载和缓存,则显示下载进度条num_classes:唯一类的总数pretrained_backbone:还向目标探测器提供主干网络
然后我们在第 41 行将模型置于评估模式。
加载完模型后,让我们继续为对象检测准备输入图像:
# load the image from disk
image = cv2.imread(args["image"])
orig = image.copy()
# convert the image from BGR to RGB channel ordering and change the
# image from channels last to channels first ordering
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image.transpose((2, 0, 1))
# add the batch dimension, scale the raw pixel intensities to the
# range [0, 1], and convert the image to a floating point tensor
image = np.expand_dims(image, axis=0)
image = image / 255.0
image = torch.FloatTensor(image)
# send the input to the device and pass the it through the network to
# get the detections and predictions
image = image.to(DEVICE)
detections = model(image)[0]
第 44 行和第 45 行从磁盘加载我们的输入image并克隆它,这样我们可以在稍后的脚本中在其上绘制边界框预测。
然后,我们通过以下方式对图像进行预处理:
- 将颜色通道排序从 BGR 转换为 RGB(因为 PyTorch 模型是在 RGB 排序的图像上训练的)
- 将颜色通道排序从“通道最后”(OpenCV 和 Keras/TensorFlow 默认)交换到“通道优先”(PyTorch 默认)
- 添加批次维度
- 从范围【0,255】到【0,1】缩放像素强度
- 将图像从 NumPy 数组转换为浮点数据类型的张量
然后图像被移动到合适的设备上(行 60 )。在这一点上,我们通过model传递image来获得我们的边界框预测。
现在让我们循环我们的边界框预测:
# loop over the detections
for i in range(0, len(detections["boxes"])):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections["scores"][i]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the detections,
# then compute the (x, y)-coordinates of the bounding box
# for the object
idx = int(detections["labels"][i])
box = detections["boxes"][i].detach().cpu().numpy()
(startX, startY, endX, endY) = box.astype("int")
# display the prediction to our terminal
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
print("[INFO] {}".format(label))
# draw the bounding box and label on the image
cv2.rectangle(orig, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(orig, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
# show the output image
cv2.imshow("Output", orig)
cv2.waitKey(0)
线路 64 在来自网络的所有检测上循环。然后,我们获取与第 67 条线上的检测相关联的confidence(即概率)。
我们过滤掉不满足我们在第 71 行上的最小置信度测试的弱检测。这样做有助于过滤掉误报检测。
从那里,我们:
- 提取对应概率最大的类别标签的
idx(第 75 行 - 获取边界框坐标并将其转换成整数(第 76 行和第 77 行)
- 将预测显示到我们的终端(行 80 和 81 )
- 在我们的输出图像上画出预测的边界框和类标签(行 84-88 )
我们通过显示上面画有边界框的输出图像来结束脚本。
【PyTorch 结果的物体检测
我们现在可以看到一些 PyTorch 物体检测结果了!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
接下来,让我们应用对象检测:
$ python detect_image.py --model frcnn-resnet \
--image images/example_01.jpg --labels coco_classes.pickle
[INFO] car: 99.54%
[INFO] car: 99.18%
[INFO] person: 85.76%
我们在这里使用的对象检测器是一个具有 ResNet50 主干的更快的 R-CNN。由于网络的设计方式,更快的 R-CNN 往往非常擅长检测图像中的小物体——这一点可以从以下事实中得到证明:不仅在输入图像中检测到了每辆汽车,而且还检测到了其中一名司机(人眼几乎看不到他)。
这是另一个使用我们更快的 R-CNN 物体探测器的示例图像:
$ python detect_image.py --model frcnn-resnet \
--image images/example_06.jpg --labels coco_classes.pickle
[INFO] dog: 99.92%
[INFO] person: 99.90%
[INFO] chair: 99.42%
[INFO] tv: 98.22%
在这里,我们可以看到我们的输出对象检测是相当准确的。我们的模型在场景的前景中准确地检测到了我和 Jemma,一只小猎犬。它还检测背景中的电视和椅子。
让我们尝试最后一张图片,这是一个更复杂的场景,它真实地展示了更快的 R-CNN 模型在检测小物体方面有多好:
$ python detect_image.py --model frcnn-resnet \
--image images/example_05.jpg --labels coco_classes.pickle \
--confidence 0.7
[INFO] horse: 99.88%
[INFO] person: 99.76%
[INFO] person: 99.09%
[INFO] dog: 93.22%
[INFO] person: 83.80%
[INFO] person: 81.58%
[INFO] truck: 71.33%
注意这里我们是如何手动指定我们的--confidence命令行参数0.7的,这意味着预测概率 > 70% 的物体检测将被认为是真阳性检测(如果你记得,detect_image.py脚本默认最小置信度为 90%)。
注: 降低我们的默认置信度会让我们检测到更多的物体,但可能会以误报为代价。
也就是说,正如图 5 的输出所示,我们的模型已经做出了高度准确的预测。我们不仅检测到了前景物体,如狗、马和马背上的人,还检测到了背景物体,包括背景中的卡车和多人。
为了获得更多使用 PyTorch 进行对象检测的经验,我建议您将frcnn-mobilenet和retinanet替换为--model命令行参数,然后比较输出结果。
用 PyTorch 实现实时物体检测
在上一节中,您学习了如何在 PyTorch 中将对象检测应用于单个图像。本节将向您展示如何使用 PyTorch 将对象检测应用于视频流。
正如您将看到的,以前实现的大部分代码都可以重用,只需稍作修改。
打开项目目录结构中的detect_realtime.py脚本,让我们开始工作:
# import the necessary packages
from torchvision.models import detection
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import pickle
import torch
import time
import cv2
第 2-11 行导入我们需要的 Python 包。所有这些导入基本上与我们的detect_image.py脚本相同,但是有两个显著的增加:
- 访问我们的网络摄像头
FPS:测量我们的对象检测管道的大约每秒帧数吞吐率
接下来是我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="frcnn-resnet",
choices=["frcnn-resnet", "frcnn-mobilenet", "retinanet"],
help="name of the object detection model")
ap.add_argument("-l", "--labels", type=str, default="coco_classes.pickle",
help="path to file containing list of categories in COCO dataset")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们的第一个开关--model控制我们想要使用哪个 PyTorch 对象检测器。
--labels参数提供了 COCO 类文件的路径。
最后,--confidence开关允许我们提供一个最小的预测概率,以帮助过滤掉微弱的假阳性检测。
下一个代码块处理设置我们的推理设备(CPU 或 GPU),以及加载我们的类标签:
# set the device we will be using to run the model
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the list of categories in the COCO dataset and then generate a
# set of bounding box colors for each class
CLASSES = pickle.loads(open(args["labels"], "rb").read())
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
当在视频流中执行对象检测时,我 强烈推荐 使用 GPU——CPU 对于任何接近实时性能的东西来说都太慢了。
然后我们定义我们的MODELS字典,就像前面的脚本一样:
# initialize a dictionary containing model name and its corresponding
# torchvision function call
MODELS = {
"frcnn-resnet": detection.fasterrcnn_resnet50_fpn,
"frcnn-mobilenet": detection.fasterrcnn_mobilenet_v3_large_320_fpn,
"retinanet": detection.retinanet_resnet50_fpn
}
# load the model and set it to evaluation mode
model = MODELS[args["model"]](pretrained=True, progress=True,
num_classes=len(CLASSES), pretrained_backbone=True).to(DEVICE)
model.eval()
第 41-43 行从磁盘加载 PyTorch 对象检测model并将其置于评估模式。
我们现在可以访问我们的网络摄像头了:
# initialize the video stream, allow the camera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
fps = FPS().start()
我们插入一个小的sleep语句,让我们的相机传感器预热。
对FPS的start方法的调用允许我们开始计算大约每秒帧数的吞吐率。
下一步是循环视频流中的帧:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
orig = frame.copy()
# convert the frame from BGR to RGB channel ordering and change
# the frame from channels last to channels first ordering
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = frame.transpose((2, 0, 1))
# add a batch dimension, scale the raw pixel intensities to the
# range [0, 1], and convert the frame to a floating point tensor
frame = np.expand_dims(frame, axis=0)
frame = frame / 255.0
frame = torch.FloatTensor(frame)
# send the input to the device and pass the it through the
# network to get the detections and predictions
frame = frame.to(DEVICE)
detections = model(frame)[0]
第 56-58 行从视频流中读取一个frame,调整它的大小(输入帧越小,推断速度越快),然后克隆它,以便我们以后可以在它上面绘图。
我们的预处理操作与之前的脚本相同:
- 从 BGR 转换到 RGB 通道排序
- 从“信道最后”切换到“信道优先”排序
- 添加批次维度
- 从范围【0,255】到【0,1】缩放帧中的像素亮度
- 将帧转换为浮点 PyTorch 张量
预处理后的frame然后被移动到适当的设备,之后进行预测(第 73 行和第 74 行)。
物体检测模型结果的处理与predict_image.py相同:
# loop over the detections
for i in range(0, len(detections["boxes"])):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections["scores"][i]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# detections, then compute the (x, y)-coordinates of
# the bounding box for the object
idx = int(detections["labels"][i])
box = detections["boxes"][i].detach().cpu().numpy()
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box and label on the frame
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
cv2.rectangle(orig, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(orig, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
最后,我们可以在窗口中显示输出帧:
# show the output frame
cv2.imshow("Frame", orig)
key = cv2.waitKey(1) & 0xFF
# if the 'q' key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
我们继续监控我们的 FPS,直到我们点击 OpenCV 打开的窗口并按下q键退出脚本,之后我们停止我们的 FPS 定时器并显示(1)脚本运行的时间和(2)大约每秒帧数的吞吐量信息。
PyTorch 实时物体检测结果
让我们学习如何使用 PyTorch 对视频流应用对象检测。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,您可以执行detect_realtime.py脚本:
$ python detect_realtime.py --model frcnn-mobilenet \
--labels coco_classes.pickle
[INFO] starting video stream...
[INFO] elapsed time: 56.47
[INFO] approx. FPS: 6.98
使用带有 MobileNet 背景的更快的 R-CNN 模型(速度最佳),我们实现了大约每秒 7 FPS。我们还没有达到真正的实时速度 > 20 FPS ,但是有了更快的 GPU 和更多的优化,我们可以轻松达到。
总结
在本教程中,您学习了如何使用 PyTorch 和预训练的网络执行对象检测。您获得了在三个流行网络中应用对象检测的经验:
- 使用 ResNet50 主干的更快的 R-CNN
- 更快的 R-CNN 和 MobileNet 主干网
- 具有 ResNet50 主干网的 RetinaNet
当涉及到准确性和检测小物体时,更快的 R-CNN 将表现得非常好。然而,这种准确性是有代价的——更快的 R-CNN 模型往往比单次检测器(SSD)和 YOLO 慢得多。
为了帮助加速更快的 R-CNN 架构,我们可以用更轻、更高效(但不太准确)的 MobileNet 主干网取代计算成本高昂的 ResNet 主干网。这样做会提高你的速度。
否则,RetinaNet 是速度和准确性之间的一个很好的折衷。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
PyTorch:训练你的第一个卷积神经网络(CNN)
原文:https://pyimagesearch.com/2021/07/19/pytorch-training-your-first-convolutional-neural-network-cnn/
在本教程中,您将获得关于使用 PyTorch 深度学习库训练您的第一个卷积神经网络(CNN)的温和介绍。这个网络将能够识别手写的平假名字符。
今天的教程是 PyTorch 基础知识五部分系列的第三部分:
- py torch 是什么?
- py torch 简介:用 PyTorch 训练你的第一个神经网络
- PyTorch:训练你的第一个卷积神经网络(今天的教程)
- 使用预训练网络的 PyTorch 图像分类(下周教程)
- 使用预训练网络的 PyTorch 对象检测
上周你学习了如何使用 PyTorch 库训练一个非常基本的前馈神经网络。该教程侧重于简单的数字数据。
今天,我们将进行下一步,学习如何使用 Kuzushiji-MNIST (KMNIST)数据集训练 CNN 识别手写平假名字符。
正如您将看到的,在图像数据集上训练 CNN 与在数字数据上训练基本的多层感知器(MLP)没有什么不同。我们仍然需要:
- 定义我们的模型架构
- 从磁盘加载我们的数据集
- 循环我们的纪元和批次
- 预测并计算我们的损失
- 适当地调零我们的梯度,执行反向传播,并更新我们的模型参数
此外,这篇文章还会给你一些 PyTorch 的DataLoader实现的经验,这使得处理数据集变得超级容易——精通 PyTorch 的DataLoader是你作为深度学习实践者想要发展的一项关键技能(这是我在 PyImageSearch 大学专门开设了一门课程的主题)。
要学习如何用 PyTorch 训练你的第一个 CNN, 继续阅读。
PyTorch:训练你的第一个卷积神经网络(CNN)
在本教程的剩余部分,您将学习如何使用 PyTorch 框架训练您的第一个 CNN。
我们将首先配置我们的开发环境来安装torch和torchvision,然后回顾我们的项目目录结构。
然后,我将向您展示包含平假名字符的 KMNIST 数据集(MNIST 数字数据集的替代物)。在本教程的后面,您将学习如何训练 CNN 识别 KMNIST 数据集中的每个平假名字符。
然后,我们将使用 PyTorch 实现三个 Python 脚本,包括 CNN 架构、训练脚本和用于对输入图像进行预测的最终脚本。
在本教程结束时,您将熟悉使用 PyTorch 训练 CNN 所需的步骤。
我们开始吧!
配置您的开发环境
要遵循本指南,您需要在系统上安装 PyTorch、OpenCV 和 scikit-learn。
幸运的是,使用 pip 安装这三个都非常容易:
$ pip install torch torchvision
$ pip install opencv-contrib-python
$ pip install scikit-learn
如果您需要帮助配置 PyTorch 的开发环境,我强烈推荐您 阅读 PyTorch 文档——py torch 的文档非常全面,可以让您快速上手并运行。
**如果你需要帮助安装 OpenCV,一定要参考我的 pip 安装 OpenCV 教程。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
kmn ist 数据集
我们今天使用的数据集是库祖什基-MNIST 数据集,简称 KMNIST。该数据集旨在替代标准的 MNIST 数字识别数据集。
KMNIST 数据集由 70,000 幅图像及其对应的标注组成(60,000 幅用于训练,10,000 幅用于测试)。
KMNIST 数据集中总共有 10 个类(即 10 个平假名字符),每个类都是均匀分布和表示的。我们的目标是训练一个 CNN,它可以准确地对这 10 个角色进行分类。
幸运的是,KMNIST 数据集内置于 PyTorch 中,这让我们非常容易使用!
项目结构
在我们开始实现任何 PyTorch 代码之前,让我们先回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,以检索源代码和预训练模型。
然后,您将看到以下目录结构:
$ tree . --dirsfirst
.
├── output
│ ├── model.pth
│ └── plot.png
├── pyimagesearch
│ ├── __init__.py
│ └── lenet.py
├── predict.py
└── train.py
2 directories, 6 files
我们今天要复习三个 Python 脚本:
- 著名的 LeNet 架构的 PyTorch 实现
train.py:使用 PyTorch 在 KMNIST 数据集上训练 LeNet,然后将训练好的模型序列化到磁盘(即model.pth)- 从磁盘加载我们训练好的模型,对测试图像进行预测,并在屏幕上显示结果
一旦我们运行train.py,目录output将被填充plot.png(我们的训练/验证损失和准确性的图表)和model.pth(我们的训练模型文件)。
回顾了我们的项目目录结构后,我们可以继续用 PyTorch 实现我们的 CNN。
用 PyTorch 实现卷积神经网络(CNN)
我们在这里用 PyTorch 实现的卷积神经网络(CNN)是开创性的 LeNet 架构,由深度学习的创始人之一 Yann LeCunn 首先提出。
按照今天的标准,LeNet 是一个非常浅的神经网络,由以下几层组成:
(CONV => RELU => POOL) * 2 => FC => RELU => FC => SOFTMAX
正如您将看到的,我们将能够用 PyTorch 用 60 行代码(包括注释)实现 LeNet。
用 PyTorch 学习 CNN 的最好方法是实现一个,所以说,打开pyimagesearch模块中的lenet.py文件,让我们开始工作:
# import the necessary packages
from torch.nn import Module
from torch.nn import Conv2d
from torch.nn import Linear
from torch.nn import MaxPool2d
from torch.nn import ReLU
from torch.nn import LogSoftmax
from torch import flatten
第 2-8 行导入我们需要的包。让我们逐一分析:
Module:我们没有使用SequentialPyTorch 类来实现 LeNet,而是子类化了Module对象,这样你就可以看到 PyTorch 是如何使用类来实现神经网络的Conv2d: PyTorch 实现卷积层Linear:全连接层MaxPool2d:应用 2D 最大池来减少输入体积的空间维度ReLU:我方 ReLU 激活功能LogSoftmax:在构建 softmax 分类器时使用,以返回每个类别的预测概率flatten:展平多维体的输出(例如,CONV 或池层),以便我们可以对其应用完全连接的层
有了我们的导入,我们可以使用 PyTorch 实现我们的LeNet类:
class LeNet(Module):
def __init__(self, numChannels, classes):
# call the parent constructor
super(LeNet, self).__init__()
# initialize first set of CONV => RELU => POOL layers
self.conv1 = Conv2d(in_channels=numChannels, out_channels=20,
kernel_size=(5, 5))
self.relu1 = ReLU()
self.maxpool1 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# initialize second set of CONV => RELU => POOL layers
self.conv2 = Conv2d(in_channels=20, out_channels=50,
kernel_size=(5, 5))
self.relu2 = ReLU()
self.maxpool2 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# initialize first (and only) set of FC => RELU layers
self.fc1 = Linear(in_features=800, out_features=500)
self.relu3 = ReLU()
# initialize our softmax classifier
self.fc2 = Linear(in_features=500, out_features=classes)
self.logSoftmax = LogSoftmax(dim=1)
第 10 行定义了LeNet类。注意我们是如何子类化Module对象的——通过将我们的模型构建为一个类,我们可以很容易地:
- 重用变量
- 实现定制函数来生成子网/组件(在实现更复杂的网络时经常使用,如 ResNet、Inception 等)。)
- 定义我们自己的
forward传递函数
最棒的是,当定义正确时,PyTorch 可以自动应用其签名的模块来执行自动微分——反向传播由 PyTorch 库为我们处理!*
*LeNet的构造函数接受两个变量:
numChannels:输入图像的通道数(1表示灰度,3表示 RGB)classes:数据集中唯一类标签的总数
第 13 行调用父构造函数(即Module),它执行许多 PyTorch 特定的操作。
从那里,我们开始定义实际的 LeNet 架构。
第 16-19 行初始化我们的第一组CONV => RELU => POOL层。我们的第一个 CONV 层一共学习了 20 个滤镜,每个滤镜都是 5×5 。然后应用一个 ReLU 激活函数,接着是一个 2×2 max-pooling 层,步长为 2×2 以减少我们输入图像的空间维度。
然后我们在第 22-25 行的上有了第二组CONV => RELU => POOL层。我们将 CONV 层中学习到的滤镜数量增加到 50,但是保持 5×5 的内核大小。再次应用 ReLU 激活,然后是最大池。
接下来是我们的第一组也是唯一一组完全连接的层(28 和 29 )。我们定义该层的输入数量(800)以及我们期望的输出节点数量(500)。FC 层之后是 ReLu 激活。
最后,我们应用我们的 softmax 分类器(第 32 行和第 33 行)。将in_features的数量设置为500,这是来自上一层的输出维度。然后我们应用LogSoftmax,这样我们可以在评估过程中获得预测的概率。
理解这一点很重要,在这一点上我们所做的只是初始化变量。这些变量本质上是占位符。PyTorch 完全不知道网络架构是什么,只知道一些变量存在于类定义中。
为了构建网络架构本身(也就是说,哪一层是其他层的输入),我们需要覆盖Module类的forward方法。
forward功能有多种用途:
- 它通过类的构造函数(即
__init__)中定义的变量将层/子网连接在一起 - 它定义了网络体系结构本身
- 它允许模型向前传递,产生我们的输出预测
- 此外,由于 PyTorch 的自动模块,它允许我们执行自动区分和更新我们的模型权重
现在让我们检查一下forward功能:
def forward(self, x):
# pass the input through our first set of CONV => RELU =>
# POOL layers
x = self.conv1(x)
x = self.relu1(x)
x = self.maxpool1(x)
# pass the output from the previous layer through the second
# set of CONV => RELU => POOL layers
x = self.conv2(x)
x = self.relu2(x)
x = self.maxpool2(x)
# flatten the output from the previous layer and pass it
# through our only set of FC => RELU layers
x = flatten(x, 1)
x = self.fc1(x)
x = self.relu3(x)
# pass the output to our softmax classifier to get our output
# predictions
x = self.fc2(x)
output = self.logSoftmax(x)
# return the output predictions
return output
forward方法接受一个参数x,它是网络的一批输入数据。
然后,我们将我们的conv1、relu1和maxpool1层连接在一起,形成网络的第一个CONV => RELU => POOL层(第 38-40 行)。
在线 44-46 上执行类似的操作,这次构建第二组CONV => RELU => POOL层。
此时,变量x是一个多维张量;然而,为了创建我们完全连接的层,我们需要将这个张量“展平”成本质上相当于 1D 值列表的东西——第 50 行上的flatten函数为我们处理这个操作。
从那里,我们将fc1和relu3层连接到网络架构(线 51 和 52 ),然后连接最后的fc2和logSoftmax ( 线 56 和 57 )。
然后将网络的output返回给调用函数。
我想再次重申在构造函数中初始化变量相对于在forward函数中构建网络本身的重要性:
- 你的
Module的构造器只初始化你的层类型。PyTorch 跟踪这些变量,但是它不知道这些层是如何相互连接的。 - 为了让 PyTorch 理解您正在构建的网络架构,您定义了
forward函数。 - 在
forward函数中,你获取在你的构造函数中初始化的变量并连接它们。 - PyTorch 可以使用您的网络进行预测,并通过自动签名模块进行自动反向传播
祝贺你用 PyTorch 实现了你的第一个 CNN!
用 PyTorch 创建我们的 CNN 培训脚本
随着 CNN 架构的实现,我们可以继续用 PyTorch 创建我们的训练脚本。
打开项目目录结构中的train.py文件,让我们开始工作:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.lenet import LeNet
from sklearn.metrics import classification_report
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torchvision.datasets import KMNIST
from torch.optim import Adam
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
import argparse
import torch
import time
第 2 行和第 3 行导入matplotlib并设置合适的后台引擎。
从那里,我们导入了许多著名的包:
LeNet:我们的 PyTorch 实现了上一节中的 LeNet CNNclassification_report:用于显示我们测试集的详细分类报告random_split:从一组输入数据中构建随机训练/测试分割- PyTorch 的棒极了的数据加载工具,让我们可以毫不费力地建立数据管道来训练我们的 CNN
ToTensor:一个预处理功能,自动将输入数据转换成 PyTorch 张量- 内置于 PyTorch 库中的 Kuzushiji-MNIST 数据集加载器
- 我们将用来训练神经网络的优化器
- PyTorch 的神经网络实现
现在让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to output trained model")
ap.add_argument("-p", "--plot", type=str, required=True,
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们有两个命令行参数需要解析:
--model:训练后输出序列化模型的路径(我们将这个模型保存到磁盘,这样我们就可以用它在我们的predict.py脚本中进行预测)--plot:输出训练历史图的路径
继续,我们现在有一些重要的初始化要处理:
# define training hyperparameters
INIT_LR = 1e-3
BATCH_SIZE = 64
EPOCHS = 10
# define the train and val splits
TRAIN_SPLIT = 0.75
VAL_SPLIT = 1 - TRAIN_SPLIT
# set the device we will be using to train the model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
第 29-31 行设置我们的初始学习率、批量大小和训练的时期数,而第 34 和 35 行定义我们的训练和验证分割大小(75%的训练,25%的验证)。
第 38 行然后决定我们的device(即,我们将使用我们的 CPU 还是 GPU)。
让我们开始准备数据集:
# load the KMNIST dataset
print("[INFO] loading the KMNIST dataset...")
trainData = KMNIST(root="data", train=True, download=True,
transform=ToTensor())
testData = KMNIST(root="data", train=False, download=True,
transform=ToTensor())
# calculate the train/validation split
print("[INFO] generating the train/validation split...")
numTrainSamples = int(len(trainData) * TRAIN_SPLIT)
numValSamples = int(len(trainData) * VAL_SPLIT)
(trainData, valData) = random_split(trainData,
[numTrainSamples, numValSamples],
generator=torch.Generator().manual_seed(42))
第 42-45 行使用 PyTorch 在KMNIST类中的构建加载 KMNIST 数据集。
对于我们的trainData,我们设置train=True,而我们的testData加载了train=False。当处理 PyTorch 库中内置的数据集时,这些布尔值很方便。
download=True标志表示 PyTorch 将自动下载 KMNIST 数据集并缓存到磁盘,如果我们以前没有下载过的话。
还要注意transform参数——这里我们可以应用一些数据转换(超出了本教程的范围,但很快会涉及到)。我们需要的唯一转换是将 PyTorch 加载的 NumPy 数组转换为张量数据类型。
加载了我们的训练和测试集后,我们在第 49-53 行上驱动我们的训练和验证集。使用 PyTorch 的random_split函数,我们可以很容易地拆分我们的数据。
我们现在有三组数据:
- 培养
- 确认
- 测试
下一步是为每一个创建一个DataLoader:
# initialize the train, validation, and test data loaders
trainDataLoader = DataLoader(trainData, shuffle=True,
batch_size=BATCH_SIZE)
valDataLoader = DataLoader(valData, batch_size=BATCH_SIZE)
testDataLoader = DataLoader(testData, batch_size=BATCH_SIZE)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDataLoader.dataset) // BATCH_SIZE
valSteps = len(valDataLoader.dataset) // BATCH_SIZE
构建DataLoader对象是在行的 56-59 行完成的。我们只为trainDataLoader设置了shuffle=True,因为我们的验证和测试集不需要洗牌。
我们还导出每个时期的训练步骤和验证步骤的数量(行 62 和 63 )。
此时,我们的数据已经为训练做好了准备;然而,我们还没有一个模型来训练!
现在让我们初始化 LeNet:
# initialize the LeNet model
print("[INFO] initializing the LeNet model...")
model = LeNet(
numChannels=1,
classes=len(trainData.dataset.classes)).to(device)
# initialize our optimizer and loss function
opt = Adam(model.parameters(), lr=INIT_LR)
lossFn = nn.NLLLoss()
# initialize a dictionary to store training history
H = {
"train_loss": [],
"train_acc": [],
"val_loss": [],
"val_acc": []
}
# measure how long training is going to take
print("[INFO] training the network...")
startTime = time.time()
67-69 行初始化我们的model。由于 KMNIST 数据集是灰度的,我们设置numChannels=1。我们可以通过调用我们的trainData的dataset.classes来轻松设置classes的数量。
我们还调用to(device)将model移动到我们的 CPU 或 GPU。
第 72 和 73 行初始化我们的优化器和损失函数。我们将使用 Adam 优化器进行训练,并将负对数似然用于我们的损失函数。
当我们在模型定义中结合nn.NLLoss类和LogSoftmax类时,我们得到分类交叉熵损失(它是等价于训练一个具有输出Linear层和nn.CrossEntropyLoss损失的模型)。基本上,PyTorch 允许你以两种不同的方式实现分类交叉熵。
习惯于看到这两种方法,因为一些深度学习实践者(几乎是任意地)更喜欢其中一种。
然后我们初始化H,我们的训练历史字典(第 76-81 行)。在每个时期之后,我们将用给定时期的训练损失、训练准确度、测试损失和测试准确度来更新该字典。
最后,我们启动一个计时器来测量训练需要多长时间( Line 85 )。
至此,我们所有的初始化都已完成,所以是时候训练我们的模型了。
注意: 请确保您已经阅读了本系列的前一篇教程,py torch 简介:使用 PyTorch 训练您的第一个神经网络,因为我们将在该指南中学习概念。
以下是我们的培训循环:
# loop over our epochs
for e in range(0, EPOCHS):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (x, y) in trainDataLoader:
# send the input to the device
(x, y) = (x.to(device), y.to(device))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFn(pred, y)
# zero out the gradients, perform the backpropagation step,
# and update the weights
opt.zero_grad()
loss.backward()
opt.step()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
在第 88 行,我们循环我们想要的历元数。
然后,我们继续:
- 将模型置于
train()模式 - 初始化当前时期的训练损失和验证损失
- 初始化当前纪元的正确训练和验证预测的数量
第 102 行展示了使用 PyTorch 的DataLoader类的好处——我们所要做的就是在DataLoader对象上开始一个for循环。PyTorch 自动产生一批训练数据。在引擎盖下,DataLoader也在洗牌我们的训练数据(如果我们做任何额外的预处理或数据扩充,它也会在这里发生)。
对于每一批数据(行 104 ),我们进行正向传递,获得我们的预测,并计算损失(行 107 和 108 )。
接下来是 所有重要步骤 之:
- 调零我们的梯度
- 执行反向传播
- 更新我们模型的权重
说真的,别忘了这一步!未能按照正确的顺序完成这三个步骤将会导致错误的训练结果。每当你用 PyTorch 编写一个训练循环时,我强烈建议你在做任何事情之前插入那三行代码,这样你就能被提醒确保它们在正确的位置。**
**我们通过更新我们的totalTrainLoss和trainCorrect簿记变量来包装代码块。
此时,我们已经循环了当前时期训练集中的所有批次的数据,现在我们可以在验证集上评估我们的模型:
# switch off autograd for evaluation
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (x, y) in valDataLoader:
# send the input to the device
(x, y) = (x.to(device), y.to(device))
# make the predictions and calculate the validation loss
pred = model(x)
totalValLoss += lossFn(pred, y)
# calculate the number of correct predictions
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
在验证或测试集上评估 PyTorch 模型时,您需要首先:
- 使用
torch.no_grad()上下文关闭梯度跟踪和计算 - 将模型置于
eval()模式
从那里,你循环所有的验证DataLoader ( 第 128 行),将数据移动到正确的device ( 第 130 行),并使用数据进行预测(第 133 行)并计算你的损失(第 134 行)。
然后你可以得到正确预测的总数(行 137 和 138 )。
我们通过计算一些统计数据来完善我们的训练循环:
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDataLoader.dataset)
valCorrect = valCorrect / len(valDataLoader.dataset)
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}\n".format(
avgValLoss, valCorrect))
第 141 行和第 142 行计算我们的平均训练和验证损失。第 146 行和第 146 行做同样的事情,但是为了我们的训练和验证准确性。
然后,我们获取这些值并更新我们的训练历史字典(行 149-152 )。
最后,我们在我们的终端上显示训练损失、训练精度、验证损失和验证精度(行 149-152 )。
我们快到了!
既然训练已经完成,我们需要在测试集上评估我们的模型(之前我们只使用了训练集和验证集):
# finish measuring how long training took
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# we can now evaluate the network on the test set
print("[INFO] evaluating network...")
# turn off autograd for testing evaluation
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# initialize a list to store our predictions
preds = []
# loop over the test set
for (x, y) in testDataLoader:
# send the input to the device
x = x.to(device)
# make the predictions and add them to the list
pred = model(x)
preds.extend(pred.argmax(axis=1).cpu().numpy())
# generate a classification report
print(classification_report(testData.targets.cpu().numpy(),
np.array(preds), target_names=testData.classes))
第 162-164 行停止我们的训练计时器,显示训练花了多长时间。
然后,我们设置另一个torch.no_grad()上下文,并将我们的模型置于eval()模式下(第 170 行和第 172 行)。
评估由以下人员执行:
- 初始化一个列表来存储我们的预测( Line 175
- 在我们的
testDataLoader( 行 178 上循环 - 将当前一批数据发送到适当的设备(行 180 )
- 对当前一批数据进行预测( Line 183
- 用来自模型的顶级预测更新我们的
preds列表(行 184 )
最后,我们展示一个详细的classification_report。
这里我们要做的最后一步是绘制我们的训练和验证历史,然后将我们的模型权重序列化到磁盘:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# serialize the model to disk
torch.save(model, args["model"])
第 191-201 行为我们的培训历史生成一个matplotlib图。
然后,我们调用torch.save将我们的 PyTorch 模型权重保存到磁盘,这样我们就可以从磁盘加载它们,并通过单独的 Python 脚本进行预测。
总的来说,回顾这个脚本向您展示了 PyTorch 在训练循环中给予您的更多控制——这既是一件好的事情,也是一件坏的事情:
- 如果你想让完全控制训练循环,并且需要实现自定义程序,那么是好的
- 当你的训练循环很简单,一个等价于
model.fit的 Keras/TensorFlow 就足够了,这就糟糕了
正如我在本系列的第一部分中提到的, 什么是 PyTorch ,py torch 和 Keras/TensorFlow 都不比对方好,只是每个库有不同的注意事项和用例。
用 PyTorch 训练我们的 CNN
我们现在准备使用 PyTorch 来训练我们的 CNN。
请务必访问本教程的 “下载” 部分,以检索本指南的源代码。
在那里,您可以通过执行以下命令来训练您的 PyTorch CNN:
$ python train.py --model output/model.pth --plot output/plot.png
[INFO] loading the KMNIST dataset...
[INFO] generating the train-val split...
[INFO] initializing the LeNet model...
[INFO] training the network...
[INFO] EPOCH: 1/10
Train loss: 0.362849, Train accuracy: 0.8874
Val loss: 0.135508, Val accuracy: 0.9605
[INFO] EPOCH: 2/10
Train loss: 0.095483, Train accuracy: 0.9707
Val loss: 0.091975, Val accuracy: 0.9733
[INFO] EPOCH: 3/10
Train loss: 0.055557, Train accuracy: 0.9827
Val loss: 0.087181, Val accuracy: 0.9755
[INFO] EPOCH: 4/10
Train loss: 0.037384, Train accuracy: 0.9882
Val loss: 0.070911, Val accuracy: 0.9806
[INFO] EPOCH: 5/10
Train loss: 0.023890, Train accuracy: 0.9930
Val loss: 0.068049, Val accuracy: 0.9812
[INFO] EPOCH: 6/10
Train loss: 0.022484, Train accuracy: 0.9930
Val loss: 0.075622, Val accuracy: 0.9816
[INFO] EPOCH: 7/10
Train loss: 0.013171, Train accuracy: 0.9960
Val loss: 0.077187, Val accuracy: 0.9822
[INFO] EPOCH: 8/10
Train loss: 0.010805, Train accuracy: 0.9966
Val loss: 0.107378, Val accuracy: 0.9764
[INFO] EPOCH: 9/10
Train loss: 0.011510, Train accuracy: 0.9960
Val loss: 0.076585, Val accuracy: 0.9829
[INFO] EPOCH: 10/10
Train loss: 0.009648, Train accuracy: 0.9967
Val loss: 0.082116, Val accuracy: 0.9823
[INFO] total time taken to train the model: 159.99s
[INFO] evaluating network...
precision recall f1-score support
o 0.93 0.98 0.95 1000
ki 0.96 0.95 0.96 1000
su 0.96 0.90 0.93 1000
tsu 0.95 0.97 0.96 1000
na 0.94 0.94 0.94 1000
ha 0.97 0.95 0.96 1000
ma 0.94 0.96 0.95 1000
ya 0.98 0.95 0.97 1000
re 0.95 0.97 0.96 1000
wo 0.97 0.96 0.97 1000
accuracy 0.95 10000
macro avg 0.95 0.95 0.95 10000
weighted avg 0.95 0.95 0.95 10000
在我的 CPU 上训练 CNN 花了大约 160 秒。使用我的 GPU 训练时间下降到≈82 秒。
在最后一个时期结束时,我们获得了 99.67%的训练精度和 98.23%的验证精度。
当我们在我们的测试集上进行评估时,我们达到了 ≈95%的准确率,考虑到平假名字符的复杂性和我们的浅层网络架构的简单性,这已经相当不错了(使用更深的网络,如 VGG 启发的模型或 ResNet-like 将允许我们获得更高的准确率,但对于使用 PyTorch 的 CNN 入门来说,这些模型更复杂)。
此外,如图 4 所示,我们的训练历史曲线是平滑的,表明很少/没有过度拟合发生。
在进入下一部分之前,看一下您的output目录:
$ ls output/
model.pth plot.png
注意model.pth文件——这是我们保存到磁盘上的经过训练的 PyTorch 模型。我们将从磁盘加载该模型,并在下一节中使用它进行预测。
实施我们的 PyTorch 预测脚本
我们在此审查的最后一个脚本将向您展示如何使用保存到磁盘的 PyTorch 模型进行预测。
打开项目目录结构中的predict.py文件,我们将开始:
# set the numpy seed for better reproducibility
import numpy as np
np.random.seed(42)
# import the necessary packages
from torch.utils.data import DataLoader
from torch.utils.data import Subset
from torchvision.transforms import ToTensor
from torchvision.datasets import KMNIST
import argparse
import imutils
import torch
import cv2
第 2-13 行导入我们需要的 Python 包。我们将 NumPy 随机种子设置在脚本的顶部,以便在不同的机器上有更好的可重复性。
然后我们导入:
DataLoader:用于加载我们的 KMNIST 测试数据Subset:建立测试数据的子集ToTensor:将我们的输入数据转换成 PyTorch 张量数据类型- 内置于 PyTorch 库中的 Kuzushiji-MNIST 数据集加载器
- 我们的 OpenCV 绑定,我们将使用它进行基本的绘图并在屏幕上显示输出图像
接下来是我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to the trained PyTorch model")
args = vars(ap.parse_args())
这里我们只需要一个参数,--model,即保存到磁盘上的经过训练的 PyTorch 模型的路径。想必这个开关会指向output/model.pth。
继续,让我们设定我们的device:
# set the device we will be using to test the model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the KMNIST dataset and randomly grab 10 data points
print("[INFO] loading the KMNIST test dataset...")
testData = KMNIST(root="data", train=False, download=True,
transform=ToTensor())
idxs = np.random.choice(range(0, len(testData)), size=(10,))
testData = Subset(testData, idxs)
# initialize the test data loader
testDataLoader = DataLoader(testData, batch_size=1)
# load the model and set it to evaluation mode
model = torch.load(args["model"]).to(device)
model.eval()
第 22 行决定了我们是在 CPU 还是 GPU 上执行推理。
然后,我们从 KMNIST 数据集中加载测试数据到线 26 和 27 。我们使用Subset类在的第 28 行和第 29 行上从这个数据集中随机抽取总共10个图像(这创建了一个完整测试数据的较小“视图”)。
创建一个DataLoader来通过第 32 行上的模型传递我们的测试数据子集。
然后,我们从磁盘的第 35 行的上加载我们的序列化 PyTorch 模型,并将其传递给相应的device。
最后,model被置于评估模式(行 36 )。
现在让我们对测试集的一个样本进行预测:
# switch off autograd
with torch.no_grad():
# loop over the test set
for (image, label) in testDataLoader:
# grab the original image and ground truth label
origImage = image.numpy().squeeze(axis=(0, 1))
gtLabel = testData.dataset.classes[label.numpy()[0]]
# send the input to the device and make predictions on it
image = image.to(device)
pred = model(image)
# find the class label index with the largest corresponding
# probability
idx = pred.argmax(axis=1).cpu().numpy()[0]
predLabel = testData.dataset.classes[idx]
第 39 行关闭梯度跟踪,而第 41 行在测试集中的所有图像上循环。
对于每个图像,我们:
- 抓取当前图像并将其转换成一个 NumPy 数组(这样我们以后可以用 OpenCV 在上面绘图)
- 提取地面实况分类标签
- 将
image发送到适当的device - 使用我们训练过的 LeNet 模型对当前
image进行预测 - 提取预测概率最高的类别标签
剩下的只是一点想象:
# convert the image from grayscale to RGB (so we can draw on
# it) and resize it (so we can more easily see it on our
# screen)
origImage = np.dstack([origImage] * 3)
origImage = imutils.resize(origImage, width=128)
# draw the predicted class label on it
color = (0, 255, 0) if gtLabel == predLabel else (0, 0, 255)
cv2.putText(origImage, gtLabel, (2, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, color, 2)
# display the result in terminal and show the input image
print("[INFO] ground truth label: {}, predicted label: {}".format(
gtLabel, predLabel))
cv2.imshow("image", origImage)
cv2.waitKey(0)
KMNIST 数据集中的每个图像都是单通道灰度图像;但是,我们想使用 OpenCV 的cv2.putText函数在image上绘制预测的类标签和真实标签。
为了在灰度图像上绘制 RGB 颜色,我们首先需要通过将灰度图像在深度方向上总共堆叠三次来创建灰度图像的 RGB 表示( Line 58 )。
此外,我们调整了origImage的大小,以便我们可以更容易地在屏幕上看到它(默认情况下,KMNIST 图像只有 28×28 像素,很难看到,尤其是在高分辨率显示器上)。
从那里,我们确定文本color并在输出图像上绘制标签。
我们通过在屏幕上显示输出origImage来结束脚本。
用我们训练过的 PyTorch 模型进行预测
我们现在准备使用我们训练过的 PyTorch 模型进行预测!
请务必访问本教程的 “下载” 部分,以检索源代码和预训练的 PyTorch 模型。
从那里,您可以执行predict.py脚本:
$ python predict.py --model output/model.pth
[INFO] loading the KMNIST test dataset...
[INFO] Ground truth label: ki, Predicted label: ki
[INFO] Ground truth label: ki, Predicted label: ki
[INFO] Ground truth label: ki, Predicted label: ki
[INFO] Ground truth label: ha, Predicted label: ha
[INFO] Ground truth label: tsu, Predicted label: tsu
[INFO] Ground truth label: ya, Predicted label: ya
[INFO] Ground truth label: tsu, Predicted label: tsu
[INFO] Ground truth label: na, Predicted label: na
[INFO] Ground truth label: ki, Predicted label: ki
[INFO] Ground truth label: tsu, Predicted label: tsu
正如我们的输出所示,我们已经能够使用 PyTorch 模型成功地识别每个平假名字符。
总结
在本教程中,您学习了如何使用 PyTorch 深度学习库训练您的第一个卷积神经网络(CNN)。
您还学习了如何:
- 将我们训练过的 PyTorch 模型保存到磁盘
- 在一个单独的 Python 脚本中从磁盘加载它
- 使用 PyTorch 模型对图像进行预测
这种在训练后保存模型,然后加载它并使用模型进行预测的顺序,是一个您应该熟悉的过程-作为 PyTorch 深度学习实践者,您将经常这样做。
说到从磁盘加载保存的 PyTorch 模型,下周你将学习如何使用预先训练的 PyTorch 来识别日常生活中经常遇到的 1000 个图像类。这些模型可以为您节省大量时间和麻烦——它们高度准确,不需要您手动训练它们。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*******
PyTorch:迁移学习和图像分类
原文:https://pyimagesearch.com/2021/10/11/pytorch-transfer-learning-and-image-classification/
在本教程中,您将学习如何使用 PyTorch 深度学习库为图像分类执行迁移学习。
本教程是我们关于计算机视觉和深度学习从业者的中级 PyTorch 技术的 3 部分系列中的第 2 部分:
- py torch 中的图像数据加载器 (上周的教程)
- PyTorch:迁移学习和图像分类(本教程)
- py torch 分布式培训简介(下周博文)
如果您不熟悉 PyTorch 深度学习库,我们建议您阅读以下介绍性系列,以帮助您学习基础知识并熟悉 PyTorch 库:
看完以上教程,你可以回到这里,用 PyTorch 学习迁移学习。
学习如何用 PyTorch 进行图像分类的迁移学习, 继续阅读。
PyTorch:迁移学习和图像分类
在本教程的第一部分,我们将学习什么是迁移学习,包括 PyTorch 如何让我们进行迁移学习。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
从这里,我们将实现几个 Python 脚本,包括:
- 存储重要变量的配置脚本
- 数据集加载器辅助函数
- 一个在磁盘上构建和组织数据集的脚本,这样 PyTorch 的
ImageFolder和DataLoader类就可以很容易地被利用 - 通过特征提取执行基本迁移学习的驱动程序脚本
- 第二个驱动程序脚本通过用全新的、刚刚初始化的 FC 头替换预训练网络的全连接(FC)层头来执行微调
- 最终的脚本允许我们用训练好的模型进行推理
我们今天要复习的内容很多,所以让我们开始吧!
什么是迁移学习?
从头开始训练一个卷积神经网络带来了许多挑战,最明显的是训练网络的数据量和训练发生的时间量。****
****迁移学习**是一种技术,它允许我们使用为某项任务训练的模型作为不同任务的机器学习模型的起点。
例如,假设在 ImageNet 数据集上为图像分类训练了一个模型。在这种情况下,我们可以采用这个模型,并“重新训练”它去识别它最初从未训练去识别的类!
想象一下,你会骑自行车,想骑摩托车。你骑自行车的经验——保持平衡、保持方向、转弯和刹车——将帮助你更快地学会骑摩托车。
这就是迁移学习在 CNN 中的作用。使用迁移学习,您可以通过冻结参数、更改输出层和微调权重来直接使用训练有素的模型。
本质上,您可以简化整个训练过程,并在很短的时间内获得高精度的模型。
如何用 PyTorch 进行迁移学习?
迁移学习有两种主要类型:
- 通过特征提取转移学习:我们从预训练的网络中移除 FC 层头,并将其替换为 softmax 分类器。这种方法非常简单,因为它允许我们将预训练的 CNN 视为特征提取器,然后将这些特征通过逻辑回归分类器。
- 通过微调转移学习:当应用微调时,我们再次从预训练的网络中移除 FC 层头,但这一次我们构建了一个全新的、刚刚初始化的 FC 层头,并将其置于网络的原始主体之上。CNN 主体中的权重被冻结,然后我们训练新的层头(通常具有非常小的学习率)。然后我们可以选择解冻网络的主体,并训练整个网络。
第一种方法更容易使用,因为涉及的代码更少,需要调整的参数也更少。然而,第二种方法往往更准确,导致模型更好地概括。
通过特征提取和微调的迁移学习都可以用 PyTorch 实现——我将在本教程的剩余部分向您展示如何实现。
配置您的开发环境
为了遵循这个指南,你需要在你的机器上安装 OpenCV、imutils、matplotlib和tqdm。
幸运的是,所有这些都是 pip 可安装的:
$ pip install opencv-contrib-python
$ pip install torch torchvision
$ pip install imutils matplotlib tqdm
如果你需要帮助为 PyTorch 配置开发环境,我强烈推荐你 阅读 PyTorch 文档——py torch 的文档很全面,会让你很快上手并运行。
如果你需要帮助安装 OpenCV,一定要参考我的 pip 安装 OpenCV 教程。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
花卉照片数据集
让我们来看看 Flowers 数据集,并可视化该数据集中的一些图像。图 2 展示了图像的外观。
我们将用于微调实验的数据集是由 TensorFlow 开发团队管理的花卉图像数据集。
泰国数据集 3,670 张图片,属于五种不同的花卉品种:
- 雏菊: 633 张图片
- 蒲公英: 898 张图片
- 玫瑰: 641 张图片
- 向日葵: 699 张图片
- 郁金香: 799 张图片
我们的工作是训练一个图像分类模型来识别这些花卉品种中的每一种。我们将通过 PyTorch 应用迁移学习来实现这一目标。
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── flower_photos
│ ├── daisy [633 entries exceeds filelimit, not opening dir]
│ ├── dandelion [898 entries exceeds filelimit, not opening dir]
│ ├── roses [641 entries exceeds filelimit, not opening dir]
│ ├── sunflowers [699 entries exceeds filelimit, not opening dir]
│ ├── tulips [799 entries exceeds filelimit, not opening dir]
│ └── LICENSE.txt
├── output
│ ├── finetune.png
│ └── warmup.png
├── pyimagesearch
│ ├── config.py
│ └── create_dataloaders.py
├── build_dataset.py
├── feature_extraction_results.png
├── fine_tune.py
├── fine_tune_results.png
├── inference.py
└── train_feature_extraction.py
目录包含了我们的花卉图片集。
我们将在这个花卉数据集上训练我们的模型。然后,output目录将被我们的训练/验证图填充。
在pyimagesearch模块中,我们有两个 Python 文件:
- 包含在我们的驱动脚本中使用的重要配置变量。
create_dataloaders.py:实现get_dataloader助手函数,负责创建一个DataLoader实例来解析来自flower_photos目录的文件
我们有四个 Python 驱动脚本:
build_dataset.py:取flower_photos目录,建立dataset目录。我们将创建特殊的子目录来存储我们的训练和验证分割,允许 PyTorch 的ImageFolder脚本解析目录并训练我们的模型。train_feature_extraction.py:通过特征提取进行迁移学习,将输出模型序列化到磁盘。fine_tune.py:通过微调进行迁移学习,并将模型保存到磁盘。inference.py:接受一个经过训练的 PyTorch 模型,并使用它对输入的花朵图像进行预测。
项目目录结构中的.png文件包含我们输出预测的可视化。
创建我们的配置文件
在实施任何迁移学习脚本之前,我们首先需要创建配置文件。
这个配置文件将存储我们的驱动程序脚本中使用的重要变量和参数。我们不再在每个脚本中重新定义它们,而是在这里简单地定义它们一次(从而使我们的代码更加清晰易读)。
打开pyimagesearch模块中的config.py文件,插入以下代码:
# import the necessary packages
import torch
import os
# define path to the original dataset and base path to the dataset
# splits
DATA_PATH = "flower_photos"
BASE_PATH = "dataset"
# define validation split and paths to separate train and validation
# splits
VAL_SPLIT = 0.1
TRAIN = os.path.join(BASE_PATH, "train")
VAL = os.path.join(BASE_PATH, "val")
第 7 行定义了DATA_PATH,我们输入flower_photos目录的路径。
然后我们设置BASE_PATH变量指向我们的dataset目录(第 8 行)。这个目录将通过我们的build_dataset.py脚本创建和填充。当我们运行迁移学习/推理脚本时,我们将从BASE_PATH目录中读取图像。
第 12 行将我们的验证分割设置为 10%,这意味着我们将 90%的数据用于训练,10%用于验证。
我们还在第 13 行和第 14 行定义了TRAIN和VAL子目录。一旦我们运行build_dataset.py,我们将在dataset中有两个子目录:
dataset/traindataset/val
每个子目录将为五个花卉类别中的每一个类别存储其各自的图像。
我们将微调 ResNet 架构,在 ImageNet 数据集上进行预训练。这意味着我们必须为图像像素缩放设置一些重要的参数:
# specify ImageNet mean and standard deviation and image size
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
IMAGE_SIZE = 224
# determine the device to be used for training and evaluation
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
第 17 行和第 18 行定义了 RGB 颜色空间中像素强度的平均值和标准偏差。
这些值是由研究人员在 ImageNet 数据集上训练他们的模型获得的。他们遍历 ImageNet 数据集中的所有图像,从磁盘加载它们,并计算 RGB 像素强度的平均值和标准偏差。
然后,在训练之前,将平均值和标准偏差值用于图像像素归一化。
即使我们没有使用 ImageNet 数据集进行迁移学习,我们仍然需要执行与 ResNet 接受培训时相同的预处理步骤;否则,模型将不能正确理解输入图像。
第 19 行将我们的输入IMAGE_SIZE设置为224 × 224像素。
DEVICE变量控制我们是使用 CPU 还是 GPU 进行训练。
接下来,我们有一些变量将用于特征提取和微调:
# specify training hyperparameters
FEATURE_EXTRACTION_BATCH_SIZE = 256
FINETUNE_BATCH_SIZE = 64
PRED_BATCH_SIZE = 4
EPOCHS = 20
LR = 0.001
LR_FINETUNE = 0.0005
当执行特征提取时,我们将通过我们的网络分批传递图像256 ( 线 25 )。
我们将使用64 ( 第 26 行)的图像批次,而不是通过微调来执行迁移学习。
当执行推理时(即通过inference.py脚本进行预测),我们将使用4的批量大小。
最后,我们设置我们将训练模型的EPOCHS的数量、特征提取的学习速率和微调的学习速率。这些值是通过运行简单的超参数调整实验确定的。
我们将通过设置输出文件路径来结束我们的配置脚本:
# define paths to store training plots and trained model
WARMUP_PLOT = os.path.join("output", "warmup.png")
FINETUNE_PLOT = os.path.join("output", "finetune.png")
WARMUP_MODEL = os.path.join("output", "warmup_model.pth")
FINETUNE_MODEL = os.path.join("output", "finetune_model.pth")
第 33 行和第 34 行为我们的输出训练历史和序列化模型设置文件路径,用于特征提取。
第 35 行和第 36 行也是如此,只是为了微调。
实现我们的数据加载器助手
PyTorch 允许我们轻松地从存储在磁盘目录中的图像构建DataLoader对象。
注: 如果你以前从未使用过 PyTorch 的DataLoader对象,我建议你阅读我们的PyTorch 教程简介 ,以及我们关于 py torch 图像数据加载器的指南。
打开pyimagesearch模块内的create_dataloaders.py文件,我们开始吧:
# import the necessary packages
from . import config
from torch.utils.data import DataLoader
from torchvision import datasets
import os
第 2-5 行导入我们需要的 Python 包,包括:
config:我们在上一节中创建的配置文件DataLoader: PyTorch 的数据加载类,用于高效处理数据批处理- 【PyTorch 的一个子模块,提供对
ImageFolder类的访问,用于从磁盘上的输入目录中读取图像 os:用于确定 CPU 上核心/工作线程的数量,从而加快数据加载速度
在那里,我们定义了get_dataloader函数:
def get_dataloader(rootDir, transforms, batchSize, shuffle=True):
# create a dataset and use it to create a data loader
ds = datasets.ImageFolder(root=rootDir,
transform=transforms)
loader = DataLoader(ds, batch_size=batchSize,
shuffle=shuffle,
num_workers=os.cpu_count(),
pin_memory=True if config.DEVICE == "cuda" else False)
# return a tuple of the dataset and the data loader
return (ds, loader)
该函数接受四个参数:
rootDir:磁盘上包含我们数据集的输入目录的路径(即dataset目录)transforms:要执行的数据转换列表,包括预处理步骤和数据扩充batchSize:从DataLoader中产出的批次大小shuffle:是否打乱数据——我们将打乱数据进行训练,但不会打乱进行验证
第 9 行和第 10 行创建了我们的ImageFolder类,用于从rootDir中读取图像。这也是我们应用transforms的地方。
然后在第 11-14 行的上创建DataLoader。在这里我们:
- 传入我们的
ImageFolder对象 - 设置批量大小
- 指示是否将执行随机播放
- 设置
num_workers,这是我们机器上 CPUs 内核的数量 - 设置我们是否使用 GPU 内存
产生的ImageFolder和DataLoader实例被返回给行 17 上的调用函数。
创建我们的数据集组织脚本
现在我们已经创建了配置文件并实现了DataLoader助手函数,让我们创建用于构建dataset目录的build_dataset.py脚本,以及train和val子目录。
打开项目目录结构中的build_dataset.py文件,插入以下代码:
# USAGE
# python build_dataset.py
# import necessary packages
from pyimagesearch import config
from imutils import paths
import numpy as np
import shutil
import os
第 5-9 行导入我们需要的 Python 包。我们的进口产品包括:
config:我们的 Python 配置文件paths:imutils的子模块,用于收集给定目录中图像的路径numpy:数值数组处理shutil:用于将文件从一个位置复制到另一个位置os:用于在磁盘上创建目录的操作系统模块
接下来,我们有我们的copy_images函数:
def copy_images(imagePaths, folder):
# check if the destination folder exists and if not create it
if not os.path.exists(folder):
os.makedirs(folder)
# loop over the image paths
for path in imagePaths:
# grab image name and its label from the path and create
# a placeholder corresponding to the separate label folder
imageName = path.split(os.path.sep)[-1]
label = path.split(os.path.sep)[1]
labelFolder = os.path.join(folder, label)
# check to see if the label folder exists and if not create it
if not os.path.exists(labelFolder):
os.makedirs(labelFolder)
# construct the destination image path and copy the current
# image to it
destination = os.path.join(labelFolder, imageName)
shutil.copy(path, destination)
copy_images函数需要两个参数:
imagePaths:给定输入目录下所有图像的路径folder:存储复制图像的输出基础目录(即dataset目录)
第 13 行和第 14 行快速检查一下folder目录是否存在。如果目录不存在,我们创建它。
从那里,我们循环所有的imagePaths ( 第 17 行)。对于每个path,我们:
- 抓取文件名(第 20 行)
- 从图像路径中提取类别标签(第 21 行)
- 构建基本输出目录(第 22 行)
如果labelFolder子目录尚不存在,我们在的第 25 行和第 26 行创建它。
从那里,我们构建到destination文件的路径(第 30 行)并复制它(第 31 行)。
现在让我们使用这个copy_images函数:
# load all the image paths and randomly shuffle them
print("[INFO] loading image paths...")
imagePaths = list(paths.list_images(config.DATA_PATH))
np.random.shuffle(imagePaths)
# generate training and validation paths
valPathsLen = int(len(imagePaths) * config.VAL_SPLIT)
trainPathsLen = len(imagePaths) - valPathsLen
trainPaths = imagePaths[:trainPathsLen]
valPaths = imagePaths[trainPathsLen:]
# copy the training and validation images to their respective
# directories
print("[INFO] copying training and validation images...")
copy_images(trainPaths, config.TRAIN)
copy_images(valPaths, config.VAL)
第 35 行和第 36 行从我们的输入DATA_PATH(即flower_photos目录)中读取所有的imagePaths,然后随机洗牌。
第 39-42 行根据我们的VAL_SPLIT百分比创建我们的培训和验证分割。
最后,我们使用copy_images函数将trainPaths和valPaths复制到它们各自的输出目录中(第 47 行和第 48 行)。
下一节将使这个过程更加清晰,包括为什么我们要费这么大劲以这种特定的方式组织数据集目录结构。
在磁盘上构建数据集
我们现在准备构建数据集目录。请务必使用本教程的 “下载” 部分来访问源代码和示例图像。
从那里,打开一个 shell 并执行以下命令:
$ python build_dataset.py
[INFO] loading image paths...
[INFO] copying training and validation images...
脚本执行后,您将看到一个新的dataset目录已经创建:
$ tree dataset --dirsfirst --filelimit 10
dataset
├── train
│ ├── daisy [585 entries exceeds filelimit, not opening dir]
│ ├── dandelion [817 entries exceeds filelimit, not opening dir]
│ ├── roses [568 entries exceeds filelimit, not opening dir]
│ ├── sunflowers [624 entries exceeds filelimit, not opening dir]
│ └── tulips [709 entries exceeds filelimit, not opening dir]
└── val
├── daisy [48 entries exceeds filelimit, not opening dir]
├── dandelion [81 entries exceeds filelimit, not opening dir]
├── roses [73 entries exceeds filelimit, not opening dir]
├── sunflowers [75 entries exceeds filelimit, not opening dir]
└── tulips [90 entries exceeds filelimit, not opening dir]
注意,dataset目录有两个子目录:
train:包含五类中每一类的训练图像。val:存储五类中每一类的验证图像。
通过创建一个train和val目录,我们现在可以很容易地利用 PyTorch 的ImageFolder类来构建一个DataLoader,这样我们就可以微调我们的模型。
实现特征提取和迁移学习 PyTorch
我们要实现的迁移学习的第一个方法是特征提取。
通过特征提取进行迁移学习的工作原理是:
- 采用预先训练的 CNN(通常在 ImageNet 数据集上)
- 从 CNN 移除 FC 层头
- 将网络主体的输出视为具有空间维度
M × N × C的任意特征提取器
从那以后,我们有两个选择:
- 采用一个标准的逻辑回归分类器(如 scikit-learn 库中的分类器),并根据从每幅图像中提取的特征对其进行训练
- 或者,更简单地说,在网络主体的顶部放置一个 softmax 分类器
这两种选择都是可行的,而且或多或少与另一种“相同”。
当提取的要素数据集适合计算机的 RAM 时,第一个选项非常有用。这样,您可以加载整个数据集,实例化您最喜欢的逻辑回归分类器模型的实例,然后训练它。
当你的数据集太大而不适合你的机器内存时,就会出现问题。当这种情况发生时,你可以使用类似于在线学习的东西来训练你的逻辑回归分类器,但是这只是引入了另一组库和依赖。
相反,更简单的方法是利用 PyTorch 的能力,在提取的特征基础上创建一个类似逻辑回归的分类器,然后使用 PyTorch 函数训练它。这是我们今天要实施的方法。
打开项目目录结构中的train_feature_extraction.py文件,让我们开始吧:
# USAGE
# python train_feature_extraction.py
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from imutils import paths
from torchvision.models import resnet50
from torchvision import transforms
from tqdm import tqdm
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
import torch
import time
第 5-15 行导入我们需要的 Python 包。值得注意的进口包括:
config:我们的 Python 配置文件create_dataloaders:从我们的输入dataset目录中创建一个 PyTorchDataLoader的实例resnet50:我们将使用的 ResNet 模型(在 ImageNet 数据集上进行了预训练)transforms:允许我们定义一组预处理和/或数据扩充程序,这些程序将依次应用于输入图像- 用于创建格式良好的进度条的 Python 库
torch和nn:包含 PyTorch 的神经网络类和函数
处理好我们的导入后,让我们继续定义我们的数据预处理和增强管道:
# define augmentation pipelines
trainTansform = transforms.Compose([
transforms.RandomResizedCrop(config.IMAGE_SIZE),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(90),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
valTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
我们使用 PyTorch 的transforms子模块中的Compose函数构建数据处理/扩充步骤。
首先,我们创建一个trainTransform,给定一个输入图像,它将:
- 随机调整图像大小并将其裁剪至
IMAGE_SIZE尺寸 - 随机执行水平翻转
- 在
[-90, 90]范围内随机旋转 - 将生成的图像转换为 PyTorch 张量
- 执行均值减法和缩放
然后我们有了我们的valTransform,它:
- 将输入图像调整到
IMAGE_SIZE尺寸 - 将图像转换为 PyTorch 张量
- 执行均值减法和缩放
注意,我们不在验证转换器内部执行数据扩充——没有必要为我们的验证数据执行数据扩充。
随着我们的训练和验证Compose对象的创建,让我们应用我们的get_dataloader函数:
# create data loaders
(trainDS, trainLoader) = create_dataloaders.get_dataloader(config.TRAIN,
transforms=trainTansform,
batchSize=config.FEATURE_EXTRACTION_BATCH_SIZE)
(valDS, valLoader) = create_dataloaders.get_dataloader(config.VAL,
transforms=valTransform,
batchSize=config.FEATURE_EXTRACTION_BATCH_SIZE, shuffle=False)
第 32-34 行创建我们的训练数据加载器,而第 35-37 行创建我们的验证数据加载器。
这些加载器中的每一个都将分别从dataset/train和dataset/val目录中产生图像。
另外,注意我们没有对我们的验证数据进行混排(就像我们没有对验证数据进行数据扩充一样)。
现在,让我们通过特征提取为迁移学习准备 ResNet50 模型:
# load up the ResNet50 model
model = resnet50(pretrained=True)
# since we are using the ResNet50 model as a feature extractor we set
# its parameters to non-trainable (by default they are trainable)
for param in model.parameters():
param.requires_grad = False
# append a new classification top to our feature extractor and pop it
# on to the current device
modelOutputFeats = model.fc.in_features
model.fc = nn.Linear(modelOutputFeats, len(trainDS.classes))
model = model.to(config.DEVICE)
第 40 行从磁盘加载在 ImageNet 上预先训练的 ResNet。
由于我们将使用 ResNet 进行特征提取,因此在网络主体中不需要进行实际的“学习”,我们冻结网络主体中的所有层(第 44 行和第 45 行)。
在此基础上,我们创建了一个由单个 FC 层组成的新 FC 层头。实际上,当使用分类交叉熵损失进行训练时,这一层将充当我们的代理 softmax 分类器。
然后,这个新层被添加到网络主体中,而model本身被移动到我们的DEVICE(我们的 CPU 或 GPU)。
接下来,我们初始化损失函数和优化方法:
# initialize loss function and optimizer (notice that we are only
# providing the parameters of the classification top to our optimizer)
lossFunc = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.fc.parameters(), lr=config.LR)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // config.FEATURE_EXTRACTION_BATCH_SIZE
valSteps = len(valDS) // config.FEATURE_EXTRACTION_BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "train_acc": [], "val_loss": [],
"val_acc": []}
我们将使用 Adam 优化器和分类交叉熵损失来训练我们的模型(第 55 和 56 行)。
我们还计算我们的模型将采取的步骤数,作为批量大小的函数,分别用于我们的训练集和测试集(行 59 和 60 )。
现在,该训练模型了:
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.EPOCHS)):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (i, (x, y)) in enumerate(trainLoader):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFunc(pred, y)
# calculate the gradients
loss.backward()
# check if we are updating the model parameters and if so
# update them, and zero out the previously accumulated gradients
if (i + 2) % 2 == 0:
opt.step()
opt.zero_grad()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
在第 69 行的上,我们循环我们想要的历元数。
对于trainLoader中的每一批数据,我们:
- 将图像和类标签移动到我们的 CPU/GPU ( Line 85 )。
- 对数据进行预测(行 88 )
- 计算损失,计算梯度,更新模型权重,并将梯度归零(第 89-98 行)
- 累计我们在该时期的总训练损失(行 102 )
- 计算正确预测的总数(行 103 和 104 )
现在纪元已经完成,我们可以根据验证数据评估模型:
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (x, y) in valLoader:
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation loss
pred = model(x)
totalValLoss += lossFunc(pred, y)
# calculate the number of correct predictions
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
请注意,我们关闭了亲笔签名,并将模型置于评估模式——这是使用 PyTorch 评估时的一个要求,所以不要忘记这样做!
从那里,我们循环遍历valLoader中的所有数据点,对它们进行预测,并计算我们的总损失和正确验证预测的数量。
以下代码块汇总了我们的训练/验证损失和准确性,更新了我们的训练历史,然后将损失/准确性信息打印到我们的终端:
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(valDS)
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
我们的最终代码块绘制了我们的训练历史并将我们的模型序列化到磁盘:
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.WARMUP_PLOT)
# serialize the model to disk
torch.save(model, config.WARMUP_MODEL)
在这个脚本执行之后,您将在您的output目录中找到一个名为warmup_model.pth的文件——这个文件是您的序列化 PyTorch 模型,它可以用于在inference.py脚本中进行预测。
具有特征提取的 PyTorch 迁移学习
我们现在准备通过 PyTorch 的特征提取来执行迁移学习。
确保你有:
- 使用本教程的 “下载” 部分访问源代码、示例图像等。
- 执行了
build_dataset.py脚本来创建我们的数据集目录结构
假设您已经完成了这两个步骤,您可以继续运行train_feature_extraction.py脚本:
$ python train_feature_extraction.py
[INFO] training the network...
0% 0/20 [00:00<?, ?it/s][INFO] EPOCH: 1/20
Train loss: 1.610827, Train accuracy: 0.4063
Val loss: 2.295713, Val accuracy: 0.6512
5% 1/20 [00:17<05:24, 17.08s/it][INFO] EPOCH: 2/20
Train loss: 1.190757, Train accuracy: 0.6703
Val loss: 1.720566, Val accuracy: 0.7193
10% 2/20 [00:33<05:05, 16.96s/it][INFO] EPOCH: 3/20
Train loss: 0.958189, Train accuracy: 0.7163
Val loss: 1.423687, Val accuracy: 0.8120
15% 3/20 [00:50<04:47, 16.90s/it][INFO] EPOCH: 4/20
Train loss: 0.805547, Train accuracy: 0.7811
Val loss: 1.200151, Val accuracy: 0.7793
20% 4/20 [01:07<04:31, 16.94s/it][INFO] EPOCH: 5/20
Train loss: 0.731831, Train accuracy: 0.7856
Val loss: 1.066768, Val accuracy: 0.8283
25% 5/20 [01:24<04:14, 16.95s/it][INFO] EPOCH: 6/20
Train loss: 0.664001, Train accuracy: 0.8044
Val loss: 0.996960, Val accuracy: 0.8311
...
75% 15/20 [04:13<01:24, 16.83s/it][INFO] EPOCH: 16/20
Train loss: 0.495064, Train accuracy: 0.8480
Val loss: 0.736332, Val accuracy: 0.8665
80% 16/20 [04:30<01:07, 16.86s/it][INFO] EPOCH: 17/20
Train loss: 0.502294, Train accuracy: 0.8435
Val loss: 0.732066, Val accuracy: 0.8501
85% 17/20 [04:46<00:50, 16.85s/it][INFO] EPOCH: 18/20
Train loss: 0.486568, Train accuracy: 0.8471
Val loss: 0.703661, Val accuracy: 0.8801
90% 18/20 [05:03<00:33, 16.82s/it][INFO] EPOCH: 19/20
Train loss: 0.470880, Train accuracy: 0.8480
Val loss: 0.715560, Val accuracy: 0.8474
95% 19/20 [05:20<00:16, 16.85s/it][INFO] EPOCH: 20/20
Train loss: 0.489092, Train accuracy: 0.8426
Val loss: 0.684679, Val accuracy: 0.8774
100% 20/20 [05:37<00:00, 16.86s/it]
[INFO] total time taken to train the model: 337.24s
总训练时间刚刚超过 5 分钟。我们得到了 84.26% 的训练准确率和 87.74% 的验证准确率。
图 3 显示了我们的训练历史。
对于我们在培训过程中投入的这么少的时间来说,还不算太坏!
用 PyTorch 微调 CNN
到目前为止,在本教程中,您已经学习了如何通过特征提取来执行迁移学习。
这种方法在某些情况下工作得很好,但它的简单性有其缺点,即模型的准确性和概括能力都会受到影响。
迁移学习的大部分形式适用 微调 ,这就是本节的题目。
与特征提取类似,我们首先从网络中移除 FC 层头,但这次我们创建了一个全新的层头,包含一组线性、ReLU 和 dropout 层,类似于您在现代最先进的 CNN 上看到的内容。
然后,我们执行以下操作的某种组合:
- 冻结网络体中的所有层并训练层头
- 冷冻所有层,训练层头,然后解冻身体并训练
- 简单地让所有层解冻并一起训练它们
确切地说,你使用哪种方法是你自己进行的实验——一定要测量哪种方法给你带来的损失最小,准确度最高!
让我们学习如何通过 PyTorch 的迁移学习来应用微调。打开项目目录结构中的fine_tune.py文件,让我们开始吧:
# USAGE
# python fine_tune.py
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from imutils import paths
from torchvision.models import resnet50
from torchvision import transforms
from tqdm import tqdm
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
import shutil
import torch
import time
import os
我们从第 5-17 行开始,导入我们需要的 Python 包。请注意,这些导入与我们之前的脚本基本上是相同的。
然后,我们定义我们的训练和验证转换,就像我们对特征提取所做的那样:
# define augmentation pipelines
trainTansform = transforms.Compose([
transforms.RandomResizedCrop(config.IMAGE_SIZE),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(90),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
valTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
对于我们的数据加载器来说也是如此——它们以与特征提取完全相同的方式进行实例化:
# create data loaders
(trainDS, trainLoader) = create_dataloaders.get_dataloader(config.TRAIN,
transforms=trainTansform, batchSize=config.FINETUNE_BATCH_SIZE)
(valDS, valLoader) = create_dataloaders.get_dataloader(config.VAL,
transforms=valTransform, batchSize=config.FINETUNE_BATCH_SIZE,
shuffle=False)
真正的变化发生在我们从磁盘加载 ResNet 并修改架构本身的时候,所以让我们仔细检查这一部分:
# load up the ResNet50 model
model = resnet50(pretrained=True)
numFeatures = model.fc.in_features
# loop over the modules of the model and set the parameters of
# batch normalization modules as not trainable
for module, param in zip(model.modules(), model.parameters()):
if isinstance(module, nn.BatchNorm2d):
param.requires_grad = False
# define the network head and attach it to the model
headModel = nn.Sequential(
nn.Linear(numFeatures, 512),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, len(trainDS.classes))
)
model.fc = headModel
# append a new classification top to our feature extractor and pop it
# on to the current device
model = model.to(config.DEVICE)
第 41 行从磁盘加载我们的 ResNet 模型,并在 ImageNet 数据集上预先训练权重。
在这个特定的微调示例中,我们将构建一个新的 FC 层头,然后同时训练FC 层头和网络主体。
*然而,我们首先需要密切关注网络架构中的批处理规范化层。这些图层具有特定的平均值和标准偏差值,这些值是最初在 ImageNet 数据集上训练网络时获得的。
我们不想在训练期间更新这些统计数据,所以我们在的第 46-48 行冻结了BatchNorm2d的任何实例。
如果您在使用批量标准化的网络中执行微调,请确保在开始训练 之前冻结这些层 !
从那里,我们构造了新的headModel,它由一系列 FC = > RELU = >退出层(第 51-59 行)组成。
最终Linear层的输出是数据集中类的数量(第 58 行)。
最后,我们将新的headModel添加到网络中,从而替换旧的 FC 层头。
注: 如果你想要更多关于迁移学习、特征提取、微调的细节,建议你阅读以下教程——用 Keras 迁移学习和深度学习; 微调与 Keras 和深度学习;以及 Keras:深度学习 大数据集上的特征提取。
完成“网络手术”后,我们可以继续实例化我们的损失函数和优化器:
# initialize loss function and optimizer (notice that we are only
# providing the parameters of the classification top to our optimizer)
lossFunc = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=config.LR)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // config.FINETUNE_BATCH_SIZE
valSteps = len(valDS) // config.FINETUNE_BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "train_acc": [], "val_loss": [],
"val_acc": []}
从那里,我们开始我们的培训渠道:
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.EPOCHS)):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (i, (x, y)) in enumerate(trainLoader):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFunc(pred, y)
# calculate the gradients
loss.backward()
# check if we are updating the model parameters and if so
# update them, and zero out the previously accumulated gradients
if (i + 2) % 2 == 0:
opt.step()
opt.zero_grad()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
在这一点上,微调我们模型的代码与特征提取方法的代码相同,所以您可以推迟到上一节来详细回顾代码。
培训完成后,我们可以进入新时代的验证阶段:
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (x, y) in valLoader:
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation loss
pred = model(x)
totalValLoss += lossFunc(pred, y)
# calculate the number of correct predictions
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(valDS)
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
验证完成后,我们绘制培训历史并将模型序列化到磁盘:
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.FINETUNE_PLOT)
# serialize the model to disk
torch.save(model, config.FINETUNE_MODEL)
执行完train_feature_extraction.py脚本后,您将在您的output目录中找到一个名为finetune_model.pth的训练模型。
您可以使用此模型和inference.py对新图像进行预测。
PyTorch 微调结果
现在让我们使用 PyTorch 进行微调。
同样,确保你有:
- 使用本教程的 【下载】 部分下载源代码、数据集等。
- 执行了
build_dataset.py脚本来创建我们的dataset目录
从那里,您可以执行以下命令:
$ python fine_tune.py
[INFO] training the network...
0% 0/20 [00:00<?, ?it/s][INFO] EPOCH: 1/20
Train loss: 0.857740, Train accuracy: 0.6809
Val loss: 2.498850, Val accuracy: 0.6512
5% 1/20 [00:18<05:55, 18.74s/it][INFO] EPOCH: 2/20
Train loss: 0.581107, Train accuracy: 0.7972
Val loss: 0.432770, Val accuracy: 0.8665
10% 2/20 [00:38<05:40, 18.91s/it][INFO] EPOCH: 3/20
Train loss: 0.506620, Train accuracy: 0.8289
Val loss: 0.721634, Val accuracy: 0.8011
15% 3/20 [00:57<05:26, 19.18s/it][INFO] EPOCH: 4/20
Train loss: 0.477470, Train accuracy: 0.8341
Val loss: 0.431005, Val accuracy: 0.8692
20% 4/20 [01:17<05:10, 19.38s/it][INFO] EPOCH: 5/20
Train loss: 0.467796, Train accuracy: 0.8368
Val loss: 0.746030, Val accuracy: 0.8120
25% 5/20 [01:37<04:53, 19.57s/it][INFO] EPOCH: 6/20
Train loss: 0.429070, Train accuracy: 0.8523
Val loss: 0.607376, Val accuracy: 0.8311
...
75% 15/20 [04:51<01:36, 19.33s/it][INFO] EPOCH: 16/20
Train loss: 0.317167, Train accuracy: 0.8880
Val loss: 0.344129, Val accuracy: 0.9183
80% 16/20 [05:11<01:17, 19.32s/it][INFO] EPOCH: 17/20
Train loss: 0.295942, Train accuracy: 0.9013
Val loss: 0.375650, Val accuracy: 0.8992
85% 17/20 [05:30<00:58, 19.38s/it][INFO] EPOCH: 18/20
Train loss: 0.282065, Train accuracy: 0.9046
Val loss: 0.374338, Val accuracy: 0.8992
90% 18/20 [05:49<00:38, 19.30s/it][INFO] EPOCH: 19/20
Train loss: 0.254787, Train accuracy: 0.9116
Val loss: 0.302762, Val accuracy: 0.9264
95% 19/20 [06:08<00:19, 19.25s/it][INFO] EPOCH: 20/20
Train loss: 0.270875, Train accuracy: 0.9083
Val loss: 0.385452, Val accuracy: 0.9019
100% 20/20 [06:28<00:00, 19.41s/it]
[INFO] total time taken to train the model: 388.23s
由于我们的模型更加复杂(由于向网络主体添加了新的 FC 层头),培训现在需要~6.5分钟。
然而,在图 4 中,我们获得了比我们的简单特征提取方法 更高的准确度(分别为 90.83%/90.19%对 84.26%/87.74%):
虽然执行微调确实需要更多的工作,但您通常会发现精确度更高,并且您的模型会更好地泛化。
实施我们的 PyTorch 预测脚本
到目前为止,您已经学习了使用 PyTorch 应用迁移学习的两种方法:
- 特征抽出
- 微调
这两种方法都使模型获得了 80-90%的准确性…
但是我们如何使用这些模型进行预测呢?
答案是使用我们的inference.py脚本:
# USAGE
# python inference.py --model output/warmup_model.pth
# python inference.py --model output/finetune_model.pth
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from torchvision import transforms
import matplotlib.pyplot as plt
from torch import nn
import argparse
import torch
我们从一些导入开始我们的inference.py脚本,包括:
config:我们的配置文件create_dataloaders:我们的助手实用程序从图像的输入目录(在本例中是我们的dataset/val目录)创建一个DataLoader对象transforms:按顺序应用数据预处理- 在屏幕上显示我们的输出图像和预测
torch和nn:我们的 PyTorch 绑定argparse:解析任何命令行参数
说到命令行参数,现在让我们来解析它们:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
args = vars(ap.parse_args())
这里我们只需要一个参数,--model,它是驻留在磁盘上的经过训练的 PyTorch 模型的路径。
现在让我们为输入图像创建一个变换对象:
# build our data pre-processing pipeline
testTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
# calculate the inverse mean and standard deviation
invMean = [-m/s for (m, s) in zip(config.MEAN, config.STD)]
invStd = [1/s for s in config.STD]
# define our de-normalization transform
deNormalize = transforms.Normalize(mean=invMean, std=invStd)
就像上一节中的验证转换器一样,我们在这里要做的就是:
- 将我们的输入图像调整到
IMAGE_SIZE尺寸 - 将图像转换为 PyTorch 张量
- 对输入图像应用平均缩放
然而,为了在屏幕上显示输出图像,我们实际上需要“反规格化”它们。第 28 和 29 行计算反均值和标准差,而第 32 行创建一个deNormalize变换。
使用deNormalize转换,我们将能够“撤销”testTransform,然后从我们的屏幕显示输出图像。
现在让我们为我们的config.VAL目录构建一个DataLoader:
# initialize our test dataset and data loader
print("[INFO] loading the dataset...")
(testDS, testLoader) = create_dataloaders.get_dataloader(config.VAL,
transforms=testTransform, batchSize=config.PRED_BATCH_SIZE,
shuffle=True)
从那里,我们可以设置我们的目标计算设备并加载我们训练过的 PyTorch 模型:
# check if we have a GPU available, if so, define the map location
# accordingly
if torch.cuda.is_available():
map_location = lambda storage, loc: storage.cuda()
# otherwise, we will be using CPU to run our model
else:
map_location = "cpu"
# load the model
print("[INFO] loading the model...")
model = torch.load(args["model"], map_location=map_location)
# move the model to the device and set it in evaluation mode
model.to(config.DEVICE)
model.eval()
第 40-47 行检查我们是否在使用我们的 CPU 或 GPU。
第 51-55 行继续:
- 从磁盘加载我们训练过的 PyTorch 模式
- 把它移到我们的目标
DEVICE - 将模型置于评估模式
现在让我们从testLoader中随机抽取一组测试数据:
# grab a batch of test data
batch = next(iter(testLoader))
(images, labels) = (batch[0], batch[1])
# initialize a figure
fig = plt.figure("Results", figsize=(10, 10))
最后,我们可以根据测试数据做出预测:
# switch off autograd
with torch.no_grad():
# send the images to the device
images = images.to(config.DEVICE)
# make the predictions
print("[INFO] performing inference...")
preds = model(images)
# loop over all the batch
for i in range(0, config.PRED_BATCH_SIZE):
# initalize a subplot
ax = plt.subplot(config.PRED_BATCH_SIZE, 1, i + 1)
# grab the image, de-normalize it, scale the raw pixel
# intensities to the range [0, 255], and change the channel
# ordering from channels first tp channels last
image = images[i]
image = deNormalize(image).cpu().numpy()
image = (image * 255).astype("uint8")
image = image.transpose((1, 2, 0))
# grab the ground truth label
idx = labels[i].cpu().numpy()
gtLabel = testDS.classes[idx]
# grab the predicted label
pred = preds[i].argmax().cpu().numpy()
predLabel = testDS.classes[pred]
# add the results and image to the plot
info = "Ground Truth: {}, Predicted: {}".format(gtLabel,
predLabel)
plt.imshow(image)
plt.title(info)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
线 65 关闭自动签名计算(将 PyTorch 模型置于评估模式时的要求),而线 67 将images发送到适当的DEVICE。
线 71 使用我们训练过的model对images进行预测。
为了可视化这些预测,我们首先需要在第 74 行的处对它们进行循环。在循环中,我们继续:
- 初始化一个子图来显示图像和预测(第 76 行
- 通过“撤销”平均缩放和交换颜色通道顺序来反规格化图像(第 81-84 行)
- 抓住地面实况标签(第 87 行和第 88 行)
- 抓取预测标签(行 91 和 92
- 将图像、地面实况和预测标签添加到绘图中(第 95-99 行)
然后输出的可视化显示在我们的屏幕上。
用我们训练过的 PyTorch 模型进行预测
现在让我们使用我们的inference.py脚本和我们训练过的 PyTorch 模型进行预测。
前往本教程的 “下载” 部分,访问源代码、数据集等。,从那里,您可以执行以下命令:
$ python inference.py --model output/finetune_model.pth
[INFO] loading the dataset...
[INFO] loading the model...
[INFO] performing inference...
你可以在图 5 中看到结果。
在这里,你可以看到我们已经正确地对我们的花图像进行了分类——最棒的是,由于迁移学习,我们能够以很小的努力获得如此高的准确度。
总结
在本教程中,您学习了如何使用 PyTorch 执行迁移学习。
具体来说,我们讨论了两种类型的迁移学习:
- 通过特征提取进行迁移学习
- 通过微调转移学习
第一种方法通常更容易实现,需要的精力也更少。然而,它往往不如第二种方法准确。
我通常建议使用特征提取方法来获得基线精度。如果精度足以满足您的应用,那就太棒了!您已经完成了,您可以继续构建项目的其余部分。
但是,如果精确度不够,那么您应该进行微调,看看是否可以提高精确度。
无论是哪种情况,迁移学习,无论是通过特征提取还是微调,都会为你节省大量的时间和精力,而不是从头开始训练你的模型。
引用信息
Rosebrock,a .“py torch:迁移学习和图像分类”, PyImageSearch ,2021,https://PyImageSearch . com/2021/10/11/py torch-Transfer-Learning-and-Image-class ification/
@article{Rosebrock_2021_Transfer,
author = {Adrian Rosebrock},
title = {{PyTorch}: Transfer Learning and Image Classification},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/10/11/pytorch-transfer-learning-and-image-classification/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****
使用 Keras、TensorFlow 和深度学习的 R-CNN 对象检测
原文:https://pyimagesearch.com/2020/07/13/r-cnn-object-detection-with-keras-tensorflow-and-deep-learning/
在本教程中,您将学习如何使用 Keras、TensorFlow 和深度学习来构建 R-CNN 对象检测器。
今天的教程是我们关于深度学习和物体检测的 4 部分系列的最后一部分:
- 第一部分: 用 Keras、TensorFlow、OpenCV 把任何 CNN 图像分类器变成物体检测器
- 第二部分: OpenCV 选择性搜索对象检测
- 第三部分: 用 OpenCV、Keras 和 TensorFlow 进行物体检测的区域建议
- 第四部分: 用 Keras 和 TensorFlow 进行 R-CNN 物体检测(今日教程)
上周,您学习了如何使用区域建议和选择性搜索来取代图像金字塔和滑动窗口的传统计算机视觉对象检测管道:
- 使用选择性搜索,我们生成了候选区域(称为“建议”),这些区域中的可能会包含一个感兴趣的对象。
- 这些提议被传递给预先训练好的 CNN,以获得实际的分类。
- 然后,我们通过应用置信度过滤和非极大值抑制来处理结果。
我们的方法运行得很好,但也带来了一些问题:
如果我们想在我们自己的定制数据集上训练一个对象检测网络会怎么样?
我们如何使用选择性搜索来训练网络?
使用选择性搜索将如何改变我们的物体检测推理脚本?
事实上,这些问题与 Girshick 等人在他们开创性的深度学习对象检测论文 中不得不考虑的问题相同,丰富的特征层次用于精确的对象检测和语义分割。
这些问题都将在今天的教程中得到回答——当你读完它时,你将拥有一个功能完整的 R-CNN,类似于 Girshick 等人实现的那个(但被简化了)!
要了解如何使用 Keras 和 TensorFlow 构建 R-CNN 对象检测器,继续阅读。
使用 Keras、TensorFlow 和深度学习的 R-CNN 对象检测
今天关于使用 Keras 和 TensorFlow 构建 R-CNN 对象检测器的教程是我们关于深度学习对象检测器系列中最长的教程。
我建议你相应地安排好你的时间——你可能需要 40 到 60 分钟来完整地阅读这篇教程。慢慢来,因为博文中有许多细节和细微差别(不要害怕阅读教程 2-3 遍,以确保你完全理解它)。
我们将从讨论使用 Keras 和 TensorFlow 实现 R-CNN 对象检测器所需的步骤开始我们的教程。
从那里,我们将回顾我们今天在这里使用的示例对象检测数据集。
接下来,我们将实现我们的配置文件以及一个助手实用函数,该函数用于通过 Union (IoU) 上的交集来计算对象检测精度。
然后,我们将通过应用选择性搜索来构建我们的对象检测数据集。
选择性搜索,以及一点后处理逻辑,将使我们能够识别输入图像中的区域,这些区域中包含而不包含潜在的感兴趣对象。
我们将这些区域用作我们的训练数据,微调 MobileNet(在 ImageNet 上预先训练)来分类和识别我们数据集中的对象。
最后,我们将实现一个 Python 脚本,通过对输入图像应用选择性搜索,对选择性搜索生成的区域建议进行分类,然后将输出的 R-CNN 对象检测结果显示到我们的屏幕上,该脚本可用于推断/预测。
我们开始吧!
使用 Keras 和 TensorFlow 实现 R-CNN 对象检测器的步骤
实现 R-CNN 对象检测器是一个有点复杂的多步骤过程。
如果您还没有,请确保您已经阅读了本系列之前的教程,以确保您已经掌握了适当的知识和先决条件:
- 用 Keras、TensorFlow、OpenCV 把任何 CNN 图像分类器变成物体检测器
- OpenCV 选择性搜索对象检测
- 使用 OpenCV、Keras 和 TensorFlow 进行对象检测的区域建议
我假设你对选择性搜索是如何工作的,如何在对象检测管道中使用区域建议,以及如何微调网络有一定的了解。
也就是说,下面你可以看到我们实施 R-CNN 目标检测器的 6 个步骤:
- 步骤#1: 使用选择性搜索建立对象检测数据集
- 步骤#2: 微调用于对象检测的分类网络(最初在 ImageNet 上训练)
- 步骤#3: 创建一个对象检测推理脚本,该脚本利用选择性搜索来建议可能包含我们想要检测的对象的区域
- 步骤#4: 使用我们的微调网络对通过选择性搜索提出的每个区域进行分类
- 步骤#5: 应用非最大值抑制来抑制弱的重叠边界框
- 步骤#6: 返回最终的物体检测结果
正如我前面已经提到的,本教程很复杂,涵盖了许多细微的细节。
因此,如果您需要反复查看以确保您理解我们的 R-CNN 对象检测实现,请不要对自己太苛刻。
*记住这一点,让我们继续审查我们的 R-CNN 项目结构。
我们的目标检测数据集
如图 2 所示,我们将训练一个 R-CNN 物体检测器来检测输入图像中的浣熊。
这个数据集包含 200 张图像和 217 只浣熊(一些图像包含不止一只浣熊)。
这个数据集最初是由受人尊敬的数据科学家 Dat Tran 策划的。
浣熊数据集的 GitHub 存储库可以在这里找到;然而,为了方便起见,我将数据集包含在与本教程相关的“下载”中。
如果您还没有,请确保使用这篇博客文章的 “下载” 部分来下载浣熊数据集和 Python 源代码,以便您能够完成本教程的其余部分。
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
如果您还没有,请使用 “下载” 部分来获取今天教程的代码和数据集。
在里面,您会发现以下内容:
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── no_raccoon [2200 entries]
│ └── raccoon [1560 entries]
├── images
│ ├── raccoon_01.jpg
│ ├── raccoon_02.jpg
│ └── raccoon_03.jpg
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ ├── iou.py
│ └── nms.py
├── raccoons
│ ├── annotations [200 entries]
│ └── images [200 entries]
├── build_dataset.py
├── detect_object_rcnn.py
├── fine_tune_rcnn.py
├── label_encoder.pickle
├── plot.png
└── raccoon_detector.h5
8 directories, 13 files
实现我们的对象检测配置文件
在我们深入项目之前,让我们首先实现一个存储关键常量和设置的配置文件,我们将在多个 Python 脚本中使用它。
打开pyimagesearch模块中的config.py文件,插入以下代码:
# import the necessary packages
import os
# define the base path to the *original* input dataset and then use
# the base path to derive the image and annotations directories
ORIG_BASE_PATH = "raccoons"
ORIG_IMAGES = os.path.sep.join([ORIG_BASE_PATH, "images"])
ORIG_ANNOTS = os.path.sep.join([ORIG_BASE_PATH, "annotations"])
我们首先在第行的第 6-8 行定义到原始浣熊数据集图像和对象检测注释(即,边界框信息)的路径。
接下来,我们定义即将构建的数据集的路径:
# define the base path to the *new* dataset after running our dataset
# builder scripts and then use the base path to derive the paths to
# our output class label directories
BASE_PATH = "dataset"
POSITVE_PATH = os.path.sep.join([BASE_PATH, "raccoon"])
NEGATIVE_PATH = os.path.sep.join([BASE_PATH, "no_raccoon"])
# define the number of max proposals used when running selective
# search for (1) gathering training data and (2) performing inference
MAX_PROPOSALS = 2000
MAX_PROPOSALS_INFER = 200
然后设置构建数据集时要使用的正负区域的最大数量:
# define the maximum number of positive and negative images to be
# generated from each image
MAX_POSITIVE = 30
MAX_NEGATIVE = 10
最后,我们总结了特定于模型的常数:
# initialize the input dimensions to the network
INPUT_DIMS = (224, 224)
# define the path to the output model and label binarizer
MODEL_PATH = "raccoon_detector.h5"
ENCODER_PATH = "label_encoder.pickle"
# define the minimum probability required for a positive prediction
# (used to filter out false-positive predictions)
MIN_PROBA = 0.99
第 28 行为我们的分类网络(MobileNet,在 ImageNet 上预先训练)设置输入空间维度。
然后我们定义输出文件路径到我们的浣熊分类器和标签编码器(第 31 和 32 行)。
在推断过程中(用于滤除假阳性检测)阳性预测所需的最小概率在第 36 行上设置为 99%。
用并集交集(IoU)测量目标检测精度
为了衡量我们的对象检测器在预测边界框方面做得有多好,我们将使用并集上的交集(IoU)度量。
IoU 方法计算预测边界框和地面实况边界框之间重叠面积与联合面积的比率:
检查这个等式,可以看到交集除以并集就是一个简单的比率:
- 在分子中,我们计算预测边界框和真实边界框之间的重叠区域的。
- 分母是并集的区域,或者更简单地说,是由预测边界框和真实边界框包围的区域。
- 将重叠的面积除以并集的面积得到我们的最终分数—上的交集(因此得名)。
*我们将使用 IoU 来衡量对象检测的准确性,包括给定的选择性搜索建议与真实边界框的重叠程度(这在我们为训练数据生成正面和负面示例时非常有用)。
如果你有兴趣了解更多关于 IoU 的知识,一定要参考我的教程, 交集超过并集(IoU)用于对象检测。
否则,现在让我们简要回顾一下我们的 IoU 实现——打开pyimagesearch目录中的iou.py文件,并插入以下代码:
def compute_iou(boxA, boxB):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# compute the area of intersection rectangle
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# compute the area of both the prediction and ground-truth
# rectangles
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the intersection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
comptue_iou函数接受两个参数boxA和boxB,这两个参数是我们试图计算联合交集(IoU)的基础事实和预测边界框。就我们的计算而言,参数的顺序并不重要。
在里面,我们开始计算右上角和左下角的 (x,y)——边界框的坐标(第 3-6 行)。
使用边界框坐标,我们计算边界框的交集(重叠区域)(行 9 )。这个值是 IoU 公式的分子。
为了确定分母,我们需要导出预测边界框和真实边界框的面积(第 13 行和第 14 行)。
然后通过将交集面积(分子)除以两个边界框的并集面积(分母),小心减去交集面积(否则交集面积将被加倍计算),可以在行 19 上计算交集。
第 22 行返回 IoU 结果。
实现我们的对象检测数据集构建器脚本
在我们可以创建我们的 R-CNN 对象检测器之前,我们首先需要构建我们的数据集,完成我们今天教程的六个步骤列表中的步骤#1 。
我们的 build_dataset.py 剧本将:
- 1.接受我们的输入
raccoons数据集 - 2.遍历数据集中的所有图像
- 2a。加载给定的输入图像
- 2b。加载并解析输入图像中任何浣熊的边界框坐标
- 3.对输入图像运行选择性搜索
- 4.使用 IoU 来确定选择性搜索的哪些区域提议与地面实况边界框充分重叠,哪些没有
- 5.将区域建议保存为重叠(包含浣熊)或不重叠(不包含浣熊)
一旦我们的数据集建立起来,我们将能够进行步骤# 2——微调一个对象检测网络。
现在,我们已经在较高的层次上理解了数据集构建器,让我们来实现它。打开build_dataset.py文件,按照以下步骤操作:
# import the necessary packages
from pyimagesearch.iou import compute_iou
from pyimagesearch import config
from bs4 import BeautifulSoup
from imutils import paths
import cv2
import os
除了我们的 IoU 和配置设置(行 2 和 3 ),这个脚本还需要 Beautifulsoup 、 imutils 和 OpenCV 。如果您遵循了上面的“配置您的开发环境”一节,那么您的系统已经拥有了所有这些工具。
现在我们的导入已经完成,让我们创建两个空目录并构建一个包含所有浣熊图像的列表:
# loop over the output positive and negative directories
for dirPath in (config.POSITVE_PATH, config.NEGATIVE_PATH):
# if the output directory does not exist yet, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
# grab all image paths in the input images directory
imagePaths = list(paths.list_images(config.ORIG_IMAGES))
# initialize the total number of positive and negative images we have
# saved to disk so far
totalPositive = 0
totalNegative = 0
我们的正面和负面目录将很快包含我们的浣熊或无浣熊图像。第 10-13 行创建这些目录,如果它们还不存在的话。
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# show a progress report
print("[INFO] processing image {}/{}...".format(i + 1,
len(imagePaths)))
# extract the filename from the file path and use it to derive
# the path to the XML annotation file
filename = imagePath.split(os.path.sep)[-1]
filename = filename[:filename.rfind(".")]
annotPath = os.path.sep.join([config.ORIG_ANNOTS,
"{}.xml".format(filename)])
# load the annotation file, build the soup, and initialize our
# list of ground-truth bounding boxes
contents = open(annotPath).read()
soup = BeautifulSoup(contents, "html.parser")
gtBoxes = []
# extract the image dimensions
w = int(soup.find("width").string)
h = int(soup.find("height").string)
# loop over all 'object' elements
for o in soup.find_all("object"):
# extract the label and bounding box coordinates
label = o.find("name").string
xMin = int(o.find("xmin").string)
yMin = int(o.find("ymin").string)
xMax = int(o.find("xmax").string)
yMax = int(o.find("ymax").string)
# truncate any bounding box coordinates that may fall
# outside the boundaries of the image
xMin = max(0, xMin)
yMin = max(0, yMin)
xMax = min(w, xMax)
yMax = min(h, yMax)
# update our list of ground-truth bounding boxes
gtBoxes.append((xMin, yMin, xMax, yMax))
# load the input image from disk
image = cv2.imread(imagePath)
# run selective search on the image and initialize our list of
# proposed boxes
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(image)
ss.switchToSelectiveSearchFast()
rects = ss.process()
proposedRects= []
# loop over the rectangles generated by selective search
for (x, y, w, h) in rects:
# convert our bounding boxes from (x, y, w, h) to (startX,
# startY, startX, endY)
proposedRects.append((x, y, x + w, y + h))
# initialize counters used to count the number of positive and
# negative ROIs saved thus far
positiveROIs = 0
negativeROIs = 0
# loop over the maximum number of region proposals
for proposedRect in proposedRects[:config.MAX_PROPOSALS]:
# unpack the proposed rectangle bounding box
(propStartX, propStartY, propEndX, propEndY) = proposedRect
# loop over the ground-truth bounding boxes
for gtBox in gtBoxes:
# compute the intersection over union between the two
# boxes and unpack the ground-truth bounding box
iou = compute_iou(gtBox, proposedRect)
(gtStartX, gtStartY, gtEndX, gtEndY) = gtBox
# initialize the ROI and output path
roi = None
outputPath = None
我们在行 84 和 85 上初始化这两个计数器。
从第行第 88 开始,我们循环通过选择性搜索生成的区域建议(直到我们定义的最大建议数)。在内部,我们:
# check to see if the IOU is greater than 70% *and* that
# we have not hit our positive count limit
if iou > 0.7 and positiveROIs <= config.MAX_POSITIVE:
# extract the ROI and then derive the output path to
# the positive instance
roi = image[propStartY:propEndY, propStartX:propEndX]
filename = "{}.png".format(totalPositive)
outputPath = os.path.sep.join([config.POSITVE_PATH,
filename])
# increment the positive counters
positiveROIs += 1
totalPositive += 1
假设这个特定区域通过了检查,以查看我们是否有 IoU > 70% 和我们还没有达到当前图像的正面例子的极限(行 105 ,我们简单地:
# determine if the proposed bounding box falls *within*
# the ground-truth bounding box
fullOverlap = propStartX >= gtStartX
fullOverlap = fullOverlap and propStartY >= gtStartY
fullOverlap = fullOverlap and propEndX <= gtEndX
fullOverlap = fullOverlap and propEndY <= gtEndY
# check to see if there is not full overlap *and* the IoU
# is less than 5% *and* we have not hit our negative
# count limit
if not fullOverlap and iou < 0.05 and \
negativeROIs <= config.MAX_NEGATIVE:
# extract the ROI and then derive the output path to
# the negative instance
roi = image[propStartY:propEndY, propStartX:propEndX]
filename = "{}.png".format(totalNegative)
outputPath = os.path.sep.join([config.NEGATIVE_PATH,
filename])
# increment the negative counters
negativeROIs += 1
totalNegative += 1
在这里,我们的条件(第 127 行和第 128 行)检查是否满足以下所有条件:
- 有没有完全重叠
- 欠条足够小
- 没有超过我们对当前图像的反面例子数量的限制
# check to see if both the ROI and output path are valid
if roi is not None and outputPath is not None:
# resize the ROI to the input dimensions of the CNN
# that we'll be fine-tuning, then write the ROI to
# disk
roi = cv2.resize(roi, config.INPUT_DIMS,
interpolation=cv2.INTER_CUBIC)
cv2.imwrite(outputPath, roi)
准备用于对象检测的图像数据集
我们现在准备为 R-CNN 对象检测构建我们的图像数据集。
如果您还没有,请使用本教程的 “下载” 部分下载源代码和示例图像数据集。
从那里,打开一个终端,并执行以下命令:
$ time python build_dataset.py
[INFO] processing image 1/200...
[INFO] processing image 2/200...
[INFO] processing image 3/200...
...
[INFO] processing image 198/200...
[INFO] processing image 199/200...
[INFO] processing image 200/200...
real 5m42.453s
user 6m50.769s
sys 1m23.245s
$ ls -l dataset/raccoon/*.png | wc -l
1560
$ ls -l dataset/no_raccoon/*.png | wc -l
2200
下面是这两个类的示例:
从图 6 (左) 可以看出,“无浣熊”类具有通过选择性搜索生成的样本图像块,这些样本图像块没有与任何浣熊地面真实边界框明显重叠。
然后,在图 6 (右) 上,我们有了我们的“浣熊”级图像。
您会注意到,这些图像中的一些彼此相似,在某些情况下几乎是重复的——这实际上是预期的行为。
请记住,选择性搜索试图识别图像中可能包含潜在对象的区域。
因此,选择性搜索在相似区域多次发射是完全可行的。
您可以选择保留这些区域(如我所做的那样),或者添加额外的逻辑来过滤掉明显重叠的区域(我将这作为一个练习留给您)。
使用 Keras 和 TensorFlow 微调对象检测网络
有了通过前面两个部分(步骤#1 )创建的数据集,我们现在准备好微调分类 CNN 来识别这两个类(步骤#2 )。
当我们将这个分类器与选择性搜索相结合时,我们将能够构建我们的 R-CNN 对象检测器。
出于本教程的目的,我选择了 微调MobileNet V2 CNN,它是在 1000 级 ImageNet 数据集上预先训练的。如果您不熟悉迁移学习和微调的概念,我建议您仔细阅读:
- 使用 Keras 的迁移学习和深度学习 (确保至少从头至尾阅读“两种类型的迁移学习:特征提取和微调”部分)
- 【Keras 微调】深度学习 (我强烈推荐完整阅读本教程)
# import the necessary packages
from pyimagesearch import config
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import pickle
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
# initialize the initial learning rate, number of epochs to train for,
# and batch size
INIT_LR = 1e-4
EPOCHS = 5
BS = 32
--plot 命令行参数定义了我们的精度/损失图的路径(第 27-30 行)。
然后,我们建立训练超参数,包括我们的初始学习率、训练时期数和批量大小(第 34-36 行)。
加载我们的数据集很简单,因为我们已经在步骤#1 中完成了所有的艰苦工作:
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class labels
print("[INFO] loading images...")
imagePaths = list(paths.list_images(config.BASE_PATH))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the input image (224x224) and preprocess it
image = load_img(imagePath, target_size=config.INPUT_DIMS)
image = img_to_array(image)
image = preprocess_input(image)
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator(
rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# load the MobileNetV2 network, ensuring the head FC layer sets are
# left off
baseModel = MobileNetV2(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers:
layer.trainable = False
# compile our model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
H = model.fit(
aug.flow(trainX, trainY, batch_size=BS),
steps_per_epoch=len(trainX) // BS,
validation_data=(testX, testY),
validation_steps=len(testX) // BS,
epochs=EPOCHS)
# make predictions on the testing set
print("[INFO] evaluating network...")
predIdxs = model.predict(testX, batch_size=BS)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testY.argmax(axis=1), predIdxs,
target_names=lb.classes_))
# serialize the model to disk
print("[INFO] saving mask detector model...")
model.save(config.MODEL_PATH, save_format="h5")
# serialize the label encoder to disk
print("[INFO] saving label encoder...")
f = open(config.ENCODER_PATH, "wb")
f.write(pickle.dumps(lb))
f.close()
# plot the training loss and accuracy
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
使用 matplotlib,我们绘制精度和损耗曲线以供检查(第 144-154 行)。我们将得到的图形导出到包含在--plot命令行参数中的路径。
用 Keras 和 TensorFlow 训练我们的 R-CNN 目标检测网络
我们现在准备微调我们的手机,这样我们就可以创建一个 R-CNN 对象检测器!
如果您还没有,请到本教程的 “下载” 部分下载源代码和样本数据集。
从那里,打开一个终端,并执行以下命令:
$ time python fine_tune_rcnn.py
[INFO] loading images...
[INFO] compiling model...
[INFO] training head...
Train for 94 steps, validate on 752 samples
Train for 94 steps, validate on 752 samples
Epoch 1/5
94/94 [==============================] - 77s 817ms/step - loss: 0.3072 - accuracy: 0.8647 - val_loss: 0.1015 - val_accuracy: 0.9728
Epoch 2/5
94/94 [==============================] - 74s 789ms/step - loss: 0.1083 - accuracy: 0.9641 - val_loss: 0.0534 - val_accuracy: 0.9837
Epoch 3/5
94/94 [==============================] - 71s 756ms/step - loss: 0.0774 - accuracy: 0.9784 - val_loss: 0.0433 - val_accuracy: 0.9864
Epoch 4/5
94/94 [==============================] - 74s 784ms/step - loss: 0.0624 - accuracy: 0.9781 - val_loss: 0.0367 - val_accuracy: 0.9878
Epoch 5/5
94/94 [==============================] - 74s 791ms/step - loss: 0.0590 - accuracy: 0.9801 - val_loss: 0.0340 - val_accuracy: 0.9891
[INFO] evaluating network...
precision recall f1-score support
no_raccoon 1.00 0.98 0.99 440
raccoon 0.97 1.00 0.99 312
accuracy 0.99 752
macro avg 0.99 0.99 0.99 752
weighted avg 0.99 0.99 0.99 752
[INFO] saving mask detector model...
[INFO] saving label encoder...
real 6m37.851s
user 31m43.701s
sys 33m53.058s
在我的 3Ghz 英特尔至强 W 处理器上微调 MobileNet 花费了大约 6m30 秒,正如您所看到的,我们获得了大约 99%的准确率。
正如我们的训练图所示,几乎没有过度拟合的迹象:
随着我们的 MobileNet 模型针对浣熊预测进行了微调,我们已经准备好将所有的部分放在一起,并创建我们的 R-CNN 对象检测管道!
将碎片放在一起:实现我们的 R-CNN 对象检测推理脚本
到目前为止,我们已经完成了:
- 步骤#1: 使用选择性搜索建立对象检测数据集
- 步骤#2: 微调用于对象检测的分类网络(最初在 ImageNet 上训练)
在这一点上,我们将把我们训练好的模型用于在新图像上执行对象检测推断。
完成我们的对象检测推理脚本需要步骤# 3–步骤#6 。现在让我们回顾一下这些步骤:
- 步骤#3: 创建一个对象检测推理脚本,该脚本利用选择性搜索来建议可能包含我们想要检测的对象的区域
- 步骤#4: 使用我们的微调网络对通过选择性搜索提出的每个区域进行分类
- 步骤#5: 应用非最大值抑制来抑制弱的重叠边界框
- 步骤#6: 返回最终的物体检测结果
我们将进一步执行步骤#6 并显示结果,这样我们就可以直观地验证我们的系统正在工作。
现在让我们实现 R-CNN 对象检测管道—打开一个新文件,将其命名为detect_object_rcnn.py,并插入以下代码:
# import the necessary packages
from pyimagesearch.nms import non_max_suppression
from pyimagesearch import config
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the our fine-tuned model and label binarizer from disk
print("[INFO] loading model and label binarizer...")
model = load_model(config.MODEL_PATH)
lb = pickle.loads(open(config.ENCODER_PATH, "rb").read())
# load the input image from disk
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
# run selective search on the image to generate bounding box proposal
# regions
print("[INFO] running selective search...")
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(image)
ss.switchToSelectiveSearchFast()
rects = ss.process()
# initialize the list of region proposals that we'll be classifying
# along with their associated bounding boxes
proposals = []
boxes = []
# loop over the region proposal bounding box coordinates generated by
# running selective search
for (x, y, w, h) in rects[:config.MAX_PROPOSALS_INFER]:
# extract the region from the input image, convert it from BGR to
# RGB channel ordering, and then resize it to the required input
# dimensions of our trained CNN
roi = image[y:y + h, x:x + w]
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
roi = cv2.resize(roi, config.INPUT_DIMS,
interpolation=cv2.INTER_CUBIC)
# further preprocess the ROI
roi = img_to_array(roi)
roi = preprocess_input(roi)
# update our proposals and bounding boxes lists
proposals.append(roi)
boxes.append((x, y, x + w, y + h))
# convert the proposals and bounding boxes into NumPy arrays
proposals = np.array(proposals, dtype="float32")
boxes = np.array(boxes, dtype="int32")
print("[INFO] proposal shape: {}".format(proposals.shape))
# classify each of the proposal ROIs using fine-tuned model
print("[INFO] classifying proposals...")
proba = model.predict(proposals)
# find the index of all predictions that are positive for the
# "raccoon" class
print("[INFO] applying NMS...")
labels = lb.classes_[np.argmax(proba, axis=1)]
idxs = np.where(labels == "raccoon")[0]
# use the indexes to extract all bounding boxes and associated class
# label probabilities associated with the "raccoon" class
boxes = boxes[idxs]
proba = proba[idxs][:, 1]
# further filter indexes by enforcing a minimum prediction
# probability be met
idxs = np.where(proba >= config.MIN_PROBA)
boxes = boxes[idxs]
proba = proba[idxs]
# clone the original image so that we can draw on it
clone = image.copy()
# loop over the bounding boxes and associated probabilities
for (box, prob) in zip(boxes, proba):
# draw the bounding box, label, and probability on the image
(startX, startY, endX, endY) = box
cv2.rectangle(clone, (startX, startY), (endX, endY),
(0, 255, 0), 2)
y = startY - 10 if startY - 10 > 10 else startY + 10
text= "Raccoon: {:.2f}%".format(prob * 100)
cv2.putText(clone, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
# show the output after *before* running NMS
cv2.imshow("Before NMS", clone)
从那里,我们在 NMS 可视化(线 101 )之前显示。
让我们应用 NMS,看看结果如何比较:
# run non-maxima suppression on the bounding boxes
boxIdxs = non_max_suppression(boxes, proba)
# loop over the bounding box indexes
for i in boxIdxs:
# draw the bounding box, label, and probability on the image
(startX, startY, endX, endY) = boxes[i]
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 255, 0), 2)
y = startY - 10 if startY - 10 > 10 else startY + 10
text= "Raccoon: {:.2f}%".format(proba[i] * 100)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
# show the output image *after* running NMS
cv2.imshow("After NMS", image)
cv2.waitKey(0)
我们通过线 104,应用非最大值抑制(NMS ),有效地消除对象周围的重叠矩形。
从那里,行 107-119 绘制边界框、标签和概率,并在 NMS 结果后显示,直到按下一个键。
使用 TensorFlow/Keras、OpenCV 和 Python 实现您的基本 R-CNN 对象检测脚本非常棒。
使用 Keras 和 TensorFlow 的 R-CNN 物体检测结果
至此,我们已经使用 Keras、TensorFlow 和 OpenCV 完全实现了一个基本的 R-CNN 对象检测管道。
你准备好看它的行动了吗?
首先使用本教程的 “下载” 部分下载源代码、示例数据集和预训练的 R-CNN 检测器。
从那里,您可以执行以下命令:
$ python detect_object_rcnn.py --image images/raccoon_01.jpg
[INFO] loading model and label binarizer...
[INFO] running selective search...
[INFO] proposal shape: (200, 224, 224, 3)
[INFO] classifying proposals...
[INFO] applying NMS...
在这里,您可以看到在应用我们的 R-CNN 对象检测器后发现了两个浣熊包围盒:
通过应用非最大值抑制,我们可以抑制较弱的一个,留下一个正确的边界框:
让我们尝试另一个图像:
$ python detect_object_rcnn.py --image images/raccoon_02.jpg
[INFO] loading model and label binarizer...
[INFO] running selective search...
[INFO] proposal shape: (200, 224, 224, 3)
[INFO] classifying proposals...
[INFO] applying NMS...
同样,这里我们有两个边界框:
对我们的 R-CNN 对象检测输出应用非最大值抑制留给我们最终的对象检测:
让我们看最后一个例子:
$ python detect_object_rcnn.py --image images/raccoon_03.jpg
[INFO] loading model and label binarizer...
[INFO] running selective search...
[INFO] proposal shape: (200, 224, 224, 3)
[INFO] classifying proposals...
[INFO] applying NMS...
如您所见,只检测到一个边界框,因此 NMS 之前/之后的输出是相同的。
现在你知道了,构建一个简单的 R-CNN 物体探测器并不像看起来那么难!
我们能够使用 Keras、TensorFlow 和 OpenCV 在仅 427 行代码、包括评论中构建一个简化的 R-CNN 对象检测管道!
我希望当您开始构建自己的基本对象检测器时,可以使用这个管道。
总结
在本教程中,您学习了如何使用 Keras、TensorFlow 和深度学习实现基本的 R-CNN 对象检测器。
我们的 R-CNN 对象检测器是 Girshick 等人在他们开创性的对象检测论文 的初始实验中可能已经创建的内容的精简、基本版本,丰富的特征层次用于精确的对象检测和语义分割。
我们实施的 R-CNN 对象检测管道是一个 6 步流程,包括:
- 步骤#1: 使用选择性搜索建立对象检测数据集
- 步骤#2: 微调用于对象检测的分类网络(最初在 ImageNet 上训练)
- 步骤#3: 创建对象检测推理脚本,该脚本利用选择性搜索来建议可能包含我们想要检测的对象的区域
- 步骤#4: 使用我们的微调网络对通过选择性搜索提出的每个区域进行分类
- 步骤#5: 应用非最大值抑制来抑制弱的重叠边界框
- 步骤#6: 返回最终的物体检测结果
总的来说,我们的 R-CNN 物体检测器表现相当不错!
我希望您可以使用这个实现作为您自己的对象检测项目的起点。
如果你想了解更多关于实现自己的定制深度学习对象检测器的信息,请务必参考我的书, 使用 Python 进行计算机视觉的深度学习 ,我在其中详细介绍了对象检测。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
Raspberry Pi 和 Movidius NCS 人脸识别
原文:https://pyimagesearch.com/2020/01/06/raspberry-pi-and-movidius-ncs-face-recognition/

在本教程中,您将学习如何使用 Movidius NCS 将 Raspberry Pi 上的人脸检测和人脸识别速度提高 243%以上!
如果你曾经试图在树莓派上执行基于深度学习的人脸识别,你可能会注意到明显的滞后。
是人脸检测还是人脸识别模型本身有问题?
不,绝对不行。
问题是你的 Raspberry Pi CPU 处理帧的速度不够快。你需要更强的计算能力。
正如本教程的标题所示,我们将把我们的 Raspberry Pi 与英特尔 Movidius 神经计算棒协处理器配对。NCS Myriad 处理器将处理要求更高的人脸检测,而 RPi CPU 将处理提取人脸嵌入。RPi CPU 处理器还将使用来自面部嵌入的结果来处理最终的机器学习分类。
将最昂贵的深度学习任务卸载到 Movidius NCS 的过程释放了 Raspberry Pi CPU 来处理其他任务。然后每个处理器处理适当的负载。我们当然正在将我们的 Raspberry Pi 推向极限,但除了使用完全不同的单板计算机(如 NVIDIA Jetson Nano)之外,我们没有太多选择。
到本教程结束时,你将拥有一个运行速度为 6.29FPS 的全功能人脸识别脚本,运行在 RPi 和 Movidius NCS 上,与只使用 RPi 相比, 243%的加速比!
注:本教程包括转贴自我的新计算机视觉书《树莓派》的内容(黑客包第 14 章)。您可以了解更多信息,并在这里领取您的副本。
要了解如何使用 Raspberry Pi 和 Movidius 神经计算棒进行人脸识别,继续阅读!
Raspberry Pi 和 Movidius NCS 人脸识别
在本教程中,我们将学习如何使用 Movidius NCS 进行人脸识别。
首先,你需要了解使用深度度量学习的深度学习人脸识别,以及如何创建人脸识别数据集。不理解这两个概念,你可能会在阅读本教程时感到迷失。
在阅读本教程之前,您应该阅读以下任何:
1. 人脸识别用 OpenCV,Python,还有深度学习 ,我第一篇关于深度学习人脸识别的博文。
2. OpenCV 人脸识别 ,我的第二篇关于使用 OpenCV 自带的模型进行深度学习人脸识别的博文。这篇文章还包括一个标题为“缺点,限制,以及如何获得更高的人脸识别准确率”的部分,我强烈推荐阅读。
3. 计算机视觉的树莓的《树莓上的人脸识别》(黑客捆绑*第五章)。
此外,您必须阅读以下:
1. 如何构建自定义人脸识别数据集 ,一个解释三种方法构建你的人脸识别数据集的教程。
2. 计算机视觉的树莓派的《第一步:收集你的数据集》(黑客捆绑包*第 5 章 5.4.2 节)、
成功阅读并理解这些资源后,您将为 Raspberry Pi 和 Movidius NCS 人脸识别做好准备。
在本教程的剩余部分,我们将开始用 OpenVINO 设置我们的 Raspberry Pi,包括安装必要的软件。
从那里,我们将回顾我们的项目结构,确保我们熟悉今天的可下载 zip 的布局。
然后我们将回顾为 NCS 提取嵌入的过程。我们将在嵌入数据的基础上训练一个机器学习模型。
最后,我们将开发一个快速演示脚本,以确保我们的脸被正确识别。
让我们开始吧。
配置您的 Raspberry Pi + OpenVINO 环境
Figure 1: Configuring OpenVINO on your Raspberry Pi for face recognition with the Movidius NCS.
本教程需要一个树莓 Pi (推荐 3B+或 4B)和 Movidius NCS2 (或更高版本,一旦将来发布更快的版本)。较低的树莓 Pi 和 NCS 型号可能很难跟上。另一个选择是使用功能强大的笔记本电脑/台式机,而不使用 OpenVINO。
在这个项目中,为您的 Raspberry Pi 配置英特尔 Movidius NCS 无疑具有挑战性。
建议你(1)拿一个 的副本给计算机视觉 ,还有(2)把预先配置好的 收录闪存。img 到你的 microSD。的。这本书附带的 img 是物有所值的,因为它会节省你无数个小时的辛苦和挫折。
对于那些固执的想要自己配置他们的 Raspberry Pi + OpenVINO 的人来说,这里有一个简单的指南:
- 前往我的 BusterOS 安装指南 并按照所有指示创建一个名为
cv的环境。推荐使用 Raspberry Pi 4B 型号(1GB、2GB 或 4GB)。 - 前往我的 OpenVINO 安装指南 并创建第二个名为
openvino的环境。一定要用 OpenVINO 4.1.1,因为 4.1.2 有问题。
在这一点上,你的 RPi 将有和一个普通的 OpenCV 环境以及一个 OpenVINO-OpenCV 环境。在本教程中,您将使用openvino环境。
现在,只需将 NCS2 插入蓝色 USB 3.0 端口(RPi 4B 具有 USB 3.0 以获得最高速度),并使用以下任一方法启动您的环境:
选项 A: 在我的 预配置的 Raspbian 上使用 shell 脚本。img (在我的 OpenVINO 安装指南的“推荐:创建一个用于启动您的 OpenVINO 环境的 shell 脚本”部分中描述了相同的 shell 脚本)。
从现在开始,您可以用一个简单的命令来激活您的 OpenVINO 环境(与上一步中的两个命令相反:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
选项 B: 一二冲法。
打开终端并执行以下操作:
$ workon openvino
$ source ~/openvino/bin/setupvars.sh
第一个命令激活我们的 OpenVINO 虚拟环境。第二个命令用 OpenVINO 设置 Movidius NCS(非常重要)。从那里,我们在环境中启动 Python 3 二进制文件并导入 OpenCV。
选项 A 和选项 B 都假设你要么使用我的 预配置的 Raspbian。img 或者说你按照我的 OpenVINO 安装指南自己用你的树莓 Pi 安装了 OpenVINO。
注意事项:
- 某些版本的 OpenVINO 很难读取. mp4 视频。这是 PyImageSearch 已经向英特尔团队报告的一个已知 bug。我们的已预先配置。img 包括一个修复——Abhishek Thanki 编辑了源代码,并从源代码编译了 OpenVINO。这篇博文已经够长了,所以我不能包含从源代码编译的说明。如果您遇到这个问题,请鼓励英特尔解决这个问题,或者(A) 使用我们的客户门户说明从源代码编译,或者(B)拿一份Raspberry Pi for Computer Vision并使用预配置的. img
- 如果我们发现其他注意事项,我们会添加到此列表中。
项目结构
去拿今天的。从这篇博文的 【下载】 部分解压文件。
我们的项目按以下方式组织:
|-- dataset
| |-- abhishek
| |-- adrian
| |-- dave
| |-- mcCartney
| |-- sayak
| |-- unknown
|-- face_detection_model
| |-- deploy.prototxt
| |-- res10_300x300_ssd_iter_140000.caffemodel
|-- face_embedding_model
| |-- openface_nn4.small2.v1.t7
|-- output
| |-- embeddings.pickle
| |-- le.pickle
| |-- recognizer.pickle
|-- setupvars.sh
|-- extract_embeddings.py
|-- train_model.py
|-- recognize_video.py
包括一个 5 人dataset/的例子。每个子目录包含相应人的 20 个图像。
我们的人脸检测器将检测/定位待识别图像中的人脸。预训练的 Caffe 人脸检测器文件(由 OpenCV 提供)包含在face_detection_model/目录中。请务必参考这篇深度学习人脸检测博文,以了解更多关于检测器的信息以及如何将其投入使用。
我们将使用包含在face_embedding_model/目录中的预训练的 OpenFace PyTorch 模型来提取人脸嵌入。作为 OpenFace 项目的一部分,卡耐基梅隆大学的团队对openface_nn4.small2.v1.t7文件进行了训练。
当我们执行extract_embeddings.py时,会生成两个 pickle 文件。如果您选择的话,embeddings.pickle和le.pickle都将存储在output/目录中。嵌入由数据集中每个人脸的 128 维向量组成。
然后,我们将通过执行train_model.py脚本,在嵌入的基础上训练一个支持向量机(SVM)机器学习模型。训练我们 SVM 的结果将被序列化到output/目录中的recognizer.pickle。
注意:如果您选择使用您自己的数据集(而不是我在下载中提供的数据集),您应该删除output/目录中包含的文件,并生成与您自己的人脸数据集相关联的新文件。
recognize_video.py脚本只需激活您的相机,并在每一帧中检测+识别人脸。
我们的环境设置脚本
除非设置了额外的系统环境变量OPENCV_DNN_IE_VPU_TYPE,否则我们的 Movidius 人脸识别系统将无法正常工作。
除了启动虚拟环境的之外,一定要设置这个环境变量。
这可能会在 OpenVINO 的未来版本中有所改变,但是目前,与本教程相关的项目中提供了一个 shell 脚本。
打开setup.sh并检查脚本:
#!/bin/sh
export OPENCV_DNN_IE_VPU_TYPE=Myriad2
第一行的上的“shebang”(#!)表示这个脚本是可执行的。
第 3 行使用export命令设置环境变量。当然,您可以在终端中手动键入命令,但是这个 shell 脚本让您不必记住变量名和设置。
让我们继续执行 shell 脚本:
$ source setup.sh
假设您已经执行了这个脚本,那么您应该不会在项目的其余部分看到任何奇怪的与 OpenVINO 相关的错误。
如果您在下一部分遇到以下错误信息,请务必执行setup.sh:
Traceback (most recent call last):
File "extract_embeddings.py", line 108 in
cv2.error: OpenCV(4.1.1-openvino) /home/jenkins/workspace/OpenCV/
OpenVINO/build/opencv/modules/dnn/src/op*inf*engine.cpp:477
error: (-215:Assertion failed) Failed to initialize Inference Engine
backend: Can not init Myriad device: NC_ERROR in function 'initPlugin'
利用 Movidius NCS 提取人脸嵌入
Figure 2: Raspberry Pi facial recognition with the Movidius NCS uses deep metric learning, a process that involves a “triplet training step.” The triplet consists of 3 unique face images — 2 of the 3 are the same person. The NN generates a 128-d vector for each of the 3 face images. For the 2 face images of the same person, we tweak the neural network weights to make the vector closer via distance metric. (image credit: Adam Geitgey)
为了执行深度学习人脸识别,我们需要实值特征向量来训练模型。本节中的脚本用于提取数据集中所有面的 128 维特征向量。
同样,如果您不熟悉面部嵌入/编码,请参考上述三个资源之一。
让我们打开extract_embeddings.py来回顾一下:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--embeddings", required=True,
help="path to output serialized db of facial embeddings")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
第 2-8 行导入提取人脸嵌入所需的包。
第 11-22 行解析五个命令行参数:
--dataset:人脸图像输入数据集的路径。--embeddings:输出嵌入文件的路径。我们的脚本将计算面部嵌入,我们将序列化到磁盘。--detector:OpenCV 基于 Caffe 的深度学习人脸检测器的路径,用于实际定位图像中的人脸。--embedding-model:OpenCV 深度学习火炬嵌入模型的路径。这个模型将允许我们提取一个 128-D 的面部嵌入向量。--confidence:筛选周人脸检测的可选阈值。
我们现在准备好加载我们的面部检测器和面部嵌入器 :
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
detector.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
# load our serialized face embedding model from disk and set the
# preferable target to MYRIAD
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
embedder.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
这里我们加载人脸检测器和嵌入器:
detector:通过线 26-29 加载。我们使用基于 Caffe 的 DL 人脸检测器来定位图像中的人脸。embedder:装在33 线上。这个模型是基于 Torch 的,负责通过深度学习特征提取提取面部嵌入。
注意,我们使用各自的cv2.dnn函数来加载两个独立的模型。dnn模块由英特尔 OpenVINO 开发人员优化。
正如你在行 30 和行 36 看到的,我们调用setPreferableTarget并传递无数常量设置。这些调用确保 Movidius 神经计算棒将为我们进行深度学习。
接下来,让我们获取图像路径并执行初始化:
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize our lists of extracted facial embeddings and
# corresponding people names
knownEmbeddings = []
knownNames = []
# initialize the total number of faces processed
total = 0
建立在第 40 行上的imagePaths列表包含数据集中每个图像的路径。imutils功能,paths.list_images自动遍历目录树,找到所有图像路径。
我们的嵌入和相应的名称将保存在两个列表中:(1) knownEmbeddings,和(2) knownNames ( 第 44 行和第 45 行)。
我们还将记录我们已经处理了多少张脸的total变量(第 48 行)。
让我们开始在imagePaths上循环——这个循环将负责从每个图像中找到的人脸中提取嵌入:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
我们开始在线 51 的imagePaths上循环。
首先,我们从路径中提取人名( Line 55 )。为了解释其工作原理,请考虑 Python shell 中的以下示例:
$ python
>>> from imutils import paths
>>> import os
>>> datasetPath = "../datasets/face_recognition_dataset"
>>> imagePaths = list(paths.list_images(datasetPath))
>>> imagePath = imagePaths[0]
>>> imagePath
'dataset/adrian/00004.jpg'
>>> imagePath.split(os.path.sep)
['dataset', 'adrian', '00004.jpg']
>>> imagePath.split(os.path.sep)[-2]
'adrian'
>>>
请注意,通过使用imagePath.split并提供拆分字符(操作系统路径分隔符——Unix 上的“/”和非 Unix 系统上的“\”),该函数生成了一个文件夹/文件名(字符串)列表,这些名称沿着目录树向下排列。我们获取倒数第二个索引,即人名,在本例中是adrian。
最后,我们通过加载image并将其调整到已知的宽度(第 60 行和第 61 行)来结束上面的代码块。
让我们检测和定位人脸:
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
在的第 65-67 行,我们构造了一个blob。blob 将图像打包成与 OpenCV 的dnn模块兼容的数据结构。要了解这个过程的更多信息,请阅读 深度学习:OpenCV 的 blobFromImage 如何工作 。
从那里,我们通过让imageBlob通过检测器网络(线 71 和 72 )来检测图像中的人脸。
现在,让我们来处理detections:
# ensure at least one face was found
if len(detections) > 0:
# we're making the assumption that each image has only ONE
# face, so find the bounding box with the largest probability
j = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, j, 2]
# ensure that the detection with the largest probability also
# means our minimum probability test (thus helping filter out
# weak detection)
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, j, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI and grab the ROI dimensions
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
detections列表包含概率和边界框坐标来定位图像中的人脸。假设我们至少有一个检测,我们将进入if-语句的主体(第 75 行)。
我们假设图像中只有张人脸,因此我们提取具有最高confidence的检测,并检查以确保置信度满足用于过滤弱检测的最小概率阈值(第 78-84 行)。
当我们达到阈值时,我们提取面部 ROI 并抓取/检查尺寸以确保面部 ROI 足够大(第 87-96 行)。
从那里,我们将利用我们的embedder CNN 和提取人脸嵌入:
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# add the name of the person + corresponding face
# embedding to their respective lists
knownNames.append(name)
knownEmbeddings.append(vec.flatten())
total += 1
我们构建另一个斑点,这一次是从脸部 ROI ( 而不是像我们之前做的那样整个图像)在线 101 和 102 上。
随后,我们将faceBlob通过embedder CNN ( 行 103 和 104 )。这会生成一个 128 维的矢量(vec)来量化面部。我们将利用这些数据,通过机器学习来识别新面孔。
然后我们简单地将name和嵌入vec分别添加到knownNames和knownEmbeddings(第 108 行和第 109 行)。
我们也不能忘记我们设置的用于跟踪total张面孔数量的变量——我们继续增加行 110 的值。
我们继续这个循环遍历图像、检测人脸以及为数据集中的每个图像提取人脸嵌入的过程。
当循环结束时,剩下的就是将数据转储到磁盘:
# dump the facial embeddings + names to disk
print("[INFO] serializing {} encodings...".format(total))
data = {"embeddings": knownEmbeddings, "names": knownNames}
f = open(args["embeddings"], "wb")
f.write(pickle.dumps(data))
f.close()
我们将名称和嵌入数据添加到字典中,然后在第 113-117 行将它序列化到 pickle 文件中。
此时,我们已经准备好通过执行我们的脚本来提取嵌入。在运行嵌入脚本之前,确保您的openvino环境和附加环境变量已经设置,如果您在上一节中没有这样做的话。这里有一个最快的方法来提醒你:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
$ source setup.sh
在那里,打开一个终端,执行以下命令,用 OpenCV 和 Movidius 计算人脸嵌入:
$ python extract_embeddings.py \
--dataset dataset \
--embeddings output/embeddings.pickle \
--detector face_detection_model \
--embedding-model face_embedding_model/openface_nn4.small2.v1.t7
[INFO] loading face detector...
[INFO] loading face recognizer...
[INFO] quantifying faces...
[INFO] processing image 1/120
[INFO] processing image 2/120
[INFO] processing image 3/120
[INFO] processing image 4/120
[INFO] processing image 5/120
...
[INFO] processing image 116/120
[INFO] processing image 117/120
[INFO] processing image 118/120
[INFO] processing image 119/120
[INFO] processing image 120/120
[INFO] serializing 116 encodings...
此过程在 RPi 4B 上用57 秒完成,NCS2 插入 USB 3.0 端口。在加载模型时,您可能会注意到开始时的延迟。从那里开始,每幅图像将会被快速处理。
注意:通常我不推荐使用 Raspberry Pi 来提取嵌入,因为这个过程可能需要大量时间(对于大型数据集,建议使用全尺寸、更强大的计算机)。由于我们相对较小的数据集(120 张图片)和 Movidius NCS 的额外“魅力”,这一过程在合理的时间内完成。
正如你所看到的,我们已经为数据集中的 120 张人脸照片提取了 120 个嵌入。embeddings.pickle文件现在也可以在output/文件夹中找到:
ls -lh output/*.pickle
-rw-r--r-- 1 pi pi 66K Nov 20 14:35 output/embeddings.pickle
序列化嵌入文件大小为 66KB 嵌入文件根据数据集的大小线性增长。请务必回顾本教程后面的“如何获得更高的人脸识别准确度”部分,了解足够大的数据集对于实现高准确度的重要性。
在面部嵌入的顶部训练 SVM 模型
Figure 3: Python machine learning practitioners will often apply Support Vector Machines (SVMs) to their problems (such as deep learning face recognition with the Raspberry Pi and Movidius NCS). SVMs are based on the concept of a hyperplane and the perpendicular distance to it as shown in 2-dimensions (the hyperplane concept applies to higher dimensions as well). For more details, refer to my Machine Learning in Python blog post.
在这一点上,我们已经为每张脸提取了 128 维嵌入,但是我们如何基于这些嵌入来识别一个人呢?
答案是我们需要训练一个“标准”的机器学习模型(比如 SVM、k-NN 分类器、随机森林等。)在嵌入的顶部。
对于小数据集,k-最近邻(k-NN)方法可以用于通过 dlib ( 戴维斯·金)和face_recognition ( 亚当·盖特基)库创建的 128 维嵌入的人脸识别。
然而,在本教程中,我们将在嵌入的基础上构建一个更强大的分类器(支持向量机)——如果您愿意,也可以在基于 dlib 的人脸识别管道中使用相同的方法。
打开train_model.py文件并插入以下代码:
# import the necessary packages
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--embeddings", required=True,
help="path to serialized db of facial embeddings")
ap.add_argument("-r", "--recognizer", required=True,
help="path to output model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to output label encoder")
args = vars(ap.parse_args())
我们在第 2-6 行导入我们的包和模块。我们将使用 scikit-learn 实现的支持向量机(SVM),一种常见的机器学习模型。
第 9-16 行解析三个必需的 命令行参数:
--embeddings:序列化嵌入的路径(我们通过运行前面的extract_embeddings.py脚本将它们保存到磁盘)。--recognizer:这将是识别面对的我们的输出模型。我们将把它保存到磁盘上,以便在接下来的两个识别脚本中使用。--le:我们的标签编码器输出文件路径。我们将把我们的标签编码器序列化到磁盘,以便我们可以在图像/视频人脸识别脚本中使用它和识别器模型。
让我们加载我们的面部嵌入和编码我们的标签:
# load the face embeddings
print("[INFO] loading face embeddings...")
data = pickle.loads(open(args["embeddings"], "rb").read())
# encode the labels
print("[INFO] encoding labels...")
le = LabelEncoder()
labels = le.fit_transform(data["names"])
在这里,我们在第 20 行上加载了上一节中的嵌入。我们不会在这个模型训练脚本中生成任何嵌入——我们将使用之前生成并序列化的嵌入。
然后我们初始化我们的 scikit-learn LabelEncoder并编码我们的名字标签(第 24 和 25 行)。
现在是时候训练我们的 SVM 模型来识别人脸了:
# train the model used to accept the 128-d embeddings of the face and
# then produce the actual face recognition
print("[INFO] training model...")
params = {"C": [0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0],
"gamma": [1e-1, 1e-2, 1e-3, 1e-4, 1e-5]}
model = GridSearchCV(SVC(kernel="rbf", gamma="auto",
probability=True), params, cv=3, n_jobs=-1)
model.fit(data["embeddings"], labels)
print("[INFO] best hyperparameters: {}".format(model.best_params_))
我们正在使用一个具有径向基函数(RBF)核的机器学习支持向量机(SVM),它通常比线性核更难调整。因此,我们将经历一个称为“网格搜索”的过程,这是一种为模型找到最佳机器学习超参数的方法。
第 30-33 行设置我们的 gridsearch 参数并执行这个过程。注意n_jobs=1。如果使用一个更强大的系统,可以运行多个作业并行执行网格搜索。我们在一个树莓派,所以我们将使用一个工人。
第 34 行处理在人脸嵌入向量上训练我们的人脸识别model。
注:你可以也应该尝试替代的机器学习分类器。 PyImageSearch 大师课程深入涵盖了流行的机器学习算法。
从这里开始,我们将把人脸识别器模型和标签编码器序列化到磁盘:
# write the actual face recognition model to disk
f = open(args["recognizer"], "wb")
f.write(pickle.dumps(model.best_estimator_))
f.close()
# write the label encoder to disk
f = open(args["le"], "wb")
f.write(pickle.dumps(le))
f.close()
要执行我们的培训脚本,请在您的终端中输入以下命令:
$ python train_model.py --embeddings output/embeddings.pickle \
--recognizer output/recognizer.pickle --le output/le.pickle
[INFO] loading face embeddings...
[INFO] encoding labels...
[INFO] training model...
[INFO] best hyperparameters: {'C': 100.0, 'gamma': 0.1}
现在让我们检查一下output/文件夹:
ls -lh output/*.pickle
-rw-r--r-- 1 pi pi 66K Nov 20 14:35 output/embeddings.pickle
-rw-r--r-- 1 pi pi 470 Nov 20 14:55 le.pickle
-rw-r--r-- 1 pi pi 97K Nov 20 14:55 recognizer.pickle
借助我们的序列化人脸识别模型和标签编码器,我们可以识别图像或视频流中的人脸。
基于 Movidius NCS 的视频流实时人脸识别
在本节中,我们将编写一个快速演示脚本,使用您的 PiCamera 或 USB 网络摄像头识别人脸。继续打开recognize_video.py并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import pickle
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
在这一点上,我们的进口应该是熟悉的。
我们的五个命令行参数在的第 12-24 行被解析:
--detector:OpenCV 深度学习人脸检测器的路径。我们将使用这个模型来检测面部感兴趣区域在图像中的位置。--embedding-model:OpenCV 深度学习人脸嵌入模型的路径。我们将使用这个模型从人脸 ROI 中提取 128 维人脸嵌入图,我们将把数据输入识别器。--recognizer:我们的识别器模型的路径。我们在上一节中训练了 SVM 识别器。这个模型实际上将决定谁是 T2。--le:我们的标签编码器之路。这包含了我们的面部标签,如adrian或unknown。--confidence:过滤弱脸的可选阈值检测。
一定要研究这些命令行参数——了解这两种深度学习模型和 SVM 模型之间的区别至关重要。如果您发现自己在本脚本的后面感到困惑,您应该参考这里。
现在我们已经处理了导入和命令行参数,让我们将三个模型从磁盘加载到内存中:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
detector.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
# load our serialized face embedding model from disk and set the
# preferable target to MYRIAD
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
embedder.setPreferableTarget(cv2.dnn.DNN_BACKEND_OPENCV)
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
我们在这个街区装了三个模型。冒着被重复的风险,下面是这些模型之间的差异的简要总结:
detector:一个预训练的 Caffe DL 模型来检测人脸在图像中的位置 ( 第 28-32 行)。embedder:一个预先训练好的火炬 DL 模型来计算我们的 128-D 人脸嵌入(37 线和 38 线)。recognizer:我们的 SVM 人脸识别模型(41 线)。
一个和两个是预训练的深度学习模型,意味着它们是由 OpenCV 按原样提供给你的。Movidius NCS 将仅使用探测器 ( 线 32 )进行推断。如果在 Pi CPU 上运行嵌入器会更好。
第三个recognizer模型不是深度学习的一种形式。相反,它是我们的 SVM 机器学习人脸识别模型。RPi CPU 将不得不使用它来处理面部识别预测。
我们还加载了我们的标签编码器,它保存了我们的模型可以识别的人的名字( Line 42 )。
让我们初始化我们的视频流:
# initialize the video stream, then allow the camera sensor to warm up
print("[INFO] starting video stream...")
#vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# start the FPS throughput estimator
fps = FPS().start()
第 47 行初始化并启动我们的VideoStream对象。我们等待摄像机传感器在线 48 预热。
第 51 行初始化我们的 FPS 计数器用于基准测试。
帧处理从我们的while循环开始:
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
frame = vs.read()
# resize the frame to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
frame = imutils.resize(frame, width=600)
(h, w) = frame.shape[:2]
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
我们从线 56 的网络摄像头上抓拍到一张frame。我们resize帧(线 61 ),然后在检测脸部所在位置(线 65-72 )之前构建斑点。
给定我们的新detections,让我们在画面中识别人脸。但是,首先我们需要过滤弱detections并提取人脸 ROI:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
在这里,我们对第 75 条线上的detections进行循环,并提取第 78 条线上的的每个的置信度。
然后,我们将置信度与命令行args字典中包含的最小概率检测阈值进行比较,确保计算出的概率大于最小概率(第 81 行)。
从那里,我们提取出face ROI ( 第 84-89 行,并确保其空间维度足够大(第 92 和 93 行)。
识别脸部 ROI 的名称只需要几个步骤:
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(cv2.resize(face,
(96, 96)), 1.0 / 255, (96, 96), (0, 0, 0),
swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
首先,我们构造一个faceBlob(来自face ROI)并通过embedder来生成一个 128-D 向量,该向量量化了人脸(第 98-102 行
然后,我们将vec通过我们的 SVM 识别器模型(第 105 行,其结果是我们对谁在面部 ROI 中的的预测。
我们取最大概率索引,并查询我们的标签编码器以找到name ( 行 106-108 )。
注意:您可以通过对概率应用额外的阈值测试来进一步过滤掉弱的人脸识别。例如,插入 if proba < T(其中T是您定义的变量)可以提供一个额外的过滤层,以确保更少的误报人脸识别。
现在,让我们显示这个特定帧的人脸识别结果:
# draw the bounding box of the face along with the
# associated probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# update the FPS counter
fps.update()
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
为了结束脚本,我们:
- 在人脸和人名周围画一个包围框和对应的预测概率(第 112-117 行)。
- 更新我们的
fps计数器( Line 120 )。 - 显示带注释的帧(第 123 行)并等待按下
q键,此时我们退出循环(第 124-128 行)。 - 停止我们的
fps计数器并在终端中打印统计数据(第 131-133 行)。 - 通过关闭窗口和释放指针(行 136 和 137 )进行清理。
基于 Movidius NCS 结果的人脸识别
现在,我们已经(1)提取了人脸嵌入,(2)在嵌入上训练了机器学习模型,以及(3)在视频流驱动脚本中编写了我们的人脸识别,让我们看看最终的结果。
确保您遵循了以下步骤:
- 步骤#1: 收集你的人脸识别数据集。
- 步骤#2: 提取面部嵌入(通过
extract_embeddings.py脚本)。 - 步骤#3: 使用
train_model.py在嵌入集合上训练机器学习模型(例如今天例子中的支持向量机)。
在这里,设置您的 Raspberry Pi 和 Movidius NCS 进行面部识别:
- 连接您的 PiCamera 或 USB 摄像头,并配置实时人脸识别脚本的 Line 46 或 Line 47 (但不是两者)来启动您的视频流。
- 插入您的英特尔 m ovidius NC S2(NC S1 也是兼容的)。
- 启动您的
openvino虚拟环境,并设置如下所示的关键环境变量:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
$ source setup.sh
使用 OpenVINO 4.1.1 很关键。较新的 4.1.2 有许多问题导致它不能很好地工作。
从那里,打开一个终端并执行以下命令:
$ python recognize_video.py --detector face_detection_model \
--embedding-model face_embedding_model/openface_nn4.small2.v1.t7 \
--recognizer output/recognizer.pickle \
--le output/le.pickle
[INFO] loading face detector...
[INFO] loading face recognizer...
[INFO] starting video stream...
[INFO] elasped time: 60.30
[INFO] approx. FPS: 6.29
注意:确保您用于部署的 scikit-learn 版本与您用于培训的版本相匹配。如果版本不匹配,那么当您试图从磁盘加载模型时,可能会遇到问题。特别是你可能会遇到AttributeError: 'SVC' object has no attribute '_n_support'。如果您在笔记本电脑/台式机/云环境中进行培训并部署到 Raspberry Pi,这一点尤为重要。版本很容易不同步,所以一定要通过pip freeze | grep scikit在两个地方检查它们。要在您的环境中安装一个特定的版本,只需使用这个命令:pip install scikit-learn==0.22.1,根据需要替换这个版本。
如你所见,人脸已经被正确识别。更重要的是,与严格使用 CPU 的 2.59 FPS 相比,我们使用 Movidius NCS 实现了 6.29 FPS 。使用 RPi 4B 和 Movidius NCS2,加速达到 243% 。
我请 PyImageSearch 团队成员 Abhishek Thanki 录制了一段我们的 Movidius NCS 人脸识别演示。您可以在下面找到演示:
正如你所看到的,Raspberry Pi 和 Movidius NCS 的结合能够近乎实时地识别 Abhishek 的面部——仅使用和Raspberry Pi CPU 不足以获得这样的速度。
我的人脸识别系统无法正确识别人脸

Figure 4: Misclassified faces occur for a variety of reasons when performing Raspberry Pi and Movidius NCS face recognition.
提醒一下,请务必参考以下两个资源:
- OpenCV 人脸识别 包含一个名为“弊端、局限性,以及如何获得更高的人脸识别准确率”的章节。
- “如何获得更高的人脸识别准确率”,第十四章的一个章节,树莓上的人脸识别(树莓用于计算机视觉 ) 。
在 OpenCV 无法正确识别人脸的情况下,这两种资源都可以帮助您。
简言之,您可能需要:
- 更多数据。这是人脸识别系统失败的首要原因。作为一般规则,我建议你的数据集中每人有 20-50 张人脸图像。
- 当每个面部 ROI 经历嵌入过程时,执行面部对准。
- 来调整你的机器学习分类器超参数。
同样,如果你的人脸识别系统不匹配人脸或将人脸标记为“未知”,请务必花时间改进你的人脸识别系统。
摘要
在本教程中,我们使用 OpenVINO 和我们的 Movidius NCS 来执行人脸识别。
我们的人脸识别渠道由四个阶段组成:
- 步骤#1: 创建你的面部图像数据集。当然,如果您遵循当今项目的相同数据集目录结构,您可以换入自己的人脸数据集。
- 步骤#2: 提取数据集中每个人脸的人脸嵌入。
- 步骤#3: 在人脸嵌入的基础上训练机器学习模型(支持向量机)。
- 步骤#4: 利用 OpenCV 和我们的 Movidius NCS 来识别视频流中的人脸。
我们将我们的 Movidius NCS 仅用于以下深度学习任务之一:
- 人脸检测:在图像中定位人脸(运动)
- 提取人脸嵌入:生成 128 维向量,对人脸进行数值量化(CPU)
然后,我们使用 Raspberry Pi CPU 来处理用于对 128-D 嵌入进行预测的非 DL 机器学习分类器。
这看起来好像 CPU 正在做更多的任务,只是要记住,深度学习人脸检测是一个非常计算“昂贵”的操作。
这种职责分离的过程允许 CPU 发号施令,同时使用 NCS 来承担重任。我们使用 Movidius NCS 在视频流中进行人脸识别,实现了 243% 的加速。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中留下您的电子邮件!***
Raspberry Pi:利用 OpenCV 进行深度学习对象检测
原文:https://pyimagesearch.com/2017/10/16/raspberry-pi-deep-learning-object-detection-with-opencv/
https://www.youtube.com/embed/O7fjwRQn-Zg?feature=oembed
树莓 Pi 人脸识别
原文:https://pyimagesearch.com/2018/06/25/raspberry-pi-face-recognition/
在上周的博文中,你学习了如何用 Python、OpenCV 和深度学习 执行 人脸识别。
但正如我在帖子中暗示的那样,为了在 Raspberry Pi 上执行人脸识别,你首先需要考虑一些优化——否则,人脸识别管道将彻底失败。
也就是说,在 Raspberry Pi 上执行人脸识别时,您应该考虑:
- 你在哪个机器上 为你的训练集计算你的人脸识别嵌入 (例如,在 Raspberry Pi 上,在笔记本电脑/台式机上,在带有 GPU 的机器上)
- 你用于 人脸检测的方法 (哈尔喀斯,HOG +线性 SVM,或 CNN)
- 你如何从你的相机传感器 轮询帧 (线程与非线程)
当在 Raspberry Pi 上执行准确的人脸识别时,所有这些考虑因素和相关假设都是至关重要的,我将在这里指导您完成这些工作。
要了解更多关于使用 Raspberry Pi 进行人脸识别的信息,请跟随。
树莓 Pi 人脸识别
这篇文章假设你已经通读了上周关于 OpenCV 人脸识别的文章——如果你还没有阅读,请回到文章中阅读,然后再继续。
在今天博客文章的第一部分,我们将讨论在训练图像集上计算面部嵌入时应该考虑的因素。
在那里,我们将回顾可用于在 Raspberry Pi 上执行人脸识别的源代码,包括许多不同的优化。
最后,我将提供一个使用我的 Raspberry Pi 在视频流中识别人脸(包括我自己)的演示。
为面部识别配置您的 Raspberry Pi
让我们为今天的博文配置我们的 Raspberry Pi。
首先,如果你还没有安装 OpenCV 的话,安装它。你可以按照我在这个 OpenCV 安装教程 页面上链接的说明来获取最新的说明。
接下来,让我们将 Davis King 的 dlib toolkit 软件安装到您安装 OpenCV 的同一个 Python 虚拟环境中(假设您正在使用一个虚拟环境):
$ workon <your env name> # optional
$ pip install dlib
如果你想知道戴维斯·金是谁,看看我 2017 年对戴维斯的采访!
从那里,只需使用 pip 安装 Adam Geitgey 的面部识别模块:
$ workon <your env name> # optional
$ pip install face_recognition
别忘了安装我的便利功能包:
$ workon <your env name> # optional
$ pip install imutils
PyImageConf 2018,一场 PyImageSearch 大会

您愿意在加州旧金山举行的 PyImageSearch 大会上接受我、Davis King、Adam Geitgey 和其他人的现场培训吗?
无论是戴维斯·金(dlib的创造者)还是亚当·盖特基(的作者)机器学习都很有趣! 系列)将在 PyImageConf 2018 授课,你不想错过!你还可以向其他 杰出的计算机视觉深度学习行业演讲人、 包括我!
你会遇到业内的其他人,你可以向他们学习并与之合作。您甚至可以在晚间活动中与与会者交流。
只剩下少数几张票了,一旦我总共卖出 200 张,我就没有地方给你了。不要拖延!
I want to attend PyImageConf 2018!
项目结构
如果你今天想在你的树莓派上执行面部识别,请前往这篇博客文章的 【下载】 部分并获取代码。从那里,将 zip 文件复制到您的 Raspberry Pi(我使用 SCP)中,让我们开始吧。
在您的 Pi 上,您应该解压缩归档文件,更改工作目录,并查看项目结构,就像我下面所做的那样:
$ unzip pi-face-recognition.zip
...
$ cd pi-face-recognition
$ tree
.
├── dataset
│ ├── adrian
│ │ ├── 00000.png
│ │ ├── 00001.png
│ │ ├── 00002.png
│ │ ├── 00003.png
│ │ ├── 00004.png
│ │ └── 00005.png
│ └── ian_malcolm
│ ├── 00000000.jpg
│ ├── 00000001.jpg
│ ├── 00000003.jpg
│ ├── 00000005.jpg
│ ├── 00000007.jpg
│ ├── 00000008.jpg
│ └── 00000009.jpg
├── encode_faces.py
├── encodings.pickle
├── haarcascade_frontalface_default.xml
└── pi_face_recognition.py
3 directories, 17 files
我们的项目有一个包含两个子目录的目录:
- 这个目录应该包含你希望你的面部识别系统识别的每个人的子目录。
- 这个子目录包含了我的照片。你想把它换成你自己的照片?。
ian_malcolm/:侏罗纪公园的角色、伊恩·马尔科姆的照片都在这个文件夹里,但是你很可能会用你想认识的其他人的目录来替换这个目录。
从那里开始,我们在pi-face-recognition/中有四个文件:
- 这个文件将在我们的数据集中找到人脸,并将它们编码成 128 维向量。
- 我们的人脸编码(128 维向量,每个人脸一个)存储在这个 pickle 文件中。
- 为了检测和定位帧中的人脸,我们依靠 OpenCV 预先训练的 Haar 级联文件。
- 这是我们的主要执行脚本。我们将在这篇文章的后面回顾它,这样你就能理解代码和在引擎盖下发生了什么。从那里开始,你可以随意地为你自己的项目进行修改。
现在我们已经熟悉了项目文件和目录,让我们讨论为您的 Raspberry Pi 构建人脸识别系统的第一步。
第一步:收集你的面部数据集

Figure 1: A face recognition dataset is necessary for building a face encodings file to use with our Python + OpenCV + Raspberry Pi face recognition method.
在应用人脸识别之前,我们首先需要收集我们想要识别的示例图像的数据集。
我们可以通过多种方式收集此类图像,包括:
- 通过使用相机+面部检测来收集样本面部,从而执行面部注册
- 使用各种 API(例如、谷歌、脸书、推特等。)来自动下载示例面孔
- 手动收集图像
这篇文章假设你已经收集了一个人脸数据集,但如果你还没有,或者正在收集人脸数据集,请确保阅读我的博客文章 如何创建自定义人脸识别数据集 来帮助你开始。
为了这篇博文,我收集了两个人的照片:
仅使用这少量的图像,我将演示如何创建一个能够部署到 Raspberry Pi 的准确的人脸识别应用程序。
第二步:计算你的人脸识别嵌入
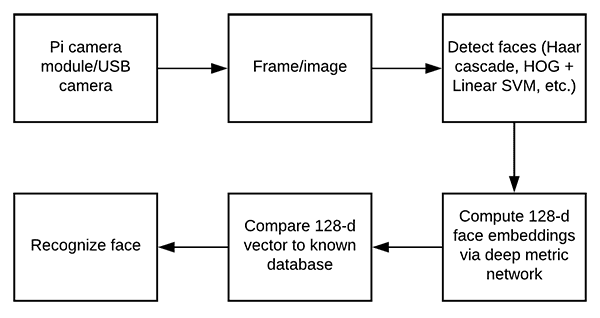
Figure 2: Beginning with capturing input frames from our Raspberry Pi, our workflow consists of detecting faces, computing embeddings, and comparing the vector to the database via a voting method. OpenCV, dlib, and face_recognition are required for this face recognition method.
我们将使用深度神经网络来计算 128-d 向量(即,128 个浮点值的列表),该向量将量化数据集中的每个面部。我们已经在上周的博客文章中回顾了(1)我们的深度神经网络如何执行面部识别以及(2)相关的源代码,但是为了完整起见,我们也将在这里回顾代码。
让我们从 【下载】 中打开encode_faces.py与这篇博文相关的评论:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
首先,我们需要导入所需的包。值得注意的是,这个脚本需要安装imutils、face_recognition和 OpenCV。向上滚动到“为面部识别配置您的 Raspberry Pi”部分,安装必要的软件。
从那里,我们用argparse处理我们的命令行参数:
--dataset:我们数据集的路径(我们使用上周博文中的方法 2 创建了一个数据集)。- 我们的面部编码被写到这个参数指向的文件中。
--detection-method:在我们能够编码图像中的张脸之前,我们首先需要检测张脸。我们的两种人脸检测方法包括hog或cnn。这两个标志是唯一适用于--detection-method的标志。
注: 树莓派是不具备运行 CNN 检测方法的能力。如果你想运行 CNN 检测方法,你应该使用一个有能力的计算,如果你正在处理一个大数据集,最好是一个带有 GPU 的计算。否则,使用hog人脸检测方法。
现在我们已经定义了参数,让我们获取数据集中图像文件的路径(并执行两次初始化):
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the list of known encodings and known names
knownEncodings = []
knownNames = []
从这里开始,我们将继续遍历数据集中的每个面:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the input image and convert it from BGR (OpenCV ordering)
# to dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input image
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
# compute the facial embedding for the face
encodings = face_recognition.face_encodings(rgb, boxes)
# loop over the encodings
for encoding in encodings:
# add each encoding + name to our set of known names and
# encodings
knownEncodings.append(encoding)
knownNames.append(name)
在循环内部,我们:
- 从路径中提取人物的
name(行 32 )。 - 加载并转换
image到rgb( 第 36 和 37 行)。 - 定位图像中的人脸(第 41 行和第 42 行)。
- 计算面部嵌入,并将它们添加到
knownEncodings中,同时将它们的name添加到knownNames( 第 45-52 行)中相应的列表元素中。
让我们将面部编码导出到磁盘,以便在面部识别脚本中使用:
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = {"encodings": knownEncodings, "names": knownNames}
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
第 56 行用两个键"encodings"和"names"构造一个字典。与键相关联的值包含编码和名称本身。
然后在第 57-59 行的上将data字典写入磁盘。
要创建我们的面部嵌入,打开一个终端并执行以下命令:
$ python encode_faces.py --dataset dataset --encodings encodings.pickle \
--detection-method hog
[INFO] quantifying faces...
[INFO] processing image 1/11
[INFO] processing image 2/11
[INFO] processing image 3/11
...
[INFO] processing image 9/11
[INFO] processing image 10/11
[INFO] processing image 11/11
[INFO] serializing encodings...
运行脚本后,您将拥有一个 pickle 文件。我的文件被命名为encodings.pickle——这个文件包含我们数据集中每个人脸的 128-d 人脸嵌入。
等等!你在树莓派上运行这个脚本吗?
没问题,用--detection-method hog命令行参数就行了。--detection-method cnn不能在树莓派上工作,但如果你用一台有能力的机器对你的脸进行编码,肯定可以使用。如果你不熟悉命令行参数,只要确保快速阅读这篇文章,你很快就会成为专家!
第三步:在你的 Raspberry Pi 上识别视频流中的人脸
Figure 3: Face recognition on the Raspberry Pi using OpenCV and Python.
我们的pi_face_recognition.py脚本与上周的 recognize_faces_video.py脚本非常相似,只有一个显著的变化。在这个脚本中,我们将使用 OpenCV 的 Haar cascade 来检测和定位面部。从那里,我们将继续用同样的方法来实际上识别这张脸。
事不宜迟,让我们开始编码吧:
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import face_recognition
import argparse
import imutils
import pickle
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", required=True,
help = "path to where the face cascade resides")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
args = vars(ap.parse_args())
首先,让我们导入包并解析命令行参数。我们从imutils以及imutils本身导入了两个模块(VideoStream和FPS)。我们还导入了face_recognition和cv2 (OpenCV)。列出的其余模块是 Python 安装的一部分。请参阅“为面部识别配置您的 Raspberry Pi”安装软件。
然后我们解析两个命令行参数:
--cascade:OpenCV 的 Haar cascade 路径(包含在本文的源代码下载中)。--encodings:我们面部编码系列数据库的路径。我们刚刚在前一节构建了编码。
从这里开始,在我们开始从我们的相机循环帧之前,让我们实例化几个对象:
# load the known faces and embeddings along with OpenCV's Haar
# cascade for face detection
print("[INFO] loading encodings + face detector...")
data = pickle.loads(open(args["encodings"], "rb").read())
detector = cv2.CascadeClassifier(args["cascade"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# start the FPS counter
fps = FPS().start()
在这一部分中,我们:
- 加载面部编码
data( 第 22 行)。 - 使用哈尔级联方法实例化我们的脸
detector(第 23 行)。 - 初始化我们的
VideoStream—我们将使用 USB 摄像头,但是 如果你想使用 PiCamera 与你的 Pi ,只需注释第 27 行并取消注释第 28 行。 - 等待相机预热(第 29 行)。
- 开始我们的每秒帧数,
fps,计数器(第 32 行)。
从这里,让我们开始从相机捕捉帧并识别人脸:
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream and resize it
# to 500px (to speedup processing)
frame = vs.read()
frame = imutils.resize(frame, width=500)
# convert the input frame from (1) BGR to grayscale (for face
# detection) and (2) from BGR to RGB (for face recognition)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# detect faces in the grayscale frame
rects = detector.detectMultiScale(gray, scaleFactor=1.1,
minNeighbors=5, minSize=(30, 30))
# OpenCV returns bounding box coordinates in (x, y, w, h) order
# but we need them in (top, right, bottom, left) order, so we
# need to do a bit of reordering
boxes = [(y, x + w, y + h, x) for (x, y, w, h) in rects]
# compute the facial embeddings for each face bounding box
encodings = face_recognition.face_encodings(rgb, boxes)
names = []
我们继续抓取一个frame并对其进行预处理。预处理步骤包括调整大小,然后转换成灰度和rgb ( 第 38-44 行)。
用伊恩·马尔科姆的话说:
你们的科学家太专注于他们是否能做到,他们没有停下来想想他们是否应该。
他指的是成长中的恐龙。至于人脸识别,我们可以并且我们应该用我们的树莓派检测和识别人脸。我们只需要小心不要用复杂的深度学习方法让 Pi 有限的内存超载。因此,我们将使用一种稍微过时但非常突出的方法来进行人脸检测— Haar cascades!
哈尔级联也被称为 Viola-Jones 算法,他们的论文发表于 2001 年。
这篇被高度引用的论文提出了他们的方法,以实时检测多尺度图像中的对象。对于 2001 年来说,这是一个巨大的发现和知识共享——哈尔瀑布至今仍广为人知。
我们将利用 OpenCV 训练过的人脸 Haar 级联,这可能需要一点点参数调整(与用于人脸检测的深度学习方法相比)。
detectMultiScale方法的参数包括:
gray:灰度图像。scaleFactor:指定每个图像比例下图像尺寸缩小多少的参数。minNeighbors:指定每个候选矩形应该有多少个邻居来保留它的参数。minSize:可能的最小物体(面)尺寸。小于该值的对象将被忽略。
有关这些参数以及如何调整它们的更多信息,请务必参考我的书, 实用 Python 和 OpenCV 以及 PyImageSearch 大师课程。
我们的面部检测的结果是rects,一个面部包围盒矩形的列表,它对应于帧中的面部位置(行 47 和 48 )。我们转换并重新排列这个列表在第 53 行的坐标。
然后,我们计算第 56 行的上的每个人脸的 128-d encodings,从而量化人脸。
现在让我们循环面部编码并检查匹配:
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number
# of votes (note: in the event of an unlikely tie Python
# will select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
上面代码块的目的是识别人脸。在这里我们:
- 检查
matches( 行 63 和 64 )。 - 如果找到匹配,我们将使用投票系统来决定谁的脸最有可能是(68-87)。这种方法的工作原理是检查数据集中哪个人匹配最多(如果出现平局,则选择字典中的第一个条目)。
然后,我们简单地在每张脸周围画出矩形,并附上预测的人名:
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# draw the predicted face name on the image
cv2.rectangle(frame, (left, top), (right, bottom),
(0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
# display the image to our screen
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
在绘制了框和文本之后,我们显示图像并检查是否按下了 quit(“q”)键。我们还更新了我们的fps计数器。
最后一点。让我们清理并将性能诊断写入终端:
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
人脸识别结果
请务必使用 “下载” 部分来获取这篇博文的源代码和示例数据集。
从那里,打开您的 Raspberry Pi 终端并执行以下命令:
$ python pi_face_recognition.py --cascade haarcascade_frontalface_default.xml \
--encodings encodings.pickle
[INFO] loading encodings + face detector...
[INFO] starting video stream...
[INFO] elasped time: 20.78
[INFO] approx. FPS: 1.21

我在下面附上了一个演示视频和附加评论,所以请一定要看:
https://www.youtube.com/embed/DMwk4c4bTJE?feature=oembed
Raspberry Pi:面部标志 OpenCV 和 dlib 睡意检测
今天的博文是期待已久的关于树莓派上实时睡意检测的教程!
$ workon cv
$ pip install RPi.GPIO
$ pip install gpiozero
在那里,如果您想检查虚拟环境中的所有组件是否安装正确,您可以直接运行 Python 解释器:
$ workon cv
$ python
>>> import RPi.GPIO
>>> import gpiozero
>>> import numpy
>>> import dlib
>>> import cv2
>>> import imutils
注意:我假设您正在使用的虚拟环境已经*安装了上述软件包。我的cv虚拟环境已经安装了 NumPy、dlib、OpenCV 和 imutils,所以通过使用pip安装RPi.GPIO和gpiozero安装各自的 GPIO 包,我能够从同一个环境中访问所有六个库。你可以pip install每个包(OpenCV 除外)。要在你的 Raspberry Pi 上安装一个优化的 OpenCV,只需按照上一篇文章进行操作。如果您在安装 dlib 时遇到问题,请遵循本指南。
*
驾驶员睡意检测算法与我们在之前的教程中实现的算法相同。
首先,我们将应用 OpenCV 的 Haar 级联来检测图像中的人脸,这归结为找到边界框 (x,y)——人脸在帧中的坐标。
给定面部的边界框,我们可以应用 dlib 的面部标志预测器来获得用于定位眼睛、眉毛、鼻子、嘴和下颌线的 68 个显著点:

Figure 2: Visualizing the 68 facial landmark coordinates from the iBUG 300-W dataset.
正如我在本教程的中讨论的,dlib 的 68 个面部标志是可索引的,这使我们能够使用简单的 Python 数组切片提取各种面部结构。
给定与眼睛相关联的面部标志,我们可以应用由苏库波娃和 Čech's 在他们 2017 年的论文 中介绍的眼睛纵横比(耳朵)算法,利用面部标志 :
Figure 3: Top-left: A visualization of eye landmarks when then the eye is open. Top-right: Eye landmarks when the eye is closed. Bottom: Plotting the eye aspect ratio over time. The dip in the eye aspect ratio indicates a blink (Image credit: Figure 1 of Soukupová and Čech).
在左上角的图中,我们有一只完全睁开的眼睛,并且绘制了眼睛面部标志。然后在右上角的上我们有一只眼睛是闭着的。底部的随后绘制出眼睛长宽比随时间的变化曲线。我们可以看到,眼睛的纵横比是恒定的(表示眼睛是睁开的),然后迅速下降到接近零,然后再次增加,表示眨眼已经发生。**
你可以在这篇关于眨眼检测的文章中阅读更多关于眨眼检测算法和眼睛长宽比的内容。
在我们的困倦检测器的情况下,我们将监控眼睛纵横比,以查看值是否下降但不再增加,从而暗示驾驶员/用户已经闭上眼睛。
一旦实现,我们的算法将从在提取眼睛区域时定位面部标志开始:
Figure 4: Me with my eyes open — I’m not drowsy, so the Eye Aspect Ratio (EAR) is high.
然后,我们可以监控眼睛的纵横比,以确定眼睛是否闭合:
Figure 5: The EAR is low because my eyes are closed — I’m getting drowsy.
然后如果眼睛纵横比在足够长的时间内低于预定义的阈值,则最终发出警报(指示驾驶员/用户疲劳):
Figure 6: My EAR has been below the threshold long enough for the drowsiness alarm to come on.
在下一节中,我们将使用 OpenCV、dlib 和 Python 在 Raspberry Pi 上实现上述优化的睡意检测算法。
基于 OpenCV 和 dlib 的树莓 Pi 实时睡意检测器
在您最喜欢的编辑器或 IDE 中打开一个新文件,并将其命名为pi_drowsiness_detection.py。从那里,让我们开始编码:
# import the necessary packages
from imutils.video import VideoStream
from imutils import face_utils
import numpy as np
import argparse
import imutils
import time
import dlib
import cv2
第 1-9 行处理我们的导入—确保您的虚拟环境中安装了这些导入。
让我们从这里定义一个距离函数:
def euclidean_dist(ptA, ptB):
# compute and return the euclidean distance between the two
# points
return np.linalg.norm(ptA - ptB)
在第行第 11-14 行,我们定义了一个使用 NumPy 计算欧几里德距离的便利函数。欧几里得无疑是最广为人知且必须使用的距离度量。欧几里得距离通常被描述为两点之间的“直线”距离。
现在让我们定义我们的眼睛纵横比(EAR)函数,它用于计算垂直眼睛标志之间的距离与水平眼睛标志之间的距离的比率:
def eye_aspect_ratio(eye):
# compute the euclidean distances between the two sets of
# vertical eye landmarks (x, y)-coordinates
A = euclidean_dist(eye[1], eye[5])
B = euclidean_dist(eye[2], eye[4])
# compute the euclidean distance between the horizontal
# eye landmark (x, y)-coordinates
C = euclidean_dist(eye[0], eye[3])
# compute the eye aspect ratio
ear = (A + B) / (2.0 * C)
# return the eye aspect ratio
return ear
当眼睛睁开时,返回值将近似恒定,并且在眨眼期间将向零减小。如果眼睛是闭着的,眼睛纵横比将保持恒定在一个小得多的值。
从那里,我们需要解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", required=True,
help = "path to where the face cascade resides")
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-a", "--alarm", type=int, default=0,
help="boolean used to indicate if TrafficHat should be used")
args = vars(ap.parse_args())
我们在第 33-40 行中定义了两个必需参数和一个可选参数:
--cascade:用于人脸检测的 Haar cascade XML 文件的路径。--shape-predictor:dlib 面部标志预测器文件的路径。--alarm:一个布尔值,表示当检测到困倦时是否应该使用交通蜂鸣器。
--cascade和--shape-predictor文件都可以在文章末尾的 【下载】 部分找到。
如果设置了--alarm标志,我们将设置流量:
# check to see if we are using GPIO/TrafficHat as an alarm
if args["alarm"] > 0:
from gpiozero import TrafficHat
th = TrafficHat()
print("[INFO] using TrafficHat alarm...")
如第 43-46 行所示,如果提供的参数大于 0,我们将导入 TrafficHat 函数来处理我们的蜂鸣器警报。
让我们也定义一组重要的配置变量:
# define two constants, one for the eye aspect ratio to indicate
# blink and then a second constant for the number of consecutive
# frames the eye must be below the threshold for to set off the
# alarm
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 16
# initialize the frame counter as well as a boolean used to
# indicate if the alarm is going off
COUNTER = 0
ALARM_ON = False
线 52 和 53 上的两个常数分别定义了认为困倦时眼睛必须闭上的耳阈值和连续帧数。
然后,我们初始化帧计数器和一个报警布尔值(行 57 和 58 )。
从那里,我们将加载我们的哈尔级联和面部标志预测文件:
# load OpenCV's Haar cascade for face detection (which is faster than
# dlib's built-in HOG detector, but less accurate), then create the
# facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = cv2.CascadeClassifier(args["cascade"])
predictor = dlib.shape_predictor(args["shape_predictor"])
第 64 行与我们之前关于睡意检测的帖子中的面部检测器初始化不同——这里我们使用了更快的检测算法(哈尔级联),同时牺牲了准确性。Haar cascades 比 dlib 的人脸检测器(基于 HOG +线性 SVM)更快,这使它成为树莓派的绝佳选择。
第 65 行的没有变化,在这里我们加载 dlib 的shape_predictor,同时提供文件的路径。
接下来,我们将初始化每只眼睛的面部标志的索引:
# grab the indexes of the facial landmarks for the left and
# right eye, respectively
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
这里,我们提供数组切片索引,以便从面部标志集中提取眼睛区域。
我们现在准备开始我们的视频流线程:
# start the video stream thread
print("[INFO] starting video stream thread...")
vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
time.sleep(1.0)
如果您正在使用 PiCamera 模块 ,请务必注释掉 第 74 行和取消注释 第 75 行以将视频流切换到树莓 Pi 摄像机。否则,如果您使用的是 USB 摄像头,您可以保持不变。
我们有一秒钟的睡眠时间,以便摄像头传感器可以预热。
从这里开始,让我们循环视频流中的帧:
# loop over frames from the video stream
while True:
# grab the frame from the threaded video file stream, resize
# it, and convert it to grayscale
# channels)
frame = vs.read()
frame = imutils.resize(frame, width=450)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector.detectMultiScale(gray, scaleFactor=1.1,
minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
如果你读过上一篇文章,这个循环的开始应该看起来很熟悉。我们读取一帧,调整它的大小(为了效率),并将其转换为灰度(行 83-85 )。
然后我们用我们的检测器在第 88-90 行上检测灰度图像中的人脸。
现在让我们循环检查检测结果:
# loop over the face detections
for (x, y, w, h) in rects:
# construct a dlib rectangle object from the Haar cascade
# bounding box
rect = dlib.rectangle(int(x), int(y), int(x + w),
int(y + h))
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
第 93 行开始了一个冗长的 for 循环,这里被分解成几个代码块。首先,我们提取rects检测的坐标和宽度+高度。然后,在的第 96 行和第 97 行,我们使用从哈尔级联包围盒中提取的信息构建了一个 dlib rectangle对象。
从那里,我们确定面部区域的面部标志(线 102 )并将面部标志 (x,y)-坐标转换为 NumPy 数组。
给定我们的 NumPy 数组,shape,我们可以提取每只眼睛的坐标并计算耳朵:
# extract the left and right eye coordinates, then use the
# coordinates to compute the eye aspect ratio for both eyes
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# average the eye aspect ratio together for both eyes
ear = (leftEAR + rightEAR) / 2.0
利用眼睛标志的索引,我们可以对shape数组进行切片,以获得每只眼睛的 (x,y)——坐标(行 107 和 108 )。
然后我们在第 109 行和第 110 行计算每只眼睛的耳朵。
Soukupová和 ech 建议将两只眼睛的纵横比平均在一起,以获得更好的估计值(第 113 行)。
下一个模块严格用于可视化目的:
# compute the convex hull for the left and right eye, then
# visualize each of the eyes
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
通过使用cv2.drawContours并提供每只眼睛的cv2.convexHull计算值(第 117-120 行,我们可以在我们的帧上可视化每个眼睛区域。这几行代码对于调试我们的脚本非常有用,但是如果您正在制作一个没有屏幕的嵌入式产品,就没有必要了。
从那里,我们将检查我们的眼睛纵横比(ear)和帧计数器(COUNTER),以查看眼睛是否闭合,同时发出警报,以在需要时提醒昏昏欲睡的驾驶员:
# check to see if the eye aspect ratio is below the blink
# threshold, and if so, increment the blink frame counter
if ear < EYE_AR_THRESH:
COUNTER += 1
# if the eyes were closed for a sufficient number of
# frames, then sound the alarm
if COUNTER >= EYE_AR_CONSEC_FRAMES:
# if the alarm is not on, turn it on
if not ALARM_ON:
ALARM_ON = True
# check to see if the TrafficHat buzzer should
# be sounded
if args["alarm"] > 0:
th.buzzer.blink(0.1, 0.1, 10,
background=True)
# draw an alarm on the frame
cv2.putText(frame, "DROWSINESS ALERT!", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# otherwise, the eye aspect ratio is not below the blink
# threshold, so reset the counter and alarm
else:
COUNTER = 0
ALARM_ON = False
在行 124 上,我们对照EYE_AR_THRESH检查ear——如果它小于阈值(眼睛闭上),我们增加我们的COUNTER ( 行 125 )并随后检查它以查看眼睛是否已经闭了足够的连续帧来发出警报(行 129 )。
如果闹钟没响,我们就打开它几秒钟,叫醒昏昏欲睡的司机。这是在行 136-138 上完成的。
可选地(如果你用屏幕实现这个代码),你可以在框架上画出警报,就像我在第行第 141 和 142 行所做的那样。
这让我们想到了ear不小于EYE_AR_THRESH的情况——在这种情况下,我们将COUNTER重置为 0,并确保我们的闹铃关闭(第 146-148 行)。
我们差不多完成了——在最后一个代码块中,我们将在frame上绘制耳朵,显示frame,并做一些清理工作:
# draw the computed eye aspect ratio on the frame to help
# with debugging and setting the correct eye aspect ratio
# thresholds and frame counters
cv2.putText(frame, "EAR: {:.3f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
如果你正在集成一个屏幕或者调试,你可能希望在框架上显示计算出的眼睛纵横比,就像我在第行第 153 和 154 上所做的那样。该画面显示在线 157 和 158 的实际屏幕上。
当按下键盘上的“q”键时,程序停止(行 157 和 158 )。
你可能会想,“我不会在我的车里安装键盘的!”如果你在办公桌前使用网络摄像头和电脑进行调试,你肯定会这么做。如果你想使用 TrafficHAT 上的按钮来打开/关闭睡意检测算法,这是非常好的——第一个在评论中发布使用 Pi 按钮打开和关闭睡意检测器的解决方案的读者应该得到一杯冰冷的精酿啤酒或一杯热的 artisan 咖啡。
最后,我们通过关闭任何打开的窗口并停止视频流来清理(行 165 和 166 )。
睡意检测结果
要在自己的树莓 Pi 上运行这个程序,请务必使用本文底部的 【下载】 部分来获取源代码、面部检测 Haar cascade 和 dlib 面部标志检测器。
我没有足够的时间在我的车里连接所有的东西,并在时记录屏幕,就像我之前做的那样。在开车的时候录制树莓 Pi 屏幕也是相当具有挑战性的。
相反,我将在我的办公桌上演示——然后你可以将这个实现用于你自己的汽车内,在你认为合适的时候进行睡意检测。
您可以在下面看到我的设置图像:

Figure 7: My desk setup for coding, testing, and debugging the Raspberry Pi Drowsiness Detector.
要运行该程序,只需执行以下命令:
$ python pi_detect_drowsiness.py --cascade haarcascade_frontalface_default.xml \
--shape-predictor shape_predictor_68_face_landmarks.dat --alarm 1
我在下面的树莓派上放了一段自己演示实时睡意检测器的视频:
https://www.youtube.com/embed/UxeQzUUQM0E?feature=oembed
Raspbian + OpenCV 预配置预安装。
原文:https://pyimagesearch.com/2016/11/21/raspbian-opencv-pre-configured-and-pre-installed/

更新:2019 年 9 月 16 日
自从我在 2015 年 2 月写了第一篇关于在 Raspberry Pi B+上安装 OpenCV + Python 的 PyImageSearch 教程以来,我的梦想就是提供一个 可下载的、预配置的 Raspbian。预装 OpenCV 的 img 文件。
自 2016 年 11 月(本帖最初发布日期)这个梦想已经成为现实。
我很高兴地宣布,我的可下载 Raspbian 附带了以下产品。img 文件 预配置预安装:
- 实用 Python 和 OpenCV ( 快速入门和硬拷贝捆绑)
- 计算机视觉的树莓 (业余爱好者、黑客、和完整捆绑)
有两个文件包含在内:
Raspbian3B_4B.img.gz(与 RPi 3B、3B+、4B [1GB、2GB 和 4GB 型号]兼容)RaspbianZeroW.img.gz(兼容 Pi Zero W)
你所要做的就是下载。img 文件,使用 BalenaEtcher 将相应的文件闪存到您的 SD 卡中,然后启动您的 Pi。
从那里开始,您将拥有一个完整的 Python + OpenCV 开发环境,完全没有配置、编译和安装 OpenCV 的麻烦。
了解更多关于拉斯扁人的信息。img 文件,继续阅读。
Raspbian Buster + OpenCV 4 开箱即用
我回顾了最近在 Raspberry Pi 上安装 OpenCV 的教程,并计算了执行每一步所需的时间。
你知道我发现了什么吗?
即使你确切地知道你正在做什么,在你的 Raspberry Pi 上编译和安装 OpenCV 也要花费大量的时间:
- 树莓码头 4B 上超过 55 分钟
- 历时 2.2 小时 编译出树莓派 3B+。
- 历时 14 个小时在 Raspberry Pi Zero W 上编译
在过去,我曾经给那些在 Pi 上成功安装 OpenCV 的新手读者发邮件,询问他们完成编译和安装过程需要多长时间。
也许并不奇怪,我发现新手读者在他们的树莓派 3B+上安装 OpenCV 的时间增加了近4 倍到超过 8.7 小时(零 W) 甚至更长。我没有对 Raspberry Pi 4 进行过类似的调查,但我猜测大多数人会花大约 4 个小时来配置他们的 Raspberry Pi 4。
显然,对于许多试图学习 OpenCV 和计算机视觉的 PyImageSearch 读者来说,入门的障碍是将 OpenCV 本身安装在他们的 Raspberry Pi 上。
为了帮助这些读者充分利用他们的树莓派,我决定发布我自己的个人 Raspbian。预配置和预安装了 OpenCVT3 的 img 文件。
通过捆绑预先配置的 Raspbian。img 连同要么(1) 实用 Python 和 OpenCV ,和/或(2) 计算机视觉的树莓派 我的目标是:
- 跳过在您的 Raspberry Pi 上安装 OpenCV + Python 的繁琐过程,开始您的计算机视觉教育。
- 为你提供一本书,里面有你可能得到的对计算机视觉和图像处理世界的最好的介绍。
当然,我将继续创建、支持、为任何使用我提供的关于在 Raspberry Pi 上安装 OpenCV + Python 的免费教程的 PyImageSearch 读者提供帮助。
同样,这个预先配置的 Raspbian。img 的目标读者是 PyImageSearch 的读者,他们希望 节省时间 和 快速启动他们的计算机视觉教育。
如果这听起来不像你,不要担心,我完全理解——我仍然会提供免费教程来帮助你在你的 Raspberry Pi 上安装和运行 OpenCV。请记住,我的客户从我这里获得优先支持(当你在那个页面时,一定要查看我的其他常见问题)。
Raspbian Buster + OpenCV 4 预配置预安装
本文档的其余部分描述了如何 安装和使用 预配置的 Raspbian。img 文件包含在您购买的 : 中
- 实用 Python 和 OpenCV ( 快速入门和硬拷贝捆绑)
- 计算机视觉的树莓 (业余爱好者、黑客、和完整捆绑)
在本指南的末尾,您还可以找到关于 Raspbian + OpenCV 的常见问题的答案。img 文件。如果您有 FAQ 中未涉及的问题,请给我发消息。
下载并解压缩归档文件
当您收到购买链接时,一定要下载这本书、代码、视频和 Raspbian。每个文件都是. zip 格式的。Raspbian.zip包含预配置的图像和一个README.txt文件。
继续使用你最喜欢的解压工具(7zip,Keka 等)解压文件。).没有必要提取包含的。gz 文件,因为我们将直接使用它们。
解压缩Raspbian.zip后,你的文件夹应该是这样的:
Figure 1: After downloading the Raspbian.zip file, unpack it to obtain the .img.gz file that you’ll flash to your SD card directly with BalenaEtcher.
使用 BalenaEtcher 将操作系统映像写入 32GB microSD 卡
这个拉斯扁人。img 在 32GB microSD 卡上只能工作。的。对于 8GB 或 16GB 的卡,img 太大。据我所知,树莓 Pi 不支持 64GB+ microSD 卡。
**我推荐优质的闪迪 32GB 98MB/s 卡。它们在亚马逊和许多在线分销商处都有售。
来编写预先配置的 Raspbian。只需按照官方的 Raspberry Pi 文档进行操作。推荐的工具是 BalenaEtcher (兼容 Mac、Linux、Windows)。
BalenaEtcher 可以处理压缩文件比如。gz (加载到蚀刻机前不需要解压. img . gz)。
Figure 2: Flashing your pre-configured Raspbian .img with BalenaEtcher for your Raspberry Pi.
第一次启动您的 Pi
写完拉斯扁之后。img 到您的卡,将卡插入您的 Pi 并启动它。
用户名是pi,密码是raspberry。
在第一次启动时,您的 Raspbian 文件系统需要扩展以适应 SD 卡。
这意味着你必须手动运行raspi-config => Advanced => Expand Filesystem。
扩展完成后,您的 Pi 将重新启动,您将能够正常使用它(只有在第一次启动时才需要扩展文件系统)。
下面是自动扩展后我的 Pi 上的磁盘利用率的屏幕截图:
Figure 3: After booting my Raspberry Pi for the first time your filesystem will be expanded to utilize the entire disk.
请注意,我的整个32GB 卡是可用的,其中 35%在使用中。
默认 WiFi
默认情况下,您的 Raspberry Pi 将尝试使用密码短语computervision连接到名为pyimagesearch的网络。
如果你陷入困境,这很有用:
- 也许你刚刚刷新了你的 microSD,你需要快速连接。
- 也许您不在典型的无线网络附近,并且您想要热点化您的电话,以便您的 Pi 和笔记本电脑通过您的电话的无线网络连接。适用于 iPhone 和 Android。
- 也许你忘记了你的键盘/鼠标/HDMI 屏幕,你需要通过 SSH 和 VNC 做所有的事情,但是你现在不能轻易地连接到你的 Pi。参考本教程关于远程开发和与您的 Raspberry Pi 连接。
我们在野外已经用这种方法联系过很多次了。这很方便,但存在安全风险。虽然我们不建议长期使用这个无线网络,因为这个密码是公开的(在几乎所有的部署应用程序中,您应该从 Pi 中删除 network +密码),但如果您只是闪存了一个 microSD,这是一个很好的连接方式。我们还建议更改与您的 Raspberry Pi 用户名相关的默认密码。
在您的树莓 Pi 上使用 Python 和 OpenCV
为了通过 Python 3 绑定访问 OpenCV 4(和 OpenCV 3 ),我们利用了 Python 虚拟环境。每个 Python 虚拟环境完全相互独立,确保没有依赖性或版本问题。
在本节的剩余部分,我将解释(1)什么是 Python 虚拟环境,以及(2)如何访问 Python 3 + OpenCV 3/4 环境。
什么是 Python 虚拟环境?
最核心的是,Python 虚拟环境允许我们为每个 Python 项目创建隔离的、独立的环境。这意味着每个项目可以有自己的一组 依赖项、而不管另一个项目有哪些依赖项。
在 OpenCV 的上下文中,这允许我们为 OpenCV 4 拥有一个虚拟环境,然后为 OpenCV 3 拥有另一个虚拟环境。此外,我们可以拥有英特尔 OpenVINO 和谷歌 Coral 虚拟环境。
要详细了解 Python 虚拟环境,请参考本教程。
Python 2.7 支持已被否决
2020 年 1 月 1 日,Python.org 将不再更新 Python 2.7(安全更新也是如此)。在这里阅读 Python 2.7 的日落公告。
PyImageSearch 官方不再支持 Python 2.7。所有未来的代码只兼容 Python 3。
上有哪些虚拟环境?imgs?
树莓派 3B/3B+/4B 。img 包含以下环境:
py3cv4: Python 3.7 和 OpenCV 4.1.1py3cv3: Python 3.7 和 OpenCV 3.4.7openvino: Python 3.7 和 OpenCV 4 . 1 . 1——OpenVINO(OpenVINO是英特尔深度学习+硬件优化的工具包)coral: Python 3.7 和 OpenCV 4.1.1gopigo: Python 3.7 和 OpenCV 4.1.1
树莓派零瓦特。img 包含以下环境:
py3cv4: Python 3.7 和 OpenCV 4.1.1py3cv3: Python 3.7 和 OpenCV 3.4.7
访问虚拟环境
有两种方法可以访问 Raspbian .imgs 上的虚拟环境。
选项 1: 使用workon命令
例如,如果您希望使用 Python 3 + OpenCV 4.1.1 环境,只需使用 workon 命令和环境名:
$ workon py3cv4
(py3cv4) $
注意,bash 提示符的前面是括号中的环境名。
注意:OpenVINO环境要求你使用下面的选项 2** 方法。
选项 2: 使用source命令
您也可以对位于您的主目录中的启动脚本使用以下命令:
$ source ~/start_py3cv4.sh
Starting Python 3.7 with OpenCV 4.1.1 bindings...
(py3cv4) $
如果您使用 OpenVINO,将通过“开始”脚本自动调用英特尔提供的附加脚本:
$ source ~/start_openvino.sh
Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
[setupvars.sh] OpenVINO environment initialized
(py3cv4) $
您的终端看起来将与此类似(我从 macOS 进入我的 Raspberry Pi):
Figure 4: Starting the OpenVINO environment for the Movidius NCS on a Raspberry Pi pre-configured .img.
在您的 Raspberry Pi 上执行我的书中的代码
有多种方法可以在你的 Pi 上访问实用 Python 和 OpenCV 或计算机视觉树莓 Pi的源代码。第一种是使用 Chromium,Raspbian 的内置网络浏览器来下载。zip 存档:

Figure 5: Downloading the source code from Practical Python and OpenCV using the Raspberry Pi web browser.
只需下载。直接压缩到您的 Pi。
如果代码当前位于您的笔记本电脑/台式机上,您也可以使用您最喜欢的 SFTP/FTP 客户端,将代码从您的系统传输到您的 Pi:

Figure 6: Utilize a SFTP/FTP client to transfer the Practical Python and OpenCV code from your system to the Raspberry Pi.
或者,您可能希望在阅读书籍时,使用内置的文本编辑器在 Pi 上手动编写代码:

Figure 7: Using the built-in text editor that ships with the Raspberry Pi to write code.
我建议要么通过网络浏览器下载这本书的源代码,要么使用 SFTP/FTP,因为这也包括书中使用的数据集。然而,手动编码是学习的好方法,我也强烈推荐它!
想了解更多关于如何用你的树莓 Pi 远程工作的技巧,请务必阅读我在树莓 Pi 博客上的 远程开发。
常见问题(FAQ)
在这一节中,我详细介绍了有关树莓派的常见问题的答案。img 文件。
哪些 Raspbian 映像与相应的硬件兼容?
以下是兼容性列表:
Raspbian3B_4B.img.gz:- Raspberry Pi 4B (1GB、2GB 和 4GB 型号)
- 树莓派 3B+
- 树莓派 3B
RaspbianZeroW.img.gz:- 树莓派零度 W
想自己在树莓派上安装 OpenCV + Python 怎么办?
无论如何,我鼓励你这样做。这是一个很好的练习,你会学到很多关于 Linux 环境的知识。我建议你跟随我的 的许多免费教程 安装 OpenCV + Python 你的树莓派。
同样,这个预先配置的 Raspbian 映像是为那些想要跳过安装过程和快速开始他们的教育的读者准备的。
手工安装 Python + OpenCV 需要多长时间?
我计算过数据,即使你确切地知道你在做什么,在树莓 Pi 4 上编译和安装 OpenCV 最少需要 55 分钟,在树莓 Pi Zero W 上大约需要 14 个小时
根据我对成功在树莓 Pi 上安装 OpenCV 的新手读者的调查,如果你以前从未安装过 OpenCV,或者你是不熟悉基于 Linux 的环境的 T2,这个数字会很容易地增加很多倍。
事实上,在 Raspberry Pi Zero W 上安装所有东西,包括 2 个环境(OpenCV 的 2 次编译)大约需要 6 天(包括通宵编译)。
这真的取决于你有多重视你的时间和你想多快开始学习计算机视觉。我总是鼓励你使用我的关于在 Raspberry Pi 上安装 OpenCV 的免费教程,但是如果你想节省自己的时间(和头痛),那么一定要考虑使用预配置的 Raspbian .img
Raspbian 图像包含在哪个实用 Python 和 OpenCV 包中?
预先配置好的 Raspbian 镜像包含在 实用 Python 和 OpenCV 的 快速启动包 和 硬拷贝包 中。预配置的 Raspbian 图像是而不是包含在基本包中。
Raspbian 图像包含在哪个Raspberry Pi for Computer Vision包中?
预先配置好的 Raspbian 镜像包含在所有捆绑包中: 爱好者、黑客、 和 完整捆绑包。
安装了你的 Raspbian 发行版之后,我如何访问 Python + OpenCV?
参见上面的“在您的 Raspberry Pi 上使用 Python 和 OpenCV”部分。
Wolfram 的 Mathematica 包含在你的 Raspbian 发行版中吗?
不,法律不允许我发布安装了 Mathematica 的 Raspbian 的修改版本(这是产品的一部分)。
您是如何减小 Raspbian 图像文件的大小的?
首先,我删除了不需要的软件,如 Wolfram 的 Mathematica 和 LibreOffice。仅删除这两个软件就节省了近 1GB 的空间。
从那里开始,通过将所有位归零并将文件压缩到。gz 格式。
Raspbian 包含哪个操作系统版本?
最新的。imgs 运行拉斯扁克星。
我有你以前的照片。为什么workon命令不起作用?
我以前的。img 在~/.bashrc中没有 virtualenvwrapper 设置(它们被放在~/.profile)。
因此,您需要(1)将 virtualenvwrapper 设置从~/.profile复制到~/.bashrc,或者(2)首先通过source ~/.profile获取概要文件。
树莓派上安装了哪些 Python 包?
访问任何虚拟环境后(参见“访问虚拟环境”),运行pip freeze查看安装的 Python 包的完整列表。
简而言之,我已经包含了 所有必要的 Python 包 你将需要成功地执行 树莓 Pi for Computer Vision 和 实用 Python 和 OpenCV 中的例子,包括 OpenCV、NumPy、SciPy、scikit-learn、scikit-image、mahotas 和许多其他的。单击下面的图像将其放大,这样您就可以看到所有的包:

Figure 8: A listing of the packages installed in each of the environments on the Raspberry Pi Raspbian .img.
在哪里可以了解更多关于 Python 虚拟环境的信息?
我最喜欢的资源和对 Python 虚拟环境的介绍可以在这里找到。我也在这篇博文的前半部分讨论了它们。
哪里可以购买到实用 Python 和 OpenCV 的副本?
要购买您的实用 Python 和 OpenCV 、副本,只需点击这里,选择您的包(我推荐快速入门包或硬拷贝包,然后结账。
哪里可以买到一份用于计算机视觉的 Raspberry Pi?
要购买您的计算机视觉、版树莓派,只需点击这里,选择您的捆绑包(如果您真的想掌握树莓派,我推荐黑客捆绑包或完整捆绑包,然后结账。
我可以购买。img 作为独立产品?
的。img 文件旨在作为额外的好处伴随我的书。我建议购买一本书来访问. img。
我还有一个问题。
如果您有本常见问题解答中未列出的问题,请给我发消息。
听起来不错吧?

Figure 9: Purchase (1) Raspberry Pi for Computer Vision, or (2) Practical Python and OpenCV + Case Studies to get ahold of the pre-configured Raspbian .img files!
如果你准备好把。要在你所有的树莓上使用,只需购买我的一本书。
要购买您的计算机视觉、、、版树莓派,只需点击此处、。所有包都带有预配置的 Raspbian。img 文件。
或者购买你的实用 Python 和 OpenCV 、、、的副本只需使用这个链接、、。你会发现预先配置的 Raspbian。在快速启动包和硬拷贝包中的 img 文件(基本包不包括 Raspbian。img)。
要查看我提供的所有产品, 点击这里 。**


 浙公网安备 33010602011771号
浙公网安备 33010602011771号