PyImgSearch-博客中文翻译-二-
PyImgSearch 博客中文翻译(二)
用 OpenCV 和 Python 实现自动色彩校正
原文:https://pyimagesearch.com/2021/02/15/automatic-color-correction-with-opencv-and-python/
在本教程中,您将学习如何使用颜色匹配/平衡卡在 OpenCV 中执行自动颜色校正。
上周我们发现了如何执行直方图匹配。使用直方图匹配,我们可以获取一幅图像的颜色分布,并将其与另一幅图像进行匹配。
色彩匹配的一个实际应用是通过色彩恒常性进行基本的色彩校正。 颜色恒常性的目标是正确感知物体的颜色不管光源、光照等的差异。(可以想象,说起来容易做起来难)。
摄影师和计算机视觉从业者可以通过使用颜色校正卡来帮助获得颜色恒常性,如下所示:
使用颜色校正/颜色恒常卡,我们可以:
- 在输入图像中检测颜色校正卡
- 计算卡片的直方图,它包含不同颜色、色调、阴影、黑色、白色和灰色的渐变颜色
- 将色卡中的直方图匹配应用于另一幅图像,从而尝试实现颜色恒常性
在本教程中,我们将使用 OpenCV 构建一个颜色校正系统,将我们从之前的教程中学到的所有内容整合在一起:
完成本指南后,您将了解色彩校正卡如何与直方图匹配结合使用来构建基本色彩校正器的基本原理,无论图像拍摄时的光照条件如何。
要了解如何使用 OpenCV 进行基本的色彩校正,继续阅读。
使用 OpenCV 和 Python 进行自动色彩校正
在本教程的第一部分,我们将讨论什么是色彩校正和色彩恒常性,包括 OpenCV 如何促进自动色彩校正。
然后,我们将为这个项目配置我们的开发环境,并检查我们的项目目录结构。
准备好开发环境后,我们将实现一个 Python 脚本,利用 OpenCV 来执行颜色校正。
我们将讨论我们的结果来结束本教程。
什么是自动色彩校正?
人类视觉系统受到照明和光源的显著影响。颜色恒常性是指对人类如何感知颜色的研究。
例如,看看维基百科关于颜色恒常性的文章中的下图:
看这张卡片,似乎粉色阴影(左第二张)的比底部的粉色阴影* 要强烈得多,但事实证明,它们是同一种颜色!*
这两张卡具有相同的 RGB 值。然而,我们人类的颜色感知系统会受到照片其余部分的色偏影响(即,在其顶部应用暖红色滤镜)。
如果我们试图使我们的图像处理环境正常化,这就产生了一点问题。正如我在之前关于 检测低对比度图像 的教程中所说:
为在 受控条件 下捕获的图像编写代码,要比在没有保证的 动态条件下容易得多。
如果我们能够尽可能地控制我们的图像捕获环境,那么编写代码来分析和处理这些从受控环境中捕获的图像就会变得更加容易。
这么想吧。。。假设我们可以安全地假设一个环境的照明条件。在这种情况下,我们可以放弃昂贵的计算机视觉/深度学习算法,这些算法可以帮助我们在非理想条件下获得理想的结果。相反,我们利用基本的图像处理例程,允许我们硬编码参数,包括高斯模糊大小,Canny 边缘检测阈值等。
本质上,有了受控的环境,我们可以摆脱基本的图像处理算法,而这些算法更容易实现。问题是我们需要对我们的照明条件做出安全的假设。色彩校正和白平衡有助于我们实现这一目标。
我们可以帮助控制我们的环境的一种方法是应用色彩校正,即使照明条件有一点改变。
颜色检查卡是摄影师最喜欢的工具:
摄影师将这些卡片放入他们正在拍摄的场景中。然后,他们拍摄照片,调整他们的照明(同时仍然保持卡在相机的视野内),然后继续拍摄,直到他们完成。
拍摄结束后,他们回到电脑前,将照片传输到他们的系统中,并使用工具,如 Adobe Lightroom 来实现整个拍摄过程中的颜色一致性(如果你感兴趣,这里有一个关于这个过程的教程)。
当然,作为计算机视觉从业者,我们没有使用 Adobe Lightroom 的奢侈,我们也不想通过手动调整色彩平衡来启动/停止我们的管道——这违背了使用软件来自动化现实世界流程的整个目的。
相反,我们可以利用这些相同的颜色校正卡,加上一些直方图匹配,我们可以构建一个能够执行颜色校正的系统。
在本指南的其余部分,您将利用直方图匹配和色彩校正卡(Pantone 的)来执行基本色彩校正。
潘通色彩校正卡
在本教程中,我们将使用 Pantone 的颜色匹配卡。
该卡类似于摄影师使用的颜色校正卡,但 Pantone 使用它来帮助消费者将场景中感知的颜色与 Pantone 销售的油漆色调(与该颜色最相似)相匹配。
总的想法是:
- 你把颜色校正卡放在你想要匹配的颜色上
- 你在手机上打开 Pantone 的智能手机应用程序
- 你给卡片拍了张照片
- 该应用程序自动检测卡,执行颜色匹配,然后返回 Pantone 销售的最相似的色调
出于我们的目的,我们将严格使用该卡进行颜色校正(但您可以根据自己的需要轻松扩展它)。
配置您的开发环境
要了解如何执行自动颜色校正,您需要安装 OpenCV 和 scikit-image:
两者都可以使用以下命令进行 pip 安装:
$ pip install opencv-contrib-python
$ pip install scikit-image==0.18.1
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
虽然颜色匹配和颜色校正看起来是一个复杂的过程,但是我们会发现,我们能够用不到 100 行代码(包括注释)完成整个项目。
但是在我们开始编码之前,让我们先回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像,然后查看文件夹:
$ tree . --dirsfirst
.
├── examples
│ ├── 01.jpg
│ ├── 02.jpg
│ └── 03.jpg
├── color_correction.py
└── reference.jpg
1 directory, 5 files
今天我们要回顾一个 Python 脚本,color_correction.py。该脚本将:
- 加载我们的
reference.png图像(包含我们的 Pantone 色彩校正卡) - 在
examples目录中加载一个图像(我们将对其进行颜色校正以匹配reference.png) - 通过中的 ArUco 标记检测检测配色卡参考和输入图像
- 应用直方图匹配来完善色彩校正过程
我们开始工作吧!
用 OpenCV 实现自动色彩校正
我们现在准备用 OpenCV 和 Python 实现颜色校正。
打开项目目录结构中的color_correction.py文件,让我们开始工作:
# import the necessary packages
from imutils.perspective import four_point_transform
from skimage import exposure
import numpy as np
import argparse
import imutils
import cv2
import sys
我们从第 2-8 行的开始,导入我们需要的 Python 包。值得注意的包括:
four_point_transform:应用透视变换获得输入配色卡的自上而下鸟瞰图。参见下面的教程中使用该功能的示例。exposure:包含 scikit-image 的直方图匹配功能。imutils:我的一套使用 OpenCV 进行图像处理的便捷函数。- 我们的 OpenCV 绑定。
处理好我们的导入后,我们可以继续定义find_color_card函数,这个方法负责在输入image中定位 Pantone 颜色匹配卡:
def find_color_card(image):
# load the ArUCo dictionary, grab the ArUCo parameters, and
# detect the markers in the input image
arucoDict = cv2.aruco.Dictionary_get(cv2.aruco.DICT_ARUCO_ORIGINAL)
arucoParams = cv2.aruco.DetectorParameters_create()
(corners, ids, rejected) = cv2.aruco.detectMarkers(image,
arucoDict, parameters=arucoParams)
我们的find_color_card函数只需要一个参数image,它是(大概)包含我们的颜色匹配卡的图像。
从那里,行 13-16 执行 ArUco 标记检测以找到配色卡上的四个 ArUco 标记。
接下来,让我们按左上、右上、右下和左下的顺序排列四个 ArUco 标记(应用自上而下透视变换所需的顺序):
# try to extract the coordinates of the color correction card
try:
# otherwise, we've found the four ArUco markers, so we can
# continue by flattening the ArUco IDs list
ids = ids.flatten()
# extract the top-left marker
i = np.squeeze(np.where(ids == 923))
topLeft = np.squeeze(corners[i])[0]
# extract the top-right marker
i = np.squeeze(np.where(ids == 1001))
topRight = np.squeeze(corners[i])[1]
# extract the bottom-right marker
i = np.squeeze(np.where(ids == 241))
bottomRight = np.squeeze(corners[i])[2]
# extract the bottom-left marker
i = np.squeeze(np.where(ids == 1007))
bottomLeft = np.squeeze(corners[i])[3]
# we could not find color correction card, so gracefully return
except:
return None
首先,我们将整个代码块包装在一个try/except块中。我们这样做只是为了防止使用np.where调用无法检测到所有四个标记。如果只有一个np.where调用失败,Python 将抛出一个错误。
我们的try/except块将捕获错误并返回None,暗示找不到颜色校正卡。
否则,行 25-38 按左上、右上、右下和左下的顺序提取每个单独的阿鲁科标记。
注意: 你可能想知道我怎么知道每个标记的 id 是923、1001、241和1007? 这在我之前的一套 ArUco 标记检测教程中已经解决了。如果你还没有看过那本教程,一定要看一看。
假设我们找到了所有四个 ArUco 标记,我们现在可以应用透视变换:
# build our list of reference points and apply a perspective
# transform to obtain a top-down, bird’s-eye view of the color
# matching card
cardCoords = np.array([topLeft, topRight,
bottomRight, bottomLeft])
card = four_point_transform(image, cardCoords)
# return the color matching card to the calling function
return card
第 47-49 行从我们的 ArUco 标记坐标构建一个 NumPy 数组,然后应用four_point_transform函数获得一个自上而下,颜色校正的鸟瞰图card。
将card的这个自顶向下的视图返回给调用函数。
实现了我们的find_color_card函数后,让我们继续解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-r", "--reference", required=True,
help="path to the input reference image")
ap.add_argument("-i", "--input", required=True,
help="path to the input image to apply color correction to")
args = vars(ap.parse_args())
为了执行颜色匹配,我们需要两幅图像:
- 到
--reference图像的路径包含“理想”条件下的输入场景,我们希望将任何输入图像校正到该条件下。 - 到
--input图像的路径,我们假设它有不同的颜色分布,大概是由于光照条件的变化。
我们的目标是获取--input图像并执行颜色匹配,使其分布与--reference图像的分布相匹配。
但在此之前,我们需要从磁盘加载参考和源图像:
# load the reference image and input images from disk
print("[INFO] loading images...")
ref = cv2.imread(args["reference"])
image = cv2.imread(args["input"])
# resize the reference and input images
ref = imutils.resize(ref, width=600)
image = imutils.resize(image, width=600)
# display the reference and input images to our screen
cv2.imshow("Reference", ref)
cv2.imshow("Input", image)
第 64 行和第 65 行从磁盘加载我们的输入图像,而第 68 行和第 69 行通过调整到 600 像素的宽度对它们进行预处理(以更快地处理图像)。
第 72 行和第 73 行然后将原始的ref和image显示到我们的屏幕上。
加载完我们的图像后,现在让我们将find_color_card函数应用于两幅图像:
# find the color matching card in each image
print("[INFO] finding color matching cards...")
refCard = find_color_card(ref)
imageCard = find_color_card(image)
# if the color matching card is not found in either the reference
# image or the input image, gracefully exit
if refCard is None or imageCard is None:
print("[INFO] could not find color matching card in both images")
sys.exit(0)
线 77 和 78 试图在ref和image中定位配色卡。
如果我们在任一图像中都找不到颜色匹配卡,我们优雅地退出脚本(第 82-84 行)。
否则,我们可以安全地假设我们找到了颜色匹配卡,所以让我们应用颜色校正:
# show the color matching card in the reference image and input image,
# respectively
cv2.imshow("Reference Color Card", refCard)
cv2.imshow("Input Color Card", imageCard)
# apply histogram matching from the color matching card in the
# reference image to the color matching card in the input image
print("[INFO] matching images...")
imageCard = exposure.match_histograms(imageCard, refCard,
multichannel=True)
# show our input color matching card after histogram matching
cv2.imshow("Input Color Card After Matching", imageCard)
cv2.waitKey(0)
第 88 和 89 行将我们的refCard和imageCard显示到我们的屏幕上。
然后我们应用match_histograms函数将颜色分布从refCard转移到imageCard。
最后,直方图匹配后的输出imageCard、、显示在我们的屏幕上。这个新的imageCard现在包含了原imageCard的色彩校正版本。
自动色彩校正结果
我们现在已经准备好用 OpenCV 进行自动色彩校正了!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,您可以打开一个 shell 并执行以下命令:
$ python color_correction.py --reference reference.jpg \
--input examples/01.jpg
[INFO] loading images...
[INFO] finding color matching cards...
[INFO] matching images...
在左边的,是我们的参考图像。请注意我们是如何将颜色校正卡放在蓝绿色阴影上的。我们这里的目标是确保蓝绿色的 阴影在所有输入图像中保持一致,不管光照条件如何变化。**
现在,检查右边的照片。这是我们的示例输入图像。你可以看到,由于光照条件的原因,蓝绿色比参考图像中的蓝绿色略亮。
怎样才能纠正这种表象?
答案是应用颜色校正:
在左边的,我们已经检测到参考图像中的色卡。中间的显示来自输入图像的色卡。最后右显示配色后的输入色卡。
注意右边的蓝绿色与输入参考图像中的蓝绿色更加相似(即右边的蓝绿色比中间的蓝绿色更暗)。
让我们尝试另一个图像:
$ python color_correction.py --reference reference.jpg \
--input examples/02.jpg
[INFO] loading images...
[INFO] finding color matching cards...
[INFO] matching images...
同样,我们从我们的参考图像(左)和我们的输入图像(右)开始,我们试图对它们应用颜色校正。
下面是我们应用颜色匹配后的输出:
左边的包含来自参考图像的配色卡,而中间的显示来自输入图像(02.jpg)的配色卡。你可以看到中间图中的蓝绿色明显比左边图中的蓝绿色亮。****
通过应用颜色匹配和校正,我们可以校正这个视差(右)。注意左边的和右边的*的蓝绿色更加相似。**
这是最后一个例子:
$ python color_correction.py --reference reference.jpg \
--input examples/03.jpg
[INFO] loading images...
[INFO] finding color matching cards...
[INFO] matching images...
这里的光照条件与前两者有明显的不同。左边的图像是我们的参考图像(在我的办公室拍摄),而右边的图像是输入图像(在我的卧室拍摄)。
由于卧室中的窗户以及那天阳光是如何进入窗户的,配色卡的右侧有明显的阴影,从而使这更具挑战性(并展示了这种基本颜色校正方法的一些局限性)。
下面是通过直方图匹配应用颜色校正的输出:
左边的图像是我们参考图像中的颜色匹配卡。然后我们就有了从输入图像中检测到的颜色校正卡(03.jpg)。
应用直方图匹配产生右侧的图像。虽然我们仍然有阴影,我们可以看到来自中间的较亮的蓝绿色已经被修正,以更相似地匹配来自参考图像的原始较暗的蓝绿色。
总结
在本教程中,您学习了如何使用 OpenCV 和 Python 执行基本的颜色校正。
我们通过以下方式实现了这一目标:
- 将颜色校正卡放在我们相机的视野中
- 拍摄现场照片
- 使用 ArUco 标记检测来检测颜色校正卡
- 应用直方图匹配将卡片的颜色分布转移到另一幅图像
综合起来,我们可以把这个过程看作是一个色彩校正过程(尽管是非常基本的)。
实现纯色恒常性,尤其是在没有标记/颜色校正卡的情况下实现纯色恒常性,仍然是一个活跃的研究领域,并且可能会持续很多年。但与此同时,我们可以利用直方图匹配和颜色匹配卡让我们朝着正确的方向前进。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
自动微分第 1 部分:理解数学
原文:https://pyimagesearch.com/2022/12/05/automatic-differentiation-part-1-understanding-the-math/
目录
自动微分第一部分:理解数学
在本教程中,你将学习反向传播所需的自动微分背后的数学。
本课是关于Autodiff 101-从头开始了解自动区分的两部分系列的第一部分:
- 自动微分第一部分:理解数学 (今日教程)
- 自动微分第 2 部分:使用微克实现
要了解自动微分, 只需继续阅读。
自动微分第一部分:理解数学
想象你正徒步下山。天很黑,有很多颠簸和转弯。你无法知道如何到达中心。现在想象一下,你每前进一次,都要暂停一下,拿出山丘的拓扑图,计算下一组你的方向和速度。听起来很无趣,对吧?
如果你读过我们的教程,你会知道这个类比指的是什么。小山是你的损失景观,拓扑图是多元微积分的规则集,你是神经网络的参数。目标是达到全局最小值。
这就引出了一个问题:
为什么我们今天使用深度学习框架?
脑海里首先闪现的是自动微分。我们写向前传球,就是这样;不用担心后传。每个操作符都是自动微分的,并等待在优化算法中使用(如随机梯度下降)。
今天在本教程中,我们将走过自动微分的山谷。
简介
在本节中,我们将为理解autodiff奠定必要的基础。
雅可比
让我们考虑一个函数
.  is a multivariate function that simultaneously depends on multiple variables. Here the multiple variables can be
is a multivariate function that simultaneously depends on multiple variables. Here the multiple variables can be  . The output of the function is a scalar value. This can be considered as a neural network that takes an image and outputs the probability of a dog’s presence in the image.
. The output of the function is a scalar value. This can be considered as a neural network that takes an image and outputs the probability of a dog’s presence in the image.
注意 : 让我们回忆一下,在神经网络中,我们计算的是关于参数(权重和偏差)而不是输入(图像)的梯度。因此,函数的域是参数而不是输入,这有助于保持梯度计算的可访问性。我们现在需要从使简单和有效的角度考虑我们在本教程中所做的一切,以获得关于权重和偏差(参数)的梯度。图 1 中的对此进行了说明。
神经网络由许多子层组成。所以让我们考虑一下我们的函数")
as a composition of multiple functions (primitive operations).
 \ = \ D \circ C \circ B \circ A")
该功能
is composed of four primitive functions, namely  . For anyone new to composition, we can call to be a function where
. For anyone new to composition, we can call to be a function where )))") is equal to .
is equal to .
下一步是找到的梯度
. However, before diving into the gradients of the function, let us revisit Jacobian matrices. It turns out that the derivatives of a multivariate function are a Jacobian matrix consisting of partial derivatives of the function w.r.t. all the variables upon which it depends.
考虑两个多元函数,
and  , which depend on the variables
, which depend on the variables  and
and  . The Jacobian would look like this:
. The Jacobian would look like this:
}}{\partial{x, y}} \ = \ \begin{bmatrix} \displaystyle\frac{\partial u}{\partial x} & \displaystyle\frac{\partial u}{\partial y}\ \ \displaystyle\frac{\partial v}{\partial x} & \displaystyle\frac{\partial v}{\partial y} \end{bmatrix}")
现在让我们计算函数的雅可比矩阵
. We need to note here that the function depends of  variables , and outputs a scalar value. This means that the Jacobian will be a row vector.
variables , and outputs a scalar value. This means that the Jacobian will be a row vector.
 \ = \ \displaystyle\frac{\partial{y}}{\partial{x}} \ = \ \begin{bmatrix} \displaystyle\frac{\partial y}{\partial x_{1}} & \ldots & \displaystyle\frac{\partial y}{\partial x_{n}} \end{bmatrix}")
链式法则
还记得我们的函数
is composed of many primitive functions? The derivative of such a composed function is done with the help of the chain rule. To help our way into the chain rule, let us first write down the composition and then define the intermediate values.
 = D(C(B(A(x))))")
is composed of:
")
")
")
")
现在作文已经拼出来了,我们先来求中间值的导数。
 = \displaystyle\frac{\partial{y}}{\partial{c}}")
 = \displaystyle\frac{\partial{c}}{\partial{b}}")
 = \displaystyle\frac{\partial{b}}{\partial{a}}")
 = \displaystyle\frac{\partial{a}}{\partial{x}}")
现在借助链式法则,我们推导出函数的导数
.
 \ = \ \displaystyle\frac{\partial{y}}{\partial{c}} \displaystyle\frac{\partial{c}}{\partial{b}} \displaystyle\frac{\partial{b}}{\partial{a}} \displaystyle\frac{\partial{a}}{\partial{x}}")
混合了雅可比和链式法则
在了解了雅可比矩阵和链式法则之后,让我们一起将两者形象化。如图二所示。
我们函数的导数
is just the matrix multiplication of the Jacobian matrices of the intermediate terms.
现在,这就是我们要问的问题:
我们做矩阵乘法的顺序有关系吗?
正向和反向累加
在本节中,我们试图理解雅可比矩阵乘法排序问题的答案。
在两种极端情况下,我们可以对乘法进行排序:正向累加和反向累加。
正向累加
如果我们按照与函数相同的顺序从右到左排列乘法
was evaluated, the process is called forward accumulation. The best way to think about the ordering is to place brackets in the equation, as shown in Figure 3.
 \ = \ \displaystyle\frac{\partial{y}}{\partial{c}} \left(\frac{\partial{c}}{\partial{b}} \left(\frac{\partial{b}}{\partial{a}} \displaystyle\frac{\partial{a}}{\partial{x}}\right)\right)")
使用功能
, the forward accumulation process is matrix multiplication in all the steps. This is more FLOPs.
注意: 向前累加在我们想要得到一个函数的导数的时候是很有好处的
.
理解转发累加的另一种方式是考虑雅可比矢量积(JVP)。考虑一个雅各比派")
and a vector . The Jacobian-Vector Product would look to be v")
v \ = \ \displaystyle\frac{\partial{y}}{\partial{c}} \left(\displaystyle\frac{\partial{c}}{\partial{b}} \left(\displaystyle\frac{\partial{b}}{\partial{a}} \left(\displaystyle\frac{\partial{a}}{\partial{x}} v\right)\right)\right)")
这样做是为了让我们在所有阶段都有矩阵向量乘法(这使得过程更有效)。
➤ 问题:如果我们有一个雅可比矢量积,我们如何从中获得雅可比?
➤ 回答:我们传递一个热点向量,一次得到雅可比矩阵的每一列。
因此,我们可以将前向累加视为一个过程,在此过程中,我们构建每列的雅可比矩阵。
反向积累
假设我们从左到右对乘法进行排序,方向与函数求值的方向相反。在这种情况下,这个过程叫做反向积累。该过程的示意图如图 4 所示。
 \ = \ \left(\left(\displaystyle\frac{\partial{y}}{\partial{c}} \displaystyle\frac{\partial{c}}{\partial{b}}\right) \displaystyle\frac{\partial{b}}{\partial{a}} \right)\displaystyle\frac{\partial{a}}{\partial{x}}")
事实证明,用反向累加来推导一个函数的导数
is a vector to matrix multiplication at all steps. This means that for the particular function, reverse accumulation has lesser FLOPs than forwarding accumulation.
理解前向累加的另一种方法是考虑一个矢量雅可比乘积(VJP)。考虑一个雅各比派
and a vector . The Vector-Jacobian Product would look to be ")
 \ = \ \left(\left(\left(v^{T} \displaystyle\frac{\partial{y}}{\partial{c}}\right) \displaystyle\frac{\partial{c}}{\partial{b}}\right) \displaystyle\frac{\partial{b}}{\partial{a}}\right)\displaystyle\frac{\partial{a}}{\partial{x}}")
这允许我们在所有阶段进行向量矩阵乘法(这使得过程更有效)。
➤ 问题:如果我们有一个向量雅可比乘积,我们如何从中获得雅可比?
➤ 回答:我们传递一个独热向量,一次得到雅可比矩阵的每一行。
所以我们可以把逆向累加看作是一个建立每行雅可比矩阵的过程。
现在,如果我们考虑我们之前提到的函数
, we know that the Jacobian is a row vector. Therefore, if we apply the reverse accumulation process, which means the Vector-Jacobian Product, we can obtain the row vector in one shot. On the other hand, if we apply the forward accumulation process, the Jacobian-Vector Product, we will obtain a single element as a column, and we would need to iterate to build the entire row.
这就是为什么反向累加在神经网络文献中更常用的原因。
汇总
在本教程中,我们学习了自动微分的数学,以及如何将其应用于神经网络的参数。下一篇教程将对此进行扩展,看看我们如何使用 python 包实现自动微分。该实现将涉及创建 python 包并使用它来训练神经网络的逐步演练。
你喜欢关于自动微分基础的数学教程吗?让我们知道。
推特: @PyImageSearch
参考文献
引用信息
A. R. Gosthipaty 和 R. Raha。“自动微分第一部分:理解数学”, PyImageSearch ,P. Chugh、S. Huot、K. Kidriavsteva 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/pyxml
@incollection{ARG-RR_2022_autodiff1,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Automatic Differentiation Part 1: Understanding the Math},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/pyxml},
}
自动微分第 2 部分:使用微图形实现
目录
自动微分第二部分:使用微克实现
在本教程中,您将学习如何在名为micrograd的 Python 包的帮助下进行自动微分。
本课是关于 Autodiff 101 的两部分系列的最后一课——从头开始理解自动区分:
- 自动微分第一部分:理解数学
- 自动微分第二部分:使用微克实现 (今日教程)
要学习如何使用 Python 实现自动微分,继续阅读即可。
自动微分第二部分:使用微克实现
简介
什么是神经网络?
神经网络是我们大脑的数学抽象(至少,它是这样开始的)。该系统由许多可学习的旋钮(权重和偏差)和一个简单的操作(点积)组成。神经网络接受输入,并使用一个目标函数,我们需要通过旋转旋钮来优化该函数。调谐旋钮的最佳方式是使用目标函数相对于所有单个旋钮的梯度作为信号。
如果你坐下来试着用手算一下梯度,会花很长时间。所以,为了绕过这个过程,我们使用自动微分的概念。
在之前的教程中,我们深入学习了自动微分的数学。本教程将应用概念,从头开始理解自动微分 Python 包。
我们今天要讲的这个包叫做 micrograd 。这是一个由安德烈·卡帕西创建的开源 Python 包。我们已经学习了视频讲座,Andrej 从零开始构建这个包。在这里,我们将视频讲座分解到一个博客中,并添加我们的想法来丰富内容。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
关于micrograd
micrograd是一个 Python 包,旨在理解反向累积(反向传播)过程如何在 PyTorch 或 Jax 等现代深度学习包中工作。这是一个简单的自动微分包,仅适用于标量。
导入和设置
import math
import random
from typing import List, Tuple, Union
from matplotlib import pyplot as plt
Value班
我们从定义Value类开始。为了以后进行跟踪和反向传播,将原始标量值包装到Value类中变得非常重要。
当包装在Value类中时,标量值被认为是图形的节点。当我们使用Value s 并建立一个等式时,这个等式被认为是一个有向无环图 (DAG)。在演算和图遍历的帮助下,我们自动计算节点的梯度(autodiff)并通过它们反向传播。
Value类具有以下属性:
data:需要包装在Value类中的原始浮点数据。grad:这个会保存节点的全局导数。全局导数是根节点(最终节点)相对于当前节点的偏导数。- 这是一个私有方法,计算当前节点的子节点的全局导数。
_prev:当前节点的子节点。
class Value(object):
"""
We need to wrap the raw data into a class that will store the
metadata to help in automatic differentiation.
Attributes:
data (float): The data for the Value node.
_children (Tuple): The children of the current node.
"""
def __init__(self, data: float, _children: Tuple = ()):
# The raw data for the Value node.
self.data = data
# The partial gradient of the last node with respect to this
# node. This is also termed as the global gradient.
# Gradient 0.0 means that there is no effect of the change
# of the last node with respect to this node. On
# initialization it is assumed that all the variables have no
# effect on the entire architecture.
self.grad = 0.0
# The function that derives the gradient of the children nodes
# of the current node. It is easier this way, because each node
# is built from children nodes and an operation. Upon back-propagation
# the current node can easily fill in the gradients of the children.
# Note: The global gradient is the multiplication of the local gradient
# and the flowing gradient from the parent.
self._backward = lambda: None
# Define the children of this node.
self._prev = set(_children)
def __repr__(self):
# This is the string representation of the Value node.
return f"Value(data={self.data}, grad={self.grad})"
# Build a Value node
raw_data = 5.0
print(f"Raw Data(data={raw_data}, type={type(raw_data)}")
value_node = Value(data=raw_data)
# Calling the `__repr__` function here
print(value_node)
>>> Raw Data(data=5.0, type=<class 'float'>
>>> Value(data=5.0, grad=0.0)
加法
现在我们已经构建了我们的Value类,我们需要定义原始操作和它们的_backward函数。这将有助于跟踪每个节点的操作,并通过 DAG 表达式反向传播梯度。
在本节中,我们处理加法操作。这将有助于两个值相加。当我们使用+操作符时,Python 类有一个特殊的方法__add__被调用,如图图 1 所示。
这里我们创建了custom_addition函数,这个函数后来被分配给了Value类的__add__方法。这样做是为了让我们把重点放在加法方法上,舍弃一切对加法运算不重要的东西。
加法运算非常简单:
- 将
self和other节点作为调用的参数。然后我们取他们的data并应用加法。 - 然后,结果被包装在
Value类中。 - 节点
out被初始化,这里我们提到self和other是它的孩子。
计算梯度
对于我们定义的每个原始操作,我们都会有这个部分。例如,为了计算子节点的全局梯度,我们需要定义addition操作的局部梯度。
让我们考虑一个节点
that is built by adding two children nodes  and
and  . Then, the partial derivatives of are derived in Figure 2.
. Then, the partial derivatives of are derived in Figure 2.
现在想想反向传播。损失(目标)函数的偏导数
is already deduced for . This means we have }/{(\partial{c})}") . This gradient needs to flow to the child nodes and , respectively.
. This gradient needs to flow to the child nodes and , respectively.
应用链式法则,我们得到的全局梯度
and , as shown in Figure 3.
加法运算就像一个路由器作用于流入的渐变。它将渐变路由到所有的子节点。
➤ 注: 在我们定义的_backward函数中,我们用+=运算累加子代的渐变。这样做是为了绕过一个独特的情况。假设我们有
. Here we know that the expression can be simplified to  , but our
, but our _backward for __add__ does not know how to do this. The __backward__ in __add__ treats one as self and the other as other. If the gradients are not accumulated, we will see a discrepancy with the gradients.
def custom_addition(self, other: Union["Value", float]) -> "Value":
"""
The addition operation for the Value class.
Args:
other (Union["Value", float]): The other value to add to this one.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = x + y
>>> z.data
5
"""
# If the other value is not a Value, then we need to wrap it.
other = other if isinstance(other, Value) else Value(other)
# Create a new Value node that will be the output of the addition.
out = Value(data=self.data + other.data, _children=(self, other))
def _backward():
# Local gradient:
# x = a + b
# dx/da = 1
# dx/db = 1
# Global gradient with chain rule:
# dy/da = dy/dx . dx/da = dy/dx . 1
# dy/db = dy/dx . dx/db = dy/dx . 1
self.grad += out.grad * 1.0
other.grad += out.grad * 1.0
# Set the backward function on the output node.
out._backward = _backward
return out
def custom_reverse_addition(self, other):
"""
Reverse addition operation for the Value class.
Args:
other (float): The other value to add to this one.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = y + x
>>> z.data
5
"""
# This is the same as adding. We can reuse the __add__ method.
return self + other
Value.__add__ = custom_addition
Value.__radd__ = custom_reverse_addition
# Build a and b
a = Value(data=5.0)
b = Value(data=6.0)
# Print the addition
print(f"{a} + {b} => {a+b}")
>>> Value(data=5.0, grad=0.0) + Value(data=6.0, grad=0.0) => Value(data=11.0, grad=0.0)
# Add a and b
c = a + b
# Assign a global gradient to c
c.grad = 11.0
print(f"c => {c}")
# Now apply `_backward` to c
c._backward()
print(f"a => {a}")
print(f"b => {b}")
>>> c => Value(data=11.0, grad=11.0)
>>> a => Value(data=5.0, grad=11.0)
>>> b => Value(data=6.0, grad=11.0)
➤ 注:的全局渐变
is routed to and .
乘法
在这一节中,我们处理乘法运算。当我们使用*操作符时,Python 类有一个特殊的方法__mul__被调用,如图图 4 所示。
我们将self和other节点作为调用的参数。然后我们取他们的data并应用乘法。然后结果被包装在Value类中。最后,out节点被初始化,这里我们提到self和other是它的子节点。
计算梯度
让我们考虑一个节点
that is built by multiplying two children nodes and . Then, the partial derivatives of are shown in Figure 5.
现在想想反向传播。损失(目标)函数的偏导数
is already deduced for . This means we have . This gradient needs to flow to the children nodes  and , respectively.
and , respectively.
应用链式法则,我们得到的全局梯度
and , as shown in Figure 6.
def custom_multiplication(self, other: Union["Value", float]) -> "Value":
"""
The multiplication operation for the Value class.
Args:
other (float): The other value to multiply to this one.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = x * y
>>> z.data
6
"""
# If the other value is not a Value, then we need to wrap it.
other = other if isinstance(other, Value) else Value(other)
# Create a new Value node that will be the output of
# the multiplication.
out = Value(data=self.data * other.data, _children=(self, other))
def _backward():
# Local gradient:
# x = a * b
# dx/da = b
# dx/db = a
# Global gradient with chain rule:
# dy/da = dy/dx . dx/da = dy/dx . b
# dy/db = dy/dx . dx/db = dy/dx . a
self.grad += out.grad * other.data
other.grad += out.grad * self.data
# Set the backward function on the output node.
out._backward = _backward
return out
def custom_reverse_multiplication(self, other):
"""
Reverse multiplication operation for the Value class.
Args:
other (float): The other value to multiply to this one.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = y * x
>>> z.data
6
"""
# This is the same as multiplying. We can reuse the __mul__ method.
return self * other
Value.__mul__ = custom_multiplication
Value.__rmul__ = custom_reverse_multiplication
# Build a and b
a = Value(data=5.0)
b = Value(data=6.0)
# Print the multiplication
print(f"{a} * {b} => {a*b}")
>>> Value(data=5.0, grad=0.0) * Value(data=6.0, grad=0.0) => Value(data=30.0, grad=0.0)
# Multiply a and b
c = a * b
# Assign a global gradient to c
c.grad = 11.0
print(f"c => {c}")
# Now apply `_backward` to c
c._backward()
print(f"a => {a}")
print(f"b => {b}")
>>> c => Value(data=30.0, grad=11.0)
>>> a => Value(data=5.0, grad=66.0)
>>> b => Value(data=6.0, grad=55.0)
力量
在本节中,我们处理电源的操作。Python 类有一个特殊的方法__pow__,当我们使用**操作符时会调用这个方法,如图图 7 所示。
在获得作为调用参数的self和other节点后,我们获取它们的data并应用幂运算。
计算梯度
让我们考虑一个节点
that is built by multiplying two children nodes and . Then, the partial derivatives of are derived in Figure 8.
现在想想反向传播。损失(目标)函数的偏导数
is already deduced for . This means we have . This gradient needs to flow to the child node .
应用链式法则,我们得到的全局梯度
and , as shown in Figure 9.
def custom_power(self, other):
"""
The power operation for the Value class.
Args:
other (float): The other value to raise this one to.
Usage:
>>> x = Value(2)
>>> z = x ** 2.0
>>> z.data
4
"""
assert isinstance(
other, (int, float)
), "only supporting int/float powers for now"
# Create a new Value node that will be the output of the power.
out = Value(data=self.data ** other, _children=(self,))
def _backward():
# Local gradient:
# x = a ** b
# dx/da = b * a ** (b - 1)
# Global gradient:
# dy/da = dy/dx . dx/da = dy/dx . b * a ** (b - 1)
self.grad += out.grad * (other * self.data ** (other - 1))
# Set the backward function on the output node.
out._backward = _backward
return out
Value.__pow__ = custom_power
# Build a
a = Value(data=5.0)
# For power operation we will use
# the raw data and not wrap it into
# a node. This is done for simplicity.
b = 2.0
# Print the power operation
print(f"{a} ** {b} => {a**b}")
>>> Value(data=5.0, grad=0.0) ** 2.0 => Value(data=25.0, grad=0.0)
# Raise a to the power of b
c = a ** b
# Assign a global gradient to c
c.grad = 11.0
print(f"c => {c}")
# Now apply `_backward` to c
c._backward()
print(f"a => {a}")
print(f"b => {b}")
>>> c => Value(data=25.0, grad=11.0)
>>> a => Value(data=5.0, grad=110.0)
>>> b => 2.0
否定
对于否定操作,我们将使用上面定义的__mul__操作。此外,Python 类有一个特殊的方法__neg__,当我们使用一元-操作符时,这个方法被调用,如图图 10 所示。
这意味着否定的_backward将被处理,我们不需要明确地定义它。
def custom_negation(self):
"""
Negation operation for the Value class.
Usage:
>>> x = Value(2)
>>> z = -x
>>> z.data
-2
"""
# This is the same as multiplying by -1\. We can reuse the
# __mul__ method.
return self * -1
Value.__neg__ = custom_negation
# Build `a`
a = Value(data=5.0)
# Print the negation
print(f"Negation of {a} => {(-a)}")
>>> Negation of Value(data=5.0, grad=0.0) => Value(data=-5.0, grad=0.0)
# Negate a
c = -a
# Assign a global gradient to c
c.grad = 11.0
print(f"c => {c}")
# Now apply `_backward` to c
c._backward()
print(f"a => {a}")
>>> c => Value(data=-5.0, grad=11.0)
>>> a => Value(data=5.0, grad=-11.0)
减法
减法操作可以用__add__和__neg__来处理。此外,当我们使用-操作符时,Python 类有一个特殊的方法__sub__被调用,如图图 11 所示。
这将帮助我们将_backward减法运算委托给加法和否定运算。
def custom_subtraction(self, other):
"""
Subtraction operation for the Value class.
Args:
other (float): The other value to subtract to this one.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = x - y
>>> z.data
-1
"""
# This is the same as adding the negative of the other value.
# We can reuse the __add__ and the __neg__ methods.
return self + (-other)
def custom_reverse_subtraction(self, other):
"""
Reverse subtraction operation for the Value class.
Args:
other (float): The other value to subtract to this one.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = y - x
>>> z.data
1
"""
# This is the same as subtracting. We can reuse the __sub__ method.
return other + (-self)
Value.__sub__ = custom_subtraction
Value.__rsub__ = custom_reverse_subtraction
# Build a and b
a = Value(data=5.0)
b = Value(data=4.0)
# Print the negation
print(f"{a} - {b} => {(a-b)}")
>>> Value(data=5.0, grad=0.0) - Value(data=4.0, grad=0.0) => Value(data=1.0, grad=0.0)
# Subtract b from a
c = a - b
# Assign a global gradient to c
c.grad = 11.0
print(f"c => {c}")
# Now apply `_backward` to c
c._backward()
print(f"a => {a}")
print(f"b => {b}")
>>> c => Value(data=1.0, grad=11.0)
>>> a => Value(data=5.0, grad=11.0)
>>> b => Value(data=4.0, grad=0.0)
➤ 注: 渐变并没有像纸上想象的那样流动。为什么?你能想出这个问题的答案吗?
➤ 提示: 减法运算由一个以上的原始运算组成:否定和加法。
我们将在教程的后面讨论这一点。
师
分割操作可以用__mul__和__pow__来处理。此外,当我们使用/操作符时,Python 类有一个特殊的方法__div__被调用,如图图 12 所示。
这将帮助我们将_backward除法运算委托给幂运算。
def custom_division(self, other):
"""
Division operation for the Value class.
Args:
other (float): The other value to divide to this one.
Usage:
>>> x = Value(10)
>>> y = Value(5)
>>> z = x / y
>>> z.data
2
"""
# Use the __pow__ method to implement division.
return self * other ** -1
def custom_reverse_division(self, other):
"""
Reverse division operation for the Value class.
Args:
other (float): The other value to divide to this one.
Usage:
>>> x = Value(10)
>>> y = Value(5)
>>> z = y / x
>>> z.data
0.5
"""
# Use the __pow__ method to implement division.
return other * self ** -1
Value.__truediv__ = custom_division
Value.__rtruediv__ = custom_reverse_division
# Build a and b
a = Value(data=6.0)
b = Value(data=3.0)
# Print the negation
print(f"{a} / {b} => {(a/b)}")
>>> Value(data=6.0, grad=0.0) / Value(data=3.0, grad=0.0) => Value(data=2.0, grad=0.0)
# Divide a with b
c = a / b
# Assign a global gradient to c
c.grad = 11.0
print(f"c => {c}")
# Now apply `_backward` to c
c._backward()
print(f"a => {a}")
print(f"b => {b}")
>>> c => Value(data=2.0, grad=11.0)
>>> a => Value(data=6.0, grad=3.6666666666666665)
>>> b => Value(data=3.0, grad=0.0)
➤,在除法中,我们看到了和减法一样的梯度流问题。你已经解决问题了吗?👀
RectivedLlinearUnit
在本节中,我们介绍非线性。ReLU 是不是一个原函数;我们需要为它构建函数和_backward函数。
def relu(self):
"""
The ReLU activation function.
Usage:
>>> x = Value(-2)
>>> y = x.relu()
>>> y.data
0
"""
out = Value(data=0 if self.data < 0 else self.data, _children=(self,))
def _backward():
# Local gradient:
# x = relu(a)
# dx/da = 0 if a < 0 else 1
# Global gradient:
# dy/da = dy/dx . dx/da = dy/dx . (0 if a < 0 else 1)
self.grad += out.grad * (out.data > 0)
# Set the backward function on the output node.
out._backward = _backward
return out
Value.relu = relu
# Build a
a = Value(data=6.0)
# Print a and the negation
print(f"ReLU ({a}) => {(a.relu())}")
print(f"ReLU (-{a}) => {((-a).relu())}")
>>> ReLU (Value(data=6.0, grad=0.0)) => Value(data=6.0, grad=0.0)
>>> ReLU (-Value(data=6.0, grad=0.0)) => Value(data=0, grad=0.0)
# Build a and b
a = Value(3.0)
b = Value(-3.0)
# Apply relu on both the nodes
relu_a = a.relu()
relu_b = b.relu()
# Assign a global gradients
relu_a.grad = 11.0
relu_b.grad = 11.0
# Now apply `_backward`
relu_a._backward()
print(f"a => {a}")
relu_b._backward()
print(f"b => {b}")
>>> a => Value(data=3.0, grad=11.0)
>>> b => Value(data=-3.0, grad=0.0)
全球落后
到目前为止,我们已经设计了原语和非原语(ReLU)函数及其各自的_backward方法。每个图元只能将流动渐变支持到其子图元。
我们现在必须设计一种方法,在 DAG(构建的方程)中迭代所有这样的原始方法,并在整个表达式中反向传播梯度。
为此,Value调用需要一个全局backward方法。我们在 DAG 的最后一个节点上应用backward函数。该函数执行以下操作:
- 按拓扑顺序对 DAG 进行排序
- 将最后一个节点的
grad设置为 1.0 - 遍历拓扑排序的图,并应用每个原语的
_backward方法。
def backward(self):
"""
The backward pass of the backward propagation algorithm.
Usage:
>>> x = Value(2)
>>> y = Value(3)
>>> z = x * y
>>> z.backward()
>>> x.grad
3
>>> y.grad
2
"""
# Build an empty list which will hold the
# topologically sorted graph
topo = []
# Build a set of all the visited nodes
visited = set()
# A closure to help build the topologically sorted graph
def build_topo(node: "Value"):
if node not in visited:
# If node is not visited add the node to the
# visited set.
visited.add(node)
# Iterate over the children of the node that
# is being visited
for child in node._prev:
# Apply recursion to build the topologically sorted
# graph of the children
build_topo(child)
# Only append node to the topologically sorted list
# if all its children are visited.
topo.append(node)
# Call the `build_topo` method on self
build_topo(self)
# Go one node at a time and apply the chain rule
# to get its gradient
self.grad = 1.0
for node in reversed(topo):
node._backward()
Value.backward = backward
# Now create an expression that uses a lot of
# primitive operations
a = Value(2.0)
b = Value(3.0)
c = a+b
d = 4.0
e = c**d
f = Value(6.0)
g = e/f
print(“BEFORE backward”)
for element in [a, b, c, d, e, f, g]:
print(element)
# Backward on the final node will backprop
# the gradients through the entire DAG
g.backward()
print(“AFTER backward”)
for element in [a, b, c, d, e, f, g]:
print(element)
>>> BEFORE backward
>>> Value(data=2.0, grad=0.0)
>>> Value(data=3.0, grad=0.0)
>>> Value(data=5.0, grad=0.0)
>>> 4.0
>>> Value(data=625.0, grad=0.0)
>>> Value(data=6.0, grad=0.0)
>>> Value(data=104.16666666666666, grad=0.0)
>>> AFTER backward
>>> Value(data=2.0, grad=83.33333333333333)
>>> Value(data=3.0, grad=83.33333333333333)
>>> Value(data=5.0, grad=83.33333333333333)
>>> 4.0
>>> Value(data=625.0, grad=0.16666666666666666)
>>> Value(data=6.0, grad=-17.36111111111111)
>>> Value(data=104.16666666666666, grad=1.0)
还记得我们关于__sub__和__div__的问题吗?梯度并不按照微积分的规则反向传播。实现_backward功能没有错。
但是,这两个操作(__sub__和__div__)是用不止一个原始操作(__neg__和__add__用于__sub__)构建的;__mul__和__pow__为__div__。
这会创建一个中间节点,阻止渐变正确地流向子节点(记住,_backward不应该通过整个 DAG 反向传播渐变)。
# Solve the problem with subtraction
a = Value(data=6.0)
b = Value(data=3.0)
c = a - b
c.backward()
print(f"c => {c}")
print(f"a => {a}")
print(f"b => {b}")
c => Value(data=3.0, grad=1.0)
a => Value(data=6.0, grad=1.0)
b => Value(data=3.0, grad=-1.0)
# Solve the problem with division
a = Value(data=6.0)
b = Value(data=3.0)
c = a / b
c.backward()
print(f"c => {c}")
print(f"a => {a}")
print(f"b => {b}")
>>> c => Value(data=2.0, grad=1.0)
>>> a => Value(data=6.0, grad=0.3333333333333333)
>>> b => Value(data=3.0, grad=-0.6666666666666666)
用micrograd 构建多层感知器
如果我们只是构建Value类,而不是用它来构建神经网络,那有什么好处呢?
在本节中,我们构建了一个非常简单的神经网络(多层感知器),并使用它来建模一个简单的数据集。
模块
这是父类。Module类有两个方法:
zero_grad:用于将参数的所有梯度归零。parameters:该功能被构建为可被覆盖。这将最终为我们获得神经元、层和 mlp 的参数。
class Module(object):
"""
The parent class for all neural network modules.
"""
def zero_grad(self):
# Zero out the gradients of all parameters.
for p in self.parameters():
p.grad = 0
def parameters(self):
# Initialize a parameters function that all the children will
# override and return a list of parameters.
return []
神经元
这是我们神经网络的单元,整个结构就是建立在这个单元上的。它有一个权重列表和一个偏好。神经元的功能如图图 13 所示。
class Neuron(Module):
"""
A single neuron.
Parameters:
number_inputs (int): number of inputs
is_nonlinear (bool): whether to apply ReLU nonlinearity
name (int): the index of neuron
"""
def __init__(self, number_inputs: int, name, is_nonlinear: bool = True):
# Create weights for the neuron. The weights are initialized
# from a random uniform distribution.
self.weights = [Value(data=random.uniform(-1, 1)) for _ in range(number_inputs)]
# Create bias for the neuron.
self.bias = Value(data=0.0)
self.is_nonlinear = is_nonlinear
self.name = name
def __call__(self, x: List["Value"]) -> "Value":
# Compute the dot product of the input and the weights. Add the
# bias to the dot product.
act = sum(
((wi * xi) for wi, xi in zip(self.weights, x)),
self.bias
)
# If activation is mentioned, apply ReLU to it.
return act.relu() if self.is_nonlinear else act
def parameters(self):
# Get the parameters of the neuron. The parameters of a neuron
# is its weights and bias.
return self.weights + [self.bias]
def __repr__(self):
# Print a better representation of the neuron.
return f"Neuron {self.name}(Number={len(self.weights)}, Non-Linearity={'ReLU' if self.is_nonlinear else 'None'})"
x = [2.0, 3.0]
neuron = Neuron(number_inputs=2, name=1)
print(neuron)
out = neuron(x)
print(f"Output => {out}")
>>> Neuron 1(Number=2, Non-Linearity=ReLU)
>>> Output => Value(data=2.3063230206881347, grad=0.0)
层
一层由许多Neuron构成。
class Layer(Module):
"""
A layer of neurons.
Parameters:
number_inputs (int): number of inputs
number_outputs (int): number of outputs
name (int): index of the layer
"""
def __init__(self, number_inputs: int, number_outputs: int, name: int, **kwargs):
# A layer is a list of neurons.
self.neurons = [
Neuron(number_inputs=number_inputs, name=idx, **kwargs) for idx in range(number_outputs)
]
self.name = name
self.number_outputs = number_outputs
def __call__(self, x: List["Value"]) -> Union[List["Value"], "Value"]:
# Iterate over all the neurons and compute the output of each.
out = [n(x) for n in self.neurons]
return out if self.number_outputs != 1 else out[0]
def parameters(self):
# The parameters of a layer is the parameters of all the neurons.
return [p for n in self.neurons for p in n.parameters()]
def __repr__(self):
# Print a better representation of the layer.
layer_str = "\n".join(f' - {str(n)}' for n in self.neurons)
return f"Layer {self.name} \n{layer_str}\n"
x = [2.0, 3.0]
layer = Layer(number_inputs=2, number_outputs=3, name=1)
print(layer)
out = layer(x)
print(f"Output => {out}")
>>> Layer 1
>>> - Neuron 0(Number=2, Non-Linearity=ReLU)
>>> - Neuron 1(Number=2, Non-Linearity=ReLU)
>>> - Neuron 2(Number=2, Non-Linearity=ReLU)
>>> Output => [Value(data=0, grad=0.0), Value(data=1.1705131190055296, grad=0.0), Value(data=3.0608608028649344, grad=0.0)]
x = [2.0, 3.0]
layer = Layer(number_inputs=2, number_outputs=1, name=1)
print(layer)
out = layer(x)
print(f"Output => {out}")
>>> Layer 1
>>> - Neuron 0(Number=2, Non-Linearity=ReLU)
>>> Output => Value(data=2.3123867684232247, grad=0.0)
多层感知器
多层感知器(MLP)是由许多Layer组成的。
class MLP(Module):
"""
The Multi-Layer Perceptron (MLP) class.
Parameters:
number_inputs (int): number of inputs.
list_number_outputs (List[int]): number of outputs in each layer.
"""
def __init__(self, number_inputs: int, list_number_outputs: List[int]):
# Get the number of inputs and all the number of outputs in
# a single list.
total_size = [number_inputs] + list_number_outputs
# Build layers by connecting each layer to the previous one.
self.layers = [
# Do not use non linearity in the last layer.
Layer(
number_inputs=total_size[i],
number_outputs=total_size[i + 1],
name=i,
is_nonlinear=i != len(list_number_outputs) - 1
)
for i in range(len(list_number_outputs))
]
def __call__(self, x: List["Value"]) -> List["Value"]:
# Iterate over the layers and compute the output of
# each sequentially.
for layer in self.layers:
x = layer(x)
return x
def parameters(self):
# Get the parameters of the MLP
return [p for layer in self.layers for p in layer.parameters()]
def __repr__(self):
# Print a better representation of the MLP.
mlp_str = "\n".join(f' - {str(layer)}' for layer in self.layers)
return f"MLP of \n{mlp_str}"
x = [2.0, 3.0]
mlp = MLP(number_inputs=2, list_number_outputs=[3, 3, 1])
print(mlp)
out = mlp(x)
print(f"Output => {out}")
>>> MLP of
>>> - Layer 0
>>> - Neuron 0(Number=2, Non-Linearity=ReLU)
>>> - Neuron 1(Number=2, Non-Linearity=ReLU)
>>> - Neuron 2(Number=2, Non-Linearity=ReLU)
>>> - Layer 1
>>> - Neuron 0(Number=3, Non-Linearity=ReLU)
>>> - Neuron 1(Number=3, Non-Linearity=ReLU)
>>> - Neuron 2(Number=3, Non-Linearity=ReLU)
>>> - Layer 2
>>> - Neuron 0(Number=3, Non-Linearity=None)
>>> Output => Value(data=-0.3211612402687316, grad=0.0)
训练 MLP
在本节中,我们将创建一个小型数据集,并尝试了解如何使用我们的 MLP 对数据集进行建模。
# Build a dataset
xs = [
[0.5, 0.5, 0.70],
[0.4, -0.1, 0.5],
[-0.2, -0.75, 1.0],
]
ys = [0.0, 1.0, 0.0]
# Build an MLP
mlp = MLP(number_inputs=3, list_number_outputs=[3, 3, 1])
在下面的代码片段中,我们定义了三个函数:
forward:前进功能采用mlp和输入。输入通过mlp转发,我们从mlp获得预测。- 我们有事实和预测。该函数计算两者之间的损耗。我们将优化我们的
mlp,使损失为零。 update_mlp:在这个函数中,我们用梯度信息更新mlp的参数(权重和偏差)。
def forward(mlp: "MLP", xs: List[List[float]]) -> List["Value"]:
# Get the predictions upon forwarding the input data through
# the mlp
ypred = [mlp(x) for x in xs]
return ypred
def compute_loss(ys: List[int], ypred: List["Value"]) -> "Value":
# Obtain the L2 distance of the prediction and ground truths
loss = sum(
[(ygt - yout)**2 for ygt, yout in zip(ys, ypred)]
)
return loss
def update_mlp(mlp: "MLP"):
# Iterate over all the layers of the MLP
for layer in mlp.layers:
# Iterate over all the neurons of each layer
for neuron in layer.neurons:
# Iterate over all the weights of each neuron
for weight in neuron.weights:
# Update the data of the weight with the
# gradient information.
weight.data -= (1e-2 * weight.grad)
# Update the data of the bias with the
# gradient information.
neuron.bias.data -= (1e-2 * neuron.bias.grad)
# Define the epochs for which we want to run the training process.
epochs = 50
# Define a loss list to help log the loss.
loss_list = []
# Iterate each epoch and train the model.
for idx in range(epochs):
# Step 1: Forward the inputs to the mlp and get the predictions
ypred = forward(mlp, xs)
# Step 2: Compute Loss between the predictions and the ground truths
loss = compute_loss(ys, ypred)
# Step 3: Ground the gradients. These accumulate which is not desired.
mlp.zero_grad()
# Step 4: Backpropagate the gradients through the entire architecture
loss.backward()
# Step 5: Update the mlp
update_mlp(mlp)
# Step 6: Log the loss
loss_list.append(loss.data)
print(f"Epoch {idx}: Loss {loss.data: 0.2f}")
Epoch 0: Loss 0.95
Epoch 1: Loss 0.89
Epoch 2: Loss 0.81
Epoch 3: Loss 0.74
Epoch 4: Loss 0.68
Epoch 5: Loss 0.63
Epoch 6: Loss 0.59
.
.
Epoch 47: Loss 0.24
Epoch 48: Loss 0.23
Epoch 49: Loss 0.22
# Plot the loss
plt.plot(loss_list)
plt.grid()
plt.ylabel("Loss")
plt.xlabel("Epoch")
plt.show()
损失图如图 14 所示。
# Inference
pred = mlp(xs[0])
ygt = ys[0]
print(f"Prediction => {pred.data: 0.2f}")
print(f"Ground Truth => {ygt: 0.2f}")
>>> Prediction => 0.14
>>> Ground Truth => 0.00
汇总
我们写这篇博客的主要目的是看看自动挖掘过程的内幕。在 Andrej 的micrograd库的帮助下,我们现在知道了如何构建一个非常小但有效的 autodiff 包。
我们希望 autodiff 、、反向传播、和基本神经网络训练的核心概念现在对你已经很清楚了。
让我们知道你喜欢这个教程。
推特: @PyImageSearch
引用信息
A. R. Gosthipaty 和 R. Raha。“自动微分第二部分:使用微图实现”, PyImageSearch ,P. Chugh,S. Huot,K. Kidriavsteva,A. Thanki,2022,https://pyimg.co/ra6ow
@incollection{ARG-RR_2022_autodiff2,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Automatic Differentiation Part 2: Implementation Using Micrograd},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/ra6ow},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
自动识别收据和扫描件
原文:https://pyimagesearch.com/2021/10/27/automatically-ocring-receipts-and-scans/
在本教程中,您将学习如何使用 Tesseract 和 OpenCV 来构建自动收据扫描仪。我们将使用 OpenCV 来构建系统的实际图像处理组件,包括:
- 检测图像中的收据
- 找到收据的四个角
- 最后,应用透视变换以获得收据的自上而下的鸟瞰图
要学习如何自动 OCR 收据和扫描,继续阅读。
自动识别收据和扫描件
在那里,我们将使用 Tesseract 对收据本身进行 OCR,并逐行解析出每件商品,包括商品描述和价格。
如果你是一个企业主(像我一样),需要向你的会计师报告你的费用,或者如果你的工作要求你一丝不苟地跟踪你的报销费用,那么你就会知道跟踪你的收据是多么令人沮丧、乏味和烦人。很难相信在这个时代,购物仍然通过一张很小很脆弱的纸被跟踪!
也许在未来,跟踪和报告我们的支出会变得不那么繁琐。但在此之前,收据扫描仪可以节省我们大量的时间,并避免手动编目购买的挫折。
本教程的收据扫描仪项目是构建成熟的收据扫描仪应用程序的起点。以本教程为起点,然后通过添加 GUI、将其与移动应用程序集成等方式对其进行扩展。
我们开始吧!
学习目标
在本教程中,您将学习:
- 如何使用 OpenCV 检测、提取和转换输入图像中的收据
- 如何使用 Tesseract 逐行识别收据
- 查看选择正确的 Tesseract 页面分段模式(PSM)如何产生更好结果的真实应用
用 OpenCV 和 Tesseract 对收据进行 OCR 识别
在本教程的第一部分,我们将回顾收据扫描仪项目的目录结构。
然后,我们将逐行检查我们的收据扫描器实现。最重要的是,我将向您展示在构建收据扫描仪时使用哪种 Tesseract PSM,以便您可以轻松地从收据中检测并提取每个商品和价格。
最后,我们将讨论我们的结果来结束本教程。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
|-- scan_receipt.py
|-- whole_foods.png
我们今天只需要查看一个脚本scan_receipt.py,它将包含我们的收据扫描器实现。
这张照片是我去美国连锁杂货店全食超市时拍的收据。我们将使用我们的scan_receipt.py脚本来检测输入图像中的收据,然后从收据中提取每个商品和价格。
实施我们的收据扫描仪
在我们开始实现收据扫描器之前,让我们先回顾一下将要实现的基本算法。然后,当显示包含收据的输入图像时,我们将:
- 应用边缘检测以显示背景下收据的轮廓(这假设我们在背景和前景之间有足够的对比度;否则,我们将无法检测到收据)
- 检测边缘图中的轮廓
- 循环遍历所有轮廓,找到具有四个顶点的最大轮廓(因为收据是矩形的,并且将有四个角)
- 应用透视变换,生成收据的自上而下鸟瞰图(需要提高 OCR 准确度)
- 将带有
--psm 4的 Tesseract OCR 引擎应用于收据的自顶向下的转换,允许我们逐行 OCR 收据 - 使用正则表达式解析出商品名称和价格
- 最后,在我们的终端上显示结果
这听起来像许多步骤,但是正如您将看到的,我们可以在不到 120 行代码(包括注释)内完成所有这些步骤。
说完这些,让我们深入到实现中。打开项目目录结构中的scan_receipt.py文件,让我们开始工作:
# import the necessary packages
from imutils.perspective import four_point_transform
import pytesseract
import argparse
import imutils
import cv2
import re
我们从第 2-7 行的导入我们需要的 Python 包开始。这些进口商品主要包括:
four_point_transform:应用透视变换获得输入 ROI 的自上而下鸟瞰图。在之前的教程中,我们在获取数独板的自上而下视图时使用了这个函数(这样我们就可以自动解出谜题)——今天我们将在这里做同样的事情,只是用收据代替了数独谜题。pytesseract:提供一个到 Tesseract OCR 引擎的接口。- 我们的 OpenCV 绑定
re: Python 的正则表达式包将允许我们轻松解析出收据每一行的商品名称和相关价格。
接下来,我们有命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input receipt image")
ap.add_argument("-d", "--debug", type=int, default=-1,
help="whether or not we are visualizing each step of the pipeline")
args = vars(ap.parse_args())
我们的脚本需要一个命令行参数,后跟一个可选参数:
--image:输入图像的路径包含我们想要进行 OCR 的收据(在本例中为whole_foods.png)。您也可以在这里提供您的收据图像。--debug:一个整数值,用来表示我们是否要通过我们的流水线显示调试图像,包括边缘检测、回执检测等的输出。
特别是,如果您在输入图像中找不到收据,可能是因为边缘检测过程未能检测到收据的边缘:这意味着您需要微调 Canny 边缘检测参数或使用不同的方法(例如,阈值处理、霍夫线变换等。).另一种可能性是轮廓近似步骤未能找到收据的四个角。
如果发生这些情况,为--debug命令行参数提供一个正值将会显示步骤的输出,允许您调试问题,调整参数/算法,然后继续。
接下来,让我们从磁盘加载我们的--input图像,并检查它的空间维度:
# load the input image from disk, resize it, and compute the ratio
# of the *new* width to the *old* width
orig = cv2.imread(args["image"])
image = orig.copy()
image = imutils.resize(image, width=500)
ratio = orig.shape[1] / float(image.shape[1])
在这里,我们从磁盘加载我们的原始(orig)映像,然后制作一个克隆。我们需要克隆输入图像,这样我们就有了应用透视变换的原始图像。但是,我们可以应用我们实际的图像处理操作(即,边缘检测、轮廓检测等)。)到image。
我们将image的宽度调整为 500 像素(从而作为一种降噪方式),然后计算新宽度到旧宽度的ratio。最后,这个ratio值将用于对orig图像应用透视变换。
现在让我们开始将我们的图像处理流水线应用到image上:
# convert the image to grayscale, blur it slightly, and then apply
# edge detection
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5,), 0)
edged = cv2.Canny(blurred, 75, 200)
# check to see if we should show the output of our edge detection
# procedure
if args["debug"] > 0:
cv2.imshow("Input", image)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
这里,我们通过将图像转换为灰度来执行边缘检测,使用5x5 高斯内核模糊它(以减少噪声),然后使用 Canny 边缘检测器应用边缘检测。
如果我们设置了--debug命令行参数,我们将在屏幕上显示输入图像和输出边缘图。
图 2 显示了我们的输入图像(左),接着是我们的输出边缘图(右)。注意我们的边缘图如何在输入图像中清晰地显示出收据的轮廓。
给定我们的边缘图,让我们检测edged图像中的轮廓并处理它们:
# find contours in the edge map and sort them by size in descending
# order
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
注意第 42 行,这里我们根据面积(大小)从大到小对轮廓进行排序。这个排序步骤很重要,因为我们假设输入图像中有四个角的最大轮廓就是我们的收据。
排序步骤满足了我们的第一个需求。但是我们如何知道我们是否找到了一个有四个顶点的轮廓呢?
下面的代码块回答了这个问题:
# initialize a contour that corresponds to the receipt outline
receiptCnt = None
# loop over the contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# if our approximated contour has four points, then we can
# assume we have found the outline of the receipt
if len(approx) == 4:
receiptCnt = approx
break
# if the receipt contour is empty then our script could not find the
# outline and we should be notified
if receiptCnt is None:
raise Exception(("Could not find receipt outline. "
"Try debugging your edge detection and contour steps."))
Line 45 初始化一个变量来存储与我们的收据相对应的轮廓。然后我们开始在线 48 上循环所有检测到的轮廓。
线 50 和 51 通过减少点数来逼近轮廓,从而简化形状。
第 55-57 行检查我们是否找到了一个有四个点的轮廓。如果是这样,我们可以有把握地假设我们已经找到了收据,因为这是具有四个顶点的最大轮廓。一旦我们找到轮廓,我们将它存储在循环的receiptCnt和break中。
第 61-63 行为我们的脚本提供了一种优雅的退出方式,如果我们的收据没有找到的话。通常,当脚本的边缘检测阶段出现问题时,就会发生这种情况。由于照明条件不足或者仅仅是收据和背景之间没有足够的对比度,边缘图可能由于其中有间隙或孔洞而被“破坏”。
发生这种情况时,轮廓检测过程不会将收据“视为”四角对象。相反,它看到一个奇怪的多边形对象,因此没有检测到收据。
如果发生这种情况,一定要使用--debug命令行参数来直观地检查你的边缘贴图的输出。
找到收据轮廓后,让我们对图像应用透视变换:
# check to see if we should draw the contour of the receipt on the
# image and then display it to our screen
if args["debug"] > 0:
output = image.copy()
cv2.drawContours(output, [receiptCnt], -1, (0, 255, 0), 2)
cv2.imshow("Receipt Outline", output)
cv2.waitKey(0)
# apply a four-point perspective transform to the *original* image to
# obtain a top-down bird's-eye view of the receipt
receipt = four_point_transform(orig, receiptCnt.reshape(4, 2) * ratio)
# show transformed image
cv2.imshow("Receipt Transform", imutils.resize(receipt, width=500))
cv2.waitKey(0)
第 67-71 行在我们的output图像上概述了在调试模式下的收据。然后,我们在屏幕上显示输出图像,以验证收据被正确检测到(图 3 ,左)。
在第 75 行完成一个自上而下的收据鸟瞰图。注意,我们将变换应用于更高分辨率的orig图像— 这是为什么呢?
首先,变量image已经应用了边缘检测和轮廓处理。使用透视变换image然后进行 OCR 不会得到正确的结果;我们得到的只有噪音。
相反,我们寻求高分辨率版本的收据。因此,我们将透视变换应用于orig图像。为此,我们需要将我们的receiptCnt ( x,y )坐标乘以我们的ratio,从而将坐标缩放回orig空间维度。
为了验证我们已经计算了自上而下,原始图像的鸟瞰图,我们在屏幕上的第 78 行和 79 行 ( 图 3 、右)显示了高分辨率收据。
给定收据的自上而下视图,我们现在可以对其进行 OCR:
# apply OCR to the receipt image by assuming column data, ensuring
# the text is *concatenated across the row* (additionally, for your
# own images you may need to apply additional processing to cleanup
# the image, including resizing, thresholding, etc.)
options = "--psm 4"
text = pytesseract.image_to_string(
cv2.cvtColor(receipt, cv2.COLOR_BGR2RGB),
config=options)
# show the raw output of the OCR process
print("[INFO] raw output:")
print("==================")
print(text)
print("\n")
第 85-88 行使用 Tesseract 来 OCR 收据,以--psm 4模式传递。使用--psm 4允许我们逐行 OCR 收据。每行将包括项目名称和项目价格。
第 91-94 行显示应用 OCR 后的原始数据text。
然而,的问题是宇宙魔方不知道收据上的项目是什么,而只是杂货店的名称、地址、电话号码和你通常在收据上找到的所有其他信息。
这就提出了一个问题——我们如何解析出我们不需要的信息,只留下商品名称和价格?
答案是利用正则表达式:
# define a regular expression that will match line items that include
# a price component
pricePattern = r'([0-9]+\.[0-9]+)'
# show the output of filtering out *only* the line items in the
# receipt
print("[INFO] price line items:")
print("========================")
# loop over each of the line items in the OCR'd receipt
for row in text.split("\n"):
# check to see if the price regular expression matches the current
# row
if re.search(pricePattern, row) is not None:
print(row)
如果您以前从未使用过正则表达式,它们是一种特殊的工具,允许我们定义文本模式。正则表达式库(在 Python 中,这个库是re)然后将所有文本匹配到这个模式。
第 98 行定义了我们的pricePattern。该模式将匹配任意数量的数字0-9,后跟.字符(表示价格值中的小数分隔符),再后跟任意数量的数字0-9 。
例如,这个pricePattern将匹配文本$9.75,但不会匹配文本7600,因为文本7600不包含小数点分隔符。
如果你是正则表达式的新手或者只是需要复习一下,我建议你阅读下面这个由 RealPython 撰写的系列。
第 106 行分割我们的原始 OCR'd text并允许我们单独循环每一行。
对于每一行,我们检查row是否与我们的pricePattern ( 行 109 )匹配。如果是这样,我们知道已经找到了包含商品和价格的行,所以我们将该行打印到我们的终端(第 110 行)。
祝贺您构建了您的第一个收据扫描仪 OCR 应用程序!
收据扫描仪和 OCR 结果
现在我们已经实现了我们的scan_receipt.py脚本,让我们把它投入工作。打开终端并执行以下命令:
$ python scan_receipt.py --image whole_foods.png
[INFO] raw output:
==================
WHOLE
FOODS
WHOLE FOODS MARKET - WESTPORT, CT 06880
399 POST RD WEST - (203) 227-6858
365 BACON LS NP 4.99
365 BACON LS NP 4.99
365 BACON LS NP 4.99
365 BACON LS NP 4.99
BROTH CHIC NP 4.18
FLOUR ALMOND NP 11.99
CHKN BRST BNLSS SK NP 18.80
HEAVY CREAM NP 3 7
BALSMC REDUCT NP 6.49
BEEF GRND 85/15 NP 5.04
JUICE COF CASHEW C NP 8.99
DOCS PINT ORGANIC NP 14.49
HNY ALMOND BUTTER NP 9.99
eee TAX .00 BAL 101.33
在我们的终端中可以看到 Tesseract OCR 引擎的原始输出。通过指定--psm 4,Tesseract 能够逐行对收据进行光学字符识别,捕获两个项目:
- 名称/描述
- 价格
但是,输出中有一堆其他的“噪音”,包括杂货店的名称、地址、电话号码等。我们如何解析这些信息,只给我们留下商品和它们的价格?
答案是使用正则表达式,该表达式过滤具有类似于价格的数值的行,这些正则表达式的输出如下所示:
[INFO] price line items:
========================
365 BACON LS NP 4.99
365 BACON LS NP 4.99
365 BACON LS NP 4.99
365 BACON LS NP 4.99
BROTH CHIC NP 4.18
FLOUR ALMOND NP 11.99
CHKN BRST BNLSS SK NP 18.80
BALSMC REDUCT NP 6.49
BEEF GRND 85/15 NP 5.04
JUICE COF CASHEW C NP 8.99
DOCS PINT ORGANIC NP 14.49
HNY ALMOND BUTTER NP 9.99
eee TAX .00 BAL 101.33
通过使用正则表达式,我们只提取了商品和价格,包括最终的应付余额。
我们的收据扫描仪应用程序是一个重要的实现,它展示了如何将 OCR 与一些文本处理结合起来提取感兴趣的数据。有一个完整的计算机科学领域致力于文本处理,称为自然语言处理(NLP)。
就像计算机视觉是对编写能够理解图像内容的软件的高级研究一样,NLP 也试图做同样的事情,只是针对文本。根据您尝试使用计算机视觉和 OCR 构建的内容,您可能需要花几周到几个月的时间来熟悉 NLP,这些知识将更好地帮助您理解如何处理从 OCR 引擎返回的文本。
总结
在本教程中,您学习了如何使用 OpenCV 和 Tesseract 实现一个基本的收据扫描器。我们的收据扫描仪实施需要基本的图像处理操作来检测收据,包括:
- 边缘检测
- 轮廓检测
- 使用弧长和近似值的轮廓滤波
从那里,我们使用 Tesseract,最重要的是,--psm 4,来 OCR 收据。通过使用--psm 4,我们从收据中一行一行地提取每个项目,包括项目名称和特定项目的成本。
我们的收据扫描仪最大的局限性是它需要:
- 收据和背景之间有足够的对比
- 收据的所有四个角在图像中都可见
如果这些情况不成立,我们的脚本将找不到收据。
引用信息
Rosebrock,A. “自动 OCR 识别收据和扫描”, PyImageSearch ,2021,https://PyImageSearch . com/2021/10/27/Automatically-OCR ing-Receipts-and-Scans/
@article{Rosebrock_2021_Automatically, author = {Adrian Rosebrock}, title = {Automatically {OCR}’ing Receipts and Scans}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/10/27/automatically-ocring-receipts-and-scans/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
用 Python 从头开始反向传播
原文:https://pyimagesearch.com/2021/05/06/backpropagation-from-scratch-with-python/
反向传播可以说是神经网络历史上最重要的算法——如果没有(有效的)反向传播,将不可能将深度学习网络训练到我们今天看到的深度。反向传播可以被认为是现代神经网络和深度学习的基石。
反向传播的最初形式早在 20 世纪 70 年代就被引入,但直到 1988 年由鲁梅尔哈特、辛顿和威廉姆斯撰写的开创性论文通过反向传播误差学习表示,我们才能够设计出更快的算法,更适合于训练更深层次的网络。
现在有数百(如果不是数千的话)关于反向传播的教程。我最喜欢的包括:
- 吴恩达Coursera 关于机器学习课程内部反向传播的讨论。
- 高度数学化的第 2 章— 反向传播算法如何工作来自神经网络和深度学习作者 Michael Nielsen 。
- 斯坦福的 cs231n 对反向传播的探索与分析。
- 马特·马祖尔的优秀的具体例子(有实际工作数据)展示了反向传播是如何工作的。
正如你所看到的,并不缺少反向传播指南——我将采取不同的方法,做一些让 PyImageSearch 出版物与众不同的事情,而不是重复和重复其他人已经说过几百次的话:
使用 Python 语言构建一个直观、易于理解的反向传播算法实现。T3**
在这个实现中,我们将构建一个实际的神经网络,并使用反向传播算法对其进行训练。当您完成这一部分时,您将理解反向传播是如何工作的——也许更重要的是,您将对这种算法如何用于从头开始训练神经网络有更深的理解。
反向传播
反向传播算法包括两个阶段:
- 正向传递,我们的输入通过网络传递,并获得输出预测(也称为传播阶段)。
- 反向传递,我们在网络的最后一层(即预测层)计算损失函数的梯度,并使用该梯度递归应用链规则来更新我们网络中的权重(也称为权重更新阶段)。
我们将从高层次回顾这些阶段开始。从那里,我们将使用 Python 实现反向传播算法。一旦我们实现了反向传播,我们将希望能够使用我们的网络进行预测——这只是正向传递阶段,只有一个小的调整(就代码而言)使预测更有效。
最后,我将演示如何使用反向传播和 Python 来训练一个定制的神经网络:
- XOR 数据集
- MNIST 数据集
向前传球
前向传递的目的是通过应用一系列点积和激活,在网络中传播我们的输入,直到我们到达网络的输出层(即我们的预测)。为了形象化这个过程,让我们首先考虑 XOR 数据集(表 1 ,左)。
| x0 | x [1] | y | x0 | x [1] | x [2] | |
|---|---|---|---|---|---|---|
| Zero | Zero | Zero | Zero | Zero | one | |
| Zero | one | one | Zero | one | one | |
| one | Zero | one | one | Zero | one | |
| one | one | Zero | one | one | one |
Table 1: Left: The bitwise XOR dataset (including class labels). Right: The XOR dataset design matrix with a bias column inserted (excluding class labels for brevity).
在这里,我们可以看到设计矩阵中的每个条目X(左)都是二维的——每个数据点由两个数字表示。比如第一个数据点用特征向量 (0,0) 表示,第二个数据点用 (0,1) 表示,等等。然后,我们将输出值 y 作为右列。我们的目标输出值是类标签。给定来自设计矩阵的输入,我们的目标是正确预测目标输出值。
为了在这个问题上获得完美的分类精度,我们需要一个至少有一个隐藏层的前馈神经网络,所以让我们从一个221架构开始(图 1 、顶层)。这是一个好的开始;然而,我们忘记了包含偏差项。在我们的网络中包含偏置项 b 有两种方式。我们可以:
- 使用单独的变量。
- 通过在特征向量中插入一列 1,将偏差视为权重矩阵中的可训练参数。
将一列 1 插入到我们的特征向量中是通过编程完成的,但为了确保我们理解这一点,让我们更新我们的 XOR 设计矩阵,以明确地看到这种情况发生(表 1 ,右)。如你所见,我们的特征向量中增加了一列 1。实际上,您可以将该列插入到您喜欢的任何地方,但是我们通常将它放在(1)特征向量中的第一个条目或者(2)特征向量中的最后一个条目。
由于我们已经改变了输入特征向量的大小(通常在神经网络实现本身内部执行,因此我们不需要显式修改我们的设计矩阵),这将我们(感知的)网络架构从221改变为(内部)331(图 1 、底部)。
我们仍将这种网络架构称为221,但在实施时,它实际上是331,因为权重矩阵中嵌入了偏置项。
最后,回想一下,我们的输入层和所有隐藏层都需要一个偏差项;然而,最终输出层不需要偏置。应用偏差技巧的好处是,我们不再需要明确跟踪偏差参数——它现在是权重矩阵中的一个可训练参数,从而使训练更有效,也更容易实现。
为了看到向前传球的效果,我们首先初始化网络中的权重,如图 2 中的所示。注意权重矩阵中的每个箭头都有一个相关的值——这是给定节点的当前权重值,表示给定输入被放大或缩小的量。然后,在反向传播阶段,该权重值将被更新。
在图 2 的最左边,我们给出特征向量 (0,1,1) (以及目标输出值 1 到网络)。这里我们可以看到 0 、 1 和 1 已经被分配给网络中的三个输入节点。为了通过网络传播这些值并获得最终分类,我们需要获取输入值和权重值之间的点积,然后应用激活函数(在本例中是 sigmoid 函数, σ )。
让我们计算隐藏层中三个节点的输入:
- σ((0×0.351)+(1×1.076)+(1×1.116))= 0.899
- σ((0×0.097)+(1×0.165)+(1×0.542))= 0.593
- σ((0×0.457)+(1×0.165)+(1×0.331))= 0.378
查看隐藏层的节点值(图 2 、中间),我们可以看到节点已经更新以反映我们的计算。
我们现在有了隐藏层节点的输入。为了计算输出预测,我们再次计算点积,然后是 sigmoid 激活:
((0)。 899 × 0 。 383) + (0 。593×0。* 327) + (0 。378×0。 329)) = 0 。506***
*网络的输出因此为0.506 。我们可以应用阶跃函数来确定该输出是否是正确的分类:
 = \begin{cases} 1 & \textit{if net} > 0 \ 0 & \textit{otherwise} \end{cases}")
应用具有 net = 0.506 的阶跃函数,我们看到我们的网络预测了 1 ,这实际上是正确的类标签。但是我们的网络对这个类标签不是很有信心——预测值 0.506 非常接近台阶的阈值。理想情况下,这种预测应该更接近于0.98-0.99,这意味着我们的网络已经真正了解了数据集中的潜在模式。为了让我们的网络真正“学习”,我们需要应用向后传递。
向后传球
为了应用反向传播算法,我们的激活函数必须是可微的,以便我们可以计算误差相对于给定权重 w [i,j] 、损耗( E )、节点输出 o [j] 以及网络输出 net [j] 的
②
**由于反向传播背后的演算已经在以前的作品中详尽地解释过多次(参见吴恩达、迈克尔·尼尔森和[马特·马祖尔](https://mattmazur.com/2015/ 03/17/a-step-by-step-backpropagation-example/)),我将跳过反向传播链规则更新的推导,而是在下一节中通过代码来解释它。
对于数学敏锐的人来说,请参阅上面的参考文献,以获得关于链规则及其在反向传播算法中的作用的更多信息。通过用代码解释这个过程,我的目标是帮助读者通过更直观的实现方式来理解反向传播。
用 Python 实现反向传播
让我们继续并开始实现反向传播。打开一个新文件,将其命名为neuralnetwork.py,将其存储在pyimagesearch的nn子模块中(就像我们对perceptron.py所做的那样),然后让我们开始工作:
# import the necessary packages
import numpy as np
class NeuralNetwork:
def __init__(self, layers, alpha=0.1):
# initialize the list of weights matrices, then store the
# network architecture and learning rate
self.W = []
self.layers = layers
self.alpha = alpha
在第 2 行,我们导入了实现反向传播所需的唯一包 NumPy 数值处理库。
第 5 行定义了我们的NeuralNetwork类的构造函数。构造函数需要一个参数,后跟第二个可选参数:
layers:表示前馈网络的实际架构的整数列表。例如,【2,2,1】的值意味着我们的第一个输入层有两个节点,我们的隐藏层有两个节点,我们的最终输出层有一个节点。- 这里我们可以指定神经网络的学习速率。该值在权重更新阶段应用。
第 8 行初始化每一层的权重列表W。然后我们将layers和alpha存储在第 9 行和第 10 行。
我们的权重列表W是空的,所以现在让我们开始初始化它:
# start looping from the index of the first layer but
# stop before we reach the last two layers
for i in np.arange(0, len(layers) - 2):
# randomly initialize a weight matrix connecting the
# number of nodes in each respective layer together,
# adding an extra node for the bias
w = np.random.randn(layers[i] + 1, layers[i + 1] + 1)
self.W.append(w / np.sqrt(layers[i]))
在第 14 行,我们开始循环网络中的层数(即len(layers)),但是我们在最后两层之前停止了(我们将在后面解释这个构造函数时找到确切的原因)。
网络中的每一层都是通过从标准正态分布(第 18 行)中采样值构建一个 M×N 权重矩阵来随机初始化的。矩阵是MT6×N,因为我们希望将当前层中的每个节点连接到下一层中的每个节点。
比如,我们假设layers[i] = 2和layers[i + 1] = 2。因此,我们的权重矩阵将是 2×2 来连接层之间的所有节点集。然而,我们在这里需要小心,因为我们忘记了一个重要的组成部分——偏差项。为了考虑偏差,我们给layers[i]和layers[i + 1]的数量加 1——这样做改变了我们的权重矩阵w,以具有给定当前层的 2+1 节点和下一层的 2+1 节点的形状 3×3 。我们通过除以当前层中节点数量的平方根来缩放w,从而归一化每个神经元输出的方差(http://cs231n.stanford.edu/)(第 19 行)。
构造函数的最后一个代码块处理输入连接需要偏置项,但输出不需要的特殊情况:
# the last two layers are a special case where the input
# connections need a bias term but the output does not
w = np.random.randn(layers[-2] + 1, layers[-1])
self.W.append(w / np.sqrt(layers[-2]))
同样,这些权重值是随机采样的,然后进行归一化。
我们定义的下一个函数是一个名为__repr__的 Python“魔法方法”——这个函数对于调试很有用:
def __repr__(self):
# construct and return a string that represents the network
# architecture
return "NeuralNetwork: {}".format(
"-".join(str(l) for l in self.layers))
在我们的例子中,我们将通过连接每一层中节点数量的整数值来为我们的NeuralNetwork对象格式化一个字符串。给定(2, 2, 1)的layers值,调用该函数的输出将是:
>>> from pyimagesearch.nn import NeuralNetwork
>>> nn = NeuralNetwork([2, 2, 1])
>>> print(nn)
NeuralNetwork: 2-2-1
接下来,我们可以定义我们的 sigmoid 激活函数:
def sigmoid(self, x):
# compute and return the sigmoid activation value for a
# given input value
return 1.0 / (1 + np.exp(-x))
以及 sigmoid 的导数,我们将在向后传递时使用:
def sigmoid_deriv(self, x):
# compute the derivative of the sigmoid function ASSUMING
# that x has already been passed through the 'sigmoid'
# function
return x * (1 - x)
再次注意,每当你执行反向传播时,你总是想选择一个可微的激活函数。
我们将从 scikit-learn 库获得灵感,并定义一个名为fit的函数,它将负责实际训练我们的NeuralNetwork:
def fit(self, X, y, epochs=1000, displayUpdate=100):
# insert a column of 1's as the last entry in the feature
# matrix -- this little trick allows us to treat the bias
# as a trainable parameter within the weight matrix
X = np.c_[X, np.ones((X.shape[0]))]
# loop over the desired number of epochs
for epoch in np.arange(0, epochs):
# loop over each individual data point and train
# our network on it
for (x, target) in zip(X, y):
self.fit_partial(x, target)
# check to see if we should display a training update
if epoch == 0 or (epoch + 1) % displayUpdate == 0:
loss = self.calculate_loss(X, y)
print("[INFO] epoch={}, loss={:.7f}".format(
epoch + 1, loss))
fit方法需要两个参数,后跟两个可选参数。第一个X,是我们的训练数据。第二个,y,是X中每个条目对应的类标签。然后我们指定epochs,这是我们将训练我们的网络的纪元数量。displayUpdate参数简单地控制我们在终端上打印训练进度的次数。
在第 47 行,我们通过插入一列 1 作为我们特征矩阵的最后一个条目,X来执行偏差技巧。从那里,我们开始在线 50 上循环我们的epochs号。对于每个时期,我们将在训练集中的每个单独的数据点上循环,对数据点进行预测,计算反向传播阶段,然后更新我们的权重矩阵(行 53 和 54 )。第 57-60 行简单地检查我们是否应该在我们的终端上显示一个训练更新。
反向传播算法的核心在下面的fit_partial方法中:
def fit_partial(self, x, y):
# construct our list of output activations for each layer
# as our data point flows through the network; the first
# activation is a special case -- it's just the input
# feature vector itself
A = [np.atleast_2d(x)]
fit_partial函数需要两个参数:
x:来自我们设计矩阵的单个数据点。y:对应的类标签。
然后,我们在第 67 行的上初始化一个列表A——当我们的数据点x通过网络向前传播时,这个列表负责存储每一层的输出激活。我们用x初始化这个列表,它只是输入数据点。
从这里,我们可以开始向前传播阶段:
# FEEDFORWARD:
# loop over the layers in the network
for layer in np.arange(0, len(self.W)):
# feedforward the activation at the current layer by
# taking the dot product between the activation and
# the weight matrix -- this is called the "net input"
# to the current layer
net = A[layer].dot(self.W[layer])
# computing the "net output" is simply applying our
# nonlinear activation function to the net input
out = self.sigmoid(net)
# once we have the net output, add it to our list of
# activations
A.append(out)
我们开始在线路 71 上的网络的每一层上循环。当前layer的净输入通过取激活和权重矩阵之间的点积来计算(行 76 )。当前层的净输出然后通过使净输入通过非线性 sigmoid 激活函数来计算。一旦我们有了净输出,我们就把它添加到我们的激活列表中(第 84 行)。
信不信由你,这段代码是正向传递的整体——我们只是简单地在网络的每一层上循环,取激活和权重之间的点积,通过非线性激活函数传递值,并继续下一层。因此,A中的最后一个条目是我们网络中最后一层的输出(即预测)。
既然向前传球已经完成,我们可以继续进行稍微复杂一点的向后传球:
# BACKPROPAGATION
# the first phase of backpropagation is to compute the
# difference between our *prediction* (the final output
# activation in the activations list) and the true target
# value
error = A[-1] - y
# from here, we need to apply the chain rule and build our
# list of deltas 'D'; the first entry in the deltas is
# simply the error of the output layer times the derivative
# of our activation function for the output value
D = [error * self.sigmoid_deriv(A[-1])]
反向传递的第一阶段是计算我们的error,或者简单地计算我们的预测标签和地面实况标签之间的差(行 91 )。由于激活列表A中的最后一个条目包含网络的输出,我们可以通过A[-1]访问输出预测。值y是输入数据点x的目标输出。
备注: 使用 Python 编程语言时,指定索引值-1表示我们要访问列表中最后一个条目。你可以在本教程中阅读更多关于 Python 数组索引和切片的内容:http://pyimg.co/6dfae。
接下来,我们需要开始应用链式规则来构建我们的增量列表。增量将用于更新我们的权重矩阵,通过学习率alpha进行缩放。增量列表中的第一个条目是我们输出层的误差乘以输出值的 sigmoid 的导数(第 97 行)。
给定网络中最后一层的增量,我们现在可以使用for循环反向工作:
# once you understand the chain rule it becomes super easy
# to implement with a 'for' loop -- simply loop over the
# layers in reverse order (ignoring the last two since we
# already have taken them into account)
for layer in np.arange(len(A) - 2, 0, -1):
# the delta for the current layer is equal to the delta
# of the *previous layer* dotted with the weight matrix
# of the current layer, followed by multiplying the delta
# by the derivative of the nonlinear activation function
# for the activations of the current layer
delta = D[-1].dot(self.W[layer].T)
delta = delta * self.sigmoid_deriv(A[layer])
D.append(delta)
在第 103 行上,我们开始以逆序循环遍历网络中的每一层(忽略前两层,因为它们已经在第 97 行中得到考虑),因为我们需要向后工作来计算每一层的增量更新。当前层的delta等于前一层的增量,D[-1]用当前层的权重矩阵(行 109 )来表示。为了完成delta的计算,我们通过将layer的激活传递给我们的 sigmoid 的导数(行 110 )来将其相乘。然后我们用刚刚计算的delta更新增量D列表(行 111 )。
查看这个代码块,我们可以看到反向传播步骤是迭代的——我们只是从前一层中取增量,用当前层的权重点它,然后乘以激活的导数。重复这个过程,直到我们到达网络中的第一层。
给定我们的增量列表D,我们可以进入权重更新阶段:
# since we looped over our layers in reverse order we need to
# reverse the deltas
D = D[::-1]
# WEIGHT UPDATE PHASE
# loop over the layers
for layer in np.arange(0, len(self.W)):
# update our weights by taking the dot product of the layer
# activations with their respective deltas, then multiplying
# this value by some small learning rate and adding to our
# weight matrix -- this is where the actual "learning" takes
# place
self.W[layer] += -self.alpha * A[layer].T.dot(D[layer])
记住,在反向传播步骤中,我们以反向的顺序循环我们的层。为了执行我们的权重更新阶段,我们将简单地反转D中条目的顺序,这样我们就可以从 0 到 N、网络中的总层数(行 115 )依次循环每一层。
更新我们的实际权重矩阵(即,实际“学习”发生的地方)是在行 125 完成的,这是我们的梯度下降。我们取当前layer激活A[layer]与当前layer、D[layer]的增量的点积,并将它们乘以学习速率alpha。该值被添加到当前layer、W[layer]的权重矩阵中。
我们对网络中的所有层重复这一过程。在执行权重更新阶段之后,反向传播正式完成。
一旦我们的网络在给定的数据集上得到训练,我们将希望在测试集上进行预测,这可以通过下面的predict方法来完成:
def predict(self, X, addBias=True):
# initialize the output prediction as the input features -- this
# value will be (forward) propagated through the network to
# obtain the final prediction
p = np.atleast_2d(X)
# check to see if the bias column should be added
if addBias:
# insert a column of 1's as the last entry in the feature
# matrix (bias)
p = np.c_[p, np.ones((p.shape[0]))]
# loop over our layers in the network
for layer in np.arange(0, len(self.W)):
# computing the output prediction is as simple as taking
# the dot product between the current activation value 'p'
# and the weight matrix associated with the current layer,
# then passing this value through a nonlinear activation
# function
p = self.sigmoid(np.dot(p, self.W[layer]))
# return the predicted value
return p
predict函数只是一个美化了的向前传递。该函数接受一个必需参数,后跟第二个可选参数:
X:我们将要预测类别标签的数据点。addBias:一个布尔值,指示我们是否需要添加一列 1 到X来执行偏置技巧。
在线 131 上,我们初始化p,输出预测作为输入数据点X。这个值p将通过网络中的每一层,传播直到我们达到最终的输出预测。
在第 134-137 行,我们做了一个检查,看看偏差项是否应该嵌入到数据点中。如果是这样,我们插入一列 1 作为矩阵的最后一列(正如我们在上面的fit方法中所做的)。
从那里,我们通过在线路 140 上循环我们网络中的所有层来执行正向传播。通过获取当前激活p和当前layer的权重矩阵之间的点积来更新数据点p,随后通过我们的 sigmoid 激活函数传递输出(行 146 )。
假设我们在网络中的所有层上循环,我们将最终到达最后一层,这将给我们最终的类标签预测。我们将预测值返回给第 149 行上的调用函数。
我们将在NeuralNetwork类中定义的最后一个函数将用于计算整个训练集的损失:
def calculate_loss(self, X, targets):
# make predictions for the input data points then compute
# the loss
targets = np.atleast_2d(targets)
predictions = self.predict(X, addBias=False)
loss = 0.5 * np.sum((predictions - targets) ** 2)
# return the loss
return loss
calculate_loss函数要求我们传入数据点X以及它们的基本事实标签targets。我们对线 155 上的X进行预测,然后计算线 156 上的误差平方和。然后,损失返回到线 159 上的调用函数。随着我们的网络学习,我们应该看到这种损失减少。
使用 Python 的反向传播示例#1:按位异或
现在我们已经实现了我们的NeuralNetwork类,让我们继续在按位 XOR 数据集上训练它。正如我们从感知机的工作中所知,这个数据集是而不是线性可分的——我们的目标是训练一个可以模拟这种非线性函数的神经网络。
继续打开一个新文件,将其命名为nn_xor.py,并插入以下代码:
# import the necessary packages
from pyimagesearch.nn import NeuralNetwork
import numpy as np
# construct the XOR dataset
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
第 2 行和第 3 行导入我们需要的 Python 包。注意我们是如何导入新实现的NeuralNetwork类的。第 6 行和第 7 行然后构建 XOR 数据集。
我们现在可以定义我们的网络架构并对其进行训练:
# define our 2-2-1 neural network and train it
nn = NeuralNetwork([2, 2, 1], alpha=0.5)
nn.fit(X, y, epochs=20000)
在第 10 行的上,我们实例化了我们的NeuralNetwork以拥有一个221架构,这意味着有:
- 具有两个节点的输入层(即我们的两个输入)。
- 具有两个节点的单个隐藏层。
- 具有一个节点的输出图层。
11 号线共训练我们的网络 20000 个纪元。
一旦我们的网络被训练,我们将循环我们的 XOR 数据集,允许网络预测每个数据集的输出,并在屏幕上显示预测结果:
# now that our network is trained, loop over the XOR data points
for (x, target) in zip(X, y):
# make a prediction on the data point and display the result
# to our console
pred = nn.predict(x)[0][0]
step = 1 if pred > 0.5 else 0
print("[INFO] data={}, ground-truth={}, pred={:.4f}, step={}".format(
x, target[0], pred, step))
第 18 行将阶跃函数应用于 sigmoid 输出。如果预测是 > 0.5 ,我们将返回1,否则,我们将返回0。应用这个步骤函数允许我们将输出类标签二进制化,就像 XOR 函数一样。
要使用 Python 的反向传播来训练我们的神经网络,只需执行以下命令:
$ python nn_xor.py
[INFO] epoch=1, loss=0.5092796
[INFO] epoch=100, loss=0.4923591
[INFO] epoch=200, loss=0.4677865
...
[INFO] epoch=19800, loss=0.0002478
[INFO] epoch=19900, loss=0.0002465
[INFO] epoch=20000, loss=0.0002452
平方损失图如下所示(图 3 )。正如我们所看到的,在整个训练过程中,损耗慢慢减少到接近于零。此外,查看输出的最后四行,我们可以看到我们的预测:
[INFO] data=[0 0], ground-truth=0, pred=0.0054, step=0
[INFO] data=[0 1], ground-truth=1, pred=0.9894, step=1
[INFO] data=[1 0], ground-truth=1, pred=0.9876, step=1
[INFO] data=[1 1], ground-truth=0, pred=0.0140, step=0
对于每一个数据点,我们的神经网络能够正确地学习 XOR 模式,表明我们的多层神经网络能够学习非线性函数。
为了证明学习 XOR 函数至少需要一个隐藏层,回到行 10 ,这里我们定义了221架构:
# define our 2-2-1 neural network and train it
nn = NeuralNetwork([2, 2, 1], alpha=0.5)
nn.fit(X, y, epochs=20000)
并改成 2-1 架构:
# define our 2-1 neural network and train it
nn = NeuralNetwork([2, 1], alpha=0.5)
nn.fit(X, y, epochs=20000)
在此基础上,您可以尝试重新培训您的网络:
$ python nn_xor.py
...
[INFO] data=[0 0], ground-truth=0, pred=0.5161, step=1
[INFO] data=[0 1], ground-truth=1, pred=0.5000, step=1
[INFO] data=[1 0], ground-truth=1, pred=0.4839, step=0
[INFO] data=[1 1], ground-truth=0, pred=0.4678, step=0
无论你如何摆弄学习率或权重初始化,你永远无法逼近异或函数。这一事实就是为什么具有通过反向传播训练的非线性激活函数的多层网络如此重要——它们使我们能够学习数据集中的模式,否则这些模式是非线性可分离的。
用 Python 反向传播例子:MNIST 样本
作为第二个更有趣的例子,让我们检查一下用于手写数字识别的 MNIST 数据集的子集(图 4 )。MNIST 数据集的这个子集内置在 scikit-learn 库中,包括 1797 个示例数字,每个数字都是 8×8 灰度图像(原始图像是 28×28 )。展平后,这些图像由一个 8×8 = 64 -dim 矢量表示。
现在,让我们继续在这个 MNIST 子集上训练我们的NeuralNetwork实现。打开一个新文件,命名为nn_mnist.py,我们开始工作:
# import the necessary packages
from pyimagesearch.nn import NeuralNetwork
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn import datasets
我们从第 2-6 行开始,导入我们需要的 Python 包。
在那里,我们使用 scikit-learn 辅助函数从磁盘加载 MNIST 数据集:
# load the MNIST dataset and apply min/max scaling to scale the
# pixel intensity values to the range [0, 1] (each image is
# represented by an 8 x 8 = 64-dim feature vector)
print("[INFO] loading MNIST (sample) dataset...")
digits = datasets.load_digits()
data = digits.data.astype("float")
data = (data - data.min()) / (data.max() - data.min())
print("[INFO] samples: {}, dim: {}".format(data.shape[0],
data.shape[1]))
我们还通过将每个数字缩放到范围【0,1】(第 14 行)来执行最小/最大归一化。
接下来,让我们构建一个培训和测试分割,使用 75%的数据进行测试,25%的数据进行评估:
# construct the training and testing splits
(trainX, testX, trainY, testY) = train_test_split(data,
digits.target, test_size=0.25)
# convert the labels from integers to vectors
trainY = LabelBinarizer().fit_transform(trainY)
testY = LabelBinarizer().fit_transform(testY)
我们还将把我们的类标签整数编码成向量,这个过程叫做一键编码。
从那里,我们准备好训练我们的网络:
# train the network
print("[INFO] training network...")
nn = NeuralNetwork([trainX.shape[1], 32, 16, 10])
print("[INFO] {}".format(nn))
nn.fit(trainX, trainY, epochs=1000)
在这里,我们可以看到我们正在训练一个采用64321610架构的NeuralNetwork。由于数字 0-9 有十个可能的输出类,所以输出层有十个节点。
然后我们允许我们的网络训练 1000 个纪元。一旦我们的网络经过训练,我们就可以在测试集上对其进行评估:
# evaluate the network
print("[INFO] evaluating network...")
predictions = nn.predict(testX)
predictions = predictions.argmax(axis=1)
print(classification_report(testY.argmax(axis=1), predictions))
线 34 计算testX中每个数据点的输出predictions。predictions数组具有(450, 10)的形状,因为在测试集中有 450 个数据点,每个数据点有十种可能的类别标签概率。
为了找到对于每个数据点具有最大概率的类别标签,我们使用行 35 上的argmax函数—该函数将返回具有最高预测概率的标签的索引。然后,我们在屏幕的第 36行显示一个格式良好的分类报告。
要在 MNIST 数据集上训练我们的定制NeuralNetwork实现,只需执行以下命令:
$ python nn_mnist.py
[INFO] loading MNIST (sample) dataset...
[INFO] samples: 1797, dim: 64
[INFO] training network...
[INFO] NeuralNetwork: 64-32-16-10
[INFO] epoch=1, loss=604.5868589
[INFO] epoch=100, loss=9.1163376
[INFO] epoch=200, loss=3.7157723
[INFO] epoch=300, loss=2.6078803
[INFO] epoch=400, loss=2.3823153
[INFO] epoch=500, loss=1.8420944
[INFO] epoch=600, loss=1.3214138
[INFO] epoch=700, loss=1.2095033
[INFO] epoch=800, loss=1.1663942
[INFO] epoch=900, loss=1.1394731
[INFO] epoch=1000, loss=1.1203779
[INFO] evaluating network...
precision recall f1-score support
0 1.00 1.00 1.00 45
1 0.98 1.00 0.99 51
2 0.98 1.00 0.99 47
3 0.98 0.93 0.95 43
4 0.95 1.00 0.97 39
5 0.94 0.97 0.96 35
6 1.00 1.00 1.00 53
7 1.00 1.00 1.00 49
8 0.97 0.95 0.96 41
9 1.00 0.96 0.98 47
avg / total 0.98 0.98 0.98 450
我还包括了一个平方损失图(图 5 )。请注意,我们的损失一开始非常高,但在培训过程中迅速下降。我们的分类报告表明,我们正在我们的测试集上获得 ≈98% 的分类精度;然而,我们在对数字4和5进行分类时遇到了一些麻烦(准确率分别为 95%和 94%)。在本书的后面,我们将学习如何在完整的 MNIST 数据集上训练卷积神经网络,并进一步提高我们的准确性。
反向传播总结
今天,我们学习了如何使用 Python 从头开始实现反向传播算法。反向传播是专门用于训练多层前馈网络的梯度下降算法族的推广。
反向传播算法包括两个阶段:
- 正向传递,我们通过网络传递我们的输入,以获得我们的输出分类。
- 反向传递(即,权重更新阶段),其中我们计算损失函数的梯度,并使用该信息迭代地应用链规则来更新我们的网络中的权重。
不管我们是使用简单的前馈神经网络还是复杂的深度卷积神经网络,反向传播算法仍然用于训练这些模型。这是通过确保网络内部的激活函数是可微的来实现的,允许应用链式法则。此外,网络内部需要更新其权重/参数的任何其他层也必须与反向传播兼容。
我们使用 Python 编程语言实现了反向传播算法,并设计了一个多层前馈NeuralNetwork类。然后在 XOR 数据集上训练该实现,以证明我们的神经网络能够通过应用具有至少一个隐藏层的反向传播算法来学习非线性函数。然后,我们将相同的反向传播+ Python 实现应用于 MNIST 数据集的子集,以证明该算法也可用于处理图像数据。
在实践中,反向传播不仅难以实现(由于计算梯度的错误),而且在没有特殊优化库的情况下很难实现高效,这就是为什么我们经常使用 Keras、TensorFlow 和 mxnet 等库,这些库已经使用优化策略(正确地】实现了反向传播。*****
用 OpenCV 跟踪球
原文:https://pyimagesearch.com/2015/09/14/ball-tracking-with-opencv/
![]()
今天是 PyImageSearch 上的第 100 篇博文。
100 个帖子。很难相信,但这是真的。
当我在 2014 年 1 月开始 PyImageSearch 时,我不知道这个博客会变成什么样。我不知道它会如何进化和成熟。我当然不知道它会变得如此受欢迎。100 篇博文下来,我觉得答案现在已经很明显了,虽然我挣扎着要把它用文字表达出来(讽刺,既然我是作家)直到我看到这条来自 @si2w 的推文:
我完全同意。我希望 PyImageSearch 的其他读者也能如此。
这是一段不可思议的旅程,我真的要感谢你,PyImageSearch 的读者们。没有你,这个博客真的不可能出现。
也就是说,为了让第 100 篇博文与众不同,我想我会做一些有趣的事情——用 OpenCV 跟踪球:
https://www.youtube.com/embed/dKpRsdYSCLQ?feature=oembed
用 OpenCV 和 Python 实现银行支票 OCR(下)
原文:https://pyimagesearch.com/2017/07/31/bank-check-ocr-opencv-python-part-ii/

今天的博文是我们关于使用 OpenCV、Python 和计算机视觉技术 OCR 识别银行支票账户和路由号码的两部分系列文章的第二部分。
上周我们学习了如何从输入图像中提取 MICR E-13B 数字和符号。今天我们将利用这些知识,用它来让实际识别每个字符,从而让我们能够 OCR 识别实际的银行支票和银行代号。
要了解如何使用 Python 和 OpenCV 对银行支票进行 OCR,请继续阅读。
用 OpenCV 和 Python 实现银行支票 OCR
在本系列的第一部分中,我们学习了如何本地化银行支票上使用的 14 种 MICR E-13B 字体字符。
这些字符中有 10 个是数字,它们构成了我们实际的账号和路由号。剩下的四个字符是银行使用的特殊符号,用于区分银行代号、帐号和支票上的任何其他编码信息。
下图显示了我们将在本教程中进行 OCR 的所有 14 个字符:

Figure 1: The fourteen MICR E-13B characters used in bank checks. We will write Python + OpenCV code to recognize each of these characters.
下面的列表显示了四个符号:
- ⑆公交(划行支行路由公交#)
- ⑈ On-us(划定客户账号)
- ⑇金额(划入交易金额)
- ⑉破折号(分隔数字的一部分,如路由或帐户)
由于 OpenCV 不允许我们在图像上绘制 Unicode 字符,我们将在代码中使用以下 ASCII 字符映射来表示运输、数量、 On-us 和破折号:
- T = ⑆
- U = ⑈
- A = ⑇
- D = ⑉
既然我们已经能够实际定位数字和符号,我们就可以像在我们的信用卡 OCR post 中一样应用模板匹配来执行 OCR。
使用 OpenCV 读取帐号和路由号码
为了构建我们的银行支票 OCR 系统,我们将重用上周的一些代码。如果您还没有阅读本系列的第一部分,现在花点时间回去通读一下—extract_digitis_and_symbols函数的解释对于本地化银行支票字符尤其重要和关键。
也就是说,让我们打开一个新文件,将其命名为bank_check_ocr.py,并插入以下代码:
# import the necessary packages
from skimage.segmentation import clear_border
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
2-7 号线处理我们的标准进口。如果你熟悉这个博客,这些进口应该不是什么新鲜事。如果您的系统上没有这些软件包,您可以执行以下操作来安装它们:
- 使用系统的相关说明安装 OpenCV (同时确保您遵循任何 Python virtualenv 命令)。
- 激活您的 Python virtualenv 并安装软件包:
$ workon cv$ pip install numpy$ pip install skimage$ pip install imutils
注意:对于任何 pip 命令,您可以使用--upgrade标志来更新您是否已经安装了软件。
现在我们已经安装了依赖项,让我们快速回顾一下上周在本系列第一部分中提到的函数:
def extract_digits_and_symbols(image, charCnts, minW=5, minH=15):
# grab the internal Python iterator for the list of character
# contours, then initialize the character ROI and location
# lists, respectively
charIter = charCnts.__iter__()
rois = []
locs = []
# keep looping over the character contours until we reach the end
# of the list
while True:
try:
# grab the next character contour from the list, compute
# its bounding box, and initialize the ROI
c = next(charIter)
(cX, cY, cW, cH) = cv2.boundingRect(c)
roi = None
# check to see if the width and height are sufficiently
# large, indicating that we have found a digit
if cW >= minW and cH >= minH:
# extract the ROI
roi = image[cY:cY + cH, cX:cX + cW]
rois.append(roi)
locs.append((cX, cY, cX + cW, cY + cH))
该函数只有一个目标,即基于轮廓查找和定位数字和符号。这是通过遍历轮廓列表charCnts,并在函数结束时返回的两个列表中跟踪感兴趣区域和 ROI 位置(rois和locs)来实现的。
在行 29 我们检查轮廓的外接矩形是否至少和一个手指一样宽和一样高。如果是,我们提取并附加roi ( 行 31 和 32 ),然后将 ROI 的位置附加到locs ( 行 33 )。否则,我们将采取以下措施:
# otherwise, we are examining one of the special symbols
else:
# MICR symbols include three separate parts, so we
# need to grab the next two parts from our iterator,
# followed by initializing the bounding box
# coordinates for the symbol
parts = [c, next(charIter), next(charIter)]
(sXA, sYA, sXB, sYB) = (np.inf, np.inf, -np.inf,
-np.inf)
# loop over the parts
for p in parts:
# compute the bounding box for the part, then
# update our bookkeeping variables
(pX, pY, pW, pH) = cv2.boundingRect(p)
sXA = min(sXA, pX)
sYA = min(sYA, pY)
sXB = max(sXB, pX + pW)
sYB = max(sYB, pY + pH)
# extract the ROI
roi = image[sYA:sYB, sXA:sXB]
rois.append(roi)
locs.append((sXA, sYA, sXB, sYB))
在上面的代码块中,我们已经确定了轮廓是特殊符号的一部分(如经纬仪、破折号等。).在这种情况下,我们在第 41 行的上获取当前轮廓和next两个轮廓(使用我们上周讨论过的 Python 迭代器)。
一个特殊符号的这些parts被循环,以便我们可以计算用于提取所有三个轮廓 ( 行 46-53 )周围的roi 的边界框。然后,和我们之前做的一样,我们提取roi并将其附加到rois ( 第 56 行和第 57 行),然后将其位置附加到locs ( 第 58 行)。
最后,我们需要捕捉一个StopIteration异常来优雅地退出我们的函数:
# we have reached the end of the iterator; gracefully break
# from the loop
except StopIteration:
break
# return a tuple of the ROIs and locations
return (rois, locs)
一旦我们到达了charCnts列表的末尾(并且列表中没有进一步的条目),对charCnts的next调用将导致抛出StopIteration异常。捕捉这个异常允许我们从循环中break(第 62 行和第 63 行)。
最后,我们返回一个包含rois和相应的locs的二元组。
这是对extract_digits_and_symbols功能的快速回顾——完整、详细的回顾,请参考上周的博文。
现在是时候接触新材料了。首先,我们将浏览几个代码块,大家应该也有点熟悉:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-r", "--reference", required=True,
help="path to reference MICR E-13B font")
args = vars(ap.parse_args())
第 69-74 行处理我们的命令行参数解析。在这个脚本中,我们将同时使用输入的--image和--reference MICR E-13B 字体图像。
让我们初始化我们的特殊字符(因为它们在 OpenCV 中不能用 Unicode 表示)并预处理我们的参考图像:
# initialize the list of reference character names, in the same
# order as they appear in the reference image where the digits
# their names and:
# T = Transit (delimit bank branch routing transit #)
# U = On-us (delimit customer account number)
# A = Amount (delimit transaction amount)
# D = Dash (delimit parts of numbers, such as routing or account)
charNames = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0",
"T", "U", "A", "D"]
# load the reference MICR image from disk, convert it to grayscale,
# and threshold it, such that the digits appear as *white* on a
# *black* background
ref = cv2.imread(args["reference"])
ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)
ref = imutils.resize(ref, width=400)
ref = cv2.threshold(ref, 0, 255, cv2.THRESH_BINARY_INV |
cv2.THRESH_OTSU)[1]
第 83 行和第 84 行建立了一个包括数字和特殊符号的字符名称列表。
然后,我们加载--reference图像,同时转换为灰度并调整大小,随后进行反向阈值处理(第 89-93 行)。
下面您可以看到预处理我们的参考图像的输出:

Figure 2: The MICR E-13B font for the digits 0-9 and four special symbols. We will be using this font along with template matching to OCR our bank check images.
现在我们准备在ref中查找轮廓并进行分类:
# find contours in the MICR image (i.e,. the outlines of the
# characters) and sort them from left to right
refCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
refCnts = imutils.grab_contours(refCnts)
refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]
参考图像轮廓在第 97 行和第 98 行计算,然后根据我们运行的 OpenCV 版本更新refCnts(第 99 行)。
我们在行 100 上从左到右对refCnts进行排序。
在这一点上,我们有一个有组织的参考轮廓。下一步是提取数字和符号,然后构建字符 ROI 字典:
# extract the digits and symbols from the list of contours, then
# initialize a dictionary to map the character name to the ROI
refROIs = extract_digits_and_symbols(ref, refCnts,
minW=10, minH=20)[0]
chars = {}
# loop over the reference ROIs
for (name, roi) in zip(charNames, refROIs):
# resize the ROI to a fixed size, then update the characters
# dictionary, mapping the character name to the ROI
roi = cv2.resize(roi, (36, 36))
chars[name] = roi
我们调用第 104 和 105 行上的extract_digits_and_symbols函数,提供ref图像和refCnts。
然后我们在第 106 行的上初始化一个chars字典。我们在跨越行 109-113** 的循环中填充这个字典。在字典中,字符name(键)与roi图像(值)相关联。**
接下来,我们将实例化一个内核,加载并提取支票图像底部的 20%,其中包含帐号:
# initialize a rectangular kernel (wider than it is tall) along with
# an empty list to store the output of the check OCR
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (17, 7))
output = []
# load the input image, grab its dimensions, and apply array slicing
# to keep only the bottom 20% of the image (that's where the account
# information is)
image = cv2.imread(args["image"])
(h, w,) = image.shape[:2]
delta = int(h - (h * 0.2))
bottom = image[delta:h, 0:w]
我们将应用一个矩形内核来执行一些形态学操作(在第 117 行初始化)。我们还初始化了一个output列表来包含检查底部的字符。我们将把这些字符打印到终端上,稍后还会把它们画在支票图像上。
第 123-126 行简单加载image,抓取尺寸,提取支票图像底部的 20%。
注意:这不是旋转不变的——如果你的支票可能会被旋转,上下颠倒或垂直显示,那么你需要先添加逻辑来旋转它。在支票上应用自上而下的透视变换(比如在我们的文档扫描仪帖子中)可以帮助完成任务。
下面您可以找到我们的示例检查输入图像:

Figure 3: The example input bank check that we are going to OCR and extract the routing number and account number from (source).
接下来,让我们将支票转换为灰度并应用形态学变换:
# convert the bottom image to grayscale, then apply a blackhat
# morphological operator to find dark regions against a light
# background (i.e., the routing and account numbers)
gray = cv2.cvtColor(bottom, cv2.COLOR_BGR2GRAY)
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKernel)
在行 131 上,我们将支票图像的底部转换成灰度,在行 132 上,我们使用 blackhat 形态学算子来寻找浅色背景下的深色区域。这个操作使用了我们的rectKernel。
结果显示了我们帐户和路由号码:

Figure 5: Applying black hat morphological operation reveals our bank account number and routing number from the rest of the check.
现在让我们计算在 x 方向上的沙尔梯度:
# compute the Scharr gradient of the blackhat image, then scale
# the rest back into the range [0, 255]
gradX = cv2.Sobel(blackhat, ddepth=cv2.CV_32F, dx=1, dy=0,
ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
使用我们的 blackhat 算子,我们用cv2.Sobel函数(第 136 和 137 行)计算沙尔梯度。我们在线 138 上采用gradX的逐元素绝对值。
然后我们在第 139-141 行的上将gradX缩放到范围【0-255】:

Figure 6: Computing the Scharr gradient magnitude representation of the bank check image reveals vertical changes in the gradient.
让我们看看是否可以缩小字符之间的间隙,并将图像二值化:
# apply a closing operation using the rectangular kernel to help
# cloes gaps in between rounting and account digits, then apply
# Otsu's thresholding method to binarize the image
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
在第行第 146 处,我们在应用关闭操作时再次使用了我们的内核。我们通过在行 147 和 148 上执行二进制阈值来遵循这一点。
此操作的结果如下所示:

Figure 7: Thresholding our gradient magnitude representation reveals possible regions that contain the bank check account number and routing number.
在预处理支票图像时,我们的形态学+阈值操作无疑会留下“假阳性”检测区域,我们可以应用一些额外的处理来帮助消除这些操作:
# remove any pixels that are touching the borders of the image (this
# simply helps us in the next step when we prune contours)
thresh = clear_border(thresh)
第 152 行通过移除图像边界像素来简单地清除边界;结果是微妙的,但将证明是非常有用的:
![]()
Figure 8: To help remove noise we can clear any connected components that lie on the border of the image.
如上图所示,我们已经清楚地在支票上找到了三组数字。但是,我们实际上是如何从每一个个体群体中提取出 T1 的呢?下面的代码块将向我们展示如何操作:
# find contours in the thresholded image, then initialize the
# list of group locations
groupCnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
groupCnts = imutils.grab_contours(groupCnts)
groupLocs = []
# loop over the group contours
for (i, c) in enumerate(groupCnts):
# compute the bounding box of the contour
(x, y, w, h) = cv2.boundingRect(c)
# only accept the contour region as a grouping of characters if
# the ROI is sufficiently large
if w > 50 and h > 15:
groupLocs.append((x, y, w, h))
# sort the digit locations from left-to-right
groupLocs = sorted(groupLocs, key=lambda x:x[0])
在第 156-158 行,我们发现我们的轮廓也处理了令人讨厌的 OpenCV 版本不兼容性。
接下来,我们初始化一个列表来包含我们的号码组位置(行 159 )。
在groupCnts上循环,我们确定轮廓边界框(第 164 行,并检查框参数是否符合字符分组的条件——如果是,我们将 ROI 值附加到groupLocs ( 第 168 和 169 行)。
使用 lambdas,我们从左到右对数字位置进行排序(行 172 )。
我们的分组区域显示在这张图片上:

Figure 9: Applying contour filtering allows us to find the (1) account number, (2) routing number, and (3) additional information groups on the bank check.
接下来,让我们循环一遍组位置:
# loop over the group locations
for (gX, gY, gW, gH) in groupLocs:
# initialize the group output of characters
groupOutput = []
# extract the group ROI of characters from the grayscale
# image, then apply thresholding to segment the digits from
# the background of the credit card
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
cv2.imshow("Group", group)
cv2.waitKey(0)
# find character contours in the group, then sort them from
# left to right
charCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
charCnts = imutils.grab_contours(charCnts)
charCnts = contours.sort_contours(charCnts,
method="left-to-right")[0]
在这个循环中,首先,我们初始化一个groupOutput列表,这个列表稍后将被追加到output列表中(第 177 行)。
随后,我们从图像中提取字符分组 ROI(行 182 )并对其进行阈值处理(行 183 和 184 )。
出于开发和调试的目的(第 186 行和第 187 行),我们将该组显示在屏幕上,并在继续之前等待按键(如果您愿意,可以随意从脚本中删除这段代码)。
我们在第 191-195 行的找到并分类组内的人物轮廓。该步骤的结果如图图 10** 所示。**

Figure 10: By using the (x, y)-coordinates of the locations, we can extract each group from the thresholded image. Given the group, contour detection allows us to detect each individual character.
现在,让我们用函数提取数字和符号,然后在rois上循环:
# find the characters and symbols in the group
(rois, locs) = extract_digits_and_symbols(group, charCnts)
# loop over the ROIs from the group
for roi in rois:
# initialize the list of template matching scores and
# resize the ROI to a fixed size
scores = []
roi = cv2.resize(roi, (36, 36))
# loop over the reference character name and corresponding
# ROI
for charName in charNames:
# apply correlation-based template matching, take the
# score, and update the scores list
result = cv2.matchTemplate(roi, chars[charName],
cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# the classification for the character ROI will be the
# reference character name with the *largest* template
# matching score
groupOutput.append(charNames[np.argmax(scores)])
在行 198 上,我们向extract_digits_and_symbols函数提供group和charCnts,该函数返回rois和locs。
我们循环遍历rois,首先初始化一个匹配分数列表的模板,然后将roi调整到已知的尺寸。
我们遍历角色名并执行模板匹配,将查询图像roi与第行 212 和 213 上的可能的角色图像(它们存储在chars字典中并由charName索引)进行比较。
为了提取与该操作的score匹配的模板,我们使用了cv2.minMaxLoc函数,随后,我们将它添加到第 215 行的scores中。
这个代码块的最后一步是从scores中获取最大值score,并使用它来查找角色名——我们将结果追加到groupOutput ( 第 220 行)。
你可以在我们之前关于信用卡 OCR 的博客文章中读到更多关于这种基于模板匹配的 OCR 方法的内容。
接下来,我们将利用原始的image将groupOutput结果附加到一个名为output的列表中。
# draw (padded) bounding box surrounding the group along with
# the OCR output of the group
cv2.rectangle(image, (gX - 10, gY + delta - 10),
(gX + gW + 10, gY + gY + delta), (0, 0, 255), 2)
cv2.putText(image, "".join(groupOutput),
(gX - 10, gY + delta - 25), cv2.FONT_HERSHEY_SIMPLEX,
0.95, (0, 0, 255), 3)
# add the group output to the overall check OCR output
output.append("".join(groupOutput))
行 224 和 225 处理在groups和行周围绘制一个红色矩形在图像上绘制组输出字符(路由、检查和检查号)。
最后,我们将groupOutput字符添加到一个output字符串中(第 231 行)。
我们的最后一步是将 OCR 文本写入我们的终端,并显示最终的输出图像:
# display the output check OCR information to the screen
print("Check OCR: {}".format(" ".join(output)))
cv2.imshow("Check OCR", image)
cv2.waitKey(0)
我们将 OCR 结果打印到终端,将图像显示到屏幕上,然后等待,直到按下键退出第 234-236 行的。
让我们在下一节看看我们的银行支票 OCR 系统是如何执行的。
银行支票 OCR 结果
要应用我们的银行支票 OCR 算法,请确保您使用本文的 【下载】 部分下载源代码+示例图片。
从那里,执行以下命令:
$ python bank_check_ocr.py --image example_check.png \
--reference micr_e13b_reference.png
我们努力工作的成果如下:
Figure 11: Using OpenCV and Python, we have been able to correctly OCR our bank account number and routing number from an image of a check.
改进我们的银行支票 OCR 系统
在这个特殊的例子中,我们能够使用基本的模板匹配作为我们的字符识别算法。
然而,模板匹配对于字符识别来说并不是最可靠的方法,尤其是对于真实世界的图像来说,这些图像可能会更嘈杂,更难分割。
在这些情况下,最好是训练自己的 HOG +线性 SVM 分类器或卷积神经网络。为此,您需要创建一个支票图像数据集,并手动标记和提取图像中的每个数字。我建议每个字符有 1000-5000 个数字,然后训练你的分类器。
从那里,你将能够享受到更高的字符分类精度——最大的问题是简单地创建/获得这样一个数据集。
由于支票本质上包含敏感信息,因此通常很难找到一个数据集,它不仅(1)代表真实世界的银行支票图像,而且(2)便宜/易于许可。
许多数据集属于银行本身,这使得计算机视觉研究人员和开发人员很难使用它们。
摘要
在今天的博文中,我们学习了如何使用 OpenCV、Python 和模板匹配对图像应用回溯 OCR。事实上,这与我们用于信用卡 OCR 的方法相同——主要区别在于我们必须特别小心地提取每个 MICR E-13B 符号,尤其是当这些符号包含多个轮廓时。
然而,虽然我们的模板匹配方法在这个特定的示例图像上工作正常,但真实世界的输入可能会有更多的噪声,使我们更难使用简单的轮廓技术提取数字和符号。
在这些情况下,最好是定位每个数字和字符,然后应用机器学习来获得更高的数字分类精度。定向梯度直方图+线性 SVM 和深度学习等方法将在包含更多噪声的真实世界图像上获得更好的数字和符号识别精度。
如果你有兴趣了解更多关于 HOG +线性 SVM 和深度学习的知识,一定要看看 PyImageSearch 大师课程。
在您离开之前,请务必在下面的表格中输入您的电子邮件地址,以便在以后发布博文时得到通知!
用 OpenCV 和 Python 实现银行支票 OCR(上)
原文:https://pyimagesearch.com/2017/07/24/bank-check-ocr-with-opencv-and-python-part-i/

今天这篇博文的灵感来自于李伟,一位 PyImageSearch 的读者,他上周给我发了一封电子邮件,问我:
嗨阿德里安,
感谢你的 PyImageSearch 博客。我每周都读它,并期待你每周一的新帖子。我真的很喜欢上周的信用卡 OCR 教程。
我在想:同样的技术可以用于银行支票 OCR 吗?
我正在做一个项目,需要我从支票图像中 OCR 银行账户和路由号码,但我正在努力提取数字/符号。你能写一篇关于这个的博文吗?
谢谢你。
很棒的问题,李伟,谢谢提问。
简短的回答是 是的 ,您可以使用我们用于信用卡 OCR 的相同模板匹配技术,并将其应用于银行支票 OCR…
但是有一个条件。
正如李伟发现的那样,从支票中提取银行代号、账号数字和符号的要难得多。
**原因是因为银行支票使用特殊的字体,其中一个特定的符号由多个部分组成——这意味着我们需要设计一种方法,可以自动计算这些符号的边界框并提取它们,就像这篇文章顶部的图像一样。
要开始用 OpenCV 和 Python 构建自己的银行支票 OCR 系统,继续阅读。
用 OpenCV 和 Python 实现银行支票 OCR(上)
由于用 OpenCV 和 Python 对银行支票进行 OCR 比对信用卡进行 OCR 要复杂得多,我决定将本指南分成两部分(仅仅一篇文章就太长了)。
在第一部分(今天的博文),我们将讨论两个话题:
- 首先,我们将了解 MICR E-13B 字体,这种字体被美国、英国、加拿大和其他国家用于支票识别。
- 其次,我们将讨论如何从 MICR E-13B 参考图像中提取数字和符号。这将使我们能够提取每个字符的 ROI,然后用它们来 OCR 银行支票。我们将使用 OpenCV contours 和一点 Python 迭代器“魔力”来完成这个任务。
下周,在本系列的第二部分,我将回顾我们如何使用我们的参考 ROI 和模板匹配来实际识别这些提取的符号和数字。
MICR E-13B 字体

Figure 1: The MICR E-13B font, commonly used for bank check recognition. We’ll be OCR’ing this bank check font using Python and OpenCV
MICR(磁性墨水字符识别)是一种用于处理文档的金融行业技术。你经常会在帐户报表和支票的底部找到这种 E-13B 格式的磁性墨水。
MICR 的 E-13B 变体包含 14 个字符:
- 数字:数字 0-9
- ⑆公交:银行分行分隔符
- ⑇金额:事务处理金额分隔符
- 美国⑈:客户帐号分隔符
- ⑉破折号:数字分隔符(例如,在路由和帐号之间)
对于上面显示的四个符号,我们稍后将利用每个符号仅包含三个轮廓的事实。
既然我们已经了解了 MICR E-13B 检查字体,让我们在深入研究代码之前做一些考虑。
银行支票字符识别比看起来要难

Figure 2: Extracting digits and symbols from a bank check isn’t as simple as computing contours and extracting them as some symbols consist of multiple parts.
在我们之前的帖子信用卡 OCR 帖子中,我们有一个更简单的任务,为每个数字计算单一轮廓的边界框。
然而,MICR E-13B 的情况并非如此。
在银行支票上使用的 MICR E-13B 字体中,每个数字仍然有一个轮廓。
然而,控制符号对于每个角色有三个轮廓,使得任务稍微更具挑战性。
我们不能使用简单的轮廓和包围盒方法。相反,我们需要设计自己的方法来可靠地提取数字和符号。
在下一节中,我们将逐步完成这些步骤。
用 OpenCV 提取 MICR 数字和符号
考虑到与提取银行支票字符相关的挑战,似乎我们已经完成了我们的工作。
让我们开始解决这个问题,打开一个新文件,命名为bank_check_ocr.py,并插入以下代码:
# import the necessary packages
from skimage.segmentation import clear_border
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
2-7 号线处理我们的进口包裹。确保您的环境中安装了以下软件:
- OpenCV:从页面中选择适合您系统的安装指南。
scikit-image:可通过pip install -U scikit-image进行 pip 安装。numpy:通过pip install numpy安装imutils:可通过pip install --upgrade imutils进行 pip 安装。我经常给 imutils 添加功能,所以如果你已经有了一个副本,这将是一个用显示的--upgrade标志更新它的好时机。
提示:https://pyimagesearch.com/tag/install你可以通过查看与我的博客相关的“安装”标签找到安装教程。
既然我们已经导入了相关的包(并在需要时安装了它们),让我们构建一个从 MICR 字体中提取字符的函数:
def extract_digits_and_symbols(image, charCnts, minW=5, minH=15):
# grab the internal Python iterator for the list of character
# contours, then initialize the character ROI and location
# lists, respectively
charIter = charCnts.__iter__()
rois = []
locs = []
第 9 行开始一个提取 MICR 数字和符号的函数(这个函数会很长)。这个函数被分解成五个容易理解的部分,我们将在本节的剩余部分回顾它们。
首先,我们的函数有 4 个参数:
image:MICR E-13B 字体图像(在代码下载中提供)。charCnts:包含参考图像中人物轮廓的列表(我们将在后面的帖子中解释如何获取这些章节)。minW:可选参数,表示最小字符宽度。这有助于我们解释当我们遇到 2 或 3 个小轮廓时,它们一起构成了一个 MICR 人物。默认值是 5 个像素的宽度。minH:最小字符高度。该参数是可选的,默认值为 15 像素。用法理性同minW。
在第 13 行的上,我们为我们的charCnts列表初始化了一个迭代器。列表对象本质上是“可迭代的”,这意味着可用的__iter__和__next__方法是由生成器生成的。
注意:由于我们对列表迭代器没有任何特殊要求(除了典型的从左到右遍历),我们使用内置在标准 Python 列表中的迭代器。如果我们有特殊的需求,我们可以创建一个特殊的类和一个定制的生成器+迭代器。不幸的是,Python 迭代器没有像 Java 等语言中那样的“hasNext”方法——相反,当 iterable 对象中没有更多的项时,Python 会抛出一个异常。我们用这个函数中的 try-catch 块来解释这个异常。
第 14 行和第 15 行初始化空列表来保存我们的rois(感兴趣区域),和locs (ROI 位置)。我们将在函数末尾的元组中返回这些列表。
让我们开始循环,看看迭代器是如何工作的:
# keep looping over the character contours until we reach the end
# of the list
while True:
try:
# grab the next character contour from the list, compute
# its bounding box, and initialize the ROI
c = next(charIter)
(cX, cY, cW, cH) = cv2.boundingRect(c)
roi = None
在我们的函数中,我们在第 19 行开始一个无限循环——我们的退出条件将是循环体的一部分(当我们捕获到一个StopIterator异常时)。为了捕捉这个异常,我们需要在第 20 行的上打开一个 try-catch 块。
对于循环的每次迭代,我们通过简单地调用next(charIter) ( 第 23 行)来获取next角色轮廓。
让我们在第 24 行的上计算轮廓c周围的外接矩形。从这个函数调用中,我们可以提取出 (x,y)——矩形的坐标和宽度/高度。
我们在第 25 行的上初始化一个roi,稍后我们将在其中存储角色图像。
接下来,我们将检查边界框的宽度和高度,并采取相应的措施:
# check to see if the width and height are sufficiently
# large, indicating that we have found a digit
if cW >= minW and cH >= minH:
# extract the ROI
roi = image[cY:cY + cH, cX:cX + cW]
rois.append(roi)
locs.append((cX, cY, cX + cW, cY + cH))
如果字符计数器的尺寸分别大于或等于最小宽度和高度(第 29 行),我们采取以下措施:
- 使用我们的边界矩形调用中的坐标和宽度/高度从图像中提取出
roi(第 31 行)。 - 将
roi追加到rois( 第 32 行)。 - 将一个元组追加到
locs( 第 33 行)。这个元组由矩形两个角的 (x,y) 坐标组成。我们稍后将返回这个位置列表。
否则,我们假设我们正在使用 MICR E-13B 字符符号,并需要应用一组更高级的处理操作:
# otherwise, we are examining one of the special symbols
else:
# MICR symbols include three separate parts, so we
# need to grab the next two parts from our iterator,
# followed by initializing the bounding box
# coordinates for the symbol
parts = [c, next(charIter), next(charIter)]
(sXA, sYA, sXB, sYB) = (np.inf, np.inf, -np.inf,
-np.inf)
# loop over the parts
for p in parts:
# compute the bounding box for the part, then
# update our bookkeeping variables
(pX, pY, pW, pH) = cv2.boundingRect(p)
sXA = min(sXA, pX)
sYA = min(sYA, pY)
sXB = max(sXB, pX + pW)
sYB = max(sYB, pY + pH)
# extract the ROI
roi = image[sYA:sYB, sXA:sXB]
rois.append(roi)
locs.append((sXA, sYA, sXB, sYB))
if-else 的else块具有分析特殊符号的逻辑,这些特殊符号包含在 MICR E-13B 字体中发现的多个轮廓。我们做的第一件事是在第 41 行的上建立符号的parts。列表parts包含三个轮廓:(1)我们已经在行 23** 上抓取的轮廓,(2)下一个轮廓,以及(3)下一个轮廓。这就是迭代器的工作方式— 每次我们调用 next 时,都会得到后续的项目。**
正如我们需要知道一个有一个轮廓的角色的边界框,我们需要知道一个有三个轮廓的角色的边界框。为此,初始化四个边界框参数,sXA到sYB ( 第 42 行和第 43 行)。
现在我们将遍历列表parts,它理想地表示一个字符/符号。第 46 行开始这个循环,首先我们计算第 49 行上第一个项目p的外接矩形。
使用边界矩形参数,我们比较并计算相对于先前值的最小值和最大值(第 50-53 行)。这就是我们首先将sXA到sYB初始化为正/负无穷大值的原因——为了代码的简洁性和可读性,这是一种方便的方法。
现在我们已经找到了围绕符号的方框的坐标,让我们从图像中提取出roi,将roi附加到rois,并将方框坐标元组附加到locs ( 第 56-58 行)。
函数的剩余代码块处理 while 循环退出条件和返回语句。
# we have reached the end of the iterator; gracefully break
# from the loop
except StopIteration:
break
# return a tuple of the ROIs and locations
return (rois, locs)
如果在charIter(我们的迭代器对象)上调用next抛出了一个StopIteration异常,那么我们已经到达了最后一个轮廓,并试图抓取一个不存在的轮廓。在这种情况下,我们break退出了我们的循环。该逻辑显示在行 62 和 63 上。
最后,我们在第 66 行的上返回一个方便的元组中的rois和locs。
现在,我们已经准备好解析命令行参数,并继续执行脚本:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-r", "--reference", required=True,
help="path to reference MICR E-13B font")
args = vars(ap.parse_args())
在第 69-74 行上,我们建立了两个必需的命令行参数:
--image:我们的查询图片。我们不会使用这个论点,直到下周的帖子。--reference:我们参考 MICR E-13B 字体图片。
接下来,我们将为每个符号/字符创建“名称”,并将它们存储在一个列表中。
# initialize the list of reference character names, in the same
# order as they appear in the reference image where the digits
# their names and:
# T = Transit (delimit bank branch routing transit #)
# U = On-us (delimit customer account number)
# A = Amount (delimit transaction amount)
# D = Dash (delimit parts of numbers, such as routing or account)
charNames = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0",
"T", "U", "A", "D"]
上面的代码块相当简单——我们只是为我们在参考图像中从左到右遇到的符号建立名称。这些charNames以列表形式在行 83 和 84 中指定。
注: 由于 OpenCV 不支持 unicode 中的绘图字符,我们需要定义“T”为 transit,“U”为 on-us,“A”为 amount,“D”为 dash。
接下来,我们将把参考图像加载到内存中,并执行一些预处理:
# load the reference MICR image from disk, convert it to grayscale,
# and threshold it, such that the digits appear as *white* on a
# *black* background
ref = cv2.imread(args["reference"])
ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)
ref = imutils.resize(ref, width=400)
ref = cv2.threshold(ref, 0, 255, cv2.THRESH_BINARY_INV |
cv2.THRESH_OTSU)[1]
在上面的模块中,我们完成了四项任务:
- 将
--reference图像作为ref( 第 89 行)载入内存。 - 转换为灰度(第 90 行)。
- 调整到
width=400( 行 91 )。 - 使用 Otsu 方法的二进制逆阈值(第 92-93 行)。
这些简单操作的结果可以在图 3 中看到:

Figure 3: Thresholding our MICR E-13B image to reveal the individual characters and symbols.
这段代码的其余部分是被分解成两部分的。首先,我将向您展示一个逻辑和简单的轮廓方法以及生成的图像。然后,我们将转移到一个更高级的方法,该方法利用了我们在脚本顶部编写的函数— extract_digits_and_symbols。
**对于这两个部分,我们将使用一些共同的数据,包括ref(我们刚刚预处理的参考图像)和refCnts(我们即将提取的参考轮廓)。
# find contours in the MICR image (i.e,. the outlines of the
# characters) and sort them from left to right
refCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
refCnts = imutils.grab_contours(refCnts)
refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]
# create a clone of the original image so we can draw on it
clone = np.dstack([ref.copy()] * 3)
# loop over the (sorted) contours
for c in refCnts:
# compute the bounding box of the contour and draw it on our
# image
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(clone, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output of applying the simple contour method
cv2.imshow("Simple Method", clone)
cv2.waitKey(0)
为了从参考图像中提取轮廓,我们使用 OpenCV 的cv2.findContours函数(第 97 行和第 98 行)。
注: OpenCV 2.4,3,4 返回轮廓的方式不同,所以 Line 99 有一定的逻辑来说明这一点。
接下来,我们在行 100 上从左到右对轮廓进行排序。
我们将在图像上进行绘制,因此我们将所有通道复制到第 103 行的一个名为clone的图像上。
在显示结果之前,简单轮廓方法的最后一步是在排序后的轮廓上循环(行 106 )。在这个循环中,我们计算每个轮廓的边界框(线 109 ,然后在它周围画一个矩形(线 110 )。
通过显示图像(行 113 )并在此暂停直到按下一个键(行 114 )来显示结果—参见图 4 :

Figure 4: The naïve method of extracting bank check symbols with OpenCV can extract digits, but fails to correctly compute the bounding box for each of the control symbols.
你看到这种方法的问题了吗?问题是我们有 22 个边界框,而不是想要的 14 个边界轮廓(每个角色一个)。显然,这个问题可以用更先进的方法来解决。
更高级的方法如下所示:
# extract the digits and symbols from the list of contours, then
# initialize a dictionary to map the character name to the ROI
(refROIs, refLocs) = extract_digits_and_symbols(ref, refCnts,
minW=10, minH=20)
chars = {}
# re-initialize the clone image so we can draw on it again
clone = np.dstack([ref.copy()] * 3)
# loop over the reference ROIs and locations
for (name, roi, loc) in zip(charNames, refROIs, refLocs):
# draw a bounding box surrounding the character on the output
# image
(xA, yA, xB, yB) = loc
cv2.rectangle(clone, (xA, yA), (xB, yB), (0, 255, 0), 2)
# resize the ROI to a fixed size, then update the characters
# dictionary, mapping the character name to the ROI
roi = cv2.resize(roi, (36, 36))
chars[name] = roi
# display the character ROI to our screen
cv2.imshow("Char", roi)
cv2.waitKey(0)
# show the output of our better method
cv2.imshow("Better Method", clone)
cv2.waitKey(0)
还记得我们在这个脚本开头写的那个长函数extract_digits_and_symbols吗?它现在已经在118 线和119 线投入使用。
接下来,我们初始化一个空字典chars,它将保存每个符号的name和roi。
我们按照这个动作,用一个新的ref副本覆盖clone图像(第 123 行)(去掉我们刚刚画的矩形)。
最后,我们循环字符(第 126 行)。我们有三个列表,我们可以方便地将它们合并成一个包含三元组的相同长度的列表。这个三元组列表就是我们要循环的。
在 for 循环的主体中,首先我们在我们的clone图像上为每个字符画一个矩形(第 129-130 行)。
其次,我们将roi的大小调整为 36 乘 36 像素(第 134 行),并用name和roi作为键值对更新我们的chars字典。
最后一步(主要用于调试/开发目的),是在屏幕上显示每个roi,直到按下一个键。
产生的“更好的方法”图像显示在屏幕上(行 142 ),直到按下一个键(行 143 ),然后结束我们的脚本。
图 5 显示了结果:

Figure 5: By examining contour properties of each character/symbol, we can use Python iterator magic to correctly build the bounding boxes for each bank check control character.
数字和符号提取结果
现在我们已经编码了我们的 MICR E-13B 数字和符号提取器,让我们试一试。
一定要使用这篇博文的 【下载】 部分下载源代码+示例图片。
从那里,执行以下脚本:
$ python bank_check_ocr.py --image example_check.png \
--reference micr_e13b_reference.png
如下面的 GIF 所示,我们已经正确地提取了每个字符:
Figure 6: Extracting each individual bank check digit and symbol using OpenCV and Python.
在这个博客系列的第二部分中,我们将学习如何使用 Python 和 OpenCV 对这些银行支票字符进行 OCR。
摘要
正如今天的博客文章所展示的,OCR 识别银行支票比 OCR 识别信用卡更困难——这主要是因为银行支票符号由多个部分组成。
我们不能假设我们的参考字体图像中的每个轮廓都映射到一个单独的字符。
相反,我们需要插入额外的逻辑来检查每个轮廓的尺寸,并确定我们正在检查的是数字还是符号。
在我们已经找到一个符号的情况下,我们需要抓取接下来的两个轮廓来构建我们的边界框(因为银行支票控制字符由三个不同的部分组成)。
现在我们知道了如何从图像中提取银行支票的数字和符号,我们可以继续使用 Python 和 OpenCV 对银行支票进行 OCR。
要在下一次银行支票 OCR 发布时得到通知,只需在下面的表格中输入您的电子邮件地址!
下周见。****
Python 和 OpenCV 中的基本图像操作:调整大小(缩放)、旋转和裁剪
你准备好开始建立你的第一个图像搜索引擎了吗?没那么快!让我们先来看一些基本的图像处理和操作,它们在你的图像搜索引擎之旅中会派上用场。如果你已经是一个图像处理专家,这篇文章对你来说可能会很无聊,但是还是读一读吧——你可能会学到一两个技巧。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
对于这个基本图像处理的介绍,我假设您已经掌握了如何创建和执行 Python 脚本的基本知识。我还假设您已经安装了 OpenCV。如果你需要帮助安装 OpenCV,请查看 OpenCV 网站上的快速入门指南。
继续我对《侏罗纪公园》的痴迷让我们以《侏罗纪公园》吉普车为例来玩玩:

Figure 1: Our example image — a Jurassic Park Tour Jeep.
继续将此图像下载到您的计算机上。您将需要它来开始使用一些 Python 和 OpenCV 示例代码。
准备好了吗?开始了。
首先,让我们加载图像并显示在屏幕上:
# import the necessary packages
import cv2
# load the image and show it
image = cv2.imread("jurassic-park-tour-jeep.jpg")
cv2.imshow("original", image)
cv2.waitKey(0)
在我的电脑上执行这个 Python 代码片段会产生以下结果:

Figure 2: Loading and Displaying the Jurassic Park tour jeep.
如您所见,图像现在正在显示。让我们继续分解代码:
- 第 2 行:第一行只是告诉 Python 解释器导入 OpenCV 包。
- 第 5 行:我们现在正在从磁盘上加载图像。
imread函数返回一个 NumPy 数组,代表图像本身。 - 第 6 行和第 7 行:调用
imshow在我们的屏幕上显示图像。第一个参数是一个字符串,即我们窗口的“名称”。第二个参数是对我们在第 5 行从磁盘上下载的图像的引用。最后,调用waitKey会暂停脚本的执行,直到我们按下键盘上的一个键。使用参数“0”表示任何按键都不会暂停执行。

仅仅加载和显示图像并不有趣。让我们调整这张图片的大小,让它变得更小。我们可以通过使用图像的shape属性来检查图像的尺寸,因为图像毕竟是一个 NumPy 数组:
# print the dimensions of the image
print image.shape
当执行该代码时,我们看到 (388,647,3) 被输出到我们的终端。这意味着图像有 388 行、 647 列和 3 通道(RGB 分量)。当我们写矩阵时,通常是以(【行数 x 列数】)的形式写它们,这与用 NumPy 指定矩阵大小的方式相同。
然而,当处理图像时,这可能会变得有点混乱,因为我们通常按照宽度 x 高度来指定图像。看着矩阵的形状,我们可能认为我们的图像是 388 像素宽和 647 像素高。然而,这是不正确的。我们的图像实际上是 647 像素宽和 388 像素高,这意味着高度是形状中的第个条目,宽度是第个个条目。如果您刚刚开始使用 OpenCV,这一点可能会有点混乱,记住这一点很重要。
因为我们知道我们的图像是 647 像素宽,让我们调整它的大小,使其宽度为 100 像素:
# we need to keep in mind aspect ratio so the image does
# not look skewed or distorted -- therefore, we calculate
# the ratio of the new image to the old image
r = 100.0 / image.shape[1]
dim = (100, int(image.shape[0] * r))
# perform the actual resizing of the image and show it
resized = cv2.resize(image, dim, interpolation = cv2.INTER_AREA)
cv2.imshow("resized", resized)
cv2.waitKey(0)
执行这段代码,我们可以看到新的调整后的图像只有 100 像素宽:

Figure 3: We have now resized the image to 100px wide.
让我们分解代码并检查它:
- 第 15 行和第 16 行:我们要记住图像的长宽比,也就是图像的宽度和高度的比例关系。在这种情况下,我们调整图像的大小,使其宽度为 100 像素,因此,我们需要计算新宽度与旧宽度的比率
r。然后,我们通过使用 100 个像素的宽度和旧图像的高度(T4)来构建图像的新维度。这样做可以让我们保持图像的长宽比。 - 第 19-21 行:图像的实际大小调整发生在这里。第一个参数是我们想要调整大小的原始图像,第二个参数是新图像的计算尺寸。第三个参数告诉我们调整大小时使用的算法。现在不要担心那个。最后,我们显示图像并等待按键。
调整图像大小并没有那么糟糕。现在,让我们假设我们是侏罗纪公园电影中的霸王龙——让我们把这辆吉普车倒过来:
# grab the dimensions of the image and calculate the center
# of the image
(h, w) = image.shape[:2]
center = (w / 2, h / 2)
# rotate the image by 180 degrees
M = cv2.getRotationMatrix2D(center, 180, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("rotated", rotated)
cv2.waitKey(0)
那么吉普车现在是什么样子?你猜对了——上下颠倒了。

Figure 4: The jeep has now been flipped upside. We could have also rotated the jeep by any arbitrary angle.
这是我们到目前为止看到的最复杂的例子。让我们来分解一下:
- 第 25 行:为了方便起见,我们抓取图像的宽度和高度,并将它们存储在各自的变量中。
- 第 26 行:计算图像的中心——我们简单地将宽度和高度除以 2。
- 第 29 行:计算一个可用于旋转(和缩放)图像的矩阵。第一个参数是我们计算的图像的中心。如果你想围绕任意点旋转图像,这里就是你要提供那个点的地方。第二个参数是我们的旋转角度(度)。第三个参数是我们的缩放因子,在本例中为 1.0,因为我们希望保持图像的原始比例。如果我们想将图像的大小减半,我们将使用 0.5。类似地,如果我们想将图像的大小加倍,我们将使用 2.0。
- 第 30 行:通过提供图像、旋转矩阵和输出尺寸,执行实际的旋转。
- 第 31-32 行:显示旋转后的图像。
旋转图像绝对是迄今为止我们做过的最复杂的图像处理技术。
让我们继续裁剪图像,捕捉格兰特的特写:
# crop the image using array slices -- it's a NumPy array
# after all!
cropped = image[70:170, 440:540]
cv2.imshow("cropped", cropped)
cv2.waitKey(0)
看看格兰特。他看起来像看到生病的三角龙吗?
Figure 5: Cropping is simple with Python and OpenCV — we’re just slicing NumPy arrays!
裁剪在 Python 和 OpenCV 中已经死了,就像 Dennis Nedry 一样。我们所做的就是分割数组。我们首先向切片提供 startY 和 endY 坐标,然后是 startX 和 endX 坐标。就是这样。我们已经裁剪了图像!
作为最后一个例子,让我们将裁剪后的图像保存到磁盘,只保存为 PNG 格式(原始图像是 JPG):
# write the cropped image to disk in PNG format
cv2.imwrite("thumbnail.png", cropped)
我们在这里所做的只是提供文件的路径(第一个参数),然后是我们想要保存的图像(第二个参数)。就这么简单。
Figure 6: We have now saved ‘thumbnail.png’ to disk.
如您所见,OpenCV 为我们处理了格式的改变。
现在你知道了!Python 和 OpenCV 中的基本图像操作!继续自己玩代码,在你最喜欢的侏罗纪公园图片上试试。
用 Python 和 OpenCV 实现基本的运动检测和跟踪
原文:https://pyimagesearch.com/2015/05/25/basic-motion-detection-and-tracking-with-python-and-opencv/
最后更新于 2021 年 7 月 8 日。
那个狗娘养的。我知道他拿走了我最后一瓶啤酒。
这些话是一个男人永远不应该说的。但是当我关上冰箱门的时候,我在愤怒的厌恶的叹息中喃喃自语。
你看,我刚刚花了 12 个多小时为即将到来的 PyImageSearch 大师课程写内容。我的大脑被烧焦了,几乎像半熟的炒鸡蛋一样从耳朵里漏出来。晚上结束后,我想做的就是放松,看我一直最喜欢的电影《侏罗纪公园》,同时啜饮一杯来自 Smuttynose 的冰镇冰精 IPA,Smuttynose 是一家我最近变得相当喜欢的啤酒厂。
但是那个狗娘养的詹姆斯昨晚过来喝了我最后一瓶啤酒。
嗯, 据称是 。
我实际上无法证明任何事情。事实上,我并没有真正看到喝着啤酒,我的脸埋在笔记本电脑里,手指在键盘上浮动,狂热地敲打着教程和文章。但我感觉他是罪魁祸首。他是我唯一喝 IPAs 的(前)朋友。
所以我做了任何男人都会做的事。
我在厨房橱柜顶上安装了一个树莓派,以自动检测他是否试图再次拉啤酒偷屎:
过度?
也许吧。
但是我很重视我的啤酒。如果詹姆斯再想偷我的啤酒,我会当场抓住他。
- 【2021 年 7 月更新:添加了关于 OpenCV 中可使用的替代背景减除和运动检测算法的新章节。
关于运动检测的两部分系列
这是两部分系列中的第一篇关于建立家庭监控的运动检测和跟踪系统。
本文的其余部分将详细介绍如何使用计算机视觉技术构建一个基本的运动检测和跟踪系统,用于家庭监控。这个例子将与来自你的网络摄像头的预先录制的视频和实时流一起工作;然而,我们将在我们的笔记本电脑/台式机上开发这个系统。
在本系列的第二篇文章中,我将向您展示如何更新代码以与您的 Raspberry Pi 和相机板配合使用,以及如何扩展您的家庭监控系统以捕捉任何检测到的运动并将其上传到您的个人 Dropbox。
也许在这一切结束时,我们可以抓住赤手詹姆斯…
一点点关于背景减法
背景减除在许多计算机视觉应用中是至关重要的。我们用它来计算通过收费站的汽车数量。我们用它来计算进出商店的人数。
我们用它来进行运动检测。
在本文开始编码之前,我想说在 OpenCV 中有很多方法来执行运动检测、跟踪和分析。有些很简单。其他的就很复杂了。两种主要方法是基于高斯混合模型的前景和背景分割形式:
- KaewTraKulPong 等人提出的一种改进的自适应背景混合模型,通过
cv2.BackgroundSubtractorMOG函数进行实时跟踪,并带有阴影检测 。 - 改进的自适应高斯混合模型用于背景减除 由 Zivkovic,以及 高效的自适应密度估计每图像像素用于背景减除 的任务,也由 Zivkovic,可通过
cv2.BackgroundSubtractorMOG2函数获得。
在 OpenCV 的新版本中,我们有基于贝叶斯(概率)的前景和背景分割,实现自 Godbehere 等人 2012 年的论文 在可变光照条件下对人类参观者的视觉跟踪,用于响应音频艺术装置 。我们可以在cv2.createBackgroundSubtractorGMG函数中找到这个实现(不过我们将等待 OpenCV 3 完全使用这个函数)。
所有这些方法都与从前景中分割出背景有关(它们甚至为我们提供了辨别实际运动和阴影以及小的光照变化的机制)!
那么,这为什么如此重要呢?为什么我们要关心哪些像素属于前景,哪些像素属于背景?
在运动检测中,我们倾向于做出以下假设:
我们视频流的背景很大程度上是静止不变的。因此,如果我们可以对背景建模,我们就可以监控它的实质性变化。如果有实质性的变化,我们可以检测到——这种变化通常对应于我们视频上的运动。
显然,在现实世界中,这个假设很容易失败。由于阴影、反射、照明条件和环境中任何其他可能的变化,我们的背景在视频的不同帧中可能看起来非常不同。如果背景看起来不一样,它会打乱我们的算法。这就是为什么最成功的背景减除/前景检测系统利用固定安装的摄像机和在受控的照明条件下。
我上面提到的方法虽然非常强大,但是计算量也很大。因为我们的最终目标是在这个 2 部分系列的最后将这个系统部署到 Raspberry Pi,所以我们最好坚持简单的方法。我们将在以后的博客文章中回到这些更强大的方法,但目前我们将保持它的简单和高效。
在这篇博文的剩余部分,我将详细介绍(可以说)你可以建立的最基本的运动检测和跟踪系统。它不会是完美的,但它将能够在 Pi 上运行,并且仍然能够提供好的结果。
用 Python 和 OpenCV 实现基本的运动检测和跟踪
好吧,你准备好帮我开发一个家庭监控系统来抓那个偷啤酒的混蛋了吗?
打开一个编辑器,创建一个新文件,命名为motion_detector.py,让我们开始编码:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", help="path to the video file")
ap.add_argument("-a", "--min-area", type=int, default=500, help="minimum area size")
args = vars(ap.parse_args())
# if the video argument is None, then we are reading from webcam
if args.get("video", None) is None:
vs = VideoStream(src=0).start()
time.sleep(2.0)
# otherwise, we are reading from a video file
else:
vs = cv2.VideoCapture(args["video"])
# initialize the first frame in the video stream
firstFrame = None
2-7 线进口我们必要的包装。所有这些看起来应该都很熟悉,除了imutils包,这是我创建的一组方便的函数,用来简化基本的图像处理任务。如果您的系统上还没有安装 imutils ,您可以通过 pip: pip install imutils进行安装。
接下来,我们将解析第 10-13 行的命令行参数。我们将在这里定义两个开关。第一个是可选的。它只是定义了一个预先录制的视频文件的路径,我们可以在其中检测运动。如果您不提供视频文件的路径,那么 OpenCV 将利用您的网络摄像头来检测动作。
我们还将定义--min-area,它是被视为实际“运动”的图像区域的最小尺寸(以像素为单位)。正如我将在本教程后面讨论的,我们经常会发现图像的小区域发生了实质性的变化,可能是由于噪声或光照条件的变化。实际上,这些小区域根本不是真正的运动——所以我们将定义一个区域的最小尺寸来对抗和过滤掉这些误报。
第 16-22 行处理抓取对我们vs对象的引用。在视频文件路径是而不是提供的情况下(第 16-18 行),我们将抓取一个对网络摄像头的引用,并等待它预热。如果视频文件是由提供的,那么我们将在的第 21 行和第 22 行创建一个指向它的指针。
最后,我们将通过定义一个名为firstFrame的变量来结束这段代码。
任何关于firstFrame是什么的猜测?
如果您猜测它存储了视频文件/网络摄像头流的第一帧,那么您猜对了。
假设:我们视频文件的第一帧将包含无运动和仅有背景——因此,我们可以仅使用视频的第一帧来模拟我们视频流的背景。
显然,我们在这里做了一个相当大的假设。但是,我们的目标是在树莓 Pi 上运行这个系统,所以我们不能太复杂。正如你将在这篇文章的结果部分看到的,我们能够在跟踪一个人在房间里走动时轻松地检测到运动。
# loop over the frames of the video
while True:
# grab the current frame and initialize the occupied/unoccupied
# text
frame = vs.read()
frame = frame if args.get("video", None) is None else frame[1]
text = "Unoccupied"
# if the frame could not be grabbed, then we have reached the end
# of the video
if frame is None:
break
# resize the frame, convert it to grayscale, and blur it
frame = imutils.resize(frame, width=500)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
# if the first frame is None, initialize it
if firstFrame is None:
firstFrame = gray
continue
现在我们有了对视频文件/网络摄像头流的引用,我们可以开始循环第 28 行的每一帧。
对第 31 行上的vs.read()的调用返回了一个帧,我们确保我们在第 32 行上正确地抓取了该帧。
我们还将定义一个名为text的字符串,并对其进行初始化,以表明我们正在监视的房间是“未被占用的”。如果房间里确实有活动,我们可以更新这个字符串。
如果没有从视频文件中成功读取一帧,我们将从第 37 行和第 38 行的循环中断开。
现在我们可以开始处理我们的帧,并为运动分析做准备(第 41-43 行)。我们首先将它的宽度缩小到 500 像素——不需要直接从视频流中处理大的原始图像。我们还将图像转换为灰度,因为颜色与我们的运动检测算法无关。最后,我们将应用高斯模糊来平滑我们的图像。
重要的是要明白,即使是视频流的连续帧也不会完全相同!
由于数码相机传感器的微小差异,没有两帧是 100%相同的——一些像素肯定会有不同的亮度值。也就是说,我们需要考虑这一点,并将高斯平滑应用于整个 21 x 21 区域(第 43 行)的平均像素强度。这有助于消除可能干扰我们运动检测算法的高频噪声。
正如我上面提到的,我们需要以某种方式模拟图像的背景。同样,我们将假设视频流的第一帧包含无运动,并且是我们背景看起来像什么的好例子。如果firstFrame没有初始化,我们将存储它以供参考,并继续处理视频流的下一帧(第 46-48 行)。
以下是示例视频的第一帧:

Figure 2: Example first frame of a video file. Notice how it’s a still-shot of the background, no motion is taking place.
上面的帧满足了视频的第一帧仅仅是静态背景的假设——没有运动发生。
给定这个静态背景图像,我们现在准备实际执行运动检测和跟踪:
# compute the absolute difference between the current frame and
# first frame
frameDelta = cv2.absdiff(firstFrame, gray)
thresh = cv2.threshold(frameDelta, 25, 255, cv2.THRESH_BINARY)[1]
# dilate the thresholded image to fill in holes, then find contours
# on thresholded image
thresh = cv2.dilate(thresh, None, iterations=2)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# loop over the contours
for c in cnts:
# if the contour is too small, ignore it
if cv2.contourArea(c) < args["min_area"]:
continue
# compute the bounding box for the contour, draw it on the frame,
# and update the text
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
text = "Occupied"
现在我们已经通过firstFrame变量对背景进行了建模,我们可以利用它来计算视频流中初始帧和后续新帧之间的差异。
计算两个帧之间的差是一个简单的减法,其中我们取它们对应的像素强度差的绝对值(行 52 ):
delta = |背景 _ 模型–当前 _ 帧|
帧增量的示例如下所示:
Figure 3: An example of the frame delta, the difference between the original first frame and the current frame.
注意图像的背景是如何清晰地变成黑色的。然而,包含运动的区域(比如我在房间里走动的区域)要比亮得多。这意味着较大的帧增量表示图像中正在发生运动。
然后,我们将对第 53 条线上的frameDelta进行阈值处理,以显示图像中仅在像素强度值上有显著变化的区域。如果 delta 小于 25 ,我们丢弃该像素并将其设置为黑色(即背景)。如果 delta 大于 25 ,我们会将其设置为白色(即前景)。下面是我们的阈值化增量图像的一个示例:

Figure 4: Thresholding the frame delta image to segment the foreground from the background.
再次注意,图像的背景是黑色的,而前景(以及运动发生的地方)是白色的。
给定这个阈值图像,很容易应用轮廓检测来找到这些白色区域的轮廓(行 58-60 )。
我们开始循环第 63 行上的每个轮廓,在这里我们将过滤第 65行和第 66** 行上的无关的小轮廓。**
如果轮廓面积大于我们提供的--min-area,我们将在第 70 行和第 71 行绘制包围前景和运动区域的边界框。我们还将更新我们的text状态字符串,以表明该房间“已被占用”。
# draw the text and timestamp on the frame
cv2.putText(frame, "Room Status: {}".format(text), (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
cv2.putText(frame, datetime.datetime.now().strftime("%A %d %B %Y %I:%M:%S%p"),
(10, frame.shape[0] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)
# show the frame and record if the user presses a key
cv2.imshow("Security Feed", frame)
cv2.imshow("Thresh", thresh)
cv2.imshow("Frame Delta", frameDelta)
key = cv2.waitKey(1) & 0xFF
# if the `q` key is pressed, break from the lop
if key == ord("q"):
break
# cleanup the camera and close any open windows
vs.stop() if args.get("video", None) is None else vs.release()
cv2.destroyAllWindows()
这个例子的其余部分简单地包装了一切。我们在左上角的图像上画出房间状态,然后在左下角画出时间戳(让它看起来像“真实的”安全录像)。
第 81-83 行显示了我们的工作结果,让我们可以直观地看到视频中是否检测到任何运动,以及帧增量和阈值图像,以便我们可以调试我们的脚本。
注意:如果你下载了这篇文章的代码,并打算将其应用到你自己的视频文件中,你可能需要调整cv2.threshold和--min-area参数的值,以获得最佳的照明条件。
最后,行 91 和 92 清理并释放视频流指针。
结果
显然,我想在偷啤酒的詹姆斯再次拜访我之前,确保我们的运动检测系统正常工作——我们将在本系列的第 2 部分讨论这个问题。为了使用 Python 和 OpenCV 测试我们的运动检测系统,我创建了两个视频文件。
首先,example_01.mp4监视我公寓的前门,并检测门何时打开。第二张,example_02.mp4是用安装在我厨房橱柜上的树莓 Pi 拍摄的。它俯视厨房和客厅,检测人们走动时的动作。
让我们试试我们的简单检测器。打开终端并执行以下命令:
$ python motion_detector.py --video videos/example_01.mp4
下面是来自运动检测的一些静止帧的. gif:
Figure 5: A few example frames of our motion detection system in Python and OpenCV in action.
请注意,直到门打开时才检测到运动——然后我们能够检测到自己走进门。你可以在这里看到完整的视频:
https://www.youtube.com/embed/fi4LORwk8Fc?feature=oembed
bat-country:一个可扩展的轻量级 Python 包,用于深度做梦,带有 Caffe 和卷积神经网络

我们不能停在这里,这是蝙蝠国。
就在几天前,谷歌研究博客发表了一篇文章,展示了一种独特、有趣、甚至可能令人不安的方法,来可视化卷积神经网络(CNN)各层内部的情况。
注:在你走之前,我建议看看用蝙蝠国生成的图片——大部分出来都很棒,尤其是《侏罗纪公园》的图片。
他们的方法是将 CNN 颠倒过来,输入一张图像,然后逐渐将图像调整到网络“认为”的特定对象或类别的样子。
至少可以说,结果是惊人的。较低的级别显示图像中类似边缘的区域。中间层能够表示物体的基本形状和组成部分(门把手、眼睛、鼻子等)。).最后,最后一层能够形成完整的解释(狗、猫、树等)。)————而且经常是以一种迷幻的、恍惚的方式。
除了他们的成果,谷歌还发布了一款优秀的 IPython 笔记本,让你可以四处玩耍,创造一些你自己的神游图像。
IPython 笔记本确实很棒。玩起来很有趣。因为这是一台 IPython 笔记本,所以入门相当容易。但是我想更进一步。把它做成模块化。更多可定制。更像一个 Python 模块,它的行为和表现就像一个 Python 模块。当然,它必须是 pip-installable (你需要自带 Caffe 安装)。
这就是为什么我把 bat-country 放在一起,这是一个易于使用、高度可扩展的轻量级 Python 模块,通过卷积神经网络和 Caffe 实现无概念和深度做梦。
相比之下,我在这里的贡献实在是微不足道。所有真正的研究都是由谷歌完成的——我只是拿着 IPython 笔记本,把它变成一个 Python 模块,同时牢记可扩展性的重要性,比如自定义步骤函数。
在我们深入这篇文章的其余部分之前,我想花一点时间提醒大家注意贾斯廷·约翰逊的 cnn-vis ,这是一个用于生成概念图像的命令行工具。他的工具非常强大,更像谷歌(可能)用于他们自己的研究出版物的工具。如果你正在寻找一个更高级、更完整的包,一定要去看看 cnn-vis。你可能也会对 Vision.ai 的联合创始人托马斯·马利西维茨的 clouddream docker 图像感兴趣,以快速启动并运行咖啡馆。
但是与此同时,如果你有兴趣玩一个简单易用的 Python 包,可以去从 GitHub 获取源代码或者通过pip install bat-country安装它
这篇博文的其余部分组织如下:
- 一个简单的例子。 3 行代码生成你自己的深梦/无概念图像。
- 要求。运行
bat-country所需的库和包(大部分只是 Caffe 及其相关的依赖项)。 - 引擎盖下是怎么回事?对
bat-country的解剖以及如何扩展它。 - 展示和讲述。如果这篇文章有你不想错过的部分, 就是这个 。我收集了一些非常棒的图片,这些图片是我在周末用
bat-country生成的。至少可以说,结果非常不真实。
bat-country:一个可扩展的轻量级 Python 包,用于 Caffe 和 CNN 的深度梦想
我想再次说明,蝙蝠国的代码很大程度上是基于 T2 谷歌研究团队的工作。我在这里的贡献主要是将代码重构为一个可用的 Python 包,使这个包可以通过定制的预处理、解处理、阶跃函数等进行扩展。,并确保该包是 pip 可安装的。话虽如此,让我们先来看看蝙蝠国。
一个简单的例子。
正如我提到的,简单是bat-country的目标之一。假设您已经在系统上安装了 Caffe 和bat-country,只需 3 行 Python 代码就可以生成一个深度梦境/幻觉图像:
# we can't stop here...
bc = BatCountry("caffe/models/bvlc_googlenet")
image = bc.dream(np.float32(Image.open("/path/to/image.jpg")))
bc.cleanup()
执行完这段代码后,您可以获取由dream方法返回的image,并将其写入文件:
result = Image.fromarray(np.uint8(image))
result.save("/path/to/output.jpg")
就是这样!在 GitHub 这里可以看到demo.py 的视图源代码。
要求。
bat-country 软件包要求在你的系统上已经安装了 Caffe,一个来自伯克利的开源 CNN 实现。本节将详细介绍在您的系统上安装 Caffe 的基本步骤。然而,一个很好的替代方法是使用 Vision.ai 的 Tomasz 提供的 Docker 图像。使用 Docker 镜像会让你轻松地启动并运行。但是对于那些想要自己安装的人,请继续阅读。
第一步:安装咖啡
看看官方安装说明让 Caffe 开始运行。我建议不要在你自己的系统上安装 Caffe,而是创建一个Amazon ec2g 2.2x 大型实例(这样你就可以访问 GPU)并从那里开始工作。
步骤 2:为 Caffe 编译 Python 绑定
再次使用来自 T2 咖啡馆的官方安装说明。为来自requirements.txt的所有包创建一个单独的虚拟环境是一个好主意,但肯定不是必需的。
这里要做的一个重要步骤是更新您的$PYTHONPATH以包含您的 Caffe 安装目录:
export PYTHONPATH=/path/to/caffe/python:$PYTHONPATH
在 Ubuntu 上,我也喜欢将这个导出保存在我的.bashrc文件中,这样我每次登录或者打开一个新的终端时都会加载它,但这取决于你。
步骤 3:可选地安装 cuDNN
Caffe 在 CPU 上开箱即可正常工作。但是如果你真的想让 Caffe 尖叫,你应该使用 GPU。安装 cuDNN 并不是一个太难的过程,但是如果你以前从未做过,请准备好花一些时间来完成这个步骤。
步骤 4:设置你的$CAFFE_ROOT
$CAFFE_ROOT目录是您的 Caffe 安装的基础目录:
export CAFEE_ROOT=/path/to/caffe
下面是我的$CAFFE_ROOT的样子:
export CAFFE_ROOT=/home/ubuntu/libraries/caffe
同样,我建议把它放在你的.bashrc文件中,这样你每次登录时都会加载它。
步骤 5:下载预先训练好的 GoogLeNet 模型
你需要一个预先训练好的模型来生成深度梦境图像。让我们继续使用 Google 在其博客文章中使用的 GoogLeNet 模型。Caffe 包提供了一个为您下载模型的脚本:
$ cd $CAFFE_ROOT
$ ./scripts/download_model_binary.py models/bvlc_googlenet/
步骤 6:安装 bat-country
这个bat-country包安装起来非常简单。最简单的方法是使用 pip:
$ pip install bat-country
但是如果你想做一些黑客工作,你也可以从 GitHub 下载源码:
$ git clone https://github.com/jrosebr1/bat-country.git
$ cd bat-country
... do some hacking ...
$ python setup.py install
引擎盖下发生了什么——以及如何扩展蝙蝠国
绝大多数的bat-country代码来自谷歌的 IPython 笔记本。我的贡献非常小,只是重新分解代码,使其像 Python 模块一样运行和表现——并且便于轻松修改和定制。
要考虑的第一个重要方法是BatCountry构造函数,它允许你传入定制的 CNN,比如 GoogLeNet、MIT Places,或者来自 Caffe Model Zoo 的其他模型。你所需要做的就是修改base_path、deploy_path、model_path和图像mean。mean本身将不得不根据原始训练集来计算。更多细节请看一下 BatCountry 构造函数。
BatCountry的内部负责修补模型以计算梯度,以及加载网络本身。
现在,假设您想要覆盖标准梯度上升函数,以最大化给定图层的 L2 范数激活。您需要做的就是向dream方法提供您的自定义函数。下面是一个简单的例子,它覆盖了渐变上升函数的默认行为,使用了较小的step和较大的jitter:
def custom_step(net, step_size=1.25, end="inception_4c/output",
jitter=48, clip=True):
src = net.blobs["data"]
dst = net.blobs[end]
ox, oy = np.random.randint(-jitter, jitter + 1, 2)
src.data[0] = np.roll(np.roll(src.data[0], ox, -1), oy, -2)
net.forward(end=end)
dst.diff[:] = dst.data
net.backward(start=end)
g = src.diff[0]
src.data[:] += step_size / np.abs(g).mean() * g
src.data[0] = np.roll(np.roll(src.data[0], -ox, -1), -oy, -2)
if clip:
bias = net.transformer.mean["data"]
src.data[:] = np.clip(src.data, -bias, 255 - bias)
image = bc.dream(np.float32(Image.open("image.jpg")),
step_fn=custom_step)
同样,这只是一个实现自定义步骤函数的演示,并不意味着什么太激动人心的事情。
您还可以通过将自定义的preprocess_fn和deprocess_fn传递给dream来覆盖默认的preprocess和deprocess函数:
def custom_preprocess(net, img):
# do something interesting here...
pass
def custom_deprocess(net, img):
# do something interesting here...
pass
image = bc.dream(np.float32(Image.open("image.jpg")),
preprocess_fn=custom_preocess, deprocess_fn=custom_deprocess)
最后,bat-country 还支持可视化网络的每个倍频程、迭代和层:
bc = BatCountry(args.base_model)
(image, visualizations) = bc.dream(np.float32(Image.open(args.image)),
end=args.layer, visualize=True)
bc.cleanup()
for (k, vis) in visualizations:
outputPath = "{}/{}.jpg".format(args.vis, k)
result = Image.fromarray(np.uint8(vis))
result.save(outputPath)
要在 GitHub 上查看完整的demo_vis.py脚本,只需点击这里。
展示和讲述。
周末,我玩bat-country玩得很开心,特别是《T2》中的恐惧和厌恶、《黑客帝国》中的和《侏罗纪公园》中的的图像。我还附上了一些我最喜欢的桌面壁纸和照片,是我最近在美国西部度假时拍的,很好玩。**
对于每个原始图像(上),我分别使用conv2/3x3、inception_3b/5x5_reduce、inception_4c/output图层生成了一个“深梦”。
conv2/3x3和inception_3b/5x5_reduce层是网络中的较低层,提供更多“类似边缘”的特征。inception_4c/output层是产生狗、蜗牛、鸟和鱼幻觉的最终输出。
拉斯维加斯的恐惧和厌恶




[电影]侏罗纪公园

This is DEFINITELY my personal favorite.





黑客帝国




羚羊峡谷(亚利桑那州佩奇)

天使登陆(锡安峡谷;犹他州斯普林代尔)


动物园(亚利桑那州凤凰城)

摘要
在这篇博文中,我介绍了 bat-country ,这是一个易于使用、高度可扩展的轻量级 Python 模块,通过卷积神经网络和 Caffe 实现无概念和深度做梦。
绝大部分代码基于由谷歌研究博客发布的 IPython 笔记本。我自己的贡献并不太令人兴奋,我只是简单地(1)将代码包装在 Python 类中,(2)使其更容易扩展和定制,以及(3)将其推送到 PyPI,使其可通过 pip 安装。
如果你正在使用 Caffe 寻找一个更强大的深度做梦工具,我真的建议看看贾斯廷·约翰逊的 cnn-vis 。如果你想快速安装并运行你自己的 Caffe(更不用说,它有一个深度做梦的网络界面),看看托马斯的 docker 实例。
无论如何,我希望你喜欢这个bat-country!请随意用你自己用这个包生成的图片来评论这篇文章。
2014 年最佳 Python 书籍
原文:https://pyimagesearch.com/2014/05/12/best-python-books-2014/
更新:2022 年 12 月
距离我们第一次发表这个帖子已经过去很久了。
我们现在有两个 Python 教育产品可供选择。
2014 年还没过半,但今年已经有一些非常棒的 Python 书籍发布了,它们并没有得到太多关注。
这些书有的与计算机视觉有关,有的与机器学习和统计分析有关,有的与并行计算有关。
虽然不是所有这些书都与构建基于内容的图像检索系统或图像搜索引擎直接相关,但它们在某种程度上是有关联的。
例如,您将如何部署图像搜索引擎?当然,是通过使用 Python web 框架。
你打算如何索引你的图像数据集?我希望你使用并行计算。
一定要花点时间来看看这些书。你不会失望的。
如果你认为我错过了一本特别重要的书,请留言或给我发信息。
2014 年最佳 Python 书籍
![Parallel Programming with Python]() #1。用 Python 进行并行编程
#1。用 Python 进行并行编程

如果你是这个博客的读者,你会知道我喜欢动手操作、容易理解的教程和解决问题的指南。让我们面对现实吧,并行计算在理论和实践层面上都是有意义的。但最大的问题是,你实际上是如何做到的?
这本书回答了你所有的并行计算问题,讨论了管道和队列,使用我最喜欢的 Python 包之一的分布式任务,以及如何执行异步 I/O。
在计算机视觉和图像搜索引擎的背景下,并行计算实际上是必须的。假设我们的任务是从包含数百万张图像的数据集中提取特征。在单核机器上索引这个数据集需要几周甚至几个月的时间。
解决方案是将索引分布到多个进程甚至多台机器上。
为了跨多个进程和机器并行索引图像,您首先需要了解您如何实际上做到这一点。
我高度推荐这本书,建议你把它加入你的阅读清单。
![matplotlib Plotting Cookbook]() #2。 Matplotlib 绘图食谱
#2。 Matplotlib 绘图食谱

回想一下我的帖子中最喜欢的 9 个构建图像搜索引擎的 Python 库。
您知道哪个 Python 包成功了吗?
没错。Matplotlib。
当我为我的论文运行实验和收集结果时,matplotlib 总是让绘图变得简单和容易。
无论你是发表研究成果的科研人员、从事项目的大学学生,还是朝九晚五的程序员或开发人员,在你的一生中,你都可能不得不制作一些图表和数字。
虽然 matplotlib 的文档非常棒,但是没有什么比 cookbook 方法更好的了——使用实际的 Python 脚本来解决实际的绘图问题。
看看这本书,让我知道你的想法。
![Getting Started with Beautiful Soup]() #3。美汤入门
#3。美汤入门

在你甚至可以考虑建立一个基于内容的图像检索系统或图像搜索引擎之前,有一个非常重要,绝对关键的步骤你必须首先采取。
这一步就是收集你的数据集。
有道理,对吧?
如果你没有任何可以搜索的东西,你就不能建立一个图片搜索引擎!
在某些情况下,您的数据集可能已经存在。如果您正在学术界进行研究,并且需要将您的结果与利用公共数据集的其他方法进行比较,这一点尤其正确。
但是在商业、企业和创业方面,情况并不总是这样。
这里有一个来自我个人经历的例子…
当我第一次构建 Chic Engine 时,我不得不创建一个网络爬虫来抓取与时尚内容相关的网页和图像,如衬衫、鞋子、夹克等。
为了创建这个网络爬虫,我使用了 Beautiful Soup,它使得解析和导航 DOM(文档对象模型)树变得非常简单。
老实说,我花了不到 30 分钟的时间创建了一个爬虫来抓取亚马逊和商店风格的最新时尚发现。谢谢你,漂亮的汤。
一旦我编写了屏幕抓取器,我就利用多线程和多处理方法(类似于上面提到的 Python 中的并行编程中讨论的)来快速抓取和抓取我的内容。
在我收集了所有我需要的数据后,我使用(再次)并行方法索引我的数据集。
注意到并行计算的趋势了吗?
没有美汤套餐,这一切都不可能实现。
![Flask Web Development]() #4。 Flask Web 开发:用 Python 开发 Web 应用
#4。 Flask Web 开发:用 Python 开发 Web 应用

如果它不在网络上,那么它可能不存在。
这不完全是真实的说法,但我想你明白我的感受。
例如,假设你刚刚建立了下一个大的创业公司。
或者更好的是,下一个谷歌图片搜索或 TinEye。
你打算怎么把它弄出去?用户将如何利用你的新技术?
你可能会创建一些网站,甚至是一个 API。
为了做到这一点,您可能需要一个 Python web 框架。
但是你选哪个呢?
当我坚定地站在 Django 阵营的时候,这本关于 T2 烧瓶微观框架的书将会让你立刻把你的新算法部署到网络上。
说到 Django,我强烈推荐拿起一本 两勺 Django 1.6——Daniel green feld 和 Audrey Roy 出色地完成了这本书的编写工作,是 Django 开发者的必备品。
![Statistics Data Mining and Machine Learning]() #5。天文学中的统计学、数据挖掘和机器学习:调查数据分析的实用 Python 指南
#5。天文学中的统计学、数据挖掘和机器学习:调查数据分析的实用 Python 指南

“大数据”有多大?数据“大”意味着什么?
大数据就像蛋糕一样,只是一个谎言吗?
虽然我们可能对大数据有不同的定义,但有一点是肯定的:天文学家和天体物理学家交互的数据量正在达到Pb域。
告诉我,你的算法有多好?
他们能(有效地)处理 1pb 的数据吗?
如果您正在处理大量数据,那么与统计、数据挖掘和机器学习相关的 Python 代码和数据集非常值得一看。
![Raspberry Pi Cookbook]() #6。Python 程序员的树莓派食谱
#6。Python 程序员的树莓派食谱

就我个人而言,我发现当我把手弄脏的时候我学得最好——当我埋头于代码中,而我只是试着踩水的时候。
这就是我如此热衷于编程食谱的原因…
你可以直接跳到实际可行的例子中。你可以破解密码。然后让它再次工作,同时根据您的喜好进行调整。
如果你一直在考虑摆弄树莓派,一定要看看提姆考克斯的这本书。
![Practical Python and OpenCV]() #7。实用 Python 和 OpenCV
#7。实用 Python 和 OpenCV

好吧。我明显有偏见。但是…
如果你曾经对使用 OpenCV 和 Python 学习计算机视觉和图像处理的基础知识感到好奇,那么 这本书就是为你准备的 。
而且我可以在一个周末 教你基本的 。
我知道,这听起来很疯狂。
参见,实用 Python 和 OpenCV 涵盖了计算机视觉和图像处理的基础知识。我已经包含了大量的代码示例,可以让您快速、轻松地上手。
说真的,这是你使用 Python 和 OpenCV 学习计算机视觉和图像处理基础知识的保证快速入门指南。不管你是开发人员、程序员还是学生,我都可以在一个周末教你基础知识。
因此,如果你对计算机视觉以及如何让机器看到并解释照片和图像有一点点兴趣,请花一点时间来看看我的书。
不会让人失望的,我保证。
摘要
所以你有它!
2014 年最好的 Python 书籍(目前为止)!
今年还没过半,我们已经有了一些惊人的 Python 内容需要消化。老实说,这只是表明 Python 社区是多么的专注和伟大。
基于 OpenCV 和深度学习的黑白图像彩色化

在本教程中,您将学习如何使用 OpenCV、深度学习和 Python 为黑白图像着色。
图像彩色化是获取输入灰度(黑白)图像然后生成输出彩色图像的过程,该图像表示输入的语义颜色和色调(例如,晴朗的晴天的海洋必须是貌似“蓝色”的——它不能被模型着色为“粉红”)。
以前的图像彩色化方法要么:
- 依赖于重要的人类互动和注释
- 产生的去饱和彩色化
相反,我们今天将在这里使用的新方法依赖于深度学习。我们将利用卷积神经网络能够彩色化黑白图像,其结果甚至可以“愚弄”人类!
要学习如何用 OpenCV 执行黑白图像着色,继续阅读!
基于 OpenCV 和深度学习的黑白图像彩色化
在本教程的第一部分,我们将讨论如何利用深度学习来给黑白图像着色。
接下来,我们将利用 OpenCV 为两者的黑白图像着色:
- 形象
- 视频流
然后,我们将探索我们工作的一些例子和演示。
如何用深度学习将黑白图像彩色化?
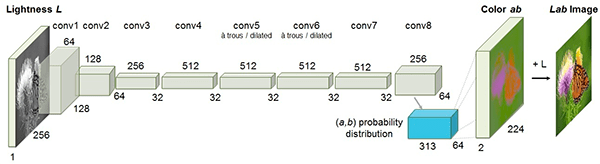
Figure 1: Zhang et al.’s architecture for colorization of black and white images with deep learning.
今天我们要介绍的技术来自张等人 2016 年的论文,【彩色图像着色】。
以前的黑白图像彩色化方法依赖于人工注释*,并且经常产生不像真正彩色化那样“可信”的去饱和结果。
张等人决定通过使用卷积神经网络来解决图像彩色化的问题,以“幻觉”输入灰度图像在彩色化时的样子。
为了训练网络,张等人从 ImageNet 数据集开始,并将所有图像从 RGB 色彩空间转换到 Lab 色彩空间。
类似于 RGB 颜色空间,Lab 颜色空间有三个通道。但是与RGB 颜色空间不同,Lab 对颜色信息的编码不同:
- L 通道仅对亮度进行编码
- a 通道编码绿-红。
- 并且 b 通道编码蓝黄色
对 Lab 色彩空间的全面回顾超出了本文的范围(参见本指南了解更多关于 Lab 的信息),但这里的要点是 Lab 在表现人类如何看待颜色方面做得更好。
由于 L 通道只对强度、进行编码,我们可以使用 L 通道作为网络的灰度输入。
从那里,网络必须学会预测 a 和 b 频道。给定输入 L 通道和预测 ab 通道,我们就可以形成我们的最终输出图像。
整个(简化)过程可以概括为:
- 将所有训练图像从 RGB 颜色空间转换到 Lab 颜色空间。
- 将 L 信道作为网络的输入,训练网络预测 ab 信道。
- 将输入的 L 通道与预测的 ab 通道组合。
- 将实验室图像转换回 RGB。
为了产生更合理的黑白图像彩色化,作者还利用了一些额外的技术,包括均值退火和专门的颜色再平衡损失函数(这两者都超出了本文的范围)。
关于图像彩色化算法和深度学习模型的更多细节,请务必参考张等人的官方出版物
项目结构
使用本文的 “下载” 部分下载源代码、模型和示例图片。
解压 zip 文件后,您应该导航到项目目录。
从那里,让我们使用tree命令来检查项目结构:
$ tree --dirsfirst
.
├── images
│ ├── adrian_and_janie.png
│ ├── albert_einstein.jpg
│ ├── mark_twain.jpg
│ └── robin_williams.jpg
├── model
│ ├── colorization_deploy_v2.prototxt
│ ├── colorization_release_v2.caffemodel
│ └── pts_in_hull.npy
├── bw2color_image.py
└── bw2color_video.py
2 directories, 9 files
在images/目录中,我们有四个黑白图像样本。
我们的 Caffe 模型和 prototxt 与 cluster points NumPy 文件一起位于model/目录中。
我们今天将复习两个剧本:
bw2color_image.pybw2color_video.py
图像脚本可以处理你传入的任何黑白(也称为灰度)图像。
我们的视频脚本将使用您的网络摄像头或接受一个输入视频文件,然后执行着色。
用 OpenCV 给黑白图像着色
让我们继续用 OpenCV 实现黑白图像着色脚本。
打开bw2color_image.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input black and white image")
ap.add_argument("-p", "--prototxt", type=str, required=True,
help="path to Caffe prototxt file")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--points", type=str, required=True,
help="path to cluster center points")
args = vars(ap.parse_args())
我们的着色脚本只需要三个导入:NumPy、OpenCV 和argparse。
让我们继续,使用argparse解析命令行参数。该脚本要求将这四个参数直接从终端传递给脚本:
--image:输入黑白图像的路径。- 我们到 Caffe prototxt 文件的路径。
--model。我们通向 Caffe 预训练模型的道路。--points:NumPy 聚类中心点文件的路径。
有了上面的四个标志和相应的参数,脚本将能够在不改变任何代码的情况下运行不同的输入。
让我们继续将我们的模型和聚类中心加载到内存中:
# load our serialized black and white colorizer model and cluster
# center points from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
pts = np.load(args["points"])
# add the cluster centers as 1x1 convolutions to the model
class8 = net.getLayerId("class8_ab")
conv8 = net.getLayerId("conv8_313_rh")
pts = pts.transpose().reshape(2, 313, 1, 1)
net.getLayer(class8).blobs = [pts.astype("float32")]
net.getLayer(conv8).blobs = [np.full([1, 313], 2.606, dtype="float32")]
第 21 行直接从命令行参数值加载我们的 Caffe 模型。OpenCV 可以通过cv2.dnn.readNetFromCaffe函数读取 Caffe 模型。
第 22 行然后直接从命令行参数路径加载聚类中心点到点文件。这个文件是 NumPy 格式的,所以我们使用np.load。
从那里,第 25-29 行 :
- 用于再平衡的负载中心 ab 通道量化。
- 将每个点视为 1×1 卷积,并将它们添加到模型中。
现在让我们加载、缩放和转换我们的图像:
# load the input image from disk, scale the pixel intensities to the
# range [0, 1], and then convert the image from the BGR to Lab color
# space
image = cv2.imread(args["image"])
scaled = image.astype("float32") / 255.0
lab = cv2.cvtColor(scaled, cv2.COLOR_BGR2LAB)
为了从文件路径加载我们的输入图像,我们在第 34 行的上使用cv2.imread。
预处理步骤包括:
- 将像素强度缩放到范围【0,1】(第 35 行)。
- 从 BGR 转换到 Lab 色彩空间(第 36 行)。
让我们继续我们的预处理:
# resize the Lab image to 224x224 (the dimensions the colorization
# network accepts), split channels, extract the 'L' channel, and then
# perform mean centering
resized = cv2.resize(lab, (224, 224))
L = cv2.split(resized)[0]
L -= 50
接下来,我们将输入图像的尺寸调整为 22 4×2 24 ( Line 41 ),这是网络所需的输入尺寸。
然后我们只抓取L通道(即输入)并执行均值减法(第 42 行和第 43 行)。
现在我们可以通过网络把输入 L 通道传给预测 ab 通道:
# pass the L channel through the network which will *predict* the 'a'
# and 'b' channel values
'print("[INFO] colorizing image...")'
net.setInput(cv2.dnn.blobFromImage(L))
ab = net.forward()[0, :, :, :].transpose((1, 2, 0))
# resize the predicted 'ab' volume to the same dimensions as our
# input image
ab = cv2.resize(ab, (image.shape[1], image.shape[0]))
通过网络的L通道的前向传递发生在48 和 49 线上(如果你需要,这里是对 OpenCV 的blobFromImage 的复习)。
注意,在我们调用了net.forward之后,在同一行上,我们继续提取预测的ab量。我在这里让它看起来很简单,但是如果你想了解更多的细节,请参考张等人在 GitHub 上的文档和演示。
从那里,我们将预测的ab体积调整到与输入图像相同的尺寸(第 53 行)。
现在是后处理的时候了。请继续听我说,我们实际上是在反向执行之前的一些步骤:
# grab the 'L' channel from the *original* input image (not the
# resized one) and concatenate the original 'L' channel with the
# predicted 'ab' channels
L = cv2.split(lab)[0]
colorized = np.concatenate((L[:, :, np.newaxis], ab), axis=2)
# convert the output image from the Lab color space to RGB, then
# clip any values that fall outside the range [0, 1]
colorized = cv2.cvtColor(colorized, cv2.COLOR_LAB2BGR)
colorized = np.clip(colorized, 0, 1)
# the current colorized image is represented as a floating point
# data type in the range [0, 1] -- let's convert to an unsigned
# 8-bit integer representation in the range [0, 255]
colorized = (255 * colorized).astype("uint8")
# show the original and output colorized images
cv2.imshow("Original", image)
cv2.imshow("Colorized", colorized)
cv2.waitKey(0)
后处理包括:
- 从 原始 输入图像中抓取
L通道(行 58 )并将原始L通道和 预测ab通道串联在一起形成colorized( 行 59 )。 - 将
colorized图像从 Lab 色彩空间转换为 RGB ( 第 63 行)。 - 剪裁任何落在范围【0,1】(行 64 )之外的像素强度。
- 使像素强度回到范围【0,255】(行 69 )。在预处理步骤中(第 35 行),我们除以
255,现在我们乘以255。我还发现这种缩放和"uint8"转换并不是必需的,但它有助于代码在 OpenCV 3.4.x 和 4.x 版本之间工作。
最后,我们的原始image和colorized图像都显示在屏幕上!
图像彩色化结果
现在我们已经实现了我们的图像着色脚本,让我们试一试。
确保你已经使用了这篇博文的 【下载】 部分来下载源代码、着色模型和示例图像。
从那里,打开一个终端,导航到您下载源代码的位置,并执行以下命令:
$ python bw2color_image.py \
--prototxt model/colorization_deploy_v2.prototxt \
--model model/colorization_release_v2.caffemodel \
--points model/pts_in_hull.npy \
--image images/robin_williams.jpg
[INFO] loading model...

Figure 2: Grayscale image colorization with OpenCV and deep learning. This is a picture of famous late actor, Robin Williams.
在左边可以看到罗宾·威廉姆斯(Robin Williams)的原始输入图像,这位著名的演员和喜剧演员于~5 年前去世。
在右边,你可以看到黑白彩色化模型的输出。
让我们试试另一张图片,这是阿尔伯特·爱因斯坦的:
$ python bw2color_image.py \
--prototxt model/colorization_deploy_v2.prototxt \
--model model/colorization_release_v2.caffemodel \
--points model/pts_in_hull.npy \
--image images/albert_einstein.jpg
[INFO] loading model...
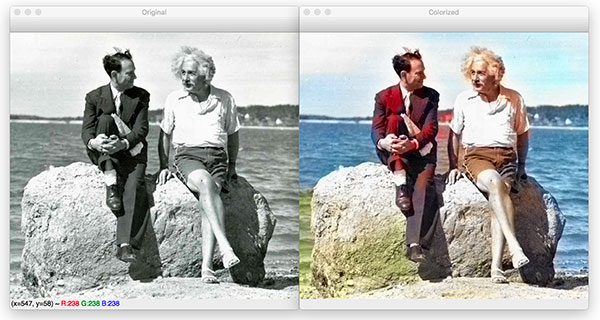
Figure 3: Image colorization using deep learning and OpenCV. This is an image of Albert Einstein.
这个图像彩色化让我印象特别深刻。
注意,水是一种合适的蓝色,而爱因斯坦的衬衫是白色的,裤子是卡其色的——所有这些都是看似合理的颜色。
这是另一个例子,这是马克·吐温的作品,他是我一直以来最喜欢的作家之一:
$ python bw2color_image.py \
--prototxt model/colorization_deploy_v2.prototxt \
--model model/colorization_release_v2.caffemodel \
--points model/pts_in_hull.npy
--image images/mark_twain.jpg
[INFO] loading model...

Figure 4: A black/white image of Mark Twain has undergone colorization via OpenCV and deep learning.
在这里,我们可以看到草和树叶被正确地染成了绿色,尽管你可以看到这些绿色融入了吐温的鞋子和手。
最终的图像展示了 OpenCV 不太好的黑白图像彩色化:
$ python bw2color_image.py \
--prototxt model/colorization_deploy_v2.prototxt \
--model model/colorization_release_v2.caffemodel \
--points model/pts_in_hull.npy
--image images/adrian_and_janie.png
[INFO] loading model...

Figure 5: Janie is the puppers we recently adopted into our family. This is her first snow day. Black and white cameras/images are great for snow, but I wanted to see how image colorization would turn out with OpenCV and deep learning.
这张照片是几周前的一场暴风雪中,我和我的小猎犬珍妮的合影。
在这里你可以看到,虽然雪,珍妮,我的夹克,甚至背景中的凉亭都是正确的颜色,但我的蓝色牛仔裤实际上是红色的。
并非所有的图像彩色化都是完美的,但是今天的结果确实证明了张等人的方法的合理性。
用 OpenCV 实现实时黑白视频彩色化
我们已经看到了如何将黑白图像彩色化应用到图像上——但是我们能对视频流做同样的事情吗?
你打赌我们能。
这个脚本遵循与上面相同的过程,除了我们将处理一个视频流的帧。我将更详细地回顾它,并把重点放在帧抓取+处理方面。
打开bw2color_video.py并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str,
help="path to optional input video (webcam will be used otherwise)")
ap.add_argument("-p", "--prototxt", type=str, required=True,
help="path to Caffe prototxt file")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--points", type=str, required=True,
help="path to cluster center points")
ap.add_argument("-w", "--width", type=int, default=500,
help="input width dimension of frame")
args = vars(ap.parse_args())
我们的视频脚本需要两个额外的导入:
- 允许我们从网络摄像头或视频文件中抓取帧
time用于暂停,让网络摄像头预热
现在让我们初始化我们的VideoStream:
# initialize a boolean used to indicate if either a webcam or input
# video is being used
webcam = not args.get("input", False)
# if a video path was not supplied, grab a reference to the webcam
if webcam:
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# otherwise, grab a reference to the video file
else:
print("[INFO] opening video file...")
vs = cv2.VideoCapture(args["input"])
根据我们使用的是webcam还是视频文件,我们将在这里创建我们的vs(即“视频流”)对象。
从那里,我们将加载彩色深度学习模型和聚类中心(与我们在之前的脚本中所做的方式相同):
# load our serialized black and white colorizer model and cluster
# center points from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
pts = np.load(args["points"])
# add the cluster centers as 1x1 convolutions to the model
class8 = net.getLayerId("class8_ab")
conv8 = net.getLayerId("conv8_313_rh")
pts = pts.transpose().reshape(2, 313, 1, 1)
net.getLayer(class8).blobs = [pts.astype("float32")]
net.getLayer(conv8).blobs = [np.full([1, 313], 2.606, dtype="float32")]
现在我们将开始对输入帧进行无限循环。我们将在循环中直接处理帧:
# loop over frames from the video stream
while True:
# grab the next frame and handle if we are reading from either
# VideoCapture or VideoStream
frame = vs.read()
frame = frame if webcam else frame[1]
# if we are viewing a video and we did not grab a frame then we
# have reached the end of the video
if not webcam and frame is None:
break
# resize the input frame, scale the pixel intensities to the
# range [0, 1], and then convert the frame from the BGR to Lab
# color space
frame = imutils.resize(frame, width=args["width"])
scaled = frame.astype("float32") / 255.0
lab = cv2.cvtColor(scaled, cv2.COLOR_BGR2LAB)
# resize the Lab frame to 224x224 (the dimensions the colorization
# network accepts), split channels, extract the 'L' channel, and
# then perform mean centering
resized = cv2.resize(lab, (224, 224))
L = cv2.split(resized)[0]
L -= 50
来自我们vs的每一帧在线 55 和 56 上被抓取。对一个None类型的frame进行检查——当这种情况发生时,我们已经到达了一个视频文件的末尾(如果我们正在处理一个视频文件),我们可以从循环中break(行 60 和 61 )。
预处理(如前)在行 66-75 上进行。这是我们调整大小、缩放和转换为实验室的地方。然后我们抓取L通道,并执行均值减法。
现在让我们应用深度学习着色并对结果进行后处理:
# pass the L channel through the network which will *predict* the
# 'a' and 'b' channel values
net.setInput(cv2.dnn.blobFromImage(L))
ab = net.forward()[0, :, :, :].transpose((1, 2, 0))
# resize the predicted 'ab' volume to the same dimensions as our
# input frame, then grab the 'L' channel from the *original* input
# frame (not the resized one) and concatenate the original 'L'
# channel with the predicted 'ab' channels
ab = cv2.resize(ab, (frame.shape[1], frame.shape[0]))
L = cv2.split(lab)[0]
colorized = np.concatenate((L[:, :, np.newaxis], ab), axis=2)
# convert the output frame from the Lab color space to RGB, clip
# any values that fall outside the range [0, 1], and then convert
# to an 8-bit unsigned integer ([0, 255] range)
colorized = cv2.cvtColor(colorized, cv2.COLOR_LAB2BGR)
colorized = np.clip(colorized, 0, 1)
colorized = (255 * colorized).astype("uint8")
我们通过网络对L的深度学习正向传递产生了预测的ab通道。
然后我们将对来自我们的colorized图像的结果进行后处理(第 86-95 行)。这是我们调整大小的地方,抓取我们的 原始 L,并连接我们预测的ab。在那里,我们从 Lab 转换到 RGB、剪辑和缩放。
如果您仔细阅读了上面的内容,您会记得我们接下来要做的就是显示结果:
# show the original and final colorized frames
cv2.imshow("Original", frame)
cv2.imshow("Grayscale", cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY))
cv2.imshow("Colorized", colorized)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# if we are using a webcam, stop the camera video stream
if webcam:
vs.stop()
# otherwise, release the video file pointer
else:
vs.release()
# close any open windows
cv2.destroyAllWindows()
我们的原始网络摄像头frame与我们的灰度图像和colorized结果一起显示。
如果"q" key被按下,我们将break从循环中清除。
这就是全部了!
视频彩色化结果
让我们继续,给我们的视频黑白彩色脚本一个尝试。
确保使用本教程的 【下载】 部分下载源代码和着色模型。
从那里,打开一个终端,并执行以下命令,让彩色运行在您的网络摄像头:
$ python bw2color_video.py \
--prototxt model/colorization_deploy_v2.prototxt \
--model model/colorization_release_v2.caffemodel \
--points model/pts_in_hull.npy

Figure 6: Black and white image colorization in video with OpenCV and deep learning demo.
如果您想在视频文件上运行着色程序,您可以使用以下命令:
$ python bw2color_video.py \
--prototxt model/colorization_deploy_v2.prototxt \
--model model/colorization_release_v2.caffemodel \
--points model/pts_in_hull.npy
--input video/jurassic_park_intro.mp4
https://www.youtube.com/embed/r3Mmh_k2F0E?feature=oembed*
使用 OpenCV 和 Python 对人脸进行模糊和匿名处理
原文:https://pyimagesearch.com/2020/04/06/blur-and-anonymize-faces-with-opencv-and-python/
在本教程中,您将学习如何使用 OpenCV 和 Python 对人脸进行模糊和匿名处理。
今天这篇博文的灵感来自于上周我收到的一封来自 PyImageSearch 读者李伟的邮件:
嗨,阿德里安,我正在为我的大学做一个研究项目。
我负责创建数据集,但我的教授要求我通过检测面部并模糊它们来“匿名化”每张图像,以确保隐私得到保护,并且没有面部被识别出来(显然这是我们机构在公开分发数据集之前的一项要求)。
有没有人脸匿名化的教程?如何使用 OpenCV 模糊人脸?
谢谢,
李伟
李提出了一个很好的问题——我们经常在项目中使用人脸检测,通常作为人脸识别流程的第一步。
但是如果我们想做人脸识别的“反面”呢?如果我们想通过模糊化来匿名化人脸,从而使不可能识别人脸呢?
面部模糊和匿名化的实际应用包括:
- 公共/私人区域的隐私和身份保护
- 在线保护儿童(例如,在上传的照片中模糊未成年人的面部)
- 新闻摄影和新闻报道(例如,模糊未签署弃权书的人的面孔)
- 数据集监管和分发(例如,匿名化数据集中的个人)
- …还有更多!
要学习如何用 OpenCV 和 Python 对人脸进行模糊化和匿名化,继续阅读!
使用 OpenCV 和 Python 对人脸进行模糊和匿名处理
在本教程的第一部分,我们将简要讨论什么是人脸模糊,以及我们如何使用 OpenCV 来匿名化图像和视频流中的人脸。
从那里,我们将讨论用 OpenCV 和 Python 模糊人脸的四步方法。
然后,我们将回顾我们的项目结构,并使用 OpenCV 实现两种面部模糊方法:
- 使用高斯模糊来匿名化图像和视频流中的人脸
- 应用“像素化模糊”效果来匿名化图像和视频中的人脸
给定我们的两个实现,我们将创建 Python 驱动程序脚本来将这些面部模糊方法应用于图像和视频。
然后,我们将回顾我们的面部模糊和匿名化方法的结果。
什么是人脸虚化,如何用于人脸匿名化?

Figure 1: In this tutorial, we will learn how to blur faces with OpenCV and Python, similar to the face in this example (image source).
人脸模糊是一种计算机视觉方法,用于匿名化图像和视频中的人脸。
面部模糊和匿名化的一个例子可以在上面的图 1 中看到——注意面部是如何模糊的,人的身份是无法辨认的。
我们使用面部模糊来帮助保护图像中人的身份。
执行面部模糊和匿名化的 4 个步骤

Figure 2: Face blurring with OpenCV and Python can be broken down into four steps.
使用 OpenCV 和计算机视觉应用面部模糊是一个四步过程。
步骤#1 是执行面部检测。

Figure 3: The first step for face blurring with OpenCV and Python is to detect all faces in an image/video (image source).
这里可以使用任何人脸检测器,只要它能够产生图像或视频流中人脸的边界框坐标。
您可以使用的典型人脸检测器包括
- 瀑布式头发
- 猪+线性 SVM
- 基于深度学习的人脸检测器。
有关如何在图像中检测人脸的更多信息,您可以参考本人脸检测指南。
一旦检测到人脸,第 2 步是提取感兴趣区域(ROI):

Figure 4: The second step for blurring faces with Python and OpenCV is to extract the face region of interest (ROI).
你的人脸检测器会给你一个边界框 (x,y)——一张人脸在图像中的坐标。
这些坐标通常代表:
- 面部包围盒的起始 x- 捐赠
- 面的终点 x- 坐标
- 面部位置的起始 y-
- 终点 y 面的坐标
然后,您可以使用这些信息来提取面部 ROI 本身,如上面的图 4 所示。
给定面部 ROI,步骤#3 实际上是模糊/匿名面部:

Figure 5: The third step for our face blurring method using OpenCV is to apply your blurring algorithm. In this tutorial, we learn two such blurring algorithms — Gaussian blur and pixelation.
通常,您将应用高斯模糊来匿名化面部。如果你发现最终的结果更加美观,你也可以应用一些方法来像素化这张脸。
具体如何“模糊”图像由你决定——重要的是面部被匿名化了。
在脸部模糊和匿名的情况下,步骤#4 是将模糊的脸部存储回原始图像:

Figure 6: The fourth and final step for face blurring with Python and OpenCV is to replace the original face ROI with the blurred face ROI.
使用来自面部检测(即步骤#2)的原始 (x,y)-坐标,我们可以获取模糊/匿名的面部,然后将其存储回原始图像中(如果您使用 OpenCV 和 Python,此步骤使用 NumPy 数组切片来执行)。
原始图像中的人脸已经被模糊化和匿名化——此时,人脸匿名化管道已经完成。
在本教程的剩余部分,让我们看看如何用 OpenCV 实现面部模糊和匿名化。
如何安装 OpenCV 进行人脸虚化
按照我的面部模糊教程,你需要在你的系统上安装 OpenCV。我推荐使用我的教程之一安装 OpenCV 4:
我向 99%的读者推荐 pip 安装方法——这也是我通常安装 OpenCV 用于面部模糊等快速项目的方法。
如果您认为您可能需要完整安装 OpenCV 和专利算法,您应该根据您的操作系统考虑第二个或第三个要点。这两个指南都需要从源代码编译,这也需要相当长的时间,但是可以(1)给你完整的 OpenCV 安装和(2)允许你为你的操作系统和系统架构优化 OpenCV。
一旦安装了 OpenCV,您就可以继续学习本教程的其余部分。
注意:我不支持 PyImageSearch 的 Windows 操作系统。见我的 FAQ 页面。
项目结构
继续使用本教程的 “下载” 部分下载源代码、示例图像和预训练的人脸检测器模型。从那里,让我们检查内容:
$ tree --dirsfirst
.
├── examples
│ ├── adrian.jpg
│ ├── chris_evans.png
│ ├── robert_downey_jr.png
│ ├── scarlett_johansson.png
│ └── tom_king.jpg
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── pyimagesearch
│ ├── __init__.py
│ └── face_blurring.py
├── blur_face.py
└── blur_face_video.py
3 directories, 11 files
面部模糊第一步是执行面部检测以定位图像/帧中的面部。我们将使用基于深度学习的 Caffe 模型,如face_detector/目录中所示。
我们的两个 Python 驱动脚本,blur_face.py和blur_face_video.py,首先检测人脸,然后在图像和视频流中执行人脸模糊。我们将逐步介绍这两个脚本,以便您可以将它们用于自己的项目。
首先,我们将回顾一下face_blurring.py文件中的面部模糊辅助函数。
使用高斯模糊和 OpenCV 模糊面部

Figure 7: Gaussian face blurring with OpenCV and Python (image source).
我们将实现两个辅助函数来帮助我们实现面部模糊和匿名:
anonymize_face_simple:在脸部 ROI 上执行简单的高斯模糊(如上面的图 7- 创建一个像素化的模糊效果(我们将在下一节讨论)
我们来看看anonymize_face_simple的实现——打开pyimagesearch模块中的face_blurring.py文件,插入下面的代码:
# import the necessary packages
import numpy as np
import cv2
def anonymize_face_simple(image, factor=3.0):
# automatically determine the size of the blurring kernel based
# on the spatial dimensions of the input image
(h, w) = image.shape[:2]
kW = int(w / factor)
kH = int(h / factor)
# ensure the width of the kernel is odd
if kW % 2 == 0:
kW -= 1
# ensure the height of the kernel is odd
if kH % 2 == 0:
kH -= 1
# apply a Gaussian blur to the input image using our computed
# kernel size
return cv2.GaussianBlur(image, (kW, kH), 0)
我们的面部模糊工具需要 NumPy 和 OpenCV 导入,如第 2 行和第 3 行所示。
从第 5 行的,开始,我们定义了我们的anonymize_face_simple函数,它接受一个输入人脸image和模糊内核尺度factor。
第 8-18 行导出模糊内核的宽度和高度,作为输入图像尺寸的函数:
- 内核尺寸越大,越大,输出面会越模糊
- 内核尺寸越小,输出面的越少就会越模糊
因此,增加该因子会增加应用到面部的模糊量。
当应用模糊时,我们的内核尺寸必须是奇数整数,这样内核就可以放在输入图像的中心 T2 坐标(x,y)上(更多关于内核必须是奇数整数的信息,请参见我的关于 OpenCV 卷积的教程)。
一旦我们有了内核尺寸,kW和kH,第 22 行将高斯模糊内核应用到脸image上,并将模糊的脸返回给调用函数。
在下一节中,我们将介绍另一种匿名方法:像素化模糊。
用 OpenCV 创建像素化的人脸模糊

Figure 8: Creating a pixelated face effect on an image with OpenCV and Python (image source).
我们将为面部模糊和匿名化实现的第二种方法创建了像素化的模糊效果——这种方法的一个例子可以在图 8 中看到。
请注意我们是如何对图像进行像素化处理,并使人的身份变得难以辨认的。
这种像素化类型的面部模糊通常是大多数人听到“面部模糊”时想到的——这与你在晚间新闻中看到的面部模糊类型相同,主要是因为它比高斯模糊更“美观”(这确实有点“不和谐”)。
让我们学习如何用 OpenCV 实现这种像素化的面部模糊方法——打开face_blurring.py文件(我们在上一节中使用的同一个文件),并添加以下代码:
def anonymize_face_pixelate(image, blocks=3):
# divide the input image into NxN blocks
(h, w) = image.shape[:2]
xSteps = np.linspace(0, w, blocks + 1, dtype="int")
ySteps = np.linspace(0, h, blocks + 1, dtype="int")
# loop over the blocks in both the x and y direction
for i in range(1, len(ySteps)):
for j in range(1, len(xSteps)):
# compute the starting and ending (x, y)-coordinates
# for the current block
startX = xSteps[j - 1]
startY = ySteps[i - 1]
endX = xSteps[j]
endY = ySteps[i]
# extract the ROI using NumPy array slicing, compute the
# mean of the ROI, and then draw a rectangle with the
# mean RGB values over the ROI in the original image
roi = image[startY:endY, startX:endX]
(B, G, R) = [int(x) for x in cv2.mean(roi)[:3]]
cv2.rectangle(image, (startX, startY), (endX, endY),
(B, G, R), -1)
# return the pixelated blurred image
return image
从第 24 行,开始,我们定义我们的anonymize_face_pixilate函数和参数。这个函数接受一张脸image和像素数blocks。
第 26-28 行抓取我们的人脸图像尺寸,并将其分成 MxN 个块。
从那里,我们继续在 x 和 y 两个方向上循环方块(线 31 和 32 )。
为了计算当前块的开始和结束边界坐标,我们使用我们的步长索引,i和j ( 第 35-38 行)。
随后,我们提取当前块 ROI 并计算 ROI 的平均 RGB 像素强度(行 43 和 44 )。
然后,我们使用计算出的平均 RGB 值在块上标注一个rectangle,从而创建类似“像素化”的效果(第 45 行和第 46 行)。
注:要了解更多 OpenCV 绘图函数,一定要花点时间上我的 OpenCV 教程。
最后,行 49 将我们像素化的脸image返回给调用者。
用 OpenCV 实现图像中的人脸模糊
现在我们已经实现了两种面部模糊方法,让我们学习如何使用 OpenCV 和 Python 将它们应用于模糊图像中的面部。
打开项目结构中的blur_face.py文件,并插入以下代码:
# import the necessary packages
from pyimagesearch.face_blurring import anonymize_face_pixelate
from pyimagesearch.face_blurring import anonymize_face_simple
import numpy as np
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-f", "--face", required=True,
help="path to face detector model directory")
ap.add_argument("-m", "--method", type=str, default="simple",
choices=["simple", "pixelated"],
help="face blurring/anonymizing method")
ap.add_argument("-b", "--blocks", type=int, default=20,
help="# of blocks for the pixelated blurring method")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们最值得注意的导入是前面两个部分的面部像素化和面部模糊功能(第 2 行和第 3 行)。
我们的脚本接受五个命令行参数,其中前两个是必需的:
--image:包含人脸的输入图像的路径--face:人脸检测器型号目录的路径--method:使用此标志可以选择simple模糊或pixelated方法。默认方法是简单方法--blocks:对于像素化人脸匿名,您必须提供想要使用的块数,或者您可以保留默认的20--confidence:过滤弱脸检测的最小概率默认设置为 50%
给定我们的命令行参数,我们现在准备执行面部检测:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNet(prototxtPath, weightsPath)
# load the input image from disk, clone it, and grab the image spatial
# dimensions
image = cv2.imread(args["image"])
orig = image.copy()
(h, w) = image.shape[:2]
# construct a blob from the image
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
print("[INFO] computing face detections...")
net.setInput(blob)
detections = net.forward()
首先,我们加载基于 Caffe 的人脸检测器模型(第 26-29 行)。
然后,我们加载并预处理我们的输入--image,为推理生成一个blob(第 33-39 行)。阅读我的OpenCV 的 blobFromImage 如何工作 教程,了解第 38 行和第 39 行函数调用背后的“为什么”和“如何”。
深度学习人脸检测推理(步骤#1 )发生在第 43 和 44 行。
接下来,我们将开始遍历detections:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is greater
# than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = image[startY:endY, startX:endX]
这里,我们循环检测并检查置信度,确保它满足最小阈值(第 47-54 行)。
假设如此,我们然后通过行 57-61 提取脸部 ROI ( 步骤#2 )。
然后我们将匿名化这张脸(步骤#3 ):
# check to see if we are applying the "simple" face blurring
# method
if args["method"] == "simple":
face = anonymize_face_simple(face, factor=3.0)
# otherwise, we must be applying the "pixelated" face
# anonymization method
else:
face = anonymize_face_pixelate(face,
blocks=args["blocks"])
# store the blurred face in the output image
image[startY:endY, startX:endX] = face
根据--method,我们将执行简单的模糊或像素化来匿名化face ( 第 65-72 行)。
第 4 步需要用我们匿名的face ROI ( 第 75 行)覆盖image中的原始人脸 ROI。
然后对输入--image中的所有人脸重复步骤#2-#4 ,直到我们准备好显示结果:
# display the original image and the output image with the blurred
# face(s) side by side
output = np.hstack([orig, image])
cv2.imshow("Output", output)
cv2.waitKey(0)
作为总结,原始图像和修改后的图像并排显示,直到按下一个键(行 79-81 )。
图像中的面部模糊和匿名结果
让我们现在把我们的面部模糊和匿名化的方法工作。
继续使用本教程的 “下载” 部分下载源代码、示例图像和预训练的 OpenCV 人脸检测器。
从那里,打开一个终端,并执行以下命令:
$ python blur_face.py --image examples/adrian.jpg --face face_detector
[INFO] loading face detector model...
[INFO] computing face detections...

Figure 9: Left: A photograph of me. Right: My face has been blurred with OpenCV and Python using a Gaussian approach.
在左边的,你可以看到原始的输入图像(即我),而右边的显示我的脸已经用高斯模糊方法模糊了——如果没有看到原始图像,你不会知道那是我(我猜除了纹身)。
*让我们尝试另一个图像,这一次应用像素化模糊技术:
$ python blur_face.py --image examples/tom_king.jpg --face face_detector --method pixelated
[INFO] loading face detector model...
[INFO] computing face detections...

Figure 10: Tom King’s face has been pixelated with OpenCV and Python; you can adjust the block settings until you’re comfortable with the level of anonymity. (image source)
在左边的,我们有汤姆·金的原始输入图像,他是我最喜欢的漫画作家之一。
然后,在右边的,我们有像素化模糊方法的输出——没有看到原始图像,你将不知道图像中是谁的脸。
*### 用 OpenCV 实现实时视频中的人脸模糊
我们之前的例子只处理了图像中人脸的模糊和匿名化— 但是如果我们想将人脸模糊和匿名化应用到实时视频流中呢?
这可能吗?
当然是了!
打开项目结构中的blur_face_video.py文件,让我们学习如何使用 OpenCV 在实时视频中模糊人脸:
# import the necessary packages
from pyimagesearch.face_blurring import anonymize_face_pixelate
from pyimagesearch.face_blurring import anonymize_face_simple
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--face", required=True,
help="path to face detector model directory")
ap.add_argument("-m", "--method", type=str, default="simple",
choices=["simple", "pixelated"],
help="face blurring/anonymizing method")
ap.add_argument("-b", "--blocks", type=int, default=20,
help="# of blocks for the pixelated blurring method")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们从 2-10 号线的进口开始。对于视频中的人脸识别,我们将使用我的 imutils 包 ( Line 4 )中的VideoStream API。
我们的命令行参数与之前的相同(第 13-23 行)。
然后,我们将加载我们的面部检测器并初始化我们的视频流:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNet(prototxtPath, weightsPath)
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
我们的视频流访问我们计算机的网络摄像头( Line 34 )。
然后,我们将继续循环流中的帧,并执行步骤#1 —面部检测:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# grab the dimensions of the frame and then construct a blob
# from it
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
net.setInput(blob)
detections = net.forward()
一旦检测到人脸,我们将确保它们满足最低置信度阈值:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = frame[startY:endY, startX:endX]
# check to see if we are applying the "simple" face
# blurring method
if args["method"] == "simple":
face = anonymize_face_simple(face, factor=3.0)
# otherwise, we must be applying the "pixelated" face
# anonymization method
else:
face = anonymize_face_pixelate(face,
blocks=args["blocks"])
# store the blurred face in the output image
frame[startY:endY, startX:endX] = face
在高置信度detections上循环,我们在行 55-69 上提取face ROI ( 步骤#2 )。
为了完成步骤#3 ,我们通过第 73-80 行应用我们选择的匿名--method。
最后,对于的第 4 步,我们替换了摄像机的frame ( 第 83 行)中的匿名face。
为了结束我们的面部模糊循环,我们在屏幕上显示frame(模糊的面部):
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
如果按下q键,我们break退出面部模糊循环并执行清理。
干得好——在下一部分,我们将分析结果!
实时人脸模糊 OpenCV 结果
我们现在准备将 OpenCV 的人脸模糊应用于实时视频流。
首先使用本教程的 【下载】 部分下载源代码和预训练的 OpenCV 人脸检测器。
然后,您可以使用以下命令启动blur_face_video.py:
$ python blur_face_video.py --face face_detector --method simple
[INFO] loading face detector model...
[INFO] starting video stream...
注意我的脸在视频流中是如何使用高斯模糊方法模糊的。
我们可以通过提供--method pixelated标志来应用像素化脸部模糊方法:
$ python blur_face_video.py --face face_detector --method pixelated
[INFO] loading face detector model...
[INFO] starting video stream...
同样,我的脸使用 OpenCV 匿名化/模糊化,但是使用更“美观”的像素化方法。
处理错过的面部检测和“检测闪烁”
我们在这里应用的面部模糊方法假设可以在输入视频流的每一帧中检测到面部。
但是,如果我们的人脸检测器错过了的检测,比如在本部分顶部的视频中,会发生什么呢?
如果我们的人脸检测器错过了一个人脸检测,那么人脸就不能模糊,从而违背了人脸模糊和匿名的目的。
那么在这种情况下我们该怎么办呢?
通常,最简单的方法是取人脸的最后已知位置(即之前的检测位置),然后模糊该区域。
人脸不会移动得很快,所以模糊最后一个已知位置将有助于确保人脸匿名,即使人脸检测器错过了人脸。
一个更高级的选择是使用专用的物体追踪器,类似于我们在人/脚步计数器指南中所做的。
使用这种方法,您可以:
- 检测视频流中的人脸
- 为每个面创建一个对象跟踪器
- 使用对象跟踪器和面部检测器来关联面部的位置
- 如果面部检测器错过了检测,则依靠跟踪器来提供面部的位置
这种方法在计算上比简单的“最后已知位置”更复杂,但也比“T2”更稳健。
我将把这些方法的实现留给您(尽管我想在以后的教程中介绍它们,因为它们是实现起来非常有趣的方法)。
摘要
在本教程中,您学习了如何使用 OpenCV 和 Python 对图像和实时视频流中的人脸进行模糊和匿名处理。
面部模糊和匿名化是一个四步过程:
- 步骤#1: 应用面部检测器(即,哈尔级联、HOG +线性 SVM、基于深度学习的面部检测器)来检测图像中面部的存在
- 步骤#2: 使用包围盒 (x,y)-坐标从输入图像中提取人脸 ROI
- 步骤#3: 模糊图像中的面部,通常使用高斯模糊或像素化模糊,从而匿名化面部并保护图像中的人的身份
- 步骤#4: 将模糊/匿名化的面部存储回原始图像中
然后我们只用 OpenCV 和 Python 实现了整个管道。
我希望这篇教程对你有所帮助!
要下载这篇文章的源代码(包括示例图像和预先训练的人脸检测器),*只需在下面的表格中输入您的电子邮件地址!***
使用 OpenCV 进行模糊检测
原文:https://pyimagesearch.com/2015/09/07/blur-detection-with-opencv/

在我和我父亲杰玛之间,这只超级可爱、超级活跃、特别有爱心的家庭小猎犬可能是有史以来最受关注的狗狗。自从我们把她作为一只 8 周大的小狗,到现在,仅仅三年后,我们已经积累了超过 6000 张狗的 和 的照片。
过度?
也许吧。但是我喜欢狗。很多。尤其是小猎犬。所以毫不奇怪,作为一个养狗的人,我花很多时间和 Jemma 最喜欢的玩具玩拔河游戏,和她在厨房地板上打滚打闹,是的,用我的 iPhone 给她拍了很多照片。
在过去的这个周末,我坐下来试着整理 iPhoto 中的大量照片。这不仅是一项艰巨的任务,我开始很快注意到一种模式——有许多照片模糊过度 。
无论是因为低于标准的摄影技巧,还是因为试图跟上超级活跃的 Jemma 在房间里跑来跑去,或者是因为她在我准备拍摄完美照片时的混乱,许多照片都包含了相当多的模糊。
现在,对于普通人来说,我想他们会删除这些模糊的照片(或者至少将它们移到一个单独的文件夹中)——但作为一名计算机视觉科学家,这是不可能的。
相反,我打开了一个编辑器,编写了一个快速的 Python 脚本来用 OpenCV 执行模糊检测。
在这篇博文的剩余部分,我将展示如何使用 OpenCV、Python 和拉普拉斯算子来计算图像中的模糊量。在这篇文章结束时,你将能够将拉普拉斯 方法的方差应用于你自己的照片,以检测模糊量。
拉普拉斯的方差

Figure 1: Convolving the input image with the Laplacian operator.
当我弄清楚如何检测图像中的模糊量时,我的第一站是通读优秀的调查工作, 焦点形状的焦点测量算子分析【2013 佩尔图斯等人】。在他们的论文中,佩尔图斯等人回顾了近 36 种不同的方法来估算图像的焦距。
如果你有信号处理方面的背景知识,首先要考虑的方法是计算图像的快速傅立叶变换,然后检查低频和高频的分布——如果高频很少,则图像可能会模糊。然而,定义什么是低数量的高频,什么是高数量的高频可能会很成问题,经常导致低于标准的结果。
相反,如果我们可以计算一个单浮点值来表示给定图像的模糊程度,这不是很好吗?
佩尔图斯等人回顾了许多计算这种“模糊度度量”的方法,其中一些简单明了,只使用基本的灰度像素强度统计,另一些更先进,基于特征,评估图像的局部二进制模式。
在快速浏览了论文之后,我找到了我一直在寻找的实现:Pech-Pacheco 等人在他们 2000 年的 ICPR 论文 中的拉普拉斯 的变体 。
方法简单。直白。有合理的推理。而可以在 中实现的只有一行代码 :
cv2.Laplacian(image, cv2.CV_64F).var()
您只需简单地获取图像的一个通道(大概是灰度)并用下面的 3 x 3 内核对其进行卷积:
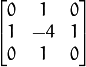
Figure 2: The Laplacian kernel.
然后取响应的方差(即标准差的平方)。
如果方差低于预定义的阈值,则认为图像模糊;否则,图像是不模糊。
这种方法有效的原因是由于拉普拉斯算子本身的定义,该算子用于测量图像的二阶导数。拉普拉斯算子突出显示图像中包含快速亮度变化的区域,非常像 Sobel 和 Scharr 算子。就像这些算子一样,拉普拉斯算子通常用于边缘检测。这里的假设是,如果图像包含高方差,则存在广泛的响应,包括边缘状和非边缘状,代表正常的聚焦图像。但是,如果有非常低的方差,那么就有一个微小的反应扩散,表明在图像中有很少的边缘。我们知道,图像越模糊,边缘越少。
显然,这里的技巧是设置正确的阈值,这可能与域有关。过低的阈值会错误地将图像标记为模糊,而实际上它们并不模糊。阈值太高,那么实际上模糊的图像将不会被标记为模糊。这种方法在您可以计算可接受的焦点测量范围,然后检测异常值的环境中效果最好。
检测图像中的模糊量
现在,我们已经了解了我们将用来计算表示给定图像“模糊”程度的单一指标的方法,让我们来看看以下 12 张图像的数据集:

Figure 3: Our dataset of images. Some are blurry, some are not. Our goal is to perform blur detection with OpenCV and mark the images as such.
如你所见,有些图像模糊不清,有些则不然。我们这里的目标是正确地将每张图像标记为模糊或非模糊。
也就是说,打开一个新文件,命名为detect_blur.py,让我们开始编码:
# import the necessary packages
from imutils import paths
import argparse
import cv2
def variance_of_laplacian(image):
# compute the Laplacian of the image and then return the focus
# measure, which is simply the variance of the Laplacian
return cv2.Laplacian(image, cv2.CV_64F).var()
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to input directory of images")
ap.add_argument("-t", "--threshold", type=float, default=100.0,
help="focus measures that fall below this value will be considered 'blurry'")
args = vars(ap.parse_args())
我们从在第 2-4 行导入必要的包开始。如果你的机器上还没有我的 imutils 包,你会想现在安装它:
$ pip install imutils
从那里,我们将在第 6 行的上定义我们的variance_of_laplacian函数。这个方法将只接受一个参数image(假设是一个单通道,比如一个灰度图像),我们要为它计算焦点度量。从那里,第 9 行简单地将image与 3 x 3 拉普拉斯算子进行卷积,并返回方差。
第 12-17 行处理解析我们的命令行参数。我们需要的第一个开关是--images,它是包含我们想要测试模糊度的图像数据集的目录的路径。
我们还将定义一个可选参数--thresh,它是我们将用于模糊测试的阈值。如果给定图像的焦距测量值低于这个阈值,我们会将该图像标记为模糊。需要注意的是,您可能需要为自己的图像数据集调整这个值。值100似乎很适合我的数据集,但是这个值对于图像的内容来说是相当主观的,所以你需要自己使用这个值来获得最佳结果。
信不信由你,最难的部分已经完成了!我们只需要写一点代码来从磁盘加载图像,计算拉普拉斯的方差,然后将图像标记为模糊或不模糊:
# loop over the input images
for imagePath in paths.list_images(args["images"]):
# load the image, convert it to grayscale, and compute the
# focus measure of the image using the Variance of Laplacian
# method
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
fm = variance_of_laplacian(gray)
text = "Not Blurry"
# if the focus measure is less than the supplied threshold,
# then the image should be considered "blurry"
if fm < args["threshold"]:
text = "Blurry"
# show the image
cv2.putText(image, "{}: {:.2f}".format(text, fm), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 3)
cv2.imshow("Image", image)
key = cv2.waitKey(0)
我们在第 20 行开始循环我们的图像目录。对于这些图像中的每一个,我们将从磁盘中加载它,将其转换为灰度,然后使用 OpenCV 应用模糊检测(第 24-27 行)。
如果焦点度量超过了命令行参数提供的阈值,我们将把图像标记为“模糊”。
最后,第 35-38 行将text和计算出的焦距度量写入图像,并将结果显示到我们的屏幕上。
使用 OpenCV 应用模糊检测
现在我们已经编写好了detect_blur.py脚本,让我们试一试。打开一个 shell 并发出以下命令:
$ python detect_blur.py --images images

Figure 4: Correctly marking the image as “blurry”.
这张图的对焦度是 83.17 ,低于我们的阈值100;因此,我们正确地将此图像标记为模糊。

Figure 5: Performing blur detection with OpenCV. This image is marked as “blurry”.
这张图像的焦距为 64.25(T1),这也导致我们将其标记为“模糊”。

Figure 6: Marking an image as “non-blurry”.
图 6 在 1004.14 处具有非常高的焦距测量值——比前两个数字高几个数量级。这张图像清晰不模糊,焦点对准。

Figure 7: Applying blur detection with OpenCV and Python.
这张照片中唯一模糊的部分来自杰玛摇尾巴的动作。

Figure 8: Basic blur detection with OpenCV and Python.
报告的焦距测量值低于图 7 ,但我们仍然能够正确地将图像归类为“非模糊”。

Figure 9: Computing the focus measure of an image.
然而,我们可以清楚地看到上面的图像是模糊的。

Figure 10: An example of computing the amount of blur in an image.
大的聚焦度量分数表示图像不模糊。

Figure 11: The subsequent image in the dataset is marked as “blurry”.
然而,这张图像包含大量的模糊。

Figure 12: Detecting the amount of blur in an image using the variance of Laplacian.

Figure 13: Compared to Figure 12 above, the amount of blur in this image is substantially reduced.

Figure 14: Again, this image is correctly marked as not being “blurred”.

Figure 15: Lastly, we end our example by using blur detection in OpenCV to mark this image as “blurry”.
摘要
在这篇博文中,我们学习了如何使用 OpenCV 和 Python 执行模糊检测。
我们实现了拉普拉斯方法的方差,给我们一个浮点值来表示图像的“模糊度”。这种方法快速、简单且易于应用,我们只需将输入图像与拉普拉斯算子进行卷积,然后计算方差。如果方差低于预定义的阈值,我们将图像标记为“模糊”。
值得注意的是,threshold 是正确调优的一个关键参数,您通常需要在每个数据集的基础上对其进行调优。太小的值,您会意外地将图像标记为模糊,而实际上它们并不模糊。如果阈值太大,您会将图像标记为不模糊,而实际上它们是模糊的。
请务必使用本文底部的表格下载代码,并尝试一下!
利用深度学习、Keras 和 TensorFlow 破解验证码
原文:https://pyimagesearch.com/2021/07/14/breaking-captchas-with-deep-learning-keras-and-tensorflow/
在过去的、中,我们已经处理了为我们预先编译和标记的数据集——,但是如果我们想要着手创建我们自己的定制数据集,然后在其上训练 CNN,那会怎么样呢?在本教程中,我将展示一个完整的深度学习案例研究,为您提供以下示例:
- 下载一组图像。
- 为你的训练图像添加标签和注释。
- 在您的自定义数据集上训练 CNN。
- 评估和测试训练好的 CNN。
我们将要下载的图像数据集是一组验证码图像,用于防止机器人自动注册或登录到给定的网站(或者更糟糕的是,试图强行进入某人的帐户)。
一旦我们下载了一组验证码图片,我们需要手动标记验证码中的每个数字。我们将会发现,获取和标记一个数据集可以成功一半(如果不是更多的话)。根据您需要多少数据、获取数据的难易程度以及您是否需要标记数据(即,为图像分配一个地面实况标签),这可能是一个在时间和/或资金方面都很昂贵的过程(如果您付钱给其他人来标记数据)。
因此,只要有可能,我们就尝试使用传统的计算机视觉技术来加快贴标过程。如果我们使用图像处理软件,如 Photoshop 或 GIMP,手动提取验证码图像中的数字来创建我们的训练集,可能需要我们连续工作天才能完成任务。
然而,通过应用一些基本的计算机视觉技术,我们可以在不到一个小时的时间内下载并标记我们的训练集。这是我鼓励深度学习从业者也投资于他们的计算机视觉教育的众多原因之一。
要学习如何用深度学习、Keras、TensorFlow 破解验证码, 继续阅读。
利用深度学习、Keras 和 TensorFlow 破解验证码
我还想提一下,现实世界中的数据集不像基准数据集,如 MNIST、CIFAR-10 和 ImageNet,它们对图像进行了整齐的标记和组织,我们的目标只是在数据上训练一个模型并对其进行评估。这些基准数据集可能具有挑战性,但在现实世界中,斗争往往是获得(标记的)数据本身 —在许多情况下,标记的数据比通过在数据集上训练网络获得的深度学习模型更有价值。
例如,如果你正在运营一家公司,负责为美国政府创建一个定制的自动车牌识别(ALPR)系统,你可能会投资年来建立一个强大的大规模数据集,同时评估各种识别车牌的深度学习方法。积累如此庞大的标签数据集将会给你带来超越其他公司的竞争优势——在这种情况下,数据本身*比最终产品更有价值。
你的公司更有可能被收购,仅仅是因为你对这个巨大的、有标签的数据集拥有独家权利。建立一个令人惊叹的深度学习模型来识别车牌只会增加你公司的价值,但同样,标记的数据获取和复制成本高昂,所以如果你拥有难以(如果不是不可能)复制的数据集的关键,请不要搞错:你公司的主要资产是数据,而不是深度学习。
让我们看看如何获得图像数据集,对它们进行标记,然后应用深度学习来破解验证码系统。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
用 CNN 破解验证码
以下是如何考虑打破验证码。记住负责任的披露的概念——当涉及计算机安全时,你应该总是这样做。
当我们创建一个 Python 脚本来自动下载一组我们将用于训练和评估的图像时,这个过程就开始了。
下载完我们的图像后,我们需要使用一点计算机视觉来帮助我们标记图像,使这个过程比在 GIMP 或 Photoshop 等图片软件中简单地裁剪和标记更容易和更快。一旦我们标记了我们的数据,我们将训练 LeNet 架构-正如我们将发现的那样,我们能够在不到 15 个时期内破解验证码系统并获得 100%的准确性。
责任披露说明
住在美国东北部/中西部,没有电子通行证很难在主要高速公路上行驶。E-ZPass 是一种电子收费系统,用于许多桥梁、州际公路和隧道。旅行者只需购买一个 E-ZPass 应答器,将其放在汽车的挡风玻璃上,就可以在不停车的情况下快速通过收费站,因为他们的 E-ZPass 帐户附带的信用卡会收取任何通行费。
E-ZPass 让过路费变成了一个“愉快”得多的过程(如果有这种东西的话)。而不是在需要进行实际交易的地方没完没了地排队等候(例如,把钱交给收银员,收到找你的钱,拿到报销的打印收据,等等)。),你可以直接在快车道上飞驰而过,不需要停下来——这在旅行中节省了大量时间,也减少了很多麻烦(尽管你仍然需要支付过路费)。
我花了很多时间在马里兰州和康涅狄格州之间旅行,这是美国 I-95 走廊沿线的两个州。I-95 走廊,尤其是在新泽西州,包含了过多的收费站,所以 E-ZPass 通行证对我来说是一个显而易见的决定。大约一年前,我的 E-ZPass 帐户附带的信用卡到期了,我需要更新它。我去 E-ZPass 纽约网站(我购买 E-ZPass 的州)登录并更新我的信用卡,但我突然停了下来(图 2 )。
你能发现这个系统的缺陷吗?他们的“验证码”只不过是普通白色背景上的四个数字,这是一个重大的安全风险——即使是具有基本计算机视觉或深度学习经验的人也可以开发一个软件来破解这个系统。
这就是 责任披露 概念的由来。负责任的披露是一个计算机安全术语,用于描述如何披露漏洞。检测到威胁后,你没有立即将它发布到互联网上让每个人都看到,而是尝试首先联系利益相关者,以确保他们知道存在问题。然后,风险承担者可以尝试修补软件并解决漏洞。
简单地忽略漏洞和隐藏问题是一种错误的安全措施,应该避免。在理想的情况下,漏洞在公开披露之前就被解决了。
然而,当利益相关者不承认这个问题或者没有在合理的时间内解决这个问题时,就会产生一个道德难题——你会隐藏这个问题,假装它不存在吗?或者你公开它,把更多的注意力放在问题上,以便更快地解决问题?负责任的披露声明你首先把问题带给利益相关者(负责任的)——如果问题没有解决,那么你需要披露问题(披露)。
为了展示 E-ZPass NY 系统是如何面临风险的,我训练了一个深度学习模型来识别验证码中的数字。然后,我编写了第二个 Python 脚本来(1)自动填充我的登录凭证和(2)破解验证码,允许我的脚本访问我的帐户。
在这种情况下,我只是自动登录到我的帐户。使用这个“功能”,我可以自动更新信用卡,生成我的通行费报告,甚至在我的 E-ZPass 上添加一辆新车。但是一些邪恶的人可能会利用这种方法强行进入客户的账户。
在 我写这篇文章的一年前,我通过电子邮件、电话和推特联系了 E-ZPass 关于这个问题的 。他们确认收到了我的信息;然而,尽管进行了多次联系,但没有采取任何措施来解决这个问题。
在本教程的剩余部分,我将讨论我们如何使用 E-ZPass 系统来获取 captcha 数据集,然后我们将在其上标记和训练深度学习模型。我将而不是分享自动登录账户的 Python 代码——这超出了负责任披露的范围,所以请不要向我索要该代码。
请记住,所有的知识都伴随着责任。这些知识在任何情况下都不应用于邪恶或不道德的目的。这个案例研究是作为一种方法存在的,以演示如何获取和标记自定义数据集,然后在其上训练深度学习模型。
我必须声明,我不对如何使用该代码负责——将此作为学习的机会,而不是作恶的机会。
验证码破解目录结构
为了构建验证码破解系统,我们需要更新pyimagesearch.utils子模块并包含一个名为captchahelper.py的新文件:
|--- pyimagesearch
| |--- __init__.py
| |--- datasets
| |--- nn
| |--- preprocessing
| |--- utils
| | |--- __init__.py
| | |--- captchahelper.py
这个文件将存储一个名为preprocess的实用函数,以帮助我们在将数字输入到我们的深度神经网络之前处理它们。
我们还将在我们的 pyimagesearch 模块之外创建第二个目录,这个目录名为captcha_breaker,包含以下文件和子目录:
|--- captcha_breaker
| |--- dataset/
| |--- downloads/
| |--- output/
| |--- annotate.py
| |--- download_images.py
| |--- test_model.py
| |--- train_model.py
目录是我们所有的项目代码存储的地方,用来破解图像验证码。dataset目录是我们存储标记的数字的地方,我们将手工标记这些数字。我喜欢使用以下目录结构模板来组织我的数据集:
root_directory/class_name/image_filename.jpg
因此,我们的dataset目录将具有以下结构:
dataset/{1-9}/example.jpg
其中dataset是根目录,{1-9}是可能的数字名称,example.jpg是给定数字的一个例子。
downloads目录将存储原始验证码。从易通行网站下载的 jpg 文件。在output目录中,我们将存储我们训练过的 LeNet 架构。
顾名思义,download_images.py脚本将负责实际下载示例验证码并将它们保存到磁盘。一旦我们下载了一组验证码,我们将需要从每张图片中提取数字,并手工标记每个数字——这将由annotate.py完成。
train_model.py脚本将在标记的数字上训练 LeNet,而test_model.py将把 LeNet 应用于 captcha 图像本身。
自动下载示例图像
构建验证码破解程序的第一步是下载验证码图片。
如果您将“https://www . e-zpassny . com/vector/jcaptcha . do”复制并粘贴到您的 web 浏览器中,并多次点击刷新,您会注意到这是一个动态程序,每次刷新都会生成一个新的验证码。因此,为了获得我们的示例 captcha 图像,我们需要请求这个图像几百次并保存结果图像。
要自动获取新的验证码图片并保存到磁盘,我们可以使用download_images.py:
# import the necessary packages
import argparse
import requests
import time
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
ap.add_argument("-n", "--num-images", type=int,
default=500, help="# of images to download")
args = vars(ap.parse_args())
第 2-5 行导入我们需要的 Python 包。requests库使得使用 HTTP 连接变得容易,并且在 Python 生态系统中被大量使用。如果您的系统上尚未安装requests,您可以通过以下方式安装:
$ pip install requests
然后我们在第 8-13 行解析我们的命令行参数。我们需要一个命令行参数--output,它是存储原始验证码图像的输出目录的路径(我们稍后将手工标记图像中的每个数字)。
第二个可选开关--num-images,控制我们将要下载的验证码图片的数量。我们将这个值默认为500总图像数。由于每个验证码中有四个数字,这个500的值将会给我们500×4 = 2,000个数字,我们可以用它们来训练我们的网络。
我们的下一个代码块初始化我们将要下载的验证码图片的 URL,以及到目前为止生成的图片总数:
# initialize the URL that contains the captcha images that we will
# be downloading along with the total number of images downloaded
# thus far
url = "https://www.e-zpassny.com/vector/jcaptcha.do"
total = 0
我们现在可以下载验证码图片了:
# loop over the number of images to download
for i in range(0, args["num_images"]):
try:
# try to grab a new captcha image
r = requests.get(url, timeout=60)
# save the image to disk
p = os.path.sep.join([args["output"], "{}.jpg".format(
str(total).zfill(5))])
f = open(p, "wb")
f.write(r.content)
f.close()
# update the counter
print("[INFO] downloaded: {}".format(p))
total += 1
# handle if any exceptions are thrown during the download process
except:
print("[INFO] error downloading image...")
# insert a small sleep to be courteous to the server
time.sleep(0.1)
在的第 22 行,我们开始循环我们想要下载的--num-images。在行 25 上请求下载图像。然后我们将图像保存到磁盘的第 28-32 行。如果下载图像时出现错误,我们在第 39 行和第 40 行的try/except块会捕捉到错误,并允许我们的脚本继续运行。最后,我们在第 43 行插入一个小 sleep 来礼貌地对待我们请求的 web 服务器。
您可以使用以下命令执行download_images.py:
$ python download_images.py --output downloads
这个脚本需要一段时间来运行,因为我们已经(1)发出了一个下载图像的网络请求,并且(2)在每次下载后插入了一个 0.1 秒的暂停。
一旦程序执行完毕,您会看到您的download目录中充满了图像:
$ ls -l downloads/*.jpg | wc -l
500
然而,这些只是原始验证码图片 —我们需要提取和标记验证码中的每个数字来创建我们的训练集。为了实现这一点,我们将使用一点 OpenCV 和图像处理技术来使我们的生活更容易。
注释和创建我们的数据集
那么,你如何标记和注释我们的验证码图片呢?我们是否打开 Photoshop 或 GIMP,使用“选择/选取框”工具复制出一个给定的数字,保存到磁盘,然后令人厌烦地重复?如果我们这样做了,我们可能需要天的不间断工作来标记原始验证码图片中的每个数字。
*相反,更好的方法是使用 OpenCV 库中的基本图像处理技术来帮助我们。要了解如何更有效地标记数据集,请打开一个新文件,将其命名为annotate.py,并插入以下代码:
# import the necessary packages
from imutils import paths
import argparse
import imutils
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of images")
ap.add_argument("-a", "--annot", required=True,
help="path to output directory of annotations")
args = vars(ap.parse_args())
第 2-6 行导入我们需要的 Python 包,而第 9-14 行解析我们的命令行参数。该脚本需要两个参数:
--input:原始验证码图片的输入路径(即downloads目录)。--annot:输出路径,我们将在这里存储标记的数字(即,dataset目录)。
我们的下一个代码块获取--input目录中所有图像的路径,并初始化一个名为counts的字典,该字典将存储给定数字(键)被标记的总次数(值):
# grab the image paths then initialize the dictionary of character
# counts
imagePaths = list(paths.list_images(args["input"]))
counts = {}
实际的注释过程从下面开始:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# display an update to the user
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
try:
# load the image and convert it to grayscale, then pad the
# image to ensure digits caught on the border of the image
# are retained
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.copyMakeBorder(gray, 8, 8, 8, 8,
cv2.BORDER_REPLICATE)
在第 22 行,上,我们开始循环每个单独的imagePaths。对于每幅图像,我们从磁盘中加载(第 31 行),将其转换为灰度(第 32 行),并在每个方向上用八个像素填充图像的边界(第 33 行和第 34 行)。图 3 显示了原始图像(左)和填充图像(右)之间的差异。
我们执行这个填充,以防我们的任何手指碰到图像的边界。如果手指碰到了边界,我们将无法从图像中提取它们。因此,为了防止这种情况,我们特意填充了输入图像,使给定的数字不可能接触到边界。
我们现在准备通过 Otsu 的阈值方法对输入图像进行二值化:
# threshold the image to reveal the digits
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
这个函数调用自动为我们的图像设定阈值,这样我们的图像现在是二进制——黑色像素代表背景,而白色像素是我们的前景,如图图 4 所示。
对图像进行阈值处理是我们图像处理流程中的关键步骤,因为我们现在需要找到每个数字的轮廓:
# find contours in the image, keeping only the four largest
# ones
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:4]
第 42 和 43 行找到图像中每个手指的轮廓(即轮廓)。以防图像中有“噪声”,我们根据轮廓的面积对其进行分类,只保留四个最大的轮廓(即我们的手指本身)。
给定我们的轮廓,我们可以通过计算边界框来提取每个轮廓:
# loop over the contours
for c in cnts:
# compute the bounding box for the contour then extract
# the digit
(x, y, w, h) = cv2.boundingRect(c)
roi = gray[y - 5:y + h + 5, x - 5:x + w + 5]
# display the character, making it large enough for us
# to see, then wait for a keypress
cv2.imshow("ROI", imutils.resize(roi, width=28))
key = cv2.waitKey(0)
在第 48 行,我们在阈值图像中找到的每个轮廓上循环。我们调用cv2.boundingRect来计算包围盒( x,y)——数字区域的坐标。然后,在线 52 上从灰度图像中提取该感兴趣区域(ROI)。我在图 5 中加入了从原始验证码图片中提取的数字样本作为蒙太奇。
第 56 行将数字 ROI 显示到我们的屏幕上,调整到足够大以便我们容易看到。然后等待你键盘上的按键——但是明智地选择你的按键!您按下的键将被用作数字的标签。
要了解如何通过cv2.waitKey调用进行标记,请看下面的代码块:
# if the '`' key is pressed, then ignore the character
if key == ord("`"):
print("[INFO] ignoring character")
continue
# grab the key that was pressed and construct the path
# the output directory
key = chr(key).upper()
dirPath = os.path.sep.join([args["annot"], key])
# if the output directory does not exist, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
如果按下波浪号键“`”(波浪号),我们将忽略该字符(行 60 和 62 )。如果我们的脚本意外地在输入图像中检测到“噪声”(即除了数字之外的任何东西),或者如果我们不确定数字是什么,就可能需要忽略一个字符。否则,我们假设按下的键是数字的标签(第 66 行),并使用该键构建到我们的输出标签(第 67 行)的目录路径。
例如,如果我按下键盘上的7键,dirPath将会是:
dataset/7
因此,所有包含数字“7”的图像将被存储在dataset/7子目录中。第 70 行和第 71 行检查dirPath目录是否不存在——如果不存在,我们创建它。
一旦我们确保dirPath正确存在,我们只需将示例数字写入文件:
# write the labeled character to file
count = counts.get(key, 1)
p = os.path.sep.join([dirPath, "{}.png".format(
str(count).zfill(6))])
cv2.imwrite(p, roi)
# increment the count for the current key
counts[key] = count + 1
第 74 行为当前数字获取目前为止写入磁盘的示例总数。然后,我们使用dirPath构建示例数字的输出路径。在执行第 75 行和第 76 行之后,我们的输出路径p可能看起来像:
datasets/7/000001.png
同样,请注意所有包含数字 7 的示例 ROI 将如何存储在datasets/7子目录中——这是在标记图像时组织数据集的一种简单、方便的方式。
如果在处理图像时出现错误,我们的最后一个代码块处理我们是否想从脚本中control-c退出或:
# we are trying to control-c out of the script, so break from the
# loop (you still need to press a key for the active window to
# trigger this)
except KeyboardInterrupt:
print("[INFO] manually leaving script")
break
# an unknown error has occurred for this particular image
except:
print("[INFO] skipping image...")
如果我们希望control-c提前退出脚本,第 85 行会检测到这一点,并允许我们的 Python 程序优雅地退出。第 90 行捕捉所有其他错误并简单地忽略它们,允许我们继续贴标过程。
当标记一个数据集时,你最不希望发生的事情是由于图像编码问题导致的随机错误,从而导致你的整个程序崩溃。如果发生这种情况,您必须重新开始标记过程。显然,您可以构建额外的逻辑来检测您离开的位置。
要标记您从 E-ZPass NY 网站下载的图像,只需执行以下命令:
$ python annotate.py --input downloads --annot dataset
在这里,你可以看到数字 7 显示在我的屏幕上的图 6 。
然后,我按下键盘上的7键来标记它,然后该数字被写入到dataset/7子目录中的文件中。
然后,annotate.py脚本前进到下一个数字让我标记。然后,您可以对原始 captcha 图像中的所有数字进行标记。您将很快意识到标注数据集可能是一个非常繁琐、耗时的过程。给所有 2000 个数字贴上标签应该花不到半个小时——但你可能会在头五分钟内感到厌倦。
记住,实际上获得你的标签数据集是成功的一半。从那里可以开始实际的工作。幸运的是,我已经为你标记了数字!如果您查看本教程附带下载中包含的dataset目录,您会发现整个数据集已经准备就绪:
$ ls dataset/
1 2 3 4 5 6 7 8 9
$ ls -l dataset/1/*.png | wc -l
232
在这里,您可以看到九个子目录,每个子目录对应一个我们希望识别的数字。在每个子目录中,都有特定数字的示例图像。现在我们已经有了标记数据集,我们可以继续使用 LeNet 架构来训练我们的验证码破解程序。
数字预处理
正如我们所知,我们的卷积神经网络需要在训练期间传递一个具有固定宽度和高度的图像。然而,我们标记的数字图像大小不一——有些比宽高,有些比高宽。因此,我们需要一种方法来填充输入图像并将其调整到固定的大小,而不使扭曲它们的纵横比。
我们可以通过在captchahelper.py中定义一个preprocess函数来调整图像的大小和填充图像,同时保持纵横比:
# import the necessary packages
import imutils
import cv2
def preprocess(image, width, height):
# grab the dimensions of the image, then initialize
# the padding values
(h, w) = image.shape[:2]
# if the width is greater than the height then resize along
# the width
if w > h:
image = imutils.resize(image, width=width)
# otherwise, the height is greater than the width so resize
# along the height
else:
image = imutils.resize(image, height=height)
我们的preprocess函数需要三个参数:
image:我们要填充和调整大小的输入图像。width:图像的目标输出宽度。height:图像的目标输出高度。
在第 12 和 13 行,我们检查宽度是否大于高度,如果是,我们沿着较大的维度(宽度)调整图像的大小,否则,如果高度大于宽度,我们沿着高度调整大小(第 17 和 18 行),这意味着宽度或高度(取决于输入图像的维度)是固定的。
然而,相反的维度比它应该的要小。要解决这个问题,我们可以沿着较短的维度“填充”图像,以获得固定的大小:
# determine the padding values for the width and height to
# obtain the target dimensions
padW = int((width - image.shape[1]) / 2.0)
padH = int((height - image.shape[0]) / 2.0)
# pad the image then apply one more resizing to handle any
# rounding issues
image = cv2.copyMakeBorder(image, padH, padH, padW, padW,
cv2.BORDER_REPLICATE)
image = cv2.resize(image, (width, height))
# return the pre-processed image
return image
第 22 行和第 23 行计算达到目标width和height所需的填充量。第 27 行和第 28 行将填充应用于图像。应用这个填充应该把我们的图像带到我们的目标width和height;然而,在某些情况下,我们可能会在给定的维度上偏离一个像素。解决这种差异的最简单的方法是简单地调用cv2.resize ( Line 29 )来确保所有图像的宽度和高度都相同。
我们没有立即调用函数顶部的cv2.resize的原因是,我们首先需要考虑输入图像的纵横比,并尝试首先正确填充它。如果我们不保持图像的长宽比,那么我们的数字将变得扭曲。
*### 训练验证码破解者
既然已经定义了我们的preprocess函数,我们就可以继续在图像 captcha 数据集上训练 LeNet 了。打开train_model.py文件并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.optimizers import SGD
from pyimagesearch.nn.conv import LeNet
from pyimagesearch.utils.captchahelper import preprocess
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import os
第 2-14 行导入我们需要的 Python 包。请注意,我们将使用 SGD 优化器和 LeNet 架构来训练数字模型。在通过我们的网络之前,我们还将对每个数字使用我们新定义的preprocess函数。
接下来,让我们回顾一下命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
args = vars(ap.parse_args())
train_model.py脚本需要两个命令行参数:
--dataset:带标签的验证码数字的输入数据集的路径(即磁盘上的dataset目录)。- 在这里,我们提供了训练后保存我们的序列化 LeNet 权重的路径。
我们现在可以从磁盘加载数据和相应的标签:
# initialize the data and labels
data = []
labels = []
# loop over the input images
for imagePath in paths.list_images(args["dataset"]):
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = preprocess(image, 28, 28)
image = img_to_array(image)
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
在的第 25 和 26 行,我们分别初始化我们的data和labels列表。然后,我们在第 29 行的标签中循环每个图像。对于数据集中的每个图像,我们从磁盘中加载它,将其转换为灰度,并对其进行预处理,使其宽度为 28 像素,高度为 28 像素(第 31-35 行)。然后图像被转换成 Keras 兼容的数组并添加到data列表中(第 34 行和第 35 行)。
以下列格式组织数据集目录结构的主要好处之一是:
root_directory/class_label/image_filename.jpg
您可以通过从文件名中抓取倒数第二个组件来轻松提取类标签(第 39 行)。例如,给定输入路径dataset/7/000001.png,label将是7,然后将其添加到labels列表中(第 40 行)。
我们的下一个代码块处理将原始像素亮度值归一化到范围[0, 1],随后构建训练和测试分割,并对标签进行一键编码:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
# convert the labels from integers to vectors
lb = LabelBinarizer().fit(trainY)
trainY = lb.transform(trainY)
testY = lb.transform(testY)
然后,我们可以初始化 LeNet 模型和 SGD 优化器:
# initialize the model
print("[INFO] compiling model...")
model = LeNet.build(width=28, height=28, depth=1, classes=9)
opt = SGD(lr=0.01)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
我们的输入图像将有 28 像素的宽度,28 像素的高度,和一个单通道。我们正在识别的共有 9 个数字类(没有0类)。
给定初始化的模型和优化器,我们可以训练网络 15 个时期,评估它,并将其序列化到磁盘:
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=15, verbose=1)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"])
我们的最后一个代码块将处理绘制训练集和测试集随时间的准确性和损失:
# plot the training + testing loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 15), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 15), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 15), H.history["accuracy"], label="acc")
plt.plot(np.arange(0, 15), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
要在我们的自定义 captcha 数据集上使用 SGD 优化器来训练 LeNet 架构,只需执行以下命令:
$ python train_model.py --dataset dataset --model output/lenet.hdf5
[INFO] compiling model...
[INFO] training network...
Train on 1509 samples, validate on 503 samples
Epoch 1/15
0s - loss: 2.1606 - acc: 0.1895 - val_loss: 2.1553 - val_acc: 0.2266
Epoch 2/15
0s - loss: 2.0877 - acc: 0.3565 - val_loss: 2.0874 - val_acc: 0.1769
Epoch 3/15
0s - loss: 1.9540 - acc: 0.5003 - val_loss: 1.8878 - val_acc: 0.3917
...
Epoch 15/15
0s - loss: 0.0152 - acc: 0.9993 - val_loss: 0.0261 - val_acc: 0.9980
[INFO] evaluating network...
precision recall f1-score support
1 1.00 1.00 1.00 45
2 1.00 1.00 1.00 55
3 1.00 1.00 1.00 63
4 1.00 0.98 0.99 52
5 0.98 1.00 0.99 51
6 1.00 1.00 1.00 70
7 1.00 1.00 1.00 50
8 1.00 1.00 1.00 54
9 1.00 1.00 1.00 63
avg / total 1.00 1.00 1.00 503
[INFO] serializing network...
正如我们所看到的,在仅仅 15 个时期之后,我们的网络在训练集和验证集上都获得了 100%的分类准确率。这也不是过度拟合的情况——当我们研究图 7 中的训练和验证曲线时,我们可以看到,在第 5 个时期,验证和训练损失/精度彼此匹配。
如果您检查output目录,您还会看到序列化的lenet.hdf5文件:
$ ls -l output/
total 9844
-rw-rw-r-- 1 adrian adrian 10076992 May 3 12:56 lenet.hdf5
然后我们可以在新的输入图像上使用这个模型。
测试验证码破解程序
现在我们的验证码破解程序已经训练好了,让我们在一些示例图片上测试一下。打开test_model.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from pyimagesearch.utils.captchahelper import preprocess
from imutils import contours
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
像往常一样,我们的 Python 脚本从导入 Python 包开始。我们将再次使用preprocess函数为分类准备数字。
接下来,我们将解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of images")
ap.add_argument("-m", "--model", required=True,
help="path to input model")
args = vars(ap.parse_args())
--input开关控制我们希望破解的输入验证码图像的路径。我们可以从 E-ZPass NY 网站下载一组新的验证码,但为了简单起见,我们将从现有的原始验证码文件中提取图像样本。--model参数只是驻留在磁盘上的序列化权重的路径。
我们现在可以加载我们预先训练好的 CNN,随机抽取 10 张验证码图片进行分类:
# load the pre-trained network
print("[INFO] loading pre-trained network...")
model = load_model(args["model"])
# randomly sample a few of the input images
imagePaths = list(paths.list_images(args["input"]))
imagePaths = np.random.choice(imagePaths, size=(10,),
replace=False)
有趣的部分来了——破解验证码:
# loop over the image paths
for imagePath in imagePaths:
# load the image and convert it to grayscale, then pad the image
# to ensure digits caught near the border of the image are
# retained
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.copyMakeBorder(gray, 20, 20, 20, 20,
cv2.BORDER_REPLICATE)
# threshold the image to reveal the digits
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
在的第 30 行,我们开始循环每一个被采样的imagePaths。就像在annotate.py的例子中,我们需要提取验证码中的每个数字。这种提取是通过从磁盘加载图像,将其转换为灰度,并填充边界以使手指不能接触到图像的边界来完成的(第 34-37 行)。我们在这里添加额外的填充,这样我们就有足够的空间让在图像上绘制和可视化正确的预测。
第 40 行和第 41 行对图像进行阈值处理,使得数字显示为白色前景对黑色背景。
我们现在需要找到thresh图像中手指的轮廓:
# find contours in the image, keeping only the four largest ones,
# then sort them from left-to-right
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:4]
cnts = contours.sort_contours(cnts)[0]
# initialize the output image as a "grayscale" image with 3
# channels along with the output predictions
output = cv2.merge([gray] * 3)
predictions = []
我们可以通过调用thresh图像上的cv2.findContours来找到数字。这个函数返回一个( x,y )坐标列表,指定每个数字的轮廓。
然后,我们执行两个阶段的排序。第一阶段根据轮廓的大小对轮廓进行分类,只保留最大的四个轮廓。我们(正确地)假设具有最大尺寸的四个轮廓是我们想要识别的数字。然而,这些轮廓上没有保证的空间排序——我们希望识别的第三个数字可能在cnts列表中排在第一位。因为我们从左到右阅读数字,我们需要从左到右排序轮廓。这是通过sort_contours功能(http://pyimg.co/sbm9p)完成的。
第 53 行获取我们的gray图像,并通过将灰度通道复制三次(红色、绿色和蓝色通道各一次)将其转换为三通道图像。然后我们通过 CNN 在第 54 行初始化我们的predictions列表。
鉴于验证码中数字的轮廓,我们现在可以破解它:
# loop over the contours
for c in cnts:
# compute the bounding box for the contour then extract the
# digit
(x, y, w, h) = cv2.boundingRect(c)
roi = gray[y - 5:y + h + 5, x - 5:x + w + 5]
# pre-process the ROI and then classify it
roi = preprocess(roi, 28, 28)
roi = np.expand_dims(img_to_array(roi), axis=0) / 255.0
pred = model.predict(roi).argmax(axis=1)[0] + 1
predictions.append(str(pred))
# draw the prediction on the output image
cv2.rectangle(output, (x - 2, y - 2),
(x + w + 4, y + h + 4), (0, 255, 0), 1)
cv2.putText(output, str(pred), (x - 5, y - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 255, 0), 2)
在第 57 行,我们循环遍历数字的每个轮廓(已经从左到右排序)。然后我们在第 60 和 61 行提取手指的 ROI,接着在第 64 和 65 行对其进行预处理。
第 66 行调用我们model的.predict方法。由.predict返回的概率最大的索引将是我们的类标签。我们将1加到这个值上,因为索引值从零开始;然而,没有零类,只有数字 1-9 的类。该预测随后被添加到第 67 行的predictions列表中。
第 70 行和第 71 行在当前数字周围绘制一个边界框,而第 72 行和第 73 行在output图像本身上绘制预测的数字。
我们的最后一个代码块处理将破解的验证码作为字符串写入我们的终端,并显示output图像:
# show the output image
print("[INFO] captcha: {}".format("".join(predictions)))
cv2.imshow("Output", output)
cv2.waitKey()
要查看我们的验证码破解程序,只需执行以下命令:
$ python test_model.py --input downloads --model output/lenet.hdf5
Using TensorFlow backend.
[INFO] loading pre-trained network...
[INFO] captcha: 2696
[INFO] captcha: 2337
[INFO] captcha: 2571
[INFO] captcha: 8648
在图 8 的、中,我已经包含了从我的test_model.py运行中生成的四个样本。在的每一个案例中,我们都正确地预测了数字串,并使用基于少量训练数据训练的简单网络架构破解了图像验证码。
总结
在本教程中,我们学习了如何:
- 收集原始图像数据集。
- 为我们的培训图像添加标签和注释。
- 在我们的标记数据集上训练一个定制的卷积神经网络。
- 在示例图像上测试和评估我们的模型。
为了做到这一点,我们从纽约的 E-ZPass 网站上搜集了 500 张验证码图片。然后,我们编写了一个 Python 脚本来帮助我们完成标记过程,使我们能够快速标记整个数据集,并将结果图像存储在一个有组织的目录结构中。
在我们的数据集被标记后,我们使用分类交叉熵损失在数据集上使用 SGD 优化器来训练 LeNet 架构,结果模型在零过拟合的测试集上获得了 100%的准确性。最后,我们将预测数字的结果可视化,以确认我们已经成功地设计了一种破解验证码的方法。
我想再次提醒你,本教程仅作为如何获取图像数据集并对其进行标记的示例。在任何情况下你都不应该出于邪恶的原因使用这个数据集或结果模型。如果你发现计算机视觉或深度学习可以被用来利用漏洞,一定要练习负责任的披露,并尝试向适当的利益相关者报告这个问题;不这样做是不道德的(滥用这一准则也是不道德的,从法律上讲,我不能对此负责)。
其次,本教程(下一个关于深度学习的微笑检测的教程也是如此)利用了计算机视觉和 OpenCV 库来帮助构建一个完整的应用程序。如果你打算成为一名认真的深度学习实践者,我强烈建议学习图像处理和 OpenCV 库的基础知识——即使对这些概念有一个基本的了解也能让你:
- 欣赏更高层次的深度学习。
- 开发更强大的应用程序,使用深度学习进行图像分类
- 利用图像处理技术更快地实现您的目标。
在上面的注释和创建我们的数据集部分,我们可以找到一个使用基本图像处理技术的很好的例子,在那里我们能够快速注释和标记我们的数据集。如果不使用简单的计算机视觉技术,我们将不得不使用图像编辑软件(如 Photoshop 或 GIMP)手工裁剪并保存示例数字到磁盘。相反,我们能够编写一个快速而肮脏的应用程序,自动从验证码中提取每个数字——我们所要做的就是按下键盘上正确的键来标记图像。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****
基于 Keras 和深度学习的乳腺癌分类
原文:https://pyimagesearch.com/2019/02/18/breast-cancer-classification-with-keras-and-deep-learning/

在本教程中,您将学习如何训练 Keras 深度学习模型来预测乳腺组织学图像中的乳腺癌。
回到 2012-2013 年,我在美国国立卫生研究院(NIH)和美国国立癌症研究所(NCI)工作,开发一套图像处理和机器学习算法,以自动分析乳腺组织学图像的癌症风险因素,这项任务需要训练有素的病理学家数小时才能完成。我们的工作有助于促进乳腺癌危险因素预测的进一步发展
那时深度学习并不像现在这样流行和“主流”。例如,ImageNet 图像分类挑战赛于 2009 年才开始,直到 2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 才凭借臭名昭著的 AlexNet 架构赢得了比赛。
为了分析乳房组织学图像中的细胞结构,我们转而利用基本的计算机视觉和图像处理算法,但以一种新的方式将它们结合起来。这些算法运行得非常好——但也需要相当多的工作来整合。
今天我认为在乳腺癌分类的背景下探索深度学习是值得的。
就在去年,我的一位近亲被诊断出患有癌症。同样,我愿意打赌,这个博客的每一个读者都认识某个曾经患过癌症的人。
作为深度学习的研究人员、从业人员和工程师,我们必须获得将深度学习应用于医学和计算机视觉问题的实践经验,这一经验可以帮助我们开发深度学习算法,以更好地帮助病理学家预测癌症。
要了解如何训练一个用于乳腺癌预测的 Keras 深度学习模型,继续阅读!
基于 Keras 和深度学习的乳腺癌分类
2020-06-11 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将回顾我们的乳腺癌组织学图像数据集。
在此基础上,我们将创建一个 Python 脚本来将输入数据集分成三个集合:
- 一套训练设备
- 验证集
- 测试设备
接下来,我们将使用 Keras 来定义一个卷积神经网络,我们将它恰当地命名为“CancerNet”。
最后,我们将创建一个 Python 脚本,在我们的乳腺组织学图像上训练 CancerNet。
我们将通过回顾我们的结果来结束这篇博文。
乳腺癌组织学图像数据集
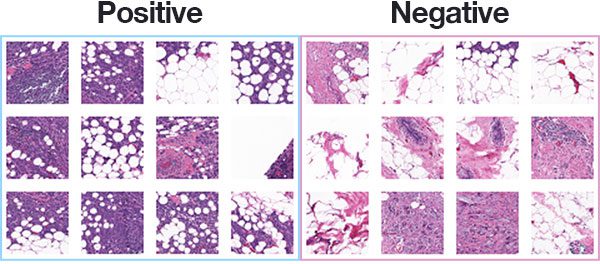
Figure 1: The Kaggle Breast Histopathology Images dataset was curated by Janowczyk and Madabhushi and Roa et al. The most common form of breast cancer, Invasive Ductal Carcinoma (IDC), will be classified with deep learning and Keras.
我们在今天的帖子中使用的数据集是浸润性导管癌(IDC),这是所有乳腺癌中最常见的一种。
该数据集最初由 Janowczyk 和 Madabhushi 和 Roa 等人策划,但在 Kaggle 的网站上可以在公共领域获得。
原始数据集由 162 张 40 倍扫描的幻灯片图像组成。
幻灯片图像自然是巨大的(就空间维度而言),所以为了使它们更容易处理,总共提取了 50×50 像素的 277,524 个面片,包括:
- 198,738 例阴性病例(即无乳腺癌)
- 78786 个阳性病例(即表明在该贴片中发现了乳腺癌)
在类别数据中明显存在不平衡,其中 的负数据点数是正数据点数的 2 倍 。
数据集中的每个图像都有特定的文件名结构。数据集中的图像文件名示例如下:
10253_idx5_x1351_y1101_class0.png
我们可以将这个文件名解释为:
- 患者编号: 10253_idx5
- x-作物坐标:1351
- y-作物坐标:1101
- 分类标签: 0 (0 表示无 IDC,1 表示 IDC)
上面的图 1 显示了正面和负面样本的例子——我们的目标是训练一个深度学习模型,能够辨别这两个类别之间的差异。
为癌症分类准备您的深度学习环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐或支持 CV/DL 项目的窗口。
项目结构
去抢今天博文的 【下载】 。
从那里,解压缩文件:
$ cd path/to/downloaded/zip
$ unzip breast-cancer-classification.zip
现在您已经提取了文件,是时候将数据集放入目录结构中了。
继续创建以下目录:
$ cd breast-cancer-classification
$ mkdir datasets
$ mkdir datasets/orig
然后,前往 Kaggle 的网站并登录。在那里,您可以单击以下链接将数据集下载到项目文件夹中:
点击这里下载 KaggleT3 的数据
注意:你需要在 Kaggle 的网站上创建一个账户(如果你还没有账户的话)来下载数据集。
请务必保存。breast-cancer-classification/datasets/orig文件夹中的 zip 文件。
现在回到您的终端,导航到您刚刚创建的目录,并解压缩数据:
$ cd path/to/breast-cancer-classification/datasets/orig
$ unzip archive.zip -x "IDC_regular_ps50_idx5/*"
从那里,让我们回到项目目录,使用tree命令检查我们的项目结构:
$ cd ../..
$ tree --dirsfirst -L 4
.
├── datasets
│ └── orig
│ ├── 10253
│ │ ├── 0
│ │ └── 1
│ ├── 10254
│ │ ├── 0
│ │ └── 1
│ ├── 10255
│ │ ├── 0
│ │ └── 1
...[omitting similar folders]
│ ├── 9381
│ │ ├── 0
│ │ └── 1
│ ├── 9382
│ │ ├── 0
│ │ └── 1
│ ├── 9383
│ │ ├── 0
│ │ └── 1
│ └── 7415_10564_bundle_archive.zip
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── cancernet.py
├── build_dataset.py
├── train_model.py
└── plot.png
840 directories, 7 files
如您所见,我们的数据集在datasets/orig文件夹中,然后按假患者 ID 分类。这些图像被分为良性(0/)或恶性(1/)目录。
今天的pyimagesearch/模块包含了我们的配置和 CancerNet。
今天,我们将按顺序查看以下 Python 文件:
- 包含我们的数据集构建器和模型训练器都将使用的配置。
build_dataset.py:通过将图像分成训练集、验证集和测试集来构建我们的数据集。cancernet.py:包含我们 CancerNet 乳腺癌分类 CNN。- 负责培训和评估我们的 Keras 乳腺癌分类模型。
配置文件
在建立数据集和训练网络之前,让我们先来看看配置文件。
对于跨越多个 Python 文件的深度学习项目(比如这个),我喜欢创建一个存储所有相关配置的单一 Python 配置文件。
让我们来看看config.py:
# import the necessary packages
import os
# initialize the path to the *original* input directory of images
ORIG_INPUT_DATASET = "datasets/orig"
# initialize the base path to the *new* directory that will contain
# our images after computing the training and testing split
BASE_PATH = "datasets/idc"
# derive the training, validation, and testing directories
TRAIN_PATH = os.path.sep.join([BASE_PATH, "training"])
VAL_PATH = os.path.sep.join([BASE_PATH, "validation"])
TEST_PATH = os.path.sep.join([BASE_PATH, "testing"])
# define the amount of data that will be used training
TRAIN_SPLIT = 0.8
# the amount of validation data will be a percentage of the
# *training* data
VAL_SPLIT = 0.1
首先,我们的配置文件包含从 Kaggle 下载的原始输入数据集的路径( Line 5 )。
在创建训练、测试和验证分割之后,我们从那里指定存储我们的图像文件的基本路径(第 9 行)。
使用BASE_PATH,我们得到训练、验证和测试输出目录的路径(第 12-14 行)。
我们的TRAIN_SPLIT是将用于训练 ( 第 17 行)的数据的百分比。这里我将其设置为 80%,剩下的 20%将用于测试。
在训练数据中,我们会保留一些图像用于验证。第 21 行规定训练数据的 10%(在我们拆分测试数据之后)将用于验证。
我们现在有了构建乳腺癌图像数据集所需的信息,所以让我们继续。
构建乳腺癌图像数据集
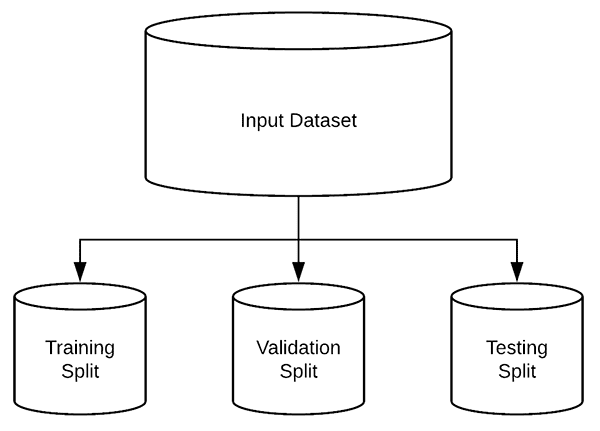
Figure 2: We will split our deep learning breast cancer image dataset into training, validation, and testing sets. While this 5.8GB deep learning dataset isn’t large compared to most datasets, I’m going to treat it like it is so you can learn by example. Thus, we will use the opportunity to put the Keras ImageDataGenerator to work, yielding small batches of images. This eliminates the need to have the whole dataset in memory.
我们的乳腺癌图像数据集由 198,783 张图像组成,每张图像为 50×50 像素。
如果我们试图一次将整个数据集加载到内存中,我们将需要 5.8GB 多一点。
对于大多数现代机器,尤其是有 GPU 的机器,5.8GB 是一个合理的大小;然而,我将假设你的机器没有那么大的内存。
相反,我们将在磁盘上组织我们的数据集,这样我们就可以使用 Keras 的 ImageDataGenerator 类从磁盘 生成批量图像,而不必将整个数据集保存在内存中。
但是首先我们需要组织我们的数据集。现在让我们构建一个脚本来实现这一点。
打开build_dataset.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import random
import shutil
import os
# grab the paths to all input images in the original input directory
# and shuffle them
imagePaths = list(paths.list_images(config.ORIG_INPUT_DATASET))
random.seed(42)
random.shuffle(imagePaths)
# compute the training and testing split
i = int(len(imagePaths) * config.TRAIN_SPLIT)
trainPaths = imagePaths[:i]
testPaths = imagePaths[i:]
# we'll be using part of the training data for validation
i = int(len(trainPaths) * config.VAL_SPLIT)
valPaths = trainPaths[:i]
trainPaths = trainPaths[i:]
# define the datasets that we'll be building
datasets = [
("training", trainPaths, config.TRAIN_PATH),
("validation", valPaths, config.VAL_PATH),
("testing", testPaths, config.TEST_PATH)
]
这个脚本要求我们import我们的config设置和paths来收集所有的图像路径。我们还将使用random随机打乱路径,shutil复制图像,os连接路径并创建目录。这些进口中的每一项都列在第 2-6 行的中。
首先,我们将获取数据集的所有imagePaths和shuffle(第 10-12 行)。
然后我们计算训练/测试分割的指数(第 15 行)。使用那个索引,i,我们的trainPaths和testPaths是通过切片imagePaths ( 行 16 和 17 )构建的。
我们的trainPaths进一步拆分,这次保留一部分用于验证,valPaths ( 第 20-22 行)。
第 25-29 行定义了一个名为datasets的列表。里面是三个元组,每个元组都包含将所有的imagePaths组织成训练、验证和测试数据所需的信息。
现在让我们开始循环查看datasets列表:
# loop over the datasets
for (dType, imagePaths, baseOutput) in datasets:
# show which data split we are creating
print("[INFO] building '{}' split".format(dType))
# if the output base output directory does not exist, create it
if not os.path.exists(baseOutput):
print("[INFO] 'creating {}' directory".format(baseOutput))
os.makedirs(baseOutput)
# loop over the input image paths
for inputPath in imagePaths:
# extract the filename of the input image and extract the
# class label ("0" for "negative" and "1" for "positive")
filename = inputPath.split(os.path.sep)[-1]
label = filename[-5:-4]
# build the path to the label directory
labelPath = os.path.sep.join([baseOutput, label])
# if the label output directory does not exist, create it
if not os.path.exists(labelPath):
print("[INFO] 'creating {}' directory".format(labelPath))
os.makedirs(labelPath)
# construct the path to the destination image and then copy
# the image itself
p = os.path.sep.join([labelPath, filename])
shutil.copy2(inputPath, p)
在第 32 行的上,我们定义了一个数据集分割的循环。在内部,我们:
- 创建基本输出目录(第 37-39 行)。
- 对当前分割中的所有输入图像执行嵌套循环(行 42 ):
- 从输入路径中提取
filename(第 45 行),然后从文件名中提取类label(第 46 行)。 - 构建我们的输出
labelPath并创建标签输出目录(第 49-54 行)。 - 最后,将每个文件复制到它的目的地(行 58 和 59 )。
- 从输入路径中提取
现在我们的脚本已经编写好了,接下来通过执行以下命令来创建培训、测试和验证分割目录结构:
$ python build_dataset.py
[INFO] building 'training' split
[INFO] 'creating datasets/idc/training' directory
[INFO] 'creating datasets/idc/training/0' directory
[INFO] 'creating datasets/idc/training/1' directory
[INFO] building 'validation' split
[INFO] 'creating datasets/idc/validation' directory
[INFO] 'creating datasets/idc/validation/0' directory
[INFO] 'creating datasets/idc/validation/1' directory
[INFO] building 'testing' split
[INFO] 'creating datasets/idc/testing' directory
[INFO] 'creating datasets/idc/testing/0' directory
[INFO] 'creating datasets/idc/testing/1' directory
$
$ tree --dirsfirst --filelimit 10
.
├── datasets
│ ├── idc
│ │ ├── training
│ │ │ ├── 0 [143065 entries]
│ │ │ └── 1 [56753 entries]
│ │ ├── validation
│ │ | ├── 0 [15962 entries]
│ │ | └── 1 [6239 entries]
│ │ └── testing
│ │ ├── 0 [39711 entries]
│ │ └── 1 [15794 entries]
│ └── orig [280 entries]
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── cancernet.py
├── build_dataset.py
├── train_model.py
└── plot.png
14 directories, 8 files
我们脚本的输出显示在命令下面。
我还再次执行了tree命令,这样您就可以看到我们的数据集现在是如何构建成我们的训练、验证和测试集的。
注意:我没有费心扩展我们最初的datasets/orig/结构——如果你需要复习,可以向上滚动到“项目结构”部分。
癌症网:我们的乳腺癌预测

Figure 3: Our Keras deep learning classification architecture for predicting breast cancer (click to expand)
下一步是实现我们将用于这个项目的 CNN 架构。
为了实现该架构,我使用了 Keras 深度学习库,并设计了一个名为“CancerNet”的网络,该网络:
- 专门使用 3×3 CONV 滤波器,类似于 VGGNet
- 在执行最大池化之前,将多个 3×3 CONV 滤波器堆叠在彼此之上(同样,类似于 VGGNet)
- 但与 VGGNet 不同,使用深度方向可分离卷积而不是标准卷积层
深度可分卷积在深度学习中并不是一个“新”的想法。
事实上,谷歌大脑实习生 Laurent Sifre 在 2013 年首次利用了它们。
安德鲁·霍华德在 2015 年与 MobileNet 合作时使用了它们。
也许最值得注意的是,Francois Chollet 在 2016-2017 年创作著名的 Xception 建筑时使用了它们。
对标准卷积层和深度方向可分离卷积之间差异的详细解释超出了本教程的范围(关于这一点,请参考本指南,但要点是深度方向可分离卷积:
- 效率更高。
- 需要更少的内存。
- 需要更少的计算。
- 在某些情况下,可以比标准卷积执行得更好。
我还没有在 PyImageSearch 的任何教程中使用过深度方向可分离卷积,所以我想今天用它玩会很有趣。
话虽如此,让我们开始实施 CancerNet 吧!
打开cancernet.py文件并插入以下代码:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import SeparableConv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
class CancerNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们的 Keras 进口列在2-10 线。我们将使用 Keras 的Sequential API 来构建CancerNet。
你在 PyImageSearch 博客上没见过的一个导入是SeparableConv2D。这种卷积层类型允许深度方向的卷积。有关更多详情,请参考文档。
其余的导入/图层类型都在我的入门教程 Keras 教程 和用 Python 进行计算机视觉深度学习中有更详细的讨论。
*让我们在第 12 行定义我们的CancerNet类,然后在第 14 行继续build它。
build方法需要四个参数:
width、height和depth:这里我们指定网络的输入图像体积形状,其中depth是每个图像包含的颜色通道的数量。classes:我们的网络将预测的类的数量(对于CancerNet,将是2)。
我们继续在行 17 上初始化我们的model,随后,指定我们的inputShape ( 行 18 )。在使用 TensorFlow 作为后端的情况下,我们现在准备添加层。
其他指定"channels_first"的后端要求我们将depth放在inputShape的前面,图像尺寸跟在后面(第 23-25 行)。
让我们定义我们的DEPTHWISE_CONV => RELU => POOL层:
# CONV => RELU => POOL
model.add(SeparableConv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV => RELU => POOL) * 2
model.add(SeparableConv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(SeparableConv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV => RELU => POOL) * 3
model.add(SeparableConv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(SeparableConv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(SeparableConv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
这里定义了三个DEPTHWISE_CONV => RELU => POOL块,增加了过滤器的堆叠和数量。我也申请了BatchNormalization和Dropout。
让我们添加完全连接的头部:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
我们的FC => RELU层和 softmax 分类器构成了网络的头部。
softmax 分类器的输出将是我们的模型将预测的每个类别的预测百分比。
最后,我们的model返回到训练脚本。
我们的培训脚本
我们需要实现的最后一块拼图是我们实际的训练脚本。
创建一个名为train_model.py的新文件,打开它,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers import Adagrad
from tensorflow.keras.utils import to_categorical
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from pyimagesearch.cancernet import CancerNet
from pyimagesearch import config
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们的进口来自 7 个地方:
- 一个科学绘图包,是 Python 事实上的标准。在的第 3 行上,我们设置 matplotlib 使用
"Agg"后端,这样我们就可以将我们的训练图保存到磁盘上。 tensorflow.keras:我们将利用ImageDataGenerator、LearningRateScheduler、Adagrad优化器和utils。- 从 scikit-learn 我们需要它的一个
classification_report和一个confusion_matrix的实现。 - 我们将使用我们新定义的 CancerNet(训练和评估它)。我们还需要配置来获取三个数据分割的路径。这个模块不是pip-installable;它收录了今天帖子的 【下载】 版块。
- 我已经把我的便利功能作为一个可安装在 pip 上的包公开了。我们将使用
paths模块获取每个图像的路径。 numpy:数据科学家使用 Python 进行数值处理的典型工具。- Python:
argparse和os都内置于 Python 安装中。我们将使用argparse解析命令行参数。
让我们解析我们唯一的命令行参数,--plot。有了运行时在终端中提供的这个参数,我们的脚本将能够动态地接受不同的绘图文件名。如果不使用绘图文件名指定命令行参数,将使用默认值plot.png。
现在,我们已经导入了所需的库,并解析了命令行参数,让我们定义训练参数,包括我们的训练图像路径,并考虑类不平衡:
# initialize our number of epochs, initial learning rate, and batch
# size
NUM_EPOCHS = 40
INIT_LR = 1e-2
BS = 32
# determine the total number of image paths in training, validation,
# and testing directories
trainPaths = list(paths.list_images(config.TRAIN_PATH))
totalTrain = len(trainPaths)
totalVal = len(list(paths.list_images(config.VAL_PATH)))
totalTest = len(list(paths.list_images(config.TEST_PATH)))
# calculate the total number of training images in each class and
# initialize a dictionary to store the class weights
trainLabels = [int(p.split(os.path.sep)[-2]) for p in trainPaths]
trainLabels = to_categorical(trainLabels)
classTotals = trainLabels.sum(axis=0)
classWeight = dict()
# loop over all classes and calculate the class weight
for i in range(0, len(classTotals)):
classWeight[i] = classTotals.max() / classTotals[i]
第 28-30 行定义训练时期的数量、初始学习率和批量大小。
从那里,我们获取我们的训练图像路径,并确定每个分割中的图像总数(行 34-37 )。
然后,我们将继续采取措施解决类不平衡/偏斜问题(第 41-48 行)。
让我们初始化我们的数据扩充对象:
# initialize the training data augmentation object
trainAug = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=20,
zoom_range=0.05,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.05,
horizontal_flip=True,
vertical_flip=True,
fill_mode="nearest")
# initialize the validation (and testing) data augmentation object
valAug = ImageDataGenerator(rescale=1 / 255.0)
数据扩充是一种正则化形式,对于几乎所有深度学习实验都很重要,以帮助模型泛化。该方法在将训练样本传递到网络中进行训练之前,有目的地扰动训练样本,稍微改变它们的外观。这部分缓解了收集更多训练数据的需要,尽管更多的训练数据很少会损害您的模型。
我们的数据扩充对象trainAug在行 51-60 被初始化。如您所见,随机旋转、移位、剪切和翻转将在数据生成时应用于数据。将我们的图像像素强度重新调整到范围【0,1】由trainAug发生器和线 63 上定义的valAug发生器处理。
现在让我们初始化每个生成器:
# initialize the training generator
trainGen = trainAug.flow_from_directory(
config.TRAIN_PATH,
class_mode="categorical",
target_size=(48, 48),
color_mode="rgb",
shuffle=True,
batch_size=BS)
# initialize the validation generator
valGen = valAug.flow_from_directory(
config.VAL_PATH,
class_mode="categorical",
target_size=(48, 48),
color_mode="rgb",
shuffle=False,
batch_size=BS)
# initialize the testing generator
testGen = valAug.flow_from_directory(
config.TEST_PATH,
class_mode="categorical",
target_size=(48, 48),
color_mode="rgb",
shuffle=False,
batch_size=BS)
在这里,我们初始化训练、验证和测试生成器。每个生成器将按需提供一批图像,如参数batch_size所示。
让我们继续初始化我们的model并开始训练吧!
# initialize our CancerNet model and compile it
model = CancerNet.build(width=48, height=48, depth=3,
classes=2)
opt = Adagrad(lr=INIT_LR, decay=INIT_LR / NUM_EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# fit the model
H = model.fit(
x=trainGen,
steps_per_epoch=totalTrain // BS,
validation_data=valGen,
validation_steps=totalVal // BS,
class_weight=classWeight,
epochs=NUM_EPOCHS)
2020-06-11 更新: 以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict(我们的下一个代码块)的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
我们的模型由第 93-95 行的优化器初始化。
然后我们用一个"binary_crossentropy" loss函数compile我们的模型(因为我们只有两类数据),以及学习率衰减(第 96 行和第 97 行)。
第 100-106 行开始我们的培训过程。
训练完成后,我们将根据测试数据评估模型:
# reset the testing generator and then use our trained model to
# make predictions on the data
print("[INFO] evaluating network...")
testGen.reset()
predIdxs = model.predict(x=testGen, steps=(totalTest // BS) + 1)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(testGen.classes, predIdxs,
target_names=testGen.class_indices.keys()))
第 112 行对我们所有的测试数据进行预测(再次使用一个生成器对象)。
为每个样本抓取最高预测指数(行 116 ),然后将classification_report方便地打印到终端(行 119 和 120 )。
让我们收集其他评估指标:
# compute the confusion matrix and and use it to derive the raw
# accuracy, sensitivity, and specificity
cm = confusion_matrix(testGen.classes, predIdxs)
total = sum(sum(cm))
acc = (cm[0, 0] + cm[1, 1]) / total
sensitivity = cm[0, 0] / (cm[0, 0] + cm[0, 1])
specificity = cm[1, 1] / (cm[1, 0] + cm[1, 1])
# show the confusion matrix, accuracy, sensitivity, and specificity
print(cm)
print("acc: {:.4f}".format(acc))
print("sensitivity: {:.4f}".format(sensitivity))
print("specificity: {:.4f}".format(specificity))
这里我们计算confusion_matrix,然后导出精度、sensitivity和specificity ( 第 124-128 行)。矩阵和这些值中的每一个都打印在我们的终端中(第 131-134 行)。
最后,让我们生成并存储我们的训练图:
# plot the training loss and accuracy
N = NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-11 更新: 为了使这个绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“acc”而没有“ACC”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
我们的训练历史图由训练/验证损失和训练/验证准确性组成。这些是随时间绘制的,这样我们可以发现过度拟合/欠拟合。
乳腺癌预测结果
我们现在已经实现了所有必要的 Python 脚本!
让我们继续在我们的乳腺癌数据集上训练 CancerNet。
继续之前,请确保您已经:
- 使用“为癌症分类准备深度学习环境”部分中列出的必要库/包配置您的深度学习环境。
- 使用本教程的 【下载】 部分下载源代码。
- 从 Kaggle 的网站上下载了乳腺癌数据集。
- 解压缩数据集并执行
build_dataset.py脚本来创建必要的图像+目录结构。
在您勾选了以上四项之后,打开一个终端并执行以下命令:
$ python train_model.py
Found 199818 images belonging to 2 classes.
Found 22201 images belonging to 2 classes.
Found 55505 images belonging to 2 classes.
Epoch 1/40
6244/6244 [==============================] - 142s 23ms/step - loss: 0.5954 - accuracy: 0.8211 - val_loss: 0.5407 - val_accuracy: 0.7796
Epoch 2/40
6244/6244 [==============================] - 135s 22ms/step - loss: 0.5520 - accuracy: 0.8333 - val_loss: 0.4786 - val_accuracy: 0.8097
Epoch 3/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5423 - accuracy: 0.8358 - val_loss: 0.4532 - val_accuracy: 0.8202
...
Epoch 38/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5248 - accuracy: 0.8408 - val_loss: 0.4269 - val_accuracy: 0.8300
Epoch 39/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5254 - accuracy: 0.8415 - val_loss: 0.4199 - val_accuracy: 0.8318
Epoch 40/40
6244/6244 [==============================] - 133s 21ms/step - loss: 0.5244 - accuracy: 0.8422 - val_loss: 0.4219 - val_accuracy: 0.8314
[INFO] evaluating network...
precision recall f1-score support
0 0.93 0.83 0.88 39853
1 0.66 0.85 0.75 15652
accuracy 0.84 55505
macro avg 0.80 0.84 0.81 55505
weighted avg 0.86 0.84 0.84 55505
[[33107 6746]
[ 2303 13349]]
acc: 0.8370
sensitivity: 0.8307
specificity: 0.8529

Figure 4: Our CancerNet classification model training plot generated with Keras.
查看我们的输出,您可以看到我们的模型达到了 ~83%的准确度;然而,我们对【良性/非癌症】的正确分类率为 93%,这一事实严重影响了原始准确性。
为了在更深层次上理解我们模型的性能,我们计算了灵敏度和特异性。
我们的灵敏度测量了也预测为阳性的真阳性的比例(83.07%)。
相反,特异性衡量我们的真阴性 (85.29%)。
在这里,我们需要非常小心我们的假阴性——我们不想把某人归类为“没有癌症”,而事实上他们是“癌症阳性”。
我们的假阳性率也很重要——我们不想错误地将某人归类为“癌症阳性”,然后让他们接受痛苦、昂贵和侵入性的治疗,而他们实际上并不需要。
机器学习/深度学习工程师和从业者必须在敏感性和特异性之间保持平衡,但当涉及到深度学习和医疗保健/健康治疗时,这种平衡变得极其重要。
关于灵敏度、特异性、真阳性、假阴性、真阴性和假阳性的更多信息,请参考本指南。
摘要
在本教程中,您学习了如何使用 Keras 深度学习库来训练用于乳腺癌分类的卷积神经网络。
为了完成这项任务,我们利用了由 Janowczyk 和 Madabhushi 和 Roa 等人策划的乳腺癌组织学图像数据集
组织学图像本身是巨大的(就磁盘上的图像大小和加载到内存中时的空间尺寸而言),因此为了使图像更易于我们使用,Kaggle 社区倡导团队的一部分 Paul Mooney 将数据集转换为 50×50 像素的图像补丁,然后将修改后的数据集直接上传到 Kaggle 数据集存档。
属于两类的总共 277,524 幅图像被包括在数据集中:
- 阳性(+):78786
- 阴性(-): 198,738
这里我们可以看到数据中有一个类不平衡,负样本比正样本多 2x 多。
类别不平衡,以及数据集的挑战性,导致我们获得了 ~83%的分类准确度、 ~83%的灵敏度,以及 ~85%的特异性。
我邀请你使用这个代码作为模板,开始你自己的乳腺癌分类实验。
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!*
使用 OMR、Python 和 OpenCV 的气泡式多项选择扫描仪和测试评分器

在过去的几个月里,我的收件箱收到了相当多的请求,要求我使用计算机视觉和图像处理技术来构建一个类似气泡表/扫描仪的测试阅读器。
虽然我在做这个关于机器学习和深度学习的系列时获得了很多乐趣,但如果我说这个小小的迷你项目不是一个短暂的、受欢迎的休息,那我就是在撒谎。运行 PyImageSearch 博客,我最喜欢的部分之一是演示如何使用计算机视觉建立解决问题的实际解决方案。
事实上,这个项目之所以如此特别是因为我们将结合以前许多博文中的技术,包括构建文档扫描仪、轮廓排序和透视变换。使用从这些以前的帖子中获得的知识,我们将能够快速完成这个气泡表扫描仪和测试分级机。
你看,上周五下午,我很快地用 Photoshopped 处理了一份示例 bubble 试卷,打印了几份,然后着手编写实际实现的代码。
总的来说,我对这个实现非常满意,我认为你完全可以使用这个气泡表分级器/OMR 系统作为你自己项目的起点。
要了解更多关于利用计算机视觉、图像处理和 OpenCV 对泡泡试卷进行自动评分的信息,继续阅读。
使用 OMR、Python 和 OpenCV 的气泡纸扫描仪和测试分级机
在这篇博文的剩余部分,我将讨论什么是光学标记识别 (OMR)。然后,我将演示如何使用严格地说计算机视觉和图像处理技术以及 OpenCV 库来实现气泡纸测试扫描仪和分类器。
一旦我们实现了我们的 OMR 系统,我将提供我们的测试评分员在几个示例考试中的样本结果,包括那些被恶意填写的。
最后,我将讨论当前气泡页扫描仪系统的一些缺点,以及我们如何在未来的迭代中改进它。
什么是光学标记识别(OMR)?
光学标记识别,或简称为 OMR,是自动分析人类标记的文档并解释其结果的过程。
可以说,OMR 最著名、最容易识别的形式是,与你在小学、中学甚至高中参加的考试没有什么不同。
**如果你不熟悉“气泡纸测试”或“Scantron 测试”的商标/公司名称,它们只是你作为学生参加的多项选择测试。考试中的每个问题都是选择题,你用 2 号铅笔在正确答案对应的“泡泡”上做标记。
你经历过的最著名的冒泡测试(至少在美国)是在填写大学入学申请之前参加高中的 sat 考试。
我相信【that 使用 Scantron 提供的软件来进行 OMR 和学生考试评分,但是我很可能错了。我之所以注意到这一点,是因为 Scantron 在美国超过 98%的学区使用。
简而言之,我想说的是,光学标记识别以及对人类标记的表格和考试进行评分和解释的能力有一个巨大的市场。
使用 OMR、Python 和 OpenCV 实现气泡纸扫描仪和分级机
现在我们已经了解了 OMR 的基本知识,让我们使用 Python 和 OpenCV 来构建一个计算机视觉系统,它可以读取和等级气泡表测试。
当然,我会一路提供大量的视觉示例图像,这样你就可以准确地理解我在应用什么技术和我为什么要使用它们。
以下是我为这个项目收集的一个填写在气泡表考试中的例子:

Figure 1: The example, filled in bubble sheet we are going to use when developing our test scanner software.
在我们构建测试分类器的过程中,我们将使用这张图片作为示例。在本课的稍后部分,您还将找到附加的示例考试。
我还包含了一个空白的考试模板,作为一个 PSD (Photoshop)文件,这样你就可以随意修改了。你可以使用这篇文章底部的 【下载】 部分下载代码、示例图片和模板文件。
构建气泡纸扫描仪和分级机的 7 个步骤
这篇博文的目标是使用 Python 和 OpenCV 构建一个气泡表扫描器和测试分类器。
为此,我们的实施需要满足以下 7 个步骤:
- 步骤#1: 在图像中检测检查。
- 步骤#2: 应用透视变换来提取检查的俯视鸟瞰图。
- 步骤#3: 从透视变换后的考试中提取泡泡集(即可能的答案选择)。
- 步骤#4: 将问题/泡泡按行排序。
- 步骤#5: 确定每行的标记(即“冒泡”)答案。
- 步骤#6: 在我们的答案中查找正确答案,以确定用户的选择是否正确。
- 步骤#7: 对考试中的所有问题重复上述步骤。
本教程的下一节将介绍我们算法的实际实现。
用 Python 和 OpenCV 实现气泡图扫描仪
首先,打开一个新文件,命名为test_grader.py,让我们开始工作:
# import the necessary packages
from imutils.perspective import four_point_transform
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
# define the answer key which maps the question number
# to the correct answer
ANSWER_KEY = {0: 1, 1: 4, 2: 0, 3: 3, 4: 1}
在第 2-7 行,我们导入了我们需要的 Python 包。
你应该已经在你的系统上安装了 OpenCV 和 Numpy,但是你可能没有最新版本的 imutils ,这是我的一套方便的函数,可以使执行基本的图像处理操作更加容易。要安装imutils(或升级到最新版本),只需执行以下命令:
$ pip install --upgrade imutils
第 10-12 行解析我们的命令行参数。这里我们只需要一个开关--image,它是到输入气泡表测试图像的路径,我们将对它进行正确性评分。
第 17 行然后定义了我们的ANSWER_KEY。
顾名思义,ANSWER_KEY提供了问题编号到正确气泡的索引的整数映射。
在这种情况下, 0 的键表示第一个问题,而 1 的值表示【B】为正确答案(因为“B”是字符串【ABCDE】中的索引 1 )。作为第二个例子,考虑映射到值 4 的键1—这将表明第二个问题的答案是“E”。
为了方便起见,我在这里用简单的英语写下了整个答案:
- 问题 1: B
- 问题 2: E
- 问题 3: 答
- 第四个问题: D
- 问题 5: B
接下来,让我们预处理我们的输入图像:
# load the image, convert it to grayscale, blur it
# slightly, then find edges
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 75, 200)
在第 21 行,我们从磁盘中加载图像,然后将其转换为灰度(第 22 行),并对其进行模糊处理以减少高频噪声(第 23 行)。
然后,我们将 Canny 边缘检测器应用于第 24 行的以找到检查的边缘/轮廓。
下面我附上了应用边缘检测后的考试截图:

Figure 2: Applying edge detection to our exam neatly reveals the outlines of the paper.
请注意文档的边缘是如何被清晰地定义的,检查的所有四个顶点都出现在图像中。
在我们的下一步中,获取文档的轮廓极其重要,因为我们将使用它作为标记对检查应用透视变换,从而获取文档的俯视鸟瞰图:
# find contours in the edge map, then initialize
# the contour that corresponds to the document
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
docCnt = None
# ensure that at least one contour was found
if len(cnts) > 0:
# sort the contours according to their size in
# descending order
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# loop over the sorted contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# if our approximated contour has four points,
# then we can assume we have found the paper
if len(approx) == 4:
docCnt = approx
break
现在我们已经有了考试的大纲,我们应用cv2.findContours函数来查找与考试本身相对应的行。
我们通过在线 37 上按照轮廓的面积(从最大到最小)对轮廓进行分类(当然,是在确保在线 34 上找到至少一个轮廓之后)。这意味着较大的轮廓将被放在列表的前面,而较小的轮廓将出现在列表的后面。
我们假设我们的检查将是图像的主焦点,因此比图像中的其他对象大。这个假设允许我们“过滤”我们的轮廓,简单地通过调查它们的区域并且知道对应于检查的轮廓应该在列表的前面附近。
然而,轮廓面积和尺寸是不够的——我们还应该检查轮廓上顶点的数量。
为了做到这一点,我们在第 40 行的上循环我们的每个(排序的)轮廓。对于它们中的每一个,我们近似轮廓,这实质上意味着我们简化轮廓中的点数,使其成为“更基本”的几何形状。你可以在这篇关于构建移动文档扫描仪的文章中读到更多关于轮廓近似的内容。
在第 47 行第 47 行第 47 行第 47 行第 47 行第 47 行第 47 行第 41 行,我们检查我们的近似轮廓是否有四个点,如果有,我们认为我们已经找到了测试。
下面我提供了一个示例图像,演示了在原始图像上绘制的docCnt变量:

Figure 3: An example of drawing the contour associated with the exam on our original image, indicating that we have successfully found the exam.
果然这个区域对应的是考试大纲。
既然我们已经使用轮廓找到了检查的轮廓,我们可以应用透视变换来获得文档的自上而下的鸟瞰图:
# apply a four point perspective transform to both the
# original image and grayscale image to obtain a top-down
# birds eye view of the paper
paper = four_point_transform(image, docCnt.reshape(4, 2))
warped = four_point_transform(gray, docCnt.reshape(4, 2))
在这种情况下,我们将使用我实现的four_point_transform函数,它:
- 以特定的、可重复的方式排列轮廓的 (x,y)-坐标。
- 对区域应用透视变换。
你可以在这篇文章以及这篇更新的关于坐标排序的文章中了解更多关于透视变换的信息,但是现在,简单地理解一下,这个函数处理“倾斜的”考试并对其进行变换,返回文档的自顶向下视图:

Figure 4: Obtaining a top-down, birds-eye view of both the original image (left) along with the grayscale version (right).
好吧,现在我们有进展了。
我们在原始图像中找到了我们的考试。
我们应用透视变换来获得文档的 90 度视角。
但是我们如何着手对文件进行评分呢?
该步骤从二值化开始,或者从图像的背景中对前景进行阈值分割/分割的过程:
# apply Otsu's thresholding method to binarize the warped
# piece of paper
thresh = cv2.threshold(warped, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
在应用 Otsu 的阈值方法后,我们的检查现在是一个二进制图像:

Figure 5: Using Otsu’s thresholding allows us to segment the foreground from the background of the image.
注意图像的背景是黑色,而前景是白色。
这种二值化将允许我们再次应用轮廓提取技术来找到检查中的每个气泡:
# find contours in the thresholded image, then initialize
# the list of contours that correspond to questions
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
questionCnts = []
# loop over the contours
for c in cnts:
# compute the bounding box of the contour, then use the
# bounding box to derive the aspect ratio
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# in order to label the contour as a question, region
# should be sufficiently wide, sufficiently tall, and
# have an aspect ratio approximately equal to 1
if w >= 20 and h >= 20 and ar >= 0.9 and ar <= 1.1:
questionCnts.append(c)
第 64-67 行处理在我们的thresh二进制图像上寻找轮廓,随后初始化questionCnts,这是对应于考试上的问题/气泡的轮廓列表。
为了确定图像的哪些区域是气泡,我们首先遍历每个单独的轮廓(行 70 )。
对于这些轮廓中的每一个,我们计算边界框(线 73 ),这也允许我们计算纵横比,或者更简单地说,宽度与高度的比率(线 74 )。
为了将轮廓区域视为气泡,该区域应该:
- 足够宽和高(在这种情况下,两个维度都至少有 20 个像素)。
- 具有大约等于 1 的纵横比。
只要这些检查有效,我们就可以更新我们的questionCnts列表,并将该区域标记为气泡。
下面我附上了一张截图,它在我们的图片上画出了questionCnts的输出:

Figure 6: Using contour filtering allows us to find all the question bubbles in our bubble sheet exam recognition software.
请注意只有考试的问题区域被突出显示,其他什么都没有。
我们现在可以进入 OMR 系统的“分级”部分:
# sort the question contours top-to-bottom, then initialize
# the total number of correct answers
questionCnts = contours.sort_contours(questionCnts,
method="top-to-bottom")[0]
correct = 0
# each question has 5 possible answers, to loop over the
# question in batches of 5
for (q, i) in enumerate(np.arange(0, len(questionCnts), 5)):
# sort the contours for the current question from
# left to right, then initialize the index of the
# bubbled answer
cnts = contours.sort_contours(questionCnts[i:i + 5])[0]
bubbled = None
首先,我们必须从上到下对我们的questionCnts进行排序。这将确保考试中靠近顶端的行问题将出现在排序列表中的第个行。
我们还初始化了一个 bookkeeper 变量来跟踪correct答案的数量。
在第 90 行,我们开始循环我们的问题。由于每个问题有 5 个可能的答案,我们将应用 NumPy 数组切片和轮廓排序从左到右对当前轮廓集进行排序。
这种方法有效的原因是因为我们已经从上到下对轮廓进行了排序。我们知道每个问题的 5 个泡泡将依次出现在我们的列表中——,但是我们不知道这些泡泡是否会从左到右排序。在行 94 上的轮廓排序调用解决了这个问题,并确保轮廓的每一行从左到右排序成行。
为了形象化这个概念,我在下面附上了一个截图,用不同的颜色描绘了每一行问题:

Figure 7: By sorting our contours from top-to-bottom, followed by left-to-right, we can extract each row of bubbles. Therefore, each row is equal to the bubbles for one question.
给定一排气泡,下一步是确定填充哪个气泡。
我们可以通过使用我们的thresh图像并计算每个气泡区域中非零像素(即前景像素)的数量来实现这一点:
# loop over the sorted contours
for (j, c) in enumerate(cnts):
# construct a mask that reveals only the current
# "bubble" for the question
mask = np.zeros(thresh.shape, dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1)
# apply the mask to the thresholded image, then
# count the number of non-zero pixels in the
# bubble area
mask = cv2.bitwise_and(thresh, thresh, mask=mask)
total = cv2.countNonZero(mask)
# if the current total has a larger number of total
# non-zero pixels, then we are examining the currently
# bubbled-in answer
if bubbled is None or total > bubbled[0]:
bubbled = (total, j)
行 98 处理在该行中每个排序的气泡上的循环。
然后,我们为第行 101 上的当前气泡构建一个遮罩,然后对被遮罩区域中非零像素的数量进行计数(行 107 和 108 )。我们计数的非零像素越多,前景像素就越多,因此具有最大非零计数的气泡是考生冒泡的气泡的索引(第 113 行和第 114 行)。
下面我提供了一个例子,创建一个遮罩并应用到与问题相关的每个气泡上:

Figure 8: An example of constructing a mask for each bubble in a row.
显然,与“B”相关联的气泡具有最多的阈值像素,因此是用户已经在他们的检查上标记的气泡。
下一个代码块处理在ANSWER_KEY中查找正确答案,更新任何相关的簿记员变量,最后在我们的图像上绘制标记的气泡:
# initialize the contour color and the index of the
# *correct* answer
color = (0, 0, 255)
k = ANSWER_KEY[q]
# check to see if the bubbled answer is correct
if k == bubbled[1]:
color = (0, 255, 0)
correct += 1
# draw the outline of the correct answer on the test
cv2.drawContours(paper, [cnts[k]], -1, color, 3)
基于应试者是正确的还是不正确的,产生了在考试中抽取哪种颜色。如果应试者的答案正确,我们将用绿色突出显示他们的答案。但是,如果考生犯了错误并标记了错误答案,我们会通过用红色突出显示正确的答案让他们知道:

Figure 9: Drawing a “green” circle to mark “correct” or a “red” circle to mark “incorrect”.
最后,我们的最后一个代码块处理考试评分并在屏幕上显示结果:
# grab the test taker
score = (correct / 5.0) * 100
print("[INFO] score: {:.2f}%".format(score))
cv2.putText(paper, "{:.2f}%".format(score), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
cv2.imshow("Original", image)
cv2.imshow("Exam", paper)
cv2.waitKey(0)
下面您可以看到我们完全评分的示例图像的输出:

Figure 10: Finishing our OMR system for grading human-taken exams.
在这种情况下,读者在考试中获得了 80 分。他们唯一错过的问题是第 4 题,他们错误地将【C】标为正确答案(正确答案是【D】)。
为什么不用圆检测?
阅读完本教程后,您可能会想知道:
“嗨阿德里安,一个答案泡泡是一个圆。那么为什么你提取轮廓而不是应用霍夫圆来寻找图像中的圆呢?”
问得好。
首先,在图像到图像的基础上调整霍夫圆的参数可能是一个真正的痛苦。但这只是次要原因。
真正的原因是:
用户错误。
有多少次,不管是有意还是无意,你在泡泡表上填了线以外的内容?我不是专家,但我不得不猜测,每 20 分中至少有 1 分是考生“稍微”超出标准的。
你猜怎么着?
霍夫圆不能很好地处理其轮廓的变形——在这种情况下,您的圆检测将完全失败。
因此,我建议使用轮廓和轮廓属性来帮助你过滤气泡和答案。cv2.findContours函数不关心气泡是“圆的”、“完全圆的”,还是“哦,我的上帝,那是什么鬼东西?”。
相反,cv2.findContours函数将返回一组斑点给你,它们将是你图像中的前景区域。然后你可以对这些区域进行处理和过滤,找到你的问题(就像我们在本教程中所做的那样),然后继续你的工作。
我们的气泡纸测试扫描仪和分级机结果
要查看我们的气泡表测试分类器,请务必使用教程底部的 “下载” 部分下载源代码和示例图像。
我们已经在这篇文章的前面看到了test_01.png作为我们的例子,所以让我们试试test_02.png:
$ python test_grader.py --image images/test_02.png
这里我们可以看到一个特别邪恶的用户参加了我们的考试。他们对测试不满意,在测试的前面写下了 "#yourtestsux" 和一个激发 "#breakthesystem" 的无政府状态。他们还在所有答案上标注了【A】。
用户在考试中仅获得可怜的 20%的分数,这也许不足为奇,完全是因为运气:

Figure 11: By using contour filtering, we are able to ignore the regions of the exam that would have otherwise compromised its integrity.
让我们尝试另一个图像:
$ python test_grader.py --image images/test_03.png
这一次,这位读者做得稍微好一点,得了 60 分:

Figure 12: Building a bubble sheet scanner and test grader using Python and OpenCV.
在这个特殊的例子中,读者只需沿着对角线标记所有答案:
$ python test_grader.py --image images/test_04.png

Figure 13: Optical Mark Recognition for test scoring using Python and OpenCV.
不幸的是,对于应试者来说,这个策略并没有得到很好的回报。
让我们看最后一个例子:
$ python test_grader.py --image images/test_05.png
Figure 14: Recognizing bubble sheet exams using computer vision.
这个学生显然提前学习了,考试得了满分。
扩展 OMR 和测试扫描仪
无可否认,去年夏天/初秋是我一生中最忙的时期之一,所以我需要在上周五的一个下午时间盒开发 OMR 和测试扫描仪软件。
虽然我已经实现了一个可以工作的气泡纸测试扫描仪的框架,但是仍然有一些地方需要改进。最明显需要改进的地方是处理未填充气泡的逻辑。
在当前的实现中,我们(天真地)假设读者在每个问题行中填写了一个和仅一个气泡。
然而,由于我们简单地通过计数一行中阈值像素的数量,然后以降序排序来确定特定气泡是否被“填充”,这可能导致两个问题:
- 如果用户没有给出特定问题的答案,会发生什么?
- 如果用户居心叵测,在同一行将多个气泡标记为“正确”怎么办?
幸运的是,检测和处理这些问题并不是非常具有挑战性,我们只需要插入一点逻辑。
对于问题#1,如果读者选择而不是来冒泡特定行的答案,那么我们可以在行 108 上放置一个最小阈值,在那里我们计算cv2.countNonZero:

Figure 15: Detecting if a user has marked zero bubbles on the exam.
如果这个值足够大,那么我们可以将气泡标记为“已填充”。相反,如果total太小,那么我们可以跳过这个特定的气泡。如果在这一行的末尾没有足够大阈值计数的或气泡,我们可以将该问题标记为考生“跳过”。
一组类似的步骤可以应用于问题#2,其中用户将多个气泡标记为对单个问题正确:

Figure 16: Detecting if a user has marked multiple bubbles for a given question.
同样,我们需要做的就是应用我们的阈值和计数步骤,这一次跟踪是否有多个气泡具有超过某个预定义值的total。如果是这样,我们可以使问题无效,并将问题标记为不正确。
摘要
在这篇博文中,我演示了如何使用计算机视觉和图像处理技术构建气泡表扫描仪和测试分级机。
具体来说,我们实现了光学标记识别 (OMR)方法,这有助于我们捕获带有人类标记的文档和自动分析结果的能力。
最后,我提供了一个 Python 和 OpenCV 实现,您可以用它来构建自己的冒泡表测试评分系统。
如有任何问题,欢迎在评论区留言!
但是在此之前,请务必在下面的表格中输入您的电子邮件地址,以便在 PyImageSearch 博客上发布以后的教程时得到通知!**
如何在 5 分钟内建立一个强大的移动文档扫描仪
原文:https://pyimagesearch.com/2014/09/01/build-kick-ass-mobile-document-scanner-just-5-minutes/

用 OpenCV 构建一个文档扫描仪只需要三个简单的步骤:
- 第一步:检测边缘。
- 第二步:利用图像中的边缘找到代表被扫描纸张的轮廓(轮廓)。
- 步骤 3: 应用透视变换获得文档的自顶向下视图。
真的。就是这样。
只需三个步骤,您就可以向 App Store 提交自己的文档扫描应用程序了。
听起来有趣吗?
请继续阅读。并解开秘密,建立一个自己的移动扫描仪应用程序。
OpenCV 和 Python 版本:
这个例子将在 Python 2.7/3+ 和 OpenCV 2.4/3+ 上运行
如何在 5 分钟内建立一个强大的移动文档扫描仪
https://www.youtube.com/embed/yRer1GC2298?feature=oembed
用 OpenCV 构建 Raspberry Pi 安全摄像机
原文:https://pyimagesearch.com/2019/03/25/building-a-raspberry-pi-security-camera-with-opencv/

在本教程中,您将学习如何使用 OpenCV 和计算机视觉构建一个 Raspberry Pi 安全摄像机。Pi 安全摄像头将支持物联网,使我们的 Raspberry Pi 能够在安全摄像头被触发时发送 TXT/MMS 消息通知、图像和视频剪辑。
早在我读大学的时候,我就对鹰嘴豆泥非常着迷。鹰嘴豆泥和皮塔饼/蔬菜是我午餐的选择。
我喜欢它
我靠它生活。
我非常保护我的鹰嘴豆泥——大学生们因为偷彼此的冰箱和食物而臭名昭著。没人能碰我的鹰嘴豆泥。
但是——我不止一次成为这种鹰嘴豆泥盗窃案的受害者,我永远不会忘记这件事!
我一直不知道是谁偷了我的鹰嘴豆泥,尽管我和妻子是我们家唯一的住户,我还是经常把鹰嘴豆泥藏在冰箱后面(没人会看到的地方)或者水果和蔬菜下面(大多数人都不想吃)。
当然,那时候我对计算机视觉和 OpenCV 还没有现在这么熟悉。如果我知道我现在在做什么,我会建一个 Raspberry Pi 安全摄像头来捕捉鹰嘴豆泥抢劫的过程!
今天,我正在引导我的内在大学生,让鹰嘴豆大盗安息。如果他再回来,小心,我的冰箱被监控了!
要了解如何使用 Raspberry Pi 和 OpenCV 构建安全摄像头,请继续阅读!
用 OpenCV 构建 Raspberry Pi 安全摄像机
在本教程的第一部分,我们将简要回顾如何使用 Raspberry Pi 构建支持物联网的安全摄像头。
接下来,我们将检查我们的项目/目录结构,并安装库/包以成功构建项目。
我们还将简要回顾一下亚马逊 AWS/S3 和 Twilio ,这两项服务在一起使用时将使我们能够:
- 当安全摄像头被触发时,上传图像/视频剪辑。
- 通过短信将图像/视频片段直接发送到我们的智能手机。
从那里,我们将实现该项目的源代码。
最后,我们将把所有的部件组合在一起,将我们的 Raspberry Pi 安全摄像机投入使用!
带有树莓 Pi 的物联网安全摄像头

Figure 1: Raspberry Pi + Internet of Things (IoT). Our project today will use two cloud services: Twilio and AWS S3. Twilio is an SMS/MMS messaging service. S3 is a file storage service to help facilitate the video messages.
我们将使用 Raspberry Pi 和 OpenCV 构建一个非常简单的物联网安全摄像头。
当摄像头被触发时,安全摄像头将能够记录视频剪辑,将视频剪辑上传到云,然后发送包含视频本身的 TXT/MMS 消息。
我们将构建这个项目特别是,目标是检测冰箱何时打开,何时关闭——其间的一切都将被捕获和记录。
因此,在光线差异较大的相同“开放”和“封闭”环境中,这款安全摄像机的工作效果最佳。例如,您也可以将它部署在一个可以打开/关闭的邮箱中。
您可以轻松地将这种方法扩展到其他形式的检测,包括简单运动检测和家庭监控、物体检测等等。我将把它作为一个练习留给读者去实现——在这种情况下,您可以使用这个项目作为实现任何附加计算机视觉功能的“模板”。
项目结构
去抢今天博文的 【下载】 。
解压文件后,您将看到以下目录结构:
$ tree --dirsfirst
.
├── config
│ └── config.json
├── pyimagesearch
│ ├── notifications
│ │ ├── __init__.py
│ │ └── twilionotifier.py
│ ├── utils
│ │ ├── __init__.py
│ │ └── conf.py
│ └── __init__.py
└── detect.py
4 directories, 7 files
今天我们将回顾四个文件:
- 这个注释过的 JSON 文件保存了我们的配置。我给你提供了这个文件,,但是你需要为 Twilio 和 S3 插入你的 API 密匙。
pyimagesearch/notifications/twilionotifier.py:包含发送 SMS/MMS 消息的TwilioNotifier类。在我的即将出版的《覆盆子 Pi》书中,我用 Python 发送文本、图片和视频消息时使用的就是这个类。pyimagesearch/utils/conf.py:Conf类负责加载注释后的 JSON 配置。- 今天项目的核心包含在这个驱动程序脚本中。它会观察显著的光线变化,开始录制视频,并在有人偷了我的鹰嘴豆泥或我藏在冰箱里的任何东西时提醒我。
现在我们已经了解了目录结构和其中的文件,让我们继续配置我们的机器,学习 S3 + Twilio。从那里,我们将开始回顾今天项目中的四个关键文件。
安装软件包/库先决条件
今天的项目要求你在你的 Raspberry Pi 上安装一些 Python 库。
在我即将出版的 本书 中,所有这些软件包都将预装在一个定制的 Raspbian 映像中。你所要做的就是下载 Raspbian。img 文件,闪存到你的 micro-SD 卡,开机!从那里开始,您将拥有一个预配置的开发环境,其中包含您需要的所有计算机视觉+深度学习库!
注意:如果你现在就想要我的定制 Raspbian 图像(带有OpenCV 3 和 OpenCV 4 的),你应该获取一份包含 Raspbian 的实用 Python 和 OpenCV +案例研究的快速入门包或硬拷贝包。img 文件。**
**这本入门书还会教你 OpenCV 基础知识,这样你就可以学习如何自信地构建自己的项目。如果你打算为计算机视觉书籍 抓住我的即将到来的 树莓派,这些基础和概念将大有帮助。
与此同时,您可以通过这个最小的软件包安装来复制今天的项目:
opencv-contrib-python:OpenCV 库。- 我的便利函数和类包。
- Twilio 软件包允许您发送文本/图片/视频信息。
boto3:boto3包将与亚马逊 S3 文件存储服务通信。我们的视频将存储在 S3。- 允许注释 JSON 文件(因为我们都喜欢文档!)
要安装这些包,我建议你按照我的 pip 安装 opencv 指南来设置一个 Python 虚拟环境。
然后,您可以 pip 安装所有需要的软件包:
$ workon <env_name> # insert your environment name such as cv or py3cv4
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install twilio
$ pip install boto3
$ pip install json-minify
现在我们的环境已经配置好了,每次您想要激活它时,只需使用workon命令。
让我们回顾一下 S3、博特欧和特维利奥!
什么是亚马逊 AWS 和 S3?

Figure 2: Amazon’s Simple Storage Service (S3) will be used to store videos captured from our IoT Raspberry Pi. We will use the boto3 Python package to work with S3.
亚马逊网络服务(AWS)有一项服务叫做简单存储服务,俗称 S3。
S3 服务是一种非常流行的用于存储文件的服务。我实际上用它来存放一些更大的文件,比如这个博客上的 gif。
今天我们将使用 S3 来托管由 Raspberry Pi 安全摄像头生成的视频文件。
S3 是由“桶”组成的。一个桶包含文件和文件夹。它也可以用自定义权限和安全设置来设置。
一个名为boto3的包将帮助我们将文件从我们的物联网 Raspberry Pi 转移到 AWS S3。
在我们进入boto3之前,我们需要设置一个 S3 桶。
让我们继续创建一个存储桶、资源组和用户。我们将授予资源组访问 bucket 的权限,然后将用户添加到资源组。
步骤#1: 创建一个存储桶
亚马逊有很好的文档说明如何在这里创建一个 S3 桶。
步骤#2: 创建资源组+用户。将用户添加到资源组。
在创建您的 bucket 之后,您需要创建一个 IAM 用户 + 资源组并定义权限。
第三步:拿好你的钥匙。您需要将它们粘贴到今天的配置文件中。
观看这些幻灯片,引导您完成步骤 1-3 ,但也要参考文档,因为幻灯片很快就会过时:

Figure 3: The steps to gain API access to Amazon S3. We’ll use boto3 along with the access keys in our Raspberry Pi IoT project.
获取您的 Twilio API 密钥

Figure 4: Twilio is a popular SMS/MMS platform with a great API.
Twilio(T1),一个电话号码服务和一个 API ,允许语音、短信、彩信等等。
Twilio 将成为我们的树莓派和手机之间的桥梁。我想知道鹰嘴豆大盗打开我冰箱的确切时间,以便我采取应对措施。
让我们现在设置 Twilio。
第一步:创建一个账户,获得一个免费号码。
继续并注册 Twilio ,您将获得一个临时试用号。如果您愿意,您可以在以后购买一个号码+配额。
第二步:获取您的 API 密钥。
现在我们需要获得我们的 API 密钥。这里有一个屏幕截图,显示了在哪里创建并复制它:
Figure 5: The Twilio API keys are necessary to send text messages with Python.
关于 Twilio 的最后一点是,它确实支持流行的 What's App 消息平台。对 What's App 的支持受到国际社会的欢迎,然而,它目前正在进行测试。今天我们将只演示标准的 SMS/MMS。我就交给你了,和 What's App 一起探索 Twilio。
我们的 JSON 配置文件
这个项目需要指定许多变量,我决定不硬编码它们,而是将它们放在一个专用的 JSON 配置文件中,使我们的代码更加模块化和有组织。
由于 JSON 本身不支持注释,我们的Conf类将利用 JSON-minify 来解析注释。如果 JSON 不是您选择的配置文件,您也可以尝试 YAML 或 XML。
现在让我们来看看带注释的 JSON 文件:
{
// two constants, first threshold for detecting if the
// refrigerator is open, and a second threshold for the number of
// seconds the refrigerator is open
"thresh": 50,
"open_threshold_seconds": 60,
第 5 行和第 6 行包含两种设置。第一个是用于确定冰箱何时打开的光阈值。第二个是确定有人把门开着之前的秒数的阈值。
现在让我们来处理 AWS + S3 配置:
// variables to store your aws account credentials
"aws_access_key_id": "YOUR_AWS_ACCESS_KEY_ID",
"aws_secret_access_key": "YOUR_AWS_SECRET_ACCESS_KEY",
"s3_bucket": "YOUR_AWS_S3_BUCKET",
第行第 9-11 行的每个值都可以在您的 AWS 控制台中获得(我们刚刚在“什么是亚马逊 AWS 和 S3?”上一节)。
最后是我们的 Twilio 配置:
// variables to store your twilio account credentials
"twilio_sid": "YOUR_TWILIO_SID",
"twilio_auth": "YOUR_TWILIO_AUTH_ID",
"twilio_to": "YOUR_PHONE_NUMBER",
"twilio_from": "YOUR_TWILIO_PHONE_NUMBER"
}
Twilio 安全设置在第 14 行和第 15 行。"twilio_from"值 必须与您的 Twilio 电话号码中的 相匹配。如果你使用试用版,你只有一个号码。如果你用错了号码,超出了配额,等等。,Twilio 可能会向您的电子邮件地址发送一条错误消息。
在美国,电话号码可以这样格式化:"+1-555-555-5555"。
加载 JSON 配置文件
我们的配置文件包含注释(用于文档目的),不幸的是这意味着我们不能使用 Python 的内置json包,它不能加载带注释的文件。
相反,我们将使用 JSON-minify 和自定义 Conf 类的组合来加载我们的 JSON 文件作为 Python 字典。
现在让我们来看看如何实现Conf类:
# import the necessary packages
from json_minify import json_minify
import json
class Conf:
def __init__(self, confPath):
# load and store the configuration and update the object's
# dictionary
conf = json.loads(json_minify(open(confPath).read()))
self.__dict__.update(conf)
def __getitem__(self, k):
# return the value associated with the supplied key
return self.__dict__.get(k, None)
这个类相对简单。注意,在构造函数中,我们使用json_minify ( 第 9 行)解析出注释,然后将文件内容传递给json.loads。
__getitem__方法将使用字典语法从配置中获取任何值。换句话说,我们不会直接调用这个方法,而是简单地使用 Python 中的字典语法来获取与给定键相关联的值。
上传关键视频剪辑并通过短信发送
一旦我们的安全摄像头被触发,我们需要方法来:
- 将图像/视频上传到云(因为 Twilio API 不能直接提供“附件”)。
- 利用 Twilio API 实际发送文本消息。
为了保持代码整洁有序,我们将把这个功能封装在一个名为TwilioNotifier的类中——现在让我们回顾一下这个类:
# import the necessary packages
from twilio.rest import Client
import boto3
from threading import Thread
class TwilioNotifier:
def __init__(self, conf):
# store the configuration object
self.conf = conf
def send(self, msg, tempVideo):
# start a thread to upload the file and send it
t = Thread(target=self._send, args=(msg, tempVideo,))
t.start()
在的第 2-4 行,我们导入了 Twilio Client,亚马逊的boto3,以及 Python 的内置Thread。
从那里开始,我们的TwilioNotifier类和构造函数在的第 6-9 行中定义。我们的构造函数接受一个参数,即配置,我们假设它是通过Conf类从磁盘加载的。
这个项目只演示了发送消息。我们将在即将发布的博客文章以及《Raspberry Pi 计算机视觉》一书中演示如何用 Twilio 接收信息。
send方法在第 11-14 行中定义。该方法接受两个关键参数:
- 字符串文本
msg - 视频文件,
tempVideo。一旦视频成功存储在 S3,它将从 Pi 中删除以节省空间。因此这是一个临时的 T2 视频。
send方法启动一个Thread来实际发送消息,确保执行的主线程不被阻塞。
因此,核心文本消息发送逻辑在下一个方法中,_send:
def _send(self, msg, tempVideo):
# create a s3 client object
s3 = boto3.client("s3",
aws_access_key_id=self.conf["aws_access_key_id"],
aws_secret_access_key=self.conf["aws_secret_access_key"],
)
# get the filename and upload the video in public read mode
filename = tempVideo.path[tempVideo.path.rfind("/") + 1:]
s3.upload_file(tempVideo.path, self.conf["s3_bucket"],
filename, ExtraArgs={"ACL": "public-read",
"ContentType": "video/mp4"})
_send方法在行 16 定义。它作为一个独立的线程运行,以便不影响驱动程序脚本流。
线程启动时会传入参数(msg和tempVideo)。
_send方法首先通过以下方式将视频上传到 S3 自动气象站:
- 用访问密钥和秘密访问密钥初始化
s3客户端(第 18-21 行)。 - 上传文件(第 25-27 行)。
第 24 行简单地从视频路径中提取filename,因为我们以后会用到它。
让我们继续发送消息:
# get the bucket location and build the url
location = s3.get_bucket_location(
Bucket=self.conf["s3_bucket"])["LocationConstraint"]
url = "https://s3-{}.amazonaws.com/{}/{}".format(location,
self.conf["s3_bucket"], filename)
# initialize the twilio client and send the message
client = Client(self.conf["twilio_sid"],
self.conf["twilio_auth"])
client.messages.create(to=self.conf["twilio_to"],
from_=self.conf["twilio_from"], body=msg, media_url=url)
# delete the temporary file
tempVideo.cleanup()
要发送消息并让视频出现在手机消息应用程序中,我们需要发送实际的文本字符串以及 S3 视频文件的 URL。
注意:这个必须是一个可以公开访问的网址,*所以要确保你的 S3 设置是正确的。*
URL 在第 30-33 行生成。
从那里,我们将在第 36 行和第 37 行的上创建一个 Twilio client(不要与我们的 boto3 s3客户端混淆)。
第 38 行和第 39 行实际上发送了消息。注意to、from_、body和media_url参数。
最后,我们将删除临时视频文件以节省一些宝贵的空间( Line 42 )。如果我们不这样做,如果您的磁盘空间已经很低,您的 Pi 可能会用尽空间。
Raspberry Pi 安全摄像机驱动程序脚本
现在我们有了(1)我们的配置文件,(2)一个加载配置的方法,以及(3)一个与 S3 和 Twilio APIs 交互的类,让我们为覆盆子 Pi 安全摄像机创建主驱动程序脚本。
这个脚本的工作方式相对简单:
- 它监控摄像机看到的平均光量。
- 当冰箱门打开时,灯亮了,Pi 检测到灯,Pi 开始记录。
- 冰箱门关上,灯灭,Pi 检测到无光,Pi 停止录制+给我或你发视频信息。
- 如果有人打开冰箱的时间超过了配置文件中指定的秒数,我会收到一条单独的文本消息,表明门是开着的。
让我们继续实现这些特性。
打开detect.py文件并插入以下代码:
# import the necessary packages
from __future__ import print_function
from pyimagesearch.notifications import TwilioNotifier
from pyimagesearch.utils import Conf
from imutils.video import VideoStream
from imutils.io import TempFile
from datetime import datetime
from datetime import date
import numpy as np
import argparse
import imutils
import signal
import time
import cv2
import sys
2-15 线进口我们需要的包装。值得注意的是,我们将使用我们的TwilioNotifier、Conf类、VideoStream、imutils和 OpenCV。
让我们定义一个中断信号处理程序并解析我们的配置文件路径参数:
# function to handle keyboard interrupt
def signal_handler(sig, frame):
print("[INFO] You pressed `ctrl + c`! Closing refrigerator monitor" \
" application...")
sys.exit(0)
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True,
help="Path to the input configuration file")
args = vars(ap.parse_args())
我们的脚本将无头运行,因为我们不需要冰箱里的 HDMI 屏幕。
在的第 18-21 行,我们定义了一个signal_handler类来优雅地从键盘上捕捉“ctrl+c”事件。这样做并不总是必要的,但是如果您需要在脚本退出之前执行一些事情(比如有人禁用了您的安全摄像头!),可以放在这个函数里。
我们有一个命令行参数需要解析。--conf标志(配置文件的路径)可以直接在终端中提供,也可以在重启脚本中启动。你可以在这里了解更多关于命令行参数的信息。
让我们执行初始化:
# load the configuration file and initialize the Twilio notifier
conf = Conf(args["conf"])
tn = TwilioNotifier(conf)
# initialize the flags for fridge open and notification sent
fridgeOpen = False
notifSent = False
# initialize the video stream and allow the camera sensor to warmup
print("[INFO] warming up camera...")
# vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# signal trap to handle keyboard interrupt
signal.signal(signal.SIGINT, signal_handler)
print("[INFO] Press `ctrl + c` to exit, or 'q' to quit if you have" \
" the display option on...")
# initialize the video writer and the frame dimensions (we'll set
# them as soon as we read the first frame from the video)
writer = None
W = None
H = None
我们的初始化发生在第 30-52 行。让我们回顾一下:
- 第 30 行和第 31 行实例化我们的
Conf和TwilioNotifier对象。 - 初始化两个状态变量以确定冰箱何时打开以及何时发送通知(行 34 和 35 )。
- 我们将从第 39-41 行的开始我们的
VideoStream。我选择了使用摄像头,所以线 39** (USB 摄像头)被注释掉了。如果您使用的是 USB 网络摄像头,您可以轻松地交换它们。** - 第 44 行开始我们的
signal_handler线程在后台运行。 - 我们的视频
writer和帧尺寸在第 50-52 行初始化。
是时候开始循环帧了:
# loop over the frames of the stream
while True:
# grab both the next frame from the stream and the previous
# refrigerator status
frame = vs.read()
fridgePrevOpen = fridgeOpen
# quit if there was a problem grabbing a frame
if frame is None:
break
# resize the frame and convert the frame to grayscale
frame = imutils.resize(frame, width=200)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# if the frame dimensions are empty, set them
if W is None or H is None:
(H, W) = frame.shape[:2]
我们的while循环从线 55 开始。我们从视频流(第 58 行)进入read a frame。frame在第 62 行和第 63 行上进行健全性检查,以确定我们是否拥有来自我们相机的合法图像。
线 59 设置我们的fridgePrevOpen旗。前一个值必须始终在循环开始时设置,并且它基于稍后将确定的当前值。
我们的frame被调整到一个在智能手机上看起来合理的尺寸,也有利于我们的 MMS 视频的更小的文件大小( Line 66 )。
在第 67 行,我们从frame创建了一个灰度图像——我们很快就需要这个来确定帧中的平均光量。
在循环的第一次迭代中,我们的尺寸是通过第 70 行和第 71 行设置的。
现在让我们确定冰箱是否打开:
# calculate the average of all pixels where a higher mean
# indicates that there is more light coming into the refrigerator
mean = np.mean(gray)
# determine if the refrigerator is currently open
fridgeOpen = mean > conf["thresh"]
确定冰箱是否打开是一个非常简单的两步过程:
- 平均灰度图像的所有像素强度(第 75 行)。
- 将平均值与我们配置中的阈值进行比较(第 78 行)。我相信
50(在config.json文件中)的值对于大多数冰箱来说是一个合适的阈值,这些冰箱的灯随着门的打开和关闭而打开和关闭。也就是说,您可能想自己尝试调整这个值。
fridgeOpen变量只是一个布尔值,表示冰箱是否打开。
现在让我们决定是否需要开始捕捉视频:
# if the fridge is open and previously it was closed, it means
# the fridge has been just opened
if fridgeOpen and not fridgePrevOpen:
# record the start time
startTime = datetime.now()
# create a temporary video file and initialize the video
# writer object
tempVideo = TempFile(ext=".mp4")
writer = cv2.VideoWriter(tempVideo.path, 0x21, 30, (W, H),
True)
如行 82 的条件所示,只要冰箱刚刚打开(即之前没有打开过),我们就会初始化我们的视频writer。
我们将继续抓取startTime,创建一个tempVideo,并用临时文件路径(第 84-90 行)初始化我们的视频writer。常量0x21用于 H264 视频编码。
现在我们将处理冰箱先前打开的情况:
# if the fridge is open then there are 2 possibilities,
# 1) it's left open for more than the *threshold* seconds.
# 2) it's closed in less than or equal to the *threshold* seconds.
elif fridgePrevOpen:
# calculate the time different between the current time and
# start time
timeDiff = (datetime.now() - startTime).seconds
# if the fridge is open and the time difference is greater
# than threshold, then send a notification
if fridgeOpen and timeDiff > conf["open_threshold_seconds"]:
# if a notification has not been sent yet, then send a
# notification
if not notifSent:
# build the message and send a notification
msg = "Intruder has left your fridge open!!!"
# release the video writer pointer and reset the
# writer object
writer.release()
writer = None
# send the message and the video to the owner and
# set the notification sent flag
tn.send(msg, tempVideo)
notifSent = True
如果冰箱以前是开着的,让我们检查一下,以确保它没有开得太久而触发“入侵者让你的冰箱开着!”警戒。
孩子们可能会不小心让冰箱开着,或者可能在假期后,你有很多食物阻止冰箱门一直关着。你不想你的食物变质,所以你可能需要这些警告!
要发送该消息,timeDiff必须大于配置中设置的阈值(第 98-102 行)。
这条消息将包括一个给你的msg和视频,如第 107-117 行所示。定义msg,释放writer,设置通知。
现在让我们来看看最常见的场景,即冰箱以前是开着的,但现在是关着的(例如,某个小偷偷了你的食物,或者当你饿了的时候可能是你):
# check to see if the fridge is closed
elif not fridgeOpen:
# if a notification has already been sent, then just set
# the notifSent to false for the next iteration
if notifSent:
notifSent = False
# if a notification has not been sent, then send a
# notification
else:
# record the end time and calculate the total time in
# seconds
endTime = datetime.now()
totalSeconds = (endTime - startTime).seconds
dateOpened = date.today().strftime("%A, %B %d %Y")
# build the message and send a notification
msg = "Your fridge was opened on {} at {} " \
"for {} seconds.".format(dateOpened
startTime.strftime("%I:%M%p"), totalSeconds)
# release the video writer pointer and reset the
# writer object
writer.release()
writer = None
# send the message and the video to the owner
tn.send(msg, tempVideo)
从行 120 开始的案例将发送一条视频消息,指示“您的冰箱于 {{ day }} 在 {{ time }} 被打开 {{ seconds }} ”
在行 123 和 124 上,如果需要,我们的notifSent标志被重置。如果通知已经被发送,我们将这个值设置为False,有效地为循环的下一次迭代重置它。
否则,如果通知没有被发送,我们会计算出totalSeconds冰箱被打开(行 131 和 132 )。我们还将记录开门的日期( Line 133 )。
我们的msg字符串填充了这些值(第 136-138 行)。
然后释放视频writer并发送消息和视频(行 142-147 )。
我们的最后一个块完成了循环并执行清理:
# check to see if we should write the frame to disk
if writer is not None:
writer.write(frame)
# check to see if we need to release the video writer pointer
if writer is not None:
writer.release()
# cleanup the camera and close any open windows
cv2.destroyAllWindows()
vs.stop()
为了完成循环,我们将把frame写入视频writer对象,然后返回到顶部抓取下一帧。
当循环退出时,writer被释放,视频流停止。
干得好!您使用树莓派和摄像头完成了一个简单的物联网项目。
现在是放置诱饵的时候了。我知道我的小偷和我一样喜欢鹰嘴豆泥,所以我跑去商店,回来把它放在冰箱里。
RPi 安全摄像机结果

Figure 6: My refrigerator is armed with an Internet of Things (IoT) Raspberry Pi, PiCamera, and Battery Pack. And of course, I’ve placed some hummus in there for me and the thief. I’ll also know if someone takes a New Belgium Dayblazer beer of mine.
当在你的冰箱中部署 Raspberry Pi 安全摄像头来捕捉鹰嘴豆泥强盗时,你需要确保它在没有无线连接到你的笔记本电脑的情况下继续运行。
有两个很好的部署选项:
- 重启时运行计算机视觉 Python 脚本。
- 让一个
screen会话运行,Python 计算机视觉脚本在其中执行。
如果您只想让您的 Pi 在接通电源时运行脚本,请务必访问第一个链接。
虽然这篇博文不适合全屏演示,但这里有一些基本的东西:
- 通过
sudo apt-get install screen安装屏幕 - 打开到您的 Pi 的 SSH 连接并运行它:
screen - 如果从你的笔记本电脑到你的 Pi 的连接消失或关闭, 不要惊慌! 屏幕会话仍在运行。您可以通过再次进入 Pi 并运行
screen -r来重新连接。你会回到你的虚拟窗口。 - 屏幕的键盘快捷键:
- “ctrl+a,c”:新建一个“窗口”。
- ctrl+a,p】、 ctrl + a,n】:分别在“上一个”和“下一个”窗口中循环。
** 关于screen的更深入的回顾,参见文档。这里有一个屏幕键盘快捷键小抄。*
*一旦你习惯了在重启时启动一个脚本或者使用screen,拿一个可以提供足够电流的 USB 电池组。如图 4 中的所示,我们使用的是连接到 Pi 电源输入的 RavPower 2200mAh 电池组。产品规格声称可以给 iPhone 充电 6 次以上,它似乎也可以运行大约+/-10 小时(取决于算法)。
继续插入电池组,连接并部署脚本(如果您没有设置为在引导时启动)。
这些命令是:
$ screen
# wait for screen to start
$ source ~/.profile
$ workon <env_name> # insert the name of your virtual environment
$ python detect.py --conf config/config.json
如果你不熟悉命令行参数,请阅读本教程。如果在重新启动时部署脚本,命令行参数也是必需的。
让我们看看它的实际效果吧!
Figure 7: Me testing the Pi Security Camera notifications with my iPhone.
我在下面附上了树莓 Pi 安全摄像头的完整 dem0:
https://www.youtube.com/embed/SZE8tdnMbfA?feature=oembed***
用 VP-Trees 和 OpenCV 构建图像哈希搜索引擎
在本教程中,您将学习如何使用 OpenCV、Python 和 VP-tree 构建一个可伸缩的图像哈希搜索引擎。
图像哈希算法用于:
- 仅使用一个整数唯一量化图像的内容。
- 根据计算出的哈希在图像数据集中找到 重复的 或 近似重复的图像 。
早在 2017 年,我用 OpenCV 和 Python 写了一篇图像哈希教程(这是本教程的 必读 )。该指南向您展示了如何在给定的数据集中找到相同/重复的图像。
然而,最初的教程— 有一个可伸缩性问题,即它不能伸缩!
为了找到个近似重复的个图像,我们最初的图像哈希方法需要我们执行线性搜索,将查询哈希与我们数据集中的每个单独的图像哈希进行比较。
在一个实际的、真实世界的应用程序中,速度太慢了——我们需要找到一种方法来将搜索减少到亚线性时间复杂度。
但是我们怎样才能如此显著地减少搜索时间呢?
答案是一种叫做 VP 树的特殊数据结构。
使用 VP-Tree,我们可以将搜索复杂度从 O(n) 降低到 O(log n) ,从而实现我们的次线性目标!
在本教程的剩余部分,你将学习如何:
- 构建一个图像哈希搜索引擎,在数据集中找到相同的和近似相同的图像。
- 利用一种专门的数据结构,称为 VP 树,可用于将图像哈希搜索引擎扩展到数百万张图像。
要了解如何用 OpenCV 构建您的第一个图像哈希搜索引擎,请继续阅读!
用 VP-Trees 和 OpenCV 构建图像哈希搜索引擎
在本教程的第一部分,对于 PyImageSearch 的新手,我将回顾一下图像搜索引擎到底是什么。
然后,我们将讨论图像哈希和感知哈希的概念,包括如何使用它们来构建图像搜索引擎。
我们还将看看与图像哈希搜索引擎相关的问题,包括算法的复杂性。
注意:如果你还没有读过我的关于用 OpenCV 和 Python图像散列的教程,请务必现在就去读。该指南是在您继续此处之前的必读内容。
从那里,我们将简要回顾有利点树(VP-Trees ),它可以用来显著地提高图像哈希搜索引擎的效率和性能。
利用我们的知识,我们将使用 VP-Trees 实现我们自己的定制图像哈希搜索引擎,然后检查结果。
什么是图像搜索引擎?

Figure 1: An example of an image search engine. A query image is presented and the search engine finds similar images in a dataset.
在这一部分,我们将回顾图像搜索引擎的概念,并引导您找到一些额外的资源。
PyImageSearch 植根于图片搜索引擎——这是我在 2014 年创建博客时的主要兴趣。这个教程对我来说是一个有趣的分享,因为我对作为计算机视觉主题的图像搜索引擎情有独钟。
图像搜索引擎很像文本搜索引擎,只是我们没有使用文本作为查询,而是使用图像。
当你使用 文字搜索引擎 时,如 Google、Bing 或 DuckDuckGo 等。,你输入你的搜索查询——一个单词或短语。感兴趣的索引网站作为结果、返回给你,理想情况下,你会找到你想要的。
类似地,对于一个 图像搜索引擎 ,你呈现一个查询图像(不是文本单词/短语)。然后,图像搜索引擎仅基于图像的内容返回相似的图像结果。
当然,在任何类型的搜索引擎中都会发生很多事情——当我们今天构建图像搜索引擎时,请记住查询/结果这一关键概念。
要了解更多关于图片搜索引擎的信息,我建议你参考以下资源:
- 用 Python 和 OpenCV 构建图像搜索引擎的完整指南
- 一个伟大的指南,为那些想开始与足够的知识是危险的。
- 图片搜索引擎博客类别
- 这个类别链接返回我在 PyImageSearch 博客上的所有图片搜索引擎内容。
- PyImageSearch 大师
- 我的旗舰计算机视觉课程有 13 个模块,其中一个模块致力于基于内容的图像检索(图像搜索引擎的一个好听的名字)。
阅读这些指南,对什么是图像搜索引擎有一个基本的了解,然后回到这篇文章来学习图像哈希搜索引擎。
什么是图像哈希/感知哈希?
Figure 2: An example of an image hashing function. Top-left: An input image. Top-right: An image hashing function. Bottom: The resulting hash value. We will build a basic image hashing search engine with VP-Trees and OpenCV in this tutorial.
图像哈希,也叫感知哈希,是这样的过程:
- 检查图像的内容。
- 构造散列值(即整数),该散列值仅基于图像的内容唯一地量化输入图像。
*使用图像哈希的一个好处是用于量化图像的存储空间非常小。
例如,假设我们有一个带有 3 个通道的 800x600px 的图像。如果我们使用 8 位无符号整数数据类型将整个图像存储在内存中,该图像将需要 1.44MB 的 RAM。
当然,在量化图像时,我们很少存储原始图像像素。
相反,我们将使用诸如关键点检测器和局部不变描述符(即 SIFT、SURF 等)的算法。).
应用这些方法通常可以为每幅图像产生 100 到 1000 个特征。
如果我们假设检测到 500 个关键点,每个关键点产生一个具有 32 位浮点数据类型的 128-d 的特征向量,我们将需要总共 0.256MB 来存储我们的数据集中每个单独图像的量化。
另一方面,图像哈希允许我们仅使用 32 位整数来量化图像,只需要 4 字节的内存!

Figure 3: An image hash requires far less disk space in comparison to the original image bitmap size or image features (SIFT, etc.). We will use image hashes as a basis for an image search engine with VP-Trees and OpenCV.
再者,图像哈希也应该是可比的 。
假设我们计算三个输入图像的图像哈希,其中两个图像几乎相同:
Figure 4: Three images with different hashes. The Hamming Distance between the top two hashes is closer than the Hamming distance to the third image. We will use a VP-Tree data structure to make an image hashing search engine.
为了比较我们的图像哈希,我们将使用汉明距离。在这种情况下,汉明距离用于比较两个整数之间的不同位数。
在实践中,这意味着我们在对两个整数进行异或运算时要计算 1 的个数。
因此,回到我们上面的三个输入图像,我们两个相似图像之间的汉明距离应该比第三个不太相似图像之间的汉明距离小(表示更相似):

Figure 5: The Hamming Distance between image hashes is shown. Take note that the Hamming Distance between the first two images is smaller than that of the first and third (or 2nd and 3rd). The Hamming Distance between image hashes will play a role in our image search engine using VP-Trees and OpenCV.
再次注意,两幅图像之间的汉明距离比第三幅图像之间的距离小
- 两个哈希之间的越小,图像的越相似。
- 相反,两个哈希之间的海明距离越大,T2 越小,图像越相似。
还要注意相同图像之间的距离(即,沿着图 5 的对角线)都是零——如果两个输入图像是相同的,则两个散列之间的汉明距离将是零,否则距离将是> 0,值越大表示相似性越小。
有许多图像哈希算法,但最流行的一种算法叫做差分哈希,它包括四个步骤:
- 步骤#1: 将输入图像转换为灰度。
- 步骤#2: 将图像调整到固定尺寸, N + 1 x N ,忽略长宽比。通常我们设置 N=8 或 N=16 。我们使用 N + 1 作为行数,这样我们可以计算图像中相邻像素之间的差异(因此为“差异散列”)。
- 第三步:计算差值。如果我们设置 N=8 ,那么每行有 9 个像素,每列有 8 个像素。然后我们可以计算相邻列像素之间的差异,产生 8 差异。 8 个差异的 8 行(即 8×8 )产生 64 个值。
- 第四步:最后,我们可以建立散列。实际上,我们实际需要做的只是比较列的“大于”运算,产生二进制值。这些 64 二进制值被压缩成一个整数,形成我们最终的散列。
通常,图像哈希算法用于在大型数据集中找到个近似重复的图像。
我已经在本教程 中详细介绍了图像哈希技术,所以如果这个概念对你来说是新的,我建议你在继续之前先阅读一下那个指南。
什么是图像哈希搜索引擎?
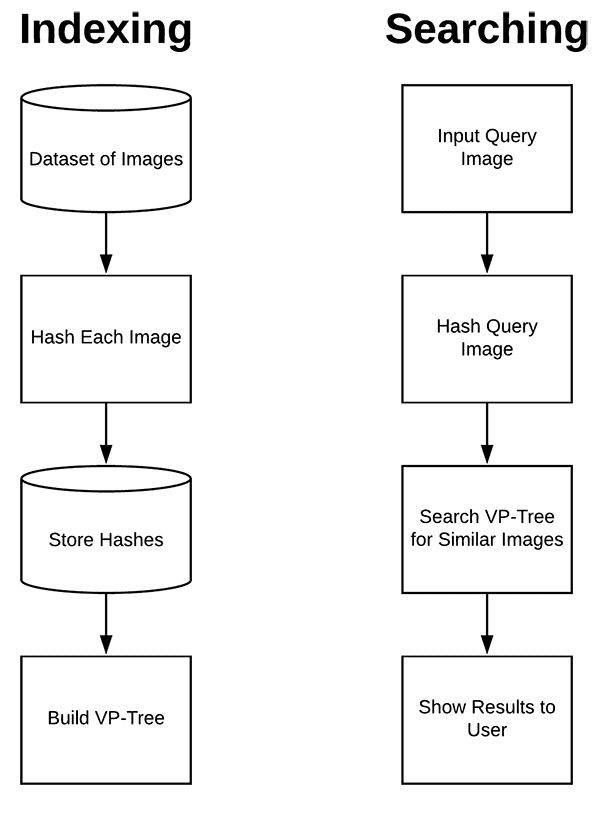
Figure 6: Image search engines consist of images, an indexer, and a searcher. We’ll index all of our images by computing and storing their hashes. We’ll build a VP-Tree of the hashes. The searcher will compute the hash of the query image and search the VP tree for similar images and return the closest matches. Using Python, OpenCV, and vptree, we can implement our image hashing search engine.
图像哈希搜索引擎由两个组件组成:
- 索引:获取图像的输入数据集,计算散列,并将它们存储在数据结构中,以便于快速、高效的搜索。
- 搜索/查询:接受来自用户的输入查询图像,计算散列,并在我们的索引数据集中找到所有近似相同的图像。
图像哈希搜索引擎的一个很好的例子是 TinEye ,它实际上是一个反向图像搜索引擎。
反向图像搜索引擎:
- 接受输入图像。
- 在网络上查找该图像的所有近似副本,告诉您可以在哪里找到近似副本的网站/URL。
使用本教程,你将学会如何构建自己的 TinEye!
是什么让缩放图像哈希搜索引擎有问题?
构建图像哈希搜索引擎的最大问题之一是可扩展性——图像越多,执行搜索的时间就越长。
例如,假设我们有以下场景:
- 我们有一个 100 万张图片的数据集。
- 我们已经计算了这 1,000,000 幅图像的图像哈希。
- 一个用户走过来,给我们一张图片,然后让我们在数据集中找到所有几乎相同的图片。
你会如何着手进行搜索呢?
您会逐一遍历所有 1,000,000 个图像哈希,并将它们与查询图像的哈希进行比较吗?
不幸的是,这是行不通的。即使你假设每次汉明距离比较需要 0.00001 秒,总共有 1,000,000 张图片,你也要用 10 秒来完成搜索——对任何类型的搜索引擎来说都太慢了。
相反,要构建一个可扩展的图像哈希搜索引擎,您需要利用专门的数据结构。
什么是 VP-tree,它们如何帮助扩展图像哈希搜索引擎?

Figure 7: We’ll use VP-Trees for our image hash search engine using Python and OpenCV. VP-Trees are based on a recursive algorithm that computes vantage points and medians until we reach child nodes containing an individual image hash. Child nodes that are closer together (i.e. smaller Hamming Distances in our case) are assumed to be more similar to each other. (image source)
为了扩展我们的图像哈希搜索引擎,我们需要使用一种特殊的数据结构:
- 减少我们的搜索从线性复杂度,
O(n)… - …低至子线性复杂度,理想情况下为
O(log n)。
为了完成这个任务,我们可以使用优势点树(VP-Trees) 。VP-Trees 是一种度量树,它通过选择空间中的给定位置(即“有利位置”)然后将数据点划分成两组来在度量空间中操作:
- 在有利位置附近的点
- 离有利位置远的点
然后,我们递归地应用这个过程,将这些点划分成越来越小的集合,从而创建一个树,其中树中的邻居具有较小的距离。
为了可视化构造 VP 树的过程,考虑下图:
Figure 8: A visual depiction of the process of building a VP-Tree (vantage point tree). We will use the vptree Python implementation by Richard Sjogren. ([image source](https://www.researchgate.net/figure/Illustration-of-the-VP- tree-partitioning-method-and-hierarchical- structure_fig2_220451935))
首先,我们选择空间中的一个点(表示为圆心的v)——我们称这个点为有利点。有利位置是树中离父有利位置最远的点。
然后,我们计算所有点的中位数, X 。
一旦有了μ,我们就把 X 分成两组, S1 和 S2 :
- 所有距离为 < = μ 的点都属于 S1 。
- 所有距离为 > μ 的点都属于 S2 。
然后,我们递归地应用这个过程,构建一个树,直到我们剩下一个子节点。
子节点只包含一个数据点(在本例中,是一个单独的散列)。因此,树中距离较近的子节点具有:
- 它们之间的距离越来越小。
- 并且因此被假设为比树中的其余数据点彼此更加相似。
在递归地应用 VP-Tree 构造方法之后,我们最终得到一个数据结构,顾名思义,这是一个树:
Figure 9: An example VP-Tree is depicted. We will use Python to build VP-Trees for use in an image hash search engine.
注意我们如何递归地将数据集的子集分成越来越小的子集,直到我们最终到达子节点。
VP-Trees 需要O(n log n)来构建,但是一旦我们构建了它,一个搜索只需要O(log n),,因此将我们的搜索时间减少到子线性复杂度!
在本教程的后面,您将学习使用 Python 的 VP-Trees 来构建和扩展我们的图像哈希搜索引擎。
注意:这部分是对 VP-Trees 的一个温和的介绍。如果你有兴趣了解更多,我建议(1)查阅数据结构教科书,(2)遵循 Steve Hanov 的博客中的指南,或者(3)阅读 Ivan Chen 的文章。
加州理工学院-101 数据集

Figure 10: The CALTECH-101 dataset consists of 101 object categories. Our image hash search engine using VP-Trees, Python, and OpenCV will use the CALTECH-101 dataset for our practical example.
我们今天要处理的数据集是 CALTECH-101 数据集,它由 101 个类别的 9144 幅图像组成(每个类别有 40 到 800 幅图像)。
数据集足够大从图像哈希的介绍角度来看是有趣的,但也足够小以至于你可以运行本指南中的示例 Python 脚本,而不必等待你的系统完成对图像的咀嚼。
你可以从他们的官方网页下载加州理工 101 数据集,或者你可以使用下面的wget命令:
$ wget http://www.vision.caltech.edu/Image_Datasets/Caltech101/101_ObjectCategories.tar.gz
$ tar xvzf 101_ObjectCategories.tar.gz
项目结构
让我们检查一下我们的项目结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── hashing.py
├── 101_ObjectCategories [9,144 images]
├── queries
│ ├── accordion.jpg
│ ├── accordion_modified1.jpg
│ ├── accordion_modified2.jpg
│ ├── buddha.jpg
│ └── dalmation.jpg
├── index_images.py
└── search.py
pyimagesearch模块包含hashing.py,它包含三个散列函数。我们将在下面的“实现我们的散列实用程序”一节中回顾这些函数。
我们的数据集在101_ObjectCategories/文件夹(CALTECH-101)中,包含 101 个包含我们图像的子目录。请务必阅读上一节,了解如何下载数据集。
在queries/目录中有五个查询图像。我们将搜索与这些图像具有相似散列的图像。accordion_modified1.jpg和accordion_modiied2.jpg图像将对我们的 VP-Trees 图像哈希搜索引擎提出独特的挑战。
今天项目的核心在于两个 Python 脚本:index_images.py和search.py:
- 我们的索引器将计算所有 9144 张图片的哈希,并将哈希组织在一个 VP-Tree 中。这个索引将驻留在两个
.pickle文件中:(1)所有计算散列的字典,和(2)VP-Tree。 - 搜索器将计算查询图像的散列,并通过汉明距离在 VP 树中搜索最近的图像。结果将返回给用户。
如果这听起来很多,不要担心!本教程将一步一步地分解每件事。
配置您的开发环境
对于这篇博文,您的开发环境需要安装以下软件包:
对我们来说幸运的是,一切都是 pip 可安装的。我给你的建议是跟随第一个 OpenCV 链接到pip——在你系统的虚拟环境中安装 OpenCV。从这里开始,您只需在同一个环境中 pip-install 所有其他的东西。
它看起来会像这样:
# setup pip, virtualenv, and virtualenvwrapper (using the "pip install OpenCV" instructions)
$ workon <env_name>
$ pip install numpy
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install vptree
用虚拟环境的名称替换<env_name>。只有在您按照这些指令设置了virtualenv和virtualenvwrapper 后,workon命令才可用。
实现我们的图像哈希工具
在我们构建图像哈希搜索引擎之前,我们首先需要实现一些辅助工具。
打开项目结构中的hashing.py文件,插入以下代码:
# import the necessary packages
import numpy as np
import cv2
def dhash(image, hashSize=8):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# resize the grayscale image, adding a single column (width) so we
# can compute the horizontal gradient
resized = cv2.resize(gray, (hashSize + 1, hashSize))
# compute the (relative) horizontal gradient between adjacent
# column pixels
diff = resized[:, 1:] > resized[:, :-1]
# convert the difference image to a hash
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
我们从导入 OpenCV 和 NumPy 开始(第 2 行和第 3 行)。
我们要看的第一个函数dhash,用于计算给定输入图像的差分散列。回想一下,我们的dhash需要四个步骤:(1)转换为灰度,(2)调整大小,(3)计算差异,(4)构建散列。让我们进一步分析一下:
- 第 7 行将图像转换为 灰度 。
- 第 11 行 将 的图像调整为 N + 1 行乘 N 列,忽略纵横比。这确保了产生的图像散列将匹配相似的照片,而不管它们的初始空间尺寸。
- 第 15 行计算相邻列像素间的 水平梯度差 。假设
hashSize=8,将是 8 行 8 个差异(有 9 行允许 8 个比较)。因此,我们将得到 8×8=64 的 64 位散列。 - 第 18 行将差分图像转换为 哈希 。
更多详情,请参考这篇博文。
接下来,我们来看看convert_hash函数:
def convert_hash(h):
# convert the hash to NumPy's 64-bit float and then back to
# Python's built in int
return int(np.array(h, dtype="float64"))
当我第一次为本教程编写代码时,我发现我们正在使用的 VP-Tree 实现在内部将点转换为 NumPy 64 位浮点。那没问题;然而,散列必须是整数,如果我们将它们转换成 64 位浮点数,它们就变成了不可散列的数据类型。为了克服 VP-Tree 实现的限制,我想到了convert_hash hack:
- 我们接受一个输入散列,
h。 - 该散列然后被转换成 NumPy 64 位浮点数。
- 然后将 NumPy 浮点数转换回 Python 内置的整数数据类型。
这种方法确保了哈希在整个哈希、索引和搜索过程中得到一致的表示。
然后我们有了最后一个助手方法hamming,它用于计算两个整数之间的汉明距离:
def hamming(a, b):
# compute and return the Hamming distance between the integers
return bin(int(a) ^ int(b)).count("1")
当在两个整数(第 27 行)之间进行异或运算(^)时,汉明距离只是 1 的数目的一个count。
实现我们的图像哈希索引器
在执行搜索之前,我们首先需要:
- 循环我们的输入图像数据集。
- 计算每个图像的差异散列。
- 使用散列建立一棵 VP 树。
让我们现在就开始这个过程。
打开index_images.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch.hashing import convert_hash
from pyimagesearch.hashing import hamming
from pyimagesearch.hashing import dhash
from imutils import paths
import argparse
import pickle
import vptree
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True, type=str,
help="path to input directory of images")
ap.add_argument("-t", "--tree", required=True, type=str,
help="path to output VP-Tree")
ap.add_argument("-a", "--hashes", required=True, type=str,
help="path to output hashes dictionary")
args = vars(ap.parse_args())
第 2-9 行导入该脚本所需的包、函数和模块。特别是的第 2-4 行导入了我们的三个散列相关函数:convert_hash、hamming和dhash。第 8 行导入了我们将要使用的vptree实现。
接下来,第 12-19 行解析我们的命令行参数:
- 我们将要索引的图片的路径。
--tree:输出 VP-tree.pickle文件的路径,该文件将被序列化到磁盘。--hashes:以.pickle格式存储的输出哈希字典的路径。
现在让我们计算所有图像的哈希:
# grab the paths to the input images and initialize the dictionary
# of hashes
imagePaths = list(paths.list_images(args["images"]))
hashes = {}
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# load the input image
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
image = cv2.imread(imagePath)
# compute the hash for the image and convert it
h = dhash(image)
h = convert_hash(h)
# update the hashes dictionary
l = hashes.get(h, [])
l.append(imagePath)
hashes[h] = l
第 23 和 24 行抓取图像路径并初始化我们的hashes字典。
第 27 行然后开始在所有imagePaths上循环。在循环内部,我们:
- 加载
image( 行 31 )。 - 计算并转换散列值,
h( 第 34 行和第 35 行)。 - 获取所有图像路径的列表,
l,具有相同的散列值(第 38 行)。 - 将此
imagePath添加到列表中,l( 第 39 行)。 - 用 hash 作为键更新我们的字典,用相同的对应 hash 作为值更新我们的图像路径列表(第 40 行)。
从这里开始,我们构建我们的 VP 树:
# build the VP-Tree
print("[INFO] building VP-Tree...")
points = list(hashes.keys())
tree = vptree.VPTree(points, hamming)
为了构建 VP-Tree,第 44 行和第 45 行向VPTree构造函数传递(1)一个数据点列表(即散列整数值本身),以及(2)我们的距离函数(汉明距离方法)。
在内部,VP-Tree 计算所有输入points之间的汉明距离,然后构建 VP-Tree,使得具有较小距离的数据点(即,更相似的图像)在树空间中靠得更近。请务必参考“什么是 VP-tree,它们如何帮助扩展图像哈希搜索引擎?”剖面图和图 7、8、9 。
随着我们的hashes字典的填充和 VP-Tree 的构建,我们现在将它们作为.pickle文件序列化到磁盘:
# serialize the VP-Tree to disk
print("[INFO] serializing VP-Tree...")
f = open(args["tree"], "wb")
f.write(pickle.dumps(tree))
f.close()
# serialize the hashes to dictionary
print("[INFO] serializing hashes...")
f = open(args["hashes"], "wb")
f.write(pickle.dumps(hashes))
f.close()
提取图像哈希并构建 VP 树
现在我们已经实现了索引脚本,让我们把它投入使用。确保您已经:
- 使用上述说明下载了 CALTECH-101 数据集。
- 使用本教程的 “下载” 部分下载源代码和示例查询图像。
- 提取了。源代码的 zip 文件,并将目录更改为项目。
从那里,打开一个终端并发出以下命令:
$ time python index_images.py --images 101_ObjectCategories \
--tree vptree.pickle --hashes hashes.pickle
[INFO] processing image 1/9144
[INFO] processing image 2/9144
[INFO] processing image 3/9144
[INFO] processing image 4/9144
[INFO] processing image 5/9144
...
[INFO] processing image 9140/9144
[INFO] processing image 9141/9144
[INFO] processing image 9142/9144
[INFO] processing image 9143/9144
[INFO] processing image 9144/9144
[INFO] building VP-Tree...
[INFO] serializing VP-Tree...
[INFO] serializing hashes...
real 0m10.947s
user 0m9.096s
sys 0m1.386s
正如我们的输出所示,我们能够在 10 秒多一点的时间内散列所有 9,144 个图像。
运行脚本后检查项目目录,我们会发现两个.pickle文件:
$ ls -l *.pickle
-rw-r--r-- 1 adrianrosebrock 796620 Aug 22 07:53 hashes.pickle
-rw-r--r-- 1 adrianrosebrock 707926 Aug 22 07:53 vptree.pickle
hashes.pickle (796.62KB)文件包含我们计算的散列,将散列整数值映射到具有相同散列的文件路径。vptree.pickle (707.926KB)是我们构建的 VP 树。
在下一节中,我们将使用这个 VP 树来执行查询和搜索。
实现我们的图像哈希搜索脚本
图像哈希搜索引擎的第二个组成部分是搜索脚本。搜索脚本将:
- 接受输入查询图像。
- 计算查询图像的哈希。
- 使用查询散列搜索 VP 树,以找到所有重复/近似重复的图像。
现在让我们实现我们的图像哈希搜索器——打开search.py文件并插入以下代码:
# import the necessary packages
from pyimagesearch.hashing import convert_hash
from pyimagesearch.hashing import dhash
import argparse
import pickle
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--tree", required=True, type=str,
help="path to pre-constructed VP-Tree")
ap.add_argument("-a", "--hashes", required=True, type=str,
help="path to hashes dictionary")
ap.add_argument("-q", "--query", required=True, type=str,
help="path to input query image")
ap.add_argument("-d", "--distance", type=int, default=10,
help="maximum hamming distance")
args = vars(ap.parse_args())
第 2-9 行为我们的搜索脚本导入必要的组件。注意,我们再次需要dhash和convert_hash函数,因为我们必须为我们的--query图像计算散列。
第 10-19 行解析我们的命令行参数(前三行是必需的):
- 到我们在磁盘上预先构建的 VP 树的路径。
--hashes:我们在磁盘上预先计算的散列字典的路径。--query:我们查询图像的路径。--distance:用10的default设置哈希之间的最大汉明距离。如果您愿意,您可以覆盖它。
需要注意的是,--distance的越大,的越多,VP-Tree 将进行比较,因此搜索器将会越慢。在不影响结果质量的前提下,尽量让你的--distance尽可能的小。
*接下来,我们将(1)加载我们的 VP-Tree + hashes 字典,以及(2)计算我们的--query图像的散列:
# load the VP-Tree and hashes dictionary
print("[INFO] loading VP-Tree and hashes...")
tree = pickle.loads(open(args["tree"], "rb").read())
hashes = pickle.loads(open(args["hashes"], "rb").read())
# load the input query image
image = cv2.imread(args["query"])
cv2.imshow("Query", image)
# compute the hash for the query image, then convert it
queryHash = dhash(image)
queryHash = convert_hash(queryHash)
第 23 行和第 24 行加载预先计算的索引,包括 VP 树和hashes字典。
从那里,我们加载并显示--query图像(第 27 行和第 28 行)。
然后我们接受查询image并计算queryHash ( 第 31 行和第 32 行)。
此时,是时候使用我们的 VP 树:执行搜索了
# perform the search
print("[INFO] performing search...")
start = time.time()
results = tree.get_all_in_range(queryHash, args["distance"])
results = sorted(results)
end = time.time()
print("[INFO] search took {} seconds".format(end - start))
第 37 行和第 38 行通过向 VP 树查询相对于queryHash具有最小汉明距离的散列来执行搜索。results是sorted,所以“更相似的”散列在results列表的前面。
这两行都夹有时间戳,用于基准测试,其结果通过行 40 打印。
最后,我们将循环遍历results并显示它们中的每一个:
# loop over the results
for (d, h) in results:
# grab all image paths in our dataset with the same hash
resultPaths = hashes.get(h, [])
print("[INFO] {} total image(s) with d: {}, h: {}".format(
len(resultPaths), d, h))
# loop over the result paths
for resultPath in resultPaths:
# load the result image and display it to our screen
result = cv2.imread(resultPath)
cv2.imshow("Result", result)
cv2.waitKey(0)
线 43 开始在results上循环:
- 当前散列值
h的resultPaths取自散列字典(第 45 行)。 - 每个
result图像在键盘上按键时显示(第 50-54 行)。
图像哈希搜索引擎结果
我们现在准备测试我们的图像搜索引擎!
但在此之前,请确保您已经:
- 使用上述说明下载了 CALTECH-101 数据集。
- 使用本教程的 “下载” 部分下载源代码和示例查询图像。
- 提取了。源代码的 zip 文件,并将目录更改为项目。
- 运行
index_images.py文件以生成hashes.pickle和vptree.pickle文件。
完成上述所有步骤后,打开终端并执行以下命令:
python search.py --tree vptree.pickle --hashes hashes.pickle \
--query queries/buddha.jpg
[INFO] loading VP-Tree and hashes...
[INFO] performing search...
[INFO] search took 0.015203237533569336 seconds
[INFO] 1 total image(s) with d: 0, h: 8.162938100012111e+18
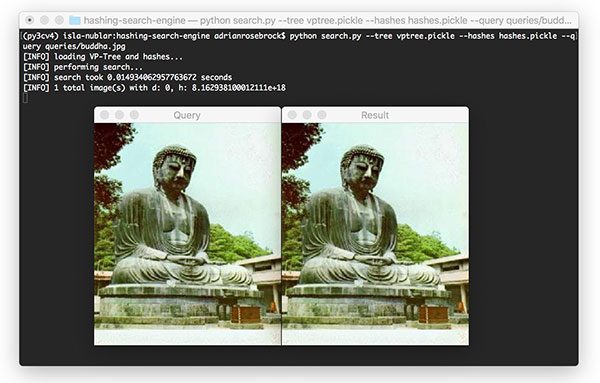
Figure 11: Our Python + OpenCV image hashing search engine found a match in the VP-Tree in just 0.015 seconds!
在左边的,你可以看到我们输入的佛像查询图片。在右边的,你可以看到我们已经在索引数据集中找到了重复的图像。
搜索本身只用了 0.015 秒。
此外,注意输入查询图像和数据集中散列图像之间的距离为零,表示两个图像是相同的。
让我们再试一次,这次用一张斑点狗的图片:
$ python search.py --tree vptree.pickle --hashes hashes.pickle \
--query queries/dalmation.jpg
[INFO] loading VP-Tree and hashes...
[INFO] performing search...
[INFO] search took 0.014827728271484375 seconds
[INFO] 1 total image(s) with d: 0, h: 6.445556196029652e+18
Figure 12: With a Hamming Distance of 0, the Dalmation query image yielded an identical image in our dataset. We built an OpenCV + Python image hash search engine with VP-Trees successfully.
我们再次看到,我们的图像哈希搜索引擎在我们的索引数据集中找到了相同的斑点狗(由于汉明距离为零,我们知道这些图像是相同的)。
下一个例子是手风琴:
$ python search.py --tree vptree.pickle --hashes hashes.pickle \
--query queries/accordion.jpg
[INFO] loading VP-Tree and hashes...
[INFO] performing search...
[INFO] search took 0.014187097549438477 seconds
[INFO] 1 total image(s) with d: 0, h: 3.380309217342405e+18
Figure 13: An example of providing a query image and finding the best resulting image with an image hash search engine created with Python and OpenCV.
我们再次在索引数据集中找到了完全相同的匹配图像。
我们知道我们的图像哈希搜索引擎非常适合相同的图像…
……但是稍微修改过的图像呢?
我们的哈希搜索引擎性能还会好吗?
让我们试一试:
$ python search.py --tree vptree.pickle --hashes hashes.pickle \
--query queries/accordion_modified1.jpg
[INFO] loading VP-Tree and hashes...
[INFO] performing search...
[INFO] search took 0.014217138290405273 seconds
[INFO] 1 total image(s) with d: 4, h: 3.380309217342405e+18

Figure 14: Our image hash search engine was able to find the matching image despite a modification (red square) to the query image.
这里,我在手风琴式查询图像的左下角添加了一个红色小方块。这个加法会 改变差值哈希值!
然而,如果你看一下输出结果,你会发现我们仍然能够检测到近似复制的图像。
通过比较哈希之间的汉明距离,我们能够找到近似重复的图像。哈希值的差异是 4,表示两个哈希值之间有 4 位不同。
接下来,让我们尝试第二个查询,这个比第一个修改得更多
$ python search.py --tree vptree.pickle --hashes hashes.pickle \
--query queries/accordion_modified2.jpg
[INFO] loading VP-Tree and hashes...
[INFO] performing search...
[INFO] search took 0.013727903366088867 seconds
[INFO] 1 total image(s) with d: 9, h: 3.380309217342405e+18
Figure 15: On the left is the query image for our image hash search engine with VP-Trees. It has been modified with yellow and purple shapes as well as red text. The image hash search engine returns the correct resulting image (right) from an index of 9,144 in just 0.0137 seconds, proving the robustness of our search engine system.
尽管通过添加一个大的蓝色矩形、一个黄色圆圈和文本对查询进行了巨大的修改,但我们仍然能够在不到 0.014 秒的时间内找到数据集中几乎重复的图像!
每当您需要在数据集中查找重复或近似重复的图像时,一定要考虑使用图像哈希和图像搜索算法——如果使用正确,它们会非常强大!
摘要
在本教程中,您学习了如何使用 OpenCV 和 Python 构建一个基本的图像哈希搜索引擎。
为了构建一个可扩展的图像哈希搜索引擎,我们需要利用 VP- Trees,这是一种专门的度量树数据结构,它递归地划分点数据集,使得树中距离较近的节点比距离较远的节点更相似。
通过使用 VP-Trees,我们能够构建一个图像哈希搜索引擎,能够在 0.01 秒内找到数据集中的重复和近似重复的图像。
此外,我们证明了我们的哈希算法和 VP-Tree 搜索的组合能够在我们的数据集 中找到匹配,即使我们的查询图像被修改、损坏或更改!
如果您正在构建一个计算机视觉应用程序,需要在大型数据集中快速找到重复或近似重复的图像,那么一定要尝试一下这种方法。
要下载这篇文章的源代码,并在以后的文章在 PyImageSearch 上发表时得到通知,*只需在下面的表格中输入您的电子邮件地址!***
构建图像搜索引擎:定义图像描述符(第 1 步,共 4 步)
周一,我从头到尾向你展示了如何构建一个令人敬畏的指环王图片搜索引擎。这很有趣,我们学到了很多东西。我们使用了 OpenCV 图像描述符。更重要的是,我们要看看一些真实世界的代码,看看一个图像搜索引擎到底是如何构建的。
但是让我们后退一步。
在那篇博文中,我提到了构建图片搜索引擎的四个步骤:
- 定义您的描述符:您将使用哪种类型的描述符?你描述的是图像的哪个方面?
- 索引您的数据集:将您的描述符应用到数据集中的每个图像。
- 定义你的相似性度量:你如何确定两幅图像有多“相似”?
- 搜索:实际的搜索是如何进行的?如何将查询提交到您的图像搜索引擎?
虽然周一的帖子是一篇“让我们动手写点代码”类型的文章,但接下来的几篇博客帖子将会更上一层楼。但是如果你计划建立一个自己的图片搜索引擎,这是你需要了解的四个步骤。
今天我们将只关注第一步:定义我们的图像描述符。
我们将在接下来的几周内探索剩余的步骤。
定义您的图像描述符
在我们的指环王图像搜索引擎中,我们使用 3D 颜色直方图来表征每张图像的颜色。这个 OpenCV 图像描述符是一个全局图像描述符,并应用于整个图像。对于我们的数据集来说,3D 颜色直方图是一个很好的选择。我们从电影中利用的五个场景都有相对不同的颜色分布,因此颜色直方图更容易返回相关的结果。
当然,颜色直方图不是我们可以使用的唯一图像描述符。我们还可以利用一些方法来描述图像中物体的纹理和形状。
让我们来看看:
颜色
正如我们已经看到的,颜色是描述图像的最基本的方面,也可以说是计算上最简单的。我们可以使用每个通道的像素强度的平均值、标准偏差和偏差来表征图像的颜色。我们也可以使用颜色直方图,就像我们在其他博客文章中看到的那样。颜色直方图是应用于整个图像的全局图像描述符。
使用简单颜色方法的一个好处是,我们可以很容易地获得图像大小(比例)和方向(图像如何旋转)的不变性。
这怎么可能?
好吧,让我们来看看这个不同比例和方向的侏罗纪公园的霸王龙模型,以及从每个图像中提取的直方图。
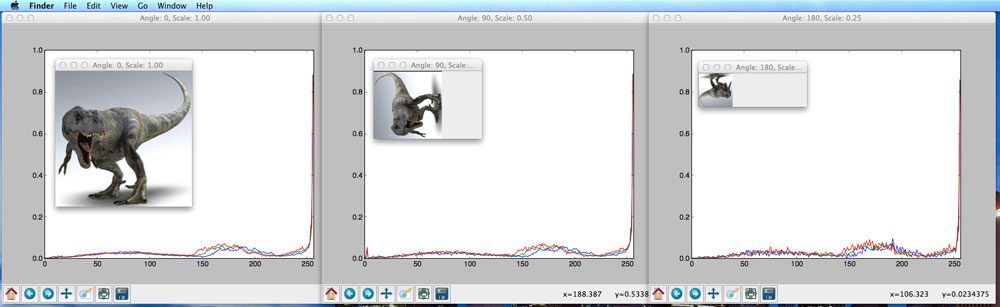
Figure 1: No matter how we rotate and scale the T-Rex image, we still have the same histogram.
正如你所看到的,我们用不同的角度和比例因子来旋转和调整图像的大小。箱的数量沿 X 轴绘制,放置在每个箱中的像素百分比沿 Y 轴绘制。
在每种情况下,直方图都是相同的,因此表明颜色直方图不会随着图像的缩放和旋转而改变。
图像描述符的旋转和尺度不变性都是图像搜索引擎的期望属性。如果用户向我们的图像搜索引擎提交一个查询图像,系统应该找到相似的图像,不管查询图像如何调整大小或旋转。当描述符对旋转和缩放等变化具有鲁棒性时,我们称它们为不变量,因为即使图像被旋转和缩放,描述符也是不变量(即不变)。
纹理
纹理试图模拟图像中物体的感觉、外观和整体触觉质量;然而,纹理往往难以表现。例如,我们如何构建一个图像描述符来描述霸王龙的鳞片是“粗糙”还是“粗糙”?
大多数试图对纹理建模的方法检查的是灰度图像,而不是彩色图像。如果我们使用灰度图像,我们只需要一个像素强度的 NxN 矩阵。我们可以检查这些像素对,然后构建这样的像素对在彼此的 X 像素内出现的频率分布。这种类型的分布称为灰度共生矩阵(GLCM)。
一旦我们有了 GLCM,我们就可以计算统计数据,例如对比度、相关性和熵等等。
也存在其他纹理描述符,包括对灰度图像进行傅立叶或小波变换,并检查变换后的系数。
最后,最近比较流行的纹理描述符之一,梯度方向直方图,在图像中的人物检测中非常有用。
形状
当讨论形状时,我不是在讨论图像所表示的 NumPy 数组的形状(维度,根据宽度和高度)。相反,我说的是图像中特定物体的形状。
当使用形状描述符时,第一步通常是应用分割或边缘检测技术,使我们能够严格关注我们想要描述的形状的轮廓。然后,一旦我们有了轮廓,我们可以再次计算统计矩来表示形状。
让我们看一个使用皮卡丘图像的例子:

Figure 2: The image on the left is not suited for shape description. We first need to either perform edge detection (middle) or examine the countered, masked region (right).
在左边,我们有皮卡丘的全彩色图像。通常,我们不会用这种类型的图像来描述形状。相反,我们会将图像转换为灰度并执行边缘检测(中心)或利用皮卡丘的遮罩(即我们想要描述的图像的相关部分)。
OpenCV 提供了 Hu 矩方法,它被广泛用作简单的形状描述符。
在接下来的几周里,我将展示我们如何使用各种形状描述符来描述图像中物体的形状。
摘要
在这篇文章中,我们讨论了构建图像搜索引擎的第一步:选择图像描述符。我们需要检查我们的数据集,并决定我们要描述图像的哪些方面。执行搜索时,图像的颜色分布是否重要?图像中物体的纹理呢?还是外形?或者我们需要描述这三者的特征?
选择描述符只是第一步。下周,我们将探索如何将图像描述符应用到数据集中的每个图像。
下载:
你可以在这里下载代码和示例图片的. zip 文件。
构建图像搜索引擎:定义相似性度量(第 3 步,共 4 步)
首先,让我们快速回顾一下。
两周前,我们探索了构建图像搜索引擎的第一步:定义你的图像描述符。我们探索了图像的三个容易描述的方面:颜色、纹理和形状。
从那里,我们继续到步骤 2:索引你的数据集。索引是通过应用图像描述符从数据集中的每个图像提取特征来量化数据集的过程。
索引也是一项可以轻松实现并行的任务——如果我们的数据集很大,我们可以通过在机器上使用多个内核/处理器来轻松加速索引过程。
最后,不管我们是使用串行还是并行处理,我们都需要将得到的特征向量写入磁盘以备后用。
现在,是时候进入构建图像搜索引擎的第三步了:定义你的相似性度量
定义您的相似性度量
今天我们将对不同种类的距离和相似性度量进行粗略的回顾,我们可以用它们来比较两个特征向量。
注意:根据你使用的距离函数,在这个过程中你需要注意很多很多的“陷阱”。我将回顾每一个距离函数,并在本博客的后面提供如何正确使用它们的例子,但不要在没有首先理解特征向量应该如何缩放、归一化等的情况下盲目地将距离函数应用于特征向量。,否则您可能会得到奇怪的结果。
那么距离度量和相似性度量之间有什么区别呢?
为了回答这个问题,我们首先需要定义一些变量。
设d是我们的距离函数,并且x、y和z是实值特征向量,那么必须满足以下条件:
- 非否定性:
d(x, y) >= 0。这仅仅意味着我们的距离必须是非负的。 - 重合公理:
d(x, y) = 0当且仅当x = y。只有当两个向量具有相同的值时,距离为零(意味着向量相同)才是可能的。 - 对称:
d(x, y) = d(y, x)。为了使我们的距离函数被认为是一个距离度量,距离中参数的顺序应该无关紧要。指定d(x, y)而不是d(y, x)对我们的距离度量没有影响,两个函数调用应该返回相同的值。 - 三角形不等式::T0。你还记得你高中的三角函数课吗?所有这些条件表明,任意两条边的长度之和必须大于剩余的一条边。
如果所有四个条件都成立,那么我们的距离函数可以被认为是距离度量。
那么这是否意味着我们应该只使用距离度量,而忽略其他类型的相似性度量呢?
当然不是!
但是理解术语是很重要的,尤其是当你开始自己构建图像搜索引擎的时候。
让我们来看看五个比较流行的距离度量和相似性函数。我包含了该函数对应的 SciPy 文档的链接,以防您想自己使用这些函数。
- 欧几里得: 可以说是最广为人知且必须使用的距离度量。欧几里得距离通常被描述为两点之间的“直线”距离。
- 曼哈顿: 也称“城市街区”。想象你自己在一辆出租车里,沿着城市街区转来转去,直到你到达目的地。
- 切比雪夫: 任意单一维度上的点之间的最大距离。
- 余弦: 在进入向量空间模型、tf-idf 加权、高维正空间之前,我们不会太多地使用这个相似度函数,但是余弦相似度函数极其重要。值得注意的是,余弦相似性函数不是一个合适的距离度量——它违反了三角形不等式和重合公理。
- 汉明: 给定两个(通常为二进制)向量,汉明距离衡量两个向量之间“不一致”的次数。两个相同的向量将没有分歧,因此完全相似。
这份清单绝非详尽无遗。有大量的距离函数和相似性度量。但是在我们开始深入细节和探索何时何地使用每个距离函数之前,我只想提供一个关于构建图像搜索引擎的 10,000 英尺的概述。
现在,让我们计算一些距离:
>>> from scipy.spatial import distance as dist
>>> import numpy as np
>>> np.random.seed(42)
>>> x = np.random.rand(4)
>>> y = np.random.rand(4)
>>> x
array([ 0.37454012, 0.95071431, 0.73199394, 0.59865848])
>>> y
array([ 0.15601864, 0.15599452, 0.05808361, 0.86617615])
我们要做的第一件事是导入我们需要的包:SciPy 的distance模块和 NumPy 本身。从这里开始,我们需要用一个显式值作为伪随机数生成器的种子。通过提供一个显式值(在本例中为 42),它确保了如果您自己执行这段代码,您会得到与我相同的结果。
最后,我们生成我们的“特征向量”。这些是长度为 4 的实值列表,值在范围[0,1]内。
是时候计算一些实际距离了:
>>> dist.euclidean(x, y)
1.0977486080871359
>>> dist.cityblock(x, y)
1.9546692556997436
>>> dist.chebyshev(x, y)
0.79471978607371352
那么这告诉我们什么呢?
欧几里得距离小于曼哈顿距离。直觉上,这是有道理的。欧几里得距离是“直线距离”(意思是可以走两点之间最短的路径,就像飞机从一个机场飞到另一个机场)。相反,曼哈顿距离更类似于驾车穿过城市街区——我们正在进行急转弯,就像在一张网格纸上行驶,因此曼哈顿距离更大,因为我们在两点之间行驶的时间更长。
最后,切比雪夫距离是矢量中任意两个分量之间的最大距离。在这种情况下,从| 0.95071431–0.15599452 |可以找到 0.794 的最大距离。
现在,让我们来看看海明距离:
>>> x = np.random.random_integers(0, high = 1, size =(4,))
>>> y = np.random.random_integers(0, high = 1, size =(4,))
>>> x
array([1, 1, 1, 0])
>>> y
array([1, 0, 1, 1])
>>> dist.hamming(x, y)
0.5
在前面的例子中,我们有个实值的个特征向量。现在我们有了二进制 特征向量。汉明距离比较了x和y特征向量之间不匹配的数量。在这种情况下,它发现了两个不匹配—第一个是在x[1]和y[1],第二个是在x[3]和y[3]。
假设我们有两个不匹配,并且向量的长度是 4,那么不匹配与向量长度的比率是 2 / 4 = 0.5,因此我们的汉明距离。
摘要
构建图像搜索引擎的第一步是决定图像描述符。从那里,可以将图像描述符应用于数据集中的每个图像,并提取一组特征。这个过程被称为“索引数据集”。为了比较两个特征向量并确定它们有多“相似”,需要相似性度量。
在这篇博文中,我们粗略地探索了距离和相似度函数,它们可以用来衡量两个特征向量有多“相似”。
流行的距离函数和相似性度量包括(但当然不限于):欧几里德距离、曼哈顿(城市街区)、切比雪夫、余弦距离和汉明。
在这篇博客的后面,我们不仅会更详细地探讨这些距离函数,我还会介绍更多,包括专门用于比较直方图的方法,如相关法、交集法、卡方法和土方距离法。
在这一点上,你应该有一个基本的想法是什么需要建立一个图像搜索引擎。开始使用简单的颜色直方图从图像中提取特征。然后使用上面讨论的距离函数对它们进行比较。记下你的发现。
最后,在下面注册我的时事通讯,以便在我发布新的图片搜索引擎文章时得到更新。作为回报,我会给你一份关于计算机视觉和图像搜索引擎的 11 页的资源指南。
构建图像搜索引擎:索引数据集(第 2 步,共 4 步)
上周三的博文回顾了构建图像搜索引擎的第一步:定义你的图像描述符。
然后,我们研究了图像的三个方面,这三个方面很容易描述:
- 颜色:表征图像颜色的图像描述符试图对图像每个通道中的像素强度分布进行建模。这些方法包括基本的颜色统计,如平均值、标准差和偏斜度,以及颜色直方图,包括“平坦”和多维。
- 纹理:纹理描述符寻求对图像中对象的感觉、外观和整体触觉质量进行建模。一些(但不是全部)纹理描述符将图像转换成灰度,然后计算灰度共生矩阵(GLCM)并计算该矩阵上的统计,包括对比度、相关性和熵等。也存在更高级的纹理描述符,例如傅立叶和小波变换,但是仍然利用灰度图像。
- 形状:许多形状描述符方法依赖于提取图像中物体的轮廓(即轮廓)。一旦我们有了轮廓,我们就可以计算简单的统计来描述轮廓,这正是 OpenCV 的 Hu 矩所做的。这些统计可以用来表示图像中对象的形状(轮廓)。
注:如果你还没看过我的功能齐全的图片搜索引擎,那就来看看我的如何使用《指环王》截图构建一个简单的图片搜索引擎。
当选择一个描述符来从我们的数据集中提取特征时,我们必须问自己,我们对描述图像的哪些方面感兴趣?图像的颜色重要吗?外形呢?触觉质量(纹理)对返回相关结果重要吗?
让我们来看一下 17 种花的数据集的样本,这是一个包含 17 种花卉的数据集,例如:

Figure 1 – A sample of the Flowers 17 Dataset. As we can see, some flowers might be indistinguishable using color or shape alone (i.e. Tulip and Cowslip have similar color distributions). Better results can be obtained by extracting both color and shape features.
如果我们想要描述这些图像,目的是构建一个图像搜索引擎,我会使用的第一个描述符是 color 。通过描述花瓣的颜色,我们的搜索引擎将能够返回相似色调的花。
然而,仅仅因为我们的图像搜索引擎将返回相似颜色的花,并不意味着所有的结果都是相关的。许多花可以有相同的颜色,但却是完全不同的种类。
为了确保从我们的花卉搜索引擎返回更多相似品种的花卉,我将探索描述花瓣的形状。
现在我们有两个描述符——颜色来描述花瓣的不同色调,以及形状来描述花瓣本身的轮廓。
结合使用这两个描述符,我们将能够为我们的 flowers 数据集构建一个简单的图像搜索引擎。
当然,我们需要知道如何索引我们的数据集。
现在,我们简单地知道我们将使用什么描述符来描述我们的图像。
但是我们如何将这些描述符应用到我们的整个数据集呢?
为了回答这个问题,今天我们将探索构建图像搜索引擎的第二步:索引你的数据集。
索引您的数据集
定义:索引是通过应用图像描述符从数据集中的每个图像中提取特征来量化数据集的过程。通常,这些功能存储在磁盘上以备后用。
使用上面的 flowers 数据库示例,我们的目标是简单地遍历数据集中的每个图像,提取一些特征,并将这些特征存储在磁盘上。
原则上这是一个非常简单的概念,但实际上,它可能会变得非常复杂,具体取决于数据集的大小和规模。出于比较的目的,我们会说 Flowers 17 数据集是小的。它总共只有 1,360 幅图像(17 个类别 x 每个类别 80 幅图像)。相比之下,像 TinEye 这样的图像搜索引擎拥有数十亿的图像数据集。
让我们从第一步开始:实例化您的描述符。
1.实例化您的描述符
在我的如何构建图像搜索引擎指南中,我提到我喜欢将图像描述符抽象成类而不是函数。
此外,我喜欢在类的构造函数中放入相关的参数(比如直方图中的格数)。
我为什么要这么做呢?
使用类(在构造函数中带有描述符参数)而不是函数的原因是,它有助于确保将带有完全相同参数的完全相同的描述符应用于我的数据集中的每一幅图像。
如果我需要使用cPickle将我的描述符写入磁盘,并在以后再次加载它,比如当用户执行查询时,这就特别有用。
为了比较两个图像,您需要使用图像描述符以相同的方式表示它们。如果您的目的是比较两个图像的相似性,那么从一个图像中提取 32 个柱的直方图,然后从另一个图像中提取 128 个柱的直方图是没有意义的。
例如,让我们看看 Python 中通用图像描述符的框架代码:
class GenericDescriptor:
def __init__(self, paramA, paramB):
# store the parameters for use in the 'describe' method
self.paramA = paramA
self.paramB = paramB
def describe(self, image):
# describe the image using self.paramA and self.paramB
# as supplied in the constructor
pass
你首先注意到的是__init__ method。这里我为描述符提供了相关的参数。
接下来,你看到了describe method。这个方法只有一个参数:我们想要描述的image。
每当我调用describe方法时,我知道在构造函数期间存储的参数将用于我的数据集中的每一幅图像。这确保了我的图像被一致地用相同的描述符参数描述。
虽然类与函数的争论现在看起来没什么大不了的,但是当你开始构建更大、更复杂的图像搜索引擎时,使用类有助于确保描述符的一致性。
2.串行还是并行?
这一步更好的标题可能是“单核还是多核?”
本质上,从数据集中的影像中提取要素是一项可以并行执行的任务。
根据数据集的大小和规模,利用多核处理技术在多个内核/处理器之间分割提取每个图像的特征向量可能是有意义的。
然而,对于使用计算简单的图像描述符(如颜色直方图)的小型数据集,使用多核处理不仅是多余的,还会增加代码的复杂性。
如果你刚刚开始使用计算机视觉和图像搜索引擎,这就特别麻烦。
为什么要增加额外的复杂性呢?调试具有多个线程/进程的程序比调试只有一个执行线程的程序困难得多。
除非您的数据集非常大,并且可以从多核处理中受益,否则我暂时不会将索引任务分成多个进程。现在还不值得头疼。不过,将来我肯定会写一篇博文,讨论让索引任务并行化的最佳实践方法。
3.写入磁盘
这一步似乎有点显而易见。但是,如果您要竭尽全力从数据集中提取要素,最好将索引写入磁盘以备后用。
对于小型数据集,使用简单的 Python 字典可能就足够了。关键字可以是图像文件名(假设您在数据集内有唯一的文件名)和使用图像描述符从该图像中提取的要素值。最后,您可以使用cPickle将索引转储到文件中。
如果您的数据集较大或者您计划进一步操作您的要素(即缩放、归一化、降维),您最好使用 [h5py](http://www.h5py.org/) 将您的要素写入磁盘。
`一种方法比另一种好吗?
老实说,这要看情况。
如果你刚刚开始使用计算机视觉和图像搜索引擎,并且你有一个小的数据集,我会暂时使用 Python 的内置字典类型和cPickle。
如果你有这个领域的经验,并且有 NumPy 的经验,那么我会建议尝试一下h5py,然后将其与上面提到的字典方法进行比较。
目前,我将在我的代码示例中使用cPickle;然而,在接下来的几个月里,我也将开始在我的例子中引入h5py。
摘要
今天,我们探讨了如何索引图像数据集。索引是从影像数据集中提取要素,然后将要素写入永久存储(如硬盘)的过程。
索引数据集的第一步是确定您将使用哪个图像描述符。你需要问你自己,你试图描述图像的哪一方面?颜色分布?质地和触感如何?图像中物体的形状?
在确定了要使用的描述符之后,需要遍历数据集,将描述符应用于数据集中的每一幅图像,提取特征向量。这可以通过利用多处理技术串行或并行完成。
最后,从数据集中提取要素后,需要将要素索引写入文件。简单的方法包括使用 Python 内置的字典类型和cPickle。更高级的选项包括使用h5py。
下周我们将进入构建图像搜索引擎的第三步:确定如何比较特征向量的相似性。`
使用 Python 构建暹罗网络的影像对
原文:https://pyimagesearch.com/2020/11/23/building-image-pairs-for-siamese-networks-with-python/
在本教程中,您将学习如何为训练连体网络构建图像对。我们将使用 Python 实现我们的图像对生成器,这样无论您是否使用 TensorFlow、Keras、PyTorch 等,您都可以使用相同的代码。
本教程是暹罗网络介绍的第一部分:
- 第一部分: 用 Python 为暹罗网络构建图像对(今天的帖子)
- 第二部分: 用 Keras、TensorFlow 和深度学习训练暹罗网络(下周教程)
- 第三部分: 使用连体网络比较图像(从现在起两周后的教程)
暹罗网络是极其强大的网络,负责人脸识别、签名验证和处方药识别应用(仅举几例)的显著增长。
事实上,如果你跟随我的关于 OpenCV 人脸识别 或 人脸识别与 OpenCV、Python 和深度学习 的教程,你会看到这些帖子中使用的深度学习模型是连体网络!
深度学习模型如 FaceNet、VGGFace、dlib 的 ResNet 人脸识别模型都是连体网络的例子。
此外,暹罗网络使更高级的训练程序成为可能,如一次性学习和少量学习 —与其他深度学习架构相比,暹罗网络需要非常少的训练示例才能有效。
今天我们将:
- 复习暹罗网络的基础知识
- 讨论图像对的概念
- 看看我们如何使用图像对来训练一个连体网络
- 实现 Python 代码以生成暹罗网络的图像对
下周我将向你展示如何实现和训练你自己的暹罗网络。最后,我们将建立图像三元组的概念,以及如何使用三元组损失和对比损失来训练更好、更准确的连体网络。
但是现在,让我们来理解图像对,这是实现基本暹罗网络时的一个基本要求。
要了解如何为连体网络构建图像对,继续阅读。
使用 Python 构建暹罗网络的图像对
在本教程的第一部分,我将提供暹罗网络的高级概述,包括:
- 它们是什么
- 我们为什么使用它们
- 何时使用它们
- 他们是如何被训练的
然后我们将讨论暹罗网络中“图像对”的概念,包括为什么在训练暹罗网络时构建图像对是一个要求。
从这里,我们将回顾我们的项目目录结构,然后实现一个 Python 脚本来生成图像对。无论您使用的是 Keras、TensorFlow、PyTorch 等,您都可以在自己的暹罗网络训练程序中使用此图像对生成功能。
最后,我们将通过回顾我们的结果来结束本教程。
暹罗网络的高级概述
术语“连体双胞胎”,也称为“连体双胞胎”,是两个在子宫内结合的同卵双胞胎。这些双胞胎身体上彼此相连(即不能分开),通常共享相同的器官,主要是下肠道、肝脏和泌尿道。
就像连体双胞胎一样,连体网络也是。
转述肖恩·本赫尔,暹罗网络是一类特殊的神经网络:
- 暹罗网络包含两个(或更多)相同的子网。
- 这些子网具有相同的架构、参数和权重。
- 任何参数更新都会在两个子网中镜像,这意味着如果您更新了一个中的权重,那么另一个中的权重也会更新。
我们在执行验证、识别或识别任务时使用暹罗网络,最常见的例子是人脸识别和签名验证。
例如,假设我们的任务是检测签名伪造。不是训练一个分类模型来正确地分类我们数据集中每个独特个体的签名(这将需要重要的训练数据),而是从我们的训练集中取两张图像,并询问神经网络这些签名是否来自同一个人,会怎么样?
- 如果两个签名相同,那么暹罗网络报告“是”。
- 否则,如果两个签名不相同,从而意味着潜在的伪造,暹罗网络报告“否”。
这是一个验证任务的例子(相对于分类、回归等)。),虽然这听起来像是一个更难的问题,但在实践中它实际上变得容易得多**—我们需要明显更少的训练数据,并且我们的准确性实际上通过使用暹罗网络而不是分类网络来提高。
另一个额外的好处是,当我们的分类模型在进行分类时需要选择“以上都不是”时,我们不再需要一个“包罗万象”的类(这在实践中很容易出错)。相反,我们的暹罗网络优雅地处理了这个问题,报告说这两个签名是不同的。
请记住,暹罗网络体系结构不必关心传统意义上的分类,即从 N 个可能的类别中选择 1 个。更确切地说,暹罗网络只需要能够报告“相同”(属于同一类)或“不同”(属于不同类)。
下面是 Dey 等人 2017 年的出版物中使用的暹罗网络架构的可视化, SigNet:用于书写者独立离线签名验证的卷积暹罗网络 :
在左边的中,我们向图章模型提交了两个签名。我们的目标是确定这些签名是否属于同一个人。
中间的表示暹罗网络本身。**这两个子网络具有相同的架构和参数,并且相互镜像**—如果一个子网络中的权重被更新,那么其他子网络中的权重也会被更新。
这些子网络中的最终层通常(但不总是)是嵌入层,其中我们可以计算输出之间的欧几里德距离,并调整子网络的权重,以使它们输出正确的决策(是否属于同一类)。
右边的显示了我们的损失函数,它结合了子网的输出,然后检查暹罗网络是否做出了正确的决定。
训练暹罗网络时常用的损失函数包括:
- 二元交叉熵
- 三重损失
- 对比损失
你可能会惊讶地看到二进制交叉熵被列为训练暹罗网络的损失函数。
请这样想:
每个图像对或者是“相同的”(1),意味着它们属于同一类,或者是“不同的”(0),意味着它们属于不同的类。这自然有助于二进制交叉熵,因为只有两种可能的输出(尽管三重损失和对比损失往往明显优于标准二进制交叉熵)。
既然我们对暹罗网络有了一个较高层次的概述,现在让我们来讨论图像对的概念。
暹罗网络中“像对”的概念
阅读完上一节后,您应该明白,连体网络由两个相互镜像的子网组成(即,当一个网络中的权重更新时,另一个网络中的权重也会更新)。
由于有两个子网络,我们必须有两个输入到连体模型(正如你在前面章节顶部的图 2 中看到的)。
当训练暹罗网络时,我们需要有个正对和个负对:
- 正对:属于同一类的两幅图像(例如。同一个人的两个图像、同一签名的两个示例等。)
- 负对:属于不同类的两幅图像(例如。不同人的两个图像、不同签名的两个示例等。)
当训练我们的暹罗网络时,我们随机抽取正对和负对的样本。这些对作为我们的训练数据,以便暹罗网络可以学习相似性。
在本教程的剩余部分,您将学习如何生成这样的图像对。在下周的教程中,您将学习如何定义暹罗网络架构,然后在我们的 pairs 数据集上训练暹罗模型。
配置您的开发环境
在这一系列关于暹罗网络的教程中,我们将使用 Keras 和 TensorFlow,所以我建议你现在就花时间配置你的深度学习开发环境。
我建议您按照这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
确保您使用了本教程的 【下载】 部分来下载源代码。从那里,让我们检查项目目录结构:
$ tree . --dirsfirst
.
└── build_siamese_pairs.py
0 directories, 1 file
为暹罗网络实现我们的图像对生成器
让我们开始为暹罗网络实现图像对生成。
打开build_siamese_pairs.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.datasets import mnist
from imutils import build_montages
import numpy as np
import cv2
第 2-5 行导入我们需要的 Python 包。
我们将使用 MNIST 数字数据集作为我们的样本数据集(为了方便起见)。也就是说,我们的make_pairs函数将与任何图像数据集的一起工作,只要你提供两个单独的image和labels数组(你将在下一个代码块中学习如何做)。
def make_pairs(images, labels):
# initialize two empty lists to hold the (image, image) pairs and
# labels to indicate if a pair is positive or negative
pairImages = []
pairLabels = []
下一步是计算数据集中唯一类标签的总数:
# calculate the total number of classes present in the dataset
# and then build a list of indexes for each class label that
# provides the indexes for all examples with a given label
numClasses = len(np.unique(labels))
idx = [np.where(labels == i)[0] for i in range(0, numClasses)]
第 16 行使用np.unique函数在我们的labels列表中查找所有唯一的类标签。取np.unique输出的len,得到数据集中唯一类标签的总数。在 MNIST 数据集的情况下,有 10 个唯一的类标签,对应于数字 0-9。
第 17 行然后使用 Python 数组理解为每个类标签构建一个索引列表。为了提高性能,我们在这里使用 Python 列表理解;然而,这段代码可能有点难以理解,所以让我们将它分解为一个专用的for循环,以及一些print语句:
>>> for i in range(0, numClasses):
>>> idxs = np.where(labels == i)[0]
>>> print("{}: {} {}".format(i, len(idxs), idxs))
0: 5923 [ 1 21 34 ... 59952 59972 59987]
1: 6742 [ 3 6 8 ... 59979 59984 59994]
2: 5958 [ 5 16 25 ... 59983 59985 59991]
3: 6131 [ 7 10 12 ... 59978 59980 59996]
4: 5842 [ 2 9 20 ... 59943 59951 59975]
5: 5421 [ 0 11 35 ... 59968 59993 59997]
6: 5918 [ 13 18 32 ... 59982 59986 59998]
7: 6265 [ 15 29 38 ... 59963 59977 59988]
8: 5851 [ 17 31 41 ... 59989 59995 59999]
9: 5949 [ 4 19 22 ... 59973 59990 59992]
>>>
第 17 行构建了这个索引列表,但是以一种超级紧凑、高效的方式。
给定我们的idx循环列表,让我们现在开始产生我们的积极和消极对:
# loop over all images
for idxA in range(len(images)):
# grab the current image and label belonging to the current
# iteration
currentImage = images[idxA]
label = labels[idxA]
# randomly pick an image that belongs to the *same* class
# label
idxB = np.random.choice(idx[label])
posImage = images[idxB]
# prepare a positive pair and update the images and labels
# lists, respectively
pairImages.append([currentImage, posImage])
pairLabels.append([1])
接下来,让我们生成我们的负对:
# grab the indices for each of the class labels *not* equal to
# the current label and randomly pick an image corresponding
# to a label *not* equal to the current label
negIdx = np.where(labels != label)[0]
negImage = images[np.random.choice(negIdx)]
# prepare a negative pair of images and update our lists
pairImages.append([currentImage, negImage])
pairLabels.append([0])
# return a 2-tuple of our image pairs and labels
return (np.array(pairImages), np.array(pairLabels))
第 39 行抓取labels 不等于当前label的所有索引。然后,我们随机选择这些指标中的一个作为我们的负面图像,negImage ( Line 40 )。
# load MNIST dataset and scale the pixel values to the range of [0, 1]
print("[INFO] loading MNIST dataset...")
(trainX, trainY), (testX, testY) = mnist.load_data()
# build the positive and negative image pairs
print("[INFO] preparing positive and negative pairs...")
(pairTrain, labelTrain) = make_pairs(trainX, trainY)
(pairTest, labelTest) = make_pairs(testX, testY)
# initialize the list of images that will be used when building our
# montage
images = []
第 51 行从磁盘加载 MNIST 训练和测试分割。
然后,我们在行 55 和 56 上生成训练和测试对。
# loop over a sample of our training pairs
for i in np.random.choice(np.arange(0, len(pairTrain)), size=(49,)):
# grab the current image pair and label
imageA = pairTrain[i][0]
imageB = pairTrain[i][1]
label = labelTrain[i]
# to make it easier to visualize the pairs and their positive or
# negative annotations, we're going to "pad" the pair with four
# pixels along the top, bottom, and right borders, respectively
output = np.zeros((36, 60), dtype="uint8")
pair = np.hstack([imageA, imageB])
output[4:32, 0:56] = pair
# set the text label for the pair along with what color we are
# going to draw the pair in (green for a "positive" pair and
# red for a "negative" pair)
text = "neg" if label[0] == 0 else "pos"
color = (0, 0, 255) if label[0] == 0 else (0, 255, 0)
# create a 3-channel RGB image from the grayscale pair, resize
# it from 60x36 to 96x51 (so we can better see it), and then
# draw what type of pair it is on the image
vis = cv2.merge([output] * 3)
vis = cv2.resize(vis, (96, 51), interpolation=cv2.INTER_LINEAR)
cv2.putText(vis, text, (2, 12), cv2.FONT_HERSHEY_SIMPLEX, 0.75,
color, 2)
# add the pair visualization to our list of output images
images.append(vis)
这里的最后一步是构建我们的蒙太奇并将其显示到我们的屏幕上:
# construct the montage for the images
montage = build_montages(images, (96, 51), (7, 7))[0]
# show the output montage
cv2.imshow("Siamese Image Pairs", montage)
cv2.waitKey(0)
第 94 行构建了一个 7×7 的蒙太奇,其中蒙太奇中的每个图像是 96×51 像素。
输出的连体图像对可视化显示在我们屏幕的第 97 和 98 行。
连体网络图像对生成结果
我们现在准备运行我们的暹罗网络图像对生成脚本。确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端,并执行以下命令:
$ python build_siamese_pairs.py
[INFO] loading MNIST dataset...
[INFO] preparing positive and negative pairs...
图 5 显示了我们的图像对生成脚本的输出。对于每一对图像,我们的脚本都将它们标记为正对(绿色)或负对(红色)。
例如,位于第一行第一列的对是一个正对,,因为两个数字都是 9。
然而,位于第一行第三列的数字对是一个负对,因为一个数字是“2”,而另一个是“0”。
在训练过程中,我们的暹罗网络将学习如何区分这两个数字。
一旦您了解如何以这种方式训练暹罗网络,您就可以替换 MNIST 数字数据集,并包含您自己的任何需要验证的数据集,包括:
- 人脸识别:给定两张包含人脸的独立图像,确定两张照片中的是否是同一个人。
- 签名验证:当呈现两个签名时,确定其中一个是否是伪造的。
- 处方药丸识别:给定两种处方药丸,确定它们是相同的药物还是不同的药物。
暹罗网络使所有这些应用成为可能— 下周我将向你展示如何训练你的第一个暹罗网络!
总结
在本教程中,您学习了如何使用 Python 编程语言为暹罗网络构建影像对。
我们的图像对生成实现是库不可知的,这意味着无论你的底层深度学习库是 Keras、TensorFlow、PyTorch 等,你都可以使用这个代码。
图像对生成是暹罗网络的一个基本方面。一个连体网络需要了解 同一类【正对】的两个图像和 不同类【负对】的两个图像的区别。
在训练过程中,我们可以更新我们网络的权重,这样它就可以区分相同类别的两幅图像和不同类别的两幅图像。
这听起来像是一个复杂的训练过程,但是正如我们下周将会看到的,它实际上是非常简单的(当然,一旦有人向你解释了它!).
敬请关注下周的培训暹罗网络教程,你不会想错过它。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
构建图像搜索引擎:搜索和排序(第 4 步,共 4 步)
原文:https://pyimagesearch.com/2014/02/24/building-image-search-engine-searching-ranking-step-4-4/
我们现在处于构建图像搜索引擎的最后一步——接受查询图像并执行实际搜索。
让我们花点时间回顾一下我们是如何走到这一步的:
- 第一步:定义你的图像描述符 。在我们考虑建立一个图像搜索引擎之前,我们需要考虑如何仅使用一系列数字(即特征向量)来表示和量化我们的图像。我们探索了图像的三个容易描述的方面:颜色、纹理和形状。我们可以使用这些方面中的一个,或者多个。
- 第二步:索引你的数据集 。现在我们已经选择了一个描述符,我们可以应用该描述符从数据集中的每个图像中提取特征。从影像数据集中提取特征的过程称为“索引”。这些特性随后被写入磁盘供以后使用。索引也是一项任务,通过利用我们机器上的多个内核/处理器,可以很容易地实现并行。
- 第三步:定义你的相似性度量 。在步骤 1 中,我们定义了一种从图像中提取特征的方法。现在,我们需要定义一种方法来比较我们的特征向量。距离函数应该接受两个特征向量,然后返回一个指示它们有多“相似”的值。相似性函数的常见选择包括(但不限于)欧几里德距离、曼哈顿距离、余弦距离和卡方距离。
最后,我们现在准备执行构建图像搜索引擎的最后一步:搜索和排名。
该查询
在执行搜索之前,我们需要一个查询。
上次你去谷歌的时候,你在搜索框里输入了一些关键词,对吗?您输入到输入表单中的文本就是您的“查询”。
然后,谷歌获取你的查询,对其进行分析,并将其与庞大的网页索引进行比较,对其进行排序,然后将最相关的网页返回给你。
同样,当我们构建一个图像搜索引擎时,我们需要一个查询图像。
查询图像有两种风格:一种是内部查询图像,另一种是外部查询图像。
顾名思义,内部查询图像已经属于我们的索引。我们已经对它进行了分析,从中提取了特征,并存储了它的特征向量。
第二种类型的查询图像是外部查询图像。这相当于把我们的文本关键词输入谷歌。我们以前从未见过这个查询图像,因此无法对其做出任何假设。我们简单地应用我们的图像描述符,提取特征,根据与查询的相似性对索引中的图像进行排序,并返回最相关的结果。
你可能还记得,当我写关于构建你的第一个图像搜索引擎的指南时,我包括了对内部和外部查询的支持。
我为什么这么做?
让我们回想一下我们的相似性度量,假设我们使用的是欧几里德距离。欧几里德距离有一个很好的属性,叫做重合公理,意味着当且仅当两个特征向量相同时,函数返回值 0(表示完全相似)。
如果我要搜索已经在我的索引中的图像,那么两个特征向量之间的欧几里德距离将为零,这意味着完全相似。这张图片将被放在我的搜索结果的顶部,因为它是最相关的。这是有意义的,也是预期的行为。
如果我搜索一张已经在我的索引中的图片,却没有在#1 结果位置找到它,那该多奇怪啊。这可能意味着我的代码中某处有一个 bug,或者我在图像描述符和相似性度量方面做了一些非常糟糕的选择。
总的来说,使用内部查询图像是一种健全性检查。它可以让你确保你的图像搜索引擎按预期运行。
一旦确认图像搜索引擎工作正常,就可以接受不属于索引的外部查询图像。
搜索
那么实际执行搜索的过程是怎样的呢?查看下面的大纲:
1.接受来自用户的查询图像
用户可以从他们的桌面或移动设备上传图像。随着图像搜索引擎变得越来越流行,我怀疑大多数查询将来自 iPhones 和机器人等设备。用手机拍下你感兴趣的地方、物体或事物的照片,然后自动分析并返回相关结果,这既简单又直观。
2.描述查询图像
现在您已经有了一个查询图像,您需要使用与在索引阶段完全相同的图像描述符来描述它。例如,如果我在索引数据集中的图像时使用每通道 32 个像素的 RGB 颜色直方图,那么在描述查询图像时,我将使用相同的每通道 32 个像素的直方图。这确保了我的图像有一个一致的表现。在应用我的图像描述符之后,我现在有了查询图像的特征向量。
3.执行搜索
要执行最基本的搜索方法,您需要遍历索引中的所有特征向量。然后,使用相似性度量将索引中的特征向量与查询中的特征向量进行比较。您的相似性度量将告诉您这两个特征向量有多“相似”。最后,根据相似性对结果进行排序。
如果你想看看“执行搜索”这一步是如何操作的,那就去看看我的如何构建你的第一个图片搜索引擎帖子。在第 3 步,我给你 Python 代码,可以用来执行搜索。
对于小型数据集,循环遍历整个索引可能是可行的。但是如果你有一个大的图像数据集,比如 Google 或者 TinEye,这是不可能的。您无法计算查询要素与数据集中已有的数十亿个要素向量之间的距离。
对于有信息检索经验的读者(传统上专注于构建文本搜索引擎),我们也可以使用 tf-idf 索引和倒排索引来加速这个过程。然而,为了使用这种方法,我们需要确保我们的特征能够适合向量空间模型,并且足够稀疏。构建一个利用这种方法的图像搜索引擎超出了本文的范围;然而,将来当我们开始构建更复杂的搜索引擎时,我肯定会再次访问它。
4.向用户显示您的结果
现在我们已经有了相关图片的排序列表,我们需要将它们显示给用户。如果用户在桌面上,这可以通过一个简单的网络界面来完成,或者如果用户在移动设备上,我们可以使用某种应用程序来显示图像。在构建图像搜索引擎的整体环境中,这一步相当琐碎,但是您仍然应该考虑用户界面以及用户将如何与您的图像搜索引擎交互。
摘要
现在你有了,建立一个图片搜索引擎的四个步骤,从前到后:
- 定义您的图像描述符。
- 索引您的数据集。
- 定义你的相似度。
- 执行搜索,根据与用户的相关性对索引中的图像进行排序,并向用户显示结果。
那么你是怎么看待这一系列帖子的呢?信息丰富吗?你学到什么了吗?或者你更喜欢有更多代码示例的帖子,比如霍比特人和直方图?
请在下面留下评论,我很想听听你的想法。
一如既往,请务必在下面注册,下载我的图像搜索引擎资源指南 PDF。你会收到我没有在这个博客上发表的独家提示、技巧和诀窍。你会是第一个知道我即将推出新书的人!
用 Python 构建 Pokedex:用 OpenCV 比较形状描述符(第 6 步,共 6 步)
原文:https://pyimagesearch.com/2014/05/19/building-pokedex-python-comparing-shape-descriptors-opencv/
这是用 Python 和 OpenCV 构建真实 Pokedex 的最后一步。
这是一切汇集的地方。
我们将把所有的碎片粘在一起,组成一个基于形状特征的图像搜索引擎。
我们探索了使用计算机视觉建造一个 Pokedex 需要什么。然后我们搜索网页,建立了一个口袋妖怪的数据库。我们已经使用 Zernike moments 索引了口袋妖怪精灵数据库。我们已经分析了查询图像,并使用边缘检测和轮廓发现技术找到了我们的游戏男孩屏幕。我们已经使用cv2.warpPerspective函数执行了透视扭曲和变换。
原来如此。最后一步。是时候将所有这些步骤结合到一个工作的 Pokedex 中了。
你准备好了吗?
我是。这是一个伟大的系列职位。我准备好把它带回家了。
以前的帖子
这篇文章是关于如何使用 Python、OpenCV、计算机视觉和图像处理技术构建真实 Pokedex 的一系列博客文章的一部分。如果这是你正在阅读的系列文章中的第一篇,一定要花时间去消化它,理解我们在做什么。但是在你读完之后,一定要回到之前的文章。有大量与计算机视觉、图像处理和图像搜索引擎相关的精彩内容,你一定不想错过!
最后,如果您有任何问题,请发邮件给我。我喜欢和读者聊天。我很乐意回答你关于计算机视觉的任何问题。
- 步骤 1: 用 Python 构建 Pokedex:入门(第 1 步,共 6 步)
- 第二步: 用 Python 构建 Pokedex:抓取口袋妖怪精灵(第二步,共六步)
- 第三步: 用 Python 构建 Pokedex:使用形状描述符索引我们的精灵(第三步,共六步)
- 第 4 步: 用 Python 构建 Pokedex:寻找游戏男孩屏幕(第 4 步,共 6 步)
- 第 5 步: 用 Python 构建 Pokedex:OpenCV 和透视扭曲(第 5 步,共 6 步)
用 Python 构建 Pokedex:比较形状描述符
当我们结束前一篇文章时,我们已经将透视扭曲和变换应用到我们的 Game Boy 屏幕上,以获得自上而下/鸟瞰视图:
Figure 1: Performing a perspective transformation using Python and OpenCV on the Game Boy screen and cropping out the Pokemon.
然后,我们提取了与口袋妖怪在屏幕中的位置相对应的 ROI(感兴趣区域)。

Figure 2: Cropping the Pokemon from our Game Boy screen using Python and OpenCV.
从这里开始,需要做两件事。
首先,我们需要使用 Zernike 矩从裁剪的口袋妖怪(我们的“查询图像”)中提取特征。
Zernike 矩用于表征图像中物体的形状。你可以在这里阅读更多关于他们的信息。
其次,一旦我们有了形状特征,我们需要将它们与我们的形状特征数据库进行比较。在构建 Pokedex 的第二步中,我们从口袋妖怪精灵数据库中提取了 Zernike 矩。我们将使用 Zernike 特征向量之间的欧几里德距离来确定两个口袋妖怪精灵有多“相似”。
现在我们有了一个计划,让我们定义一个Searcher类,它将用于比较查询图像和我们的 Pokemon 精灵索引:
# import the necessary packages
from scipy.spatial import distance as dist
class Searcher:
def __init__(self, index):
# store the index that we will be searching over
self.index = index
def search(self, queryFeatures):
# initialize our dictionary of results
results = {}
# loop over the images in our index
for (k, features) in self.index.items():
# compute the distance between the query features
# and features in our index, then update the results
d = dist.euclidean(queryFeatures, features)
results[k] = d
# sort our results, where a smaller distance indicates
# higher similarity
results = sorted([(v, k) for (k, v) in results.items()])
# return the results
return results
我们在第二条线上做的第一件事是导入 SciPy distance包。这个包包含了许多距离函数,但具体来说,我们将使用欧几里德距离来比较特征向量。
第 4 行定义了我们的Searcher类,第 5-7 行定义了构造函数。我们将接受一个单一的参数,我们特性的index。我们将假设我们的index是一个标准的 Python 字典,以口袋妖怪的名字作为键,以形状特征(即用于量化口袋妖怪形状和轮廓的数字列表)作为值。
第 9 行定义了我们的search方法。这个方法只接受一个参数——我们的查询特性。我们将查询特征与索引中的每个值(特征向量)进行比较。
我们在第 11 行的上初始化我们的results字典。口袋妖怪的名字将是关键,特征向量之间的距离将作为值。
最后,我们可以对14-18 行进行比较。我们首先循环遍历我们的index,然后我们计算查询特征和第 17 行的索引中的特征之间的欧几里德距离。最后,我们使用当前的 Pokemon 名称作为键,距离作为值来更新我们的results字典。
我们通过在行 22 上对results进行排序来结束我们的search方法,其中特征向量之间的距离越小表示图像越“相似”。然后我们在第 25 行返回我们的results。
在实际比较特征向量方面,所有繁重的工作都由我们的Searcher类来完成。它从数据库中获取预先计算的特征的索引,然后将该索引与查询特征进行比较。然后根据相似性对这些结果进行排序,并将其返回给调用函数。
现在我们已经定义了 Searcher 类,让我们创建search.py,它将把所有东西粘在一起:
# import the necessary packages
from pyimagesearch.searcher import Searcher
from pyimagesearch.zernikemoments import ZernikeMoments
import numpy as np
import argparse
import pickle
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-", "--index", required = True,
help = "Path to where the index file will be stored")
ap.add_argument("-q", "--query", required = True,
help = "Path to the query image")
args = vars(ap.parse_args())
# load the index
index = open(args["index"], "rb").read()
index = pickle.loads(index)
第 2-8 行处理导入我们需要的所有包。出于组织的目的,我将我们的Searcher类放在了pyimagesearch包中。这同样适用于第 3 行的ZernikeMoments形状描述符和第 7 行的imutils。imutils包简单地包含了一些方便的方法,可以很容易地调整图像的大小。然后,我们导入 NumPy 来操作我们的数组(因为 OpenCV 将图像视为多维 NumPy 数组),argparse解析我们的命令行参数,cPickle加载我们预先计算的特性索引,cv2将我们绑定到 OpenCV 库中。
第 11-16 行解析我们的命令行参数。--index开关是到我们预先计算的索引的路径,而--query是到我们裁剪的查询图像的路径,这是步骤 5 的输出。
第 19 行和第 20 行简单地使用pickle从磁盘上加载我们预先计算的 Zernike 矩指数。
现在让我们从磁盘上加载查询图像并对其进行预处理:
# load the query image, convert it to grayscale, and
# resize it
image = cv2.imread(args["query"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = imutils.resize(image, width = 64)
这段代码非常简单明了,但是我们还是来看一下吧。
第 24 行使用cv2.imread函数从磁盘上加载我们的查询图像。然后,我们将查询图像转换成第 25 行的灰度图像。最后,我们在第 26 行的上调整图像的宽度为 64 像素。
我们现在需要为形状描述符准备查询图像,方法是对其进行阈值处理并找到轮廓:
# threshold the image
thresh = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY_INV, 11, 7)
# initialize the outline image, find the outermost
# contours (the outline) of the pokemon, then draw
# it
outline = np.zeros(image.shape, dtype = "uint8")
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
cv2.drawContours(outline, [cnts], -1, 255, -1)
第一步是在第 29 行和第 30 行对我们的查询图像进行阈值处理。我们将使用cv2.adaptiveThreshold函数应用自适应阈值,并将低于阈值的所有像素设置为黑色(0),高于阈值的所有像素设置为白色(255)。
我们的阈值输出如下所示:
Figure 3: Applying local thresholding our query image using cv2.adaptiveThreshold.
接下来,我们在第 36-38 行的上用我们的查询图像的相同维度初始化一个“空白”零数组。这个图像将持有我们的口袋妖怪的轮廓/剪影。
对第 36 行上cv2.findContours的调用在我们的阈值图像中找到所有轮廓。cv2.findContours函数会破坏你在中传递的图像,所以一定要用 NumPy copy()方法复制一份。
然后,我们对线 39 做一个重要的假设。我们将假设具有最大面积的轮廓(使用cv2.contourArea函数计算)对应于我们的口袋妖怪的轮廓。
这个假设是合理的。鉴于我们已经成功地从原始图像中裁剪出了口袋妖怪,面积最大的轮廓对应于我们的口袋妖怪当然是合理的。
从这里,我们使用 cv2.drawContours 函数在第 40 行上绘制最大的轮廓。
您可以在下面看到绘制等高线的输出:
Figure 4: Drawing the largest contours using cv2.contourArea and cv2.drawContours.
我们代码的其余部分非常简单:
# compute Zernike moments to characterize the shape of
# pokemon outline
desc = ZernikeMoments(21)
queryFeatures = desc.describe(outline)
# perform the search to identify the pokemon
searcher = Searcher(index)
results = searcher.search(queryFeatures)
print "That pokemon is: %s" % results[0][1].upper()
# show our images
cv2.imshow("image", image)
cv2.imshow("outline", outline)
cv2.waitKey(0)
我们在半径为 21 像素的线 44 上初始化我们的ZernikeMoments形状描述符。这就是我们在索引口袋妖怪精灵数据库时使用的半径完全相同的描述符。因为我们的目的是比较我们的口袋妖怪图像的相似性,使用一个描述符进行索引,然后使用另一个描述符进行比较是没有意义的。如果您的目的是比较图像的相似性,获得一致的图像特征表示是很重要的。
线 45 然后从上面的图 4 中看到的轮廓/剪影图像中提取我们的 Zernike 矩。
为了执行我们的实际搜索,我们首先在行 48 上初始化我们的Searcher,并在行 49 上执行搜索。
因为我们的结果是按照相似性排序的(首先是较小的欧几里德距离),所以列表中的第一个元组将包含我们的标识。我们在第 50 行的处打印出我们确定的口袋妖怪的名字。
最后,我们显示我们的查询图像和轮廓,并等待在第 53-55 行上的按键。
要执行我们的脚本,发出以下命令:
$ python search.py --index index.cpickle --query cropped.png
当我们的脚本执行完毕时,您会看到类似下面的内容:
Figure 5: The results of our identification. Sure enough, our Pokemon is a Marowak
果不其然,我们的口袋妖怪是一只马罗瓦克。
以下是使用波波作为查询影像时的结果:
Figure 6: Identifying Pidgey with our Pokedex.
和 Kadabra:
Figure 7: Identifying Kadabra with our Pokedex.
你会注意到 Kabdra 大纲并没有完全“填充”。幸运的是,我们的 Zernike moments 形状功能足够强大,可以处理这种情况。但这可能是一个信号,表明我们在预处理图像时应该更加小心。我将把它留给读者作为未来的工作。
无论如何,在所有情况下,我们的口袋妖怪图像搜索引擎能够毫无问题地识别口袋妖怪。
谁说 Pokedex 是虚构的?
显然,通过利用计算机视觉和图像处理技术,我们能够在现实生活中建立一个!
摘要
在这篇文章中,我们总结了用 Python 和 OpenCV 构建 Pokedex 的系列文章。
我们利用了许多重要的计算机视觉和图像处理技术,如灰度转换、阈值处理和轮廓查找。
然后我们用 Zernike 矩来描述我们口袋妖怪的形状。
为了构建一个实际的图像搜索引擎,我们需要一个查询图像。我们捕获了 Game Boy 屏幕的原始照片,然后应用透视扭曲和变换来获得屏幕的俯视图/鸟瞰图。
最后,本文使用 OpenCV 和 Python 比较了我们的形状描述符。
最终结果是一个现实生活中的工作 Pokedex!
只需将您的智能手机对准 Game Boy 屏幕,抓拍一张照片,我给你的 Python 脚本就会处理好剩下的事情!
包扎
我希望你和我一样喜欢这一系列的博文!
我花了很多时间来写这样的帖子,如果你能花点时间在下面的表格中输入你的电子邮件地址,我会非常感激,这样我可以在写更多文章的时候和你保持联系。
用 Python 构建 Pokedex:找到游戏男孩屏幕(第 4 步,共 6 步)
原文:https://pyimagesearch.com/2014/04/21/building-pokedex-python-finding-game-boy-screen-step-4-6/

Figure 1: Finding a Game Boy screen in an image using Python and OpenCV.
快速提问。
Pokedex 是如何工作的?
好吧,你只需简单地指出它是一个口袋妖怪,Pokedex 检查它的物理特征,口袋妖怪立即被识别出来。
在这种情况下,我们的智能手机摄像头就是我们的“Pokedex”。我们将智能手机对准我们的 Game Boy,拍下它的照片,我们的竞争对手 Pokemon 就被识别出来了(如果你不相信我,你可以通过观看这个 YouTube 剪辑来看看我的 Pokedex 的运行情况)。
然而,我们的图像中有很多我们不需要的信息。
我们不需要游戏机的外壳。我们不需要 A、B、上、下、左、右、开始或选择按钮。我们当然不关心我们的图像是在什么背景上拍摄的。
我们只关心游戏机屏幕。
因为一旦我们找到游戏男孩屏幕,我们就可以裁剪出口袋妖怪,并进行识别。
在这篇文章中,我将向你展示如何使用 Python 和 OpenCV 自动在图像中找到一个游戏机屏幕。具体来说,我们将使用 OpenCV 轮廓功能和cv2包中的findContours功能。
**准备好了吗?
开始了。
以前的帖子
这篇文章是正在进行的关于如何使用 Python、OpenCV、计算机视觉和图像处理技术构建现实生活中的 Pokedex 的系列博客文章的一部分。如果这是你正在阅读的系列文章中的第一篇,一定要花时间通读并检查一下。
能够在图像中找到 Game Boy 屏幕不仅仅是很酷,而且超级实用。我能想到 10-15 种不同的方法来建立一个小的移动应用程序业务,只需要使用游戏截图和移动技术,比如智能手机。
听起来有趣吗?不要害羞。给我发消息,我们可以多聊一会儿。
无论如何,在你读完这篇文章之后,回到这个系列的前几篇文章中去寻找一些额外的背景和信息。
- 步骤 1: 用 Python 构建 Pokedex:入门(第 1 步,共 6 步)
- 第二步: 用 Python 构建 Pokedex:抓取口袋妖怪精灵(第二步,共六步)
- 第三步: 用 Python 构建 Pokedex:使用形状描述符索引我们的精灵(第三步,共六步)
用 Python 构建 Pokedex:寻找游戏男孩屏幕
在我们能够在图像中找到游戏机屏幕之前,我们首先需要一个游戏机的图像:

Figure 2: Our original Game Boy query image. Our goal is to find the screen in this image.
顺便说一句,如果你想要原始的图像,请务必下载这篇文章底部的源代码。我已经附上了我的免费的 11 页图片搜索引擎资源指南 PDF,只是为了感谢你下载代码。
好了,现在我们有了我们的图像,我们的目标是找到我们的游戏男孩的屏幕并突出显示它,就像我们在这篇文章顶部的图 1 的中间截图中所做的那样。
启动您最喜欢的文本编辑器,创建一个名为find_screen.py的新文件。我们就要把手弄脏了:
# import the necessary packages
from pyimagesearch import imutils
from skimage import exposure
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-q", "--query", required = True,
help = "Path to the query image")
args = vars(ap.parse_args())
2-7 线只处理我们包裹的进口。我们将利用skimage,但是在本系列的下一篇博客文章之前,我不会再讨论这个问题,所以现在不要担心这个问题。我们将像往常一样使用 NumPy,argparse解析我们的命令行参数,cv2包含我们的 OpenCV 绑定。
我们只需要一个命令行参数:--query指向我们的查询图像在磁盘上存储的路径。
接下来,让我们加载查询图像并开始处理图像:
# load the query image, compute the ratio of the old height
# to the new height, clone it, and resize it
image = cv2.imread(args["query"])
ratio = image.shape[0] / 300.0
orig = image.copy()
image = imutils.resize(image, height = 300)
# convert the image to grayscale, blur it, and find edges
# in the image
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 11, 17, 17)
edged = cv2.Canny(gray, 30, 200)
在第 17 行上,我们从磁盘上加载查询图像。我们使用--query命令行参数提供了查询图像的路径。
为了使我们的处理步骤更快,我们需要调整图像的大小。图像越小,处理速度越快。代价是,如果你把你的图像做得太小,那么你就会错过图像中有价值的细节。
在这种情况下,我们希望我们的新图像高度为 300 像素。在第 18 行的上,我们计算旧高度到新高度的ratio,然后我们在第 19 行的上制作原始图像的克隆。最后,第 20 行处理将图像调整到 300 像素的高度。
从那里,我们在第 24 行把我们的图像转换成灰度。然后,我们使用cv2.bilateralFilter功能稍微模糊图像。双边滤波具有去除图像中的噪声同时仍然保留实际边缘的良好特性。边缘很重要,因为我们需要它们来找到游戏男孩图像的屏幕。
最后,我们在第 26 行上应用 Canny 边缘检测。
顾名思义,Canny 边缘检测器可以在我们的图像中找到类似边缘的区域。看看下面的图片,明白我的意思:

Figure 3: Applying edge detection to our Game Boy image. Notice how we can clearly see the outline of the screen.
我们可以清楚地看到,有一个矩形边缘区域对应于我们的游戏男孩的屏幕。但是我们如何找到它呢?让我展示给你看:
# find contours in the edged image, keep only the largest
# ones, and initialize our screen contour
cnts = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
为了在我们的边缘图像中找到 Game Boy 屏幕,我们需要在图像中找到轮廓。轮廓是指物体的轮廓或剪影——在这种情况下,是指 Game Boy 屏幕的轮廓。
为了找到图像中的轮廓,我们需要第 30 行的 OpenCV cv2.findContours函数。这个方法需要三个参数。第一个是我们想要找到边缘的图像。我们传递我们的边缘图像,确保首先克隆它。cv2.findContours方法是破坏性的(意味着它处理你传入的图像),所以如果你打算以后再次使用那个图像,一定要克隆它。第二个参数cv2.RETR_TREE告诉 OpenCV 计算轮廓之间的层次(关系)。我们也可以使用cv2.RETR_LIST选项。最后,我们告诉 OpenCV 使用cv2.CV_CHAIN_APPROX_SIMPLE压缩轮廓以节省空间。
作为回报,cv2.findContours函数给我们一个已经找到的轮廓列表,但是由于不同版本的 OpenCV 处理轮廓的方式,我们必须在第 31 行解析它。
现在我们有了轮廓,我们将如何确定哪一个对应于游戏男孩屏幕呢?
嗯,我们应该做的第一件事是减少我们需要处理的轮廓的数量。我们知道,相对于图像中的其他区域,Game Boy 屏幕的面积相当大。第 32 行处理我们的轮廓排序,从最大到最小,通过使用cv2.contourArea计算轮廓的面积。我们现在只有 10 个最大的等高线。最后,我们初始化screenCnt,对应于第 33 行上的游戏男孩屏幕的轮廓。
我们现在准备确定哪个轮廓是 Game Boy 屏幕:
# loop over our contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.015 * peri, True)
# if our approximated contour has four points, then
# we can assume that we have found our screen
if len(approx) == 4:
screenCnt = approx
break
在第 36 行,我们开始遍历查询图像中的 10 个最大轮廓。然后,我们使用cv2.arcLength和cv2.approxPolyDP来近似轮廓。这些方法用于逼近轮廓的多边形曲线。为了逼近轮廓,您需要提供逼近精度等级。在这种情况下,我们使用轮廓周长的 1.5%。精度是一个需要考虑的重要值。如果您打算将这些代码应用到您自己的项目中,那么您可能不得不考虑精度值。
让我们停下来想想我们的游戏男孩屏幕的形状。
我们知道游戏机屏幕是长方形的。
我们知道矩形有四条边,因此有四个顶点。
在行 43 上,我们检查近似轮廓有多少个点。如果轮廓有四个点,它(可能)是我们的游戏机屏幕。假设轮廓有四个点,然后我们将近似轮廓存储在线 44 上。
我之所以能够进行这种四点检查,是因为我只需要研究非常少量的轮廓。我只保留了 10 个最大的轮廓,把其他的都扔掉了。另一个具有平方近似值的大轮廓的可能性非常低。
绘制我们的屏幕轮廓,我们可以清楚地看到,我们已经找到了游戏男孩屏幕:
如果你想自己画等高线,就用下面的代码:
```py`
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 3)
cv2.imshow("Game Boy Screen", image)
cv2.waitKey(0)
这就是你找到游戏机屏幕的第一部分。
在这篇文章的第二步,我将向你展示如何在游戏机屏幕上进行透视变换,就像你从上面“俯视”你的游戏机一样。然后,我们将裁剪出真正的口袋妖怪。看看下面的截图就明白我的意思了:
# 摘要
在这篇文章中,我展示了如何使用 Python、OpenCV、计算机视觉和图像处理技术在图像中找到 Game Boy 屏幕。
我们对我们的图像执行边缘检测,使用 OpenCV 和`cv2.findContours`函数找到图像中最大的轮廓,并对它们进行近似以找到它们的基本形状。具有四个点的最大轮廓对应于我们的游戏男孩屏幕。
能够在图像中找到 Game Boy 屏幕不仅仅是很酷,而且超级实用。我可以想出 10-15 种不同的方法来建立一个小企业,只需要游戏截图和移动技术,比如智能手机。
听起来有趣吗?不要害羞。给我发消息,我们可以多聊一会儿。
在下一篇文章中,我将向你展示如何将透视变换应用到我们的 Game Boy 屏幕上,这样我们就可以鸟瞰图像了。从那里,我们可以很容易地裁剪出口袋妖怪。`**
# 用 Python 构建 Pokedex:入门(第 1 步,共 6 步)
> 原文:<https://pyimagesearch.com/2014/03/10/building-pokedex-python-getting-started-step-1-6/>
[](https://pyimagesearch.com/wp-content/uploads/2014/03/ashandpokedex.png)
> 所以你是在告诉我,我们要用 Python 建立一个 Pokedex,可以 ***视觉上*** 识别口袋妖怪?就像电视剧里那样?小智
是的阿什。这正是我要告诉你的。接下来的一系列博客文章将致力于为 Game Boy 构建一个可以从原始的红、蓝、绿(JP)游戏中视觉识别口袋妖怪的 Pokedex。
不相信我?看看这个视频:
<https://www.youtube.com/embed/pDuBit0LWQ4?feature=oembed>
# 用 Python 构建 Pokedex:使用形状描述符索引我们的精灵(第 3 步,共 6 步)
> 原文:<https://pyimagesearch.com/2014/04/07/building-pokedex-python-indexing-sprites-using-shape-descriptors-step-3-6/>
[](https://pyimagesearch.com/wp-content/uploads/2014/03/whos-that-pokemon-pikachu.png)
Using shape descriptors to quantify an object is a lot like playing Who’s that Pokemon as a kid.
那么,我们的 Pokedex 将如何“知道”图像中的口袋妖怪是什么呢?我们将如何描述每一个口袋妖怪?我们要描述口袋妖怪的颜色吗?质地?还是外形?
你还记得小时候玩的那个口袋妖怪是谁吗?
你仅仅根据它的轮廓和轮廓就能识别出口袋妖怪。
我们将在这篇文章中应用同样的原则,并使用形状描述符量化口袋妖怪的轮廓。
你可能已经熟悉一些形状描述符,比如 Hu 矩。今天我要给大家介绍一个更强大的形状描述符——Zernike 矩,基于正交于单位圆的 Zernike 多项式。
听起来很复杂?
相信我,真的不是。只用几行代码,我将向您展示如何轻松计算 Zernike 矩。
# 以前的帖子
这篇文章是正在进行的关于如何使用 Python、OpenCV、计算机视觉和图像处理技术构建现实生活中的 Pokedex 的系列博客文章的一部分。如果这是你正在阅读的系列文章中的第一篇,请继续通读(这里有很多关于如何利用形状描述符的精彩内容),然后返回到之前的文章中添加一些内容。
* **步骤 1:** [用 Python 构建 Pokedex:入门(第 1 步,共 6 步)](https://pyimagesearch.com/2014/03/10/building-pokedex-python-getting-started-step-1-6/)
* **第二步:** [用 Python 构建 Pokedex:抓取口袋妖怪精灵(第二步,共六步)](https://pyimagesearch.com/2014/03/24/building-pokedex-python-scraping-pokemon-sprites-step-2-6/)
# 用 Python 构建 Pokedex:使用形状描述符索引我们的精灵
[](https://pyimagesearch.com/wp-content/uploads/2014/03/pokemonsprites.png)
**Figure 1:** Our database of Pokemon Red, Blue, and Green sprites.
此时,我们已经有了口袋妖怪精灵图像数据库。我们收集、抓取并下载了我们的精灵,但是现在我们需要根据它们的轮廓(也就是它们的形状)来量化它们。
还记得玩“那个口袋妖怪是谁?”小时候?这就是我们的形状描述符将为我们做的。
对于那些没有看过口袋妖怪(或者可能需要他们的记忆慢跑)的人来说,这篇文章顶部的图像是口袋妖怪电视节目的截图。在进入广告时段之前,一个像这样的屏幕会弹出口袋妖怪的轮廓。目标是仅根据轮廓猜测口袋妖怪的名字。
这基本上就是我们的 Pokedex 将要做的——玩那个口袋妖怪是谁,但是是以一种自动化的方式。以及计算机视觉和图像处理技术。
## 泽尔尼克矩
在深入研究大量代码之前,让我们先快速回顾一下 Zernike moments。
图像矩用于描述图像中的对象。使用图像矩,您可以计算诸如对象的面积、质心(对象的中心,以 x、y 坐标表示)以及关于对象如何旋转的信息等值。通常,我们基于图像的轮廓或外形来计算图像矩,但这不是必需的。
OpenCV 提供了`[HuMoments](http://docs.opencv.org/modules/imgproc/doc/structural_analysis_and_shape_descriptors.html#humoments)`函数,可以用来描述物体的结构和形状。然而,一个更强大的形状描述符可以在`[mahotas](http://luispedro.org/software/mahotas)`包— `[zernike_moments](http://mahotas.readthedocs.org/en/latest/api.html#mahotas.features.zernike_moments)`中找到。与 Hu 矩类似,Zernike 矩用于描述物体的形状;然而,由于 Zernike 多项式彼此正交,所以矩之间没有冗余信息。
使用 Zernike 矩进行形状描述时,需要注意的一点是图像中对象的缩放和平移。根据图像在图像中的转换位置,您的 Zernike 时刻会有很大不同。同样,根据图像的大小(即物体的缩放比例),Zernike 矩也不会相同。然而,Zernike 矩的大小与对象的旋转无关,这在处理形状描述符时是一个非常好的特性。
为了避免描述符基于图像的平移和缩放而具有不同的值,我们通常首先执行分割。也就是说,我们将前景(图像中我们感兴趣的对象)与背景(“噪声”,或图像中我们不想描述的部分)分割开来。一旦我们有了分割,我们就可以在对象周围形成一个紧密的包围盒并将其裁剪掉,从而获得平移不变性。
最后,我们可以将对象的大小调整为常数 *NxM* 像素,从而获得缩放不变性。
由此,直接应用 Zernike 矩来表征物体的形状。
正如我们将在这一系列博文的后面看到的,我将在应用 Zernike 矩之前利用缩放和平移不变性。
## 泽尼克描述符
好了,概述够了。让我们动手写一些代码。
```py
# import the necessary packages
import mahotas
class ZernikeMoments:
def __init__(self, radius):
# store the size of the radius that will be
# used when computing moments
self.radius = radius
def describe(self, image):
# return the Zernike moments for the image
return mahotas.features.zernike_moments(image, self.radius)
正如你从霍比特人和直方图的帖子中可能知道的,我倾向于将我的图像描述符定义为类而不是函数。这是因为你很少单独从一幅图像中提取特征。相反,您可以从影像数据集中提取要素。并且您很可能对不同图像的描述符使用完全相同的参数。
例如,如果您的目的是比较图像#1 和图像#2,那么从图像# 1 中提取 32 个面元的灰度直方图和从图像# 2 中提取 16 个面元的灰度直方图是没有意义的。相反,您利用相同的参数来确保在整个数据集上有一个一致的表示。
也就是说,让我们来看看这段代码:
- 第 2 行:这里我们导入的是
mahotas包,里面包含了很多有用的图像处理功能。该包还包含我们的 Zernike moments 的实施。 - 第 4 行:让我们为描述符定义一个类。我们就叫它
ZernikeMoments。 - 第 5-8 行:我们需要一个构造函数给我们的
ZernikeMoments类。它只需要一个参数——以像素为单位的多项式的radius。半径越大,计算中包含的像素就越多。这是一个重要的参数,如果您在本系列博客帖子之外使用 Zernike moments,您可能需要对其进行调整和修改,以获得足够的性能结果。 - 第 10-12 行:这里我们定义了
describe方法,它量化了我们的图像。这个方法需要描述一个图像,然后调用zernike_moments的mahotas实现,用行 5 中提供的指定radius计算矩。
总的来说,这段代码不多。它主要是对zernike_moments的mahotas实现的包装。但是正如我所说的,我喜欢将我的描述符定义为类而不是函数,以确保参数使用的一致性。
接下来,我们将通过量化每个口袋妖怪精灵的形状来索引我们的数据集。
索引我们的口袋妖怪精灵
现在我们已经定义了形状描述符,我们需要将它应用到数据库中的每个口袋妖怪精灵。这是一个相当简单的过程,所以我会让代码做大部分的解释。让我们打开我们最喜欢的编辑器,创建一个名为index.py的文件,然后开始工作:
# import the necessary packages
from pyimagesearch.zernikemoments import ZernikeMoments
from imutils.paths import list_images
import numpy as np
import argparse
import pickle
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--sprites", required = True,
help = "Path where the sprites will be stored")
ap.add_argument("-i", "--index", required = True,
help = "Path to where the index file will be stored")
args = vars(ap.parse_args())
# initialize our descriptor (Zernike Moments with a radius
# of 21 used to characterize the shape of our pokemon) and
# our index dictionary
desc = ZernikeMoments(21)
index = {}
第 2-8 行处理导入我们需要的包。为了便于组织,我将我们的ZernikeMoments类放在了pyimagesearch子模块中。在构造多维数组时,我们将使用numpy,argparse解析命令行参数,pickle将索引写入文件,glob获取 sprite 图像的路径,而cv2用于 OpenCV 函数。
然后,第 11-16 行解析我们的命令行参数。--sprites开关是我们收集的口袋妖怪精灵目录的路径,--index指向我们的索引文件将被存储的地方。
第 21 行处理初始化我们的ZernikeMoments描述符。我们将使用 21 像素的半径。经过几次实验,我确定了 21 个像素的值,并确定了哪个半径获得了最好的性能结果。
最后,我们在第 22 行的上初始化我们的index。我们的索引是一个内置的 Python 字典,其中的键是 Pokemon sprite 的文件名,值是计算出的 Zernike 矩。在这种情况下,所有的文件名都是唯一的,所以字典是一个很好的选择,因为它很简单。
量化我们口袋妖怪精灵的时间到了:
# loop over the sprite images
for spritePath in list_images(args["sprites"]):
# parse out the pokemon name, then load the image and
# convert it to grayscale
pokemon = spritePath[spritePath.rfind("/") + 1:].replace(".png", "")
image = cv2.imread(spritePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# pad the image with extra white pixels to ensure the
# edges of the pokemon are not up against the borders
# of the image
image = cv2.copyMakeBorder(image, 15, 15, 15, 15,
cv2.BORDER_CONSTANT, value = 255)
# invert the image and threshold it
thresh = cv2.bitwise_not(image)
thresh[thresh > 0] = 255
现在我们准备从数据集中提取 Zernike 矩。让我们把这段代码拆开,并确保我们理解发生了什么:
- 第 25 行:我们使用
glob来获取所有口袋妖怪精灵图像的路径。我们所有的精灵都有一个. png 的文件扩展名。如果你以前从未使用过glob,这是一个非常简单的方法来获取一组具有公共文件名或扩展名的图像的路径。现在我们有了图像的路径,我们一个接一个地循环它们。 - 第 28 行:我们首先要做的是从文件名中提取出口袋妖怪的名字。这将作为索引字典中的唯一键。
- 第 29 行和第 30 行:这段代码非常简单明了。我们从磁盘上加载当前图像,并将其转换为灰度。
- 第 35 行和第 36 行:就我个人而言,我发现
copyMakeBorder函数的名字非常令人困惑。名字本身并不能真正描述它的功能。实际上,copyMakeBorder沿着图像的北、南、东、西方向“填充”图像。我们传入的第一个参数是口袋妖怪精灵。然后,我们用 15 个白色(255)像素在所有方向填充这个图像。这一步不是必须的,但它让你对第 39 行的阈值有更好的理解。 - 第 39 行和第 40 行:正如我提到的,在应用 Zernike 矩之前,我们需要口袋妖怪图像的轮廓(或遮罩)。为了找到轮廓,我们需要应用分割,丢弃图像的背景(白色)像素,只关注口袋妖怪本身。这实际上很简单——我们需要做的就是翻转像素值(黑色像素变成白色,白色像素变成黑色)。然后,任何值大于零(黑色)的像素被设置为 255(白色)。
看看我们下面的阈值图像:
Figure 2: Our Abra sprite is pictured on the top and the thresholded image on the bottom.
这个过程给了我们口袋妖怪的面具。现在我们需要面具最外面的轮廓——口袋妖怪的实际轮廓。
# initialize the outline image, find the outermost
# contours (the outline) of the pokemone, then draw
# it
outline = np.zeros(image.shape, dtype = "uint8")
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
cv2.drawContours(outline, [cnts], -1, 255, -1)
首先,我们需要一个空白的图像来存储我们的轮廓——我们在第 45 行的上添加了一个名为outline的变量,并用零填充它,其宽度和高度与我们的精灵图像相同。
然后,我们在线路 46 和 47 上给cv2.findContours打电话。我们传入的第一个参数是我们的阈值图像,后面是一个标志cv2.RETR_EXTERNAL,告诉 OpenCV 只查找最外面的轮廓。最后,我们使用cv2.CHAIN_APPROX_SIMPLE标志告诉 OpenCV 压缩和逼近轮廓以节省内存。
第 48 行处理各种版本 OpenCV 的轮廓解析。
正如我提到的,我们只对最大的轮廓感兴趣,这对应于口袋妖怪的轮廓。因此,在第 49 行上,我们根据面积对轮廓进行降序排序。我们只保留最大的轮廓,而丢弃其他轮廓。
最后,我们使用cv2.drawContours功能在轮廓图像上绘制轮廓。轮廓被绘制为带有白色像素的填充蒙版:
Figure 3: Outline of our Abra. We will be using this image to compute our Zernike moments.
我们将使用这个轮廓图像来计算我们的泽尼克时刻。
计算轮廓的 Zernike 矩实际上很容易:
# compute Zernike moments to characterize the shape
# of pokemon outline, then update the index
moments = desc.describe(outline)
index[pokemon] = moments
在第 54 行的上,我们调用了ZernikeMoments类中的describe方法。我们需要做的就是传入图像的轮廓,剩下的就交给describe方法了。作为回报,我们得到了用于表征和量化口袋妖怪形状的 Zernike 矩。
那么我们如何量化和表现口袋妖怪的形状呢?
让我们来调查一下:
>>> moments.shape
(25,)
这里我们可以看到我们的特征向量是 25 维的(意味着我们的列表中有 25 个值)。这 25 个值代表了口袋妖怪的轮廓。
我们可以像这样查看 Zernike 矩特征向量的值:
>>> moments
[ 0.31830989 0.00137926 0.24653755 0.03015183 0.00321483 0.03953142
0.10837637 0.00404093 0.09652134 0.005004 0.01573373 0.0197918
0.04699774 0.03764576 0.04850296 0.03677655 0.00160505 0.02787968
0.02815242 0.05123364 0.04502072 0.03710325 0.05971383 0.00891869
0.02457978]
所以你有它!口袋妖怪大纲现在只使用 25 个浮点值进行量化!使用这 25 个数字,我们将能够区分所有最初的 151 个口袋妖怪。
最后在第 55 行的上,我们用口袋妖怪的名字作为关键字,用我们计算的特征作为我们的值来更新我们的索引。
我们需要做的最后一件事是将我们的索引转储到文件中,以便在执行搜索时使用:
# write the index to file
f = open(args["index"], "wb")
f.write(pickle.dumps(index))
f.close()
要执行我们的脚本来索引我们所有的口袋妖怪精灵,发出以下命令:
$ python index.py --sprites sprites --index index.cpickle
一旦脚本完成执行,我们所有的口袋妖怪将在形状方面量化。
在这一系列博客文章的后面,我将向您展示如何从 Game Boy 屏幕中自动提取一个口袋妖怪,然后将其与我们的索引进行比较。
摘要
在这篇博文中,我们探索了 Zernike 矩以及它们如何被用来描述和量化物体的形状。
在这种情况下,我们使用 Zernike 矩来量化最初 151 个口袋妖怪的轮廓。想到这个最简单的方法就是玩“那个口袋妖怪是谁?”小时候。给你一个口袋妖怪的轮廓,然后你必须只用轮廓猜口袋妖怪是什么。我们在做同样的事情——只不过我们是自动做的。
这个描述和量化一组图像的过程称为“索引”。
既然我们已经量化了口袋妖怪,我将在这一系列帖子的后面向你展示如何搜索和识别口袋妖怪。
用 Python 构建 Pokedex:OpenCV 和透视变形(第 5 步,共 6 步)
原文:https://pyimagesearch.com/2014/05/05/building-pokedex-python-opencv-perspective-warping-step-5-6/
Figure 1: Performing a perspective transformation using Python and OpenCV on the Game Boy screen and cropping out the Pokemon.
我们离完成现实生活中的 Pokedex 越来越近了!
在我之前的博客文章中,我向你展示了如何使用 Python 和 OpenCV 在图像中找到一个游戏机屏幕。
这篇文章将向你展示如何应用扭曲变换来获得 Game Boy 屏幕的“鸟瞰图”。从那里,我们将能够裁剪出真正的口袋妖怪,并将其输入我们的口袋妖怪识别算法。
以前的帖子
这篇文章是正在进行的关于如何使用 Python、OpenCV、计算机视觉和图像处理技术构建现实生活中的 Pokedex 的系列博客文章的一部分。如果这是你正在阅读的系列文章中的第一篇,一定要看看!但是在你读完之后,一定要回去看看以前的帖子——那里有大量令人敬畏的计算机视觉和图像处理内容。
最后,如果你有任何问题,请随时给我发电子邮件。我很乐意聊天。
- 步骤 1: 用 Python 构建 Pokedex:入门(第 1 步,共 6 步)
- 第二步: 用 Python 构建 Pokedex:抓取口袋妖怪精灵(第二步,共六步)
- 第三步: 用 Python 构建 Pokedex:使用形状描述符索引我们的精灵(第三步,共六步)
- 第 4 步: 用 Python 构建 Pokedex:寻找游戏男孩屏幕(第 4 步,共 6 步)
在 Python 中构建 Pokedex:OpenCV 透视转换示例
当我们结束了上一篇关于用 Python 构建 Pokedex 的文章时,我们能够通过应用边缘检测、找到轮廓、然后近似轮廓来找到我们的游戏男孩屏幕,就像这样:
Figure 2: Finding a Game Boy screen in an image using Python and OpenCV.
然而,你可能会注意到 Game Boy 的屏幕有点倾斜——屏幕肯定是向右倾斜的。
屏幕的视角也不对。理想情况下,我们希望 Game Boy 屏幕有一个自上而下的鸟瞰图,如图 1 所示。
我们将如何实现这一目标?
让我们跳到一些代码中。
我们将基于前一篇文章中的代码进行构建,所以如果我们看起来像是跳到了一个文件的中间,那是因为我们确实是这样。
# now that we have our screen contour, we need to determine
# the top-left, top-right, bottom-right, and bottom-left
# points so that we can later warp the image -- we'll start
# by reshaping our contour to be our finals and initializing
# our output rectangle in top-left, top-right, bottom-right,
# and bottom-left order
pts = screenCnt.reshape(4, 2)
rect = np.zeros((4, 2), dtype = "float32")
# the top-left point has the smallest sum whereas the
# bottom-right has the largest sum
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# compute the difference between the points -- the top-right
# will have the minumum difference and the bottom-left will
# have the maximum difference
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
# multiply the rectangle by the original ratio
rect *= ratio
在第 53 行上,我们正在重塑与屏幕轮廓相对应的轮廓。轮廓有四个点,屏幕矩形区域的四个点。我们只是重塑了点的 NumPy 数组,使它们更容易处理。
为了应用透视变换,我们需要知道轮廓的左上角、右上角、右下角和左下角。然而,仅仅因为我们有对应于 Game Boy 屏幕的轮廓,我们就不能保证点的顺序。不能保证左上角的点是轮廓列表中的第一个点。这可能是第二点。还是第四点。
为了解决这个问题,我们必须对这些要点进行严格的排序。我们从第 54 行的开始,初始化我们的矩形(4, 2)来存储有序的点。
第 58-60 行处理抓取左上角和右下角的点。第 58 行通过指定axis=1将 (x,y) 坐标相加。左上角点的总和最小(行 59 ),而右下角点的总和最大(行 60 )。
现在我们需要通过取 (x,y) 坐标之间的差来抓取线 65-67 上的右上角和左下角的点。右上角的点将具有最小的差异(线 66 ),而左下角的点将具有最大的差异(线 67 )。
请注意我们的点现在是如何按照强加的顺序存储的:左上、右上、右下和左下。当我们应用视角转换时,保持一致的顺序是很重要的。
如果你还记得以前的帖子,我们调整了图像的大小,以使图像处理和边缘检测更快更准确。我们跟踪这个调整大小的ratio有一个很好的理由——当我们裁剪掉游戏男孩屏幕时,我们想要裁剪掉原来的 游戏男孩屏幕,而不是更小的、调整过大小的那个。
为了提取原始的、大的 Game Boy 屏幕,我们将我们的rect乘以ratio,从而将点转换为原始图像大小。
接下来,我们需要计算 Game Boy 屏幕的大小,以便我们可以分配内存来存储它:
# now that we have our rectangle of points, let's compute
# the width of our new image
(tl, tr, br, bl) = rect
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
# ...and now for the height of our new image
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
# take the maximum of the width and height values to reach
# our final dimensions
maxWidth = max(int(widthA), int(widthB))
maxHeight = max(int(heightA), int(heightB))
# construct our destination points which will be used to
# map the screen to a top-down, "birds eye" view
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# calculate the perspective transform matrix and warp
# the perspective to grab the screen
M = cv2.getPerspectiveTransform(rect, dst)
warp = cv2.warpPerspective(orig, M, (maxWidth, maxHeight))
让我们拆开这段代码,看看发生了什么:
- 第 74 行:在这里我们打开我们的
rect并分别抓取左上角、右上角、右下角和左下角的点。 - 第 75 行:为了确定图像的宽度,我们计算右下角和左下角点的 x 坐标之间的距离。
- 第 76 行:同样,我们计算右上角和左上角点的 x 坐标之间的距离。
- 第 79 行和第 80 行:就像我们计算了 x 坐标点之间的距离一样,我们现在需要为 y 坐标点做同样的事情。
- 第 84 行和第 85 行:现在我们有了距离,我们取
widthA和widthB的最大值来确定我们转换后的图像的宽度。然后我们对heightA和heightB重复这个过程来确定新图像的尺寸。 - 第 89-93 行:还记得我说过要点的顺序很重要吗?为了计算 Game Boy 屏幕的鸟瞰图,我们需要构建一个矩阵
dst来处理映射。dst 中的第一个条目是图像的原点—左上角。然后,我们根据计算出的宽度和高度指定右上、右下和左下的点。 - 第 97 行:为了计算透视变换,我们需要实际的变换矩阵。这个矩阵是通过调用
cv2.getPerspectivetransformation 并传入原始图像中 Game Boy 屏幕的坐标来计算的,后面是我们为输出图像指定的四个点。作为回报,我们得到了我们的转换矩阵M。 - 最后,我们可以通过调用
cv2.warpPerspective函数来应用我们的转换。第一个参数是我们想要扭曲的原始图像,第二个是我们从cv2.getPerspective获得的变换矩阵M,最后一个参数是一个元组,用来表示输出图像的宽度和高度。
如果一切顺利,我们现在应该有一个自上而下/鸟瞰我们的游戏男孩屏幕:
Figure 2: Obtaining a top-down/birds-eye-view of an image using Python, OpenCV, and perspective warping and transformations.
但是我们还没有完成!
我们仍然需要从屏幕的右上方裁剪出真正的口袋妖怪。
此外,你会注意到我们的 Marowak 似乎有点“模糊”, Game Boy 本身的屏幕比我们希望的要暗。我们需要看看我们是否可以重新缩放我们图像的强度,以帮助减轻这种阴影,并使提取 Marowak 的轮廓变得更容易,之后允许我们计算 Pokemon 轮廓的形状特征。
# convert the warped image to grayscale and then adjust
# the intensity of the pixels to have minimum and maximum
# values of 0 and 255, respectively
warp = cv2.cvtColor(warp, cv2.COLOR_BGR2GRAY)
warp = exposure.rescale_intensity(warp, out_range = (0, 255))
# the pokemon we want to identify will be in the top-right
# corner of the warped image -- let's crop this region out
(h, w) = warp.shape
(dX, dY) = (int(w * 0.4), int(h * 0.45))
crop = warp[10:dY, w - dX:w - 10]
# save the cropped image to file
cv2.imwrite("cropped.png", crop)
# show our images
cv2.imshow("image", image)
cv2.imshow("edge", edged)
cv2.imshow("warp", imutils.resize(warp, height = 300))
cv2.imshow("crop", imutils.resize(crop, height = 300))
cv2.waitKey(0)
我们要做的第一件事是在行 103 将扭曲的图像转换成灰度。然后,我们利用 skimage Python 库。我们调用了exposure子包中的rescale_intensity方法。该方法采用我们的扭曲图像,然后通过找到最小值和最大值来重新缩放灰度像素强度。然后,最小值变成黑色(值为 0),最大值变成白色(值为 255)。落入该范围的所有像素都相应地缩放。
这种重新缩放的输出如下所示:
![]()
Figure 3: Re-scaling the intensity of pixels using scikit-image.
请注意阴影区域是如何变得不明显的。
从这里开始,我们需要的只是一些简单的裁剪。
我们在行 108 上抓取扭曲的 Game Boy 屏幕的高度和宽度,然后在行 109 上确定一个宽度为 40%、高度为 45%的区域——我们要识别的口袋妖怪将位于图像的这个区域内:
Figure 4: Cropping the Pokemon from our Game Boy screen using Python and OpenCV.
注意:我是通过反复试验来确定这些百分比的。没有什么奇特的计算机视觉魔术在上演。只是你的标准测试和调试,以找到正确的百分比。
我们从 Game Boy 屏幕的第 110 行的中裁剪出口袋妖怪,并将其写入第 113 行的文件中。在这个系列的下一篇(也是最后一篇)博文中,我们将使用这个裁剪后的图像来执行口袋妖怪的实际识别。
最后,第 116-120 行只是向我们展示了我们的劳动成果:
要在 Game Boy 屏幕中对口袋妖怪执行我们的脚本,只需执行以下命令:
$ python find_screen.py --query queries/query_marowak.jpg
摘要
在这篇博文中,我们使用 Python 和 OpenCV 应用了透视和扭曲变换。我们利用cv2.getPerspectiveTransform和cv2.warpPerspective函数来完成这些转换。然后我们回顾了一个透视图转换 OpenCV 的例子。
我们应用这些技术来获得 Game Boy 屏幕的俯视图/鸟瞰图,从而可以裁剪出我们想要识别的口袋妖怪。这个例子演示了 OpenCV 透视转换。
最后,我们使用scikit-image来重新调整灰度裁剪图像的像素强度。
我的下一篇文章将总结这一系列的文章,并把所有的事情联系起来。我们会拿着我们的口袋妖怪,然后通过我们的识别算法运行它。
从那里,我们将有一个现实生活中的工作 Pokedex!
用 Python 构建 Pokedex:抓取口袋妖怪精灵(第 2 步,共 6 步)
原文:https://pyimagesearch.com/2014/03/24/building-pokedex-python-scraping-pokemon-sprites-step-2-6/
![]()
Figure 1: Our database of Pokemon Red, Blue, and Green sprites.
如果我们能建立一个真实生活的 Pokedex 会怎么样?
你知道,就像小智一样——用你的 Pokedex 指向一只口袋妖怪(或者在这种情况下,给一只口袋妖怪拍照),识别它,并获得它的统计数据。
虽然这个想法源于口袋妖怪电视剧,但我将向你展示如何将它变成现实。
以前的帖子:
在我们深入讨论细节之前,这里有一些以前的帖子,你可以查看一下关于构建我们的 Pokedex 的上下文和更多细节:
第二步:抓取我们的口袋妖怪数据库
在开始构建我们的口袋妖怪搜索引擎之前,我们首先需要收集数据。这篇文章正是致力于此——搜集和建立我们的口袋妖怪数据库。我把这篇文章组织成了一个 Python web 抓取教程;当你读完这篇文章的时候,你将会像专业人士一样用 Python 抓取网页。
我们的数据来源
我最终决定刮口袋妖怪 DB 因为他们有一些容易获得的最高质量的精灵。他们的 HTML 格式很好,使得下载口袋妖怪精灵图像很容易。
不过我稍微作弊了一下,把网页的相关部分复制粘贴成了明文文件。以下是一些 HTML 的示例:
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n2"></i></span><span class="infocard-data"><a href="/sprites/ivysaur" class="ent-name">Ivysaur</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n3"></i></span><span class="infocard-data"><a href="/sprites/venusaur" class="ent-name">Venusaur</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n4"></i></span><span class="infocard-data"><a href="/sprites/charmander" class="ent-name">Charmander</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n5"></i></span><span class="infocard-data"><a href="/sprites/charmeleon" class="ent-name">Charmeleon</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n6"></i></span><span class="infocard-data"><a href="/sprites/charizard" class="ent-name">Charizard</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n7"></i></span><span class="infocard-data"><a href="/sprites/squirtle" class="ent-name">Squirtle</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n8"></i></span><span class="infocard-data"><a href="/sprites/wartortle" class="ent-name">Wartortle</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n9"></i></span><span class="infocard-data"><a href="/sprites/blastoise" class="ent-name">Blastoise</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n10"></i></span><span class="infocard-data"><a href="/sprites/caterpie" class="ent-name">Caterpie</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n11"></i></span><span class="infocard-data"><a href="/sprites/metapod" class="ent-name">Metapod</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n12"></i></span><span class="infocard-data"><a href="/sprites/butterfree" class="ent-name">Butterfree</a></span></span>
<span class="infocard"><span class="infocard-img"><i class="pki" data-sprite="pkiAll n13"></i></span><span class="infocard-data"><a href="/sprites/weedle" class="ent-name">Weedle</a></span></span>
...
你可以使用本文底部的表格下载完整的 HTML 文件。
抓取和下载
现在我们有了原始的 HTML,我们需要解析它并为每个口袋妖怪下载精灵。
我非常喜欢大量的例子和代码,所以让我们直接进入主题,想想我们该怎么做:
# import the necessary packages
from bs4 import BeautifulSoup
import argparse
import requests
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--pokemon-list", required = True,
help = "Path to where the raw Pokemon HTML file resides")
ap.add_argument("-s", "--sprites", required = True,
help = "Path where the sprites will be stored")
args = vars(ap.parse_args())
第 2-4 行处理导入我们将使用的包。我们将使用BeautifulSoup解析 HTML,使用requests下载口袋妖怪图像。最后,argparse用于解析我们的命令行参数。
要安装 Beautiful soup,只需使用 pip:
$ pip install beautifulsoup4
然后,在第 7-12 行我们解析我们的命令行参数。开关--pokemon-list是我们将要解析的 HTML 文件的路径,而--sprites是下载和存储口袋妖怪精灵的目录的路径。
现在,让我们从 HTML 文件中提取口袋妖怪的名字:
# construct the soup and initialize the list of pokemon
# names
soup = BeautifulSoup(open(args["pokemon_list"]).read())
names = []
# loop over all link elements
for link in soup.findAll("a"):
# update the list of pokemon names
names.append(link.text)
在第 16 行的处,我们使用BeautifulSoup来解析我们的 HTML——我们简单地从磁盘上加载我们的 HTML 文件,然后将它传递给构造函数。BeautifulSoup其他的就交给他了。然后第 17 行初始化列表来存储我们的口袋妖怪names。
然后,我们开始循环第 20 行上的所有链接元素。这些链接的 href 属性指向一个特定的口袋妖怪。但是,我们不需要跟踪每个链接。相反,我们只是获取元素的内部文本。这段文字包含了我们的口袋妖怪的名字。
# loop over the pokemon names
for name in names:
# initialize the parsed name as just the lowercase
# version of the pokemon name
parsedName = name.lower()
# if the name contains an apostrophe (such as in
# Farfetch'd, just simply remove it)
parsedName = parsedName.replace("'", "")
# if the name contains a period followed by a space
# (as is the case with Mr. Mime), then replace it
# with a dash
parsedName = parsedName.replace(". ", "-")
# handle the case for Nidoran (female)
if name.find(u'\u2640') != -1:
parsedName = "nidoran-f"
# and handle the case for Nidoran (male)
elif name.find(u'\u2642') != -1:
parsedName = "nidoran-m"
现在我们有了一个口袋妖怪名字的列表,我们需要循环遍历它们(第 25 行)并正确格式化名字,这样我们就可以下载文件了。最终,经过格式化和净化的名称将用于下载 sprite 的 URL 中。
让我们来看看这些步骤:
- 第 28 行:净化口袋妖怪名字的第一步是将其转换成小写。
- 第 32 行:我们需要处理的第一个特例是删除撇号。撇号出现在名称“Farfetch'd”中。
- 第 37 行:然后,我们需要替换一个句号和空格的出现。这发生在“哑剧先生”这个名字里。请注意“.”在名字中间。这个需要去掉。
- 第 40-45 行:现在,我们需要处理尼多朗家族中出现的 unicode 字符。“男性”和“女性”的符号在实际游戏中使用,但是为了下载 Nidorans 的精灵,我们需要手动构造文件名。
现在,我们终于可以下载口袋妖怪精灵了:
# construct the URL to download the sprite
print "[x] downloading %s" % (name)
url = "http://img.pokemondb.net/sprites/red-blue/normal/%s.png" % (parsedName)
r = requests.get(url)
# if the status code is not 200, ignore the sprite
if r.status_code != 200:
print "[x] error downloading %s" % (name)
continue
# write the sprite to file
f = open("%s/%s.png" % (args["sprites"], name.lower()), "wb")
f.write(r.content)
f.close()
第 49 行构建口袋妖怪精灵的 URL。URL 的基础是http://img.pokemondb.net/sprites/red-blue/normal/——我们通过添加口袋妖怪的名字加上“.”来完成 URL 的构建。png "文件扩展名。
使用requests包在一行(行 50 )上下载实际图像。
第 53-55 行检查请求的状态代码。如果状态代码不是 200,表明下载不成功,那么我们处理错误并继续循环 Pokemon 名称。
最后第 58-60 行将精灵保存到文件中。
运行我们的刮擦
现在我们的代码已经完成,我们可以通过发出以下命令来执行我们的抓取:
$ python parse_and_download.py --pokemon-list pokemon_list.html --sprites sprites
这个脚本假设包含口袋妖怪 HTML 的文件存储在pokemon_list.html中,下载的口袋妖怪精灵将存储在sprites目录中。
脚本运行完成后,您应该有一个充满 Pokemon 精灵的目录:
![]()
Figure 1: After parse_and_download.py has finished running, you should have a directory filled with Pokemon sprites, like this.
就这么简单!只需一点代码和一些关于如何抓取图像的知识,我们就可以用不到 75 行代码构建一个 Python 脚本来抓取口袋妖怪精灵。
注:在我写完这篇博文后, thegatekeeper07 建议使用 Veekun 口袋妖怪数据库。使用这个数据库可以让你跳过抓取步骤,你可以下载一个口袋妖怪精灵的 tarball。如果你决定采取这种方法,这是一个很好的选择;但是,您可能需要稍微修改我的源代码来使用 Veekun 数据库。只是一些需要记住的事情!
摘要
这篇文章充当了 Python 网页抓取教程:我们从红色、蓝色和绿色版本下载了最初的 151 个口袋妖怪的精灵图像。
我们利用BeautifulSoup和requests包下载我们的口袋妖怪。这些软件包对于使刮削变得容易和简单,并使头痛最小化是必不可少的。
现在我们有了口袋妖怪的数据库,我们可以索引它们,并使用形状描述符来描述它们的形状。我们将在下一篇博文中讨论这个问题。
如果您希望在本系列文章发布时收到电子邮件更新,请在下表中输入您的电子邮件地址:
用 Python 和 OpenCV 捕捉鼠标点击事件
原文:https://pyimagesearch.com/2015/03/09/capturing-mouse-click-events-with-python-and-opencv/
在美国东海岸长大,我想我现在应该已经习惯了下雪——但我没有。小时候,我喜欢雪。我喜欢滑雪橇、滑雪和打雪仗。
但是现在,作为一个成年人,雪只是意味着不便。这意味着旅行将会很糟糕。意思是不能开车去健身房。这意味着被困在公寓里。
也就是说,我将在东海岸的这个下雪天写一篇关于用 Python 和 OpenCV 捕捉鼠标点击事件的博文。
https://www.youtube.com/embed/OzxT3tsp1pI?feature=oembed
使用 Keras 更改输入形状尺寸以进行微调
原文:https://pyimagesearch.com/2019/06/24/change-input-shape-dimensions-for-fine-tuning-with-keras/
在本教程中,您将学习如何使用 Keras 更改用于微调的输入形状张量维度。通读本指南后,你将理解如何将迁移学习应用于不同图像尺寸的图像,而不是 CNN 最初训练的图像尺寸。
几周前,我发表了一篇关于 Keras 迁移学习和深度学习的教程——在这篇教程发表后不久,我收到了 Francesca Maepa 的一个问题,她提出了以下问题:
你是否知道一个好的博客或教程,展示如何在一个比预训练模型更小的数据集上实现迁移学习?
我创建了一个非常好的预训练模型,并希望将一些特征用于预训练模型,并将它们转移到缺少某些特征训练数据集的目标域,但我不确定这样做是否正确。
弗朗西丝卡问了一个很好的问题。
通常我们认为卷积神经网络接受固定大小的输入(即 224×224 、 227×227 、 299×299 等)。).
但是如果你想:
- 利用预先培训的网络进行迁移学习…
- …然后更新输入形状尺寸,以接受尺寸不同于原始网络训练尺寸的图像。
为什么您可能想要利用不同的图像尺寸?
有两个常见的原因:
- 你的输入图像尺寸 比 CNN 训练的 小得多,增加它们的尺寸会引入太多的伪像,并极大地损害损失/准确性。
- 你的图像是 高分辨率 的,包含难以察觉的小物体。调整到 CNN 的原始输入尺寸会损害准确性,你假设增加分辨率将有助于改善你的模型。
在这些情况下,您可能希望更新 CNN 的输入形状维度,然后能够执行迁移学习。
那么问题就变成了,这样的更新可能吗?
是的,事实上,它是。
使用 Keras 更改输入形状尺寸以进行微调
2020-06-04 更新:此博文现已兼容 TensorFlow 2+!
在本教程的第一部分,我们将讨论输入形状张量的概念,以及它在 CNN 输入图像维度中的作用。
从那里,我们将讨论我们将在这篇博文中使用的示例数据集。然后,我将向您展示如何:
- 使用 Keras 将输入图像尺寸更新为预训练的 CNN。
- 微调更新的 CNN。我们开始吧!
什么是输入形状张量?

Figure 1: Convolutional Neural Networks built with Keras for deep learning have different input shape expectations. In this blog post, you’ll learn how to change input shape dimensions for fine-tuning with Keras.
当使用 Keras 和深度学习时,您可能会利用或遇到通过以下方式加载预训练网络的代码:
model = VGG16(weights="imagenet")
上面的代码初始化 VGG16 架构,然后加载模型的权重(在 ImageNet 上预先训练)。
当我们的项目需要对 ImageNet (本教程演示的)中有类别标签的输入图像进行分类时,我们通常会使用这个代码。
执行迁移学习或微调时,您可以使用以下代码来删除全连接(FC)层头:
model = VGG16(weights="imagenet", include_top=False)
我们仍然指示应该使用预训练的 ImageNet 权重,但是现在我们设置include_top=False,指示不应该加载 FC 头。
最后,我们可以更新我们的代码以包含一个 input_tensor 维度:
model = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
我们仍在加载 VGG16,并在 ImageNet 上预先训练了权重,我们仍在忽略 FC 图层头……但现在我们指定了一个输入形状 224×224 x3 (这是 VGG16 最初训练的输入图像尺寸,如图图 1 ,左)。
这一切都很好,但是如果我们现在想在 128×128 像素的图像上微调我们的模型呢?
这实际上只是对我们的模型初始化的简单更新:
model = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(128, 128, 3)))
图 1 ( 右)提供了更新输入张量维度的网络的可视化——注意输入量现在是 128x128x3 (我们更新后的更小维度)与之前的 224x224x3 (原始的更大维度)的对比。
通过 Keras 更新 CNN 的输入形状尺寸就是这么简单!
但是有一些警告需要注意。
我能把输入尺寸做成我想要的吗?
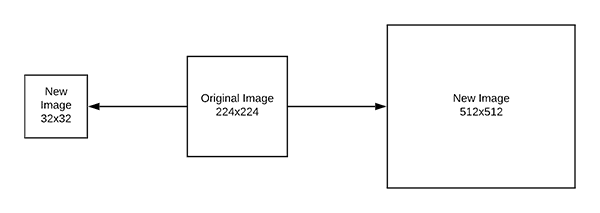
Figure 2: Updating a Keras CNN’s input shape is straightforward; however, there are a few caveats to take into consideration,
从精确度/损失角度和网络本身的限制来看,你可以更新的图像尺寸是有限的。
考虑 CNN 通过两种方法减少体积的事实:
- 池化(如 VGG16 中的最大池化)
- 交错卷积(例如在 ResNet 中)
如果您的输入图像尺寸太小,那么 CNN 将在向前传播期间自然减少体积尺寸,然后有效地“用完”数据。
在这种情况下,您的输入尺寸太小。
例如,当使用 48×48 输入图像时,我收到了以下错误消息:
ValueError: Negative dimension size caused by subtracting 4 from 1 for 'average_pooling2d_1/AvgPool' (op: 'AvgPool') with input shapes: [?,1,1,512].
注意 Keras 是如何抱怨我们的体积太小的。对于其他预先训练的网络,您也会遇到类似的错误。当您看到这种类型的错误时,您知道您需要增加输入图像的尺寸。
您也可以使您的输入尺寸过大。
您不会遇到任何错误本身,但是您可能会看到您的网络无法获得合理的准确性,因为网络中没有足够的层来:
- 学习强健的、有辨别能力的过滤器。
- 通过池化或步长卷积自然减少卷大小。
如果发生这种情况,你有几个选择:
- 探索在更大输入维度上训练的其他(预训练)网络架构。
- 彻底调整你的超参数,首先关注学习率。
- 向网络添加额外的层。对于 VGG16,您将使用 3×3 CONV 层和最大池。对于 ResNet,您将包括具有步长卷积的残差图层。
最后的建议将要求您更新网络架构,然后在新初始化的层上执行微调。
要了解更多关于微调和转移学习的信息,以及我在训练网络时的技巧、建议和最佳实践,请务必参考我的书, 用 Python 进行计算机视觉的深度学习 。
我们的示例数据集

Figure 3: A subset of the Kaggle Dogs vs. Cats dataset is used for this Keras input shape example. Using a smaller dataset not only proves the point more quickly, but also allows just about any computer hardware to be used (i.e. no expensive GPU machine/instance necessary).
我们今天将在这里使用的数据集是 Kaggle 的狗与猫数据集的一个子集。
我们还使用 Python 的计算机视觉深度学习 中的这个数据集来教授训练网络的基础知识,确保拥有 CPU 或 GPU 的读者可以在训练模型时跟随并学习最佳实践。
数据集本身包含 2,000 幅图像,属于 2 个类别(“猫”和“狗”):
- Cat:1000 张图片
- 狗:1000 张图片
数据集的可视化可以在上面的图 3 中看到。
在本教程的剩余部分,您将学习如何获取该数据集并:
- 更新预训练 CNN 的输入形状尺寸。
- 用较小的图像尺寸微调 CNN。
配置您的开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
*这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
项目结构
继续从今天博文的 “下载部分获取代码+数据集。
**一旦你提取了。zip 存档,您可以使用tree命令检查项目结构:
$ tree --dirsfirst --filelimit 10
.
├── dogs_vs_cats_small
│ ├── cats [1000 entries]
│ └── dogs [1000 entries]
├── plot.png
└── train.py
3 directories, 2 files
我们的数据集包含在dogs_vs_cats_small/目录中。这两个子目录包含我们的类的图像。如果您正在使用不同的数据集,请确保其结构是<dataset>/<class_name>。
今天我们将复习train.py剧本。训练脚本生成包含我们的准确度/损失曲线的plot.png。
使用 Keras 更新输入形状尺寸
现在是时候用 Keras 和预先训练好的 CNN 来更新我们的输入图像尺寸了。
打开项目结构中的train.py文件,插入以下代码:
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
import os
第 2-20 行导入所需的包:
tensorflow.keras和sklearn是深度学习/机器学习。一定要参考我的泛深度学习的书, 用 Python 进行计算机视觉的深度学习 ,从这些工具中更熟悉我们使用的类和函数。pathsfrom imutils 遍历一个目录,使我们能够列出一个目录中的所有图像。matplotlib将允许我们绘制我们的训练准确度/损失历史。numpy是一个用于数值运算的 Python 包;我们将它付诸实施的方法之一是“均值减法”,一种缩放/归一化技术。cv2是 OpenCV。argparse将用于读取和解析命令行参数。
现在让我们继续解析命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-e", "--epochs", type=int, default=25,
help="# of epochs to train our network for")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
我们的脚本通过第 23-30 行的接受三个命令行参数:
--dataset:输入数据集的路径。我们使用的是狗和猫的精简版本,但您也可以使用其他二进制的 2 类数据集,只需很少或不需要修改(前提是它们遵循类似的结构)。--epochs:我们在训练期间通过网络传递数据的次数;默认情况下,我们将训练25个时期,除非提供了不同的值。--plot:输出精度/损耗图的路径。除非另有说明,否则该文件将被命名为plot.png并放在项目目录中。如果您正在进行多个实验,请确保每次为您的图指定不同的名称,以便将来进行比较。
接下来,我们将加载并预处理我们的图像:
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the image, swap color channels, and resize it to be a fixed
# 128x128 pixels while ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (128, 128))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
首先,我们在行 35 上抓取我们的imagePaths,然后初始化我们的data和labels ( 行 36 和 37 )。
第 40-52 行在imagePaths上循环,同时首先提取标签。加载每个图像,交换颜色通道,并调整图像的大小。图像和标签分别添加到data和labels列表中。
VGG16 在 224×224 px 图像上进行训练;不过,我想请将您的注意力转移到的 48 号线。请注意我们是如何将图像调整到 128×128 px 的。这种调整大小是对不同维度的图像应用迁移学习的一个例子。
虽然第 48 行还没有完全回答弗朗西丝卡·梅帕的问题,但我们正在接近答案。
让我们继续一键编码我们的标签并拆分我们的数据:
# convert the data and labels to NumPy arrays
data = np.array(data)
labels = np.array(labels)
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, stratify=labels, random_state=42)
第 55 行和第 56 行将我们的data和labels转换成 NumPy 数组格式。
然后,第 59-61 行对我们的标签执行一键编码。本质上,这个过程将我们的两个标签(“猫”和“狗”)转换成数组,指示哪个标签是活动的/热的。如果训练图像代表一只狗,那么值将是[0, 1],其中“狗”是热的。否则,对于“猫”,该值将是[1, 0]。
为了强调这一点,例如,如果我们有 5 类数据,一个热编码的数组可能看起来像[0, 0, 0, 1, 0],其中第 4 个元素是热的,表示图像来自第 4 类。详细内容请参考 用 Python 进行计算机视觉的深度学习 。
第 65 行和第 66 行标记了我们数据的 75%用于训练,剩下的 25%用于通过train_test_split函数进行测试。
现在让我们初始化我们的数据增强生成器。我们还将为均值减法建立我们的 ImageNet 均值:
# initialize the training data augmentation object
trainAug = ImageDataGenerator(
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# initialize the validation/testing data augmentation object (which
# we'll be adding mean subtraction to)
valAug = ImageDataGenerator()
# define the ImageNet mean subtraction (in RGB order) and set the
# the mean subtraction value for each of the data augmentation
# objects
mean = np.array([123.68, 116.779, 103.939], dtype="float32")
trainAug.mean = mean
valAug.mean = mean
第 69-76 行初始化数据扩充对象,用于在训练期间对我们的输入图像执行随机操作。
第 80 行也利用了ImageDataGenerator类进行验证,但是没有任何参数——除了执行均值减法,我们不会操作验证图像。
训练和验证/测试生成器都将执行均值减法。均值减法是一种经证明可提高精确度的缩放/归一化技术。行 85 包含每个相应 RGB 通道的平均值,而行 86 和 87 则填充该值。稍后,我们的数据生成器将自动对我们的训练/验证数据执行均值减法。
注意:我已经在这篇博客文章以及用 Python 进行计算机视觉深度学习的实践者包中详细介绍了数据增强。DL4CV 中还介绍了均值减法等缩放和归一化技术。
我们正在用 VGG16 进行迁移学习。现在让我们初始化基本模型:
# load VGG16, ensuring the head FC layer sets are left off, while at
# the same time adjusting the size of the input image tensor to the
# network
baseModel = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(128, 128, 3)))
# show a summary of the base model
print("[INFO] summary for base model...")
print(baseModel.summary())
92 和 93 行使用 3 个通道加载VGG16输入形状尺寸 128×128 。
记住,VGG16 最初是在 224×224 图像 — 上训练的,现在我们正在更新输入形状尺寸以处理 128×128 图像。
实际上,我们已经完全回答了弗朗西丝卡·梅帕的问题!我们通过两步完成了输入尺寸的更改:
- 我们将所有输入图像的尺寸调整为 128×128 。
- 然后我们设置输入
shape=(128, 128, 3)。
第 97 行将在我们的终端打印一份模型摘要,以便我们检查。或者,你可以通过学习第 19 章的【可视化网络架构】用 Python 进行计算机视觉的深度学习来图形化地可视化模型。
因为我们正在执行迁移学习,所以include_top参数被设置为False ( 第 92 行)——我们砍掉了头!
现在我们将通过安装一个新的头部并缝合到 CNN 上来进行手术:
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(4, 4))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel)
# place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers:
layer.trainable = False
线 101 从baseModel获取输出,并将其设置为headModel的输入。
从那里,行 102-106 构造头部的其余部分。
根据行 92 ,已经用 ImageNet 权重初始化了baseModel。在行 114 和 115 上,我们将 VGG16 中的基础层设置为不可训练(即,它们在反向传播阶段不会被更新)。一定要看我之前的微调教程进一步解释。
我们现在准备用我们的数据来编译和训练模型:
# compile our model (this needs to be done after our setting our
# layers to being non-trainable)
print("[INFO] compiling model...")
opt = Adam(lr=1e-4)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network for a few epochs (all other layers
# are frozen) -- this will allow the new FC layers to start to become
# initialized with actual "learned" values versus pure random
print("[INFO] training head...")
H = model.fit(
x=trainAug.flow(trainX, trainY, batch_size=32),
steps_per_epoch=len(trainX) // 32,
validation_data=valAug.flow(testX, testY),
validation_steps=len(testX) // 32,
epochs=args["epochs"])
2020-06-04 更新:以前,TensorFlow/Keras 需要使用一种叫做.fit_generator的方法来完成数据扩充。现在,.fit方法也可以处理数据扩充,使代码更加一致。这也适用于从.predict_generator到.predict的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
我们的model是用Adam优化器和一个1e-4学习率(第 120-122 行)编译的。
我们使用"binary_crossentropy"进行 2 级分类。如果有两类以上的数据,一定要用"categorical_crossentropy"。
第 128-133 行然后训练我们的转移学习网络。我们的培训和验证生成器将在此过程中投入使用。
培训完成后,我们将评估网络并绘制培训历史:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX.astype("float32"), batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = args["epochs"]
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-04 更新:为了使该绘图片段与 TensorFlow 2+兼容,更新了H.history字典键,以完全拼出“精度”而没有“acc”(即H.history["val_accuracy"]和H.history["accuracy"])。“val”没有拼成“validation”,这有点令人困惑;我们必须学会热爱 API 并与之共存,并永远记住这是一项正在进行的工作,世界各地的许多开发人员都为此做出了贡献。
第 137-139 行评估我们的model并打印分类报告用于统计分析。
然后,我们使用matplotlib来绘制我们在训练期间的准确度和损失历史(第 142-152 行)。绘图图形通过线 153 保存到磁盘。
使用更新的输入维度微调 CNN

Figure 4: Changing Keras input shape dimensions for fine-tuning produced the following accuracy/loss training plot.
要使用更新的输入维度来微调我们的 CNN,首先确保您已经使用了本指南的“下载”部分来下载(1)源代码和(2)示例数据集。
从那里,打开一个终端并执行以下命令:
$ python train.py --dataset dogs_vs_cats_small --epochs 25
Using TensorFlow backend.
[INFO] loading images...
[INFO] summary for base model...
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 128, 128, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 128, 128, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 128, 128, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 64, 64, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 64, 64, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 64, 64, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 32, 32, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 32, 32, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 32, 32, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 32, 32, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 16, 16, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 16, 16, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 16, 16, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 16, 16, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 8, 8, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
我们的第一组输出显示了我们更新的输入形状尺寸。
请注意我们的input_1(即InputLayer)的输入尺寸为 128x128x3 ,而 VGG16 的输入尺寸为普通的 224x224x3 。
然后,输入图像将通过网络向前传播,直到最后的MaxPooling2D层(即block5_pool).
在这一点上,我们的输出体积具有尺寸 4x4x512 (作为参考,具有 224x224x3 输入体积的 VGG16 在这一层之后将具有形状 7x7x512 )。
请参阅“我可以将输入尺寸设为我想要的任何尺寸吗?”一节了解更多细节。
然后,我们展平该体积并应用来自headModel的 FC 层,最终导致我们的最终分类。
一旦我们的模型构建完成,我们就可以对其进行微调:
_________________________________________________________________
None
[INFO] compiling model...
[INFO] training head...
Epoch 1/25
46/46 [==============================] - 4s 94ms/step - loss: 4.8791 - accuracy: 0.5334 - val_loss: 2.3190 - val_accuracy: 0.6854
Epoch 2/25
46/46 [==============================] - 3s 73ms/step - loss: 3.3768 - accuracy: 0.6274 - val_loss: 1.2106 - val_accuracy: 0.8167
Epoch 3/25
46/46 [==============================] - 3s 76ms/step - loss: 2.7036 - accuracy: 0.6887 - val_loss: 0.9802 - val_accuracy: 0.8333
Epoch 4/25
46/46 [==============================] - 3s 73ms/step - loss: 2.1932 - accuracy: 0.7105 - val_loss: 0.8585 - val_accuracy: 0.8583
Epoch 5/25
46/46 [==============================] - 3s 73ms/step - loss: 1.9197 - accuracy: 0.7425 - val_loss: 0.6756 - val_accuracy: 0.9021
...
46/46 [==============================] - 3s 76ms/step - loss: 0.6613 - accuracy: 0.8495 - val_loss: 0.4479 - val_accuracy: 0.9083
Epoch 21/25
46/46 [==============================] - 3s 74ms/step - loss: 0.6561 - accuracy: 0.8413 - val_loss: 0.4484 - val_accuracy: 0.9000
Epoch 22/25
46/46 [==============================] - 4s 95ms/step - loss: 0.5216 - accuracy: 0.8508 - val_loss: 0.4476 - val_accuracy: 0.9021
Epoch 23/25
46/46 [==============================] - 3s 70ms/step - loss: 0.5484 - accuracy: 0.8488 - val_loss: 0.4420 - val_accuracy: 0.9021
Epoch 24/25
46/46 [==============================] - 3s 70ms/step - loss: 0.5658 - accuracy: 0.8492 - val_loss: 0.4504 - val_accuracy: 0.8938
Epoch 25/25
46/46 [==============================] - 3s 70ms/step - loss: 0.5334 - accuracy: 0.8529 - val_loss: 0.4096 - val_accuracy: 0.8979
[INFO] evaluating network...
precision recall f1-score support
cats 0.91 0.88 0.89 250
dogs 0.89 0.91 0.90 250
accuracy 0.90 500
macro avg 0.90 0.90 0.90 500
weighted avg 0.90 0.90 0.90 500
在微调结束时,我们看到我们的模型已经获得了 90%的准确度,考虑到我们的小图像数据集,这是相当不错的。
如图 4 所示,我们的训练也相当稳定,没有过度适应的迹象。
更重要的是,您现在知道如何更改预训练网络的输入图像形状尺寸,然后使用 Keras 应用特征提取/微调!
当您需要将迁移学习应用到预先训练的网络时,请务必使用本教程作为模板,该网络的图像尺寸与最初训练时不同。
摘要
在本教程中,您学习了如何更改输入形状尺寸,以便使用 Keras 进行微调。
当我们想要应用迁移学习时,我们通常会执行这样的操作,包括特征提取和微调。
使用本指南中的方法,您可以为预训练的 CNN 更新您的输入图像尺寸,然后执行迁移学习;但是,有两个警告需要注意:
- 如果你的输入图像太小,Keras 就会出错。
- 如果您的输入图像太大,您可能无法获得想要的精度。
请务必参考“我可以随意输入尺寸吗?”关于这些警告的更多细节,包括如何解决它们的建议。
我希望你喜欢这个教程!
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,只需在下面的表格中输入您的电子邮件地址!***
Charizard 解释了如何使用特征向量来描述和量化图像
如果你没有注意到,术语“特征向量”在这个博客中经常使用。虽然我们已经看到了很多,但我想用一整篇文章来定义特征向量到底是什么。
什么是图像特征向量?
图像特征向量:图像的一种抽象,用于表征和数字量化图像的内容。通常为实数、整数或二进制值。简单地说,特征向量是用来表示图像的一系列数字。
如你所知,构建任何图像搜索引擎的第一步是定义你将要使用的图像描述符的类型。你是在尝试表征一幅图像的颜色,提取颜色特征吗?质地?或者图像中物体的形状?
一旦选择了图像描述符,就需要将图像描述符应用于图像。这个图像描述符处理量化图像所需的逻辑,并将其表示为一系列数字。
图像描述符的输出是一个特征向量:用来描述图像特征的数字列表。有道理吗?
问自己两个问题
在定义图像描述符和预期输出时,您可以遵循以下通用模板。该模板将有助于确保您始终知道您所描述的内容以及描述符的输出所代表的内容。为了应用这个模板,您只需要问自己两个问题:
- 我使用的是什么图像描述符?
- 我的图像描述符的预期输出是什么?
让我们把这个解释更具体一点,并通过一些例子。
如果你是这个博客的常客,你应该知道我对《侏罗纪公园》和《指环王》都很着迷。下面介绍我的第三个执念:口袋妖怪。下面是我们将在这篇博文中使用的示例图像——一只沙里卡。

Figure 1: Our example image – a Charizard.
现在,启动一个 Python shell 并跟随它:
>>> import cv2
>>> image = cv2.imread("charizard.png")
>>> image.shape
(198, 254, 3)
这里我们只是导入cv2,我们的 Python 包与 OpenCV 接口。然后,我们从磁盘上加载我们的 Charizard 图像,并检查图像的尺寸。
查看图像的尺寸,我们看到它的高度为 198 像素,宽度为 254 像素,有 3 个通道,分别用于红色、绿色和蓝色通道。
原始像素特征向量
可以说,你可以使用的最基本的颜色特征向量是原始像素强度本身。虽然我们通常不会在图像搜索引擎中使用这种表示,但它有时会在机器学习和分类上下文中使用,值得一提。
让我们问自己上面模板中提到的两个问题:
- 我使用的是什么图像描述符?我使用的是原始像素描述符。
- 我的描述符的预期输出是什么?对应于我的图像的原始 RGB 像素强度的数字列表。
由于图像表示为 NumPy 数组,因此计算图像的原始像素表示非常简单:
>>> raw = image.flatten()
>>> raw.shape
(150876,)
>>> raw
array([255, 255, 255, ..., 255, 255, 255], dtype=uint8)
我们现在可以看到,我们的图像已经通过 NumPy 的flatten方法被“展平”。图像的红色、绿色和蓝色分量已经被展平到单个列表(而不是多维数组)中来表示图像。我们的展平数组具有 150,876 的形状,因为图像中存在 198 x 254 = 50,292 个像素,每个像素有 3 个值,因此 50,292 x 3 = 150,876 。
颜色平均值
我们之前的例子不太有趣。
如果我们想量化我们的 Charizard 的颜色,而不必使用原始像素强度的整个图像呢?
量化图像颜色的一个简单方法是计算每个颜色通道的平均值。
同样,让我们填写模板:
- 我使用的是什么图像描述符?一个颜色均值描述符。
- 我的图像描述符的预期输出是什么?图像各通道的平均值。
现在让我们看看代码:
>>> means = cv2.mean(image)
>>> means
(181.12238527002307, 199.18315040165433, 206.514296508391, 0.0)
我们可以使用cv2.mean方法计算每个颜色通道的平均值。这个方法返回一个有四个值的元组,我们的颜色特征。第一个值是蓝色通道的平均值,第二个值是绿色通道的平均值,第三个值是红色通道的平均值。记住,OpenCV 将 RGB 图像存储为一个 NumPy 数组,但是顺序相反。我们实际上是按照 BGR 顺序倒着读的,因此蓝色值先出现,然后是绿色,最后是红色。
第四个值可以忽略,它的存在只是为了 OpenCV 的内置Scalar类可以在内部使用。该值可以这样忽略:
>>> means = means[:3]
>>> means
(181.12238527002307, 199.18315040165433, 206.514296508391)
现在我们可以看到我们的图像描述符(cv2.mean函数)的输出是一个包含三个数字的特征向量:分别是蓝色、绿色和红色通道的平均值。
颜色平均值和标准偏差
让我们计算每个通道的平均值和标准差。
同样,这是我们的模板:
- 我使用的是什么图像描述符?颜色均值和标准差描述符。
- 我的图像描述符的预期输出是什么?图像各通道的均值和标准差。
现在是代码:
>>> (means, stds) = cv2.meanStdDev(image)
>>> means, stds
(array([[ 181.12238527],
[ 199.1831504 ],
[ 206.51429651]]), array([[ 80.67819854],
[ 65.41130384],
[ 77.77899992]]))
为了获取每个通道的均值和标准差,我们使用了cv2.meanStdDev函数,毫不奇怪,它返回一个元组——一个用于均值,一个用于标准差。同样,这个数字列表是我们的颜色特征。
让我们将平均值和标准偏差合并成一个单一的颜色特征向量:
>>> import numpy as np
>>> stats = np.concatenate([means, stds]).flatten()
>>> stats
array([ 181.12238527, 199.1831504 , 206.51429651, 80.67819854,
65.41130384, 77.77899992])
现在我们的特征向量stats有六个条目,而不是三个。我们现在表示图像中每个通道的平均值以及每个通道的标准偏差。
颜色直方图
回到聪明的女孩:计算机视觉和图像搜索引擎利用颜色直方图的指南和霍比特人和直方图,我们也可以使用 3D 颜色直方图来描述我们的 Charizard。
- 我使用的是什么图像描述符?一个 3D 颜色直方图。
- 我的图像描述符的预期输出是什么?用来表征图像颜色分布的数字列表。
>>> hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
这里我们有一个 3D 直方图,每个通道有 8 个面元。让我们检查一下直方图的形状:
>>> hist.shape
(8, 8, 8)
我们的直方图有一个形状(8, 8, 8)。如果它是多维的,我们怎么用它作为特征向量呢?
我们简单地把它展平:
>>> hist = hist.flatten()
>>> hist.shape
(512,)
通过将我们的图像描述符定义为 3D 颜色直方图,我们可以提取一系列数字(即我们的特征向量)来表示图像中的颜色分布。
摘要
在这篇博文中,我们提供了图像特征向量的正式定义。特征向量是图像本身的抽象,并且在最基本的层面上,仅仅是用于表示图像的数字列表。我们还回顾了一些如何提取颜色特征的例子。
构建任何图像搜索引擎的第一步都是定义图像描述符。一旦我们定义了我们的图像描述符,我们就可以将我们的描述符应用于图像。图像描述符的输出是我们的特征向量。
然后,我们定义了一个两步模板,您可以在定义图像描述符时使用它。你只需要问自己两个问题:
- 我使用的是什么图像描述符?
- 我的图像描述符的预期输出是什么?
第一个问题定义了你要描述的图像的哪个方面,是颜色、形状还是纹理。第二个问题定义了描述符应用于图像后的输出。
使用这个模板,你可以确保你总是知道你在描述什么以及如何描述。
最后,我们提供了三个简单的图像描述符和特征向量的例子,使我们的讨论更加具体。
使用 Python 检查 OpenCV 版本
原文:https://pyimagesearch.com/2015/08/10/checking-your-opencv-version-using-python/
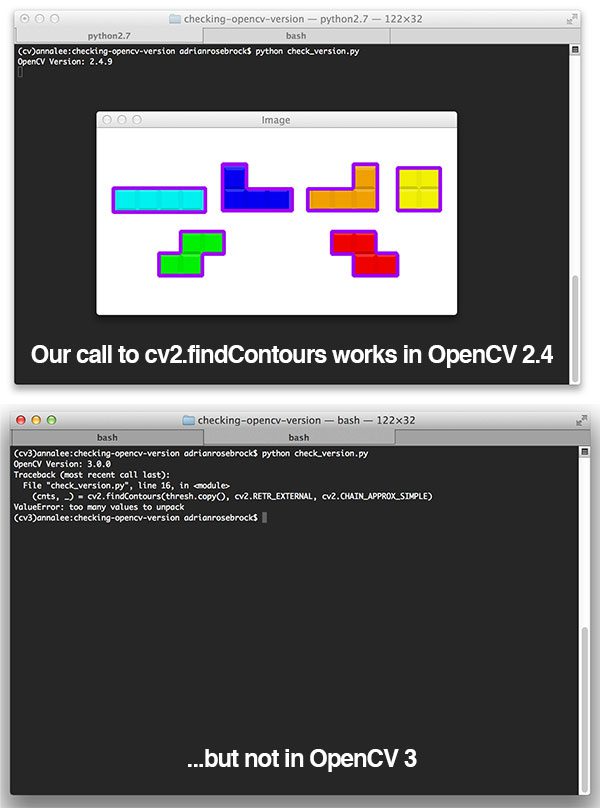
这是不可避免的——OpenCV 3 的发布必然会打破与 OpenCV 2.4.X 函数的向后兼容性 : cv2.findContours和cv2.normalize马上浮现在我的脑海中。
那么,如何确保无论您的生产环境使用哪个版本的 OpenCV,您的代码都能工作呢?
简单的回答是,您需要围绕每个有问题的函数创建if语句(或者将函数抽象成一个单独的方法,该方法根据您的 OpenCV 版本处理调用适当的函数)。
为了做到这一点,您需要能够使用 Python 从内部检查您的 OpenCV 版本——这正是本博客的其余部分将向您展示的!
使用 Python 检查 OpenCV 版本
OpenCV 版本包含在一个特殊的cv2.__version__变量中,您可以这样访问它:
$ python
>>> import cv2
>>> cv2.__version__
'3.0.0'
cv2.__version__变量只是一个字符串,你可以把它分成主要版本和次要版本:
>>> (major, minor, _) = cv2.__version__.split(".")
>>> major
'3'
>>> minor
'0'
当然,每次你需要检查你的 OpenCV 版本的时候都必须执行这个操作有点痛苦。为了解决这个问题,我在我的 imutils 包中添加了三个新函数,这是一系列方便的函数,使 OpenCV 和 Python 的基本图像处理功能变得更容易。
下面可以看到我的is_cv2、is_cv3、check_opencv_version功能:
def is_cv2():
# if we are using OpenCV 2, then our cv2.__version__ will start
# with '2.'
return check_opencv_version("2.")
def is_cv3():
# if we are using OpenCV 3.X, then our cv2.__version__ will start
# with '3.'
return check_opencv_version("3.")
def is_cv4():
# if we are using OpenCV 3.X, then our cv2.__version__ will start
# with '4.'
return check_opencv_version("4.")
def check_opencv_version(major, lib=None):
# if the supplied library is None, import OpenCV
if lib is None:
import cv2 as lib
# return whether or not the current OpenCV version matches the
# major version number
return lib.__version__.startswith(major)
这里的代码相当简单——我只是检查cv2.__version__字符串是否以2开头,这表明我们使用的是 OpenCV 2。x,一个3,表示我们用的是 OpenCV 3,或者一个4,表示我们用的是 OpenCV 4。
同样,这些函数已经包含在 imutils 包中,您可以使用 pip 来安装:
$ pip install imutils
如果您已经安装了imutils,您可以通过以下方式升级到最新版本:
$ pip install --upgrade imutils
检查您的 OpenCV 版本:一个真实的例子
既然我们已经知道了如何使用 Python 检查 OpenCV 版本,并定义了几个方便的函数来简化版本检查,那么让我们看看如何在实际例子中使用这些函数。
我们的目标是检测下图中的轮廓:
Figure 1: We are going to utilize OpenCV 2.4.X and OpenCV 3 to detect the contours (i.e. outlines) of the Tetris blocks.
为了检测图像中的轮廓,我们需要使用cv2.findContours功能。然而,正如我们所知,cv2.findContours的返回签名在 OpenCV 的版本 3 和 2.4 之间略有变化(cv2.findContours的 OpenCV 3 版本在元组中返回一个额外的值),因此我们需要在调用cv2.findContours之前对 OpenCV 版本进行检查,以确保我们的脚本不会出错。让我们来看看如何进行这项检查:
# import the necessary packages
from __future__ import print_function
import imutils
import cv2
# load the Tetris block image, convert it to grayscale, and threshold
# the image
print("OpenCV Version: {}".format(cv2.__version__))
image = cv2.imread("tetris_blocks.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 225, 255, cv2.THRESH_BINARY_INV)[1]
# check to see if we are using OpenCV 2.X or OpenCV 4
if imutils.is_cv2() or imutils.is_cv4():
(cnts, _) = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
# check to see if we are using OpenCV 3
elif imutils.is_cv3():
(_, cnts, _) = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
# draw the contours on the image
cv2.drawContours(image, cnts, -1, (240, 0, 159), 3)
cv2.imshow("Image", image)
cv2.waitKey(0)
正如你所看到的,我们需要做的就是调用is_cv2、is_cv4和is_cv3,然后将我们的版本特定的代码包装在if语句块中——就这样!
现在,当我使用 OpenCV 2.4 执行我的脚本时,它工作起来没有任何问题:
Figure 2: Our call to cv2.findContours is working in OpenCV 2.4.X.
OpenCV 3 也是如此:
Figure 3: And the same is true for OpenCV 3 since we are using the is_cv2 and is_cv3 functions to detect OpenCV versions with Python.
摘要
在这篇博文中,我们学习了如何使用 Python 检查 OpenCV 版本。OpenCV 版本包含在一个名为cv2.__version__的特殊字符串变量中。我们需要做的就是检查这个变量,然后我们就能确定我们的 OpenCV 版本。
最后,我在 imutils 包中定义了一些方便的方法,使检查 OpenCV 版本变得更容易和更 Pythonic 化。如果您发现自己需要始终如一地检查 OpenCV 版本,请考虑检查库。
选择研究主题并阅读其文献
原文:https://pyimagesearch.com/2022/03/16/choosing-the-research-topic-and-reading-its-literature/
选择研究课题并阅读其文献
你开始着手你的第一个研究项目了吗?你想发表一篇研究论文但不知道从哪里或如何开始?几年前,我处于类似的境地:我对机器学习研究完全陌生,不知道从哪里以及如何开始。
幸运的是,我有机会成为机器学习和视觉小组( Lab1055 )的一员。在正确的指导下,几经挫折,边走边学,我在 ICCV 的一个研讨会上发表了我的研究。作为 Lab1055 的一员,我学到的知识和原则帮助我进行研究,并在视觉会议、研讨会和期刊(如 ECCV、WACV、ECML、PRL、CVPR 等)上发表论文。).
通过这个微型博客系列,我想分享这些学习和原则。我希望这些能帮助你进入研究领域,并从中获得一些成果。
在这个系列中,你将学习如何发表小说研究。
本课是关于如何发表小说研究的五部分系列的第一部分:
- 选择研究课题并阅读其文献(本教程)
- 构思解决方案和计划实验
- 计划并撰写研究论文
- 计划事情不顺利时的后续步骤
- 确保你的研究保持可见性和一般提示
要学会如何选择你的研究课题并着手阅读它的文献(图 1),只要坚持阅读。
选择你的研究课题
现在很难想出有什么问题是机器学习没有应用的。一切似乎都被虚拟地解决了。这就是为什么在这个广阔的空间里选择一个研究课题是一项棘手而艰巨的任务。这里有一些想法可以帮助你缩小搜索范围。
找一些让你兴奋并且与社区相关的事情
毫无疑问,这个话题会引起你的兴趣。然而,并不是每一个让你兴奋的话题都能让社区受益。因此,一个人应该寻找自己感兴趣的、与社区相关的东西。例如,如果图像分类引起了您的兴趣,您应该尝试少镜头、零镜头、无监督、自我监督或领域广义分类。
这些主题在社区中获得了更多的关注,因为它们对可用训练数据的现实世界约束进行建模,而不像传统的监督分类那样假设大量数据。识别这些趋势或相关主题的一种方法是对最近的人工智能会议进行逐个主题的分析。例如,图 2 显示了 ICLR 2021 提交的前 50 个关键词。它表明,GNNs、元学习、少镜头、无监督、有监督和鲁棒性等主题比分类、CNN 等主题更受欢迎,更相关,也更具趋势性。
尽量找一个文学不是很拥挤的领域
当文献拥挤时,试图在你的研究中保持新奇变得具有挑战性和竞争性。拥挤的文学不仅仅是有太多的论文要读;它反映了社区在类似主题上工作或发布的活跃程度。鉴于这些新作品的出版速度,你很可能会在成果或新颖性方面被它们抢先一步。
与你的顾问或导师一起工作
我强烈建议你与你的导师(博士、研究科学家等等)以及任何顾问合作,以确定有前途的和相关的主题。从事与你的导师或指导者的专业知识交叉的工作可以极大地增加你产生新研究的机会。凭借他们的专业知识和研究经验,你可以得到适当的指导和反馈,帮助你改进和发表你的作品。
避免计算密集型项目
注意解决这个问题通常需要多少计算。避免那些不可用或负担不起的高强度计算。这是为了防止项目后期出现任何令人失望的情况。例如,从事大规模图像生成工作的人应该跟踪生成更高分辨率图像所需的计算。这是该文献中的一个标准和基本实验。
识别低挂的果实和潜在的缺口
在文献中找出唾手可得的果实可能是选择你的主题的最简单的方法之一。唾手可得的成果是研究课题,研究起来很简单,但却不为人所知。这些可以简单到
-
合二为一:
- Mancini et al. (2020) 第一个将零射击学习和领域泛化结合起来,提出了一种简单的基于课程的类/领域混合策略,以训练在两个领域的语义转移下进行泛化的模型。
- 等(2021) 提出了第一个增量式的少镜头实例分割方法:iMTFA,它学习合并到类代表中的对象实例的判别嵌入。
- Chauhan et al. (2020) 首先提出研究图神经网络(GNNs)中的少镜头图分类主题,以识别未知类,给出有限的标记图示例。
-
**应用一类新的算法或架构:
- 邓等(2021) 首先提出了一个简单有效的基于变压器的可视化接地框架。他们的 TransVG 方法优于依赖复杂模块和手动设计的机制来执行查询推理和多模态融合的最新技术。**
-
**提出新的基准或评估:
- Hendrycks 等人(2021) 提出了四个新的真实世界分布偏移数据集,由图像风格、图像模糊度、地理位置、相机操作等变化组成。
- Gulrajani 和 Lopez-Paz (2020) 实现了领域泛化(DG)的测试床 DomainBed,包括 7 个多领域数据集、9 个基线算法和 3 个模型选择标准。此外,他们在自己的环境下测试现有的 DG 方法,以了解这些算法在现实环境中的实用性。**
**但是,请记住,因为这些通常很容易识别和处理,所以您必须迅速行动,成为第一个提出它们的人。另一个好的策略是找出当前空间管道中的缺陷/缺口,并努力消除它们。这可能包括差距,如在不牺牲性能的情况下提高管道的计算/时间效率、对变化的鲁棒性等。
作为研究课题的分析和理解
提供对特定空间的整体理解的综合分析本身就是一个研究课题。分析什么最有效、任何有趣的现象、权衡、限制或标准化基准可以帮助您和社区更好地了解这个空间,并确定未来要解决的潜在差距。最棒的是,他们通过引用和讨论获得了社区的大量关注。
举个例子,
- Naseer 等人(2021) 展示并分析了视觉变压器(vit)的几个有趣的特性,如它们对严重遮挡、扰动和域转移的鲁棒性;与 CNN 相比,它们的纹理偏差更小,迁移学习能力更强。
- Xian 等人(2017) 通过深入比较和分析大量最新方法,讨论了零炮学习公式和算法的局限性,包括经典的零炮设置和更现实的广义零炮设置。
- 陈等(2019) 对几种少镜头分类算法进行一致性对比分析。他们表明,更深的主干显著降低了各种先进方法之间的性能差异。此外,在现实的跨领域评估设置中,基线方法优于其他最先进的算法。
识别应用
将现有想法应用于相关主题(例如,医学图像、编辑、导航等。)也可以作为一个潜在的研究课题。以下是这类论文的例子。
- Papadopoulos 等人(2019) 旨在通过建立一个反映一组有序指令的生成模型来教机器制作披萨。他们学习通过 GANs 添加或删除特定成分的可组合模块操作。
- Machiraju 和 Balasubramanian (2020) 研究了自主导航领域的自然对手,其中不利的天气条件(如雾)对这些系统的预测有重大影响。这些天气条件可以像自然对手一样帮助测试模型。
- Richardson 等人(2021) 提出了一种 StyleGAN 编码器,能够直接将真实图像编码到风格空间中,并表明通过 StyleGAN 解决翻译任务显著简化了训练过程,并对解决没有像素到像素对应的任务具有更好的支持。
阅读文献
随着深度学习相关出版物的指数级增长(图 3 ),有必要设计有效的策略来处理定速文献。所以,现在你已经决定了要研究哪个主题,让我们来看看一些流行的资源/工具,以便更好地理解这个主题,浏览它的文献,并随时了解社区中正在进行的研究。
调查分析试卷
如果你想了解基本原理,不同类别的算法介绍,或他们如何比较,调查论文可能是最好的起点。它们通常很容易定位和跟踪。另一方面,分析性论文可以通过解释差距、限制、权衡、最佳策略、有趣的结果等来帮助你更好地理解主题。
GitHub 编译
探索 GitHub 获取编译(如牛逼视觉变形金刚、牛逼零拍学习、牛逼自我监督学习、牛逼视觉接地气等)。)专门针对你的主题的研究论文。对于 kickstart,阅读初始文件(以获得基本面)和顶级文件(以了解趋势走向)。它们还包括任何实现、博客、视频等的链接。,并定期更新以反映最新内容。您可以通过使用搜索词“awesome < topic name >”轻松找到这些汇编。
会议与研讨会论文集
在顶级会议(如 CVPR、NeurIPS、ICCV、ICML、ICLR、ECCV、ACL、EMNLP、KDD 等)之后。)是了解最新研究的绝佳方式。作为一个例子,图 4 通过 h-index 对各种计算机视觉会议进行排名。另一个跟上时代的好方法是参加特定领域的研讨会,在那里你可以找到与你的主题更相关的研究报告、演示和提交。此外,这些研讨会通常会巩固一个特定的研究领域,让你更好地了解当前的趋势。
例如,关于元学习的研讨会一直是一个受欢迎的 NeurIPS 研讨会,重点是推进元学习方法。ICML 大学的另一个受欢迎的研讨会,深度学习中的不确定性和鲁棒性,旨在使深度神经网络更加可靠。在 CVPR 举行的现实世界计算机视觉系统中的对抗性机器学习和在线挑战聚焦于现实世界机器学习和计算机视觉系统安全性的最新研究和未来方向。最后, 3DVR 研讨会 (CVPR 2021)讨论了机器人 3D 视觉的独特挑战和机遇。
在线工具和平台
这里有几个工具,你可以用它们来轻松搜索与你的主题相关的论文:
- 有了关联论文,你可以构建一个与特定领域相关的论文图表,并发现你感兴趣领域的先前或衍生作品。它还允许您为任何未来的用例创建一个参考书目。
- Arxiv Sanity 允许研究人员跟踪最近的论文,搜索论文,根据与任何论文的相似性对论文进行排序,查看最近的热门论文,将论文添加到个人图书馆,并获得(新的或旧的)Arxiv 论文的个性化推荐。
- Alpha Signal 为您提供研究论文趋势和值得一读的每周摘要。
- 使用谷歌学术,你可以添加你的个性化关键词、领域、研究人员,并在任何相关论文上传时收到通知。
- 在我看来,Twitter 是迄今为止最好的了解最新消息的地方。如果你关注正确的人、研究实验室和会议,你会发现大量的内容、见解和合作机会。最棒的是,您可以直接与社区分享您的想法或提出问题。图 5 和图 6 推荐几个研究人员、学术和行业实验室,你可以跟随它们为自己创建一个优秀的 feed。
阅读策略
在你读完基础和介绍性的文章后,设计一个阅读策略,这将帮助你有效地过滤掉相关的内容,并为你节省几个小时阅读不相关的文章。
- 检查工作的高水平总结的摘要。
- 寻找任何介绍性的数字或插图(以获得该方法的感觉)。
- 浏览关键结果,等等。
论文以一致的格式组织(摘要、介绍、相关工作、方法论、实验和结论),使得找到任何具体的东西变得简单。除此之外,你可以通过查看他们的海报、聚焦视频或博客来获得一个很好的概述。
Keshav (2020) 提出了一种阅读论文的三步法。
- 第一遍让你对论文有个大概的了解。它包括阅读摘要、引言、结论;浏览参考文献,决定论文是否与你相关,是否需要其他途径。第一遍之后,你应该能够回答关于工作的类别、背景、贡献、正确性和清晰性的问题。
- 第二遍让你通过关注数字、插图或图表来掌握论文的内容,标记任何未读的参考资料以备将来阅读。这一关将帮助你了解作品是否与你的主题相关(可以是潜在的基线、相关作品,甚至是你主题的解决方案)。如果是的话,那就进行第三遍来完全理解它。
- 第三步是仔细阅读论文,找出它的优缺点。特别是,你应该能够指出隐含的假设,遗漏的相关工作的引用,以及实验或分析技术的潜在问题。
把你自己当成一个评审者,问一些相关的问题,以确保一个彻底的评估。例如,是否有作者没有考虑的更简单的方法/指南?作者的假设合理吗?他们的方法在技术上是否合理,或者他们是否有任何限制(昂贵的计算、训练/推理开销等)。)?
创造性地思考,以确定提出的想法是否可以扩展、整合或有一些应用。突出重要的内容、思想或批评,或者用几段话概括。这将极大地帮助你重读论文或在论文的相关工作部分写相关内容。
汇总
在这个巨大的机器/深度学习空间中,选择研究主题可能很困难。并不是每一个激起你兴趣的话题都可以变成一个成功的研究话题。因此,一个人应该寻找与研究社区相关的领域,与他们的兴趣保持一致,而不是在拥挤的空间里。此外,请注意解决这些问题通常需要的计算,并避免在计算不可用或负担不起的情况下工作。
在你缩小了你的主题列表后,咨询你的导师和顾问,看看他们是否对其中任何一个特别感兴趣或有经验。然后,从它们开始,寻找任何唾手可得的果实。但是,如果你想成为第一个拥有它的人,请不要忘记赶快行动。同时,寻找任何约束、差距、折衷或有趣的现象,这些都可能导致很好的分析或需要解决的问题。
进行文献综述可能是一项艰巨的任务。从调查论文和 GitHub 汇编开始,理解基本原理并浏览最近的方法。接下来,跟踪顶级会议及其特定领域研讨会的进程,了解最新的研究进展。利用 Twitter 等在线工具和平台,获取与您的问题相关的精选内容。寻找博客、海报或聚焦视频,快速获得论文概述。最后,但也是最重要的,设计一个阅读策略,在不浪费时间的情况下分析文章。
我希望这一课能帮助你缩小研究主题的搜索范围,并有效地处理相关文献。请继续收听下一课,思考解决方案,规划您的实验。
引用信息
曼格拉,P. “选择研究课题并阅读其文献”, PyImageSearch ,p .丘格,r .拉哈,k .库德里亚夫采娃,s .霍特,2022,【https://pyimg.co/oravw】T4
@incollection{Mangla_2022_Choosing,
author = {Puneet Mangla},
title = {Choosing the Research Topic and Reading Its Literature},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/oravw},
}
聪明的女孩:计算机视觉和图像搜索引擎利用颜色直方图指南

这是……这是直方图。格兰特博士
好吧。所以这可能不是准确的报价。但我认为格兰特博士如果知道颜色直方图的力量也会同样激动不已。
更重要的是,停电时,直方图不会吃掉游客。
那么,到底什么是直方图呢?直方图表示图像中颜色的分布。它可以被可视化为一个图形(或绘图),给出强度(像素值)分布的高层次直觉。在本例中,我们假设 RGB 颜色空间,因此这些像素值将在 0 到 255 的范围内。如果您在不同的色彩空间中工作,像素范围可能会有所不同。
绘制直方图时,X 轴充当我们的“箱”。如果我们构建一个有 256 个面元的直方图,那么我们可以有效地计算每个像素值出现的次数。相比之下,如果我们只使用 2 个(等间距的)面元,那么我们计算一个像素在范围[0, 128)或[128, 255]内的次数。然后,在 Y 轴上绘制被装箱到 X 轴值的像素数。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
通过简单地检查图像的直方图,您可以对对比度、亮度和强度分布有一个大致的了解。
这篇文章会给你一个 OpenCV 直方图的例子,从开始到结束。
图像搜索引擎的应用
在图像搜索引擎的上下文中,直方图可以充当特征向量(即,用于量化图像并将其与其他图像进行比较的数字列表)。为了在图像搜索引擎中使用颜色直方图,我们假设具有相似颜色分布的图像在语义上是相似的。我将在这篇文章后面的“缺点”部分详细讨论这个假设;但是,暂时让我们假设具有相似颜色分布的图像具有相似的内容。
可以使用距离度量来比较颜色直方图的“相似性”。常见的选择包括:欧几里得、相关、卡方、交集和 Bhattacharyya。在大多数情况下,我倾向于使用卡方距离,但选择通常取决于被分析的图像数据集。无论您使用哪种距离度量,我们都将使用 OpenCV 来提取颜色直方图。
游览侏罗纪公园
让我们想象一下,我们正和格兰特博士一行人一起进行他们的第一次侏罗纪公园之旅。我们带着手机来记录整个经历(让我们也假设拍照手机在当时是一个“东西”)。假设我们没有像丹尼斯·内德瑞那样让我们的脸被恐龙吃掉,我们可以稍后从我们的智能手机上下载图片到我们的电脑上,并为每张图片计算直方图。
在旅行的最开始,我们花了很多时间在实验室里,了解 DNA,并见证了一只小迅猛龙的孵化。这些实验室有很多“钢铁”和“灰色”的颜色。后来,我们上了吉普车,开进了公园。公园本身就是一片丛林——到处都是绿色。
那么基于这两种颜色分布,你觉得上面的格兰特博士图像更像哪一种呢?
嗯,我们看到照片的背景中有相当多的绿色植物。十有八九,格兰特博士照片的颜色分布会与我们在丛林之旅中拍摄的照片以及我们在实验室中拍摄的照片更加“相似”。
使用 OpenCV 计算直方图
现在,让我们开始构建一些我们自己的颜色直方图。
我们将使用 OpenCV 中的cv2.calcHist函数来构建直方图。在我们进入任何代码示例之前,让我们快速回顾一下这个函数:
cv2.calcHist(images, channels, mask, histSize, ranges)
- 图像:这是我们想要计算直方图的图像。包装成列表:
[myImage]。 - 通道:一个索引列表,在这里我们指定要计算直方图的通道的索引。要计算灰度图像的直方图,列表应该是
[0]。为了计算所有三个红色、绿色和蓝色通道的直方图,通道列表应该是[0, 1, 2]。 - 蒙版:我还没有在这个博客中介绍蒙版,但本质上,蒙版是一个与我们的原始图像形状相同的
uint8图像,其中零值的像素被忽略,值大于零的像素被包括在直方图计算中。使用掩模允许我们只计算图像的特定区域的直方图。现在,我们将只使用一个值None作为遮罩。 - histSize: 这是我们在计算直方图时想要使用的箱数。同样,这是一个列表,我们为每个通道计算一个直方图。箱子的大小不必都一样。以下是每个通道 32 个箱的示例:
[32, 32, 32]。 - 范围:可能的像素值范围。通常,这是每个通道的
[0, 256],但是如果您使用 RGB 以外的颜色空间(如 HSV),范围可能会有所不同。
现在我们已经了解了cv2.calcHist函数,让我们来写一些实际的代码。
# import the necessary packages
from matplotlib import pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
args = vars(ap.parse_args())
# load the image and show it
image = cv2.imread(args["image"])
cv2.imshow("image", image)
这段代码还不是很令人兴奋。我们所做的就是导入我们需要的包,设置一个参数解析器,并加载我们的图像。
# convert the image to grayscale and create a histogram
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray", gray)
hist = cv2.calcHist([gray], [0], None, [256], [0, 256])
plt.figure()
plt.title("Grayscale Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
plt.plot(hist)
plt.xlim([0, 256])
现在事情变得更有趣了。在第 2 行,我们将图像从 RGB 色彩空间转换为灰度。第 4 行计算实际的直方图。继续将代码的参数与上面的函数文档进行匹配。我们可以看到,我们的第一个参数是灰度图像。灰度图像只有一个通道,因此我们使用值[0]作为channels。我们没有掩码,所以我们将mask值设置为None。我们将在直方图中使用 256 个柱,可能的值范围从 0 到 256。
对plt.show()的调用显示:
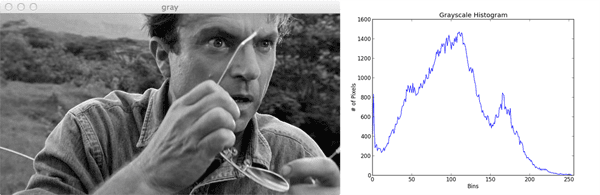
Figure 1: Dr. Grant grayscale histogram.
还不错。我们如何解释这个直方图?嗯,箱(0-255)被绘制在 X 轴上。Y 轴计算每个箱中的像素数量。大多数像素在大约 50 到大约 125 的范围内。观察直方图的右尾部,我们看到在 200 到 255 的范围内只有很少的像素。这意味着图像中很少有“白”像素。
现在我们已经看到了灰度直方图,让我们来看看我所说的“扁平”颜色直方图:
# grab the image channels, initialize the tuple of colors,
# the figure and the flattened feature vector
chans = cv2.split(image)
colors = ("b", "g", "r")
plt.figure()
plt.title("'Flattened' Color Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
features = []
# loop over the image channels
for (chan, color) in zip(chans, colors):
# create a histogram for the current channel and
# concatenate the resulting histograms for each
# channel
hist = cv2.calcHist([chan], [0], None, [256], [0, 256])
features.extend(hist)
# plot the histogram
plt.plot(hist, color = color)
plt.xlim([0, 256])
# here we are simply showing the dimensionality of the
# flattened color histogram 256 bins for each channel
# x 3 channels = 768 total values -- in practice, we would
# normally not use 256 bins for each channel, a choice
# between 32-96 bins are normally used, but this tends
# to be application dependent
print "flattened feature vector size: %d" % (np.array(features).flatten().shape)
与灰度直方图相比,计算扁平化的颜色直方图肯定需要更多的代码。让我们把这段代码拆开,更好地了解发生了什么:
- 第 29 行和第 30 行:我们要做的第一件事是将图像分成三个通道:蓝色、绿色和红色。通常,我们读到的是红、绿、蓝(RGB)。但是,OpenCV 以相反的顺序将图像存储为 NumPy 数组:BGR。这一点值得注意。然后,我们初始化一组表示颜色的字符串。
- 第 31-35 行:这里我们只是设置我们的 PyPlot 图,并初始化我们的级联直方图列表。
- 第 38 行:让我们开始循环频道。
- 第 42 行和第 43 行:我们现在正在为每个通道计算直方图。本质上,这与计算单通道灰度图像的直方图是一样的。然后,我们将颜色直方图连接到我们的特征列表。
- 第 46 和 47 行:使用当前通道名称绘制直方图。
- 第 55 行:在这里,我们只是检查我们的扁平颜色直方图的形状。我称之为“扁平”直方图,并不是因为(1)直方图没有“峰值”或者(2)我调用 NumPy 的 flatten()方法。我称之为“扁平”直方图,因为直方图是像素计数的单一列表。稍后,我们将探索多维直方图(2D 和 3D)。展平的直方图就是将每个单独通道 的直方图连接在一起。
现在让我们绘制颜色直方图:
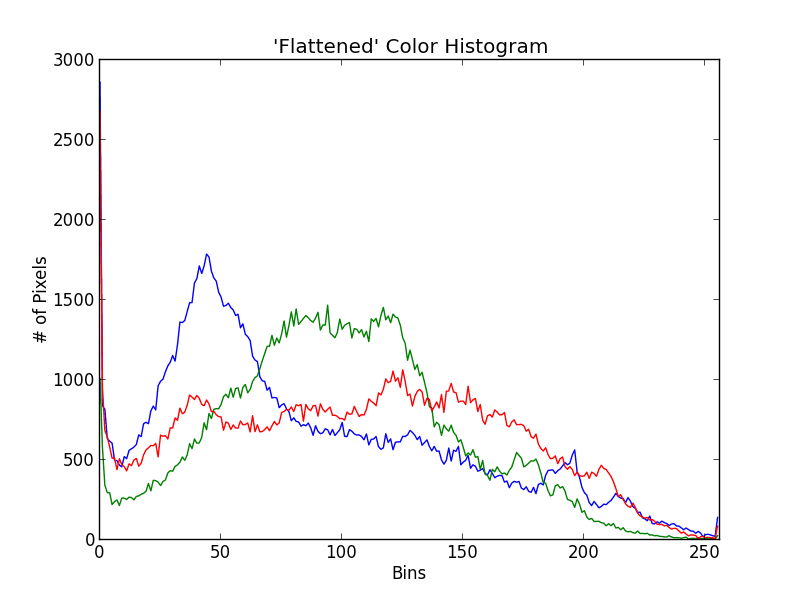
Figure 2: Color histograms for each Red, Green, and Blue channel of the Dr. Grant image.
太棒了。这很简单。这个直方图告诉我们什么?嗯,在仓#50 周围的深蓝色像素值中有一个峰值。这个蓝色范围指的是格兰特的蓝色衬衫。从箱#50 到#125 的更大范围的绿色像素指的是背景中格兰特博士后面的森林。
多维直方图
到目前为止,我们一次只计算了一个通道的直方图。现在我们转向多维直方图,一次考虑两个通道。
我喜欢用和这个词来解释多维直方图。比如我们可以问一个问题比如
“有多少像素的红色值为 10 ,的蓝色值为 30?”有多少像素的绿色值为 200 红色值为 130?通过使用连接词和,我们能够构建多维直方图。
就这么简单。让我们检查一些代码来自动完成构建 2D 直方图的过程:
# let's move on to 2D histograms -- I am reducing the
# number of bins in the histogram from 256 to 32 so we
# can better visualize the results
fig = plt.figure()
# plot a 2D color histogram for green and blue
ax = fig.add_subplot(131)
hist = cv2.calcHist([chans[1], chans[0]], [0, 1], None,
[32, 32], [0, 256, 0, 256])
p = ax.imshow(hist, interpolation = "nearest")
ax.set_title("2D Color Histogram for Green and Blue")
plt.colorbar(p)
# plot a 2D color histogram for green and red
ax = fig.add_subplot(132)
hist = cv2.calcHist([chans[1], chans[2]], [0, 1], None,
[32, 32], [0, 256, 0, 256])
p = ax.imshow(hist, interpolation = "nearest")
ax.set_title("2D Color Histogram for Green and Red")
plt.colorbar(p)
# plot a 2D color histogram for blue and red
ax = fig.add_subplot(133)
hist = cv2.calcHist([chans[0], chans[2]], [0, 1], None,
[32, 32], [0, 256, 0, 256])
p = ax.imshow(hist, interpolation = "nearest")
ax.set_title("2D Color Histogram for Blue and Red")
plt.colorbar(p)
# finally, let's examine the dimensionality of one of
# the 2D histograms
print "2D histogram shape: %s, with %d values" % (
hist.shape, hist.flatten().shape[0])
是的,这是相当多的代码。但这只是因为我们正在为 RGB 通道的每种组合计算 2D 颜色直方图:红色和绿色,红色和蓝色,绿色和蓝色。
既然我们正在处理多维直方图,我们需要记住我们正在使用的仓的数量。在前面的例子中,出于演示的目的,我使用了 256 个箱。然而,如果我们对 2D 直方图中的每个维度使用 256 个面元,那么我们得到的直方图将具有 65,536 个单独的像素计数。这不仅浪费资源,而且不切实际。计算多维直方图时,大多数应用程序使用 8 到 64 个区间。如第 64 行和第 65 行所示,我现在使用 32 个而不是 256 个。
通过检查cv2.calcHist函数的第一个参数,可以看出这段代码中最重要的内容。这里我们看到我们正在传递两个通道的列表:绿色和蓝色通道。这就是全部了。
那么 2D 直方图是如何存储在 OpenCV 中的呢?这是 2D 数字阵列。因为我为每个通道使用了 32 个面元,所以现在我有一个 32×32 的直方图。我们可以简单地通过展平它来将这个直方图视为一个特征向量(行 88 和 89 )。展平直方图会产生一个包含 1024 个值的列表。
我们如何可视化 2D 直方图?让我们来看看。
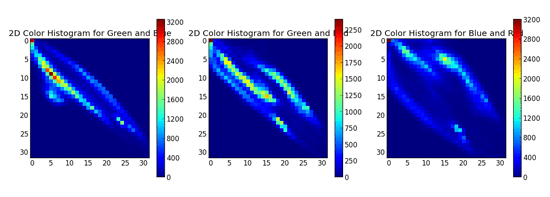
Figure 3: 2D color histograms for Dr. Grant.
在上图中,我们看到了三个图表。第一个是绿色和蓝色通道的 2D 颜色直方图,第二个是绿色和红色的直方图,第三个是蓝色和红色的直方图。蓝色阴影代表低像素计数,而红色阴影代表高像素计数(即 2D 直方图中的峰值)。当 X=5 且 Y=10 时,我们可以在绿色和蓝色 2D 直方图(第一幅图)中看到这样一个峰值。
使用 2D 直方图一次考虑两个通道。但是如果我们想考虑所有三个 RGB 通道呢?你猜对了。我们现在要构建一个 3D 直方图。
# our 2D histogram could only take into account 2 out
# of the 3 channels in the image so now let's build a
# 3D color histogram (utilizing all channels) with 8 bins
# in each direction -- we can't plot the 3D histogram, but
# the theory is exactly like that of a 2D histogram, so
# we'll just show the shape of the histogram
hist = cv2.calcHist([image], [0, 1, 2],
None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
print "3D histogram shape: %s, with %d values" % (
hist.shape, hist.flatten().shape[0])
这里的代码非常简单——它只是上面代码的扩展。我们现在为每个 RGB 通道计算一个 8×8×8 的直方图。我们无法形象化这个直方图,但可以看到形状确实是(8, 8, 8)有 512 个值。同样,将 3D 直方图视为特征向量可以通过简单地展平阵列来完成。
色彩空间
本文中的例子只探索了 RGB 颜色空间,但是可以在 OpenCV 中为任何颜色空间构建直方图。讨论色彩空间超出了本文的范围,但是如果你感兴趣,可以查看关于转换色彩空间的文档。
缺点
在这篇文章的前面,我们假设具有相似颜色分布的图像在语义上是相似的。对于小而简单的数据集,事实上可能是这样。然而,在实践中,这一假设并不总是成立的。
让我们想想这是为什么。
首先,根据定义,颜色直方图忽略了图像中物体的形状和纹理。这意味着颜色直方图没有对象形状或对象纹理的概念。此外,直方图还忽略任何空间信息(即,像素值来自图像中的何处)。直方图的扩展,颜色相关图,可以用于编码像素之间的空间关系。
我们来想想 Chic Engine ,我的视觉时尚搜索引擎 iPhone app。我对不同类型的衣服有不同的分类,比如鞋子和衬衫。如果我用颜色直方图来描述一只红鞋子和一件红衬衫,直方图会假设它们是同一个对象。很明显它们都是红色的,但是语义到此为止——它们根本不一样。颜色直方图根本无法“模拟”鞋子或衬衫是什么。
最后,颜色直方图对“噪声”很敏感,例如拍摄图像的环境中的光照变化和量化误差(选择要增加的面元)。通过使用不同于 RGB 的颜色空间(例如 HSV 或 Lab*)可以潜在地减轻这些限制。
然而,尽管如此,直方图仍然被广泛用作图像描述符。它们实现起来非常简单,计算速度也非常快。虽然它们有其局限性,但如果在正确的环境中正确使用,它们会非常强大。
直到周一!
基于 K 均值聚类的 OpenCV 颜色量化
原文:https://pyimagesearch.com/2014/07/07/color-quantization-opencv-using-k-means-clustering/

有没有看过 一台扫描仪黑黑的?
这部电影是数码拍摄的,但后来在后期处理步骤中赋予了动画效果——但这是一个艰苦的过程。对于电影中的每一帧,动画师一帧一帧地追踪原始镜头。
请花一秒钟考虑一下一部电影中的帧数…每一帧都必须用手描摹。
的确是一项艰巨的任务。
那么,如果有一种方法可以利用计算机视觉创造出一种黑暗的扫描仪动画效果呢?
这可能吗?
你打赌。
在这篇博文中,我将向你展示如何使用 k-means 聚类和颜色量化在图像中创建一个黑暗的扫描仪类型的效果。
要了解我是如何做到的,请继续阅读。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
那么,什么是颜色量化呢?
颜色量化是减少图像中不同颜色数量的过程。
通常,目的是尽可能保留图像的颜色外观,同时减少颜色的数量,无论是出于内存限制还是压缩。
在我自己的工作中,我发现颜色量化最适用于构建基于内容的图像检索(CBIR)系统。
如果你对这个术语不熟悉,CBIR 只是“图片搜索引擎”的一种花哨的学术说法。
不过,请花点时间考虑一下 CBIR 背景下的颜色量化。
任何给定的 24 位 RGB 图像都有 256 x 256 x 256 种可能的颜色。当然,我们可以基于这些强度值构建标准的颜色直方图。
但是另一种方法是显式量化图像,然后减少颜色的数量,比如 16 或 64。这产生了显著更小的空间和(理想地)更小的噪声和变化。
在实践中,您可以使用这种技术来构建更严格的颜色直方图。
事实上,著名的QBIC·CBIR系统(证明图像搜索引擎是可能的原始 CBIR 系统之一)利用二次距离中的量化颜色直方图来计算相似性。
现在我们已经了解了什么是颜色量化,让我们来探索如何利用它来创建图像中的扫描仪深色类型的效果。
用 OpenCV 进行颜色量化
让我们把手弄脏吧。
打开一个新文件,命名为quant.py,开始编码:
# import the necessary packages
from sklearn.cluster import MiniBatchKMeans
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
ap.add_argument("-c", "--clusters", required = True, type = int,
help = "# of clusters")
args = vars(ap.parse_args())
我们要做的第一件事是在2-5 号线导入我们需要的包。我们将使用 NumPy 进行数值处理,arparse用于解析命令行参数,而cv2用于 OpenCV 绑定。我们的 k-means 实现将由 scikit-learn 处理;具体来说, MiniBatchKMeans 类。
你会发现MiniBatchKMeans比普通的 K-Means 要快得多,尽管质心可能不那么稳定。
这是因为MiniBatchKMeans在数据集的小“批”上操作,而 K-Means 在数据集的群体上操作,因此使得每个质心的均值计算以及质心更新循环慢得多。
一般来说,我通常喜欢从MiniBatchKMeans开始,如果(且仅如果)我的结果很差,我会切换到正常的 K 均值。
第 7-12 行然后处理解析我们的命令行参数。我们需要两个开关:--image,这是我们想要应用颜色量化的图像的路径,和--clusters,这是我们的输出图像将具有的颜色数量。
现在真正有趣的代码开始了:
# load the image and grab its width and height
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
# convert the image from the RGB color space to the L*a*b*
# color space -- since we will be clustering using k-means
# which is based on the euclidean distance, we'll use the
# L*a*b* color space where the euclidean distance implies
# perceptual meaning
image = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
# reshape the image into a feature vector so that k-means
# can be applied
image = image.reshape((image.shape[0] * image.shape[1], 3))
# apply k-means using the specified number of clusters and
# then create the quantized image based on the predictions
clt = MiniBatchKMeans(n_clusters = args["clusters"])
labels = clt.fit_predict(image)
quant = clt.cluster_centers_.astype("uint8")[labels]
# reshape the feature vectors to images
quant = quant.reshape((h, w, 3))
image = image.reshape((h, w, 3))
# convert from L*a*b* to RGB
quant = cv2.cvtColor(quant, cv2.COLOR_LAB2BGR)
image = cv2.cvtColor(image, cv2.COLOR_LAB2BGR)
# display the images and wait for a keypress
cv2.imshow("image", np.hstack([image, quant]))
cv2.waitKey(0)
首先,我们在第 15 行的处加载我们的图像,并在第 16 行的处分别获取它的高度和宽度。
第 23 行处理将我们的图像从 RGB 颜色空间转换到 Lab*颜色空间。
为什么我们要费心做这种转换呢?
因为在 Lab*颜色空间中,颜色之间的欧几里德距离具有实际的感知意义——这不是 RGB 颜色空间的情况。
假设 k-means 聚类也假设欧几里得空间,我们最好使用 Lab*而不是 RGB。
为了聚集我们的像素强度,我们需要在第 27 行上重塑我们的图像。这一行代码简单地获取了一个 (M,N,3)(M x N像素,每个像素有三个分量)并将其重塑为一个 (M x N,3) 特征向量。这种整形很重要,因为 k-means 采用二维数组,而不是三维图像。
从那里,我们可以在第 31-33 行上应用我们实际的小批量 K 均值聚类。
第 31 行使用我们在命令行参数中指定的集群数量来实例化我们的MiniBatchKMeans类,而第 32 行执行实际的集群。
除了实际的聚类,行 32 处理一些极其重要的事情——“预测”原始图像中每个像素的量化颜色将会是什么。通过确定输入像素最接近哪个质心来处理该预测。
从那里,我们可以使用一些花哨的数字索引,在第 33 行的处获得这些预测的标签并创建我们的量化图像。这一行所做的就是使用预测标签在质心数组中查找 Lab*颜色。
第 36 行和第 37 行然后处理将我们的 (M x N,3) 特征向量整形回一个 (M,N,3) 维度图像,接着将我们的图像从 Lab*颜色空间转换回 RGB。
最后,行 44 和 45 显示我们的原始和量化图像。
现在编码完成了,让我们看看结果。
使用计算机视觉创造出一种黑暗的扫描仪效果
因为现在是世界杯赛季,所以让我们从一个足球图像开始。
Figure 1: Applying color quantization with OpenCV using k-means clustering.
在这里,我们可以在左边的看到我们的原始图像,在右边的看到我们的量化图像。**
我们可以清楚地看到,当仅使用 k=4 颜色时,我们失去了原始图像的许多颜色细节,尽管尝试对图像的原始颜色空间进行建模——草地仍然是绿色的,足球仍然是白色的,天空仍然带有一丝蓝色。
但是当我们增加 k=8 和 k=16 的颜色时,我们肯定会开始看到改进的结果。
非常有趣的是,只需要 16 种颜色就可以很好地再现原始图像,因此我们的扫描仪产生了暗效果。
让我们尝试另一个图像:

Figure 2: Apply color quantization using OpenCV to a nature scene.
同样,原始自然场景图像在左边的处,量化输出在右边的处。**
就像世界杯图像一样,请注意,随着量化集群数量的增加,我们能够更好地模拟原始颜色空间。

Figure 3: Applying color quantization using OpenCV to Jurassic Park.
最后,看一下图 3 看一个来自侏罗纪公园的截屏。注意颜色的数量是如何减少的——这在哈蒙德的白衬衫中显而易见。
在聚类的数量和量化图像的质量之间存在明显的折衷。
第一个权衡是,随着聚类数量的增加,执行聚类所需的时间也会增加。
第二个权衡是,随着聚类数量的增加,存储输出图像所需的内存量也会增加;但是,在这两种情况下,内存占用仍然比原始图像小,因为您使用的调色板要小得多。
摘要
在这篇博文中,我向你展示了如何使用 OpenCV 和 k-means 聚类来执行颜色量化,以在图像中创建一种扫描仪深色类型的效果。
虽然颜色量化不能完美地模仿电影效果,但它确实证明了通过减少图像中的颜色数量,您可以为图像创建更具色调分离、更生动的感觉。
当然,颜色量化有更多的实际应用,而不仅仅是视觉上的吸引力。
色彩量化通常用于内存有限或需要压缩的系统中。
在我个人的工作中,我发现在构建 CBIR 系统时最好使用颜色量化。事实上, QBIC ,一个开创性的图像搜索引擎,证明了通过使用量化的颜色直方图和二次距离,图像搜索引擎确实是可能的。
因此,请花一点时间使用下面的表格下载代码。然后创建一些你自己的量化图像,发给我。我很期待看到你的结果!
使用 Raspberry Pi 相机模块的常见错误
原文:https://pyimagesearch.com/2016/08/29/common-errors-using-the-raspberry-pi-camera-module/

今天的博文将从我们最近在 PyImageSearch 博客上的深度学习教程趋势中转移一下注意力,而是专注于我最近收到的大量电子邮件中的一个主题— 使用 Raspberry Pi 相机模块时的常见错误。
我想以提到达夫·琼斯开始这篇文章,他是 picamera 库的维护者和主要贡献者。Dave 是我有幸与之互动的最活跃的开源贡献者之一(他也是一个非常好的人)。
几个月前,我在使用(当时)最新的picamera==1.11库,遇到了一些错误。在检查了picamera GitHub、之后,我注意到一个关于我的问题的问题已经被发布了。我确认了这个 bug 的存在,Dave 随后找到了这个 bug——并在当天结束前修复了它,甚至向 PyPI 存储库发布了一个新的更新版本。
不言而喻,如果没有戴夫,树莓派上的计算机视觉和 OpenCV 就不会这么有趣,或者一半容易上手。
在过去的几年里,我在使用 Raspberry Pi 和picamera库时遇到了一些“常见”错误。我今天的目标是记录这些错误,这样你就可以很容易地修复它们。
事实上,我今天在这里记录的大多数问题根本不是真正的“错误”——它们只是对picamera库如何与您的 Raspberry Pi 设置一起工作的误解。
使用 Raspberry Pi 相机模块的常见错误
在我们查看使用 Raspberry Pi 相机模块时的常见错误之前,让我们首先讨论如何简单地访问视频流picamera。
如何访问您的 picamera 视频流
首先,我假设你已经按照 中的说明使用 OpenCV 和 Python 访问了 Raspberry Pi 相机,并在你的 Pi 上安装了picamera库。
如果您还没有安装picamera,这可以通过使用pip来完成:
$ pip install "picamera[array]"
我们将[array]部分添加到命令中,以确保我们可以将帧作为 NumPy 数组读取,从而使模块与 OpenCV 兼容。
在pip安装完picamera后,您可以使用以下命令检查版本号:
$ pip freeze
报道的 picamera 版本应该是至少是 1.12。
关于 Python 虚拟环境的快速说明
如果你是 PyImageSearch 博客的常客,你会知道我经常使用 Python 虚拟环境——正因为如此,你可能也一样。
*在我们继续之前,花点时间看看您是否正在使用 Python 虚拟环境,方法是使用您的~/.profile文件并列出您系统上所有可用的虚拟环境:
$ source ~/.profile
$ lsvirtualenv
如果您得到一个与没有找到lsvirtualenv命令相关的错误,那么您是而不是在利用 Python 虚拟环境(或者您可能在编辑您的~/.profile文件时犯了一个错误)。如果您没有使用 Python 虚拟环境,那么您可以跳过下一段,转到下一小节。
假设您正在使用 Python 虚拟环境,您可以执行workon命令来访问您系统上的每个单独的 Python 虚拟环境。在 PyImageSearch 博客上的大多数安装教程中,我们将我们的 Python 虚拟环境命名为cv,是“计算机视觉”的缩写:
$ workon cv
用于访问您的 Raspberry Pi 相机模块的 Python 模板
为了访问picamera视频流,我创建了一个简单的、可扩展的模板,我将在下面为你详述。
打开一个新文件,将其命名为test_video.py,并插入以下代码:
# import the necessary packages
from picamera.array import PiRGBArray
from picamera import PiCamera
import time
import cv2
# initialize the camera and grab a reference to the raw camera capture
camera = PiCamera()
camera.resolution = (640, 480)
camera.framerate = 32
rawCapture = PiRGBArray(camera, size=(640, 480))
# allow the camera to warmup
time.sleep(0.1)
第 2-5 行处理导入我们需要的 Python 包。
然后我们初始化第 8 行上的camera对象,这允许我们访问 Raspberry Pi 相机模块。我们将视频流的分辨率定义为 640 x 480 ,最大帧率为 32 FPS ( 第 9 行和第 10 行)。
从那里,我们在第 11 行的上初始化我们的PiRGBArray对象,传入原始的camera对象,然后显式地重新声明分辨率。这个PiRGBArray对象允许我们以 NumPy 格式从 Raspberry Pi 相机模块中读取帧,从而使帧与 OpenCV 兼容。
最后,我们等待 0.1 秒,让 Raspberry Pi 摄像头传感器预热。
我们的下一个代码块实际处理从我们的 Raspberry Pi 相机传感器捕获帧:
# capture frames from the camera
for frame in camera.capture_continuous(rawCapture, format="bgr", use_video_port=True):
# grab the raw NumPy array representing the image - this array
# will be 3D, representing the width, height, and # of channels
image = frame.array
# show the frame
cv2.imshow("Frame", image)
key = cv2.waitKey(1) & 0xFF
# clear the stream in preparation for the next frame
rawCapture.truncate(0)
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
在的第 17 行,我们开始循环使用capture_continuous函数从camera捕获的帧。我们向这个方法传递三个参数。
第一个是rawCapture,我们想要读取每一帧的格式。然后我们指定format为bgr,因为 OpenCV 希望图像通道是 BGR 顺序而不是 RGB。最后,use_video_port布尔值表示我们正在将流视为视频。
一旦我们有了frame,我们就可以通过.array属性(第 20 行)访问原始的 NumPy 数组。
我们使用 OpenCV GUI 函数在第 23 行和第 24 行 将帧显示到屏幕上。
但是在我们继续下一帧之前,我们首先需要通过调用rawCapture对象上的.truncate方法来准备我们的流。如果你不这样做,你的 Python 脚本将抛出一个错误——确切的错误我们将在本指南后面回顾。
最后,如果按下q键(第 30 行和第 31 行,我们从循环中断开。
要执行test_video.py脚本,只需打开终端/命令行提示符并执行以下命令:
$ python test_video.py
注意:如果您正在使用 Python 虚拟环境,您将希望使用workon命令切换到安装了 OpenCV + picamera 库的 Python 环境。
如果一切顺利,您应该会看到 Raspberry Pi 视频流显示在您的提要中:

Figure 1: Displaying the Raspberry Pi video stream to our screen.
否则,如果你得到一个错误——继续阅读。下面我详细列出了我遇到的最常见的错误信息。
无法连接到您的 picamera 模块?
下面的错误信息看起来熟悉吗?
$ python test_video.py
mmal: mmal_vc_component_create: failed to create component 'vc.ril.camera' (1:ENOMEM)
mmal: mmal_component_create_core: could not create component 'vc.ril.camera' (1)
Traceback (most recent call last):
File "test_video.py", line 11, in <module>
camera = PiCamera()
File "/home/pi/.virtualenvs/cv2/local/lib/python2.7/site-packages/picamera/camera.py", line 488, in __init__
self.STEREO_MODES[stereo_mode], stereo_decimate)
File "/home/pi/.virtualenvs/cv2/local/lib/python2.7/site-packages/picamera/camera.py", line 526, in _init_camera
"Camera is not enabled. Try running 'sudo raspi-config' "
picamera.exc.PiCameraError: Camera is not enabled. Try running 'sudo raspi-config' and ensure that the camera has been enabled.
如果你收到这个错误信息,那么你可能忘记了(1)运行raspi-config,92)启用摄像机,以及(3)重启你的 Pi。
如果你在运行raspi-config后仍然得到一个错误信息,那么你的相机可能安装不正确。在这种情况下,我建议观看一下这个安装视频,然后尝试再次安装您的 Raspberry Pi 相机模块(确保首先关闭您的 Pi!)
https://www.youtube.com/embed/GImeVqHQzsE?feature=oembed*
使用 siamese 网络、Keras 和 TensorFlow 比较图像的相似性
在本教程中,您将学习如何使用 siamese 网络和 Keras/TensorFlow 深度学习库来比较两幅图像的相似性(以及它们是否属于相同或不同的类别)。
这篇博文是我们关于暹罗网络基础的三部分系列的第三部分:
- 第一部分: 用 Python 构建连体网络的图像对(两周前的帖子)
- Part #2: 用 Keras、TensorFlow、深度学习 训练暹罗网络(上周教程)
- 第三部分: 使用连体网络比较图像(本教程)
上周我们学习了如何训练我们的暹罗网络。我们的模型在我们的测试集上表现良好,正确地验证了两幅图像是属于相同的类别还是不同的类别。训练之后,我们将模型序列化到磁盘上。
上周的教程发布后不久,我收到了一封来自 PyImageSearch 读者 Scott 的电子邮件,他问:
“你好,阿德里安——感谢暹罗网络上的这些指南。我听到有人在深度学习领域提到它们,但老实说,我从来没有真正确定它们是如何工作的,或者它们做了什么。这个系列确实帮助我消除了疑虑,甚至帮助了我的一个工作项目。
我的问题是:
我们如何利用训练好的暹罗网络,从训练和测试集之外的图像中对其进行预测?
这可能吗?
没错,斯科特。这正是我们今天要讨论的内容。
要了解如何使用暹罗网络比较图像的相似性,继续阅读。
使用 siamese 网络、Keras 和 TensorFlow 比较图像的相似性
在本教程的第一部分,我们将讨论如何使用一个经过训练的暹罗网络来预测两个图像对之间的相似性,更具体地说,这两个输入图像是属于相同的还是不同的类别。
然后,您将学习如何使用 Keras 和 TensorFlow 为暹罗网络配置开发环境。
一旦您的开发环境配置完毕,我们将检查我们的项目目录结构,然后使用我们的 siamese 网络实现一个 Python 脚本来比较图像的相似性。
我们将讨论我们的结果来结束本教程。
暹罗网络如何预测图像对之间的相似性?
在上周的教程中,你学习了如何训练一个连体网络来验证两对数字是属于相同的还是不同的类。然后,我们在训练后将我们的连体模型序列化到磁盘上。
那么问题就变成了:
“我们如何使用我们训练过的暹罗网络来预测两幅图像之间的相似度?”
答案是我们利用了我们的暹罗网络实现中的最后一层,即 sigmoid 激活函数。
sigmoid 激活函数有一个范围为【0,1】的输出,这意味着当我们向我们的暹罗网络呈现一个图像对时,该模型将输出一个值 > = 0 和 < = 1。
值0意味着两幅图像完全不相似,,而值1意味着两幅图像非常相似。
这种相似性的一个例子可以在本节顶部的图 1 中看到:
- 将一个“7”与一个“0”进行比较,相似性得分很低,只有 0.02。
- 然而,将一个“0”与另一个“0”进行比较,具有非常高的相似性得分 0.93。
一个好的经验法则是使用相似性临界值0.5 (50%)作为阈值:
- 如果两个图像对的图像相似度为 < = 0.5,,则它们属于不同的类。
- 相反,如果对具有预测的相似性 > 0.5,,那么它们属于相同的类。
通过这种方式,您可以使用暹罗网络来(1)比较图像的相似性,以及(2)确定它们是否属于同一类别。
使用暹罗网络的实际使用案例包括:
- 人脸识别:给定两张包含人脸的独立图像,确定两张照片中的是否是同一个人。
- 签名验证:当呈现两个签名时,确定其中一个是否是伪造的。
- 处方药标识:给定两个处方药,确定是同一药物还是不同药物。
配置您的开发环境
这一系列关于暹罗网络的教程利用了 Keras 和 TensorFlow。如果您打算继续学习本教程或本系列的前两部分,我建议您现在花时间配置您的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们深入本教程之前,让我们先花点时间回顾一下我们的项目目录结构。
首先确保使用本教程的 “下载” 部分下载源代码和示例图像。
接下来,让我们来看看这个项目:
$ tree . --dirsfirst
.
├── examples
│ ├── image_01.png
...
│ └── image_13.png
├── output
│ ├── siamese_model
│ │ ├── variables
│ │ │ ├── variables.data-00000-of-00001
│ │ │ └── variables.index
│ │ └── saved_model.pb
│ └── plot.png
├── pyimagesearch
│ ├── config.py
│ ├── siamese_network.py
│ └── utils.py
├── test_siamese_network.py
└── train_siamese_network.py
4 directories, 21 files
在examples目录中,我们有许多示例数字:
我们将对这些数字进行采样,然后使用我们的暹罗网络比较它们的相似性。
output目录包含训练历史图(plot.png)和我们训练/序列化的暹罗网络模型(siamese_model/)。这两个文件都是在上周关于训练你自己的定制暹罗网络模型的教程中生成的— 确保你在继续之前阅读该教程,因为它是今天的必读内容!
pyimagesearch模块包含三个 Python 文件:
config.py:我们的配置文件,存储输出文件路径、训练配置等重要变量(包括图像输入尺寸、批量大小、时期等。)siamese_network.py:我们实施我们的暹罗网络架构utils.py:包含助手配置功能,用于生成图像对、计算欧几里德距离和绘制训练历史路径
train_siamese_network.py脚本:
- 导入配置、暹罗网络实现和实用程序功能
- 从磁盘加载 MNIST 数据集
- 生成图像对
- 创建我们的训练/测试数据集分割
- 训练我们的暹罗网络
- 将训练好的连体网络序列化到磁盘
我不会今天讲述这四个脚本,因为我已经在上周关于如何训练暹罗网络的教程 中讲述了它们。为了完整起见,我已经在今天的教程的项目目录结构中包含了这些文件,但是,要全面回顾这些文件,它们做什么,以及它们是如何工作的,请参考上周的教程。
最后,我们有今天教程的重点,test_siamese_network.py。
我们开始工作吧!
实现我们的暹罗网络图像相似性脚本
我们现在准备使用 Keras 和 TensorFlow 实现图像相似性的连体网络。
首先,确保您使用本教程的 【下载】 部分下载源代码、示例图像和预训练的暹罗网络模型。
从那里,打开test_siamese_network.py,并跟随:
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
from tensorflow.keras.models import load_model
from imutils.paths import list_images
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
我们首先导入我们需要的 Python 包(第 2-9 行)。值得注意的进口包括:
config:包含重要的配置,包括驻留在磁盘上的经过训练/序列化的暹罗网络模型的路径utils:包含在我们的暹罗网络Lambda层中使用的euclidean_distance函数— 我们需要导入这个包来抑制任何关于从磁盘加载UserWarnings层的Lambdaload_model:Keras/tensor flow 函数,用于从磁盘加载我们训练好的暹罗网络list_images:抓取我们examples目录中所有图像的路径
让我们继续解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of testing images")
args = vars(ap.parse_args())
这里我们只需要一个参数,--input,它是我们在磁盘上的目录的路径,该目录包含我们想要比较相似性的图像。运行这个脚本时,我们将提供项目中examples目录的路径。
解析完命令行参数后,我们现在可以获取--input目录中的所有testImagePaths:
# grab the test dataset image paths and then randomly generate a
# total of 10 image pairs
print("[INFO] loading test dataset...")
testImagePaths = list(list_images(args["input"]))
np.random.seed(42)
pairs = np.random.choice(testImagePaths, size=(10, 2))
# load the model from disk
print("[INFO] loading siamese model...")
model = load_model(config.MODEL_PATH)
第 20 行获取包含我们想要进行相似性比较的数字的所有示例图像的路径。第 22 行从这些testImagePaths中随机产生总共 10 对图像。
# loop over all image pairs
for (i, (pathA, pathB)) in enumerate(pairs):
# load both the images and convert them to grayscale
imageA = cv2.imread(pathA, 0)
imageB = cv2.imread(pathB, 0)
# create a copy of both the images for visualization purpose
origA = imageA.copy()
origB = imageB.copy()
# add channel a dimension to both the images
imageA = np.expand_dims(imageA, axis=-1)
imageB = np.expand_dims(imageB, axis=-1)
# add a batch dimension to both images
imageA = np.expand_dims(imageA, axis=0)
imageB = np.expand_dims(imageB, axis=0)
# scale the pixel values to the range of [0, 1]
imageA = imageA / 255.0
imageB = imageB / 255.0
# use our siamese model to make predictions on the image pair,
# indicating whether or not the images belong to the same class
preds = model.predict([imageA, imageB])
proba = preds[0][0]
第 29 行开始循环所有图像对。对于每个图像对,我们:
- 从磁盘加载两个图像(行 31 和 32 )
- 克隆两个图像,以便我们稍后可以绘制/可视化它们(第 35 行和第 36 行)
- 添加一个通道尺寸(行 39 和 40 )以及一个批次尺寸(行 43 和 44 )
- 将像素亮度从范围【0,255】缩放到【0,1】,就像我们上周训练暹罗网络 ( 第 47 行和第 48 行)
一旦imageA和imageB被预处理,我们通过调用我们的暹罗网络模型上的.predict方法(第 52 行)来比较它们的相似性,从而得到两幅图像的概率/相似性分数(第 53 行)。
最后一步是在屏幕上显示图像对和相应的相似性得分:
# initialize the figure
fig = plt.figure("Pair #{}".format(i + 1), figsize=(4, 2))
plt.suptitle("Similarity: {:.2f}".format(proba))
# show first image
ax = fig.add_subplot(1, 2, 1)
plt.imshow(origA, cmap=plt.cm.gray)
plt.axis("off")
# show the second image
ax = fig.add_subplot(1, 2, 2)
plt.imshow(origB, cmap=plt.cm.gray)
plt.axis("off")
# show the plot
plt.show()
第 56 行和第 57 行为该对创建一个matplotlib图形,并将相似性得分显示为图的标题。
第 60-67 行在图上画出图像对中的每一个图像,而第 70 行将输出显示到我们的屏幕上。
恭喜你实现了图像比较和相似性的暹罗网络!让我们在下一节看到我们努力的成果。
使用带有 Keras 和 TensorFlow 的暹罗网络的图像相似性结果
我们现在准备使用我们的暹罗网络来比较图像的相似性!
在我们检查结果之前,请确保您:
- 我已经阅读了我们之前关于训练连体网络的教程,所以你可以理解我们的连体网络模型是如何被训练和生成的
- 使用本教程的 “下载” 部分下载源代码、预训练的暹罗网络和示例图像
从那里,打开一个终端,并执行以下命令:
$ python test_siamese_network.py --input examples
[INFO] loading test dataset...
[INFO] loading siamese model...
注:你得到的是与TypeError: ('Keyword argument not understood:', 'groups')相关的错误吗?如果是这样,请记住本教程“下载”部分中包含的预训练模型是使用 TensorFlow 2.3 训练的。因此,在运行test_siamese_network.py时,您应该使用 TensorFlow 2.3。如果您更喜欢使用 TensorFlow 的不同版本,只需运行* train_siamese_network.py 来训练模型并生成一个新的 siamese_model 序列化到磁盘。从那里你就可以无误地运行test_siamese_network.py。*
上面的图 4 显示了我们的图像相似性结果的蒙太奇。
对于第一个图像对,一个包含一个“7”,而另一个包含一个“1”——显然这不是同一个图像,相似度得分较低,为 42%。我们的暹罗网络已经正确地将这些图像标记为属于不同的类。
下一个图像对由两个“0”数字组成。我们的暹罗网络已经预测到非常高的相似性分数为 97%,表明这两幅图像属于相同的类。
您可以在图 4 的中看到所有其他图像对的相同模式。具有高相似性分数的图像属于相同类,而具有低相似性分数的图像对属于不同类。
由于我们使用 sigmoid 激活层作为我们的暹罗网络(其输出值在范围【0,1】)中的最后一层,一个好的经验法则是使用相似性截止值0.5 (50%)作为阈值:
- 如果两个图像对的图像相似度为 < = 0.5 ,那么它们属于不同的类。
- 相反,如果对的预测相似度为 > 0.5 ,那么它们属于相同的类。
当使用暹罗网络计算图像相似性时,您可以在自己的项目中使用这条经验法则。
总结
在本教程中,你学习了如何比较两幅图像的相似性,更具体地说,它们是属于同一个类别还是属于不同的类别。我们使用 siamese 网络以及 Keras 和 TensorFlow 深度学习库完成了这项任务。
这篇文章是我们介绍暹罗网络的三部分系列的最后一部分。为了便于参考,下面是该系列中每个指南的链接:
- 第一部分: 用 Python 为连体网络构建图像对
- Part #2: 用 Keras、TensorFlow、深度学习训练暹罗网络
- 第三部分: 使用暹罗网络、Keras 和 TensorFlow 比较图像的相似性(本教程)
在不久的将来,我将报道更多关于暹罗网络的高级系列,包括:
- 图像三元组
- 对比损失
- 三重损失
- 用暹罗网络进行人脸识别
- 用连体网络进行一次性学习
敬请关注这些教程;你不想错过他们!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
BagofWords 和 Word2Vec 的比较
原文:https://pyimagesearch.com/2022/07/18/comparison-between-bagofwords-and-word2vec/
目录
BagofWords 和 Word2Vec 的比较
在过去的几周里,我们学习了重要的自然语言处理(NLP)技术,如单词袋和 Word2Vec。在某种形式上,两者都是 NLP 中表征学习的一部分。
总的来说,以一种让计算机理解文本的方式来表示特征确实有助于 NLP 的发展。但是上面提到的两种技术完全不同。这就引出了一个问题,是什么让我们选择一个而不是另一个?
在本教程中,您将对单词包和 Word2Vec 进行比较。
本课是关于 NLP 101 的 4 部分系列的最后一课:
*要知道单词袋和单词 2Vec, 的区别,只要坚持阅读。
BagofWords 和 Word2Vec 的比较
让我们简要回顾一下什么是 NLP 中的表征学习。向计算机教授文本数据是极其困难和复杂的。在本系列的第一篇博客文章中,我们回顾了自然语言处理的简史。
在那里,我们确定了在 NLP 中引入统计和表征学习是如何将 NLP 的总体进展向更积极的方向改变的。我们学习了单词袋(BOW),这是一种源于表征学习的技术。接下来是更复杂、更全面的 Word2Vec 方法。
这两种技术都涉及到将我们的输入数据表达到一个表示(嵌入)空间中。我们发现的关联越多,我们对模型学习效果的验证就越多。
让我们更上一层楼,更深入地探究为什么这些技术既相似又截然不同。
简述弓和字 2 vec
单词包架构包括将每个输入句子转换成单词包。看一下图一。
这里的嵌入矩阵的列数等于总词汇表中的单词数。每个句子被表示为每个单词出现或不出现的组合。
例如,如果给定数据集的词汇大小为 300,大小为 5 的输入句子现在将变成大小为 300 的向量,其中 5 个出现的单词的位被打开,而 295 位被关闭。
Word2Vec 采用不同的方法来利用向量。在这里,我们考虑每个单词,而不是每个句子都被表示为实体。我们选择一个有限维的嵌入空间,其中每行代表词汇表中的一个单词。
在整个训练过程中,每个单词在每个维度上都有一定的值(或权重),代表其矢量形式。这些权重由每个单词的上下文(即相邻单词)确定。
因此,句子“天空是蓝色的。”和“蓝天很美。”意味着蓝色这个词会和我们嵌入空间的天空联系在一起。
这两种方法都很巧妙,并且各有千秋。但是让我们进一步仔细检查每个算法。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南 预配置 在您的网络浏览器中运行 Google Colab 的生态系统!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
!tree .
.
├── datadf.csv
├── LICENSE
├── outputs
│ ├── loss_BOW.png
│ ├── loss_W2V.png
│ ├── terminal_outputs.txt
│ ├── TSNE_BOW.png
│ └── TSNE_W2V.png
├── pyimagesearch
│ ├── BOWmodel.py
│ ├── config.py
│ ├── data_processing.py
│ └── __init__.py
├── README.md
├── train_BOW.py
└── train_Word2Vec.py
2 directories, 14 files
我们有两个子目录:outputs和pyimagesearch。
在outputs目录中,我们有这个项目的所有结果和可视化。
在pyimagesearch目录中,我们有:
BOWmodel.py:包含了词袋的模型架构。config.py:包含整个配置管道。data_processing.py:包含几个数据处理工具的脚本。__init__.py:使pyimagesearch目录的行为像一个 python 包。
在主目录中,我们有:
train_BOW.py:词袋架构训练脚本。train_Word2Vec.py:word 2 vec 架构的训练脚本。datadf.csv:我们项目的训练数据。
配置先决条件
在pyimagesearch目录中,config.py脚本包含了我们项目的整个配置管道。
# import the necessary packages
import os
# define Bag-of-Words parameters
EPOCHS = 30
# define the Word2Vec parameters
EMBEDDING_SIZE = 2
ITERATIONS = 1000
# define the path to the output directory
OUTPUT_PATH = "outputs"
# define the path to the Bag-of-Words output
BOW_LOSS = os.path.join(OUTPUT_PATH, "loss_BOW")
BOW_TSNE = os.path.join(OUTPUT_PATH, "TSNE_BOW")
# define the path to the Word2vec output
W2V_LOSS = os.path.join(OUTPUT_PATH, "loss_W2V")
W2V_TSNE = os.path.join(OUTPUT_PATH, "TSNE_W2V")
在第 5 行的上,我们定义了单词袋模型将被训练的时期的数量。
在第 8 行和第 9 行,我们为 Word2Vec 模型定义参数,即 Word2Vec 模型将训练的嵌入维数和迭代次数。
接下来,定义outputs目录(第 12 行),接着是损失和 TSNE 图的单独定义(第 15-20 行)。
处理数据
我们将继续讨论数据处理脚本data_processing.py。这个脚本包含了帮助我们管理数据的函数。
# import the necessary packages
import re
import tensorflow as tf
def preprocess(sentDf, stopWords, key="sentence"):
# loop over all the sentences
for num in range(len(sentDf[key])):
# strip the sentences off the stop-words
newSent = ""
for word in sentDf["sentence"].iloc[num].split():
if word not in stopWords:
newSent = newSent + " " + word
# update the sentences
sentDf["sentence"].iloc[num] = newSent
# return the preprocessed data
return(sentDf)
在第 5 行的上,我们有第一个函数preprocess,它接受以下参数:
sentDf:输入数据帧。- 要从我们的数据集中省略的单词列表。
key:默认设置为sentence。它将用于访问数据帧的右列。
循环第 7 行的句子,我们首先初始化一个空字符串来存储我们在第 9 行处理过的数据。现在,句子中的每个单词都被迭代(第 10 行),停用词被省略。
我们用第 15 行上的新句子(没有停用词)更新数据帧。
def prepare_tokenizerBOW(df, topWords, sentKey="sentence", outputKey="sentiment"):
# prepare separate tokenizers for the data and labels
tokenizerData = tf.keras.preprocessing.text.Tokenizer(num_words=topWords,
oov_token="<unk>",
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~')
tokenizerLabels = tf.keras.preprocessing.text.Tokenizer(num_words=5,
oov_token="<unk>",
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~')
# fit the tokenizers on their respective data
tokenizerData.fit_on_texts(df["sentence"])
tokenizerLabels.fit_on_texts(df["sentiment"])
# return the tokenizers
return (tokenizerData, tokenizerLabels)
我们的下一个函数是第 20 行的上的prepare_tokenizerBOW,它接受以下参数:
df:输入数据帧去掉了停止字。topWords:初始化 tensorflow 标记器所需的参数。sentKey:从数据框中进入句子的键。outputKey:从数据框中访问标签的键。
这个函数专门用于单词包体系结构,其中我们将为数据及其标签使用两个独立的标记化器。相应地,我们创建了两个记号赋予器,并把它们放在各自的文本中(第 22-31 行)。
def prepare_tokenizerW2V(df, topWords, sentKey="sentence", outputKey="sentiment"):
# prepare tokenizer for the Word2Vec data
tokenizerWord2Vec = tf.keras.preprocessing.text.Tokenizer(num_words=topWords,
oov_token="<unk>",
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~')
# fit the tokenizer on the data
tokenizerWord2Vec.fit_on_texts(df["sentence"])
tokenizerWord2Vec.fit_on_texts(df["sentiment"])
# return the tokenizer
return (tokenizerWord2Vec)
这个脚本中的最后一个函数是第 36 行的上的prepare_tokenizerW2V,它接受以下参数:
df:输入数据帧去掉了停止字。topWords:初始化 tensorflow 标记器所需的参数。sentKey:从数据框中进入句子的键。outputKey:从数据框中访问标签的键。
在第行第 38-40 行,我们已经为 Word2Vec 方法初始化了一个单独的标记化器,并将其安装到第行第 43 和 44 行的数据和标签上。因为这两种方法不同,所以我们使用单一的记号赋予器。
创建词袋模型
接下来,我们将定义单词袋模型的架构。让我们进入BOWmodel.py脚本。
#import the necessary packages
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.losses import sparse_categorical_crossentropy
def build_shallow_net(inputDims, numClasses):
# define the model
model = Sequential()
model.add(Dense(512, input_dim=inputDims, activation="relu"))
model.add(Dense(128, activation="relu"))
model.add(Dense(numClasses, activation="softmax"))
# compile the keras model
model.compile(loss=sparse_categorical_crossentropy,
optimizer="adam",
metrics=["accuracy"]
)
# return model
return model
在第 7 行的上,我们有build_shallow_Net,它接受以下参数:
inputDims:输入的维度等于词汇表中的字数。numClasses:输出类的数量。
在第 9-12 行,我们定义了一个由两个密集层和最后一个softmax密集层组成的序列模型。因为我们处理的是小数据,所以像这样的简单模型就可以了。
在的第 15-17 行,我们用sparse_categorical_crossentropy损失和adam优化器编译模型,准确性作为我们的度量。
训练词袋模型
为了训练单词包架构,我们将进入train_BOW.py脚本。
# USAGE
# python -W ignore train_BOW.py
# set seed for reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.data_processing import preprocess
from pyimagesearch.BOWmodel import build_shallow_net
from pyimagesearch.data_processing import prepare_tokenizerBOW
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from tqdm import tqdm
import pandas as pd
import numpy as np
import nltk
import os
# prepare stop-words using the NLTK package
nltk.download("stopwords")
stopWords = nltk.corpus.stopwords.words("english")
# initialize the dataframe from csv format
dataDf = pd.read_csv("datadf.csv")
# preprocess the dataframe
processedDf = preprocess(dataDf, stopWords)
这个脚本的第一步是创建stopWords列表。为此,我们将借助nltk包(线 22 和 23 )。接下来,我们使用csv格式的输入文件初始化数据帧(第 26 行)。随后使用preprocess功能从输入句子中删除停用词(第 29 行)。
# store the number of classification heads
numClasses = len(processedDf["sentiment"].unique())
# create the tokenizers for data and labels
(tokenizerData, tokenizerLabels) = prepare_tokenizerBOW(processedDf, topWords=106)
# create integer sequences of the data using tokenizer
trainSeqs = tokenizerData.texts_to_sequences(processedDf["sentence"])
trainLabels = tokenizerLabels.texts_to_sequences(processedDf["sentiment"])
# create the Bag-of-Words feature representation
encodedDocs = tokenizerData.texts_to_matrix(processedDf["sentence"].values,
mode="count"
)
# adjust the train label indices for training
trainLabels = np.array(trainLabels)
for num in range(len(trainLabels)):
trainLabels[num] = trainLabels[num] - 1
# initialize the model for training
BOWModel = build_shallow_net(inputDims = tokenizerData.num_words-1,
numClasses=numClasses
)
# fit the data into the model and store training details
history = BOWModel.fit(encodedDocs[:, 1:],
trainLabels.astype('float32'),
epochs=config.EPOCHS
)
在线 32 上,存储输出类别的数量。接下来,使用行 35 上的prepare_tokenizerBOW函数获得数据和标签的标记符。
现在我们可以使用第 38 行和第 39 行上的texts_to_sequences函数将我们的单词转换成整数序列。
使用texts_to_matrix函数,通过将mode参数设置为count ( 第 42-44 行),我们将输入文本转换为单词包表示。这将计算一个单词在一个句子中出现的次数,给我们句子和每个单词出现的向量表示。
在第行第 47-49 行,我们调整标签的索引用于训练。单词袋模型被初始化(第 52-54 行,并且该模型相应地在输入数据上被训练(第 57-60 行)。由于记号赋予器创建添加了未知单词记号作为它的第一个条目,我们已经考虑了除了从第 1 个索引开始而不是从第 0 个索引开始的所有单词。
# create output directory if it doesn't already exist
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# plot the loss for BOW model
print("[INFO] Plotting loss...")
plt.plot(history.history["loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.savefig(config.BOW_LOSS)
# get the weights for the first model layer
representationsBOW = BOWModel.get_weights()[0]
# apply dimensional reduction using TSNE
tsneEmbed = (TSNE(n_components=2)
.fit_transform(representationsBOW)
)
# initialize a index counter
indexCount = 1
# initialize the tsne figure
plt.figure(figsize=(25, 5))
# loop over the tsne embeddings and plot the corresponding words
print("[INFO] Plotting TSNE embeddings...")
for (word, embedding) in tsneEmbed[:100]:
plt.scatter(word, embedding)
plt.annotate(tokenizerData.index_word[indexCount], (word, embedding))
indexCount += 1
plt.savefig(config.BOW_TSNE)
在第 63 和 64 行上,我们创建了输出文件夹,如果它还不存在的话。
在第 67-71 行上,我们借助模型历史变量绘制了模型损失。
现在,我们要绘制单词袋表示空间。请注意,模型的第一层的输入维度等于单词数。如果我们假设每一列对应于数据集中的每个单词,则该层的权重可以被认为是我们的嵌入空间。
因此,在第 74 行处抓取该层的权重,并应用 TSNE 嵌入进行降维(行 77-79** )。我们继续为每个用于推理的单词绘制 TSNE 图。**
训练 Word2Vec 模型
现在我们将继续讨论Word2Vec模型。为了训练它,我们必须执行train_Word2Vec.py。
# USAGE
# python -W ignore train_Word2Vec.py
# set seed for reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.data_processing import preprocess
from pyimagesearch.data_processing import prepare_tokenizerW2V
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import tensorflow as tf
from tqdm import tqdm
import pandas as pd
import numpy as np
import nltk
import os
# prepare stop-words using the NLTK package
nltk.download("stopwords")
stopWords = nltk.corpus.stopwords.words("english")
# initialize the dataframe from csv format
dataDf = pd.read_csv("datadf.csv")
# preprocess the dataframe
processedDf = preprocess(dataDf, stopWords)
正如单词包脚本中所做的,该脚本的第一步是创建stopWords列表。为此,我们将借助nltk包(线 22 和 23 )。接下来,我们使用csv格式的输入文件初始化数据帧(第 26 行)。随后使用preprocess功能从输入句子中删除停用词(第 29 行)。
# store the number of classification heads
numClasses = len(processedDf["sentiment"].unique())
# create the tokenizers for data and labels
(tokenizerData) = prepare_tokenizerW2V(processedDf, topWords=200)
# create integer sequences of the data using tokenizer
trainSeqs = tokenizerData.texts_to_sequences(processedDf["sentence"])
trainLabels = tokenizerData.texts_to_sequences(processedDf["sentiment"])
# create the representational matrices as variable tensors
contextVectorMatrix = tf.Variable(
np.random.rand(200, config.EMBEDDING_SIZE)
)
centerVectorMatrix = tf.Variable(
np.random.rand(200, config.EMBEDDING_SIZE)
)
# initialize the optimizer and create an empty list to log the loss
optimizer = tf.optimizers.Adam()
lossList = list()
在第 32 行上,我们存储输出类的数量。接下来,在行 35 上创建覆盖数据和标签的单个记号赋予器。
使用记号赋予器的texts_to_sequences函数将单词序列转换成整数序列(第 38 行和第 39 行)。
对于 Word2Vec 架构,我们然后在第 42-47 行初始化上下文和中心单词矩阵。随后是Adam优化器和一个空的丢失列表初始化(行 50 和 51 )。
# loop over the training epochs
print("[INFO] Starting Word2Vec training...")
for iter in tqdm(range(config.ITERATIONS)):
# initialize the loss per epoch
lossPerEpoch = 0
# loop over the indexes and labels
for idxs,trgt in zip(trainSeqs, trainLabels):
# convert label into integer
trgt = trgt[0]
# initialize the gradient tape
with tf.GradientTape() as tape:
# initialize the combined context vector
combinedContext = 0
# update the combined context with each index
for count,index in enumerate(idxs):
combinedContext += contextVectorMatrix[index,:]
# standardize the vector
combinedContext /= len(idxs)
# matrix multiply the center vector matrix
# with the combined context
output = tf.matmul(centerVectorMatrix,
tf.expand_dims(combinedContext ,1))
# calculate the softmax output and
# grab the relevant index for loss calculation
softOut = tf.nn.softmax(output, axis=0)
loss = softOut[trgt]
logLoss = -tf.math.log(loss)
# update the loss per epoch and apply the gradients to the
# embedding matrices
lossPerEpoch += logLoss.numpy()
grad = tape.gradient(
logLoss, [contextVectorMatrix, centerVectorMatrix]
)
optimizer.apply_gradients(
zip(grad, [contextVectorMatrix, centerVectorMatrix])
)
# update the loss list
lossList.append(lossPerEpoch)
在第行第 55 上,我们开始迭代训练时期,并初始化第行第 57 上的一个lossPerEpoch变量。
接下来,我们循环训练序列和标签的索引和标签(行 60 ),并且首先将标签列表转换成单个变量(行 62 )。
我们在行 65 初始化一个梯度带。句子索引用于从上下文矩阵中提取上下文向量,并且输出被加在一起,随后进行归一化(第 67-74 行)。
组合的上下文向量乘以中心向量矩阵,结果通过一个softmax函数(第 78-83 行)。抓取相关的中心词索引进行损失计算,并计算索引的负对数(第 84 行和第 85 行)。
一旦退出循环,lossPerEpoch变量就会被更新。梯度被应用于两个嵌入矩阵(第 89-95 行)。
最后,一旦一个时期结束,lossPerEpoch变量被添加到损失列表中(第 98 行)。
# create output directory if it doesn't already exist
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# plot the loss for evaluation
print("[INFO] Plotting Loss...")
plt.plot(lossList)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.savefig(config.W2V_LOSS)
# apply dimensional reductionality using tsne for the
# representation matrices
tsneEmbed = (
TSNE(n_components=2)
.fit_transform(contextVectorMatrix.numpy())
)
# initialize a index counter
indexCount = 1
# initialize the tsne figure
plt.figure(figsize=(25, 5))
# loop over the tsne embeddings and plot the corresponding words
print("[INFO] Plotting TSNE Embeddings...")
for (word, embedding) in tsneEmbed[:100]:
if indexCount != 108:
plt.scatter(word, embedding)
plt.annotate(tokenizerData.index_word[indexCount], (word, embedding))
indexCount += 1
plt.savefig(config.W2V_TSNE)
在第 101 行和第 102 行,如果输出文件夹还不存在,我们创建它。
在第 105-109 行上,我们绘制了 Word2Vec 模型的损耗。随后从嵌入矩阵创建 TSNE 图(第 113-131 行)。将对应于其指数的单词绘制在 TSNE 图上,以评估所形成的关联。
训练结果和可视化
让我们看看这两种体系结构的培训进展如何。
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
Epoch 1/30
1/1 [==============================] - 0s 452ms/step - loss: 1.4033 - accuracy: 0.2333
Epoch 2/30
1/1 [==============================] - 0s 4ms/step - loss: 1.2637 - accuracy: 0.7000
Epoch 3/30
1/1 [==============================] - 0s 4ms/step - loss: 1.1494 - accuracy: 0.8667
...
Epoch 27/30
1/1 [==============================] - 0s 5ms/step - loss: 0.0439 - accuracy: 1.0000
Epoch 28/30
1/1 [==============================] - 0s 4ms/step - loss: 0.0374 - accuracy: 1.0000
Epoch 29/30
1/1 [==============================] - 0s 3ms/step - loss: 0.0320 - accuracy: 1.0000
Epoch 30/30
1/1 [==============================] - 0s 3ms/step - loss: 0.0275 - accuracy: 1.0000
[INFO] Plotting loss...
[INFO] Plotting TSNE embeddings...
使用我们的小输入数据集,词袋模型很快达到了 100%的准确性,并适合数据。然而,我们将根据 TSNE 地块做出最终评估。损失图可在图 3 的中看到。
损失下降得相当快。对于给定的数据集,我们的模型完美地过度拟合了它。
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[INFO] Starting Word2Vec training...
100% 1000/1000 [04:52<00:00, 3.42it/s]
[INFO] Plotting Loss...
[INFO] Plotting TSNE Embeddings...
由于 Word2Vec 模型是我们直接构建的,我们将根据图 4 中的损失图来评估损失。
Word2Vec 的损失,虽然比单词袋更困难(因为有更多的标签),但对于我们的小数据集来说,下降得很好。让我们看看 TSNE 的情节!
在图 5 和图 6 中,我们分别得到了单词袋和 Word2Vec 的 TSNE 图。
仔细观察(点击放大图片),我们可以看到,虽然没有形成明确的分组,但有一些相似的上下文词或多或少彼此接近。例如,我们可以看到像“汉堡”和“比萨饼”这样的食物彼此靠近。
然而,我们必须记住,在词袋中,完整的句子被认为是输入。这就是为什么单词没有明确的分组。另一个原因可能是维度缩减导致了信息的丢失。添加另一个密集层使其更少依赖于我们正在考虑的层的权重。
在图 6 中,我们有 Word2Vec 的 TSNE 图。
很快,我们可以看到几个分组。您可以在代码的合作版本中放大这些图像,并检查分组。标准连续词袋和我们今天所做的区别在于,我们没有考虑句子中的窗口和中心词,而是为每个句子指定了一个明确的标签。
这使得矩阵在训练时更容易创建分组。这里的结果显然比袋的话。然而,如果你想得出自己的结论,别忘了在你自己的数据上尝试一下。
汇总
在今天的教程中,我们学习了单词袋和 Word2Vec 之间的根本区别。这两者都是 NLP 世界中的巨大垫脚石,但是理解为什么这两种技术都以自己的方式坚持使用嵌入是很重要的。
我们在一个小数据集上工作,以理解这两种方法分歧的本质。尽管弓形结构显示了较低的最终损失值,但 TSNE 曲线显示了显著的差异。这留下了一个有趣的结论,关于嵌入空间的理解。
回顾一下我们在本系列中的第二篇博客文章,我们会发现 Word2Vec 方法具有非常高的损耗值。尽管如此,可视化非常直观,显示了许多视觉分组。高损失的原因可以解释为基于每个句子出现的几个中心词的许多“标签”。
然而,这个问题在这里不再普遍,因为我们对每个句子都有固定的标签。所以很自然地,Word2Vec 方法显示了这个数据集的即时分组。
这可以在更大的数据集上进一步实验,以得出更明确的结论。然而,今天的结果质疑评估方法时使用的正确指标。
引用信息
Chakraborty,D. “词袋和 Word2Vec 之间的比较”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/txq23
@incollection{Chakraborty_2022_Comparison,
author = {Devjyoti Chakraborty},
title = {Comparison Between {BagofWords} and {Word2Vec}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/txq23},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
支持 CUDA 的 OpenCV 编译
原文:https://pyimagesearch.com/2016/07/11/compiling-opencv-with-cuda-support/

light,这样你就在支持 GPU 的系统上安装了 NVIDIA CUDA Toolkit 和 cuDNN 库。
接下来呢?
让我们也安装支持 CUDA 的 OpenCV。
虽然 OpenCV 本身在深度学习中并不发挥关键作用,但它被其他深度学习库如 Caffe 使用,特别是在“实用”程序中(如建立图像数据集)。简而言之,安装 OpenCV 使得编写代码变得更加容易,从而简化了在将图像输入深度神经网络之前对图像进行预处理的过程。
正因为如此,我们应该将 OpenCV 安装到与我们的深度学习库相同的环境中,至少让我们的生活更加轻松。
此外,在支持 GPU 的 CUDA 环境中,我们可以对 OpenCV 进行许多编译时优化,允许它利用 GPU 来加快计算速度(但主要是针对 C++应用程序,对 Python 来说没那么多,至少目前是这样)。
我将假设你将把 OpenCV 安装到与上周的博文相同的环境中——在这种情况下,我将继续我在 Amazon EC2 上使用 Ubuntu 14.04 g2.2xlarge 实例的例子。
说实话,我已经在 的许多以前的博客文章中介绍过在 Ubuntu 上安装 OpenCV,但是我也将在这里解释这个过程。总的来说,指令几乎相同,但是在cmake命令中有一些重要的变化 ,允许我们编译支持 CUDA 的 OpenCV。
当你读完这篇博文的时候,你已经在你的深度学习开发环境中编译并安装了支持 CUDA 的 OpenCV。
安装支持 CUDA 的 OpenCV
在我们可以用 CUDA 支持编译 OpenCV 之前,我们首先需要安装一些先决条件:
$ sudo apt-get install libjpeg8-dev libtiff5-dev libjasper-dev libpng12-dev
$ sudo apt-get install libgtk2.0-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libatlas-base-dev gfortran
$ sudo apt-get install libhdf5-serial-dev
$ sudo apt-get install python2.7-dev
如果你是 PyImageSearch 博客的追随者,那么你也会知道我是使用pip、virtualenv和virtualenvwrapper为我们的每个项目创建隔离的、独立的 Python 虚拟环境的大粉丝。您可以使用下面列出的命令安装虚拟环境包(或者,如果您的计算机上已经安装了 Python 虚拟环境,您可以跳过此步骤):
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf get-pip.py ~/.cache/pip
如果这是你第一次使用 Python 虚拟环境,我建议你阅读这篇博文的前半部分来熟悉它们。RealPython.com 博客也有一篇关于 Python 虚拟环境的优秀文章,供外行参考。
接下来,让我们使用 update 我们的~/.bashrc文件。使用您喜欢的命令行文本编辑器(如nano、vi或emacs)打开该文件:
$ nano ~/.bashrc
然后,向下滚动到文件的底部,添加以下几行,保存并退出编辑器:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
此时,我们可以创建我们的cv虚拟环境:
$ source ~/.bashrc
$ mkvirtualenv cv
$ pip install numpy
注意:同样,如果你是第一次使用 Python 虚拟环境,你会想读一下这篇博文的前半部分,以便更好地理解 Python 虚拟环境。我还在本网站的其他 OpenCV 安装指南中更详细地解释了它们以及如何正确使用它们。
现在,让我们下载并解压 OpenCV。如果你使用默认的 Amazon EC2 g2.2xlarge 实例,那么 我强烈建议 下载 OpenCV 源代码并在/mnt进行编译。
默认的 g2.2xlarge 实例只有大约 8GB 的空间,一旦考虑到系统文件、NVIDIA 驱动程序等因素。,没有足够的空间从源代码编译 OpenCV:

Figure 1: The default disk size for the g2.2xlarge instance is only 8GB, which doesn’t leave enough space to compile OpenCV from source.
然而,/mnt卷有 64GB 的空间,对于我们的编译来说绰绰有余:

Figure 2: However, if we use the ‘/mnt’ volume instead, we have 64GB — far more than what is required to compile OpenCV.
如果您确实在 Amazon EC2 实例上,请确保将目录更改为/mnt,并在下载源代码之前专门为您的 OpenCV 编译器创建一个目录:
$ cd /mnt
$ sudo mkdir opencv_compile
$ sudo chown -R ubuntu opencv_compile
$ cd opencv_compile
上面的命令将在/mnt卷中创建一个名为opencv_compile的新目录,然后授予ubuntu用户随意修改它的权限。
注:/mnt卷就是亚马逊所说的“短暂存储”。当系统停止/重新启动时,放在这个卷上的所有数据都将丢失。你不想使用/mnt来存储长期数据,但是使用/mnt来编译 OpenCV 是完全可以的。一旦 OpenCV 被编译,它将被安装到系统驱动器中——您的 OpenCV 安装不会在重启之间消失。
对于本教程,我将使用 OpenCV 3.1。但是你也可以使用 OpenCV 2.4.X 或者 OpenCV 3.0。使用以下命令下载源代码:
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.1.0.zip
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.1.0.zip
$ unzip opencv.zip
$ unzip opencv_contrib.zip
为了防止.zip档案的网址被切断,我把它们包括在下面:
- https://github . com/itseez/opencv/archive/3 . 1 . 0 . zip
- https://github.com/Itseez/opencv_contrib/archive/3.1.0.zip
我们现在准备使用cmake来配置我们的构建。运行这个命令时要特别小心,因为我将介绍一些您可能不熟悉的配置变量:
$ cd opencv-3.1.0
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D WITH_CUDA=ON \
-D ENABLE_FAST_MATH=1 \
-D CUDA_FAST_MATH=1 \
-D WITH_CUBLAS=1 \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-3.1.0/modules \
-D BUILD_EXAMPLES=ON ..
首先,请注意WITH_CUDA=ON标志。从技术上讲,这个标志将被默认设置为ON,因为 CMake 足够智能,可以检测到 CUDA 工具包已经安装。但是,为了以防万一,我们将手动设置变量为WITH_CUDA=ON,以确保编译了 CUDA 支持。
在此基础上,我们添加了一些优化,主要是围绕使用 cuBLAS ,这是 CUDA 运行时中 BLAS(基本线性代数子程序)库的一个实现。
我们还指出,我们希望利用“快速数学”优化,这是一系列针对速度进行了优化的极快的数学例程(它们是用汇编语言编写的),本质上几乎不执行错误检查。再说一遍,FastMath 库只追求速度,没有其他目的。
运行完cmake之后,看一下“NVIDIA CUDA”部分——它看起来应该和我的相似,我已经在下面包括了:

Figure 3: Examining the output of CMake to ensure OpenCV will be compiled with CUDA support.
请注意 CUDA 支持将如何使用 cuBLAS 和“快速数学”优化来编译。
假设您自己的 CMake 命令已正确退出,现在您可以编译并安装 OpenCV:
$ make -j8
$ sudo make install
$ sudo ldconfig
如果一切顺利,make命令应该会成功运行:

Figure 4: OpenCV with CUDA support has successfully compiled.
同样,假设您的编译没有错误地完成,OpenCV 现在应该安装在/usr/local/lib/python2.7/site-packages中。您可以使用ls命令来验证这一点:
$ ls -l /usr/local/lib/python2.7/site-packages
total 2092
-rw-r--r-- 1 root staff 2138812 Jun 2 14:11 cv2.so
注意:你要找到并记下你的cv2.so文件在你系统的什么地方!每当我们创建一个虚拟环境时(我们会做很多来探索各种深度学习库),你会想要将cv2.so文件符号链接到你的 Python 虚拟环境的site-packages目录中,这样你就可以访问 OpenCV。
最后一步是将cv2.so文件(我们的 Python 绑定)符号链接到cv虚拟环境中:
$ cd ~/.virtualenvs/cv/lib/python2.7/site-packages/
$ ln -s /usr/local/lib/python2.7/site-packages/cv2.so cv2.so
为了验证我们的安装,打开一个新的终端,使用workon命令访问cv虚拟环境,启动一个 Python shell,然后导入 OpenCV:
$ cd ~
$ workon cv
$ python
>>> import cv2
>>> cv2.__version__
'3.1.0'
>>>
最后,既然已经安装了 OpenCV,让我们执行一点清理并删除用于安装的源文件:
$ cd /mnt
$ sudo rm -rf opencv_compile
我再一次强调这一点——你 需要 来熟悉 Python 虚拟环境、site-packages目录以及如何使用符号链接。我推荐以下教程来帮助理解它们:
- Python 虚拟环境:https://real Python . com/blog/Python/Python-Virtual-Environments-a-primer/
- 关于 site-packages:https://python 4 天文学家. github . io/installation/packages . html
- 符号链接:【https://kb.iu.edu/d/abbe】T2
摘要
在今天的博文中,我详细介绍了如何在 CUDA 支持下将 OpenCV 安装到我们的深度学习环境中。虽然 OpenCV 本身并不直接用于深度学习,但其他深度学习库(例如 Caffe) 间接使用 OpenCV。
此外,通过安装支持 CUDA 的 OpenCV,我们可以利用 GPU 来进一步优化操作(至少在 C++应用程序中——目前还没有太多对 Python + OpenCV + GPU 的支持)。
下周,我将详细介绍如何安装用于深度学习和卷积神经网络的 Keras Python 包——从那里开始,真正的乐趣将开始!
使用 Python 和 OpenCV 构建图像搜索引擎的完整指南
原文:https://pyimagesearch.com/2014/12/01/complete-guide-building-image-search-engine-python-opencv/
https://www.youtube.com/embed/zrgB9Nvhz58?feature=oembed
使用 TensorFlow 和 Keras 的 NeRF 的计算机图形和深度学习:第 1 部分
几天前,在浏览我的图片库时,我看到了三张图片,如图 1 所示。
我们可以看到,这些照片是一个楼梯,但从不同的角度。我拍了三张照片,因为我不确定仅凭一张照片就能捕捉到这美丽的一幕。我担心我会错过正确的视角。
这让我想到,“如果有一种方法可以从这些照片中捕捉整个 3D 场景,会怎么样?”
这样,你(我的观众)就能确切地看到我那天所看到的。
在 NeRF:将场景表示为用于视图合成的神经辐射场中,Mildenhall 等人(2020) 提出了一种方法,事实证明这正是我所需要的。
让我们看看通过复制论文的方法我们取得了什么,如图图 2 所示。例如,给算法一些不同视角的一盘热狗的图片(上)就可以精确地生成整个 3D 场景(下)。
神经辐射场(NeRF)汇集了深度学习和计算机图形学。虽然我们 PyImageSearch 已经写了很多关于深度学习的文章,但这将是我们第一次谈论计算机图形学。这个系列的结构将最适合初学者。 我们期望没有计算机图形学知识的人 。
注: 一个更简单的 NeRF 实现为我们赢得了 TensorFlow 社区聚焦奖 。
要了解计算机图形学和图像渲染,继续阅读。
使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 1 部分
计算机图形学是现代技术的奇迹之一。渲染真实 3D 场景的应用范围从电影、太空导航到医学。
本课是关于使用 TensorFlow 和 Keras 的 NeRF 的计算机图形和深度学习的 3 部分系列的第 1 部分:
- 使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 1 部分(本教程)
- 使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第二部分(下周教程)
- 使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 3 部分
在本教程中,我们将涵盖计算机图形世界中的相机工作。我们还将向您介绍我们将要工作的数据集。
我们将本教程分为以下几个小节:
- 世界坐标框架:表示物理的 3D 世界
- 摄像机坐标框架:表示虚拟 3D 摄像机世界
- 坐标变换:从一个坐标系映射到另一个坐标系
- 投影变换:在 2D 平面(相机传感器)上形成图像
- 数据集:了解 NeRF 的数据集
想象一下。你带着相机出去,发现了一朵美丽的花。你想想你想捕捉它的方式。现在是时候调整相机方向,校准设置,并点击图片。
将世界场景转换为图像的整个过程被封装在一个通常称为前向成像模型的数学模型中。我们可以将模型可视化在图 3 中。
前向成像模型从世界坐标框架中的一点开始。然后我们使用坐标转换将它转换到摄像机坐标框架。之后,我们使用投影变换将摄像机坐标变换到图像平面上。
世界坐标框架
我们在现实世界中看到的所有形状和物体都存在于 3D 参照系中。我们称这个参考系为世界坐标系统。使用这个框架,我们可以很容易地定位三维空间中的任何点或物体。
让我们来点
in the 3D space as shown in Figure 4.
在这里,
,  , and
, and  represent the three axes in the world coordinate frame. The location of the point is expressed through the vector
represent the three axes in the world coordinate frame. The location of the point is expressed through the vector  .
.

摄像机坐标框
和世界坐标系一样,我们有另一个参照系,叫做相机坐标系,如图图 5 所示。
这一帧位于摄像机 的中心。与世界坐标框架不同,这不是一个静态的参考框架。我们可以像移动相机拍照一样移动这个框架。
同一点
from Figure 4 can now be located with both frames of reference, as shown in Figure 6.
而在世界坐标框架中,该点由定位
vector, in the camera coordinate frame, it is located by the  vector as shown in Figure 6.
vector as shown in Figure 6.

注: 点的位置不变。只是看待这个点的方式随着参照系的变化而变化。
坐标变换
我们建立了两个坐标框架:世界和相机。现在让我们定义两者之间的映射。
让我们来点
from Figure 6. Our goal is to build a bridge between the camera coordinates  and world coordinates
and world coordinates  .
.
From Figure 5, we can say that
")
在哪里
-
 表示摄像机坐标框架相对于世界坐标框架的方向。方向由矩阵表示。
表示摄像机坐标框架相对于世界坐标框架的方向。方向由矩阵表示。
 →世界坐标系中的
→世界坐标系中的 方向。
方向。 →世界坐标系中的
→世界坐标系中的 方向。
方向。 →世界坐标系中
→世界坐标系中 的方向。
的方向。 -
 代表摄像机坐标框架相对于世界坐标框架的位置。位置由向量表示。
代表摄像机坐标框架相对于世界坐标框架的位置。位置由向量表示。
 表示摄像机坐标框架相对于世界坐标框架的方向。方向由矩阵表示。
表示摄像机坐标框架相对于世界坐标框架的方向。方向由矩阵表示。
 →世界坐标系中的
→世界坐标系中的 方向。
方向。 →世界坐标系中的
→世界坐标系中的 方向。
方向。 →世界坐标系中
→世界坐标系中 的方向。
的方向。 代表摄像机坐标框架相对于世界坐标框架的位置。位置由向量表示。
代表摄像机坐标框架相对于世界坐标框架的位置。位置由向量表示。我们可以将上面的等式展开如下
 \ \Rightarrow X_{c} = R \times X_w - R \times C_w \ \Rightarrow X_{c} = R \times X_w + t")
其中
represents the translation matrix ") . The mapping between the two coordinate systems has been devised but is not yet complete. In the above equation, we have a matrix multiplication along with a matrix addition. It is always preferable to compress things to a single matrix multiplication if we can. To do so we will use a concept called homogeneous coordinates.
. The mapping between the two coordinate systems has been devised but is not yet complete. In the above equation, we have a matrix multiplication along with a matrix addition. It is always preferable to compress things to a single matrix multiplication if we can. To do so we will use a concept called homogeneous coordinates.
The homogeneous coordinate system allows us to represent an  dimensional point
dimensional point ![x = [x_0, x_1, \dots, x_n]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/37c282989d37059c7e32664a10e715bd.png "x = [x_0, x_1, \dots, x_n]") in an
in an  dimensional space
dimensional space ![\tilde{x} = [\tilde{x}_0, \tilde{x}_1, \dots, \tilde{x}_n, w]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/7034faeccb017d1c8887949d74b61369.png "\tilde{x} = [\tilde{x}_0, \tilde{x}_1, \dots, \tilde{x}_n, w]") with a fictitious variable
with a fictitious variable  such that
such that

使用齐次坐标系我们可以转换
(3D) to  (4D).
(4D).

有了齐次坐标,我们可以把方程压缩成矩阵乘法。

其中
is the matrix that holds the orientation and position of the camera coordinate frame. We can call this matrix the Camera Extrinsic since it represents values like rotation and translation, both of which are external properties of the camera.

射影变换
我们从一个点开始
and its (homogeneous) world coordinates . With the help of the camera extrinsic matrix , was transformed into its (homogeneous) camera coordinates  .
.
Now we come to the final stage of actually materializing an image from the 3D camera coordinates as shown in Figure 7.
要理解射影变换,我们唯一需要的就是相似三角形。我们来做一个类似三角形的入门。
我们已经在图 8 和图 9 中看到了类似的三角形。具有相似的三角形

是的,你猜对了,
and  are similar triangles in Figure 10.
are similar triangles in Figure 10.
从相似三角形的性质,我们可以推导出

因此,它遵循:

现在,重要的是要记住,实际的图像平面不是虚拟平面,而是图像传感器阵列。3D 场景落在该传感器上,这导致图像的形成。因此
and  in the image plane can be substituted with pixel values
in the image plane can be substituted with pixel values  .
.

图像平面中的像素从左上角(0, 0)开始,因此也需要相对于图像平面的中心移动像素。

在这里,
and  are the center points of the image plane.
are the center points of the image plane.
现在我们有一个来自 3D 摄像机空间的点,用来表示
in the image plane. Again to make matrices agree, we have to express the pixel values using homogeneous representation.
的齐次表示
, where  and
and 

这可以进一步表示为:

最后,我们有:

这可以简单地表达为

其中
is the set of vectors containing the location of the point in camera coordinate space and  is the set of values containing the location of the point on the image plane. Respectively,
is the set of values containing the location of the point on the image plane. Respectively,  represents the set of values needed to map a point from the 3D camera space to the 2D space.
represents the set of values needed to map a point from the 3D camera space to the 2D space.

我们可以叫
the camera intrinsic since it represents values like focal length and center of the image plane along and axes, both of which are internal properties of the camera.
数据集
理论够了!给我看一些代码。
在本节中,我们将讨论我们将要处理的数据。作者开源了他们的数据集,你可以在这里找到它。数据集的链接发表在 NeRF 的官方知识库中。数据集的结构如图图 11 所示。
有两个文件夹,nerf_synthetic和nerf_llff_data。接下来,我们将使用这个系列的合成数据集。
让我们看看nerf_synthetic文件夹里有什么。nerf_synthetic文件夹中的数据如图图 12 所示。
这里有很多人造物体。让我们下载其中一个,看看里面有什么。我们选择了“ship”数据集,但是可以随意下载其中的任何一个。
解压缩数据集后,您会发现包含图像的三个文件夹:
trainvaltest
以及包含照相机的方向和位置的三个文件。
transforms_train.jsontransforms_val.jsontransforms_test.json
为了更好地理解 json 文件,我们可以打开一个空白的 Colab 笔记本,上传transforms_train.json。我们现在可以对它进行探索性的数据分析。
# import the necessary packages
import json
import numpy as np
# define the json training file
jsonTrainFile = "transforms_train.json"
# open the file and read the contents of the file
with open(jsonTrainFile, "r") as fp:
jsonTrainData = json.load(fp)
# print the content of the json file
print(f"[INFO] Focal length train: {jsonTrainData['camera_angle_x']}")
print(f"[INFO] Number of frames train: {len(jsonTrainData['frames'])}")
# OUTPUT
# [INFO] Focal length train: 0.6911112070083618
# [INFO] Number of frames train: 100
我们从在线 2 和 3 上导入必要的包json和numpy开始。
然后我们加载 json 并在第 6-10 行读取它的值。
JSON 文件有两个父键,分别叫做camera_angle_x和frames。我们看到camera_angle_x对应于相机的视野,frames是每个图像(帧)的元数据集合。
在第 13 行和第 14 行,我们打印 json 键的值。第 17 行和第 18 行显示输出。
让我们再深入调查一下frames。
# grab the first frame
firstFrame = jsonTrainData["frames"][0]
# grab the transform matrix and file name
tMat = np.array(firstFrame["transform_matrix"])
fName = firstFrame["file_path"]
# print the data
print(tMat)
print(fName)
# OUTPUT
# array([[-0.92501402, 0.27488998, -0.26226836, -1.05723763],
# [-0.37993318, -0.66926789, 0.63853836, 2.5740304 ],
# [ 0\. , 0.6903013 , 0.72352195, 2.91661024],
# [ 0\. , 0\. , 0\. , 1\. ]])
# ./train/r_0
我们在第 20 行抓取第一帧。每一帧都是一个字典,包含两个键transform_matrix和file_path,如第 23 行和第 24 行**所示。file_path是考虑中的图像(帧)的路径,transform_matrix是该图像的摄像机到世界矩阵。
在第 27 行和第 28 行,我们打印了transform_matrix和file_path。第 31-35 行显示输出。**
汇总
在本教程中,我们研究了计算机图形学中的一些基本主题。这对于理解 NeRF 至关重要。虽然这是基本的,但仍然是向前迈进的重要一步。
我们可以回忆一下我们在三个简单步骤中学到的内容:
- 正向成像模式(拍照)
- 世界到相机(3D 到 3D)转换
- 相机到图像(3D 到 2D)转换
此时,我们也熟悉了所需的数据集。这涵盖了所有的先决条件。
下周我们将看看这篇论文的各种基本概念: NeRF:将场景表示为用于视图合成的神经辐射场。我们还将学习如何使用 TensorFlow 和 Python 实现这些概念。
我们希望你喜欢这个教程,一定要下载数据集并尝试一下。
引用信息
gothipaty,A. R .,和 Raha, R. “使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 1 部分”, PyImageSearch ,2021,https://PyImageSearch . com/2021/11/10/Computer-Graphics-and-Deep-Learning-with-NeRF-using-tensor flow-and-Keras-Part-1/
@article{Gosthipaty_Raha_2021_pt1,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Computer Graphics and Deep Learning with {NeRF} using {TensorFlow} and {Keras}: Part 1},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/11/10/computer-graphics-and-deep-learning-with-nerf-using-tensorflow-and-keras-part-1/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
使用 TensorFlow 和 Keras 的 NeRF 的计算机图形和深度学习:第 2 部分
NeRF 的独特性,从它在计算机图形学和深度学习领域打开的门的数量就可以证明。这些领域从医学成像、3D 场景重建、动画产业、场景的重新照明到深度估计。
在我们上周的教程中,我们熟悉了 NeRF 的先决条件。我们还探索了将要使用的数据集。现在,最好提醒我们自己最初的问题陈述。
如果有一种方法可以从一组稀疏的 2D 图片中捕捉到整个 3D 场景,会怎么样?
在本教程中,我们将重点介绍 NeRF 从稀疏图像集中捕捉 3D 场景的算法。
本课是关于使用 TensorFlow 和 Keras 的 NeRF 的计算机图形和深度学习的 3 部分系列的第 2 部分:
- 计算机图形学与使用 TensorFlow 和 Keras 的 NeRF 深度学习:第一部分 (上周教程)
- 使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第二部分(本周教程)
- 使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 3 部分(下周教程)
要了解神经辐射场或 NeRF, 只要继续阅读。
使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第二部分
在本教程中,我们直接进入 NeRF 的概念。我们将本教程分为以下几个部分:
- NeRF 简介:NeRF 概述
- 输入数据管道:
tf.data输入数据管道- 公用事业和图像:为图像建立
tf.data管道 - 生成光线:为光线建立
tf.data管道 - 采样点:来自射线的采样点
- 公用事业和图像:为图像建立
- NeRF 多层感知器:NeRF 多层感知器(MLP)架构
- 体绘制:了解体绘制过程
- 光度损失:了解 NeRF 中使用的损失
- 增强 NeRF: 增强 NeRF 的技术
- 位置编码:了解位置编码
- 分层抽样:了解分层抽样
在本教程结束时,我们将能够理解 NeRF 中提出的概念。
配置您的开发环境
要遵循本指南,您需要在系统上安装 TensorFlow 库。
幸运的是,TensorFlow 可以在 pip 上安装:
$ pip install tensorflow
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
让我们来看看目录结构:
$ tree --dirsfirst
.
├── dataset
│ ├── test
│ │ ├── r_0_depth_0000.png
│ │ ├── r_0_normal_0000.png
│ │ ├── r_0.png
│ │ ├── ..
│ │ └── ..
│ ├── train
│ │ ├── r_0.png
│ │ ├── r_10.png
│ │ ├── ..
│ │ └── ..
│ ├── val
│ │ ├── r_0.png
│ │ ├── r_10.png
│ │ ├── ..
│ │ └── ..
│ ├── transforms_test.json
│ ├── transforms_train.json
│ └── transforms_val.json
├── pyimagesearch
│ ├── config.py
│ ├── data.py
│ ├── encoder.py
│ ├── __init__.py
│ ├── nerf.py
│ ├── nerf_trainer.py
│ ├── train_monitor.py
│ └── utils.py
├── inference.py
└── train.py
父目录有两个 python 脚本和两个文件夹。
dataset文件夹包含三个子文件夹:train、test和val,用于训练、测试和验证图像。pyimagesearch文件夹包含我们将用于训练的所有 python 脚本。- 最后,我们有两个驱动脚本:
train.py和inference.py。我们将在下周的教程中学习训练和推理。
注: 出于时间的考虑,我们将 NeRF 的实现分为两部分。这篇博客介绍了这些概念,而下周的博客将涵盖训练和推理脚本。
NeRF简介
先说论文的前提。你可以从几个特定的角度看到特定场景的图像。现在,您希望从一个全新的视图生成场景的图像。这个问题属于新颖的图像合成,如图图 2 所示。
我们想到的新颖视图合成的直接解决方案是在训练数据集上使用生成对抗网络 (GAN)。对于甘斯,我们把自己限制在图像的 2D 空间。
米尔登霍尔等人(2020) 另一方面,问一个简单的问题。
为什么不从图像本身获取全部的 3d 能量呢?
让我们花点时间试着理解这个想法。
我们现在正在看一个转换的问题陈述。从新颖的视图合成,我们已经从一组稀疏的 2D 图像过渡到了 *3D 场景捕捉。
这个新的问题陈述也将作为小说观点综合问题的解决方案。如果我们手头有 3D 场景,生成一个新颖的视图有多困难?*
注意,NeRF 不是第一个解决这个问题的人。它的前辈已经使用了各种方法,包括卷积神经网络( CNN )和基于梯度的网格优化。然而,根据该论文,由于更高的空间和时间复杂性,这些方法不能扩展到更好的分辨率。NeRF 旨在优化底层的连续体场景函数。
如果您第一眼看不到所有这些术语,请不要担心。博客的其余部分致力于将这些主题细分为最细微的细节,并逐一解释。
我们从一组稀疏的图像及其对应的相机元数据(方向和位置)开始。接下来,我们想要实现整个场景的 3D 表现,如图图 3 所示。
下图显示了 NeRF 的步骤:
-
生成光线:在这一步,我们让光线穿过图像的每个像素。光线(光线 A 和光线 B)是与图像相交并穿过 3D 框(场景)的红线(图 4 )。
-
采样点:在这一步我们在如图图 5 所示的射线上采样点
") 。我们必须注意,这些点位于射线上,使它们成为盒子内部的 3D 点。
。我们必须注意,这些点位于射线上,使它们成为盒子内部的 3D 点。
") 。我们必须注意,这些点位于射线上,使它们成为盒子内部的 3D 点。
。我们必须注意,这些点位于射线上,使它们成为盒子内部的 3D 点。每个点都有唯一的位置")
and a direction component ") linked as shown (Figure 6). The direction of each point is the same as the direction of the ray.
linked as shown (Figure 6). The direction of each point is the same as the direction of the ray.
-
深度学习:我们将这些点传入一个 MLP ( 图 7 ,预测该点对应的颜色和密度。
-
体绘制:我们考虑单条光线(此处为光线 A),将所有采样点发送到 MLP,得到相应的颜色和密度,如图图 8 。在我们获得每个点的颜色和密度之后,我们可以应用经典的体绘制(在后面的部分中定义)来预测光线穿过的图像像素(这里是像素 P)的颜色。
-
光度损失:像素的预测颜色(如图图 9) 与像素的实际颜色之差,造成光度损失。这最终允许我们在 MLP 上执行反向传播,并使损失最小化。
输入数据管道
至此,我们对 NeRF 有了一个鸟瞰。然而,在进一步描述该算法之前,我们需要首先定义一个输入数据管道。
我们从上周的教程中得知,我们的数据集包含图像和相应的摄像机方位。所以现在,我们需要建立一个产生图像和相应的光线的数据管道。
在本节中,我们将使用tf.data API 逐步构建这个数据管道。tf.data确保以高效的方式构建和使用数据集。如果你想对tf.data有个初步了解,可以参考这篇教程。
整个数据管道被写入pyimagesearch/data.py文件。所以,让我们打开文件,开始挖掘吧!
效用和图像
# import the necessary packages
from tensorflow.io import read_file
from tensorflow.image import decode_jpeg
from tensorflow.image import convert_image_dtype
from tensorflow.image import resize
from tensorflow import reshape
import tensorflow as tf
import json
我们从在2-8 行导入必要的包开始
tensorflow构建数据管道json用于读取和处理 json 数据
def read_json(jsonPath):
# open the json file
with open(jsonPath, "r") as fp:
# read the json data
data = json.load(fp)
# return the data
return data
在的第 10-17 行,我们定义了read_json函数。该函数获取json文件(jsonPath)的路径,并返回解析后的data。
我们用行 12 上的open函数打开json文件。然后,有了文件指针,我们读取内容并用第 14 行的json.load函数解析它。最后,第 17 行返回解析后的 json 数据。
def get_image_c2w(jsonData, datasetPath):
# define a list to store the image paths
imagePaths = []
# define a list to store the camera2world matrices
c2ws = []
# iterate over each frame of the data
for frame in jsonData["frames"]:
# grab the image file name
imagePath = frame["file_path"]
imagePath = imagePath.replace(".", datasetPath)
imagePaths.append(f"{imagePath}.png")
# grab the camera2world matrix
c2ws.append(frame["transform_matrix"])
# return the image file names and the camera2world matrices
return (imagePaths, c2ws)
在第 19-37 行上,我们定义了get_image_c2w函数。该函数获取解析后的 json 数据(jsonData)和数据集的路径(datasetPath),并返回图像的路径(imagePaths)及其对应的摄像机到世界(c2ws)矩阵。
在的第 21-24 行,我们定义了两个空列表:imagePaths和c2ws。在的第 27-34 行,我们迭代经过解析的 json 数据,并将图像路径和摄像机到世界矩阵添加到空列表中。在迭代了整个数据之后,我们返回两个列表(第 37 行)。
使用tf.data.Dataset实例,我们将需要一种方法来转换数据集,同时将它提供给模型。为了有效地做到这一点,我们使用了 map 功能。map函数接受tf.data.Dataset实例和一个应用于数据集每个元素的函数。
pyimagesearch/data.py的后半部分定义了与map函数一起使用来转换数据集的函数。
class GetImages():
def __init__(self, imageWidth, imageHeight):
# define the image width and height
self.imageWidth = imageWidth
self.imageHeight = imageHeight
def __call__(self, imagePath):
# read the image file
image = read_file(imagePath)
# decode the image string
image = decode_jpeg(image, 3)
# convert the image dtype from uint8 to float32
image = convert_image_dtype(image, dtype=tf.float32)
# resize the image to the height and width in config
image = resize(image, (self.imageWidth, self.imageHeight))
image = reshape(image, (self.imageWidth, self.imageHeight, 3))
# return the image
return image
在继续之前,让我们讨论一下为什么我们选择用 __call__ 方法构建一个类,而不是构建一个可以用map函数应用的函数。
问题是传递给map函数的函数除了数据集的元素之外不能接受任何东西。这是一个强加的限制,我们需要绕过它。
为了克服这个问题,我们创建了一个类,可以保存一些在函数调用中使用的属性(这里是imageWidth和imageHeight)。
在第 39-60 行的中,我们用一个自定义的__call__和__init__函数构建了GetImages类。
__init__:我们将使用这个函数来初始化参数imageWidth和imageHeight ( 第 40-43 行)
__call__:这个方法使得对象可调用。我们将使用这个函数来读取来自imagePaths ( 行 47 )的图像。接下来,它现在被解码成可用的 jpeg 格式(第 50 行)。然后,我们将图像从uint8转换为float32,并对其进行整形(第 53-57 行)。
生成射线
计算机图形中的光线可以参数化为
=\vec{o}+t\vec{d}")
在哪里
") 是雷
是雷 是雷的起源
是雷的起源 是光线方向的单位矢量
是光线方向的单位矢量 是参数(如时间)
是参数(如时间)
") 是雷
是雷 是雷的起源
是雷的起源 是光线方向的单位矢量
是光线方向的单位矢量为了建立射线方程,我们需要原点和方向。在 NeRF 的上下文中,我们通过将光线的原点作为图像平面的像素位置,并将方向作为连接像素和相机光圈的直线来生成光线。这在图 10 中进行了说明。
我们可以使用下面的等式容易地设计出 2D 图像相对于照相机坐标框架的像素位置。

定位像素点的原点很容易,但是获取光线的方向有点困难。在上一节中,我们有

来自数据集的相机到世界矩阵是
that we need.
![C_{ex}^{-1} = \left[\begin{matrix} r_{11}^\prime & r_{12}^\prime & r_{13}^\prime & t_x^\prime\ r_{21}^\prime & r_{22}^\prime & r_{23}^\prime & t_y^\prime\ r_{31}^\prime & r_{32}^\prime & r_{33}^\prime & t_z^\prime\ 0 & 0 & 0 & 1\ \end{matrix}\right]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/82264ac2f8ccffa9c00d3166b7c687d2.png "C_{ex}^{-1} = \left[\begin{matrix} r_{11}^\prime & r_{12}^\prime & r_{13}^\prime & t_x^\prime\ r_{21}^\prime & r_{22}^\prime & r_{23}^\prime & t_y^\prime\ r_{31}^\prime & r_{32}^\prime & r_{33}^\prime & t_z^\prime\ 0 & 0 & 0 & 1\ \end{matrix}\right]")
为了定义方向向量,我们不需要整个摄像机到世界矩阵;相反,我们使用
upper matrix that defines the camera’s orientation.

有了旋转矩阵,我们可以通过下面的等式得到单位方向向量。

艰难的计算现在已经结束。对于简单的部分,光线的原点将是相机到世界矩阵的平移向量。

让我们看看如何将它翻译成代码。我们将继续处理pyimagesearch/data.py文件。
class GetRays:
def __init__(self, focalLength, imageWidth, imageHeight, near,
far, nC):
# define the focal length, image width, and image height
self.focalLength = focalLength
self.imageWidth = imageWidth
self.imageHeight = imageHeight
# define the near and far bounding values
self.near = near
self.far = far
# define the number of samples for coarse model
self.nC = nC
在第 62-75 行的,上,我们创建了带有自定义__call__和__init__函数的类GetRays。
__init__:我们初始化行 66-68** 上的focalLength、imageWidth和imageHeight,以及摄像机视场的near和far边界(行 71 和 72 )。我们将需要它来构造进入场景的光线,如图 8 所示。
def __call__(self, camera2world):
# create a meshgrid of image dimensions
(x, y) = tf.meshgrid(
tf.range(self.imageWidth, dtype=tf.float32),
tf.range(self.imageHeight, dtype=tf.float32),
indexing="xy",
)
# define the camera coordinates
xCamera = (x - self.imageWidth * 0.5) / self.focalLength
yCamera = (y - self.imageHeight * 0.5) / self.focalLength
# define the camera vector
xCyCzC = tf.stack([xCamera, -yCamera, -tf.ones_like(x)],
axis=-1)
# slice the camera2world matrix to obtain the rotation and
# translation matrix
rotation = camera2world[:3, :3]
translation = camera2world[:3, -1]
__call__:我们将camera2world矩阵输入到这个方法中,然后这个方法返回
rayO:原点rayD:方向点的集合tVals:采样点
在第 79-83 行上,我们创建了一个图像尺寸的网格。这与图 10 所示的图像平面相同。
接下来,我们使用从我们的以前的博客中得到的公式获得相机坐标(第 86 和 87 行)。

我们通过堆叠摄像机坐标来定义摄像机向量xCyCzC的齐次表示(行 90 和 91 )。
在第 95 和 96 行上,我们从摄像机到世界矩阵中提取旋转矩阵和平移向量。
# expand the camera coordinates to
xCyCzC = xCyCzC[..., None, :]
# get the world coordinates
xWyWzW = xCyCzC * rotation
# calculate the direction vector of the ray
rayD = tf.reduce_sum(xWyWzW, axis=-1)
rayD = rayD / tf.norm(rayD, axis=-1, keepdims=True)
# calculate the origin vector of the ray
rayO = tf.broadcast_to(translation, tf.shape(rayD))
# get the sample points from the ray
tVals = tf.linspace(self.near, self.far, self.nC)
noiseShape = list(rayO.shape[:-1]) + [self.nC]
noise = (tf.random.uniform(shape=noiseShape) *
(self.far - self.near) / self.nC)
tVals = tVals + noise
# return ray origin, direction, and the sample points
return (rayO, rayD, tVals)
然后我们使用旋转矩阵将摄像机坐标转换为世界坐标(行 99-102 )。
接下来,我们计算方向rayD(105 和 106 线)和原点向量rayO(109 线)。
在行 112-116 上,我们从光线中采样点。
注: 我们将在下一节学习射线上的采样点。
最后我们在第 119 的行返回rayO、rayD和tVals。
样点
生成光线后,我们需要从光线中绘制样本 3D 点。为此,我们建议两种方法。
- 定期采样点:方法名称不言自明。这里,我们以固定的间隔对射线上的点进行采样,如图 11 中的所示。
采样公式如下:

其中
and  are the farthest and nearest points on the ray, respectively. We divide the entire ray into equidistant parts, and the divisions serve as the sample points.
are the farthest and nearest points on the ray, respectively. We divide the entire ray into equidistant parts, and the divisions serve as the sample points.
- 随机采样点:在这种方法中,我们在采样点的过程中加入了随机性。这里的想法是,如果样本点来自射线的随机位置,模型将暴露于新数据。这将使它正规化,以产生更好的结果。该策略如图图 12 所示。
这由下面的等式证明:
![t_i = U \left[t_n\displaystyle\frac{i-1}{N}(t_f-t_n),t_n+\displaystyle\frac{i}{N}(t_f-t_n)\right]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/9d746a59390eaf4391db20cbca786738.png "t_i = U \left[t_n\displaystyle\frac{i-1}{N}(t_f-t_n),t_n+\displaystyle\frac{i}{N}(t_f-t_n)\right]")
其中
refers to uniform sampling. Here, we take a random point from the space between two adjacent points.
NeRF 多层感知器
每个样本点是 5 维的。点的空间位置是一个三维矢量(
), and the direction of the point is a 2D vector ( ). Mildenhall et al. (2020) advocate expressing the viewing direction as a 3D Cartesian unit vector
). Mildenhall et al. (2020) advocate expressing the viewing direction as a 3D Cartesian unit vector  .
.
这些 5D 点作为 MLP 的输入。这个具有 5D 点的射线场在论文中被称为神经辐射场。
MLP 网络预测每个输入点的颜色
and volume density  . Color refers to the (
. Color refers to the ( ) content of the point. The volume density can be interpreted as the differential probability of a ray terminating at an infinitesimal particle at that point.
) content of the point. The volume density can be interpreted as the differential probability of a ray terminating at an infinitesimal particle at that point.
MLP 架构如图 13 所示。
这里需要注意的重要一点是:
我们通过限制网络来预测体积密度
,从而鼓励表示具有多视图一致性
as a function of only the location
while allowing the RGB color
to be predicted as a function of both locations and viewing direction.
有了这些理论,我们就可以开始在 TensorFlow 中构建 NeRF 架构了。所以,我们打开文件pyimagesearch/nerf.py开始挖吧。
# import the necessary packages
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import concatenate
from tensorflow.keras import Input
from tensorflow.keras import Model
我们从在2-5 号线进口必要的包装开始。
def get_model(lxyz, lDir, batchSize, denseUnits, skipLayer):
# build input layer for rays
rayInput = Input(shape=(None, None, None, 2 * 3 * lxyz + 3),
batch_size=batchSize)
# build input layer for direction of the rays
dirInput = Input(shape=(None, None, None, 2 * 3 * lDir + 3),
batch_size=batchSize)
# creating an input for the MLP
x = rayInput
for i in range(8):
# build a dense layer
x = Dense(units=denseUnits, activation="relu")(x)
# check if we have to include residual connection
if i % skipLayer == 0 and i > 0:
# inject the residual connection
x = concatenate([x, rayInput], axis=-1)
# get the sigma value
sigma = Dense(units=1, activation="relu")(x)
# create the feature vector
feature = Dense(units=denseUnits)(x)
# concatenate the feature vector with the direction input and put
# it through a dense layer
feature = concatenate([feature, dirInput], axis=-1)
x = Dense(units=denseUnits//2, activation="relu")(feature)
# get the rgb value
rgb = Dense(units=3, activation="sigmoid")(x)
# create the nerf model
nerfModel = Model(inputs=[rayInput, dirInput],
outputs=[rgb, sigma])
# return the nerf model
return nerfModel
接下来,在第 7-46 行,我们在函数get_model中创建我们的 MLP 模型。该方法接受以下输入:
lxyz:用于 xyz 坐标位置编码的维数lDir:用于方向向量的位置编码的维数batchSize:数据的批量denseUnits:MLP 每层的单元数skipLayer:我们希望跳过连接的层
在的第 9-14 行,我们定义了rayInput和dirInput层。接下来,我们用跳过连接创建 MLP(第 17-25 行)。
为了与纸张(多视图一致性)对齐,只有rayInput通过模型产生sigma(体积密度)和第 28-31 行上的一个特征向量。最后,将特征向量与dirInput ( 第 35 行)串接,产生颜色(第 39 行)。
在的第 42 和 43 行、和上,我们使用 Keras 功能 API 构建了nerfModel。最后,我们返回第 46 行上的nerfModel。
体绘制
在这一节中,我们研究如何实现体绘制。我们使用从 MLP 预测的颜色和体积密度来渲染 3D 场景。
来自网络的预测被插入到经典体绘制方程中,以导出一个特定点的颜色。例如,下面给出了相同的等式:
= \displaystyle\int_{tn}^{tf}T(t)\sigma(r(t))c(r(t),d)dt")
听起来很复杂?
让我们把这个等式分解成几个简单的部分。
") 是物体的颜色点。
是物体的颜色点。 = o+ td") 是馈入网络的射线,其中变量代表以下内容:
是馈入网络的射线,其中变量代表以下内容:
 为射线的原点
为射线的原点 是射线的方向
是射线的方向 是用于积分的近点和远点之间的均匀样本的集合
是用于积分的近点和远点之间的均匀样本的集合
)") 是体积密度,也可以解释为光线终止于
是体积密度,也可以解释为光线终止于 点的微分概率。
点的微分概率。)") 是光线在点上的颜色
是光线在点上的颜色
") 是物体的颜色点。
是物体的颜色点。 = o+ td") 是馈入网络的射线,其中变量代表以下内容:
是馈入网络的射线,其中变量代表以下内容:
 为射线的原点
为射线的原点)") 是体积密度,也可以解释为光线终止于
是体积密度,也可以解释为光线终止于这些是等式的组成部分。除了这些,还有一个术语")
 = \exp{(- \displaystyle\int_{tn}^t\sigma(r(s))ds)}")
这代表从近点沿光线的透射率
to the current point . Think of this as a measure of how much the ray can penetrate the 3D space to a certain point.
现在,当我们把所有的项放在一起时,我们终于可以理解这个等式了。
= \displaystyle\int_{tn}^{tf}T(t)\sigma(r(t))c(r(t),d)dt")
3D 空间中对象的颜色被定义为(
) the transmittance (), volume density (}") ), the color of the current point (
), the color of the current point ()") ) and the direction of the ray sampled for all points existing between the near (
) and the direction of the ray sampled for all points existing between the near ( ) and far (
) and far ( ) of the viewing plane.
) of the viewing plane.
Let’s look at how to express this in code. First, we will look at the render_image_depth in the pyimagesearch/utils.py file.
def render_image_depth(rgb, sigma, tVals):
# squeeze the last dimension of sigma
sigma = sigma[..., 0]
# calculate the delta between adjacent tVals
delta = tVals[..., 1:] - tVals[..., :-1]
deltaShape = [BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, 1]
delta = tf.concat(
[delta, tf.broadcast_to([1e10], shape=deltaShape)], axis=-1)
# calculate alpha from sigma and delta values
alpha = 1.0 - tf.exp(-sigma * delta)
# calculate the exponential term for easier calculations
expTerm = 1.0 - alpha
epsilon = 1e-10
# calculate the transmittance and weights of the ray points
transmittance = tf.math.cumprod(expTerm + epsilon, axis=-1,
exclusive=True)
weights = alpha * transmittance
# build the image and depth map from the points of the rays
image = tf.reduce_sum(weights[..., None] * rgb, axis=-2)
depth = tf.reduce_sum(weights * tVals, axis=-1)
# return rgb, depth map and weights
return (image, depth, weights)
在第 15-42 行上,我们正在构建一个render_image_depth函数,它接受以下输入:
rgb:光线点的红绿蓝颜色矩阵sigma:采样点的体积密度tVals:采样点
它产生体绘制图像(image)、深度图(depth)和权重(分层采样所需)。
- 在第 17 行的上,为了便于计算,我们对
sigma进行了整形。接下来,我们计算相邻tVals( 行 20-23 )之间的间距(delta)。 - 接下来我们使用
sigma和delta( 第 26 行)创建alpha。 - 我们创建透射比和权重向量(第 33-35 行 ) 。
- 在行 38 和 39 ,我们创建图像和深度图。
最后,我们在第 42 的行返回image、depth和weights。
光度损失
我们将 NeRF 使用的损失函数称为光度损失。这是通过将合成图像的颜色与真实图像进行比较来计算的。数学上,这可以表示为:

其中
is the real image and  is the synthesized image. This function, when applied to the entire pipeline, is still fully differentiable. This allows us to train the model parameters (
is the synthesized image. This function, when applied to the entire pipeline, is still fully differentiable. This allows us to train the model parameters ( ) using backpropagation.
) using backpropagation.
喘息者
让我们花一点时间来意识到我们已经走了多远。像我们图 14 中的朋友一样深呼吸。
在我们博客系列的第一部分中,我们已经学习了计算机图形学及其基础知识。在本教程中,我们将这些概念应用到 3D 场景表现中。我们这里有:
- 从给定的
json文件中构建了一个图像和一个光线数据集。 - 使用随机采样策略从光线中采样点。
- 将这些观点传递给了 MLP。
- 使用 MLP 预测的颜色和体积密度渲染一幅新图像。
- 建立了一个损失函数(光度损失),我们将使用它来优化 MLP 的参数。
这些步骤足以训练一个 NeRF 模型并呈现新颖的视图。然而,这种香草架构最终会产生低质量的渲染。为了缓解这些问题,米尔登霍尔等人(2020) 提出了额外的增强措施。
在下一节中,我们将了解这些增强功能及其使用 TensorFlow 的实现。
增强 NeRF
米尔登霍尔等人(2020) 提出了两种方法来增强来自 NeRF 的渲染。
- 位置编码
- 分层抽样
位置编码
位置编码是一种流行的编码格式,用于像变形金刚这样的架构中。米尔登霍尔等人(2020) 证明使用这种方法可以更好地渲染高频特征,如纹理和细节。
Rahaman et al. (2019) 提出深度网络偏向于学习低频函数。为了解决这个问题,NeRF 建议映射输入向量")
to a higher dimensional representation. Since the 5D input space is the position of the points, we are essentially encoding the positions from which it gets the name.
假设我们有 10 个位置索引为
. The indices are in the decimal system. If we encode the digits in the binary system, we will get something, as shown in Figure 15.
二进制是一种简单的编码系统。这里我们面临的唯一问题是,二进制系统填充了个零,使其成为一种稀疏表示。我们想让这个系统连续和紧凑。
NeRF 中使用的编码函数如下:
 = (\sin(2^0{\pi}p),\cos(2^0{\pi}p),\dots,\sin(2^{L-1}{\pi}p),\cos(2^{L-1}{\pi}p))")
为了比较二进制和 NeRF 编码,让我们看一下图 16 。
正弦和余弦函数使编码连续,而
term makes it similar to the binary system.
位置编码功能的可视化")
is given in Figure 17. The blue line depicts the cosine component, while the red line is the sine component.
我们可以在pyimagesearch/encode.py文件中一个名为encoder_fn的函数中非常简单地创建它。
# import the necessary packages
import tensorflow as tf
def encoder_fn(p, L):
# build the list of positional encodings
gamma = [p]
# iterate over the number of dimensions in time
for i in range(L):
# insert sine and cosine of the product of current dimension
# and the position vector
gamma.append(tf.sin((2.0 ** i) * p))
gamma.append(tf.cos((2.0 ** i) * p))
# concatenate the positional encodings into a positional vector
gamma = tf.concat(gamma, axis=-1)
# return the positional encoding vector
return gamma
我们从导入tensorflow ( 线 2 )开始。在第 4-19 行中,我们定义了编码器函数,它接受以下参数:
p:每个待编码元素的位置L:编码将发生的维度
在第 6 行的上,我们定义了一个保存位置编码的列表。接下来,我们遍历维度,并将编码后的值添加到列表中(第 9-13 行)。第 16-19 行用于将同一个列表转换成张量并最终返回。
分层抽样
米尔登霍尔等人(2020) 发现了原始结构的另一个问题。随机采样方法将沿着每条相机光线对N点进行采样。这意味着我们不知道应该在哪里采样。这最终导致低效的渲染。
他们提出以下解决方案来补救这种情况:
-
建立两个相同的 NeRF MLP 模型,粗略的网络和精细的网络。
-
使用随机采样策略沿相机光线采样一组
 点,如图图 12 所示。这些点将用于查询粗略网络。
点,如图图 12 所示。这些点将用于查询粗略网络。 -
粗略网络的输出用于产生沿每条射线的点的更有根据的采样。这些样本偏向于 3D 场景中更相关的部分。
为此,我们重写颜色方程:
= \displaystyle\int_{tn}^{tf}T(t)\sigma(r(t))c(r(t),d)dt")
作为所有样本颜色的加权和
 。
。 = \displaystyle\sum_1^{N_{c}}(w_i c_i)")
这里的术语是
)") 。
。 -
当归一化时,权重产生分段常数概率密度函数。

将权重转化为概率密度函数的整个过程在图 18 中可视化。
-
从概率密度函数中,我们使用逆变换采样方法对第二组
 位置进行采样,如图图 19 所示。
位置进行采样,如图图 19 所示。 -
现在我们既有
 和
和 组采样点。我们将这些点发送到精细网络来产生光线的最终渲染颜色。
组采样点。我们将这些点发送到精细网络来产生光线的最终渲染颜色。
 点,如图图 12 所示。这些点将用于查询粗略网络。
点,如图图 12 所示。这些点将用于查询粗略网络。= \displaystyle\int_{tn}^{tf}T(t)\sigma(r(t))c(r(t),d)dt")
 。
。 = \displaystyle\sum_1^{N_{c}}(w_i c_i)")
)") 。
。
 位置进行采样,如图图 19 所示。
位置进行采样,如图图 19 所示。将权重转换为一组新的样本点的过程可以通过一个名为sample_pdf的函数来表示。首先,让我们参考一下pyimagesearch文件夹中的utils.py文件。
def sample_pdf(tValsMid, weights, nF):
# add a small value to the weights to prevent it from nan
weights += 1e-5
# normalize the weights to get the pdf
pdf = weights / tf.reduce_sum(weights, axis=-1, keepdims=True)
# from pdf to cdf transformation
cdf = tf.cumsum(pdf, axis=-1)
# start the cdf with 0s
cdf = tf.concat([tf.zeros_like(cdf[..., :1]), cdf], axis=-1)
# get the sample points
uShape = [BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, nF]
u = tf.random.uniform(shape=uShape)
# get the indices of the points of u when u is inserted into cdf in a
# sorted manner
indices = tf.searchsorted(cdf, u, side="right")
# define the boundaries
below = tf.maximum(0, indices-1)
above = tf.minimum(cdf.shape[-1]-1, indices)
indicesG = tf.stack([below, above], axis=-1)
# gather the cdf according to the indices
cdfG = tf.gather(cdf, indicesG, axis=-1,
batch_dims=len(indicesG.shape)-2)
# gather the tVals according to the indices
tValsMidG = tf.gather(tValsMid, indicesG, axis=-1,
batch_dims=len(indicesG.shape)-2)
# create the samples by inverting the cdf
denom = cdfG[..., 1] - cdfG[..., 0]
denom = tf.where(denom < 1e-5, tf.ones_like(denom), denom)
t = (u - cdfG[..., 0]) / denom
samples = (tValsMidG[..., 0] + t *
(tValsMidG[..., 1] - tValsMidG[..., 0]))
# return the samples
return samples
这段代码片段受到了官方 NeRF 实现的启发。在第 44-86 行,我们创建了一个名为sample_pdf的函数,它接受以下参数:
tValsMid:两个相邻tVals的中点weights:体绘制功能中使用的权重nF:精细模型使用的点数
在第 46-49 行,我们根据权重定义概率密度函数,然后将其转换为累积分布函数(cdf)。然后使用逆变换采样将其转换回精细模型的采样点(第 52-86 行)。
我们推荐这本补充阅读材料,更好地理解分层抽样。
信用点
本教程的灵感来自于米尔登霍尔等人(2020) 的工作。
汇总
我们已经研究了 NeRF 论文中提出的核心概念,并且使用 TensorFlow 实现了它们。
我们可以通过以下步骤回忆到目前为止所学的内容:
- 为 5D 场景表示构建图像和光线数据集
- 使用任何采样策略从光线中采样点
- 通过纳夫 MLP 模型传递这些点
- 基于 MLP 模型输出的体绘制
- 计算光度损失
- 使用位置编码和分层采样来提高渲染质量
在下周的教程中,我们将讲述如何利用所有这些概念来训练 NeRF 模型。此外,我们还将渲染来自 2D 图像的 3D 场景的 360 度视频。我们希望你喜欢本周的教程,一如既往,你可以下载源代码并亲自试用。
引用信息
gothipaty,A. R .和 Raha,R. “使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第二部分”, PyImageSearch ,2021 年,https://PyImageSearch . com/2021/11/17/Computer-Graphics-and-Deep-Learning-with-NeRF-using-tensor flow-and-Keras-Part-2/
@article{Gosthipaty_Raha_2021_pt2,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Computer Graphics and Deep Learning with {NeRF} using {TensorFlow} and {Keras}: Part 2},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/11/17/computer-graphics-and-deep-learning-with-nerf-using-tensorflow-and-keras-part-2/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 TensorFlow 和 Keras 的 NeRF 的计算机图形和深度学习:第 3 部分
让我们把时钟拨回一两个星期。在第一篇教程中,我们学习了计算机图形学和图像渲染的基础知识。在第二篇教程中,我们更深入的研究了 NeRF 提出的核心思想,并用 TensorFlow 和 Keras 实现了它们。
我们首先提醒自己我们要解决的原始问题:
如果有一种方法可以从一组稀疏的 2D 图片中捕捉到整个 3D 场景,会怎么样?
为了解决这个问题,我们已经走了很长的路。我们已经创建了构建 NeRF 所需的架构和组件。但是我们还不知道每一部分是如何融入更大的画面中的。
在本教程中,我们集合所有细节来训练 NeRF 模型。
本课是关于使用 TensorFlow 和 Keras 的 NeRF 的计算机图形和深度学习的 3 部分系列的最后一部分:
- 计算机图形学与使用 TensorFlow 和 Keras 的 NeRF 深度学习:第 1 部分 (第一周教程)
- 计算机图形学与使用 TensorFlow 和 Keras 的 NeRF 深度学习:第二部分 (上周教程)
- 使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 3 部分(本周教程)
要了解使用神经辐射场或 NeRF 的体绘制, 继续阅读。
使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第三部分
在本周的教程中,我们将明确地着眼于训练我们上周建立的 NeRF 多层感知器(MLP)。我们将本教程分为以下几个部分:
- NeRF 集合:如何训练一个 NeRF
- NeRF 训练师:一个助手模型,训练粗糙的和精细的 NeRF 模型
- 自定义回调:帮助我们可视化培训过程的自定义回调
- 把所有的东西绑在一起:把所有的组件绑在一起
- 推理:从训练好的 NeRF 模型建立 3D 场景
配置您的开发环境
要遵循本指南,您需要在系统上安装 TensorFlow 库。
幸运的是,TensorFlow 可以在 pip 上安装:
$ pip install tensorflow
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们回忆一下上周教程中的项目目录结构。
通过访问本教程的 【下载】 部分来检索源代码。我们还希望你下载数据集,并把它放在手边。你可以在第一教程中找到关于数据集的细节。
接下来,让我们来看看目录结构:
$ tree --dirsfirst
.
├── dataset
│ ├── test
│ │ ├── r_0_depth_0000.png
│ │ ├── r_0_normal_0000.png
│ │ ├── r_0.png
│ │ ├── ..
│ │ └── ..
│ ├── train
│ │ ├── r_0.png
│ │ ├── r_10.png
│ │ ├── ..
│ │ └── ..
│ ├── val
│ │ ├── r_0.png
│ │ ├── r_10.png
│ │ ├── ..
│ │ └── ..
│ ├── transforms_test.json
│ ├── transforms_train.json
│ └── transforms_val.json
├── pyimagesearch
│ ├── config.py
│ ├── data.py
│ ├── encoder.py
│ ├── __init__.py
│ ├── nerf.py
│ ├── nerf_trainer.py
│ ├── train_monitor.py
│ └── utils.py
├── inference.py
└── train.py
dataset文件夹包含三个子文件夹,train、test和val,用于训练、测试和验证图像。
pyimagesearch文件夹包含我们将用于训练的所有 python 脚本。这些已经在上周的教程中讨论和解释过了。
接下来,我们有两个驱动脚本:train.py和inference.py。我们用train.py脚本训练我们的 NeRF 模型。使用inference.py,我们从经过训练的 NeRF 模型生成一个 360 度全景视频。
NeRF 调集
在这一节中,我们组装(双关语为)在之前的博客文章中解释的所有组件,并开始训练 NeRF 模型。本节将介绍三个 python 脚本。
nerf_trainer.py: 定制 keras 车型训练出粗和细车型train_monitor.py: 一个定制的回调,用于可视化并从培训过程中获得洞察力train.py: 最终的剧本把一切都集合在一起
把这一段当做像图 2 一样的终极战斗口号。当我们完成这一部分时,我们将准备好训练好的 NeRF 模型。
NeRF 训练师
tf.keras有一个漂亮的 fit API 被调用来训练一个模型。当培训管道变得复杂时,我们建立一个定制的tf.keras.Model和一个定制的train_step。这样,我们仍然可以利用fit功能。我们向任何想要深入了解的人推荐关于定制 fit 呼叫的官方 keras 教程。
在 NeRF 培训管道中,MLP 很简单。我们面临的唯一复杂问题是体绘制和分层采样。
请注意,我们用分层抽样训练两个模型(粗和细),而不是一个。为了封装fit调用中的所有内容,我们构建了一个定制的NeRF_Trainer模型。
NeRF_Trainer写在pyimagesearch/nerf_trainer.py中。让我们打开文件,仔细阅读脚本,以便更好地理解它。
# import the necessary packages
from tensorflow.keras.metrics import Mean
import tensorflow as tf
我们从第 2-3 行中的必要导入开始。
class Nerf_Trainer(tf.keras.Model):
def __init__(self, coarseModel, fineModel, lxyz, lDir,
encoderFn, renderImageDepth, samplePdf, nF):
super().__init__()
# define the coarse model and fine model
self.coarseModel = coarseModel
self.fineModel = fineModel
# define the dimensions for positional encoding for spatial
# coordinates and direction
self.lxyz = lxyz
self.lDir = lDir
# define the positional encoder
self.encoderFn = encoderFn
# define the volume rendering function
self.renderImageDepth = renderImageDepth
# define the hierarchical sampling function and the number of
# samples for the fine model
self.samplePdf = samplePdf
self.nF = nF
在的第 6-27 行中,__init__方法作为Nerf_Trainer模型构造器。该方法接受以下参数:
coarseModel:粗 NeRF 模型fineModel:精细的 NeRF 模型lxyz:用于xyz坐标位置编码的维数lDir:用于方向向量的位置编码的维数encoderFn:模型的位置编码功能renderImageDepth:体绘制功能samplePdf:分级采样的效用函数nF:精细模型样本数
def compile(self, optimizerCoarse, optimizerFine, lossFn):
super().compile()
# define the optimizer for the coarse and fine model
self.optimizerCoarse = optimizerCoarse
self.optimizerFine = optimizerFine
# define the photometric loss function
self.lossFn = lossFn
# define the loss and psnr tracker
self.lossTracker = Mean(name="loss")
self.psnrMetric = Mean(name="psnr")
在的第 29-40 行中,我们定义了compile方法,在编译Nerf_Trainer模型时会调用这个方法。该方法接受以下参数:
optimizerCoarse:粗模型的优化器optimizerFine:精细模型的优化器lossFn:NeRF 模型的损失函数
在的第 39 和 40 行,我们定义了两个跟踪器,即lossTracker和psnrTracker。我们使用这些跟踪器来跟踪原始图像和预测图像之间的模型损失和 PSNR。
def train_step(self, inputs):
# get the images and the rays
(elements, images) = inputs
(raysOriCoarse, raysDirCoarse, tValsCoarse) = elements
# generate the coarse rays
raysCoarse = (raysOriCoarse[..., None, :] +
(raysDirCoarse[..., None, :] * tValsCoarse[..., None]))
# positional encode the rays and dirs
raysCoarse = self.encoderFn(raysCoarse, self.lxyz)
dirCoarseShape = tf.shape(raysCoarse[..., :3])
dirsCoarse = tf.broadcast_to(raysDirCoarse[..., None, :],
shape=dirCoarseShape)
dirsCoarse = self.encoderFn(dirsCoarse, self.lDir)
现在我们从train_step方法开始(第 42-127 行)。当我们在Nerf_Trainer定制模型上做model.fit()时,这个方法被调用。以下几点解释了train_step方法:
- 第 44 行和第 45 行解包输入。
- 第 48 行和第 49 行为粗略模型生成光线。
- 第 52-56 行使用位置编码功能对光线和方向进行编码。
# keep track of our gradients
with tf.GradientTape() as coarseTape:
# compute the predictions from the coarse model
(rgbCoarse, sigmaCoarse) = self.coarseModel([raysCoarse,
dirsCoarse])
# render the image from the predictions
renderCoarse = self.renderImageDepth(rgb=rgbCoarse,
sigma=sigmaCoarse, tVals=tValsCoarse)
(imagesCoarse, _, weightsCoarse) = renderCoarse
# compute the photometric loss
lossCoarse = self.lossFn(images, imagesCoarse)
- 在第 59-70 行上,我们定义了粗模型的正向通道。在第 61 和 62 行、、上,模型接受光线和方向作为输入,并产生
rgb(颜色)和sigma(体积密度)。 - 这些输出(
rgb和sigma)然后通过renderImageDepth函数(用于体绘制)并产生图像深度图和权重(第 65-67 行)。 - 在行 70 上,我们计算粗略模型的目标图像和渲染图像之间的均方误差。
# compute the middle values of t vals
tValsCoarseMid = (0.5 *
(tValsCoarse[..., 1:] + tValsCoarse[..., :-1]))
# apply hierarchical sampling and get the t vals for the fine
# model
tValsFine = self.samplePdf(tValsMid=tValsCoarseMid,
weights=weightsCoarse, nF=self.nF)
tValsFine = tf.sort(
tf.concat([tValsCoarse, tValsFine], axis=-1), axis=-1)
# build the fine rays and positional encode it
raysFine = (raysOriCoarse[..., None, :] +
(raysDirCoarse[..., None, :] * tValsFine[..., None]))
raysFine = self.encoderFn(raysFine, self.lxyz)
# build the fine directions and positional encode it
dirsFineShape = tf.shape(raysFine[..., :3])
dirsFine = tf.broadcast_to(raysDirCoarse[..., None, :],
shape=dirsFineShape)
dirsFine = self.encoderFn(dirsFine, self.lDir)
- 在第 73-81 行,我们使用
sample_pdf函数计算精细模型的tValsFine - 接下来,我们为精细模型建立光线和方向(行 84-92 )。
# keep track of our gradients
with tf.GradientTape() as fineTape:
# compute the predictions from the fine model
rgbFine, sigmaFine = self.fineModel([raysFine, dirsFine])
# render the image from the predictions
renderFine = self.renderImageDepth(rgb=rgbFine,
sigma=sigmaFine, tVals=tValsFine)
(imageFine, _, _) = renderFine
# compute the photometric loss
lossFine = self.lossFn(images, imageFine)
- 第 94-105 行用于定义精细模型的正向传递。这与粗略模型的正向传递相同。
# get the trainable variables from the coarse model and
# apply back propagation
tvCoarse = self.coarseModel.trainable_variables
gradsCoarse = coarseTape.gradient(lossCoarse, tvCoarse)
self.optimizerCoarse.apply_gradients(zip(gradsCoarse,
tvCoarse))
# get the trainable variables from the coarse model and
# apply back propagation
tvFine = self.fineModel.trainable_variables
gradsFine = fineTape.gradient(lossFine, tvFine)
self.optimizerFine.apply_gradients(zip(gradsFine, tvFine))
psnr = tf.image.psnr(images, imageFine, max_val=1.0)
# compute the loss and psnr metrics
self.lossTracker.update_state(lossFine)
self.psnrMetric.update_state(psnr)
# return the loss and psnr metrics
return {"loss": self.lossTracker.result(),
"psnr": self.psnrMetric.result()}
- 在行 109,上,我们获得粗略模型的可训练参数。计算这些参数的梯度(行 110 )。我们使用优化器将计算的梯度应用到这些参数上(行 111 和 112
- 然后对精细模型的参数重复相同的操作(行 116-119 )。
- 线 122 和 123 用于更新损耗和峰值信噪比(PSNR)跟踪器,然后通过线 126 和 127 返回。
def test_step(self, inputs):
# get the images and the rays
(elements, images) = inputs
(raysOriCoarse, raysDirCoarse, tValsCoarse) = elements
# generate the coarse rays
raysCoarse = (raysOriCoarse[..., None, :] +
(raysDirCoarse[..., None, :] * tValsCoarse[..., None]))
# positional encode the rays and dirs
raysCoarse = self.encoderFn(raysCoarse, self.lxyz)
dirCoarseShape = tf.shape(raysCoarse[..., :3])
dirsCoarse = tf.broadcast_to(raysDirCoarse[..., None, :],
shape=dirCoarseShape)
dirsCoarse = self.encoderFn(dirsCoarse, self.lDir)
# compute the predictions from the coarse model
(rgbCoarse, sigmaCoarse) = self.coarseModel([raysCoarse,
dirsCoarse])
# render the image from the predictions
renderCoarse = self.renderImageDepth(rgb=rgbCoarse,
sigma=sigmaCoarse, tVals=tValsCoarse)
(_, _, weightsCoarse) = renderCoarse
# compute the middle values of t vals
tValsCoarseMid = (0.5 *
(tValsCoarse[..., 1:] + tValsCoarse[..., :-1]))
# apply hierarchical sampling and get the t vals for the fine
# model
tValsFine = self.samplePdf(tValsMid=tValsCoarseMid,
weights=weightsCoarse, nF=self.nF)
tValsFine = tf.sort(
tf.concat([tValsCoarse, tValsFine], axis=-1), axis=-1)
# build the fine rays and positional encode it
raysFine = (raysOriCoarse[..., None, :] +
(raysDirCoarse[..., None, :] * tValsFine[..., None]))
raysFine = self.encoderFn(raysFine, self.lxyz)
# build the fine directions and positional encode it
dirsFineShape = tf.shape(raysFine[..., :3])
dirsFine = tf.broadcast_to(raysDirCoarse[..., None, :],
shape=dirsFineShape)
dirsFine = self.encoderFn(dirsFine, self.lDir)
# compute the predictions from the fine model
rgbFine, sigmaFine = self.fineModel([raysFine, dirsFine])
# render the image from the predictions
renderFine = self.renderImageDepth(rgb=rgbFine,
sigma=sigmaFine, tVals=tValsFine)
(imageFine, _, _) = renderFine
# compute the photometric loss and psnr
lossFine = self.lossFn(images, imageFine)
psnr = tf.image.psnr(images, imageFine, max_val=1.0)
# compute the loss and psnr metrics
self.lossTracker.update_state(lossFine)
self.psnrMetric.update_state(psnr)
# return the loss and psnr metrics
return {"loss": self.lossTracker.result(),
"psnr": self.psnrMetric.result()}
@property
def metrics(self):
# return the loss and psnr tracker
return [self.lossTracker, self.psnrMetric]
现在我们定义test_step ( 第 129-194 行)。test_step和train_step是一样的。唯一的区别是我们没有计算test_step中的梯度。
最后,我们将损失跟踪器和 PSNR 跟踪器定义为类属性(第 196-199 行)。
自定义回调
这里需要注意的重要一点是,NeRF 模型非常占用内存。因此,虽然看到结果很酷,但同样重要的是将每个训练过程可视化。
为了可视化每个步骤,我们创建了一个自定义回调。我们建议阅读本教程,以便更好地理解 Keras 中的自定义回调。
我们打开pyimagesearch/train_monitor.py开始挖吧。
# import the necessary packages
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.keras.callbacks import Callback
import matplotlib.pyplot as plt
import tensorflow as tf
我们首先为这个脚本导入必要的包(第 2-5 行)。
def get_train_monitor(testDs, encoderFn, lxyz, lDir, imagePath):
# grab images and rays from the testing dataset
(tElements, tImages) = next(iter(testDs))
(tRaysOriCoarse, tRaysDirCoarse, tTvalsCoarse) = tElements
# build the test coarse ray
tRaysCoarse = (tRaysOriCoarse[..., None, :] +
(tRaysDirCoarse[..., None, :] * tTvalsCoarse[..., None]))
# positional encode the rays and direction vectors for the coarse
# ray
tRaysCoarse = encoderFn(tRaysCoarse, lxyz)
tDirsCoarseShape = tf.shape(tRaysCoarse[..., :3])
tDirsCoarse = tf.broadcast_to(tRaysDirCoarse[..., None, :],
shape=tDirsCoarseShape)
tDirsCoarse = encoderFn(tDirsCoarse, lDir)
- 在第 7 行的上,我们定义了
get_train_monitor方法,该方法构建并返回一个自定义回调。 - 在第 9 行和第 10 行、、上,我们对来自
testDs(测试数据集)的输入进行解包。 - 接下来在第 13 行和第 14 行、、我们为粗略模型生成光线。
- 在第行第 18-22 、和行,我们使用位置编码对粗略模型的光线和方向进行编码。
class TrainMonitor(Callback):
def on_epoch_end(self, epoch, logs=None):
# compute the coarse model prediction
(tRgbCoarse, tSigmaCoarse) = self.model.coarseModel.predict(
[tRaysCoarse, tDirsCoarse])
# render the image from the model prediction
tRenderCoarse = self.model.renderImageDepth(rgb=tRgbCoarse,
sigma=tSigmaCoarse, tVals=tTvalsCoarse)
(tImageCoarse, _, tWeightsCoarse) = tRenderCoarse
# compute the middle values of t vals
tTvalsCoarseMid = (0.5 *
(tTvalsCoarse[..., 1:] + tTvalsCoarse[..., :-1]))
# apply hierarchical sampling and get the t vals for the
# fine model
tTvalsFine = self.model.samplePdf(
tValsMid=tTvalsCoarseMid, weights=tWeightsCoarse,
nF=self.model.nF)
tTvalsFine = tf.sort(
tf.concat([tTvalsCoarse, tTvalsFine], axis=-1),
axis=-1)
# build the fine rays and positional encode it
tRaysFine = (tRaysOriCoarse[..., None, :] +
(tRaysDirCoarse[..., None, :] * tTvalsFine[..., None])
)
tRaysFine = self.model.encoderFn(tRaysFine, lxyz)
# build the fine directions and positional encode it
tDirsFineShape = tf.shape(tRaysFine[..., :3])
tDirsFine = tf.broadcast_to(tRaysDirCoarse[..., None, :],
shape=tDirsFineShape)
tDirsFine = self.model.encoderFn(tDirsFine, lDir)
# compute the fine model prediction
tRgbFine, tSigmaFine = self.model.fineModel.predict(
[tRaysFine, tDirsFine])
# render the image from the model prediction
tRenderFine = self.model.renderImageDepth(rgb=tRgbFine,
sigma=tSigmaFine, tVals=tTvalsFine)
(tImageFine, tDepthFine, _) = tRenderFine
# plot the coarse image, fine image, fine depth map and
# target image
(_, ax) = plt.subplots(nrows=1, ncols=4, figsize=(10, 10))
ax[0].imshow(array_to_img(tImageCoarse[0]))
ax[0].set_title(f"Corase Image")
ax[1].imshow(array_to_img(tImageFine[0]))
ax[1].set_title(f"Fine Image")
ax[2].imshow(array_to_img(tDepthFine[0, ..., None]),
cmap="inferno")
ax[2].set_title(f"Fine Depth Image")
ax[3].imshow(array_to_img(tImages[0]))
ax[3].set_title(f"Real Image")
plt.savefig(f"{imagePath}/{epoch:03d}.png")
plt.close()
# instantiate a train monitor callback
trainMonitor = TrainMonitor()
# return the train monitor
return trainMonitor
我们在自定义回调类中定义了on_epoch_end函数,以帮助可视化训练日志和数据(第 25 行)。顾名思义,该功能仅在模型训练的每个时期结束时触发
- 在第 27 和 28 行,的上,我们使用粗略模型预测颜色和体积密度。接下来,在第 31-33 行上,我们使用体积渲染函数
renderImageDepth来渲染粗糙图像。 - 然后,我们使用分层采样生成精细采样点(第 36-46 行)。
- 在第 49-51 行上,我们使用精细采样点,并通过将精细采样点与粗糙光线相乘来生成精细光线。
- 在行 52 上,我们使用位置编码对精细光线进行编码。
- 然后我们从光线中提取方向分量(行 55 ) 并对其进行整形(行 56 和 57 ),最后使用位置编码(行 58 )对方向进行编码。
- 然后使用精细光线、方向和模型来预测细化的颜色和体积密度(行 61 和 62 )。我们用这些在第 65-67 行的上渲染图像和深度图。
- 然后在行 71-86 上显现粗略图像、精细图像和深度图。
- 在行 89 上,我们实例化列车监视器回调,然后在行 92 上将其返回。
****
有了所有的组件,我们将最终能够使用下面给出的脚本来训练我们的 NeRF 模型。我们打开train.py开始翻吧。
# USAGE
# python train.py
# setting seed for reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch.data import read_json
from pyimagesearch.data import get_image_c2w
from pyimagesearch.data import GetImages
from pyimagesearch.data import GetRays
from pyimagesearch.utils import get_focal_from_fov, render_image_depth, sample_pdf
from pyimagesearch.encoder import encoder_fn
from pyimagesearch.nerf import get_model
from pyimagesearch.nerf_trainer import Nerf_Trainer
from pyimagesearch.train_monitor import get_train_monitor
from pyimagesearch import config
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError
import os
在第 6 行的上,我们设置了用于再现性的随机种子。接下来,我们开始导入必要的包(第 5-21 行)。
# get the train validation and test data
print("[INFO] grabbing the data from json files...")
jsonTrainData = read_json(config.TRAIN_JSON)
jsonValData = read_json(config.VAL_JSON)
jsonTestData = read_json(config.TEST_JSON)
focalLength = get_focal_from_fov(
fieldOfView=jsonTrainData["camera_angle_x"],
width=config.IMAGE_WIDTH)
# print the focal length of the camera
print(f"[INFO] focal length of the camera: {focalLength}...")
在第 25-27 行,我们从各自的json文件中提取训练、测试和验证数据。然后我们计算相机的焦距(第 29-34 行)并打印出来。
# get the train, validation, and test image paths and camera2world
# matrices
print("[INFO] grabbing the image paths and camera2world matrices...")
trainImagePaths, trainC2Ws = get_image_c2w(jsonData=jsonTrainData,
datasetPath=config.DATASET_PATH)
valImagePaths, valC2Ws = get_image_c2w(jsonData=jsonValData,
datasetPath=config.DATASET_PATH)
testImagePaths, testC2Ws = get_image_c2w(jsonData=jsonTestData,
datasetPath=config.DATASET_PATH)
# instantiate a object of our class used to load images from disk
getImages = GetImages(imageHeight=config.IMAGE_HEIGHT,
imageWidth=config.IMAGE_WIDTH)
# get the train, validation, and test image dataset
print("[INFO] building the image dataset pipeline...")
trainImageDs = (
tf.data.Dataset.from_tensor_slices(trainImagePaths)
.map(getImages, num_parallel_calls=config.AUTO)
)
valImageDs = (
tf.data.Dataset.from_tensor_slices(valImagePaths)
.map(getImages, num_parallel_calls=config.AUTO)
)
testImageDs = (
tf.data.Dataset.from_tensor_slices(testImagePaths)
.map(getImages, num_parallel_calls=config.AUTO)
)
我们从之前提取的 json 数据中构建图像路径和摄像机到世界矩阵(第 39-44 行)。
接下来,我们构建tf.data图像数据集(第 52-63 行)。这些分别包括训练、测试和验证数据集。
# instantiate the GetRays object
getRays = GetRays(focalLength=focalLength, imageWidth=config.IMAGE_WIDTH,
imageHeight=config.IMAGE_HEIGHT, near=config.NEAR, far=config.FAR,
nC=config.N_C)
# get the train validation and test rays dataset
print("[INFO] building the rays dataset pipeline...")
trainRayDs = (
tf.data.Dataset.from_tensor_slices(trainC2Ws)
.map(getRays, num_parallel_calls=config.AUTO)
)
valRayDs = (
tf.data.Dataset.from_tensor_slices(valC2Ws)
.map(getRays, num_parallel_calls=config.AUTO)
)
testRayDs = (
tf.data.Dataset.from_tensor_slices(testC2Ws)
.map(getRays, num_parallel_calls=config.AUTO)
)
在的第 66-68 行,我们实例化了一个GetRays类的对象。然后我们创建tf.data训练、验证和测试射线数据集(第 72-83 行)。
# zip the images and rays dataset together
trainDs = tf.data.Dataset.zip((trainRayDs, trainImageDs))
valDs = tf.data.Dataset.zip((valRayDs, valImageDs))
testDs = tf.data.Dataset.zip((testRayDs, testImageDs))
# build data input pipeline for train, val, and test datasets
trainDs = (
trainDs
.shuffle(config.BATCH_SIZE)
.batch(config.BATCH_SIZE)
.repeat()
.prefetch(config.AUTO)
)
valDs = (
valDs
.shuffle(config.BATCH_SIZE)
.batch(config.BATCH_SIZE)
.repeat()
.prefetch(config.AUTO)
)
testDs = (
testDs
.batch(config.BATCH_SIZE)
.prefetch(config.AUTO)
)
然后将图像和光线数据集压缩在一起(第 86-88 行)。所有的数据集(训练、验证和测试)然后被混洗、分批、重复和预取(第 91-109 行)。
# instantiate the coarse model
coarseModel = get_model(lxyz=config.L_XYZ, lDir=config.L_DIR,
batchSize=config.BATCH_SIZE, denseUnits=config.DENSE_UNITS,
skipLayer=config.SKIP_LAYER)
# instantiate the fine model
fineModel = get_model(lxyz=config.L_XYZ, lDir=config.L_DIR,
batchSize=config.BATCH_SIZE, denseUnits=config.DENSE_UNITS,
skipLayer=config.SKIP_LAYER)
# instantiate the nerf trainer model
nerfTrainerModel = Nerf_Trainer(coarseModel=coarseModel, fineModel=fineModel,
lxyz=config.L_XYZ, lDir=config.L_DIR, encoderFn=encoder_fn,
renderImageDepth=render_image_depth, samplePdf=sample_pdf,
nF=config.N_F)
# compile the nerf trainer model with Adam optimizer and MSE loss
nerfTrainerModel.compile(optimizerCoarse=Adam(),optimizerFine=Adam(),
lossFn=MeanSquaredError())
现在我们在(第 112-119 行)中定义粗略和精细模型。接下来,我们定义nerfTrainerModel,这是一个定制的 keras 模型,它将粗略和精细模型训练在一起(第 122-125 行)。
在的第 128 行和第 129 行,我们用合适的优化器(这里是Adam)和损失函数(这里是均方误差)编译nerfTrainerModel。
# check if the output image directory already exists, if it doesn't,
# then create it
if not os.path.exists(config.IMAGE_PATH):
os.makedirs(config.IMAGE_PATH)
# get the train monitor callback
trainMonitorCallback = get_train_monitor(testDs=testDs,
encoderFn=encoder_fn, lxyz=config.L_XYZ, lDir=config.L_DIR,
imagePath=config.IMAGE_PATH)
# train the NeRF model
print("[INFO] training the nerf model...")
nerfTrainerModel.fit(trainDs, steps_per_epoch=config.STEPS_PER_EPOCH,
validation_data=valDs, validation_steps=config.VALIDATION_STEPS,
epochs=config.EPOCHS, callbacks=[trainMonitorCallback],
)
# save the coarse and fine model
nerfTrainerModel.coarseModel.save(config.COARSE_PATH)
nerfTrainerModel.fineModel.save(config.FINE_PATH)
第 133-139 行创建输出目录并初始化trainMonitorCallback。最后,我们用训练数据集训练nerfTrainerModel,并用验证数据集进行验证(第 143-146 行)。
我们通过将训练好的粗略和精细模型存储到磁盘来结束训练过程(行 149 和 150 )。
推论
花一分钟时间祝贺自己,如图 3 。我们从基础做起,现在已经成功训练了 NeRF。这是一个漫长的旅程,我很高兴我们一起做到了这一点。
努力了这么多,还有什么比看到结果更好的。
我们已经模拟了 MLP 的整个三维场景,对吗?为什么不围绕整个场景旋转相机并点击图片呢?
在这一节中,我们将要求我们的模型从它刚刚建模的 3D 场景中合成新的视图。我们将在 中综合 360 度的新颖观点
中综合 360 度的新颖观点
axis.
如果你不熟悉
and  axes in the 3D coordinate system, you can quickly revise your concepts with Figures 4 and 5.
axes in the 3D coordinate system, you can quickly revise your concepts with Figures 4 and 5.
让我们打开inference.py来想象绕θ轴的完整旋转。
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.utils import pose_spherical
from pyimagesearch.data import GetRays
from pyimagesearch.utils import get_focal_from_fov
from pyimagesearch.data import read_json
from pyimagesearch.encoder import encoder_fn
from pyimagesearch.utils import render_image_depth
from pyimagesearch.utils import sample_pdf
from tensorflow.keras.models import load_model
from tqdm import tqdm
import tensorflow as tf
import numpy as np
import imageio
import os
我们从通常必需的进口商品开始(第 2-15 行)。
# create a camera2world matrix list to store the novel view
# camera2world matrices
c2wList = []
# iterate over theta and generate novel view camera2world matrices
for theta in np.linspace(0.0, 360.0, config.SAMPLE_THETA_POINTS,
endpoint=False):
# generate camera2world matrix
c2w = pose_spherical(theta, -30.0, 4.0)
# append the new camera2world matrix into the collection
c2wList.append(c2w)
# get the train validation and test data
print("[INFO] grabbing the data from json files...")
jsonTrainData = read_json(config.TRAIN_JSON)
focalLength = get_focal_from_fov(
fieldOfView=jsonTrainData["camera_angle_x"],
width=config.IMAGE_WIDTH)
# instantiate the GetRays object
getRays = GetRays(focalLength=focalLength, imageWidth=config.IMAGE_WIDTH,
imageHeight=config.IMAGE_HEIGHT, near=config.NEAR, far=config.FAR,
nC=config.N_C)
# create a dataset from the novel view camera2world matrices
ds = (
tf.data.Dataset.from_tensor_slices(c2wList)
.map(getRays)
.batch(config.BATCH_SIZE)
)
# load the coarse and the fine model
coarseModel = load_model(config.COARSE_PATH, compile=False)
fineModel = load_model(config.FINE_PATH, compile=False)
接下来,在第 19 行,我们建立一个空的摄像机到世界矩阵列表c2w。在第 22 行的上,我们迭代了从0到360的范围。该范围对应于我们将使用的theta值。我们保持phi为-30,距离为4。这些值theta、phi和distance被传递到函数pose_spherical中,以获得我们的摄像机到世界矩阵(第 25-28 行)。
在第 31-48 行,我们获取训练 json 数据并提取光线和焦距。然后,我们创建一个数据集,并根据需要对其进行批处理。
在第 51 行和第 52 行,我们加载预训练的粗略和精细模型。
# create a list to hold all the novel view from the nerf model
print("[INFO] grabbing the novel views...")
frameList = []
for element in tqdm(ds):
(raysOriCoarse, raysDirCoarse, tValsCoarse) = element
# generate the coarse rays
raysCoarse = (raysOriCoarse[..., None, :] +
(raysDirCoarse[..., None, :] * tValsCoarse[..., None]))
# positional encode the rays and dirs
raysCoarse = encoder_fn(raysCoarse, config.L_XYZ)
dirCoarseShape = tf.shape(raysCoarse[..., :3])
dirsCoarse = tf.broadcast_to(raysDirCoarse[..., None, :],
shape=dirCoarseShape)
dirsCoarse = encoder_fn(dirsCoarse, config.L_DIR)
# compute the predictions from the coarse model
(rgbCoarse, sigmaCoarse) = coarseModel.predict(
[raysCoarse, dirsCoarse])
# render the image from the predictions
renderCoarse = render_image_depth(rgb=rgbCoarse,
sigma=sigmaCoarse, tVals=tValsCoarse)
(_, _, weightsCoarse) = renderCoarse
# compute the middle values of t vals
tValsCoarseMid = (0.5 *
(tValsCoarse[..., 1:] + tValsCoarse[..., :-1]))
# apply hierarchical sampling and get the t vals for the fine
# model
tValsFine = sample_pdf(tValsMid=tValsCoarseMid,
weights=weightsCoarse, nF=config.N_F)
tValsFine = tf.sort(
tf.concat([tValsCoarse, tValsFine], axis=-1), axis=-1)
# build the fine rays and positional encode it
raysFine = (raysOriCoarse[..., None, :] +
(raysDirCoarse[..., None, :] * tValsFine[..., None]))
raysFine = encoder_fn(raysFine, config.L_XYZ)
# build the fine directions and positional encode it
dirsFineShape = tf.shape(raysFine[..., :3])
dirsFine = tf.broadcast_to(raysDirCoarse[..., None, :],
shape=dirsFineShape)
dirsFine = encoder_fn(dirsFine, config.L_DIR)
# compute the predictions from the fine model
(rgbFine, sigmaFine) = fineModel.predict([raysFine, dirsFine])
# render the image from the predictions
renderFine = render_image_depth(rgb=rgbFine, sigma=sigmaFine,
tVals=tValsFine)
(imageFine, _, _) = renderFine
# insert the rendered fine image to the collection
frameList.append(imageFine.numpy()[0])
我们遍历我们创建的数据集,并解开数据集中每个元素的射线原点、射线方向和采样点(行 57 和 58 )。我们使用这些渲染我们的粗糙和精细场景,就像我们在训练中做的一样。这可以从以下几点来解释:
- 然后输入被广播到合适的形状,通过编码器功能,最后进入粗略模型以预测
rgbCoarse和sigmaCoarse( 第 61-73 行)。 - 在第 76-78 行,获得的颜色和体积密度通过
render_image_depth函数生成渲染图像。 - 在的第 81-89 行,我们使用这些样本的中间值和从渲染图像中得到的权重,通过
sample_pdf函数来计算tValsFine。 - 在行 92-100 上,我们构建精细模型光线并对其进行位置编码,然后对精细光线的方向重复同样的操作。
- 我们使用来自精细模型的预测来渲染精细图像。新的视图然后被附加到
frameList( 第 103-111 行)。
# check if the output video directory exists, if it does not, then
# create it
if not os.path.exists(config.VIDEO_PATH):
os.makedirs(config.VIDEO_PATH)
# build the video from the frames and save it to disk
print("[INFO] creating the video from the frames...")
imageio.mimwrite(config.OUTPUT_VIDEO_PATH, frameList, fps=config.FPS,
quality=config.QUALITY, macro_block_size=config.MACRO_BLOCK_SIZE)
最后,我们使用这些帧来渲染对象的 360 度视频(行 115-121 )。
让我们看看我们努力工作的成果,好吗?渲染热狗物体的 360 度视频如图图 6 所示。
汇总
在本教程中,我们已经成功地实现了一个可扩展的紧凑的训练和推理脚本。在本教程的最后阶段,我们已经从稀疏的静态图像中合成了新颖的视图,并渲染出一个视频。
NeRF 是深度学习和计算机图形学领域开创性研究的典范。它取得了迄今为止很少有方法能够取得的成果,从而极大地推进了这一领域。在未来几年中,许多变体和改进也将取得成功。
告诉我们您希望我们接下来涵盖这些变体中的哪些?
发推文给我们 @PyImageSearch 我们希望你喜欢这个 3 部分的教程,和往常一样,你可以下载源代码并亲自尝试。
引用信息
gothipaty,A. R .和 Raha,R. “使用 TensorFlow 和 Keras 的 NeRF 的计算机图形学和深度学习:第 3 部分”, PyImageSearch ,2021 年,https://PyImageSearch . com/2021/11/24/Computer-Graphics-and-Deep-Learning-with-NeRF-using-tensor flow-and-Keras-Part-3/
@article{Gosthipaty_Raha_2021_pt3,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Computer Graphics and Deep Learning with {NeRF} using {TensorFlow} and {Keras}: Part 3},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/11/24/computer-graphics-and-deep-learning-with-nerf-using-tensorflow-and-keras-part-3/},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
计算机视觉和农业深度学习
原文:https://pyimagesearch.com/2022/08/10/computer-vision-and-deep-learning-for-agriculture/
目录
计算机视觉与农业深度学习
农业部门是任何经济的基础。然而,随着人口的增加,农业部门将感受到压力,需要几次扩大供应,以应对不断增长的消费。此外,气候变化、疾病和贫瘠土地等不确定因素推动该部门采用人工智能等创新方法来保护和增加作物产量。
人工智能有可能改变农业部门,帮助农民最大限度地降低疾病风险,主动适应不断变化的气候条件,使用无人机监控作物的安全性等。,同时降低劳动力成本(图 1 )。因此,农业市场的整体人工智能预计将从 2020 年的估计 1B 增长到 2026 年的 40 亿美元,2020 年至 2026 年的复合年增长率(CAGR)为 25.5%。
本系列是关于工业和大企业应用的 CV 和 DL。这个博客将涵盖在农业中使用深度学习的好处、应用、挑战和权衡。
本课是 5 课课程中的第 4 课:工业和大企业应用 101 的 CV 和 DL。
- 面向政府的计算机视觉和深度学习
- 【计算机视觉与深度学习】为客户服务
- 面向银行和金融的计算机视觉和深度学习
- 【计算机视觉与农业深度学习】 (本教程)
- 计算机视觉和电力深度学习
了解计算机视觉和农业深度学习, 继续阅读。
计算机视觉与农业深度学习
好处
在农业部门使用人工智能的主要好处(图 2 )。
风险成本最小化,收益最大化
人工智能应用程序可以分析天气和土壤条件、用水和疾病风险,通过提供宝贵的见解,如播种的正确时间、正确的作物/种子选择,帮助农民降低作物歉收的风险。提前检测植物疾病、杂草和害虫可以减少除草剂和杀虫剂等化学品的使用,并节省成本。许多公司已经开始使用机器人,这种机器人可以减少通常喷洒在作物上的物质的 80%,并将除草剂的支出降低 90%
此外,在收获、采摘和真空设备中使用 AI 可以快速识别可收获产品的位置,并帮助确定合适的水果。草莓丰收是一个经典的例子。一个机器人能以 8 英亩/天的速度摘草莓。准确的收获量需要 30 个人每天完成。这样可以节省时间,大大降低人工成本。
正确决策
利用卫星图像和天气数据,人工智能应用程序可以分析市场趋势,如哪些作物有需求,哪些作物更有利可图。这有助于农民增加收入,指导他们了解未来的价格模式、需求水平、种植哪种作物能获得最大收益、杀虫剂的使用等。
应用
农业:家畜、家禽、鱼类
家畜、乳制品(牛奶、奶酪和黄油)、家禽(鸡蛋和肉)和鱼是大部分人口每日蛋白质摄入的来源。随着食品消费需求的增加,农民感到为每个管理单位越来越多的动物维持高质量环境的压力。此外,劳动力短缺使这项任务更具挑战性。
计算机视觉模型可以分析牛、猪、羊和鸡等动物的闭路电视(CCTV)饲料,以确保适当的环境条件和福利。此外,它们可以通过房屋管理自动化、行为分析、疾病估计、重量测量、鸡蛋检查、鱼检测、识别、计数等提供有价值的见解。(图 3 和图 4 )。
家畜: AI 系统可以传输动物(牛、猪、羊)的运动,并检测动物是否在行走、饮水或进食,使巨大谷仓中的动物管理变得更加容易。这种系统还可以通过识别动物面部的不同部分,并将它们与兽医提供的标准面部模式进行比较,来识别动物是否疼痛。
家禽:基于人工智能的机器人可以重复喂养动物、收集鸡蛋和清除粪便。他们还可以在检查鸡蛋质量并剔除接近孵化、有裂缝或肮脏(含有羽毛和血液)的鸡蛋后,自动计数和包装鸡蛋。此外,AI 系统可以在孵化早期确定生育能力的准确性。
Viscon 集团推出了 VINOVO 活胚胎检测技术,利用获得专利的心跳传感器检测鸡蛋内的活胚胎。然而,孵化室中不能存活的蛋的存在可能是一种生物危害,并且会不必要地占据额外的空间。
鱼:无人机可以监控近海渔场,并对水下渔网进行检查,查看是否有任何损坏和漏洞。无人机还可以提供鱼类资源信息,跟踪环境变化,收集氧气水平,pH 值,盐度和水污染水平等数据。此外,通过传感器检测鱼的饥饿程度可以帮助农民甚至机器人相应地喂养它们。
由海鲜创新集群和 IBM 推出的 AquaCloud 平台通过监测据说对挪威野生鲑鱼种群构成威胁的海虱,实现了实际养殖、区域管理和病原体控制。
产量估算和最大化
产量估计:作物产量高估会影响盈利能力。然而,低估会导致作物浪费和额外的成本。或者,适当的作物产量估计可以帮助农民知道他们应该何时开始收割,以便通过合理销售来实现利润最大化。产量估算的挑战在于它取决于几个动态因素,如作物基因型、环境因素、管理措施及其相互作用。
现代的深度神经网络可以通过图像/视频输入来计算水果、蔬菜和鲜花的数量,从而准确预测产量。它们甚至对由树叶、树枝、光照等引起的遮挡也是鲁棒的。
使用线性回归、投影寻踪回归( Drummond 等人,2003 )、加权回归( Marko 等人,2016 )、决策树( Romero 等人,2013 )和规则挖掘的各种机器学习算法已经被提出用于作物产量估计。 Rahnemoonfar 和 Sheppard (2017) 提出了一种用于计算遮挡情况下番茄产量的估计网络。他们通过用绿色和棕色圆圈填充整张图片来模拟背景和番茄植物,从而生成用于训练的合成图像,这些图像后来被高斯滤波器模糊化。绘制几个随机大小的圆,以创建大小可变的番茄(图 5) 。
在他们的架构中,他们使用了修改过的 Inception-ResNet-A 层(图 6 ) 。它可以通过连接不同卷积层的结果来捕获多个尺度的特征。这种连接的结果然后通过校正的线性函数进行估计。
Mekhalfi 等人(2020) 提出了第一个基于视觉的猕猴桃计数和产量估计,强调猕猴桃顶端而不是整个果实,因为它可以表现出各种形状、方向和遮挡。
产量最大化: 微软目前正在与安得拉邦的农民合作,建立一个机器学习系统,可以帮助推荐最赚钱的作物、合适的播种期、市场需求和趋势、土地准备、农场庭院肥料应用、种子处理、最佳播种深度、最佳灌溉系统、适量的化肥和农药等。,这可以增加他们 30%的作物产量。该模型使用微软的 Cortana 智能套件。
ML 模型可以通过考虑给定产品的总需求来确定给定作物的价格弹性曲线是无弹性的、单一的还是高度弹性的。了解这些数据可以帮助农民预测价格,并为农业企业每年节省数百万美元的收入损失。
诸如支持向量机(SVM)、随机森林、逻辑回归、深度神经网络等算法。,可以很容易地预测价格弹性。这种模型的相关特征包括天气参数(降雨量、温度等。)、使用的肥料、土地类型、土壤相关信息等。
监控
入侵检测:来自闭路电视的监控信号可以执行人脸识别,识别大型农场中的入侵和异常情况,并向农民发送警报以采取适当的行动。这有助于避免家畜和野生动物毁坏庄稼和牲畜的风险。
生长和压力监测:计算机视觉系统可以使用无人机的反馈来监测作物的生长模式、干湿点、特定的水分模式以及化肥和农药的效果。此外,传感器可以提供有关土壤营养、含水量、pH 值和盐度的数据,可以对这些数据进行分析,以选择合适的肥料和灌溉模式(图 7 )。
来自植物的高分辨率图像和多个传感器数据可以用作机器学习算法的输入,以实现数据融合和特征识别,从而进行胁迫识别。整个方法可以分为四个阶段(识别、分类、量化和预测),以便做出更好的决策。
这种压力的一个例子是水压力。这是由于根系/土壤的水分供应有限或蒸腾作用增加造成的。机器学习技术可以通过监测和识别这种情况来估计叶片含水量(LWC)。LWC 是作物生长早期植物生产力和产量的重要指标。基于回归和集成的方法可以很容易地预测 LWC 值,该值可以与其他参数结合,通过分类模型对水分胁迫水平进行分类。
杂草管理:杂草消耗大量土壤养分,导致作物产量显著下降。研究表明,作物和杂草之间的竞争造成了超过 110 亿美元的损失。因此,它们的检测和管理对农民来说非常重要。计算机视觉系统可以分析无人机饲料,从作物中分离出杂草,并通过激光和喷雾在线清除杂草。
农业机器人 BoniRob 使用摄像头和计算机视觉算法来识别杂草,并通过将螺栓插入土壤来清除杂草。该算法已经学会通过分析叶子的大小、形状和颜色来区分作物和杂草。这使得 BoniRob 能够在田地中穿行,并在线清除不需要的植物(图 8) 。
疾病识别和预防:健康监控牲畜和作物是另一个重要应用,CCTVs 和无人机的反馈可用于通过行为分析监控牲畜健康。 CattleEye 是一家使用头顶摄像机和计算机视觉算法来监控牛的健康和行为的公司的优秀例子。在 RGB 和近红外光下扫描作物使得使用无人机设备生成多光谱图像成为可能。有了它,就有可能确定哪些植物已经被感染,包括它们在广阔的田野中的位置,以便立即采取补救措施。多光谱图像将超光谱图像与 3D 扫描相结合。
可以对叶子和果实进行监测,看是否有任何会破坏作物产量的传染性疾病。计算机视觉算法可以分析树叶的颜色和斑点的存在,以区分它们与健康的树叶。然而,这里的一个挑战是获得带标签的植物/作物图像,这可以在某种程度上通过使用生成对抗网络(GANs)生成合成数据点来解决。这就是 DC-GAN(深度卷积 GAN)通过生成合成图像显著缓解类别不平衡问题的地方。诸如 EfficientNet 这样的深度学习模型可以被训练来分类和检测作物/植物疾病。
Plantix 是一个很棒的应用程序,可以将你的智能手机转换成作物医生,可以在几秒钟内检测出作物中的病虫害。除了检测之外,它还提供处理作物的解决方案(图 9 )。
挑战
不确定因素
在农业领域部署人工智能模型最具挑战性的部分是确保该模型能够适应不断变化的环境条件。大多数农业活动都有内在的不确定性,因为降雨、湿度、阳光、温度和水的可用性等因素是我们无法控制的。因此,对于深度学习模型来说,看似优秀的解决方案可能并不是最佳的,因为外部参数的变化。
数据成本和稀缺性
人工智能系统需要大量的监督数据来进行精确的预测。就农业而言,尽管可以快速收集空间数据,但由于其季节性,时态数据很难管理。例如,特定作物的数据只能在作物生长的一年中获得一次。这种限制使得在合理的时间内产生鲁棒的深度学习模型具有挑战性。
此外,农业数据分散在数百万个没有通过中央系统连接的农场中。这使得收集不同的样本变得困难。解决这个问题的一个方法是使用卫星图像数据。然而,这将不得不处理隐私问题,因为农民必须首先提供同意。
错误的代价
一个错误的建议或预测在农业上的成本会有很高的反响。它与客户服务和信息技术等其他领域非常不同,在这些领域,不正确的预测不会产生很大的影响。然而,遵循一个错误的建议可能意味着损失整整一年的作物产量,直接影响农民的生活和全球粮食安全。解决这个问题的一个方法是在将人工智能系统部署到整个农场之前,先在一小部分农民的土地上进行实验。
另一种处理方法是通过概率方法。在概率模型中,预测由概率分布表示,预测旁边是统计置信区间。在发布预测时,模型会考虑其可信度。如果可信度不高,预测将被丢弃,从而将与人工智能解决方案规定的变化相关的风险边缘化。
漫长的领养过程
农民不精通技术,这意味着他们必须完全依赖第三方来理解和分析人工智能系统给出的建议。这使得他们一开始不愿意采用这项技术。一个简单的解决方案是为他们提供更简单的技术,比如农业交易平台。一旦他们理解并习惯了这些简单的解决方案,通过研讨会向他们提供人工智能功能将是合理的。
汇总
农业部门是任何经济的基础。随着人口和粮食需求的增加,农民被迫采用人工智能(AI)等创新方法来保护和增加作物产量。因此,人工智能有可能改变我们对农业的看法,如下所示:
- 农业:计算机视觉模型可以使用牛、猪、羊和鸡等动物的闭路电视饲料,通过房屋管理自动化、行为分析、疾病估计、重量测量、鸡蛋检查、鱼类检测、识别、计数等提供有价值的见解。
- 产量估算:深度神经网络可以提供鲁棒(树叶、树枝、光照等造成的遮挡。2)通过图像/视频馈送计数水果、蔬菜和花的数量来预测产量。
- 产量最大化:ML 模型可以预测给定作物的价格弹性曲线,这可以帮助农民预测价格,并为农业企业每年节省数百万美元的收入损失。
- 安全监控:人脸识别系统可以识别大型农场中的入侵和异常情况,并向农民发送警报以采取适当的行动。这有助于避免家畜和野生动物毁坏庄稼和牲畜的风险。
- 健康监测:可以监测叶子和果实中任何可能破坏作物产量的传染性疾病。计算机视觉算法可以分析树叶的颜色和斑点的存在,以区分它们与健康的树叶。
- 杂草管理:计算机视觉系统可以分析无人机饲料,从作物中分割杂草,并通过激光和喷雾在线清除杂草。
然而,在农业领域使用人工智能也带来了挑战:
- 最具挑战性的部分是确保模型能够适应不断变化的环境条件,如降雨、湿度、阳光、温度和水的可用性,这些都是我们无法控制的。
- 由于农业的季节性,时态数据很难管理。
- 一个错误的建议可能意味着一整年的作物产量损失,直接影响农民的生活和全球粮食安全。
- 采用是困难的,因为农民必须依赖第三方来理解和分析人工智能系统给出的建议。
我希望这篇文章能帮助你理解在农业领域使用深度学习的好处、应用、挑战和权衡。请继续关注另一堂课,我们将讨论深度学习和计算机视觉在电力方面的应用。
引用信息
Mangla,P. “计算机视觉和农业深度学习”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/tqlmn
@incollection{Mangla_2022_CVDL4Agri,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Agriculture},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/tqlmn},
}
面向银行和金融的计算机视觉和深度学习
原文:https://pyimagesearch.com/2022/07/20/computer-vision-and-deep-learning-for-banking-and-finance/
目录
面向银行和金融的计算机视觉和深度学习
银行是任何经济体的金融支柱。作为主要的信贷提供者,它们通过提供和管理短期和长期融资来帮助企业、机构和个人。在过去几十年中,全球银行经历了一场数字革命,为人工智能(AI)的采用奠定了基础。因此,金融机构已经开始使用人工智能来改善客户体验,管理投资组合和风险,增强数据安全性,并提供良好的贷款。
根据 Business Insider 的报道,大约 90%的银行知道在他们的运营和服务中使用人工智能的好处。此外,他们中的许多人(约 75%)已经开始在实施和部署人工智能解决方案方面进行巨额投资。
这个系列是关于工业和大企业应用的计算机视觉(CV)和深度学习(DL)的。此外,本博客将涵盖在银行和金融领域使用深度学习的好处、应用、挑战和权衡。
本课是 5 课课程中的第 3 课:工业和大企业应用 101 的 CV 和 DL。
- 面向政府的计算机视觉和深度学习
- 【计算机视觉与深度学习】为客户服务
- (本教程)
- 用于农业的计算机视觉和深度学习
- 计算机视觉和电力深度学习
**要了解计算机视觉和深度学习对银行和金融的影响, 继续阅读。
面向银行和金融的计算机视觉和深度学习
好处
以下是将深度学习用于银行和金融的一些好处。
降低成本
人工智能可以帮助自动化银行工作流程和操作,以帮助比人类更高效、更准确地执行重复性任务。这使得该系统更具成本效益,更不容易出错。此外,基于人工智能的服务可以全天候提供客户支持,并降低人工代理的相关成本。
根据 Business Insider ( 图 1 ),通过使用人工智能应用,到 2023 年,银行将节省约 4470 亿美元。前台和中台将占 4160 亿美元。根据 TCS research ,“银行和金融服务高管发现,对人工智能的投资帮助他们降低了 13%的生产成本。此外,高管们报告称,他们的人工智能计划领域的平均收入增长了 17%。”
客户支持
银行应用中的人工智能帮助客户解决他们的问题,即使是在周末和节假日。基于人工智能的虚拟助理和聊天机器人为信用报告、贷款要约、支付警报、欺诈活动、财务摘要和客户分析提供个性化内容(例如,美国银行的 erica 虚拟助理,见图 2 )。
增强安全性
欺诈活动在银行和金融领域非常突出,旨在愚弄人类。然而,人工智能算法可以以更高的准确性检测到这些欺诈活动。此外,这些算法通过监控电汇、防止非法交易、检测洗钱以及通过观察客户行为和模式实施金融犯罪,帮助银行确保法规合规性。
更好的决策
人工智能帮助银行做出更好的决策,以提供安全和有利可图的贷款并管理投资组合。目前,银行使用信用评分、信用历史和客户参考来确定客户的信用度。人工智能可以观察客户的行为和模式,以确定信用历史有限的客户是否可能成为良好的信用客户。
应用
投资组合管理
AI 在银行业最好的优势之一就是投资组合管理。此外,先进的人工智能技术可以让一切触手可及,不再需要亲临银行。
AI 算法可以对从年报、新闻文章、Twitter 帖子和经济报告中提取的文本进行基本面分析。这些算法可以发现各种资产类别之间隐藏的相关性,并利用一系列金融或公司层面的变量准确定位表现良好的股票。LASSO regression/framework例如,还可以调查在所有其他市场或行业中,哪个国内行业或市场回报是最重要的回报预测指标。
基本面分析的结果可以优化金融投资组合中的资产配置。例如,人工智能技术通常比更传统的方法提供更好的回报和协方差估计。此外,与使用传统方法创建的投资组合相比,它们可以帮助构建更符合绩效目标的投资组合。例如,遗传算法可以解决带有约束的复杂优化问题(例如,限制资产数量或设置最小持有阈值,参见图 3 )。
风险管理
有两种类型的风险管理:市场风险和信用风险。市场风险是指由于市场波动造成损失的可能性。相反,信用风险是指交易对手不履行其合同义务导致价值损失的风险。
风险管理是人工智能可以超越的另一个领域。人工智能技术可以整合来自新闻报道、在线帖子和金融合同的定性和定量数据,以预测风险变量,验证并使用它们来最小化风险,并确保客户可以接受绝对风险(图 4 )。
市场风险: 卫星图像正在被分析,以预测超市的销售或未来的农作物收成。无监督的人工智能方法可以通过评估模型生成的所有预测来检测风险模型输出中的异常,自动识别任何异常,并监督人工智能技术来创建基准预测,作为模型验证实践的一部分。比较模型结果和基准预测将表明风险模型是否产生与人工智能显著不同的预测。
信用风险:资产经理需要监控个人及其交易的整个投资组合的信用风险。该实践包括对与发行金融产品(如股票、债券、互换和期权)的机构相关的偿付能力风险进行建模。多元判别分析、logit、probit 模型、支持向量机(SVMs)、遗传算法、深度神经网络(DNNs)以及它们的集成被广泛用于信用风险建模。
金融机构(例如,摩根大通、美洲银行、摩根士丹利和 S&P 环球)使用 Kensho ,该公司提供结合云计算和自然语言处理(NLP)的分析解决方案。因此,该系统可以用简单的英语回答复杂的金融问题。同样, Ayasdi 为企业了解和管理风险提供内部反洗钱(AML)解决方案。
诈骗安全
银行和金融机构非常容易进行欺诈活动。因此,拥有一个安全可靠的系统来保护客户的利益变得至关重要。因此,金融机构必须密切监控潜在的欺诈方案,包括电话/短信欺诈、使用网上银行的非法汇款和非法股票交易。最常见的欺诈活动包括:
- 未授权交易:客户不批准或不知道的交易。根据福布斯报道,大约 80%的手机银行用户担心信用卡诈骗。
- 网络钓鱼诈骗:那一年通过电子邮件和手机短信进行的网络钓鱼诈骗超过 5400 万美元。
- 身份盗窃:根据 Javelin 的 2021 年身份欺诈研究,2020 年身份欺诈造成的总经济损失约为 130 亿美元。
大多数欺诈检测系统使用基于规则的算法在“支付金额”和“存款数量”等条件下触发警报然而,这种模糊的规则可能会导致误报和不必要的警报,增加工作人员的工作量。为了提高效率,人工智能可以学习欺诈监控人员过去做出的判断,并根据相似的模式自动过滤掉误报。这些算法考虑了交易金额、时间、用卡频率、购买的 IP 地址等变量。(图 5 )。
Vectra 是一个由人工智能驱动的平台,可以自动进行威胁检测,发现明确以金融机构为目标的隐藏攻击者。 Shape Security ,另一个人工智能支持的服务,通过精确定位虚假用户,提供针对信用申请欺诈、凭据填充、刮擦和礼品卡破解的安全保护。
监管合规
银行和金融机构必须遵守银行业监管机构制定的合规规则。不遵守这些规则可能会导致罚款和吊销银行执照。此外,合规性规则会经常发生变化,在此期间,银行需要改变和更新其工作流程以符合新的法规。在此期间,他们也容易受到网络和欺诈攻击。
基于人工智能的软件可以帮助银行确定哪些合规规则是相关的,以及哪些工作流程和服务受到影响并需要更新。此外,NLP 可以通过分析和分类文档并提取有用的信息,如可能受监管变化影响的客户信息、产品和流程,使金融机构和客户了解最新的监管变化(图 6 )。
Quill 提供了一项基于自然语言处理的服务,它可以自动选择一个数据图表,并生成几个句子来解释这些见解。Quill 生成的可疑活动报告(银行和金融机构需要向监管机构提交的强制性报告)足够强大,可以确保银行保持合规。
进行监控,另一个 NLP 工具,可以分析已被记录的人工代理对话,以确定银行员工在与客户互动时的行为是否合规。
贷款和信贷决策
提供安全、有信誉和有利可图的贷款对银行的运转至关重要。目前,银行业过于局限于使用信用评分、信用历史和客户参考等变量来确定寻求贷款的客户的信誉。然而,使用人工智能和机器学习(ML)模型,银行可以利用其他非传统来源,如银行交易、投资和纳税申报表,来更好地确定客户的信誉、贷款限额和定价(图 7 )。
信用资格: 多年来,基于规则的算法(例如,逻辑回归)一直被用于确定客户的信用度。然而,这些天来,大型银行和金融机构已经开始构建复杂的模型,能够分析从社交媒体、浏览历史、电信等收集的结构化和非结构化数据。端到端自动化系统提供了个人违约的可能性。此外,银行可以通过将计算机化系统与人工审查(针对高风险信贷)相结合来完善其资质模型。
限额评估: AI 和 ML 算法可以确定一个客户可以借款的最大额度。系统利用损益表、纳税申报表、月度和年度支出以及客户投资来确定客户的可支配收入和定期贷款支付能力。
定价: 银行根据客户的信誉和最高贷款限额有效地决定利率。这有助于他们提供有竞争力的利率,降低风险成本,并优化贷款组合中总资产规模、风险和利息收入的平衡。
像 Enova 和 Ocrolus 这样的平台正在利用人工智能和人工智能来分析个人的银行对账单、工资单、税务文件、抵押表格和发票,并为企业和银行提供高级分析,以促进安全贷款。
肯尼亚的一家初创公司 mSurvey 正在使用手机应用程序收集必要的数据,为客户提供和建立实时档案。AI 和 ML 算法可以很容易地利用这种实时性来确定它们的信用度。
流程自动化
日常银行工作包括:
- 填写表格(例如,信用卡、申请表、银行开户等。)
- 交换中支票
- 了解你的客户
- 消除客户疑虑等。
使用基于人工智能的服务,员工可以高效地完成平凡而耗时的任务。例如,银行应用程序经常要求客户自拍并提供身份证以执行 KYC 验证。该应用程序背后的人工智能算法会检查自拍是否与身份证的照片匹配,同时验证身份证不是假的。
Arya.ai ( 图 8 )使用 6 种不同的人工智能模型自动进行支票处理和清算,用于各种领域,包括日期、磁性墨水字符识别(MICR)、文字和数字金额、账号以及签名提取和验证。在标准的生产基础设施上,它每秒可以处理 15-20 张支票。
Adobe 自动化表单转换服务使用深度学习将 PDF 表单转换为设备友好、响应迅速且基于 HTML5 的自适应格式,以消除基于纸张的表单,并使表单完成更具交互性。
挑战
AI 偏向
当人类在阅读/注释数据或建立机器学习管道时带来他们的假设时,人工智能偏见就会出现。一个有偏差的模型可以通过基于社会经济因素使其预测有偏差而严重影响信贷决策能力。偏置系统的直观方法是从数据中去除这些变量。然而,当您降低数据质量时,性能往往会下降。
调整算法是另一种方法,目的是惩罚模型参数,如果它们区别对待少数或受保护的类。例如,作为一种规范,可以使用不公平得分,它衡量属于其他阶层和风险状况的人的不同结果之间的差距。
可交代性
可解释性对金融机构来说至关重要,因为它们必须向潜在客户提供其信贷发放决策背后的逻辑原理。例如,想象一下,一个人收到了不良信用评分,在他最需要贷款的时候,他的贷款被拒绝了。仅仅说“是电脑干的”听起来不太好。此外,一个可解释的模型可以帮助银行代理人理解模型的决策是否因社会经济因素而有偏差。有时,使用大而复杂的模型来获得额外的分数并不是一个好主意,因为它们的可解释性很差。
客户不信任和数据安全
客户的不信任是在银行业采用人工智能的最大挑战。每个人对自己的血汗钱都有保守的一面,让他们接触黑盒算法对许多人来说似乎不是正确的选择。风险和投资组合管理中的任何错误都会让客户付出代价。此外,人工智能系统中的任何漏洞都可能泄露客户的机密和敏感数据。
图 9 提到了在银行业使用人工智能的另一个挑战。
汇总
金融机构已经开始以下列方式使用人工智能,以使其系统更具成本效益、更少出错和更安全:
- 投资组合管理: AI 算法可以对从年报、新闻文章、Twitter 帖子和经济报告中提取的文本进行基本面分析。这种分析也用于优化金融投资组合中的资产配置。
- 风险管理:人工智能技术可以整合来自新闻报道、在线帖子和金融合同的定性和定量数据,以预测风险变量,验证并使用它们来最小化风险,并确保客户可以接受绝对风险。
- 欺诈安全: AI 可以学习欺诈监控人员过去做出的判断,并根据相似的模式自动过滤掉误报。
- 法规遵从: AI 可以识别哪些遵从规则是相关的,哪些工作流和服务受到影响,需要更新。NLP 可以提取受法规变化影响的有用信息。
- 贷款和信贷:人工智能和 ML 模型可以利用非传统来源,如银行交易、投资和纳税申报单,来更好地确定客户的信誉、贷款限额和定价。
- 流程自动化:借助基于人工智能的服务,员工可以高效地完成日常且耗时的任务,如填写表格(如信用卡、申请、银行开户等。)、清算支票、处理 kyc、消除客户疑虑等。
然而,在银行应用中使用人工智能也带来了挑战:
- 一个有偏差的模型可以通过基于社会经济因素使其预测有偏差而严重影响信贷决策能力。
- 可解释性对金融机构来说至关重要,因为它们必须向潜在客户提供其信贷发放决策背后的逻辑原理。
- 每个人对自己的血汗钱都有保守的一面,让他们接触黑盒算法对许多人来说似乎不是正确的选择。
- 人工智能系统的任何漏洞都可能泄露客户的机密和敏感数据。
我希望这篇文章能帮助你理解在银行和金融领域使用深度学习的好处、应用、挑战和权衡。请继续关注另一堂课,我们将讨论深度学习和计算机视觉在农业中的应用。
引用信息
Mangla,P. “银行和金融的计算机视觉和深度学习”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/up7ad
@incollection{Author_2022_BF,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Banking and Finance},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/up7ad},
}
用于客户服务的计算机视觉和深度学习
原文:https://pyimagesearch.com/2022/07/06/computer-vision-and-deep-learning-for-customer-service/
目录
计算机视觉和深度学习为客户服务
为了在当今竞争激烈的市场中脱颖而出,通过提供最好的产品和服务来留住您的客户至关重要。根据微软 2017 年的一份报告 ( 图 1) ,大约 55%的客户因为糟糕的客户体验而停止了与分支机构的业务往来。
人工智能(AI)提供了具有成本效益的解决方案,以增强业务流程并提供更令人满意的客户服务。云服务(如 Google、AWS 和 Azure)进一步简化了基于人工智能的 API 与移动或桌面应用程序的集成,加快了其在大型企业和行业中的采用。
根据 Zoominfo 的数据,80%的销售和营销领导者表示,他们已经在客户体验中使用人工智能,特别是聊天机器人软件,或者在 2020 年之前已经这样做了。Juniper Research 预计,到 2022 年,聊天机器人将每年节省超过 80 亿美元的成本。
本系列是关于工业和大企业应用的 CV 和 DL。此外,本博客将涵盖使用深度学习为客户服务的好处、应用、挑战和权衡。
本课是 5 课课程中的第 2 课:工业和大企业应用 101 的 CV 和 DL。
- 面向政府的计算机视觉和深度学习
- 【本教程】
- 面向银行和金融的计算机视觉和深度学习
- 用于农业的计算机视觉和深度学习
- 计算机视觉和电力深度学习
了解计算机视觉和深度学习为客户服务, 继续看。
计算机视觉和深度学习为客户服务
好处
以下是使用深度学习进行客户服务的一些好处。
提供高级个性化
人工智能算法可以评估过去与潜在客户的互动,并使用这些有价值的信息为客户提供个性化服务。这让顾客参与进来,感觉被倾听,更有价值。如果顾客高兴地离开,很可能会增加企业的销售额和品牌价值。
相反,传统的非人工智能算法无法实现这种程度的个性化。在大多数情况下,代理必须在系统之间复制详细信息,并手动交互体验。这样的过程经常导致错误和数据丢失。
更快更划算
在追求更好的客户服务时,需要考虑的一个重要因素是等待和响应时间。如果有一件事是顾客普遍讨厌的,那就是被迫等待——尤其是当他们需要帮助的时候。由于劳动力有限,基于代理的客户服务通常等待时间很长。这也会导致响应时间延迟。
随着基于云的人工智能算法越来越有效,客户的查询现在可以立即得到解决。此外,自然语言处理(NLP)工具可以帮助系统理解语言,比人类代理更快更有效地解决问题,并节省成本。
根据 Juniper Research 的数据,聊天机器人的互动为银行和医疗保健部门节省了 4 分钟和 0.70 美元。
提高客户分析能力
当客户需要帮助时,机器学习算法提取用于做出未来预测的数据。这可以确保他们在销售过程中不会遇到任何麻烦。
此外,该算法可以识别个性化广告活动中可以利用的趋势。例如,如果你知道购买你的花瓶的顾客中有 85%是 55 岁以上的人,你可以开始向 55 岁以上的人推销这些花瓶,并希望看到利润增加。
应用
邮件支持
电子邮件可能会花很多时间来阅读和理解客户想要什么,以及公司可以如何帮助他们。此外,如果电子邮件没有发送给正确的人/机构,则必须手动将其转发给适当的机构,这可能会进一步延迟响应。
人工智能可以通过扫描和标记电子邮件,将邮件发送给正确的机构或个人,从而显著缩短响应时间。它还可以提供自动化的建议、参考、解决方案等。写一份适当的回答客户询问的草稿。随着人工智能算法的发展和从更大的数据集学习的能力,它们也可以用于为呼叫中心的工作人员提取电子邮件草稿的一部分。
DigitalGenius ( 图 3) 提供这种解决方案作为他们的主要客户服务产品。他们的技术可以扫描和标记电子邮件,并将其发送给正确的人。这为人类提供了过去解决过的类似问题,使得回复更加快速有效。
学生准备公司 Magoosh 利用 T2 的 DigitalGenius 解决方案改善了它的客户服务团队。Magoosh 将其对客户端查询的响应时间缩短了近 50%。现在他们可以在 24 小时内回复每个客户。此外,DigitalGenius 表示,超过 83%的电子邮件可以通过他们的解决方案进行分类和标记。
优步的客户痴迷票务助手(COTA) ( 图 4) 为遍布全球 400 多个城市的平台上每天浮现的数千张门票提供最精准的解决方案。COTA 通过自然语言处理“理解”该票据,然后将该票据路由到适当的团队。
机器学习算法为人类客户代理确定排名前三的解决方案,然后他们挑选他们认为最可行的推荐解决方案。这是向客户建议的解决方案。据优步称,多亏了 COTA,更好的票务路线将效率提高了 10%。
聊天机器人和助手
聊天机器人被放在公司网站上。公司可以在一天中的任何时间使用应用程序来解决简单和常见的客户查询(工作时间以外,当官方代表离线时也是如此)。配备基于人工智能的算法的机器人可以理解自然语言,并分享适当的回应,或者在没有答案的情况下将客户路由到适当的机构。
好的一面是聊天机器人有这样的互动。因此,它的反应会更准确。此外,从客户那里收到的反馈使聊天机器人能够改进其性能。
IBM Watson Assistant ( 图 5) 是一个低代码的可视化构建器,允许任何人在不编写代码的情况下构建强大的 AI 机器人。除了回答问题之外,该助理还可以与现有的客户服务无缝集成,以解决实际问题(例如,采购、日程安排等)。).沃森助手也足够聪明,可以记住以前的客户支持交互,并从以前的行为中获得洞察力。
互联网、电视和移动服务提供商 Optimum 使用基于聊天机器人的服务来处理客户发送的文字,并提取有助于理解如何最好地帮助客户的关键词。
数字助理(如 Cortona、谷歌助理、Siri、Alexa 等。)提供更个性化的体验,不应与聊天机器人混淆。聊天机器人模拟与代理的互动,而虚拟助理专注于客户旅程中的特定领域,以帮助客户。此外,通过使用自然语言处理,虚拟助理可以更人性化地做出响应。
语音识别
当问题非常复杂,无法通过电子邮件或短信解决时,就需要音频电话或语音帮助。此外,不同的口音、母语、噪音、糟糕的发音和未知的语音模式都会使语音辅助具有挑战性。
呼叫中心管理和呼叫路由中改进的语音识别人工智能算法可以为客户提供更无缝的体验,以及更高效的处理。深度学习算法可以分析音频来预测客户的情绪语调。如果客户对自动系统的反应是否定的,电话可以被转接到人工操作员和经理那里。
例如, Cogito (图 6) 已经使用行为科学和深度学习技术构建了一个可以实时分析对话的工具。他们的算法知道对话中的语气和内容。该工具基于音量和音高的变化以及模仿检测来洞察客户的感受。
这些信息可以帮助人工代表获得额外的信息、提高通话质量的提示以及关于他们表现的反馈。据 Cogito 称,回拨率下降了 10%,客户满意度增长了 28%。
个性化
人工智能可以使用实时数据来提供个性化的内容、产品和服务,从而为客户提供附加值。启用个性化可以帮助企业增加收入,因为客户可能会购买对他们有价值的产品和服务。此外,通过为每位客户提供独特的旅程和体验,它有助于留住客户。
根据埃森哲的一份报告,41%的美国消费者因为缺乏个性化和信任而放弃了一个品牌。然而,个性化在许多领域都很有用:
产品推荐: 亚马逊通过机器学习向客户推荐他们可能喜欢的产品。这为客户提供了个性化的体验,并带来了愉快的体验。该算法使用过去的客户订单和他们的浏览历史来提出建议。
基于位置的产品推荐: 家得宝利用人工智能根据购物者的位置提供本地化的设计趋势和产品。例如,西海岸的客户收到的建议与东海岸的客户不同。
艺术作品个性化 : 网飞使用艺术作品个性化 ( 图 7) 算法为每部电影或连续剧标题显示个性化的视觉效果。例如,那些倾向于观看某种类型或演员的电影的人可能会看到反映该类型或演员的图像。
分析学
通过客户与上述服务的交互收集的大量数据可用于得出有用的见解和模式。公司使用机器学习来发现数据中的趋势,发现客户的兴趣和行为,并对其进行分析,以对其服务和产品进行必要的调整,从而更好地服务于客户。据 Gartner 称,到 2040 年,40%的客户体验项目将使用数据分析。
例如,加拿大航空使用机器学习算法来研究在线预订期间与客户发起的数千次对话,以及存储在他们服务器上的用户会话。因此,该公司可以通过查看客户的投诉来确定他们的在线预订平台以及最有问题的设备和浏览器的问题。正因为如此,他们能够快速确定这些问题的优先级并加以解决,并节省客户支持的人力成本。
Easyjet 根据顾客过去的预订和旅行,使用顾客数据向顾客建议他们下一步想去哪里。度假租赁公司 Twiddy ,通过分析季节趋势和房屋的大小/位置,向房主提供定价建议。他们还分析租赁量和需求如何每周变化,从而为客户提供有用和可操作的信息。
微软的 Dynamics 365 客户服务洞察 ( 图 8) 在 NLP 中使用先进的 AI,通过帮助代理商和客户服务经理做出更好的决策来提高客户满意度。它提供了对客户满意度的洞察——增强分析和人工智能功能,以减少搜索时间,增加与客户互动的时间。
挑战与权衡
在客户服务应用中使用人工智能带来了挑战(图 9) :
整合问题与维护
将基于人工智能的工具与公司现有的基础设施相集成可能具有挑战性。收集历史数据的艰巨任务,托管复杂的云技术,高昂的维护成本,以及让他们足够聪明以从反馈和不断变化的环境中学习的需要,使整个过程变得复杂。
失业与升级
工作角色需要改变,因为这些基于人工智能的工具将把大部分工作从代理人手中拿走。这可能涉及代理学习新技能,以接管更多技术驱动的任务,而不是他们通常处理的电话查询。因此,必须进行许多投资,以提供适当的培训和举办实践研讨会。这可能会引起一些员工的不满,导致失业或减薪。
数据安全
人工智能系统接受了大量机密数据的训练。随着客户服务的自动化,系统中的任何突然违规都可能导致敏感客户信息的泄露。这对客户和公司都是有害的。在法律案件中,对它提出指控。
实施一个由人工智能支持的在线系统,通过 PCI(支付卡行业)合规性进行安全实践,可以帮助聚合成千上万笔交易的信息,并提前检测欺诈活动。因此,这些付款可以在发生之前消除,从而最大限度地降低泄露客户数据的风险。
缺乏情感和创造力
AI ≠人类。即使人工智能被训练得像人类一样,但它永远不会是一样的。它会像它的数据一样好,但永远缺乏人类的情感和创造力。并非所有的客户询问都是客观的。有些是主观的,涉及只有人类才有能力的创造性思维。制造人工智能驱动的客户服务将涉及让他们足够聪明,以解决新奇和开箱即用的查询。但是,人工智能缺乏这种技能,因为它系统中的一切都是按照指南进行连接的。
汇总
人工智能提供了具有成本效益的解决方案,以增强业务流程并提供更令人满意的客户服务。从数据中提取的数据机器学习算法可用于在客户需要帮助时做出未来预测。这些应用包括
- 电子邮件支持系统可以与基于人工智能的票务服务集成,该服务可以自动扫描和标记客户查询邮件,以将其定向到正确的部门或个人。
- 聊天机器人和虚拟助手可以用于公司的网站和应用程序,以解决和解决一般的客户查询和故障排除。
- 呼叫中心管理和呼叫路由中的语音识别系统可以为客户提供更无缝的体验,以及更高效的处理。这些系统可以分析音频来预测客户的情绪语调。
- 个性化的内容、产品以及定制和独特的服务可以帮助企业增加收入,因为客户可能会购买对他们有价值的产品和服务。
- 分析可以在通过客户互动收集的数据上运行,并可用于得出有用的见解和模式。公司使用机器学习来发现数据中的趋势,并发现客户的兴趣和行为。
然而,在客户服务应用中使用人工智能也带来了挑战:
- 收集历史数据、托管复杂的云技术、高昂的维护成本,以及让它们足够聪明以从反馈中学习的需求,使得整个集成过程变得复杂。
- 工作角色需要改变,因为代理需要额外的培训和研讨会来承担更多技术驱动的任务。
- 系统中突然出现的安全漏洞可能会泄露客户的机密和敏感信息。
- 让服务变得足够智能,以处理新颖和现成的查询是另一项具有挑战性的任务。
我希望这篇文章能帮助你理解在客户服务中使用深度学习的好处、应用、挑战和权衡。请继续关注另一堂课,我们将讨论深度学习和计算机视觉在银行和金融领域的应用。
引用信息
Mangla,P. “用于客户服务的计算机视觉和深度学习”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/0r254
@incollection{Mangla_2022_CustomerService,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Customer Service},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/0r254},
}
电的计算机视觉和深度学习
原文:https://pyimagesearch.com/2022/08/24/computer-vision-and-deep-learning-for-electricity/
目录
计算机视觉和深度学习为电
普遍获得负担得起、可靠和可持续的现代能源是可持续发展目标(SDG)。然而,发电不足、输电和配电基础设施差、可负担性、不确定的气候问题、能源生产的多样化和分散化以及不断变化的需求模式正在给发电带来复杂的挑战。
根据 2019 年国际能源署(IEA) 的报告,8.6 亿人用不上电,30 亿人使用明火和以煤油、生物质或煤为燃料的简单炉灶做饭。结果,400 多万人过早死于相关疾病。
人工智能(AI)在降低能源成本、减少能源浪费以及促进和加速可再生和清洁能源在全球电网中的使用方面具有巨大潜力。此外,它还有助于改善电力系统的规划、运行和控制。例如,通过广泛安装智能电表和传感器创建的嵌入信息层的智能电网允许数据收集,这些数据用于构建人工智能算法(图 1) 。
这个系列是关于工业和大企业应用的计算机视觉(CV)和深度学习(DL)的。此外,本博客将涵盖电力(电力部门)使用深度学习的好处、应用、挑战和权衡。
本课是关于工业和大型企业应用 101 的 CV 和 DL 的 5 部分系列的最后一课。
要了解计算机视觉和深度学习对于电, 只要坚持阅读。
计算机视觉和深度学习为电
好处
效率
深度学习算法通过试错来学习。当对能源模式进行训练时,这些算法可以提高电力生产效率。例如,在挪威, Agder Energy 与 Agder 大学合作开发深度学习算法,以优化水电厂的用水。尽管水似乎是无穷无尽的能源,但只有有限的一部分可以用来发电。
可靠性
人工智能可以预测电力需求和供应,储存低需求时期产生的多余太阳能/风能/水能,并在高需求时期使用。这可以通过分析大量的气象数据并使用这些数据来预测是否收集、存储或分配电力,从而提高太阳能和风能的可靠性。此外,AI 还可以在间歇性机组被吸收之前和之后进一步探索电网,并从中学习,以帮助减少拥堵和可再生能源削减。
不确定的气候因素也破坏了电力生产的可靠性。一般来说,各国都有收集了 40 多年的可靠电力生产数据,这些数据可以输入到深度学习模型中,以预测电力生产。
**如今,断电和盗窃问题非常普遍。通过数字电表收集并输入连接到人工智能服务的单个设备的日常功耗数据,可以识别和聚类与类似地区的客户档案相关的异常模式。这些数据预测客户行为,并预测哪些客户可能会非正式地连接到电网。巴西商业杂志exam将 Ampla 的防盗系统评为解决这一问题的顶级创新之一。
应用
故障预测与维护
设备故障是能源行业的常见问题,可能会造成严重后果。因此,它们的识别和维护至关重要。例如,配电网络中的故障可能由于闪电、绝缘缺陷、破坏、树枝和动物干扰导致短路而发生。在人工智能的帮助下,传感器可以监控设备并在故障发生前检测到故障,从而节省资源、金钱、时间和生命。
这些基于人工智能的故障预测系统可以与无人机结合,实现自动化维护(图 2) 。首先,AI 系统可以分析天气和需求预测,以生成无人机航班时刻表。然后,在飞行过程中,无人机将捕捉网络的高分辨率图像,这些图像将被发送到基于云的人工智能应用程序,以识别网络的健康状况,并将其分类为“正常运行”、“故障”或“次优运行”。结果,AI 应用程序生成资产检查报告,该报告可用于创建维护/维修工作单。
人工智能故障检测解决方案既经济又划算。这种解决方案有助于运营商确定整个系统的健康状况,以采取积极措施来防止灾难。例如,施耐德电气利用微软的机器学习能力,远程监控和配置石油和天然气领域的泵。因此,泵故障的早期检测可以节省高达 100 万美元的维修成本。
地热能源是预测诊断使用大量数据来检测可能导致电厂关闭的问题的另一个例子。使用物联网(IoT)和人工智能优化了避免涡轮机停机的化学剂喷洒等预防措施(数量、成分和时间)。
长短期记忆(LSTM)网络、支持向量机(SVMs)和主成分分析(PCA)广泛用于电力系统的故障检测。例如, Wang et al. (2019) 提出了一种基于堆叠稀疏自动编码器的网络,采用和 PCA 来演示其在真实世界数据中的应用。他们还使用基于人工神经网络(ANN)的方法来说明该模型在检测故障时间和位置时的有效性。此外, Shafiullah 和 Abido (2019) 提出了一种半监督 ML 模型,该模型由 K-最近邻(KNN)模型和决策树模型组成,用于处理标记和未标记数据。最后, Helbing 和 Ritter (2018) 通过在早期阶段检测故障来评估深度人工神经网络在风力涡轮机故障检测中的有效性。
高效决策
像 Alexa、Google Home 和 Google Nest 这样的智能设备可以帮助客户与他们的恒温器和其他电器进行交互,以监控他们的能耗。此外,配备自动电表的人工智能系统可以优化家庭的能源消耗和存储。例如,它可以在能源昂贵/有限时关闭电器,并在能源充足时储存电池(太阳能)。
通过利用电网数据、智能电表数据、天气数据和能源使用信息,AI 可以研究和改善建筑性能,优化资源消耗,并提高居民的舒适度和成本效率(图 3) 。此外,它可以提高电力预测需求和发电量,这将有助于向可再生能源的过渡,因为它们的生产率往往取决于天气、风力、水流、化石燃料等不一致的因素。此外,基于人工智能的预测与储能基础设施相结合,可以减少对这种备份系统的需求。
由于太阳能系统在家庭和工业中的使用正在显著增加,消费者将成为分布式网络的一部分,充当生产者并为发电做出贡献。在这样一个分布式生态系统中,人工智能可以预测分布式发电为电网做出贡献的最佳时间,而不是从电网中汲取资源(图 4) 。
此外,在像美国这样解除管制的市场中,人工智能可以根据消费者的能源偏好、预算和消费模式建议能源供应商,从而帮助消费者。例如,卡内基梅隆大学的研究人员创建了一个名为 Lumator 的机器学习系统,该系统可以获取客户的偏好和消费数据。该数据包含关于不同费率计划、限时促销费率和其他产品报价的信息,并为最合适的电力供应交易提供建议。
随着客户习惯的不断变化,当有更好的交易时,系统会自动切换到新能源计划,而不会中断供应。这些解决方案可以帮助消费者将他们对可再生能源的偏好转化为实际需求,从而有助于增加可再生能源的份额,并可用于向生产者传达消费者对可再生能源的需求水平。
能源交易
交易能源不同于交易商品,因为它必须即时交付。这对能源交易商来说是一个巨大的挑战。负荷预测帮助能源交易商和地区供应商计算发电量和能源价格。人工智能算法可以通过预测能源需求和提供实时能源价格来提高交易效率,这可以帮助交易者做出正确的买卖决定。这些算法可以通过消耗更多来自微观天气条件的数据、米级消耗数据和 Twitter ( 图 5) 等社交媒体帖子,做出更准确的预测。
当被问及人工智能和机器学习在能源市场的未来时,Inspired 的首席数据科学家 Larisa Chizhova 回答说:“我可以肯定,我们正在见证能源市场从人工到完全自动化的电子交易的过渡,类似于 10-20 年前在金融领域发生的事情。人工智能和机器学习的使用在这一转变中发挥了重要作用。作为人类,我们只能从我们看到的数据中得出很少的结论,我们很容易错过重要的趋势。在海量的交易、天气和负荷数据中寻找交易信号是机器要处理的任务。”
已经对 LSTMs 和 SVM 进行了研究,以实现单个家庭级别的负荷预测。然而,由于易变的用户行为,该方法利用历史负载和电器测量来提供比现有经典方法更好的结果。另一类称为自下而上分层方法的技术提出利用智能电表的新视角。K-means 聚类首先用于根据客户能源使用行为的相似性对客户进行分组。然后将深度神经网络(DNNs)用于不同的集群,最后,通过将所有集群的电力消耗相加来获得总负载。
概率预测提供了更多关于未来电力消费不确定性的信息。初始概率预测基于递归神经网络(RNNs)。在下一阶段使用 copula 模型来获得多元分布。该方法可以提供精确的预测分布;此外,产生的情景将有利于能源聚合商和贸易商。
结合点对点(P2P)区块链技术,人工智能可以帮助刺激电动汽车(EV)充电站的部署(图 6 )。在电动汽车所有者方面,人工智能技术可以帮助选择充电站的适用性和管理。相比之下,在充电站方面,基于区块链技术的平台可以实现充电站的发现和智能签约。AI 将通过请求基于区块链的充电平台来启动充电过程。该请求包含电动车位置、首选充电时间等。同时,充电站将不断向交易平台发送查询,以满足新的需求。匹配后,开始竞价过程,并重复直到价格匹配。最后,AI 在消费者的手机/平板电脑屏幕上显示路线图。电动汽车的所有者和充电站之间执行智能合同,其记录存储在区块链平台上。
非正式关系造成的损失
非正式电力连接造成的损失是电力部门面临的另一个挑战。全球每年因盗窃和欺诈电力造成的损失高达 960 亿美元,仅在美国就高达 60 亿美元。AI 可以分析客户使用模式、支付历史等方面的差异。,来检测这种非正式的联系。此外,当与自动化仪表结合使用时,它们可以改善监测。
例如,巴西正遭受高窃电问题的困扰。卢森堡大学创造了一种 ML 算法,可以通过分析电表信息来检测异常用电。当应用于来自 360 万巴西家庭的五年信息时,该算法产生了良好的结果。
目前,检测异常用电模式的最流行方案是从智能电网收集电力消耗数据,将它们上传到中央数据库,并通过智能算法进行分析。流行的反窃电算法包括聚类,它检测供电和计费功率不同的区域。K-means 聚类提取的典型负荷曲线实现了负荷预测(图 7 )。
然而,电力监控数据是动态的。因此,数据分析的难点在于从不断更新的动态数据流中发现异常数据,从而准确预测盗窃用户。rnn 可以有效地监控和分析时序动态数据流,通过将系统的当前状态数据与先前状态数据相结合来产生神经元输出。
西班牙公用事业公司 Naturgy 开发了一种基于人工智能的解决方案,用于检测其供电系统中的非技术性损耗(NTL)。该解决方案从历史活动中构建了一个“预测模型”,并为所有客户分配了一个分数,以便该实用程序可以检查具有高 NTL 可能性的案例。此外,检测设计的准确率为 36-50%,远高于人工规划的检测。
挑战
与应用人工智能技术的其他部门一样,电力部门也面临挑战(例如,治理、透明度、安全、保密、隐私、就业和经济影响)。
数据保护与安全
当连接到数字系统时,我们不断地与中央权威机构共享数据。任何系统漏洞都可能泄露机密信息,这些信息可能会被用来对付消费者(图 8 )。一次成功的网络攻击可能会像自然灾害一样具有破坏性。2015 年,世界上第一次成功的攻击发生在乌克兰,导致数千人断电。
网络安全对于保护人工智能电网不泄露客户数据正变得越来越重要。日益增长的黑客威胁已经成为一个令人严重关切的普通问题,主要是因为智能计量和自动化控制占全球电网投资的近 10%,相当于每年 300 亿美元用于数字基础设施。
耗电量
处理大量数据本身就消耗能量。因此,在电厂中使用基于人工智能的系统时,分析如何设计节能和气候中立的数据中心至关重要。此外,工程师应该记住数据中心和可再生能源发电厂的物理邻近性,以及当可用电力较少时电力密集型计算操作的延迟。
缺乏知识、数据和透明度
在农村和低收入地区,移动电话和数字技术的可及性有限。由于智能电表依赖于持续的数据通信,配备人工智能的电力系统的可靠性无法得到保证。此外,低通信意味着机器学习模型学习的数据不足,使它们容易受到不准确数据的影响。
此外,虽然人工智能在电力行业的应用是多种多样的,但有必要就电力行业的各个方面对人工智能行业进行更深入的教育(例如,电力行业使用基于云的应用程序的监管限制)。
汇总
由于不确定的气候问题、不断变化的需求模式、能源生产的多样化和分散化,能源部门面临着许多挑战。采用人工智能(AI)可以帮助能源部门降低成本和浪费,并通过以下方式加速可再生能源的使用:
- 故障预测和维护:在 AI 的帮助下,传感器可以监控设备并在故障发生前检测到故障,从而节省资源、金钱、时间和生命。这些基于人工智能的故障预测系统可以与无人机结合,实现自动化维护。
- 高效决策:像 Alexa 和 Google Home 这样的智能设备可以与客户的恒温器和其他电器进行交互,以监控他们的能耗。此外,配备自动电表的人工智能系统可以优化家庭的能源消耗和存储。
- 能源交易:人工智能算法可以通过预测能源需求和提供实时能源价格来提高交易效率,这可以帮助交易者做出正确的买卖决策。
- 非正式联系造成的损失: AI 可以分析客户使用模式、支付历史等方面的差异。,来检测这种非正式的联系。此外,当与自动化仪表结合使用时,它们可以改善监测。
然而,能源领域的人工智能也面临着挑战。
- 数据保护和安全:任何系统漏洞都可能泄露机密信息,这些信息可能会被用来攻击消费者。
- 功耗:处理大量数据本身就要消耗能量。因此,在电厂中使用基于人工智能的系统时,分析如何设计节能和气候中立的数据中心至关重要。
- 缺乏知识、数据和透明度:由于智能电表依赖于持续的数据通信,配备人工智能的电力系统的可靠性无法得到保证。此外,低通信意味着机器学习模型学习的数据不足,使它们容易受到不准确数据的影响。
我希望这篇文章能帮助你理解在电学中使用深度学习的好处、应用、挑战和权衡。请继续关注下一课,我们将讨论深度学习和计算机视觉在石油和天然气领域的应用。
咨询服务
你的人工智能工业应用需要帮助吗?了解有关我们的咨询服务的更多信息。
引用信息
Mangla,P. “计算机视觉和电力深度学习”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/p3ncy
@incollection{Mangla_2022_CVDL4Elec,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Electricity},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/p3ncy},
}
面向政府的计算机视觉和深度学习
原文:https://pyimagesearch.com/2022/06/22/computer-vision-and-deep-learning-for-government/
目录
面向政府的计算机视觉和深度学习
由于其从观察到的数据或行为中学习和预测的能力,深度学习已经彻底改变了大型行业和企业(图 1) 。根据 Yann LeCun 的说法,深度学习在行业中的影响始于 21 世纪初。那时,卷积神经网络(CNN)已经处理了美国大约 10%到 20%的支票。硬件(例如,GPU、TPU、云计算)的进步进一步促进了人们对将深度学习用于行业应用的兴趣。
政府部门可能是最大的部门,因为它的服务和政策会影响到公众。因此,政府机构大量投资人工智能(AI)以改善决策。深度学习使政府能够在降低成本的同时提高效率。这些应用包括识别逃税模式、跟踪传染性病例的传播、改善监视和安全等。
这个系列将教你工业和大企业应用的计算机视觉(CV)和深度学习(DL)。这个博客将涵盖在政府部门使用深度学习的好处、应用、挑战和权衡。
本课是 5 课课程的第 1 课:工业和大型企业应用 101 的 CV 和 DL。
- 【本教程】
- 用于客户服务的计算机视觉和深度学习
- 面向银行和金融的计算机视觉和深度学习
- 用于农业的计算机视觉和深度学习
- 计算机视觉和电力深度学习
了解计算机视觉和深度学习为政, 继续阅读。
面向政府的计算机视觉和深度学习
好处
在公共部门使用深度学习的好处有三方面:
- 运营效率: 德勤 ( 图 2) 据估计,自动化每年可以为美国政府雇员节省 9670 万至 12 亿小时,每年可能节省 33 亿至 411 亿美元。虽然这可能导致政府减少雇员人数,但他们可以被加强到更有回报的工作中,这需要横向思维、同理心和创造力。
- 改进的服务:由于人工智能系统可以提供个性化的内容,它们可以帮助政府向教育等领域提供更好的个性化服务。
- 更好的决策:由于政府每天都在收集大量的数据,他们可以使用深度学习来适当地分析这些数据,以改善他们的服务,做出更好的决策和政策,并节省成本。
应用
联邦网络防御
政府部门是最容易受到网络攻击的行业之一。根据一份报告显示,在过去的五年中,信息技术已经被确定为五个最受攻击的行业之一,另外三个是医疗保健、制造、金融服务和运输行业。黑客泄露机密数据和蓝图会危及整个国家的安全。图 3 显示了不同国家的网络事件报告。
随着攻击变得越来越复杂,政府必须拥有能够抵御此类攻击的技术。因此,人工智能在建立保护墙以阻止任何可能的数据和网络攻击方面有很大的作用。
人工智能可以绘制事件图,并使用数据模型来识别时间模式,并对新旧网络攻击进行分类,而无需任何更新。它可以监控网络点、电子邮件、用户行为和其他因素,以防止网络威胁,如网络钓鱼、社会工程、未经授权的访问、It 违规等。
最近, NVIDIA 和 Booz Allen Hamilton 联手打造机器学习和深度学习解决方案,以更快更有效地检测网络威胁。它首先从传感器技术中读取网络数据,对其进行处理,并使用人工智能实时分析数据。
它通过人工智能增强了已建立的网络防御,使用实时网络数据主动检测边缘或数据中心的敌对攻击。这使企业能够跟上不断发展的对手,减少纯人工智能防御工具中的误报,并在不彻底检查防御系统的情况下提高效率。
NVIDIA Morpheus ( 图 4) 是一个机器学习框架,可以识别、捕获新的或以前难以识别的网络威胁和异常,并采取行动。这些包括未加密数据的泄露、网络钓鱼攻击和恶意软件。它通过应用实时遥测、策略执行和边缘处理来分析安全数据,而不会影响成本或性能。
交通拥堵
**交通拥挤是许多城市地区的一个严重问题,并且很难预测。去年,英国的驾车者因道路拥堵损失了 178 个小时,人均损失 1317 英镑(1608.1 美元),使该国的整体经济损失近 80 亿英镑。
人工智能驱动的系统可以在很大程度上帮助减少交通流量。由于它考虑了道路、高峰时间和用户便利性等每个小细节,它可以帮助通勤者根据系统更新计划他们的旅程(图 5) 。
该系统可以分析
- 不同车道和区域的交通模式
- 分析有关路况和事故的关键信息
- 识别效率最低的车辆,跟踪它们的路径,并改变车辆前方的信号
这些好处可以帮助司机大幅减少通勤时间,提前规划行程,以避免交通拥堵,最大限度地降低油耗。
西门子移动最近建立了一个基于人工智能的监控系统,处理来自交通摄像头的视频。它会自动检测交通异常情况,并向交通管理部门发出警报。该系统有效地估计道路交通密度,从而相应地调整交通信号,以实现更顺畅的移动。
设计了一种新的机器学习算法 TranSEC 来解决城市交通拥堵问题。该工具使用通过优步司机和其他公开可用的传感器收集的交通数据,并随时间绘制街道交通流量。它利用国家实验室的计算资源,使用机器学习工具创建了一幅城市交通的大图(图 6)。
识别罪犯
随着面部识别系统日益完善,政府可以利用闭路电视(CCTVs)和其他来源的数据来识别嫌疑人可能出现的公共场所的在逃罪犯。
由于任何人都是由其独特的面部特征决定的,因此人工智能系统可以匹配任何查询图像并提供相似性得分。警方追踪罪犯首先需要将罪犯的图像输入人工智能监控系统。然后,相机会将它检测到的所有人脸与查询图像进行比较和分析,并返回可能的匹配。
总部位于印度的初创公司基于人工智能的人脸检测(ABHED) 开发了一个专有的人工智能技术栈,涉及高级图像分析、语言和文本无关的说话人识别引擎、面部识别和文本处理、命名实体识别和摘要 API。该应用程序可以集成第一信息报告(FIR)数据库和生物特征信息,包括语音、指纹和面部图像。这些算法可以在几毫秒内进行深度面部分析,准确率接近 95%。
该公司还开发了内置摄像头的智能眼镜(图 7) 。这款眼镜使用这家初创公司的面部识别技术来识别人群中的个人。当执法人员观察周围人的面部时,使用存储在数据库中的信息来识别面部,并实时显示在眼镜上。
刑事司法 DNA 分析
**刑事司法的另一个潜在应用领域是 DNA 分析。DNA 分析产生大量电子格式的复杂数据,其中一些可能超出了人类的分析能力。
锡拉丘兹大学的研究人员与奥农达加县法医科学中心和纽约市首席法医办公室法医生物学部门合作,研究一种基于机器学习的新方法混合物去卷积。该团队使用数据挖掘和人工智能算法来分离和识别个体 DNA 图谱,以最大限度地减少单独使用一种方法所固有的潜在弱点。
追踪疾病蔓延
COVID 告诉我们,传染病对全球人口健康的威胁是巨大的。重要的是在它变成疫情之前应对这些威胁。由于人工智能能够解决人类无法解决的问题,它为公共卫生从业者和决策者带来了巨大的潜力,可以彻底改变医疗保健和人口健康。
以下是政府可以利用人工智能防止传染病传播并采取积极措施的一些方法:
- 建立一个人工智能算法可以识别来自不同地点的具有类似症状的患者,并在事情变得严重之前警告他们。比如蓝点(图 8)。
- 构建一个图表,并使用图形神经网络等机器学习算法来识别与已知病毒携带者的接触。
- 建立一个系统,收集关于已知病毒、动物种群、人口统计和社会实践的数据,以预测新疾病可能出现的热点。这可用于采取主动措施,防止疫情爆发。
除此之外,政府可以从 Twitter 流中提取有意义的信息,如地缘政治事件和用户的反应,以跟踪和预测他们在疾病流行期间的行为。
公关
通过使用深度学习算法,政府可以更好地与公众互动;理解他们的疑问、要求和抱怨;获得反馈;并主动解决这些问题。深度学习的力量可以用来分析 Twitter、脸书和 LinkedIn 帖子,并识别与投诉、反馈或查询相关的帖子。
聊天机器人可以广泛应用于一些政府活动中。它们用于安排会议、回答公众询问、向政府内的适当部门直接提出请求、协助填写表格、帮助招聘团队等。
使用机器学习和深度学习改进语音到文本翻译系统,可以通过在公共服务环境中提供实时翻译来消除公民和政府官员之间的沟通障碍。
挑战与权衡
失业
失业和人工智能处于权衡之中。随着深度学习系统的使用增加,政府应该关注失业率的增加。为了减轻失业的潜在风险,政府应该重新雇用其雇员从事更主观、高价值、创造性的工作,或者转向私营部门。
根据欧洲委员会的欧洲晴雨表调查,该调查展示了欧洲公民对数字化和自动化对日常生活的影响的看法(图 9) :
- 74%的人同意,由于机器人和人工智能的使用,消失的工作岗位将多于创造的新工作岗位。
- 72%的人同意机器人和人工智能抢了人的工作。
- 44%目前工作的受访者认为他们目前的工作至少可以部分由机器人或人工智能完成。
公平性
深度学习模型和它的数据一样好,人是创造它的人。然而,算法的扭曲或人类解读数据的方式也可能导致偏差。
当涉及到受保护的个人类别或避免对受法律保护的类别产生不同影响时,确保在政府任务中部署的深度学习系统中做出无偏见的决策非常重要。在人工智能系统中建立公平性的关键步骤是评估公平性度量的模型。
也许确保公平的最佳方式是强制预测平等。预测等式意味着算法在如何为特定子群做出决策方面同样更好或更差。这意味着每组的假阳性或假阴性的数量成比例地相同。
以下是一些衡量和解决深度学习系统中公平性问题的方法。
-
故意视而不见是一种有意掩盖数据中的变量的方法,这些变量代表或关联到种族、性别、种姓和其他社会经济变量。它创建了一个算法,该算法仅仅是无意识的,而没有考虑任何公平性。
然而,公平是以降低性能为代价的,因为屏蔽变量降低了用于训练深度学习模型的数据质量。换句话说,一个模型可能对较大的群体是准确的,但对数据较少的群体的某些子集是不准确的。
-
人口统计和统计上的对等是确保人工智能算法公平性的另一种方式,在这种算法中,你从数据的少数和多数子集中选择相同数量的数据点。这确保了每个数据点在训练过程中获得相同的权重。另一种类似的方法是为不同的子集设置不同的阈值,以确保每个组的结果均等。
可交代性
人工智能可解释的决策系统可以鼓励他们的使用,因为利益相关者现在可以理解决策是如何和为什么达成的。
像公平和可解释性一样,也会导致性能的权衡。简单的体系结构和算法比复杂的体系结构和算法更容易解释,但是复杂的体系结构可能更准确,也更少偏见。图 10 说明了可解释人工智能的概念。
稳定
随着时间的推移,人工智能系统的性能可能会下降,因为它们是用几年前收集的数据开发的,不符合最新的场景。例如,在前 COVID 时代为跟踪和识别疾病传播而建立的系统现在可能已经不再适用。类似地,随着网络攻击的发展,几年后配备人工智能的网络防御系统可能不会那么有效。
应该用最近收集的数据点定期更新系统,以缓解这个问题。增量算法可以让系统更容易适应新数据,而不会忘记过去的数据。
为了估计算法退化的速度,可以在不同时期的回顾性数据上测试其性能。如果模型在一年前失效的测试数据上表现很好,但在两年前失效的数据上表现不好,那么在一年到两年之间重新训练模型可能有助于避免退化。
收养
采用人工智能给政府在应用程序中使用人工智能带来了困难的挑战。由于公共部门的员工年龄比私营部门大得多,因此实施文化变革更加困难。对失业的担忧使其更具挑战性。
由于政府对公众负责,评估人工智能算法性能的 KPI 比私营部门更主观,更复杂,更以活动为导向,私营部门主要受利润驱动。政府监察机构、工会和反对党是利益相关者,他们对人工智能的看法将决定公众如何看待政府中的人工智能。这可能会增加转型的难度。
汇总
政府正在大力投资深度学习,以创造更好的服务,为公众做出更好的决策,并大幅降低运营成本。这些应用包括
- 网络防御,人工智能可用于绘制事件地图,并使用数据模型来识别时间模式,并对新旧网络攻击进行分类,而无需任何更新
- 交通拥堵,深度学习算法可以分析交通模式、路况和事故,以帮助司机减少通勤时间,提前规划旅程
- 通过将罪犯的面部特征与查询图像进行匹配来识别罪犯
- 通过交叉检查具有相似症状的患者或预测新疾病可能出现的热点来跟踪传染病的传播
- 公共关系,政府可以更好地与公众互动,了解他们的疑问、要求和投诉,获得反馈,并主动解决这些问题
然而,在公共部门使用人工智能有其挑战和权衡:
- 随着深度学习系统的增加,失业率也在增加。
- 确保系统不偏向社会经济变量(如性别、种姓、种族等)。)
- 让系统变得可解释鼓励了他们的使用,因为涉众现在可以理解决策是如何和为什么达成的。
- 人工智能系统的性能随时间退化。
- 更难实施文化变革。对失业的恐惧使得这种采纳更具挑战性。
我希望这篇文章能帮助你理解在公共部门使用深度学习的好处、应用、挑战和权衡。请继续关注另一堂课,我们将讨论深度学习和计算机视觉在客户服务中的应用。
引用信息
Mangla,P. “政府的计算机视觉和深度学习”, PyImageSearch ,P. Chugh,R. Raha,K. Kudriavtseva 和 S. Huot 编辑。,2022 年,【https://pyimg.co/gratl
@incollection{Mangla_2022_Government,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Government},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/gratl},
}
面向医疗保健的计算机视觉和深度学习
原文:https://pyimagesearch.com/2023/01/02/computer-vision-and-deep-learning-for-healthcare/
目录
面向医疗保健的计算机视觉和深度学习
如今,几乎一半的世界人口无法获得适当的医疗保健,许多人因为高昂的医疗费用而陷入贫困。据估计,每年需要超过 1 400 亿美元才能实现与健康相关的可持续发展目标。此外,需要大量医疗技术、数字技术和人工智能(AI)投资来弥合新兴市场的医疗服务差距。
许多与健康相关的初创公司和技术创新者已经开始将人工智能与他们的产品和解决方案集成在一起,展示了改善诊断、降低成本和正确访问远程医疗服务的前景。新冠肺炎也加快了向数字健康应用过渡的步伐,包括那些集成人工智能的应用。
旨在整合人工智能技术的健康创业公司和科技公司在人工智能专用投资中占很大比例,2018 年高达 20 亿美元(图 1 )。这些投资从数字诊断到临床医生决策支持,再到精准医疗。埃森哲估计,美国的健康人工智能市场预计将以每年 40%的速度增长。
本系列是关于工业和大企业应用的 CV 和 DL。这个博客将涵盖在医疗保健中使用深度学习的好处、应用、挑战和权衡。
本课是关于工业和大企业应用 102 的 CV 和 DL 的 5 课课程中的第 4 课。
- 计算机视觉与石油天然气深度学习
- 用于交通运输的计算机视觉和深度学习
- 计算机视觉与深度学习用于物流
- (本教程)
- 用于教育的计算机视觉和深度学习
**要了解用于医疗保健的计算机视觉和深度学习, 继续阅读。
面向医疗保健的计算机视觉和深度学习
好处
解锁健康研究数据
医疗保健相关数据的数量正以指数速度增长。它具有巨大的潜力,可以被挖掘和分析,以促进更好和更个性化的护理,减少医疗差错,并实现早期疾病诊断。然而,在新兴市场拥有足够高质量和结构良好的数据具有挑战性。公司正在通过清理和结构化数据以及叠加分析来解决数据互操作性方面的弱点,以做出有意义的预测,从而改善健康状况。
除了为研究构建数据,机器学习(ML)可以将患者与临床试验相匹配,加快药物发现,并在应用于大数据时识别有效的生命科学疗法。例如, SOPHiA GENETICS AI 技术每 4 分钟计算一次基因组图谱。它已经分析了成千上万的基因组图谱,以便在他们的研究社区中将患者与临床试验相匹配。
医疗效率
软件即服务公司利用病历、会诊记录、诊断图像、公共信息和药物处方等数据来自动化多个工作流,如随访预约。这些服务通过解决寻找合适的提供商或专家的困难、服务质量缺乏透明度等问题,正在影响新兴市场。
例如,中国的平安好医生是最大的在线平台之一,它使用人工智能技术对患者进行预分类,以通过其内部医疗团队提供 24/7 在线咨询服务。
**由于医疗保健服务供应不足,新兴市场表达了参与数字医疗保健的强烈意愿,以获得健康相关问题的答案,诊断疾病并推荐治疗方法。这意味着大范围的数字健康解决方案可以降低患者细分的成本,尤其是在农村地区。
印度平台 DocsApp 开发了一个名为 CLARA 的临床人工智能平台,将患者与专家联系起来,并促进远程诊断和治疗。此外,潜在的患者将个人信息和健康问题输入到应用程序中。
机器学习使用公共数据源和客户信息来生成可能的诊断并推荐专家。然后,如果患者希望通过聊天或电话进行咨询,他们可以选择查看专家的用户评级和证书,并在线支付费用。在低收入和农村地区,通过短信接收建议是一个改变游戏规则的选择,在这些地区,视频咨询所需的 3G-4G 连接和智能设备普及率缺失或不足。
人工智能在医疗保健中的其他重要作用如图图 2 所示。
应用
医学遗传学和基因组学研究
人工智能可以通过分析和识别大型复杂数据集中的模式来帮助药物发现,将患者与临床试验相匹配,以及识别有效的生命科学疗法,从而使医学研究界受益。人工智能还可以帮助研究人员识别导致特定疾病的基因突变,并帮助预测治疗效果。例如,癌症研究所癌症数据库将来自患者的遗传和临床数据与来自科学研究的信息相结合。它使用人工智能来预测癌症药物的新目标。
基因组医学的进一步应用(如肿瘤诊断和管理)促进了“精准医学”的发展,这是一种数据驱动的治疗方法,考虑了基因、环境和生活方式因素的可变性,以实现个性化医疗护理(图 3 )。人工智能可以识别模式,并提供关于人类生理如何工作以及对不同化学物质、病毒和环境做出反应的见解。机器学习算法还可以识别 DNA 序列中的模式,并预测患者患病的概率。
这些算法可以设计潜在的药物疗法,识别疾病的遗传原因,并帮助理解基因表达的潜在机制。它们还被用于发现精神分裂症、双相情感障碍和抑郁症的生物标志物,以改善诊断或为未来的研究提供假设。人工智能还可以进行数据提取,搜索系统综述,评估健康技术。
人工智能支持的液体活检(图 4 ) 也使医生能够通过确定他们当前的治疗是最佳的还是替代治疗可能有益于患者,来更好地预测患者的结果。液体活检分析血液样本中的 DNA,消除了对侵入性方法的需求。一项这样的创新旨在预测癌症患者的复发,比目前的护理标准提前 7 个月。
人工智能还可以提高基因编辑的准确性(一种在细胞或有机体水平上改变 DNA 的方法)。在未来,使用大型数据集和机器学习可能会预测编辑 DNA 的最佳位置,以减轻次优的基因编辑结果,使研究人员能够专注于对患者风险较小的基因。编辑卵子、精子或胚胎基因组也可以预防疾病的遗传风险,从而降低出生前感染的风险。
临床护理
医学影像与放射学
机器学习和深度学习正在用于放射学(图 5** ) 以创建工具,这些工具可以改善癌症、乳腺癌和 CT 结肠成像中息肉检测的诊断和分类。此外,深度学习算法可以用速度和能力自动提取和分类图像,帮助使用 CT 和 MRI 的神经成像诊断中风。
基于超分辨率的人工智能算法也可以提高扫描的图像质量,由于管理中风患者的时间限制,扫描质量通常较低。当与 X 射线和 MRI 结合时,AI 可以自动描绘肿瘤并提高结核病诊断。配合正电子发射断层扫描(PET),可以辅助阿尔茨海默病的早期诊断。
AI 可以作为内窥镜检查中的决策支持工具,预测病变的病理,并防止非癌性息肉的不必要的息肉切除术。此外,医学成像的同时发展与旨在改善患者和临床医生安全以及患者体验的人工智能工具有关。这些应用包括使 CTs 能够在超低辐射剂量下进行的应用,可以在当前时间框架的三分之二内进行的 MRI 检查,以及使用放射性示踪剂剂量减少高达 99%的 pet。
病理学
数字病理学(图 6 ) 已经创建了大量数据来训练人工智能算法,这些算法可以识别模式,并帮助平衡世界上病理学家的短缺。为了帮助病理学家,人工智能可以用于
- 自动化复杂且耗时的任务,如对象量化、基于形态学的组织分类和目标识别
- 使用可用数据计算个性化治疗
- 将误诊和开错处方的风险降至最低
- 通过允许农村地区的医生咨询专门的病理学家来促进远程医学
- 通过人眼识别视觉上可辨别的标记(例如,肿瘤中的分子标记)
皮肤科
AI 可以支持皮肤科医生针对一般皮肤和特定癌症做出临床决策(图 7 )。这些应用大多数旨在诊断和预防皮肤病发作。这将最大限度地减少不必要的活检,并帮助临床医生协助检测皮肤病。这些人工智能算法学会区分恶性黑色素瘤和良性病变,同时识别有助于识别癌症的新病变特征,否则使用视觉诊断将难以确定。通过早期检测,机器学习可以分析皮肤痣的变化和发展。个人可以使用人工智能应用程序扫描他们的身体,以找到可疑的标记。AI 还用于诊断痤疮、银屑病、脂溢性皮炎和指甲真菌。
神经科
除了神经成像,AI 在神经科学中也有出色的应用,可以支持大规模的假设生成,并提供对大脑相互作用、结构和机制的见解(图 8 )。例如,这些算法可以通过区分正常休息和中风相关的瘫痪来识别中风的早期预警信号。他们还可以通过检查生理参数之间的模式来预测缺血性中风患者的 3 个月结果。
研究人员已经展示了人工智能评估帕金森病(PD)严重程度的能力。通过提供预后评估和预测结果,AI 也用于患有脊髓损伤的患者。此外,还开发了算法,提供关于患者特定运动缺陷的数据,用于机器人辅助康复装置,以帮助人们重新学习走路。它也被用于四肢瘫痪患者的电刺激系统,以恢复一些运动。
心理健康
心理健康对人类的正常运作很重要。由于其敏感性,当接受护理的人与医疗保健提供者互动时,管理精神健康更有效。自然语言处理(NLP)算法和机器学习可以收集和适应新的信息,这些信息可以帮助医疗保健提供商刺激参与者与临床医生的互动。对话代理、聊天机器人和虚拟助手可以模仿类似人类的存在。它们可以帮助提高在线支持社区的可搜索性,诊断重度抑郁症,并为抑郁症和焦虑症患者提供认知行为治疗。
这些虚拟代理人还可以在人类主持人不可用时充当青少年心理健康在线社区的主持人。这样的代理可以评估参与者帖子的情绪、情感和关键词,用于推荐适当的步骤和行动。
糖尿病
1 型和二型糖尿病在当今人群中普遍存在,正因为如此,关于血糖和趋势的大量数据是容易获得的。深度神经网络和支持向量机正在开发糖尿病前期筛查工具。该工具使用来自韩国全国调查的数据,该调查定义了 9 个变量,如家族史、腰围和身体活动,以预测糖尿病(例如,糖尿病视网膜病变,见图 9 )。
此外,人工胰腺系统正在探索人工智能,以支持将连续葡萄糖监测器连接到胰岛素泵的计算机程序。这确保了个性化的胰岛素输送,因为人工智能算法可以在不确定的环境中从数据中学习。例如,糖尿病可能会引发其他身体和心脏相关的疾病。人工智能也可以用来预测这些编译,而它们仍然是可治疗的。这些模型基于现有调查的数据进行训练,这些调查评估了 A1C 血红蛋白等风险因素之间的关系。
护眼
人工智能可以通过对患者进行护理点诊断来取代现有的视觉程序。深度学习正被用于区分健康的眼睛和患有年龄相关性黄斑变性的眼睛。它可以从视网膜眼底图像预测心血管疾病,自动分级年龄相关性黄斑变性,筛查青光眼,并诊断白内障。
挑战
图 10 列出了在医疗保健行业使用人工智能的相关风险和挑战。以下是最重要的。
监管摩擦
医疗保健是一个高风险的游戏,有充分的理由建立严格的监管框架。然而,在一些国家,提供诊断和治疗的虚拟护理的治理和法律框架未经检验或不完善。鉴于疫情期间远程医疗选项的紧迫性和必要性,新冠肺炎领导几个国家暂时取消了对远程医疗的限制,而其他国家则视而不见。
以患者数据为基础的人工智能创新还必须通过几项数据法规,从存储到安全性和互操作性。这在平衡患者同意、隐私和保护等高标准与对大型结构化数据集的需求之间形成了权衡,这些数据集用于培训新的人工智能应用程序,使医疗保健个性化、高效和预防性。
非代表性 AI:潜在偏差和误诊
正如前面所讨论的,医疗保健组织内部的隐私限制限制了可用于训练 AI 算法的结构化数据集的大小。此外,由于这一限制,所得数据无法跨市场进行缩放,因为不同种族的人群可能有其他疾病倾向。
此外,在临床诊断应用中使用机器学习有几个风险,研究人员仍在努力解决。将机器学习应用于临床医学的一些危险包括:
- 分布偏移是由系统训练的数据分布差异和操作中使用的数据分布差异引起的。随着时间的推移,疾病模式的变化会导致这种转变。此外,人工智能可能无法很好地处理稀缺或更难收集的数据,例如罕见的医疗条件和代表性不足的社区,如黑人、亚洲人和少数民族人口。
- 人工智能系统通常是黑盒决策者,很难或者不可能确定产生人工智能输出的底层逻辑。这给验证人工智能系统的输出和识别数据中的错误或偏差带来了问题。
- 对影响不敏感是一个系统,旨在以漏诊或过度诊断为代价做出准确的决策。这是一个人类临床医生被训练用判断来解决的困境。
- 有害的意想不到的后果是由只根据历史数据或使用不相关数据点训练的系统造成的,这些数据点错过了重要的预测因素,导致了遗漏或不准确的诊断或过度诊断。
对患者和医护人员的影响
人工智能系统可以限制基于风险或用户最佳利益的选择,从而对个人自主权产生负面影响。如果医疗保健专业人员无法解释人工智能系统如何做出诊断,这可能会削弱患者对系统的信任。旨在模仿人类/医生的应用程序将增加用户无法判断他们是在与自然人还是与技术交流的可能性。这可能被视为一种欺骗或欺诈。
另一方面,医疗保健专业人员可能会觉得,如果人工智能挑战他们的专业知识,他们的自主权和权威就会受到威胁。此外,医疗保健专业人员对个体患者的道德义务可能会受到人工智能决策支持系统的使用的影响。此外,随着人工智能的引入,专业人士可能不得不学习新的技能和专业知识。另一个担忧是,人工智能可能会让医疗保健专业人员自满,不太可能检查结果和质疑错误。
制度惯性
医疗创新的商业化需要监管和制度生态系统来促进与学术界、风险资本家、天使投资者和企业家的合作。其他地理上集中的投资流将意味着健康差距巨大的国家在开发和传播医疗保健选择的适当解决方案方面将面临更多障碍。
小型创新者必须与大型数字平台合作,利用现有的技术创新来促进医疗保健产品在新兴市场的传播。此外,金融机构和政府的发展需要通过鼓励最佳实践治理安排和将人工智能嵌入新的和现有医疗机构所需的人力资本投资,在分配中发挥重要作用。
汇总
在健康技术和人工智能方面正在进行重大投资,以通过以下方式弥合新兴市场的健康服务差距。
- 医学研究:人工智能可以通过分析和识别大型复杂数据集中的模式来帮助药物发现,将患者与临床试验相匹配,以及识别有效的生命科学疗法,从而使医学研究界受益。
- 临床护理:从放射学、医学成像、神经病学、糖尿病和精神健康,人工智能已经显示出有希望的结果。
然而,交通领域的人工智能也带来了挑战。
- 监管摩擦:医疗保健是一个高风险的游戏,有充分的理由制定严格的监管框架。然而,在一些国家,提供诊断和治疗的虚拟护理的治理和法律框架未经检验或不完善。
- 非代表性 AI: 有限的数据无法跨市场进行缩放,因为不同种族的人群可能有其他疾病倾向。这导致了一种转变,即 AI 可能无法很好地处理稀缺或更难收集的数据,例如罕见的医疗状况和代表性不足的社区(例如,黑人、亚洲人和少数民族人口)。
- 对患者和医疗保健专业人员的影响:人工智能系统可以根据风险或用户的最佳利益来限制选择,从而对个人自主权产生负面影响。如果医疗保健专业人员无法解释人工智能系统如何做出诊断,这可能会削弱患者对系统的信任。
- 制度惯性:地理上集中的投资流将意味着健康差距巨大的国家在开发和推广医疗保健选择的适当解决方案时将面临更多障碍。
我希望这篇文章能帮助你理解在医疗保健中使用深度学习的好处、应用、挑战和权衡。敬请关注最后一课,我们将讨论深度学习和计算机视觉在教育中的应用。
咨询服务
你的人工智能工业应用需要帮助吗?了解有关我们的咨询服务的更多信息。
引用信息
Mangla,P. “医疗保健的计算机视觉和深度学习”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2023 年,【https://pyimg.co/h52u4
@incollection{Mangla_2023_CVDLH,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Healthcare},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
note = {https://pyimg.co/h52u4},
}
面向物流的计算机视觉和深度学习
原文:https://pyimagesearch.com/2022/11/14/computer-vision-and-deep-learning-for-logistics/
目录
计算机视觉与深度学习用于物流
在当今竞争激烈的市场中,拥有高效灵活的供应链是一项重要的资产。因此,公司正在寻找优化供应链的方法,以帮助他们做出决策,提高运营效率和客户满意度,并减少对环境的影响。
据麦肯锡报道(图 1 ),人工智能将在 2030 年定义一种新的“物流范式”。它将在未来 20 年内每年产生 1.3-2 万亿美元的收入,因为它在重复但关键的任务上继续优于人类。在另一项类似的研究、中,麦肯锡报告称,通过使用人工智能,企业可以将物流、库存和服务成本分别降低 15%、35%和 65%。
本系列是关于工业和大企业应用的 CV 和 DL。这个博客将涵盖在物流中使用深度学习的好处、应用、挑战和权衡。
本课是 5 课课程中的第 3 课:工业和大型企业应用的 CV 和 DL 102。
- 计算机视觉与石油天然气深度学习
- 用于交通运输的计算机视觉和深度学习
- 【计算机视觉与深度学习】用于物流 (本教程)
- 用于医疗保健的计算机视觉和深度学习
- 用于教育的计算机视觉和深度学习
要了解计算机视觉和深度学习对于物流来说, 只要坚持阅读。
计算机视觉与深度学习用于物流
好处
丰富数据质量
机器学习和自然语言处理可以依靠每天涌入物流公司的海量信息。他们可以理解术语和短语,建立联系以创建一个能够在运输中实现最佳数据使用的环境,避免风险,创建更好的解决方案,最大限度地利用资源并削减成本。这些丰富的数据可以帮助物流公司了解所需劳动力和资产的准确数量,并帮助他们优化日常运营。
战略资产定位
2021 年,从中国运送一个标准的 40 英尺集装箱到美国东海岸要花费超过 20,000 美元。人工智能算法可以帮助规划者和物流公司安全地定位和保护他们的资产。这些算法可以通过减少空集装箱的装运和减少道路上的车辆数量来提高预测能力匹配的利用率。通过减少和重新安排运输到高需求地点所需的车辆,可以保证资产位置的效率和成本降低。
改进的预测分析
计算从 A 点到 B 点的单次运输的最佳运输需要通过数据分析、容量估计和网络分析进行排序。人脑几乎不可能完成这些操作,因为它们既费时又容易出错。这就是人工智能的预测能力发挥作用的地方。人工智能可以很容易地汇编准确的数据,结合外部因素,并执行所有这些逻辑程序,以估计即将到来的需求。这可以帮助物流公司在运输行业中获得竞争优势,并削减不必要的成本。
例如,国际运输领导者 DHL 使用一个平台来监控在线和社交媒体帖子,以识别潜在的供应链问题。他们的人工智能系统可以识别短缺、访问问题、供应商状态等。
图 2 展示了 AI 在供应链每一步的好处。
应用
预测和计划
人工智能支持的需求预测方法比 ARIMA(自回归综合移动平均)和指数平滑等传统预测方法更准确。这些方法考虑了人口统计、天气、历史销售、当前趋势以及在线和社交媒体帖子。改进的需求预测性能有助于制造商通过减少调度的车辆数量来降低运营成本,从而提高资产利用率。
通常有两种需求预测模型:中长期预测和短期预测。公司通常使用中期到长期的预算和计划来购买新资产(如仓库、车辆、配送中心等)。).这些预测的范围可以是 1-3 年。
但业内最广泛使用的预测是短期的,这极大地影响了运营规划,并提高了低利润率公司的底线。它们通常从几天到几周不等。例如,预测可以以超过 98%的准确率预测两周前的车辆需求/销售,以 95%的准确率预测六周前的需求/销售(图 3 )。
在需求预测的帮助下,公司可以确保手头有适量的材料,并计划他们的生产活动。结果可以与关于成本、容量等的其他相关数据相结合。此外,假设在供应链管理过程中出现任何问题(例如,客户决定不下订单)。在这种情况下,预测性解决方案可以通过在潜在问题发生之前识别它们并进行相应的调整来避免没有人想要的产品的过量生产。
为了预测未来一周的购买量, OTTO 开发了一种深度学习算法,分析了 30 亿条数据记录和 200 个变量,包括交易、OTTO 网站上的搜索查询和天气预报。因此,该系统对未来 30 天内将要出售的商品做出了 90%的预测。这帮助 OTTO 每月提前订购约 200,000 件商品,并在客户下订单时更快地一次性发货。
优化
路线优化:路线优化使最后一英里配送的成本合理化,这是物流行业的一项重大开销。AI 可以分析历史行程、现有路线以及地理、环境和交通数据,以使用最短路径图算法,并为物流卡车确定最有效的方式(图 4 )。这将减少运输成本和碳足迹。
Zalando 已经训练了一个名为 OCaPi 算法(optimal cart pick)的神经网络,它可以让员工之间的拣货工作更加有效,并加快拣货过程。该算法不仅考虑员工的路线,还考虑转盘运载器的路径,当员工从货架上收集物品时,转盘运载器有时会停在横向过道中。这样,它就能找到最短的路线。
成本和价格优化:根据需求和供应,商品价格会有所波动。基于过去关于销售、数量、市场条件、货币汇率和通货膨胀的历史数据,预测分析可以帮助公司最大限度地降低错误定价的风险。这些模型可以告诉公司是否应该降低价格或增加利润,帮助他们在市场中脱颖而出(图 5 )。
库存优化:库存优化帮助企业充分利用供应链。过多的库存而没有销售会导致贬值和损失——尤其是食品、药品等易腐商品。预测模型可以帮助组织始终保持正确的供应水平,从而降低投资成本和因生产过剩或库存不足造成的浪费。此外,这些模型可以使用有关客户行为和即将到来的事件(如假期)的历史数据来进行预测。
自动化仓库
**自动化仓储有两种类型:帮助搬运货物的设备和改善货物搬运的设备。在第一种类型中,自动导向车(AGV)可以实现箱子和托盘的移动。他们可以配备软件来改造标准叉车,使其实现自主。其他新技术,如 swarm 机器人(如亚马逊的 Kiva 机器人),可以帮助将货架上的商品移动到目的地和传送带上。此外,先进的自动化存储/检索系统可以在大型货架上存储货物,并有机器人穿梭器,可以使用连接到结构的轨道在三维空间移动。
比如零售巨头亚马逊2012 年收购 Kiva Systems,2015 年更名为亚马逊机器人。今天,亚马逊有 20 万个机器人在他们的仓库里工作。在亚马逊 175 个履行中心中的 26 个,机器人帮助挑选、分类、运输和装载包裹。
搬运设备可以自动进行货物的拣选、分类和码垛。他们通常有传感器,可以确定物体的形状和结构。然后,使用类似的 AI 算法,这些设备可以过滤掉任何不好的东西(例如,Magazino 的新 TORU cube )。甚至传送带也可以通过使用人工智能自动传感器来推进,这些传感器可以扫描包裹任何一侧的条形码,并确定适当的行动。
除了这些机器人机器,各种其他创新也可以提高仓库中人的生产率。
- 外骨骼可以通过手套或对腿部的额外支撑,用机械动力增强人类的运动。该系统允许人们移动更多的货物(例如,更重的物品)或者更有效和安全地移动货物。
- AI 可以通过会计信息(例如,产品尺寸、重量等)使用计算机视觉对库存中存储的商品进行自动分类和识别。).AI 可以在没有人类协助的情况下快速定位仓库中的这些物品。
- 如果人工智能机器人负责操作危险设备和储存库存,员工的安全将得到改善。计算机视觉算法可以跟踪员工的工作,监控各种安全问题,并识别任何可疑行为。
预见性维护
预测性维护(图 7 ) 涉及通过分析实时传感器数据来检测工厂机器故障。为了使预测性维护正常工作,传感器必须记录与部件运动相关的所有参数。例如,这些因素包括码头的打开和关闭事件、控制系统动作、压力缸和滚轮磨损。
下一步是规定维护(图 7 ) ,它包括根据对下一次故障、服务日期和时间、要供应的备件等的预测,主动安排非高峰时段的维护。该计划可能会影响相关设备的参数,从而使可能加剧损坏的动作不再以全功率执行。而是尽可能仔细地优化基础设施的使用,以便不在预定的维护日期之前触发故障。
此外,假设这是一种仅仅依靠传感器的情况是不正确的。现代传感器和传感器的链接使得检测不正确的传感器值以及人工智能结合其他测量值对这些值进行插值成为可能。然而,问题并不总是机器。传感器本身可能存在故障,但不一定会导致计划内停机。
后台及客户体验
后台运营:每个企业都有手工完成的后台任务。自动化人工智能解决方案可以应用于此类任务,以下列方式提高后台运营效率:
- 自动化文件处理:文件自动化技术可用于通过自动化数据输入、错误核对和文件处理来快速处理发票/提货单/价目表文件(图 8 )。
- 调度和跟踪:人工智能系统可以调度运输,组织货物管道,分配和管理不同的员工到特定的车站,并跟踪仓库中的包裹。
- 报告生成:机器人流程自动化(RPA)工具可以自动生成定期报告,分析其内容并通知利益相关者和员工。
客户体验:预测解决方案可以洞察客户的行为,从而帮助改善客户体验。他们可以确定客户下一步可能会购买什么,何时可以取消或退回产品,购买角色的最新趋势等。这种策略有助于公司留住客户,同时吸引新客户。这些预测算法还可以根据客户的选择和行为对客户进行细分,使公司能够根据需求更早地调整供应链和产品价格。
销售和营销团队可以根据客户的产品有效地锁定特定的客户群。然后,经理可以了解他们的营销策略如何影响客户的购买决策(例如,为什么有些人停止使用他们的产品)。是什么让他们转投其他品牌?预测分析还可以分析社交媒体帖子,如 Twitter、脸书和其他产品上的提及,以便及时获得消费者的反馈并改善他们的服务。
挑战
在物流行业应用人工智能有其自身的风险和挑战。
限制访问历史数据
为了让这些预测性人工智能解决方案有效工作,公司必须访问跨各个业务部门和供应链收集的大量历史高质量数据。质量和数量取决于公司的规模、地理位置和已经采用的 IT 解决方案。因此,企业需要投入资源和时间来建立解决方案和设备,以战略性地收集有关其业务的相关信息。一个好的建议将是从低投资的人工智能设计冲刺研讨会开始,以处理数据收集和预测建模实施。
缺乏 360°视野
企业仍然依赖于缺乏与整个供应链网络中的其他系统集成的遗留解决方案。软件解决方案通常不能覆盖所有流程,并且与不同的供应商不兼容,这使得跨平台合并数据变得更加困难。缺乏对供应链的 360 度全方位了解是运用预测分析的最大挑战。
缺乏人工智能专业人才
各行业需要聘请顶尖的数据科学家和机器学习专家来构建和设计他们的算法和系统。不幸的是,对这类专家的需求超过了供给,这使得企业很难找到并雇用在业务领域知识、数据科学、数学和统计方面具有扎实专业知识的分析专业人员。因此,许多公司未能实施预测分析解决方案,因为他们没有足够的合格员工来开展复杂的人工智能项目。
汇总
公司正在寻找优化供应链的方法,以帮助他们做出决策,提高运营效率和客户满意度,并减少对环境的影响。人工智能正在定义一种新的“物流范式”,为物流行业的各种任务提供服务:
- 预测和计划:在需求预测的帮助下,公司可以确保手头有适量的材料,并计划他们的生产活动。结果可以与关于成本、容量等的其他相关数据相结合。
- 优化: AI 可以分析历史行程、现有路线以及地理、环境和交通数据,以使用最短路径图算法,并为物流卡车确定最有效的方式。此外,基于过去关于销售、数量、市场条件、货币汇率和通货膨胀的历史数据,预测分析可以帮助公司最大限度地降低错误定价的风险。
- 自动化仓库:自动导向车(AGVs)可以实现箱子和托盘的移动。他们可以配备软件来改造标准叉车,使其实现自主。
- 预测和规定维护:它涉及通过分析实时传感器数据来检测工厂机器故障,并根据对下一次故障、服务日期和时间、要供应的备件等的预测,主动安排非高峰时段的维护。
- 后台操作:通过自动化数据输入、错误核对和文档处理,文档自动化技术可用于快速处理发票/提单/价目表文档。
然而,物流行业的人工智能也带来了挑战。
- 对历史数据的有限访问:为了让这些预测性人工智能解决方案有效工作,公司必须访问从各个业务部门和供应链收集的大量历史高质量数据。质量和数量取决于公司的规模、地理位置和已经采用的 IT 解决方案。
- 缺乏 360°视野:企业仍然依赖于遗留解决方案,这些解决方案缺乏与整个供应链网络中其他系统的集成。软件解决方案通常不能覆盖所有流程,并且与不同的供应商不兼容,这使得跨平台合并数据变得更加困难。
- 缺乏具有人工智能技能的专业人士:各行业需要聘请顶尖的数据科学家和机器学习专家来构建和设计他们的算法和系统。不幸的是,对这类专家的需求超过了供给,这使得企业很难找到并雇用在业务领域知识、数据科学、数学和统计方面具有扎实专业知识的分析专业人员。
我希望这篇文章能帮助你理解在物流领域使用深度学习的好处、应用、挑战和权衡。请继续关注即将到来的课程,我们将讨论深度学习和计算机视觉在医疗保健行业的应用。
咨询服务
你的人工智能工业应用需要帮助吗?了解有关我们的咨询服务的更多信息。
引用信息
Mangla,P. “用于物流的计算机视觉和深度学习”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/ux28n
@incollection{Mangla_2022_CVDLL,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Logistics},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/ux28n},
}
用于石油和天然气的计算机视觉和深度学习
原文:https://pyimagesearch.com/2022/09/19/computer-vision-and-deep-learning-for-oil-and-gas/
目录
计算机视觉与石油天然气深度学习
尽管可再生能源广泛传播,石油和天然气仍是能源部门的高价值商品。然而,商品周期、资本规划挑战和不断增加的运营风险促使石油和天然气行业做出更加明智和高效的决策。
在一份 2018 年安永&扬(EY)调查中,人工智能(AI)/机器学习(ML)甚至没有排在全球七大石油和天然气巨头使用的前五大技术中(图 1 )。此外,他们认为在未来几年,像机器人流程自动化(RPA) (25%)和高级分析(25%)这样的技术,而不是 AI/ML,将对他们的业务产生最重要和积极的影响。
AI/ML 在石油和天然气行业有着巨大的潜力,如果不考虑它,该行业的领导者可能会被蒙在鼓里。它可以帮助降低成本、增加容量和能力、加快决策速度,并在管理风险的同时提高质量。这将允许机器和人类以集体智能的方式一起工作,推动该部门进入数字时代。
本系列是关于工业和大企业应用的 CV 和 DL。该博客将涵盖石油和天然气领域使用深度学习的优势、应用、挑战和权衡。
这是 5 节课课程中的第一节:工业和大企业应用的 CV 和 DL 102。
- 【计算机视觉与石油天然气深度学习】 (本教程)
- 用于交通运输的计算机视觉和深度学习
- 用于物流的计算机视觉和深度学习
- 用于医疗保健的计算机视觉和深度学习
- 用于教育的计算机视觉和深度学习
了解计算机视觉和石油天然气深度学习, 继续阅读。
好处
**石油和天然气工厂的工作环境对员工来说是有毒和危险的。暴露在不同的温度和烟雾中会危及员工的生命。此外,任何不符合安全标准的行为都可能导致伤害和严重处罚。经过训练的算法可以在出现任何偏差的情况下进行分析并发送警报,并帮助人们对员工和工厂的安全和安保保持主动。
产量优化与估算
由于油价多变,该行业需要在每一步优化其生产。流量、压力等因素。,影响油气产量。利用传感器数据,人工智能算法可以生成实时更新,这有助于保持有利的操作设置。
降低生产和维护成本
不同的温度和天气条件会导致石油和天然气在管道中分散时发生腐蚀和降解。结合物联网(IoT),AI 可以使用知识图和预测智能来检测损坏和腐蚀的早期迹象。公司还可以计划维护活动,避免因设备故障而停机。此外,采用和集成人工智能驱动的缺陷检测解决方案是经济的,与现有的过程相比是值得的。
更多的好处见图 2 。
应用
维护
预见性维护
一个普通的离岸公司在一年中会经历大约 27 天的计划外停机时间,花费高达 3800 万美元。因此,基于人工智能的预测性维护解决方案有望大幅增长。人工智能模型可以预测设备故障,降低代价高昂的事故风险,减少停机时间,并提高对安全标准的遵守。
物联网传感器可以生成万亿字节的数据,记录压力、流量、土壤运动和腐蚀,这些数据可以通过人工智能进行分析,以实时更新设备健康状况。例如, 雪佛龙转向物联网开发,推出预测性维护解决方案,帮助识别腐蚀和管道损坏(图 3 )。他们使用安装在管道上的传感器来测量各种变量,如 pH 值、气体和水的 CO2/H2S 含量,以及管道的内径和厚度。
人工智能还能够预测和防止气蚀,气蚀是离心泵中发生的一种现象,当流体压力突然降低时,会产生气泡,这些气泡随后会破裂并引起危险的冲击波。此外,配备人工智能的系统可以自动将流体流向不同的泵,并防止破裂的气泡损坏管道。
维护使用数字双胞胎
许多海上结构已经超过了它们的设计寿命。让它们退役可能会导致失去它们生产的石油和天然气,升级它们将需要巨额投资。多年来,该部门一直依赖于结构的数字副本,称为数字双胞胎,用于监控其物理资产(如管道、钻机、阀门等)的健康状况。).
使用光探测和测距(LiDAR)为工厂建设生成 3D 点云和分析,专家可以预测结构的行为并评估其维护需求,从而大幅延长其寿命。
然而,这些模型没有考虑资产的实际、真实物理条件的变化,这些变化可能会影响其性能。为了抑制这种限制, Ramboll 正在开发数据挖掘和模式识别算法,通过结构监控来识别实际需求,并相应地更新数字孪生(图 4 )。这确保了对结构进行测试、评估和优化,从而降低了在实际操作条件下进行现场全面测试的成本。
维护防喷器
防喷器(bop)对于在最具挑战性的压力条件下保持密封或防止钻井过程中可能发生的不受控制的流动/地层井涌至关重要。然而,由于其位置偏远、监控有限和故障排除困难,防喷器的故障可能是灾难性的。
深水海底等数字公司目前正在利用人工智能和人工智能来实时了解防喷器的健康状况,并减少钻机非生产时间(NPT)。模式识别算法可以利用来自故障、警报和水下控制系统的钻机数据。
优化
优化油藏管理
石油和天然气行业必须积极寻找新的油井,单次钻井的成本可能高达 1 . 5 亿美元。对地表深处的地质结构和流体动力学进行近乎完美的描述是高效油田开发所必需的。然而,经过几十年收集的数据通常是不完整的、非结构化的和高度无组织的,这使得成功率低于 20%。
像 Lucidworks 这样的公司正在部署基于人工智能的解决方案,以准确快速地发现水量和天然气量减少的更好的油井。ML 可应用于钻井,从地层渗透性、热梯度、压差、地震振动等方面获取信息。这有助于地球科学家做出明智的决策,发现新能源,并减少新井对环境的影响。
优化采购
基于人工智能的采购解决方案可以生成互联的数字供应网络(DSN),从而在石油和天然气行业的规划和执行中实现动态性、灵活性和效率。此外,它还可以帮助企业实现从采购到付款的自动化,识别关键和非关键的供应链瓶颈,并通过供应商、材料、地理位置等获得计划和实际数字的可见性。
此外,人工智能可以通过对高度复杂和大型数据集的数据处理和分析来增强采购专家的决策能力,以解决传统问题。
优化财务规划
对需求、销售和财务状况的更好预测可以帮助公司规划生产和分销供应。例如,人工智能算法可以很容易地预测对特定产品的需求,帮助公司确保他们在正确的时间在正确的地方产生影响,以按时为客户订单服务,并知道应该关注哪些地区。此外,经营加油站的公司也可以从预测消费品需求中受益,以减少其库存资本。
石油和天然气行业有一个复杂的供应链,涉及原油采购、采购价格、到炼油厂的运输、炼油作业、龙门架作业和最终产品零售等决策。因此,人工智能可以帮助协调运营团队和仓库,并确保关键零件的可用性。此外,它还可以支持适当的计划和执行、最佳路线选择等。
简而言之,人工智能可以帮助预测原油和成品的市场价格,进行适当的规划和调度,实现自然篮子的优化,创建智能仓库,维护库存,处理航运业务,风险对冲,改善交付时间,降低整体成本。
安全保障
工作场所安全
石油和天然气行业很容易在无人看管的场所发生贵重设备被盗、故意破坏和蓄意破坏,从而导致泄漏和损坏。渗漏造成的地下水污染是一个严重且代价高昂的问题,会导致罚款、刑事指控和对声誉的严重影响。此外,由于其经济重要性,石油和天然气行业也可能成为恐怖袭击和破坏行为的潜在目标。
人工智能可以全天候监控无人值守操作场所的安全问题,如入侵,并在出现安全问题或未经授权的人员进入时向相关机构发送即时警报(例如 Chooch 人工智能)。此外,自动化和有效的虚警过滤技术减少了同时观看多个屏幕的需要,使安全官员能够专注于真正的威胁(图 5 )。
此外,由于恶劣的天气条件、极端的操作条件和危险的过程,石油和天然气行业面临着火灾、爆炸和泄漏的持续风险,威胁着工人的生命。一个这样的事件发生在加利福尼亚州的特索罗马丁内斯炼油厂,硫酸泄漏烧伤了两名员工。因此,他们必须遵守广泛的法规,以确保工作场所的安全。计算机视觉算法可以帮助现场检查和实时监控。此外,来自摄像头的视频分析可以验证工人是否遵守安全程序,如穿戴防护设备和防止因光滑表面导致的滑倒事故。
缺陷检测和资产保护
材料降解和腐蚀会导致严重的事故和损坏。 Popoola 等人(2013) 指出,“石油和天然气生产行业每年的腐蚀成本估计为 13.72 亿美元。”为了解决这个问题,基于人工智能的工具被用来监控和检查设备的健康状况,并在出现任何缺陷时触发警报。这种系统还可以监测泄漏、毒性水平和系统故障。
AI 主导的网络安全
在 Ponemon Institute 的一项调查中,西门子报告称,70%的石油和天然气组织遭遇了安全威胁。例如,假设一名网络攻击者阻断了视频流,使他能够监控海上钻井作业或延迟井流信息。这些信息对于防喷器阻止流体喷发是必要的,因为流体喷发会产生毁灭性的影响。此外,黑客还可以改变有杆抽油泵的电机速度和热容量,减慢甚至停止钻井过程。
西门子和 SparkCognition 最近通过 DeepArmor Industrial ( 图 6 )彻底改变了网络安全,该公司利用人工智能(AI)来监控和检测网络攻击,以保护石油和天然气行业的终端运营技术。
协助
石油和天然气行业严重依赖少数大师级专家的专业知识。不幸的是,当这些人退休时,他们的知识就丢失了,新员工必须通过埋藏在数千页文档中的程序信息。牢记这一点,IBM 利用其沃森人工智能技术创造了一个数字助理,以帮助经验不足的员工进行日常工作和故障排除。
人工智能从 60 万页的文档和报告中学习,为常见问题提供专家级的答案。在虚拟助手的帮助下,工程师现在花在研究解决方案上的时间减少了 75%,所有这些都是通过免提语音命令实现的。此外,辅助中使用的 AI 算法还可以随着新员工获得经验而从他们那里学习新信息(图 7 )。
探索
海底的裂缝和断裂,被称为“渗漏”,是原油和天然气的潜在来源。碳氢化合物像淡水泉一样到达地表,形成石油渗漏。在北美地区地表下发现的石油中,天然石油泄漏至少占 60% 。水下泄漏的石油会向大气中释放甲烷和其他轻烃,从而破坏环境。对这些渗漏进行勘探和开发可以保护环境,并为石油和天然气运营商提供有利可图的能源。
埃克森美孚公司与麻省理工学院的工程师一起开发了一种基于人工智能的软件,美国宇航局的火星好奇号火星车使用这种软件来设计适合海洋探索的人工智能水下机器人。这些人工智能机器可以监控海洋的深度,绘制地图,并检测自然渗漏(图 8 )。
挑战
根据 EY 对超级大公司的调查(图 9) ,50%的大型石油和天然气公司面临的主要挑战是管理内部发展、服务提供商和收购之间的平衡。因此,理解人工智能更广泛的挑战而不仅仅是商业影响是至关重要的。石油和天然气公司面临的其他人工智能挑战包括:
收养
采用 AI/ML 需要从根本上改变工作的执行方式和决策方式。他们还需要大量的努力和投资来教育现有员工使用这些服务。此外,必须聘请数据和人工智能专家来支持人工智能基础设施(算法和数据集)和定制工具的开发。因此,需要最高管理层的支持来获得赞助,确保适当的投资,并推动转型。
数据
人工智能算法需要大量高质量的数据才能正确工作。油气田会产生大量的原始数据。然而,数据的质量和准确性往往很低,这使得人工智能算法的训练很困难。公司需要重新设计和调整他们的组织结构和流程,以获得高质量的数据。此外,数据存储需要集中化,以允许不同仓库中的人员访问软件。
另一个关键方向是采用智能算法,如小数据学习,旨在用少量例子训练人工智能算法。同样,对预训练模型的有效适应可以增加人工智能辅助工具的适用性。
开放协作
虽然开放协作正在成为科技和人工智能领域的新标准,但石油和天然气公司并不以协作闻名,尤其是在竞争对手之间以及人工智能等领域。尽管公司宣布开放他们的数据来源,并声称跨公司和跨境数据共享的必要性,但现实相当悲观。因此,石油和天然气公司需要重新思考与能够提供良好人工智能人才来源的大学合作和互动的策略。
汇总
由于商品周期、资本规划挑战和不断增加的运营风险,石油和天然气行业已经开始使用人工智能进行更加智能和高效的决策。人工智能可以帮助降低成本,增加容量和能力,加快决策速度,提高质量,同时以下列方式管理风险。
- 维护:人工智能可以根据物联网传感器生成的数据(压力、流量、土壤运动和腐蚀)来实时更新设备健康状况。
- 优化:人工智能可以帮助预测原油和成品的市场价格,进行适当的规划和调度,实现自然篮子的优化,创建智能仓库,维护库存,处理运输操作,风险对冲,缩短交付时间,降低总体成本。
- 安全性:人工智能可以全天候监控无人值守的操作场所,以发现入侵等安全问题,并在出现任何安全问题或未经授权的人员进入时,立即向相关部门发送警报。
- 协助:在基于人工智能的虚拟助理的帮助下,工程师们现在花在研究解决方案上的时间更少了,所有这些都是免提语音命令。
- 探索:适合海洋探索的人工智能水下机器人可以监测海洋深度,绘制地图,并探测自然渗漏。
然而,石油和天然气行业的人工智能也面临着挑战。
- 采用:转移到人工智能范式需要在教育现有员工使用这些服务方面投入大量精力和投资。此外,必须聘请数据和人工智能专家来支持人工智能基础设施(算法和数据集)和定制工具的开发。
- 数据:油气田可以产生大量的原始数据。然而,数据的质量和准确性往往很低,这使得训练 AI 算法很困难。
- 协作:石油和天然气公司并不以协作闻名,尤其是在竞争对手之间和人工智能等领域。
我希望这篇文章能帮助你理解在石油和天然气领域使用深度学习的好处、应用、挑战和权衡。请继续关注另一堂课,我们将讨论深度学习和计算机视觉在交通领域的应用。
咨询服务
你的人工智能工业应用需要帮助吗?了解有关我们的咨询服务的更多信息。
引用信息
Mangla,P. “石油和天然气的计算机视觉和深度学习”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/zfg51
@incollection{Mangla_2022_CVDLOG,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Oil and Gas},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/zfg51},
}
```**
# 用于交通运输的计算机视觉和深度学习
> 原文:<https://pyimagesearch.com/2022/10/03/computer-vision-and-deep-learning-for-transportation/>
* * *
## **目录**
* * *
## [**用于交通运输的计算机视觉和深度学习**](#TOC)
交通运输是我们日常生活的重要组成部分,因为它能够将货物从一个地方运送到另一个地方,进行贸易、商业和交流,从而建立文明。在过去的一百年里,交通部门经历了多次变革。今天,我们正处于通过人工智能(AI)实现交通运输重大突破的阶段。
人工智能已经在改变交通行业,让汽车、火车、轮船和飞机实现自动驾驶,让交通更加顺畅。除了让我们的生活变得更容易,它还可以为每个人提供一种更安全、更清洁、更智能、更高效的交通方式。例如,人工智能主导的自动交通工具可以帮助减少许多交通事故中的人为错误。
2017 年,全球交通相关人工智能技术市场规模达到 12 亿至 14 亿美元。此外,预计到 2023 年,以 12-14.5%的复合年增长率(CAGR)增长到 35 亿美元(**图 1** )。
此外,高端计算硬件(如 CPU 和 GPU)和物联网技术(如 LTE 和 5G)的可访问性和可负担性为人工智能在交通领域的多种应用创造了可能性。本系列是关于工业和大企业应用的 CV 和 DL。这个博客将涵盖在交通领域使用深度学习的好处、应用、挑战和权衡。
本课是 5 课课程的第 2 课:**工业和大型企业应用的 CV 和 DL 102**。
1. [*计算机视觉与石油天然气深度学习*](https://pyimg.co/zfg51)
2. [***【计算机视觉与深度学习】用于交通运输***](https://pyimg.co/1u4c9) **(本教程)**
3. *用于物流的计算机视觉和深度学习*
4. *用于医疗保健的计算机视觉和深度学习*
5. *用于教育的计算机视觉和深度学习*
**要了解计算机视觉和深度学习对于交通运输,** ***就继续看下去吧。***
* * *
## [**用于交通运输的计算机视觉和深度学习**](#TOC)
* * *
### [**好处**](#TOC)
* * *
#### [**安全可靠性**](#TOC)
90%以上的交通事故都是人为错误(如超速、分心和酒后驾驶)造成的。因此,对于一个在旅游业或运输业工作的人来说,安全和可靠性无疑是最重要的因素。乘客需要知道他们和他们的物品是安全的,他们乘坐的车辆或运营商是可靠的。
随着人工智能技术的出现,安全水平可以达到更高的峰值。人工智能分析大量数据的能力将允许旅游和交通运营商,以及最终公众自己,以显著改善的方式安排公共和私人交通服务。研究人员认为,到 2050 年,在一些发达国家,人工智能车辆可以将交通死亡人数减少 90%。
* * *
#### [**效率**](#TOC)
发展中国家在物流绩效指数(LPI)上的排名低于发达国家,因为基础设施不足和海关手续不良导致效率低下。人工智能无疑将提高交通系统的能源效率,这是旅行的一个重要方面。特别是,人工智能可以在电子物流中发挥作用,互联网相关技术被应用于供需链,以匹配托运人和交付服务提供商。
* * *
#### [](#TOC)**污染**
**交通工具的排放物是污染加剧和全球变暖的重要因素。随着世界越来越关注环境问题,需要大幅减少旅行和运输行业的排放,以确保其长期可持续性。人工智能可以帮助部署新的和创新的解决方案,通过让科学家发现更环保的方法来运行交通工具和机械,以应对日益严重的污染。麦肯锡预测,无人驾驶卡车将降低约 45%的运营成本。因此,对环境的影响也将大大减少(**图 2** )。
* * *
### [**应用**](#TOC)
* * *
#### [**公路运输**](#TOC)
道路运输是当前人工智能广泛应用的最重要的领域之一。在世界范围内,汽车制造商和技术公司正在探索各种人工智能技术和算法,以开发用于商业和个人用途的智能汽车。这种车辆使用各种传感器,如 GPS、摄像头和雷达,并结合致动器(将输入信号转换为运动的设备)、控制单元和软件来执行智能动作(例如,自动驾驶)。
* * *
##### [**卡车列队**](#TOC)
卡车队列是指将几辆重型货车(HGV)在最短的距离内连接起来,以允许它们同时加速或制动(**图 3** )。人类驾驶引导 HGV,并且 HGV 中跟随的驾驶员可能仅在复杂交通状况或意外事件的情况下出现。预计在人工智能的干预下,司机跟随重型货车的责任将逐步减少。
* * *
##### [**交通管理**](#TOC)
目前,人工智能算法广泛用于车辆,以改善经济中的交通流量。例如,短途拼车平台优步在其服务的各个方面都使用了人工智能技术,从匹配骑手和司机到路线优化。人工智能算法还被应用于道路交通管理,以分析交通模式和流量,并为司机提供最快路线的信息。这减轻了他们的交通拥堵,减少了他们的通勤时间。这种算法还可以通过实时旋转的交通信号和信号灯来保持交通流量,以满足地面交通流量的需求。
例如,从卡耐基梅隆大学分离出来的 Rapid Flow Technologies ( **图 4** )的 [Surtrac](https://www.rapidflowtech.com/surtrac/how-it-works#:~:text=Surtrac%20is%20an%20intelligent%20traffic,a%20single%20machine%20scheduling%20problem.) 已经协调了匹兹堡三条主要道路上的九个交通信号网络,以安装交通控制解决方案。他们的解决方案减少了 25%的旅行时间,平均减少了 40%的等待时间。汽车尾气排放也减少了 20%。
* * *
#### [**航空**](#TOC)
航空业对人工智能技术的采用并不陌生。然而,随着人工智能的最新进展,该行业将对其业务开展方式产生重大影响。管理日益增长的空中交通是一个重要的领域,自动化和计算能力的进步会有所帮助。国际航空运输协会(IATA)的报告指出,利用增强的计算能力开发无人驾驶飞机系统(UAS)和 UAS 交通管理将为改善现有的交通管理系统、分离标准和空域规划设计创造新的机会。
[单一欧洲天空空中交通管理研究(SESAR)](https://www.sesarju.eu/) 联合项目已经支持了几个人工智能研究项目和空中交通管理(ATM),涵盖的问题包括:
* 不同飞行阶段交通的可预测性
* 机场客流的改善
* 更高的自动化程度
机器学习在航空业的一个潜在应用是将对客户行为的历史和实时洞察转化为实时策略(例如,调整呈现给客户的网站内容)。这还包括社交媒体情绪分析,它根据客户的社交媒体行为预测客户的需求。例如, [BigData4ATM](https://www.nommon.es/research-projects/bigdata4atm/) 项目着眼于人工智能如何分析不同的以乘客为中心的地理定位数据,以识别乘客行为、门到门出行时间和出行方式选择的模式(**图 5** )。通过智能设备和相关服务,研究人员可以访问大规模、详细的纵向(动态)数据,以测试关于乘客行为的假设。
人工智能可以发挥作用的另一个领域是地勤。这包括高度潜在的用例,如安全检查、飞机移动操作(推和拖)、飞机周转操作(加油、配餐、装卸、除冰和防冰)以及停机坪上的地面运输(乘客、行李、货物和邮件)。它还可以通过消化大量的历史和实时数据来促进机场安全。
此外,飞机制造商正在使用人工智能解决飞行员在驾驶舱面临的问题和飞机的预测性维护。例如,一家英国初创公司 [Aerogility 正在与 EasyJet](https://aerogility.com/easyjet-deploys-aerogility-fleet-maintenance-solution/#:~:text=easyJet%2C%20Europe's%20leading%20airline%2C%20is,increased%20cost%20efficiency%20for%20maintenance.) 合作,为其机队实现日常维护规划自动化,包括预测大修、发动机车间访问和起落架大修。空客制造商使用类似的工具 Skywise 来提供预测性维护和数据分析。
几家公司也开始在无人机上使用人工智能技术来运送各种规模和类型的货物。例如,总部位于加州的初创公司 [Nautilus](https://www.iadb.in/2022/02/08/nautiluss-next-gen-cargo-drone-aims-to-propel-air-cargo-industry-to-new-heights/?utm_source=rss&utm_medium=rss&utm_campaign=nautiluss-next-gen-cargo-drone-aims-to-propel-air-cargo-industry-to-new-heights) 正在开发一种载重 90 吨的货运无人机。
* * *
#### [**铁路运输**](#TOC)
铁路是最具创新性的经济部门之一,首次允许乘客进行更长距离的旅行。他们也是工业革命中的一个重要因素。人工智能可以帮助改善铁路运营商和基础设施管理者的制造、运营和维护。它将改善管理,降低成本,提高与直接竞争对手或其他运输方式的竞争力。
* * *
##### [**智能列车自动化**](#TOC)
人工智能在铁路运输中最重要的贡献之一是列车运行的自动化(ATO),它将管理列车运行的责任从司机转移到具有不同自治程度的列车控制系统。这通常包括将火车司机的感官和智力能力转移到自动驾驶模块,准备对可能的危险做出反应。此外,设计模块应理解并整合乘客在铁路站台上的行为,允许列车自动无危险地关闭车门。
欧盟的研发联合企业 Shift2Rail ( **图 6** )正在为所有铁路段(干线/高速、城市/郊区、区域和货运线路)开发和验证标准 ATO。此外,他们正在开展与 ATO 相关的活动,以优化资源利用。随着集装箱运输市场的增长,许多项目正在开发,以更好地同步集装箱列车的运动,以改善实时信息和数据交换。
* * *
##### [**作战情报**](#TOC)
在铁路中,在潜在故障发生之前识别并意识到它们以避免服务中断是有价值的。今天,AI 可以使用传感器(放置在关键地方)提供的数据来提取有价值的见解和信息,并建议维护行动。这将有助于培训运营商减少他们在发生故障时需要保留的车队储备,因为人工智能允许他们提高可靠性和有效性。其他优势包括:
* “临近预报”和预测铁路车辆状况的基础设施
* 更快、更不全面的维修
* 维护成本降低
* 更高的客户满意度
为了说明一些人工智能应用,法国运营商[法国国家铁路公司(SNCF)](https://www.sncf.com/en/network-expertise/rolling-stock-division/predictive-maintenance-pioneers) 已经开始对受电弓应用预测性维护,受电弓由于磨损效应而变得脆弱(**图 7** )。该公司表示,随着时间的推移,它将能够预测向列车供电的接触网上 80%的事故。据 SNCF 称,预测性维护还将涉及列车道岔的事故减少了 30%,这项技术已经应用于许多列车系统和子系统。
[SNCF](https://www.sncf.com/en/network-expertise/rolling-stock-division/predictive-maintenance-pioneers) 轨道预测性维护解决方案(**图 7** )包括以下内容:
* **步骤 1:** 列车经过地面仪器时,独立与物联网通信
* **第二步:**数据传输到数据存储服务器
* 第三步:科学家和铁路专家分析数据
* **步骤 4:** 一旦数据被分析,它就被计算机化的维护管理软件检索使用
* * *
##### [**资产智能**](#TOC)
铁路中的人工智能也可用于评估铁路资产的长期性能,并建议其产品设计中需要改进的领域。人工智能可以分析铁路基础设施和列车子系统产生的数据,以帮助设备制造商建立物理实体的数字表示,即所谓的数字孪生。这使得 IT、运营和工程技术能够访问整体状况,并了解资产退化、故障和客户行为。这些改进代表了设备制造商和铁路运营商的竞争优势。
[国际工程公司 Laing O'Rourke](https://internetofbusiness.com/iom-2018-how-laing-orourke-uses-digital-twins-to-build-a-better-business/) 使用人工智能和 asset digital twin 来安排维护工作,使该公司能够将安排活动减少到仅 19 秒。
* * *
#### [**航运、航海、港口**](#TOC)
在过去几十年里,船舶交通显著增长,提高了海上安全的风险。此外,随着港口集装箱运输量的增加,需要对港口码头和更好的连接进行改造。不断增长的船舶尺寸加大了船舶对港口和城市的压力。
此外,日益增多的环境问题促使该行业在全球海运业激烈的国际竞争中适应更环保的规则。人工智能可以分析这些信息,为更好的决策提供见解,提高安全性和能效,并优化物流。
* * *
##### [**海运**内河航运](#TOC)
海上作业需要适应不断变化的条件,并根据几个参数做出决策。来自高级导航系统(例如,雷达、电子导航图、自动驾驶系统、波浪雷达、溢油探测器和其他传感器)的数据由人工智能算法进行分析,以提取洞察力并执行技术操作和维护。自动识别系统(AIS)传输数据(例如,船舶 ID、位置、航向、速度和目的地)。
通过记录船舶运动和先进的图像识别系统的结合,即使船舶的 AIS 关闭,也可以识别船舶。这可以检测海上作业中的异常情况,提高海平面安全。此外,机器学习算法可以预测由于恶劣天气条件和交通拥堵造成的延误,并估计未来对油价的需求。
自主船是人工智能在这一领域的一个明显应用。例如,EU-资助的[海上无人驾驶网络智能导航(MUNIN)](http://www.unmanned-ship.org/munin/wp-content/uploads/2016/02/MUNIN-final-brochure.pdf) 项目已经开发并测试了自主商船的概念,该船主要由自动船上决策系统引导,但由岸上的远程操作员控制(**图 8** )。此外,该船仅在深海航行期间使用独立操作,而不是在拥挤的水域或在其港口接近期间。
* * *
##### [**港口**](#TOC)
随着全球大型港口信息量的不断增长,一种叫做港口呼叫优化的新应用变得非常流行。它结合使用物联网、云计算和地理信息来优化港口运营,提高生产效率,并改善与客户的关系。此外,分析后的数据可用于预测和实时规划,以改善决策并支持港口的经济增长。
通过使用更先进的数字技术,港口可以变得“智能”(**图 9** )以:
* 提供无缝供应链
* 优化相关资源、服务和监管的配置
* 自主装载和卸载(首先卸载哪些集装箱以及如何堆叠它们)
* 设备调度(优化起重机和车辆的使用)
* 泊位可用性规划
新加坡、鹿特丹、天津和迪拜被认为是智能化程度最高的港口。
集装箱港口运营期间收集的数据将被存储和分析,作为未来人工智能辅助工具的基础,预计有一天这些工具将管理整个交付周期,并进一步优化码头运营。此外,这些技术进步被理解为更广泛的供应链变革的一部分。
* * *
### [**挑战**](#TOC)
运输部门的人工智能有几个相关的风险和挑战。然而,这些风险和挑战可能会产生重大的社会经济影响,必须加以管理。
**失业:**根据全球政策解决方案中心的一份报告,由于美国向自动驾驶汽车(AVs)的快速过渡,超过 400 万人将失业。这些工作包括送货司机、重型卡车司机、公共汽车司机和出租车司机。此外,人工智能可能会加速以服务为基础的经济增长,这将加速低技能工人的失业。
**投资:**交通运输市场人工智能发展的一个重要制约因素是其在人才、硬件和软件方面的高投资性质。对人工智能专家的需求正在急剧增长,缺乏熟练的人工智能人才将成为发达国家采用人工智能的最大障碍。此外,需要巨额投资和资本存量来利用技术人员和商业惯例。
**基础设施落后和不发达:**像印度这样的低收入发展中国家在采用人工智能方面面临巨大挑战,因为它们的基础设施质量低下。这包括道路、港口、维护和修理站。缺乏可靠的电力来源和薄弱的电信设施使事情变得更加困难。技术研究投资和复杂基础设施占 GDP 比例很低的国家,在利用人工智能的力量方面可能会面临更大的挑战。
**监管要求和隐私问题**:人工智能的监管要求总是难以预测。尽管研究表明,AVs 减少了交通死亡,但如果发生事故、伤害或死亡,谁最终负责仍不清楚。同样,要求用户提供个人数据来开发健壮的机器学习模型需要隐私法。这些法律必须与电信网络中拥有更多数据的好处相权衡。
* * *
* * *
## [**汇总**](#TOC)
人工智能可以通过以下方式为每个人提供更安全、更清洁、更智能、更高效的交通方式。
* **公路运输:**公路车辆可以使用各种传感器,如 GPS、摄像头和雷达,并结合执行器(将输入信号转化为运动的设备)、控制单元和软件来执行智能操作,如自动驾驶。
* **航空:**将对客户行为的历史和实时洞察转化为实时策略(例如,调整呈现给客户的网站内容)。
* 铁路:人工智能可以帮助改善铁路运营商和基础设施管理者的制造、运营和维护。它将改善管理,降低成本,提高与直接竞争对手或其他运输方式的竞争力。
* **海洋和航运:**来自高级导航系统(例如,雷达、电子导航图、自动驾驶系统、波浪雷达、溢油探测器和其他传感器)的数据通过人工智能算法进行分析,以提取洞察力并进行技术运营和维护。
然而,交通领域的人工智能也带来了挑战。
* 工作岗位的流失:人工智能可能会加速以服务为基础的经济增长,这将加速低技能工人的失业。
* **投资:**交通运输市场人工智能发展的一个重要制约因素是其在人才、硬件和软件方面的高投资性质。对人工智能专家的需求正在急剧增长,缺乏熟练的人工智能人才将成为最大的障碍。
* **基础设施落后和不发达:**像印度这样的低收入发展中国家在采用人工智能方面面临巨大挑战,因为它们的基础设施质量低下。这包括道路、港口、维护和修理站。
* **监管要求和隐私问题:**人工智能的监管要求总是难以预测。尽管研究表明,AVs 减少了交通死亡,但如果发生事故、伤害或死亡,谁最终负责仍不清楚。
我希望这篇文章能帮助你理解在交通运输中使用深度学习的好处、应用、挑战和权衡。请继续关注另一堂课,我们将讨论深度学习和计算机视觉在物流中的应用。
* * *
### [**咨询服务**](#TOC)
你的人工智能工业应用需要帮助吗?了解有关我们的[咨询服务](https://pyimagesearch.com/consulting-2/)的更多信息。
* * *
### [**引用信息**](#TOC)
**Mangla,P.** “用于运输的计算机视觉和深度学习”, *PyImageSearch* ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva 和 R. Raha 编辑。,2022 年,【https://pyimg.co/1u4c9
```py
@incollection{Mangla_2022_CVDLT,
author = {Puneet Mangla},
title = {Computer Vision and Deep Learning for Transportation},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2022},
note = {https://pyimg.co/1u4c9},
}
计算机视觉讲座——云中的教程、摘要和简历
原文:https://pyimagesearch.com/2014/08/11/computer-vision-talks-tutorials-digests-cv-cloud/
今天,我把一船的钱扔在了一个崭新的立式办公桌上。
我为什么要这么做?为什么我要把口袋翻出来,把我仅有的一点钱花在一张超贵的桌子上?
因为我相信健身。我相信健康的生活方式。我相信积极。
*说到活跃… 计算机视觉社区本身需要更加活跃。
作为开发人员、程序员、研究人员,无论什么级别、什么经验,我们都需要更多地互相接触。我们需要进行更有价值的对话。我们需要更好地共享资源。
为了实现这一点,我想花一点时间,给你一个有价值的计算机视觉资源的线索——计算机视觉对话。
计算机视觉对话
由 Eugene Khvedchenya 创办和运营的计算机视觉讲座包括计算机视觉讨论、教程和对计算机视觉最热门话题的评论(看看5 月和6 月的摘要,我想你会同意 Eugene 的每月评论非常值得一读)。
Eugene 还是《通过实用计算机视觉项目掌握 OpenCV》一书的作者,该书包括解决常见计算机视觉问题的分步教程。
他的书是为有一点计算机视觉经验的 C/C++程序员写的(所以你至少应该知道一些基本知识)。
最后,Eugene 还在做一个非常酷的项目, CloudCV ,旨在通过简单的 API 调用将“计算机视觉带到云端”。
可以肯定地说,Eugene 在计算机视觉领域做了很多了不起的工作。一定要在计算机视觉讲座上花点时间看看他。
特色研究员
你在计算机视觉领域做着有趣的工作吗?给我发消息我们聊聊。我很乐意讨论你的项目,甚至在 PyImageSearch 博客上展示你的作品。*
用 OpenCV 和 Python 计算图像的“丰富度”
原文:https://pyimagesearch.com/2017/06/05/computing-image-colorfulness-with-opencv-and-python/

今天这篇博文的灵感来自于我在 Twitter 上收到的一个 PyImageSearch 读者的问题, @makingyouthink 。
转述一下我自己和@makingyouthink 交换的推文,问题是:
你见过测量自然图像色彩的 Python 实现吗(Hasler 和 Süsstrunk,2003)?
我想用它作为一个图像/产品搜索引擎。通过给每张图片一个“色彩量”,我可以根据图片的颜色对它们进行分类。
图像色彩有许多实际用途,包括评估压缩算法、评估给定相机传感器模块对颜色的敏感度、计算图像的“美学质量”,或者简单地创建大量图像可视化,以显示按色彩排列的数据集中的图像光谱。
今天我们将学习如何计算图像的色彩,正如哈斯勒和苏斯特朗克在 2003 年的论文 测量自然图像的色彩中所描述的那样。然后,我们将使用 OpenCV 和 Python 实现我们的色彩度量。
在实现了色彩度量之后,我们将根据颜色对给定的数据集进行排序,并使用我们上周创建的图像蒙太奇工具显示结果。
要了解用 OpenCV 计算图像“色彩度”,请继续阅读。
用 OpenCV 和 Python 计算图像的“丰富度”
今天的博文有三个核心部分。
首先,我们将介绍在 Hasler 和 Süsstrunk 的论文中描述的色彩度量方法。
然后,我们将在 Python 和 OpenCV 中实现图像色彩计算。
最后,我将演示如何将色彩度量应用于一组图像,并根据图像的“色彩”程度对其进行排序。我们将利用我们方便的图像蒙太奇程序进行可视化。
要下载这篇博文的源代码+示例图片,请务必使用下面的 “下载” 部分。
测量图像的色彩
在他们的论文中,Hasler 和 Süsstrunk 首先让 20 名非专业参与者按照 1-7 的颜色等级给图片打分。这项调查是在一组 84 张图片上进行的。标度值为:
- 不丰富多彩
- 略带色彩
- 色彩适中
- 色彩一般
- 相当丰富多彩
- 非常丰富多彩
- 极其丰富多彩
为了设置基线,作者向参与者提供了 4 幅示例图像以及它们对应的从 1 到 7 的色彩值。
通过一系列的实验计算,他们得出了一个简单的度量标准,即将与观众的结果相关联。
他们通过这些实验发现,简单的对立色彩空间表示以及这些值的平均值和标准偏差与 95.3%的调查数据相关。
我们现在导出它们的图像色彩度量:

 - B")
以上两个等式显示了对手颜色空间表示,其中 R 是红色,G 是绿色,B 是蓝色。在第一个等式中,
is the difference of the Red channel and the Green channel. In the second equation,  is represents half of the sum of the Red and Green channels minus the Blue channel.
is represents half of the sum of the Red and Green channels minus the Blue channel.
接下来,标准差(
) and mean ( ) are computed before calculating the final colorfulness metric,
) are computed before calculating the final colorfulness metric,  .
.



正如我们将会发现的,这是一种非常有效和实用的计算图像色彩的方法。
在下一节中,我们将使用 Python 和 OpenCV 代码实现这个算法。
在 OpenCV 中实现图像色彩度量
现在我们对色彩度有了基本的了解,让我们用 OpenCV 和 NumPy 来计算一下。
在本节中,我们将:
- 导入我们必需的 Python 包。
- 解析我们的命令行参数。
- 遍历数据集中的所有图像,并计算相应的色彩度量。
- 根据图像的色彩对其进行分类。
- 在蒙太奇中显示“最丰富多彩”和“最不丰富多彩”的图像。
首先打开您最喜欢的文本编辑器或 IDE,创建一个名为colorfulness.py的新文件,并插入以下代码:
# import the necessary packages
from imutils import build_montages
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
第 2-7 行导入我们需要的 Python 包。
如果您的系统上没有安装imutils(在撰写本文时, v0.4.3 ,那么请确保您通过pip安装/升级它:
$ pip install --upgrade imutils
注意:如果你正在使用 Python 虚拟环境(正如我所有的 OpenCV 安装教程所做的),确保你首先使用workon命令访问你的虚拟环境,然后安装/升级 imutils 。
接下来,我们将定义一个新函数,image_colorfullness:
def image_colorfulness(image):
# split the image into its respective RGB components
(B, G, R) = cv2.split(image.astype("float"))
# compute rg = R - G
rg = np.absolute(R - G)
# compute yb = 0.5 * (R + G) - B
yb = np.absolute(0.5 * (R + G) - B)
# compute the mean and standard deviation of both `rg` and `yb`
(rbMean, rbStd) = (np.mean(rg), np.std(rg))
(ybMean, ybStd) = (np.mean(yb), np.std(yb))
# combine the mean and standard deviations
stdRoot = np.sqrt((rbStd ** 2) + (ybStd ** 2))
meanRoot = np.sqrt((rbMean ** 2) + (ybMean ** 2))
# derive the "colorfulness" metric and return it
return stdRoot + (0.3 * meanRoot)
第 9 行定义了image_colorfulness函数,该函数将一个image作为唯一的参数,并返回上一节中描述的颜色度量。
注意:第 11 行、第 14 行和第 17 行*使用的色彩空间超出了本文的范围。如果你有兴趣学习更多关于色彩空间的知识,一定要参考* 实用 Python 和 OpenCV 以及 PyImageSearch 大师课程。
为了将图像分解成红色、绿色和蓝色(RGB)通道,我们调用了第 11 行的上的cv2.split。该函数以 BGR 顺序返回一个元组,因为这是图像在 OpenCV 中的表示方式。
接下来我们使用一个非常简单的对手颜色空间。
在参考文献中,我们在第 14 行的上计算红绿对手rg。这是红色通道减去蓝色通道的简单差值。
类似地,我们计算在线 17 的黄蓝对手。在这个计算中,我们取红色+绿色通道总和的一半,然后减去蓝色通道。这就产生了我们想要的对手,yb。
从那里,在第 20 行和第 21 行上,我们计算rg和yb的平均值和标准偏差,并将它们存储在各自的元组中。
接下来,我们将第 24 行的上的rbStd(红蓝标准差)与ybStd(黄蓝标准差)结合起来。我们将每个的平方相加,然后求平方根,将其存储为stdRoot。
类似地,我们通过平方rbMean和ybMean来组合它们,将它们相加,并在行 25 上求平方根。我们将这个值存储为meanRoot。
计算图像色彩的最后一步是将stdRoot和 1/3 meanRoot相加,然后将值返回给调用函数。
既然我们的 image image_colorfulness度量已经定义,我们可以解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to input directory of images")
args = vars(ap.parse_args())
这里我们只需要一个命令行参数,--images,它是驻留在您机器上的图像目录的路径。
现在,让我们遍历数据集中的每个图像,并计算相应的色彩度度量:
# initialize the results list
print("[INFO] computing colorfulness metric for dataset...")
results = []
# loop over the image paths
for imagePath in paths.list_images(args["images"]):
# load the image, resize it (to speed up computation), and
# compute the colorfulness metric for the image
image = cv2.imread(imagePath)
image = imutils.resize(image, width=250)
C = image_colorfulness(image)
# display the colorfulness score on the image
cv2.putText(image, "{:.2f}".format(C), (40, 40),
cv2.FONT_HERSHEY_SIMPLEX, 1.4, (0, 255, 0), 3)
# add the image and colorfulness metric to the results list
results.append((image, C))
第 38 行初始化一个列表results,它将保存一个包含图像路径和图像的相应色彩的 2 元组。
我们开始遍历由命令行参数指定的数据集中的图像,第 41 行上的--images。
在这个循环中,我们首先在行 44 上加载图像,然后我们在行 45 、上将image调整为一个width=250像素,保持纵横比。
我们的image_colorfulness函数调用是在第 46 行上进行的,这里我们提供了唯一的参数image,在C中存储了相应的颜色度量。
在第 49 和 50 行,我们使用cv2.putText在图像上绘制色彩度。要了解关于该函数参数的更多信息,请参见 OpenCV 文档( 2.4 、 3.0 )。
在for循环的最后一行,我们将元组(imagePath, C)添加到results列表中(第 53 行)。
注意:通常,对于一个大型数据集,您不会希望将每个图像都存储在内存中。为了方便起见,我们在这里这样做。在实践中,您将加载图像,计算色彩度量,然后维护图像 ID/文件名和相应色彩度量的列表。这是一种更有效的方法;然而,为了这个例子,我们将图像存储在内存中,这样我们就可以在教程的后面轻松地构建我们的“最多彩”和“最不多彩”图像的蒙太奇。
至此,我们已经回答了我们 PyImageSearch 读者的问题。已经为所有图像计算了色彩度度量。
如果您像@makingyouthinkcom 一样将它用于图像搜索引擎,您可能希望显示您的结果。
这正是我们接下来要做的,我们将:
- 根据相应的色彩度量对图像进行分类。
- 确定 25 幅色彩最丰富的图片和 25 幅色彩最不丰富的图片。
- 以蒙太奇的方式展示我们的结果。
现在让我们着手处理这三项任务:
# sort the results with more colorful images at the front of the
# list, then build the lists of the *most colorful* and *least
# colorful* images
print("[INFO] displaying results...")
results = sorted(results, key=lambda x: x[1], reverse=True)
mostColor = [r[0] for r in results[:25]]
leastColor = [r[0] for r in results[-25:]][::-1]
在第 59 行的上,我们利用 Python Lambda 表达式对results进行逆序排序(根据它们的颜色度量)。
然后在第 60 行的上,我们将 25 幅最丰富多彩的图像存储到一个列表中,mostColor。
类似地,在第 61 行的上,我们加载了最不鲜艳的图像,也就是结果列表中的最后 25 幅图像。我们颠倒这个列表,以便图像按升序显示。我们将这些图像存储为leastColor。
现在,我们可以使用我们上周学过的的build_montages函数来可视化mostColor和leastColor图像。
# construct the montages for the two sets of images
mostColorMontage = build_montages(mostColor, (128, 128), (5, 5))
leastColorMontage = build_montages(leastColor, (128, 128), (5, 5))
最丰富多彩和最不丰富多彩的蒙太奇分别建立在第 64 行和第 65 行上。这里我们指出蒙太奇中的所有图像将被调整到 128 x 128,并且将有 5 列 5 行的图像。
现在我们已经组装好了蒙太奇,我们将在屏幕上显示每个蒙太奇。
# display the images
cv2.imshow("Most Colorful", mostColorMontage[0])
cv2.imshow("Least Colorful", leastColorMontage[0])
cv2.waitKey(0)
在第 68 行和第 69 行,我们在一个单独的窗口中显示每个剪辑。
第 70 行上的cv2.waitKey调用暂停了我们脚本的执行,直到我们选择了一个当前活动的窗口。当按键时,窗口关闭,脚本退出。
图像色彩结果
现在让我们使用这个脚本,看看结果。今天我们将使用流行的 UKBench 数据集的一个样本(1000 张图片),这是一个包含日常物品的图片集。
我们的目标是按照最丰富多彩和最不丰富多彩对图像进行排序。
要运行该脚本,启动终端并执行以下命令:
$ python colorfulness.py --images ukbench_sample
Figure 1: (Left) Least colorful images. (Right) Most colorful images.
请注意,我们的图像色彩度量已经很好地将本质上是黑白的非彩色图像(左)与充满活力的“彩色”图像(右)分离开来。
摘要
在今天的博文中,我们学习了如何使用 Hasler 和 Süsstrunk 在他们 2003 年的论文测量自然图像的色彩中详述的方法来计算图像的“色彩”。
他们的方法是基于对手色彩空间中像素亮度值的平均值和标准偏差。这一指标是通过检查实验指标和参与者在研究中赋予图像的色彩之间的相关性得出的。
然后,我们实现了图像色彩度量,并将其应用于 UKBench 数据集。正如我们的结果所表明的,Hasler 和 Süsstrunk 方法是一种快速简便的量化图像色彩内容的方法。
享受使用这种方法在你自己的数据集中试验图像色彩的乐趣吧!
在您离开之前,请务必在下面的表格中输入您的电子邮件地址,以便在 PyImageSearch 博客上发布新教程时得到通知。
使用 Python 为深度学习配置 Ubuntu
原文:https://pyimagesearch.com/2017/09/25/configuring-ubuntu-for-deep-learning-with-python/

当涉及到学习深度学习等新技术时,配置您的开发环境往往是成功的一半。在你开始学习深度学习之前,不同的操作系统、硬件、依赖性和实际的库本身可能会导致许多令人头疼的问题。
深度学习库更新和发布的速度进一步加剧了这些问题——新功能推动了创新,但经常会打破以前的版本。您的环境可能会很快过时,因此必须成为安装和配置深度学习环境的专家。
既然用 Python 进行计算机视觉深度学习的 已经正式发布,我将在本周发布三篇帖子,在这些帖子中,我将演示如何建立自己的深度学习环境,以便你可以在投入阅读之前有一个良好的开端。
我将演示如何为以下操作系统和外围设备配置您自己的本地开发环境:
- 用 Python 为深度学习配置 Ubuntu(即你目前正在阅读的帖子)
- 使用 Python 为深度学习设置 Ubuntu(有 GPU 支持)
- 使用 Python 为深度学习配置 macOS
当你开始走上深度学习和计算机视觉掌握的道路时,我会一直陪在你身边。
要开始用 Python 配置你的 Ubuntu 机器进行深度学习,继续阅读。
使用 Python 为深度学习配置 Ubuntu
伴随我的深度学习新书的是一个可下载的预配置的 Ubuntu VirtualBox 虚拟机,预装了 Keras、TensorFlow、OpenCV 等计算机视觉/机器学习库。到目前为止,这是使用 Python 进行计算机视觉的深度学习的最快方式。
也就是说,通常希望在裸机上安装您的环境,这样您就可以利用您的物理硬件。对于本系列的 GPU 安装教程部分,这是一个要求,你必须在金属上——虚拟机只是不会削减它,因为它无法访问你的物理 GPU。
今天,我们的博客分为四个相对简单的步骤:
- 步骤 1:安装 Ubuntu 系统依赖项
- 步骤 2:创建您的 Python 3 虚拟环境
- 步骤 3:编译并安装 OpenCV
- Step #4: Install Keras
记下这些步骤,你会看到用 Python 的计算机视觉深度学习支持 T2 Python 3。
Python 3 将成为 PyImageSearch 的标准,因为它很稳定,坦率地说是未来的标准。许多组织一开始对采用 Python 3 犹豫不决(包括我在内,因为在 OpenCV 3 之前没有 Python 3 对 OpenCV 的支持),但是此时如果你不采用 Python 3,你将被远远甩在后面。预计 PyImageSearch 大师的课程内容也将在不久的将来与 Python 3 兼容。
请注意,我们选择了 Keras 作为我们的深度学习库。Keras 因其易用性以及与 Tensorflow 和 Theano 的兼容性而“脱颖而出”。
我的深度学习书籍专注于基础知识和轻松进入该领域,而不是向你介绍一堆库——所以对于初学者包和实践者包,我用 Keras 演示了各种任务和练习(以及手动实现一些基本的神经网络概念)。 ImageNet 包也利用了 mxnet。
虽然我们将在我的书中主要使用 Keras,但是有许多 Python 的深度学习库,我鼓励你熟悉我最喜欢的 9 个 Python 深度学习库。
首先,你需要一些空闲时间来访问 Ubuntu 机器的终端——如果你的机器在云中或其他地方,SSH 是非常合适的。我们开始吧!
步骤 1:安装 Ubuntu 系统依赖项
这一步的目的是为您的系统准备 OpenCV 所必需的依赖项。
本教程中的所有步骤都将通过使用您的终端来完成。首先,打开你的命令行并更新apt-get包管理器来刷新和升级预安装的包/库:
$ sudo apt-get update
$ sudo apt-get upgrade
我们还需要安装一些开发工具,以及图像和视频 I/O、优化和创建绘图/可视化所需的先决条件:
$ sudo apt-get install build-essential cmake git unzip pkg-config
$ sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng12-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libhdf5-serial-dev graphviz
$ sudo apt-get install libopenblas-dev libatlas-base-dev gfortran
$ sudo apt-get install python-tk python3-tk python-imaging-tk
我们将通过为 Python 2.7 和 Python 3.5 安装 Python 开发头文件和库来结束步骤#1(这样您就可以同时拥有这两个版本)。
$ sudo apt-get install python2.7-dev python3-dev
注意: 如果你没有安装 Python 开发头文件和静态库,你会在步骤#3 中遇到问题,在那里我们运行cmake来配置我们的构建。如果没有安装这些头文件,那么cmake命令将无法自动确定 Python 解释器和 Python 库的正确值。简而言之,这一部分的输出看起来是“空的”,您将无法构建 Python 绑定。当您到达步骤#3 时,花时间将您的命令输出与我的进行比较。
让我们继续创建一个虚拟环境来存放 OpenCV 和 Keras。
步骤 2:创建您的 Python 虚拟环境
在本节中,我们将在您的系统上设置一个 Python 虚拟环境。
安装 pip
我们现在准备开始为构建配置我们的 Python 开发环境。第一步是安装pip,一个 Python 包管理器:
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python get-pip.py
$ sudo python3 get-pip.py
安装 virtualenv 和 virtualenvwrapper
我在我做过的每一个安装教程中都提到过这一点,但是今天我要在这里再说一遍:我是和的超级粉丝。这些 Python 包允许你为你正在进行的每个项目创建独立的 Python 环境。
简而言之,使用这些包可以让你解决“项目 X 依赖于 1.x 版本,但项目 Y 需要 4.x 的困境。使用 Python 虚拟环境的一个奇妙的副作用是,您可以让您的系统保持整洁,没有混乱。
虽然你当然可以在没有 Python 虚拟环境的情况下使用 Python 绑定来安装 OpenCV, 我强烈推荐你使用它们 ,因为其他 PyImageSearch 教程利用了 Python 虚拟环境。在本指南的剩余部分,我还假设您已经安装了virtualenv和virtualenvwrapper。
如果你想要一个完整、详细的解释,为什么 Python 虚拟环境是一个最佳实践,你绝对应该读一读这篇在 RealPython 上的精彩博文。在本教程的前半部分,我也提供了一些关于为什么我个人更喜欢 Python 虚拟环境的评论。
让我再次重申,在 Python 社区中,利用某种虚拟环境是的标准做法,所以我建议你也这样做:
$ sudo pip install virtualenv virtualenvwrapper
$ sudo rm -rf ~/.cache/pip get-pip.py
一旦我们安装了virtualenv和virtualenvwrapper,我们需要更新我们的~/.bashrc文件,在文件的底部包含以下行:
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
~/.bashrc文件只是一个 shell 脚本,每当您启动一个新的终端时,Bash 都会运行它。您通常使用该文件来设置各种配置。在本例中,我们设置了一个名为WORKON_HOME的环境变量,指向 Python 虚拟环境所在的目录。然后我们从virtualenvwrapper加载任何必要的配置。
要更新您的~/.bashrc文件,只需使用标准的文本编辑器。我会推荐使用nano、vim或emacs。你也可以使用图形编辑器,但是如果你刚刚开始使用,nano可能是最容易操作的。
一个更简单的解决方案是使用cat命令,完全避免编辑器:
$ echo -e "\n# virtualenv and virtualenvwrapper" >> ~/.bashrc
$ echo "export WORKON_HOME=$HOME/.virtualenvs" >> ~/.bashrc
$ echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.bashrc
$ echo "source /usr/local/bin/virtualenvwrapper.sh" >> ~/.bashrc
编辑完我们的~/.bashrc文件后,我们需要重新加载修改:
$ source ~/.bashrc
注意: 在~/.bashrc上调用source对于我们当前的 shell 会话来说,只需要一次。每当我们打开一个新的终端,~/.bashrc的内容就会自动执行(包括我们的更新)。
为深度学习和计算机视觉创建虚拟环境
现在我们已经安装了virtualenv和virtualenvwrapper,下一步是实际上创建Python 虚拟环境——我们使用mkvirtualenv命令来完成。
在过去的安装教程中,我介绍了 Python 2.7 或 Python 3 的选择。在 Python 3 开发周期的这一点上,我认为它是稳定和正确的选择。如果你有特定的兼容性需求,你可以选择使用 Python 2.7,但是为了我的新深度学习书的目的,我们将使用 Python 3 。
也就是说,对于下面的命令,确保您的 Python ( -p)标志设置为python3:
$ mkvirtualenv dl4cv -p python3
无论你决定使用哪个 Python 版本,最终结果都是我们创建了一个名为dl4cv(计算机视觉深度学习的简称)的 Python 虚拟环境。
您可以随意命名这个虚拟环境(并创建任意数量的 Python 虚拟环境),但目前,我建议坚持使用dl4cv名称,因为这是我将在本教程剩余部分以及本系列剩余安装指南中使用的名称。
验证您是否处于“dl4cv”虚拟环境中
如果你重启了你的 Ubuntu 系统;注销并重新登录;或者打开一个新的终端,您需要使用workon命令来重新访问您的dl4cv虚拟环境。下面是一个workon命令的例子:
$ workon dl4cv
要验证您是否在dl4cv虚拟环境中,只需检查您的命令行— 如果您在提示前看到文本(dl4cv),那么您**在dl4cv虚拟环境中是**:
Figure 1: Inside the dl4cv virtual environment denoted by ‘(dl4cv)’ in the prompt.
否则如果你 没有 看到dl4cv文本,那么你 在dl4cv虚拟环境中就不是 :
Figure 2: Outside of the dl4cv virtual environment. Simply execute the ‘workon dl4cv’ command to get into the environment.
安装 NumPy
在我们编译 OpenCV 之前的最后一步是安装 NumPy ,一个用于数值处理的 Python 包。要安装 NumPy,请确保您处于dl4cv虚拟环境中(否则 NumPy 将被安装到 Python 的系统版本中,而不是dl4cv环境中)。
从那里执行以下命令:
$ pip install numpy
步骤 3:编译并安装 OpenCV
在这一节中,我们将安装和编译 OpenCV。我们将从下载和解压缩 OpenCV 3.3 开始。然后我们将从源代码构建和编译 OpenCV。最后,我们将测试 OpenCV 是否已经安装。
下载 OpenCV
首先让我们将 opencv 和 opencv_contrib 下载到您的主目录中:
$ cd ~
$ wget -O opencv.zip https://github.com/Itseez/opencv/archive/3.3.0.zip
$ wget -O opencv_contrib.zip https://github.com/Itseez/opencv_contrib/archive/3.3.0.zip
您可能需要扩展上面的命令来复制并通过完整路径到opencv_contrib文件。
然后,让我们解压缩这两个文件:
$ unzip opencv.zip
$ unzip opencv_contrib.zip
运行 CMake
让我们创建一个build目录并运行 CMake:
$ cd ~/opencv-3.3.0/
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D WITH_CUDA=OFF \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.3.0/modules \
-D BUILD_EXAMPLES=ON ..
对于 CMake,为了兼容性,您的标志与我的标志匹配是很重要的。此外,确保您的opencv_contrib版本与您下载的 OpenCV 版本完全相同(在本例中是版本3.3.0)。
在我们进入实际的编译步骤之前,请确保您检查了 CMake 的输出!
首先滚动到标题为Python 3的部分。
确保您的 Python 3 部分如下图所示:
Figure 3: Checking that Python 3 will be used when compiling OpenCV 3 for Ubuntu.
注意解释器指向我们位于虚拟环境中的二进制文件,而 T2 指向我们的 NumPy 安装。
在任何一种情况下,如果您 没有 看到这些变量路径中的dl4cv虚拟环境,那么 几乎肯定是因为您在运行 CMake 之前不在dl4cv虚拟环境中!
如果是这种情况,使用workon dl4cv访问dl4cv虚拟环境,并重新运行上面概述的命令(我还建议删除build目录并重新创建它)。
编译 OpenCV
现在,我们已经准备好用 4 个内核编译 OpenCV:
$ make -j4
注意: 你可以尝试一个版本的-j4标志对应你的 CPU 的核心数来实现编译时加速。在这种情况下,我使用了-j4,因为我的机器有四个内核。如果遇到编译错误,您可以运行命令make clean,然后在没有并行标志make的情况下编译。
从那里,你需要做的就是安装 OpenCV 3.3,然后如果你愿意的话,释放一些磁盘空间:
$ sudo make install
$ sudo ldconfig
$ cd ~
$ rm -rf opencv-3.3.0 opencv.zip
$ rm -rf opencv_contrib-3.3.0 opencv_contrib.zip
编译完成后,您应该会看到类似如下的输出:
Figure 4: OpenCV compilation is complete.
将 OpenCV 符号链接到您的虚拟环境
要将 OpenCV 绑定符号链接到dl4cv虚拟环境中,发出以下命令:
$ cd ~/.virtualenvs/dl4cv/lib/python3.5/site-packages/
$ ln -s /usr/local/lib/python3.5/site-packages/cv2.cpython-35m-x86_64-linux-gnu.so cv2.so
$ cd ~
注意,在这个例子中,我使用的是 Python 3.5 。如果您使用的是 Python 3.6 (或更新版本),您将需要更新路径以使用您的 Python 版本。
其次,您的.so文件(也就是实际的 OpenCV 绑定)可能是上面显示的一些变体,所以一定要通过仔细检查路径来使用合适的文件。
测试您的 OpenCV 3.3 安装
现在我们已经安装并链接了 OpenCV 3.3,让我们做一个快速的健全性测试来看看事情是否正常:
$ python
>>> import cv2
>>> cv2.__version__
'3.3.0'
在启动 Python ( workon dl4cv)之前,确保您处于dl4cv虚拟环境中。当您打印出版本时,它应该与您安装的 OpenCV 版本相匹配(在我们的例子中,OpenCV 3.3.0)。
就这样——假设您没有遇到导入错误,您就可以继续进行步骤#4 了,我们将在这里安装 Keras。
Step #4: Install Keras
对于这一步,通过发出workon dl4cv命令,确保您处于dl4cv环境中。然后安装我们的各种 Python 计算机视觉、图像处理和机器学习库:
$ pip install scipy matplotlib pillow
$ pip install imutils h5py requests progressbar2
$ pip install scikit-learn scikit-image
Next, install Tensorflow:
$ pip install tensorflow
注意我们是如何使用 TensorFlow 的 CPU 版本 的。我将在单独的教程中介绍 GPU 版本 。
安装 Keras 非常简单,这要归功于pip:
$ pip install keras
同样,在dl4cv虚拟环境中执行此操作。
您可以从 Python shell 测试我们的 Keras 安装:
$ python
>>> import keras
Using TensorFlow backend.
>>>
您应该看到 Keras 已经被正确导入 和tensor flow 后端正在被使用。
在您结束安装教程之前,花点时间熟悉一下~/.keras/keras.json文件:
{
"image_data_format": "channels_last",
"backend": "tensorflow",
"epsilon": 1e-07,
"floatx": "float32"
}
确保image_data_format设置为channels_last并且backend为tensorflow。
恭喜你!你现在已经准备好用 Python 开始你的 计算机视觉深度学习 之旅了。
摘要
在今天的博客文章中,我演示了如何在 Ubuntu 机器上仅使用 CPU 来设置深度学习环境。在学习新技术、算法和库时,配置开发环境是成功的一半。
如果你有兴趣更详细地研究深度学习,一定要看看我的新书, 用 Python 进行计算机视觉的深度学习 。
本系列接下来的几篇博客文章将涵盖包括 macOS 和 Ubuntu(有 GPU 支持)在内的替代环境。
当然,如果你对预配置的深度学习开发环境感兴趣,看看我的 Ubuntu 虚拟机和亚马逊 EC2 实例。
如果您有兴趣了解更多关于计算机视觉和深度学习的知识, 请务必在下面的表格中输入您的电子邮件地址,以便在新的博客帖子+教程发布时收到通知!**
设置深度学习硬件时的注意事项
原文:https://pyimagesearch.com/2016/06/13/considerations-when-setting-up-deep-learning-hardware/

在上周的博客文章中,我讨论了我对用于深度学习的 NVIDIA DIGITS DevBox 的投资。
这是一笔不小的投资,高达惊人的 15,000 美元——比我想象中花在办公室电脑上的钱还要多(我通常喜欢云中的硬件,在那里我不需要与它进行物理交互)。
也就是说,这项投资将在未来几个月推动 PyImageSearch 博客的发展。我已经做出了承诺做更多更多深度学习教程——特别是涉及卷积神经网络和图像分类*的教程。
事实上,在阵亡将士纪念日的周末,我花了两个小时在 Trello 头脑风暴,计划下一年在 PyImageSearch 博客上的教程。
大部分涉及深度学习。
所以,说了这么多,让我们来看看如果你决定购买自己的 DevBox 或构建自己的深度学习系统,你应该记住的一些考虑因素。
设置深度学习硬件时的注意事项
NVIDIA DevBox 不是像笔记本电脑或台式机那样的“普通”硬件。虽然你可以简单地把它插在墙上启动,但你真的不应该这样做,。
在你第一次启动你的系统之前,你需要考虑你将如何处理电涌,电池备份,以及盒子将在你的家里或办公室的什么地方“活动”(这对于保持系统冷却是至关重要的)。
当我在 NVIDIA DIGITS DevBox 的背景下写这篇博文时,如果你决定从头开始构建自己的深度学习系统,这些建议也将适用于你。
买一个 UPS——但不是随便什么 UPS
首先你需要弄一个不间断电源 (UPS)。顾名思义,当您的主电源出现故障时,UPS 会为您的系统提供应急电源—您可以将 UPS 想象成一个大型(非常)重型电池组,以便在断电时保持系统运行。一旦备用电池电量严重不足,UPS 甚至可以启动关机程序。
但是,在你跑到当地的电器商店或跳上 Amazon.com 之前,你需要问自己一个关键问题— 我的系统将消耗多少功率?
微波测试
在最大负载下,NVIDIA DevBox 功耗可以达到 1350W (这是由于系统中的 4 个 Titan X GPUs)。
在美国,1350W 相当于更高端的微波,所以你应该进行我喜欢称之为“微波测试”。
检查你的微波炉的瓦数,如果它与你想要建立的深度学习系统的瓦数相近,就把微波炉拖到你计划连接深度学习系统的房间,打开它,让它运行几分钟。
如果几分钟后你没有让电路过载,那么你可能状态很好。
我强调术语可能是,因为这不是一个完美的测试。运行一个瓦数相似的微波炉几分钟(T2)和运行一个系统几天(T4)甚至几周(T7)高负荷是不一样的。当运行你的深度学习系统时,你将在更长的时间内消耗更多的能量。
因此,做进一步的研究并确保你的家/办公室为这种持续的电力消耗正确布线是至关重要的。在某些情况下,您可能需要咨询电工。
突袭致死
你知道当你有一个 RAID 阵列(独立磁盘冗余阵列)运行时,突然断电,你的系统立即关闭会发生什么吗?
坏事。坏事会发生。
您的数据可能会处于不一致的“脏”状态,您的系统可能需要创建整个数组(如果可能的话)。正如这篇 为什么停电对你的数据不利 的文章建议,RAID 0 可以(潜在地)被在一次停电中完成销毁。
幸运的是,大多数现代 Unix 内核和 RAID 工具都有内置的预防措施,有助于防止电源故障期间的灾难性损失。
但是为什么要冒这个险呢?
购买一台 UPS,它可以在断电和电池电量极低的情况下启动安全、干净的关机。
注:我为什么要说突袭?因为 NVIDIA DIGITS DevBox 配有 3 个 3TB RAID5 磁盘,带有独立的 SSD 缓存。我最不希望发生的事情就是(1)重建阵列,或者(2)由于断电而丢失数据。
陆地飓风

图 1: 一个 derecho,也被称为“陆地飓风”,在 2012 年几乎摧毁了我拥有的每一台电脑和硬盘[ 来源。
每一个听说过 这个名词的人?
它被定义为“一场广泛、长期、直线的风暴,与一群陆基、快速移动的雷暴相关联” [ 维基百科。
飓风是极具破坏性的雷暴,能够产生飓风、龙卷风、暴雨和山洪暴发。有些人甚至把飓风称为。这些类型的风暴主要发生在北美,但在世界其他地方发生的频率要低得多。
**理解这些风暴迅速发展是很重要的。在某些情况下,当暴风雨来临的时候,你甚至可能听不到雷声——它正在快速移动。请记住,风暴本身正以每小时 60 英里或更高的速度移动——大多数雷暴甚至没有达到每小时 60 英里的阵风。
我在 UMBC 大学读研究生的第一年,我的家乡马里兰州在 2012 年 6 月 29 日星期五遭到了历史性的袭击。这场风暴是北美历史上最具破坏性的、致命和快速移动风暴之一。
*我独自一人呆在公寓里。说实话,这是我一生中最可怕的经历之一。
几分钟内,极高的风速(> 60 英里/小时,阵风接近 100 英里/小时)刮倒了电线和大树。
道路被淹。
残酷的地面闪电划过黑暗不祥的天空,紧接着几乎是瞬间的震耳欲聋的雷声,无情地从晚上 10 点持续到第二天凌晨 4 点。
28 人在风暴中死亡,因为大树倒在他们的房屋上,把他们压在下面。
当风暴结束时,我的家乡马里兰州卡顿斯维尔的大部分地区已经停电超过 6 天了。马里兰州的部分地区连续几周没有电力供应,这在现代美国是前所未闻的。
我为什么要告诉你这些?
在暴风雨中,我公寓外面的一条电线被闪电击中。电涌穿过电线,到达公寓,进入我的 UPS。
那天晚上我的 APC UPS 没电了……
……但是我的电子产品没有。
我的笔记本电脑和硬盘是安全的。
从那天晚上开始,我总是总是 买了 APC——我他妈的确定任何类型的敏感设备或重要数据都在 UPS 后面。
当然,如果电涌足够强,没有电涌保护器可以救你。但是你最好尽你最大的努力来确保你不会在雷雨期间(或者任何其他反常的自然行为)丢失你的设备(或者更重要的是,数据)。
在这种情况下,我只是失去了我的 UPS——我可能会失去更多。
但不是任何 UPS 都可以
因此,正如我上面提到的,您应该使用具有以下功能的 UPS:
- 电池备用
- 过电压保护
这一切都很好,但你也需要考虑你画的瓦特数。
大多数消费级 UPS 的最大功率为 900 瓦(T1),事实上,我有这款完全一样的 UPS(T3 ),我将其用于笔记本电脑和外部硬盘,最大功率为 865 瓦。
考虑到我需要在最大负载下消耗高达 1350W 的功率,我显然需要一个工业级的服务器级 UPS。
在做了大量的研究后,我发现了一些能够轻松应对更高瓦数和更大电流的 UPS。我最终选择了 APC SMT2200RM2U UPS ,它的价格实际上是我正在考虑的其他 UPS 的两倍,但正如我所说的,我对 APC 有一种信任和亲和力,所以我决定花更多的钱。
这款机架式 UPS 可以处理 1980W 和 2200VA,对于我的 NVIDIA DevBox 来说绰绰有余。
绞尽脑汁
在我收到我的 UPS 后,我进行了一个快速测试,以确保 NVIDIA DevBox 可以与它一起工作。果不其然,确实如此(虽然这张图片贴出来几乎让人尴尬):

Figure 2: Testing my NVIDIA DevBox with UPS backup.
当我和其他几位企业家同事在 Slack 频道上发布这张照片时,我在 SysDoc.io 的朋友尼克·库克(Nick Cook)差点砸了一块砖。
Nick 很快指出了将 UPS 直接放在地毯上,然后将 DevBox 放在 UPS 上的问题。他说的完全正确——我需要把它们都架起来,以帮助冷却并保证设备的安全。
所以,我再次去做了我的研究,并最终购买了 Tripp Lite 18U SmartRack 。我本来可以选择较小的机架,但我决定:
- 如果我愿意,允许我自己在未来扩展并包含新的系统。
- 给 NVIDIA DevBox 多一点冷却的“喘息空间”。
注:NVIDIA DIGITS DevBox 是而不是制造的可机架安装的。而是买了一个重型架子,把架子架起来,然后把 DevBox 放在架子上面。
机架本身装在一个相当大的纸板容器中交付:

Figure 3: My rack, still in the box.
与我的 UPS 和 DevBox 相比,该机架可以轻松包含这两者,从而留出了增长空间:

Figure 4: The rack itself is more than large enough to house both the UPS and DevBox.
然后,我花了一下午的时间安装 UPS 和 DevBox:
Figure 5: Fitting the UPS and DevBox into the rack.
在这个空间里看起来很不错:

Figure 6: The rack, all locked up.
在冬季,DevBox 还可以作为一个不错的加热器:

Figure 7: My office, now that the NVIDIA DIGTS DevBox, UPS, and rack have been fully installed.
摘要
在这篇博客文章中,我详细介绍了在设置深度学习硬件时应该记住的注意事项和建议。无论您是使用 NVIDIA DIGITS DevBox,还是构建自定义解决方案,请确保您:
- 确定你的房子、公寓或办公室是否正确布线,以获得所需的安培数/瓦特数。
- 投资 UPS 来保护您的投资,尤其是如果您使用 RAID 配置的驱动器。
- 如果有必要,把它们都架起来。
既然深度学习环境已经准备就绪,我将在下周详细介绍如何安装用于深度学习的 CUDA 工具包和 cuDNN,以便您可以利用 GPU 进行快速训练。
注意:NVIDIA dev box 已经安装了 CUDA 和 cuDNN,所以我将从头开始设置一个亚马逊 EC2 实例。你将能够使用这些说明来建立你自己的深度学习机器,以便你可以跟随未来的教程。
请务必使用下面的表格注册 PyImageSearch 时事通讯,以便在将来发布博文时得到通知!****
具有 Keras 和 TensorFlow 的暹罗网络的对比损耗
在本教程中,您将了解对比损失,以及如何使用它来训练更准确的暹罗神经网络。我们将使用 Keras 和 TensorFlow 实现对比损失。

之前,我撰写了一个关于连体神经网络基础的三部分系列:
本系列涵盖了 siamese 网络的基础知识,包括:
- 生成图像对
- 实现暹罗神经网络架构
- 使用二进制交叉条目训练暹罗网络
尽管二元交叉熵肯定是损失函数的一个有效选择,但它不是唯一的 T2 选择(甚至不是 T4 最佳选择)。
最先进的暹罗网络在训练时倾向于使用某种形式的对比损失或三重损失 —这些损失函数更适合暹罗网络,并有助于提高精度。
本指南结束时,你将了解如何实现暹罗网络,然后用对比损失来训练它们。
要学习如何训练一个有对比损失的连体神经网络,只要继续阅读。
具有 Keras 和 TensorFlow 的暹罗网络的对比损耗
在本教程的第一部分,我们将讨论什么是对比损失,更重要的是,如何使用它来更准确和有效地训练暹罗神经网络。
然后,我们将配置我们的开发环境,并检查我们的项目目录结构。
我们今天要实现许多 Python 脚本,包括:
- 配置文件
- 用于生成图像对、绘制培训历史和实施自定义图层的辅助工具
- 我们的对比损失实现
- 训练脚本
- 测试/推理脚本
我们将逐一回顾这些脚本;然而,其中一些已经在我之前的关于暹罗神经网络的指南中涉及到了,所以在适当的时候,我会让你参考我的其他教程以获得更多的细节。
我们还将花大量时间讨论我们的对比损失实现,确保您理解它在做什么,它如何工作,以及我们为什么要利用它。
在本教程结束时,您将拥有一个全功能的对比损失实现,能够训练一个连体神经网络。
什么是对比损失?对比损失如何用于训练连体网络?
在我们之前关于连体神经网络的系列教程中,我们学习了如何使用二进制交叉熵损失函数来训练连体网络:
二元交叉熵在这里是一个有效的选择,因为我们本质上做的是两类分类:
- 呈现给网络的两个图像属于同一类别
- 或者两幅图像属于不同的类别
以这种方式,我们有一个分类问题。因为我们只有两个类,二进制交叉熵是有意义的。
然而,实际上有一个损失函数更适合用于暹罗网络的称为对比损失:
解释一下 Harshvardhan Gupta ,我们需要记住,暹罗网络的目标不是将一组图像对分类,而是将它们区分开来。本质上,对比损失是评估暹罗网络区分图像对的工作有多好。这种差别很微妙,但却非常重要。
要打破这个等式:
 值是我们的标签。如果图像对属于同一类,则为
值是我们的标签。如果图像对属于同一类,则为 ,如果图像对属于不同类,则为
,如果图像对属于不同类,则为 。
。 变量是姐妹网络嵌入的输出之间的欧几里德距离。
变量是姐妹网络嵌入的输出之间的欧几里德距离。- max 函数取
 和边距、
和边距、 的最大值,减去距离。
的最大值,减去距离。
 值是我们的标签。如果图像对属于同一类,则为
值是我们的标签。如果图像对属于同一类,则为 ,如果图像对属于不同类,则为
,如果图像对属于不同类,则为 。
。 变量是姐妹网络嵌入的输出之间的欧几里德距离。
变量是姐妹网络嵌入的输出之间的欧几里德距离。 的最大值,减去距离。
的最大值,减去距离。在本教程的后面,我们将使用 Keras 和 TensorFlow 实现这个损失函数。
如果你想了解更多关于对比损失的数学动机的细节,一定要参考 Hadsell 等人的论文, 通过学习不变映射来降维。
配置您的开发环境
这一系列关于暹罗网络的教程利用了 Keras 和 TensorFlow。如果您打算继续学习本系列前两部分的教程,我建议您现在花时间配置您的深度学习开发环境。
您可以利用这两个指南中的任何一个在您的系统上安装 TensorFlow 和 Keras:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
今天关于连体网络对比损失的教程建立在我之前的三个教程的基础上,这三个教程涵盖了构建图像对、实现和训练连体网络以及使用连体网络进行推理的基础知识:
今天,我们将从这些指南(包括项目目录结构本身)中获取知识,因此,在今天继续之前,请考虑之前的指南必读材料。
一旦您跟上了进度,我们就可以继续审查我们的项目目录结构:
$ tree . --dirsfirst
.
├── examples
│ ├── image_01.png
│ ├── image_02.png
│ ├── image_03.png
...
│ └── image_13.png
├── output
│ ├── contrastive_siamese_model
│ │ ├── assets
│ │ ├── variables
│ │ │ ├── variables.data-00000-of-00001
│ │ │ └── variables.index
│ │ └── saved_model.pb
│ └── contrastive_plot.png
├── pyimagesearch
│ ├── config.py
│ ├── metrics.py
│ ├── siamese_network.py
│ └── utils.py
├── test_contrastive_siamese_network.py
└── train_contrastive_siamese_network.py
6 directories, 23 files
我再一次强调回顾我之前关于暹罗网络系列教程的重要性。在今天继续之前,这样做是的一个绝对要求。
实现我们的配置文件
我们的配置文件保存了用于训练我们的暹罗网络的重要变量。
打开项目目录结构中的config.py 文件,让我们看看里面的内容:
# import the necessary packages
import os
# specify the shape of the inputs for our network
IMG_SHAPE = (28, 28, 1)
# specify the batch size and number of epochs
BATCH_SIZE = 64
EPOCHS = 100
# define the path to the base output directory
BASE_OUTPUT = "output"
# use the base output path to derive the path to the serialized
# model along with training history plot
MODEL_PATH = os.path.sep.join([BASE_OUTPUT,
"contrastive_siamese_model"])
PLOT_PATH = os.path.sep.join([BASE_OUTPUT,
"contrastive_plot.png"])
第 16-19 行定义了序列化模型和训练历史的输出文件路径。
关于配置文件的更多细节,请参考我的教程 带有 Keras、TensorFlow 和深度学习的暹罗网络。
创建我们的助手实用函数
# import the necessary packages
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import numpy as np
然后我们有了我们的make_pairs函数,我在我的 用 Python 为暹罗网络构建图像对教程中详细讨论了这个函数(确保你在继续之前阅读了该指南):
def make_pairs(images, labels):
# initialize two empty lists to hold the (image, image) pairs and
# labels to indicate if a pair is positive or negative
pairImages = []
pairLabels = []
# calculate the total number of classes present in the dataset
# and then build a list of indexes for each class label that
# provides the indexes for all examples with a given label
numClasses = len(np.unique(labels))
idx = [np.where(labels == i)[0] for i in range(0, numClasses)]
# loop over all images
for idxA in range(len(images)):
# grab the current image and label belonging to the current
# iteration
currentImage = images[idxA]
label = labels[idxA]
# randomly pick an image that belongs to the *same* class
# label
idxB = np.random.choice(idx[label])
posImage = images[idxB]
# prepare a positive pair and update the images and labels
# lists, respectively
pairImages.append([currentImage, posImage])
pairLabels.append([1])
# grab the indices for each of the class labels *not* equal to
# the current label and randomly pick an image corresponding
# to a label *not* equal to the current label
negIdx = np.where(labels != label)[0]
negImage = images[np.random.choice(negIdx)]
# prepare a negative pair of images and update our lists
pairImages.append([currentImage, negImage])
pairLabels.append([0])
# return a 2-tuple of our image pairs and labels
return (np.array(pairImages), np.array(pairLabels))
def euclidean_distance(vectors):
# unpack the vectors into separate lists
(featsA, featsB) = vectors
# compute the sum of squared distances between the vectors
sumSquared = K.sum(K.square(featsA - featsB), axis=1,
keepdims=True)
# return the euclidean distance between the vectors
return K.sqrt(K.maximum(sumSquared, K.epsilon()))
最后,我们有一个助手实用程序plot_training,它接受一个plotPath,绘制我们在训练过程中的训练和验证对比损失,然后将该图保存到磁盘:
def plot_training(H, plotPath):
# construct a plot that plots and saves the training history
plt.style.use("ggplot")
plt.figure()
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="lower left")
plt.savefig(plotPath)
让我们继续实现暹罗网络架构本身。
实施我们的暹罗网络架构
我们的连体神经网络架构本质上是一个基本的 CNN:
# import the necessary packages
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.layers import MaxPooling2D
def build_siamese_model(inputShape, embeddingDim=48):
# specify the inputs for the feature extractor network
inputs = Input(inputShape)
# define the first set of CONV => RELU => POOL => DROPOUT layers
x = Conv2D(64, (2, 2), padding="same", activation="relu")(inputs)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.3)(x)
# second set of CONV => RELU => POOL => DROPOUT layers
x = Conv2D(64, (2, 2), padding="same", activation="relu")(x)
x = MaxPooling2D(pool_size=2)(x)
x = Dropout(0.3)(x)
# prepare the final outputs
pooledOutput = GlobalAveragePooling2D()(x)
outputs = Dense(embeddingDim)(pooledOutput)
# build the model
model = Model(inputs, outputs)
# return the model to the calling function
return model
关于模型架构和实现的更多细节,可以参考我的教程 暹罗网络与 Keras、TensorFlow、深度学习 。
用 Keras 和 TensorFlow 实现对比损失
对比损失的完整实现非常简洁,只有 18 行,包括注释:
# import the necessary packages
import tensorflow.keras.backend as K
import tensorflow as tf
def contrastive_loss(y, preds, margin=1):
# explicitly cast the true class label data type to the predicted
# class label data type (otherwise we run the risk of having two
# separate data types, causing TensorFlow to error out)
y = tf.cast(y, preds.dtype)
# calculate the contrastive loss between the true labels and
# the predicted labels
squaredPreds = K.square(preds)
squaredMargin = K.square(K.maximum(margin - preds, 0))
loss = K.mean(y * squaredPreds + (1 - y) * squaredMargin)
# return the computed contrastive loss to the calling function
return loss
建议大家复习一下“什么是对比损失?对比损失如何用于训练连体网络?”部分,并将我们的实现与等式进行比较,这样您可以更好地理解对比损耗是如何实现的。
创建我们的对比损失训练脚本
我们现在准备实施我们的培训脚本!该脚本负责:
- 从磁盘加载 MNIST 数字数据集
- 对其进行预处理并构建图像对
- 实例化暹罗神经网络架构
- 用对比损失训练连体网络
- 将训练网络和训练历史图序列化到磁盘
这段代码的大部分与我们之前关于 Keras、TensorFlow 和 Deep Learning 的 暹罗网络的帖子相同,所以虽然我仍然打算完整地介绍我们的实现,但我会将详细的讨论推迟到之前的帖子(当然,还要指出沿途的细节)。
在你的项目目录结构中打开train_contrastive_siamese_network.py 文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.siamese_network import build_siamese_model
from pyimagesearch import metrics
from pyimagesearch import config
from pyimagesearch import utils
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Lambda
from tensorflow.keras.datasets import mnist
import numpy as np
# load MNIST dataset and scale the pixel values to the range of [0, 1]
print("[INFO] loading MNIST dataset...")
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX / 255.0
testX = testX / 255.0
# add a channel dimension to the images
trainX = np.expand_dims(trainX, axis=-1)
testX = np.expand_dims(testX, axis=-1)
# prepare the positive and negative pairs
print("[INFO] preparing positive and negative pairs...")
(pairTrain, labelTrain) = utils.make_pairs(trainX, trainY)
(pairTest, labelTest) = utils.make_pairs(testX, testY)
第 15 行用预先提供的训练和测试分割加载 MNIST 数据集。
然后,我们通过以下方式预处理数据集:
- 将图像中的输入像素亮度从范围【0,255】缩放到【0,1】(第 16 行和第 17 行)
- 添加通道尺寸(第 20 行和第 21 行)
- 构建我们的图像对(第 25 行和第 26 行
接下来,我们可以实例化暹罗网络架构:
# configure the siamese network
print("[INFO] building siamese network...")
imgA = Input(shape=config.IMG_SHAPE)
imgB = Input(shape=config.IMG_SHAPE)
featureExtractor = build_siamese_model(config.IMG_SHAPE)
featsA = featureExtractor(imgA)
featsB = featureExtractor(imgB)
# finally, construct the siamese network
distance = Lambda(utils.euclidean_distance)([featsA, featsB])
model = Model(inputs=[imgA, imgB], outputs=distance)
第 30-34 行创建我们的姐妹网络:
- 我们首先创建两个输入,图像对中的每个图像一个输入(行 30 和 31 )。
- 然后,我们构建姐妹网络架构,它充当我们的特征提取器( Line 32 )。
- 该对中的每个图像将通过我们的特征提取器,产生一个量化每个图像的向量(行 33 和 34 )。
# compile the model
print("[INFO] compiling model...")
model.compile(loss=metrics.contrastive_loss, optimizer="adam")
# train the model
print("[INFO] training model...")
history = model.fit(
[pairTrain[:, 0], pairTrain[:, 1]], labelTrain[:],
validation_data=([pairTest[:, 0], pairTest[:, 1]], labelTest[:]),
batch_size=config.BATCH_SIZE,
epochs=config.EPOCHS)
# serialize the model to disk
print("[INFO] saving siamese model...")
model.save(config.MODEL_PATH)
# plot the training history
print("[INFO] plotting training history...")
utils.plot_training(history, config.PLOT_PATH)
第 42 行使用contrastive_loss 函数编译我们的模型架构。
然后,我们继续使用我们的训练/验证图像对来训练模型(行 46-50 ),然后将模型序列化到磁盘(行 54 )并绘制训练历史(行 58 )。
用对比损失训练一个连体网络
我们现在准备使用 Keras 和 TensorFlow 来训练我们的具有对比损失的暹罗神经网络。
确保您使用本指南的 “下载” 部分下载源代码、助手实用程序和对比损失实现。
从那里,您可以执行以下命令:
$ python train_contrastive_siamese_network.py
[INFO] loading MNIST dataset...
[INFO] preparing positive and negative pairs...
[INFO] building siamese network...
[INFO] compiling model...
[INFO] training model...
Epoch 1/100
1875/1875 [==============================] - 81s 43ms/step - loss: 0.2038 - val_loss: 0.1755
Epoch 2/100
1875/1875 [==============================] - 80s 43ms/step - loss: 0.1756 - val_loss: 0.1571
Epoch 3/100
1875/1875 [==============================] - 80s 43ms/step - loss: 0.1619 - val_loss: 0.1394
Epoch 4/100
1875/1875 [==============================] - 81s 43ms/step - loss: 0.1548 - val_loss: 0.1356
Epoch 5/100
1875/1875 [==============================] - 81s 43ms/step - loss: 0.1501 - val_loss: 0.1262
...
Epoch 96/100
1875/1875 [==============================] - 81s 43ms/step - loss: 0.1264 - val_loss: 0.1066
Epoch 97/100
1875/1875 [==============================] - 80s 43ms/step - loss: 0.1262 - val_loss: 0.1100
Epoch 98/100
1875/1875 [==============================] - 82s 44ms/step - loss: 0.1262 - val_loss: 0.1078
Epoch 99/100
1875/1875 [==============================] - 81s 43ms/step - loss: 0.1268 - val_loss: 0.1067
Epoch 100/100
1875/1875 [==============================] - 80s 43ms/step - loss: 0.1261 - val_loss: 0.1107
[INFO] saving siamese model...
[INFO] plotting training history...
在我的 3 GHz 英特尔至强 W 处理器上,每个周期花费了大约 80 秒。有了 GPU,训练会更快。
我们的培训历史可以在图 7 中看到。请注意,我们的验证损失实际上比我们的培训损失低,这是我在本教程中讨论的一个现象。
使我们的验证损失低于我们的训练损失意味着我们可以“更努力地训练”以提高我们的暹罗网络准确性,通常是通过放松正则化约束、深化模型和使用更积极的学习速率。
但是现在,我们的训练模式已经足够了。
实施我们的对比损失测试脚本
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
from tensorflow.keras.models import load_model
from imutils.paths import list_images
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of testing images")
args = vars(ap.parse_args())
# grab the test dataset image paths and then randomly generate a
# total of 10 image pairs
print("[INFO] loading test dataset...")
testImagePaths = list(list_images(args["input"]))
np.random.seed(42)
pairs = np.random.choice(testImagePaths, size=(10, 2))
# load the model from disk
print("[INFO] loading siamese model...")
model = load_model(config.MODEL_PATH, compile=False)
# loop over all image pairs
for (i, (pathA, pathB)) in enumerate(pairs):
# load both the images and convert them to grayscale
imageA = cv2.imread(pathA, 0)
imageB = cv2.imread(pathB, 0)
# create a copy of both the images for visualization purpose
origA = imageA.copy()
origB = imageB.copy()
# add channel a dimension to both the images
imageA = np.expand_dims(imageA, axis=-1)
imageB = np.expand_dims(imageB, axis=-1)
# add a batch dimension to both images
imageA = np.expand_dims(imageA, axis=0)
imageB = np.expand_dims(imageB, axis=0)
# scale the pixel values to the range of [0, 1]
imageA = imageA / 255.0
imageB = imageB / 255.0
# use our siamese model to make predictions on the image pair,
# indicating whether or not the images belong to the same class
preds = model.predict([imageA, imageB])
proba = preds[0][0]
- 从磁盘加载两个图像(行 31 和 32 )
- 克隆图像,以便我们可以在其上可视化/绘图(第 35 行和第 36 行)
- 为两幅图像添加一个通道维度,这是推理的要求(第 39 行和第 40 行)
- 向图像添加一个批次维度,这也是推理的一个要求(第 43 行和第 44 行)
- 将像素强度从范围【0,255】缩放到【0,1】,就像我们在训练中所做的那样
然后,图像对在第 52 和 53 条线上通过我们的连体网络,从而计算出姐妹网络生成的向量之间的欧几里德距离。
再次提醒,请记住,距离越小,距离越近,距离越近,距离越近。相反,距离越大,图像越不相似。
最后一个代码块处理图像对中两个图像的可视化以及它们的计算距离:
# initialize the figure
fig = plt.figure("Pair #{}".format(i + 1), figsize=(4, 2))
plt.suptitle("Distance: {:.2f}".format(proba))
# show first image
ax = fig.add_subplot(1, 2, 1)
plt.imshow(origA, cmap=plt.cm.gray)
plt.axis("off")
# show the second image
ax = fig.add_subplot(1, 2, 2)
plt.imshow(origB, cmap=plt.cm.gray)
plt.axis("off")
# show the plot
plt.show()
恭喜你实现了一个暹罗网络的推理脚本!关于这个实现的更多细节,请参考我以前的教程, 使用 siamese 网络、Keras 和 TensorFlow 比较图像的相似性。
使用我们的暹罗网络和对比损耗模型进行预测
$ python test_contrastive_siamese_network.py --input examples
[INFO] loading test dataset...
[INFO] loading siamese model...
查看图 8 ,您将会看到我们向我们的暹罗网络呈现了多组示例图像对,这些图像对经过了对比损失训练。
相同类别的图像具有较小的距离,而不同类别的图像具有较大的类别。
因此,您可以设置一个阈值 T ,作为距离的截止值。如果计算的距离 D 是T,则图像对必须属于同一类。否则,如果 D > = T ,则图像是不同的类。
阈值 T 的设定应通过实验根据经验进行:
- 训练网络。
- 计算图像对的距离。
- 手动可视化配对及其相应的差异。
- 找到一个最大化正确分类并最小化错误分类的临界值。
在这种情况下,设置 T=0.16 将是一个合适的阈值,因为它允许我们正确地标记属于同一类别的所有图像对,而不同类别的所有图像对都被如此对待。
总结
在本教程中,您了解了对比损失,包括对于训练暹罗网络来说,它是一个比二元交叉熵更好的损失函数。
这里你需要记住的是,一个连体网络并不是专门为分类而设计的。相反,它被用于区分,这意味着它不仅应该能够区分一个图像对是否属于同一类,还应该能够区分两个图像是否相同/相似。
对比损失在这种情况下效果更好。
我建议你在训练自己的暹罗神经网络时,尝试二进制交叉熵和对比损失,但我认为你会发现总体而言,对比损失做得更好。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号