PyImgSearch-博客中文翻译-八-
PyImgSearch 博客中文翻译(八)
基于 TensorFlow 和 Keras 的 Luong 注意力神经机器翻译
目录
神经机器翻译用 Luong 的注意力使用 TensorFlow 和 Keras
之前关于神经机器翻译的教程是我们第一次涉及注意力(巴丹瑙的注意力)的地方。我们不仅学习了背后的数学知识,还从头开始动手训练了 TensorFlow 模型。如果你还没有阅读它,请在阅读本教程之前阅读它。
在本教程中,您将了解如何利用 Luong 的注意力实现神经机器翻译,以及它如何增强 Bahdanau 的注意力中引入的注意力机制。
谷歌翻译够了。我们还有一个互动演示,你可以看到训练有素的模型在行动。
要学习如何将 Luong 的注意力应用到神经机器翻译任务中, 只要保持阅读。
神经机器翻译用 Luong 的注意力使用 TensorFlow 和 Keras
简介
在学术论文基于注意力的神经机器翻译的有效方法中,Luong 等人为提供了更有效的建立注意力的方法。这里我们要注意,注意力背后的基本直觉是不变的。Luong 等人提供的补充是迭代变化,使注意力过程更简单和更高效。
在 Bahdanau 等人、 Luong 等人工作的基础上。在正常的注意力架构中添加他们自己的扭曲,建议微妙的变化,以突破旧架构的限制。
注意: 我们不会深入整个代码演练,因为在 Bahdanau 的注意力教程中已经介绍过了。本教程将涵盖重大变化以及如何在 TensorFlow 和 Keras 中实现它们。
配置您的开发环境
要遵循该指南,您需要在系统上安装tensorflow和tensorflow-text。
幸运的是,TensorFlow 可以在 pip 上安装:
$ pip install tensorflow==2.8.0
$ pip install tensorflow-text==2.8.0
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
├── download.sh
├── inference.py
├── output
│ └── loss.png
├── pyimagesearch
│ ├── config.py
│ ├── dataset.py
│ ├── __init__.py
│ ├── loss.py
│ ├── models.py
│ ├── schedule.py
│ └── translator.py
├── requirements.txt
└── train.py
在pyimagesearch目录中,我们有:
config.py:任务的配置文件dataset.py:数据集管道的实用程序loss.py:保存训练模型所需损失的代码片段models.py:翻译模型的编码器和解码器schedule.py:培训管道的学习率计划程序- 训练和推理模型
在核心目录中,我们有四个脚本:
download.sh:下载训练数据的 shell 脚本requirements.txt:本教程需要的 python 包train.py:运行脚本来训练模型inference.py:推理脚本
卢昂的注意力
Luong 等人建议对解码器的架构进行一些小但必要的改变。我们先讲编码器,注意层,然后是解码器。在讨论架构时,我们还会将其与 Bahdanau 等人的架构进行比较。考虑图 2 中的图表。
编码器架构
在本文中,作者为编码器选择了一种单向(而不是 Bahdanau 实现中的双向)递归神经架构。单向 RNNs 加快了计算速度。
对于编码器,我们选择一个门控循环单元(GRU ),它接受当前输入
and past hidden state  as input while processing them into the present hidden state
as input while processing them into the present hidden state  .
.
在将整个源句子传递给编码器之后,我们有了所有隐藏状态的集合。
解码器架构
在每个时间步,
, in the decoding phase, the main motive is to capture the present hidden state of the decoder,  , and then to derive a context vector,
, and then to derive a context vector,  , that captures relevant source-side information.
, that captures relevant source-side information.
具体来说,给定目标隐藏状态,
, and the source-side context vector, , we employ a simple concatenation layer to combine the information from both vectors to produce an attentional hidden state as follows:
 注意力向量
注意力向量
, is then fed through the softmax layer to produce the probability of the next decoder word.
数学术语说够了,让我们只关注作者提议改变注意力层的部分。
Bahdanau 从:
Luong 从:
输入进料方式
在目前的提议下,作者发现他们没有把注意力放在解码器的循环单元上。这意味着解码系统不知道源句子的哪一部分在前一步被注意到了。
考虑到这一点,他们现在建议将注意力与输入和隐藏状态一起提供给下一个解码器单元。这被证明是一个游戏规则的改变。虽然 Bahdanau 的模型中已经安装了这种机制,但 Luong 的模型必须明确地做到这一点。
图 3 显示了 Luong 等人设想的整个编码和解码机制。
实施的注意
由于所有的方法和功能都与 Bahdanau 的注意力相同,我们将在本教程中讨论 Luong 的注意力模块。整个代码演练在本系列的上一篇博文中有所介绍。
如果您还没有阅读,请务必在继续下一步之前阅读。如果您已经这样做了,让我们打开pyimagesearch目录中的models.py并浏览它。
class LuongAttention(Layer):
def __init__(self, attnUnits, **kwargs):
super().__init__(**kwargs)
# initialize the attention units
self.attnUnits = attnUnits
def build(self, inputShape):
# build the additive attention layer
self.attention = Attention()
def get_config(self):
# return the configuration of the layer
return {
"attnUnits": self.attnUnits,
}
def call(self, hiddenStateEnc, hiddenStateDec, mask):
# grab the source and target mask
sourceMask = mask[0]
targetMask = mask[1]
# apply attention to align the representations
(contextVector, attentionWeights) = self.attention(
inputs=[hiddenStateDec, hiddenStateEnc, hiddenStateEnc],
mask=[targetMask, sourceMask],
return_attention_scores=True
)
# return the context vector and the attention weights
return (contextVector, attentionWeights)
我们首先在LuongAttention类的__init__函数中初始化行 80 上的关注单元。
接下来,在的第 82-84 行,我们在build函数中构建关注层。我们返回get_config函数(第 86-90 行)中的注意单元。
在第 92 行的上,我们定义了call方法。首先,我们提取第 94 行和第 95 行上的sourceMask和targetMask。
在第行第 98-102 行,我们注意对齐表示。我们使用 TensorFlow 的整洁的注意力 API 来实现这一点。你可以从官方 TensorFlow 文档这里了解更多信息。
最后在的第 105 行,我们返回contextVector和attentionWeights。
汇总
本教程向我们展示了 Luong 的注意力改善神经机器翻译任务的具体方式。我们还学习了如何简单地使用 Keras 和 TensorFlow 实现注意力模块。
Bahdanau 和 Luong 的关注既不是最先进的技术,也没有在 NLP 系统中广泛使用。但它们确实为接下来的事情提供了一块垫脚石和一个具体的基础。
我们将带着另一个关于注意力及其用途的教程回来,但在那之前,这里有一点值得思考的东西:
“如果我们在一个架构中只使用注意力,会发生什么??"
引用信息
A. R. Gosthipaty 和 R. Raha。“使用 TensorFlow 和 Keras 的 Luong 注意力的神经机器翻译”, PyImageSearch ,P. Chugh,S. Huot,K. Kidriavsteva,A. Thanki,eds .,2022 年,【https://pyimg.co/tpf3l
@incollection{ARG-RR_2022_Luong,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Neural Machine Translation with {Luong’s} Attention Using {TensorFlow} and {Keras}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/tpf3l},
}
**要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
神经机器翻译
原文:https://pyimagesearch.com/2022/08/15/neural-machine-translation/
目录
神经机器翻译
在本教程中,您将了解神经机器翻译的核心概念和注意力的初级读本。
本课是 NLP 102 的三部分系列的最后一部分:
*要了解神经机器翻译的工作原理及其背后的数学原理,请继续阅读。
神经机器翻译
简介
想象一下,你在网上找到一篇关于一个非常有趣的话题的文章。幸运的是,它不是你的母语,也不是你在交谈时感到舒服的语言。你暗自发笑,但随后找到了一个翻译文本的选项(如图图 1 所示)。
你感谢科技之神,阅读这篇文章,然后继续你的一天。但是有东西点击了,网页可能已经超过 2500 个单词,然而翻译在几秒钟内就完成了。因此,除非有一个速度超快的人在浏览器内部的某个地方敲击键盘,否则这一定是由算法完成的。
但是算法怎么这么准呢?是什么让这样的算法在世界上任何一种语言中都表现得很健壮?
这是自然语言处理的一个特殊领域,称为神经机器翻译,定义为在人工神经网络的帮助下进行翻译的行为。
在本教程中,我们将了解:
- 神经机器翻译如何工作
- 这项任务的两篇非常重要的论文的概述
- 我们将在后面的教程中使用的数据集
配置您的开发环境
要遵循本指南,您需要在系统上安装 TensorFlow 和 TensorFlow 文本库。
幸运的是,两者都是 pip 可安装的:
$ pip install tensorflow
$ pip install tensorflow-text
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
概率神经机器翻译概述
如果这听起来有点拗口,不要担心,我们保证这一切很快就会有意义。但是,在我们继续之前,让我们先花点时间来回忆一下概率。
")
refers to a probability of the event  occurring given
occurring given  has occurred. Now imagine
has occurred. Now imagine  and
and  as a sequence of French and English words, respectively. If we apply the same definition of conditional probability here, it will mean
as a sequence of French and English words, respectively. If we apply the same definition of conditional probability here, it will mean ") is the probability of a sequence of words in French
is the probability of a sequence of words in French ") occurring, given there is a sequence of words in English
occurring, given there is a sequence of words in English ") .
.
这意味着翻译(从英语到法语)的任务是最大化这种可能性
, as shown in Figure 3. )")
神经网络的任务是学习条件分布,然后当给定一个源句子时,通过最大化这个条件概率来搜索合适的目标句子。
数学背后的神经机器翻译
神经机器翻译(NMT)是利用人工神经网络来最大化这种条件概率的过程。
一个 NMT 架构通常包括一个编码器和一个解码器,如图图 4 所示。
在 Bahdanau 和 Luong 之前,编码器和解码器仅使用递归来解决机器翻译任务。在这一节中,我们将讨论仅使用 rnn 作为编码器和解码器来建模翻译背后的数学。
让我们考虑编码器中 RNN 隐藏状态的方程。
这里
is a network (can be an RNN, LSTM, or GRU). The main motivation here is to understand that the current hidden state ( ) depends on the current input (
) depends on the current input ( ) and the previous hidden state (). This recursive cell output feeding to the next has already been explained in our Introduction to RNN blog post. We advise you to quickly read our RNN series (if not done already) to get a primer on the same.
) and the previous hidden state (). This recursive cell output feeding to the next has already been explained in our Introduction to RNN blog post. We advise you to quickly read our RNN series (if not done already) to get a primer on the same.
NMT 的编码器创建一个瓶颈固定大小向量(上下文向量,
) from all the hidden states of the encoder. The context vector () will be used by the decoder to get to the target sequence.

can be any non-linearity. You will most likely find to be the last hidden state 
解码器预测下一个字
given the context vector () and all the previously predicted words { }.
}.
现在让我们重写概率方程。
")
is the hidden state of the decoder. Just like the hidden state of the encoder, can be any recurrent architecture (RNN, LSTM, or GRU).

can be any non-linearity that outputs the probability of the next word given all the previously generated words and the context vector.
对于翻译任务,我们必须生成最大化条件概率的目标词")
.
TL;DR: 本质上发生的是一个可变长度的序列被传递给一个编码器,它将整个序列的表示压缩成一个固定的上下文向量。这个上下文向量然后被传递给解码器,解码器将其转换成目标序列。
前方是什么?
在引言中,我们提到了两篇开创性的论文:
-
通过联合学习对齐和翻译的神经机器翻译 : 在本文中,作者认为将变长序列编码成定长上下文向量会恶化翻译的性能。为了解决这个问题,他们提出了一个软注意方案。注意到位后,上下文向量现在将对整个输入序列有一个完整的概述。
对于每一个翻译的单词,只为当前翻译构建一个动态上下文向量。
-
基于注意力的神经机器翻译的有效途径 : 本文作者改进了其前辈的几个关键因素(神经机器翻译通过联合学习对齐和翻译)。
这些包括为编码器引入单向 RNN,以及用乘法加法代替加法。本文旨在建立一种更好、更有效(顾名思义)的基于注意力的神经机器翻译方法。
数据集
你想知道如何编写代码并拥有自己的翻译算法吗?
我们将在即将发表的两篇讨论 Bahdanau 和 Luong 关注点的博文中用到这个数据集。
由于这是一个文本翻译任务,我们将需要一个文本对来完成这个任务。我们使用来自 http://www.manythings.org/anki/的法语到英语的数据集
您可以使用以下代码片段将数据集下载到 Colab 笔记本或您的本地系统中:
$ wget https://www.manythings.org/anki/fra-eng.zip
$ unzip fra-eng.zip
$ rm _about.txt fra-eng.zip
我们将在接下来的教程中详细介绍数据集的加载和处理。
汇总
本教程介绍神经机器翻译。我们学习如何用概率术语表达神经机器翻译。我们看到了 NMT 建筑通常是如何实地设计的。
接下来,我们将了解 Bahdanau 和 Luong 注意事项及其在 TensorFlow 和 Keras 中的代码实现。
引用信息
A. R. Gosthipaty 和 R. Raha。“神经机器翻译”, PyImageSearch ,P. Chugh,S. Huot,K. Kidriavsteva,和 A. Thanki 合编。,2022 年,【https://pyimg.co/4yi97
@incollection{ADR_2022_NMT,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Neural Machine Translation},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/4yi97},
}
用 OpenCV 进行神经类型转换
原文:https://pyimagesearch.com/2018/08/27/neural-style-transfer-with-opencv/

在本教程中,您将学习如何使用 OpenCV、Python 和深度学习将神经风格转换应用于图像和实时视频。在本指南结束时,你将能够通过神经风格转移生成美丽的艺术作品。
最初的神经风格转移算法是 Gatys 等人在他们 2015 年的论文 中介绍的一种艺术风格 的神经算法(其实这正是我在 里面教你如何用 Python 实现和训练用于计算机视觉的深度学习的确切算法)。
2016 年,Johnson 等人发表了用于实时风格转移的 感知损失和超分辨率 ,利用感知损失将神经风格转移框架化为类超分辨率问题。最终的结果是一个神经风格转换算法,它比 Gatys 等人的方法快了三个数量级(虽然有一些缺点,我将在指南的后面讨论它们)。
在这篇文章的其余部分,你将学习如何将神经风格转换算法应用到你自己的图像和视频流中。
要学习如何使用 OpenCV 和 Python 应用神经风格转移,继续阅读!
用 OpenCV 进行神经类型转换
https://www.youtube.com/embed/DRpydtvjGdE?feature=oembed
Python 中对象检测的非最大抑制
原文:https://pyimagesearch.com/2014/11/17/non-maximum-suppression-object-detection-python/
康涅狄格州很冷。非常冷。有时候早上起床都很难。老实说,如果没有大量南瓜香料拿铁的帮助,没有秋叶上美丽的日出,我不认为我会离开我舒适的床。
但是我有工作要做。今天的工作包括写一篇关于 Felzenszwalb 等人的非最大抑制方法的博文。
如果你还记得的话,上周我们讨论了用于目标检测的方向梯度直方图。
该方法可分为 6 步流程,包括:
- 取样正面图像
- 消极图像取样
- 训练线性 SVM
- 执行硬负挖掘
- 使用硬负样本重新训练你的线性 SVM
- 在测试数据集上评估您的分类器,利用非最大抑制来忽略冗余、重叠的边界框
应用这些步骤后,你将拥有一个平滑的物体检测器,就像约翰·科尔特兰一样:

Figure 1: My Python object detection framework applied to face detection. Even in low contrast images, faces can be easily detected.
(注:本文中使用的图像取自麻省理工学院+ CMU 正面人脸图像数据集 )
这些是使用方向梯度直方图建立对象分类器所需的最少步骤。该方法的扩展包括 Felzenszwalb 等人的可变形零件模型和 Malisiewicz 等人的样本 SVM 。
然而,无论您选择哪种 HOG +线性 SVM 方法,您都将(几乎 100%确定)检测到图像中对象周围的多个边界框。
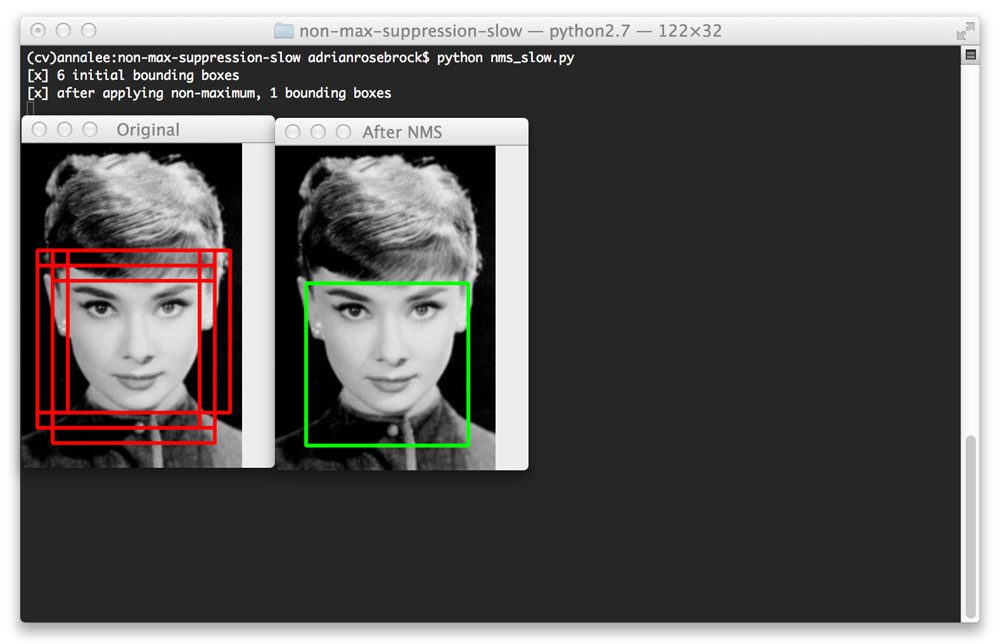
例如,看看这篇文章顶部奥黛丽·赫本的照片。我使用 HOG 和线性 SVM 将我的 Python 框架分叉用于对象检测,并训练它检测人脸。显然,它已经在图像中找到了赫本女士的脸——但是探测总共发射了六次!
**虽然每个检测事实上可能是有效的,但我肯定不希望我的分类器向我报告说它发现了六张脸,而实际上只有一张脸,即 T2 的脸。就像我说的,这是利用物体检测方法时的常见“问题”。
其实我根本就不想称之为“问题”!这是一个好问题。这表明您的检测器工作正常。如果你的检测器(1)报告了一个假阳性(即检测到了一个没有人脸的人脸)或者(2)没有检测到人脸,那就更糟了。
为了解决这种情况,我们需要应用非最大值抑制(NMS),也称为非最大值抑制。
当我第一次实现我的 Python 对象检测框架时,我不知道一个好的非最大抑制的 Python 实现,所以我联系了我的朋友 Tomasz Malisiewicz 博士,我认为他是对象检测和 HOG 方面的“专家”。
Tomasz 是这方面无所不知的权威,他向我推荐了 MATLAB 中的两个实现,后来我用 Python 实现了这两个实现。我们将回顾 Felzenszwalb etl al 的 first 方法。那么,下周我们就来回顾一下托马斯自己实现的(更快的)非最大值抑制法。
所以不要耽搁,让我们动手吧。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
Python 中对象检测的非最大抑制
打开一个文件,将其命名为nms.py,让我们开始在 Python 中实现 Felzenszwalb 等人的非最大值抑制方法:
# import the necessary packages
import numpy as np
# Felzenszwalb et al.
def non_max_suppression_slow(boxes, overlapThresh):
# if there are no boxes, return an empty list
if len(boxes) == 0:
return []
# initialize the list of picked indexes
pick = []
# grab the coordinates of the bounding boxes
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
# compute the area of the bounding boxes and sort the bounding
# boxes by the bottom-right y-coordinate of the bounding box
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(y2)
我们将从第 2 行的开始,导入一个包 NumPy,我们将利用它进行数值处理。
从那里,我们在第 5 行的上定义我们的non_max_suppression_slow函数。这个函数接受参数,第一个是我们的边界框集,形式为 (startX,startY,endX,endY) ,第二个是我们的重叠阈值。我将在本文稍后讨论重叠阈值。
第 7 行和第 8 行快速检查边界框。如果列表中没有边界框,只需向调用者返回一个空列表。
从那里,我们在第 11 行上初始化我们挑选的边界框列表(即我们想要保留的边界框,丢弃其余的)。
让我们继续在行 14-17 上解开边界框每个角的 (x,y) 坐标——这是使用简单的 NumPy 数组切片完成的。
然后我们使用我们的切片 (x,y) 坐标计算行 21 上每个边界框的面积。
务必密切关注线 22 。我们应用np.argsort来抓取边界框的y 坐标 的 排序 坐标的索引。我们根据右下角排序是绝对关键的,因为我们将需要在这个函数的后面计算其他边界框的重叠率。
*现在,让我们进入非极大值抑制函数的核心部分:
# keep looping while some indexes still remain in the indexes
# list
while len(idxs) > 0:
# grab the last index in the indexes list, add the index
# value to the list of picked indexes, then initialize
# the suppression list (i.e. indexes that will be deleted)
# using the last index
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
suppress = [last]
我们从第 26 行的开始循环我们的索引,在这里我们将继续循环,直到我们用完了要检查的索引。
从那里,我们将获取第 31 行的idx列表的长度,获取第 32 行的idx列表中最后一个条目的值,将索引i附加到我们的边界框列表中以保留在第 33 行上,最后用第 34**** 行的索引列表的最后一个条目的索引初始化我们的suppress列表(我们想要忽略的框列表)。
那是一口。因为我们处理的是索引列表中的索引,所以解释起来并不容易。但是一定要在这里停下来检查一下这些代码,因为理解这些代码很重要。
是时候计算重叠率并确定我们可以忽略哪些边界框了:
# loop over all indexes in the indexes list
for pos in xrange(0, last):
# grab the current index
j = idxs[pos]
# find the largest (x, y) coordinates for the start of
# the bounding box and the smallest (x, y) coordinates
# for the end of the bounding box
xx1 = max(x1[i], x1[j])
yy1 = max(y1[i], y1[j])
xx2 = min(x2[i], x2[j])
yy2 = min(y2[i], y2[j])
# compute the width and height of the bounding box
w = max(0, xx2 - xx1 + 1)
h = max(0, yy2 - yy1 + 1)
# compute the ratio of overlap between the computed
# bounding box and the bounding box in the area list
overlap = float(w * h) / area[j]
# if there is sufficient overlap, suppress the
# current bounding box
if overlap > overlapThresh:
suppress.append(pos)
# delete all indexes from the index list that are in the
# suppression list
idxs = np.delete(idxs, suppress)
# return only the bounding boxes that were picked
return boxes[pick]
这里我们开始循环第 37 行的列表中的(剩余)索引,获取第 39 行的当前索引的值。
使用来自行 32 的idx列表中的 最后一个 条目和来自行 39 的idx列表中的 当前 条目,我们找到最大的(x,y)* 坐标为起始边界框和最小的(x,y)***
**这样做可以让我们在较大的边界框中找到当前最小的区域(这也是我们最初根据右下角的 y 坐标对idx列表进行排序如此重要的原因)。从那里,我们计算第 50 和 51 行上的区域的宽度和高度。
现在,我们正处于重叠阈值发挥作用的时刻。在第 55 行,我们计算overlap,它是由当前最小区域的面积除以当前边界框的面积定义的比率,其中“当前”由第 39 行的索引j定义。
如果overlap比率大于行 59 上的阈值,那么我们知道两个边界框充分重叠,因此我们可以抑制当前边界框。overlapThresh的常用值通常在 0.3 和 0.5 之间。
第 64 行然后从idx列表中删除被抑制的边界框,我们继续循环直到idx列表为空。
最后,我们在第 67 行返回一组挑选的边界框(没有被抑制的边界框)。
让我们继续创建一个驱动程序,这样我们就可以执行这段代码并看到它的运行。打开一个新文件,将其命名为nms_slow.py,并添加以下代码:
# import the necessary packages
from pyimagesearch.nms import non_max_suppression_slow
import numpy as np
import cv2
# construct a list containing the images that will be examined
# along with their respective bounding boxes
images = [
("images/audrey.jpg", np.array([
(12, 84, 140, 212),
(24, 84, 152, 212),
(36, 84, 164, 212),
(12, 96, 140, 224),
(24, 96, 152, 224),
(24, 108, 152, 236)])),
("images/bksomels.jpg", np.array([
(114, 60, 178, 124),
(120, 60, 184, 124),
(114, 66, 178, 130)])),
("images/gpripe.jpg", np.array([
(12, 30, 76, 94),
(12, 36, 76, 100),
(72, 36, 200, 164),
(84, 48, 212, 176)]))]
# loop over the images
for (imagePath, boundingBoxes) in images:
# load the image and clone it
print "[x] %d initial bounding boxes" % (len(boundingBoxes))
image = cv2.imread(imagePath)
orig = image.copy()
# loop over the bounding boxes for each image and draw them
for (startX, startY, endX, endY) in boundingBoxes:
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 0, 255), 2)
# perform non-maximum suppression on the bounding boxes
pick = non_max_suppression_slow(boundingBoxes, 0.3)
print "[x] after applying non-maximum, %d bounding boxes" % (len(pick))
# loop over the picked bounding boxes and draw them
for (startX, startY, endX, endY) in pick:
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
# display the images
cv2.imshow("Original", orig)
cv2.imshow("After NMS", image)
cv2.waitKey(0)
我们从在第 2 行的上导入我们的non_max_suppression_slow函数开始。出于组织目的,我将该函数放在了pyimagesearch包中,但是您可以将该函数放在您认为合适的任何地方。从那里,我们为数值处理导入 NumPy,为第 3-4 行的 OpenCV 绑定导入cv2。****
然后,我们在第 8 行的上定义一个images的列表。该列表由 2 元组组成,其中元组中的第一个条目是图像的路径,第二个条目是边界框的列表。这些边界框是从我的 HOG +线性 SVM 分类器获得的,该分类器在不同的位置和尺度检测潜在的“人脸”。我们的目标是为每幅图像获取一组边界框,并应用非最大抑制。
我们首先在第 27 行的上循环图像路径和边界框,并在第 30 行的上加载图像。
为了可视化非最大抑制的效果,我们首先在第 34 行和第 35 行上绘制原始(非抑制)边界框。
然后我们在第 38 行上应用非最大抑制,并在第 42-43 行上绘制拾取的边界框。
最终得到的图像显示在第 46-48 行上。
动作中的非最大抑制
要查看 Felzenszwalb 等人的非最大抑制方法,请从本页底部下载本文的源代码和附带图像,导航到源代码目录,并发出以下命令:
$ python nms_slow.py
首先,你会看到奥黛丽·赫本的形象:
Figure 2: Our classifier initially detected six bounding boxes, but by applying non-maximum suppression, we are left with only one (the correct) bounding box.
注意六个边界框是如何被检测到的,但是通过应用非最大值抑制,我们能够将这个数量减少到一个。
第二幅图像也是如此:
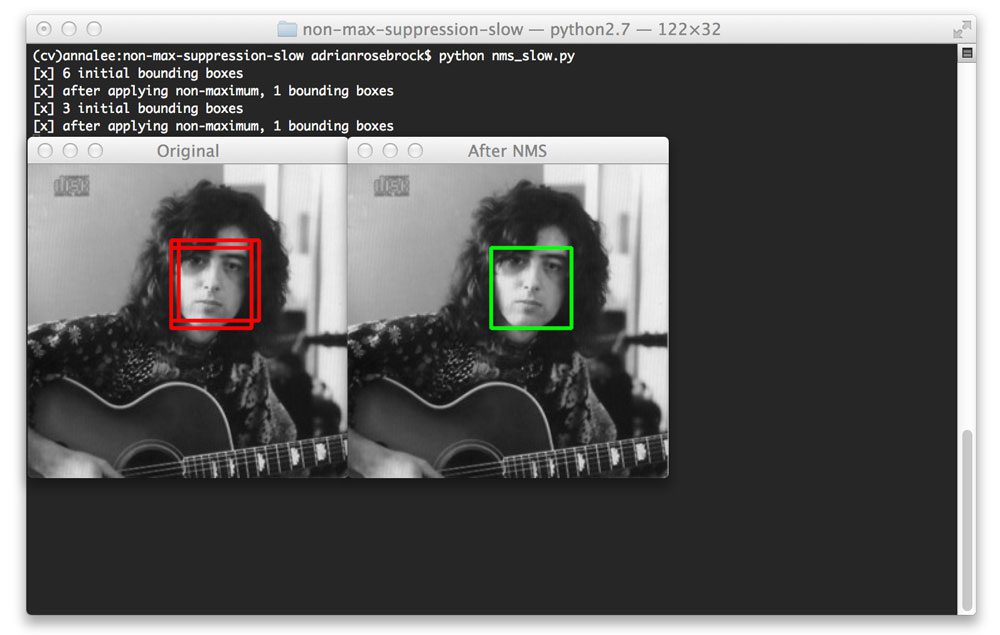
Figure 3: Initially detecting three bounding boxes, but by applying non-maximum suppression we can prune the number of overlapping bounding boxes down to one.
这里我们已经找到了对应于同一个面的三个包围盒,但是非最大抑制将要把这个数目减少到一个包围盒。
到目前为止,我们只检查了包含一张脸的图像。但是包含多张脸的图片呢?让我们来看看:
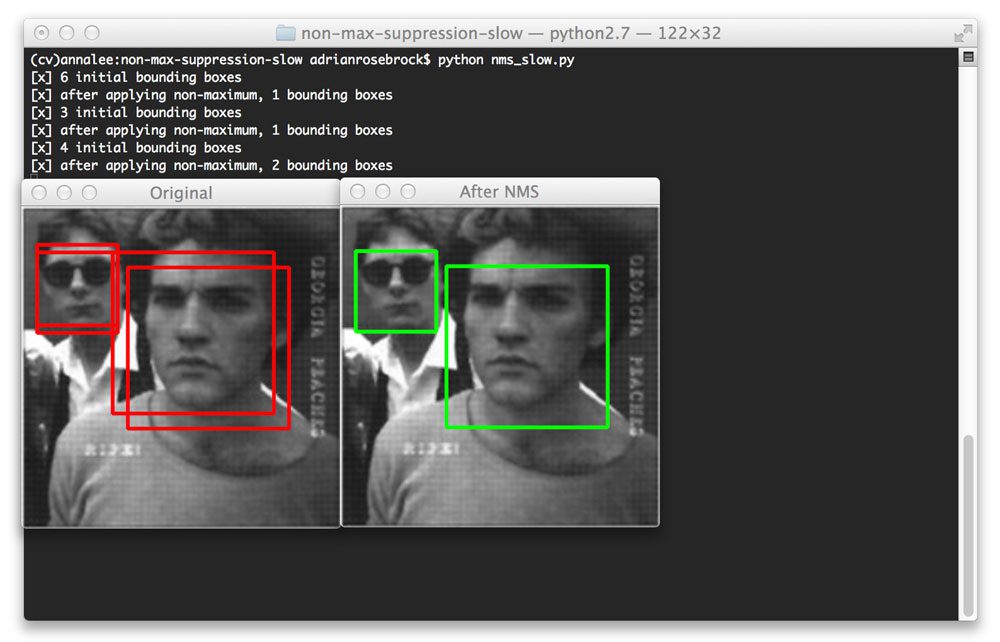
Figure 4: Non-maximum suppression correctly handles when there are multiple faces, suppressing the smaller overlapping bounding boxes, but retaining the boxes that do not overlap.
即使对于包含多个对象的图像,非最大抑制也能够忽略较小的重叠边界框,只返回较大的边界框。非最大值抑制在这里返回两个边界框,因为每个面的边界框。即使它们和重叠,重叠率也不会超过提供的阈值 0.3。
摘要
在这篇博文中,我展示了如何应用 Felzenszwalb 等人的方法进行非最大抑制。
当使用梯度方向直方图描述符和线性支持向量机进行对象分类时,您几乎总是检测围绕您想要检测的对象的多个边界框。
你应该首先应用非最大值抑制来忽略明显相互重叠的边界框,而不是返回所有找到的边界框。
然而,对于非最大抑制,对 Felzenszwalb 等人的方法还有待改进。
在我的下一篇文章中,我将实现我的朋友托马斯·马利西维茨博士建议的方法,据报道这种方法要快 100 倍!
请务必使用下面的表格下载这篇文章的代码!当我们下周检查 Tomasz 的非最大抑制算法时,您肯定希望手头有它!*****
现在招聘:计算机视觉和 OpenCV 通信协调员

自从我在 2014 年 1 月发表第一篇文章以来,PyImageSearch 博客已经成长了很多。这是一个不可思议的旅程,我要感谢读者朋友们在过去的 2.5 年里对我的支持。
然而,由于 PyImageSearch 的迅猛增长,我现在每天收到 100 多封电子邮件——已经到了我无法全部跟上的地步。
信不信由你,在过去的 2.5 年里,我是 PyImageSearch 的唯一员工(T1),并且我亲自(t 2)回复了(T4)在这段时间里收到的每一封(T5)电子邮件。
老实说,和你交流是我一天中最重要的事情之一。
例如:
你有没有发邮件给我一个关于计算机视觉的问题,不管是基础的还是高级的?
对,我接了。
你给我发邮件了吗,询问关于 实用 Python 和 OpenCV ?或者询问关于 PyImageSearch 大师课程?
回应的人是我。
你需要某种技术支持吗?
我在那里提供帮助。
但是由于工作量,已经到了 的地步,我需要一个通信协调员 来帮我:
- 对电子邮件和询问进行优先排序和分类。
- 回答关于 PyImageSearch 博客内容的一般问题和评论。
- 如果读者有你能回答的问题,给他们指出正确的方向。
- 将您无法回答的更高级的问题/业务咨询归类,以便我亲自回答。
简而言之,这项工作的主要角色包括两个要素:
- 帮我回答关于计算机视觉和 OpenCV 的问题。
- 对收到的电子邮件和问题进行分类,这样当我登录回复时就有了一个清晰的、按优先顺序排列的视图。
这将帮助我更好地服务于 PyImageSearch 社区,因为我将能够专注于特别需要我的经验和专业知识的任务。
工作详细信息
- 兼职:每天 2-4 小时,周一至周五每天
- 按小时支付(这是灵活的——我也会考虑固定的每周或每月付款)
- 远程工作
- 基于经验的薪酬(每小时 25-55 美元,视经验而定)
**当然,如果你非常适合这份工作,这份工作的角色和责任也会增加。把这当成你和我合作的切入点。
技能和要求
要想在这个职位上取得成功,你需要具备以下技能和素质:
- 你对自己要求很高。
- 在英语中,你有很强的 书面和口头沟通技巧。
- 你以前有计算机视觉的经验(经验越多越好)。
- 您了解 OpenCV 库,并且在以前的项目中使用过它(经验越多越好)。
- 你有能力对涉及计算机视觉、图像处理和 OpenCV 的问题写出清晰、连贯的回答。
- 你喜欢回答问题,提供反馈,提出建议,真正帮助别人。
- 你的回答很专业。
- 回答问题的时候可以保持积极的态度。
- 您已经掌握了基本的 Python 编程技能。
- 您有基本的 Unix 经验。
奖励积分,如果:
- 你是 PyImageSearch 博客的长期读者。
- 你已经通读了 实用 Python 和 OpenCV 的书。
- 您已经从 PyImageSearch 大师课程毕业。
- 你已经获得了大学水平的学位,并且完成了与计算机视觉相关的课程/期末项目/论文,或者有类似的真实世界经验。
- 你的 StackOverflow 声誉很好。
- 你对覆盆子酱有经验。
我适合这份工作吗?
如果符合以下条件,你就是这份工作的合适人选:
- 你喜欢计算机视觉而喜欢帮助别人。
- 你想在的小公司和成功的企业家一起工作,并帮助塑造 PyImageSearch 的未来。
接受这份工作比回答关于计算机视觉、图像处理和 OpenCV 的问题更有意义。这是一个和我一起工作和向我学习的机会。申请这份工作,你不一定要成为企业家,但我希望你对创业和小企业感兴趣(在某种程度上)。
这项工作什么时候开始?
尽快——我的目标是 8 月中旬开始工作,但如果你有情况阻止你那时开始工作,我会灵活处理(当然,你必须是适合这份工作的人)。
我如何申请?
申请这份工作,请使用此链接:
http://www . survey gizmo . com/S3/2904895/PyImageSearch-communication s-Coordinator-Application
我将接受申请,直到 7 月 31 日美国东部时间晚上 11:59,所以请务必在那之前收到你的申请!
我申请后会发生什么?
在你申请之后,我会亲自审核你的申请。
从那以后,我会通过电子邮件跟你联系,询问任何其他问题,如果有必要,安排一次正式的面试,等等。,一般在 3-4 天内。
我还会要求你回答几封样本邮件,以了解你的写作风格和计算机视觉/OpenCV 知识。不要担心,这些例子没有任何“正确”或“错误”的答案,我只是需要了解你是如何写作和与他人互动的。**如果你申请了,一定要留意你的收件箱,看看下一系列的邮件!****
现在招聘:内容作者
原文:https://pyimagesearch.com/2020/06/08/now-hiring-content-writer/

在过去的五年里,PyImageSearch 取得了惊人的增长。曾经是 OpenCV 上的一个小博客,现在是学习计算机视觉(CV)和深度学习(DL)的首选地。
当我第一次开始 PyImageSearch 的时候,我是所有博客文章、书籍和课程的唯一作者。我写了每一行代码,写了每一个字。
几年前,我请戴夫·霍夫曼来帮助我完成写作。他帮我撰写博客文章和章节,给我提纲和草稿,添加内容,定稿,润色。此外,戴夫还帮助《计算机视觉的树莓派》出版。
我们是时候扩展业务,寻找另一位内容作者来进一步帮助我们撰写博客文章和书籍/课程了。
- 你是一个有才华的作家吗?
- 你能拿出大纲/草稿,然后解释复杂的算法和错综复杂的代码吗?
- 你能写出“就像 Adrian 一样”这样让 PyImageSearch 的读者容易消化、理解和跟随吗?
- 通过与我们“挑剔但有趣”的编辑团队合作,你是否对了解自己的写作风格,包括如何成为一名更好的作家感到兴奋?
如果是这样,来为我们工作吧!我们希望你能加入我们的团队。
工作详细信息
- 兼职:每周 15-20 小时
- 如果你感兴趣并且非常适合这个职位,可以提升为全职
- 完全遥控
- 薪酬基于每小时,每月或每个博客帖子/项目支付选项的经验
角色和职责
- 为博客文章和章节准备草稿/提纲,然后制作经过精心研究的高质量内容,以供在线出版和印刷
- 编写尊重 PyImageSearch 使命的内容:作为计算机视觉、深度学习和 OpenCV 社区学习的黄金标准的教程
- 在发送到我们的编辑团队之前,校对和编辑博客文章
- 向编辑提交作品,以供输入、修改和批准
- 遵循编辑日历,必要时与其他团队成员合作,以确保高质量、及时的交付
- 理解、遵循并执行我们用来将博客文章的最终草稿插入 WordPress(我们的博客平台)的记录流程
- 直接与 Adrian 和内容经理合作
技能和要求
- 计算机科学、英语、新闻或相关领域的学士学位
- 熟悉 Adrian、PyImageSearch 品牌、现有发表的博客帖子/文章以及书籍和课程目录
- 优秀的英语写作和编辑技能
- 出色的以简单易懂的方式解释复杂技术内容的能力
- 在计算机视觉、深度学习和 OpenCV 方面有丰富的经验
- 能够在对话风格、易于理解的解释等方面“像阿德里安一样写作”。
- 使用多种资源完成研究的经验
- 精通内容管理系统(例如、WordPress、Medium 等。)
- 与内容经理、编辑和团队其他成员沟通和合作
- 能够定期、反复、可靠地按时完成任务
- 能够在很少或没有日常监督的情况下独立工作
- 能够同时处理多个不同目标的项目
- 优秀的时间管理技能
- 严格遵守 PyImageSearch 使用的样式指南
以下为理想但非必需:
- 已发表文章组合
- 撰写销售文案的经验
- 对阿德里安的工作非常熟悉
- 在概念(我们用来写内容的协作工具)中工作的经验
我适合这份工作吗?
如果符合以下条件,你就是这份工作的合适人选:
- 你是一个优秀的作家和沟通者
- 你有上进心
- 你为自己的工作感到自豪,对分配给你的任务拥有自主权,并能坚持不懈地执行,直到完成一件作品
- 你想在计算机视觉、深度学习和人工智能领域产生影响
这项工作什么时候开始?
尽快——我的目标是 7 月初/中旬开始工作,但如果你的生活状况不允许你那时开始工作,我会灵活处理(当然,你必须是适合这份工作的人)。
我如何申请?
申请内容作者职位,请使用此链接:
https://www . cogn itoforms . com/pyimagesearch 1/PyImageSearchContentWriterApplicationForm
除了基本的申请流程, 你会看到我要求你起草一篇博文样本的几个部分。我请求您这样做是为了:
- 观察你如何写作和交流
- 衡量你的英语水平
- 看看你能在多大程度上遵循提示和指示
- 确定你“像阿德里安一样写作”做得有多好
每次我在 PyImageSearch 博客上发布一个职位,都会收到 400 多份申请。对于这个新职位,我估计会有 1,000 多名申请人— 在早些时候收到你的申请,这样我就有更多的时间来审查它,并仔细考虑你是否适合这个职位!
我将在美国东部时间 6 月 26 日星期五晚上 11:59 分之前接受申请,所以请务必在那之前提交申请!
我申请后会发生什么?
你申请后,我会亲自审核你的申请。
如果我认为你非常适合这个职位,我会通过电子邮件与你联系,询问任何其他问题,如果有必要,安排一次正式面试等。通常在 3-4 个工作日内。
我保证会考虑周到,不会“让你陷入困境”——如果你不适合这个职位,我一定会在申请期结束后的三周内通知你。
现在招聘:招生顾问
原文:https://pyimagesearch.com/2020/06/08/now-hiring-enrollment-advisor/

在过去的五年里,PyImageSearch 取得了惊人的增长。曾经是 OpenCV 上的一个小博客,现在是学习计算机视觉和深度学习的首选地。
当我刚开始做 PyImageSearch 的时候,我提供的唯一产品是实用 Python 和 OpenCV ,这是一本通过 OpenCV 库教授图像处理和计算机视觉基础知识的简短书籍。
从那时起,我们的图书和课程供应已经显著扩展,不仅在数量上,而且在质量上:
** 用 Python 进行计算机视觉的深度学习: 我们深入潜入计算机视觉和深度学习的世界。这本书被许多人认为是将深度学习应用于计算机视觉的“黄金标准”。
- PyImageSearch 大师: 本课程涵盖 13 个模块,分为 168 课。这类似于计算机视觉方面的大学调查课程,但更注重实践和操作。
- 计算机视觉的树莓 Pi:专注于将计算机视觉和深度学习算法应用于嵌入式设备,如树莓 Pi、Movidius NCS、Google Coral、NVIDIA Jetson Nano 等。
鉴于 PyImageSearch 如此受欢迎,我们每天定期收到 200 多封电子邮件,其中大约 20-25%来自对我们的书籍/课程感兴趣的读者, 但不确定哪本书/课程最适合他们个人。
起初,我们试图创建常见问题并保存回复邮件,以帮助读者获得他们需要的建议,同时确保我们可以快速解决读者的询问。
然而,我们发现个人接触总是最有效的。
仔细想想就明白了:
一个潜在的学生不想要一个保存的回复,他们也不想被链接到一个通用的 FAQ 条目——他们想要的是一个个人指导手来帮助他们学习计算机视觉和深度学习。
如果我刚刚开始从事计算机视觉/深度学习,并准备投资深造,我会希望有个人指导,以确保我在时间和财务上的投资获得正回报。
在过去的两年里,PyImageSearch 团队和我分头行动,以各种身份担任招生顾问,指导学生并为他们指出最适合他们个人的书籍和/或课程。
这在一段时间内有效,但随着学生咨询数量的增加,以及我们在团队中的责任的增加,我们意识到作为招生顾问的时间分配是不可持续的:
- 潜在的学生询问邮件被遗漏了。
- 我们没有给未来的学生他们应得的个人接触。
- 我们在其他项目上落后了。
- 总的来说,我们都有点紧张,试图平衡我们在团队中的各种责任。
解决方案是:
聘请一名招生顾问,他的唯一职责是引导潜在学生选择适合他们的书籍或课程,确保我们的学生成功学习 CV/DL。
学院和大学有招生顾问来帮助学生选择正确的课程来顺利完成他们的学位。像 Udacity 这样的大型在线教育公司也提供招生顾问来帮助他们的学生。
PyImageSearch 也该这么做了。
我们致力于帮助我们的学生学习计算机视觉、深度学习和 OpenCV — 你愿意作为招生顾问为我们工作并帮助我们的学生取得成功吗?
工作详细信息
- 兼职:周一至周五每天 2-4 小时的集中工作
- 在大减价期间(如黑色星期五),每天 6-8 小时
- 假设每年有 10-15 个“大甩卖日”——你会提前知道甩卖日期,并据此制定计划
- 完全遥控
- 基于经验的薪酬,可选择奖金和/或佣金(根据您的喜好,每小时和每月固定薪酬均可)
角色和职责
当我们学习一项新的、具有挑战性的技能(如计算机视觉和深度学习)时,我们所有人真正需要的是一只有帮助的、指导的手——一只告诉我们要学习什么, 在哪里 我们可以找到这样的资源,以及 我们如何 去实现我们的目标的手。
*运行 PyImageSearch 的过程中,我最喜欢的部分之一就是成为他人的向导。
回到 2018 年,保罗·李博士给 PyImageSearch 团队和我发了电子邮件,询问我们的书籍和课程之间的差异,包括哪一本最适合他:
*“你的 ImageNet 包和你的 Guru 课程有什么区别?
Guru 课程包括您的 ImageNet 包吗?谢了。
-保罗" *
然后,我们通过电子邮件帮助 Paul:
- 我们讨论了 PyImageSearch 大师课程和我们的 计算机视觉深度学习与 Python 书籍的 ImageNet 捆绑包之间的区别。
- 我们帮助保罗不仅看到了研究深度学习的价值,也看到了研究传统计算机视觉的价值。
- 当 Paul 选择 ImageNet 捆绑包和 Gurus 课程时,我们帮助他开始运行。
保罗随后浏览了这本书和这门课程,在他购买后一年多一点的时间里,他进行了新颖的计算机视觉和深度学习研究,并在著名的美国心脏协会杂志上发表了一篇论文 ( 在这里可以找到对保罗·李博士的完整采访/案例研究)。
真的,当我们有一只指导之手时,会发生令人难以置信的事情——尽管仍有艰苦的工作要做,但这些碎片似乎更快地散落在一起。
作为一名招生顾问,对学生既要有同情心,又要有同理心:
- 你需要明白他们的目标是什么
- 你需要理解他们从何而来,以及他们迄今为止所做的努力
- 你需要能够指导他们接下来的步骤来实现他们的目标
一只指导之手可以走很长的路,正如保罗·李博士的经历所示,真正关心学生的回报是巨大的。
作为招生顾问,您的角色和职责包括:
- 联系潜在学生并建议他们哪些 PyImageSearch 书籍/课程最适合他们
- 跟进潜在学生,回答他们对我们的书/课程的任何问题或异议
- 完成销售并在我们的书籍/课程中招收学生
- 销售结束后,将付费学生交给技术支持团队成员
技能和要求
技能和经验
- 你有销售、营销、文案和/或电子邮件支持的背景
- 你知道什么是销售漏斗吗
- 您对销售流程有着深刻的理解:发现潜在客户资格评估推介处理问题/异议完成销售跟进
- 你有能力完成销售并跟进潜在的学生
- 你知道如何使用基本的营销和销售工具,包括客户关系管理系统、电子邮件客户端和聊天客户端
能力
- 在英语中,你拥有强大的 书面和口头沟通技巧
- 你有能力给希望购买我们的书籍/课程的潜在学生写清晰、连贯的回复
- 你喜欢帮助别人
- 在回应和与未来的学生一起工作时,你可以保持积极的态度
- 你以前在计算机视觉、深度学习和 OpenCV 方面有一些经验
- 你熟悉 PyImageSearch 品牌和我
- 你熟悉我的书和课程(最好是你自己已经读过/浏览过)
- 你知道我在 PyImageSearch 博客上有(和没有)哪些话题吗
值
- 你对未来的学生有同理心,渴望帮助他们找到合适的书籍/课程来支持他们的教育和实现他们的目标
- 你对自己要求很高
- 你采取主动,让自己负责任
我适合这份工作吗?
如果符合以下条件,你就是这份工作的合适人选:
- 你喜欢计算机视觉而喜欢帮助别人
- 你想在一家致力于帮助他人学习 CV/DL 的小公司工作
接受这份工作比回答潜在学生的问题更重要——这是一个和我一起工作并向我学习的机会。
这项工作什么时候开始?
尽快——我的目标是 7 月初/中旬开始工作,但如果你的生活状况不允许你那时开始工作,我会灵活处理(当然,你必须是适合这份工作的人)。
我如何申请?
申请招生顾问职位,请使用此链接:
https://www . cogn itoforms . com/pyimagesearch 1/pyimagesearchlenturementadvisorapplicationform
除了基本的申请流程,您还会看到,我要求您回复 8 封“示例邮件”给:
- 衡量你的销售和营销经验
- 和未来的学生一起工作时,衡量你的同理心/同情心水平
- 测试你完成销售的能力
每次我在 PyImageSearch 博客上发布一个职位,都会收到 400 多份申请。对于这个新职位,我估计会有 1,000 多名申请人— 在早些时候收到你的申请,这样我就有更多的时间来审查它,并仔细考虑你是否适合这个职位!
我将在美国东部时间 6 月 26 日星期五晚上 11:59 分之前接受申请,所以请务必在那之前提交申请!
我申请后会发生什么?
你申请后,我会亲自审核你的申请。
如果我认为你非常适合这个职位,我会通过电子邮件与你联系,询问任何其他问题,如有必要,安排一次正式面试等。通常在 3-4 个工作日内。
我保证会考虑周到,不会“让你陷入困境”——如果你不适合这个职位,我一定会在申请期结束后的三周内通知你。**
现招聘:技术项目经理
原文:https://pyimagesearch.com/2020/06/08/now-hiring-technical-project-manager/

在过去的五年里,PyImageSearch 取得了惊人的增长。曾经是 OpenCV 上的一个小博客,现在是学习计算机视觉(CV)和深度学习(DL)的首选地。
我们已经在 CV/DL 上创作了 350 多个免费教程,每周一发布一个新的教程。
目前,我们提供四种教育书籍/课程,每年都有新的 CV/DL 教育产品发布。
当 PyImageSearch 开始的时候,只有我一个人——我们只有一个产品。从那时起,我们提供的书籍和课程显著增加,不仅在数量上,而且在质量上。**
为了管理现有T2 内容的更新,以及开发新的内容,我们需要一名技术项目经理来提供端到端项目开发流程的专家监督。**
工作详细信息
- 灵活的工作时间——根据技能和经验提供全职和兼职选择
- 完全遥控
- 基于经验的薪酬,可选择基于绩效的奖金
角色和职责
- 在项目的整个执行过程中自上而下地监督管理项目,以确保遵守范围、预算和时间表标准所定义的成功
- 制定全面的端到端项目计划,将公司目标与项目交付成果相结合,从构思到实施
- 确定并实施用于促进团队项目的项目管理软件
- 识别潜在的问题/障碍,并制定解决方案来消除团队障碍,确保不断取得进展
- 监控项目进度,并就可衡量的里程碑、可交付成果等做出详细的计划报告。总结项目进度(包括任何可预见的问题)
- 主动与所有相关团队成员沟通
- 为团队成员提供鼓励
- 为所有团队成员创建和实施流程和策略
- 确定当前流程出现问题的领域
- 组织流程,使其能够以最小的复杂性重复执行
- 为预定项目建立、计划和开发要求和标准
- 分配和监督团队成员的日常任务,同时确保团队成员的活动符合公司的里程碑
- 定期召开团队会议,解决与项目相关的任何问题或挑战
- 为团队成员确定和定义明确的可交付成果、日期和角色/职责,以便项目能够按时按预算交付
- 更新和维护所有内部团队文件
技能和要求
- 计算机科学、工程或相关领域的学士学位(或同等工作经验)
- 项目管理或相关技术领域硕士学位优先
- 有认证机构颁发的专业项目管理证书者优先
- 对项目管理流程、策略和方法的理解
- 体验企业内部的指导、辅导和人才培养
- 优秀的时间管理和组织技能,以及运用这些技能为他人建立指导方针的经验
- 强烈的个人责任感
- 运用思考和解决问题技能的管理经验
- 强大的团队领导能力
- 能够预测挑战并寻求主动避开障碍
我适合这份工作吗?
如果符合以下条件,你就是这份工作的合适人选:
- 你是一个强有力的团队领导,能够指导他人,帮助他们实现其全部潜力并获得最大效率
- 你有上进心
- 你为自己的工作感到自豪,对分配给你的任务负责,并坚持不懈地执行,直到项目完成
- 你想在计算机视觉、深度学习和人工智能领域产生影响
这项工作什么时候开始?
尽快——我的目标是 6 月底/7 月初开始工作,但如果你的生活环境不允许你那时开始工作,我也会灵活处理(当然,你必须适合这份工作)。
我如何申请?
要申请技术项目经理职位,请使用此链接:
https://www . cognit oforms . com/pyimagesearch 1/pyimagesearchectoriprojectmanagerapplicationform
每次我在 PyImageSearch 博客上发布一个职位,都会收到 400 多份申请。对于这个新职位,我估计会有 1,000 多名申请人— 在早些时候收到你的申请,这样我就有更多的时间来审查它,并仔细考虑你是否适合这个职位!
我将在美国东部时间 6 月 26 日星期五晚上 11:59 分之前接受申请,所以请务必在那之前提交申请!
我申请后会发生什么?
你申请后,我会亲自审核你的申请。
如果我认为你非常适合这个职位,我会通过电子邮件与你联系,询问任何其他问题,如有必要,安排一次正式面试等。通常在 3-4 个工作日内。
我保证会考虑周到,不会“让你陷入困境”——如果你不适合这个职位,我一定会在申请期结束后的三周内通知你。**
英伟达杰特森纳米。为深度学习和计算机视觉预先配置的 img

在本教程中,您将学习如何使用我的预配置的 NVIDIA Jetson Nano。计算机视觉和深度学习 img。这个。img 包括 TensorFlow,Keras,TensorRT,OpenCV 等。预装!
如果你曾经配置过 NVIDIA 的产品,比如 TX1、TX2,甚至 Nano,你就会知道使用 NVIDIA 的 Jetpack 和安装库远非简单明了。
今天,我很高兴地宣布我的预配置 NVIDIA Jetson Nano。img!
这个。img 将节省您设置 NVIDIA Jetson Nano 的时间,如果不是几天的话。它是由我在 PyImageSearch 的团队开发和支持的,旨在节省您的时间,让您快速开发自己的嵌入式 CV/DL 项目,并跟随我的新书Raspberry Pi for Computer Vision。
如果你购买了计算机视觉的树莓 Pi 的完整套装的副本,你将获得这个附带的. img
你所要做的就是(1)下载。img 文件,(2)使用 balenaEtcher 将其闪存到您的 microSD 卡,以及(3)启动您的 NVIDIA Jetson Nano。
从那里,您将有一个完整的软件列表,可以在虚拟环境中运行,而没有配置、编译和安装软件的所有麻烦。图像上突出显示的软件包括但不限于 Python、OpenCV、TensorFlow、TensorFlow Lite、Keras 和 TensorRT。
了解更多关于 Jetson Nano 的信息。img,继续看。
英伟达杰特森纳米。img 针对深度学习和计算机视觉进行了预配置
通常,设置你的 NVIDIA Jetson Nano 需要三天才能使它完全能够处理深度学习驱动的推理。这包括:
- 系统级包
- 从源代码编译的 OpenCV(支持 CUDA)
- 英伟达发布的 TensorFlow 1.13.1
- 滕索特
- 所需的 Python 库
- 研究时间,反复试验,从头开始,用头敲键盘
是的,我们 PyImageSearch 在 2-3 天的时间里做了所有这些事情。我们一直都在做这种事情。如果你没有同样的经历,你可能会花一周时间弄清楚如何配置杰特森纳米。而且即使你很有经验,也许你只是目前没有时间(你宁愿专注于培训和部署)。
**让我们面对现实吧:系统管理工作一点也不有趣,而且非常令人沮丧。
通过捆绑预配置的 Nano。img 连同 树莓为计算机视觉完成捆绑,我的目标是:
- 跳过在 Jetson Nano 上安装 Python、OpenCV、TensorFlow/Keras、TensorRT 等的繁琐过程,启动您的计算机视觉和深度学习教育
- 为你提供一本书,里面有你可能得到的关于嵌入式计算机视觉和深度学习的最佳介绍
这种预先配置的纳米。img 面向 PyImageSearch 的读者,他们希望 节省时间 和 启动他们的计算机视觉教育。
如果听起来不像你,不用担心。我仍然会提供免费教程来帮助您配置您的 Jetson Nano。请记住,PyImageSearch 的客户获得优先支持。
杰森·纳诺。img 设置说明
本文档的其余部分描述了如何 安装和使用NVIDIA Jetson Nano。img 包含在您购买的用于计算机视觉的 树莓 Pi完整套装中。
本指南的结尾讨论了许多有关的常见问题(FAQ)。img 文件。如果您有 FAQ 中未涉及的问题,请给我们发送消息。
步骤#1:下载并解压归档文件

Figure 1: After you download and unzip your NVIDIA Jetson Nano pre-configured .img, you’ll be presented with both UbuntuNano.img.gz and README.pdf files. The .gz file is ready to be flashed with balenaEtcher.
当你收到购买链接时,一定要下载这本书,code, Raspbian。img 和 Nano .img。每个文件都是. zip 格式。UbuntuNano.zip档案包含预先配置的。img 和一个README.pdf文件。
继续使用你最喜欢的解压工具(7zip,Keka,WinRAR 等)解压文件。).一旦你。解压缩后,您将看到一个. img.gz 文件。没有必要提取包含的. img.gz 文件,因为我们将直接使用 balenaEtcher 对它们进行刷新。
解压缩UbuntuNano.zip后,你的文件夹应该看起来像图 1 。
步骤 2:编写。使用 balenaEtcher 将 img 复制到 32GB 的 microSD

Figure 2: Flashing the NVIDIA Jetson Nano .img preconfigured for Deep Learning and Computer Vision.
这辆杰特森·纳诺。img 在 32GB microSD 卡上只能工作。请勿尝试使用 8GB、16GB、64GB、128GB 或更高的卡。虽然从技术上来说,Jetson Nano 支持 32GB 和更高的 microSDs,但我们的。img 只能闪存到 32GB 的存储卡。
另外,我推荐*高质量的 Sandisk 32GB 98MB/s 卡。它们在亚马逊和许多在线分销商处都有售。购买非品牌的廉价卡的读者经常会遇到可靠性问题。
编写预配置的 Nano。img 到你的卡,只需使用名为 balenaEtcher 的免费工具(兼容 Mac、Linux 和 Windows)。
BalenaEtcher 可以处理压缩文件比如。gz (加载到蚀刻机之前不需要解压. img . gz)。
简单来说:
- 选择
UnuntuNano.img.gz文件。 - 指定目标设备(您的 32GB microSD )。
- 点击闪光灯!按钮。
刷新可能需要大约 30 分钟或更长时间(远远少于手动安装软件所需的时间)。保持耐心——也许在系统闪烁的时候去散散步、读本书或喝杯茶。没有什么比看着水沸腾或等待油漆变干更好的了,所以抑制你的兴奋,离开你的屏幕。
第三步:第一次启动你的 NVIDIA Jetson Nano

Figure 3: The microSD card reader slot on your NVIDIA Jetson Nano is located under the heatsink as shown. Simply insert the NVIDIA Jetson Nano .img pre-configured for Deep Learning and Computer Vision and start executing code.
使用预先配置的 PyImageSearch 刷新您的 microSD 后。如图 3 所示,将卡插入散热器下的 Jetson Nano。
从那里,启动您的 Jetson Nano,并输入用户名和密码:
- 用户名:图片搜索
- 密码: pyimagesearch
如果您在登录时遇到问题,很可能是由于您的非美国键盘布局。您可能需要插入一个美国键盘,或者仔细地将您现有的键盘按键映射到用户名和密码。
在登录程序之前或之后的任何时间点,继续将以太网电缆插入 Nano 和您的网络交换机—Jetson Nano 开箱后不具备 WiFi 功能。如果您希望使用 WiFi,请滚动到“向 Jetson Nano 添加 WiFi 模块”部分。
步骤#4:打开终端并激活预配置的虚拟环境

Figure 4: To start the Python virtual environment, simply use the workon command in your terminal. You’ll then be working inside a preconfigured deep learning and computer vision environment on your NVIDIA Jetson Nano using the PyImageSearch .img.
我的预配置杰特森纳米。img 配备了深度学习和计算机视觉部署所需的所有软件。你可以在一个名为py3cv4的 Python 虚拟环境下找到该软件。
要访问 Python 虚拟环境,只需通过以下方式激活它:
$ workon py3cv4
注意图 4 中的【the bash 提示符前面是括号中的环境名。
在 Jetson Nano 上执行 PyImageSearch 书籍中的代码
有多种方法可以在您的 Nano 上访问用于计算机视觉的 Raspberry Pi 的源代码。第一种是使用 web 浏览器下载。zip 存档:
Figure 5: Downloading the Nano .img, source code, and book volumes from Raspberry Pi for Computer Vision using the Raspberry Pi web browser.
只需下载源代码。直接压缩到您的 Pi。
如果代码当前位于您的笔记本电脑/台式机上,您也可以使用您最喜欢的 SFTP/FTP 客户端,将代码从您的系统传输到您的 Pi:

Figure 6: Utilize an SFTP/FTP client to transfer the code from your system to the Raspberry Pi.
或者您可能希望使用 Sublime 等文本编辑器在 Nano 上手动编写代码:

Figure 7: Using a text editor to type Python code (left). Executing Python code inside the NVIDIA Jetson Nano preconfigured .img virtual environment, which is ready to go for computer vision and deep learning (right).
我建议要么通过网络浏览器下载这本书的源代码,要么使用 SFTP/FTP,因为这也包括书中使用的数据集。然而,手动编码是一种很好的学习方式,我也强烈推荐它!
要获得更多关于如何用你的杰特森纳米远程工作的技巧,请务必阅读我的博客文章 【远程开发】 (尽管文章的标题包含“树莓派”,但这些概念也适用于杰特森纳米)。
如何在您的 Jetson Nano 上测试和使用 USB 或 PiCamera

Figure 8: The NVIDIA Jetson Nano is compatible with a PiCamera connected to its MIPI port. You can use the PyImageSearch preconfigured Jetson Nano .img for computer vision and deep learning.
Raspberry Pi 用户会很高兴地知道,你在抽屉里为启示录(即,深度学习的僵尸对象检测)储存的各种 PiCamera 模块与 Jetson Nano 兼容!
在本节中,我们不会检测僵尸。相反,我们将使用一个简短的 Python 脚本简单地测试我们的 USB 和 PiCamera。
在我们开始之前,请前往这篇博文的 【下载】 部分,并获取。包含代码的 zip。
在里面你会发现一个名为test_camera_nano.py的单独的 Python 脚本。现在我们来回顾一下:
# import the necessary packages
from imutils.video import VideoStream
import imutils
import time
import cv2
# grab a reference to the webcam
print("[INFO] starting video stream...")
#vs = VideoStream(src=0).start()
vs = VideoStream(src="nvarguscamerasrc ! video/x-raw(memory:NVMM), " \
"width=(int)1920, height=(int)1080,format=(string)NV12, " \
"framerate=(fraction)30/1 ! nvvidconv ! video/x-raw, " \
"format=(string)BGRx ! videoconvert ! video/x-raw, " \
"format=(string)BGR ! appsink").start()
time.sleep(2.0)
这里我们从imutils导入我们的VideoStream类。我们将使用这个类来处理(1)PiCamera 或(2)USB 摄像头。
让我们继续在第 9-14 行设置我们的流
- USB 摄像头:目前已在第 9 行中注释掉,要使用您的 USB 网络摄像头,您只需提供
src=0或另一个设备序号,如果您有多个 USB 摄像头连接到您的 Nano。 - PiCamera: 目前活跃在线 10-14 上,一个很长的
src字符串用于与 Nano 上的驱动程序一起工作,以访问插入 MIPI 端口的 PiCamera。如您所见,格式字符串中的宽度和高度表示 1080p 分辨率。您也可以使用 PiCamera 与兼容的其他分辨率。
现在我们的相机流已经准备好了,我们将循环帧并用 OpenCV 显示它们:
# loop over frames
while True:
# grab the next frame
frame = vs.read()
# resize the frame to have a maximum width of 500 pixels
frame = imutils.resize(frame, width=500)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# release the video stream and close open windows
vs.stop()
cv2.destroyAllWindows()
在循环内部,我们抓取一个frame并resize它,保持纵横比(第 20-23 行)。虽然您不需要调整相框的大小,但我们这样做是为了确保它适合我们的屏幕,以防您的相机分辨率比您的屏幕大。
从那里,我们显示帧并捕捉按键;当按下q键时,我们break并清理。
让我们学习执行我们的 Jetson 纳米相机测试脚本。
首先,决定是使用 USB 网络摄像头还是 PiCamera。适当地注释/取消注释第 9-14 行。在脚本的当前形式中,我们选择 PiCamera。
然后,激活您的虚拟环境(它是在上预先配置的。img):
$ workon py3cv4
从那里,执行脚本:
$ python test_camera_nano.py
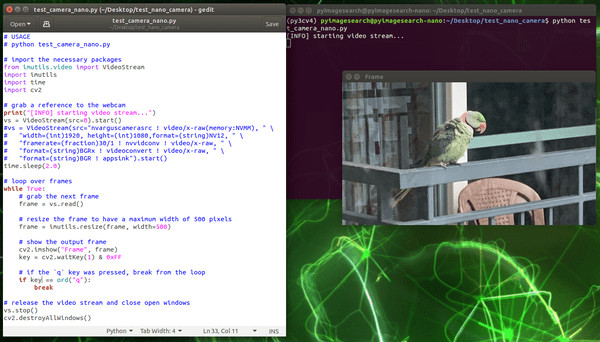
FIgure 9: Testing a PiCamera with the NVIDIA Jetson Nano using a preconfigured .img for computer vision and deep learning.
正如你在图 9 中看到的,NVIDIA Jetson Nano 正在用摄像机观看 Abhishek Thanki 邻居的鸟。
考虑到 Jetson Nano 支持 PiCamera,该产品在深度学习能力方面比 Raspberry Pi 更上一层楼。
可选:为 Jetson Nano 添加 WiFi 模块

Figure 10: The NVIDIA Jetson Nano does not come with WiFi capability, but you can use a USB WiFi module (top-right) or add a more permanent module under the heatsink (bottom-center). Also pictured is a 5V 4A (20W) power supply (top-left) which you may wish to use to power your Jetson Nano if you have lots of hardware attached to it.
开箱即用,Jetson Nano 硬件的第一个修订版没有有 WiFi。NVIDIA 真的搞砸了——更便宜的 Raspberry Pis 都有,大多数人都习惯了有 WiFi 的物联网设备。
但是你有选择!
如果你想要 WiFi(大部分人都有),你必须自己加一个 WiFi 模块。为您的 Jetson Nano 添加 WiFi 的两个绝佳选择包括:
- USB 转 WiFi 适配器(图 10 、右上)。不需要任何工具,可以移植到其他设备上。图为 Geekworm 双频 USB 1200m 。
- WiFi 模块如 Intel 双频 Wireless-Ac 8265 W/Bt(Intel 8265 NGW)和 2x Molex Flex 2042811100 Flex 天线 ( 图 10 、中底)。您必须在 Jetson Nano 的主散热器下安装 WiFi 模块和天线。这种升级需要 2 号十字螺丝刀、无线模块和天线(更不用说大约 10-20 分钟的时间)。
[图 11: NVIDIA Jetson Nano Wifi 模块安装步骤。]
上面的动画展示了我们在为 Jetson Nano 安装英特尔 WiFi 模块时收集的部分照片。这里的一个好处是,Ubuntu 18.04 不需要手动安装特殊的驱动程序来使用 WiFi 模块。它是“即插即用”的——一旦你启动,只需选择你的 WiFi 网络,并在需要时输入凭证。
对于大多数用户来说,在散热器下插一个 WiFi 模块并不方便,也不实用。这可能不值得努力,尤其是如果你只是开发一个概念验证产品。
为此,强烈推荐 USB WiFi 棒。有很多选项,我们建议尝试找到一个带有 Ubuntu 18.04 内置驱动程序的选项。不幸的是,图中的 Geekworm 产品需要手动安装驱动程序(你需要一个有线连接来安装驱动程序或耐心和一个拇指驱动器)。
常见问题(FAQ)
问:如果我想自己配置我的 Jetson Nano 怎么办?
答:请继续关注关于如何手动配置 Jetson Nano 的教程。一定要安排 2-5 天的时间来安装所有的东西。
问:手工安装深度学习和计算机视觉软件需要多长时间?
如果你知道自己在做什么,至少要花两天时间。我们建议预算 3-5 天来解决出现的问题。
问:哪个 的树莓 捆绑的是 Nano。img 包含在内?
答:纳米。img 仅附带完整套装。
问:上的操作系统版本是什么?img?
答:这个。img 运行 Ubuntu 18.04。
问:为什么我们在完整捆绑包中使用两个不同版本的 Tensorflow ?
答:这主要是因为 OpenVINO(用于在 NCS 上部署模型)和 TensorRT(用于为 Jetson Nano 优化模型)都不支持 Tensorflow 2.0。在撰写这些章节时,我们发现 Tensorflow 1.13.1 是最稳定的版本。
问:上安装了哪些软件包。img?
A: 请参见图 12 查看. img 上所有软件包的列表,也欢迎您安装您需要的其他软件包!

Figure 12: The PyImageSearch Jetson Nano preconfigured .img comes with CUDA-capable TensorFlow and OpenCV among the other listed packages shown. The .img is ready to go for IoT deep learning and computer vision.
问:在哪里可以了解更多关于 Python 虚拟环境的信息?
我最喜欢的资源和对 Python 虚拟环境的介绍可以在这里找到。我也在这篇博文的前半部分讨论了它们。
问:我可以购买吗?img 作为独立产品?
的。img 文件旨在为计算机视觉 的 Raspberry Pi 提供支持,确保您可以开箱即用地运行文本中的示例(更不用说开发自己的项目)。
我建议购买一份来访问. img。
问:我还有一个问题。
如果您有本常见问题解答中未列出的问题,请给我发消息。
我被卖了!我怎样才能获得图片搜索。img?

Figure 13: Pick up your copy of Raspberry Pi for Computer Vision to gain access to the book, code, and three preconfigured .imgs: (1) NVIDIA Jetson Nano, (2) Raspberry Pi 3B+ / 4B, and (3) Raspberry Pi Zero W. This book will help you get your start in edge, IoT, and embedded computer vision and deep learning.
购买计算机视觉 树莓 Pi的完整套装副本的 PyImageSearch 读者将获得 Jetson Nano。img 作为书的一部分。
这本书附带的所有 Jetson Nano 代码都准备在这个. img 上运行。我们为这个的用户提供全面支持。img(我们很难支持定制安装,因为我们没有坐在您自己的 Nano 前面)。
如果你刚刚开始使用嵌入式计算机视觉,并想开始使用树莓 Pi,只需拿起一份爱好者或黑客包,这两个包都带有我们预配置的 Raspbian。img 。
同样,完整包是唯一一个带有 Jetson Nano .img 的包。
要购买您的计算机视觉、、、版覆盆子 Pi,只需点击此处、、、。
要查看 PyImageSearch 提供的所有产品, 点击这里 。***
OAK-D:使用 DepthAI API 理解和运行神经网络推理
目录
OAK-D:用 DepthAI API 理解并运行神经网络推理
在本教程中,您将学习 DepthAI API 的核心概念,并利用它在 OAK-D 设备上运行一些深度学习和计算机视觉应用程序。
这是我们关于 OAK-101 的 4 部分系列的第 2 课:
- OpenCV AI Kit 介绍(橡树)
- OAK-D:用德泰 API (今日教程)
- 橡树 101:第三部
- 橡树 101:第四部
要了解 DepthAI API 如何工作,并在 OAK-D 上运行神经网络推理, 继续阅读即可。
OAK-D:用 DepthAI API 理解并运行神经网络推理
简介
在我们之前的教程OpenCV AI Kit(OAK)介绍中,我们通过讨论 Luxonis 旗舰产品:OAK-1 和 OAK-D,成为最受欢迎的具有深度功能的 edge AI 设备,对 OAK 进行了初步介绍。我们还讨论了 OAK-D 的 OAK-D Lite 变体,它在第二次 Kickstarter 活动中推出,具有更小的重量和外形,但具有与 OAK-D 相同的空间 AI 功能。
鉴于您已经学习了我们的第一篇教程,您应该非常了解 OAK 系列以及 Lite、Pro 和 Compute Module (CM)等提供 USB 和 PoE 连接的产品。本教程的重点是讨论可以在 OAK 设备上运行的大约十种不同的应用程序,从图像分类到对象检测到人类关键点估计。
今天,我们将深入了解 OAK 设备的内部结构,并了解 DepthAI API 的架构和组件,该 API 为主机提供了与 OAK 设备进行连接、配置和通信的能力。我们将揭开 DepthAI API 内部的魔力,它允许各种计算机视觉和深度学习应用程序在 OAK 设备上运行。
最后,我们将使用来自 OpenVino 模型动物园的预训练公共模型,在 OAK-D 设备上运行几个计算机视觉和深度学习示例。我们相信这将是一个很好的方法,让您接触 DepthAI Python API,并通过代码实际了解 OAK 设备的底层发生了什么。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 和 DepthAI 库。此外,我们强烈建议您遵循 Luxonis 安装指南,其中详细介绍了不同平台的安装过程。在今天的教程中,主机平台是 macOS 系统,如果你碰巧也使用 macOS 平台,那么在安装 Python 包之前,运行这里提到的命令bash和。
幸运的是,OpenCV 和 DepthAI 都可以通过 pip 安装:
$ pip install opencv-python
$ pip install depthai
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
├── main.py
├── models
│ └── mobilenet-ssd_openvino_2021.4_6shave.blob
├── pyimagesearch
│ ├── __init__.py
│ ├── color_camera_preview.py
│ ├── config.py
│ ├── left_right_mono_camera_preview.py
│ ├── object_detection_mobilenet.py
│ └── utils.py
├── requirements.txt
└── results
├── color_camera.png
├── mono_camera.png
└── object_detection.png
在pyimagesearch目录中,我们有:
config.py:实验的配置文件utils.py:物体检测流水线的实用程序color_camera_preview.py:保存运行彩色摄像机馈送的代码left_right_mono_camera_preview.py:用于测试 OAK-D 的立体摄像机对object_detection_mobilenet.py:在 OAK-D 上运行神经网络推理的对象检测代码
在核心目录中,我们有四个脚本:
models:包含blob格式的 mobilenet 对象检测模型的目录requirements.txt:本教程需要的 Python 包results:包含实验输出main.py:主要的 Python 驱动程序脚本,允许你运行三个任务中的一个
德泰简介
DepthAI 是一个空间 AI 平台,允许机器像人类一样感知世界,可以理解物体或特征是什么,以及它们在物理世界中的位置(而不仅仅是在像素空间中)。它的目标是结合并优化五个关键属性:深度学习、计算机视觉、深度感知、性能(例如,运行高分辨率帧和 FPS(每秒帧数)、使用多个传感器),以及低功耗嵌入式解决方案。
DepthAI 平台是围绕一个名为英特尔 Movidius VPU 的神经网络加速器构建的,这是一个每秒能够执行 4 万亿次运算的 Myriad X 芯片。它通过一个易于使用的 Python API 将深度感知与神经网络推理结合起来。
DepthAI 是定制硬件、固件和软件 API 的完整生态系统。最重要的是,它是模块化的,您可以将这项技术集成到您的产品中。图 2 展示了 DepthAI 的一个例子,它融合了 AI 能力与深度感知,基本上是利用每个对象的深度信息进行对象检测(估计空间坐标,即 XYZ)。
你在以上段落中读到的大部分术语已经在我们之前的教程OpenCV AI Kit(OAK)简介中解决了,所以我们建议你如果还没有的话查看一下那个帖子。
在今天的教程中,重点更多地放在了 DepthAI 的软件堆栈上,所以让我们直接进入主题吧!
德泰软件栈
像任何其他嵌入式硬件一样,OAK 设备也需要被编程以释放其能力并在其上运行应用程序。到目前为止,我们知道 OAK 设备有不同的变体:独立的,主机驻留在 OAK 上(例如,CM),以及普通的 OAK 设备(例如,OAK-D),需要通过 USB 与主机连接。
为了通过主机对 OAK 设备进行编程,在 DepthAI 中提供了一个垂直软件栈(图 3 ),其中后续组件作为对前一组件的抽象:
- DepthAI API
- DepthAI SDK
- 德泰演示
德泰 API
DepthAI API 允许主机(例如,计算机或任何微处理器)使用 Python API ( depthai-python)和 C++ API ( depthai-core)与 OAK 设备连接、配置和通信。depthai-python库为 C++ depthai-core库提供 Python 绑定。在今天的教程中,我们将重点介绍德泰的 Python API。
DepthAI API 提供了一个使用管道概念的编程模型,管道由节点组成。消息通过节点间的链接从一个节点发送到另一个节点。上面的图 3 显示了主机和 OAK 设备之间连接的高级架构、DepthAI 提供的软件堆栈以及设备内部的内容。
管道
它是称为节点的处理元素的链,以及它们之间的链接,通过它消息从一个节点发送到另一个节点。如上面图 3 所示,Node A与Node B连接,通过它们交换消息(Node A向另一个节点发送消息,XLinkOut)。
Pipeline 告诉 DepthAI 要执行什么操作,您定义 pipeline 中的所有资源和工作流。无论您是否想要为摄像机和神经网络输出创建一个color camera、neural network或XLinkOut,所有这些都是作为管道内的节点创建的。
管道内部的这种流动为用户的 OAK 设备提供了广泛的灵活性。当管道对象被传递给Device对象时,管道被序列化为 JSON 并通过 XLink 发送到 OAK 设备。
创建管道对象非常简单。首先需要调用depthai.Pipeline(),如图图 4 。然后,您可以使用 pipeline 对象用节点填充它,配置它们,并将它们链接在一起。
例如,如图 4 所示,使用 pipeline 对象,您可以指定与该管道一起使用的 OpenVINO 版本。你需要更改版本的原因是,比方说,你的神经网络是用不同于 DepthAI 支持的最新 OpenVINO 版本编译的。所以必须指定管道的 OpenVINO 版本。
设备 API
一旦创建了管道,您就可以使用Device API 将管道上传到设备,该 API 在视觉处理单元(VPU)上执行。当您在代码中创建设备时,固件与管道和其他资产(例如,神经网络斑点)一起上传。
直觉上它更像是在主机上;您定义在其中创建节点的管道,配置它们并绑定它们,最后将它们移动到 OAK 设备(图 5 )。然后所有写在with depthai.Device(pipeline) as device:里面的代码都直接在设备上执行。
连接
它是一个节点的输出和另一个节点的输入之间的链接。为了定义管道数据流,连接定义了向何处发送消息以实现预期的结果。
消息
按照连接的定义,消息在节点之间传输。节点相互通信的唯一方式是从一个节点向另一个节点发送消息。
可以在设备和主机上创建消息。例如,捕捉静态图像的 OAK 设备摄像机通过一个XLinkIn节点接收消息。
以下是在 DepthAI 中定义的一些消息:
-
CameraControl:该信息控制彩色和单色摄像机。该消息处理诸如捕捉静止图像、配置自动对焦、场景、效果等事情。 -
EdgeDetectorConfig:该消息配置EdgeDetector节点,用于修改水平和垂直 Sobel 滤波器内核。 -
这个消息可以用来在运行时调整图像的大小、扭曲和旋转。消息从主机通过
XLinkIn节点发送到ColorCamera节点。 -
ImgDetections:这确实是最令人兴奋的消息之一,它包含了一个图片中的detections列表。和大多数神经网络探测器一样,detections有class label、confidence score和bounding box coordinates。
检测节点YoloDetectionNetwork和MobileNetDetectionNetwork输出ImgDetections消息。我们将在node部分讨论它们。
ImgFrame:顾名思义,这个消息携带 RAW8 编码的帧数据:灰度和 RGB 分别用于单色相机和彩色相机。它还携带深度/视差图像。ColorCamera和MonoCamera节点是图像帧消息的来源。
然后,这可以用于显示目的,更重要的是,作为神经网络的输入。
节点
节点是管道中最重要的构件。它具有输入和输出,并具有各种可配置的属性(例如,设置相机节点的分辨率、FPS 和帧输出大小)。每个节点可以有零个、一个或多个输入和输出。例如,图 6 显示了一个有一个输入和两个输出的MobileNet Detection Network节点。
一个节点可以连接(或链接)到其他节点。图 7 展示了链接到NeuralNetwork节点输入的ColorCamera节点输出的示例。并且ColorCamera节点发送ImgFrame作为神经网络的输入。节点的输入和输出遵循一种队列机制,这种机制有助于根据队列大小保存消息。队列大小是一个可配置的参数。
现在让我们来看几个 DepthAI 中的节点示例:
边缘检测器
边缘检测器节点使用索贝尔滤波器创建图像,强调具有高空间频率的图像区域。它卷积一个奇数大小的 2D 核,比如 3×3,并在整个图像上滑动它。图 8** 显示了一个有两个输入和一个输出的EdgeDetector节点的例子。
输入和输出各有一种消息类型:
inputImage:ImgFrameinputConfig: EdgeDetectorConfigoutputImage:ImgFrame
XLink
XLink 是一个能够在设备和主机之间交换数据的中间件。XLink 进一步拆分为 XLinkIn 和 XLinkOut。
图 9 显示了通过 XLink 从主机向设备发送数据的XLinkIn节点。
XLinkIn节点的例子有
- 将配置发送到设备进行图像转换,如裁剪、扭曲、旋转
- OAK 设备的彩色摄像机接收消息以捕捉静止图像
- 控制彩色相机参数,如曝光、灵敏度、白平衡、亮度/色度去噪、设备端裁剪、相机触发器等。
XLinkOut
它与XLinkIn相反,通过XLink将数据从设备发送到主机(如图图 10 )。
XLinkOut节点的例子有
- 向主机发送 OAK 摄像机流
- 神经网络检测输出到主机
然后,用户可以将这些输出用于显示目的。
神经网络
该节点对输入数据进行神经推理(图 11 )。只要视觉处理单元(VPU)支持所有层,任何 OpenVINO 神经网络都可以使用该节点运行。这允许你从 OpenVINO 的开放模型动物园库和德普泰模型动物园库中挑选 200 多个预训练模型,并直接在 OAK 设备上运行。
神经网络文件必须在。blob 格式与 VPU 兼容。
输入和输出消息类型:
input:Any message typeout: NNDatapassthrough:ImgFrame
这是一个更一般的NeuralNetwork节点,所以输入消息是Any message type,这意味着您可以向NeuralNetwork节点传递类似音频系列数据或文本数据的东西。
【mobile netdetectiontwork】
MobileNetDetectionNetwork节点与NeuralNetwork节点非常相似。唯一不同的是,这个节点专门用于 MobileNet NeuralNetwork节点,它在设备上解码NeuralNetwork节点的结果。这意味着这个节点的out不是一个 NNData (一个字节数组),而是一个ImgDetections节点,可以很容易地在您的代码中用于显示目的和许多其他后处理操作。
参考上面的 图 6 ,其中显示了MobileNetDetectionNetwork节点。节点的输入和输出消息类型有:
input:ImgFrameout:img 检测passthrough:ImgFrame
与NeuralNetwork节点不同,MobileNet 检测网络节点具有作为ImgFrame的输入,因为这些检测模型(YOLO/SSD)基于图像并且不能接受任何其他数据类型。
【yolodetectitiontwork】
图 12 显示的是YoloDetectionNetwork节点,与NeuralNetwork节点非常相似。唯一不同的是,这个节点是专门为微小的 Yolo V3/V4 NeuralNetwork设计的,它在设备上解码神经网络的结果。与MobileNetDetectionNetwork节点一样,YoloDetectionNetwork节点返回ImgDetections。
上述节点的输入和输出消息类型有:
input:ImgFrameout:img 检测passthrough:ImgFrame
【yolospatialdataprotection network】
YoloSpatialDetectionNetwork节点的工作方式类似于YoloDetectionNetwork节点(图 13 )。但是,除了检测结果,它还使用SpatialImageDetections输出边界框的空间位置。
该网络节点在YoloDetectionNetwork节点之上镜像SpatialLocatorCalculator节点的功能。
SpatialLocatorCalculator节点根据来自inputDepth的depth图计算 ROI(感兴趣区域)的空间坐标。然后,它对 ROI 中的深度值进行平均,并移除超出范围的深度值。
因此,简而言之,它是YoloDetectionNetwork和SpatialLocationCalculator节点的组合。
上述节点的输入和输出消息类型有:
input:ImgFrameinputDepth:ImgFramepassthrough:ImgFrameout:SpatialImageDetectionsboundingBoxMapping:SpatialLocationCalculatorConfigpassthroughDepth:ImgFrame
SpatialImageDetections消息类似于ImgDetections消息,但是除了检测之外,它还包括被检测物体的 XYZ 坐标。
德泰 SDK
德泰软件开发工具包(SDK)是德泰 API 的包装器。它易于使用,并提供了更多的抽象,但降低了可定制性因素。与 DepthAI API 类似,SDK 是一个 Python 包,包含方便的类和函数,有助于使用 DepthAI API 完成大多数常见任务。图 14** 显示了 DepthAI SDK 的高级架构。
它由处理开发生命周期不同方面的经理组成:
- 管道管理器:帮助建立处理管道
- 预览管理器:帮助显示来自 OAK 摄像机的图像或视频流
- 神经网络管理器:帮助建立神经网络,并处理所有与神经网络相关的功能。它可以创建适当的
NeuralNetwork节点和连接,并解码神经网络输出 - 编码管理器:帮助从 OAK 相机创建视频
- Blob 管理器:帮助下载 MyriadX blobs 形式的神经网络,VPU 需要它在 OAK 设备上运行神经网络推理
我们不会深入每个经理的细节,因为它需要一个单独的帖子,此外,我们将在今天的教程中运行的示例使用 DepthAI API,而不是 SDK。
了解 DepthAI API 管道
在这一节中,我们将尝试理解 DepthAI API 管道如何为对象检测这样的用例工作。图 15 显示了 OAK 设备和主机(如计算机/嵌入式硬件)之间的对象检测工作流程。
如果你很好地理解了图 15,那么理解代码对你来说就是小菜一碟。
装置侧
上面的图 15 有五个节点:ColorCamera、MobileNetDetectionNetwork和三个XLinkOut节点。
回想一下上面的内容,在 DepthAI 中,我们主要是做管道,所以在设备端,我们先定义pipeline ( depthai.Pipeline())。
使用那个pipeline,我们创建一个ColorCamera节点(Node 1),显示为中等亮度的红色。这个节点就像我们的对象检测管道的垫脚石,因为它将使 OAK 设备彩色摄像机能够捕捉图像帧。
类似地,我们创建了MobileNetDetectionNetwork节点(Node 2,它将对从Node 1接收到的帧执行对象检测。最后,我们使用链接和连接的概念将摄像机输出与一个NeuralNetwork节点的输入链接起来。
通过调用camRgb.preview,你得到摄像机的输出,然后你用.link(nn.input)把它和神经网络的输入联系起来。不是这么简单吗?
同理,你可以通过XLinkOut Node 3 ( xoutRgb)将摄像头输出发送到主机端。NeuralNetwork节点还通过XLinkOut Node 4和Node 5向主机端发送信息。此信息包括检测网络输出和网络元数据,如图层名称。
主机端
在主机端,我们通过设置OutputQueue从 OAK 设备检索相机帧和神经网络推理输出。如上面的图 15 所示,相机帧通过 XLink(或 XLinkOut)发送到主机,并由主机使用OutputQueue通过传递参数rgb检索。
主机端的inRgb是指来自摄像机的帧。类似地,对于推理结果和神经网络元数据,遵循相同的过程,只是这一次,OutputQueue的参数是nn和nnNetwork。
一旦有了相机帧和神经网络结果,就可以在主机端对它们进行后处理。例如,用边界框坐标和对象标签注释图像帧。
图 16 显示了由一个工具生成的物体检测的管线图,该工具动态地创建沉积管线图。这个工具对于在不直接阅读代码的情况下深入了解 DepthAI 程序非常有用。
下面你可以看到上面管道图的每个节点 id,以及它们如何连接到对象检测管道中的每个其他节点。
节点(id):
= = = = = = = = = = =
color camera(0)
detection network(1)
XLinkOut(2)
XLinkOut(3)
XLinkOut(4)
Connections:
= = = = = = = = = = = = =
0 detection network(1):out network→XLinkOut(4):
1 detection network(1)中的[8]:out→XLinkOut(3):
2
理论到此为止,对吧?现在让我们将这些理论知识付诸实践,并在 OAK-D 设备上运行来自 Luxonis GitHub 库的一些 DepthAI 示例。
橡树演示示例
在本节中,我们将通过几个使用 OAK 深度硬件的深度示例,即:
- 用 OAK-D 测试彩色摄像机馈送
- 运行 OAK-D 的单声道摄像机(左和右)
- 基于 MobileNet 模型的目标检测
配置先决条件
在我们开始实现之前,让我们检查一下项目的配置管道。我们将转到位于pyimagesearch目录中的config.py脚本。
# Set the color camera preview size and interleaved
COLOR_CAMERA_PREVIEW_SIZE = 300, 300
CAMERA_INTERLEAVED = False
CAMERA_FPS = 40
# Queue parameters for rgb and mono camera frames at host side
COLOR_CAMERA_QUEUE_SIZE = 4
QUEUE_BLOCKING = False
# Object detection class labels
CLASS_LABELS = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"]
MOBILENET_DETECTION_MODEL_PATH = 'models/mobilenet-ssd_openvino_2021.' \
'4_6shave.blob'
# Neural network hyperparameters
NN_THRESHOLD = 0.5
INFERENCE_THREADS = 2
PRINT_NEURAL_NETWORK_METADATA = True
# Frame text color pattern
TEXT_COLOR = (255, 0, 0)
TEXT_COLOR2 = (255, 255, 255)
从第 2-4 行,我们设置摄像机参数,如帧的预览尺寸(主机端的显示窗口尺寸)、摄像机 FPS 以及摄像机交错或平面选项。
然后,我们为rgb和mono摄像机设置OutputQueue参数,如队列大小以及是否有阻塞或非阻塞队列(第 7 行和第 8 行)。
在第 11-16 行上,我们定义了对象检测参数,如 Pascal-VOC 数据集的类标签和 mobilenet 检测模型路径。
然后定义推理线程的目标检测置信度阈值数。这些是特定于第 20-22 行上的对象检测模型的神经网络超参数。
配置管道的最后一步是设置 OpenCV 相关的文本颜色模式,这将被用于在主机端注释输出帧(第 25 和 26 行)。
测试 OAK-D 的彩色相机(RGB)进纸
既然已经定义了配置管道,我们可以转到第一个实验的代码演练(即运行 OAK-D 的 RGB 彩色摄像机)。这个实验将帮助您了解如何创建彩色摄像机节点,以及如何通过XLinkOut节点在主机端显示摄像机画面。
# import the necessary packages
import cv2
import depthai as dai
from pyimagesearch import config
def create_color_camera_pipeline():
# Create pipeline
pipeline = dai.Pipeline()
# Define source and output
# camera node
camRgb = pipeline.create(dai.node.ColorCamera)
# XLinkOut node for displaying frames
xoutRgb = pipeline.create(dai.node.XLinkOut)
# set stream name as rgb
xoutRgb.setStreamName('rgb')
# set camera properties like the preview window, interleaved
camRgb.setPreviewSize(config.COLOR_CAMERA_PREVIEW_SIZE)
camRgb.setInterleaved(config.CAMERA_INTERLEAVED)
camRgb.setColorOrder(dai.ColorCameraProperties.ColorOrder.RGB)
# link the camera preview to XLinkOut node input
camRgb.preview.link(xoutRgb.input)
# return pipeline to the calling function
return pipeline
我们首先从2-5行的pyimagesearch模块导入所需的包,如cv2、depthai和config。
然后,在第 8-30 行的上,我们定义了create_color_camera_pipeline()方法,它将构建彩色摄像机管道。我们首先创建pipeline对象(第 10 行),然后定义源,即彩色摄像机节点和用于显示彩色帧(第 14-16 行)的输出(XLinkOut)节点。
然后在第 19 行,节点XLinkOut(即xoutRgb变量)被赋予一个流名为rgb;该名称将作为参数传递给OutputQueue以获取彩色帧。
从第 22-24 行,我们设置摄像机属性/参数,如显示窗口大小、颜色通道顺序和摄像机交错。
下一步是将camRgb输出与线 27 上xoutRgb(XLinkOut节点)的输入相连。
在第 30 行上,我们将管道返回到调用函数。
def color_camera(pipeline):
# Connect to device and start pipeline
with dai.Device(pipeline) as device:
print('Connected cameras: ', device.getConnectedCameras())
# Print out usb speed like low/high
print('Usb speed: ', device.getUsbSpeed().name)
# Output queue will be used to get the rgb
# frames from the output defined above
qRgb = device.getOutputQueue(
name='rgb',
maxSize=config.COLOR_CAMERA_QUEUE_SIZE,
blocking=config.QUEUE_BLOCKING,
)
while True:
# blocking call, will wait until a new data has arrived
inRgb = qRgb.get()
# Convert the rgb frame data to OpenCV format and
# display 'bgr' (opencv format) frame
cv2.imshow('rgb', inRgb.getCvFrame())
# break out from the while loop if 'q' key is pressed
if cv2.waitKey(1) == ord('q'):
break
在第 33 行上,我们定义了color_camera方法,该方法将pipeline作为参数。然后,我们连接到 OAK 设备,启动线 35 上的管道。最后,我们打印附加信息,如连接的摄像机和 USB 速度,如主机&设备通过其通信的低/高(在行 36-38 )。
接下来,在第 42-46 行上,定义了OutputQueue,它接受参数:流名称、摄像机队列大小和队列阻塞。这个队列帮助从输出中获取彩色摄像机帧。
最后,现在大部分繁重的工作已经完成,在行 48 上,定义了一个无限的while循环,它一直运行到按下q键(行 56 )。在行 50 的while循环中,我们使用队列对象qRgb获取实际的帧,然后使用cv2.imshow函数(行 53 )将其转换为 OpenCV bgr格式并显示在主机屏幕上。
测试 OAK-D 的单声道摄像机(左右)进给
下面的实验是学习如何访问 OAK-D 的单声道摄像机(左和右)并在主机端显示提要。这将更容易理解,因为你已经完成了之前的实验。在这里,我们将创建两个摄像机节点和两个XLinkOut节点来显示单声道摄像机输入。
# import the necessary packages
from pyimagesearch import config
import depthai as dai
import cv2
def create_mono_camera_pipeline():
# create pipeline
pipeline = dai.Pipeline()
# define sources and outputs: creating left and right camera nodes
monoLeft = pipeline.create(dai.node.MonoCamera)
monoRight = pipeline.create(dai.node.MonoCamera)
# XLinkOut nodes for displaying frames from left and right camera
xoutLeft = pipeline.create(dai.node.XLinkOut)
xoutRight = pipeline.create(dai.node.XLinkOut)
# set XLinkOut stream name as left and right for later using in
# OutputQueue
xoutLeft.setStreamName('left')
xoutRight.setStreamName('right')
# set mono camera properties like which camera socket to use,
# camera resolution
monoLeft.setBoardSocket(dai.CameraBoardSocket.LEFT)
monoLeft.setResolution(
dai.MonoCameraProperties.SensorResolution.THE_720_P)
monoRight.setBoardSocket(dai.CameraBoardSocket.RIGHT)
monoRight.setResolution(
dai.MonoCameraProperties.SensorResolution.THE_720_P,
)
# link the left and right camera output to XLinkOut node input
monoRight.out.link(xoutRight.input)
monoLeft.out.link(xoutLeft.input)
# return pipeline to the calling function
return pipeline
我们首先从2-4行的pyimagesearch模块导入所需的包,如cv2、depthai和config。
然后,在第 6-31 行的上,我们定义了create_mono_camera_pipeline()方法,它将为左右摄像机构建摄像机管道。我们首先创建pipeline对象(行 8** ),然后定义源和输出(行 11 和 12 )。这一次我们创建了两个相机节点:左和右,以及两个XLinkOut节点,用于显示左和右相机馈送。**
在第 15 和 16 行,两个XLinkOut节点(即xoutLeft和xoutRight变量)被赋予一个流名left和right;该名称将作为参数传递给两个不同的OutputQueue以获取彩色帧。
从第 25-31 行,我们为两台摄像机设置摄像机属性/参数(例如,摄像机插座和摄像机分辨率)。
下一步是将left和right摄像机输出与线 34 和 35 上的xoutLeft和xoutRight(两个XLinkOut节点)的输入连接起来。
在第 38 行上,我们将管道返回到调用函数。
def mono_cameras_preview(pipeline):
# connect to device and start pipeline
with dai.Device(pipeline) as device:
# output queues will be used to get the grayscale
# frames from the outputs defined above
qLeft = device.getOutputQueue(
name='left',
maxSize=config.COLOR_CAMERA_QUEUE_SIZE,
blocking=config.QUEUE_BLOCKING,
)
qRight = device.getOutputQueue(
name='right',
maxSize=config.COLOR_CAMERA_QUEUE_SIZE,
blocking=config.QUEUE_BLOCKING,
)
while True:
# instead of get (blocking), we use tryGet (non-blocking)
# which will return the available data or None otherwise
inLeft = qLeft.tryGet()
inRight = qRight.tryGet()
# check if data is available from left camera node
if inLeft is not None:
# convert the left camera frame data to OpenCV format and
# display grayscale (opencv format) frame
cv2.imshow('left', inLeft.getCvFrame())
# check if data is available from right camera node
if inRight is not None:
# convert the right camera frame data to OpenCV format and
# display grayscale (opencv format) frame
cv2.imshow('right', inRight.getCvFrame())
# break out from the while loop if 'q' key is pressed
if cv2.waitKey(1) == ord('q'):
break
在第 41 行上,我们定义了mono_cameras_preview方法,该方法将pipeline作为参数。然后我们连接到 OAK 设备,并启动线 43 上的管道。
接下来,从第 46-55 行,定义了两个OutputQueue,它们接受参数:流名称(left和right)、摄像机队列大小和队列阻塞。这些队列帮助从输出中获取left和right(灰度)相机帧。
在线 57 上,定义了一个无限的while循环,一直运行到按下q键(线 76 )。在第 60 行和第 61 行的while循环中,我们使用队列对象qLeft和qRight获取帧数据。请注意,在彩色摄像机示例中,我们使用了tryGet()方法,而不是get()。这是因为tryGet()方法是非阻塞调用,如果队列中没有帧,它将返回数据或不返回任何数据。请尝试一下get()方法,看看你有没有发现什么不同。
最后,如果left和right帧不是None,则使用cv2.imshow功能将帧数据转换为 OpenCV 灰度格式并显示在主机屏幕上(第 64-73 行)。
在 Pascal-VOC 数据集上预处理 MobileNet 模型的目标检测
现在我们知道了如何创建一个管道,摄像机节点,XLinkOut节点,OutputQueue等。,我们可以结合这些知识,创建一个检测图像中常见对象的对象检测应用程序。
我们将使用 MobileNet-SSD 模型:旨在执行对象检测的单次多盒检测(SSD)网络。这个模型最初是在 Caffe 框架中实现的。要更深入地了解 MobileNet-SSD 模型,请查看存储库。
在我们浏览对象检测代码之前,让我们回顾一下对象检测管道的实用程序。为此,我们将转到位于pyimagesearch目录中的utils.py脚本。
# import the necessary packages
from pyimagesearch import config
import numpy as np
import cv2
# color pattern for annotating frame with object category, bounding box,
# detection confidence
color = config.TEXT_COLOR
# MobilenetSSD label list
labelMap = config.CLASS_LABELS
# nn data (bounding box locations) are in <0..1>
# range - they need to be normalized with frame width/height
def frameNorm(frame, bbox):
normVals = np.full(len(bbox), frame.shape[0])
normVals[::2] = frame.shape[1]
return (np.clip(np.array(bbox), 0, 1) * normVals).astype(int)
# displayFrame method iterates over the detections of a frame,
# denormalizes the bounding box coordinates and annotates the frame with
# class label, detection confidence, bounding box
def displayFrame(name, frame, detections):
for detection in detections:
bbox = frameNorm(
frame, (
detection.xmin, detection.ymin,
detection.xmax, detection.ymax,
),
)
cv2.putText(
frame, labelMap[detection.label], (
bbox[0] + 10,
bbox[1] + 20,
),
cv2.FONT_HERSHEY_TRIPLEX, 0.5, color,
)
cv2.putText(
frame, f'{int(detection.confidence * 100)}%',
(bbox[0] + 10, bbox[1] + 40), cv2.FONT_HERSHEY_TRIPLEX,
0.5, color,
)
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]),
color, 2)
# show the frame
cv2.imshow(name, frame)
# method that prints the detection network output layer name
def print_neural_network_layer_names(inNN):
toPrint = 'Output layer names:'
for ten in inNN.getAllLayerNames():
toPrint = f'{toPrint} {ten},'print(toPrint)
在第 2-4 行,我们导入了 opencv、numpy 等必要的包。
然后,我们定义颜色模式,用类标签、置信度得分和边界框来注释帧。类别标签列表labelMap在行第 11 上定义,这将有助于将类别 id 转换成人类可读的形式。
由于神经网络预测(边界框坐标)在范围[0,1]内被规格化,因此需要用图像帧的宽度和高度对它们进行反规格化。frameNorm方法有助于在第 15-18 行完成这项任务。
在的第 24-48 行中,我们定义了displayFrame方法,该方法迭代帧的每次检测,使用frameNorm方法反规格化边界框坐标,并用类别标签、检测置信度和边界框坐标注释该帧。最后,它在主机端显示带注释的框架。
最后,在第 51-54 行,print_neural_network_layer_names帮助打印物体检测网络层名称。
现在定义了助手方法,我们可以最终转移到对象检测推理实现(即位于pyimagesearch目录中的object_detection_mobilenet.py脚本)。
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.utils import print_neural_network_layer_names
from pyimagesearch.utils import displayFrame
import depthai as dai
import time
import cv2
def create_detection_pipeline():
# create pipeline
pipeline = dai.Pipeline()
# define camera node
camRgb = pipeline.create(dai.node.ColorCamera)
# define the MobileNetDetectionNetwork node
nn = pipeline.create(dai.node.MobileNetDetectionNetwork)
# define three XLinkOut nodes for RGB frames, Neural network detections
# and Neural network metadata for sending to host
xoutRgb = pipeline.create(dai.node.XLinkOut)
nnOut = pipeline.create(dai.node.XLinkOut)
nnNetworkOut = pipeline.create(dai.node.XLinkOut)
# set the XLinkOut node names
xoutRgb.setStreamName('rgb')
nnOut.setStreamName('nn')
nnNetworkOut.setStreamName('nnNetwork')
# set camera properties like the preview window, interleaved and
# camera FPS
camRgb.setPreviewSize(config.COLOR_CAMERA_PREVIEW_SIZE)
camRgb.setInterleaved(config.CAMERA_INTERLEAVED)
camRgb.setFps(config.CAMERA_FPS)
# define neural network hyperparameters like confidence threshold,
# number of inference threads. The NN will make predictions
# based on the source frames
nn.setConfidenceThreshold(config.NN_THRESHOLD)
nn.setNumInferenceThreads(config.INFERENCE_THREADS)
# set mobilenet detection model blob path
nn.setBlobPath(config.MOBILENET_DETECTION_MODEL_PATH)
nn.input.setBlocking(False)
# link the camera preview to XLinkOut node input
camRgb.preview.link(xoutRgb.input)
# camera frames linked to NN input node
camRgb.preview.link(nn.input)
# NN out (image detections) linked to XLinkOut node
nn.out.link(nnOut.input)
# NN unparsed inference results (metadata) linked to XLinkOut node
nn.outNetwork.link(nnNetworkOut.input)
# return pipeline to the calling function
return pipeline
我们首先导入所需的包,如用于计算 FPS 的time模块、用于显示帧和其他图像实用程序的cv2、config模块以及我们上面定义的实用程序,如第 2-7 行上的displayFrame方法。
在的第 9-59 行,我们定义了create_detection_pipeline()方法,它将为目标检测实验奠定基础。我们从在第 11 行的上创建pipeline开始。然后从第 14-23 行,我们创建源和输出。首先,我们创建ColorCamera节点,这是最重要的节点(即MobileNetDetectionNetwork节点),它将执行神经网络推理并对设备上的预测进行解码。
为 RGB 帧、神经网络检测和神经网络元数据创建了三个XLinkOut节点。所有这些信息都将被发送到主机。
然后,将流名称分配给所有三个XLinkOut节点,即rgb、nn和nnNetwork;这些将用于稍后从OutputQueue检索数据(在行 26-28 )。
从第 32-34 行,设置摄像机参数(例如,预览窗口大小和摄像机 FPS)。
然后,我们在第 39-44 行上定义神经网络超参数(例如,检测置信度阈值、推理线程数和模型文件路径等。).
最后一步是链接输入和输出节点(行 47-56 ):
- 彩色摄像机输出链接到
XLinkOut节点的输入。 - 摄像机输出连接到
NeuralNetwork节点的输入,用于执行预测。 - 神经网络的输出连接到另一个
XLinkOut节点的输入,该节点将输出目标检测预测。 - 最后,负责承载神经网络未解析推理结果(元数据)的节点链接到
nnNetwork节点。
然后pipeline对象返回到线 59 上的调用函数。
def object_detection_mobilenet(pipeline):
# connect to device and start pipeline
with dai.Device(pipeline) as device:
# output queues will be used to get the rgb frames
# and nn data from the outputs defined above
qRgb = device.getOutputQueue(
name='rgb',
maxSize=config.COLOR_CAMERA_QUEUE_SIZE,
blocking=config.QUEUE_BLOCKING,
)
qDet = device.getOutputQueue(
name='nn',
maxSize=config.COLOR_CAMERA_QUEUE_SIZE,
blocking=config.QUEUE_BLOCKING,
)
qNN = device.getOutputQueue(
name='nnNetwork',
maxSize=config.COLOR_CAMERA_QUEUE_SIZE,
blocking=config.QUEUE_BLOCKING,
)
# initialize frame, detections list, and startTime for
# computing FPS
frame = None
detections = []
startTime = time.monotonic()
counter = 0
# color pattern for displaying FPS
color2 = config.TEXT_COLOR2
# boolean variable for printing NN layer names on console
printOutputLayersOnce = config.PRINT_NEURAL_NETWORK_METADATA
while True:
# instead of get (blocking), we use tryGet (non-blocking)
# which will return the available data or None otherwise
# grab the camera frames, image detections, and NN
# metadata
inRgb = qRgb.tryGet()
inDet = qDet.tryGet()
inNN = qNN.tryGet()
# check if we frame is available from the camera
if inRgb is not None:
# convert the camera frame to OpenCV format
frame = inRgb.getCvFrame()
# annotate the frame with FPS information
cv2.putText(
frame, 'NN fps: {:.2f}'.
format(counter / (time.monotonic() - startTime)),
(2, frame.shape[0] - 4),
cv2.FONT_HERSHEY_TRIPLEX, 0.4, color2,
)
# check if detections are available
if inDet is not None:
# fetch detections & increment the counter for FPS computation
detections = inDet.detections
counter += 1
# check if the flag is set and NN metadata is available
if printOutputLayersOnce and inNN is not None:
# call the `neural network layer names method and pass
# inNN queue object which would help extract layer names
print_neural_network_layer_names(inNN)
printOutputLayersOnce = False
# if the frame is available, draw bounding boxes on it
# and show the frame
if frame is not None:
displayFrame('object_detection', frame, detections)
# break out from the while loop if 'q' key is pressed
if cv2.waitKey(1) == ord('q'):
break
既然管道已经创建,我们可以开始获取帧和神经网络预测。在的第 62-138 行中,定义了将pipeline作为参数的object_detection_mobilenet()方法。然后,我们连接到设备并启动线 6 4 上的管道。
从行 67-81 ,定义了三个输出队列,即rgb、nn和nnNetwork,以获取 RGB 帧和神经网络数据。接下来,我们初始化用于计算 FPS 的frame变量、detections列表和startTime(第 85-87 行)。我们还定义了一个名为printOutputLayersOnce的布尔变量,用于在控制台上打印神经网络层名称。
在第 96 行的上,我们开始了一个无限的while循环。
在循环内部,我们首先使用上面定义的三个OutputQueue(行 101-103 )获取摄像机帧、图像检测和网络元数据。
在行 106 ,我们检查摄像机画面是否不是None。然后,我们将它们转换成 OpenCV 格式,并用 FPS 信息对帧进行注释(第 108-116 行)。
然后,如果当前帧有任何检测,我们提取检测并增加第行 119-122 的 FPS 计算的计数器。
接下来,我们打印网络层名称。如果布尔变量设置为True,调用displayFrame对帧进行注释,并在屏幕上显示输出(第 128-134 行)。
最后,如果在行 137 和 138 上按下q键,我们就脱离循环。
结果
现在让我们看看所有三个实验的结果(见图 17-19 )。
-
彩色相机预览
-
左右单声道摄像机馈送

Figure 18: Mono Camera Feed from OAK-D (top: left camera; bottom: right camera).
- 基于 MobileNet 模型的目标检测
汇总
在本教程中,我们学习了 DepthAI 软件堆栈的概念,并利用它在 OAK-D 设备上运行了一些深度学习和计算机视觉的应用程序。
具体来说,我们讨论了 DepthAI API,其中我们学习了管道、消息和节点的概念。然后,我们讨论了几种类型的节点(例如,XLink、NeuralNetwork、EdgeDetector、YoloDetectionNetwork等)。).
我们还讨论了 DepthAI SDK,它是 DepthAI API 之上的一个包装器。但是,更重要的是,我们讨论了对象检测用例的端到端 DepthAI 管道。
我们进一步深入研究了 OAK 演示示例。此外,我们利用 DepthAI API 用 Python 编写了三个示例:在 OAK-D 上运行彩色相机馈送、单色相机馈送和对象检测。
最后,我们简要检查了用 OAK-D 进行的三个实验的结果。
引用信息
Sharma,a .“OAK-D:使用 DepthAI API 理解和运行神经网络推理”, PyImageSearch ,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/8ynbk
@incollection{Sharma_2022_OAK-D,
author = {Aditya Sharma},
title = {{OAK-D}: Understanding and Running Neural Network Inference with {DepthAI} {API}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/8ynbk},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
使用 Google Coral USB 加速器进行对象检测和图像分类

几周前,我发表了一篇关于如何开始使用 Google Coral USB 加速器的教程。该教程旨在帮助您配置设备并运行您的第一个演示脚本。
今天我们将更进一步,学习如何在您自己的定制 Python 脚本中使用 Google Coral !
在今天的教程中,您将了解到:
- 使用 Coral USB 加速器进行图像分类
- 使用 Google Coral 加速器进行视频图像分类
- 使用 Google Coral 进行物体检测
- 使用 Coral USB 加速器检测视频中的对象
阅读本指南后,您将对如何在自己的应用程序中利用 Google Coral 进行图像分类和对象检测有深刻的理解。
要了解如何使用 Google Coral USB 加速器执行图像分类和对象检测,请继续阅读!
使用 Google Coral USB 加速器进行对象检测和图像分类
https://www.youtube.com/embed/TlubMGSfRug?feature=oembed
对象检测:使用 Keras、TensorFlow 和深度学习的包围盒回归
在本教程中,您将学习如何训练一个自定义深度学习模型,通过 Keras 和 TensorFlow 的边界框回归来执行对象检测。
今天的教程受到了我从 PyImageSearch 读者 Kyle 那里收到的一条消息的启发:
嗨,阿德里安,
非常感谢你的 关于区域提议物体探测器的四部分系列教程。 它帮助我了解了 R-CNN 物体探测器的基本工作原理。
但是我对“包围盒回归”这个术语有点困惑那是什么意思?包围盒回归是如何工作的?包围盒回归如何预测图像中对象的位置?
问得好,凯尔。
基本的 R-CNN 物体检测器,比如我们在 PyImageSearch 博客上提到的那些,依赖于区域提议生成器的概念。
这些区域提议算法(例如,选择性搜索)检查输入图像,然后识别潜在对象可能在哪里。请记住,他们完全不知道是否一个物体存在于一个给定的位置,只知道图像的区域看起来很有趣并需要进一步检查。
在 Girshick 等人的 R-CNN 的经典实现中,这些区域建议用于从预训练的 CNN(减去全连接层头)中提取输出特征,然后输入到 SVM 中进行最终分类。在该实现中,来自区域提议的位置被视为边界框,而 SVM 为边界框区域产生了类别标签。
本质上,最初的 R-CNN 架构实际上并没有“学习”如何检测边界框——它是而不是端到端可训练的(未来的迭代,如更快的 R-CNN,实际上是端到端可训练的)。
但这也带来了问题:
- 如果我们想训练一个端到端的物体探测器呢?
- 有没有可能构建一个可以输出边界框坐标的 CNN 架构,这样我们就可以真正地训练这个模型来做出更好的物体探测器预测?
- 如果是这样,我们如何着手训练这样一个模型?
所有这些问题的关键在于边界框回归的概念,这正是我们今天要讨论的内容。在本教程结束时,您将拥有一个端到端的可训练对象检测器,能够为图像中的对象生成边界框预测和类别标签预测。
要了解如何使用 Keras、TensorFlow 和深度学习通过包围盒回归来执行对象检测,请继续阅读。
物体检测:使用 Keras、TensorFlow 和深度学习的包围盒回归
在本教程的第一部分,我们将简要讨论包围盒回归的概念,以及如何使用它来训练端到端的对象检测器。
然后,我们将讨论用于训练边界框回归器的数据集。
从那里,我们将回顾项目的目录结构,以及一个简单的 Python 配置文件(因为我们的实现跨越多个文件)。给定我们的配置文件,我们将能够实现一个脚本,通过 Keras 和 TensorFlow 的包围盒回归来实际训练我们的对象检测模型。
训练好我们的模型后,我们将实现第二个 Python 脚本,这个脚本处理新输入图像上的推理(即,进行对象检测预测)。
我们开始吧!
什么是包围盒回归?
我们可能都熟悉通过深度神经网络进行图像分类的概念。执行图像分类时,我们:
- 向 CNN 展示输入图像
- 向前通过 CNN
- 输出一个包含 N 个元素的向量,其中 N 是类别标签的总数
- 选择具有最大概率的类别标签作为我们最终预测的类别标签
从根本上讲,我们可以把图像分类看作是预测一个类标签。
但不幸的是,这种类型的模型不能转化为对象检测。我们不可能为输入图像中的(x,y)坐标边界框的每个可能组合构造一个类别标签。
相反,我们需要依赖一种不同类型的机器学习模型,称为回归。与产生标签的分类不同,回归使我们能够预测连续值。
通常,回归模型适用于以下问题:
- 预测房屋价格(,我们在本教程中实际上已经做过
- 预测股票市场
- 确定疾病在人群中传播的速度
- 等。
这里的要点是,回归模型的输出不像分类模型那样局限于被离散化到“箱”中(记住,分类模型只能输出一个类标签,仅此而已)。
相反,回归模型可以输出特定范围内的任何真实值。
通常,我们在训练期间将值的输出范围缩放到【0,1】,然后在预测之后将输出缩放回来(如果需要)。
为了执行用于对象检测的包围盒回归,我们需要做的就是调整我们的网络架构:
- 在网络的顶端,放置一个具有四个神经元的全连接层,分别对应于左上和右下(x,y)坐标。
- 给定四个神经元层,实现一个 sigmoid 激活函数,使得输出在范围 [0,1]内返回。
- 对训练数据使用诸如均方误差或平均绝对误差的损失函数来训练模型,该训练数据包括(1)输入图像和(2)图像中对象的边界框。
在训练之后,我们可以向我们的包围盒回归器网络呈现输入图像。然后,我们的网络将执行向前传递,然后实际上预测对象的输出边界框坐标。
在本教程中,我们将通过包围盒回归为一个单类对象检测,但下周我们将把它扩展到多类对象检测。
我们的对象检测和包围盒回归数据集
我们今天在这里使用的示例数据集是 CALTECH-101 数据集的子集,可用于训练对象检测模型。
具体来说,我们将使用由 800 张图像和图像中飞机的相应边界框坐标组成的飞机类。我已经在图 2 中包含了飞机示例图像的子集。
我们的目标是训练一个能够准确预测输入图像中飞机边界框坐标的目标检测器。
注意:没有必要从加州理工学院 101 的网站上下载完整的数据集。我已经在与本教程相关的“下载”*部分包含了飞机图像的子集,包括一个 CSV 文件的边界框。*
配置您的开发环境
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
这样说来,你是:
- 时间紧迫?
- 在你雇主被行政锁定的笔记本电脑上学习?
- 想要跳过与包管理器、bash/ZSH 概要文件和虚拟环境的争论吗?
- 准备好立即运行代码了吗(并尽情地试验它)?
那今天就加入 PyImageSearch 加吧!在您的浏览器 — 中访问运行在**谷歌的 Colab 生态系统上的 PyImageSearch 教程 Jupyter 笔记本!****
项目结构
去拿吧。本教程的 【下载】 部分的 zip 文件。在里面,您将找到数据子集以及我们的项目文件:
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── images [800 entries]
│ └── airplanes.csv
├── output
│ ├── detector.h5
│ ├── plot.png
│ └── test_images.txt
├── pyimagesearch
│ ├── __init__.py
│ └── config.py
├── predict.py
└── train.py
4 directories, 8 files
创建我们的配置文件
在实现边界框回归训练脚本之前,我们需要创建一个简单的 Python 配置文件,该文件将存储在训练和预测脚本中重用的变量,包括图像路径、模型路径等。
打开config.py文件,让我们看一看:
# import the necessary packages
import os
# define the base path to the input dataset and then use it to derive
# the path to the images directory and annotation CSV file
BASE_PATH = "dataset"
IMAGES_PATH = os.path.sep.join([BASE_PATH, "images"])
ANNOTS_PATH = os.path.sep.join([BASE_PATH, "airplanes.csv"])
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the output serialized model, model training plot,
# and testing image filenames
MODEL_PATH = os.path.sep.join([BASE_OUTPUT, "detector.h5"])
PLOT_PATH = os.path.sep.join([BASE_OUTPUT, "plot.png"])
TEST_FILENAMES = os.path.sep.join([BASE_OUTPUT, "test_images.txt"])
# initialize our initial learning rate, number of epochs to train
# for, and the batch size
INIT_LR = 1e-4
NUM_EPOCHS = 25
BATCH_SIZE = 32
我们的深度学习超参数包括初始学习速率、时期数和批量大小。这些参数放在一个方便的地方,以便您可以跟踪您的实验输入和结果。
用 Keras 和 TensorFlow 实现我们的包围盒回归训练脚本
实现了配置文件后,我们可以开始创建边界框回归训练脚本了。
该脚本将负责:
- 从磁盘加载我们的飞机训练数据(即类标签和边界框坐标)
- 从磁盘加载 VGG16(在 ImageNet 上预先训练),从网络中移除完全连接的分类层头,并插入我们的边界框回归层头
- 在我们的训练数据上微调包围盒回归图层头
我假设你已经习惯了修改网络架构并对其进行微调。
如果您对这个概念还不太熟悉,我建议您在继续之前阅读上面链接的文章。
边界框回归是一个最好通过代码解释的概念,所以打开项目目录中的train.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch import config
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import cv2
import os
我们的训练脚本从选择导入开始。其中包括:
config:我们在上一节开发的配置文件,由路径和超参数组成VGG16:CNN 架构作为我们微调方法的基础网络tf.keras:从 TensorFlow/Keras 导入,包括图层类型、优化器和图像加载/预处理例程train_test_split: Scikit-learn 的便利实用程序,用于将我们的网络分成训练和测试子集matplotlib: Python 的事实绘图包numpy: Python 的标准数值处理库cv2: OpenCV
同样,您需要遵循“配置您的开发环境”一节,以确保您已经安装了所有必要的软件,或者选择在 Jupyter 笔记本中运行该脚本。
现在,我们的环境已经准备就绪,包也已导入,让我们来处理我们的数据:
# load the contents of the CSV annotations file
print("[INFO] loading dataset...")
rows = open(config.ANNOTS_PATH).read().strip().split("\n")
# initialize the list of data (images), our target output predictions
# (bounding box coordinates), along with the filenames of the
# individual images
data = []
targets = []
filenames = []
这里,我们加载我们的边界框注释 CSV 数据(第 19 行)。文件中的每条记录都由一个图像文件名和与该图像关联的任何对象边界框组成。
然后我们进行三次列表初始化:
data:即将容纳我们所有的图像- 很快就会拥有我们所有的预测和包围盒坐标
filenames:与实际图像相关联的文件名data
这是三个相互对应的独立列表。我们现在开始一个循环,试图从 CSV 数据填充列表:
# loop over the rows
for row in rows:
# break the row into the filename and bounding box coordinates
row = row.split(",")
(filename, startX, startY, endX, endY) = row
遍历 CSV 文件中的所有行(第 29 行),我们的第一步是解开特定条目的filename和边界框坐标(第 31 行和第 32 行)。
为了对 CSV 数据有所了解,让我们来看一下内部情况:
image_0001.jpg,49,30,349,137
image_0002.jpg,59,35,342,153
image_0003.jpg,47,36,331,135
image_0004.jpg,47,24,342,141
image_0005.jpg,48,18,339,146
image_0006.jpg,48,24,344,126
image_0007.jpg,49,23,344,122
image_0008.jpg,51,29,344,119
image_0009.jpg,50,29,344,137
image_0010.jpg,55,32,335,106
如您所见,每行包含五个元素:
- 文件名
- 起始x-坐标
- 开始 y 坐标
- 终点x-坐标
- 终点y-坐标
这些正是我们脚本的第 32 行解包到这个循环迭代的便利变量中的值。
我们仍在循环中工作,接下来我们将加载一个图像:
# derive the path to the input image, load the image (in OpenCV
# format), and grab its dimensions
imagePath = os.path.sep.join([config.IMAGES_PATH, filename])
image = cv2.imread(imagePath)
(h, w) = image.shape[:2]
# scale the bounding box coordinates relative to the spatial
# dimensions of the input image
startX = float(startX) / w
startY = float(startY) / h
endX = float(endX) / w
endY = float(endY) / h
让我们结束我们的循环:
# load the image and preprocess it
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
# update our list of data, targets, and filenames
data.append(image)
targets.append((startX, startY, endX, endY))
filenames.append(filename)
现在我们已经加载了数据,让我们为训练对其进行分区:
# convert the data and targets to NumPy arrays, scaling the input
# pixel intensities from the range [0, 255] to [0, 1]
data = np.array(data, dtype="float32") / 255.0
targets = np.array(targets, dtype="float32")
# partition the data into training and testing splits using 90% of
# the data for training and the remaining 10% for testing
split = train_test_split(data, targets, filenames, test_size=0.10,
random_state=42)
# unpack the data split
(trainImages, testImages) = split[:2]
(trainTargets, testTargets) = split[2:4]
(trainFilenames, testFilenames) = split[4:]
# write the testing filenames to disk so that we can use then
# when evaluating/testing our bounding box regressor
print("[INFO] saving testing filenames...")
f = open(config.TEST_FILENAMES, "w")
f.write("\n".join(testFilenames))
f.close()
在这里我们:
# load the VGG16 network, ensuring the head FC layers are left off
vgg = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
# freeze all VGG layers so they will *not* be updated during the
# training process
vgg.trainable = False
# flatten the max-pooling output of VGG
flatten = vgg.output
flatten = Flatten()(flatten)
# construct a fully-connected layer header to output the predicted
# bounding box coordinates
bboxHead = Dense(128, activation="relu")(flatten)
bboxHead = Dense(64, activation="relu")(bboxHead)
bboxHead = Dense(32, activation="relu")(bboxHead)
bboxHead = Dense(4, activation="sigmoid")(bboxHead)
# construct the model we will fine-tune for bounding box regression
model = Model(inputs=vgg.input, outputs=bboxHead)
完成微调需要四个步骤:
- 用预先训练好的 ImageNet 砝码加载
VGG16,砍掉旧全连接分类层头(第 79、80 行)。 - 冻结 VGG16 网络体中的所有图层(行 84 )。
- 通过构建一个新的全连接图层头来执行网络手术,该图层头将输出对应于图像中对象的左上和右下边界框坐标的四个值(行 87-95 )。
- 通过将新的可训练头部(包围盒回归层)缝合到现有的冷冻体(线 98 )上,完成网络手术。
现在让我们训练(即微调)我们新形成的野兽:
# initialize the optimizer, compile the model, and show the model
# summary
opt = Adam(lr=config.INIT_LR)
model.compile(loss="mse", optimizer=opt)
print(model.summary())
# train the network for bounding box regression
print("[INFO] training bounding box regressor...")
H = model.fit(
trainImages, trainTargets,
validation_data=(testImages, testTargets),
batch_size=config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
verbose=1)
# serialize the model to disk
print("[INFO] saving object detector model...")
model.save(config.MODEL_PATH, save_format="h5")
# plot the model training history
N = config.NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.title("Bounding Box Regression Loss on Training Set")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
训练我们的基本包围盒回归器和对象检测器
实现了包围盒回归网络后,让我们继续训练它。
首先使用本教程的 【下载】 部分下载源代码和示例飞机数据集。
从那里,打开一个终端,并执行以下命令:
$ python train.py
[INFO] loading dataset...
[INFO] saving testing filenames...
我们的脚本从从磁盘加载我们的飞机数据集开始。
然后,我们构建我们的训练/测试分割,然后将测试集中的图像的文件名保存到磁盘上(这样我们就可以在以后使用我们训练过的网络进行预测时使用它们)。
从那里,我们的训练脚本输出具有边界框回归头的 VGG16 网络的模型摘要:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 128) 3211392
_________________________________________________________________
dense_1 (Dense) (None, 64) 8256
_________________________________________________________________
dense_2 (Dense) (None, 32) 2080
_________________________________________________________________
dense_3 (Dense) (None, 4) 132
=================================================================
Total params: 17,936,548
Trainable params: 3,221,860
Non-trainable params: 14,714,688
注意block5_pool (MaxPooling2D) — 后面的图层,这些图层对应我们的包围盒回归图层头。
训练时,这些层将学习如何预测边界框 (x,y)-图像中对象的坐标!
接下来是我们的实际培训流程:
[INFO] training bounding box regressor...
Epoch 1/25
23/23 [==============================] - 37s 2s/step - loss: 0.0239 - val_loss: 0.0014
Epoch 2/25
23/23 [==============================] - 38s 2s/step - loss: 0.0014 - val_loss: 8.7668e-04
Epoch 3/25
23/23 [==============================] - 36s 2s/step - loss: 9.1919e-04 - val_loss: 7.5377e-04
Epoch 4/25
23/23 [==============================] - 37s 2s/step - loss: 7.1202e-04 - val_loss: 8.2668e-04
Epoch 5/25
23/23 [==============================] - 36s 2s/step - loss: 6.1626e-04 - val_loss: 6.4373e-04
...
Epoch 20/25
23/23 [==============================] - 37s 2s/step - loss: 6.9272e-05 - val_loss: 5.6152e-04
Epoch 21/25
23/23 [==============================] - 36s 2s/step - loss: 6.3215e-05 - val_loss: 5.4341e-04
Epoch 22/25
23/23 [==============================] - 37s 2s/step - loss: 5.7234e-05 - val_loss: 5.5000e-04
Epoch 23/25
23/23 [==============================] - 37s 2s/step - loss: 5.4265e-05 - val_loss: 5.5932e-04
Epoch 24/25
23/23 [==============================] - 37s 2s/step - loss: 4.5151e-05 - val_loss: 5.4348e-04
Epoch 25/25
23/23 [==============================] - 37s 2s/step - loss: 4.0826e-05 - val_loss: 5.3977e-04
[INFO] saving object detector model...
训练边界框回归器后,将生成以下训练历史图:
我们的对象检测模型以高损失开始,但是能够在训练过程中下降到较低损失的区域(即,模型学习如何做出更好的边界框预测)。
培训完成后,您的output目录应该包含以下文件:
$ ls output/
detector.h5 plot.png test_images.txt
plot.png文件包含我们的训练历史图,而test_images.txt包含我们的测试集中图像的文件名(我们将在本教程的后面对其进行预测)。
用 Keras 和 TensorFlow 实现我们的包围盒预测器
此时,我们已经将边界框预测器序列化到磁盘上— ,但是我们如何使用该模型来检测输入图像中的对象呢?
我们将在这一部分回答这个问题。
打开一个新文件,将其命名为predict.py,并插入以下代码:
# import the necessary packages
from pyimagesearch import config
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.models import load_model
import numpy as np
import mimetypes
import argparse
import imutils
import cv2
import os
至此,你应该认识到除了imutils(我的计算机视觉便利包)和潜在的mimetypes(内置于 Python 可以从文件名和 URL 中识别文件类型)。
让我们解析一下命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input image/text file of image filenames")
args = vars(ap.parse_args())
# determine the input file type, but assume that we're working with
# single input image
filetype = mimetypes.guess_type(args["input"])[0]
imagePaths = [args["input"]]
# if the file type is a text file, then we need to process *multiple*
# images
if "text/plain" == filetype:
# load the filenames in our testing file and initialize our list
# of image paths
filenames = open(args["input"]).read().strip().split("\n")
imagePaths = []
# loop over the filenames
for f in filenames:
# construct the full path to the image filename and then
# update our image paths list
p = os.path.sep.join([config.IMAGES_PATH, f])
imagePaths.append(p)
- 默认:我们的
imagePaths由来自--input( 第 22 行)的一条单独的图像路径组成。 - 文本文件:如果第 26 行上的文本
filetype的条件/检查符合True,那么我们覆盖并从--input文本文件(第 29-37 行)中的所有filenames(每行一个)填充我们的imagePaths。
给定一个或多个测试图像,让我们开始用我们的深度学习 TensorFlow/Keras model执行包围盒回归:
# load our trained bounding box regressor from disk
print("[INFO] loading object detector...")
model = load_model(config.MODEL_PATH)
# loop over the images that we'll be testing using our bounding box
# regression model
for imagePath in imagePaths:
# load the input image (in Keras format) from disk and preprocess
# it, scaling the pixel intensities to the range [0, 1]
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image) / 255.0
image = np.expand_dims(image, axis=0)
在加载我们的model ( 第 41 行)后,我们开始循环图像(第 45 行)。在里面,我们首先在中加载并预处理图像,就像我们在中做的一样。这包括:
- 将图像大小调整为 224×224 像素(第 48 行
- 转换为数组格式并将像素缩放到范围【0,1】(第 49 行)
- 添加批量维度(第 50 行)
从那里,我们可以执行包围盒回归推理并注释结果:
# make bounding box predictions on the input image
preds = model.predict(image)[0]
(startX, startY, endX, endY) = preds
# load the input image (in OpenCV format), resize it such that it
# fits on our screen, and grab its dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
# scale the predicted bounding box coordinates based on the image
# dimensions
startX = int(startX * w)
startY = int(startY * h)
endX = int(endX * w)
endY = int(endY * h)
# draw the predicted bounding box on the image
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
第 53 行对输入图像进行边界框预测。注意preds包含了我们的边界框预测的 (x,y) 坐标;为了方便起见,我们通过线 54 解包这些值。
现在我们有了注释所需的一切。要在图像上标注边界框,我们只需:
- 用 OpenCV 从磁盘加载原始的
Image并resize它,同时保持纵横比(第 58 和 59 行) - 将预测边界框坐标从范围 [0,1] 缩放到范围 [0,
w] 和 [0,h] 其中w**h为输入image( 第 60-67 行)的宽度和高度 - 绘制缩放的边界框(第 70 行和第 71 行)
最后,我们在屏幕上显示输出。按下一个键在循环中循环,一个接一个地显示结果,直到所有的测试图像都已完成(行 74 和 75 )。
干得好!让我们在下一部分检查我们的结果。
使用 Keras 和 TensorFlow 的包围盒回归和对象检测结果
我们现在准备好测试我们的包围盒回归对象检测模型了!
确保您已经使用本教程的 【下载】 部分下载了源代码、图像数据集和预训练的对象检测模型。
从这里开始,让我们尝试对单个输入图像应用对象检测:
$ python predict.py --input datasimg/image_0697.jpg
[INFO] loading object detector...
正如你所看到的,我们的边界框回归器已经在输入图像中正确地定位了飞机,证明了我们的目标检测模型实际上已经学会了如何仅仅从输入图像中预测边界框坐标!
接下来,让我们通过提供到test_images.txt文件的路径作为--input命令行参数,将边界框回归器应用到测试集中的每个图像的:
$ python predict.py --input output/test_images.txt
[INFO] loading object detector...
如图 6 所示,我们的目标检测模型在预测输入图像中飞机的位置方面做得非常好!
限制
在这一点上,我们已经成功地训练了一个包围盒回归模型——但是这个架构的一个明显的限制是它只能预测一个类的包围盒。
如果我们想要执行多类物体检测 呢?我们不仅有“飞机”类,还有“摩托车”、“汽车”和“卡车”
用包围盒回归进行多类物体检测可能吗?
没错,我会在下周的教程中讲述这个话题。我们将学习多类对象检测如何需要改变包围盒回归架构(提示:我们 CNN 中的两个分支)并训练这样一个模型。 敬请期待!
总结
在本教程中,您学习了如何使用边界框回归训练端到端对象检测器。
为了完成这项任务,我们利用了 Keras 和 TensorFlow 深度学习库。
与仅输出类标签的分类模型不同,回归模型能够产生实值输出。
回归模型的典型应用包括预测房价、预测股票市场和预测疾病在一个地区的传播速度。
然而,回归模型并不局限于价格预测或疾病传播— 我们也可以将它们用于物体检测!
诀窍是更新你的 CNN 架构:
- 将具有四个神经元(左上和右下边界框坐标)的全连接层放置在网络的顶部
- 在该层上放置一个 sigmoid 激活函数(使得输出值位于范围【0,1】)
- 通过提供(1)输入图像和(2)图像中对象的目标边界框来训练模型
- 随后,使用均方误差、平均绝对误差等来训练您的模型。
最终结果是一个端到端的可训练对象检测器,类似于我们今天构建的这个!
你会注意到我们的模型只能预测一种类型的类标签——我们如何扩展我们的实现来处理多标签?
这可能吗?
当然是这样——下周请继续关注本系列的第二部分!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
基于深度学习和 OpenCV 的物体检测
原文:https://pyimagesearch.com/2017/09/11/object-detection-with-deep-learning-and-opencv/
最后更新于 2021 年 7 月 7 日。
几周前,我们学习了如何使用深度学习和 OpenCV 3.3 的深度神经网络(dnn)模块对图像进行分类。
虽然这篇原始的博客文章演示了我们如何将一幅图像归类到 ImageNet 的 1000 个单独的类别标签中的一个,但是无法告诉我们 一个对象驻留在图像中的什么地方 。
*为了获得图像中对象的边界框 (x,y)-坐标,我们需要应用对象检测。
物体检测不仅能告诉我们在图像中是什么,还能告诉我们物体在哪里。****
****在今天博文的剩余部分,我们将讨论如何使用深度学习和 OpenCV 来应用对象检测。
- 【2021 年 7 月更新:增加了一个关于替代的基于深度学习的对象检测器的部分,包括关于如何从头训练 R-CNN 的文章,以及关于边界框回归的更多细节。
基于深度学习和 OpenCV 的物体检测
在今天关于使用深度学习进行物体检测的帖子的第一部分中,我们将讨论单次检测器和移动探测器。
当将这些方法结合在一起时,可以用于资源受限设备(包括 Raspberry Pi、智能手机等)上的超快速实时对象检测。)
从那里,我们将发现如何使用 OpenCV 的dnn模块来加载一个预先训练的对象检测网络。
这将使我们能够通过网络传递输入图像,并获得图像中每个对象的输出边界框 (x,y)- 坐标。
最后,我们将看看将 MobileNet 单镜头检测器应用于示例输入图像的结果。
在未来的博客文章中,我们将扩展我们的脚本来处理实时视频流。
用于目标检测的单次检测器
说到基于深度学习的对象检测,您可能会遇到三种主要的对象检测方法:
- 更快的 R-CNNs (任等,2015)
- 你只看一次(YOLO) (雷德蒙等人,2015)
- 【刘等,2015】
更快的 R-CNN 可能是使用深度学习进行对象检测的最“听说过”的方法;然而,这种技术可能很难理解(特别是对于深度学习的初学者),很难实现,并且很难训练。
此外,即使使用“更快”的实现 R-CNN(其中“R”代表“区域提议”),该算法也可能相当慢,大约为 7 FPS。
如果我们寻求纯粹的速度,那么我们倾向于使用 YOLO,因为这种算法更快,能够在 Titan X GPU 上处理 40-90 FPS。YOLO 的超快速变体甚至可以达到 155 FPS。
YOLO 的问题在于,它的精确度有待提高。
固态硬盘最初由谷歌开发,是两者之间的平衡。该算法比更快的 R-CNN 更简单(我认为在最初的开创性论文中解释得更好)。
我们还可以享受比任等人更快的 FPS 吞吐量。每秒 22-46 帧,这取决于我们使用的网络版本。固态硬盘也往往比 YOLO 更准确。要了解更多关于固态硬盘的知识,请参见刘等。
MobileNets:高效(深度)神经网络
当构建对象检测网络时,我们通常使用现有的网络架构,如 VGG 或 ResNet,然后在对象检测管道内使用它。问题是这些网络架构可能非常大,大约 200-500MB。
诸如此类的网络架构由于其庞大的规模和由此产生的计算量而不适用于资源受限的设备。
相反,我们可以使用谷歌研究人员的另一篇论文 MobileNets (Howard et al .,2017)。我们称这些网络为“移动网络”,因为它们是为诸如智能手机等资源受限的设备而设计的。MobileNets 通过使用深度方向可分离卷积(上图图 2 )与传统 CNN 不同。
深度方向可分离卷积背后的一般思想是将卷积分成两个阶段:
- 一个 3×3 深度方向卷积。
- 随后是 1×1 逐点卷积。
这允许我们实际上减少网络中的参数数量。
问题是我们牺牲了准确性——移动互联网通常不如它们的大兄弟们准确……
但是它们更加节约资源。
有关移动互联网的更多详情,请参见 Howard 等人的。
结合 MobileNets 和单次检测器,实现快速、高效的基于深度学习的对象检测
如果我们将 MobileNet 架构和单次检测器(SSD)框架相结合,我们将获得一种快速、高效的基于深度学习的对象检测方法。
我们将在这篇博文中使用的模型是 Howard 等人的原始 TensorFlow 实现的 Caffe 版本,并由川崎 305 训练(参见 GitHub )。
MobileNet SSD 首先在 COCO 数据集(上下文中的常见对象)上进行训练,然后在 PASCAL VOC 上进行微调,达到 72.7% mAP(平均精度)。
因此,我们可以检测图像中的 20 个对象(背景类+1),包括飞机、自行车、鸟、船、瓶子、公共汽车、汽车、猫、椅子、牛、餐桌、狗、马、摩托车、人、盆栽植物、羊、沙发、火车、和电视监视器。
基于深度学习的 OpenCV 物体检测
在本节中,我们将使用 OpenCV 中的 MobileNet SSD +深度神经网络(dnn)模块来构建我们的对象检测器。
我建议使用这篇博文底部的 【下载】 代码下载源代码+训练好的网络+示例图片,这样你就可以在你的机器上测试它们了。
让我们继续,开始使用 OpenCV 构建我们的深度学习对象检测器。
打开一个新文件,将其命名为deep_learning_object_detection.py,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
在的第 2-4 行中,我们导入了这个脚本所需的包——dnn模块包含在cv2中,同样,假设您使用的是 OpenCV 3.3 。
然后,我们解析我们的命令行参数(第 7-16 行):
--image:输入图像的路径。- 【the Caffe prototxt 文件的路径。
--model:预训练模型的路径。--confidence:过滤弱检测的最小概率阈值。默认值为 20%。
同样,前三个参数的示例文件包含在这篇博文的 “下载” 部分。我强烈建议您从这里开始,同时也提供一些您自己的查询图片。
接下来,让我们初始化类标签和边界框颜色:
# initialize the list of class labels MobileNet SSD was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
第 20-23 行构建了一个名为CLASSES的列表,包含我们的标签。接下来是一个列表,COLORS,它包含了边界框相应的随机颜色(第 24 行)。
现在我们需要加载我们的模型:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
上面几行是不言自明的,我们只需打印一条消息并加载我们的model ( 第 27 行和第 28 行)。
接下来,我们将加载我们的查询图像并准备我们的blob,我们将通过网络对其进行前馈:
# load the input image and construct an input blob for the image
# by resizing to a fixed 300x300 pixels and then normalizing it
# (note: normalization is done via the authors of the MobileNet SSD
# implementation)
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843,
(300, 300), 127.5)
注意这个块中的注释,我们加载我们的image ( 第 34 行),提取高度和宽度(第 35 行),并从我们的图像(第 36 行)计算一个 300 乘 300 像素blob。
现在我们准备好做繁重的工作了——我们将让这个 blob 通过神经网络:
# pass the blob through the network and obtain the detections and
# predictions
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
在行 41 和 42 上,我们设置网络的输入,并计算输入的前向传递,将结果存储为detections。根据您的型号和输入大小,计算向前传递和相关的检测可能需要一段时间,但对于这个示例,它在大多数 CPU 上相对较快。
让我们循环遍历我们的detections并确定什么和物体在图像中的位置:
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the `detections`,
# then compute the (x, y)-coordinates of the bounding box for
# the object
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# display the prediction
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
print("[INFO] {}".format(label))
cv2.rectangle(image, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(image, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
我们首先循环我们的检测,记住在单个图像中可以检测多个对象。我们还对与每个检测相关联的置信度(即概率)进行检查。如果置信度足够高(即高于阈值),那么我们将在终端中显示预测,并在带有文本和彩色边框的图像上绘制预测。让我们一行一行地分解它:
循环遍历我们的detections,首先我们提取confidence值(第 48 行)。
如果confidence高于我们的最小阈值(行 52 ),我们提取类别标签索引(行 56 )并计算被检测对象周围的边界框(行 57 )。
然后,我们提取盒子的 (x,y)-坐标(第 58 行),稍后我们将使用它来绘制矩形和显示文本。
接下来,我们构建一个文本label,包含CLASS名称和confidence ( 第 61 行)。
使用标签,我们将它打印到终端(行 62 ),然后使用我们之前提取的 (x,y)-坐标(行 63 和 64 )在对象周围绘制一个彩色矩形。
一般来说,我们希望标签显示在矩形的上方,但是如果没有空间,我们将它显示在矩形顶部的正下方( Line 65 )。
最后,我们使用刚刚计算的y-值(第 66 和 67 行)将彩色文本覆盖到image上。
剩下的唯一一步是显示结果:
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
我们将结果输出图像显示到屏幕上,直到按下一个键为止(行 70 和 71 )。
OpenCV 和深度学习对象检测结果
要下载代码+预先训练好的网络+示例图片,请务必使用这篇博文底部的 “下载” 部分。
从那里,解压缩归档文件并执行以下命令:
$ python deep_learning_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel --image images/example_01.jpg
[INFO] loading model...
[INFO] computing object detections...
[INFO] loading model...
[INFO] computing object detections...
[INFO] car: 99.78%
[INFO] car: 99.25%
我们的第一个结果显示,识别和检测汽车的置信度接近 100%。
在这个示例中,我们使用基于深度学习的对象检测来检测飞机:
$ python deep_learning_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel --image images/example_02.jpg
[INFO] loading model...
[INFO] computing object detections...
[INFO] loading model...
[INFO] computing object detections...
[INFO] aeroplane: 98.42%
深度学习检测和定位模糊对象的能力在下图中得到展示,我们看到一匹马(和它的骑手)跳过两侧有两株盆栽植物的围栏:
$ python deep_learning_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel --image images/example_03.jpg
[INFO] loading model...
[INFO] computing object detections...
[INFO] horse: 96.67%
[INFO] person: 92.58%
[INFO] pottedplant: 96.87%
[INFO] pottedplant: 34.42%
在本例中,我们可以看到啤酒瓶以令人印象深刻的 100%置信度被检测到:
$ python deep_learning_object_detection.py --prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel --image images/example_04.jpg
[INFO] loading model...
[INFO] computing object detections...
[INFO] bottle: 100.00%
随后是另一个马图像,它也包含狗、汽车和人:
$ python deep_learning_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel --image images/example_05.jpg
[INFO] loading model...
[INFO] computing object detections...
[INFO] car: 99.87%
[INFO] dog: 94.88%
[INFO] horse: 99.97%
[INFO] person: 99.88%
最后,一张我和杰玛的照片,一只家庭猎犬:
$ python deep_learning_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt.txt \
--model MobileNetSSD_deploy.caffemodel --image images/example_06.jpg
[INFO] loading model...
[INFO] computing object detections...
[INFO] dog: 95.88%
[INFO] person: 99.95%
不幸的是,此图像中的电视监视器无法识别,这可能是由于(1)我挡住了它,以及(2)电视周围的对比度差。也就是说,我们已经使用 OpenCV 的dnn模块展示了出色的对象检测结果。
替代深度学习对象检测器
在这篇文章中,我们使用 OpenCV 和单镜头检测器(SSD)模型进行基于深度学习的对象检测。
然而,我们可以应用个深度学习对象检测器,包括:
- YOLO 用 OpenCV 检测物体
- 【YOLO】和微小——YOLO 上的物体探测树莓派和 m ovidius NCS
- 更快的 R-CNN 和 OpenCV
- 屏蔽 R-CNN 和 OpenCV (技术上是一种“实例分割”模型)
- RetinaNet 天体探测器
此外,如果您有兴趣了解如何训练自己的定制深度学习对象检测器,包括更深入地了解 R-CNN 系列对象检测器,请务必阅读这个由四部分组成的系列:
- 用 Keras、TensorFlow、OpenCV 把任何 CNN 图像分类器变成物体检测器
- OpenCV 选择性搜索目标检测
- 用 OpenCV、Keras 和 TensorFlow 进行区域提议对象检测
- R-CNN 物体检测用 Keras、TensorFlow、深度学习
从那里,我建议更详细地研究一下边界框回归的概念:
摘要
在今天的博文中,我们学习了如何使用深度学习和 OpenCV 执行对象检测。
具体来说,我们使用了 MobileNets +单次检测器和 OpenCV 3.3 的全新(全面改造)dnn模块来检测图像中的对象。
作为一个计算机视觉和深度学习社区,我们非常感谢 Aleksandr Rybnikov 的贡献,他是dnn模块的主要贡献者,使深度学习可以从 OpenCV 库中访问。你可以在这里找到亚历山大最初的 OpenCV 示例脚本——为了这篇博文的目的,我修改了它。
在未来的博客文章中,我将展示我们如何修改今天的教程,以处理实时视频流,从而使我们能够对视频执行基于深度学习的对象检测。我们一定会利用高效的帧 I/O 来提高我们整个流水线的 FPS。
在 PyImageSearch 上发布未来的博客文章(如实时对象检测教程)时,我们会通知您,只需在下面的表格中输入您的电子邮件地址。*****
用 dlib 进行目标跟踪
原文:https://pyimagesearch.com/2018/10/22/object-tracking-with-dlib/

本教程将教你如何使用 dlib 和 Python 来执行对象跟踪。看完今天的博文,你将能够用 dlib 实时视频追踪物体。
几个月前,我们讨论了质心跟踪,这是一种简单而有效的方法,可以(1) 为图像中的每个对象分配唯一的 id,然后(2) 在它们在视频流中四处移动时跟踪每个对象和相关的 id。
这种对象跟踪算法的最大缺点是,必须在每个输入帧上运行单独的对象检测器——在大多数情况下,这种行为是不可取的,因为对象检测器,包括 HOG +线性 SVM、更快的 R-CNN 和 SSD,运行起来可能计算量很大。
另一种方法是:
- 执行一次对象检测(或每隔 N 帧执行一次)
- 然后应用专用跟踪算法,该算法可以在对象在后续帧中移动时保持对对象的跟踪,而不必执行对象检测
这样的方法可能吗?
答案是肯定的,特别是,我们可以使用 dlib 对相关跟踪算法的实现。
在今天博文的剩余部分,你将学习如何应用 dlib 的相关性跟踪器来实时跟踪视频流中的对象。
要了解更多关于 dlib 的相关性跟踪器,继续阅读。
用 dlib 进行目标跟踪
我们将从简要讨论 dlib 的基于相关性的对象跟踪实现开始今天的教程。
从那以后,我将向您展示如何在您自己的应用程序中使用 dlib 的对象跟踪器。
最后,我们将通过讨论 dlib 的对象跟踪器的一些限制和缺点来结束今天的讨论。
什么是相关性跟踪器?
https://www.youtube.com/embed/-8-KCoOFfqs?feature=oembed
使用 Tesseract、OpenCV 和 Python 对文档、表单或发票进行 OCR
在本教程中,您将学习如何使用 Tesseract、OpenCV 和 Python 对文档、表单或发票进行 OCR。
上周,我们讨论了如何接受输入图像并将其与模板图像对齐,如下所示:
在左边的,是我们的模板图像(例如,来自美国国税局的表单)。中间的图是我们希望与模板对齐的输入图像(从而允许我们将两幅图像中的字段匹配在一起)。最后,右边的显示了将两幅图像对齐的输出。
此时,我们可以将表单中的文本字段与模板中的每个对应字段相关联,这意味着我们知道输入图像的哪些位置映射到姓名、地址、EIN 等。模板的字段:
了解字段的位置和内容使我们能够对每个单独的字段进行 OCR,并跟踪它们以进行进一步的处理,如自动数据库输入。
但这也带来了问题:
- 我们如何着手实现这个文档 OCR 管道呢?
- 我们需要使用什么 OCR 算法?
- 这个 OCR 应用程序会有多复杂?
正如您将看到的,我们将能够用不到 150 行代码实现我们的整个文档 OCR 管道!
注:本教程是我即将出版的书 OCR with OpenCV、Tesseract 和 Python 中的一章的一部分。
要了解如何使用 OpenCV、Tesseract 和 Python 对文档、表格或发票进行 OCR,请继续阅读。
使用 Tesseract、OpenCV 和 Python 对文档、表格或发票进行 OCR
在本教程的第一部分,我们将简要讨论为什么我们可能想要 OCR 文档、表单、发票或任何类型的物理文档。
从那里,我们将回顾实现文档 OCR 管道所需的步骤。然后,我们将使用 OpenCV 和 Tesseract 在 Python 脚本中实现每个单独的步骤。
最后,我们将回顾对示例图像应用图像对齐和 OCR 的结果。
为什么要在表格、发票和文件上使用 OCR?
尽管生活在数字时代,我们仍然强烈依赖于物理纸面痕迹、尤其是大型组织,如政府、企业公司和大学/学院。
对实体文件跟踪的需求,加上几乎每份文件都需要组织、分类,甚至与组织中的多人共享这一事实,要求我们也数字化文件上的信息,并将其保存在我们的数据库中。
这些大型组织雇佣数据输入团队,他们的唯一目的是获取这些物理文档,手动重新键入信息,然后将其保存到系统中。
光学字符识别算法可以自动数字化这些文档,提取信息,并通过管道将它们输入数据库进行存储,减少了对庞大、昂贵甚至容易出错的手动输入团队的需求。
在本教程的其余部分,您将学习如何使用 OpenCV 和 Tesseract 实现一个基本的文档 OCR 管道。
使用 OpenCV 和 Tesseract 实现文档 OCR 管道的步骤
用 OpenCV 和 Tesseract 实现文档 OCR 管道是一个多步骤的过程。在这一节中,我们将发现创建 OCR 表单管道所需的五个步骤。
步骤#1 涉及定义输入图像文档中字段的位置。我们可以通过在我们最喜欢的图像编辑软件中打开我们的模板图像来做到这一点,如 Photoshop、GIMP 或任何内置于操作系统中的照片应用程序。从那里,我们手动检查图像并确定边界框 (x,y)——我们想要进行 OCR 的每个字段的坐标,如图图 4: 所示
然后,我们接受一个包含要进行 OCR 的文档的输入图像(步骤#2 ),并将其提交给我们的 OCR 管道(图 5 ):
然后我们可以(步骤#3 )应用自动图像对齐/配准来将输入图像与模板表单对齐(图 6 )。
步骤#4 遍历所有文本字段位置(我们在步骤#1 中定义),提取 ROI,并对 ROI 应用 OCR。在这个步骤中,我们能够 OCR 文本本身并且将它与原始模板文档中的文本字段相关联,如图图 7: 所示
最后的步骤#5 是显示我们输出的 OCR 文档,如图图 8: 所示
对于真实世界的用例,作为步骤#5 的替代方案,您可能希望将信息直接传输到会计数据库中。
我们将学习如何开发一个 Python 脚本,通过使用 OpenCV 和 Tesseract 创建 OCR 文档管道来完成本章中的第 1 步到第 5 步。
项目结构
如果你想跟随今天的教程,找到 “下载” 部分并获取代码和图像存档。使用你最喜欢的解压工具解压文件。从那里,打开文件夹,您将看到以下内容:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── alignment
│ │ ├── __init__.py
│ │ └── align_images.py
│ └── __init__.py
├── scans
│ ├── scan_01.jpg
│ └── scan_02.jpg
├── form_w4.png
└── ocr_form.py
3 directories, 7 files
scans/scan_01.jpg:一个例子 IRS W-4 文件,已经填了我的真实姓名,但是假的税务数据。scans/scan_02.jpg:一个类似的 IRS W-4 文件的例子,其中填写了虚假的税务信息。form_w4.png:官方 2020 IRS W-4 表格模板。这个空表单没有输入任何信息。我们需要它和现场位置,这样我们就可以排列扫描,并最终从扫描中提取信息。我们将使用外部照片编辑/预览应用程序手动确定字段位置。
我们只需要回顾一个 Python 驱动脚本:ocr_form.py。这个表单解析器依赖于两个辅助函数:
align_images:包含在alignment子模块内,上周首次推出。本周我们不会再复习这个方法,所以如果你错过了,一定要参考我之前的教程!cleanup_text:这个函数出现在我们的驱动程序脚本的顶部,简单地消除 OCR 检测到的非 ASCII 字符(我将在下一节分享更多关于这个函数的内容)。
如果您准备好了,就直接进入下一个实现部分吧!
使用 OpenCV 和 Tesseract 实现我们的文档 OCR 脚本
我们现在准备使用 OpenCV 和 Tesseract 实现我们的文档 OCR Python 脚本。
打开一个新文件,将其命名为ocr_form.py,并插入以下代码:
# import the necessary packages
from pyimagesearch.alignment import align_images
from collections import namedtuple
import pytesseract
import argparse
import imutils
import cv2
def cleanup_text(text):
# strip out non-ASCII text so we can draw the text on the image
# using OpenCV
return "".join([c if ord(c) < 128 else "" for c in text]).strip()
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image that we'll align to template")
ap.add_argument("-t", "--template", required=True,
help="path to input template image")
args = vars(ap.parse_args())
我们将图像与模板对齐,然后根据需要对各个字段进行 OCR。
现在,我们没有创建一个“智能表单 OCR 系统”,在这个系统中,所有的文本都被识别,字段都是基于正则表达式模式设计的。这当然是可行的——这是我即将出版的 OCR 书中介绍的一种先进方法。
相反,为了保持本教程的轻量级,我已经为我们关心的每个字段手动定义了OCR_Locations。好处是我们能够给每个字段一个名称,并指定精确的 (x,y)-坐标作为字段的边界。现在让我们在步骤#1 中定义文本字段的位置:
# create a named tuple which we can use to create locations of the
# input document which we wish to OCR
OCRLocation = namedtuple("OCRLocation", ["id", "bbox",
"filter_keywords"])
# define the locations of each area of the document we wish to OCR
OCR_LOCATIONS = [
OCRLocation("step1_first_name", (265, 237, 751, 106),
["middle", "initial", "first", "name"]),
OCRLocation("step1_last_name", (1020, 237, 835, 106),
["last", "name"]),
OCRLocation("step1_address", (265, 336, 1588, 106),
["address"]),
OCRLocation("step1_city_state_zip", (265, 436, 1588, 106),
["city", "zip", "town", "state"]),
OCRLocation("step5_employee_signature", (319, 2516, 1487, 156),
["employee", "signature", "form", "valid", "unless",
"you", "sign"]),
OCRLocation("step5_date", (1804, 2516, 504, 156), ["date"]),
OCRLocation("employee_name_address", (265, 2706, 1224, 180),
["employer", "name", "address"]),
OCRLocation("employee_ein", (1831, 2706, 448, 180),
["employer", "identification", "number", "ein"]),
]
这里,行 24 和 25 创建了一个命名元组,由以下内容组成:
name = "OCRLocation":我们元组的名称。"id":该字段的简短描述,便于参考。使用此字段描述表单字段的实际内容。例如,它是邮政编码字段吗?"bbox":列表形式字段的边框坐标,使用如下顺序:[x, y, w, h]。在这种情况下, x 和 y 是左上坐标, w 和 h 是宽度和高度。"filter_keywords":我们不希望在 OCR 中考虑的单词列表,如图 12 所示的表单域指令。
第 28-45 行定义了官方 2020 IRS W-4 税表的 八个字段,如图图 9:****
# load the input image and template from disk
print("[INFO] loading images...")
image = cv2.imread(args["image"])
template = cv2.imread(args["template"])
# align the images
print("[INFO] aligning images...")
aligned = align_images(image, template)
$ convert /path/to/taxes/2020/forms/form_w4.pdf ./form_w4.png
ImageMagick 足够智能,能够根据文件扩展名和文件本身识别出您想要将 PDF 转换为 PNG 图像。如果您愿意,可以很容易地修改命令来生成 JPG。
你有许多表格吗?只需使用 ImageMagick 的mogrify命令,它支持通配符(参考文档)。
假设您的文档是 PNG 或 JPG 格式,您可以像我们今天的教程一样,在 OpenCV 和 PyTesseract 中使用它!
注意我们的输入图像(左)是如何与模板文档(右)对齐的。
下一步(步骤#4 )是循环遍历我们的每个OCR_LOCATIONS和应用光学字符识别到每个文本字段使用宇宙魔方和宇宙魔方的力量:
# initialize a results list to store the document OCR parsing results
print("[INFO] OCR'ing document...")
parsingResults = []
# loop over the locations of the document we are going to OCR
for loc in OCR_LOCATIONS:
# extract the OCR ROI from the aligned image
(x, y, w, h) = loc.bbox
roi = aligned[y:y + h, x:x + w]
# OCR the ROI using Tesseract
rgb = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(rgb)
首先,我们初始化parsingResults列表来存储每个文本字段的 OCR 结果(第 58 行)。从那里,我们继续循环每个OCR_LOCATIONS(从行 61 开始),这是我们之前手动定义的。
# break the text into lines and loop over them
for line in text.split("\n"):
# if the line is empty, ignore it
if len(line) == 0:
continue
# convert the line to lowercase and then check to see if the
# line contains any of the filter keywords (these keywords
# are part of the *form itself* and should be ignored)
lower = line.lower()
count = sum([lower.count(x) for x in loc.filter_keywords])
# if the count is zero then we know we are *not* examining a
# text field that is part of the document itself (ex., info,
# on the field, an example, help text, etc.)
if count == 0:
# update our parsing results dictionary with the OCR'd
# text if the line is *not* empty
parsingResults.append((loc, line))
虽然我已经在这个字段中填写了我的名字,“Adrian”,文本“(a)名字和中间名首字母”仍将由 Tesseract 进行 OCR 识别——上面的代码会自动过滤掉字段中的说明文本,确保只返回人工输入的文本。
我们快到了,坚持住!让我们继续后处理我们的parsingResults来清理它们:
# initialize a dictionary to store our final OCR results
results = {}
# loop over the results of parsing the document
for (loc, line) in parsingResults:
# grab any existing OCR result for the current ID of the document
r = results.get(loc.id, None)
# if the result is None, initialize it using the text and location
# namedtuple (converting it to a dictionary as namedtuples are not
# hashable)
if r is None:
results[loc.id] = (line, loc._asdict())
# otherwise, there exists an OCR result for the current area of the
# document, so we should append our existing line
else:
# unpack the existing OCR result and append the line to the
# existing text
(existingText, loc) = r
text = "{}\n{}".format(existingText, line)
# update our results dictionary
results[loc["id"]] = (text, loc)
我们最终的results字典(第 91 行)将很快保存清理后的解析结果,包括文本位置的唯一 ID(键)和经过 OCR 处理的文本的二元组及其位置(值)。让我们通过在行 94 上循环我们的parsingResults来开始填充我们的results。我们的循环完成三项任务:
- 我们获取当前文本字段 ID 的任何现有结果。
- 如果没有当前结果,我们简单地将文本
line和文本loc(位置)存储在results字典中。 - 否则,我们将把
line附加到由新行分隔的任何existingText中,并更新results字典。
我们终于准备好执行步骤# 5——可视化我们的 OCR results:
# loop over the results
for (locID, result) in results.items():
# unpack the result tuple
(text, loc) = result
# display the OCR result to our terminal
print(loc["id"])
print("=" * len(loc["id"]))
print("{}\n\n".format(text))
# extract the bounding box coordinates of the OCR location and
# then strip out non-ASCII text so we can draw the text on the
# output image using OpenCV
(x, y, w, h) = loc["bbox"]
clean = cleanup_text(text)
# draw a bounding box around the text
cv2.rectangle(aligned, (x, y), (x + w, y + h), (0, 255, 0), 2)
# loop over all lines in the text
for (i, line) in enumerate(text.split("\n")):
# draw the line on the output image
startY = y + (i * 70) + 40
cv2.putText(aligned, line, (x, startY),
cv2.FONT_HERSHEY_SIMPLEX, 1.8, (0, 0, 255), 5)
# show the input and output images, resizing it such that they fit
# on our screen
cv2.imshow("Input", imutils.resize(image, width=700))
cv2.imshow("Output", imutils.resize(aligned, width=700))
cv2.waitKey(0)
如您所见,第 143 行和第 144 行首先应用方面感知的大小调整,因为在向用户显示结果和原始数据之前,高分辨率扫描往往不适合普通的计算机屏幕。要停止程序,只需在其中一个窗口处于焦点时按任意键。
用 Python、OpenCV 和 Tesseract 实现您的自动化 OCR 系统做得很好!在下一部分,我们将对它进行测试。
使用 OpenCV 和 Tesseract 的 OCR 结果
我们现在准备使用 OpenCV 和 Tesseract 对文档进行 OCR。
确保使用本教程的 “下载” 部分下载与本文相关的源代码和示例图片。
从那里,打开一个终端,并执行以下命令:
$ python ocr_form.py --image scans/scan_01.jpg --template form_w4.png
[INFO] loading images...
[INFO] aligning images...
[INFO] OCR'ing document...
step1_first_name
================
Adrian
step1_last_name
===============
Rosebrock
step1_address
=============
PO Box 17598 #17900
step1_city_state_zip
====================
Baltimore, MD 21297-1598
step5_employee_signature
========================
Adrian Rosebrock
step5_date
==========
2020/06/10
employee_name_address
=====================
PylmageSearch
PO BOX 1234
Philadelphia, PA 19019
employee_ein
============
12-3456789
这里,我们有我们的输入图像及其相应的模板:
这是图像对齐和文档 OCR 管道的输出:
请注意我们是如何成功地将输入图像与文档模板对齐,本地化每个字段,然后对每个单独的字段进行 OCR 的。
我们的实现还忽略了属于文档本身一部分的字段中的任何一行文本。
例如,名字段提供说明文本(a)名和中间名首字母";然而,我们的 OCR 管道和关键字过滤过程能够检测到这是文档本身的一部分(即,不是某个人输入的内容),然后简单地忽略它。
总的来说,我们已经能够成功地对文档进行 OCR 了!
让我们尝试另一个示例图像,这次视角略有不同:
$ python ocr_form.py --image scans/scan_02.jpg --template form_w4.png
[INFO] loading images...
[INFO] aligning images...
[INFO] OCR'ing document...
step1_first_name
================
Adrian
step1_last_name
===============
Rosebrock
step1_address
=============
PO Box 17598 #17900
step1_city_state_zip
====================
Baltimore, MD 21297-1598
step5_employee_signature
========================
Adrian Rosebrock
step5_date
==========
2020/06/10
employee_name_address
=====================
PyimageSearch
PO BOX 1234
Philadelphia, PA 19019
employee_ein
============
12-3456789
同样,这是我们的输入图像及其模板:
下图包含我们的输出,您可以看到图像已与模板对齐,OCR 已成功应用于每个字段:
同样,我们已经能够成功地将输入图像与模板文档对齐,然后对每个单独的字段进行 OCR!
总结
在本教程中,您学习了如何使用 OpenCV 和 Tesseract 对文档、表单或发票进行 OCR。
我们的方法依赖于图像对齐,这是一个接受输入图像和模板图像的过程,然后将它们对齐,以便它们可以整齐地“叠加”在彼此之上。在光学字符识别的环境中,图像对齐允许我们将模板中的每个文本字段与我们的输入图像对齐,这意味着一旦我们对文档进行了 OCR,我们就可以将 OCR 文本与每个字段相关联(例如、姓名、地址等。).
应用图像对齐后,我们使用 Tesseract 来识别输入图像中预先选择的文本字段,同时过滤掉不相关的说明信息。
我希望你喜欢这个教程——更重要的是,我希望你可以在自己的项目中应用图像对齐和 OCR 时使用它。
如果你想了解更多关于光学字符识别的知识,一定要看看我的书 OCR with OpenCV,Tesseract,和 Python 。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OCR:使用 OpenCV、Keras 和 TensorFlow 进行手写识别
原文:https://pyimagesearch.com/2020/08/24/ocr-handwriting-recognition-with-opencv-keras-and-tensorflow/
在本教程中,您将学习如何使用 OpenCV、Keras 和 TensorFlow 执行 OCR 手写识别。
这篇文章是我们关于 Keras 和 TensorFlow 的光学字符识别的两部分系列文章的第二部分:
- Part 1: 用 Keras 和 TensorFlow 训练 OCR 模型(上周的帖子)
- 第二部分: 用 Keras 和 TensorFlow 进行基本的手写识别(今天的帖子)
正如你将在下面看到的,手写识别比使用特定字体/字符的传统 OCR 更难。
*这个概念如此具有挑战性的原因是,与计算机字体不同,手写风格几乎有无限种变化。我们每个人都有自己独特的风格,这是 T2 特有的。
例如,我妻子的书法令人惊叹。她的笔迹不仅清晰可辨,而且风格独特,你会认为是专业书法家写的:
另一方面,我……我的笔迹看起来像有人用一只精神错乱的松鼠骗过了一个医生:
几乎无法辨认。我经常被那些至少看了我的笔迹的人问 2-3 个澄清问题,关于一个特定的单词或短语是什么。而且不止一次,我不得不承认我也看不懂它们。
说说尴尬!真的,他们让我离开小学真是个奇迹。
手写风格的这些变化给光学字符识别引擎带来了相当大的问题,这些引擎通常是在计算机字体上训练的,而不是手写字体。
更糟糕的是,字母可以相互“连接”和“接触”,这使得手写识别变得更加复杂,使得 OCR 算法难以区分它们,最终导致不正确的 OCR 结果。
手写识别可以说是 OCR 的“圣杯”。我们还没有到那一步,但是在深度学习的帮助下,我们正在取得巨大的进步。
今天的教程将作为手写识别的介绍。您将看到手写识别运行良好的示例,以及无法正确 OCR 手写字符的其他示例。我真的认为您会发现阅读本手写识别指南的其余部分很有价值。
要了解如何使用 OpenCV、Keras 和 TensorFlow 进行手写识别,继续阅读。
OCR:使用 OpenCV、Keras 和 TensorFlow 进行手写识别
在本教程的第一部分,我们将讨论手写识别以及它与“传统的”OCR 有何不同。
然后,我将简要回顾使用 Keras 和 TensorFlow 训练我们的识别模型的过程——在本教程中,我们将使用这个训练好的模型来 OCR 手写。
注意:如果你还没有阅读上周的帖子,我强烈建议你现在就阅读,然后再继续,因为这篇帖子概述了我们训练的用于 OCR 字母数字样本的模型。作为本教程的先决条件,你应该对上周的概念和脚本有一个牢固的理解。
我们将回顾我们的项目结构,然后实现一个 Python 脚本来使用 OpenCV、Keras 和 TensorFlow 执行手写识别。
为了总结今天的 OCR 教程,我们将讨论我们的手写识别结果,包括哪些有效,哪些无效。
什么是手写识别?手写识别和传统的 OCR有什么不同?
传统的 OCR 算法和技术假设我们使用某种固定的字体。在 20 世纪早期,这可能是微缩胶片使用的字体。
在 20 世纪 70 年代,专门为 OCR 算法开发了专门的字体,从而使它们更加精确。
到了 2000 年,我们可以使用电脑上预装的字体来自动生成训练数据,并使用这些字体来训练我们的 OCR 模型。
这些字体都有一些共同点:
- 它们是以某种方式设计的。
- 每个字符之间有一个可预测的和假定的空格(从而使分割更容易)。
- 字体的风格更有利于 OCR。
从本质上来说,工程/计算机生成的字体使得 OCR 更加容易。
不过,手写识别是一个完全不同的领域。考虑到变化的极端数量和字符如何经常重叠。每个人都有自己独特的写作风格。
字符可以被拉长、俯冲、倾斜、风格化、挤压、连接、微小、巨大等。(并以这些组合中的任何一种出现)。
数字化手写识别非常具有挑战性,而且离解决问题还很远,但是深度学习正在帮助我们提高手写识别的准确性。
手写识别——我们迄今为止所做的工作
在上周的教程中,我们使用 Keras 和 TensorFlow 训练了一个深度神经网络,既能识别 数字 ( 0-9 )和 字母字符 ( A-Z )。
为了训练我们的网络来识别这些字符集,我们利用了 MNIST 数字数据集以及 NIST 特殊数据库 19 (用于 A-Z 字符)。
我们的模型在手写识别测试集上获得了 96%的准确率。
今天,我们将学习如何在我们自己的自定义图像中使用该模型进行手写识别。
配置您的 OCR 开发环境
如果您尚未配置 TensorFlow 和上周教程中的相关库,我首先建议您遵循下面的相关教程:
上面的教程将帮助您在一个方便的 Python 虚拟环境中,用这篇博客文章所需的所有软件来配置您的系统。
项目结构
如果你还没有,去这篇博文的 “下载” 部分,获取今天教程的代码和数据集。
在里面,您会发现以下内容:
$ tree --dirsfirst --filelimit 10
.
└── ocr-handwriting-recognition
├── images
│ ├── hello_world.png
│ ├── umbc_address.png
│ └── umbc_zipcode.png
├── pyimagesearch
│ ├── az_dataset
│ │ ├── __init__.py
│ │ └── helpers.py
│ ├── models
│ │ ├── __init__.py
│ │ └── resnet.py
│ └── __init__.py
├── a_z_handwritten_data.csv
├── handwriting.model
├── ocr_handwriting.py
├── plot.png
└── train_ocr_model.py
5 directories, 13 files
pyimagesearch模块:- 包括用于 I/O 助手功能的子模块
az_dataset和用于实现 ResNet 深度学习模型的子模块models
- 包括用于 I/O 助手功能的子模块
a_z_handwritten_data.csv:包含 Kaggle A-Z 数据集的 CSV 文件train_ocr_model.py:上周的主 Python 驱动文件,我们用它来训练 ResNet 模型并显示我们的结果。我们的模型和训练图文件包括:- 我们在上周的教程中创建的自定义 OCR ResNet 模型
plot.png:我们最近 OCR 训练运行的结果图
images/子目录:包含三个 PNG 测试文件,供我们使用 Python 驱动程序脚本进行 OCRocr_handwriting.py:本周的主要 Python 脚本,我们将使用它来 OCR 我们的手写样本
使用 OpenCV、Keras 和 TensorFlow 实现我们的手写识别 OCR 脚本
让我们打开ocr_handwriting.py并查看它,从导入和命令行参数开始:
# import the necessary packages
from tensorflow.keras.models import load_model
from imutils.contours import sort_contours
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained handwriting recognition model")
args = vars(ap.parse_args())
接下来,我们将加载我们在上周的教程中开发的自定义手写 OCR 模型:
# load the handwriting OCR model
print("[INFO] loading handwriting OCR model...")
model = load_model(args["model"])
Keras 和 TensorFlow 的load_model实用程序使加载我们的序列化手写识别模型变得非常简单(第 19 行)。回想一下,我们的 OCR 模型使用 ResNet 深度学习架构来分类对应于数字 0-9 或字母 A-Z 的每个字符。
注:关于 ResNet CNN 架构的更多细节,请参考使用 Python 的计算机视觉深度学习从业者捆绑包。
因为我们已经从磁盘加载了模型,所以让我们抓取图像,对其进行预处理,并找到角色轮廓:
# load the input image from disk, convert it to grayscale, and blur
# it to reduce noise
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# perform edge detection, find contours in the edge map, and sort the
# resulting contours from left-to-right
edged = cv2.Canny(blurred, 30, 150)
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sort_contours(cnts, method="left-to-right")[0]
# initialize the list of contour bounding boxes and associated
# characters that we'll be OCR'ing
chars = []
加载图像(第 23 行)后,我们将其转换为灰度(第 24 行),然后应用高斯模糊降低噪点(第 25 行)。
我们的下一步将涉及一个大的轮廓处理循环。让我们更详细地分析一下,以便更容易理解:
# loop over the contours
for c in cnts:
# compute the bounding box of the contour
(x, y, w, h) = cv2.boundingRect(c)
# filter out bounding boxes, ensuring they are neither too small
# nor too large
if (w >= 5 and w <= 150) and (h >= 15 and h <= 120):
# extract the character and threshold it to make the character
# appear as *white* (foreground) on a *black* background, then
# grab the width and height of the thresholded image
roi = gray[y:y + h, x:x + w]
thresh = cv2.threshold(roi, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
(tH, tW) = thresh.shape
# if the width is greater than the height, resize along the
# width dimension
if tW > tH:
thresh = imutils.resize(thresh, width=32)
# otherwise, resize along the height
else:
thresh = imutils.resize(thresh, height=32)
从第 40 行的开始,我们循环每个轮廓并执行一系列的四步:****
步骤 1: 选择适当大小的轮廓并提取它们:
- 第 42 行计算轮廓的边界框。
- 接下来,我们确保这些边界框的大小是合理的,并过滤掉那些过大或过小的边界框。
- 对于每个满足我们的尺寸标准的边界框,我们提取与字符(行 50 )相关联的感兴趣区域(
roi)。
步骤 2: 使用阈值算法清理图像,目标是在黑色背景上有白色字符:
- 对
roi( 行 51 和 52 )应用 Otsu 的二进制阈值法。这导致了由黑色背景上的白色字符组成的二进制图像。
第三步:将每个字符的大小调整为带边框的 32×32 像素图像:
- 根据宽度是否大于高度或者高度是否大于宽度,我们相应地调整阈值字符 ROI 的大小(第 57-62 行)。
但是等等!在我们继续从第 40 行开始的循环之前,我们需要填充这些 ROI 并将其添加到chars列表中:
# re-grab the image dimensions (now that its been resized)
# and then determine how much we need to pad the width and
# height such that our image will be 32x32
(tH, tW) = thresh.shape
dX = int(max(0, 32 - tW) / 2.0)
dY = int(max(0, 32 - tH) / 2.0)
# pad the image and force 32x32 dimensions
padded = cv2.copyMakeBorder(thresh, top=dY, bottom=dY,
left=dX, right=dX, borderType=cv2.BORDER_CONSTANT,
value=(0, 0, 0))
padded = cv2.resize(padded, (32, 32))
# prepare the padded image for classification via our
# handwriting OCR model
padded = padded.astype("float32") / 255.0
padded = np.expand_dims(padded, axis=-1)
# update our list of characters that will be OCR'd
chars.append((padded, (x, y, w, h)))
完成提取和准备的字符集后,我们可以执行 OCR:
# extract the bounding box locations and padded characters
boxes = [b[1] for b in chars]
chars = np.array([c[0] for c in chars], dtype="float32")
# OCR the characters using our handwriting recognition model
preds = model.predict(chars)
# define the list of label names
labelNames = "0123456789"
labelNames += "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
labelNames = [l for l in labelNames]
我们快完成了!是时候看看我们的劳动成果了。为了查看我们的手写识别结果是否符合我们的预期,让我们将它们可视化并显示出来:
# loop over the predictions and bounding box locations together
for (pred, (x, y, w, h)) in zip(preds, boxes):
# find the index of the label with the largest corresponding
# probability, then extract the probability and label
i = np.argmax(pred)
prob = pred[i]
label = labelNames[i]
# draw the prediction on the image
print("[INFO] {} - {:.2f}%".format(label, prob * 100))
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(image, label, (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 0), 2)
# show the image
cv2.imshow("Image", image)
cv2.waitKey(0)
总结起来,我们循环每个预测和相应的边界框(行 98 )。
注意:如果你是使用 pip 安装方法安装 OpenCV 4.3.0 的 Ubuntu 用户,有一个 bug 会阻止我们使用cv2.imshow正确显示结果。解决方法是简单地在尺寸过小的显示框中单击鼠标,然后按下q键,重复几个周期,直到显示放大到合适的尺寸。
恭喜你!您已经完成了对输入图像执行 OCR 的主要 Python 驱动程序文件。
让我们看看我们的结果。
手写识别 OCR 结果
首先使用本教程的 “下载” 部分下载源代码、预训练的手写识别模型和示例图像。
打开终端并执行以下命令:
$ python ocr_handwriting.py --model handwriting.model --image images/hello_world.png
[INFO] loading handwriting OCR model...
[INFO] H - 92.48%
[INFO] W - 54.50%
[INFO] E - 94.93%
[INFO] L - 97.58%
[INFO] 2 - 65.73%
[INFO] L - 96.56%
[INFO] R - 97.31%
[INFO] 0 - 37.92%
[INFO] L - 97.13%
[INFO] D - 97.83%
在这个例子中,我们试图对手写文本“Hello World”进行 OCR。
我们的手写识别模型在这里表现很好,但是犯了两个错误。
首先,它混淆了字母【O】和数字【0】(零)——这是一个可以理解的错误。
其次,也是更令人担忧的一点,手写识别模型混淆了“世界”中的“O”和“2”。
下一个例子包含我的母校的手写姓名和邮政编码,这所学校位于 UMBC 巴尔的摩县的马里兰大学:
$ python ocr_handwriting.py --model handwriting.model --image images/umbc_zipcode.png
[INFO] loading handwriting OCR model...
[INFO] U - 34.76%
[INFO] 2 - 97.88%
[INFO] M - 75.04%
[INFO] 7 - 51.22%
[INFO] B - 98.63%
[INFO] 2 - 99.35%
[INFO] C - 63.28%
[INFO] 5 - 66.17%
[INFO] 0 - 66.34%
我们的手写识别算法在这里几乎完美地执行了。我们能够正确地识别“UMBC”中的每一个手写字符;然而,邮政编码被错误地识别了——我们的模型混淆了“1”和“7”。
*如果我们将去倾斜应用到我们的角色数据,我们也许能够改进我们的结果。
让我们检查最后一个例子。此图片包含 UMBC 的完整地址:
$ python ocr_handwriting.py --model handwriting.model --image images/umbc_address.png
[INFO] loading handwriting OCR model...
[INFO] B - 97.71%
[INFO] 1 - 95.41%
[INFO] 0 - 89.55%
[INFO] A - 87.94%
[INFO] L - 96.30%
[INFO] 0 - 71.02%
[INFO] 7 - 42.04%
[INFO] 2 - 27.84%
[INFO] 0 - 67.76%
[INFO] Q - 28.67%
[INFO] Q - 39.30%
[INFO] H - 86.53%
[INFO] Z - 61.18%
[INFO] R - 87.26%
[INFO] L - 91.07%
[INFO] E - 98.18%
[INFO] L - 84.20%
[INFO] 7 - 74.81%
[INFO] M - 74.32%
[INFO] U - 68.94%
[INFO] D - 92.87%
[INFO] P - 57.57%
[INFO] 2 - 99.66%
[INFO] C - 35.15%
[INFO] I - 67.39%
[INFO] 1 - 90.56%
[INFO] R - 65.40%
[INFO] 2 - 99.60%
[INFO] S - 42.27%
[INFO] O - 43.73%
这就是我们的手写识别模型 真正的纠结的地方。如你所见,在单词、【山顶】、、、【巴尔的摩】、和邮政编码中有多个错误。
鉴于我们的手写识别模型在训练和测试期间表现如此之好,难道我们不应该期待它在我们自己的自定义图像上也表现良好吗?
要回答这个问题,让我们进入下一部分。
局限性、缺点和下一步措施
虽然我们的手写识别模型在我们的测试集上获得了 96%的准确率,但我们在自己定制的图像上的手写识别准确率略低于此。
最大的问题之一是,我们使用 MNIST(数字)和 NIST(字母字符)数据集的变体来训练我们的手写识别模型。
这些数据集虽然研究起来很有趣,但不一定会转化为现实世界的项目,因为图像已经为我们进行了预处理和清理— 现实世界的角色并没有那么“干净”
此外,我们的手写识别方法要求字符被单独分割。
对于某些字符来说,这可能是可能的,但是我们中的许多人(尤其是草书作者)在快速书写时会将字符联系起来。这使得我们的模型误以为一组人物实际上是一个单个人物,最终导致错误的结果。
最后,我们的模型架构有点过于简单。
虽然我们的手写识别模型在训练和测试集上表现良好,但该架构(结合训练数据集本身)不够健壮,不足以概括为“现成的”手写识别模型。
为了提高我们手写识别的准确性,我们应该研究长短期记忆网络(LSTMs)的进展,它可以自然地处理相连的字符。
我们将在未来关于 PyImageSearch 的教程中介绍如何使用 LSTMs,以及在我们即将出版的 OpenCV、Tesseract 和 Python 书的 OCR 中。
新书:OpenCV、Tesseract 和 Python 的 OCR
光学字符识别(OCR)是一个简单的概念,但在实践中很难:创建一个接受输入图像的软件,让该软件自动识别图像中的文本,然后将其转换为机器编码的文本(即“字符串”数据类型)。
尽管 OCR 是一个如此直观的概念,但它却难以置信的困难(T2)。计算机视觉领域已经存在了 50 多年(机械 OCR 机器可以追溯到 100 多年前),但我们仍然没有“解决”OCR,创造出一个现成的 OCR 系统,几乎可以在任何情况下工作。
更糟糕的是,试图编写能够执行 OCR 的定制软件更加困难:
- 如果你是 OCR 领域的新手,像 Tesseract 这样的开源 OCR 包可能很难使用。
- 使用 Tesseract 获得高精度通常需要您知道要使用哪些选项、参数和配置— 不幸的是,没有多少高质量的 Tesseract 教程或在线书籍。
- OpenCV 和 scikit-image 等计算机视觉和图像处理库可以帮助您对图像进行预处理,以提高 OCR 的准确性……但是您使用的是哪些算法和技术呢?
- 深度学习几乎在计算机科学的每个领域都带来了前所未有的准确性。OCR 应该使用哪些深度学习模型、图层类型和损失函数?
如果你曾经发现自己很难将 OCR 应用到一个项目中,或者如果你只是对学习 OCR 感兴趣,我的新书, 光学字符识别(OCR)、OpenCV 和宇宙魔方 就是为你准备的。
不管你目前在计算机视觉和 OCR 方面的经验水平如何,读完这本书后,你将拥有解决你自己的 OCR 项目所必需的知识。
如果您对 OCR 感兴趣,已经有了 OCR 项目的想法,或者您的公司需要它,请点击下面的按钮预订您的副本:
总结
在本教程中,您学习了如何使用 Keras、TensorFlow 和 OpenCV 执行 OCR 手写识别。
我们的手写识别系统利用基本的计算机视觉和图像处理算法(边缘检测、轮廓和轮廓过滤)从输入图像中分割出字符。
从那里,我们通过我们训练的手写识别模型来识别每个字符。
我们的手写识别模型表现很好,但在某些情况下,结果还可以改进(理想情况下,使用更多的训练数据,这些数据代表我们希望识别的手写内容的)——训练数据的质量越高,我们的手写识别模型就越准确!
其次,我们的手写识别管道没有处理字符可能被连接的情况,从而导致多个连接的字符被视为一个单个字符,从而混淆了我们的 OCR 模型。
处理相连的手写字符仍然是计算机视觉和 OCR 领域中一个开放的研究领域;然而,深度学习模型,特别是 LSTMs,已经显示出在提高手写识别准确性方面的重大承诺。
我将在以后的教程中介绍使用 LSTMs 进行更高级的手写识别。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
带 OpenCV 和宇宙魔方的 OCR 护照
原文:https://pyimagesearch.com/2021/12/01/ocr-passports-with-opencv-and-tesseract/
本课是关于 OCR 120 的 4 部分系列的第 4 部分:
- Tesseract 页面分割模式(PSMs)讲解:如何提高你的 OCR 准确率(2 周前的教程)
- 通过基本图像处理改善 OCR 结果(上周教程)
- 使用拼写检查来提高 Tesseract OCR 的准确性(之前的教程)
- 带 OpenCV 和 Tesseract 的 OCR 护照(今天的教程)
要学习如何使用 OpenCV 和 Tesseract 对护照进行光学字符识别, 继续阅读。
带 OpenCV 和宇宙魔方的 OCR 护照
到目前为止,在本课程中,我们一直依赖于 Tesseract OCR 引擎来检测输入图像中的文本。然而,正如我们在之前的教程、中发现的,有时宇宙魔方需要一点帮助,在之前我们实际上可以 OCR 文本。
本教程将进一步探讨这一想法,展示计算机视觉和图像处理技术可以在复杂的输入图像中定位文本区域。一旦文本被定位,我们可以从输入图像中提取文本 ROI,然后使用 Tesseract 对其进行 OCR。
作为一个案例研究,我们将开发一个计算机视觉系统,它可以在扫描护照时自动定位机器可读区域。MRZ 包含护照持有人的姓名、护照号码、国籍、出生日期、性别和护照到期日期等信息。
通过自动识别该区域,我们可以帮助运输安全管理局(TSA)代理和移民官员更快地处理旅客,减少长队(更不用说排队等候的压力和焦虑)。
学习目标
在本教程中,您将:
- 了解如何使用图像处理技术和 OpenCV 库来本地化输入图像中的文本
- 提取本地化的文本并用 Tesseract 进行 OCR
- 构建一个示例 passport reader 项目,它可以自动检测、提取和 OCR 护照图像中的 MRZ
用图像处理在图像中寻找文本
在本教程的第一部分,我们将简要回顾什么是护照 MRZ。从那以后,我将向您展示如何实现一个 Python 脚本来从输入图像中检测和提取 MRZ。一旦 MRZ 被提取出来,我们就可以用宇宙魔方来识别 MRZ。
什么是机器可读区域?
护照是一种旅行证件,看起来像一个小笔记本。此文件由您所在国家的政府签发,包含识别您个人身份的信息,包括您的姓名、地址等。
你通常在国际旅行时使用你的护照。一旦你到达目的地国家,移民官员会检查你的护照,确认你的身份,并在你的护照上盖你的到达日期。
在你的护照里,你会找到你的个人身份信息(图 1 )。如果你看护照的底部,你会看到 2-3 行等宽字符。
1 类护照有三行,每行 30 个字符,而 3 类护照有两行,每行 44 个字符。
这些线被称为护照上的 MRZ。
MRZ 对您的个人识别信息进行编码,包括:
- 名字
- 护照号码
- 国籍
- 出生日期/年龄
- 性
- 护照到期日期
在电脑和核磁共振成像系统出现之前,美国运输安全管理局和移民官员必须检查你的护照,并繁琐地验证你的身份。这是一项耗时的任务,对官员来说很单调,对在长长的移民队伍中耐心等待的游客来说很沮丧。
MRZs 允许 TSA 代理快速扫描您的信息,验证您的身份,并使您能够更快地通过队列,从而减少队列长度(并减轻旅客和官员的压力)。
在本教程的其余部分,您将学习如何用 OpenCV 和 Tesseract 实现一个自动护照 MRZ 扫描仪。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
在我们构建 MRZ 阅读器和扫描护照图像之前,让我们先回顾一下这个项目的目录结构:
|-- passports
| |-- passport_01.png
| |-- passport_02.png
|-- ocr_passport.py
我们这里只有一个 Python 脚本,ocr_passport.py,顾名思义,它用于从磁盘加载护照图像并扫描它们。
在passports目录中,我们有两个图像,passport_01.png和passport_02.png——这些图像包含扫描的护照样本。我们的ocr_passport.py脚本将从磁盘加载这些图像,定位它们的 MRZ 地区,然后对它们进行 OCR。
在护照图像中定位 MRZs】
让我们学习如何使用 OpenCV 和图像处理来定位护照图像的 MRZ。
打开项目目录结构中的ocr_passport.py文件,插入以下代码:
# import the necessary packages
from imutils.contours import sort_contours
import numpy as np
import pytesseract
import argparse
import imutils
import sys
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
args = vars(ap.parse_args())
我们从第 2-8 行的开始,导入我们需要的 Python 包。到本文的这一点,你应该开始觉得这些导入非常标准了。唯一的例外可能是第 2 行上的sort_contours导入——这个函数做什么?
sort_contours函数将接受通过使用 OpenCV 的cv2.findContours函数找到的一组输入轮廓。然后,sort_contours将对这些轮廓进行水平排序(从左到右或从右到左)或垂直排序(从上到下或从下到上)。
我们执行这个排序操作,因为 OpenCV 的cv2.findContours不能保证轮廓的排序。我们需要对它们进行显式排序以访问护照图像底部的的 MRZ 行。执行该排序操作将使得检测 MRZ 区域远更容易(正如我们将在该实现中稍后看到的)。
第 11-14 行解析我们的命令行参数。这里只需要一个参数,即输入路径--image。
完成导入和命令行参数后,我们可以继续加载输入图像,并为 MRZ 检测做准备:
# load the input image, convert it to grayscale, and grab its
# dimensions
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
(H, W) = gray.shape
# initialize a rectangular and square structuring kernel
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (25, 7))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 21))
# smooth the image using a 3x3 Gaussian blur and then apply a
# blackhat morpholigical operator to find dark regions on a light
# background
gray = cv2.GaussianBlur(gray, (3, 3), 0)
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKernel)
cv2.imshow("Blackhat", blackhat)
第 18 行和第 19 行从磁盘加载我们的输入image,然后将其转换为灰度,这样我们就可以对其应用基本的图像处理例程(再次提醒,记住我们的目标是检测护照的 MRZ,而不必利用机器学习)。然后我们在第 20 行获取输入图像的空间尺寸(宽度和高度)。
第 23 行和第 24 行初始化了两个内核,我们稍后将在应用形态学操作时使用它们,特别是关闭操作。目前,请注意第一个内核是矩形的,宽度大约是高度的 3 倍。第二个内核是方形的。这些内核将允许我们填补 MRZ 字符之间的空白和 MRZ 线之间的空白。
在行 29 应用高斯模糊以减少高频噪声。然后,我们对第 30 行的模糊灰度图像应用 blackhat 形态学操作。
blackhat 算子用于显示亮背景(即护照背景)下的暗区域(即 MRZ 文本)。由于护照文本在浅色背景下总是黑色的(至少在这个数据集中),所以 blackhat 操作是合适的。图 3 显示了应用 blackhat 算子的输出。
在图 3 中,左侧显示我们的原始输入图像,而右侧显示 blackhat 操作的输出。请注意,在此操作之后,文本是可见的,而大部分背景噪声已被移除。
MRZ 检测的下一步是使用 Scharr 算子计算 blackhat 图像的梯度幅度表示:
# compute the Scharr gradient of the blackhat image and scale the
# result into the range [0, 255]
grad = cv2.Sobel(blackhat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
grad = np.absolute(grad)
(minVal, maxVal) = (np.min(grad), np.max(grad))
grad = (grad - minVal) / (maxVal - minVal)
grad = (grad * 255).astype("uint8")
cv2.imshow("Gradient", grad)
第 35 行和第 36 行计算沿着 blackhat 图像的 x 轴的 Scharr 梯度,显示图像中在亮背景下较暗的区域,并包含梯度中的垂直变化,例如 MRZ 文本区域。然后,我们使用最小/最大缩放(第 37-39 行)将该渐变图像缩放回范围[0, 255] 。生成的梯度图像随后显示在我们的屏幕上(图 4 )。
下一步是尝试检测 MRZ 的实际线:
# apply a closing operation using the rectangular kernel to close
# gaps in between letters -- then apply Otsu's thresholding method
grad = cv2.morphologyEx(grad, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(grad, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv2.imshow("Rect Close", thresh)
# perform another closing operation, this time using the square
# kernel to close gaps between lines of the MRZ, then perform a
# series of erosions to break apart connected components
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
thresh = cv2.erode(thresh, None, iterations=2)
cv2.imshow("Square Close", thresh)
首先,我们使用矩形内核应用一个关闭操作(第 44-46 行)。这种闭合操作是为了闭合 MRZ 字符之间的间隙。然后,我们使用 Otsu 方法应用阈值处理来自动对图像进行阈值处理(图 4 )。正如我们所看到的,每条 MRZ 线都出现在我们的阈值图上。
然后,我们用正方形内核(第 52 行)进行闭合操作,来闭合实际线条之间的间隙。sqKernel是一个21 x 21 内核,它试图闭合线条之间的间隙,产生一个对应于 MRZ 的大矩形区域。
然后进行一系列腐蚀,以分离在闭合操作期间可能已经结合的连接部件(线 53 )。这些侵蚀也有助于去除与 MRZ 无关的小斑点。
这些操作的结果可以在图 4 中看到。注意 MRZ 区域是如何在图像底部三分之一的中成为一个大的矩形斑点。
现在我们的 MRZ 区域可见了,让我们在thresh图像中找到轮廓——这个过程将允许我们检测和提取 MRZ 区域:
# find contours in the thresholded image and sort them from bottom
# to top (since the MRZ will always be at the bottom of the passport)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sort_contours(cnts, method="bottom-to-top")[0]
# initialize the bounding box associated with the MRZ
mrzBox = None
第 58-61 行检测阈值图像中的轮廓。然后我们从下到上对它们进行排序。你可能会问,为什么自下而上?
简单:MRZ 地区总是位于输入护照图像的底部三分之一处。我们使用这个先验知识来开发图像的结构。如果我们知道我们正在寻找一个大的矩形区域,总是出现在图像的底部*, 为什么不先搜索底部呢?
每当应用图像处理操作时,总是要看看是否有一种方法可以利用你对问题的了解。不要让你的图像处理管道过于复杂。使用任何领域知识使问题变得简单。
第 64 行然后初始化mrzBox,与 MRZ 区域相关的边界框。
我们将尝试在下面的代码块中找到mrzBox:
# loop over the contours
for c in cnts:
# compute the bounding box of the contour and then derive the
# how much of the image the bounding box occupies in terms of
# both width and height
(x, y, w, h) = cv2.boundingRect(c)
percentWidth = w / float(W)
percentHeight = h / float(H)
# if the bounding box occupies > 80% width and > 4% height of the
# image, then assume we have found the MRZ
if percentWidth > 0.8 and percentHeight > 0.04:
mrzBox = (x, y, w, h)
break
我们在线 67 上的检测轮廓上开始一个循环。我们计算每个轮廓的边界框,然后确定边界框在图像中所占的百分比(第 72 行和第 73 行)。
我们计算边界框有多大(相对于原始输入图像),以过滤我们的轮廓。请记住,我们的 MRZ 是一个很大的矩形区域,几乎跨越护照的整个宽度。
因此,行 77 通过确保检测到的边界框跨越至少图像宽度的 80%以及高度的 4%来利用这一知识。假设当前边界框区域通过了这些测试,我们从循环中更新我们的mrzBox和break。
我们现在可以继续处理 MRZ 地区本身:
# if the MRZ was not found, exit the script
if mrzBox is None:
print("[INFO] MRZ could not be found")
sys.exit(0)
# pad the bounding box since we applied erosions and now need to
# re-grow it
(x, y, w, h) = mrzBox
pX = int((x + w) * 0.03)
pY = int((y + h) * 0.03)
(x, y) = (x - pX, y - pY)
(w, h) = (w + (pX * 2), h + (pY * 2))
# extract the padded MRZ from the image
mrz = image[y:y + h, x:x + w]
第 82-84 行处理没有找到 MRZ 地区的情况——这里,我们退出脚本。如果没有包含护照的图像意外地通过脚本,或者如果护照图像质量低/噪音太大,我们的基本图像处理管道无法处理,就会发生这种情况。
假设我们确实找到了 MRZ,下一步就是填充边界框区域。我们进行这种填充是因为我们在试图检测 MRZ 本身时应用了一系列腐蚀(回到线 53 )。
但是,我们需要填充这个区域,这样 MRZ 字符就不会碰到 ROI 的边界。如果字符接触到图像的边界,Tesseract 的 OCR 程序可能不准确。
第 88 行解包边界框坐标。然后我们在每个方向上填充 MRZ 地区 3%(第 89-92 行)。
一旦 MRZ 被填充,我们使用数组切片将其从图像中提取出来(行 95 )。
提取 MRZ 后,最后一步是应用 Tesseract 对其进行 OCR:
# OCR the MRZ region of interest using Tesseract, removing any
# occurrences of spaces
mrzText = pytesseract.image_to_string(mrz)
mrzText = mrzText.replace(" ", "")
print(mrzText)
# show the MRZ image
cv2.imshow("MRZ", mrz)
cv2.waitKey(0)
Line 99 OCRs 识别护照上的 MRZ 地区。然后,我们显式地从 MRZ 文本(第 100 行)中删除任何空格,因为 Tesseract 可能在 OCR 过程中意外地引入了空格。
然后,我们通过在终端上显示 OCR 的mrzText并在屏幕上显示最终的mrz ROI 来完成我们的护照 OCR 实现。你可以在图 5 中看到结果。
文本斑点定位结果
我们现在准备测试我们的文本本地化脚本。
打开终端并执行以下命令:
$ python ocr_passport.py --image passports/passport_01.png
P<GBRJENNINGS<<PAUL<MICHAEL<<<<<<<<<<<<<<<<<
0123456784GBR5011025M0810050<<<<<<<<<<<<<<00
图 6 (左)显示我们的原始输入图像,而图 6 (右)显示通过我们的图像处理管道提取的 MRZ。我们的终端输出显示,我们已经使用宇宙魔方正确地识别了 MRZ 地区。
让我们尝试另一个护照图像,这是一个有三条 MRZ 线而不是两条的 Type-1 护照:
$ python ocr_passport.py --image passports/passport_02.png
IDBEL590335801485120100200<<<<
8512017F0901015BEL<<<<<<<<<<<7
REINARTZ<<ULRIKE<KATLIA<E<<<<<<
如图 7 所示,我们检测了输入图像中的 MRZ,然后提取出来。然后,MRZ 被传递到 Tesseract 进行 OCR,我们的终端输出显示了结果。
然而,我们的 MRZ OCR 并不是 100%准确——注意在“KATIA”中的【T】和【I】之间有一个【L】**
为了获得更高的 OCR 准确性,我们应该考虑在护照中使用的字体上专门训练一个定制的 Tesseract 模型,使 Tesseract 更容易识别这些字符。
*## 总结
在本教程中,您学习了如何实现 OCR 系统,该系统能够本地化、提取和 OCR 护照 MRZ 中的文本。
当您构建自己的 OCR 应用程序时,不要盲目地将 Tesseract 扔向它们,看看什么能坚持下来。而是作为一个计算机视觉从业者仔细审视问题。
问问你自己:
- 我可以使用图像处理来定位图像中的文本,从而减少对 Tesseract 文本定位的依赖吗?
- 我可以使用 OpenCV 函数自动提取这些区域吗?
- 检测文本需要哪些图像处理步骤?
本教程中介绍的图像处理管道是您可以构建的文本本地化管道的示例。它将而不是在所有情况下都有效。尽管如此,计算梯度和使用形态学操作来填补文本中的空白将在数量惊人的应用中发挥作用。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
带有 Keras、TensorFlow 和深度学习的 OCR
原文:https://pyimagesearch.com/2020/08/17/ocr-with-keras-tensorflow-and-deep-learning/

在本教程中,您将学习如何使用 Keras、TensorFlow 和深度学习来训练光学字符识别(OCR)模型。本文是 Keras 和 TensorFlow 关于 OCR 的两部分系列文章的第一部分:
- 第一部分: 用 Keras 和 TensorFlow 训练 OCR 模型(今天的帖子)
- 第二部分: 用 Keras 和 TensorFlow 进行基本的手写识别(下周的帖子)
现在,我们将主要关注如何训练定制的 Keras/TensorFlow 模型来识别字母数字字符(即,数字 0-9 和字母 A-Z )。
基于今天的帖子,下周我们将学习如何使用这个模型来正确分类自定义输入图像中的手写字符。
这个两部分系列的目标是更深入地了解深度学习如何应用于手写分类,更具体地说,我们的目标是:
- 熟悉一些众所周知的、随时可用的数字和字母手写数据集
- 了解如何训练深度学习模型识别手写数字和字母
- 获得将我们定制的模型应用于一些真实样本数据的经验
- 了解现实世界中嘈杂数据的一些挑战,以及我们可能希望如何扩充我们的手写数据集来改进我们的模型和结果
我们将从使用众所周知的手写数据集的基础知识开始,并在这些数据上训练 ResNet 深度学习模型。
要了解如何使用 Keras、TensorFlow 和深度学习来训练 OCR 模型,继续阅读。
使用 Keras、TensorFlow 和深度学习的 OCR
在本教程的第一部分,我们将讨论使用 Keras 和 TensorFlow 实现和训练自定义 OCR 模型所需的步骤。
然后,我们将检查用于训练模型的手写数据集。
从那里,我们将实现几个助手/实用程序函数,帮助我们从磁盘加载手写数据集,然后对它们进行预处理。
给定这些助手函数,我们将能够使用 Keras 和 TensorFlow 创建自定义 OCR 训练脚本。
培训结束后,我们将回顾 OCR 工作的结果。
我们开始吧!
我们的深度学习 OCR 数据集
为了训练我们的定制 Keras 和 TensorFlow 模型,我们将利用两个数据集:
- 标准 MNIST 0-9 数据集由乐存等人
- Sachin Patel 的 Kaggle A-Z 数据集,基于 NIST 特殊数据库 19
标准 MNIST 数据集内置于流行的深度学习框架中,包括 Keras、TensorFlow、PyTorch 等。MNIST 0-9 岁数据集的样本可以在图 1 中看到(左 )。MNIST 数据集将允许我们识别数字 0-9。这些数字中的每一个都包含在一个 28 x 28 灰度图像中。你可以在这里阅读更多关于 MNIST 的信息。
但是字母 A-Z 呢?标准的 MNIST 数据集不包括字符 A-Z — 的例子,我们如何识别它们呢?
答案是使用 NIST 特殊数据库 19 ,其中包括 A-Z 人物。这个数据集实际上涵盖了 62 个 ASCII 十六进制字符,分别对应于数字 0-9 ,大写字母 A-Z ,小写字母 a-z 。
为了让数据集更容易使用,Kaggle 用户 Sachin Patel 已经在一个易于使用的 CSV 文件中发布了数据集。该数据集从 NIST 特殊数据库 19 中提取大写字母 A-Z ,并将其重新缩放为 28 x 28 灰度像素,与我们的 m NIST 数据格式相同。
对于这个项目,我们将只使用和ka ggle A-Z 数据集,这将使我们的预处理变得轻而易举。在图 1 (右图)中可以看到它的一个样本。
我们将实施一些方法和实用程序,使我们能够:
- 从磁盘加载 MNIST 0-9 数字和字母 A-Z 的数据集
- 将这些数据集组合成一个单一的、统一的角色数据集
- 处理由于每个字符具有不同数量的样本而导致的分类标签偏斜/不平衡
- 在组合数据集上成功训练 Keras 和 TensorFlow 模型
- 绘制训练的结果,并可视化验证数据的输出
配置您的 OCR 开发环境
要针对本教程配置您的系统,我首先建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。
项目结构
让我们回顾一下项目结构。
一旦您从本文的 【下载】 部分获取文件,您将看到以下目录结构:
$ tree --dirsfirst --filelimit 10
.
├── pyimagesearch
│ ├── az_dataset
│ │ ├── __init__.py
│ │ └── helpers.py
│ ├── models
│ │ ├── __init__.py
│ │ └── resnet.py
│ └── __init__.py
├── a_z_handwritten_data.csv
├── handwriting.model
├── plot.png
└── train_ocr_model.py
3 directories, 9 files
现在,我们已经了解了情况,让我们深入研究 I/O 助手函数,我们将使用它来加载我们的数字和字母。
我们的 OCR 数据集辅助函数
为了训练我们的定制 Keras 和 TensorFlow OCR 模型,我们首先需要实现两个助手工具,这两个工具将允许我们从磁盘中加载和ka ggle A-Z 数据集和 MNIST 0-9 数字。
这些 I/O 助手函数被恰当地命名为:
load_az_dataset:为 Kaggle A-Z 字母load_mnist_dataset:为 MNIST 0-9 位数字
# import the necessary packages
from tensorflow.keras.datasets import mnist
import numpy as np
def load_az_dataset(datasetPath):
# initialize the list of data and labels
data = []
labels = []
# loop over the rows of the A-Z handwritten digit dataset
for row in open(datasetPath):
# parse the label and image from the row
row = row.split(",")
label = int(row[0])
image = np.array([int(x) for x in row[1:]], dtype="uint8")
# images are represented as single channel (grayscale) images
# that are 28x28=784 pixels -- we need to take this flattened
# 784-d list of numbers and repshape them into a 28x28 matrix
image = image.reshape((28, 28))
# update the list of data and labels
data.append(image)
labels.append(label)
我们的函数load_az_dataset接受一个参数datasetPath,它是 Kaggle A-Z CSV 文件的位置(第 5 行)。然后,我们初始化数组来存储数据和标签(第 7 行和第 8 行 ) 。
Sachin Patel 的 CSV 文件中的每一行包含 785 列——一列用于类别标签(即“ A-Z ”),加上 784 列对应于 28 x 28 灰度像素。我们来解析一下。
从第行第 11 开始,我们将遍历 CSV 文件的每一行,解析出标签和相关图像。第 14 行解析标签,这将是与字母 A-Z 相关联的整数标签。例如,字母“A”具有对应于整数“0”的标签,字母“Z”具有整数标签值“25”。
接下来,第 15 行解析我们的图像,并将其转换为一个无符号 8 位整数的 NumPy 数组,该数组对应于来自【0,255】的每个像素的灰度值。
我们将我们的图像(第 20 行)从一个平面的 784 维阵列重塑为一个 28 x 28 的阵列,对应于我们每个图像的尺寸。
然后,我们将把每个图像和标签分别附加到我们的数据和标签数组中(第 23 行和第 24 行)。
为了完成这个函数,我们将把数据和标签转换成 NumPy 数组,并返回图像数据和标签:
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels, dtype="int")
# return a 2-tuple of the A-Z data and labels
return (data, labels)
def load_mnist_dataset():
# load the MNIST dataset and stack the training data and testing
# data together (we'll create our own training and testing splits
# later in the project)
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
data = np.vstack([trainData, testData])
labels = np.hstack([trainLabels, testLabels])
# return a 2-tuple of the MNIST data and labels
return (data, labels)
最后,行 42 将图像数据和相关联的标签返回给调用函数。
恭喜你!现在,您已经完成了 I/O helper 函数,可以加载用于 OCR 和深度学习的数字和字母样本。接下来,我们将检查用于训练和查看结果的主驱动程序文件。
使用 Keras 和 TensorFlow 训练我们的 OCR 模型
在本节中,我们将使用 Keras、TensorFlow 和非常流行和成功的深度学习架构 ResNet 的 PyImageSearch 实现来训练我们的 OCR 模型。
请记住将您的模型保存到下周,届时我们将实现手写识别的自定义解决方案。
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.models import ResNet
from pyimagesearch.az_dataset import load_mnist_dataset
from pyimagesearch.az_dataset import load_az_dataset
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import build_montages
import matplotlib.pyplot as plt
import numpy as np
import argparse
import cv2
这是一个很长的导入语句列表,但是不要担心。这意味着我们有很多已经编写好的软件包,可以让我们的生活变得更加轻松。
- 我们从我们的
pyimagesearch.model导入ResNet,它包含了我们自己对流行的 ResNet 深度学习架构的定制实现(第 9 行)。 - 接下来,我们从
pyimagesearch.az_dataset导入我们的 I/O 助手函数load_mnist_data( 第 10 行)和load_az_dataset( 第 11 行)。
接下来,我们将使用一个我编写的自定义包,名为 imutils 。
从imutils开始,我们导入build_montages来帮助我们从一系列图像(第 17 行)中构建一个蒙太奇。更多关于构建蒙太奇的信息,请参考我的 蒙太奇与 OpenCV 教程。
我们最终将导入 Matplotlib ( 第 18 行)和 OpenCV ( 第 21 行)。
现在,让我们回顾一下我们的三个命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-a", "--az", required=True,
help="path to A-Z dataset")th
ap.add_argument("-m", "--model", type=str, required=True,
help="path to output trained handwriting recognition model")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output training history file")
args = vars(ap.parse_args())
到目前为止,我们已经准备好了导入、便利函数和命令行args。我们还剩下几个步骤来设置 ResNet 的培训、编译和训练它。
现在,我们将为 ResNet 设置训练参数,并使用我们已经讨论过的帮助器函数加载数字和字母数据:
# initialize the number of epochs to train for, initial learning rate,
# and batch size
EPOCHS = 50
INIT_LR = 1e-1
BS = 128
# load the A-Z and MNIST datasets, respectively
print("[INFO] loading datasets...")
(azData, azLabels) = load_az_dataset(args["az"])
(digitsData, digitsLabels) = load_mnist_dataset()
第 35-37 行为我们的 ResNet 模型的训练初始化参数。
然后,我们分别加载 Kaggle A-Z 和 MNIST 0-9 位数据的数据和标签(第 41 行和第 42 行),使用了我们在本文开始时讨论过的 I/O 助手函数。
接下来,我们将执行一些步骤来准备我们的数据和标签,以与我们在 Keras 和 TensorFlow 中的 ResNet 深度学习模型兼容:
# the MNIST dataset occupies the labels 0-9, so let's add 10 to every
# A-Z label to ensure the A-Z characters are not incorrectly labeled
# as digits
azLabels += 10
# stack the A-Z data and labels with the MNIST digits data and labels
data = np.vstack([azData, digitsData])
labels = np.hstack([azLabels, digitsLabels])
# each image in the A-Z and MNIST digts datasets are 28x28 pixels;
# however, the architecture we're using is designed for 32x32 images,
# so we need to resize them to 32x32
data = [cv2.resize(image, (32, 32)) for image in data]
data = np.array(data, dtype="float32")
# add a channel dimension to every image in the dataset and scale the
# pixel intensities of the images from [0, 255] down to [0, 1]
data = np.expand_dims(data, axis=-1)
data /= 255.0
当我们将字母和数字组合成单个字符数据集时,我们希望消除标签重叠处的任何歧义,以便组合字符集中的每个标签都是唯一的。
目前,我们对 A-Z 的标注从【0,25】,对应字母表中的每个字母。我们手指的标签从 0 到 9 ,所以有重叠——如果我们只是将它们直接组合起来,这将是一个问题。
没问题!有一个非常简单的解决方法。我们将在所有的 A-Z 标签上加 10,这样它们的整数标签值都大于数字标签值(第 47 行)。现在,我们对数字 0-9 和字母 A-Z 有了一个统一的标签模式,标签的值没有任何重叠。
我们有两个最后的步骤来准备我们的数据用于 ResNet。在第 61 行,我们将为数据集中的每个图像添加一个额外的“通道”维度,使其与 Keras/TensorFlow 中的 ResNet 模型兼容。最后,我们将从【0,255】到【0.0,1.0】(行 62 )的范围缩放我们的像素强度。
我们的下一步是为 ResNet 准备标签,对标签进行加权以说明每个类(字符)在数据中出现的次数的偏差,并将数据划分为测试和训练部分:
# convert the labels from integers to vectors
le = LabelBinarizer()
labels = le.fit_transform(labels)
counts = labels.sum(axis=0)
# account for skew in the labeled data
classTotals = labels.sum(axis=0)
classWeight = {}
# loop over all classes and calculate the class weight
for i in range(0, len(classTotals)):
classWeight[i] = classTotals.max() / classTotals[i]
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.20, stratify=labels, random_state=42)
# construct the image generator for data augmentation
aug = ImageDataGenerator(
rotation_range=10,
zoom_range=0.05,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.15,
horizontal_flip=False,
fill_mode="nearest")
# initialize and compile our deep neural network
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model = ResNet.build(32, 32, 1, len(le.classes_), (3, 3, 3),
(64, 64, 128, 256), reg=0.0005)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
注:关于 ResNet 的更多细节,请务必参考使用 Python 的计算机视觉深度学习的实践者包,在那里您将学习如何实现和调整强大的架构。
接下来,我们将训练网络,定义标签名称,并评估网络的性能:
# train the network
print("[INFO] training network...")
H = model.fit(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS,
class_weight=classWeight,
verbose=1)
# define the list of label names
labelNames = "0123456789"
labelNames += "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
labelNames = [l for l in labelNames]
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BS)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
注:以前,TensorFlow/Keras 需要使用名为 .fit_generator 的方法,以便使用数据生成器(如数据扩充对象)训练模型。现在, .fit 方法也可以处理生成器/数据扩充,使代码更加一致。这也适用于从 .predict_generator 到 .predict 的迁移。请务必查看我关于 fit 和 fit_generator 以及数据扩充的文章。
接下来,我们为每个单独的字符建立标签。第 111-113 行将我们所有的数字和字母连接起来,形成一个数组,数组中的每个成员都是一个数字。
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
# construct a plot that plots and saves the training history
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# initialize our list of output test images
images = []
# randomly select a few testing characters
for i in np.random.choice(np.arange(0, len(testY)), size=(49,)):
# classify the character
probs = model.predict(testX[np.newaxis, i])
prediction = probs.argmax(axis=1)
label = labelNames[prediction[0]]
# extract the image from the test data and initialize the text
# label color as green (correct)
image = (testX[i] * 255).astype("uint8")
color = (0, 255, 0)
# otherwise, the class label prediction is incorrect
if prediction[0] != np.argmax(testY[i]):
color = (0, 0, 255)
# merge the channels into one image, resize the image from 32x32
# to 96x96 so we can better see it and then draw the predicted
# label on the image
image = cv2.merge([image] * 3)
image = cv2.resize(image, (96, 96), interpolation=cv2.INTER_LINEAR)
cv2.putText(image, label, (5, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.75,
color, 2)
# add the image to our list of output images
images.append(image)
# construct the montage for the images
montage = build_montages(images, (96, 96), (7, 7))[0]
# show the output montage
cv2.imshow("OCR Results", montage)
cv2.waitKey(0)
第 138 行初始化我们的测试图像数组。
从第行第 141 开始,我们随机选择 49 个字符(形成一个 7×7 网格)并继续:
- 使用我们基于 ResNet 的
model( 第 143-145 行)对角色进行分类 - 从我们的测试数据(第 149 行)中抓取单个字符
image - 通过行 150-154 将注释文本
color设置为绿色(正确)或红色(不正确) - 为我们的单通道
image创建一个 RGB 表示,并将其包含在我们的可视化蒙太奇(第 159 行和第 160 行)中 - 注释彩色文本
label( 第 161 行和第 162 行) - 将
image添加到我们的输出images数组中(行 165
为了结束,我们将每个带注释的角色图像组装到一个 OpenCV 蒙太奇可视化网格中,显示结果直到按下一个键(第 168-172 行)。
恭喜你!一路上我们学到了很多!接下来,我们将看到我们努力工作的成果。
Keras 和 TensorFlow OCR 训练结果
回想一下上一节,我们的脚本(1)加载 MNIST 0-9 数字和 Kaggle A-Z 字母,(2)在数据集上训练一个 ResNet 模型,以及(3)生成一个可视化,以便我们可以确保它正常工作。
在本节中,我们将执行 OCR 模型训练和可视化脚本。
首先,使用本教程的 【下载】 部分下载源代码和数据集。
从那里,打开一个终端,并执行以下命令:
$ python train_ocr_model.py --az a_z_handwritten_data.csv --model handwriting.model
[INFO] loading datasets...
[INFO] compiling model...
[INFO] training network...
Epoch 1/50
2765/2765 [==============================] - 93s 34ms/step - loss: 0.9160 - accuracy: 0.8287 - val_loss: 0.4713 - val_accuracy: 0.9406
Epoch 2/50
2765/2765 [==============================] - 87s 31ms/step - loss: 0.4635 - accuracy: 0.9386 - val_loss: 0.4116 - val_accuracy: 0.9519
Epoch 3/50
2765/2765 [==============================] - 87s 32ms/step - loss: 0.4291 - accuracy: 0.9463 - val_loss: 0.3971 - val_accuracy: 0.9543
...
Epoch 48/50
2765/2765 [==============================] - 86s 31ms/step - loss: 0.3447 - accuracy: 0.9627 - val_loss: 0.3443 - val_accuracy: 0.9625
Epoch 49/50
2765/2765 [==============================] - 85s 31ms/step - loss: 0.3449 - accuracy: 0.9625 - val_loss: 0.3433 - val_accuracy: 0.9622
Epoch 50/50
2765/2765 [==============================] - 86s 31ms/step - loss: 0.3445 - accuracy: 0.9625 - val_loss: 0.3411 - val_accuracy: 0.9635
[INFO] evaluating network...
precision recall f1-score support
0 0.52 0.51 0.51 1381
1 0.97 0.98 0.97 1575
2 0.87 0.96 0.92 1398
3 0.98 0.99 0.99 1428
4 0.90 0.95 0.92 1365
5 0.87 0.88 0.88 1263
6 0.95 0.98 0.96 1375
7 0.96 0.99 0.97 1459
8 0.95 0.98 0.96 1365
9 0.96 0.98 0.97 1392
A 0.98 0.99 0.99 2774
B 0.98 0.98 0.98 1734
C 0.99 0.99 0.99 4682
D 0.95 0.95 0.95 2027
E 0.99 0.99 0.99 2288
F 0.99 0.96 0.97 232
G 0.97 0.93 0.95 1152
H 0.97 0.95 0.96 1444
I 0.97 0.95 0.96 224
J 0.98 0.96 0.97 1699
K 0.98 0.96 0.97 1121
L 0.98 0.98 0.98 2317
M 0.99 0.99 0.99 2467
N 0.99 0.99 0.99 3802
O 0.94 0.94 0.94 11565
P 1.00 0.99 0.99 3868
Q 0.96 0.97 0.97 1162
R 0.98 0.99 0.99 2313
S 0.98 0.98 0.98 9684
T 0.99 0.99 0.99 4499
U 0.98 0.99 0.99 5802
V 0.98 0.99 0.98 836
W 0.99 0.98 0.98 2157
X 0.99 0.99 0.99 1254
Y 0.98 0.94 0.96 2172
Z 0.96 0.90 0.93 1215
accuracy 0.96 88491
macro avg 0.96 0.96 0.96 88491
weighted avg 0.96 0.96 0.96 88491
[INFO] serializing network...
如您所见,我们的 Keras/TensorFlow OCR 模型在测试集上获得了 ~96%的准确率。
培训历史如下所示:
正如该图所证明的,几乎没有过度拟合的迹象,这意味着我们的 Keras 和 TensorFlow 模型在我们的基本 OCR 任务中表现良好。
让我们来看看测试集的一些输出示例:
如你所见,我们的 Keras/TensorFlow OCR 模型表现相当好!
$ ls *.model
handwriting.model
这个文件是我们的序列化 Keras 和 TensorFlow OCR 模型 —我们将在下周的手写识别教程中使用它。
将我们的 OCR 模型应用于手写识别
此时,您可能会想:
嗨阿德里安,
我们训练了一个 Keras/TensorFlow OCR 模型,这很酷——但是它只在我的硬盘上有什么好处呢?
如何用它做预测,实际识别笔迹?
请放心,这个问题将在下周的教程中解决——敬请关注;你不会想错过的!
总结
在本教程中,您学习了如何使用 Keras 和 TensorFlow 训练自定义 OCR 模型。
我们的模型被训练来识别字母数字字符,包括数字0-9以及字母T5 A-Z。总的来说,我们的 Keras 和 TensorFlow OCR 模型能够在我们的测试集上获得 ~96%的准确率。****
在下周的教程中,您将学习如何使用我们训练过的 Keras/TensorFlow OCR 模型,并将其用于自定义输入图像的手写识别。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
用光学字符识别名片
原文:https://pyimagesearch.com/2021/11/03/ocring-business-cards/
在之前的教程中,我们学习了如何通过以下方式自动 OCR 和扫描收据:
- 检测输入图像中的收据
- 应用透视变换以获得收据的自上而下的视图
- 利用宇宙魔方来识别收据上的文字
- 使用正则表达式提取价格数据
要学习如何使用 Python 对名片进行光学字符识别,继续阅读。**
OCR 识别名片
在本教程中,我们将使用一个非常相似的工作流程,但这次将其应用于名片 OCR。更具体地说,我们将学习如何从名片中提取姓名、头衔、电话号码和电子邮件地址。
然后,您将能够将这个实现扩展到您的项目中。
学习目标
在本教程中,您将:
- 了解如何检测图像中的名片
- 对名片图像应用 OCR
- 利用正则表达式提取:
- 名字
- 职称
- 电话号码
- 电子邮件地址
名片 OCR
在本教程的第一部分,我们将回顾我们的项目目录结构。然后,我们将实现一个简单而有效的 Python 脚本,允许我们对名片进行 OCR。
我们将通过讨论我们的结果以及后续步骤来结束本教程。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
我们首先需要回顾我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里,看一下目录结构:
|-- larry_page.png
|-- ocr_business_card.py
|-- tony_stark.png
我们只需要回顾一个 Python 脚本,ocr_business_card.py。这个脚本将加载示例名片图像(即larry_page.png和tony_stark.png),对它们进行 OCR,然后输出名片上的姓名、职务、电话号码和电子邮件地址。
最棒的是,我们将能够在 120 行代码(包括注释)内完成我们的目标!
实现名片 OCR
我们现在准备实现我们的名片 OCR 脚本!首先,在我们的项目目录结构中打开ocr_business_card.py文件,并插入以下代码:
# import the necessary packages
from imutils.perspective import four_point_transform
import pytesseract
import argparse
import imutils
import cv2
import re
我们这里的导入类似于之前关于 OCR 收据的教程中的导入。
我们需要我们的four_point_transform函数来获得一个自顶向下的,名片的鸟瞰图。获得此视图通常会产生更高的 OCR 准确性。
pytesseract包用于与 Tesseract OCR 引擎接口。然后我们有了 Python 的正则表达式库re,它将允许我们解析名片中的姓名、职位、电子邮件地址和电话号码。
导入工作完成后,我们可以转到命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--debug", type=int, default=-1,
help="whether or not we are visualizing each step of the pipeline")
ap.add_argument("-c", "--min-conf", type=int, default=0,
help="minimum confidence value to filter weak text detection")
args = vars(ap.parse_args())
我们的第一个命令行参数--image,是磁盘上输入图像的路径。我们假设该图像包含一张在前景和背景之间具有足够对比度的名片,确保我们可以成功地应用边缘检测和轮廓处理来提取名片。
然后我们有两个可选的命令行参数,--debug和--min-conf。--debug命令行参数用于指示我们是否正在调试我们的图像处理管道,并在我们的屏幕上显示更多处理过的图像(当您无法确定为什么会检测到名片时,这很有用)。
然后我们有了--min-conf,成功文本检测所需的最小置信度(在 0-100 的范围内)。您可以增加--min-conf来删除弱文本检测。
现在让我们从磁盘加载输入图像:
# load the input image from disk, resize it, and compute the ratio
# of the *new* width to the *old* width
orig = cv2.imread(args["image"])
image = orig.copy()
image = imutils.resize(image, width=600)
ratio = orig.shape[1] / float(image.shape[1])
这里,我们从磁盘加载我们的输入--image,然后克隆它。我们把它做成一个克隆体,提取轮廓处理后的原高分辨率版名片。
然后,我们将image的宽度调整为 600 像素,然后计算新的宽度与旧的宽度的比率(当我们想要获得原始高分辨率名片的自上而下的视图时,这是一个要求)。
下面我们继续我们的图像处理流程。
# convert the image to grayscale, blur it, and apply edge detection
# to reveal the outline of the business card
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 30, 150)
# detect contours in the edge map, sort them by size (in descending
# order), and grab the largest contours
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
# initialize a contour that corresponds to the business card outline
cardCnt = None
首先,我们采取我们的原始image然后将其转换为灰度,模糊,然后应用边缘检测,其结果可以在图 2 中看到。
请注意,名片的轮廓/边框在边缘图上是可见的。然而,假设在边缘图中有任何间隙。在这种情况下,名片将而不是通过我们的轮廓处理技术检测出来,所以你可能需要调整 Canny 边缘检测器的参数,或者在光线条件更好的环境中捕捉你的图像。
从那里,我们检测轮廓,并根据计算出的轮廓面积按降序(从大到小)对它们进行排序。我们在这里的假设是,名片轮廓将是最大的检测轮廓之一,因此这个操作。
我们还初始化cardCnt ( Line 40 ),这是对应名片的轮廓。
现在让我们循环最大的等高线:
# loop over the contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# if this is the first contour we've encountered that has four
# vertices, then we can assume we've found the business card
if len(approx) == 4:
cardCnt = approx
break
# if the business card contour is empty then our script could not
# find the outline of the card, so raise an error
if cardCnt is None:
raise Exception(("Could not find receipt outline. "
"Try debugging your edge detection and contour steps."))
第 45 和 46 行执行轮廓近似。
如果我们的近似轮廓有四个顶点,那么我们可以假设我们找到了名片。如果发生这种情况,我们从循环中退出break,并更新我们的cardCnt。
如果我们到达了for循环的末尾,仍然没有找到有效的cardCnt,我们优雅地退出脚本。请记住,如果在图像中找不到名片,我们将无法处理它!
我们的下一个代码块处理显示一些调试图像以及获取名片的自顶向下视图:
# check to see if we should draw the contour of the business card
# on the image and then display it to our screen
if args["debug"] > 0:
output = image.copy()
cv2.drawContours(output, [cardCnt], -1, (0, 255, 0), 2)
cv2.imshow("Business Card Outline", output)
cv2.waitKey(0)
# apply a four-point perspective transform to the *original* image to
# obtain a top-down bird's-eye view of the business card
card = four_point_transform(orig, cardCnt.reshape(4, 2) * ratio)
# show transformed image
cv2.imshow("Business Card Transform", card)
cv2.waitKey(0)
第 62-66 行检查我们是否处于--debug模式,如果是,我们在output图像上绘制名片的轮廓。
然后,我们将四点透视变换应用于原始的高分辨率图像,从而获得名片的俯视鸟瞰图,即 T2。
我们将cardCnt乘以我们计算的ratio,因为cardCnt是针对缩减的图像尺寸计算的。乘以ratio将cardCnt缩放回orig图像的尺寸。
然后,我们在屏幕上显示转换后的图像(第 73 行和第 74 行)。
有了我们获得的名片的自上而下视图,我们可以继续进行 OCR:
# convert the business card from BGR to RGB channel ordering and then
# OCR it
rgb = cv2.cvtColor(card, cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(rgb)
# use regular expressions to parse out phone numbers and email
# addresses from the business card
phoneNums = re.findall(r'[\+\(]?[1-9][0-9 .\-\(\)]{8,}[0-9]', text)
emails = re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", text)
# attempt to use regular expressions to parse out names/titles (not
# necessarily reliable)
nameExp = r"^[\w'\-,.][^0-9_!¡?÷?¿/\\+=@#$%ˆ&*(){}|~<>;:[\]]{2,}"
names = re.findall(nameExp, text)
第 78 行和第 79 行 OCR 名片,产生text输出。
但问题是,我们如何从名片本身提取信息?答案是利用正则表达式。
第 83 行和第 84 行利用正则表达式从text中提取电话号码和电子邮件地址(瓦利亚,2020 ),而第 88 行和第 89 行对姓名和职务做同样的处理( 名和姓的正则表达式,2020 )。
对正则表达式的回顾超出了本教程的范围,但是要点是它们可以用来匹配文本中的特定模式。
例如,电话号码由特定的数字模式组成,有时还包括破折号和括号。电子邮件地址也遵循一种模式,包括一个文本字符串,后跟一个“@”符号,然后是域名。
只要你能可靠地保证文本的模式,正则表达式就能很好地工作。也就是说,它们也不是完美的,所以如果你发现你的名片 OCR 准确率明显下降,你可能需要研究更高级的自然语言处理(NLP)算法。
这里的最后一步是向终端显示我们的输出:
# show the phone numbers header
print("PHONE NUMBERS")
print("=============")
# loop over the detected phone numbers and print them to our terminal
for num in phoneNums:
print(num.strip())
# show the email addresses header
print("\n")
print("EMAILS")
print("======")
# loop over the detected email addresses and print them to our
# terminal
for email in emails:
print(email.strip())
# show the name/job title header
print("\n")
print("NAME/JOB TITLE")
print("==============")
# loop over the detected name/job titles and print them to our
# terminal
for name in names:
print(name.strip())
这个最后的代码块循环遍历提取的电话号码(第 96 和 97 行)、电子邮件地址(第 106 和 107 行)和姓名/职务(第 116 和 117 行),将它们显示到我们的终端。
当然,您可以提取这些信息,写入磁盘,保存到数据库,等等。不过,为了简单起见(并且不知道您的名片 OCR 项目规范),我们将把它作为一个练习留给您,让您保存您认为合适的数据。
名片 OCR 结果
我们现在准备将 OCR 应用于名片。打开终端并执行以下命令:
$ python ocr_business_card.py --image tony_stark.png --debug 1
PHONE NUMBERS
=============
562-555-0100
562-555-0150
EMAILS
======
NAME/JOB TITLE
==============
Tony Stark
Chief Executive Officer
Stark Industries
图 3 (上)展示了我们名片本地化的结果。请注意我们是如何在输入图像中正确检测出名片的。
从那里,图 3 (底部)显示应用名片的透视变换的结果,因此产生了自上而下的,图像的鸟瞰图。
一旦我们有了图像的自上而下视图(通常需要获得更高的 OCR 准确度),我们就可以应用 Tesseract 对其进行 OCR,其结果可以在上面的终端输出中看到。
请注意,我们的脚本已经成功提取了托尼·斯塔克名片上的两个电话号码。
没有报告电子邮件地址,因为名片上没有电子邮件地址。
然后,我们还会显示姓名和职位。有趣的是,我们可以成功地对所有文本进行 OCR,因为姓名文本比电话号码文本更失真。我们的透视变换有效地处理了所有的文本,即使当你离相机越远,扭曲的程度就越大。这就是透视变换的要点,也是它对我们的 OCR 的准确性如此重要的原因。
让我们尝试另一个例子图片,这是一个老拉里·佩奇(谷歌的联合创始人)的名片:
$ python ocr_business_card.py --image larry_page.png --debug 1
PHONE NUMBERS
=============
650 330-0100
650 618-1499
EMAILS
======
larry@google.com
NAME/JOB TITLE
==============
Larry Page
CEO
Google
图 4 (上)显示本地化页面名片的输出。下面的按钮显示了图像自上而下的变换。
这个自顶向下的转换通过 Tesseract OCR,产生 OCR 处理的文本作为输出。我们获取经过 OCR 处理的文本,应用正则表达式,从而获得上面的结果。
检查结果,您可以看到我们已经成功地从名片中提取了 Larry Page 的两个电话号码、电子邮件地址和姓名/职务。
总结
在本教程中,您学习了如何构建一个基本的名片 OCR 系统。本质上,这个系统是我们收据扫描器的扩展,但是有不同的正则表达式和文本本地化策略。
如果您需要构建一个名片 OCR 系统,我建议您以本教程为起点,但是请记住,您可能希望利用更高级的文本后处理技术,例如真正的自然语言处理(NLP)算法,而不是正则表达式。
对于电子邮件地址和电话号码,正则表达式可以很好地工作,但是对于姓名和职位可能无法获得高准确性。如果到了那个时候,你应该考虑尽可能地利用 NLP 来改善你的结果。
*### 引用信息
罗斯布鲁克,a .“OCR 识别名片”, PyImageSearch ,2021,【https://pyimagesearch.com/2021/11/03/ocring-business-cards/】T4
@article{Rosebrock_2021_OCR_BCards, author = {Adrian Rosebrock}, title = {{OCR}’ing Business Cards}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/11/03/ocring-business-cards/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!**
视频流的光学字符识别
原文:https://pyimagesearch.com/2022/03/07/ocring-video-streams/
在本教程中,您将学习如何 OCR 视频流。
本课是关于使用 Python 进行光学字符识别的 4 部分系列的第 3 部分:
- 多栏表格 OCR
- OpenCV 快速傅立叶变换(FFT)用于图像和视频流中的模糊检测
- OCR 识别视频流(本教程)
- 使用 OpenCV 和 GPU 提高文本检测速度
对视频流进行光学字符识别
在我们之前的教程中,你学习了如何使用快速傅立叶变换(FFT)来检测图像和文档中的模糊。使用这种方法,我们能够检测出模糊、低质量的图像,然后提醒用户应该尝试捕捉更高质量的版本,以便我们可以对其进行 OCR。
记住,编写对高质量图像进行操作的计算机视觉代码总是比低质量图像更容易。使用 FFT 模糊检测方法有助于确保只有更高质量的图像进入我们的管道。
然而,FFT 模糊检测器还有另一个用途,它可以用来从视频流中丢弃低质量的帧,否则无法进行 OCR。
由于光照条件的快速变化(例如,在明亮的晴天走进黑暗的房间),摄像机镜头自动聚焦,或者最常见的运动模糊,视频流自然会有低质量的帧。
对这些帧进行光学字符识别几乎是不可能的。因此,我们可以简单地通过检测到帧模糊,忽略它,然后只对高质量的帧进行 OCR,而不是试图对视频流中的每个帧进行 OCR(这会导致低质量帧的无意义结果)?
这样的实现可能吗?
没错,我们将在本教程的剩余部分讲述如何将模糊检测器应用于 OCR 视频流。
在本教程中,您将:
- 了解如何对视频流进行 OCR
- 应用我们的 FFT 模糊检测器来检测和丢弃模糊、低质量的帧
- 构建一个显示视频流 OCR 阶段的输出可视化脚本
- 将所有部件放在一起,在视频流中完全实现 OCR
OCR 实时视频流
在本教程的第一部分,我们将回顾我们的项目目录结构。
然后,我们将实现一个简单的视频编写器实用程序类。这个类将允许我们从一个输入视频中创建一个输出模糊检测和 OCR 结果的视频。
给定我们的视频编写器助手函数,然后我们将实现我们的驱动程序脚本来对视频流应用 OCR。
我们将讨论我们的结果来结束本教程。
学习如何 OCR 视频流, 继续阅读。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果您需要帮助配置 OpenCV 的开发环境,我们强烈推荐阅读我们的 pip 安装 OpenCV 指南——它将在几分钟内让您启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
让我们从查看视频 OCR 项目的目录结构开始:
|-- pyimagesearch
| |-- __init__.py
| |-- helpers.py
| |-- blur_detection
| | |-- __init__.py
| | |-- blur_detector.py
| |-- video_ocr
| | |-- __init__.py
| | |-- visualization.py
|-- output
| |-- ocr_video_output.avi
|-- video
| |-- business_card.mp4
|-- ocr_video.py
在pyimagesearch模块中,我们有两个子模块:
- 我们将用来帮助检测视频流中的模糊的子模块。
- 包含一个助手函数,它将我们的视频 OCR 的输出作为一个单独的视频文件写到磁盘上。
video目录包含business_card.mp4,一个包含我们想要 OCR 的名片的视频。output目录包含在我们的输入视频上运行驱动脚本ocr_video.py的输出。
实现我们的视频编写器实用程序
在我们实现我们的驱动程序脚本之前,我们首先需要实现一个基本的助手实用程序,它将允许我们将视频 OCR 脚本的输出作为一个单独的输出视频写入磁盘。
可视化脚本的输出示例可以在图 2 中看到。请注意,输出有三个部分:
- 检测到名片且注释模糊/不模糊的原始输入框(上)
- 检测到文本的名片的自顶向下变换(中)
- 从自上而下转换(底部)的 OCR 文本本身
在本节中,我们将实现一个助手实用函数来构建这样一个输出可视化。
请注意,这个视频编写器实用程序与 OCR 没有任何关系。相反,它只是一个简单的 Python 类,我实现它来编写视频 I/O。为了完整起见,我在本教程中只是回顾一下。
如果您发现自己很难跟上类的实现,不要担心——这不会影响您的 OCR 知识。也就是说,如果你想学习更多关于使用视频和 OpenCV 的知识,我推荐你跟随我们的使用视频教程。**
**现在让我们开始实现我们的视频作者实用程序。打开我们项目的video_ocr目录下的visualization.py文件,我们开始吧:
# import the necessary packages
import numpy as np
class VideoOCROutputBuilder:
def __init__(self, frame):
# store the input frame dimensions
self.maxW = frame.shape[1]
self.maxH = frame.shape[0]
我们从定义我们的VideoOCROutputBuilder类开始。我们的构造函数只需要一个参数,我们的输入frame。然后我们将frame的宽度和高度分别存储为maxW和maxH。
考虑到我们的构造函数,让我们创建负责构造你在图 2 中看到的可视化的build方法。
def build(self, frame, card=None, ocr=None):
# grab the input frame dimensions and initialize the card
# image dimensions along with the OCR image dimensions
(frameH, frameW) = frame.shape[:2]
(cardW, cardH) = (0, 0)
(ocrW, ocrH) = (0, 0)
# if the card image is not empty, grab its dimensions
if card is not None:
(cardH, cardW) = card.shape[:2]
# similarly, if the OCR image is not empty, grab its
# dimensions
if ocr is not None:
(ocrH, ocrW) = ocr.shape[:2]
build方法接受三个参数,其中一个是必需的(另外两个是可选的):
frame:来自视频的输入帧card:应用了自上而下透视变换后的名片,检测到名片上的文字ocr:OCR 识别的文本本身
第 13 行抓取输入frame的空间尺寸,而第 14 和 15 行初始化card和ocr图像的空间尺寸。
由于card和ocr都可能是None,我们不知道它们是否是有效图像。如果是,行 18-24 进行此项检查,如果通过,则抓取card和ocr的宽度和高度。
我们现在可以开始构建我们的output可视化:
# compute the spatial dimensions of the output frame
outputW = max([frameW, cardW, ocrW])
outputH = frameH + cardH + ocrH
# update the max output spatial dimensions found thus far
self.maxW = max(self.maxW, outputW)
self.maxH = max(self.maxH, outputH)
# allocate memory of the output image using our maximum
# spatial dimensions
output = np.zeros((self.maxH, self.maxW, 3), dtype="uint8")
# set the frame in the output image
output[0:frameH, 0:frameW] = frame
第 27 行通过找到穿过frame、card和ocr的max高度,计算出output可视化的最大宽度。第 28 行通过将所有三个高度相加来确定可视化的高度(我们做这个相加操作是因为这些图像需要堆叠在另一个之上)。
第 31 行和第 32 行用我们目前发现的最大宽度和高度值更新我们的maxW和maxH簿记变量。
给定我们最新更新的maxW和maxH,第 36 行使用我们目前发现的最大空间维度为我们的output图像分配内存。
随着output图像的初始化,我们将frame存储在output ( 第 39 行)的顶部。
我们的下一个代码块处理将card和ocr图像添加到output帧:
# if the card is not empty, add it to the output image
if card is not None:
output[frameH:frameH + cardH, 0:cardW] = card
# if the OCR result is not empty, add it to the output image
if ocr is not None:
output[
frameH + cardH:frameH + cardH + ocrH,
0:ocrW] = ocr
# return the output visualization image
return output
第 42 行和第 43 行验证一个有效的card图像已经被传递到函数中,如果是的话,我们将它添加到output图像中。第 46-49 行做同样的事情,只针对ocr图像。
最后,我们将output可视化返回给调用函数。
祝贺实现了我们的VideoOCROutputBuilder类!让我们在下一节中使用它!
实现我们的实时视频 OCR 脚本
我们现在准备实现我们的ocr_video.py脚本。让我们开始工作:
# import the necessary packages
from pyimagesearch.video_ocr import VideoOCROutputBuilder
from pyimagesearch.blur_detection import detect_blur_fft
from pyimagesearch.helpers import cleanup_text
from imutils.video import VideoStream
from imutils.perspective import four_point_transform
from pytesseract import Output
import pytesseract
import numpy as np
import argparse
import imutils
import time
import cv2
我们从第 2-13 行开始,导入我们需要的 Python 包。值得注意的进口包括:
- 我们的可视化构建器
- 我们的 FFT 模糊检测器
cleanup_text:用于清理 OCR 文本,剔除非 ASCII 字符,以便我们可以使用 OpenCV 的cv2.putText函数在输出图像上绘制 OCR 文本four_point_transform:应用透视变换,这样我们就可以获得一张我们正在进行 OCR 的名片的自上而下/鸟瞰图pytesseract:提供一个到 Tesseract OCR 引擎的接口
考虑到我们的导入,让我们继续我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str,
help="path to optional input video (webcam will be used otherwise)")
ap.add_argument("-o", "--output", type=str,
help="path to optional output video")
ap.add_argument("-c", "--min-conf", type=int, default=50,
help="minimum confidence value to filter weak text detection")
args = vars(ap.parse_args())
我们的脚本提供了三个命令行参数:
--input:磁盘上可选输入视频文件的路径。如果没有提供视频文件,我们将使用我们的网络摄像头。--output:我们将要生成的可选输出视频文件的路径。--min-conf:用于过滤弱文本检测的最小置信度值。
现在我们可以继续初始化了:
# initialize our video OCR output builder used to easily visualize
# output to our screen
outputBuilder = None
# initialize our output video writer along with the dimensions of the
# output frame
writer = None
outputW = None
outputH = None
第 27 行初始化我们的outputBuilder。这个对象将在我们的while循环的主体中被实例化,该循环从我们的视频流中访问帧(我们将在本教程的后面介绍)。
然后我们在第 31-33 行初始化输出视频写入器和输出视频的空间尺寸。
让我们继续访问我们的视频流:
# create a named window for our output OCR visualization (a named
# window is required here so that we can automatically position it
# on our screen)
cv2.namedWindow("Output")
# initialize a Boolean used to indicate if either a webcam or input
# video is being used
webcam = not args.get("input", False)
# if a video path was not supplied, grab a reference to the webcam
if webcam:
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# otherwise, grab a reference to the video file
else:
print("[INFO] opening video file...")
vs = cv2.VideoCapture(args["input"])
第 38 行为我们的输出可视化创建一个名为Output的命名窗口。我们显式地在这里创建了一个命名窗口,这样我们就可以使用 OpenCV 的cv2.moveWindow函数来移动屏幕上的窗口。我们需要执行这个移动操作,因为输出窗口的大小是动态的,它会随着输出的增加和缩小而增加。
Line 42 确定我们是否使用网络摄像头作为视频输入。如果是这样,第 45-48 行访问我们的网络摄像头视频流;否则,行 51-53 抓取一个指向驻留在磁盘上的视频的指针。
访问我们的视频流后,现在是开始循环播放帧的时候了:
# loop over frames from the video stream
while True:
# grab the next frame and handle if we are reading from either
# a webcam or a video file
orig = vs.read()
orig = orig if webcam else orig[1]
# if we are viewing a video and we did not grab a frame then we
# have reached the end of the video
if not webcam and orig is None:
break
# resize the frame and compute the ratio of the *new* width to
# the *old* width
frame = imutils.resize(orig, width=600)
ratio = orig.shape[1] / float(frame.shape[1])
# if our video OCR output builder is None, initialize it
if outputBuilder is None:
outputBuilder = VideoOCROutputBuilder(frame)
第 59 行和第 60 行从视频流中读取原始(orig)帧。如果设置了webcam变量,并且orig帧为None,那么我们已经到达了视频文件的末尾,因此我们从循环中断开。
否则,行 69 和 70 将帧的宽度调整为 700 像素(这样处理起来更容易更快),然后计算新宽度的ratio到旧宽度。在这个循环的后面,当我们将透视变换应用到原始的高分辨率帧时,我们将需要这个比率。
第 73 和 74 行使用调整后的frame初始化我们的VideoOCROutputBuilder。
接下来是更多的初始化,然后是模糊检测:
# initialize our card and OCR output ROIs
card = None
ocr = None
# convert the frame to grayscale and detect if the frame is
# considered blurry or not
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
(mean, blurry) = detect_blur_fft(gray, thresh=15)
# draw whether or not the frame is blurry
color = (0, 0, 255) if blurry else (0, 255, 0)
text = "Blurry ({:.4f})" if blurry else "Not Blurry ({:.4f})"
text = text.format(mean)
cv2.putText(frame, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, color, 2)
第 77 和 78 行初始化我们的card和ocrROI。card ROI 将包含名片的自顶向下转换(如果在当前frame中找到名片),而ocr将包含 OCR 处理的文本本身。
然后我们在行 82 和 83 上执行文本/文档模糊检测。我们首先将frame转换成灰度,然后应用我们的detect_blur_fft函数。
第 86-90 行画在frame上,表示当前帧是否模糊。
让我们继续我们的视频 OCR 管道:
# only continue to process the frame for OCR if the image is
# *not* blurry
if not blurry:
# blur the grayscale image slightly and then perform edge
# detection
blurred = cv2.GaussianBlur(gray, (5, 5,), 0)
edged = cv2.Canny(blurred, 75, 200)
# find contours in the edge map and sort them by size in
# descending order, keeping only the largest ones
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
# initialize a contour that corresponds to the business card
# outline
cardCnt = None
# loop over the contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# if our approximated contour has four points, then we
# can assume we have found the outline of the business
# card
if len(approx) == 4:
cardCnt = approx
break
在继续之前,我们检查以确认帧是而不是模糊的。假设检查通过,我们开始在输入帧中寻找名片,方法是用高斯核平滑帧,然后应用边缘检测(第 97 和 98 行)。
然后,我们将轮廓检测应用于边缘图,并按面积对轮廓进行排序,从最大到最小(行 102-105 )。我们这里的假设是,名片将是输入帧中最大的 ROI,也有四个顶点。
为了确定我们是否找到了名片,我们遍历了第 112 行上的最大轮廓。然后我们应用轮廓近似(线 114 和 115** )并检查近似轮廓是否有四个点。**
假设轮廓有四个点,我们假设已经找到了我们的卡片轮廓,所以我们存储轮廓变量(cardCnt),然后从循环(第 120-122 行)中存储break。
如果我们找到了我们的名片轮廓,我们现在尝试 OCR 它:
# ensure that the business card contour was found
if cardCnt is not None:
# draw the outline of the business card on the frame so
# we visually verify that the card was detected correctly
cv2.drawContours(frame, [cardCnt], -1, (0, 255, 0), 3)
# apply a four-point perspective transform to the
# *original* frame to obtain a top-down bird's-eye
# view of the business card
card = four_point_transform(orig,
cardCnt.reshape(4, 2) * ratio)
# allocate memory for our output OCR visualization
ocr = np.zeros(card.shape, dtype="uint8")
# swap channel ordering for the business card and OCR it
rgb = cv2.cvtColor(card, cv2.COLOR_BGR2RGB)
results = pytesseract.image_to_data(rgb,
output_type=Output.DICT)
第 125 行证实我们确实找到了我们的名片轮廓。然后我们通过 OpenCV 的cv2.drawContours函数在frame上绘制卡片轮廓。
接下来,我们通过使用我们的four_point_transform函数(第 133 行和第 134 行)对原始的高分辨率图像应用透视变换(这样我们可以更好地对其进行 OCR 识别)。我们还为我们的输出ocr可视化分配内存,在应用自顶向下转换后使用card的相同空间维度(第 137 行)。
第 140-142 行然后对名片应用文本检测和 OCR。
下一步是用 OCR 文本本身注释输出ocr可视化:
# loop over each of the individual text localizations
for i in range(0, len(results["text"])):
# extract the bounding box coordinates of the text
# region from the current result
x = results["left"][i]
y = results["top"][i]
w = results["width"][i]
h = results["height"][i]
# extract the OCR text itself along with the
# confidence of the text localization
text = results["text"][i]
conf = int(results["conf"][i])
# filter out weak confidence text localizations
if conf > args["min_conf"]:
# process the text by stripping out non-ASCII
# characters
text = cleanup_text(text)
# if the cleaned up text is not empty, draw a
# bounding box around the text along with the
# text itself
if len(text) > 0:
cv2.rectangle(card, (x, y), (x + w, y + h),
(0, 255, 0), 2)
cv2.putText(ocr, text, (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 0, 255), 1)
第 145 行循环所有文本检测。然后,我们继续:
- 抓取文本 ROI 的边界框坐标(行 148-151 )
- 提取 OCR 文本及其相应的置信度/概率(行 155 和 156 )
- 验证文本检测是否有足够的可信度,然后从文本中剔除非 ASCII 字符(行 159-162 )
- 在
ocr可视化上绘制 OCR 文本(第 167-172 行
本例中的其余代码块更侧重于簿记变量和输出:
# build our final video OCR output visualization
output = outputBuilder.build(frame, card, ocr)
# check if the video writer is None *and* an output video file
# path was supplied
if args["output"] is not None and writer is None:
# grab the output frame dimensions and initialize our video
# writer
(outputH, outputW) = output.shape[:2]
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 27,
(outputW, outputH), True)
# if the writer is not None, we need to write the output video
# OCR visualization to disk
if writer is not None:
# force resize the video OCR visualization to match the
# dimensions of the output video
outputFrame = cv2.resize(output, (outputW, outputH))
writer.write(outputFrame)
# show the output video OCR visualization
cv2.imshow("Output", output)
cv2.moveWindow("Output", 0, 0)
key = cv2.waitKey(1) & 0xFF
# if the 'q' key was pressed, break from the loop
if key == ord("q"):
break
第 175 行使用我们的VideoOCROutputBuilder类的.build方法创建我们的output帧。
然后我们检查是否提供了一个--output视频文件路径,如果是,实例化我们的cv2.VideoWriter,这样我们就可以将output帧可视化写到磁盘上(第 179-185 行)。
类似地,如果writer对象已经被实例化,那么我们将输出帧写入磁盘(第 189-193 行)。
第 196-202 行向我们的屏幕显示output画面:
我们的最后一个代码块释放了视频指针:
# if we are using a webcam, stop the camera video stream
if webcam:
vs.stop()
# otherwise, release the video file pointer
else:
vs.release()
# close any open windows
cv2.destroyAllWindows()
整体来看,这似乎是一个复杂的脚本。但是请记住,我们刚刚用不到 225 行代码(包括注释)实现了一个完整的视频 OCR 管道。仔细想想,代码并不多——而且这一切都是通过使用 OpenCV 和 Tesseract 实现的!
实时视频 OCR 结果
我们现在准备好测试我们的视频 OCR 脚本了!打开终端并执行以下命令:
$ python ocr_video.py --input video/business_card.mp4 --output output/ocr_video_output.avi
[INFO] opening video file...
图 3 显示了来自output目录中的ocr_video_output.avi文件的屏幕截图。
请注意左边的部分,我们的脚本已经正确地检测到一个模糊的帧,并且没有对它进行 OCR。如果我们试图对这个帧进行 OCR,结果将会是无意义的,使最终用户感到困惑。
相反,我们等待更高质量的帧(右),然后对其进行 OCR。如您所见,通过等待更高质量的帧,我们能够正确地对名片进行 OCR。
如果你需要对视频流应用 OCR,我强烈建议使用某种低质量和高质量的帧检测器。除非你 100%确信 视频是在理想的受控条件下拍摄的,并且每一帧都是高质量的,否则不要试图对视频流的每一帧进行 OCR。
总结
在本教程中,您学习了如何对视频流进行 OCR。然而,首先,我们需要检测模糊、低质量的帧,以便对视频流进行 OCR。
由于光照条件的快速变化、相机镜头自动对焦和运动模糊,视频自然会有低质量的帧。我们需要检测这些低质量的帧并丢弃它们,而不是尝试对这些低质量的帧进行 OCR,这最终会导致低 OCR 准确度(或者更糟,完全无意义的结果)。
检测低质量帧的一种简单方法是使用模糊检测。因此,我们利用 FFT 模糊检测器来处理视频流。结果是 OCR 管道能够在视频流上操作,同时仍然保持高精度。
我希望你喜欢这个教程!我希望你能把这种方法应用到你的项目中。
引用信息
Rosebrock,a .“OCR ' ing Video Streams”, PyImageSearch ,D. Chakraborty,P. Chugh,A. R. Gosthipaty,S. Huot,K. Kidriavsteva,R. Raha 和 A. Thanki 编辑。,2022 年,【https://pyimg.co/k43vd
@incollection{Rosebrock_2022_OCR_Video_Streams,
author = {Adrian Rosebrock},
title = {{OCR}’ing Video Streams},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/k43vd},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
使用 Keras 和 Creme 进行在线/增量学习
原文:https://pyimagesearch.com/2019/06/17/online-incremental-learning-with-keras-and-creme/

在本教程中,您将学习如何使用 Keras 和 Creme 在太大而无法放入内存的数据集上执行在线/增量学习。
几周前,我向你展示了如何使用 Keras 进行特征提取和在线学习——我们使用该教程来执行迁移学习和识别类,最初的 CNN 从未在上进行过训练。
为了完成这项任务,我们需要使用 Keras 根据从图像中提取的特征来训练一个非常简单的前馈神经网络。
但是,如果我们不想让训练一个神经网络呢?
如果我们想在数据的基础上训练一个逻辑回归、朴素贝叶斯或决策树模型会怎么样?或者,如果我们想在训练这样一个模型之前执行特征选择或特征处理呢?
您可能很想使用 scikit-learn —但是您很快就会意识到 scikit-learn 并没有将增量学习作为“一等公民”对待—scikit-learn 中只包含了一些在线学习实现,至少可以说它们使用起来很笨拙。
相反,你应该使用 Creme ,它:
- 实现了许多用于分类、回归、特征选择和特征预处理的流行算法。
- 有一个类似于 scikit-learn 的 API。
- 并且使得执行在线/增量学习变得超级容易。
在本教程的剩余部分,我将向您展示如何:
- 使用 Keras +预训练的 CNN从图像数据集中提取鲁棒的、有区别的特征。
- 利用 Creme 对数据集执行增量学习,该数据集太大,无法装入内存。
我们开始吧!
要了解如何使用 Keras 和 Creme 进行在线/增量学习,继续阅读!
使用 Keras 和 Creme 进行在线/增量学习
在本教程的第一部分,我们将讨论我们可能想要进行在线学习或增量学习的情况。
然后我们将讨论为什么 Creme 机器学习库是增量学习的合适选择。
在本教程中,我们将使用 Kaggle 的狗与猫数据集,我们将花一些时间简要回顾该数据集。
从那里,我们将从项目中查看我们的目录结构。
一旦我们理解了目录结构,我们将实现一个 Python 脚本,该脚本将用于使用 Keras 和在 ImageNet 上预先训练的 CNN 从狗与猫数据集提取特征。
给定我们提取的特征(这些特征将太大而不适合 RAM),我们将使用 Creme 以增量学习的方式训练逻辑回归模型,确保:
- 我们仍然可以训练我们的分类器,尽管提取的特征太大而不适合存储。
- 我们仍然可以获得高精度,即使我们不能一次访问“所有”功能。
为什么选择在线学习/增量学习?
Figure 1: Multi-class incremental learning with Creme allows for machine learning on datasets which are too large to fit into memory (image source).
无论您处理的是图像数据、文本数据、音频数据,还是数字/分类数据,您最终都会遇到一个太大而不适合内存的数据集。
然后呢?
你可以研究这些选项中的一个——在某些情况下,它们是完全合理的探索途径。
但是我的第一选择是应用在线/渐进式学习。
使用增量学习,您可以处理太大而不适合 RAM 的数据集,并应用流行的机器学习技术,包括:
- 特征预处理
- 特征选择
- 分类
- 回归
- 使聚集
- 集成方法
- …还有更多!
渐进式学习非常强大,今天你将学习如何将它应用到你自己的数据中。
为什么选择 Creme 进行增量学习?
![]()
Figure 2: Creme is a library specifically tailored to incremental learning. The API is similar to that of scikit-learn’s which will make you feel at home while putting it to work on large datasets where incremental learning is required.
神经网络和深度学习是增量学习的一种形式——我们可以一次对一个样本或一批样本训练这样的网络。
然而,仅仅因为我们能够应用神经网络解决问题并不意味着我们应该。
相反,我们需要为工作带来合适的工具。仅仅因为你手里有一把锤子,并不意味着你会用它来敲螺丝。
增量学习算法包含一组用于以增量方式训练模型的技术。
当数据集太大而无法放入内存时,我们通常会利用增量学习。
然而,scikit-learn 库确实包含少量在线学习算法:
- 它没有把增量学习作为一等公民对待。
- 这些实现很难使用。
进入 Creme 库 —一个专门用于 creme ntal 学习 Python 的库。
这个图书馆本身相当新,但上周我花了一些时间对它进行了研究。
我真的很喜欢这种体验,并发现 scikit-learn 启发的 API 非常容易使用。
在阅读完本教程的其余部分后,我想你会同意我说的话, Creme 是一个很棒的小库,我希望开发人员和维护人员一切顺利——我希望这个库继续成长。
狗和猫的数据集

Figure 3: In today’s example, we’re using Kaggle’s Dogs vs. Cats dataset. We’ll extract features with Keras producing a rather large features CSV. From there, we’ll apply incremental learning with Creme.
我们今天将在这里使用的数据集是 Kaggle 的狗对猫数据集。
数据集包括 25,000 个均匀分布的示例:
- 狗:12500 张图片
- 猫:12500 张图片
我们的目标是将迁移学习应用于:
- 使用 Keras 和预训练的 CNN 从数据集中提取要素。
- 通过 Creme 使用在线/增量学习,以增量方式在特征之上训练分类器。
设置您的 Creme 环境
虽然 Creme 需要一个简单的 pip 安装,但是对于今天的例子,我们还需要安装一些其他的包。当今必需的产品包包括:
要针对本教程配置您的系统,我建议您遵循以下任一教程:
这两个教程都将帮助您在一个方便的 Python 虚拟环境中,用这篇博文所需的所有软件来配置您的系统。请注意 PyImageSearch 不推荐也不支持 CV/DL 项目的窗口。
从那里,安装 Creme:
$ workon dl4cv
$ pip install creme
让我们通过启动一个 Python 解释器来确保一切都已正确安装:
$ workon cv
$ python
>>> import cv2
>>> import imutils
>>> import sklearn
>>> import tensorflow
>>> import creme
>>>
如果没有错误,您的环境就可以进行增量学习了。
项目结构
Figure 4: Download train.zip from the Kaggle Dogs vs. Cats downloads page for this incremental learning with Creme project.
要设置您的项目,请遵循以下步骤:
- 使用这篇博文的 “下载” 部分,按照说明下载代码。
- 将代码下载到系统中的某个地方。例如,您可以将它下载到您的
~/Desktop或~/Downloads文件夹中。 - 打开一个终端,
cd进入压缩文件调整的同一个文件夹。通过unzip keras-creme-incremental-learning.zip解压/解压文件。让你的终端开着。 - 登录 Kaggle ( 下载数据需要 )。
- 前往 Kaggle 狗狗大战猫 【数据】页面。
- 点击 旁边的小下载按钮只下载 的 train.zip 文件。将其保存到
~/Desktop/keras-creme-incremental-learning/(或您提取博文文件的任何地方)。 - 回到您的终端,通过
unzip train.zip提取数据集。
现在让我们回顾一下我们的项目结构:
$ tree --dirsfirst --filelimit 10
.
├── train [25000 entries]
├── train.zip
├── features.csv
├── extract_features.py
└── train_incremental.py
1 directory, 4 files
您应该会看到一个包含 25,000 个文件的train/目录。这是你真正的狗和猫的图像所在的地方。让我们列举几个例子:
$ ls train | sort -R | head -n 10
dog.271.jpg
cat.5399.jpg
dog.3501.jpg
dog.5453.jpg
cat.7122.jpg
cat.2018.jpg
cat.2298.jpg
dog.3439.jpg
dog.1532.jpg
cat.1742.jpg
如您所见,类标签(或者“猫”或者“狗”)包含在文件名的前几个字符中。我们稍后将解析出类名。
回到我们的项目树,train/目录下是train.zip和features.csv。这些文件是 而不是 包含在 【下载】 中。你应该已经从 Kaggle 的网站下载并提取了train.zip。我们将在下一节学习如何提取特征并生成大的 12GB+ features.csv文件。
我们将要讨论的两个 Python 脚本是extract_features.py和train_incremental.py。让我们从用 Keras 提取特征开始!
使用 Keras 提取特征
在我们可以执行增量学习之前,我们首先需要执行迁移学习和从我们的狗对猫数据集提取特征。
为了完成这项任务,我们将使用 Keras 深度学习库和 ResNet50 网络(预先在 ImageNet 上进行了培训)。使用 ResNet50,我们将允许我们的图像向前传播到预先指定的层。
然后,我们将获取该层的输出激活,并将它们视为一个特征向量。一旦我们有了数据集中所有图像的特征向量,我们将应用增量学习。
*让我们开始吧。
打开extract_features.py文件并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet50 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from imutils import paths
import numpy as np
import argparse
import pickle
import random
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-c", "--csv", required=True,
help="path to output CSV file")
ap.add_argument("-b", "--batch-size", type=int, default=32,
help="batch size for the network")
args = vars(ap.parse_args())
在第 2-12 行,提取特征所需的所有包都被导入。最值得注意的是这包括ResNet50。 ResNet50 是我们用于迁移学习的卷积神经网络(CNN)(Line 3)。
--dataset:我们的输入数据集的路径(即狗对猫)。--csv:输出 CSV 文件的文件路径。--batch-size:默认情况下,我们将使用批量大小32。这将容纳大多数 CPU 和 GPU。
让我们继续加载我们的模型:
# load the ResNet50 network and store the batch size in a convenience
# variable
print("[INFO] loading network...")
model = ResNet50(weights="imagenet", include_top=False)
bs = args["batch_size"]
在第 27 行的上,我们加载model,同时指定两个参数:
weights="imagenet":加载预训练的 ImageNet 权重用于迁移学习。include_top=False:我们不包括 softmax 分类器的全连接头。换句话说,我们砍掉了网络的头。
**加载了重量,加载了没有头部的模型,我们现在可以进行迁移学习了。我们将直接使用网络的输出值,将结果存储为特征向量。
我们的每个特征向量将是 100,352 维(即7×7×2048,这是没有 FC 层报头的 ResNet50 的输出体积的尺寸)。
从这里,让我们拿起imagePaths并提取我们的标签:
# grab all image paths in the input directory and randomly shuffle
# the paths
imagePaths = list(paths.list_images(args["dataset"]))
random.seed(42)
random.shuffle(imagePaths)
# extract the class labels from the image paths, then encode the
# labels
labels = [p.split(os.path.sep)[-1].split(".")[0] for p in imagePaths]
le = LabelEncoder()
labels = le.fit_transform(labels)
在第 32-34 行的上,我们继续抓取所有imagePaths并随机洗牌。
从那里,我们的类labels被从路径本身中提取出来(第 38 行)。每个图像路径的格式为:
train/cat.0.jpgtrain/dog.0.jpg- 等。
在 Python 解释器中,我们可以测试第 38 行的完整性。随着您开发解析+列表理解,您的解释器可能如下所示:
$ python
>>> import os
>>> label = "train/cat.0.jpg".split(os.path.sep)[-1].split(".")[0]
>>> label
'cat'
>>> imagePaths = ["train/cat.0.jpg", "train/dog.0.jpg", "train/dog.1.jpg"]
>>> labels = [p.split(os.path.sep)[-1].split(".")[0] for p in imagePaths]
>>> labels
['cat', 'dog', 'dog']
>>>
第 39 行和第 40 行然后实例化并安装我们的标签编码器,确保我们可以将字符串类标签转换为整数。
让我们定义 CSV 列并将它们写入文件:
# define our set of columns
cols = ["feat_{}".format(i) for i in range(0, 7 * 7 * 2048)]
cols = ["class"] + cols
# open the CSV file for writing and write the columns names to the
# file
csv = open(args["csv"], "w")
csv.write("{}\n".format(",".join(cols)))
我们将把提取的特征写入一个 CSV 文件。
Creme 库要求 CSV 文件有一个标题,并包含每个列的名称,即:
- 类别标签的列名
- 每个功能的名称
第 43 行为每个 7 x 7 x 2048 = 100,352 特征创建列名,而第 44 行定义类名列(将存储类标签)。
因此,我们的 CSV 文件的前五行和十列将如下所示:
$ head -n 5 features.csv | cut -d ',' -f 1-10
class,feat_0,feat_1,feat_2,feat_3,feat_4,feat_5,feat_6,feat_7,feat_8
1,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
1,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
注意class是第一列。然后这些列从feat_0一直延伸到feat_100351,总共有 100,352 个特征。如果您编辑该命令以打印 10 列以上——比方说 5000 列——那么您会看到并非所有的值都是 0。
接下来,让我们分批循环查看图像:
# loop over the images in batches
for (b, i) in enumerate(range(0, len(imagePaths), bs)):
# extract the batch of images and labels, then initialize the
# list of actual images that will be passed through the network
# for feature extraction
print("[INFO] processing batch {}/{}".format(b + 1,
int(np.ceil(len(imagePaths) / float(bs)))))
batchPaths = imagePaths[i:i + bs]
batchLabels = labels[i:i + bs]
batchImages = []
我们将以bs ( 线 52 )的批量循环imagePaths。
第 58 和 59 行然后抓取该批路径和标签,而第 60 行初始化一个列表来保存该批图像。
让我们遍历当前批处理:
# loop over the images and labels in the current batch
for imagePath in batchPaths:
# load the input image using the Keras helper utility while
# ensuring the image is resized to 224x224 pixels
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
# preprocess the image by (1) expanding the dimensions and
# (2) subtracting the mean RGB pixel intensity from the
# ImageNet dataset
image = np.expand_dims(image, axis=0)
image = imagenet_utils.preprocess_input(image)
# add the image to the batch
batchImages.append(image)
循环遍历批处理中的路径(行 63 ,我们将加载每个image,对其进行预处理,并将其聚集到batchImages。image本身装载在线 66 上。
我们将通过以下方式对图像进行预处理:
- 通过行 66 上的
target_size参数调整到 224×224 像素。 - 转换成数组格式(第 67 行)。
- 添加批次尺寸(行 72 )。
- 执行均值减法(第 73 行)。
注:如果这些预处理步骤出现在国外,请参考用 Python 进行计算机视觉的深度学习我在那里详细讲述。
最后,通过线 76 将image添加到批次中。
为了提取特征,我们现在将通过我们的网络传递这批图像:
# pass the images through the network and use the outputs as our
# actual features, then reshape the features into a flattened
# volume
batchImages = np.vstack(batchImages)
features = model.predict(batchImages, batch_size=bs)
features = features.reshape((features.shape[0], 7 * 7 * 2048))
# loop over the class labels and extracted features
for (label, vec) in zip(batchLabels, features):
# construct a row that consists of the class label and extracted
# features
vec = ",".join([str(v) for v in vec])
csv.write("{},{}\n".format(label, vec))
# close the CSV file
csv.close()
我们的一批图像经由线 81 和 82 通过网络发送。
请记住,我们已经删除了网络的全连接头层。相反,正向传播在平均池层之前停止。我们将把这一层的输出视为一个列表features,也称为“特征向量”。
卷的输出维度为 (batch_size,7 x 7 x,2048) 。因此,我们可以将features转换成一个形状为(batch_size, 7 * 7 * 2048)、、的 NumPy 数组,将 CNN 的输出视为一个特征向量。
为了保持我们的批处理效率,features和相关的类标签被写入我们的 CSV 文件(第 86-90 行)。
在 CSV 文件中,类label是每一行中的第一个字段(使我们能够在训练期间轻松地从该行中提取它)。特征vec如下。
特征 CSV 文件通过第 93 行的关闭,这是我们脚本的最后一步。
使用 Keras 进行特征提取
现在我们已经编码了extract_features.py,让我们将它应用到我们的数据集。
确保你有:
- 使用本教程的 【下载】 部分下载源代码。
- 从 Kaggle 的网站下载了狗与猫的数据集。
打开终端并执行以下命令:
$ python extract_features.py --dataset train --csv features.csv
Using TensorFlow backend.
[INFO] loading network...
[INFO] processing batch 1/782
[INFO] processing batch 2/782
[INFO] processing batch 3/782
...
[INFO] processing batch 780/782
[INFO] processing batch 781/782
[INFO] processing batch 782/782
使用 NVIDIA K80 GPU,整个特征提取过程花费了20 分 45 秒。
你也可以使用你的 CPU,但是记住特征提取过程将花费更长的时间。
在您的脚本完成运行后,看看features.csv的输出大小:
$ ls -lh features.csv
-rw-rw-r-- 1 ubuntu ubuntu 12G Jun 10 11:16 features.csv
生成的文件超过 12GB!
如果我们将该文件加载到 RAM 中,假设特征向量为 32 位浮点数, 我们将需要 10.03GB!
你的机器可能有也可能没有那么多内存…但这不是重点。最终,您会遇到一个太大的数据集,无法在主存中处理。到时候,你需要使用增量学习。
使用 Creme 的增量学习
如果您正在学习本教程,那么我将假设您已经使用 Keras 和 ResNet50(在 ImageNet 上进行了预训练)从狗和猫的数据集中提取了特征。
但是现在呢?
我们假设提取的特征向量的整个数据集太大,不适合内存— 我们如何在这些数据上训练机器学习分类器?
打开train_incremental.py文件,让我们看看:
# import the necessary packages
from creme.linear_model import LogisticRegression
from creme.multiclass import OneVsRestClassifier
from creme.preprocessing import StandardScaler
from creme.compose import Pipeline
from creme.metrics import Accuracy
from creme import stream
import argparse
第 2-8 行导入使用 Creme 进行增量学习所需的包。我们将利用 Creme 对LogisticRegression的实现。Creme 的stream模块包括一个超级方便的 CSV 数据生成器。在整个培训过程中,我们将使用 Creme 内置的metrics工具计算并打印出当前的Accuracy。
现在让我们使用 argparse 来解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--csv", required=True,
help="path to features CSV file")
ap.add_argument("-n", "--cols", type=int, required=True,
help="# of feature columns in the CSV file (excluding class column")
args = vars(ap.parse_args())
我们的两个命令行参数包括:
--csv:输入 CSV 特征文件的路径。--cols:我们的特征向量的维数(即我们的特征向量有多少列)。
现在我们已经解析了我们的命令行参数,我们需要指定 CSV 文件的数据类型来正确使用 Creme 的stream模块:
# construct our data dictionary which maps the data types of the
# columns in the CSV file to built-in data types
print("[INFO] building column names...")
types = {"feat_{}".format(i): float for i in range(0, args["cols"])}
types["class"] = int
第 21 行为 CSV 的每个特性列构建了一个数据类型(浮点)列表。我们将有 100,352 辆车。
类似地,第 22 行指定我们的class列是整数类型。
接下来,让我们初始化数据生成器并构建管道:
# create a CSV data generator for the extracted Keras features
dataset = stream.iter_csv(args["csv"], target="class", converters=types)
# construct our pipeline
model = Pipeline([
("scale", StandardScaler()),
("learn", OneVsRestClassifier(classifier=LogisticRegression()))
])
第 25 行创建一个 CSV 迭代器,它将stream特征+类标签添加到我们的模型中。
第 28-31 行然后构建模型管道,它:
- 首先执行标准缩放(缩放数据以使平均值和单位方差为零)。
- 然后以增量方式(一次一个数据点)训练我们的逻辑回归模型。
逻辑回归是一个二元分类器,这意味着它只能用于预测两个类别(这正是狗和猫的数据集)。
然而,如果您想让识别 > 2 类,您需要将LogisticRegression包装在一个OneVsRestClassifier中,它适合每个类一个二元分类器。
*让我们使用 Creme 来训练我们的模型:
# initialize our metric
print("[INFO] starting training...")
metric = Accuracy()
# loop over the dataset
for (i, (X, y)) in enumerate(dataset):
# make predictions on the current set of features, train the
# model on the features, and then update our metric
preds = model.predict_one(X)
model = model.fit_one(X, y)
metric = metric.update(y, preds)
print("INFO] update {} - {}".format(i, metric))
# show the accuracy of the model
print("[INFO] final - {}".format(metric))
第 35 行初始化我们的metric(即精度)。
从那里,我们开始循环我们的数据集(行 38 )。在循环内部,我们:
- 对当前数据点进行预测(行 41 )。有 25,000 个数据点(图像),所以这个循环将运行那么多次。
- 基于预测更新
model权重(第 42 行)。 - 更新并显示我们的精确度
metric( 第 43 和 44 行)。
最后,模型的精度显示在终端(行 47 )。
增量学习结果
我们现在准备使用 Keras 和 Creme 应用增量学习。确保你有:
- 使用本教程的 【下载】 部分下载源代码。
- 从 Kaggle 的网站下载了狗与猫的数据集。
从那里,打开一个终端并执行以下命令:
$ python train_incremental.py --csv features.csv --cols 100352
[INFO] building column names...
[INFO] starting training...
[INFO] update 0 - Accuracy: 0.00%
[INFO] update 1 - Accuracy: 0.00%
[INFO] update 2 - Accuracy: 33.33%
[INFO] update 3 - Accuracy: 50.00%
[INFO] update 4 - Accuracy: 60.00%
[INFO] update 5 - Accuracy: 66.67%
[INFO] update 6 - Accuracy: 71.43%
[INFO] update 7 - Accuracy: 62.50%
[INFO] update 8 - Accuracy: 66.67%
[INFO] update 9 - Accuracy: 70.00%
[INFO] update 10 - Accuracy: 72.73%
[INFO] update 11 - Accuracy: 75.00%
[INFO] update 12 - Accuracy: 76.92%
[INFO] update 13 - Accuracy: 78.57%
[INFO] update 14 - Accuracy: 73.33%
[INFO] update 15 - Accuracy: 75.00%
[INFO] update 16 - Accuracy: 76.47%
[INFO] update 17 - Accuracy: 77.78%
[INFO] update 18 - Accuracy: 78.95%
[INFO] update 19 - Accuracy: 80.00%
[INFO] update 20 - Accuracy: 80.95%
[INFO] update 21 - Accuracy: 81.82%
...
[INFO] update 24980 - Accuracy: 97.61%
[INFO] update 24981 - Accuracy: 97.61%
[INFO] update 24982 - Accuracy: 97.61%
[INFO] update 24983 - Accuracy: 97.61%
[INFO] update 24984 - Accuracy: 97.61%
[INFO] update 24985 - Accuracy: 97.61%
[INFO] update 24986 - Accuracy: 97.61%
[INFO] update 24987 - Accuracy: 97.61%
[INFO] update 24988 - Accuracy: 97.61%
[INFO] update 24989 - Accuracy: 97.61%
[INFO] update 24990 - Accuracy: 97.61%
[INFO] update 24991 - Accuracy: 97.60%
[INFO] update 24992 - Accuracy: 97.60%
[INFO] update 24993 - Accuracy: 97.60%
[INFO] update 24994 - Accuracy: 97.60%
[INFO] update 24995 - Accuracy: 97.60%
[INFO] update 24996 - Accuracy: 97.60%
[INFO] update 24997 - Accuracy: 97.60%
[INFO] update 24998 - Accuracy: 97.60%
[INFO] update 24999 - Accuracy: 97.60%
[INFO] final - Accuracy: 97.60%
仅在 21 个样本之后,我们的逻辑回归模型获得了 81.82%的准确度。
让模型在所有 25,000 个样本上训练,我们达到了 97.6% 的准确度,这是相当可观的。这个过程在我的系统上花费了 6hr48m 的时间。
同样,这里的关键点是,我们的逻辑回归模型是以一种增量方式训练的——我们被而不是要求一次将整个数据集存储在内存中。相反,我们可以一次一个样本地训练我们的逻辑回归分类器。
摘要
在本教程中,您学习了如何使用 Keras 和 Creme 机器学习库执行在线/增量学习。
使用在 ImageNet 上预先训练的 Keras 和 ResNet50,我们应用迁移学习从狗与猫数据集提取特征。
在狗和猫的数据集中,我们总共有 25,000 张图片。ResNet50 的输出音量为 7 x 7 x 2048 = 100,352-dim。假设我们的 100,352 维特征向量为 32 位浮点,这意味着试图一次在内存中存储整个数据集将需要 10.03GB 的 RAM。
并非所有机器学习从业者的机器上都有那么多内存。
更重要的是——**即使你有足够的内存来存储这个数据集,你最终也会遇到一个超过你机器物理内存的数据集。****
*当这种情况出现时,你应该应用在线/增量学习。
使用 Creme 库,我们一次训练一个多类逻辑回归分类器,使我们能够在狗对猫数据集上获得 97.6%的准确度 。
我希望你喜欢今天的教程!
在需要在线/增量学习的地方,可以随意使用这篇博文中的代码作为自己项目的起点。
要下载这篇文章的源代码,并在 PyImageSearch 上发布未来教程时得到通知,*只需在下面的表格中输入您的电子邮件地址!******
OpenCV 3.0 发布——以及 PyImageSearch 博客即将发生的变化。
已经过去很久了,但是 OpenCV 3.0 终于发布了!
这次更新绝对是近年来对该库进行的最大范围的检修之一,并且拥有更高的稳定性、性能提升和 OpenCL 支持。
但是到目前为止,Python 世界中最激动人心的更新是:
Python 3 支持!
在 Python 2.7 中困了多年, 我们现在终于可以在 Python 3.0 中使用 OpenCV 了! 确实劲爆的消息!
所以你可能会问“这对 PyImageSearch 意味着什么?”
我们是不是马上放弃 OpenCV 2.4.X,转到 OpenCV 3.0?Python 2.7 正式结束了吗?
简而言之就是 没有 。
OpenCV 3.0 的发布是一个令人振奋的消息,但对于计算机视觉社区来说,这也是一个 T2 的过渡期。我们中的一些人将依赖于以前的 OpenCV 2.4.X 版本。其他人会争先恐后地获取最新的 3.0 版本。也许我们中的其他人不会真的关心我们使用的是什么版本,只要我们的代码按预期执行和运行。
由于这些各种各样的原因,我将继续编写与OpenCV 2.4 . x 和 OpenCV 3.0 相关的内容。
*我认为现在放弃在 OpenCV 2.4.X 上写内容将是一个巨大的错误。它比较老。更成立。而且用的更广。
然而,在 OpenCV 3.0 成熟并发布几个小版本之前忽视它将是一个同样巨大的错误。OpenCV 3.0 确实是未来——我们需要这样对待它。
正因为如此,我想出了以下计划:
我们将混合使用 OpenCV 2.4.X 和 OpenCV 3.0。
OpenCV 3.0 是全新的。它闪闪发光。很性感。我们肯定会拿掉包装纸,找点乐子。
但是我们仍然会在 OpenCV 2.4.X 中做大量的教程。记住,OpenCV 2.4.X 仍然是计算机视觉和图像处理的事实上的库,并且将继续如此,直到 v3.0 稍微成熟一点并获得实质性的采用率。**
所有新的博客帖子都将标上 OpenCV + Python 版本。
PyImageSearch 上发布的所有新文章、教程和博客帖子都将包括假定的 OpenCV 版本 和 Python 版本 ,以确保您知道我们使用的是哪种开发环境。
你也可以期待一些 OpenCV 3.0 在各种平台上的安装教程即将推出。
所有旧的博客帖子也将标上 OpenCV + Python 版本。
就像所有的新帖子将列出 OpenCV 和 Python 的假定版本一样,我也将回去更新所有的旧博客帖子,以包括 OpenCV 和 Python 的必需版本。
这种改变不会在一夜之间发生,但我会每周更新几篇旧文章。
更新后的帖子将包括这样一个部分:

Figure 1: All blog posts on PyImageSearch will include a section that explicitly defines which Python and OpenCV versions are being used.
那么实用 Python 和 OpenCV +案例分析呢?
你可能想知道我的书, 实用 Python 和 OpenCV +案例分析 —它们会更新到 OpenCV 3.0 吗?
答案是肯定的,实用 Python 和 OpenCV +案例分析绝对会更新到覆盖 OpenCV 3.0。
我已经从书中找到了示例代码,并且正在更新代码示例。
这本书的第一次更新将包括修订后的源代码,供那些希望使用 Python 3 和 OpenCV 3.0 运行所提供的示例的人使用。
第二次更新会将书中的实际代码解释转移到 OpenCV 3.0。
我很可能会提供《T2》《T3》的 2.4.X 和 3.0 版本。
**不管怎样,OpenCV 的更新绝对不会损害实用 Python 和 OpenCV +案例研究的完整性。**如果你想在 OpenCV 上快速上手,一定要考虑 购买一个副本 。正如我在上面承诺的,这本书也将更新到 OpenCV 3.0。
*## T2 将会有一个过渡期。
正如我在上面提到的,我们将混合 OpenCV 2.4.X 和 OpenCV 3.0 的文章和教程。
开始时,大多数教程将使用 2.4.X 版本。
但是随着 OpenCV 3.0 的成熟,我们将随着它的成熟而开始引入越来越多的 3.0 教程。
过渡期到底需要多长时间?
很难确定过渡期的确切时间,因为它取决于多种因素:
-
这取决于开发人员和程序员是否愿意更新到 OpenCV 的新版本,以及是否愿意冒破坏遗留代码的风险(根据我最初的测试,这种风险非常高)。
-
要看 OpenCV 3.0 教程的实际需求。
-
这取决于你的反馈
我的 猜测 是,我们可能需要 6-12 个月才能在 PyImageSearch 上定期使用 OpenCV 3.0,但谁知道呢——我的估计可能会相差很远。它可以更短。可能会更久。
实际上,我的直觉告诉我,在 3.1 发布之前,我们不会完全过渡。请记住,PyImageSearch 是一个教学博客,因此所有代码示例都像宣传的那样工作非常重要。
不管怎样,我对你们的承诺是,随着 OpenCV 的发展,我将发展 PyImageSearch 博客——我们将继续确保 PyImageSearch 是进入网站学习计算机视觉+ OpenCV 的。
如果有的话,你将看到的唯一真正的变化是我发了更多的帖子。
我认为你在 PyImageSearch 博客上看到的唯一大变化可能是更多的博客文章。
每周一我都会继续发表本周的 大 博文。然后你可能会在本周晚些时候看到另一篇简短的博客文章,详细介绍了 OpenCV 3.0 的一个特殊警告。正如我所说的,这将是一个过渡期,每篇发布的帖子将详细描述假定的 Python 和 OpenCV 版本。
那么你认为呢?
你喜欢这个计划吗?讨厌这个计划?
留下你的评论或给我发一条消息——你的输入和回应让这个博客成为可能!**
OpenCV 3 采用率
原文:https://pyimagesearch.com/2015/11/23/opencv-3-adoption-rate/
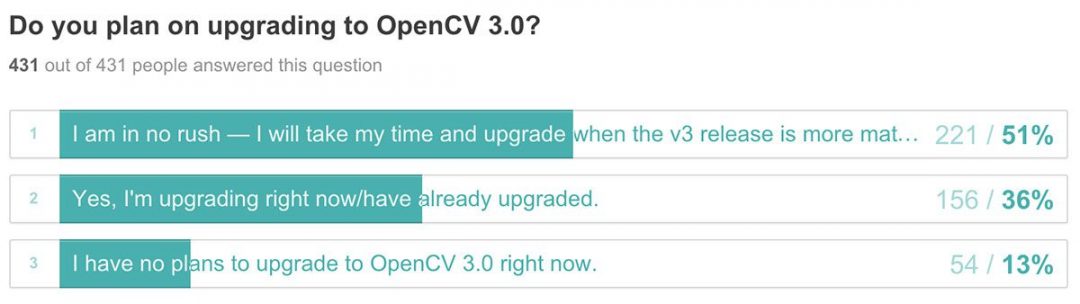
众所周知,OpenCV 3.0 是在 2015 年 6 月正式发布的。这次新的更新包含了大量的新特性和优化,包括 Python 3 绑定。
但大家心头的大问题是: “我该不该转 OpenCV 3?如果是,我应该什么时候切换?”
决定何时甚至是否应该切换到 OpenCV 3 不一定是最容易的决定,尤其是 (1)如果你正在将 OpenCV 部署到生产环境中,或者(2)你正在计算机视觉领域进行研究。
为了帮助回答你是否应该转换到 OpenCV 3(以及“什么时候”你应该转换),我给 PyImageSearch 的一部分读者发了电子邮件,请他们做一个关于 OpenCV 使用的四个问题的快速调查。
结果很有见地——但在我分享我的主要观点之前,我会让你从这些结果中得出自己的结论。
OpenCV 3 采用率
几个月前,我给一些最活跃的 PyImageSearch 读者发了电子邮件,请他们回答一个简短的关于 OpenCV 使用的 4 个问题的调查。我收到了 431 份答复,这些答复是我今天收集在这里的。对于大多数问题,读者可以为适用于他们的每个答案选择多个答案。
问题 1:你目前使用的是哪个版本的 OpenCV?
- OpenCV 2.4.X
- OpenCV 3.0(包括测试版、RC 版和正式版)
- 其他的
这个问题的目的仅仅是建立一个大多数人使用 OpenCV 版本的基线。不出所料,OpenCV 2.4.X 优于 OpenCV 3.0:
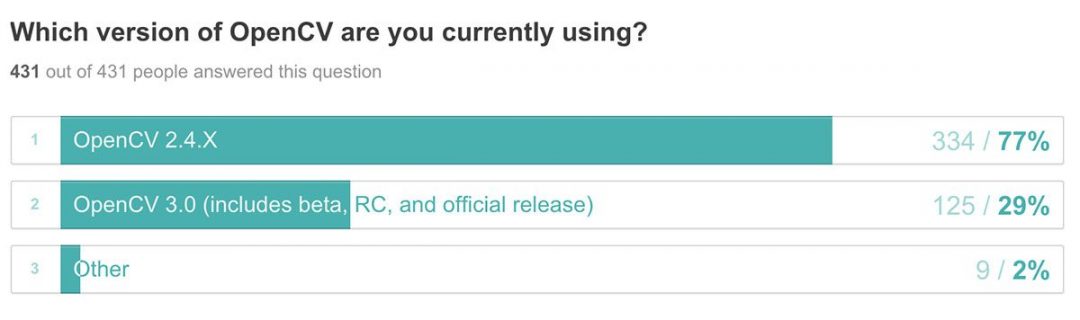
Figure 1: OpenCV 2.4.X is currently being used over 2.65x more than OpenCV 3
毫不奇怪,大多数人仍然在使用 OpenCV 2.4.X。然而,29%的开发人员、研究人员和程序员已经开始在某种程度上使用 OpenCV 3.0。对于一个全新的主版本的库来说,在短短几个月内达到 29%的使用率是非常了不起的。
这种采用趋势会持续下去吗?
是的,我相信会的。然而,我认为我们还需要一年时间才能看到 OpenCV 3.0 达到 50%的采用率,与 OpenCV 2.4.X 持平。
这主要是因为 OpenCV 2.4 的 仍然是计算机视觉开发事实上的标准 。OpenCV 2.4 出现的时间更长。更稳定。它应用了更多的漏洞补丁。目前,它已被部署到世界各地的生产环境和研究实验室中,在这些地方,交换的成本是不小的,而且可能相当昂贵。
比如随着 OpenCV 3 的发布,cv2.findContours等常用函数有不同于 OpenCV 2.4 的返回签名。cv2.normalize函数签名也发生了变化。默认情况下 OpenCV 3 中不再包含 SIFT 和 SURF】,需要我们安装opencv_contrib包。
这些变化是“交易破坏者”吗?
绝对不行。但是对于大型代码库来说,切换的成本是不小的,特别是因为这只是 OpenCV 的 v3.0 版本,随着版本的成熟,可能会有更多的变化。
问题 2:你目前使用的是哪个版本的 Python?
- Python 2.7+版本
- Python 3+
- 其他的
结果如下:
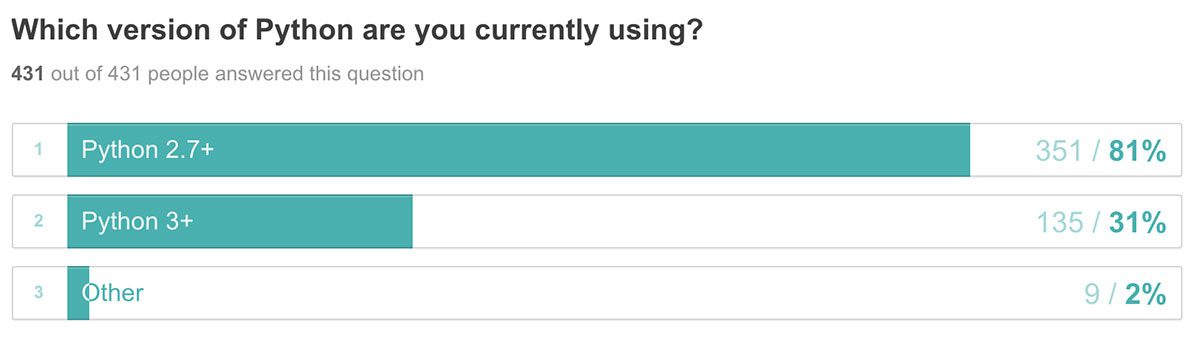
Figure 2: Python 2.7 is currently favored over Python 3 for computer vision development.
Python 2.7 的使用率是 Python 3 的 2.6 倍,这一事实并不令人惊讶。首先,Python 科学界不愿意切换到 Python 3——尽管现在这种情况正在迅速改变,因为 NumPy 、 SciPy 、 scikit-learn ,以及令人敬畏的 2to3 工具为 Python 3 的采用铺平了道路。
其次,OpenCV 2.4.X 是 唯一兼容 Python 2.7 的。直到 OpenCV 3.0 发布,我们才获得 Python 3 支持。
简单地说:如果你在 2015 年 6 月之前用 OpenCV 做任何开发,你肯定是在用 Python 2.7(T3)做 T2。
事实上,看到 OpenCV 用户已经达到 31%的 Python 3 使用率是相当令人惊讶的!我猜想使用 Python 3 的计算机视觉开发人员的比例会低得多。但是话又说回来,您很可能正在从事与计算机视觉无关的其他项目,这些项目中的库与 Python 3 兼容。
综上所述,考虑到 OpenCV 3 和 Python 3+的集成,我完全预计这个数字会在明年上升。
问题 3:你在什么类型的“设置”中使用 OpenCV?
- 家庭/爱好
- 学术的
- 科学的
- 生产
- 其他的
同样,用户可以选择所有适用的答案。下面你可以看到结果:
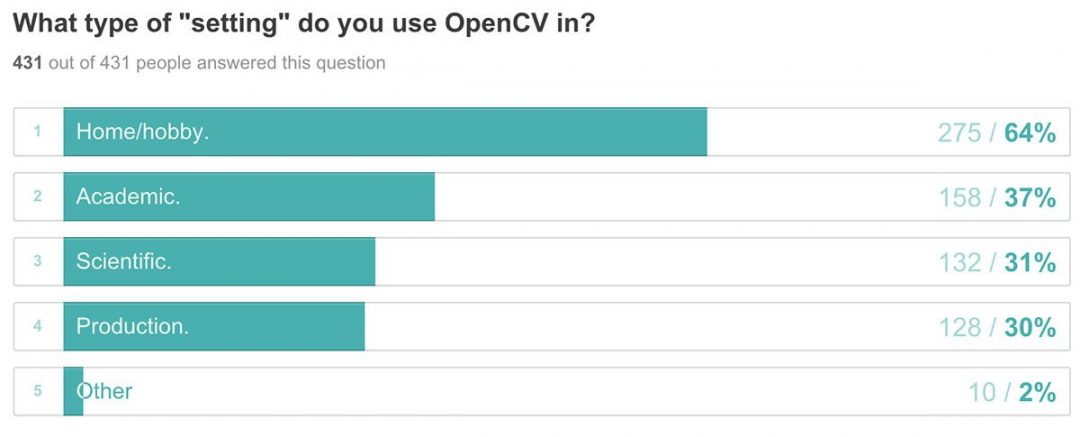
Figure 3: Interestingly, of the 431 respondents, most developers are using OpenCV 3 in the “home/hobby” setting.
需要注意的是,这些答案并不相互排斥。仅仅因为你可能在做学术或科学研究,并不意味着你不能在一天结束后回家做你的业余爱好计算机视觉项目(事实上,我愿意做我们很多人都在做的事情)。
同样,“学术”和“科学”也有很多重叠的地方。如果你在大学里写作和发表论文,那么你肯定会在学术环境中使用 OpenCV。但是你也在进行 T2 科学研究。
然而,如果你正在建造一个最先进的计算机视觉产品,那么你是在生产环境中进行科学研究,但是这个研究不一定是学术。
我个人认为 OpenCV 3 对这些数字影响不大。
家庭和业余爱好用户将更有可能玩 OpenCV 并尝试一下,尤其是当他们访问 OpenCV.org 网站并看到 OpenCV 3.0 是最新的稳定版本时。
但是在生产、科学或学术环境中,考虑到遗留代码和其他依赖性,从 OpenCV 2.4 转换到 OpenCV 3 的成本要高得多。此外,如果你正在做科学/学术研究,你可能依赖OpenCV 2.4 来运行与各种实验相关的遗留代码。
问题 4:你计划升级到 OpenCV 3.0 吗?
- 我不着急——我会慢慢来,等 v3 版本更成熟时再升级。
- 是的,我正在升级/已经升级了。
- 我现在没有升级到 OpenCV 3.0 的计划。
对于这个问题,读者只能选择 一个 的答案。
Figure 4: Most OpenCV users are waiting for OpenCV 3.0 to mature a bit.
我个人对这个问题的回答并不太惊讶。OpenCV 是一个有着悠久历史的大而成熟的库。推出新版本需要一段时间,尤其是主要版本。事实上,自从 v2.0 发布以来,大约已经有 6 年 了。而 3 年 在 v2.3 和 v2.4 之间——说一说发布之间的长时间!
鉴于库的新版本需要一段时间才能发布,采用率也有点慢是有道理的。我们都好奇新版本,但我们可能不会完全采用最新版本,直到我们(1)有时间/资源更新我们的旧代码库,或者(2)我们开始一个新项目,可以从零开始而不用担心依赖性。
我的外卖
如果要我用一句话来总结我的观点,那就是:
不要因为切换到 OpenCV 3.0 而紧张。
如果你从零开始: 如果你开始一个全新的项目,在那里你不必担心依赖关系和遗留代码, 切换到 OpenCV 3.0 没有坏处。事实上,在这种特殊的情况下, 我会鼓励你使用 OpenCV 3 ,因为你会提高采用率并推动库向前发展。请记住库将会进化,如果你现在想使用 OpenCV 3.0 ,你可能需要在 OpenCV 3.1 发布后更新你的代码。
如果你有一个现有的 OpenCV 项目: 除非 OpenCV 3 中有 2.4.X 中没有的新特性,或者你绝对必须有 Python 3 支持,否则迁移你的整个代码库可能还为时过早。在我看来,OpenCV 3.0 在很大程度上仍处于起步阶段:仍有问题需要解决,仍有缺陷需要修复。我会考虑等到 v3.1 甚至 v3.2 发布后,再认真考虑做出大的改变。
如果你在学术、科学或生产环境中: 我会建议不要在这个时候做出改变,只要你有一个现有的实验代码库。正如我之前提到的,OpenCV 2.4.X 仍然是计算机视觉开发的事实上的标准。2.4 版本更加成熟和稳定。通过坚持使用 2.4 版本直到 v3 成熟,您可以省去很多麻烦。
阿德里安在做什么?
就我个人而言,我的笔记本电脑上同时安装了 OpenCV 2.4 和 OpenCV 3。我每天都使用这两个版本,主要是为了适应 OpenCV 3 环境(更不用说使用 Python 3 了),并帮助解答与版本差异相关的任何问题。但是我仍然在我的所有生产环境中使用 OpenCV 2.4。最终,我会完全切换到 OpenCV 3——但我不认为这实际上会发生在 v3.1 或 v3.2 版本上。
摘要
最近,我向最活跃的 PyImageSearch 读者发出了一份调查,询问他们是否计划转向 OpenCV 3。我收到了 431 份调查反馈,并在这篇博文中展示了调查结果。
总的来说,大多数读者并不急于切换到 OpenCV 3。
虽然我可以回报这种感觉,但我每天都使用 OpenCV 2.4 和 3.0。如果您在家庭/业余爱好环境中使用 OpenCV,无论如何,请升级到 OpenCV 3 并使用它。但是如果你在生产、学术或科学环境中,我会考虑等到 v3 版本稍微成熟一点。一个主要的例外是,如果你正在开始一个的全新项目,在那里你没有任何依赖或遗留代码——在这种情况下,我会鼓励你使用 OpenCV 3。
具有深度学习的 OpenCV 年龄检测
原文:https://pyimagesearch.com/2020/04/13/opencv-age-detection-with-deep-learning/
在本教程中,您将学习如何使用 OpenCV、深度学习和 Python 来执行自动年龄检测/预测。
在本教程结束时,你将能够以相当高的准确度自动预测静态图像文件和实时视频流的年龄。
要了解如何使用 OpenCV 和深度学习进行年龄检测,继续阅读!
具有深度学习的 OpenCV 年龄检测
在本教程的第一部分,您将了解年龄检测,包括从图像或视频流中自动预测一个人的年龄所需的步骤(以及为什么年龄检测最好被视为一个分类问题,而不是一个回归问题)。
在此基础上,我们将讨论我们基于深度学习的年龄检测模型,然后学习如何将该模型用于以下两个方面:
- 静态图像中的年龄检测
- 实时视频流中的年龄检测
然后我们将回顾我们的年龄预测工作的结果。
什么是年龄检测?

Figure 1: In this tutorial, we use OpenCV and a pre-trained deep learning model to predict the age of a given face (image source).
年龄检测是指自动从一张人脸照片中单独识别一个人年龄的过程。
通常,您会看到年龄检测实施为两个阶段的过程:
- 阶段#1: 检测输入图像/视频流中的人脸
- 阶段#2: 提取脸部感兴趣区域(ROI),并应用年龄检测器算法来预测人的年龄
对于阶段#1,可以使用能够为图像中的人脸产生边界框的任何人脸检测器,包括但不限于哈尔级联、HOG +线性 SVM、单镜头检测器(SSDs)等。
具体使用哪种人脸检测器取决于您的项目:
- Haar cascades 将非常快,能够在嵌入式设备上实时运行——问题是它们不太准确,并且很容易出现假阳性检测
- HOG +线性 SVM 模型比哈尔级联更精确,但速度更慢。他们也不能容忍遮挡(即,不是整个面部都可见)或视点变化(即,面部的不同视图)
- 基于深度学习的人脸检测器是最鲁棒的,将为您提供最佳的准确性,但比哈尔级联和 HOG +线性 SVM 需要更多的计算资源
在为您的应用选择人脸检测器时,请花时间考虑您的项目要求——对于您的使用案例,速度还是精度更重要?我还建议对每个面部检测器进行一些实验,这样你就可以让实验结果来指导你的决定。
一旦您的面部检测器在图像/视频流中生成了面部的边界框坐标,您就可以进入第二阶段——识别该人的年龄。
给定边界框 (x,y)-人脸坐标,首先提取人脸 ROI,忽略图像/帧的其余部分。这样做可以让年龄检测器将单独聚焦在人脸上,而不是图像中任何其他不相关的“噪音”。
面部 ROI 然后通过模型,产生实际年龄预测。
有许多年龄检测器算法,但最流行的是基于深度学习的年龄检测器——我们将在本教程中使用这样一种基于深度学习的年龄检测器。
我们的年龄检测器深度学习模型

Figure 2: Deep learning age detection is an active area of research. In this tutorial, we use the model implemented and trained by Levi and Hassner in their 2015 paper (image source, Figure 2).
我们今天在这里使用的深度学习年龄检测器模型是由 Levi 和 Hassner 在他们 2015 年的出版物中实现和训练的, 使用卷积神经网络 进行年龄和性别分类。
在论文中,作者提出了一个简单的类似 AlexNet 的架构,它可以学习总共八个年龄段:
- 0-2
- 4-6
- 8-12
- 15-20
- 25-32
- 38-43
- 48-53
- 60-100
你会注意到这些年龄段是不连续的——这是故意这样做的,因为用于训练模型的 Adience 数据集如此定义了年龄范围(我们将在下一节了解为什么这样做)。
在这篇文章中,我们将使用一个预训练的年龄检测器模型,但如果你有兴趣学习如何从头开始训练它,请务必阅读用 Python 进行计算机视觉深度学习的,,在那里我将向你展示如何做到这一点。
为什么我们不把年龄预测当作一个回归问题?

Figure 3: Age prediction with deep learning can be framed as a regression or classification problem.
你会从上一节中注意到,我们已经将年龄离散化为“桶”,从而将年龄预测视为一个分类问题——**为什么不将其框架化为回归问题,而不是**(就像我们在房价预测教程中所做的那样)?
*从技术上讲,没有理由不能将年龄预测视为一项回归任务。甚至有一些模型就是这样做的。
问题在于,年龄预测天生就是主观的,仅仅基于外表的。
*一个 50 多岁的人,一生中从未吸烟,外出时总是涂防晒霜,并每天护理皮肤,可能会比一个 30 多岁的人看起来年轻,他每天抽一盒烟,从事体力劳动,没有防晒措施,也没有适当的皮肤护理制度。
让我们不要忘记衰老最重要的驱动因素,遗传——有些人只是比其他人更容易衰老。
例如,看看下面这张马修·派瑞(她在电视情景喜剧《老友记》中扮演钱德勒·宾)的照片,并将其与詹妮弗·安妮斯顿(她和佩里一起扮演瑞秋·格林)的照片进行比较:

Figure 4: Many celebrities and figure heads work hard to make themselves look younger. This presents a challenge for deep learning age detection with OpenCV.
你能猜到马修·派瑞(50 岁)实际上比詹妮弗·安妮斯顿(51 岁)小一岁吗?
除非你事先了解这些演员,否则我很怀疑。
但是,另一方面,你能猜到这些演员是 48-53 岁吗?
我敢打赌你可能会。
虽然人类天生就不擅长预测单一的年龄值,但我们实际上非常擅长预测年龄段。
*这当然是一个加载的例子。
詹妮弗·安妮斯顿的遗传基因近乎完美,再加上一位极具天赋的整形外科医生,她似乎永远不会衰老。
但是这也说明了我的观点——人们故意试图隐瞒他们的年龄。
如果一个人努力准确预测一个人的年龄,那么一个机器肯定也会努力。
一旦你开始将年龄预测视为一个回归问题,模型就很难准确预测代表这个人形象的单个值。
然而,如果你把它当作一个分类问题,为模型定义桶/年龄段,我们的年龄预测模型变得更容易训练,通常比单独基于回归的预测产生更高的准确性。
简单地说:将年龄预测视为分类稍微“放松”了这个问题,使它更容易解决——通常,我们不需要一个人的精确的年龄;粗略的估计就足够了。
项目结构
一定要从这篇博文的 “下载” 部分获取代码、模型和图片。提取文件后,您的项目将如下所示:
$ tree --dirsfirst
.
├── age_detector
│ ├── age_deploy.prototxt
│ └── age_net.caffemodel
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── images
│ ├── adrian.png
│ ├── neil_patrick_harris.png
│ └── samuel_l_jackson.png
├── detect_age.py
└── detect_age_video.py
3 directories, 9 files
前两个目录由我们的年龄预测器和人脸检测器组成。这些深度学习模型中的每一个都是基于咖啡的。
我已经为年龄预测提供了三张测试图片;你也可以添加自己的图片。
在本教程的剩余部分,我们将回顾两个 Python 脚本:
detect_age.py:单幅图像年龄预测detect_age_video.py:视频流中的年龄预测
这些脚本中的每一个都检测图像/帧中的人脸,然后使用 OpenCV 对它们执行年龄预测。
实现我们的 OpenCV 图像年龄检测器
让我们从使用 OpenCV 在静态图像中实现年龄检测开始。
打开项目目录中的detect_age.py文件,让我们开始工作:
# import the necessary packages
import numpy as np
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-f", "--face", required=True,
help="path to face detector model directory")
ap.add_argument("-a", "--age", required=True,
help="path to age detector model directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
为了启动我们的年龄检测器脚本,我们导入了 NumPy 和 OpenCV。我推荐使用我的 pip 安装 opencv 教程来配置你的系统。
此外,我们需要导入 Python 内置的os模块来连接我们的模型路径。
最后,我们导入 argparse 来解析命令行参数。
我们的脚本需要四个命令行参数:
--image:为年龄检测提供输入图像的路径--face:我们预训练的人脸检测器模型目录的路径--age:我们预先培训的年龄检测器型号目录--confidence:过滤弱检测的最小概率阈值
正如我们在上面了解到的,我们的年龄检测器是一个分类器,它根据预定义的桶使用一个人的面部 ROI 来预测他的年龄——我们不把这当作一个回归问题。现在让我们来定义这些年龄范围:
# define the list of age buckets our age detector will predict
AGE_BUCKETS = ["(0-2)", "(4-6)", "(8-12)", "(15-20)", "(25-32)",
"(38-43)", "(48-53)", "(60-100)"]
我们的年龄由预先训练好的年龄检测器的桶(即类别标签)来定义。我们将使用这个列表和一个相关联的索引来获取年龄桶,以便在输出图像上进行注释。
给定我们的导入、命令行参数和年龄桶,我们现在准备加载我们的两个预训练模型:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
faceNet = cv2.dnn.readNet(prototxtPath, weightsPath)
# load our serialized age detector model from disk
print("[INFO] loading age detector model...")
prototxtPath = os.path.sep.join([args["age"], "age_deploy.prototxt"])
weightsPath = os.path.sep.join([args["age"], "age_net.caffemodel"])
ageNet = cv2.dnn.readNet(prototxtPath, weightsPath)
这里,我们加载两个模型:
- 我们的人脸检测器在图像中找到并定位人脸(行 25-28 )
- 年龄分类器确定特定面部属于哪个年龄范围(行 32-34
这些模型都是用 Caffe 框架训练出来的。我将在 PyImageSearch 大师 课程中讲述如何训练 Caffe 分类器。
现在我们所有的初始化都已经完成了,让我们从磁盘加载一个图像并检测面部感兴趣区域:
# load the input image and construct an input blob for the image
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
print("[INFO] computing face detections...")
faceNet.setInput(blob)
detections = faceNet.forward()
第 37-40 行加载并预处理我们的输入--image。我们使用 OpenCV 的blobFromImage方法——请务必在我的教程中阅读更多关于 blobFromImage 的内容。
为了让在我们的图像中检测人脸,我们通过 CNN 发送blob,产生一个detections列表。现在让我们循环一下面部 ROI 检测:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the ROI of the face and then construct a blob from
# *only* the face ROI
face = image[startY:endY, startX:endX]
faceBlob = cv2.dnn.blobFromImage(face, 1.0, (227, 227),
(78.4263377603, 87.7689143744, 114.895847746),
swapRB=False)
当我们在detections上循环时,我们过滤掉弱的confidence面(线 51-55 )。
对于满足最低置信度标准的人脸,我们提取 ROI 坐标(第 58-63 行)。在这一点上,我们从图像中截取了一小部分,只包含一张脸。我们继续通过行 64-66 从这个 ROI(即faceBlob)创建一个斑点。
现在我们将执行年龄检测:
# make predictions on the age and find the age bucket with
# the largest corresponding probability
ageNet.setInput(faceBlob)
preds = ageNet.forward()
i = preds[0].argmax()
age = AGE_BUCKETS[i]
ageConfidence = preds[0][i]
# display the predicted age to our terminal
text = "{}: {:.2f}%".format(age, ageConfidence * 100)
print("[INFO] {}".format(text))
# draw the bounding box of the face along with the associated
# predicted age
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# display the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
使用我们的面部斑点,我们进行年龄预测(第 70-74 行),产生age桶和ageConfidence。我们使用这些数据点以及面部 ROI 的坐标来注释原始输入--image ( 行 77-86 )并显示结果(行 89 和 90 )。
在下一部分,我们将分析我们的结果。
OpenCV 年龄检测结果
让我们将 OpenCV 年龄检测器投入使用。
首先使用本教程的 “下载” 部分下载源代码、预训练的年龄检测器模型和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python detect_age.py --image images/adrian.png --face face_detector --age age_detector
[INFO] loading face detector model...
[INFO] loading age detector model...
[INFO] computing face detections...
[INFO] (25-32): 57.51%

Figure 5: Age detection with OpenCV has correctly identified me in this photo of me when I was 30 years old.
在这里,你可以看到我们的 OpenCV 年龄检测器以 57.51%的置信度预测我的年龄为 25-32 岁——事实上,年龄检测器是正确的(拍摄那张照片时我 30 岁)。
让我们再举一个例子,这个著名的演员之一,尼尔·帕特里克·哈里斯小时候:
$ python detect_age.py --image images/neil_patrick_harris.png --face face_detector --age age_detector
[INFO] loading face detector model...
[INFO] loading age detector model...
[INFO] computing face detections...
[INFO] (8-12): 85.72%

Figure 6: Age prediction with OpenCV results in a high confidence that Neil Patrick Harris was 8-12 years old when this photo was taken.
我们的年龄预测又一次正确了——这张照片拍摄时,尼尔·帕特里克·哈里斯看起来肯定在 8-12 岁年龄段。
让我们尝试另一个图像;这张照片是我最喜欢的演员之一,臭名昭著的塞缪尔·L·杰克逊:
$ python detect_age.py --image images/samuel_l_jackson.png --face face_detector --age age_detector
[INFO] loading face detector model...
[INFO] loading age detector model...
[INFO] computing face detections...
[INFO] (48-53): 69.38%

Figure 7: Deep learning age prediction with OpenCV isn’t always accurate, as is evident in this photo of Samuel L. Jackson. Age prediction is subjective for humans just as it is for software.
在这里,我们的 OpenCV 年龄检测器不正确——塞缪尔·L·杰克逊大约 71 岁,这使得我们的年龄预测相差大约 18 岁。
也就是说,看看这张照片——杰克逊先生看起来真的有 71 岁吗?
我猜是 50 年代末到 60 年代初。至少在我看来,他肯定不像一个 70 出头的人。
但这恰恰证明了我在这篇文章前面的观点:
视觉年龄预测的过程很困难,当计算机或人试图猜测某人的年龄时,我会认为这是主观的。
为了评估一个年龄探测器,你不能依赖这个人的实际年龄。相反,你需要测量预测的年龄和感知的年龄之间的准确度。
为实时视频流实施 OpenCV 年龄检测器
此时,我们可以在静态图像中执行年龄检测,但实时视频流呢?
我们也能做到吗?
你打赌我们能。我们的视频脚本与我们的图像脚本非常接近。不同的是,我们需要建立一个视频流,并在循环中对每一帧进行年龄检测。这篇综述将集中在视频特性上,所以请务必根据需要参考上面的演练。
要看视频中如何进行年龄识别,先来看看detect_age_video.py。
# import the necessary packages
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
import os
我们有三个新的导入:(1) VideoStream、( 2) imutils和(3) time。每一个导入都允许我们为我们的视频流设置和使用网络摄像头。
我决定定义一个方便的函数来接受一个frame,定位人脸,预测年龄。通过将检测和预测逻辑放在这里,我们的帧处理循环将变得不那么臃肿(您也可以将此功能卸载到一个单独的文件中)。现在让我们深入了解一下这个实用程序:
def detect_and_predict_age(frame, faceNet, ageNet, minConf=0.5):
# define the list of age buckets our age detector will predict
AGE_BUCKETS = ["(0-2)", "(4-6)", "(8-12)", "(15-20)", "(25-32)",
"(38-43)", "(48-53)", "(60-100)"]
# initialize our results list
results = []
# grab the dimensions of the frame and then construct a blob
# from it
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
faceNet.setInput(blob)
detections = faceNet.forward()
我们的detect_and_predict_age助手函数接受以下参数:
- 来自网络摄像头视频流的单帧图像
faceNet:初始化的深度学习人脸检测器ageNet:我们初始化的深度学习年龄分类器minConf:过滤弱脸检测的置信度阈值
这些参数与我们的单一图像年龄检测器脚本的命令行参数相似。
再次,我们的AGE_BUCKETS被定义(第 12 行和第 13 行)。
然后我们初始化一个空列表来保存人脸定位和年龄检测的results。
20-26 行处理进行人脸检测。
接下来,我们将处理每个detections:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > minConf:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the ROI of the face
face = frame[startY:endY, startX:endX]
# ensure the face ROI is sufficiently large
if face.shape[0] < 20 or face.shape[1] < 20:
continue
你应该认识到第 29-43 行——它们在detections上循环,确保高confidence,并提取一个face ROI。
第 46 行和第 47 行是新的——它们确保人脸 ROI 在我们的流中足够大,原因有二:
- 首先,我们要过滤掉帧中的假阳性人脸检测。
- 第二,年龄分类结果对于远离相机的面部(即,可察觉的小)将是不准确的。
为了完成我们的助手工具,我们将执行年龄识别并返回我们的结果:
# construct a blob from *just* the face ROI
faceBlob = cv2.dnn.blobFromImage(face, 1.0, (227, 227),
(78.4263377603, 87.7689143744, 114.895847746),
swapRB=False)
# make predictions on the age and find the age bucket with
# the largest corresponding probability
ageNet.setInput(faceBlob)
preds = ageNet.forward()
i = preds[0].argmax()
age = AGE_BUCKETS[i]
ageConfidence = preds[0][i]
# construct a dictionary consisting of both the face
# bounding box location along with the age prediction,
# then update our results list
d = {
"loc": (startX, startY, endX, endY),
"age": (age, ageConfidence)
}
results.append(d)
# return our results to the calling function
return results
这里我们预测人脸年龄,提取age桶和ageConfidence ( 第 56-60 行)。
第 65-68 行在字典中安排人脸定位和预测年龄。检测处理循环的最后一步是将字典添加到results列表中(第 69 行)。
一旦所有的detections都被处理并且任何的results都准备好了,我们就把结果return给调用者。
定义了我们的助手函数后,现在我们可以继续处理视频流了。但是首先,我们需要定义命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--face", required=True,
help="path to face detector model directory")
ap.add_argument("-a", "--age", required=True,
help="path to age detector model directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们的脚本需要三个命令行参数:
--face:我们预训练的人脸检测器模型目录的路径--age:我们预先培训的年龄检测器型号目录--confidence:过滤弱检测的最小概率阈值
从这里,我们将加载我们的模型并初始化我们的视频流:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
faceNet = cv2.dnn.readNet(prototxtPath, weightsPath)
# load our serialized age detector model from disk
print("[INFO] loading age detector model...")
prototxtPath = os.path.sep.join([args["age"], "age_deploy.prototxt"])
weightsPath = os.path.sep.join([args["age"], "age_net.caffemodel"])
ageNet = cv2.dnn.readNet(prototxtPath, weightsPath)
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
第 86-89 行加载并初始化我们的人脸检测器,而第 93-95 行加载我们的年龄检测器。
然后我们使用VideoStream类初始化我们的网络摄像头(第 99 行和第 100 行)。
一旦我们的网络摄像头预热,我们将开始处理帧:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# detect faces in the frame, and for each face in the frame,
# predict the age
results = detect_and_predict_age(frame, faceNet, ageNet,
minConf=args["confidence"])
# loop over the results
for r in results:
# draw the bounding box of the face along with the associated
# predicted age
text = "{}: {:.2f}%".format(r["age"][0], r["age"][1] * 100)
(startX, startY, endX, endY) = r["loc"]
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
在我们的循环中,我们:
- 抓取下一个
frame,并将其调整到已知宽度(行 106 和 107 ) - 通过我们的
detect_and_predict_age便利功能发送frame,以(1)检测面部和(2)确定年龄(行 111 和 112 - 在
frame( 第 115-124 行)上标注results - 显示并捕捉按键(行 127 和 128 )
- 如果按下
q键,退出并清理(行 131-136
在下一部分,我们将启动我们的年龄检测器,看看它是否工作!
利用 OpenCV 结果进行实时年龄检测
现在让我们将 OpenCV 的年龄检测应用于实时视频流。
确保您已经使用本教程的 【下载】 部分下载了源代码和预训练的年龄检测器。
从那里,打开一个终端,并发出以下命令:
$ python detect_age_video.py --face face_detector --age age_detector
[INFO] loading face detector model...
[INFO] loading age detector model...
[INFO] starting video stream...
在这里,你可以看到我们的 OpenCV 年龄检测器准确地预测我的年龄范围为 25-32 岁(在我写这篇文章的时候我已经 31 岁了)。
如何提高年龄预测结果?
Levi 和 Hassner 训练的年龄预测模型的最大问题之一是严重偏向25-32 岁的年龄组,如下面来自他们的原始出版物的混淆矩阵表所示:

Figure 8: The Levi and Hassner deep learning age detection model is heavily biased toward the age range 25-32. To combat this in your own models, consider gathering more training data, applying class weighting, data augmentation, and regularization techniques. (image source: Table 4)
不幸的是,这意味着我们的模型可能会预测 25-32 岁的年龄组,而实际上实际年龄属于不同的年龄段——我在为本教程收集结果时以及在我自己的年龄预测应用程序中注意到了这一点。
你可以通过来对抗这种偏见
- 收集其他年龄组的其他训练数据,以帮助平衡数据集
- 应用类别加权处理类别不平衡
- 更加积极地进行数据扩充
- 在训练模型时实现额外的正则化
其次,年龄预测结果通常可以通过使用面部对准来改善。
面对齐识别面的几何结构,然后尝试基于平移、缩放和旋转获得面的规范对齐。
在许多情况下(但不总是),人脸对齐可以改善人脸应用结果,包括人脸识别、年龄预测等。
为了简单起见,我们在本教程中没有而不是应用人脸对齐,但是你可以按照本教程学习更多关于人脸对齐的知识,然后将其应用到你自己的年龄预测应用中。
性别预测呢?
我选择故意不在本教程中涉及性别预测。
虽然使用计算机视觉和深度学习来识别一个人的性别似乎是一个有趣的分类问题,但这实际上是一个道德问题。
仅仅因为某人在视觉上的长相、穿着、或以某种方式出现,并不意味着 他们认同那个(或任何)性别。
试图将性别提取到二元分类中的软件只会进一步将我们束缚在性别是什么的陈旧观念上。因此,我鼓励你尽可能不要在自己的申请中使用性别识别。
如果您必须执行性别识别,请确保您对自己负责,并确保您没有构建试图使他人符合性别刻板印象的应用程序(例如,基于感知的性别定制用户体验)。
性别认同没有什么价值,它只会带来更多的问题,而不是解决更多的问题。尽可能避免它。
摘要
在本教程中,您学习了如何使用 OpenCV 和深度学习进行年龄检测。
为此,我们利用了 Levi 和 Hassner 在 2015 年的出版物《使用卷积神经网络进行年龄和性别分类》中的预训练模型。该模型允许我们以相当高的准确度预测八个不同的年龄组;然而,我们必须认识到,年龄预测是一个具有挑战性的问题。
有许多因素决定了一个人看起来有多老,包括他们的生活方式、工作、吸烟习惯,以及最重要的遗传基因。其次,请记住人们故意试图隐瞒他们的年龄——如果一个人难以准确预测某人的年龄,那么机器学习模型肯定也会难以预测。
因此,你必须根据感知年龄而不是实际年龄来评估所有的年龄预测结果。在您自己的计算机视觉项目中实施年龄检测时,请记住这一点。
我希望你喜欢这个教程!
要下载这篇帖子的源代码(包括预先训练的年龄检测器模型),只需在下面的表格中输入您的电子邮件地址!***
OpenCV 增强现实技术
原文:https://pyimagesearch.com/2021/01/04/opencv-augmented-reality-ar/
在本教程中,你将学习 OpenCV 增强现实的基础知识。

增强现实采用真实世界的环境,然后通过计算机生成的程序增强这些环境,从而不断丰富环境。通常,这是使用视觉、听觉和触觉/触觉交互的某种组合来完成的。
由于 PyImageSearch 是一个计算机视觉博客,我们将主要关注增强现实的视觉方面,更具体地说:
- 拍摄输入图像
- 检测标记/基准点
- 无缝地将新的图像转换到场景中
本教程重点介绍 OpenCV 增强现实的基础知识。下周我将向你展示如何用 OpenCV 来执行实时增强现实。
要了解如何使用 OpenCV 执行增强现实,请继续阅读。
OpenCV 增强现实(AR)
在本教程的第一部分,我们将简要讨论什么是增强现实,包括 OpenCV 如何帮助促进增强现实。
从那里,我们将配置我们的增强现实开发环境,然后审查我们的项目目录结构。
然后,我们将使用 OpenCV 实现一个 Python 脚本来执行基本的增强现实。
本教程将以对我们结果的讨论结束。
什么是增强现实?
我们过去只能通过五种感官来看世界:视觉、听觉、嗅觉、味觉和触觉。
现在这种情况正在改变。
智能手机正在从字面上和象征意义上改变世界,改变三种感官:视觉、听觉和触觉。或许有一天,增强现实也能增强嗅觉和味觉。
增强现实,顾名思义,用计算机生成的感知信息来增强我们周围的真实世界。
也许近年来最大的增强现实成功故事是口袋妖怪 Go 应用 (图 2) 。
为了玩 Pokemon Go,用户在智能手机上打开应用程序,然后访问他们的相机。然后,玩家通过他们的相机观察世界,走过真实世界的环境,包括城市街道,宁静的公园,拥挤的酒吧和餐馆。
口袋妖怪 Go 应用程序将生物(称为口袋妖怪)放置在这个虚拟世界中。然后,玩家必须捕捉这些口袋妖怪,并收集所有的口袋妖怪。
围绕增强现实和虚拟现实应用建立了整个公司,包括 Oculus 和 MagicLeap 。
虽然增强现实(正如我们今天所理解的)自 20 世纪 80 年代末 90 年代初就已经存在,但它仍然处于初级阶段。
我们在很短的时间内取得了令人难以置信的进步,我相信最好的还在后面(很可能在未来 10-20 年内)。
但在我们开始构建最先进的增强现实应用程序之前,我们首先需要学习基础知识。
在本教程中,你将学习 OpenCV 增强现实的基础知识。
配置您的开发环境
为了学习增强现实的基础知识,您需要安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在你的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们可以用 OpenCV 实现增强现实之前,我们首先需要回顾一下我们的项目目录结构。
首先确保使用本教程的 “下载” 部分下载源代码和示例图像。
$ tree . --dirsfirst
.
├── examples
│ ├── input_01.jpg
│ ├── input_02.jpg
│ └── input_03.jpg
├── sources
│ ├── antelope_canyon.jpg
│ ├── jp.jpg
│ └── squirrel.jpg
├── markers.pdf
└── opencv_ar_image.py
2 directories, 7 files
就像我们在关于 ArUco markers 的系列中所做的一样,我们的目标是检测四个 ArUco 标签中的每一个,按照左上、右上、左下和右下的顺序对它们进行排序,然后通过将源图像转换到卡片上来应用增强现实。
说到源图像,我们的sources目录中总共有三个源图像:
一旦我们检测到我们的表面,我们将使用 OpenCV 将这些源图像中的每一个转换到卡片上,产生如下所示的输出:
虽然它不会帮助您执行颜色匹配,但您仍然可以将它用于本示例的目的(即,检测其上的 ArUco 标记,然后将源图像转换到输入)。
只需将markers.pdf 印在一张纸上,剪下来,然后放在你相机的视野中。从那里你将能够跟随。
回顾了我们的目录结构后,让我们继续用 OpenCV 实现增强现实。
用 OpenCV 实现增强现实
我们现在准备用 OpenCV 实现增强现实!
打开项目目录结构中的opencv_ar_image.py 文件,让我们开始工作:
# import the necessary packages
import numpy as np
import argparse
import imutils
import sys
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image containing ArUCo tag")
ap.add_argument("-s", "--source", required=True,
help="path to input source image that will be put on input")
args = vars(ap.parse_args())
# load the input image from disk, resize it, and grab its spatial
# dimensions
print("[INFO] loading input image and source image...")
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
(imgH, imgW) = image.shape[:2]
# load the source image from disk
source = cv2.imread(args["source"])
# load the ArUCo dictionary, grab the ArUCo parameters, and detect
# the markers
print("[INFO] detecting markers...")
arucoDict = cv2.aruco.Dictionary_get(cv2.aruco.DICT_ARUCO_ORIGINAL)
arucoParams = cv2.aruco.DetectorParameters_create()
(corners, ids, rejected) = cv2.aruco.detectMarkers(image, arucoDict,
parameters=arucoParams)
# if we have not found four markers in the input image then we cannot
# apply our augmented reality technique
if len(corners) != 4:
print("[INFO] could not find 4 corners...exiting")
sys.exit(0)
作为参考,我们的输入图像如下所示:
我们的目标是检测 Pantone 卡上的四个 ArUco 标记。一旦我们有了卡片及其 ArUco 标记,我们就可以获取source 图像并将其转换到卡片表面,从而形成增强现实输出。
整个增强现实过程取决于首先找到这些 ArUco 标记。如果你还没有,回去看看我以前的关于 ArUco markers 的教程——那些指南会帮助你快速上手。从现在开始,我假设你对 ArUco markers 很满意。
第 29-32 行继续:
- 加载我们的 ArUco 字典(从我们之前的 ArUco 标记教程中,我们知道 Pantone 卡是使用
DICT_ARUCO_ORIGINAL字典生成的) - 初始化我们的 ArUco 探测器参数
- 检测输入中的 ArUco 标记
image
如果没有找到四个 ArUco 标记,我们就优雅地退出脚本(第 36-38 行)。同样,我们的增强现实过程在这里依赖于成功找到所有四个标记。
假设我们的脚本仍在执行,我们可以有把握地假设所有四个 ArUco 标记都被成功检测到。
从那里,我们可以获取 ArUco 标记的 id 并初始化refPts ,这是一个包含了 ArUco 标记边界框的 (x,y) 坐标的列表:
# otherwise, we've found the four ArUco markers, so we can continue
# by flattening the ArUco IDs list and initializing our list of
# reference points
print("[INFO] constructing augmented reality visualization...")
ids = ids.flatten()
refPts = []
# loop over the IDs of the ArUco markers in top-left, top-right,
# bottom-right, and bottom-left order
for i in (923, 1001, 241, 1007):
# grab the index of the corner with the current ID and append the
# corner (x, y)-coordinates to our list of reference points
j = np.squeeze(np.where(ids == i))
corner = np.squeeze(corners[j])
refPts.append(corner)
在第行第 49 处,我们循环了 Pantone 彩色图像中的四个 ArUco 标记 id。这些 id 是使用我们的 ArUco 标记检测博客帖子获得的。如果您使用自己的 ArUco 标记 id,您需要更新此列表并插入 id。
# unpack our ArUco reference points and use the reference points to
# define the *destination* transform matrix, making sure the points
# are specified in top-left, top-right, bottom-right, and bottom-left
# order
(refPtTL, refPtTR, refPtBR, refPtBL) = refPts
dstMat = [refPtTL[0], refPtTR[1], refPtBR[2], refPtBL[3]]
dstMat = np.array(dstMat)
# grab the spatial dimensions of the source image and define the
# transform matrix for the *source* image in top-left, top-right,
# bottom-right, and bottom-left order
(srcH, srcW) = source.shape[:2]
srcMat = np.array([[0, 0], [srcW, 0], [srcW, srcH], [0, srcH]])
# compute the homography matrix and then warp the source image to the
# destination based on the homography
(H, _) = cv2.findHomography(srcMat, dstMat)
warped = cv2.warpPerspective(source, H, (imgW, imgH))
为了用 OpenCV 执行增强现实,我们需要计算一个单应矩阵,然后用它来执行透视扭曲。
然而,为了计算单应性,我们需要一个源矩阵和目的矩阵。
# construct a mask for the source image now that the perspective warp
# has taken place (we'll need this mask to copy the source image into
# the destination)
mask = np.zeros((imgH, imgW), dtype="uint8")
cv2.fillConvexPoly(mask, dstMat.astype("int32"), (255, 255, 255),
cv2.LINE_AA)
# this step is optional, but to give the source image a black border
# surrounding it when applied to the source image, you can apply a
# dilation operation
rect = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
mask = cv2.dilate(mask, rect, iterations=2)
# create a three channel version of the mask by stacking it depth-wise,
# such that we can copy the warped source image into the input image
maskScaled = mask.copy() / 255.0
maskScaled = np.dstack([maskScaled] * 3)
# copy the warped source image into the input image by (1) multiplying
# the warped image and masked together, (2) multiplying the original
# input image with the mask (giving more weight to the input where
# there *ARE NOT* masked pixels), and (3) adding the resulting
# multiplications together
warpedMultiplied = cv2.multiply(warped.astype("float"), maskScaled)
imageMultiplied = cv2.multiply(image.astype(float), 1.0 - maskScaled)
output = cv2.add(warpedMultiplied, imageMultiplied)
output = output.astype("uint8")
第 85 行和第 86 行是可选的,但是我喜欢放大蒙版,从而稍微放大。这样做可以在将warped 源图像应用到输入image 的区域周围创建一个漂亮的黑色小边框。同样,这是可选的,但它提供了一个很好的效果。
接下来,我们使用蒙版,从范围【0,255】缩放到【0,1】。然后,我们沿深度方向堆叠遮罩,创建遮罩的 3 通道表示。我们执行这个操作,以便将扭曲的源图像复制到输入图像中。
现在剩下的就是:
# show the input image, source image, output of our augmented reality
cv2.imshow("Input", image)
cv2.imshow("Source", source)
cv2.imshow("OpenCV AR Output", output)
cv2.waitKey(0)
这三幅图像将显示在我们的屏幕上,直到点击 OpenCV 打开的一个窗口并按下键盘上的一个键。
OpenCV 增强现实结果
我们现在已经准备好用 OpenCV 执行增强现实了!首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python opencv_ar_image.py --image examples/input_01.jpg \
--source sources/squirrel.jpg
[INFO] loading input image and source image...
[INFO] detecting markers...
[INFO] constructing augmented reality visualization...
在右边的你可以看到我们松鼠的源图像。这个源图像将被转换成左边的场景(通过增强现实)。**
左图像包含一个输入颜色校正卡,带有我们的opencv_ar_image.py脚本检测到的 ArUco 标记(即标记/基准标签)。
找到标记后,我们应用一个变换,将源图像扭曲到输入中,从而生成输出( bottom )。
请注意松鼠图像是如何被转换到颜色校正卡本身上的,完美地保持了纵横比、比例、视角等。颜色校正卡。
让我们尝试另一个例子,这个例子使用不同的源和输入图像:
$ python opencv_ar_image.py --image examples/input_02.jpg \
--source sources/antelope_canyon.jpg
[INFO] loading input image and source image...
[INFO] detecting markers...
[INFO] constructing augmented reality visualization...
在右边 ( 图 12 )我们有一张几年前我在亚利桑那州佩奇探索羚羊峡谷的照片。
左边的图像包含我们的输入图像,其中我们的输入源图像将被应用于构建增强现实场景。
我们的 Python 脚本能够检测四个 ArUco 标签标记,然后应用转换,从而在底部生成图像。
同样,请注意源图像是如何完美地转换为输入图像的,同时保持了输入图像的比例、纵横比以及最重要的视角。
让我们看最后一个例子:
$ python opencv_ar_image.py --image examples/input_03.jpg \
--source sources/jp.jpg
[INFO] loading input image and source image...
[INFO] detecting markers...
[INFO] constructing augmented reality visualization...
图 13 显示了我们的结果。
这次我们有了一张我最喜欢的电影《侏罗纪公园》的源图(右)。
然后,我们检测输入图像(左)中的 AprilTag 标记,然后应用变换来构建我们的增强现实图像(下图)。
下周,您将学习如何实时执行相同的技术,从而创建更无缝、更有趣、更身临其境的增强现实体验。
学分
用于执行透视扭曲和遮罩的代码受到了 Satya Mallick 在 LearnOpenCV 的实现的启发。我将它们的实现作为参考,然后对其进行了修改,以适用于我的示例图像,并在代码和文章中提供了额外的细节和注释。如果你有兴趣,可以看看萨提亚的文章。
总结
在本教程中,您学习了使用 OpenCV 增强现实的基础知识。
然而,为了构建一个真正的增强现实体验,我们需要创建一个更加身临其境的环境,一个利用实时视频流的环境。
事实上,这正是我们下周要讨论的内容!
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV:用 Python 实现自动牌照/车牌识别(ANPR)
https://www.youtube.com/embed/dta7Ll-CKcQ?feature=oembed
OpenCV 按位与、或、异或和非
原文:https://pyimagesearch.com/2021/01/19/opencv-bitwise-and-or-xor-and-not/
在本教程中,您将学习如何对 OpenCV 应用按位 AND、OR、XOR 和 NOT。
在我们之前关于使用 OpenCV 进行 裁剪的教程中,您学习了如何从图像中裁剪和提取感兴趣的区域(ROI)。
在这个特殊的例子中,我们的 ROI 必须是矩形的。。。但是如果你想裁剪一个非矩形区域呢?
那你会怎么做?
答案是同时应用位运算和遮罩(我们将在关于使用 OpenCV 进行图像遮罩的指南中讨论如何实现)。
现在,我们将讨论基本的位运算——在下一篇博文中,我们将学习如何利用这些位运算来构造掩码。
要学习如何用 OpenCV 应用位运算符,继续阅读。
OpenCV 按位与、或、异或、非
在深入本教程之前,我假设您已经理解了四种基本的按位运算符:
- 和
- 运筹学
- 异或(异或)
- 不
如果你以前从未使用过位操作符,我建议你阅读一下来自 RealPython 的这篇优秀的(非常详细的)指南。
虽然你没有也没有来复习那本指南,但我发现理解对数字应用位运算符的基础的读者可以很快掌握对图像应用位运算符。
不管怎样,计算机视觉和图像处理是高度可视化的,我在本教程中精心制作了这些例子,以确保你理解如何用 OpenCV 将按位运算符应用于图像。
我们将从配置我们的开发环境开始,然后回顾我们的项目目录结构。
从这里,我们将实现一个 Python 脚本来执行 OpenCV 的 AND、OR、XOR 和 NOT 位操作符。
我们将以讨论我们的结果来结束本指南。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
准备好学习如何使用 OpenCV 应用位运算符了吗?
太好了,我们开始吧。
请务必使用本指南的 【下载】 部分访问源代码,并从那里查看我们的项目目录结构:
$ tree . --dirsfirst
.
└── opencv_bitwise.py
0 directories, 1 file
今天我们只回顾一个脚本opencv_bitwise.py,它将对示例图像应用 AND、OR、XOR 和 NOR 运算符。
在本指南结束时,您将会很好地理解如何在 OpenCV 中应用位操作符。
实现 OpenCV AND、OR、XOR 和 NOT 位运算符
在这一节中,我们将回顾四种位运算:与、或、异或和非。虽然这四个操作非常基础和低级,但对图像处理至关重要——尤其是在本系列后面的蒙版处理中。
位运算以二进制方式运行,并表示为灰度图像。如果给定像素的值为零,则该像素被“关闭”,如果该像素的值大于零,则该像素被“打开”。
让我们继续,跳到一些代码中:
# import the necessary packages
import numpy as np
import cv2
# draw a rectangle
rectangle = np.zeros((300, 300), dtype="uint8")
cv2.rectangle(rectangle, (25, 25), (275, 275), 255, -1)
cv2.imshow("Rectangle", rectangle)
# draw a circle
circle = np.zeros((300, 300), dtype = "uint8")
cv2.circle(circle, (150, 150), 150, 255, -1)
cv2.imshow("Circle", circle)
对于代码导入的前几行,我们需要的包包括:NumPy 和我们的 OpenCV 绑定。
我们在第 6 行上将矩形图像初始化为一个 300 x 300 的 NumPy 数组。然后我们在图像的中心绘制一个 250 x 250 的白色矩形。
类似地,在第 11 行,我们初始化另一个图像来包含我们的圆,我们在第 12 行再次以图像的中间为中心,半径为 150 像素。
图 2 展示了我们的两种形状:
如果我们考虑这些输入图像,我们会看到它们只有两个像素强度值——要么像素是0(黑色),要么像素大于零(白色)。我们把只有两个像素亮度值的图像称为二值图像。
另一种看待二进制图像的方式就像我们客厅里的开关。想象一下, 300 x 300 图像中的每个像素都是一个灯开关。如果开关 关闭 ,则像素值为零。但如果像素是 上的 ,则具有大于零的值。
在图 2 中,我们可以看到分别构成矩形和圆形的白色像素的像素值都为开,而周围像素的值为关。
在我们演示按位运算时,保持开/关的概念:
# a bitwise 'AND' is only 'True' when both inputs have a value that
# is 'ON' -- in this case, the cv2.bitwise_and function examines
# every pixel in the rectangle and circle; if *BOTH* pixels have a
# value greater than zero then the pixel is turned 'ON' (i.e., 255)
# in the output image; otherwise, the output value is set to
# 'OFF' (i.e., 0)
bitwiseAnd = cv2.bitwise_and(rectangle, circle)
cv2.imshow("AND", bitwiseAnd)
cv2.waitKey(0)
正如我上面提到的,如果一个给定的像素的值大于零,它就被“打开”,如果它的值为零,它就被“关闭”。按位函数对这些二元条件进行运算。
为了利用位函数,我们假设(在大多数情况下)我们正在比较两个像素(唯一的例外是 NOT 函数)。我们将比较每个像素,然后构造我们的按位表示。
让我们快速回顾一下我们的二元运算:
- AND: 当且仅当两个像素都大于零时,按位 AND 为真。
- OR: 如果两个像素中的任何一个大于零,则按位 OR 为真。
- 异或:按位异或为真当且仅当两个像素中的一个大于零,但不是两个都大于零。
- NOT: 按位 NOT 反转图像中的“开”和“关”像素。
在第 21 行,我们使用cv2.bitwise_and函数对矩形和圆形图像进行按位 AND 运算。如上所述,当且仅当两个像素都大于零时,按位 AND 运算才成立。我们的按位 AND 的输出可以在图 3 中看到:
我们可以看到我们的正方形的边缘丢失了——这是有意义的,因为我们的矩形没有圆形覆盖的面积大,因此两个像素都没有“打开”
现在让我们应用按位“或”运算:
# a bitwise 'OR' examines every pixel in the two inputs, and if
# *EITHER* pixel in the rectangle or circle is greater than 0,
# then the output pixel has a value of 255, otherwise it is 0
bitwiseOr = cv2.bitwise_or(rectangle, circle)
cv2.imshow("OR", bitwiseOr)
cv2.waitKey(0)
我们使用cv2.bitwise_or函数对第 28 行的进行按位或运算。如果两个像素中的任何一个大于零,则按位 OR 为真。看看图 4 中位或的输出:
在这种情况下,我们的正方形和长方形已经合并。
接下来是按位异或:
# the bitwise 'XOR' is identical to the 'OR' function, with one
# exception: the rectangle and circle are not allowed to *BOTH*
# have values greater than 0 (only one can be 0)
bitwiseXor = cv2.bitwise_xor(rectangle, circle)
cv2.imshow("XOR", bitwiseXor)
cv2.waitKey(0)
我们使用cv2.bitwise_xor函数对行 35 进行逐位异或运算。
当且仅当两个像素中的一个大于零时,XOR 运算为真,但两个像素不能都大于零。
XOR 运算的输出显示在图 5:
在这里,我们看到正方形的中心被移除了。同样,这是有意义的,因为 XOR 运算不能使两个像素都大于零。
最后,我们得到了按位 NOT 函数:
# finally, the bitwise 'NOT' inverts the values of the pixels;
# pixels with a value of 255 become 0, and pixels with a value of 0
# become 255
bitwiseNot = cv2.bitwise_not(circle)
cv2.imshow("NOT", bitwiseNot)
cv2.waitKey(0)
我们使用cv2.bitwise_not函数在行 42 上应用一个按位非运算。本质上,按位 NOT 函数翻转像素值。所有大于零的像素被设置为零,所有等于零的像素被设置为255:
注意我们的圆是如何被反转的——最初,圆是黑底白字,现在圆是白底黑字。
OpenCV 按位 AND、OR、XOR 和 NOT 结果
要使用 OpenCV 执行位运算,请务必访问本教程的 “下载” 部分下载源代码。
从那里,打开一个 shell 并执行以下命令:
$ python opencv_bitwise.py
您的输出应该与我在上一节中的输出相匹配。
总结
在本教程中,您学习了如何使用 OpenCV 执行按位 AND、OR、XOR 和 NOT 运算。
虽然按位操作符本身似乎没什么用,但当你开始使用阿尔法混合和蒙版时,它们是必要的,我们将在另一篇博文中讨论这个概念。
在继续之前,请花时间练习并熟悉按位运算。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
轮廓中心
原文:https://pyimagesearch.com/2016/02/01/opencv-center-of-contour/
今天,我们将开始一个新的 3 部分系列教程。
*在本系列中,我们将学习如何:
- 计算轮廓/形状区域的中心。
- 仅使用轮廓属性识别各种形状,如圆形、正方形、矩形、三角形和五边形。
- 标记形状的颜色。
虽然今天的帖子有点基础(至少在最近 PyImageSearch 博客上的一些更高级的概念的背景下),但它仍然解决了我经常被问到的一个问题:
“我如何使用 Python 和 OpenCV 计算轮廓的中心?
在今天的帖子中,我将回答这个问题。
在本系列的后续文章中,我们将利用轮廓知识来识别图像中的形状。
轮廓中心

Figure 1: An example image containing a set of shapes that we are going to compute the center of the contour for.
在上面的图片中,你可以看到从建筑用纸上剪下的各种形状。注意这些形状并不完美。长方形不完全是长方形,圆形也不完全是圆形。这些是人类绘制和人类裁剪的形状,暗示每种形状类型都有变化。
考虑到这一点,今天教程的目标是(1) 检测图像中每个形状的轮廓,然后是(2) 计算轮廓的中心——也称为区域的质心。
为了实现这些目标,我们需要执行一些图像预处理,包括:
- 转换为灰度。
- 模糊,以减少高频噪声,使我们的轮廓检测过程更加准确。
- 图像的二值化。典型地,边缘检测和阈值处理用于这个过程。在这篇文章中,我们将应用阈值。
在我们开始编码之前,确保您的系统上安装了 imutils Python 包:
$ pip install --upgrade imutils
从那里,我们可以继续前进并开始。
打开一个新文件,命名为center_of_shape.py,我们将得到代码:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
# load the image, convert it to grayscale, blur it slightly,
# and threshold it
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.threshold(blurred, 60, 255, cv2.THRESH_BINARY)[1]
我们从的第 2-4 行开始,导入我们需要的包,然后解析我们的命令行参数。这里我们只需要一个开关--image,它是我们想要处理的图像在磁盘上的路径。
然后,我们获取该图像,从磁盘中加载,并通过应用灰度转换、使用 5 x 5 内核的高斯平滑以及最后的阈值处理(第 14-17 行)对其进行预处理。
阈值操作的输出如下所示:
Figure 2: Thresholding our image returns a binary image, where the shapes appear as white on a black foreground.
注意在应用阈值处理后,形状是如何在黑色背景上表现为白色前景。
下一步是使用轮廓检测找到这些白色区域的位置:
# find contours in the thresholded image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
对第 20 行和第 21 行上的cv2.findContours的调用返回对应于图像上每个白点的一组轮廓(即轮廓)。第 22 行然后根据我们使用的是 OpenCV 2.4、3 还是 4 获取合适的元组值。你可以在这篇文章中读到更多关于cv2.findContours的返回签名如何在 OpenCV 版本之间改变的信息。
我们现在准备处理每个轮廓:
# loop over the contours
for c in cnts:
# compute the center of the contour
M = cv2.moments(c)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
# draw the contour and center of the shape on the image
cv2.drawContours(image, [c], -1, (0, 255, 0), 2)
cv2.circle(image, (cX, cY), 7, (255, 255, 255), -1)
cv2.putText(image, "center", (cX - 20, cY - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# show the image
cv2.imshow("Image", image)
cv2.waitKey(0)
在第 25 行的上,我们开始循环每个单独的轮廓,随后计算第 27 行上轮廓区域的图像矩。
在计算机视觉和图像处理中,图像矩常用于表征图像中物体的形状。这些矩捕获形状的基本统计属性,包括对象的面积、T2 质心(即中心 (x,y)-对象的坐标)方位,以及其他期望的属性。
这里我们只对轮廓的中心感兴趣,我们在线 28 和 29 上计算。
从那里,第 32-34 行处理:
- 通过调用
cv2.drawContours绘制当前形状周围的轮廓轮廓。 - 在形状的 中心
(cX, cY)-坐标处放置一个白色圆圈。 - 在白色圆圈附近写文字
center。
要执行我们的脚本,只需打开一个终端并执行以下命令:
$ python center_of_shape.py --image shapes_and_colors.png
您的结果应该如下所示:
Figure 3: Looping over each of the shapes individually and then computing the center (x, y)-coordinates for each shape.
请注意每个形状是如何被成功检测到的,然后计算轮廓的中心并绘制在图像上。
摘要
在本课中,我们学习了如何使用 OpenCV 和 Python 计算轮廓的中心。
本帖是三部曲系列中关于造型分析的第篇。
在下周的帖子中,我们将学习如何 识别图像中的形状 。
然后,从现在开始两周,我们将学习如何 分析每个形状的颜色用特定的颜色 (即“红色”、“绿色”、“蓝色”等)给形状贴上标签。).
为了在这些帖子发布时得到通知,请务必使用下面的表格输入您的电子邮件地址!*
OpenCV 色彩空间(cv2.cvtColor)
原文:https://pyimagesearch.com/2021/04/28/opencv-color-spaces-cv2-cvtcolor/
在本教程中,您将了解 OpenCV 中的色彩空间、cv2.cvtColor函数,以及在构建计算机视觉和图像处理管道时照明条件/环境的重要性。
为了说明照明条件的重要性,我想以我在开发名为 ID My Pill 的 iPhone 应用程序时的一个个人故事开始今天的教程。
ID My Pill 是一个 iPhone 应用程序和 web API,允许您在智能手机的快照中识别处方药。你只需给你的处方药拍一张照片,ID My Pill 就会使用计算机视觉和机器学习技术立即识别并验证它们是正确的药物。
药片是否被正确识别与无关与我用来开发它的编程语言无关。这与我建造的计算机视觉库没有任何关系,我的药丸就在那里。成功的药丸识别与我在后台开发的药丸识别算法完全无关。
*事实上,在执行一行代码之前,就已经决定了一颗药丸是否能被成功识别。
当然,我说的是照明条件。
在非常差的光照条件下拍摄的药丸,在这种条件下有大量的阴影、冲刷或缺乏对比度,根本无法识别。美国市场上有超过 27,000 种处方药丸(其中一半以上是圆形和/或白色的),数量惊人的药丸彼此几乎完全相同。并且考虑到这种大量视觉上相似的药丸,非理想的照明条件可能完全破坏药丸识别算法的结果。
信不信由你,(几乎)所有计算机视觉系统和应用的成功都是在开发人员编写一行代码之前决定的。
在本文的其余部分,我们将讨论照明条件的重要性以及它在计算机视觉系统的成功开发中所起的重要作用。
我们还将讨论色彩空间,以及如何利用它们来构建更强大的计算机视觉应用。
要了解 OpenCV 中的色彩空间和cv2.cvtColor函数, 只需继续阅读。
OpenCV 色彩空间(cv2.cvtColor )
在本教程的第一部分,我们将讨论任何计算机视觉和图像处理管道中照明条件的重要性。
然后,我们将回顾在照明条件下工作时你应该努力达到的三个目标:
- 高调
- 可概括的
- 稳定的
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们将实现 Python 代码来处理 OpenCV 中的四种颜色空间/模型:
- RGB
- hsv 色彩模型
- Lab*
- 灰度等级
我们将讨论我们的结果来结束本教程。
光照条件在图像处理和计算机视觉中的重要性
计算机视觉领域正在迅速扩展和发展。我们每天都在这个领域看到新的进展,而这些进展是我们曾经认为不可能的。
我们看到深度学习以惊人的高精度对图像进行分类、检测对象和分割图像。
像 Raspberry Pi、Google Coral 和 Jetson Nano 这样的微型计算机可以用来构建复杂的监控系统。
工业界每天都看到越来越多的商用计算机视觉应用推向市场。
虽然这个领域在成长、变化和发展,但我可以向你保证一个绝对不变的事实:每一个计算机视觉算法、应用和系统曾经开发过,以及将开发出来,都将取决于输入系统的图像质量。
我们当然能够使我们的系统在恶劣的照明条件下更加稳健,但是我们永远无法克服在恶劣条件下拍摄的图像,。
所以让我再说一遍,因为我真的想确保它坚持: 照明可以意味着你的计算机视觉算法的成败。
我看到计算机视觉开发人员犯的最常见的一个错误是忽略了光照及其对算法性能的影响。
给定环境中的光线质量对实现你的目标绝对至关重要——事实上,我甚至可以说,它可能是最重要的因素。
相机实际上并不是在“拍摄”物体本身。相反,它捕捉的是物体反射的光。这也意味着图像中的不同对象将需要不同的照明条件来获得“好”的结果(其中“好”是根据算法的最终目标来定义的)。
为了说明照明条件的重要性,今天早上我拍了一张自己在浴室镜子里的自拍照:
但是哎呀——我忘了关照相机的闪光灯了!镜子是反射表面,因此光线会直接从表面反弹并进入我的相机传感器。照片很差,几乎不可能编写代码来检测我的脸,因为闪光灯干扰了我脸的下部。
相反,当我关掉闪光灯,使用来自上方的柔光,而不是针对反射表面时,我得到了我想要的结果:
在这里,我的脸清晰可见,几乎察觉不到。
同样,你根本无法弥补糟糕的照明条件。当开发一个应用程序来检测图像中的人脸时,您更喜欢哪种类型的图像?图 2 中的那张,因为闪光灯的缘故,我的脸几乎看不见。或者是图 3 中我的脸清晰可见的图像?
显然,图 3 是首选,也是一个很好的例子,说明了为什么在开发计算机视觉应用时需要考虑照明条件。
一般来说,你的照明条件应该有三个主要目标。下面我们来回顾一下。
目标#1:高对比度
你应该寻求最大化图像中感兴趣区域之间的对比度(即,你想要检测、提取、描述、分类、操作的“对象”)。应该与图像的其余部分具有足够高的对比度,以便它们容易被检测到)。
例如,在构建我们的简单文档扫描仪时,我们确保我们想要检测的纸张是在暗背景上的亮,从而确保有足够的对比度,并且可以轻松检测到纸张:
只要有可能,尽量确保环境的背景和前景之间有高对比度——这将使编写代码准确理解背景和前景更加容易。
目标 2:一般化
你的照明条件应该足够一致,这样它们才能很好地从一个物体到另一个物体。
如果我们的目标是识别图像中的各种美国硬币,我们的照明条件应该足够普遍,以便于硬币识别,无论我们检查的是一便士、五分、一角还是二角五分。
目标 3:稳定
拥有稳定、一致且可重复的照明条件是计算机视觉应用开发的圣杯。然而,这通常很难(如果不是不可能的话)保证——如果我们正在开发旨在户外照明条件下工作的计算机视觉算法,这一点尤其如此。随着一天中时间的变化,云在太阳上滚动,雨开始下,我们的照明条件将明显改变。
即使在我服用我的药丸的情况下,拥有一个真正稳定的光照条件也是不可能的。来自世界各地的用户会在非常不同的照明条件下(室外、室内、荧光灯、石英卤素灯,你能想到的)拍摄药物照片,而我根本无法控制它。
但是让我们说,ID My 药丸不是为消费者开发的,以验证他们的处方药丸。相反,让我们假设在工厂传送带上使用了 ID My 药丸,以确保传送带上的每个药丸都是相同的药物,并且在相同的生产环境中不存在不同类型药物的“交叉污染”或“泄漏”。
在药丸工厂的场景中,我更有可能获得稳定的照明条件。这是因为我可以:
- 将相机放在我想要的任何地方来拍摄药丸的照片
- 完全控制照明环境——我可以增加或减少灯光,或者设置一个完全独立的“照片亭”,远离任何可能污染标识的其他光源
如你所见,真正稳定的照明条件通常很难(如果不是不可能的话)保证。但是非常重要的是,在你写一行代码之前,你至少要考虑你的照明条件的稳定性。
这是我的关键要点:
在你写一行代码之前,尽可能多地争取获得你理想的照明条件。控制(或至少承认)你的照明条件比编写代码补偿劣质照明要有利得多(也容易得多)。
色彩空间与色彩模型
本教程中我们要讨论的第二个主题是色彩空间和色彩模型。
简单地说,色彩空间只是一种特定的颜色组织,它允许我们一致地表示和再现颜色。
例如,想象一下浏览你当地的家装仓库,为你的客厅寻找你想要的颜色。你家装店里的这些色样很可能是根据色样的颜色和色调以某种连贯的方式组织起来的。显然,这是一个非常简单的例子,色彩空间可以更加严格和结构化数学。
另一方面,颜色模型是在颜色空间中用数字表示颜色的抽象方法。众所周知,RGB 像素被表示为一个由红、绿、蓝值组成的 3 整数元组。
作为一个整体,颜色空间定义了颜色模型和用于定义实际颜色的抽象映射函数。选择一个颜色空间也非正式地意味着我们在选择颜色模型。
这两者之间的区别是微妙的,但作为完整性的问题,这一点很重要。
在本教程的其余部分,我们将讨论开发计算机视觉应用程序时会遇到的四种主要色彩空间:
- RGB
- 单纯疱疹病毒,
- Lab*
- 灰度(从技术上讲,它不是一个颜色空间,但是您将在开发的几乎所有计算机视觉应用程序中使用它)。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们实现色彩空间和利用 OpenCV 的cv2.cvtColor函数之前,让我们首先检查一下我们的项目目录结构。
首先通过访问本教程的 【下载】 部分来检索源代码和示例图像:
$ tree . --dirsfirst
.
├── adrian.png
└── color_spaces.py
0 directories, 2 files
我们要回顾一个 Python 脚本,color_spaces.py。该脚本将从磁盘加载adrian.png,并演示如何使用 RGB、HSV 和 Lab*色彩空间。
您还将学习如何将图像转换为灰度。
RGB 颜色空间
我们要讨论的第一个色彩空间是 RGB ,它代表图像的红色、绿色和蓝色成分。你很可能已经非常熟悉 RGB 色彩空间,因为大多数色彩应用程序和计算机视觉/图像处理库默认使用 RGB。
要定义 RGB 颜色模型中的颜色,我们需要做的就是定义单个像素中包含的红色、绿色和蓝色的数量。每个红色、绿色和蓝色通道可以具有在范围 [0,255] (总共 256 个“阴影”)中定义的值,其中 0 表示没有表示, 255 表示完全表示。
RGB 色彩空间是加色色彩空间的一个例子:每种颜色添加得越多,像素就变得越亮,越接近白色:
如你所见,红色和绿色相加导致黄色。红色和蓝色相加得到粉红色。把红、绿、蓝三种颜色加在一起,我们就产生了白色。
RGB 色彩空间通常被视为一个立方体:
由于 RGB 颜色被定义为一个三值元组,每个值在范围【0,255】内,因此我们可以认为立方体包含 256×256×256 = 16,777,216 种可能的颜色,这取决于我们在每个桶中放入多少红色、绿色和蓝色。
然而,对于开发基于计算机视觉的应用程序来说,这并不是最友好的颜色空间。事实上,它的主要用途是在显示器上显示颜色。
例如,如果我们想确定我们需要多少红色、绿色和蓝色来创造一种颜色。
你能想象需要 R=252,G=198,B=188 来创建我的白种人肤色吗,如图图 8 :
或者这么多 R=22,G=159,B=230 来获得 PyImageSearch 徽标的蓝色阴影:
很不直观,对吧?
但是,尽管 RGB 颜色空间可能很不直观,几乎所有您要处理的图像都将在 RGB 颜色空间中表示(至少最初是这样)。
说了这么多,让我们看看显示 RGB 图像的每个通道的代码。
打开项目目录结构中的color_spaces.py文件,让我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
这里我们只需要一个参数--image,默认为adrian.png(如果您将代码和示例图像下载到本教程中,它位于我们的项目目录中)。
现在让我们加载我们的图像:
# load the original image and show it
image = cv2.imread(args["image"])
cv2.imshow("RGB", image)
# loop over each of the individual channels and display them
for (name, chan) in zip(("B", "G", "R"), cv2.split(image)):
cv2.imshow(name, chan)
# wait for a keypress, then close all open windows
cv2.waitKey(0)
cv2.destroyAllWindows()
第 12 行和第 13 行将我们的输入image加载到磁盘,并显示在我们的屏幕上。
然后,我们按照蓝色、绿色、红色的顺序循环每个图像通道,因为 OpenCV 在第 16 行上以相反的顺序将图像表示为 NumPy 数组。
对于这些频道中的每一个,我们将它们显示在屏幕的第 17 行上。
当您执行此脚本时,您将看到以下输出:
在左上角的上,我们有原始的 RGB 图像,它由红色、绿色和蓝色通道加在一起组成(分别是右上角的、右下角的和左下角的)。
因此,虽然 RGB 是最常用的颜色空间,但它不是最直观的颜色空间。让我们看看 HSV 颜色空间,它在定义颜色范围时更直观,也更容易理解。
HSV 颜色空间
HSV 色彩空间转换 RGB 色彩空间,将其重塑为圆柱体而不是立方体:
正如我们在 RGB 部分看到的,颜色的“白色”或“亮度”是每个红色、绿色和蓝色分量的叠加组合。但是现在在 HSV 颜色空间中,亮度被赋予了它自己的独立维度。
让我们来定义每个 HSV 组件是什么:
- 色调:我们要检查的是哪种“纯”色。例如,“红色”的所有阴影和色调将具有相同的色调。
- 饱和度:颜色有多“白”。一个完全饱和的颜色应该是“纯的”,比如“纯红色”饱和度为零的颜色是纯白色。
- 值:值可以让我们控制颜色的明度。零值表示纯黑色,而增加该值会产生更亮的颜色。
值得注意的是,不同的计算机视觉库将使用不同的范围来表示每个色调、饱和度和值组件。
在 OpenCV 的情况下,图像被表示为 8 位无符号整数数组。因此,色调值被定义为范围【0,179】(对于总共 180 个可能的值,因为【0,359】对于 8 位无符号数组是不可能的)——色调实际上是一个度数(
) on the HSV color cylinder. And both saturation and value are defined on the range [0, 255].
让我们看一些将图像从 RGB(或者更确切地说,BGR)色彩空间转换到 HSV 的示例代码:
# convert the image to the HSV color space and show it
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
cv2.imshow("HSV", hsv)
# loop over each of the individual channels and display them
for (name, chan) in zip(("H", "S", "V"), cv2.split(hsv)):
cv2.imshow(name, chan)
# wait for a keypress, then close all open windows
cv2.waitKey(0)
cv2.destroyAllWindows()
为了将我们的图像转换到 HSV 颜色空间,我们调用了cv2.cvtColor函数。
这个函数接受两个参数:我们想要转换的实际图像,后面是输出颜色空间。
由于 OpenCV 以 BGR 顺序而不是 RGB 表示我们的图像,我们指定了cv2.COLOR_BGR2HSV标志来表示我们想要从 BGR 转换到 HSV。
接下来,我们将循环每个单独的色调、饱和度和值通道,并将它们显示在屏幕上:
请注意左下方的值部分本质上是一个灰度图像——这是因为该值控制我们颜色的实际亮度,而色调和饱和度定义了实际的颜色和阴影。
HSV 颜色空间在计算机视觉应用中大量使用——尤其是当我们对跟踪图像中某个对象的颜色感兴趣时。使用 HSV 比 RGB 更容易定义一个有效的颜色范围。
Lab*颜色空间
我们要讨论的最后一个色彩空间是 Lab* 。
虽然 RGB 颜色空间很容易理解(特别是当你第一次开始使用计算机视觉时),但在定义颜色的精确阴影或指定颜色的特定范围时,它就不直观了。
另一方面,HSV 颜色空间更直观,但在表示人类如何看到和解释图像中的颜色方面做得不是最好。
例如,让我们计算红色和绿色之间的欧几里德距离;红色和紫色;以及 RGB 颜色空间中的红色和海军蓝:
>>> import math
>>> red_green = math.sqrt(((255 - 0) ** 2) + ((0 - 255) ** 2) + ((0 - 0) ** 2))
>>> red_purple = math.sqrt(((255 - 128) ** 2) + ((0 - 0) ** 2) + ((0 - 128) ** 2))
>>> red_navy = math.sqrt(((255 - 0) ** 2) + ((0 - 0) ** 2) + ((0 - 128) ** 2))
>>> red_green, red_purple, red_navy
(360.62445840513925, 180.31361568112376, 285.3226244096321)
这就引出了一个问题:这些距离值实际上代表什么?
红色在某种程度上更像紫色而不是绿色吗?
答案是简单的“不”,即使我们已经在立方体和圆柱体等物体上定义了颜色空间,这些距离实际上是任意的,并且实际上没有办法“测量”RGB 和 HSV 颜色空间中各种颜色之间的感知差异。
这就是 Lab*颜色空间的由来——它的目标是模仿人类观察和解释颜色的方法。
这意味着 Lab颜色空间中两个任意颜色之间的欧几里德距离具有实际的感知意义。*
感性意义的加入使得 Lab*色彩空间不如 RGB 和 HSV 那样直观易懂,但在计算机视觉中大量使用。
本质上,Lab*颜色空间是一个 3 轴系统:
我们在下面定义了每个通道:
- L 通道:像素的“明度”。该值沿垂直轴上下移动,从白色到黑色,中性灰色位于轴的中心。
- a 通道:源自 L 通道的中心,在光谱的一端定义纯绿色,在另一端定义纯红色。
- b 通道:也起源于 L 通道的中心,但与 a 通道垂直。b 通道在一个光谱上定义纯蓝色,在另一个光谱上定义纯黄色。
同样,虽然 Lab*颜色空间不如 HSV 和 RGB 颜色空间直观,也不容易理解,但它在计算机视觉中被大量使用。这是由于颜色之间的距离具有实际的感知意义,允许我们克服各种照明条件的问题。它也是一个强大的彩色图像描述符。
现在,让我们看看如何将我们的图像转换到 Lab*色彩空间:
# convert the image to the L*a*b* color space and show it
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
cv2.imshow("L*a*b*", lab)
# loop over each of the individual channels and display them
for (name, chan) in zip(("L*", "a*", "b*"), cv2.split(lab)):
cv2.imshow(name, chan)
# wait for a keypress, then close all open windows
cv2.waitKey(0)
cv2.destroyAllWindows()
到 Lab色彩空间的转换再次由cv2.cvtColor函数处理,但是这一次我们提供了cv2.COLOR_BGR2LAB标志来指示我们想要从 BGR 转换到 Lab色彩空间。
从那里,我们分别循环 L、a和 b*通道,并将它们显示在屏幕上:
类似于我们的 HSV 示例,我们有 L -通道,它专用于显示给定像素的亮度。a和 b*决定了像素的阴影和颜色。
灰度
我们要讨论的最后一个颜色空间实际上并不是一个颜色空间——它只是 RGB 图像的灰度表示。
图像的灰度表示丢弃了图像的颜色信息,也可以使用cv2.cvtColor功能来实现:
# show the original and grayscale versions of the image
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Original", image)
cv2.imshow("Grayscale", gray)
cv2.waitKey(0)
当我们的输出是灰度图像时:
图像的灰度表示通常被称为“黑白”,但这在技术上是不正确的。灰度图像是单通道图像,像素值在【0,255】范围内(即 256 个唯一值)。
真正的黑白图像被称为二进制图像,因此只有两个可能的值: 0 或 255 (即只有两个唯一值)。
将灰度图像称为黑白图像时要小心,以避免这种歧义。
然而,将 RGB 图像转换为灰度图像并不像您想象的那样简单。从生物学上讲,我们的眼睛更敏感,因此感知的绿色和红色比蓝色多。
因此,当转换为灰度时,每个 RGB 通道是而不是均匀加权的,如下所示:

相反,我们对每个通道进行不同的加权,以说明我们对每个通道的颜色感知程度:

同样,由于我们眼睛中的视锥细胞和感受器,我们能够感知的绿色是红色的近两倍。同样,我们注意到红色的数量是蓝色的两倍多。因此,我们确保在从 RGB 转换到灰度时考虑到这一点。
当我们不需要颜色时(例如在检测人脸或构建对象分类器时,对象的颜色无关紧要),通常使用图像的灰度表示。因此,丢弃颜色可以让我们节省内存,提高计算效率。
OpenCV 色彩空间结果
准备好可视化 RGB、HSV 和 Lab*色彩空间的输出了吗?
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
然后,您可以使用以下命令执行我们的演示脚本:
$ python color_spaces.py
这个脚本的输出应该匹配我上面提供的图像和数字。
总结
在本教程中,我们了解了照明条件及其在计算机视觉应用中的重要作用。关键的一点是,在你写一行代码之前,一定要考虑到你的光线条件!
在你可以真正控制光照条件的情况下,你会过得更好。总的来说,你会发现控制你的照明条件比编写代码来补偿低质量图像更容易。
其次,我们回顾了计算机视觉中三种非常常见的颜色空间:RGB、HSV 和 Lab*。
RGB 颜色空间是计算机视觉中最常见的颜色空间。这是一个加色空间,颜色是根据红、绿、蓝的组合值定义的。
虽然很简单,但不幸的是,RGB 颜色空间对于定义颜色来说并不直观,因为很难准确地指出多少红色、绿色和蓝色组成了某种颜色——想象一下,查看照片的特定区域,并试图仅用肉眼识别有多少红色、绿色和蓝色!
幸运的是,我们有 HSV 颜色空间来弥补这个问题。HSV 颜色空间也很直观,因为它允许我们沿着圆柱体而不是 RGB 立方体定义颜色。HSV 颜色空间还为亮度/白度提供了自己单独的维度,使其更容易定义颜色的深浅。
然而,RGB 和 HSV 颜色空间都无法模拟人类感知颜色的方式— 使用 RGB 和 HSV 模型,无法从数学上定义两种任意颜色的感知差异。
这正是 Lab颜色空间被开发出来的原因。虽然更复杂,但 Lab提供了感知一致性,这意味着两种任意颜色之间的距离具有实际意义。
综上所述,你会发现大多数计算机视觉应用都会使用 RGB 颜色空间。虽然它有很多缺点,但它的简单性无可匹敌——对于大多数系统来说,它已经足够了。
还会有使用 HSV 颜色空间的时候——特别是如果你对根据图像中的颜色来跟踪图像中的对象感兴趣的时候。使用 HSV 很容易定义颜色范围。
对于基本的图像处理和计算机视觉,你可能不会经常使用 Lab颜色空间。但是,当您关心跨多个设备的色彩管理、色彩传输或色彩一致性时,Lab色彩空间将是您最好的朋友。它也是一个优秀的彩色图像描述符。
最后,我们讨论了将图像从 RGB 转换为灰度。虽然图像的灰度表示在技术上不是颜色空间,但它与 RGB、HSV 和 Lab*一样值得一提。当颜色不重要时,我们经常使用图像的灰度表示——这使我们能够节省内存并提高计算效率。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
OpenCV 连通分量标记和分析
原文:https://pyimagesearch.com/2021/02/22/opencv-connected-component-labeling-and-analysis/
在本教程中,您将学习如何使用 OpenCV 执行连接组件标记和分析。具体来说,我们将重点介绍 OpenCV 最常用的连通分量标注函数cv2.connectedComponentsWithStats。
连通分量标记(也称为连通分量分析、斑点提取或区域标记)是图论的算法应用,用于确定二进制图像中“斑点”状区域的连通性。
我们经常在使用轮廓的相同情况下使用连通分量分析;然而,连通分量标记通常可以为我们提供二值图像中斑点的更细粒度过滤。
使用轮廓分析时,我们经常受到轮廓层次的限制(即一个轮廓包含在另一个轮廓内)。有了连通分量分析,我们可以更容易地分割和分析这些结构。
连通分量分析的一个很好的例子是计算二进制(即,阈值化)牌照图像的连通分量,并基于它们的属性(例如,宽度、高度、面积、坚实度等)过滤斑点。).这正是我们今天要做的事情。
连通分量分析是添加到 OpenCV 工具带的另一个工具!
要了解如何使用 OpenCV 执行连接组件标记和分析,请继续阅读。
OpenCV 连通分量标记和分析
在本教程的第一部分,我们将回顾 OpenCV 提供的四个(是的,四个)函数来执行连通分量分析。这些函数中最受欢迎的是cv2.connectedComponentsWithStats。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
接下来,我们将实现两种形式的连通分量分析:
- 第一种方法将演示如何使用 OpenCV 的连接组件分析功能,计算每个组件的统计数据,然后分别提取/可视化每个组件。
- 第二种方法展示了一个连接组件分析的实际例子。我们对车牌进行阈值处理,然后使用连通分量分析来提取和车牌字符。
我们将在本指南的最后讨论我们的结果。
OpenCV 的连接组件函数
OpenCV 提供了四个连通分量分析函数:
cv2.connectedComponentscv2.connectedComponentsWithStatscv2.connectedComponentsWithAlgorithmcv2.connectedComponentsWithStatsWithAlgorithm
最流行的方法是cv2.connectedComponentsWithStats,它返回以下信息:
- 连接组件的边界框
- 组件的面积(像素)
- 质心/中心 (x,y)-组件的坐标
第一种方法cv2.connectedComponents与第二种方法相同,只是没有返回上述统计信息。在绝大多数情况下,你会需要统计数据,所以简单地用cv2.connectedComponentsWithStats代替是值得的。
第三种方法cv2.connectedComponentsWithAlgorithm,实现了更快、更有效的连通分量分析算法。
如果 OpenCV 编译支持并行处理,那么cv2.connectedComponentsWithAlgorithm和cv2.connectedComponentsWithStatsWithAlgorithm将比前两个运行得更快。
但是一般来说,坚持使用cv2.connectedComponentsWithStats直到你对使用连接组件标签感到舒适为止。
配置您的开发环境
要了解如何执行连接组件分析,您需要在计算机上安装 OpenCV:
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们用 OpenCV 实现连接组件分析之前,让我们先看一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像:
$ tree . --dirsfirst
.
├── basic_connected_components.py
├── filtering_connected_components.py
└── license_plate.png
0 directories, 3 files
我们将对应用连接成分分析,自动从车牌中过滤出字符(license_plate.png)。
为了完成这项任务并了解有关连通分量分析的更多信息,我们将实现两个 Python 脚本:
- 演示了如何应用连接组件标签,提取每个组件及其统计数据,并在我们的屏幕上显示它们。
filtering_connected_components.py:应用连接组件分析,但通过检查每个组件的宽度、高度和面积(以像素为单位)来过滤掉非牌照字符。
用 OpenCV 实现基本连接组件
让我们开始用 OpenCV 实现连通分量分析。
打开项目文件夹中的basic_connected_components.py文件,让我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-c", "--connectivity", type=int, default=4,
help="connectivity for connected component analysis")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-11 行解析我们的命令行参数。
我们有两个命令行参数:
--image:我们的输入图像驻留在磁盘上的路径。--connectivity:或者4或者8连接(你可以参考本页了解更多关于四对八连接的细节)。
让我们继续预处理我们的输入图像:
# load the input image from disk, convert it to grayscale, and
# threshold it
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
第 15-18 行继续:
- 从磁盘加载我们的输入
image - 将其转换为灰度
- 使用 Otsu 的阈值方法对其进行阈值处理
阈值处理后,我们的图像将如下所示:
请注意车牌字符是如何在黑色背景上显示为白色的。然而,在输入图像中也有一串噪声,其也作为前景出现。
我们的目标是应用连通分量分析来过滤掉这些噪声区域,只给我们留下和车牌字符。
但是在我们开始之前,让我们先来学习如何使用cv2.connectedComponentsWithStats函数:
# apply connected component analysis to the thresholded image
output = cv2.connectedComponentsWithStats(
thresh, args["connectivity"], cv2.CV_32S)
(numLabels, labels, stats, centroids) = output
对第 21 行和第 22 行上的cv2.connectedComponentsWithStats的调用使用 OpenCV 执行连通分量分析。我们在这里传入三个参数:
- 二进制
thresh图像 --connectivity命令行参数- 数据类型(应该保留为
cv2.CV_32S)
然后,cv2.connectedComponentsWithStats返回一个 4 元组:
- 检测到的独特标签的总数(即总成分数)
- 名为
labels的遮罩与我们的输入图像thresh具有相同的空间维度。对于labels中的每个位置,我们都有一个整数 ID 值,对应于像素所属的连通分量。在本节的后面,您将学习如何过滤labels矩阵。 stats:统计每个连接的组件,包括包围盒坐标和面积(以像素为单位)。- 每个相连组件的
centroids(即中心) (x,y)-坐标。
现在让我们学习如何解析这些值:
# loop over the number of unique connected component labels
for i in range(0, numLabels):
# if this is the first component then we examine the
# *background* (typically we would just ignore this
# component in our loop)
if i == 0:
text = "examining component {}/{} (background)".format(
i + 1, numLabels)
# otherwise, we are examining an actual connected component
else:
text = "examining component {}/{}".format( i + 1, numLabels)
# print a status message update for the current connected
# component
print("[INFO] {}".format(text))
# extract the connected component statistics and centroid for
# the current label
x = stats[i, cv2.CC_STAT_LEFT]
y = stats[i, cv2.CC_STAT_TOP]
w = stats[i, cv2.CC_STAT_WIDTH]
h = stats[i, cv2.CC_STAT_HEIGHT]
area = stats[i, cv2.CC_STAT_AREA]
(cX, cY) = centroids[i]
第 26 行遍历 OpenCV 返回的所有唯一连接组件的 id。
然后我们会遇到一个if/else语句:
- 第一个连接的组件,ID 为
0,是总是的背景。我们通常会忽略背景,但是如果你需要它,请记住 ID0包含它。 - 否则,如果
i > 0,那么我们知道这个组件更值得探索。
第 44-49 行向我们展示了如何解析我们的stats和centroids列表,允许我们提取:
- 组件的起始
x坐标 - 组件的起始
y坐标 - 组件的宽度(
w) - 组件的高度(
h) - 质心 (x,y)-组件的坐标
现在让我们来看一下当前组件的边界框和质心:
# clone our original image (so we can draw on it) and then draw
# a bounding box surrounding the connected component along with
# a circle corresponding to the centroid
output = image.copy()
cv2.rectangle(output, (x, y), (x + w, y + h), (0, 255, 0), 3)
cv2.circle(output, (int(cX), int(cY)), 4, (0, 0, 255), -1)
第 54 行创造了一个我们可以借鉴的output图像。然后,我们将组件的边界框绘制成绿色矩形(线 55 )并将质心绘制成红色圆形(线 56 )。
我们的最后一个代码块演示了如何为当前连接的组件创建一个遮罩:
# construct a mask for the current connected component by
# finding a pixels in the labels array that have the current
# connected component ID
componentMask = (labels == i).astype("uint8") * 255
# show our output image and connected component mask
cv2.imshow("Output", output)
cv2.imshow("Connected Component", componentMask)
cv2.waitKey(0)
第 61 行首先找到labels中所有与当前组件 IDi相等的位置。然后,我们将结果转换为一个无符号的 8 位整数,对于背景,值为0,对于前景,值为255。
然后,output图像和componentMask显示在我们屏幕上的64-66 行。
OpenCV 连通分量分析结果
我们现在准备好用 OpenCV 执行连接组件标记了!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像:
$ python basic_connected_components.py --image license_plate.png
[INFO] examining component 1/17 (background)
[INFO] examining component 2/17
[INFO] examining component 3/17
[INFO] examining component 4/17
[INFO] examining component 5/17
[INFO] examining component 6/17
[INFO] examining component 7/17
[INFO] examining component 8/17
[INFO] examining component 9/17
[INFO] examining component 10/17
[INFO] examining component 11/17
[INFO] examining component 12/17
[INFO] examining component 13/17
[INFO] examining component 14/17
[INFO] examining component 15/17
[INFO] examining component 16/17
[INFO] examining component 17/17
下面的动画展示了我在 17 个检测到的组件之间循环切换的过程:
第一个连通的组件其实就是我们的后台。我们通常跳过这个组件,因为背景并不经常需要。
然后显示其余的 16 个组件。对于每个组件,我们绘制了边界框(绿色矩形)和质心/中心(红色圆圈)。
您可能已经注意到,这些连接的组件中有一些是车牌字符,而其他的只是“噪音”
这就提出了一个问题:
有没有可能只检测车牌字符的成分?如果是这样,我们该怎么做?
我们将在下一节讨论这个问题。
如何用 OpenCV 过滤连通组件
我们之前的代码示例演示了如何用 OpenCV 从中提取连接的组件,但是没有演示如何用过滤它们。
现在让我们来学习如何过滤连接的组件:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-c", "--connectivity", type=int, default=4,
help="connectivity for connected component analysis")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包,而第 7-12 行解析我们的命令行参数。
这些命令行参数与我们之前脚本中的参数相同,所以我建议你参考本教程的前面部分,以获得对它们的详细解释。
从那里,我们加载我们的图像,预处理它,并应用连接组件分析:
# load the input image from disk, convert it to grayscale, and
# threshold it
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
# apply connected component analysis to the thresholded image
output = cv2.connectedComponentsWithStats(
thresh, args["connectivity"], cv2.CV_32S)
(numLabels, labels, stats, centroids) = output
# initialize an output mask to store all characters parsed from
# the license plate
mask = np.zeros(gray.shape, dtype="uint8")
第 16-19 行加载我们的输入图像,并以与我们在之前的脚本中相同的方式对其进行预处理。然后,我们对第 22-24 行的应用连通分量分析。
第 28 行初始化一个输出mask来存储我们在执行连通分量分析后找到的所有牌照字符。
说到这里,我们现在来看一下每个独特的标签:
# loop over the number of unique connected component labels, skipping
# over the first label (as label zero is the background)
for i in range(1, numLabels):
# extract the connected component statistics for the current
# label
x = stats[i, cv2.CC_STAT_LEFT]
y = stats[i, cv2.CC_STAT_TOP]
w = stats[i, cv2.CC_STAT_WIDTH]
h = stats[i, cv2.CC_STAT_HEIGHT]
area = stats[i, cv2.CC_STAT_AREA]
注意,我们的for循环从 ID 1开始,这意味着我们跳过了背景值0。
然后我们在第 35-39 行的上提取当前连接组件的边界框坐标和area。
我们现在准备过滤我们连接的组件:
# ensure the width, height, and area are all neither too small
# nor too big
keepWidth = w > 5 and w < 50
keepHeight = h > 45 and h < 65
keepArea = area > 500 and area < 1500
# ensure the connected component we are examining passes all
# three tests
if all((keepWidth, keepHeight, keepArea)):
# construct a mask for the current connected component and
# then take the bitwise OR with the mask
print("[INFO] keeping connected component '{}'".format(i))
componentMask = (labels == i).astype("uint8") * 255
mask = cv2.bitwise_or(mask, componentMask)
第 43-45 行展示了我们正在根据它们的宽度、高度和面积过滤连接的组件,丢弃那些太小或太大的组件。
注: 想知道我是怎么想出这些值的?我使用了print语句来显示每个连接组件的宽度、高度和面积,同时将它们分别可视化到我的屏幕上。我记下了车牌字符的宽度、高度和面积,并找到了它们的最小/最大值,每端都有一点公差。对于您自己的应用程序,您也应该这样做。
第 49 行验证keepWidth、keepHeight、keepArea都是True,暗示他们都通过了测试。
如果确实如此,我们计算当前标签 ID 的componentMask(就像我们在basic_connected_components.py脚本中所做的那样)并将牌照字符添加到我们的mask中。
最后,我们在屏幕上显示我们的输入image并输出牌照字符mask。
# show the original input image and the mask for the license plate
# characters
cv2.imshow("Image", image)
cv2.imshow("Characters", mask)
cv2.waitKey(0)
正如我们将在下一节看到的,我们的mask将只包含牌照字符。
过滤连通分量结果
让我们来学习如何使用 OpenCV 过滤连接的组件!
请务必访问本指南的 “下载” 部分,以检索源代码和示例图像—从那里,您可以执行以下命令:
$ python filtering_connected_components.py --image license_plate.png
[INFO] keeping connected component 7
[INFO] keeping connected component 8
[INFO] keeping connected component 9
[INFO] keeping connected component 10
[INFO] keeping connected component 11
[INFO] keeping connected component 12
[INFO] keeping connected component 13
图 5 显示了过滤我们连接的组件的结果。在顶部,我们有包含牌照的原始输入图像。底部有过滤连接成分的结果,导致只是车牌字符本身。
如果我们正在构建一个自动牌照/车牌识别(ALPR/ANPR)系统,我们将获取这些字符,然后将它们传递给光学字符识别(OCR)算法进行识别。但这一切都取决于我们能否将字符二值化并提取出来,而连通分量分析使我们能够做到这一点!
总结
在本教程中,您学习了如何执行连接的组件分析。
OpenCV 为我们提供了四个用于连通分量标记的函数:
cv2.connectedComponentscv2.connectedComponentsWithStatscv2.connectedComponentsWithAlgorithmcv2.connectedComponentsWithStatsWithAlgorithm()
其中最受欢迎的就是我们今天使用的cv2.connectedComponentsWithStats函数。
当处理图像中的斑点状结构时,连通分量分析实际上可以取代轮廓检测、计算轮廓统计数据并过滤它们的过程。
连通分量分析是您工具箱中的一项便捷功能,因此请务必练习使用它。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV 轮廓近似
原文:https://pyimagesearch.com/2021/10/06/opencv-contour-approximation/
在本教程中,我们将了解 OpenCV 的轮廓近似的一步一步的实现和利用。
当我第一次偶然发现轮廓逼近的概念时,我想到的第一个问题是:为什么是?在我的机器学习及其相关领域的旅程中,我一直被教导数据就是一切。数据就是货币。你拥有的越多,你就越有可能成功。图 1 恰当地描述了这个场景。
因此,我不太理解逼近曲线数据点的概念。那不是更简单吗?那不会让我们丢失数据吗?我大吃一惊。
在今天的教程中,我们将学习 OpenCV 轮廓逼近,更准确地说,称为 Ramer–Douglas–peu cker 算法。您会惊讶地发现它对许多高优先级的实际应用程序是多么重要。
在这篇博客中,你将了解到:
- 什么是轮廓近似
- 理解轮廓近似所需的先决条件
- 如何实现轮廓逼近
- 轮廓逼近的一些实际应用
学习如何实现轮廓逼近, 只需继续阅读。
OpenCV 轮廓近似(cv2.approxPolyDP )
让我们想象一个场景:你是一个自动驾驶机器人。你根据雷达(激光雷达、声纳等)收集的数据移动。).你必须不断地处理大量的数据,这些数据将被转换成你能理解的格式。然后,你会做出搬家所需的决定。在这种情况下,你最大的障碍是什么?是故意留在你路上的那块砖头吗?还是一条曲折的道路挡在你和目的地之间?
原来,简单的答案是…所有的人。想象一下,在给定时间内,你要获取多少数据来评估一种情况。原来数据一直在两面讨好。数据一直是我们的敌人吗?
虽然更多的数据确实给你的解决方案提供了更好的视角,但它也带来了计算复杂性和存储等问题。现在,你就像一个机器人,需要做出合理快速的决定来穿越你面前的路线。
这意味着简化复杂的数据将是您的首要任务。
假设你得到了一个你将要走的路线的俯视图。类似于图 2。
如果给定道路的确切宽度和其他参数,有一种方法可以简化这张地图,会怎么样?考虑到你的尺寸足够小,可以忽略多余的转弯(你可以直接走而不用沿着道路的确切曲线走的部分),如果你可以删除一些多余的顶点,对你来说会更容易。类似图 3 的东西:
注意一些顶点是如何反复平滑的,从而产生一条更加线性的路线。很巧妙,不是吗?
这只是轮廓逼近在现实世界中的众多应用之一。在我们继续之前,让我们正式了解它是什么。
什么是轮廓逼近?
轮廓近似法使用了Ramer–Douglas–peu cker(RDP)算法,旨在通过减少给定阈值的顶点来简化折线。通俗地说,我们选择一条曲线,减少它的顶点数,同时保留它的大部分形状。比如看一下图 4 。
这张来自维基百科 RDP 文章的信息丰富的 GIF 向我们展示了这种算法是如何工作的。我在这里给出算法的大概思路。
给定曲线的起点和终点,算法将首先找到与连接两个参考点的直线距离最大的顶点。姑且称之为max_point。如果max_point的距离小于阈值,我们会自动忽略起点和终点之间的所有顶点,并使曲线成为直线。
如果max_point位于阈值之外,我们将递归重复该算法,现在使max_point成为引用之一,并重复如图图 4 所示的检查过程。
注意某些顶点是如何被系统地消除的。最终,我们保留了大部分信息,但状态不太复杂。
这样一来,让我们看看如何使用 OpenCV 来利用 RDP 的力量!
配置您的开发环境
为了遵循这个指南,您需要在您的系统上安装 OpenCV 库和imutils 包。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install imutils
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们来看看项目结构。
$ tree . --dirsfirst
.
├── opencv_contour_approx.py
└── shape.png
0 directories, 2 files
父目录包含一个脚本和一个图像:
opencv_contour_approx.py:项目中唯一需要的脚本包含了所有涉及到的编码。- 我们将在其上测试轮廓近似的图像。
用 OpenCV 实现轮廓逼近
在跳到轮廓近似之前,我们将通过一些先决条件来更好地理解整个过程。所以,事不宜迟,让我们跳进opencv_contour_approx.py开始编码吧!
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="shape.png",
help="path to input image")
args = vars(ap.parse_args())
创建一个参数解析器实例是为了在用户选择想要修改的图像时给他们一个简单的命令行界面体验(第 8-11 行)。默认图像被设置为shape.png,该图像已经存在于目录中。然而,我们鼓励读者用他们自己的自定义图像来尝试这个实验!
# load the image and display it
image = cv2.imread(args["image"])
cv2.imshow("Image", image)
# convert the image to grayscale and threshold it
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 200, 255,
cv2.THRESH_BINARY_INV)[1]
cv2.imshow("Thresh", thresh)
然后使用 OpenCV 的imread读取并显示作为参数提供的图像(第 14 行和第 15 行)。
图像将看起来像图 6 :
由于我们将在图像中使用形状的边界,我们将图像从 RGB 转换为灰度(线 18** )。一旦采用灰度格式,可以使用 OpenCV 的threshold函数(行 19-21** )轻松分离出形状。结果见图 7:
注意,由于我们在**行 2 0** 上选择了cv2.THRESH_BINARY_INV作为参数,因此高亮度像素变为0,而周围的低亮度像素变为255。
# find the largest contour in the threshold image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
c = max(cnts, key=cv2.contourArea)
# draw the shape of the contour on the output image, compute the
# bounding box, and display the number of points in the contour
output = image.copy()
cv2.drawContours(output, [c], -1, (0, 255, 0), 3)
(x, y, w, h) = cv2.boundingRect(c)
text = "original, num_pts={}".format(len(c))
cv2.putText(output, text, (x, y - 15), cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 255, 0), 2)
# show the original contour image
print("[INFO] {}".format(text))
cv2.imshow("Original Contour", output)
cv2.waitKey(0)
使用 OpenCV 的findContours函数,我们可以挑出给定图像中所有可能的轮廓(取决于给定的参数)(线 24 和 25T5)。我们使用了RETR_EXTERNAL参数,它只返回可用轮廓的单一表示。你可以在这里阅读更多相关信息。
使用的另一个参数是CHAIN_APPROX_SIMPLE。这将删除单链线连接中的许多顶点,这些顶点本质上是多余的。
然后我们从轮廓数组中抓取最大的轮廓(这个轮廓属于形状)并在原始图像上跟踪它(线 26-36** )。为此,我们使用 OpenCV 的drawContours函数。我们还使用putText函数在图像上书写。输出如图 8** 所示:
现在,让我们演示一下轮廓近似可以做什么!
# to demonstrate the impact of contour approximation, let's loop
# over a number of epsilon sizes
for eps in np.linspace(0.001, 0.05, 10):
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, eps * peri, True)
# draw the approximated contour on the image
output = image.copy()
cv2.drawContours(output, [approx], -1, (0, 255, 0), 3)
text = "eps={:.4f}, num_pts={}".format(eps, len(approx))
cv2.putText(output, text, (x, y - 15), cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 255, 0), 2)
# show the approximated contour image
print("[INFO] {}".format(text))
cv2.imshow("Approximated Contour", output)
cv2.waitKey(0)
如前所述,我们需要一个值eps,它将作为测量顶点的阈值。相应地,我们开始在一个范围内循环 epsilon 的(eps)值,以将其馈送给轮廓近似函数(线45T5)。
在线 47** 上,使用cv2.arcLength计算轮廓的周长。然后我们使用cv2.approxPolyDP功能并启动轮廓近似过程(线48)。eps × peri值作为近似精度,由于eps的递增性质,它将随着每个历元而变化。**
我们继续在每个时期追踪图像上的合成轮廓以评估结果(**线 51-60** )。
让我们看看结果!
轮廓近似结果
在进行可视化之前,让我们看看轮廓近似如何影响这些值。
$ python opencv_contour_approx.py
[INFO] original, num_pts=248
[INFO] eps=0.0010, num_pts=43
[INFO] eps=0.0064, num_pts=24
[INFO] eps=0.0119, num_pts=17
[INFO] eps=0.0173, num_pts=12
[INFO] eps=0.0228, num_pts=11
[INFO] eps=0.0282, num_pts=10
[INFO] eps=0.0337, num_pts=7
[INFO] eps=0.0391, num_pts=4
[INFO] eps=0.0446, num_pts=4
[INFO] eps=0.0500, num_pts=4
请注意,随着eps值的增加,轮廓中的点数不断减少。这表明近似法确实有效。请注意,在的eps值为 0.0391 时,点数开始饱和。让我们用可视化来更好地分析这一点。
轮廓近似可视化
通过图 9-12 ,我们记录了一些时期的轮廓演变。
注意曲线是如何逐渐变得越来越平滑的。随着阈值的增加,它变得越线性。当eps的值达到 0.0500 时,轮廓现在是一个完美的矩形,只有 4 个点。这就是拉默-道格拉斯-普克算法的威力。
学分
受 OpenCV 文档启发的扭曲形状图像。
总结
在这个数据驱动的世界中,简化数据同时保留大部分信息可能是最受欢迎的场景之一。今天,我们学习了如何使用 RDP 来简化我们的任务。它对矢量图形和机器人领域的贡献是巨大的。
RDP 还扩展到其他领域,如距离扫描,在那里它被用作去噪工具。我希望这篇教程能帮助你理解如何在工作中使用轮廓逼近。
引用信息
Chakraborty,d .“OpenCV 轮廓近似(cv2.approxPolyDP),” PyImageSearch ,2021,https://PyImageSearch . com/2021/10/06/OpenCV-Contour-Approximation/
@article{dev2021opencv, author = {Devjyoti Chakraborty}, title = {Open{CV} Contour Approximation ( cv2.approx{PolyDP} )}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/10/06/opencv-contour-approximation/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
采用 NVIDIA GPUs 的 OpenCV“dnn ”: YOLO、SSD 和 Mask R-CNN 快 1549%
在本教程中,您将了解如何使用 OpenCV 的“dnn”模块和 NVIDIA GPU,将对象检测 (YOLO 和 SSD)和实例分割 (Mask R-CNN)的速度提高 1549%。
上周,我们发现了如何使用 NVIDIA GPU 配置和安装 OpenCV 及其“深度神经网络”(dnn)模块进行推理。
使用 OpenCV 的 GPU 优化的dnn模块,我们能够将一个给定网络的计算从 CPU 推送到 GPU ,只需要三行代码:
# load the model from disk and set the backend target to a
# CUDA-enabled GPU
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
今天,我们将更详细地讨论完整的代码示例,在本教程结束时,您将能够应用:
- 单触发探测器在 65.90 FPS
- YOLO 物体检测在 11.87 FPS
- 在 11.05 FPS 处屏蔽 R-CNN 实例分割
要了解如何使用 OpenCV 的dnn模块和 NVIDIA GPU 进行更快的对象检测和实例分割,请继续阅读!
采用 NVIDIA GPUs 的 OpenCV“dnn ”: YOLO、SSD 和 Mask R-CNN 的速度提高了 1,549%
在本教程中,您将学习如何使用 OpenCV 的“深度神经网络”(dnn)模块和支持 NVIDIA/CUDA 的 GPU 来实现单次检测器、YOLO 和掩模 R-CNN。
在 NVIDIA GPU 支持下编译 OpenCV 的“dnn”模块

Figure 1: Compiling OpenCV’s DNN module with the CUDA backend allows us to perform object detection with YOLO, SSD, and Mask R-CNN deep learning models much faster.
如果你还没有,确保你仔细阅读了上周的教程关于配置和安装 OpenCV 与 NVIDIA GPU 对“dnn”模块的支持——该教程之后是本教程的绝对先决条件。
如果不安装 OpenCV 并启用 NVIDIA GPU 支持,OpenCV 会仍然使用你的 CPU 进行推理;但是,如果您试图将计算传递给 GPU,OpenCV 将会出错。
项目结构
在我们回顾今天项目的结构之前,先从这篇博文的 【下载】 部分获取代码和模型文件。
从那里,解压缩文件并在终端中使用tree命令检查项目层次结构:
$ tree --dirsfirst
.
├── example_videos
│ ├── dog_park.mp4
│ ├── guitar.mp4
│ └── janie.mp4
├── opencv-ssd-cuda
│ ├── MobileNetSSD_deploy.caffemodel
│ ├── MobileNetSSD_deploy.prototxt
│ └── ssd_object_detection.py
├── opencv-yolo-cuda
│ ├── yolo-coco
│ │ ├── coco.names
│ │ ├── yolov3.cfg
│ │ └── yolov3.weights
│ └── yolo_object_detection.py
├── opencv-mask-rcnn-cuda
│ ├── mask-rcnn-coco
│ │ ├── colors.txt
│ │ ├── frozen_inference_graph.pb
│ │ ├── mask_rcnn_inception_v2_coco_2018_01_28.pbtxt
│ │ └── object_detection_classes_coco.txt
│ └── mask_rcnn_segmentation.py
└── output_videos
7 directories, 15 files
在今天的教程中,我们将回顾三个 Python 脚本:
ssd_object_detection.py:用 CUDA 对 20 个 COCO 类进行基于 Caffe 的 MobileNet SSD 对象检测。yolo_object_detection.py:用 CUDA 对 80 个 COCO 类进行 YOLO V3 物体检测。- 使用 CUDA 对 90 个 COCO 类进行基于 TensorFlow 的初始 V2 分割。
除了我们的 MobileNet SSD 之外,每个模型文件和类名文件都包含在各自的文件夹中(类名直接在脚本中硬编码在 Python 列表中)。让我们按照今天的顺序来查看文件夹名称:
opencv-ssd-cuda/opencv-yolo-cuda/opencv-mask-rcnn-cuda/
从这三个目录名可以明显看出,我们将使用 OpenCV 的 DNN 模块,该模块在 CUDA 支持下编译。如果你的 OpenCV 没有为你的 NVIDIA GPU 编译 CUDA 支持,那么你需要使用上周教程中的说明配置你的系统。
使用 OpenCV 的 NVIDIA GPU 支持的“dnn”模块实现单次检测器(SSD)
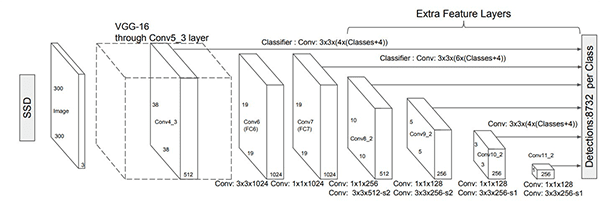
Figure 2: Single Shot Detectors (SSDs) are known for being fast and efficient. In this tutorial, we’ll use Python + OpenCV + CUDA to perform even faster deep learning inference using an NVIDIA GPU.
我们将关注的第一个物体探测器是单次发射探测器(SSD),我们最初在 2017 年讨论过的:
当时我们只能在 CPU 上运行这些固态硬盘;然而,今天我将向您展示如何使用 NVIDIA GPU 将推理速度提高高达 211%。
打开项目目录结构中的ssd_object_detection.py文件,并插入以下代码:
# import the necessary packages
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-i", "--input", type=str, default="",
help="path to (optional) input video file")
ap.add_argument("-o", "--output", type=str, default="",
help="path to (optional) output video file")
ap.add_argument("-d", "--display", type=int, default=1,
help="whether or not output frame should be displayed")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
ap.add_argument("-u", "--use-gpu", type=bool, default=False,
help="boolean indicating if CUDA GPU should be used")
args = vars(ap.parse_args())
这里我们已经导入了我们的包。请注意,我们不需要 CUDA 的任何特殊导入。CUDA 功能内置于(通过我们上周的编译)我们在线的cv2导入中。
接下来让我们解析我们的命令行参数:
--prototxt:我们预训练的 Caffe MobileNet SSD“deploy”proto txt 文件路径。--model:我们的预训练 Caffe MobileNet 固态硬盘模型之路。--input:我们输入的视频文件的可选的路径。如果没有提供,默认情况下将使用您的第一台摄像机。--output:我们输出视频文件的可选路径。--display:可选的布尔标志,指示我们是否将输出帧显示到 OpenCV GUI 窗口。显示帧会消耗 CPU 周期,因此对于真正的基准测试,您可能希望关闭显示(默认情况下是打开的)。--confidence:过滤弱检测的最小概率阈值。默认情况下,该值设置为 20%;但是,如果您愿意,您可以覆盖它。--use-gpu:一个布尔值,表示是否应该使用 CUDA GPU。默认情况下,该值为False(即关闭)。如果您希望您的支持 NVIDIA CUDA 的 GPU 通过 OpenCV 用于对象检测,您需要向该参数传递一个1值。
接下来,我们将指定我们的类和相关的随机颜色:
# initialize the list of class labels MobileNet SSD was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
然后我们将加载基于 Caffe 的模型:
# load our serialized model from disk
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# check if we are going to use GPU
if args["use_gpu"]:
# set CUDA as the preferable backend and target
print("[INFO] setting preferable backend and target to CUDA...")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
正如第 35 行所示,我们使用 OpenCV 的dnn模块来加载我们的 Caffe 对象检测模型。
检查是否应使用支持 NVIDIA CUDA 的 GPU。从那里,我们相应地设置后端和目标(第 38-42 行)。
让我们开始处理帧,并使用我们的 GPU 执行对象检测(当然,前提是--use-gpu命令行参数打开):
# initialize the video stream and pointer to output video file, then
# start the FPS timer
print("[INFO] accessing video stream...")
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
writer = None
fps = FPS().start()
# loop over the frames from the video stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# resize the frame, grab the frame dimensions, and convert it to
# a blob
frame = imutils.resize(frame, width=400)
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 0.007843, (300, 300), 127.5)
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# `detections`, then compute the (x, y)-coordinates of
# the bounding box for the object
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the prediction on the frame
label = "{}: {:.2f}%".format(CLASSES[idx],
confidence * 100)
cv2.rectangle(frame, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
在这里,我们访问我们的视频流。请注意,该代码旨在兼容视频文件和实时视频流,这就是为什么我选择不使用我的线程视频流类。
在帧上循环,我们:
- 读取和预处理输入帧。
- 从帧构造一个斑点。
- 使用单次检测器和我们的 GPU 检测物体(如果设置了
--use-gpu标志)。 - 过滤对象,仅允许高
--confidence对象通过。 - 注释边界框、类别标签和概率。如果你需要复习 OpenCV 绘图基础知识,一定要参考我的 OpenCV 教程:学习 OpenCV 指南。
最后,我们总结一下:
# check to see if the output frame should be displayed to our
# screen
if args["display"] > 0:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# if an output video file path has been supplied and the video
# writer has not been initialized, do so now
if args["output"] != "" and writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
# if the video writer is not None, write the frame to the output
# video file
if writer is not None:
writer.write(frame)
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
在剩余的行中,我们:
- 如果需要,显示带注释的视频帧。
- 如果我们正在显示,捕捉按键。
- 将带注释的输出帧写入磁盘上的视频文件。
- 更新、计算和打印 FPS 统计数据。
伟大的工作开发您的 SSD + OpenCV + CUDA 脚本。在接下来的部分中,我们将使用 GPU 和 CPU 来分析结果。
单发探测器:OpenCV 的“dnn”模块和 NVIDIA GPU 将物体探测速度提高了 211%
要查看我们的单次检测器,请确保使用本教程的 “下载” 部分下载(1)源代码和(2)与 OpenCV 的dnn模块兼容的预训练模型。
从那里,执行下面的命令,通过在我们的 CPU: 上运行它,为我们的 SSD 获得一个基线
$ python ssd_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt \
--model MobileNetSSD_deploy.caffemodel \
--input ../example_videos/guitar.mp4 \
--output ../output_videos/ssd_guitar.avi \
--display 0
[INFO] accessing video stream...
[INFO] elasped time: 11.69
[INFO] approx. FPS: 21.13
这里我们在 CPU 上获得了 ~21 FPS,这对于一个物体探测器来说是相当不错的!
为了看到探测器真的飞起来,让我们提供--use-gpu 1命令行参数,指示 OpenCV 将dnn计算推送到我们的 NVIDIA Tesla V100 GPU:
$ python ssd_object_detection.py \
--prototxt MobileNetSSD_deploy.prototxt \
--model MobileNetSSD_deploy.caffemodel \
--input ../example_videos/guitar.mp4 \
--output ../output_videos/ssd_guitar.avi \
--display 0 \
--use-gpu 1
[INFO] setting preferable backend and target to CUDA...
[INFO] accessing video stream...
[INFO] elasped time: 3.75
[INFO] approx. FPS: 65.90
使用我们的 NVIDIA GPU,我们现在达到了 ~66 FPS ,这将我们的每秒帧数吞吐率提高了超过 211%! 正如视频演示所示,我们的固态硬盘相当精确。
注:正如Yashas的评论所述,MobileNet SSD 的性能可能会很差,因为 cuDNN 没有针对所有 NVIDA GPUs 上的深度卷积进行优化的内核。如果您看到您的 GPU 结果类似于您的 CPU 结果,这可能是问题所在。
为 OpenCV 的支持 NVIDIA GPU/CUDA 的“dnn”模块实现 YOLO 对象检测
Figure 3: YOLO is touted as being one of the fastest object detection architectures. In this section, we’ll use Python + OpenCV + CUDA to perform even faster YOLO deep learning inference using an NVIDIA GPU.
虽然 YOLO 肯定是速度最快的基于深度学习的物体检测器之一,但 OpenCV 包含的 YOLO 模型绝对不是——在 CPU 上,YOLO 努力打破 3 FPS。
因此,如果你打算在 OpenCV 的dnn模块中使用 YOLO,你最好使用 GPU。
让我们看看如何将 YOLO 物体检测器(yolo_object_detection.py)与 OpenCV 的支持 CUDA 的dnn模块一起使用:
# import the necessary packages
from imutils.video import FPS
import numpy as np
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-y", "--yolo", required=True,
help="base path to YOLO directory")
ap.add_argument("-i", "--input", type=str, default="",
help="path to (optional) input video file")
ap.add_argument("-o", "--output", type=str, default="",
help="path to (optional) output video file")
ap.add_argument("-d", "--display", type=int, default=1,
help="whether or not output frame should be displayed")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="threshold when applyong non-maxima suppression")
ap.add_argument("-u", "--use-gpu", type=bool, default=0,
help="boolean indicating if CUDA GPU should be used")
args = vars(ap.parse_args())
我们的导入几乎与我们之前的脚本相同,只是进行了一次交换。在这个脚本中,我们不需要imutils,但是我们需要 Python 的os模块用于文件 I/O。
让我们回顾一下我们的命令行参数:
--yolo:预训练的 YOLO 模型目录的基本路径。--input:我们输入的视频文件的可选的路径。如果没有提供,默认情况下将使用您的第一台摄像机。--output:我们输出视频文件的可选路径。--display:可选的布尔标志,指示我们是否将输出帧用于 OpenCV GUI 窗口。显示帧会消耗 CPU 周期,因此对于真正的基准测试,您可能希望关闭显示(默认情况下是打开的)。--confidence:过滤弱检测的最小概率阈值。默认情况下,该值设置为 50%;但是,如果您愿意,您可以覆盖它。--threshold:非极大值抑制 (NMS)阈值默认设置为 30%。--use-gpu:一个布尔值,表示是否应该使用 CUDA GPU。默认情况下,该值为False(即关闭)。如果您希望您的支持 NVIDIA CUDA 的 GPU 通过 OpenCV 用于对象检测,您需要向该参数传递一个1值。
接下来,我们将加载我们的类标签并分配随机颜色:
# load the COCO class labels our YOLO model was trained on
labelsPath = os.path.sep.join([args["yolo"], "coco.names"])
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the YOLO weights and model configuration
weightsPath = os.path.sep.join([args["yolo"], "yolov3.weights"])
configPath = os.path.sep.join([args["yolo"], "yolov3.cfg"])
# load our YOLO object detector trained on COCO dataset (80 classes)
print("[INFO] loading YOLO from disk...")
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
# check if we are going to use GPU
if args["use_gpu"]:
# set CUDA as the preferable backend and target
print("[INFO] setting preferable backend and target to CUDA...")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
# determine only the *output* layer names that we need from YOLO
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# initialize the width and height of the frames in the video file
W = None
H = None
# initialize the video stream and pointer to output video file, then
# start the FPS timer
print("[INFO] accessing video stream...")
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
writer = None
fps = FPS().start()
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# if the frame dimensions are empty, grab them
if W is None or H is None:
(H, W) = frame.shape[:2]
# construct a blob from the input frame and then perform a forward
# pass of the YOLO object detector, giving us our bounding boxes
# and associated probabilities
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
net.setInput(blob)
layerOutputs = net.forward(ln)
# initialize our lists of detected bounding boxes, confidences,
# and class IDs, respectively
boxes = []
confidences = []
classIDs = []
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability)
# of the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > args["confidence"]:
# scale the bounding box coordinates back relative to
# the size of the image, keeping in mind that YOLO
# actually returns the center (x, y)-coordinates of
# the bounding box followed by the boxes' width and
# height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top
# and and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates,
# confidences, and class IDs
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# apply non-maxima suppression to suppress weak, overlapping
# bounding boxes
idxs = cv2.dnn.NMSBoxes(boxes, confidences, args["confidence"],
args["threshold"])
# ensure at least one detection exists
if len(idxs) > 0:
# loop over the indexes we are keeping
for i in idxs.flatten():
# extract the bounding box coordinates
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# draw a bounding box rectangle and label on the frame
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
text = "{}: {:.4f}".format(LABELS[classIDs[i]],
confidences[i])
cv2.putText(frame, text, (x, y - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# check to see if the output frame should be displayed to our
# screen
if args["display"] > 0:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# if an output video file path has been supplied and the video
# writer has not been initialized, do so now
if args["output"] != "" and writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
# if the video writer is not None, write the frame to the output
# video file
if writer is not None:
writer.write(frame)
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
$ python yolo_object_detection.py --yolo yolo-coco \
--input ../example_videos/janie.mp4 \
--output ../output_videos/yolo_janie.avi \
--display 0
[INFO] loading YOLO from disk...
[INFO] accessing video stream...
[INFO] elasped time: 51.11
[INFO] approx. FPS: 2.47
$ python yolo_object_detection.py --yolo yolo-coco \
--input ../example_videos/janie.mp4 \
--output ../output_videos/yolo_janie.avi \
--display 0 \
--use-gpu 1
[INFO] loading YOLO from disk...
[INFO] setting preferable backend and target to CUDA...
[INFO] accessing video stream...
[INFO] elasped time: 10.61
[INFO] approx. FPS: 11.87
-
正如我在我最初的 YOLO + OpenCV 博客中讨论的,我真的不确定为什么 YOLO 获得如此低的帧每秒吞吐率。YOLO 一直被认为是 T4 最快的目标探测器之一。
也就是说,似乎转换后的模型或 OpenCV 处理推理的方式有问题——不幸的是,我不知道确切的问题是什么,但我欢迎评论部分的反馈。
为 OpenCV 的支持 CUDA 的“dnn”模块实现屏蔽 R-CNN 实例分割
![]()
Figure 4: Mask R-CNNs are both difficult to train and can be taxing on a CPU. In this section, we’ll use Python + OpenCV + CUDA to perform even faster Mask R-CNN deep learning inference using an NVIDIA GPU. (image source)
在这一点上,我们已经看了固态硬盘和 YOLO,两种不同类型的基于深度学习的对象检测器— 但是像 Mask R-CNN 这样的实例分割网络又如何呢?我们能否利用我们的 NVIDIA GPUs 和 OpenCV 的支持 CUDA 的
dnn模块来提高 Mask R-CNN 的每秒帧数处理速率?你打赌我们能!
打开目录结构中的
mask_rcnn_segmentation.py,了解如何:# import the necessary packages from imutils.video import FPS import numpy as np import argparse import cv2 import os # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-m", "--mask-rcnn", required=True, help="base path to mask-rcnn directory") ap.add_argument("-i", "--input", type=str, default="", help="path to (optional) input video file") ap.add_argument("-o", "--output", type=str, default="", help="path to (optional) output video file") ap.add_argument("-d", "--display", type=int, default=1, help="whether or not output frame should be displayed") ap.add_argument("-c", "--confidence", type=float, default=0.5, help="minimum probability to filter weak detections") ap.add_argument("-t", "--threshold", type=float, default=0.3, help="minimum threshold for pixel-wise mask segmentation") ap.add_argument("-u", "--use-gpu", type=bool, default=0, help="boolean indicating if CUDA GPU should be used") args = vars(ap.parse_args())首先我们处理我们的进口。它们和我们之前的 YOLO 剧本一模一样。
从那里我们将解析命令行参数:
--mask-rcnn:你的预训练掩模 R-CNN 模型目录的基本路径。--input:我们输入的视频文件的可选的路径。如果没有提供,默认情况下将使用您的第一台摄像机。--output:我们输出视频文件的可选路径。--display:可选的布尔标志,指示我们是否将输出帧显示到 OpenCV GUI 窗口。显示帧会消耗 CPU 周期,因此对于真正的基准测试,您可能希望关闭显示(默认情况下是打开的)。--confidence:过滤弱检测的最小概率阈值。默认情况下,该值设置为 50%;但是,如果您愿意,您可以覆盖它。--threshold:逐像素分割的最小阈值。默认情况下,该值设置为 30%。--use-gpu:一个布尔值,表示是否应该使用 CUDA GPU。默认情况下,该值为False(即:关)。如果您希望您的支持 NVIDIA CUDA 的 GPU 通过 OpenCV 用于实例分割,您需要向该参数传递一个1值。
有了导入和命令行参数,现在我们将加载类标签并分配随机颜色:
# load the COCO class labels our Mask R-CNN was trained on labelsPath = os.path.sep.join([args["mask_rcnn"], "object_detection_classes_coco.txt"]) LABELS = open(labelsPath).read().strip().split("\n") # initialize a list of colors to represent each possible class label np.random.seed(42) COLORS = np.random.randint(0, 255, size=(len(LABELS), 3), dtype="uint8")从那里我们将加载我们的模型。
# derive the paths to the Mask R-CNN weights and model configuration weightsPath = os.path.sep.join([args["mask_rcnn"], "frozen_inference_graph.pb"]) configPath = os.path.sep.join([args["mask_rcnn"], "mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"]) # load our Mask R-CNN trained on the COCO dataset (90 classes) # from disk print("[INFO] loading Mask R-CNN from disk...") net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath) # check if we are going to use GPU if args["use_gpu"]: # set CUDA as the preferable backend and target print("[INFO] setting preferable backend and target to CUDA...") net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA) net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)在这里,我们抓住了路径,我们的预训练掩模 R-CNN 的权重和模型。
然后,我们从磁盘加载模型,如果设置了
--use-gpu命令行标志,则将目标后端设置为 GPU。当只使用你的 CPU 时,分段会像糖蜜一样慢。如果您设置了--use-gpu标志,您将会以极快的速度处理您的输入视频或相机流。让我们开始处理帧:
# initialize the video stream and pointer to output video file, then # start the FPS timer print("[INFO] accessing video stream...") vs = cv2.VideoCapture(args["input"] if args["input"] else 0) writer = None fps = FPS().start() # loop over frames from the video file stream while True: # read the next frame from the file (grabbed, frame) = vs.read() # if the frame was not grabbed, then we have reached the end # of the stream if not grabbed: break # construct a blob from the input frame and then perform a # forward pass of the Mask R-CNN, giving us (1) the bounding box # coordinates of the objects in the image along with (2) the # pixel-wise segmentation for each specific object blob = cv2.dnn.blobFromImage(frame, swapRB=True, crop=False) net.setInput(blob) (boxes, masks) = net.forward(["detection_out_final", "detection_masks"])在抓取一帧后,我们将其转换为一个斑点,并通过我们的网络执行一次前向传递来预测对象
boxes和masks。现在我们准备处理我们的结果:
# loop over the number of detected objects for i in range(0, boxes.shape[2]): # extract the class ID of the detection along with the # confidence (i.e., probability) associated with the # prediction classID = int(boxes[0, 0, i, 1]) confidence = boxes[0, 0, i, 2] # filter out weak predictions by ensuring the detected # probability is greater than the minimum probability if confidence > args["confidence"]: # scale the bounding box coordinates back relative to the # size of the frame and then compute the width and the # height of the bounding box (H, W) = frame.shape[:2] box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H]) (startX, startY, endX, endY) = box.astype("int") boxW = endX - startX boxH = endY - startY # extract the pixel-wise segmentation for the object, # resize the mask such that it's the same dimensions of # the bounding box, and then finally threshold to create # a *binary* mask mask = masks[i, classID] mask = cv2.resize(mask, (boxW, boxH), interpolation=cv2.INTER_CUBIC) mask = (mask > args["threshold"]) # extract the ROI of the image but *only* extracted the # masked region of the ROI roi = frame[startY:endY, startX:endX][mask] # grab the color used to visualize this particular class, # then create a transparent overlay by blending the color # with the ROI color = COLORS[classID] blended = ((0.4 * color) + (0.6 * roi)).astype("uint8") # store the blended ROI in the original frame frame[startY:endY, startX:endX][mask] = blended # draw the bounding box of the instance on the frame color = [int(c) for c in color] cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2) # draw the predicted label and associated probability of # the instance segmentation on the frame text = "{}: {:.4f}".format(LABELS[classID], confidence) cv2.putText(frame, text, (startX, startY - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)在结果循环中,我们:
- 根据
confidence进行过滤。 - 调整大小和绘制/注释对象透明的彩色遮罩。
- 在输出帧上标注边界框、标签和概率。
从这里开始,我们将继续完成我们的循环,计算 FPS 统计,并清理:
# check to see if the output frame should be displayed to our # screen if args["display"] > 0: # show the output frame cv2.imshow("Frame", frame) key = cv2.waitKey(1) & 0xFF # if the `q` key was pressed, break from the loop if key == ord("q"): break # if an output video file path has been supplied and the video # writer has not been initialized, do so now if args["output"] != "" and writer is None: # initialize our video writer fourcc = cv2.VideoWriter_fourcc(*"MJPG") writer = cv2.VideoWriter(args["output"], fourcc, 30, (frame.shape[1], frame.shape[0]), True) # if the video writer is not None, write the frame to the output # video file if writer is not None: writer.write(frame) # update the FPS counter fps.update() # stop the timer and display FPS information fps.stop() print("[INFO] elasped time: {:.2f}".format(fps.elapsed())) print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))伟大的工作开发你的面具 R-CNN + OpenCV + CUDA 脚本!在下一节中,我们将比较 CPU 和 GPU 的结果。
关于实现的更多细节,请参考这篇关于带 OpenCV 的 Mask R-CNN 的博文。
mask R-CNN:OpenCV 的“dnn”NVIDIA GPU 模块将实例分割速度提高了 1,549%
我们最后的测试将是使用 CPU 和 NVIDIA GPU 来比较 Mask R-CNN 的性能。
确保您已经使用本教程的 【下载】 部分下载了源代码和预训练的 OpenCV 模型文件。
然后你可以打开一个命令行,在 CPU: 上测试屏蔽 R-CNN 模型
$ python mask_rcnn_segmentation.py \ --mask-rcnn mask-rcnn-coco \ --input ../example_videos/dog_park.mp4 \ --output ../output_videos/mask_rcnn_dog_park.avi \ --display 0 [INFO] loading Mask R-CNN from disk... [INFO] accessing video stream... [INFO] elasped time: 830.65 [INFO] approx. FPS: 0.67Mask R-CNN 架构的计算成本高得令人难以置信,因此在 CPU 上看到 0.67 FPS 的结果是意料之中的。
但是 GPU 呢?
一个 GPU 能够将我们的 Mask R-CNN 推向接近实时的性能吗?
要回答这个问题,只需向
mask_rcnn_segmentation.py脚本提供--use-gpu 1命令行参数:$ python mask_rcnn_segmentation.py \ --mask-rcnn mask-rcnn-coco \ --input ../example_videos/dog_park.mp4 \ --output ../output_videos/mask_rcnn_dog_park.avi \ --display 0 \ --use-gpu 1 [INFO] loading Mask R-CNN from disk... [INFO] setting preferable backend and target to CUDA... [INFO] accessing video stream... [INFO] elasped time: 50.21 [INFO] approx. FPS: 11.05在我的 NVIDIA Telsa V100 上,我们的 Mask R-CNN 模型现在达到了 11.05 FPS,这是一个巨大的 1,549%的改进!
让几乎所有与 OpenCV 的“dnn”模块兼容的型号都能在 NVIDIA GPU 上运行
如果你一直在关注今天帖子中的每个源代码示例,你会注意到它们都遵循一种特定的模式来将计算推送到支持 NVIDIA CUDA 的 GPU:
- 从磁盘加载训练好的模型。
- 将 OpenCV 后端设置为 CUDA。
- 将计算推送到支持 CUDA 的设备上。
这三点整齐地翻译成只有三行代码:
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"]) net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA) net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)一般来说,当使用 OpenCV 的
dnn模块时,你可以遵循相同的方法——如果你有一个与 OpenCV 和dnn兼容的模型,那么它很可能可以简单地通过将 CUDA 设置为后端和目标来用于 GPU 推理。您真正需要做的是用您用来从磁盘加载网络的任何方法替换掉
cv2.dnn.readNetFromCaffe函数,包括:cv2.dnn.readNetcv2.dnn.readNetFromDarknetcv2.dnn.readNetFromModelOptimizercv2.dnn.readNetFromONNXcv2.dnn.readNetFromTensorflowcv2.dnn.readNetFromTorchcv2.dnn.readTensorFromONNX
你需要参考你的模型被训练的确切框架来确认它是否与 OpenCV 的
dnn库兼容——我希望将来也能涵盖这样的教程。下一步是什么?我推荐 PyImageSearch 大学。
![]() Course information:
Course information:
60+ total classes • 64+ hours of on-demand code walkthrough videos • Last updated: Dec 2022
★★★★★ 4.84 (128 Ratings) • 15,800+ Students Enrolled我坚信,如果你有合适的老师,你可以掌握计算机视觉和深度学习的 T2。
你认为学习计算机视觉和深度学习一定会很费时间、让人不知所措、很复杂吗?还是必须涉及复杂的数学和方程?还是需要计算机科学的学位?
那是不是的情况。
要掌握计算机视觉和深度学习,你只需要有人用简单、直观的术语向你解释事情。这正是我所做的。我的使命是改变教育和复杂的人工智能主题的教学方式。
如果你认真学习计算机视觉,你的下一站应该是 PyImageSearch 大学,这是当今最全面的计算机视觉、深度学习和 OpenCV 在线课程。在这里,你将学习如何成功地和自信地将计算机视觉应用到你的工作、研究和项目中。和我一起掌握计算机视觉。
在 PyImageSearch 大学你会发现:
- ✓ 60 多门课程关于基本的计算机视觉、深度学习和 OpenCV 主题
- ✓ 60+结业证书
- ✓ 64+小时的点播视频
- ✓ 全新课程定期发布 ,确保您能跟上最新技术
- ✓Google Colab 中预先配置的 Jupyter 笔记本
- ✓在您的 web 浏览器中运行所有代码示例——适用于 Windows、macOS 和 Linux(不需要开发环境配置!)
- ✓访问 PyImageSearch 上所有 500+教程的集中代码仓库
- ✓ 轻松一键下载代码、数据集、预训练模型等。
- ✓ 在手机、笔记本、台式机等设备上访问。
摘要
在本教程中,您学习了如何应用 OpenCV 的“深度神经网络”(
dnn)模块进行 GPU 优化推理。直到 OpenCV 4.2 发布之前,OpenCV 的
dnn模块具有极其有限的计算能力——大多数读者只能在他们的 CPU 上运行推理,这当然不太理想。然而,由于 dlib 的 Davis King、Yashas Samaga(他实现了 OpenCV 的“dnn”NVIDIA GPU 支持)和 Google Summer of Code 2019 计划, OpenCV 现在可以享受 NVIDIA GPU 和 CUDA 支持,使比以往任何时候都更容易将最先进的网络应用到您自己的项目中。
要下载这篇文章的源代码,包括预先训练的 SSD、YOLO 和 Mask R-CNN 模型,只需在下面的表格中输入您的电子邮件地址!
![]()
下载源代码和 17 页的免费资源指南
在下面输入您的电子邮件地址,获得代码的. zip 文件和一份关于计算机视觉、OpenCV 和深度学习的 17 页免费资源指南。在里面你会找到我亲手挑选的教程、书籍、课程和图书馆,帮助你掌握 CV 和 DL!
Download the code!Website
 Course information:
Course information:
OpenCV 边缘检测(cv2。Canny)
原文:https://pyimagesearch.com/2021/05/12/opencv-edge-detection-cv2-canny/
在本教程中,您将学习如何使用 OpenCV 和 Canny 边缘检测器执行边缘检测。
之前,我们讨论了图像梯度以及它们如何成为计算机视觉和图像处理的基础构件之一。
今天,我们将看到图像渐变是多么重要;具体来说,通过检查 Canny 边缘检测器。
Canny 边缘检测器可以说是所有计算机视觉和图像处理领域中最知名、最常用的边缘检测器。虽然 Canny edge 检测器并不容易理解,但我们将把这些步骤分解成小块,这样我们就能了解它的内部情况。
幸运的是,由于 Canny 边缘检测器广泛应用于几乎所有的计算机视觉应用中,OpenCV 已经在cv2.Canny函数中为我们实现了它。
我们还将探索如何使用这个函数来检测我们自己的图像中的边缘。
要了解如何使用 OpenCV 和 Canny 边缘检测器进行边缘检测, 继续阅读。
OpenCV 边缘检测(cv2。Canny )
在本教程的第一部分,我们将讨论什么是边缘检测,以及为什么我们在计算机视觉和图像处理应用中使用它。
然后,我们将回顾图像中的边缘类型,包括:
- 台阶边缘
- 斜坡边缘
- 山脊边缘
- 屋顶边缘
有了这些审查,我们可以讨论四个步骤的过程,以 Canny 边缘检测
- 高斯平滑
- 计算梯度大小和方向
- 非极大值抑制
- 滞后阈值
然后我们将学习如何使用 OpenCV 和cv2.Canny函数实现 Canny 边缘检测器。
什么是边缘检测?
正如我们在之前关于图像渐变的博客文章中发现的,渐变幅度和方向允许我们揭示图像中物体的结构。
但是对于边缘检测的过程,梯度幅度对噪声极其敏感。
例如,让我们检查下图的渐变表示:
在左边的,我们有正面和背面的原始输入图像。在右边的,我们有图像梯度表示。
如你所见,渐变表示有点嘈杂。当然,我们已经能够检测出药丸的实际轮廓。但是我们也在药片本身留下了许多代表药片印记的“噪音”。
那么,如果我们只想检测药丸的轮廓呢?
这样,如果我们只有轮廓,我们就可以使用轮廓检测之类的方法从图像中提取药丸。那不是很好吗?
不幸的是,简单的图像渐变不能让我们(轻松地)实现我们的目标。
相反,我们必须使用图像梯度作为构建模块来创建一个更健壮的方法来检测边缘 Canny 边缘检测器。
狡猾的边缘检测器
Canny 边缘检测器是一种多步算法,用于检测图像中的各种边缘。该算法本身是由 John F. Canny 在他 1986 年的论文 中介绍的一种边缘检测的计算方法 。
如果您查看许多图像处理项目,您很可能会看到 Canny 边缘检测器在源代码中的某个地方被调用。无论我们是寻找相机到物体的距离、构建文档扫描仪,还是在图像中寻找游戏机屏幕,Canny 边缘检测器通常会被视为一个重要的预处理步骤。
更正式地说,一个被定义为或者更简单地说,一个像素值的差异和变化。**
***下面是一个应用 Canny 边缘检测器从上方检测药丸图像边缘的示例:
在左边的,是我们的原始输入图像。在右边的,我们有输出,或者通常所说的边缘图。请注意,我们只有药片的轮廓作为一条清晰的白色细线——药片本身不再有任何“噪音”。
在我们深入研究 Canny 边缘检测算法之前,让我们先来看看图像中有哪些类型的边缘:
步边
当从间断的一侧到另一侧存在像素强度的突然变化时,形成阶跃边缘。请看下图中的台阶边缘示例:
顾名思义,该图实际上看起来像一个台阶——有一个陡峭的
step in the graph, indicating an abrupt change in pixel value. These types of edges tend to be easy to detect.
斜坡边缘
斜坡边缘类似于阶梯边缘,只是像素强度的变化不是瞬时的。相反,像素值的变化发生在一个短的但有限的距离内。
在这里,我们可以看到一个边缘在缓慢地“加速”变化,但强度的变化不会像阶跃边缘那样立即发生:
山脊边缘
一个脊边类似于组合两个斜坡边,一个正好撞上另一个。我喜欢把坡道边缘想象成在一座大山丘或山上上下行驶:
首先,你慢慢地爬山。然后你到达顶部,在那里它在短时间内保持水平。然后你骑马下山。
在边缘检测的情况下,当图像强度突然变化时,会出现斜坡边缘,但在一小段距离后会返回初始值。
屋顶边缘
最后,我们有屋顶边缘,,它是一种屋脊边缘:
与屋脊边缘不同,屋脊边缘的顶部有一个短而有限的平台,而屋顶边缘没有这样的平台。相反,我们在边缘的两边慢慢上升,但是顶部是一个顶峰,我们只是回落到底部。
Canny 边缘检测简而言之
现在,我们已经讨论了图像中各种类型的边缘,让我们来讨论实际的 Canny 边缘检测算法,这是一个多步骤的过程,包括:
- 对图像应用高斯平滑以帮助减少噪声
- 使用 Sobel 核计算
 和
和 图像梯度
图像梯度 - 应用非最大值抑制以仅保留指向梯度方向的梯度幅值像素的局部最大值
- 定义并应用
 和
和 阈值进行滞后阈值处理
阈值进行滞后阈值处理
 和
和 图像梯度
图像梯度让我们来讨论这些步骤。
步骤#1:高斯平滑
这一步相当直观和简单。正如我们从关于平滑和模糊的教程中了解到的那样,平滑图像让我们可以忽略很多细节,而是专注于实际的结构。
这在边缘检测的环境中也是有意义的——我们对图像的实际细节不感兴趣。相反,我们希望应用边缘检测来找到图像中对象的结构和轮廓,以便我们可以进一步处理它们。
步骤#2:梯度幅度和方向
现在我们有了一个平滑的图像,我们可以计算梯度方向和大小,就像我们在之前的文章中所做的一样。
然而,正如我们所看到的,梯度幅度对噪声非常敏感,并不是最佳的边缘检测器。我们需要在这个过程中增加两个步骤来提取更好的边缘。
步骤#3:非最大值抑制
非极大值抑制听起来像是一个复杂的过程,但实际上不是——它只是一个简单的边缘细化过程。
在计算我们的梯度幅度表示之后,边缘本身仍然相当嘈杂和模糊,但是实际上对于给定的区域应该只有一个边缘响应,而不是一整块像素报告它们自己是边缘。
为了补救这一点,我们可以使用非最大值抑制来应用边缘细化。为了应用非最大值抑制,我们需要检查梯度幅度
and orientation at each pixel in the image and:
- 将当前像素与其周围的
 邻域进行比较
邻域进行比较 - 确定方向指向哪个方向:
- 如果它指向北方或南方,那么检查北方和南方的星等
- 如果方向指向东方或西方,则检查东方和西方像素
- 如果中心像素的幅值大于与其比较的两个像素的幅值,则保持该幅值;否则,丢弃它
 邻域进行比较
邻域进行比较Canny 边缘检测器的一些实现对的值取整
to either  ,
,  ,
,  , or
, or  , and then use the rounded angle to compare not only the north, south, east, and west pixels, but also the corner top-left, top-right, bottom-right, and bottom-left pixels as well.
, and then use the rounded angle to compare not only the north, south, east, and west pixels, but also the corner top-left, top-right, bottom-right, and bottom-left pixels as well.
但是,让我们简单地看一个对角度 应用非最大值抑制的例子
应用非最大值抑制的例子
degrees:
在上面的例子中,我们假设梯度方向是
(it’s actually not, but that’s okay, this is only an example).
假设我们的梯度方向指向北方,我们需要检查南北两个像素。 93 的中心像素值大于 26 的南部像素值,所以我们将丢弃 26 。然而,检查北像素我们看到值是 162 —我们将保持 162 的这个值,并抑制(即设置为 0 )自 93 < 162 以来的 93 的值。
这里是另一个应用非最大值抑制的例子
:
注意中心像素如何比东西像素少。根据我们上面的非极大值抑制规则(规则#3),我们需要丢弃 93 的像素值,并分别保留 104 和 139 的东值和西值。
如您所见,边缘检测的非极大值抑制并不像看起来那么难!
步骤#4:滞后阈值
最后,我们有滞后阈值步骤。就像非极大值抑制一样,其实比听起来容易多了。
即使在应用非最大值抑制后,我们可能需要移除图像中技术上不是边缘的区域,但在计算梯度幅度和应用非最大值抑制后,仍然作为边缘响应。
为了忽略图像的这些区域,我们需要定义两个阈值:
and  .
.
任何梯度值
is sure to be an edge.
任何梯度值
is definitely not an edge, so immediately discard these regions.
以及落入范围 的任何梯度值
的任何梯度值
needs to undergo additional tests:
- 如果特定的梯度值连接到一个强边缘(即
 ),则将该像素标记为边缘。
),则将该像素标记为边缘。 - 如果渐变像素是而不是连接到一个强边缘,那么丢弃它。
滞后阈值实际上可以更直观地解释:
- 在图的上方,我们可以看到 A 是一条确定的边,因为
 。
。 - B 也是一条边,即使
 既然连接到一条确定的边, A 。
既然连接到一条确定的边, A 。 - C 不是一条边,因为
 与一条强边不相连。
与一条强边不相连。 - 最后, D 由于
 不是边,自动丢弃。
不是边,自动丢弃。
 。
。 既然连接到一条确定的边, A 。
既然连接到一条确定的边, A 。 与一条强边不相连。
与一条强边不相连。 不是边,自动丢弃。
不是边,自动丢弃。设置这些阈值范围并不总是一个简单的过程。
如果阈值范围太宽,那么我们将得到许多错误的边缘,而不是将要找到只是图像中一个物体的结构和轮廓。
类似地,如果阈值范围太窄,我们将根本找不到很多边缘,并且有可能完全错过对象的结构/轮廓!
在这一系列文章的后面,我将演示我们如何能够毫不费力地自动调整这些阈值范围。但是暂时,让我们看看边缘检测在 OpenCV 内部实际上是如何执行的。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们使用 OpenCV 和 Canny 边缘检测器计算边缘之前,让我们先回顾一下我们的项目目录结构。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像:
$ tree . --dirsfirst
.
├── images
│ ├── clonazepam_1mg.png
│ └── coins.png
└── opencv_canny.py
1 directory, 3 files
我们要查看一个 Python 脚本opencv_canny.py,它将应用 Canny 边缘检测器。
在images目录中,我们有两个示例图像,我们将对它们应用 Canny 边缘检测器。
用 OpenCV 实现 Canny 边缘检测器
我们现在准备使用 OpenCV 和cv2.Canny函数实现 Canny 边缘检测器!
打开项目结构中的opencv_cann.py文件,让我们查看代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
args = vars(ap.parse_args())
我们从的第 2 行和第 3 行开始,导入我们需要的 Python 包——我们只需要用argparse输入命令行参数,用cv2输入 OpenCV 绑定。
命令行参数在的第 6-9 行被解析。需要一个开关--image,它是我们希望应用边缘检测的输入图像的路径。
现在让我们加载图像并对其进行预处理:
# load the image, convert it to grayscale, and blur it slightly
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# show the original and blurred images
cv2.imshow("Original", image)
cv2.imshow("Blurred", blurred)
虽然 Canny 边缘检测可以通过分别检测每个单独的红色、绿色和蓝色通道中的边缘并将结果组合在一起而应用于 RGB 图像,但我们几乎总是希望将边缘检测应用于单通道灰度图像(第 13 行 ) —这可以确保边缘检测过程中的噪声更少。
其次,虽然 Canny 边缘检测器在边缘检测之前应用了模糊,但我们也希望(通常)在边缘检测器之前应用额外的模糊,以进一步降低噪声,并允许我们找到图像中的对象( Line 14 )。
第 17 行和第 18 行然后在屏幕上显示我们的原始图像和模糊图像。
我们现在准备执行边缘检测:
# compute a "wide", "mid-range", and "tight" threshold for the edges
# using the Canny edge detector
wide = cv2.Canny(blurred, 10, 200)
mid = cv2.Canny(blurred, 30, 150)
tight = cv2.Canny(blurred, 240, 250)
# show the output Canny edge maps
cv2.imshow("Wide Edge Map", wide)
cv2.imshow("Mid Edge Map", mid)
cv2.imshow("Tight Edge Map", tight)
cv2.waitKey(0)
应用 cv2。在行 22-24 上执行检测边缘的 Canny 功能。
cv2.Canny的第一个参数是我们想要检测边缘的图像——在本例中,是我们的灰度模糊图像。然后我们提供
and thresholds, respectively.
在行 22、上,我们在行 23 上应用一个宽阈值,在行 24 上应用一个中范围阈值,以及一个紧阈值。
注: 你可以通过在 图 11 和 图 12 上绘制阈值来说服自己这些是宽、中、紧阈值。
最后,行 27-30 在我们的屏幕上显示输出边缘图。
Canny 边缘检测结果
让我们让精明的边缘检测器为我们工作。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python opencv_canny.py --image images/coins.png
在上图中,左上角的图像是我们输入硬币的图像。然后,我们稍微模糊图像,以帮助平滑细节,并帮助检测右上角的的边缘。
宽范围、中范围和窄范围边缘图分别显示在底部上。
使用宽边缘贴图可以捕捉硬币的轮廓,但也可以捕捉硬币内部的许多面和符号的边缘。
中档边缘图也有类似的表现。
最后,窄范围边缘图能够只捕捉硬币的轮廓,而丢弃其余部分。
让我们看另一个例子:
$ python opencv_canny.py --image images/clonazepam_1mg.png
与图 11 的不同,图 12** 的精明阈值给了我们几乎相反的结果。**
使用宽范围边缘图,我们能够找到药丸的轮廓。
中档边缘图也给了我们药丸的轮廓,还有一些印在药丸上的数字。
最后,紧密的边缘图对我们没有任何帮助——药丸的轮廓几乎完全消失了。
我们如何选择最优的 Canny 边缘检测参数?
正如您所知,根据您的输入图像,您将需要显著不同的滞后阈值——调整这些值可能是一件非常痛苦的事情。您可能想知道,有没有一种方法能够可靠地调整这些参数,而不是简单地猜测、检查和查看结果?
答案是 是的!
我们将在下一课中讨论这一技巧。
总结
在本课中,我们学习了如何使用图像梯度(计算机视觉和图像处理的最基本构建模块之一)来创建边缘检测器。
具体来说,我们关注的是 Canny 边缘检测器,这是计算机视觉社区中最知名、最常用的边缘检测器。
从那里,我们检查了 Canny 边缘检测器的步骤,包括:
- 缓和
- 计算图像梯度
- 应用非最大值抑制
- 利用滞后阈值
然后我们利用 Canny 边缘检测器的知识,用它来应用 OpenCV 的cv2.Canny函数来检测图像中的边缘。
然而,Canny 边沿检测器的最大缺点之一是调整迟滞步长的上下阈值。如果我们的阈值太宽,我们会得到太多的边。如果我们的阈值太窄,我们根本检测不到很多边缘!
为了帮助我们调整参数,您将在本系列的下一篇教程中学习如何应用自动 Canny 边缘检测。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!****
用于人脸识别的 OpenCV 特征脸
原文:https://pyimagesearch.com/2021/05/10/opencv-eigenfaces-for-face-recognition/
在本教程中,您将学习如何使用 Eigenfaces 算法、OpenCV 和 scikit-learn 实现人脸识别。
我们的之前的教程介绍了人脸识别的概念——检测图像/视频中人脸的存在,然后识别人脸。
我们现在要学习如何利用线性代数,更具体地说,主成分分析来识别人脸。
从理论和历史的角度来看,理解这个算法是很重要的,所以请确保您完全阅读了指南并消化了它。
要学习如何实现特征脸进行人脸识别, 继续阅读。
用于人脸识别的 OpenCV 特征脸
在本教程的第一部分,我们将讨论特征脸算法,包括它如何利用线性代数和主成分分析(PCA)来执行人脸识别。
从那里,我们将配置我们的开发环境,然后审查我们的项目目录结构。
然后,我将向您展示如何使用 OpenCV 和 scikit-learn 实现用于人脸识别的特征脸。
我们开始吧!
特征脸、主成分分析(PCA)和人脸识别
特征脸算法的基础首先由 Sirovich 和 Kirby 在他们 1987 年的论文“用于表征人脸的低维过程、中提出,然后由 Turk 和 Pentland 在他们 1991 年的 CVPR 论文“使用特征脸的面部识别、、”中正式提出。
这些论文被认为是计算机视觉历史上的一项开创性工作——尽管此后有人提出了其他可以胜过特征脸的方法,但我们花时间理解和欣赏这种算法仍然很重要。我们今天将在这里讨论 Eigenfaces 的技术内部工作原理。
特征脸算法的第一步是输入一组 N 张人脸图像:
为了使人脸识别成功(并且有些健壮),我们应该确保我们想要识别的每个人都有多张图像。
现在让我们考虑一个包含人脸的图像:
当应用特征脸时,每个脸被表示为灰度, K×K 像素位图(图像不必是正方形的,但是为了这个例子,如果我们假设正方形图像,则更容易解释)。
为了应用特征脸算法,我们需要从图像中形成一个单一向量。这是通过将每个图像“展平”成一个 来实现的
来实现的
-dim vector:
同样,我们在这里所做的是拍摄一张 K×K 的图像,并将所有的行连接在一起,形成一个单一的长
list of grayscale pixel intensities.
在数据集中的每个图像被展平后,我们形成一个这样的展平图像矩阵,其中 Z 是数据集中图像的总数:
我们的整个数据集现在包含在一个矩阵中,
*给定这个矩阵 M ,我们现在准备应用主成分分析(PCA) ,这是特征脸算法的基石。
与 PCA 基础的线性代数相关的完整回顾超出了本课的范围(有关该算法的详细回顾,请参见吴恩达对主题的讨论),但该算法的一般概述如下:
- 计算矩阵中每列的平均值
 ,给出图像数据集中每个 (x,y)-坐标的 的平均像素强度值。
,给出图像数据集中每个 (x,y)-坐标的 的平均像素强度值。 - 从每列
 中减去
中减去 ——这被称为表示将数据居中,是执行 PCA 时的一个必需步骤。
——这被称为表示将数据居中,是执行 PCA 时的一个必需步骤。 - 现在我们的矩阵 M 已经被均值居中,计算协方差矩阵。
- 对协方差矩阵进行特征值分解,得到特征值
 和特征向量
和特征向量 。
。 - 将
 按
按 排序,最大到最小。
排序,最大到最小。 - 取对应特征值幅度最大的前 N 个特征向量。
- 通过将输入数据投影(即取点积)到由顶部的 N 个特征向量— 创建的空间上来变换输入数据,这些特征向量被称为我们的 特征面。
 ,给出图像数据集中每个 (x,y)-坐标的 的平均像素强度值。
,给出图像数据集中每个 (x,y)-坐标的 的平均像素强度值。 中减去
中减去 和特征向量
和特征向量 。
。 排序,最大到最小。
排序,最大到最小。同样,关于手动计算协方差矩阵和执行特征值分解的完整回顾不在本课的讨论范围之内。如需更详细的回顾,请参见吴恩达的机器学习课程或咨询林赛·史密斯的这本优秀的主成分分析初级读本。
然而,在我们使用特征脸算法执行实际的面部识别之前,让我们实际讨论这些特征脸表示:
上面矩阵中的每一行都是带有的特征脸
entries — exactly like our original image
这是什么意思?因为这些特征脸的每一个表现实际上都是一个
vector, we can reshape it into a K×K bitmap:
左边的图像只是我们数据集中所有人脸的平均值,而右边的数字显示了我们人脸数据集中与平均值最显著的偏差。**
这可以被认为是人们面部变化最大的维度的可视化。较亮的区域对应较高的变化,较暗的区域对应很小或没有变化。在这里,我们可以看到,我们的特征脸表示捕捉了眼睛、头发、鼻子、嘴唇和脸颊结构的相当大的差异。
现在我们已经了解了特征脸表示是如何构建的,让我们继续学习如何使用特征脸来实际识别人脸。
使用特征脸识别人脸
给定我们的特征脸向量,我们可以通过取(展平的)输入人脸图像和 N 个特征脸之间的点积来表示新的人脸。这使得我们可以将每张脸表示为主要成分的线性组合:
查询脸=特征脸#1 的 36%+-特征脸#2 的 8%+…+特征脸 N 的 21%
为了执行实际的人脸识别,Sirovich 和 Kirby 建议采用投影特征脸表示之间的欧几里德距离,这实质上是一个 k-NN 分类器:
欧几里德距离(表示为函数, d )越小,两张脸就越“相似”——通过取与具有最小欧几里德距离的脸相关联的标签来找到整体识别。
例如,在图 7 的中,顶部图像对的距离为0,因为两张脸相同(即相同的图像)。
中间的图像对的距离为0.07——虽然图像不同,但它们包含相同的脸。
第三个图像对具有大得多的距离(9.81),表明呈现给特征脸算法的两个人脸是而不是同一个人。
在实践中,我们常常不依赖于简单的 k-NN 算法进行识别。通过使用更高级的机器学习算法,如支持向量机(SVMs)、随机森林等,可以提高精确度。今天这里介绍的实现将利用支持向量机。
配置您的开发环境
要了解如何使用 Eigenfaces 算法进行人脸识别,您需要在计算机上安装 OpenCV、scikit-image 和 scikit-learn:
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
$ pip install scikit-image
$ pip install scikit-learn
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
加州理工学院人脸数据集
加州理工学院人脸挑战赛是人脸识别算法的基准数据集。总的来说,该数据集由大约 27 个不同的人的 450 幅图像组成。每个对象都是在各种照明条件、背景场景和面部表情下拍摄的,如图图 9 所示。
本教程的总体目标是应用 Eigenfaces 人脸识别算法来识别加州理工学院人脸数据集中的每个主题。
注意:我已经在与本教程相关的“下载”中包含了加州理工学院人脸数据集的一个稍微修改的版本。 稍加修改的版本包括一个更容易解析的目录结构,每个主题都有假名,这使得更容易评估我们的人脸识别系统的准确性。同样,您 不需要 从加州理工学院的服务器上下载加州理工学院的人脸数据集——只需使用与本指南相关的“下载”即可。
项目结构
在我们用 OpenCV 实现 Eigenfaces 之前,让我们先回顾一下我们的项目目录结构。
请务必访问本教程的 “下载” 部分,以检索源代码、预训练的人脸检测器模型和加州理工学院人脸数据集。
取消归档后。zip 您应该有以下结构:
$ tree --dirsfirst --filelimit 20
.
├── caltech_faces [26 entries exceeds filelimit, not opening dir]
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── pyimagesearch
│ ├── __init__.py
│ └── faces.py
└── eigenfaces.py
4 directories, 7 files
我们的项目目录结构基本上与上周我们讨论用本地二进制模式(LBPs) 实现人脸识别时的目录结构相同:
face_detector:存储 OpenCV 预先训练好的基于深度学习的人脸检测器pyimagesearch:包含detect_faces和load_face_dataset助手函数,它们分别执行人脸检测和从磁盘加载我们的加州理工学院人脸数据集- 我们训练特征脸模型的驱动脚本
caltech_faces目录的结构如下:
$ ls -l caltech_faces/
abraham
alberta
allen
carmen
conrad
cynthia
darrell
flyod
frank
glen
gloria
jacques
judy
julie
kathleen
kenneth
lewis
mae
phil
raymond
rick
ronald
sherry
tiffany
willie
winston
$ ls -l caltech_faces/abraham/*.jpg
caltech_faces/abraham/image_0022.jpg
caltech_faces/abraham/image_0023.jpg
caltech_faces/abraham/image_0024.jpg
...
caltech_faces/abraham/image_0041.jpg
在这个目录中有一个子目录,包含我们想要识别的每个人的图像。如你所见,我们为每个想要识别的人准备了多张图片。这些图像将作为我们的训练数据,以便我们的 LBP 人脸识别器可以了解每个人的长相。
实现人脸检测和加州理工学院人脸数据集加载
在本节中,我们将实现两个函数,这两个函数有助于使用加州理工学院人脸数据集:
detect_faces:接受输入图像并执行人脸检测,返回边界框 (x,y)-图像中所有人脸的坐标load_face_dataset:遍历加州理工学院人脸数据集中的所有图像,执行人脸检测,并将人脸 ROI 和类别标签(即个人姓名)返回给调用函数
这两个功能在上周的关于使用局部二进制模式(LBPs)和 OpenCV 的 人脸识别的教程中都有详细介绍。出于完整性的考虑,我今天在这里包含了这两个函数,但是您应该参考以前的文章来获得关于它们的更多细节。
也就是说,打开pyimagesearch模块内的faces.py,让我们看看发生了什么:
# import the necessary packages
from imutils import paths
import numpy as np
import cv2
import os
def detect_faces(net, image, minConfidence=0.5):
# grab the dimensions of the image and then construct a blob
# from it
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network to obtain the face detections,
# then initialize a list to store the predicted bounding boxes
net.setInput(blob)
detections = net.forward()
boxes = []
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the detection
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > minConfidence:
# compute the (x, y)-coordinates of the bounding box for
# the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# update our bounding box results list
boxes.append((startX, startY, endX, endY))
# return the face detection bounding boxes
return boxes
detect_faces函数接受我们的输入人脸检测器net,一个应用人脸检测的输入image,以及用于过滤弱/假阳性检测的minConfidence。
然后,我们对输入图像进行预处理,使其通过面部检测模型(行 11 和 12 )。该函数执行调整大小、缩放和均值减法。
第 16 行和第 17 行执行面部检测,产生一个detections列表,我们在第 21 行循环该列表。
假设检测到的人脸的confidence大于minConfidence,我们提取边界框坐标并更新我们的boxes列表。
然后将boxes列表返回给调用函数。
我们的第二个函数load_face_dataset,遍历加州理工学院人脸数据集中的所有图像,并对每张图像应用人脸检测:
def load_face_dataset(inputPath, net, minConfidence=0.5,
minSamples=15):
# grab the paths to all images in our input directory, extract
# the name of the person (i.e., class label) from the directory
# structure, and count the number of example images we have per
# face
imagePaths = list(paths.list_images(inputPath))
names = [p.split(os.path.sep)[-2] for p in imagePaths]
(names, counts) = np.unique(names, return_counts=True)
names = names.tolist()
# initialize lists to store our extracted faces and associated
# labels
faces = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# load the image from disk and extract the name of the person
# from the subdirectory structure
image = cv2.imread(imagePath)
name = imagePath.split(os.path.sep)[-2]
# only process images that have a sufficient number of
# examples belonging to the class
if counts[names.index(name)] < minSamples:
continue
load_face_dataset要求我们将inputPath提供给加州理工学院人脸数据集、人脸检测模型(net)、正面检测的最小置信度以及每个人脸所需的最小数量的示例图像。
第 46 行获取加州理工学院人脸数据集中所有输入图像的路径,而第 47-49 行从子目录结构中提取个人姓名,并计算与每个人相关联的图像数量。
然后我们循环第 57 行的上的所有imagePaths,从磁盘加载image并提取这个人的name。
如果这个特定的name的图像少于minSamples,我们会丢弃该图像,并且在训练我们的面部识别器时不会考虑这个人。我们这样做是为了避免类不平衡的问题(处理类不平衡超出了本教程的范围)。
如果通过了minSamples测试,我们将继续执行面部检测:
# perform face detection
boxes = detect_faces(net, image, minConfidence)
# loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
# extract the face ROI, resize it, and convert it to
# grayscale
faceROI = image[startY:endY, startX:endX]
faceROI = cv2.resize(faceROI, (47, 62))
faceROI = cv2.cvtColor(faceROI, cv2.COLOR_BGR2GRAY)
# update our faces and labels lists
faces.append(faceROI)
labels.append(name)
# convert our faces and labels lists to NumPy arrays
faces = np.array(faces)
labels = np.array(labels)
# return a 2-tuple of the faces and labels
return (faces, labels)
对于每个检测到的人脸,我们提取人脸 ROI,将其调整为固定大小(执行 PCA 时的要求),然后将图像从彩色转换为灰度。
得到的一组faces和labels被返回给调用函数。
注: 如果你想了解更多关于这两个函数如何工作的细节,我建议你阅读我之前的指南,关于使用局部二进制模式(LBPs)和 OpenCV 的 人脸识别,其中我详细介绍了detect_faces和load_face_dataset。
用 OpenCV 实现特征脸
现在让我们用 OpenCV 实现用于人脸识别的特征脸!
打开项目目录结构中的eigenfaces.py文件,让我们开始编码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from skimage.exposure import rescale_intensity
from pyimagesearch.faces import load_face_dataset
from imutils import build_montages
import numpy as np
import argparse
import imutils
import time
import cv2
import os
第 2-15 行导入我们需要的 Python 包。我们主要的进口产品包括:
LabelEncoder:用于将类别标签(即个人姓名)编码为整数而不是字符串(这是利用 OpenCV 的 LBP 人脸识别器的一个要求)PCA:进行主成分分析- 我们的支持向量机(SVM)分类器,我们将在数据集的特征脸表示上训练它
train_test_split:从我们的加州理工学院人脸数据集构建一个训练和测试分割rescale_intensity:用于可视化特征脸表示
我们现在可以转到命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, required=True,
help="path to input directory of images")
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-n", "--num-components", type=int, default=150,
help="# of principal components")
ap.add_argument("-v", "--visualize", type=int, default=-1,
help="whether or not PCA components should be visualized")
args = vars(ap.parse_args())
我们的命令行参数包括:
--input:我们的输入数据集的路径,该数据集包含我们想要训练 LBP 人脸识别器的个人的图像--face:OpenCV 深度学习人脸检测器之路--confidence:用于过滤弱检测的最小概率--num-components:应用 PCA 时主成分的数量(我们稍后将更详细地讨论这个变量)--visualize:是否可视化数据的特征脸表示
接下来,让我们从磁盘加载我们的人脸检测模型:
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNet(prototxtPath, weightsPath)
从那里,让我们加载加州理工学院人脸数据集:
# load the CALTECH faces dataset
print("[INFO] loading dataset...")
(faces, labels) = load_face_dataset(args["input"], net,
minConfidence=0.5, minSamples=20)
print("[INFO] {} images in dataset".format(len(faces)))
# flatten all 2D faces into a 1D list of pixel intensities
pcaFaces = np.array([f.flatten() for f in faces])
# encode the string labels as integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# construct our training and testing split
split = train_test_split(faces, pcaFaces, labels, test_size=0.25,
stratify=labels, random_state=42)
(origTrain, origTest, trainX, testX, trainY, testY) = split
第 41 行和第 42 行从磁盘加载 CALTECH Faces 数据集,产生一个 2 元组:
faces:来自加州理工人脸数据集的人脸 ROIlabels:每个面部 ROI 中的个人姓名
请记住,每张脸都是 2D, M×N 的图像;然而,为了应用 PCA,我们需要每张脸的 1D 表示。因此,第 46 行将所有的 2D 面展平成像素强度的 1D 列表。
然后我们将labels编码为整数而不是字符串。
第 53-55 行然后构建我们的训练和测试分割,使用 75%的数据进行训练,剩下的 25%用于评估。
现在让我们在 1D 人脸列表上执行 PCA:
# compute the PCA (eigenfaces) representation of the data, then
# project the training data onto the eigenfaces subspace
print("[INFO] creating eigenfaces...")
pca = PCA(
svd_solver="randomized",
n_components=args["num_components"],
whiten=True)
start = time.time()
trainX = pca.fit_transform(trainX)
end = time.time()
print("[INFO] computing eigenfaces took {:.4f} seconds".format(
end - start))
这里,我们指出 N ,初始化PCA类时我们要使用的主成分的数量。在我们找到顶部的--num-components之后,我们使用它们将原始训练数据投影到特征脸子空间。
现在我们已经执行了 PCA,让我们来看一下主要组件:
# check to see if the PCA components should be visualized
if args["visualize"] > 0:
# initialize the list of images in the montage
images = []
# loop over the first 16 individual components
for (i, component) in enumerate(pca.components_[:16]):
# reshape the component to a 2D matrix, then convert the data
# type to an unsigned 8-bit integer so it can be displayed
# with OpenCV
component = component.reshape((62, 47))
component = rescale_intensity(component, out_range=(0, 255))
component = np.dstack([component.astype("uint8")] * 3)
images.append(component)
# construct the montage for the images
montage = build_montages(images, (47, 62), (4, 4))[0]
# show the mean and principal component visualizations
# show the mean image
mean = pca.mean_.reshape((62, 47))
mean = rescale_intensity(mean, out_range=(0, 255)).astype("uint8")
cv2.imshow("Mean", mean)
cv2.imshow("Components", montage)
cv2.waitKey(0)
第 71 行检查是否设置了--visualize命令行参数,如果设置了,我们初始化一个images列表来存储我们的可视化。
从那里,我们循环遍历每个顶部 PCA 组件(行 76 ),将图像重新整形为 47×62 像素位图图像(行 80 ),然后将像素强度重新调整到范围【0,255】(行 81 ) 。
为什么我们要为重新缩放操作费心呢?
简单——我们的特征值分解产生实值特征向量,但是为了用 OpenCV 和cv2.imshow可视化图像,我们的图像必须是在【0,255】—范围内的无符号 8 位整数,第 81 行和第 82 行为我们处理这个操作。
然后将结果component添加到我们的images列表中,以便可视化。
在线 86 上,我们制造了一个顶级组件montage。
然后我们以类似的方式在第 90-94 行显示平均特征向量表示。
考虑到可视化,让我们在特征脸表示上训练我们的 SVM:
# train a classifier on the eigenfaces representation
print("[INFO] training classifier...")
model = SVC(kernel="rbf", C=10.0, gamma=0.001, random_state=42)
model.fit(trainX, trainY)
# evaluate the model
print("[INFO] evaluating model...")
predictions = model.predict(pca.transform(testX))
print(classification_report(testY, predictions,
target_names=le.classes_))
第 98 和 99 行初始化我们的 SVM 并训练它。
然后,我们使用该模型对我们的测试数据进行预测,在进行预测之前,小心地将测试数据投影到特征值子空间上。
这个投影是一个 需求 。如果您忘记执行投影,将会发生以下两种情况之一:
- 您的代码将出错(由于特征向量和 SVM 模型之间的维度不匹配)
- SVM 将返回无意义分类(因为模型的训练数据被投影到特征脸表示中)
第 104 和 105 行然后显示分类报告,显示我们的特征脸识别模型的准确性。
最后一步是对我们的测试数据进行采样,对其进行预测,并将结果分别显示在我们的屏幕上:
# generate a sample of testing data
idxs = np.random.choice(range(0, len(testY)), size=10, replace=False)
# loop over a sample of the testing data
for i in idxs:
# grab the predicted name and actual name
predName = le.inverse_transform([predictions[i]])[0]
actualName = le.classes_[testY[i]]
# grab the face image and resize it such that we can easily see
# it on our screen
face = np.dstack([origTest[i]] * 3)
face = imutils.resize(face, width=250)
# draw the predicted name and actual name on the image
cv2.putText(face, "pred: {}".format(predName), (5, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.putText(face, "actual: {}".format(actualName), (5, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
# display the predicted name and actual name
print("[INFO] prediction: {}, actual: {}".format(
predName, actualName))
# display the current face to our screen
cv2.imshow("Face", face)
cv2.waitKey(0)
我们在上周的 LBP 人脸识别指南中详细介绍了这个代码块,所以如果你想了解更多细节,请务必参考它。
OpenCV Eigenfaces 人脸识别结果
我们现在已经准备好使用 OpenCV 和 Eigenfaces 算法来识别人脸了!
首先访问本教程的 “下载” 部分,检索源代码和加州理工学院人脸数据集。
从那里,打开一个终端并执行以下命令:
$ python eigenfaces.py --input caltech_faces --visualize 1
[INFO] loading face detector model...
[INFO] loading dataset...
[INFO] 397 images in dataset
[INFO] creating eigenfaces...
[INFO] computing eigenfaces took 0.1049 seconds
[INFO] training classifier...
[INFO] evaluating model...
precision recall f1-score support
abraham 1.00 1.00 1.00 5
allen 1.00 0.75 0.86 8
carmen 1.00 1.00 1.00 5
conrad 0.86 1.00 0.92 6
cynthia 1.00 1.00 1.00 5
darrell 1.00 1.00 1.00 5
frank 0.83 1.00 0.91 5
gloria 1.00 1.00 1.00 5
jacques 0.86 1.00 0.92 6
judy 1.00 1.00 1.00 5
julie 1.00 1.00 1.00 5
kenneth 1.00 1.00 1.00 6
mae 1.00 1.00 1.00 5
raymond 1.00 1.00 1.00 6
rick 1.00 1.00 1.00 6
sherry 1.00 0.83 0.91 6
tiffany 1.00 1.00 1.00 5
willie 1.00 1.00 1.00 6
accuracy 0.97 100
macro avg 0.97 0.98 0.97 100
weighted avg 0.97 0.97 0.97 100
一旦我们的人脸图像从磁盘中加载,计算特征脸表示(即特征值分解)就非常快,只需十分之一秒多一点。
给定特征脸,然后我们训练我们的 SVM。在我们的测试集上评估,我们看到我们获得了 **≈ 97%的准确率**。不算太差!
现在让我们继续在单独的图像中识别面部:
[INFO] prediction: frank, actual: frank
[INFO] prediction: abraham, actual: abraham
[INFO] prediction: julie, actual: julie
[INFO] prediction: tiffany, actual: tiffany
[INFO] prediction: julie, actual: julie
[INFO] prediction: mae, actual: mae
[INFO] prediction: allen, actual: allen
[INFO] prediction: mae, actual: mae
[INFO] prediction: conrad, actual: conrad
[INFO] prediction: darrell, actual: darrell
图 10 显示了使用特征脸的人脸识别结果剪辑。注意我们是如何正确识别每一张脸的。
用于人脸识别的特征脸问题
对特征脸算法最大的批评之一是训练和识别人脸时需要严格的面部对齐:
由于我们是在像素级别上操作的,所以对于我们数据集中的所有图像,诸如眼睛、鼻子和嘴的面部特征需要被近乎完美地对准*。这不仅是一项具有挑战性的任务,而且在条件不太理想的现实世界中也很难保证。*
在我们的例子中,加州理工学院人脸数据集中的大多数人脸都是从正面拍摄的,没有视点变化,头部倾斜等。由于这张脸,我们不需要明确地应用面部对齐,一切都按照我们的意愿进行;然而,值得注意的是,这种情况很少*在现实世界条件下发生。
上周我们讨论了用于人脸识别的局部二进制模式。虽然 LBP 也可能因为没有足够的面部对齐而受到影响,但结果远没有那么明显,并且该方法更加鲁棒,因为我们将面部图像分成 7×7 个单元,并为每个单元计算 LBP 直方图
通过将图像量化为级联的特征向量,我们通常能够为我们的人脸识别器增加额外的准确性——因为增加了鲁棒性,我们通常使用 LBPs 进行人脸识别,而不是原始的特征脸算法。
总结
在本教程中,我们讨论了特征脸算法。
Eigenfaces 的第一步是提供一个图像数据集,其中包含你想识别的每个人的多幅图像。
从那里,我们将每张图片展平成一个向量,并存储在一个矩阵中。主成分分析应用于该矩阵,其中我们取具有相应最大特征值幅度的顶部 N 个特征向量——这些 N 个特征向量是我们的特征面。
对于许多机器学习算法来说,通常很难将特定方法的结果可视化。但是对于 Eigenfaces 来说,其实还是挺容易的!每个特征脸只是一个
flattened vector that can be reshaped into a  image, allowing us to visualize each eigenface.
image, allowing us to visualize each eigenface.
为了识别人脸,我们首先将图像投影到特征脸子空间,然后利用具有欧几里德距离的 k-NN 分类器来寻找最近的邻居。这些最近的邻居用于确定整体标识。然而,我们可以通过使用更高级的机器学习算法来进一步提高准确性,这正是我们在本课中所做的。
上周我们讨论了用于人脸识别的局部二进制模式。在实践中,这种方法往往比特征脸更鲁棒,获得更高的人脸识别精度。
虽然这两种方法都不如我们现代的深度学习人脸识别模型准确,但从历史的角度来理解仍然很重要,当应用深度学习模型时,在计算上是不可行的。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知), 只需在下面的表格中输入您的电子邮件地址!***
基于 Haar 级联的 OpenCV 人脸检测
原文:https://pyimagesearch.com/2021/04/05/opencv-face-detection-with-haar-cascades/
在本教程中,您将学习如何使用 OpenCV 和 Haar 级联执行人脸检测。
这个指南,以及接下来的两个,受到了我从 PyImageSearch 阅读器 Angelos 收到的一封电子邮件的启发:
嗨,阿德里安,
过去三年来,我一直是 PyImageSearch 的忠实读者,感谢所有的博客帖子!
我的公司做大量的人脸应用工作,包括人脸检测、识别等。
我们刚刚开始了一个使用嵌入式硬件的新项目。我没有奢侈地使用你们之前覆盖的 OpenCV 的深度学习人脸检测器 ,它在我的设备上太慢了。
你建议我做什么?
首先,我建议 Angelos 研究一下协处理器,如 Movidius NCS 和 Google Coral USB 加速器。这些设备可以实时运行计算昂贵的基于深度学习的人脸检测器(包括 OpenCV 的深度学习人脸检测器)。
也就是说,我不确定这些协处理器是否是 Angelos 的一个选项。它们可能成本过高、需要太多的功率消耗等。
我想了想安杰洛的问题,然后翻了翻档案,看看我是否有可以帮助他的教程。
令我惊讶的是,我意识到我从来没有用 OpenCV 的 Haar cascades 编写过一个关于人脸检测的专门教程。
虽然我们可以通过深度学习人脸检测器获得显著更高的准确性和更鲁棒的人脸检测,但 OpenCV 的 Haar cascades 仍有其一席之地:
- 它们很轻
- 即使在资源受限的设备上,它们也是超级快的
- 哈尔级联模型很小(930 KB)
是的,哈尔级联有几个问题,即它们容易出现假阳性检测,并且不如它们的 HOG +线性 SVM、SSD、YOLO 等准确。,同行。然而,它们仍然是有用和实用的,尤其是在资源受限的设备上。
今天,您将学习如何使用 OpenCV 执行人脸检测。下周我们将讨论 OpenCV 中包含的其他 Haar 级联,即眼睛和嘴巴检测器。在两周内,你将学会如何使用 dlib 的 HOG +线性 SVM 人脸检测器和深度学习人脸检测器。
要了解如何使用 OpenCV 和 Haar cascades 执行人脸检测,继续阅读。
利用哈尔级联进行 OpenCV 人脸检测
在本教程的第一部分,我们将配置我们的开发环境,然后回顾我们的项目目录结构。
然后,我们将实现两个 Python 脚本:
- 第一个将应用哈尔级联检测静态图像中的人脸
- 第二个脚本将利用 OpenCV 的哈尔级联来检测实时视频流中的人脸
我们将讨论我们的结果来结束本教程,包括哈尔级联的局限性。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们学习如何用 OpenCV 的 Haar 级联应用人脸检测之前,让我们先回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像:
$ tree . --dirsfirst
.
├── images
│ ├── adrian_01.png
│ ├── adrian_02.png
│ └── messi.png
├── haar_face_detector.py
├── haarcascade_frontalface_default.xml
└── video_face_detector.py
1 directory, 6 files
我们今天要复习两个 Python 脚本:
haar_face_detector.py:对输入图像应用 Haar 级联人脸检测。video_face_detector.py:利用哈尔级联进行实时人脸检测。
haarcascade_frontalface_default.xml文件是我们预先训练好的人脸检测器,由 OpenCV 库的开发者和维护者提供。
然后,images目录包含我们将应用哈尔级联的示例图像。
利用 OpenCV 和 Haar 级联实现人脸检测
让我们开始用 OpenCV 和 Haar 级联实现人脸检测。
打开项目目录结构中的haar_face_detector.py文件,让我们开始工作:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
ap.add_argument("-c", "--cascade", type=str,
default="haarcascade_frontalface_default.xml",
help="path to haar cascade face detector")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包。我们将需要argparse进行命令行参数解析,imutils用于 OpenCV 便利函数,以及cv2用于 OpenCV 绑定。
第 7-13 行解析我们需要的命令行参数,包括:
--image:我们要应用 Haar 级联人脸检测的输入图像的路径。--cascade:驻留在磁盘上的预训练 Haar 级联检测器的路径。
解析完命令行参数后,我们可以从磁盘加载 Haar cascade:
# load the haar cascade face detector from
print("[INFO] loading face detector...")
detector = cv2.CascadeClassifier(args["cascade"])
# load the input image from disk, resize it, and convert it to
# grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
对第 17 行上cv2.CascadeClassifier的调用从磁盘加载我们的人脸检测器。
然后,我们加载我们的输入image,调整它的大小,并将其转换为灰度(我们将 Haar 级联应用于灰度图像)。
最后一步是检测和注释:
# detect faces in the input image using the haar cascade face
# detector
print("[INFO] performing face detection...")
rects = detector.detectMultiScale(gray, scaleFactor=1.05,
minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
print("[INFO] {} faces detected...".format(len(rects)))
# loop over the bounding boxes
for (x, y, w, h) in rects:
# draw the face bounding box on the image
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
第 28-30 行然后在我们的输入image中检测实际的人脸,返回一个边界框列表,或者仅仅是开始和结束的 (x,y)-人脸在每个图像中的坐标。
让我们来看看这些参数的含义:
scaleFactor: 每种图像比例下图像缩小多少。该值用于创建比例金字塔。在图像中以多个尺度检测人脸(一些人脸可能更靠近前景,因此更大,其他人脸可能更小,并且在背景中,因此使用变化的尺度)。值1.05表示我们在金字塔的每一层将图像尺寸缩小 5%。minNeighbors: 每个窗口应该有多少个邻居,窗口中的区域才被认为是面部。级联分类器将检测人脸周围的多个窗口。此参数控制需要检测多少个矩形(邻居)才能将窗口标记为面。minSize: 一组宽度和高度(以像素为单位)表示窗口的最小尺寸。小于该尺寸的边界框被忽略。从(30, 30)开始并从那里进行微调是一个好主意。
最后,给定边界框列表,我们逐个循环,并在第 34-36 行的上围绕面部画出边界框。
哈尔卡斯克德人脸检测结果
让我们来测试一下我们的 Haar cascade 人脸检测器吧!
首先访问本教程的 “下载” 部分,以检索源代码、示例图像和预训练的 Haar cascade 人脸检测器。
从那里,您可以打开一个 shell 并执行以下命令:
$ python haar_face_detector.py --image images/messi.png
[INFO] loading face detector...
[INFO] performing face detection...
[INFO] 2 faces detected...
如图 2 所示,我们已经能够成功检测输入图像中的两张人脸。
让我们尝试另一个图像:
$ python haar_face_detector.py --image images/adrian_01.png
[INFO] loading face detector...
[INFO] performing face detection...
[INFO] 1 faces detected...
果然,我的脸被检测到了。
下图提出了一点问题,并展示了哈尔级联的最大限制之一,即假阳性检测:
$ python haar_face_detector.py --image images/adrian_02.png
[INFO] loading face detector...
[INFO] performing face detection...
[INFO] 2 faces detected...
虽然你可以看到我的脸被正确地检测到,但在图像的底部我们也有一个假阳性检测。
哈尔喀斯倾向于对你选择的detectMultiScale参数非常敏感。scaleFactor和minNeighbors是你最常调的。
当你以假阳性检测结束时(或者根本没有检测到人脸),你应该返回到你的detectMultiScale功能,并尝试通过试错来调整参数。
例如,我们的原始对detectMultiScale的调用如下所示:
rects = detector.detectMultiScale(gray, scaleFactor=1.05,
minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
通过实验,我发现当通过将minNeighbors从5更新为7来消除假阳性时,我仍然能够检测到我的面部:
rects = detector.detectMultiScale(gray, scaleFactor=1.05,
minNeighbors=7, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
这样做之后,我们获得了正确的结果:
$ python haar_face_detector.py --image images/adrian_02.png
[INFO] loading face detector...
[INFO] performing face detection...
[INFO] 1 faces detected...
这一更新之所以有效,是因为minNeighbors参数旨在帮助控制误报检测。
当应用人脸检测时,Haar cascades 在图像上从左到右和从上到下滑动窗口,计算 T2 积分图像。
当 Haar cascade 认为一张脸在一个区域中时,它将返回更高的置信度得分。如果在给定区域中有足够高的置信度得分,那么 Haar 级联将报告阳性检测。
通过增加minNeighbors,我们可以要求哈尔级联找到更多的邻居,从而消除我们在图 4中看到的假阳性检测。
上面的例子再次强调了哈尔级联的主要局限性。虽然它们速度很快,但您通过以下方式付出了代价:
- 误报检测
- 精确度较低(与 HOG +线性 SVM 和基于深度学习的人脸检测器相反)
- 手动参数调谐
也就是说,在资源有限的环境中,你无法击败哈尔级联人脸检测的速度。
利用哈尔级联实现实时人脸检测
我们之前的例子演示了如何将 Haar 级联的人脸检测应用于单个图像。
现在让我们了解如何在实时视频流中执行人脸检测:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import imutils
import time
import cv2
第 2-6 行导入我们需要的 Python 包。类允许我们访问我们的网络摄像头。
我们只有一个命令行参数需要解析:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", type=str,
default="haarcascade_frontalface_default.xml",
help="path to haar cascade face detector")
args = vars(ap.parse_args())
--cascade参数指向我们预先训练的驻留在磁盘上的 Haar cascade 人脸检测器。
然后,我们加载人脸检测器并初始化视频流:
# load the haar cascade face detector from
print("[INFO] loading face detector...")
detector = cv2.CascadeClassifier(args["cascade"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
让我们开始从视频流中读取帧:
# loop over the frames from the video stream
while True:
# grab the frame from the video stream, resize it, and convert it
# to grayscale
frame = vs.read()
frame = imutils.resize(frame, width=500)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# perform face detection
rects = detector.detectMultiScale(gray, scaleFactor=1.05,
minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
在我们的while循环中,我们:
- 从相机中读取下一个
frame - 将它的宽度调整为 500 像素(较小的帧处理速度更快)
- 将框架转换为灰度
第 33-35 行然后使用我们的 Haar 级联执行人脸检测。
最后一步是在我们的frame上绘制检测到的人脸的边界框:
# loop over the bounding boxes
for (x, y, w, h) in rects:
# draw the face bounding box on the image
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
第 38 行循环遍历rects列表,包含:
- 面部的起始
x坐标 - 面部的起始
y坐标 - 边界框的宽度(
w) - 边界框的高度(
h)
然后我们在屏幕上显示输出frame。
实时哈尔级联人脸检测结果
我们现在已经准备好使用 OpenCV 实时应用人脸检测了!
请务必访问本教程的 “下载” 部分,以检索源代码和预训练的 Haar cascade。
从那里,打开一个 shell 并执行以下命令:
$ python video_face_detector.py
[INFO] loading face detector...
[INFO] starting video stream...
如你所见,我们的 Haar cascade 人脸检测器正在实时运行,没有任何问题!
如果您需要在嵌入式设备上获得实时人脸检测,尤其是,那么可以考虑利用 Haar 级联人脸检测器。
是的,它们不如更现代的面部检测器准确,是的,它们也容易出现假阳性检测,但好处是你会获得巨大的速度,并且你需要更少的计算能力。
否则,如果你在笔记本电脑/台式机上,或者你可以使用 Movidius NCS 或谷歌 Coral USB 加速器等协处理器,那么就使用基于深度学习的人脸检测。你将获得更高的准确度,并且仍然能够实时应用面部检测。
总结
在本教程中,您学习了如何使用 OpenCV 和 Haar 级联执行人脸检测。
而哈尔级联明显不如它们的 HOG +线性 SVM、SSD、YOLO 等精确。,同行,他们是速度非常快,轻巧。这使得它们适合在嵌入式设备上使用,特别是在像 Movidius NCS 和 Google Coral USB 加速器这样的协处理器不可用的情况下。
下周我们将讨论其他 OpenCV 哈尔级联,包括眼睛和嘴巴探测器。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV 人脸识别
原文:https://pyimagesearch.com/2018/09/24/opencv-face-recognition/
最后更新于 2022 年 12 月 30 日。
在本教程中,您将学习如何使用 OpenCV 进行人脸识别。为了构建我们的人脸识别系统,我们将首先执行人脸检测,使用深度学习从每个人脸中提取人脸嵌入,根据嵌入训练人脸识别模型,然后最终使用 OpenCV 识别图像和视频流中的人脸。
本教程将使用 OpenCV 在我们的人脸数据集上执行人脸识别。
当然,你可以交换你自己的人脸数据集!所有你需要做的就是按照我的目录结构插入你自己的脸部图像。
作为奖励,我还包括了如何标记“未知”的脸,这些脸不能被充分信任地分类。
要了解如何执行 OpenCV 人脸识别,继续阅读!
- 【2021 年 7 月更新: 增加了一节关于替代人脸识别方法的考虑,包括如何将暹罗网络用于人脸识别。
- 【2022 年 12 月更新:更新链接和内容。
OpenCV 人脸识别
在今天的教程中,您将学习如何使用 OpenCV 库执行人脸识别。
你可能想知道这个教程和我几个月前写的关于 dlib 人脸识别的教程有什么不同?
请记住,dlib 人脸识别帖子依赖于两个重要的外部库:
- dlib (明显)
- face_recognition (这是一套简单易用的人脸识别工具,包装了 dlib)
虽然我们使用 OpenCV 来促进面部识别,但是 OpenCV 本身并不负责识别面部。
在今天的教程中,我们将学习如何将深度学习和 OpenCV(除了 scikit-learn 之外没有其他库)一起应用于:
- 检测人脸
- 计算 128-d 面部嵌入以量化面部
- 在嵌入的基础上训练支持向量机(SVM)
- 识别图像和视频流中的人脸
所有这些任务都将通过 OpenCV 来完成,使我们能够获得一个“纯粹的”OpenCV 人脸识别管道。
OpenCV 的人脸识别是如何工作的
为了建立我们的 OpenCV 人脸识别管道,我们将在两个关键步骤中应用深度学习:
- 应用面部检测,检测图像中面部的存在和位置,但不识别它
- 提取 128 维特征向量(称为“嵌入”),这些向量对图像中的每张脸进行量化
我之前已经讨论过OpenCV 的人脸检测是如何工作的,所以如果你之前没有检测过人脸,请参考一下。
负责实际量化图像中每张脸的模型来自于 OpenFace 项目,这是深度学习人脸识别的 Python 和 Torch 实现。这个实现来自于 Schroff 等人 2015 年的 CVPR 出版物, FaceNet:一个用于人脸识别和聚类的 统一嵌入 。
回顾整个 FaceNet 实现超出了本教程的范围,但是管道的要点可以在上面的图 1 中看到。
首先,我们将图像或视频帧输入到人脸识别管道中。给定输入图像,我们应用人脸检测来检测图像中人脸的位置。
顾名思义,人脸对齐是(1)识别人脸的几何结构和(2)基于平移、旋转和缩放尝试获得人脸的规范对齐的过程。
虽然是可选的,但人脸对齐已被证明可以提高某些管道中人脸识别的准确性。
在我们(可选地)应用了面部对齐和裁剪之后,我们将输入面部通过我们的深度神经网络:
FaceNet 深度学习模型计算 128-d 嵌入,量化人脸本身。
但是网络实际上是如何计算人脸嵌入的呢?
答案在于培训过程本身,包括:
- 网络的输入数据
- 三重损失函数
为了用深度学习来训练人脸识别模型,每个输入批数据包括三幅图像:
- 主播
- 正面的图像
- 负像
主播就是我们现在的脸,身份 A 。
第二个图像是我们的正面图像——这个图像也包含了人 A 的脸。
另一方面,反面形象 没有同样的身份 ,可能属于人物 B 、 C ,甚至 Y !
重点是锚和正面图像都属于同一个人/脸,而负面图像不包含同一张脸。
神经网络计算每个面部的 128-d 嵌入,然后调整网络的权重(通过三元组损失函数),使得:
- 锚和正图像的 128-d 嵌入更靠近在一起
- 而与此同时,将父亲这一负面形象的根深蒂固推开
以这种方式,网络能够学习量化人脸,并返回适用于人脸识别的高度鲁棒和有区别的嵌入。
此外,我们实际上可以 重用open face 模型用于我们自己的应用程序,而不必显式地训练它!
即使我们今天使用的深度学习模型(很可能)从未见过我们将要通过它的人脸,该模型仍将能够计算每个人脸的嵌入——理想情况下,这些人脸嵌入将足够不同,以便我们可以训练一个“标准”机器学习分类器(SVM,SGD 分类器,随机森林等)。)在人脸嵌入之上,并因此获得我们的 OpenCV 人脸识别管道。
如果你有兴趣了解更多关于三重丢失的细节以及如何使用它来训练人脸嵌入模型,请务必参考我之前的博客文章以及施罗夫等人的出版物。
我们的人脸识别数据集
我们今天使用的数据集包含三个人:
- 一个男人
- 一个女人
- “未知”,用来表示我们不认识的人的脸,并希望这样标记(这里我只是从电影侏罗纪公园中采样的脸,我在以前的帖子中使用过——你可能想插入你自己的“未知”数据集)。
每个类总共包含六幅图像。
如果你正在建立自己的人脸识别数据集,理想情况下,我会建议你希望识别的每个人有 10-20 张图像——请务必参考这篇博客文章的“缺点,限制,以及如何获得更高的人脸识别准确率”部分了解更多细节。
项目结构
一旦你从这篇文章的 “下载” 部分获得了压缩文件,继续解压文件并导航到目录。
从那里,您可以使用tree命令在您的终端中打印目录结构:
$ tree --dirsfirst
.
├── dataset
│ ├── adrian [6 images]
│ ├── trisha [6 images]
│ └── unknown [6 images]
├── images
│ ├── adrian.jpg
│ ├── patrick_bateman.jpg
│ └── trisha_adrian.jpg
├── face_detection_model
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── output
│ ├── embeddings.pickle
│ ├── le.pickle
│ └── recognizer.pickle
├── extract_embeddings.py
├── openface_nn4.small2.v1.t7
├── train_model.py
├── recognize.py
└── recognize_video.py
7 directories, 31 files
这个项目有相当多的活动部分— 现在花点时间仔细阅读这一部分,以便熟悉今天项目中的所有文件。
我们的项目在根文件夹中有四个目录:
dataset/:包含我们的脸部图像,按名称组织到子文件夹中。- 包含三个测试图像,我们将使用它们来验证我们的模型的操作。
face_detection_model/:包含 OpenCV 提供的预训练 Caffe 深度学习模型,用于检测人脸。这个模型检测图像中的和定位图像中的人脸。output/:包含我输出的 pickle 文件。如果您正在使用自己的数据集,也可以将输出文件存储在这里。输出文件包括:embeddings.pickle:序列化的面部嵌入文件。已经为数据集中的每个面计算了嵌入,并存储在该文件中。- 我们的标签编码器。包含我们的模型可以识别的人的姓名标签。
recognizer.pickle:我们的线性支持向量机(SVM)模型。这是一个机器学习模型,而不是深度学习模型,它负责实际上识别的脸。
让我们总结一下根目录中的五个文件:
extract_embeddings.py:我们将在步骤#1 中查看这个文件,它负责使用深度学习特征提取器来生成描述人脸的 128-D 向量。我们数据集中的所有人脸都将通过神经网络来生成嵌入。openface_nn4.small2.v1.t7:产生 128 维人脸嵌入的 Torch 深度学习模型。我们将在步骤#1、#2 和#3 以及奖金部分使用这个深度学习模型。train_model.py:我们的线性 SVM 模型将在步骤#2 中由这个脚本训练。我们将检测面部,提取嵌入,并且将我们的 SVM 模型拟合到嵌入数据。recognize.py:在步骤#3 中,我们将识别图像中的人脸。我们将检测面部,提取嵌入,查询我们的 SVM 模型来确定谁是图像中的。我们将在人脸周围画出方框,并用名称标注每个方框。recognize_video.py:我们的花絮部分描述了如何识别视频流帧中的是谁,就像我们在静态图像上的步骤#3 中所做的一样。
让我们进入第一步!
步骤#1:从人脸数据集中提取嵌入
现在我们已经了解了人脸识别的工作原理,并回顾了我们的项目结构,让我们开始构建 OpenCV 人脸识别管道。
打开extract_embeddings.py文件并插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--embeddings", required=True,
help="path to output serialized db of facial embeddings")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们在2-8 号线导入我们需要的包。你需要安装 OpenCV 和imutils。要安装 OpenCV,只需遵循我的一个指南(我推荐 OpenCV 3.4.2,所以在遵循指南的同时一定要下载正确的版本)。我的 imutils 包可以用 pip 安装:
$ pip install --upgrade imutils
接下来,我们处理命令行参数:
--dataset:人脸图像输入数据集的路径。--embeddings:输出嵌入文件的路径。我们的脚本将计算面部嵌入,我们将序列化到磁盘。--detector:OpenCV 基于 Caffe 的深度学习人脸检测器的路径,用于实际定位图像中的人脸。--embedding-model:OpenCV 深度学习火炬嵌入模型的路径。这个模型将允许我们提取一个 128-D 的面部嵌入向量。--confidence:筛选周人脸检测的可选阈值。
现在我们已经导入了包并解析了命令行参数,让我们从磁盘加载面部检测器和嵌入器:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
这里我们加载人脸检测器和嵌入器:
detector:通过线 26-29 加载。我们使用基于咖啡的 DL 人脸检测器来定位图像中的人脸。embedder:装在33 线上。这个模型是基于 Torch 的,负责通过深度学习特征提取提取面部嵌入。
注意,我们使用各自的cv2.dnn函数来加载两个独立的模型。dnn模块直到 OpenCV 3.3 才这样可用,但是我推荐你使用 OpenCV 3.4.2 或更高版本来写这篇博文。
接下来,让我们获取图像路径并执行初始化:
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize our lists of extracted facial embeddings and
# corresponding people names
knownEmbeddings = []
knownNames = []
# initialize the total number of faces processed
total = 0
建立在第 37 行上的imagePaths列表包含数据集中每个图像的路径。我通过我的imutils函数paths.list_images让这变得简单了。
我们的嵌入和对应的名字将保存在两个列表中:knownEmbeddings和knownNames ( 第 41 行和第 42 行)。
我们还将通过一个名为total ( Line 45 )的变量来跟踪我们已经处理了多少张脸。
让我们开始在图像路径上循环——这个循环将负责从每个图像中找到的人脸中提取嵌入:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
我们开始在线 48 的imagePaths处循环。
首先,我们从路径中提取这个人的name(行 52 )。为了解释这是如何工作的,请考虑我的 Python shell 中的以下示例:
$ python
>>> from imutils import paths
>>> import os
>>> imagePaths = list(paths.list_images("dataset"))
>>> imagePath = imagePaths[0]
>>> imagePath
'dataset/adrian/00004.jpg'
>>> imagePath.split(os.path.sep)
['dataset', 'adrian', '00004.jpg']
>>> imagePath.split(os.path.sep)[-2]
'adrian'
>>>
请注意,通过使用imagePath.split并提供拆分字符(操作系统路径分隔符 unix 上的“/”和 Windows 上的“\”),该函数如何生成一个文件夹/文件名称(字符串)列表,这些名称沿着目录树向下排列。我们获取倒数第二个索引,persons name,在本例中是'adrian'。
最后,我们通过将image和resize加载到一个已知的width ( 第 57 行和第 58 行)来包装上面的代码块。
让我们检测和定位人脸:
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
在第 62-64 行上,我们构造了一个斑点。要了解这个过程的更多信息,请阅读 深度学习:OpenCV 的 blobFromImage 如何工作 。
从那里,我们通过让imageBlob通过detector网络(线 68 和 69 )来检测图像中的人脸。
让我们来处理一下detections:
# ensure at least one face was found
if len(detections) > 0:
# we're making the assumption that each image has only ONE
# face, so find the bounding box with the largest probability
i = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, i, 2]
# ensure that the detection with the largest probability also
# means our minimum probability test (thus helping filter out
# weak detections)
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI and grab the ROI dimensions
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
detections列表包含在图像中定位人脸的概率和坐标。
假设我们至少有一个检测,我们将进入 if 语句的主体(第 72 行)。
我们假设图像中只有张人脸,因此我们提取具有最高confidence的检测,并检查以确保置信度满足用于过滤弱检测的最小概率阈值(第 75-81 行)。
假设我们已经达到了阈值,我们提取face ROI 并获取/检查尺寸以确保face ROI 足够大(第 84-93 行)。
从那里,我们将利用我们的embedder CNN 并提取面部嵌入:
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# add the name of the person + corresponding face
# embedding to their respective lists
knownNames.append(name)
knownEmbeddings.append(vec.flatten())
total += 1
我们构建另一个斑点,这次是从第 98 和 99 行的脸部 ROI(不是我们之前做的整个图像)开始。
随后,我们将faceBlob通过嵌入器 CNN ( 行 100 和 101 )。这将生成一个描述人脸的 128 维向量(vec)。我们将利用这些数据,通过机器学习来识别新面孔。
然后我们简单地将name和嵌入vec分别添加到knownNames和knownEmbeddings(第 105 行和第 106 行)。
我们也不能忘记我们设置的用于跟踪total面数的变量——我们继续增加行 107 的值。
我们继续这个循环遍历图像、检测人脸以及为数据集中的每个图像提取人脸嵌入的过程。
当循环结束时,剩下的就是将数据转储到磁盘:
# dump the facial embeddings + names to disk
print("[INFO] serializing {} encodings...".format(total))
data = {"embeddings": knownEmbeddings, "names": knownNames}
f = open(args["embeddings"], "wb")
f.write(pickle.dumps(data))
f.close()
我们将名称和嵌入数据添加到字典中,然后在 pickle 文件的第 110-114 行的中序列化data。
此时,我们已经准备好通过运行脚本来提取嵌入。
为了跟随这个人脸识别教程,使用帖子的 “下载” 部分下载源代码、OpenCV 模型和示例人脸识别数据集。
从那里,打开一个终端,执行以下命令,用 OpenCV 计算人脸嵌入:
$ python extract_embeddings.py --dataset dataset \
--embeddings output/embeddings.pickle \
--detector face_detection_model \
--embedding-model openface_nn4.small2.v1.t7
[INFO] loading face detector...
[INFO] loading face recognizer...
[INFO] quantifying faces...
[INFO] processing image 1/18
[INFO] processing image 2/18
[INFO] processing image 3/18
[INFO] processing image 4/18
[INFO] processing image 5/18
[INFO] processing image 6/18
[INFO] processing image 7/18
[INFO] processing image 8/18
[INFO] processing image 9/18
[INFO] processing image 10/18
[INFO] processing image 11/18
[INFO] processing image 12/18
[INFO] processing image 13/18
[INFO] processing image 14/18
[INFO] processing image 15/18
[INFO] processing image 16/18
[INFO] processing image 17/18
[INFO] processing image 18/18
[INFO] serializing 18 encodings...
在这里,您可以看到我们已经提取了 18 个人脸嵌入,在我们的输入人脸数据集中,每个图像一个(每类 6 个)。
第二步:训练人脸识别模型
在这一点上,我们已经为每张脸提取了 128 维嵌入,但是我们如何基于这些嵌入来识别一个人呢?答案是我们需要训练一个“标准”的机器学习模型(比如 SVM、k-NN 分类器、随机森林等。)在嵌入的顶部。
在我的之前的人脸识别教程中,我们发现了如何在通过 dlib 和 face_recognition 库创建的 128-d 嵌入上使用 k-NN 的修改版本进行人脸识别。
今天,我想分享我们如何在嵌入的基础上构建一个更强大的分类器——如果你愿意,你也可以在基于 dlib 的人脸识别管道中使用同样的方法。
打开train_model.py文件并插入以下代码:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--embeddings", required=True,
help="path to serialized db of facial embeddings")
ap.add_argument("-r", "--recognizer", required=True,
help="path to output model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to output label encoder")
args = vars(ap.parse_args())
在运行这个脚本之前,我们需要在我们的环境中安装一个机器学习库 scikit-learn 。您可以通过 pip 安装它:
$ pip install scikit-learn
我们在第 2-5 行导入我们的包和模块。我们将使用 scikit-learn 实现的支持向量机(SVM),一种常见的机器学习模型。
在那里,我们解析我们的命令行参数:
--embeddings:序列化嵌入的路径(我们通过运行前面的extract_embeddings.py脚本导出它)。--recognizer:这将是识别面对的我们的输出模型。它以 SVM 为原型。我们将保存它,以便在接下来的两个识别脚本中使用。--le:我们的标签编码器输出文件路径。我们将把我们的标签编码器序列化到磁盘,以便我们可以在图像/视频人脸识别脚本中使用它和识别器模型。
这些参数中的每一个都是必需的。
让我们加载我们的面部嵌入和编码我们的标签:
# load the face embeddings
print("[INFO] loading face embeddings...")
data = pickle.loads(open(args["embeddings"], "rb").read())
# encode the labels
print("[INFO] encoding labels...")
le = LabelEncoder()
labels = le.fit_transform(data["names"])
在这里,我们从第 19 行的的步骤#1** 加载我们的嵌入。我们不会在这个模型训练脚本中生成任何嵌入——我们将使用之前生成并序列化的嵌入。**
然后我们初始化我们的 scikit-learn LabelEncoder并编码我们的名字labels ( 第 23 和 24 行)。
现在是时候训练我们的 SVM 模型来识别人脸了:
# train the model used to accept the 128-d embeddings of the face and
# then produce the actual face recognition
print("[INFO] training model...")
recognizer = SVC(C=1.0, kernel="linear", probability=True)
recognizer.fit(data["embeddings"], labels)
在第 29 行我们初始化我们的 SVM 模型,在第 30 行我们fit模型(也称为“训练模型”)。
这里我们使用的是线性支持向量机(SVM ),但是如果你愿意的话,你也可以尝试其他的机器学习模型。
在训练模型之后,我们将模型和标签编码器作为 pickle 文件输出到磁盘。
# write the actual face recognition model to disk
f = open(args["recognizer"], "wb")
f.write(pickle.dumps(recognizer))
f.close()
# write the label encoder to disk
f = open(args["le"], "wb")
f.write(pickle.dumps(le))
f.close()
我们在这个块中向磁盘写入两个 pickle 文件——面部识别器模型和标签编码器。
此时,确保您首先执行了从步骤#1 开始的代码。您可以从 “下载” 部分获取包含代码和数据的 zip 文件。
既然我们已经完成了对train_model.py的编码,让我们将它应用于我们提取的人脸嵌入:
$ python train_model.py --embeddings output/embeddings.pickle \
--recognizer output/recognizer.pickle \
--le output/le.pickle
[INFO] loading face embeddings...
[INFO] encoding labels...
[INFO] training model...
$ ls output/
embeddings.pickle le.pickle recognizer.pickle
在这里,您可以看到我们的 SVM 已经过嵌入训练,并且(1) SVM 本身和(2)标签编码已经写入磁盘,使我们能够将它们应用于输入图像和视频。
第三步:用 OpenCV 识别人脸
我们现在已经准备好用 OpenCV 进行人脸识别了!
在本节中,我们将从识别图像中的人脸开始,然后在下一节中继续学习识别视频流中的人脸。
打开项目中的recognize.py文件,插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们在线 2-7 上import我们需要的包裹。此时,您应该已经安装了这些软件包。
我们的六个命令行参数在第 10-23 行被解析:
--image:输入图像的路径。我们将尝试识别此图像中的面孔。--detector:OpenCV 深度学习人脸检测器的路径。我们将使用这个模型来检测面部感兴趣区域在图像中的位置。--embedding-model:OpenCV 深度学习人脸嵌入模型的路径。我们将使用这个模型从人脸 ROI 中提取 128 维人脸嵌入图,我们将把数据输入识别器。--recognizer:我们的识别器模型的路径。我们在第二步中训练了我们的 SVM 识别器。这实际上将是决定谁是的一张脸。--le:我们的标签编码器之路。这包含了我们的面部标签,如'adrian'或'trisha'。--confidence:过滤弱脸的可选阈值检测。
一定要研究这些命令行参数——知道两种深度学习模型和 SVM 模型之间的区别很重要。如果您发现自己在本脚本的后面感到困惑,您应该参考这里。
现在我们已经处理了导入和命令行参数,让我们将三个模型从磁盘加载到内存中:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
我们在这个街区装了三个模型。冒着重复的风险,我想明确地提醒您这些模型之间的差异:
detector:一个预训练的 Caffe DL 模型来检测人脸在图像中的位置 ( 第 27-30 行)。embedder:一个预先训练好的火炬 DL 模型来计算我们的 128-D 人脸嵌入 ( 第 34 行)。recognizer:我们的线性 SVM 人脸识别模型(37 线)。我们在步骤 2 中训练了这个模型。
1 和 2 都是经过预训练的,这意味着它们是由 OpenCV 按原样提供给您的。它们被埋在 GitHub 上的 OpenCV 项目中,但是为了方便起见,我把它们放在了今天帖子的 【下载】 部分。我还按照我们用 OpenCV 识别人脸的顺序对模型进行了编号。
我们还加载了我们的标签编码器,它保存了我们的模型可以识别的人的名字( Line 38 )。
现在让我们加载我们的图像并检测张脸:
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image dimensions
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
在这里我们:
- 将图像载入内存并构建一个斑点(第 42-49 行)。点击了解
cv2.dnn.blobFromImage。 - 通过我们的
detector( 第 53 行和第 54 行)定位图像中的人脸。
给定我们的新detections,让我们在图像中识别人脸。但是首先我们需要过滤弱的detections并提取face ROI:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
你会从步骤#1 中认出这个方块。我在这里再解释一遍:
- 我们循环遍历行 57 上的
detections并提取行 60 上每个的confidence。 - 然后,我们将
confidence与命令行args字典中包含的最小概率检测阈值进行比较,确保计算出的概率大于最小概率(第 63 行)。 - 从那里,我们提取出
faceROI ( 第 66-70 行,并确保其空间维度足够大(第 74 和 75 行)。
识别face ROI 的名称只需要几个步骤:
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255, (96, 96),
(0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
首先,我们构造一个faceBlob(从face ROI)并通过embedder来生成一个描述人脸的 128-D 向量(第 80-83 行
然后,我们将vec通过我们的 SVM 识别器模型(第 86 行,其结果是我们对谁在面部 ROI 中的的预测。
我们取最高概率指数(第 87 行)并查询我们的标签编码器以找到name ( 第 89 行)。在这两者之间,我提取了第 88 行上的概率。
注意:您可以通过对概率应用额外的阈值测试来进一步过滤掉弱的人脸识别。例如,插入if proba < T(其中T是您定义的变量)可以提供一个额外的过滤层,以确保有更少的误报人脸识别。
现在,让我们显示 OpenCV 人脸识别结果:
# draw the bounding box of the face along with the associated
# probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
对于循环中我们认识的每一张脸(包括“未知的”)人:
- 我们在第 93 行的上构造一个包含
name和概率的text字符串。 - 然后,我们在脸部周围画一个矩形,并将文本放在框的上方(第 94-98 行)。
最后,我们在屏幕上显示结果,直到按下一个键(行 101 和 102 )。
是时候用 OpenCV 识别图像中的人脸了!
要将我们的 OpenCV 人脸识别管道应用于我提供的图像(或您自己的数据集+测试图像),请确保您使用博文的 【下载】 部分下载代码、训练好的模型和示例图像。
从那里,打开一个终端并执行以下命令:
$ python recognize.py --detector face_detection_model \
--embedding-model openface_nn4.small2.v1.t7 \
--recognizer output/recognizer.pickle \
--le output/le.pickle \
--image images/adrian.jpg
[INFO] loading face detector...
[INFO] loading face recognizer...

Figure 4: OpenCV face recognition has recognized me at the Jurassic World: Fallen Kingdom movie showing.
在这里你可以看到我喝着啤酒,穿着我最喜欢的《侏罗纪公园》衬衫,还有一个特别的《侏罗纪世界》T2 杯和一本纪念册。我的人脸预测只有 47.15%的把握;但是,这种信心却高于【未知】班。
让我们尝试另一个 OpenCV 人脸识别示例:
$ python recognize.py --detector face_detection_model \
--embedding-model openface_nn4.small2.v1.t7 \
--recognizer output/recognizer.pickle \
--le output/le.pickle \
--image images/trisha_adrian.jpg
[INFO] loading face detector...
[INFO] loading face recognizer...
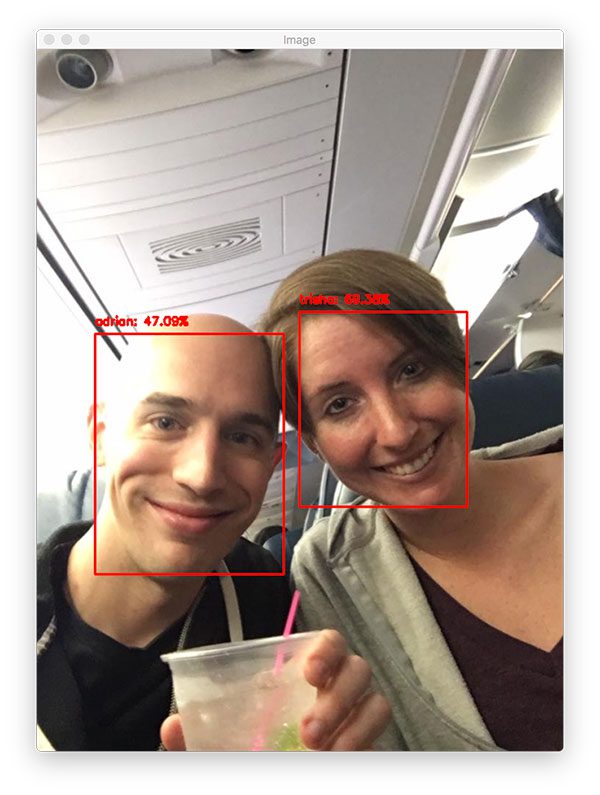
Figure 5: Face detecion on an airplane with OpenCV + deep learning facial recognition.
在最后一个例子中,让我们看看当我们的模型无法识别实际的人脸时会发生什么:
$ python recognize.py --detector face_detection_model \
--embedding-model openface_nn4.small2.v1.t7 \
--recognizer output/recognizer.pickle \
--le output/le.pickle \
--image images/patrick_bateman.jpg
[INFO] loading face detector...
[INFO] loading face recognizer...

Figure 6: Facial recognition with OpenCV has determined that this person is “unknown”.
第三个图像是一个“未知”人的例子,实际上是来自 《美国惊魂记》 的 Patrick Bateman 相信我,这不是你想在你的图像或视频流中看到的人!
额外收获:在视频流中识别人脸
作为奖励,我决定在视频流中包含一个专门用于 OpenCV 人脸识别的部分!
实际的管道本身与识别图像中的人脸几乎相同,只有一些更新,我们将一路回顾。
打开recognize_video.py文件,让我们开始吧:
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import pickle
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
我们的导入与上面的步骤#3 部分相同,除了线 2 和 3 处我们使用了imutils.video模块。我们将使用VideoStream从相机中捕捉帧,使用FPS计算每秒帧数。
命令行参数也是一样的,只是我们没有通过命令行传递静态图像的路径。相反,我们将获取对我们的网络摄像头的引用,然后处理视频。如果您需要查看参数,请参考步骤 3 。
我们的三个型号和标签编码器在这里加载:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
这里我们加载人脸detector,人脸embedder模型,人脸recognizer模型(线性 SVM),以及标签编码器。
同样,如果您对三种型号或标签编码器感到困惑,请务必参考步骤#3 。
让我们初始化视频流并开始处理帧:
# initialize the video stream, then allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# start the FPS throughput estimator
fps = FPS().start()
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
frame = vs.read()
# resize the frame to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
frame = imutils.resize(frame, width=600)
(h, w) = frame.shape[:2]
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
我们的VideoStream对象在行 43 初始化并启动。我们等待摄像机传感器在线 44 上预热。
我们还初始化我们的每秒帧数计数器(行 47 )并开始在行 50 的帧上循环。我们从线 52 上的网络摄像头抓取一个frame。
从这里开始,一切都与第三步相同。我们resize帧( L ine 57 ),然后我们从帧中构造一个斑点+检测人脸的位置(行 61-68 )。
现在我们来处理检测结果:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
就像上一节一样,我们开始循环遍历detections并过滤掉弱的(第 71-77 行)。然后,我们提取face ROI,并确保空间维度足够大,足以进行下一步操作(第 84-89 行)。
现在是时候执行 OpenCV 人脸识别了:
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
# draw the bounding box of the face along with the
# associated probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# update the FPS counter
fps.update()
在这里我们:
- 构建
faceBlob( 第 94 和 95 行)并通过深度学习计算面部嵌入(第 96 和 97 行)。 - 在计算概率的同时识别出最有可能的
name(第 100-103 行)。 - 围绕人脸和人物的
name+概率(第 107 -112 行)画一个边界框。
我们的fps计数器在行 115 更新。
让我们显示结果并清理:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
为了结束脚本,我们:
- 显示带注释的
frame( 第 118 行)并等待按下“q”键,此时我们将退出循环(第 119-123 行)。 - 停止我们的
fps计数器并在终端中打印统计数据(第 126-128 行)。 - 通过关闭窗口和释放指针(行 131 和 132 )进行清理。
要在视频流上执行我们的 OpenCV 人脸识别管道,打开一个终端并执行以下命令:
$ python recognize_video.py --detector face_detection_model \
--embedding-model openface_nn4.small2.v1.t7 \
--recognizer output/recognizer.pickle \
--le output/le.pickle
[INFO] loading face detector...
[INFO] loading face recognizer...
[INFO] starting video stream...
[INFO] elasped time: 12.52
[INFO] approx. FPS: 16.13
如你所见,我们的人脸检测器正在工作!我们的 OpenCV 人脸识别管道在我的 iMac 上也获得了大约 16 FPS。在我的 MacBook Pro 上,我获得了大约 14 FPS 的吞吐速率。
缺点、局限性以及如何获得更高的人脸识别准确率

Figure 8: All face recognition systems are error-prone. There will never be a 100% accurate face recognition system.
不可避免地,您会遇到 OpenCV 无法正确识别人脸的情况。
在这种情况下你会怎么做?
以及如何提高自己的 OpenCV 人脸识别准确率?在这一节中,我将详细介绍一些建议的方法来提高面部识别管道的准确性
你可能需要更多的数据

Figure 9: Most people aren’t training their OpenCV face recognition models with enough data. (image source)
我的第一个建议可能是最明显的一个,但它值得分享。
在我之前的关于人脸识别的教程中,一些 PyImageSearch 的读者问为什么他们的人脸识别准确率很低,并且人脸被错误分类——对话是这样的(转述):
他们:嗨 Adrian,我正在尝试对我同学的人脸数据集进行人脸识别,但准确率真的很低。如何提高人脸识别的准确率?
我:你一个人有多少张人脸图像?
他们:只有一两个。
我:收集更多数据。
我得到的印象是,大多数读者已经知道他们需要更多的人脸图像,但他们每人只有一两张示例人脸,但我怀疑他们希望我从我的提示和技巧包中拿出一种计算机视觉技术来解决这个问题。
不是这样的。
如果你发现自己的人脸识别准确率很低,而且每个人只有几个样本人脸,那么就收集更多的数据——没有什么“计算机视觉技巧”可以把你从数据收集过程中拯救出来。
投资您的数据,您将拥有更好的 OpenCV 人脸识别渠道。总的来说,我会推荐一个每人至少 10-20 张面孔的。
注:你可能在想,“但是阿德里安,你在今天的帖子中只收集了每人 6 张图片!”是的,你是对的——我那样做是为了证明一点。我们今天在这里讨论的 OpenCV 人脸识别系统是可行的,但总是可以改进的。有时候,较小的数据集会给你想要的结果,尝试较小的数据集并没有错,但是当你没有达到想要的精度时,你会想要收集更多的数据。
执行面对齐

Figure 9: Performing face alignment for OpenCV facial recognition can dramatically improve face recognition performance.
OpenCV 用来计算 128 维人脸嵌入的人脸识别模型来自于 OpenFace 项目。
OpenFace 模型在已对齐的面上会表现得更好。
面部对齐是一个过程:
- 识别图像中人脸的几何结构。
- 尝试基于平移、旋转和缩放获得面部的规范对齐。
正如您在本部分顶部的图 9 中看到的,我有:
- 检测图像中的人脸并提取感兴趣区域(基于边界框坐标)。
- 应用面部标志检测提取眼睛的坐标。
- 计算每只眼睛的质心以及眼睛之间的中点。
- 并且基于这些点,应用仿射变换来将面部尺寸调整到固定的大小和维度。
如果我们将面对齐应用于数据集中的每个面,那么在输出坐标空间中,所有面应该:
- 在图像中居中。
- 旋转,使眼睛位于一条水平线上(即旋转面部,使眼睛位于同一 y 坐标)。
- 被缩放以使面的大小大致相同。
将人脸对齐应用到我们的 OpenCV 人脸识别管道超出了今天教程的范围,但是如果您想使用 OpenCV 和 OpenFace 进一步提高人脸识别的准确性,我建议您应用人脸对齐。
看看我的博文, 人脸对齐用 OpenCV 和 Python 。
调整您的超参数
我的第二个建议是,你可以尝试在你正在使用的任何机器学习模型(即,在提取的人脸嵌入之上训练的模型)上调整你的超参数。
对于本教程,我们使用线性 SVM;然而,我们没有调优C值,该值通常是要调优的 SVM 中最重要的值。
C值是一个“严格”参数,它控制您希望在多大程度上避免对训练集中的每个数据点进行错误分类。
更大的C值将更加严格,并且更加努力地对每个输入数据点进行正确分类,甚至冒着过度拟合的风险。
较小的C值将更“软”,允许训练数据中的一些错误分类,但理想情况下更好地推广到测试数据。
有趣的是,根据 OpenFace GitHub 中的一个分类示例,他们实际上建议而不是调整超参数,因为根据他们的经验,他们发现设置C=1在大多数设置中都能获得令人满意的人脸识别结果。
尽管如此,如果你的人脸识别精度不够,通过网格搜索或随机搜索调整你的超参数的额外努力和计算成本可能是值得的。
使用 dlib 的嵌入模型(但不是用于人脸识别的 k-NN)
在我使用 OpenCV 的人脸识别模型和 dlib 的人脸识别模型的经验中,我发现 dlib 的人脸嵌入更具鉴别性,尤其是对于较小的数据集。
此外,我发现 dlib 的模型不太依赖于:
- 预处理,如面部对齐
- 在提取的人脸嵌入之上使用更强大的机器学习模型
如果你看一下我最初的人脸识别教程,你会注意到我们利用了一个简单的 k-NN 算法来进行人脸识别(做了一个小小的修改,去掉了距离超过阈值的最近邻居投票)。
k-NN 模型工作得非常好,但正如我们所知,存在更强大的机器学习模型。
为了进一步提高准确性,你可能想使用 dlib 的嵌入模型,然后不应用 k-NN,而是按照今天帖子中的步骤#2 训练一个更强大的人脸嵌入分类器。
你在运行今天的 Python 人脸识别脚本时遇到过“用法”错误吗?
每周我都会收到类似这样的电子邮件:
嗨,阿德里安,我无法运行博客文章中的代码。
我的错误是这样的:
usage: extract_embeddings.py [-h] -i DATASET -e EMBEDDINGS
-d DETECTOR -m EMBEDDING_MODEL [-c CONFIDENCE]
extract_embeddings.py: error: the following arguments are required:
-i/--dataset, -e/--embeddings, -d/--detector, -m/--embedding-model
或者这个:
我使用 Spyder IDE 来运行代码。当我在命令框中遇到“用法”信息时,它没有运行。
本教程中有三个单独的 Python 脚本,而且,每个脚本都要求您(正确地)提供各自的命令行参数。
如果你是命令行参数的新手,那很好,但是在你尝试运行这些脚本之前,你需要阅读 Python、argparse 和命令行参数是如何工作的 !
老实说,人脸识别是一种先进的技术。命令行参数是一个初学者/新手的概念。一定要先走后跑,否则你会绊倒的。现在花点时间学习命令行参数。
其次,我总是包含确切的命令,您可以将其复制并粘贴到您的终端或命令行中,然后运行脚本。你可能想修改命令行参数来适应你自己的图像或视频数据,,但本质上我已经为你做了这些工作。有了命令行参数的知识,你可以将参数更新为指向你自己的数据、,而不必修改任何一行代码。
对于想使用像 Spyder 或 PyCharm 这样的 IDE 的读者,我建议您先学习如何在命令行/终端中使用命令行参数。程序,但是使用命令行来执行您的脚本。
**我还建议您不要试图为命令行参数配置您的 IDE,直到您通过首先键入它们来理解它们是如何工作的。事实上,你可能会爱上命令行,因为它比每次你想改变参数时点击 GUI 菜单来输入参数要快得多。一旦您很好地掌握了命令行参数的工作方式,您就可以在 IDE 中单独配置它们了。
通过快速搜索我的收件箱,我发现我已经回答了 500-1000 个与命令行参数相关的问题。我估计我在博客上回复了另外 1000 多个这样的问题。
不要让我阻止你评论帖子或给我发邮件寻求帮助——请吧。 但是如果你是编程新手,我强烈建议你阅读并尝试我的命令行参数博客文章 中讨论的概念,因为如果你需要帮助,我会把它链接到你的教程。
备选 OpenCV 人脸识别方法
在本教程中,您学习了如何使用 OpenCV 和预训练的 FaceNet 模型执行人脸识别。
与我们之前的基于深度学习的人脸识别教程不同,我们之前的教程使用了另外两个库/包(dlib 和 face_recognition),今天这里介绍的方法只使用了的 OpenCV,因此消除了其他依赖性。
然而,值得注意的是,在创建自己的人脸识别系统时,还有其他方法可以利用。
我建议从连体网络开始。暹罗网络是专门的深度学习模型,它:
- 可以用很少的数据成功训练
- 学习两个图像之间的相似性得分(即,两张脸有多相似)
- 是现代人脸识别系统的基石
我有一整套关于暹罗网络的教程,我建议你阅读一下以熟悉它们:
- 用 Python 为连体网络构建图像对
- 与 Keras、TensorFlow、深度学习的连体网络
- 使用暹罗网络、Keras 和 TensorFlow 比较图像的相似性
- 与 Keras 和 TensorFlow 的暹罗网络损耗对比
此外,还有一些基于非深度学习的人脸识别方法可以考虑:
这些方法不如基于深度学习的人脸识别方法准确,但计算效率更高,在嵌入式系统上运行更快。
摘要
在今天的博文中,我们使用 OpenCV 进行了人脸识别。
我们的 OpenCV 人脸识别管道是使用四阶段流程创建的:
- 创建你的面部图像数据集
- 提取图像中每个人脸的人脸嵌入(再次使用 OpenCV)
- 在人脸嵌入的基础上训练模型
- 使用 OpenCV 识别图像和视频流中的人脸
当然,如果您遵循上面详述的项目的目录结构,您可以交换您自己的面部数据集。
如果你需要帮助收集你自己的人脸数据集,一定要参考这篇关于建立人脸识别数据集的文章。
希望你喜欢今天的 OpenCV 人脸识别教程!
下载本文的源代码、模型和示例数据集加入 PyImageSearch 大学,我们的 OpenCV 和人脸检测课程**
OpenCV 快速傅立叶变换(FFT ),用于图像和视频流中的模糊检测
在本教程中,您将学习如何使用 OpenCV 和快速傅立叶变换(FFT)在图像和实时视频流中执行模糊检测。
今天的教程是我之前关于 OpenCV 模糊检测的博文的延伸。原始模糊检测方法:
- 依赖于计算拉普拉斯算子的方差
- 仅用一行代码就可以实现
- 使用起来非常简单吗
缺点是拉普拉斯方法需要大量的手动调谐来定义图像被认为模糊与否的“阈值”。如果你能控制你的照明条件、环境和图像捕捉过程,它会工作得很好——但如果不能,至少可以说,你会得到混合的结果。
我们今天要讨论的方法依赖于计算图像的快速傅立叶变换。它仍然需要一些手动调整,但正如我们将发现的,我们将涉及的 FFT 模糊检测器比拉普拉斯方法的方差更加鲁棒和可靠。
在本教程结束时,你将拥有一个全功能的 FFT 模糊检测器,可以应用于图像和视频流。
要了解如何使用 OpenCV 和快速傅立叶变换(FFT)来执行模糊检测,请继续阅读。
注:博文更新于 2022 年 1 月 22 日。
OpenCV 快速傅立叶变换(FFT)用于模糊检测
在本教程的第一部分,我们将简要讨论:
- 什么是模糊检测
- 为什么我们可能想要检测图像/视频流中的模糊
- 以及快速傅立叶变换如何让我们发现模糊。
在此基础上,我们将实现针对图像和实时视频的 FFT 模糊检测器。
我们将通过回顾 FFT 模糊检测器的结果来结束本教程。
什么是模糊检测,我们什么时候需要检测模糊?
模糊检测,顾名思义,就是检测图像是否模糊的过程。
模糊检测的可能应用包括:
- 自动图像质量分级
- 通过自动丢弃模糊/低质量的照片,帮助专业摄影师在照片拍摄过程中整理 100 到 1000 张照片
- 对实时视频流应用 OCR,但仅对非模糊帧应用昂贵的 OCR 计算
这里的关键要点是,为在理想条件下捕获的图像编写计算机视觉代码总是更容易。
不是试图处理图像质量非常差的边缘情况,而是简单地检测并丢弃质量差的图像(例如具有明显模糊的图像)。
这种模糊检测程序可以自动丢弃质量差的图像,或者简单地告诉最终用户“嘿,伙计,再试一次。让我们在这里捕捉更好的图像。”
请记住,计算机视觉应用程序应该是智能的,因此出现了术语人工智能——有时,“智能”可以只是检测输入数据的质量是否很差,而不是试图理解它。
什么是快速傅立叶变换(FFT)?
快速傅立叶变换是用于计算离散傅立叶变换的方便的数学算法。它用于将信号从一个域转换到另一个域。
FFT 在许多学科中都很有用,包括音乐、数学、科学和工程。例如,电气工程师,特别是处理无线、电源和音频信号的工程师,需要 FFT 计算将时间序列信号转换到频域,因为有些计算在频域中更容易完成。相反,可以使用 FFT 将频域信号转换回时域。
就计算机视觉而言,我们通常认为 FFT 是一种图像处理工具,它在两个领域中表示图像:
- 傅立叶(即频率)域
- 空间域
因此,FFT 以实数和虚数分量表示图像。
通过分析这些值,我们可以执行图像处理程序,如模糊、边缘检测、阈值处理、纹理分析和是的,甚至模糊检测。
回顾快速傅立叶变换的数学细节超出了这篇博客的范围,所以如果你有兴趣了解更多,我建议你阅读这篇关于 FFT 及其与图像处理的关系的文章。
对于有学术倾向的读者来说,看看亚伦·博比克在佐治亚理工学院的计算机视觉课程中精彩的幻灯片。
最后,傅立叶变换的维基百科页面更加详细地介绍了数学,包括它在非图像处理任务中的应用。
项目结构
首先使用本教程的 【下载】 部分下载源代码和示例图像。提取文件后,您将拥有一个如下组织的目录:
$ tree --dirsfirst
.
├── images
│ ├── adrian_01.png
│ ├── adrian_02.png
│ ├── jemma.png
│ └── resume.png
├── pyimagesearch
│ ├── __init__.py
│ └── blur_detector.py
├── blur_detector_image.py
└── blur_detector_video.py
2 directories, 8 files
在下一节中,我们将实现基于 FFT 的模糊检测算法。
用 OpenCV 实现 FFT 模糊检测器
我们现在准备用 OpenCV 实现我们的快速傅立叶变换模糊检测器。
我们将要介绍的方法是基于刘等人 2008 年在发表的之后的实现,图像局部模糊检测和分类。
在我们的目录结构中打开blur_detector.py文件,并插入以下代码:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
def detect_blur_fft(image, size=60, thresh=10, vis=False):
# grab the dimensions of the image and use the dimensions to
# derive the center (x, y)-coordinates
(h, w) = image.shape
(cX, cY) = (int(w / 2.0), int(h / 2.0))
# compute the FFT to find the frequency transform, then shift
# the zero frequency component (i.e., DC component located at
# the top-left corner) to the center where it will be more
# easy to analyze
fft = np.fft.fft2(image)
fftShift = np.fft.fftshift(fft)
这里,使用 NumPy 的内置算法,我们计算 FFT ( 第 15 行)。
然后,我们将结果的零频率分量(DC 分量)移到中心,以便于分析(第 16 行)。
现在我们已经有了image的 FFT,让我们来看看设置了vis标志后的结果:
# check to see if we are visualizing our output
if vis:
# compute the magnitude spectrum of the transform
magnitude = 20 * np.log(np.abs(fftShift))
# display the original input image
(fig, ax) = plt.subplots(1, 2, )
ax[0].imshow(image, cmap="gray")
ax[0].set_title("Input")
ax[0].set_xticks([])
ax[0].set_yticks([])
# display the magnitude image
ax[1].imshow(magnitude, cmap="gray")
ax[1].set_title("Magnitude Spectrum")
ax[1].set_xticks([])
ax[1].set_yticks([])
# show our plots
plt.show()
# zero-out the center of the FFT shift (i.e., remove low
# frequencies), apply the inverse shift such that the DC
# component once again becomes the top-left, and then apply
# the inverse FFT
fftShift[cY - size:cY + size, cX - size:cX + size] = 0
fftShift = np.fft.ifftshift(fftShift)
recon = np.fft.ifft2(fftShift)
在此,我们:
- 通过线 43 将 FFT 偏移的中心归零(即去除低频)
- 应用逆移位将 DC 组件放回左上角(行 44 )
- 应用逆 FFT ( 行 45 )
从这里开始,我们还有三个步骤来确定我们的image是否模糊:
# compute the magnitude spectrum of the reconstructed image,
# then compute the mean of the magnitude values
magnitude = 20 * np.log(np.abs(recon))
mean = np.mean(magnitude)
# the image will be considered "blurry" if the mean value of the
# magnitudes is less than the threshold value
return (mean, mean <= thresh)
实现基于 FFT 的模糊检测算法做得很好。但是我们还没有完成。在下一节中,我们将把我们的算法应用于静态图像,以确保它按照我们的预期执行。
用 FFT 检测图像中的模糊
# import the necessary packages
from pyimagesearch.blur_detector import detect_blur_fft
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path input image that we'll detect blur in")
ap.add_argument("-t", "--thresh", type=int, default=20,
help="threshold for our blur detector to fire")
ap.add_argument("-v", "--vis", type=int, default=-1,
help="whether or not we are visualizing intermediary steps")
ap.add_argument("-d", "--test", type=int, default=-1,
help="whether or not we should progressively blur the image")
args = vars(ap.parse_args())
# load the input image from disk, resize it, and convert it to
# grayscale
orig = cv2.imread(args["image"])
orig = imutils.resize(orig, width=500)
gray = cv2.cvtColor(orig, cv2.COLOR_BGR2GRAY)
# apply our blur detector using the FFT
(mean, blurry) = detect_blur_fft(gray, size=60,
thresh=args["thresh"], vis=args["vis"] > 0)
# draw on the image, indicating whether or not it is blurry
image = np.dstack([gray] * 3)
color = (0, 0, 255) if blurry else (0, 255, 0)
text = "Blurry ({:.4f})" if blurry else "Not Blurry ({:.4f})"
text = text.format(mean)
cv2.putText(image, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
color, 2)
print("[INFO] {}".format(text))
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
# check to see if are going to test our FFT blurriness detector using
# various sizes of a Gaussian kernel
if args["test"] > 0:
# loop over various blur radii
for radius in range(1, 30, 2):
# clone the original grayscale image
image = gray.copy()
# check to see if the kernel radius is greater than zero
if radius > 0:
# blur the input image by the supplied radius using a
# Gaussian kernel
image = cv2.GaussianBlur(image, (radius, radius), 0)
# apply our blur detector using the FFT
(mean, blurry) = detect_blur_fft(image, size=60,
thresh=args["thresh"], vis=args["vis"] > 0)
# draw on the image, indicating whether or not it is
# blurry
image = np.dstack([image] * 3)
color = (0, 0, 255) if blurry else (0, 255, 0)
text = "Blurry ({:.4f})" if blurry else "Not Blurry ({:.4f})"
text = text.format(mean)
cv2.putText(image, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, color, 2)
print("[INFO] Kernel: {}, Result: {}".format(radius, text))
# show the image
cv2.imshow("Test Image", image)
cv2.waitKey(0)
图像结果中的 FFT 模糊检测
我们现在准备使用 OpenCV 和快速傅立叶变换来检测图像中的模糊。
首先确保使用本教程的 “下载” 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python blur_detector_image.py --image images/adrian_01.png
[INFO] Not Blurry (42.4630)
这里你可以看到我在锡安国家公园 — 的地铁里徒步的输入图像,图像被正确地标记为没有模糊。
让我们尝试另一个图像,这是我家的狗 Jemma:
$ python blur_detector_image.py --image images/jemma.png
[INFO] Blurry (12.4738)
$ python blur_detector_image.py --image images/adrian_02.png --test 1
[INFO] Not Blurry (32.0934)
[INFO] Kernel: 1, Result: Not Blurry (32.0934)
[INFO] Kernel: 3, Result: Not Blurry (25.1770)
[INFO] Kernel: 5, Result: Not Blurry (20.5668)
[INFO] Kernel: 7, Result: Blurry (13.4830)
[INFO] Kernel: 9, Result: Blurry (7.8893)
[INFO] Kernel: 11, Result: Blurry (0.6506)
[INFO] Kernel: 13, Result: Blurry (-5.3609)
[INFO] Kernel: 15, Result: Blurry (-11.4612)
[INFO] Kernel: 17, Result: Blurry (-17.0109)
[INFO] Kernel: 19, Result: Blurry (-19.6464)
[INFO] Kernel: 21, Result: Blurry (-20.4758)
[INFO] Kernel: 23, Result: Blurry (-20.7365)
[INFO] Kernel: 25, Result: Blurry (-20.9362)
[INFO] Kernel: 27, Result: Blurry (-21.1911)
[INFO] Kernel: 29, Result: Blurry (-21.3853
如果您使用上面看到的test例程,您将应用一系列有意的模糊,并使用我们的快速傅立叶变换(FFT)方法来确定图像是否模糊。这个测试程序是有用的,因为它允许你调整你的模糊阈值参数。
我鼓励你自己去做,看看结果。欢迎在 Twitter @PyImageSearch 上与我们分享。
在这里,你可以看到随着我们的图像变得越来越模糊,平均 FFT 幅度值降低。
我们的 FFT 模糊检测方法也可以应用于非自然场景图像。
例如,假设我们想要构建一个自动文档扫描仪应用程序——这样的计算机视觉项目应该自动拒绝模糊的图像。
然而,文档图像与自然场景图像有很大的不同,本质上对模糊更加敏感。
任何类型的模糊都会严重影响 OCR 准确度。
因此,我们应该增加我们的--thresh值(我还将包括--vis参数,这样我们可以直观地看到 FFT 幅度值是如何变化的):
$ python blur_detector_image.py --image images/resume.png --thresh 27 --test 1 --vis 1
[INFO] Not Blurry (34.6735)
[INFO] Kernel: 1, Result: Not Blurry (34.6735)
[INFO] Kernel: 3, Result: Not Blurry (29.2539)
[INFO] Kernel: 5, Result: Blurry (26.2893)
[INFO] Kernel: 7, Result: Blurry (21.7390)
[INFO] Kernel: 9, Result: Blurry (18.3632)
[INFO] Kernel: 11, Result: Blurry (12.7235)
[INFO] Kernel: 13, Result: Blurry (9.1489)
[INFO] Kernel: 15, Result: Blurry (2.3377)
[INFO] Kernel: 17, Result: Blurry (-2.6372)
[INFO] Kernel: 19, Result: Blurry (-9.1908)
[INFO] Kernel: 21, Result: Blurry (-15.9808)
[INFO] Kernel: 23, Result: Blurry (-20.6240)
[INFO] Kernel: 25, Result: Blurry (-29.7478)
[INFO] Kernel: 27, Result: Blurry (-29.0728)
[INFO] Kernel: 29, Result: Blurry (-37.7561)
如果你运行这个脚本(你应该这样做),你会看到我们的图像很快变得模糊不清,并且 OpenCV FFT 模糊检测器正确地将这些图像标记为模糊。
利用 OpenCV 和 FFT 检测视频中的模糊
到目前为止,我们已经将快速傅立叶变换模糊检测器应用于图像。
但是有没有可能将 FFT 模糊检测应用到视频流中呢?
整个过程也能在实时完成吗?
让我们找出答案——打开一个新文件,将其命名为blur_detector_video.py,并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from pyimagesearch.blur_detector import detect_blur_fft
import argparse
import imutils
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--thresh", type=int, default=10,
help="threshold for our blur detector to fire")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=500)
# convert the frame to grayscale and detect blur in it
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
(mean, blurry) = detect_blur_fft(gray, size=60,
thresh=args["thresh"], vis=False)
第 17 行和第 18 行初始化我们的网络摄像头流,让摄像头有时间预热。
从那里,我们开始在线 21 上的帧处理循环。在里面,我们抓取一帧并将其转换为灰度(第 24-28 行),就像我们的单个图像模糊检测脚本一样。
# draw on the frame, indicating whether or not it is blurry
color = (0, 0, 255) if blurry else (0, 255, 0)
text = "Blurry ({:.4f})" if blurry else "Not Blurry ({:.4f})"
text = text.format(mean)
cv2.putText(frame, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, color, 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
此时,我们的最后一个代码块应该看起来非常熟悉,因为这是我们第三次看到这些代码行。在这里我们:
- 标注模糊(红色
text)或不模糊(绿色text)以及mean值(第 33-37 行) - 显示结果(第 40 行)
- 如果按下
q键,退出(第 41-45 行,并执行内务清理(第 48 和 49 行)
快速傅立叶变换视频模糊检测结果
我们现在准备好了解我们的 OpenCV FFT 模糊检测器是否可以应用于实时视频流。
确保使用本教程的 【下载】 部分下载源代码。
从那里,打开一个终端,并执行以下命令:
$ python blur_detector_video.py
[INFO] starting video stream...
当我移动我的笔记本电脑时,运动模糊被引入画面。
如果我们正在实现一个计算机视觉系统来自动提取关键、重要的帧,或者创建一个自动视频 OCR 系统,我们会想要丢弃这些模糊的帧——使用我们的 OpenCV FFT 模糊检测器,我们完全可以做到这一点!
摘要
在今天的教程中,您学习了如何使用 OpenCV 的快速傅立叶变换(FFT)实现来执行图像和实时视频流中的模糊检测。
虽然不像拉普拉斯模糊检测器的方差那么简单,但 FFT 模糊检测器更加稳定,在现实应用中往往能提供更好的模糊检测精度。
问题是 FFT 方法仍然需要我们手动设置阈值,特别是 FFT 幅度的平均值。
一个理想的模糊检测器将能够检测图像和视频流中的模糊,而不需要这样的阈值。
为了完成这项任务,我们需要一点机器学习——我将在未来的教程中介绍自动模糊检测器。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV 翻转图像(cv2.flip)
原文:https://pyimagesearch.com/2021/01/20/opencv-flip-image-cv2-flip/
在本教程中,您将学习如何使用 OpenCV 和cv2.flip函数翻转图像。

与图像旋转类似,OpenCV 也提供了沿 x- 或 y 轴翻转图像的方法。尽管翻转操作用得不多了,但它们仍然很有学习价值——原因你可能不会马上想到。
例如,让我们想象一下,为一家小型创业公司工作,该公司希望建立一个机器学习分类器来检测图像中的人脸。我们需要一个样本人脸的数据集,我们的算法可以用它来“学习”什么是人脸。但不幸的是,该公司只为我们提供了 20 张人脸的微小数据集,我们没有获得更多数据的手段。
那我们该怎么办?
我们应用翻转操作来扩充我们的数据集!
我们可以水平翻转每个人脸图像(因为人脸仍然是人脸,无论是否镜像),并使用这些镜像版本作为附加的训练数据。
虽然这个例子听起来很傻很做作,但事实并非如此。强大的、数据饥渴的深度学习算法故意在训练时间使用翻转来生成额外的数据(通过一种叫做数据增强的技术)。
所以,如你所见,你在这里学习的图像处理技术真的是大型计算机视觉系统的基础!
要学习如何用 OpenCV 和cv2.flip,翻转图像,只要继续阅读。
OpenCV 翻转图像(cv2.flip )
在本教程的第一部分,我们将讨论什么是图像翻转,以及 OpenCV 如何帮助我们翻转图像。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我们将实现一个 Python 脚本来使用 OpenCV 执行图像翻转。
什么是图像翻转?
我们可以围绕x-轴、y-轴翻转图像,或者两者都翻转。
通过在启动代码之前查看图像翻转的输出,可以更好地解释图像翻转。查看图 1 以查看水平翻转的图像:
注意左边的,是我们的原始图像,右边的,是水平镜像的图像。
我们可以垂直地做同样的事情:
我们还可以结合水平和垂直翻转:
在本教程的后面,您将发现如何使用 OpenCV 执行这些图像翻转操作。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在回顾任何使用 OpenCV 剪辑图像的代码之前,让我们先回顾一下我们的项目目录结构。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,看一眼您的项目文件夹:
$ tree . --dirsfirst
.
├── opencv_flip.py
└── opencv_logo.png
0 directories, 2 files
我们的opencv_flip.py脚本将从磁盘加载opencv_logo.png图像,然后演示如何使用cv2.flip函数翻转图像。
用 OpenCV 实现图像翻转
我们要探索的下一个图像转换是翻转。我们可以绕着 x- 或 y 轴翻转图像,或者两者都翻转。
在我们进入代码之前,通过查看图像翻转的输出可以更好地解释翻转图像。查看图 5 查看水平翻转的图像:
现在您已经看到了图像翻转的样子,我们可以研究代码了:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="opencv_logo.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
这里我们只需要一个参数,--image,它是我们想要翻转的输入图像的路径。我们将这个值默认为项目目录中的opencv_logo.png图像。
现在让我们水平翻转图像:
# load the original input image and display it to our screen
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# flip the image horizontally
print("[INFO] flipping image horizontally...")
flipped = cv2.flip(image, 1)
cv2.imshow("Flipped Horizontally", flipped)
我们从第行的第 12 行和第 13 行开始,从磁盘加载我们的输入图像,并将其显示到我们的屏幕上。
水平翻转图像是通过调用行 17 上的cv2.flip函数来完成的,其输出如图图 5 所示。
cv2.flip方法需要两个参数:我们想要翻转的image和用于确定如何翻转图像的特定代码/标志。
使用翻转代码值1表示我们围绕 y 轴水平翻转图像。
指定翻转代码0表示我们想要围绕 x 轴垂直翻转图像:
# flip the image vertically
flipped = cv2.flip(image, 0)
print("[INFO] flipping image vertically...")
cv2.imshow("Flipped Vertically", flipped)
图 6 显示垂直翻转图像的输出:
最后,使用负翻转代码围绕两个轴翻转图像。
# flip the image along both axes
flipped = cv2.flip(image, -1)
print("[INFO] flipping image horizontally and vertically...")
cv2.imshow("Flipped Horizontally & Vertically", flipped)
cv2.waitKey(0)
在这里,您可以看到我们的图像水平和垂直翻转:
翻转图像非常简单——可能是本系列中最简单的例子之一!
OpenCV 图像翻转结果
要使用 OpenCV 翻转图像,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,打开一个 shell 并执行以下命令:
$ python opencv_flip.py
[INFO] flipping image horizontally...
[INFO] flipping image vertically...
[INFO] flipping image horizontally and vertically...
您的 OpenCV 翻转结果应该与我在上一节中的结果相匹配。
总结
在本教程中,您学习了如何使用 OpenCV 和cv2.flip函数水平和垂直翻转图像。
不可否认,图像翻转是我们讨论过的最简单的图像处理概念之一。然而,仅仅因为一个概念很简单并不意味着它没有更强大的用途。
正如我在本教程的介绍中提到的,翻转被一致地用于机器学习/深度学习中,以生成更多的训练数据样本,从而创建更强大和鲁棒的图像分类器。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
OpenCV 伽马校正
原文:https://pyimagesearch.com/2015/10/05/opencv-gamma-correction/
您知道人眼感知颜色和亮度的方式与智能手机或数码相机上的传感器不同吗?
你看,当两倍于的光子数击中数码相机的传感器时,它就接收到两倍于的信号(呈线性关系)。然而,这不是我们人类眼睛的工作方式。相反,我们认为加倍的光量只是的一小部分更亮(一种非线性关系)!此外,我们的眼睛对暗色调的变化也比亮色调更敏感(另一种非线性关系)。
为了说明这一点,我们可以应用伽马校正,这是我们的眼睛和相机传感器的灵敏度之间的转换。
在这篇文章的剩余部分,我将演示如何使用 Python 和 OpenCV 实现一个超级快速、非常简单的伽马校正函数。
伽马校正和幂律变换
伽马校正也称为幂律变换。首先,我们的图像像素强度必须从范围【0,255】缩放到【0,1.0】。从那里,我们通过应用下面的等式获得我们的输出伽马校正图像:
O = I ^ (1 / G)
其中 I 是我们的输入图像, G 是我们的伽马值。然后,输出图像 O 被缩放回范围【0,255】。
伽马值 < 1 将使图像向光谱的较暗一端移动,而伽马值 > 1 将使图像看起来较亮。 G=1 的伽马值对输入图像没有影响:
OpenCV 伽马校正
现在我们了解了什么是伽马校正,让我们使用 OpenCV 和 Python 来实现它。打开一个新文件,命名为adjust_gamma.py,然后我们开始:
# import the necessary packages
from __future__ import print_function
import numpy as np
import argparse
import cv2
def adjust_gamma(image, gamma=1.0):
# build a lookup table mapping the pixel values [0, 255] to
# their adjusted gamma values
invGamma = 1.0 / gamma
table = np.array([((i / 255.0) ** invGamma) * 255
for i in np.arange(0, 256)]).astype("uint8")
# apply gamma correction using the lookup table
return cv2.LUT(image, table)
第 2-5 行简单导入我们必要的包,这里没什么特别的。
我们在第 7 行的上定义我们的adjust_gamma函数。该方法需要一个参数image,这是我们想要对其应用伽马校正的图像。第二个(可选)值是我们的gamma值。在这种情况下,我们默认使用gamma=1.0,但是您应该提供任何必要的值来获得看起来不错的校正图像。
使用 OpenCV 和 Python 有两种(简单的)方法来应用伽马校正。第一种方法是简单地利用 Python + OpenCV 将图像表示为 NumPy 数组这一事实。我们需要做的就是将像素亮度缩放到范围【0,1.0】,应用变换,然后缩放回范围【0,255】。总的来说,NumPy 方法包括除法、乘幂,然后是乘法——这往往非常快,因为所有这些运算都是矢量化的。
然而,由于 OpenCV,有一种更快的方式来执行伽马校正。我们需要做的就是建立一个表(即字典),将输入像素值映射到输出伽马校正值。OpenCV 然后可以获取这个表,并在 O(1) 时间内快速确定给定像素的输出值。
例如,以下是gamma=1.2的示例查找表:
0 => 0
1 => 2
2 => 4
3 => 6
4 => 7
5 => 9
6 => 11
7 => 12
8 => 14
9 => 15
10 => 17
左栏是应用幂律变换后的输入像素值,而右栏是输出像素值。
第 11 行和第 12 行通过循环范围【0,255】内的所有像素值来构建这个查找表。像素值随后被缩放到范围 [0,1.0] ,随后被提升到反伽马的幂——该值随后被存储在table中。
最后,我们需要做的就是应用cv2.LUT函数(第 15 行)获取输入image和table,并为每个像素值找到正确的映射——这是一个简单(但非常快速)的操作!
让我们继续我们的例子:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the original image
original = cv2.imread(args["image"])
第 17-21 行处理解析命令行参数。这里我们只需要一个开关--image,它是我们的输入图像在磁盘上驻留的路径。第 24 行获取我们图像的路径并加载它。
让我们通过使用各种伽马值并检查每个值的输出图像来探索伽马校正:
# loop over various values of gamma
for gamma in np.arange(0.0, 3.5, 0.5):
# ignore when gamma is 1 (there will be no change to the image)
if gamma == 1:
continue
# apply gamma correction and show the images
gamma = gamma if gamma > 0 else 0.1
adjusted = adjust_gamma(original, gamma=gamma)
cv2.putText(adjusted, "g={}".format(gamma), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 3)
cv2.imshow("Images", np.hstack([original, adjusted]))
cv2.waitKey(0)
在的第 27 行上,我们开始遍历【0,3.0】范围内的gamma值(np.arange函数是不包含),每一步递增 0.5 。
在我们的gamma值是 1.0 的情况下,我们简单地忽略它(第 29 和 30 行),因为gamma=1.0不会改变我们的输入图像。
从那里,第 33-38 行对我们的图像进行伽马校正,并显示输出结果。
要查看 gamma 校正的效果,只需打开一个终端并执行以下命令:
$ python adjust_gamma.py --image example_01.png

Figure 2: When applying gamma correction with G < 1, the output image is will darker than the original input image.
请注意gamma=0.5经过伽马校正的图像(右)比已经相当暗的输入图像(左)暗得多——我们在原始图像中几乎看不到狗脸的任何细节,更不用说经过伽马校正的版本了!
然而,在gamma=1.5处,图像开始变亮,我们可以看到更多细节:

Figure 3: As the gamma value reaches 1.0 and starts to exceed it, the image lightens up and we can see more detail.
当我们到达gamma=2.0时,图像中的细节完全可见。

Figure 4: Now at gamma=2.0, we can fully see the details on the dogs face.
虽然在gamma=2.5,图像开始出现“褪色”:

Figure 5: However, if we carry gamma correction too far, the image will start to appear washed out.
让我们试试另一个图像:
$ python adjust_gamma.py --image example_02.png

Figure 6: After applying gamma correction with gamma=0.5, we cannot see any detail in this image.
就像在example_01.png中一样, 0.5 的灰度值会使输入图像看起来比实际更暗。除了天空和看起来像是山脉的东西,我们真的看不清这张照片的任何细节。
然而,当我们使用gamma=1.5进行伽马校正时,情况发生了变化:
Figure 7: Optimal results are obtained near gamma=1.5.
现在我们可以看到图像变得更亮了——我们甚至可以开始看到前景中有树,这从左边的原始输入图像中并不完全明显。
在gamma=2.0处,图像开始出现褪色,但是原始图像和伽马校正图像之间的差异仍然相当大:
Figure 8: But again, we can carry gamma correction too far and washout our image.
摘要
在这篇博文中,我们了解了伽马校正,也称为幂律变换。然后,我们使用 Python 和 OpenCV 实现了伽马校正。
我们应用伽马校正的原因是因为我们的眼睛感知颜色和亮度与数码相机中的传感器不同。当数码相机上的传感器捕捉到两倍于光子数量的信号时,信号就会变成两倍的 T2 信号。然而,我们的眼睛不是这样工作的。相反,我们的眼睛感知到的光量是原来的两倍,而仅仅是一小部分光变亮了。因此,当数码相机在亮度之间具有线性关系时,我们的眼睛具有非线性关系。为了说明这种关系,我们应用伽马校正。**
请务必下载这篇文章的代码,并尝试将伽玛校正应用到您自己的照片。试着浏览你的照片集,找到那些要么过暗要么非常亮 然后褪色的照片。然后对这些图像进行伽玛校正,看看它们是否变得更具视觉吸引力。
OpenCV 获取和设置像素
原文:https://pyimagesearch.com/2021/01/20/opencv-getting-and-setting-pixels/
在本教程中,您将学习如何使用 OpenCV 和 Python 获取和设置像素值。

您还将了解到:
- 什么是像素
- OpenCV 中图像坐标系的工作原理
- 如何访问/获取图像中的单个像素值
- 如何设置/更新图像中的像素
- 如何使用数组切片来抓取图像区域
在本教程结束时,您将对如何使用 OpenCV 访问和操作图像中的像素有很深的理解。
要学习如何用 OpenCV 获取和设置像素,继续阅读。
OpenCV 获取和设置像素
在本教程的第一部分,你会发现什么是像素(即,图像的建筑块)。我们还将回顾 OpenCV 中的图像坐标系,包括访问单个像素值的正确符号。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
回顾了我们的项目目录结构后,我们将实现一个 Python 脚本,opencv_getting_setting.py。顾名思义,这允许我们使用 OpenCV 访问和操作像素。
我们将讨论我们的结果来结束本教程。
我们开始吧!
什么是像素?
像素是图像的原始构件。每个图像都由一组像素组成。没有比像素更精细的粒度了。
通常,像素被认为是出现在我们图像中给定位置的光的“颜色”或“强度”。
如果我们把一幅图像想象成一个网格,网格中的每个方块包含一个像素。让我们来看看图 1 中的示例图像:

Figure 1: This image is 600 pixels wide and 450 pixels tall for a total of 600 x 450 = 270,000 pixels.
大多数像素以两种方式表示:
- 灰度/单通道
- 颜色
在灰度图像中,每个像素的值在 0 到 255 之间,其中 0 对应“黑色”,255 对应“白色”0 到 255 之间的值是不同的灰度,越接近 0 的值越暗,越接近 255 的值越亮:

Figure 2: Image gradient demonstrating pixel values going from black (0) to white (255).
图 2 中的灰度梯度图像展示了左手边的较暗像素和右手边逐渐变亮的像素。
然而,彩色像素通常在 RGB 颜色空间中表示——一个值用于红色分量,一个值用于绿色分量,一个值用于蓝色分量,导致每个像素总共有 3 个值:

Figure 3: The RGB cube.
存在其他颜色空间(HSV(色调、饱和度、值)、Lab*等。),但是让我们从基础开始,从那里开始向上移动。
红、绿、蓝三种颜色中的每一种都由一个从 0 到 255 范围内的整数表示,这表示颜色的“多少”。假设像素值只需要在范围【0,255】,内,我们通常使用 8 位无符号整数来表示每个颜色强度。
然后,我们将这些值组合成一个格式为(red, green, blue)的 RGB 元组。这个元组代表我们的颜色。
为了构造一个白色,我们将完全填充红色、绿色和蓝色的桶,就像这样:(255, 255, 255) —因为白色代表所有的颜色。
然后,为了创建黑色,我们将完全清空每个桶:(0, 0, 0)——因为黑色是没有颜色的。
为了创建一个纯粹的红色,我们将完全填充红色桶(只有红色桶):(255, 0, 0)。
你开始看出规律了吗?
请看下图,让这个概念更加清晰:

Figure 4: Here, we have four examples of colors and the “bucket” amounts for each of the Red, Green, and Blue components, respectively.
在左上角的例子中,我们有颜色白色——红色、绿色和蓝色的桶都被完全填满,形成白色。
在右上角的,我们有黑色——红色、绿色和蓝色的桶现在完全空了。
类似地,为了在左下方的中形成红色,我们简单地完全填充红色桶,让其他绿色和蓝色桶完全空着。
最后,蓝色是通过仅填充蓝色桶形成的,如右下方的所示。
以下是一些以 RGB 元组表示的常见颜色,供您参考:
- 黑色:
(0, 0, 0) - 白色:
(255, 255, 255) - 红色:
(255, 0, 0) - 绿色:
(0, 255, 0) - 蓝色:
(0, 0, 255) - 阿卡:
(0, 255, 255) - 紫红色:
(255, 0, 255) - 栗色:
(128, 0, 0) - 海军:
(0, 0, 128) - 橄榄:
(128, 128, 0) - 紫色:
(128, 0, 128) - 缇尔:
(0, 128, 128) - 黄色:
(255, 255, 0)
现在我们对像素有了很好的理解,让我们快速回顾一下坐标系。
OpenCV 中图像坐标系概述
正如我在图 1 中提到的,图像被表示为像素网格。把我们的网格想象成一张绘图纸。**使用这张图纸,点 (0,0) 对应于图像左上角的(即原点)。当我们向下移动并向右移动时, x 和 y 的值都会增加。
*让我们看一下图 5 中的图像,以便更清楚地说明这一点:

Figure 5: In OpenCV, pixels are accessed by their (x, y)-coordinates. The origin, (0, 0), is located at the top-left of the image. OpenCV images are zero-indexed, where the x-values go left-to-right (column number) and y-values go top-to-bottom (row number).
这里,我们在一张图表纸上有字母“I”。我们看到我们有一个总共 64 个像素的 8 x 8 网格。
位于 (0,0) 的点对应于我们图像中左上角的像素,而点 (7,7) 对应于右下角的。**
**需要注意的是,我们是从零开始计数,而不是从一开始计数。Python 语言是零索引的,意思是我们总是从零开始计数。记住这一点,你会在以后避免很多困惑。
最后,向右的第 4 列和向下的第 5 行的像素由点 (3,4) 索引,记住我们是从零开始计数而不是从一开始计数。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?

Figure 6: Having trouble configuring your development environment? Want access to pre-configured Jupyter Notebooks running on Google Colab? Be sure to join PyImageSearch Plus — you will be up and running with this tutorial in a matter of minutes.
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们开始看代码之前,让我们回顾一下我们的项目目录结构:
$ tree . --dirsfirst
.
├── adrian.png
└── opencv_getting_setting.py
0 directories, 2 files
我们今天要回顾一个 Python 脚本opencv_getting_setting.py,它将允许我们访问和操作来自图像adrian.png的图像像素。
用 OpenCV 获取和设置像素
让我们来学习如何用 OpenCV 获取和设置像素。
打开项目目录结构中的opencv_getting_setting.py文件,让我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to the input image")
args = vars(ap.parse_args())
2 号线和 3 号线导入我们需要的 Python 包。对于 OpenCV 绑定,我们只需要argparse作为命令行参数cv2。
--image命令行参数指向我们想要操作的驻留在磁盘上的图像。默认情况下,--image命令行参数被设置为adrian.png。
接下来,让我们加载这个图像并开始访问像素值:
# load the image, grab its spatial dimensions (width and height),
# and then display the original image to our screen
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
cv2.imshow("Original", image)
第 13-15 行从磁盘加载我们的输入image,获取它的宽度和高度,并将图像显示到我们的屏幕:

Figure 7: Loading our input image from disk and displaying it with OpenCV.
OpenCV 中的图像由 NumPy 数组表示。要访问一个特定的图像像素,我们需要做的就是将 (x,y) 坐标作为image[y, x]:
# images are simply NumPy arrays -- with the origin (0, 0) located at
# the top-left of the image
(b, g, r) = image[0, 0]
print("Pixel at (0, 0) - Red: {}, Green: {}, Blue: {}".format(r, g, b))
# access the pixel located at x=50, y=20
(b, g, r) = image[20, 50]
print("Pixel at (50, 20) - Red: {}, Green: {}, Blue: {}".format(r, g, b))
# update the pixel at (50, 20) and set it to red
image[20, 50] = (0, 0, 255)
(b, g, r) = image[20, 50]
print("Pixel at (50, 20) - Red: {}, Green: {}, Blue: {}".format(r, g, b))
第 19 行访问位于 (0,0) 的像素,即图像左上角的。作为回报,我们依次接收蓝色、绿色和红色强度(BGR)。
*最大的问题是:
为什么 OpenCV 在 BGR 通道排序中表示图像,而不是标准的 RGB?
答案是,当 OpenCV 最初被开发时,BGR 订购的是的标准!后来才采用 RGB 顺序。BGR 排序是 OpenCV 中的标准,所以习惯于看到它。
行 23 然后使用image[20, 50]的数组索引访问位于 x = 50 , y = 20 的像素。
但是等等。。。那不是落后吗?既然 x = 50 和 y = 20 不应该改为image[50, 20]吗?
没那么快!
让我们后退一步,认为一个图像只是一个具有宽度(列数)和高度(行数)的矩阵。如果我们要访问矩阵中的一个单独的位置,我们将把它表示为x值(列号)和y值(行号)。
因此,要访问位于 x = 50 , y = 20 的像素,首先传递y-值(行号),然后传递x-值(列号),结果是image[y, x]。
注: 我发现用image[y, x]的语法访问单个像素的概念是很多学生犯的错误。花点时间说服自己image[y, x]是正确的语法,因为 x 值是你的列号(即宽度),y 值是你的行号(即高度)。
第 27 行和第 28 行更新位于 x = 50 , y = 20 的像素,设置为红色,在 BGR 排序中为(0, 0, 255)。第 29 行然后将更新后的像素值打印到我们的终端,从而表明它已经被更新。
接下来,让我们学习如何使用 NumPy 数组切片从图像中获取感兴趣的大块/区域:
# compute the center of the image, which is simply the width and height
# divided by two
(cX, cY) = (w // 2, h // 2)
# since we are using NumPy arrays, we can apply array slicing to grab
# large chunks/regions of interest from the image -- here we grab the
# top-left corner of the image
tl = image[0:cY, 0:cX]
cv2.imshow("Top-Left Corner", tl)
在第 33 行,我们计算图像的中心 (x,y)-坐标。这是通过简单地将宽度和高度除以 2 来实现的,确保整数转换(因为我们不能访问“分数像素”位置)。
然后,在第 38 行,我们使用简单的 NumPy 数组切片来提取图像的[0, cX)和[0, cY)区域。事实上,这个区域对应于图像左上角的!为了抓取图像的大块,NumPy 希望我们提供四个索引:
** 起始 y : 第一个值是起始 y 坐标。这是我们的数组切片沿着 y 轴开始的地方。在上面的例子中,我们的切片从 y = 0 开始。
- 结束 y : 正如我们提供了一个起始 y 值一样,我们必须提供一个结束 y 值。当 y = cY 时,我们的切片沿 y 轴停止。
- 起始 x : 我们必须提供的第三个值是切片的起始x-坐标。为了抓取图像左上角的区域,我们从 x = 0 开始。
- End x : 最后,我们需要提供 x 轴的值,让我们的切片停止。当 x = cX 时我们停止。
一旦我们提取了图像左上角的,行 39 显示了裁剪结果。请注意,我们的图像只是原始图像左上角的😗*
**
Figure 8: Extracting the top-left corner of the image using array slicing.
让我们进一步扩展这个例子,这样我们就可以练习使用 NumPy 数组切片从图像中提取区域:
# in a similar fashion, we can crop the top-right, bottom-right, and
# bottom-left corners of the image and then display them to our
# screen
tr = image[0:cY, cX:w]
br = image[cY:h, cX:w]
bl = image[cY:h, 0:cX]
cv2.imshow("Top-Right Corner", tr)
cv2.imshow("Bottom-Right Corner", br)
cv2.imshow("Bottom-Left Corner", bl)
与上面的例子类似,行 44 提取图像右上角,行 45 提取右下角,行 46 左下角。**
**最后,图像的所有四个角都显示在屏幕上的第 47-49 行上,就像这样:

Figure 9: Using array slicing to extract the four corners of an image with OpenCV.
理解 NumPy 数组切片是一项非常重要的技能,作为一名计算机视觉从业者,您将会反复使用这项技能。如果你不熟悉 NumPy 数组切片,我建议你花几分钟时间阅读一下关于 NumPy 索引、数组和切片的基础知识。
我们要做的最后一项任务是使用数组切片来改变像素区域的颜色:
# set the top-left corner of the original image to be green
image[0:cY, 0:cX] = (0, 255, 0)
# Show our updated image
cv2.imshow("Updated", image)
cv2.waitKey(0)
在第 52 行的上,你可以看到我们再次访问图像左上角的;但是,这一次,我们将这个区域的值设置为(0, 255, 0)(绿色)。
*第 55 行和第 56 行显示了我们工作的结果:

Figure 10: Setting the top-left corner of the image to be “green.”
OpenCV 像素获取和设置结果
现在让我们学习如何使用 OpenCV 获取和设置单个像素值!
确保您已经使用了本教程的 【下载】 部分来访问源代码和示例图像。
从那里,您可以执行以下命令:
$ python opencv_getting_setting.py --image adrian.png
Pixel at (0, 0) - Red: 233, Green: 240, Blue: 246
Pixel at (50, 20) - Red: 229, Green: 238, Blue: 245
Pixel at (50, 20) - Red: 255, Green: 0, Blue: 0
一旦我们的脚本开始运行,您应该看到一些输出打印到您的控制台。
第一行输出告诉我们,位于 (0,0) 的像素的值为 R = 233 、 G = 240 、 B = 246 。所有三个通道的桶几乎都是白色的,表明像素非常亮。
接下来的两行输出显示,我们已经成功地将位于 (50,20) 的像素更改为红色,而不是(几乎)白色。
您可以参考“使用 OpenCV 获取和设置像素”部分的图像和截图,了解我们图像处理流程中每个步骤的图像可视化。
总结
在本教程中,您学习了如何使用 OpenCV 获取和设置像素值。
您还了解了像素(图像的构建块)以及 OpenCV 使用的图像坐标系。
不像你在基础代数中学习的坐标系,原点表示为 (0,0) ,在左下角,图像的原点实际上位于图像左上角。
随着x-值的增加,我们进一步向图像的右侧移动。随着y-值的增加,我们进一步向下*图像。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!************
OpenCV GrabCut:前景分割和提取
原文:https://pyimagesearch.com/2020/07/27/opencv-grabcut-foreground-segmentation-and-extraction/
在本教程中,您将学习如何使用 OpenCV 和 GrabCut 来执行前景分割和提取。
在深度学习和实例/语义分割网络如 Mask R-CNN,U-Net 等之前。, GrabCut 是将图像的前景从背景中准确分割出来的方法。
GrabCut 算法的工作原理是:
- 接受带有的输入图像,或者是 (1)一个边界框,它指定了我们想要分割的图像中对象的位置,或者是(2)一个遮罩,它的近似于分割
- 迭代地执行以下步骤:
- 步骤#1: 通过高斯混合模型(GMM)估计前景和背景的颜色分布
- 步骤#2: 在像素标签上构建马尔可夫随机场(即,前景对背景)
- 步骤#3: 应用图割优化以达到最终分割
听起来很复杂,不是吗?
幸运的是,OpenCV 通过cv2.grabCut函数实现了 GrabCut,这使得应用 GrabCut 变得轻而易举(当然,前提是您知道该函数的参数以及如何调整它们)。
但是在你说:
嘿,阿德里安,GrabCut 算法不是旧闻了吗?
难道我们不应该应用 Mask R-CNN、U-Net 或其他图像分割网络来分割背景和前景吗?
以上是深度学习和传统计算机视觉如何融合在一起的完美例子。
如果你以前用过 Mask R-CNN 或者 U-Net,你就知道这些深度神经网络超级强大,但是面具并不总是完美的。实际上,你可以使用 GrabCut 来清理这些分段掩码(我将在以后的文章中向你展示如何做)。
但与此同时,让我们了解一下 GrabCut 的基本原理。
学习如何使用 OpenCV 和 GrabCut 进行前景分割,继续阅读。
OpenCV GrabCut:前景分割和提取
在本教程的第一部分,我们将讨论 GrabCut,它通过cv2.grabCut函数在 OpenCV 中的实现,以及它的相关参数。
从这里,我们将学习如何通过以下两种方式用 OpenCV 实现 GrabCut:
- 使用边界框进行 GrabCut 初始化
- 使用掩码近似的 GrabCut 初始化
之后,我们将应用 GrabCut 并检查我们的结果。
OpenCV 中的 GrabCut
cv2.grabCut函数具有以下签名:
grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) ->
mask, bgdModel, fgdModel
为了获得对实现的完整理解,让我们回顾一下这些参数:
img:输入图像,GrabCut 假设其为 8 位 3 通道图像(即 BGR 通道排序中的无符号 8 位整数)。mask:输入/输出屏蔽。此遮罩被假定为单通道图像,具有无符号 8 位整数数据类型。如果使用边界框初始化(即cv2.GC_INIT_WITH_RECT),该遮罩会自动初始化;否则,GrabCut 会假设您正在执行掩码初始化(cv2.GC_INIT_WITH_MASK)。rect:包含要分割区域的边框矩形。该参数仅在将mode设置为cv2.GC_INIT_WITH_MASK时使用。bgModel:grab cut 内部对背景建模时使用的临时数组。fgModel:grab cut 对前景建模时使用的临时数组。iterCount:grab cut 对前景和背景建模时将执行的迭代次数。迭代次数越多,GrabCut 运行的时间越长,理想情况下结果会更好。mode:或者cv2.GC_INIT_WITH_RECT或者cv2.GC_INIT_WITH_MASK,分别取决于你是用边界框还是遮罩初始化 GrabCut。
现在我们已经了解了cv2.grabCut函数,包括它的参数和返回值,让我们继续将 GrabCut 应用于一个示例计算机视觉项目。
配置您的开发环境
按照我的 pip install opencv 教程(包含 Ubuntu、macOS 和 Raspbian 的说明),您现在可以使用包含 OpenCV 的 Python 虚拟环境来设置您的系统。
请注意 PyImageSearch 不推荐也不支持 Windows 用于计算机视觉和深度学习开发。
项目结构
在我们继续之前,使用今天教程的 【下载】 部分。与这篇博文相关的 zip 文件。从那里,让我们用tree命令直接在终端中检查文件和文件夹的布局:
$ tree --dirsfirst
.
├── images
│ ├── adrian.jpg
│ ├── lighthouse.png
│ └── lighthouse_mask.png
├── grabcut_bbox.py
└── grabcut_mask.py
1 directory, 5 files
使用这两个 Python 脚本,我们将学习如何使用两种方法执行 GrabCut(边界框初始化与遮罩初始化)。在下一节中,我们将从包围盒方法开始。
使用 OpenCV 的 GrabCut:使用边界框初始化
让我们开始用 OpenCV 实现 GrabCut 我们将从回顾边界框实现方法开始。
这里,我们将指定要在图像中分割的对象的边界框。边界框可以通过以下方式生成:
- 手动检查图像并标记边界框的 (x,y)-坐标
- 应用哈尔级联
- 利用 HOG +线性 SVM 检测目标
- 利用基于深度学习的对象检测器,如更快的 R-CNN、SSDs、YOLO 等。
只要算法生成了包围盒,就可以配合 GrabCut 使用。
出于我们今天演示脚本的目的,我们将手动定义边界框 (x,y)-坐标(即,而不是应用自动对象检测器)。
*现在我们来看看 GrabCut 的包围盒初始化方法。
打开一个新文件,将其命名为grabcut_bbox.py,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str,
default=os.path.sep.join(["images", "adrian.jpg"]),
help="path to input image that we'll apply GrabCut to")
ap.add_argument("-c", "--iter", type=int, default=10,
help="# of GrabCut iterations (larger value => slower runtime)")
args = vars(ap.parse_args())
我们从选择的导入开始这个脚本,即 OpenCV 和 NumPy(其余的构建在 Python 中)。请参考上面的“配置您的开发环境”部分,在您的系统上安装 Python、OpenCV 和相关软件。
我们的脚本处理两个命令行参数:
# load the input image from disk and then allocate memory for the
# output mask generated by GrabCut -- this mask should hae the same
# spatial dimensions as the input image
image = cv2.imread(args["image"])
mask = np.zeros(image.shape[:2], dtype="uint8")
# define the bounding box coordinates that approximately define my
# face and neck region (i.e., all visible skin)
rect = (151, 43, 236, 368)
第 25 行定义图像中面部的边界框坐标。这些 (x,y)-坐标是通过鼠标悬停在图像中的像素上并由我记录下来的方式手动确定的。你可以用大多数照片编辑软件来完成,包括 Photoshop 或免费的替代软件,如 GIMP 和你在网上找到的其他应用程序。
# allocate memory for two arrays that the GrabCut algorithm internally
# uses when segmenting the foreground from the background
fgModel = np.zeros((1, 65), dtype="float")
bgModel = np.zeros((1, 65), dtype="float")
# apply GrabCut using the the bounding box segmentation method
start = time.time()
(mask, bgModel, fgModel) = cv2.grabCut(image, mask, rect, bgModel,
fgModel, iterCount=args["iter"], mode=cv2.GC_INIT_WITH_RECT)
end = time.time()
print("[INFO] applying GrabCut took {:.2f} seconds".format(end - start))
# the output mask has for possible output values, marking each pixel
# in the mask as (1) definite background, (2) definite foreground,
# (3) probable background, and (4) probable foreground
values = (
("Definite Background", cv2.GC_BGD),
("Probable Background", cv2.GC_PR_BGD),
("Definite Foreground", cv2.GC_FGD),
("Probable Foreground", cv2.GC_PR_FGD),
)
# loop over the possible GrabCut mask values
for (name, value) in values:
# construct a mask that for the current value
print("[INFO] showing mask for '{}'".format(name))
valueMask = (mask == value).astype("uint8") * 255
# display the mask so we can visualize it
cv2.imshow(name, valueMask)
cv2.waitKey(0)
# we'll set all definite background and probable background pixels
# to 0 while definite foreground and probable foreground pixels are
# set to 1
outputMask = np.where((mask == cv2.GC_BGD) | (mask == cv2.GC_PR_BGD),
0, 1)
# scale the mask from the range [0, 1] to [0, 255]
outputMask = (outputMask * 255).astype("uint8")
# apply a bitwise AND to the image using our mask generated by
# GrabCut to generate our final output image
output = cv2.bitwise_and(image, image, mask=outputMask)
这里我们产生了两种可视化效果:
- GrabCut 输出掩码
- 输出图像(背景被遮挡)
# show the input image followed by the mask and output generated by
# GrabCut and bitwise masking
cv2.imshow("Input", image)
cv2.imshow("GrabCut Mask", outputMask)
cv2.imshow("GrabCut Output", output)
cv2.waitKey(0)
既然 GrabCut with bounding box 初始化已经实现,让我们继续将它应用到我们的输入图像。
边界框 GrabCut 结果
首先使用这篇博文的 【下载】 部分下载源代码和示例图片。
从那里,打开一个终端,并执行以下命令:
$ python grabcut_bbox.py
[INFO] applying GrabCut took 1.08 seconds
[INFO] showing mask for 'Definite Background'
[INFO] showing mask for 'Probable Background'
[INFO] showing mask for 'Definite Foreground'
[INFO] showing mask for 'Probable Foreground'
在左侧,您可以看到原始输入图像,而在右侧,您可以看到同一张脸,在脸/脖子区域周围绘制了一个边界框(该边界框对应于grabcut_bbox.py脚本中的rect变量)。
我们的目标是使用 GrabCut 和 OpenCV 从上面的图像中自动分割出面部和颈部区域。
接下来,你可以从第 45-60 行看到我们的输出,在这里我们可视化了明确的和可能的背景和前景分割:
最后,我们有 GrabCut 本身的输出:
在左边的,是我们的原始输入图像。
右边的和显示的是 GrabCut 生成的输出蒙版,而底部的显示的是将蒙版应用到输入图像的输出——注意我的脸部和颈部区域是如何通过 GrabCut 干净地分割和提取的。
使用 OpenCV 的 GrabCut:使用掩码初始化
之前,我们学习了如何使用边界框初始化 OpenCV 的 GrabCut——但是实际上还有第二个方法来初始化 grab cut。
使用遮罩,我们可以提供图像中对象的近似分割。 GrabCut 然后可以迭代地应用图切割来改进分割,并从图像中提取前景。
这些掩码可以通过以下方式生成:
- 在 Photoshop、GIMP 等照片编辑软件中手动创建。
- 应用基本的图像处理操作,例如阈值处理、边缘检测、轮廓滤波等。
- 利用基于深度学习的分段网络(例如,屏蔽 R-CNN 和 U-Net)
如何生成遮罩与 GrabCut 无关。只要你有一个近似图像中对象分割的遮罩,你就可以使用 GrabCut 来进一步改善分割。
让我们看看 GrabCut with mask 初始化是如何工作的。
打开项目目录结构中的grabcut_mask.py文件,并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str,
default=os.path.sep.join(["images", "lighthouse.png"]),
help="path to input image that we'll apply GrabCut to")
ap.add_argument("-mask", "--mask", type=str,
default=os.path.sep.join(["images", "lighthouse_mask.png"]),
help="path to input mask")
ap.add_argument("-c", "--iter", type=int, default=10,
help="# of GrabCut iterations (larger value => slower runtime)")
args = vars(ap.parse_args())
同样,我们最著名的进口产品是 OpenCV 和 NumPy。如果您需要设置系统来执行 GrabCut with mask 初始化,请遵循“配置您的开发环境”部分的说明。
# load the input image and associated mask from disk
image = cv2.imread(args["image"])
mask = cv2.imread(args["mask"], cv2.IMREAD_GRAYSCALE)
# apply a bitwise mask to show what the rough, approximate mask would
# give us
roughOutput = cv2.bitwise_and(image, image, mask=mask)
# show the rough, approximated output
cv2.imshow("Rough Output", roughOutput)
cv2.waitKey(0)
# any mask values greater than zero should be set to probable
# foreground
mask[mask > 0] = cv2.GC_PR_FGD
mask[mask == 0] = cv2.GC_BGD
# allocate memory for two arrays that the GrabCut algorithm internally
# uses when segmenting the foreground from the background
fgModel = np.zeros((1, 65), dtype="float")
bgModel = np.zeros((1, 65), dtype="float")
# apply GrabCut using the the mask segmentation method
start = time.time()
(mask, bgModel, fgModel) = cv2.grabCut(image, mask, None, bgModel,
fgModel, iterCount=args["iter"], mode=cv2.GC_INIT_WITH_MASK)
end = time.time()
print("[INFO] applying GrabCut took {:.2f} seconds".format(end - start))
# the output mask has for possible output values, marking each pixel
# in the mask as (1) definite background, (2) definite foreground,
# (3) probable background, and (4) probable foreground
values = (
("Definite Background", cv2.GC_BGD),
("Probable Background", cv2.GC_PR_BGD),
("Definite Foreground", cv2.GC_FGD),
("Probable Foreground", cv2.GC_PR_FGD),
)
# loop over the possible GrabCut mask values
for (name, value) in values:
# construct a mask that for the current value
print("[INFO] showing mask for '{}'".format(name))
valueMask = (mask == value).astype("uint8") * 255
# display the mask so we can visualize it
cv2.imshow(name, valueMask)
cv2.waitKey(0)
# set all definite background and probable background pixels to 0
# while definite foreground and probable foreground pixels are set
# to 1, then scale teh mask from the range [0, 1] to [0, 255]
outputMask = np.where((mask == cv2.GC_BGD) | (mask == cv2.GC_PR_BGD),
0, 1)
outputMask = (outputMask * 255).astype("uint8")
# apply a bitwise AND to the image using our mask generated by
# GrabCut to generate our final output image
output = cv2.bitwise_and(image, image, mask=outputMask)
# show the input image followed by the mask and output generated by
# GrabCut and bitwise masking
cv2.imshow("Input", image)
cv2.imshow("GrabCut Mask", outputMask)
cv2.imshow("GrabCut Output", output)
cv2.waitKey(0)
同样,为了结束我们的脚本,我们显示了应用遮罩后 GrabCut 的输入image、GrabCut outputMask和output。
现在已经实现了 GrabCut mask 初始化,让我们继续用我们自己的示例图像来测试它。
屏蔽 GrabCut 结果
我们现在准备使用 OpenCV 和 GrabCut 通过遮罩初始化来分割图像。
首先使用本教程的 【下载】 部分下载源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python grabcut_mask.py
[INFO] applying GrabCut took 0.56 seconds
[INFO] showing mask for 'Definite Background'
[INFO] showing mask for 'Probable Background'
[INFO] showing mask for 'Definite Foreground'
[INFO] showing mask for 'Probable Foreground'
在左边的,你可以看到我们的原始输入图像。在右侧你可以看到通过屏蔽初始化应用 GrabCut 的输出。
右边的图像显示了与灯塔相关的遮罩。为了这篇博文/例子,我在 Photoshop 中手工创建了这个蒙版;然而,这里可以使用任何能够产生掩模的算法(例如通过阈值处理、边缘检测、轮廓的基本图像处理;基于深度学习的细分;等等。)注意蒙版/分割不是很“干净”——我们可以很容易地看到背景的蓝天“漏”进了我们的蒙版。
从那里,我们可以分别想象背景和前景的确定和可能的遮罩:
作为参考,左边的显示我们的输入图像。
右边的显示了 GrabCut 生成的输出遮罩,而底部的显示了将 GrabCut 创建的遮罩应用到原始输入图像的输出。**
注意,我们已经清理了我们的分割——天空的蓝色背景已经被移除,而灯塔作为前景被留下。
唯一的问题是,灯塔中实际聚光灯所在的区域被标记为背景:
这里的问题是,灯塔中灯光所在的区域或多或少是透明的,导致蓝天背景透过,从而导致 GrabCut 将这个区域标记为背景。
你可以通过更新你的蒙版来解决这个问题,当从磁盘加载你的蒙版时使用明确的背景(即cv.GC_BGD)。我将把这作为一个练习留给你,读者,去实现。
为什么 GrabCut 是好的,但不是完美的
GrabCut 是我最喜欢的计算机视觉算法之一,但它并不完美。
此外,基于深度学习的分割网络,如更快的 R-CNN 和 U-Net,可以自动生成可以从背景中分割对象(前景)的遮罩——这是否意味着 GrabCut 在深度学习时代无关紧要?
其实,远非如此。
虽然更快的 R-CNN 和 U-Net 是超级强大的方法,但它们会导致面具有点乱。我们可以使用 GrabCut 来帮助清理这些面具。我将在以后的博客文章中向你展示如何做到这一点。
摘要
在本教程中,您学习了如何使用 OpenCV 和 GrabCut 算法来执行前景分割和提取。
GrabCut 算法通过cv2.grabCut函数在 OpenCV 中实现,并且可以通过以下任一方式初始化:
- 一个边界框,指定要在输入图像中分割的对象的位置
- 近似图像中对象的像素位置的遮罩
GrabCut 算法采用边界框/遮罩,然后迭代地逼近前景和背景。
而基于深度学习的图像分割网络(例如屏蔽 R-CNN 和 U-Net)在实际检测图像中物体的和近似屏蔽时往往更强大,我们知道这些屏蔽可能不够完美——我们实际上可以使用 GrabCut 来清理这些分割网络返回的“混乱”屏蔽!
在未来的教程中,我将向您展示如何做到这一点。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
OpenCV 头发瀑布
原文:https://pyimagesearch.com/2021/04/12/opencv-haar-cascades/
在本教程中,您将了解 OpenCV Haar 级联以及如何将它们应用于实时视频流。

Haar cascades 由 Viola 和 Jones 在他们 2001 年的开创性出版物《使用简单特征的增强级联 的 快速对象检测》中首次介绍,可以说是 OpenCV 的最流行的对象检测算法。
当然,许多算法比哈尔级联更准确(HOG +线性 SVM、SSDs、更快的 R-CNN、YOLO,仅举几个例子),但它们今天仍然相关和有用。
哈尔瀑布的一个主要好处是它们非常快——很难超越它们的速度。
Haar cascades 的缺点是它们倾向于假阳性检测,当应用于推断/检测时需要参数调整,并且一般来说,不如我们今天拥有的更“现代”的算法准确。
也就是说,哈尔喀斯是:
- 计算机视觉和图像处理文献的重要部分
- 仍然与 OpenCV 一起使用
- 仍然有用,特别是在资源有限的设备中工作时,当我们负担不起使用计算成本更高的对象检测器时
在本教程的剩余部分,您将了解 Haar 级联,包括如何在 OpenCV 中使用它们。
学习如何使用 OpenCV Haar cascades,继续阅读。
开 CV 发瀑布
在本教程的第一部分,我们将回顾什么是哈尔级联,以及如何使用 OpenCV 库哈尔级联。
从那里,我们将配置我们的开发环境,然后检查我们的项目结构。
回顾了我们的项目目录结构后,我们将继续使用 OpenCV 实时应用我们的 Haar 级联。
我们将在本指南的最后讨论我们的结果。
什么是哈尔喀斯?
保罗·维奥拉(Paul Viola)和迈克尔·琼斯(Michael Jones)在他们 2001 年的论文 中首次发表了使用简单特征 的增强级联的快速对象检测,这项原创工作已经成为计算机视觉文献中被引用最多的论文之一。
在他们的论文中,Viola 和 Jones 提出了一种算法,能够检测图像中的对象,而不管它们在图像中的位置和比例。此外,该算法可以实时运行,使得检测视频流中的对象成为可能。
具体来说,Viola 和 Jones 专注于检测图像中的人脸。尽管如此,该框架仍可用于训练任意“物体”的检测器,如汽车、建筑物、厨房用具,甚至香蕉。
虽然 Viola-Jones 框架肯定打开了对象检测的大门,但它现在被其他方法远远超越,如使用梯度方向直方图(HOG) +线性 SVM 和深度学习。我们需要尊重这种算法,至少对引擎下发生的事情有一个高层次的理解。
还记得我们讨论过图像和卷积以及我们如何从左到右和从上到下在图像上滑动一个小矩阵,为内核的每个中心像素计算输出值吗?事实证明,这种滑动窗口方法在检测图像中的对象时也非常有用:
在图 2 中,我们可以看到我们在多尺度下滑动一个固定大小的窗口穿过我们的图像。在每个阶段,我们的窗口都会停下来,计算一些特征,然后将该区域分类为是,该区域确实包含人脸,或者否,该区域不包含人脸。
这需要一点机器学习。我们需要一个训练有素的分类器来使用正面和负面的人脸样本:
- 正数据点是包含面部的区域的例子
- 负数据点是不包含面部的区域的例子
给定这些正面和负面的数据点,我们可以“训练”一个分类器来识别图像的给定区域是否包含人脸。
对我们来说幸运的是,OpenCV 可以使用预先训练好的 Haar 级联来执行开箱即用的人脸检测:
这确保了我们不需要提供自己的正样本和负样本,不需要训练自己的分类器,也不需要担心参数调整是否完全正确。相反,我们只需加载预训练的分类器,并检测图像中的人脸。
然而,在幕后,OpenCV 正在做一些非常有趣的事情。对于沿滑动窗口路径的每个停靠点,计算五个矩形特征:
如果你熟悉小波,你可能会发现它们与哈尔基函数和哈尔小波(哈尔级联由此得名)有一些相似之处。
为了获得这五个矩形区域中每一个的特征,我们简单地从黑色区域下的像素总和中减去白色区域下的像素总和。有趣的是,这些特征在人脸检测中具有实际的重要性:
- 眼睛区域往往比脸颊区域更暗。
- 鼻子区域比眼睛区域更亮。
因此,给定这五个矩形区域和它们相应的和的差,我们可以形成能够分类面部部分的特征。
然后,对于整个特征数据集,我们使用 AdaBoost 算法来选择哪些特征对应于图像的面部区域。
然而,正如您可以想象的,使用固定的滑动窗口并在图像的每个 (x,y)-坐标上滑动它,然后计算这些类似 Haar 的特征,最后执行实际的分类可能在计算上是昂贵的。
为了解决这个问题,Viola 和 Jones 引入了级联或阶段的概念。在滑动窗口路径的每一站,窗口都必须通过一系列测试,其中每一个后续测试都比前一个测试在计算上更昂贵。如果任何一个测试失败,该窗口将被自动丢弃。
Haar cascade 的一些好处是,由于使用了积分图像(也称为总面积表),它们在计算 Haar 类特征时非常快。通过使用 AdaBoost 算法,它们对于特征选择也非常有效。
也许最重要的是,它们可以检测图像中的人脸,而不管人脸的位置或比例。
最后,用于对象检测的 Viola-Jones 算法能够实时运行。
哈尔叶栅的问题和局限性
然而,也不全是好消息。该检测器对于面部的正面图像往往是最有效的。
众所周知,Haar cascades 容易出现假阳性 —当没有人脸出现时,Viola-Jones 算法可以轻松报告图像中的人脸。
最后,正如我们将在本课的剩余部分看到的,调整 OpenCV 检测参数可能会非常繁琐。有时候,我们可以检测出一幅图像中的所有面孔。还会有(1)图像的区域被错误地分类为面部,和/或(2)面部被完全遗漏的其他情况。
如果你对维奥拉-琼斯算法感兴趣,看看官方的维基百科页面和原始论文。维基百科页面在将算法分解成易于理解的部分方面做得非常好。
如何配合 OpenCV 使用 Haar cascades?
OpenCV 库维护着一个预先训练好的哈尔级联库。这些哈尔级联大多用于:
- 人脸检测
- 眼睛检测
- 嘴部检测
- 全身/部分身体检测
提供了其他预先训练的哈尔级联,包括一个用于俄罗斯车牌,另一个用于猫脸检测。
我们可以使用cv2.CascadeClassifer函数从磁盘加载预训练的 Haar 级联:
detector = cv2.CascadeClassifier(path)
一旦 Haar 级联加载到内存中,我们可以使用detectMultiScale函数对其进行预测:
results = detector.detectMultiScale(
gray, scaleFactor=1.05, minNeighbors=5,
minSize=(30, 30), flags=cv2.CASCADE_SCALE_IMAGE)
result是一个边界框列表,包含边界框的起始x和y坐标,以及它们的宽度(w和高度(h)。
在本教程的后面部分,您将获得对cv2.CascadeClassifier和detectMultiScale的实践经验。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们了解 OpenCV 的 Haar 级联功能之前,我们首先需要回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,以检索源代码和预训练的 Haar cascades:
$ tree . --dirsfirst
.
├── cascades
│ ├── haarcascade_eye.xml
│ ├── haarcascade_frontalface_default.xml
│ └── haarcascade_smile.xml
└── opencv_haar_cascades.py
1 directory, 4 files
我们将对一个实时视频流应用三个哈尔级联。这些哈尔级联位于cascades目录中,包括:
haarcascade_frontalface_default.xml:检测人脸haarcascade_eye.xml:检测脸部的左右眼- 虽然文件名暗示这个模型是一个“微笑检测器”,但它实际上是检测一张脸上“嘴”的存在
我们的opencv_haar_cascades.py脚本将从磁盘加载这三个哈尔级联,并将它们应用到一个视频流中,所有这些都是实时的。
实现 OpenCV Haar 级联对象检测(人脸、眼睛和嘴巴)
回顾我们的项目目录结构,我们可以实现我们的 OpenCV Haar 级联检测脚本。
打开项目目录结构中的opencv_haar_cascades.py文件,我们就可以开始工作了:
# import the necessary packages
from imutils.video import VideoStream
import argparse
import imutils
import time
import cv2
import os
第 2-7 行导入我们需要的 Python 包。我们需要VideoStream来访问我们的网络摄像头,argparse用于命令行参数,imutils用于我们的 OpenCV 便利函数,time插入一个小的 sleep 语句,cv2用于我们的 OpenCV 绑定,以及os来构建文件路径,不知道你在哪个操作系统上(Windows 使用不同于 Unix 机器的路径分隔符,比如 macOS 和 Linux)。
我们只有一个命令行参数需要解析:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascades", type=str, default="cascades",
help="path to input directory containing haar cascades")
args = vars(ap.parse_args())
--cascades命令行参数指向包含我们预先训练的面部、眼睛和嘴巴哈尔级联的目录。
我们继续从磁盘加载这些哈尔级联中的每一个:
# initialize a dictionary that maps the name of the haar cascades to
# their filenames
detectorPaths = {
"face": "haarcascade_frontalface_default.xml",
"eyes": "haarcascade_eye.xml",
"smile": "haarcascade_smile.xml",
}
# initialize a dictionary to store our haar cascade detectors
print("[INFO] loading haar cascades...")
detectors = {}
# loop over our detector paths
for (name, path) in detectorPaths.items():
# load the haar cascade from disk and store it in the detectors
# dictionary
path = os.path.sep.join([args["cascades"], path])
detectors[name] = cv2.CascadeClassifier(path)
第 17-21 行定义了一个字典,将检测器的名称(键)映射到其对应的文件路径(值)。
第 25 行初始化我们的detectors字典。它将拥有与detectorPaths相同的密钥,但是一旦通过cv2.CascadeClassifier从磁盘加载,它的值将是 Haar cascade。
在第 28 行,我们分别遍历了每个 Haar 级联名称和路径。
对于每个检测器,我们构建完整的文件路径,从磁盘加载,并存储在我们的detectors字典中。
随着我们的三个哈尔级联中的每一个从磁盘加载,我们可以继续访问我们的视频流:
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# loop over the frames from the video stream
while True:
# grab the frame from the video stream, resize it, and convert it
# to grayscale
frame = vs.read()
frame = imutils.resize(frame, width=500)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# perform face detection using the appropriate haar cascade
faceRects = detectors["face"].detectMultiScale(
gray, scaleFactor=1.05, minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
第 36-37 行初始化我们的VideoStream,插入一个小的time.sleep语句让我们的摄像头传感器预热。
从那里,我们继续:
- 循环播放视频流中的帧
- 阅读下一篇
frame - 调整它的大小
- 将其转换为灰度
一旦帧被转换成灰度,我们应用人脸检测器 Haar cascade 来定位输入帧中的任何人脸。
下一步是循环每个面部位置,应用我们的眼睛和嘴巴哈尔瀑布:
# loop over the face bounding boxes
for (fX, fY, fW, fH) in faceRects:
# extract the face ROI
faceROI = gray[fY:fY+ fH, fX:fX + fW]
# apply eyes detection to the face ROI
eyeRects = detectors["eyes"].detectMultiScale(
faceROI, scaleFactor=1.1, minNeighbors=10,
minSize=(15, 15), flags=cv2.CASCADE_SCALE_IMAGE)
# apply smile detection to the face ROI
smileRects = detectors["smile"].detectMultiScale(
faceROI, scaleFactor=1.1, minNeighbors=10,
minSize=(15, 15), flags=cv2.CASCADE_SCALE_IMAGE)
第 53 行在所有面部边界框上循环。然后,我们使用边界框信息在线 55 上提取脸部 ROI。
下一步是将我们的眼睛和嘴巴检测器应用到面部区域。
在第行 58-60、上对脸部 ROI 应用眼睛检测,而在第行 63-65 上执行嘴检测。
就像我们对所有面部检测进行循环一样,我们需要对眼睛和嘴巴检测进行同样的操作:
# loop over the eye bounding boxes
for (eX, eY, eW, eH) in eyeRects:
# draw the eye bounding box
ptA = (fX + eX, fY + eY)
ptB = (fX + eX + eW, fY + eY + eH)
cv2.rectangle(frame, ptA, ptB, (0, 0, 255), 2)
# loop over the smile bounding boxes
for (sX, sY, sW, sH) in smileRects:
# draw the smile bounding box
ptA = (fX + sX, fY + sY)
ptB = (fX + sX + sW, fY + sY + sH)
cv2.rectangle(frame, ptA, ptB, (255, 0, 0), 2)
# draw the face bounding box on the frame
cv2.rectangle(frame, (fX, fY), (fX + fW, fY + fH),
(0, 255, 0), 2)
第 68-72 行在所有检测到的眼睛边界框上循环。然而,注意行 70 和 71 如何相对于原始帧图像尺寸导出眼睛边界框。
如果我们使用原始的eX、eY、eW和eH值,它们将是原始帧的faceROI、、而不是、,因此我们将面部边界框坐标添加到眼睛坐标。
我们在第 75-79 行上执行相同的一系列操作,这次是嘴部边界框。
最后,我们可以通过在屏幕上显示我们的输出frame来结束:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
然后,我们通过关闭 OpenCV 打开的所有窗口并停止视频流来进行清理。
哈尔级联结果
我们现在准备用 OpenCV 应用哈尔叶栅!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python opencv_haar_cascades.py --cascades cascades
[INFO] loading haar cascades...
[INFO] starting video stream...
上面的视频显示了应用我们的三个 OpenCV Haar 级联进行人脸检测、眼睛检测和嘴巴检测的结果。
我们的结果实时运行没有问题,但正如您所见,检测本身是而不是最准确的:
- 我们检测我的脸没有问题,但是嘴巴和眼睛会发出一些假阳性信号。
- 当我眨眼时,会发生两种情况之一:(1)眼睛区域不再被检测到,或者(2)它被错误地标记为嘴
- 在许多帧中往往有多个嘴部检测
OpenCV 的人脸检测 Haar cascades 趋于最准确。您可以在自己的应用程序中随意使用它们,在这些应用程序中,您可以容忍一些误报检测和一些参数调整。
也就是说,对于面部结构检测,我强烈建议使用面部标志代替——它们比眼睛和嘴巴哈尔瀑布本身更稳定,甚至更快。
*## 总结
在本教程中,您学习了如何使用 OpenCV 应用 Haar 级联。
具体来说,您学习了如何将哈尔级联应用于:
- 人脸检测
- 眼睛检测
- 嘴部检测
我们的人脸检测结果是最稳定和准确的。不幸的是,在许多情况下,眼睛检测和嘴巴检测结果是不可用的——对于面部特征/部位提取,我建议您使用面部标志。
我最后说一句,还有很多更准确的人脸检测方法,包括 HOG +线性 SVM 和基于深度学习的物体检测器,包括 SSDs,更快的 R-CNN,YOLO 等。尽管如此,如果你需要纯速度,你就是打不过 OpenCV 的哈尔卡斯。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
OpenCV 直方图均衡和自适应直方图均衡(CLAHE)
在本教程中,您将学习使用 OpenCV 执行直方图均衡化和自适应直方图均衡化。
直方图均衡化是一种基本的图像处理技术,它通过更新图像直方图的像素强度分布来调整图像的全局对比度。这样做可以使低对比度区域在输出图像中获得更高的对比度。
本质上,直方图均衡的工作原理是:
- 计算图像像素强度的直方图
- 均匀地展开和分布最频繁的像素值(即直方图中具有最大计数的像素值)
- 给出累积分布函数(CDF)的线性趋势
应用直方图均衡化的结果是具有更高全局对比度的图像。
我们可以通过应用一种称为对比度受限自适应直方图均衡化(CLAHE)的算法来进一步改善直方图均衡化,从而产生更高质量的输出图像。
除了摄影师使用直方图均衡化来校正曝光不足/曝光过度的图像之外,最广泛使用的直方图均衡化应用可以在医学领域中找到。
您通常会看到直方图均衡化应用于 X 射线扫描和 CT 扫描,以提高射线照片的对比度。这样做有助于医生和放射科医生更好地解读扫描结果,做出准确的诊断。
本教程结束时,您将能够使用 OpenCV 对图像成功应用基本直方图均衡和自适应直方图均衡。
要学会用 OpenCV 使用直方图均衡化和自适应直方图均衡化,继续阅读即可。
OpenCV 直方图均衡和自适应直方图均衡(CLAHE)
在本教程的第一部分,我们将讨论什么是直方图均衡化,以及我们如何使用 OpenCV 应用直方图均衡化。
从那里,我们将配置我们的开发环境,然后查看本指南的项目目录结构。
然后,我们将实现两个 Python 脚本:
simple_equalization.py:使用 OpenCV 的cv2.equalizeHist函数执行基本直方图均衡。adaptive_equalization.py:使用 OpenCV 的cv2.createCLAHE方法进行自适应直方图均衡。
我们将在本指南的最后讨论我们的结果。
什么是直方图均衡化?
直方图均衡化是一种基本的图像处理技术,可以提高图像的整体对比度。
应用直方图均衡化从计算输入灰度/单通道图像中像素强度的直方图开始:
请注意我们的直方图有许多峰值,表明有大量像素被归入相应的桶中。使用直方图均衡化,我们的目标是将这些像素分散到存储桶中,这样就不会有那么多像素被分入存储桶中。
从数学上来说,这意味着我们试图将线性趋势应用于我们的累积分布函数(CDF):
直方图均衡化应用前后可以在图 3 中看到:
请注意输入图像的对比度如何显著提高,但代价是也提高了输入图像中噪声的对比度。
这就提出了一个问题:
有没有可能在不增加噪点的同时提高图像对比度?
答案是“是的”,你只需要应用自适应直方图均衡化。
通过自适应直方图均衡化,我们将输入图像划分为一个 M x N 网格。然后,我们对网格中的每个单元应用均衡,从而产生更高质量的输出图像:
缺点是自适应直方图均衡从定义上来说在计算上更复杂(但是考虑到现代的硬件,两种实现仍然相当快)。
如何使用 OpenCV 进行直方图均衡化?
OpenCV 通过以下两个函数实现了基本直方图均衡和自适应直方图均衡:
cv2.equalizeHistcv2.createCLAHE
应用cv2.equalizeHist函数非常简单,只需将图像转换为灰度,然后对其调用cv2.equalizeHist:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
equalized = cv2.equalizeHist(gray)
执行自适应直方图均衡要求我们:
- 将输入图像转换为灰度/从中提取单个通道
- 使用
cv2.createCLAHE实例化 CLAHE 算法 - 对 CLAHE 对象调用
.apply方法以应用直方图均衡化
这比听起来容易得多,只需要几行代码:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
equalized = clahe.apply(gray)
注意,我们向cv2.createCLAHE提供了两个参数:
clipLimit:这是对比度限制的阈值tileGridSize:将输入图像分成M×N个小块,然后对每个局部小块应用直方图均衡化
在本指南的剩余部分,您将练习使用cv2.equalizeHist和cv2.createCLAHE。
配置您的开发环境
要了解如何使用 OpenCV 应用直方图均衡,您需要安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们用 OpenCV 实现直方图均衡化之前,让我们先回顾一下我们的项目目录结构。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,检查项目目录结构:
$ tree . --dirsfirst
.
├── images
│ ├── boston.png
│ ├── dog.png
│ └── moon.png
├── adaptive_equalization.py
└── simple_equalization.py
1 directory, 5 files
我们今天将讨论两个 Python 脚本:
simple_equalization.py:使用 OpenCV 应用基本直方图均衡。adaptive_equalization.py:使用 CLAHE 算法执行自适应直方图均衡化。
我们的images目录包含我们将应用直方图均衡化的示例图像。
用 OpenCV 实现标准直方图均衡
回顾了我们的项目目录结构后,让我们继续用 OpenCV 实现基本的直方图均衡化。
打开项目文件夹中的simple_equalization.py文件,让我们开始工作:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to the input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。
这里我们只需要一个参数,--image,它是我们在磁盘上输入图像的路径,我们希望在这里应用直方图均衡化。
解析完命令行参数后,我们可以进入下一步:
# load the input image from disk and convert it to grayscale
print("[INFO] loading input image...")
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# apply histogram equalization
print("[INFO] performing histogram equalization...")
equalized = cv2.equalizeHist(gray)
第 13 行从磁盘加载我们的image,而第 14 行将我们的图像从 RGB 转换成灰度。
第 18 行使用cv2.equalizeHist功能执行基本直方图均衡化。我们必须传入的唯一必需参数是灰度/单通道图像。
注意:使用 OpenCV 进行直方图均衡化时,我们必须提供灰度/单通道图像。 如果我们试图传入一个多通道图像,OpenCV 会抛出一个错误。要对多通道图像执行直方图均衡化,您需要(1)将图像分割到其各自的通道中,(2)均衡化每个通道,以及(3)将通道合并在一起。
最后一步是显示我们的输出图像:
# show the original grayscale image and equalized image
cv2.imshow("Input", gray)
cv2.imshow("Histogram Equalization", equalized)
cv2.waitKey(0)
这里,我们显示输入的gray图像以及直方图均衡化的图像。
OpenCV 直方图均衡结果
我们现在准备用 OpenCV 应用基本的直方图均衡化!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python simple_equalization.py --image images/moon.png
[INFO] loading input image...
[INFO] performing histogram equalization...
在顶部的,我们有月球的原始输入图像。底部显示应用直方图均衡化后的输出。请注意,我们提高了图像的整体对比度。
让我们试试另一张照片,这张曝光不足的照片:
$ python simple_equalization.py --image images/dog.png
[INFO] loading input image...
[INFO] performing histogram equalization...
狗(左)因曝光不足而显得褪色。通过应用直方图均衡(右),我们修正了这个效果,提高了狗的对比度。
下图突出显示了通过直方图均衡化进行全局对比度调整的局限性之一:
$ python simple_equalization.py --image images/boston.png
[INFO] loading input image...
[INFO] performing histogram equalization...
左边上的图片显示了几年前我和妻子在波士顿过圣诞节。由于相机上的自动调节,我们的脸相当黑,很难看到我们。
通过应用直方图均衡化(右),我们可以看到,不仅我们的脸是可见的,我们还可以看到坐在我们后面的另一对夫妇!如果没有直方图均衡,您可能会错过另一对。
然而,我们的产出并不完全令人满意。首先,壁炉里的火完全熄灭了。如果你研究我们的脸,特别是我的脸,你会看到我的前额现在完全被洗掉了。
为了改善我们的结果,我们需要应用自适应直方图均衡化。
用 OpenCV 实现自适应直方图均衡
至此,我们已经看到了基本直方图均衡化的一些局限性。
自适应直方图均衡化虽然在计算上有点昂贵,但可以产生比简单直方图均衡化更好的结果。但是不要相信我的话——你应该自己看看结果。
打开项目目录结构中的adaptive_equalization.py文件,插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to the input image")
ap.add_argument("-c", "--clip", type=float, default=2.0,
help="threshold for contrast limiting")
ap.add_argument("-t", "--tile", type=int, default=8,
help="tile grid size -- divides image into tile x time cells")
args = vars(ap.parse_args())
这里我们只需要两个导入,argparse用于命令行参数,cv2用于 OpenCV 绑定。
然后,我们有三个命令行参数,其中一个是必需的,另两个是可选的(但是在使用 CLAHE 进行实验时对调整和使用很有用):
--image:我们的输入图像在磁盘上的路径,我们希望在这里应用直方图均衡。--clip:对比度限制的阈值。您通常希望将这个值留在2-5的范围内。如果你设置的值太大,那么实际上,你所做的是最大化局部对比度,这反过来会最大化噪声(这与你想要的相反)。相反,尽量将该值保持在最低水平。--tile:CLAHE 的平铺网格尺寸。从概念上讲,我们在这里做的是将输入图像分成tile x tile个单元,然后对每个单元应用直方图均衡化(使用 CLAHE 提供的附加功能)。- 现在让我们用 OpenCV 来应用 CLAHE:
# load the input image from disk and convert it to grayscale
print("[INFO] loading input image...")
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# apply CLAHE (Contrast Limited Adaptive Histogram Equalization)
print("[INFO] applying CLAHE...")
clahe = cv2.createCLAHE(clipLimit=args["clip"],
tileGridSize=(args["tile"], args["tile"]))
equalized = clahe.apply(gray)
第 17 行和第 18 行从磁盘加载我们的输入图像,并将其转换为灰度,就像我们对基本直方图均衡化所做的那样。
第 22 和 23 行通过cv2.createCLAHE函数初始化我们的clahe对象。这里,我们提供了通过命令行参数提供的clipLimit和tileGridSize。
对.apply方法的调用将自适应直方图均衡应用于gray图像。
最后一步是在屏幕上显示输出图像:
# show the original grayscale image and CLAHE output image
cv2.imshow("Input", gray)
cv2.imshow("CLAHE", equalized)
cv2.waitKey(0)
这里,我们显示我们的输入图像gray以及来自 CLAHE 算法的输出图像equalized。
自适应直方图均衡结果
现在让我们用 OpenCV 应用自适应直方图均衡化!
访问本教程的 “下载” 部分来检索源代码和示例图像。
从那里,打开一个 shell 并执行以下命令:
$ python adaptive_equalization.py --image images/boston.png
[INFO] loading input image...
[INFO] applying CLAHE...
在左边的,是我们的原始输入图像。然后,我们在右侧的应用自适应直方图均衡化——将这些结果与应用基本直方图均衡化的图 4、的结果进行比较。
*请注意自适应直方图均衡化如何提高了输入图像的对比度。我和我妻子更容易被看到。背景中那对曾经几乎看不见的夫妇可以被看到。额头上的神器比较少等等。
直方图均衡化建议
当构建自己的图像处理管道并发现应该应用直方图均衡化时,我建议使用cv2.equalizeHist从简单的直方图均衡化开始。但是如果你发现结果很差,反而增加了输入图像的噪声,那么你应该通过cv2.createCLAHE尝试使用自适应直方图均衡化。
学分
我感谢 Aruther Cotse(犹他大学)关于使用直方图进行图像处理的精彩报告。Cotse 的工作启发了这篇文章中的一些例子。
此外,我感谢维基百科关于直方图均衡化页面的贡献者。如果您对直方图均衡化背后的更多数学细节感兴趣,请务必参考该页面。
示例moon.png图片来自EarthSky上的这篇文章,而dog.png图片来自本页面。
总结
在本教程中,您学习了如何使用 OpenCV 执行基本直方图均衡和自适应直方图均衡。
基本直方图均衡化旨在通过“分散”图像中常用的像素强度来提高图像的整体对比度。
虽然简单的直方图均衡易于应用且计算效率高,但问题T2 在于它会增加噪声。本来可以轻易滤除的基本噪声现在进一步污染了信号(即我们想要处理的图像成分)。
如果发生这种情况,我们可以应用自适应直方图均衡来获得更好的结果。
自适应直方图均衡化的工作原理是将图像划分为一个 M x N 网格,然后对每个网格局部应用直方图均衡化。结果是输出图像总体上具有更高的对比度,并且(理想地)噪声仍然被抑制。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
OpenCV 图像直方图(cv2.calcHist)
原文:https://pyimagesearch.com/2021/04/28/opencv-image-histograms-cv2-calchist/
在本教程中,您将学习如何使用 OpenCV 和cv2.calcHist函数计算图像直方图。
直方图在计算机视觉的几乎每个方面都很普遍。
我们使用灰度直方图进行阈值处理。我们使用直方图进行白平衡。我们使用颜色直方图来跟踪图像中的对象,例如使用 CamShift 算法。
我们使用颜色直方图作为特征,包括多维的颜色直方图。
在抽象意义上,我们使用图像梯度直方图来形成 HOG 和 SIFT 描述符。
甚至在图像搜索引擎和机器学习中使用的非常流行的视觉单词包表示也是直方图!
我敢肯定这不是你第一次在研究中碰到直方图。
那么,为什么直方图如此有用呢?
因为直方图捕捉了一组数据的频率分布。事实证明,检查这些频率分布是构建简单图像处理技术的一种非常好的方式……以及非常强大的机器学习算法。
在这篇博客文章中,你将会看到关于图像直方图的介绍,包括如何计算灰度和颜色直方图。在以后的博客文章中,我将介绍更高级的直方图技术。
学习如何使用 OpenCV 和cv2.calcHist函数计算图像直方图, 继续阅读。
OpenCV 图像直方图(cv2.calcHist )
在本教程的第一部分,我们将讨论什么是图像直方图。从那以后,我将向您展示如何使用 OpenCV 和cv2.calcHist函数来计算图像直方图。
接下来,我们将配置我们的开发环境,并检查我们的项目目录结构。
然后,我们将实现三个 Python 脚本:
- 一个用于计算灰度直方图
- 另一个是计算颜色直方图
- 以及演示如何只为输入图像的屏蔽区域计算直方图的最终脚本
我们开始吧!
什么是图像直方图?
直方图表示图像中像素强度(彩色或灰度)的分布。它可以被可视化为一个图形(或绘图),给出强度(像素值)分布的高层次直觉。在本例中,我们将假设一个 RGB 颜色空间,因此这些像素值将在 0 到 255 的范围内。
绘制直方图时,x-轴充当我们的“仓”如果我们用256条构建一个直方图,那么我们可以有效地计算每个像素值出现的次数。
相比之下,如果我们只使用2(等间距)的面元,那么我们计算一个像素在【0,128】或【128,255】范围内的次数。
然后,在 y 轴上绘制归入 x 轴值的像素数。
让我们看一个示例图像来更清楚地说明这一点:
在图 1 中,我们绘制了一个直方图,沿 x 轴有 256 个面元,沿 y 轴有落入给定面元的像素百分比。检查直方图,注意有三个主峰。
直方图中的第一个峰值大约在 x= 65 处,我们看到像素数量出现了一个尖锐的峰值——很明显,图像中存在某种具有非常暗的值的对象。
然后,我们在直方图中看到一个缓慢上升的峰值,我们在大约 x=100 处开始上升,最后在大约 x=150 处结束下降。这个区域可能是指图像的背景区域。
最后,我们看到在范围 x=150 到 x=175 内有大量的像素。很难说这个区域到底是什么,但它肯定占据了图像的很大一部分。
注: 我是故意 而不是 揭示我用来生成这个直方图的图像。我只是在展示我看柱状图时的思维过程。在不知道数据来源的情况下,能够解释和理解你正在查看的数据是一项很好的技能。
通过简单地检查图像的直方图,您可以对对比度、亮度和强度分布有一个大致的了解。如果这个概念对你来说是新的或陌生的,不要担心——我们将在本课的后面检查更多像这样的例子。
使用 OpenCV 通过 cv2.calcHist 函数计算直方图
让我们开始构建一些自己的直方图。
我们将使用cv2.calcHist函数来构建直方图。在我们进入任何代码示例之前,让我们快速回顾一下这个函数:
cv2.calcHist(images, channels, mask, histSize, ranges)
images: 这是我们想要计算直方图的图像。包装成列表:[myImage]。channels: 一个索引列表,我们在其中指定想要计算直方图的通道的索引。要计算灰度图像的直方图,列表应该是[0]。为了计算所有三个红色、绿色和蓝色通道的直方图,通道列表应该是[0, 1, 2]。mask: 还记得在我的 用 OpenCV 向导进行图像蒙版中学习蒙版吗?嗯,这里我们可以供应一个口罩。如果提供了屏蔽,将只为屏蔽的像素计算直方图。如果我们没有掩码或者不想应用掩码,我们可以只提供值None。histSize: 这是我们在计算直方图时想要使用的箱数。同样,这是一个列表,我们为每个通道计算一个直方图。箱子的大小不必都一样。以下是每个通道 32 个仓的示例:[32, 32, 32]。ranges: 可能的像素值范围。通常情况下,这是每个通道的 [0,256] (即而不是一个错别字—cv2.calcHist函数的结束范围是不包含的,因此您将希望提供 256 而不是 255 的值),但是如果您使用 RGB 以外的颜色空间[如 HSV],范围可能会有所不同。)
在接下来的小节中,您将获得使用 OpenCV 的cv2.calcHist函数计算图像直方图的实践经验。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们从回顾我们的项目目录结构开始。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。从那里,您将看到以下目录结构:
$ tree . --dirsfirst
.
├── beach.png
├── color_histograms.py
├── grayscale_histogram.py
└── histogram_with_mask.py
0 directories, 4 files
我们今天要复习三个 Python 脚本:
grayscale_histogram.py:演示了如何从一个输入的单通道灰度图像中计算像素强度直方图color_histograms.py:显示如何计算 1D(即“展平”)、2D 和 3D 颜色直方图histogram_with_mask.py:演示如何只为输入图像的蒙版区域计算直方图
我们的单个图像beach.png,作为这三个脚本的输入。
使用 OpenCV 创建灰度直方图
让我们学习如何使用 OpenCV 计算灰度直方图。打开项目结构中的grayscale_histogram.py文件,我们将开始:
# import the necessary packages
from matplotlib import pyplot as plt
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the image")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包。我们将使用matplotlib的pyplot模块来绘制图像直方图,argparse用于命令行参数,cv2用于 OpenCV 绑定。
我们只有一个命令行参数需要解析,--image,它是驻留在磁盘上的输入图像的路径。
接下来,让我们从磁盘加载输入图像,并将其转换为灰度:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
灰度转换完成后,我们可以使用cv2.calcHist函数来计算图像直方图:
# compute a grayscale histogram
hist = cv2.calcHist([image], [0], None, [256], [0, 256])
继续将cv2.calcHist调用的参数与上面“使用 OpenCV 计算 cv2.calcHist 函数的直方图”一节中的函数文档进行匹配。
我们可以看到,我们的第一个参数是灰度图像。一幅灰度图像只有一个通道,所以我们为通道设置了一个值[0]。我们没有掩码,所以我们将掩码值设置为None。我们将在直方图中使用 256 个面元,可能的值范围从0到255。
计算出图像直方图后,我们在屏幕上显示灰度图像,并绘制出未标准化的图像直方图:
# matplotlib expects RGB images so convert and then display the image
# with matplotlib
plt.figure()
plt.axis("off")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_GRAY2RGB))
# plot the histogram
plt.figure()
plt.title("Grayscale Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
plt.plot(hist)
plt.xlim([0, 256])
非标准化直方图统计分布的原始频率。考虑数一数袋子里不同颜色的 M & M 的数量。我们最终会得到每种颜色的整数计数。
另一方面,如果我想要每种颜色的百分比呢?
嗯,这很容易得到!我会简单地用每个整数除以袋子里 M&M 的总数。因此,我没有使用原始频率直方图,而是以归一化直方图结束,该直方图计算每种颜色的百分比。根据定义,归一化直方图的总和正好是1。
那么,我为什么更喜欢标准化的直方图而不是非标准化的直方图呢?
事实证明,是有的。让我们做一个小小的思维实验:
在这个思维实验中,我们想要比较两幅图像的直方图。这些图像在各个方面、形状和形式上都是相同的,只有一个例外。第一幅图像的尺寸是第二幅图像的尺寸的一半。
当我们去比较直方图时,虽然分布的形状看起来相同,但我们会注意到沿 y 轴的像素计数会显著不同。事实上,第一幅图像的 y 轴计数将是第二幅图像的y轴计数的一半。
这是为什么?
我们正在比较原始频率计数和百分比计数!
考虑到这一点,让我们看看如何归一化直方图,并获得每个像素的百分比计数:
# normalize the histogram
hist /= hist.sum()
# plot the normalized histogram
plt.figure()
plt.title("Grayscale Histogram (Normalized)")
plt.xlabel("Bins")
plt.ylabel("% of Pixels")
plt.plot(hist)
plt.xlim([0, 256])
plt.show()
直方图的归一化只需要一行代码,我们可以在第 34 行的处看到:这里我们简单地将直方图中每个仓的原始频率计数除以计数的总和,这样我们得到的是每个仓的百分比,而不是每个仓的原始计数。
然后我们在第 37-43 行上绘制归一化直方图。
灰度直方图结果
我们现在可以用 OpenCV 计算灰度直方图了!
请务必访问本指南的 “下载” 部分,以检索源代码和示例图像。从那里,您可以执行以下命令:
$ python grayscale_histogram.py --image beach.png
那么,我们如何解释这个直方图呢?
嗯,在 x 轴上绘制了面元 (0-255) 。并且 y 轴计算每个箱中的像素数量。大多数像素落在大约 60 到 180 的范围内。观察直方图的两个尾部,我们可以看到很少有像素落在范围【0,50】和【200,255】内——这意味着图像中很少有“黑”和“白”像素。
注意图 4 包含一个非标准化直方图,这意味着它包含面元内的原始整数计数。
如果我们想要的是 百分比计数 (这样当所有的值加起来和1),我们可以检查归一化直方图:
现在,容器计数表示为百分比而不是原始计数。
根据您的应用,您可能需要非标准化或标准化的图像直方图。在这一课中,我已经演示了如何计算两种类型的,这样你就可以使用两种方法。
使用 OpenCV 创建颜色直方图
在上一节中,我们探讨了灰度直方图。现在让我们继续计算图像每个通道的直方图。
打开项目目录中的color_histograms.py文件,我们将开始:
# import the necessary packages
from matplotlib import pyplot as plt
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the image")
args = vars(ap.parse_args())
第 2-5 行导入我们需要的 Python 包。我们的导入与grayscale_histogram.py相同,但是有一个例外——我们现在正在导入imutils,它包含一个方便的opencv2matplotlib函数,用 matplotlib 处理 RGB 与 BGR 图像的显示。
然后我们在第 8-11 行解析我们的命令行参数。我们只需要一个参数--image,它是我们的输入图像在磁盘上的路径。
现在让我们计算三个直方图,输入 RGB 图像的每个通道一个直方图:
# load the input image from disk
image = cv2.imread(args["image"])
# split the image into its respective channels, then initialize the
# tuple of channel names along with our figure for plotting
chans = cv2.split(image)
colors = ("b", "g", "r")
plt.figure()
plt.title("'Flattened' Color Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
# loop over the image channels
for (chan, color) in zip(chans, colors):
# create a histogram for the current channel and plot it
hist = cv2.calcHist([chan], [0], None, [256], [0, 256])
plt.plot(hist, color=color)
plt.xlim([0, 256])
第 14 行从磁盘加载我们的图像。然后我们在第 18 行将图像分割成各自的 BGR 通道。
第 19 行定义了通道名称(字符串)列表,而第 20-23 行初始化我们的 matplotlib 图。
然后我们在线 26 上到达一个for回路。在这里,我们开始循环图像中的每个通道。
然后,对于每个通道,我们在第 28 行上计算直方图。代码与计算灰度图像直方图的代码相同;然而,我们对每个红色、绿色和蓝色通道都这样做,这使我们能够表征像素强度的分布。我们将直方图添加到第 29 行的图上。
现在让我们来看看 2D 直方图的计算。到目前为止,我们一次只计算了一个通道的直方图。现在我们转向多维直方图,一次考虑两个通道。
我喜欢用和这个词来解释多维直方图。
例如,我们可以问这样一个问题:
- 有多少像素的红色值为 10 而蓝色值为 30?
- 有多少像素的绿色值为 200 红色值为 130?
通过使用连接词和,我们能够构建多维直方图。
就这么简单。让我们来看一些代码来自动完成构建 2D 直方图的过程:
# create a new figure and then plot a 2D color histogram for the
# green and blue channels
fig = plt.figure()
ax = fig.add_subplot(131)
hist = cv2.calcHist([chans[1], chans[0]], [0, 1], None, [32, 32],
[0, 256, 0, 256])
p = ax.imshow(hist, interpolation="nearest")
ax.set_title("2D Color Histogram for G and B")
plt.colorbar(p)
# plot a 2D color histogram for the green and red channels
ax = fig.add_subplot(132)
hist = cv2.calcHist([chans[1], chans[2]], [0, 1], None, [32, 32],
[0, 256, 0, 256])
p = ax.imshow(hist, interpolation="nearest")
ax.set_title("2D Color Histogram for G and R")
plt.colorbar(p)
# plot a 2D color histogram for blue and red channels
ax = fig.add_subplot(133)
hist = cv2.calcHist([chans[0], chans[2]], [0, 1], None, [32, 32],
[0, 256, 0, 256])
p = ax.imshow(hist, interpolation="nearest")
ax.set_title("2D Color Histogram for B and R")
plt.colorbar(p)
# finally, let's examine the dimensionality of one of the 2D
# histograms
print("2D histogram shape: {}, with {} values".format(
hist.shape, hist.flatten().shape[0]))
是的,这是相当多的代码。但这只是因为我们正在为 RGB 通道的每种组合计算 2D 颜色直方图:红色和绿色,红色和蓝色,绿色和蓝色。
既然我们正在处理多维直方图,我们需要记住我们正在使用的仓的数量。在前面的例子中,我使用了 256 个箱子进行演示。
然而,如果我们为 2D 直方图中的每个维度使用 256 个面元,那么我们得到的直方图将具有 65,536 个单独的像素计数(因为 256 × 256 = 65,536 )。这不仅浪费资源,而且不切实际。计算多维直方图时,大多数应用程序使用 8 到 64 个区间。正如第 36 行和第 37 行所示,我现在使用 32 个 bin,而不是 256 个。
通过检查cv2.calcHist函数的第一个参数,可以看出这段代码最重要的一点。这里我们看到我们正在传递两个通道的列表:绿色和蓝色通道。这就是全部了。
那么 2D 直方图是如何存储在 OpenCV 中的呢?这是 2D 数字阵列。由于我为每个通道使用了 32 个面元,现在我有了一个 32 × 32 直方图。
正如我们在运行这个脚本时将会看到的,我们的 2D 直方图将会有一个维度为32×32 = 1024(行 60 和 61 )。
使用 2D 直方图一次考虑两个通道。但是如果我们想考虑所有三个 RGB 通道呢?你猜对了。我们现在要构建一个 3D 直方图:
# our 2D histogram could only take into account 2 out of the 3
# channels in the image so now let's build a 3D color histogram
# (utilizing all channels) with 8 bins in each direction -- we
# can't plot the 3D histogram, but the theory is exactly like
# that of a 2D histogram, so we'll just show the shape of the
# histogram
hist = cv2.calcHist([image], [0, 1, 2],
None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
print("3D histogram shape: {}, with {} values".format(
hist.shape, hist.flatten().shape[0]))
这里的代码非常简单——它只是上面的 2D 直方图代码的扩展。我们现在正在为每个 RGB 通道计算一个8×8×8直方图。我们无法将这个直方图可视化,但我们可以看到形状确实是具有512值的(8, 8, 8)。
最后,让我们在屏幕上显示我们的原始输入image:
# display the original input image
plt.figure()
plt.axis("off")
plt.imshow(imutils.opencv2matplotlib(image))
# show our plots
plt.show()
imutils中的opencv2matplotlib便利功能用于将 BGR 图像转换为 RGB。如果你曾经使用过 Jupyter 笔记本,这个方便的方法也是很棒的。
颜色直方图结果
我们现在可以用 OpenCV 计算颜色直方图了!
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。从那里,您可以执行color_histograms.py脚本:
$ python color_histograms.py --image beach.png
在左边的,你可以看到我们的输入图像包含一个宁静的海滩场景。在右边的,我们有我们的“扁平”颜色直方图。**
我们看到在仓 100 周围的绿色直方图中有一个尖峰。我们看到图像中的大多数绿色像素都包含在【85,200】*范围内——这些区域从海滩图像中的绿色植被和树木到浅绿色都是中等范围的。
在我们的图像中,我们还可以看到许多较亮的蓝色像素。考虑到我们既能看到清澈的大海又能看到万里无云的蓝天,这并不奇怪。
现在让我们来可视化我们的 2D 直方图:
第一个是绿色和蓝色通道的 2D 颜色直方图,第二个是绿色和红色的直方图,第三个是蓝色和红色的直方图。蓝色阴影代表低像素计数,而红色阴影代表高像素计数(即 2D 直方图中的峰值)。
我们倾向于在绿色和蓝色直方图中看到许多峰值,其中 x=28 和 y=27 。这个区域对应于植被和树木的绿色像素以及天空和海洋的蓝色像素。
此外,我们可以通过命令行输出来研究图像直方图的形状:
2D histogram shape: (32, 32), with 1024 values
3D histogram shape: (8, 8, 8), with 512 values
每个 2D 直方图为 32×32。相乘,这意味着每个直方图是 32×32 = 1024-d ,意味着每个直方图由总共 1024 个值表示。
另一方面,我们的 3D 直方图是8×8×8,因此当相乘时,我们看到我们的 3D 图像直方图由 512 个值表示。
使用 OpenCV 计算屏蔽区域的图像直方图
到目前为止,我们已经学会了如何计算输入图像的整体直方图?但是如果你想只为输入图像的 特定区域 计算图像直方图呢?
例如,您可能正在构建一个自动识别和匹配服装的计算机视觉应用程序。你首先要从图像中分割出服装。之后,你需要计算一个颜色直方图来量化衣服的颜色分布…但是你不想在计算中包括背景像素,这些像素不属于衣服本身。
那么,在这种情况下你会怎么做呢?
是否可以只为输入图像的特定区域计算颜色直方图?
你打赌它是。
在您的项目目录结构中打开histogram_with_mask.py,我将向您展示它是如何完成的:
# import the necessary packages
from matplotlib import pyplot as plt
import numpy as np
import cv2
第 2-4 行导入我们需要的 Python 包。我们将使用matplotlib进行绘图,使用 NumPy 进行数值数组处理,使用cv2进行 OpenCV 绑定。
现在让我们定义一个方便的函数plot_histogram,它将把我们的大多数 matplotlib 调用封装到一个简单易用的函数中:
def plot_histogram(image, title, mask=None):
# split the image into its respective channels, then initialize
# the tuple of channel names along with our figure for plotting
chans = cv2.split(image)
colors = ("b", "g", "r")
plt.figure()
plt.title(title)
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
# loop over the image channels
for (chan, color) in zip(chans, colors):
# create a histogram for the current channel and plot it
hist = cv2.calcHist([chan], [0], mask, [256], [0, 256])
plt.plot(hist, color=color)
plt.xlim([0, 256])
在第 6 行,我们定义plot_histogram。这个函数接受三个参数:一个image、我们绘图的title和一个mask。如果我们没有图像的蒙版,mask默认为None。
我们的plot_histogram函数的主体只是计算图像中每个通道的直方图并绘制出来,就像本节前面的例子一样;然而,请注意,我们现在正在将mask参数传递给cv2.calcHist。
在事件中,我们 do 有一个输入蒙版,我们在这里传递它,这样 OpenCV 就知道只将 中被蒙版的像素 从输入image中包含到直方图构造中。
有了plot_histogram函数定义,我们可以继续我们脚本的其余部分:
# load the beach image and plot a histogram for it
image = cv2.imread("beach.png")
plot_histogram(image, "Histogram for Original Image")
cv2.imshow("Original", image)
我们首先在行 24 从磁盘加载我们的海滩图像,在行 25 将其显示在屏幕上,然后在行 26 为海滩图像的每个通道绘制颜色直方图。
请注意,我们这里传入的是而不是蒙版,所以我们计算的是图像的整体的颜色直方图。
现在,让我们来学习如何只为图像的蒙版区域计算颜色直方图:
# construct a mask for our image; our mask will be *black* for regions
# we want to *ignore* and *white* for regions we want to *examine*
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.rectangle(mask, (60, 290), (210, 390), 255, -1)
cv2.imshow("Mask", mask)
# display the masked region
masked = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Applying the Mask", masked)
# compute a histogram for our image, but we'll only include pixels in
# the masked region
plot_histogram(image, "Histogram for Masked Image", mask=mask)
# show our plots
plt.show()
我们将我们的mask定义为一个 NumPy 数组,其宽度和高度与第 30 行上的海滩图像相同。然后我们在第 31 条线上画一个白色矩形,从点 (60,210) 到点 (290,390) 。****
这个矩形将作为我们的蒙版——直方图计算中只考虑原始图像中属于蒙版区域的像素。
最后,我们在屏幕上显示结果图(第 43 行)。
屏蔽直方图结果
我们现在准备计算图像的掩蔽直方图。
请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。从那里,您可以执行histogram_with_mask.py脚本:
$ python histogram_with_mask.py
首先,我们显示原始输入图像及其相应的通道直方图,其中未应用掩蔽:
从这里,我们构建一个矩形蒙版,并使用按位 and 来可视化图像的蒙版区域:
最后,让我们将整个图像的直方图与仅从图像的遮罩区域计算的直方图进行比较:
在左侧,我们有原始图像的直方图,而在右侧,我们有屏蔽图像的直方图。
对于屏蔽图像,大多数红色像素落在范围【10,25】内,表明红色像素对我们的图像贡献很小。这是有道理的,因为我们的海洋和天空是蓝色的。
然后出现绿色像素,但这些像素朝向分布的较亮端,对应于绿色树叶和树木。
最后,我们的蓝色像素落在较亮的范围,显然是我们的蓝色海洋和天空。
最重要的是,把我们的被遮罩的颜色直方图 (右) 与未被遮罩的颜色直方图 (左) 上图。注意颜色直方图的显著差异。
通过利用遮罩,我们能够将计算仅应用于图像中我们感兴趣的特定区域——在本例中,我们只想检查蓝天和海洋的分布。
总结
在本教程中,您学习了所有关于图像直方图的知识,以及如何使用 OpenCV 和cv2.calcHist函数来计算它们。
直方图非常简单,但却是非常强大的工具。它们广泛用于阈值处理、颜色校正,甚至图像特征!确保你很好地掌握了直方图,你将来肯定会用到它们。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
OpenCV 图像翻译
原文:https://pyimagesearch.com/2021/02/03/opencv-image-translation/
在本教程中,您将学习如何使用 OpenCV 翻译和移动图像。
平移是图像沿着 x- 和 y- 轴的移动。要使用 OpenCV 翻译图像,我们必须:
- 从磁盘加载图像
- 定义仿射变换矩阵
- 应用
cv2.warpAffine功能执行翻译
这听起来像是一个复杂的过程,但是正如您将看到的,只用两行代码就可以完成!
要学习如何用 OpenCV 翻译图像,继续阅读。
OpenCV 图片翻译
在本教程的第一部分,我们将讨论什么是翻译矩阵,以及如何使用 OpenCV 和 NumPy 定义它。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
回顾了我们的项目目录结构后,我们将继续实现一个 Python 脚本来使用 OpenCV 执行翻译。
我们将详细回顾这个脚本,以及脚本生成的结果。
本指南结束时,您将了解如何使用 OpenCV 执行图像翻译。
用 OpenCV 定义翻译矩阵
为了用 OpenCV 执行图像转换,我们首先需要定义一个称为仿射变换矩阵的 2 x 3 矩阵:
出于翻译的目的,我们只关心
and  values:
values:
 值为负值会将图像移动到左侧
值为负值会将图像移动到左侧 的正值将图像向右移动
的正值将图像向右移动- 负值为
 将图像上移**
将图像上移**  的正值会将图像下移**
的正值会将图像下移**
 的正值将图像向右移动
的正值将图像向右移动 将图像上移**
将图像上移**例如,假设我们想将一幅图像向右移动 25 像素,向下移动 50 像素。我们的转换矩阵如下所示(实现为 NumPy 数组)😗
M = np.float32([
[1, 0, 25],
[0, 1, 50]
])
现在,如果我们想将一幅图像向左移动 7 个像素并向上移动 23 个像素,我们的平移矩阵将如下所示:
M = np.float32([
[1, 0, -7],
[0, 1, -23]
])
作为最后一个例子,假设我们想把我们的图像向左平移 30 像素,向下平移 12 像素:
M = np.float32([
[1, 0, -30],
[0, 1, 12]
])
正如你所看到的,定义图像平移的仿射变换矩阵非常简单!
一旦定义了变换矩阵,我们就可以使用cv2.warpAffine函数简单地执行图像转换,就像这样:
shifted = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
在本指南的后面,我们将看到一个定义图像转换矩阵和应用cv2.warpAffine函数的完整例子。
配置您的开发环境
为了遵循本指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们使用 OpenCV 执行图像翻译之前,让我们首先回顾一下我们的项目目录结构:
$ tree . --dirsfirst
.
├── opencv_logo.png
└── opencv_translate.py
0 directories, 2 files
我们有一个单独的 Python 脚本opencv_translate.py,我们将详细讨论它。
该脚本将从磁盘加载opencv_logo.png图像,然后使用 OpenCV 库对其进行翻译/转换。
使用 OpenCV 进行图像翻译
平移是图像沿着 x- 和 y- 轴的移动。使用平移,我们可以将图像向上、向下、向左或向右,以及以上任意组合。
数学上,我们定义了一个平移矩阵, M,,我们可以用它来平移图像:
通过一些代码可以更好地解释这个概念:
# import the necessary packages
import numpy as np
import argparse
import imutils
import cv2
在的第 2-5 行,我们简单地导入我们将要使用的包。至此,使用 NumPy、argparse、cv2应该感觉司空见惯了。
不过,我在这里介绍一个新的包: imutils 。这不是包含在 NumPy 或 OpenCV 中的包。相反,它是我个人编写的一个库,包含一些“方便”的方法,可以更容易地执行常见的任务,如平移、旋转和调整大小(用更少的代码)。
如果您的机器上还没有安装imutils,您可以使用pip安装它:
$ pip install imutils
现在让我们解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="opencv_logo.png",
help="path to the input image")
args = vars(ap.parse_args())
我们只需要一个参数--image,它指向我们想要从磁盘加载并应用 OpenCV 翻译操作的输入图像。默认情况下,我们将把--image参数设置为opencv_logo.png。
现在让我们从磁盘加载我们的映像,并执行我们的第一次转换:
# load the image and display it to our screen
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# shift the image 25 pixels to the right and 50 pixels down
M = np.float32([[1, 0, 25], [0, 1, 50]])
shifted = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
cv2.imshow("Shifted Down and Right", shifted)
第 14 行和第 15 行从磁盘加载我们的输入image,然后显示到我们的屏幕上:
第一次实际的翻译发生在第 18-20 行,在这里我们通过定义我们的翻译矩阵M开始。
这个矩阵告诉我们图像向左或向右或移动了多少像素,然后图像向上或向下移动了多少像素,再次记住平移矩阵的形式为:
M = np.float32([
[1, 0, shiftX],
[0, 1, shiftY]
])
我们的转换矩阵 M 被定义为浮点数组——这很重要,因为 OpenCV 希望这个矩阵是浮点类型的。矩阵的第一行是![[1, 0, t_{x}]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/2a846e454798946191383f14e2baa985.png "[1, 0, t_{x}]")
, where is the number of pixels we will shift the image left or right. Negative values of will shift the image to the left, and positive values will shift the image to the right.
然后,我们将矩阵的第二行定义为![[0, 1, t_{y}]](https://github.com/OpenDocCN/geekdoc-dl-zh/raw/master/pyimagesearch/img/d1bfa5faa7708ec64a4d6e8cb8afdc91.png "[0, 1, t_{y}]")
, where  is the number of pixels we will shift the image up or down. Negative values of will shift the image up, and positive values will shift the image down.
is the number of pixels we will shift the image up or down. Negative values of will shift the image up, and positive values will shift the image down.
使用这个符号,在的第 18 行,我们可以看到
and  , indicating that we are shifting the image 25 pixels to the right and 50 pixels down.
, indicating that we are shifting the image 25 pixels to the right and 50 pixels down.
现在我们已经定义了翻译矩阵,实际的翻译发生在使用cv2.warpAffine函数的第 19 行。第一个参数是我们希望移动的图像,第二个参数是我们的转换矩阵,M。最后,我们手动提供图像的尺寸(宽度和高度)作为第三个参数。
第 20 行显示了翻译的结果,我们可以在下面看到:
注意图像是如何被清晰地向下和向右移动到。**
让我们研究另一个使用 OpenCV 进行图像翻译的例子。
# now, let's shift the image 50 pixels to the left and 90 pixels
# up by specifying negative values for the x and y directions,
# respectively
M = np.float32([[1, 0, -50], [0, 1, -90]])
shifted = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
cv2.imshow("Shifted Up and Left", shifted)
第 25 行集
and  , implying that we are shifting the image 50 pixels to the left and 90 pixels up. The image is shifted left and up rather than right and down because we are providing negative values for both and .
, implying that we are shifting the image 50 pixels to the left and 90 pixels up. The image is shifted left and up rather than right and down because we are providing negative values for both and .
图 6 显示了为两个提供负值的输出
and :
再一次,注意我们的图像是如何“移动”到左边的 50 像素和上面的 90 像素的。
然而,手动构造这个转换矩阵并调用cv2.warpAffine方法需要一点努力——而且也不一定是漂亮的代码!
这就是我的imutils包进来的地方。每次我们想翻译一幅图像时,不必定义我们的矩阵M并调用cv2.warpAffine,相反,我们可以调用imutils.translate来为我们处理操作:
# use the imutils helper function to translate the image 100 pixels
# down in a single function call
shifted = imutils.translate(image, 0, 100)
cv2.imshow("Shifted Down", shifted)
cv2.waitKey(0)
平移操作的输出可以在图 7 中看到:
使用imutils.translate的好处是更干净的代码——不管怎样,imutils.translate和cv2.warpAffine的输出是一样的。
注: 如果有兴趣看imutils.translate函数的实现, 简单参考我的 GitHub repo 。
OpenCV 图像翻译结果
要使用 OpenCV 执行图像翻译,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
然后,您可以执行以下命令:
$ python opencv_translate.py
您的结果应该看起来像我从上一节。
总结
在本教程中,您学习了如何使用 OpenCV 执行图像翻译。
您通过首先定义仿射变换矩阵来完成此任务:
然后,您指定想要如何移动图像:
 值为负值会将图像移动到左侧
值为负值会将图像移动到左侧 的正值将图像向右移动
的正值将图像向右移动- 负值为
 将图像上移**
将图像上移**  的正值会将图像下移**
的正值会将图像下移**
*虽然用 OpenCV 执行图像翻译只需要两行代码,但这并不是世界上最“漂亮”的代码。为了方便起见,您可以使用imutils.translate函数在一个简单、易读的函数调用中执行图像转换。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***
OpenCV 加载图像(cv2.imread)
原文:https://pyimagesearch.com/2021/01/20/opencv-load-image-cv2-imread/
- 从磁盘加载输入图像
- 确定图像的宽度、高度和通道数
- 将加载的图像显示到我们的屏幕上
- 将图像作为不同的图像文件类型写回磁盘
在本指南结束时,您将会很好地理解如何使用 OpenCV 从磁盘加载图像。
要了解如何使用 OpenCV 和 cv2.imread ,从磁盘加载图像,请继续阅读。
OpenCV 加载图像(cv2.imread)
在本教程的第一部分,我们将讨论如何使用 OpenCV 和cv2.imread函数从磁盘加载图像。
从那里,您将学习如何配置您的开发环境来安装 OpenCV。
然后我们将回顾我们的项目目录结构,接着实现load_image_opencv.py ,这是一个 Python 脚本,它将使用 OpenCV 和cv2.imread函数从磁盘加载输入图像。
我们将讨论我们的结果来结束本教程。
我们如何用 OpenCV 从磁盘加载图像?
cv2.imread函数接受一个参数,即图像在磁盘上的位置的路径:
image = cv2.imread("path/to/image.png")
配置您的开发环境
在使用 OpenCV 加载图像之前,您需要在系统上安装这个库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助配置 OpenCV 4.3+的开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码了吗?
那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
让我们回顾一下我们的项目结构。从 “下载” 部分获取源代码,解压缩内容,并导航到保存它的位置:
$ tree . --dirsfirst
.
├── 30th_birthday.png
├── jurassic_park.png
├── load_image_opencv.py
└── newimage.jpg
0 directories, 4 files
现在让我们使用 OpenCV 实现我们的图像加载 Python 脚本!
实现我们的 OpenCV 图像加载脚本
让我们开始学习如何使用 OpenCV 从磁盘加载输入图像。
创建一个名为load_image_opencv.py的 Python 脚本,并插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the image from disk via "cv2.imread" and then grab the spatial
# dimensions, including width, height, and number of channels
image = cv2.imread(args["image"])
(h, w, c) = image.shape[:3]
# display the image width, height, and number of channels to our
# terminal
print("width: {} pixels".format(w))
print("height: {} pixels".format(h))
print("channels: {}".format(c))
我们现在可以将图像尺寸(宽度、高度和通道数量)打印到终端进行查看(第 18-20 行)。
在未来的博客文章中,我们将讨论什么是图像通道,但现在请记住,彩色图像的通道数量将是三个,分别代表像素颜色的红色、绿色和蓝色(RGB)成分。
但是,如果我们不知道 OpenCV 是否正确地读取了图像,那么在内存中保存图像又有什么用呢?让我们在屏幕上显示图像进行验证:
# show the image and wait for a keypress
cv2.imshow("Image", image)
cv2.waitKey(0)
# save the image back to disk (OpenCV handles converting image
# filetypes automatically)
cv2.imwrite("newimage.jpg", image)
现在,您应该能够将 OpenCV 应用于:
- 从磁盘加载图像
- 在屏幕上显示它
- 将其写回磁盘
我们将在下一节回顾这些操作的一些结果。
OpenCV 图像加载结果
现在是使用 OpenCV 从磁盘加载图像的时候了!
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从那里,打开一个终端,并执行以下命令:
$ python load_image_opencv.py --image 30th_birthday.png
width: 720 pixels
height: 764 pixels
channels: 3
几年前,在我 30 岁生日的时候,我妻子租了一辆近似《侏罗纪公园》(我最喜欢的电影)的复制品,让我们开了一整天。
$ ls
30th_birthday.png jurassic_park.png load_image_opencv.py newimage.jpg
$ python load_image_opencv.py --image jurassic_park.png
width: 577 pixels
height: 433 pixels
channels: 3
继续本教程中的侏罗纪公园主题,这里我们有一张雷·阿诺(塞缪尔·L·杰克逊饰演)的照片。
该图像的宽度为 577 像素,高度为 433 像素,有三个通道。
说到最后一项,现在让我们试一试…
如果我们将一个无效的图像路径传递给“cv2.imread”会发生什么?
$ python load_image_opencv.py --image path/does/not/exist.png
Traceback (most recent call last):
File "load_image_opencv.py", line 17, in <module>
(h, w, c) = image.shape[:3]
AttributeError: 'NoneType' object has no attribute 'shape'
在这里,我特意提供了一个在我的磁盘上不存在的镜像路径。
总结
OpenCV 可以方便地读写各种图像文件格式(如 JPG、PNG、TIFF)。该库还简化了在屏幕上显示图像,并允许用户与打开的窗口进行交互。
如果 OpenCV 无法读取图像,您应该仔细检查输入的文件名是否正确,因为cv2.imread函数在失败时会返回一个NoneType Python 对象。如果文件不存在或者 OpenCV 不支持图像格式,该函数将失败。
我们还根据底层 NumPy 数组形状的值将图像尺寸打印到终端(宽度、高度和通道数量)。然后,我们的脚本使用 JPG 格式将图像保存到磁盘,利用 OpenCV 的能力自动将图像转换为期望的文件类型。
在本系列的下一篇教程中,您将学习 OpenCV 图像基础知识,包括什么是像素、图像坐标系概述以及如何访问单个像素值。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
如何:OpenCV 加载图像
几个月前,我在讲授一个关于计算机视觉基础的在线研讨会。
你知道我最常被问到的问题是什么吗?
如何使用 OpenCV 加载图像并显示在我的屏幕上?
这是一个非常基本的概念,但我认为许多教师(包括我自己)很快跳过这个问题,并立即进入更高级的技术,如模糊,边缘检测和阈值处理。
在屏幕上显示图像是调试计算机视觉程序的一种简单方法,所以让我们花几分钟来回答这个问题。
如何:OpenCV 加载图像
这篇文章的目的是向您展示如何使用 OpenCV 从磁盘读取图像,在屏幕上显示图像,然后等待按键关闭窗口并终止脚本。
虽然简单地在屏幕上显示图像本身并不实用,但这是一项重要的技术,当你开发(更重要的是调试)自己的计算机视觉应用程序时,你会经常用到这项技术。
你看,在你的屏幕上显示一个图像很像你调试一个复杂程序时的一个print语句。
当谈到调试时,没有什么比几个恰当放置的print语句更能找出问题的来源。
计算机视觉也是如此。
打几个恰当的电话给cv2.imshow会很快帮助你解决问题。
所以,让我们直接跳到一些代码中:
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
cv2.imshow("image", image)
cv2.waitKey(0)
第 1-2 行处理导入我们将需要的包— argparse解析命令行参数和cv2OpenCV 绑定。
然后,在的第 4-6 行我们解析我们的命令行参数。我们只需要一个开关--image,它是我们的映像驻留在磁盘上的路径。
使用 OpenCV 加载图像是通过调用cv2.imread函数在第 8 行完成的。这个函数接受一个参数,即图像在磁盘上驻留的路径,该路径作为命令行参数提供。
最后,我们可以在屏幕的第 10-11 行显示我们的图像。
将图像显示到我们的屏幕是由cv2.imshow功能处理的。cv2.imshow的第一个参数是一个包含窗口名称的字符串。该文本将出现在窗口的标题栏中。第二个参数是我们在第 8 行从磁盘加载的图像。
在我们调用了cv2.imshow函数之后,我们需要等待使用第 11 行上的cv2.waitKey函数的按键。
非常重要的是我们要调用这个函数, 否则我们的窗口会自动关闭!
看,cv2.waitKey函数暂停 Python 脚本的执行,并等待按键。如果我们移除第 11 行,那么包含我们图像的窗口将自动关闭。通过调用cv2.waitKey,我们能够暂停脚本的执行,从而在屏幕上显示我们的图像,直到我们按下键盘上的任何键。
唯一的参数cv2.waitKey是一个整数,它是以毫秒为单位的延迟。如果这个值是正数,那么在经过指定的毫秒数后,窗口将自动关闭。如果毫秒数为零,那么函数将无限期等待,直到按下一个键。
cv2.waitKey的返回值或者是被按下的键的代码,或者是-1,表示在所提供的毫秒数过去之前没有按下任何键。
我们可以通过发出以下命令来执行我们的脚本:
$ python load_image.py --image doge.jpg
然后,您应该会在屏幕上看到一个图像:
Figure 1: Loading an image using OpenCV and displaying it to our screen.
明明出现了一只野总督!我已经没有扑克牌了…
按下键盘上的任意键将会取消暂停脚本并关闭窗口。
摘要
在这篇博文中,我回答了我最常被问到的一个问题:“我如何使用 OpenCV 加载图像并在我的屏幕上显示它?”
为了从磁盘上加载一个图像并使用 OpenCV 显示它,首先需要调用cv2.imread函数,将图像的路径作为唯一的参数传入。
然后,调用cv2.imshow将在屏幕上显示您的图像。
但是一定要使用cv2.waitKey等待按键,否则cv2.imshow创建的窗口将自动关闭。
在一个周末学习计算机视觉的基础知识

如果你有兴趣学习计算机视觉的基础知识,但不知道从哪里开始,你绝对应该看看我的新电子书, 实用 Python 和 OpenCV 。
在这本书里,我涵盖了计算机视觉和图像处理的基础…我可以在一个周末教你!
我知道,这听起来好得难以置信。
但是我向你保证,这本书是你学习计算机视觉基础的快速入门指南。读完这本书后,你将很快成为一名 OpenCV 大师!
所以如果你想学习 OpenCV 的基础知识,一定要看看我的书。你不会失望的。
OpenCV 形态学运算
原文:https://pyimagesearch.com/2021/04/28/opencv-morphological-operations/
在本教程中,您将学习如何使用 OpenCV 应用形态学运算。
我们将讨论的形态学运算包括:
- 侵蚀
- 扩张
- 开始
- 关闭
- 形态梯度
- 布莱克有
- 大礼帽(也称为“白帽子”)
这些图像处理操作应用于灰度或二进制图像,并用于 OCR 算法的预处理、检测条形码、检测车牌等。
有时,巧妙使用形态学运算可以让你避免更复杂(计算成本更高)的机器学习和深度学习算法。
作为一个认真的计算机视觉从业者,你需要去理解形态学运算。
要学习如何用 OpenCV 应用形态学运算, 继续阅读。
OpenCV 形态学运算
形态学操作是应用于二进制或灰度图像的简单变换。更具体地说,我们对图像内部的形状和结构应用形态学操作。
我们可以使用形态学操作来增加图像中物体的大小,以及减少它们的大小。我们还可以利用形态学操作来闭合对象之间的间隙,以及打开它们。
形态学操作使用结构元素“探测”图像。该结构元素定义了每个像素周围要检查的邻域。并且基于给定的操作和结构化元素的大小,我们能够调整我们的输出图像。
对结构化元素的这种解释可能听起来含糊不清——那是因为它确实如此。有许多不同的形态变换执行彼此“相反”的运算,正如加法是减法的“相反”,我们可以将腐蚀形态运算视为膨胀的“相反”。
如果这听起来令人困惑,不要担心——我们将回顾每种形态变换的许多例子,当你读完本教程时,你将对形态运算有一个清晰的认识。
为什么要学习形态学运算?
形态学运算是我在图像处理中最喜欢涉及的话题之一。
这是为什么呢?
因为这些转变是如此强大。
我经常看到计算机视觉研究人员和开发人员试图解决一个问题,并立即投入到高级计算机视觉、机器学习和深度学习技术中。似乎一旦学会挥舞锤子,每个问题看起来都像钉子。
然而,有时使用不太先进的技术可以找到更“优雅”的解决方案。当然,这些技术可能不会漂浮在最新最先进算法的时髦词汇上,但它们可以完成工作。
例如,我曾经在 PyImageSearch 博客上写过一篇关于检测图像中的条形码的文章。我没有使用任何花哨的技术。我没有使用任何机器学习。事实上,我能够检测图像中的条形码,只需要使用我们在本系列中已经讨论过的介绍性主题。
很疯狂,不是吗?
但是说真的,请注意这些转换——在您的计算机视觉职业生涯中,会有这样的时候,当您准备好解决一个问题时,却发现一个更优雅、更简单的解决方案可能已经存在了。很有可能,你会在形态学运算中找到那个优雅的解决方案。
让我们继续,从讨论使形态学操作成为可能的组件开始:结构化元素。
“结构化元素”的概念
还记得我们关于图像内核和卷积的教程吗?
嗯,你可以(从概念上)把一个结构化元素想象成一种内核或者遮罩。然而,我们不是应用卷积,而是对像素执行简单的测试。
就像在图像内核中一样,对于图像中的每个像素,结构化元素从左到右和从上到下滑动。就像内核一样,结构化元素可以是任意大小的邻域。
例如,让我们看看下面中心像素红色的 4-邻域和 8-邻域:
这里,我们可以看到中心像素(即红色像素)位于邻域的中心:
- 4 邻域(左)将中心像素周围的区域定义为北、南、东、西的像素。
- 8-邻域(右)扩展了该区域,使其也包括拐角像素
这只是两个简单结构元素的例子。但我们也可以将它们做成任意的矩形或圆形结构——这完全取决于您的特定应用。
在 OpenCV 中,我们可以使用cv2.getStructuringElement函数或者 NumPy 本身来定义我们的结构化元素。就我个人而言,我更喜欢使用cv2.getStructuringElement函数,因为它给了你对返回元素更多的控制,但同样,这是个人的选择。
如果结构化元素的概念不完全清楚,那也没关系。在这节课中,我们将回顾许多例子。目前,要理解结构化元素的行为类似于内核或遮罩——但是我们不是将输入图像与我们的结构化元素进行卷积,而是只应用简单的像素测试。
现在我们对结构化元素有了基本的了解,让我们配置我们的开发环境,回顾项目目录结构,然后编写一些代码。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 ,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们开始用 OpenCV 实现形态学操作之前,让我们先回顾一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像:
$ tree . --dirsfirst
.
├── car.png
├── morphological_hats.py
├── morphological_ops.py
├── pyimagesearch_logo.png
└── pyimagesearch_logo_noise.png
0 directories, 5 files
今天我们要复习两个 Python 脚本:
morphological_ops.py:应用 OpenCV 的形态学操作,包括腐蚀、膨胀、打开、关闭和形态学渐变。morphological_hats.py:用 OpenCV 应用黑帽和礼帽/白帽操作。
三个。这两个脚本将使用我们的项目结构中包含的 png 图像来演示各种形态学操作。
侵蚀
就像沿着河岸奔流的水侵蚀土壤一样,图像中的侵蚀会“侵蚀”前景对象,使其变小。简单地说,图像中靠近对象边界的像素将被丢弃,“侵蚀”掉。
腐蚀的工作原理是定义一个结构元素,然后在输入图像上从左到右和从上到下滑动这个结构元素。
只有当结构化元素内的所有像素都为 > 0 时,输入图像中的前景像素才会被保留。否则,像素被设置为 0 (即背景)。
腐蚀对于移除图像中的小斑点或断开两个连接的对象非常有用。
我们可以通过使用cv2.erode函数来执行腐蚀。让我们打开一个新文件,命名为morphological.py_ops.py,并开始编码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入argparse(用于命令行参数)和cv2(我们的 OpenCV 绑定)。
我们只有一个命令行参数需要解析,我们的输入--image将被腐蚀。
在本课的大多数示例中,我们将对 PyImageSearch 徽标应用形态学操作,如下所示:
正如我在本课前面提到的,我们通常(但不总是)对二进制图像应用形态学运算。正如我们将在本课稍后看到的,也有例外,特别是当使用黑帽和白帽操作符时,但目前,我们将假设我们正在处理一个二进制图像,其中背景像素是黑,前景像素是白。
让我们从磁盘加载我们的输入--image,然后应用一系列腐蚀:
# load the image, convert it to grayscale, and display it to our
# screen
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Original", image)
# apply a series of erosions
for i in range(0, 3):
eroded = cv2.erode(gray.copy(), None, iterations=i + 1)
cv2.imshow("Eroded {} times".format(i + 1), eroded)
cv2.waitKey(0)
第 13 行从磁盘加载我们的输入image,而第 14 行将其转换为灰度。由于我们的图像已经预先分割,我们现在正在处理一个二进制图像。
给定我们的标志图像,我们在线 18-21 上应用一系列腐蚀。for循环控制我们将要应用侵蚀的次数,或者说迭代。随着侵蚀次数的增加,前景 logo 会开始“侵蚀”消失。
我们通过调用cv2.erode函数在第 19 行上执行实际的侵蚀。这个函数有两个必需参数和第三个可选参数。
第一个参数是我们想要侵蚀的image——在本例中,它是我们的二进制图像(即 PyImageSearch 徽标)。
cv2.erode的第二个参数是结构化元素。如果这个值是None,那么将使用一个 3×3 结构元素,与我们上面看到的 8 邻域结构元素相同。当然,你也可以在这里提供你自己的定制结构元素来代替None。
最后一个参数是将要进行侵蚀的iterations的数量。随着迭代次数的增加,我们会看到越来越多的 PyImageSearch 徽标被蚕食。
最后,第 20 行和第 21 行向我们展示了我们被侵蚀的图像。
当您执行这个脚本时,您将看到我们侵蚀操作的以下输出:
在最顶端,我们有自己的原始图像。然后在图像下面,我们看到徽标分别被腐蚀了 1、2 和 3 次。注意随着侵蚀迭代次数的增加,越来越多的徽标被侵蚀掉。
同样,腐蚀对于从图像中移除小斑点或断开两个连接的组件最有用。记住这一点,看看 PyImageSearch 标志中的字母“p”。注意“p”的圆形区域是如何在两次腐蚀后从主干上断开的——这是一个断开图像两个相连部分的例子。
膨胀
侵蚀的对立面是膨胀。就像腐蚀会侵蚀前景像素一样,膨胀会增长前景像素。
扩张增加前景对象的大小,对于将图像的破碎部分连接在一起特别有用。
就像腐蚀一样,膨胀也利用结构元素——如果结构元素中的任何像素为 > 0 ,则结构元素的中心像素 p 被设置为白色。
*我们使用cv2.dilate函数来应用扩展:
# close all windows to cleanup the screen
cv2.destroyAllWindows()
cv2.imshow("Original", image)
# apply a series of dilations
for i in range(0, 3):
dilated = cv2.dilate(gray.copy(), None, iterations=i + 1)
cv2.imshow("Dilated {} times".format(i + 1), dilated)
cv2.waitKey(0)
第 24 行和第 25 行简单地关闭所有打开的窗口,显示我们的原始图像,给我们一个新的开始。
然后第 28 行开始循环迭代次数,就像我们对 cv2.erode 函数所做的一样。
通过调用cv2.dilate函数在行 29 上执行实际的膨胀,其中实际的函数签名与cv2.erode的签名相同。
第一个参数是我们要扩张的image;第二个是我们的结构元素,当设置为None时,它是一个 3×3 8 邻域结构元素;最后一个参数是我们将要应用的膨胀数iterations。
我们的膨胀的输出可以在下面看到:
同样,在顶部我们有我们的原始输入图像。在输入图像下方,我们的图像分别放大了 1、2 和 3 倍。
与前景区域被慢慢侵蚀的侵蚀不同,膨胀实际上增长了我们的前景区域。
当连接一个物体的断裂部分时,膨胀特别有用——例如,看看底部的图像,我们已经应用了 3 次迭代的膨胀。至此,**和之间的空隙被全部的和**字母连接起来。
开启
一开口就是一个接着是一个 膨胀 。
*执行打开操作允许我们从图像中移除小斑点:首先应用腐蚀来移除小斑点,然后应用膨胀来重新生长原始对象的大小。
让我们看一些将开口应用于图像的示例代码:
# close all windows to cleanup the screen, then initialize a list of
# of kernels sizes that will be applied to the image
cv2.destroyAllWindows()
cv2.imshow("Original", image)
kernelSizes = [(3, 3), (5, 5), (7, 7)]
# loop over the kernels sizes
for kernelSize in kernelSizes:
# construct a rectangular kernel from the current size and then
# apply an "opening" operation
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, kernelSize)
opening = cv2.morphologyEx(gray, cv2.MORPH_OPEN, kernel)
cv2.imshow("Opening: ({}, {})".format(
kernelSize[0], kernelSize[1]), opening)
cv2.waitKey(0)
第 35 行和第 36 行通过关闭所有打开的窗口并重新显示我们的原始图像来执行清理。
看看我们在第 37 行,kernelSizes定义的新变量。这个变量分别定义了我们将要应用的结构化元素的宽度和高度。
我们在第 40 行上循环这些kernelSizes,然后调用第 43 行上的cv2.getStructuringElement来构建我们的结构化元素。
cv2.getStructuringElement函数需要两个参数:第一个是我们想要的结构化元素的类型,第二个是结构化元素的大小(我们从第 40 行的for 循环中获取)。
我们传入一个值cv2.MORPH_RECT来表示我们想要一个矩形结构元素。但是你也可以传入一个值cv2.MORPH_CROSS来得到一个十字形结构元素(十字形就像一个 4 邻域结构元素,但是可以是任何大小),或者传入一个cv2.MORPH_ELLIPSE来得到一个圆形结构元素。
具体使用哪种结构化元素取决于您的应用程序——我将把它作为一个练习留给读者,让他们来体验每一种结构化元素。
通过调用cv2.morphologyEx函数,在线 42 上执行实际的打开操作。这个函数在某种意义上是抽象的——它允许我们传递我们想要的任何形态学操作,后面是我们的内核/结构化元素。
cv2.morphologyEx的第一个必需参数是我们想要应用形态学操作的图像。第二个参数是形态学运算的实际类型——在本例中,它是一个开运算。最后一个必需的参数是我们正在使用的内核/结构化元素。
最后,第 45-47 行显示应用我们的打开的输出。
正如我上面提到的,打开操作允许我们移除图像中的小斑点。我继续给 PyImageSearch 徽标添加了一些 blobs(在我们的项目目录结构中的pyimagesearch_logo_noise.png):
当您将我们的开形态学操作应用于这个噪声图像时,您将收到以下输出:
请注意,当我们使用大小为 5×5 的内核时,小的随机斑点几乎完全消失了。当它到达一个大小为 7×7 的内核时,我们的打开操作不仅移除了所有的随机斑点,还在字母“p”和字母“a”上“打开”了洞。
关闭
与打开正好相反的是 关闭 。一个闭合是一个 膨胀 后跟一个 侵蚀 。
顾名思义,闭合用于闭合对象内部的孔或者将组件连接在一起。
下面的代码块包含执行结束的代码:
# close all windows to cleanup the screen
cv2.destroyAllWindows()
cv2.imshow("Original", image)
# loop over the kernels sizes again
for kernelSize in kernelSizes:
# construct a rectangular kernel form the current size, but this
# time apply a "closing" operation
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, kernelSize)
closing = cv2.morphologyEx(gray, cv2.MORPH_CLOSE, kernel)
cv2.imshow("Closing: ({}, {})".format(
kernelSize[0], kernelSize[1]), closing)
cv2.waitKey(0)
执行结束操作也是通过调用cv2.morphologyEx来完成的,但是这次我们将通过指定cv2.MORPH_CLOSE标志来表明我们的形态学操作是一个结束操作。
我们将回到使用我们的原始图像(没有随机斑点)。随着结构化元素大小的增加,应用关闭操作的输出如下所示:
请注意关闭操作是如何开始弥合徽标中字母之间的间隙的。此外,像“e”、“s”和“a”这样的字母实际上是要填写的。
形态梯度
形态梯度是膨胀和侵蚀之间的差异。**用于确定图像中特定对象的轮廓:
# close all windows to cleanup the screen
cv2.destroyAllWindows()
cv2.imshow("Original", image)
# loop over the kernels a final time
for kernelSize in kernelSizes:
# construct a rectangular kernel and apply a "morphological
# gradient" operation to the image
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, kernelSize)
gradient = cv2.morphologyEx(gray, cv2.MORPH_GRADIENT, kernel)
cv2.imshow("Gradient: ({}, {})".format(
kernelSize[0], kernelSize[1]), gradient)
cv2.waitKey(0)
需要注意的最重要的一行是第 72 行,在这里我们调用了cv2.morphologyEx——但是这次我们提供了cv2.MORPH_GRADIENT标志来表示我们想要应用形态渐变操作来显示我们的徽标的轮廓:
请注意在应用形态学梯度操作后,PyImageSearch 徽标的轮廓是如何清晰显示的。
礼帽/白帽和黑帽
一个 大礼帽 (也称 白礼帽 )形态学操作的区别是原始(灰度/单通道) 输入图像 和 开口 。
大礼帽操作用于在暗背景上显示图像的亮区域。
到目前为止,我们只对二值图像应用了形态学运算。但是我们也可以将形态学操作应用于灰度图像。事实上,大礼帽/白礼帽和黑礼帽操作符都更适合灰度图像,而不是二值图像。
为了演示如何应用形态学运算,让我们看看下面的图像,我们的目标是检测汽车的牌照区域:
那么我们该如何着手做这件事呢?
嗯,看一下上面的例子图像,我们看到牌照是亮的,因为它是汽车本身的暗背景下的白色区域。寻找车牌区域的一个很好的起点是使用 top hat 操作符。
为了测试 top hat 操作符,创建一个新文件,将其命名为morphological_hats.py,并插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
第 2 行和第 3 行导入我们需要的 Python 包,而第 6-9 行解析我们的命令行参数。我们只需要一个参数,--image,到我们的输入图像的路径(在我们的项目结构中我们假设它是car.png)。
让我们从磁盘加载我们的输入--image:
# load the image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# construct a rectangular kernel (13x5) and apply a blackhat
# operation which enables us to find dark regions on a light
# background
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 5))
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKernel)
第 12 行和第 13 行从磁盘放置我们的输入image并将其转换为灰度,从而为我们的黑帽和白帽操作做准备。
第 18 行定义了一个宽度为 13 像素、高度为 5 像素的矩形结构元素。正如我在本课前面提到的,结构化元素可以是任意大小的。在本例中,我们应用了一个宽度几乎是高度 3 倍的矩形元素。
这是为什么呢?
因为车牌的宽度大约是高度的 3 倍!
通过对你想要在图像中检测的物体有一些基本的先验知识,我们可以构建结构元素来更好地帮助我们找到它们。
第 19 行应用黑帽运算符。
以类似的方式,我们也可以应用礼帽/白帽操作:
# similarly, a tophat (also called a "whitehat") operation will
# enable us to find light regions on a dark background
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
# show the output images
cv2.imshow("Original", image)
cv2.imshow("Blackhat", blackhat)
cv2.imshow("Tophat", tophat)
cv2.waitKey(0)
要指定礼帽/白帽操作符而不是黑帽,我们只需将操作符的类型改为cv2.MORPH_TOPHAT。
下面您可以看到应用礼帽运算符的输出:
请注意右侧(即礼帽/白帽)区域是如何在深色背景的背景下浅色清晰地显示出来的——在这种情况下,我们可以清楚地看到汽车的牌照区域已经显露出来。
但也要注意,车牌字符本身没有包括在内。这是因为车牌字符在浅色背景下是深色。
为了帮助解决这个问题,我们可以应用一个黑帽运算符:
为了显示我们的车牌字符,您将首先通过 top hat 操作符分割出车牌本身,然后应用黑帽操作符(或阈值)来提取单个车牌字符(可能使用像轮廓检测这样的方法)。
运行我们的形态学操作演示
要运行我们的形态学操作演示,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
您可以使用以下命令执行morphological_ops.py脚本:
$ python morphological_ops.py --image pyimagesearch_logo.png
使用以下命令可以启动morphological_hats.py脚本:
$ python morphological_hats.py --image car.png
这些脚本的输出应该与我上面提供的图像和图形相匹配。
总结
在本教程中,我们学习了形态学操作是应用于灰度或二进制图像的图像处理变换。这些操作需要一个结构化元素,用于定义操作所应用的像素邻域。
我们还回顾了您将在自己的应用程序中使用的最重要的形态学运算:
- 侵蚀
- 扩张
- 开始
- 关闭
- 形态梯度
- Top hat/white hat
- 布莱克有
形态学运算通常用作更强大的计算机视觉解决方案的预处理步骤,如 OCR、自动车牌识别(ANPR)和条形码检测。
虽然这些技术很简单,但它们实际上非常强大,并且在预处理数据时非常有用。不要忽视他们。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!******
OpenCV 对象跟踪
原文:https://pyimagesearch.com/2018/07/30/opencv-object-tracking/
https://www.youtube.com/embed/mZrJs-YWlc0?feature=oembed
OpenCV OCR 和带 Tesseract 的文本识别
原文:https://pyimagesearch.com/2018/09/17/opencv-ocr-and-text-recognition-with-tesseract/
最后更新于 2021 年 7 月 5 日

https://www.youtube.com/embed/D5tER75G55g?feature=oembed
OpenCV 全景拼接
原文:https://pyimagesearch.com/2016/01/11/opencv-panorama-stitching/

在今天的博文中,我将演示如何使用 Python 和 OpenCV 执行 图像拼接和 全景构建。给定两幅图像,我们将它们“缝合”在一起,创建一个简单的全景图,如上例所示。
为了构建我们的图像全景,我们将利用计算机视觉和图像处理技术,例如:关键点检测和局部不变描述符;关键点匹配;RANSAC 和透视扭曲。
既然有 主要区别 如何 OpenCV 2.4.X 和 OpenCV 3。x 处理关键点检测和局部不变描述符(比如 SIFT 和 SURF),我已经特别注意提供与 和 两个版本兼容的代码(当然前提是你编译的 OpenCV 3 有opencv_contrib支持)。
在未来的博客文章中,我们将扩展我们的全景拼接代码,以处理多个图像,而不是只有两个。
继续阅读,了解如何使用 OpenCV 进行全景拼接。
OpenCV 全景拼接
我们的全景拼接算法包括四个步骤:
- 步骤#1: 检测关键点(狗、哈里斯等。)并提取局部不变描述符(SIFT、SURF 等)。)来自两个输入图像。
- 步骤#2: 匹配两幅图像之间的描述符。
- 步骤#3: 使用 RANSAC 算法使用我们匹配的特征向量来估计单应矩阵。
- 步骤#4: 使用从步骤#3 获得的单应矩阵应用扭曲变换。
我们将把所有这四个步骤封装在panorama.py中,在这里我们将定义一个用于构建全景图的Stitcher类。
Stitcher类将依赖于 imutils Python 包,所以如果您的系统上还没有安装它,那么您现在就想安装它:
$ pip install imutils
让我们开始复习panorama.py:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3(or_better=True)
我们从2-4 号线开始,导入我们需要的包。我们将使用 NumPy 进行矩阵/数组操作,imutils用于一组 OpenCV 便利方法,最后cv2用于 OpenCV 绑定。
从那里,我们在第 6 行的上定义了Stitcher类。Stitcher的构造函数只是通过调用is_cv3方法来检查我们使用的 OpenCV 版本。由于 OpenCV 2.4 和 OpenCV 3 在处理关键点检测和局部不变描述符的方式上有很大的不同,所以确定我们正在使用的 OpenCV 版本是很重要的。
接下来,让我们开始研究stitch方法:
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
stitch方法只需要一个参数images,它是我们将要拼接在一起形成全景图的(两幅)图像的列表。
我们还可以选择提供ratio,用于匹配特征时的大卫·劳的比率测试(在本教程后面的比率测试中有更多信息);reprojThresh,这是 RANSAC 算法允许的最大像素“回旋空间”,最后是showMatches,一个布尔值,用于指示关键点匹配是否应该可视化。
第 15 行解包images列表(同样,我们假设它只包含两个图像)。images列表的排序很重要:我们希望图像按照从左到右的顺序提供。如果图像没有按照顺序或提供,那么我们的代码仍然会运行——但是我们的输出全景图将只包含一个图像,而不是两个。
一旦我们打开了images列表,我们就在的第 16 行和第 17 行上调用detectAndDescribe方法。该方法简单地从两幅图像中检测关键点并提取局部不变描述符(即 SIFT)。
给定关键点和特征,我们使用matchKeypoints ( 第 20 行和第 21 行)来匹配两幅图像中的特征。我们将在本课稍后定义此方法。
如果返回的匹配M是None,那么没有足够的关键点被匹配来创建全景,所以我们简单地返回到调用函数(第 25 和 26 行)。
否则,我们现在准备应用透视变换:
# otherwise, apply a perspective warp to stitch the images
# together
(matches, H, status) = M
result = cv2.warpPerspective(imageA, H,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# check to see if the keypoint matches should be visualized
if showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,
status)
# return a tuple of the stitched image and the
# visualization
return (result, vis)
# return the stitched image
return result
假设M不是None,我们在第 30 行解包元组,给我们一个关键点列表matches,从 RANSAC 算法导出的单应矩阵H,以及最后的status,一个指示matches中的哪些关键点使用 RANSAC 被成功空间验证的索引列表。
给定我们的单应矩阵H,我们现在准备将两幅图像拼接在一起。首先,我们调用cv2.warpPerspective,它需要三个参数:我们想要变形的图像(在本例中,是右侧的图像)、 3 x 3 变换矩阵(H),以及输出图像的最终形状。我们通过对两幅图像的宽度求和,然后使用第二幅图像的高度,从输出图像中导出形状。
第 30 行检查我们是否应该可视化关键点匹配,如果是,我们调用drawMatches并将全景和可视化的元组返回给调用方法(第 37-42 行*)。
否则,我们只需返回拼接后的图像( Line 45 )。
既然已经定义了stitch方法,让我们看看它调用的一些助手方法。我们从detectAndDescribe开始:
def detectAndDescribe(self, image):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# check to see if we are using OpenCV 3.X
if self.isv3:
# detect and extract features from the image
descriptor = cv2.xfeatures2d.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
# otherwise, we are using OpenCV 2.4.X
else:
# detect keypoints in the image
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
# extract features from the image
extractor = cv2.DescriptorExtractor_create("SIFT")
(kps, features) = extractor.compute(gray, kps)
# convert the keypoints from KeyPoint objects to NumPy
# arrays
kps = np.float32([kp.pt for kp in kps])
# return a tuple of keypoints and features
return (kps, features)
顾名思义,detectAndDescribe方法接受一幅图像,然后检测关键点并提取局部不变描述符。在我们的实现中,我们使用高斯(狗)关键点检测器的差和 SIFT 特征提取器。
在的第 52 行我们检查我们是否在使用 OpenCV 3.X。如果是,那么我们使用cv2.xfeatures2d.SIFT_create函数来实例化我们的狗关键点检测器和 SIFT 特征提取器。对detectAndCompute的调用处理关键点和特征的提取(行 54 和 55 )。
需要注意的是,你的必须的已经编译了 OpenCV 3。启用 opencv_contrib 支持的 x。如果没有,您将得到一个错误,如AttributeError: 'module' object has no attribute 'xfeatures2d'。如果是这样的话,请前往我的 OpenCV 3 教程页面,在那里我详细介绍了如何安装 OpenCV 3 并为各种操作系统和 Python 版本启用opencv_contrib支持。
第 58-65 行处理如果我们使用 OpenCV 2.4。cv2.FeatureDetector_create函数实例化了我们的关键点检测器(DoG)。对detect的调用返回我们的关键点集合。
从那里,我们需要使用关键字SIFT初始化cv2.DescriptorExtractor_create来设置我们的 SIFT 特性extractor。调用extractor的compute方法返回一组特征向量,这些向量量化了图像中每个检测到的关键点周围的区域。
最后,我们的关键点从KeyPoint对象转换成一个 NumPy 数组(第 69 行)并返回给调用方法(第 72 行)。
接下来,让我们看看matchKeypoints方法:
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB,
ratio, reprojThresh):
# compute the raw matches and initialize the list of actual
# matches
matcher = cv2.DescriptorMatcher_create("BruteForce")
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
# loop over the raw matches
for m in rawMatches:
# ensure the distance is within a certain ratio of each
# other (i.e. Lowe's ratio test)
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
matches.append((m[0].trainIdx, m[0].queryIdx))
matchKeypoints函数需要四个参数:与第一幅图像相关联的关键点和特征向量,随后是与第二幅图像相关联的关键点和特征向量。还提供了 David Lowe 的ratio测试变量和 RANSAC 重投影阈值。
将特征匹配在一起实际上是一个相当简单的过程。我们简单地循环两个图像的描述符,计算距离,并找到每对描述符的最小距离。由于这是计算机视觉中非常常见的做法,OpenCV 有一个名为cv2.DescriptorMatcher_create的内置函数,为我们构建特征匹配器。BruteForce值表示我们将对进行彻底的计算来自两幅图像的所有特征向量之间的欧几里德距离,并找到具有最小距离的描述符对。
对行 79 上的knnMatch的调用使用 k=2 在两个特征向量集之间执行 k-NN 匹配(指示返回每个特征向量的前两个匹配)。
我们想要前两个匹配而不仅仅是前一个匹配的原因是因为我们需要应用 David Lowe 的比率测试来进行假阳性匹配修剪。
再次,第 79 行计算每对描述符的rawMatches——但是有可能这些对是假阳性的,这意味着图像补片实际上不是真正的匹配。为了尝试修剪这些假阳性匹配,我们可以单独循环每个rawMatches(行 83 )并应用劳氏比率测试,该测试用于确定高质量的特征匹配。劳氏比的典型值通常在【0.7,0.8】范围内。
一旦我们使用劳氏比率测试获得了matches,我们就可以计算两组关键点之间的单应性:
# computing a homography requires at least 4 matches
if len(matches) > 4:
# construct the two sets of points
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# compute the homography between the two sets of points
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC,
reprojThresh)
# return the matches along with the homograpy matrix
# and status of each matched point
return (matches, H, status)
# otherwise, no homograpy could be computed
return None
计算两组点之间的单应性最少需要四个匹配的初始组。对于更可靠的单应性估计,我们应该具有实质上不止四个匹配点。
最后,我们的Stitcher方法中的最后一个方法drawMatches用于可视化两幅图像之间的关键点对应关系:
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# initialize the output visualization image
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# loop over the matches
for ((trainIdx, queryIdx), s) in zip(matches, status):
# only process the match if the keypoint was successfully
# matched
if s == 1:
# draw the match
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# return the visualization
return vis
该方法要求我们传入两幅原始图像、与每幅图像相关联的关键点集、应用 Lowe's ratio 测试后的初始匹配,以及最后由单应性计算提供的status列表。使用这些变量,我们可以通过从第一幅图像中的关键点 N 到第二幅图像中的关键点 M 画一条直线来可视化“内侧”关键点。
现在我们已经定义了我们的Stitcher类,让我们继续创建stitch.py驱动程序脚本:
# import the necessary packages
from pyimagesearch.panorama import Stitcher
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--first", required=True,
help="path to the first image")
ap.add_argument("-s", "--second", required=True,
help="path to the second image")
args = vars(ap.parse_args())
我们从在2-5 号线进口我们需要的包装开始。注意我们如何将panorama.py和Stitcher类放入pyimagesearch模块中,只是为了保持代码整洁。
注意:如果你在阅读这篇文章时遇到了组织代码的困难,请务必使用这篇文章底部的表格下载源代码。的。代码下载的 zip 文件将立即运行,不会出现任何错误。
从那里,第 8-14 行解析我们的命令行参数:--first,它是我们全景图中第一个图像的路径(最左边的图像的),和--second,它是全景图中第二个图像的路径(最右边的图像的)。
记住,这些图像路径需要按照从左到右的顺序提供!
驱动程序脚本的其余部分简单地处理加载我们的图像,调整它们的大小(以便它们适合我们的屏幕),以及构建我们的全景:
# load the two images and resize them to have a width of 400 pixels
# (for faster processing)
imageA = cv2.imread(args["first"])
imageB = cv2.imread(args["second"])
imageA = imutils.resize(imageA, width=400)
imageB = imutils.resize(imageB, width=400)
# stitch the images together to create a panorama
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# show the images
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
一旦我们的图像被加载并调整了大小,我们就在的第 23 行初始化我们的Stitcher类。然后我们调用stitch方法,传入我们的两个图像(,从左到右的顺序),并指示我们想要可视化这两个图像之间的关键点匹配。
最后,行 27-31 将我们的输出图像显示到我们的屏幕上。
全景拼接结果
2014 年年中,我去了趟亚利桑那州和犹他州,去欣赏国家公园。一路上,我在许多地方停留,包括布莱斯峡谷、大峡谷和塞多纳。鉴于这些地区有美丽的风景,我自然拍了一堆照片——其中一些非常适合构建全景。我在今天的博客中包含了这些图像的样本,以演示全景拼接。
说了这么多,让我们试试我们的 OpenCV 全景缝合器。打开终端,发出以下命令:
$ python stitch.py --first images/bryce_left_01.png \
--second images/bryce_right_01.png

Figure 1: (Top) The two input images from Bryce canyon (in left-to-right order). (Bottom) The matched keypoint correspondences between the two images.
在此图的顶部,我们可以看到两幅输入图像(调整大小以适合我的屏幕,raw。jpg 文件的分辨率要高得多)。在底部,我们可以看到两幅图像之间匹配的关键点。
使用这些匹配的关键点,我们可以应用透视变换并获得最终的全景图:

Figure 2: Constructing a panorama from our two input images.
正如我们所看到的,这两个图像已经成功地拼接在一起!
注: 在许多这样的示例图像上,你会经常看到一条可见的“接缝”贯穿拼接图像的中心。这是因为我用我的 iPhone 或数码相机拍摄了许多照片,自动对焦在打开**,因此每次拍摄 的焦点略有不同。当您对每张照片使用相同的焦点时,图像拼接和全景构建效果最佳。我从未打算用这些度假照片进行图像拼接,否则我会小心调整相机传感器。在这两种情况下,只要记住接缝是由于不同的传感器属性在我拍照时,并不是故意的。
让我们试试另一组图像:
$ python stitch.py --first images/bryce_left_02.png \
--second images/bryce_right_02.png
Figure 3: Another successful application of image stitching with OpenCV.
同样,我们的Stitcher类能够从两幅输入图像中构建一幅全景图。
现在,让我们继续前往大峡谷:
$ python stitch.py --first images/grand_canyon_left_01.png \
--second images/grand_canyon_right_01.png

Figure 4: Applying image stitching and panorama construction using OpenCV.
在上面的输入图像中,我们可以看到两幅输入图像之间有很大的重叠。全景图的主要增加部分是在拼接图像的右侧,我们可以看到更多的“突出部分”被添加到输出中。
这是大峡谷的另一个例子:
$ python stitch.py --first images/grand_canyon_left_02.png \
--second images/grand_canyon_right_02.png

Figure 5: Using image stitching to build a panorama using OpenCV and Python.
从这个例子中,我们可以看到大峡谷的广阔区域已经被添加到全景图中。
最后,让我们用一个来自亚利桑那州塞多纳的图像拼接示例来结束这篇博文:
$ python stitch.py --first images/sedona_left_01.png \
--second images/sedona_right_01.png

Figure 6: One final example of applying image stitching.
就我个人而言,我发现塞多纳的红岩国家是我去过的最美丽的地区之一。如果你有机会,一定要来,你不会失望的。
现在你有了,使用 Python 和 OpenCV 的图像拼接和全景图构建!
摘要
在这篇博文中,我们学习了如何使用 OpenCV 执行图像拼接和全景构建。为OpenCV 2.4 和 OpenCV 3 的图像拼接提供了源代码。
我们的图像拼接算法需要四个步骤:(1)检测关键点和提取局部不变描述符;(2)图像间的描述符匹配;(3)应用 RANSAC 估计单应矩阵;以及(4)使用单应矩阵应用扭曲变换。
虽然简单,但在为两幅图像构建全景图时,该算法在实践中效果很好。在未来的博客文章中,我们将回顾如何构建全景图,并为超过两张图像执行图像拼接。
无论如何,我希望你喜欢这篇文章!请务必使用下面的表格下载源代码并尝试一下。*
OpenCV 人员计数器
原文:https://pyimagesearch.com/2018/08/13/opencv-people-counter/
最后更新于 2021 年 7 月 8 日。
在本教程中,你将学习如何用 OpenCV 和 Python 构建一个“人计数器”。使用 OpenCV,我们将实时统计进出百货商店的人数。
用 OpenCV 建立一个人计数器是 PyImageSearch 上最受欢迎的话题之一,一年来我一直想写一篇关于人计数的博客文章——今天能发表这篇文章并与大家分享,我非常激动。
享受教程,让我知道你在帖子底部的评论区的想法!
要开始使用 OpenCV 构建人员计数器,请继续阅读!
- 【2021 年 7 月更新:添加了如何通过使用跨多个进程/内核的多对象跟踪来提高人员计数器的效率、速度和 FPS 吞吐率的部分。
用 Python 实现 OpenCV 人物计数器
https://www.youtube.com/embed/3iiodzoG80A?feature=oembed
OpenCV 和 Python 颜色检测
原文:https://pyimagesearch.com/2014/08/04/opencv-python-color-detection/
最后更新于 2021 年 7 月 9 日。
所以,我来了。乘坐美国国家铁路客运公司 158 次列车,在一次漫长的商务旅行后回家。
天气很热。空调几乎不工作了。一个婴儿就在我旁边尖叫,而陪同的母亲孤独地看着窗外,显然质疑生孩子是否是正确的人生决定。
更糟糕的是, 无线网络无法工作。
幸运的是,我带来了我的游戏机和口袋妖怪游戏集。
当我把我那可靠的蓝色版本放进我的游戏机时,我对自己说,与其第一千次与小茂战斗,也许我可以做一点计算机视觉。
老实说,能够只用颜色来分割每一个游戏卡带难道不是很酷吗?
给自己拿一杯水来对抗失灵的空调,拿一副耳塞来挡住哭闹的孩子。因为在这篇文章中,我将向你展示如何使用 OpenCV 和 Python 来执行颜色检测。
- 【2021 年 7 月更新:增加了如何使用颜色匹配卡和直方图匹配提高颜色检测准确度的新部分。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
OpenCV 和 Python 颜色检测
让我们开始吧。
打开您最喜欢的编辑器,创建一个名为detect_color.py的文件:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", help = "path to the image")
args = vars(ap.parse_args())
# load the image
image = cv2.imread(args["image"])
我们将从在2-4 号线进口必要的包装开始。我们将使用 NumPy 进行数值处理,argparse解析我们的命令行参数,而cv2用于 OpenCV 绑定。
第 7-9 行然后解析我们的命令行参数。我们只需要一个开关--image,它是我们的映像驻留在磁盘上的路径。
然后,在第 12 行上,我们从磁盘上加载我们的映像。
现在,有趣的部分来了。
我们希望能够检测图像中的每一个 Game Boy 墨盒。这意味着我们必须识别图像中的红色、蓝色、黄色和灰色颜色。
让我们继续定义这个颜色列表:
# define the list of boundaries
boundaries = [
([17, 15, 100], [50, 56, 200]),
([86, 31, 4], [220, 88, 50]),
([25, 146, 190], [62, 174, 250]),
([103, 86, 65], [145, 133, 128])
]
我们在这里所做的是在 RGB 颜色空间(或者更确切地说,BGR,因为 OpenCV 以逆序将图像表示为 NumPy 数组)中定义一个列表boundaries,其中列表中的每个条目都是一个具有两个值的元组:一个列表是下限的限制,一个列表是上限的限制。
例如,我们来看看元组([17, 15, 100], [50, 56, 200])。
这里,我们说的是,我们图像中所有具有 R > = 100 、 B > = 15 、 G > = 17 以及 R < = 200 、 B < = 56 和 G < = 50 的像素将被视为红色。
现在我们有了边界列表,我们可以使用cv2.inRange函数来执行实际的颜色检测。
让我们来看看:
# loop over the boundaries
for (lower, upper) in boundaries:
# create NumPy arrays from the boundaries
lower = np.array(lower, dtype = "uint8")
upper = np.array(upper, dtype = "uint8")
# find the colors within the specified boundaries and apply
# the mask
mask = cv2.inRange(image, lower, upper)
output = cv2.bitwise_and(image, image, mask = mask)
# show the images
cv2.imshow("images", np.hstack([image, output]))
cv2.waitKey(0)
我们开始在第 23 行的上循环我们的上下boundaries,然后在第 25 和 26 行的上将上下限值转换成 NumPy 数组。这两行看起来可以省略,但是当你使用 OpenCV Python 绑定时,OpenCV 期望这些限制是 NumPy 数组。此外,由于这些是落在范围【0,256】内的像素值,我们可以使用无符号 8 位整数数据类型。
要使用 OpenCV 执行实际的颜色检测,请看一下第 29 行,这里我们使用了cv2.inRange函数。
cv2.inRange函数需要三个参数:第一个是我们将要执行颜色检测的image,第二个是您想要检测的颜色的lower极限,第三个参数是您想要检测的颜色的upper极限。
调用cv2.inRange后,返回一个二进制掩码,其中白色像素(255)代表落入上下限范围内的像素,黑色像素(0)不属于。
注意:我们正在 RGB 颜色空间中执行颜色检测。但是您也可以在 HSV 或 Lab色彩空间中轻松做到这一点。你只需要调整你的上限和下限到各自的颜色空间。*
为了创建输出图像,我们在第 31 行应用蒙版。这一行简单地调用了cv2.bitwise_and,只显示了image中在mask中有相应白色(255)值的像素。
最后,我们的输出图像显示在行 34 和 35 上。
还不错。只有 35 行代码,绝大多数是导入、参数解析和注释。
让我们继续运行我们的脚本:
$ python detect_color.py --image pokemon_games.png
如果您的环境配置正确(意味着您安装了带有 Python 绑定的 OpenCV),您应该会看到如下输出图像:
如你所见,红色口袋妖怪子弹很容易被发现!
现在让我们试试蓝色的:
不,没问题!
黄色版本也有类似的故事:
最后,还发现了灰色 Game Boy 墨盒的轮廓:
通过色彩校正提高色彩检测的准确性
在本教程中,您学习了如何通过硬编码较低和较高的 RGB 颜色范围来执行颜色校正。
假设给你一个 1000 张图像的数据集,要求你找出 RGB 值分别在 (17,15,100) 和 (50,56,200)范围内的所有“红色”对象。
如果您的整个图像数据集是在受控的照明条件下拍摄的,并且每张图像都使用了相同的照明,那么这不会是一项困难的任务——您可以使用上面提到的硬编码 RGB 值。
但是…假设你的图像数据集不是在受控的光线条件下拍摄的。有些是用荧光灯拍摄的,有些是在阳光明媚的时候在户外拍摄的,有些是在黑暗沉闷的时候拍摄的。
在不同的光照下,颜色看起来会有很大的不同,当这种情况发生时,您硬编码的较低和较高 RGB 范围将会失败。
一个潜在的解决方案是使用不同的颜色空间,这可以更好地模仿人类感知颜色的方式 HSV 和 Lab*颜色空间是很好的选择。
更好的选择是使用颜色校正卡。你将一张卡片(就像上面图 5 中的那张)放在包含我们正在捕捉的物体的场景中,然后你通过以下方式对所有这些图像进行后处理:
- 检测颜色校正卡
- 确定色块区域
- 执行直方图匹配以将色彩空间从一幅图像转移到另一幅图像
通过这种方式,您可以确保所有图像的颜色一致,即使它们可能是在不同的光照条件下拍摄的。
要了解更多关于这种技术的信息,我建议阅读以下两个教程:
摘要
在这篇博文中,我展示了如何使用 OpenCV 和 Python 进行颜色检测。
要检测图像中的颜色,你需要做的第一件事就是为你的像素值定义上上限和下下限。
一旦定义了上限和下限,然后调用cv2.inRange方法返回一个掩码,指定哪些像素落在指定的上限和下限范围内。
最后,现在你有了蒙版,你可以用cv2.bitwise_and函数把它应用到你的图像上。
我的火车离家只有几站,所以我最好把这个帖子包起来。希望你觉得有用!
如果你有任何问题,一如既往,欢迎留言或给我发消息。
OpenCV 和 Python K-Means 颜色聚类
原文:https://pyimagesearch.com/2014/05/26/opencv-python-k-means-color-clustering/

花点时间看看上面的侏罗纪公园电影海报。
主色有哪些?(即图像中表现最多的颜色)
嗯,我们看到背景大部分是黑色的。霸王龙周围有一些红色的。实际标志周围还有一些黄色的。****
****对于人类来说,分辨这些颜色非常简单。
但是,如果我们想创建一个算法来自动提取这些颜色呢?
你可能认为颜色直方图是你最好的选择…
但是实际上我们可以应用一种更有趣的算法——k-means 聚类。
在这篇博文中,我将向你展示如何使用 OpenCV、Python 和 k-means 聚类算法来寻找图像中最主要的颜色。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
k 均值聚类
那么 k-means 到底是什么?
K-means 是一种聚类算法。
目标是将 n 个数据点划分成 k 个集群。每个 n 个数据点将被分配到一个具有最近平均值的聚类中。每个聚类的平均值称为其“质心”或“中心”。
总的来说,应用 k-means 产生了原始的 n 个数据点的 k 个独立的聚类。特定聚类内的数据点被认为比属于其他聚类的数据点彼此“更相似”。
在我们的例子中,我们将对 RGB 图像的像素强度进行聚类。给定一个 MxN 大小的图像,我们因此有 MxN 个像素,每个像素由三个分量组成:分别是红色、绿色和蓝色。
我们将把这些 MxN 像素视为我们的数据点,并使用 k-means 对它们进行聚类。
属于给定聚类的像素在颜色上比属于单独聚类的像素更相似。
k-means 的一个注意事项是,我们需要提前 指定我们想要生成的 类的数量。有算法可以自动选择 k 的最优值,但是这些算法不在本帖讨论范围之内。
OpenCV 和 Python K-Means 颜色聚类
好了,让我们动手使用 OpenCV、Python 和 k-means 对像素强度进行聚类:
# import the necessary packages
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import argparse
import utils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
ap.add_argument("-c", "--clusters", required = True, type = int,
help = "# of clusters")
args = vars(ap.parse_args())
# load the image and convert it from BGR to RGB so that
# we can dispaly it with matplotlib
image = cv2.imread(args["image"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# show our image
plt.figure()
plt.axis("off")
plt.imshow(image)
第 2-6 行处理导入我们需要的包。我们将使用 k-means 的 scikit-learn 实现来使我们的生活变得更容易——可以说,不需要重新实现轮子。我们还将使用matplotlib来显示我们的图像和大多数主色。为了解析命令行参数,我们将使用argparse。utils包包含两个助手函数,我将在后面讨论。最后,cv2包包含了我们对 OpenCV 库的 Python 绑定。
第 9-13 行解析我们的命令行参数。我们只需要两个参数:--image,它是我们的映像驻留在磁盘上的路径,以及--clusters,我们希望生成的集群的数量。
第 17-18 行我们从磁盘上下载图像,然后将其从 BGR 转换到 RGB 色彩空间。记住,OpenCV 将图像表示为多维 NumPy 数组。但是,这些图像是以 BGR 顺序而不是 RGB 顺序存储的。为了补救这一点,我们简单地使用了cv2.cvtColor函数。
最后,我们使用第 21-23 行上的matplotlib在屏幕上显示我们的图像。
正如我在这篇文章前面提到的,我们的目标是从 n 个数据点中生成 k 个聚类。我们将把我们的 MxN 图像作为我们的数据点。
为了做到这一点,我们需要将我们的图像重塑为一系列像素,而不是像素的矩阵:
# reshape the image to be a list of pixels
image = image.reshape((image.shape[0] * image.shape[1], 3))
这段代码应该是不言自明的。我们只是简单地将 NumPy 数组改造成一个 RGB 像素列表。
这 2 行代码:
既然已经准备好了数据点,我们可以使用 k-means 来编写这些 2 行代码以找到图像中最主要的颜色:
# cluster the pixel intensities
clt = KMeans(n_clusters = args["clusters"])
clt.fit(image)
我们使用 k-means 的 scikit-learn 实现来避免重新实现算法。OpenCV 中还内置了一个 k-means,但是如果您以前在 Python 中做过任何类型的机器学习(或者如果您曾经打算这样做),我建议使用 scikit-learn 包。
我们在第 29 行的上实例化KMeans,提供我们希望生成的集群数量。对第 30 行的fit()方法的调用聚集了我们的像素列表。
这就是使用 Python 和 k-means 对我们的 RGB 像素进行聚类的全部内容。

Scikit-learn 为我们打理一切。
然而,为了显示图像中最主要的颜色,我们需要定义两个辅助函数。
让我们打开一个新文件utils.py,并定义centroid_histogram函数:
# import the necessary packages
import numpy as np
import cv2
def centroid_histogram(clt):
# grab the number of different clusters and create a histogram
# based on the number of pixels assigned to each cluster
numLabels = np.arange(0, len(np.unique(clt.labels_)) + 1)
(hist, _) = np.histogram(clt.labels_, bins = numLabels)
# normalize the histogram, such that it sums to one
hist = hist.astype("float")
hist /= hist.sum()
# return the histogram
return hist
如您所见,这个方法只有一个参数clt。这是我们在color_kmeans.py中创建的 k-means 聚类对象。
k-means 算法将图像中的每个像素分配到最近的聚类中。我们在第 8 行的处获取聚类数,然后在第 9 行的处创建分配给每个聚类的像素数直方图。
最后,我们归一化直方图,使其总和为 1,并在第 12-16 行将它返回给调用者。
本质上, 这个函数所做的就是计算属于每个簇的像素数量。
现在是我们的第二个助手函数,plot_colors:
def plot_colors(hist, centroids):
# initialize the bar chart representing the relative frequency
# of each of the colors
bar = np.zeros((50, 300, 3), dtype = "uint8")
startX = 0
# loop over the percentage of each cluster and the color of
# each cluster
for (percent, color) in zip(hist, centroids):
# plot the relative percentage of each cluster
endX = startX + (percent * 300)
cv2.rectangle(bar, (int(startX), 0), (int(endX), 50),
color.astype("uint8").tolist(), -1)
startX = endX
# return the bar chart
return bar
plot_colors函数需要两个参数:hist,它是从centroid_histogram function生成的直方图,以及centroids,它是由 k-means 算法生成的质心(聚类中心)列表。
在第 21 行的上,我们定义了一个 300×50 像素矩形来保存图像中最主要的颜色。
我们开始在第 26 行的上循环颜色和百分比贡献,然后在第 29 行的上绘制当前颜色对图像的贡献百分比。然后我们将颜色百分比条返回给第 34 行的调用者。
同样,这个函数执行一个非常简单的任务——基于centroid_histogram函数的输出生成一个图形,显示有多少像素被分配给每个聚类。
现在我们已经定义了两个助手函数,我们可以把所有东西粘在一起了:
# build a histogram of clusters and then create a figure
# representing the number of pixels labeled to each color
hist = utils.centroid_histogram(clt)
bar = utils.plot_colors(hist, clt.cluster_centers_)
# show our color bart
plt.figure()
plt.axis("off")
plt.imshow(bar)
plt.show()
在第 34 行上,我们计算分配给每个簇的像素数量。然后在第 35 行上,我们生成一个图形,这个图形可视化了分配给每个簇的像素数。
第 38-41 行然后显示我们的图形。
要执行我们的脚本,发出以下命令:
$ python color_kmeans.py --image images/jp.png --clusters 3
如果一切顺利,您应该会看到类似下面的内容:

Figure 1: Using Python, OpenCV, and k-means to find the most dominant colors in our image.
这里您可以看到我们的脚本生成了三个集群(因为我们在命令行参数中指定了三个集群)。最主要的颜色是黑色、黄色和红色,这三种颜色在《侏罗纪公园》电影海报中都有大量出现。
让我们把这个应用到矩阵的截屏上:
Figure 2: Finding the four most dominant colors using k-means in our The Matrix image.
这次我们告诉 k-means 生成四个聚类。正如你所看到的,黑色和各种色调的绿色是图像中最主要的颜色。
最后,让我们为这个蝙蝠侠图像生成五个颜色集群:

Figure 3: Applying OpenCV and k-means clustering to find the five most dominant colors in a RGB image.
所以你有它。
使用 OpenCV、Python 和 k-means 对 RGB 像素强度进行聚类,以找到图像中最主要的颜色,这实际上非常简单。Scikit-learn 为我们处理所有繁重的工作。这篇文章中的大部分代码是用来把所有的部分粘在一起的。
摘要
在这篇博文中,我向您展示了如何使用 OpenCV、Python 和 k-means 来查找图像中最主要的颜色。
K-means 是一种聚类算法,根据 n 个数据点生成 k 个聚类。集群的数量 k 必须提前指定。虽然有算法可以找到 k 的最优值,但是它们超出了这篇博文的范围。
为了找到图像中最主要的颜色,我们将像素作为数据点,然后应用 k-means 对它们进行聚类。
我们使用 k-means 的 scikit-learn 实现来避免必须重新实现它。
我鼓励你将 k-means 聚类应用于我们自己的图像。一般来说,您会发现集群数量越少( k < = 5 )会得到最好的结果。****
OpenCV 调整图像大小(cv2.resize)
原文:https://pyimagesearch.com/2021/01/20/opencv-resize-image-cv2-resize/
在本教程中,您将学习如何使用 OpenCV 和cv2.resize函数来调整图像的大小。
缩放,或简称为调整大小,是根据宽度和高度增加或减少图像大小的过程。
调整图像大小时,记住纵横比很重要,纵横比是图像的宽高比。忽略宽高比会导致调整后的图像看起来被压缩和扭曲:
在左边的,我们有我们的原始图像。在右边的,我们有两幅图像由于没有保持长宽比而失真了。它们已经通过忽略图像的宽高比而被调整了大小。
一般来说,在调整大小时,您会希望保持图像的纵横比,尤其是当这些图像作为输出呈现给用户时。不过,例外确实适用。当我们探索机器学习/深度学习技术时,我们会发现我们的内部算法经常忽略图像的长宽比;但是一旦我们理解了计算机视觉的基本原理。
我们还需要记住调整大小函数的插值方法。插值的正式定义是:
在一组离散的已知数据点范围内构造新数据点的方法。
在这种情况下,“已知点”是我们原始图像的像素。插值函数的目的是获取这些像素的邻域,并使用它们来增大或减小图像的大小。
一般来说,减小图像的尺寸更有益(也更具视觉吸引力)。这是因为插值函数只需从图像中移除像素。另一方面,如果我们要增加图像的大小,插值函数将不得不“填充”先前不存在的像素之间的间隙。
例如,看看图 2 中的图像:
左边的是我们的原始图像。在中间,我们已经将图像的大小调整到一半——除了图像被调整大小,图像的“质量”没有任何损失然而,在右边的,我们已经大幅增加了图像尺寸。它现在看起来“像素化”和“放大”
正如我上面提到的,你通常会减少图片的尺寸,而不是增加图片的尺寸(当然也有例外)。通过减小图像尺寸,我们可以处理更少的像素(更不用说要处理更少的“噪声”),从而实现更快、更准确的图像处理算法。
请记住,虽然高分辨率图像对人眼具有视觉吸引力,但它们会损害计算机视觉和图像处理管道:
- 根据定义,图像越大,数据就越多,因此算法处理数据的时间就越长
- 高分辨率图像非常详细——但是从计算机视觉/图像处理的角度来看,我们对图像的结构成分更感兴趣,而不是超级精细的细节
- 大分辨率图像几乎总是被向下采样,以帮助图像处理系统运行得更快、更准确
在本教程结束时,您将了解如何使用 OpenCV 调整图像大小。
要学习如何使用 OpenCV 和cv2.resize方法调整图像大小,继续阅读。
OpenCV 调整图像大小(cv2.resize )
在本教程的第一部分,我们将配置我们的开发环境,并回顾我们的项目目录结构。
然后我会给你看:
- 使用 OpenCV 和
cv2.resize调整图像大小的基础知识(不考虑纵横比) - 如何使用
imutils.resize调整图像大小(支持宽高比) - OpenCV 中可供您使用的插值方法(当您需要对图像进行下采样或上采样时非常有用)
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
使用 OpenCV 的cv2.resize函数调整图像大小相对简单,但是在查看任何代码之前,让我们首先查看一下我们的项目目录结构。
首先访问本教程的 “下载” 部分,检索源代码和示例图像。
从这里开始,项目文件夹应该如下所示:
$ tree . --dirsfirst
.
├── adrian.png
└── opencv_resize.py
0 directories, 2 files
我们的opencv_resize.py文件将加载输入的adrian.png图像,然后执行几个调整大小的操作,从而演示如何使用 OpenCV 的cv2.resize函数来调整图像的大小。
用 OpenCV 实现基本的图像大小调整
到目前为止,在这个系列中,我们已经讨论了两种图像转换:平移和旋转。现在,我们将探索如何调整图像的大小。
也许,毫不奇怪,我们使用cv2.resize函数来调整图像的大小。正如我上面提到的,当使用这个函数时,我们需要记住图像的长宽比。
但是在我们深入细节之前,让我们先来看一个例子:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="adrian.png",
help="path to the input image")
args = vars(ap.parse_args())
我们从第 2-4 行开始,导入我们需要的 Python 包。
第 7-10 行解析我们的命令行参数。我们只需要一个参数--image,我们想要调整大小的输入图像的路径。
现在让我们从磁盘加载这个图像:
# load the original input image and display it on our screen
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# let's resize our image to be 150 pixels wide, but in order to
# prevent our resized image from being skewed/distorted, we must
# first calculate the ratio of the *new* width to the *old* width
r = 150.0 / image.shape[1]
dim = (150, int(image.shape[0] * r))
# perform the actual resizing of the image
resized = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
cv2.imshow("Resized (Width)", resized)
第 13 行和第 14 行从磁盘加载我们的输入image并显示在我们的屏幕上:
当调整图像大小时,我们需要记住图像的长宽比。纵横比是图像的宽度和高度的比例关系:
aspect_ratio = image_width / image_height
如果我们不注意长宽比,我们的调整大小将返回看起来扭曲的结果(见图 1 )。
计算调整后的比率在第 19 行处理。在这行代码中,我们将新的图像宽度定义为 150 像素。为了计算新高度与旧高度的比率,我们简单地将比率r定义为新宽度(150 像素)除以旧宽度,我们使用image.shape[1]访问旧宽度。
现在我们有了我们的比率,我们可以在第 20 行计算图像的新尺寸。同样,新图像的宽度将是 150 像素。然后通过将旧的高度乘以我们的比率并将其转换为整数来计算高度。通过执行此操作,我们保留了图像的原始纵横比。
图像的实际尺寸调整发生在第 23 行上。第一个参数是我们希望调整大小的图像,第二个参数是我们为新图像计算的尺寸。最后一个参数是我们的插值方法,这是在幕后处理我们如何调整实际图像大小的算法。我们将在本教程的后面讨论 OpenCV 提供的各种插值方法。
最后,我们在第 24 行的处显示了调整后的图像:
在我们研究的例子中,我们只通过指定宽度来调整图像的大小。但是如果我们想通过设置高度来调整图像的大小呢?所需要的只是改变用于保持纵横比的调整大小比率的计算:
# let's resize the image to have a height of 50 pixels, again keeping
# in mind the aspect ratio
r = 50.0 / image.shape[0]
dim = (int(image.shape[1] * r), 50)
# perform the resizing
resized = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
cv2.imshow("Resized (Height)", resized)
cv2.waitKey(0)
在第 28 行,我们重新定义了我们的比率,r。我们的新图像将有 50 像素的高度。为了确定新高度与旧高度的比值,我们用旧高度除以 50。
然后,我们定义新图像的尺寸。我们已经知道新图像的高度为 50 像素。新的宽度是通过将旧的宽度乘以比率获得的,这允许我们保持图像的原始纵横比。
然后,我们对第 32 行的图像进行实际的尺寸调整,并在第 33 行的图像上显示:
在这里,我们可以看到,我们已经调整了原始图像的宽度和高度,同时保持了纵横比。如果我们不保持长宽比,我们的图像会看起来失真,如图 1 所示。
调整图像大小非常简单,但是必须计算纵横比、定义新图像的尺寸,然后执行调整大小需要三行代码。这三行代码虽然看起来不多,但会使我们的代码变得非常冗长和混乱。
相反,我们可以使用imutils.resize函数,它自动为我们处理计算和维护纵横比:
# calculating the ratio each and every time we want to resize an
# image is a real pain, so let's use the imutils convenience
# function which will *automatically* maintain our aspect ratio
# for us
resized = imutils.resize(image, width=100)
cv2.imshow("Resized via imutils", resized)
cv2.waitKey(0)
在这个例子中,你可以看到一个单一的函数处理图像大小:imutils.resize。
我们传入的第一个参数是我们想要调整大小的image。然后,我们指定关键字参数width,这是我们新图像的目标宽度。然后,该函数为我们处理大小调整:
当然,我们也可以通过改变函数调用来调整图像的高度:
resized = imutils.resize(image, height=75)
其结果可以在图 8 中看到:
请注意,调整后的输出图像现在比原始图像小了很多,但纵横比仍然保持不变。
比较 OpenCV 插补方法
到目前为止,我们只使用了cv2.INTER_AREA方法进行插值。正如我在本文开头提到的,插值函数的目标是检查像素的邻域,并使用这些邻域在不引入失真(或至少尽可能少的失真)的情况下以光学方式增大或减小图像的大小。
第一种方法是最近邻插值法,由cv2.INTER_NEAREST标志指定。这种方法是最简单的插值方法。该方法不是计算相邻像素的加权平均值或应用复杂的规则,而是简单地找到“最近的”相邻像素并假定亮度值。虽然这种方法快速简单,但调整大小后的图像质量往往相对较差,并可能导致“块状”伪像。
其次,我们有cv2.INTER_LINEAR方法,它执行双线性插值——这是 OpenCV 在调整图像大小时默认使用的方法。双线性插值背后的一般思想可以在任何小学数学教科书中找到—斜率截距形式:

很明显,我有点概括了。不过,要点是我们做的不仅仅是简单地找到“最近的”像素并假设其值(就像最近邻插值法)。我们现在取邻近的像素,并使用这个邻域来计算插值(而不是仅仅假设最近的像素值)。
第三,我们有cv2.INTER_AREA插值方法。对这种方法如何工作进行全面回顾超出了本教程的范围。尽管如此,我还是建议您阅读这篇文章,它提供了这种方法的一般系数规则的高级概述。
最后,我们还有cv2.INTER_CUBIC和cv2.INTER_LANCZOS4。
这些方法较慢(因为它们不再使用简单的线性插值,而是使用样条),并且在正方形像素邻域上使用双三次插值。
cv2.INTER_CUBIC方法对一个 4 x 4 像素邻居和一个 8 x 8 像素邻居上的cv2.INTER_LANCZOS4进行操作。一般来说,我很少看到实践中使用的cv2.INTER_LANCZOS4方法。
现在我们已经讨论了 OpenCV 提供的插值方法,让我们编写一些代码来测试它们:
# construct the list of interpolation methods in OpenCV
methods = [
("cv2.INTER_NEAREST", cv2.INTER_NEAREST),
("cv2.INTER_LINEAR", cv2.INTER_LINEAR),
("cv2.INTER_AREA", cv2.INTER_AREA),
("cv2.INTER_CUBIC", cv2.INTER_CUBIC),
("cv2.INTER_LANCZOS4", cv2.INTER_LANCZOS4)]
# loop over the interpolation methods
for (name, method) in methods:
# increase the size of the image by 3x using the current
# interpolation method
print("[INFO] {}".format(name))
resized = imutils.resize(image, width=image.shape[1] * 3,
inter=method)
cv2.imshow("Method: {}".format(name), resized)
cv2.waitKey(0)
我们首先在第 45-50 行定义我们的插值方法列表。
从那里,我们循环每个插值方法,并在第 57 行和第 58 行调整图像大小(上采样,使其比原始图像大 3 倍)。
然后调整结果显示在我们屏幕的第 60 行。
让我们来看看最近邻插值的输出:
注意图 9 中的在调整大小后的图像中有“块状”伪像。
从这里,我们可以看看双线性插值:
请注意,块状伪像消失了,图像看起来更加平滑。
接下来,面积插值:
块状文物又回来了。据我所知,cv2.INTER_AREA的表现与cv2.INTER_NEAREST非常相似。
然后我们继续双三次插值:
双三次插值进一步消除了块状伪像。
最后是cv2.LANCOSZ4方法,看起来与双三次方法非常相似:
注: 我会在本文后面讨论你应该在自己的项目中使用哪些插值方法。
OpenCV 图像大小调整结果
要使用 OpenCV 调整图像大小,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
我们已经在前面的章节中回顾了我们的opencv_resize.py脚本的结果,但是如果您想通过您的终端执行这个脚本,只需使用下面的命令:
$ python opencv_resize.py
[INFO] cv2.INTER_NEAREST
[INFO] cv2.INTER_LINEAR
[INFO] cv2.INTER_AREA
[INFO] cv2.INTER_CUBIC
[INFO] cv2.INTER_LANCZOS4
您的 OpenCV 调整结果应该与我在前面章节中的结果相匹配。
应该使用哪种 OpenCV 插值方法?
既然我们已经回顾了如何使用 OpenCV 调整图像的大小,您可能想知道:
使用 OpenCV 调整图像大小时,我应该使用什么插值方法?
一般来说,cv2.INTER_NEAREST非常快,但不能提供最高质量的结果。因此,在非常资源受限的环境中,考虑使用最近邻插值法。否则,你可能不会经常使用这种插值方法(尤其是当你试图增加图像尺寸时)。
当增加(上采样)图像尺寸时,考虑使用cv2.INTER_LINEAR和cv2.INTER_CUBIC。cv2.INTER_LINEAR方法往往比cv2.INTER_CUBIC方法稍快,但无论哪种方法都能为您的图像提供最佳效果。
当减小(下采样)图像尺寸时,OpenCV 文档建议使用cv2.INTER_AREA。同样,您也可以使用cv2.INTER_NEAREST进行缩减采样,但是cv2.INTER_AREA通常会产生更美观的结果。
最后,作为一般规则,cv2.INTER_LINEAR插值方法被推荐为上采样或下采样的默认方法——它只是以适中的计算成本提供最高质量的结果。
总结
在本教程中,您学习了如何使用 OpenCV 和cv2.resize函数调整图像大小。
调整图像大小时,请务必记住:
- 图像的宽高比,这样调整后的图像看起来不会失真
- 用于执行调整大小的插值方法(参见上文标题为“比较 OpenCV 插值方法”的章节,帮助您决定应该使用哪种插值方法)
一般来说,你会发现cv2.INTER_LINEAR是你的插值方法的一个很好的默认选择。
最后,重要的是要注意,如果你关心图像质量,从大的图像到小的图像几乎总是更可取的。增加图像的尺寸通常会引入伪像并降低其质量。
如果你发现自己的算法在低分辨率图像上表现不佳,你可以使用超分辨率算法来增加图像大小。考虑升级你用来拍摄照片的相机,而不是让低质量的图像在你的算法中工作。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
OpenCV:解决非类型错误
原文:https://pyimagesearch.com/2016/12/26/opencv-resolving-nonetype-errors/

每周我都会收到并回复至少 2-3 封电子邮件和 3-4 篇关于 OpenCV 和 Python 中NoneType错误的博文评论。
对于初学者来说,这些错误可能很难诊断——从定义上来说,它们提供的信息并不多。
由于这个问题被问得如此频繁,我决定写一整篇博文来讨论这个话题。
虽然导致NoneType错误的原因几乎是无限的,但根据我作为一名计算机视觉开发人员的经验,以及在 PyImageSearch 上与其他程序员聊天的经验,在超过 95%的情况下,OpenCV 中的NoneType错误是由以下原因之一造成的:
- 传递给
cv2.imread的图像路径无效。 - 通过
cv2.VideoCapture和相关的.read方法从视频流/视频文件中读取帧时出现问题。
要了解更多关于 OpenCV 中的NoneType错误(以及如何避免这些错误),只需继续阅读。
OpenCV:解决非类型错误
在这篇博文的第一部分,我将详细讨论 Python 编程语言中的什么是 NoneType错误。
然后我将讨论在一起使用 OpenCV 和 Python 时会遇到NoneType错误的两个主要原因。
最后,我将把一个实际例子放在一起,这个例子不仅导致一个NoneType错误,而且也解决了错误。
什么是非类型错误?
使用 Python 编程语言时,您不可避免地会遇到类似这样的错误:
AttributeError: 'NoneType' object has no attribute ‘something’
其中something可以用实际属性的名称来代替。
当我们认为我们正在处理一个特定类或对象的实例时,我们会看到这些错误,但实际上我们有 Python 内置类型 None。
顾名思义,None代表一个值的缺失,比如函数调用返回意外结果或者完全失败。
下面是一个从 Python shell 生成NoneType错误的例子:
>>> foo = None
>>> foo.bar = True
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'bar'
>>>
这里我创建了一个名为foo的变量,并将其设置为None。
然后我尝试将foo的bar属性设置为True,但是由于foo是一个NoneType对象,Python 不允许这样做——因此出现了错误消息。
95%的 OpenCV NoneType 错误有两个原因
当使用 OpenCV 和 Python 绑定时,您一定会在某些时候遇到NoneType错误。
根据我的经验, 超过 95%的时间 这些NoneType错误可以追溯到cv2.imread或cv2.VideoCapture的问题。
我在下面提供了每个案例的详细信息。
案例 1: cv2.imread
如果您收到一个NoneType错误并且您的代码正在调用cv2.imread,那么错误的可能原因是提供给cv2.imread的 无效文件路径 。
如果您给了函数一个无效的文件路径(例如,一个不存在的文件的路径),cv2.imread函数不会显式抛出错误消息。相反,cv2.imread将简单地返回None。
任何时候你试图通过cv2.imread访问从磁盘加载的None图像的属性,你都会得到一个NoneType错误。
下面是一个尝试从磁盘加载不存在的映像的示例:
$ python
>>> import cv2
>>> path = "path/to/image/that/does/not/exist.png"
>>> image = cv2.imread(path)
>>> print(image.shape)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'shape'
如您所见,cv2.imread欣然接受了图像路径(尽管它并不存在),意识到图像路径无效,并返回None。对于那些习惯了抛出异常的这类函数的 Python 程序员来说,这尤其令人困惑。
作为额外的奖励,我还会提到AssertionFailed异常。
如果您试图将一个无效的图像(例如,NoneType图像)传递给另一个 OpenCV 函数,Python + OpenCV 会抱怨图像没有任何宽度、高度或深度信息——这怎么可能,毕竟“图像”是一个None对象!
下面是一个错误消息的例子,当从磁盘加载一个不存在的映像,然后立即调用 OpenCV 函数时,您可能会看到这个错误消息:
>>> import cv2
>>> path = "path/to/image/that/does/not/exist.png"
>>> image = cv2.imread(path)
>>> gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
OpenCV Error: Assertion failed (scn == 3 || scn == 4) in cvtColor, file /tmp/opencv20150906-42178-3d0iam/opencv-2.4.12/modules/imgproc/src/color.cpp, line 3739
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
cv2.error: /tmp/opencv20150906-42178-3d0iam/opencv-2.4.12/modules/imgproc/src/color.cpp:3739: error: (-215) scn == 3 || scn == 4 in function cvtColor
>>>
这些类型的错误可能更难调试,因为有多种原因导致AssertionError可能被抛出。但是在大多数情况下,您的第一步应该是确保您的映像是从磁盘正确加载的。
使用cv2.imread可能会遇到的最后一个更罕见的问题是,您的映像确实存在于磁盘上的,但是您没有使用安装的给定映像 I/O 库来编译 OpenCV。
例如,假设您在磁盘上有一个. JPEG 文件,并且您知道您有指向它的正确路径。
然后你尝试通过cv2.imread加载 JPEG 文件,并注意到一个NoneType或AssertionError。
怎么会这样呢?
文件存在!
在这种情况下,您可能忘记了在启用 JPEG 文件支持的情况下编译 OpenCV。
在 Debian/Ubuntu 系统中,这是由于没有安装libjpeg造成的。
对于 macOS 系统,您可能忘记了通过自制软件安装jpeg库。
要解决这个问题,不管是什么操作系统,您都需要重新编译和安装 OpenCV。有关如何在您的特定系统上编译和安装 OpenCV 的更多详细信息,请参见本页。
案例二:cv2。视频采集和。阅读
就像我们在使用cv2.imread时会看到NoneType错误和AssertionError异常一样,在处理视频流/视频文件时也会看到这些错误。
为了访问一个视频流,OpenCV 使用了cv2.VideoCapture,它接受一个参数:
- 一个 字符串 表示磁盘上视频文件的路径。
- 一个 整数 代表你电脑上网络摄像头的指数。
使用 OpenCV 处理视频流和视频文件比简单地通过cv2.imread加载图像更复杂,但同样的规则也适用。
如果你试图调用一个实例化的cv2.VideoCapture的.read方法(不管它是视频文件还是网络摄像头流)并注意到一个NoneType错误或AssertionError,那么你可能会遇到以下问题:
- 输入视频文件的路径(可能不正确)。
- 没有安装正确的视频编解码器,在这种情况下,您需要安装编解码器,然后重新编译和重新安装 OpenCV(参见本页获取完整的教程列表)。
- 您的网络摄像头无法通过 OpenCV 访问。这可能有很多原因,包括缺少驱动程序、传递给
cv2.VideoCapture的索引不正确,或者只是您的网络摄像头没有正确连接到您的系统。
同样,处理视频文件比处理简单的图像文件更复杂,所以要确保你在解决这个问题时系统化。
首先,尝试通过 OpenCV 之外的另一个软件访问你的网络摄像头。
或者,尝试在电影播放器中加载您的视频文件。
如果这两种方法都有效,那么您的 OpenCV 安装可能有问题。
否则,很可能是编解码器或驱动程序问题。
创建和解决 OpenCV NoneType 错误的示例
为了演示动作中的NoneType错误,我决定创建一个高度简化的Python+OpenCV 脚本,代表你可能在 PyImageSearch 博客上看到的内容。
*打开一个新文件,将其命名为display_image.py,并插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the image file")
args = vars(ap.parse_args())
# load the image from disk and display the width, height,
# and depth
image = cv2.imread(args["image"])
(h, w, d) = image.shape
print("w: {}, h: {}, d: {}".format(w, h, d))
# show the image
cv2.imshow("Image", image)
cv2.waitKey(0)
这个脚本所做的就是:
- 解析命令行参数。
- (尝试)从磁盘加载图像。
- 将图像的宽度、高度和深度打印到终端。
- 将图像显示到我们的屏幕上。
对于大多数熟悉命令行的Python 开发者来说,这个脚本不会给你带来任何麻烦。
但是如果你是命令行新手,对命令行参数不熟悉/不舒服,如果不小心的话,你很容易遇到NoneType错误。
*你可能会说,怎么做?
答案在于没有正确使用/理解命令行参数。
在运行这个博客的过去几年里,我已经看到许多来自读者的电子邮件和博客帖子评论,他们试图修改.add_argument函数来提供他们图像文件的路径。
不要这样做——你不必改变一个单行的参数解析代码。
相反,你应该做的是花接下来的 10 分钟通读这篇精彩的文章,这篇文章解释了什么是命令行参数以及如何在 Python 中使用它们:
https://pyimagesearch . com/2018/03/12/python-arg parse-command-line-arguments/
如果你想在 PyImageSearch 博客上学习教程,这是的必读材料。
使用命令行,因此命令行参数,是成为一名计算机科学家的一个重要部分— 缺乏命令行技能只会伤害你。你以后会感谢我的。
回到示例,让我们检查我的本地目录的内容:
$ ls -l
total 800
-rw-r--r-- 1 adrianrosebrock staff 541 Dec 21 08:45 display_image.py
-rw-r--r-- 1 adrianrosebrock staff 403494 Dec 21 08:45 jemma.png
如我们所见,我有两个文件:
- 我即将执行的 Python 脚本。
- 我将从磁盘上加载的照片。
如果我执行以下命令,我将看到屏幕上显示的jemma.png图像,以及图像尺寸的信息:
$ python display_image.py --image jemma.png
w: 376, h: 500, d: 3

Figure 1: Loading and displaying an image to my screen with OpenCV and Python.
然而,让我们试着加载一个不存在的图像路径:
$ python display_image.py --image i_dont_exist.png
Traceback (most recent call last):
File "display_image.py", line 17, in <module>
(h, w, d) = image.shape
AttributeError: 'NoneType' object has no attribute 'shape'
果然有我们的NoneType错误。
在这种情况下,这是因为我没有向cv2.imread提供有效的图像路径。
摘要
在这篇博文中,我讨论了 OpenCV 和 Python 中的NoneType错误和AssertionError异常。
在绝大多数情况下,这些错误可以归因于cv2.imread或cv2.VideoCapture方法。
每当您遇到这些错误之一, 确保您可以在继续之前加载您的图像/读取您的帧 。在超过 95%的情况下,你的图像/框架没有被正确地阅读。
否则,如果您正在使用命令行参数并且不熟悉它们,就有可能您没有正确使用它们。在这种情况下,一定要通过阅读这篇关于命令行参数的教程来自学——你以后会感谢我的。
无论如何,我希望这篇教程对你的 OpenCV 精通之旅有所帮助!
如果你刚刚开始学习计算机视觉和 OpenCV,我强烈建议你看看我的书, 实用 Python 和 OpenCV ,这将帮助你掌握基本原理。
否则,请确保在下面的表格中输入您的电子邮件地址,以便在将来发布博客帖子和教程时得到通知!**
OpenCV 旋转图像
原文:https://pyimagesearch.com/2021/01/20/opencv-rotate-image/
在本教程中,您将学习如何使用 OpenCV 旋转图像。此外,我还将向您展示如何使用来自 imutils 库、imutils.rotate和imutils.rotate_bound的两个便利函数来旋转图像,这使得使用 OpenCV 旋转图像更容易(并且需要更少的代码)。
之前,我们学习了如何平移(即移动)图像,向上、向下、向左和向右(或任何组合)。我们现在进入下一个图像处理主题——旋转。
旋转就像它听起来的那样:将图像旋转某个角度,
. We’ll use to represent how many degrees (not radians) we are rotating an image.
我还将向您展示一些使用 OpenCV 更容易旋转图像的技术。
要学习如何用 OpenCV 旋转图像,继续阅读。
OpenCV 旋转图像
在本教程的第一部分,我们将讨论 OpenCV 如何旋转图像以及可用于旋转的函数。
从那里,我们将配置我们的开发环境,并审查我们的项目目录结构。
然后,我将向您展示使用 OpenCV 旋转图像的三种方法:
- 使用
cv2.rotate函数:内置于 OpenCV 中,但需要构造一个旋转矩阵并显式应用仿射扭曲,这使得代码更加冗长。 - 使用
imutils.rotate功能:我的 imutils 库的一部分。使得在单个函数调用中使用 OpenCV 旋转图像成为可能。 - 使用
imutils.rotate_bound函数:也是我的 imutils 库的一部分。确保图像的任何部分都不会在旋转过程中被切掉。
我们将通过查看 OpenCV 旋转结果来结束本教程。
OpenCV 如何旋转图像?
类似于平移,也许并不奇怪,旋转一个角度
can be defined by constructing a matrix, M, in the form:

给定一个 (x,y)-笛卡尔平面,这个矩阵可以用来旋转一个矢量
degrees (counterclockwise) about the origin. In this case, the origin is normally the center of the image; however, in practice, we can define any arbitrary (x, y)-coordinate as our rotation center.
从原始图像中, I ,然后通过简单的矩阵乘法得到旋转后的图像, R,:
然而,OpenCV 还提供了(1)缩放(即调整大小)图像和(2)提供围绕其执行旋转的任意旋转中心的能力。
因此,我们修改后的旋转矩阵 M 为:
 \times c_{x} - \beta \times c_{y} \-\beta & \alpha & \beta \times c_{x} + (1 - \alpha) \times c_{y}\end{bmatrix}")
其中
and  and
and  and
and  are the respective (x, y)-coordinates around which the rotation is performed.
are the respective (x, y)-coordinates around which the rotation is performed.
如果数学开始变得有点难以理解,不要担心——我们将跳转到一些代码中,使这些概念更加清晰。
配置您的开发环境
要遵循这个指南,您需要在您的系统上安装 OpenCV 库。
幸运的是,OpenCV 可以通过 pip 安装:
$ pip install opencv-contrib-python
如果你需要帮助为 OpenCV 配置开发环境,我强烈推荐阅读我的 pip 安装 OpenCV 指南——它将在几分钟内让你启动并运行。
在配置开发环境时遇到了问题?
话虽如此,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码?
*那今天就加入 PyImageSearch 加吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南已经过预配置,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在我们使用 OpenCV 实现旋转之前,让我们先回顾一下我们的项目目录结构。
请确保您访问了本教程的 “下载” 部分,以检索源代码和示例图像,并从那里窥视一下内部:
$ tree . --dirsfirst
.
├── opencv_logo.png
└── opencv_rotate.py
0 directories, 2 files
这里,我们有opencv_rotate.py。该脚本将加载opencv_logo.png(或者您选择的任何其他图像),然后对其应用一系列旋转,从而演示如何使用 OpenCV 执行旋转。
用 OpenCV 实现图像旋转
我们现在准备用 OpenCV 实现图像旋转。
打开项目目录结构中的opencv_rotate.py文件,插入以下代码:
# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, default="opencv_logo.png",
help="path to the input image")
args = vars(ap.parse_args())
第 2-4 行导入我们需要的 Python 包。我们将使用argparse作为命令行参数,使用 imutils 作为我的 OpenCV 便利函数集(即imutils.rotate和imutils.rotate_bound方法),使用cv2作为 OpenCV 绑定。
我们只有一个命令行参数,--image,它是我们想要旋转的输入图像的路径(默认为opencv_logo.png)。
接下来,让我们从磁盘加载我们的输入图像,并做一些基本的调整大小:
# load the image and show it
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# grab the dimensions of the image and calculate the center of the
# image
(h, w) = image.shape[:2]
(cX, cY) = (w // 2, h // 2)
# rotate our image by 45 degrees around the center of the image
M = cv2.getRotationMatrix2D((cX, cY), 45, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("Rotated by 45 Degrees", rotated)
# rotate our image by -90 degrees around the image
M = cv2.getRotationMatrix2D((cX, cY), -90, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("Rotated by -90 Degrees", rotated)
我们首先加载输入图像并将其显示在屏幕上:
当我们旋转一幅图像时,我们需要指定要围绕哪个点旋转。在大多数情况下,你会希望围绕图像的中心旋转;然而,OpenCV 允许你指定任何你想要旋转的任意点(如上所述)。
让我们继续,围绕图像的中心旋转。第 18 行和第 19 行抓取图像的宽度和高度,然后将每个分量除以2来确定图像的中心。
就像我们定义一个矩阵来平移图像,我们也定义一个矩阵来旋转图像。我们不用使用 NumPy 手工构建矩阵(这可能有点乏味),我们只需调用第 22 行上的cv2.getRotationMatrix2D方法。
cv2.getRotationMatrix2D函数有三个参数。第一个参数是我们旋转图像的点(在这种情况下,图像的中心cX和cY)。
然后我们指定,我们将旋转图像的(逆时针)度数。在这种情况下,我们将图像旋转 45 度。
最后一个论点是图像的比例。我们还没有讨论调整图像的大小,但是在这里你可以指定一个浮点值,其中 1.0 表示使用图像的原始尺寸。但是,如果您指定的值为 2.0 ,图像大小会翻倍,同样的,值为 0.5 图像大小会减半。
一旦我们从cv2.getRotationMatrix2D函数中得到旋转矩阵M,我们就可以使用cv2.warpAffine方法在第 23 行将旋转应用于我们的图像。
这个函数的第一个参数是我们想要旋转的image。然后我们指定我们的旋转矩阵M和图像的输出尺寸(宽度和高度)。第 24 行显示我们的图像旋转了 45 度:
第 27-29 行做同样的事情,但是这次围绕中心cX和cY坐标旋转图像-90度(顺时针)。
注: 记住,在 OpenCV 中, 正度数表示逆时针旋转 而 负度数表示顺时针旋转 。 牢记这一点;否则,您可能会在对自己的图像应用旋转时感到困惑!
图 4 显示了这些调整大小操作的输出:
如你所见,我们的图像被旋转了。花点时间注意 OpenCV 不会自动为我们整个旋转后的图像分配空间以适合框架。
这是有意的行为!如果您希望整个图像在旋转后适合视图,您需要修改宽度和高度,在cv2.warpAffine函数中表示为(w, h)。正如我们将在后面的脚本中看到的,imutils.rotate_bound函数会为我们处理所有的事情。
到目前为止,我们只围绕图像的中心旋转了图像。但是如果我们想围绕某个任意点旋转图像呢?
让我们来看看这是如何实现的:
# rotate our image around an arbitrary point rather than the center
M = cv2.getRotationMatrix2D((10, 10), 45, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("Rotated by Arbitrary Point", rotated)
到目前为止,这段代码看起来应该相当标准,可以执行一次旋转。但是,请注意cv2.getRotationMatrix2D函数的第一个参数。这里,我们指出我们想要围绕 x = 10 、 y = 10 ,或者大约图像左上角的旋转图像。
*当我们应用这种旋转时,我们的输出图像如下所示:
我们可以看到旋转的中心不再是图像的中心。
然而,就像翻译一幅图像一样,调用cv2.getRotationMatrix2D和cv2.warpAffine会变得非常乏味——更不用说它还会使我们的代码变得更加冗长。
让我们通过调用imutils.rotate来减少需要编写的代码量,这是一个方便的函数,它包装了对cv2.getRotationMatrix2D和cv2.warpAffine的调用:
# use our imutils function to rotate an image 180 degrees
rotated = imutils.rotate(image, 180)
cv2.imshow("Rotated by 180 Degrees", rotated)
在这里,我们将图像旋转了 180 度,但是我们可以通过使用rotate方法使我们的代码不那么冗长。
图 6 显示了我们旋转的输出:
正如您在前面的示例中看到的,如果图像的一部分在旋转过程中被剪切掉,OpenCV 不会分配足够的空间来存储整个图像。
解决方法是使用imutils.rotate_bound函数:
# rotate our image by 33 degrees counterclockwise, ensuring the
# entire rotated image still renders within the viewing area
rotated = imutils.rotate_bound(image, -33)
cv2.imshow("Rotated Without Cropping", rotated)
cv2.waitKey(0)
该功能将自动扩展图像阵列,使整个旋转图像适合它。
应用rotate_bound功能的结果可以在图 7 中看到,这里我们逆时针旋转图像 33 度:
这就是全部了!
注:imutils.rotate_bound函数反转正/负值与顺时针/逆时针旋转的关系。这里,负值将逆时针旋转,而正值将顺时针旋转。
使用 OpenCV 应用图像旋转时,有三种选择:
cv2.getRotationMatrix2D和cv2.warpAffineimutils.rotateimutils.rotate_bound
您可以根据自己的应用需求混合搭配它们。
OpenCV 图像旋转结果
要使用 OpenCV 旋转图像,请务必访问本教程的 “下载” 部分,以检索源代码和示例图像。
我们已经在上一节中回顾了该脚本的结果,但是当您准备自己运行该脚本时,可以使用以下命令:
$ python opencv_rotate.py
您的 OpenCV 旋转结果应该与我在上一节中的结果相匹配。
总结
在本教程中,您学习了如何使用 OpenCV 旋转图像。要使用 OpenCV 将图像旋转任意角度,我们需要:
- 使用
cv2.getRotationMatrix2D函数构建 2D 旋转矩阵 - 使用
cv2.warpAffine函数执行仿射变形,提供我们的输入图像和计算的旋转矩阵M
结果是图像被旋转了
degrees.
使用 OpenCV 的函数旋转图像的问题是,它们需要两行代码——一行构建旋转矩阵,另一行执行变换。
为了让 OpenCV 的图像旋转更容易,我在我的 imutils 库中实现了两个方法:
imutils.rotate:在一行代码中执行 OpenCV 图像旋转。imutils.rotate_bound:也使用 OpenCV 执行图像旋转,但确保图像(旋转后)仍然可见,并且图像的任何部分都不会被剪切掉。
我建议您熟悉这三种旋转技术,因为在开发您自己的图像处理管道时,您可能会用到它们中的每一种。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),*只需在下面的表格中输入您的电子邮件地址!***
OpenCV,RPi。树莓 Pi 上的 GPIO 和 GPIO 零
原文:https://pyimagesearch.com/2016/05/09/opencv-rpi-gpio-and-gpio-zero-on-the-raspberry-pi/
https://www.youtube.com/embed/mujkoqxyJLw?feature=oembed
OpenCV 显著性检测
原文:https://pyimagesearch.com/2018/07/16/opencv-saliency-detection/

今天的教程是关于显著性检测,即应用图像处理和计算机视觉算法来自动定位图像中最“显著”区域的过程。
本质上,显著性是照片或场景中“突出”的部分,使你的眼脑连接快速(基本上是无意识地)聚焦于最重要的区域。
例如,考虑这篇博文顶部的图,你看到一个足球场,上面有球员。当看照片时,你的眼睛会自动聚焦在球员身上,因为他们是照片中最重要的部分。这个自动定位图像或场景重要部分的过程被称为显著性检测。
显著性检测应用于计算机视觉和图像处理的许多方面,但是显著性的一些更流行的应用包括:
- 物体检测——不是穷尽地应用滑动窗口和图像金字塔,而是仅将我们的(计算昂贵的)检测算法应用于图像中最显著、最有可能包含物体的感兴趣区域
- 广告和营销 —设计让我们一眼就能“流行”和“突出”的标志和广告
- 机器人学——设计视觉系统与我们相似的机器人
在今天博文的剩余部分,你将学习如何使用 Python 和 OpenCV 的显著性模块执行显著性检测— 继续阅读了解更多!
用 Python 实现 OpenCV 显著性检测
今天的帖子是受 PyImageSearch 大师课程 成员杰夫·诺瓦的启发。
在私人 PyImageSearch 大师社区论坛的一个帖子中,Jeff 写道:
Figure 1: Jeff Nova’s OpenCV saliency question in the PyImageSearch Gurus Community forums.
问得好,杰夫!
老实说,我完全忘记了 OpenCV 的显著模块。
Jeff 的问题促使我对 OpenCV 中的显著性模块做了一些研究。经过几个小时的研究、反复试验和简单地摆弄代码,我能够使用 OpenCV 执行显著性检测。
由于没有太多关于如何执行显著性检测的教程,特别是关于 Python 绑定的,我想写一个教程与你分享。
享受它,我希望它能帮助你把显著性检测带到你自己的算法中。
三种不同的显著性检测算法
在 OpenCV 的saliency模块中,显著性检测有三种主要形式:
- 静态显著性:这类显著性检测算法依靠图像特征和统计来定位图像中最感兴趣的区域。
- 运动显著性:这类算法通常依赖于视频或逐帧输入。运动显著性算法处理帧,跟踪“移动”的对象。移动的物体被认为是显著的。
- 对象性:计算“对象性”的显著性检测算法生成一组“提议”,或者更简单地说,它认为对象可能位于图像中的什么位置的边界框。
记住,计算显著性是而不是物体检测。底层显著性检测算法不知道图像中是否有特定对象。
相反,显著性检测器只是报告它认为一个对象可能位于图像中的何处——这取决于您和您的实际对象检测/分类算法:
- 处理由显著性检测器提出的区域
- 预测/分类该区域,并根据该预测做出任何决策
显著性检测器通常是能够实时运行的非常快速的算法。然后,显著性检测器的结果被传递到计算量更大的算法中,您可能不想对输入图像的每个像素都运行这些算法。
OpenCV 的显著性检测器
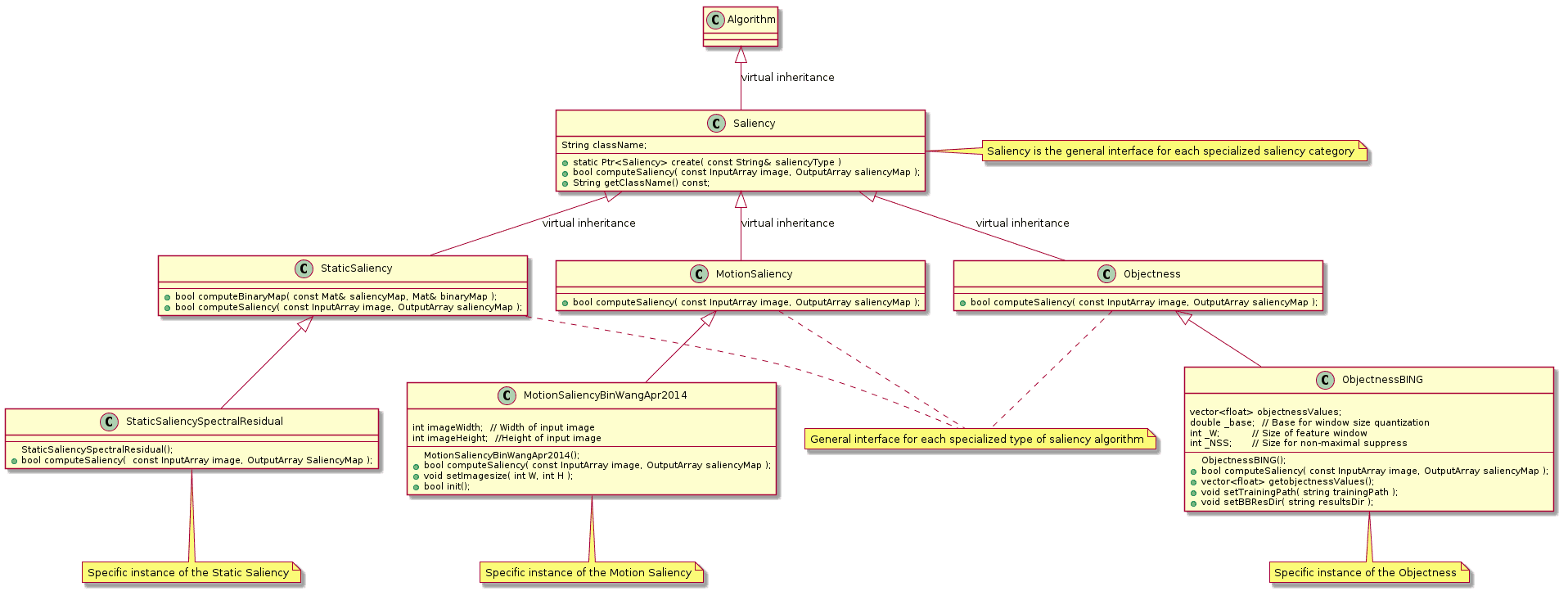
Figure 2: OpenCV’s saliency module class diagram. Click for the high-resolution image.
要使用 OpenCV 的显著性检测器,您需要 OpenCV 3 或更高版本。OpenCV 关于他们的saliency模块的官方文档可以在这个页面上找到。
请记住,您需要在启用contrib模块的情况下编译 OpenCV。如果你跟随了我在 PyImageSearch 上的 OpenCV 安装教程,你将会安装contrib模块。
注意:我发现 OpenCV 3.3 不支持运动显著性方法(将在本文后面介绍),但支持所有其他显著性实现。如果你发现自己需要运动显著性,请确保你使用的是 OpenCV 3.4 或更高版本。
您可以通过打开一个 Python shell 并尝试导入它来检查是否安装了saliency模块:
$ python
>>> import cv2
>>> cv2.saliency
<module 'cv2.saliency'>
如果导入成功,恭喜您——您已经安装了contrib个额外的模块!但是如果导入失败,你需要遵循我的指南来安装 OpenCV 和contrib模块。
OpenCV 为我们提供了四种使用 Python 绑定的显著性检测器实现,包括:
cv2.saliency.ObjectnessBING_create()cv2.saliency.StaticSaliencySpectralResidual_create()cv2.saliency.StaticSaliencyFineGrained_create()cv2.saliency.MotionSaliencyBinWangApr2014_create()
上面的每个构造函数都返回一个实现.computeSaliency方法的对象——我们在输入图像上调用这个方法,返回一个二元组:
- 一个布尔值,指示显著性计算是否成功
- 输出显著图,我们可以用它来导出图像中最“有趣”的区域
在今天博文的剩余部分,我将向你展示如何使用这些算法来执行显著性检测。
显著性检测项目结构
请务必访问博文的 “下载” 部分,以获取 Python 脚本、图像文件和经过训练的模型文件。
从那里,我们可以使用tree命令在终端中查看项目结构:
$ tree --dirsfirst
.
├── images
│ ├── barcelona.jpg
│ ├── boat.jpg
│ ├── neymar.jpg
│ └── players.jpg
├── objectness_trained_model [9 entries]
│ ├── ObjNessB2W8HSV.idx.yml.gz
│ ├── ...
├── static_saliency.py
├── objectness_saliency.py
└── motion_saliency.py
2 directories, 16 files
在我们的项目文件夹中,有两个目录:
image/:测试图像的选择。- 这是我们的物体显著性的模型目录。包括 9 个。包含对象模型 iteslf 的 yaml 文件。
我们今天将回顾三个示例脚本:
static_saliency.py:这个脚本实现了两种形式的静态显著性(基于图像特征和统计)。我们将首先回顾这个脚本。objectness_saliency.py:使用 BING 对象显著性方法生成对象提议区域列表。- 这个脚本将利用你计算机的网络摄像头,实时处理活动帧。显著区域是使用本指南稍后介绍的 Wang 和 Dudek 2014 方法计算的。
静态凸极
OpenCV 实现了两种静态显著性检测算法。
- 第一种方法来自 Montabone 和 Soto 的 2010 年出版物, 使用移动平台和从视觉显著机制 导出的新颖特征的人体检测。该算法最初用于检测图像和视频流中的人,但也可以推广到其他形式的显著性。
- 第二种方法是由侯和张在他们 2007 年的论文中提出的, 显著性检测:一种谱残差方法。
该静态显著性检测器对图像的对数谱进行操作,计算该谱中的显著性残差,然后将相应的显著位置映射回空间域。请务必参考该文件以了解更多详细信息。
让我们继续尝试这两种静态显著性检测器。打开static_salency.py并插入以下代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the input image
image = cv2.imread(args["image"])
在第 2 行和第 3 行上,我们导入argparse和cv2。argparse模块将允许我们解析单个命令行参数——图像--input(第 6-9 行 ) 。 OpenCV(带有contrib模块)拥有我们计算静态显著图所需的一切。
如果你没有安装 OpenCV,你可以遵循我的 OpenCV 安装指南。冒着被打破记录的风险,我将重复我的建议,你应该至少获得 OpenCV 3.4,因为在这篇博文中,我在 OpenCV 3.3 的运动显著性方面遇到了麻烦。
然后,我们通过第 12 行将图像加载到内存中。
我们的第一个静态显著性方法是静态谱显著性。让我们继续计算图像的显著性图并显示它:
# initialize OpenCV's static saliency spectral residual detector and
# compute the saliency map
saliency = cv2.saliency.StaticSaliencySpectralResidual_create()
(success, saliencyMap) = saliency.computeSaliency(image)
saliencyMap = (saliencyMap * 255).astype("uint8")
cv2.imshow("Image", image)
cv2.imshow("Output", saliencyMap)
cv2.waitKey(0)
使用cv2.saliency模块并调用StaticSaliencySpectralResidual_create()方法,实例化一个静态光谱残差saliency对象(第 16 行)。
从那里我们调用第 17 行上的computeSaliency方法,同时传入我们的输入image。
结果如何?
结果是一个saliencyMap,一个浮点灰度图像,它突出显示了图像中最突出的区域。浮点值的范围是【0,1】,接近 1 的值是“感兴趣”的区域,接近 0 的值是“不感兴趣”的区域。
我们准备好可视化输出了吗?
没那么快!在我们可以显示地图之前,我们需要将行 18 上的值缩放到范围【0,255】。
从那里,我们可以将原始的image和saliencyMap图像显示到屏幕上(第 19 行和第 20 行),直到按下一个键(第 21 行)。
我们要应用的第二种静态显著方法叫做“细粒度”。下一个块模仿我们的第一个方法,除了我们正在实例化细粒度对象。我们还将执行一个阈值来演示一个二进制地图,您可能会处理轮廓(即,提取每个显著区域)。让我们看看它是如何做到的:
# initialize OpenCV's static fine grained saliency detector and
# compute the saliency map
saliency = cv2.saliency.StaticSaliencyFineGrained_create()
(success, saliencyMap) = saliency.computeSaliency(image)
# if we would like a *binary* map that we could process for contours,
# compute convex hull's, extract bounding boxes, etc., we can
# additionally threshold the saliency map
threshMap = cv2.threshold(saliencyMap.astype("uint8"), 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# show the images
cv2.imshow("Image", image)
cv2.imshow("Output", saliencyMap)
cv2.imshow("Thresh", threshMap)
cv2.waitKey(0)
在的第 25 行,我们实例化了细粒度的静态saliency对象。从那里我们计算第 26 条线上的saliencyMap。
OpenCV 代码的贡献者以不同于光谱显著性的方式实现了细粒度显著性。这次我们的值已经在范围【0,255】内缩放,所以我们可以继续在第 36 行上显示。
您可能执行的一个任务是计算二值阈值图像,以便您可以找到可能的对象区域轮廓。这在行 31 和 32 上执行,并在行 37 上显示。接下来的步骤将是在发现和提取轮廓之前的一系列腐蚀和膨胀(形态学操作)。我会把它作为一个练习留给你。
要执行静态显著性检测器,请务必下载源代码和示例(参见下面的 “下载” 部分),然后执行以下命令:
$ python static_saliency.py --image images/neymar.jpg
巴西职业足球运动员小内马尔的图像首先经历光谱方法:
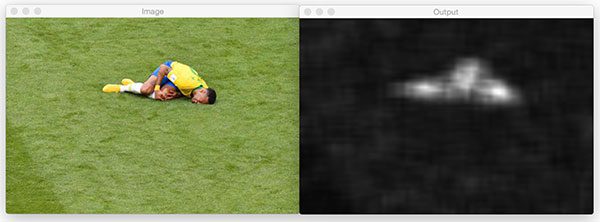
Figure 3: Static spectral saliency with OpenCV on a picture of an injured Neymar Jr., a well known soccer player.
然后,在按下键之后,显示细粒度方法显著性图图像。这一次,我还展示了显著图的一个阈值(这也可以很容易地应用于光谱方法):
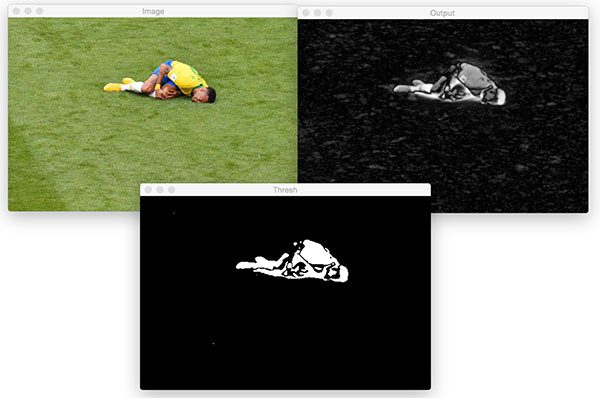
Figure 4: Static saliency with OpenCV using the fine grained approach (top-right) and binary threshold of the saliency map (bottom).
与先前光谱显著性图中的模糊斑点相比,细粒度图更类似于人。在底部中心的阈值图像将是提取可能物体的 ROI 的管道中的有用起点。
现在让我们在一张船的照片上尝试这两种方法:
$ python static_saliency.py --image images/boat.jpg
船只的静态光谱显著图:
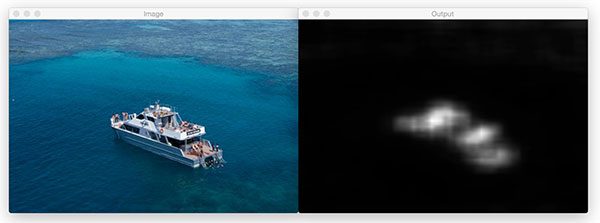
Figure 5: Static spectral saliency with OpenCV on a picture of a boat.
细粒度:

Figure 6: Static fine grained saliency of a boat image (top-right) and binary threshold of the saliency map (bottom).
最后,让我们在三个足球运动员的图片上尝试光谱和细粒度静态显著性方法:
$ python static_saliency.py --image images/players.jpg
这是光谱显著性的输出:
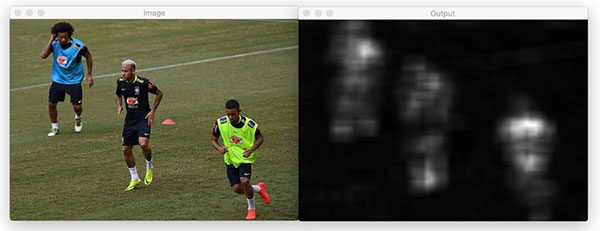
Figure 7: A photo of three players undergoes static spectral saliency with OpenCV.
以及细粒度的显著性检测:
Figure 8: Three soccer players are highlighted in a saliency map created with OpenCV. This time a fine grained approach was used (top-right). Then, a binary threshold of the saliency map was computed which would be useful as a part of a contour detection pipeline (bottom).
客体显著性
OpenCV 包括一个目标显著性检测器—. BING:二值化赋范梯度用于 300fps 的目标估计 ,Cheng 等人(2014)。
与 OpenCV 中其他实现完全独立的显著性检测器不同,BING 显著性检测器需要九个独立的模型文件,用于各种窗口大小、颜色空间和数学运算。
这九个模型文件加在一起非常小(~10KB)并且速度极快,这使得 BING 成为显著性检测的一个极好的方法。
要了解如何使用 OpenCV 的 objectness 显著性检测器,请打开objectness_saliency.py并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to BING objectness saliency model")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-n", "--max-detections", type=int, default=10,
help="maximum # of detections to examine")
args = vars(ap.parse_args())
# load the input image
image = cv2.imread(args["image"])
在2-4 行,我们导入我们需要的包。对于这个脚本,我们将使用 NumPy、argparse和 OpenCV。
从那里我们解析第 7-14 行的三个命令行参数:
--model:BING 客体显著性模型的路径。--image:我们的输入图像路径。--max-detections:检测的最大数量,默认设置为10。
接下来,我们将我们的image加载到内存中(第 17 行)。
让我们计算对象显著性:
# initialize OpenCV's objectness saliency detector and set the path
# to the input model files
saliency = cv2.saliency.ObjectnessBING_create()
saliency.setTrainingPath(args["model"])
# compute the bounding box predictions used to indicate saliency
(success, saliencyMap) = saliency.computeSaliency(image)
numDetections = saliencyMap.shape[0]
在线 21 上,我们初始化目标saliency探测器,然后在线 22 上建立训练路径。
给定这两个动作,我们现在可以计算第 25 行上的对象saliencyMap。
可用显著性检测的数量可以通过检查返回的 NumPy 数组的形状来获得(行 26 )。
现在,让我们循环查看每个检测(直到我们设置的最大值):
# loop over the detections
for i in range(0, min(numDetections, args["max_detections"])):
# extract the bounding box coordinates
(startX, startY, endX, endY) = saliencyMap[i].flatten()
# randomly generate a color for the object and draw it on the image
output = image.copy()
color = np.random.randint(0, 255, size=(3,))
color = [int(c) for c in color]
cv2.rectangle(output, (startX, startY), (endX, endY), color, 2)
# show the output image
cv2.imshow("Image", output)
cv2.waitKey(0)
在第 29 行上,我们开始循环检测,直到我们的命令行args字典中包含的最大检测计数。
在循环内部,我们首先提取边界框坐标(行 31 )。
然后我们copy图像用于显示目的(第 34 行),接着分配一个随机的color给边界框(第 35-36 行)。
要查看 OpenCV 的 objectness 显著性检测器,请务必下载源代码+示例图像,然后执行以下命令:
$ python objectness_saliency.py --model objectness_trained_model
--image images/barcelona.jpg

Figure 9: The objectness saliency detector (BING method) with OpenCV produces a total of 10 object region proposals as shown in the animation.
在这里,你可以看到物体显著性方法很好地提出了输入图像中莱昂内尔·梅西和路易斯·绍雷兹站在/跪在球场上的区域。
你可以想象将这些提议的边界框区域中的每一个都传递到分类器或对象检测器中以进行进一步的预测——最好的是,这种方法在计算上比穷尽性地应用一系列图像金字塔和滑动窗口更加高效。
运动显著性
最终的 OpenCV 显著性检测器来自于王和杜德克在 2014 年发表的 一种快速自调整背景差分算法 。
该算法设计用于视频馈送,其中在视频馈送中移动的对象被认为是显著的。
打开motion_saliency.py并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
import imutils
import time
import cv2
# initialize the motion saliency object and start the video stream
saliency = None
vs = VideoStream(src=0).start()
time.sleep(2.0)
在这个脚本中,我们将直接使用我们的网络摄像头,所以我们首先从行 2 上的 imutils 导入VideoStream类。我们还将imutils本身、time,以及 OpenCV ( 第 3-5 行)。
既然我们的导入已经完成,我们将初始化我们的运动显著性对象,并开始线程化的VideoStream对象(第 9 行)。
从这里,我们将开始循环并在每个周期的顶部捕获一帧:
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream and resize it
# to 500px (to speedup processing)
frame = vs.read()
frame = imutils.resize(frame, width=500)
# if our saliency object is None, we need to instantiate it
if saliency is None:
saliency = cv2.saliency.MotionSaliencyBinWangApr2014_create()
saliency.setImagesize(frame.shape[1], frame.shape[0])
saliency.init()
在的第 16 行我们抓取一个frame,然后在的第 17 行调整它的大小。减小frame的尺寸将允许环路内的图像处理和计算机视觉技术运行得更快。需要处理的数据越少,我们的管道就能运行得越快。
第 20-23 行实例化 OpenCV 的 motion saliency对象,如果它还没有建立的话。对于这个脚本,我们使用的是 Wang 方法,因为它的构造函数名副其实。
接下来,我们将计算显著图并显示我们的结果:
# convert the input frame to grayscale and compute the saliency
# map based on the motion model
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
(success, saliencyMap) = saliency.computeSaliency(gray)
saliencyMap = (saliencyMap * 255).astype("uint8")
# display the image to our screen
cv2.imshow("Frame", frame)
cv2.imshow("Map", saliencyMap)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
我们将frame转换为灰度(第 27 行),随后计算我们的saliencyMap ( 第 28 行)——王方法需要灰度帧。
由于saliencyMap包含范围【0,1】中的浮点值,我们缩放到范围【0,255】,并确保该值是无符号的 8 位整数(第 29 行)。
从那里,我们在第 32 和 33 行的上显示原始的frame和saliencyMap。
然后我们检查是否按下了 quit 键(“q”),如果是,我们就退出循环并清理(第 34-42 行)。否则,我们将继续处理并在屏幕上显示显著图。
要执行运动显著性脚本,请输入以下命令:
$ python motion_saliency.py
下面我录制了一个 OpenCV 的运动显著性算法的示例演示:
https://www.youtube.com/embed/tBaKusWUp3s?feature=oembed
OpenCV 用于目标检测的选择性搜索
原文:https://pyimagesearch.com/2020/06/29/opencv-selective-search-for-object-detection/
今天,您将学习如何使用 OpenCV 选择性搜索进行对象检测。
今天的教程是我们关于深度学习和对象检测的 4 部分系列的第 2 部分:
- Part 1: 用 Keras 和 TensorFlow 把任何深度学习图像分类器变成物体检测器
- 第二部分: OpenCV 选择性搜索进行物体检测(今日教程)
- 第三部分: 用 OpenCV、Keras 和 TensorFlow 进行物体检测的区域提议(下周教程)
- 第四部分: 用 Keras 和 TensorFlow 进行 R-CNN 物体探测(两周内出版)
选择性搜索(Selective Search)由 Uijlings 等人在其 2012 年的论文中首次提出,是计算机视觉、深度学习和对象检测研究的关键部分。
在他们的工作中,Uijlings 等人证明了:
- 如何对图像进行 过分割以自动识别图像中可能包含物体的位置**
- 这种选择性搜索比穷尽式计算图像金字塔和滑动窗口(且不损失准确性)更高效
- 并且该选择性搜索可以用任何利用图像金字塔和滑动窗口的对象检测框架替换
***自动区域提议算法,如选择性搜索,为 Girshick 等人的开创性 R-CNN 论文铺平了道路,该论文产生了高度准确的基于深度学习的对象检测器。
此外,选择性搜索和对象检测的研究使研究人员能够创建最先进的区域提议网络(RPN)组件,这些组件甚至比选择性搜索更准确和更高效(参见 Girshick 等人 2015 年关于更快 R-CNN 的后续论文)。
但是在我们进入 RPNs 之前,我们首先需要了解选择性搜索是如何工作的,包括我们如何使用 OpenCV 利用选择性搜索进行对象检测。
要了解如何使用 OpenCV 的选择性搜索进行对象检测,继续阅读。
OpenCV 对象检测选择性搜索
在本教程的第一部分,我们将讨论通过选择性搜索的区域建议的概念,以及它们如何有效地取代使用图像金字塔和滑动窗口来检测图像中的对象的传统方法。
从这里,我们将详细回顾选择性搜索算法,包括它如何通过以下方式过度分割图像:
- 颜色相似性
- 纹理相似性
- 尺寸相似性
- 形状相似性
- 最终的元相似性,它是上述相似性度量的线性组合
然后,我将向您展示如何使用 OpenCV 实现选择性搜索。
区域提议与滑动窗口和图像金字塔
在上周的教程中,你学习了如何通过应用图像金字塔和滑动窗口将任何图像分类器转变为对象检测器。
作为复习,图像金字塔创建输入图像的多尺度表示,允许我们以多尺度/尺寸检测物体:
滑动窗口在图像金字塔的每一层上操作,从左到右和从上到下滑动,从而允许我们定位给定物体在图像中的位置:
图像金字塔和滑动窗口方法存在许多问题,但两个主要问题是:
- 慢得令人痛苦。 即使使用循环优化方法和多重处理,遍历每个图像金字塔层并通过滑动窗口检查图像中的每个位置在计算上也是昂贵的。
- 他们对参数选择很敏感。您的图像金字塔比例和滑动窗口大小的不同值会导致在阳性检测率、误检和漏检方面产生显著不同的结果。
鉴于这些原因,计算机视觉研究人员已经开始研究创建自动区域提议生成器,以取代滑动窗口和图像金字塔。
总的想法是,区域提议算法应该检查图像,并试图找到图像中可能包含对象的区域(将区域提议视为显著性检测)。
区域提议算法应该:
- 比滑动窗口和图像金字塔更快更有效
- 准确检测图像中可能包含物体的区域
- 将这些“候选提议”传递给下游分类器,以实际标记区域,从而完成对象检测框架
问题是,什么类型的区域提议算法可以用于对象检测?
什么是选择性搜索,选择性搜索如何用于物体检测?
在 OpenCV 中实现的选择性搜索算法是由 Uijlings 等人在他们 2012 年的论文 中首次提出的,用于对象识别的选择性搜索 。
选择性搜索通过使用超像素算法对图像进行过度分割来工作(代替 SLIC,Uijlings 等人使用来自 Felzenszwalb 和 Huttenlocher 2004 年论文 的 Felzenszwalb 方法,高效的基于图形的图像分割 )。
运行 Felzenszwalb 超像素算法的示例如下所示:
从那里开始,选择性搜索寻求将超像素合并在一起,找到图像中可能包含物体的区域。
选择性搜索基于五个关键相似性度量以分层方式合并超像素:
- 颜色相似度:计算图像每个通道的 25-bin 直方图,将它们串联在一起,得到最终的描述符为 25×3=75-d. 任意两个区域的颜色相似度用直方图相交距离来度量。
- 纹理相似度:对于纹理,选择性搜索提取每个通道 8 个方向的高斯导数(假设 3 通道图像)。这些方向用于计算每个通道的 10-bin 直方图,生成最终的纹理描述符,即 8x10x=240-d. 为了计算任何两个区域之间的纹理相似性,再次使用直方图相交。
- 大小相似性:选择性搜索使用的大小相似性度量标准更倾向于将较小的区域更早分组,而不是更晚。任何以前使用过层次凝聚聚类(HAC)算法的人都知道,HAC 容易使聚类达到临界质量,然后将它们接触到的所有东西结合起来。通过强制较小的区域更早地合并,我们可以帮助防止大量的集群吞噬所有较小的区域。
- 形状相似性/兼容性:选择性搜索中形状相似性背后的思想是它们应该彼此兼容。如果两个区域“适合”彼此,则认为它们“兼容”(从而填补了我们区域提案生成中的空白)。此外,不接触的形状不应合并。
- 最终元相似性度量:最终元相似性充当颜色相似性、纹理相似性、尺寸相似性和形状相似性/兼容性的线性组合。
*应用这些层次相似性度量的选择性搜索的结果可以在下图中看到:
在金字塔的底层,我们可以看到来自 Felzenszwalb 方法的原始过分割/超像素生成。
在中间层,我们可以看到区域被连接在一起,最终形成最终的提议集( top )。
如果你有兴趣了解更多关于选择性搜索的基础理论,我建议你参考以下资源:
- 高效的基于图的图像分割 (Felzenszwalb 和 Huttenlocher,2004)
- 【乌伊林斯等,2012】
- 【选择性搜索进行物体检测(c++/Python)(Chandel/Mallick,2017)
选择性搜索生成区域,非类标签
我看到的选择性搜索的一个常见误解是,读者错误地认为选择性搜索取代了整个对象检测框架,如 HOG +线性 SVM、R-CNN 等。
事实上,几周前,PyImageSearch 的读者 Hayden 发来了一封电子邮件,提出了完全相同的问题:
你好,Adrian,我正在用 OpenCV 使用选择性搜索来检测对象。
然而,选择性搜索只是返回边界框——我似乎想不出如何获得与这些边界框相关联的标签。
所以,事情是这样的:
- 选择性搜索是否生成图像中 可能 包含对象的区域。
- 但是,选择性搜索并不知道在那个区域是什么(把它想成是显著性检测的表亲)。**
- 选择性搜索意味着用 取代 这种计算成本高、效率极低的方法,这种方法穷尽性地使用图像金字塔和滑动窗口来检查潜在物体的图像位置。
- 通过使用选择性搜索,我们可以更有效地检查图像中*可能包含物体的区域,然后将这些区域传递给 SVM、CNN 等。进行最终分类。*****
如果你正在使用选择性搜索,只要记住选择性搜索算法将而不是*给你类别标签预测——假设你的下游分类器将为你做那件事(下周博客文章的主题)。**
但与此同时,让我们学习如何在我们自己的项目中使用 OpenCV 选择性搜索。
项目结构
一定要抓住。本教程的压缩文件来自 【下载】 部分。一旦您提取了文件,您可以使用tree命令来查看里面的内容:
$ tree
.
├── dog.jpg
└── selective_search.py
0 directories, 2 files
我们的项目非常简单,由一个 Python 脚本(selective_search.py)和一个测试图像(dog.jpg)组成。
在下一节中,我们将学习如何用 Python 和 OpenCV 实现我们的选择性搜索脚本。
用 OpenCV 和 Python 实现选择性搜索
我们现在准备用 OpenCV 实现选择性搜索!
打开一个新文件,将其命名为selective_search.py,并插入以下代码:
# import the necessary packages
import argparse
import random
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-m", "--method", type=str, default="fast",
choices=["fast", "quality"],
help="selective search method")
args = vars(ap.parse_args())
# load the input image
image = cv2.imread(args["image"])
# initialize OpenCV's selective search implementation and set the
# input image
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(image)
# check to see if we are using the *fast* but *less accurate* version
# of selective search
if args["method"] == "fast":
print("[INFO] using *fast* selective search")
ss.switchToSelectiveSearchFast()
# otherwise we are using the *slower* but *more accurate* version
else:
print("[INFO] using *quality* selective search")
ss.switchToSelectiveSearchQuality()
"fast"方法:switchToSelectiveSearchFast"quality"方法:switchToSelectiveSearchQuality
通常,更快的方法将是合适的;但是,根据您的应用程序,您可能希望牺牲速度来获得更好的质量结果(稍后将详细介绍)。
让我们继续使用我们的图像执行选择性搜索:
# run selective search on the input image
start = time.time()
rects = ss.process()
end = time.time()
# show how along selective search took to run along with the total
# number of returned region proposals
print("[INFO] selective search took {:.4f} seconds".format(end - start))
print("[INFO] {} total region proposals".format(len(rects)))
要运行选择性搜索,我们只需在我们的ss对象上调用process方法(第 37 行)。我们已经围绕这个调用设置了时间戳,所以我们可以感受一下算法有多快;第 42 行向我们的终端报告选择性搜索基准。
随后,行 43 告诉我们选择性搜索操作找到的区域建议的数量。
现在,如果我们不将结果可视化,找到我们的区域提案会有什么乐趣呢?毫无乐趣。最后,让我们在图像上绘制输出:
# loop over the region proposals in chunks (so we can better
# visualize them)
for i in range(0, len(rects), 100):
# clone the original image so we can draw on it
output = image.copy()
# loop over the current subset of region proposals
for (x, y, w, h) in rects[i:i + 100]:
# draw the region proposal bounding box on the image
color = [random.randint(0, 255) for j in range(0, 3)]
cv2.rectangle(output, (x, y), (x + w, y + h), color, 2)
# show the output image
cv2.imshow("Output", output)
key = cv2.waitKey(0) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
OpenCV 选择性搜索结果
我们现在已经准备好使用 OpenCV 对我们自己的图像进行选择性搜索。
首先使用这篇博文的 【下载】 部分下载源代码和示例图片。
从那里,打开一个终端,并执行以下命令:
$ python selective_search.py --image dog.jpg
[INFO] using *fast* selective search
[INFO] selective search took 1.0828 seconds
[INFO] 1219 total region proposals
在这里,你可以看到 OpenCV 的选择性搜索“快速模式”运行了大约 1 秒钟,生成了 1219 个边界框——图 4 中的可视化显示了我们在选择性搜索生成的每个区域上循环,并将它们可视化到我们的屏幕上。
如果您对这种可视化感到困惑,请考虑选择性搜索的最终目标:到用更有效的区域提议生成方法取代传统的计算机视觉对象检测技术,如滑动窗口和图像金字塔。
因此,选择性搜索将而不是告诉你ROI 中的是什么,但是它会告诉你 ROI“足够有趣”以传递给下游分类器(例如、SVM、CNN 等。)进行最终分类。
让我们对同一幅图像应用选择性搜索,但这一次,使用--method quality模式:
$ python selective_search.py --image dog.jpg --method quality
[INFO] using *quality* selective search
[INFO] selective search took 3.7614 seconds
[INFO] 4712 total region proposals
“高质量”选择性搜索方法生成的区域提案增加了 286%,但运行时间也延长了 247%。
您是否应该使用“快速”或“高质量”模式取决于您的应用。
在大多数情况下,“快速”选择性搜索就足够了,但是您可以选择使用“高质量”模式:
- 当执行推理并希望确保为下游分类器生成更多高质量区域时(当然,这意味着实时检测不是一个问题)
- 当使用选择性搜索来生成训练数据时,从而确保生成更多的正区域和负区域供分类器学习
在哪里可以了解更多关于 OpenCV 的物体检测选择性搜索?
在下周的教程中,您将学习如何:
- 使用选择性搜索来生成对象检测建议区域
- 取一个预先训练的 CNN,并对每个区域进行分类(丢弃任何低置信度/背景区域)
- 应用非最大值抑制来返回我们的最终对象检测
在两周内,我们将使用选择性搜索来生成训练数据,然后微调 CNN 以通过区域提议来执行对象检测。
到目前为止,这是一个很棒的系列教程,你不想错过接下来的两个!
总结
在本教程中,您学习了如何使用 OpenCV 执行选择性搜索来生成对象检测建议区域。
选择性搜索的工作原理是通过基于五个关键要素组合区域来对图像进行过度分割:
- 颜色相似性
- 纹理相似性
- 尺寸相似性
- 形状相似性
- 和最终相似性度量,其是上述四个相似性度量的线性组合
值得注意的是,选择性搜索本身并不执行对象检测。
相反,选择性搜索返回可能包含一个对象的建议区域。
这里的想法是,我们用一个更便宜、更高效的选择性搜索来取代我们的计算昂贵、效率极低的滑动窗口和图像金字塔。
下周,我将向您展示如何通过选择性搜索生成建议区域,然后在它们之上运行图像分类器,允许您创建一个基于深度学习的特定对象检测器!
敬请关注下周的教程。
要下载这篇文章的源代码(并在本系列的下一篇教程发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*******
OpenCV 形状描述符:Hu 矩示例
原文:https://pyimagesearch.com/2014/10/27/opencv-shape-descriptor-hu-moments-example/
那么 OpenCV 提供了什么类型的形状描述符呢?
最值得注意的是 Hu 矩,它可用于描述、表征和量化图像中物体的形状。
Hu 矩通常从图像中物体的轮廓或外形中提取。通过描述物体的轮廓,我们能够提取形状特征向量(即一列数字)来表示物体的形状。
然后,我们可以使用相似性度量或距离函数来比较两个特征向量,以确定形状有多“相似”。
在这篇博文中,我将向你展示如何使用 Python 和 OpenCV 提取 Hu 矩形状描述符。
OpenCV 和 Python 版本:
这个例子将运行在 Python 2.7/Python 3.4+ 和 OpenCV 2.4.X/OpenCV 3.0+ 上。
OpenCV 形状描述符:Hu 矩示例
正如我提到的,Hu 矩被用来描述图像中物体的轮廓或“轮廓”。
通常,我们在应用某种分割后获得这个形状(即,将背景像素设置为黑色,将前景像素设置为白色)。阈值化是获得我们的分割的最常见的方法。
在我们执行了阈值处理后,我们得到了图像中物体的轮廓。
我们也可以找到剪影的轮廓并画出来,这样就创建了物体的轮廓。
不管我们选择哪种方法,我们仍然可以应用 Hu 矩形状描述符,只要我们在所有图像上获得一致的表示。
例如,如果我们的目的是以某种方式比较形状特征,则从一组图像的轮廓提取 Hu 矩形状特征,然后从另一组图像的轮廓提取 Hu 矩形状描述符是没有意义的。
无论如何,让我们开始提取我们的 OpenCV 形状描述符。
首先,我们需要一张图片:

Figure 1: Extracting OpenCV shape descriptors from our image
这张图像是一个菱形,其中黑色像素对应图像的背景,白色像素对应前景。这是图像中一个物体的剪影的例子。如果我们只有菱形的边界,它将是物体的轮廓。
无论如何,重要的是要注意,我们的 Hu 矩形状描述符将只在白色像素上计算。
现在,让我们提取我们的形状描述符:
>>> import cv2
>>> image = cv2.imread("diamond.png")
>>> image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
我们需要做的第一件事是导入我们的cv2包,它为我们提供了 OpenCV 绑定。
然后,我们使用cv2.imread方法从磁盘上加载我们的钻石图像,并将其转换为灰度。
我们将图像转换为灰度,因为 Hu 矩需要单通道图像,形状量化只在白色像素中进行。
从这里,我们可以使用 OpenCV 计算 Hu 矩形状描述符:
>>> cv2.HuMoments(cv2.moments(image)).flatten()
array([ 6.53608067e-04, 6.07480284e-16, 9.67218398e-18,
1.40311655e-19, -1.18450102e-37, 8.60883492e-28,
-1.12639633e-37])
为了计算我们的 Hu 矩,我们首先需要使用cv2.moments计算与图像相关的最初 24 个矩。
从那里,我们将这些矩传递到cv2.HuMoments,它计算胡的七个不变矩。
最后,我们展平数组以形成我们的形状特征向量。
该特征向量可用于量化和表示图像中物体的形状。
摘要
在这篇博文中,我向你展示了如何使用 Hu Moments OpenCV 形状描述符。
在以后的博文中,我将向你展示如何比较 Hu 矩特征向量的相似性。
请务必在下面的表格中输入您的电子邮件地址,以便在我发布新的精彩内容时得到通知!
OpenCV 形状检测
原文:https://pyimagesearch.com/2016/02/08/opencv-shape-detection/
最后更新于 2021 年 7 月 7 日。
本教程是我们关于形状检测和分析的三部分系列的第二篇文章。
上周我们学习了如何使用 OpenCV 计算轮廓的中心。
今天,我们将利用轮廓属性来实际标记图像中的和形状,就像这篇文章顶部的图一样。
- 【2021 年 7 月更新:增加了新的章节,包括如何利用特征提取、机器学习和深度学习进行形状识别。
OpenCV 形状检测
在开始本教程之前,让我们快速回顾一下我们的项目结构:
|--- pyimagesearch
| |--- __init__.py
| |--- shapedetector.py
|--- detect_shapes.py
|--- shapes_and_colors.png
如您所见,我们定义了一个pyimagesearch模块。在这个模块中,我们有shapedetector.py,它将存储我们的ShapeDetector类的实现。
最后,我们有detect_shapes.py驱动程序脚本,我们将使用它从磁盘加载图像,分析它的形状,然后通过ShapeDetector类执行形状检测和识别。
在我们开始之前,确保您的系统上安装了 imutils 包,这是一系列 OpenCV 便利函数,我们将在本教程的后面使用:
$ pip install imutils
定义我们的形状检测器
构建形状检测器的第一步是编写一些代码来封装形状识别逻辑。
让我们继续定义我们的ShapeDetector。打开shapedetector.py文件并插入以下代码:
# import the necessary packages
import cv2
class ShapeDetector:
def __init__(self):
pass
def detect(self, c):
# initialize the shape name and approximate the contour
shape = "unidentified"
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.04 * peri, True)
第 4 行开始定义我们的ShapeDetector类。这里我们将跳过__init__构造函数,因为不需要初始化任何东西。
然后我们在第 8 行上有我们的detect方法,它只需要一个参数c,即我们试图识别的形状的轮廓(即轮廓)。
为了执行形状检测,我们将使用轮廓逼近。
顾名思义,轮廓近似是一种用减少的点集来减少曲线中点数的算法——因此有了术语近似。
这种算法通常被称为 Ramer-Douglas-Peucker 算法,或者简称为分裂合并算法。
轮廓近似是基于曲线可以由一系列短线段近似的假设。这导致了由原始曲线定义的点的子集组成的结果近似曲线。
轮廓近似实际上已经通过cv2.approxPolyDP方法在 OpenCV 中实现了。
为了执行轮廓近似,我们首先计算轮廓的周长(线 11 ),然后构建实际的轮廓近似(线 12 )。
第二个参数cv2.approxPolyDP的常用值通常在原始轮廓周长的 1-5%范围内。
注:有兴趣更深入地看看轮廓逼近吗?一定要去看看 PyImageSearch 大师课程,在那里我详细讨论了计算机视觉和图像处理基础知识,比如轮廓和连通分量分析。
给定我们的近似轮廓,我们可以继续执行形状检测:
# if the shape is a triangle, it will have 3 vertices
if len(approx) == 3:
shape = "triangle"
# if the shape has 4 vertices, it is either a square or
# a rectangle
elif len(approx) == 4:
# compute the bounding box of the contour and use the
# bounding box to compute the aspect ratio
(x, y, w, h) = cv2.boundingRect(approx)
ar = w / float(h)
# a square will have an aspect ratio that is approximately
# equal to one, otherwise, the shape is a rectangle
shape = "square" if ar >= 0.95 and ar <= 1.05 else "rectangle"
# if the shape is a pentagon, it will have 5 vertices
elif len(approx) == 5:
shape = "pentagon"
# otherwise, we assume the shape is a circle
else:
shape = "circle"
# return the name of the shape
return shape
理解一个轮廓由一系列顶点组成是很重要的。我们可以检查列表中条目的数量来确定物体的形状。
例如,如果近似轮廓有三个顶点,那么它一定是一个三角形(第 15 行和第 16 行)。
如果一个轮廓有个四顶点,那么它一定是一个正方形或者是一个矩形 ( 线 20 )。为了确定哪一个,我们计算形状的纵横比,纵横比就是轮廓边界框的宽度除以高度(行 23 和 24 )。如果长宽比大约为 1.0,那么我们正在检查一个正方形(因为所有边的长度都大致相等)。否则,形状为矩形。
如果一个轮廓有个五顶点,我们可以把它标为五边形 ( 第 31 和 32 线)。
否则,通过排除过程(当然,在这个例子的上下文中),我们可以假设我们正在检查的形状是一个圆 ( 第 35 行和第 36 行)。
最后,我们将识别出的形状返回给调用方法。
用 OpenCV 进行形状检测
既然已经定义了我们的ShapeDetector类,让我们创建detect_shapes.py驱动程序脚本:
# import the necessary packages
from pyimagesearch.shapedetector import ShapeDetector
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
我们从线 2-5 开始,导入我们需要的包。注意我们是如何从pyimagesearch的shapedetector子模块中导入ShapeDetector类的实现的。
第 8-11 行处理解析我们的命令行参数。这里我们只需要一个开关--image,它是我们想要处理的图像在磁盘上的路径。
接下来,让我们预处理我们的图像:
# load the image and resize it to a smaller factor so that
# the shapes can be approximated better
image = cv2.imread(args["image"])
resized = imutils.resize(image, width=300)
ratio = image.shape[0] / float(resized.shape[0])
# convert the resized image to grayscale, blur it slightly,
# and threshold it
gray = cv2.cvtColor(resized, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.threshold(blurred, 60, 255, cv2.THRESH_BINARY)[1]
# find contours in the thresholded image and initialize the
# shape detector
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
sd = ShapeDetector()
首先,我们在行 15 从磁盘加载我们的图像,并在行 16 调整它的大小。然后,我们在第 17 行的处记录旧高度的ratio到新调整后的高度——我们将在本教程的后面部分找到我们这样做的确切原因。
从那里,行 21-23 处理将调整大小的图像转换为灰度,平滑它以减少高频噪声,最后对它进行阈值处理以显示图像中的形状。
阈值处理后,我们的图像应该是这样的:
注意我们的图像是如何被二值化的——形状显示为白色前景的 T2 和黑色背景的 T4。
最后,我们在二进制图像中找到轮廓,根据 OpenCV 版本从cv2.findContours 中获取正确的元组值,最后初始化ShapeDetector ( 第 27-30 行)。
最后一步是识别每个轮廓:
# loop over the contours
for c in cnts:
# compute the center of the contour, then detect the name of the
# shape using only the contour
M = cv2.moments(c)
cX = int((M["m10"] / M["m00"]) * ratio)
cY = int((M["m01"] / M["m00"]) * ratio)
shape = sd.detect(c)
# multiply the contour (x, y)-coordinates by the resize ratio,
# then draw the contours and the name of the shape on the image
c = c.astype("float")
c *= ratio
c = c.astype("int")
cv2.drawContours(image, [c], -1, (0, 255, 0), 2)
cv2.putText(image, shape, (cX, cY), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (255, 255, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
在第 33 行的处,我们开始循环每个单独的轮廓。对于它们中的每一个,我们计算轮廓的中心,然后执行形状检测和标记。
由于我们正在处理从调整大小的图像(而不是原始图像)中提取的轮廓,我们需要将轮廓和中心 (x,y)-坐标乘以我们的调整大小ratio ( 第 43-45 行)。这将为我们提供原始图像的轮廓和质心的正确的 (x,y)-坐标。
最后,我们在图像上绘制轮廓和标记的形状(第 44-48 行),然后显示我们的结果(第 51 和 52 行)。
要查看我们的形状检测器的运行情况,只需执行以下命令:
$ python detect_shapes.py --image shapes_and_colors.png
从上面的动画中可以看到,我们的脚本分别遍历每个形状,对每个形状执行形状检测,然后在对象上绘制形状的名称。
使用特征提取和机器学习确定物体形状
这篇文章演示了简单的轮廓属性,包括轮廓检测、轮廓近似和检查轮廓中的点数,如何用于识别图像中的形状。
然而,还有更先进的形状检测技术。这些方法利用特征提取/图像描述符,并使用一系列数字(即“特征向量”)来量化图像中的形状。
你应该研究的第一个方法是经典的胡矩形符。Hu 矩通过cv2.HuMoments函数内置到 OpenCV 库中。应用cv2.HuMoments的结果是用于量化图像中形状的七个数字的列表。
然后我们有 Zernike moments 基于胡 moments 的研究和工作。应用 Zernike 矩的结果是用于量化图像中形状的 25 个数字的列表。Zernike 矩往往比 Hu 矩更强大,但可能需要一些手动参数调整(特别是矩的半径)。
可以用深度学习进行形状识别吗?
简而言之,是的,绝对的。基于深度学习的模型 excel 以及物体和形状识别。如果您正在处理简单的形状,那么即使是浅层的 CNN 也可能胜过 Hu 矩、Zernike 矩和基于轮廓的形状识别方法——当然,前提是您有足够的数据来训练 CNN!
如果你有兴趣学习如何训练你自己的定制深度学习形状识别算法,请确保你参加了我在 PyImageSearch 大学的深度学习课程。
摘要
在今天的博文中,我们学习了如何使用 OpenCV 和 Python 进行形状检测。
为了实现这一点,我们利用轮廓近似,这是一个将曲线上的点数减少到更简单的近似版本的过程。
然后,基于这个轮廓近似值,我们检查了每个形状的顶点数。给定顶点数,我们能够准确地标记每个形状。
本课是形状检测和分析三部分系列的一部分。上周我们讲述了如何计算轮廓的中心。今天我们讨论了 OpenCV 的形状检测。下周我们将讨论如何使用颜色通道统计 标记形状 的实际颜色。
请务必在下面的表格中输入您的电子邮件地址,以便在下一篇帖子发布时得到通知— 您不会想错过它的!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号