
Octopus-博客中文翻译-四-
Octopus 博客中文翻译(四)
原文:Octopus Blog
Golang 用于 AWS - Octopus 部署中的自动化

当我们想到自动化时,首先想到的是代码。我们可能会被问到的几个问题是:
- 什么编程语言最适合自动化?
- 团队需要学习什么样的简单明了的语言?
默认情况下,Golang 是一种基于过程的语言。这意味着它主要基于编写函数。当您想到自动化代码时,例如 PowerShell 或 Python,您可能会想到为脚本编写一些函数。正因为如此,Golang 是一个天然的选择。
在这篇博文中,您将学习如何使用 Golang 实现 AWS 自动化,就像使用 PowerShell 或 Python 一样。
先决条件
要跟进这篇博文,您需要以下内容:
- GoLang 的初级知识。
- AWS 的初级知识。
- Visual Studio 代码(VS 代码)。
- Golang 装机。
- 本地主机上的 AWS 配置。您可以通过安装 AWS CLI 并运行
aws configure来做到这一点。 - 正在运行的 EC2 实例。
确定使用什么包
在运行任何代码之前,您需要导入一些包,也称为库。在 Golang 中导入 AWS 包的主要方法是直接指向包所在的 GitHub 库。
要开始添加 Golang 代码,您需要一个保存代码的地方。为了这篇博文的目的,您可以在桌面上保存一个目录,并在 VS 代码中打开它。
- 创建一个新文件并命名为
main.go来存储 AWS 的 Golang 代码。 - 添加以下代码以创建主包并导入包列表:
package main
import (
"fmt"
"os"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/ec2"
)
特定于 AWS 的三个软件包是:
- github.com/aws/aws-sdk-go/aws:允许您连接到 AWS 包,特别是认证和指定您想要在 AWS 中工作的区域。
- github.com/aws/aws-sdk-go/aws/session:允许你创建一个新的会话来连接 AWS。
- github.com/aws/aws-sdk-go/service/ec2:允许您处理特定的 EC2 服务数据,如 EC2 状态、负载平衡器、公共 IP 等。
使用上面的软件包,您可以连接到 AWS 并开始使用可用的 Golang EC2 功能。
设置功能
上一节向您展示了如何设置主包和特定于 AWS 的包,需要导入这些包以便在编程级别与 AWS 进行交互。既然已经导入了 AWS 包,是时候开始编写ListInstances函数了,它将列出来自特定实例 ID 的元数据,您可以在运行时传入这些元数据。
AWS 连接
- 在
import下,设置一个名为listInstances的函数,在运行时传递一个名为instanceID的参数:
func listInstances(instanceID string) {
}
- 在该函数中,要设置的第一段代码是使用本地主机上现有的 AWS 配置连接到 AWS。该变量将被称为
awsConnect,并包含错误处理。session包用于调用aws包来指向本地主机上现有的 AWS 配置。然后,指定一个特定的区域(如果需要,可以随意更改):
awsConnect, err := session.NewSession(&aws.Config{
Region: aws.String("us-east-2")},
)
错误处理
接下来,为变量中配置的err添加错误处理。如果出现错误,它会简单地输出到屏幕上:
if err != nil {
fmt.Println(err)
}
启动 AWS 连接
启动 AWS 连接是通过EC2包中的New()方法完成的,并使用指向本地 AWS 配置的awsConnect变量:
ec2sess := ec2.New(awsConnect)
输出 EC2 信息
为了输出 EC2 实例元数据,ec2包与DescribeInstancesInput方法一起使用。在DescribeInstancesInput方法中,instanceID变量被传入(关于main函数的instanceID参数将在下一节中详细解释)。
传入实例 ID 后,有两个打印语句:
- 让用户知道 EC2 信息正在打印。
- 使用
DescribeInstances方法打印实例信息:
instanceInfo := &ec2.DescribeInstancesInput{
InstanceIds: []*string{aws.String(instanceID)},
}
fmt.Println("Listing EC2 Instance info...")
fmt.Println(ec2sess.DescribeInstances(instanceInfo))
}
配置主要功能
在上一节中,您配置了完成所有跑腿工作的主要功能。在本节中,您将配置主函数。main 函数执行以下操作:
- 运行
listInstances功能。 - 设置在
listInstances功能中用作参数的instanceID变量。
主函数中的instanceID变量使用了os.Args包,所以你可以在运行时传入值。这使得代码可以重用,因为它没有任何硬编码的 EC2 实例 id:
func main() {
instanceID := os.Args[1]
listInstances(instanceID)
}
运行代码
在前面三节中,您设置了检索 EC2 元数据信息所需的所有代码。整个程序应该是这样的:
package main
import (
"fmt"
"os"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/ec2"
)
func main() {
instanceID := os.Args[1]
listInstances(instanceID)
}
func listInstances(instanceID string) {
awsConnect, err := session.NewSession(&aws.Config{
Region: aws.String("us-east-2")},
)
if err != nil {
fmt.Println(err)
}
ec2sess := ec2.New(awsConnect)
instanceInfo := &ec2.DescribeInstancesInput{
InstanceIds: []*string{aws.String(instanceID)},
}
fmt.Println("Listing EC2 Instance info...")
fmt.Println(ec2sess.DescribeInstances(instanceInfo))
}
程序正确编写后,就该运行它了:
- 打开终端,进入
main.go程序所在的目录(cd)。 - 运行以下命令来运行 Golang 程序:
go run main.go instance_id
该程序成功完成后,您应该会看到类似于以下屏幕截图的输出:

恭喜你。您已经成功使用 Golang 从 AWS 检索 EC2 信息。
结论
自动化有几种方法,也有许多不同的编程语言来实现,但这并不意味着所有的编程语言都是自动化的最佳选择。当您为自动化编写脚本时,您需要一种易于阅读、直截了当并且为编写小函数而构建的编程语言。
在这篇博文中,您了解了如何编写一个小函数来检索 EC2 实例上的元数据,以及如何在 AWS 中自动执行这些任务。
介绍 Octopus Deploy 的 Google 云平台集成- Octopus Deploy
原文:https://octopus.com/blog/google-cloud-platform-integration
根据我们的公开路线图,我们引入了对谷歌云平台(GCP) 的内置支持。
随着这一增加,Octopus 现在为三大云提供商提供内置支持:
这满足了我们客户不断变化的需求,特别是那些拥有 GCP Kubernetes 集群并在 GCP 虚拟机上运行触角的客户。
Octopus 与 GCP 的内置集成允许您:
- 通过专用帐户类型连接到 GCP 并进行身份验证-这允许您集中和保护您的 GCP 身份验证,并在您的部署和操作手册中使用它
- 在现成的定制脚本中使用 GCP 命令行工具 gcloud
- 用地形创建和拆除 GCP 的基础设施
- 访问由谷歌容器注册中心(GCR) 托管的 Docker 图像
- 使用 Octopus 和 Kubernetes 在 GCP 部署、扩展和管理容器化应用程序
GCP 集成在 Octopus Deploy 2021.2 和更新版本中可用。Octopus Cloud 客户已经在运行该版本,内部客户现在可以下载该版本。
在我们的发布公告中了解更多关于 Octopus 2021.2 (Q3)发布的信息。
如何部署到谷歌云
为了看到这种新的集成,这篇文章解释了如何在 Octopus 中添加一个新的 Google Cloud 帐户,并运行一个gcloud脚本来创建一个新的 Kubernetes 集群。
谷歌云账户

要与 GCP 整合,首先要在 Octopus 中定义一个谷歌云账户。在 基础设施➜账户 中这样做,以及你已经拥有的任何 AWS 或 Azure 账户。
Octopus 管理 Google Cloud steps 使用的 GCP 凭证。这意味着您不需要担心部署过程或 runbook 中的认证,并且您可以运行预认证的gcloud脚本。
Google Cloud 帐户受到 JSON 凭证密钥文件的保护,该文件可以从分配给执行部署的实例的服务帐户中检索到。
了解关于创建谷歌云账户的更多信息,并查看谷歌云文档以获取关于创建服务账户和下载密钥文件的说明。
Google 云帐户变量

创建 Google Cloud 帐户后,可以通过类型为 Google Cloud Account 的项目变量在项目中访问它们。项目变量可用于部署和运行手册流程。
在我们的文档中了解有关设置 Google Cloud 帐户变量的更多信息。
运行 gcloud 脚本
Octopus Deploy 帮助你用 Google 云平台在目标上运行脚本。在本例中,我们创建了一个新的 Kubernetes 集群。
这些脚本通常依赖于目标工作人员可用的工具,但是有几个选项可以快速启动:
- 如果你用的是章鱼云,内置的“Windows 2016”动态工人已经预装了
gcloud。 - 另一个选项是使用 Octopus
worker-toolsDocker 图像和用于 workers 的执行容器。 - 一般来说,我们建议为您的员工提供您自己的工具。这使您可以控制工具版本,并可以确保它们与您试图执行的脚本兼容。
工人将部署工作从 Octopus 服务器转移到工人池中运行的其他机器上。Octopus Cloud 使用它们来执行定制脚本,它们也通常用于运行云平台和数据库部署的部署和运行手册工作。
当对 GCP 执行脚本时,Octopus 会自动使用您提供的 Google Cloud 帐户信息向目标实例验证您的身份。或者,您可以使用与目标实例关联的服务帐户。
【T2 
在本例中,您添加了一个新的 runbook 流程,以使用gcloud命令行界面创建一个新的 Kubernetes 集群。
为此,使用一个gcloud container clusters create命令将脚本中的Run g cloud步骤添加到您的自动化流程中。

您需要根据自己的需要定制脚本,但它应该是这样的:
echo "Create cluster"
gcloud container \
--quiet \
clusters create $(get_octopusvariable "Cluster Name") \
--no-enable-basic-auth \
--cluster-version "1.20.6-gke.1000" \
--release-channel "regular" \
--machine-type "e2-medium" \
--image-type "COS" \
--disk-type "pd-standard" \
--disk-size "100" \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_only","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--num-nodes "3" \
--enable-stackdriver-kubernetes \
--enable-ip-alias \
--network "projects/<your project>/global/networks/default" \
--subnetwork "projects/<your project>/regions/australia-southeast1/subnetworks/default" \
--default-max-pods-per-node "110" \
--no-enable-master-authorized-networks \
--addons HorizontalPodAutoscaling,HttpLoadBalancing,GcePersistentDiskCsiDriver \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--enable-shielded-nodes
结论
我们希望你喜欢在谷歌云平台上部署基础设施。
试试吧,让我们知道你的想法。如果您有任何问题或意见,我们很乐意倾听。请使用下面的评论区或加入章鱼社区 Slack 的对话。
愉快的部署!
章鱼部署 Gradle 插件-章鱼部署

对于上传到 Octopus 的包,如果您运行的构建服务器本身不受支持,您可以使用 Octopus 命令行(CLI)或 Octopus REST API。对于 Gradle 项目,我们( Liftric )创建了一个小的 Gradle 插件来帮助我们获得与官方支持的 CI-Servers 相似的、没有麻烦的体验:octopus-deploy-plugin。
目前,它支持以下用例:
- 创建并上传包构建信息
- 上传包
- 从 git 历史生成构建信息提交
- 进展八达通部署释放
设置示例项目
让我们生成一个 Spring Boot 启动项目来快速启动一个示例项目:
start.spring.io
示例项目必须是一个 Gradle 项目,并且该语言必须使用 Kotlin 在 Kotlin(而不是 Groovy)中生成 Gradle 构建文件。octopus- deploy-plugin 也可以与 Groovy 构建文件一起使用,但是所有的例子都使用 Gradle Kotlin DSL。
还必须添加弹簧腹板和 Spring Boot 致动器相关性。这添加了一个最小的 web 服务和一个健康端点,我们可以打开它来验证项目是否成功运行:

解压缩演示项目后,我们可以构建并运行它来验证它是否按预期工作:
./gradlew build
java -jar build/libs/demo-0.0.1-SNAPSHOT.jar
现在我们可以通过在http://localhost:8080/actuator/health调用健康端点来验证这一点。
配置 Octopus 部署插件
接下来,我们将添加 Gradle 插件并添加基本配置。完整的配置使用 Gradle Lazy 配置方法(Provider API ),该方法允许我们依赖其他提供者/任务进行配置,而无需在 Gradle 配置时对值进行硬编码。查看构建生命周期文档,了解为什么惰性配置方法是更好的方法。
com.liftric.octopus-deploy-plugin是插件 ID,当前版本是1.6.0:
plugins {
id("org.springframework.boot") version "2.4.0"
id("io.spring.dependency-management") version "1.0.10.RELEASE"
kotlin("jvm") version "1.4.10"
kotlin("plugin.spring") version "1.4.10"
id("com.liftric.octopus-deploy-plugin") version "1.6.0"
}
如果我们调用./gradlew任务,我们将看到插件添加的任务:
Octopus tasks
-------------
commitsSinceLastTag - Calls git log to receive all commits since the
previous tag or the first commit of the current history.
createBuildInformation - Creates the octopus build-information file.
firstCommitHash - Calls git log to get the first commit hash of the
current history tree
previousTag - Calls git describe to receive the previous tag name. Will
fail if no tag is found.
uploadBuildInformation - Uploads the created octopus build-information
file.
uploadPackage - Uploads the package to octopus.
现在我们必须配置插件(顶级扩展):
octopus {
packageName.set(project.name)
version.set(project.version.toString())
serverUrl.set("https://<cloud-instance-name>.octopus.app/")
apiKey.set("API-XXXXYYYYZZZZZXXXXYYYYYZZZZZ")
val bootJar by tasks.existing(Jar::class)
pushPackage.set(bootJar.get().archiveFile)
}
对于名称(packageName)和version,我们重用了由start.spring.io生成器设置的项目值(插件块下的版本,名称在settings.gradle.kts中配置)。对于自动版本控制,可能会使用类似于researchgate/gradle-release插件的东西,但是静态值对于我们的例子来说是很好的。
serverUrl需要您的 Octopus Deploy 实例的基本 URL,该示例使用云实例命名模式。了解如何创建 API 密匙。
在非原型项目中,出于安全原因,建议不要将秘密存储在构建脚本/存储库本身中。在 Liftric,我们使用 Hashicorp Vault 作为我们的秘密管理工具,甚至提供了一个访问它的小 Gradle 插件:https://github.com/Liftric/vault-client-plugin。读取安全/秘密环境变量(如 Gitlab 的屏蔽变量),或从 repo-external 文件(如~ ~/)读取。octopus)可能是成熟的秘密管理解决方案的替代方案。
最后,我们导入bootJar任务提供程序,并将archiveFile文件属性绑定到pushPackage属性,这样插件就知道上传哪个文件。
推送构建信息
uploadBuildInformation任务为package version组合构建并上传build-information:
./gradlew uploadBuildInformation
如果您想调试生成的构建信息,调用./gradlew createBuildInformation只构建它而不上传。内容将被打印,但也可以在build/octopus/build-information.json处查看。
推送包
uploadPackage任务上传目标pushPackage文件:
./gradlew uploadPackage
Octopus Deploy 在包上传期间有一个怪癖:它希望文件的格式是demo-0.0.1-SNAPSHOT.jar,它将上传版本为0.1-SNAPSHOT的包demo-0,这意味着我们必须修改我们的引导 jar 工件的命名:
tasks.withType<Jar> {
archiveFileName.set("${archiveBaseName.get().removeSuffix("-
")}.${archiveVersion.get()}.${archiveExtension.get()}")
}
现在创建了正确的 jar 文件名:demo.0.0.1-SNAPSHOT.jar,它与我们生成的构建信息相匹配。
了解更多信息
octopus-deploy-plugin 的完整特性集记录在项目的报告中。
集成 Octopus 和 Grafana - Octopus 部署

Octopus 长期以来一直通过/api/reporting/deployments/xml API 端点公开部署数据。有了 Octopus 的 Grafana datasource 的 EAP 版本,这些信息可以很容易地可视化,允许团队跟踪他们的部署成功和频率。
在这篇文章和截屏中,我将向您展示如何安装 Grafana 插件,导入示例仪表板,以及定制图表来显示对您重要的信息。
截屏
https://www.youtube.com/embed/bPmjJkkEa3g
VIDEO
安装插件
这个插件可以通过项目的 GitHub 发布页面获得。
ZIP 文件需要解压到 Grafana 插件目录下的子目录中。在 Linux 上,这个目录通常是/var/lib/grafana/plugins,对于 Windows,默认目录是INSTALL_DIR\data\plugins。
对于这个例子,我将部署到 Ubuntu 20.04,我将使用以下命令提取 zip 文件:
unzip octopus_grafana_datasource.zip -d /var/lib/grafana/plugins/octopus
允许加载未签名的插件
Grafana 区分了签名插件和未签名插件。Octopus 插件是未签名的,必须在 Grafana 中明确允许。这是通过编辑grafana.ini文件来完成的。在我的 Ubuntu 虚拟机上,这可以在/etc/grafana/grafana.ini找到。
我们需要配置的设置是[plugins]部分下的allow_loading_unsigned_plugins。该设置必须列出 Octopus 插件的 ID:
[plugins]
allow_loading_unsigned_plugins = octopus-deploy-xmlfeed
Grafana 必须重启以加载新的配置,然后加载 Octopus 插件。
配置数据源
Octopus 数据源有两个属性:
- 章鱼服务器
- Octopus API 密钥

Octopus 数据源配置。
导入示例仪表板
我们已经提供了一个显示通用部署指标的示例仪表板。该仪表板可从 Grafana 仪表板库获得。要导入它,点击左侧面板上的仪表盘图标,点击管理,然后点击导入。在通过 grafana.com导入选项下,可以加载https://grafana.com/grafana/dashboards/13413的示例仪表板 URL:

导入样本仪表板。
选择上面创建的数据源并完成导入后,将显示以下仪表板:

样本仪表板。
仪表板变量
该插件将空间、环境、项目、渠道和租户作为仪表板查询变量公开:

配置为查询变量的环境的例子。
然后,这些变量会显示在仪表板的顶部,以自定义在图表中显示哪些部署。变量可以通过空间名称过滤器、项目名称过滤器、环境名称过滤器、通道名称过滤器和租户名称过滤器字段在查询中引用:

查询中使用的变量。
可用指标
该插件公开了许多指标:
- 成功:设置为 1 表示部署成功,否则设置为 0。
- 失败:设置为 1 表示部署失败,否则设置为 0。
- 取消:设置为 1 表示取消部署,否则设置为 0。
- 超时:超时部署设置为 1,否则设置为 0。
- 总持续时间:在给定时间段内部署所花费的总时间。
- 平均持续时间:给定时间段内部署的平均时间。
- 总恢复时间:在给定的时间段内,一次失败的部署和下一次成功的部署之间的总时间。
- 平均恢复时间:在给定的时间段内,一次失败的部署和下一次成功的部署之间的平均时间。
- 总部署提前期:在给定时间段内,从创建发布到完成部署的总时间。
- 平均部署提前期:在给定时间段内,从创建发布到完成部署的平均时间。
计算总部署提前期和平均部署提前期值需要额外调用 Octopus API,因此如果不需要这些值,就不应该选择它们。
结论
我们希望 Grafana 插件能让您深入了解部署的进展情况。这是一个 EAP 版本,所以我们预计会有错误和功能差距,并且只建议在这个阶段进行测试,但是如果您有任何建议或问题,请通过常规支持渠道联系我们。
愉快的部署!
Octopus 2.0 引导失败:RFC - Octopus 部署
这是由尼克写的一篇文章,他本周一直致力于这个专题。
一个破碎的构建是令人讨厌的,有时令人沮丧和适得其反,但很少是危机。当出现问题时,构建服务器理所当然地“快速失败”,并且当问题被纠正时,期望从零开始执行全新的构建。
在 Octopus 1.0 中,我们也使用了这个模型。但是,中断的部署与中断的构建有一点不同:如果部署在生产中中断,那么通常会有一个升级和“所有人都在甲板上”直到部署成功完成。部署中断会导致停机,尽管在理想情况下,冗余和回滚可能会挽救局面,但通常:
- 回滚过程,尤其是对于数据库,很难可靠地实现
- 一旦纠正了故障原因,执行复杂的部署可能会非常耗时
- 一台机器的故障,比如说,五台服务器中的一台,最好忽略掉,而不是停止剩下的部署任务
有时失败的原因很简单,如缺少依赖项、计算机上的 Windows 功能或配置设置、锁定的文件或只读路径。从中断到部署的最快方法是让一个人参与进来,当有意义时,忽略或重试失败的活动。
因此,在 Octopus 2.0 中,虽然我们的默认策略仍然是像第一个版本一样“快速失败”,但我们正在探索在出现问题时让人类参与解决问题的可能性。我们称这个特性为引导失败。
为了避免解决问题的人之间的意外“竞赛”,你需要在采取行动之前负责解决失败。
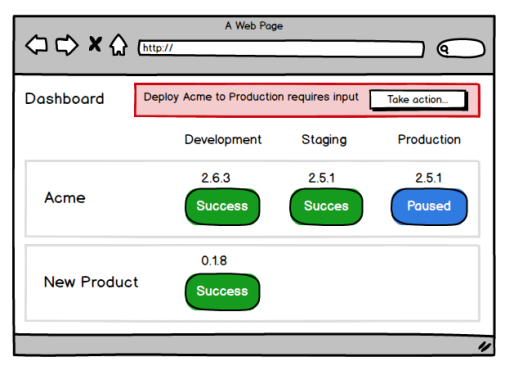
一旦您决定对失败采取行动,您就可以查看关于错误的完整信息以及部署的其余部分的进度。

选择忽略失败将导致部署继续,尽管有错误,可能导致更多的失败。重试失败的动作将导致 Octopus 再次尝试,而选择失败将导致部署像今天一样结束。
许多故障发生在大型环境中的多台机器上。为了保持开销最小,我们将允许忽略和重试动作在一个步骤中对所有类似的活动应用一次。
引导式故障将针对每个环境启用,因此它可以在生产等关键环境中启用,而不会妨碍持续部署的构建和测试脚本。该行为也将能够在每次部署的基础上被覆盖。
你怎么想呢?引导失败对你部署 Octopus 有帮助吗?我们希望在下面的评论中得到您的反馈。
Halibut:一个安全的通信栈。网络/单章鱼部署
我最近在 CodeProject 上写了一篇关于比目鱼的文章,比目鱼是 WCF 的一个开源、安全的替代品。大比目鱼是在我研究如何让章鱼触手代理服务在 Mono 下运行时出现的。
作为一个自动化部署工具,Octopus 需要能够将包和配置信息推送到可能在本地网络或云中的机器上。为了安全地做到这一点,八达通的用户建立了双向信任关系。
在 Octopus Deploy 中,我们使用 X.509 证书和 WCF 的 wsHttpBinding 栈。建立连接后,每一方都要验证另一方提供的证书的指纹。如果公钥不是我们所期望的,我们拒绝连接。
在未来的版本中,我们希望给 Octopus 增加 Mono 支持,这样我们就可以将包部署到 Linux 和其他类似 Unix 的操作系统上。但是有一个问题: WCF 的
wsHttpBinding在 Mono 上不被支持。面对这个问题,我们需要想出一个替代的通信栈。
在 Mono 上运行触须会很棒。当然,有些事情需要有所不同。例如,我们可能会调用 Shell 脚本,将 Octopus 变量作为环境变量传递,而不是调用 PowerShell 脚本。但是,如果我们能取代 WCF 作为通讯栈,我们将会走得很好。
切换通信栈有点棘手,尤其是因为 Octopus 需要使用旧协议来将现有代理升级到新协议。我希望我们能在未来的版本中透明地做到这一点,大概是在 Octopus 2.0 左右。
哈希 API 密钥以提高安全性- Octopus 部署
在 Octopus Deploy 中,当使用用户名/密码认证时,我们总是小心翼翼地用盐来散列密码,并且我们从不存储纯文本。在早期版本中,我们使用 SHA1 散列,去年三月我们改用 PBKDF2 。
然而,当使用我们的 HTTP API 时,您也可以使用 API 密钥进行认证。像大多数应用程序一样,我们将 API 密钥存储为一个纯文本字符串(尽管Octopus 数据库本身是加密的)。

许多基于网络的应用程序都是这样工作的——登录后,你会发现一个纯文本的 API 密匙。这意味着密钥可能以纯文本的形式存储在数据库中,或者可以被解密。这意味着,如果有人能够以某种方式从数据库中读取内容,他们就有可能获取您的 API 密钥并使用它来冒充您。
亚马逊网络服务最近做了一个改变。过去,您可以在需要时随时返回 AWS 门户获取 API 密钥。现在,当你要一个 API 密匙的时候,他们会给你一次,你应该自己保存它。我不知道他们是否计划开始存储散列的密钥,但这可能是有意义的。
在 Octopus Deploy 2.2 中,我们将做一些类似的事情。我们将使用 PBKDF2 存储经过散列和加盐的 API 密钥,就像我们存储密码一样。您将无法再从门户网站获取您的 API 密钥,因为就像密码存储一样,它是不可逆的。我们还将使保留多个 API 密钥成为可能,并在其中一个密钥泄露、意外共享或不再需要时停用它们。

当您请求一个 API 密钥时,您可以给它一个名称。我们假设您将立即使用 API 键进行特定的集成。

生成密钥后,您只能看到密钥一次,我们只存储散列版本。如果你需要再次使用它,把它放在一个安全的地方,比如一个密码管理工具。

为了改进审计,我们还将添加在您对任何审计事件使用 API 密钥时使用的身份验证方法。这样,如果一个 API 键被破坏并被用来做一些淘气的事情,你就知道该停用哪个 API 键。
Selenium 系列:无头浏览器- Octopus Deploy
原文:https://octopus.com/blog/selenium/10-headless-browsers/headless-browsers
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
你现在应该已经注意到,用 WebDriver 运行测试会打开一个浏览器窗口,加载网页并与之进行交互,就好像通过某种看不见的鼠标指针一样。虽然在浏览器中观察测试的进展是很有用的,但有时还是希望测试在屏幕外完成。例如,作为连续部署过程的一部分运行测试,不需要任何人在测试执行时监视浏览器。事实上,有时甚至没有一个监视器连接到运行测试的系统上;这就是所谓的无头环境。那么我们如何在这样的无头环境中运行测试呢?
像 PhantomJS 这样的项目就是为了解决这个问题而创建的。PhantomJS 是一个基于 WebKit 的 web 浏览器,WebKit 是支持 Apple Safari 等浏览器的库。然而与传统浏览器不同的是,PhantomJS 没有 GUI,它被设计为由 WebDriver 等技术控制。因为它没有 GUI,所以 PhantomJS 可以在持续集成服务器上运行,而这些服务器传统上是在无头服务器上托管的。这意味着您可以在中央服务器上运行 WebDriver 测试来响应应用程序的更改,而不必在桌面环境中启动浏览器窗口。
最近,像 Firefox 和 Chrome 这样的浏览器增加了对无头浏览的本地支持。这对任何编写 WebDriver 测试的人来说都是一个很大的好处,因为这意味着测试可以在最终用户已经安装的浏览器上运行,同时仍然允许测试在一个无头服务器上运行。
如今幻想曲的发展已经停滞。项目的一个维护者已经下台,PhantomJS 最新发布已经 2 年多了。但好消息是,配置 Chrome 和 Firefox 在无头环境中运行测试非常容易。
在我们开始配置无头浏览器之前,我们需要为配置驱动程序类添加一些额外的支持。
WebDriver 使用一个名为DesiredCapabilities的类作为浏览器驱动设置的通用容器。DesiredCapabilities类本质上是一个键/值对的容器,带有一些配置常用设置的方便方法。
首先,我们将方法getDesiredCapabilities()添加到AutomatedBrowser接口:
public interface AutomatedBrowser {
// ...
DesiredCapabilities getDesiredCapabilities();
// ...
}
然后我们在AutomatedBrowserBase类中添加一个默认方法。
该方法与典型的默认装饰方法实现略有不同,如果没有父AutomatedBrowser实例返回DesiredCapabilities类的实例,我们返回一个新的DesiredCapabilities实例,而不是null。这确保了如果没有装饰者提供任何DesiredCapabilities,我们总是可以依赖返回的默认实例:
@Override
public DesiredCapabilities getDesiredCapabilities() {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getDesiredCapabilities();
}
return new DesiredCapabilities();
}
DesiredCapabilities类用于所有浏览器通用的配置设置。每个驱动程序都有一个相应的“选项”类,用于配置浏览器的特定设置。这两个对象合并在一起以构建完整的配置设置集。
下面是为支持这两个配置类而更新的ChromeDecorator类的代码。我们创建了一个ChromeOptions类的实例,merge()用getDesiredCapabilities()返回的公共设置,并将合并的结果传递给ChromeDriver()构造函数。
这段代码还没有配置任何额外的设置,但是它演示了如何将DesiredCapabilities类与浏览器特定的选项类结合使用:
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class ChromeDecorator extends AutomatedBrowserBase {
public ChromeDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
}
@Override
public void init() {
final ChromeOptions options = new ChromeOptions();
options.merge(getDesiredCapabilities());
final WebDriver webDriver = new ChromeDriver(options);
getAutomatedBrowser().setWebDriver(webDriver);
getAutomatedBrowser().init();
}
}
我们对FirefoxDecorator类采用相同的模式,将FirefoxDriver类与DesiredCapabilities类合并:
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
public class FirefoxDecorator extends AutomatedBrowserBase {
public FirefoxDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
}
@Override
public void init() {
final FirefoxOptions options = new FirefoxOptions();
options.merge(getDesiredCapabilities());
final WebDriver webDriver = new FirefoxDriver(options);
getAutomatedBrowser().setWebDriver(webDriver);
getAutomatedBrowser().init();
}
}
通过配置ChromeOptions或FirefoxOptions实例,可以在无头模式下启动浏览器。
为了在无头模式下启动 Chrome,我们将一些参数传递给chrome可执行文件。ChromeOptions类通过方法setHeadless()提供了配置这些参数的简单方法。
让我们来看看允许我们在无头模式下运行 Chrome 的ChromeDecorator类的代码:
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class ChromeDecorator extends AutomatedBrowserBase {
final boolean headless;
public ChromeDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.headless = false;
}
public ChromeDecorator(final boolean headless, final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.headless = headless;
}
@Override
public void init() {
final ChromeOptions options = new ChromeOptions();
options.setHeadless(headless);
options.merge(getDesiredCapabilities());
final WebDriver webDriver = new ChromeDriver(options);
getAutomatedBrowser().setWebDriver(webDriver);
getAutomatedBrowser().init();
}
}
首先,我们提供一个名为headless的实例变量来跟踪 Chrome 浏览器的这个实例是否应该以无头模式运行。为了设置这个变量,我们重载构造函数:
final boolean headless;
public ChromeDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.headless = false;
}
public ChromeDecorator(final boolean headless, final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.headless = headless;
}
在init()方法中,我们调用setHeadless()来启用或禁用无头模式(尽管默认情况下给定的无头模式是禁用的,调用setHeadless(false)不会改变任何事情):
options.setHeadless(headless);
看一下ChomeOptions.setHeadless()方法,我们可以看到通过将--headless和--disable-gpu参数传递给 Chrome 来启用无头模式:
public ChromeOptions setHeadless(boolean headless) {
args.remove("--headless");
if (headless) {
args.add("--headless");
args.add("--disable-gpu");
}
return this;
}
然后,我们用一个参数来更新AutomatedBrowserFactory getChromeBrowser()方法,以定义 Chrome 浏览器是否应该是无头的:
private AutomatedBrowser getChromeBrowser(final boolean headless) {
return new ChromeDecorator(headless,
new ImplicitWaitDecorator(10,
new WebDriverDecorator()
)
);
}
最后,我们更新了getAutomatedBrowser()方法,允许创建一个 Chrome 的无头实例:
public AutomatedBrowser getAutomatedBrowser(String browser) {
if ("Chrome".equalsIgnoreCase(browser)) {
return getChromeBrowser(false);
}
if ("ChromeHeadless".equalsIgnoreCase(browser)) {
return getChromeBrowser(true);
}
// ...
}
有了这些变化,我们就可以更新测试,在 Chrome 的一个无头实例上运行它们。
当测试运行时,您将看不到浏览器窗口。但是测试将在后台执行,并像以前一样通过:
@Test
public void formTestByIDHeadless() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("ChromeHeadless");
// ...
}
创建 Firefox 的无头实例的过程与 Chrome 几乎完全相同。
首先用一个设置headless实例变量的构造函数来更新FirefoxDecorator类,并且调用 options 类中的setHeadless()来配置驱动程序上的无头模式:
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
public class FirefoxDecorator extends AutomatedBrowserBase {
final boolean headless;
public FirefoxDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.headless = false;
}
public FirefoxDecorator(final boolean headless, final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.headless = headless;
}
@Override
public void init() {
final FirefoxOptions options = new FirefoxOptions();
options.setHeadless(headless);
options.merge(getDesiredCapabilities());
final WebDriver webDriver = new FirefoxDriver(options);
getAutomatedBrowser().setWebDriver(webDriver);
getAutomatedBrowser().init();
}
}
查看FirefoxOptions.setHeadless()方法,我们可以看到通过将-headless参数传递给 Firefox 来启用无头模式:
public FirefoxOptions setHeadless(boolean headless) {
args.remove("-headless");
if (headless) {
args.add("-headless");
}
return this;
}
然后更新AutomatedBrowserFactory getFirefoxBrowser()方法以支持设置无头模式:
private AutomatedBrowser getFirefoxBrowser(final boolean headless) {
return new FirefoxDecorator(headless,
new ImplicitWaitDecorator(10,
new WebDriverDecorator()
)
);
}
并且更新了getAutomatedBrowser()方法以支持创建 Firefox 的 headless 实例:
public AutomatedBrowser getAutomatedBrowser(String browser) {
//...
if ("Firefox".equalsIgnoreCase(browser)) {
return getFirefoxBrowser(false);
}
if ("FirefoxHeadless".equalsIgnoreCase(browser)) {
return getFirefoxBrowser(true);
}
//...
}
然后,就像 Chrome 浏览器一样,测试可以更新为使用 Firefox 的 headless 版本:
@Test
public void formTestByIDHeadlessFirefox() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("FirefoxHeadless");
// ...
}
在像 PhantomJS 这样行为不太像真正的浏览器的专用浏览器上运行测试曾经是测试人员的一个痛点,但却是一个不可避免的祸害。通过支持无头浏览,Chrome 和 Firefox 等浏览器为测试人员在无头服务器上的自动化测试中使用最终用户使用的相同浏览器铺平了道路。当我们与 Travis CI 和 AWS Lambda 等平台集成时,我们将在以后的帖子中利用这些无头浏览器。
此外,通过暴露通过DesiredCapabilities类配置浏览器的能力,我们提供了一个钩子,我们可以利用新的 decorators 来添加功能,如自定义代理,这正是我们将在下一篇文章中做的。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
高可用性性能优势- Octopus 部署
Octopus Deploy 高可用性是我们为 Octopus Deploy 已成为关键基础架构的客户提供的产品。除了额外的可靠性之外,高可用性还提供了优于单个 Octopus 服务器的性能增益。我们的目标是随着您向高可用性集群添加节点,提供线性的性能提升。进入触手军。
我们在 Amazon EC2 上测试了高可用性,配置如下:
- m3.2xlarge 上的 Octopus 服务器(8 个 vCPU,30GB 内存)
- m3.large 上的章鱼触手(2 个 vCPU,7.5GB 内存)
- m3.large 上的 SQL Server 2014 Express
- m3.large 上的 Samba 文件共享
- 弹性负载平衡器 ping/API
我们对 150 个从 10MB 到 1000MB 的包的部署进行了排队,有些是脚本,有些是工件。部署的包的总大小刚刚超过 50GB,计算了大量的增量压缩,给 CPU 和文件共享带来了压力。
结果是:

一台八达通服务器在 35 分钟内完成所有部署,而两台八达通服务器需要 18 分钟,三台八达通服务器需要 11 分钟。两台 Octopus 服务器的速度是一台的两倍,三台服务器的速度是一台的三倍。这是我们希望实现的线性性能提升。
瓶颈
在进行这些测试时,我们遇到了一些影响集群执行部署速度的瓶颈。以下是我们发现的一些瓶颈:
- 使用外部 NuGet 提要对性能有很大的影响,因为节点中的所有 Octopus 服务器都是同时从提要中获取包的。使用 Octopus 服务器内置的包存储库消除了这个瓶颈。
- 让多个服务器部署到同一个触手会限制速度。在这些测试中,没有触手重叠。
- 每个 Octopus 服务器节点并发运行任务的限制会影响性能。我们使用默认值 5。
我们有一些最后的测试和工作要做,然后我们将在几周内提供高可用性供试用。我们希望你会喜欢它!

我们正在招聘:支持工程师(x2,美国)-章鱼部署
现在我们的全职团队都在澳大利亚。对于产品开发来说,没什么区别。但这确实使在美国时区提供支持变得困难。凌晨 5:00 的支持电话很难打,我们可能没有心情在早上的那个时间诊断生产问题。
传统上,Octopus 的支持一直是一种被动的立场——人们尝试我们的软件,如果他们遇到问题,他们会伸出援手,我们会提供支持。我的目标是将我们的支持能力从被动发展为主动支持。
考虑到这一点,我们目前正在为美国招聘两名全职支持团队成员。如果你知道章鱼,并且住在美国或美国友好的时区,为什么不加入我们呢?帮助我们从生产部署中消除远程桌面!
如果您同意我们的观点,即支持是公司最重要的工作之一,支持人员应该就功能设计和产品更改进行咨询,并且您真的很想打动和取悦客户,那么我们很乐意聘用您。支持工程师
(我们还在招聘一名布里斯班的测试工程师
空心广口瓶介绍-章鱼部署
我过去曾经写过关于应用服务器和 UberJAR 之间的区别。简而言之,应用服务器是一个并行托管多个 JavaEE 应用程序的环境,而 UberJAR 是一个自包含的可执行 JAR 文件,它启动并托管单个应用程序。
在这两种风格之间还有另一种风格的 JAR 文件,叫做空心 JAR。
什么是空心罐子?
空心 JAR 是一个单独的可执行 JAR 文件,像 UberJAR 一样,包含启动一个应用程序所需的代码。但是与 UberJAR 不同,空心 JAR 不包含应用程序代码。
然后,典型的中空 JAR 部署将由两个文件组成:中空 JAR 本身,以及保存应用程序代码的 WAR 文件。然后,空心 JAR 引用 WAR 文件来执行,从那时起,这两个文件就像 UberJAR 一样运行。
乍一看,用两个文件组成一个空心 JAR 部署,而不是用一个文件组成 UberJAR,这似乎没有什么效果,但是有一些好处。
主要的好处来自于空心 JAR 部署对的 JAR 组件不会经常改变。虽然您可能期望每天多次部署 WAR 半部署的新版本,但是 JAR 半部署将在几周或几个月内保持静态。这在构建分层容器图像时特别有用,因为只需要将修改后的 WAR 文件添加为容器图像层。
同样,您也可以使用 AWS 自动伸缩组这样的技术来减少构建时间。因为 JAR 文件不经常更改,所以可以将它放入 AMI 中,而 WAR 文件可以在 EC2 实例部署时通过 EC2 用户数据字段中的脚本下载。
建造一个中空的罐子
要想看到实际使用的空心罐子,让我们来看看如何用野生蜂群来制作一个。
对于这个演示,我们将构建运行一个 Ticket Monster 演示应用程序所需的一对空心 JAR 部署文件。Ticket Monster 是一个示例应用程序,创建它是为了演示一系列 JavaEE 技术,旨在构建一个在传统应用服务器上运行的 WAR 文件。
为了构建中空罐子的一半,我们将使用 SwarmTool 。与 WildFly Swarm 不同,它通常需要在 Maven 项目中进行特殊配置来构建 UberJAR 或空心 JAR,SwarmTool 通过检查现有的 WAR 文件并构建一个空心 JAR 来容纳它。这是一种将现有应用程序迁移到 Swarm 平台的简洁方式,无需修改现有的构建过程。
首先,从https://github.com/jboss-developer/ticket-monster克隆票怪源代码。我们感兴趣的代码在demo子文件夹下。
为了适应 Java 9 和 SwarmTool,我们需要对demo子文件夹下的pom.xml文件做两处修改。
首先,我们需要添加对javax.xml.bind:jaxb-api的依赖。这是因为java.xml包不再是 Java 9 的一部分。如果您尝试在 Java 9 下编译应用程序而没有这个额外的依赖项,您将收到以下错误:
java.lang.NoClassDefFoundError: javax/xml/bind/JAXBException
下面的 XML 添加了所需的依赖项:
<dependencies>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
第二个变化是将 Ticket Monster 使用的 Jackson 库嵌入到 WAR 文件中。在原始源代码中,Jackson 库的作用域是provided,这意味着我们期望应用服务器(或者在我们的例子中是 Hollow JAR)提供这个库。
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-jackson-provider</artifactId>
<scope>provided</scope>
</dependency>
然而,我们将使用的 Swarm 版本与 Ticket Monster 应用程序使用的 Jackson 库版本不同。这种不匹配意味着 Swarm 提供的 Jackson 库版本无法识别 Ticket Monster 使用的@JsonIgnoreProperties注释,从而导致一些序列化错误。
幸运的是,所需要的只是使用默认的作用域,这将把 Jackson 库的正确版本嵌入到 WAR 文件中。嵌入在 WAR 文件中的依赖项优先,因此应用程序将按预期运行。
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-jackson-provider</artifactId>
</dependency>
我们现在可以像构建任何其他 WAR 项目一样构建 Ticket Monster 应用程序。以下命令将构建 WAR 文件。
mvn package
现在我们需要使用 SwarmTool 来构建空心罐子。在本地下载 SwarmTool JAR 文件。
wget https://repo1.maven.org/maven2/org/wildfly/swarm/swarmtool/2017.12.1/swarmtool-2017.12.1-standalone.jar
然后造一个空心罐子。
java -jar swarmtool-2017.12.1-standalone.jar -d com.h2database:h2:1.4.196 --hollow target/ticket-monster.war
-d com.h2database:h2:1.4.196参数指示 SwarmTool 将内存数据库依赖关系中的 H2 添加到空心 JAR 中。SwarmTool 可以通过扫描应用程序代码引用的类来检测启动 WAR 文件所需的大多数依赖项。然而,它不能像数据库驱动程序那样检测依赖性,所以我们需要手动告诉 SwarmTool 包含这种依赖性。
--hollow参数指示 SwarmTool 构建一个不嵌入 WAR 文件的空心 JAR。如果我们不使用这个参数,WAR 文件将被嵌入到生成的 JAR 文件中,创建一个 UberJAR 而不是一个空心的 JAR。
现在,我们有了两个文件,它们组成了我们的 Hollow JAR 部署。位于target/ticket-monster.war的 WAR 文件包含我们的应用程序,而ticket-monster-swarm.jar文件是我们的空心罐子。
执行空心罐子
要运行该应用程序,请使用以下命令。
java -jar ticket-monster-swarm.jar target/ticket-monster.war
然后,您可以打开 http://localhost:8080 来查看该应用程序。

结论
空心 JAR 是一种简洁的解决方案,它在保留 UberJAR 的便利性的同时,在部署策略上提供了很大的灵活性。你可以从博客文章中找到更多关于不同策略的信息,关于肥胖、瘦、空心和优步。
如果您对 Java 应用程序的自动化部署感兴趣,下载 Octopus Deploy 的试用版,并查看我们的文档。
家庭自动化的经验教训- Octopus 部署

在 Octopus Deploy,我们痴迷于自动化。正如你所料,这种痴迷超越了部署,我们许多人都涉足家庭自动化领域。
家庭自动化允许我们做一些事情,比如当我们的车进入车道时,让我们的车库门自动打开,或者如果有人被锁在外面,用手机打开门。
虽然家庭自动化是一个有趣的爱好,但它也伴随着挑战。在这篇文章中,我回顾了我在家里使用智能产品时学到的一些经验。
第一课:Z-Wave、Zigbee 和 WiFi
也许我学到的最重要的一课是,并非所有的智能设备都以相同的方式通信,它们可能需要特殊的设备来操作。
智能设备分为三个不同的通信类别:
Z-Wave 和 Zigbee 不会直接连接到您的家庭网络。它们需要中间的东西来接收和传输指令。这些设备通常以集线器的形式出现,集线器是连接到您的网络的一个硬件,可以是有线的,也可以是无线的。
一些中心是品牌特定的,例如 Phillips Hue,除了他们的品牌之外,不与任何东西交流。其他集线器更通用,兼容大多数东西,可能包括 Z-Wave 和 Zigbee 功能。三星 SmartThings 就是一个很好的例子。
虽然集线器是最常见的设备,但也可以通过 USB 适配器与 Z-Wave 和/或 Zigbee 设备通信。我将在这篇文章的后面深入探讨这个问题。
z 波
Z-Wave 是一种网状网络技术,使用低能量无线电波(通常为 900 MHz 频段)进行通信。作为一种网状网络技术,Z-Wave 设备连接到恒定的电源,如智能插头或智能灯泡,它们可以像中继器一样工作,允许您将设备放置在远离集线器的地方。
Zigbee
Zigbee 类似于 Z-Wave,因为它也是一种低能量无线电波网状网络技术。然而,Zigbee 使用 2.4 GHz 频段进行通信,类似于 WiFi 的 B/G/N 频段。
如上所述,Zigbee 设备也需要使用集线器来进行通信。就像 Z-Wave 一样,连接到恒定功率的设备充当中继器,以扩展 Zigbee 网络的范围。
无线局域网(wireless fidelity 的缩写)
WiFi 设备是三种设备中唯一不需要集线器进行通信的设备。这些设备连接到你的 WiFi 网络,所以更容易与谷歌家庭助手或亚马逊 Alexa 等东西进行通信。
大多数支持 WiFi 的智能设备工作在 2.4 GHz 频段,这是有意义的,因为他们的数据需求通常很小,而 2.4 的范围更大。与 Z-Wave 和 Zigbee 不同,WiFi 设备依赖于接入点位置,不提供范围扩展功能。
第 2 课:网状网络父设备
Zigbee 和 Z-Wave 设备都将自己连接到网状网络上的父设备。一旦联系上,他们不会主动寻找“更好”的父母,直到与第一个父母的沟通中断。
要更新 Z-Wave 以使用新的父设备,您可能需要从网络中移除该设备并重新添加它(一些应用程序具有“修复网络”功能,该功能将强制它寻找新的父设备)。
然而,Zigbee 可以找到一个新的父母,如果你关掉旧的,迫使它去找别的东西。
我学到的教训是:如果孩子仍然可以与父母沟通,它“认为”它仍然在线,即使父母不再与其父母或集线器沟通。
第三课:有这样一个应用程序
在我的家庭自动化之旅中,早期的问题之一是每个品牌的设备都需要自己的应用程序来控制它们,或者至少执行初始设置。为每个品牌设置一个账户来配置设备很快就变得很繁琐。

我的建议是,确定你想用你的家庭自动化做什么,研究可用的品牌,尽量减少你需要的应用程序的数量。大多数 WiFi 设备都兼容 Google Home 或亚马逊 Alexa,因此一旦配置好,你就不一定需要他们的应用程序来控制设备。
第 4 课:当心应用程序需求
我碰到一个智能插头,广告上说价格很低。在购买之前,我阅读了评论,发现它的应用程序需要访问你的联系人。那对我来说是一个危险信号。
第五课:Google Home、Amazon Alexa 和 Apple HomeKit 的兼容性
最受欢迎的两种语音控制设备是谷歌 Home 和亚马逊 Alexa。绝大多数支持 WiFi 的智能设备将同时支持这两种技术。然而,也有一些没有,所以在购买前要仔细检查。
Apple HomeKit 的生态系统较小,所以如果这是你的自动化平台,请对你正在考虑的设备进行研究。
就 Zigbee 或 Z-Wave 而言,仅仅因为你的集线器兼容,并不意味着谷歌、亚马逊或苹果将与连接到它们的设备一起工作。
例如,我有一个三星 SmartThings hub 来控制我的 Z-Wave 和 Zigbee 设备。我的集线器连接到一些门传感器,用于简单的开/关检测。虽然我的 SmartThings hub 同时连接到 Google Home 和亚马逊 Alexa,但只有 Alexa 可以使用打开/关闭功能。谷歌把门传感器显示为设备,但不知道用它们做什么(没有高级配置)。
第 6 课:基本程序/自动化
使用智能设备执行基本自动化(通常称为例程)有多种方式:
- 设备的应用程序
- 亚马逊/谷歌
设备的应用程序
如第 3 课所述,每个品牌的设备都有自己的应用程序。这些应用程序允许你设置不同类型的自动操作,但是,它们只适用于自己的品牌。例如,我可以使用 Kasa 应用程序设置一个程序,在黄昏时打开我的 TP-Link 智能灯泡。然而,如果我想让我的 Feit 电灯也打开,我需要在 Feit Electric 应用程序中设置相同的自动化。
亚马逊/谷歌
亚马逊 Alexa 和谷歌 Home 允许你将单个品牌账户链接到他们的平台,并授权他们控制你的设备。这为您提供了更多的灵活性,因为您可以创建一个自动化来控制多个品牌的多个设备。
在 Google 或 Amazon 上运行的例程增加了动作和触发之间的延迟,因为需要所有的通信。例如,我有一个例程,当门传感器处于打开状态时,它会打开壁橱中的智能灯泡。这两款设备都是通过 Zigbee 连接到 SmartThings hub 的。如果在 SmartThings 应用程序中定义了该例程,灯几乎会立即亮起。如果在 Alexa 中设置了该例程,则在灯打开之前需要整整一秒钟。
第 7 课:高级自动化
设备应用程序、谷歌和亚马逊让你能够进行普通的、基本的自动化操作,就像上面的门传感器和智能灯泡。然而,它们都不允许你做高级或复杂的自动操作,例如如果门关闭并且检测到运动,或者如果门关闭并且没有检测到运动,但是湿度高于特定阈值,不要关灯(很可能有人正在洗澡)。对于这种程度的自动化,你需要实现像 IFTTT 或家庭助理这样的东西。
IFTTT
IFTTT 代表If This Then than,是一个众所周知的高级家庭自动化平台。
IFTTT 是一款适用于苹果和谷歌产品的应用,你可以用它来为你的智能设备定义高级例程。它有免费(有限制)和付费两种形式。
家庭助理
家庭助理是一个运行在 Docker 容器中的应用程序,具有可配置的存储选项,如 SQLLite、MySQL 或 PostgreSQL。(我的运行在带有 MySQL 后端的 Raspberry Pi 上的 Docker Swarm 中,因为 SQLLite 和 CIFS 合不来。)
家政助理备受推崇。它拥有大量的追随者,并在每次迭代中增加了更多的集成。家庭助理可以使用 USB 适配器而不是集线器来控制 Z-Wave 或 Zigbee 设备。
特洛伊·亨特最近写了一篇关于家庭助手的文章,涵盖了它可以解决的其他问题。
第八课:成本
和大多数爱好一样,家庭自动化可能很贵。即使是基本的智能设备,如插头或灯泡,每个也要 15 到 40 美元不等(价格通常取决于通信类型),集线器可能要 100 美元以上。
第九课:了解他人
虽然家庭自动化和高级例程的配置很有趣,但当它们不起作用时,也会同样令人沮丧。想象一下浴室的灯在洗澡的时候熄灭了!
结论
家庭自动化是一个有趣的爱好,如果你钻研先进的自动化领域,它会是一个巨大的时间陷阱。我希望我分享的经验能帮助你踏上家庭自动化之旅。
在亚马逊 S3 托管 Maven repo-Octopus Deploy

包存储库是任何 CI/CD 管道中的核心需求,因为可重复的部署需要在使用标准 API 的工具之间共享正确版本化的工件。
尽管 Maven 是 Java 的同义词,但是 Maven 仓库为几乎所有类型的工件提供了非常灵活的解决方案。Maven 存储库通常存储 JAR 和 WAR 文件,但是它们也可以轻松地存储 ZIP 或 TAR.GZ 文件。
Maven 仓库有些独特,因为它们没有服务器端服务或 API,而是由客户端解析的静态文件组成。这意味着 Maven 仓库可以由几乎任何文件系统托管,包括 HTTP、FTP、WebDAV 或 SVN。
Maven 通过一个名为 Maven Wagon 的抽象接口来公开这种文件处理。在这篇博文中,我们将使用一个名为 S3StorageWagon 的第三方库将文件上传到 AWS S3 的 Maven 仓库。
编译代码
如果您有兴趣将 S3StorageWagon 集成到您的 Maven 项目中,这篇博客文章解释了这个过程,但是我们将做一些稍微不同的事情,并使用 deploy:deploy-file 将单个文件复制到 S3 的 Maven repo 中,而不需要完整的 Maven 项目。
第一步是从 GitHub 克隆 S3StorageWagon 源代码。使用以下命令编译项目并收集依赖项:
mvn "-Dmaven.javadoc.skip=true" "-DskipTests" package dependency:copy-dependencies
在CloudStorageMaven\S3StorageWagon\target目录中,您会找到文件s3-storage-wagon-2.3.jar。把这个拷贝给${maven.home}/lib。
我们还需要在s3-storage-wagon-2.3.jar文件旁边复制一些额外的依赖项。附加到 build 命令的dependency:copy-dependencies目标将所有的依赖项放到了CloudStorageMaven/S3StorageWagon/dependencies目录中。
在一个完美的世界中,我们可以将所有的 JAR 文件从CloudStorageMaven/S3StorageWagon/dependencies复制到${maven.home}/lib,但是事实证明,这样做会引入一些冲突。通过一个反复试验的过程,我发现这些 JAR 文件需要被复制:
- 云存储核心 2.3.jar
- aws-java-sdk-core-1.11.595.jar
- aws-java-sdk-kms-1.11.595.jar
- S3 11 版。595 .冲突
- aws-java-sdk-sts-1.11.595.jar
- 杰克逊-注解-2.6.0.jar
- 杰克逊核心 2.6.7.jar
- 杰克逊数据绑定
- 杰克逊数据格式
- httpclient-4.5.5.jar
- httpcore-4.4.10.jar
- joda-time-2.8.1.jar
自从这篇博文发表以来,这些 JAR 文件的具体版本可能已经发生了变化,但是库将保持不变。
定义存储库
下一步是在 Maven settings.xml文件中定义存储库。该文件通常位于~/.m2/settings.xml下。下面显示了一个示例:
<settings
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<activeProfiles>
<activeProfile>s3</activeProfile>
</activeProfiles>
<profiles>
<profile>
<id>s3</id>
<repositories>
<repository>
<id>octopus-s3-repo</id>
<url>s3://octopus-maven-repo/snapshot</url>
</repository>
</repositories>
</profile>
</profiles>
<servers>
<server>
<id>octopus-s3-repo</id>
<username>AWS ACCESS KEY</username>
<password>AWS SECRET KEY</password>
<configuration>
<region>us-east-1</region>
<publicRepository>true</publicRepository>
</configuration>
</server>
</servers>
</settings>
这些是重要的设置:
- 定义为
<url>s3://octopus-maven-repo/snapshot</url>的 URL 包括s3协议,这意味着 S3 货车库用于任何传输。 - 定义为
<username>AWS ACCESS KEY</username>和<password>AWS SECRET KEY</password>的 AWS 凭证是有权访问 S3 存储桶的用户的 IAM 凭证。这个用户是在后面的步骤中创建的。 - 用值
<publicRepository>true</publicRepository>将存储库定义为 public 意味着任何人都可以通过 HTTP 从 repo 下载工件。
创建 S3 时段和用户
我们需要创建一个名为octopus-maven-repo的 S3 桶,并创建一个可以访问桶中文件的用户。以下 IAM 策略授予 IAM 用户对octopus-maven-repo存储桶的完全访问权限:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::octopus-maven-repo",
"arn:aws:s3:::octopus-maven-repo/*"
]
}
]
}
请记住,S3 存储桶名称是全球唯一的,您必须为您的存储桶指定一个唯一的名称。
下载 IAM 用户的访问密钥和密钥,并替换settings.xml文件中<username>AWS ACCESS KEY</username>和<password>AWS SECRET KEY</password>元素中的值。
修复公共权限
AWS 最近通过一个额外的安全层锁定了公共 S3 桶,默认情况下阻止所有公共访问。如果您的存储库将允许公共访问,您需要禁用阻止公共访问的设置。在下面的截图中,您可以看到 S3 铲斗的Block all public access设置已经关闭:

上传文件
最后一步是将文件上传到新的存储库中。以下命令将template.zip文件作为工件上传,文件组为org.example,ID 为template,版本为0.0.1-SNAPSHOT:
mvn deploy:deploy-file \
"-DgroupId=org.example" \
"-DartifactId=template" \
"-Dversion=0.0.1-SNAPSHOT" \
"-Dpackaging=zip" \
"-Dfile=template.zip" \
"-DrepositoryId=octopus-s3-repo" \
"-Durl=s3://octopus-maven-repo/snapshot"
然后,生成的文件将作为版本化工件保存在 S3:

食用章鱼的饲料
使用 S3 作为 Maven 知识库的好处是客户端可以通过 HTTP 访问它。因为我们将我们的存储库配置为公共的,Maven 客户端(比如 Octopus)可以通过 HTTP URLhttps://octopus-maven-repo.s3.amazonaws.com/snapshot访问工件。


结论
使用 S3 托管 Maven 知识库是一种快速创建公共知识库的方法,不需要任何特殊的软件或托管解决方案。通过使用定制的 Wagon 提供者将工件上传到 S3,然后通过 HTTP 访问相同的文件,我们可以创建一个功能完整的 Maven 存储库,供 Octopus 使用。
章鱼 3.0 如何击败 2.6-章鱼部署
原文:https://octopus.com/blog/how-octopus-3.0-blows-2.6-out-of-the-water
在 Octopus Deploy,我们一直在努力工作,以创建一个更新,让您的脸上露出微笑。在 2.x 版本中,当我们亲爱的用户测试 Octopus 时,我们经历了一些成长的烦恼。我们对 Octopus 3.0 的目标之一是提供一个主要的性能改进。为了实现这一目标,我们已经:
- 重写了我们的持久层,用 SQL Server 替换了 Raven
- 重写了我们的通讯层,把海龙换成了大比目鱼
- 对日志记录和编排进行了巨大的改进
- 开始测试和测量大规模部署
昨天,作为我们 bug-bash 的一部分,我们在 Octopus 2.6 和 3.0 上执行了一个复杂的部署来比较性能。部署涉及:
- 200 个 NuGet feeds
- 50 个步骤,带 3 个子包步骤
- 从 10MB 到 1000MB 的软件包
- 5 个变量集,每个有 5000 个变量
我们对结果很满意,希望你也一样。3.0 的部署用时 2 小时 41 分钟,而 2.6 用时 4 小时 18 分钟。您会在下面的图表中注意到,3.0 的 CPU 和内存使用率下降的速度比 2.6 快得多:

章鱼服务器 2.6 锤 CPU,两个多小时保持 100%左右。相比之下,Octopus Server 3.0 在部署之初(50 分钟)有一个峰值,然后在部署的剩余时间里持续低于 20%。

什么?!是的,Octopus Server 2.6 使用了将近 3.5GB,而 Octopus Server 3.0 使用了不到 500MB。
在 Octopus 3.0 中,您可以期待显著的性能改进,尤其是对于大型复杂的部署场景。我们将继续研究我们可以改进 Octopus 的方法,并衡量我们的改进,以便您可以相信 Octopus Deploy 可以处理您扔给它的任何部署。此外,还有许多很酷的新功能。即将推出!
Octopus 如何补充您的构建服务器- Octopus Deploy
原文:https://octopus.com/blog/how-octopus-complements-build-server
在过去的几个月里,我们在 Jenkins 和 GitHub Actions 中探索了两个构建服务器选项。正如我们所发现的,Jenkins 是一个传统的构建服务器,在其中心有一个自我管理的实例,而 GitHub Actions 执行类似的任务,但作为一个服务在您可能已经使用的产品中。根据您的需求,这两者都值得作为持续集成和持续部署(CI/CD)工作流的一部分。
然而,作为位于包和它们的目的地之间的部署工具,Octopus 是与构建服务器无关的。Octopus 支持市场上所有主要的自动化服务,但为什么要将它们连接到 Octopus?
构建服务器也可以部署,但是它们不能解决 Octopus 所面临的问题。
在这篇文章中,我们来看看 Octopus 如何补充您选择的构建服务器,并完成您的开发管道。
构建服务器提供持续集成,Octopus 提供持续部署
我们在这个博客上谈论了很多关于 CI/CD 的内容。虽然“CI”和“CD”组合成一个引人注目的首字母缩略词,并且都相信重复会带来自信,但它们是两个不同的概念。
CI 的存在主要是为了服务开发者。它是关于自动化那些曾经让他们慢下来的任务,比如编译、构建和测试代码。这些都是构建服务器擅长的功能,所以开发人员将构建服务器称为“CI 平台”并不意外。
当一个版本在一个管道环境中工作时,CD 过程通常会涉及到许多团队。CD 与 CI 的根本区别在于需要在几个阶段进行人工干预。
让我们看看 Octopus 如何帮助管理这些手动操作。
在您的部署过程中构建人机交互
当一个版本通过一个典型的开发管道(至少包括开发、QA 和生产环境)时,您可能需要以下类型的人工检查或操作:
- 开发人员可能希望在一个版本进入 QA 之前检查开发中已部署的变更。
- QA 团队通常测试产品,就像你期望客户使用它一样。这不同于构建期间的自动化代码测试。
- 在部署到生产之前,一个版本可能需要领导的签署(因此也需要您的客户的签署)。
在 Octopus 中,您可以将手动干预步骤构建到您的部署流程中。例如,如果您需要部署暂停并检查 QA 确认或管理层签署,这很容易添加。
这有助于保持您的部署快速进行。
使用共享空间管理手动交互的访问权限
有时,执行手动检查的人不需要看到完整的部署情况。您可以使用 Octopus Deploy 的空间功能来确保团队只看到他们需要的内容。
您可以这样设置 Octopus 访问:
- 开发团队只能部署到开发
- QA 团队可以从开发提升到 QA
- 经理只能确认、同意或拒绝部署到下一阶段
- 项目经理只能看到仪表板和报告功能
- 团队只能看到他们附属的项目
这为您的实例提供了安全性,并通过减少每个人的混乱而使您的信息更加清晰。

章鱼让你对发布充满信心
Octopus 有助于在您的产品投入生产之前增强信心。它以几种方式做到这一点。
章鱼符合你的环境结构
虽然构建服务器在技术上可以将包部署到任何目标,但是它们往往缺乏环境的概念。
环境是用于特定目的的部署目标的集合,例如区域服务器场、虚拟代理和云服务。
一个理想的部署应该至少经过两个环境才能到达用户手中。例如,极简环境结构看起来像这样:
- 开发——开发人员用来消除错误的环境
- 测试——测试应用程序的环境如用户所愿
- 生产——用户访问您的应用程序的实时环境
一些管道可能会添加额外的环境,如用户验收测试(UAT)或试运行。不管怎样,我们的想法是在你的产品发布之前建立信心。
这就是为什么使用 Octopus,您可以部署到环境中,而不是每个单独的目标。
如果您有复杂的项目,只需要在您的环境中达到某些目标,我们有工具来帮助您管理这些,例如变量和租户。
Octopus 通过生命周期控制部署顺序
当设置您的环境时,Octopus 会自动创建一个“生命周期”。生命周期控制着包在部署时在环境中的移动顺序。
这意味着:
- 你永远不会不小心跳过一个环境
- 版本总是以正确的顺序升级
- 用户只有在你希望的时候才能得到你的发布
但是,您可以有多个生命周期。例如,您可能想要不同项目的特殊生命周期,或者使用它们来帮助建立一个受欢迎的部署模式。
【T2 
Octopus 在项目的整个生命周期中只使用一个部署过程
使用 Octopus,您只需为每个项目设置一次部署过程。除非您在部署到 Dev 时遇到问题,否则这个过程在您的整个管道中都将保持不变。
当您准备好投入生产时,您可以信任您的部署过程,因为它以前工作过。可重复部署带来信心!

Octopus 很容易连接到开发管道的两端
我们已经探索了如何,由于插件和连接器,Octopus 可以连接到您选择的构建服务器。您可以在以下市场找到我们针对流行 CI 平台的插件:
Octopus 也很容易连接到您的部署目标。无论是物理服务器、容器还是任何主要的云提供商——Octopus 都可以部署在那里。我们在 Octopus 中构建了很多这样的东西,以使它尽可能简单。在您定义了一些环境之后,使用我们简单的设置向导来设置您的部署目标。

Octopus 为项目状态提供了清晰度
如果构建服务器的部署失败,您可能需要查看日志来找出问题所在。这对于技术人员来说可能没问题,但是对于参与部署的每个人来说并不理想,比如发布经理、领导或者 QA 团队。
令人欣慰的是,Octopus 的仪表板可以很容易地检查每个环境有什么版本,也可以跨您的所有项目。即使在部署期间。

Octopus 的 Runbooks 功能是其最有用的附加功能之一,允许您自动执行一系列日常或紧急操作任务。
这可能包括执行:
- 事故恢复
- 备份、恢复和测试
- 基础设施的启动和拆除
- 系统服务的停止、启动和重启
- 文件清理
- 运行你需要的任何语言的脚本
我们将从下个月开始更详细地介绍章鱼手册,但同时,查看我们的手册文档以获取更多信息。
结论
在我们的持续集成和构建服务器系列中,我们介绍了 Jenkins 和 GitHub 行动中的两个重要选项。我们研究了它们如何帮助您的团队,并提供了设置建议。
我们还解释了 CI 和 CD 是解决不同问题的不同概念,但它们是同一枚硬币的两面,结合起来可以实现更大的目标。
最后,我们深入探讨了 Octopus 如何帮助您完善完整的 CI/CD 渠道。但是不要只相信我们的话,注册一个免费试用版来亲自体验一下。
浏览 DevOps 工程师手册以了解有关 DevOps、CI/CD 和部署管道的更多信息。
愉快的部署!
章鱼部署到底有多安全?-章鱼部署
原文:https://octopus.com/blog/how-secure-is-octopus-deploy-anyway

不需要太多的研究就可以得出结论,大多数 It 部门真的关心他们使用的工具的安全性。使用 SaaS 的产品通常是一种信任的练习,章鱼云也不例外。您相信我们会保护您的数据安全,我们也相信您会公平地使用我们的平台,所以这是一个合理的问题,我们到底有多安全?
客户一直在询问我们的安全状况,尤其是章鱼云。现在,我们请他们在线阅读我们的文档,并为他们回答一些特别的问题。
我们的安全态势如何?
这是我们不断思考的问题,多年来已经做了很多工作。举几个突出的例子,我们有很棒的 RBAC 系统,支持许多流行的认证提供商,我们有可靠的审计功能来帮助您保护您的实例,并在您实施我们的产品时保持这种状态。我们已经做了一些功课,比如 GDPR 合规,我们对开源许可的使用,以及在我们的状态页面上指出事件。
当新功能被创建时,我们通常会有一个内部 bug bash,我们会定期进行渗透测试,这些测试是由该领域的知名公司和我们自己进行的。
我们的态度一直是,为我们产品的安全性做一些实质性的事情比勾选一些合规性方框更重要。
相信我们的话
话虽如此,要求人们相信我们的话只能让我们到此为止,也只能持续这么久。你如何核实我们的工作?现在,你不能,除了我们的行动和我们的记录。
为了帮助您验证我们的立场,我们正在努力为我们的产品和支持其发展的事物获得 ISO 27001 合规认证。在短期内,我们将分享来自云安全联盟(CAIQ Lite v3.1)的自我评估问卷,以便让潜在的云客户了解我们目前的状况。最终,实现 ISO 27001 合规性不仅有利于我们的八达通云客户,也有利于我们的自主托管客户。
所有人都说,这将是一个艰难的旅程,但我们认为我们已经准备好了。我们已经定义了我们希望采用的高级路线图,因此您可以更详细地了解我们的计划。
信任,但要验证我们
尽管我们一直致力于实现 ISO 27001 合规性,但我们仍然专注于实际的安全改进,毕竟:
证书并不能让你安全,但我们的目标是让获得证书的过程有助于确认我们值得你的信任,并帮助我们提高我们的安全水平。
我们认识到安全不是一种状态;这是一种生活方式的选择。我个人认为能够回答“您的安全状况如何?”用其他企业可以理解的通用语言有很大的价值。
它迫使我们以更全面的方式考虑我们的安全。认证将为我们提供一个常用的路线图,用于分析我们当前的状况并做出进一步的改进,但它也将迫使我们以更系统的方式思考风险管理。
轮到你了
在我们进行这一过程时,了解您的优先事项对我们来说非常重要。我们怎样做才能值得您的企业信任?认证对你来说重要吗?如果重要,是哪些?也许我们应该考虑其他的事情?我们很乐意听取您对此的想法和意见。
如何使用 Octopus Deploy 从《我的世界》部署- Octopus Deploy
原文:https://octopus.com/blog/how-to-deploy-from-minecraft-with-octopus-deploy
想象一个部署简单的世界。你可以在你最喜欢的视频游戏中按下一个按钮,你的最新版本就可以投入生产了。有些人可能会嘲笑:“我的电子表格,RDP 和手动配置文件编辑永远不会被一个虚拟按钮取代!”请允许我介绍 OctoCraft 展开:
https://www.youtube.com/embed/RjUIQmdIlEc
VIDEO
在《我的世界》这边,你需要的只是一个 Bukkit 和一份 T2《我的世界》的拷贝。Bukkit 允许创建自定义的《我的世界》插件。 OctoCraft Deploy 只是一个与 Octopus Deploy API 交互的《我的世界》插件。
Octopus Deploy 是 API first 。您可以通过 UI 做的任何事情都可以通过 API 来完成。即使用 Java。 OctoCraft Deploy 调用 Octopus Deploy API 来创建一个发布,将这个发布部署到一个环境中,然后监控部署的状态。你可以在这里找到完整的 API 文档。
例如,要创建发行版:
创建一个发布到 API 的方法。
public HttpResponse Post(String path, String json) throws ClientProtocolException, IOException {
HttpClient client = new DefaultHttpClient();
HttpPost post = new HttpPost(url + path);
post.setHeader(API_KEY_HEADER, apiKey);
post.setEntity(new StringEntity(json, ContentType.TEXT_PLAIN));
return client.execute(post);
}
将序列化到 post 请求的 POJO。
public class ReleasePost {
private String projectId;
private String version;
public ReleasePost(String projectId, String version) {
this.projectId = projectId;
this.version = version;
}
@JsonProperty("ProjectId")
public String getProjectId() {
return projectId;
}
@JsonProperty("Version")
public String getVersion() {
return version;
}
}
做好创建发布的所有艰苦工作。
private Release createRelease(Project project) throws ClientProtocolException, IOException {
ReleasePost releasePost = new ReleasePost(project.getId(), "1.i");
String content = new String();
String json = objectMapper.writeValueAsString(releasePost);
HttpResponse response = webClient.Post(RELEASES_PATH, json);
content = EntityUtils.toString(response.getEntity());
return objectMapper.readValue(content, Release.class);
}
GitHub 上的完整源代码。
如何处理锁定的文件和部署-八达通部署
锁定的文件是否阻碍了您的部署?您是否尝试过在 PowerShell 步骤中关闭网站,但仍然出现锁定文件错误?你不是唯一一个。
这是我们收到的非常常见的支持请求。错误消息,例如:
无法将包复制到指定的目录“c:\MyDeploymentLocation”。目录中的一个或多个文件可能被另一个进程锁定。
可能会令人沮丧,并且试图通过停止您认为可能正在访问文件的进程来找到锁的来源有点像猜谜游戏。
引入手柄

猜不到了!句柄是一个来自 SysInternals 的工具,用来显示所有打开文件的程序(并因此被锁定!)
如果您查看您的特定错误并找到文件名:
The process cannot access the file 'c:\MyDeploymentLocation\Web.config'
然后,您可以使用句柄来查找打开文件内容,例如:
C:\Handle> handle C:\MyDeploymentLocation
Handle v3.51
Copyright (C) 1997-2013 Mark Russinovich
Sysinternals - www.sysinternals.com
explorer.exe pid: 3732 type: File C7C: C:\MyDeploymentLocation\Web.config
这将允许您使用一个 PowerShell 脚本步骤来首先停止这些进程,允许您在没有锁定文件妨碍的情况下完成部署!
更新:
当 Handle.exe 第一次运行时,系统会提示您接受最终用户许可协议。接受协议存储在每个用户的注册表中。如果你从 Octopus Deploy 触手代理运行 Handle.exe,它挂起了,这很可能是因为触手是在一个没有接受许可协议的用户帐户下运行的。您可以通过在调用 Handle.exe 之前运行以下命令来自动接受许可协议:
& reg.exe ADD "HKCU\Software\Sysinternals\Handle" /v EulaAccepted /t REG_DWORD /d 1 /f
我们如何在 Octopus 3.0 中使用 SQL Server-Octopus Deploy
在之前的一篇文章中,我宣布我们将把 Octopus 3.0 的从 RavenDB 切换到 SQL Server。那篇帖子谈到了我们为什么要离开 RavenDB,但没有过多解释我们计划如何使用 SQL Server。在这篇文章中,我想谈谈我们如何使用 SQL Server,并讨论一些小的突破性变化。
我们刚刚完成了将 Octopus 3.0 移植到 SQL Server 的大部分工作。我们有一套自动化的 API 测试,安装和配置 Octopus 服务器,注册一些触角,并使用 REST API 测试应用程序。这些测试现在已经通过,并且完全针对 SQL Server 运行:

版本
我们确保 Octopus 在以下情况下工作:
- SQL Server 2005、2008、2012、2014 及以上版本;从 Express 到 Enterprise 的任何版本
- SQL Azure
为了使入门体验顺畅和容易,Octopus 安装程序将为您提供自动下载和静默安装 SQL Server Express edition 的选项,这是免费的。当然,你也可以把它连接到一个集群 SQL Server 企业服务器上,尽管其他 SQL Server 版本的许可费用需要和微软讨论。-)
高可用性
如今,Octopus 实际上使用几种不同的数据存储:
- 大多数数据存储在 RavenDB 中
- 部署日志(总是被附加到)存储在磁盘上,因为除非你是 Schlemiel the Painter 否则不可能附加到附件
- 关于正在进行的部署和其他任务的状态也存储在磁盘上
- 内置存储库中的 NuGet 包存储在磁盘上,元数据存储在 Lucene.NET 索引中
虽然我们支持使用外部(集群)RavenDB 实例,但大多数客户并不真正能够设置和管理它,所以我们几乎总是使用嵌入式版本的 RavenDB。因为我们在许多地方都有数据,所以我们需要在产品中构建我们自己的备份和恢复功能。
对于 Octopus 3.0,我们将确保我们有一个伟大的高可用性故事。大多数企业已经熟悉了如何设置一个集群 SQL Server 实例,并且现场有 DBA 可以帮助管理它。因此,我们的第一个设计原则将是一切(几乎)都需要在 SQL Server 中。具体来说:
- 我们目前存储在 Raven 中的所有文档都将转到 SQL Server
- 部署日志将被压缩(它们压缩得非常好)并存储在 SQL 中
- 正在进行的部署状态:我们将依赖于内存中的状态(参见下面的重大变化部分)
- NuGet 包仍将在磁盘上(您可以更改它们的存储位置,并将它们放在文件共享/SAN 上),但元数据将存储在 SQL 中
此外,我们将确保您可以设置多个 Octopus Deploy 服务器,所有这些服务器都指向同一个 SQL 数据库/使用同一个包目录。安装向导和命令行工具将使设置虹吸管变得容易:

这不会完全是网络规模,但是 Stack Exchange 已经很好地证明了通过横向扩展应用服务器和纵向扩展数据库,你可以走得很远。
重大变化:有一个场景我们将不再支持:在部署期间重启 Octopus 服务器。
以前,您可以启动一个长时间运行的部署,然后关闭 Octopus 服务器,再次启动它,它很有可能会从停止的地方继续运行。我说“机会”是因为不可能测试所有的场景,我们知道在一些领域它不起作用,部署会处于一种奇怪的状态,他们说他们在运行,但实际上没有。通过移除这个特性,我们将能够简化事情并获得更好的性能,因为我不认为它曾经完全可靠地工作过,所以这应该是一个不错的改变。如果这影响到你,请在下面的评论中告诉我!
作为文档存储的 SQL
使用像 RavenDB 这样的文档数据库时,我们喜欢(也将会怀念)的一个特性是无需大量连接就能存储和加载大而深的对象图。例如,Octopus 允许您定义变量,它们是可以应用于许多不同字段的键/值对。有些客户有成千上万个这样的东西,我们在每个版本中都给它们拍快照,所以用传统的关系模式建模会使事情变得非常复杂。我们实际上永远不会查询这些数据,我们只需要在部署期间将它们全部加载到内存中。
相反,我们将 SQL 视为文档存储。每种文档类型都有自己的表,我们查询的字段将作为常规列存储。但是我们不查询的所有字段和深层对象图都存储为 JSON blob (a nvarchar(max))。

因为我们不做任何连接,所以我们不需要 ORM 来帮助将对象图缝合在一起。相反,我们保持接近金属,本质上使用一些围绕SqlConnection / SqlCommand的包装器,这些包装器使用 JSON.NET 反序列化 JSON blobs,然后设置额外的字段。自定义 JSON.NETJsonContractResolver不包括映射为表列的属性,因此值不会存储两次。
这种设计的唯一缺点是,有一些地方我们必须对表进行LIKE %x%查询——例如,查找所有标记有给定角色的机器(角色列表存储为 Machine 表上用管道分隔的 nvarchar 列)。然而,在所有这些情况下,我们期望这些表有几千个条目,所以我真的不认为这有什么关系。如果测试显示不是这样,我们要么使用全文搜索,要么在一个类似 CQRS 的索引表中引入一个新表。
备份、恢复和维护
由于我们的所有数据都将位于 SQL Server 或文件共享(NuGet 包)中,因此在此阶段,我希望能够删除我们的自定义备份/恢复功能,而只依赖 SQL Server 备份。我们将提供一些关于如何配置的指导,如果你有一段时间忘记进行 SQL 备份,我们将在 Octopus UI 中提供一些反馈,但总的来说,我认为 SQL Server 的内置备份/恢复功能比我们可能构建的任何功能都要好。
移民
从 2.6 到 3.0 的升级体验非常简单:您将安装 3.0,选择/创建一个要使用的 SQL Server 数据库,然后选择要导入的 Octopus 2.6 备份。我们将根据需要转换数据,然后您很快就可以开始运行了。感觉会更像是在 2.5 到 2.6 之间升级,而不是从 1.6 升级到 2.0。
到目前为止,我们已经完成了几乎所有到 SQL Server 的转换,并且还没有进行任何 API 更改,因此没有任何针对我们的 2。X REST API 将在 3.0 上工作。
测试
我们收集(选择加入)使用统计数据,并且有一些大型的 Octopus 安装——300 多个项目,1000 多台机器,超过 20,000 次部署。我们将使用这些数据来模拟类似的环境,并确保我们不会发布任何比我们已经拥有的更慢的东西。
我们将首先运行端到端测试,并将当前的 2.6 版本与即将到来的 3.0 版本进行比较,以确保我们当前的操作在较小的数据集上不会变慢。然后,我们将继续进行负载测试,以确保在没有疯狂硬件需求的情况下,我们可以处理比目前至少大 5 倍的安装。
如果有人对这些指标感兴趣,请在评论中告诉我,我会在这个系列的第三篇文章 😃
我们如何创建触手军队-章鱼部署
作为一个独立的软件供应商,面临的挑战之一是在类似于您的客户正在使用的基础设施上使用您的软件。Octopus Deploy 安装在各种操作系统上,并部署在可以想象到的每种网络配置上,目标范围从单个触手到一千个触手怪物。我们典型的开发配置由一个服务器和驻留在同一台机器上的一个或两个触角组成。在这种配置下,一切都很好,直到章鱼被部署到野外,它才开始瓦解。
触手军团
触手部队是我们试图复制章鱼将运行的最苛刻的配置。在章鱼发布之前,我们发动了触手军团并试图打破发布。目前,触手军团由位于新加坡和巴西的 800 只触手组成,这两个地区因其区域间的高延迟而被选中。在这种配置中,我们有 40 台触手虚拟机,每台机器有 20 个触手实例。
供应触手部队
我们使用亚马逊 AWS 为触手军提供基础设施。一个配置文件指定了我们在测试环境中需要什么:
{
"OctopusServerConfiguration" : {
"Environments" : [ "Development", "Test", "Production" ],
"InstanceType" : {
"Value" : "m3.medium"
},
"NumberOfInstances" : 1,
"Platform" : "OctopusServer",
"PrimaryStorage" : 40,
"Projects" : [ {
"Name" : "Multi release project",
"DeploymentSteps" : [ {
"Name" : "Deploy package",
"PackageId" : "100mb",
"PackageUrl" : "https://s3-ap-southeast-1.amazonaws.com/octopus-testing/100mb.1.0.0.nupkg.zip"
} ],
"Releases" : [ {
"Environment" : "Development",
"RepeatAfterMinutes" : 10,
"RunAfterMinutes" : 5
} ]
}],
"RegionEndpoint" : "ap-southeast-1",
"ServerInstallerDownloadPath" : "http://download.octopusdeploy.com/octopus/Octopus.2.5.12.666-x64.msi",
"ToolsInstallerDownloadPath" : "http://download.octopusdeploy.com/octopus-tools/2.5.10.39/OctopusTools.2.5.10.39.zip"
},
"TentacleConfiguration" : [ {
"InstanceType" : {
"Value" : "m3.medium"
},
"Mode" : "Listening",
"NumberOfInstances" : 5,
"NumberOfTentaclesPerInstance" : 5,
"Platform" : "Server2012_R2",
"PrimaryStorage" : 40,
"RegionEndpoint" : "ap-southeast-1",
"TentacleInstallerDownloadPath" : "http://octopusdeploy.com/downloads/latest/OctopusTentacle64"
} ],
"VPCConfiguration" : [ {
"RegionEndpoint" : "ap-southeast-1"
} ]
}
通过配置文件,我们可以指定:
- 该平台(我们测试了 2008 年 32 台服务器、2008 年 64 台服务器、2012 年 r 2 服务器)
- 章鱼服务器和触手的版本
- 触须的数量和它们的位置
- 环境、项目和自动部署
- 域控制器配置
该配置被提供给一个调用 AWS API 的应用程序,以提供所需的机器。一旦配置好机器,就可以通过 PowerShell 对它们进行设置。除了 Octopus 服务器和 tentacles,我们还提供 NAT,如果需要,还提供区域到区域 VPN。触手军队最终看起来像这样:

到无限和更远
触手军团帮助我们更好地与那些给章鱼施加压力的顾客建立联系。我们已经能够识别章鱼挣扎的区域,并通过我们的 UI 感受到管理大量触角的体验。随着更多的工作,我们将收集指标,以便我们可以对我们的发布进行基准测试,并验证我们在 Octopus 上继续做出的改进。我们还将提供触须军团作为服务,允许任何团队成员启动测试环境,并将触须军团集成到我们的自动化流程中。
Octopus 如何使用 RavenDB - Octopus 部署
当我开始构建 Octopus Deploy 时,我想构建一些足够好的东西来发布测试版并开始获得反馈。我有很多使用 SQL Server 和 NHibernate/EF 的经验,所以我决定使用 SQL Server + EF 代码优先堆栈作为我的持久层。
在最近的 1.0 RC 版本中,我把 Octopus 换成了使用 RavenDB 。在这篇文章中,我将解释改变的原因,并展示它是如何被使用的。
SQL Server 让我们失望的地方
测试进行了大约 6 个月后,使用 SQL Server 的决定开始变得越来越受限制。我得到了很多反馈和建议,并且有了很多特色创意。但是我注意到自己根据数据库的复杂程度来权衡特性。我会避免实现意味着太多连接或太多中间表的特性建议。我觉得 SQL 表的僵化本质和笛卡尔乘积的专制对应用程序设计有太多的影响。
不用说,这是一种糟糕的产品设计方式。应用程序的需求应该优先于数据库的需求,而不是相反。然而,我发现自己在决定坚持的事情上几乎是“节俭”的。
SQL Server 也使安装过程变得更加复杂。作为一种热缩包装产品,安装体验对八达通来说非常重要,因为这是客户对该产品的第一次体验。假设用户要么安装 SQL Express,要么使用外部 SQL Server。
这两个都有问题。SQL Express 意味着用户需要运行另一个安装程序。使用独立的 SQL 实例意味着各种各样的安全配置更改,以允许 Octopus IIS 进程和 Windows 服务与数据库对话。我觉得销售一个旨在使自动化部署变得容易的产品是愚蠢的,然而却有如此复杂的安装过程!
为什么是 RavenDB?
上面的安装问题表明 SQL Server 不是收缩包装产品的好选择。但是有许多嵌入式关系数据库可能已经工作了——例如 SQLite 或 SQL CE。是什么让 RavenDB 更有吸引力?
有两个原因。第一个是我们的问题领域——部署自动化——似乎自然地导致面向文档的数据模型超过关系模型。对于关系模型,我发现自己担心连接,而我的大多数用例实际上只围绕单个文档。
第二个原因是建筑上的。Octopus 分为两个独立的进程,如下图所示:运行部署和计划任务的 Windows 服务,以及 IIS 网站。

任何嵌入式选项都需要嵌入到一个进程中,但是可以通过另一个进程访问。有了 RavenDB,这就很容易了 Octopus 服务器托管一个嵌入式 RavenDB 实例,该实例也使用 Ravens 嵌入式 HTTP 侦听器在端口 10930 上进行侦听,web 站点在该端口上连接到 RavenDB。这给了我很大的灵活性;您实际上可以使用相同的嵌入式数据库来旋转我们的辅助 Octopus 服务器和网站实例。
这也极大地简化了我们的安装过程。现在,当你安装 Octopus 时,唯一提到的数据库是一个“存储”标签,你可以在这里选择数据的存储位置:

文件设计
使用像 RavenDB 这样的文档数据库时,我不得不做的最大调整是弄清楚文档的外观。在 Octopus 中,我们有以下主要文档:
- 环境:名称、描述、机器、健康检查结果
- 项目:变量,步骤
- 发布:变量和步骤快照、发布细节、选定的包版本
- 部署:目标环境,选项
- 任务:开始、结束、持续时间、输出日志
- 用户:姓名,电子邮件
- 组:名称、子组、成员用户
这种设计的优势是显而易见的——例如,当我们处理一个版本时,我们经常需要知道步骤(要安装的包,要运行的脚本,等等)。).因此,我们在单个文档中获取信息,而不是内部连接。这使它更好地工作。
文档也使得继承关系的建模更加容易。例如,Octopus 会有许多类型的“步骤”:部署包、运行 PowerShell 脚本、等待用户手动干预等等。这些是使用抽象基类建模的。这当然有可能用关系数据库来表示,但是这一点也不好玩。在 RavenDB,它是乐趣。我可以随心所欲地构建特性,而不用担心疯狂的连接或级联删除。我觉得解放了。
我们如何使用 RavenDB
我有一个理论,应用程序中 90%的性能问题不是由糟糕的算法引起的,而是由糟糕的架构引起的——例如,在控制器和 ORM 之间有服务、管理器和存储库的层。
在 Octopus 中,我们让事情变得简单——ASP.NET MVC 控制器直接与 RavenDB IDocumentSession交互:
public class GroupsController : OctopusController
{
readonly IDocumentSession session;
public GroupsController(IDocumentSession session)
{
this.session = session;
}
public ActionResult Index(int skip = 0)
{
var groups = session.Query<Group>().OrderBy(g => g.CanBeDeleted).OrderBy(g => g.Name).ToList();
return View(new GroupsModel(groups));
}
}
或者最多一个控制器调用一个命令或者一个构建器,直接与会话交互。例如,此命令保存一个 NuGet 提要:
public class SaveFeedCommand
{
readonly IDocumentSession session;
public SaveFeedCommand(IDocumentSession session)
{
this.session = session;
}
public void Execute(EditFeedPostModel input)
{
var feed = string.IsNullOrWhiteSpace(input.Id) ? new Feed(input.Name, input.FeedUri) : session.Load<Feed>(input.Id);
feed.Name = input.Name;
feed.FeedUri = input.FeedUri;
if (input.ChangePassword || !input.IsExisting)
{
feed.SetCredentials(input.Username, input.Password ?? string.Empty);
}
session.Store(feed);
}
}
我们使用标准的ActionFilter模式在请求开始时打开文档会话,在请求完成时保存更改。
问题
我和一个刚刚开始在一个项目中使用 MongoDB 的朋友聊过,他正在努力解决的一个问题是需要定义 map/reduce 索引。我最喜欢的 RavenDB 特性之一是,通常,你可以只使用 LINQ 支持,RavenDB 将隐式创建索引。
不过,我们确实使用了少量的自定义索引,这些索引主要用于预测。例如,在 Octopus 中,Group包含该组中用户的 ID 列表——例如,“团队领导”组可能包含“Bob”和“Alice”的 ID。通常,我们需要反向查询这种关系,以回答诸如“Alice 是哪个组的成员”这样的问题。这是通过使用 map/reduce 索引实现的:
public class UserGroups : AbstractIndexCreationTask<Group, UserGroups.Result>
{
public UserGroups()
{
Map = groups => from g in groups
from u in g.Users
select new Result {UserId = u, GroupIds = new[] {g.Id}};
Reduce = results => from r in results
group r by r.UserId into g
select new Result { UserId = g.Key, GroupIds = g.SelectMany(i => i.GroupIds).ToArray() };
}
public class Result
{
public string UserId { get; set; }
public string[] GroupIds { get; set; }
}
}
目前,我们只有三个自定义索引——我们的大多数查询都使用通过 LINQ 查询创建的隐式索引。
贮藏
有些人在遇到性能问题时,会想“我知道,我会使用缓存”。现在他们有两个性能问题。
众所周知,缓存失效是很难纠正的,所以在 Octopus 中我们实际上避免了它——只有几个地方我们显式地使用了缓存,而且它们都不是为了缓存数据库结果(它们实际上是 NuGet 提要查找)。
现在,这个特性在 RavenDB 中经常被忽略,但是 RavenDB 实际上提供了开箱即用的缓存。不,真的,再读一遍。 RavenDB 为您提供开箱即用的缓存。这是巨大的!更重要的是,它没有失效问题。
Ayende 在他的博客上解释了这个特性,但是让我把它解释成 SQL Server 实现了这个特性。首先,您发出如下查询:
SELECT * FROM User where IsActive = true
返回 100 个结果。
几秒钟后,可能在另一个 HTTP 请求中,您发出相同的查询:
SELECT * FROM User where IsActive = true
除了执行查询并再次点击磁盘并第二次传输结果之外,想象一下,如果 SQL 简单地返回一条消息,告诉您自上次查询以来没有发生任何变化,并且您应该重用原始结果(如果您仍然拥有它们)。
SQL Server 能做到这一点吗?不,它不能。您可以发出一个花费 SQL Server 10 秒钟执行的查询,然后立即再次发出该查询,它将再花费 10 秒钟计算与之前相同的结果,尽管它应该知道什么都没有改变。
使用 RavenDB,如果内存中已经有了结果,那么可以提交来自原始 HTTP 结果的 ETag,RavenDB 将通过检查索引状态来告诉您结果是否已经改变。Raven 客户端库可以为您做到这一点。这是一个很棒的功能,值得更多的宣传。
自动备份
我曾经在一个使用运行在虚拟机上的 TeamCity 的团队中工作过。一天,虚拟机崩溃了。我们一直使用嵌入式数据库,从未建立任何备份系统。所以数据丢失了,我们花了几天时间才重新设置好。
当你安装 Octopus 时,它会每两个小时自动备份一次自己的数据库。默认情况下,它备份在与 RavenDB 数据库相同的文件夹下,但是我们让它非常容易更改——例如,您可能会将它指向一个备份的文件共享:

我们通过嵌入RavenDB smugger库来实现这一点,并有一个预定的 Octopus 任务来自动执行将数据库“导出”到一个配置好的文件夹中。
RavenDB 确实有一个备份/恢复特性,它有一些好处(例如,备份索引结果),但也有一些缺点(它对创建备份的机器和恢复备份的机器之间的操作系统兼容性有更严格的要求)。由于无法恢复的备份不是很有用,为了安全起见,我选择使用导入/导出功能,而不是默认的备份/恢复。
我们应该两者都支持吗?
我被问到的一个问题是:
你能为数据存储选择吗?例如,用户可以选择在安装过程中是使用 RavenDB 还是 SQL Server。
如果我选择了另一种关系模型,这是有可能的——例如,NHibernate 支持大量的数据库提供者。但是 NHibernate 不支持 RavenDB,这并不是因为它只是没有实现,而是因为它们是根本不同的模型。试图同时支持这两者意味着无法真正利用其中任何一个的特性,最终我会得到两个世界中最糟糕的结果。
此外,在要求 SQL Server 将数据存储放在安装产品的用户的前端和中心的同时,我希望使用 RavenDB 的选择将淡出后台。当应用程序维护自己时,谁会关心使用哪种技术呢?这是一个实现细节。
结论
切换到 RavenDB 需要一点时间,大部分时间是重新编写应用程序,以充分利用面向文档的持久性模型提供的优势。RavenDB 的嵌入式特性使得我们的安装过程变得更加简单,我感觉应用程序受到的约束也少了很多。
RavenDB 是一个非常棒的产品,虽然 SQL Server 仍然有它的一席之地,但我觉得 RavenDB 已经达到了一个真正的最佳状态。除了报告解决方案之外,我实在想不出我在过去工作过的任何一个基于 SQL Server 的应用程序作为文档存储不会更好。
时间将会证明 NoSQL 运动将会如何发展,但是就我个人而言,我觉得使用文档数据库比使用关系数据库要快乐得多,尤其是对于这个应用程序。
我们如何使用遥测技术来改善八达通部署-八达通部署
原文:https://octopus.com/blog/how-we-use-telemetry-to-improve-octopus
多年来,Octopus Deploy 已经发展到在应用程序中包含许多新功能和新领域。客户使用它们来查看仪表板、创建或部署版本、创作项目或针对其基础架构运行操作手册。为了更好地为客户服务,我们想知道体验的速度和响应速度。
像许多软件公司一样,我们收集遥测数据来衡量客户如何使用和体验产品。我们收集的一些遥测是 API 调用和数据库操作的计时,我们称之为性能遥测。我们在定制的工程仪表板上展示这种遥测技术,代号为“乌鸦之巢”。
乌鸦巢提供了用户体验产品的高层次概述。当客户想要访问一个页面或轮询一个端点时,就会触发一个 web 请求,而 Crow's Nest 会测量该请求需要多长时间。
我们还在多个版本中跟踪这些请求,以确保 Octopus Deploy 的响应能力不断提高。
Apdex
我们计算一个 Apdex(应用性能指数)分数,该分数旨在将测量结果转化为关于用户满意度的见解。公式是:
Apdex = (SatisfiedCount + ToleratingCount * 0.5) / TotalCount
Apdex 使用返回 2xx 响应的 API (web)请求。Apdex 排除了某些经常被调用并被缓存的请求。
- 在小于或等于 50 毫秒内返回的请求被视为在满足的阈值范围内。
- 大于 50 毫秒小于 200 毫秒的请求被认为是在可容忍的阈值范围内。
Apdex 给出了测试客户体验的统一尺度。数字越大,表示用户体验越好。我们可以改变阈值来试验给定的特定耐受性偏好的 Apdex 分数。
这篇文章中的例子显示了默认的阈值。这些可在应用程序中实时配置,以根据不同标准查看 Apdex 分数。
计算中仅包括具有 2xx 状态的 web 请求。2xx 状态表示 web 请求成功。对任何给定数据发送遥测数据的实例少于 50 个的版本会被过滤掉,以去除异常值。这些 web 请求的响应时间评估了客户对其服务的满意度。
可视化 Apdex 和 Octopus 部署
有几种方法可以可视化 Apdex。下图显示了我们如何使用 Crow's Nest 来显示 Apdex 并获得有价值的见解。
面向云和部署的 Apdex
蓝线表示 Octopus Cloud 和部署服务器中最近版本的 Apdex 性能。在此期间,云 Apdex 性能一直保持在 90 左右。部署服务器是内部 Octopus 实例,不会向客户发布。
橙色图表显示,自 2048 年 2 月 21 日起,Apdex 出现显著下降,在修正回归后,该指数于 2021 年 2 月 4155 日回升。
回顾一下不同的版本是如何影响用户体验的是很有帮助的。如果性能显著下降,我们可以进行根本原因分析来确定和解决原因。

按版本和许可的 Apdex
我们可以比较不同版本和许可证的 Apdex 分数。许可证分为云、内部、试用和整体。这些数字有很大的可变性,因为它们代表了所有客户。

Apdex 总分
每个客户都有一个总体 Apdex 分数,它表示客户体验的响应度。

Apdex 路线
单个路线的性能在客户视图中。我们对网络请求进行计时,并根据路由对结果进行分组。从这些计时中,我们显示了平均值、中间值和第 95 百分位时间。
通过按路由存储请求,我们避免了传输大量数据。在以后的版本中,我们可以使用这些度量来识别性能最差的路由。

Apdex 路线差异
我们可以使用乌鸦巢来查看不同版本之间的路线差异。项目路线在 2020.6 年和 2021.1 年之间有所改善,如 Apdex 得分的绿色差异指标所示。

Apdex 路线视图
历史业绩在每条路线上都是可见的。这使我们可以看到路由的性能在每个版本中是如何变化的。
例如,上述证书路由的性能从 2020.2 下降到 2020.6。Apdex 评分从 62 分降至 16 分。
在 2021.1 中,我们确定了 Apdex 分数下降的原因并解决了该问题,使 Apdex 分数提高到 77 分。

未来的改进
乌鸦巢帮助我们计划下一步的工作。它突出了最需要注意的领域,应该首先解决。在监控我们的整体应用程序健康状况时,它也给了我们另一个信号。
结论
遥测技术是一种强大的工具,可以为企业提供完整的用户体验。
遥测和 Apdex 提供了每个用户和每条路线性能的全面可见性。我们可以比较不同版本和许可证的性能。比较版本可以量化每次更新的效果。表现不佳的路由在每个用户或整个 Octopus Deploy 平台上都是可见的。
我们的 Crow's Nest 工具有助于改善客户体验,带来更灵敏的交互和更愉快的部署。
我们的工作方式- 2016 版- Octopus 部署
自从我们分享一些关于我们如何工作的经验教训以来,已经过去 12 个月了。自那篇文章发表以来,章鱼的大小几乎翻了一番,这种增长带来了许多变化。现在我们的团队页面上有 21 张面孔,我们已经调整了构建和支持 Octopus Deploy 的方式。
空间
Octopus Deploy 的总部设在澳大利亚的布里斯班,我们的大部分团队住在这里,尽管我们有一些团队成员分散在世界各地(墨尔本、布宜诺斯艾利斯以及很快多伦多)。我们大部分时间在家工作,但我们在布里斯班的中央商务区/市中心也有办公室。我们的发展带来的最直接的问题是办公室太小,容纳不下整个团队。这意味着我们不能再在周三见面,这预示着一种新的工作方式。我们以前在 sprint 中遵循粗略的 scrum 方法,周三是我们的 sprint 回顾和计划日。这是协作和分享的关键一天,因为整个团队都在办公室。一旦我们不能舒适地适应办公室,变革之风就开始了。Paul 分享了他的新愿景,即我们将转向开放式分配的工作方式。
开放分配
Octopus 的开放分配意味着每个人都有很大的自由来选择他们的工作。Paul 设定总体方向和优先事项,但我们从这一点开始自我组织。团队涌现,人们加入他们感兴趣/适合的团队。每个团队建立一个敏捷初始平台来确定他们的目的以及他们想要如何工作来实现它。任务和截止日期是没有分配的。我们一起努力找出完成工作的最佳方式。开放式分配建立在信任的基础上,而信任是我们工作方式的核心。
小团队
有趣的是,随着我们的成长,没有人会无所事事。如果有什么不同的话,那就是我们现在似乎比以往任何时候都更忙。:)我们最近发布了 Octopus 3.4 ,并且出现了几个小团队来处理一些令人敬畏的新工作。
客户支持又名团队真棒!
我们有一个专门的客户支持团队,最近人数增加了一倍,达到四人。客户支持对我们来说非常重要,我们的目标是提供积极、友好的支持。部署自动化是一个大而多样的主题,但我们在这里帮助从下载到部署。我们也有一个开发人员一直在团队中,每周轮换一次。这有助于每个人更好地了解我们的客户如何使用八达通和他们遇到的一些问题。
值得注意的是,我们的客户支持团队从一开始就参与了新功能的发布。设计讨论、功能演示和 bug bashes 都有支持代表,因为我们相信没有人比他们更了解我们的客户。
火和运动
Octopus 已经创建了一个名为 fire and motion 的新团队,其具体目标是继续让现有客户高兴他们选择了 Octopus,而继续让我们的开发者高兴他们选择了 Octopus,并开始每天使用它工作。这个名字来自乔尔·斯波尔斯基的一篇优秀文章。“开火和移动”的想法来自步兵战斗,在这种战斗中,获胜的唯一策略是开火和向前移动。一切都是为了进步和前进。编写代码、修复 bug、更新文档等。应对竞争就是停止你自己的行动。
我们在很大程度上采纳了这个想法,以不断提高日常使用八达通的乐趣。从历史上看,我们每隔几个月发布一次功能发布,然后进入一段时间的错误修复和增强,直到我们开始下一个功能发布。我们正在改变这种情况,让一个团队专门为我们现有的客户改进 Octopus。不过,这并不全是错误修复。还有一些很棒的增强功能即将推出!😃
特色团队
Octopus 最初是为与微软合作的团队提供的友好的部署自动化工具。NET 及相关技术部署到 Windows 服务器上。在 Octopus 版本中,我们增加了对 Linux 的支持作为部署目标,这极大地拓宽了我们的视野。虽然我们仍然主要关注微软友好的技术,但这个群体已经大大扩展了。就我个人而言,我认为现在是在微软领域做开发人员的大好时机。微软正在开放其平台以支持 Windows、Linux 和 macOS,他们正在以前所未有的速度扩展其 Azure 云平台。这对我们来说是一个挑战,我们必须跟上每一件事情的发展,但这正是我们的增长优势所在。我们现在可以分成更小的、专注的功能团队来处理新的技术和基础设施。一个很好的例子是。NET 核心和 Windows 纳米服务器,包括 Docker 支持。我们正在积极地为 Docker 添加一个精彩的故事,为此工作的团队最近发布了一篇 RFC(征求意见)博客文章,详细介绍了我们如何添加支持。请在这里关注更多新特性的博文,以及如何在开发过程中帮助塑造这些新特性。
我们最近发布了 Octopus 3.4,我们花了 8 个多月的时间来设计、开发和发布这个版本。这有点反常,因为多租户部署是如此庞大和复杂的特性。我们的目标是缩短这个周期,以便更快地将更棒的功能推向市场。一个很好的例子是,我们最近向发布了新的 IIS 网站和 Windows 服务步骤,包括虚拟目录支持。这是一个较小的版本,但是我们在它们准备好的时候就发布了它们,而不是推迟到下一个版本。期待未来有更多这样的事情发生!
每日站立
在过去的 12 个月里,我们大大改进了我们的日常单口相声。最初,我们每天早上都会在谷歌聚会上举行传统的全公司起立鼓掌。随着团队的成长,我们发现这变得越来越不相关,所以我们尝试轮换站立“警察”的角色,以帮助保持专注。但我们发现这也不太管用,于是我们在 Slack 中使用一个#standup通道尝试了异步每日站立。这个想法是,这可能是一个非常低摩擦的方式来分享你的工作和任何障碍。也就是说,如果每个团队发现他们需要在技术问题或工作进展上同步,他们可以自由地对此进行进一步管理。我们今年大部分时间都在这样做,而且效果很好。每个人都可以很容易地跟上其他团队在做什么,这不需要很多时间。
适合正确工作的正确工具...
我们继续调整我们用来沟通和完成工作的工具。如果我们发现某些东西不起作用,而且这是一个常见的主题,那么我们就会考虑改变它。
我们仍然使用 Slack 、 Waffle.io 和 Google Hangouts ,但是我们最近增加了 Bluejeans 和 Trello 来改进我们的产品开发。
松弛的
Slack 仍然是我们的主要沟通工具,但我们已经改变了使用它的方式。当我加入 Octopus 时,我们使用 Slack 做任何事情,每个人都属于几乎每个频道。我们非常健谈,一切都很棒。然后,我们发现大多数人都在不停地试图跟上通知,不管是白天还是晚上,这是不健康的。其他团队已经写了完全放弃 Slack,但是我们决定宣布 Slack 破产并改变我们使用它的方式。我们删除了许多嘈杂、不相关的频道,并鼓励每个人只加入与他们相关的频道。这使得 Slack 成为一个更好的工具,我们不需要经常检查通知。
添加牛仔裤
我们一直使用 Google Hangouts 来发布会议和特别面对面的对话,但我们发现获取 Hangouts 的私人录音是一件麻烦的事情。所以我们做了一些调查,问了一些朋友,找到了牛仔裤。Bluejeans 有一个很棒的视频通信产品,可以跨平台工作,并且可以轻松快速地录制和回放。我们试用了它,发现它工作得很好,所以我们把它添加到我们的工具集中。我们仍然使用 Hangouts 进行快速会议,但如果需要保存或共享,我们会使用 Bluejeans,这很有效。
添加 Trello
Trello 是一个帮助组织和管理列表信息的极好的服务。我们过去在 bug bashes 中使用它来捕获和优先处理 bug,但是我们已经开始在我们的小团队中更多地使用它。它是如此的快速和灵活,当项目走向发布时,它是一个非常简单的管理项目工作的方法。我们通常在看板风格中使用它来反映正在进行的工作,并将事情向右移动。我们还有一个“主页”板,显示所有正在进行的公司活动,一目了然。这使得它很容易保持在其他团队发生的事情的顶部,而不需要跳到他们的团队特定的董事会。
总结
这就是本期我们如何工作的全部内容。目前一切都很顺利,但我们仍在学习,所以他们可能会再次改变。最终结果是更有规律地发布高质量的版本,让我们的客户满意!
我希望这是对我们如何构建和支持 Octopus 的一个有趣的观察。请随意添加评论以分享您的团队所做的任何更改,或者添加一个有助于您的团队更好地沟通的酷新工具。
我们的工作方式。最近的一些教训-章鱼部署
最近,我们的一位出色客户向我们提出了一个问题,除了说了一些关于我们的非常好的事情(我们喜欢这样的反馈)之外,他还问道:
“我很想知道你们使用什么样的工具和方法来保持一切顺利运行?”
大约六个月前,Paul 写了一篇关于我们如何工作的博客,但我们仍然是一个小团队,一个不怕尝试新事物的团队,所以事情总是在变化。
这里有一个关于这里发生了什么,发生了什么变化,以及我们在这个过程中学到的一些经验教训。
混乱和无序
不久前,我们有一个松散地基于 Scrum 的流程,让我们每两周就有可能发布一些东西。
然后我们做了一件我们努力帮助你不要做的事...那就是 8 个月没有主要发布了!
当你这样做的时候,这意味着当你在做事情和构建特性的时候,还有大量的、无法量化的“事情”要做。我相信你也有过这样的经历,你已经完成了 90%,然而最后 10%的收尾工作却花了 90%的时间。
就是没有合适的时间框工作的问题。许多尝试 Scrum 但没有投入生产的团队也遇到了这个问题。没有严格的截止日期,很容易变得有点自满,留下一些未完成的角落。
公平地说,我们同时处理了大量的架构变更,试图让所有的东西同时工作是相当浪费的。
截止日期、Bug Bashes、群集和看板
我们用了几样东西来摆脱困境。我们为我们的预发布设定了一个日期,并查看了我们需要什么来让我们到达那个点。
我们现在相当定期地做一些我们称之为“bug bash”的事情。我们都安装了一个构建,并花了一个下午试图用各种方法破坏它。我们寻找 bug,不一致,可用性问题,以及其他任何会影响体验的东西。我们把它们都存放在像特雷罗这样的地方。
因此,考虑到预发布,我们这样做了,并开始一次修复一个。这意味着我们有一个非常有限的工作在进行中,我们都非常密切地合作,让一切都通过我们的特雷罗董事会,并进入一个构建。
一旦我们发布了公共预发布,我们就保持这种状态,发布了许多版本,并在我们的板上不断地集中讨论这些问题,以快速修复它们并将其纳入新版本。
连续交货
正如保罗上周所说,我们正努力保持这种势头,并更经常地发货,因为它能做一些事情。它让我们专注于“完成”,并帮助 Octopus 每天更好地部署。如果我们(或客户)发现了一个 bug,如果我们可以在第二天发布一个补丁,为什么我们要故意将这个 bug 发布给每个下载我们产品的人两周呢?
我们一直在做一些有趣的事情来自动化我们的许多发布过程,我们也将很快开始分享。
更小的团队,更短的站立
当我们还小的时候,对每个人来说跨越一切是有意义的,我们都在一次冲刺中完成。最近几个月,虽然我们碰到了一个点(很多人都熟悉),我们的站立不集中,你经常需要后续对话来实际计划你的一天。但是我们喜欢在早上看到每个人的脸,所以我们不想把他们放在一起。
所以我们分成了更小的团队,每个团队都有更专注的单口相声。
你看,在我们发布 3.0 的同时,我们也重建了我们的网站。我们改变了设计,从 RavenDB 转移到 SQL Server(使用我们为该产品编写的同一个库,我们可能很快就会开源它),将它转移到 Azure,并进行了一系列其他更改。
因为我们更有规律地发布这两种产品,所以“站立”更多地是关于“我们需要为下一个版本做什么”,这比标准的“我昨天做了什么,我今天在做什么”类型的问题更集中。
人们也经常提前几分钟加入聚会,所以我们可以聊聊天,聊聊天。
每周回顾和计划
我们尽量每周都在同一个房间进行回顾和计划。这并不过分正式,任何有值得展示的东西的人都会做一个简短的介绍、演示或讨论。今天晚些时候,我们将分开来看看下周的优先事项,并讨论任何需要一个小组的事情。这有助于我们在做什么和为什么做的问题上达成共识。
适用于分布式(或非分布式)劳动力的工具
虽然我们大部分时间都在布里斯班,而且我们有一个办公室,但我们仍然经常在家工作。我们为此使用的工具有所改变,但这是每个人都想知道的有趣之处。
松弛的
我们喜欢 T2 的 Slack T3,几乎可以用它做任何事情。我们所有的其他工具都将它们的信息传输到它里面,所以它是我们公司的持续脉动。这是团队内部合作的一个很好的工具。它可能会有点吵,但你总是可以关闭一段时间,然后在重新上线时补上历史记录。如果有人需要你,提到你的名字就可以在你选择的移动设备上变成一个通知,这样你就可以非常灵活地工作了。添加自己的表情符号也很有趣!

谷歌视频
我们使用 Google Hangouts 已经有一段时间了,但我们使用它的次数越来越多。经常会出现文本聊天不起作用的时候,我们已经非常善于认识到这一点,并跳转到一个地方。我认为这是以分布式方式工作的诀窍,知道何时升级到更高保真的交流媒介。
华夫饼. io
这是我们工具库的新成员。我们使用 GitHub 来处理代码和问题,以前我们使用 HuBoard 来处理我们的问题。HuBoard 不错,但我们发现华夫饼。io 对我们来说更好一点。通过一些 GitHub web 挂钩,它让我们可以在 board 和 GitHub 之间进行实时双向同步(直接在 GitHub 中工作对很多事情来说更容易,HuBoard 需要刷新才能获得更改)。它还有一个很棒的功能,即链接问题和板上的拉请求,这些请求会移动到“待审核”栏。
课程
他们说,生意场上最危险的一句话是“但我们一直是这么做的”。能够发现问题并做出改变是非常重要的。这是我们“我们如何工作”的最新版本,随着时间的推移,我相信它会再次发生变化。
其他的一些教训是,运输迫使我们把注意力集中在完成事情上,运输经常会在你的团队中根深蒂固。与此相反的是,同时处理太多事情会分散对运输的关注,这使得运输变得更加困难。
纠正这一点并【群集】回到正轨是扭转你的团队的好方法。
使用 Octopus Deploy 和 Pulumi 将基础设施作为代码:第一部分——Octopus Deploy

Pulumi 是一个基础设施代码解决方案,允许你用你已经熟悉的语言定义你的基础设施,比如 Go、Python 或 JavaScript。
在这篇文章中,我将向您展示如何使用用 Go (Golang)编写的 Pulumi 项目创建 Azure 资源组,以及如何使用 Octopus Deploy 部署它。
先决条件
要跟进这篇文章,你需要:
- 一个 GitHub 账号。
- 至少一个 Linux 部署目标。
- Azure 订阅。
- 在 Octopus 中配置的 Azure 帐户。
- 一个免费的账户。
为什么普鲁米和章鱼部署?
Pulumi 是一个多语言云开发平台,允许您使用编程语言(如 Go、C#、Python、TypeScript、JavaScript、F#、VB)来构建云服务。无论您是想构建虚拟机、网络、无服务器实现,还是其他任何东西,Pulumi 都可以提供帮助。
对于 Pulumi 支持的每种语言,都有一个 SDK 可以用来与不同的云服务进行交互。例如,您可以使用 Azure SDK 创建一个资源组。
使用 Octopus Deploy,您可以使用 community steps 在 Windows 和 Linux 服务器上运行 Pulumi 项目。这应该涵盖您需要工作的任何环境。
创建 Pulumi 项目
-
登录到 Pulumi。
-
点击 +新建项目。
-
选择 Azure 为云。
-
选择语言的转到,点击下一步。
-
添加项目的详细信息。您可以保留默认值,也可以添加自定义元数据。
- 项目名称:正在创建的项目的名称。
- 项目描述:正在创建的项目的描述。
- 栈:栈名(dev,prod 等。).
- 配置:对于配置,您会看到几种不同的类型可供使用:
- 公共
- 美国政府
- 德国的
- 瓷器;(China)中国
对于一个开发环境,只要你没有任何规定,保持它
public就可以了。完成后,点击创建项目。 -
如果您还没有在本地安装 Pulumi,您应该现在安装它。你可以在 Windows 上使用 Chocolatey ,或者在 MacOs 上使用 Homebrew 。
-
为您的项目创建一个新目录,并将目录(
cd)更改为新创建的项目目录。 -
接下来,将项目从 Pulumi 拉到您刚刚创建的目录中,运行以下命令,然后按照说明进行操作:
pulumi new azure-go -s AdminTurnedDevOps/azure-go-new-resource-group/dev
- 从 Pulumi 中取出项目后,就该部署它了:
pulumi up
使用 Pulumi 编写代码
现在您已经创建了 Pulumi 项目,并且它在您的本地机器上是可用的,您已经拥有了使用 Go 与 Pulumi 进行交互所需要的一切。
该项目包括:
- 一个 go.mod 文件,它指定了所需的包。
- 指定项目和项目名称的 YAML 配置文件。
- main.go 文件,其中已经包含了 go 代码。
对于每个 Pulumi 项目,默认情况下您会看到 starter 代码,它会向您显示使用了哪些 SDK 和软件包。
Azure 示例
让我们从头开始创建一些东西,而不是使用 main.go 文件中的默认代码。
首先要指定的是包名和导入。因为代码来自main,所以您使用的包也将是main。
从标准库中,fmt和log将用于打印输出到屏幕上。这两个 Pulumi 包分别用于 Azure SDK 和 Pulumi SDK:
package main
import (
"fmt"
"log"
"github.com/pulumi/pulumi-azure/sdk/v3/go/azure/core"
"github.com/pulumi/pulumi/sdk/v2/go/pulumi"
)
接下来,创建包含三个参数的资源组函数:
- 来自 Pulumi 的上下文
- 资源组名称
- 位置
func newResourceGroup(ctx *pulumi.Context, resourceGroupName string, location string) {
if ctx == nil {
log.Println("Pulumi CTX is not working as expected... please check issues on the SDK: github.com/pulumi/pulumi/sdk/v2/go/pulumi")
} else {
pulumi.Run(func(ctx *pulumi.Context) error {
resourceGroup, err := core.NewResourceGroup(ctx, resourceGroupName, &core.ResourceGroupArgs{Location: pulumi.String(location)})
if err != nil {
log.Println(err)
}
fmt.Println(resourceGroup)
return nil
})
}
if语句检查ctx是否是nil,并允许我们查看 SDK 在上下文中是否有问题。
else语句包括执行 Pulumi 程序主体的Run()函数。正如你在 GitHub 上的 SDK 中看到的,它需要一个匿名函数,特别是在上下文中传递。
代码的核心在core.NewResourceGroup中,它创建了资源组。您还可以添加一些错误处理:
func main() {
resourceGroupName := "octopuspulumitest"
location := "eastus"
ctx := &pulumi.Context{}
newResourceGroup(ctx, resourceGroupName, location)
}
main函数执行newResourceGroup()函数,并在运行时传入一些参数。还有一个 Pulumi 上下文的空初始化,因为这是newResourceGroup()中需要的参数之一。
完成的代码片段如下所示:
package main
import (
"fmt"
"log"
"github.com/pulumi/pulumi-azure/sdk/v3/go/azure/core"
"github.com/pulumi/pulumi/sdk/v2/go/pulumi"
)
func main() {
resourceGroupName := "octopuspulumitest"
location := "eastus"
ctx := &pulumi.Context{}
newResourceGroup(ctx, resourceGroupName, location)
}
func newResourceGroup(ctx *pulumi.Context, resourceGroupName string, location string) {
if ctx == nil {
log.Println("Pulumi CTX is not working as expected... please check issues on the SDK: github.com/pulumi/pulumi/sdk/v2/go/pulumi")
} else {
pulumi.Run(func(ctx *pulumi.Context) error {
resourceGroup, err := core.NewResourceGroup(ctx, resourceGroupName, &core.ResourceGroupArgs{Location: pulumi.String(location)})
if err != nil {
log.Println(err)
}
fmt.Println(resourceGroup)
return nil
})
}
}
结论
最初配置 Pulumi 有多个步骤,但正如您所见,它非常强大。您可以使用您喜欢使用的编程语言,并在一个环境中创建您需要的基础设施或服务。
在我的下一篇帖子中,我将向您展示如何打包 Go 代码并使用 Octopus Deploy 部署它。
观看网络研讨会
https://www.youtube.com/embed/SA3-efF5PWk
VIDEO
我们定期举办网络研讨会。请参见第页的网上研讨会,了解以往网上研讨会的档案以及即将举办的网上研讨会的详细信息。
愉快的部署!
使用 Octopus Deploy 和 Pulumi 将基础设施作为代码:第二部分——Octopus Deploy

在本系列关于使用 Pulumi 和 Octopus Deploy 进行基础设施开发的第一部分中,我向您展示了如何使用一个新项目配置 Pulumi,并使用 Pulumi SDK 编写代码,该 SDK 使用 Go 指定 Azure。
在这篇文章中,我将讨论部署,并向您展示如何用 Octopus Deploy 打包和部署第一部分中的 Go 代码。
使用 GitHub repo
有不同的场景可用于构建和打包应用程序:
- 构建服务器。
- 从藏物仓库里取出一个包裹。
- 拉上包裹的拉链。
- 加上很多其他的。
在这篇文章中,我们使用 GitHub,它涵盖了一个免费的通用场景。
创建 GitHub Repo
首先,创建一个新的 GitHub repo:
- 登录github.com。
- 在存储库下,单击新建。
- 给存储库起一个名字,例如,我用了名字
pulumi-azure-resource-group。 - 因为这个存储库没有任何敏感信息,所以保留它
public也没问题。 - 点击创建存储库。
本地拉下回购,推送代码
- 克隆 GitHub repo 并将您的 Pulumi 项目(来自第一部分)复制到您的本地 repo 中。
- 提交并将代码推送到 GitHub repo。

创建一个版本
为了让 Octopus Deploy 从 GitHub 获取外部提要,GitHub repo 需要一个从 repo 内部代码构建的版本。
- 在 GitHub repo 中,在发布下,点击创建新发布。
【T2 
- 给版本一个名称和版本号。
- 点击发布发布。这将创建一个版本。
为 Pulumi 配置 Octopus 项目
代码现在已经编写好了,被推送到 GitHub,并准备好打包使用 Octopus Deploy 进行部署。为此,创建一个新项目并使用 Pulumi 社区步骤模板。
创建外部源
- 登入八达通网站。
- 转到 库➜外部进给 。
- 点击添加进给。
- 对于馈送类型,选择 GitHub 库馈送。
- 给它起名叫
Pulumi Azure Resource Group。
您不必添加任何凭据,因为回购是公开的。
创建新项目和项目组
- 导航到项目。
- 点击添加组。
- 将群组命名为
Pulumi。 - 在新组中,添加一个名为 Golang-Pulumi 的新项目。
创建项目变量
为了将 Pulumi 步骤模板部署到 Azure,它需要对 Azure 进行身份验证。通过使用类型为 Azure Account 的项目变量来实现这一点。
- 导航到您创建的项目,在变量下,点击项目。
- 创建一个新的帐户类型变量 Azure Account 。确保变量名为 Azure ,因为步骤模板在项目变量中搜索变量名为 Azure 的变量。
- 选择有权部署资源的 Azure 帐户。
- 保存变量。
添加部署包步骤
- 从您的项目中选择流程并点击添加步骤。
- 选择包,然后选择部署包。
- 点击配置功能,选择自定义安装目录。
- 取消勾选。净配置变量和。网络配置转换并点击确定。
- 指定名称、目标角色和包详细信息。确保包细节指向 GitHub 提要和存储 Pulumi Azure 项目的 repo。
- 对于自定义安装目录,选择 Pulumi Azure 代码将驻留的位置。这也是 Pulumi 步骤创建 Azure 资源组的地方。
- 保存该步骤。
添加一个运行 Pulumi (Linux)步骤
-
从您的项目中,选择流程并点击添加步骤。
-
选择 社区步骤➜ Pulumi ➜运行 Pulumi (Linux) 并安装该步骤。
-
指定名称和目标角色。
-
为运行 Pulumi (Linux)步骤模板添加参数:
- 栈名:Pulumi 中项目的全称,使用以下格式:
OrganizationName/ProjectName/StackName。比如我的是AdminTurnedDevOps/azure-go-new-resource-group/dev。您可以在 Pulumi 门户中找到您的堆栈名称的信息。 - 创建堆栈:您可以忽略此选项,因为堆栈已经存在。
- 命令:普鲁米有几个命令,但是你只需要
pulumi up。不必键入完整的命令,只需键入up。 - 命令参数:命令参数
--yes是必需的。例如,当您从命令行运行 Pulumi 时,有一个创建资源的选项。两个选项是yes或no。因为我们在步骤模板中没有这些弹出窗口,所以我们使用了--yes标志。 - Pulumi 访问令牌:这是一个 API 密钥,可以在 Pulumi 门户的设置下生成。
- Pulumi 工作目录:工作目录是您从 Deploy a Package 步骤复制代码的地方。
- 恢复依赖关系:该步骤用于 NodeJS 恢复依赖关系。您没有使用 NodeJS,所以取消选中该框。
- 栈名:Pulumi 中项目的全称,使用以下格式:
-
完成后,保存该步骤。
部署代码
现在是时候创建一个新版本,并运行持续部署过程,使用 Pulumi 和 Octopus Deploy 创建一个新的 Azure 资源组。
- 在 Octopus 项目中,点击创建发布。
- 点击保存。
- 通过点击部署到并选择环境,部署到您选择的环境。
- 点击展开。
现在,您已经使用 Octopus Deploy 和 Pulumi 成功地创建了一个 Azure 资源组。
结论
将 Octopus Deploy 和 Pulumi 等工具结合起来,您可以从开始到结束自动执行整个工作流程,而无需手动流程。
观看网络研讨会
https://www.youtube.com/embed/SA3-efF5PWk
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解以往网络研讨会的档案以及即将举办的网络研讨会的详细信息。
愉快的部署!
PowerShell 和 IIS: 20 个实例- Octopus 部署
在 Octopus Deploy,我们用 IIS 做了大量工作。如果把我们所有客户的部署遥测数据加起来,我们已经完成了超过一百万个网站和服务的部署。在这一过程中,我们学到了很多东西,包括如何使用 PowerShell IIS 模块,它们如何在幕后工作,以及如何可靠地使用它们。我在这篇文章中的目标是分享这些知识,并建立一个单一的地方,当人们需要使用 PowerShell IIS 模块时,我们可以为他们指明方向。
这篇文章包括:
applicationHost.config文件和 IIS 配置的工作原理。- Windows Server 2016/Windows 10 中引入的新
IISAdministrationPowerShell 模块。 - 自 Windows 2008 以来使用的较旧的
WebAdministrationPowerShell 模块。 - 我们从数百万个使用 PowerShell IIS 模块的实际部署中学到了什么。
- 很多很多实际例子,2008-2016 年在所有 Windows Server OS 上测试,还有关于 Nano Server 的信息。
所有这些例子的源代码都存在于一个 GitHub 库中,我们在运行不同版本 Windows Server OS 的测试机器上自动运行这些例子,所以我对它们的工作相当有信心。当然,如果您遇到任何麻烦,可以在 GitHub 库的问题列表中发布问题,或者向我们发送请求!😄
在我们进入实际例子之前,这篇文章的开头有相当多的理论。有很多网站展示了如何完成基本的 IIS 任务;在这篇文章的结尾,我的目标是让你成为自动化 IIS 配置的专家并且例子把它放到了上下文中。
如何存储 IIS 配置
如果你打开 IIS 管理器用户界面,浏览任何网站或应用程序池,你会发现你可以调整的旋钮和刻度盘并不短缺。有成千上万种可能的设置,从使用什么样的身份验证方法,到应该如何编写日志文件,到运行您的进程的应用程序池应该多久回收一次。

所有这些设置都在哪里?
自 IIS 7 (Windows 2008)以来,几乎所有这些设置都位于以下两个位置之一:
- 与应用程序一起部署的
web.config文件。 - 一个
applicationHost.config文件,它是服务器范围的。
如果你是一个 ASP.NET 开发者,你肯定对web.config文件很熟悉,但是你可能以前没见过applicationHost.config。您通常会在以下位置找到它:
C:\Windows\System32\inetsrv\config\applicationHost.config
如果您使用 IIS,值得花时间仔细查看一下这个文件,因为您会发现各种有趣的设置。例如,下面是如何定义应用程序池的:
<configuration>
<!-- snip -->
<system.applicationHost>
<!-- snip -->
<applicationPools>
<add name="DefaultAppPool" managedRuntimeVersion="v4.0" />
<add name=".NET v2.0 Classic" managedRuntimeVersion="v2.0" managedPipelineMode="Classic" />
<add name=".NET v2.0" managedRuntimeVersion="v2.0" />
<add name=".NET v4.5 Classic" managedRuntimeVersion="v4.0" managedPipelineMode="Classic" />
<add name=".NET v4.5" managedRuntimeVersion="v4.0" />
<add name="OctoFX AppPool" autoStart="false" startMode="AlwaysRunning">
<processModel identityType="LocalSystem" />
</add>
和网站:
<configuration>
<!-- snip -->
<system.applicationHost>
<!-- snip -->
<sites>
<site name="Default Web Site" id="1">
<application path="/" applicationPool="Default Web Site">
<virtualDirectory path="/" physicalPath="C:\inetpub\wwwroot" />
</application>
<bindings>
<binding protocol="http" bindingInformation="*:80:" />
</bindings>
</site>
为什么熟悉applicationHost.config文件很重要?嗯,归结起来就是:
我们下面讨论的所有 IIS 的 PowerShell 模块都只是用于编辑这个大 XML 文件的包装器。
如果您理解了这一点,您会发现理解 PowerShell IIS 模块的工作方式会容易得多,并且您将能够解决如何配置不明显的设置。
IIS PowerShell 模块和操作系统版本
IIS 在很大程度上依赖于 Windows 内核提供的服务,因此 IIS 的每个版本都与 Windows 的一个版本相结合。因为 IIS 的每个版本都带来了新的特性,所以在提供 PowerShell 模块方面有不同的尝试。下表概述了这些组合中的每一种:
| 操作系统 | IIS 版本 | PowerShell 模块 |
|---|---|---|
| Windows Server 2008 | 七 | Add-PsSnapIn WebAdministration |
| Windows Server 2008 R2 版 | 7.5 | Import-Module WebAdministration |
| Windows Server 2012 | 8 | Import-Module WebAdministration |
| Windows Server 2012 R2 版 | 8.5 | Import-Module WebAdministration |
| Windows Server 2016 | 10 | Import-Module WebAdministration或 |
或Import-Module IISAdministration |
||
| Windows Server 2016 - Nano | 10 | Import-Module IISAdministration |
让我们快速浏览一下历史。
IIS 7 和 web 管理“管理单元”
IIS 6 支持运行 ASP.NET 应用程序,但它是在非托管(非。NET)代码,所有模块和扩展都是非托管的。IIS 7 是 IIS 支持的第一个版本。NET 模块和新的集成管道模式。Windows Server 2008 附带了 IIS 7,但是 PowerShell 是如何安装的?
PowerShell 1.0 使用了 SnapIns ( 模块在 PowerShell 2.0 中引入),但是大部分支持的命令与后来的模块版本中使用的命令相同。在 Windows 2008(R2 之前)上,您可以加载 PowerShell IIS 支持:
Add-PsSnapIn WebAdministration
# Use commands like: Get-Website, New-Website, New-WebAppPool
更复杂的是,PowerShell 2.0 可以在 Windows Server 2008 上升级,但 PowerShell IIS 模块不能,您仍然需要使用管理单元。
IIS 7.5+和 web 管理模块
Windows Server 2008 R2 于 2011 年发布,包含 PowerShell 2.0 FC ,这意味着 IIS 命令现在可以作为一个模块使用。您可以使用以下命令加载它们:
Import-Module WebAdministration
# Use commands like: Get-Website, New-Website, New-WebAppPool
IIS 10 和 IISAdministration 模块
Windows Server 2016/Windows 10 自带的 IIS 10 为你提供了两种选择。您可以继续使用旧模块:
Import-Module WebAdministration
# Use commands like: Get-Website, New-Website, New-WebAppPool - same as before
或者您可以使用全新的 IISAdministration模块:
Import-Module IISAdministration
# Use commands like: Get-IISSite, New-IISSite, New-IISAppPool
为什么要改变?下图解释了每个模块是如何构建的。

当 IIS 7 发布时,为了更容易地从托管代码中使用applicationHost.config,微软创建了一个名为Microsoft.Web.Administration.dll的. NET 库。你可以在 GAC 中找到它,你可以从 C#代码中引用它并使用它:
using (var manager = new ServerManager())
{
foreach (var site in manager.Sites)
{
Console.WriteLine("Site: " + site.Name);
}
}
如果您浏览类库文档,您会发现它很大程度上是 XML 配置文件的包装。例如,Application类继承自ConfigurationElement基类。
出于某种原因,WebAdministration PowerShell 模块从未直接构建在这个类库之上,而是复制了它的大部分。当你在反编译器中观察它时,这种重复是非常明显的。
有了新的IISAdministration模块,微软基本上已经:
- 在
Microsoft.Web.AdministrationDLL 的基础上重新构建它 - 已删除
IIS:\驱动器 PowerShell 提供程序。 - 创建了新的
IIS*cmdlet,提供了进入Microsoft.Web.Administration类的“跳转点”。
作为用户,IISAdministration版本的模块有一个很大的优势;命令返回的类型更加有用。虽然它们仍然是 XML 包装器,但是它们用有用的属性和方法进行了修饰,使得对象更加可用,而不依赖于命令:
Import-Module IISAdministration
$site = Get-IISSite -Name "Default Web Site"
$site.ServerAutoStart = $true # Make the website start when the server starts
$site.Applications.Count # How many applications belong to the site?
$site.Bindings[0].Protocol # Get the protocol (HTTP/HTTPS) of the first binding
如果您使用的是旧的WebAdministration,那么您几乎必须使用 PowerShell CmdLets 或采用 XML 来做所有事情。举个简单的例子,没有办法从Get-Website返回的站点导航到它的应用程序。这个新模块在 PowerShell 管道中也能更好地工作。
总的来说,虽然我认为微软在新模块中的重构是一个很好的举措,但我希望它不是一个突破性的变化。我可以想象这简化了他们的维护,但他们没有构建一流的 PowerShell/IIS 体验,而是构建了一些返回的 cmdlets。NET 对象,然后对它们进行标准的方法调用。
纳米服务器打破了一切!
也许这有点苛刻,但也有一定的道理。事情是这样的:
- Nano Server 是一个非常精简的 Windows 版本,设计用于容器或作为 VM;就是几百 MB,瞬间开机。我对此非常兴奋。
- Nano 服务器无法完全运行。NET 框架,它只能运行。网芯。
- PowerShell 构建于。NET 框架。
- 为了能够在 Nano 服务器(和 Linux!),他们在上重建了 PowerShell。网芯。
- 旧的
WebAdministration模块也需要完整的。NET 框架。他们将一个版本的Microsoft.Web.Administration.dll移植到。NET Core(毕竟,它只是一个大的 XML 包装器)所以IISAdministration模块可以工作,但是他们从来没有移植过WebAdministration模块。 - 微软没有将 WebAdministration 移植到 Nano 服务器的计划。
这意味着如果你的脚本需要在 Nano 服务器上运行,你只能使用IISAdministration模块,我们已经知道并喜欢的旧的WebAdministration模块不再工作了。

编写在多种操作系统上运行的脚本
在 Octopus,我们部署 IIS 网站的代码必须支持所有这些操作系统。我们发现的加载WebAdministration模块的最简单和最可靠的方法是,不管你使用的是什么操作系统:
Add-PSSnapin WebAdministration -ErrorAction SilentlyContinue
Import-Module WebAdministration -ErrorAction SilentlyContinue
# Use commands like: Get-Website, New-Website, New-WebAppPool
如果你想确定你已经加载了至少一个模块(IIS 可能没有安装),你可以看看我们在 Octopus 中是怎么做的。
以这种方式编写的脚本应该可以在操作系统之间移植,除非你在 Nano 服务器上运行它。在这种情况下,您需要使用新模块,而不是IIS*cmdlet。
重述 IIS 理论
站点、应用程序和虚拟目录
我们将在这篇文章中大量使用这些术语,所以我认为有必要稍微回顾一下。让我们看看这个 IIS 服务器:

这里我们有一个 IIS 服务器,它服务于多个网站(网站 1 和网站 2)。每个网站都有绑定,指定它监听的协议(HTTP/HTTPS,有时是其他)、端口(80/443/其他)和主机头。
Website2 还有很多应用 (App1,App1.1,App1.2,App2)和虚拟目录 (App.1.1.vdir1,vdir1,Vdir1.1,Vdir2)。
不要让 IIS 管理器的截图欺骗了你。在幕后,IIS 对这些站点、应用程序和虚拟目录之间的关系有着完全不同的看法。来自IIS 团队:
简而言之,站点包含一个或多个应用程序,应用程序包含一个或多个虚拟目录,虚拟目录映射到计算机上的物理目录。
这可能需要几分钟来理解,但这很重要。IIS 管理器显示了上面的树,因为这是用户考虑他们的站点、应用程序和 vdirs 的方式,但下面是 IIS 实际上如何对数据建模:
- 站点:网站 1
- 网站:网站 2
- 应用: /
- 虚拟目录: /
- 虚拟目录: /Vdir1
- 虚拟目录: /Vdir1/Vdir1.1
- 虚拟目录: /Vdir2
- 应用: /App1
- 应用: /App1/App1.1
- 虚拟目录: /
- 虚拟目录: /App1.1.vdir1
- 应用: /App1/App1.1/App1.2
- 应用: /App2
- 应用: /Vdir1/Vdir1。附录 3
- 应用: /
这是微软的对象模型。网络管理。NET 程序集提供的模型,但它也是 XML 在applicationHost.config中使用的模型:
<sites>
<site name="Website2" id="2">
<application path="/" applicationPool="MyAppPool">
<virtualDirectory path="/" physicalPath="..." />
<virtualDirectory path="/Vdir1" physicalPath="..." />
<virtualDirectory path="/Vdir1/Vdir1.1" physicalPath="..." />
<virtualDirectory path="/Vdir2" physicalPath="..." />
</application>
<application path="/App1" applicationPool="MyAppPool">
<virtualDirectory path="/" physicalPath="..." />
</application>
<application path="/App1/App1.1" applicationPool="MyAppPool">
<virtualDirectory path="/" physicalPath="..." />
<virtualDirectory path="/App1.1.vdir1" physicalPath="..." />
</application>
<application path="/App1/App1.1/App1.2" applicationPool="MyAppPool">
<virtualDirectory path="/" physicalPath="..." />
</application>
<application path="/App2" applicationPool="MyAppPool">
<virtualDirectory path="/" physicalPath="..." />
</application>
<application path="/Vdir1/Vdir1.App3" applicationPool="MyAppPool">
<virtualDirectory path="/" physicalPath="..." />
</application>
...
一些注意事项:
- 在 IIS 中,对象模型并不像 IIS 管理器中的树那样疯狂。网站有应用程序。应用程序有虚拟目录。就是这样。通过存储路径来模拟深度嵌套的关系。
- 尽管 IIS 管理器显示 VDir1 内部有一个应用程序,但实际上该应用程序属于该站点。
- Website1 只是一个站点,没有任何应用程序或虚拟目录,但这只是 IIS 管理器让我们的生活又变得简单了。实际上有一个应用程序和一个虚拟目录,它们只是使用“/”作为路径。
- 所有这些东西的物理路径实际上是由虚拟目录定义的。
web administrationPowerShell 模块实际上做了相当大的努力来隐藏这一点,您可以像 IIS Manager 一样导航 IIS。但是新的 IISAdministration 模块放弃了这个漏洞百出的抽象,以这种方式向你展示世界。
位置部分
IIS 配置的一个令人困惑的行为是,当您在 IIS 管理器中进行更改时,不同的设置会存储在不同的位置:
- 在上面显示的
<sites>元素中。 - 在 applicationHost.config 的
<location>部分中 - 在您自己的 web.config 文件中。
例如,当你改变一个网站的物理路径或绑定时,它会存储在<sites>中。
当你改变设置,比如是否启用目录浏览,这将进入虚拟目录的物理路径中的web.config文件(记住,网站和应用都有虚拟目录!).
当您更改身份验证模式(匿名、基本、Windows 等)时。)应该适用,这是写在applicationHost.config底部的<location>部分:
<location path="Website2/Vdir1">
<system.webServer>
<security>
<authentication>
<anonymousAuthentication enabled="false" />
</authentication>
</security>
</system.webServer>
</location>
似乎适用的规则是:
- 如果它是一个设置,应该是它所应用的东西的本地设置,它被存储在。例如,当我更改网站 2 的应用程序池时,我不希望它也更改分配给其中应用程序的应用程序池。
- 如果这是一个应用程序开发人员可能想要自己设置的设置,它会转到 web.config。
- 如果这是一个由 IIS 管理员设置的设置,而不是由应用程序开发人员设置的,但这是他们期望沿着路径继承的东西,那么就用
applicationHost.config中的<location>来设置。例如,如果我在根网站禁用匿名身份验证,我希望这适用于它下面的所有内容。如果我为一个虚拟目录重新启用它,我希望该路径下的其他应用程序和虚拟目录继承新值。
值得注意的是,你实际上对规则#3 有一些控制。IIS 锁定某些设置,例如认证设置,这样它们就不会被恶意的应用程序开发者覆盖。但是你可以自己解锁它们,允许单个应用程序在自己的 web.config 文件中覆盖它们。
最简单的方法是在 IIS 管理器中进行更改,然后查看是 applicationHost.config 还是您的 web.config 发生了更改。
IIS:\驱动器提供程序与 CmdLets
使用 PowerShell IIS 模块有两种受支持的范例:
IIS:\驱动 PowerShell 提供程序,它让您可以像使用文件系统一样使用 IIS。- 基于任务的助手 cmdlets,如
New-Website。
事实上,如果您反编译 cmdlet,大多数 cmdlet 实际上都包装了 IIS 驱动方法。当您调用New-Website时,cmdlet 实际上会这样做:
# When you call this
New-Website -Name "MySite" -Port 8080 -PhysicalPath "C:\Test"
# It actually generates and calls:
New-Item -Path "IIS:\Sites\MySite" -Type Site -Bindings @{protocol="http";bindingInformation="*:8080:"}
Set-ItemProperty -Path "IIS:\Sites\MySite" -name PhysicalPath -value "C:\Test"
在 Octopus,我们发现虽然我们经常从 cmdlet 方法开始,但我们的脚本通常都转向使用IIS drive 方法,因为它允许更高级的设置。这就是为什么下面显示的大多数例子使用这种方法。
注意,IIS:\驱动方法是不被 IISAdministration 模块支持的,它实际上已经过时了。
重试,重试,重试
正如我已经讨论过的,所有的 PowerShell IIS 模块实际上只是 XML 文件的包装器。并且当多个进程读写文件时,文件不会做得很好。各种东西可以锁定文件,病毒扫描程序,备份解决方案,IIS 重启,有人使用 IIS 管理器用户界面。在 Octopus 的一段时间里,我们最持久的支持问题之一是当文件被锁定时出现的问题。
实际上,在数百万客户部署中,唯一可靠地为我们工作的解决方案——并且摆脱了支持投诉——是重试。很多。我们是这样做的。首先,我们创建一个可以重试执行 PowerShell 块的函数:
function Execute-WithRetry([ScriptBlock] $command) {
$attemptCount = 0
$operationIncomplete = $true
$maxFailures = 5
while ($operationIncomplete -and $attemptCount -lt $maxFailures) {
$attemptCount = ($attemptCount + 1)
if ($attemptCount -ge 2) {
Write-Host "Waiting for $sleepBetweenFailures seconds before retrying..."
Start-Sleep -s $sleepBetweenFailures
Write-Host "Retrying..."
}
try {
# Call the script block
& $command
$operationIncomplete = $false
} catch [System.Exception] {
if ($attemptCount -lt ($maxFailures)) {
Write-Host ("Attempt $attemptCount of $maxFailures failed: " + $_.Exception.Message)
} else {
throw
}
}
}
}
然后,我们使用 IIS 执行的每个操作都包含在这个函数中:
# Start App Pool
Execute-WithRetry {
$state = Get-WebAppPoolState $applicationPoolName
if ($state.Value -eq "Stopped") {
Write-Host "Application pool is stopped. Attempting to start..."
Start-WebAppPool $applicationPoolName
}
}
例子
这篇文章的其余部分将用来展示大量如何使用 PowerShell IIS 模块的真实例子。
创建站点(简单)
Import-Module WebAdministration
New-Website -Name "Website1" -Port 80 -IPAddress "*" -HostHeader "" -PhysicalPath "C:\Sites\Website1"
Import-Module IISAdministration
New-IISSite -Name "Website1" -BindingInformation "*:80:" -PhysicalPath "C:\Sites\Website1"
# Examples of -BindingInformation:
# "*:80:" - Listens on port 80, any IP address, any hostname
# "10.0.0.1:80:" - Listens on port 80, specific IP address, any host
# "*:80:myhost.com" - Listens on port 80, specific hostname
创建网站(高级)
最有可能的是,当你创建一个真实的站点时,你会想要指定一些额外的设置。为此,您可以在创建站点后获取它,并添加额外的设置。由于我们正在进行多项更改,因此可以使用延迟提交将它们一次性写入 applicationHost.config。
这里我们将添加一个额外的绑定,并设置站点 ID:
Import-Module WebAdministration
New-Item -Path "IIS:\Sites" -Name "Website1" -Type Site -Bindings @{protocol="http";bindingInformation="*:8021:"}
Set-ItemProperty -Path "IIS:\Sites\Website1" -name "physicalPath" -value "C:\Sites\Website1"
Set-ItemProperty -Path "IIS:\Sites\Website1" -Name "id" -Value 4
New-ItemProperty -Path "IIS:\Sites\Website1" -Name "bindings" -Value (@{protocol="http";bindingInformation="*:8022:"}, @{protocol="http";bindingInformation="*:8023:"})
Start-Website -Name "Website1"
Import-Module IISAdministration
$manager = Get-IISServerManager
$site = $manager.Sites.Add("Website1", "http", "*:8022:", "C:\Sites\Website1")
$site.Id = 4
$site.Bindings.Add("*:8023:", "http")
$site.Bindings.Add("*:8024:", "http")
$manager.CommitChanges()
在虚拟目录中创建应用程序
大多数时候,当人们想到将一个. NET 应用程序部署到一个虚拟目录时,他们指的是在一个网站下面创建一个应用程序。下面的例子创建了一个可以在http://site/MyApp看到的应用程序。我们还分配了一个应用程序池:
Import-Module WebAdministration
New-Item -Type Application -Path "IIS:\Sites\Website1\MyApp" -physicalPath "C:\Sites\MyApp"
Import-Module IISAdministration
$manager = Get-IISServerManager
$app = $manager.Sites["Website1"].Applications.Add("/MyApp", "C:\Sites\MyApp")
$manager.CommitChanges()
创建应用程序池
您需要将每个应用程序(网站或虚拟目录中的应用程序)分配到一个应用程序池。应用程序池定义了处理应用程序请求的可执行进程。
IIS 附带了一些已经为公共选项定义的应用程序池,但是我总是建议为您部署的每个网站或应用程序创建您自己的应用程序池。这提供了应用程序之间的进程级隔离,并允许您围绕每个应用程序可以做什么来设置不同的权限。下面的示例显示了许多常见的应用程序池设置。对于 IIS 管理模块,没有内置的 CmdLets 来创建应用程序池,所以您必须直接使用ServerManager对象来创建:
Import-Module WebAdministration
New-Item -Path "IIS:\AppPools" -Name "My Pool" -Type AppPool
# What version of the .NET runtime to use. Valid options are "v2.0" and
# "v4.0". IIS Manager often presents them as ".NET 4.5", but these still
# use the .NET 4.0 runtime so should use "v4.0". For a "No Managed Code"
# equivalent, pass an empty string.
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "managedRuntimeVersion" -value "v4.0"
# If your ASP.NET app must run as a 32-bit process even on 64-bit machines
# set this to $true. This is usually only important if your app depends
# on some unmanaged (non-.NET) DLL's.
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "enable32BitAppOnWin64" -value $false
# Starts the application pool automatically when a request is made. If you
# set this to false, you have to manually start the application pool or
# you will get 503 errors.
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "autoStart" -value $true
# What account does the application pool run as?
# "ApplicationPoolIdentity" = best
# "LocalSysten" = bad idea!
# "NetworkService" = not so bad
# "SpecificUser" = useful if the user needs special rights. See other examples
# below for how to do this.
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "processModel" -value @{identitytype="ApplicationPoolIdentity"}
# Older applications may require "Classic" mode, but most modern ASP.NET
# apps use the integrated pipeline.
#
# On newer versions of PowerShell, setting the managedPipelineMode is easy -
# just use a string:
#
# Set-ItemProperty -Path "IIS:\AppPools\My Pool 3" `
# -name "managedPipelineMode" `
# -value "Integrated"
#
# However, the combination of PowerShell and the IIS module in Windows
# Server 2008 and 2008 R2 requires you to specify the value as an integer.
#
# 0 = Integrated
# 1 = Classic
#
# If you hate hard-coding magic numbers you can do this (or use the string
# if 2008 support isn't an issue for you):
#
# Add-Type -Path "${env:SystemRoot}\System32\inetsrv\Microsoft.Web.Administration.dll"
# $pipelineMode = [Microsoft.Web.Administration.ManagedPipelineMode]::Integrated
# Set-ItemProperty -Path "..." -name "managedPipelineMode" -value ([int]$pipelineMode)
#
# If this DLL doesn't exist, you'll need to install the IIS Management
# Console role service.
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "managedPipelineMode" -value 0
# This setting was added in IIS 8\. It's different to autoStart (which means
# "start the app pool when a request is made") in that it lets you keep
# an app pool running at all times even when there are no requests.
# Since it was added in IIS 8 you may need to check the OS version before
# trying to set it.
#
# "AlwaysRunning" = application pool loads when Windows starts, stays running
# even when the application/site is idle.
# "OnDemand" = IIS starts it when needed. If there are no requests, it may
# never be started.
if ([Environment]::OSVersion.Version -ge (new-object 'Version' 6,2)) {
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "startMode" -value "OnDemand"
}
Import-Module IISAdministration
$manager = Get-IISServerManager
$pool = $manager.ApplicationPools.Add("My Pool")
# Older applications may require "Classic" mode, but most modern ASP.NET
# apps use the integrated pipeline
$pool.ManagedPipelineMode = "Integrated"
# What version of the .NET runtime to use. Valid options are "v2.0" and
# "v4.0". IIS Manager often presents them as ".NET 4.5", but these still
# use the .NET 4.0 runtime so should use "v4.0". For a "No Managed Code"
# equivalent, pass an empty string.
$pool.ManagedRuntimeVersion = "v4.0"
# If your ASP.NET app must run as a 32-bit process even on 64-bit machines
# set this to $true. This is usually only important if your app depends
# on some unmanaged (non-.NET) DLL's.
$pool.Enable32BitAppOnWin64 = $false
# Starts the application pool automatically when a request is made. If you
# set this to false, you have to manually start the application pool or
# you will get 503 errors.
$pool.AutoStart = $true
# "AlwaysRunning" = application pool loads when Windows starts, stays running
# even when the application/site is idle.
# "OnDemand" = IIS starts it when needed. If there are no requests, it may
# never be started.
$pool.StartMode = "OnDemand"
# What account does the application pool run as?
# "ApplicationPoolIdentity" = best
# "LocalSysten" = bad idea!
# "NetworkService" = not so bad
# "SpecificUser" = useful if the user needs special rights
$pool.ProcessModel.IdentityType = "ApplicationPoolIdentity"
$manager.CommitChanges()
分配应用程序池
一旦定义了应用程序池,就必须向其分配应用程序。以下示例显示了如何将虚拟目录中的网站或应用程序分配到新的应用程序池:
Import-Module WebAdministration
# Assign the application pool to a website
Set-ItemProperty -Path "IIS:\Sites\Website1" -name "applicationPool" -value "My Pool"
# Assign the application pool to an application in a virtual directory
Set-ItemProperty -Path "IIS:\Sites\Website1\MyApp" -name "applicationPool" -value "My Pool"
Import-Module IISAdministration
$manager = Get-IISServerManager
# Assign to a website
$website = $manager.Sites["Website1"]
$website.Applications["/"].ApplicationPoolName = "My Pool"
# Assign to an application in a virtual directory
$website = $manager.Sites["Website1"]
$website.Applications["/MyApp"].ApplicationPoolName = "My Pool"
$manager.CommitChanges()
检查站点、虚拟目录或应用程序池是否已经存在
在项目过程中,您将多次将应用程序重新部署到 IIS,因此您不能假设脚本是第一次运行。以下示例显示了在进行更改之前检查站点、应用程序或应用程序池是否已经存在的模式:
Import-Module WebAdministration
# The pattern here is to use Test-Path with the IIS:\ drive provider
if ((Test-Path "IIS:\AppPools\My Pool") -eq $False) {
# Application pool does not exist, create it...
# ...
}
if ((Test-Path "IIS:\Sites\Website1") -eq $False) {
# Site does not exist, create it...
# ...
}
if ((Test-Path "IIS:\Sites\Website1\MyApp") -eq $False) {
# App/virtual directory does not exist, create it...
# ...
}
Import-Module IISAdministration
$manager = Get-IISServerManager
# The pattern here is to get the things you want, then check if they are null
if ($manager.ApplicationPools["My Pool"] -eq $null) {
# Application pool does not exist, create it...
# ...
}
if ($manager.Sites["Website1"] -eq $null) {
# Site does not exist, create it...
# ...
}
if ($manager.Sites["Website1"].Applications["/MyApp"] -eq $null) {
# App/virtual directory does not exist, create it...
# ...
}
$manager.CommitChanges()
更改站点或应用程序的物理路径
当部署一个应用程序的新版本时,我的偏好(以及 Octopus Deploy 的工作方式)是部署到磁盘上一个全新的新文件夹,然后更新 IIS 以指向它。所以你从:
C:\Sites\Website1\1.0 <--- IIS points here
您部署新版本:
C:\Sites\Website1\1.0 <--- IIS points here
C:\Sites\Website1\1.1
然后,您可以对配置文件等进行任何必要的更改。然后更新 IIS 以指向它:
C:\Sites\Website1\1.0
C:\Sites\Website1\1.1 <--- Now IIS points here
如果您需要快速回滚,您可以将旧文件夹留在磁盘上,并指向它:
C:\Sites\Website1\1.0 <--- IIS points here (we rolled back manually)
C:\Sites\Website1\1.1
Import-Module WebAdministration
# The pattern here is to use Test-Path with the IIS:\ drive provider
Set-ItemProperty -Path "IIS:\Sites\Website1" -name "physicalPath" -value "C:\Sites\Website1\1.1"
Set-ItemProperty -Path "IIS:\Sites\Website1\MyApp" -name "physicalPath" -value "C:\Sites\Website1\1.1"
Import-Module IISAdministration
$manager = Get-IISServerManager
# Remember, in the IIS Administration view of the world, sites contain
# applications, and applications contain virtual directories, and it is
# virtual directories that point at a physical path on disk.
# Change for a top-level website
$manager.Sites["Website1"].Applications["/"].VirtualDirectories["/"].PhysicalPath = "C:\Sites\Website1\1.1"
# Change for an app within a website
$manager.Sites["Website1"].Applications["/MyApp"].VirtualDirectories["/"].PhysicalPath = "C:\Sites\Website1\1.1"
$manager.CommitChanges()
更改身份验证方法
IIS 支持多种身份验证方法。如上所述,默认情况下这些被锁定到applicationHost.config,如果您想要自动启用它们,下面的示例显示了如何启用/禁用:
- 匿名认证
- 基本认证
- 摘要认证
- Windows 身份验证
IIS 管理器还将ASP.NET impersonation和Forms authentication显示为同一级别的设置,但这些实际上是在你的应用程序的web.config文件中设置的,所以我在这里省略了它们:
Import-Module WebAdministration
# The pattern here is to use Test-Path with the IIS:\ drive provider.
Set-WebConfigurationProperty `
-Filter "/system.webServer/security/authentication/windowsAuthentication" `
-Name "enabled" `
-Value $true `
-Location "Website1/MyApp" `
-PSPath IIS:\ # We are using the root (applicationHost.config) file
# The section paths are:
#
# Anonymous: system.webServer/security/authentication/anonymousAuthentication
# Basic: system.webServer/security/authentication/basicAuthentication
# Windows: system.webServer/security/authentication/windowsAuthentication
Import-Module IISAdministration
$manager = Get-IISServerManager
# ServerManager makes it easy to get the various config files that belong to
# an app, or at the applicationHost level. Since this setting is locked
# to applicationHost, we need to get the applicationHost configuration.
$config = $manager.GetApplicationHostConfiguration()
# Note that we have to specify the name of the site or application we are
# editing, since we are working with individual <location> sections within
# the global applicationHost.config file.
$section = $config.GetSection(`
"system.webServer/security/authentication/windowsAuthentication", `
"Website1")
$section.Attributes["enabled"].Value = $true
# The section paths are:
#
# Anonymous: system.webServer/security/authentication/anonymousAuthentication
# Basic: system.webServer/security/authentication/basicAuthentication
# Windows: system.webServer/security/authentication/windowsAuthentication
# Changing options for an application in a virtual directory is similar,
# just specify the site name and app name together:
$section = $config.GetSection(`
"system.webServer/security/authentication/windowsAuthentication", `
"Website1/MyApp")
$section.Attributes["enabled"].Value = $true
$manager.CommitChanges()
更改日志记录设置
HTTP 请求日志记录由 IIS 提供,可以在服务器范围内指定,也可以在单个站点级别指定。应用程序和虚拟目录可以禁用日志记录,但它们自己不能进行任何日志记录。以下示例显示了如何在站点级别设置日志记录。
日志记录设置存储在站点下面的applicationHost.config中:
<system.applicationHost>
<!-- ... -->
<sites>
<site name="Default Web Site" id="1">
<bindings>
<binding protocol="http" bindingInformation="*:80:" />
</bindings>
<logFile logFormat="IIS" directory="%SystemDrive%\inetpub\logs\LogFiles1" period="Hourly" />
</site>
<siteDefaults>
<logFile logFormat="W3C" directory="%SystemDrive%\inetpub\logs\LogFiles" />
<traceFailedRequestsLogging directory="%SystemDrive%\inetpub\logs\FailedReqLogFiles" />
</siteDefaults>
<!-- ... -->
Import-Module WebAdministration
$settings = @{ `
logFormat="W3c"; ` # Formats: W3c, Iis, Ncsa, Custom
enabled=$true; `
directory="C:\Sites\Logs"; `
period="Daily"; `
}
Set-ItemProperty "IIS:\Sites\Website1" -name "logFile" -value $settings
Import-Module IISAdministration
$manager = Get-IISServerManager
$site = $manager.Sites["Website1"]
$logFile = $site.LogFile
$logFile.LogFormat = "W3c" # Formats: W3c, Iis, Ncsa, Custom
$logFile.Directory = "C:\Sites\Logs"
$logFile.Enabled = $true
$logFile.Period = "Daily"
$manager.CommitChanges()
以特定用户身份运行应用程序池
您通常可以通过运行您的应用程序池作为ApplicationPoolIdentity帐户来获得。这将为每个不同的应用程序池自动创建一个虚拟帐户,将它们彼此隔离开来。在本地机器上,您可以向每个单独的应用程序池授予对资源(如文件系统)的访问权。对于远程资源(如不同机器上的 SQL Server),应用程序池标识充当网络服务,因此您可以在机器级别授予访问权限。了解关于应用程序池标识的更多信息。
为了更好地控制应用程序池的功能,您应该在特定的自定义用户帐户下运行它。您需要使用 aspnet_regiis 来为您的自定义帐户提供作为应用程序池运行和执行 ASP.NET 请求所需的所有权限。然后,您可以将应用程序池设置为以该用户身份运行:
Import-Module WebAdministration
New-Item -Path "IIS:\AppPools" -Name "My Pool" -Type AppPool
$identity = @{ `
identitytype="SpecificUser"; `
username="My Username"; `
password="My Password" `
}
Set-ItemProperty -Path "IIS:\AppPools\My Pool" -name "processModel" -value $identity
Import-Module IISAdministration
$manager = Get-IISServerManager
$pool = $manager.ApplicationPools.Add("My Pool")
$pool.ProcessModel.IdentityType = "SpecificUser"
$pool.ProcessModel.Username = "My User"
$pool.ProcessModel.Password = "Password"
$manager.CommitChanges()
摘要
如果您第一次着手自动化您的 IIS 部署,我希望您会发现本文中的背景信息和示例很有用。正如我提到的,这些例子在 GitHub 库的中,我们在 Windows 2008 R2 到 Windows Server 2016 上运行它们。如果你发现任何问题或者对这篇文章应该包括的其他例子有想法,请在评论中告诉我或者发送一个请求!
了解更多信息
将 ASP.NET web 应用从 IIS 内部迁移到 Azure 应用服务- Octopus Deploy

团队正在将他们的应用程序和基础设施迁移到云中。在微软的 IIS web 服务器上运行的 ASP.NET web 应用的自然迁移路径是迁移到微软的 Azure 云平台上的应用服务。改变应用程序的托管方式相对简单,但确保 CI/CD 流程仍然可重复且可靠也很重要。
在这篇博客文章中,我介绍了如何使用 Octopus Deploy 更新现有 web 应用程序的部署过程,将它从本地迁移到云中。
示例应用程序
在本迁移指南中,我们将使用 Random Quotes web 应用程序作为示例。这个 web 应用程序随机检索并显示名人名言。这是一个简单的应用程序,具有 ASP.NET 前端和 SQL Server 后端,有助于说明所需的更改,而不会让人不知所措。
注意:这是一个基于 ASP.NET 的 web 应用程序,但它也可以是一个 Spring Boot Java web 应用程序或 Ruby on Rails 应用程序。我们将重点放在部署流程的变化上,因此技术堆栈不那么重要了。
部署过程:之前和之后
更新我们的部署流程非常简单。

我们现有的本地部署流程有两个步骤:
- 执行命令行工具来更新数据库的脚本步骤。
- 第二步是将我们的 web 应用程序包部署到 IIS 并配置绑定。

我们新的基于云的部署流程与此类似,但是,它被更新为部署到云提供商。我们的第一步仍然是运行一个脚本步骤来更新我们的数据库。第二步已经改变,现在是部署 Azure 应用服务步骤。它捕获了将我们的 web 应用程序部署到 Azure 应用程序服务所需的一切,包括更新我们的配置文件。
迁移到 Octopus 云(可选)
随着团队逐渐远离本地虚拟机,一种常见的模式是将其 CI/CD 平台迁移到云中。例如,公司可能会从使用 TeamCity 和 Octopus 内部部署到 TeamCity Cloud 和 Octopus Cloud 。
我们最近推出了项目导出和导入支持,使项目从一个 Octopus 实例转移到另一个实例变得容易。这是自助服务,意味着开发人员可以自己完成这项工作,无需系统管理员的帮助。也就是说,我们建议让运营团队参与进来,让他们了解情况。
注意:这个过程要求两个 Octopus 实例都运行 Octopus 2021.1 或更新版本。
本地 Octopus 实例:

- 导航至项目控制板。选择溢出菜单(三个垂直省略号),然后点击导出项目按钮。
- 选择您想要导出的项目。
- 设置密码以保护导出的文件。
- 点击导出按钮,下载工件。
Octopus 云实例:

- 导航到项目仪表板。选择溢出菜单(三个垂直省略号),然后点击导入项目按钮。
- 从本地服务器中选择导出的 ZIP 文件,并输入密码。
- 查看导入预览并点击导入按钮。
完成之后,您应该会看到新项目被导入到 Octopus Cloud 实例中。
最后一步是将您的应用程序包(即 NuGet、JAR、WAR 和 ZIP 文件)导入 Octopus Cloud。如果您只想移动最新的包,可以手动完成此操作,或者可以通过自动保存历史记录。
注意:我建议阅读我们的文档,以了解导出/导入项目特性的局限性。
将 Octopus 配置为基于云的部署
本节将介绍过渡到基于云的部署所需的步骤。
更新您的基础设施

要迁移到 Azure 解决方案,我们需要创建基于云的基础设施,并更新 Octopus 以与之集成。在 Azure 门户中,我创建了多个应用服务,我将迁移到一个 Azure SQL 数据库。
接下来,我们需要在 Octopus 中配置一个 Azure 帐户,并添加一个或多个 Azure Web App 部署目标。
Octopus 中的 Azure 帐户捕获了使用 Azure 订阅进行身份验证所需的一切,然后您可以使用它来配置您的 Azure web 应用程序目标。
导航到基础架构,然后导航到帐户以添加一个或多个 Azure 帐户。配置一个 Azure 帐户需要四个特定的 id,这有点难以找到。我不会在这里详述,但建议查看我们的 Azure 账户文档来配置这个集成。

接下来,我们需要添加一个或多个 Azure Web App 部署目标。这些应用程序服务取代了运行 IIS 的本地虚拟机,我们正在向这些虚拟机部署 web 应用程序。
添加 Azure web 应用部署目标:
- 导航到基础设施,然后部署目标。
- 点击添加目标按钮,选择 Azure,然后选择 Azure Web App。
- 配置名称、角色并选择 Azure 帐户和 Azure Web 应用。
- 点击保存按钮。
根据您的开发、测试和生产环境,对不同的订阅重复上述步骤。
更新您的部署流程
我们需要更新我们的部署流程,以支持我们向云的迁移。我们可以使用 Octopus channels 来支持旧的和新的部署流程,但是我们正在远离我们的内部基础架构,因此我将删除旧的基于 IIS 的部署步骤。
首先,回顾一下更新数据库步骤。这个脚本步骤使用数据库连接字符串来连接数据库,因此这里不需要任何更改。不过,我们确实需要确保我们的 Octopus 实例可以连接到我们的 Azure SQL 数据库。我需要更新 Azure SQL 数据库防火墙,以允许章鱼云静态 IP 地址连接到它。
接下来,我们需要添加一个新的 Azure 应用服务部署步骤。我们已经配置了基础设施,所以这并不困难。

这个截图显示了我们的步骤配置。我们使用一个 worker 以web角色部署到 Azure web app 目标,我们指定包、应用服务和连接字符串配置更新。Octopus 最近推出了一个改进的 Azure 应用服务部署步骤,它允许我们在该步骤中直接配置更新。
例如,Random Quotes 显示两个配置值,以显示应用程序版本及其部署到的环境。为此,我们使用以下 JSON 字符串和类似的数据库连接字符串:
[
{
"name": "AppSettings.EnvironmentName",
"value": "#{AppSettings:EnvironmentName}",
"slotSetting": false
},
{
"name": "AppSettings.AppVersion",
"value": "#{AppSettings:AppVersion}",
"slotSetting": false
}
]
注意:这个语法使用与 Azure 门户批量编辑特性相同的模式。这对我来说是新的,但是很容易学。
更新您的配置变量

我们还需要更新我们的项目变量来支持云。首先,我们需要更改数据库连接字符串。在这种情况下,我用单独的变量编写了数据库连接字符串,使其易于更新。我还删除了 IIS 绑定和端口配置中未使用的变量。
探索操作手册
现在我们已经转移到了云,值得一提的是 runbooks 可以帮助的一些领域。常见场景包括:
- 按计划供应和拆除开发和测试基础设施,以节省资金。
- 运行常规数据库维护作业,如索引和清理。
- 切换蓝/绿部署以在测试后推出新版本。
我不会在这篇文章中详细介绍,但在云基础设施中利用 runbook 自动化是很自然的下一步。
结论
团队正在淘汰旧虚拟机,并转向基于云的 CI/CD 基础架构和应用托管。在这篇博文中,我演示了如何将现有的 web 应用程序从本地迁移到云中,以及如何从本地的 Octopus 服务器迁移到 Octopus 云。
愉快的部署!
Selenium 系列:实现黄瓜-章鱼部署
原文:https://octopus.com/blog/selenium/25-implementing-cucumber/implementing-cucumber
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
到目前为止,我们所有的代码都是用 Java 编写的,并且我们实现了像页面对象模型这样的设计模式来增加代码的可读性和可维护性。
但是归根结底,这些代码仍然是用 Java 编写的,对设计、测试和维护 web 应用程序感兴趣的利益相关者中很少有人是 Java 专家。这意味着无论我们的代码有多干净和设计得多好,它都不是非开发人员能够阅读和理解的。
集成 Cucumber 库是让测试对非开发人员来说更容易理解的一种解决方案。我们可以使用 cumber 库作为 Java 代码和一种叫做 Gherkin 的语言之间的粘合剂,我们将在本文中这样做。
小黄瓜语言
小黄瓜语言被设计成提供一种描述需求、行为和与系统交互的自然语言。小黄瓜使用一个惯例,所有的步骤都以单词Given、When、Then和And开始。这方面的一个例子是步骤:
Given an employee named Bob making $12 per hour.
When Bob works 40 hours in one week;
Then Bob will be paid $480 on Friday evening.
即使对小黄瓜语言没有任何特别的理解,这种风格也非常易读。
我们想利用这种能力用自然语言描述一个系统,并将其应用于 WebDriver 测试。这将允许我们编写如下测试:
Given I open the URL "https://ticket-monster.herokuapp.com"
When I click the "Buy tickets now" button
And I click the "Concert" link
And I click the "Rock concert of the decade" link
And I select the option "Toronto : Roy Thomson Hall" from the "Venues" drop-down list
And I click the "Book" button
And I select the option "A - Premier platinum reserve" from the "Sections" drop-down list
Then I verify the text from the "Adult Price" label equals "@ $167.75"
这些步骤测试的场景与我们在 Java 中测试的场景非常相似。与 Java 代码不同,任何人都可以阅读这个测试并理解它的含义。更好的是,只需少量的培训,任何人都可以编写这些测试。
首先,我们需要添加两个依赖项:cucumber-java和cucumber-junit。cucumber-java库提供了许多注释,我们将使用它们将小黄瓜步骤链接到 Java 方法。cucumber-junit库允许我们执行小黄瓜特性和场景,作为 JUnit 测试的一部分。当我们开始编写测试时,我们将了解更多关于特性和场景的信息:
<project
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- ... -->
<properties>
<!-- ... -->
<cucumber.version>2.3.1</cucumber.version>
</properties>
<!-- ... -->
<dependencies>
<!-- ... -->
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-java</artifactId>
<version>${cucumber.version}</version>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-junit</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Cucumber 的工作方式是给方法附加注释,将 Gherkin 步骤与正则表达式匹配,然后将这些正则表达式中的组与方法中的参数匹配。
这些注释被称为@Given、@When、@And和@Then。与小黄瓜语言本身一样,这些注释是可以互换的,并且不需要将注释与小黄瓜步骤中使用的相应前缀相匹配。
例如,我们可以用@And注释来注释一个打开给定 URL 的方法:
@And("^I open the URL \"([^\"]*)\"$")
public void goTo(String url) {
}
但是然后在一个带有步骤前缀Given的小黄瓜步骤中引用它,就像这样:
Given I open the URL "http://google.com"
让我们分解一下分配给注释的正则表达式。
| 模式 | 模式含义 |
|---|---|
^ |
匹配字符串的开头 |
I open the URL \" |
匹配文字字符串I open the URL " |
( |
启动捕获组 |
[^"]* |
匹配除双引号以外的任何字符零次或多次 |
) |
结束捕获组 |
\" |
匹配文字字符串" |
| ` | 模式 |
| --- | --- |
^ |
匹配字符串的开头 |
I open the URL \" |
匹配文字字符串I open the URL " |
( |
启动捕获组 |
[^"]* |
匹配除双引号以外的任何字符零次或多次 |
) |
结束捕获组 |
\" |
匹配文字字符串" |
| 匹配字符串的结尾 |
为了理解这些正则表达式,我们可以使用像 http://regex-testdrive.com/en/这样的在线工具。这里我们已经输入了正则表达式和一个我们想要匹配正则表达式的目标字符串。点击Test按钮,我们就会看到这场比赛的结果。
可以看到这个匹配返回了两个组。正则表达式中的 Group 0 总是返回匹配的完整字符串,在我们的例子中是完整的句子I open the URL "http://google.com"。组 1 只返回括号中的字符,在本例中是 URLhttp://google.com。

这些正则表达式组就是 Cucumber 从字符串中提取数据并将其传递给相关方法的方式。在我们的例子中,该方法采用单个字符串参数。Cucumber 会将 group 1 的值传递给第一个参数。
所以我们的任务是将注释@Given、@When、@And和@Then添加到将执行一些有用工作的方法中。分配给注释的正则表达式定义了我们可以用来编写测试的小黄瓜方言。
在选择要应用这些注释的类时,有一些重要的考虑因素。
首先是注释必须放在具体的方法上。这意味着我们不能将注释应用于接口中定义的方法。
第二是注释所应用到的类不能被扩展。Cucumber 不支持带有注释的类的继承。
第三,当执行带有 Cucumber 注释的方法时,Cucumber 将管理包含该方法的类的生命周期。这意味着在创建类的新实例时,像AutomatedBrowserFactory这样的工厂将被绕过。
这让我们陷入了某种困境。考虑到这些限制,我们可以在哪里应用注释呢?
我们不能将注释放在AutomatedBrowser接口上,因为我们需要将注释添加到具体的类中。
乍一看,我们可能能够将注释放在WebDriverDecorator类上,因为这里定义了我们的大部分功能。然而,装饰器只有在特定的组合中构建时才有用。我们已经使用了AutomatedBrowserFactory类来为我们构建这些装饰器组合,但是因为 Cucumber 将控制带注释的类的生命周期,它将绕过AutomatedBrowserFactory使我们的装饰器变得无用。
唯一的另一个选项是AutomatedBrowserBase类,但是它已经被每个 decorator 类继承了,Cucumber 不支持它。
幸运的是,Cucumber 对用注释扩展类的限制有一个解决办法。你可能已经注意到,我们将AutomatedBrowserBase类单独放在它自己的包com.octopus.decoratorbase中。为一个单独的类准备一个包可能看起来很奇怪,但这是经过深思熟虑的。通过将包中的AutomatedBrowserBase类与所有扩展它的 decorator 类隔离开来,我们可以解决 Cucumber 的局限性。
为了了解这个变通方法是如何工作的,让我们从创建一个测试类开始,这个测试类使用了我们在cucumber-junit Maven 依赖项中包含的代码。
package com.octopus;
import cucumber.api.CucumberOptions;
import cucumber.api.junit.Cucumber;
import org.junit.runner.RunWith;
@RunWith(Cucumber.class)
@CucumberOptions(glue = "com.octopus.decoratorbase")
public class CucumberTest {
}
这个测试类有两个注释,将它与 Cucumber 库集成在一起。
首先是@RunWith标注。这个 JUnit 注释接受一个类,可以用来修改测试的运行方式。在这种情况下,Cucumber 类修改测试,在与测试类相同的包中查找任何*.feature文件,并执行它们:
@RunWith(Cucumber.class)
第二个标注是@CucumberOptions。这个注释用于定制 Cucumber 如何运行它找到的*.feature文件。这里我们已经将包com.octopus.decoratorbase作为包含“glue”类的包进行了传递。Glue 类只是带有注释@Given、@When、@And或@Then的类。
Cucumber 将对这个包中的类以及任何子包进行分类。在这个包里面和下面的 Glue 类不能互相扩展。
这意味着因为AutomatedBrowserBase类是这个包中找到的唯一的类,Cucumber 确信不存在非法的类层次结构。com.octopus.decorators包下的所有装饰器类都扩展了AutomatedBrowserBase类,这没关系,因为 Cucumber 不知道这些装饰器类。
因此,通过将AutomatedBrowserBase类隔离在它自己的包中,我们可以将它用作黄瓜胶类:
@CucumberOptions(glue = "com.octopus.decoratorbase")
除了这两个注释,CucumberTest类应该是空的。与传统的 JUnit 测试类不同,在传统的 JUnit 测试类中,测试是在方法中定义的,所有 Cucumber 测试都是在外部*.feature文件中定义的。
因为AutomatedBrowserBase类中的方法是小黄瓜测试执行测试的唯一方式,我们需要公开一些方法来创建和销毁AutomatedBrowser实例。通常我们会在 JUnit 测试中执行这个逻辑,在测试开始时调用AutomatedBrowserFactory.getAutomatedBrowser(),在测试结束时调用automatedBrowser.destroy()。为了向 Cucumber 公开这个功能,我们创建了方法openBrowser()和closeBrowser():
public class AutomatedBrowserBase implements AutomatedBrowser {
static private final AutomatedBrowserFactory AUTOMATED_BROWSER_FACTORY
= new AutomatedBrowserFactory();
// ...
@Given("^I open the browser \"([^\"]*)\"$")
public void openBrowser(String browser) {
automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser(browser);
automatedBrowser.init();
}
@Given("^I close the browser$")
public void closeBrowser() {
if (automatedBrowser != null) {
automatedBrowser.destroy();
automatedBrowser = null;
}
}
// ...
}
让我们更详细地看看这两种方法:
@Given("^I open the browser \"([^\"]*)\"$")
附加到openBrowser()方法的注释@Given("^I open the browser \"([^\"]*)\"$")的工作方式与前面的@And("^I open the URL \"([^\"]*)\"$")示例相同。注释@Given和@And可以互换。通常@Given用在执行某种初始化或管理功能的方法上,但这只是惯例而不是规则。
分配给@Given注释的正则表达式遵循相同的模式,使用脱字符(^)和美元($)字符来结束表达式,字符串I open the browser的文字匹配,以及引号内的非贪婪捕获组。
然后捕获组的值被传递给名为browser的参数:
public void openBrowser(String browser) {
从这一点来看,该方法的工作方式与其他任何方法一样。在这种情况下,我们调用AutomatedBrowserFactory.getAutomatedBrowser()来构建指定的AutomatedBrowser配置,然后调用init()函数来初始化它:
automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser(browser);
automatedBrowser.init();
附加到closeBrowser()方法的注释@Given("^I close the browser$")没有捕获组,这意味着它所附加的方法没有参数。这里的正则表达式只能匹配文字字符串I close the browser:
@Given("^I close the browser$")
public void closeBrowser() {
这个方法负责在由openBrowser()方法创建的AutomatedBrowser实例上调用destroy()方法:
if (automatedBrowser != null) {
automatedBrowser.destroy();
automatedBrowser = null;
}
}
我们现在有足够的证据来进行一个非常简单的黄瓜测试。在src/test/resources/com/octopus目录下创建以下名为simpletest.feature的文件。
默认情况下,目录src/test/resources/com/octopus是 Maven 为com.octopus包放置资源的地方。记住,我们需要将这个文件放在与测试类相同的包中,这样才能找到它。文件名可以是我们想要的任何东西,但是它必须有被 Cucumber 识别的.feature扩展名。

Feature: A simple test
Scenario: Open and close the browser
Given I open the browser "ChromeNoImplicitWait"
Then I close the browser
让我们把这个文件分解一下。
所有小黄瓜特征文件都以一个Feature:部分开始。功能是一组相关的场景:
Feature: A simple test
接下来我们有了Scenario:。场景类似于传统单元测试类中的方法,因为它是自包含的,并且演示了被测试系统的某些方面:
Scenario: Open and close the browser
最后,我们有在AutomatedBrowserBase类中定义的两个步骤。
请注意,这里使用的步骤前缀与注释的名称并不完全匹配。虽然如果这些步骤与注释名匹配就好了,但这不是必需的。
还要注意,我们定义的正则表达式并没有捕捉到单词Given、When、Then或And,尽管完整的步骤总是以这样的单词开始。我们定义的正则表达式从匹配这个初始单词之后的步骤的内容开始:
Given I open the browser "ChromeNoImplicitWait"
Then I close the browser
要运行测试,点击测试类旁边的图标并选择Run 'CucumberTest'。

运行测试将找到simpletest.feature文件并执行它。该功能文件将依次打开 Chrome,然后立即关闭它。在测试结果中,我们可以看到我们成功地运行了 1 个场景,导致了 2 个步骤的运行。

我们现在已经为创建一种小黄瓜方言奠定了基础,这种方言将允许我们编写可以使用 WebDriver 验证的自然语言测试。然而,要创建端到端测试,我们还有很多工作要做。在下一篇文章中,我们将向 Cucumber 展示更多的AutomatedBrowser类,并努力创建一个可读的端到端测试。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
实施自动化数据库部署流程- Octopus Deploy
原文:https://octopus.com/blog/implementing-db-deployment-process

使用 TeamCity、Redgate 和 Octopus Deploy 实现理想的自动化数据库部署过程需要多次迭代。我重点介绍了如何自动化 SQL Server 的部署,但是这些经验也适用于其他数据库和工具。迭代是学习工具和听取反馈的结果。在本文中,我将带您经历自动化数据库部署过程中的几次迭代。
本文是系列文章的最后一篇。这里是其他文章的链接,以防你错过。
我们所有的数据库部署文章都可以在这里找到。
概述
所有这些工作都是在我以前工作过的公司完成的。该公司有四个环境。
- 发展
- 试验
- 脚手架
- 生产
开发人员、数据库开发人员和首席开发人员都拥有对development和test的系统管理员权限。他们对staging和production拥有只读权限。只有数据库管理员拥有所有环境的系统管理员权限。
在自动化数据库部署之前,我们的流程是:
- 开发人员在
test中对数据库进行了更改。所有开发人员在test中都有 sysadmin 权限。他们应该在development进行变更,但是test有所有的数据来验证变更。这是他们的代码所指向的服务器。 - 开发人员在 SSMS 更改连接,并对
development进行更改。所有开发人员在development中都有 sysadmin 权限。 - 数据库开发人员或首席开发人员运行 Redgate SQL Compare 来生成
test和staging之间的增量脚本。任何复杂的数据库更改(移动列、合并列等。)被删除并手动编写脚本。脚本保存在共享文件夹中。除了 DBA 之外,每个人都对staging拥有只读权限。数据库管理员必须运行脚本。 - 通过电子邮件通知 DBA 在
staging运行共享文件夹中的脚本。它们运行脚本并将输出发送给请求者。 - 在转到
production之前,可以将多个数据库更改推送到staging。因此,数据库开发人员或首席开发人员会在staging和production之间生成一个新的 Redgate SQL 比较增量脚本。就像以前一样,任何复杂的数据库更改(移动列、合并列等。)被删除并手动编写脚本。脚本保存在共享文件夹中。除了 DBA 之外,每个人都对production拥有只读权限。 - DBA 通过变更请求得到通知,在
production中运行一组脚本。他们运行脚本,将结果保存到变更请求系统,该系统会向请求者发送电子邮件。
这个过程中有几个缺陷。
- 多个部署流程,如何将变更部署到
development和test与staging和production不同。 - 手动生成脚本。
- 在每个环境中手动运行每个脚本。
- 每个环境唯一的增量脚本。
- 独特的 delta 脚本意味着很难或者几乎不可能测试。
- 没有提到跟踪变更以及需要部署什么。
- 共享开发环境。
- 到了去
staging的时候才进行点评。 - 因此,在
production部署期间,“所有人都在甲板上”。
此时,我们使用的工具是:
- Git 正在作为 TFS 版本控制的替代品进行试点。
- 团队城市正在作为 TFS 2012 的替代项目进行试点。
- 没有部署服务器。
- 没有数据库部署工具(这就是 Redgate 的工具的用武之地)。
自动化数据库部署 v1
当你有一把锤子时,所有的东西看起来都像钉子。正如我的前一篇文章中所详述的,我首先着手在现有的过程中实现自动化。在那之前,我只知道上面的过程,或者某种形式的过程。
我的重点是:
- 强制每个人在
development中进行数据库更改,并自动部署到test。 - 自动生成
staging和production的增量脚本。
理想情况下,我们会自动部署到staging和production。这将要求构建服务器(在本例中为 TeamCity)在这些环境中运行一个具有权限的代理。数据库管理员说得很清楚,TeamCity 无权部署到staging或production。
我已经让 TeamCity 编写了代码。我需要将数据库注入到现有的构建过程中。Redgate 为 TeamCity 提供了一个插件。查看 Redgate 的 TeamCity 插件的文档可以发现它支持三个功能:
- 构建一个包。
- 将包与数据库同步。
- 测试那个包裹。
为了使构建包过程能够工作,必须使用 Redgate 的 SQL 源代码控制将数据库置于源代码控制中。在将数据库放入源代码控制之前,我应该已经解决了每个环境之间的差异。需要不同的用户和角色成员。缺少表、不同的存储过程和其他模式变化,没有那么多。
增量需要通过以下三种方式之一来解决:
- 如果只是错过了改变,那就去应用它。
- 如果变更是有意的,并且不应该包含在源代码控制中(备份表或测试表),您可以利用过滤器来排除那些项目。
- 如果差异是环境造成的,比如用户和角色成员,您将需要查看文档以了解您需要包含哪些开关。
难题的最后一部分是自动生成 delta 脚本。谢天谢地,Redgate 的模式比较工具有一个 CLI 版本。
知道了这一点,我的攻击计划是:
- 解决所有的差异。
- 将
development中的内容放入源代码控制中。接下来,所有数据库更改都必须在development中进行,并签入源代码控制。 - 让 TeamCity 从源代码控制中构建包。
- 让 TeamCity 将该包与
development同步。 - 让 TeamCity 将该包与
test同步。 - 让 TeamCity 运行模式比较 CLI,为
staging和production生成增量脚本。
步骤 1 和 3 相互冲突。所以我们跳过这一步。
- 解决所有的差异。
- 将
development中的内容放入源代码控制中。接下来,所有数据库更改都必须在development中进行,并签入源代码控制。 - 让 TeamCity 从源代码控制中构建包。
让 TeamCity 将该包与development同步。- 让 TeamCity 将该包与
test同步。 - 让 TeamCity 运行模式比较 CLI,为
staging和production生成增量脚本。
我不打算介绍如何将数据库放入源代码控制中。我已经写了那篇文章。
我完成了四个团队城市项目。

项目将源代码控制中的内容打包。

我正在利用 TeamCity 的快照依赖和工件依赖。为了利用这一点,我需要将创建的包标记为工件。

10_Dev和20_Test遵循相同的流程。首先,我需要配置构建的依赖关系。依赖关系包括快照依赖关系和工件依赖关系。

现在我已经配置了包和依赖项,我可以添加步骤来将test数据库与包同步。请注意,为了部署最新的包,我将使用来自00_Build项目的值覆盖内部版本号。

建造是非常不同的。首先,我像以前一样配置依赖项。

它不运行同步步骤,而是运行一个 PowerShell 脚本来生成用于转移和生产的增量脚本。

自动化数据库部署的缺陷 v1
让我们重新审视现有流程的缺陷,看看我们在这一努力之后做得如何。
这个过程中有几个缺陷。
- 两种不同的工艺,一种是针对
development和test,另一种是针对staging和production的略有不同。这种情况仍在发生。 - 手动生成脚本。解决了。
- 在每个环境中手动运行每个脚本。这仅针对
test解决。 - 每个环境唯一的增量脚本。这仍在发生
- 独特的 delta 脚本意味着很难或者几乎不可能测试。这仍在发生
- 没有提到跟踪变更以及需要部署什么。解决了。
- 共享开发环境。这仍在发生
- 直到该去
staging的时候,评论才出现。这仍在发生 - 因此,在
production部署期间,“所有人都在甲板上”。这不是什么大问题,但仍在发生
此外,我还引入了几个新问题。
- 从
30_Staging生成脚本到在staging或production中运行脚本之间的小时数或天数。 - 当
30_Staging运行时,很难知道将使用什么版本来生成增量脚本。 - 只有最新的变化,你不能选择旧版本。
新进程
在我之前的文章中,我讨论了 Redgate 如何帮助我所在公司的一个工作组。让我们回顾一下我们提出的流程。
- 开发人员/数据库开发人员/首席开发人员创建一个分支。
- 所有数据库更改和代码更改都在该分支上进行。
- 变更已完成并签入分支。
- 创建了一个合并请求,这启动了一个构建。构建验证更改是有效的 SQL。
- 数据库开发人员或首席开发人员审查合并请求中的数据库更改,并提供修复反馈。
- 分支机构被批准并合并。
- 构建服务器启动一个构建,验证更改是否是有效的 SQL,如果是,将它们打包并推送到部署服务器。构建服务器告诉部署服务器部署到
development。 - 部署服务器部署到
development。 - 一个开发人员/数据库开发人员/首席开发人员告诉部署服务器部署到
test。 - 部署服务器部署到
test。 - 数据库变更在
test进行验证。 - 一个开发人员/数据库开发人员/首席开发人员告诉部署服务器部署到
staging。部署服务器使用数据库工具来生成审查脚本。 - 部署服务器向 DBA 通知对
staging的部署请求。他们审查变更并提供修复反馈。 - DBA 批准对
staging的更改。 - 部署服务器完成对
staging的部署。 - 在
staging中验证数据库变更。 - 变更请求被提交给 DBA,以将部署服务器中的特定包升级到
production。 - 几小时后,DBA 告诉部署服务器部署到
production。部署服务器使用数据库工具来生成审查脚本。 - DBA 审查该脚本作为最后的完整性检查。
- 部署服务器完成对
production的部署。
自动化数据库部署过程的下一次迭代将实现这一点。
自动化数据库部署 v2
Octopus Deploy 被添加到自动化数据库部署的 v2 中。这是我们不知道我们需要的部署服务器。部署服务器使我们能够:
- 简化 TeamCity,它只需构建一个包并将其推送到 Octopus Deploy。
- 在所有环境中使用相同的流程和工具。
- 拥有数据库变更的审计历史记录。不仅如此,它还提供了了解谁部署了变更的能力。
团队城市被简化为两个项目。

会像以前一样构建包。10_Dev推送该包并在 Octopus Deploy 中触发部署到development。我们的文档很好地向您展示了如何做到这一点。

经过一段时间的反复试验,Octopus Deploy 中的部署过程变成了这样:

在这个过程中,反复试验是围绕步骤 1 和 4 进行的。首先,我从 TeamCity 运行相同的 CLI 脚本来生成 delta 脚本以供审查。这与正在部署的不同。最终,我了解了 Redgate 提供的创建数据库发布和从数据库发布部署步骤模板。
使用 Redgate 提供的 step 模板自动生成并上传 delta 脚本作为 Octopus 工件。DBA 可以下载这些文件,并在批准部署到staging或production时进行审查。

按照这个流程,DBA 非常乐意让 Octopus 部署到staging和production。他们可以在部署期间审查脚本,并且审查脚本的人会被审计。此外,他们很高兴看到只需要按一个按钮。正如一位数据库管理员所说,“这太简单了。”
决定这笔交易的是控制谁可以按下部署按钮的能力。所有开发人员(包括数据库开发人员和首席开发人员)都可以部署到development、test和staging。

虽然 DBA 可以部署到production,但是他们无权更改部署过程,只有开发人员可以这么做。

虽然开发人员可以部署到staging,但是 DBA 才是批准变更的人。

这些安全策略和手动干预在这个过程中建立了很多信任。
自动化数据库部署 v2 的缺陷
让我们看看我们的问题列表。
- 两种不同的工艺,一种针对
development和test,另一种针对staging和production略有不同。解决了。 - 手动生成脚本。解决了。
- 在每个环境中手动运行每个脚本。解决了。
- 每个环境唯一的增量脚本。减轻,这就是工具的工作原理。
- 独特的 delta 脚本意味着很难或者几乎不可能测试。由于使用了相同的流程,减少了导致错误的机会。
- 没有提到跟踪变更以及需要部署什么。解决了。
- 共享开发环境。解决了。
- 到了去
staging的时候,评论才发生。解决了。,数据库开发人员审核特性分支变更,DBA 在staging审核。因此,在production部署期间,“所有人都在甲板上”。解决了。 - 从
30_Staging生成脚本到在staging或production运行脚本之间的小时或天。解决了。 - 当
30_Staging运行时,很难知道哪个版本将用于生成增量脚本。解决了。 - 只有最新的变化,你不能选择旧版本。解决了。
太棒了,所有原来的问题,加上 v1 的问题,都被解决或减轻了。但是有趣的事情发生了。这个过程奏效了,随着时间的推移,我们开始对production和staging进行越来越多的部署。
- 在编写流程时,DBA 必须在每个
production部署期间在线。 - 开发人员必须等到数据库管理员在部署之前完成对他们在
staging中的脚本的审查。数据库管理员跟不上。 - 开发人员的本地数据库中没有测试数据;这导致他们将未完成的变更推送到
test。然后他们将代码指向test,这样他们就有数据可以测试。
自动化数据库部署 2.1 版
工作组召开了会议,我们同意对流程进行以下更改:
- DBA 将只批准
staging中的变更。 staging中的批准将在部署发生后进行。- DBA 只想在部署到
production失败时得到通知。 - DBA 希望在试运行部署期间看到
production的增量脚本。不会 100%一样,但也足够近,让他们复习。实际的production部署脚本将在production部署期间创建,并保存为工件。 - 每次部署后生成
test的备份。然后,开发人员可以在他们的实例上恢复备份,以获取测试数据。
最终的过程如下所示:
完成这些更改后,DBA 可以利用 Octopus Deploy 中的Deploy Later功能。他们不再需要每次部署到production都在线。
【T2 
结论
经过这一过程后,部署到production就不再是一件大事了。数据库管理员只需要在production部署期间出现故障时跳转到在线,这种情况越来越少,但需要几次迭代才能到达。
最让我惊讶的是,从开始到结束,一切都发生了多大的变化。我实话实说。如果我遇到一个有最终数据库部署流程的客户,我会有很多问题。但是在实现它的公司的上下文中是有意义的。这符合他们的要求。不要对你的迭代次数和最终结果感到惊讶。每个公司都不一样。
愉快的部署!
如果你喜欢这篇文章,好消息,我们有一个关于自动化数据库部署的完整系列。
Selenium 系列:隐式和显式等待- Octopus 部署
原文:https://octopus.com/blog/selenium/7-implicit-and-explicit-waits/implicit-and-explicit-waits
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
在我们的测试网页中,我们有一个setTimeout()方法调用,它在 5 秒钟后创建了一个 ID 为newdiv_element的新的<div>。这种动态更新在现代 web 开发中很常见,并且广泛用于使用 React 和 Angular 等库编写的单页面应用程序(spa)。
然而,这些动态元素在编写测试时提出了挑战。让我们创建一个新的测试,尝试点击这个动态元素:
package com.octopus;
import org.junit.Test;
import java.net.URISyntaxException;
public class WaitTest {
private static final AutomatedBrowserFactory AUTOMATED_BROWSER_FACTORY = new AutomatedBrowserFactory();
@Test
public void clickDynamicElement() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("newdiv_element");
} finally {
automatedBrowser.destroy();
}
}
}
运行该测试将导致如下异常:
org.openqa.selenium.NoSuchElementException: no such element: Unable to
locate element: {"method":"id","selector":"newdiv_element"}

这个例外并不奇怪。我们的测试试图点击一个 5 秒内不会被创建的元素。
我们可以在测试中自己等待几秒钟。通过在尝试单击元素之前添加代码Thread.sleep(6000);,我们可以确保元素是可用的:
package com.octopus;
import org.junit.Test;
import java.net.URISyntaxException;
public class WaitTest {
private static final AutomatedBrowserFactory AUTOMATED_BROWSER_FACTORY = new AutomatedBrowserFactory();
@Test
public void clickDynamicElement() throws URISyntaxException, InterruptedException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
Thread.sleep(6000);
automatedBrowser.clickElementWithId("newdiv_element");
} finally {
automatedBrowser.destroy();
}
}
}
虽然这个测试会通过,但它不是一个可靠的解决方案。
在我们的测试网页中,我们可以知道元素将在 5 秒后出现,因为对setTimeout()的调用非常清楚地在 5 秒后创建了元素。然而,现实世界中的 web 应用程序不太可能以这种可预测的方式创建测试需要与之交互的元素。最有可能的是,元素将被创建以响应 API 调用、页面导航或其他处理,并且我们的测试代码没有办法知道这些事件将花费多长时间。
幸运的是,WebDriver 提供了两种等待动态元素可用的方法:隐式等待和显式等待。
隐式等待是两者中比较简单的。使用隐式等待,我们定义了一个全局时间量来等待我们的测试与之交互的元素出现在网页中。
我们可以用一个名为ImplicitWaitDecorator的新装饰器实现隐式等待,它将调用manage().timeouts().implicitlyWait():
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import java.util.concurrent.TimeUnit;
public class ImplicitWaitDecorator extends AutomatedBrowserBase {
private final int waitTime;
public ImplicitWaitDecorator(final int waitTime, final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
this.waitTime = waitTime;
}
@Override
public void init() {
getAutomatedBrowser()
.getWebDriver()
.manage()
.timeouts()
.implicitlyWait(waitTime, TimeUnit.SECONDS);
getAutomatedBrowser().init();
}
}
然后,我们可以通过编辑AutomatedBrowserFactory类来利用这个装饰器:
private AutomatedBrowser getChromeBrowser() {
return new ChromeDecorator(
new ImplicitWaitDecorator(10,
new WebDriverDecorator()
)
);
}
配置好隐式等待时间后,我们可以运行原始测试(即没有Thread.sleep()的测试),它将会通过。这是因为 WebDriver 将等待 10 秒钟,等待我们搜索的任何元素出现在网页中。这给了我们在 5 秒钟后创建的动态元素足够的时间出现在页面上。

显式等待是 WebDriver 提供的第二种等待元素可用的方法。与应用于我们试图在页面中找到的任何元素的隐式等待不同,显式等待可以用于逐个元素的情况。
为了利用显式等待,我们向AutomatedBrowser接口添加了一个新方法,该方法将等待元素的时间量作为参数:
void clickElementWithId(String id, int waitTime);
一个默认方法被添加到AutomatedBrowserBase类中:
@Override
public void clickElementWithId(final String id, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithId(id, waitTime);
}
}
然后在WebDriverDecorator类中定义该方法:
@Override
public void clickElementWithId(final String id, final int waitTime) {
if (waitTime <= 0) {
clickElementWithId(id);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.id(id)))).click();
}
}
显式等待分为三个部分。
我们首先定义我们希望等待一个元素的时间。这是通过创建一个WebDriverWait类的实例来实现的:
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
然后我们在产生的WebDriverWait实例上调用until()方法。
最后,我们使用ExpectedCondition类上的一个静态方法来指示我们正在搜索的元素在返回给我们之前必须处于什么状态。
因为我们试图点击元素,所以我们希望确保元素是可点击的。这是通过调用ExpectedConditions.elementToBeClickable()方法来完成的:
wait.until(ExpectedConditions.elementToBeClickable((By.id(id)))).click();
这段代码的最终结果是,我们通过 ID 查找的元素只有在指定的持续时间内处于可点击状态时才会被点击。
为了测试显式等待,我们创建了一个新的测试,它使用了新的clickElementWithId()方法:
@Test
public void clickDynamicElementWithExplicitWait() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("newdiv_element", 10);
} finally {
automatedBrowser.destroy();
}
}
和以前一样,测试将等待动态元素被创建,然后单击它,测试将通过。
但是你可能会问,为什么有人会费心使用显式等待呢?它们需要更多的代码来实现,那么显式等待比隐式等待有什么好处呢?
为了演示为什么显式等待是有用的,让我们尝试单击 ID 为div3_element的 div。如果您回头看看示例 web 页面的源代码,您会看到这个元素被style="display: none"隐藏了,并且在对setTimeout()的调用中没有被隐藏。
虽然对于查看页面的人来说,隐藏的元素和根本不存在的元素没有什么区别,但是这种区别对于我们的测试非常重要。
让我们创建一个依赖于隐式等待来单击隐藏元素的测试:
@Test
public void clickHiddenElement() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("div3_element");
} finally {
automatedBrowser.destroy();
}
}
运行该测试将引发异常:
org.openqa.selenium.ElementNotVisibleException: element not visible

我们得到这个异常是因为隐式等待立即返回了<div>,因为它出现在网页上。隐式等待不考虑元素是否被禁用或隐藏。如果元素在页面上可用,则隐式等待被满足,测试继续。或者,在我们的例子中,失败了,因为你不能点击一个不可见的元素。
将此行为与使用显式等待测试进行比较:
@Test
public void clickHiddenElementWithExplicitWait() throws URISyntaxException {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
try {
automatedBrowser.init();
automatedBrowser.goTo(FormTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("div3_element", 10);
} finally {
automatedBrowser.destroy();
}
}
这个测试成功了,因为在继续测试之前,我们明确地等待目标元素处于一个非常特定的状态(一个可点击的状态)。因为我们在等待元素是可点击的,而不仅仅是出现在页面上,所以测试按预期进行。
显式等待允许我们在尝试与元素交互之前定义元素的期望状态,从而提供了更高级别的控制。隐式等待要普遍得多,只等待元素出现在页面上。
实际上,显式等待允许我们编写更加健壮的测试。最初还需要做一些工作来支持显式等待,但是在用利用显式等待的方法填充了WebDriverDecorator类之后,它们就很容易使用了。
让我们看看如何重载WebDriverDecorator中的方法来利用显式等待。
从下拉列表中选择一个选项,等待<select>元素被点击:
@Override
public void selectOptionByTextFromSelectWithId(final String optionText, final String id, final int waitTime) {
if (waitTime <= 0) {
selectOptionByTextFromSelectWithId(id, optionText);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
new Select(wait.until(ExpectedConditions.elementToBeClickable((By.id(id))))).selectByVisibleText(optionText);
}
}
同样,我们在试图填充像<textarea>这样的元素之前,等待它们变成可点击的:
@Override
public void populateElementWithId(final String id, final String text, final int waitTime) {
if (waitTime <= 0) {
populateElementWithId(id, text);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.id(id)))).sendKeys(text);
}
}
当从一个元素返回文本时,它只需要出现在页面上,所以我们调用ExpectedConditions.presenceOfElementLocated():
@Override
public String getTextFromElementWithId(final String id, final int waitTime) {
if (waitTime <= 0) {
return getTextFromElementWithId(id);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
return
wait.until(ExpectedConditions.presenceOfElementLocated((By.id(id)))).getText();
}
}
使用 XPaths 和 CSS 选择器查找元素的方法重复了相同的模式。我们不会逐一查看所有这些方法,但是您可以在下面的填充类和接口的副本中看到它们。
下面是为显式等待定义的所有方法的AutomatedBrowser接口:
package com.octopus;
import org.openqa.selenium.WebDriver;
public interface AutomatedBrowser {
WebDriver getWebDriver();
void setWebDriver(WebDriver webDriver);
void init();
void destroy();
void goTo(String url);
void clickElementWithId(String id);
void clickElementWithId(String id, int waitTime);
void selectOptionByTextFromSelectWithId(String optionText, String id);
void selectOptionByTextFromSelectWithId(String optionText, String id, int waitTime);
void populateElementWithId(String id, String text);
void populateElementWithId(String id, String text, int waitTime);
String getTextFromElementWithId(String id);
String getTextFromElementWithId(String id, int waitTime);
void clickElementWithXPath(String xpath);
void clickElementWithXPath(String xpath, int waitTime);
void selectOptionByTextFromSelectWithXPath(String optionText, String xpath);
void selectOptionByTextFromSelectWithXPath(String optionText, String xpath, int waitTime);
void populateElementWithXPath(String xpath, String text);
void populateElementWithXPath(String xpath, String text, int waitTime);
String getTextFromElementWithXPath(String xpath);
String getTextFromElementWithXPath(String xpath, int waitTime);
void clickElementWithCSSSelector(String cssSelector);
void clickElementWithCSSSelector(String cssSelector, int waitTime);
void selectOptionByTextFromSelectWithCSSSelector(String optionText, String cssSelector);
void selectOptionByTextFromSelectWithCSSSelector(String optionText, String cssSelector, int waitTime);
void populateElementWithCSSSelector(String cssSelector, String text);
void populateElementWithCSSSelector(String cssSelector, String text, int waitTime);
String getTextFromElementWithCSSSelector(String cssSelector);
String getTextFromElementWithCSSSelector(String cssSelector, int waitTime);
}
下面是新方法的默认实现的AutomatedBrowserBase类:
package com.octopus.decoratorbase;
import com.octopus.AutomatedBrowser;
import org.openqa.selenium.WebDriver;
public class AutomatedBrowserBase implements AutomatedBrowser {
private AutomatedBrowser automatedBrowser;
public AutomatedBrowserBase() {
}
public AutomatedBrowserBase(final AutomatedBrowser automatedBrowser) {
this.automatedBrowser = automatedBrowser;
}
public AutomatedBrowser getAutomatedBrowser() {
return automatedBrowser;
}
@Override
public WebDriver getWebDriver() {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getWebDriver();
}
return null;
}
@Override
public void setWebDriver(final WebDriver webDriver) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().setWebDriver(webDriver);
}
}
@Override
public void init() {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().init();
}
}
@Override
public void destroy() {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().destroy();
}
}
@Override
public void goTo(String url) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().goTo(url);
}
}
@Override
public void clickElementWithId(final String id) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithId(id);
}
}
@Override
public void clickElementWithId(final String id, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithId(id, waitTime);
}
}
@Override
public void selectOptionByTextFromSelectWithId(final String optionText, final String id) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().selectOptionByTextFromSelectWithId(optionText, id);
}
}
@Override
public void selectOptionByTextFromSelectWithId(final String optionText, final String id, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().selectOptionByTextFromSelectWithId(optionText, id, waitTime);
}
}
@Override
public void populateElementWithId(final String id, final String text) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().populateElementWithId(id, text);
}
}
@Override
public void populateElementWithId(final String id, final String text, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().populateElementWithId(id, text, waitTime);
}
}
@Override
public String getTextFromElementWithId(final String id) {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getTextFromElementWithId(id);
}
return null;
}
@Override
public String getTextFromElementWithId(final String id, final int waitTime) {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getTextFromElementWithId(id, waitTime);
}
return null;
}
@Override
public void clickElementWithXPath(final String xpath) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithXPath(xpath);
}
}
@Override
public void clickElementWithXPath(final String xpath, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithXPath(xpath, waitTime);
}
}
@Override
public void selectOptionByTextFromSelectWithXPath(final String optionText, final String xpath) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().selectOptionByTextFromSelectWithXPath(optionText, xpath);
}
}
@Override
public void selectOptionByTextFromSelectWithXPath(final String optionText, final String xpath, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().selectOptionByTextFromSelectWithXPath(optionText, xpath, waitTime);
}
}
@Override
public void populateElementWithXPath(final String xpath, final String
text) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().populateElementWithXPath(xpath, text);
}
}
@Override
public void populateElementWithXPath(final String xpath, final String text, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().populateElementWithXPath(xpath, text, waitTime);
}
}
@Override
public String getTextFromElementWithXPath(final String xpath) {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getTextFromElementWithXPath(xpath);
}
return null;
}
@Override
public String getTextFromElementWithXPath(final String xpath, final int waitTime) {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getTextFromElementWithXPath(xpath,
waitTime);
}
return null;
}
@Override
public void clickElementWithCSSSelector(final String cssSelector) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithCSSSelector(cssSelector);
}
}
@Override
public void clickElementWithCSSSelector(final String cssSelector, final
int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().clickElementWithCSSSelector(cssSelector, waitTime);
}
}
@Override
public void selectOptionByTextFromSelectWithCSSSelector(final String optionText, final String cssSelector) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().selectOptionByTextFromSelectWithCSSSelector(optionText,
cssSelector);
}
}
@Override
public void selectOptionByTextFromSelectWithCSSSelector(final String optionText, final String cssSelector, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().selectOptionByTextFromSelectWithCSSSelector(optionText,
cssSelector, waitTime);
}
}
@Override
public void populateElementWithCSSSelector(final String cssSelector, final String text) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().populateElementWithCSSSelector(cssSelector, text);
}
}
@Override
public void populateElementWithCSSSelector(final String cssSelector, final String text, final int waitTime) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().populateElementWithCSSSelector(cssSelector, text, waitTime);
}
}
@Override
public String getTextFromElementWithCSSSelector(final String cssSelector) {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getTextFromElementWithCSSSelector(cssSelector);
}
return null;
}
@Override
public String getTextFromElementWithCSSSelector(final String cssSelector, final int waitTime) {
if (getAutomatedBrowser() != null) {
return getAutomatedBrowser().getTextFromElementWithCSSSelector(cssSelector, waitTime);
}
return null;
}
}
下面是带有 XPath 和 CSS 选择器方法的显式等待实现的WebDriverDecorator类:
package com.octopus.decorators;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.support.ui.WebDriverWait;
public class WebDriverDecorator extends AutomatedBrowserBase {
private WebDriver webDriver;
public WebDriverDecorator() {
}
@Override
public WebDriver getWebDriver() {
return webDriver;
}
@Override
public void setWebDriver(final WebDriver webDriver) {
this.webDriver = webDriver;
}
@Override
public void destroy() {
if (webDriver != null) {
webDriver.quit();
}
}
@Override
public void goTo(final String url) {
webDriver.get(url);
}
@Override
public void clickElementWithId(final String id) {
webDriver.findElement(By.id(id)).click();
}
@Override
public void clickElementWithId(final String id, final int waitTime) {
if (waitTime <= 0) {
clickElementWithId(id);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.id(id)))).click();
}
}
@Override
public void selectOptionByTextFromSelectWithId(final String optionText, final String selectId) {
new Select(webDriver.findElement(By.id(selectId))).selectByVisibleText(optionText);
}
@Override
public void selectOptionByTextFromSelectWithId(final String optionText, final String id, final int waitTime) {
if (waitTime <= 0) {
selectOptionByTextFromSelectWithId(id, optionText);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
new Select(wait.until(ExpectedConditions.elementToBeClickable((By.id(id))))).selectByVisibleText(optionText);
}
}
@Override
public void populateElementWithId(final String id, final String text) {
webDriver.findElement(By.id(id)).sendKeys(text);
}
@Override
public void populateElementWithId(final String id, final String text,
final int waitTime) {
if (waitTime <= 0) {
populateElementWithId(id, text);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.id(id)))).sendKeys(text);
}
}
@Override
public String getTextFromElementWithId(final String id) {
return webDriver.findElement(By.id(id)).getText();
}
@Override
public String getTextFromElementWithId(final String id, final int
waitTime) {
if (waitTime <= 0) {
return getTextFromElementWithId(id);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
return wait.until(ExpectedConditions.presenceOfElementLocated((By.id(id)))).getText();
}
}
@Override
public void clickElementWithXPath(final String xpath) {
webDriver.findElement(By.xpath(xpath)).click();
}
@Override
public void clickElementWithXPath(final String xpath, final int waitTime) {
if (waitTime <= 0) {
clickElementWithXPath(xpath);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.xpath(xpath)))).click();
}
}
@Override
public void selectOptionByTextFromSelectWithXPath(final String optionText, final String xpath) {
new Select(webDriver.findElement(By.xpath(xpath))).selectByVisibleText(optionText);
}
@Override
public void selectOptionByTextFromSelectWithXPath(final String
optionText, final String xpath, final int waitTime) {
if (waitTime <= 0) {
selectOptionByTextFromSelectWithXPath(xpath, optionText);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
new Select(wait.until(ExpectedConditions.elementToBeClickable((By.xpath(xpath))))).selectByVisibleText(optionText);
}
}
@Override
public void populateElementWithXPath(final String xpath, final String
text) {
webDriver.findElement(By.xpath(xpath)).sendKeys(text);
}
@Override
public void populateElementWithXPath(final String xpath, final String
text, final int waitTime) {
if (waitTime <= 0) {
populateElementWithXPath(xpath, text);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.xpath(xpath)))).sendKeys(text);
}
}
@Override
public String getTextFromElementWithXPath(final String xpath) {
return webDriver.findElement(By.xpath(xpath)).getText();
}
@Override
public String getTextFromElementWithXPath(final String xpath, final int
waitTime) {
if (waitTime <= 0) {
return getTextFromElementWithXPath(xpath);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
return wait.until(ExpectedConditions.presenceOfElementLocated((By.xpath(xpath)))).getText();
}
}
@Override
public void clickElementWithCSSSelector(final String cssSelector) {
webDriver.findElement(By.cssSelector(cssSelector)).click();
}
@Override
public void clickElementWithCSSSelector(String css, final int waitTime) {
if (waitTime <= 0) {
clickElementWithCSSSelector(css);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.cssSelector(css)))).click();
}
}
@Override
public void selectOptionByTextFromSelectWithCSSSelector(final String optionText, final String cssSelector) {
new
Select(webDriver.findElement(By.cssSelector(cssSelector))).selectByVisibleText(optionText);
}
@Override
public void selectOptionByTextFromSelectWithCSSSelector(final String optionText, final String css, final int waitTime) {
if (waitTime <= 0) {
selectOptionByTextFromSelectWithCSSSelector(css, optionText);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
new Select(wait.until(ExpectedConditions.elementToBeClickable((By.cssSelector(css))))).selectByVisibleText(optionText);
}
}
@Override
public void populateElementWithCSSSelector(final String cssSelector,
final String text) {
webDriver.findElement(By.cssSelector(cssSelector)).sendKeys(text);
}
@Override
public void populateElementWithCSSSelector(String css, final String text, final int waitTime) {
if (waitTime <= 0) {
populateElementWithCSSSelector(css, text);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
wait.until(ExpectedConditions.elementToBeClickable((By.cssSelector(css)))).sendKeys(text);
}
}
@Override
public String getTextFromElementWithCSSSelector(final String cssSelector) {
return webDriver.findElement(By.cssSelector(cssSelector)).getText();
}
@Override
public String getTextFromElementWithCSSSelector(String css, final int waitTime) {
if (waitTime <= 0) {
return getTextFromElementWithCSSSelector(css);
} else {
final WebDriverWait wait = new WebDriverWait(webDriver, waitTime);
return wait.until(ExpectedConditions.presenceOfElementLocated((By.cssSelector(css)))).getText();
}
}
}
既然我们已经看到了隐式和显式等待是如何工作的,那么理解同时使用它们的一些意想不到的后果是很重要的。在下一篇文章中,我们将了解隐式和显式等待混合时的一些意外行为。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
导入和部署您的第一个 Octopus 项目- Octopus Deploy
原文:https://octopus.com/blog/importing-deploying-your-first-octopus-project
设置您的第一个部署可能具有挑战性。有新的系统需要学习,有多种配置需要调整。
在这篇文章中,我将指导您使用 Octopus Deploy 完成第一次部署。
为了简化这个过程,我配置了一个项目,将一个示例应用程序部署到一个 Azure web 应用程序。
使用 Octopus 2021.1 中引入的导出/导入特性,我导出了一个 Octopus 项目,并向您展示了如何导入和部署这个项目。
部署后,应用程序将对您可见,并可与您的同事共享。
正在设置
这篇文章的惟一先决条件是运行 Octopus Deploy 实例,要么在 Octopus Cloud 中,要么在自托管 Octopus 服务器中。
我将带您通过五个步骤在 Octopus 中部署 web 应用程序:
- 导入现有项目
- 配置 Azure 帐户
- 上传我提供的包
- 添加您的部署目标
- 部署到 Azure web 应用程序
如果您还没有设置 Octopus 部署实例,现在需要通过选择以下选项之一来设置:
准备好 Octopus 实例后,第一步是导入一个现有的项目。
导入现有项目
导出/导入功能可以将一个或多个项目导出到 zip 文件中,然后可以将其导入到其他空间中。目标空间可以在不同的 Octopus 服务器实例中,甚至可以在自托管和 Octopus 云实例之间移动。
从项目页面上的溢出菜单可以访问导出/导入特性。

您需要将以下项目导入您的 Octopus 实例:
在 Octopus Web Portal 中,导航到项目,然后导入项目,点击选择 zip 文件,上传项目 ZIP。点击导入完成。
这个项目的密码是html。

导入项目意味着您不必手动配置项目的环境或部署步骤。这只是一个小项目,但有些项目很大,包括复杂的部署步骤,因此导入项目比重新创建项目容易得多。使用导出/导入功能可以确保您的环境和部署步骤跨空间保持不变。
恭喜您,您成功导入了该项目!
在部署 web 应用程序之前,还有一些其他项目需要配置。导出和导入项目不会捕获项目的部署目标或所需的包。部署目标需要新实例上的新连接。由于包的文件可能很大,因此它们被排除在导出的项目之外。
配置 Azure 帐户
您需要配置一个 Azure 帐户和 web 应用程序作为 Octopus 部署的目标。其他目标也是可能的,比如 AWS,或者 Linux 和 Windows 服务器。
通过导航到 Azure 门户在 Azure 中创建一个帐户。
使用 Azure 门户创建 Azure 服务主体
https://www.youtube.com/embed/QDwDi17Dkfs
VIDEO
- 在 Azure 门户中,打开左上方的菜单,导航到 Azure Active Directory ,然后是属性。
- 从租户 ID 字段中复制值。这是你的租户 ID 。
- 接下来,您需要您的应用程序 ID :
- 如果你创建了一个 AAD 注册的应用,导航到 Azure Active Directory ,然后选择应用注册,点击查看所有应用,选择应用并复制应用 ID 。请注意,Azure UI 默认为自有应用标签。点击所有应用选项卡查看所有应用注册。
- 如果您还没有创建注册的应用程序,请导航到 Azure Active Directory ,然后选择应用程序注册,点击新注册并为您的应用程序添加详细信息,然后点击保存。记下应用 ID 。
- 通过导航到证书&机密,然后导航到新客户端机密,生成一次性密码。添加新的秘密,输入描述,点击保存。记下显示的应用程序密码,以便在 Octopus 中使用。如果您不想接受默认的密码一年到期,您可以更改到期日期。
您现在拥有以下内容:
- 租户 ID
- 应用程序 ID
- 应用程序密码/秘密
接下来,您需要配置您的资源权限。
资源权限
资源权限确保您注册的应用程序有权使用您的 Azure 资源。
- 在 Azure 门户中,导航到资源组,并选择您希望注册的应用程序访问的资源组。如果资源组不存在,通过转到主页创建一个,然后转到资源组,然后选择创建。创建之后,记下资源组的 Azure 订阅 ID。
- 点击访问控制(IAM) 选项。在角色分配下,如果您的应用未列出,请点击添加角色分配。选择适当的角色(贡献者是一个常见选项)并搜索您的新应用程序名称。从搜索结果中选择它,然后点击保存。
下一步是建立一个 Azure web 应用程序并配置其属性。
Web 应用程序设置
- 在您的资源组中点击创建,然后点击 Web App
- 在运行时栈和操作系统下创建一个 Windows 节点应用
- 记下你的 Azure 应用名称,因为这将是你的 web 应用的地址:[your-site].azurewebsites.net
- 设置 web 应用程序后,通过导航到配置,然后路径映射,然后虚拟应用程序和目录,将 web 应用程序的路径默认路由到主路径
- 将物理路径设置为
site\wwwroot\guide并将虚拟路径设置为/
在八达通上加入服务主账户
使用以下值,您可以将您的帐户添加到 Octopus:
- 应用程序 ID
- 租户 ID
- 应用程序密码/密钥
- 导航至基础设施,然后选择账户
- 选择添加账号,然后点击 Azure 订阅
- 在 Octopus 中给帐户起一个你想要的名字
- 给账户一个描述
- 添加您的 Azure 订阅 ID -这可以在 Azure 门户网站的订阅下找到
- 添加应用 ID 、租户 ID 和应用密码/关键字
点击保存并测试以确认帐户可以与 Azure 交互。Octopus 将尝试使用帐户凭据来访问 Azure 资源管理(ARM) API,并列出该订阅中的资源组。
您可能需要将您针对的 Azure 数据中心的 IP 地址列入安全列表。请参见通过防火墙部署到 Azure了解更多详细信息。
新创建的服务主体可能需要几分钟才能通过凭据测试。如果您已经仔细检查了您的凭据值,请等待 15 分钟,然后重试。
现在你已经在 Azure 和 Octopus 中设置了 Azure 帐户,你上传了 Azure 的包。
上传现有包
您正在部署的 web 应用程序需要一些代码来部署。Octopus 通过包将这些代码提供给部署目标。
包是将部署到目标的代码。在这种情况下,它将是您的 web 应用程序可以显示的可部署教程。
这个包系统可以方便地交换或更新包,以便以后重新部署。以下是您将用于部署 Octopus Deploy 的包:
您可以手动将软件包上传到 Octopus web 门户中的 Octopus 内置存储库。
- 导航至库选项卡
- 点击上传包
- 选择想要上传的包,点击上传
在下一步中,您将设置应用程序将被部署到的部署目标。
添加部署目标
- 转到基础设施,然后选择部署目标
- 选择一个 Azure Web 应用
- 输入一个显示名称
- 填写环境和目标角色
- 选择之前创建的 Azure 帐户和 web 应用
- 点击保存

部署到 Azure web 应用程序
您可以在导入项目、设置 Azure 帐户、设置部署目标并上传包之后部署应用程序。
- 转到项目,然后选择 HTML ,然后点击 CREATE RELEASE 并逐步将 web 应用从 Azure 生产环境部署到 Azure。

请转到[your-site].azurewebsites.net 检查您的应用程序,在那里您将看到以下页面:
结论
干得好!您已经获得了一个现有的项目,并通过 Octopus Deploy 将一个包部署到一个 Azure web 应用程序。您可以与您的团队分享,教他们如何导入和部署他们的第一个 Octopus 项目。
如果您需要部署方面的帮助或有任何问题,请联系我们位于customersuccess@octopus.com的客户成功团队。
愉快的部署!
在 Octopus - Octopus Deploy 中导入 Kubernetes YAML
原文:https://octopus.com/blog/importing-kubernetes-yaml-in-octopus

如果您在 Octopus 之外使用 Kubernetes 已经有一段时间了,那么您可能已经有了 YAML 资源定义。由于 Octopus 2020.2 中引入的新功能,将此 YAML 迁移到 Octopus 很容易,这为您提供了导入、导出和编辑原始 YAML 的两全其美的能力,同时让您的 Kubernetes 资源由 Octopus 以自以为是的方式进行管理。
在这篇博文中,我将向您展示如何将现有的 YAML 定义迁移到 Octopus 部署中。
样本 YAML
下面是 YAML,它定义了一个部署资源和一个服务来公开 Docker 映像包含的 web 应用程序:
apiVersion: apps/v1
kind: Deployment
metadata:
name: randomquotes
spec:
selector:
matchLabels:
app: randomquotes
replicas: 1
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: randomquotes
spec:
containers:
- name: randomquotes
image: mcasperson/mywebapp:0.1.7
ports:
- name: web
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: randomquotes
spec:
selector:
app: randomquotes
ports:
- name: web
port: 80
Kubernetes 中的一个常见模式是让服务公开一个部署,然后潜在地让 web 流量通过入口指向它。上面的 YAML 是部署和服务模式的一个简单例子。
Octopus 中的 Kubernetes 步骤提供了一种在单个步骤中捕获这种模式的方法,抽象出了一些将这些资源链接在一起的管道。让我们把我们的原始 YAML,并用它来建立一个章鱼的步骤。
创建章鱼步骤
我们将使用部署 Kubernetes 容器步骤来定义上面 YAML 中的部署和服务。该步骤是部署与可选服务、入口、秘密和配置映射的自以为是的组合,并处理将所有内容链接在一起所需的管道:

因为我们不部署入口、机密或配置映射,所以我们可以从该步骤中删除这些功能。这简化了用户界面,使我们能够专注于正在创建的资源:

编辑 YAML 部分是 Octopus 2020.2 中的新增功能,它允许将该步骤创建的 Kubernetes 资源编辑为 YAML:
【T2 
点击编辑 YAML 按钮显示该步骤中当前设置的 YAML 表示。因为我们刚刚添加了步骤,所以显示的值只是默认值或占位符:

我们可以用上面示例中的部署 YAML 覆盖这些值:

然后在表单中填充部署属性和容器定义。请注意,映像版本(或标记)已被删除,因为在创建部署时应该选择它:

然后我们可以为服务重复这个过程,它有自己的编辑 YAML 部分:

保存详细信息后,将使用服务属性和端口填充服务:

需要注意的一点是,服务标签没有被导入,因为它们没有被步骤公开。这一步的观点之一是所有资源(在我们的例子中是部署和服务)共享部署上定义的标签。通过 Octopus 自动添加的附加标签,在部署时将服务和部署联系起来,使我们无需在服务上维护选择器标签:

出口 YAML
在前面的部分中,我们使用了编辑 YAML 部分来导入我们现有的 YAML。这进而用我们现有资源定义的细节填充了该步骤。
现在该步骤已经填充完毕,可以使用编辑 YAML 部分来导出 YAML。单击部署或服务部分中的编辑 YAML 按钮,将在表单中显示作为标准 YAML 资源的详细信息。值得注意的是,输出的 YAML 与之前粘贴的并不完全相同。一些名为octopusexport的默认标签已被添加到部署和 pod 规范中,以将两者链接在一起:

同样,服务 YAML 还包括一些默认标签,用于将服务链接到 pod:

但是,除了资源如何相互引用的一些小变化之外,生成的 YAML 保留了最初导入的 YAML 的所有重要细节。这使得在固执己见的 Octopus 步骤中复制 Kubernetes YAML 定义变得很容易,或者如果您发现这比通过 UI 编辑值更容易,就简单地就地编辑 YAML。
YAML 进口的局限性
需要注意的是,该步骤将仅导入其认可的 YAML 值。如果您的部署 YAML 包含一个无法识别的字段,它将被忽略。此功能不提供将未识别的值与 UI 公开的值合并的方法。
如果您有无法识别的值,您可以利用部署原始 Kubernetes YAML 步骤,该步骤将按原样将 YAML 部署到 Kubernetes,并且将仅基于章鱼变量语法执行变量替换。
但是,如果您发现自己遇到了固执己见步骤的限制,复制并粘贴它生成的 YAML 是一种简单的方法,可以转到原始的 YAML 步骤。
结论
很容易找到 Kubernetes 资源,比如与服务、入口、秘密和配置图相结合的部署。Octopus 通过部署 Kubernetes 容器步骤捕获了这种资源组合。
如果您已经有了现有的 Kubernetes YAML,那么部署 Kubernetes 容器步骤允许您通过将 YAML 复制并粘贴到编辑 YAML 部分来快速填充其值。
部署 Kubernetes 容器步骤不会(也永远不会)暴露底层 Kubernetes 资源可用的每一个可能的值,如果您发现自己已经超越了这个固执己见的步骤,那么编辑 YAML 部分提供了一个快速的方法来提取该步骤产生的 YAML,用于一般步骤,如部署原始 Kubernetes YAML 。
改进部署步骤的交付- Octopus Deploy
原文:https://octopus.com/blog/improving-delivery-deployment-steps
我们一直在研究一种新的方法来开发您在 Octopus Deploy 中使用的部署步骤,我们称之为步骤包框架。
在本帖中,我们将探索:
- 为什么我们要建立一个新的框架
- 新框架是什么以及我们的设计决策
- 我们如何测试和迭代新框架
- 八达通用户的利益
- 如何使用我们新的 step 包 feed 将步骤传递到 Octopus 服务器实例
为什么要创建一个新的步骤包框架?
为了尽可能方便地在任何地方部署您的软件,Octopus Deploy 是一款固执己见的产品。Octopus Server 在理解您要部署到的公共目标时工作得最好,从服务器上的 IIS 实例到云中的 Amazon ECS 集群。
为了帮助指导您完成与这些服务交互的过程,我们创建了自以为是的步骤。例如,Octopus 部署步骤允许您:
- 部署或更新 Amazon ECS 服务
- 针对 Azure 或 Kubernetes 运行脚本
- 使用地形模板创建或破坏基础设施
步骤包框架是我们如何开发这些新步骤的一个发展,供您在 Octopus Deploy 中使用。
为了理解为什么需要一个新的框架,我们必须首先看看我们试图解决的问题。
我们之前如何为 Octopus 部署创建步骤
随着 Octopus Deploy 的发展,step 开发经历了几个架构实现。最初,步骤是在 Octopus Deploy 的核心中开发的。这允许组成一个步骤的组件和使用这些组件执行定义的部署的实际过程之间的紧密集成。

这种方法的一个优点是,创建这些步骤的开发人员拥有所有的库和依赖项,可以在开发时开发一个步骤。这种方法还支持与我们的 React 前端紧密集成。
然而,在 Octopus 的核心中开发有几个缺点,特别是当我们开发更多步骤时:
- 步骤只能作为整个 Octopus Deploy 安装程序的一部分提供。这意味着要尝试新功能,您必须升级整个 Octopus 实例。由于 Octopus 通常位于关键任务基础设施的中间,升级周期长且不频繁,这意味着您可能无法使用新的步骤。
- 对现有步骤的任何必要更改,包括错误修复,都必须通过整个发布管道,并且在问题解决之前需要完整的实例升级。这意味着即使很小的补丁也可能需要几周才能更新,而不是几天或几小时。
- 开发一个新的步骤需要理解 Octopus 的几个主要组成部分以及它们是如何相互联系的。这导致交付时间增加,并且很难构建实验步骤。
- 独立于 Octopus 的版本化步骤在任何实际意义上都是不可能的。例如,如果云提供商发布了他们服务的新的主要版本,我们必须在现有步骤中构建许多交换机,而不是仅仅发布现有步骤的新版本,可以与原始版本一起使用。
在快速变化的环境中,新的云服务频繁出现,我们意识到我们需要更灵活的方法来继续提供世界一流的体验。随着 Octopus 中步骤数量的增加,step package 框架被用来解决这些问题。
介绍步骤包框架
step package framework 是一个 TypeScript 库集合,支持创建步骤并将其集成到 Octopus Server 中。它提供了一个 CLI,使步骤作者能够构建和打包他们的新步骤。
使用步骤包框架构建的新步骤现在称为步骤包。步骤包由几个组件组成:
- 描述 Octopus Server 应该在流程编辑器中呈现的 UI 元素的 UI 定义
- 输入模式和验证器
- 步骤执行器,即在部署时执行的代码
与前面的实现不同,所有这些元素现在都存在于 step 包本身中,而不是在 Octopus 服务器中。
这些新步骤是针对 step 包框架中公开的 API 构建的,而不是像 steps 以前那样针对 Octopus Server 中可用的接口。step 包框架将 step 包及其所有组成部分集成到 Octopus 服务器中。
step 包框架通过向 Octopus 服务器提供 2 个组件来实现这一点:
- 首先是获取、注册 step 包并将其集成到 Octopus Server 中的组件集合,这样就可以将 step 包添加并配置到部署流程中。
- 其次是步进引导程序。引导程序在步骤包执行时调用,它向步骤包提供运行时配置,然后执行步骤包中定义的执行器代码。

除了新的框架之外,我们还需要创建一个新的机制来交付 Octopus 服务器版本之外的 step 包。为此,我们构建了一个全局可访问的步骤包 feed 来发布打包的步骤。与 NPM 或 NuGet feeds 的操作方式不同,任何经过身份验证的用户都可以发布包,step package feed 只包含由 Octopus Deploy 开发和发布的包。在编写、构建和打包一个步骤之后,就可以将它发送到任何地方的 Octopus 实例了。我们通过将它发布到 step package feed 来实现这一点。
设计决策
在设计 step package 框架时,我们为自己设定了几个约束条件来帮助塑造最终设计:
- 步骤必须易于编写,即使对于对 Octopus 工作原理知之甚少的人来说也是如此。
- 底层 Octopus 服务器组件的复杂性不能泄露到单个步骤的代码中。
- 步骤必须以生态系统惯用的方式编写。例如,如果我们使用 JavaScript,它必须以大多数 JavaScript 开发人员期望的方式编写。
- 将外部组件或框架引入您的步骤应该很容易。
- 配置步骤的 UI 代码应该是声明性的和抽象的,这样步骤作者就不需要知道呈现了哪些特定组件或它们的内部工作方式。
- 步骤必须进行版本控制,并在 Octopus 服务器的带外分发
- 步骤作者应该能够确定地告诉他们从 Octopus 服务器接收到什么输入。
当涉及到我们的设计决策时,我们必须在这些指导原则上进行权衡,因为它们并不完全兼容。我们以这些权衡和约束为指导,做出了以下设计决策。
步骤必须用大多数程序员熟悉的语言编写
从一开始,我们就想向尽可能多的人展示编写步骤的新方法,所以我们必须选择一种编程语言。一些考虑因素是:
- 这种语言是否足够流行以至于外部库和 API 可以很容易地获得,从而消除那些没有广泛用于构建 web 应用程序的系统级语言。
- 它是否足以表达复杂的部署场景。虽然现在有很多强大的脚本语言可供选择,比如 Lua 和 Groovy,但是随着规模和复杂性的增加,它们会变得难以管理。
- 一个丰富的类型系统,为 step 作者提供关于传入数据的足够信息,并允许编译时代码验证。
我们发现 JavaScript 足够流行和富于表现力,可以满足前两个条件。通过添加 TypeScript,我们还可以构建一个表达式类型系统,保护 step 作者编写无效代码,并为如何使用 step 包框架提供指导。
此外,JavaScript 项目可以集成到一个可分发的文件中,简化了发布和本地部署,尤其是在频繁跨网络移动时(Octopus 就是这种情况)。
执行环境
自然,今天的本地 JavaScript 执行是 Node.js 的同义词。这适合 Octopus,因为它是跨平台的,得到广泛支持,并且足够轻便,可以在任何环境中快速启动。它还是可移植的,因此我们可以将环境和可执行文件直接发送到目的地(例如,发送到部署目标或工作人员),而不用担心兼容性问题。
声明式用户界面
在早期,我们探索了表示一个步骤的用户界面的不同选项。一种选择是利用 React,让用户编写自己的组件,使用 React 的机制来更改渲染器。
然而,我们出于多种原因决定不这么做:
- 这种灵活性导致了很大的兼容性,这意味着保持 Octopus 服务器和众多步骤及其版本的同步是很困难的。
- 我们永远无法支持 React 生态系统中所有可用的库。因此,很难说哪些库受到支持,因此为 Octopus 步骤编写 React 代码与为 web 编写 React 代码将是不同的体验。
- 关于 React 代码有一些隐含的假设:您可以添加自己的原始组件并为它们编写样式,但是这些假设都不适用于受约束的环境。
考虑到这一点,我们决定将 Octopus Server 中 UI 的工作机制和步骤如何定义它们的部分分离开来。我们没有要求 step 作者在我们的原语之上编写他们自己的组件,而是让开发人员将他们的输入与他们想要表示这些输入的语义组件联系起来。例如,下面的代码显示了一个文本字段:
text({
input: inputs.myTextInput,
label: "Some text field",
helpText: "The help text for the field"
})
由于代码是声明性的,不依赖于文本框的任何特定实现,我们可以轻松地将其替换为其他内容,而 step 作者不必做任何工作。
另一个好处是,我们可以使用类型系统来引导开发人员使用正确的组件。例如,我们可以检查在构建时只有数字输入用于数字组件。
声明式风格还允许在 Octopus 服务器和 step 包之间定义良好的契约,帮助我们减少兼容性表面,并更慎重地考虑框架版本之间的变更。
版本控制
我们新框架的最大目标是能够快速发布新的步骤,而不必发布新版本的 Octopus 服务器。实现这个目标的结果是,步骤也必须有它们自己的版本控制、升级和迁移机制。这也意味着 Octopus 服务器必须准确地知道:
- 它支持哪些 step 版本
- 如何从步骤的一个版本迁移到另一个版本
- 哪些步骤版本可以静默迁移,哪些迁移需要额外的用户输入
- 如何处理不兼容的步骤
我们通过在等式两边产生粒度兼容性清单来解决这个问题。Octopus Server 的每个版本都有一组可以保证兼容的内部组件,我们在构建时将这些组件的特定版本注入到 step 包中。然后,我们不仅可以很容易地判断一个 step 包是否兼容,还可以判断该包的哪些特定部分已经兼容,哪些部分需要迁移到最新版本。
我们还在 Octopus 服务器中建立了版本号的隐式保证,这样 step 作者可以确保,例如,如果他们开始为版本 2022.1 构建 step,他们的 step 将始终在该版本上运行,无论我们后来发布了多少次要版本和修补程序。
尝试新的框架
在 Octopus,我们认为验证产品创意的最佳方式是在真实环境中亲自使用产品,这被称为“狗食”。
在我们完成 step package 框架的第一次迭代之后,是时候改进和验证我们的假设和设计决策了。为此,我们使用新框架构建了两个功能全面的步骤:
- 部署 ECS 服务
- 更新 ECS 服务
这两个步骤的区别在于,“部署 ECS 服务”步骤从头开始构建新的 ECS 服务定义并将其部署为云形成模板,而“更新 ECS 服务”步骤更新现有的一组定义。
有了这两个新步骤,我们从一个空白页开始,就像任何其他步骤作者在将来使用框架时会做的那样。这让我们能够测试框架设计中的决策是否能够成立。大多数情况下,他们做到了,但是我们学到了一些教训,这导致了进一步的改进。
框架改进
对新 UI 组件的需求
步骤 UI 组件是步骤包框架的一部分,它允许步骤作者定义步骤的用户界面。当 ECS 项目开始时,该框架支持大多数基本的 UI 组件,这些组件可用于构建与其他内置 Octopus 步骤具有相同外观和感觉的界面。然而,团队意识到需要一些高级组件,比如容器图像选择器组件。
需要新 UI 组件的一个特性是允许将步骤信息导出到 CloudFormation 模板。在我们的声明式 UI 中实现这些新的 UI 组件提出了一些挑战。由于这是所有步骤包的共享组件集,我们必须考虑如何使新组件足够通用,以便它可以被其他步骤包使用,但仍然支持 ECS 步骤所需的所有功能。这个挑战是框架中的一个有意识的权衡,它以只向步骤公开 Octopus 功能的子集为代价,大大降低了创作新步骤的复杂性。
端到端测试框架
团队在开发 ECS 步骤时考虑的一个关键方面是如何编写集成测试。需要进行测试来构建云服务中所需的所有资源,以便可以执行被测试步骤的部署。
在测试实际运行之前,我们需要在 AWS 中设置大量的资源。我们决定用一个 Terraform 模板来旋转集成测试的资源,以消除对静态资源的需求。
意识到这些需求也适用于未来其他类型的步骤,例如使用 Azure 或 GCP 基础设施的步骤,我们开发了一个测试框架,该框架从客户端提供的 Terraform 模板中获取并设置基础设施。客户端声明所需的云提供商(Azure、AWS 或 GCP)并提供凭证。然后,该框架输出一个随机资源代码,该代码既可用于 step 作者自己的 Terraform 模板,也可用于访问和验证资源的测试。
该测试框架促进了我们在 ECS 步骤中实施的多个集成测试的开发,并且对于在主要云提供商中执行需要基础架构设置的任何步骤的步骤作者来说,是一个必不可少的工具。
局部测试步骤的痛苦
用 step 包框架构建的步骤是从 Octopus Server 独立开发的。因此,当我们想要直观地看到这些步骤如何工作时,我们需要手动地将正在开发的步骤包集成到 Octopus Server 中。为此,我们需要:
- 从步骤项目中构建并输出压缩的步骤包
- 将 zip 文件复制到 Octopus 服务器存储库中的本地文件夹
- 删除该步骤先前版本的任何缓存文件
- 重启/重建八达通服务器
在开发 ECS 步骤的过程中,这个过程非常耗时。因此,我们实现了一个本地 feed,允许 Octopus Server 定期在本地获取 step 包,并将它们加载到正在运行的 Octopus Server 实例中。这使得 step 作者可以方便地应用他们的 step 包更改,而无需重新启动他们的 Octopus 服务器。
步骤包框架如何让您受益
step 包框架是为了帮助 Octopus 以一种新的方式开发 steps 而构建的,但是这对于作为 Octopus Deploy 用户的你来说意味着什么呢?
- 我们现在可以独立于 Octopus Server 构建步骤,因此它们不再与我们的发布管道绑定。
- 我们现在可以在安装或升级 Octopus 服务器之外发布步骤,让您无需升级即可更快地访问步骤。
请注意,虽然 step 软件包是与 Octopus 服务器分开打包和交付的,但它们仍需要安装在服务器上才能使用。
分步包装的交付
在步骤包提要上有了步骤包之后,下一次 Octopus 服务器实例检查新步骤提要时,它将下载步骤包并立即在 Octopus 服务器实例中可用。如果您使用的是 Octopus Server 2022.1 或更高版本,并且您的实例已配置为允许它连接到我们的 step package feed,则此功能可用。这将按计划进行,也可以手动触发。你可以在配置 > 功能 > 步骤模板更新下找到这个同步的状态。

步骤包更新
在下载了一个步骤包并将其处理到 Octopus 服务器实例中之后,它会根据当前版本和新版本之间的差异,更新部署过程中该步骤包的使用情况。
Step 包使用语义版本化格式:major.minor.patch。如果发布了新的次要版本或修补版本的 step 包,您的流程将会自动更新。
在部署编辑器的步骤的关于这个步骤部分中可以找到关于正在使用的步骤包版本的详细信息。

如果发布了主要版本,那么使用这些步骤的部署过程不会自动更新以使用新版本。这是因为主要版本更新需要用户干预,以便将来成功部署。要使用新的主要版本,您需要手动更新每个部署过程以使用新的主要版本。

如果有新的主要版本可用,您将在步骤编辑器中看到以下横幅。

升级到使用新的主要版本非常简单,只需点击升级按钮,用新要求的参数更新您的部署流程,然后点击保存。
结论
step 包框架正在改变我们为您的 Octopus 服务器实例构建和交付新步骤的方式。这意味着可以更快地交付新步骤,而无需升级。
随着我们推出更多的功能,我们期待着使用该框架为您带来新的和改进的步骤。
愉快的部署!
感谢雷·纳姆、叶戈尔·帕夫利欣和马特·谢泼德对本文的贡献。
提高 PowerShell 兼容性- Octopus Deploy
Octopus 允许在部署期间执行 PowerShell 脚本。PowerShell 非常强大,是实现部署自动化的一个很好的工具,所以它是我们非常依赖的一个特性。
为了调用 PowerShell 脚本,我们目前使用 Runspace 类在 Octopus 触手进程中托管 PowerShell。我们将 PowerShell 脚本从一个文件读入一个字符串并执行它,就像您在 PowerShell 控制台中输入它一样。
虫子,哦,虫子...
通过在我们自己的进程中托管 PowerShell,与直接使用 PowerShell.exe 运行脚本相比有一些不同。自从 Octopus 首次发布以来,我们一直在不断提高兼容性水平,我们已经进行了大量的集成测试,这些测试是在不同的 Windows 配置上运行的(2003、2008,包括 R2 和 2012、x86 和 x64)。大多数时候,它只是工作。除了它不在的时候!
几乎每周我们都会收到一份类似于以下内容的错误报告:
我有一个 PowerShell 脚本,当我从 PowerShell 运行它时运行良好,但是当我在触手下运行它时,我得到...
示例:
虽然有很多关于“如何托管 PowerShell 是一个. NET 应用程序”的例子,但我从未见过关于“如何托管一个 100%兼容 PowerShell.exe 的‘一切正常工作’!”的权威指南. NET 应用程序中的主机”,这两者之间有很大的区别。有很多开源应用程序使用与我们非常相似的托管代码,但是它们似乎都有这些问题。
过程。开始救援!
为了避免看到更多的错误报告,从 Octopus 1.4 开始,我们将切换到一个新的 PowerShell 调用模型。我们要打电话给 PowerShell.exe,告诉他结果。
如果你有兴趣大致了解我们将如何调用 PowerShell,查看这个要点。它还有一个好处,就是比我们目前的模型简单一百倍。
这带来的一个问题是向后兼容性和对现有脚本的支持,现有脚本可能会在新模型下崩溃。
多种 PowerShell 模式?
最初,我计划支持多种 PowerShell 调用模式,这样就可以选择是否使用内存(当前)模式还是 PowerShell(新)模式。用户可以在设置包或脚本步骤时进行选择。
但是这太复杂了。谁想在调用 PowerShell 脚本的四种方法中进行选择?我们想要处理四种不同 PowerShell 调用 mdoels 的错误报告吗?此外,就 Octopus 而言,在进程中托管 PowerShell 没有任何优势。它实际上更慢,因为我们必须创建和拆除 AppDomain。除了遗留支持之外,我根本找不到任何保留现有模型的理由。
退一步说,鼓励人们编写只在触手下运行时有效,而在 PowerShell.exe 下运行时无效的脚本是个好主意吗?如果“锁定”是我们的策略那么也许。但我们在 NuGet 和 PowerShell 等标准平台上构建 Octopus 正是为了避免这种情况。
这意味着什么
目前的计划是:
- 从 1.4 开始,使新模型成为调用 PowerShell 脚本的默认模型(因此它应该“适合”所有人)
- 通过设置一个特殊变量来请求“遗留”PowerShell 模式,使旧模型可用,然后在未来的版本(可能是 1.5 或 1.6)中删除该选项
我不认为在我们的“遗留”(托管)模式下会有很多人依赖某个行为的情况,但如果有,我们会在一两个版本中支持他们。否则,人们应该准备转向新的 PowerShell 模式。在 99%的情况下,它会工作。在那 1%没有的地方,无论如何都应该修复。
用 TFS 配章鱼?我们想听听你的意见!-章鱼部署
一段时间以来,我们为 JetBrains TeamCity 开发了一个插件,使得在构建完成时部署发布变得非常容易。不幸的是,集成 Octopus Deploy 和 Microsoft Team Foundation Server 的故事从来没有这么顺利过。作为一项规则,使 TFS 和八达通一起工作通常涉及:
- 自定义 MSBuild 脚本
- 团队构建工作流更改
我真的很想改善这种体验;事实上,我希望 Octopus 成为 TFS 客户最简单、最有吸引力的自动化部署体验。
为了做到这一点,我们计划与 TFS 进行更深入的整合,要么作为 Octopus 中的一项功能,要么作为连接两者的外部服务。目标是在团队构建完成后,用 Octopus 自动创建和部署发布,不需要任何工作流更改。
例如:
- 团队构建完成时自动创建发布
- 在发行说明中,包含与该版本关联的所有工作项的链接
- 将版本部署到冒烟测试环境中
- 当团队构建的构建质量发生变化时,将其部署到另一个环境中
我们仍处于集思广益阶段,这就是我们需要你帮助的地方。如果您使用(或计划使用)TFS 和章鱼,我们希望您填写这份 30 秒的调查。它只有 5 个问题,我们不要求您在 10 分的范围内给任何问题打分!
基础设施作为代码与开发人员的平台-八达通部署
原文:https://octopus.com/blog/infrastructure-as-code-with-terraform-for-developers

当你认为基础设施是代码或软件定义的基础设施时,通常首先想到的是 DevOps 或基础设施团队,但 Terraform 并非如此。Terraform 是用 Hashicorp 配置语言( HCL )编写的,这是一种功能齐全且不可变的编程语言。
循环、if 语句、变量以及任何编程语言中的大部分逻辑都存在于 Terraform 中。Terraform 是一款适合所有人的产品,非常适合基础设施、开发团队和开发人员。在这篇博文中,你将了解基础设施作为代码对开发者有用的五大原因。
先决条件
要跟进这篇博文,您应该具备以下条件:
- 对发展主题的理解。
- 至少用一种编程语言编写过代码。
面向开发人员的基础设施
不久前,也许是 10-15 年前,开发和运营之间还存在一些问题。开发人员会编写代码,但他们没有任何基础设施来测试它。甚至有这样的情况,他们不得不等待个月来测试他们的代码,不知道它是否实际工作(在某些情况下,它没有)。这有几个原因:
- 基础设施不可用。
- 开发人员不知道如何部署基础设施。
- 没有开发人员可以与之交互来部署基础架构的自动化解决方案。
让我们看一下每个要点,看看问题是从哪里开始的,以及它们是如何被发现的。
- 基础设施不可用。
这有点困难。基础设施根本不可用。正如我们今天所知,虚拟化刚刚起步,云技术还处于起步阶段。开发人员只需等待运营部门准备好基础设施,在大多数情况下,这不是运营部门的错。服务器必须交付、安装和堆叠、配置,然后最终交付使用。这没有给开发留下太多的回旋余地。幸运的是,那个时代已经离我们很远了,我们现在有像 Azure、AWS 这样的平台和像 ESXi 这样的虚拟化工具。
- 开发人员不知道如何部署基础设施。
这就是开发人员开始深入基础设施的能力开始成为现实的地方。虚拟化和云技术已经存在,因此部署基础架构要高效得多。这里唯一的问题是仍然没有一个说开发者语言的解决方案。开发人员如何以他们理解并适合他们优势的方式部署基础设施?
- 没有开发人员可以与之交互来部署基础架构的自动化解决方案。
这就是像 Terraform 这样的工具发挥作用的地方。既然基础设施作为代码和软件定义的基础设施存在,开发人员部署测试环境来帮助他们测试代码就容易多了。

来源:https://unsplash.com/photos/vXInUOv1n84
所有的工程师,包括开发人员,都有一种方法来定义对他们有意义的基础设施,那就是用代码。
一种可重复的语言
开发人员已经有足够多的代码需要担心。他们正在为应用程序、错误修复、功能请求和清理技术债务构建解决方案。有了 Terraform,开发者就不用担心创建数百个基础设施作为代码环境。相反,他们可以使用相同的代码来部署多个环境。
例如,假设您与多个客户合作。也许你有多个 Azure 订阅或 AWS 账户,这取决于你使用的是什么云。如果你必须在 Azure 上为每个客户端部署容器,比如每个客户端十个,那么你必须为每个客户端编写大量代码。代替这样做,你可以有相同的可重复的代码并且简单地改变变量,这些变量存在于一个单独的文件中。
让我们看一个例子。
下面的代码创建了一个 Azure 容器实例,这是一种在 Azure 中运行 Docker 容器而不使用 Kubernetes 的方法。不要太在意语法,相反,看看那个var.关键词。通过使用变量,您可以为每个客户端创建一个变量文件,并在任何 Azure 环境中使用相同的配置。Terraform 背后的理念是尽可能地重复,并且只对不会改变的值进行硬编码:
resource "azurerm_container_group" "example" {
name = "var.name"
location = var.location
resource_group_name = var.resourceGroup
ip_address_type = "public"
os_type = "Linux"
container {
name = "nginx-web-app"
image = "Nginx:latest"
cpu = "0.5"
memory = "1.5"
ports {
port = 443
protocol = "TCP"
}
}
自动化测试
当你写代码时,首先应该想到的是如何测试代码。事实上,有一种开发实践叫做测试驱动开发( TTD ),它围绕着这样一个事实:首先编写代码测试,然后根据测试为应用程序定义代码。
在写这篇文章的时候,Terraform 有两个主要的工具来编写测试:
- 地形测试
- 厨房-平台
Terratest 是一个用 Golang 编写的模拟测试框架。因为是用 Go 写的,所以需要懂一点 Go 才能用。
我个人不在 Go 中写代码,但是我得到了一个不错的 Terratest 测试。网上有很多例子,如果你以前用另一种编程语言写过,同样的规则也适用于 Go(方法、函数、库、变量等等)。).
下面是一个 Terratest 示例,它创建了一个 Terraform 环境,然后像标准模拟测试一样删除它。这个包名为test,它导入了两个库,Terratest Terraform 模块和testing Golang 库。然后,该函数启动并创建(应用)一个地形环境,然后销毁它。defer用于运行最后那段代码:
package test
import (
"github.com/gruntwork-io/terratest/modules/terraform"
"testing"
)
func vnet_test(t *testing.T) {
terraformOptions := &terraform.Options{
}
defer terraform.Destroy(t, terraformOptions)
terraform.InitAndApply(t, terraformOptions)
}
Kitchen-terraform 是一个用 Ruby 编写的框架。最初,厨房测试套件主要用于 Chef,Chef 是作为代码语言的另一个基础设施,但后来扩展到了其他工具。因为 Ruby 是一种相当流行的编程语言,也是被认为更容易使用的编程语言之一,所以 kitchen-terraform 越来越受欢迎。
下面是一个使用厨房平台的例子。代码通过/etc/os-release来确认 Linux 发行版是 Ubuntu:
control "operating_system" do
describe "the operating system" do
subject do
command("cat /etc/os-release").stdout
end
it "is Ubuntu" do
is_expected.to match /Ubuntu/
end
end
end
Terraform 供应商开发计划
使用 Terraform 是一回事,但许多开发人员希望创建自己的使用 Terraform 的方式。例如,在其他编程语言中,您可能想要创建自己的模块供工作或社区使用。通过 Terraform 供应商开发计划,Terraform 让您能够做到这一点。该计划允许供应商建立 Terraform 提供商,当提供商建立后,HashiCorp 将亲自测试它,验证它,并将其放在官方提供商网站上。
如果你不想走官方路线,让 Terraform 测试提供者,也有基于社区的 Terraform 提供者,它们是开源的,对全世界开放。这是一个伟大的方式,不仅可以回馈社区,还可以建立自己的艺术作品。
下面是社区提供者的一个小列表。如您所见,从 DNS 到密码认证再到 git,有几个提供者:

来源:https://www . terraform . io/docs/providers/type/community-index . html
说到官方提供商,你会看到 Azure、AWS、VMWare 等平台的提供商:

来源:https://www.terraform.io/docs/providers/index.html
开发人员和运营人员使用相同的语言
既然你已经了解了 Terraform 的一些关键技术方面,那么让我们来谈谈文化方面。任何组织中的文化都是成功的关键。不管代码有多好,应用程序有多受欢迎,或者办公室里的小吃有多棒。如果文化不起作用,整个事情都会崩溃。对于一个应用程序来说,它需要一个托管的地方。对于托管应用程序的操作,他们需要托管应用程序。本质上,开发者和运营需要协同工作。
将基础架构编写为代码和软件定义的基础架构为开发人员和运营人员提供了一种交流方式。基础设施是基础设施,代码是代码。不管它在创建或托管什么是一回事,但基础设施和代码的存在是事实。要做到这两点,像 Terraform 这样的解决方案是前进的道路。
从文化角度来看,另一件大事是运营和开发团队中的每个人都可以学到一些新东西。如果运营团队不是大程序员,他们可以学习编码,这是他们的另一个工具。不仅仅是学习,他们还和开发人员一起工作,并向他们提问。这使纽带更加紧密。同样的规则也适用于将基础设施作为代码编写的开发人员。如果他们试图部署带有代码的虚拟机,而他们不了解网络的某些方面,他们需要坐下来与运营团队合作。
结论
在这篇文章中,我谈到了:
- 为什么 Terraform 从技术角度和文化角度对开发者很重要。
- 面向开发人员的基础设施,以及为什么它可以用于不同的阶段,包括部署。
- HCL 是可重复的,以及如何在任何环境中使用相同的配置。
- 通过实现单元测试和模拟测试来测试 Terraform。
- 不同的平台提供商不仅可以使用,而且可以由社区为社区创造。
为了挑战,尝试一下吧!编写一些 Terraform 代码,在您选择的云平台中创建一个容器。然后使用 Octopus Deploy 或您喜欢的 CICD 平台之一将应用程序部署到容器中。
资源
与 Olo - Octopus Deploy 的 Jason Dunnivant 一起进入 DevOps
本帖开启了我们的 Inside DevOps 系列,在这里我们分享了从 DevOps 前线学到的经验教训。
杰森·邓尼万特, Olo 的发布工程师,首先出场。Olo 是 SaaS 领先的开放式餐厅平台,让每个接触点都充满热情。
Jason,我向你伸出手来开始我们的博客系列,因为我被你对 DevOps 的奉献所吸引。你甚至有章鱼部署的纹身!
杰森:如你所见,我是你们产品的忠实粉丝。

杰森·邓尼凡特和他的章鱼部署纹身
DevOps 对你来说是什么?你是怎么定义的?
Jason :对我来说,DevOps 是一种将尽可能多的事情自动化的方法,所以人们不需要手工去做。有了 DevOps 思维模式,我们可以将软件工程师从日常任务中解放出来,例如提供基础设施,让他们专注于他们喜欢做的事情——开发软件。
你的 DevOps 之旅是如何开始的?
杰森:我的职业道路对于一个软件人来说可能并不典型。我在军队服役,有心理学学位。我在一家加油站工作,攻读学位,这时我收到了一份技术支持的工作邀请。然后,我转到了网络管理岗位。我的经理告诉我,我是一个聪明的家伙,所以我开始学习如何编码,并成为一名开发人员。在过去的几年里,我一直是 Olo 的发布工程师。
你的心理学学位有任何帮助吗?
杰森:这让我能够接替他人的位置,这在我的技术支持时期非常重要。这种技能在我目前的工作中仍然适用。
DevOps 最具挑战性的部分是什么?
Jason :我认为 DevOps 最具挑战性的部分是它涵盖了软件操作的许多方面,人们会带着许多不同的请求来找你。然而,我发现最好的方法是保持开放的心态,不要害怕尝试以前没有做过的事情。
你工作中最有回报的部分是什么?
杰森:去帮助别人。开发者只是想开发,我可以让他们的生活更轻松。
您或您的组织实施了哪些 DevOps 最佳实践?
杰森:我们公司实施了很多最佳实践。一个是使用微服务,这样我们可以更快地发布,并且独立于我们软件平台的其他组件。我们将我们的系统与 300 多种其他软件技术集成在一起,因此这种方法可以让我们更快地将软件投入生产。我们一天两次甚至更频繁地发布到生产环境,我们努力实现“单个吉拉票证部署”,在这种情况下,我们将修复程序快速推向生产环境,只需关闭一个初始票证。这在很大程度上是可能的,因为我们使用章鱼。我们的部署流程有 100 多个步骤,但我们可以在大约 20 分钟内完成部署,所以对我们来说这几乎不是什么大事,这是一个精心安排的部署流程,没有人会为此感到紧张。
另一个最佳实践是让开发团队参与部署过程。我们通过在 Octopus 中使用配置代码(CAC)来实现这一点。开发团队使用他们熟悉的环境来添加和修改部署步骤,然后与我的团队一起通过审查和批准过程。这样,我们可以更快地扩展和向客户交付功能,同时确保萨班斯-奥克斯利法案(SOX)所要求的职责分离。
你会给刚开始开发工作的人什么建议?
Jason :弄脏你的手——创建你的 Azure 环境,下载 Octopus,然后开始玩它。
有什么 DevOps 的书推荐阅读?
杰森:我其实最近没怎么看书,但是我每天都在和队友一起学习新的东西,所以我是潜移默化的学习。但是对我最有帮助的一本书是 Justin Domingus 和 John Arundel 的Cloud Native devo PS with Kubernetes:Building,Deploying,and Scaling Modern Applications in the Cloud。
谢谢推荐;我们会确保将它添加到我们的 DevOps 阅读清单。最后一个问题:你身上有哪一点会让我们感到惊讶?
杰森:关于我的一个有趣的事实是,我是佛罗里达州鱼类和野生动物保护委员会的一名讨厌的鳄鱼捕手。
哦,哇——很难打败那个!Jason,再次感谢你花时间陪我,祝你部署愉快!
杰森:随时恭候!
如果你想在我们的系列节目《Inside DevOps》中出镜,请联系 LinkedIn 上的 Joanna,安排时间进行一次简短的聊天。
Insight Partners 向 Octopus Deploy 投资 1.725 亿美元

今天,我很高兴地宣布,Insight Partners 已投资 1.725 亿美元收购 Octopus Deploy 的少数股权,作为合作伙伴加入我们,展望我们公司未来十年的发展。
Insight Partners 是世界上最大、最成功的风险基金之一,也是企业 DevOps 软件公司中最多产的投资者之一,投资项目包括 SonarSource、JFrog、Pluralsight 和 Veeam。他们的规模和专业知识对我们的持续发展和成功至关重要。
Octopus Deploy 是一家自举软件公司,这是我们一直引以为豪的。我们用来建立公司的每一分钱都来自我们的客户,而不是投资者。我们发展非常迅速,但我们一直保守地管理公司,并一直保持着很高的利润(30%以上)。我们从来没有真正认为自己是一家“创业公司”——反正不是风险投资那种。因此,我们理解今天的宣布可能会有点令人惊讶。
十年的酝酿
当我开始 Octopus 的时候,我痴迷于部署和让团队更容易。我非常相信持续交付的力量,但是沮丧的是,如此多的 CD 以编译并通过单元测试的代码结束,但是没有被部署到任何地方。除了“人员”之外,部署过去是——现在仍然是——持续交付中最困难的部分。
那是在 2011 年,当时我写了一篇关于编写 Octopus Deploy 的博客。很多人开始关注,有些人今天正在看这个公告。成百上千有远见的开发人员和软件团队开始跟随我们的旅程,并在早期测试版中尝试 Octopus。
2012 年,当索尼娅和我把 Octopus 从一个夜间和周末项目变成一项业务时,我们希望为尽可能多的公司解决部署问题,但我们的愿望并不强烈,也没有特别大的发展计划。我们经历了一个又一个里程碑——第一次发布、第一次销售、第一次招聘、第一间办公室。我仍然清楚地记得收到第一张邮寄的美元支票,想知道这里的银行是否能接受它,并试图找出为什么美国客户一直要求“W9”。
从那以后,我们惊人地成长起来。我们已经帮助 25,000 家公司自动化了 1.8 亿次部署,超过 350,000 人使用 Octopus Deploy。我们有第二受欢迎的团队城市插件(仅次于。NET Core),而我们是 Azure DevOps 最受欢迎的第三方部署插件。
最近,我们在企业中取得了令人难以置信的成功,这是增长最快的客户群。虽然 Octopus 有助于团队在企业层面实现自动化部署,但它也有助于降低复杂性并满足合规性需求,尤其是在我们所处的多云/混合云世界中。
Octopus Deploy 的发展超出了我们的预期,现在我们在澳大利亚、美国和英国雇佣了 109 名员工。来自我们客户的信息很明确:我们有一个人们喜欢使用的强大产品(我们的净推广得分是 65+,这在企业软件中是闻所未闻的),但总是有更多的事情要做。
下一个十年
几年来,我一直在断断续续地与 Insight 以及其他一些风投公司进行交流。我们从未寻求投资,但我们开始受到关注,风险投资公司会主动联系我们,我们会礼貌地拒绝他们中的大多数,偶尔会接个电话。这很快就让人厌倦了,但我们还是和少数人保持联系,而洞察力是最重要的。
然后在 2020 年 10 月,Insight Partners 带着非常坚定的信念再次找到我们,我们已经建立了一些特殊的东西。在我们不知道的情况下,他们已经和我们的几十个客户谈过了,真正了解了这些客户对八达通的重视程度。他们非常确信我们所构建的是特别的——他们从我们的客户那里得到了响亮而清晰的信息,即 Octopus 是企业部署自动化领域的第一大类领导者——并且他们就如何帮助我们继续发展提出了强有力的建议。
大概那个时候,我们大概 80 人,规划 2021 年。如果一切按计划进行,我们计划在 2021 年快速增长到 180+,在 2022 年增长到 300+。这听起来很多,但我们仅基于收入就能承受这种增长,没有必要进行投资来提供资金。
尽管如此,我开始思考未来的种种挑战。我们的业务模式和增长并不依赖于融资,而是依赖于公司内外的聪明人。当我仔细考虑 Insight pitch 并花更多时间与他们在一起时,我发现自己学到了很多东西,并真正享受其中,我意识到有他们比没有他们更能实现我们的长期计划。把他们想象成我们团队的一部分是非常容易和自然的。我们签署了一份条款清单,并开始了尽职调查过程。
尽职调查和法律工作已于 12 月底全部完成。由于我们是一家澳大利亚公司,这笔交易需要得到澳大利亚政府外国投资审查委员会的批准。FIRB 的时间框架是 30 天到 6 个月,所以我想我们应该考虑他们花了三个月才发现他们的绿色印章是一种祝福!
会有什么变化?
就我们对业务的看法而言,一切都没有改变。索尼娅和我仍然拥有公司的大部分股份,只要我觉得自己是最佳人选,我就打算继续担任首席执行官。使八达通成为 Insight 的一个好投资的是我们非常一致:Insight 和我们一样有非常长远的眼光;我们的成长目标是一致的;我们都认为八达通应该保持增长,盈利,管理保守的公司。
我注意到的一个变化是内在能量、兴奋、雄心和专注的普遍感觉。思考下一个十年和我们的发展方向让我们清楚地知道我们想要实现什么,每个人都很兴奋。我们已经为未来几年的产品和客户体验制定了宏伟的计划,我们在 Insight 的朋友们一直是我们的好伙伴。
谢谢你
像这样的投资通常被视为对公司的认可,但我认为在这种情况下,它实际上是对你,我们的客户的认可。所以我想对你们说声谢谢。
当你告诉你的经理你发现了一个帮助自动化部署的伟大工具时,他们可能认为你是一个英雄。但是当你告诉他们这个供应商是一家来自澳大利亚的小型创业公司,而你甚至不确定他们是否有销售人员可以和你的经理交谈时,他们可能开始担心你了。你为什么不选择大公司的产品,或者知名的企业供应商的产品?毫无疑问,这是一场艰苦的战斗。但你还是做了。您让我们有机会帮助您的部署变得更愉快,并向您的同事介绍了我们。说真的,没有你我们今天不会在这里。
我们的目标是继续成为企业部署自动化的首选。NET 和 JVM 堆栈,继续建立一个可持续的业务,你可以依靠它存在很长一段时间,并继续值得你的业务。我非常有信心,我们在 Insight 的朋友将在我们未来十年的旅程中给予我们巨大的支持。
创始人兼首席执行官保罗·斯托弗
来自我们的优化 Octopus 网络研讨会- Octopus Deploy 的见解
原文:https://octopus.com/blog/insights-from-our-optimizing-octopus-webinar
在我们最近的网络研讨会中,Clear Measure 的 Chris Thomas 与 Derek Campbell 一起讨论了如何优化 Octopus Deploy 以获得最佳体验。
通过一点规划、维护和对其功能的巧妙使用,您可以保持 Octopus 平稳运行,并更容易看到正在发生的事情。
观看下面的网上研讨会或继续滚动查看网上研讨会的主要观点。
https://www.youtube.com/embed/M5MbNkGkIPo
VIDEO
数据库维护
正如 Chris 在网上研讨会中指出的,很容易忘记 Octopus 服务器是在 SQL 数据库上运行的。使用像微软 SQL Server Management Studio(SSMS)这样的工具进行一些基本的内务处理,可以提高那些与缓慢的实例作斗争的人的速度。
如果你在章鱼云上,数据库维护是你永远不需要担心的事情。直接跳到如何最好的组织章鱼吧。
检查 SQL 报告中的问题
首先,我们建议在 SSMS 运行一个“索引物理统计”报告来查找问题。
要运行该报告,请从列表中右键单击您的数据库,然后选择 报告➜标准报告➜指数物理统计 。
打开报告后,检查操作建议栏中的建议。
您还可以展开 # Partitions 列中的项目来查看碎片信息。
- 如果碎片超过 35%,您应该安排一些时间来整理数据库碎片。
- 低于 30%通常是可以的,但是随着百分比的增加,还有改进的空间。
制定维护计划
您可以使用 SSMS 的 SQL Server 维护计划向导来优化和维护您的 SQL 数据库。
展开左侧窗格中的管理文件夹,右键单击维护计划,选择维护计划向导。
将计划设置为按适合您业务的时间表运行,并选择以下维护任务:
- 检查数据库完整性
- 重组索引
- 重建索引
- 更新统计数据
如果需要,可以使用其他数据库,尽管我们建议不要因为性能原因而缩小数据库。
随着向导的进行,您可能希望更改每个选定任务的设置。我们发现缺省值已经足够了,但是您可以根据需要进行更改。
开心了就运行维护计划。
如果你喜欢使用脚本,试试 Ola Hallengren 的 SQL Server 维护解决方案,它可以实现我们上面概述的所有功能。
整理章鱼
保持 Octopus 井井有条不仅有助于提高性能,还能让团队更容易阅读和导航仪表板。这里有一些建议可以让你的仪表盘保持简洁和易于导航。
不要使用超过你需要的环境
虽然您可以创建许多环境,但是您的环境编号应该反映您的开发管道(例如,开发、QA、试运行、UAT 和生产)。
我们建议使用少于 10 个环境来减少:
- 性能问题
- 项目冗余和重叠
- 仪表板上不必要的混乱

我们发现一些客户使用了比管理大量项目或部署目标所需更多的环境。Octopus 包含了更好的选项,比如项目组和租户。
将您的项目分组
如果您有许多项目,您可以将它们分组,以帮助减少仪表板上的视觉干扰。

要创建项目组,请执行以下操作:
- 点击 Octopus 顶部菜单中的项目。
- 点击右上角的添加组。
- 为您的群组命名并描述,然后点击保存。
要将现有项目添加到组中:
- 点击 Octopus 顶部菜单中的项目。
- 点击你需要移动到新组的项目。
- 点击左侧菜单底部的设置。
- 点击项目组,然后从项目组下拉菜单中选择目的组。
若要将新项目添加到群组:
- 点击八达通顶部菜单中的项目。
- 点击右上角的添加项目。
- 为您的新项目命名,然后单击显示高级。
- 从项目组下拉菜单中选择一个组。
- 点击保存完成新项目的创建。
使用租户
我们设计租户是为了帮助交付软件即服务(SaaS)的客户,但他们也有助于组织以下事项:
- 地理区域或数据中心
- 开发人员、测试人员或团队
- 特征分支

查看我们关于租户的文档了解更多信息。
另外,请观看我们与 Adam Close 和 Mark Harrison 的后续网络研讨会,使用 Octopus Deploy 实现更好的多租户部署。
删除您的旧版本和构建
从 Octopus 中删除任何你不再需要的东西是一个很好的做法。Octopus Server 默认设置为保留所有内容(Octopus Cloud 默认为 30 天),但您可以使用生命周期保留策略来自动删除旧版本和构建版本。
要检查您的保留策略:
- 点击 Octopus 顶部菜单中的库。
- 从左侧菜单中点击生命周期。
在这里,您可以更改现有和默认生命周期的保留策略,或者创建新的策略。
通过设置保留策略,Octopus 将在您设置的天数或释放次数后删除文件,为您节省宝贵的磁盘空间。

请参阅我们的文档,了解有关以下内容的更多详细信息:
接下来呢?
要获得更多帮助,你可以浏览一下 Octopus Deploy 文档,或者欢迎你通过我们的支持渠道联系我们。
愉快的部署!
如何用 Octopus Deploy 安装和配置 NGINX
你好,部署者!在过去的几天里,我学到了很多关于配置 NGINX 的知识。我已经为两个 web 应用程序配置了一个简单的反向代理,希望以后再也不要这样做了。为了我未来的自己,我在 Octopus 中建立了一个项目来做这项工作。配置更改、证书到期或部署到另一台机器都可以通过一个按钮来完成,而不是试图记住我在过去几天里所做的所有调整。它是这样工作的:您好部署者!在过去的几天里,我学到了很多关于配置 NGINX 的知识。我已经为两个 web 应用程序配置了一个简单的反向代理,希望以后再也不要这样做了。为了我未来的自己,我在 Octopus 中建立了一个项目来做这项工作。配置更改、证书到期或部署到另一台机器都可以通过一个按钮来完成,而不是试图记住我在过去几天里所做的所有调整。它是这样工作的:

安装 NGINX
要使用 NGINX,我们必须安装 NGINX。一个简单的 bash 脚本确保安装了 NGINX:
sudo apt-get install --assume-yes nginx
安装站点配置
有两个配置文件指导 NGINX 如何将请求转发到我们的 web 应用程序。它们看起来像这样:
server {
listen 80; listen [::]:80;
server_name somewhere.octopus.com;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2; listen [::]:443 ssl http2;
server_name somewhere.octopus.com;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl on;
ssl_certificate /etc/ssl/octopus.crt;
ssl_certificate_key /etc/ssl/octopus.key;
ssl_session_tickets off;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES256-SHA;
ssl_prefer_server_ciphers on;
http2_idle_timeout 5m; # up from 3m default
location / {
proxy_pass http://unix:/var/discourse/shared/standalone/nginx.http.sock:;
proxy_set_header Host $http_host;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
}
}
这些文件存在于源代码控制中,并被打包供 Octopus 使用。这一步将文件复制到它们在sites-available NGINX 配置目录中的目的地,然后在sites-enabled目录中创建一个符号链接。当 NGINX 启动时,它从sites-enabled目录加载配置,并开始向这些站点转发请求。有一个部署后 bash 脚本,类似于:
sudo rm /etc/nginx/sites-enabled/*
sudo rm /etc/nginx/sites-available/*
sudo cp somewhere.nginx /etc/nginx/sites-available/somewhere
sudo ln -s /etc/nginx/sites-available/somewhere /etc/nginx/sites-enabled/somewhere
安装 SSL 证书
Octopus 对 SSL 证书有一流的支持。该步骤将 SSL 证书和密钥文件复制到上面站点配置中指定的位置(/etc/ssl)。NGINX 需要一个用于密钥的 PEM 文件和一个用于证书的 PEM 文件。证书文件必须包含整个证书链,即主证书和任何中间证书。为了让 Octopus 以正确的格式提供证书,我用主证书、中间证书和私钥创建了一个 PEM 文件。它看起来像这样:
-----BEGIN CERTIFICATE-----
PRIMARY_CERTIFICATE
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
INTERMEDIATE_CERTIFICATE
-----END CERTIFICATE-----
-----BEGIN RSA PRIVATE KEY-----
PRIVATE_KEY
-----END RSA PRIVATE KEY-----
证书在八达通证书图书馆。该步骤有一个名为sslCert的变量,它引用库证书。在该步骤中,变量用于创建证书和密钥文件,然后将它们复制到/etc/ssl 目录中各自的位置。注意RawOriginal用于维护证书链:
KEY=$(get_octopusvariable "sslCert.PrivateKeyPem")
echo "$KEY" > ssl.key
sudo mv ssl.key /etc/ssl/octopus.key
CERT=$(get_octopusvariable "sslCert.RawOriginal")
echo "$CERT" | base64 -d > ssl.crt
sudo mv ssl.crt /etc/ssl/octopus.crt
正在启动 NGINX
最后,是时候启动(或重启)NGINX 了。这一步是重启 NGINX 服务的简单 bash 脚本:
sudo service nginx restart
结论
随着可重复部署过程的建立,我现在可以对配置文件进行更改或更新证书,而不必花费数小时重新学习如何配置 NGINX。我的一个同事可以拿起这个项目,看看 NGINX 是如何配置的,这样他们就可以在几分钟内开始做贡献,而不是费力地阅读文档或试图对我所做的进行逆向工程。最棒的是,如果老板让我重新配置 NGINX,我可以重用我的 Octopus Deploy 项目,然后在海滩上度过一天的剩余时间。愉快的部署!
使用 Octopus Deploy 安装 MSI-Octopus Deploy
Octopus Deploy 允许您部署各种软件。这背后的部分原因是 Octopus 支持脚本作为部署过程的一部分,以允许几乎无限的灵活性。Octopus Deploy 库让我们和社区扩展 Octopus Deploy 的功能。
我们库的最新成员是新的微软软件安装程序(MSI)步骤模板。如果您在项目中使用 MSI 安装程序,并且需要部署一个到您的一个触角,这个脚本将帮助您做到这一点。
它是如何工作的
MSI 步骤模板步骤将在文件系统上安装、修复或删除 MSI 文件。运行该步骤将构建命令来调用带有适当参数的给定 MSI 的安装程序。安装日志被写入磁盘,然后在安装完成后记录在 Octopus 日志中。为了使用 Step 模板,目标系统上必须安装有 Windows Installer 3.0 。目标 MSI 还必须支持安静(无用户界面)安装。这个版本的脚本也不支持需要重启机器的 MSI,并且总是运行带有norestart标志的安装。
部署
如果您的构建过程生成了一个 MSI 安装程序来与 Octopus Deploy 一起使用,那么它必须捆绑在 Octopus Deploy Nuget 包中。要捆绑安装程序,你需要运行octo.exe 包命令。这个命令将调用 NuGet 并自动生成一个 nuspec。您只需要一个包含您要打包的文件的目录,在本例中只需要 MSI。最终的 NuGet 包看起来会像下面这样。

Octo pack 使用许多命令行参数来避免需要 nuspec 文件。最少可能的用法只需要像这样指定包 idocto pack --id=MyCompany.MyApp。参数的完整列表如下所示。
Usage: octo pack [<options>]
Where [<options>] is any of:
--id=VALUE The ID of the package; e.g. MyCompany.MyApp
--overwrite [Optional] Allow an existing package file of the same ID/version to be overwritten
--include=VALUE [Optional, Multiple] Add a file pattern to include, relative to the base path e.g. /bin/- *.dll - if none are specified, defaults to **
--basePath=VALUE [Optional] The root folder containing files and folders to pack; defaults to '.'
--outFolder=VALUE [Optional] The folder into which the generated NUPKG file will be written; defaults to '.'
--version=VALUE [Optional] The version of the package; must be a valid SemVer; defaults to a timestamp-based version
--author=VALUE [Optional, Multiple] Add an author to the package metadata; defaults to the current user
--title=VALUE [Optional] The title of the package
--description=VALUE [Optional] A description of the package; defaults to a generic description
--releaseNotes=VALUE [Optional] Release notes for this version of the package
--releaseNotesFile=VALUE [Optional] A file containing release notes for this version of the package
配置
要在本地 Octopus 部署实例中使用 step 模板,您需要从 Octopus 部署库中导入它。在库中点击绿色的Copy to clipboard按钮,并将其粘贴到Library > Step templates > Import下的导入窗口。
一旦它在库中,您可以将其添加为项目部署过程中的新步骤。请注意,您仍然需要一个包部署步骤来将 MSI 安装到您的服务器上,然后安装程序步骤可以运行。MSI 步骤有三个自定义属性,MSI 的路径、安装程序操作和任何安装程序属性。通常你只需要指定要安装的 MSI 的位置,它可以使用一个 octopus 变量#{Octopus.Action[Step 1].Output.Package.InstallationDirectoryPath}\installer.msi来构建。注意,所使用的变量包括提取安装程序的步骤的名称,所以Step 1必须替换为您的步骤名称。

保存步骤后,您的项目就可以部署 MSI 文件了。
从头开始安装 Jenkins-Octopus 部署
在 2017 JetBrains 开发者生态系统调查中,Jenkins 在 CI 系统中排名第一。凭借丰富的插件和庞大的用户群,Jenkins 是构建软件项目的强大解决方案,在这篇博文中,我们将看看如何启动并运行一个基本的 Jenkins 实例。
首先,我安装了全新的 Ubuntu 17.10。
我们需要安装一些标准 Ubuntu 安装中没有的便利工具。Jenkins 只需要git和openjdk-8-jdk,但是我经常使用其他工具来保证安装它们是理所当然的。
sudo apt-get install htop vim iftop git openssh-server openjdk-8-jdk
安装 Jenkins
为了安装 Jenkins,我们将使用这里的自定义回购文件。
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
deb https://pkg.jenkins.io/debian-stable binary/
sudo apt-get update
sudo apt-get install jenkins
初始 Jenkins 配置
在 web 浏览器中打开 http://localhost:8080。您将看到一条来自 Jenkins 的消息,要求您输入在文件/var/lib/jenkins/secrets/initialAdminPassword中找到的密码。

然后会提示您要安装的插件。此时,我安装了建议的插件。稍后我们会再添加一些。

给 Jenkins 几分钟时间安装建议的插件。

创建您的第一个管理员用户。

你完了!

安装附加插件
我们需要一些额外的插件来构建一个 Maven 项目,并用 Octopus 部署它。
点击管理詹金斯➜管理插件。
点击Available标签。
勾选以下插件:
点击Download now and install after restart。
勾选Restart Jenkins when installation is complete and no jobs are running选项。
詹金斯重启后,你将拥有你需要的所有插件。

应用自定义 Jenkins 主题
我们之前安装的简单主题插件允许我们用一个 CSS 文件更新 Jenkins 的外观。
点击管理詹金斯➜配置系统,在Theme部分下将 URL http://afonsof.com/jenkins-material-theme/dist/material-<color>.css添加到URL of theme CSS字段。你可以在 Jenkins 材料主题网站上找到一个颜色列表来替换http://afonsof.com/jenkins-material-theme/dist/material-blue.css

我想你会同意这些主题大大改善了詹金斯的外观。

准备詹金斯
我们需要配置一些工具,以便在构建项目时使用。特别是,我们希望添加一个 Maven 安装以在我们的构建中使用,一个 Java 安装以运行 Maven,以及一个 Octopus CLI 定制工具以推送和部署文件。
我发现让 Jenkins 为我下载并安装这些工具更容易,这些工具可以在管理 Jenkins ➜全球工具配置下进行配置。
配置 Java
为了构建我们的应用程序,我们需要一份 Java。在JDK部分点击ADD JDK按钮。

给这个工具起个名字(我用的是Java 9)并选择要安装的 JDK 版本。
我们将在下一篇博文中引用这些工具的名称,在这篇博文中,我们将使用Jenkinsfile构建和部署一个 Java 应用程序。

输入下载 JDK 所需的 Oracle 凭据。

配置 Maven
我们的 Java 项目将被配置为使用 Maven,因此我们需要一个可用的 Maven 实例来完成构建。在Maven部分点击ADD MAVEN按钮。

给这个工具命名,并选择最新版本的 Maven。

配置 Octopus CLI
虽然在 Jenkins 中没有自带的 Octopus CLI 工具,但是我们安装的自定义工具插件确实允许我们很容易地将 CLI 作为 Jenkins 工具公开。
在Custom Tools部分,创建一个名为Octo CLI的新工具,并在Download URL for binary archive字段中输入 Ubuntu CLI 的 URL。
确保将Label字段留空。

你可以从 Octopus 下载页面获得 Octo CLI 的下载链接。

虽然 Octo CLI 支持的 Ubuntu 最新版本是 16.04,但我在 Ubuntu 17.10 中使用它推送包和创建版本时没有任何问题。
结论
至此,我们已经基本安装了 Jenkins,并配置了构建和部署 Java 应用程序所需的所有工具。
在下一篇博文中,我们将看看如何使用 Jenkins Pipelines 来配置一个要构建并推送到 Octopus 的 Java 应用程序。
如果您对 Java 应用程序的自动化部署感兴趣,下载 Octopus Deploy 的试用版,并查看我们的文档。
Selenium 系列:安装工具- Octopus Deploy
原文:https://octopus.com/blog/selenium/28-installing-the-tools/installing-the-tools
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
到目前为止,我们一直在本地或在 Travis CI 平台上连续运行测试。然而,一个接一个地运行 UI 测试并不能很好地伸缩。随着更多测试的加入,以及更多组合和边缘案例的测试,我们经常会发现 UI 测试套件需要几个小时才能完成。
如果对 UI 测试有一个合理的批评,那就是它比其他形式的测试慢得多。如果没有更好的方式来运行 UI 测试,它们将成为 CI 管道中的瓶颈。那么我们能做些什么来使测试在更短的时间内完成呢?
一年前,我们的一个 UI 测试套件运行了几个小时。上个月,花了 16 分钟。今天,只需要 39 秒。
这是对亚马逊上的一篇博文的介绍,该博文讲述了一个开发团队如何使用 Chrome headless 和 AWS Lambda 将 UI 测试时间从数小时减少到数秒。这种测试时间的减少正是我们所期待的,在这篇文章中,我们将学习如何使用 AWS Lambda 大规模运行我们的 UI 测试。
Lambda 是 AWS 提供的一项服务,它允许短期应用程序以接近无限的规模运行。Lambda 负责提供操作系统和部署代码,您只需为应用程序实际运行的时间付费。Lambda 最好的特性是所有的缩放都由你负责。当你向 Lambda 中托管的应用程序发出更多请求时,平台将自动扩展以确保性能得到维持,如果请求减少,Lambda 将缩小规模。这种缩放是自动的,对我们的代码是透明的。
因为我们经常可以并发运行 UI 测试,所以通过 Lambda 托管我们的测试应用程序,我们可以显著减少执行测试套件所需的总时间,这要归功于这种自动伸缩。
让我们先来看看 AWS Lambda 控制台。从Services菜单中,点击Lambda链接。

因为我们还没有创建任何 Lambda 函数,Lambda 控制台提供了一个欢迎页面,在这里我们可以开始使用一些示例代码。

该页面中的代码是可编辑的,并且是一个真正的 Lambda 函数。这里的例子是用 JavaScript 编写的,但是即使您不熟悉 JavaScript,做一些简单的修改并观察它们是如何运行的也是很容易的。在下面的示例中,文本Hello World!已被替换为This is a test of Lambda!。点击Run按钮,然后在页面上显示这个 Lambda 的输出。

恭喜你!你刚刚跑完了你的第一个 Lambda。但这只是 JavaScript 代码,对吗?也许它正在浏览器中运行,这并不令人印象深刻。因此,让我们编写一些不能在浏览器中运行的代码来证明这些代码确实是在服务器上运行的。
与其用另一个字符串改变回调字符串,不如传递process.platform,它将返回代码运行的底层操作系统的名称。注意,我们得到的结果是linux。所以这段代码确实是在 Linux 服务器上运行,而不是在浏览器中。

那么运行代码的 Linux 服务器在哪里呢?这就是 Lambda 的美妙之处,我们不需要考虑服务器。AWS 负责确保服务器可用,无需管理。我们需要做的就是将代码部署为 Lambda 函数并调用它。AWS 会处理剩下的事情。
在我们开始之前,我们需要安装一些额外的工具来简化 Lambda 函数的部署。
我们将使用无服务器平台将我们的 Lambda 函数部署到 AWS。Serverless 为我们提供了一些简单的命令,负责上传我们的代码,部署到 Lambda,以及设置 Lambda 所需的各种选项。
Serverless 是一个 Node.js 应用程序,这意味着我们需要在本地安装 Node.js 才能使用它。你可以从 https://nodejs.org/en/download/下载并安装 Node.js。
您可以通过从终端或 PowerShell 运行命令node --version来确认 Node.js 已安装:
$ node --version
v8.11.2
然后无服务器应用程序安装有npm,它是节点包管理器的缩写。此命令会将无服务器应用程序下载并安装到您的本地计算机上。
在 Linux 或 MacOS 机器上,您可以使用sudo命令安装无服务器:
$ sudo npm install serverless -g
在 Windows PC 上,您可以使用以下命令安装无服务器。
注意,您可能需要使用管理员权限从 PowerShell 或命令行窗口运行此命令:
$ npm install serverless -g
然后,您可以通过运行serverless --version来确认无服务器命令是否可用:
$ serverless --version
1.27.2
最后一项任务是用无服务器将用来访问 AWS 的密钥来配置您的系统。为此,我们需要打开 IAM 控制台。在 AWS 控制台中点击Services菜单,并点击IAM链接。

点击Users链接。

点击Add user按钮。

在User name字段中为新用户命名,并选择Programmatic access选项。这个选项意味着用户将有能力生成一个访问密钥和秘密密钥,无服务器应用程序将使用这个密钥对来部署我们的代码。
点击Next: permissions按钮继续。

我们将授予新用户管理员权限。为此,点击Attach existing policies directly按钮并选择AdministratorAccess策略。
点击Next: review按钮继续。

点击Create user按钮完成。

现在,您将看到新用户的访问密钥和秘密访问密钥。
这是你看到秘密访问密钥的唯一机会。一旦此屏幕关闭,就无法再查看此密钥,因此请务必将此密钥保存在安全的地方。
要查看秘密访问密钥,请单击Show链接。

请将这些密钥保存在安全的地方,以便以后使用。或者,您可以点击Download .csv按钮下载包含这些密钥的文件。
完成后,点击Close按钮。

为了允许无服务器应用程序使用这些凭证,我们需要在我们的用户主目录中创建一个名为.aws/credentials的文件。
- 在 Windows 中,该文件保存在
C:\Users\username\.aws\credentials下。 - 在 Linux 中,这个文件保存在
/home/username/.aws/credentials下。 - 在 MacOS 中,这个文件保存在
/Users/username/.aws/credentials下。
该文件的内容应该如下所示,其中的键值替换为 AWS 用户的键值:
[default]
aws_access_key_id = AKIAJM25BFQYTRVXQSNQ
aws_secret_access_key = 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
我们现在已经安装了无服务器应用程序并配置了 AWS 凭证,这意味着我们可以使用无服务器应用程序将代码部署到 AWS。然而,不像运行一个独立的 Java 应用程序作为 Lambda 函数,不需要太多额外的配置就可以工作,我们需要完成一些额外的步骤来提供一个可以运行 WebDriver 测试的环境,我们将在下一篇文章中解决这个问题。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
从头开始安装 Tomcat-Octopus Deploy
Tomcat 是目前最流行的 Java web 服务器,对于任何希望托管 Java web 应用程序的人来说都是一个可靠的选择。
Tomcat 的一个优点是它非常容易上手,通常只需要下载和解压部署档案。但是有几个步骤是每个 Tomcat 管理员都应该知道的,以便充分利用他们的 Tomcat 安装。
在这篇博客文章中,我们将介绍设置 Tomcat 服务器的过程。
安装 Java
作为一个 Java web 服务器,Tomcat 需要安装 Java 才能运行。
Tomcat 7 至少需要 Java 6,Tomcat 8 至少需要 Java 7,Tomcat 9 至少需要 Java 8 。
请记住,您需要安装一个既支持 Tomcat 本身又支持 Tomcat 将要托管的应用程序的 Java 版本。如果您的应用程序是为 Java 8 编译的,那么 Tomcat 也需要与 Java 8 一起运行。
杰尔还是 JDK?
Java 安装以 Java 运行时环境(JRE)或 Java 开发工具包(JDK)的形式提供。
JRE 提供了运行 Java 应用程序所需的所有功能,包括 Tomcat。JDK 提供了 JRE,以及一些开发人员用来编译和管理 Java 应用程序的附加工具。
Tomcat 可以和 JRE 或者 JDK 一起工作。开发人员通常使用 JDK,它是一个较大的软件包,所以如果您有疑问,请安装 JRE。
OpenJDK 还是甲骨文 JDK?
OpenJDK 是 Java 平台的开源实现。它通常包含在 Linux 包管理器中,包名类似于openjdk-8-jre或openjdk-8-jdk。
OpenJDK 是项目的名称,虽然它的名称中包含缩写“JDK ”,但 OpenJDK 项目同时提供了 JRE 和 JDK。
Oracle JDK 是 Oracle 提供的 Java 实现。通常,您必须从 Oracle 网站手动下载并安装 Oracle JDK。
使用 OpenJDK 还是 Oracle JDK 是个人选择的问题。我将在 Linux 发行版中使用 OpenJDK,因为使用包管理器安装很容易。在 Windows 或 MacOS 中,我会安装 Oracle JDK。
下载 Tomcat
Tomcat 可以从 Apache Tomcat 主页下载。
Tomcat 可以作为 zip、tar.gz、Windows zip 或 Windows exe 下载。
在写这篇博文的时候,Tomcat 8.5 是最新的官方版本,Tomcat 9 接近最终版本。仍然支持 Tomcat 7,所有以前的版本都被认为是过时的。
下载 Tomcat for Linux
如果你在 Linux 中运行 Tomcat,那么 tar.gz 包就是你需要的。这比 zip 包更可取,因为 tar.gz 格式保留了 shell 脚本上的可执行标志。
如果你在 Linux 中下载 zip 包,你需要用命令chmod +x <scriptname>在脚本bin/startup.sh和bin/shutdown.sh上手动设置可执行标志。
下载 Tomcat for Windows
如果你在 Windows 中运行 Tomcat,那么你可以下载任何格式的文件。但是,我建议 Windows 用户下载 Windows zip 或 exe 包。
这些包包括tcnative-1.dll库,它是 Tomcat 本地库的一部分。Tomcat Native 用于让 Tomcat 访问 Apache 可移植运行时 (APR)。APR 反过来用于通过 OpenSSL 提供 HTTPS 等功能,这比使用原生 Java HTTPS 实现(也称为 JSSE 实现)可以提供更好的性能。
此外,Windows 软件包还包括用于将 Tomcat 安装为 Windows 服务的可执行文件。

配置 JAVA_HOME 环境变量
Tomcat 脚本使用JAVA_HOME环境变量来查找将用于启动 Tomcat web 服务器的 Java 可执行文件。
在 Windows 中配置 JAVA_HOME 环境变量
Windows 在系统属性中定义环境变量。
打开System控制面板小程序内的Advanced System Settings。

点击Environment Variables...按钮。

在System Variables下,点击New...按钮。

输入JAVA_HOME作为Variable name,输入 Java 安装目录作为Variable value。

点击OK按钮保存您的更改。

打开 Powershell 并键入Write-Host $env:JAVA_HOME来查看环境变量的值。

在 Linux 中配置 JAVA_HOME 环境变量
在 Linux 中有多种方法来定义环境变量。最常见的是将环境变量添加到/etc/environment文件中。
例如,您可以配置JAVA_HOME环境变量来引用 Oracle JRE 8 安装,代码如下:
JAVA_HOME="/usr/lib/jvm/java-8-oracle/jre"
Java 安装的位置取决于您使用的 Linux 发行版以及 Java 发行版。例如,如果您使用包管理器安装了 Java,那么您很可能安装了 OpenJDK。OpenJDK 将被安装到与 Oracle JDK 不同的目录中。
手动运行 Tomcat
要手动启动 Tomcat,您需要为 Windows 运行bin\startup.bat批处理文件,或者为 Linux 运行bin/startup.sh shell 脚本。

将 Tomcat 安装为服务
生产 Tomcat 实例通常作为服务启动。这允许 Tomcat 在操作系统启动时启动,在操作系统关闭时关闭,并使用操作系统内置的服务管理工具进行管理。
将 Tomcat 安装为 Windows 服务
将 Tomcat 作为 Windows 服务安装的最简单方法是运行Windows Service Installer exe,这是 Tomcat 下载包选项之一。该安装程序提供了一个向导,将 Tomcat 配置为 Windows 服务。


或者,您可以使用bin\service.bat脚本将 Tomcat 手动配置为 Windows 服务。例如,运行命令service.bat install MyService将在名为MyService的 Windows 服务下配置 Tomcat。
有关手动配置 Tomcat Windows 服务的更多信息,请参见文档。
我测试的 Tomcat 版本附带的service.bat文件在 Java 9 JDK 上不能很好地工作。我在 Java 9 JDK 上运行service.bat时收到了错误The JAVA_HOME environment variable is not defined correctly。
这是因为 Java 9 已经取消了jre文件夹,但是service.bat批处理文件希望这个文件夹存在。
参见这个 StackOverflow 的回答,了解 Java 9 中新文件夹结构的更多细节。
解决方法是将 Java 8 JDK 与 Java 9 一起安装,并在运行service.bat时覆盖JAVA_HOME环境变量,或者使用Windows Service Installer exe 来创建服务。
将 Tomcat 安装为 Linux 服务
不幸的是,Tomcat 没有为 Linux 操作系统提供服务定义文件。这些服务定义文件根据您运行的 Linux 发行版以及您使用的是 init.d 还是 systemd 而有所不同。
然而,定义自己的服务是相当容易的。
首先,我喜欢将 Tomcat 解压到/opt目录中。/opt目录是为所有不属于默认安装的软件和附加包保留的,这很好地描述了我们的 Tomcat 安装。
Linux 发行版太多了,无法为所有发行版提供服务脚本。然而,我提供了一个 initd 脚本示例,它是基于我在网上找到的例子。
该脚本假设在 Linux 中已经配置了一个名为tomcat的用户,并且 Tomcat 已经提取到了/opt/apache-tomcat-9目录中。您需要调整脚本以匹配您的本地环境。
该文件将保存在/etc/init.d/tomcat下。您还需要通过运行命令chmod +x /etc/init.d/tomcat来确保该文件是可执行的。如果您的 Linux 发行版使用 systemd,那么可以使用命令systemctl enable tomcat启用这个遗留的 initd 脚本。
#!/bin/bash
### BEGIN INIT INFO
# Provides: tomcat
# Required-Start: $local_fs $remote_fs $network
# Required-Stop: $local_fs $remote_fs $network
# Should-Start: $named
# Should-Stop: $named
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start Tomcat.
# Description: Start the Tomcat servlet engine.
### END INIT INFO
## run as a different user
TOMCAT_USER=tomcat
export CATALINA_HOME="/opt/apache-tomcat-9"
export CATALINA_PID="$CATALINA_HOME/bin/tomcat.pid"
start() {
echo "Starting Tomcat..."
/bin/su -s /bin/bash ${TOMCAT_USER} -c $CATALINA_HOME/bin/startup.sh
}
stop() {
echo "Stopping Tomcat..."
/bin/su -s /bin/bash ${TOMCAT_USER} -c "$CATALINA_HOME/bin/shutdown.sh -force"
}
case $1 in
start|stop) $1;;
restart) stop; start;;
*) echo "Usage : $0 <start|stop|restart>"; exit 1;;
esac
exit 0
Linux 标准库(LSB)定义了 initd 脚本中使用的约定。### BEGIN INIT INFO和### END INIT INFO之间的注释记录在初始化脚本的注释约定中。
配置用户
Tomcat 内置了许多管理工具。这些管理工具的链接在默认的 Tomcat 欢迎页面上以名为Server Status、Manager App和Host Manager的链接形式提供。默认情况下,一旦使用bin\startup.bat或bin/startup.sh脚本或者通过启动服务手动启动了 Tomcat,就可以在 http://localhost:8080 查看欢迎页面。

在使用这些管理工具之前,您必须首先在 Tomcat 中配置用户。
用户在conf/tomcat-users.xml文件中定义。
用户被分配到组中。Tomcat 定义了一些授予管理工具访问权限的标准组。manager-gui组用于允许访问基于浏览器的管理工具,即您将通过点击欢迎页面上的Server Status、Manager App和Host Manager链接来访问的工具。
下面是一个conf/tomcat-users.xml文件的例子,它定义了一个名为tomcat的用户,其密码为adminpass,并被分配给manager-gui角色。
<tomcat-users xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://tomcat.apache.org/xml tomcat-users.xsd"
version="1.0">
<role rolename="manager-gui"/>
<user username="tomcat" password="adminpass" roles="manager-gui"/>
</tomcat-users>
当您尝试打开其中一个管理工具时,系统会提示您输入用户名和密码。在这个提示符下,您可以输入tomcat用户名和adminpass提示符。
要了解 Tomcat 用来管理对管理工具的访问的组的更多信息,请参见标题为“配置管理器应用程序访问”的 Tomcat 管理器文档。
结论
在这篇博客文章中,我们已经看到了许多需要做出的决定,包括运行什么版本的 Java,如何将 Tomcat 配置为一个服务,以及如何将用户添加到 Tomcat 的安装中。
如果您对将 Java 应用程序自动部署到 Tomcat 感兴趣,下载 Octopus Deploy 的试用版,并查看我们的文档。
从头开始安装 wild fly-Octopus Deploy
WildFly 和 Red Hat JBoss Enterprise Application Platform 是目前最流行的 Java EE 应用服务器之一。WildFly 可免费用于开发和生产目的,这篇博客文章介绍了 WildFly 启动和运行所需的步骤。
WildFly 和 JBoss EAP 的关系
WildFly 和 Red Hat JBoss 企业应用平台(简称 JBoss EAP)都是开源的 Java EE 应用服务器。
WildFly 在 WildFly 网站的社区支持下免费开放。WildFly 相当频繁地发布重大更新,并且发布的支持窗口很短。
JBoss EAP 是作为 Red Hat 订阅的一部分提供的。JBoss EAP 基于与 WildFly 相同的技术,尽管在 JBoss EAP 版本和 WildFly 版本之间没有一对一的映射。JBoss EAP 版本的支持窗口比 WildFly 长得多,并且由 Red Hat 支持。
我还没有找到任何关于 WildFly 支持窗口的官方文档,尽管这个论坛帖子确实表明只有当前的主要版本是“受支持的”,所有以前的版本都被认为是遗留版本。
Java EE 术语
围绕企业 Java 平台的术语在过去几年中发生了变化,这是一个非常混乱的来源,尤其是对于非开发人员来说。
Java 2 平台企业版(J2EE)是在 1999 年与 J2EE 1.2 一起推出的,J2EE 的名字一直使用到 2003 年 J2EE 1.4。
在 2005 年,随着 Java EE 5 的发布,这个名称被改为 Java 企业版(Java EE)。Java EE 名称一直使用到 2017 年的 Java EE 8。
2017 年,甲骨文开源了 Java EE 平台,现在由 Eclipse Foundation 以 Eclipse Enterprise for Java (EE4J)的名字管理。
纯 Servlet 与 Java EE
WildFly 作为一个纯 Servlet 或完整的 Java EE 应用服务器发行版提供。
对于那些希望部署不依赖于 Java EE 标准的应用程序的人来说,Serlvet-Only 发行版是一个不错的选择。例如,用 Spring 库编写的应用程序只需要一个 servlet 应用服务器就可以运行。
完整的应用服务器发行版包括对完整的 Java EE 规范的支持,并且是纯 Servlet 发行版的超集。
旧的 Java EE 应用服务器会因为加载可能没有被任何已部署的应用程序使用的库而产生内存开销,但是现在 WildFly 只加载所需的库做得很好。因此,尽管完整的应用服务器发行版是一个更大的包,但这并不一定意味着它在运行时会消耗更多的内存。
对于这篇博文,我们将使用完整的应用服务器发行版。
安装 Java
作为一个 Java web 服务器,WildFly 需要安装 Java 才能运行。
WildFly 11 至少需要 Java 8 才能运行。
杰尔还是 JDK?
Java 安装以 Java 运行时环境(JRE)或 Java 开发工具包(JDK)的形式提供。
JRE 提供了运行 Java 应用程序所需的所有功能,包括 WildFly。JDK 提供了 JRE,以及一些开发人员用来编译和管理 Java 应用程序的附加工具。
野花可以和 JRE 或者 JDK 一起工作。开发人员通常使用 JDK,它是一个较大的软件包,所以如果您有疑问,请安装 JRE。
OpenJDK 还是甲骨文 JDK?
OpenJDK 是 Java 平台的开源实现。它通常包含在 Linux 包管理器中,包名类似于openjdk-8-jre或openjdk-8-jdk。
OpenJDK 是项目的名称,虽然它的名称中包含缩写“JDK ”,但 OpenJDK 项目同时提供了 JRE 和 JDK。
Oracle JDK 是 Oracle 提供的 Java 实现。通常,你必须从甲骨文网站手动下载并安装甲骨文 JDK。
使用 OpenJDK 还是 Oracle JDK 是个人的选择。我将在 Linux 发行版中使用 OpenJDK,因为使用包管理器安装很容易。在 Windows 或 MacOS 中,我会安装 Oracle JDK。
疯狂下载
野花有 zip 或 tar.gz 包装。对于 Windows 用户来说,两者都可以。对于 Linux 用户来说,tar.gz 包是首选,因为它将保留 shell 脚本的可执行标志。
在写这篇博文的时候,WildFly 11.0.0 是最后一个主要版本,这也是这篇博文将要提到的版本。
独立与域
WildFly 可以在两种不同的模式下运行:独立模式或域模式。
当运行管理自己的配置和部署的 WildFly 实例时,使用独立模式。
域模式用于将应用程序配置和部署到多个 WildFly 实例。在域模式下,域控制器将配置和应用程序分发给域从属设备。
不应将域与集群混淆。域的存在只是为了分发设置和应用程序,这些设置可能会也可能不会构建集群环境。同样,如果单独配置了所需的设置,独立实例也可以加入集群。
手动运行 WildFly
WildFly 可以在域或独立模式下启动。每种模式都有单独的脚本启动。
要在独立模式下启动 WildFly,请在 Windows 中运行bin\standalone.bat脚本,在 Linux 中运行bin/standalone.sh脚本。
要在域模式下启动 WildFly,在 Windows 中运行bin\domain.bat脚本,在 Linux 中运行bin/domain.sh脚本。
配置 WildFly 内存设置
WildFly 使用的内存设置在JAVA_OPTS环境变量中定义。如果没有这个环境变量,缺省值在 Windows 的bin/standalone.conf.bat和bin/domain.conf.bat文件中定义,或者在 Linux 的bin/standalone.conf和bin/domain.conf文件中定义。
在 Windows 配置文件中,您会看到如下命令:
if not "x%JAVA_OPTS%" == "x" (
echo "JAVA_OPTS already set in environment; overriding default settings with values: %JAVA_OPTS%"
goto JAVA_OPTS_SET
)
rem # ...
set "JAVA_OPTS=-Xms64M -Xmx512M -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m"
在 Linux 配置文件中,您会看到如下命令:
if [ "x$JAVA_OPTS" = "x" ]; then
JAVA_OPTS="-Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true"
JAVA_OPTS="$JAVA_OPTS -Djboss.modules.system.pkgs=$JBOSS_MODULES_SYSTEM_PKGS -Djava.awt.headless=true"
else
echo "JAVA_OPTS already set in environment; overriding default settings with values: $JAVA_OPTS"
fi
要覆盖这些配置文件中分配给JAVA_OPTS的默认值,您可以定义JAVA_OPTS环境变量。环境变量优先于默认值。否则,您可以直接编辑配置文件中的默认值。
通过查看 Oracle 文档,可以找到关于此处显示的设置的更多信息。例如,这个文档列出了 Java 8 的选项。
一些 Java 设置是特定于版本的。确保使用特定于你正在运行的 Java 版本的设置。
配置管理员用户
为了登录到管理控制台或将 WildFly 配置为 Windows 服务,您首先需要定义一个管理用户。为 Windows 添加了bin\add-user.bat脚本,为 Linux 添加了bin/add-user.sh脚本。
你可以运行 add-user 脚本 WildFly 正在运行。新用户将被自动挑选。
一旦脚本运行,您将会被询问一些问题:
- 添加什么类型的用户-管理用户
- 用户名
- 密码
- 用户将属于什么组-留空
- 用户是否用于 AS 过程互连-否
我在下面粘贴了add-user脚本的输出。请注意,我用新密码更新了现有的禁用用户admin。
$ ./add-user.sh
What type of user do you wish to add?
a) Management User (mgmt-users.properties)
b) Application User (application-users.properties)
(a): a
Enter the details of the new user to add.
Using realm 'ManagementRealm' as discovered from the existing property files.
Username : admin
User 'admin' already exists and is disabled, would you like to...
a) Update the existing user password and roles
b) Enable the existing user
c) Type a new username
(a): a
Password recommendations are listed below. To modify these restrictions edit the add-user.properties configuration file.
- The password should be different from the username
- The password should not be one of the following restricted values {root, admin, administrator}
- The password should contain at least 8 characters, 1 alphabetic character(s), 1 digit(s), 1 non-alphanumeric symbol(s)
Password : <enter password>
Re-enter Password : <enter password>
What groups do you want this user to belong to? (Please enter a comma separated list, or leave blank for none)[ ]:
Updated user 'admin' to file '/Users/matthewcasperson/Downloads/wildfly-11.0.0.CR1/standalone/configuration/mgmt-users.properties'
Updated user 'admin' to file '/Users/matthewcasperson/Downloads/wildfly-11.0.0.CR1/domain/configuration/mgmt-users.properties'
Updated user 'admin' with groups to file '/Users/matthewcasperson/Downloads/wildfly-11.0.0.CR1/standalone/configuration/mgmt-groups.properties'
Updated user 'admin' with groups to file '/Users/matthewcasperson/Downloads/wildfly-11.0.0.CR1/domain/configuration/mgmt-groups.properties'
Is this new user going to be used for one AS process to connect to another AS process?
e.g. for a slave host controller connecting to the master or for a Remoting connection for server to server EJB calls.
yes/no? no
该脚本将修改域和独立模式的mgmt-users.properties和mgmt-groups.properties文件(即standalone\configuration和domain\configuration目录下的属性文件)。这意味着无论你打算在哪个模式下使用 WildFly,用户都是可用的。
将 WildFly 安装为服务
生产 WildFly 实例通常作为服务启动。这允许 WildFly 在操作系统启动时启动,在操作系统关闭时关闭,并使用操作系统内置的服务管理工具进行管理。
将 WildFly 安装为 Windows 服务
WildFly 附带了一个名为service.bat的脚本,可以用来添加 Windows 服务。这些服务通过 WildFly 管理接口进行管理,默认情况下该接口监听端口9990。jbossuser和jbosspass字段需要匹配用add-user.bat脚本创建的凭证。
此命令会将独立实例配置为 Windows 服务。
bin\service\service.bat install /jbossuser admin /jbosspass password /controller localhost:9990 /startup /name "WildFly 11 Standalone"
此命令会将域控制器配置为 Windows 服务。
bin\service\service.bat install /jbossuser admin /jbosspass password /controller localhost:9990 /startup /host /hostconfig host-master.xml /name "WildFly 11 Domain Controller"
此命令会将域从属配置为 Windows 服务。
bin\service\service.bat install /jbossuser admin /jbosspass password /controller localhost:9990 /startup /host /hostconfig host-slave.xml /name "WildFly 11 Domain Slave"
将 WildFly 安装为 Linux 服务
WildFly 在docs/contrib/scripts/init.d和docs/contrib/scripts/systemd目录中附带了 init.d 和 systemd 服务定义文件。
在我们配置任何 Linux 服务之前,我们需要添加一个将运行 WildFly 的用户。这个用户将被称为wildfly,可以通过运行命令sudo useradd wildfly来创建。
接下来确保野花已经被提取到/opt/wildfly。/opt目录是为所有不属于默认安装的软件和附加包保留的,这很好地描述了我们的 WildFly 安装(也是所提供的服务脚本中的默认路径)。
最后,使用命令sudo chown wildfly:wildfly -R /opt/wildfly确保wildfly用户是/opt/wildfly目录的所有者。
配置 systemd 服务
以下步骤将配置 WildFly 由 systemd 管理。
- 用命令
cp /opt/wildfly/docs/contrib/scripts/systemd/launch.sh /opt/wildfly/bin将launch.sh脚本复制到bin目录中。 - 用命令
sudo cp /opt/wildfly/docs/contrib/scripts/systemd/wildfly.service /etc/systemd/system将 WildFly systemd 单元复制到/etc/systemd/system中。 - 用命令
sudo mkdir /etc/wildfly创建/etc/wildfly目录。 - 用命令
sudo cp /opt/wildfly/docs/contrib/scripts/systemd/wildfly.conf /etc/wildfly将配置文件复制到/etc/wildfly中。 - 使用命令
sudo systemctl enable wildfly启用 WildFly 服务。 - 用命令
sudo systemctl start wildfly启动 WildFly 服务。
此时 WildFly 将会运行,您可以使用命令sudo systemctl status wildfly来验证这一点。
$sudo systemctl status wildfly
● wildfly.service - The WildFly Application Server
Loaded: loaded (/etc/systemd/system/wildfly.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2017-10-24 16:48:53 AEST; 1min 38s ago
Main PID: 5448 (launch.sh)
Tasks: 68 (limit: 4915)
CGroup: /system.slice/wildfly.service
├─5448 /bin/bash /opt/wildfly/bin/launch.sh standalone standalone.xml 0.0.0.0
├─5449 /bin/sh /opt/wildfly/bin/standalone.sh -c standalone.xml -b 0.0.0.0
└─5502 java -D[Standalone] -server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.
Oct 24 16:48:53 matthew-VirtualBox systemd[1]: Started The WildFly Application Server.
配置 init.d 服务
以下步骤将配置 WildFly 由 init.d 管理。
- 将适当的初始化脚本从
wildfly-init-redhat.sh或wildfly-init-debian.sh复制到/etc/init.d/wildfly。例如,如果您有一个基于 Red Hat 的发行版,您可以使用命令sudo cp /opt/wildfly/docs/contrib/scripts/init.d/wildfly-init-redhat.sh /etc/init.d/wildfly来复制文件。如果你有基于 Debian 的发行版,用命令sudo cp /opt/wildfly/docs/contrib/scripts/init.d/wildfly-init-debian.sh /etc/init.d/wildfly复制文件。 - 用命令
sudo cp /opt/wildfly/docs/contrib/scripts/init.d/wildfly.conf /etc/default将文件wildfly.conf复制到/etc/default。 - 用命令
sudo service wildfly start启动服务。
此时 WildFly 将会运行,您可以使用命令sudo service wildfly status进行验证。在这个取自 Centos 7 的示例中,init.d 脚本由 systemd 管理。
$ sudo service wildfly status
● wildfly.service - LSB: WildFly Application Server
Loaded: loaded (/etc/rc.d/init.d/wildfly; bad; vendor preset: disabled)
Active: active (running) since Tue 2017-10-24 19:34:44 AEST; 8min ago
Docs: man:systemd-sysv-generator(8)
Process: 3071 ExecStart=/etc/rc.d/init.d/wildfly start (code=exited, status=0/SUCCESS)
CGroup: /system.slice/wildfly.service
├─3102 /bin/sh /opt/wildfly/bin/standalone.sh -c standalone.xml
└─3151 java -D[Standalone] -server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256...
Oct 24 19:34:40 localhost.localdomain systemd[1]: Starting LSB: WildFly Application Server...
打开管理控制台
当 WildFly 被手动或作为服务启动时,可以从 http://localhost:9990 获得管理控制台。
当您第一次加载管理控制台时,您将被要求输入您用add-user脚本创建的凭证。
出于我不明白的原因,Chrome 不会提示你保存用来访问管理控制台的凭证,除非你刷新页面。

管理控制台提供了部署 web 应用程序、更改设置、监控性能、查看日志文件等功能。
我们之前创建的管理员用户可以访问管理控制台的所有方面。如果你需要细粒度的控制,考虑使用基于角色的访问控制(RBAC)。
结论
在这篇文章中,我们已经看到了如何在 Windows 和 Linux 中手动运行 WildFly 和作为一个服务,配置一个管理员用户,并打开管理控制台。
如果您对将 Java 应用程序自动部署到 WildFly 感兴趣,下载 Octopus Deploy 的试用版,并查看我们的文档。
了解更多信息
使用 PowerShell 与 Octopus Deploy API 交互
原文:https://octopus.com/blog/interacting-with-the-octopus-deploy-api-using-powershell

任何平台或解决方案都需要一个应用编程接口(API)来与之交互,而不需要通过 UI 点击上百万个按钮。API 是引擎盖下的引擎。它是您在编程级别与应用、平台甚至物联网(IoT)设备进行交互的方式。
在这篇博文中,您将学习如何使用微软和 Azure 领域中最流行的编程语言之一 PowerShell 与 Octopus Deploy API 进行交互。
先决条件
要跟进这篇博文,您需要以下内容:
- PowerShell 的中级知识。
- 例如,一个文本编辑器或 IDE,对代码。
- Octopus 云实例或本地 Octopus 服务器。
你可以从八达通服务器或八达通云免费开始使用。
代码
当您考虑使用 PowerShell 之类的东西与 API 交互时,您通常会选择包装器路线。顾名思义,包装器就是包装 API 调用的代码。
在这篇博文中,我们将看看生命周期 API 的包装器。
下面是您将使用的代码:
# The function is created and is called Get-Lifecycle
function Get-Lifecycle {
# The cmdletbinding() attribute to ensure the function is an advanced function, which gives us the ability to use PowerShell features like the $PSCmdlet class, error action preferences, etc.
[cmdletbinding()]
# The one parameter called is the Octopus Deploy server URL. It's a mandatory parameter.
param(
[parameter(Position = 0, Mandatory = $true)]
[ValidateNotNullOrEmpty()]
[alias('URL')]
[string]$OctopusBaseURL
)
# You're prompted to securely pass in the API key
$octopusAPIKey = Read-Host 'Input API Key' -AsSecureString
# The API key is passed in with the X-Octopus-ApiKey authentication method
$headers = @{ "X-Octopus-ApiKey" = $octopusAPIKey }
# The header is converted to plain test so Octopus can read the API key
$header = @{ "X-Octopus-ApiKey" = $octopusAPIKey | ConvertFrom-SecureString -AsPlainText }
# Invoke-WebRequest occurs, AKA, makes the API call to Octopus Deploy and returns the Lifecycles
$listLifecycles = $(Invoke-WebRequest -Method GET -Uri $OctopusBaseURL/lifecycles -Headers $header).content
$convert = $listLifecycles | ConvertFrom-Json
$convert
}
API
Octopus Deploy API 可以用一个 swagger 定义来看待,它允许您描述您的 API,以便机器(或编程语言)可以读取它们。因为 Octopus Deploy API 使用了 Swagger,所以它很容易从 Octopus Deploy 服务器上读取:
- 打开 web 浏览器。
- 键入您的 Octopus Deploy 服务器 URL。
- 在服务器 URL 的末尾,添加以下内容:
/api/swaggerjson
您将看到一个类似于下面截图的 JSON 输出。

大摇大摆输出的好处是,我们不必搜索或猜测 API 上的任何内容。例如,在上面的截图中,我们看到在paths下有一个对账户的 API 调用:
/api/accounts/all
从一开始,您就知道 API 的前景是什么样的,并且对如何与 API 进行交互有了一个很好的想法。
一旦知道了如何与 API 交互,就该考虑身份验证了。
证明
理解与 API 的交互当然是至关重要的,但是如果你不能对它进行认证,你将整天吃着403 unauthorized三明治。在这一节中,我们将了解一下在 Octopus 中非常简单的认证过程。
当您使用 PowerShell 与 API 进行交互时,您可能会发现需要以下内容:
- UTF8 编码
- Base64 转换身份验证
- 标题哈希表中的多个键/值对
- 不记名代币
- 肯定的。NET 命名空间,如
System.Net.WebClient或System.Net.NetworkCredentials
有了 Octopus,认证相当容易。事实上,您所需要的只是一个可以从 Octopus 服务器生成的 API 密匙。它不需要以任何方式进行转换或操作。
检索 API 密钥
- 登入八达通网站。
- 在登录名下,进入个人资料。
- 在 Profile 下,点击 My API Keys 。
- 点击新 API 键按钮。将 API 密钥存储在安全的位置,因为您将在下一节中用到它。
进行 API 调用
现在我们已经有了所有的东西,也就是 API 键和代码,是时候通过运行函数来查看 API 调用了。
- 打开 VS 代码,将上一节中的代码保存到您选择的位置,例如桌面。
- 高亮显示代码,点击右键,选择运行选择,如下图所示。使用运行选择选项将功能存储在内存中。

- 在终端中,运行以下 cmdlet:
Get-Lifecycle -OctopusBaseURL server_url/api
- 出现提示时,输入 API 密钥。
- 在您为 Octopus 服务器键入一个 API 密钥后,您将看到一个类似于下面截图的输出,其中包含生命周期信息:

恭喜你。您已经成功地使用 PowerShell 与 Octopus Deploy API 进行了交互。
结论
有几种与 API 交互的方式。简而言之,你可以用任何编程语言与几乎任何 API 进行交互。即使没有包装器或可用的 SDK,您也可以通过使用几个curls来制作自己的。如果你不想把时间花在点击 UI 上,你可能想通过编程的方式与一个平台交互,比如 Octopus Deploy。
介绍八达通 1.0 (RC) -八达通部署
大约一年前,我发布了第一个章鱼测试版。这么快就推出这样一款新产品有点可怕,我不确定会得到什么样的反馈。但是我没必要担心。该产品自发布以来已经走过了很长的路,方向也发生了很大的变化,这要感谢一个非常棒的(并且非常有耐心!)一群测试者。
本周,经过漫长的孵化,章鱼 1.0 RC 发布了。观看下面的视频,看看它现在是什么样子:
http://www.youtube.com/embed/1MVOvW7ot9g
VIDEO
如果你在 1.0 之前使用 Octopus,你会注意到有很多变化:
- 全新的外观和感觉
- 我们不使用 SQL Server,而是使用 RavenDB 作为后端
- 更干净、更友好的 URL
- 更详细的发布和部署详细信息页面
- 安全性和权限
在接下来的几周里,我会在这个闪亮的新博客上记录这些变化。哦,对了,我有没有提到我们还有一个新网站?
Octopus 现在已经成熟成为一个真正的应用,是时候结束测试期了。当前的1.0.13系列发行版将是最后的测试版,我们会整理一些东西。7 月 4 日,我将发布最终的 1.0 版本,我们可以告别 beta 标签了。
对于参与测试的每一个人,我真诚地感谢你们帮助使章鱼成为今天的产品!
介绍 Buildkite 集成- Octopus Deploy
原文:https://octopus.com/blog/introducing-buildkite-integration
章鱼部署现在与 Buildkite 整合。我们新的 Buildkite 插件将允许您的构建代理创建和部署版本,推送构建信息,并作为管道的一部分运行 runbooks。
这篇文章向您展示了如何使用 Buildkite 插件来执行各种操作,Octopus Deploy 是 Buildkite 中管道的一部分。
什么是 Buildkite?
Buildkite 是一个在基础设施上运行持续集成(CI)管道的平台。这使得它快速、安全且可扩展。
构建是通过代理进行的。这些是小型的、可靠的、跨平台的构建运行程序,通过 YAML 定义的工作流来控制。
代理也可以通过插件进行扩展。这些为工作流提供了额外的功能。它们执行 Docker 容器中的步骤,从凭证存储中读取值,并向构建添加测试摘要注释。
与 Octopus Deploy 集成 Buildkite
以下插件支持 Buildkite 与 Octopus Deploy 的集成:
这些插件要求在 Buildkite 代理上安装 Octopus CLI 。

创建版本
在 Octopus Deploy 中,一个发布是您的部署过程和相关资产(包、脚本、变量)的快照,因为它们在您的发布创建时就存在。该发行版有一个版本号,您可以根据需要多次部署该发行版,即使自该发行版创建以来部分部署过程已经更改(这些更改将包含在未来的发行版中,但不包含在当前版本中)。
当您部署该版本时,您正在执行带有所有相关细节的部署过程,因为它们在创建该版本时就存在了。
通过 Buildkite 在 Octopus Deploy 中创建一个发布会将create-release-build kite-plugin合并到您的管道中:
steps:
- label: Create a release in Octopus Deploy 🐙
- plugins:
- OctopusDeploy/create-release#v0.0.1:
api_key: "${MY_OCTOPUS_API_KEY}"
project: "HelloWorld"
server: "${MY_OCTOPUS_SERVER}"
我们强烈建议您将环境变量用于敏感值,如 API 键或服务器地址。

推送构建信息
当部署一个版本时,了解哪个构建产生了工件,它包含什么提交,以及它与哪个工作项相关联是很有用的。构建信息特性允许你从构建服务器上传信息到 Octopus Deploy,手动或者通过插件。
构建信息与包相关联,包括:
- 构建 URL:指向生成包的构建的链接
- 提交:与构建相关的源提交的详细信息
- 问题:从提交消息中解析的问题引用
从 Buildkite 推送构建信息到 Octopus Deploy 可以通过push-build-information-build kite-plugin完成:
steps:
- label: Push build info to Octopus Deploy 🐙
plugins:
- OctopusDeploy/push-build-information#v0.0.1:
api_key: "${MY_OCTOPUS_API_KEY}"
packages: "HelloWorld"
package_version: "1.0.0"
server: "${MY_OCTOPUS_SERVER}"
运行操作手册
Runbooks 可自动执行日常维护和紧急操作任务,例如基础设施供应、数据库管理以及网站故障转移和恢复。runbook 包括运行基础设施的所有必要权限,因此团队中的任何人都可以执行 run book,并且因为它们是在 Octopus 中管理的,所以有完整的审计跟踪。Runbooks 可以使用提示变量,因此需要人工交互。
可以使用run-runbook-Buildkite-plugin通过 build kite 在 Octopus Deploy 中运行 run book:
steps:
- label: Run runbook in Octopus Deploy 🐙
plugins:
- OctopusDeploy/run-runbook#v0.0.1:
api_key: "${MY_OCTOPUS_API_KEY}"
environments: "Test"
project: "Hello World"
runbook: "Greeting"
server: "${MY_OCTOPUS_SERVER}"
结论
通过我们新的 Buildkite 插件提供的集成代表了我们最初的设计和发布。我们计划构建额外的插件,并通过 Bash 脚本提供集成来消除对 Octopus CLI 的依赖。
如果您是现有的 Octopus Deploy 客户,请查看作为构建管道一部分的 Buildkite 。如果你是一个现有的 Buildkite 客户,请查看 Octopus Deploy 了解部署情况。如果您还没有尝试过这两种产品,请将它们都视为您 CI/CD 渠道的一部分。
愉快的部署!
介绍 Octopus 服务器 Linux Docker 映像- Octopus Deploy

作为我们为 Octopus Cloud 提供可扩展、经济高效的托管解决方案的努力的一部分,我们将所有 V1 托管的实例迁移到我们新的 V2 基础设施,在 Kubernetes 内的 Linux 容器中运行 Octopus,我们对结果非常满意。
今天,我想宣布提前进入章鱼服务器 Linux Docker 镜像。该图像基于支持我们的托管解决方案的相同代码。这些映像允许 Linux 用户在其选择的操作系统上托管 Octopus。
入门指南
以下 Docker 撰写模板是最简单的入门方式。该模板用一个命令配置 Microsoft SQL Server 和 Octopus。
下面是docker-compose.yml文件:
version: '3'
services:
db:
image: ${SQL_IMAGE}
environment:
SA_PASSWORD: ${SA_PASSWORD}
ACCEPT_EULA: ${ACCEPT_EULA}
# Prevent SQL Server from consuming the defult of 80% physical memory.
MSSQL_MEMORY_LIMIT_MB: 2048
ports:
- 1401:1433
healthcheck:
test: [ "CMD", "/opt/mssql-tools/bin/sqlcmd", "-U", "sa", "-P", "${SA_PASSWORD}", "-Q", "select 1"]
interval: 10s
retries: 10
octopus-server:
image: octopusdeploy/octopusdeploy:${OCTOPUS_SERVER_TAG}
privileged: true
environment:
ACCEPT_EULA: ${ACCEPT_OCTOPUS_EULA}
OCTOPUS_SERVER_NODE_NAME: ${OCTOPUS_SERVER_NODE_NAME}
DB_CONNECTION_STRING: ${DB_CONNECTION_STRING}
ADMIN_USERNAME: ${ADMIN_USERNAME}
ADMIN_PASSWORD: ${ADMIN_PASSWORD}
ADMIN_EMAIL: ${ADMIN_EMAIL}
OCTOPUS_SERVER_BASE64_LICENSE: ${OCTOPUS_SERVER_BASE64_LICENSE}
MASTER_KEY: ${MASTER_KEY}
ADMIN_API_KEY: ${ADMIN_API_KEY}
ports:
- 8080:8080
depends_on:
- db
.env文件定义了 Docker Compose 使用的环境变量:
务必更改ACCEPT_EULA和ACCEPT_OCTOPUS_EULA值!
# It is highly recommended this value is changed as it's the password used for the database user.
SA_PASSWORD=N0tS3cr3t!
# Tag for the Octopus Server image. See https://hub.docker.com/repository/docker/octopusdeploy/octopusdeploy for the tags.
OCTOPUS_SERVER_TAG=2020.3.1
# Sql Server image. Set this variable to the version you wish to use. Default is to use the latest.
SQL_IMAGE=mcr.microsoft.com/mssql/server
# The default created user username for login to the Octopus Server
ADMIN_USERNAME=admin
# It is highly recommended this value is changed as it's the default user password for login to the Octopus Server
ADMIN_PASSWORD=Passw0rd123
# Email associated with the default created user. If empty will default to octopus@example.local
ADMIN_EMAIL=
# Accept the Microsoft Sql Server Eula found here: https://hub.docker.com/r/microsoft/mssql-server-windows-express/
ACCEPT_EULA=N
# Use of this Image means you must accept the Octopus Deploy Eula found here: https://octopus.com/company/legal
ACCEPT_OCTOPUS_EULA=N
# Unique Server Node Name - If left empty will default to the machine Name
OCTOPUS_SERVER_NODE_NAME=
# Database Connection String. If using database in sql server container, it is highly recommended to change the password.
DB_CONNECTION_STRING=Server=db,1433;Database=OctopusDeploy;User=sa;Password=N0tS3cr3t!
# Your License key for Octopus Deploy. If left empty, it will try and create a free license key for you
OCTOPUS_SERVER_BASE64_LICENSE=
# Octopus Deploy uses a Master Key for encryption of your database. If you're using an external database that's already been setup for Octopus Deploy, you can supply the Master Key to use it. If left blank, a new Master Key will be generated with the database creation.
MASTER_KEY=
# The API Key to set for the administrator. If this is set and no password is provided then a service account user will be created. If this is set and a password is also set then a standard user will be created.
ADMIN_API_KEY=
您可以使用以下命令创建容器:
docker-compose up
图像启动后,可以在http://localhost:8080访问 Octopus。
提示和技巧
如果你有敏锐的眼光,你可能已经注意到我们推出了将privileged标志设置为true的 Octopus 容器。这是支持 Docker-in-Docker 特性所必需的,该特性在容器中默认启用。Docker-in-Docker 允许 Octopus 为工人使用执行容器。
随着 Octopus 的发展,我们面临的挑战之一是与云服务和 Kubernetes 等平台交互所需的支持工具的数量、组合和版本。为了解决这个问题,可以在 Docker 容器中执行像 Kubernetes 这样的目标的部署和健康检查。Octopus 为 Windows 和 Linux 提供了广泛的通用工具,最终用户也可以创建自己的映像。
为了从托管 Octopus 的容器中运行这些图像,Docker 守护进程在后台运行,这需要使用privileged标志。这允许对执行容器的完全访问,意味着 Linux 用户拥有部署到云服务和 Kubernetes 的开箱即用支持(尽管 Service Fabric 仍然需要 Windows 工作人员进行部署)。
要禁用 Docker-in-Docker,请将环境变量DISABLE_DIND设置为Y。
这意味着最终用户不再需要使用kubectl等工具管理单独的工作人员,相反,他们可以利用提供的工作人员工具映像:

Kubernetes 健康检查需要 kubectl,它由 Worker tools 映像提供。
在 Kubernetes 跑章鱼
正如这篇文章的引言所提到的,在 Linux 上运行 Octopus 的驱动力是允许它在 Kubernetes 上运行,并且这个选项现在对于那些想要在他们自己的 Kubernetes 集群中托管 Octopus 的人是可用的。
由于高可用性(HA)和 Kubernetes 是携手并进的,所以这里提供的解决方案支持使用多个 HA 节点扩展 Octopus 服务器实例。
部署 HA Octopus 集群时,需要考虑多个方面,包括:
- 高可用性数据库。
- 工件、日志和内置提要的共享文件系统。
- web 流量的负载平衡器。
- 直接访问每个 Octopus 节点进行轮询触角。
- 可能导致数据库模式升级的启动和升级过程。
我们不会深入讨论部署 HA SQL 数据库的细节。出于本文的目的,我们将向集群部署一个 MS SQL Express 实例。下面的 YAML 创建了一个持久卷声明来存储数据库文件、一个在内部公开数据库的服务以及数据库本身:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
---
apiVersion: v1
kind: Service
metadata:
name: mssql
spec:
type: ClusterIP
ports:
-
port: 1433
targetPort: 1433
protocol: TCP
selector:
app: mssql
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mssql-deployment
labels:
app: mssql
spec:
selector:
matchLabels:
app: mssql
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 10
volumes:
- name: mssqldb
persistentVolumeClaim:
claimName: mssql-data
containers:
- name: mssql
image: mcr.microsoft.com/mssql/server:2019-latest
ports:
- containerPort: 1433
env:
- name: MSSQL_PID
value: Express
- name: ACCEPT_EULA
value: 'Y'
- name: SA_PASSWORD
value: Password01!
volumeMounts:
- name: mssqldb
mountPath: /var/opt/mssql
为了在 Octopus 节点之间共享公共文件,我们需要访问三个共享卷,多个 pods 可以同时读写这些卷。这些是通过持久卷声明创建的,访问模式为ReadWriteMany,表示它们在多个 pod 之间共享。下面的 YAML 创建了共享持久卷声明,它将托管任务日志、内置提要和工件:
注意,存储类名azurefile是特定于 Azure AKS 的,其他 Kubernetes 提供者将为他们的共享文件系统公开不同的名称。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: repository-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: azurefile
resources:
requests:
storage: 1Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: artifacts-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: azurefile
resources:
requests:
storage: 1Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: task-logs-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: azurefile
resources:
requests:
storage: 1Gi
Octopus web 接口是一个 React 单页面应用程序(SPA ),可以将所有后端请求定向到任何 Octopus 节点。这意味着我们可以通过一个用于 web 接口的负载平衡器来公开所有 Octopus 节点。下面是一个负载平衡器服务的 YAML,它将端口 80 上的 web 流量定向到标签为app:octopus的 pod:
apiVersion: v1
kind: Service
metadata:
name: octopus-web
spec:
type: LoadBalancer
ports:
- name: web
port: 80
targetPort: 8080
protocol: TCP
selector:
app: octopus
与 web 界面不同,轮询触角必须能够单独连接每个 Octopus 节点,以接受新任务。我们的 Octopus HA 集群假设有两个节点,下面的负载平衡器为每个节点创建单独的公共 IP。
注意statefulset.kubernetes.io/pod-name: octopus-0和statefulset.kubernetes.io/pod-name: octopus-1的选择器。这些标签被添加到作为有状态集合的一部分而创建的 pod 中,其值是有状态集合名称和 pod 索引的组合:
apiVersion: v1
kind: Service
metadata:
name: octopus-0
spec:
type: LoadBalancer
ports:
- name: web
port: 80
targetPort: 8080
protocol: TCP
- name: tentacle
port: 10943
targetPort: 10943
protocol: TCP
selector:
statefulset.kubernetes.io/pod-name: octopus-0
apiVersion: v1
kind: Service
metadata:
name: octopus-1
spec:
type: LoadBalancer
ports:
- name: web
port: 80
targetPort: 8080
protocol: TCP
- name: tentacle
port: 10943
targetPort: 10943
protocol: TCP
selector:
statefulset.kubernetes.io/pod-name: octopus-1
最后,我们将上述所有资源组合成一个有状态集,创建 Octopus 节点。
有状态集提供了一种部署 pod 的机制,这些 pod 具有固定的名称、一致的排序和一次推出一个 pod 的初始部署过程,确保每个 pod 在下一个开始之前都是健康的(尽管重新部署需要特殊的考虑,我将在后面介绍)。在部署 Octopus 时,这个功能非常好用,因为我们需要确保 Octopus 实例按顺序启动,这样只有一个实例尝试对数据库模式应用更新。
下面的 YAML 创建了一个包含两个 pods 的有状态集合。这些 pod 将被称为octopus-0和octopus-1,这也将是分配给statefulset.kubernetes.io/pod-name标签的值,这又是我们如何链接暴露各个 pod 的服务。然后,pod 为工件、日志和内置提要挂载共享卷。
preStop钩子用于在节点停止之前排空节点。这使节点有时间完成任何正在运行的任务,并防止它开始新的任务。当服务器启动并运行时,postStart start 挂钩执行相反的操作并禁用消耗模式。
readinessProbe用于确保节点在 pod 被标记为就绪之前响应网络流量。startupProbe用于延迟livenessProbe直到节点启动,livenessProbe连续运行以确保节点正常运行:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: octopus
spec:
selector:
matchLabels:
app: octopus
serviceName: "octopus"
replicas: 2
template:
metadata:
labels:
app: octopus
spec:
terminationGracePeriodSeconds: 10
volumes:
- name: repository-vol
persistentVolumeClaim:
claimName: repository-claim
- name: artifacts-vol
persistentVolumeClaim:
claimName: artifacts-claim
- name: task-logs-vol
persistentVolumeClaim:
claimName: task-logs-claim
containers:
- name: octopus
image: octopusdeploy/octopusdeploy:2020.3.1
securityContext:
privileged: true
env:
- name: ACCEPT_EULA
# "Y" means accepting the EULA at https://octopus.com/company/legal
value: "Y"
- name: OCTOPUS_SERVER_NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: DB_CONNECTION_STRING
value: Server=mssql,1433;Database=Octopus;User Id=SA;Password=Password01!
- name: ADMIN_USERNAME
value: admin
- name: ADMIN_PASSWORD
value: Password01!
- name: ADMIN_EMAIL
value: admin@example.org
- name: OCTOPUS_SERVER_BASE64_LICENSE
# Your license key goes here. When using more than one node, a HA license is required. Without a HA license, the stateful set can have a replica count of 1.
value: License goes here
- name: MASTER_KEY
# Replace this, as this value protects secrets in Octopus
value: 6EdU6IWsCtMEwk0kPKflQQ==
ports:
- containerPort: 8080
name: web
- containerPort: 10943
name: tentacle
volumeMounts:
- name: repository-vol
mountPath: /repository
- name: artifacts-vol
mountPath: /artifacts
- name: task-logs-vol
mountPath: /taskLogs
lifecycle:
preStop:
exec:
command:
- /bin/bash
- -c
- '[[ -f /Octopus/Octopus.Server ]] && EXE="/Octopus/Octopus.Server" || EXE="dotnet /Octopus/Octopus.Server.dll"; $EXE node --instance=OctopusServer --drain=true --wait=600 --cancel-tasks;'
# postStart must finish in 5 minutes or the container will fail to create
postStart:
exec:
command:
- /bin/bash
- -c
- 'URL=http://localhost:8080; x=0; while [ $x -lt 9 ]; do response=$(/usr/bin/curl -k $URL/api/octopusservernodes/ping --write-out %{http_code} --silent --output /dev/null); if [ "$response" -ge 200 ] && [ "$response" -le 299 ]; then break; fi; if [ "$response" -eq 418 ]; then [[ -f /Octopus/Octopus.Server ]] && EXE="/Octopus/Octopus.Server" || EXE="dotnet /Octopus/Octopus.Server.dll"; $EXE node --instance=OctopusServer --drain=false; now=$(date); echo "${now} Server cancelling drain mode." break; fi; now=$(date); echo "${now} Server is not ready, can not disable drain mode."; sleep 30; done;'
readinessProbe:
exec:
command:
- /bin/bash
- -c
- URL=http://localhost:8080; response=$(/usr/bin/curl -k $URL/api/serverstatus/hosted/internal --write-out %{http_code} --silent --output /dev/null); /usr/bin/test "$response" -ge 200 && /usr/bin/test "$response" -le 299 || /usr/bin/test
initialDelaySeconds: 30
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 60
livenessProbe:
exec:
command:
- /bin/bash
- -c
- URL=http://localhost:8080; response=$(/usr/bin/curl -k $URL/api/octopusservernodes/ping --write-out %{http_code} --silent --output /dev/null); /usr/bin/test "$response" -ge 200 && /usr/bin/test "$response" -le 299 || /usr/bin/test "$response" -eq 418
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 10
startupProbe:
exec:
command:
- /bin/bash
- -c
- URL=http://localhost:8080; response=$(/usr/bin/curl -k $URL/api/octopusservernodes/ping --write-out %{http_code} --silent --output /dev/null); /usr/bin/test "$response" -ge 200 && /usr/bin/test "$response" -le 299 || /usr/bin/test "$response" -eq 418
failureThreshold: 30
periodSeconds: 60
有状态集的初始部署完全按照 Octopus 的要求工作;一次一个 pod 在下一个之前成功启动。这使第一个节点有机会用任何需要的更改来更新 SQL 模式,所有其他节点启动并共享已经配置好的数据库。
有状态集的一个限制是它们处理更新的方式。例如,如果更新了 Docker 映像版本,则默认使用滚动更新策略。滚动更新会删除并重新创建每个 pod,这意味着在更新过程中会混合新旧版本的 Octopus。这是行不通的,因为新版本可能会应用旧版本无法使用的模式更新,最多会导致不可预测的结果,并可能导致数据损坏。
此问题的典型解决方案是使用重新创建部署策略。不幸的是,有状态集不支持重建策略。
这意味着有状态集不能就地更新,而是必须删除,然后部署新版本。这个新的、有状态集的新副本将一个接一个地启动新的 pod,从而允许数据库更新按预期完成。
一旦完全部署,该配置将有三个负载平衡器,并依次有三个公共 IP。
octopus-web服务用于访问 web 界面。正如我们前面提到的,web 应用程序可以向任何节点发出请求,因此跨所有节点的负载平衡意味着即使一个节点关闭,web 界面也是可访问的。
octopus-0服务用于将轮询触角指向第一个节点,而octopus-1服务用于将轮询触角指向第二个节点。我们还通过这些服务公开了 web 接口,这为支持团队提供了与给定节点直接交互的能力,但是octopus-web服务应该用于日常工作。文档提供了将轮询触角连接到 HA 节点的细节。
为了更大程度的可靠性,pod 反相似性规则可用于确保 Octopus pods 不被放置在同一个节点上。这确保了节点的丢失不会导致 Octopus 集群停机。
章鱼舵图
为了方便起见,上面描述的 Kubernetes 资源被捆绑到一个 Helm 图表中。要添加 Helm 存储库,请运行以下命令:
helm repo add octopus https://octopus-helm-charts.s3.amazonaws.com
helm repo update
然后使用以下命令安装图表:
helm install octopus octopus/octopusdeploy --set octopus.licenseKeyBase64=<your Octopus license key base64 encoded> --set octopus.acceptEula=Y --set mssql-linux.acceptEula.value=Y
图表的默认值配置为创建一个带有ReadWriteOnce卷的单节点 Octopus 集群。默认情况下,Kubernetes 集群很好地支持这些值。
要部署 HA 集群,您需要定义一些特定于您要部署到的集群的附加值。例如,当部署到 Azure AKS 时,以下值用于创建在三个 Octopus HA 节点之间共享的ReadWriteMany卷:
helm install octopus octopus/octopusdeploy --set octopus.replicaCount=3 --set octopus.storageClassName=azurefile --set octopus.licenseKeyBase64=<your Octopus license key base64 encoded> --set octopus.acceptEula=Y --set mssql-linux.acceptEula.value=Y
图表源代码可在 GitHub 上获得。
添加部署目标
除了云部署之外,自托管部署也通过触手的 Linux 版本得到支持。DEB 和 RPM 包都提供了,或者你可以下载一个独立的文档。
当然,如果你需要管理跨操作系统的部署和操作,你仍然可以将 Windows Tentacles 连接到 Linux 版本的 Octopus。
从这里去哪里
Linux Docker 映像和示例 Kubernetes 资源已经作为我们早期访问计划(EAP)的一部分发布,因此我们预计会有一些错误和粗糙的边缘,并且我们不支持这个版本用于生产部署。然而,如果你遇到任何问题,我们很乐意通过我们的支持渠道了解它们,这样我们就可以解决问题。
愉快的部署!
介绍 Octopus Cloud - Octopus Deploy

当我 2017 年 9 月刚开始在 Octopus 工作时,“托管”(我们当时这样称呼它)已经流传了一段时间,但真正的工作还没有真正开始。2017 年底,一个团队正式成立,将托管带入生活,汇集了我们团队在云架构、基础设施和安全方面的技能。这是一次疯狂的旅程,但我们终于到达了终点——章鱼云将在未来几周内向公众开放。
随着发布即将到来,我想花一点时间来写一下我们到这一点的旅程:为什么我们决定建立章鱼云,哪些事情真的很好,其他事情真的没有用,以及我们在这个过程中吸取的一些教训。
这篇文章还推出了一个章鱼云博客系列,后续文章更深入地挖掘了我们面临和克服的一些具体挑战,以及我们的团队和公司如何在这个云原生世界中进行变革。喝杯咖啡安顿下来。
为什么要把章鱼放在云端?(章鱼简史)
当 Octopus 作为 Paul Stovell 的许多伟大想法之一首次出现时,编程和开发的前景非常不同;可靠且可重复地部署到内部和自托管服务器是一件非常痛苦的事情。当时,应用程序通常运行在托管服务器上,因此在同一个网络(或 WAN)上拥有托管部署服务器是完全有意义的。
5 年后,情况看起来完全不同了。许多团队专门(或主要)为云开发:web 应用程序、微服务、“无服务器”(将代码转储到其他人的服务器上,给他们制造问题)都存在于这个模糊的“其他空间”中。当您的所有部署目标都位于云中时,拥有一个托管的本地部署服务器没有任何意义。无论如何,许多团队都在 Azure 或 AWS 上的云虚拟机上运行他们的 Octopus,我们甚至开始称之为“自托管”(而不是“内部”),因为无论如何,许多人都没有自己运行服务器。
因此,我们问自己,如果我们是客户,当我们所有的代码都在云中时,我们会想要在某个地方部署和管理服务器来运行 Octopus 吗?当然,答案是否定的!当我们开始听到类似“Octopus 是我唯一的虚拟机”的评论时,我们知道是时候改变现状了。
我们是如何做到的(以及为什么真的很难)
听起来很简单,对吧?“就把它放在云中”是我经常听到的话,通常是从那些真的不知道这有多难的人那里听到的。剧透:这并不容易。一点也不。现在仍然不是。在将 Octopus 推向极限和争论 AWS 之间,我们都学到了很多——在随后的帖子中,我们将更深入地讨论这些话题。
“在服务器上运行”(又名“请摧毁我们的服务器”)
简而言之,Octopus 是从零开始构建的,目的是使开发人员能够进行无缝、弹性的开箱即用部署,而且能够根据需要进行修改和调整,以使他们的特定配置正常工作。这意味着 Octopus 有大量的开关,您可以根据自己的需要调整部署。而当你自己控制服务器的时候,那完全没问题。但是允许任何任意脚本和可执行文件在我们的服务器上不受限制地运行确实让我们非常紧张。然而,这迫使我们对安全性和我们的执行架构进行了一些非常有趣的讨论,并为一些令人兴奋的新功能铺平了道路(阅读一下 Workers ,即将推出)。
将章鱼推向极限(又名“我们能有多有创造力?”)
我们在构建 Octopus Cloud 时做出了一个决定,我们应该吃我们自己的狗粮,并使用 Octopus 作为我们管理云实例的主要驱动程序。这意味着我们运行一个特殊的、幸运的 Octopus 实例来处理我们的大部分管理流程,从启动所有 AWS 基础设施和安全配置,到当我们达到特定限制时部署新的数据库服务器和存储网关,以及重复部署来运行监控和维护任务。这是一个有趣的旅程,我们不得不变得非常有创造力,但它也启动了一些真正有趣的内部可用性和性能对话,我们以前没有接触过。
抓住脉搏(又名“凌晨 3 点警报灾难”)
我们(主要)是一支澳大利亚团队,这是我们真正引以为豪的事情!但是,当我们的许多客户都不在澳大利亚时,这种支持也有不利的一面。因此,对我们来说,一个很大的考虑是确保我们对章鱼云的问题保持敏感和响应,无论它们可能在什么时候发生。当您的部署依赖我们时,如果出现问题,我们不能让您无所适从。因此,章鱼云故事的很大一部分是挂钩有意义的指标和明智的警报的旅程,这样如果有任何不好的事情发生,我们就会收到通知。
作为旁注,我雄心勃勃地自愿成为我们第一周 24/7 随叫随到的试验品,我有一些非常愤怒的凌晨 3 点试图读取我手机上的堆栈跟踪,因为“我的手机比太阳更亮”(直接引用我的另一半的话)而被打在我的身边。
打破筒仓(又名“不要成为知识囤积龙”)
每个人都有自己的兴趣和特定的技能,呆在那个舒适区而不去外面冒险真的很诱人。对我来说,我很擅长 MVC 和 web-appy-Azure 之类的东西,但我在 Angular 方面很糟糕,我认为 AWS 讨厌我。我试着坚持做我最了解的事情,认为这是我技能的最佳运用。虽然这在技术上是正确的,但它鼓励了巨大的知识支柱的形成,“哦,这是一个 MVC 的问题?最好和安迪谈谈,”当人们生病时,这就成了一个问题,而当你随叫随到,只知道自己的事情,其他什么都不知道时,这就成了一个更大的问题。我们做了很多配对工作,都钻研了让我们相当不舒服的东西,所以我们都有完整堆栈的工作知识。但私底下我还是很吸 Angular 的(宋承宪不要告诉任何人)。
下一步是什么?(我试图解读水晶球)
章鱼云是一个非常棒的地方。我们目前只接受邀请的早期访问,非常乐意向任何渴望尝试云实例的人敞开大门。但是,像许多大型事业一样,真正的旅程还在前面。对于我们用户来说,章鱼云真的是一个“怎么样”,而不是一个“什么”。Octopus 本身也是你们多年来一直在使用的伟大系统,我们只是以一种不同的(更无缝的)方式带给你们。云团队的前进之路将是利用我们已经构建的平台并在其上进行改进:更快的配置、更低的成本、更高的性能等等。你可能甚至没有注意到这些改进,但我们仍然会努力工作。
谢谢你坚持到最后!我真的希望这是一个有趣的见解,让我们了解我们是如何走到这一步的,以及我们接下来可能会去哪里。请关注更多的帖子,不要害怕在下面的评论中提出任何问题。如果您有技术问题,请阅读我们的常见问题。
直到我们再次交谈,愉快(几乎云)部署!
介绍八达通 ID -八达通部署

一年前,当章鱼云宣布时,我们推出了它和一些基本的账户管理功能。没有任何方便的方法来跟踪你所有的自主管理的八达通卡许可证。您还必须创建一个新的用户名和密码来管理您的帐户,并创建另一个用户名和密码来登录您的新 Octopus Cloud 实例。
我们希望让您与 Octopus 的互动体验尽可能简单,因此今天我们将介绍我们使用 Octopus ID 进行单点登录的计划,首先介绍一些新的帐户功能,我们希望这些功能可以让您的生活更加轻松,让您的部署速度比以往任何时候都快。
使用谷歌或微软轻松登录

您现在可以使用您现有的谷歌或微软帐户登录您的帐户。对于拥有旧电子邮件和密码帐户的现有用户,不要担心,我们将继续支持这一点,并且我们将根据您的电子邮件地址自动链接多种身份验证方法。您只需要验证您的电子邮件地址,如下所示。

您也可以选择个人资料照片,或通过简单的个人资料屏幕控制您的身份验证方法:

跟踪您的自托管八达通许可证
如果你曾经开始试用或购买了一份自托管的 Octopus Deploy,你会通过电子邮件收到一个许可密钥。如果您的组织有多个这样的许可证,手动跟踪这些密钥可能会很麻烦。
现在,您可以将自己托管的许可证密钥导入您的帐户。当您导入许可证时,如果您的电子邮件被列为最终用户联系人,我们将使用您的 Octopus ID 自动检测您的许可证,或者您可以只粘贴许可证密钥。链接后,您将可以方便地访问自助服务选项,如续订许可证或更改许可证限制。

启动新的云测试
您还可以使用您的帐户轻松尝试在云中部署 Octopus,一如既往,免费 30 天。只需登录,点击链接创建一个新的云实例,点击几下就可以开始运行了。
未来计划
今天,您已经可以使用您的 Octopus ID 来创建云实例并管理您的自托管许可证。将来,我们计划将以下服务添加到您可以使用八达通 ID 解锁的服务列表中。
与您的团队共享许可证
没有简单的方法邀请其他人来管理您的八达通云订阅或自托管许可证密钥。我们计划邀请其他人来管理它们。
支持论坛
目前,在支持论坛上寻求帮助需要你注册另一组证书。我们计划调整论坛,改为允许您重复使用您的八达通 ID 无缝地进入,并让您更快地获得您需要的帮助。
章鱼云实例
这大概会是章鱼 ID 最大的好处。我们计划为新的 Octopus 云实例的用户提供集成的 Octopus ID 认证。我们期望从中获得一些好处。例如,在运行一个新的云实例时,不需要为实例上的初始管理员用户创建和跟踪另一个用户名和密码。其次,我们希望 Octopus ID 将使组织为其实例设置 Google 或 Microsoft 身份验证变得更加简单。
您可以设置一个规则,比如“任何有效登录到这个 Microsoft ID 租户的人都可以访问这个 Octopus 实例”。
包扎
我们希望你与 Octopus 的互动尽可能轻松。有了 Octopus ID,我们希望您会发现新的登录选项和帐户管理功能非常有用,我们期待很快在我们的支持论坛和您的所有 Octopus Cloud 实例中为您带来更多单点登录的好处。
愉快的部署!
介绍 Octopus 示例- Octopus Deploy

虽然乍看起来可能不像,但 Octopus Deploy 是一个庞大的产品。产品如此庞大,以至于在 Octopus 工作多年的人仍然不完全了解它。为了解决我们产品的巨大规模,我们开发了大量的文档,并制作了各种演示常见用法的视频。然而,并不是每个人都喜欢钻研文档或搜索视频来解决他们想要完成的事情。有些人只是想得到产品来解决问题。为此,我们创建了 Octopus Samples 实例。
样品
Samples 实例是为有使用 Octopus Deploy 经验的人准备的,他们希望了解如何解决特定的问题。示例中的示例是根据真实场景建模的,通常有些复杂,这意味着新用户可能会觉得难以理解。
正在登录
Samples 是一个公开的实例,任何人都可以使用。在浏览器中打开https://samples . octopus . app并选择 Guest(我有一个账户选项是为解决方案团队成员准备的。)

Guest access 使实例中的所有可用空间和项目都可用,允许您查看项目的所有方面,包括部署过程、步骤细节、操作手册和变量。但是,版本创建和执行部署受到限制。
航行
Samples 实例中的示例分布在多个空间中,以便更容易找到您想要的内容。命名约定将模式或目标作为每个空间名称的前缀,例如:
- 模式-租赁
- 模式- Voltron
- 目标码头工人
- 目标杂交
模式
以 Pattern 为前缀的空格展示了您可以实现的不同类型的模式。例子包括:
多项目部署协调
这些只是可用的一些模式空间。
目标
以为前缀的空格 Target 演示了如何部署到特定的技术,例如不同的数据库类型:
或 web 服务器:
同样,这并不是一个详尽的可用列表。
运行手册
Samples 实例中的所有示例都是功能齐全的,并执行到实际目标的部署。我们使用操作手册来供应和配置部署的目标。全空间基础设施是在太空的空间基础设施项目中创建的;

创建项目特定基础设施的操作手册包含在项目本身中。在这些操作手册中,你可以找到不同的方法来实现基础设施,如在云服务上运行的代码,如亚马逊 AWS (CloudFormation),微软 Azure (ARM 模板),甚至谷歌云平台。
构建服务器
示例实例中的大多数示例都由兼容的生成服务器中的生成提供支持。每个项目都包含一个链接,指向构建它的构建定义。我们实现了以下示例:
- Azure DevOps
- 团队城市
- 詹金斯
- 竹子
- 切尔莱西
- GitHub 操作
- 比特桶管道
结论
Octopus Deploy 尽最大努力为客户提供成功所需的工具。无论你的学习方式是阅读,视觉,或通过例子,章鱼有你涵盖。
为您的运营团队介绍运营操作手册- Octopus Deploy

部署只是应用程序生命周期中的一个阶段。为了保持应用程序平稳运行,还需要执行许多其他常见任务。DevOps 的很大一部分是开发和运营团队一起工作,Octopus 似乎是使用的完美工具,因为它已经了解了您的基础设施、帐户和项目配置。

如果我们以 Octopus.com 的 Octopus Deploy 网站为例,我们使用 Octopus 来部署我们的网站并管理我们的基础设施、变量、证书和帐户。但是我们也有一些日常和紧急任务,作为运营网站的一部分。例如,备份数据库、恢复数据库、测试恢复、从数据库中删除 PII、将净化的数据库恢复到测试环境以及故障转移到灾难恢复站点。
目前,这些任务在一个项目的部署过程中,或者作为单独的脚本执行。为部署执行所有这些步骤没有意义,仅仅为了备份数据库而进行部署也没有意义。
Operations Runbooks 使我们能够简化部署流程,并在部署的不同时间间隔运行操作任务。我们的操作手册列表是:
- 故障转移到灾难恢复站点。
- 切换回主生产站点。
- 备份数据库(并测试恢复是否有效)。
- 用(清理的)生产数据刷新测试数据库。
使用 runbooks,概览和任务列表向我们显示了确切的操作以及它们分别执行的运行,让我们了解了网站的真实状态。
Octopus 部署中的操作手册
可以从项目中访问操作手册。这意味着您可以将与运行应用程序相关的所有内容放在一起。如果您的操作任务只适用于您的基础架构,而不一定与应用程序相关,例如清理机器上的文件,我们建议您为这些类型的操作创建一个单独的项目。
在项目菜单中,与部署相关的所有内容都在一个新的部署菜单项下。操作手册在操作菜单下,随着我们将来增加新的操作,你可以期待看到这个部分的增长。可以在部署和操作之间共享的资源不在这些范围之内。

创建和运行操作手册
添加操作手册可以从操作➜操作手册部分完成,向操作手册添加步骤与向部署流程添加步骤的工作方式相同。
如果您在部署流程中有操作步骤,可以将它们克隆到操作手册中。

runbooks 运行时,会在运行时创建一个快照,这样可以更快地执行操作。我们没有设计依赖生命周期的操作手册,所以只要你有许可,你可以在任何环境下运行操作手册。

克隆步骤
如果您的部署流程中有更适合于 Runbook 的步骤,您可以将该步骤复制到 Runbook 中。
新权限
您可以使用新的权限RunbookView和RunbookEdit(用于创建、编辑和删除)来启用或限制用户运行 runbooks。Runbooks 为运行和快照重新使用现有的ProcessEdit、Deployment和Release权限。
运营操作手册早期访问
我们已经在 Octopus 2019.10 中发布了 run book 作为早期访问功能,我们鼓励您尝试任何非特定应用程序流程的 run book。
我们早期访问计划的目标是获得反馈并验证其设计。EAP 中的变量、触发器和其他方面有一些限制,但是 runbooks 文档提供了您需要开始的所有细节以及当前的限制。
我们喜欢反馈,所以请在#runbooks频道加入我们的社区松弛期的讨论。您也可以在我们的公共路线图页面上注册更新。
结论
我们很高兴分享这第一版操作手册,并看到团队如何在他们的项目中使用它。
在配置中引入 slugs 作为代码- Octopus Deploy
原文:https://octopus.com/blog/introducing-slugs-config-as-code
当我们开始开发配置为代码特性时,我们决定用 Octopus 配置语言(OCL)中的名称替换 id。然而,这种方法有几个缺点,导致我们在 OCL 用鼻涕虫代替名字。
这篇文章探讨了在 OCL 使用名字时的权衡,什么是 slugs,以及为什么我们选择在 Config as Code 中实现它们。
OCL 的身份证
传统上,Octopus 使用惟一的 id 来引用来自部署流程、操作手册和变量等地方的共享资源。
就其本身而言,id 不是非常具有描述性的,它们只是由资源类型和一个唯一的数字组成。例如,环境的 ID 可能类似于Environments-42。
Octopus 中的 id 缺乏上下文。光有一个 ID 还不足以知道这个 ID 指的是什么。对于 API 之类的东西来说,这不是问题,因为 API 响应通常被设计成由其他程序读取。
然而,OCL 是给人写和读的。在 OCL 使用 id 会让人一眼难以理解,如下例所示:
step "Run a Script" {
action {
environments = ["Environments-42"]
worker_pool = "WorkerPools-4"
...
}
}
断章取义,不清楚这是干什么的。Environments-42是什么环境?WorkerPools-4是哪个工人池?这些 id 在很多地方都不公开,所以试图弄清楚它们指的是什么可能是一个挑战。
如果你只是想读 OCL,这不是一个很好的经历。
OCL 的名字
在 OCL,我们没有使用 IDs,而是决定使用资源的名称。
Octopus 中的名字非常独特,我们可以放心地用它们来识别资源。名称也很容易一眼识别,使 OCL 更具可读性和用户友好性。
step "Run a Script" {
action {
environments = ["Staging"]
worker_pool = "Hosted Ubuntu"
...
}
}
看看上面的 OCL,与在 OCL 使用 IDs 相比,更容易理解发生了什么。
在我们决定在 OCL 使用名字之后,我们也决定在 API 和 UI 中为版本控制的项目使用名字来代替id。
我们这样做是为了改善从 UI 中查看受版本控制的部署流程时的用户体验。如果 OCL 中有任何损坏的引用(比如名称中的打字错误),我们会在发现损坏的引用的地方显示一个警告,并允许从 UI 或 API 修复它
虽然这种方法最初奏效,但它存在一些长期的缺点。
使用名称的权衡
在整个 Octopus 代码库中,我们通常假设所有对共享资源的引用都是使用 IDs 进行的。当我们在 OCL 引入名字时,我们打破了这个假设。
ID 属性可以包含一个有效的 ID 或一个可能存在也可能不存在的资源的名称。
这导致了内部和外部的一些突破性的变化,因为“names as id”方法也影响了我们的 API,这意味着 API 消费者(包括我们自己)也必须知道响应中的名称和 id。
因为从技术上讲,id 作为名称也是有效的,所以可能不清楚给定的值是 ID 还是名称,让用户自己去猜测。
看看下面的 JSON,有几个问题:
- 属性名称以
Id为后缀,但是,名称仍然存在。这是令人困惑和误导的。 - 不清楚
EnvironmentId属性的值指的是什么。Environment-1是名字还是 ID?- 如果我有一个 ID 为
Environment-1的环境和另一个名为Environment-1的环境,这是指哪一个呢?
{
"EnvironmentId": "Environment-1",
"WorkerPoolId": "Hosted Ubuntu"
}
使用名称作为 id 还会导致喋喋不休的 API 客户端,因为消费者需要向 API 发出额外的请求才能获取名称引用的资源。
需要使用通用列表样式的端点(例如,/environments?partialName=foobar)来查找所有匹配的资源,然后需要消费者手动过滤结果。这些请求可能并不便宜,尤其是在进行分页并且需要对单个资源发出多个请求的情况下。
在 OCL,由名称引起的另一个小问题是无法在不破坏引用的情况下重命名资源。这是意料之中的,但仍有改进的余地。
介绍鼻涕虫
考虑到使用名字作为 id 的缺点,我们考虑使用 slugs。
Slugs 是人类可读的、URL 友好的、唯一的标识符。它们通常用在名称不太合适的地方,比如 URL(包括这篇文章的 URL)。
Slugs 通常是根据名称自动生成的。例如,一个名为Test Environment (AU-EAST)的环境会生成test-environment-au-east,删除任何不友好的字符,同时保持可读性。
章鱼的鼻涕虫
为了保持较小的范围,我们首先将 slugs 添加到可以从部署流程中引用的任何内容中。迄今为止,这包括:
- 帐目
- 频道
- 部署行动
- 部署步骤
- 部署目标
- 环境
- 饲料
- 生活过程
- 组
- 工人池
随着需求的增加,我们将为更多的资源类型添加 slugs。
项目已经有了 slugs 的概念,它大多符合我们自己的目标。我们设法重新调整了现有项目 slug 逻辑的大部分用途,并通过一些调整将其应用于上述资源类型。
- 任何新创建的或现有的资源都会根据它们的名称自动生成它们的 slugs。
- Slugs 可以独立于名称进行修改,允许在不破坏任何引用的情况下重命名资源。这改变了项目段塞的现有行为。
- 通常不建议修改 slugs,因为这可能会导致需要手动更新的外部引用被破坏(例如,在 OCL 定义的部署流程)。
OCL 的蛞蝓
在我们将 slugs 添加到所有必要的资源之后,我们开始在我们的 OCL 中使用 slugs。
这被证明是相对简单的,因为我们可以重用现有的 ID 来命名转换代码,并添加一些逻辑来在 ID 和 slugs 之间进行转换。
我们还更新了部署步骤和动作的 OCL 语法,这样 slugs 可以与名称分开指定。
step "run-a-script" {
name = "Run a Script"
action {
environments = ["staging-au-east"]
worker_pool = "hosted-ubuntu"
...
}
}
现在更容易理解它指的是哪个环境和工人池。我们还受益于这些 slugs 是独一无二的,可以在项目和空间之间重复使用。
隔离抽象泄漏
在撰写本文时,使用 slugs 引用共享资源只有在 OCL 才有意义。我们的前端和后端都没有准备好使用 slugs 来引用这些资源,更新它们来这样做将是一项重要的任务。
因为 slugs 可以用作上下文唯一的 ID,所以当从 Octopus 中读取和写入 OCL 时,我们可以在传统 ID 和 slugs 之间进行映射。这允许我们在 OCL 使用 slugs,同时在 Octopus 服务器、API 和前端使用 IDs。
如果 Octopus 遇到一个无法映射到 ID 的 slug,就会返回一个验证错误,而不是允许中断的引用。我们可以保持我们正在处理的数据的有效性。
虽然这牺牲了从 UI 和 API 查看和编辑中断的引用的能力,但我们相信这是正确的方向,因为它使我们的 API 恢复了一致的形状,并提高了 Octopus server 在与 OCL 一起工作时的稳定性和可预测性。
蛞蝓的未来
随着 slugs 的大部分基础工作已经完成,我们可以开始向更多的资源类型添加 slugs,并开始在 Octopus 代码库中更多地使用它们。
Config as Code 之外的许多其他团队也对在其领域中使用 slugs 表现出了兴趣,所以请继续关注我们接下来如何使用 slugs。
愉快的部署!
介绍测试版迁移工具- Octopus Deploy
最近我写了 Octopus Deploy 最初是如何使用微软 SQL Server 数据库来存储部署信息的,以及我如何在 1.0 版本中切换到 RavenDB】。
许多客户的数据都在 0.9 以上。* Octopus 的版本,无法升级到 1.0,因为没有办法迁移数据。我一直在开发一个工具,将这些数据从 SQL Server 导入 RavenDB,现在它已经包含在最新的 Octopus Deploy 版本中。
在这篇文章中,我将带你完成迁移过程。显然这篇文章只对 0.9 的客户有兴趣。*数据库。
移民
开始从 0.9 迁移到 1.0 之前:
- 制作 SQL Server 数据库的备份
- 下载安装最新的 Octopus Deploy 服务器。按照常规完成安装向导(详见安装指南)。
- 确保 Octopus Windows 服务正在运行
至此,您应该已经安装了 1.0 Octopus,但是没有任何旧数据。现在,从“开始”菜单中,查找 Octopus Beta 迁移工具快捷方式:

该向导将要求您输入 SQL Server 数据库的连接字符串(它应该会从您以前的安装中自动检测到该字符串):

一旦测试了连接字符串的工作情况,就可以开始导入了:

迁移后
一旦导入完成,你可以像往常一样浏览你的 Octopus 门户网站。您应该会发现之前的所有数据都已导入。
然而,你还需要做一个额外的步骤。Octopus 和触手的安全模型已经改变(我们现在交换拇指纹),所以你必须在你所有的机器上运行新的触手安装程序,并在 Octopus 门户网站中编辑每台导入的机器,以注册机器拇指纹。
解决了这个问题,您现在将拥有一个愉快的 1.0 安装了!
如果您在迁移过程中有任何问题,请在我们的支持论坛上告诉我们。
介绍八达通控制中心-八达通部署
原文:https://octopus.com/blog/introducing-the-octopus-control-center

在 Octopus Deploy,我们不只是想打造世界上最好的部署工具;我们希望与我们的每一次互动都是世界级的。
我们知道我们可以用八达通帐户做得更好,所以我们重新设计了它,让它对你更有用,并为我们未来的功能打下坚实的基础。
八达通账户是如何演变的
章鱼账户是随着时间的推移拼凑起来的。我们在 2018 年 7 月发布了章鱼云 V1,构建了第一个迭代。
我们需要一个地方来放置账户管理工具,比如账单。接下来是 Octopus ID,然后是服务器许可证管理等自助服务功能,我们继续一次添加一个功能,没有停下来考虑整体体验。
作为客户,你应该享受八达通的每一个接触点,所以现在八达通账户已经建立,我们已经花时间重新设计它,并考虑整个体验。
什么变了?
- 它现在被称为控制中心,以便更好地识别它的用途。
- 控制中心有更多的指示器来帮助导航,包括:
- 描述性的页面标题、嵌套页面的标志以及帮助定位的活动状态。
- 我们在所有页面上都展示了您正在查看的组织,因此您可以维护上下文。
- 您的云实例的详细信息在单独的页面上,以便将来提供更强大的用户管理功能。
我们已经在整个控制中心交付了新的设计,所有现有的功能和特性都像以前一样继续工作。

结论
控制中心现在是一个独特的空间来管理您的帐户,直观的导航使您更容易找到您需要的东西。这些变化也为我们决定实现的未来特性铺平了道路。
我们希望重新设计能让它使用起来更愉快。如果您有进一步改进的建议,请告诉我们。
愉快的部署!
介绍 Octopus Deploy - Octopus Deploy 的 Workato 连接器
用于 Octopus Deploy 的 Workato 连接器现已上市。我们对 Workato 的支持将使 Octopus Deploy 客户的各种工作流场景成为可能。
Workato 是一个企业集成平台即服务(iPaaS ),可以帮助您构建工作流程自动化。您通过低代码/无代码可视化设计器构建工作流,支持数百种不同的平台和系统。在 Ruby 中,Workato 连接器被定义为一个 JSON 配置,并通过 Workato 开发环境注册。
我们知道 IT 团队仍然在工作流自动化中发挥着重要作用,但是产品团队和业务运营团队也越来越多地参与进来。这需要快速实现,可以用 Workato 的低代码接口进行优化。
Octopus 的 Workato 连接器让您可以快速地将 Octopus 集成到您的工作流程中。它支持使用 Octopus Deploy 执行许多操作,包括:
- 创建版本
- 创建客户、渠道、部署、环境和项目等资源
- 部署版本
- 获取部署流程
- 从 Octopus Deploy 获取各种资源(包括部署目标、提要、运行手册、团队和租户)
- 运行操作手册
- 创建通过触发器响应 Octopus 中事件的食谱
如果需要,还可以向连接器添加其他操作。
在我们的发布公告中了解更多关于 Octopus 2021.2 (Q3)发布的信息。
入门指南
使用 Octopus Deploy 连接器在 Workato 中创建工作流非常简单:
- 在 work to社区图书馆的自定义连接器部分搜索
Octopus。导航到连接器将提供其描述及其源代码。 - 要使用连接器,点击安装连接器按钮。

在配置连接器之前,您需要在 Octopus Deploy 中创建一个 API 键。连接器使用这个 API 键代表您对 Octopus Deploy 执行操作。关于如何做到这一点的信息在我们的如何创建 API 密钥文档中提供。
创建 API 键之后,您需要在 Workato 中的 Octopus Deploy 连接器和您希望集成到工作流中的 Octopus 实例之间建立连接:
【T2 
主机地址是指向 Octopus Deploy 的 URL。请确保在配置中包含了要定位的空间。
点击连接后,您可以开始在 Workato 中创建工作流。
Octopus 部署工作示例
Workato 是一个灵活而强大的集成平台,您可以构建无限的工作流来满足您团队的需求。下面是两个可能的例子,我们很想看到它们在现实环境中的应用。
示例:在 Octopus 部署中发生事件时通知松弛通道
客户经常使用的工作流是在 Octopus Deploy 中发生特定事件时通知空闲通道:

这是通过新的订阅事件触发器实现的,该触发器响应 Octopus Deploy 引发的实时事件。当发生这种情况时,会向松弛通道通知事件的详细信息(例如,创建了新的部署)。
示例:在 ServiceNow 中批准;与詹金斯一起建造;章鱼展开时释放
此场景提供了一个更详细的示例,说明了您可以使用 Workato 创建的工作流类型:

在此工作流中,来自 ServiceNow 实例的实时批准事件会触发一系列操作。具体来说,在 Jenkins 中开始构建,然后在 Octopus Deploy 中创建一个版本。作为工作流程的一部分,可以检查条件并将其用于推动决策。这些类似于编程语言中的控制流语句,如if - then - else语句。
结论
Workato 的自动化配方允许您通过可视化设计器构建工作流,为系统集成提供了一个低代码工具。
除了在 Slack、微软团队、吉拉或其他系统中触发 runbook 自动化之外,Workato 还使 Octopus 和 Workato 用户可以在开发、测试或生产部署后轻松发布其他系统的更新。这些可能是简单的通知,或第三方系统中的更新票证。
Workato 的强大之处在于它能够轻松地将其他系统与 Octopus Deploy 集成在一起。
愉快的部署!
构建服务器和持续集成简介- Octopus Deploy
当您开发和部署软件时,首先要解决的事情之一是如何将您的代码和工作应用程序部署到人们可以与您的软件交互的生产环境中。
大多数开发团队理解版本控制对协调代码提交的重要性,并构建服务器来编译和打包他们的软件,但是持续集成(CI)是一个大话题。
在我们关于持续集成的博客系列中,我们将详细介绍持续集成,以及两个最流行的构建服务器 Jenkins 和 GitHub Actions 如何帮助您的 CI 流程。
为什么构建服务器很重要
构建服务器有 3 个主要目的:
- 一天多次从您的存储库中编译提交的代码
- 运行自动测试来验证代码
- 创建可部署的包并交给部署工具,比如 Octopus Deploy
没有构建服务器,您会被复杂的手动过程和它们引入的不必要的时间限制所拖累。例如,如果没有构建服务器:
- 您的团队可能需要在每天的截止日期之前或者在变更窗口期间提交代码
- 截止日期过后,没有人可以再次提交,直到有人手动创建并测试一个构建
- 如果代码有问题,截止日期和手动过程会进一步延迟修复
没有构建服务器,团队就要克服自动化所消除的不必要的障碍。构建服务器将全天为您重复这些任务,没有那些人为的延迟。
但是 CI 不仅仅意味着花费在手工任务上的时间更少或者任意截止日期的死亡。通过每天多次自动采取这些步骤,您可以更快地解决问题,并且您的结果变得更加可预测。构建服务器最终会帮助您更加自信地通过管道进行部署。
詹金斯是什么?
Jenkins 是市场上最受欢迎的 CI 平台。开源且免费使用,您可以在大多数操作系统上独立运行 Jenkins 来自动构建和测试您的代码。
詹金斯最大的好处之一是它的灵活性。这是一个可扩展的平台,意味着您可以随着您的团队或项目需求的增长而扩展其功能。得益于其庞大的社区,有超过 1800 个插件,这使得它很容易与无数的行业工具集成。
这意味着 Jenkins 足够灵活,可以满足您的 CI 需求,您也可以为其他自动化目的定制它。
什么是 GitHub Actions?
GitHub Actions 是较新的 CI 平台之一。它通过使用存储库事件来触发虚拟“运行者”上的自动化工作流,从而消除了对单独构建服务器的需求。
如果你使用 GitHub 作为你的代码仓库,好消息是你已经有了访问权限——GitHub Actions 包含在你现有的仓库中。
关键在哪里?虽然公共存储库可以免费使用 GitHub 操作,但对其他人来说,它是按需付费的,按工作流运行的时间按分钟计费。不过,所有用户每月都有免费的通话时间,只有超出套餐允许的时间,你才需要付费。
像 Jenkins 一样, GitHub 也有一个 actions marketplace ,充满了社区创建的应用和工作流,以帮助持续集成等等。
作为 GitHub 的官方技术合作伙伴,Octopus Deploy 在 GitHub 市场上有一系列验证的 Octopus 操作来帮助您的部署。
还可以了解更多关于用 GitHub 构建,用 Octopus 部署。
下一步是什么?
在我们的 CI 系列中,我们分享了 Jenkins 和 GitHub 行动指南,以及更多内容。
如果你还没有使用 Octopus Deploy,你可以注册免费试用。
您还可以查看一些关于构建服务器和 CI 的其他帖子:
愉快的部署!
DevOps - Octopus 部署简介
DevOps 是一个很大的术语,涉及面很广,适用于许多围绕和支持软件开发的事物。
对于门外汉来说,DevOps 可能很难理解。是一种文化吗?开发过程的指导方针?一套工具?某人的工作?
所有这些问题的答案都是肯定的。以上都是。
在本帖中,我们从表面上看一下构成 DevOps 的各个部分。我们探索概念、工具、独特的角色,并解释 Octopus 的适用范围。
DevOps 作为一个概念
在现代开发中,尽可能快速可靠地交付软件和更新比以往任何时候都更加重要。
DevOps 背后的概念是关于消除软件交付中的障碍。
典型的障碍包括:
- 手动流程
- 办公室政治
- 反作用支持工作流
克服这些障碍的原因很简单:如果产品是软件,那么所有的过程都应该致力于交付软件,而不是反对软件。
让我们看看在考虑 DevOps 方法时我们必须考虑什么。
DevOps 作为一种文化
在传统的组织中,开发人员和那些支持他们的人(比如操作或数据库团队)通常是独立的实体,很少交互。
这意味着每个团队都有自己的信念、责任和优先事项。虽然并不矛盾,但在追求业务最佳化的过程中,这些优先级经常会发生冲突。
将 DevOps 作为一种文化意味着通过引入共同的目标来消除这种摩擦。
实现这一目标的方法可能会有所不同,这取决于人们的工作方式有多根深蒂固。但是,目标是确保所有团队:
- 通过清晰、诚实的沟通和反馈建立信任
- 在产品的整个生命周期中进行协作
- 拥有快速决策所需的信息
- 敢于冒险,不怕失败,不怕指责
- 对产品的成功负有集体责任
- 回顾在下一个生命周期中哪些可行,哪些不可行
为什么自动化对开发运维如此重要
在 DevOps 中,能自动化就应该自动化。
自动化的好处很简单:
- 团队可以更加关注产品
- 结果是可重复和可预测的
- 团队可以更快更灵活地应对问题
因此,持续集成和持续部署(CI/CD)成为 DevOps 的重要组成部分也就不足为奇了。
开发运维在行动:开发运维的不同方法
鉴于 DevOps 的概念性本质,组织有许多方法来采用它。
Alex Yates 在他关于“DevOps 工程师”命名的文章中强调了两种值得重新审视的方法。
CALMS(文化、自动化、精益、测量、共享)
CALMS 是 DevOps 手册中探索的一个框架。
CALMS 是一个缩写,其中每个字母描述了采用 DevOps 所需的行动:
- 文化——消除隔阂,分担责任
- 自动化 -减少花费在手工任务上的时间
- 精益 -简化流程以减少浪费的时间
- 测量 -收集和审查数据,找出需要改进的地方
- 分享——团队之间坦诚的合作
CALMS 也是 Atlassian 在发展 DevOps 文化的道路上采取的方法,用它来衡量进步和成功。你可以在他们的 DevOps 网站上阅读Atlassian 如何使用 CALMS。
三种方式(流动、反馈、持续实验和学习)
在DevOps 手册和 DevOps 小说凤凰计划和独角兽计划中,三种方式将 devo PS 归结为 3 个关键原则:
- 流动
- 反馈
- 不断的实验和学习
让我们快速看一下这些原则是什么意思。
第一种方式:流动
第一种方式是细化发生在开发者和客户之间的每一个过程。
这意味着:
- 不要在一个生命周期内尝试太多,专注于短距离冲刺
- 消除武断的过程,给团队他们需要的东西,让事情继续发展
第二种方式:反馈循环
第二种方式是关于更快的反馈。
更快的反馈意味着更快的反应,因此您可以:
- 在问题因迭代而成为根深蒂固的大问题之前解决它们
- 使用较少的反向工程进行故障排除
- 调整流程以更好地满足客户和团队的需求
第三条路:实验和学习
第三种方式是认识到冒险是可以的,失败是学习的一个重要部分。这也是关于交流成功的。
通过认识到这一点,它允许您的团队:
- 创造性地思考
- 从错误中学习
- 测试您的 DevOps 文化的弹性
开发人员角色
鉴于这个概念是关于一个统一的目的,DevOps 实际上是每个人的角色。也就是说,每个人都知道自己的责任仍然很重要。采用 DevOps 意味着增加一些专家角色,这些角色和开发人员一样,比如编码员、QA、设计师等等。
让我们快速看一下 DevOps 中需要的一些常见的额外角色以及它们的作用。一些命名约定和更精细的职责可能因组织而异。DevOps 工程师手册更详细地探讨了团队结构。
DevOps 工程师
DevOps 工程师的确切职能经常被争论。然而,人们的共识是,这个角色的存在是为了让其他人尽可能顺利地履行自己的职责。
DevOps 工程师既是指挥者又是问题解决者,负责监督全局,管理:
- 工作流程
- 基础架构设置和配置(包括扩展)
- 系统权限
- 不同团队的需求
构建管理器
构建经理维护组成持续集成(CI)的自动化系统。
这意味着确保代码得到编译、构建、测试和交付部署。
发布经理
发布经理指导为发布而提升的构建。他们交流发布中包含的内容,并通过管道环境规划他们的路线。
这就是我们所说的持续部署和持续交付(CD)——我们创建 Octopus 来帮助完成的过程。
生产部经理
产品经理几乎是开发者和最终用户之间的管道。
他们与开发人员合作,帮助确保产品具有客户需要的特性和修复。
数据分析师
数据分析师搜索数据以发现模式并找到需要改进的地方。
这有助于您发现影响用户体验的事情,例如功能问题或产品导航。
大多数开发运维方法认为产品生命周期应该是这样的:
- 计划
- 密码
- 建设
- 试验
- 包裹
- 释放;排放;发布
- 部署
- 操作
- 班长
冲洗重复!
找到合适的工具来帮助你管理每个阶段是很重要的。我们来看几个例子。
规划
规划阶段对于产品的方向和未来是最重要的。有效的规划有助于您关注用户在下一个生命周期结束时获得的改进和特性。
考虑到许多过程可能变得非常概念化,有一系列工具允许协作和项目管理。
松弛和缩放是我们在 Octopus 的主要工具,但其他受欢迎的选项包括:
代码库和源代码控制
源代码控制对任何开发团队都很重要。源代码管理跟踪并检查每一段新的代码和文件更改。
大多数开发人员使用 Git 进行源代码控制。Git 既是一个系统,也是一种哲学,允许分布式开发,并通过分支帮助避免风险。
因此,代码仓库是 Git 托管代码的托管服务。
常见选项包括:
构建和测试
构建服务器(也称为 CI 平台)可以通过自动执行以下操作来节省时间:
- 代码编译
- 代码验证测试
- 包创建
常见选项包括:
我们在 2022 年第一季度深入研究了詹金斯和 GitHub 行动。读一读,看看它们是否适合你。
包裹
软件打包工具将您的代码变成可部署的工件。您从包存储库中托管和部署这些工件。
常见选项包括:
发布和部署
大多数代码库和构建服务器都允许您以某种方式管理发布和部署到目标。然而,它们不能解决专用发布管理或部署工具所能解决的问题。
当然, Octopus 是我们的部署工具,我们认为它非常棒。稍后我们将讨论章鱼在中的。
其他受欢迎的选项包括:
操作
操作涉及管道基础设施的设置、运行和维护。
常见选项包括:
run book也是与运营相关的一个重要特性。我们在最后会多谈一点章鱼手册。
监视
监控工具从您的产品和相关系统中收集重要数据。这可以为有关性能和客户使用的决策提供信息。
常见选项包括:
章鱼在哪里适合 DevOps
Octopus 在两个关键方面非常适合 DevOps 环境:
- 在您的 CI/CD 管道中提供连续部署,并使复杂的部署变得简单。
- octopus run book-run book 允许您自动执行日常或紧急操作任务。这可能包括:
- 事故恢复
- 备份、恢复和测试
- 基础设施的启动和拆除
- 系统服务的停止、启动和重启
- 文件清理
- 运行你需要的任何语言的脚本
如果你还没有使用 Octopus Deploy,你可以注册免费试用。
阅读我们的 Runbooks 系列的其余部分或浏览 DevOps 工程师手册以了解有关 DevOps 和 CI/CD 的更多信息。
愉快的部署!
HCL 和 HCL 工具简介- Octopus 部署
原文:https://octopus.com/blog/introduction-to-hcl-and-hcl-tooling

HashiCorp 配置语言(HCL) 是一种独特的配置语言。它被设计用于 HashiCorp 工具,特别是 Terraform,但是 HCL 已经扩展为一种更通用的配置语言。它在视觉上类似于 JSON,并内置了额外的数据结构和功能。
HCL 由三个子语言组成:
- 结构的
- 表示
- 模板
当组合起来时,这些子语言形成了一个结构良好的 HCL 配置文件。这种结构有助于准确、轻松地描述 Terraform 工具所需的环境配置。
最近,HCL 已经放弃使用该语言的版本 1,转而使用版本 2。这篇文章假设我们谈论的是 HCL2 而不是 HCL1。
HCL2 是 HCL 和 HashiCorp 插值语言(HIL)的组合。HIL 增加了字符串插值和更强的在变量声明中使用函数的能力。
除了 Terraform 之外,HCL 还可以用于其他工具。随着时间的推移,不同的解析器变得可用,比如 Go、Java 和 Python。在这篇文章中,我将讨论如何开始使用 HCL,以及哪些工具可以利用它的独特特性。
HCL 语言和特性
HCL 是一种 JSON 兼容语言,它增加了一些功能来帮助您最大限度地使用 Terraform 工具。这些特性使 HCL 成为一种强大的配置语言,并解决了 JSON 的一些缺点。
- 注释有单行和多行两种形式:
- 单线:
#或//。 - 多行:
/* */(无块注释嵌套)。
- 单线:
- 变量赋值使用
key = value结构,其中空格无关紧要,值可以是一个原语,比如字符串、数字、布尔值、对象或列表。 - 字符串用引号括起来,可以包含任何 UTF-8 字符。
- 数字可以用多种不同的方式书写和解析:
- 十进制数是默认值。
- 十六进制:用
0x作为数字的前缀。 - 八进制:在数字前加一个
0。 - 科学数字:使用符号,如
1e10。
- 使用
[]创建数组和{ key = value }创建列表很容易。
这个概述只是触及了 HCL 的皮毛。通过研究一个示例配置文件并分析其工作原理,可以更容易地了解 HCL 的工作原理。
创建简单的 HCL 配置文件
为了了解 HCL 配置的实际情况,让我们创建一个简单的配置,演示一些可用的功能:
/*
Define the default configuration values here
*/
default_address = "127.0.0.1"
default_message = upper("Incident: ${incident}")
default_options = {
priority: "High",
color: "Red"
}
incident_rules {
# Rule number 1
rule "down_server" "infrastructure" {
incident = 100
options = var.override_options ? var.override_options : var.default_options
server = default_address
message = default_message
}
}
你可能注意到我们对default_message变量使用了函数调用和字符串插值。upper()函数将使字符串大写,而${}构造用给定字符串中的值替换其中的变量。
与其他配置语言相比,另一个突出的特性是rule "down_server" "infrastructure"格式。这是一个type label label格式。在这个例子中,我们定义了应用程序中使用的规则类型和规则类别。
你也可以看到我们为options变量使用了一个三元条件。如果override_options变量存在,我们就使用那个值,否则我们就使用default_options。这种配置展示了 HCL 利用逻辑、字符串插值和语言内部操作的强大能力。
轻松编辑 HCL 配置
Visual Studio Code (VS Code)是目前最流行的编辑器之一,由微软免费提供。VS 代码有扩展,为基本编辑器增加了额外的功能。其中包括:
- 一个 HCL 扩展来提供适当的语言着色。
- Terraform 扩展也增加了 HCL 支持,尽管是以 HashiCorp 工具之一命名的。这个扩展提供了语法突出显示和基本验证。
Atom 编辑器是 VS 代码的替代编辑器,也很受欢迎。它还提供了一个 HCL 语法高亮包。
到目前为止,我已经讨论了在 HashiCorp 工具的上下文中使用 HCL,但是还有其他工具使用 HCL 文件用于不同的应用程序。
一个例子是 hclq 命令行处理器。这个命令行处理器提供了以下功能:
- 配置的检查和验证。
- 用
grep或sed解析文件的替代方法。 - 值插值的预处理。
请注意,该工具目前没有 HCL2 支持,但它是计划中的。
许多组织现在使用 Go 编程语言,因此在 Go 程序中使用 HCL 可能是一个有吸引力的选择。有一个 Go 包可以把 HCL 解码成可用的 Go 结构。
该模块使用 HCL 配置,并将输入解码为抽象语法树(AST ),从而可以在 Go 中轻松操作配置。将 HCL2 集成到服务器端 Go 程序中,可以让你使用简单易懂的复杂配置。
对于 Python 来说,有一个 HCL2 解析器不支持 HCL1,但是对于大多数项目来说这是不必要的。Python HCL2 使用解析工具包 Lark 构建,使得将 HCL2 配置集成到任何 Python 项目中变得容易。
结论
HashiCorp 配置语言最初是特定于 HashiCorp 的,但已经发展到在各种项目中变得更有吸引力。
最近的 HCL2 重写进一步合并了字符串插值和附加函数。这增加了已经很灵活的语言的可用性。易于理解的内置模板化的配置语言的强大功能,正在迅速使 HCL2 成为复杂配置的首选语言。
愉快的部署!
Adam Bertram 拥有 20 多年的 IT 经验,是一名经验丰富的在线商务专家。他是多家科技公司的顾问、微软 MVP、博客作者、培训师、出版作家和内容营销人员。在 adamtheautomator.com 的网站上关注亚当的文章,在 LinkedIn 的网站上联系,或者在 Twitter 的 @adbertram 上关注他。
Tekton 管道初步观察——Octopus 部署
原文:https://octopus.com/blog/introduction-to-tekton-pipelines

Kubernetes 正在迅速从 Docker 编排平台演变为通用云操作系统。通过 operators Kubernetes 获得了本地管理高级概念和业务流程的能力,这意味着您不再管理 pod、服务和部署的构建模块,而是描述这些构建模块可以创建的东西,如 web 服务器、数据库、连续部署、证书管理等。
当部署到 Kubernetes 集群时,Tekton 管道能够以简单值或 Docker 图像等复杂对象的形式定义和执行构建任务、输入和输出,并在管道中组合这些资源。这些新的 Kubernetes 资源和管理它们的控制器导致了一个由 Kubernetes 集群托管的无头 CI/CD 平台。
在这篇文章中,我们将看看一个运行在 MicroK8S 上的简单构建管道。
准备测试 Kubernetes 集群
在这篇文章中,我使用 MicroK8S 来提供 Kubernetes 集群。MicroK8S 在这里很有用,因为它提供了一系列官方插件,其中一个是 Docker 图像注册表。因为我们的管道构建了一个 Docker 映像,所以我们需要一个地方来托管它,而 MicroK8S registry 插件只需一个命令就能为我们提供该功能:
microk8s.enable registry
我们还需要从 MicroK8S 集群内部启用 DNS 查找。这是通过启用 DNS 插件来实现的:
microk8s.enable dns
安装 Tekton 管道
Tekton 管道的安装很简单,只需一个kubectl(或本例中的microk8s.kubectl)命令:
microk8s.kubectl apply --filename https://storage.googleapis.com/tekton-releases/pipeline/latest/release.yaml
我们现在可以在 Kubernetes 集群中创建 Tekton 资源。
“Hello World”任务
任务包含为完成工作而执行的各个步骤。在下面的例子中,我们有一个单步执行的任务,它在一个从ubuntu图像构建的容器中执行带有参数Hello World的echo命令。
下面的 YAML 显示了我们的helloworldtask.yml文件:
apiVersion: tekton.dev/v1alpha1
kind: Task
metadata:
name: echo-hello-world
spec:
steps:
- name: echo
image: ubuntu
command:
- echo
args:
- "Hello World"
使用以下命令在 Kubernetes 集群中创建任务资源:
microk8s.kubectl apply -f helloworldtask.yml
任务描述了如何完成工作,但是创建任务资源并不会导致采取任何操作。任务运行资源引用任务,任务运行资源的创建触发 Tekton 执行被引用任务中的步骤。
下面的 YAML 显示了我们的helloworldtaskrun.yml文件:
apiVersion: tekton.dev/v1alpha1
kind: TaskRun
metadata:
name: echo-hello-world-task-run
spec:
taskRef:
name: echo-hello-world
使用以下命令在 Kubernetes 集群中创建任务运行资源:
microk8s.kubectl apply -f helloworldtaskrun.yml
建立码头工人形象
为了超越这个 hello world 示例,我们将看看 Tekton 构建管道的典型用例,即编译和推送 Docker 映像。为了演示这个功能,我们将构建我们的 RandomQuotes 示例应用程序。
我们从管道资源开始管道。管道资源提供了一种为构建过程定义输入的解耦方法。
我们需要的第一个输入是保存代码的 Git 存储库。管道资源有许多已知的类型,这里我们定义了一个git管道资源,指定保存代码的 URL 和分支:
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: randomquotes-git
spec:
type: git
params:
- name: revision
value: master
- name: url
value: https://github.com/OctopusSamples/RandomQuotes-Java.git
接下来,我们定义存放编译图像的 Docker 注册表。这就是 MicroK8S 注册表插件有用的地方,因为它在 http://registry . container-registry . SVC . cluster . local:5000 公开了一个 Docker 注册表。
下面是类型为image的管道资源,它定义了我们将创建为registry.container-registry.svc.cluster.local:5000/randomquotes的 Docker 映像:
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: randomquotes-image
spec:
type: image
params:
- name: url
value: registry.container-registry.svc.cluster.local:5000/randomquotes
定义了输入源代码和目的 Docker 映像后,我们可以创建一个任务来创建 Docker 映像并将其推送到存储库。
传统上,Docker 客户机直接在主机操作系统上构建 Docker 映像。然而,在 Kubernetes 中,一切都是在 Docker 内部运行的,这就引出了一个问题:如何在 Docker 内部运行 Docker?
在过去的几年中,出现了大量的工具来执行 Docker CLI 和 daemon 提供的过程,但不依赖于 Docker 本身。这些工具包括用于解包和重新打包 Docker 映像的 umoci ,用于从 Docker 文件构建 Docker 映像的 Kaniko 和 Buildah ,以及用于运行 Docker 映像的 Podman 。
我们将在 Tekton 任务中使用 Kaniko 在 Kubernetes 提供的 Docker 容器中构建 Docker 映像。下面的 YAML 显示了完整的任务:
apiVersion: tekton.dev/v1alpha1
kind: Task
metadata:
name: build-docker-image-from-git-source
spec:
inputs:
resources:
- name: docker-source
type: git
params:
- name: pathToDockerFile
type: string
description: The path to the dockerfile to build
default: /workspace/docker-source/Dockerfile
- name: pathToContext
type: string
description:
The build context used by Kaniko
(https://github.com/GoogleContainerTools/kaniko#kaniko-build-contexts)
default: /workspace/docker-source
outputs:
resources:
- name: builtImage
type: image
steps:
- name: build-and-push
image: gcr.io/kaniko-project/executor:v0.17.1
# specifying DOCKER_CONFIG is required to allow kaniko to detect docker credential
env:
- name: "DOCKER_CONFIG"
value: "/tekton/home/.docker/"
command:
- /kaniko/executor
args:
- --dockerfile=$(inputs.params.pathToDockerFile)
- --destination=$(outputs.resources.builtImage.url)
- --context=$(inputs.params.pathToContext)
这项任务有一些重要的方面值得指出。
该任务中有两个属性与我们上面创建的管道资源相关。
git类型的输入资源:
inputs:
resources:
- name: docker-source
type: git
和类型image的输出:
outputs:
resources:
- name: builtImage
type: image
有两个额外的输入参数定义 Docker 构建过程使用的路径:
spec:
inputs:
params:
- name: pathToDockerFile
type: string
description: The path to the dockerfile to build
default: /workspace/docker-source/Dockerfile
- name: pathToContext
type: string
description:
The build context used by Kaniko
(https://github.com/GoogleContainerTools/kaniko#kaniko-build-contexts)
default: /workspace/docker-source
注意路径/workspace/docker-source是git资源使用的约定,其中docker-source目录匹配输入的名称。
然后我们有一个构建 Docker 映像的单一步骤。构建在从gcr.io/kaniko-project/executor:v0.17.1映像创建的容器中执行,该容器提供 Kaniko:
spec:
steps:
- name: build-and-push
image: gcr.io/kaniko-project/executor:v0.17.1
# specifying DOCKER_CONFIG is required to allow kaniko to detect docker credential
env:
- name: "DOCKER_CONFIG"
value: "/tekton/home/.docker/"
command:
- /kaniko/executor
args:
- --dockerfile=$(inputs.params.pathToDockerFile)
- --destination=$(outputs.resources.builtImage.url)
- --context=$(inputs.params.pathToContext)
最后,任务运行用于将任务和管道资源绑定在一起。该资源将任务docker-source输入映射到randomquotes-git管道资源,将builtImage输出映射到randomquotes-image管道资源。
创建此资源会触发构建的发生:
apiVersion: tekton.dev/v1alpha1
kind: TaskRun
metadata:
name: build-docker-image-from-git-source-task-run
spec:
taskRef:
name: build-docker-image-from-git-source
inputs:
resources:
- name: docker-source
resourceRef:
name: randomquotes-git
params:
- name: pathToDockerFile
value: Dockerfile
- name: pathToContext
value: /workspace/docker-source
outputs:
resources:
- name: builtImage
resourceRef:
name: randomquotes-image
与构件交互
Tekton 本身并不提供任何与作业交互的仪表板或 GUI。但是,有一个 CLI 工具用于管理 Tekton 作业。
Tekton CLI 工具假设配置了kubectl,但是 MicroK8S 维护了一个名为microk8s.kubectl的独立工具。配置kubectl最简单的方法是使用以下命令,该命令将 MicroK8S 配置文件复制到kubectl的标准位置:
sudo microk8s.kubectl config view --raw > $HOME/.kube/config
此时,我们可以使用以下命令获得任务的状态:
tkn taskrun logs build-docker-image-from-git-source-task-run

泰克顿适合你吗?
无头构建服务器的想法很有意思。
通过用 Docker 映像构建构建,Tekton 消除了维护一套专用构建代理的开销。如今,每种工具和语言都提供了一个受支持的 Docker 映像,使得跟上主流语言版本六个月发布周期的新常态变得更加容易。
Kubernetes 也是服务于软件构建的弹性和短期需求的天然平台。当您可以有五个节点在它们之间调度构建时,为什么有十个专门的代理处于空闲状态?
但是,我怀疑 Tekton 本身对于大多数工程团队来说太低级了。任何以前使用过kubectl的人都会熟悉tkn CLI 工具,但是很难从终端理解构建的整体状态。更不用说用kubectl create -f taskrun.yml创建的版本很快就过时了。
有一个仪表板可用,但与现有的 CI 工具相比,它是一个基本的用户界面。

也就是说,Tekton 是构建面向开发人员的工具的强大基础。 Jenkins X 和 OpenShift Pipelines 就是这样两个利用 Tekton 的平台。
结论
Kubernetes 解决了运行应用程序的许多需求,如身份验证、授权、CLI 工具、资源管理、健康检查等等。Kubernetes 集群可以通过一个命令托管一个全功能的 CI 服务器,这一事实证明了 Kubernetes 的灵活性。
有了像 Jenkins X 和 OpenShift Pipelines 这样的项目,Tekton 开始了进入主流开发工作流的旅程。但是作为一个独立的项目,Tekton 有点太接近金属了,以至于大多数开发团队都无法使用,仅仅是因为很少有人有经验来支持它。
如何全局使用 Octopus Deploy - Octopus Deploy
ioGlobal 是一家澳大利亚公司,为资源和环境行业提供应用地球化学、资源分析和数据系统自动化解决方案。他们在五月份开始使用 Octopus Deploy,并且 Stacy Andrews 很友好地分享了他的经验。
告诉我们你自己的情况
Stacy Andrews,ioGlobal 私人有限公司,首席技术官。寻求开发商业软件的职业软件开发人员(主要在采矿业)。
您使用 Octopus 部署了哪些类型的应用程序?
我们主要使用 Octopus 部署 Web 应用程序。ASP.NET Web forms(版本 4)和 MVC(版本 3)以及相关的支持服务,它们是基于 OpenRasta 的 Web 服务(托管在 IIS 中)和基于 NServiceBus 的服务的组合。
你的环境是什么样的?
Octopus Deploy 目前正在管理以下系统的部署…
-
我们有许多内部测试环境(在任何时候,我们都有 3 个以上的环境用于各种用途,每个环境有 3 个虚拟机(独立的应用服务器、数据库服务器和报告服务器)。
-
我们有一个暂存环境,由北美的 RackSpace 托管。
-
我们有两个生产环境。一个在澳大利亚,由 Amcom 主办。一个在北美,由 RackSpace 托管。
-
我们有一个由 Amazon Web Services 托管的灾难恢复/预览环境。
我们有系统的现场托管版本;一家与 BHPB 合作,另一家与 Anglo Platinum 合作(由于防火墙/安全限制,这些公司目前没有使用 Octopus)。
在使用 Octopus 之前,部署流程是怎样的?
麻烦而复杂。我们将直接从内部构建服务器上运行的 powershell 脚本进行部署。这意味着我们在构建脚本中混合了部署问题(针对环境配置等)。
同样,我们必须为我们的生产环境手动运行这些脚本。
你认为 Octopus Deploy 的优势是什么?
其设置简单。一旦它开始运行,它就不会碍事了。
它使用了普遍可用的技术(NuGet、config transformation、powershell ),所以有大量的 doco。
你认为 Octopus Deploy 的弱点是什么?
如果您在错误的页面上,UI 中的一些工作流可能会令人困惑。
不能等待内置的持续部署工具(目前我们需要从 PS 脚本进行编排)。
你会对其他评估 Octopus Deploy 的人说些什么?
如果您从没有自动部署到使用 Octopus Deploy 慢慢来,慢慢干。从 web 应用程序开始(Octopus 让它非常容易部署)。
通读文档;它写得很好,有许多常识性的建议。
如果你有困难,可以看看 ioGlobal 的设置!
章鱼部署 Java 支持 RFC -章鱼部署
章鱼最初是用。NET 开发人员的想法,并附带了许多约定,使部署。网络应用简单。在基本层面上,Octopus 提供了作为传输层的触手,以及执行 PowerShell 的能力。在此基础之上,还有将应用程序部署到 IIS 或设置 Windows 服务的内置步骤,以及需要处理的约定。NET 配置文件或转换。
当然,你已经可以使用八达通不仅仅是。NET 应用程序——您可以压缩一个 Java 应用程序,并将其推送到 Windows 机器上,然后使用 PowerShell 来配置它。或者最近你可以用 SSH 和 Bash 做同样的事情。这足以让 Java 部署工作——我最近展示了如何部署到 WildFly 和 Tomcat ,以及将 Spring Boot 应用程序部署为 Windows 服务。
你可以让它工作,但是目前还没有任何 Java 应用程序的高级约定。你可以说 Octopus 目前支持 Java 应用程序,但不像它支持的那样,为它们提供一流的支持。网络应用。
Octopus 中一流的 Java 支持
今天,我们宣布我们的长期愿景,让我们的 Java 部署故事与我们的。NET 部署故事——我们希望它们都是平等的、一流的体验。今天的 RFC 着眼于我们最初的计划,看看这意味着什么——我们计划很快构建什么——但我们也希望从您那里得到指导:Octopus 中一流的 Java 支持对您来说意味着什么?
目标
本 RFC 中概述的特性的目标是为在 Windows 和 Linux 上运行的 Tomcat 和 wildly/JBoss EAP 部署 Java 应用程序提供一流的支持。
应用服务器支持
最初 Octopus Deploy 将支持 Tomcat 和 WildFly / JBoss EAP。选择这些应用服务器是因为它们有很大的市场份额,当结合起来时,它们代表了生产中大约三分之二的 Java 服务器。
我们将针对红帽 JBoss EAP 6 及以上,Wildfly 10 及以上,Tomcat 7 及以上。
我们不可能一开始就实现对所有应用服务器的支持,但是如果你希望看到对 WebSphere、WebLogic、Glassfish、Payara 等的支持。请添加评论。
支持这些应用服务器意味着向 Octopus Deploy 添加以下步骤:
- 部署包
- 文件复制(即将 WAR 文件复制到
webapps或deployments目录,或者分解 WAR 文件) - 通过 Tomcat 管理器进行 HTTP 上传
- 使用 WildFly CLI 工具进行 CLI 部署
- 证书管理
- 导出 JKS Java 密钥库
- 在 WildFly 或 Tomcat 中配置密钥库
- 创建和部署 WildFly 保管库以存储可在 WildFly 配置文件中引用的敏感信息。
配置支持
为了支持 Java 应用程序中的各种配置文件,将添加一些步骤,以便能够转换 Java 包中任意位置的 XML、YAML 和属性文件。这将允许 Octopus Deploy 支持 Spring 和 Java Servlet 或 JavaEE 应用程序广泛使用的 XML 配置文件,以及 Spring 外部化配置。
Linux 支持
由于 Linux 很受 Java 开发人员的欢迎,部署服务的现有步骤将被扩展到同时支持 init 和 systemd。
目前我们要求 Mono 安装在 Linux 服务器上。我们已经把乌贼和触手的部分转移到。NET 核心,所以这应该消除 Mono 依赖。
包装支持
目前 Octopus Deploy 接受 ZIP 和 Nuget 包。为了支持 Java,将本机支持 JAR、WAR、EAR 和 RAR 包格式。这将允许上传 Java 包,而不需要先将它们打包成 ZIP 文件。
Octopus 还将支持 Maven 存储库作为一级包提要,这是目前支持 NuGet 和 Docker Registry 的方式。
版本支持
将添加对 Maven 版本控制方案的支持,以允许 Octopus Deploy 比较两个 Java 包的版本。版本信息将在Implementation-Version键下的META-INF/manifest.mf文件中找到。
反馈
如果您对我们提议的更改有任何建议或意见,请留下您的评论。如果您希望看到 Octopus Deploy 支持 Java 部署场景,或者如果您有特定的功能需求,您的反馈是很有价值的。
作为租户管理 JavaScript 库的所有消费者——Octopus Deploy
原文:https://octopus.com/blog/javacript-library-users-as-tenants
在我的上一篇文章中,您学习了如何使用 Octopus 将一个散列命名的 JavaScript 库包部署到云存储中。在云存储中,它通过一个自动更新的库变量集中的变量被其他项目引用。
这是在 Octopus 中管理可重用前端代码的良好开端。当发布发生时,它让你的包的每个消费者保持你的库的最新版本。使用最新版本可能正是您需要的行为,尤其是如果您只有几个引用中小型 JavaScript 库的内部项目。然而,如果随着组织规模的扩大而继续这种模式,某些场景可能会造成困境。
激励示例
后端版本需要旧的 JS 库
当需要修补程序时,可能会发生这种情况。随着前端库的增长,您不会为了一个不相关的修复而急于升级。您可以在项目级别覆盖库变量。如果这种情况偶尔发生,这将是一个合理的解决方案,但如果这是正常的开发流程,并且多个团队引用您的脚本并希望在方便的时候升级,清楚地了解谁在哪个版本的库是有帮助的。您还希望能够回滚一个破坏了一个消费者的更改,或者升级一个由于旧版本库中的已知错误而失败的不同网站。在这些情况下,您不仅要向特定的环境发布 JavaScript,还要向特定的消费者发布。
消费者不是内部的
也许您创建了一个小部件,用户可以通过复制粘贴您网站上的代码片段将其添加到自己的网站上。或者,一个库开始时是一个内部项目,但后来被证明是通用的,足以让你的公司通过 CDN 向全世界提供它。
在这些情况下,您将无法修改脚本的 HTML 引用。您必须将发布 JavaScript 的概念与发布使用它的代码分开,并且您必须以新的方式解决缓存破坏问题。
房客们来救援了
租户是代表 JavaScript 库消费者的一个很好的概念。租户通常用来代表应用程序的客户。在这种情况下,您的客户可能是内部客户,但在 Octopus,扩大我们的工程团队表明,将其他团队视为内部客户是有帮助的。
您正在更新不同网站上的脚本依赖关系,而不是将软件部署到不同客户的基础架构中,但是在 Octopus 中如何管理它的所有要求都是一样的,就好像您正在为不同的客户部署适当版本的服务器端应用程序一样。
这里有一个按照本文中的说明操作后你最终得到的仪表板的例子。在这个例子中,假设您正在将您的共享脚本部署到一个公司 WordPress 博客、一个外部客户和您公司的主网站。

其中的每一个都被表示为一个租户,您将使用一个公共变量为其分配一个惟一的标识符,因为这些都不是按照环境来划分范围的。
设置您的消费者密钥变量
在 Octopus 门户网站中,导航至库选项卡,然后导航至变量集部分。然后点击添加新变量集,填写如下对话框:
- 新变量集名称 -
Consumer - 变量集描述 -
Key string used to identify a consumer of our JavaScript library
点击保存。

选择您新创建的变量集,然后点击变量模板,然后点击添加模板按钮。按如下方式填写详细信息:
- 变量名 -
BundleConsumerKey - 标签 -
Bundle Consumer Key - 帮助文字 -
This key will be used by the consumer in a data attribute in the script tag, so the script can look up the URL of the bundle to download - 控制类型 -
Single-line text box - 要显示的控件类型 -
Default value

为每个租户创建一个消费者
导航到租户选项卡,单击添加租户按钮,并创建一个名为Blog的租户。
单击您新创建的租户,导航到其变量部分,然后单击公共变量。
将Bundle Consumer Key的变量设置为值Blog。

重复这个过程,创建Bundle Consumer Key值为Customer的External customer租户,以及Bundle Consumer Key值为Mainsite的Main Website租户。
现在你需要一个项目来与这些租户互动。
设置您的项目
您可以使用以下过程部署到您的租户。

你基本上使用了与前一篇文章相同的过程。但是在更新变量集中的包 URL 之前,您会停下来,因为这个租用部署过程的最后一步是不同的。
根据上一篇文章,在 Octopus Deploy 中创建一个流程,包括以下步骤:
现在您已经有了上传 JavaScript 包的项目的基础,您需要进行修改以启用租用部署。
要求项目的所有部署都有租户
导航到项目的设置,并选择要求所有部署都有租户的选项。

将所有消费者租户连接到您的项目
对于您的每个租户,单击连接项目按钮,将您的 JavaScript 项目连接到test和production环境的租户。

允许所有租户使用您的亚马逊 S3 帐户
如果您正在使用一个 account 变量,您会发现有一个额外的步骤允许使用它向您的任何租户释放。将帐户限制为租户的能力对于帮助防止错误的客户使用错误的帐户非常重要,但是为了简单起见,假设您正在向所有消费者引用的一个 S3 存储桶发布帐户。

更新捆绑包 URL 的新部署步骤
为了控制每个租户引用的包 URL,您的新流程为租户和环境的每个组合上传一个小的 JSON 文件到您的 S3 bucket 的根目录。该文件的名称格式为consumerkey.enivornment.json。这里有一个Customer.production.json的例子:
{
"url": "https://bundle-s3.s3.ap-southeast-2.amazonaws.com/release_0.0.112/js/app.69e902e8.js"
}
要在部署过程的最后一步生成这些 JSON 文件,请添加一个运行 AWS CLI 脚本步骤,该步骤引用您的包,并配置为使用您的 S3 帐户。
现在添加以下 PowerShell 脚本:
$bundle = Get-ChildItem -Path MyBundle/js/*.js | Select-Object -First 1
$releaseId = $OctopusParameters["Octopus.Release.Number"]
$bundleUrl = $bucketUrl + 'release_' + $releaseId + '/js/' + $bundle.Name
$env = $OctopusParameters["Octopus.Environment.Name"];
echo "{""url"":""$bundleUrl""}" | aws s3 cp - "s3://#{s3-bucket-name}/#{BundleConsumerKey}.$env.json" --acl public-read
aws s3 cp MyBundle/bundle-loader.js s3://#{s3-bucket-name}/bundle-loader.js --acl public-read
这还不能成功运行,因为您必须将bundle-loader.js添加到您的包中的代码中。
动态缓存破坏
你希望bundle-loader.js位于你的包的根部。为了在 Vue JS 中实现这一点,在 Vue 项目中的public文件夹的根目录下创建文件。
下面是bundle-loader.js的来源:
(async () => {
const { consumerKey, environment } = document.currentScript.dataset;
const redirectFileUrl = `${document.currentScript.src.substring(0, document.currentScript.src.lastIndexOf('/'))}/${consumerKey}.${environment}.json`;
const response = await fetch(redirectFileUrl, { cache: "no-store" });
const bundleInfo = await response.json();
var script = document.createElement('script');
script.src = bundleInfo.url
document.head.appendChild(script);
}
)();
消费者现在引用bundle-loader.js而不是直接引用捆绑包。它将在不缓存的情况下获取小的 JSON 文件,然后动态添加一个新的script标记来引用租户和环境的正确版本。这些在引用bundle-loader.js的script标签的数据属性中指定。
下面是一个在 ASP.NET 核心 MVC 中实现的消费者页面的例子:
@page
@inject BundleSettings bundleSettings
<script src="@bundleSettings.BaseUrl/bundle-loader.js" data-consumer-key="@bundleSettings.ConsumerKey" data-environment="@bundleSettings.EnvironmentName"></script>
<div id="app"></div>
现在,当您发布新版本的库时,不需要对消费者进行任何修改来更新他们的 JavaScript 引用。
结论
租户是 Octopus 的一个强大而通用的特性。在这篇文章中,我展示了它们非常适合为共享 JavaScript 库的消费者建模。
租户变量的灵活性为高级场景打开了大门,例如发布 NPM 包或为不同的消费者发布 JavaScript 库的定制版本。这种方法确实增加了一点复杂性,如果您只想让所有用户使用不经常改变的 JavaScript 依赖项的最新版本,那么多租户部署可能是多余的。
我已经证明,当您需要时,采用一个更简单的部署流程来实现多租户并不困难。从一个简单的 JavaScript 库部署过程开始是很好的,但是如果您需要完全控制谁使用哪个版本的库,租户可以满足您的需求。
愉快的部署!
为 JavaScript 项目提供环境特定的配置——Octopus Deploy
将单页面应用程序(SPA)作为独立的 JavaScript 应用程序进行开发和部署是很常见的,但是,在将这些项目集成到典型的持续部署管道中时,会出现一个常见的问题。

作为优秀的 DevOps 实践者,我们知道我们应该构建一次,部署多次,但是我们如何让这适用于我们的前端应用程序呢?
来自 JSON 的 JavaScript 配置
一些支持者相信十二因素应用中列出的戒律,并认为应用程序的所有配置都应该从单个环境变量中提取出来。依我的拙见,这种方法非常有限,原因有几个。
- 首先,这对于基于浏览器的运行时来说并不容易,在这种情况下,您有一个静态网站需要服务,并且需要在浏览器中获得该配置。
- 其次,这增加了您的托管环境的复杂性,因此您需要确保运行您的应用程序的每个进程都有自己的环境变量集合,这些环境变量在重启后持续存在,并且不会泄漏到其他实例(例如,您的测试虚拟机托管同一应用程序的多个实例)。
- 最后,当您只有一个需要在不同环境中不同的 URL 时,这可能很简单,但是在许多应用程序中,配置可能包括许多不同的变量,其中一些是深度嵌套的值。试图通过环境变量来管理和整合层次化信息有很多缺点。
最终,不将配置存储在代码中,而是存储在环境变量中的 12 因素应用程序解决方案,有点虚假的困境。我们知道在代码中存储配置既不是提供配置的最灵活也不是最安全的方式,但它是推荐的替代方案。任何好的部署工具都应该能够提供以自包含方式运行应用程序所需的特定于环境的变量。
配置为 JSON
创建一个简单的config.json文件,包含应用程序所需的配置。这个配置中的值可以是开发时需要的值。不需要在源代码中创建config.staging.json或config.prod.json文件,环境配置将由 Octopus(或您选择的部署工具)在部署时提供。避免这些环境配置文件,使我们的 CD 过程更加灵活,并避免将我们的基础设施阶段泄露到源代码中。在运行时,我们的代码需要做的就是像其他资源一样从服务器检索这个config.json文件。

对于那些担心从应用程序的根目录获得一个/config.json的人来说,请记住,如果这些值被嵌入到您的 javascript 文件中,那么它们就像一样开放。如果您担心泄露敏感信息,那么前端可能不是存储这些信息的合适位置。一个好的副作用是,只需自己从浏览器加载配置,就可以非常容易地检查静态内容是否已经成功部署。通过将构建号和发布日期作为属性包含在配置文件中,我可以很容易地检查它们是否被部署到了正确的位置,以及它们是否通过了各种 cdn 和缓存。
例子
让我们通过几个例子来说明如何实现这一点。在您使用的任何框架中,有许多方法可以实现这种模式,因此您可能希望修改下面的示例来满足您的需要。
NodeJs 应用
NodeJs 是一个非常简单的用例。只要我们将配置文件包含在分布式应用程序中,我们就可以像加载任何其他模块一样直接加载它:
const config = require("./config");
console.log(`Hello ${config.message}`);
如果你尝试,你不可能得到比这更简单的配置。

不需要检测环境,加载config.prod.json并与config.json中的默认值结合,或者与环境变量合并。
React 应用
使用 React,我们希望将所有应用程序文件缩小并合并到一个 JavaScript 文件中,以优化运行时体验。我们不希望将配置文件嵌入到单个应用程序文件中,因为这使得我们更难以在部署时使用我们的环境特定值进行更新。相反,我们决定在加载配置文件时显示一个闪屏。这可以通过几个步骤来完成。

从应用程序中的一个简单的config.json文件开始,我们提供了一个可以在开发和本地测试中使用的值。当我们按原样构建我们的应用程序时,该文件将被复制到我们的分发目录中:
config/config.js
{ "message": "My Dev Machine" }
在这个场景中,我们使用 Webpack 来开发我们的代码,因此,我们包含了一行代码来将我们的config.json文件复制到输出目录:
webpack.config.js
const HtmlWebPackPlugin = require("html-webpack-plugin");
const CopyWebpackPlugin = require('copy-webpack-plugin');
module.exports = {
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, use: { } },
{ test: /\.html$/, use: [ { loader: "html-loader" }] }
]
},
plugins: [
new HtmlWebPackPlugin({ template: "./src/index.html", filename: "./index.html" }),
new CopyWebpackPlugin([ { from: 'src/config/config.json', to: 'config.json', toType: 'file' } ], { })
]
};
我们的入口点index.js文件将使用一个ConfigLoader组件在运行时加载配置文件,并在完成时显示Home组件:
index.js
import React, { Component } from 'react';
import ReactDOM from 'react-dom';
import ConfigLoader from './components/ConfigLoader';
import Home from './components/Home';
class App extends Component {
render() {
// When the configuration is loaded, render the Home module
return <ConfigLoader ready={() => <Home />} />;
}
}
ReactDOM.render(<App />, document.getElementById('root'));
Home组件显示通过配置提供的信息:
components/Home.js
import React, { Component } from 'react';
import config from './config';
export default class Home extends Component {
render() { return <div className="App">
<header className="App-header">
<h1 className="App-title">Welcome to {config.message}</h1>
</header>
</div>;
}
}
如您所见,我们正在导入一个config模块。这不是上面创建的原始 JSON 文件。这是一个特殊的模块,我将在下面向您展示。由于该组件在ConfigLoader组件加载了config.json文件后才会呈现,我们可以假设 config 对象拥有我们需要的所有属性,在本例中只有message。
ConfigLoader组件简单地调用我们的配置模块上的load方法,并在配置加载后通过其 props 呈现请求的组件:
components/ConfigLoader.js
import { Component } from 'react';
import {load} from "./config";
export default class ConfigLoader extends Component {
constructor(props){
super(props);
this.state = {isLoaded: false};
}
componentDidMount() {
// Once the configuration is loaded set `isLoaded` to true so we know to render our component
load().then(config => this.setState({isLoaded: true, config}));
}
render() {
// If we haven't yet loaded the config, show either a "splash" component provided via a `loading` props or return nothing.
if(!this.state.isLoaded) {
return this.props.loading ? this.props.loading() : null;
}
// The config is loaded so show the component set on the `ready()` props
return this.props.ready(this.state.config);
}
}
真正的奇迹发生在我们的config.json组件中。我们最初提供一个空对象来代替我们的配置。我们这样做是为了当我们通过 HTTP fetch 命令加载配置时,我们有效地将属性从加载的对象复制到导出的对象上。这是因为导出的对象在第一次加载该模块时被有效地缓存:
components/config.js
const config = {};
export default config;
function load() {
return fetch('config.json')
.then(result => result.json())
.then((newconfig) => {
for(let prop in config) {
delete config[prop]
}
for(let prop in newconfig) {
config[prop] = newconfig[prop]
}
return config;
});
}
export {load}
在开发过程中,我们可以修改配置文件,Webpack 将触发刷新,就像我们正在更新任何其他文件一样。

在我们的应用程序中,我们希望使用配置的任何地方(如上面的Home组件),我们可以加载并简单地使用config模块并直接访问属性,因为所有向下的模块只有在ConfigLoader组件检索到配置后才会呈现。只要我们将config.json文件作为 CD 管道的一部分进行转换,我们将获得应用程序提供和使用的适当值。
这是一个相当简单的演示,根据您的用例,您可能希望将配置分派到 redux 存储中,或者您可能还希望处理更复杂的场景,如缓存破坏等。
Angular 应用
我将无耻地插入 Pam Loahoud 关于为 Angular 创建可编辑的配置文件的另一篇博客文章,而不是过多地重复上面关于不同框架的相同观点,因为这基本上遵循了与上面例子相同的基本前提。
在 Pam 的例子中,它归结为创建一个服务来检索静态托管的config.json文件:
import { Injectable } from '@angular/core’;
import { Http, Response } from '@angular/http';
import { environment } from '../environments/environment';
import { IAppConfig } from './models/app-config.model';
@Injectable()
export class AppConfig {
static settings: IAppConfig;
constructor(private http: Http) {}
load() {
const jsonFile = `assets/config/config.${environment.name}.json`;
return new Promise<void>((resolve, reject) => {
this.http.get(jsonFile).toPromise().then((response : Response) => {
AppConfig.settings = <IAppConfig>response.json();
resolve();
}).catch((response: any) => {
reject(`Could not load file '${jsonFile}': ${JSON.stringify(response)}`);
});
});
}
}
然后更新app.module.ts文件以在启动时调用该服务:
import { APP_INITIALIZER } from '@angular/core';
import { AppConfig } from './app.config';
export function initializeApp(appConfig: AppConfig) {
return () => appConfig.load();
}
@NgModule({
imports: [ , , , ],
declarations: [ . . . ],
providers: [
AppConfig,
{ provide: APP_INITIALIZER,
useFactory: initializeApp,
deps: [AppConfig], multi: true }
],
bootstrap: [
AppComponent
]
})
export class AppModule { }
就像 React 示例一样,当它在启动期间运行时,您可以在整个应用程序中使用配置:
export class DataService {
protected apiServer = AppConfig.settings.apiServer;
. . .
if (AppConfig.settings.aad.requireAuth) { . . . }
}
我喜欢使用 typescript 在开发时提供配置的类型检查。再说一次,在您构建的包中有了单个配置文件,关键是让您的部署工具执行适当的配置替换和转换。
JavaScript 配置
在 Jenkinsfile 中构建 Docker 映像并发布到 ECR - Octopus Deploy
在本文中,您将学习如何使用 Jenkins 构建 Octopus Deploy underwater app 并将其推送到 Amazon Elastic Container Registry(ECR)。
先决条件
要跟进,您需要:
- 亚马逊网络服务(AWS)帐户
- 詹金斯的例子
- GitHub 账户
有关在您选择的环境中安装 Jenkins 的说明,您可以参考我们的指南:
这个帖子使用了 Octopus 水下应用库。您可以派生存储库并跟随它。
或者,jenkins-ecr 分支包含模板文件来完成本文中的步骤。你需要用你自己的价值观来代替一些价值观。我把我的价值观写在这篇文章里作为参考。
亚马逊网络服务设置
要为 Jenkins 设置 AWS,您需要创建一个访问密钥和一个 ECR 存储库来存储图像。
要创建访问密钥,请前往亚马逊控制台,然后 IAM ,然后用户、【你的用户】、安全凭证,以及创建访问密钥。
您的浏览器将下载一个包含访问密钥 ID 和秘密访问密钥的文件。这些值将在 Jenkins 中用于向 Amazon 认证。
要创建存储库,请转到亚马逊控制台,然后是 ECR ,然后是创建存储库。
您需要为发布的每个图像建立一个图像存储库。给存储库起一个您想让图像起的名字。
你会在亚马逊 ECR 下看到你的仓库,然后是仓库。记下它所在的区域,在 URI 场。

Jenkins 设置
首先,你需要安装一些插件来与 Docker 和 Amazon 交互。
进入仪表板,然后管理詹金斯,然后管理插件。
您需要以下插件:
你可以在可用的标签中搜索这些插件。安装后,它们出现在已安装选项卡中。
您使用一个 Jenkinsfile 来编译、构建、测试和推送图像到 Amazon ECR。Jenkinsfile 是定义 Jenkins 管道的配置文件。Jenkins Pipeline 是 Jenkins 对工件执行的一系列步骤,以实现期望的结果。在这种情况下,它是映像到 Amazon ECR 的克隆、构建、测试和推送。
使用 Jenkinsfile 的强大之处在于将它签入源代码控制中,以管理文件的不同版本。
在您的 Jenkins 实例中,转到管理 Jenkins ,然后管理凭证,然后 Jenkins 存储,然后全局凭证(无限制),最后添加凭证。

填写以下字段,将其他所有内容保留为默认值:
- 种类 - AWS 凭证
- ID-AWS-凭据,例如
- 访问密钥 ID -之前的访问密钥 ID
- 秘密访问密钥 -之前的秘密访问密钥
点击确定保存。

转到詹金斯仪表板,然后是新项目。
给你的管线命名,选择管线项,然后确定。
填写管道的以下字段,其他内容保持默认:
- GITScm 轮询的 GitHub hook 触发器 -勾选该框
- 定义 -来自 SCM 的管道脚本
- 单片机 - Git
- 存储库 URL——分叉回购和 jenkins-ecr 分支的 URL
- 凭证 -存储库的区域
- 分支说明符 -
*/jenkins-ecr
点击保存。
GitHub 设置
对于这个示例,您使用一个示例 web 应用程序,该应用程序显示一个带有有用链接的水下动画场景。
您需要设置一个 webhook,以便 Jenkins 知道存储库何时更新。为此,转到设置,然后转到 Webhooks 。

填写以下字段,其他内容保持默认。
- 有效负载 URL -
http://[jenkins-url]/github-webhook/ - 内容类型 -
application/json - 您希望哪个事件触发此 webhook? -选择刚推事件
点击添加 webhook 保存。
将 Jenkins 文件添加到存储库的根级别。您需要参考您的 Amazon ECR 存储库。请注意以下所需的更改:
pipeline {
agent any
options {
skipStagesAfterUnstable()
}
stages {
stage('Clone repository') {
steps {
script{
checkout scm
}
}
}
stage('Build') {
steps {
script{
app = docker.build("underwater")
}
}
}
stage('Test'){
steps {
echo 'Empty'
}
}
stage('Deploy') {
steps {
script{
docker.withRegistry('https://720766170633.dkr.ecr.us-east-2.amazonaws.com', 'ecr:us-east-2:aws-credentials') {
app.push("${env.BUILD_NUMBER}")
app.push("latest")
}
}
}
}
}
}
Jenkinsfile 由不同的阶段组成。Jenkins 将按顺序运行这些阶段,如果构建失败,您将看到哪个阶段失败了。
将您的代码提交给 GitHub。该提交将在 Jenkins 中触发一个构建作业。转到您的 Jenkins 实例 URL 查看构建。
我必须通过点击 Build now 按钮来触发 Jenkins 作业。在此之后,webhook 触发器在每次推送时都起作用。

构建完成后,转到 Amazon ECR,查看构建并推送到存储库的新映像。它用 Jenkins build 号和latest标记最新的推送。

结论
在本文中,您设置了一个 Jenkins 管道来构建 GitHub 存储库,并将其推送到 Amazon ECR。Jenkinsfile 可以推送到其他容器注册中心,比如 Google 和微软提供的注册中心。根据构建要求,它还可以包括其他阶段。
在映像被推送之后,您可以使用像 Octopus Deploy 这样的工具将映像部署到目标环境。如果你还没有使用 Octopus Deploy,你可以注册免费试用。
查看我们关于使用 Jenkins、Kubernetes 和 Octopus Deploy 进行部署的其他帖子:
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解有关即将举办的活动和实时流媒体录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
如何在 Docker - Octopus 部署上安装 Jenkins
Docker 在通用应用程序包的竞争中胜出。每个主要的操作系统都支持 Docker 映像,所有的云提供商都支持部署 Docker 映像,每个主要的工具或平台都提供官方的 Docker 映像。詹金斯也不例外,提供图片詹金斯/詹金斯。
在这篇文章中,你将学习如何从 Docker 镜像运行 Jenkins,配置它,定制它,并使用镜像来代替传统的基于包的安装。
先决条件
要运行 Docker 映像,您必须安装 Docker。 Docker 提供了在 Linux、macOS 和 Windows 上安装的详细说明。
请注意,虽然最近版本的 Windows 获得了对运行 Docker 映像的本机支持,但 Jenkins 只提供基于 Linux 的 Docker 映像。Windows 和 macOS 可以通过虚拟化运行 Linux Docker 映像,因此这里显示的大多数命令同样适用于所有操作系统,但本文将重点关注 Linux。
Jenkins Docker 图像入门
安装 Docker 后,可以使用以下命令运行 Jenkins:
docker run -p 8080:8080 -p 50000:50000 -v jenkins_home:/var/jenkins_home jenkins/jenkins:lts-jdk11
让我们分解这个命令,以了解它在做什么。
docker run用于运行一个 Docker 镜像作为容器。
您可以将 Docker 映像视为一个只读工件,其中包含运行特定应用程序所需的文件。与大多数应用程序工件不同,Docker 映像包含一个完整的操作系统和支持正在运行的核心应用程序所需的所有相关系统工具。在 Jenkins 的例子中,这意味着 Docker 映像包含支持最小 Linux 操作系统所需的文件,以及运行 Jenkins 所需的 Java 版本。
容器是操作系统中的一个隔离环境,Docker 映像在其中执行。尽管 Docker 通常不提供虚拟机所提供的那种隔离保证,但容器确实提供了一种轻松并行运行可信代码的方式。
-p参数将本地端口映射到 Docker 容器公开的端口。第一个参数是本地端口,后跟一个冒号,然后是容器端口。
于是参数-p 8080:8080将本地端口 8080 映射到容器端口 8080(也就是 web 端口),-p 50000:50000将本地端口 50000 映射到容器端口 50000(也就是代理端口)。这意味着您可以在本地机器上打开 http://localhost:8080,Docker 将流量定向到容器托管的 web 服务器。
参数-v jenkins_home:/var/jenkins_home创建一个名为jenkins_home的卷,如果它还不存在的话,并把它挂载到容器内的路径/var/jenkins_home下。
虽然 Docker 映像是只读的,但 Docker 容器公开了一个读/写文件系统,允许任何正在运行的应用程序保存更改。但是,这些更改对于容器来说是本地的,如果容器被破坏,这些更改就会丢失。或者,如果您想要使用不同的容器,例如,如果您想要升级到较新版本的 Jenkins,对旧容器的更改也会丢失。
Docker 卷允许容器在容器生命周期之外保存数据,并与不同的容器共享数据。您可以将卷视为登录企业网络时通常会在会话中看到的网络驱动器。通过将可变数据保存到卷中,您可以销毁并重新创建 Jenkins 容器,或者基于较新的 Docker 映像创建新的容器,同时保留您对 Jenkins 配置所做的任何更改。
最后一个参数jenkins/jenkins:lts-jdk11是 Docker 图像的名称。这个特殊的图片可以在 Dockerhub 上找到,Dockerhub 是众多 Docker 注册中心中的一个,可以用来存放 Docker 图片。
注意,与 Docker 标签相关联的图像可以随着时间而改变。许多注册中心使用“浮动”标签来表示图像的最新版本。在 Jenkins 图像的情况下,带有标签lts-jdk11的图像随着每次 LTS 发布而更新。
为了确保您的本地机器有最新的映像,您必须手动运行docker pull jenkins/jenkins:lts-jdk11。但是请注意,任何现有的容器都将继续使用旧的映像,您必须创建一个新的容器来引用任何更新的映像。
更具体的标签,像2.303.2-lts-jdk11,一般不会被覆盖,所以没有理由在这些图像上运行docker pull。
要查看此命令创建的容器,请运行:
docker container ls
您将看到容器的基本细节,以及一个(通常很幽默的)名称,如nostalgic_tharp:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
801f4e834173 jenkins/jenkins:lts-jdk11 "/sbin/tini -- /usr/…" About a minute ago Up About a minute 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 0.0.0.0:50000->50000/tcp, :::50000->50000/tcp nostalgic_tharp
要定义容器名,请传递参数--name:
docker run -d --name jenkins -p 8080:8080 -p 50000:50000 jenkins/jenkins:lts-jdk11
第一次引导 Jenkins 时,Docker 日志将包含如下消息:
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
1883c809f01b4ed585fb5c3e0156543a
This may also be found at: /var/jenkins_home/secrets/initialAdminPassword
这个由数字和字母组成的随机字符串是初始管理员密码,是完成 Jenkins 配置所必需的。
当您在日志中看到以下消息时,打开 http://localhost:8080 :
Jenkins is fully up and running
现在您有机会完成 Jenkins 实例的初始配置。请看一下之前关于传统 Jenkins 安装的帖子,了解完成初始配置的更多细节。
您可能已经注意到,使用上面的命令运行 Docker 会将您的终端附加到容器输出流。要在后台运行 Docker 图像,使用-d或--detach参数:
docker run -d -p 8080:8080 -p 50000:50000 -v jenkins_home:/var/jenkins_home jenkins/jenkins:lts-jdk11
向 Jenkins 服务器添加附加软件
因为 Jenkins 是用 Java 编写的,所以通过运行 Jenkins Docker 映像创建的默认服务器拥有编译和测试 Java 应用程序所需的大部分软件。
要构建用其他语言编写的应用程序,您需要将外部 Jenkins 代理与所需的软件连接起来,并在这些软件上运行作业。使用代理是一种可伸缩的解决方案,如果您在生产环境中使用 Jenkins,那么您应该考虑这种解决方案。
对于本地测试,一个更方便的解决方案是构建一个定制的 Docker 映像,其中内置了所需的工具。为此,您需要创建一个名为Dockerfile的文件,内容如下:
FROM jenkins/jenkins:lts-jdk11
USER root
RUN apt update && \
apt install -y --no-install-recommends gnupg curl ca-certificates apt-transport-https && \
curl -sSfL https://apt.octopus.com/public.key | apt-key add - && \
sh -c "echo deb https://apt.octopus.com/ stable main > /etc/apt/sources.list.d/octopus.com.list" && \
apt update && apt install -y octopuscli
USER jenkins
Dockerfile文件用于构建新的 Docker 映像。你可以从 Docker 文档中找到Dockerfile中可用命令的完整参考。上面的示例使用了一小部分命令,但展示了一个基于 Jenkins 提供的图像的典型自定义图像。
该文件以FROM命令开始,该命令指示 Docker 从提供的图像构建新图像。这意味着您的新映像已经安装并配置了 Jenkins 和任何支持工具:
FROM jenkins/jenkins:lts-jdk11
为了安装新软件,您必须切换到root用户。就像普通的 Linux 操作系统一样,只有特权用户才能从软件包管理器安装新软件:
USER root
下一个命令执行软件安装。本示例使用来自 Octopus 网站的说明安装 Octopus CLI:
RUN apt update && \
apt install -y --no-install-recommends gnupg curl ca-certificates apt-transport-https && \
curl -sSfL https://apt.octopus.com/public.key | apt-key add - && \
sh -c "echo deb https://apt.octopus.com/ stable main > /etc/apt/sources.list.d/octopus.com.list" && \
apt update && apt install -y octopuscli
让一个普通用户帐户运行 Docker 容器中的应用程序被认为是最佳实践。jenkins用户是在基本映像中创建的,因此您可以使用最后一个命令切换回该用户:
USER jenkins
要使用Dockerfile构建新的 Docker 映像,请运行:
docker build . -t myjenkins
该命令构建一个名为myjenkins的新映像。要运行新映像,首先使用jenkins_home卷停止任何现有容器:
docker container stop nostalgic_tharp
然后运行您的新映像,挂载现有的jenkins_home卷,以保留您现有的所有 Jenkins 配置:
docker run -p 8080:8080 -p 50000:50000 -v jenkins_home:/var/jenkins_home myjenkins
安装附加的 Jenkins 插件
安装新插件最简单的方法是使用 Jenkins web UI。任何新插件都存储到外部卷,因此即使您创建、销毁和更新容器,它们也是可用的。
您还可以通过调用包含在基础 Jenkins 映像中的jenkins-plugin-cli脚本来自动化安装插件的过程,作为自定义 Docker 映像的一部分。
这里有一个Dockerfile安装 Octopus Jenkins 插件的例子:
FROM jenkins/jenkins:lts-jdk11
USER root
RUN apt update && \
apt install -y --no-install-recommends gnupg curl ca-certificates apt-transport-https && \
curl -sSfL https://apt.octopus.com/public.key | apt-key add - && \
sh -c "echo deb https://apt.octopus.com/ stable main > /etc/apt/sources.list.d/octopus.com.list" && \
apt update && apt install -y octopuscli
RUN jenkins-plugin-cli --plugins octopusdeploy:3.1.6
USER jenkins
这个Dockerfile类似于前面的例子,但是包括一个新的RUN语句来安装 Octopus 插件:
RUN jenkins-plugin-cli --plugins octopusdeploy:3.1.6
插件 ID ( octopusdeploy)和版本(3.1.6)可从 Jenkins 插件网站找到:

发布自定义 Docker 图像
要发布您的自定义 Docker 图像,您需要一个 Docker 注册表帐户。DockerHub 是一个受欢迎的选择,它提供公共图像的免费托管。
创建一个免费账户,然后使用命令登录:
docker login
要构建可以发布到 DockerHub 的映像,运行以下命令,用您的 DockerHub 用户名替换username:
docker build . -t username/myjenkins
使用以下命令发布图像:
docker push username/myjenkins
我的 DockerHub 用户名是mcasperson,所以我运行这些命令来构建和发布一个图像:
docker build . -t mcasperson/myjenkins
docker push mcasperson/myjenkins
然后我的自定义 Docker 图像就可以从 DockerHub 获得了。
传递 Java 参数
高级 Jenkins 配置通常通过传递 Java 参数来执行,通常是以系统属性的形式。
Jenkins Docker 映像允许在JAVA_OPTS环境变量中定义 Java 参数。这个环境变量由启动 Jenkins 的 Docker 映像脚本读取,并作为 Java 参数传递。
要定义JAVA_OPTS环境变量,请将--env参数传递给docker run命令:
docker run -p 8080:8080 -p 50000:50000 -v jenkins_home:/var/jenkins_home --env JAVA_OPTS=-Dhudson.footerURL=http://mycompany.com jenkins/jenkins:lts-jdk11
Jenkins 系统属性列表可在 Jenkins 文档中找到。
传递詹金斯论点
除了系统属性之外,Jenkins 还接受许多应用程序参数。
应用程序参数通过将它们附加到 Docker run 命令的末尾来定义。以下示例传递了配置 Jenkins 监听端口 8081 的参数--httpPort:
docker run -p 8080:8081 -p 50000:50000 -v jenkins_home:/var/jenkins_home jenkins/jenkins:lts-jdk11 --httpPort=8081
应用程序参数也可以在JENKINS_OPTS环境变量中定义:
docker run -p 8080:8081 -p 50000:50000 -v jenkins_home:/var/jenkins_home --env JENKINS_OPTS=--httpPort=8081 jenkins/jenkins:lts-jdk11
在 Winstone GitHub 库中可以找到应用参数列表。Winstone 是 Jenkins 中默认的嵌入式 servlet 容器。
备份 Docker 卷
您可以运行以下命令来备份保存在托管/var/jenkins_home目录的 Docker 卷中的数据。它将卷挂载到一个新的容器中,将当前工作目录挂载到容器的/backup目录中,并创建一个名为backup.tar的归档文件,其中包含/var/jenkins目录的内容:
docker run --rm -v jenkins_home:/var/jenkins_home -v $(pwd):/backup ubuntu tar cvf /backup/backup.tar /var/jenkins_home
这个命令可以在 Jenkins 容器运行时运行,因为 Docker 卷可以在运行的容器之间共享。然而,建议您在执行备份之前停止 Jenkins:
尽管 Jenkins 利用了 COW,但建议您在执行备份之前尽可能停止 Jenkins,因为管道工作流 XML 文件可能会在不一致的状态下被捕获(例如,如果备份没有在该确切时刻拍摄每个文件的“即时快照”)。
将 Docker 图像作为服务运行
当底层操作系统重启时,Jenkins 的生产实例必须自动重启。然而,这不是您使用上面显示的 Docker 命令启动的容器的默认行为,因此任何 Jenkins 容器在 OS 重启后都将保持停止状态。
要解决这个问题,您可以将 Docker 容器作为 systemd 服务运行。这允许您管理 Jenkins 容器,就像管理安装了包管理器的 Jenkins 实例一样。
要创建新的 systemd 服务,请将以下内容保存到文件/etc/systemd/system/docker-jenkins.service:
[Unit]
Description=Jenkins
[Service]
SyslogIdentifier=docker-jenkins
ExecStartPre=-/usr/bin/docker create -m 0b -p 8080:8080 -p 50000:50000 --restart=always --name jenkins jenkins/jenkins:lts-jdk11
ExecStart=/usr/bin/docker start -a jenkins
ExecStop=-/usr/bin/docker stop --time=0 jenkins
[Install]
WantedBy=multi-user.target
要加载新的服务文件,请运行以下命令:
sudo systemctl daemon-reload
要启动该服务,请运行命令:
sudo systemctl start docker-jenkins
要使服务能够在重启时运行,请运行以下命令:
sudo systemctl enable docker-jenkins
要查看服务日志,请运行命令:
sudo journalctl -u docker-jenkins -f
结论
从 Docker 映像运行 Jenkins 提供了一种在自包含的预配置环境中启动 Jenkins 的便捷方法。
在这篇文章中,你学会了如何:
- 把詹金斯放在码头集装箱里
- 安装附加工具和插件
- 传递 Java 系统属性和 Jenkins 应用程序参数
- 备份 Docker 卷
- 将 Docker 容器配置为 systemd 服务
然而,在工作站或服务器上运行 Docker 镜像仅仅是个开始。在下一篇文章中,您将学习如何将 Jenkins 部署到 Kubernetes 集群中。
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解即将举办的活动和现场直播的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
在 Jenkins - Octopus 部署中使用动态构建代理来自动扩展
如果你在运行一个只有几个开发人员的小项目,那么 Jenkins 的一个实例是不错的。但是随着您的团队和产品的成长,您会发现单个实例可能无法保持稳定。当提交数量增加时,Jenkins 需要运行的流程也会增加,单个实例的性能很快就会下降,并使您的团队慢下来。
谢天谢地,Jenkins 是一个可扩展的平台。可扩展性意味着,随着您处理需求的增长,Jenkins 也可以随之增长。
Jenkins 的可伸缩性将一个实例视为一个控制器,将作业定向到称为代理的其他实例。控制器知道每个代理的容量,并会将您的构建和测试发送到当时最合适的代理。通过使用动态构建代理,这个过程可以自动发生,允许 Jenkins 对您的需求做出反应。
感谢像 Kubernetes 和 Amazon Web Services (AWS)这样的虚拟环境,您不需要数量有限的代理或物理硬件。动态设置中的 Jenkins 足够聪明:
- 如果没有合适的代理,则增加新的代理
- 清理未使用的代理
- 替换损坏的安装
而且完全不需要人工干预。
在这篇文章中,我们从头到尾看了两种设置动态伸缩的流行方法,分别是 Kubernetes 和 Amazon Web Services (AWS) 。
方法 1:使用 Kubernetes 进行扩展
Kubernetes 是一个工具,它可以自动调整保持应用程序平稳运行所需的容器数量。这使得它成为帮助扩展 Jenkins 实例的好选择。
通过将您的 Jenkins 控制器部署到 Kubernetes,您的持续集成(CI)设置变得更易于管理、复制或在出现问题时重新创建。
容器是不太复杂的虚拟机,很容易部署到大多数操作系统或云服务。
开始之前
本指南只是一个示例,在更改现有的 Jenkins 设置之前,您应该尝试缩放。
在本例中,您在本地 minikube 集群上设置了可伸缩性,并使用下面的工具进行配置。如果您正在跟进,请按照列出的顺序安装工具:
- Docker 桌面–只有在 Windows 上才需要。确保 Docker Desktop 被设置为管理 Linux 容器而不是 Windows 容器。
- minikube–允许您在计算机上安装 Kubernetes 集群。
- chocolate y–只有在 Windows 上才需要。它是一个命令行软件管理包,用于安装 Kubectl。
- ku bectl–控制 Kubernetes 集群的命令行工具。使用这个 Chocolatey 命令行来安装 Kubectl:
choco install kubernetes-cli
您可以使用您习惯的任何工具来设置可伸缩性,但是您可能需要稍微调整我们的说明。
步骤 1:创建一个 Jenkins 控制器映像
首先,您必须创建一个 dockerfile 文件并使用它来构建一个 Jenkins 控制器映像。
dockerfile 是一个文本文件,用于在 Docker 中创建图像,然后您可以将它推送到 Docker Hub。
我们的示例 dockerfile 将创建一个包含 Jenkins 以及 Blue Ocean 和 Kubernetes 插件的图像。
要创建 dockerfile 文件并构建映像:
-
创建一个名为
Dockerfile的文本文件,并添加以下 Jenkins 建议的脚本。如果你需要的话,你可以在列表中添加更多的插件——只需添加它们的名字,用空格分开:FROM jenkins/jenkins:lts-slim # Pipelines with Blue Ocean UI and Kubernetes RUN jenkins-plugin-cli --plugins blueocean kubernetes -
保存并关闭文件。如果在 Windows 上使用记事本,您必须删除。' txt '文件扩展名。
-
打开终端,使用 CD 命令移动到包含该文件的文件夹。使用以下命令创建镜像:
docker build . -t [username]/jenkinsdockerfile -
构建需要一点时间来处理,但是完成后你会在 Docker 桌面上或者用
docker images命令看到图像。
当您在下一步中创建 minikube 群集时,它不会看到本地存储在您的计算机上的映像,因为群集运行在虚拟环境中。要解决这个问题,您可以将图像推送到 Docker Hub。
如果在 Windows 上,您可以在 Docker 桌面中完成此操作:
- 点击 Docker 桌面左侧的图片。
- 将光标悬停在您的图像上,单击菜单图标(3 个垂直点)并选择按键控制。
或者,您可以在终端中使用以下命令行:
Docker push -t [username]/[image name]
步骤 2:创建一个 Kubernetes 集群
打开一个终端窗口,使用以下命令创建一个 Kubernetes 集群:
minikube start
设置群集可能需要一段时间。完成后,给它一个新的名称空间,使集群更容易使用和引用。在终端中使用以下命令创建名称空间“jenkins”:
kubectl create namespace jenkins
步骤 3:使用 YAML 部署文件安装 Jenkins
将下面的代码复制到一个文本文件中,保存为jenkins.yaml。确保将图像行更改为指向您的图像,例如【Docker 用户名】/【图像名称】。
# Service account docs:
# https://support.cloudbees.com/hc/en-us/articles/360038636511-Kubernetes-Plugin-Authenticate-with-a-ServiceAccount-to-a-remote-cluster
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jenkins
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: jenkins
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jenkins
subjects:
- kind: ServiceAccount
name: jenkins
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
spec:
replicas: 1
selector:
matchLabels:
app: jenkins
template:
metadata:
labels:
app: jenkins
spec:
containers:
- name: jenkins
image: [docker username]/jenkins
ports:
- containerPort: 8080
- containerPort: 50000
volumeMounts:
- name: jenkins-home
mountPath: /var/jenkins_home
volumes:
- name: jenkins-home
emptyDir: { }
serviceAccountName: jenkins
---
apiVersion: v1
kind: Service
metadata:
name: jenkins
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
selector:
app: jenkins
---
apiVersion: v1
kind: Service
metadata:
name: jenkins-agent
spec:
selector:
app: jenkins
type: NodePort
ports:
- port: 50000
targetPort: 50000
要将映像部署到命名空间,请从文件的目录中运行以下命令:
kubectl apply -f jenkins.yaml -n jenkins jenkins.yaml
YAML 脚本现在将在 Kubernetes pod 中创建一个 Jenkins 实例。这个过程可能需要一段时间,但是您可以使用下面的命令来检查进度。当状态栏显示为运行时,表示准备就绪;
kubectl get pods -n jenkins
步骤 4:找到您的 Jenkins 实例 URL 并连接到它
运行以下命令找出实例的 IP 地址,并记下它:
minikube ip
现在我们需要发现端口。运行以下命令:
kubectl get services -n jenkins
端口列将以 8080:54321 格式显示实例的端口。记下冒号后的 5 个数字。
现在,您可以将 minikube IP 和端口结合起来组成 URL。例如,如果 IP 是 123.123.123.123,端口号是 54321,那么您的 Jenkins URL 将是 http://123.123.123.123:54321。
如果您的 URL 不起作用,可能是您的防火墙阻止了该实例。请向网络管理员寻求帮助。如果您在自己的计算机上遇到这个问题,您可以使用kubectl port-forward svc/jenkins -n jenkins 8080:8080暂时转发您的端口。这将使您的 URL http://localhost:8080。
转到您的网络浏览器中的 URL,您应该会看到入门屏幕。这将要求一次性管理员密码。对于 Kubernetes 集群,您需要通过命令行找到它。
首先,您需要 Kubernetes pod 的名称。使用以下命令:
kubectl get pods -n Jenkins
你的 pod 名字看起来会像这样:Jenkins-27 BC 5 DCD 98-xk9mp。
现在运行下面的命令,用您刚刚记下的名字替换[podname]。
kubectl logs [podname] -n jenkins
滚动结果,找到由星号分隔的管理员密码。将它粘贴到您的 Jenkins 实例中,您就可以完成安装了。参见 Jenkins 文档了解如何首次设置 Jenkins。
步骤 5:获取最终信息并安装 Jenkins 插件
现在你可以在 Jenkins 中设置插件了。在 web 浏览器中返回 Jenkins:
- 从菜单中点击管理詹金斯。
- 点击管理节点和云。
- 点击配置云。
- 从下拉列表中选择 Kubernetes ,然后点击 Kubernetes 云详情。
- 填写以下字段并点击保存:
- Kubernetes 网址–输入
https://kubernetes.default - Kubernetes 名称空间–输入
jenkins - 詹金斯网址–输入
http://jenkins.jenkins.svc.cluster.local:8080 - 詹金斯隧道–回车
jenkins-agent.jenkins.svc.cluster.local:50000
- Kubernetes 网址–输入
- 滚动到底部,点击 Pod 模板,然后添加 Pod 模板,以及 Pod 模板详情。
- 填写以下字段并点击保存:
- 名称–输入
jenkins-agent - 名称空间–输入
jenkins - 标签–输入
jenkins-agent - 用途 -从下拉列表中选择尽可能使用该节点
- 名称–输入
第六步:测试一切正常
为了测试 Jenkins 是否能够适当地伸缩,您可以创建一些简单的构建作业来检查它们是如何分布的。
首先,设置 Jenkins,使其不会在控制器上运行作业(除非您另外告诉它):
- 从菜单中点击管理詹金斯。
- 点击配置系统。
- 从用法下拉菜单中选择仅构建标签表达式与该节点匹配的作业,然后点击保存。
然后创建 2 个“Hello World”构建作业:
- 在 Jenkins 仪表盘上点击新项目。
- 输入合适的名称,如
Testing 1,选择自由式项目,点击确定。 - 在构建标题下,从下拉框中选择执行 shell 。
- 在命令框中输入
echo "Hello World",点击保存: - 重复这些步骤,但是把你的第二份工作叫做
Testing 2。
同时运行两个生成作业。如果工作正常,它们会出现在 Jenkins 左侧的构建队列中。在构建作业期间,它们出现在标题为构建执行器状态的标题下,带有我们之前设置的“jenkins-agent”前缀。您还可以检查构建历史,仔细检查作业运行的确切位置以及它是否成功。
方法 2:使用 Amazon Web Services (AWS)和 EC2 Fleet 插件进行扩展
管理 Jenkins 可伸缩性的另一种方法是使用 EC2(亚马逊弹性计算云)容器和 EC2 Fleet 插件。
此选项适合以下团队:
- 已经可以访问 AWS
- 想要轻松地向现有的 Jenkins 实例添加可伸缩性
- 更喜欢使用 UI 而不是命令行来执行安装
尽管 AWS 是有成本的,但你的财务限额是在账户级别设定的。
配置 AWS
如果您没有帐户,请注册 AWS 如果您已经有访问权限,请登录您的帐户。
步骤 1:创建策略
首先创建一个策略,允许访问使用 AWS EC2 Spot Fleet 和自动缩放组:
- 点击顶部的服务菜单,选择安全、身份、&合规,然后选择 IAM 。
- 在访问管理标题下的左侧菜单中点击策略。
- 从右侧点击创建策略。
- 使用可视化编辑器创建一个新策略,以同时使用 EC2 专色车队和自动缩放组。或者,使用 JSON 编辑器并粘贴插件设置指南中的代码。点击下一步:标签。
- 如果需要,添加标签,然后点击下一步:查看。
- 为策略命名并进行描述,然后单击创建策略。
步骤 2:创建具有编程访问权限的 IAM 用户
现在,您创建一个具有编程访问权限的用户,并为其分配新策略:
- 点击顶部的服务菜单,选择安全、身份、&合规,然后选择 IAM 。
- 在访问管理标题下的左侧菜单中点击用户。
- 点击右侧的添加用户。
- 给你的账户取一个合适的名字,选择访问键-编程访问,点击下一步:权限。
- 点击直接附加现有策略按钮。搜索您在上一步中创建的策略,勾选左侧的复选框,然后单击 Next: Tags 。
- 如果需要,添加标签,然后点击下一步:查看。
- 查看您的新用户并点击创建用户。
步骤 3:设置凭证以将 AWS 连接到 Jenkins
接下来,创建将 AWS 连接到 Jenkins 所需的两种身份验证方法。
首先,为新创建的 IAM 用户设置一个访问键 ID。这将允许 Jenkins 查看与您的 AWS 设置相关的信息。要设置访问密钥 ID:
- 点击顶部的服务菜单,选择安全、身份、&合规,然后选择 IAM 。
- 在访问管理标题下的左侧菜单中点击用户。
- 搜索并单击您在步骤 2 中创建的 IAM 用户。
- 转到安全凭证选项卡并点击创建访问密钥。
- 记下访问密钥 ID 和秘密访问密钥(点击显示查看)并将其保存在安全的地方,如密码管理器。在这个阶段,您只能看到秘密访问密钥,如果丢失了,您需要创建一个新的密钥。
现在,您创建一个密钥对。这允许 Jenkins 连接到 AWS 在伸缩时将创建的实例。要设置密钥对:
- 点击顶部的服务菜单,选择计算,点击 EC2 。
- 点击网络&安全标题下左侧菜单中的密钥对。
- 点击创建密钥对。
- 完成以下选项并点击创建密钥对:
- 名称–给密钥对起一个描述性的名称。
- 密钥对类型 -保留为 RSA 。
- 私钥文件格式–选择。pem 。
- 标签–如果需要,添加标签。
- 私钥将自动下载到文本文件中。保管好这个文件,你以后会需要的。
步骤 4:创建 AWS EC2 Spot 车队或自动伸缩组
您可以创建 EC2 Spot 车队或自动缩放组。在本例中,我们创建了一个 EC2 Spot 车队,但是如果您想了解更多关于创建自动缩放组的信息,请查看 AWS 文档。
在开始之前,你也应该清楚地知道你想要使用什么亚马逊机器映像(AMI)。AMI 是一个预先构建的映像,包括操作系统和软件,您的 EC2 机群将从这些操作系统和软件创建额外的机器。
您的 AMI 映像应该包含 Java 11,因为没有它 Jenkins 将无法扩展。我们使用 AWS Marketplace 的open JDK 11 Java 11 Ubuntu 18.04 AMI,然而,如果你需要一些特定的东西,你可以构建自己的 AMI。关于 AMIs 的更多信息,请参见 AWS 文档。
要创建 EC2 Spot 车队:
- 点击顶部的服务菜单,选择计算,点击 EC2 。
- 在实例标题下的左侧菜单中点击现场请求。
- 点击请求 Spot 实例。
- 至少设置以下选项,其他选项可以根据需要进行更改:
- AMI–记得选择包含 Java 11 的 AMI。
- 密钥对名称–选择我们在步骤 3 中创建的密钥对名称。
- 保持目标产能–勾选此框。
- 滚动到底部,完成后点击发射。
AWS 需要一些时间来创建你的舰队。然后就可以配置 Jenkins 了。
配置 Jenkins
步骤 1:在 Jenkins 中安装 EC2 Fleet 插件
要安装 EC2 Fleet 插件:
- 从菜单中点击管理詹金斯。
- 点击管理插件。
- 点击可用的选项卡,开始在过滤字段中输入
EC2 Fleet。插件应该出现在预测的搜索结果中。 - 勾选插件左侧的复选框,然后点击安装而不重启。
Jenkins 将安装插件和所有依赖项,包括其他插件、扩展和 Amazon 软件开发工具包(SDK)。
如果你还没有,你也应该安装凭证绑定插件。
步骤 2:向 Jenkins 添加 AWS IAM 帐户和密钥对
要添加您的 AWS IAM 帐户:
- 从菜单中点击管理詹金斯。
- 向下滚动到安全标题并点击管理凭证。
- 在 Jenkins 标题下的商店范围内点击 Jenkins 。
- 点击系统标题下的全局凭证(无限制)。
- 如果没有凭证,可以点击添加一些凭证怎么样?链接,否则从左边点击添加凭证。
- 填写以下字段并点击确定:
- 种类–从下拉菜单中选择 AWS 凭证。
- ID–给凭证起一个名字,用于在 Jenkins 中识别凭证。
- 描述–输入有意义的描述。
- 访问密钥 ID–输入您在 AWS 中创建 IAM 帐户时的访问密钥 ID。
- 秘密访问密钥–输入您在 AWS 中创建 IAM 帐户时的访问字符串。
要添加您的密钥对:
- 从菜单中点击管理詹金斯。
- 向下滚动到安全标题并点击管理凭证。
- 点击 Jenkins 范围内的商店标题下的 Jenkins。
- 点击系统标题下的全局凭证(无限制)。
- 点击左边添加凭证。
- 填写以下字段并点击确定:
- 种类–从下拉列表中选择 SSH 用户名和私钥。
- ID–给凭证一个名称,用于在 Jenkins 中识别凭证。
- 描述–输入有意义的描述。
- 用户名–该用户名用于您选择的 AMI。
- 私钥–勾选直接输入单选按钮,点击添加按钮,粘贴您之前下载的密钥对文件的内容。
步骤 3:将 Jenkins 连接到您的 AWS EC2 Spot 车队
现在您将 Jenkins 连接到 AWS EC2 Spot 舰队:
- 从菜单中点击管理詹金斯。
- 点击管理节点和云。
- 点击配置云。
- 从添加新云下拉列表中选择 Amazon EC2 Fleet 。填写以下字段并点击保存:
- 名称–输入在 Jenkins 中使用的描述性名称。
- AWS 凭证–从 AWS 凭证下拉列表中选择您的访问密钥 ID。
- 区域–从下拉列表中选择您的 EC2 舰队的区域。
- EC2 车队–任何连接到您的访问密钥 ID 的 EC2 Spot 车队都会出现在这里。如果凭证没有显示,您可能需要点击测试连接。
- 启动器–通过 SSH 选择启动代理,从两个新的下拉框中选择您在步骤 2 中添加的密钥对凭证和非验证验证策略。
第四步:测试一切正常
几分钟后,转到您的詹金斯仪表板。在左侧的构建执行器状态下,您应该看到您的控制器实例和您的新 EC2 车队。如果 EC2 机群显示任何错误,请单击其名称查看日志以确定问题。
为了测试 Jenkins 现在可以适当地伸缩,您可以创建简单的构建作业来检查它们是如何分布的。
首先,您要设置 Jenkins,这样它就不会在控制器上运行作业(除非您另外告诉它):
- 从菜单中点击管理詹金斯。
- 点击配置系统。
- 从用法下拉菜单中选择仅构建标签表达式与此节点匹配的作业,然后点击保存。
现在创建一个“Hello World”构建作业:
- 在 Jenkins 仪表盘上点击新项目。
- 输入合适的名称,如
Testing,选择自由式项目,点击确定。 - 在构建标题下,从下拉框中选择执行 shell 。
- 在命令框中输入
echo "Hello World",点击保存:
运行构建作业,如果工作正常,您会看到它出现在您的舰队下,在左侧的构建执行者状态中。一旦完成,您还可以检查您的构建历史,以检查作业运行的确切位置。
在 AWS 中更改缩放选项
在它设置和运行之后,您可以更改您希望 Jenkins 在 AWS 中扩展的方式。
- 登录 AWS。
- 点击顶部的服务菜单,选择计算,点击 EC2 。
- 在实例标题下的左侧菜单中点击现场请求。
- 点击您的 EC2 Spot 车队的请求 ID 。
- 滚动到页面底部查看缩放选项。点击自动缩放标题下的配置按钮。
- 根据需要更改设置并保存。
下一步是什么?
有关缩放詹金斯的更多信息,请通读他们的官方缩放文档。
你也可以阅读我们关于配置 Jenkins 的其他帖子:
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解有关即将举办的活动和实时流录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
使用 Docker 和 Jenkins - Octopus Deploy 部署到亚马逊 EKS
在本文中,我将向您展示如何使用 Jenkinsfile 工作流构建 Docker 图像,并将图像发布到 Amazon Elastic Container Registry(ECR)。Jenkins 将触发对 Amazon Elastic Kubernetes 服务(EKS)的部署。
Jenkins 是一个构建服务器,可以自动构建您的代码库。Jenkins 通过 Jenkinsfile 实现这一点,Jenkins file 是一个配置文件,它指定了构建、推送和部署应用程序的步骤。
亚马逊 EKS 是一种托管云服务,提供 Kubernetes 集群来处理工作负载应用程序。Kubernetes 集群还接受一个由 YAML 语法指定的配置文件。
此工作流的强大之处在于,可以为流程的所有阶段指定配置文件,并在不同的环境中稍加修改即可重用。
先决条件
要跟进,您需要:
对于这个例子,您需要扩展存储库来包含一个部署 YAML 文件。Jenkins 将使用此部署文件部署到 EKS。将此文件添加到存储库的根级别。
这个帖子使用了 Octopus 水下应用库。您可以分叉存储库,并使用主分支来跟进。
jenkins-deploy 分支包含完成本文中的步骤所需的模板文件。你必须用你自己的价值观来代替一些价值观,但是我已经在这篇文章中列出了我的价值观作为参考。
因为您正在使用 Kubernetes,所以需要用一个配置文件来配置代理。亚马逊的文档向你展示如何配置你的代理。
AWS 还需要 aws-iam-authenticator 二进制文件。
亚马逊网络服务设置
要为 Jenkins 设置 AWS,您需要创建一个访问密钥和一个 ECR 存储库来存储图像。
要创建访问密钥,请转到亚马逊控制台,然后 IAM ,然后用户、[your user],然后安全凭证,然后创建访问密钥。
您的浏览器下载一个包含访问密钥 ID 和秘密访问密钥的文件。Jenkins 使用这些值向 Amazon 认证。
要创建存储库,请转到亚马逊控制台,然后转到 ECR ,然后转到创建存储库。
您需要为发布的每个图像建立一个图像存储库。给存储库起一个您想让图像起的名字。
你会在亚马逊 ECR 下看到你的仓库,然后是仓库。记下它所在的区域,在 URI 场。

AWS 集群设置
使用我们上一篇文章中的指南在 AWS 中设置集群,在 AWS 中创建 ESK 集群。
在存储库的根级别创建一个名为deployment.yml的文件。
apiVersion: apps/v1
kind: Deployment
metadata:
name: underwater-app-jenkins
labels:
app: octopus-underwater-app
spec:
selector:
matchLabels:
app: octopus-underwater-app
replicas: 3
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: octopus-underwater-app
spec:
containers:
- name: octopus-underwater-app
image: 720766170633.dkr.ecr.us-east-2.amazonaws.com/octopus-underwater-app:latest
ports:
- containerPort: 80
protocol: TCP
imagePullPolicy: Always
在存储库的根级别创建一个名为Jenkinsfile的文件。
pipeline {
agent any
options {
skipStagesAfterUnstable()
}
stages {
stage('Clone repository') {
steps {
script{
checkout scm
}
}
}
stage('Build') {
steps {
script{
app = docker.build("octopus-underwater-app")
}
}
}
stage('Test'){
steps {
echo 'Empty'
}
}
stage('Push') {
steps {
script{
docker.withRegistry('https://720766170633.dkr.ecr.us-east-2.amazonaws.com', 'ecr:us-east-2:aws-credentials') {
app.push("${env.BUILD_NUMBER}")
app.push("latest")
}
}
}
}
stage('Deploy'){
steps {
sh 'kubectl apply -f deployment.yml'
}
}
}
}
Jenkins 将克隆、构建、测试、推送和部署映像到 EKS 集群。Jenkins 通过您之前创建的部署文件来完成这项工作。
Jenkins 是一个持续集成(CI)工具,专注于构建映像并将其推送到远程存储库。使用它作为连续部署(CD)工具是可能的,但是,它不能通过不同的部署阶段跟踪一个版本。
像 Octopus Deploy 这样的连续部署工具可以在部署复杂时帮助您管理发布。Octopus 实现了专用持续部署工具的优势。如果你还没有使用 Octopus Deploy,你可以注册免费试用。

查看 web 应用程序
您需要本地端口转发来检查服务。使用此命令检查 web 应用程序。端口 28015 是根据 Kubernetes 文档中的示例选择的:
kubectl port-forward deployment/underwater-app-jenkins 28015:80
在浏览器中进入 IP 地址http://127.0.0.1:28015/查看您的网络应用程序。

结论
在本文中,您和 Jenkins 一起在 EKS 部署了一个 web 应用程序。这个例子演示了 Jenkins 如何配置部署代码库所需的步骤。亚马逊 EKS 公司提供了 Kubernetes 基础设施来处理 web 应用程序负载。这个过程中的所有步骤都是通过指定配置文件来执行的。这些配置文件提供了跨不同环境的可重用性。
查看我们关于使用 Jenkins、Kubernetes 和 Octopus Deploy 进行部署的其他帖子:
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
阅读我们的持续集成系列的其余部分。
愉快的部署!
如何使用 Helm - Octopus Deploy 安装 Jenkins 实例
Kubernetes (K8s)已经成为托管 Docker 容器的最广泛使用的平台之一。Kubernetes 提供高级编排功能、网络功能、集成安全性、用户管理、高可用性、卷管理、广泛的支持工具生态系统等等。
一个支持工具是 Helm ,它为 Kubernetes 提供包管理功能。Helm 部署的应用程序在图表中定义,Jenkins 提供了一个 Helm 图表来将 Jenkins 实例部署到 Kubernetes。
在本文中,您将学习如何使用 Helm 和 connect 代理安装 Jenkins 实例来执行构建任务。
先决条件
要阅读这篇文章,您需要一个 Kubernetes 集群和 Helm 客户端。
所有主要的云提供商都提供托管的 Kubernetes 集群:
如果您想在本地 PC 上运行一个开发 Kubernetes 集群, kind 允许您创建和销毁用于测试的集群。帖子用种类创建测试 Kubernetes 集群提供了在本地运行 Kubernetes 的指导。
您还必须安装 Helm 客户端。舵文档提供安装说明。
添加 Jenkins 图表存储库
詹金斯掌舵图由https://charts . Jenkins . io提供。要使此图表存储库可用,请运行以下命令:
helm repo add jenkins https://charts.jenkins.io
helm repo update
部署简单的 Jenkins 实例
要使用默认设置部署 Jenkins 实例,请运行命令:
helm upgrade --install myjenkins jenkins/jenkins
helm upgrade命令通常用于升级现有版本。然而,--install参数确保了如果发布不存在,它就会被创建。这意味着helm upgrade --install创建和更新一个版本,消除了根据该版本是否存在而修改安装和升级命令的需要。
发布的名称是myjenkins,最后一个参数jenkins/jenkins定义了要安装的图表。
输出如下所示:
$ helm upgrade --install myjenkins jenkins/jenkins
Release "myjenkins" does not exist. Installing it now.
NAME: myjenkins
LAST DEPLOYED: Tue Oct 19 08:13:11 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1\. Get your 'admin' user password by running:
kubectl exec --namespace default -it svc/myjenkins -c jenkins -- /bin/cat /run/secrets/chart-admin-password && echo
2\. Get the Jenkins URL to visit by running these commands in the same shell:
echo http://127.0.0.1:8080
kubectl --namespace default port-forward svc/myjenkins 8080:8080
3\. Login with the password from step 1 and the username: admin
4\. Configure security realm and authorization strategy
5\. Use Jenkins Configuration as Code by specifying configScripts in your values.yaml file, see documentation: http:///configuration-as-code and examples: https://github.com/jenkinsci/configuration-as-code-plugin/tree/master/demos
For more information on running Jenkins on Kubernetes, visit:
https://cloud.google.com/solutions/jenkins-on-container-engine
For more information about Jenkins Configuration as Code, visit:
https://jenkins.io/projects/jcasc/
NOTE: Consider using a custom image with pre-installed plugins
注释中列出的第一个命令返回用户admin的密码:
$ kubectl exec --namespace default -it svc/myjenkins -c jenkins -- /bin/cat /run/secrets/chart-admin-password && echo
notes 中列出的第二个命令建立了到 Kubernetes 集群中服务的隧道。
在 Kubernetes 中,服务是配置集群网络以公开一个或多个 pod 的资源。默认的服务类型是ClusterIP,它通过私有 IP 地址公开 pod。我们就是通过这个私有 IP 地址来访问 Jenkins web UI 的。
Kubernetes pod 是托管一个或多个容器的资源。这意味着 Jenkins 实例作为 pod 中的一个容器运行:
$ kubectl --namespace default port-forward svc/myjenkins 8080:8080
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080
建立隧道后,在本地 PC 上打开 http://localhost:8080 ,您将被定向到 Kubernetes 集群中的 Jenkins 实例。使用用户名admin和第一个命令返回的密码登录。
现在,您已经有了一个运行在 Kubernetes 中的功能性的(如果是基本的)Jenkins 实例。
通过公共 IP 地址暴露詹金斯
通过隧道访问 Jenkins 对于调试很有用,但对于生产服务器来说不是很好的体验。要通过公开可用的 IP 地址访问 Jenkins,您必须覆盖图表中定义的默认配置。可以定义数百个值,通过运行以下命令可以获得完整的列表:
helm show values jenkins/jenkins
配置将 Jenkins pod 公开为LoadBalancer的服务是公开访问 Jenkins 的最简单的方法。
类型为LoadBalancer的服务通过公共 IP 地址公开 pod。如何创建公共 IP 地址的问题留给集群来解决。例如,EKS、AKS 和 GKE 等托管的 Kubernetes 平台创建了一个网络负载平衡器,将流量导入 K8s 集群。
注意,LoadBalancer服务在使用本地测试 Kubernetes 集群时需要额外的配置,比如 kind 创建的集群。更多信息请参考种类文档。
要将服务配置为LoadBalancer,您需要创建一个名为values.yaml的文件,其内容如下:
controller:
serviceType: LoadBalancer
然后,使用命令values.yaml中定义的值升级 Helm 版本:
helm upgrade --install -f values.yaml myjenkins jenkins/jenkins
通过添加新的指令来返回服务的公共 IP,输出有了细微的变化:
$ helm upgrade --install -f values.yaml myjenkins jenkins/jenkins
Release "myjenkins" has been upgraded. Happy Helming!
NAME: myjenkins
LAST DEPLOYED: Tue Oct 19 08:45:23 2021
NAMESPACE: default
STATUS: deployed
REVISION: 4
NOTES:
1\. Get your 'admin' user password by running:
kubectl exec --namespace default -it svc/myjenkins -c jenkins -- /bin/cat /run/secrets/chart-admin-password && echo
2\. Get the Jenkins URL to visit by running these commands in the same shell:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
You can watch the status of by running 'kubectl get svc --namespace default -w myjenkins'
export SERVICE_IP=$(kubectl get svc --namespace default myjenkins --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}")
echo http://$SERVICE_IP:8080/login
3\. Login with the password from step 1 and the username: admin
4\. Configure security realm and authorization strategy
5\. Use Jenkins Configuration as Code by specifying configScripts in your values.yaml file, see documentation: http:///configuration-as-code and examples: https://github.com/jenkinsci/configuration-as-code-plugin/tree/master/demos
For more information on running Jenkins on Kubernetes, visit:
https://cloud.google.com/solutions/jenkins-on-container-engine
For more information about Jenkins Configuration as Code, visit:
https://jenkins.io/projects/jcasc/
NOTE: Consider using a custom image with pre-installed plugins
使用步骤 2 中的新说明,运行以下命令获取服务的公共 IP 地址或主机名:
kubectl get svc --namespace default myjenkins --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}"
我已将 Jenkins 部署到 EKS 集群,这是我的基础架构命令的结果:
$ kubectl get svc --namespace default myjenkins --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}"
a84aa6226d6e5496882cfafdd6564a35-901117307.us-west-1.elb.amazonaws.com
要访问 Jenkins,打开http://service _ IP _ or _ hostname:8080。
您可能会注意到,当您通过 Jenkins 的公共 IP 地址访问它时,它会报告以下错误:
It appears that your reverse proxy set up is broken.

这可以通过在controller.jenkinsUrl属性中定义公共 URL 来解决,用 Jenkins 实例的 IP 地址或主机名替换a84aa6226d6e5496882cfafdd6564a35-901117307.us-west-1.elb.amazonaws.com:
controller:
jenkinsUrl: http://a84aa6226d6e5496882cfafdd6564a35-901117307.us-west-1.elb.amazonaws.com:8080/
安装附加插件
列出要安装在controller.additionalPlugins阵列中的任何附加插件:
controller:
additionalPlugins:
- octopusdeploy:3.1.6
插件 ID 和版本可在 Jenkins 插件网站上找到:

这种方法很方便,但是缺点是 Jenkins 实例需要联系 Jenkins 更新站点来检索它们,作为第一次引导的一部分。
一种更健壮的方法是下载插件作为定制映像的一部分,这可以确保插件被嵌入到 Docker 映像中。它还允许在 Jenkins 控制器上安装额外的工具。上一篇文章详细介绍了构建和发布自定义 Docker 图像。
请注意,除了任何自定义插件之外,自定义 Docker 映像还必须安装以下插件。这些插件是舵图正常工作所必需的:
- 库伯内特斯
- 工作流聚合器
- 饭桶
- 代码配置
下面是一个包含强制插件的示例Dockerfile:
FROM jenkins/jenkins:lts-jdk11
USER root
RUN apt update && \
apt install -y --no-install-recommends gnupg curl ca-certificates apt-transport-https && \
curl -sSfL https://apt.octopus.com/public.key | apt-key add - && \
sh -c "echo deb https://apt.octopus.com/ stable main > /etc/apt/sources.list.d/octopus.com.list" && \
apt update && apt install -y octopuscli
RUN jenkins-plugin-cli --plugins octopusdeploy:3.1.6 kubernetes:1.29.2 workflow-aggregator:2.6 git:4.7.1 configuration-as-code:1.52
USER jenkins
要使用自定义图像,您可以在values.yml中用以下属性定义它。此示例使用了推送到我的 DockerHub 帐户的自定义 Jenkins 图像:
controller:
image: "docker.io/mcasperson/myjenkins"
tag: "latest"
installPlugins: false
你可以在Jenkins-complete-image repository中找到一个为 Java、DotNET Core、PHP、Python、Ruby 安装工具的例子Dockerfile。
詹金斯配置代码
Jenkins Configuration as Code(JC ASC)是一个插件,它提供了一种通过 YAML 文件配置 Jenkins 的自以为是的方法。这为直接引用 Jenkins API 编写 Groovy 脚本提供了一种替代方法,这种方法功能强大,但要求管理员能够熟练地编写代码。
JCasC 是在controller.JCasC.configScript属性下定义的。configScript下的子键有您选择的由小写字母、数字和连字符组成的名称,并作为一种总结它们定义的文本块的方式。
分配给这些键的值是多行字符串,它们反过来定义了一个 JCasC YAML 文件。竖线(|)字符为定义多行字符串提供了一种方便的方法,但在其他方面并不重要。
最终结果给出了连续的 YAML 文档的外观。请记住,管道字符后面出现的内容只是一个多行文本值,碰巧也是 YAML。
以下示例配置了 Jenkins 控制器可用的执行器数量,JCasC YAML 定义在一个名为this-is-where-i-configure-the-executors的夸张键下,以强调这些键可以有任何名称:
controller:
JCasC:
configScripts:
this-is-where-i-configure-the-executors: |
jenkins:
numExecutors: 5
作为比较,同样的配置也可以用下面的 Groovy 脚本来实现,该脚本在一个定制的 Docker 映像中保存为/usr/share/jenkins/ref/init.groovy.d/executors.groovy:
import jenkins.model.*
Jenkins.instance.setNumExecutors(5)
甚至这个简单的例子也强调了 JCasC 的好处:
- 每个 JCasC 属性都记录在 http://Jenkins host/configuration-as-code/reference 中(用您自己的 Jenkins 实例的主机名替换
jenkinshost,而编写 Groovy 脚本需要了解 Jenkins API 。 - JCasC 配置是普通的 YAML,比用 Groovy 编写的脚本更容易理解。
- JCasC 坚持己见,为通用配置提供了一致的方法。Groovy 脚本可以用多种方式解决同一个问题,这意味着包含多行代码的脚本需要软件工程师的专业知识才能理解。
尽管有这么多好处,JCasC 并不能完全替代设置系统属性或运行 Groovy 脚本。例如, JCasC 将不支持禁用 CSRF 的功能,这意味着该选项只能通过系统属性公开。
备份 Jenkins 卷
Kubernetes 中的卷比常规 Docker 中的卷稍微复杂一些,因为 K8s 卷倾向于托管在运行 pod 的节点之外。这是因为 pod 可以在节点之间重新定位,因此需要从任何节点访问卷。
更复杂的是,与 Docker 卷不同,只有专门的 Kubernetes 卷可以在 pod 之间共享。这些共享卷被称为ReadWriteMany卷。不过,通常情况下,Kubernetes 卷仅由单个 pod 使用,被称为ReadWriteOnce卷。
Jenkins Helm 图表配置了一个ReadWriteOnce卷来托管 Jenkins 主目录。因为该卷只能由装入该卷的 pod 访问,所以所有备份操作都必须由该 pod 执行。
幸运的是,Helm chart 提供了全面的备份选项,能够执行备份并将它们保存到云存储提供商。
但是,您可以使用两个命令来编排简单的、与云无关的备份。
第一个命令在 pod 内部执行tar,将/var/jenkins_home目录备份到/tmp/backup.tar.gz档案中。注意,吊舱名称myjenkins-0来源于舵释放名称myjenkins:
kubectl exec -c jenkins myjenkins-0 -- tar czf /tmp/backup.tar.gz /var/jenkins_home
第二个命令将备份归档文件从 pod 复制到您的本地计算机:
kubectl cp -c jenkins myjenkins-0:/tmp/backup.tar.gz ./backup.tar.gz
此时backup.tar.gz可以被复制到一个更永久的位置。
添加 Jenkins 代理
除了在 Kubernetes 集群上安装 Jenkins 之外,还可以在集群中动态创建 Jenkins 代理。这些代理是在 Jenkins 中安排新任务时创建的,并在任务完成后自动清理。
代理的默认设置在values.yaml文件中的agent属性下定义。以下示例定义了一个带有 Jenkins 标签default的代理,该代理是在以名称default为前缀的 pod 中创建的,并且具有 CPU 和内存限制:
agent:
podName: default
customJenkinsLabels: default
resources:
limits:
cpu: "1"
memory: "2048Mi"
在additionalAgents属性下定义了更多的专业代理。这些 pod 模板继承了在agent属性中定义的值。
以下示例定义了第二个 pod 模板,将 pod 名称和 Jenkins 标签更改为maven,并指定新的 Docker 图像jenkins/jnlp-agent-maven:latest:
agent:
podName: default
customJenkinsLabels: default
resources:
limits:
cpu: "1"
memory: "2048Mi"
additionalAgents:
maven:
podName: maven
customJenkinsLabels: maven
image: jenkins/jnlp-agent-maven
tag: latest
要找到代理定义,导航到管理 Jenkins ,然后管理节点和云,最后配置云。

要使用代理来执行管道,请如下定义agent块:
pipeline {
agent {
kubernetes {
inheritFrom 'maven'
}
}
// ...
}
例如,Java 应用程序的管道使用maven代理模板:
pipeline {
// This pipeline requires the following plugins:
// * Pipeline Utility Steps Plugin: https://wiki.jenkins.io/display/JENKINS/Pipeline+Utility+Steps+Plugin
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * Octopus Deploy: https://plugins.jenkins.io/octopusdeploy/
// * JUnit: https://plugins.jenkins.io/junit/
// * Maven Integration: https://plugins.jenkins.io/maven-plugin/
parameters {
string(defaultValue: 'Spaces-1', description: '', name: 'SpaceId', trim: true)
string(defaultValue: 'SampleMavenProject-SpringBoot', description: '', name: 'ProjectName', trim: true)
string(defaultValue: 'Dev', description: '', name: 'EnvironmentName', trim: true)
string(defaultValue: 'Octopus', description: '', name: 'ServerId', trim: true)
}
tools {
jdk 'Java'
}
agent {
kubernetes {
inheritFrom 'maven'
}
}
stages {
stage('Environment') {
steps {
echo "PATH = ${PATH}"
}
}
stage('Checkout') {
steps {
// If this pipeline is saved as a Jenkinsfile in a git repo, the checkout stage can be deleted as
// Jenkins will check out the code for you.
script {
/*
This is from the Jenkins "Global Variable Reference" documentation:
SCM-specific variables such as GIT_COMMIT are not automatically defined as environment variables; rather you can use the return value of the checkout step.
*/
def checkoutVars = checkout([$class: 'GitSCM', branches: [[name: '*/master']], userRemoteConfigs: [[url: 'https://github.com/mcasperson/SampleMavenProject-SpringBoot.git']]])
env.GIT_URL = checkoutVars.GIT_URL
env.GIT_COMMIT = checkoutVars.GIT_COMMIT
env.GIT_BRANCH = checkoutVars.GIT_BRANCH
}
}
}
stage('Dependencies') {
steps {
// Download the dependencies and plugins before we attempt to do any further actions
sh(script: './mvnw --batch-mode dependency:resolve-plugins dependency:go-offline')
// Save the dependencies that went into this build into an artifact. This allows you to review any builds for vulnerabilities later on.
sh(script: './mvnw --batch-mode dependency:tree > dependencies.txt')
archiveArtifacts(artifacts: 'dependencies.txt', fingerprint: true)
// List any dependency updates.
sh(script: './mvnw --batch-mode versions:display-dependency-updates > dependencieupdates.txt')
archiveArtifacts(artifacts: 'dependencieupdates.txt', fingerprint: true)
}
}
stage('Build') {
steps {
// Set the build number on the generated artifact.
sh '''
./mvnw --batch-mode build-helper:parse-version versions:set \
-DnewVersion=\\${parsedVersion.majorVersion}.\\${parsedVersion.minorVersion}.\\${parsedVersion.incrementalVersion}.${BUILD_NUMBER}
'''
sh(script: './mvnw --batch-mode clean compile', returnStdout: true)
script {
env.VERSION_SEMVER = sh (script: './mvnw -q -Dexec.executable=echo -Dexec.args=\'${project.version}\' --non-recursive exec:exec', returnStdout: true)
env.VERSION_SEMVER = env.VERSION_SEMVER.trim()
}
}
}
stage('Test') {
steps {
sh(script: './mvnw --batch-mode -Dmaven.test.failure.ignore=true test')
junit(testResults: 'target/surefire-reports/*.xml', allowEmptyResults : true)
}
}
stage('Package') {
steps {
sh(script: './mvnw --batch-mode package -DskipTests')
}
}
stage('Repackage') {
steps {
// This scans through the build tool output directory and find the largest file, which we assume is the artifact that was intended to be deployed.
// The path to this file is saved in and environment variable called JAVA_ARTIFACT, which can be consumed by subsequent custom deployment steps.
script {
// Find the matching artifacts
def extensions = ['jar', 'war']
def files = []
for(extension in extensions){
findFiles(glob: 'target/**.' + extension).each{files << it}
}
echo 'Found ' + files.size() + ' potential artifacts'
// Assume the largest file is the artifact we intend to deploy
def largestFile = null
for (i = 0; i < files.size(); ++i) {
if (largestFile == null || files[i].length > largestFile.length) {
largestFile = files[i]
}
}
if (largestFile != null) {
env.ORIGINAL_ARTIFACT = largestFile.path
// Create a filename based on the repository name, the new version, and the original file extension.
env.ARTIFACTS = "SampleMavenProject-SpringBoot." + env.VERSION_SEMVER + largestFile.path.substring(largestFile.path.lastIndexOf("."), largestFile.path.length())
echo 'Found artifact at ' + largestFile.path
echo 'This path is available from the ARTIFACTS environment variable.'
}
}
// Octopus requires files to have a specific naming format. So copy the original artifact into a file with the correct name.
sh(script: 'cp ${ORIGINAL_ARTIFACT} ${ARTIFACTS}')
}
}
stage('Deployment') {
steps {
octopusPushPackage(additionalArgs: '', packagePaths: env.ARTIFACTS.split(":").join("\n"), overwriteMode: 'OverwriteExisting', serverId: params.ServerId, spaceId: params.SpaceId, toolId: 'Default')
octopusPushBuildInformation(additionalArgs: '', commentParser: 'GitHub', overwriteMode: 'OverwriteExisting', packageId: env.ARTIFACTS.split(":")[0].substring(env.ARTIFACTS.split(":")[0].lastIndexOf("/") + 1, env.ARTIFACTS.split(":")[0].length()).replace("." + env.VERSION_SEMVER + ".zip", ""), packageVersion: env.VERSION_SEMVER, serverId: params.ServerId, spaceId: params.SpaceId, toolId: 'Default', verboseLogging: false, gitUrl: env.GIT_URL, gitCommit: env.GIT_COMMIT, gitBranch: env.GIT_BRANCH)
octopusCreateRelease(additionalArgs: '', cancelOnTimeout: false, channel: '', defaultPackageVersion: '', deployThisRelease: false, deploymentTimeout: '', environment: params.EnvironmentName, jenkinsUrlLinkback: false, project: params.ProjectName, releaseNotes: false, releaseNotesFile: '', releaseVersion: env.VERSION_SEMVER, serverId: params.ServerId, spaceId: params.SpaceId, tenant: '', tenantTag: '', toolId: 'Default', verboseLogging: false, waitForDeployment: false)
octopusDeployRelease(cancelOnTimeout: false, deploymentTimeout: '', environment: params.EnvironmentName, project: params.ProjectName, releaseVersion: env.VERSION_SEMVER, serverId: params.ServerId, spaceId: params.SpaceId, tenant: '', tenantTag: '', toolId: 'Default', variables: '', verboseLogging: false, waitForDeployment: true)
}
}
}
}
通过运行以下命令,您可以确认在任务执行期间在集群中创建了代理:
kubectl get pods
在下面的示例中,pod java-9-k0hmj-vcvdz-wknh4正在被创建以执行上面的示例管道:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
java-9-k0hmj-vcvdz-wknh4 0/1 ContainerCreating 0 1s
myjenkins-0 2/2 Running 0 49m
结论
在 Kubernetes 集群中托管 Jenkins 及其代理允许您创建一个可伸缩且响应迅速的构建平台,动态地创建和销毁代理以处理弹性工作负载。多亏了 Jenkins Helm 图表,安装 Jenkins 和配置节点只需要几行 YAML。
在这篇文章中,你学会了如何:
- 将詹金斯部署到库伯内特斯
- 将詹金斯暴露在公共 IP 地址上
- 在安装过程中安装附加插件
- 通过 JCasC 配置 Jenkins
- 备份 Jenkins 主目录
- 创建 Kubernetes 代理,根据需要创建和销毁这些代理
查看我们关于安装 Jenkins 的其他帖子:
试试我们免费的 Jenkins 管道生成器工具,用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会页面,了解关于即将举办的活动和实时流录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
如何在 Windows 和 Linux 上安装 Jenkins-Octopus Deploy
原文:https://octopus.com/blog/jenkins-install-guide-windows-linux
传统的 Jenkins 安装方法是使用在 Jenkins 网站上提供的安装程序,或者通过您本地操作系统的软件包管理器。安装过程通常很简单,但是需要注意一些技巧。
在这篇文章中,我们将介绍 Jenkins 在 Windows 和 Linux 上的安装,以及如何定制安装。
詹金斯 LTS 和每周发行之间的选择
Jenkins 提供了两种发布渠道:
- 长期支持(LTS)
- 每周发布
LTS 版本往往更加稳定和可预测,每个次要版本中的功能更少,但包括任何重要的错误和安全修复。
每周发布的版本包含了所有最新的特性,但是在社区中用于查找 bug 的“烘烤时间”更少。
如果你喜欢稳定性,并且不需要所有的最新功能,那么就选择 LTS 版本。如果你想尽快获得最新的特性,并且不介意偶尔的小故障,那就选择每周发布。
如何在 Windows 上安装 Jenkins
Jenkins 提供了 MSI 下载,允许它通过传统的 Windows 向导式安装过程作为 Windows 服务安装。但是在开始安装之前,您必须满足一些先决条件。
正在安装 OpenJDK
Jenkins 需要 Java 来运行,OpenJDK 项目提供了一个免费的开源发行版,您可以使用它来运行 Jenkins。
有许多 OpenJDK 发行版可供选择,包括:
我通常使用 Azul Zulu 发行版,但任何发行版都可以。
从您选择的 OpenJDK 发行版下载并安装 JDK 11,并记下它的安装目录,因为在 Jenkins 安装期间您将需要该路径。
添加 Jenkins Windows 服务帐户
Jenkins 作为 Windows 服务运行,并且需要一个 Windows 帐户来运行该服务。安装程序提供了使用现有的 LocalService 帐户的选项,但是指出不推荐使用该选项。建议的解决方案是创建一个专门用于运行 Jenkins 的新帐户。
要从命令行执行此任务,您必须首先安装 Carbon PowerShell 模块。Carbon 为管理 Windows 提供了许多有用的 CMDLets,您将使用其中的一个来授予新的 Jenkins 用户作为服务登录的权限。
运行以下 PowerShell 命令从 PowerShell Gallery 安装 Carbon:
Install-Module -Name 'Carbon' -AllowClobber
默认情况下,PowerShell 会阻止您从外部来源运行代码。若要删除此警告,请运行以下命令:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
然后你进口碳:
Import-Module 'Carbon'
下一步是创建一个名为jenkins的用户来运行 Jenkins Windows 服务:
net user jenkins Password01! /ADD
最后,您必须授予jenkins用户作为服务登录的权限:
Grant-CPrivilege -Identity "jenkins" -Privilege SeServiceLogonRight
安装 Jenkins
从 Jenkins 下载页面下载 MSI,双击 MSI 文件开始安装 Jenkins,点击下一步按钮:

默认安装目录就可以了,所以点击下一个按钮:

现在会提示您提供运行 Windows 服务的用户的详细信息。输入您之前创建的用户的凭证,并点击测试凭证按钮。测试通过后,点击下一个按钮:

8080 默认端口没问题。点击测试端口按钮,确保端口可用,然后点击下一个按钮:

现在提示您输入先前安装的 Java 发行版的路径。祖鲁 11 发行版的默认路径是C:\Program Files\Zulu\zulu-11。为您选择的发行版输入适当的路径,然后单击下一个按钮:

您可能希望通过 Windows 防火墙暴露 Jenkins,以允许外部客户端访问它。更改要安装的防火墙例外特性,点击下一步按钮:

现在所有的安装值都已配置好,所以点击安装按钮:

安装完成后,点击完成按钮:

关于巧克力的一个注记
Chocolatey 是一个 Windows 包管理器,它提供了一个安装詹金斯的选项。然而,在撰写本文时,Chocolatey 上可用的 Jenkins 的最新版本是 2.222.4,这已经是一年前的事了。事实上,该版本太旧了,以至于在最初的 Jenkins 配置中出现的大多数推荐插件都无法安装!
当你读到这篇文章的时候,Jenkins 可能已经更新了 Chocolatey,但是我警告不要使用 Chocolatey 来安装 Jenkins,因为它确实有过不被维护的历史。
Windows 服务配置
Windows 服务有一个唯一入口点来响应服务控制管理器(SCM)命令。像 Jenkins 这样的 Java 应用程序不公开这个接口。这意味着 Java 应用程序必须在包装器中运行,才能作为 Windows 服务进行管理。
默认情况下,该包装器位于C:\Program Files\Jenkins\jenkins.exe位置,由C:\Program Files\Jenkins\jenkins.xml文件配置:

这个 XML 文件包含service/arguments元素,它定义了执行时传递给 Jenkins 的命令行参数。它还包括service/env元素来定义 Jenkins 可用的环境变量。
高级 Jenkins 配置选项通常需要传递参数或定义环境变量。例如,在 Jenkins 中禁用跨站点请求伪造(CSRF)保护需要传递-Dhudson.security.csrf.GlobalCrumbIssuerConfiguration.DISABLE_CSRF_PROTECTION=true参数,该参数在service/arguments元素中配置:

詹金斯系统属性列表可以在詹金斯文档中找到。
Windows 上的 JENKINS_HOME 目录
JENKINS_HOME目录包括所有的配置、插件和在 Jenkins 服务器上执行的任何构建的工作目录。在 Windows 上,该目录默认位于%LocalAppData%\Jenkins\.jenkins,当使用上面创建的jenkins用户运行 Jenkins 服务时,该目录将解析为C:\Users\jenkins\AppData\Local\Jenkins\.jenkins。
如何在 Ubuntu 和 Debian 上安装 Jenkins
Jenkins 提供了一个包存储库,用于在 Debian 和 Ubuntu 上安装软件。
首先,安装存储库密钥:
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
然后添加一个 Jenkins apt 存储库条目:
sudo sh -c 'echo deb https://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
更新您的本地包索引,然后最后安装 Jenkins:
sudo apt-get update
sudo apt-get install openjdk-11-jdk
sudo apt-get install jenkins
如何在 RHEL 和 Fedora 上安装 Jenkins
Jenkins 提供了一个包存储库,用于在 Red Hat Enterprise Linux (RHEL)和 Fedora 上安装软件。
首先,安装存储库密钥:
sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins.repo
sudo rpm --import https://pkg.jenkins.io/redhat-stable/jenkins.io.key
然后安装 OpenJDK 和 Jenkins:
sudo yum install epel-release
sudo yum install java-11-openjdk-devel
sudo yum install jenkins
Linux 服务配置
虽然 Ubuntu、Debian、RHEL 和 Fedora 的所有现代版本都使用 systemd ,但 Jenkins 服务仍然作为旧的 init 脚本在/etc/init.d/jenkins下提供。
为了启动服务,我们运行service命令:
sudo service jenkins start
init 脚本/etc/init.d/jenkins包含了相当多的 Bash 脚本,但是从管理员的角度来看,这是最有趣的一行:
eval "daemonize -u \"$JENKINS_USER\" -p \"$JENKINS_PID_FILE\" \"$JENKINS_JAVA_CMD\" $JENKINS_JAVA_OPTIONS \"-DJENKINS_HOME=$JENKINS_HOME\" -jar \"$JENKINS_WAR\" $PARAMS"
您可以从上面的代码中确定要传递给 Jenkins 的 Java 选项包含在JENKINS_JAVA_OPTIONS变量中。要填充这个变量,在### END INIT INFO后添加一行如下所示的代码。本例禁用 CSRF 保护:
###############################################################################
#
# chkconfig: 35 99 01
# description: Jenkins Automation Server
#
###############################################################################
### BEGIN INIT INFO
# Provides: jenkins
# Required-Start: $local_fs $remote_fs $network $time $named
# Should-Start: $time sendmail
# Required-Stop: $local_fs $remote_fs $network $time $named
# Should-Stop: $time sendmail
# Default-Start: 3 5
# Default-Stop: 0 1 2 6
# Short-Description: Jenkins Automation Server
# Description: Jenkins Automation Server
### END INIT INFO
[ -n "$JENKINS_JAVA_OPTIONS" ] && JENKINS_JAVA_OPTIONS="-Dhudson.security.csrf.GlobalCrumbIssuerConfiguration.DISABLE_CSRF_PROTECTION=true"
# Rest of the init script
Jenkins 系统属性列表可在 Jenkins 文档中找到。
如何在其他 Linux 发行版和 macOS 上安装 Jenkins
Jenkins 网站包括其他 Linux 发行版和 macOS 的说明。
完成 Jenkins 安装
安装完 Jenkins 后,您需要进行第一次配置。
打开 http://localhost:8080 查看 Jenkins web 控制台。系统会提示您输入随机生成的密码,该密码保存在本地计算机上的一个文件中。
打开该文件,复制密码,粘贴到管理员密码文本框中,点击继续按钮:

大多数 Jenkins 功能由插件提供。作为初始配置的一部分,系统会提示您选择安装公共插件的精选列表。这些插件通常是有用的,所以点击安装建议插件按钮:

安装插件需要几分钟时间:

系统会提示您提供 Jenkins 管理员的详细信息。填充字段,并点击保存并继续按钮:

默认网址是好的,所以点击保存并完成按钮:

Jenkins 现在已经配置好,可以使用了。点击开始使用詹金斯按钮:

结论
这篇文章分析了 Jenkins 在 Windows 和主要 Linux 发行版中的安装过程,并提供了管理 Jenkins 服务的技巧。
传统安装只是让 Jenkins 服务器启动并运行的一种方法。在下一篇文章中,你将学习如何用 Docker 安装 Jenkins。
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解关于即将举办的活动和实时流媒体录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
了解如何从 PowerShell - Octopus Deploy 调用 Jenkins REST API
虽然典型的部署工作流会看到像 Jenkins 这样的 CI 系统在 Octopus 中触发部署,但有时让 Octopus trigger 在 Jenkins 中构建是有用的。在这篇博文中,我们将看看如何使用 REST API 和 PowerShell 来触发 Jenkins 部署。
詹金斯·CSRF 保安公司
詹金斯有一个安全功能,防止跨站点请求伪造攻击,这是在詹金斯➜管理詹金斯➜配置全球安全➜防止跨站点请求伪造利用下发现的。

实际上,这意味着对 Jenkins API 的每个请求都需要在头中定义一个称为 crumb 的东西。要生成这个面包屑,我们需要向 http://Jenkins server/Jenkins/crumbIssuer/API/JSON 发出请求。
下面的 PowerShell 向您展示了如何生成面包屑:
$user = 'user'
$pass = 'password'
# The header is the username and password concatenated together
$pair = "$($user):$($pass)"
# The combined credentials are converted to Base 64
$encodedCreds = [System.Convert]::ToBase64String([System.Text.Encoding]::ASCII.GetBytes($pair))
# The base 64 credentials are then prefixed with "Basic"
$basicAuthValue = "Basic $encodedCreds"
# This is passed in the "Authorization" header
$Headers = @{
Authorization = $basicAuthValue
}
# Make a request to get a crumb. This will be returned as JSON
$json = Invoke-WebRequest -Uri 'http://jenkinsserver/jenkins/crumbIssuer/api/json' -Headers $Headers
# Parse the JSON so we can get the value we need
$parsedJson = $json | ConvertFrom-Json
# See the value of the crumb
Write-Host "The Jenkins crumb is $($parsedJson.crumb)"
REST API 链接
现在我们有了一个 crumb,我们可以用它来调用 Jenkins REST API。您可以通过每个屏幕右下角的REST API链接找到与 Jenkins 系统交互的 URL:

在这个例子中,我们想要触发一个 Jenkins 项目的构建,所以我们打开这个项目,发现REST API链接指向一个 URL,比如 http://Jenkins server/Jenkins/job/Run % 20a % 20 script/API/。如果我们打开此链接,我们会看到描述可用的常见操作的文档页面。我们特别感兴趣的是嵌入在句子to programmatically schedule a new build, post to this URL.中的链接,该链接将我们带到一个 URL,如 http://Jenkins server/Jenkins/job/Run % 20a % 20 script/build。

触发构建
我们现在有了触发构建所需的链接和 Jenkins 在每个 API 请求中需要的信息。让我们完成 PowerShell 脚本,该脚本发出在 Jenkins 中开始构建的最后一个请求:
$user = 'user'
$pass = 'password'
# The header is the username and password concatenated together
$pair = "$($user):$($pass)"
# The combined credentials are converted to Base 64
$encodedCreds = [System.Convert]::ToBase64String([System.Text.Encoding]::ASCII.GetBytes($pair))
# The base 64 credentials are then prefixed with "Basic"
$basicAuthValue = "Basic $encodedCreds"
# This is passed in the "Authorization" header
$Headers = @{
Authorization = $basicAuthValue
}
# Make a request to get a crumb. This will be returned as JSON
$json = Invoke-WebRequest -Uri 'http://jenkinsserver/jenkins/crumbIssuer/api/json' -Headers $Headers
# Parse the JSON so we can get the value we need
$parsedJson = $json | ConvertFrom-Json
# See the value of the crumb
Write-Host "The Jenkins crumb is $($parsedJson.crumb)"
# Extract the crumb filed from the returned json, and assign it to the "Jenkins-Crumb" header
$BuildHeaders = @{
"Jenkins-Crumb" = $parsedJson.crumb
Authorization = $basicAuthValue
}
Invoke-WebRequest -Uri "http://jenkinsserver/jenkins/job/Run%20a%20script/build" -Headers $BuildHeaders -Method Post
运行该脚本将显示 crumb 值,以及启动作业的 API 调用的结果。注意,结果是一个 HTTP 201 代码。此代码表示在 Jenkins 服务器上创建了一个作业:
PS C:\Users\Matthew\Desktop> .\jenkins.ps1
The Jenkins crumb is 574608b1e95315787b2fa0b74fce2441
StatusCode : 201
StatusDescription : Created
Content : {}
RawContent : HTTP/1.1 201 Created
Date: Tue, 19 Feb 2019 04:46:46 GMT
Server: Apache
X-Frame-Options: SAMEORIGIN
X-Content-Type-Options: nosniff
Location: http://jenkinsserver/jenkins/queue/item/11/
Content-L...
Headers : {[Date, System.String[]], [Server, System.String[]], [X-Frame-Options, System.String[]], [X-Content-Type-Options, System.String[]]...}
RawContentLength : 0
RelationLink : {}
在 Jenkins - Octopus 部署中运行端到端测试
端到端(E2E)测试代表了自动化测试的最后阶段。E2E 测试是长期运行的,尤其是与可以在几秒钟内完成数千次检查的单元测试相比。它们通常由外部工具执行,这些外部工具通过公共接口(如网页或 HTTP APIs)与测试中的应用程序进行交互。
在本文中,您将学习如何使用 Cypress 运行 E2E 测试来验证与网页的交互,以及如何使用 Newman(Postman 的命令行测试运行程序)来验证 HTTP APIs。
先决条件
要跟进这篇文章,您需要一个 Jenkins 实例。
有关在您选择的环境中安装 Jenkins 的说明,您可以参考我们的指南:
无论是 Cypress 还是 Newman (邮差命令行测试运行器)都需要你安装 Node.js, Node.js 网站提供下载,或者提供安装指导给包管理者。
如何用 Cypress 运行浏览器测试
Cypress 是一个浏览器自动化工具,它允许你以与最终用户非常相似的方式与网页交互,例如通过点击按钮和链接、填写表格和滚动页面。您还可以验证页面的内容,以确保显示正确的结果。
Cypress 文档提供了一个第一次测试的例子,它已经被保存到JUnit-Cypress-test GitHub repo中。测试如下所示:
describe('My First Test', () => {
it('Does not do much!', () => {
expect(true).to.equal(true)
})
})
该测试被配置为在cypress.json文件中生成一个 JUnit 报告文件:
{
"reporter": "junit",
"reporterOptions": {
"mochaFile": "cypress/results/results.xml",
"toConsole": true
}
}
Cypress 作为开发依赖项包含在package.json文件中:
{
"name": "cypress-test",
"version": "0.0.1",
"description": "A simple cypress test",
"devDependencies": {
"cypress": "8.6.0"
}
}
您可以使用下面的管道运行 Cypress 测试:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * JUnit: https://plugins.jenkins.io/junit/
agent 'any'
stages {
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/master']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/junit-cypress-test.git']]])
}
}
}
stage('Dependencies') {
steps {
sh(script: 'npm install')
}
}
stage('Test') {
steps {
sh(script: 'NO_COLOR=1 node_modules/.bin/cypress run || true')
}
}
}
post {
always {
junit(testResults: 'cypress/results/results.xml', allowEmptyResults : true)
archiveArtifacts(artifacts: 'cypress/videos/sample_spec.js.mp4', fingerprint: true)
}
}
}
Dependencies阶段将 Cypress 下载到项目目录:
stage('Dependencies') {
steps {
sh(script: 'npm install')
}
}
Test阶段将NO_COLOR环境变量设置为1,从输出中去除 ANSI 颜色代码,然后运行 Cypress。如果有任何测试失败,Cypress 会返回一个非零的退出代码,但是我们通过追加|| true来确保该命令总是返回 true,从而将构建通过或失败的决定推迟到测试处理器。
您可以在 Jenkins 中的运行单元测试中了解更多关于处理失败测试的信息:
stage('Test') {
steps {
sh(script: 'NO_COLOR=1 node_modules/.bin/cypress run || true')
}
}
post阶段处理 JUnit 报告文件,并将生成的测试视频保存为工件:
post {
always {
junit(testResults: 'cypress/results/results.xml', allowEmptyResults : true)
archiveArtifacts(artifacts: 'cypress/videos/sample_spec.js.mp4', fingerprint: true)
}
}
然后,您可以使用公开单元测试的同一个接口深入研究测试结果:

视频工件捕获测试输出:

如何用 Newman 运行 API 测试
Newman 是 Postman 的命令行测试程序。测试脚本从 Postman 导出为 JSON 文件。查询 GitHub API 的示例已保存在JUnit-Newman-test GitHub Repo中:
{
"info": {
"_postman_id": "f9b1443b-c23d-4738-901d-092cba2fc3d6",
"name": "GitHub",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "GitHub API",
"event": [
{
"listen": "test",
"script": {
"exec": [
"pm.test(\"response must be valid and have a body\", ",
"function () {\n",
" pm.response.to.be.ok;\n",
" pm.response.to.be.withBody;\n",
" pm.response.to.be.json;\n",
"\n",
" pm.expect(pm.response.json().quote != \"\").to.be.true;\n",
"});"
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://api.github.com/repos/OctopusSamples/junit-newman-test/git/trees/main",
"protocol": "http",
"host": [
"api",
"github",
"com"
],
"path": [
"repos",
"OctopusSamples",
"junit-newman-test",
"git",
"trees",
"main"
]
}
},
"response": []
}
]
}
Newman 作为开发依赖项保存在package.json文件中:
{
"devDependencies": {
"newman": "^5.3.0"
}
}
您可以使用下面的管道运行 Newman 测试:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * JUnit: https://plugins.jenkins.io/junit/
agent 'any'
stages {
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/main']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/junit-newman-test.git']]])
}
}
}
stage('Dependencies') {
steps {
sh(script: 'npm install')
}
}
stage('Test') {
steps {
sh(script: 'node_modules/.bin/newman run GitHubTree.json --reporters cli,junit --reporter-junit-export results.xml || true')
}
}
}
post {
always {
junit(testResults: 'results.xml', allowEmptyResults : true)
}
}
}
Dependencies阶段将纽曼下载到工作目录:
stage('Dependencies') {
steps {
sh(script: 'npm install')
}
}
Test阶段运行 Newman,使用--reporters cli,junit参数启用 JUnit reporter,并使用--reporter-junit-export results.xml参数将结果保存为 JUnit 报告文件。
如果任何测试失败,Newman 将返回一个非零的退出代码,因此为了将构建的成功或失败推迟到测试处理器,您需要确保命令总是使用|| true返回 true。
您可以在在 Jenkins 中运行单元测试中了解更多关于处理失败测试的信息:
stage('Test') {
steps {
sh(script: 'node_modules/.bin/newman run GitHubTree.json --reporters cli,junit --reporter-junit-export results.xml || true')
}
}
post阶段处理 JUnit 报告文件:
post {
always {
junit(testResults: 'results.xml', allowEmptyResults : true)
}
}
测试结果将通过 Jenkins web 用户界面提供:

结论
E2E 测试允许您通过应用程序的公共接口来验证应用程序,作为自动化测试的最后阶段。与单元测试不同,E2E 测试通常由外部工具来编排。例如,Cypress 提供了通过 web 浏览器自动化交互的能力,Newman 提供了用 HTTP APIs 编写脚本和验证交互的能力。
在本文中,您学习了如何:
- 运行基于 Cypress 浏览器的测试
- 运行纽曼 API 测试
- 将结果收集为 JUnit 报告文件
- 处理测试结果
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解关于即将举办的活动和实时流媒体录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
在 Jenkins - Octopus 部署中运行单元测试
在典型的开发工作流中,用单元测试验证代码变更是一个关键的过程。Jenkins 提供了许多插件来收集和处理测试结果,允许开发人员浏览结果,调试失败的测试,忽略一些测试失败,并生成关于测试历史的报告。
在本文中,您将学习如何向 Jenkins 项目添加单元测试,并配置插件来处理结果。
先决条件
要跟进这篇文章,您需要一个 Jenkins 实例。传统詹金斯安装、码头工人詹金斯安装或赫尔姆詹金斯安装指南提供了在您选择的环境中安装詹金斯的说明。
您将构建的示例应用程序是用 Java 和 DotNET Core 编写的,因此 Java 开发工具包(JDK)和 DotNET Core SDK 必须安装在执行构建的 Jenkins 控制器或代理上。
你可以从微软网站找到关于安装 DotNET Core SDK 的说明。示例项目是针对 DotNET Core 3.1 编写的。
OpenJDK 项目(及其下游项目)提供了免费的开源发行版,可以用来编译 Java 应用程序。有许多 OpenJDK 发行版可供选择,包括:
我通常使用 Azul Zulu 发行版,尽管任何发行版都可以。
Java 中的单元测试
Java 有很多单元测试框架,但是最流行的是 JUnit 。
您将使用 Random Quotes 示例应用程序来演示在 Jenkins 项目中运行的 JUnit 测试。
安装 Jenkins 插件
您必须安装 JUnit 插件来处理 JUnit 测试的结果。
要安装插件:
- 点击管理詹金斯,然后管理插件,然后可用。
- 在搜索框中输入
junit。 - 选择 JUnit 选项,点击不重启安装:

在詹金斯创建管道项目
创建新的管道项目,点击新建项目,输入项目名称RandomQuotes-Java,选择管道选项,点击确定按钮:

将以下管道脚本粘贴到管道部分,点击保存按钮:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * JUnit: https://plugins.jenkins.io/junit/
agent 'any'
stages {
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/master']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/RandomQuotes-Java.git']]])
}
}
}
stage('Test') {
steps {
sh(script: './mvnw --batch-mode -Dmaven.test.failure.ignore=true test')
}
}
stage('Package') {
steps {
sh(script: './mvnw --batch-mode package -DskipTests')
}
}
}
post {
always {
junit(testResults: 'target/surefire-reports/*.xml', allowEmptyResults : true)
}
}
}

Test阶段包含一个运行 maven test目标的步骤,通过--batch-mode以避免显示每个正在下载的依赖项的不必要的日志记录,通过-Dmaven.test.failure.ignore=true以允许该步骤成功通过,即使有失败的测试。
sh(script: './mvnw --batch-mode -Dmaven.test.failure.ignore=true test')
post部分包含always条件块,它用 JUnit 插件处理测试结果:
junit(testResults: 'target/surefire-reports/*.xml', allowEmptyResults : true)
Package阶段打包应用程序,同时跳过任何带有-DskipTests参数的测试,因为测试是在前一阶段处理的:
sh(script: './mvnw --batch-mode -Dmaven.test.skip=true clean package', returnStdout: true)
测试结果趋势图跟踪项目历史中通过、失败和跳过的测试:
DotNET 核心中的单元测试
DotNET Core 有许多流行的单元测试框架,包括 MSTest、NUnit 和 xUnit。您将使用 RandomQuotes 示例应用程序来演示从 Jenkins 管道运行 NUnit 测试。
安装 Jenkins 插件
使用 MSTest 插件处理 DotNET 核心测试结果。
安装 MSTest 插件,处理 NUnit 测试的结果。要安装插件:
- 单击管理 Jenkins ,然后单击管理插件,然后单击可用。
- 在搜索框中输入
mstest。 - 选择 MSTest 选项,点击不重启安装:

在詹金斯创建管道项目
要新建管道项目,点击新建项目,输入RandomQuotes-DotNET作为项目名称,选择管道选项,点击确定按钮:

将以下管道脚本粘贴到管道部分,点击保存按钮:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * MSTest: https://plugins.jenkins.io/mstest/
agent 'any'
stages {
stage('Environment') {
steps {
echo "PATH = ${PATH}"
}
}
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/master']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/RandomQuotes.git']]])
}
}
}
stage('Dependencies') {
steps {
sh(script: 'dotnet restore')
}
}
stage('Build') {
steps {
sh(script: 'dotnet build --configuration Release', returnStdout: true)
}
}
stage('Test') {
steps {
sh(script: 'dotnet test -l:trx || true')
}
}
}
post {
always {
mstest(testResultsFile: '**/*.trx', failOnError: false, keepLongStdio: true)
}
}
}
Test阶段调用dotnet test运行单元测试,通过参数-l:trx将测试结果写入 Visual Studio Test Results (TRX)文件。
如果任何测试失败,该命令将返回非零退出代码。为了确保在测试失败的情况下继续处理管道,如果dotnet test表示失败,则返回true:
sh(script: 'dotnet test -l:trx || true')
然后使用post部分的 MSTest 插件处理测试结果:
mstest(testResultsFile: '**/*.trx', failOnError: false, keepLongStdio: true)
如何处理失败的测试
到目前为止,您只运行了具有成功测试的构建。要模拟失败的测试,修改Checkout阶段,指向 Java Random Quotes 应用程序的failing-test分支:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * JUnit: https://plugins.jenkins.io/junit/
agent 'any'
stages {
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/failing-test']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/RandomQuotes-Java.git']]])
}
}
}
stage('Test') {
steps {
sh(script: './mvnw --batch-mode -Dmaven.test.failure.ignore=true test')
}
}
stage('Package') {
steps {
sh(script: './mvnw --batch-mode package -DskipTests')
}
}
}
post {
always {
junit(testResults: 'target/surefire-reports/*.xml', allowEmptyResults : true)
}
}
}
这个分支有总是失败的测试。来自该分支的构建被标记为不稳定,并且测试结果趋势图显示新的失败测试:

要查看测试的详细信息,请单击构建任务并单击测试结果链接。在这里,您可以深入每个测试,查看测试结果,并查看日志:

声称测试失败
上面的示例管道在一定程度上允许在测试失败时构建成功。这确保了即使测试失败,测试结果也能被 JUnit 或 MSTest 插件处理。然而,预计测试失败仍然由工程团队解决。 Claim 插件为 Jenkins 用户提供了为失败的测试负责的能力。
下面的管道允许声明失败的测试:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * JUnit: https://plugins.jenkins.io/junit/
// * Claim: https://plugins.jenkins.io/claim/
agent 'any'
options{
// This option allows broken builds to be claimed
allowBrokenBuildClaiming()
}
stages {
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/failing-test']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/RandomQuotes-Java.git']]])
}
}
}
stage('Test') {
steps {
sh(script: './mvnw --batch-mode -Dmaven.test.failure.ignore=true test')
}
}
stage('Package') {
steps {
sh(script: './mvnw --batch-mode package -DskipTests')
}
}
}
post {
always {
// The testDataPublishers argument allows failed tests to be claimed
junit(testDataPublishers: [[$class: 'ClaimTestDataPublisher']], testResults: 'target/surefire-reports/*.xml', allowEmptyResults : true)
}
}
}
失败的测试可以通过测试结果屏幕来声明:

打开索赔报告链接,可以找到所有索赔的全球报告:

当测试失败时,构建失败
您可能要求构建失败,而不是在测试失败时被标记为不稳定。您通常有两种选择来实现这一点:
- 测试命令失败
- 测试处理失败
测试命令失败
第一个选项允许运行测试的命令失败。如果测试失败,大多数测试运行者会返回一个非零的退出代码,这反过来会导致构建失败。
您可以使用下面的 Maven 命令执行测试,并在失败时返回一个非零的退出代码。没有-Dmaven.test.failure.ignore=true参数会将命令恢复为默认行为:
sh(script: './mvnw --batch-mode test')
如果任何测试失败,下面的 DotNET Core 命令也会返回非零退出代码。|| true命令链的缺失确保了返回dotnet退出代码:
sh(script: 'dotnet test -l:trx')
测试处理失败
第二个选项允许测试处理器确定构建是否失败。
MSTest 插件提供了failOnError参数,用于在任何测试失败时使该步骤失败:
mstest(testResultsFile: '**/*.trx', failOnError: true, keepLongStdio: true)
不幸的是,JUnit 插件不具备基于测试结果使构建失败的能力。
另一种方法是使用 xUnit 插件,它支持跳过和失败测试的阈值。
下面的示例管道用 xUnit 替换了 JUnit 插件:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * xUnit: https://plugins.jenkins.io/xunit/
// * Claim: https://plugins.jenkins.io/claim/
agent 'any'
options {
allowBrokenBuildClaiming()
}
stages {
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/failing-test']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/RandomQuotes-Java.git']]])
}
}
}
stage('Test') {
steps {
sh(script: './mvnw --batch-mode -Dmaven.test.failure.ignore=true test')
}
}
stage('Package') {
steps {
sh(script: './mvnw --batch-mode package -DskipTests')
}
}
}
post {
always {
xunit (testDataPublishers: [[$class: 'ClaimTestDataPublisher']], thresholds: [ skipped(failureThreshold: '0'), failed(failureThreshold: '0')], tools: [[$class: 'JUnitType', pattern: '**/surefire-reports/*.xml']])
}
}
}
下面的示例管道用 xUnit 替换了 MSTest 插件:
pipeline {
// This pipeline requires the following plugins:
// * Git: https://plugins.jenkins.io/git/
// * Workflow Aggregator: https://plugins.jenkins.io/workflow-aggregator/
// * xUnit: https://plugins.jenkins.io/xunit/
// * Claim: https://plugins.jenkins.io/claim/
agent 'any'
options {
allowBrokenBuildClaiming()
}
stages {
stage('Environment') {
steps {
echo "PATH = ${PATH}"
}
}
stage('Checkout') {
steps {
script {
checkout([$class: 'GitSCM', branches: [[name: '*/failing-tests']], userRemoteConfigs: [[url: 'https://github.com/OctopusSamples/RandomQuotes.git']]])
}
}
}
stage('Dependencies') {
steps {
sh(script: 'dotnet restore')
}
}
stage('Build') {
steps {
sh(script: 'dotnet build --configuration Release', returnStdout: true)
}
}
stage('Test') {
steps {
sh(script: 'dotnet test -l:trx || true')
}
}
}
post {
always {
xunit (testDataPublishers: [[$class: 'ClaimTestDataPublisher']], thresholds: [ skipped(failureThreshold: '0'), failed(failureThreshold: '0')], tools: [[$class: 'MSTestJunitHudsonTestType', pattern: '**/*.trx']])
}
}
}
结论
单元测试在大多数大型代码库中都很常见。通过在 Jenkins 中执行单元测试,开发团队拥有了一个报告当前和历史测试结果的真实的中心来源。
在这篇文章中,你学到了:
- 如何在 Java 和 DotNET 核心代码库中运行测试
- 如何使用 JUnit、MSTest 和 xUnit 插件收集和处理测试结果
- 如何允许 Jenkins 用户声称测试失败,以表明他们将对这些测试负责
- 当测试失败时,如何使构建失败
试试我们免费的 Jenkins 管道生成器工具,用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解有关即将举办的活动和直播录像的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
詹金斯安全提示-章鱼部署
对于这样一个开放的、可定制的平台,Jenkins 即使在默认状态下也能提供不错的安全性。鉴于它连接到无数的行业工具(包括 Octopus),尽管如此,还有一些其他的方法来帮助保护您的项目。
在本帖中,我们将探讨一些方法和工具来保证 Jenkins 实例的安全,并保护使用它的人。
保持一切更新
正如 2021 年 12 月提醒我们的,软件漏洞随时都会暴露出来。软件提供商不仅更新他们的应用程序来修复错误或添加新功能,而且还消除安全漏洞。
Jenkins 有一个安全咨询页面让你了解他们平台的漏洞。然而,保持你的实例更新仍然是一个好主意,包括它的插件。
要在 Jenkins 中检查更新:
- 从菜单中点击管理詹金斯。
- Manage Jenkins 屏幕会在顶部告诉你是否有新版本。点击或自动升级按钮立即升级。否则,您可以下载最新版本并在预定时间升级。
您也可以从同一个屏幕回滚升级——只需点击降级按钮。
要更新 Jenkins 插件:
- 从菜单中点击管理詹金斯。
- 点击管理插件。
- 确保你在更新标签上,勾选你想要安装的更新,点击立即下载,重启后安装。
- 重启 Jenkins 以完成更新。
你可以在大多数主流操作系统和容器上安装 Jenkins,所以也要保持更新。有关如何操作的更多信息,请查阅您的操作系统文档。
只有在你确定的情况下才更改 Jenkins 的安全默认值
Jenkins 在安装时启用了它的大部分安全功能,以尽可能确保安全。尽管有很多方法可以使用 Jenkins,但对于如何最好地配置或锁定您的实例,并没有“一刀切”的方法。
因此,虽然我们不能提供对您的团队最有利的建议(我们接下来将探讨一个例外),Jenkins 提供了您应该关注的重要特性的详细文档。请参见保护 Jenkins 页面获取与以下内容相关的安全帮助:
- 基本设置
- 构建行为
- 用户界面
您应该在仔细考虑后做出更改,如果可能的话,与您的网络安全专家交谈。您可以在配置全球安全页面中进行这些更改——从左侧菜单中选择管理 Jenkins 即可找到。
避免在控制器上构建
Jenkins 提供了一个内置节点,因此您可以尽快运行测试,看看它是否适合您。但是,在单个实例上运行的构建可以访问操作系统的文件系统。出于这个原因,Jenkins 建议您让作业在“代理”上运行(这发生在可伸缩的设置中,我们在上一篇文章中讨论过,在 Jenkins 中使用动态构建代理来自动伸缩)。
代理是运行作业而不是控制器的虚拟 Jenkins 实例。使用代理时,您可以阻止控制器运行内部版本,以限制对可能有害的文件的访问。
若要停止控制器运行构件:
- 从菜单中点击管理詹金斯。
- 点击管理节点和云。
- 点击内置节点右侧的齿轮。
- 您有两个选项来防止控制器上的构建。选择一个并点击保存:
- 如果您不想在控制器上构建,请将执行器数量更改为 0 。
- 如果您想在需要时在控制器上构建,从用法下拉菜单中选择仅构建标签表达式与此节点匹配的作业。
仅允许您的团队访问他们需要的内容
安全不仅仅是保护自己免受外来威胁。这也是为了从内部保护你的环境,因为事故可能会发生。在以下情况下,它们更有可能发生:
- 您正在使用单个管理员帐户运行 Jenkins 实例
- 每个人都可以接触到任何东西
- 人们可以改变他们不应该改变的事情
这里有一些管理用户访问的建议。
给每个 Jenkins 用户一个帐户
为了帮助跟踪您的用户正在做什么,为使用您的 Jenkins 实例的任何人创建个人用户帐户。这样你可以看到所有的活动和谁做了什么。
要创建额外用户:
- 从菜单中点击管理詹金斯。
- 向下滚动并选择管理用户。
- 点击左侧的创建用户。
- 填写所有字段并点击创建用户。
使用矩阵授权策略插件
我们建议使用矩阵授权策略插件在更精细的层面上管理用户对 Jenkins 的访问。例如,使用这个插件,您可以:
- 限制用户的访问权限,使他们只能查看和管理他们所属项目的内部版本
- 授予项目经理只读访问权限,以便他们可以看到构建的进展情况
要安装插件:
- 从左侧菜单中点击管理詹金斯。
- 点击管理插件。
- 点击可用的标签,开始输入
Matrix Authorization。插件会出现在预测结果中。 - 勾选插件左侧的方框,点击安装,无需重启。
要使用插件设定权限:
- 从菜单中点击管理詹金斯。
- 点击配置全局安全。
- 单击以下任一选项的单选按钮:
- 基于矩阵的安全性–允许您管理全局用户和组权限。
- 基于项目的矩阵授权策略–允许您在项目级别管理用户和组权限。
- 无论您的选择如何,请使用按钮添加用户或组,并使用表中的复选框选择他们的访问级别。完成后点击保存。
您应该考虑的其他用户访问插件
如果您已经使用其他系统进行访问管理,那么您可以使用这些系统来验证您的 Jenkins 用户。例如,微软的 Active Directory 和 OpenID 都有插件,这样你就不用在多个地方管理访问了。
我们还建议查看文件夹和基于文件夹的授权策略插件。
文件夹插件允许您在嵌套的文件夹中对作业进行分组。这个插件可以让你对共享安全需求的任务进行分组,这有助于你更密切地关注它们。
基于文件夹的授权策略插件通过让您使用角色设置文件夹访问权限,扩展了文件夹的安全性。
安全存储您的凭据
凭证绑定插件是加密和安全存储连接 Jenkins 和其他服务的凭证的最佳选择。Jenkins 也推荐它——作为他们第一次安装 Jenkins 时推荐的插件之一。另外,许多其他插件把它作为一种依赖。
此插件允许您存储和重用所有类型的身份验证方法,例如:
- 用户名和密码
- SSH 用户名和私钥
- 秘密文件
- 秘密文本
- 证书
我们将在以后的文章中详细介绍凭证绑定插件。
结论
正如您所看到的,有很多方法可以确保安全地使用 Jenkins 来保护项目免受外部和内部的风险。查看 Jenkins 的文档,了解更多关于保护实例安全的信息。
查看我们关于配置 Jenkins 的其他帖子:
尝试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解有关即将举办的活动和实时流媒体录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
我们最喜欢的 10 个 Jenkins 插件- Octopus Deploy
作为一个开源的持续集成(CI)平台,我们最喜欢 Jenkins 的一点是它强大的社区。这一点在 Jenkins 插件索引中表现得最为明显。
索引中有超过 1800 个用户创建的插件,允许您扩展 Jenkins 的功能并更改您的实例以满足您团队的需求。
这里有 10 个我们最喜欢的 Jenkins 插件,它们能给你的管道带来什么,以及如何安装它们。
1:蓝色海洋
詹金斯自己的蓝海插件用现代的外观和感觉更新了用户界面。
简单、直观的设计使创建管道、读取流程状态和发现管道问题变得更加容易。此外,它允许您创建自己的仪表板,因此您只能看到您需要的东西。
2:简单的主题
使用简单主题插件,你可以使用 CSS 和 JavaScript 改变 Jenkins 的外观和感觉。
你也可以通过插件的索引页面在 GitHub 上找到现成的主题。
3:性能发布者
如果你不确定如何阅读数据,数据是没有用的,这就是为什么 Performance Publisher 插件如此有用。
Performance Publisher 帮助您发现测试结果中的趋势。它读取由您的测试工具创建的 XML 文件,并将它们转换成易于阅读的图表和统计数据。
4: GitHub
GitHub 插件将詹金斯连接到 GitHub。这允许交叉功能,例如:
- 两个服务之间的超链接
- 构建状态报告
- 挂钩触发器
- 手动和自动模式
参见插件的 Jenkins 索引页面了解更多信息,包括示例管道。
5: Kubernetes
当您在 Kubernetes 集群中运行 Jenkins 时,Kubernetes 插件有助于自动扩展。
这个插件为每个通过变量自动连接的动态代理创建一个 pod。集群中的一个容器充当 Jenkins 代理,允许您在其他容器上运行您需要的任何作业或进程。
6:仪表板视图
仪表板视图插件让你在 Jenkins 中创建新的视图和门户。您可以从一系列 portlets 构建您的仪表板,以可理解的方式帮助您跟踪作业、测试等。
7: Maven 集成
作为一个流行的 Java 项目构建自动化工具, Maven 插件为那些在管道中运行 Apache Maven 的人提供了新的特性。
该插件扩展了 Jenkins 的兼容性,以更好地支持:
- 成功构建后触发作业和部署
- 其他报表插件的自动设置
8:文件夹
文件夹插件非常有用,詹金斯在安装时推荐了它。这个简单的插件通过让你在嵌套文件夹中分组作业来帮助你排序你的实例。
您可以根据每个文件夹的用途为其提供自己的专用视图,帮助清理 UI 中的混乱。
9:引导式多测试结果报告
bootstrapped-multi-test-results-report是一个可视化工具,可以让你制作测试结果的深度 HTML 报告。该插件支持 Cucumber、Junit、RSpec 和 TestNG 等。
查看插件网站上的示例报告。
10:管道实用程序步骤
管道实用程序步骤插件提供了许多额外的步骤来帮助您处理 Jenkins 管道中的小事情。
使用此插件,您可以:
- 查找、管理和创建文件
- 读写常见的配置文件,包括 CSV、JSON 和 YAML
- 压缩和解压缩文件
- 读写 Maven 模型数据结构
- 比较两个版本号
查看插件的 GitHub 页面,了解完整的步骤列表和使用它们所需的语法。
额外推荐:章鱼部署
如果我们不提到我们自己的 Octopus 部署插件,它将 Octopus 连接到您的 Jenkins 管道,那就不对了。
一旦 Jenkins 完成了代码的编译、测试和打包,我们的插件就可以:
- 构建完成时自动触发 Octopus 中的部署
- 如果在 Octopus 中的部署失败,则在 Jenkins 中的构建失败
请参阅我们的文档,了解更多关于将 Jenkins 与 Octopus 一起使用的信息。此外,请查看我们其他一些与詹金斯相关的博客:
如果你还没有使用 Octopus Deploy,你可以注册免费试用。
如何安装 Jenkins 插件
您可以使用install-plugin命令通过 Jenkins web UI 或 Jenkins CLI(命令行界面)安装插件。
要安装 Jenkins 插件,您必须:
- 配置 Jenkins 控制器以允许从更新中心下载元数据(在 Jenkins 设置期间配置)
- 作为 Jenkins 实例的管理员
在你安装一个插件之前,通读它的文档。Jenkins 将在安装过程中安装所有依赖插件,但请务必注意任何其他先决条件或额外步骤。
有关管理和安装插件的更多详细信息,请参见 Jenkins 的文档,包括:
Jenkins web 用户界面
要从 Jenkins web UI 搜索和安装插件:
- 从左侧菜单中点击管理詹金斯并选择管理插件。
- 单击可用的选项卡,并使用搜索框从更新中心查找插件。
- 勾选所需插件左侧的方框,然后点击不重启安装或立即下载并重启后安装。您可以安装大多数插件,无需重启。
詹金斯 CLI
使用以下命令行通过 Jenkins CLI 安装插件。将[SOURCE]替换为本地文件、URL 或更新中心,以便从以下位置安装:
java -jar jenkins-cli.jar -s http://localhost:8080/ install-plugin [SOURCE]
您也可以在命令行末尾使用这些修饰符:
-deploy:不重启安装插件-name VAL:添加一个短名称(默认情况下,Jenkins 使用源代码中出现的插件名称)-restart:插件安装成功后重启 Jenkins
下一步是什么?
这些是我们最喜欢的插件,可以帮助你的詹金斯管道,但我们只是触及了表面。在 Jenkins Index 上可以找到更多可以进一步帮助你进行 CI 工作的信息。
尝试我们免费的 Jenkins 管道生成器工具来用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解关于即将举办的活动和实时流媒体录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
使用 Atom - Octopus 部署编写和林挺 Jenkins 文件

声明性管道是 Jenkins 中的一个流行特性,允许构建过程与正在构建的代码一起提交。Jenkinsfiles 本质上是 Groovy 语法;然而,对于习惯于依赖本地编译来确保其代码有效的开发人员来说,在发现语法错误之前不得不等待 Jenkins 尝试执行他们的 Jenkinsfile 可能会令人沮丧。
Jenkins 提供了一个解决方案,它使得在执行 Jenkinsfile 之前对其进行验证成为可能。这可以从命令行手动执行,或者使用 IDE 插件来提供更加集成的体验。
在这篇博文中,我们将看看 Atom 编辑器中可用的 Jenkinsfile 林挺工具。
准备詹金斯
林挺一个 Jenkins 文件涉及到一个对 Jenkins 服务器的网络请求。有多种方法可以建立这些网络连接,但是 Jenkins 通常推荐通过 SSH 访问服务器。
这里需要注意的是,我们不是在讨论对 Jenkins 运行的操作系统的 SSH 访问。相反,Jenkins 公开了自己的 SSH 服务器。SSH 服务器在SSH Server部分下的 Jenkins 安全配置屏幕中启用。在下面的截图中,我已经在端口2222上启动了 SSH 服务器:

下一步是添加用户的公钥,这样他们就可以通过 SSH 进行身份验证。该密钥是使用以下命令创建的:
ssh-keygen -t rsa -C "your_email@example.com"
这将在默认文件~/.ssh/id_rsa.pub中创建公钥。然后,通过打开用户的详细信息,点击Configure选项,并将公钥的内容粘贴到SSH Public Keys字段,将该文件的内容分配给一个 Jenkins 用户:

Jenkins 还要求安装Pipeline插件:

完成这些更改后,我们就可以配置 Atom 了。
准备原子
Atom 中需要安装三个包:
- 语言-jenkinsfile
- 林特-詹金斯公司
- linter-ui-默认
linter-ui-default 包将要求安装许多依赖项。这些是必需的,所以允许安装它们:

linter 包需要额外的配置才能与 Jenkins 建立网络连接。
我们将使用SSH then CLI连接选项:

必须更新SSH Port和SSH User@Hostname选项,以反映我们在其上公开 Jenkins SSH 服务器的自定义端口(端口2222)和我们将 Linux 用户的公共 SSH 密钥添加到的 Jenkins 用户名:

林挺·詹金斯费尔
打开 Jenkinsfile,用 cmd-shift-p (macOS)或 ctrl-shift-p (Linux/Windows)显示命令面板,选择Linter: Lint命令:

然后,Jenkinsfile 的内容被发送到 Jenkins 服务器进行验证,并返回任何错误:

结论
Jenkins IDE 插件,就像我们在 Atom 中演示的那样,减少了 Jenkinsfile 中错误的反馈时间,使您能够更快地完成成功的构建。因为验证 Jenkinsfiles 需要连接到 Jenkins 服务器,所以需要做一些工作来配置一个安全的连接并定义所需的凭证,但是当这个初始配置完成时,只需一个命令就可以验证您的代码。
Octopus 部署的吉拉服务管理集成:早期访问预览- Octopus 部署
我们的吉拉服务管理集成作为 Octopus 2022 Q3 版本的一部分,以早期访问预览版(EAP)的形式提供。
对于使用吉拉服务管理进行变更管理的团队来说,这种集成将 Octopus 部署与吉拉服务管理中的变更请求联系起来。
您可以为特定的项目和环境启用这种集成,它支持变更请求的自动创建,或者将部署链接到现有的变更请求。
借助吉拉服务管理集成,每个受控部署都有一个更改请求,以便您的部署符合公司政策和法规要求。通过完整的部署审计日志,变更经理还可以确保所有部署都在适当的控制级别下执行。
我们的吉拉服务管理集成让您:
- 轻松配置您的工作流程,将 Octopus 与一个或多个吉拉服务管理连接相集成
- 通过提示变量将部署链接到现有的变更请求,以便您可以手动将部署与变更请求相关联
- 通过更改请求标题上的字符串匹配链接手动创建的更改请求
- 在部署时自动创建变更请求
- 查看和导出受控部署的审核日志,以便轻松实现合规性和部署后协调
在本帖中,我将向您介绍我们的吉拉服务管理集成,并向您展示如何开始。
我们的吉拉服务管理集成是早期访问预览。由于我们仍在开发这一功能,我们非常感谢您的反馈。我们还邀请您加入我们的社区 Slack 的讨论。
通过吉拉服务管理和八达通实现更好的变革管理
对于开发运维团队来说,大规模管理部署管道既复杂又耗时,而且在您加入变更管理后会变得更加困难。我们希望为使用吉拉服务管理的用户提供一个更好、更自动化的审批流程,而不是人工干预。
将吉拉服务管理与 Octopus 集成有助于使变更管理更容易,减少摩擦并简化开发团队的工作。
吉拉服务管理集成入门
在注册 EAP 之后,您需要配置一些设置来开始使用吉拉服务管理集成。
导航到设置,然后导航到吉拉服务管理集成。使用复选框启用集成,并添加一个连接。

您必须提供来自吉拉服务管理的基本 URL、用户名和令牌。有关创建 API 令牌的详细信息,请参见 Atlassian 文档。
配置您的环境和项目
配置吉拉服务管理集成后,您需要配置您的环境和项目。两者都需要启用吉拉服务管理,以便由吉拉服务管理来管理部署。
配置您的环境
要设置您的环境,请转到基础架构并选择您想要用于吉拉服务管理的环境。在吉拉服务管理集成下拉列表中,选择变更控制复选框。
对所有适用的环境重复此操作。

配置您的项目
要设置您的项目,请转到设置-常规,在副标题吉拉服务管理集成下,勾选变更控制旁边的复选框。然后选择要使用的连接。您可以使用之前设置的连接,或者如果您有多个不同业务单位的连接,您可以为项目选择正确的连接。
吉拉服务管理项目还需要输入键。

设置链接到现有变更请求的提示变量

如果要重用更改请求或使用现有的更改请求,则需要为吉拉服务管理更改请求设置提示变量。
如果您不打算重用变更请求,就没有必要设置它。
在您的项目中,在变量部分,创建一个名为Octopus.JiraServiceManagement.ChangeRequest.Number的提示变量。您可以选择打开编辑器来更改标签和描述,这样更容易使用。
在部署中创建新的变更请求
要创建新的更改请求,必须首先为吉拉服务管理更改控制配置您的项目。然后,将该项目部署到一个同样被配置为受变更控制的环境中。
如果您为变更请求配置了提示变量,将其留空将导致创建新的变更请求。
单击部署后,将出现任务摘要屏幕,并显示消息变更请求等待批准。将为创建的更改请求显示一个更改请求编号,并带有一个指向吉拉服务管理的链接。

当变更请求进展到执行的状态时,Octopus 认为变更请求已被批准。

在变更请求被批准之前,您的部署不会在 Octopus 中运行。在 Octopus 中触发自动批准之前,批准人需要将更改请求移至实施阶段。
变更请求只能处于实施阶段,以便在 Octopus 中运行部署。如果变更请求处于任何其他阶段,任务将不会开始。
要为另一个部署重用变更请求,它需要保持在实现中。
变更请求还必须在部署期间保持实施状态,因为 Octopus 会在整个任务日志中检查变更请求的状态。

使用现有的变更请求进行部署

如果您有一个现有的更改请求,您可以将部署链接到它,而不是创建一个新的。
假设您为变更请求编号创建了提示变量,那么在创建部署时,只需复制变更请求编号并将其粘贴到参数部分。
如果更改请求处于实施阶段,Octopus 会自动识别其已获批准。
结论
作为 Octopus 2022 Q3 版本的一部分,吉拉服务管理集成作为早期访问预览版(EAP)提供。它有助于自动化您的变更管理流程,从而更容易实现符合您组织的变更管理策略的自动化部署。
我们期待引入新功能,继续支持您的变更管理流程。
我们希望您尝试将这种方式与您的工作流程相结合,并告诉我们如何改进。
愉快的部署!
七月社区综合报道-八达通部署
哇,七月的人都很忙!在过去的几周里,有很多好东西被出版了。
首先,伊恩·波林又开始写博客了,他发了两篇新帖变量是你的朋友和【Octo.exe ——出口/进口项目陷阱。我们可能已经用我们的迁移工具做了很多冗余的第二篇文章(抱歉,伊恩),但是如果你正在使用 2.6 并且需要移动数据,这是一个很好的阅读。
对于我们的俄罗斯读者来说,在上有一个介绍 Octopus Deploy 的帖子。对每个人来说,仅仅是图片就值得一看,根据谷歌的说法,翻译看起来是一个很好的概述(除了无意中提到的詹姆斯·邦德)。
使用 Jenkins 作为您的构建服务器?Brian Adriance 和其他人发布了一个插件来创建和部署版本,作为你构建过程的一部分。谢谢各位。看起来很棒。
爱德华·里奇正在写一个关于的博客系列,确切地知道你发布了什么。在 Octopus 版本中包含提交和注释的一些代码,看起来不错!
Mani 这个月给我们带来了另一篇文章,这一次是关于使用 Redgate 工具通过 Octopus Deploy 自动化数据库部署。
你在用 Octopygmy 吗?这是大卫·罗伯兹的 Chrome 扩展,可以帮助你定制你的章鱼仪表盘。他刚刚更新到 3.0,所以现在是更新的好时机!
最后,8 月 3 日你在锡达拉皮兹地区或附近吗?如果是的话,去锡达拉皮兹吧。NET 用户群。Matt Ash 正在做一个关于团队城市+章鱼部署的持续牛逼的演讲。我完全支持持续的精彩,所以谢谢马特!
目前就这些。别忘了,如果你正在某个地方做演讲,或者你已经写了一篇博文,发送电子邮件或推文@OctopusDeploy,我们将帮助传播消息。
六月社区综合报道-八达通部署
对于我们在互联网世界的所有朋友来说,这是忙碌的一个月!这里有一个总结,以防你错过了其中的任何一个。
首先是史蒂夫·芬顿的电子书《探索 Octopus Deploy:部署自动化》。NET" 。你已经错过了他的免费提供的,但是如果你需要一个 2.6 版本的安装和项目设置,这是一个很好的读物。干得好,史蒂夫!
接下来是马尼马兰·钱德拉塞卡兰关于章鱼部署的所有事情的博客系列。从他的章鱼 3.0 综述开始,继续阅读。谢谢你所有的帖子,马尼!里面有些好东西!
当然,我们在 Domain 的好朋友也没闲着。贾森·布朗,常驻“多云行动诗人”有几个关于大章鱼部署的相关帖子。一篇是关于做金丝雀部署,另一篇是关于使用 T2 PoshServer 通过 GitHub 的 webhooks 触发脚本。值得一读,我不知道有人用 PowerShell 编写了 web 服务器!
就在我写完这篇文章的时候,杰森也发了这条微博...
星期五的部署不再可怕!
这篇关于克里斯·伊尔玛使用大口、TFS 和章鱼的帖子引起了我们的注意。如果您将 Gulp 作为构建过程的一部分,那么这本书值得一读。我知道其他一些人也在做类似的事情,但是克里斯是第一个写博客的人!
最后,如果你在你的组织中使用 Splunk,布里斯班当地的 Matthew Erbs 已经在你的 Octopus Deploy 日志中写了一个插件,并获得一些指标。非常酷马特!。
别忘了,如果你正在写博客,做用户群讨论或类似的事情,你可以发推特给我们 @OctopusDeploy ,我们会让全世界都知道。
DDD 珀斯
我们将成为 DDD 珀斯会议的白银赞助商。如果你在珀斯,你肯定想去那里,我喜欢 DDD 会议的形式,并且总是在那里度过美好的时光。
直到下次
唷,太多了!请密切关注 3.0 下个月达到完整版本的里程碑,如果你想玩,并且你有很多博客要看,我们希望得到任何关于预发布的反馈。
向 Kubernetes 容器公开 Octopus 变量——Octopus 部署

如果您遵循最佳实践指南,如十二因素应用,您的 Kubernetes 应用程序可能会使用环境变量将配置值具体化。在 pods 中有许多方法来定义这些环境变量,但是直到最近,它们都涉及到逐个显式地定义每个环境变量。
Kubernetes 1.16 的新特性是将配置映射或秘密的所有值作为环境变量暴露在 pod 中的能力。在 Octopus 2020.5 中,这些新的envFrom字段已经通过部署 Kubernetes 容器步骤公开。当与从原始 YAML 部署资源的能力相结合时,我们可以创建一个工作流,在这个工作流中,多组 Octopus 变量被暴露给一个容器,而不需要繁琐地将它们一一映射。
在这篇博文中,我们将看看如何以一种简化的方式将多组 Octopus 变量直接传递给容器。
定义环境变量
对于这个例子,我们将定义三个环境变量:DATABASEPASSWORD、EXTERNALSERVICE和PORT。
在 Octopus 中,我们以一种格式捕获这些变量,这种格式允许我们用一个模板循环访问它们,看起来像GroupName[VariableName].Property。这意味着我们最终有三个章鱼变量,称为:
EnvironmentVariables[DATABASEPASSWORD].ValueEnvironmentVariables[EXTERNALSERVICE].ValueEnvironmentVariables[PORT].Value:

启用自定义资源
在部署 Kubernetes 容器步骤中的一个特性叫做定制资源。我们将使用这个特性来创建保存环境变量的秘密。
自定义资源功能默认不启用,所以我们必须先通过点击配置功能按钮将其启用:

使资源不可变
部署 Kubernetes 容器步骤是一种自以为是的部署 Kubernetes 资源的方式,其中一种观点是支持主部署的资源,如秘密和配置映射,被视为不可变的。
您可以想象这样一种情况,新部署更改了它在配置映射或密码中预期的数据,如果新部署覆盖了现有的支持资源,那么任何旧部署都将处于未定义状态。使用重新创建策略时,这通常不是问题,因为在创建新的 pod 之前,所有旧的 pod 都会被删除。但是对于滚动部署或蓝/绿部署,新旧部署必须并行运行一段时间,因此它们的支持资源也应该并行运行。
在实践中,支持资源被视为不可变的这一观点意味着由Deploy Kubernetes containers步骤创建的配置映射、秘密或定制资源在每个 Octopus 部署中都被赋予了唯一的名称。这是由 Octopus 自动完成的,但是重要的是要理解分配给定制资源的名称并不是资源部署时的最终名称。
创造秘密
自定义资源是用原始 YAML 创建的。我们还可以使用 Octopus 模板特性,我们将使用它来循环前面定义的每个变量。生成的自定义资源如下所示:
apiVersion: v1
data:
#{each var in EnvironmentVariables}
#{var}: "#{var.Value | ToBase64}"
#{/each}
kind: Secret
metadata:
name: mysecret
type: Opaque
定义容器
为了将秘密公开为环境变量,我们展开容器定义的秘密环境变量部分,并单击从秘密按钮添加所有环境变量。
为了引用作为定制资源创建的秘密,我们采用在 YAML 定义的资源名称,并在它后面附加-#{Octopus.Deployment.Id | ToLower}。在我们的例子中,最后的秘密名是mysecret-#{Octopus.Deployment.Id | ToLower}:

为了证明环境变量已经正确配置,我们将部署 Docker imagemcasperson/print environment(源代码在 GitHub 上),这是一个简单的 web 应用程序,它将环境变量打印到网页上。此图像显示端口 8080:

露出容器
为了方便起见,我们将创建一个负载平衡器服务来公开我们的容器。这将为我们提供一个公共 IP,让我们的浏览器指向这个 IP 来测试示例 web 应用程序:

验证结果
在 web 浏览器中打开负载平衡器 IP 地址会显示通过秘密暴露的三个环境变量:

结论
通过精心设计我们的 Octopus 变量,使我们能够在创建自定义资源时循环访问它们,并利用 2020.5 中的部署 Kubernetes 容器步骤所公开的新的envFrom字段,我们有了一个工作流,使我们能够直接将任意数量的 Octopus 变量映射为 Kubernetes 容器中的环境变量。
由于Deploy Kubernetes containers步骤确保了每个定制资源都有一个惟一的名称,因此基本上是不可变的(至少就部署过程而言),我们还可以确信,滚动或蓝/绿部署等更高级的策略不会使旧的 Kubernetes 部署处于未定义的状态。
这种组合对于外部化许多变量的常见问题是一个强大而方便的解决方案,我们希望它将在部署 Kubernetes 应用程序时增强团队的能力。
愉快的部署!
使用 Octopus - Octopus Deploy 将微服务部署到 Kubernetes

微服务可以是一种强大的设计模式,它允许大型开发团队将代码交付到生产环境中,而不需要代码在单个代码库中进行协调,并按照通用的时间表发布。然而,部署这些微服务可能是一个挑战,因为协调 Kubernetes 资源和在环境之间推广的成本是由每个单独的微服务支付的。
Octopus 有许多有用的功能来帮助简化和管理微服务部署。在这篇文章和截屏中,我们将介绍由 Google 创建的示例微服务应用程序在线精品店的部署过程。
截屏
https://www.youtube.com/embed/pJjriVVLWQ0
VIDEO
创建部署模板
如果您查看包含所有 Kubernetes 资源定义的 YAML,您会注意到一个模式,其中每个部署都由一个匹配的服务公开。像这样将部署和服务配对是 Kubernetes 部署中的常见做法,这种模式被 Octopus 中的部署 Kubernetes 容器步骤捕获。
您还会注意到,大多数微服务的部署定义非常相似。它们都定义了:
- 一个容器
- 集装箱暴露的端口
- 资源请求和限制
- GRPC 活跃度和就绪性探测
- 环境变量
使用 diff 工具很容易看出部署资源之间的相似性:

为了删除定义部署及其相关服务所需的样板代码,我们利用了 Octopus 中一个名为步骤模板的特性。下面的 YAML 可以通过部署部分的编辑 YAML 选项添加到部署 Kubernetes 容器步骤中,它捕获了大多数微服务应用程序在其部署中使用的字段,应用程序特定的值由变量替换:
apiVersion: apps/v1
kind: Deployment
metadata:
name: "#{ServiceName}"
spec:
template:
metadata:
labels:
app: "#{ServiceName}"
spec:
terminationGracePeriodSeconds: "#{if ServiceTerminationGracePeriodSeconds}#{ServiceTerminationGracePeriodSeconds}#{/if}"
containers:
- name: server
image: "#{ServiceImage}"
ports:
- containerPort: "#{ServicePort}"
envFrom:
- secretRef:
name: "mysecret-#{Octopus.Deployment.Id | ToLower}"
resources:
requests:
cpu: "#{ServiceCPURequest}"
memory: "#{ServiceMemoryRequest}"
limits:
cpu: "#{ServceCPULimit}"
memory: "#{ServiceMemoryLimit}"
readinessProbe:
initialDelaySeconds: "#{if ServiceReadinessProbeInitialDelaySeconds}#{ServiceReadinessProbeInitialDelaySeconds}#{/if}"
periodSeconds: "#{if ServiceReadinessProbePeriodSeconds}#{ServiceReadinessProbePeriodSeconds}#{/if}"
exec:
command: ["/bin/grpc_health_probe", "-addr=:#{ServicePort}", "#{if ServiceReadinessProbeTimeout}-rpc-timeout=#{ServiceReadinessProbeTimeout}s#{/if}"]
livenessProbe:
initialDelaySeconds: "#{if ServiceLivenessProbeInitialDelaySeconds}#{ServiceLivenessProbeInitialDelaySeconds}#{/if}"
periodSeconds: "#{if ServiceLivenessProbePeriodSeconds}#{ServiceLivenessProbePeriodSeconds}#{/if}"
exec:
command: ["/bin/grpc_health_probe", "-addr=:#{ServicePort}", "#{if ServiceLivenessProbeTimeout}-rpc-timeout=#{ServiceLivenessProbeTimeout}s#{/if}"]
这个 YAML 有几个有趣的方面值得一提。
if语法(例如#{if ServiceTerminationGracePeriodSeconds}#{ServiceTerminationGracePeriodSeconds}#{/if})提供了一种方法来返回变量值(如果已经定义了的话),或者返回一个空字符串(如果变量还没有定义的话)。Octopus 将在适当的情况下忽略空的 YAML 属性,以避免在部署最终资源时出现验证错误。
单个环境变量列表已被envFrom.secretRef所取代。这允许 Kubernetes 根据保存在外部秘密中的值注入环境变量。
我们在这里引用的秘密被称为mysecret-#{Octopus.Deployment.Id | ToLower},将在稍后的步骤中作为定制资源创建。
接下来,我们有服务模板。与部署模板不同,服务模板对于所有微服务都是相同的。
该 YAML 也可以通过服务部分的编辑 YAML 选项添加到步骤中:
apiVersion: v1
kind: Service
metadata:
name: "#{ServiceName}"
spec:
type: ClusterIP
selector:
app: "#{ServiceName}"
ports:
- name: grpc
port: "#{ServicePort}"
targetPort: "#{ServicePort}"
最后,我们创建一个秘密,将暴露给 pod 的环境变量保存为定制资源。
该资源使用 Octopus 变量重复语法将所有匹配的 Octopus 变量作为字段添加到秘密资源中:
apiVersion: v1
data:
#{each var in EnvironmentVariables}
#{var}: "#{var.Value | ToBase64}"
#{/each}
kind: Secret
metadata:
name: mysecret
type: Opaque
在部署期间,Octopus 将字符串-#{Octopus.Deployment.Id | ToLower}附加到每个定制资源的名称上。这确保了每个资源都是不可变的,并且紧密耦合到与之配对的部署资源。这个秘密的最终名字将是mysecret-#{Octopus.Deployment.Id | ToLower}。这与部署envFrom.secretRef属性中的秘密名称相匹配。

注入秘密的变量采取GroupName[VariableName].VariableProperty的形式,例如EnvironmentVariables[REDIS_ADDR].Value、EnvironmentVariables[PORT].Value或EnvironmentVariables[LISTEN_ADDR].Value。这些变量应该由项目使用 step 模板来定义。
组成部署的变量随后作为参数公开:

容器映像名称被定义为一个包,允许在版本创建期间选择映像版本:

该参数在容器定义中被引用,使用让项目为 Docker 图像字段选择包选项:

部署模板
随着模板的部署,我们现在创建那些最初共享公共部署模式的微服务。由于所有常见的样板代码都已抽象出来,我们所要做的就是填充由步骤模板定义的参数:

然后使用上面提到的组语法定义环境变量:

对于那些不遵循标准模板的微服务(例如,前端应用和 redis 数据库),我们可以简单地将部署和服务 YAML 复制到适当的编辑 YAML 部分,这将为我们填充 UI:

渠道规则
不管出于什么原因,当谷歌发布组成这个样本微服务应用程序的 Docker 图像时,它们包括了一个标记有类似31df60f的散列的图像。
我们希望我们的部署忽略这个散列,而是允许选择更典型的版本标签,如v0.2.0。为此,我们需要使用通道规则。
该规则定义了[0.0,1.0]的版本范围,包括 Google 发布的所有 zero based point 版本,忽略了带有 hash 的图片:

带有纯文本标签的 Docker 图像,像redis:alpine,也可以利用频道规则。标签alpine被认为是版本0.0.0-alpine,可以匹配版本规则(,0.0)和一个预发布正则表达式^alpine$。
整个微服务堆栈由十几个单独的服务组成。这些可以从一个环境单独提升到另一个环境。如果微服务是真正独立的实体,由不同的团队管理,并按照他们自己的时间线发布,那么单独地提升服务可能是可取的。
在有些情况下,微服务仍然是紧密耦合的,并且必须以特定的顺序发布,或者在某些情况下,随时了解环境的状态至关重要。为此,Octopus 提供了部署释放步骤。
部署一个发布步骤将一个 Octopus 发布视为一个工件,在一个元项目的发布的创建过程中被选择。在我们的例子中,元项目包含一个为每个微服务部署一个发布步骤,允许一个环境中的整个微服务栈以正确的顺序和众所周知的发布版本升级到另一个环境。元项目中部署发布步骤的顺序捕获了服务之间的依赖关系,发布经理可以使用这些元项目发布的细节来准确理解在任何给定时间部署了哪个应用程序组合。
以下是我们用于将所有微服务部署到给定环境的元项目示例:

结论
在本次演示中,我们利用 Octopus 的多项功能部署了一个微服务应用堆栈:
- 我们使用 step 模板抽象出微服务的通用样板定义。
- 原始 YAML 编辑使我们能够快速定义那些不符合大多数堆栈使用的模式的少数独特微服务的部署。
- 频道规则允许我们将可用的 Docker 图像标签限制在特定的范围内。
- 部署发布步骤允许我们创建一个元项目,在一个新的环境中以正确的顺序部署所有的微服务。
这意味着,一旦定义了初始模板,我们就可以快速可靠地定义新的微服务部署,并通过部署单个元项目来填充整个环境。
愉快的部署!
混合 Kubernetes 角色、角色绑定、集群角色和集群绑定- Octopus 部署

在某种程度上,随着您的 Kubernetes 集群变得越来越复杂,基于角色的安全性问题将变得非常重要。通常,这意味着将集群分成多个命名空间,并将对命名空间资源的访问限制在特定的帐户。
为了支持这一点,Kubernetes 包含了许多资源,包括角色、集群角色、角色绑定和集群角色绑定。在高级别上,角色和角色绑定位于特定命名空间内,并授予对特定命名空间的访问权限,而集群角色和集群角色绑定不属于命名空间,并授予对整个集群的访问权限。
然而,混合这两种类型的资源是可能的。例如,当角色绑定将帐户链接到群集角色时会发生什么?本文着眼于其中的一些场景,以便更好地了解 Kubernetes 是如何实现基于角色的安全性的。
免费试用 Octopus,自动部署 Kubernetes。
准备集群
首先,我们将创建一些名称空间,并通过 Kubernetes 基于角色的访问控制(RBAC)资源授予访问权限:
$ kubectl create namespace test
$ kubectl create namespace test2
$ kubectl create namespace test3
$ kubectl create namespace test4
然后,我们将在test名称空间中创建一个服务帐户:
apiVersion: v1
kind: ServiceAccount
metadata:
name: myaccount
namespace: test
场景 1:角色和角色绑定
我们将从一个简单的示例开始,该示例创建一个角色和一个角色绑定来授予服务帐户对test名称空间的访问权限:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: test
name: testadmin
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: testadminbinding
namespace: test
subjects:
- kind: ServiceAccount
name: myaccount
apiGroup: ""
roleRef:
kind: Role
name: testadmin
apiGroup: ""
这个例子很好理解。我们所有的资源(服务帐户、角色和角色绑定)都在test名称空间中。角色授予对所有资源的访问权限,角色绑定将服务帐户和角色链接在一起。如您所料,服务帐户针对test名称空间中的资源发出的请求工作如下:
$ kubectl get roles -n test
NAME CREATED AT
testadmin 2020-08-24T23:24:59Z
场景 2:另一个名称空间中的角色和角色绑定
现在让我们在名称空间test2中创建新的角色和角色绑定。注意这里的角色绑定链接了来自test2的角色和来自test的服务帐户:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: test2
name: testadmin
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: testadminbinding
namespace: test2
subjects:
- kind: ServiceAccount
name: myaccount
namespace: test
apiGroup: ""
roleRef:
kind: Role
name: testadmin
apiGroup: ""
这是可行的,授予服务帐户对创建服务帐户的命名空间之外的资源的访问权限:
$ kubectl get roles -n test2
NAME CREATED AT
testadmin 2020-08-24T23:35:16Z
注意,roleRef属性没有namespace字段。这是RoleRef的 API 文档:

这里的含义是,角色绑定只能引用同一名称空间中的角色。
场景 3:集群角色和角色绑定
如前所述,集群角色不属于一个名称空间。这意味着群集角色不会将权限范围扩大到单个命名空间。
但是,当群集角色通过角色绑定链接到服务帐户时,群集角色权限仅适用于已创建角色绑定的命名空间。
这里,我们在名称空间test3中创建一个角色绑定,将我们的服务帐户链接到集群角色clusteradmin:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: testadminbinding
namespace: test3
subjects:
- kind: ServiceAccount
name: myaccount
namespace: test
apiGroup: ""
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: ""
我们的服务帐户现在可以访问test3名称空间中的资源:
$ kubectl get rolebindings -n test3
NAME ROLE AGE
testadminbinding ClusterRole/cluster-admin 21m
但是它不能访问其他名称空间:
$ kubectl get roles -n test4
Error from server (Forbidden): roles.rbac.authorization.k8s.io is forbidden: User "system:serviceaccount:test:myaccount" cannot list resource "roles" in API group "rbac.authorization.k8s.io" in the namespace "test4"
场景 4: ClusterRole 和 ClusterRoleBinding
在我们的最后一个场景中,我们将创建一个集群角色绑定来将集群角色链接到我们的服务帐户:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: testadminclusterbinding
subjects:
- kind: ServiceAccount
name: myaccount
apiGroup: ""
namespace: test
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: ""
再次注意roleRef上缺少一个namespace字段。这意味着群集角色绑定不能标识要链接的角色,因为角色属于名称空间,并且群集角色绑定(以及它们引用的群集角色)没有名称空间。
尽管集群角色和集群角色绑定都没有定义任何名称空间,但是我们的服务帐户现在可以访问所有内容:
$ kubectl get namespace test4
NAME STATUS AGE
test4 Active 26m
摘要
从这些示例中,我们可以观察到 RBAC 资源的一些行为和限制:
- 角色和角色绑定必须存在于同一命名空间中。
- 角色绑定可以存在于服务帐户的单独命名空间中。
- 角色绑定可以链接集群角色,但它们只授予对角色绑定的命名空间的访问权限。
- 群集角色绑定将帐户链接到群集角色,并授予对所有资源的访问权限。
- 群集角色绑定不能引用角色。
这里最有趣的含义可能是,当角色绑定引用时,集群角色可以定义在单个名称空间中表示的公共权限。这消除了在许多名称空间中拥有重复角色的需要。
愉快的部署!
现代工作文化的关键假设——八达通部署
DevOps 将组织文化的话题牢牢地带到了桌面上。虽然文化一直是敏捷和精益的元素,但对 DevOps 的研究表明,它与更多的技术能力一样重要。
DevOps 结构方程模型有几个与人和文化相关的元素,因此很明显,人的问题是 DevOps 图景的重要部分。模型中的 5 种文化能力是:
- 学习氛围
- 韦斯特伦组织文化
- 心理安全
- 工作满意度
- 身份
文化能力驱动软件交付和运营绩效,这预示着成功的业务成果。

与此同时,在过去几年中,所有行业都出现了几个人力资源热门话题:
- 为规则而工作(安静地退出)
- 大辞职/大改组
- 4 天工作周
- 混合工作
正如艾米丽·弗里曼(《傻瓜的开发计划》的作者)所说:
科技面临的最大挑战不是技术,而是人。"
那么,在 DevOps 的背景下理解文化,应该从哪里开始呢?
基本假设
1960 年,道格拉斯·麦格雷戈出版了一本名为《企业人性的一面》的书。在书中,他描述了关于人类行为的基本假设如何导致不同的管理风格。
你要么相信:
- 理论 X:人不想工作,需要奖惩激励
- 理论 Y:人们有做好工作的内在动机
工作场所中的许多决策都涉及权衡,但这些基本假设是相互排斥的。
如果你相信 X 理论,你:
- 集中决策
- 跟踪个人绩效
- 用奖励和惩罚来激励员工
使用 Y 理论,您可以:
- 专注于设定明确的目标
- 让人们引导他们自己的努力
当你遵循 Y 理论时,员工成为组织最有价值的资产。
当你使用外部奖励时,你经常会获得短期收益。这种策略最终失败了,因为它降低了内在动力。阿尔菲·科恩查阅了数百份研究报告,得出结论认为,激励会导致暂时的服从,但会对动机造成持久的伤害。
丹·平克在他著名的关于动机的书《驱动力》中对道格拉斯·麦格雷戈和阿尔菲·科恩的工作进行了扩展,该书描述了人们是如何需要环境、自主和目标来达到高绩效水平的。
麦格雷戈认为 X 理论和 Y 理论是经理在评估工作场所后会选择的两种理论。你会回顾工作和人,并决定你是否需要一个独裁的风格或一个更不干涉的方法。从那以后,我们通过对系统失败的研究了解到,高度信任和低责备的文化比官僚或病态文化更安全。
Y 理论是精益、敏捷和 DevOps 的基础,也是生殖文化的潜在假设。
任务指挥部
尽管军事组织传统上被视为 X 理论文化,现代军事单位使用任务指挥部运作。任务指挥模式通过提供明确的目标来分散决策。地面部队可以随着事件的发展做出动态反应,而不是等待命令。这是 Y 理论文化的应用。
这个项目的民间版本叫做工作场所授权,它要求:
- 你与每个人分享信息
- 你通过界限创造自治
- 你用自我导向的团队取代了等级制度
工作场所授权结合了集中的意图和分散的执行。在软件交付中,这通常包括由跨职能、自组织团队实现的共同愿景。
文化预测安全
当你觉得说出来很安全,没有人会受到责备时,侥幸逃脱和小错误会促进学习。无论是制造业、核电厂、航空业还是软件交付业,每一次事故都会带来积极的行动,使工作场所更加安全。
如果你对报告侥幸脱险感到不安全,潜在的风险就会累积,直到灾难发生。
你不一定要在安全至关重要的行业才能从这种关系中受益。预测安全性的相同文化特征也与沟通、协作、创新和解决问题有关。文化影响着信息的流动,这对所有这些活动都是至关重要的。
2022 年,我们发现组织的应用程序开发安全实践的最大预测因素是文化,而不是技术:注重性能的高信任、低责备的文化更有可能采用新兴的安全实践。"2022 年 DevOps 报告的加速状态
理论 X 管理限制了信息的流动,限制了谁可以采取行动。经理们收集信息并向下传递决策。
Y 理论领导导致强大的信息流和迅速的反应行动。信息自由流动,决策制定与工作密切相关。
变化的文化
改变团队和组织文化是软件交付中最艰难的挑战之一。即使是部署管道中最复杂的自动化任务也无法与之媲美。你需要对你未来的状态有一个清晰的愿景,这需要快速、坚定、定期地推进,以确保目标保持清晰。
你需要领导者和管理者明白,他们的角色是让自组织团队发挥每个成员的才能。您需要从集中信息和决策的系统转移到与分散责任一致的系统。
例如,假设您使用集中式工具来组织任务并将其分配给人员。在这种情况下,您需要转移到一个系统,该系统与设置一个明确的任务相一致,而不去除团队自组织和响应动态情况的能力。您可能需要完全更换工具,或者以新的方式使用工具。你的甘特图可能不得不消失,但是如果团队可以改变它的用途,你的任务跟踪应用可以保留下来。
文化变革中的领导角色是:
- 坚持不懈地推动期望的最终状态
- 强化领导者和管理者作为推动者的角色
- 确保团队变得自组织
一种健康的文化还应该清楚信息流动的重要性,并且必须为交流方式设定一个标准。
在 Octopus,我们遵循彻底坦诚的方法。这让我们可以直接交流,但要在一个我们都互相关心的框架内。彻底的坦诚让个人表现出勇气,挑战其他人,否则他们可能会保持沉默。这最终意味着我们都可以在没有有害或有毒行为的情况下做得更好。
如果没有明确、有力和持续的推动,你就不会在文化上有所建树。你必须克服惰性,对抗组织免疫反应。尽管困难重重,但这项研究的结论是,文化对高绩效至关重要。
结论
当人们在 DevOps 的背景下谈论文化时,他们指的是 Westrum 的生成文化,它基于 McGregor 的 Y 理论假设。简而言之,你应该致力于一个明确的、共同的任务,并结合分散决策。
所有现代软件交付方法都以不同的方式提到了授权团队的概念。
我们称之为现代工作场所文化,然而这种观念已经有 100 多年的历史了。使命命令可以追溯到 19 世纪,X 理论和 Y 理论在 1960 年的一本书中得到了解释,韦斯特勒姆的组织文化类型学是在 20 世纪 80 年代设计的。
你会发现文化是 DevOps 中最难啃的骨头。依靠研究和统计数据来证明生殖文化是很诱人的。然而,现实情况是,文化变革取决于引人注目的故事讲述和创建一个引人注目的组织转型后的愿景。
你可以在我们的 DevOps 工程师手册中了解更多关于 DevOps 文化
进一步阅读
相关信息:
DevOps 中的文化:
- 傻瓜的 DevOps 艾米丽·弗里曼
管理和激励:
- 企业人性的一面——道格拉斯·麦格雷戈
- 受到奖励的惩罚-阿尔菲·科恩
- 彻底的坦白——金·斯科特
- 驱动-丹粉红
文化和失败:
- 理解系统故障
- 黑箱思维-马修·塞德
愉快的部署!
为什么应该看看 Kotlin 的标准库——Octopus Deploy
随着我们在 Octopus 中增加对 Java 部署的支持,更多的集成代码正在用 Kotlin 编写。作为一名长期的 Java 开发人员,我借此机会了解了 Kotlin 语言设计者对他们的 Java 语言所做的一些改进。
大约在同一时间,我在 Pluralsight 上完成了戴夫·范彻(Dave Fancher)的 C# 函数式编程课程。我喜欢这门课,因为它提供了一些清晰而实用的建议,教你如何用 C#进行函数编程。在书中,Dave 提供了两个扩展方法,Map和Tee,这两个方法允许您转换对象并将它们传递给其他变异方法,并提供了如何以及为什么使用它们的示例。
我推荐这门课程,即使是对 Kotlin 开发人员来说,因为 Dave 提出的想法很好地映射了 Kotlin 作为其标准库的一部分提供的类似方法。
科特林run和let方法大致相当于 C# Map方法,而科特林also和apply方法大致相当于 C# Tee方法。
那么这些标准函数有什么区别呢?为了展示这些差异,我创建了一个简单的 Kotlin 项目,你可以在 GitHub 上找到它。
跑 vs 让
run和let是变换函数。它们接受被调用对象的值,并返回一个新值。
这些函数之间最明显的区别是它们暴露给块函数的变量。
run函数将调用它的对象的值公开为块内的this。
@Test
fun runExample () {
val result = "Local String".run {
System.out.println(this) // prints "Local String"
"New String"
}
System.out.println(result) // prints "New String"
}
let函数将调用它的对象的值公开为块内的it,而this从外部范围保留。
@Test
fun letExample () {
val result = "Local String".let {
System.out.println(this.name) // prints "Demo Class"
System.out.println(it) // prints "Local String"
"New String"
}
System.out.println(result) // prints "New String"
}
您可以重命名默认的it参数。这样做可以避免默认的it参数与作用域中现有的变量发生冲突(如果嵌套两个let函数,就会发生这种情况)。
@Test
fun letExample2 () {
val result = "Local String".let {me ->
System.out.println(this.name) // prints "Demo Class"
System.out.println(me) // prints "Local String"
"New String"
}
System.out.println(result) // prints "New String"
}
也 vs 适用
also和apply通常在调用它们所针对的对象的值需要用于某种变异操作时使用。来自also和apply模块的任何返回值都被忽略,并返回原始对象的值。
通过这种方式,我们可以利用原始值来执行一些变异逻辑(其返回值不被我们自己的代码使用),同时保留原始值。
像run函数一样,apply将它所调用的对象的值公开为this。
@Test
fun applyExample() {
val result = "Local String".apply {
System.out.println(this) // prints "Local String"
"New String" // return value is ignored
}
System.out.println(result) // prints "Local String"
}
像let函数一样,also将调用它的对象暴露为块内的it,而this从外部作用域保留。
@Test
fun alsoExample() {
val result = "Local String".also {
System.out.println(this.name) // prints "Demo Class"
System.out.println(it) // prints "Local String"
"New String" // return value is ignored
}
System.out.println(result) // prints "Local String"
}
并且it可以改名。
@Test
fun alsoExample2() {
val result = "Local String".also { me ->
System.out.println(this.name) // prints "Demo Class"
System.out.println(me) // prints "Local String"
"New String" // return value is ignored
}
System.out.println(result) // prints "Local String"
}
转化与突变
我将run和let描述为转换函数,将also和apply描述为变异函数。
正如您在前面的例子中看到的,run和let也很乐意让您在它们的功能块中改变状态(就像我们通过写入控制台所做的那样),因此转换和改变之间的区别是概念性的,而不是由语言强制的。
然而,这种概念上的区别是有用的,因为它允许您描述代码的意图,允许您简单地从代码的“形状”中了解代码做什么。
代码的形状是什么?
那么我所说的代码的“形状”是什么意思呢?让我们来看一个设计用于部署 AWS CloudFormation 模板的简单函数。
fun createCloudFormationStack(newStackName: String) {
val credentialsProvider = ProfileCredentialsProvider()
val client = AmazonCloudFormationClientBuilder
.standard()
.withCredentials(credentialsProvider)
.withRegion(Regions.US_EAST_1)
.build()
val templatePath = javaClass.classLoader.getResource("WordPress.template.json").file
val templateFile = File(templatePath)
val template = FileUtils.readFileToString(templateFile, Charset.defaultCharset())
val request = CreateStackRequest()
request.stackName = newStackName
request.templateBody = template
val response = client.createStack(request)
System.out.println("StackID: " + response.stackId)
}
现在让我们取出所有的函数调用,看看代码是什么形状。
val credentialsProvider = ...
val client = ...
val templateFile = ...
val template = ...
val request = ...
val response = ...
从这个代码的“形状”我们可以确定什么?
变量名给了我们一些关于我们正在创建的对象种类的指示,并且变量的顺序确实限制了对象之间的依赖种类。比如client可以依赖credentialsProvider,也可以不依赖credentialsProvider,但是credentialsProvider可以不依赖client,因为credentialsProvider是先声明的。
否则,虽然没有太多迹象表明这段代码在做什么。
让我们看一个使用标准库函数的版本。
fun createCloudFormationStack2(newStackName: String) {
val client = ProfileCredentialsProvider().let { credentials ->
AmazonCloudFormationClientBuilder
.standard()
.withCredentials(credentials)
.withRegion(Regions.US_EAST_1)
.build()
}
val template = javaClass.classLoader.getResource("WordPress.template.json").file.let { path ->
File(path)
}.let { templateFile ->
FileUtils.readFileToString(templateFile, Charset.defaultCharset())
}
CreateStackRequest().also { request ->
request.stackName = newStackName
request.templateBody = template
}.let { request ->
client.createStack(request)
}.also { response ->
System.out.println("StackID: " + response.stackId)
}
}
去掉所有的函数调用(只留下标准函数),我们得到这样的代码。
val client = ... .let { credentials ->
...
}
val template = ... .let { path ->
...
}.let { templateFile ->
...
}
... .also { request ->
...
}.let { request ->
...
}.also { response ->
...
}
这个形状告诉我们什么?
- 我们可以看出,名为
credentials的东西被转换(通过let函数)为分配给client的值。 - 我们可以看出,名为
path的东西被转换为名为templateFile的东西,后者又被转换为分配给template的值。 - 我们可以看出,一个叫做
request的东西发生了变异(通过also函数),然后转化成了一个叫做response的东西。 - 我们可以看出
response被用于一个变异函数调用中。
标准功能的好处是什么?
我们可以从代码中提取更多的上下文。
对象的转换被清楚地描述为:
credentials- > -clientpath- > -templateFile- > -templaterequest- > -response
因为标准函数允许我们将一些变量的范围缩小到单个块,所以可以使用的对象组合明显更少。template变量的构造可以利用client(即使我们不这样做,代码的形状也不会阻止它),并且client和template可以在创建request的最后一个块中使用(它们就是这样)。
将它与原始代码进行比较,在原始代码中,6 个变量中的每一个都可以利用它们的任意组合。只看第一个代码示例的形状,我们不知道所有变量是如何相关的。
减少变量也使得代码更容易推理。这个神奇的数字描述了人类记忆能力的极限,介于 5 和 9 之间。虽然这个数字不是一个硬性规定,但根据我自己的经验,它听起来是真实的。
第一版代码中的 6 个变量意味着该功能正在突破普通人记忆的极限。第二个版本中的 3 个变量,加上一两个额外的变量,当我们移入和移出let和also函数时,将这段代码很好地放在普通人的记忆容量内。
由于对also的调用,我们也能够快速识别两个变异函数。这让我们知道测试这段代码需要做多少额外的工作,因为变异函数通常表明存在需要在测试环境中模拟和验证的外部状态。
在我们的例子中,第一个变异函数是在没有构建器接口的对象上设置参数,并且不接受构造器中的属性。这不需要跟踪外部状态。
然而,第二个变异函数写入控制台,根据应用程序的上下文,这对于测试可能重要,也可能不重要。
结论
虽然它们非常简单,但 Kotlin 中的标准函数提供了一种强大的方式来描述代码的意图。它们将减少变量计数,使代码更容易推理,并突出突变。
Kubernetes 1.20 正在贬低 Docker 运行时:这是什么意思?-章鱼部署
原文:https://octopus.com/blog/kubernetes-1-20-deprecating-docker-runtime

在 11 月 11 日至 12 月 4 日的一周时间里,有很多关于 Kubernetes 放弃支持 Docker 的问题和担忧。
问题是,事实并非如此。Kubernetes 不会放弃对 Docker 的支持。他们放弃了对 Docker 运行时的运行时支持。你要记住,Docker 是一个完整的栈,而不仅仅是一个容器或者一个容器运行时。Docker 包含几个组件。
不要惊慌
我向你保证这并不像听起来那么疯狂。事实上,这整件事已经计划了好几年了。如果你是 Kubernetes 的用户,比如 Azure Kubernetes Service (AKS)或 Elastic Kubernetes Service (EKS ),对你来说没什么变化。这几乎会像以前一样继续下去。例如,如果您将 AKS 中的 Kubernetes API 版本升级到 1.19,您已经在运行 Containerd ,这是一个运行时,就像 Docker 运行时一样。
您当前用来构建容器和映像的所有东西都将继续工作,包括:
- Dockerfiles :你仍然可以在 Kubernetes 中构建 Docker 映像并运行容器。
- Docker 编写:它仍然可以在你的本地 Docker 实例上工作。
- Dockerhub : Dockerhub 还会存在。记住,Docker 是一个巨大的堆栈。Docker 图像只是该堆栈的一部分。
- 其他 Docker 注册表:它们仍然可以工作。构建、存储和维护 Docker 映像的方式保持不变。
Kubernetes 1.20 正在贬低 Docker——实际上发生了什么?
让我们来看看发生了什么,为什么会发生。
Docker 是作为一个整体构建的,但事情正在向更现代的应用程序方法转变。运行时由 Dockershim 提供,这是正在改变的事情之一,它导致了许多混乱。
Dockershim 使用 Kubernetes 为 Docker 集成实现了一个容器运行时接口。然而,远离 Dockershim 始终是一个目标(因此,名称中有“shim”)。最初创建它是为了帮助实现与 Kubernetes 的集成,但最终它只是一个额外的跳跃。正因为如此,Docker 开始开发 Containerd。
Containerd 很像 CRI-O ,是一个容器运行时,是开放容器倡议的一部分( OCI )。
Kubernetes 维护 Dockershim 成为他们肩上的一个巨大负担,因为 Dockershim 是到达 Kubernetes 运行时的额外一跳。正因为如此,Kubernetes 决定使用 CRI,这使得容器运行时的互操作性可以非常平稳地过渡。这意味着,不再需要跳。
现在,问题来了。Docker 不实现 CRI,这就是 Docker 运行时被弃用的原因。
Kubernetes 是不赞成 Dockershim -这是有计划的
除掉多克西姆一直是我的计划。因为 Dockershim 需要额外的一跳,这根本不是有效的,而且在他们开发 Containerd 时,它实际上只是一个占位符。
Kubernetes 1.20 中发生了什么
从 Kubernetes API 版本 1.20 开始,Docker 运行时将被正式弃用。如果你还有 Docker 运行时,那也没关系。但是,您应该开始考虑迁移到另一个运行时。
从 1.20 开始,如果你还在使用 Docker 运行时,kubelet 启动时会打印一个警告日志。仅此而已,只是一个警告信息。
截至目前,Kubernetes 不带 Dockershim 的最早版本是 2021 年末的 1.23 版本。简而言之,你大概有一年左右的时间来准备。
谁受到了影响
随着所有变革的进行,让我们来分析一下谁受到了影响。
首先,如果你正在编写代码,将代码容器化,然后运输,你不会受到影响。事实上,你可能根本看不出或感觉不到有什么不同。你一切都一帆风顺。
如果您是 Kubernetes 集群管理员,您会受到影响,但不会很严重。您所要做的就是用 CRI-O、Containerd 或其他符合 CRI 的运行时替换 Docker 运行时。
这里有一个关于如何实现 Containerd 的很棒的帖子和分解:https://kubernetes . io/docs/setup/production-environment/container-runtimes/# CRI-o。
结束语
幸运的是,这种变化远没有大家最初预期的那么严重。作为一名开发人员,您几乎不会注意到区别。作为一名操作人员,您必须更新到一个容器运行时,而不是 Docker 运行时。这一改变是朝着正确方向迈出的一步,消除了与 Dockershim 之间的额外跳跃。现在,Kubernetes 少了一件需要维护的事情,而且产品速度也更快了。
在 Kubernetes - Octopus Deploy 中执行金丝雀部署
当推出应用程序的新版本时,将少量流量导向新版本并观察任何错误可能是有用的。这种策略被称为金丝雀部署,意味着新版本中出现的任何错误只会影响一小部分用户。不断增加新版本的流量可以提高对没有问题的信心,如果出现任何问题,部署可以回滚到以前的版本。
Kubernetes 特别适合 canary 部署,因为它提供了管理部署和引导流量的灵活性。在这篇博文中,我们将看看如何使用 Voyager 入口控制器和 Octopus 实现金丝雀部署。
先决条件
要阅读这篇博文,您需要有一个 Kubernetes 集群,以及一个配置了管理凭证的 Octopus 中的 Kubernetes 目标。我将使用一个 Google Cloud Kubernetes 集群和一个具有Google Cloud Kubernetes Admin角色的管理 Kubernetes 目标。
Kubernetes 集群也需要安装 Helm。Google 提供了将 Helm 安装到他们的 Kubernetes 集群中的这些指令。
安装 Voyager
在开始将任何应用程序部署到 Kubernetes 之前,我们需要将 Voyager 安装到我们的集群中。Voyager 提供了许多不同的安装方法,但是我发现 Helm 对于这种情况是最方便的。
我们将利用 Octopus 本身的舵步骤来部署 Voyager 舵图。
外部供给
第一步是创建一个指向 AppsCode 图表库的外部提要。外部提要位于➜图书馆外部提要下。

舵可执行文件
Helm 对于什么版本的客户端可以与服务器上的特定版本协同工作的要求非常严格。因此,与类似于kubectl的工具不同,您经常被迫使用与安装在服务器上的helm可执行文件完全相同的客户端版本。
为了满足精确匹配的需要,Octopus 中的 Helm 步骤允许在部署图表时使用包中的可执行文件。
要获得helm可执行文件的打包版本,请前往 Helm GitHub 发布页面并下载适用于您平台的二进制文件。除非你用的是 workers,否则你的平台很可能是 Windows。

这将下载一个类似于helm-v2.11.0-windows-amd64.zip的文件。将其重命名为类似于helm-windows-amd64.2.11.0.zip的名称,因为这种文件格式更适合 Octopus 内置的提要。
然后将文件上传到内置提要,可以通过库➜包访问。在下面的截图中,你可以看到我已经上传了 Windows 和 Linux 的helm二进制文件。

展开舵图
为了部署航海家掌舵图,我们使用 Octopus 中的Run a Helm Update步骤。

下面的屏幕截图显示了填充的步骤。

这一步中有几个有趣的设置。首先是Helm Client Tool配置。我已经使用了Custom packaged helm client tool选项,并将其指向我们之前上传到内置提要的 Helm 二进制包。windows-amd64/helm.exe中的Helm executable location是指档案中的helm.exe文件。在下面的截图中,您可以看到归档的目录结构。

我们还在Explicit Key Values部分的舵图上设置了两个值。cloudProvider设置被设置为gce,因为我正在部署到谷歌云环境。其他选项包括:
- 美国化学学会
- 美国焊接协会
- 蔚蓝的
- 裸机
- 炮控设备
- gke
- 迷你库贝
- openstack
rbac.create值被设置为true,因为我的 Kubernetes 集群启用了 RBAC。
来自部署的日志为我们提供了一个命令,我们可以运行该命令来验证安装。我的命令是kubectl --namespace=default get deployments -l "release=voyager-operator, app=voyager"。

我们可以通过 Octopus 脚本控制台运行这些特别的命令,该控制台可以通过任务➜脚本控制台访问。
在这里,我对名为GoogleK8SAdmin的 Kubernetes 管理目标运行了命令。

结果显示航海家号已经安装就绪。

通过 Octopus 运行专门的脚本有很多优点,比如能够针对不同的目标运行命令,而无需在本地配置上下文,以及提供已经运行的脚本的历史记录。
金丝雀环境
我们将把 canary 部署的进展建模为 Octopus 环境。这样做有很多好处,比如在仪表板上显示当前进度,并允许轻松地回滚到以前的状态。
环境可以在基础设施➜环境下找到。
对于这个博客,我们将有三个环境:Canary 25%、Canary 75%和Canary 100%。每一个都代表将被定向到 canary 部署的不断增加的流量。

重要的是,这些环境允许Dynamic Infrastructure,我们将利用这一点来创建我们的受限 Kubernetes 目标,而不是将管理目标用于所有部署。

为了在这些环境中推进我们的应用程序,我们将创建一个包含三个阶段的生命周期,每个阶段对应一个 canary 环境。
生命周期可以在➜图书馆生命周期中找到。

最后,通过将它们添加到Environments字段,确保 Kubernetes 管理目标可以访问 canary 环境。

部署项目
我们现在已经有了开始部署应用程序的所有基础设施。下一步是创建一个新的部署项目,将应用程序容器推送到 Kubernetes。
对于这个例子,我们将使用 HTTPD 映像,这是一个 web 服务器,我们将配置它来显示一个定制的 web 页面,该页面显示已部署映像的版本。通过将版本显示为网页,我们可以观察到被导向 canary 版本的 web 流量的百分比在增加。
变量
我们将从定义一些将被部署过程使用的变量开始。
| 可变的 | 目的 | 价值 |
|---|---|---|
| 部署命名新 | 新(或金丝雀)部署资源的名称 | httpd-新 |
| 部署名称前一个 | 先前部署资源的名称 | httpd-以前的 |
| 新交通 | 要定向到新部署资源的流量 | 100(作用于Canary 100%环境),75(作用于Canary 75%环境),25(作用于Canary 25%环境) |
| 以前的交通 | 新交通的对立面 | 0(作用于Canary 100%环境)、25(作用于Canary 75%环境)、75(作用于Canary 25%环境) |
| 章鱼。action . kubernetescontainers . configmapname template | 生成使用部署资源创建的 ConfigMap 资源名称的自定义模板 | #-http canary |
| previousreplicaccount | 上一次部署的 pod 计数 | 1,0(作用于Canary 100%环境) |
| 章鱼打印评估变量 | 允许在日志中显示变量 | False(但是如果需要额外的调试,可以设置为 True) |

创建目标
流程的第一步是Run a kubectl CLI Script步骤。

这一步的目的是创建一个 Kubernetes 目标,其权限仅限于单个名称空间。我们将使用这个新的 Kubernetes 目标来部署组成应用程序的资源,而不是总是使用管理帐户来部署资源。使用受限帐户给了我们一定程度的安全性,并限制了错误配置的步骤可能在我们的集群中造成的潜在损害。
话虽如此,这一步是与管理 Kubernetes 目标一起运行的,因为我们必须从某个地方开始。
下面的 PowerShell 代码用于创建 Kubernetes 服务帐户,提取用帐户创建的令牌,使用令牌创建 Octopus 令牌帐户,并使用令牌帐户创建 Kubernetes 目标。
# The account name is the project and tenant
$projectNameSafe = $($OctopusParameters["Octopus.Project.Name"] -replace "[^A-Za-z0-9]","")
$accountName = if (![string]::IsNullOrEmpty($OctopusParameters["Octopus.Deployment.Tenant.Id"])) {
$projectNameSafe + "-" + `
$($OctopusParameters["Octopus.Deployment.Tenant.Name"] -replace "[^A-Za-z0-9]","")
} else {
$projectNameSafe
}
# The namespace is the account name, but lowercase
$namespace = $accountName.ToLower()
# The project name is used for a number of k8s names, which must be lowercase
$projectNameSafeLower = $projectNameSafe.ToLower()
#Save the namespace for other steps
Set-OctopusVariable -name "Namespace" -value $namespace
Set-OctopusVariable -name "AccountName" -value $accountName
Set-Content -Path serviceaccount.yml -Value @"
---
kind: Namespace
apiVersion: v1
metadata:
name: $namespace
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: $projectNameSafeLower-deployer
namespace: $namespace
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: $namespace
name: $projectNameSafeLower-deployer-role
rules:
- apiGroups: ["", "extensions", "apps"]
resources: ["deployments", "replicasets", "pods", "services", "ingresses", "secrets", "configmaps", "namespaces"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["voyager.appscode.com"]
resources: ["ingresses"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: $projectNameSafeLower-deployer-binding
namespace: $namespace
subjects:
- kind: ServiceAccount
name: $projectNameSafeLower-deployer
apiGroup: ""
roleRef:
kind: Role
name: $projectNameSafeLower-deployer-role
apiGroup: ""
"@
kubectl apply -f serviceaccount.yml
$data = kubectl get secret $(kubectl get serviceaccount "$projectNameSafeLower-deployer" -o jsonpath="{.secrets[0].name}" --namespace=$namespace) -o jsonpath="{.data.token}" --namespace=$namespace
$Token = [System.Text.Encoding]::ASCII.GetString([System.Convert]::FromBase64String($data))
New-OctopusTokenAccount `
-name $accountName `
-token $Token `
-updateIfExisting
New-OctopusKubernetesTarget `
-name $accountName `
-clusterUrl #{Octopus.Action.Kubernetes.ClusterUrl} `
-octopusRoles "HTTPD" `
-octopusAccountIdOrName $accountName `
-namespace $namespace `
-updateIfExisting `
-skipTlsVerification True
运行该脚本的结果是一个名为HTTPDCanary(在项目名称之后)的新 Kubernetes 目标,其角色HTTPD定位于 Kubernetes 名称空间httpdcanary(也在项目名称之后,但是小写,因为 Kubernetes 在其名称中只允许小写字符)。

PowerShell 函数New-OctopusKubernetesTarget只有在运行它的环境允许动态目标时才起作用,这就是为什么我们的Canary ##%环境被配置为允许动态目标。
创建以前的部署资源
第二步是Deploy Kubernetes containers步骤。

我们将使用这一步来部署应用程序的“稳定”版本。这是金丝雀版本最终将取代的版本。
这一步将代表角色为HTTPD的任何目标运行,正如您在上一步中回忆的那样,这是我们分配给新 Kubernetes 目标的角色。通过在有限的 Kubernetes 目标的上下文中执行部署,我们可以确保我们的部署步骤不能删除或修改名称空间httpdcanary之外的任何内容。

Deployment部分为部署资源配置一些高级细节。
Deployment name字段引用了我们之前配置的DeploymentNamePrevious变量。
Replica字段引用了PreviousReplicaCount变量。默认情况下,PreviousReplicaCount变量设置为 1,当部署到Canary 100%环境时,设置为 0。这是因为Canary 100%环境会将所有流量导向新版本的应用程序,而以前的版本不再需要任何 Pod 资源,因为它们不会接收任何流量。
我们还定义了一个标签,键为app,值为httpd。此处定义的标签将应用于部署资源和部署资源创建的 Pod 资源。稍后将使用这些标签从服务资源中选择 pod。

Deployment strategy部分保留了默认选项Recreate deployments。
实际上,部署策略的选择在我们的部署中不起作用,因为我们不是就地更新部署资源,而是并排部署两个资源。我们正在自己实现 canary 部署模式,而不是使用 Kubernetes 提供的标准模式。

在Volumes部分,我们需要将一个项目从我们稍后将创建的名为index的配置映射映射到一个名为index.html的文件。ConfigMap 将保存一些自定义内容,这些内容作为一个名为index.html的文件暴露给我们的容器,这个文件将由 HTTPD 提供。


接下来是Containers部分,我们在这里添加一个容器。
容器和映像部署都被称为httpd。

作为 web 服务器,HTTPD 公开了 80 端口。

在容器内部,我们将前面定义的卷挂载到路径/usr/local/apache2/htdocs。这条路就是 HTTPD 寻找内容的地方。因为我们将名为index的 ConfigMap 项公开为名为index.html的文件,所以我们最终在容器中装载了一个名为/usr/local/apache2/htdocs/index.html的文件。

设置好这些值后,我们将看到如下所示的容器摘要。

在Pod Annotations部分,我们用变量PreviousTraffic的值定义了一个名为ingress.appscode.com/backend-weight的注释。PreviousTraffic变量可以是0、25或75,这取决于我们要部署到的环境。
Voyager 入口控制器将该注释识别为定义发送给 Pod 资源的流量。
因此,当部署到Canary 25%环境时,PreviousTraffic被设置为75,这意味着先前的部署将接收 75%的流量。

在 ConfigMap 特性中,我们构建了最终将为index.html文件提供内容的 ConfigMap 资源。
ConfigMap 的名称被设置为#{DeploymentNamePrevious}-configmap,我们添加一个名为index的条目,其值为#{Octopus.Action[HTTPD Old].Package[httpd].PackageVersion}。
变量Octopus.Action[HTTPD Old].Package[httpd].PackageVersion将保存这个容器正在部署的 httpd 映像的版本。因此,如果 HTTPD 提供的文件包含 Docker 映像的版本,我们将会看到什么。这篇博客文章有更多关于这些变量的信息。

配置映射名称模板
如果你回头看看我们添加到这个项目中的变量,你会注意到我们定义了一个名为Octopus.Action.KubernetesContainers.ConfigMapNameTemplate的变量。此变量会影响部署期间管理此配置图的方式。
通常 Octopus 环境是独立的,用于表示从测试到生产的不同过程。也就是说,部署到测试环境不会影响生产环境,反之亦然。
我们在这里使用的环境略有不同。我们的环境代表的不是截然不同的独立环境,而是被导向新版本或金丝雀版本的流量的逐渐变化。
这是一个微妙但重要的区别,因为这意味着Canary 25%环境和Canary 75%环境是同一个逻辑环境。这意味着对Canary 75%环境的部署会覆盖对Canary 25%环境的部署。
然而,Kubernetes 的步骤是在假设环境各不相同的情况下配置的。这个假设的一个含义是,当我们将 ConfigMap 资源作为容器步骤的一部分部署到Canary 25%环境时,它将具有唯一的名称,当我们再次将 ConfigMap 部署到Canary 75%环境时,该名称不会被覆盖。当您从测试转移到生产时,不覆盖资源通常是有意义的,但是在我们的例子中,我们确实希望覆盖资源。
通过为每个部署提供一个唯一的名称,可以防止覆盖 ConfigMap 资源。默认情况下,这个惟一的名称是通过在名称末尾附加 Octopus 部署 ID 生成的。
例如,我们给配置映射命名为#{DeploymentNamePrevious}-configmap,它将解析为名称http-previous-configmap。在部署过程中,这个名称与部署 ID 结合起来产生一个唯一的名称,如http-previous-configmap-deployment-1234。
然而,我们不需要唯一的名称。我们希望名称在我们的 canary 环境之间是相同的,因此资源将被覆盖。
这就是我们将Octopus.Action.KubernetesContainers.ConfigMapNameTemplate变量设置为#{Octopus.Action.KubernetesContainers.ConfigMapName}-httpdcanary的原因。这将覆盖附加部署 ID 的默认行为,而是附加固定字符串httpdcanary。
这意味着我们的 canary 环境每次都会部署一个名为http-previous-configmap-httpdcanary的 ConfigMap 资源。而且因为名称不再唯一,所以在每个环境中都会被覆盖。
我们这样做是为了防止旧的未使用的 ConfigMap 资源填满我们的名称空间。通过在环境之间使用公共名称,我们最终为每个部署资源提供一个配置图。
创建 Canary 部署资源
第三步几乎是第二步的完全复制。在这里,我们部署了代表 canary 版本的部署资源。
由于这一步与上一步非常相似,所以我将在这里强调不同之处。
将Deployment name设置为#{DeploymentNameNew},将Replicas设置为固定值1。

Pod Annotations值被设置为#{NewTraffic}。

配置图名称设置为#{DeploymentNameNew}-configmap,项目值设置为#{Octopus.Action[HTTPD New].Package[httpd].PackageVersion}。

否则,容器、卷和部署策略的配置与上一步相同。
服务
第四步是用Deploy Kubernetes service resource步骤创建一个服务资源。

与之前的容器步骤一样,这个步骤部署在具有HTTPD角色的目标的上下文中。

我们将该服务命名为httpd-service。

将Service Type设置为Cluster IP。

该服务接受流量并将流量定向到端口 80。


该服务通过将Service Selector Labels设置为名称app和值httpd来选择它将流量导向的 Pod 资源。这些是我们在前面的容器步骤中定义的相同标签。

旅行者号入口资源
第五步也是最后一步是定义航海家号的入口资源。这个资源不是标准的 Kubernetes 资源,所以我们不能使用 Octopus 中的标准入口步骤来部署它。相反,我们再次使用Run a kubectl CLI Script步骤保存一个 YAML 文件,并用kubectl命令应用它。
Set-Content -Path "ingress.yaml" -Value @"
apiVersion: voyager.appscode.com/v1beta1
kind: Ingress
metadata:
name: httpd-ingress
spec:
backend:
serviceName: httpd-service
servicePort: "80"
"@
kubectl apply -f ingress.yaml
部署项目
让我们创建这个项目的部署。作为部署的一部分,我们有机会选择将作为部署资源的一部分进行部署的 Docker 映像的版本。
这里我把旧的或者以前的版本设置为2.4.18。在本例中,该版本代表部署的最后一个稳定版本。
然后我将新的或淡黄色的版本设置为2.4.20。这代表了我想要逐步推出的应用程序的新版本,以检查任何可能的问题。

然后,我们将把它部署到Canary 25%环境中。
我们刚刚部署了什么?
仅仅配置这些步骤,就很难理解我们到底在部署什么。一旦我们将这个项目部署到Canary 25%环境中,我们将得到这样的结果:

Voyager 入口资源将流量定向到服务资源,服务资源又将流量定向到两个部署资源(或者从技术上讲,由部署资源创建的 Pod 资源)。
由于 Pod 资源上的ingress.appscode.com/backend-weight注释,Voyager 知道将 25%的流量导向金丝雀 Pod 资源,75%导向先前的 Pod 资源。
一旦部署,每个 Voyager 入口资源创建一个相关的负载平衡器服务资源。这个负载平衡器有一个公共 IP 地址,我们可以从浏览器访问它。在我的情况下,公共 IP 是 35.194.2.130。

在浏览器中打开此页面会显示为该页面提供服务的 HTTPD 版本。
我的第一个页面显示的是版本2.4.20。这意味着我被引导到金丝雀豆荚资源。

刷新后,我看到了版本2.4.18。这意味着我被引导到以前的 Pod 资源。

当我一次又一次刷新页面时,我看到的版本2.4.18比看到的2.4.20多。这证实了大部分的流量都被导向以前版本的 HTTPD,只有 25%被导向金丝雀豆荚。
如您所料,将部署提升到Canary 75%环境会逆转流量比例。现在 75%的流量被导向金丝雀豆荚资源。
提升到Canary 100%环境就完成了我们的部署。所有流量都被发送到 canary Pods,并且之前的 Pod 资源已被移除,因为在Canary 100%环境中Replicas值为 0。
恢复部署
将 canary 部署表示为 Octopus 环境的好处是,我们可以恢复到以前的状态。比方说,在部署到Canary 75%环境之后,您开始看到在部署到Canary 25%环境时不存在的网络中断。
要回滚到Canary 25%环境,在 Octopus 中打开部署并从垂直菜单中选择Deploy to选项。

选择Canary 25%环境并点击Deploy按钮。

Octopus 然后将重新运行部署,这又会将 canary 部署恢复到 25%的流量被定向到新版本的状态。
开始下一次金丝雀部署
一旦我们部署到Canary 100%环境,我们的 Kubernetes 集群看起来就像这样:

100%的流量被发送到 canary Pod 资源,而之前的 Pod 资源已缩减为 0。
让我们开始部署新版本。现在我们的老版本或者以前的版本就是2.4.20的最后一个金丝雀版本。新的或金丝雀版本是2.4.23。

这一新部署将:
- 使用版本
2.4.20部署先前的部署资源(目前缩减为 0)。注释将此部署配置为接收 75%的流量。 - 用新版本的
2.4.23部署当前配置有版本2.4.20的 canary 部署资源。注释将此部署配置为接收 25%的流量。 - 服务和航海家号入口资源在这一点上保持不变。
第二次部署的好处是没有太多的停机时间。在进行步骤 1 中的部署时,旧的 canary 部署仍在为流量提供服务。在进行步骤 2 的部署时,步骤 1 中的部署正在为流量提供服务。在步骤 3 之后,所有流量都根据分配的百分比进行路由。
摘要
在这篇文章中,我们看了如何配置 Octopus 和 Voyager Ingress 控制器,以在 Kubernetes 中提供金丝雀部署。
通过将 canary 部署的进展建模为环境,我们创建了一个解决方案,可以将流量增量增加到 canary 版本,同时提供回滚到以前状态的可能性。
Kubernetes、容器和 Octopus -更新- Octopus 部署

几个月前,我们问章鱼社区他们是否能抽出几分钟和大脑周期来提供一些关于我们 Kubernetes 计划第一稿的反馈。你确实做到了。首先,谢谢你!我们真诚地感谢每一个分享他们想法的人。产品肯定会从中受益。
反馈中有一些共同的主题,这使我们稍微改变了方向。我们会稍微谈一下那些,然后最后给出一个总结和进度更新。
#1 更友好的库伯内特人

Octopus 的优势之一一直是用户友好。它允许您部署到 ASP.NET 网站,而不是一个 100 级的 IIS 向导。
有人指出,我们可能错过了为 Kubernetes 提供类似体验的机会;可能会让学习曲线变得平滑一点。我们同意了。
作为第一步的一部分,我们将包括一个将容器部署到 Kubernetes 的部署步骤。这一步将有一个丰富的用户界面,并将经历以下过程:
- 创建 Kubernetes 部署,包括选择部署样式和容器映像:

- 创建(或更新)Kubernetes 服务,包括映射端口:

- 配置入口规则:

最终结果(包含折叠的部分)将类似于:

Octopus 的另一个优势是管理变量,包括转换配置文件。但是如果你不能把这些文件放进你的 Kubernetes 豆荚里,这就是多余的。
Kubernetes 有配置图(和机密,用于敏感数据)的概念。我们将提供一种简单的方法来利用 Octopus 变量和配置文件的能力,并将结果推送到 ConfigMap 或 Secret。
我们对将容器部署到 Kubernetes 的步骤感到兴奋。从一个空的 YAML 文件开始,Kubernetes 的学习曲线可能会令人生畏,我们觉得 Octopus 在这方面有帮助的余地。我们对选择Blue\Green作为部署风格的能力特别感兴趣。这有望使一些复杂的场景更容易配置。我们将在以后的文章中详细讨论这一点。
2 号舵手
很多人真的喜欢赫尔姆,是吧?

似乎很大一部分 Kubernetes 用户正在使用 Helm,许多人明确表示,没有 Helm 集成会导致他们拆除 Octopus 安装并破坏托管它的服务器😉幸运的是,一旦我们调查,Helm 实际上非常适合 Octopus 架构。
所以我们也致力于增加头盔的整合。这将采用以下形式:
- 一种舵图库馈送类型

- 舵部署释放步骤

无论你是否使用头盔,我们都想提供一个很好的体验。好吧,说实话,我们有点害怕赫尔姆民兵😛
#3 不仅仅是 Kubernetes
我们还被提醒说,有许多容器场景不涉及 Kubernetes,而 Octopus 目前对这些场景有一些粗糙的边缘。例如,部署到 ECS。
为了帮助解锁目前我们不会添加一流支持的所有场景,我们对运行脚本步骤做了一些更改,使处理容器图像变得更好。
以前,从脚本步骤引用包的唯一方法是将脚本嵌入包中。这甚至不支持容器图像。这意味着在定制脚本步骤中处理容器图像通常需要将图像标签作为常规变量添加,并在创建发布之前修改它。这是可行的,但是它失去了版本控制的传统优势,例如:
- 创建发行版时选择软件包版本。
- 能够将发布版本绑定到包版本。
- 查看发行版中包含哪些包版本。
客户甚至通过在他们的部署过程中包含虚拟包(例如 NuGet 或 Zip)来模拟这些,以表示他们的容器映像,因为这些将在发布中被捕获。这很聪明,但也让我们难过。它不应该需要那种程度的独创性。
现在,您将能够从脚本步骤中引用包(包括容器映像)。这些包的版本将在创建发布时选择,然后将从您的自定义脚本中可用,作为一组变量和包本身,取决于所选的采集选项(更多详细信息,请参见规范)。
此更改将应用于以下步骤:
Run a scriptRun an Azure PowerShell ScriptRun an AWS CLI Script- 新的
Run a kubectl Script步骤(见下文)
我们还添加了一个AWS Elastic Container Registry提要类型。目前可以在 Octopus 中将 AWS ECR 配置为 feed ,但这相当复杂,并且有一个明显的缺点,即凭证会在 12 小时后超时。新的饲料将避免这个问题。
我们希望这些变化会让容器场景感觉更加自然,并且能够更好地利用 Octopus 的能力。
摘要
制作章鱼爱心容器行动的第一步将包括以下内容:
什么时候?
上面的大部分功能都已经构建好了。我们计划在 8 月份的发行版中推出这款产品。Kubernetes 的功能最初会隐藏在一个功能开关后面,因为我们认为这是一个 alpha 版本。我们有许多志愿者 K8s 实验室大鼠,我们将在未来几周内与您联系,邀请您试用它并提供反馈。
一旦我们满意我们的早期采用者喜欢它,我们将删除功能切换,并宣布它为生产就绪。
第 1 步,共 N 步
这仅仅是开始。如果我们遗漏了一些您希望得到支持的内容,请告诉我们。我们关注的问题包括:
- 一个
Docker Compose部署步骤 - Kubernetes 应用了我们最初提出的步骤
- ECS 支持
和往常一样,欢迎对这篇文章发表评论。我们还在Octopus Deploy community Slack中创建了一个#containers频道,所以你也可以来那里和我们聊天。
Kubernetes 部署策略可视化- Octopus 部署
原文:https://octopus.com/blog/kubernetes-deployment-strategies-visualized

Kubernetes 为管理员和开发人员提供的好处之一是能够智能地管理新软件或配置的部署。
Kubernetes 包括两个内置的部署策略,称为重建和滚动更新,它们直接配置在部署资源上。Octopus 提供了第三种 Kubernetes 部署策略,称为蓝绿色,通过部署 Kubernetes 容器步骤进行管理。
但是这些策略实际上是干什么的呢?在这篇博文中,我们将可视化这些部署策略,以突出它们的差异,并说明为什么您会选择一种策略而不是另一种。
测试部署
在下面的视频中,我们将观看在多节点 Kubernetes 集群上更新的部署。集群中的每个节点都有一个唯一的标签,部署会更新以将新的 pod 放在特定的节点上。
最终结果是新的部署将 pod 从一个节点转移到另一个节点。然后,我们可以观察 pod 如何在节点之间移动,以了解不同部署策略的效果。
Kubernetes 部署再造战略
Kubernetes 部署重建策略是三种策略中最简单的。当使用重建策略配置的部署被更新时,Kubernetes 将首先从现有部署中删除 pod,一旦这些 pod 被删除,新的 pod 将被创建。
在上面的视频中,您可以看到节点 1 上的所有 pod 都被删除,只有在它们被删除后,第二个节点上的新 pod 才会被创建。
重建策略确保新旧 pod 不会同时运行。当同步对不支持从两个不同客户端版本访问的后端数据存储库的更改时,这可能是有益的。然而,在新的 pod 开始接受流量之前,有一段停机时间。
Kubernetes 滚动更新
顾名思义,Kubernetes 滚动更新策略是在拆除旧单元的同时逐步部署新单元。您可以在上面的视频中看到这一点,在第一个节点上的许多 pod 被删除,同时在第二个节点上创建新的 pod。最终,第一个节点上的 pod 将被全部删除,而所有新的 pod 将在第二个节点上创建。
滚动更新策略确保在更新期间有一些 pod 可用于继续服务流量,因此没有停机时间。但是,在进行更新时,新旧 pod 会并排运行,这意味着任何数据存储或客户端都必须能够与两个版本进行交互。
Kubernetes 蓝绿色部署
与其他部署策略不同,Kubernetes 蓝绿色部署策略不是 Kubernetes 自己实现的。它包括创建全新的部署资源(即,具有新名称的部署资源),等待新部署就绪,将流量从旧部署切换到新部署,最后删除旧部署。这个过程通过部署 Kubernetes 容器步骤在 Octopus 中实现。
在上面的视频中,您可以看到在蓝/绿部署期间,第二个节点上的单元被部署和初始化,当它们准备好时,第一个节点上的单元被删除。
蓝/绿策略确保新部署在任何流量发送到它之前完全初始化并保持健康。如果新部署失败,旧部署将继续为流量提供服务。
与滚动更新策略一样,蓝/绿策略在一段时间内并排部署两个版本,因此任何后备数据存储都需要支持两个不同的客户端。但是,通过在新部署就绪时将所有流量转移到新部署,任何时候都只能访问一个版本的部署。
结论
选择正确的部署策略对于确保您的 Kubernetes 更新的可靠性以及消除或最小化停机时间至关重要。可视化可用的更新策略有助于理解它们之间的差异,在这篇文章中,我们看到了如何使用 Kubernetes 的本地策略 recreate 和 rolling updates 来创建和销毁 pod,然后使用 Octopus 实现的 blue/green 策略。
超越 Hello World:面向门外汉的 Kubernetes 章鱼部署

Docker 容器和 Kubernetes 是您 DevOps 工具箱中的优秀技术。这个超越 Hello World 博客系列涵盖了如何在现实应用中使用它们。
到目前为止,你肯定听说过 Kubernetes 这个词,但它是最新的流行词还是有更多含义?在这篇文章中,我将介绍 Kubernetes(或简称 k8s)是什么,并演示如何在 k8s 上运行真实世界的 web 应用程序 OctoPetShop 。
在 Kubernetes 的 K 和 S 之间有八个字母,因此是 k8s。
What is Kubernetes?
Kubernetes 是一种容器编排技术。从概念上讲,Kubernetes 架构非常简单。运行 Kubernetes 的机器被称为nodes。节点组成了一个 Kubernetes cluster,尽管一个集群也可能只有一个节点。节点在所谓的pod中运行容器。

桌面对接器和库比特
我的上一篇文章使用 Docker Desktop 进行 Docker 容器的本地开发,但 Docker Desktop 也包含 Kubernetes 的一个实现,这使得本地开发和测试变得轻而易举。
创建 OctoPetShop Kubernetes 组件
为了在 Kubernetes 上运行 OctoPetShop 容器图像,我们需要创建 YAML 文件来定义应用程序所需的不同资源。资源类型称为kind,容器类型称为deployment。
OctoPetShop 应用程序有三个主要组件:
- 一个 web 前端。
- 产品服务。
- 购物车服务。
除了这些组件,OctoPetShop 还需要一个数据库服务器和数据库来运行。对于 OctoPetShop,我们需要创建以下部署:
- Web 前端。
- 产品服务。
- 购物车服务。
- Microsoft SQL Server。
Kubernetes 部署
以下是前端的部署 YAML 文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: octopetshop-web-deployment
spec:
replicas: 1
selector:
matchLabels:
component: web
template:
metadata:
labels:
component: web
spec:
containers:
- name: web
image: octopussamples/octopetshop-web
ports:
- containerPort: 5000
name: http-port
- containerPort: 5001
name: https-port
env:
- name: ProductServiceBaseUrl
value: http://octopetshop-productservice-cluster-ip-service:5011/
- name: ShoppingCartServiceBaseUrl
value: http://octopetshop-shoppingcart-cluster-ip-service:5012
库贝内特斯·YAML 档案剖析
- apiVersion : Kubernetes 提供了一个 API 参考来帮助决定选择哪个版本。对于种类部署,
apps/v1是正确的选择。 - 种类:这告诉 Kubernetes 我们正在部署什么类型的资源。
- 元数据名称:这是我们部署的唯一名称。
- spec - replicas :要运行的容器实例的数量。
- 规格选择器-匹配标签:
- 选择器:选择器字段定义 Kubernetes 对象如何找到要管理的窗格。
- 标签:标签是附在对象上的键/值对,用于指定识别属性。
- 模板:pod 的模板规格。
- template-spec-containers:这个部分是这个部署将运行的容器的数组。
每个容器获得:
- 名称:我们给容器起的名字。
- 图像:用于容器的 Docker Hub 图像。
- Ports :容器将向 pod 网络公开的一组端口。
- Env :容器的环境变量数组。
其余的部署 YAML 文件见 OctoPetShop 。
部署将为我们的应用程序创建 pod,但是我们仍然需要一种方法让它们进行通信。
 【
【节点上的每个 pod 都有一个由该节点分配的内部 IP 地址。在我们的容器中,我们已经指定了向 pod 公开的端口,但是这些端口仍然只在 pod 中,而没有向节点公开。为了允许节点上的 pod 之间的连接,我们需要为每个 pod 创建一个service。
Kubernetes 服务
通过 API 可以获得许多不同的服务,但是我们将把重点放在允许我们的 OctoPetShop 应用程序运行的特定服务上。我们的 web 前端 pod 需要能够与产品服务和购物车服务 pod 对话。产品服务和购物车服务窗格需要能够与 SQL Server 窗格通信。为了实现这一点,我们需要为产品服务、购物车服务和 SQL Server pods 创建一个ClusterIP服务。下面是为产品服务创建 ClustIP 服务的 YAML:
apiVersion: v1
kind: Service
metadata:
name: octopetshop-productservice-cluster-ip-service
spec:
type: ClusterIP
selector:
component: productservice
ports:
- port: 5011
targetPort: 5011
name: http-port
- port: 5014
targetPort: 5014
name: https-port
在上面的 Kubernetes YAML 中,我们创建了一个服务,将一个 pod 端口映射到一个容器端口,以允许节点内的 pod 到容器通信。此服务不在节点级别公开端口,因此不可能进行外部访问。记录元数据名称很重要,因为该名称将创建一个 DNS 条目,以便可以通过 DNS 名称引用该服务。在之前的 web 前端 YAML 中,我们为产品服务 URL 声明了一个环境变量,其中包含 octopet shop-product service-cluster-IP-service 作为 DNS 条目。产品服务的 ClusterIP 服务就是其来源。
允许外部访问
为了允许外部访问节点,我们需要定义一个Ingress或LoadBalancer服务。在我们的例子中,我们选择了一个负载平衡器服务来允许对 web 前端的访问:
apiVersion: v1
kind: Service
metadata:
name: web-loadbalancer
spec:
selector:
component: web
ports:
- port: 80
targetPort: 5000
name: http-port
- port: 5001
targetPort: 5001
name: https-port
type: LoadBalancer
externalIP: <IPAddress>
警告
Kubernetes 乔布斯
我们的 OctoPetShop 解决方案中包括一个 DbUp 项目,它包含创建和播种数据库的脚本。DbUp 是一个控制台应用程序,它会执行然后停止,所以我们不想使用kind: Deployment,因为 Kubernetes 会试图让它保持运行。为此,我们想使用kind: Job,它专门用于在完成以下操作后终止:
apiVersion: batch/v1
kind: Job
metadata:
name: octopetshop-dbup
spec:
template:
spec:
containers:
- name: dbup
image: octopussamples/octopetshop-database
env:
- name: DbUpConnectionString
value: Data Source=octopetshop-sqlserver-cluster-ip-service;Initial Catalog=OctoPetShop; User ID=sa; Password=SomePassword
restartPolicy: Never
库贝特尔
Kubectl 是用于 Kubernetes 的命令行程序。
在 Kubernetes 开始 OctoPetShop
要运行 Kubernetes YAML 文件,您可以运行命令kubectl apply -f <YAMLFile>。但是,可以指定一个文件夹,而不是单个文件。这是 OctoPetShop repo 将所有 Kubernetes YAML 文件存储在 k8s 文件夹中的主要原因。如果您已经克隆了 repo,您可以运行kubectl apply -f k8s让整个集群运行,只需一个命令:
PS C:\GitHub\OctoPetShop> kubectl apply -f k8s
job.batch/octopetshop-dbup created
service/web-loadbalancer created
service/octopetshop-productservice-cluster-ip-service created
deployment.apps/octopetshop-productservice-deployment created
service/octopetshop-shoppingcart-cluster-ip-service created
deployment.apps/octopetshop-shoppingcartservice-deployment created
deployment.apps/sqlserver-deployment created
service/octopetshop-sqlserver-cluster-ip-service created
service/octopetshop-web-cluster-ip-service created
deployment.apps/octopetshop-web-deployment created
检查 Kubernetes pod 状态
apply 命令向我们显示,它运行了 YAML 文件,但没有运行其他文件。为了检查 pod 的状态,我们运行命令kubectl get pods:
PS C:\GitHub\blog> kubectl get pods
NAME READY STATUS RESTARTS AGE
octopetshop-dbup-9kt54 0/1 Completed 0 2m55s
octopetshop-productservice-deployment-6f955ff576-4nwtw 1/1 Running 0 2m55s
octopetshop-shoppingcartservice-deployment-9f94574f9-t96ck 1/1 Running 0 2m55s
octopetshop-web-deployment-7b6d499d69-f9jsp 1/1 Running 0 2m55s
sqlserver-deployment-784d755db-8vbwk 1/1 Running 0 2m55s
该命令向我们显示有多少 pod 正在运行,以及应该有多少 pod 正在运行。在我们的例子中,我们将副本指定为 1,因此在我们的 pod 中应该只有 1 个实例。您会注意到 octopetshop-dbup pod 已准备好 0/1 个 pod。因为我们用kind: Job定义了 octopershop-dbup,这是正常的,因为它应该在运行后终止。
显示日志
与 docker compose 不同,运行 kubectl apply 命令不会显示来自 pod 或容器的任何输出。当一个 pod 出现故障时,知道原因是很有用的。让我们更改 octopetshop-dbup 作业的密码,使其失败:
apiVersion: batch/v1
kind: Job
metadata:
name: octopetshop-dbup
spec:
template:
spec:
containers:
- name: dbup
image: octopussamples/octopetshop-database
command: [ "dotnet", "run", "--no-launch-profile" ]
env:
- name: DbUpConnectionString
value: Data Source=octopetshop-sqlserver-cluster-ip-service;Initial Catalog=OctoPetShop; User ID=sa; Password=ThisPasswordIsWrong
restartPolicy: Never
如果我们运行kubectl apply -f k8s命令,我们将看到如下所示:
PS C:\GitHub\OctoPetShop> kubectl get pods
NAME READY STATUS RESTARTS AGE
octopetshop-dbup-76cxk 1/1 Running 0 5s
octopetshop-dbup-bjsj8 0/1 Error 0 35s
octopetshop-dbup-mt9lk 0/1 Error 0 25s
octopetshop-dbup-rm97t 0/1 Error 0 49s
octopetshop-productservice-deployment-6f955ff576-bvc88 1/1 Running 0 49s
octopetshop-shoppingcartservice-deployment-9f94574f9-mkr7h 1/1 Running 0 49s
octopetshop-web-deployment-7b6d499d69-975kg 1/1 Running 0 49s
sqlserver-deployment-784d755db-7dh95 1/1 Running 0 49s
Kubernetes 三次尝试运行 octopetshop-dbup 作业,但都失败了。重试三次后,Kubernetes 将停止尝试运行 pod。为了解决这个问题,我们可以运行kubectl logs jobs/octopetshop-dbup来显示容器的输出:
PS C:\GitHub\OctoPetShop> kubectl logs job/octopetshop-dbup
Found 3 pods, using pod/octopetshop-dbup-rm97t
Master ConnectionString => Data Source=octopetshop-sqlserver-cluster-ip-service;Initial Catalog=master;User ID=sa;Password=*********************
Unhandled Exception: System.Data.SqlClient.SqlException: A connection was successfully established with the server, but then an error occurred during the pre-login handshake. (provider: TCP Provider, error: 0 - Success)
at System.Data.SqlClient.SqlInternalConnectionTds..ctor(DbConnectionPoolIdentity identity, SqlConnectionString connectionOptions, Object providerInfo, Boolean redirectedUserInstance, SqlConnectionString userConnectionOptions, SessionData reconnectSessionData, Boolean applyTransientFaultHandling)
at System.Data.SqlClient.SqlConnectionFactory.CreateConnection(DbConnectionOptions options, DbConnectionPoolKey poolKey, Object poolGroupProviderInfo, DbConnectionPool pool, DbConnection owningConnection, DbConnectionOptions userOptions)
at System.Data.ProviderBase.DbConnectionFactory.CreatePooledConnection(DbConnectionPool pool, DbConnection owningObject, DbConnectionOptions options, DbConnectionPoolKey poolKey, DbConnectionOptio at System.Data.ProviderBase.DbConnectionPool.CreateObject(DbConnection owningObject, DbConnectionOptions userOptions, DbConnectionInternal oldConnection)
at System.Data.ProviderBase.DbConnectionPool.UserCreateRequest(DbConnection owningObject, DbConnectionOptions userOptions, DbConnectionInternal oldConnection)
at System.Data.ProviderBase.DbConnectionPool.TryGetConnection(DbConnection owningObject, UInt32 waitForMultipleObjectsTimeout, Boolean allowCreate, Boolean onlyOneCheckConnection, DbConnectionOptions userOptions, DbConnectionInternal& connection)
at System.Data.ProviderBase.DbConnectionPool.TryGetConnection(DbConnection owningObject, TaskCompletionSource`1 retry, DbConnectionOptions userOptions, DbConnectionInternal& connection)
at System.Data.ProviderBase.DbConnectionFactory.TryGetConnection(DbConnection owningConnection, TaskCompletionSource`1 retry, DbConnectionOptions userOptions, DbConnectionInternal oldConnection, DbConnectionInternal& connection)
at System.Data.ProviderBase.DbConnectionInternal.TryOpenConnectionInternal(DbConnection outerConnection, DbConnectionFactory connectionFactory, TaskCompletionSource`1 retry, DbConnectionOptions userOptions)
at System.Data.SqlClient.SqlConnection.TryOpen(TaskCompletionSource`1 retry)
at System.Data.SqlClient.SqlConnection.Open()
at SqlServerExtensions.SqlDatabase(SupportedDatabasesForEnsureDatabase supported, String connectionString, IUpgradeLog logger, Int32 timeout, AzureDatabaseEdition azureDatabaseEdition, String collation)
at OctopusSamples.OctoPetShopDatabase.Program.Main(String[] args) in /src/Program.cs:line 16
在 Kubernetes 经营 OctoPetShop
YAML 成功运行后,OctoPetShop 应用程序应该正在运行。导航到 http://localhost:5000。
OctoPetShop 被编写为重定向到 https,您很可能会收到关于该站点不安全的警告。这是正常的,继续操作是安全的,因为我们没有在过程中配置证书。

结论
在踏上将 OctoPetShop 容器化的旅程,最终目标是让它在 Kubernetes 上运行之前,我将 Kubernetes 视为一个复杂的怪物。现在我已经完成了将应用程序容器化并让它运行的过程,我仍然这样认为,但是让应用程序在其上运行并没有那么难。
OctoPetShop GitHub repo 包含 OctoPetShop 应用程序的所有 docker、docker-compose 和 Kubernetes YAML 文件。
集成 OAuth 和 Kubernetes - Octopus 部署

对于组织中的任何基础设施来说,管理断开连接的用户数据库都是一个主要的难点,更不用说安全漏洞了。Kubernetes 也不例外,因为默认情况下,系统的用户是特定于 Kubernetes 本身的。
这个问题的一个常见解决方案是允许用户通过 OAuth 向 Kubernetes 进行身份验证,这意味着可以使用现有的登录提供商(如 Google 或 Microsoft)来验证用户凭证。
在这篇博文中,我们将看看如何将 Minikube 与 Google 集成,以在 Kubernetes 中提供基于浏览器的登录。
创建 OAuth 客户端
第一步是在 Google 中创建一个 OAuth 客户端。打开https://console.cloud.google.com/apis/credentials,从下拉列表中选择一个项目,或者创建一个新项目。接下来,从创建凭证下拉列表中选择 OAuth 客户端 ID 选项:

选择其他选项,将客户端名称设置为 minikube :

你现在会看到两个代码:客户端 ID 和客户端密码。记下这两个代码,因为我们稍后会用到它们:

生成这些代码后,我们就可以启动 Minikube 了。
使用 OAuth 详细信息配置 Minikube
要允许 Minikube 接受 Google 登录,我们需要传递以下参数:
--extra-config=apiserver.authorization-mode=RBAC--extra-config=apiserver.oidc-issuer-url="https://accounts.google.com"--extra-config=apiserver.oidc-client-id=<Client ID>--extra-config=apiserver.oidc-username-claim=email
这些值启用 RBAC 安全性,配置我们刚刚创建的 OAuth 客户端 ID,并指定 Google 用户的电子邮件地址成为他们的 Kubernetes 用户名。
因为我运行的是 Windows 和 PowerShell,所以我的 Minikube start 命令如下所示:
minikube start `
--extra-config=apiserver.authorization-mode=RBAC `
--extra-config=apiserver.oidc-issuer-url="https://accounts.google.com" `
--extra-config=apiserver.oidc-client-id=471129667683-049fg2q12m993hk8c5hq1jhf0ji1ske5.apps.googleusercontent.com `
--extra-config=apiserver.oidc-username-claim=email `
--vm-driver hyperv `
--hyperv-virtual-switch "External Switch"
您应该会看到如下所示的输出:
PS C:\Users\Matthew> minikube start --extra-config=apiserver.authorization-mode=RBAC `
>> --extra-config=apiserver.oidc-issuer-url="https://accounts.google.com" `
>> --extra-config=apiserver.oidc-client-id=471129667683-049fg2q12m993hk8c5hq1jhf0ji1ske5.apps.googleusercontent.com `
>> --extra-config=apiserver.oidc-username-claim=email `
>> --vm-driver hyperv `
>> --hyperv-virtual-switch "External Switch"
* minikube v1.3.1 on Microsoft Windows 10 Pro 10.0.18362 Build 18362
* Creating hyperv VM (CPUs=2, Memory=2000MB, Disk=20000MB) ...
* Preparing Kubernetes v1.15.2 on Docker 18.09.8 ...
- apiserver.authorization-mode=RBAC
- apiserver.oidc-issuer-url=https://accounts.google.com
- apiserver.oidc-client-id=471129667683-8bsdnomeq3autchmmvut6949hrh74mpg.apps.googleusercontent.com
- apiserver.oidc-username-claim=email
* Downloading kubeadm v1.15.2
* Downloading kubelet v1.15.2
* Pulling images ...
* Launching Kubernetes ...
* Waiting for: apiserver proxy etcd scheduler controller dns
* Done! kubectl is now configured to use "minikube"
此时,Minikube 已经用管理员凭证配置了一个本地~/.kube/config文件,所以我们可以直接使用kubectl。但是,任何操作都将以本地 Kubernetes 管理员的身份执行,而不是以 Google 用户的身份。不过,这没问题,因为我们还有一些额外的配置要做:
PS C:\Users\Matthew> kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 4m49s v1.15.2
添加集群角色
在为我们的新 Google 用户做准备时,我们需要定义一个ClusterRole来授予他们管理员访问权限,并定义一个ClusterRoleBinding来将用户绑定到角色。
这里是ClusterRole YAML,它让用户管理员可以访问 Minikube 集群:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin-role
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
下面是ClusterRoleBinding YAML,它将新用户(在本例中我是matthew.casperson@octopus.com)映射到我们上面定义的角色:
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin-binding
subjects:
- kind: User
name: matthew.casperson@octopus.com
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: admin-role
将这些文件的内容保存到clusterrole.yaml和clusterrolebinding.yaml,然后用命令应用它们:
kubectl apply -f clusterrole.yaml
kubectl apply -f clusterrolebinding.yaml
生成 OAuth 令牌
您可能已经熟悉 OAuth 登录,因为它们通常用于在 web 应用程序中对用户进行身份验证。
然而,从控制台应用程序对用户进行身份验证略有不同。我们仍然需要用户打开一个网页并用 Google 验证自己,但是kubectl本身不会与 web 浏览器交互,所以我们需要一些其他的方法来生成这些代码。
这就是 k8s-oidc-helper 的用武之地。这个工具生成一个我们可以在浏览器中打开的 URL。URL 显示所需的 Google 令牌,然后我们可以将其粘贴回控制台,并且k8s-oidc-helper生成kubectl验证用户所需的代码。让我们看看这个过程是如何进行的。
要安装k8s-oidc-user,确保安装了 Go 工具,然后运行:
go get github.com/micahhausler/k8s-oidc-helper
一旦安装完毕,我们就可以使用前一步生成的客户端 ID 和客户端秘密运行k8s-oidc-helper:
k8s-oidc-helper --client-id 471129667683-049fg2q12m993hk8c5hq1jhf0ji1ske5.apps.googleusercontent.com --client-secret Cz2FbfSsue2RI_KKd2EawEjG
系统将提示您打开一个 URL:
PS C:\Users\Matthew\Desktop> k8s-oidc-helper --client-id 471129667683-049fg2q12m993hk8c5hq1jhf0ji1ske5.apps.googleusercontent.com --client-secret Cz2FbfSsue2RI_KKd2EawEjG
Open this url in your browser: https://accounts.google.com/o/oauth2/auth?redirect_uri=urn:ietf:wg:oauth:2.0:oob&response_type=code&client_id=471129667683-049fg2q12m993hk8c5hq1jhf0ji1ske5.apps.googleusercontent.com&scope=openid+email+profile&approval_prompt=force&access_type=offline
Enter the code Google gave you:
打开网址,出现熟悉的谷歌登录页面。一旦您确认了您的帐户详细信息,Google 将提供一个代码粘贴回控制台:

然后,k8s-oidc-helper会给你一份部分完整的~/.kube/config文件副本,供你保存在本地。
在users部分下的代码就是我们所需要的,所以替换~/.kube/config文件中现有的users部分,并将contexts.user参数更改为新的用户名。您将得到一个类似这样的~/.kube/config文件:
apiVersion: v1
clusters:
- cluster:
certificate-authority: C:\Users\Matthew\.minikube\ca.crt
server: https://10.1.1.94:8443
name: minikube
contexts:
- context:
cluster: minikube
# Make sure this is the same as the user below
user: matthew.casperson@octopus.com
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
# This section came from k8s-oidc-helper
- name: matthew.casperson@octopus.com
user:
auth-provider:
config:
client-id: 471129667683-049fg2q12m993hk8c5hq1jhf0ji1ske5.apps.googleusercontent.com
client-secret: Cz2FbfSsue2RI_KKd2EawEjG
id-token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImY2ZjgwZjM3ZjIxYzIzZTYxZjJiZTQyMzFlMjdkMjY5ZDY2OTUzMjkiLCJ0eXAiOiJKV1QifQ.eyJpc3MiOiJhY2NvdW50cy5nb29nbGUuY29tIiwiYXpwIjoiNDcxMTI5NjY3NjgzLTA0OWZnMnExMm05OTNoazhjNWhxMWpoZjBqaTFza2U1LmFwcHMuZ29vZ2xldXNlcmNvbnRlbnQuY29tIiwiYXVkIjoiNDcxMTI5NjY3NjgzLTA0OWZnMnExMm05OTNoazhjNWhxMWpoZjBqaTFza2U1LmFwcHMuZ29vZ2xldXNlcmNvbnRlbnQuY29tIiwic3ViIjoiMTAyNjAzOTY1MzQzNTAzMjY0MDc5IiwiaGQiOiJvY3RvcHVzLmNvbSIsImVtYWlsIjoibUVFYufyutfBV5jYXNwZXJzb25Ab2N0b3B1cy5jb20iLCJlbWFpbF92ZXJpZmllZCI6dHJ1ZSwiYXRfaGFzaCI6InlMSjhGRHZVdjhQVUktVDduN0hRSEEiLCJpYXQiOjE1NjcwNDk1MTIsImV4wegvfiye2NzA1MzExMn0.Rhz_aiPvUVt3kotiv6nPeqK0JYJHjaOaaCPhMpEuEWUcNNaQjmFhIrMvbRYggtvSSnD7NYlrY02fTl9XfeBCssqhMcNpYpzehO08844w7_mjPZOLPRygZrVnWWTHvMdIHk4_oolDBYA1w6_whJ7T2ZTlRViEJJMEwkTaRCaG8BXdNg0CgvzhCpNB7BC-Dv9Xc2hvRmkzwZBJyDbtnkFfeDX9TDrQtdwbKtrhjWlTFdtlq8o0lJQKSfXRrL6fF36kQvWwSTHbB8GSfAZESsT6yaBfhKHsoByzahPw5uYjt3n5dtOoUt8kVgJfSTBzNedpsiVwpNM1YLzaBJQUGYNypQ
idp-issuer-url: https://accounts.google.com
refresh-token: 1/_lGBydf3ymsn4ybwrLZWqPVNtggmDFgrYIqDfKrpSzVK0ZjkigfuNX2ze9cyNc3-b
name: oidc
此时,当您使用kubectl时,您将被认证为 Google 用户。
请注意,任何潜在的 Google 用户都可以生成使用kubectl的代码,但是如果没有相应的ClusterRoleBinding,这些用户将实际上无权做任何事情。
结论
将 Kubernetes 与 OAuth 提供者集成在一起,就不需要再维护另一个由 Kubernetes 自己管理的断开连接的用户数据库,而且它允许您利用已经配置好的任何现有帐户提供者。k8s-oidc-user提供了一种生成所需代码的方法,之后kubectl就像对任何其他 Kubernetes 帐户一样工作。
检查 Kubernetes pod CPU 和内存- Octopus 部署
在 Linux 中,使用top或htop命令跟踪本地进程的资源使用相对容易。但是如何跟踪分布在 Kubernetes 集群中的 pod 的资源使用情况呢?
在本文中,我将向您展示如何在 Kubernetes 中查看 pods 的 CPU 和内存使用情况。
度量服务器
metrics server 为 Kubernetes 集群提供了一个轻量级和高度可伸缩的解决方案,用于收集 CPU 和内存资源。尽管度量服务器没有内置到 Kubernetes 中,但是大多数集群要么捆绑它,要么提供一个简单的解决方案来实现它。
安装度量服务后,将显示 pod 资源,命令如下:
kubectl top pod
节点资源使用情况可通过以下命令获得:
kubectl top node
以下错误表明没有安装度量服务器:
error: Metrics API not available
在这种情况下,您可以使用这里的指令安装 metrics server。
c 组资源使用
如果度量服务不可用,仍然可以通过进入交互式会话并打印 cgroup 接口文件的内容来确定单个 pod 的内存使用情况。
使用以下命令进入交互会话,将podname替换为您希望检测的 pod 的名称:
kubectl exec -it podname -- sh
使用以下命令打印当前的内存使用情况:
cat /sys/fs/cgroup/memory/memory.usage_in_bytes
使用以下命令打印当前的 cpu 使用情况:
cat /sys/fs/cgroup/cpu/cpuacct.usage
注意cpuacct.usage返回的值并不是立即有用的,因为返回的是:
该组获得的 CPU 时间(纳秒)
将这个值转换成更有用的度量标准,如 CPU 使用率,需要一些计算。这篇关于栈交换的文章提供了更多的细节,这篇 T2 的 Python 代码提供了一个有用的实例。
您可以在 Linux 内核文档中找到关于这些文件的更多信息。
cgroup2 资源使用情况
如果目录/sys/fs/cgroup/memory或/sys/fs/cgroup/cpu不存在,您可能正在使用 cgroups v2 的系统上工作。
在装有 cgroups v2 的系统上,使用以下命令打印当前的内存使用情况:
cat /sys/fs/cgroup/memory.current
使用以下命令打印当前的 cpu 使用情况:
cat /sys/fs/cgroup/cpu.stat
这将打印一个名为usage_usec的文件。与 cgroup v1 cpuacct.usage文件返回的值一样,该值必须转换为 CPU 使用率百分比才能使用。
注意,usage_usec值是以毫秒为单位测量的,不像cpuacct.usage文件返回的值是以纳秒为单位。通过将usage_usec值乘以 1000 将其转换为纳秒,此时它可以用于由cpuacct.usage文件返回的相同计算中。
你可以在 Linux 内核文档中找到关于这些文件的更多信息。
结论
metrics server 提供了一种方便的方法来检查 Kubernetes pods 和节点的 CPU 和内存资源。也可以通过检查 cgroup 接口文件来手动找到这些值,尽管需要一些手动计算来确定 CPU 使用率的百分比。
愉快的部署!
Kubernetes Pod 服务帐户验证- Octopus 部署
我们正在为在 Kubernetes 集群中运行的 Octopus 工作人员引入更简单的身份验证,使用 Kubernetes Pod 服务帐户的凭证。
在这篇文章中,我将介绍新的支持,并演示如何利用这一更新。
Octopus 引入了工人将部署工作从 Octopus 服务器转移到机器池。工作人员在几种情况下对团队有帮助,例如:
- 备份数据库
- 执行数据库模式迁移
- 配置负载平衡器
团队也可以创建一个工人池,作为在 Kubernetes 集群中运行的容器。
当在 Kubernetes 集群中将一个工作线程池作为一个容器运行时,工作线程现在可以连接回父集群,使用 pod 服务帐户令牌和在 Pod 中作为文件挂载的集群证书文件。这允许工作人员管理他们部署到的集群,而不需要从 Octopus 服务器向他们发送额外的凭证。
创建一个在 Kubernetes 集群中运行的工人池
你可以在一个 Kubernetes 集群中运行一群章鱼工人。你想这么做有两个原因:
- 为该集群创建一个专用的工作线程
- 创建一群工作程序来使用 Octopus Deploy
这可以通过部署 Docker Hub 中托管的触手映像或者使用章鱼部署操作手册来完成。请参考我们关于在 Kubernetes 集群上创建工人的帖子,获得关于使用 Octopus Deploy 将工人池部署到 Kubernetes 集群的全面说明。
在 Kubernetes 集群中运行了一组健康的工人之后,您需要在每个 Octopus 工人中安装kubectl。kubectl是 Kubernetes 命令行工具,它允许您对 Kubernetes 集群运行命令。
为此,导航到每个工作机的目录并运行以下命令:
$ curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
$ chmod +x ./kubectl
$ mv ./kubectl /usr/local/bin
您现在可以通过检查版本来确认kubectl已经成功安装。
$ kubectl version
使用 Pod 服务帐户身份验证添加 Kubernetes 目标
我们现在有一群健康的工人在 Kubernetes 集群中运行。
下一步是使用新的身份验证模式 Pod Service Account 添加部署目标。
- 导航到基础设施 ➜ 部署目标,点击添加部署目标。
- 选择 KUBERNETES 集群,点击 KUBERNETES 集群卡片上的添加。
- 输入 Kubernetes 群集的显示名称。
- 为目标选择至少一个环境。
- 为目标选择至少一个目标角色。
- 选择 Pod 服务帐户作为认证模式。
- 输入 Pod 服务帐户的令牌文件的路径。默认路径通常是
/var/run/secrets/kubernetes.io/serviceaccount/token。请注意,该路径是相对于 pod 目录的。

- 输入 Kubernetes 集群的 URL。Octopus Deploy 中的每个 Kubernetes 目标都需要集群 URL,这可以通过检索集群信息来定位(在 Kubernetes 集群中运行
kubectl cluster-info)。 - 或者,输入群集证书的路径。默认路径通常是
/var/run/secrets/kubernetes.io/serviceaccount/ca.crt。请注意,该路径是相对于 pod 目录的。如果您选择跳过 TSL 验证,您不需要输入此详细信息。![Kubernetes Cluster details]()
- 重要提示:选择包含 Kubernetes 集群内部运行的工作线程的工作线程池。否则,部署目标的运行状况检查将会失败。
![Worker Pool selection]()


创建部署流程
部署目标现在已经可以在 Kubernetes 部署流程中使用了。
您可以创建一个部署 Kubernetes 容器步骤来定位这个部署目标的目标角色。
与前面创建的部署目标相似,部署步骤需要在 Kubernetes 集群中运行一个工作池。请确保为您的步骤选择有效的工作池。
【T2 
结论
这篇文章演示了在创建一个 Kubernetes 部署目标时,如何使用 Pod 服务帐户认证模式。
这种身份验证模式的一个好处是让工作人员能够自己连接回父集群。这意味着您不需要将集群的证书数据存储在 Octopus 服务器中。
愉快的部署!
Kubernetes RFC - Octopus 部署

Kubernetes 赢得了容器编排之战(至少在本周)。也许不出所料, Kubernetes 在我们的顶级用户声音建议列表中飙升至第 7 位。
我们一直在思考 Kubernetes 在 Octopus 中的支持可能会是什么样子,我们很想听听你的想法。通常当我们在设计功能时,我们想知道一个典型的用户是什么样子,我们只需要照照镜子。对于 Kubernetes,情况并非如此。我们目前没有在内部使用 k8s(虽然随着我们构建托管产品,这种情况可能会改变),所以我们肯定需要你的帮助。
我们目前的想法是 Kubernetes 的支持将采取以下形式:
Kubernetes 集群目标
我们将引入一个新的 Kubernetes 集群目标类型,来表示新的 Kubernetes 步骤将执行的集群。

该目标将允许您配置 Kubernetes 集群的 URL 和身份验证细节。
我们可能会支持以下认证方法:
- 用户名+密码
- 证书
- API 令牌

忽必烈应用步骤
Kubernetes 支持对象管理的声明性和命令性模式。
对于 Octopus 来说,支持声明性方法似乎是一种自然的选择。这是通过 Kubernetes 应用命令实现的。我们将通过专门的 Kubernetes 应用步骤来揭示这一点。
【T2 
Apply 命令接受一个模板(JSON 或 YAML)。这在概念上类似于 Octopus 中的 AWS CloudFormation 或 Azure Resource Group 步骤的工作方式。k8s 模板可以来自一个包,也可以直接在 Octopus UI 中配置。
容器图像
k8s 模板指定容器图像。例如,下面的模板指定了 nginx 映像的版本 1.7.9。
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
当创建一个包含 Kubernetes 应用步骤的项目发布时,我们将允许您指定您希望使用的容器映像的版本。
当您部署该版本时,我们会在将它发送到 Kubernetes 集群之前,将容器映像的正确版本替换到您的模板中。
这是章鱼特制酱。它允许您对容器映像版本的特定组合进行快照,并在您的环境中进行处理。

您可以在上面的 UI 模型中看到,您选择了两个版本:
- 包含 Kubernetes 模板的包的版本(上面例子中的
AcmeWebApp)。 - 模板中容器图像的版本(在本例中为
nginx)。
变量替换
我们将在 Kubernetes 模板上执行变量替换。所以你可以直接在里面使用章鱼变量,它们会被替换掉。
不幸的是,Kubernetes 不支持模板的参数文件(例如 CloudFormation 和 Azure RM 模板支持)。这很不幸,因为参数文件似乎是模板作者告诉 Octopus 这样的工具哪些值应该作为参数提供的理想方式。
您希望如何向 Kubernetes Apply 命令提供变量?
一些选项可能是:
-
直接在模板上替换变量:例如,您可以在模板中包含
#{Octopus.Environment},它在部署时会被适当的值替换。这与像 helm 这样的工具的方法是一致的,但是也有不利的一面,你的模板在 Octopus 之外是无效的(甚至可能是无效的 JSON 或 YAML)。 -
转换文件:与 Microsoft web.config 转换类似,您可以在模板旁边放置一个转换文件。然后,转换文件可以包含被替换的 Octopus 变量,然后转换将被应用到模板。这种方法的优点是您的模板可以保持有效,并且您的转换可以存在于您的模板旁边(例如,在您的 git repo 中)。对于 JSON 模板,有现有的实现。对于 YAML,我们找不到太多...
-
显式配置的替换:我们还可以允许在步骤 UI 中提供键值对,这将指定模板中的属性被替换。我们可以支持嵌套属性(见下面的例子)。这样做的缺点是,如果您的模板结构发生变化,您必须更新 Octopus 中的部署步骤。
| 钥匙 | 价值 | 评论 |
|---|---|---|
foo |
#{Foo} |
顶级属性foo将被替换为#的值。 |
foo::bar |
#{AnotherVariable} |
嵌套属性foo.bar将被替换。 |
如前所述,我们肯定会实现选项#1(如果你的模板中没有任何 Octopus 变量占位符,那么它不会做任何事情)。但是如果你更喜欢其他提供变量的方法(包括上面没有提到的),请留下你的评论。
kubectl 脚本步骤
除了apply之外,还有许多其他的 Kubernetes 命令你可能希望执行。比如:删除资源、缩放等。
我们将通过添加一个新的 Run a Script 步骤来实现这些功能: Run a kubectl Script 。
这一步将允许您编写自己的脚本,我们确保kubectl命令行是可用的,并且针对该步骤所针对的 Kubernetes 集群进行了验证。这在概念上类似于我们的运行 AWS CLI 脚本或运行 Azure PowerShell 脚本步骤,它们分别针对 AWS 和 Azure 进行身份验证并提供 SDK。

我们需要你的帮助
我们认为这将很好地符合现有的 Octopus 概念和架构,但我们需要你告诉我们这是否符合你期望与 Kubernetes 交互的方式。
如果您目前正在使用 Kubernetes(或者正计划使用),我们很想听听您的情况。帮我们把 k8s 带到 o5s。
使用 eksctl - Octopus Deploy 创建 EKS 集群

EKS 是由 AWS 提供的托管 Kubernetes 服务。在高层次上,EKS 由两个组件组成:被管理的 EKS 控制平面和工作节点。EKS 控制平面是 AWS 中的专用资源,具有云形成类型 AWS EKS 集群。另一方面,worker 节点只是 EC2 实例,它们在部署过程中被配置为加入 Kubernetes 集群。
以前,创建所有这些资源是您自己的责任,这不是一项简单的任务。您负责创建 VPC、子网、互联网网关、自动扩展组、IAM 角色、EC2 实例等等。
幸运的是,今天我们有了 eksctl ,这是一个命令行工具,展示了一个熟悉的动词/名词参数结构,用于创建和管理 EKS 集群。
在这篇博文中,我们将看看如何使用eksctl将一个简单的 EKS 集群部署并集成到 Octopus 中。
准备 Octopus 服务器
专门对 Octopus 使用 Kubernetes 集群和 EKS 意味着在 Octopus 服务器上有可用的kubectl和aws-iam-authenticator二进制文件。
关于安装kubectl的信息可以在 Kubernetes 文档中找到,你可以从 AWS 文档中找到关于aws-iam-authenticator的更多信息。
准备章鱼图书馆
对于这个例子,我们将使用直接来自 Octopus 的eksctl。为了让eksctl在我们的脚本中可用,我们首先需要从 eksctl GitHub releases 页面下载二进制文件。
你下载的文件会被叫做类似eksctl_Windows_amd64.zip的东西。将此重命名为eksctl.0.4.3.zip(用您下载的eksctl版本替换0.4.3)。新文件名嵌入了版本,这种格式是 Octopus 所要求的。重命名后,文件可以上传到 Octopus 内置的提要中。
【T2 
eks CTL 包上传到内置 feed。
我们还需要检查 YAML 的文件来提取他们的价值。PowerShell 本身不支持 YAML 解析,这意味着我们需要使用第三方库。
使用 PowerShell 模块的一个简单方法是将 PowerShell Gallery 添加到 Octopus。提要的 URL 是 https://www.powershellgallery.com/api/v2/的。

PowerShell Gallery Nuget feed。
准备凭据
EKS 集群使用 AWS 凭据进行身份验证。AWS 账户在 Octopus 中作为专用账户类型公开。您可以在他们的文档中找到关于生成 AWS 访问键的更多信息。

AWS 账户。
准备环境
我们将利用动态创建的基础设施来创建指向新 EKS 集群的新 Kubernetes 目标。
为了使动态基础设施能够作为部署的一部分被创建,环境需要启用Dynamic Infrastructure选项。

允许创建动态基础设施的环境。
章鱼项目
在我们的 Octopus 项目中,我们需要设置的第一件事是变量。我们之前创建的 AWS 帐户被项目中的一个AWS Account变量类型引用。

项目变量,定义指向 AWS 账户的单个变量。
现在我们可以添加一个Run an AWS CLI Script步骤来调用eksctl来创建 EKS 集群,然后创建 Octopus Kubernetes 目标。
该步骤引用了我们之前设置的 AWS account 变量来执行登录。该步骤还定义了将在其中进行部署的 AWS 区域。

AWS CLI 脚本步骤使用的凭据和区域。
我们的脚本将引用另外两个包:包含eksctl可执行文件的包,以及来自 PowerShell Gallery 提要的powershell-yaml模块。这两个附加包都被设置为提取。
这里,我们利用引用的包以两种不同的方式丰富了部署。
eksctl包是一个使用参考包为我们的脚本提供额外的二进制工具的例子。特别是 AWS 生态系统有丰富的第一和第三方 CLI 工具(例如, SAM CLI 、 S3cmd 、 eksctl 、 Beanstalk CLI 和 ECS CLI ),可以通过这种方式捆绑在一起。
powershell-yaml包是利用 PowerShell Gallery 向我们的 PowerShell 脚本公开模块的一个例子。这样就不需要让这些模块在全球范围内可用,或者将它们与定制脚本捆绑在一起。

引用的包,将在部署过程中下载和提取。
最后,我们有剧本本身。以下是完整的代码:
Import-Module -Name .\powershell-yaml
$clusterName = "mycluster"
# Check to see if the cluster exists
eksctl\eksctl get cluster --name $clusterName 2>&1
# If the cluster does not exist, create it. Otherwise get the kubeconfig file
if ($LASTEXITCODE -ne 0) {
eksctl\eksctl create cluster --name $clusterName --kubeconfig eks.yaml
} else {
eksctl\eksctl utils write-kubeconfig --name $clusterName --kubeconfig eks.yaml
}
# Convert the kubeconfig from YAML
$kubeConfig = Get-Content -Path eks.yaml -Raw
$kubeConfigObject = ConvertFrom-Yaml $kubeConfig
# Extract the cluster URL
$clusterUrl = $kubeConfigObject.clusters[0].cluster.server
# Create an Octopus target
New-OctopusKubernetesTarget `
-name $clusterName `
-octopusRoles "EKS" `
-clusterUrl $clusterUrl `
-octopusAccountIdOrName $AWS `
-clusterName $clusterName `
-namespace "default" `
-updateIfExisting `
-skipTlsVerification True
让我们来分解这个代码。
我们从导入来自 PowerShell Gallery Nuget 提要的powershell-yaml模块开始。这将使我们稍后能够访问像ConvertFrom-Yaml这样的功能:
Import-Module -Name .\powershell-yaml
EKS 集群的名称是在一个变量中定义的,因为它将在脚本中多次使用:
$clusterName = "mycluster"
然后我们通过调用eksctl来检查 EKS 集群是否已经存在。
Octopus 步骤应该被设计成幂等的,这意味着不管任何外部系统的状态如何,它们都可以运行多次。不幸的是,eksclt没有公开幂等命令,这意味着如果您试图创建一个已经存在的集群,您将会收到一个错误。通过检查集群是否已经存在,我们可以实现自己的创建或更新逻辑。
注意,eksctl可执行文件已经被提取到了eksctl目录,因此我们调用了eksctl\eksctl:
# Check to see if the cluster exists
eksctl\eksctl get cluster --name $clusterName 2>&1
如果集群不存在(我们从调用eksctl get cluster的返回代码中确定),我们就创建它。--name参数定义了 EKS 集群的名称,而--kubeconfig参数定义了保存客户端连接到集群所需的详细信息的文件名:
# If the cluster does not exist, create it. Otherwise get the kubeconfig file
if ($LASTEXITCODE -ne 0) {
eksctl\eksctl create cluster --name $clusterName --kubeconfig eks.yaml
}
如果集群已经存在,我们将保存 kubeconfig 详细信息:
else {
eksctl\eksctl utils write-kubeconfig --name $clusterName --kubeconfig eks.yaml
}
此时,不管 EKS 集群是新创建的还是已经存在的,我们都有一个名为eks.yaml的文件,其中包含了客户端连接到集群所需的详细信息。通常这个配置文件会被kubectl命令行工具直接使用,但是在这个例子中,我们想要获取该文件的细节,并使用它们来创建一个 Octopus Kubernetes 目标。
为了提取文件的细节,我们使用作为powershell-yaml库的一部分导入的ConvertFrom-Yaml函数将其从原始 YAML 转换为 PowerShell 对象:
# Convert the kubeconfig from YAML
$kubeConfig = Get-Content -Path eks.yaml -Raw
$kubeConfigObject = ConvertFrom-Yaml $kubeConfig
然后,我们提取 EKS 集群的 URL:
# Extract the cluster URL
$clusterUrl = $kubeConfigObject.clusters[0].cluster.server
最后一步是使用New-OctopusKubernetesTarget函数在 Octopus 中创建新的 Kubernetes 目标。此功能记录在这里。
请注意,$AWS变量是由 Octopus 提供的,它被设置为 AWS 帐户的 ID:
# Create an Octopus target
New-OctopusKubernetesTarget `
-name $clusterName `
-octopusRoles "EKS" `
-clusterUrl $clusterUrl `
-octopusAccountIdOrName $AWS `
-clusterName $clusterName `
-namespace "default" `
-updateIfExisting `
-skipTlsVerification True
部署这个项目将导致创建 EKS 集群(如果它还不存在的话),生成eks.yaml文件,以及新创建或更新的 Octopus Kubernetes 目标。
【T2 
部署日志。
然后,我们可以在基础设施页面上看到新的 Kubernetes 目标。

通过调用 New-octopus kubernetastarget 创建的 Kubernetes 目标。
结论
以前,创建 EKS 集群是一个复杂的过程,需要多个步骤来配置控制平面、工作节点以及所有相关的网络和安全性。
如今,使用eksctl工具,创建一个完整的 EKS 集群只需一个命令。在本文中,我们看到了如何在 Octopus 中编写执行eksctl的脚本来创建 EKS 集群和 Octopus Kubernetes 目标。
Kubernetes 使用 KIND - Octopus 部署进行测试

有许多创建本地测试 Kubernetes 环境的解决方案,如 minikube 或 MicroK8s ,但一个名为 KIND 的新项目提供了一种可能会引起 Kubernetes 开发人员和管理员兴趣的新方法。
KIND 在 Docker 中代表 Kubernetes,顾名思义,它使用 Docker 创建一个 Kubernetes 集群来托管节点。这是一种新颖的方法,它利用 Docker 简单、独立的部署和清理来创建测试 Kubernetes 基础设施。
实物安装
确保已经安装了 Docker 和 Go ,然后使用命令安装 KIND:
GO111MODULE="on" go get sigs.k8s.io/kind@v0.6.1
这将把kind可执行文件放在目录$GOPATH/bin/kind中,默认情况下这个目录是~/go/bin/kind。
假设 Go bin目录在PATH中,使用以下命令构建一个测试集群:
kind create cluster --name mycluster
第一个集群需要一点时间来下载 KIND Docker 映像,尽管后续集群的创建不到一分钟。
KIND 会将新的集群细节作为上下文添加到您的~/.kube/config文件中,因此您可以使用以下命令测试集群是否启动并运行:
kubectl cluster-info --context kind-mycluster
您可以使用以下命令将此上下文设置为默认上下文:
kubectl config use-context kind-mycluster
使用 Kubernetes 星团
我在使用 KIND 时遇到的最直接的问题是访问部署到集群的服务。
默认情况下,KIND 只公开 Kubernetes API 服务器。这意味着kubectl将按预期工作。因此您可以部署到集群并查询资源,但是访问您的服务需要一些额外的工作。
一个解决方案是使用kubectl作为代理:
kubectl proxy --port=8080
Kubernetes 服务可以通过一个特殊的 URL 获得,比如 http://localhost:8080/API/v1/namespaces/default/services/web server:http-web/proxy/。
Kubernetes 文档有关于这些代理 URL 的更多细节:
要创建包含服务端点、后缀和参数的代理 URL,只需在服务的代理 URL 后面追加:http://kubernetes _ master _ address/API/v1/namespaces/namespace _ name/services/[https:]service _ name[:port _ name]/proxy
端口转发消除了构建特殊 URL 的需要。使用如下命令启动端口转发:
kubectl port-forward svc/webserver 8081:80
该服务现在在本地端口 8081 上可用,将流量定向到服务端口 80。这意味着 URL http://localhost:8081 可以用来访问服务。
您也可以在入口控制器上使用端口转发:
kubectl port-forward svc/nginx-release-nginx-ingress 8081:80
此命令允许您通过已配置的任何入口规则访问服务。
KIND 文档还提供了一些关于如何暴露入口控制器的附加细节,以获得更持久的解决方案。
第一印象
一旦我解决了访问我的服务的问题,KIND 在测试版中表现得非常好。Helm 等外部工具运行良好,我可以向集群部署定制的仪表板。
我很欣赏这种类型如此独立的事实。因为所有东西都是 Docker 容器,所以创建集群很快,当它被清理后,系统上就没有任何东西在运行了。
结论
如今,让 Kubernetes 集群在本地运行并不困难,但是 KIND 让创建集群变得特别容易。诚然,Kubernetes 在 Docker 上运行来编排 Docker 有点弯脑子,但为了方便也不能打。
KIND 的真正价值是能够将它作为自动化测试的一部分来运行。我个人没有这方面的用例,但我确信它会兑现承诺。
我会认真考虑从现在开始使用 KIND over minikube 进行本地测试。
在 Kubernetes 集群- Octopus 部署上创建工人

客户经常问他们是否可以在 Kubernetes (K8s)集群中运行一个 Octopus worker。你想这么做有几个原因:为该集群创建一个专用的 worker,或者简单地创建一组 worker 来与 Octopus Deploy 一起使用。使用触手图像,这是可能的,但是你甚至可以用它来部署 Octopus 本身。
在这篇文章中,我演示了如何部署触手容器作为 Octopus 实例上的工作器。
创建工人池
首先,我们需要为我们的容器工人创建一个新的工人池:
- 在 Octopus 门户网站中,导航至基础设施选项卡。
- 选择工人池。
- 然后点击添加工人池。
- 为该池命名,然后单击保存。
创建好我们的池后,我们可以继续操作手册了。
创建外部源
要配置 Octopus Deploy 来部署映像,我们首先需要创建一个外部提要,因为内置的存储库只是一个 NuGet 提要类型。
在这篇文章中,我创建了一个指向 Docker Hub 的外部提要。还支持其他 docker 提要,如 Artifactory 和 Nexus。

创建一本操作手册
应使用操作手册开展基础设施活动。这篇文章假设你熟悉在 Octopus 中创建项目,所以我们将跳过这一部分。
- 在您的项目中创建一个操作手册。我叫矿创造 K8s 的工人。
- 向您的流程添加一个部署 Kubernetes 容器步骤。
这个步骤模板很大,所以我们将检查最少的组件来使它工作。
部署科
至少要填写以下内容:
- 部署名称:K8s 内部署的名称。
- 副本:要运行的容器数量。我把我的设置为 3,所以我有三个工人。
Containers section
点击添加容器,填写以下组件:
- 名称:容器的名称
- 包装图像
- Package feed :选择您为图像配置的 feed(在我的例子中是 Docker Hub)
- 包 ID :
octopusdeploy/tentacle
- 环境变量:点击添加环境变量,添加如下:
- ServerApiKey :注册工人的 API 键
- 服务器 Url :你的 Octopus 实例的 Url
- 接受 _EULA :
Y - TargetWorkerPool :要添加的池的名称
- ServerPort :
10943(设置这个环境变量为轮询模式配置 worker) - 空间:要添加工作者的空间的名称(变量
#{Octopus.Space.Name}的八进制数将获取当前空间的名称)
Windows K8s 群集将主机名限制为 16 个字符。如果您使用的是 Windows K8s,请使用下游 API 特性并添加一个额外的环境变量,target name:metadata . name

上面没有列出的任何内容都使用表单默认值。
执行操作手册
点击运行在您选择的环境中运行操作手册。
运行手册成功完成后,选择基础设施选项卡,您将看到工人已被添加到工人池。
我们可以通过在员工身上升级 Calamari 来验证功能。使用省略号菜单选择升级 3 名工人的鱿鱼选项。

结论
在本文中,我演示了如何使用 Octopus Deploy 将 workers 部署到 Kubernetes 集群。
愉快的部署!
硒系列:启动黄瓜测试-章鱼部署
原文:https://octopus.com/blog/selenium/32-launching-cucumber-tests/launching-cucumber-tests
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
现在我们有了一个可以运行的简单 Lambda 函数,以及一个部署应用程序的无服务器配置,我们可以创建一个启动 WebDriver 测试的 Lambda 函数。
下面是LambdaEntry类的新代码,它将从一个小黄瓜特性文件启动一个 WebDriver 测试:
package com.octopus;
import org.apache.commons.io.FileUtils;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
public class LambdaEntry {
private static final String CHROME_HEADLESS_PACKAGE =
"https://s3.amazonaws.com/webdriver-testing-resources/stable-headless-chromium-amazonlinux-2017-03.zip";
private static final String CHROME_DRIVER =
"https://s3.amazonaws.com/webdriver-testing-resources/chromedriver_linux64.zip";
public String runCucumber(final String feature) throws Throwable {
File driverDirectory = null;
File chromeDirectory = null;
File outputFile = null;
File featureFile = null;
try {
driverDirectory = downloadChromeDriver();
chromeDirectory = downloadChromeHeadless();
outputFile = Files.createTempFile("output", ".json").toFile();
featureFile = writeFeatureToFile(feature);
cucumber.api.cli.Main.run(
new String[]{
"--monochrome",
"--glue", "com.octopus.decoratorbase",
"--format", "json:" + outputFile.toString(),
featureFile.getAbsolutePath()},
Thread.currentThread().getContextClassLoader());
return FileUtils.readFileToString(outputFile, Charset.defaultCharset());
} finally {
FileUtils.deleteQuietly(driverDirectory);
FileUtils.deleteQuietly(chromeDirectory);
FileUtils.deleteQuietly(outputFile);
FileUtils.deleteQuietly(featureFile);
}
}
private File downloadChromeDriver() throws IOException {
final File extractedDir = downloadAndExtractFile(CHROME_DRIVER, "chrome_driver");
final String driver = extractedDir.getAbsolutePath() + "/chromedriver";
System.setProperty("webdriver.chrome.driver", driver);
new File(driver).setExecutable(true);
return extractedDir;
}
private File downloadChromeHeadless() throws IOException {
final File extractedDir = downloadAndExtractFile(CHROME_HEADLESS_PACKAGE, "chrome_headless");
final String chrome = extractedDir.getAbsolutePath() + "/headless-chromium";
System.setProperty("chrome.binary", chrome);
new File(chrome).setExecutable(true);
return extractedDir;
}
private File downloadAndExtractFile(final String download, final String tempDirPrefix) throws IOException {
File downloadedFile = null;
try {
downloadedFile = File.createTempFile("download", ".zip");
FileUtils.copyURLToFile(new URL(download), downloadedFile);
final File extractedDir = Files.createTempDirectory(tempDirPrefix).toFile();
unzipFile(downloadedFile.getAbsolutePath(), extractedDir.getAbsolutePath());
return extractedDir;
} finally {
FileUtils.deleteQuietly(downloadedFile);
}
}
private void unzipFile(final String fileZip, final String outputDirectory) throws IOException {
final byte[] buffer = new byte[1024];
try (final ZipInputStream zis = new ZipInputStream(new FileInputStream(fileZip))) {
ZipEntry zipEntry = zis.getNextEntry();
while (zipEntry != null) {
final String fileName = zipEntry.getName();
final File newFile = new File(outputDirectory + "/" + fileName);
try (final FileOutputStream fos = new FileOutputStream(newFile)) {
int len;
while ((len = zis.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
}
zipEntry = zis.getNextEntry();
}
zis.closeEntry();
}
}
private File writeFeatureToFile(final String feature) throws IOException {
final File featureFile = File.createTempFile("cucumber", ".feature");
try {
final URL url = new URL(feature);
FileUtils.copyURLToFile(url, featureFile);
} catch (final MalformedURLException ex) {
try (PrintWriter out = new PrintWriter(featureFile)) {
out.println(feature);
}
}
return featureFile;
}
}
让我们来分解这个类。
以下常量是我们上传到 S3 的 Chrome Lambda 发行版和 Linux 二进制驱动程序的 URL。这些网址对你来说是不同的,因为你将它们上传到一个不同的 S3 桶。
不要在你自己的测试中使用这些 URL,但是总是使用你控制的 S3 桶的 URL。使用指向您自己的 S3 存储桶的 URL 可以确保您的代码只依赖于您拥有和管理的资源。
private static final String CHROME_HEADLESS_PACKAGE =
"https://s3.amazonaws.com/webdriver-testing-resources/stable-headless-chromium-amazonlinux-2017-03.zip";
private static final String CHROME_DRIVER =
"https://s3.amazonaws.com/webdriver-testing-resources/chromedriver_linux64.zip";
我们仍然使用runCucumber()方法作为 Lambda 入口点:
public String runCucumber(String feature) throws Throwable {
这四个文件将在 Lambda 每次运行时创建。我们需要跟踪我们创建的所有资源,以便它们可以在事后被清理,因为 Lambda 可能会重用底层的 Linux 实例来进行连续的函数调用。如果我们要创建文件而不清理它们,我们可能会耗尽分配给 Lambda 函数的所有可用空间,代码将无法正常工作:
File driverDirectory = null;
File chromeDirectory = null;
File outputFile = null;
File featureFile = null;
每次调用runCucumber()方法时,我们下载 Linux 二进制驱动程序和 Chrome Lambda 发行版。这些文件太大,无法与 Lambda 代码捆绑在一起分发,所以我们必须在运行时下载它们。通过将这些文件上传到 S3,我们利用了 S3 和 Lambda 都是 AWS 提供的服务,Lambda 可以快速可靠地访问 S3 的文件:
try {
driverDirectory = downloadChromeDriver();
chromeDirectory = downloadChromeHeadless();
Cucumber 可以用特性文件执行的结果生成一个 JSON 报告文件。我们将使用这个文件作为 Lambda 的返回值。这里我们创建一个临时文件,可以用来保存 JSON 结果:
outputFile = Files.createTempFile("output", ".json").toFile();
我们创建的最后一个文件是 Gherkin 特征文件。该文件的内容是在功能参数中传递给方法的字符串:
featureFile = writeFeatureToFile(feature);
现在我们已经有了所有的文件,我们可以运行黄瓜。
以前,我们利用 Cucumber 提供的 JUnit 集成来启动特性文件,作为测试类的一部分。但是我们不是从 Lambda 运行 JUnit,所以我们需要一种新的方式来启动 Cucumber。
幸运的是,Cucumber 还提供了一种在命令行中使用传统的cucumber.api.cli.Main类中的static void main()方法来运行它的方法。这个main()方法然后调用run()方法。我们使用这个run()方法作为启动 Cucumber 的一种方式,就好像它是从命令行直接运行的一样。
传递给run()方法的第一个参数是一个字符串数组,它保存通常在命令行上提供的参数。我们使用了许多选项来定制输出,链接到我们的 glue 类,并保存一个报告文件。
--monochrome选项从打印到控制台的消息中删除彩色文本。在日志文件中查看时,这些彩色消息翻译得不好。--glue选项将 Cucumber 链接到保存我们的注释类的包。这与我们之前传递给 JUnit 注释的选项相同。--format选项定义了 Cucumber 生成的报告文件。它被设置为值json:<output file>,输出文件是我们之前创建的临时文件。- 最后一个参数是特征文件本身。
第二个参数是 Cucumber 使用的类加载器。我们传递Thread.currentThread().getContextClassLoader()的值,就像cucumber.api.cli.Main.main()方法一样:
cucumber.api.cli.Main.run(
new String[]{
"--monochrome",
"--glue", "com.octopus.decoratorbase",
"--format", "json:" + outputFile.toString(),
featureFile.getAbsolutePath()},
Thread.currentThread().getContextClassLoader());
一旦运行了 Gherkin 特征文件,我们就读取报告文件的内容并返回它:
return `FileUtils.readFileToString(outputFile, Charset.defaultCharset());`
我们创建的所有文件都使用FileUtils.deleteQuietly()方法从 Apache Commons IO 库中删除。这个方法不抛出任何异常,这意味着我们试图删除每个文件,忽略任何错误。
由于运行我们代码的 Linux 实例最终将被销毁,并为下一次 Lambda 调用分配一个新的实例,因此无法删除的临时文件可能不会造成任何持久的危害:
} finally {
FileUtils.deleteQuietly(driverDirectory);
FileUtils.deleteQuietly(chromeDirectory);
FileUtils.deleteQuietly(outputFile);
FileUtils.deleteQuietly(featureFile);
}
}
downloadChromeDriver()方法是我们下载和配置 Linux Chrome 二进制驱动程序的地方。
我们首先调用downloadAndExtractFile()方法,传入驱动程序 URL 和用于存放提取文件的临时目录的前缀:
private File downloadChromeDriver() throws IOException {
final File extractedDir = downloadAndExtractFile(CHROME_DRIVER, "chrome_driver");
然后,我们获取驱动程序的路径,将webdriver.chrome.driver系统属性设置为驱动程序路径,并确保驱动程序文件的可执行标志设置为 true。
要在 Linux 中执行一个文件,该文件必须将可执行标志设置为true。这不同于像 Windows 这样的操作系统,它使用像.exe这样的扩展名来表示可执行文件。
final String driver = extractedDir.getAbsolutePath() + "/chromedriver";
System.setProperty("webdriver.chrome.driver", driver);
new File(driver).setExecutable(true);
然后返回存放 Chrome 驱动程序的目录,以便在测试完成后可以清理它:
return extractedDir;
}
downloadChromeHeadless()方法遵循与downloadChromeDriver()方法相同的模式,只是这次我们下载的是 Chrome Lambda 发行版。
它首先将 Chrome 发行版下载到一个前缀为chrome_headless的临时目录中:
private File downloadChromeHeadless() throws IOException {
final File extractedDir = downloadAndExtractFile(CHROME_HEADLESS_PACKAGE, "chrome_headless");
我们获取 Chrome 可执行文件的路径,将chrome.binary系统属性设置为该路径,并确保该文件启用了可执行标志。
chrome.binary系统属性不是一个被 WebDriver 识别的属性,但它是一个我们将在稍后发布 Chrome 时访问的属性:
final String chrome = extractedDir.getAbsolutePath() + "/headless-chromium";
System.setProperty("chrome.binary", chrome);
new File(chrome).setExecutable(true);
然后返回临时目录,以便在测试完成后可以清理它:
return extractedDir;
}
前面的方法都调用了downloadAndExtractFile()方法来下载和解压一个 ZIP 文件。
我们首先创建一个指向临时文件的变量,我们将把远程文件下载到这个临时文件中:
private File downloadAndExtractFile(final String download, final String tempDirPrefix) throws IOException {
File downloadedFile = null;
然后,我们创建临时文件,并使用 Apache Commons IO 库中的FileUtils.copyURLToFile()方法将远程文件下载到其中:
try {
downloadedFile = File.createTempFile("download", ".zip");
FileUtils.copyURLToFile(new URL(download), downloadedFile);
然后,我们创建一个临时目录,将下载的文件提取到该目录中,并将该目录返回给调用方法:
final File extractedDir = Files.createTempDirectory(tempDirPrefix).toFile();
unzipFile(downloadedFile.getAbsolutePath(), extractedDir.getAbsolutePath());
return extractedDir;
不再需要下载的文件,因此将其删除:
} finally {
FileUtils.deleteQuietly(downloadedFile);
}
}
为了提取 ZIP 文件,我们使用了unzipFile()方法:
private void unzipFile(final String fileZip, final String outputDirectory) throws IOException {
我们首先创建一个可以读取 ZIP 文件内容的缓冲区:
final byte[] buffer = new byte[1024];
然后,我们从 ZIP 文件中创建一个ZipInputStream实例。ZipInputStream类是标准 Java 库的一部分,我们将使用这个类来读取 ZIP 文件的内容:
try (final ZipInputStream zis = new ZipInputStream(new
FileInputStream(fileZip))) {
ZIP 文件中的文件由ZipEntry类表示。这里我们从ZipInputStream得到第一个ZipEntry:
ZipEntry zipEntry = zis.getNextEntry();
然后,当我们有一个ZipEntry对象要处理时,我们进入一个循环:
while (zipEntry != null) {
ZipEntry的名称是文件名:
final String fileName = zipEntry.getName();
ZipEntry名称与输出目录相结合,创建提取文件的路径:
final File newFile = new File(outputDirectory + "/" + fileName);
然后,我们用提取的文件创建一个输出流:
try (final FileOutputStream fos = new FileOutputStream(newFile)) {
然后将ZipEntry的内容读入我们之前创建的缓冲区,然后将缓冲区写入输出文件。这就是我们如何将ZipEntry文件的压缩内容转换成输出文件的未压缩内容:
int len;
while ((len = zis.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
对来自ZipInputStream的每个ZipEntry对象重复该过程:
}
zipEntry = zis.getNextEntry();
}
一旦我们完成,关闭ZipInputStream:
zis.closeEntry();
}
}
这个类中的最后一个方法是writeFeatureToFile(),我们用它来编写小黄瓜特征文件:
private File writeFeatureToFile(final String feature) throws IOException
{
我们创建一个临时文件来保存特征文件的内容:
final File featureFile = File.createTempFile("cucumber", ".feature");
然后,我们尝试下载文件,就好像特性参数是一个 URL 一样:
try {
final URL url = new URL(feature);
FileUtils.copyURLToFile(url, featureFile);
如果下载文件失败,我们假设这是因为特征参数不是 URL,而是组成特征文件的原始文本。这意味着我们可以向特性参数提供 URL 或原始文本,而writeFeatureToFile()方法可以检测该做什么:
} catch (final MalformedURLException ex) {
try (PrintWriter out = new PrintWriter(featureFile)) {
out.println(feature);
}
}
然后返回结果文件:
return featureFile;
}
要在 Lambda 中运行 Chrome,我们需要传递一些参数,允许 Chrome 在受限的 Lambda 环境中工作。
为了传递参数,我们将创建一个名为ChromeHeadlessLambdaDecorator的新装饰类:
package com.octopus.decorators;
import com.octopus.AutomatedBrowser;
import com.octopus.decoratorbase.AutomatedBrowserBase;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class ChromeHeadlessLambdaDecorator extends AutomatedBrowserBase
{
public ChromeHeadlessLambdaDecorator(final AutomatedBrowser automatedBrowser) {
super(automatedBrowser);
}
@Override
public void init() {
final ChromeOptions options = new ChromeOptions();
options.addArguments("--disable-gpu");
options.addArguments("--headless");
options.addArguments("--window-size=1366,768");
options.addArguments("--single-process");
options.addArguments("--no-sandbox");
options.addArguments("--user-data-dir=/tmp/user-data");
options.addArguments("--data-path=/tmp/data-path");
options.addArguments("--homedir=/tmp");
options.addArguments("--disk-cache-dir=/tmp/cache-dir");
if (System.getProperty("chrome.binary") != null) {
options.setBinary(System.getProperty("chrome.binary"));
}
options.merge(getDesiredCapabilities());
final WebDriver webDriver = new ChromeDriver(options);
getAutomatedBrowser().setWebDriver(webDriver);
getAutomatedBrowser().init();
}
}
--disable-gpu和--headless参数配置 Chrome 在无头模式下运行。
我们也可以在ChromeOptions类上调用setHeadless()方法。直接传递参数或调用setHeadless()会获得相同的结果:
options.addArguments("--disable-gpu");
options.addArguments("--headless");
--window-size参数定义了浏览器窗口的大小:
options.addArguments("--window-size=1366,768");
在 Lambda 环境中运行 Chrome 需要--single-process和--no-sandbox参数。你可以在https://github.com/adieuadieu/serverless-chrome/issues/15找到更多关于为什么需要这些论证的信息。
options.addArguments("--single-process");
options.addArguments("--no-sandbox");
--user-data-dir、--data-path、--homedir和--disk-cache-dir参数确保 Chrome 只尝试写入/tmp目录。目录是 Lambda 环境中少数几个进程可以写文件的地方之一。
options.addArguments("--user-data-dir=/tmp/user-data");
options.addArguments("--data-path=/tmp/data-path");
options.addArguments("--homedir=/tmp");
options.addArguments("--disk-cache-dir=/tmp/cache-dir");
如果定义了chrome.binary系统属性(它是在LambdaEntry.downloadChromeHeadless()方法中设置的),那么我们获取系统属性的值,并用它来设置 Chrome 二进制文件的位置。这就是我们的代码如何找到自定义的 Chrome 可执行文件:
if (System.getProperty("chrome.binary") != null) {
options.setBinary(System.getProperty("chrome.binary"));
}
为了利用这个新的装饰器,我们通过AutomatedBrowserFactory类公开它。
我们在这里不使用BrowserMobDecorator,因为 Chrome 64 在无头模式下使用代理有一个已知的问题。你可以在这里找到更多关于这个问题的细节。
package com.octopus;
import com.octopus.decorators.*;
public class AutomatedBrowserFactory {
public AutomatedBrowser getAutomatedBrowser(String browser) {
// ...
if ("ChromeNoImplicitWaitLambda".equalsIgnoreCase(browser)) {
return getChromeBrowserNoImplicitWaitLambda();
}
// ...
}
// ...
private AutomatedBrowser getChromeBrowserNoImplicitWaitLambda() {
return new ChromeHeadlessLambdaDecorator(
new WebDriverDecorator()
);
}
// ...
}
要部署新的 Lambda 功能,运行package Maven 生命周期,并运行serverless deploy将代码上传到 AWS。
我们现在准备通过传递一个小黄瓜特征文件来测试 Lambda 函数。然而,如果你还记得在上一篇文章中我们说过 Lambda 函数的每个输入都必须是有效的 JSON。我们的小黄瓜特性文件肯定不是用 JSON 编写的,所以我们需要某种方法将文本转换成 JSON 字符串。
下面的 web 页面提供了一个非常简单的表单,它接受原始文本并将其转换为 JSON 字符串:
<html>
<head>
<script>
function convert() {
var output = document.getElementById("input")
.value
.replace(/\\/g, "\\\\")
.replace(/"/g, "\\\"")
.split("\n")
.join("\\n");
document.getElementById("output").value = "\"" + output + "\"";
}
</script>
</head>
<body>
<textarea id="input" style="width: 100%;" rows="20"></textarea>
<br/>
<input type="button" onclick="convert()" value="Convert" style="width: 100%">
<br/>
<input type="text" id="output" style="width: 100%">
</body>
</html>
这是进行转换的代码。它取<textarea>中文本的值,并:
- 用双反斜杠替换任何反斜杠(即转义任何反斜杠)。
- 用反斜杠和双引号替换任何双引号(即转义双引号)。
- 在换行符上拆分字符串。
- 用字符串
\n重新连接结果数组。
var output = document.getElementById("input")
.value
.replace(/\\/g, "\\\\")
.replace(/"/g, "\\\"")
.split("\n")
.join("\\n");
此代码将转换以下文本:
Feature: TicketMonster
Scenario: Purchase Tickets with default wait time and aliases
Given I open the browser "ChromeNoImplicitWaitLambda"
And I set the following aliases:
| Venue | venueSelector |
| Book | bookButton |
| Section | sectionSelect |
| Adult Ticket Count | tickets-1 |
| Add Tickets | add |
| Checkout | submit |
And I set the default explicit wait time to "10" seconds
When I open the URL "https://ticket-monster.herokuapp.com"
And I click the "Buy tickets now" button
And I click the "Concert" link
And I click the "Rock concert of the decade" link
And I select the option "Toronto : Roy Thomson Hall" from the "Venue" drop-down list
And I click the "Book" button
And I select the option "A - Premier platinum reserve" from the "Section" drop-down list
And I populate the "Adult Ticket Count" text box with the text "2"
And I click the "Add Tickets" button
And I populate the "email" text box with the text "email@example.org"
And I click the "Checkout" button
Then I close the browser
到这个字符串中:
"Feature: TicketMonster\n Scenario: Purchase Tickets with default wait
time and aliases\n Given I open the browser
\"ChromeNoImplicitWaitLambda\"\n And I set the following
aliases:\n | Venue | venueSelector |\n | Book | bookButton |\n
| Section | sectionSelect |\n | Adult Ticket Count | tickets-1
|\n | Add Tickets | add |\n | Checkout | submit |\n And I set
the default explicit wait time to \"10\" seconds\n When I open the
URL \"https://ticket-monster.herokuapp.com\"\n And I click the
\"Buy tickets now\" button\n And I click the \"Concert\"
link\n And I click the \"Rock concert of the decade\" link\n And I
select the option \"Toronto : Roy Thomson Hall\" from the
\"Venue\" drop-down list\n And I click the \"Book\" button\n
And I select the option \"A - Premier platinum reserve\" from the
\"Section\" drop-down list\n And I populate the \"Adult Ticket
Count\" text box with the text \"2\"\n And I click the \"Add
Tickets\" button\n And I populate the \"email\" text box with the
text \"email@example.org\"\n And I click the \"Checkout\"
button\n Then I close the browser"
这是执行转换后的网页截图。

这个 JSON 字符串可以在测试 Lambda 时作为输入传递。
打开 Lambda 控制台,打开cucumber-chrome-aws-dev-runCucumber功能。然后点击下拉列表旁边的Test按钮可以点击Configure测试事件。

给测试事件命名,粘贴 JSON 字符串,并点击Create按钮。

然后点击Test按钮。

Gherkin 特性在没有 Lambda 函数的情况下运行,结果被传回。

我们现在能够在 Chrome 的一个无头实例中作为 Lambda 函数运行 Cucumber 测试,因为 Lambda 函数将扩展以适应本质上无限数量的请求(您的预算不会受到影响),我们现在有了一个解决方案,允许我们并行运行大量的测试。
然而,必须通过 Lambda web 控制台运行测试并不理想。如果我们可以用 HTTP 请求直接启动这些测试,那就方便多了,这是我们将在下一篇文章中实现的。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
比较精益、敏捷和持续交付——Octopus 部署
随着 DevOps 和持续交付的发展,精益和敏捷背后的原则还适用吗?它们与 5 个持续交付原则相比如何,任何差异对于软件开发团队意味着什么?
轻量级软件交付的开端
在整个 20 世纪 90 年代,软件开发行业正在酝酿一场革命。早期的分阶段模型将交付过程分为基于技能的步骤,设计和文档用于运行批准过程来控制项目。
交付软件的过程是沉重而缓慢的,几乎没有迹象表明开销降低了他们试图减轻的风险。
出现了一组轻量级方法,旨在生成快速反馈,并基于新信息迭代地调整计划。开发人员使用小批量来管理风险,并提供频繁的机会来改变方向,而不是控制和批准。
敏捷宣言在 2001 年从这个适应性的轻量级方法社区中出现,精益软件开发在几年后出现。
敏捷和精益为软件开发提供了基于价值观和原则的方法。您可以通过一组定义每种方法哲学的核心语句来测试一种方法是敏捷的还是精益的。

连续交付出现在精益和敏捷社区中,提供了最具体的实践和能力来实现频繁和安全的软件交付。除了极限编程,大多数软件开发方法都处理需求管理和通信结构。持续交付承担了价值流的其余部分,并提供了一条高效可靠的交付渠道。
InfoQ 发布了一份关于软件开发文化和方法的年度报告。他们仿照杰弗里·摩尔的跨越鸿沟概念设计了这份报告。众所周知,Moore 将技术采用生命周期形象化为跨越 3 个标准差的钟形曲线。
该图表分为对新技术持不同态度的 5 组:
- 创新者(-3)
- 早期采用者(-2)
- 早期多数(-1)
- 后期多数(+1)
- 落后者(+3)
早期多数和晚期多数代表了采用生命周期的三分之二。尽管如此,新技术(或者,在 InfoQ 的案例中,一个新想法)要成为主流,它必须跨越从早期采用者到主流多数的鸿沟。

虽然软件交付的自适应模式被嵌入到后期的大多数中,但是持续交付模式所需的能力仍然在跨越鸿沟。一些实践(比如 DevSecOps)已经取得了飞跃,而其他关键元素,比如团队拓扑和授权团队,仍然处于早期采用阶段。
因此,随着 DevOps 和持续交付越来越受欢迎,这是将持续交付的 5 个原则与 12 个敏捷原则和 7 个精益原则进行比较的好时机。
比较敏捷、精益和持续交付原则
敏捷、精益和持续交付都提供了一套原则。这有助于我们比较它们的基本结构。
在精益和持续交付中还有其他的技术和能力,在敏捷中没有类似的元素。敏捷宣言旨在成为对其他特定方法的敏捷性的一个广泛的试金石,例如极限编程、Scrum 和有纪律的敏捷,所以它没有定义进一步的细节。
精益通过描述涵盖整个软件开发过程的技术,以及关于计划、设计、测试和维护的建议,扩展了它的原则。
连续交付使用部署管道来集中精力改进变更流程,从代码提交到产品中运行的软件。详细描述了具体的技术能力,以使能够尽早且持续地交付有价值的软件。
这些原则是这三种方法中唯一可直接比较的要素。
持续交付原则
连续交货有 5 个原则:
- 将质量建立在
- 小批量工作
- 计算机执行重复的任务,而人解决问题
- 坚持不懈地追求持续改进
- 每个人都有责任

这些原则可以安排成一种强化关系,其中前 3 项原则作为持续改进的驱动力,每个相关人员都有责任。
敏捷原则比较
总的来说,持续交付原则与敏捷宣言是一致的。

例如,小批量工作被广泛认为有助于实现几个敏捷原则:
- 我们最优先考虑的是通过早期和持续交付有价值的软件来满足客户。
- 欢迎不断变化的需求,即使是在开发的后期。敏捷流程利用变化为客户带来竞争优势。
- 频繁地交付工作软件,从几个星期到几个月,优先选择较短的时间尺度。
- 工作软件是进步的主要衡量标准。
- 敏捷过程促进可持续发展。发起人、开发人员和用户应该能够无限期地保持恒定的步调。
- 简单——最大化未完成工作量的艺术——至关重要。
“小批量工作”原则的措辞简明扼要,在实践中易于遵循。这种持续交付原则有助于实现一半的敏捷原则。
当你把这五个原则结合起来时,还有一个放大效应。为了“频繁地交付工作软件”,你需要小批量地工作,增加自动化,并在。
连续交付不包括两个敏捷原则:
- 业务人员和开发人员必须在整个项目中每天一起工作。
- 向开发团队传达信息的最有效的方法是面对面的交谈。
连续交付以交付管道为中心,这意味着识别、开始和启动的过程不是连续交付的直接关注点。此外,在连续交付书的前页,作者强调这本书是根据它所包含的思想创作的。贡献者和编辑使用不同的工具在不同的地方工作。他们使用版本控制和自动化构建来形成这本书的交付渠道。他们没有每天一起工作,也没有面对面地交流信息。
作为一个行业,许多没有尝试远程工作的组织现在准备尝试分布式工作。随着异步通信变得越来越普遍和熟悉,这将进一步挑战实时面对面协调的需求。
关于字数,持续交付原则用 21 个字来表达,而不是敏捷原则的 180 个字。后见之明和敏锐编辑的结合给了我们一个指南针来检查我们的方向,在持续交付的具体实践中提供了细节。
很容易陷入实施持续交付的细节中——工具、架构、实践、政治——如果你发现自己迷失了,尝试重温这些原则,你可能会发现它帮助你重新关注什么是重要的。”——Jez Humble
你不必扔掉敏捷宣言就能前进;这是持续交付和开发运维所基于的地理位置的一部分。业界将继续发现新的更好的软件开发方法。越来越明显的是,技术实践和文化能力至关重要。
精益原则比较
精益原则已经很简单且可行。精益和持续交付之间完全一致,没有未映射的区域。

有了敏捷,持续交付为 10 个敏捷原则提供了简明的替代方案。在精益的情况下,持续交付完全符合这些原则。每种方法都提供了适用于不同组织部门的不同视角。
在一个完全采用精益和持续交付的组织中,各自的原则对不同的团队都有帮助。精益原则和技术是领导工具,而持续交付提供了一种特定于个人贡献者交付努力的方法。
例如,对于消除浪费、快速交付,以及通过持续交付将完整性构建到系统中,自动化是一个实用的攻击媒介。
结论
持续交付提供了一套简明的原则,与 12 条敏捷原则中的 10 条相一致,并补充了精益,提供了实现类似目标的不同视角。
所有这三套原则都与现代管理哲学相一致,并且提供了不同的方法来回顾和重新关注你的软件交付工作。
您可以使用持续交付原则来指导您的软件交付工作,并参考敏捷和精益原则来为您的改进工作找到进一步的灵感。
了解更多信息
愉快的部署!
在 Windows - Octopus Deploy 上使用 Docker 进行开发和测试的经验教训
原文:https://octopus.com/blog/lessons-learned-using-docker-for-development-and-testing

在 Windows 开发者机器上使用 Docker 进行开发和测试有多难?Docker 有我想的那么大那么吓人吗?几周前,我挑战自己回答这些问题。事实证明,Windows 上的 Docker 既没有我想象的那么大,也没有我想象的那么可怕。也就是说,有一点学习曲线,我想与你分享我学到的一些教训。
场景
我本质上是一个. NET 开发者。我喜欢使用 Visual Studio。Visual Studio 内置的 Docker 功能非常好用。这几乎太容易了。右键单击一个项目,并配置它在 Docker 中运行。启动调试器,我要去比赛了。
我想后退一步,学习 Docker 实际上是如何工作的,尤其是在 Windows 上,而我正好有一个完美的场景来完成这个任务。我演示了许多 CI/CD 管道,无论是在会议上还是与客户的一对一交流中。虽然我不是每天都在会议上发言或做演示,但是一直运行 CI/CD 管道会消耗资源。我可以在 Docker 中运行 CI/CD 管道吗?
我的 CI/CD 管道使用 GitHub 进行源代码控制,TeamCity 作为构建服务器,Octopus Deploy 作为部署服务器(大惊喜,我知道),SQL Server 作为数据库后端。当我写这篇文章的时候,CI/CD 管道的核心与我过去从事的应用程序没有太大的不同。您可以用托管在 NGINX 中的 Angular 应用程序、托管在 IIS 中的 ASP.NET Web API 或使用 SQL Server 作为数据库的 Windows 服务来替换所有 CI/CD 组件。
通过学习如何在 Docker 中托管 CI/CD 管道,我还学习了如何在 Docker 中托管几乎任何其他应用程序。
第一课:使用 Docker Compose 很难引导一个有状态的应用程序
Docker Compose 通过将应用程序定义为 YAML 文件,可以轻松配置多个容器。当所有容器都是无状态的时候,Docker Compose 工作得很好,但是添加一个有状态的容器会使事情变得棘手。在我的 CI/CD 管道中,我在配置 SQL Server 容器时直接遇到了这个问题。SQL Server 容器包含 Octopus Deploy 的数据库。简而言之,我想要一个引导脚本来:
- 如果 Octopus 部署数据库不存在,则创建它。
- 将 Octopus Deploy 数据库挂载到容器中(如果存在的话)。
当数据库不存在时,Docker 合成文件为:
SQLServer:
image: microsoft/mssql-server-windows-developer
environment:
- ACCEPT_EULA=Y
- SA_PASSWORD=Password_01
ports:
- '1433:1433'
volumes:
- c:\Docker\Volumes\SQLServer\Databases:c:\SQLData
但是,创建数据库后,Docker 合成文件会发生变化:
SQLServer:
image: microsoft/mssql-server-windows-developer
environment:
- ACCEPT_EULA=Y
- SA_PASSWORD=Password_01
- attach_dbs=[{'dbName':'OctopusDeploy','dbFiles':['C:\\SQLData\\OctopusDeploy.mdf','C:\\SQLData\\OctopusDeploy_log.ldf']}]
ports:
- '1433:1433'
volumes:
- c:\Docker\Volumes\SQLServer\Databases:c:\SQLData
可以从包含 attach_dbs 环境变量的 Docker 合成文件开始。如果指定了找不到的数据库文件,容器将继续运行。
【T2 
如果这是我需要运行的唯一容器,那没什么大不了的。打开 SSMS,添加数据库,我就可以走了。然而,我在 Docker 组合文件中有另一个容器 Octopus Deploy,它要求数据库在那里。且章鱼部署容器需要在那里,以便章鱼触须工作。对于完全托管在 Docker 容器中的 Octopus Deploy,Docker 合成文件必须:
- 在 Docker 容器中启动 SQL Server。
- 如果 Octopus 部署数据库不存在,则创建它。
- 启动 Octopus 部署 Docker 容器。
- 配置 Octopus Deploy,并创建触须可以注册的 API 密钥。
- 启动 Octopus 部署触手 Docker 容器。
Octopus Deploy 服务器和 Octopus Deploy 触手容器都需要延迟它们的启动,直到它们的依赖容器就绪。在每种情况下, ready 意味着不同的东西,但是 Docker Compose 怎么知道呢?简单的事实是,它不能。如果你看看 Docker 网站上提供的例子,你会发现处理重试和等待是代码的责任。
我用的是预建的 Docker 图像,所以我没有那个闲心。对于 Octopus Deploy 和 Octopus Deploy 触手容器,我可以利用 Docker Compose 文件中的命令选项,但是这会覆盖默认命令并阻止服务在容器中安装和启动。
最后,我选择遍历 Docker Compose 文件。为了保持重启次数最少,我决定同时进行 TeamCity 和 Octopus 部署。
- 将 SQL Server 添加到 Docker Compose,并使用
docker-compose up启动它。 - 创建数据库,并更新 Docker 合成文件,以确保它们在重新启动时附加到 SQL Server。
- 跑
docker-compose down把所有东西都拆了。 - 将 TeamCity 和 Octopus Deploy 添加到 Docker Compose 并启动它。
- 配置团队城市和八达通部署。
- 使用与之前相同的命令拆除所有东西。
- 将 TeamCity 构建代理和 Octopus Deploy 触手添加到 Docker Compose 文件并启动它。
Docker Compose 是应用程序配置的理想状态。如果我想让我的 CI/CD 管道具有可移植性,我会包含一个引导脚本来下载映像并配置一切。Docker 合成文件将是最终状态。如果我想让我正在开发的应用程序在 Docker 中运行,我会添加必要的代码,让它知道等待。
经验 2:基于 Windows 的容器比基于 Linux 的容器消耗更多的资源,运行方式也不同
基于 Linux 的容器运行在 Hyper-V 虚拟机Docker Desktop VM上。该虚拟机被分配了 vCPUs 并分配了内存。

每个基于 Windows 的容器都在自己的进程中运行,在任务管理器中显示为Vnmem。他们可以根据需要消耗任意多的资源,特别是 CPU。

我在 CI/CD 管道中的第一次尝试就启动了 11 个 Docker 容器。不用说,它消耗了大量资源。在启动后的大约 10 分钟内,当这些容器运行它们的引导脚本时,笔记本电脑的 CPU 跳到 100%。当我了解到每个容器都是一个独立的进程时,我将容器的数量缩减为 5 个。
此外,基于 Windows 的映像会消耗更多的磁盘空间。以下是我笔记本电脑上基于 Linux 的 Docker 图片。记下 SQL Server 映像,mcr.microsoft.com/mssql/server。它包括映像的所有依赖项。

与基于 Windows 的图像相比。当包含所有依赖项时,SQL Server 映像的大小是它的 10 倍。

第 3 课:容器比只读映像更接近无头虚拟机
当我读到短语Docker Image时,我想象了一个 ISO 文件,它是不可更改的。Docker 容器就不是这样了。图像是容器的基础。事实上,许多 Docker 映像都包含一个配置脚本来启动任何必要的配置。Octopus 部署图像做到了这一点。当您第一次使用 Octopus Deploy 映像启动一个容器时,它会运行几个Octopus.Server.exe命令,比如configure、admin、license和metrics。这里可以看到章鱼运行的脚本。
当 Docker 容器运行时,可以对其进行更改。可以在上面安装新的软件,但是重要的是要注意,当容器被销毁时,这些更改会丢失。容器通常会因为配置的更新或更改而被销毁和重新创建。
第四课:。NET Framework 连接字符串要求在使用 Docker Compose 时通过 IP 地址引用 SQL Server
让 SQL Server 在容器中运行很容易。下一个问题是,我如何让 Octopus Deploy 看到 SQL Server。Docker Compose 提供了命名 Docker 容器的能力,它做了大量的幕后工作,因此其他容器可以通过名称相互引用。我以为那会有用。网络连接字符串。例如:
Server=SQLServer,1433;Initial Catalog=OctopusDeploy;Persist Security Info=False;User ID=sa;Password=Password_01;MultipleActiveResultSets=False;Connection Timeout=30;
它没有工作。网络连接字符串。Octopus Deploy 是一个. NET Framework 应用程序,它在同一个 Docker 网络上无法通过容器名称找到 SQL Server。只有当连接字符串使用服务器的 IP 地址时,它才起作用。但是,每次运行docker-compose up时,IP 地址都会改变。我通过在 Docker Compose 文件中创建新网络解决了这个问题:
networks:
cicd_net:
ipam:
driver: default
config:
- subnet: 172.28.0.0/16
使用这个网络,我硬编码了每个容器的 IP 地址:
SQLServer:
image: microsoft/mssql-server-windows-developer
environment:
- ACCEPT_EULA=Y
- SA_PASSWORD=Password_01
- attach_dbs=[{'dbName':'OctopusDeploy','dbFiles':['C:\\SQLData\\OctopusDeploy.mdf','C:\\SQLData\\OctopusDeploy_log.ldf']}]
ports:
- '1433:1433'
volumes:
- c:\Docker\Volumes\SQLServer\Databases:c:\SQLData
- c:\Docker\Volumes\SQLServer\Backups:c:\Backups
networks:
cicd_net:
ipv4_address: 172.28.1.1
产生的连接字符串是:
Server=172.28.1.1,1433;Initial Catalog=OctopusDeploy;Persist Security Info=False;User ID=sa;Password=Password_01;MultipleActiveResultSets=False;Connection Timeout=30;
Octopus Deploy 的 Docker 合成文件如下所示:
version: '3.7'
services:
SQLServer:
image: microsoft/mssql-server-windows-developer
environment:
- ACCEPT_EULA=Y
- SA_PASSWORD=Password_01
- attach_dbs=[{'dbName':'OctopusDeploy','dbFiles':['C:\\SQLData\\OctopusDeploy.mdf','C:\\SQLData\\OctopusDeploy_log.ldf']}]
ports:
- '1433:1433'
volumes:
- c:\Docker\Volumes\SQLServer\Databases:c:\SQLData
- c:\Docker\Volumes\SQLServer\Backups:c:\Backups
networks:
cicd_net:
ipv4_address: 172.28.1.1
OctopusDeploy:
image: octopusdeploy/octopusdeploy
ports:
- '81:81'
- '10943:10943'
depends_on:
- SQLServer
environment:
- sqlDbConnectionString=Server=172.28.1.1,1433;Initial Catalog=OctopusDeploy;Persist Security Info=False;User ID=sa;Password=Password_01;MultipleActiveResultSets=False;Connection Timeout=30;
- masterKey=YtnHskuInxiyH5MUIFEdVA==
volumes:
- c:\Docker\Volumes\Octopus\Server:c:\Octopus
- c:\Docker\Volumes\Octopus\Server\Artifacts:c:\Artifacts
- c:\Docker\Volumes\Octopus\Server\Repository:c:\Repository
- c:\Docker\Volumes\Octopus\Server\TaskLogs:c:\TaskLogs
links:
- SQLServer
networks:
cicd_net:
ipv4_address: 172.28.1.2
OctopusDeploy_Worker01:
image: octopusdeploy/tentacle
ports:
- '85:80'
depends_on:
- OctopusDeploy
environment:
- serverApiKey=API-JSZTATMYECVBOY9CPWARAANHM0
- serverUrl="http://172.28.1.2:81"
- targetWorkerPool=DatabaseWorker
- serverPort=10943
- targetName=DockerTentacle-DatabaseWorker01
volumes:
- C:\Docker\Volumes\Octopus\Worker01:c:\Applications
- c:\Docker\Volumes\SQLServer\Backups:c:\Backups
links:
- OctopusDeploy
networks:
cicd_net:
ipv4_address: 172.28.1.3
networks:
cicd_net:
ipam:
driver: default
config:
- subnet: 172.28.0.0/16
第 5 课:将 Docker 容器卷指向不同的文件夹使得本地开发和测试更加容易
了解 Docker 的工作原理打开了一个可能性的世界。对于这个例子,我在笔记本电脑上使用 SQL Server 开发一个. NET 应用程序。过去,我在笔记本电脑上运行 SQL Server 作为 Windows 服务。
想象一下,我正在开发一个有大量数据库变更的特性,QA 设法在测试环境中造成了一个错误,它阻塞了测试环境,他们需要立即修复这个错误以发布一个版本。在 Docker 之前,当这种情况发生时,我会做以下事情:
- 将所有挂起的更改提交到分支。
- 检查测试中的提交。
- 将代码指向测试数据库并开始调试。
QA 是天生好奇的人,当我还在调试的时候,他们会在 UI 周围转一转,这样会运行正确的代码来修复错误。事后看来,我不应该将笔记本电脑上运行的代码指向测试数据库。我这样做是因为通常坏数据发生在数据模型的一部分。要将这一个坏数据放到我的笔记本电脑上,我必须克隆整个数据模型。
我可以使用像 Redgate 的 SQL 数据比较工具来解决这个问题。或者我可以为我的应用程序编写一个定制的克隆工具。但是为了让它们正常工作,我会在我的本地数据库上恢复任何挂起的数据库更改。这非常烦人,因为我可能会删除我正在开发的特性的一堆测试数据。我可以将测试数据库备份并恢复到我的本地机器上,但是我不想覆盖我现有的数据库,这意味着要进入并更改连接字符串。
如果我将 SQL Server 作为 Docker 容器运行,我可以编写一个脚本来:
- 停止当前的 SQL Server Docker 容器。
- 将数据库从测试服务器备份到共享位置。
- 启动新的 SQL Server Docker 容器。
- 将备份还原到该容器中。
- 数据库名(MyAppDatabase)和服务器名(localhost)将和以前一样,所以不需要更改连接字符串。
这只是一个例子。想象一下这对 QA 也有什么帮助。不是每个 QA 人员都必须连接一个中央数据库,而是给他们几个脚本来让应用程序在本地运行。他们可能有一个原始的数据库,可以克隆并用于测试运行。
结论
Docker 并不是一个又大又吓人的工具。它有一点学习曲线,特别是如果你想在生产中使用它。但是在本地使用它却出奇的顺利。当我开始构建我的 CI/CD 管道时,我理解了 Docker 的核心概念。我运行了一个容器,但是从来没有多个容器互相通信。总而言之,我用了不到一周的时间就在 Docker 容器中建立并运行了 CI/CD 管道。正如你在上面看到的,一路上我确实碰到了一些砖墙。我的希望是,当你遇到同样的困境时,这篇文章能减轻打击。
让我们谈谈许可-八达通部署
Octopus Deploy 许可似乎有点复杂,随着 3.0 的出现,许多客户都在询问他们如何符合 3.0 的条件,或者他们需要做些什么来确保他们为 3.0 做好准备。
关于我们的执照
当您购买 Octopus Deploy 许可证时,您购买的是带有一年支持和维护的永久许可证。这意味着,在维护有效期间,您可以使用该许可证进行任何升级,此后,只要您愿意,就可以继续使用该版本,但您的升级将受到限制。
今年早些时候,我们改变了对所需升级和维护日期的政策。以前,每个版本都有一个构建日期,您的维护期必须在此日期内,这样您才能成功升级。
我们的政策已经改变,所以任何补丁版本都是免费的,只要你有资格获得相应的主要或次要版本。例如,我们的 2.6 版本的构建日期是 2014 年 12 月中旬。2.6 在几个月的时间里发布了 5 个补丁,但是即使你的维护过期了,只要你符合 2.6 的条件,你就有资格获得所有的补丁。
这是因为所有的补丁版本都是针对当前主/次版本的错误修复,它们永远不会包含新功能。主要版本和次要版本总是需要有效的维护日期,因为它们被视为功能更新。我们的维护使我们能够不断升级和改进我们的产品。如果您符合上一个功能发布的条件,您还可以在下一个功能发布之前预览任何预发布版本。
获得 3.0 的资格
如果您有一个现有的 2.0 许可证,并且在发布当天有一个有效的维护日期,那么您就有资格使用 3.0,除了安装和运行之外,您不需要做任何事情!如果您拥有 2.0 版许可证,但维护期已过,则需要续订许可证才能使用 3.0 版。您可以通过将您的许可证密钥输入我们的续订表来完成此操作。
如果您的许可证密钥中的维护日期为 2015 年 7 月 15 日或更早,则您有资格获得 3.0 和任何 3.0.X 修补程序。
升级您的许可证
虽然我们涵盖了许可成本,但我们不能忽略我们的升级过程是如何进行的。Octopus 有三个版本,每个版本都有自己的项目数量、部署目标(机器和触角)和用户限制。选择你的版本不应该有压力。您可以从小版本开始升级到更高版本,我们将只收取您已支付的费用与您希望升级到的版本的价格之间的差额。它还会重置您的维护期!你不认为你应该受到惩罚,章鱼应该随着你的需要而成长。要申请升级报价,您需要发送电子邮件至sales@octopusdeploy.com。
Octopus 服务器实例
许多客户不知道许可和 Octopus 服务器实例。每个付费许可证(无论版本)允许 3 个单独的 Octopus 服务器实例。如果您需要 3 个以上的实例,您将需要额外的许可证。我们确实为一家公司的多个许可证提供折扣,所以请再次向我们的销售部门发送电子邮件以获取报价!
库变量集权限更改- Octopus 部署
原文:https://octopus.com/blog/libraryvariableset-permission-changes
Octopus 中的库变量集是一个非常受欢迎和有用的特性,它们使得定义用于多个项目的变量成为可能。
它们总是被设计成全球性的,随着许多客户使用八达通的增长,这就出现了一些我们正在解决的复杂问题。
为了对库变量集中的变量进行一致且可配置的访问,我们需要对两个权限(LibraryVariableSetView和LibraryVariableSetEdit)的工作和行为方式进行突破性的改变。

TL;速度三角形定位法(dead reckoning)
- 您将能够将库变量集查看和编辑权限的范围扩大到环境和租户
- 将引入对
LibraryVariableSetView和LibraryVariableSetEdit的断路行为改变。如果您有自动配置权限,这可能会影响您,请继续阅读以了解更多信息。
背景
当引入库变量集以及权限LibraryVariableSetView和LibraryVariableSetEdit时,Octopus 的世界变得更加简单。选择将这两个权限的行为紧密耦合到第三个权限EnvironmentView。
这一决定限制了对这两种权限进行一致粒度控制的能力,许多客户要求我们在这方面进行改进。
但是更改权限一直是一个挑战。Octopus 看不到客户是如何配置权限的。我们也尽最大努力不在章鱼身上做突破性的改变。因此,我们对这种类型的变化格外谨慎。
改进可变集合访问
随着 Octopus Server 版本 2020.1.2 中这一变化的引入,您将能够对用户在库变量集中可以查看和编辑的内容授予粒度访问权限,而与他们可以查看的环境无关。这一变化为增加库变量集的功能向前迈出了一大步。
LibraryVariableSetView和LibraryVariableSetEdit与EnvironmentView的分离赋予了这些权限类似于VariableView和VariableEdit的能力(它们现在都长大了)。
在LibraryVariableSetView和LibraryVariableSetEdit上支持的作用域是Environments和Tenants。接下来,您可以将一个库变量集中的变量范围设置为部署目标,如果这些目标被租用,那么访问权限也将对租户范围为LibraryVariableSetView和LibraryVariableSetEdit的用户强制执行。环境范围将像以前视图一样工作,但是这个变化将环境范围扩展到了LibraryVariableSetEdit。
例子
LibraryVariableSetView和LibraryVariableSetEdit权限将响应类似于VariableView和VariableEdit的作用域。现在,您可以更好地控制库变量集中的变量,与用户可以看到的环境无关。
假设我们在“QA 团队”中有一个用户,他有能力看到所有当前的环境:开发、测试和生产。这是通过没有应用范围的“环境查看者”角色授予他们的。他们还被授予“项目部署者”角色,该角色包含LibraryVariableSetView这限制了他们查看任何集合中的库变量的能力,只能查看开发和测试范围内的库变量,不包括生产:

通过库变量集中的一整套变量,可以在所有环境中使用:

我们可以在应用程序的其他区域看到有权访问名为生产环境的用户,但现在看不到为其定义的变量:

影响和迁移
为了保持此类用户的当前访问级别,Octopus 需要调整用户角色并在您的设备上引入新的团队。
我们相信大多数客户不会因此受到负面影响。作为开发和测试的一部分,我们与一些拥有大型实例的客户进行了交谈。
这一变化突出了一些不希望的错误配置(见下文,看看这是否影响你)。这些客户已经针对他们权限中的缺口采取了行动,并对他们的团队设置进行了适当的更改。这种迁移不会给他们带来变化,因为他们采取了较早的访问权限调整步骤。
这对我有影响吗?
如果您配置了自定义用户角色,并且这些角色包含LibraryVariableSetView和LibraryVariableSetEdit但不包含EnvironmentView,您可能会受到影响。
这里有一些例子来说明这是否会影响到你。
受影响的示例
我们将在以下情况下迁移用户访问权限:
- 您已经定义了一个
Custom User Role,它包含LibraryVariableSetView或LibraryVariableSetEdit,您已经使用这个角色为一组用户定义了权限,并且没有其他角色授予这些用户访问权限。在这种情况下,在 Octopus Server 2020.1.2 的这一变化之前,LibraryVariableSetView并没有像预期的那样工作,因为用户缺少EnvironmentView。 - 您正在使用具有
LibraryVariableSetView或LibraryVariableSetEdit的用户角色,其作用域与用户在EnvironmentView权限上的作用域不同。在这种情况下,我们必须将他们当前在EnvironmentView上的相同范围应用到LibraryVariableSetView和LibraryVariableSetEdit。
不受影响的示例
如果满足以下条件,将不会发生权限迁移更改:
- 您已经定义了许多自定义用户角色(或者修改了的内置角色),但是在您选择了
LibraryVariableSetView或LibraryVariableSetEdit的地方,您也选择了EnvironmentView。 - 您已经定义了一个带有
LibraryVariableSetView或LibraryVariableSetEdit的自定义用户角色(或修改了一个内置角色),它缺少EnvironmentView,但是对于所有使用第一个用户角色的团队,您还选择了另一个用户角色来授予EnvironmentView,并且范围选择在两者之间匹配。
如何检查我的实例?
如果您怀疑您的用户可能配置了这样的访问权限,请使用配置➜测试权限页面来验证用户拥有LibraryVariableSetView但没有EnvironmentView。
您还可以在我们的 API repo 中运行这个 LinqPad 脚本来帮助确定所需的迁移级别。

这种迁移将如何进行?
该迁移将在 Octopus 服务器启动期间进行。如果您想查看发生了什么变化,请查看服务器日志文件。
突破性变化
这是一个突破性的变化。
如果您依赖于LibraryVariableSetView和LibraryVariableSetEdit如何工作的现有行为,它们的行为会有所不同,并且您需要修改授予这种访问权限的任何自动化。
如果您对此有疑问,请联系八达通支持。我们可以满怀信心地帮助您确定这是否会对您产生任何影响,以及在您升级到此版本之前,您可以采取哪些步骤来改进您的权限配置。
许可和支持/维护更改- Octopus 部署
我们计划对支持和升级条款进行更改,以使其更加公平。
以前,当谈到升级时,我们会说:
产品同一主要版本的所有更新(例如,从 1。x)是免费的。此外,如果在购买后的 6 个月内发布了新的主要版本(例如 2.0),您将收到该主要版本的免费更新。否则,当更新到任何新的主要版本时,您将获得 50%的折扣。我们的目标是大约每 12 个月发布一次新的主要版本。
这意味着,例如:
- 在 2.0 发布前 5 个月购买许可证的客户可以获得免费升级
- 在 2.0 发布前 7 个月购买许可证的客户可以享受 50%的折扣
- 在 2.0 发布前 13 个月购买许可证的客户可以享受 50%的折扣
这似乎是一个常见的模型,许多公司都在使用,所以我没有太多考虑。然而,它有许多我当初起草保单时没有想到的缺点:
- 这意味着一些顾客会在 12 个月内购买两次,而另一些则不会。这似乎不公平。
- 如果你想继续获得新功能,这意味着一笔不可预测的费用,在某些环境下可能很难获得批准。最好能确定续约的时间,不应该少于 12 个月。
- 这促使我们推迟发布有用的特性,直到我们提高了主要版本号(尽管我认为我们还没有做到);这很糟糕
对政策的修改
对于 2.0,我想使它成为一个更简单的策略。
- 从您收到许可证密钥的那天起,您将获得 12 个月的升级/错误修复/新功能。
- 如果您想在 12 个月后继续获得新功能,可以选择续订。否则,您可以继续使用您可以访问的上一个版本(也就是说,您拥有付费版本的永久许可,以及在 12 个月内发布的任何升级)。
这将意味着一个更可预测的更新周期,也意味着我们可以在新功能准备好的时候发布它们,而不用担心版本号对升级的影响。
更新
如果您在现有维护期结束后的 3 个月内续订,续订费用将为原价的 50%,如果您在此之后续订,则为原价的 85%。续订会将您的维护期延长 12 个月。
追溯保险单的日期
如果/当这一政策变化生效时,我们将追溯它:
- 在 7-12 个月前购买的客户也将获得免费升级到 2.0,并将继续获得升级,直到购买许可证后的 12 个月
- 超过 12 个月前购买许可证的客户在续订使用 2.0 时仍将获得 50%的折扣,但他们将继续获得我们为 1.0 发布的任何补丁。x 分支免费,因为他们会在旧模式下
这应该意味着,在旧协议下,没有人会变得更糟,也没有人会被要求在 12 个月内续约。
欢迎反馈
这个变化还没有确定下来,所以如果你有任何问题,我很乐意听到它!你可以在下面的框中留下评论,或者发邮件到paul@octopusdeploy.com给我。
RFC:生命周期- Octopus 部署
生命周期是 Octopus 中的一个新概念,它将允许我们处理许多我们一直渴望解决的与相关的建议:
- 在环境之间自动升级(触发器)
- 将一个版本标记为坏的(因此它不能再被部署)
- 在测试部署完成之前阻止生产部署(门)

生命周期和阶段
生命周期由许多阶段组成,每个阶段都指定了有关升级的触发器和规则。最简单的生命周期,即开箱即用且默认的生命周期,就是:
Phase 1: Anything Goes
- 允许手动部署到:所有环境
换句话说,这个生命周期简单地说“发布可以以任何顺序部署到任何环境中”。完全混乱了!
自定义生命周期可能会将世界分为预生产和生产阶段:
Phase 1: Pre-Production
- 自动部署到:开发
- 允许手动部署到: UAT1、UAT2、UAT3、Staging
- 提升前的最低环境: 3
Phase 2: Production
- 自动部署到:
- 允许手动部署到:生产
- 提升前的最低环境:
最后,一个更加结构化的生命周期可能是这样的:
Phase 1: Development
- 自动部署到:开发
- 允许手动部署到:
- 提升前的最低环境: 1
Phase 2: Test
- 自动部署到:
- 允许手动部署到: UAT1、UAT2、UAT3
- 提升前的最低环境: 2
Phase 3: Staging
- 自动部署到:
- 允许手动部署到:暂存
- 提升前的最低环境: 1
Phase 4: Production
- 自动部署到:
- 允许手动部署到:生产
- 提升前的最低环境: 1
请注意,测试阶段解锁了 3 个不同的测试环境,在发布进入阶段之前,用户必须部署到其中的至少两个环境中。
假设
为了简单起见,我们对这个特性做了一些假设。
首先,阶段的进展总是线性的——你从阶段 1 开始,然后到阶段 2,然后是阶段 3,等等。你不能跳过一个阶段,也没有分支。
第二,随着生命周期的深入,可以部署的环境是累积的。例如,在上面的第三个例子中,如果发布处于阶段 3 (Staging ),您可以部署到开发、UAT1/2/3 或 Staging,而不是生产。
自动升级
由于每个阶段都可以配置为部署到一个或多个环境,因此您可以使用此选项来自动在环境之间进行升级。例如,在成功部署到开发环境之后,您可能会自动升级到测试环境。
请记住,您可以将此功能与现有的手动干预步骤系统混合使用,以便在部署之前/之后和升级之前暂停审批。
自动发布创建
当您将一个生命周期分配给一个项目时,您还可以配置该项目,以便在检测到一个新的 NuGet 包时立即创建发布。

目前,我认为这将仅限于我们内置的 NuGet 存储库(不适用于外部提要中的包)。
当与上述特性相结合时,这是非常令人兴奋的——从 NuGet 包的推送中,我们可以创建和部署没有外部集成的版本。
标记一个问题
通常,我们假设如果一个版本被成功部署,它就可以被提升了。就像现在,您可以使用手动步骤来强制审查/批准,作为部署结束时的一个明确步骤。
然而,有时部署看起来很好并获得批准,只是到后来您才发现问题——可能是删除客户数据的可怕错误。如果发生这种情况,您可以标记部署的问题:

当一个问题被标记时,部署在整个生命周期中并不计入进度——如果我们标记了一个与试运行部署相关的问题,我们将不能升级到生产,即使试运行是成功的。
启用场景
我想通过推送一个 NuGet 包,从开发一直到生产,自动提升部署
- 使用“自动创建发布”选项
- 在管道的每个阶段,设置“自动部署到”环境,以便发布自动通过管道进行
除非您已经部署到暂存,否则禁止生产部署
简单地将它们放在不同的阶段,除非有成功的试运行部署,否则不要解锁生产环境。
即使试运行成功,如果我们后来发现应用程序有问题,也要阻止生产部署
在生命周期中,使用“标记一个问题”特性来防止发布进展到下一个阶段,或者将它恢复到前一个阶段。
生命周期将消耗项目组
目前,Octopus 中的项目组用于组织项目集合,限制它们可以部署到的环境,并设置保留策略。
当引入生命周期时,您将通过生命周期来控制项目可以部署到哪些环境,以及要应用的保留策略。项目组只是被留下来组织项目集合,仅此而已。
你觉得怎么样?这个特性会对你有用吗?你的生命周期会是什么样的?
PowerShell 模板的 Linux worker-Octopus 部署

Octopus Deploy 有 400 多个步骤模板,您可以在部署中使用。这些模板中有许多是用 PowerShell 编写的,随着 Linux 触手的引入,一些 step 模板已经被转换成 Bash 版本,然而,使用 PowerShell Core,将现有模板转换成 Bash 是不必要的。
在本文中,我演示了如何在带有 PowerShell Core 的 Linux Worker 上使用现有的 Octopus Deploy 步骤模板。
创建手臂模板
为此,我首先需要一台 Linux 机器。我在 Azure 中使用的是从 Runbook 升级而来的 Ubuntu Linux 虚拟机。
Azure 资源管理器(ARM)模板
使用 ARM 模板在 Azure 中创建 VM 非常简单。微软做了一件了不起的工作,让这一代 ARM 模板变得快速而简单。完成定义虚拟机配置方式的过程,并在完成后导出模板。

ARM 模板参数
您在生成 ARM 模板时所做的具体选择并不重要,因为您可以参数化一切并使用 Octopus Deploy 变量来控制它们。在上图中,像Virtual machine name、Username和OS disk type这样的项目都将是我们模板中的参数,以使它更加通用。这在创建我们的 Runbook 时更有意义。
八达通部署手册
操作手册是 Octopus 部署的最新功能之一。Runbooks 允许您利用 Octopus Deploy 的强大功能来执行操作任务,如恢复数据库或回收 IIS 应用程序池。与部署不同,runbooks 被设计为可以在任何时间任何环境中运行,并且不受生命周期的限制(除了它们只能在您的应用程序使用的环境中执行之外)。在这种情况下,我们将使用 runbooks 来加速我们的 Linux 虚拟机。
创建操作手册
在您的 Octopus Deploy 项目中有一个操作手册,位于 Operations:

点击 Runbooks ,然后点击添加 RUNBOOK :

为了加速我们的 Linux Worker VM,我们的 Runbook 将包括:
- 创建新的 Azure 资源组
- 将我们的云初始化脚本转换为 Base64 字符串(稍后将详细介绍)
- 运行 ARM 模板
- 等待虚拟机可用
- 执行健康检查
这篇文章更侧重于演示带有 PowerShell core 的 Linux,所以我们不会对 runbooks 进行过多的描述。
创建资源组
创建一个新的资源组是可选的,主要是为了整洁和方便删除在执行 ARM 模板时创建的资源。使用现有的资源组完全没问题。使用一个运行一个 Azure 脚本的步骤,你可以用一个脚本快速创建一个资源组:
$resourceGroupName = $OctopusParameters["Azure.Worker.ResourceGroup.Name"]
$resourceGroupLocation = $OctopusParameters["Azure.Location.Abbr"]
Try {
Get-AzureRmResourceGroup -Name $resourceGroupName
$createResourceGroup = $false
} Catch {
$createResourceGroup = $true
}
if ($createResourceGroup -eq $true){
New-AzureRmResourceGroup -Name $resourceGroupName -Location $resourceGroupLocation
}
将云初始化脚本转换为 Base64 字符串
ARM 模板有两种不同的方式来执行 init 脚本:
- 自定义脚本扩展:使用自定义脚本扩展,您可以为包含脚本的文件(如 Gist )提供一个 URI。这种方法的优点是对脚本文件使用源代码控制。
- CustomData 参数(本文使用该方法):CustomData 参数允许我们将脚本作为字符串包含进来,并作为参数传递。调配 Windows 虚拟机时,该值可以是一个字符串。对于 Linux,这个值必须首先经过 Base64 编码,这可以在运行脚本任务中轻松完成
对于本例,我希望我的 init 脚本执行以下操作:
- 安装 Linux 触手
- 安装 PowerShell 核心
- 配置触手并将其自身注册到我的云实例
安装 Linux 触手
脚本的这一部分将涵盖触手的安装。如果你读过我们关于 Linux 触手的其他博客文章,它应该看起来很熟悉:
serverUrl="#{Global.Base.Url}" # The url of your Octous server
thumbprint="#{Global.Server.Thumbprint}" # The thumbprint of your Octopus Server
apiKey="#{Global.Api.Key}" # An Octopus Server api key with permission to add machines
name="#{Octopus.Space.Name}-#{Octopus.Environment.Name}" # The name of the Tentacle at is will appear in the Octopus portal
publicHostName="#{Azure.Worker.DNS.Prefix}.centralus.cloudapp.azure.com" # The url to the tentacle
workerPoolName="#{Azure.Worker.Pool.Name}"
configFilePath="/etc/octopus/default/tentacle-default.config"
applicationPath="/home/Octopus/Applications/"
spaceName="#{Octopus.Space.Name}"
sudo apt install --no-install-recommends gnupg curl ca-certificates apt-transport-https && \
curl -sSfL https://apt.octopus.com/public.key | sudo apt-key add - && \
sudo sh -c "echo deb https://apt.octopus.com/ stable main > /etc/apt/sources.list.d/octopus.com.list" && \
sudo apt update && sudo apt install tentacle -y
安装 PowerShell 核心
这个位将会把 PowerShell 核心安装到 Ubuntu 上(更多信息参见微软的文档):
# Download the Microsoft repository GPG keys
wget -q https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-prod.deb
# Register the Microsoft repository GPG keys
sudo dpkg -i packages-microsoft-prod.deb
# Update the list of products
sudo apt-get update
# Enable the "universe" repositories
sudo add-apt-repository universe
# Install PowerShell
sudo apt-get install -y powershell
配置触手并将其自身注册到我的云实例
最后,我们需要脚本来配置触手,然后将它注册到我们的实例中。该脚本使用在上面的安装部分中定义的变量:
sudo /opt/octopus/tentacle/Tentacle create-instance --config "$configFilePath"
sudo /opt/octopus/tentacle/Tentacle new-certificate --if-blank
sudo /opt/octopus/tentacle/Tentacle configure --port 10933 --noListen False --reset-trust --app "$applicationPath"
sudo /opt/octopus/tentacle/Tentacle configure --trust $thumbprint
echo "Registering the Tentacle $name as a worker with server $serverUrl in $workerPoolName"
sudo /opt/octopus/tentacle/Tentacle register-worker --server "$serverUrl" --apiKey "$apiKey" --name "$name" --space "$spaceName" --publicHostName "$publicHostName" --workerpool "$workerPoolName"
# Install and start the service
sudo /opt/octopus/tentacle/Tentacle service --install --start
设置好脚本后,我们需要将它转换为 Base64 字符串,然后将其分配给一个输出变量,以便可以在 ARM 模板中使用。下面是在一个运行脚本的步骤中调用的Convert cloud init script:
# Define cloud init script
$cloudInitScript = @'
#!/bin/bash
# Install Octopus listening tentacle
serverUrl="#{Global.Base.Url}" # The URL of your Octopus server
thumbprint="#{Global.Server.Thumbprint}" # The thumbprint of your Octopus Server
apiKey="#{Global.Api.Key}" # An Octopus Server api key with permission to add machines
name="#{Octopus.Space.Name}-#{Octopus.Environment.Name}" # The name of the Tentacle at is will appear in the Octopus portal
publicHostName="#{Azure.Worker.DNS.Prefix}.centralus.cloudapp.azure.com" # The url to the tentacle
workerPoolName="#{Azure.Worker.Pool.Name}"
configFilePath="/etc/octopus/default/tentacle-default.config"
applicationPath="/home/Octopus/Applications/"
spaceName="#{Octopus.Space.Name}"
sudo apt install --no-install-recommends gnupg curl ca-certificates apt-transport-https && \
curl -sSfL https://apt.octopus.com/public.key | sudo apt-key add - && \
sudo sh -c "echo deb https://apt.octopus.com/ stable main > /etc/apt/sources.list.d/octopus.com.list" && \
sudo apt update && sudo apt install tentacle -y
sudo /opt/octopus/tentacle/Tentacle create-instance --config "$configFilePath"
sudo /opt/octopus/tentacle/Tentacle new-certificate --if-blank
sudo /opt/octopus/tentacle/Tentacle configure --port 10933 --noListen False --reset-trust --app "$applicationPath"
sudo /opt/octopus/tentacle/Tentacle configure --trust $thumbprint
echo "Registering the Tentacle $name as a worker with server $serverUrl in $workerPoolName"
sudo /opt/octopus/tentacle/Tentacle register-worker --server "$serverUrl" --apiKey "$apiKey" --name "$name" --space "$spaceName" --publicHostName "$publicHostName" --workerpool "$workerPoolName"
# Download the Microsoft repository GPG keys
wget -q https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-prod.deb
# Register the Microsoft repository GPG keys
sudo dpkg -i packages-microsoft-prod.deb
# Update the list of products
sudo apt-get update
# Enable the "universe" repositories
sudo add-apt-repository universe
# Install PowerShell
sudo apt-get install -y powershell
# Install and start the Tentacle service
sudo /opt/octopus/tentacle/Tentacle service --install --start
'@
Write-Output "Converting cloudInitScript to base64"
# Convert to Base64
$cloudInitScript = [System.Convert]::ToBase64String([system.Text.Encoding]::UTF8.GetBytes($cloudInitScript))
# Set output variable
Set-OctopusVariable -name "CloudInitScript" -value $cloudInitScript
将我们的脚本转换为 Base64 字符串后,我们可以将其传递给我们的 ARM 模板:

等待虚拟机
这一步是另一个运行脚本的步骤,它等待新创建的虚拟机响应,并让我们知道它可供使用。下面是脚本(Test-NetConnect如果目的地不可达则返回警告,这在我们等待虚拟机可用时是正常的):
# Define variables
$publicDNS = "#{Azure.Worker.DNS.Prefix}.#{Azure.Region.Name}.cloudapp.azure.com"
$connectionTest = Test-NetConnection -ComputerName $publicDNS -Port 10933 -WarningAction SilentlyContinue -InformationLevel Quiet
while ($connectionTest -eq $false)
{
# Give it five seconds
Start-Sleep -Seconds 5
# Server not quite ready
$connectionTest = Test-NetConnection -ComputerName $publicDNS -Port 10933 -WarningAction SilentlyContinue -InformationLevel Quiet
}
执行健康检查
我们运行手册的最后一步是对新创建的工人执行健康检查。健康检查内置步骤模板在这里对我们不起作用,因为它是针对部署目标而不是工作人员设计的。这个步骤是另一个运行脚本的步骤,它调用 Octopus Deploy API 来启动对一个工人的健康检查:
# Define parameters
$baseUrl = $OctopusParameters['Global.Base.Url']
$apiKey = $OctopusParameters['Global.Api.Key']
$spaceId = $OctopusParameters['Octopus.Space.Id']
$spaceName = $OctopusParameters['Octopus.Space.Name']
$environmentName = $OctopusParameters['Octopus.Environment.Name']
# Get worker pool
$workerPool = (Invoke-RestMethod -Method Get -Uri "$baseUrl/api/$spaceId/workerpools/all" -Headers @{"X-Octopus-ApiKey"="$apiKey"}) | Where-Object {$_.Name -eq "#{PoolName}"}
# Get worker
$worker = (Invoke-RestMethod -Method Get -Uri "$baseUrl/api/$spaceId/workerpools/$($workerPool.Id)/workers" -Headers @{"X-Octopus-ApiKey"="$apiKey"}).Items | Where-Object {$_.Name -eq "$spaceName-$environmentName"}
# Build payload
$jsonPayload = @{
Name = "Health"
Description = "Check $spaceName-$environmentName health"
Arguments = @{
Timeout = "00:05:00"
MachineIds = @(
$worker.Id
)
OnlyTestConnection = "false"
}
SpaceId = "$spaceId"
}
# Execute health check
Invoke-RestMethod -Method Post -Uri "$baseUrl/api/tasks" -Body ($jsonPayload | ConvertTo-Json -Depth 10) -Headers @{"X-Octopus-ApiKey"="$apiKey"}
完成后,您的操作手册应该如下所示:

在具有 PowerShell 核心的 Linux 上执行 PowerShell 步骤模板
现在有趣的部分来了!在这个例子中,我使用了 MariaDB -如果不存在就创建数据库步骤模板。顾名思义,它连接到一个 MariaDB 服务器并创建一个数据库(如果它不存在的话)。这个步骤模板不仅完全是用 PowerShell 编写的,它还使用了一个名为 SimplySql 的第三方 PowerShell 模块。在执行过程中,如果模板检测到没有安装 SimplySql,它会将它下载到一个临时文件夹中,并使用Import-Module使它包含在部署中:

当包含在部署中时,我们可以看到 Linux Worker 使用 PowerShell 核心来执行该步骤:

下面是步骤*的日志输出:
PowerShell module SimplySql is not installed, downloading temporary copy ...
Installing package 'SimplySql'
Downloaded 0.00 MB out of 6.53 MB.
[ ]
Installing package 'SimplySql'
Unzipping
[ooooooooooooooooooooooooooooooooooooooooooooooo ]
Installing package 'SimplySql'
Process Package Manifest
[oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo ]
Importing module SimplySql ...
Database d_petclinic_dbup already exists.
*日志已格式化,便于阅读。
如您所见,step 模板检测到 SimplySql 模块没有安装,下载 SimplySql 并导入它。然后,它连接到 MariaDB 服务器,发现数据库已经存在,并使用 PowerShell 完成所有工作。
结论
在 Linux 世界中采用 Octopus Deploy 的一个促成因素是可以使用的模板选择有限。有了 PowerShell Core,可以在 Linux 机器上执行的模板的选择就成指数级增加了。
通过 minikube - Octopus Deploy 使用本地映像
minikube 为 DevOps 团队提供了一个本地开发 Kubernetes 集群。在本地开发 Kubernetes 应用程序通常需要构建和部署本地 Docker 映像。虽然 minikube 将下载托管在外部 Docker 注册表上的任何 Docker 映像,但公开本地构建的映像需要将映像加载到 minikube 集群中,并注意一些抛出无用错误消息的边缘情况。
在本文中,我将向您展示如何将本地构建的 Docker 映像部署到 minikube。
构建 Docker 图像
章鱼水下样本应用程序提供了一个简单的 Docker 图像用于测试。运行以下命令来克隆 git repo:
git clone https://github.com/OctopusSamples/octopus-underwater-app.git
输入项目目录:
cd octopus-underwater-app
然后使用以下命令构建映像:
docker build . -t underwater
最后,使用以下命令运行 Docker 映像:
docker run -p 5000:80 underwater
然后在http://localhost:5000可以获得示例 web 应用程序。
将图像推送到 minikube
使用以下命令将本地映像推送到 minikube 是一个简单的过程:
minikube image load underwater
部署映像
要部署映像,请将以下 YAML 保存到名为underwater.yaml的文件中:
apiVersion: apps/v1
kind: Deployment
metadata:
name: underwater
labels:
app: web
spec:
selector:
matchLabels:
app: web
replicas: 1
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: web
spec:
containers:
- name: underwater
image: underwater
imagePullPolicy: Never
ports:
- containerPort: 80
然后使用以下命令部署应用程序:
kubectl apply -f underwater.yaml
然后,应用程序被成功部署到 minikube 集群。
需要注意的是,Docker 图像没有标签,这意味着它有默认标签latest。因此,上面 YAML 中的image属性可以替换为以下文本,因为这两个图像引用是等效的:
image: underwater:latest
使用带有latest标签的图像有特殊含义,需要将imagePullPolicy设置为Never(或IfNotPresent)。要了解原因,您需要了解默认的图像拉取策略。
使用最新图像
Kubernetes 文档提供了关于默认图像拉取策略的建议:
- 如果省略 imagePullPolicy 字段,并且容器图像的标记为:latest,imagePullPolicy 将自动设置为 Always
- 如果省略 imagePullPolicy 字段,并且不指定容器图像的标记,imagePullPolicy 将自动设置为 Always。
- 如果省略 imagePullPolicy 字段,并且为容器图像指定的标记不是:latest,则 imagePullPolicy 会自动设置为 IfNotPresent。
为了理解这一点的重要性,部署以下没有设置imagePullPolicy值的 YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: underwater
labels:
app: web
spec:
selector:
matchLabels:
app: web
replicas: 1
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: web
spec:
containers:
- name: underwater
image: underwater
ports:
- containerPort: 80
使用以下命令查看由此部署创建的单元的状态:
kubectl get pods
您会看到状态为ImagePullBackOff:
NAME READY STATUS RESTARTS AGE
underwater-847d6f9646-pvzxb 0/1 ImagePullBackOff 0 15m
这是因为您部署了一个带有latest标签的图像,并且没有指定imagePullPolicy,这意味着使用了默认值Always。这反过来意味着 minikube 试图下载图片docker.io/underwater:latest,因为没有注册的图片默认为docker.io。图像docker.io/underwater:latest不存在,因此出现ImagePullBackOff错误。
有两种方法可以解决这个问题:
- 将
imagePullPolicy设置为Never或IfNotPresent - 为图像添加标签,例如
docker build . -t underwaterapp:0.0.1和minikube image load underwater:0.0.1
结论
在 minikube 中使用本地构建的 Docker 映像是一个简单的过程,但是您需要了解有关映像拉取策略的规则,以确保 Kubernetes 不会试图从默认的 Docker 注册表中下载不存在的映像。
愉快的部署!
推出对 Octopus 服务器的长期支持- Octopus Deploy

注意:LTS 计划于 2019 年 1 月启动。了解更多关于LTS 项目如何影响你。
我们计划在 2018 年第四季度发布我们的第一个含长期支持(LTS) 的 Octopus 服务器版本。这篇文章解释了我们在 LTS 世界的八达通服务器计划,以及你将如何受益。我们还探索了这个决定的一些背景,以及我们将在幕后使用的一些机制。
我们认为许多自托管客户将希望主要使用 Octopus 服务器版本并获得长期支持,但如果您使用自托管并希望及时了解我们正在做的一切,您也可以继续享用这块蛋糕!
介绍八达通服务器 LTS 计划
我们将在三个月的周期上发布一个新版本的 Octopus 服务器,提供六个月的长期支持。这意味着在任何时间点都会有两个当前的 LTS 版本。
每一个 LTS 版本都将包含我们在这三个月中稳定下来的所有特性和错误修复。提供长期支持的 Octopus 服务器版本将:
- 获得长达六个月的关键错误修复和安全补丁。
- 没有新的特性,小的改进,或者小的错误修复——这些将会在下一个 LTS 版本中出现。
修补
在决定补丁包含或排除的内容时,我们将使用以下经验法则:
安装补丁应该比不安装补丁更安全。
当你决定是否在你的八达通服务器上安装补丁时,你应该使用同样的经验法则。
公告
我们将在一篇带有LTS标签的博客文章中宣布 Octopus Server 的每个新 LTS 版本,明确说明哪些版本仍在长期支持范围内,哪些版本的长期支持已经过期。
Octopus Server 的每个版本都会在下载页面和产品本身内部清楚地表明它是否是 LTS 版本。
选择的权力
我们意识到不是每个顾客都是一样的。我们想让任何人都能轻松回答这个问题:安装 Octopus 服务器的最佳版本是什么?
我们想给你选择的权力,以及简单的指导来帮助你做出明智的选择。
介绍快速车道和慢速车道
在幕后,我们计划继续以过去几年的方式工作:发布错误修复和小的改进,快速周转,并与我们的客户密切合作,设计和测试新功能。我们添加的是一个特殊的发布节奏,该版本基于当时最稳定的版本,具有一些额外的质量保证,并提供六个月的长期支持。
在内部,我们认为这是两条“释放通道”:
- 这条快车道正是我们今天所做的。我们通常每 4-6 周发布一次新特性,每隔几天发布一次错误修复和小的增强补丁。
- 慢车道是我们将稳定和发布长期支持版本的地方,以及任何包含关键错误修复和安全补丁的补丁,最长六个月。
章鱼云在快车道上
章鱼云客户将使用快车道上发布的产品:我们为您做出选择。一旦它们准备好,你将获得最新的和最好的特性,以及最快的错误修复和小的增强。
自主:选择的力量
自主接待的客户可以自己决定。我们建议选择一条车道并坚持下去,但你可以在适合你的情况时换车道。
如果这听起来像您的场景,请选择长期支持的慢车道版本:
- “比起拥有最新的功能,我们更喜欢稳定性。”
- “我们大约每三个月升级一次 Octopus。”
- “在升级我们的生产设备之前,我们在测试环境中评估 Octopus。”
如果这听起来像你的场景,你应该选择快车道发布:
- "我们希望最新和最大的功能和小的改进和错误修复真正快速周转."
- “我们希望与 Octopus 团队紧密合作,这样我们就可以帮助他们构建世界上最好的自动化工具!”
问与答(Question and Answer)
我已经介绍了我们长期支持计划的广泛细节,我将在这里回答一些常见问题。如果你有任何问题,请在评论中提问!
你如何选择在 LTS 补丁中包含什么?
我们将使用这个经验法则:安装一个补丁应该比不安装那个补丁更安全。我们将在 LTS 补丁中包含某些内容,例如:
- 我们发现了一个安全漏洞,这将导致我们提出 CVE 报告。
- 我们发现了一个无法解决的问题。
- 我们发现了一个仅在当前 LTS 版本中存在的问题。
- 我们发现了一些对修补有商业意义的东西。
我们不会:
- 船舶数百 LTS 补丁-我们希望稳定和高信噪比。
- 在 LTS 补丁中提供新功能。
- LTS 板块的拆船变化。
我们能在慢车道和快车道之间移动吗?
是的,你可以有控制地变换车道。“加速”到一个快车道发布会导致你运行一个更高版本的 Octopus 服务器——这只是一个正常的升级。如果您想“减速”回到长期支持的慢车道版本,只需等到下一个 LTS 版本发布并升级到该版本。
你会保持每月发布快车道的节奏吗?
我们目前大约每月发布一次版本。我们认为可预测的节奏对于使用长期支持的慢车道版本的客户来说更重要——这将有助于他们计划升级。
- 在慢车道中,我们的目标是严格按照三个月的节奏发布 LTS 版本。
- 在快车道中,我们的目标是每月发布一次新版本,但是,有时我们可能会决定更早发布一个快车道版本,或者在发布之前花一些额外的时间来强化一个快车道版本。
如果您喜欢更可预测的节奏,请选择具有长期支持的慢车道版本。
你会改变你的版本策略吗?
不完全是。我们将为 Octopus 服务器的每个版本选择下一个版本号,就像我们今天做的一样,但有一些额外的上下文:
- 我们将把
LTS添加到长期支持版本的某个部分。
包扎
我们正在引入对八达通的长期支持(LTS ),你可以放心。
如果你有任何担心或问题,请在下面的评论中联系我们!
维护您自己版本的 Azure CLI - Octopus Deploy
原文:https://octopus.com/blog/maintaining-own-version-azure-cli
Octopus Deploy 之前支持 Azure 命令行界面(CLI)作为其定制工人工具的一部分。然而,从 Octopus 2021.1 开始,Octopus 不再保持当前的 Azure CLI 版本。如果您的部署使用预捆绑版本,您将收到一条警告,建议您维护您的工作映像。
提供了与 Octopus Deploy 捆绑在一起的 Azure 工具,以方便需要针对 Azure 目标运行脚本的用户。Octopus 捆绑了 Azure 资源管理器 PowerShell 模块(AzureRM)和 Azure CLI 的版本。从 Octopus 2021.1 开始,我们建议使用运行部署所需的版本来维护您自己的 Worker 容器。通过这种方式,提供的工具与部署指定的需求相匹配。
在这篇文章中,我将向您展示如何使用最新的 Azure CLI 版本创建自定义 Docker 映像,如何在 Docker Hub 上托管它,以及如何在 Octopus 部署中使用它。
安装和推送自定义容器
首先,创建一个 Dockerfile 文件,指定操作系统和 Azure CLI 安装命令。将安装最新版本的 CLI(2 . 28 . 0)。
FROM ubuntu:18.04
ARG DEBIAN_FRONTEND=noninteractive
ARG Azure_Cli_Version=2.28.0\*
# Install wget, apt-utils, and software-properties-common
RUN apt-get update && \
apt-get install -y wget apt-utils && \
apt-get install -y software-properties-common
# Install the Azure CLI
RUN wget --quiet -O - https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor | tee /etc/apt/trusted.gpg.d/microsoft.asc.gpg > /dev/null && \
echo "deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ bionic main" | tee /etc/apt/sources.list.d/azure-cli.list && \
apt-get update && \
apt-get install -y azure-cli=${Azure_Cli_Version}
# Tidy up
RUN apt-get clean
如果需要,该文档可以包括其他形式的工具。
我们建议每个人维护他们的工具版本,以获得一致的部署结果。
运行 Docker buildx 命令来构建映像并将其推送到 Docker Hub。(请注意,这些说明是针对 M1 Mac 电脑的。)
使用多个平台确保 Octopus Deploy 将下载适当的版本。
docker buildx build --platform linux/amd64,linux/arm64,linux/arm/v7 -t terenceocto/azcli:latest --push .
成功后,Docker 将在 Docker Hub 上托管映像。

确认成功
通过指定自定义容器,可以使用内置的 Azure CLI 来显示和确认 CLI 的版本号。

使用定制容器指令,在 Octopus UI 中指定新的定制图像,并再次打印出版本。Azure CLI 现在是最新版本。

结论
从 Octopus 2021.1 开始,Azure CLI 和其他工具不再是最新的。您应该为您的映像提供支持您的部署的工具。
在本文中,您学习了如何使用最新的 Azure CLI 设置 Docker 映像,并在 Octopus 部署中使用它。
愉快的部署!
使用实例调度程序管理 AWS 成本- Octopus Deploy
原文:https://octopus.com/blog/managing-aws-costs-instance-scheduler
云计算的承诺是允许团队有效地按需扩展和缩减。虽然内部基础架构可以通过关闭来节省电力和冷却成本,但基于云的资源可以通过停止任何未使用的资源来避免几乎所有费用(存储费用通常适用于停止的资源)。
AWS 提供了实例调度器来按需关闭和重启 EC2 和 RDS 资源。对于拥有 Octopus 资源的团队来说,这是一个很好的解决方案,比如在 AWS 中运行的 Workers,他们在一天中的大部分时间都没有被使用。
在这篇文章中,您将学习如何安装实例调度器,如何用自定义周期配置它,以及如何标记自动关闭和重启的资源。
先决条件
这篇文章假设您将在 Linux Worker 上运行脚本。你需要安装 Python 3、jq、curl和unzip来完成本文中的步骤。要在 Ubuntu 中安装这些工具,请运行以下命令:
apt-get install jq curl unzip python3
要在 Fedora、RHEL、Centos 和 Amazon Linux 中安装这些工具,请运行以下命令:
yum install jq curl unzip python3
实例调度器由一个名为 Scheduler CLI 的定制 Python 应用程序管理。
CLI 需要 Python 3。如果您安装了 Python 2 和 Python 3,您可以使用以下命令强制使用 Python 3:
alias python=python3
运行以下命令安装 CLI:
curl -O https://s3.amazonaws.com/solutions-reference/aws-instance-scheduler/latest/scheduler-cli.zip
unzip scheduler-cli.zip
python setup.py install
一个公共的 Octopus 实例已经配置了一个项目,该项目部署了实例调度器。
部署实例调度程序模板
实例调度器作为下载的 CloudFormation 模板分发。您将使用 Octopus 中的部署 AWS CloudFormation 模板步骤来部署它。
如果您在尝试保存模板时看到错误Template could not be parsed: An item with the same key has already been added. Key: 14,这是因为其中一个参数复制了AllowedValues数组中的一个选项。在下面的截图中,你可以看到LogRetentionDays参数有重复的值14。要解决该错误,请删除重复的值:

您可以保留这些参数的默认值,尽管您可能希望定义DefaultTimezone参数来反映您的本地时区。
我们为这个步骤创建了一个实例。
添加新周期
实例调度器通过在 DynamoDB 数据库中定义多个周期来工作。Scheduler CLI 提供了一个方便的界面,通过该界面可以查看和操作这些时间段。
下面的脚本调用scheduler-cli describe-periods列出当前定义的时间段,然后将结果 JSON 通过管道传递给jq,后者检查是否存在一个名为aus_weekday的时间段。如果不存在,则通过调用scheduler-cli create-period添加句点。如果确实存在,则通过调用scheduler-cli update-period更新周期。
这个脚本是创建幂等部署所必需的,在幂等部署中,可以在任何时候重新部署部署,而不管数据库的现有状态如何。
该脚本与 Octopus 中的运行 AWS CLI 脚本步骤一起运行。你可以在我们的实例中看到这一点:
alias python=python3
scheduler-cli describe-periods --stack common-instance-scheduler | jq -e '.Periods|any(.Name == "aus_weekday")' > /dev/null
if [[ 0 -ne $? ]]; then
scheduler-cli create-period --name "aus_weekday" --begintime 05:00 --endtime 17:00 --weekdays mon-fri --stack common-instance-scheduler
else
scheduler-cli update-period --name "aus_weekday" --begintime 05:00 --endtime 17:00 --weekdays mon-fri --stack common-instance-scheduler
fi
标记资源
实例调度器根据标记识别要关闭和重启的资源。实例调度程序寻找的默认标记名为Schedule(尽管可以通过更改 CloudFormation 模板中的TagName参数来修改标记名)。标签的值被设置为一个句点的名称。
在下面的截图中,您可以看到一个 worker EC2 实例有一个名为Schedule的标记设置为aus_weekday。这意味着这个 EC2 实例将在每个工作日的 17:00 关闭,并在 05:00 重新启动。这使得 EC2 实例的运行成本降低了一半以上,因为它现在会在夜间和周末关闭:

结论
AWS 实例调度程序是一个方便的解决方案,允许您自动关闭和重启 EC2 和 RDS 实例,这可以显著降低并非全天 24 小时都需要的资源的运行成本。
在本文中,您了解了如何使用 Octopus 部署实例调度程序,使用调度程序 CLI 添加新的周期,以及标记您的资源以允许调度程序在夜间和周末关闭它们。
阅读我们的 Runbooks 系列的其余部分。
愉快的部署!
识别 AWS 影子 IT 资源- Octopus 部署
术语“影子 IT”通常指由开发运维团队成员部署的临时 IT 资源,用于解决紧急需求,但缺乏支持长期基础架构的持续维护和管理。
在 AWS 中,影子 IT 采用虚拟机、S3 存储桶、虚拟专用云以及任何其他类型的动态创建的资源的形式,通常通过 web 控制台实现。
在这篇文章中,我解释了一些与 shadow IT 相关的问题,以及如何识别 AWS 帐户中的非托管资源。
影子 IT 的问题
假设您是 DevOps 团队的一名新成员,负责解决一个名为“Web 服务器”的 AWS 虚拟机故障。谁创建了这个虚拟机?它托管哪些应用程序?备份位于何处?如何重新创建虚拟机?
这些信息都无法从 VM 资源本身获得,特别是当它失败到无法再登录时。由于无法获得这些信息,几乎不可能提供支持。
任何未能围绕创建新的云资源实现标准实践的成长中的团队,很可能会在几年后发现自己不知道任何给定资源做了什么。这带来了安全挑战,因为不清楚谁负责像操作系统补丁这样的任务,或者当最初应用许可的“允许所有”规则集时,什么网络规则是合适的。这也使得很难知道资源的当前状态是否正确,或者是否有人意外地进行了不期望的更改。
在 AWS 中,描述资源属性(如谁拥有它以及它的用途)的第一步是应用一组标准化的标签。下一步是确保所有资源都是用声明性模板创建的,如 CloudFormation,它允许在需要时重新创建资源,还允许检测不需要的手动更改,即漂移。
为了识别不兼容的资源,您将创建两个简单的 runbooks 来扫描您的 AWS 帐户中没有预期标记的资源。
识别未标记的资源
下面的 Bash 脚本扫描整个 AWS 帐户,查找缺少任何所需标记的资源。在这个例子中,标签Team、Deployment Project和Environment指的是拥有资源的团队、部署它的 CI 或 Octopus 项目,以及资源所属的环境(比如开发或生产):
REQUIREDTAGS=("Team" "Deployment Project" "Environment")
OUTPUT=$(aws resourcegroupstaggingapi get-resources --tags-per-page 100)
for ((i = 0; i < ${#REQUIREDTAGS[@]}; i++)); do
COUNT=$(echo ${OUTPUT} | jq -r "[.ResourceTagMappingList[] | select(contains({Tags: [{Key: \"${REQUIREDTAGS[$i]}\"} ]}) | not)] | length")
echo "==========================================================="
echo "The following ${COUNT} resources lack the ${REQUIREDTAGS[$i]} tag."
echo "==========================================================="
echo ${OUTPUT} | jq -r ".ResourceTagMappingList[] | select(contains({Tags: [{Key: \"${REQUIREDTAGS[$i]}\"} ]}) | not) | .ResourceARN"
done
识别非托管资源
查找不是由 CloudFormation 模板创建的资源(即非托管资源)与上面的脚本非常相似。
几乎所有的 AWS 资源都支持标签,当这些资源由 CloudFormation 模板创建时,会自动应用aws:cloudformation:stack-id标签。这意味着识别非托管资源就像找到任何缺少aws:cloudformation:stack-id标签的资源一样简单。
下面的 Bash 脚本扫描所有资源,除了缺少aws:cloudformation:stack-id标签的 CloudFormation 栈:
OUTPUT=$(aws resourcegroupstaggingapi get-resources --tags-per-page 100)
COUNT=$(echo $OUTPUT | jq -r '[.ResourceTagMappingList[] | select(contains({Tags: [{Key: "aws:cloudformation:stack-id"} ]}) | not) | select(.ResourceARN | test("arn:aws:cloudformation:[a-z]+-[a-z]+-[0-9]+:[0-9]+:stack/.*") | not)] | length')
echo "==========================================================="
echo "The following ${COUNT} resources were not created by CloudFormation"
echo "==========================================================="
echo $OUTPUT | jq -r '.ResourceTagMappingList[] | select(contains({Tags: [{Key: "aws:cloudformation:stack-id"} ]}) | not) | select(.ResourceARN | test("arn:aws:cloudformation:[a-z]+-[a-z]+-[0-9]+:[0-9]+:stack/.*") | not) | .ResourceARN'
解决不符合的资源
在缺少标记的资源上定义标记通常是通过 web 控制台或 CLI 手动添加标记。下面的脚本显示了向资源批量添加公共标记的示例:
aws resourcegroupstaggingapi tag-resources --resource-arn-list \
arn:aws:lambda:us-west-1:133577413914:function:Production-audits-0-SQS \
arn:aws:lambda:us-west-1:133577413914:function:Production-product-0-InitDB \
arn:aws:lambda:us-west-1:133577413914:function:Production-GithubActionWorkflowBuilderGithubOAuthCodeProxy \
arn:aws:lambda:us-west-1:133577413914:function:Production-audits-0-Web \
arn:aws:lambda:us-west-1:133577413914:function:Production-audits-0-InitDB \
--tags Environment=Development \
--region us-west-1
在 AWS 文档中描述了将非托管资源导入 CloudFormation 堆栈的过程。
结论
确定 AWS 客户中的影子 IT 资源是建立可由开发运维团队有效管理的基础架构的第一步。然后,通过建立一致的标记方案,您能够记录谁负责什么、资源的用途以及哪些外部过程创建了它们。
在这篇文章中,您看到了许多用于查找不兼容资源的脚本,以及关于如何添加缺失标签或将资源导入 CloudFormation 堆栈的提示。随着基础架构的规模和复杂性的增长,这些简单的步骤可以带来巨大的变化。
阅读我们的 Runbooks 系列的其余部分。
愉快的部署!
在 Jenkins - Octopus 部署中管理凭据
像八达通一样,詹金斯只是你管道中的一步,补充其他系统和服务。
您可以将 Jenkins 连接到大多数行业工具,安全地存储他们的凭证、秘密和 API 密钥。通过存储这些登录方法,Jenkins 可以在自动化过程中无缝连接到其他服务。
Jenkins 的文档推荐使用凭证绑定插件。这是 Jenkins 安装过程中安装者推荐的插件之一,所以可能你已经安装了它(并使用了它)而没有意识到。
在这篇文章中,我将带你了解如何安装这个插件以及它的不同用法。
如何安装凭证绑定插件
如果您没有安装凭证绑定插件,很容易添加:
- 从菜单中点击管理詹金斯。
- 点击管理插件。
- 点击可用的选项卡,开始在过滤器字段中输入
Credentials Binding。插件应该出现在预测的搜索结果中。 - 勾选插件左侧的复选框,然后点击安装而不重启。
Jenkins 安装插件和所有依赖项,包括其他插件和扩展。

凭证绑定插件以两种不同的方式存储您的身份验证方法:
我们来看看区别。
全局凭据
全局凭据是手动输入的登录方法,存储在 Jenkins 中。任何具有访问权限的人都可以使用凭据连接到其他服务。这些可以包括:
- 代码回购,如 GitHub 或 BitBucket
- 打包服务,比如 Docker 注册表或 TeamCity feed
- 部署工具,如 Octopus
如何在 Jenkins 中添加凭证
要在 Jenkins 中添加凭据:
- 从菜单中点击管理詹金斯。
- 向下滚动到安全标题,点击管理凭证。
- 点击詹金斯标题下商店范围内的詹金斯。
- 点击系统标题下的全球凭证(无限制)。
- 如果没有凭证,可以点击添加一些凭证怎么样?链接,否则点击左边的添加凭证。
- 从种类字段的下拉框中选择您想要存储的凭证类型,填写字段并点击确定。您可以添加以下类型的凭据:
- 用户名和密码
- SSH 用户名和私钥
- 秘密文件
- 秘密文本
- 证书
无论您选择哪个选项,都要输入有意义的 ID 和描述。
在 Jenkins 中使用全局凭据
添加凭证后,可以调用它们连接到管道中的其他工具,无论是通过 UI、插件还是 Jenkinsfile。
可以选择全局凭据的一个很好的例子是在创建管道时:
- 点击左侧菜单中的新项目。
- 输入项目名称,选择自由式项目,点击确定。
- 检查源代码管理标题下的 Git 单选按钮。将您的回购地址粘贴到存储库 URL 字段,并从凭证下拉框中选择您的凭证。
- 设置好你的物品后点击保存。

Jenkinsfiles 是代码库中的文本文件,它定义了管道做什么以及它连接到什么。Jenkinsfiles 是 Jenkins Pipeline 的一部分——Jenkins 推荐的用于持续集成和持续交付(CI/CD)的插件的集合。
这意味着您可以通过 Jenkinsfile 从存储在 Jenkins 中的凭据连接到服务。
如果您使用的是 Blue Ocean 插件,它会在您建立管道时为您创建一个 Jenkinsfile,那么您可能根本不需要使用 Jenkins file。
更多信息请参见 Jenkins 网站上的使用 Jenkinsfile 页面。
Jenkins 中的用户绑定凭据
根据您将 Jenkins 连接到的设备或您使用的插件,Jenkins 将一些凭证与登录的用户联系起来。Jenkins 只在您第一次将它与另一个服务连接时存储这些凭据。您不能在初始设置之外使用这些凭据,其他用户帐户也不能访问它们。
例如,当在蓝海(一个简化 Jenkins 用户界面的插件)中创建你的第一个管道时,Jenkins 连接到你的代码库。如果连接到 GitHub,您使用 GitHub 个人访问令牌(在您的 GitHub 帐户的开发者设置中创建)来允许 Jenkins 连接到 repo。Jenkins 只将登录用户的令牌存储在他们自己的凭据“域”中。
在 Jenkins 中,您可以在不同于全局凭证的位置找到这些凭证,尽管它们的屏幕工作方式类似。
要查看您的用户绑定凭证,请单击顶部菜单中您用户名旁边的箭头,然后单击凭证。
顶部显示您有权访问的所有凭据,包括用户和全局。向下滚动时,您会看到所有凭据存储的标题。在我的例子中,范围为用户:Andy 的商店是只有我可以使用的凭证。

下一步是什么?
更多信息参见 Jenkins 的证书文档。
查看我们关于配置 Jenkins 的其他帖子:
试试我们免费的 Jenkins 管道生成器工具用 Groovy 语法创建一个管道文件。这是您启动管道项目所需的一切。
观看我们的詹金斯管道网络研讨会
https://www.youtube.com/embed/D_7AHTML_xw
VIDEO
我们定期举办网络研讨会。请参见网络研讨会第页,了解有关即将举办的活动和实时流录制的详细信息。
阅读我们的持续集成系列的其余部分。
愉快的部署!
手动部署- RFC - Octopus 部署
随着保留策略的取消,我在 Octopus 中开发的下一个大特性是手动部署。
虽然完全自动化的部署是一个伟大的目标,但不是部署中的每个步骤都可以自动化,有时需要人工参与。生产部署可能需要:
- 部署前获得签署/批准
- 在启用新部署的网站之前,人工检查其主页是否正常工作
- 在不允许自动执行这些步骤的环境中执行数据库升级或更新某些基础架构(例如,您必须将数据库更改提交给 DBA 进行手动审查和运行)
- 部署完成后获得签署/批准
到目前为止,在 Octopus 中,我们支持的部署中唯一的“步骤”是 NuGet 包部署。我们现在引入一种新的步骤,即“手动步骤”,可以用来处理这些情况。

当您创建一个手动步骤时,您将输入一些指示,这些指示将呈现给用户以供遵循。您还将选择用户必须属于的群组。例如,如果您需要经理的批准,请创建一个拥有适当用户的“经理”组,然后选择该组。

在部署过程中,当遇到手动步骤时,部署将进入“暂停”状态。如果审批组的某人正在查看该页面,他们将看到一个屏幕,其中包含继续或取消部署的选项:

他们还可以输入将与部署一起存储的注释。例如,如果没有得到批准,经理可能会使用注释来解释原因。
一旦组中有人“继续”部署,部署任务将重新排队并运行。

该特性支持的另一个场景是预上传包的想法,因为包将在遇到第一个手动步骤之前被上传到 Tentacles。
我很想得到您对这个功能和您在上面看到的内容的反馈,以及您是否认为还有其他选项/功能缺失。我看到的一个建议是,当遇到手动步骤时,向批准组发送电子邮件,我认为这是一个好建议(尽管它可能使用不同的“发送电子邮件”步骤来实现)。关于这个特性,你还想改变什么?
手动将构建信息推送到 Octopus - Octopus 部署
原文:https://octopus.com/blog/manually-push-build-information-to-octopus

Octopus Deploy 集成了流行的构建服务器,如 Azure DevOps、Jenkins 和 TeamCity,可用的插件使打包工件和将这些工件推送到 Octopus、创建发布和启动部署变得容易。您还可以在构建中包含发行说明和提交信息,称为build information。
不幸的是,并不是每种类型的构建技术都有插件,但是因为 Octopus 是 API 优先构建的,所以我们可以使用 API 以编程方式提交构建信息。
开源代码库
让我们以 GitHub 为例,当没有构建服务器时,使用 API 提交构建信息。我的 xCertificatePermission 回购有一个版本为 1.0.0 的发行版。因为没有构建服务器参与创建这个版本,所以没有插件可以让我将构建信息从 GitHub 推送到 Octopus Deploy。
使用 API
如前所述,Octopus Deploy 是 API 优先编写的,所以我可以使用/api/build-information API 将构建信息推入 Octopus Deploy。在系统变量文档页面上,有一个专门用于构建信息的部分,它显示了 API 调用可以包含的基本信息。此外,Swagger 文档显示了返回的 JSON,它为我们提供了关于有效载荷应该是什么样子的更多信息:
{
"Id": "string",
"PackageId": "string",
"Version": "string",
"BuildEnvironment": "string",
"BuildNumber": "string",
"BuildUrl": "string",
"Branch": "string",
"VcsType": "string",
"VcsRoot": "string",
"VcsCommitNumber": "string",
"VcsCommitUrl": "string",
"IssueTrackerName": "string",
"WorkItems": [
{
"Id": "string",
"LinkUrl": "string",
"Source": "string",
"Description": "string"
}
],
"Commits": [
{
"Id": "string",
"LinkUrl": "string",
"Comment": "string"
}
],
"IncompleteDataWarning": "string",
"Created": "2020-02-20T05:28:07.028Z",
"LastModifiedOn": "2020-02-20T05:28:07.028Z",
"LastModifiedBy": "string",
"Links": {
"additionalProp1": "string",
"additionalProp2": "string",
"additionalProp3": "string"
}
}
不幸的是,这两个资源都没有描绘出如何为 API 调用设置有效负载的全貌。
JSON 示例
示例中缺少的是封装了有效负载的一些其他属性的OctopusBuildInformation散列表。对于我的xCertificatePermission示例,下面是有效载荷的样子:
$jsonBody = @{
PackageId = "twerthi/xCertificatePermission"
Version = "1.0.0"
OctopusBuildInformation =
@{
BuildEnvironment = "Jenkins"
VcsCommitNumber = "2350881a389517288b31432d469c5c4199a1fba9"
VcsType = "Git"
VcsRoot = "https://github.com/twerthi/xCertificatePermission.git"
}
} | ConvertTo-Json -Depth 10
如您所见,BuildEnvironment、VcsCommitNumber、VcsType 和 VcsRoot 元素实际上嵌入在 OctopusBuildInformation 中。使用格式良好的 JSON,我们可以调用 API:
$OctopusServerUrl = "https://YourServerUrl"
$ApiKey = "API-XXXXXXXXXXXXXXXXXXXXXXXXXX"
$Headers = @{"X-Octopus-ApiKey"="$ApiKey"}
Invoke-RestMethod -Method Post -Uri "$OctopusServerUrl/api/build-information" -Headers $Headers -Body $jsonBody
随着构建信息被推送到 Octopus Deploy,它现在与提交散列一起出现在发布中。
【T2 
解决纷争
插件确切地知道需要传递什么才能让一切正常工作。这有时会掩盖自己尝试编写时遇到的问题。下面是客户在尝试构建构建信息时遇到的一些常见问题。
提交未显示的链接
如果您的提交链接不显示或不起作用,请确保您已经将 VcsType 设置为Git或TFSVC。如果它是未知的,Octous Deploy 将不知道如何正确设置它。
工作项目不工作
Octopus Deploy 通过使用已配置的问题跟踪器集成,动态地确定哪些工作项与构建和/或提交相关联。上面的 Swagger 引用显示了 POST 返回中的工作项数组,然而,工作项数组是 POST 有效负载的而不是部分。即使它是作为有效载荷的一部分提供的,Octopus 也会忽略它。
结论
在这篇文章中,我向您展示了如何使用 API 向 Octopus Deploy 提交构建信息。
使用 Octopus Deploy 映射手动部署- Octopus Deploy
虽然 Octopus Deploy 使复杂的部署自动化变得简单,但您可能仍在运行手动部署。我们与拥有遗留应用程序的客户交谈过,这些遗留应用程序在发布过程中需要特殊的步骤,或者拥有深奥的技术,使得很难确定从哪里开始自动化之旅。
在这篇文章中,我解释了如何使用手动干预步骤对您的手动部署进行建模,以及这给您的发布过程带来的好处。
如果您是 Octopus 的新手,您可能会发现这是从您当前的部署过程向完全自动化推进的一种实用方法。现有客户可能会发现这种技术带来了他们已经从自动部署到手动发布中获得的熟悉的好处。
使用 Octopus 进行手动部署的优势
使用 Octopus 进行手动部署有很多好处。这些超出了您从任务管理应用程序中可能获得的好处。您可以:
- 使用生命周期来跟踪跨多个环境的部署
- 提供完成每个步骤的说明
- 确保授权团队成员完成每个步骤
- 提高部署的可靠性和可追溯性
- 用更少的努力满足审计要求
为了进一步的好处,您还可以自动执行手动部署中的一些步骤。
为您的手动部署建模
您需要完成 4 个步骤来模拟您的手动部署:
- 创建清单
- 为您的团队建模
- 定义生命周期
- 将您的清单转变为部署流程
第一步是帮助设计您稍后将使用的流程的书面练习。其他步骤在 Octopus 中完成,以便根据您在设计阶段发现的步骤对您的部署进行建模。
创建清单
当您有一个手动发布过程时,现有的文档或清单通常描述了安装软件的步骤。您当前的文档可能还会详细说明谁可以执行每个操作。在用 Octopus 重新创建之前,有必要花一些时间来细化这些阶段,以确定谁做什么,以什么顺序做。
如果你的文档很长,试着用提供自然任务列表的标题来分割它。
您最终应该会看到类似于以下清单的内容:
| 步骤 | 标题 | 谁 |
|---|---|---|
| 一 | 备份数据库 | 工商管理学博士(Doctor of Business Administration) |
| 2 | 升级数据库 | 工商管理学博士(Doctor of Business Administration) |
| 3 | 将新应用程序复制到服务器上的临时文件夹中 | 工作 |
| 四 | 删除临时文件夹中的配置文件 | 工作 |
| 5 | 将实时配置文件复制到临时文件夹中 | 工作 |
| 6 | 将任何新设置添加到配置文件中 | 工作 |
| 七 | 将临时文件夹复制到活动文件夹中 | 工作 |
| 8 | 按照预期检查应用程序负载 | 试验 |
如果您没有现成的核对表,您可能会发现创建和使用核对表可以确保所有步骤都按正确的顺序进行,从而提高部署的可靠性。
现在,您可以将它转移到 Octopus 中,以获得工作流管理和跟踪的好处。
为您的团队建模
示例清单包括负责部署的列中的 3 个团队:DBA、Ops 和 Test。当您在 Octopus 中创建流程时,您可以将每个步骤分配给一个负责团队。**
按照以下步骤在 Octopus 中创建每个团队:
- 导航至配置然后团队并选择添加团队。
- 输入新团队名称,例如
DBA Team,选择保存。 - 打开用户角色选项卡,选择包含用户角色。
- 从列表中选择项目部署者,选择定义范围。
- 在选择项目组下选择默认项目组,点击应用,最后保存。
项目部署者角色授予用户所有项目贡献者权限,此外还有:部署版本和执行操作手册。
您可以通过选择添加成员选项来添加团队成员。
定义生命周期
生命周期让你控制你的软件版本在你的环境之间升级的方式。对于手动部署,您可以使用生命周期来控制升级的顺序,例如,如果某个版本的软件没有首先部署到测试环境中,就可以防止它被部署到生产环境中。
您需要首先定义环境,然后使用生命周期来设置发布在环境中流动的顺序。
您可以通过以下步骤添加环境:
- 导航至基础设施然后环境并选择添加环境。
- 输入一个新环境名,例如
Test,点击保存。
您通常将部署目标添加到新环境中,但是您可以跳过这一步,直到您需要执行某种形式的自动化。
添加环境后,您可以创建一个生命周期,并将环境添加为阶段:
- 导航到库然后生命周期并选择添加生命周期。
- 输入生命周期的名称,例如
Manual Deployment Lifecycle。 - 在阶段下,选择添加阶段添加每个环境。
- 添加完阶段后,选择保存。
您的完整生命周期应该包含每个环境的一个阶段,如下所示。

将您的清单转变为部署流程
现在您的团队、环境和生命周期已经配置好了,您可以使用它们来定义您的手动部署过程。该流程存储在 Octopus Deploy 中的一个项目中,因此下一步是创建一个新项目。为此,请按照下列步骤操作:
- 导航到项目并选择添加项目。
- 添加一个新项目名称,如
Manual Deployment。 - 选择要添加新项目的项目组,例如“默认项目组”。
- 选择生命周期,例如您之前创建的“手动部署生命周期”,点击保存。
您现在可以看到您的项目列在默认项目组下。您还可以在仪表板上看到该项目。

您现在已经准备好添加步骤的所有资源,所以导航到项目,然后手动部署,然后流程开始。
您可以为每个清单项目添加一个步骤,以创建一个驱动您的手动部署的流程。对列表中的每项任务重复以下过程。
- 点击添加步骤,使用搜索词
Manual Intervention过滤步骤模板。 - 在需要手动干预的步骤上点击添加,并将你的检查表中的标题输入步骤名称,例如
Backup the database。 - 如果你有这个步骤的文档,你可以把它添加到指令字段,它使用 markdown 格式。
- 使用责任团队下的列表选择正确的团队,例如“DBA 团队”并点击保存完成步骤配置。
您可能希望调整阻止部署的默认选项,以防止同时发布。在阻止部署设置下,选择防止其他部署等待干预。
在您添加您的步骤之后,导航到项目、手工部署,然后流程并查看流程概述,它应该看起来像这个例子。

使用流程跟踪发布
虽然您没有要部署的包,但是您仍然可以使用 Octopus 中的一个发行版来跟踪部署。
- 导航到项目,然后手动部署,然后流程并选择创建发布。
- 输入一个版本,您可以输入您正在部署的应用的版本或内部版本号,然后点击保存。
现在,您可以跟踪每个环境的手动部署。如果按照您之前配置的生命周期的控制,发布首先被部署到测试环境中,那么发布只能进行到活动环境中。
- 从新版本的发布屏幕中,选择部署以测试。
- 将出现确认屏幕,查看信息并选择部署。
为发布创建了部署,并且第一个手动干预步骤备份数据库,已经准备好由 DBA 团队的成员来执行。发布有一个手动干预图标,向您显示它正在等待一个团队成员来拾取它。
 【
【只有 DBA 团队的成员可以给自己分配备份数据库任务。他们通过点击仪表板上的发布并选择分配给我来完成此操作。
手动部署的每个步骤的流程是:
- 在步骤上选择分配给我。
- 使用任务摘要中的步骤说明来完成该步骤。
- 在注释字段中输入任何注释、日志或手动步骤的输出。
- 选择继续完成该步骤。
团队成员完成一个步骤后,下一个步骤就可供相关团队成员使用。
任务日志记录了步骤完成的日期和时间、完成者以及他们输入的任何注释。
| == Success: Step 1: Backup the database ==
15:13:26 Verbose | Backup the database completed
13:21:28 Verbose | Resuming after completion
13:21:28 Info | Submitted by: Sarah (DBA) at 2022-03-03T13:21:24.3250260+00:00
...
...
| == Success: Step 8: Check the application loads as expected ==
13:25:53 Verbose | Check the application loads as expected completed
13:27:33 Verbose | Resuming after completion
13:27:33 Info | Submitted by: Tina (Test) at 2022-03-03T13:27:25.7892278+00:00
13:27:33 Info | Notes: 42 passed
| 0 failed
| PASS
第一次部署后,您可能会决定调整流程。当您创建一个版本时,会对该流程进行快照,以确保该流程在所有部署中保持一致。如果您对流程进行了任何更改,要运行新流程,请创建新版本。
寻找自动化的机会
当您第一次开始规划您的手动部署过程时,自动化可能不是您的目标。然而,您现在有了自动化的起点,并且可以回顾这些步骤,看看您是否可以通过这些成熟度级别来推进它们:
- 手动步骤
- 可以手动运行的脚本
- 自动运行并手动检查的脚本化步骤
- 自动运行的脚本化步骤
例如,数据库备份当前是手动执行的,但是您可以更新此步骤的指令,以包括运行备份的脚本。尽管脚本仍将手动运行,但每次备份更有可能以相同的方式完成。
在手动执行脚本指令后,您可以将该脚本移动到新的自动化步骤中。现有的手动干预步骤可以成为自动化按预期工作的“检查”,当您对自动化有信心时,您可以完全删除手动步骤。
您可能会发现现有的步骤模板将有助于您的自动化;例如,有用于在 AWS、Azure 和 SQL Server 上备份 SQL 数据库的步骤模板。导航到库、步骤模板、浏览库可以找到步骤模板。
结论
现在,您可以在 Octopus Deploy 中映射手动部署,并了解这样做的一些好处。您可以使用 Octopus 的流程控制和跟踪来引入或改进实用部署的十大支柱中的几个,因为您的部署将更加可重复、可见、可审计、标准化和协调。
愉快的部署!
2015 年 3 月社区综述-部署八达通
这个月,社区里的朋友给了我们很多帮助。
首先是 Gregor Suttie 关于“使用 Octopus Deploy 一周”和他对蓝/绿部署的需求的博客。
大卫·罗伯兹在二月底偷偷把这个宝石放进去:OctoPygmy——一个定制仪表板的 Chrome 扩展,通过项目组、环境或角色过滤部分 Octopus Deploy UI。我们认为这是一个很酷的想法,如果您正在管理一个大型环境,它值得一看。
在 OPTEN 博客上,Tim Pickin 一直在运行他们的一系列 Octopus Odyssey ,自动部署一个复杂的多租户 web 应用程序。一些很好的教训和想法。
你可能还记得上一期时事通讯中的卡罗林·克莱弗和她的博客系列。她在章鱼部署实验室又做了一次,这是一套为研讨会开发的练习,帮助章鱼新手启动和运行。
你在伦敦吗?如果是这样,请在 4 月 1 日前往 Zimbra 社交用户组,从 Rich Else 了解麦克米伦癌症支持社区如何使用敏捷、持续交付和 Octopus Deploy 来升级他们的在线社区平台。
同样,当我们在伦敦时,艾德·安德森最近写了一篇关于英国现状的好文章。NET web app 云部署。
接下来是我们在域的朋友 Jason,他最近使用 Octopus Deploy 来帮助一个相当棘手的 AWS 迁移。麦克吉弗会感到骄傲的。
最后但同样重要的是,如果你 4 月份在芝加哥,18 日去参加芝加哥代码营。这看起来是一个很棒的节目,伊恩·鲍林将会为介绍章鱼部署。所以,如果你知道谁需要这方面的知识,就让他们来。
Maven 知识库解释——Octopus 部署

Maven 为 Java 开发人员提供了许多特性。作为一个构建工具,Maven 提供了良好支持的项目格式和大量构建工具插件,可以创建几乎任何种类的 Java(或 JVM)应用程序。虽然 Maven 仍然很受欢迎,但这个领域也存在其他构建工具,如 Gradle。
Maven 还定义了一个几乎被 Java 开发人员普遍使用的标准包存储库。Maven 存储库相当简单,因为它是使用静态文件实现的。除了 HTTP 服务器之外,没有任何 API 和服务器来托管文件。这使得检查 Maven 存储库的内容和访问其中包含的文件变得很容易。
在这篇博文中,我将研究文件如何托管在 Maven 存储库中,并学习如何访问工件。
Maven Central 与 Maven 搜索门户
Maven Central 是一个免费的公开的开源库和应用程序库。Maven Central 有很多镜像,但是主存储库可以在https://repo1.maven.org/maven2/找到。
正如简介中提到的,Maven 存储库只不过是保存在特定格式的层次结构中的静态文件。你可以在网络浏览器中打开https://repo1.maven.org/maven2/并自己浏览目录结构,无需其他工具。
然而,能够快速搜索这些存储库是非常方便的,像https://search.maven.org/这样的网站维护存储库中工件的索引,并通过搜索公开它们。
重要的是要意识到,与公开具有搜索功能的 API 的其他工件存储库不同,Maven 存储库是独立于任何搜索服务的实体。像https://search.maven.org/这样的网站不是 Maven 知识库,也不被 Maven 客户使用;它只提供了一个方便的界面来搜索 Maven 知识库。
浏览 Maven 资源库
Maven 工件由组 ID、工件 ID 和版本标识。这三个点通常被组合成一个坐标,称为 GAV(组、工件和版本)。
Octopus 发布了一个示例 Java 应用程序,其组 ID 为com.octopus,工件 ID 为randomquotes。
组 id 通常是一个反向 DNS 名称。然而,这只是一个惯例,而不是一个要求。
组和工件 id 用于构建保存 Maven 工件的目录结构。如果你打开https://repo1.maven.org/maven2/com/octopus/randomquotes/,你会发现许多子目录包含了版本和描述它们的元数据文件。
在发布 maven 工件时,会创建位于https://repo 1 . Maven . org/Maven 2/com/octopus/random quotes/Maven-metadata . XML的文件。它列出了关于已经发布的工件的各种细节,比如版本号和工件最后更新的日期。
Maven 工件文件
浏览到特定的 Maven 工件版本,如https://repo 1 . Maven . org/Maven 2/com/octopus/random quotes/0 . 1 . 7/显示了组成一个发布的文件。
我们再次发现 Maven 和其他包存储库之间的一些差异,特别是 Maven 工件的给定版本可以包含许多单独的文件。在下面的截图中,您可以看到这个 Maven 工件的文件包含 JavaDocs、应用程序源代码和应用程序本身,作为一个 WAR 文件:

构成 Maven 版本的文件。
Maven 通过使用嵌入在工件文件名中的分类器来支持这一点。例如,文件randomquotes-0.1.7-javadoc.jar与该目录中的其他文件共享com.octopus:randomquotes:0.1.7的 GAV,但是通过分类器javadoc来区分。同样,文件randomquotes-0.1.7-sources.jar具有分类器sources。
文件randomquotes-0.1.7.war没有分类器,通常被认为是默认的工件,并且很可能是您将在自己的项目中作为依赖项部署或消费的工件。
Maven 还支持不同类型的多个文件。例如,我们可能在同一个目录中有一个名为randomquotes-0.1.7.zip的文件。文件扩展名被称为打包。
下载 Maven 文件
虽然我们可以愉快地使用 web 浏览器或 Curl 之类的工具来下载 Maven 工件,但这确实需要我们确切地知道如何构造 url。我们可以使用 Maven CLI 工具根据文件的 GAV、分类器和打包来下载文件,并让它来处理寻找正确文件的工作。
下面的命令将尝试将默认的 JAR 包下载到本地/tmp目录:
mvn org.apache.maven.plugins:maven-dependency-plugin:2.8:copy -DrepoUrl=http://central.maven.org/maven2/ -Dartifact=com.octopus:randomquotes:0.1.7 -DoutputDirectory=/tmp
如果我们运行这个,我们会收到一个错误消息Could not find artifact com.octopus:randomquotes:jar:0.1.7。生成此错误是因为此特定工件没有可用的未分类 JAR 文件;它只包含一个 WAR 文件。我们可以将这种打包类型附加到 GAV 以下载 WAR 文件:
mvn org.apache.maven.plugins:maven-dependency-plugin:2.8:copy -DrepoUrl=http://central.maven.org/maven2/ -Dartifact=com.octopus:randomquotes:0.1.7:war -DoutputDirectory=/tmp
为了下载与这个工件相关的源代码,我们可以定义源代码包的打包类型和分类器:
mvn org.apache.maven.plugins:maven-dependency-plugin:2.8:copy -DrepoUrl=http://central.maven.org/maven2/ -Dartifact=com.octopus:randomquotes:0.1.7:jar:sources -DoutputDirectory=/tmp
这些命令强调了 Maven 默认下载未分类的 JAR 文件,但是如果需要的话,它可以专门下载某种类型和分类器的包。
快照版本
Maven 有快照版本的概念。快照工件版本通常在开发过程中使用,以便不断地重新发布相同的版本。
在下面的截图中,你可以看到来自 AWS S3 托管的 Maven 仓库的文件,这些文件是为工件org.example:template:0.0.1-SNAPSHOT准备的。有多个 ZIP 文件,其名称如下:
template-0.0.1-20200305.005209-1.ziptemplate-0.0.1-20200514.001815-2.zip
这两个文件都代表推送到存储库的快照版本:

组成快照发布的文件。
终端用户通常不需要担心下载特定的快照版本。Maven 客户端将检查位于https://octopus-maven-repo . S3 . amazonaws . com/SNAPSHOT/org/example/template/0 . 0 . 1-SNAPSHOT/maven-metadata . XML的文件,读取每个文件的更新时间,并自动下载最新的文件。
注意,只有快照版本包含第二个maven-metadata.xml文件。非快照版本预计只发布一次并保持不变,因此组成非快照版本的文件可以根据 GAV、打包类型和分类器来确定,从而消除了对第二个maven-metadata.xml文件的需要。
结论
因为它们只是静态文件,所以与 Maven 仓库交互相对简单。如果您知道 url 是如何构造的,Web 浏览器和 Curl 之类的工具可以直接下载工件。
快照版本可能有点棘手,因为文件名包含必须从maven-metadata.xml文件中读取的唯一时间戳。
使用 Maven 命令行工具mvn避免了这些问题,并允许您下载只知道组 ID、工件 ID 和版本,以及可选的分类器和打包类型的文件。
Maven 版本说明- Octopus 部署

版本字符串通常很容易理解,但是 Maven 有许多规则和边缘情况不是很明显。在这篇文章中,我将看看 Maven 版本的字符串是如何工作的。
真理的来源
Maven 发行版包括一个名为 ComparableVersion 的类,它是不同版本字符串如何相互比较的事实来源。
通过针对这个类编写一些测试,我们可以探索 Maven 版本是如何工作的。
版本的排序列表
让我们从一个测试开始,该测试获取一个由ComparableVersion对象组成的数组,克隆该数组,对其进行排序,并将其与原始列表进行比较。测试通过的事实证明了原始列表从最早版本到最新版本是有序的:
private static final ComparableVersion[] VERSIONS = new ComparableVersion[]{
new ComparableVersion("NotAVersionSting"),
new ComparableVersion("1.0a1-SNAPSHOT"),
new ComparableVersion("1.0-alpha1"),
new ComparableVersion("1.0beta1-SNAPSHOT"),
new ComparableVersion("1.0-b2"),
new ComparableVersion("1.0-beta3.SNAPSHOT"),
new ComparableVersion("1.0-beta3"),
new ComparableVersion("1.0-milestone1-SNAPSHOT"),
new ComparableVersion("1.0-m2"),
new ComparableVersion("1.0-rc1-SNAPSHOT"),
new ComparableVersion("1.0-cr1"),
new ComparableVersion("1.0-SNAPSHOT"),
new ComparableVersion("1.0"),
new ComparableVersion("1.0-sp"),
new ComparableVersion("1.0-a"),
new ComparableVersion("1.0-RELEASE"),
new ComparableVersion("1.0-whatever"),
new ComparableVersion("1.0.z"),
new ComparableVersion("1.0.1"),
new ComparableVersion("1.0.1.0.0.0.0.0.0.0.0.0.0.0.1")
};
@Test
public void ensureArrayInOrder() {
ComparableVersion[] sortedArray = VERSIONS.clone();
Arrays.sort(sortedArray);
assertArrayEquals(VERSIONS, sortedArray);
}
这个列表揭示了一些关于 Maven 版本之间相互比较的有趣事实。
限定词如alpha、beta、milestone(或它们的速记等价物a、b和mc)、rc、sp、ga和final有特殊的含义。句点和破折号等分隔符可以互换使用,或者在某些情况下根本不使用。不遵循任何特定格式的版本字符串仍然是有效的和可比较的。
Maven 版本组件
虽然ComparableVersion类是版本相互比较的事实来源,但它并不解析特别有用的数据结构中的版本。为此,我们有来自构建助手插件的第二个类,名为版本信息。
VersionInformation将 Maven 版本字符串分解成 5 个部分:
- 重要的
- 较小的
- 修补
- 内部版本号
- 预选赛
主要、次要、修补和内部版本号都是整数值。
限定符可以包含任何值,尽管有些限定符确实有特殊的含义。
限定符和别名
Maven 可以识别许多特殊的限定符,这里按优先顺序列出:
- 阿尔法还是阿尔法
- beta 或 b
- 里程碑或 m
- rc 或 cr
- 快照
- (空字符串)或 ga 或 final
- sp
我们在排序版本列表中看到,这些限定符确实导致 Maven 版本按照与项目符号列表相同的顺序排序。
带有无法识别的限定符的版本被视为比非限定版本更晚的版本,无法识别的限定符被作为不区分大小写的字符串进行比较。
一些限定符有速记别名。该测试显示了各种限定符如何产生相同的 Maven 版本:
@Test
public void testAliases() {
assertEquals(new ComparableVersion("1.0-alpha1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0-beta1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0-milestone1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0-rc1"), new ComparableVersion("1.0-cr1"));
}
@Test
public void testDifferentFinalReleases() {
assertEquals(new ComparableVersion("1.0-ga"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0-final"), new ComparableVersion("1.0"));
}
请注意,速记别名后面必须有一个数字,而它们的完全对等名称后面没有数字。如果你仔细看这篇文章开头介绍的排序版本列表,你会发现版本1.0-alpha和1.0a1-SNAPSHOT是最早的两个版本,而1.0-a在列表的末尾。
所有限定符都不区分大小写,如本测试所示:
@Test
public void testCase() {
assertEquals(new ComparableVersion("1.0ALPHA1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0Alpha1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0AlphA1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0BETA1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0MILESTONE1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0RC1"), new ComparableVersion("1.0-cr1"));
assertEquals(new ComparableVersion("1.0GA"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0FINAL"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0-SNAPSHOT"), new ComparableVersion("1-snapshot"));
}
如果版本字符串不能被解析为 major.minor.patch.build,并且无法识别限定符,则整个字符串都被视为限定符。然后将这些限定符作为不区分大小写的字符串进行比较:
@Test
public void testQualifierOnly() {
assertTrue(new ComparableVersion("SomeRandomVersionOne").compareTo(
new ComparableVersion("SOMERANDOMVERSIONTWO")) < 0);
assertTrue(new ComparableVersion("SomeRandomVersionThree").compareTo(
new ComparableVersion("SOMERANDOMVERSIONTWO")) < 0);
}
分离器
从数字转换为限定符时,可以选择使用破折号或句点等分隔符:
@Test
public void testSeparators() {
assertEquals(new ComparableVersion("1.0alpha1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0alpha-1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0beta1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0beta-1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0milestone1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0milestone-1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0rc1"), new ComparableVersion("1.0-cr1"));
assertEquals(new ComparableVersion("1.0rc-1"), new ComparableVersion("1.0-cr1"));
assertEquals(new ComparableVersion("1.0ga"), new ComparableVersion("1.0"));
}
但是,当从限定符转换为数字时,情况就不一样了:
@Test
public void testUnequalSeparators() {
assertNotEquals(new ComparableVersion("1.0alpha.1"), new ComparableVersion("1.0-a1"));
}
破折号或句点可用于分隔数字:
@Test
public void testDashAndPeriod() {
assertEquals(new ComparableVersion("1-0.ga"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0-final"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1-0-ga"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1-0-final"), new ComparableVersion("1-0"));
assertEquals(new ComparableVersion("1-0"), new ComparableVersion("1.0"));
}
长版本
虽然VersionInformation类只识别 major.minor.patch.build 格式,但是ComparableVersion类可以识别任意数量的数字:
@Test
public void testLongVersions() {
assertEquals(new ComparableVersion("1.0.0.0.0.0.0"), new ComparableVersion("1"));
assertEquals(new ComparableVersion("1.0.0.0.0.0.0x"), new ComparableVersion("1x"));
}
完整的测试
这是用于生成上述示例的完整测试类:
package org.apache.maven.artifact.versioning;
import org.junit.Test;
import java.util.Arrays;
import static org.junit.Assert.assertTrue;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotEquals;
import static org.junit.Assert.assertArrayEquals;
public class VersionTest {
private static final ComparableVersion[] VERSIONS = new ComparableVersion[]{
new ComparableVersion("NotAVersionSting"),
new ComparableVersion("1.0-alpha"),
new ComparableVersion("1.0a1-SNAPSHOT"),
new ComparableVersion("1.0-alpha1"),
new ComparableVersion("1.0beta1-SNAPSHOT"),
new ComparableVersion("1.0-b2"),
new ComparableVersion("1.0-beta3.SNAPSHOT"),
new ComparableVersion("1.0-beta3"),
new ComparableVersion("1.0-milestone1-SNAPSHOT"),
new ComparableVersion("1.0-m2"),
new ComparableVersion("1.0-rc1-SNAPSHOT"),
new ComparableVersion("1.0-cr1"),
new ComparableVersion("1.0-SNAPSHOT"),
new ComparableVersion("1.0"),
new ComparableVersion("1.0-sp"),
new ComparableVersion("1.0-a"),
new ComparableVersion("1.0-RELEASE"),
new ComparableVersion("1.0-whatever"),
new ComparableVersion("1.0.z"),
new ComparableVersion("1.0.1"),
new ComparableVersion("1.0.1.0.0.0.0.0.0.0.0.0.0.0.1")
};
@Test
public void ensureArrayInOrder() {
ComparableVersion[] sortedArray = VERSIONS.clone();
Arrays.sort(sortedArray);
assertArrayEquals(VERSIONS, sortedArray);
}
@Test
public void testAliases() {
assertEquals(new ComparableVersion("1.0-alpha1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0-beta1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0-milestone1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0-rc1"), new ComparableVersion("1.0-cr1"));
}
@Test
public void testDifferentFinalReleases() {
assertEquals(new ComparableVersion("1.0-ga"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0-final"), new ComparableVersion("1.0"));
}
@Test
public void testQualifierOnly() {
assertTrue(new ComparableVersion("SomeRandomVersionOne").compareTo(
new ComparableVersion("SOMERANDOMVERSIONTWO")) < 0);
assertTrue(new ComparableVersion("SomeRandomVersionThree").compareTo(
new ComparableVersion("SOMERANDOMVERSIONTWO")) < 0);
}
@Test
public void testSeparators() {
assertEquals(new ComparableVersion("1.0alpha1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0alpha-1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0beta1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0beta-1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0milestone1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0milestone-1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0rc1"), new ComparableVersion("1.0-cr1"));
assertEquals(new ComparableVersion("1.0rc-1"), new ComparableVersion("1.0-cr1"));
assertEquals(new ComparableVersion("1.0ga"), new ComparableVersion("1.0"));
}
@Test
public void testUnequalSeparators() {
assertNotEquals(new ComparableVersion("1.0alpha.1"), new ComparableVersion("1.0-a1"));
}
@Test
public void testCase() {
assertEquals(new ComparableVersion("1.0ALPHA1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0Alpha1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0AlphA1"), new ComparableVersion("1.0-a1"));
assertEquals(new ComparableVersion("1.0BETA1"), new ComparableVersion("1.0-b1"));
assertEquals(new ComparableVersion("1.0MILESTONE1"), new ComparableVersion("1.0-m1"));
assertEquals(new ComparableVersion("1.0RC1"), new ComparableVersion("1.0-cr1"));
assertEquals(new ComparableVersion("1.0GA"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0FINAL"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0-SNAPSHOT"), new ComparableVersion("1-snapshot"));
}
@Test
public void testLongVersions() {
assertEquals(new ComparableVersion("1.0.0.0.0.0.0"), new ComparableVersion("1"));
assertEquals(new ComparableVersion("1.0.0.0.0.0.0x"), new ComparableVersion("1x"));
}
@Test
public void testDashAndPeriod() {
assertEquals(new ComparableVersion("1-0.ga"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1.0-final"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1-0-ga"), new ComparableVersion("1.0"));
assertEquals(new ComparableVersion("1-0-final"), new ComparableVersion("1-0"));
assertEquals(new ComparableVersion("1-0"), new ComparableVersion("1.0"));
}
}
如果您对 Java 应用程序的自动化部署感兴趣,请注册一个 Octopus Deploy 的入门许可证,并查看一下我们的文档。
从代码到部署跟踪您的工作- Octopus Deploy
在本帖中,我们很高兴地宣布 Octopus Deploy 2019.4 中的一些新功能,这些功能专注于收紧您的 CI/CD 渠道中的反馈循环。这些特性通过传递更多关于构建的信息,加强了构建服务器和 Octopus 之间的集成。
八达通 2019.4 包括:
- 构建信息和工作项跟踪
- 发行说明模板和发行说明自动生成
- 八达通与吉拉整合
我们将在另一篇文章中介绍发行说明模板,现在让我们来看看其余的特性。
构建信息和工作项跟踪
构建软件的固有思想是,随着时间的推移,产品是已经构建、发布和部署的特性、问题和错误的积累。
接下来,我们希望跟踪软件的每个版本中添加了哪些特性、问题和缺陷,以及哪些正在部署。我们使用广义的术语工作项来指代一个特性、问题或者 bug。换句话说,Octopus 可以跟踪从代码到构建到部署的工作项目,这可以更深入地了解软件的任何给定版本中包含的内容。
在发行版之间交流变更的最常见方式是使用发行说明,工作项的引入并没有改变 Octopus 处理发行说明的方式,但是我们添加了构建信息和工作项作为单独的附加信息。我们所做的一个改变是部署现在也有了发布说明,或者更确切地说,我们称之为发布变更。这些是根据部署中的版本自动收集的,因此您不需要手动输入它们。
“等等,”我听到你说。“在部署中释放 s ?难道我们不部署一个版本吗?”是的,但是请记住,构建软件是一个累积的过程,因此我们部署的是自上次部署到该环境/租户以来发生的所有版本的集合。
好了,这有点拗口,让我们来看一个例子。

此图描述了随着时间的推移而发生的多个发布和部署,以及每个部署的工作项详细信息。在这个场景中,每个版本都被立即部署到开发环境中,这是最简单的情况,因为只涉及到一个版本。
1.0.3的部署展示了一个更复杂的工作项汇总。当1.0.3被部署到登台环境中时,它包含了来自版本1.0.2和1.0.3的工作项。类似地,当它被部署到 Prod 环境中时,它也包含了来自1.0.1的工作项。
它是如何工作的?
为了完成这项工作,我们更新了构建服务器插件,增加了一个新的Octopus Metadata步骤。这一步收集关于构建和提交的元数据,并将所有这些包含在对 Octopus 的调用中。这类似于推送包,需要元数据描述的包的 packageID 和版本。
这个包本身不一定是你推给八达通的。这是一个重要的部分,Octopus 正在接收给定 packageID 和版本的元数据,并存储这些元数据以供创建发布和部署时使用。包本身可以是任何格式,来自任何提要,包括来自容器库中的容器图像。
元数据包括指向创建包的版本的链接,以及包中包含的任何工作项。
对于确实被推送到 Octopus 的包,当您在库中查看它们时,您将会看到元数据。

此元数据也会出现在“发布”、“部署预览”和“任务”页面上。对于来自外部提要的包,发布是在 Octopus 门户中看到包的元数据的第一个点。

部署变量
正如我们上面提到的,部署已经扩展到包括“发布变更”重要的一点是部署总是将来自版本的发布说明聚集到发布变更中,即使没有元数据和工作项。
我们将在另一篇文章中对此进行更多讨论。
部署发布步骤
什么时候包裹不是包裹?当它是一个中的子项目时,部署一个发布步骤。这种情况也包括在内。元数据和工作项不仅会在子项目的发布/部署中进行计算,而且还会在“父”项目的发布/部署中进行汇总。
构建服务器
在最初的版本中,我们的 Bamboo 和 TeamCity 插件已经更新,包含了新的元数据步骤。
我们仍在为 Azure DevOps 插件更新,应该很快就可以使用。
詹金斯的支持也将到来,但我们现在没有一个时间表。
吉拉
到目前为止,我们谈论的一切都是以服务器和 Octopus 为中心构建的,这对任何使用 Octopus 的人都适用。让我们看看如果你使用托管吉拉你还能得到什么。
Octopus 中新的吉拉问题跟踪器扩展与吉拉的部署仪表板功能相结合,因此您可以获得部署反馈,就像使用 BitBucket 管道一样。
当您在 Octopus 中进行部署时,它会将信息实时反馈给吉拉,您将看到部署出现在吉拉。

吉拉集成特性的一个子集也可用于那些具有本地实例的用户,请参见我们的文档了解更多详细信息。
包裹
CI/CD 管道中主要部分之间更紧密的集成有助于简化信息流。这些与吉拉的新集成特性就是一个很好的例子,所以如果你正在使用吉拉和八达通,现在是时候集成了!
微服务和框架- Octopus 部署
通过微服务交付软件是一种现代开发方法,对开发者和客户都有很多好处。
使用微服务意味着在单独、独立的服务中开发应用程序。然后,用户通过前端访问整个应用程序及其功能,不会意识到交付的差异。
尽管有好处,但在开发微服务之前还有一些事情要考虑,比如软件的结构和团队的流程。幸运的是,许多微服务框架的存在有助于减轻一些负担。
在本帖中,我们来看看:
- 微服务开发的优势
- 框架的概念以及为什么应该考虑框架
- 编程语言和适合它们的框架
微服务的优势
让我们想象一下,你正在用微服务建立一个零售网站。您可能会决定将以下功能开发为单独的服务:
- 网站前端(HTML,CSS 等)
- 搜索
- 航行
- 产品数据库
- 行动号召
- 旋转木马
- 网站小工具(例如,新的、流行的或特价商品)
- 客户产品评论
- 结账和支付系统
- 支持实时聊天
与作为单一对象交付的传统网站相比,微服务具有以下优势:
- 产品可靠性-一个组件的问题不太可能影响您的业务。例如,如果您的客户评论组件关闭,人们仍然可以搜索和购买东西。
- 更快的修复——如果你的结账系统损坏了,你可以在几分钟内用一个新的图像替换它。
- 可重复使用的组件-如果您打开第二个零售网站,两者可以共享相同的实时聊天功能。
- 可扩展性——您可以轻松扩展网站资源,以满足每个组件的流量需求。
然而,需要考虑成本和网络流量的权衡。Terence Wong 在他的文章中更深入地探讨了这些问题。
微服务框架以及为什么应该考虑它们
如果你想通过微服务来交付你的产品,有很多方法来规划它将如何工作。
你可以从头开始,一路摸索出一个简单的产品结构,除了你的代码和一些容器之外什么都没有。
这种方法对于功能很少的小项目可能很好,但是如果您需要突然扩展,事情会变得很复杂。您可能会看到一些意想不到的影响,例如:
- 产品很难排除故障
- 新团队成员努力找出事物如何组合的风险
- 寻找你不知道自己拥有的依赖
这就是从一开始就采用已建立的微服务框架使事情变得更容易的地方。
顾名思义,框架是软件开发的现成架构。一个框架:
- 当软件存在于您的基础设施中时,有助于形成软件的形状
- 为团队提供清晰度和关注点
- 拥有帮助开发的工具
- 帮助团队中的每个人朝着同一个方向努力
最重要的是,框架节省了您规划、开发和支持的时间。框架是软件交付的成熟途径。既然已经有人为你做了,为什么还要花时间去犯错误或绘制结构呢?
微服务中交付的项目有无数可用的框架。你所考虑的将取决于你的项目和你使用的编程语言。
微服务的流行框架
让我们来看看针对不同开发语言的一些流行的框架选项。不过,这并不是一个完整的列表。市场上还有很多其他的框架,我们建议在选择一个之前先做一下研究。
所有这些框架都是开源的。
Node.js 和 JavaScript
分子的
分子微服务框架承诺:
- 高速性能
- 通过现有或自行开发的插件进行扩展
- 通过内置负载平衡器、断路器等实现容错
- 与流行的日志服务兼容
寇阿相思树
Koa 是一个微服务框架,号称比它的前身 Express 更精简、更可定制。它还旨在简化服务器的创建。
回送 4
LoopBack 4 是一个微服务框架,包括:
- OpenAPI 规范驱动的 REST APIs
- 通过组件、混合和存储库的依赖注入
- GraphQL 支持
Java 语言(一种计算机语言,尤用于创建网站)
微型机器人
Micronaut 是一个可靠的选择,因为它与类似 Java 的语言兼容,比如 Groovy 和 Kotlin。
它提供:
- 内置云支持
- 简单的单元测试
- 快速配置
- 支持 API 服务,如 OpenAPI 和 Swagger
轴突框架
由 AxonIQ 开发的微服务框架,适合使用:
弹簧云函数
来自 Java 框架提供商 Spring 的微服务框架。
Spring Cloud Functions 拥有一个框架,可以很容易地从小规模起步并不断发展。
它的 Spring Cloud 特性有助于与许多服务注册中心的连接,并且还为您的项目提供了一个 API 网关。
他们还通过千分尺提供可选的度量标准。
夸库斯
专门针对想要使用 Kubernetes 的 Java 开发人员, Quarkus 是一个微服务框架,旨在与 GraalVM 和 HotSpot 一起使用。
计算机编程语言
瓶
Flask 是一个用于 Python 开发项目的极简但功能强大的微服务框架。
猎鹰
Falcon 是一个微服务框架,与其他 Python 框架配合得很好。
它是:
樱桃派
作为另一个轻量级 Python 产品, CherryPy 声称就像它的名字一样简单。
它是:
- 符合 HTTP 和 WSGI
- 能够在多个端口上运行
- 可通过插件扩展
去
去微
围棋微承诺:
- 内置认证
- 动态配置
- 通过 DNS 进行服务发现
- 负载平衡
- 消息编码
- 异步和事件流
回声
附和的承诺:
- 零动态内存分配的 HTTP 路由
- 可量测性
- 让我们加密自动 TLS 证书
- 模板
- 数据绑定和呈现
纤维
Fiber 的开发者将 Fiber 描述为 Express 框架的 Go 等价物。它建立在 Fasthttp 之上,提供了简单的路由定义,并有助于传递静态文件。
。NET 和 C#
ASP。网
ASP.NET 是微软构建网络应用和服务的框架。ASP.NET 对微服务特别有用,因为它支持 Docker 镜像,并且可以方便地为每个服务创建 API。
下一步是什么?
在这篇文章中,我们讨论了微服务的好处,探索了为什么使用微服务框架是一个好主意,并列举了一些流行的框架选项。
我们还有一些关于集装箱化的帖子,包括:
- 您应该考虑的注册中心
- 更详细地看集装箱化的好处
- 深入探讨云流程编排和云自动化
- 看看“一切都是代码”
愉快的部署!
将 426 个 Nancy API 端点迁移到 ASP.NET 核心控制器- Octopus Deploy
原文:https://octopus.com/blog/migrating-nancy-api-endpoints-to-asp-net
当 Octopus Deploy 在 2011 年宣布时, NancyFx 的低调方法使其成为我们 API 层的理想框架。在 Nancy 之上,我们添加了一个定制层,以便于添加符合我们惯例的新路线。
但随着我们的成长,这种定制层成了新手的困惑之源。我们周围的世界也发生了变化,到 2020 年,南希不再被抚养。
因此,我们将 Octopus Deploy 迁移到一种新的、更标准化的 API 编写方式。它利用了加入公司的开发人员的现有知识。我们选择了 ASP.NET 控制器。
Octopus Deploy API 包含 426 个不同的端点,分布在 73 个 Nancy 模块中(这些端点集合成一个类)。每个模块都定义了与特定资源类型相关的端点。
对我们来说,这显然是一项意义重大的任务。所以我们采用了一个策略:去风险,使能,完成。
德列兹
我们想出了一个办法,让 ASP.NET 和南希共处:
- 传入的请求被传递到 ASP.NET 中间件。
- 如果请求匹配 ASP.NET 路由,则调用相关的控制器。
- 如果没有找到匹配,那么请求被传递给 Nancy。
接下来,我们从单个 Nancy 模块开始,一个接一个地迁移端点。每个端点分三步完成:
- 分析和测试
- 移动
- 核实
分析和测试
我们使用了 Assent 测试来捕捉来自一个端点的整个 HTTP 响应,包括快乐路径和任何边缘情况。这些测试还测量了端点的响应时间,因此我们可以检查任何性能退化。
移动
对于一个简单的 GET 端点,迁移可能很简单。对于改变状态的端点,事情可能会更耗时。诸如验证之类的规则被考虑、理解并移植到 ASP.NET 控制器模式中。
核实
之前添加的测试在 CI 中重新运行,提醒我们任何性能退化、功能变化或响应内容的变更。然后对变更以及变更是否可接受做出客观的决定。
使能够
这种方法是成功的,证明了迁移整个 Octopus Deploy API 是可能的。
这也向我们展示了:
- Nancy 端点通常需要大约 100 毫秒来返回响应。
- 对 ASP.NET 端点的第一次调用将在大约 200 毫秒内返回,但后续调用仅用了 30-40 毫秒。
一个由 4 名工程师组成的团队花了 6 个月的时间专注于迁移。
为了优化迁移,我们瞄准了相似且不太复杂的端点。为了找出哪些端点符合这些标准,我们编写了一个 C#脚本,在 LINQPad 中执行,它反映了 Octopus Deploy 代码库,并按公共代码和基类对端点进行了分组。
为了获得相对复杂性的度量,我们根据基于代码行数和圈复杂度的度量进行了排序。这种分组和排序允许我们关注迁移的机制,同时避免过多的领域复杂性。
我们学到了一些东西:
- 由于 ASP.NET 的性能改进,没有必要继续测试性能退化。
- 基于快照的测试很难编写,因为您必须考虑和“清理”端点调用之间发生变化的数据,例如时间戳或 id。
- 对于检查边缘情况的测试,断言您真正关心的响应部分更简单,比如响应代码和错误文本。
- 测试需要数据,而数据的创建并不容易,因此将这一点从测试的细节中分离出来非常重要。
- 为您如何迁移建立和记录可重复的模式是至关重要的,这样工程团队中的其他人也可以进行迁移。
- 理解特定于端点的域可能是迁移中最困难的部分。
我们还发现这种类型的工作可能是重复的,有降低开发人员积极性的风险。为了解决这个问题,我们庆祝了一路上的里程碑。这些包括迁移的端点百分比,以及特定分组或类型的所有端点的迁移。
我们还用经典燃尽图的变化来跟踪我们的进展。

结束
从一开始,我们就同意,当 API 100%迁移到 ASP.NET 时,将会看到最大的庆祝和好处。
六个月后,我们已经迁移了 40%的 API 端点,因此我们已经进入了迁移的新阶段,整个工程团队都同意,如果您正在更改一个区域,请用测试覆盖它,并在您处于该区域时迁移该区域中剩余的 Nancy 端点。
这种方法利用了开发人员的领域知识,并将迁移工作分散到整个工程团队中。
结论
- 像这样的迁移是可以完成的,但这需要大量的时间投入。
- 重要的是量化工作,并找到最有效的方法来组织工作。
- 这是非常并行的工作。
- 建立和记录模式允许组织中的任何开发人员提供帮助。
- 你必须接受一定程度的风险。
- 衡量进展可以让你庆祝过程中的关键里程碑。
愉快的部署!
在 Windows 上安装 Minikube-Octopus Deploy

多亏了 Minikube 项目,开始测试 Kubernetes 集群变得更加容易。通过使用 Windows 10 中的 HyperV 功能,只需几分钟就可以创建一个测试 Kubernetes 集群。
在本文中,我们将介绍配置 HyperV、安装kubectl和 Minikube 以及与测试 Kubernetes 集群交互的过程。
创建外部交换机
Minikube 需要一个外部 HyperV 开关来操作,你可能会发现你默认没有。
要查看开关列表,打开HyperV Manager并从动作列表中选择Virtual Switch Manager...:

hyper v 操作菜单。
在下面的屏幕截图中,您可以看到没有现有的外部交换机,因此我们需要通过选择External选项并单击Create Virtual Switch按钮来创建一个:

现有交换机列表。
将虚拟交换机连接到电脑的本地网络适配器(在本例中为无线网络适配器)。点击OK按钮创建开关:

创建新的 HyperV 外部交换机。
您将收到网络连接将被中断的警告。点击Yes继续。

创建新交换机导致网络中断的警告。
安装 kubectl
我们用来与 Kubernetes 交互的命令行工具叫做kubectl,我们将在配置 Minikube 之前安装它。kubectl有两种安装方式:
安装 Minikube
我们现在准备安装 Minikube。您可以通过两种方式安装 Minikube:
安装 Minikube 后,以管理员身份打开 PowerShell 终端:

以管理员身份启动终端。
然后,可以使用以下命令启动 Minikube:
minikube start `
--vm-driver hyperv `
--hyperv-virtual-switch "External Switch"
将创建一个名为minikube的新虚拟机:

运行 Minikube start 后创建的 Minikube 虚拟机。
安装完成后,我们可以通过kubectl与 Minikube 集群交互:

Minikube 集群已成功启动。
运行一些命令
Minikube 安装将使用测试集群的详细信息更新~/.kube/config处的文件,即kubectl使用的配置文件:
PS C:\Users\Matthew> cat ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority: C:\Users\Matthew\.minikube\ca.crt
server: https://10.1.1.122:8443
name: minikube
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: C:\Users\Matthew\.minikube\client.crt
client-key: C:\Users\Matthew\.minikube\client.key
我们可以通过列出节点来测试安装是否正常工作:
PS C:\Users\Matthew> kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 6m47s v1.15.2
将 Octopus 连接到 Minikube
要从 Octopus 使用 Minikube,我们需要上传客户端证书。Minikube 将证书和密钥分割成两个文件(由~/.kube/config文件中的client-certificate和client-key属性引用),所以我们使用 OpenSSL 将它们合并成一个 PFX 文件:
& "C:\Program Files\OpenSSL-Win64\bin\openssl.exe" pkcs12 `
-passout pass: `
-export `
-out certificateandkey.pfx `
-in C:\Users\Matthew\.minikube\client.crt `
-inkey C:\Users\Matthew\.minikube\client.key
生成的certificateandkey.pfx文件可以上传到 Octopus:

由 Minikube 创建并由 OpenSSL 组合的证书和密钥。
为了让 Octopus 与本地虚拟机通信,我们需要在本地 PC 上创建一个 Worker 触手:

与 Minikube 集群运行在同一台机器上的轮询工作器触手。
我们现在可以创建一个指向 Minikube 集群的本地 URL 的 Kubernetes 目标,这可以从~/.kube/config文件中的这一行找到:
server: https://10.1.1.122:8443
Kubernetes 目标将使用我们之前上传的证书进行身份验证,为了方便起见跳过 TLS 验证,默认使用本地的触手工作器。
您可以通过~/.kube/config文件中的certificate-authority属性上传证书引用,并将其设置为服务器证书。

一个 Kubernetes 目标,配置为使用本地 Worker 触手,与内部 Minikube IP 地址对话。
定义好目标后,我们可以使用 Octopus 脚本控制台与之交互:

脚本控制台是运行临时脚本的便捷方式。
该命令将通过 Worker Tentacle 执行,以与本地 Minikube 集群进行交互:

脚本结果,它反映了在本地运行 kubectl 时的结果。
结论
Minikube 是测试 Kubernetes 集群启动和运行的简单方法。在 Windows 中,Minikube 使用 HyperV,并且需要外部开关来操作。一旦启动,Minikube 配置kubectl,我们就可以开始对测试集群运行命令。
也可以从 Octopus 与 Minikube 集群进行交互。通过在 Minikube VM 所在的同一台 PC 上使用 Worker 触手,Kubernetes 目标可以向集群的私有 IP 发出命令。
有关部署到 Kubernetes 的更多信息,请参见我们的文档。
Tomcat - Octopus 部署中的组合键
在之前的博客文章中,我们看到了 Tomcat 8.5+如何使用 SNI 将证书映射到请求的主机名。
Tomcat 8.5+可以更进一步,为每个主机支持多种证书类型。这对于在旧浏览器上支持 RSA,而在兼容浏览器上支持 ECDSA 非常有用。
在这篇博文中,我们将看看如何为 Tomcat 配置多种证书类型。
创建自签名 RSA 密钥
要生成 RSA 私钥和自签名证书,请使用以下命令:
openssl req -x509 -newkey rsa:4096 -keyout rsa.key -out rsa.crt -days 365
创建自签名 ECDSA 密钥
要创建 ECDSA 私钥,请使用以下命令:
openssl ecparam -genkey -out ecdsa.key -name prime256v1
name参数是命令返回的列表中的一个:
openssl ecparam -list_curves
OpenSSL 支持大量的曲线,但是浏览器通常只支持非常少的曲线。 SSL Labs 允许你测试你的浏览器对命名曲线的支持。在下面的截图中可以看到 Firefox 57 支持的曲线:x25519、secp256r1、secp384r1、secp521r1。
secp256r1是 OpenSSL prime256v1曲线。

然后使用以下命令从私钥创建证书:
openssl req -x509 -new -key ecdsa.key -out ecdsa.crt
用多个键配置 Tomcat
为了支持两种证书类型,可以将多个<Certificate>元素添加到一个<SSLHostConfig>元素中。当定义了多个<Certificate>元素时,每个元素必须有一个惟一的type属性。RSA 证书具有RSA类型,ECDSA 证书具有EC类型。
这是 Tomcat server.xml配置文件的一个片段,其中包含使用上面的 OpenSSL 命令创建的两个自签名证书和私钥。
<Connector SSLEnabled="true" port="62000" protocol="org.apache.coyote.http11.Http11AprProtocol">
<SSLHostConfig>
<Certificate certificateFile="${catalina.base}/conf/ecdsa.crt" certificateKeyFile="${catalina.base}/conf/ecdsa.key" type="EC"/>
<Certificate certificateFile="${catalina.base}/conf/rsa.crt" certificateKeyFile="${catalina.base}/conf/rsa.key" type="RSA"/>
</SSLHostConfig>
</Connector>
这个片段使用 APR 协议,该协议接受由 OpenSSL 创建的 PEM 文件。有关在 Tomcat 中启用 APR 的更多信息,请参见构建 Apache 可移植运行时。
验证配置
高科桥有一个验证 web 服务器安全配置的在线服务。
在这个截图中,我们可以看到 Tomcat 服务器已经公开了 RSA 和 ECDSA 证书。
【T2 
结论
Tomcat 在为单个 HTTPS 端口支持 RSA 和 ECDSA 证书的能力方面是非常独特的。这使得 Tomcat 可以在不牺牲安全性的情况下,为各种客户端提供 HTTPS。这种配置可以简单地通过定义两个具有不同type属性的<Connector>元素来实现。
如果您对 Java 应用程序的自动化部署感兴趣,下载 Octopus Deploy 的试用版,并查看我们的文档。
Selenium 系列:混合隐式和显式等待- Octopus Deploy
原文:https://octopus.com/blog/selenium/8-mixing-waits/mixing-waits
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
我们已经看到有两种类型的等待:隐式和显式。两者都是彼此独立实现的,那么当您在一个测试中既有隐式等待又有显式等待时会发生什么呢?
为了找到答案,让我们创建一个实现这两种等待的测试。
在我们的AutomatedBrowserFactory类中,我们创建了ImplicitWaitDecorator类,作为打开 Chrome 浏览器的AutomatedBrowser的构造的一部分。所以我们知道测试将利用隐式等待:
private AutomatedBrowser getChromeBrowser() {
return new ChromeDecorator(
new ImplicitWaitDecorator(10,
new WebDriverDecorator()
)
);
}
让我们创建一个测试,尝试单击一个在页面上永远找不到的元素。
在@Test注释上添加的expected异常表明,只有在抛出TimeoutException异常的情况下,这个测试才会通过,我们希望抛出这个异常,因为永远不会有 ID 为This ID does not exist的元素:
@Test(expected = TimeoutException.class)
public void mixedTestShortExplicitWait() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
final long start = System.currentTimeMillis();
try {
automatedBrowser.init();
automatedBrowser.goTo(WaitTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("This ID does not exist", 1);
} finally {
automatedBrowser.destroy();
final long duration = System.currentTimeMillis() - start;
System.out.println("Duration: " + duration / 1000);
}
}
为了跟踪我们等待元素的时间,我们从测试开始前获取当前系统时间开始:
final long start = System.currentTimeMillis();
在finally块中,我们显示当前系统时间和测试开始时间之间的差异。这让我们大致了解了完成测试需要多长时间:
final long duration = System.currentTimeMillis() - start;
System.out.println("Duration: " + duration / 1000);
当试图单击元素时,我们使用需要等待时间的方法,这反过来意味着我们实现了显式等待。在这个测试中,我们使用 1 秒的显式等待。请记住,这种显式等待是对作为AutomatedDriver一部分配置的 10 秒隐式等待的补充:
automatedBrowser.clickElementWithId("This ID does not exist", 1);
运行该测试显示,测试总是需要 10 秒以上才能完成。

当代码使用仅 1 秒钟的显式等待来等待丢失的元素时,这个结果可能会令人惊讶。它表明,当混合一个短的显式等待和一个长的隐式等待时,测试将在隐式等待的整个时间内暂停。
让我们颠倒一下测试,添加一个更长的显式等待。这一次我们将使用 20 秒的显式等待:
@Test(expected = TimeoutException.class)
public void mixedTestLongExplicitWait() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
final long start = System.currentTimeMillis();
try {
automatedBrowser.init();
automatedBrowser.goTo(WaitTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("This ID does not exist", 20);
} finally {
automatedBrowser.destroy();
final long duration = System.currentTimeMillis() - start;
System.out.println("Duration: " + duration / 1000);
}
}
运行该测试显示,测试总是需要 20 多秒才能完成。这是一个更符合预期的结果,显示了分配给隐式和显式等待的时间使用得越多。

让我们尝试第三个场景,其中我们为 5 秒后创建的 div 元素使用 2 秒的显式等待时间。如果您还记得以前的帖子,ID 为newdiv_element的 div 被创建,并在 5 秒钟后使用 JavaScript 函数动态添加到页面中。
您可以向测试中添加类似的步骤,以确保 web 应用程序在可接受的时间内执行操作,而不会让用户等待继续他们的进程。
@Test
public void shortExplicitWaitForDynamicElement() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Chrome");
final long start = System.currentTimeMillis();
try {
automatedBrowser.init();
automatedBrowser.goTo(WaitTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("newdiv_element", 2);
} finally {
automatedBrowser.destroy();
final long duration = System.currentTimeMillis() - start;
System.out.println("Duration: " + duration / 1000);
}
}
这个测试通过了。即使我们已经明确地为一个我们知道在 5 秒钟内不会被创建的元素等待了 2 秒钟,这个元素还是被找到并被点击了。

这种行为是违反直觉的,如果我们使用 2 秒的等待时间来执行应用程序的性能要求,这个测试将会产生一个误报。
让我们纠正这个限制。对于最后一个场景,我们需要获得一个没有隐式等待的AutomatedBrowser实例。为此,我们将在AutomatedBrowserFactory职业中增加两个新选项:ChromeNoImplicitWait和FirefoxNoImplicitWait。
这些选项依次调用getChromeBrowserNoImplicitWait()和getFirefoxBrowserNoImplicitWait()方法,它们构建没有定义隐式等待的AutomatedBrowser对象:
package com.octopus;
import com.octopus.decorators.*;
public class AutomatedBrowserFactory {
public AutomatedBrowser getAutomatedBrowser(String browser) {
if ("ChromeNoImplicitWait".equalsIgnoreCase(browser)) {
return getChromeBrowserNoImplicitWait();
}
if ("FirefoxNoImplicitWait".equalsIgnoreCase(browser)) {
return getFirefoxBrowserNoImplicitWait();
}
// ...
}
// ...
private AutomatedBrowser getChromeBrowserNoImplicitWait() {
return new ChromeDecorator(
new WebDriverDecorator()
);
}
private AutomatedBrowser getFirefoxBrowserNoImplicitWait() {
return new FirefoxDecorator(
new WebDriverDecorator()
);
}
}
然后,我们使用显式等待重新创建相同的测试,等待的时间比生成元素所需的时间要短。但是这一次,我们通过将ChromeNoImplicitWait选项传递给工厂来运行测试,没有任何隐式等待:
@Test(expected = TimeoutException.class)
public void shortExplicitWaitNoImplicitWaitForDynamicElement() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("ChromeNoImplicitWait");
final long start = System.currentTimeMillis();
try {
automatedBrowser.init();
automatedBrowser.goTo(WaitTest.class.getResource("/form.html").toURI().toString());
automatedBrowser.clickElementWithId("newdiv_element", 2);
} finally {
automatedBrowser.destroy();
final long duration = System.currentTimeMillis() - start;
System.out.println("Duration: " + duration / 1000);
}
}
这一次我们得到了抛出TimeoutException的测试的预期结果。
这些测试告诉我们隐式和显式等待并不相互排斥。尽管它们是独立定义的,彼此之间没有明显的影响,但隐式等待时间确实会影响显式等待操作。
因为显式等待允许我们编写更健壮的测试,在一段时间内强制元素的状态,并为要完成的每个交互提供单独的持续时间,所以在我们的测试中使用显式等待是有意义的。我们在这里看到的是,为了利用显式等待,我们还需要禁用隐式等待。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
Selenium 系列:修改 HTTP 请求- Octopus Deploy
原文:https://octopus.com/blog/selenium/14-modifying-http-requests/modifying-http-requests
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
除了捕获网络流量,BrowserMob 还让我们能够修改浏览器发出的网络请求。在许多情况下,当运行测试时,修改请求可以证明是有用的,包括:
- 模拟外部服务的失败。
- 防止像图像这样的资产被加载,这可以提高测试的性能。
- 测试期间阻止第三方服务,如社交媒体服务。
通过代理的典型网络请求如下所示。代理位于浏览器和外部资源之间,来回传递请求。

下图显示了我们试图实现的请求和响应。
- 浏览器向类似 PNG 图像的资源的 URL 发出请求。
- 该请求被定向到代理。
- 代理使用请求过滤器来检查请求。
- 请求因空响应而短路。永远不会联系外部 URL。
- 空响应被发送回浏览器。

为了支持修改请求,我们向AutomatedBrowser接口添加了一个新方法:
void blockRequestTo(String url, int responseCode);
该方法接受要修改的请求的 URL,以及请求该 URL 时应该返回的 HTTP 响应代码。
我们将默认方法添加到AutomatedBrowserBase类中:
@Override
public void blockRequestTo(final String url, final int responseCode) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().blockRequestTo(url, responseCode);
}
}
然后在BrowserMobDecorator类中实现该方法:
@Override
public void blockRequestTo(String url, int responseCode) {
proxy.addRequestFilter((request, contents, messageInfo) -> {
if (Pattern.compile(url).matcher(messageInfo.getOriginalUrl()).matches()) {
final HttpResponse response = new DefaultHttpResponse(
request.getProtocolVersion(),
HttpResponseStatus.valueOf(responseCode));
response.headers().add(HttpHeaders.CONNECTION, "Close");
return response;
}
return null;
});
getAutomatedBrowser().blockRequestTo(url, responseCode);
}
我们来分解一下这个方法。
我们首先向 BrowserMob 代理对象添加一个请求过滤器。请求过滤器作为一个 lambda 提供,它有三个参数:
request:包含 HTTP 请求的细节,比如 URL、HTTP 方法类型(GET、POST 等)、头等等。contents:包含请求体。messageInfo:包含一些关于请求的附加信息,比如没有经过过滤器修改的原始请求细节。
proxy.addRequestFilter((request, contents, messageInfo) -> {
在 lambda 中,我们检查传递给alterRequestTo()方法的 URL 是否与请求的 URL 匹配。我们将 URL 视为正则表达式,以便在匹配 URL 时更加灵活:
if (Pattern.compile(url).matcher(messageInfo.getOriginalUrl()).matches()) {
如果 URL 匹配,我们返回一个代表 HTTP 响应的DefaultHttpResponse实例。这个响应有两个参数。
第一个是 HTTP 协议版本,我们将其设置为与请求相同的版本。
第二个是 HTTP 响应代码,我们将其设置为传递给alterRequestTo()方法的值:
final HttpResponse response = new DefaultHttpResponse(
request.getProtocolVersion(),
HttpResponseStatus.valueOf(responseCode));
然后我们需要指出这个请求不应该使用 HTTP 保持活动功能。这是通过将 HTTP 报头Connection设置为Close来实现的。
如果我们不设置这个头,浏览器将试图保持连接打开(或保持连接活动),您会看到页面似乎加载了很长时间:
response.headers().add(HttpHeaders.CONNECTION, "Close");
返回这个对象意味着请求将被短路。请求不再传递给 URL,而是由 BrowserMob 直接处理,在这种情况下,使用空响应和提供的 HTTP 响应代码:
return response;
如果 URL 与请求不匹配,我们返回null,这表示这个过滤器什么也不做,请求将像平常一样通过远程服务器:
return null;
最后一步是在测试中修改一些请求:
@Test
public void modifyRequests() {
final AutomatedBrowser automatedBrowser =
AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Firefox");
automatedBrowser.init();
automatedBrowser.blockRequestTo(".*?\\.png", 201);
automatedBrowser.blockRequestTo("https://.*?twitter\\.com/", 500);
automatedBrowser.goTo("https://octopus.com/");
}
对blockRequestTo()的调用将为任何对 PNG 图像的请求返回一个空响应。我们使用 HTTP 返回代码201来表示响应成功但为空。这是我们通过阻止下载图像来加快测试速度的一个例子:
automatedBrowser.blockRequestTo(".*?\\.png", 201);
下一行代码块请求 Twitter 提供的服务。因为我们返回了一个 HTTP 响应代码500,它用于指示处理请求的服务器端错误,我们可以使用这些改变的请求作为模拟这些外部服务失败的一种方式。您可能还会发现,通过移除测试 web 应用程序不需要的更多网络流量,阻止这些可选服务可以加快测试速度:
automatedBrowser.blockRequestTo("https://.*?twitter\\.com/", 500);
你会注意到我们在这里没有调用automatedBrowser.destory()。这是为了让我们能够查看因网络请求被更改而产生的网页。如您所见,通常显示的图像现在不再显示,因为这些请求被拦截并作为空响应返回。
【T2 
这里需要注意的一点是,一旦测试完成,就不可能再以任何有意义的方式与网页进行交互。这是因为 BrowserMob 已经关闭,这意味着配置浏览器的代理不再可用,因此所有未来的网络请求都将失败。
要与网页交互,您需要从浏览器设置中手动删除代理设置。下面的截图显示了我们在上一篇文章中看到的 Firefox 代理设置。选择No proxy选项将允许在浏览器关闭后使用浏览器。

记住,由于没有调用destory()方法,我们现在负责手动关闭测试启动的驱动程序二进制文件。

阻止对图像之类的东西的网络请求可以加速 WebDriver 测试,这在针对无头浏览器运行测试时特别有用,因为没有人监视正在运行的测试,下载永远不会被看到的图像没有什么好处。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
Selenium 系列:修改 HTTP 响应- Octopus Deploy
原文:https://octopus.com/blog/selenium/15-modifying-http-responses/modifying-http-responses
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
在上一篇文章中,我们研究了如何使用 BrowserMob 拦截请求并立即返回空响应。当您想要阻止某些资源被下载时,这是一个有用的解决方案,它可以通过阻止对可选资源(如图像)的网络请求来加速测试。
BrowserMob 提供的另一个有用的特性是改变网站响应的能力。这可以用来模拟响应,以确保测试是确定性的,或者允许测试针对特定的边缘情况。
修改响应时,网络请求和响应遵循下图所示的流程。
- 浏览器发出请求。
- 该请求被定向到代理。
- 代理将请求转发到外部 URL。
- 来自外部 URL 的响应通过响应过滤器传递。
- 响应滤波器改变响应。
- 更改后的响应被传递回浏览器。

为了演示这一点,我们将创建一个非常简单的网页,查询 Yahoo weather API 来获取夏威夷的日落时间。该数据是从对https://query.yahooapis.com/v1/public/yql?的请求中检索的 q = select % 20 astronomy . sunset % 20 from % 20 weather . forecast % 20 where % 20 woeid % 20 in % 20(select % 20 woeid % 20 from % 20 geo . places(1)% 20 where % 20 text % 3D % 22 maui % 2C % 20 hi % 22)&format = json&env = store % 3A % 2F % 2f datatables . org % 2 falltableswithkeys,它返回如下所示的 JSON 响应:
{
"query": {
"count": 1,
"created": "2018-04-28T07:15:45Z",
"lang": "en-US",
"results": {
"channel": {
"astronomy": {
"sunset": "6:49 pm"
}
}
}
}
}
为了在网页中显示这个响应,我们有以下 HTML:
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<script>
var xhr = new XMLHttpRequest();
xhr.open(
"GET",
"https://query.yahooapis.com/v1/public/yql?q=select%20astronomy.sunset%20from%20weather.forecast%20where%20woeid%20in%20(select%20woeid%20from%20geo.places(1)%20where%20text%3D%22maui%2C%20hi%22)&format=json&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys",
true);
xhr.onload = function(e) {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
var sunset =
JSON.parse(xhr.responseText).query.results.channel.astronomy.sunset;
var newHeading = document.createElement("h1");
newHeading.setAttribute("id", "sunset");
newHeading.textContent = "Sunset in Hawaii is at " + sunset;
document.body.appendChild(newHeading);
} else {
console.error(xhr.statusText);
}
}
};
xhr.onerror = function(e) {
console.error(e);
};
xhr.send(null);
</script>
</body>
</html>
将该 HTML 保存到文件src/test/resources/apitest.html.
这个 web 页面向 Yahoo API 发出一个查询,并在成功响应后创建一个带有文本Sunset in Hawaii is at x:xx pm的<h1>元素(其中时间来自 API 响应)。
以下是该页面在 Chrome 中打开时的截图。输出强调了 Yahoo 服务中一个有趣的错误,它返回了文字字符串7:4 pm。我假设这意味着太阳在晚上 7:40 落山。不过,这对我们来说不成问题,因为我们将用一个已知的好值替换这个错误的响应。

即使没有返回时间中的 bug,日落时间也不是一个固定值。显然,在整个一年中,我们可以期待这个时间会有所改变。但是,如果我们需要测试的日落时间总是在晚上 7:00,那该怎么办呢?这可以通过 BrowserMob 响应过滤器实现。
我们首先向AutomatedBrowser接口添加一个新方法:
void alterResponseFrom(String url, int responseCode, String responseBody);
通常的默认方法被添加到the AutomatedBrowserBase类中:
@Override
public void alterResponseFrom(final String url, final int responseCode, final String responseBody) {
if (getAutomatedBrowser() != null) {
getAutomatedBrowser().alterResponseFrom(url, responseCode, responseBody);
}
}
然后在BrowserMobDecorator类中,我们实现这个方法:
@Override
public void alterResponseFrom(final String url, final int responseCode, final String responseBody) {
proxy.addResponseFilter((response, contents, messageInfo) -> {
if (Pattern.compile(url).matcher(messageInfo.getOriginalUrl()).matches()) {
contents.setTextContents(responseBody);
response.setStatus(HttpResponseStatus.valueOf(responseCode));
}
});
getAutomatedBrowser().alterResponseFrom(url, responseCode, responseBody);
}
像alterRequestTo()方法一样,alterResponseFrom()方法增加了一个 BrowserMob 过滤器。然而,这一次,我们添加了一个响应过滤器,它允许我们获取一个现有的响应,并根据我们的需要进行调整。
我们首先打电话给addResponseFilter():
proxy.addResponseFilter((response, contents, messageInfo) -> {
像以前一样,我们检查 URL 正则表达式是否匹配传递给alterResponseFrom()方法的参数:
if (Pattern.compile(url).matcher(messageInfo.getOriginalUrl()).matches()) {
如果 URL 匹配,我们替换响应体,并更改响应 HTTP 代码:
contents.setTextContents(responseBody);
response.setStatus(HttpResponseStatus.valueOf(responseCode));
为了演示这一新功能,我们创建了一个新的测试:
@Test
public void mockRequests() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Firefox");
try {
automatedBrowser.init();
automatedBrowser.alterResponseFrom(
".*?query\\.yahooapis\\.com.*",
200,
"{\"query\":{\"count\":1,\"created\":\"2018-04-28T05:20:30Z\",\"lang\":\"en-US\",\"results\":{\"channel\":{\"astronomy\":{\"sunset\":\"7:00 pm\"}}}}}");
automatedBrowser.goTo(FormTest.class.getResource("/apitest.html").toURI().toString());
final String sunset = automatedBrowser.getTextFromElementWithId("sunset", 60);
Assert.assertTrue(sunset, sunset.contains("7:00 pm"));
} finally {
automatedBrowser.destroy();
}
}
这个测试的重要部分是对alterResponseFrom()方法的调用。在这里,我们将 URL 与对query.yahooapis.com的调用相匹配,并用我们自己的定制 JSON 替换响应。在本例中,自定义 JSON 将日落时间定义为7:00 pm:
automatedBrowser.alterResponseFrom(
".*?query\\.yahooapis\\.com.*",
200,
"{\"query\":{\"count\":1,\"created\":\"2018-04-28T05:20:30Z\",\"lang\":\"en-US\",\"results\":{\"channel\":{\"astronomy\":{\"sunset\":\"7:00 pm\"}}}}}");
打开网页后,我们检查打印到页面上的消息是否反映了这个硬编码的日落时间:
final String sunset = automatedBrowser.getTextFromElementWithId("sunset", 60);
Assert.assertTrue(sunset, sunset.contains("7:00 pm"));
这个测试通过的事实证明,我们已经修改了 API 的响应,以包含我们自己的定制 JSON 响应。
知道 Yahoo API 可以返回类似于7:4 pm的时间,谨慎的做法是创建一个模拟这种边缘情况的测试。但是假设 API 返回的时间不是我们所能控制的,那么测试一个无效时间被返回的场景将会非常困难,因为明天调用 API 可能会导致一个完全有效的时间被返回。
这里是另一个测试,但是这次返回无效的日落时间。在这个例子中,我们简单的网页显示这个时间,这可能不是我们想要的,但是通过使用 BrowserMob 修改响应,我们作为测试人员可以确保在我们的测试中可靠地捕捉到这个边缘情况:
@Test
public void mockRequests2() throws URISyntaxException {
final AutomatedBrowser automatedBrowser = AUTOMATED_BROWSER_FACTORY.getAutomatedBrowser("Firefox");
try {
automatedBrowser.init();
automatedBrowser.alterResponseFrom(
".*?query\\.yahooapis\\.com.*",
200,
"{\"query\":{\"count\":1,\"created\":\"2018-04-28T05:20:30Z\",\"lang\":\"en-US\",\"results\":{\"channel\":{\"astronomy\":{\"sunset\":\"7:4 pm\"}}}}}");
automatedBrowser.goTo(FormTest.class.getResource("/apitest.html").toURI().toString());
final String sunset = automatedBrowser.getTextFromElementWithId("sunset", 60);
Assert.assertTrue(sunset, sunset.contains("7:4 pm"));
} finally {
automatedBrowser.destroy();
}
}
修改来自外部服务的响应是一种有效的方法,可以确保响应具有预期的值,为您的测试提供可靠的输入,或者允许测试模拟难以重现的条件。通过在浏览器收到响应之前在代理中进行这些更改,我们可以准确地测试 web 应用程序将如何响应由实时服务返回的相同响应。
这篇文章是关于创建 Selenium WebDriver 测试框架的系列文章的一部分。
RFC:监控和服务管理- Octopus 部署
作为一个自动化部署工具,Octopus 正好位于 DevOps 连续体的中间。构建服务器知道您正在构建的应用程序,但不知道它们部署在哪里。监控服务可能知道您已经部署的端点,但不知道它们在逻辑上如何联系在一起。章鱼对这两者都很了解。假设你在使用内置的约定和触须,Octopus 已经知道:
- 你有什么样的环境
- 您的应用程序由哪些 Windows 服务和 IIS 网站组成
- 您在哪些机器上部署了这些服务和 IIS 应用程序
此外,它在每台机器上都有一个智能代理服务,能够做许多有趣的事情。
鉴于我们拥有所有这些信息,难道我们不应该更多地利用它们吗?Octopus 仪表板显示您的最后一次生产部署是否成功。如果它还向您显示您部署的内容是否仍在运行,那会怎么样?
这里有一个大概的说明:

在本例中,我们部署了一个系统,该系统由一个 IIS web 应用程序(运行在两个服务器上)和一个 Windows 服务(运行在四个服务上)组成。
如果启用了监控,触手代理将会密切关注它在部署过程中配置的任何服务或网站。如果状态发生变化,它会将此信息发送回 Octopus。
不过,它不仅仅局限于监视状态:您还可以启动/停止这些服务。您昨天部署到 30 台机器上的 Windows 服务在其中 7 台机器上突然崩溃了吗?没问题,只需点击按钮,选择你想重启的 7,点击执行按钮。肯定胜过使用远程桌面!另外,会有很好的审计记录。
请注意,我们并不想成为一个 Pingdom 或 Nagios 。但是,如果您正在部署十几个小型 NServiceBus Windows 服务,并且没有很多监控或操作系统,这可能是一个方便的小工具。
这只是我们在 2014 年考虑的众多重要功能之一,我甚至不知道我们是否会实际构建它。我希望得到您的反馈。这样的功能对您或您的运营团队有用吗?你还会用它来监视什么?会有什么帮助?
整体服务对微服务——章鱼部署
单片和微服务是构建软件的两种方法。您选择哪一个可以显著影响开发和性能。
在这篇文章中,我讨论了:
- 单片和微服务的区别
- 对于企业软件应用程序,哪一个更好
- 两种方法的挑战
什么是单片和微服务?
monolith 是一个单一的可执行软件应用程序。它包含一个代码库,用于定义运行应用程序所需的用户界面、应用程序逻辑和数据库。整体式应用程序是作为一个单一的、不可分割的单元构建和维护的,并从一个中心位置提供服务。例如,使用数据库存储客户记录的内部会计软件、用于保存记录的 web 服务器以及其他组件,所有这些都由内部服务器提供。
相比之下,微服务架构将应用程序分解成更小的独立单元。微服务通过应用编程接口(API)连接起来,做成整个应用。
API 允许微服务相互通信来执行任务。例如,一个微服务向另一个微服务发送输入数据。第二个微服务将输入数据发送给其他几个微服务,依此类推。相同的会计软件可以运行在云上,数据库、web 服务器和其他组件分布在多个地理区域。
微服务是模块化的。它们的组件是独立构建的,只有在需要创建应用程序时才会关联起来。通过软件重用,为微服务构建的数据库组件可以是两个不同软件应用程序的一部分。
下图直观地展示了单片和微服务之间的区别。关键的一点是,monoliths 是具有若干服务的大型单元,而使用微服务的应用程序是由若干独立的微服务组成的。

企业软件应用哪个好?
传统上,软件应用程序是作为整体构建的。然而,随着云技术的进步,特别是容器化,微服务在交付软件方面变得流行起来。谷歌趋势显示,微服务在 2013 年后开始流行。也是在 2013 年,领先的集装箱化技术 Docker 发布。

微服务比单片更灵活,因为微服务之间有更多的隔离。构建、测试和部署一个单一的应用程序涉及到整个代码库。您可以构建每个微服务并独立测试,而无需构建更大的应用程序。微服务的灵活性也意味着它们比整体服务更具可重用性。要重用来自 monolith 的代码,您需要为新的应用程序创建接口。通过 API,微服务可以与其他应用程序直接交互,从而更容易重用。
容器是一个轻量级的、可移植的计算环境,其中包含了独立运行所需的所有文件。容器化是使应用程序作为容器运行的过程。容器化有助于微服务通过扩展获得普及和广泛采用。微服务应用利用 Kubernetes 等云编排工具来调度和扩展工作负载。
假设一个应用程序包含一个数据库和一个 web 前端,但是这个数据库还服务于另一个应用程序。Kubernetes 节点通过增加或减少每个服务的负载来动态管理前端和数据库的负载。Kubernetes 节点服务于 2 个应用程序,并且只使用任务所需的资源。monolith 只能通过添加更多节点来扩展整个应用程序,从而产生不必要的成本。
企业软件应用程序大规模运行,并与其他产品竞争市场份额。我们在 DORA metrics 上的帖子讨论了部署频率、交付周期、平均恢复时间(MTTR)和变更失败率等基于敏捷性的指标对于提高盈利能力、市场份额和生产效率的重要性。微服务比单片更敏捷、更灵活,允许微服务应用更快地投放市场,并实现大规模成本节约。微服务可以通过反馈迭代交付,而不是作为单一的可执行文件交付。微服务的优势使其非常适合企业软件应用。
使用微服务的挑战
尽管有很多好处,但在单片上使用微服务还是存在挑战。使用微服务的应用程序可以对一个函数进行数百次 API 调用,而 monolith 应用程序只需要一次。对于需要多个函数的应用程序来说,Monoliths 可以有更高的性能,因为每个函数不需要多个 API 调用。
整体架构和微服务架构都可能很复杂。当开发一个整体时,你最终会得到一个大的应用程序代码库。单个开发人员或团队不太可能完全理解应用程序。
微服务包含多个交互服务,每个服务可以使用不同的框架,这使得它更加复杂。随着服务数量的增长,微服务中的服务数量也增加了对文档的需求。
微服务中的停机时间可能会对应用程序产生级联效应。尽管微服务是独立的,但它们是相互联系的。如果一个微服务发送不正确的输出,这可能会导致其他微服务的行为不可预测。微服务是分散的,这就引入了网络问题。防火墙、延迟和安全性在微服务中是比在单片服务中更重要的问题,在单片服务中,应用程序是独立的,并且在中央位置运行。
结论
单片和微服务是软件开发的两种方法。2013 年左右,随着云和容器技术的改进,微服务开始流行。Monoliths 是一个单一的可执行程序,提供了高性能,但灵活性较低。微服务是独立的服务,它们组成了一个更大的应用程序,提供高敏捷性、灵活性和可伸缩性。这些优势使微服务更适合企业软件应用,只要你意识到挑战。
愉快的部署!
使用 Octopus Deploy 的多云 Kubernetes-Octopus Deploy
在云平台上容器化应用是一个热门话题。三大云提供商(Azure、亚马逊网络服务(AWS)和谷歌云平台(GCP))都实施了 Kubernetes (K8s)平台服务:
- 蓝色库柏服务(AK)
- Elastic Kubernetes Service (EKS)
- 谷歌 Kubernetes 引擎(GKE)
在本文中,我演示了使用 Octopus Deploy 从一个 K8s 云平台迁移到另一个平台是多么容易。
创建集群
在开始部署之前,在上面提到的每个云提供商(Azure、AWS 和 GCP)中创建一个集群。每个提供程序都有可供您使用的命令行界面(CLI)。
使用 Octopus Deploy 的 Runbooks 特性来创建集群。此外,您需要使用Workers特性的执行容器,因为 Worker tools 镜像包含了所有三个平台以及 kubectl 的 CLI。
(以下截图是在用章鱼云。Octopus 的自托管实例需要创建一个安装了 Docker 的 Worker 来使用这个特性。)

您需要为 Docker 注册中心(如 Docker Hub)配置一个外部提要,以使用执行容器特性。
蔚蓝的
要使用 AKS,首先需要创建一个 Azure 服务主体。
这篇文章假设你熟悉如何创建 Azure 服务主体,所以不做讨论。
创建服务主体后,将其添加为 Octopus Deploy 中的 Azure 帐户。
您需要以下信息才能将其添加到 Octopus:
- 订阅 ID
- 目录(租户)ID
- 应用程序(客户端)ID
- 应用程序密钥/密码(应用程序注册的客户端密码)
微软开发了 Azure CLI 来连接你所有的 Azure 资源。使用 CLI,您可以创建一个 K8s 集群,并通过 3 个步骤将其添加到 Octopus Deploy:
- 创建资源组
- 创建 K8s 集群
- 将集群添加为部署目标
创建资源组
流程中的前两步使用了运行 Azure 脚本步骤模板。
向 runbook 添加一个步骤,选择 Azure 类别,然后选择运行 Azure 脚本步骤。

运行 Azure 脚本需要您之前配置的 Azure 帐户,因此选择该帐户,然后添加以下脚本:
$resourceGroupName = "<ResourceGroupName>"
$resourceGroupLocation = "<ResourceGroupRegionCode>"
if ((az group exists --name $resourceGroupName) -eq $false)
{
Write-Output "Creating resource group $resourceGroupName in $resourceGroupLocation"
az group create --location $resourceGroupLocation --name $resourceGroupName
}
创建 K8s 集群
创建了资源组之后,您现在可以创建 K8s 集群了。
重复创建资源组的步骤,向 runbook 流程添加另一个Run Azure 脚本。
添加以下脚本:
# Get the variables
$clusterName = "<Name of cluster to create>"
$resourceGroupName = "<Resource group name you created from previous step>"
$azureLocation = "<Azure region code>"
$dnsPrefix = "<DNS prefix>"
$azureNodeSize = "<VM size to be used for nodes>"
$azureServicePrincipalClientId = "<Client ID>"
$azureServicePrincipalSecretKey = "<Key/Password for Service Principal Account>"
# Create the Azure Kubernetes cluster
$azureKubernetesCluster = az aks create --name $clusterName --resource-group $resourceGroupName --dns-name-prefix $dnsPrefix --location $azureLocation --node-count 1 --node-vm-size $azureNodeSize --generate-ssh-keys --service-principal $azureServicePrincipalClientId --client-secret $azureServicePrincipalSecretKey
$azureKubernetesCluster = $azureKubernetesCluster | ConvertFrom-JSON
$azureKubernetesCluster
如果您将 Azure 帐户添加为变量,您可以直接从变量中检索客户端 ID 和密钥/密码,而无需再次输入。例如,如果创建名为Azure.Account.Name的变量,可以使用以下语法:
$clientId = $OctopusParameters['Azure.Account.Name.Client']
$secretKey = $OctopusParameters['Azure.Account.Name.Password']
将集群添加为部署目标
第三步也是最后一步是注册集群,将 Octopus Deploy 作为部署目标。
Octopus Deploy cmdlet New-OctopusKubernetesTarget使得创建 K8s 集群作为目标成为一行操作。
向操作手册添加一个运行脚本步骤,并使用以下脚本:
# Get the variables
$clusterName = "<Name of the cluster>"
$resourceGroupName = "<Name of the resource group the cluster is in>"
# Add new Kubernetes cluster target
New-OctopusKubernetesTarget -Name "<Display name of target>" -clusterName $clusterName -clusterResourceGroup $resourceGroupName -octopusRoles "<Role list>" -octopusAccountIdOrName "<Name of Azure Account>" -namespace "default" -skipTlsVerification $true
自动警报系统
与 Azure 类似,首先在 Octopus Deploy 中创建一个 AWS 帐户,以便与您的 AWS 资源进行交互。
这篇文章假设你熟悉如何创建 AWS IAM 用户。
要在 Octopus 中创建 AWS 帐户,您需要以下内容:
亚马逊开发了 AWS CLI,可以用来与你所有的 AWS 资源接口。使用 CLI,您可以创建一个 K8s 集群,并分两步将其添加到 Octopus Deploy:
- 创建 EKS 集群
- 将集群添加为部署目标
创建 AWS 帐户的另一种方法是在虚拟机上使用 IAM 角色来执行集群的创建。使用 IAM 角色将在创建 EKS 集群步骤中指定。
创建 EKS 集群
要创建 EKS 集群,首先在 runbook 中添加一个Run AWS CLI 脚本。向操作手册添加一个步骤,选择 AWS 类别:

运行 AWS CLI 脚本的能够使用 IAM 角色或在不同的 AWS 服务角色下执行。对于这篇文章,您使用前面创建的 AWS 帐户。除了帐户之外,模板还需要知道 AWS 地区代码。添加之后,添加以下脚本来创建 EKS 集群:
# Get variables
$clusterName = "<Name of the cluster>"
$region = "<AWS Region code>"
$roleArn = "<AWS Role Arn that can create K8s clusters>"
$subnet1Id = "<ID of first subnet to use in your AWS VPC>"
$subnet2Id = "<ID of second subnet to use in your AWS VPC>"
$securityGroupId = "<ID of the security group to use in your AWS VPC>"
# Create EKS cluster
$eksCluster = aws eks create-cluster --name $clusterName --role-arn $roleArn --resources-vpc-config subnetIds=$subnet1Id,$subnet2Id,securityGroupIds=$securityGroupId
$eksCluster = $eksCluster | ConvertFrom-JSON
# Wait until the cluster is in a CREATING state
Write-Host "Waiting for cluster to be done creating..."
while ($eksCluster.Cluster.Status -eq "CREATING")
{
# Wait for cluster to be done creating
$eksCluster = aws eks describe-cluster --name $clusterName --instance-types "t3.medium" --instance-count 1
$eksCluster = $eksCluster | ConvertFrom-JSON
}
# Display the final status of the cluster
Write-Host "Status of cluster: $($eksCluster.Cluster.Status)"
Write-Host "Creating node group..."
aws eks create-nodegroup --cluster-name $clusterName --nodegroup-name "$clusterName-workers" --subnets $subnet1Id $subnet2Id --instance-types "t3.medium" --node-role $nodeRoleArn
# Save the endpoint to an output variable
Set-OctopusVariable -name "EKSURL" -value $eksCluster.Cluster.Endpoint
在三种 CLI 实现中,EKS 是唯一一种要求您在单独的命令中定义节点的实现。
将集群添加为部署目标
向 runbook 添加一个运行脚本步骤(参见 Azure 部分的截图以供参考)。再次使用New-OctopusKubernetesTarget cmdlet,但是参数略有不同:
# Get the variables
$clusterName = "<Name of cluster>"
$region = "<AWS region code>"
$eksUrl = $OctopusParameters['Octopus.Action[Create EKS Cluster].Output.EKSURL']
# Add new Kubernetes cluster target
New-OctopusKubernetesTarget -Name "<Display name of target" -clusterName $clusterName -octopusRoles "<Role list>" -octopusAccountIdOrName "<Name of AWS Account>" -namespace "default" -skipTlsVerification $true -clusterUrl $eksUrl
GCP
与其他两种方法一样,您首先需要在 Octopus Deploy 中创建一个 Google Cloud 帐户。
这篇文章假设你熟悉如何在 GCP 创建一个服务账户,所以不讨论这部分。
要创建 Google Cloud 帐户,您需要在向服务帐户添加Key时生成的 JSON 密钥文件。
谷歌开发了 gcloud CLI,它可以与你所有的 GCP 资源进行交互。使用 CLI,您可以创建一个 K8s 集群,并分两步将其添加到 Octopus Deploy:
- 创建 GKE 集群
- 将集群添加为部署目标
创建 GKE 集群
要创建 GKE 集群,您需要在 runbook 的脚本步骤中添加一个 Run gcloud。选择 谷歌云类别➜在脚本步骤中运行 Gcloud。

与 AWS 类似,在脚本中运行 g cloud步骤可以使用 VM 服务帐户来执行操作以及模拟。对于这篇文章,请使用您之前创建的 Google 帐户。
填写以下内容:
- 谷歌云账户
- 项目(谷歌云项目)
- 区域或地带
接下来,粘贴以下脚本:
# Get variables
$clusterName = "<Cluster name>"
# Get the GKE default kubernetes version
$kubernetesVersion = (gcloud container get-server-config --flatten="channels" --filter="channels.channel=STABLE" --format="json" | ConvertFrom-JSON)
$kubernetesVersion = $kubernetesVersion.defaultClusterVersion
# Create the GKE cluster
$gkeCluster = (gcloud container clusters create $clusterName --cluster-version=$kubernetesVersion --num-nodes=1 --format="json" | ConvertFrom-JSON)
# Save the end point
Set-OctopusVariable -name "GKEURL" -value $gkeCluster.Endpoint
将集群添加为部署目标
在 runbook 中添加一个运行脚本步骤(参考 Azure 部分的截图)。在撰写本文时,New-OctopusKubernetesTarget cmdlet 还没有更新到可以与 GCP 一起使用,所以注册目标的脚本看起来会有点不同。
# Get the variables
$clusterName = "<Cluster name>"
$octopusUrl = "<Url of your Octopus server>"
$apiKey = "<API Key for registering target>"
$spaceId = $OctopusParameters['Octopus.Space.Id']
$headers = @{ "X-Octopus-ApiKey" = $apiKey }
# Add new Kubernetes cluster target
$newMachine = @{
Name = "<Display name of target>"
Endpoint = @{
CommunicationStyle = "Kubernetes"
Authentication = @{
AuthenticationType = "KubernetesGoogleCloud"
AccountId = "<Google Account>"
UseVmServiceAccount = $false
ImpersonateServiceAccount = $false
Project = "<Google Project Name>"
Region = "<Google region code>"
ClusterName = $clusterName
}
AccountType = "GoogleCloudAccount"
DefaultWorkerPoolId = "<Your worker pool id>"
Container = @{
FeedId = "<Your external feed id>"
Image = "octopusdeploy/worker-tools:3.0.0-ubuntu.18.04"
}
}
Roles = @("Test1")
EnvironmentIds = @($OctopusParameters['Octopus.Environment.Id'])
}
# Call API to register cluster
Invoke-RestMethod -Method Post -Uri "$octopusUrl/api/$spaceId/machines" -Body ($newMachine | ConvertTo-JSON -Depth 10) -Headers $headers
在 GKE 的情况下,您需要指定一个用于健康检查的工作池,并使用执行容器特性。这是因为 Octopus Cloud 中的Hosted Windows Worker Pool 没有安装 gcloud CLI,在尝试检查 GKE 集群的运行状况时会失败。
2021 年 11 月更新——New-OctopusKubernetesTarget已经更新,可以在 GKE 使用。
New-OctopusKubernetesTarget -Name "<Display name of target>" -clusterName $clusterName -octopusRoles "Test1" -octopusAccountIdOrName "<Google Account>" -namespace "default" -skipTlsVerification $true -octopusDefaultWorkerPoolIdOrName "Hosted Ubuntu" -healthCheckContainerImageFeedIdOrName "Docker Hub" -healthCheckContainerImage "octopusdeploy/worker-tools:3-ubuntu.18.04" -clusterRegion <Google region> -clusterProject <Google project name>
如果所有三个 runbooks 都被执行,您应该有 3 个 Kubernetes 集群。

转换云提供商 K8s 服务
考虑以下场景:您的组织选择使用 AWS 作为其云提供商。您使用以下过程将您的应用程序 PetClinic 部署到 EKS:
- 部署 MySQL :这一步将 MySQL 容器部署到 K8s 集群,作为数据库后端。
- 运行 flyway :该步骤执行一个 K8s 作业,该作业将在 MySQL 容器上创建和播种数据库。
- 使用负载平衡器部署 petclinic web:该步骤为 pet clinic web 前端创建一个部署,并在其前面放置一个负载平衡器。
- 部署 Kubernetes 入口资源:这一步在负载均衡器前面创建一个 NGINX 入口控制器。
您的组织刚刚被另一家公司收购,您必须遵守他们的标准,包括云提供商。新的母公司使用 GCP 的所有应用程序,现在您的工作是将 PetClinic 从 EKS 转换到 GKE。
与 Azure Web App 或 AWS Elastic Beanstalk 不同,K8s 部署的 Octopus 部署步骤不是特定于提供者的。同样的过程适用于任何注册为部署目标的 K8s 集群。
大多数向新平台的迁移都是从部署到旧平台和新平台开始的,因此您可以确保它们的功能相同。运行您的 GKE runbook 在 GCP 创建一个 K8s 集群。集群在 Octopus 中注册并显示为健康状态后,创建新版本或重新部署现有版本。
在下面的屏幕截图中,您可以看到两个目标的部署都是成功的,没有对部署过程进行任何更改:

如果您运行 runbook 来创建 AKS 集群,您可以看到所有三个目标的部署都是成功的。

结论
Octopus Deploy 只需要将 API 端点部署到 Kubernetes 集群。无论 K8s 集群是内部部署、云提供商 K8s 服务还是云中运行 Kubernetes 的虚拟机,都没有关系。如果 Octopus Deploy 可以与 K8s API 端点通信,那么它就可以部署到目标,而不必更改流程。
观看网络研讨会
https://www.youtube.com/embed/qlsk8zdTcLA
VIDEO
我们定期举办网络研讨会。请参见网络研讨会页面了解过去的网络研讨会以及即将举办的网络研讨会的详细信息。
愉快的部署!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号