DataQuest-博客中文翻译-一-
DataQuest 博客中文翻译(一)
您现在可以加入的 10 个数据科学项目
原文:https://www.dataquest.io/blog/10-data-science-projects-join/
February 6, 2018Editor’s note: This post was written as part of a collaboration with data.world, a site for sharing and hosting data. Authors Shannon Peifer and Gabriela Swider are on the data.world team. Finding the right data can be difficult. And even once you have it, how do you collaborate with others to make sense of it? People work harder and learn more when they’re able to discover data they’re passionate about. Sharing those passions with other data scientists makes problem-solving easier. Here are some great projects from people doing just that.
1.移除脸书页面:参与度指标和帖子通过 @d1gi
作为杰出的数据新闻工作的一个例子,该数据集通过挖掘 2016 年美国总统选举期间通过脸书的外部影响数据,直面了一些社会上最大的社交媒体问题。该调查随后被一些出版物报道,包括
《华盛顿邮报》和《T2 时报》和《纽约时报》。Tow 数字新闻中心的 Jonathan Albright 在这里展示的数据是五个所谓的外国影响 ops 页面中每一个页面上未推广的有机到达帖子的目录。随着每个帖子的完整文本存档,这些数据揭示了使用脸书平台的更大潜在影响,而不仅仅是一次广告购买。具体来说,这里介绍的工作表明,这五个关闭的页面的内容有更广泛的曝光。此外,关于这个数据集的讨论是我们今年在 data.world 上看到的最引人入胜的讨论。Jonathan 鼓励你将这个数据集用于自己的研究和分析。这个集合数据集也是展示 data.world 上其他数据新闻工作的极好资源
Interactive visualization by Jonathan Albright
Our team can’t wait to see what the new year has in store for the data.world community. Stay in the loop on the best new data sets and projects of 2018 by
2.币量经由@天窗猴
如果你有先见之明,在去年的这个时候投资比特币,你可能会处于有利地位。如果没有,您可以使用
比特币后悔计算器在这个数据集中找出你本可以获利多少。该项目将使用 IFTTT 上的 data.world sync 小程序,从数据聚合和可视化服务 Coin Metrics 获取最新的每日硬币数据。在数据集讨论中查看十几种加密货币的价格趋势和各种支持可视化。
Data visualization by Patrick McGarry
3.联邦项目如何应对阿片类药物的流行?via@ USA spending
在美国,阿片类药物滥用导致的用药过量率上升是一个影响全国家庭的惊人趋势。财政部通过 USAspending.gov 发布在 data.world 上的最新数据包括详细的项目描述和机构信息,让人们深入了解联邦政府解决这一问题的努力。
@haotianxu91 深挖这个数据集,看看联邦数据能否与阿片类药物滥用治疗和预防项目联系起来。在这里探索他的发现。通过 data.world 将数据公之于众,许多地方、州和联邦政府机构在支出方面正在朝着更好的问责制和透明度迈进。在 data.world 上通过搜索机构的 data.world 组织名称来查找更多政府数据。
Insight by Haotian Xu
4.通过@链接数据
链接电影数据库
在 data.world,我们相信
(不久的)数据的未来是关联的,我们很高兴看到更多的社区成员释放关联数据的真正潜力,并使用 SPARQL,一种用于数据库的语义查询语言(和我们的 owl 吉祥物同名)。该数据集中的一个查询重现了 SPARQL 中著名的“六度凯文·贝肯”问题——对于数据库中的任意两个演员,该查询将找到(如果存在的话)恰好六个连接的路径,通过他们一起出演的电影中的其他演员。准备好玩“SPARQL 六度?”只需用您选择的演员替换查询的第 7 行和第 8 行中的演员姓名,然后点击“运行查询”(警告:这可能太有趣了,不能只运行一次)。
5.哈维飓风:最需要邻里经由@ alyssa analyses
39 个县被列入哈维飓风总统宣布的灾区名单。虽然大多数遭受财产损失的地区需要援助来支付修复和重建费用,但资源有限的地区更多地受益于联邦灾难恢复计划的精心选择。SP 集团确定了那些最容易受到财产损失负面影响的社区,并在 data.world 上公布了数据。他们不是唯一这样做的人;
在 data.world 上搜索“哈维飓风”会返回由各种社区成员和组织创建的数十个数据集,所有这些数据集都旨在通过让最需要的人更容易获得重要数据来帮助飓风恢复工作。
Data visualization by Alyssa Spina
6.新泽西州法医数据经由 @stevestirling
2017 年见证了
根据柯林斯字典,“假新闻”一词的使用增加了 365%。尽管对媒体的怀疑和不信任越来越多,但今年我们已经看到新闻领域发生了重大转变,数据成为全球顶级新闻媒体可信度的基石。这个数据集中的数据是在长达数月的记录之争后从新泽西的州法医办公室获得的,在公布后的 24 小时内,即将上任的州长菲尔·墨菲承诺在即将到来的立法会议上对该系统进行“大规模改革”。我们喜欢这个数据集,因为它是一个令人难以置信的例子,说明数据驱动的新闻如何帮助通知社区,甚至影响公共政策。在死亡&机能障碍:新泽西州如何辜负死者,背叛生者,是国家耻辱中阅读更多关于新泽西州前进媒体 18 个月的调查。
7.药费经由 @data4democracy
Data for Democracy 始于 2016 年 12 月的一项实验,当时来自世界各地的人们开始通过使用 Slack 进行规划,使用 GitHub 进行代码,使用 data.world 进行数据协作,来协作解决与数据相关的问题。在没有规则或正式组织结构的情况下,重点是以最小的延迟完成真实且有影响力的工作。该数据集是该组织发起的第一批项目之一,该组织已发展到包括全球 2000 多名电子志愿者。使用这个数据集和 data.world R 包,社区成员珍妮·汤普森能够收集一个仪表板所需的数据,创建并发布一个派生数据集,并构建一个闪亮的仪表板,从站点中提取实时数据。阅读 R Views 中詹妮弗的故事,看看她是如何做到的。
8.全国足迹账户— 2017 版经@足迹
格林纳达、圭亚那和冈比亚有什么共同点?它们都在全球足迹网络的生态足迹最低的国家名单上。全球足迹网络的国家足迹账户衡量自 1961 年以来各国的生态资源使用和资源能力。该组织在 data.world 上发布了 2017 年版背后的数据,导致了一些分析,这些分析有助于我们更好地理解经济增长(GDP)与自然资源消耗之间的关系。加入全球足迹网络,在 2018 年做出改变,减少我们的集体生态足迹。这是很好的第一步:计算你自己的生态足迹
此处。
Data visualization by Noah Rippner
9. Tableau Desktop 101:通过 @tableauhelp
接替数据分析师的工作
TableauHelp 创建了这个很棒的教程来帮助人们升级他们的 Tableau 游戏。数据项目包括一个指南、教程和练习,用于通过一个沉浸式用例学习业务数据分析和可视化的基础知识。想学习如何创建各种视图来浏览 Tableau 中的数据吗?

10.@改头换面星期一
这些数据正使世界变得更加互联,一次一个星期一。来自社会数据项目的成员
改头换面星期一每周发布一个图表及其数据的链接,然后社区重新制作图表。无论是简单的条形图还是复杂的信息图,他们都鼓励每个人参与其中。在 https://www.makeovermonday.co.uk/的加入挑战。
商业分析的 10 大投资组合项目(2022)
原文:https://www.dataquest.io/blog/10-great-portfolio-projects-for-business-analysis/
August 10, 2022
如果你想得到一份商业分析师的工作,你需要一个相关项目的投资组合。为什么?至少有两个合理的理由:
- 创建业务分析师项目是练习技能的绝佳方式。做不同的练习是好的,但是构建一个端到端的项目可以让您应用各种技能来解决现实世界的挑战。
- 你的商业分析师项目组合在你找工作的过程中是必不可少的。要获得一个商业分析师职位的面试机会,你需要的不仅仅是一份引人注目的简历和一份列出你所有证书和品质的清单。你真正需要的是展示你的技能——最好的方法是用项目组合。
在这篇文章中,我们将分享 10 个伟大的项目,你可以把它们添加到你的文件夹中,以帮助磨练你的技能和获得下一次面试。
1.销售数据分析
作为一名业务分析师,您可能会处理销售数据,因为它对您公司的商业成功起着至关重要的作用。无论这意味着理解当前的销售还是预测未来的销售,这都是雇主寻求的一项关键技能。
销售记录通常包含公司客户、客户销售订单、付款历史、产品类别等信息。这些数据使您可以分析客户的人口统计数据,他们购买哪些产品,何时购买,他们产生了多少收入,他们对促销的反应如何,等等。
如何构建您的项目
可以拿一个可用的数据集(比如这个:销售产品数据)从各个方面分析销售数据。这里的主要目标是提取关键绩效指标(KPI ),使您能够做出数据驱动的决策,并改善您公司的业务。
以下是您可以在销售数据分析项目中尝试回答的一些问题:
- 销售总数是多少?
- 每月平均销售额是多少?
- 每月收入多少?
- 客户的主要统计数据是什么?
- 哪个市场(国家)的平均销售额最高?
- 按部门划分的利润是多少?
- 销售最好和最差的时期是什么时候?
- 哪些产品卖得最好?
- 公司应该订购或多或少的哪些产品?
- 公司应该如何调整针对 VIP 客户和参与度较低的客户的营销策略?
- 公司应该获得新客户吗?他们应该在这上面花多少钱?
2.客户流失率预测
客户流失率也是一个关键的业务指标,可以帮助您改善您的业务。它表示在规定的时间内停止使用贵公司产品或服务的人数百分比。
这一指标尤其适用于基于订阅的业务,在这种业务中,产品的停产很容易被发现:客户已经停止使用您的产品或取消了他们的订阅,因此公司失去了一个客户。
高客户流失率可能表明你的业务存在严重问题:低质量的产品、负面的客户体验、缺乏客户支持等。这就是为什么任何业务的一个关键目标是尽量减少客户流失。
如何构建您的项目
你可以建立自己的项目来预测客户流失率。要做到这一点,需要一个可用的数据集(就像这个:客户流失预测 2020 )并分析一家公司的数据,以确定基于各种因素(如呼叫客户服务的次数和呼叫的总费用)可能流失的客户。
3.客户评论情感分析
顾客评论情感分析是一个在顾客购买了公司产品后检测顾客感受的过程。该公司可以从产品评论、反馈表、帮助中心的入场券、在线调查等渠道收集这些信息。
每个公司都对进行客户反馈情绪分析感兴趣,因为这是一种确定客户投诉的可能原因的安全方法,并加强让客户满意的产品功能。因此,企业可以采取措施及时解决问题,改善客户体验,降低客户流失率,调整营销活动,并实现利润最大化。
如何构建您的项目
要构建一个客户评论情感分析项目,您需要找到一个可用的数据集(例如,带有酒店评论的情感分析),其中包含从某个公司的客户评论中提取的文本数据。或者,考虑自己从网上解析这样的数据。你在这个项目中的任务是对文本数据进行预处理,并使用专门的统计和语言工具对其进行探索,以识别积极、消极和中性的体验,以及理想情况下它们的强度和主观性。
注意文本分析技术的一些内在弱点。例如,他们并不总是能够理解俚语或者很少使用的缩写——或者发现讽刺。
4.市场篮子分析
购物篮分析探究顾客的购物模式。换句话说,我们必须回答这个问题,哪些产品通常会一起购买?举一个简单的日常例子,当有人买鞋时,他们可能也有兴趣买鞋油。然而,在现实世界的市场篮子分析中,例子可能不那么明显。
检测特定的产品关联有助于零售商调整他们的推荐系统,改进营销策略,保持库存平衡,并将相关商品放在商店中彼此靠近的位置。从长远来看,这种方法可以增加公司的销售额,提高客户满意度,并找到新的商机。
如何构建您的项目
作为一个业务分析师项目理念,您可以获取一个零售公司的大量数据(例如,用于购物篮分析(MBA)的杂货数据集)并调查客户的历史交易。你应该专注于对客户购买行为的描述性分析,揭示经常一起购买的有趣产品组合,并为公司提出有价值的建议。
5。价格优化
对任何现代公司来说,估算产品的最优价格都是最重要的任务之一。这既包括刚刚上市的新公司,也包括试图适应不断变化的经济环境的现有公司,或者计划按地理位置或细分市场扩大业务的公司。
为了成功地解决价格优化问题,商业分析师需要调查历史价格、关键价格因素、公司经营所在的市场(及其经济背景)、潜在客户的概况等。
如何构建您的项目
对于这个项目,您可以获取一个零售公司的价格数据数据集(例如, Retail Price Optimization ),其中包含产品名称、历史价格、产品类别和特性、销售量以及时间和地理符号等信息。这里的任务是选择和分析相关的价格形成因素及其对价格的影响程度。你的主要目标应该是计算产品的最优售价,从而为公司提供高效的、基于数据的建议。
6。股市数据分析
股票市场数据分析包括对一般股票市场、特定投资领域或特定交易工具的探索。交易员和投资者需要这种分析来了解市场过去和当前的趋势,从而做出更好的买卖决策。
股票市场每天都会产生大量关于公司价格和交易量的数据。
考虑回答以下问题:
- 公司在某一天涨价(或降价)的频率是多少?
- 一年来的月平均收盘价的大致趋势是什么?
- 交易量有季节性规律吗?
- 公司的每日最高价和最低价之间有关系吗?
- 每日最高价和最低价的巨大差异是否与更高或更低的交易量相一致?
- 最近一年的模式是否与前几年一致?
如何构建您的项目
为了构建您的项目,您可以选择一个特定的数据集(如微软股票数据、亚马逊股票数据,或英特尔股票数据,探索公司的历史股票表现,并找到对未来的见解。
7。客户细分
客户细分包括根据客户的购买行为、财务水平、兴趣、需求和对企业的忠诚度,将公司的客户分成不同的群体。这使得该公司能够将其营销活动和优惠导向正确的目标受众。这种策略有助于企业节省时间,优化工作,最大限度地提高每个客户的利润,并改善客户体验。
如何构建您的项目
对于您的客户细分项目,您可以找到一个包含某个组织的客户数据的可用数据集(就像这个:客户细分分类)。然后,从公司客户的支付能力和购买模式相似性的角度分析数据。最有可能的是,你会发现这种模式取决于广泛的人口统计和地理因素。另一方面,你也可以考虑其他标准,比如零售客户和批发客户。在项目结束时,尝试确定一些建议,说明公司应该向每个细分市场宣传哪些现有产品或正在开发的产品。
请记住,要使您的客户细分模型有效地满足公司的需求,它应该提供合理数量的类别。
8。欺诈检测
欺诈是许多行业普遍存在的问题,如银行、销售和保险。最常见的欺诈活动形式是信用卡欺诈,但还有其他形式,如身份盗窃或网络攻击。这个问题尤其具有挑战性,因为欺诈者的策略在不断变化,变得越来越复杂。这意味着没有一种通用的欺诈检测解决方案。
如何构建您的项目
一个关于欺诈检测的项目将是你的业务分析师投资组合的一项资产。您需要做的是获取一个包含在线交易数据的数据集(例如,这个数据集:信用卡欺诈检测),并使用统计方法对其进行可疑操作分析。欺诈交易有什么共同特征吗?提前了解这些特征(或特征组合)将有助于公司及时识别欺诈行为并采取预防措施。
9。预期寿命分析
预期寿命是某个国家(或地区)健康状况的重要指标。这一指标不仅取决于该国的医学水平,还取决于其环境条件、经济和政治背景以及社会趋势。
分析人均国内生产总值(GDP)和预期寿命之间的相关性是您下一个业务分析项目的好主意。
如何构建您的项目
找到一个合适的数据集(例如,预期寿命(世卫组织)),提供不同国家和地区的预期寿命和人均国内生产总值的信息,使用适当的图表探索和可视化数据,并形成有意义的见解。你可能会注意到每个国家或地区的一些趋势,以及总体趋势。思考以下问题:
- 对于每个地理单元,人均 GDP 和预期寿命之间是否有明显的相关性?
- 预期寿命最高和最低的地理单元是什么?他们的 GDP 呢?
- 在预期寿命较低的地区,还会发生哪些潜在问题?
- 总的来说,现代世界的预期寿命在增长吗?而 GDP 呢?
10。构建商务智能应用
在作为业务分析师的日常工作中,您需要使用商业智能(BI)应用程序,如 Microsoft Power BI。因此,在申请业务分析师工作之前熟悉商业智能,并在项目组合中展示您的商业智能技能是非常重要的。自己构建一个商务智能应用程序是一个很好的方法。
如何构建您的项目
对于这个项目,考虑获取某个公司的可用数据,为其构建一个数据模型,并对与该公司产品相关的各种指标创建一系列分析和可视化。此类指标可能是产品流行度,它显示了客户对不同产品的参与程度,以及产品评级,它表明了客户满意度。尝试回答以下问题:
- 随着时间的推移,哪些产品有所改进?
- 哪些产品随着时间的推移变质了?
- 就受欢迎程度和客户满意度而言,这两类产品(改善与恶化)是否有一些不同的模式?
根据你的调查结果,你可以向公司建议哪些产品需要改进。你可以找到一个这样的项目,作为我们在 Dataquest 开发的业务分析师路径的一部分,在不到一年的时间里,带你从初学者到工作就绪。
外卖
在这个项目总结中,我们考虑了 10 个商业分析师项目的好主意,以添加到您的投资组合中。为您的投资组合构建业务分析师项目是练习您的技能并展示您在业务分析方面的熟练程度的完美方式。
通过学习 Dataquest,您将创建高质量的业务分析项目。我们在本文中讨论的项目想法有一半来自于业务分析师职业道路。对于这些项目中的每一个,您都将收到要分析的数据和要遵循的指导。不言而喻,我们非常欢迎您在所提供的说明的基础上,更深入地挖掘数据,并提取您自己的见解。
祝你好运!
你应该知道的 15 个数据科学 Python 库
原文:https://www.dataquest.io/blog/15-python-libraries-for-data-science/
February 5, 2020
Python 是数据科学家和软件开发人员用于数据科学任务的最流行的语言之一。它可用于预测结果、自动化任务、简化流程以及提供商业智能见解。
在普通 Python 中处理数据是可能的,但是有相当多的开源库使得 Python 数据任务变得非常非常容易。
你肯定听说过其中的一些,但是有没有你可能错过的有用的库呢?这里列出了 Python 生态系统中最重要的数据科学任务库,涵盖了数据处理、建模和可视化等领域。
数据挖掘
1.刺儿头
Scrapy 是最受欢迎的 Python 数据科学库之一,它帮助构建爬行程序(蜘蛛机器人),可以从网络上检索结构化数据,例如 URL 或联系信息。这是一个很好的收集数据的工具,例如,Python 机器学习模型。
开发人员使用它从 API 收集数据。这个成熟的框架在其界面设计中遵循了“不要重复自己”的原则。因此,该工具鼓励用户编写通用代码,这些代码可以重用来构建和扩展大型爬虫。
2.美丽的风景
BeautifulSoup 是另一个非常受欢迎的网页抓取和数据抓取库。如果你想收集一些网站上的数据,但不是通过适当的 CSV 或 API,BeautifulSoup 可以帮助你收集数据,并将其整理成你需要的格式。
数据处理和建模
3.NumPy
NumPy(数值 Python)是科学计算和执行基本和高级数组操作的完美工具。
这个库提供了许多在 Python 中对 n 数组和矩阵执行操作的便利特性。它有助于处理存储相同数据类型值的数组,并使对数组执行数学运算(及其矢量化)更加容易。事实上,NumPy 数组类型上数学运算的向量化提高了性能并加快了执行时间。
4.轨道
这个有用的库包括线性代数、积分、优化和统计模块。它的主要功能是建立在 NumPy 之上的,所以它的数组使用这个库。SciPy 非常适合各种科学编程项目(科学、数学和工程)。它在子模块中提供了高效的数值例程,如数值优化、积分等。大量的文档使得使用这个库变得非常容易。
5.熊猫
Pandas 是一个库,用来帮助开发人员直观地处理“标签”和“关系”数据。它基于两种主要的数据结构:“系列”(一维,像一个项目列表)和“数据框”(二维,像一个有多个列的表)。Pandas 允许将数据结构转换为 DataFrame 对象,处理丢失的数据,从 DataFrame 中添加/删除列,输入丢失的文件,用直方图或绘图框绘制数据。这是数据争论、操作和可视化的必备工具。
(想学熊猫?查看 Dataquest 的 NumPy 和熊猫基础课程,或者我们众多免费熊猫教程中的一个。)
6. Keras
Keras 是一个用于构建神经网络和建模的伟大的库。它使用起来非常简单,并为开发人员提供了很好的可扩展性。该库利用其他包(Theano 或 TensorFlow)作为其后端。此外,微软整合了 CNTK(微软认知工具包)作为另一个后端。如果你想使用紧凑的系统快速进行实验,这是一个很好的选择——极简主义的设计方法真的有回报!
7. SciKit-Learn
这是基于 Python 的数据科学项目的行业标准。Scikits 是 SciPy 堆栈中的一组包,它们是为特定功能(例如图像处理)而创建的。Scikit-learn 使用 SciPy 的数学运算向最常见的机器学习算法展示了一个简洁的接口。
数据科学家使用它来处理标准的机器学习和数据挖掘任务,如聚类、回归、模型选择、维度减少和分类。另一个优势?它配有高质量的文档,并提供高性能。
8.指针
PyTorch 是一个非常适合希望轻松执行深度学习任务的数据科学家的框架。该工具允许使用 GPU 加速执行张量计算。它还用于其他任务,例如,创建动态计算图和自动计算梯度。PyTorch 基于 Torch,这是一个用 C 实现的开源深度学习库,封装器在 Lua 中。
9. TensorFlow
TensorFlow 是一个流行的用于机器学习和深度学习的 Python 框架,由 Google Brain 开发。它是对象识别、语音识别和许多其他任务的最佳工具。它有助于处理需要处理多个数据集的人工神经网络。该库包括各种层助手(tflearn、tf-slim、skflow),这使得它的功能更加强大。TensorFlow 不断推出新版本,包括潜在安全漏洞的修复或 TensorFlow 和 GPU 集成的改进。
10. XGBoost
使用这个库在梯度提升框架下实现机器学习算法。XGBoost 具有可移植性、灵活性和高效性。它提供并行树提升,帮助团队解决许多数据科学问题。另一个优势是,开发人员可以在 Hadoop、SGE 和 MPI 等主流分布式环境中运行相同的代码。
数据可视化
11. Matplotlib
这是一个标准的数据科学库,有助于生成数据可视化,如二维图表和图形(直方图、散点图、非笛卡尔坐标图)。Matplotlib 是那些在数据科学项目中非常有用的绘图库之一,它提供了一个面向对象的 API,用于将绘图嵌入到应用程序中。
正是由于这个库,Python 可以与 MatLab 或 Mathematica 这样的科学工具竞争。然而,开发人员在使用这个库生成高级可视化时,需要编写比平时更多的代码。请注意,流行的绘图库可以与 Matplotlib 无缝协作。
12. Seaborn
Seaborn 基于 Matplotlib,是一个有用的 Python 机器学习工具,用于可视化统计模型——热图和其他类型的可视化,这些模型汇总数据并描述整体分布。使用这个库时,您可以从大量的可视化图库中获益(包括复杂的图形,如时间序列、联合图和小提琴图)。
13.散景
这个库是一个很好的工具,可以使用 JavaScript 小部件在浏览器中创建交互式和可伸缩的可视化。Bokeh 完全独立于 Matplotlib。它侧重于交互性,并通过现代浏览器呈现可视化——类似于数据驱动文档(d3.js)。它提供了一组图形、交互能力(比如链接图或添加 JavaScript 小部件)和样式。
14.阴谋地
这款基于网络的数据可视化工具提供了许多有用的现成图形,您可以在 Plot.ly 网站上找到它们。该库在交互式 web 应用程序中工作得非常好。它的创建者正忙于用新的图形和特性来扩展库,以支持多链接视图、动画和相声集成。
15.pydot
这个库有助于生成有向图和无向图。它充当 Graphviz(用纯 Python 编写)的接口。在这个库的帮助下,你可以很容易地显示图形的结构。当你开发基于神经网络和决策树的算法时,这是很方便的。
结论
这个列表并不完整,因为 Python 生态系统提供了许多其他工具来帮助完成机器学习任务和构建算法。参与使用 Python 的数据科学项目的数据科学家和软件工程师将使用许多这些工具,因为它们对于用 Python 构建高性能 ML 模型是必不可少的。
你知道其他对 ML 项目有用的库吗?请告诉我们您认为对 Python 数据生态系统至关重要的其他工具!
这篇文章是一家专注于 Python 的软件开发公司 Sunscrapers 的客座贡献。Sunscrapers 主办并赞助了许多 Python 活动和会议,鼓励其工程师分享他们的知识并参与开源项目。
18 位在数据科学、人工智能、大数据和机器学习领域鼓舞人心的女性
原文:https://www.dataquest.io/blog/18-inspiring-women-in-ai-big-data-data-science-machine-learning/
March 23, 2018
女性在 STEM 领域——科学、技术、工程和数学——的代表性不足。例如,1960 年,女性占计算机和数学行业从业人员的 27%。但根据 2015 年对美国人口普查数据的分析,随着越来越多的女性加入劳动力大军,这一数字在几十年间并没有增长,而是在 2013 年下降到了 26%。
然而,我们希望 STEM 中的女性人数会增加,为了纪念国际妇女节,这里有 18 位在人工智能、分析、大数据、数据科学、机器学习和机器人领域鼓舞人心的女性的简介。
-
凯莉·格里姆斯·博斯托克,谷歌杰出的工程师。Grimes 在 Google 度过了她的职业生涯,目前她在技术研究所小组中从事数据驱动的资源规划、成本分析和分布式集群管理软件的工作。Grimes 拥有斯坦福大学统计学博士学位和哈佛大学人类学学士学位。
-
Meta S. Brown , @metabrown312 ,是一名顾问、演讲者和作家,致力于推广商业分析的应用。作为一名实干分析师,她处理过高达 9 亿美元的风险项目,是尖端商业分析领域公认的专家。
-
詹妮弗·蔡斯,@詹妮弗·蔡斯,杰出的科学家,微软研究院常务董事。Chayes 在“大数据中的女性”活动的职业小组讨论中说:“你不应该让你对自己能力的恐惧或对你可能是骗子或其他事情的恐惧对你做出的决定产生任何影响。你应该把你大脑的那一部分拿出来,对你的分享说声谢谢,然后把它放在一边。我们都有大脑的那一部分,如果我听从了大脑的那一部分,我的生活就会非常无聊。”Chayes 拥有普林斯顿大学的数学物理学博士学位。
-
西尔维亚·基亚帕, @csilviavr ,是 DeepMind 的高级研究科学家,从事概率建模和深度学习的交叉研究。在加入 DeepMind 之前,她曾在剑桥微软研究院、剑桥大学统计实验室和马克斯·普朗克生物控制论研究所工作。
-
吉尔·戴奇,@吉尔·戴奇,SAS 研究所 SAS 最佳实践副总裁。她是几本书的作者,包括最近的一本,新 IT:技术领导者如何在数字时代实现商业战略。Dyche 目前正在进行一个兼职项目,这是一本电子书,倡导对动物收容所的做法进行简单的改进,以提高宠物收养率。
-
Jana Eggers, @jeggers ,Nara Logics 首席执行官,这是一家受神经科学启发的人工智能公司,提供了一个推荐和决策支持的平台。她的职业生涯使她从 3 人创业发展到 5 万人的企业。她开设了欧洲物流软件办公室,作为美国航空公司的一部分,1996 年在 Lycos 涉足互联网,创建了 Intuit 的企业创新实验室,帮助定义 Spreadshirt 的大规模定制,并在洛斯阿拉莫斯国家实验室研究导电聚合物。
-
Carla Gentry, @data_nerd ,是社交媒体上最具数据科学影响力的人之一。她目前是 Samtec 的数字营销经理。她与许多财富 500 强公司合作过。她能够利用庞大复杂的数据库,解读业务需求,并带回量化支出、利润和趋势的情报。对于这位好奇的数学家/经济学家来说,被称为数据呆子是一种勇气的象征,因为知识就是力量,公司现在也认识到了它的重要性。
-
尼基塔·约翰逊、@尼基塔·约翰逊是 RE WORK 的创始人,RE WORK 是一家活动组织公司,汇集了行业、创业公司和学术界的跨学科组合,以探索新兴技术的最新进展,特别是人工智能,以及它们对解决社会挑战的影响。
-
费-李非, @drfeifei ,是斯坦福大学计算机科学系的副教授,也是斯坦福大学人工智能实验室和斯坦福大学视觉实验室的主任,在那里,她与世界上最优秀的学生和同事一起构建智能算法,使计算机和机器人能够看到和思考,并进行认知和神经成像实验,以探索大脑是如何看到和思考的。她获得了加州理工学院的博士学位。
-
希拉里·梅森,@赫马森,是 Cloudera 的研究副总裁。她还是机器智能研究公司 Fast Forward Labs 的创始人,曾是 Accel 的常驻数据科学家和 bitly 的首席科学家。她喜欢数据和芝士汉堡。
-
计算与数学工程研究所(ICME)执行董事凯伦·马特斯(Karen Matthys)。她正致力于 30by30 运动,该运动的目标是到 2030 年将各级组织中从事计算机科学和工程工作的女性比例提高到 30%。
-
Neha Narkhede, @nehanarkhede ,是 Confluent 公司的联合创始人兼首席技术官,该公司正在开发一种流行的大数据工具,实现实时流媒体功能——Apache Kafka,这是联合创始人在 LinkedIn 工作时开发的技术。
-
Amy O'Connor, @iamamyo ,Cloudera 的大数据布道者。她于 2013 年加入 Hadoop 分销商 Cloudera,从诺基亚来到该公司,担任大数据高级总监。在 Cloudera,她为客户介绍和采用大数据解决方案提供建议。她拥有康涅狄格大学电气工程学士学位和东北大学 MBA 学位。
-
人权数据分析小组执行主任梅根·普莱斯@ HR Dag。她的组织利用统计分析来揭示用于证词的证据,以推动行动和变革。该组织已经在包括危地马拉、哥伦比亚和叙利亚在内的一些地方开展了一些项目。在叙利亚的项目中,普莱斯是首席统计师,也是最近两份报告的作者,这两份报告是由联合国人权事务高级专员办公室提供的,是关于该国有记录的死亡人数的。她是卡内基梅隆大学人权科学中心的研究员,并获得了生物统计学博士学位。
-
Monica Rogati, @mrogati ,Insight Data Science 顾问公司数据集合的股权合伙人。莫妮卡是可穿戴设备公司 Jawbone 的前数据副总裁,也是 LinkedIn 的前数据科学家。如今,她专注于为 Data Collective venture capital group 提供技术尽职调查和建议,并担任 Insight Data Science Fellows 计划的顾问,该计划是一项博士后培训奖学金,旨在弥合学术界和数据科学职业之间的差距。
-
网飞大学科学与算法副总裁 Caitlin Smallwood 。她在这家数字娱乐公司领导着一个由数学家、数据科学家和统计学家组成的高级团队。她的团队专注于预测建模、算法研究和原型制作,以及整个公司的其他深度分析。她的职业生涯包括在雅虎担任数据解决方案总监,在普华永道担任定量咨询高级经理。
-
Kelly Thompson ,SVP,沃尔玛电子商务全球品类开发和商品解决方案部。汤普森负责沃尔玛的战略、结构和运营模式,将商品销售与数据和分析结合起来。沃尔玛是世界上最大的公司之一,人们认为大公司很慢,但汤普森说她的组织实际上正在这个大公司内部建立一些更加敏捷的东西。
-
马诺拉·玛利亚·贝洛索是司马贺大学卡耐基·梅隆大学计算机科学学院的教授。她在 2014 年之前一直是 AAAI 总统,也是机器人世界杯联合会的联合创始人和前任主席。她是 AAAI、IEEE、AAAS 和 ACM 的会员。她是人工智能和机器人领域的国际专家。
这篇文章的部分内容之前发表在 KDnuggets 上。
编者按:这最初是发布在 KDNuggets 上,现在已经被 perlesson 转载。作者格里高利·皮亚泰茨基是 KDNuggets 的总裁和 ACM SIGKDD 的联合创始人。
面向初学者的 20 个数据科学项目及其源代码
原文:https://www.dataquest.io/blog/20-data-science-projects-with-source-code-for-beginners/
August 29, 2022
对数据科学家的需求非常高。雇主非常需要数据科学家,招聘人员很难填补空缺。尽管担心经济衰退迫在眉睫,但似乎“数据科学家仍然可以说出他们的价格
你有没有想过从事数据科学家的职业?现在是做出改变的最佳时机。为了获得一份有回报的数据科学工作,你需要一个数据科学项目组合,向招聘人员展示你的技能。
在本文中,我们将分享 20 个初学者必备的项目,以及它们的源代码。这些涵盖了数据科学家在数据科学工作流程)的每个阶段所需的技能范围。完成这些项目将有助于你在求职中脱颖而出。
下面是我们将要讨论的数据科学工作流程的各个阶段:
- 数据收集
- 特征提取和探索性数据分析
- 模型选择和验证
- 模型部署、持续监控和改进
数据收集
数据收集是整个数据分析过程中最重要的阶段之一;如果处理不当,可能会导致您的数据科学项目失败。正如您所猜测的,收集数据的过程并不总是像您希望的那样简单。以下是一些建议的数据科学项目,可帮助您发展数据收集技能:
1.数据收集和注释
数据科学家有多种方法来获取数据,但有时,您可能需要收集自己的数据。
想象一下,你要在雅典市中心开始做葡萄酒生意,你需要知道你需要库存哪些葡萄酒。你可能要看看人口统计学如何影响你所在地区的葡萄酒选择。例如,你可以设计并发送一份在线调查,用 Google Forms 和 Qualtrics 等工具收集你的数据。你可以阅读如何通过开展一项伟大的调查来收集自己的数据来学习如何有效地进行调查并避免常见错误。
在有监督的机器学习中,需要对数据集进行标注,以便机器能够理解。有时候,这些注释在数据收集阶段是不可用的。以一位野生动物摄影师的鸟类拼贴画为例。如果你对一个鸟类物种鉴定项目感兴趣,你必须首先得到鸟类图片的注释。自己标注数据可能又慢又费力。像亚马逊 Mechanical Turk 和 Lionbridge AI 这样的众包平台有助于填补空白。
让您的想象力与您的数据科学项目想法一起驰骋。以下是一些帮助您开始数据收集和注释的链接:
2.抓取单个网页
你对预测你所在城市的天气感兴趣。你知道你所在城市的天气数据可以在国家气象局网站上获得,但是它没有可下载的格式。
在这个关于数据科学的迷你项目中,您将学习如何使用 requests 和 BeautifulSoup 库抓取单个网页。您将学习如何进行 GET 请求调用并解析对 BeautifulSoup 的响应。您将掌握如何使用 Google Chrome 开发工具探索 HTML 页面的结构和查找标签。
这还不是全部。你将在国家气象局网站上抓取一个网页,提取带有这些标签的文本,并将数据放入熊猫数据帧中。这个数据科学迷你项目通过引入使用正则表达式从文本中提取相关信息的数据预处理来结束。
Web 抓取是一项无价的数据科学技能,我们推荐我们的 API 和 Python 中的 Web 抓取课程来帮助您入门。
以下是关于这个迷你项目的博文链接:
3.抓取多个网页
在之前的项目中,您学习了如何从单个网页中抓取数据。但是,您需要的数据可能会出现在多个网页上。网站是链接在一起的网页的集合。要抓取多个网页,你需要知道如何找到链接到你感兴趣的网页的标签。
在这个数据科学项目中,您将在之前的 web 抓取项目的基础上进行扩展。你将从 FBref.com 的[搜集英超联赛数据。您将从抓取排名网页开始,以获取将团队连接到包含其数据的网页的标签。您将继续使用 Python 请求和 BeautifulSoup 库。
你将掌握如何使用“for-loop”语句发出多个 GET 请求并解析它们对 BeautifulSoup 的响应。与前一个项目一样,您将把收集到的数据放在 pandas 数据帧中。最后,您将学习如何将 pandas DataFrame 对象写入逗号分隔值(CSV)文件,以便以后重用。下面是这个项目的视频教程的链接——以及包含其源代码的 Github 链接:](https://fbref.com/en/comps/9/Premier-League-Stats)
特征提取和探索性数据分析
真实世界的数据通常不是机器学习算法可以理解的格式。因此,需要对数据进行预处理和转换。要素提取通过创建新要素来减少数据中的要素数量。主成分分析(PCA)是最流行的特征提取算法。
探索性数据分析(EDA)旨在使用统计和可视化技术来理解特征之间的关系。用于 EDA 的一些最流行的图形技术包括箱线图、直方图、对线图、散点图、热图以及垂直和水平条形图。
这里有一些很酷的数据科学项目,可以提高你的特征提取和 EDA 技能:
4.主成分分析降维
处理高维数据集是数据科学家的常见做法。单个人的病历或图像就是这种高维数据的一个例子。如果行“r”小于或等于特征或列的数量“c ”: $ r \ le c $,则认为数据是高维的。想象你有一个 100 乘 100 的彩色图像。彩色图像有三个通道:红色、绿色和蓝色。该图像展平后的特征数量为 100 乘 100 乘 3。使用 PCA,可以在不损失太多信息的情况下降低该数据的维度。存储中的图像的维度和大小都减小了。当您有许多高分辨率图像并希望节省存储空间,或者希望提高训练机器学习算法的速度时,可以使用 PCA 压缩图像。
这正是我们在这个数据科学项目中要做的。您将了解 OpenCV 库如何处理图像,以及 Scikit-Learn 实现 PCA 算法以获取其主要成分。您还将看到如何从原始图像的主要成分中重建原始图像。
这里是这个项目的教程、源代码和数据的链接:
5.EDA 和 Seaborn
上大学非常昂贵,而且你也不能保证经济上的成功。为了获得良好的投资回报,你必须谨慎选择你的专业。许多即将进入大学的学生面临着选择一个能增加他们经济成功几率的专业的挑战。
在这个数据科学项目中,您将使用 Seaborn library 对包含 2010 年至 2012 年大学毕业生工作成果的数据进行广泛的探索性数据分析(EDA)。您将通过操作熊猫数据框架和可视化结果来学习如何设计和回答问题。你将能够回答这样的问题:
- 什么大学学历平均工资最高?
- 哪些是就业率最高和最低的?
- 一个人的性别对同学科薪资有影响吗?
- 什么专业男生比例最高?女性
- 男性还是女性主导的专业最赚钱?
以下是该项目的源代码和数据的链接:
你可以找到其他很酷的项目,比如在我们的数据可视化基础课程中找到 I-94 上的交通拥挤指示器。
6.EDA 与 Plotly
虽然 Seaborn 允许您制作漂亮的图形情节,但当您需要高度可定制和交互式的情节时,这是不够的。Plotly-Dash 允许您构建可部署的交互式和可定制的仪表板和应用程序。应用程序创建了一个抽象层,向用户隐藏了代码的复杂性。应用程序用户与仪表板交互。这使得共享您的数据科学项目变得更加容易。
本教程是对 Plotly 库的一个温和的介绍。您将对网飞数据集执行探索性数据分析。在项目结束时,你将能够回答如下问题:
- 最喜欢的流派有哪些?
- 哪些网飞节目收视率最高?
- 一年中发布关于网飞的节目的最佳时间是什么时候?
- 看的最多的电影有哪些?
这个项目在每个国家的层面上回答了其中的一些问题。以下是包含该项目的源代码和数据的教程的链接:
7.EDA 与 Matplotlib 的有趣方式
我们已经在前面的项目中探索了如何使用 Plotly 和 Seaborn 库。来自这些库的情节是非常商业化的。有时候,我们只是想做好玩的数据科学项目。
在这个数据科学项目中,您将学习如何使用 Matplotlib 库中的xkcd函数以有趣的方式执行 EDA。您将继续使用滑稽图处理网飞数据集,以调查类似以下问题:
- 电影占网飞内容的百分比是多少?电视节目?
- 各个国家的网飞含量?
- 谁是网飞最受欢迎的演员和导演?
- 网飞关注什么样的内容?
- 每个国家的顶级流派有哪些?
该项目以向您介绍 Word Cloud 结束。你将调查网飞内容的描述和标题中最常用的词。
以下是包含该项目的源代码和数据的教程的链接:
模型选择和验证
在数据科学工作流中,模型选择和验证阶段是选择评估指标以及培训和验证模型的阶段。超参数调整优化了模型的性能,评估指标量化了它们。所选择的机器学习模型是相对于评估度量表现最好的模型。
我们的机器学习基础课程将向您介绍机器学习的基础知识。您将学习如何优化机器学习模型的超参数,评估它们的性能,并选择最佳模型。
与其从一个要求你立即实现机器学习算法的项目开始,数据科学爱好者应该首先理解这些算法背后的数学。现代深度学习的先驱之一、深度学习首批书籍之一的合著者伊恩·古德费勒(Ian Goodfellow)曾在一次采访中表示,要掌握机器学习领域,理解引擎盖下发生的数学很重要。
因此,本节将从涉及从头创建机器学习算法的数据科学项目开始。在此之后,讨论转移到您必须从 Scikit-Learn、Keras 和 Tensorflow 等标准库中实现机器学习和深度学习算法的项目。
8.线性回归:标准方程
你已经使用线性回归算法很多年了,却没有意识到这一点。您还记得当您得到一个线性方程,比如\(y = 2x + 3\)和一个值\(x=2\)时,要求您找出\(y\)的值吗?当你训练一个线性回归算法时,你会得到一个类似的线性方程。当你需要找到\(y\)的值时,给定一些\(x\)的值,这就是线性回归算法进行预测。
从头开始实现线性回归算法有几种方法。在这个数据科学项目中,您将使用该算法的法线方程来实现它。在使用 NumPy 库在 Python 中实现算法之前,视频教程首先带您了解数学。使用“QR 分解”和“梯度下降”是实现该算法的更稳定的方式;然而,使用正规方程是理解其背后的数学的最简单的方法。
这里是这个项目的视频教程、源代码和数据的链接:
9.从零开始梯度下降的线性回归
梯度下降算法是一种迭代优化算法,用于寻找可微函数的局部最小值。它是用于训练线性回归和逻辑回归算法以及神经网络的重要算法。可微函数也称为“成本函数”对于线性回归算法,该成本函数是**均方误差* *。
在这个数据科学项目中,您将学习如何使用 NumPy 库和程序中生成的数据实现批量梯度下降。您将看到模型的性能如何随着每次迭代而提高,因为它是用梯度下降进行训练的。
这里是包含该项目的源代码的教程的链接:
10.从零开始梯度下降的逻辑回归
线性回归算法在分类问题上表现不佳。因此,我们需要另一种机器学习算法来处理这样的问题——例如,逻辑回归。
在这个数据科学项目中,您将学习如何使用批量梯度下降和**对数损失* *函数实现逻辑回归算法。这个项目向你介绍凸性的概念:成本函数在每次迭代中接近全局最小值。您将使用程序中生成的合成数据来训练和测试您的算法。最后,您将比较您的算法与 Scikit-Learn 的逻辑函数实现的性能。
理解梯度下降和逻辑回归如何工作是理解标准神经网络如何工作的先决条件。标准的神经网络是使用梯度下降训练的逻辑回归模型的堆栈。
以下是包含源代码和梯度下降背后的数学原理的教程链接:
11.带 Scikit-Learn 的线性回归算法
您已经了解了线性回归和逻辑回归算法背后的数学原理。你已经从零开始实现了这些算法。当您从零开始实现这些算法时,您构建了一个坚实的数学和理论基础,但您不必每次在数据科学项目中工作时都从头开始。有些库或框架已经实现了这些算法并经过了严格的测试,比如 Scikit-Learn、Tensorflow 和 PyTorch。在这个项目中,您将学习如何使用 Scikit-Learn 实现线性回归算法。您将根据 2006 年至 2010 年间在爱荷华州埃姆斯市收集的埃姆斯数据集的几个分类和数值特征来预测房价。此数据集不干净。因此,您将使用数据辩论技术来清理数据并估算缺失值。您将了解如何在现有要素的基础上设计新要素,以及可应用于数值和分类要素的不同数据转换技术。最后,您将使用均方根误差度量,针对测试集训练、预测和测量您的预测的准确性。
学习线性回归算法是掌握机器学习的重要第一步。在我们的机器学习线性回归课程中,您将学习如何预处理和转换数据,选择适当的特征,以及实现线性回归算法。以下是该项目的源代码和数据的链接:
12.扩展逻辑回归算法
默认情况下,逻辑回归算法是一个二元分类器。因此,它无法处理多类分类问题,除非我们以某种方式扩展它。有几种方法可以做到这一点。您将了解到扩展逻辑回归算法的一种最简单的方法,即更改它的一些默认参数。您将了解如何在逻辑回归算法的 Scikit-Learn 实现中设置“class_weight”和“multi_class”参数,使其能够处理不平衡数据和多类分类问题。
还没完。您将对数据集进行预处理以处理缺失值。您将使用两种分类特征-名词性和序数-并学习它们不同的转换技术。你将执行广泛的单变量和双变量 EDA 和特征工程。除了逻辑回归算法,您还将学习使用以下算法实现多分类的 Scikit-Learn:KNeighborsClassifier、多项式朴素贝叶斯、随机森林和 GradientBoosting。您将了解如何使用 GridSearch 交叉验证来优化这些算法超参数。
这个项目涵盖了我们到目前为止讨论过的整个数据科学工作流程阶段。它强调了一个事实,即找到数据科学问题的解决方案是一个迭代过程,涉及扩展、训练和优化几个机器学习算法。你可以改进这个项目的一个方法是创建一个基于所有其他使用多数规则训练的算法的分类器。这是机器学习中的一种集成技术——我们可以使用 Scikit-Learn 投票分类器函数来实现这一点。这里是该项目的源代码和数据的链接
你可以在我们的Python 中的中级机器学习课程中找到其他很酷的项目,比如预测股市。
13.集成学习分类
你在上一个项目中使用了 Randomforest 和 GradientBoosting 系综模型。但是什么是集成学习呢?这是一种机器学习技术,通过结合许多机器学习模型的预测来提高预测性能。在这个项目中,我们将使用 RandomForestClassfier 的 Scikit-Learn 实现来预测股票价格。
使用其默认设置,RandomForestClassifier 是 100 个决策树分类器模型的集合。因此,它使用多数规则基于这些决策树分类器的预测进行预测。在回归问题的情况下,它取所有预测的平均值。在这个项目中,你将学习如何预测一种金融证券的价格运动方向。尽管您将在这个项目中使用 Microsoft 股票价格,但是您可以扩展到您感兴趣的任何其他金融证券。你所需要做的就是在调用 YahooFinance API 的时候,把 MSFT 微软公司的股票代码改成你自己选择的股票代码——我们就是从这个 API 下载数据的。您将学习如何使用 Pandas 库处理时间序列数据。股票价格是连续变量,使用线性回归建模。您将学习如何通过转换目标变量将回归任务重新构建为分类任务。
有很多指标可以验证你的分类算法。本项目讨论了为数据科学项目选择指标时应该考虑的因素。此外,还将详细介绍如何创建回溯测试来验证模型性能。这个项目可以通过训练一个 GradientBoostingClassifier 并比较它与 RandomForest 分类器的性能来扩展。高级学习者可以训练长短期记忆(LSTM)模型,并将其性能与 RandomForest 和 GradientBoosting 分类器进行比较。
这里是这个项目的教程和源代码的链接:
14.用 R 分类
Python 是完成数据科学项目的优秀编程语言,但它不是唯一的语言。R 编程语言在统计和科学计算中有很长的使用历史。我们在 R path 的数据分析师可以帮助你开始使用 R 编程语言。这个项目将向你介绍如何使用 R 进行数据科学项目。你将学习如何使用 Kaggle 上的 UFC 数据训练几个机器学习算法来预测 UFC 战斗的结果。这个数据是从 UFC 统计网站上刮来的。我们建议在数据科学工作流程的数据收集阶段开展几个 web 抓取项目。这是因为网页抓取是一项重要的数据科学技能。如果你觉得数据集有点过时,请随意访问 UFC 统计网站。
在这个项目中,你将在 R 中训练以下机器学习算法:K-最近邻、逻辑回归、决策树、随机森林和极端梯度提升。您将验证模型,并将它们的性能与专家的预测进行比较。最后,你会有几个预测模型,可以用来预测即将到来的 UFC 比赛的结果。这里是这个项目的教程、源代码和数据的链接:
15.用分类算法预测客户流失
公司希望在客户真正停止与他们做生意之前,发现他们什么时候会停止与他们做生意。这将有助于公司设计促销方案来留住客户。在这个关于数据科学的项目中,您将了解公司如何使用机器学习来预测客户流失。您将使用 Kaggle 上的电信客户流失数据。
您将从预处理数据和执行 EDA 来识别模式开始。接下来,您将学习如何将数值和分类特征转换为可用于训练机器学习算法的格式。有不同的度量来评估分类算法的性能;评估分类算法的性能没有一个通用的标准。
您将了解作者为选择召回指标而提出的论点。您将使用平衡和不平衡数据集训练和比较几种机器学习算法(逻辑回归、决策树、支持向量机和 XGBoost)的性能。您将了解如何通过 GridSearch 交叉验证来调整这些模型,以优化它们的性能。这里是这个项目的教程、源代码和数据的链接:
16.集成学习的高级回归技术
我们已经看到相当多的分类问题使用了先进的集成技术。在这个项目中,我们将看到如何使用集成来提高回归模型的性能。您将使用 Kaggle 的房价数据。数据不干净,所以您将从预处理数据开始这个数据科学项目。
您将了解如何可视化和移除数据中的异常值。您将看到可视化每个要素的缺失值数量如何帮助您决定要素中缺失值百分比的适当临界值。缺失值高于截止值的特征被丢弃,并使用适当的插补技术来填充其他特征的缺失值。
您将使用条形图和直方图,执行具有离散和连续特征的广泛 EDA。然后,您将基于领域知识设计要素,并使用适当的技术转换数值和分类要素。您将为以下模型训练和优化超参数:XGBRegressor、Ridge、Lasso、支持向量回归机、LightGBM 回归机和 GradientBoostingRegressor。
最后,您将学习如何将这些回归模型堆叠成一个可用于进行预测的整体模型。在本项目结束时,您将使用最先进的回归模型,并学会使您成为一名有竞争力的数据科学家的技术。
这里是这个项目的源代码和数据的教程链接:
17.贝叶斯机器学习
垃圾短信是一种威胁。它们会塞满你的收件箱,分散你对重要邮件的注意力,并占用存储空间。这个数据科学项目向你介绍自然语言处理(NLP)领域。这是人工智能处理计算机如何处理和分析大量自然语言数据的方面。垃圾邮件分类器是自然语言处理最基本的应用之一。更高级的应用是在 Alexa 和 Google Assistant 的自动语音识别系统中。在这个数据科学项目中,您将学习如何处理文本数据并构建概率朴素贝叶斯垃圾邮件过滤器,该过滤器可以使用 Kaggle 上的垃圾短信收集数据集来帮助您区分垃圾邮件和非垃圾邮件。首先,您将对数据集进行预处理,并将其转换成一种格式,从这种格式中您可以创建一个单词袋模型。接下来,您将学习如何通过计算和比较概率来将邮件分类为垃圾邮件或非垃圾邮件。最后,您将在测试集上测试您的垃圾邮件过滤器,并计算其准确性。
在这个数据科学项目中,垃圾邮件过滤器是从零开始构建的,没有使用机器学习库中的包。您可以通过使用 NLKT、Spacy、TFIDFVectorizer 和 MultinomialNB 来扩展这个项目,以减少从头构建所涉及的繁重工作。
参加我们的条件概率课程和概率统计模块中的其他课程,以获得完成该项目所需的基础知识。以下是该项目的源代码和数据的链接:
18.Keras 深度学习简介
到目前为止,我们主要使用表格数据集。经典的机器学习算法在表格数据上表现良好。图像和文本等非结构化数据并非如此。这就是深度学习算法闪耀的地方。在本项目中,您将学习如何使用流行的 mnist 数据集创建数字分类器。
使用 Keras API 导入数据,对图像及其标签进行预处理。您将学习如何使用密集连接的层、激活函数、损失函数、优化器和度量来构建您自己的标准神经网络体系结构。然后,您将使用经过训练的神经网络进行训练、评估和预测。
到这个项目结束时,你将有一个标准的神经网络模型,可以准确地预测数字。您可以通过优化神经网络的超参数来改进这个数据科学项目:批量大小、节点、隐藏单元、使用优化器以及使用正则化和剔除。
这里是这个项目的源代码和数据的教程链接:
19.基于 Keras 和张量流的卷积神经网络
我们承认吧。我们没有无限的计算机资源来训练非常大的模型。此外,大型模型可能需要几天甚至几周的训练时间。用很少的数据训练深度学习模型,是一个数据科学家非常重要的技能。在这个项目中,您将训练一个卷积神经网络(convnet ),它可以使用少量数据以合理的准确度区分猫和狗。为了将我们所说的小数据放入上下文中,Kaggle 上的狗与猫数据集包含 25,000 张猫和狗的图像。但是只有 2000 张图片,你就可以训练一个准确率约为 80%的神经网络。
您将了解如何使用 Keras 进行数据扩充,Keras 是一种从原始数据集生成合成数据并对其进行扩充的技术。接下来,您将学习如何构建包含卷积、激活和池层的卷积神经网络架构。您将了解如何连接 convnet 架构,以完全连接以输出层结束的层。最后,您将学习如何训练这个神经网络来准确地对猫和狗进行分类。
在教程的最后,作者介绍了迁移学习的概念。研究人员用数百万数据集训练了非常深度的神经网络,并优化了模型参数。有了迁移学习,你就不用从头开始训练你的神经网络了。您可以选择一个预训练模型并添加您自己的完全连接的层,冻结预训练模型中的层,使用您的数据进行训练,然后进行预测。你会得到一个比从头开始训练更准确的模型。
以下是该项目的教程、源代码和数据的链接:
模型部署、持续监控和改进
你已经训练了一个有效的机器学习模型,但它只对你可用。机器学习的目标是解决一个问题,模型应该可供他人使用。为了使模型对更广泛的受众可用,您必须将模型投入生产,或者将其部署为 web 应用程序或嵌入到另一个系统中。
将机器学习模型投入生产后,其性能会随着时间的推移而下降。因此,监控您部署的模型的性能,重新训练以提高其性能,并重新部署是非常重要的。将模型投入生产的一个简单方法是使用交互式网络应用程序,如 Python 的Shiny和 Streamlit 。使用 Shiny 和 Streamlit 构建和部署 web 应用程序并不需要丰富的 web 开发知识。这篇文章深入讨论了如何在部署后持续监控您的机器学习模型。
20.在 Python 中使用 Streamlit 部署机器学习模型
在这个项目中,您将学习如何使用 Streamlit 开发一个简单的机器学习应用程序。首先,您将训练和验证一个 RandomForestClassifier。接下来,您将把模型保存为 pickle 文件,以备部署。之后,您将学习如何使用 Streamlit 将模型部署为交互式 web 应用程序,该应用程序使用您保存的模型进行预测。您将使用 Kaggle 钞票验证数据创建一个交互式银行验证器 web 应用程序,该应用程序接受四个输入并预测钞票是否真实。在本项目结束时,您将学习如何将您的机器学习模型部署为可供他人使用的交互式 web 应用程序。
以下是该项目的视频教程、源代码和数据的链接:
外卖食品
在本文中,我们讨论了 20 个很酷的数据科学项目,涵盖了数据科学家所需的技能范围。这些项目涵盖了构建端到端数据科学项目所需的基本技能。拥有一个数据科学项目组合有助于向潜在的招聘人员展示你的数据科学技能,这有助于你在求职中脱颖而出。这里有一份我们的项目清单,当你注册 Dataquest 时,你可以免费完成这些项目。我们还策划了 55 个对初学者友好的 Python 项目,这些项目将在这篇博客文章中丰富你的作品集。
如果你是编程新手,还没有学会基础知识,我们推荐《Python 技能路径机器学习入门》。你也可以在我们的技能路径中探索其他课程,并报名参加那些你感兴趣的课程。如果你了解基础知识,我们建议你注册我们的 Python数据科学家职业道路。在本文中,我们分享了一些校友的个人项目。大多数人一开始只是数据科学爱好者。我们的实践学习方法和互动平台帮助他们开启了数据科学家的职业生涯。为什么不加入他们呢?
当学习变得困难时:3 种让学习变得容易的方法(客座博文)
原文:https://www.dataquest.io/blog/3-ways-to-make-learning-easier/
August 4, 2020
以下是 Darya Jandossova Troncoso 的客座博文,不代表 Dataquest 的观点或意见。
学习是一个终生的过程。它从我们还是婴儿时就开始了,并伴随我们到老年。教育对我们的发展和我们如何看待世界至关重要。对知识的渴望始于年轻时对周围环境的探索,随后是正规教育及其他。
在我们的一生中,我们学会以某种方式保留信息,无论你喜欢哪种方式,理解它为什么适合你都是至关重要的。如果你理解了基础知识,你可以在基础知识的基础上进行改进和提高。您可能希望改进的一些方面包括:
- 学习更快
- 更好地理解和保留信息
- 使学习过程更容易、更有效
在试图找出如何改善这些令人担忧的领域之前,让我们调查一下最流行的学习概念和模式,以及它们如何应用于不同的现实生活中,无论你是在家学习还是在学校学习。
概念
经验学习
我们清单上的第一个概念是大卫·库伯提出的体验学习模式。这位美国教育理论家强调持续学习的理念。Kolb 的学习理论在四阶段学习周期的基础上提出了四种不同的学习风格(或偏好)。

图片来源:商务球
根据 Kolb 的说法,有四种学习风格:适应型、收敛型、发散型和同化型。正如 Kolb 所理解的,适应性学习风格(做和感觉-CE/AE)代表“动手”类型,适用于适应性学习者。他们更喜欢采取实际的、经验的方法,从真实的经历中学习。
汇聚式学习风格(做与想——AC/AE)——指汇聚者,能够解决问题,通过检验理论找到解决实际问题的方法。发散型(感觉和观察——CE/RO)——描述发散型——敏感的人,能够从不同的角度看待事物,收集信息,并在处理问题时运用想象力。
最后一种风格是同化(观想——AC/RO)。Kolb 建议同化者更喜欢简洁的,逻辑的方法。对他们来说,思想观念比人更重要;他们喜欢用抽象的想法工作,发展他们的理论。
大卫·库伯的学习风格模型早在 1984 年首次发表时就得到学者、教师和培训者的认可。他的工作建立了旨在更好地理解和解释人类学习行为的基本概念,为理解我们如何学习做出了巨大贡献。
思维风格模型
今天被广泛接受的下一个模型是安东尼·格雷果克开发的思维方式模型。这个模型提供了一种有组织的思维方式。Anthony Gregorc 利用二元性发展了他的想法,这是西方哲学中一个有着几个世纪历史的方法。在他 1977 年发表的研究中,Gregorc 定义了两种学习模式,他称之为偏好模式。后来,他提出了思维风格模型。这个模型与 Kolb 的学习风格方案相似。

图片来源:巅峰演出中心
根据 Anthony Gregorc 的说法,学习偏好模式的四个不同象限是抽象随机、抽象顺序、具体随机、具体顺序。
- 具体顺序(CS)代表逻辑的、客观的、实用的、深思熟虑的和有方法的模式。CS 学习者关注有形的结果。他们没有创造力,他们需要一个稳定的没有混乱的环境。
- 具体随机(CR)代表冒险、冲动、直觉和本能模式。CR 学习者可以同时关注过程和结果。他们很有创造力。他们喜欢变化和竞争,他们需要一个具有挑战性、刺激的环境;否则,他们很容易感到无聊和没有动力。
- 抽象顺序(AS)代表分析、反思、常规和方法模式。因为学习者更喜欢处理抽象的术语、符号、理论概念和想法。这些人喜欢安静的环境;他们关注的是过程而不是结果,当遇到智力挑战时,他们表现得很好。
- 抽象随机(AR)代表移情、精神、谨慎、感知和敏感模式。AR 学习者更喜欢充满活力、生动活泼的环境,在这里他们可以表达自己的感受和情绪。他们有音乐、文学或艺术天赋,用他们的感觉来理解他们的经历。
VAK——视觉、听觉和动觉学习者
视觉、听觉和动觉学习者(通常用首字母缩写词 VAK 来标识)模型是由心理学家沃尔特·伯克·巴尔贝和他的同事提出的,他们认识到三种学习风格或学习的“模式”:
- 视觉(图片、形状、雕塑、绘画)
- 听觉(听力、节奏、音调、圣歌)
- 动觉(手势、身体运动、物体操纵、定位)
Barbe 说,最有效的学习可能是通过结合使用所有三种模式。后来,尼尔·弗莱明斯扩展了这一模式,增加了“读/写学习”作为第四种形式。他很清楚,视觉学习者在学习时需要视觉辅助,如图形、图表、图解)。听觉可以通过听(讲座、讨论、磁带等)获得成功。).读/写学习者通过书面文字(读物、词典、参考书等)达到最佳效果。)触觉/动觉型学习者更喜欢获取知识经验(科学项目、实验、世界探索等。).
VARK 瓦尔克模型获得了极大的欢迎,并在很长一段时间内被广泛采用。还是可以找到一些基于这个概念的推荐。然而,就像一些早期的模型一样,它现在被一些人认为是一种过时的理论,有着固定的观点。
多元智能理论
另一个挑战传统智力观的理论是多元智力理论。简而言之,这个理论声称每个人都有不同的学习方式和他们在日常生活中使用的各种类型的信息。多元智能的概念起源于哈佛大学的哈沃德·加德纳。在进行了认知研究之后,他确定了七种独立的智能,之后又增加了两种。
- 言语语言智能
- 数学逻辑智能
- 音乐智能
- 视觉空间智能
- 身体动觉智能
- 人际智能
- 内省智能。
- 自然主义智能
- 存在智能
根据加德纳的理论,每个人都拥有每种智力的一部分,但有些人支配和决定每个人如何学习和应用它。正如加德纳在他的书《未受教育的头脑:儿童如何思考以及学校应该如何教育》中所写的:“我认为一套相反的假设更有可能在教育上有效。学生们以明显不同的方式学习。如果学科可以以多种方式呈现,学习可以通过多种方式进行评估,那么广大学生——也许还有整个社会——将会得到更好的服务。”
多元智能理论是由加德纳提出来挑战学院心理学家的,但它并没有提出许多教育建议。尽管如此,许多准备充分、经验丰富的教育家已经证实,在特定模式的多媒体和教学技术的帮助下,这一理论的教育含义能够解决最常见的学习问题,并显著增强每个儿童或青少年的学习过程。但是它到底是如何工作的呢?该理论提供了八种学习方法,当传统教学方法变得低效时,这些方法非常有用:
- 单词(语言智能)
- 数字或逻辑(逻辑-数学智能)。
- 图片(空间智能)。
- 音乐(音乐智能)。
- 自我反思(内省智能)。
- 真实的体验(身体动觉智能)。
- 社交经验(人际智能)。
- 自然世界的经验(自然主义者的智慧)。

图片来源:adioma.com
但是这些对你的学习之旅有什么用呢?有很多方法可以让学习更适应年龄。不管你多大,让我们来谈谈帮助你轻松学习的三个技巧。
了解你的学习风格
一旦你明白了如何学习最好,你就可以开始在此基础上再接再厉。最有可能的是,它是几种技术的结合。有些风格比其他风格更好,一旦你意识到哪种技巧可以帮助你保留最多的信息或者让你在这个过程中获得乐趣,你就可以剔除那些对你没用的部分。
如果你在努力记住你所学的东西,很可能你没有使用正确的工具。它可以简单到在你的手机或平板电脑上使用一个笔记应用,它为你提供写下事情或创建视觉学习线索的方法,以帮助你更好地记忆。通过写下笔记并同时画画,你可以同时使用多种形式,视觉、动觉和语义,基本上以三种不同的方式处理信息,这比只有一种方式要好。
了解你的学习风格还能让你明白为什么你在挣扎,知道如何学习不仅对你的学习有好处,对你生活的很多方面也有好处。总而言之,与其因为无法学习和记住你所学的东西而打击自己,不如从一个不同的角度来处理这件事,并希望意识到什么对你最有效。
不要只关注一种学习方式
每个学生都是不同的,没有理由让每个人都遵循相同的学习技巧或风格。个性化需要成为现代教育的主导方法,无论是学校、大学还是自学。多样化的学习对于培养好奇心和提高整体记忆力至关重要。
由于技术的快速发展,很多事情都成为可能。学生们可以通过各种各样的数字工具获得知识,并有很多方法展示他们的技能。获得高水平知识和技能的另一个成功方法是实践学习方式,让学生以多种方式体验和学习。这也导致了更高的保留率。
顾名思义,这种方法是为学生提供在实际动手环境中学习的能力。当他们被带离讲堂,并有机会在现实环境中使用他们所学的知识时,他们所保留的信息百分比会增加很多。
这种方法可以适用于任何年龄的学习者,它几乎适用于任何学习。
例如,在学习数据科学和编程的背景下,许多学习者观看视频讲座并努力掌握材料。切换到更具实践性的方法,让他们接受挑战,以渐进的方式为自己编写代码,可以增进理解,提高记忆力。
同样的技术可以应用于各种各样的事情。你想学什么并不重要,走出去并尝试去做通常是最好的方法..
训练你的大脑
保持头脑敏锐也很重要。这里有一些关于如何改善你的认知功能的重要建议,包括记忆回忆、注意力集中和注意细节。
- 首先,不要跳过规律的体育锻炼。做瑜伽,给自己买辆自行车,或者去游泳。除了所有其他的好处之外,锻炼还包括思考、处理和学习,它可以促进你整体的大脑活动。
- 提高认知功能的不同方法是通过学习新的爱好。它可以是任何事情,从绘画到编织,写小说或学习一种新的乐器和作曲。基本上,做一些有创造性的事情是一个很好的刺激,可以让你克服精神停滞期,同时学习一项新技能。
- 加入哈佛医学院专家提供的在线课程,比如这个课程。它提供了一种方便的方法,通过学习有用的策略和使用不同的技术来帮助你保持头脑和意识的状态,从而提高你集中注意力和增强记忆力的能力。
- 保持健康——拥有一个良好的睡眠,健康饮食,在你的饮食中加入黑巧克力,玩逻辑游戏或电脑游戏,记日记或写博客阅读——所有这些都是保持思维敏捷和忙碌的好方法。
应用上面的一些建议会帮助你成为一个更好的学习者。请耐心等待,因为这样的改善不会在一夜之间发生。在现阶段评估你对学习的准备程度,并在三个月或六个月后再做一次评估,这可能不是一个坏主意。
结论
不管你是什么年龄,学习都可能是困难的,但是有办法让它变得更容易。这是一个漫长但值得的旅程。只要确保你不会对自己太苛刻,找出你如何学习最好,并在保持健康的同时使用多种方法获得这些知识。
关于客座作者:
Darya Jandossova Troncoso 是一名摄影师、艺术家和作家,正在撰写她的第一部小说,并管理着一个数字营销博客—market splash。在业余时间,她喜欢和家人在一起,烹饪,创作艺术,学习一切关于数字营销的知识。
30 天数据科学挑战
原文:https://www.dataquest.io/blog/30-day-data-science-challenge/
September 1, 2021
我们很高兴开始为期 30 天的 Dataquest 挑战赛!原因如下:
养成学习习惯对您的数据职业至关重要,但养成新习惯可能会很困难。也许你以前尝试过建筑,但是,一次又一次,你会掉下来。出了点事。开始令人兴奋的事情变得太难了。不知不觉中,你又回到了起点。
在 Dataquest,我们的使命是让世界各地的学习者都能获得数据技能,并为我们的学习者提供成功所需的一切支持。还有什么比充满挑战和乐趣的数据科学竞赛更好的方式来完成我们的使命呢!
30 天数据挑战
这项挑战的目标是快速养成学习习惯,帮助您获得成功处理真实数据所需的基本技能。这种数据挑战对于那些希望对扩展自己的技能集和改善自己的职业生涯负责的热情学习者来说是理想的。
- 创建您的 Dataquest 帐户。已经有账户了?没问题—登录即可。
- 在我们的课程或练习题中,每天至少完成一次编码练习。
- 通过在我们的 Discord 服务器上与其他数据专家分享每天的进展,并在我们的任何社交媒体渠道上使用#DataquestChallenge 标签,保持责任感。
- 连续 30 天的学员将自动参加每月抽奖,免费获得一年的 Dataquest Premium。
你什么时候可以开始这项挑战?
我们建议尽快开始,但您可以随时参加。
这是一个持续的每月挑战,你可以在任何时候开始,只要你想增加责任感或动力。当你完成连续 30 天的记录时,我们会将你列入本月的幸运抽奖名单。
快速行动,节省更多
作为 30 天挑战赛的一部分,我们将在九月份为 Dataquest Premium 提供特别折扣!使用 Premium,您可以完全访问我们所有的课程、练习题、评估和项目,以保持您的连胜。
- 订购 Dataquest Premium Annual 的前 100 名用户将享受 60%的折扣(使用代码 30DATA60 )
- 接下来的 500 人将获得 50%的折扣(使用代码 30DATA50
- 下一个 1000 将获得 40%的折扣(使用代码30 数据 4 0)
寻找有趣数据集的 5 种方法
原文:https://www.dataquest.io/blog/5-ways-to-find-interesting-data-sets/
March 21, 2018
在数据科学项目中,有一系列广泛使用的开放数据集——你可能遇到过利用 Iris Flower classic 或纽约州 Citibike 数据的东西。
然而,很难对流量大的数据集提出新颖的问题;基于这些经典之一的项目不太可能产生引人注目的投资组合。回答尚未分析的数据集的有趣问题要容易得多。
在我目前的职位上,我花了相当多的时间在政府开放数据门户的角落里,潜伏在可以搜集数据的网站周围,打电话给全国各地的 FOIA 部门。以下是我为寻找最有趣的数据集而开发的一些技巧和诀窍。
关注数据前沿的时事通讯
时事通讯是掌握最新数据的重要来源。最好的邮件是持续不断的创造力的种子——浏览邮件至少会激发出一个新的想法。我依赖于那些专注于数据想法的组合,不寻常的可视化或分析技术的亮点,以及关于开放数据政策的最新报告。我个人最喜欢的包括:
 上个月的两行数据可视化于移民和季节性农业工人保护法案数据
上个月的两行数据可视化于移民和季节性农业工人保护法案数据
2.跟上利用数据的媒体
从彭博关于美国购物中心消亡的视频游戏到 ProPublica 发布川普的白宫访客记录,前沿媒体机构长期以来一直使用开放数据进行有意义的叙事。
事实上,《纽约时报》推出了一个名为的系列报道,图中到底发生了什么?更好地教育读者数据可视化。这些文章是一个很好的地方,可以看到可以用数据做什么,并研究它们的开放数据源。
 《华盛顿邮报》使用疟疾地图集项目、人口普查局和美国国家航空航天局的数据对这个偏僻的地方进行了可视化。
《华盛顿邮报》使用疟疾地图集项目、人口普查局和美国国家航空航天局的数据对这个偏僻的地方进行了可视化。
3.倾听开放数据空间中的重要声音
不仅数据科学的实践在发展,每天都有更多的数据被发布。像阳光基金会、开放知识基金会、开放企业和开放数据研究所这样的数据倡导团体在塑造开放数据空间方面非常活跃。
这些组织经常展示示范性的开放数据集,在缺乏透明度的地方,向政府施加压力,要求改善。通过跟踪他们的工作,你将是第一个了解新打开的数据集的人。
4.请求从未曝光的数据
信息自由法案(FOIA)允许公众要求政府机构的文件和其他数据。通过 FOIA 请求数据几乎可以保证您获得从未被分析过的数据(尽管这通常是对耐心的终极考验)。
为了弄清楚你想从联邦或州政府机构那里获得什么样的数据,看看 FOIA 倡导组织。给初来 FOIA 的人一个小提示:尽可能具体。请求您想要的文件的确切名称(如果您知道的话!),您喜欢的格式和您感兴趣的日期范围。请求越具体,你得到数据回报的可能性就越大。 英格玛公共公司的 FOIA 与国内税收署的通信。
英格玛公共公司的 FOIA 与国内税收署的通信。
5.将元数据用于您的优势
伴随着数据字典的数据集,或者描述数据集内容的一组相关的元数据,表明来源对他们的数据游戏是认真的。我经常调查同一来源发布的其他数据集,确信他们的数据集符合高标准。我一直对纽约开放数据门户网站背后的团队印象深刻,除了数据集所有者的名字、发布数据的机构及其更新频率之外,他们还经常提供数据字典。
虽然这些技巧帮助我发掘了一些真正的数据宝藏,但我一直在寻找其他的灵感来源。如果您有任何其他建议,请发送给我。
编者按:这篇文章是与公共数据公司 Enigma 合作的一部分。作者 India Kerle 是 Enigma 的数据管理员。
8 个很少使用的 Python 库&如何使用它们
原文:https://www.dataquest.io/blog/8-rarely-used-python-libraries-how-to-use-them/
August 29, 2021
最流行的 Python 库通常是 TensorFlow、Numpy、PyTorch、Pandas、Scikit-Learn、Keras 和其他一些库。虽然您可能会经常遇到这些名称,但是有成千上万的 Python 库可供您使用。在本文中,我们将重点讨论如何使用 Python 库,这些库很少被使用或听说过,但是对于解决特定的任务非常有用,或者可以用于有趣的项目。
我们将要练习的 Python 库有:
- 缺少编号
- 有平面的
- 维基百科(一个基于 wiki 技术的多语言的百科全书协作计划ˌ也是一部用不同语言写成的网络百科全书ˌ 其目标及宗旨是为全人类提供自由的百科全书)ˌ开放性的百科全书
- Wget
- 骗子
- 数字计算器
- 表情符号
- 彼得罗
首先,我们将从 Kaggle 下载一个数据集—动物护理和控制收养的动物
import pandas as pd
f = pd.read_csv('animal-data-1.csv')
rint('Number of pets:', len(df))
rint(df.head(3))
Number of pets: 10290
id intakedate intakereason istransfer sheltercode \
0 15801 2009-11-28 00:00:00 Moving 0 C09115463
1 15932 2009-12-08 00:00:00 Moving 0 D09125594
2 28859 2012-08-10 00:00:00 Abandoned 0 D12082309
identichipnumber animalname breedname basecolour speciesname \
0 0A115D7358 Jadzia Domestic Short Hair Tortie Cat
1 0A11675477 Gonzo German Shepherd Dog/Mix Tan Dog
2 0A13253C7B Maggie Shep Mix/Siberian Husky Various Dog
... movementdate movementtype istrial returndate returnedreason \
0 ... 2017-05-13 00:00:00 Adoption 0.0 NaN Stray
1 ... 2017-04-24 00:00:00 Adoption 0.0 NaN Stray
2 ... 2017-04-15 00:00:00 Adoption 0.0 NaN Stray
deceaseddate deceasedreason diedoffshelter puttosleep isdoa
0 NaN Died in care 0 0 0
1 NaN Died in care 0 0 0
2 NaN Died in care 0 0 0
[3 rows x 23 columns]
1.缺少编号
库安装:pip 安装缺失编号
Python 中什么是 Missingno?–missing no 是一个特殊的 Python 库,用于显示数据帧中缺失的值。当然,我们也可以使用任何可视化库中的 seaborn 热图或条形图来实现这一目的。但是,在这种情况下,我们必须首先使用 df.isnull()创建一个包含每列中缺失值的序列。sum(),而 missingno 已经在幕后完成了所有这些工作。该 Python 库提供了几种类型的图表:
- 矩阵显示一个数据帧中多达 50 列的数据完成密度模式,它类似于 seaborn 缺失值热图。此外,通过右侧的迷你图,它显示了数据完整性的大致形状,强调了具有最大和最小空值的行。
- 条形图按列以条形显示无效可视化。
- 热图测量范围从-1 到 1 的零相关性。本质上,它显示了一个变量的存在与否对另一个变量的存在有多么强烈的影响。没有丢失值或正好相反,完全为空的列被排除在可视化之外,没有有意义的相关性。
- 树状图和热图一样,度量列之间的空关系,但在这种情况下不是成对的,而是在列组之间,检测缺失数据的聚类。那些在图表上位置更近的变量显示出更强的零相关性。对于少于 50 列的数据帧,树状图是垂直的,否则,它翻转成水平的。
让我们在 pet 数据集上使用默认设置尝试所有这些图表:
import missingno as msno
sno.matrix(df)

msno.bar(df)

msno.heatmap(df)

msno.dendrogram(df)

我们可以对数据集进行以下观察:
- 总的来说,有一些值缺失。
- 最空的列是 deceaseddate 和 returndate。
- 大多数宠物都有芯片。
- 无效相关性:
- 被植入芯片和死亡之间有一点负面影响,
- 略显积极——被植入芯片与被归还、被归还与死亡。
有几个选项可以自定义缺少图表:figsize、fontsize、sort(按完整性对行进行排序,升序或降序)、labels(可以是 True 或 False,表示是否显示列标签)。一些参数是特定于图表的:矩阵和条形图的颜色、矩阵的迷你图(是否绘制)和 width_ratios(矩阵宽度与迷你图宽度之比)、条形图的 log(对数刻度)、热图的 cmap 颜色图、树状图的方向。让我们将其中一些应用到上面的图表中:
msno.matrix(
df,
figsize=(25,7),
fontsize=30,
sort='descending',
color=(0.494, 0.184, 0.556),
width_ratios=(10, 1)
)

最后,如果还有什么我们想要调整的,我们总是可以将 matplotlib 的任何功能添加到缺少的图形中。为此,我们应该内联添加参数,并将其赋值为 False。让我们给矩阵图添加一个标题:
import matplotlib.pyplot as plt
sno.matrix(
df,
figsize=(25,7),
fontsize=30,
sort='descending',
color=(0.494, 0.184, 0.556),
width_ratios=(10, 1),
inline=False
)
lt.title('Missing Values Pet Dataset', fontsize=55)
lt.show()

为了进一步练习,让我们只保留数据帧中最有趣的列:
columns = ['identichipnumber', 'animalname', 'breedname', 'speciesname', 'sexname', 'returndate',
'returnedreason']
f = df[columns]
2.有平面的
库安装:pip 安装制表
Python 中的制表是什么?–这个 Python 库用于用 Python 漂亮地打印表格数据。它允许智能和可定制的列对齐,数字和文本格式,通过小数点对齐。
table te()函数接受一个表格数据类型(dataframe、list 或 dictionary、dictionary、NumPy 数组)、一些其他可选参数,并输出一个格式良好的表格。让我们在 pet 数据集的一个片段上练习一下,从最基本的漂亮打印的表格开始:
from tabulate import tabulate
f_pretty_printed = df.iloc[:5, [1,2,4,6]]
rint(tabulate(df_pretty_printed))
- ----------- ----------------------- ------ -----
Jadzia Domestic Short Hair Female Stray
Gonzo German Shepherd Dog/Mix Male Stray
Maggie Shep Mix/Siberian Husky Female Stray
Pretty Girl Domestic Short Hair Female Stray
Pretty Girl Domestic Short Hair Female Stray
----------- ----------------------- ------ -----
我们可以在表中添加一个 headers 参数。如果我们指定 headers='firstrow ',则使用数据的第一行,如果 headers = ' keys 数据帧/字典的键。对于表格格式,我们可以使用 tablefmt 参数,它可以接受众多选项中的一个(以字符串形式分配):simple、github、grid、fancy_grid、pipe、orgtbl、jira、presto、pretty 等。
默认情况下,制表将包含浮点数的列靠小数点对齐,整数靠右,文本列靠左。这可以通过使用 numalign 和 stralign 参数(右、中、左、数字的小数或无)来覆盖。对于文本列,可以禁用默认的前导和尾随空格删除。
让我们自定义我们的表格:
print(tabulate(
df_pretty_printed,
headers='keys',
tablefmt='fancy_grid',
stralign='center'
))
│ │ animalname │ breedname │ sexname │ returnedreason │
════╪══════════════╪═════════════════════════╪═══════════╪══════════════════╡
0 │ Jadzia │ Domestic Short Hair │ Female │ Stray │
────┼──────────────┼─────────────────────────┼───────────┼──────────────────┤
1 │ Gonzo │ German Shepherd Dog/Mix │ Male │ Stray │
────┼──────────────┼─────────────────────────┼───────────┼──────────────────┤
2 │ Maggie │ Shep Mix/Siberian Husky │ Female │ Stray │
────┼──────────────┼─────────────────────────┼───────────┼──────────────────┤
3 │ Pretty Girl │ Domestic Short Hair │ Female │ Stray │
────┼──────────────┼─────────────────────────┼───────────┼──────────────────┤
4 │ Pretty Girl │ Domestic Short Hair │ Female │ Stray │
════╧══════════════╧═════════════════════════╧═══════════╧══════════════════╛
使用这个 Python 库时要记住的一点是,它有时会在智能手机和 iPhones 等较小的屏幕上显示,这些打印精美的表格最好在笔记本电脑和计算机上显示。
3.维基百科(一个基于 wiki 技术的多语言的百科全书协作计划ˌ也是一部用不同语言写成的网络百科全书ˌ 其目标及宗旨是为全人类提供自由的百科全书)ˌ开放性的百科全书
库安装:pip 安装维基百科
Python 中的维基百科库是什么?——维基百科图书馆,顾名思义,方便从维基百科获取信息。使用它可以完成的一些任务包括:
- 搜索维基百科–search(),
- 获取文章摘要-摘要,
- 获取完整的页面内容,包括图片、链接、维基百科页面的任何其他元数据–page(),
- 选择页面的语言–set _ lang()。
在上面印刷精美的表格中,我们看到了一个名为“西伯利亚哈士奇”的犬种。作为练习,我们将语言设置为俄语(我的母语:little _ smiling _ face:),并搜索相应维基百科页面的一些建议:
import wikipedia
ikipedia.set_lang('ru')
rint(wikipedia.search('Siberian Husky'))
['Сибирский хаски', 'Древние породы собак', 'Маккензи Ривер Хаски', 'Породы собак по классификации кинологических организаций', 'Ричардсон, Кевин Майкл']
让我们取第一个建议,取该页摘要的第一句话:
print(wikipedia.summary('Сибирский хаски', sentences=1))
Сибирский хаски — заводская специализированная порода собак, выведенная чукчами северо-восточной части Сибири и зарегистрированная американскими кинологами в 1930-х годах как ездовая собака, полученная от аборигенных собак Дальнего Востока России, в основном из Анадыря, Колымы, Камчатки у местных оседлых приморских племён — юкагиров, кереков, азиатских эскимосов и приморских чукчей — анкальын (приморские, поморы — от анкы (море)).
现在,我们将从该页面获得一张哈士奇图片的链接:
print(wikipedia.page('Сибирский хаски').images[0])
想象这个美丽的生物:

4.Wget
库安装:pip 安装 wget
Wget 库允许下载 Python 中的文件,而不需要打开它们。我们还可以添加一个保存该文件的路径作为第二个参数。
下面下载上面哈士奇的图片:
import wget
get.download('https://upload.wikimedia.org/wikipedia/commons/a/a3/Black-Magic-Big-Boy.jpg')
'Black-Magic-Big-Boy.jpg'
现在,我们可以在与此笔记本相同的文件夹中找到该图片,因为我们没有指定保存它的路径。
由于互联网上的任何网页实际上都是一个 HTML 文件,这个库的另一个非常有用的应用是抓取整个网页,包括所有的元素。让我们下载数据集所在的 Kaggle 网页:
wget.download('https://www.kaggle.com/jinbonnie/animal-data')
'animal-data'
生成的动物数据文件如下所示(我们将只显示前几行):
<!DOCTYPE html>
lt;html lang="en">
lt;head>
<title>Animal Care and Control Adopted Animals | Kaggle</title>
<meta charset="utf-8" />
<meta name="robots" content="index, follow" />
<meta name="description" content="animal situation in Bloomington Animal Shelter from 2017-2020" />
<meta name="turbolinks-cache-control" content="no-cache" />
5.骗子
库安装:pip install Faker
Python 中的 Faker 库是什么?–该模块用于生成虚假数据,包括姓名、地址、电子邮件、电话号码、工作、文本、句子、颜色、货币等。faker 生成器可以将区域设置作为参数(默认为 en_US 区域设置),以返回本地化数据。为了生成一段文本或一个句子,我们可以使用缺省的 lorem ipsum 或者,我们可以提供我们自己的单词集。为了确保所有创建的值对于某个特定的实例都是惟一的(例如,当我们想要创建一个很长的假名列表时)。应用了唯一属性。相反,如果需要生成相同的值或数据集,则使用 seed()方法。
让我们看一些例子。
from faker import Faker
ake = Faker()
rint(
'Fake color:', fake.color(), '\n'
'Fake job:', fake.job(), '\n'
'Fake email:', fake.email(), '\n'
)
Printing a list of fake Korean and Portuguese addresses
ake = Faker(['ko_KR', 'pt_BR'])
or _ in range(5):
print(fake.unique.address()) # using the `.unique` property
rint('\n')
Assigning a seed number to print always the same value / data set
ake = Faker()
aker.seed(3920)
rint('This English fake name is always the same:', fake.name())
Fake color: #212591
ake job: Occupational therapist
ake email: [[email protected]](/cdn-cgi/l/email-protection)
strada Lavínia da Luz, 62
este
5775858 Moura / SE
esidencial de Moreira, 57
orro Dos Macacos
5273529 Farias / TO
종특별자치시 강남구 가락거리 (예원박김마을)
라북도 광주시 백제고분길 (승민우리)
상남도 당진시 가락53가
his English fake name is always the same: Kim Lopez
回到我们的数据集,我们发现至少有两只不幸的宠物有着不太好听的名字:
df_bad_names = df[df['animalname'].str.contains('Stink|Pooh')]
rint(df_bad_names)
identichipnumber animalname breedname speciesname sexname \
692 NaN Stinker Domestic Short Hair Cat Male
336 981020023417175 Pooh German Shepherd Dog Dog Female
337 981020023417175 Pooh German Shepherd Dog Dog Female
returndate returnedreason
692 NaN Stray
336 2018-05-14 00:00:00 Incompatible with owner lifestyle
337 NaN Stray
最后 2 排的狗实际上是同一只,因为与主人的生活方式不兼容而被送回收容所。用我们的新技能,让我们拯救这两种动物的名声,给它们重新起个更体面的名字。因为这只狗是德国牧羊犬,我们将为她选择一个德国名字。至于猫,根据这个维基百科页面,家养短毛是美国最常见的品种,所以我们会为它取一个英文名字。
# Defining a function to rename the unlucky pets
ef rename_pets(name):
if name == 'Stinker':
fake = Faker()
Faker.seed(162)
name = fake.name()
if name == 'Pooh':
fake = Faker(['de_DE'])
Faker.seed(20387)
name = fake.name()
return name
Renaming the pets
f['animalname'] = df['animalname'].apply(rename_pets)
Checking the results
rint(df.iloc[df_bad_names.index.tolist(), :] )
identichipnumber animalname breedname speciesname \
692 NaN Steven Harris Domestic Short Hair Cat
336 981020023417175 Helena Fliegner-Karz German Shepherd Dog Dog
337 981020023417175 Helena Fliegner-Karz German Shepherd Dog Dog
sexname returndate returnedreason
692 Male NaN Stray
336 Female 2018-05-14 00:00:00 Incompatible with owner lifestyle
337 Female NaN Stray
对于一只猫和一只狗来说,史蒂文·哈里斯和海伦娜·弗利格纳-卡兹听起来有点太夸张了,但绝对比他们以前的名字好得多!
6.数字计算器
库安装:pip 安装编号器
Python 中的枚举器库是什么?–这个小 Python 包用于将自然语言 numerics 转换成数字(整数和浮点数),只包含一个函数——numerize()。
现在让我们在数据集上尝试一下。一些宠物的名字包含数字:
df_numerized_names = df[['identichipnumber', 'animalname', 'speciesname']]\
[df['animalname'].str.contains('Two|Seven|Fifty')]
f_numerized_names
| idenrichipnumber | 动物名 | 物种名称 | |
|---|---|---|---|
| Two thousand one hundred and twenty-seven | 圆盘烤饼 | 七 | 狗 |
| Four thousand and forty | 981020025503945 | 五十李 | 猫 |
| Six thousand five hundred and nineteen | 981020021481875 | 两个脚趾 | 猫 |
| Six thousand five hundred and twenty | 981020021481875 | 两个脚趾 | 猫 |
| Seven thousand seven hundred and fifty-seven | 981020029737857 | 新两个 | 猫 |
| Seven thousand seven hundred and fifty-eight | 981020029737857 | 新两个 | 猫 |
| Seven thousand seven hundred and fifty-nine | 981020029737857 | 新两个 | 猫 |
我们将把这些名字的数字部分转换成实数:
from numerizer import numerize
f['animalname'] = df['animalname'].apply(lambda x: numerize(x))
f[['identichipnumber', 'animalname', 'speciesname']].iloc[df_numerized_names.index.tolist(), :]
| idenrichipnumber | 动物名 | 物种名称 | |
|---|---|---|---|
| Two thousand one hundred and twenty-seven | 圆盘烤饼 | seven | 狗 |
| Four thousand and forty | 981020025503945 | 50 李 | 猫 |
| Six thousand five hundred and nineteen | 981020021481875 | 两个脚趾 | 猫 |
| Six thousand five hundred and twenty | 981020021481875 | 两个脚趾 | 猫 |
| Seven thousand seven hundred and fifty-seven | 981020029737857 | Mew 2 | 猫 |
| Seven thousand seven hundred and fifty-eight | 981020029737857 | Mew 2 | 猫 |
| Seven thousand seven hundred and fifty-nine | 981020029737857 | Mew 2 | 猫 |
7.表情符号
库安装:pip 安装表情符号
Python 中的表情库是什么?–通过使用这个库,我们可以根据由 Unicode Consortium 2 定义的表情符号代码,将字符串转换为表情符号,并且如果指定了 use_aliases=True,则使用别名进行补充。表情包只有两个功能:emojize()和 demojize()。默认的英语语言(language='en ')可以更改为西班牙语(es)、葡萄牙语(pt)或意大利语(it)。
import emoji
rint(emoji.emojize(':koala:'))
rint(emoji.demojize(''))
rint(emoji.emojize(':rana:', language='it'))

koala:
img role="img" class="emoji" alt="🐸" src="https://s.w.oimg/core/emoji/13.1.0/svg/1f438.svg">
/code>
```py
让我们给我们的动物表情符号。首先,我们将检查它们独特的物种名称:
print(df['speciesname'].unique())
['Cat' 'Dog' 'House Rabbit' 'Rat' 'Bird' 'Opossum' 'Chicken' 'Wildlife'
'Ferret' 'Tortoise' 'Pig' 'Hamster' 'Guinea Pig' 'Gerbil' 'Lizard'
Hedgehog' 'Chinchilla' 'Goat' 'Snake' 'Squirrel' 'Sugar Glider' 'Turtle'
Tarantula' 'Mouse' 'Raccoon' 'Livestock' 'Fish']
我们必须将这些名称转换成小写,给每个名称添加前导和尾随冒号,然后将 emojize()应用于结果:
df['speciesname'] = df['speciesname'].apply(lambda x: emoji.emojize(f':{x.lower()}:',
use_aliases=True))
rint(df['speciesname'].unique())
['' '' ':house rabbit:' '' '' ':opossum:' '' ':wildlife:' ':ferret:'
:tortoise:' '' '' ':guinea pig:' ':gerbil:' '' '' ':chinchilla:' ''
' ':squirrel:' ':sugar glider:' '' ':tarantula:' '' '' ':livestock:'
']
让我们将家兔、乌龟和松鼠重命名为表情库可以理解的同义词,并再次尝试对它们进行表情符号化:
df['speciesname'] = df['speciesname'].str.replace(':house rabbit:', '🐰')
.replace(':tortoise:', '🐢')
.replace(':squirrel:', '🐿️')
f['speciesname'] = df['speciesname'].apply(lambda x: emoji.emojize(x, variant='emoji_type'))
rint(df['speciesname'].unique())
['' '' '️' '' '' ':opossum:️' '' ':wildlife:️' ':ferret:️' '️' ''
' ':guinea pig:' ':gerbil:️' '' '' ':chinchilla:️' '' '' ''
:sugar glider:' '' ':tarantula:️' '' '' ':livestock:️' '']
剩下的物种有集合名称(野生动物和家畜),或者没有表情符号,至少现在还没有。我们将让它们保持原样,仅删除冒号,并将它们转换回标题大小写:
df['speciesname'] = df['speciesname'].str.replace(':', '').apply(lambda x: x.title())
rint(df['speciesname'].unique())
f[['animalname', 'speciesname', 'breedname']].head(3)
['' '' '️' '' '' 'Opossum️' '' 'Wildlife️' 'Ferret️' '️' '' ''
Guinea Pig' 'Gerbil️' '' '' 'Chinchilla️' '' '' '' 'Sugar Glider'
' 'Tarantula️' '' '' 'Livestock️' '']
| | 动物名 | 物种名称 | 品种名称 |
| --- | --- | --- | --- |
| Zero | 他在吃东西 |  | 国内短发 |
| one | 事实和臆想参半的 |  | 德国牧羊犬/混血 |
| Two | 不纯煤 |  | 雪普混合/西伯利亚哈士奇 |
[表情符号文档](https://pypi.org/project/emoji/)
## 8.皮阿兹特罗
库安装:pip 安装 pyaztro
**Python 中的 PyAstro 库是什么?**–PyAztro 的设计似乎更多是为了娱乐而不是工作。这个图书馆为每个星座提供了一个占星术。该预测包括那天的标志描述、该标志的日期范围、心情、幸运数字、幸运时间、幸运颜色、与其他标志的兼容性。例如:
```py
import pyaztro
yaztro.Aztro(sign='taurus').description
'You need to make a radical change in some aspect of your life - probably related to your home. It could be time to buy or sell or just to move on to some more promising location.'
太好了!我已经在跑着买新房子了
在我们的数据集中,有一只猫和一只狗叫白羊座:
df[['animalname', 'speciesname']][(df['animalname'] == 'Aries')]
| 动物名 | 物种名称 | |
|---|---|---|
| Three thousand and thirty-six | 白羊星座 |  |
| Nine thousand two hundred and fifty-five | 白羊星座 |  |
还有很多叫狮子座的宠物:
print('Leo:', df['animalname'][(df['animalname'] == 'Leo')].count())
Leo: 18
让我们假设那些是他们相应的黄道十二宫😉有了 PyAztro,我们可以查看明星们今天为这些动物准备了什么:
aries = pyaztro.Aztro(sign='aries')
eo = pyaztro.Aztro(sign='leo')
rint('ARIES: \n',
'Sign:', aries.sign, '\n',
'Current date:', aries.current_date, '\n',
'Date range:', aries.date_range, '\n',
'Sign description:', aries.description, '\n',
'Mood:', aries.mood, '\n',
'Compatibility:', aries.compatibility, '\n',
'Lucky number:', aries.lucky_number, '\n',
'Lucky time:', aries.lucky_time, '\n',
'Lucky color:', aries.color, 2*'\n',
'LEO: \n',
'Sign:', leo.sign, '\n',
'Current date:', leo.current_date, '\n',
'Date range:', leo.date_range, '\n',
'Sign description:', leo.description, '\n',
'Mood:', leo.mood, '\n',
'Compatibility:', leo.compatibility, '\n',
'Lucky number:', leo.lucky_number, '\n',
'Lucky time:', leo.lucky_time, '\n',
'Lucky color:', leo.color)
ARIES:
Sign: aries
Current date: 2021-02-06
Date range: [datetime.datetime(2021, 3, 21, 0, 0), datetime.datetime(2021, 4, 20, 0, 0)]
Sign description: It's a little harder to convince people your way is best today -- in part because it's much tougher to play on their emotions. Go for the intellectual arguments and you should do just fine.
Mood: Helpful
Compatibility: Leo
Lucky number: 18
Lucky time: 8am
Lucky color: Gold
LEO:
Sign: leo
Current date: 2021-02-06
Date range: [datetime.datetime(2021, 7, 23, 0, 0), datetime.datetime(2021, 8, 22, 0, 0)]
Sign description: Big problems need big solutions -- but none of the obvious ones seem to be working today! You need to stretch your mind as far as it will go in order to really make sense of today's issues.
Mood: Irritated
Compatibility: Libra
Lucky number: 44
Lucky time: 12am
Lucky color: Navy Blue
这些预测在 2021 年 2 月 6 日有效,所以如果你想查看我们宠物当天的星座(或者你自己的),你必须重新运行上面的代码。很明显,除了 sign 和 date_range 之外,所有的属性在 GTM 午夜时都会改变。
当然,还有许多其他有趣的 Python 库,如 PyAztro,包括:
甚至
- py nder 5–用于使用火绒。
我们可以肯定,通过使用这些罕见的 Python 库,我们永远不会感到无聊!
结论
综上所述,我希望数据集中的所有宠物都能找到它们充满爱心和关怀的主人,也希望 Python 用户能够发现更多令人惊叹的库,并将其应用到他们的项目中。
你下一步应该做什么?
- 在本课中学习如何使用 Python 识别和处理缺失数据
- 在本简介课中,学习如何进行纸牌游戏比赛
- 在这个指导项目中学习如何使用 Python分析维基百科页面
Excel 用户应该考虑学习编程的 9 个理由
原文:https://www.dataquest.io/blog/9-reasons-excel-users-should-consider-learning-programming/
December 27, 2018
微软 Excel 可能是商界最受欢迎的软件。三十多年前发布的 Excel 至今仍被全球各国每天用来存储、操作和分析数据。它的应用如此广泛,以至于成为一名 Excel 向导可以大大提高你的收入。
但是 Excel 虽然很棒,但也有它的局限性。如果您每天都在与数据打交道,这些限制是很明显的。我们采访了太平洋人寿的数据科学家 Alyssa Columbus,她给了我们 9 个理由,告诉我们为什么学习一门用于数据分析的编程语言是值得的,即使你已经是一名 Excel 高手,并且不打算在数据科学领域找工作。
在下面的观点中,Alyssa 特别比较了 Excel 和用 R 进行数据分析,R 是一种流行的数据分析编程语言。但是 Python 也有这些优势,Python 是另一种处理数据的流行编码语言。我们在这两个版本中都提供了免费的入门课程,这两个版本都将是对 Excel 的一次重大升级。
1.更强大的数据导入和操作
与 Excel 不同,Alyssa 说,“R 基本上可以读取任何类型的数据。”而它无法原生读取的数据格式仍然可以工作:“还有专门设计用于读取 XML、JSON、SPSS、Excel、SAS 和 STATA 数据文件的 R 包,你也可以从网站上抓取数据并执行 SQL 查询。”
数据操作——如子集化、合并和重新编码数据等任务——在 r 中也容易得多。任何花费大量时间试图在 Excel 中合并和清理几个大型数据集以进行分析的人都可以证明这是一个困难而耗时的过程。但是 R,以及一些流行的软件包,如dplyr、tidyr和plyr,使得这个过程更加简单和快速。
2.更简单的自动化
Excel 有一个 GUI(一个可以点击按钮而不是编写代码的用户界面)这一事实无疑使它更易于使用,但当您试图自动化一个过程或多次运行相同的分析时,这可能是一个很大的障碍。
使用编程语言可以使这个过程更快。例如,如果您需要每周对一组新的销售数据运行相同的分析,那么在 Excel 中这样做将需要每周手动打开一个不同的文件,并重新输入分析所需的公式和其他元素。但是您可以用 R 之类的语言自动进行同样的分析,编写一个简单的脚本,导入新数据并每周运行同样的分析,以您喜欢的任何格式输出结果。
3.更轻松地处理大量数据
在 Excel 中,项目是以表格或选项卡的形式组织的,如果您曾经处理过包含大量表格或每个表格中有大量数据条目的 Excel 文件,您就会知道它会变得非常慢非常快。在 Excel 中处理足够多的数据有时甚至会导致崩溃。然而,像 R 这样的编程语言可以更快地处理大量数据,而且它们不会像 Excel 那样崩溃,所以你不必担心丢失你的工作。
4.更具重现性
当你可以向别人解释你做了什么,别人可以很容易地复制你的工作来证实它(或者你可以自己复制来复查)时,数据分析是最有用的。但这在 Excel 中很难;没有办法清楚地记录或说明您在分析中采取的步骤,重新进行分析需要重新打开原始的 Excel 文件,并手动重新执行您采取的所有步骤(如果您还记得的话)。
在像 r 这样的编程语言中,再现结果要容易得多。重新运行分析就像按下“Enter”键一样简单,而且很容易在代码中添加注释,解释过程的每一步都发生了什么,这样任何人都可以仔细检查您的工作。
5.更容易发现和修复错误
当你在 Excel 中犯了一个错误时,找出错误所在可能会很困难,因为你可能需要滚动数千个数据单元格才能找到答案,或者试图手动重新跟踪你的步骤。
但是当你在像 R 这样的编码语言中出错时,你通常会得到一条错误信息,解释计算机认为哪里出错了。当然,你还应该有注释来解释你的每一行代码,这使得回过头来重新检查每一步寻找错误变得更加容易。通常,程序员也会使用一个系统来进行版本控制,所以如果你遇到了一个以前没有遇到过的错误,你就可以将你当前的代码与之前的代码进行比较,从而了解出了什么问题。
这并不意味着你总是能够立即修复错误。但是“数据分析中的错误是不可避免的,”Alyssa 说,“在 R 中比在 Excel 中更容易发现和修复这些错误。”
6.开源可访问性
Excel 很棒,但它归微软所有,这意味着在 bug、更新和功能支持方面,你最终还是要听这家总部位于华盛顿的公司的。与 Excel 不同,Alyssa 说,“R 不是一个黑匣子。您可以检查您执行的任何函数或计算的 R 代码。你甚至可以通过修改代码来修改和改进关键功能。”
Python 也是开源的,对于这两种语言来说,这也意味着任何开发人员(包括您)都可以创建包来扩充语言、增加功能或提高易用性。这两种语言都有由第三方开发人员创建的流行且广泛使用的包和库,以使数据分析和可视化更容易。
诚然,Excel 确实有一些第三方加载项,但因为它是专有软件,所以它们没有那么强大,也不容易添加任何您可能想要或需要的功能。
7.高级统计和机器学习功能
R 和 Python 都具有比 Excel 更高级的统计功能(尤其是 R,它在设计时就考虑了高级统计分析)。这两种语言还允许创建机器学习模型(通常集成了机器学习包和框架,如caret、scikit-learn和 TensorFlow)。
8.高级数据可视化功能
显然,Excel 可以创建各种各样的图表,但编程语言可以做得更多,特别是 R“通过lattice、ggplot2和shiny软件包拥有更好、更先进和最先进的图形功能,”Alyssa 说。
创建有吸引力和信息丰富的可视化的能力在商业环境中尤其重要,因为公司的决策者可能不熟悉统计分析或不擅长阅读复杂的图表。你越容易理解你的数据,你的工作就越有可能产生真正的影响。
9.跨平台稳定性
像 R 和 Python 这样的编程语言中的脚本可以在任何平台上运行,不会出现任何问题。您可以确信您的 R 脚本可以在 Windows、Mac 和 Linux 机器上运行,但是 Excel 文件并不总是如此。
当然,这并不是说您应该完全放弃 Excel!Alyssa 指出,它确实比编程语言有一些优势。由于其图形用户界面,在 Excel 中手动输入数据通常更容易,如果您只想快速浏览电子表格,浏览 Excel 文件可能比使用代码更快、更容易。Python 和 R do 都有办法以可视化表格格式呈现您正在处理的数据部分,以便更容易看到您正在处理的内容,但在 Excel 中,这种可视化数据呈现是默认的,而不是您必须有意实现的。
尽管如此,很明显,如果你正在做大量的数据分析,使用编程语言提供了一些超越 Excel 的实质性优势。如果你经常使用 Excel,即使学习一点点 R 或 Python 编程也能为你每周节省小时的 Excel 使用时间。如果你只熟悉 Excel,学习像 R 或 Python 这样的编程语言的想法可能会令人生畏。
但是并没有你想象的那么难!在 Dataquest,我们相信任何人都可以学习编码,我们提供免费的入门课程 R 和 Python ,你可以在没有任何编码经验和没有任何数学或工程背景的情况下学习。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
A/B 测试:改进产品的权威指南
原文:https://www.dataquest.io/blog/a-b-testing-the-definitive-guide-to-improving-your-product/
October 11, 2018
从“我想”到“我知道多少。”
无论你是从事产品、设计还是发展,你都可能会遇到以下问题:
- 我们如何提高转化率?
- 我们如何改进我们的漏斗?
- 这项功能的发布有多成功?
- 这些通知是否提高了保留率?
通过正确地设计、运行和解释 A/B 测试,你可以得到这些问题的答案
开始测试之旅所需的一切就是:
- 基本统计理解
- 准确和充分的(> 1000 个月独立用户)产品数据
所采用的方法是严格的,并且鼓励最佳实践,但是:
- 它不会展示频繁假设检验背后的数学原理。
- 它不会涵盖更高级的方面,如贝叶斯环境中的 A/B、多变量测试或 Bonferroni 校正。
准备好了吗?我们开始吧!
0.理解分割测试是一种改进产品的定量方法,并且很容易出错
从本质上来说,A/B 测试是一种比较用户旅程中两个版本的流程的方法,以确定哪一个执行得最好。

为了能够从你的测试中获得洞察力,你需要在每组(分别称为控制组和实验组)中有足够多的人,以及足够多的转化差异。这两个值都应该在运行您的测试之前定义,正如您将在第 3 点中看到的。
1.从您的产品漏斗中选择一个重要的转化步骤
从技术上讲,你可以测试任何东西,比如改变你的条款和条件页面上的字体。但是,您总是希望选择对您的业务成果影响最大的步骤。此外,请记住数据量的重要性——流量越大,得出结论的速度越快——以及数据质量的重要性——垃圾进,垃圾出。
糟糕的数据,糟糕的结论。数据少,结论慢。
让我们实际一点,为 Trana 做这件事,我们将在这篇文章中使用这个例子。

Getting Started – Connecting Strava – Onboarding
Trana 是一个 Facebook Messengerchat app,为其用户提供额外的跑步洞察。为此,它连接到他们的斯特拉发帐户。因此,我们要求用户链接其帐户的时刻是关键。在这一本能原理的基础上,让我们分析一下我们的全面入职漏斗。在设计了一个跟踪计划之后,这可以在诸如 Mixpanel 这样的工具中完成。

Funnel analysis in Mixpanel
我们可以看到,从入职开始到 Strava 连接,无论从绝对还是相对角度来看,关联账户都是最有影响力的行动。有自己重要的一步吗?我们继续吧!
2.分析从该步骤到所需动作的当前点击率
点击率(CTP)是给定用户点击进入下一步的概率。
它的值总是在 0 和 1 之间。因此与不同,点击率(CTR)是指点击次数/印象次数。
CTP 需要从选择的步骤到关键的行动,不一定是下一个步骤,因为你可能会以局部最大值结束。这里有一个简单的例子来理解这一点:假设您现在自动将人们从主页重定向到您产品的定价/溢价页面。你的家庭价格转换将通过屋顶,但你可能要评估人们是否更有可能成为优质用户。
简而言之:优化要着眼于结果,而不是下一步。

80% connect their Strava account, let’s improve that
我们从完整的漏斗中看到,CTP 为 80%。在这种情况下,联系他们的 Strava 帐户显然是一个重要的里程碑,因此我们可以使用这个转换概率作为目标指标。
3.构建一个假设来启动你的实验
AB 测试只不过是在方法上评估一个被称为实验的变异是否比被称为控制的当前情况表现得更好。
实验从构建假设开始。它可能来自直觉、客户反馈或团队讨论。

假设如下:通过了解 Trana 如何帮助他们更智能地运行,用户将更愿意连接他们的 Strava 帐户
4.确定样本量
这是 A/B 测试的核心,也是本指南中术语最多的部分。我很乐意回答你在 twitter 上提出的任何问题。
运行 A/B 测试包括创建一个控制和一个实验样本。抽样,给每个用户分配一个变体,将通过把你的用户分成两组来完成。
一个用户应该总是看到相同的变化,这意味着采样是确定性的,而不仅仅是 50%的概率。
我们通常根据奇数/偶数 id 进行采样,许多工具可以帮你做到这一点。
一个常见的错误是忽略抽样,直接改变你的产品,将新的转换概率与旧的进行比较。
这导致团队得出错误的结论,因为使用你的产品的人是随着时间而变化的。例如,你不能说新的信息流(来自广告的人使用的)比旧的信息流(你的朋友和家人使用的)差,因为看到它不太可能一开始就忍受你的产品。
您的样本量将由以下因素决定:
- 你的基线转化率
- 你选择的绝对最小可检测效应 (MDE/d min )。这是您能够检测到的控制转化率和实验转化率之间的最小差异。如果你有大量的周流量(相对于最终的样本大小),选择你觉得值得的最小差异。如果你不这样做,选择一个差异,导致合理的小样本量,但似乎仍然可以实现。
- Alpha (α):默认情况下保持为 95%
- Beta (β):默认情况下,keep 为 20%,这为 1-β提供了 80%的值

测试将一直运行到两个样本都有至少 1030 个观察值。根据历史流量,你可以估计那会持续多久。尽量让实验运行少于一个月。他们跑得越快,你的产品改进得越快。
计算你的样本量,记下来,然后开始测试。一旦你有了足够的数据,你就可以分析结果。
5.从您的结果中获得有效的见解
5.1 收集数据。
等到两个变量都有足够的样本量,然后继续收集数据。

Breakdown of CTP per version
实验转化率较好。这是第一个好迹象,但我们不能就此止步。所以让我们进行几项检查。
5.2 确保您的采样工作符合预期。
首先,检查取样是否偏向其中一组。以下是我们示例的计算:

5.3 检查实验是否表现得明显更好。
评估实验是否优于对照组可能是一件麻烦的事。因此,我建立了一个小工具来做这件事,把你的数字插入它来执行三个检查。下面是计算的细节。d min 是最小可检测效应,N 是样本大小,X 是转换计数,采取预期行动的人数。

Statistical but no practical significance
其中 d̂ m 是置信区间。
以下是解释结果的方法:
- d̂–m > d𝑚𝑖𝑛:
试验优于对照组(统计和实际显著性)。将流程更改为新版本。 - d̂–m > 0:
实验优于对照(仅统计显著性)。我们的例子中的就是这种情况。为了获得实际意义,你可以让测试运行更长时间。你也可以做出判断,跟着你的直觉走。 - d̂——你不能说实验的表现优于对照组。保持原来的版本,产生新的假设。
6.传达您的结果。
无论结果如何,总是沟通和记录。
我建议您在测试开始和结束时发出信号,将这些关键时刻作为利益相关者表达自己想法和了解最新变化的机会。
此外,始终记录和存档。你希望测试过程比你活得长,这样任何接手的人都有一个可供学习的实验库。
这里有一个谷歌幻灯片模板,你可以用它来交流和记录你的结果。
7.把这些都集中起来。
以下是你从“我想”到“我知道多少”应该采取的步骤:
多亏了这些惊人的资源,本指南才成为可能:
以下是你可以更进一步的方法:
编者按:这篇文章最初发表在罗宾·兰帕尔的博客上,并被 perlesson 转载。
Python 虚拟环境完全指南
原文:https://www.dataquest.io/blog/a-complete-guide-to-python-virtual-environments/
January 17, 2022
在本教程中,我们将学习 Python 虚拟环境、使用虚拟环境的好处以及如何在虚拟环境中工作。
完成本教程后,您将理解以下内容:
如果您需要在 Mac 上安装 Python,请参考教程在 Mac 上安装和运行 Python。
注意:本教程主要面向 macOS 和 Linux 用户;然而,Windows 用户也应该能够跟随。
什么是 Python 虚拟环境?
Python 虚拟环境由两个基本组件组成:运行虚拟环境的 Python 解释器和包含安装在虚拟环境中的第三方库的文件夹。这些虚拟环境与其他虚拟环境隔离,这意味着对虚拟环境中安装的依赖关系的任何更改都不会影响其他虚拟环境或系统范围的库的依赖关系。因此,我们可以用不同的 Python 版本创建多个虚拟环境,加上不同的库或不同版本的相同库。
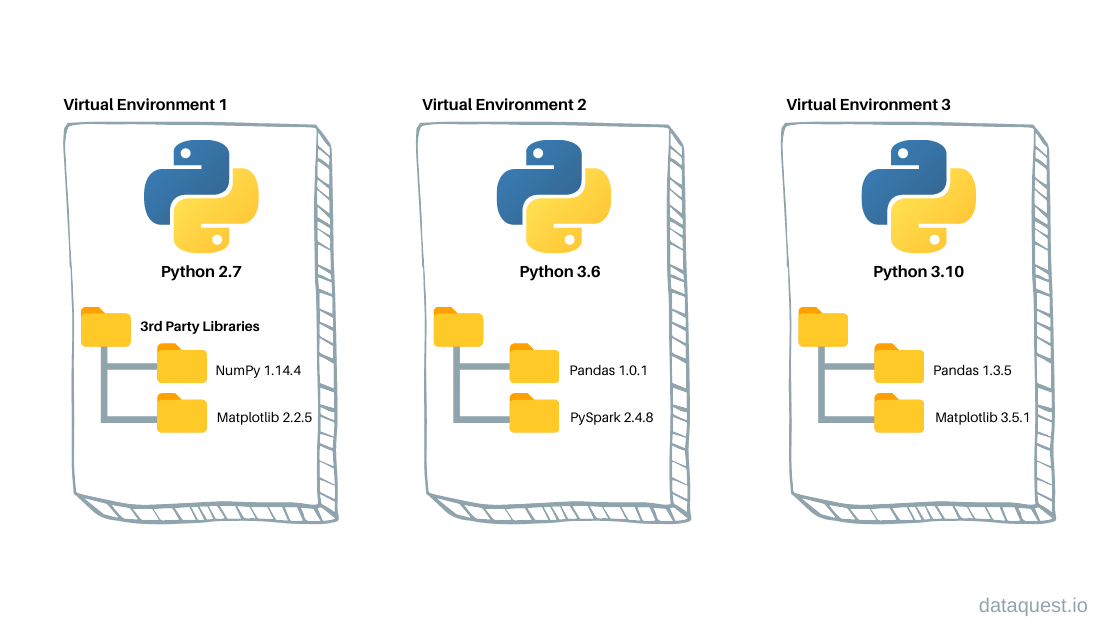
上图展示了当我们创建多个 Python 虚拟环境时,您的系统上有什么。如上图所示,虚拟环境是一个包含特定 Python 版本、第三方库和其他脚本的文件夹树;因此,系统上的虚拟环境数量没有限制,因为它们只是包含一些文件的文件夹。
为什么 Python 虚拟环境很重要?
当我们在同一台机器上有不同的 Python 项目依赖于相同包的不同版本时,Python 虚拟环境的重要性就变得显而易见了。例如,想象一下使用 matplotlib 包的两个不同的数据可视化项目,一个使用 2.2 版本,另一个使用 3.5 版本。这将导致兼容性问题,因为 Python 不能同时使用同一个包的多个版本。放大使用 Python 虚拟环境重要性的另一个用例是,当您在托管服务器或生产环境中工作时,由于特定的要求,您不能修改系统范围的包。
Python 虚拟环境创建隔离的上下文来保持不同项目所需的依赖关系是独立的,因此它们不会干扰其他项目或系统范围的包。基本上,建立虚拟环境是隔离不同 Python 项目的最佳方式,尤其是当这些项目具有不同且相互冲突的依赖关系时。作为对新 Python 程序员的一条建议,永远为每个 Python 项目建立一个单独的虚拟环境,并在其中安装所有需要的依赖项——不要全局安装软件包。
如何使用 Python 虚拟环境
到目前为止,我们已经了解了什么是虚拟环境以及我们为什么需要虚拟环境。在教程的这一部分,我们将学习如何创建、激活和(一般来说)使用虚拟环境。我们开始吧!
创建 Python 虚拟环境
首先创建一个项目文件夹,并在其中创建一个虚拟环境。为此,打开终端应用程序,编写以下命令,然后按 return 键。
~ % mkdir alpha-prj
现在,使用venv命令在项目文件夹中创建一个虚拟环境,如下所示:
~ % python3 -m venv alpha-prj/alpha-venv
注意有两种工具可以设置虚拟环境,virtualenv和venv,我们几乎可以互换使用。virtualenv支持旧的 Python 版本,需要使用pip命令安装。相比之下,venv仅用于 Python 3.3 或更高版本,包含在 Python 标准库中,无需安装。
激活 Python 虚拟环境
要激活我们在上一步中创建的虚拟环境,请运行以下命令。
~ % source alpha-prj/alpha-venv/bin/activate
正如您在激活虚拟环境后所看到的,它的名称出现在终端提示符开始处的括号中。运行 which python命令是确保虚拟环境处于活动状态的另一种方式。如果我们运行这个命令,它会显示 Python 解释器在虚拟环境中的位置。让我们检查一下虚拟环境中的位置。
(alpha-venv) ~ % which python
/Users/lotfinejad/alpha-prj/alpha-venv/bin/python
很高兴知道虚拟环境的 Python 版本与用于创建环境的 Python 版本是相同的。让我们在虚拟环境中检查 Python 版本。
(alpha-venv) ~ % python —version
Python 3.10.1
由于我使用 Python 3.10 来设置虚拟环境,因此虚拟环境使用完全相同的 Python 版本。
在 Python 虚拟环境中安装包
我们现在处于一个隔离的虚拟环境中,默认情况下只安装了pip和setup tools。让我们通过运行pip list命令来检查虚拟环境中预安装的包。
(alpha-venv) ~ % pip list
Package Version
---------- -------
pip 21.2.4
setuptools 58.1.0
在我们想用pip安装任何包之前,让我们把它升级到最新版本。因为我们是在虚拟环境中工作,所以下面的命令只在这个环境中升级pip工具,而不在其他虚拟环境或系统范围内升级。
(alpha-venv) ~ % alpha-prj/alpha-venv/bin/python3 -m pip install --upgrade pip
让我们重新运行pip list命令来查看变化。
(alpha-venv) ~ % pip list
Package Version
---------- -------
pip 21.3.1
setuptools 58.1.0
很明显pip从版本 21.2.4 更新到了 21.3.1。现在,让我们将熊猫包安装到环境中。在安装软件包之前,您需要决定安装哪个版本。如果您要安装最新版本,只需使用以下命令:
(alpha-venv) ~ % python3 -m pip install pandas
但是如果你想安装软件包的一个特定版本,你需要使用这个命令:
(alpha-venv) ~ % python3 -m pip install pandas==1.1.1
现在,让我们看看如何告诉pip我们将安装 1.2 版本之前的任何版本的熊猫。
(alpha-venv) ~ % python3 -m pip install 'pandas<1.2'
另外,我们可以要求pip在 0.25.3 版本之后安装 pandas 包,如下所示:
(alpha-venv) ~ % python3 -m pip install 'pandas>0.25.3'
在前面的命令中,我们将包规范放在引号中,因为大于>和小于<符号在命令行 shell 中有特殊的含义。这两个命令都将安装符合给定约束的 pandas 包的最新版本。然而,最佳实践是用确切的版本号指定软件包。
让我们回顾一下环境中已安装的软件包列表。
(alpha-venv) ~ % pip list
Package Version
--------------- -------
numpy 1.22.0
pandas 1.3.5
pip 21.3.1
python-dateutil 2.8.2
pytz 2021.3
setuptools 58.1.0
six 1.16.0
在安装 pandas 时,NumPy 和其他三个软件包会作为 pandas 软件包的先决条件自动安装。
再现 Python 虚拟环境
再现虚拟环境很常见。假设你的同事将要做你已经做了几周的同一个项目。她需要在她的系统上的虚拟环境中安装具有正确版本的完全相同的包。要创建相同的环境,首先需要使用pip freeze命令列出项目虚拟环境中安装的所有依赖项。
(alpha-venv) ~ % pip freeze
numpy==1.22.0
pandas==1.3.5
python-dateutil==2.8.2
pytz==2021.3
six==1.16.0
pip freeze的输出与pip list非常相似,但是它以正确的格式返回安装在一个环境中的包的列表,以使用项目所需的确切包版本来再现该环境。下一步是将包列表导出到requirements.txt文件中。为此,请运行以下命令:
(alpha-venv) ~ % pip freeze > requirements.txt
上面的命令在当前文件夹中创建一个名为requirements.txt的文本文件。requirements.txt文件包含所有的包和它们的确切版本。我们来看看文件内容。
~ % cat requirements.txt
numpy==1.21.5
pandas==1.3.5
python-dateutil==2.8.2
pytz==2021.3
six==1.16.0
干得好,您已经创建了一个requirements.txt,可以分发给您的同事,在她的系统上复制相同的虚拟环境。现在,让我们看看她应该做些什么来重现虚拟环境。这很简单。她首先需要创建一个虚拟环境,激活它,然后运行pip install -r requirements.txt命令来安装所有需要的包。
她将运行以下三个命令:
~ % python3 -m venv prj/venv
~ % source prj/venv/bin/activate
(venv) ~ % pip install -r requirements.txt
最后一个命令将requirements.txt中列出的所有包安装到您的同事正在创建的虚拟环境中。所以,如果她在自己这边运行pip freeze命令,她会得到与你相同版本的包。另一个要考虑的要点是,如果您要将项目添加到 Git 存储库中,千万不要将其虚拟环境文件夹添加到存储库中。你唯一需要添加的是requirements.txt文件。
注意一个 Python 项目文件夹包含了在虚拟环境中运行的源代码。另一方面,虚拟环境是一个包含 Python 解释器、包和类似于pip的工具的文件夹。因此,最佳实践是将它们分开,并且永远不要将项目文件放在虚拟环境文件夹中。
停用 Python 虚拟环境
一旦您完成了虚拟环境的工作,或者您想要切换到另一个虚拟环境,您可以通过运行以下命令来停用环境:
(alpha-venv) ~ % deactivate
删除 Python 虚拟环境
如果您想要删除虚拟环境,只需删除其文件夹,无需卸载。
~ % rm -rf alpha-prj/alpha-venv
如何在 Visual Studio 代码中使用 Python 虚拟环境
在这一节中,我们将介绍如何在 VS 代码中使用 Python 虚拟环境。首先,确保您已经创建并激活了虚拟环境。现在,在终端中导航到您的项目文件夹,并运行以下命令:
(alpha-venv) alpha-prj % code .
上面的命令将在 VS 代码中打开项目文件夹。如果上面的命令不起作用,打开 VS 代码,按 command + shift + P,打开命令面板,键入 shell 命令,选择安装路径中的‘代码’命令。现在,创建一个 Python 文件,并将其命名为my_script.py。最后一步是使用 Python: Select Interpreter 命令从命令面板中选择虚拟环境。为此,请按 Command + shift + P,键入 Python,并选择选择解释器。
Python: Select 解释器命令显示所有可用的环境。下图显示了我们需要选择的环境。

此时,如果您在 VS 代码中打开集成终端,您将看到虚拟环境是活动的,您可以在其中安装任何包。
在本教程中,我们学习了 Python 虚拟环境如何避免不同项目或系统范围的依赖关系之间的冲突。此外,我们还学习了如何通过在这些自包含环境之间切换来处理具有不同依赖关系的不同项目。
我们首席执行官的声明
June 5, 2020
对我们美国人来说,这是令人心碎和痛苦的几天。我们已经看到全国超过 75 个城市的抗议活动。这些抗议表达了我们对乔治·弗洛伊德、艾哈迈德·阿贝里和布里奥纳·泰勒惨遭杀害的愤怒。
抗议迫使我们审视美国赤裸裸的种族不平等。去年有 235 名黑人被警察枪杀。黑人被监禁的可能性是白人的五倍(T2)。有色人种失业的可能性是白人的 1.5 到 2 倍(T4)。
我们非常感激为自己的权利挺身而出的前辈们。但是战斗还没有结束。今天的美国没有一个公平的竞争环境。
在 Dataquest,我们有机会为我们的社区和世界做出一点贡献。正义和平等是我们共有的价值观,无论我们生活在哪里。
以下是我们正在做的一些事情:
- Dataquest 向平等正义倡议捐赠 5000 美元。
- Dataquest 将为我们的团队成员向美国或全球反对系统性不平等的组织捐赠的 5000 美元进行匹配。
- 我们让我们团队中的每个人都能在周五休假,专注于社会公正项目。这可能包括参加抗议、分析数据或以其他方式支持他人。
展望未来,我们有机会改善全世界人民接受教育的机会。我们已经开始在奖学金项目上这样做了。我们还可以做更多的事情。我不知道这会是什么样子。但是我们会努力去解决这个问题。
亚伦:“Dataquest 用我能理解的方式把事情分解了。”
February 5, 2018
Aaron Melton 在电厂工作时见识了 Python 的威力。他的团队使用 Excel 制作复杂的报告,既耗时又容易出错。他决定学习 Python 来解决这个问题,经过几个月的尝试,他让 NetworkX 开始工作了。
“这是一个伟大的时刻。我看到了如何加快我们正在做的事情。”
在这个过程中,他发现了 Dataquest,它给了他成功所需的 Python 背景。
这就是 Dataquest 的美妙之处:它从最基础的层面开始,所以一个真正的初学者可以理解这些概念
他之前曾尝试过使用 CodeAcademy 和 Coursera 上的一些课程学习编程。“我很纠结,因为我没有编码方面的背景。我花了很多时间在谷歌上搜索,我没有那么多时间去学习。”
他对自己在电厂的工作越来越不满意,但他知道自己需要更多的技能才能继续前进。一年来,他坚持不懈,不断提高自己的技能。“Dataquest 帮助我完成了那份工作。”
当亚伦准备好了,他辞职并投身于找工作,几个月后找到了一个职位。他现在是 VBO 的商业情报分析师。这还不是他的理想工作,因为他想建立机器学习模型。但这是一个开始,并允许他加强他的数学和统计技能。
“我有这些 Python 技能,但现在的问题是用统计的严谨性进行可辩护的分析。在学习 Python 的同时温习一下统计数据是个不错的主意。”
目前,他计划继续学习 Dataquest 的统计课程,这样他就可以继续成长。他确信如果没有 Dataquest 他不会走这么远。
“我真的很沮丧,在办公时间和其中一位老师 Srini 聊了聊。他真的帮了我,让我坚持下去。”
亚当:“如果没有 Dataquest,事情会变得更加困难”
原文:https://www.dataquest.io/blog/adam-it-would-have-been-much-harder-without-dataquest/
October 18, 2018
Adam Zabrodski 最初并没有打算成为一名数据科学家。在大学里,他研究岩石。但在一系列工作中,包括优步的运营管理和投资银行的“艰苦工作”,他发现自己喜欢分析和与数据打交道。
问题?亚当没有数学或计算机科学背景。他没有工具让自己对数据的兴趣更上一层楼。“很明显,我的视野受到了限制,”他说。"在 Excel 中您只能做这么多。"
他在 Coursera 和 CodeAcademy 等网站上尝试学习 Python,但没有坚持下来。他说:“Python 看起来乏味又可怕。”。
然后他去了一家开发移动和电子商务网站的机构。他看到他的队友使用 Python,并意识到它可以有多么强大。他决定再给 Python 一次机会,并决定在业余时间研究 Dataquest 的 Python 之路,最终目标是成为一名数据科学家。
然后,他突然发现自己失业了:他和他所有的同事都被解雇了。
这是一种意外的打击,可能会让不太敬业的人出轨,但由于他的日子出乎意料地空闲,亚当决定拿这些柠檬做柠檬水。他加倍学习 Dataquest 课程,每天花五个小时浏览内容。
五个月后,他完成了所有的工作,不久之后,他找到了第一份工作,成为一名数据科学家。
“我想我很惊讶这有多困难,直到不再困难,”他说。“我曾经因为一个大写的 K 而不是小写的,花了两个小时。”但他给同学们的建议是无论如何都要勇往直前:“如果你坚持下去,情况会变得更好。需要的时候休息一下,但还是要回来。”
亚当现在为世界著名的瑜伽品牌 Lululemon 工作。“我目前的头衔是高级分析师 Guest Insights,”他说,“但实际上我是一名数据科学家。我对我们的客户、随机森林执行聚类模型以预测客户流失,现在正致力于部署一些终身价值模型来帮助数字营销。”
他说,获得这份工作“如果没有 Dataquest,会困难得多”。“这是一个伟大的产品。我还是推荐给任何问我如何入门的人。”
有灵感了吗?投入并开始(或继续)自己的数据科学之旅。
如何在 R 语言中向数据帧添加一列(包含 18 个代码示例)
原文:https://www.dataquest.io/blog/add-column-to-dataframe-in-r/
June 14, 2022
在本教程中,您将学习在 R 中操作数据帧最常用的操作之一——添加列。
数据帧是 R 编程语言的基本数据结构之一。它也是一种非常通用的数据结构,因为它可以存储多种数据类型,易于修改和更新。
在本教程中,我们将考虑在 R 中操纵数据帧最常用的操作之一:如何在 base R 中向数据帧添加列。
R 中的数据帧是什么?
从技术上讲,R 中的 DataFrame 是一个特定的例子,它是一列相同长度的向量,不同的向量可以是(通常是)不同的数据类型。由于 DataFrame 具有表格形式的二维形式,因此它具有列(变量)和行(数据条目)。
在 R 中向数据帧添加列
出于各种原因,我们可能想要向 R 数据帧添加新列:基于现有变量计算新变量,基于可用变量添加新列但具有不同格式(以这种方式保留两列),追加空列或占位符列以进一步填充它,添加包含全新信息的列。
让我们探索向 r 中的数据帧添加新列的不同方法。在我们的实验中,我们将主要使用名为super_sleepers的相同数据帧,我们每次都将从以下初始数据帧中重建该数据帧:
super_sleepers_initial <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'))
print(super_sleepers_initial)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
我们的任务是将一个名为avg_sleep_hours的新列添加到该数据帧中,该列根据以下方案表示上述每种动物每天睡眠的平均时间(小时):
| 动物 | 每天平均睡眠时间 |
|---|---|
| 树袋熊 | Twenty-one |
| 刺猬 | Eighteen |
| 懒惰 | Seventeen |
| 熊猫 | Ten |
对于一些例子,我们将尝试添加另外两列:avg_sleep_hours_per_year和has_tail。
现在,让我们开始吧。
使用$符号向 R 中的数据帧添加列
因为 R 中的数据帧是一个向量列表,其中每个向量代表该数据帧的一个单独的列,所以我们可以通过将相应的新向量添加到该“列表”中来将一列添加到数据帧中。语法如下:
dataframe_name$new_column_name <- vector
让我们从初始的super_sleepers_initial数据帧重建我们的super_sleepers数据帧(我们将对每个后续实验都这样做),并向其添加一个名为avg_sleep_hours的列,由向量c(21, 18, 17, 10)表示:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n') # printing an empty line
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
super_sleepers$avg_sleep_hours <- c(21, 18, 17, 10)
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
请注意,添加到 vector 中的项数必须等于 DataFrame 中的当前行数,否则,程序会抛出一个错误:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Attempting to add a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
# with the number of items in the vector NOT EQUAL to the number of rows in the DataFrame
super_sleepers$avg_sleep_hours <- c(21, 18, 17)
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
Error in `$<-.data.frame`(`*tmp*`, avg_sleep_hours, value = c(21, 18, : replacement has 3 rows, data has 4
Traceback:
1\. `$<-`(`*tmp*`, avg_sleep_hours, value = c(21, 18, 17))
2\. `$<-.data.frame`(`*tmp*`, avg_sleep_hours, value = c(21, 18,
. 17))
3\. stop(sprintf(ngettext(N, "replacement has %d row, data has %d",
. "replacement has %d rows, data has %d"), N, nrows), domain = NA)
我们可以为新列的所有行分配一个值,无论是数字还是字符,而不是分配一个向量:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame and assigning it to 0
super_sleepers$avg_sleep_hours <- 0
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 0
2 2 hedgehog Italy 0
3 3 sloth Peru 0
4 4 panda China 0
在这种情况下,新列充当指定数据类型(在上面的例子中是数字)的实际值的占位符,我们可以在以后插入这些值。
或者,我们可以基于现有的列计算一个新列。让我们首先将avg_sleep_hours列添加到我们的 DataFrame 中,然后从中计算一个新的列avg_sleep_hours_per_year。我们想知道这些动物每年平均睡眠多少小时:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
super_sleepers$avg_sleep_hours <- c(21, 18, 17, 10)
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours_per_year` calculated from `avg_sleep_hours`
super_sleepers$avg_sleep_hours_per_year <- super_sleepers$avg_sleep_hours * 365
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
rating animal country avg_sleep_hours avg_sleep_hours_per_year
1 1 koala Australia 21 7665
2 2 hedgehog Italy 18 6570
3 3 sloth Peru 17 6205
4 4 panda China 10 3650
同样,可以使用下面的语法将一列从一个数据帧复制到另一个数据帧:df1$new_col <- df2$existing_col。让我们复制这样一种情况:
# Creating the `super_sleepers_1` dataframe with the only column `rating`
super_sleepers_1 <- data.frame(rating=1:4)
print(super_sleepers_1)
cat('\n\n')
# Copying the `animal` column from `super_sleepers_initial` to `super_sleepers_1`
# Note that in the new DataFrame, the column is called `ANIMAL` instead of `animal`
super_sleepers_1$ANIMAL <- super_sleepers_initial$animal
print(super_sleepers_1)
rating
1 1
2 2
3 3
4 4
rating ANIMAL
1 1 koala
2 2 hedgehog
3 3 sloth
4 4 panda
这种方法(即使用$操作符将列追加到数据帧)的缺点是,我们不能以这种方式添加名称包含空格或特殊符号的列。事实上,它不能包含任何不是字母(大写或小写)、数字、点或下划线的内容。此外,这种方法不适用于添加多个列。
使用方括号将列添加到 R 中的数据帧
向 R 数据帧添加新列的另一种方式是更“数据帧风格”而不是“列表风格”:通过使用括号符号。让我们看看它是如何工作的:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame:
super_sleepers['avg_sleep_hours'] <- c(21, 18, 17, 10)
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
在上面这段代码中,我们可以用下面这行代码代替:
super_sleepers['avg_sleep_hours'] <- c(21, 18, 17, 10)
这一行也可以替换为:
super_sleepers[['avg_sleep_hours']] <- c(21, 18, 17, 10)
最后,这个也可以替换:
super_sleepers[,'avg_sleep_hours'] <- c(21, 18, 17, 10)
结果是一样的,那只是语法的 3 个不同版本。
与前一种方法一样,我们可以为新列分配一个值,而不是一个向量:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame and assigning it to 'Unknown'
super_sleepers['avg_sleep_hours'] <- 'Unknown'
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia Unknown
2 2 hedgehog Italy Unknown
3 3 sloth Peru Unknown
4 4 panda China Unknown
或者,我们可以基于现有的列计算一个新列:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
super_sleepers['avg_sleep_hours'] <- c(21, 18, 17, 10)
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours_per_year` calculated from `avg_sleep_hours`
super_sleepers['avg_sleep_hours_per_year'] <- super_sleepers['avg_sleep_hours'] * 365
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
rating animal country avg_sleep_hours avg_sleep_hours_per_year
1 1 koala Australia 21 7665
2 2 hedgehog Italy 18 6570
3 3 sloth Peru 17 6205
4 4 panda China 10 3650
使用另一个选项,我们可以从另一个数据帧中复制一列:
# Creating the `super_sleepers_1` dataframe with the only column `rating`
super_sleepers_1 <- data.frame(rating=1:4)
print(super_sleepers_1)
cat('\n\n')
# Copying the `animal` column from `super_sleepers_initial` to `super_sleepers_1`
# Note that in the new DataFrame, the column is called `ANIMAL` instead of `animal`
super_sleepers_1['ANIMAL'] <- super_sleepers_initial['animal']
print(super_sleepers_1)
rating
1 1
2 2
3 3
4 4
rating ANIMAL
1 1 koala
2 2 hedgehog
3 3 sloth
4 4 panda
使用方括号而不是$运算符将列追加到 DataFrame 的优点是,我们可以添加名称包含空格或任何特殊符号的列。
使用cbind()函数向 R 中的数据帧添加一列
向 R 数据帧添加新列的第三种方式是应用代表“列绑定”的cbind()函数,该函数也可用于组合两个或更多数据帧。使用这个函数比前两个方法更通用,因为它允许一次添加几列。其基本语法如下:
df <- cbind(df, new_col_1, new_col_2, ..., new_col_N)
下面这段代码将avg_sleep_hours列添加到super_sleepers数据帧中:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
super_sleepers <- cbind(super_sleepers,
avg_sleep_hours=c(21, 18, 17, 10))
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
下一段代码一次向super_sleepers数据帧添加两个新列——avg_sleep_hours和has_tail:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding two new columns `avg_sleep_hours` and `has_tail` to the `super_sleepers` DataFrame
super_sleepers <- cbind(super_sleepers,
avg_sleep_hours=c(21, 18, 17, 10),
has_tail=c('no', 'yes', 'yes', 'yes'))
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours has_tail
1 1 koala Australia 21 no
2 2 hedgehog Italy 18 yes
3 3 sloth Peru 17 yes
4 4 panda China 10 yes
除了一次添加多列之外,使用cbind()函数的另一个优点是,它允许将该操作的结果(即向 R 数据帧添加一列或多列)分配给新的数据帧,而不改变初始数据帧:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Creating a new DataFrame `super_sleepers_new` based on `super_sleepers` with a new column `avg_sleep_hours`
super_sleepers_new <- cbind(super_sleepers,
avg_sleep_hours=c(21, 18, 17, 10),
has_tail=c('no', 'yes', 'yes', 'yes'))
print(super_sleepers_new)
cat('\n\n')
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours has_tail
1 1 koala Australia 21 no
2 2 hedgehog Italy 18 yes
3 3 sloth Peru 17 yes
4 4 panda China 10 yes
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
与前两种方法一样,在cbind()函数中,我们可以为整个新列分配一个值:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame and assigning it to 0.999
super_sleepers <- cbind(super_sleepers,
avg_sleep_hours=0.999)
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 0.999
2 2 hedgehog Italy 0.999
3 3 sloth Peru 0.999
4 4 panda China 0.999
另一个选项允许我们基于现有的列来计算它:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
super_sleepers <- cbind(super_sleepers,
avg_sleep_hours=c(21, 18, 17, 10))
print(super_sleepers)
cat('\n\n')
# Adding a new column `avg_sleep_hours_per_year` calculated from `avg_sleep_hours`
super_sleepers <- cbind(super_sleepers,
avg_sleep_hours_per_year=super_sleepers['avg_sleep_hours'] * 365)
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
rating animal country avg_sleep_hours avg_sleep_hours
1 1 koala Australia 21 7665
2 2 hedgehog Italy 18 6570
3 3 sloth Peru 17 6205
4 4 panda China 10 3650
使用以下选项,我们可以从另一个数据帧中复制一列:
# Creating the `super_sleepers_1` DataFrame with the only column `rating`
super_sleepers_1 <- data.frame(rating=1:4)
print(super_sleepers_1)
cat('\n\n')
# Copying the `animal` column from `super_sleepers_initial` to `super_sleepers_1`
# Note that in the new DataFrame, the column is still called `animal` despite setting the new name `ANIMAL`
super_sleepers_1 <- cbind(super_sleepers_1,
ANIMAL=super_sleepers_initial['animal'])
print(super_sleepers_1)
rating
1 1
2 2
3 3
4 4
rating animal
1 1 koala
2 2 hedgehog
3 3 sloth
4 4 panda
然而,与$运算符和方括号方法不同,请注意以下两个细微差别:
- 我们不能创建一个新列,然后在同一个
cbind()函数中基于新列再计算一列。例如,下面这段代码会抛出一个错误。
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n')
# Attempting to add a new column `avg_sleep_hours` to the `super_sleepers` DataFrame
# AND another new column `avg_sleep_hours_per_year` based on it
super_sleepers <- cbind(super_sleepers,
avg_sleep_hours=c(21, 18, 17, 10),
avg_sleep_hours_per_year=super_sleepers['avg_sleep_hours'] * 365)
print(super_sleepers)
rating animal country
1 1 koala Australia
2 2 hedgehog Italy
3 3 sloth Peru
4 4 panda China
Error in `[.data.frame`(super_sleepers, "avg_sleep_hours"): undefined columns selected
Traceback:
1\. cbind(super_sleepers, avg_sleep_hours = c(21, 18, 17, 10), avg_sleep_hours_per_year = super_sleepers["avg_sleep_hours"] *
. 365)
2\. super_sleepers["avg_sleep_hours"]
3\. `[.data.frame`(super_sleepers, "avg_sleep_hours")
4\. stop("undefined columns selected")
- 当我们从另一个数据帧中复制一个列,并试图在
cbind()函数中给它一个新名称时,这个新名称将被忽略,新列的调用将与它在原始数据帧中的调用完全相同。例如,在下面这段代码中,新名称ANIMAL被忽略,新列被命名为animal,就像在复制它的数据帧中一样:
# Creating the `super_sleepers_1` DataFrame with the only column `rating`
super_sleepers_1 <- data.frame(rating=1:4)
print(super_sleepers_1)
cat('\n\n')
# Copying the `animal` column from `super_sleepers_initial` to `super_sleepers_1`
# Note that in the new DataFrame, the column is still called `animal` despite setting the new name `ANIMAL`
super_sleepers_1 <- cbind(super_sleepers_1,
ANIMAL=super_sleepers_initial['animal'])
print(super_sleepers_1)
rating
1 1
2 2
3 3
4 4
rating animal
1 1 koala
2 2 hedgehog
3 3 sloth
4 4 panda
结论
在本教程中,我们讨论了为什么需要向 R 数据帧添加新列的各种原因,以及它可以存储什么样的信息。然后,我们探索了三种不同的方法:使用$符号、方括号和cbind()函数。我们考虑了每种方法的语法及其可能的变化,每种方法的优缺点,可能的附加功能,最常见的陷阱和错误,以及如何避免它们。此外,我们还学习了如何一次向 R 数据帧添加多个列。
值得注意的是,所讨论的方法并不是在 r 中向 DataFrame 添加列的唯一方法。例如,出于同样的目的,我们可以使用 mutate() 或 add_column() 函数。然而,为了能够应用这些函数,我们需要安装和加载特定的 R 包( dplyr 和 tibble ),除了我们在本教程中讨论的功能之外,它们不会给操作增加任何额外的功能。相反,使用$符号、方括号和cbind()函数不需要在基础 r 中实现任何安装
向带有熊猫的地块添加轴标签
原文:https://www.dataquest.io/blog/adding-axis-labels-to-plots-with-pandas-and-matplotlib/
December 20, 2017
熊猫绘图方法提供了一种简单的方法来绘制熊猫对象。不过,通常您会想要添加轴标签,这涉及到理解 Matplotlib 语法的复杂性。谢天谢地,有一种方法可以完全用熊猫来做这件事。让我们从导入所需的库开始:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
接下来,我们将创建一个测试数据框架,其中包含一列名称和相应的测试分数:
df = pd.DataFrame({
"name": ["Joe", "Sally", "Ananya"],
"score": np.random.randint(0,100,size=3)})
df
| 名字 | 得分 | |
|---|---|---|
| Zero | 乔(人名) | forty-two |
| one | 俏皮话 | Thirty-seven |
| Two | 安纳亚 | Ninety-eight |
用 pandas 方法绘制这个数据帧很简单。我们可以使用 DataFrame.plot.bar()方法来生成两行条形图。
df.plot.bar()
plt.show()

这给了我们立竿见影的效果,但要解读这个情节并不容易,因为我们看不到哪些分数属于哪个名字。如果你仔细观察,你可能会注意到当前的 x 轴标签是0、1和2。这些实际上对应于数据帧索引。通过使用 set_index()方法将数据帧的索引设置为我们的名称,我们可以轻松地生成轴标签并改进我们的绘图。我们将使用drop=True来删除列,并使用inplace=True来代替将变量赋回给自身或一个新的变量名。
df.set_index("name",drop=True,inplace=True)
df
| 得分 | |
|---|---|
| 名字 | |
| --- | --- |
| 乔(人名) | Thirty-three |
| 俏皮话 | Ninety-five |
| 安纳亚 | Thirty-six |
现在,让我们再次绘图,看看我们的结果:
df.plot.bar()
plt.show()

瞬间我们的剧情更好看了,清晰的传达了数据!
如果你有兴趣学习更多关于 Python 中数据可视化的知识,你可能想看看我们的Matplotlib数据可视化课程。
新课程:学习 R 中的高级数据清理
原文:https://www.dataquest.io/blog/advanced-data-cleaning-r-course/
August 9, 2019
让我们面对现实:数据清理并不是大多数人注册成为数据科学家的原因。这可能是本世纪最性感的工作的持有者必须定期做的最不性感的事情。
但这也是最重要的一点。例如,当 Kaggle 在 2017 年对数据工作者进行调查时,大约一半的人表示,脏数据是他们在工作中面临的主要障碍。数据科学家经常说,他们花在数据清理上的时间比任何其他任务都多。
为什么数据清理如此重要?因为计算的基本原则:垃圾进,垃圾出。

这就是为什么我们很高兴推出另一门新的数据清理课程!R: Advanced 中的 数据清洗是我们快速增长的 R path 中数据分析师的最新进入。它旨在帮助您将在我们的第一个 R 数据清理课程中学到的技能应用到更脏的数据集和更严峻的挑战中。
准备好迎接挑战并向您的技能集添加一些强大的新数据清理技能了吗?
(顺便说一下,如果你想在 Python 中建立数据清理技能,我们为 Python 程序员提供了类似的课程。
关于 R 数据清理,您将了解到什么
在 R: Advanced 的 数据清理中,随着您学习和应用新技能来准备数据进行分析,您将亲身体验杂乱的真实数据集,包括黑客新闻标题、黑客新闻帖子和纽约市交通数据。
您将从使用 stringr 包学习如何在 R 中使用正则表达式开始。正则表达式(通常称为 regex)为您提供了操作字符串和快速清理文本数据的强大方法。您还将学习使用 jsonite 清理和处理 JSON 格式的数据。这是一项重要的技能,因为在处理来自 web APIs 的数据时,您可能会经常遇到 JSON 数据。
使用 R 的 purrr 包,您将学习应用 map 函数来简化列表式数据的工作。您还将了解匿名函数以及它们在 R 数据清理工作流中的用处。
然后,您将深入学习本课程的最后一课,这一课的重点是处理缺失数据。您将学习可视化缺失数据的有效方法,并研究各种统计学上合理的方法来处理缺失数据,而不必从数据集中删除行。
在本课程结束时,您将能够像导入和使用 CSV 一样自如地使用 JSON 数据。您将能够使用正则表达式快速有效地操作字符串,并且通过实现映射函数和匿名函数来提高效率,您已经提高了数字数据清理能力。
最后,您将能够快速找到并可视化数据集中的缺口,并且您将掌握各种替换缺失数据的技术,无论是使用合并到数据集中的外部数据,还是使用统计技术。
为什么在 Dataquest 学习
像我们所有的课程一样,R: Advanced 中的 数据清理使用我们基于浏览器的交互式学习系统,因此您可以将您正在学习的应用为您正在学习的。
研究一再证实,应用所学知识的学生比不应用的学生表现更好,保留更多知识,我们的交互平台不仅允许您使用 R 编写代码,还允许您使用您将在现实世界数据科学工作流中使用的所有流行包。
这让你很容易从在线学习跳到现实世界的项目。

简而言之,Dataquest 平台。
说到“真实世界”,我们所有的课程都使用真实世界的数据集。当你观看视频时,很容易觉得你在学习,但实际上并没有记住那么多,但在我们的课程中,你将面临挑战,立即应用你所学的知识来解决真正的数据科学问题。
当然,你不必相信我们的话!您可以查看学生如何回答我们的学生调查,或者阅读我们的一些学生对他们的 Dataquest 体验的看法。或者你可以在 Switchup、G2 Crowd 和 Course Report 等第三方网站上查看我们的评论。
学习数据清理是任何数据分析师或数据科学家的工具箱中的关键部分。如果你已经掌握了 R 数据清理的基础知识,并想进行下一步,这个新的高级课程将让你像一个经验丰富的专业人士一样清理数据。今天就开始学习吧!
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
教程:高级 Jupyter 笔记本
原文:https://www.dataquest.io/blog/advanced-jupyter-notebooks-tutorial/
January 2, 2019
Jupyter 项目生命周期是现代数据科学和分析的核心。无论您是快速制作创意原型、演示您的工作,还是制作完整的报告,笔记本电脑都可以提供超越 ide 或传统桌面应用程序的高效优势。
继 Jupyter 笔记本初学者:教程之后,这个指南将是一个 Jupyter 笔记本教程,带你踏上从真正的香草到彻头彻尾的危险的旅程。没错!Jupyter 的无序执行的古怪世界有着令人不安的力量,当涉及到在笔记本中运行笔记本时,事情会变得很复杂。
这个 Jupyter 笔记本教程旨在理顺一些混乱的来源,传播激发你的兴趣和激发你的想象力的想法。已经有很多关于整洁的提示和技巧的伟大列表,所以在这里我们将更彻底地看看 Jupyter 的产品。
这将涉及:
- 使用 shell 命令的基础知识和一些方便的魔术进行热身,包括调试、计时和执行多种语言。
- 探索日志记录、宏、运行外部代码和 Jupyter 扩展等主题。
- 了解如何使用 Seaborn 增强图表,使用主题和 CSS 美化笔记本,以及定制笔记本输出。
- 最后深入探讨脚本执行、自动化报告管道和使用数据库等主题。
如果你是 JupyterLab 的粉丝,你会很高兴听到 99%的内容仍然适用,唯一的区别是一些 Jupyter 笔记本扩展与 JuputerLab 不兼容。幸运的是,令人敬畏的 替代品已经出现在 GitHub 上。
现在我们准备好成为朱庇特巫师了!
Shell 命令
每个用户至少都会不时地受益于从他们的笔记本中直接与操作系统交互的能力。代码单元中以感叹号开头的任何一行都将作为 shell 命令执行。这在处理数据集或其他文件以及管理 Python 包时非常有用。举个简单的例子:
!echo Hello World!!
pip freeze | grep pandas
Hello World!
pandas==0.23.4
还可以在 shell 命令中使用 Python 变量,方法是在前面加上一个与 bash 风格变量名一致的符号$。
message = 'This is nifty'
!echo $message
This is nifty
请注意,!命令执行所在的 shell 在执行完成后会被丢弃,因此像cd这样的命令将不起作用。然而,IPython magics 提供了一个解决方案。
基本魔术
Magics 是内置于 IPython 内核中的便捷命令,它使执行特定任务变得更加容易。尽管它们经常类似于 unix 命令,但在本质上,它们都是用 Python 实现的。存在的魔法比在这里介绍的要多得多,但是有必要强调各种各样的例子。在进入更有趣的案例之前,我们将从一些基础知识开始。
有两种魔法:线魔法和细胞魔法。它们分别作用于单个细胞株,也可以分布于多个细胞株或整个细胞。要查看可用的魔术,您可以执行以下操作:
%lsmagic
Available line magics:
Available cell magics:%%! %%HTML %%SVG %%bash %%capture %%cmd %%debug %%file %%html %%javascript %%js %%latex %%markdown %%perl %%prun %%pypy %%python %%python2 %%python3 %%ruby %%script %%sh %%svg %%sx %%system %%time %%timeit %%writefile
Automagic is ON, % prefix IS NOT needed for line magics.
如你所见,有很多!大多数都在官方文件中列出,该文件旨在作为参考,但在某些地方可能有些晦涩。线条魔术以百分比字符%开始,单元格魔术以两个字符%%开始。
值得注意的是,!实际上只是 shell 命令的一种奇特的魔法语法,正如您可能已经注意到的,IPython 提供了魔法来代替那些改变 shell 状态并因此被!丢失的 shell 命令。例子有%cd、%alias、%env。
让我们再看一些例子。
自动保存
首先,%autosave魔术让你改变你的笔记本多久自动保存到它的检查点文件。
%autosave 60
Autosaving every 60 seconds
就这么简单!
显示 Matplotlib 图
对于数据科学家来说,最常见的线条魔法之一当然是%matplotlib,它当然是和最流行的 Python 绘图库 Matplotlib 一起使用。
%matplotlib inline
提供inline参数指示 IPython 在单元格输出中内联显示 Matplotlib 绘图图像,使您能够在笔记本中包含图表。在导入 Matplotlib 之前,一定要包含这个魔术,因为如果不包含它,它可能无法工作;许多人在笔记本的开头,在第一个代码单元中导入它。
现在,让我们开始看看一些更复杂的特性。
排除故障
更有经验的读者可能会担心没有调试器的 Jupyter 笔记本的最终功效。但是不要害怕!IPython 内核有自己的 Python 调试器接口、pdb ,以及几个在笔记本上使用它进行调试的选项。执行%pdb line magic 将打开/关闭笔记本中所有单元格的 pdb on error 自动触发。
raise NotImplementedError()
Automatic pdb calling has been turned ON
--------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-31-022320062e1f> in <module>()
1 get_ipython().run_line_magic('pdb', '')
----> 2 raise NotImplementedError()
NotImplementedError:
> <ipython-input-31-022320062e1f>(2)<module>()
1 get_ipython().run_line_magic('pdb', '')
----> 2 raise NotImplementedError()
这暴露了一种交互模式,在这种模式下,您可以使用 pdb 命令。
另一个方便的调试魔术是%debug,您可以在出现异常后执行它,以便在失败时返回调用堆栈。
顺便说一句,还要注意上面的回溯是如何演示魔术如何被直接翻译成 Python 命令的,其中%pdb变成了get_ipython().run_line_magic('pdb', '')。改为执行这个等同于执行%pdb。
定时执行
有时在研究中,为竞争方法提供运行时比较是很重要的。IPython 提供了两个时序魔法%time和%timeit,每个都有行和单元模式。前者只是对单个语句或单元格的执行进行计时,这取决于它是用于行模式还是单元模式。
n = 1000000
Wall time: 32.9 ms
499999500000
在单元模式下:
total = 0
for i in range(n):
total += i
Wall time: 95.8 ms
%timeit与%time的显著区别在于它多次运行指定的代码并计算平均值。您可以使用-n选项指定运行次数,但是如果没有通过,将根据计算时间选择一个合适的值。
%timeit sum(range(n))
34.9 ms ± 276 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
执行不同的语言
在上面%lsmagic的输出中,你可能已经注意到了许多以各种编程、脚本或标记语言命名的单元格魔术,包括 HTML、JavaScript、 Ruby 和 LaTeX 。使用这些将使用指定的语言执行单元格。其他语言也有扩展,比如 r。
例如,要在笔记本中呈现 HTML:
%%HTML
This is <em>really</em> neat!
这真的利落!
同样, LaTeX 是一种显示数学表达式的标记语言,可以直接使用:
%%latex
Some important equations:$E = mc^2$
$e^{i pi} = -1$
一些重要的方程式:
(e = mc^2)
(e^{i \ pi } =-1 )
配置日志记录
您知道 Jupyter 有一种内置的方法可以在单元格输出上突出显示自定义错误信息吗?这对于确保任何可能使用您的笔记本的人都很难忽略诸如无效输入或参数化之类的错误和警告非常方便。一个简单的、可定制的方法是通过标准的 Python logging模块。
(注意:对于这一部分,我们将使用一些屏幕截图,以便我们可以看到这些错误在真实笔记本中的样子。)

日志输出与print语句或标准单元输出分开显示,出现在所有这些之上。

这实际上是可行的,因为 Jupyter 笔记本同时监听标准输出流、stdout和stderr,但处理方式不同;print语句和单元格输出路由到stdout,默认情况下logging已被配置为流过stderr。
这意味着我们可以配置logging在stderr上显示其他类型的消息。

我们可以像这样定制这些消息的格式:

请注意,每次运行通过logger.addHandler(handler)添加新流处理程序的单元时,每次记录的每个消息都会有一行额外的输出。我们可以将所有的日志记录配置放在靠近笔记本顶部的单元格中,或者像我们在这里所做的那样,强行替换日志记录器上所有现有的处理程序。在这种情况下,我们必须删除默认的处理程序。
将记录到一个外部文件也很容易,如果你从命令行执行你的笔记本,这可能会派上用场,后面会讨论。只是用一个FileHandler代替一个StreamHandler:
handler = logging.FileHandler(filename='important_log.log', mode='a')
最后要注意的是,这里描述的日志不要与使用%config魔法通过%config Application.log_level="INFO"改变应用程序的日志级别相混淆,因为这决定了 Jupyter 在运行时向终端输出什么。
扩展ˌ扩张
由于它是一个开源的 webapp,已经为 Jupyter 笔记本开发了大量的扩展,并且有一个很长的官方列表。事实上,在下面的使用数据库一节中,我们使用了 ipython-sql 扩展。另一个特别值得注意的是来自 Jupyter-contrib 的扩展包,它包含了用于拼写检查、代码折叠等等的独立扩展。
您可以从命令行安装和设置它,如下所示:
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
jupyter nbextension enable spellchecker/main
jupyter nbextension enable codefolding/main
这将在 Python 中安装jupyter_contrib_nbextensions包,在 Jupyter 中安装,然后启用拼写检查和代码折叠扩展。不要忘记在安装时实时刷新任何笔记本以加载更改。
请注意,Jupyter-contrib 只能在普通的 Jupyter 笔记本上运行,但是 GitHub 上现在发布了 JupyterLab 的新的扩展。
使用 Seaborn 增强图表
Jupyter 笔记本用户进行的最常见的练习之一是制作情节。但是 Python 最流行的图表库 Matplotlib 并不以吸引人的结果而闻名,尽管它是可定制的。Seaborn 立即美化 Matplotlib 图,甚至添加一些与数据科学相关的附加功能,使您的报告更漂亮,您的工作更容易。它包含在默认的 Anaconda 安装中,也可以通过pip install seaborn轻松安装。
让我们来看一个例子。首先,我们将导入我们的库并加载一些数据。
import matplotlib.pyplot as plt
import seaborn as sns
data = sns.load_dataset("tips")
Seaborn 提供了一些内置的样本数据集,用于文档、测试和学习目的,我们将在这里使用它们。这个“tips”数据集是一个 pandas DataFrame,列出了酒吧或餐馆的一些账单信息。我们可以看到账单总额、小费、付款人的性别以及其他一些属性。
data.head()
| 合计 _ 账单 | 小费 | 性 | 吸烟者 | 天 | 时间 | 大小 | |
|---|---|---|---|---|---|---|---|
| Zero | Sixteen point nine nine | One point zero one | 女性的 | 不 | 太阳 | 主餐 | Two |
| one | Ten point three four | One point six six | 男性的 | 不 | 太阳 | 主餐 | three |
| Two | Twenty-one point zero one | Three point five | 男性的 | 不 | 太阳 | 主餐 | three |
| three | Twenty-three point six eight | Three point three one | 男性的 | 不 | 太阳 | 主餐 | Two |
| four | Twenty-four point five nine | Three point six one | 女性的 | 不 | 太阳 | 主餐 | four |
我们可以很容易地在 Matplotlib 中绘制出total_bill vs tip。
plt.scatter(data.total_bill, data.tip);

在 Seaborn 绘图也一样简单!只需设置一个样式,你的 Matplotlib 图就会自动转换。
sns.set(style="darkgrid")plt.scatter(data.total_bill, data.tip);

这是多么大的改进啊,而且只需要一个导入和一行额外的代码!在这里,我们使用了深色网格样式,但是 Seaborn 总共有五种内置样式供您使用:深色网格、白色网格、深色、白色和刻度。
但是,我们并没有止步于样式化:由于 Seaborn 与 pandas 数据结构紧密集成,它自己的散点图功能释放了额外的特性。
sns.scatterplot(x="total_bill", y="tip", data=data);

现在,我们为每个数据点获得了默认的轴标签和改进的默认标记。Seaborn 还可以根据数据中的类别自动分组,为您的绘图添加另一个维度。让我们根据买单的群体是否吸烟来改变标记的颜色。
sns.scatterplot(x="total_bill", y="tip", hue="smoker", data=data);

这真是太棒了!事实上,我们可以做得更深入,但是这里的细节太多了。作为品尝者,让我们根据买单的人数来区分吸烟者和非吸烟者。
sns.scatterplot(x="total_bill", y="tip", hue="size", style="smoker", data=data);

希望能弄清楚为什么 Seaborn 将自己描述为“绘制吸引人的统计图形的高级界面”。
事实上,这已经足够高级了,例如,为绘制数据的提供带有最佳拟合线(通过线性回归确定)的一行程序,而 Matplotlib 依赖于您自己准备数据。但是如果你需要的是更吸引人的情节,它是非常可定制的;例如,如果你对默认主题不满意,你可以从一整套标准的调色板中选择,或者定义自己的主题。
Seaborn 允许你用更多的方式来可视化你的数据结构和其中的统计关系,查看他们的例子。
宏指令
像许多用户一样,您可能会发现自己一遍又一遍地编写相同的任务。也许当你开始一个新的笔记本时,你总是需要导入一堆包,一些你发现你自己为每个数据集计算的统计数据,或者一些你已经制作了无数次的标准图表?
Jupyter 允许您将代码片段保存为可执行宏,以便在所有笔记本上使用。尽管执行未知代码对其他试图阅读或使用您的笔记本的人来说不一定有用,但在您进行原型制作、调查或只是玩玩的时候,它绝对是一种方便的生产力提升。
宏只是代码,所以它们可以包含在执行前必须定义的变量。让我们定义一个来使用。
name = 'Tim'
现在,要定义一个宏,我们首先需要一些代码来使用。
print('Hello, %s!' % name)
Hello, Tim!
我们使用%macro和%store魔法来设置一个可以在所有笔记本上重复使用的宏。宏名通常以双下划线开头,以区别于其他变量,如下所示:
%macro -q __hello_world 23
\%store __hello_world
Stored '__hello_world' (Macro)
这个%macro魔术需要一个名字和一个单元格号(单元格左边方括号中的数字;在这种情况下,23 如在In [23]),我们还通过了-q,使它不那么冗长。%store实际上允许我们保存任何变量以便在其他会话中使用;这里,我们传递我们创建的宏的名称,这样我们可以在内核关闭后或在其他笔记本中再次使用它。不带任何参数运行,%store列出你保存的项目。
要从存储中加载宏,我们只需运行:
%store -r __hello_world
为了执行它,我们只需要运行一个只包含宏名的单元格。
__hello_world
Hello, Tim!
让我们修改我们在宏中使用的变量。
name = 'Ben'
当我们现在运行宏时,我们修改后的值被选中。
__hello_world
Hello, Ben!
这是因为宏只是在单元格的范围内执行保存的代码;如果name未定义,我们会得到一个错误。
但是宏并不是笔记本间共享代码的唯一方式。
执行外部代码
并非所有代码都属于 Jupyter 笔记本。事实上,尽管完全有可能在 Jupyter 笔记本上编写统计模型,甚至是完整的多部分项目,但是这些代码会变得混乱,难以维护,并且其他人无法使用。Jupyter 的灵活性无法替代编写结构良好的 Python 模块,这些模块可以轻松地导入到您的笔记本中。
总的来说,当您的快速笔记本项目开始变得更加严肃,并且您发现自己正在编写可重用的或者可以逻辑分组到 Python 脚本或模块中的代码时,您应该这样做!除了可以在 Python 中直接导入自己的模块,Jupyter 还允许您使用%load和%run外部脚本来支持组织更好、规模更大的项目和可重用性。
为每个项目一遍又一遍地导入相同的包是%load魔术的完美候选,它将外部脚本加载到执行它的单元中。
但是已经说得够多了,让我们来看一个例子!如果我们创建一个包含以下代码的文件imports.py:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
我们可以简单地通过编写一个单行代码单元格来加载它,就像这样:
%load imports.py
执行此操作将用加载的文件替换单元格内容。
# %load imports.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
现在我们可以再次运行单元来导入我们所有的模块,我们已经准备好了。
%run魔术是相似的,除了它将执行代码和显示任何输出,包括 Matplotlib 图。您甚至可以这样执行整个笔记本,但是请记住,并不是所有代码都真正属于笔记本。让我们来看看这个魔术的例子;考虑一个包含以下简短脚本的文件。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
if __name__ == '__main__':
h = plt.hist(np.random.triangular(0, 5, 9, 1000), bins=100, linewidth=0)
plt.show()
当通过%run执行时,我们得到以下结果。
%run triangle_hist.py

<matplotlib.figure.Figure at 0x2ace50fe860>
如果您希望将参数传递给脚本,只需在文件名%run my_file.py 0 "Hello, World!"后或使用变量%run $filename {arg0} {arg1}显式列出它们。此外,使用-p选项通过 Python 分析器运行代码。
脚本执行
虽然 Jupyter 笔记本电脑最重要的功能来自于它们的交互流程,但它也可以在非交互模式下运行。从脚本或命令行执行笔记本提供了一种生成自动化报告或类似文档的强大方法。
Jupyter 提供了一个命令行工具,它可以以最简单的形式用于文件转换和执行。您可能已经知道,笔记本可以转换成多种格式,可以从 UI 的“文件>下载为”下获得,包括 HTML、PDF、Python 脚本,甚至 LaTeX。该功能通过一个名为 nbconvert 的 API 暴露在命令行上。也有可能在 Python 脚本中执行笔记本,但这已经很好地记录了,下面的例子应该同样适用。
与%run类似,需要强调的是,虽然独立执行笔记本的能力使得完全在 Jupyter 笔记本中编写所有的项目成为可能,但这并不能替代将代码分解成适当的标准 Python 模块和脚本。
在命令行上
稍后将会清楚nbconvert如何让开发者创建他们自己的自动化报告管道,但是首先让我们看一些简单的例子。基本语法是:
jupyter nbconvert --to <format> notebook.ipynb
例如,要创建 PDF,只需编写:
jupyter nbconvert --to pdf notebook.ipynb
这将获取当前保存的静态内容notebook.ipynb并创建一个名为notebook.pdf的新文件。这里需要注意的是,要转换成 PDF 需要安装 pandoc(Anaconda 自带)和 LaTeX(没有)。安装说明取决于您的操作系统。
默认情况下,nbconvert不执行你的笔记本代码单元格。但是如果你也愿意,你可以指定 --execute 标志。
jupyter nbconvert --to pdf --execute notebook.ipynb
一个常见的障碍是,运行笔记本时遇到的任何错误都会暂停执行。幸运的是,您可以加入--allow-errors标志来指示nbconvert将错误消息输出到单元格输出中。
jupyter nbconvert --to pdf --execute --allow-errors notebook.ipynb
环境变量参数化
脚本执行对于不总是产生相同输出的笔记本电脑特别有用,例如,如果您正在处理随时间变化的数据,无论是从磁盘上的文件还是通过 API 下载的数据。例如,生成的文档可以很容易地通过电子邮件发送给一批订户,或者上传到亚马逊 S3 网站供用户下载。
在这种情况下,您很可能希望将笔记本参数化,以便用不同的初始值运行它们。实现这一点的最简单的方法是使用环境变量,这是在执行笔记本之前定义的。
假设我们想要为不同的日期生成几个报告;在我们笔记本的第一个单元格中,我们可以从一个环境变量中提取这些信息,我们将其命名为REPORT_DATE。%env line magic 使得将环境变量的值赋给 Python 变量变得很容易。
report_date = %env REPORT_DATE
然后,要运行笔记本(在 UNIX 系统上),我们可以这样做:
REPORT_DATE=2018-01-01 jupyter nbconvert --to html --execute report.ipynb
因为所有的环境变量都是字符串,所以我们必须解析它们以获得我们想要的数据类型。例如:
A_STRING="Hello, Tim!"
AN_INT=42
A_FLOAT=3.14
A_DATE=2017-12-31 jupyter nbconvert --to html --execute example.ipynb
我们简单地解析如下:
import datetime as dt
the_str = %env A_STRING
int_str = %env AN_INT
my_int = int(int_str)
float_str = %env A_FLOAT
my_float = float(float_str)
date_str = %env A_DATE
my_date = dt.datetime.strptime(date_str, '%Y-%m-%d')
解析日期肯定不如其他常见的数据类型直观,但像往常一样,Python 中有几个选项。
在 Windows 上
如果你想设置你的环境变量并在 Windows 上用一行代码运行你的笔记本,那就没那么简单了:
cmd /C "set A_STRING=Hello, Tim!&& set AN_INT=42 && set A_FLOAT=3.14 && set A_DATE=2017-12-31&& jupyter nbconvert --to html --execute example.ipynb"
敏锐的读者会注意到上面定义了A_STRING和A_DATE后少了一个空格。这是因为尾随空格对 Windows set命令很重要,所以虽然 Python 可以通过首先去除空格来成功解析整数和浮点数,但我们必须更加小心我们的字符串。
Papermill 参数化
使用环境变量对于简单的用例来说是很好的,但是对于任何更复杂的情况,有一些库可以让你把参数传递给你的笔记本并执行它们。GitHub 上超过 1000 颗星,大概最受欢迎的是 Papermill ,可以装pip install papermill。
Papermill 将一个新的单元注入到您的笔记本中,该单元实例化您传入的参数,为您解析数字输入。这意味着您可以直接使用变量,而不需要任何额外的设置(尽管日期仍然需要被解析)。或者,您可以在笔记本中创建一个单元格,通过单击“查看>单元格工具栏>标签”并向您选择的单元格添加“参数”标签来定义您的默认参数值。
我们之前生成 HTML 文档的例子现在变成了:
papermill example.ipynb example-parameterised.ipynb -p my_string "Hello, Tim!" -p my_int 3 -p my_float 3.1416 -p a_date 2017-12-31
jupyter nbconvert example-parameterised.ipynb --to html --output example.html
我们用-p选项指定每个参数,并使用一个中间笔记本,以便不改变原始的。完全有可能覆盖原来的example.ipynb文件,但是记住 Papermill 会注入一个参数单元格。
现在,我们的笔记本电脑设置简单多了:
# my_string, my_int, and my_float are already defined!
import datetime as dt
my_date = dt.datetime.strptime(a_date, '%Y-%m-%d')
到目前为止,我们短暂的一瞥只揭示了造纸厂的冰山一角。该库还可以跨笔记本执行和收集指标,总结笔记本的集合,并提供一个 API 来存储数据和 Matplotlib 图,以便在其他脚本或笔记本中访问。这些都在 GitHub 自述中有很好的记载,这里就不需要再赘述了。
现在应该清楚的是,使用这种技术,可以编写 shell 或 Python 脚本,这些脚本可以批量生成多个文档,并通过像 crontab 这样的工具进行调度,从而自动按计划运行。强大的东西!
造型笔记本
如果您正在寻找笔记本的特定外观,您可以创建一个外部 CSS 文件并用 Python 加载它。
from IPython.display import HTML
HTML('<style>{}</style>'.format(open('custom.css').read()))
这是因为 IPython 的 HTML 对象作为原始 HTML 直接插入到单元格输出 div 中。实际上,这相当于编写一个 HTML 单元格:
<style>.css-example { color: darkcyan; }</style>
为了证明这一点,让我们使用另一个 HTML 单元格。
%%html
<span class='css-example'>This text has a nice colour</span>
这段文字的颜色很好看
使用 HTML 单元格一两行就可以了,但是像我们第一次看到的那样,加载外部文件通常会更干净。
如果你更愿意一次性定制你所有的笔记本,你可以直接将 CSS 写入 Jupyter config 目录下的~/.jupyter/custom/custom.css文件中,尽管这只有在你自己的电脑上运行或转换笔记本时才有效。
事实上,所有上述技术也适用于转换成 HTML 的笔记本,但是不能用于转换成 pdf 的笔记本。
要探索你的样式选项,请记住 Jupyter 只是一个 web 应用程序,你可以使用浏览器的开发工具在它运行时检查它,或者研究一些导出的 HTML 输出。你会很快发现它结构良好:所有的单元格都用cell类指定,文本和代码单元格同样分别用text_cell和code_cell区分,输入和输出用input和output表示,等等。
GitHub 上还发布了各种不同的 Jupyter 笔记本流行预设计主题。最受欢迎的是 jupyterthemes ,可以通过pip install jupyterthemes获得,设置“monokai”主题就像运行jt -t monokai一样简单。如果你正在寻找 JupyterLab 的主题,GitHub 上也会弹出一个不断增长的选项列表。
隐藏单元格
虽然隐藏笔记本中有助于其他人理解的部分是不好的做法,但你的一些单元格对读者来说可能并不重要。例如,您可能希望隐藏一个向笔记本添加 CSS 样式的单元格,或者,如果您希望隐藏默认的和注入的 Papermill 参数,您可以修改您的nbconvert调用,如下所示:
jupyter nbconvert example-parameterised.ipynb --to html --output example.html --TagRemovePreprocessor.remove_cell_tags="{'parameters', 'injected-parameters'}"
事实上,这种方法可以有选择地应用于笔记本中的任何标记单元格,使得 TagRemovePreprocessor配置非常强大。顺便说一句,还有很多其他的方法来隐藏你笔记本里的电池。
使用数据库
数据库是数据科学家的面包和黄油,所以平滑你的数据库和笔记本之间的接口将是一个真正的福音。Catherine Devlin 的 IPython SQL magic 扩展让你可以用最少的样板文件将 SQL 查询直接写入代码单元,也可以将结果直接读入 pandas 数据帧。首先,继续:
pip install ipython-sql
安装好软件包后,我们通过在代码单元中执行以下魔术来开始:
%load_ext sql
这将加载我们刚刚安装到笔记本中的ipython-sql扩展。让我们连接到一个数据库!
%sql sqlite://
'Connected: @None'
这里,为了方便起见,我们只是连接到一个临时的内存数据库,但是您可能希望指定适合您的数据库的细节。连接字符串遵循 SQLAlchemy 标准:
dialect+driver://username:[email protected]:port/database
你的可能看起来更像postgresql://scott:[[email protected]](/cdn-cgi/l/email-protection)/mydatabase,其中驱动是postgresql,用户名是scott,密码是tiger,主机是localhost,数据库名是mydatabase。
注意,如果将连接字符串留空,扩展将尝试使用DATABASE_URL环境变量;在上面的脚本执行部分阅读更多关于如何定制的信息。
接下来,让我们从之前使用的 Seaborn 的 tips 数据集快速填充我们的数据库。
tips = sns.load_dataset("tips")
\%sql PERSIST tips
* sqlite://
'Persisted tips'
我们现在可以在数据库上执行查询。注意,我们可以对多行 SQL 使用多行单元格魔术%%。
SELECT * FROM tips
LIMIT 3
* sqlite://
Done.
| 指数 | 合计 _ 账单 | 小费 | 性 | 吸烟者 | 天 | 时间 | 大小 |
| Zero | Sixteen point nine nine | One point zero one | 女性的 | 不 | 太阳 | 主餐 | Two |
| one | Ten point three four | One point six six | 男性的 | 不 | 太阳 | 主餐 | three |
| Two | Twenty-one point zero one | Three point five | 男性的 | 不 | 太阳 | 主餐 | three |
您可以通过在查询前加上冒号,使用局部范围的变量来参数化查询。
meal_time = 'Dinner'
* sqlite://
Done.
| 指数 | 合计 _ 账单 | 小费 | 性 | 吸烟者 | 天 | 时间 | 大小 |
| Zero | Sixteen point nine nine | One point zero one | 女性的 | 不 | 太阳 | 主餐 | Two |
| one | Ten point three four | One point six six | 男性的 | 不 | 太阳 | 主餐 | three |
| Two | Twenty-one point zero one | Three point five | 男性的 | 不 | 太阳 | 主餐 | three |
我们的查询的复杂性不受扩展的限制,因此我们可以轻松地编写更具表达力的查询,比如查找账单总额大于平均值的所有结果。
result = %sql SELECT * FROM tips WHERE total_bill > (SELECT AVG(total_bill) FROM tips)
larger_bills = result.DataFrame()
larger_bills.head(3)
* sqlite://
Done.
| 指数 | 合计 _ 账单 | 小费 | 性 | 吸烟者 | 天 | 时间 | 大小 | |
|---|---|---|---|---|---|---|---|---|
| Zero | Two | Twenty-one point zero one | Three point five | 男性的 | 不 | 太阳 | 主餐 | three |
| one | three | Twenty-three point six eight | Three point three one | 男性的 | 不 | 太阳 | 主餐 | Two |
| Two | four | Twenty-four point five nine | Three point six one | 女性的 | 不 | 太阳 | 主餐 | four |
如您所见,转换成熊猫DataFrame也很容易,这使得从我们的查询中绘制结果变得轻而易举。让我们来看看 95%的置信区间。
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=larger_bills);

ipython-sql扩展还集成了 Matplotlib,让您可以在查询结果上直接调用.plot()、.pie()和.bar(),并可以通过.csv(filename='my-file.csv')将结果直接转储到 CSV 文件中。阅读更多关于 GitHub 自述文件。
包扎
从《Jupyter 笔记本初学者教程》开始到现在,我们已经讨论了广泛的主题,并为成为 Jupyter 大师奠定了基础。这些文章旨在展示 Jupyter 笔记本广泛的使用案例以及如何有效地使用它们。希望您已经为自己的项目获得了一些见解!
我们还可以用 Jupyter 笔记本做很多其他的事情,比如创建交互控件和图表,或者开发自己的扩展,但是让我们把这些留到以后再说。编码快乐!
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
你发帖太多了吗?使用 Python 分析您的个人脸书数据
原文:https://www.dataquest.io/blog/analyze-facebook-data-python/
August 28, 2020

截至 Q2 2020,脸书声称拥有超过 27 亿活跃用户。这意味着,如果你正在阅读这篇文章,你很可能是一个脸书用户。但是你到底有多喜欢脸书呢?你到底发了多少?我们可以使用 Python 来了解一下!
具体来说,我们将使用 Python 来创建这个图表,它显示了随着时间的推移,我们每个月发布的频率:
出于本教程的目的,我们将假设您熟悉 Python 和 Jupyter 笔记本的基础知识——如果不熟悉,请先查看这篇关于分析您的亚马逊支出的教程。
步骤 1:下载你的脸书数据
脸书实际上允许我们在网站上下载几乎所有我们做过的东西。你可以在这里下载你的数据,但你可能不想下载全部——那个文件可能很大,这取决于你使用脸书的频率和你在上面呆了多长时间。
在本教程中,我们将专门查看我们个人的脸书帖子,并尝试回答以下问题:
- 我多久发一次帖子?
- 我使用脸书的次数比以前多了还是少了?
要获得与文章相关的数据,请进入数据下载页面。将请求的文件格式从 HTML 改为 JSON,然后取消选择下面选项中的所有内容,只勾选的帖子,点击创建文件。

当您的文件创建完成并可供下载时,脸书会通知您,这可能需要一段时间,具体取决于您的脸书历史记录和选项。
下载 zip 文件,解压缩,并查找posts文件夹和一个名为your_posts_1.json的文件。这是我们将在本教程中使用的文件。
步骤 2:导入并格式化数据
接下来,我们必须将这些数据放入熊猫数据框架,因此启动 Jupyter 笔记本(如果你需要复习,这里有Jupyter 笔记本初学者指南)。我们将从导入数据并将其读入数据帧开始。
内置的pd.read_json()函数将能够自动解释数据帧中的 JSON 数据。(正如您将看到的那样,它并不完美,但它对我们这里的目的是有用的)。
import pandas as pd
# read the json file into a dataframe
df = pd.read_json('your_posts_1.json')
df.head(3)
| 时间戳 | 附件 | 数据 | 标题 | 标签 | |
|---|---|---|---|---|---|
| Zero | 2020-08-12 16:54:03 | [{ ' data ':[{ ' external _ context ':{ ' URL ':' https… | [{'post ':'在 clea 上放一个小视频… | 查理卡斯特张贴在 YT 工业业主… | 圆盘烤饼 |
| one | 2020-08-09 23:41:14 | [{ ' data ':[{ ' external _ context ':{ ' URL ':' https… | [{'post ':'更具挑战性,但不知何故不太 d… | 圆盘烤饼 | 圆盘烤饼 |
| Two | 2020-08-02 20:11:51 | [{ ' data ':[{ ' external _ context ':{ ' URL ':' https… | [{'post ':'频道上的新视频…总计… | 圆盘烤饼 | 圆盘烤饼 |
正如我们所见,这并不完美。我们的一些列在每行中都有嵌套的子列,仍然是 JSON 格式。如果我们想处理这些数据,我们就需要处理这些数据。
但是要回答我们的问题,我们在脸书上发布的内容是比以前多了还是少了? —我们真的不需要处理实际的帖子内容,或者附加的媒体文件等其他信息。我们只关心频率——发布新帖子的频率。
接下来,我们将确保时间戳列的格式正确,方法是使用to_datetime()将其转换为 datetime 对象。为了清楚起见,我们还将它重命名为'date',并删除一些不必要的列——这一步并不是绝对必要的,但它有助于让我们看起来更简单。
# rename the timestamp column
df.rename(columns={'timestamp': 'date'}, inplace=True)
#drop some unnecessary columns
df = df.drop(['attachments', 'title', 'tags'], axis=1)
# making sure it's datetime format
pd.to_datetime(df['date'])
df.head(3)
| 日期 | 数据 | |
|---|---|---|
| Zero | 2020-08-12 16:54:03 | [{'post ':'在 clea 上放一个小视频… |
| one | 2020-08-09 23:41:14 | [{'post ':'更具挑战性,但不知何故不太 d… |
| Two | 2020-08-02 20:11:51 | [{'post ':'频道上的新视频…总计… |
现在我们有了更干净的东西来工作了!如果我们想检查我们分析了多少文章,我们可以使用df.shape来计算行数。
使用df.tail()检查我们的数据帧的结尾也是一个好主意,只是为了确保它确实覆盖了我们整个脸书的使用:
print(df.shape)
df.tail(3)
(4407, 2)
| 日期 | 数据 | |
|---|---|---|
| Four thousand four hundred and four | 2005-10-20 03:23:30 | 圆盘烤饼 |
| Four thousand four hundred and five | 2005-10-20 03:23:30 | 圆盘烤饼 |
| Four thousand four hundred and six | 2005-03-07 01:05:54 | [{'post ':'湿热的美国夏季 t 恤自… |
以我的个人脸书数据为例,看起来我总共发布了超过 4000 次。我的数据始于 2005 年初,当时我显然发布了一些关于美国湿热夏季的信息。2005 年我还在上大学,所以时间是对的。
你可能会注意到有些行写着 NaN——这些帖子只包含图片,没有文字。这些图像将在'attachments列中链接,但是我们已经删除了它,所以它在这里不可见。
第三步:算出每月的帖子数量
现在我们已经得到了我们的数据,我们需要把它转换成一种格式,告诉我们一些关于发布频率的信息。考虑到我们跨越了多年的历史,逐月观察是最有意义的。这意味着我们需要按月份对我们的'date'列进行分组,并计算每个月有多少行(即文章)与之相关联。
幸运的是,pandas 的设计使得处理时间序列数据变得相对简单。我们需要做两件事:
- 将
date列设置为数据帧的索引。 - 按月对数据进行重新采样,计算每个月有多少帖子。
对于第一步,我们可以使用set_index()。第二步有点复杂,所以让我们把它分成四个独立的步骤来分解我们需要编写的代码:
- 选择我们想要重新采样的列——在本例中是
data列。 - 使用带有参数
'MS'(表示“月初”)的.resample()函数按月对数据进行重新采样。 - 使用
.size()指定我们每个月想要测量的内容——在本例中,是发布日期在该月内的行(即帖子)的数量。 - 将结果序列赋给一个名为
post_counts的变量。
实际情况是这样的:
date
2005-03-01 1
2005-04-01 0
2005-05-01 0
2005-06-01 0
2005-07-01 0
..
2020-04-01 2
2020-05-01 5
2020-06-01 7
2020-07-01 6
2020-08-01 3
Freq: MS, Name: data, Length: 186, dtype: int64
看起来棒极了!我们已经按月细分了我们的帖子数量,如果我们检查原始数据集,我们可以很快看到数量是正确的。
请注意,没有帖子的月份被正确地计为0,而不是简单地跳过。这就是为什么使用设计用于处理时间序列的resample()比使用像groupby()这样的东西更适合这种任务的原因之一,如果我们不小心的话,很容易跳过没有数据的几个月。
第四步:想象你的脸书用法
无论如何,现在我们已经过了棘手的部分,剩下的就是乐趣:可视化!为此,我们将导入 matplotlib(并使用%matplotlib inline魔法使我们的图表出现在 Jupyter 笔记本中。我们还将导入 Seaborn 和 NumPy,这将帮助我们制作一个可读性更好的图表。
一旦我们完成了导入,我们将使用 sns.set() 来设置图表的大小和字体大小。由于我们在这里处理大量数据,我们将把图表做得相当大,并确保字体足够大以便于阅读。
然后,我们将 x 标签设置为使用post_counts(日期)的索引,并使用sns.barplot()创建一个条形图。在sns.barplot()的参数中,我们将告诉该函数使用我们定义的 x 标签,在post_counts中绘制数据,并将条形颜色设为蓝色。
仅此一点就足以创建一个基本的图表,但在这种情况下,我们希望采取一些额外的步骤来使图表可读。具体来说,我们希望将 x 轴上的刻度位置安排为每 24 个月一次,这样我们就可以在结果图表中每隔一年看到一个刻度。我们还想重新格式化图表中的日期,以便只显示年份。
(由于这不是一个关于 data viz 的教程,我们不会在本教程中深入讨论它是如何工作的,但如果你想了解更多关于如何用 Python 制作出色的数据可视化的信息,我们有探索性数据可视化和通过数据可视化讲述故事课程,你可以免费试用)。
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# set figure size and font size
sns.set(rc={'figure.figsize':(40,20)})
sns.set(font_scale=3)
# set x labels
x_labels = post_counts.index
#create bar plot
sns.barplot(x_labels, post_counts, color="blue")
# only show x-axis labels for Jan 1 of every other year
tick_positions = np.arange(10, len(x_labels), step=24)
#reformat date to display year onlyplt.ylabel("post counts")
plt.xticks(tick_positions, x_labels[tick_positions].strftime("%Y"))
# display the plot
plt.show()
这是图表——你可以点击查看全图。
我们仍然有一些方法可以让这个图表更漂亮,但对于我们的目的来说,这足以理解数据并分析我们的脸书发布历史。
就我而言——上面的图表是我在脸书的个人数据——我们可以看到,我在早期很少在脸书上发帖。我收到了大量的邮件——每月数百封!—2007 年夏天,2009 年春天,恰逢旅行。
我的常规使用量在 2011 年左右开始回升,并在 2016 年左右达到峰值。在那之后,它平息了,从 2019 年开始,我在相当长的一段时间内完全停止使用脸书。高峰时,我每个月都要发帖近 100 次!
而且记住,那只是帖子,不是评论!还有一个完整的 JSON 文件用于注释,但我已经够尴尬的了。如果你想进一步分析,深入你的评论文件将是一个很好的下一步!
让我们在本教程中称之为好,并回顾我们所做的事情:
- 我们从脸书下载了个人使用数据
- 我们将 JSON 文件读入熊猫数据帧
- 我们将数据按月分解,并统计了每个月的帖子数量
- 我们想象了脸书的用法,并了解到一些事情:查理过去在脸书身上花了太多时间。
如果你喜欢做这样的项目,试试 Dataquest 的交互式浏览器课程!它们比我们在这里讲述的更加身临其境,更加深入。事实上,我们有无缝的课程序列,可以带你从完全的初学者到胜任工作的数据分析师、数据科学家或数据工程师。
既然你已经看到你在脸书浪费了多少时间,为什么不登录 Dataquest,花些时间在网上建立有价值的工作技能呢?您可以创建一个帐户并开始免费学习—不需要信用卡!
准备好继续学习了吗?
永远不要想接下来我该学什么?又来了!
在我们的 Python for Data Science 路径中,您将了解到:
- 使用 matplotlib 和 pandas 进行数据清理、分析和可视化
- 假设检验、概率和统计
- 机器学习、深度学习和决策树
- ...还有更多!
立即开始学习我们的 60+免费任务:
教程:Apache Spark 简介
October 9, 2015
概观
在由加州大学伯克利分校 AMP 实验室领导的大量开创性工作之后,Apache Spark 被开发出来,利用分布式内存数据结构来提高大多数工作负载在 Hadoop 上的数据处理速度。
在本帖中,我们将使用一个真实的数据集来介绍 Spark 的架构以及基本的转换和操作。如果你想编写并运行你自己的 Spark 代码,可以在 Dataquest 上查看这篇文章的互动版。
弹性分布式数据集(RDD 的)
Spark 中的核心数据结构是一个 RDD,即弹性分布式数据集。顾名思义,RDD 是 Spark 对分布在许多机器的 RAM 或内存中的数据集的表示。一个 RDD 对象本质上是一个元素的集合,你可以用它来保存元组列表、字典、列表等等。与 Pandas 中的数据帧类似,您将数据集加载到 RDD 中,然后可以运行该对象可访问的任何方法。
Python 中的 Apache Spark
虽然 Spark 是用 Scala 编写的,Scala 是一种编译成 JVM 字节码的语言,但是开源社区已经开发了一个名为 PySpark 的奇妙工具包,它允许你用 Python 与 RDD 的接口。多亏了一个名为 Py4J 的库,Python 可以与 JVM 对象接口,在我们的例子中是 RDD 的,这个库是 PySpark 工作的工具之一。
首先,我们将把包含所有日常节目嘉宾的数据集加载到 RDD 中。我们使用的是 FiveThirtyEight 的数据集的TSV版本。TSV 文件由制表符"\t"分隔,而不是像 CSV 文件那样由逗号","分隔。
raw_data = sc.textFile("daily_show.tsv")
raw_data.take(5)
['YEAR\tGoogleKnowlege_Occupation\tShow\tGroup\tRaw_Guest_List',
'1999\tactor\t1/11/99\tActing\tMichael J. Fox',
'1999\tComedian\t1/12/99\tComedy\tSandra Bernhard',
'1999\ttelevision actress\t1/13/99\tActing\tTracey Ullman',
'1999\tfilm actress\t1/14/99\tActing\tGillian Anderson']
sparks context(储蓄上下文)
SparkContext是管理 Spark 中集群的连接并协调集群上运行的进程的对象。SparkContext 连接到集群管理器,集群管理器管理运行特定计算的实际执行器。这里有一个来自 Spark 文档的图表,可以更好地形象化这个架构:
SparkContext 对象通常作为变量sc被引用。然后我们运行:
raw_data = sc.textFile("daily_show.tsv")
将 TSV 数据集读入 RDD 对象raw_data。RDD 对象raw_data非常类似于字符串对象的列表,数据集中的每一行对应一个对象。然后我们使用take()方法打印 RDD 的前 5 个元素:
raw_data.take(5)
要探索 RDD 对象可以访问的其他方法,请查看 PySpark 文档。take(n)将返回 RDD 的前 n 个元素。
懒惰评估
您可能会问,如果 RDD 类似于 Python 列表,为什么不直接使用括号符号来访问 RDD 中的元素呢?因为 RDD 对象分布在许多分区上,所以我们不能依赖列表的标准实现,而 RDD 对象是专门为处理数据的分布式特性而开发的。
RDD 抽象的一个优点是能够在您自己的计算机上本地运行 Spark。当在您自己的计算机上本地运行时,Spark 通过将您计算机的内存分割成分区来模拟将您的计算分布在许多机器上,无需调整或更改您编写的代码。Spark 的 RDD 实现的另一个优点是能够懒惰地评估代码,直到绝对必要时才运行计算。
在上面的代码中,Spark 没有等到raw_data.take(5)运行后才把 TSV 文件加载到 RDD 中。当调用raw_data = sc.textFile("dail_show.tsv")时,一个指向文件的指针被创建,但是只有当raw_data.take(5)需要文件来运行它的逻辑时,文本文件才被真正读入raw_data。在这节课和以后的课中,我们会看到更多这种懒惰评估的例子。
管道
Spark 大量借鉴了 Hadoop 的 Map-Reduce 模式,但在许多方面有很大不同。如果你有使用 Hadoop 和传统 Map-Reduce 的经验,请阅读 Cloudera 的这篇伟大的文章。如果您以前从未使用过 Map-Reduce 或 Hadoop,请不要担心,因为我们将在本课程中介绍您需要了解的概念。
使用 Spark 时需要理解的关键思想是数据流水线。Spark 中的每个操作或计算本质上都是一系列步骤,这些步骤可以链接在一起,连续运行,形成一个管道。管道中的每一步都返回一个 Python 值(如整数)、一个 Python 数据结构(如字典)或一个 RDD 对象。我们首先从map()函数开始。Map()map(f)函数将函数 f 应用于 RDD 中的每个元素。因为 RDD 是可迭代的对象,像大多数 Python 对象一样,Spark 在每次迭代中运行函数f,并返回一个新的 RDD。
我们将浏览一个例子,这样你会有更好的理解。如果你仔细观察,raw_data是一种很难处理的格式。虽然目前每个元素都是一个String,但我们希望将每个元素都转换成一个List,这样数据更易于管理。传统上,我们会:
1\. Use a `for` loop to iterate over the collection
2\. Split each `String` on the delimiter
3\. Store the result in a `List`
让我们来看看如何在 Spark 中使用map来实现这一点。在下面的代码块中,我们:
1\. Call the RDD function `map()` to specify we want the enclosed logic to be applied to every line in our dataset
2\. Write a lambda function to split each line using the tab delimiter "\t" and assign the resulting RDD to `daily_show`
3\. Call the RDD function `take()` on `daily_show` to display the first 5 elements (or rows) of the resulting RDD
map(f)函数被称为转换步骤,需要命名函数或 lambda 函数f。
daily_show = raw_data.map(lambda line: line.split('\t'))
daily_show.take(5)
[['YEAR', 'GoogleKnowlege_Occupation', 'Show', 'Group', 'Raw_Guest_List'],
['1999', 'actor', '1/11/99', 'Acting', 'Michael J. Fox'],
['1999', 'Comedian', '1/12/99', 'Comedy', 'Sandra Bernhard'],
['1999', 'television actress', '1/13/99', 'Acting', 'Tracey Ullman'],
['1999', 'film actress', '1/14/99', 'Acting', 'Gillian Anderson']]
Python 和 Scala,永远的朋友
PySpark 的一个精彩特性是能够将我们的逻辑(我们更喜欢用 Python 编写)与实际的数据转换分离开来。在上面的代码块中,我们用 Python 代码编写了一个 lambda 函数:
raw_data.map(lambda: line(line.split('\t')))
但是当 Spark 在我们的 RDD 上运行代码时,我们必须利用 Scala。
这个就是 PySpark 的力量。无需学习任何 Scala,我们就可以利用 Spark 的 Scala 架构带来的数据处理性能提升。更棒的是,当我们跑步时:
daily_show.take(5)
结果以 Python 友好的符号返回给我们。
转换和操作
在 Spark 中,有两种方法:
1\. Transformations - map(), reduceByKey()
2\. Actions - take(), reduce(), saveAsTextFile(), collect()
转换是懒惰的操作,总是返回对 RDD 对象的引用。然而,直到一个操作需要使用转换产生的 RDD 时,转换才真正运行。任何返回 RDD 的函数都是转换,任何返回值的函数都是操作。随着您学习本课并练习编写 PySpark 代码,这些概念将变得更加清晰。
不变
你可能想知道为什么我们不能把每一个String分开,而不是创建一个新的对象daily_show?在 Python 中,我们可以就地逐个元素地修改集合,而无需返回并分配给新对象。RDD 对象是不可变的,一旦对象被创建,它们的值就不能改变。
在 Python 中,列表对象和字典对象是可变的,这意味着我们可以改变对象的值,而元组对象是不可变的。在 Python 中修改 Tuple 对象的唯一方法是用必要的更新创建一个新的 Tuple 对象。Spark 利用 RDD 的不变性来提高速度,其机制超出了本课的范围。
ReduceByKey()
我们想得到一个直方图,或者说是一个统计数字,显示每年的来宾数量。如果daily_show是列表的列表,我们可以编写下面的 Python 代码来实现这个结果:
tally = dict()
for line in daily_show:
year = line[0]
if year in tally.keys():
tally2022 = tally2022 + 1
else:
tally2022 = 1
tally中的键将是唯一的Year值,并且该值将是数据集中包含该值的行数。如果我们想使用 Spark 达到同样的结果,我们将不得不使用一个Map步骤,然后是一个ReduceByKey步骤。
tally = daily_show.map(lambda x: (x[0], 1)).reduceByKey(lambda x,y: x+y)
print(tally)
PythonRDD[156] at RDD at PythonRDD.scala:43
说明
您可能会注意到,打印tally并没有返回我们期望的直方图。由于懒惰评估,PySpark 延迟执行map和reduceByKey步骤,直到我们真正需要它。在我们使用take()来预览tally中的前几个元素之前,我们将遍历刚刚编写的代码。
daily_show.map(lambda x: (x[0], 1)).reduceByKey(lambda x, y: x+y)
在映射步骤中,我们使用 lambda 函数创建了一个元组,由以下内容组成:
- key: x[0],列表中的第一个值
- 值:1,整数
我们的高级策略是用代表Year的键和代表1的值创建一个元组。在map步骤之后,Spark 将在内存中维护一个类似如下的元组列表:
('YEAR', 1)
('1991', 1)
('1991', 1)
('1991', 1)
('1991', 1)
...
我们希望将其简化为:
('YEAR', 1)
('1991', 4)
...
reduceByKey(f)使用我们指定的函数f将元组与相同的键组合在一起。为了查看这两步的结果,我们将使用take命令,该命令强制懒惰代码立即运行。由于tally是一个 RDD,我们不能使用 Python 的len函数来知道集合中有多少元素,而是需要使用 RDD count()函数。
tally.take(tally.count())
[('YEAR', 1),
('2013', 166),
('2001', 157),
('2004', 164),
('2000', 169),
('2015', 100),
('2010', 165),
('2006', 161),
('2014', 163),
('2003', 166),
('2002', 159),
('2011', 163),
('2012', 164),
('2008', 164),
('2007', 141),
('2005', 162),
('1999', 166),
('2009', 163)]
过滤器
与熊猫不同,Spark 对列标题一无所知,也没有把它们放在一边。我们需要一种方法来消除这种元素:
('YEAR', 1)
来自我们的收藏。虽然您可能会尝试找到一种方法来从 RDD 中删除这个元素,但是请记住,RDD 对象是不可变的,一旦创建就不能更改。
删除该元组的唯一方法是创建一个没有该元组的新 RDD 对象。Spark 附带了一个函数filter(f),允许我们从现有的只包含符合我们标准的元素的 RDD 中创建一个新的。指定一个返回二进制值的函数f、True或False,得到的 RDD 将由函数求值为True的元素组成。在 Spark 的文档中阅读更多关于filter功能的信息。
def filter_year(line):
if line[0] == 'YEAR':
return False
else:
return True
filtered_daily_show = daily_show.filter(lambda line: filter_year(line))
现在都在一起
为了展示 Spark 的能力,我们将演示如何将一系列数据转换链接到一个管道中,并观察 Spark 在后台管理一切。Spark 在编写时就考虑到了这一功能,并针对连续运行任务进行了高度优化。以前,在 Hadoop 中连续运行大量任务非常耗时,因为中间结果需要写入磁盘,而 Hadoop 并不知道完整的管道(如果你好奇,可以选择阅读:https://qr.ae/RHWrT2)。
由于 Spark 对内存的积极使用(仅将磁盘作为备份并用于特定任务)和良好架构的核心,Spark 能够显著改善 Hadoop 的周转时间。在下面的代码块中,我们将过滤掉没有列出职业的演员,小写每个职业,生成一个职业直方图,并输出直方图中的前 5 个元组。
filtered_daily_show.filter(lambda line: line[1] != '') \
.map(lambda line: (line[1].lower(), 1)) \
.reduceByKey(lambda x,y: x+y) \
.take(5)
[('radio personality', 3),
('television writer', 1),
('american political figure', 2),
('former united states secretary of state', 6),
('mathematician', 1)]
后续步骤
我们希望在本课中,我们已经激起了您对 Apache Spark 兴趣,以及我们如何使用 PySpark 来编写我们熟悉的 Python 代码,同时仍然利用分布式处理。当处理更大的数据集时,PySpark 确实大放异彩,因为它模糊了在自己的计算机上本地进行数据科学和在互联网上使用大量分布式计算(也称为云)进行数据科学之间的界限。
如果你喜欢这篇文章,看看我们在 Dataquest 上的 Spark 课程,在那里我们可以学到更多关于 Spark 中的转换&动作。
我是如何制作一个 Python 机器人来帮我在旧金山找公寓的
原文:https://www.dataquest.io/blog/apartment-finding-slackbot/
July 21, 2016
几个月前我从波士顿搬到了湾区。Priya(我的女朋友)和我听到了各种关于租赁市场的恐怖故事。在谷歌上搜索“如何在旧金山找到一套公寓”会得到几十页的建议,这个事实很好地说明了找房子是一个痛苦的过程。
波士顿很冷,但在旧金山找公寓很吓人。我们知道房东会开放房子,你必须把你所有的文件带到开放的房子里,并且愿意立即支付定金,这样你才会被考虑。
我们开始详尽地研究这个过程,发现很多找房子的事情都归结于时机。一些房东无论如何都想举行一次开放参观,但对其他人来说,成为第一批看到公寓的人之一通常意味着你可以得到它。你需要找到房源,迅速判断它是否符合你的标准,然后打电话给房东安排一次展示机会。
我们看了看互联网海报推荐的一些公寓租赁网站,如 Padmapper 和 LiveLovely ,但它们都没有给我们实时房源,我们可以一起查看和评级。它们都没有给我们指定额外标准的能力,比如只指定非常具体的社区,或者靠近交通。由于湾区的大多数公寓房源最初都在 Craigslist 上,然后被其他网站抓取,所以人们也担心可能不是所有的房源都被抓取了,或者它们的抓取速度不够快,无法实现实时提醒。我们想要一种方法:
- 当有人在 Craigslist 上发帖时,您会得到近乎实时的通知。
- 过滤掉不属于我们想要的社区的列表。
- 过滤掉不符合附加条件的列表,例如靠近公共交通。
- 就列表进行协作,并一起对它们进行评分。
- 轻松联系房东,获取我们喜欢的房源。
思考这个问题后,我意识到我们可以用四个步骤来解决这个问题:
- 从 Craigslist 上抓取列表。
- 过滤掉不符合我们标准的物品。
- 将列表发布到团队聊天工具 Slack 上,这样我们就可以对它们进行讨论和评级。
- 将整个流程包装成一个持久的循环,并将其部署到服务器上(这样它就可以连续运行)。
在这篇文章的剩余部分,我们将介绍每一个部件是如何建造的,以及最终的 Slack bot 是如何帮助我们找到公寓的。使用这个机器人,Priya 和我找到了一个价格合理的(SF!)一周内我们就喜欢上了一间卧室,比我们想象的要快得多。
如果你想在阅读这篇文章的时候看看代码,这里有到完成项目的链接,这里有到 README.md. 的链接
第一步——从 Craigslist 上抓取列表
构建我们的机器人的第一步是从 Craiglist 获取列表。不幸的是,Craiglist 没有 API,但是我们可以使用 python-craiglist 包获得帖子。python-craigslist抓取页面内容,然后使用 BeautifulSoup 从页面中提取相关片段,并将其转换为结构化数据。
这个包的代码相当短,值得通读一遍。旧金山 Craigslist 公寓列表位于https://sfbay.craigslist.org/search/sfc/apa。在下面的代码中,我们:
- 导入
CraigslistHousing,一个python-craigslist中的类。 - 用以下参数初始化该类:
- 我们想要抓取的 Craigslist 网站。与
https://sfbay.craigslist.org一样,site是 URL 的第一部分。 area—站点内我们要刮除的子区域。area是 URL 的最后一部分,就像https://sfbay.craigslist.org/sfc/,它只会在三藩市出现。category—我们想要寻找的列表类型。category是搜索 URL 的最后一部分,就像https://sfbay.craigslist.org/search/sfc/apa,它列出了所有的公寓。filters—我们想要应用于结果的任何过滤器。- 我们愿意支付的最高价格。
- 我们想要的最低价格。
- 我们想要抓取的 Craigslist 网站。与
- 使用
get_results方法从 Craigslist 获得结果,这是一个生成器。- 传递
geotagged参数,尝试向每个结果添加坐标。 - 传递
limit参数以仅获得20结果。 - 传递参数
newest只获取最新的列表。
- 传递
- 从
results生成器中获取每个result并打印出来。
from craigslist import CraigslistHousing
cl = CraigslistHousing(site='sfbay', area='sfc', category='apa', filters={'max_price': 2000, 'min_price': 1000})
results = cl.get_results(sort_by='newest', geotagged=True, limit=20)
for result in results:
print result
我们已经很快完成了机器人的第一步!我们现在能够抓取 Craigslist 并获取列表。每个result都是一个包含几个字段的字典:
{'datetime': '2016-07-20 16:39',
'geotag': (37.783166, -122.418671),
'has_image': True,
'has_map': True,
'id': '5692904929',
'name': 'Be the first in line at Brendas restaurant!SQuiet studio
available',
'price': '$1995',
'url': 'https://sfbay.craigslist.org/sfc/apa/5692904929.html',
'where': 'tenderloin'
}
以下是对字段的描述:
datetime—发布列表的时间。geotag—列表的坐标位置。- Craigslist 帖子中是否有图片。
has_map—是否有与列表关联的地图。id—列表的唯一 Craigslist id。name—Craigslist 上显示的列表名称。price—月租金。url—查看完整列表的 URL。where—创建列表的人在它所在的地方放了什么。
第二步—过滤结果
既然我们有了从 Craigslist 获取列表的方法,我们只需要一种方法来过滤它们,只看到我们喜欢的列表。
按区域过滤结果
当 Priya 和我在寻找公寓时,我们想看看几个地区的房子,包括:
为了按邻域过滤,我们首先需要定义区域周围的边界框:

在下太平洋高地周围画一个方框
上面的边界框是使用边界框创建的。一定要指定左下角的CSV选项来获取盒子的坐标。你也可以自己定义一个边界框,用谷歌地图这样的工具找到左下角和右上角的坐标。找到盒子后,我们将创建一个邻域和坐标字典:
BOXES = {
"adams_point": [
[37.80789, -122.25000],
[37.81589, -122.26081],
],
"piedmont": [
[37.82240, -122.24768],
[37.83237, -122.25386],
],
...
}
每个字典键是一个邻居名称,每个键包含一个列表列表。第一个内部列表是盒子左下角的坐标,第二个是盒子右上角的坐标。然后,我们可以通过检查列表的坐标是否在任何框内来执行过滤。以下代码将:
- 循环浏览
BOXES中的每个按键。 - 检查结果是否在盒子里。
- 如果是,设置适当的变量。
def in_box(coords, box):
if box[0][0] < coords[0] < box[1][0] and box[1][1] < coords[1] < box[0][1]:
return True
return False
geotag = result["geotag"]
area_found = False
area = ""
for a, coords in BOXES.items():
if in_box(geotag, coords):
area = a
area_found = True
不幸的是,并非 Craigslist 的所有结果都有与之相关的坐标。由发布列表的人指定一个位置,可以从该位置计算坐标。发布列表的人对 Craigslist 越熟悉,他们就越有可能包含一个位置。
通常,由更可能收取高租金的代理发布的列表具有相关联的位置。所有者发布的信息更有可能没有坐标,但通常也是更好的交易。因此,有一个故障保险来判断没有相关坐标的列表是否在我们想要的邻域中是有意义的。
我们将创建一个邻域列表,然后进行字符串匹配,看看列表是否属于其中之一。这不如使用坐标准确,因为许多列表错误地报告了他们的邻居,但总比没有好:
NEIGHBORHOODS = ["berkeley north", "berkeley", "rockridge", "adams point", ... ]
为了进行基于名称的匹配,我们可以遍历每个NEIGHBORHOODS:
location = result["where"]
for hood in NEIGHBORHOODS:
if hood in location.lower():
area = hood
一旦我们已经编写的两部分代码处理了结果,我们将删除不在我们想要居住的社区中的所有列表。我们会有一些误报,我们可能会错过一些没有指定邻居或位置的列表,但这个系统可以捕获绝大多数列表。
通过接近中天过滤结果
Priya 和我都知道我们会经常去旧金山,所以如果我们不想成为旧金山人,我们想住在公共交通附近。在湾区,公共交通的主要形式被称为 BART 。
BART 是一个部分地下的区域运输系统,连接奥克兰、伯克利、旧金山和周边地区。为了将这个功能构建到我们的 bot 中,我们首先需要定义一个中转站列表。我们可以从谷歌地图获得公交站点的坐标,然后创建一个它们的字典:
TRANSIT_STATIONS = {
"oakland_19th_bart": [37.8118051,-122.2720873],
"macarthur_bart": [37.8265657,-122.2686705],
"rockridge_bart": [37.841286,-122.2566329],
...
}
每个键都是一个中转站的名称,并有一个关联列表。该列表包含中转站的纬度和经度。一旦我们有了字典,我们就可以找到离每个结果最近的中转站。以下代码将:
- 循环浏览
TRANSIT_STATIONS中的每个键和项目。 - 使用
coord_distance功能找出两对坐标之间的距离,单位为千米。你可以在这里找到这个函数的解释。 - 查看电台是否离列表最近。
- 如果该站太远(超过
2公里,或大约1.2英里),它将被忽略。 - 如果该电台比前一个最近的电台更近,则使用该电台。
- 如果该站太远(超过
min_dist = None
near_bart = False
bart_dist = "N/A"
bart = ""
MAX_TRANSIT_DIST = 2 # kilometers
for station, coords in TRANSIT_STATIONS.items():
dist = coord_distance(coords[0], coords[1], geotag[0], geotag[1])
if (min_dist is None or dist < min_dist) and dist < MAX_TRANSIT_DIST:
bart = station
near_bart = True
if (min_dist is None or dist < min_dist):
bart_dist = dist
在这之后,我们知道离每个列表最近的中转站。
第三步——创建我们的 Slack Bot
设置
在我们筛选出我们的结果后,我们就可以发布我们要发布的内容了。如果你不熟悉 Slack,它是一个团队聊天应用。您在 Slack 中创建了一个团队,然后可以邀请成员。每个松散团队可以有多个成员交换消息的渠道。每条消息都可以由频道中的其他人进行注释,例如添加大拇指或其他表情符号。这里是关于 Slack 的更多信息。
如果你想感受一下 Slack,我们有一个数据科学 Slack 社区,你可能想加入。通过将我们的结果发布到 Slack,我们将能够与其他人合作,并找出哪些列表是最好的。为此,我们需要:
- 创建一个松散的团队,我们可以在这里做。
- 为要发布的列表创建一个频道。这里是在这方面的帮助。建议使用
#housing作为频道名称。 - 获取一个 Slack API 令牌,我们可以在这里做。这里是关于这个过程的更多信息。
完成这些步骤后,我们就可以创建将清单发布到 Slack 的代码了。
编码完毕
在获得正确的通道名和令牌后,我们可以将结果发布到 Slack。为此,我们将使用 python-slackclient ,这是一个 python 包,使得使用 Slack API 变得容易。使用 Slack 令牌初始化,然后允许我们访问许多管理团队和消息的 API 端点。以下代码将:
- 使用
SLACK_TOKEN初始化一个SlackClient。 - 从
result创建一个消息字符串,包含我们需要看到的所有信息,比如价格、列表所在的街区和 URL。 - 用用户名
pybot将消息发布到 Slack,一个机器人作为头像。
from slackclient import SlackClient
SLACK_TOKEN = "ENTER_TOKEN_HERE"
SLACK_CHANNEL = "#housing"
sc = SlackClient(SLACK_TOKEN)
desc = "{0} | {1} | {2} | {3}
| <{4}>".format(result["area"], result["price"], result["bart_dist"], result["name"], result["url"])
sc.api_call(
"chat.postMessage", channel=SLACK_CHANNEL, text=desc,
username='pybot', icon_emoji=':robot_face:')
一旦所有东西都连接上了,Slack bot 就会将清单发布到 Slack 中,如下所示:

bot 运行时列表的外观。请注意如何用表情符号给列表添加注释,比如竖起大拇指。
第四步——操作一切
既然我们已经解决了基本问题,我们将需要持久地运行代码。毕竟,我们希望我们的结果能够实时发布到 Slack 上,或者接近实时。为了将一切操作化,我们需要经历几个步骤:
- 将列表存储在数据库中,这样我们就不会重复发布到 Slack 中。
- 将设置(如
SLACK_TOKEN)与代码的其余部分分开,使它们易于调整。 - 创建一个连续运行的循环,所以我们 24/7 都在抓取结果。
存储列表
第一步是使用名为 SQLAlchemy 的 Python 包来存储我们的列表。SQLAlchemy 是一个对象关系映射器,或 ORM,它使得使用 Python 中的数据库更加容易。使用 SQLAlchemy,我们可以创建一个存储清单的数据库表和一个数据库连接,以便于向表中添加数据。
我们将结合使用 SQLAlchemy 和 SQLite 数据库引擎,它将我们所有的数据存储到一个名为listings.db的文件中。以下代码将:
- 导入 SQLAlchemy。
- 创建一个到 SQLite 数据库
listings.db的连接,该数据库将在我们当前的目录中创建。 - 定义一个名为
Listing的表,包含 Craigslist 列表中的所有相关字段。unique字段cl_id和link将阻止我们向 Slack 发布重复的列表。
- 从连接创建一个数据库会话,这将允许我们存储列表。
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime, Float, Boolean
from sqlalchemy.orm import sessionmaker
engine = create_engine('sqlite:///listings.db', echo=False)
Base = declarative_base()
class Listing(Base):
"""
A table to store data on craigslist listings.
"""
__tablename__ = 'listings'
id = Column(Integer, primary_key=True)
link = Column(String, unique=True)
created = Column(DateTime)
geotag = Column(String)
lat = Column(Float)
lon = Column(Float)
name = Column(String)
price = Column(Float)
location = Column(String)
cl_id = Column(Integer, unique=True)
area = Column(String)
bart_stop = Column(String)
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
现在我们有了数据库模型,我们只需要将每个列表存储到数据库中,这样我们就能够避免重复。
从代码中分离配置
下一步是从代码中分离出配置。我们将创建一个名为settings.py的文件来存储我们的配置。配置包括SLACK_TOKEN,这是一个秘密,我们不希望一不小心提交 git 并推送到 Github,还有其他像BOXES这样不是秘密的设置,但我们希望能够轻松编辑。我们将以下设置移至settings.py:
MIN_PRICE—我们要搜寻的最低刊登价格。MAX_PRICE—我们要搜寻的最低刊登价格。- 我们想要搜索的区域性 Craigslist 网站。
- 我们想要搜索的区域 Craiglist 站点的区域列表。
BOXES—我们想要查看的邻域的坐标框。NEIGHBORHOODS—如果列表中没有坐标,则是要匹配的邻域列表。- 我们希望离中转站最远的地方。
TRANSIT_STATIONS—中转站的坐标。- 我们想要查看的 Craigslist 房屋的子部分。
- 我们希望机器人发布的空闲频道。
我们还想创建一个被 git 忽略的名为private.py的文件,它包含以下键:
SLACK_TOKEN—张贴到我们的 Slack 团队的令牌。
你可以在这里看到完成的settings.py文件。
创建一个循环
最后,我们需要创建一个循环来持续运行我们的抓取代码。以下代码将:
- 从命令行调用时:
- 打印包含当前时间的状态消息。
- 通过调用
do_scrape函数运行 craigslist 抓取代码。 - 如果用户键入
Ctrl + C,则退出。 - 通过打印回溯并继续来处理其他异常。
- 如果没有异常,打印成功消息(对应于下面的
else条款)。 - 在再次刮擦之前休眠一段规定的时间间隔。默认情况下,这被设置为
20分钟。
from scraper import do_scrape
import settings
import time
import sys
import traceback
if __name__ == "__main__":
while True:
print("{}: Starting scrape cycle".format(time.ctime()))
try:
do_scrape()
except KeyboardInterrupt:
print("Exiting....")
sys.exit(1)
except Exception as exc:
print("Error with the scraping:", sys.exc_info()[0])
traceback.print_exc()
else:
print("{}: Successfully finished scraping".format(time.ctime()))
time.sleep(settings.SLEEP_INTERVAL)
我们还需要将SLEEP_INTERVAL添加到settings.py中,以控制抓取发生的频率。默认情况下,这被设置为20分钟。
自己运行
既然代码已经完成,让我们看看如何自己运行 Slack bot。
在本地计算机上运行
你可以在 Github 这里找到这个项目。在 README.md 中,你会找到详细的安装说明。除非你有安装程序的经验,并且正在运行 Linux,否则建议遵循 Docker 的说明。
Docker 是一个工具,它使创建和部署应用程序变得容易,并使您可以在本地机器上非常快速地开始使用这个 Slack bot。以下是用 Docker 安装和运行 Slack bot 的基本说明:
- 创建一个名为
config的文件夹,然后在里面放一个名为private.py的文件。- 您在
private.py中指定的任何设置都将覆盖settings.py中的默认值。 - 通过在
private.py中添加设置,可以自定义机器人的行为。
- 您在
- 为上述
private.py中的任何设置指定新值。- 例如,您可以将
AREAS = ['sfc']放在private.py中,以便只在旧金山查找。 - 如果你想发布到一个不叫作
housing的松弛通道,为SLACK_CHANNEL添加一个条目。 - 如果您不想查看湾区,您至少需要更新以下设置:
CRAIGSLIST_SITEAREASBOXESNEIGHBORHOODSTRANSIT_STATIONSCRAIGSLIST_HOUSING_SECTIONMIN_PRICEMAX_PRICE
- 例如,您可以将
- 按照这些说明安装 Docker。
- 要使用默认配置运行 bot:
docker run -d -e SLACK_TOKEN={YOUR_SLACK_TOKEN} dataquestio/apartment-finder
- 要使用您自己的配置运行 bot:
docker run -d -e SLACK_TOKEN={YOUR_SLACK_TOKEN} -v {ABSOLUTE_PATH_TO_YOUR_CONFIG_FOLDER}:/opt/wwc/apartment-finder/config dataquestio/apartment-finder
部署机器人
除非您想让您的计算机全天候运行,否则将 bot 部署到服务器是有意义的,这样它就可以连续运行。我们可以在名为 DigitalOcean 的主机提供商上创建一个服务器。数字海洋可以自动创建一个安装了Docker的服务器。这里有一个关于如何在数字海洋上开始使用 Docker 的指南。
如果你不知道作者说的“shell”是什么意思,这里有一个关于如何 SSH 到数字海洋水滴的教程。如果你不想跟随一个向导,你也可以在这里开始。在 DigitalOcean 上创建服务器后,您可以 ssh 到服务器,然后按照上面的 Docker 安装和使用说明进行操作。
接下来的步骤
按照上面的步骤,你应该有一个自动为你寻找公寓的 Slack 机器人。使用这个机器人,Priya 和我在旧金山找到了一个很棒的公寓,价格比我们希望的要高,但比我们认为旧金山一居室的最终价格要低。它也比我们预期的花费了更少的时间。尽管它对我们有效,但仍有相当多的扩展可以用来改进机器人:
- 从松弛状态中竖起大拇指和放下大拇指,并训练机器学习模型。
- 从 API 中自动提取中转站的位置。
- 加入像公园和其他项目的兴趣点。
- 加入步行得分或其他邻里质量得分,如犯罪。
- 自动提取房东的电话号码和电子邮件。
- 自动给房东打电话,安排看房时间(如果有人这么做,你就牛逼了)。
请随意在 Github 上向项目提交拉动请求,如果这个工具对你有帮助,请告诉我。期待看到大家如何使用!当我没有开发 slackbots 来帮助我寻找公寓时,我正在开发我的初创公司 Dataquest,这是学习 Python 和数据科学的最佳在线平台。如果你感兴趣,你可以注册并免费完成我们的基础课程。
如何在 R 语言中向数据帧添加行(有 7 个代码示例)
July 28, 2022
在本教程中,我们将介绍如何在 R 中向数据帧追加数据,这是对数据帧执行的最常见的修改之一。
数据帧是 R 编程语言中基本的数据结构之一。众所周知,它非常灵活,因为它可以包含许多数据类型,并且易于修改。在 R 中对数据帧执行的最典型的修改之一是向它添加新的观察值(行)。
在本教程中,我们将讨论在 r 中向数据帧追加一行或多行的不同方法。
开始之前,让我们创建一个简单的数据框架作为实验:
super_sleepers_initial <- data.frame(animal=c('koala', 'hedgehog'),
country=c('Australia', 'Italy'),
avg_sleep_hours=c(21, 18),
stringsAsFactors=FALSE)
print(super_sleepers_initial)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
注:在创建上述数据帧时,我们添加了可选参数
stringsAsFactors=FALSE。虽然默认情况下这个参数是TRUE,但是在大多数情况下(除非我们没有字符数据类型的列),强烈建议将它设置为FALSE,以抑制字符到因子数据类型的默认转换,从而避免不希望的副作用。作为一个实验,您可以从上面的代码中删除这个参数,运行这个和后续的代码单元,并观察结果。
在 R 中向数据帧追加一行
使用rbind()
要在 R 中向数据帧追加一行,我们可以使用内置函数rbind(),它代表“行绑定”。基本语法如下:
dataframe <- rbind(dataframe, new_row)
注意,在上面的语法中,通过new_row,我们很可能理解一个列表,而不是一个向量,除非我们的数据帧的所有列都是相同的数据类型(这种情况并不常见)。
让我们从最初的数据帧super_sleepers_initial重新构建一个新的数据帧super_sleepers,并向其追加一行:
# Reconstructing the `super_sleepers` dataframe
super_sleepers <- super_sleepers_initial
super_sleepers <- rbind(super_sleepers, list('sloth', 'Peru', 17))
print(super_sleepers)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| three | 懒惰 | 秘鲁 | Seventeen |
新行被追加到数据帧的末尾。
重要的是要记住,在这里和所有后续的例子中,新的一行(或多行)必须反映它所附加到的数据帧的结构,这意味着列表的长度必须等于数据帧中的列数,并且列表中项的数据类型序列必须与数据帧变量的数据类型序列相同。在相反的情况下,程序会抛出一个错误。
使用nrow()
向 R 数据帧追加一行的另一种方法是使用nrow()函数。语法如下:
dataframe[nrow(dataframe) + 1,] <- new_row
这个语法的字面意思是,我们计算数据帧中的行数(nrow(dataframe)),给这个数加 1(nrow(dataframe) + 1),然后在数据帧的索引处追加一个新行new_row(dataframe[nrow(dataframe) + 1,])—即作为新的最后一行。
就像以前一样,我们的new_row很可能必须是一个列表,而不是一个向量,除非 DataFrame 的所有列都是相同的数据类型,这并不常见。
让我们再增加一个“超级睡眠者”:
super_sleepers[nrow(super_sleepers) + 1,] <- list('panda', 'China', 10)
print(super_sleepers)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| three | 懒惰 | 秘鲁 | Seventeen |
| four | 熊猫 | 中国 | Ten |
新行再次追加到数据帧的末尾。
使用tidyverse中的add_row()
相反,如果我们不想在数据帧的末尾添加新行,而是想在数据帧的某个特定索引处添加新行,该怎么办呢?例如,我们发现老虎每天睡 16 个小时(即,在我们的评级中比熊猫多,所以我们需要将此观察结果作为第二个插入到数据帧的最后一行)。在这种情况下,使用基础 R 是不够的,但是我们可以使用tidyverse R 包的 add_row() 函数(我们可能需要安装它,如果它还没有安装,通过运行install.packages("tidyverse")):
library(tidyverse)
super_sleepers <- super_sleepers %>% add_row(animal='tiger',
country='India',
avg_sleep_hours=16,
.before=4)
print(super_sleepers)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| three | 懒惰 | 秘鲁 | Seventeen |
| four | 老虎 | 印度 | Sixteen |
| five | 熊猫 | 中国 | Ten |
在这里,我们应该注意以下几点:
- 我们按照与现有数据帧相同的顺序传递相同的列名,并为它们分配相应的新值。
- 在这个序列之后,我们添加了可选参数
.before并指定了必要的索引。如果我们不这样做,默认情况下,该行将被添加到数据帧的末尾。或者,我们可以使用可选参数.after,并为其分配在之后插入新观察的行的索引。 - 我们使用赋值操作符
<-来保存应用于当前数据帧的修改。
在 R 中向数据帧追加多行
使用rbind()
通常,我们需要在 R 数据帧中添加多行而不是一行。这里最简单的方法还是使用rbind()函数。更准确地说,在这种情况下,我们实际上需要组合两个数据帧:初始数据帧和包含要追加的行的数据帧。
dataframe_1 <- rbind(dataframe_1, dataframe_2)
为了了解它是如何工作的,让我们从最初的数据帧super_sleepers_initial重新构建一个新的数据帧super_sleepers,将其打印出来以回忆它的样子,并在其末尾追加两行:
# Reconstructing the `super_sleepers` DataFrame
super_sleepers <- super_sleepers_initial
print(super_sleepers)
cat('\n\n') # printing an empty line
# Creating a new DataFrame with the necessary rows
super_sleepers_2 <- data.frame(animal=c('squirrel', 'panda'),
country=c('Canada', 'China'),
avg_sleep_hours=c(15, 10),
stringsAsFactors=FALSE)
# Appending the rows of the new DataFrame to the end of the existing one
super_sleepers <- rbind(super_sleepers, super_sleepers_2)
print(super_sleepers)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| three | 松鼠 | 加拿大 | Fifteen |
| four | 老虎 | 印度 | Sixteen |
提醒一下,新行必须反映它们所附加到的数据帧的结构,这意味着两个数据帧中的列数、列名、它们的顺序和数据类型必须相同。
使用nrow()
或者,我们可以使用nrow()函数向 r 中的一个数据帧追加多行。然而,这里不推荐使用这种方法,因为语法变得非常笨拙,难以阅读。事实上,在这种情况下,我们需要计算开始和结束索引。为此,我们必须用nrow()函数做更多的操作。从技术上讲,语法如下:
dataframe_1[(nrow(dataframe_1) + 1):(nrow(dataframe_1) + nrow(dataframe_2)),] <- dataframe_2
让我们从super_sleepers_initial重新构建我们的super_sleepers,并将已经存在的数据帧super_sleepers_2的行追加到它们中:
# Reconstructing the `super_sleepers` dataframe
super_sleepers <- super_sleepers_initial
super_sleepers[(nrow(super_sleepers) + 1):(nrow(super_sleepers) + nrow(super_sleepers_2)),] <- super_sleepers_2
print(super_sleepers)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| three | 松鼠 | 加拿大 | Fifteen |
| four | 熊猫 | 中国 | Ten |
我们获得了与前一个例子相同的数据帧,并观察到前一个方法更加优雅。
使用tidyverse中的add_row()
最后,我们可以再次使用tidyverse包的add_row()函数。这种方法更加灵活,因为我们既可以在当前数据帧的末尾添加新行,也可以在索引指定的某一行之前/之后插入新行。
让我们在当前数据帧super_sleepers中的刺猬和松鼠之间插入树懒和老虎的观察结果:
library(tidyverse)
super_sleepers <- super_sleepers %>% add_row(animal=c('sloth', 'tiger'),
country=c('Peru', 'India'),
avg_sleep_hours=c(17, 16),
.before=3)
print(super_sleepers)
| | 动物 | 国家 | 平均睡眠时间 |
| one | 树袋熊 | 澳大利亚 | Twenty-one |
| Two | 刺猬 | 意大利 | Eighteen |
| three | 懒惰 | 秘鲁 | Seventeen |
| four | 老虎 | 印度 | Sixteen |
| five | 松鼠 | 加拿大 | Fifteen |
| six | 熊猫 | 中国 | Ten |
注意,为了获得上面的结果,我们可以用.after=2代替.before=3。
结论
在本教程中,我们学习了如何在 R 中向数据帧追加一行(或多行)——或者如何在数据帧的特定索引处插入一行(或多行)。特别是,我们考虑了 3 种方法:使用基 R 的rbind()或nrow()函数,或者tidyverse R 包的add_row()函数。我们特别关注每种方法的最佳用例,以及在各种情况下必须考虑的细微差别。**
用例子应用 R 中的函数[apply(),sapply(),lapply(),tapply()]
原文:https://www.dataquest.io/blog/apply-functions-in-r-sapply-lapply-tapply/
May 31, 2022
在本教程中,我们将学习 R 中的 apply()函数,包括何时使用它以及为什么它比循环更有效。
apply()函数是 R 中 apply 函数族的基本模型,它包含了一些特定的函数,如lapply()、sapply()、tapply()、mapply()、vapply()、rapply()、bapply()、eapply()等。所有这些函数都允许我们遍历一个数据结构,比如一个列表、一个矩阵、一个数组、一个数据帧或者一个给定数据结构的一个选定部分——并在每个元素上执行相同的操作。
此类操作可能意味着聚合(即计算汇总统计,如平均值、最大值、最小值、总和等。)、变换—或任何其他简单或复杂、内置或自定义的矢量化函数。apply 系列函数之间的区别在于数据结构的输入和输出类型以及它们执行的功能。
与出于同样目的使用循环结构的更保守的方法相比,apply()函数及其变体提供了显著更快的程序执行和紧凑的单行语法,而不是跨越多行的代码块。这在处理大型数据集时变得尤为重要。
如何在 R 中使用apply()函数(及其变种)
让我们探索一下 r 中一些最有用的 apply 函数。
apply()
我们将从应用组的主要功能开始:apply()。它接受数据帧、矩阵或多维数组作为输入,并根据输入对象类型和传入的函数,输出向量、列表、矩阵或数组。
apply()函数的语法非常简单,只有三个参数:
apply(X, MARGIN, FUN)
这里的X是一个输入对象(一个数据帧、一个矩阵或一个数组),MARGIN是决定函数应用的参数(它可以取值1、2或c(1,2),这意味着函数相应地应用于行、列或行和列),而FUN是应用于输入数据的函数(内置或自定义)。
让我们看一些例子。我们将使用矩阵作为输入数据结构,但同样的原理也适用于其他可能的数据结构:
my_matrix <- matrix((1:12), nrow=3)
print(my_matrix)
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
例如,我们可能希望找到矩阵中每一行的最大值。为此,我们将把1设置为MARGIN参数,并传入max函数:
print(apply(my_matrix, 1, max))
[1] 10 11 12
在上面的代码中,我们在输入矩阵上虚拟地实现了一个聚合(这是一个二维数据结构)。结果,输出是一个包含每行相应最大值的向量(这是一个一维数据结构)。
现在,让我们按列(MARGIN=2)计算矩阵值的总和:
print(apply(my_matrix, 2, sum))
[1] 6 15 24 33
输出数据结构也是一个向量。sum函数是聚合函数的另一个例子,它将输入对象的维数减少 1。
在某些情况下,我们可能需要按列计算累积和:
print(apply(my_matrix, 2, cumsum))
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 3 9 15 21
[3,] 6 15 24 33
这次,我们获得了一个与输入矩阵大小相同的矩阵,因为cumsum函数为输入矩阵的每个值计算一个值。
**注意,最后的结果(输出对象与输入对象的大小相同)对于非聚合函数来说并不总是这样。例如,我们可能想要一个按列排列的范围的值:
print(apply(my_matrix, 2, range))
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 3 6 9 12
这里,我们也得到一个矩阵作为输出对象,但是它的大小与输入对象不同(2×4 而不是 3×4)。
可以向apply()提供任何自定义功能。让我们定义一个函数来计算每个输入的均方值:
mean_squared_vals <- function(x) mean(x**2)
正如我们之前所做的那样,我们可以通过行(MARGIN=1)来应用这个函数:
print(apply(my_matrix, 1, mean_squared_vals))
[1] 41.5 53.5 67.5
我们也可以按列(MARGIN=2)应用函数:
print(apply(my_matrix, 2, mean_squared_vals))
[1] 4.666667 25.666667 64.666667 121.666667
最后——这是我们还没有尝试过的——我们可以通过行和列来应用它(MARGIN=c(1,2)):
print(apply(my_matrix, c(1,2), mean_squared_vals))
[,1] [,2] [,3] [,4]
[1,] 1 16 49 100
[2,] 4 25 64 121
[3,] 9 36 81 144
在最后一种情况下,我们得到了一个矩阵,其中每个值都是输入矩阵对应值的平方。因为我们的用户定义函数的mean组件实际上在每次迭代中只应用于一个值,所以值本身被返回。因此,在这种特殊情况下,mean操作没有任何意义。
lapply()
lapply()函数是apply()的变体,它接受一个向量、一个列表或一个数据帧作为输入,并且总是输出一个列表(函数名中的“l”代表“列表”)。指定的函数应用于输入对象的每个元素,因此结果列表的长度总是等于输入对象的长度。
该函数的语法类似于apply()的语法,只是这里不需要MARGIN参数,因为该函数对列表和向量应用元素方式,对数据帧应用列方式:
lapply(X, FUN)
让我们看看它是如何处理向量、列表和数据帧的。首先,我们将创建一个将输入值加 1 的简单函数:
add_one <- function(x) x+1
让我们在一个向量上测试它:
my_vector = c(1, 2, 3)
print(lapply(my_vector, add_one))
[[1]]
[1] 2
[[2]]
[1] 3
[[3]]
[1] 4
我们给向量的每个值加 1。
现在,我们将创建一个列表:
my_list = list(TRUE, c(1, 2, 3), 10)
print(my_list)
[[1]]
[1] TRUE
[[2]]
[1] 1 2 3
[[3]]
[1] 10
现在我们将对它应用我们的函数:
print(lapply(my_list, add_one))
[[1]]
[1] 2
[[2]]
[1] 2 3 4
[[3]]
[1] 11
由于TRUE的值为 1,加上 1,我们得到结果列表第一项的值为 2。在矢量项的情况下,每个值都加 1。
最后,让我们在数据帧上使用lapply():
my_df <- data.frame(a=1:3, b=4:6, c=7:9, d=10:12)
print(my_df)
a b c d
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
print(lapply(my_df, add_one))
$a
[1] 2 3 4
$b
[1] 5 6 7
$c
[1] 8 9 10
$d
[1] 11 12 13
正如我们前面提到的,lapply()函数适用于数据帧的列方式。
sapply()
sapply()函数是lapply()的简化形式(函数名中的“s”代表“简化”)。与lapply()(即sapply(X, FUN))语法相同;接受一个向量、一个列表或一个数据帧作为输入,就像lapply()一样,并试图将输出对象简化为最简单的数据结构。这意味着,默认情况下,sapply()函数为 vector 输出 vector,为 list 输出 list,为 DataFrame 输出 matrix。
让我们使用与前面相同的自定义函数add_one对变量my_vector、my_list和my_df进行尝试:
print(sapply(my_vector, add_one))
[1] 2 3 4
print(sapply(my_list, add_one))
[[1]]
[1] 2
[[2]]
[1] 2 3 4
[[3]]
[1] 11
print(sapply(my_df, add_one))
a b c d
[1,] 2 5 8 11
[2,] 3 6 9 12
[3,] 4 7 10 13
我们可以改变sapply()函数的默认行为,传入一个可选参数simplify=FALSE(默认为TRUE)。在这种情况下,sapply()函数变得与lapply()相同,并且总是输出任何有效输入数据结构的列表:
print(typeof(sapply(my_vector, add_one, simplify=FALSE)))
print(typeof(sapply(my_list, add_one, simplify=FALSE)))
print(typeof(sapply(my_df, add_one, simplify=FALSE)))
[1] "list"
[1] "list"
[1] "list"
tapply()
我们使用tapply()函数来计算汇总统计数据(如平均值、中值、最小值、最大值、总和等)。)针对不同的因素(即类别)。它具有以下语法:
tapply(X, INDEX, FUN)
这里的X是一个 R 对象,通常是一个向量,包含数字数据;INDEX是一个 R 对象,典型的是一个向量或者一个列表,包含因子;而FUN是要在X上应用的函数。
为了了解它是如何工作的,让我们假设我们有一组从事数据相关工作的人的工资信息:数据科学家(DS)、数据分析师(DA)和数据工程师(DE)。使用tapply()函数,我们可以按职位计算平均工资。
(旁注:作为一个粗略的指南,我们在这里使用了来自的信息,实际上是来估算 2022 年 2 月美国各职位的平均工资。)
salaries <- c(80000, 62000, 113000, 68000, 75000, 79000, 112000, 118000, 65000, 117000)
jobs <- c('DS', 'DA', 'DE', 'DA', 'DS', 'DS', 'DE', 'DE', 'DA', 'DE')
print(tapply(salaries, jobs, mean))
DA DE DS
65000 115000 78000
结论
总的来说,我们学习了很多关于在 r 中使用 apply 函数的东西。
- 如何在 R 中定义
apply()函数 - 函数的种类和最常见的函数
- 为什么 apply 系列的函数比循环更有效
- 当应用功能的每一种常见变化都适用时
- 每个变体的语法
- 每种类型的输入以及如何在不同类型的输入上使用它**
Dataquest 通过新的 Azure 奖学金计划继续推动数据的多样性
原文:https://www.dataquest.io/blog/azure-certification-scholarship-2/
October 1, 2022
Dataquest 很高兴宣布一项新的 Azure 奖学金计划。这是我们与微软奖学金计划的继续,旨在提高数据领域的包容性和多样性。该计划将为来自世界各地代表性不足的社区的学习者带来尖端的云技术。
奖学金申请期从 2022 年 10 月 1 日开始,到 2022 年 10 月 31 日结束,对任何在数据领域代表性不足的人开放。性别、种族、教育水平和收入都是将被考虑的多样性的轴心。
在完成 Microsoft Azure 中的 Dataquest 云数据基础知识后,接收者将获得免费参加考试 DP-900: Microsoft Azure 数据基础知识的机会。
提高数据领域包容性和多样性的奖学金
数据角色中存在明显的公平差距。
- 2020 年,在数据科学相关职位的所有专业人员中,只有 15%至 22%是女性(BCG)。
- 2021 年,只有 5.2%的数据科学家是拉丁裔,只有 1%是非裔美国人(萨皮亚)。
- 2021 年 94%的数据科学家至少有大专学历(联大)。
“当我开始 Dataquest 时,我的目标是帮助数百万人进入数据领域。作为一名自学成才的数据科学家,我知道迈出这一步有多难。这就是为什么我很高兴与微软合作——Power BI 是帮助人们开始新的分析角色的一项关键技能。我们的奖学金计划帮助我们继续我们的使命,并改善受教育的机会。”—Vik Paruchuri,Dataquest 创始人
互动培训倡议
Dataquest 和微软合作提供第一个交互式云数据课程,将于今年 11 月推出。本课程将向学员讲授核心数据概念,以及如何使用 Azure 数据服务在云中实现这些概念。该课程还将帮助学习者理解云和 Azure 中的数据工作的基础,并为他们在云中的进一步数据工作做准备。完成该计划后,学员将为通过考试 DP-900:微软 Azure 数据基础做好充分准备,并继续推进他们的数据职业生涯。
微软 Azure 是一个受欢迎的平台,提供从计算到分析到网络和存储的一系列云服务。随着越来越多的公司使用云来管理这些数据,精通云正成为数据职位描述中最常见的要求之一。
“我们很高兴能与 Dataquest 合作获得这些奖学金。这项计划支持我们的使命,即帮助地球上的每个人和每个组织取得更大成就。通过将微软的专业知识与交互式 Dataquest 学习平台相结合,学习者将获得准备 DP-900 考试和为数据科学职业生涯做准备所必需的数字技能。”——微软高级主管杰夫·赫希。
关于 Dataquest
Dataquest 成立于 2015 年,旨在帮助任何人学习数据科学并推进他们的职业生涯。有了 Dataquest 职业道路,学员可以在 3 到 9 个月内获得开始新工作所需的一切。学员可以随着课程的进展建立作品集,并通过完成顶点项目获得职业道路认证。
如何实现一个 B 树数据结构(2022 版)
October 19, 2022
1971 年,鲁道夫·拜尔和爱德华·m·麦克赖特在波音研究实验室创造了 B 树数据结构这个术语。他们发表了一篇题为“大型有序索引的组织和维护”的科学论文,并介绍了一种新的数据结构,用于从磁盘中快速检索数据。尽管 B 树数据结构已经发展了几十年,但是理解它的概念仍然是有价值的。
以下是我们将在本教程中涵盖的内容:
- B-树数据结构
- b 树属性
- 遍历 B 树
- 在 B 树中搜索
- 在 B 树中插入一个键
- 删除 B 树中的键
我们开始吧!
什么是 B 树数据结构?
B 树是一种自平衡的树数据结构,是二叉查找树(BST)的一般化形式。然而,与二叉树不同,每个节点可以有两个以上的子节点。换句话说,每个节点最多可以有 m 个子节点和 m-1 个键;此外,每个节点必须至少有\(\lceil \frac{m}{2} \rceil\)个子节点,以保持树的平衡。这些特征使得树的高度相对较小。
B 树数据结构保持数据有序,并允许在分摊对数时间内执行搜索、插入和删除操作。更具体地说,完成上述操作的时间复杂度是\(O(log {n})\),其中 n 是存储在树中的键的数量。
让我们假设我们必须在计算机系统中存储大量的数据。在这种常见情况下,我们肯定无法将全部数据存储在主内存(RAM)中,大部分数据应该保存在磁盘上。我们还知道辅助存储(各种类型的磁盘)比 RAM 慢得多。因此,当我们必须从辅助存储中检索数据时,我们需要优化算法来减少磁盘访问次数。
B-tree 数据结构使用先进的技术和优化的算法来搜索、插入和删除,以尽量减少磁盘访问次数,所有这些都允许 B-Tree 保持平衡,从而确保在对数时间内找到数据。
为了揭示 B 树在最小化磁盘访问方面有多强大,让我们参考《算法简介》这本书,它证明了一棵高度为 2 和 1001 个孩子的 B 树能够存储超过 10 亿个键。尽管如此,只需要两个磁盘访问就可以找到任何键(Cormen 等人,2009)。
我们将在接下来的章节中讨论 B 树的属性以及它是如何工作的。
b 树属性
在 m 阶的 B 树中有三种类型的节点,并且它们中的每一种都具有以下属性:
-
根节点
- 根节点有\(2\)到\(m\)个子节点。
-
内部节点
- 每个内部节点都有介于\(\lceil \frac{m}{2} \rceil\)和\(m\)之间的子节点,包括两端。
- 每个内部节点可以包含多达\(m-1\)个键。
-
叶节点
- 所有叶节点都在同一级别。
- 每个叶节点存储\(\lceil \frac{m-1}{2} \rceil\)和\(m-1\)之间的密钥,包括两端。
-
B 树的高度可以通过以下等式得出:
$ h \ leq log _ { m } { n+1 } { 2 } } $其中 m 是最小度数, n 是键的个数。
下图显示了 B 树数据结构。

遍历 B 树
为了遍历 B 树,遍历程序从最左边的子树开始,递归地打印它的键。它对剩余的子对象和关键点重复相同的过程,直到最右边的子对象。
在 B 树中搜索
在 B 树中搜索特定的关键字是在二叉查找树(BST)中搜索的一种推广形式。唯一的区别是 BST 执行二元决策,但是在 B 树中,每个节点的决策数等于节点的子节点数。
让我们在上面的 B 树中搜索关键字 102:
- 根的键不等于 102,所以既然 k > 100,就去右边分支最左边的节点。

-
比较 k 和 103;由于 k < 103,所以转到当前节点的左分支。
-
将 k 与叶子的键进行比较;k 存在于那里。

如图所示,如果我们要寻找的键不在父节点的范围内,那么这个键很可能在另一个分支中。该算法将继续这样做以到达叶节点。如果没有找到密钥,算法将返回 NULL。
在 B 树中插入一个键
到目前为止,我们已经讨论了遍历 B 树和在 B 树数据结构中搜索特定的键。这一节将讨论如何在 B 树中插入一个新的键。
将新节点插入 B 树包括两个步骤:找到正确的节点插入关键字,如果节点已满(节点的关键字数大于 m-1),则拆分节点。
- 如果 B 树为空:
- 分配一个根节点,并插入密钥。
- 如果 B 树不为空:
- 找到合适的插入节点。
- 如果节点未满:
- 按升序插入密钥。
- 如果节点已满:
- 在中间分割节点。
- 向上按中键,使左键成为左子节点,右键成为右子节点。
删除 B 树中的键
删除是我们可以对 B 树执行的操作之一。我们可以在叶或内部节点级别执行删除。要从 B 树中删除一个节点,我们需要遵循下面的算法:
-
如果要删除的节点是叶节点:
- 找到包含所需键的叶节点。
- 如果该节点至少有\(\lfloor \frac{m}{2} \rfloor\)个键,请从叶节点中删除该键。
- 如果该节点的键少于\(\lfloor \frac{m}{2} \rfloor\)键,则从其右侧或左侧的直接同级节点中获取一个键。为此,请执行以下操作:
- 如果左边的兄弟节点至少有\(\lfloor \frac{m}{2} \rfloor\)个键,则将有序的前置项(左边子节点上最大的键)向上推至其父节点,并将正确的键从父节点向下移动至包含该键的节点。然后,我们可以从节点中删除键。
- 如果右边的兄弟节点至少有\(\lfloor \frac{m}{2} \rfloor\)个键,则将右边子节点上最小的键按顺序上推到其父节点,并将正确的键从父节点向下移动到包含该键的节点。然后,我们可以从节点中删除键。
- 如果直接同级不包含至少\(\lfloor \frac{m}{2} \rfloor\)项,请通过联接两个叶节点和父节点的项来创建一个新的叶节点。
- 如果父树剩下的键少于\(\lfloor \frac{m}{2} \rfloor\)键,则对父树应用上述过程,直到树成为有效的 B 树。
-
如果要删除的节点是内部节点:
- 用它的有序后继者或前任者替换它。由于后继者或前趋者将总是在叶节点上,所以该过程将类似于从叶节点删除该节点。
结论
本教程讨论了 B 树和 B 树在磁盘上存储大量数据的应用。我们还讨论了 B 树中的四种主要操作:遍历、搜索、插入和删除。如果您有兴趣了解更多关于 B 树在 Python 中的实际实现,这个 GitHub repo 分享了 B 树数据结构在 Python 中的实现。
我希望你今天学到了一些新东西。请随时在 LinkedIn 或 Twitter 上与我联系。
数据科学项目:App Store 和 Google Play 的盈利应用简介
原文:https://www.dataquest.io/blog/basic-data-science-portfolio-project-tutorial/
January 29, 2019
在 Dataquest,我们强烈主张将组合项目作为获得第一份数据科学工作的一种方式。在这篇博文中,我们将带你浏览一个投资组合项目的例子。这是我们数据科学组合项目系列的第三个项目:
- Fandango 还在膨胀收视率吗?
- 在哪里为电子学习产品做广告
- App Store 和 Google Play 的盈利应用简介
在前两个项目中,我们使用了一些高级的 Python 库,比如pandas、matplotlib或seaborn。在这个项目中,我们限制自己只使用基本的 Python 来证明我们仍然可以执行增加商业价值的分析。这个项目是我们的Python for Data Science:Fundamentals课程的一部分,它假设您熟悉:
- 基本的 Python 概念(变量、列表、字典、if 语句、for 循环等。)
- 基本数据分析概念(算术平均值、百分比、频率表等。)
如果你认为你需要在前进之前填补任何空白,我们在Python for Data Science:Fundamentals课程中涵盖了上述主题,该课程是免费的。本课程还将向您提供更深入的指导,说明如何构建这个项目,并在您的浏览器中对其进行编码。该项目遵循我们的数据科学项目的风格指南中提出的指导方针。
App Store 和 Google Play 市场的盈利应用简介
我们在这个项目中的目标是找到对应用商店和 Google Play 市场有利可图的移动应用简介。我们是一家开发 Android 和 iOS 移动应用的公司的数据分析师,我们的工作是让我们的开发团队能够就他们开发的应用类型做出数据驱动的决策。在我们公司,我们只开发免费下载和安装的应用,我们的主要收入来源包括应用内广告。这意味着任何给定应用的收入主要受使用我们应用的用户数量的影响。我们这个项目的目标是分析数据,以帮助我们的开发者了解什么样的应用程序可能会吸引更多的用户。
打开和浏览数据
截至 2018 年 9 月,App Store 上有大约 200 万个 iOS 应用程序,Google Play 上有 210 万个 Android 应用程序。

Source: Statista
收集超过 400 万个应用程序的数据需要大量的时间和金钱,因此我们将尝试分析数据样本。为了避免自己花费资源收集新数据,我们应该首先尝试看看是否可以免费找到任何相关的现有数据。幸运的是,这两个数据集似乎适合我们的目的:
- 数据集包含来自 Google Play 的大约一万个 Android 应用程序的数据
- 一个数据集包含来自 App Store 的大约 7,000 个 iOS 应用程序的数据,让我们首先打开这两个数据集,然后继续研究这些数据。
from csv import reader
### The Google Play data set ###
opened_file = open('googleplaystore.csv')
read_file = reader(opened_file)
android = list(read_file)
android_header = android[0]
android = android[1:]
### The App Store data set ###
opened_file = open('AppleStore.csv')
read_file = reader(opened_file)
ios = list(read_file)
ios_header = ios[0]
ios = ios[1:]
为了更容易地浏览这两个数据集,我们将首先编写一个名为explore_data()的函数,我们可以重复使用该函数,以更可读的方式浏览行。我们还将为函数添加一个选项,以显示任何数据集的行数和列数。
### The explore_data() function ###
def explore_data(dataset, start, end, rows_and_columns=False):
dataset_slice = dataset[start:end]
for row in dataset_slice:
print(row)
print('\n') # adds a new (empty) line between rows
if rows_and_columns:
print('Number of rows:', len(dataset))
print('Number of columns:', len(dataset[0]))
### Exploring the android data set ###
print(android_header)
print('\n')
explore_data(android, 0, 3, True)
['App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', 'Android Ver']
['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']
['Coloring book moana', 'ART_AND_DESIGN', '3.9', '967', '14M', '500,000+', 'Free', '0', 'Everyone', 'Art & Design;Pretend Play', 'January 15, 2018', '2.0.0', '4.0.3 and up']
['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']
Number of rows: 10841
Number of columns: 13
我们看到 Google Play 数据集有 10841 个应用和 13 个栏目。快速浏览一下,可能对我们的分析有用的列有'App'、'Category'、'Reviews'、'Installs'、'Type'、'Price'和'Genres'。现在我们来看看 App Store 的数据集。
print(ios_header)
print('\n')
explore_data(ios, 0, 3, True)
['id', 'track_name', 'size_bytes', 'currency', 'price', 'rating_count_tot', 'rating_count_ver', 'user_rating', 'user_rating_ver', 'ver', 'cont_rating', 'prime_genre', 'sup_devices.num', 'ipadSc_urls.num', 'lang.num', 'vpp_lic']
['284882215', 'Facebook', '389879808', 'USD', '0.0', '2974676', '212', '3.5', '3.5', '95.0', '4+', 'Social Networking', '37', '1', '29', '1']
['389801252', 'Instagram', '113954816', 'USD', '0.0', '2161558', '1289', '4.5', '4.0', '10.23', '12+', 'Photo & Video', '37', '0', '29', '1']
['529479190', '*** of Clans', '116476928', 'USD', '0.0', '2130805', '579', '4.5', '4.5', '9.24.12', '9+', 'Games', '38', '5', '18', '1']
Number of rows: 7197
Number of columns: 16
在这个数据集中,我们有 7197 个 iOS 应用程序,看起来有趣的列有:'track_name'、'currency'、'price'、'rating_count_tot'、'rating_count_ver'和'prime_genre'。在这种情况下,并不是所有的列名都是不言自明的,但是关于每一列的细节可以在数据集文档中找到。
清理数据
Google Play 数据集有一个专门的讨论区,我们可以看到的一个讨论为第 10472 行概述了一个错误。让我们打印这一行,并将其与标题和正确的另一行进行比较。
print(android[10472]) # incorrect row
print('\n')
print(android_header) # header
print('\n')
print(android[0]) # correct row
['Life Made WI-Fi Touchscreen Photo Frame', '1.9', '19', '3.0M', '1,000+', 'Free', '0', 'Everyone', '', 'February 11, 2018', '1.0.19', '4.0 and up']
['App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', 'Android Ver']
['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']
第 10472 行对应 app Life Made WI-Fi 触屏相框,我们可以看到评分是 19。这显然是关闭的,因为 Google Play 应用程序的最高评级是 5。因此,我们将删除这一行。
print(len(android))
del android[10472] # don't run this more than once
print(len(android))
10841
10840
删除重复条目
如果我们探索 Google Play 数据集足够长的时间,我们会发现一些应用程序有不止一个条目。例如,应用程序 Instagram 有四个条目:
for app in android:
name = app[0]
if name == 'Instagram':
print(app)
['Instagram', 'SOCIAL', '4.5', '66577313', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device']
['Instagram', 'SOCIAL', '4.5', '66577446', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device']
['Instagram', 'SOCIAL', '4.5', '66577313', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device']
['Instagram', 'SOCIAL', '4.5', '66509917', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device']
总的来说,一个应用程序出现不止一次的情况有 1,181 个:
### Counting the duplicate apps ###
duplicate_apps = []
unique_apps = []
for app in android:
name = app[0]
if name in unique_apps:
duplicate_apps.append(name)
unique_apps.append(name)
print(len(duplicate_apps))
print(duplicate_apps[:15])
1181
['Quick PDF Scanner + OCR FREE', 'Box', 'Google My Business', 'ZOOM Cloud Meetings', 'join.me - Simple Meetings', 'Box', 'Zenefits', 'Google Ads', 'Google My Business', 'Slack', 'FreshBooks Classic', 'Insightly CRM', 'QuickBooks Accounting: Invoicing & Expenses', 'HipChat - Chat Built for Teams', 'Xero Accounting Software']
我们不希望在分析数据时对某些应用进行多次计数,因此我们需要删除重复的条目,并且每个应用只保留一个条目。我们可以做的一件事是随机删除重复的行,但我们可能会找到更好的方法。如果您检查我们为 Instagram 应用程序打印的行,主要差异发生在每行的第四个位置,这对应于评论的数量。不同的数字表明数据是在不同的时间收集的。我们可以用它来建立一个保存行的标准。我们不会随机删除行;相反,我们将保留评论数量最多的行,假设评论数量越多,评级越可靠。为此,我们将:
- 创建一个字典,其中每个键是一个唯一的应用程序名称,值是该应用程序的最高评论数
- 使用字典创建一个新的数据集,每个应用程序只有一个条目(我们只选择评论数最高的应用程序)。让我们从构建字典开始。
### Building a dictionary {'app_name': max_number_of reviews, ...} ###
reviews_max = {}
for app in android:
name = app[0]
n_reviews = float(app[3])
if name in reviews_max and reviews_max[name] < n_reviews:
reviews_max[name] = n_reviews
elif name not in reviews_max: # Don't use else here!
reviews_max[name] = n_reviews
在之前的代码单元中,我们发现有 1,181 种情况下,一个应用程序出现不止一次,因此我们的字典(唯一应用程序)的长度应该等于我们的数据集长度与 1,181 的差。
print('Expected length:', len(android) - 1181)
print('Actual length:', len(reviews_max))
Expected length: 9659
Actual length: 9659
现在,让我们使用reviews_max字典来删除重复的内容。对于重复的案例,我们将只保留评论数最高的条目。在下面的代码单元格中:
- 我们首先初始化两个空列表,
android_clean和already_added。 - 我们遍历
android数据集,对于每次迭代: - 我们分离出应用程序的名称和评论数量。我们将当前行(
app)添加到android_clean列表,将应用名称(name)添加到already_cleaned列表,如果:当前应用的评论数与reviews_max字典中描述的那个应用的评论数匹配;以及*应用程序的名称不在already_added列表中。我们需要添加这个补充条件,以考虑重复应用的最高评论数对于多个条目相同的情况(例如,盒子应用有三个条目,评论数相同)。如果我们只检查reviews_max[name] == n_reviews,我们仍然会以一些应用程序的重复条目而告终。
android_clean = []
already_added = []
for app in android:
name = app[0]
n_reviews = float(app[3])
if (reviews_max[name] == n_reviews) and (name not in already_added):
android_clean.append(app)
already_added.append(name) # make sure this is inside the if block
现在让我们快速浏览新的数据集,并确认行数为 9,659。
explore_data(android_clean, 0, 3, True)
['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']
['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']
['Sketch - Draw & Paint', 'ART_AND_DESIGN', '4.5', '215644', '25M', '50,000,000+', 'Free', '0', 'Teen', 'Art & Design', 'June 8, 2018', 'Varies with device', '4.2 and up']
Number of rows: 9659
Number of columns: 13
正如所料,我们有 9659 行。
删除非英语应用
如果你对数据集进行了足够的研究,你会注意到一些应用的名字表明它们并不面向说英语的用户。下面,我们看到两个数据集的几个例子:
print(ios[813][1])
print(ios[6731][1])
print(android_clean[4412][0])
print(android_clean[7940][0])
爱奇艺 PPS -《欢乐颂 2》电视剧热播
【脱出ゲーム】絶対に最後までプレイしないで 〜謎解き&ブロックパズル〜
中国語 AQリスニング
لعبة تقدر تربح DZ
我们对保留这类应用不感兴趣,因此我们将删除它们。一种方法是删除其名称包含英语文本中不常用的符号的每个应用程序——英语文本通常包括英语字母表中的字母、由 0 到 9 的数字组成的数字、标点符号(。, !, ?, ;等。),以及其他符号(+、*、/等。).所有这些特定于英文文本的字符都使用 ASCII 标准进行编码。每个 ASCII 字符都有一个 0 到 127 之间的对应数字与之关联,我们可以利用这一点构建一个函数来检查应用程序名称,并告诉我们它是否包含非 ASCII 字符。下面我们构建了这个函数,我们使用内置的ord()函数来找出每个字符对应的编码号。
def is_English(string):
for character in string:
if ord(character) > 127:
return False
return True
print(is_English('Instagram'))
print(is_English('爱奇艺 PPS -《欢乐颂 2》电视剧热播'))
True
False
该功能似乎工作正常,但一些英文应用程序名称使用表情符号或其他符号(、—(长破折号)、–(短破折号)等。)不在 ASCII 范围内。因此,如果我们以当前形式使用该功能,我们将删除有用的应用程序。
print(is_English('Docs To Go™ Free Office Suite'))
print(is_English('Instachat " src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">'))
print(ord('™'))
print(ord('" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">'))
False
False
8482
128540
为了最大限度地减少数据丢失的影响,我们将只移除名称中包含三个以上非 ASCII 字符的应用:
def is_English(string):
non_ascii = 0
for character in string:
if ord(character) > 127:
non_ascii += 1
if non_ascii > 3:
return False
else:
return True
print(is_English('Docs To Go™ Free Office Suite'))
print(is_English('Instachat " src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f61c.svg">'))
True
True
该功能仍不完善,极少数非英语应用可能会通过我们的过滤,但在我们的分析中,这一点似乎已经足够好了——我们不应该在这一点上花太多时间进行优化。下面,我们使用is_English()函数过滤掉两个数据集的非英语应用程序:
### The lists that will store the new data sets ###
android_english = []
ios_english = []
### android ###
for app in android_clean:
name = app[0]
if is_English(name):
android_english.append(app)
### ios ###
for app in ios:
name = app[1]
if is_English(name):
ios_english.append(app)
### Check number of entries left ###
explore_data(android_english, 0, 3, True)
print('\n')
explore_data(ios_english, 0, 3, True)
['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']
['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']
['Sketch - Draw & Paint', 'ART_AND_DESIGN', '4.5', '215644', '25M', '50,000,000+', 'Free', '0', 'Teen', 'Art & Design', 'June 8, 2018', 'Varies with device', '4.2 and up']
Number of rows: 9614
Number of columns: 13
['284882215', 'Facebook', '389879808', 'USD', '0.0', '2974676', '212', '3.5', '3.5', '95.0', '4+', 'Social Networking', '37', '1', '29', '1']
['389801252', 'Instagram', '113954816', 'USD', '0.0', '2161558', '1289', '4.5', '4.0', '10.23', '12+', 'Photo & Video', '37', '0', '29', '1']
['529479190', '*** of Clans', '116476928', 'USD', '0.0', '2130805', '579', '4.5', '4.5', '9.24.12', '9+', 'Games', '38', '5', '18', '1']
Number of rows: 6183
Number of columns: 16
我们可以看到,我们剩下 9614 个 Android 应用程序和 6183 个 iOS 应用程序。
隔离免费应用
正如我们在简介中提到的,我们只构建免费下载和安装的应用,我们的主要收入来源包括应用内广告。我们的数据集包含免费和非免费应用程序,我们只需要分离出免费应用程序进行分析。下面,我们分离出两个数据集的免费应用。
### These two lists will store the new data sets ###
android_final = []
ios_final = []
### android ###
for app in android_english:
price = app[7]
if price == '0':
android_final.append(app)
### ios ###
for app in ios_english:
price = app[4]
if price == '0.0':
ios_final.append(app)
### Checking number of entries left ###
print(len(android_final))
print(len(ios_final))
8864
3222
我们剩下 8864 个 Android 应用和 3222 个 iOS 应用,这应该足够我们分析了。
按类型分类的最常用应用
正如我们在介绍中提到的,我们的目标是确定可能吸引更多用户的应用类型,因为我们的收入在很大程度上受到使用我们应用的人数的影响。为了最大限度地降低风险和开销,我们的应用创意验证策略包括三个步骤:
- 构建该应用程序的最小 Android 版本,并将其添加到 Google Play。
- 如果用户对这个应用有很好的反应,我们就会进一步开发它。
- 如果应用程序在六个月后盈利,我们也建立一个 iOS 版本的应用程序,并将其添加到应用程序商店。因为我们的最终目标是在 App Store 和 Google Play 上添加应用程序,所以我们需要找到在这两个市场都成功的应用程序档案。例如,一个对两个市场都适用的档案可能是一个利用游戏化的生产力应用程序。让我们从了解每个市场最常见的类型开始分析。为此,我们将为 App Store 数据集的
prime_genre列以及 Google Play 数据集的Genres和Category列构建一个频率表。
我们将构建两个函数来分析频率表:
- 一个生成显示百分比的频率表的函数
- 另一个我们可以用来以降序显示百分比的函数
### Frequency tables with percentages ###
def freq_table(dataset, index):
table = {}
total = 0
for row in dataset:
total += 1
value = row[index]
if value in table:
table[value] += 1
else:
table[value] = 1
table_percentages = {}
for key in table:
percentage = (table[key] / total) * 100
table_percentages[key] = percentage
return table_percentages
### Display percentages in a descending order ###
def display_table(dataset, index):
table = freq_table(dataset, index)
table_display = []
for key in table:
key_val_as_tuple = (table[key], key)
table_display.append(key_val_as_tuple)
table_sorted = sorted(table_display, reverse = True)
for entry in table_sorted:
print(entry[1], ':', entry[0])
我们首先检查 App Store 数据集的prime_genre列的频率表。
display_table(ios_final, -5)
Games : 58.16263190564867
Entertainment : 7.883302296710118
Photo & Video : 4.9658597144630665
Education : 3.662321539416512
Social Networking : 3.2898820608317814
Shopping : 2.60707635009311
Utilities : 2.5139664804469275
Sports : 2.1415270018621975
Music : 2.0484171322160147
Health & Fitness : 2.0173805090006205
Productivity : 1.7380509000620732
Lifestyle : 1.5828677839851024
News : 1.3345747982619491
Travel : 1.2414649286157666
Finance : 1.1173184357541899
Weather : 0.8690254500310366
Food & Drink : 0.8069522036002483
Reference : 0.5586592178770949
Business : 0.5276225946617008
Book : 0.4345127250155183
Navigation : 0.186219739292365
Medical : 0.186219739292365
Catalogs : 0.12414649286157665
我们可以看到,在免费的英文 app 中,超过一半(58.16%)是游戏。娱乐应用接近 8%,其次是照片和视频应用,接近 5%。只有 3.66%的应用是为教育设计的,其次是社交网络应用,占我们数据集中应用的 3.29%。总的印象是,App Store(至少是包含免费英文应用的部分)被那些为娱乐而设计的应用(游戏、娱乐、照片和视频、社交网络、体育、音乐等)所主导。),而具有实用目的(教育、购物、实用、生产力、生活方式等)的 app。)都比较少见。然而,有趣的应用程序数量最多的事实并不意味着它们也拥有最多的用户——需求可能与提供的不一样。让我们继续检查 Google Play 数据集的Genres和Category列(这两列似乎是相关的)。
display_table(android_final, 1) # Category
FAMILY : 18.907942238267147
GAME : 9.724729241877256
TOOLS : 8.461191335740072
BUSINESS : 4.591606498194946
LIFESTYLE : 3.9034296028880866
PRODUCTIVITY : 3.892148014440433
FINANCE : 3.7003610108303246
MEDICAL : 3.531137184115524
SPORTS : 3.395758122743682
PERSONALIZATION : 3.3167870036101084
COMMUNICATION : 3.2378158844765346
HEALTH_AND_FITNESS : 3.0798736462093865
PHOTOGRAPHY : 2.944494584837545
NEWS_AND_MAGAZINES : 2.7978339350180503
SOCIAL : 2.6624548736462095
TRAVEL_AND_LOCAL : 2.33528880866426
SHOPPING : 2.2450361010830324
BOOKS_AND_REFERENCE : 2.1435018050541514
DATING : 1.861462093862816
VIDEO_PLAYERS : 1.7937725631768955
MAPS_AND_NAVIGATION : 1.3989169675090252
FOOD_AND_DRINK : 1.2409747292418771
EDUCATION : 1.1620036101083033
ENTERTAINMENT : 0.9589350180505415
LIBRARIES_AND_DEMO : 0.9363718411552346
AUTO_AND_VEHICLES : 0.9250902527075812
HOUSE_AND_HOME : 0.8235559566787004
WEATHER : 0.8009927797833934
EVENTS : 0.7107400722021661
PARENTING : 0.6543321299638989
ART_AND_DESIGN : 0.6430505415162455
COMICS : 0.6204873646209386
BEAUTY : 0.5979241877256317
Google Play 上的情况似乎有很大不同:没有那么多应用程序是为娱乐而设计的,似乎有很多应用程序是为实用目的而设计的(家庭、工具、商业、生活方式、生产力等)。).然而,如果我们进一步调查,我们会发现家庭类别(几乎占应用程序的 19%)主要是指儿童游戏。

Source: play.google.com
即便如此,与 App Store 相比,实用应用似乎在 Google Play 上有更好的表现。我们看到的Genres列的频率表也证实了这一点:
display_table(android_final, -4)
Tools : 8.449909747292418
Entertainment : 6.069494584837545
Education : 5.347472924187725
Business : 4.591606498194946
Productivity : 3.892148014440433
Lifestyle : 3.892148014440433
Finance : 3.7003610108303246
Medical : 3.531137184115524
Sports : 3.463447653429603
Personalization : 3.3167870036101084
Communication : 3.2378158844765346
Action : 3.1024368231046933
Health & Fitness : 3.0798736462093865
Photography : 2.944494584837545
News & Magazines : 2.7978339350180503
Social : 2.6624548736462095
Travel & Local : 2.3240072202166067
Shopping : 2.2450361010830324
Books & Reference : 2.1435018050541514
Simulation : 2.0419675090252705
Dating : 1.861462093862816
Arcade : 1.8501805054151623
Video Players & Editors : 1.7712093862815883
Casual : 1.7599277978339352
Maps & Navigation : 1.3989169675090252
Food & Drink : 1.2409747292418771
Puzzle : 1.128158844765343
Racing : 0.9927797833935018
Role Playing : 0.9363718411552346
Libraries & Demo : 0.9363718411552346
Auto & Vehicles : 0.9250902527075812
Strategy : 0.9138086642599278
House & Home : 0.8235559566787004
Weather : 0.8009927797833934
Events : 0.7107400722021661
Adventure : 0.6768953068592057
Comics : 0.6092057761732852
Beauty : 0.5979241877256317
Art & Design : 0.5979241877256317
Parenting : 0.4963898916967509
Card : 0.45126353790613716
Casino : 0.42870036101083037
Trivia : 0.41741877256317694
Educational;Education : 0.39485559566787
Board : 0.3835740072202166
Educational : 0.3722924187725632
Education;Education : 0.33844765342960287
Word : 0.2594765342960289
Casual;Pretend Play : 0.236913357400722
Music : 0.2030685920577617
Racing;Action & Adventure : 0.16922382671480143
Puzzle;Brain Games : 0.16922382671480143
Entertainment;Music & Video : 0.16922382671480143
Casual;Brain Games : 0.13537906137184114
Casual;Action & Adventure : 0.13537906137184114
Arcade;Action & Adventure : 0.12409747292418773
Action;Action & Adventure : 0.10153429602888085
Educational;Pretend Play : 0.09025270758122744
Simulation;Action & Adventure : 0.078971119133574
Parenting;Education : 0.078971119133574
Entertainment;Brain Games : 0.078971119133574
Board;Brain Games : 0.078971119133574
Parenting;Music & Video : 0.06768953068592057
Educational;Brain Games : 0.06768953068592057
Casual;Creativity : 0.06768953068592057
Art & Design;Creativity : 0.06768953068592057
Education;Pretend Play : 0.056407942238267145
Role Playing;Pretend Play : 0.04512635379061372
Education;Creativity : 0.04512635379061372
Role Playing;Action & Adventure : 0.033844765342960284
Puzzle;Action & Adventure : 0.033844765342960284
Entertainment;Creativity : 0.033844765342960284
Entertainment;Action & Adventure : 0.033844765342960284
Educational;Creativity : 0.033844765342960284
Educational;Action & Adventure : 0.033844765342960284
Education;Music & Video : 0.033844765342960284
Education;Brain Games : 0.033844765342960284
Education;Action & Adventure : 0.033844765342960284
Adventure;Action & Adventure : 0.033844765342960284
Video Players & Editors;Music & Video : 0.02256317689530686
Sports;Action & Adventure : 0.02256317689530686
Simulation;Pretend Play : 0.02256317689530686
Puzzle;Creativity : 0.02256317689530686
Music;Music & Video : 0.02256317689530686
Entertainment;Pretend Play : 0.02256317689530686
Casual;Education : 0.02256317689530686
Board;Action & Adventure : 0.02256317689530686
Video Players & Editors;Creativity : 0.01128158844765343
Trivia;Education : 0.01128158844765343
Travel & Local;Action & Adventure : 0.01128158844765343
Tools;Education : 0.01128158844765343
Strategy;Education : 0.01128158844765343
Strategy;Creativity : 0.01128158844765343
Strategy;Action & Adventure : 0.01128158844765343
Simulation;Education : 0.01128158844765343
Role Playing;Brain Games : 0.01128158844765343
Racing;Pretend Play : 0.01128158844765343
Puzzle;Education : 0.01128158844765343
Parenting;Brain Games : 0.01128158844765343
Music & Audio;Music & Video : 0.01128158844765343
Lifestyle;Pretend Play : 0.01128158844765343
Lifestyle;Education : 0.01128158844765343
Health & Fitness;Education : 0.01128158844765343
Health & Fitness;Action & Adventure : 0.01128158844765343
Entertainment;Education : 0.01128158844765343
Communication;Creativity : 0.01128158844765343
Comics;Creativity : 0.01128158844765343
Casual;Music & Video : 0.01128158844765343
Card;Action & Adventure : 0.01128158844765343
Books & Reference;Education : 0.01128158844765343
Art & Design;Pretend Play : 0.01128158844765343
Art & Design;Action & Adventure : 0.01128158844765343
Arcade;Pretend Play : 0.01128158844765343
Adventure;Education : 0.01128158844765343
Genres和Category列之间的区别并不明显,但是我们可以注意到的一点是Genres列更加细粒度(它有更多的类别)。我们目前只是在寻找更大的画面,所以我们只会随着Category栏的前进而工作。到目前为止,我们发现 App Store 由为娱乐而设计的应用程序主导,而 Google Play 显示了实用和娱乐应用程序更加平衡的格局。现在我们想了解一下拥有最多用户的应用类型。
App Store 上按流派分类的最受欢迎应用
找出哪种类型最受欢迎(拥有最多用户)的一种方法是计算每种应用类型的平均安装次数。对于 Google Play 数据集,我们可以在Installs列中找到这些信息,但是对于 App Store 数据集,却缺少这些信息。作为一种变通方法,我们将用户评级的总数作为代理,这可以在rating_count_tot应用程序中找到。下面,我们计算了 App Store 上每个应用类型的平均用户评分数:
### Generating a frequency table to get the unique app genres ###
genres_ios = freq_table(ios_final, -5)
### Looping over the unique genres ###
for genre in genres_ios:
total = 0
len_genre = 0
## Looping over the App Store data set ##
for app in ios_final:
genre_app = app[-5]
if genre_app == genre:
n_ratings = float(app[5])
total += n_ratings
len_genre += 1
## Compute and display the average number of user ratings ##
avg_n_ratings = total / len_genre
print(genre, ':', avg_n_ratings)
Social Networking : 71548.34905660378
Photo & Video : 28441.54375
Games : 22788.6696905016
Music : 57326.530303030304
Reference : 74942.11111111111
Health & Fitness : 23298.015384615384
Weather : 52279.892857142855
Utilities : 18684.456790123455
Travel : 28243.8
Shopping : 26919.690476190477
News : 21248.023255813954
Navigation : 86090.33333333333
Lifestyle : 16485.764705882353
Entertainment : 14029.830708661417
Food & Drink : 33333.92307692308
Sports : 23008.898550724636
Book : 39758.5
Finance : 31467.944444444445
Education : 7003.983050847458
Productivity : 21028.410714285714
Business : 7491.117647058823
Catalogs : 4004.0
Medical : 612.0
平均而言,导航应用的用户评论数量最多,但这一数字受到 Waze 和谷歌地图的严重影响,这两家公司的用户评论总数接近 50 万:
for app in ios_final:
if app[-5] == 'Navigation':
print(app[1], ':', app[5]) # print name and number of ratings
Waze - GPS Navigation, Maps & Real-time Traffic : 345046
Google Maps - Navigation & Transit : 154911
Geocaching® : 12811
CoPilot GPS – Car Navigation & Offline Maps : 3582
ImmobilienScout24: Real Estate Search in Germany : 187
Railway Route Search : 5
同样的模式也适用于社交网络应用,其平均数量受到脸书、Pinterest、Skype 等少数巨头的严重影响。这同样适用于音乐应用,潘多拉、Spotify 和 Shazam 等几家大公司严重影响了平均数量。我们的目标是找到流行类型,但导航、社交网络或音乐应用可能看起来比实际更受欢迎。拥有数十万用户评分的极少数应用似乎扭曲了平均评分数,而其他应用可能很难超过 1 万的门槛。我们可以通过删除每个流派的这些非常受欢迎的应用程序来获得更好的图片,然后重新计算平均值,但我们将把这一级别的细节留到以后。参考应用平均有 74,942 个用户评级,但实际上是《圣经》和Dictionary.com扭曲了平均评级:
for app in ios_final:
if app[-5] == 'Reference':
print(app[1], ':', app[5])
Bible : 985920
Dictionary.com Dictionary & Thesaurus : 200047
Dictionary.com Dictionary & Thesaurus for iPad : 54175
Google Translate : 26786
Muslim Pro: Ramadan 2017 Prayer Times, Azan, Quran : 18418
New Furniture Mods - Pocket Wiki & Game Tools for Minecraft PC Edition : 17588
Merriam-Webster Dictionary : 16849
Night Sky : 12122
City Maps for Minecraft PE - The Best Maps for Minecraft Pocket Edition (MCPE) : 8535
LUCKY BLOCK MOD ™ for Minecraft PC Edition - The Best Pocket Wiki & Mods Installer Tools : 4693
GUNS MODS for Minecraft PC Edition - Mods Tools : 1497
Guides for Pokémon GO - Pokemon GO News and Cheats : 826
WWDC : 762
Horror Maps for Minecraft PE - Download The Scariest Maps for Minecraft Pocket Edition (MCPE) Free : 718
VPN Express : 14
Real Bike Traffic Rider Virtual Reality Glasses : 8
教えて!goo : 0
Jishokun-Japanese English Dictionary & Translator : 0
然而,这个利基似乎显示出一些潜力。我们可以做的一件事是把另一本受欢迎的书变成一个应用程序,除了书的原始版本之外,我们还可以添加不同的功能。这可能包括书中的每日引用、书的音频版本、关于书的测验等。最重要的是,我们还可以在应用程序中嵌入字典,这样用户就不需要退出我们的应用程序,在外部应用程序中查找单词。这种想法似乎很符合应用商店由娱乐应用主导的事实。这表明市场可能已经有点饱和,充满了好玩的应用程序,这意味着一个实用的应用程序可能有更多的机会在 App Store 的大量应用程序中脱颖而出。其他似乎受欢迎的类型包括天气、书籍、饮食或金融。书籍类型似乎与我们上面描述的应用程序理念有点重叠,但其他类型对我们来说似乎不太有趣:
- 天气应用——人们通常不会花太多时间在应用上,从应用内附加服务中获利的机会也很低。此外,获得可靠的实时天气数据可能需要我们将应用程序连接到非免费的 API。
- 食物和饮料——这里的例子包括星巴克、邓肯甜甜圈、麦当劳等。因此,制作一个受欢迎的食品和饮料应用程序需要实际的烹饪和送货服务,这不在我们公司的范围内。
- 金融应用——这些应用涉及银行业务、支付账单、转账等。构建一个金融应用程序需要领域知识,我们不想仅仅为了构建一个应用程序而雇佣一个金融专家。现在我们来分析一下 Google Play 市场。
Google Play 上按流派分类的最受欢迎应用
对于 Google Play 市场,我们实际上有安装数量的数据,所以我们应该能够更清楚地了解流派的受欢迎程度。然而,安装数量似乎不够精确—我们可以看到大多数值是开放式的(100+,1,000+,5,000+等)。):
display_table(android_final, 5) # the Installs columns
1,000,000+ : 15.726534296028879
100,000+ : 11.552346570397113
10,000,000+ : 10.548285198555957
10,000+ : 10.198555956678701
1,000+ : 8.393501805054152
100+ : 6.915613718411552
5,000,000+ : 6.825361010830325
500,000+ : 5.561823104693141
50,000+ : 4.7721119133574
5,000+ : 4.512635379061372
10+ : 3.5424187725631766
500+ : 3.2490974729241873
50,000,000+ : 2.3014440433213
100,000,000+ : 2.1322202166064983
50+ : 1.917870036101083
5+ : 0.78971119133574
1+ : 0.5076714801444043
500,000,000+ : 0.2707581227436823
1,000,000,000+ : 0.22563176895306858
0+ : 0.04512635379061372
0 : 0.01128158844765343
这个数据的一个问题是不精确。例如,我们不知道一个超过 100,000 次安装的应用程序有 100,000 次安装、200,000 次安装还是 350,000 次安装。然而,我们不需要非常精确的数据——我们只想知道哪些应用类型吸引了最多的用户,我们不需要关于用户数量的精确数据。我们将保持这些数字不变,这意味着我们将认为一个安装数超过 100,000 的应用程序有 100,000 次安装,一个安装数超过 100,000 的应用程序有 1,000,000 次安装,以此类推。然而,为了执行计算,我们需要将每个安装号转换为float——这意味着我们需要删除逗号和加号字符,否则转换将失败并引发错误。我们将在下面的循环中直接这样做,在这里我们也计算每个流派(类别)的平均安装数。
### Generating a frequency table to get the unique app genres ###
categories_android = freq_table(android_final, 1)
### Looping over the unique app genres ###
for category in categories_android:
total = 0
len_category = 0
## Looping over the Google Play data set ##
for app in android_final:
category_app = app[1]
if category_app == category:
n_installs = app[5]
n_installs = n_installs.replace(',', '')
n_installs = n_installs.replace('+', '')
total += float(n_installs)
len_category += 1
## Compute and display the average number of installs ##
avg_n_installs = total / len_category
print(category, ':', avg_n_installs)
ART_AND_DESIGN : 1986335.0877192982
AUTO_AND_VEHICLES : 647317.8170731707
BEAUTY : 513151.88679245283
BOOKS_AND_REFERENCE : 8767811.894736841
BUSINESS : 1712290.1474201474
COMICS : 817657.2727272727
COMMUNICATION : 38456119.167247385
DATING : 854028.8303030303
EDUCATION : 1833495.145631068
ENTERTAINMENT : 11640705.88235294
EVENTS : 253542.22222222222
FINANCE : 1387692.475609756
FOOD_AND_DRINK : 1924897.7363636363
HEALTH_AND_FITNESS : 4188821.9853479853
HOUSE_AND_HOME : 1331540.5616438356
LIBRARIES_AND_DEMO : 638503.734939759
LIFESTYLE : 1437816.2687861272
GAME : 15588015.603248259
FAMILY : 3695641.8198090694
MEDICAL : 120550.61980830671
SOCIAL : 23253652.127118643
SHOPPING : 7036877.311557789
PHOTOGRAPHY : 17840110.40229885
SPORTS : 3638640.1428571427
TRAVEL_AND_LOCAL : 13984077.710144928
TOOLS : 10801391.298666667
PERSONALIZATION : 5201482.6122448975
PRODUCTIVITY : 16787331.344927534
PARENTING : 542603.6206896552
WEATHER : 5074486.197183099
VIDEO_PLAYERS : 24727872.452830188
NEWS_AND_MAGAZINES : 9549178.467741935
MAPS_AND_NAVIGATION : 4056941.7741935486
平均而言,通信应用程序的安装数量最多:38,456,119。这个数字被几个安装量超过 10 亿的应用程序(WhatsApp、Facebook Messenger、Skype、Google Chrome、Gmail 和 Hangouts)和其他几个安装量超过 1 亿和 5 亿的应用程序严重扭曲:
for app in android_final:
if app[1] == 'COMMUNICATION' and (app[5] == '1,000,000,000+'
or app[5] == '500,000,000+'
or app[5] == '100,000,000+'):
print(app[0], ':', app[5])
WhatsApp Messenger : 1,000,000,000+
imo beta free calls and text : 100,000,000+
Android Messages : 100,000,000+
Google Duo - High Quality Video Calls : 500,000,000+
Messenger – Text and Video Chat for Free : 1,000,000,000+
imo free video calls and chat : 500,000,000+
Skype - free IM & video calls : 1,000,000,000+
Who : 100,000,000+
GO SMS Pro - Messenger, Free Themes, Emoji : 100,000,000+
LINE: Free Calls & Messages : 500,000,000+
Google Chrome: Fast & Secure : 1,000,000,000+
Firefox Browser fast & private : 100,000,000+
UC Browser - Fast Download Private & Secure : 500,000,000+
Gmail : 1,000,000,000+
Hangouts : 1,000,000,000+
Messenger Lite: Free Calls & Messages : 100,000,000+
Kik : 100,000,000+
KakaoTalk: Free Calls & Text : 100,000,000+
Opera Mini - fast web browser : 100,000,000+
Opera Browser: Fast and Secure : 100,000,000+
Telegram : 100,000,000+
Truecaller: Caller ID, SMS spam blocking & Dialer : 100,000,000+
UC Browser Mini -Tiny Fast Private & Secure : 100,000,000+
Viber Messenger : 500,000,000+
WeChat : 100,000,000+
Yahoo Mail – Stay Organized : 100,000,000+
BBM - Free Calls & Messages : 100,000,000+
如果我们删除所有安装量超过 1 亿的通信应用,平均安装量将减少 10 倍以上:
under_100_m = []
for app in android_final:
n_installs = app[5]
n_installs = n_installs.replace(',', '')
n_installs = n_installs.replace('+', '')
if float(n_installs) < 100000000:
under_100_m.append(float(n_installs))
sum(under_100_m) / len(under_100_m)
2821347.6231027693
视频播放器类别也是如此,以 24,727,872 的安装量位居第二。这个市场被 Youtube、Google Play Movies & TV 和 MX Player 等应用程序所主导。社交应用也是如此(我们有脸书、Instagram、Google+等巨头。)、摄影应用(Google Photos 和其他流行的照片编辑器),或者生产力应用(Microsoft Word、Dropbox、Google Calendar、Evernote 等)。).同样,主要的担忧是这些应用类型可能看起来比它们实际上更受欢迎。此外,这些利基市场似乎被少数几个难以抗衡的巨头所主导。游戏类型似乎很受欢迎,但之前我们发现这部分市场似乎有点饱和,所以如果可能的话,我们希望提供不同的应用推荐。书籍和参考类书籍看起来也很受欢迎,平均安装次数为 8,767,811 次。更深入地探索这一点很有意思,因为我们发现这种类型在 App Store 上有一些潜力,我们的目标是推荐一种在 App Store 和 Google Play 上都有盈利潜力的应用类型。让我们来看看这一类型的一些应用程序及其安装数量:
for app in android_final:
if app[1] == 'BOOKS_AND_REFERENCE':
print(app[0], ':', app[5])
E-Book Read - Read Book for free : 50,000+
Download free book with green book : 100,000+
Wikipedia : 10,000,000+
Cool Reader : 10,000,000+
Free Panda Radio Music : 100,000+
Book store : 1,000,000+
FBReader: Favorite Book Reader : 10,000,000+
English Grammar Complete Handbook : 500,000+
Free Books - Spirit Fanfiction and Stories : 1,000,000+
Google Play Books : 1,000,000,000+
AlReader -any text book reader : 5,000,000+
Offline English Dictionary : 100,000+
Offline: English to Tagalog Dictionary : 500,000+
FamilySearch Tree : 1,000,000+
Cloud of Books : 1,000,000+
Recipes of Prophetic Medicine for free : 500,000+
ReadEra – free ebook reader : 1,000,000+
Anonymous caller detection : 10,000+
Ebook Reader : 5,000,000+
Litnet - E-books : 100,000+
Read books online : 5,000,000+
English to Urdu Dictionary : 500,000+
eBoox: book reader fb2 epub zip : 1,000,000+
English Persian Dictionary : 500,000+
Flybook : 500,000+
All Maths Formulas : 1,000,000+
Ancestry : 5,000,000+
HTC Help : 10,000,000+
English translation from Bengali : 100,000+
Pdf Book Download - Read Pdf Book : 100,000+
Free Book Reader : 100,000+
eBoox new: Reader for fb2 epub zip books : 50,000+
Only 30 days in English, the guideline is guaranteed : 500,000+
Moon+ Reader : 10,000,000+
SH-02J Owner's Manual (Android 8.0) : 50,000+
English-Myanmar Dictionary : 1,000,000+
Golden Dictionary (EN-AR) : 1,000,000+
All Language Translator Free : 1,000,000+
Azpen eReader : 500,000+
URBANO V 02 instruction manual : 100,000+
Bible : 100,000,000+
C Programs and Reference : 50,000+
C Offline Tutorial : 1,000+
C Programs Handbook : 50,000+
Amazon Kindle : 100,000,000+
Aab e Hayat Full Novel : 100,000+
Aldiko Book Reader : 10,000,000+
Google I/O 2018 : 500,000+
R Language Reference Guide : 10,000+
Learn R Programming Full : 5,000+
R Programing Offline Tutorial : 1,000+
Guide for R Programming : 5+
Learn R Programming : 10+
R Quick Reference Big Data : 1,000+
V Made : 100,000+
Wattpad " src="https://s.w.oimg/core/emoji/11.2.0/svg/1f4d6.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f4d6.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f4d6.svg"> Free Books : 100,000,000+
Dictionary - WordWeb : 5,000,000+
Guide (for X-MEN) : 100,000+
AC Air condition Troubleshoot,Repair,Maintenance : 5,000+
AE Bulletins : 1,000+
Ae Allah na Dai (Rasa) : 10,000+
50000 Free eBooks & Free AudioBooks : 5,000,000+
Ag PhD Field Guide : 10,000+
Ag PhD Deficiencies : 10,000+
Ag PhD Planting Population Calculator : 1,000+
Ag PhD Soybean Diseases : 1,000+
Fertilizer Removal By Crop : 50,000+
A-J Media Vault : 50+
Al-Quran (Free) : 10,000,000+
Al Quran (Tafsir & by Word) : 500,000+
Al Quran Indonesia : 10,000,000+
Al'Quran Bahasa Indonesia : 10,000,000+
Al Quran Al karim : 1,000,000+
Al-Muhaffiz : 50,000+
Al Quran : EAlim - Translations & MP3 Offline : 5,000,000+
Al-Quran 30 Juz free copies : 500,000+
Koran Read &MP3 30 Juz Offline : 1,000,000+
Hafizi Quran 15 lines per page : 1,000,000+
Quran for Android : 10,000,000+
Surah Al-Waqiah : 100,000+
Hisnul Al Muslim - Hisn Invocations & Adhkaar : 100,000+
Satellite AR : 1,000,000+
Audiobooks from Audible : 100,000,000+
Kinot & Eichah for Tisha B'Av : 10,000+
AW Tozer Devotionals - Daily : 5,000+
Tozer Devotional -Series 1 : 1,000+
The Pursuit of God : 1,000+
AY Sing : 5,000+
Ay Hasnain k Nana Milad Naat : 10,000+
Ay Mohabbat Teri Khatir Novel : 10,000+
Arizona Statutes, ARS (AZ Law) : 1,000+
Oxford A-Z of English Usage : 1,000,000+
BD Fishpedia : 1,000+
BD All Sim Offer : 10,000+
Youboox - Livres, BD et magazines : 500,000+
B&H Kids AR : 10,000+
B y H Niños ES : 5,000+
Dictionary.com: Find Definitions for English Words : 10,000,000+
English Dictionary - Offline : 10,000,000+
Bible KJV : 5,000,000+
Borneo Bible, BM Bible : 10,000+
MOD Black for BM : 100+
BM Box : 1,000+
Anime Mod for BM : 100+
NOOK: Read eBooks & Magazines : 10,000,000+
NOOK Audiobooks : 500,000+
NOOK App for NOOK Devices : 500,000+
Browsery by Barnes & Noble : 5,000+
bp e-store : 1,000+
Brilliant Quotes: Life, Love, Family & Motivation : 1,000,000+
BR Ambedkar Biography & Quotes : 10,000+
BU Alsace : 100+
Catholic La Bu Zo Kam : 500+
Khrifa Hla Bu (Solfa) : 10+
Kristian Hla Bu : 10,000+
SA HLA BU : 1,000+
Learn SAP BW : 500+
Learn SAP BW on HANA : 500+
CA Laws 2018 (California Laws and Codes) : 5,000+
Bootable Methods(USB-CD-DVD) : 10,000+
cloudLibrary : 100,000+
SDA Collegiate Quarterly : 500+
Sabbath School : 100,000+
Cypress College Library : 100+
Stats Royale for *** Royale : 1,000,000+
GATE 21 years CS Papers(2011-2018 Solved) : 50+
Learn CT Scan Of Head : 5,000+
Easy Cv maker 2018 : 10,000+
How to Write CV : 100,000+
CW Nuclear : 1,000+
CY Spray nozzle : 10+
BibleRead En Cy Zh Yue : 5+
CZ-Help : 5+
Modlitební knížka CZ : 500+
Guide for DB Xenoverse : 10,000+
Guide for DB Xenoverse 2 : 10,000+
Guide for IMS DB : 10+
DC HSEMA : 5,000+
DC Public Library : 1,000+
Painting Lulu DC Super Friends : 1,000+
Dictionary : 10,000,000+
Fix Error Google Playstore : 1,000+
D. H. Lawrence Poems FREE : 1,000+
Bilingual Dictionary Audio App : 5,000+
DM Screen : 10,000+
wikiHow: how to do anything : 1,000,000+
Dr. Doug's Tips : 1,000+
Bible du Semeur-BDS (French) : 50,000+
La citadelle du musulman : 50,000+
DV 2019 Entry Guide : 10,000+
DV 2019 - EDV Photo & Form : 50,000+
DV 2018 Winners Guide : 1,000+
EB Annual Meetings : 1,000+
EC - AP & Telangana : 5,000+
TN Patta Citta & EC : 10,000+
AP Stamps and Registration : 10,000+
CompactiMa EC pH Calibration : 100+
EGW Writings 2 : 100,000+
EGW Writings : 1,000,000+
Bible with EGW Comments : 100,000+
My Little Pony AR Guide : 1,000,000+
SDA Sabbath School Quarterly : 500,000+
Duaa Ek Ibaadat : 5,000+
Spanish English Translator : 10,000,000+
Dictionary - Merriam-Webster : 10,000,000+
JW Library : 10,000,000+
Oxford Dictionary of English : Free : 10,000,000+
English Hindi Dictionary : 10,000,000+
English to Hindi Dictionary : 5,000,000+
EP Research Service : 1,000+
Hymnes et Louanges : 100,000+
EU Charter : 1,000+
EU Data Protection : 1,000+
EU IP Codes : 100+
EW PDF : 5+
BakaReader EX : 100,000+
EZ Quran : 50,000+
FA Part 1 & 2 Past Papers Solved Free – Offline : 5,000+
La Fe de Jesus : 1,000+
La Fe de Jesús : 500+
Le Fe de Jesus : 500+
Florida - Pocket Brainbook : 1,000+
Florida Statutes (FL Code) : 1,000+
English To Shona Dictionary : 10,000+
Greek Bible FP (Audio) : 1,000+
Golden Dictionary (FR-AR) : 500,000+
Fanfic-FR : 5,000+
Bulgarian French Dictionary Fr : 10,000+
Chemin (fr) : 1,000+
The SCP Foundation DB fr nn5n : 1,000+
书籍和参考类包括各种应用程序:处理和阅读电子书的软件、各种图书馆、字典、编程或语言教程等。似乎仍然有少数非常受欢迎的应用扭曲了平均水平:
for app in android_final:
if app[1] == 'BOOKS_AND_REFERENCE' and (app[5] == '1,000,000,000+'
or app[5] == '500,000,000+'
or app[5] == '100,000,000+'):
print(app[0], ':', app[5])
Google Play Books : 1,000,000,000+
Bible : 100,000,000+
Amazon Kindle : 100,000,000+
Wattpad " src="https://s.w.oimg/core/emoji/11.2.0/svg/1f4d6.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f4d6.svg">" src="https://s.w.oimg/core/emoji/11.2.0/svg/1f4d6.svg"> Free Books : 100,000,000+
Audiobooks from Audible : 100,000,000+
然而,看起来只有几个非常受欢迎的应用程序,所以这个市场仍然显示出潜力。让我们根据受欢迎程度居中(下载量在 1,000,000 到 100,000,000 之间)的应用类型,尝试获得一些应用创意:
for app in android_final:
if app[1] == 'BOOKS_AND_REFERENCE' and (app[5] == '1,000,000+'
or app[5] == '5,000,000+'
or app[5] == '10,000,000+'
or app[5] == '50,000,000+'):
print(app[0], ':', app[5])
Wikipedia : 10,000,000+
Cool Reader : 10,000,000+
Book store : 1,000,000+
FBReader: Favorite Book Reader : 10,000,000+
Free Books - Spirit Fanfiction and Stories : 1,000,000+
AlReader -any text book reader : 5,000,000+
FamilySearch Tree : 1,000,000+
Cloud of Books : 1,000,000+
ReadEra – free ebook reader : 1,000,000+
Ebook Reader : 5,000,000+
Read books online : 5,000,000+
eBoox: book reader fb2 epub zip : 1,000,000+
All Maths Formulas : 1,000,000+
Ancestry : 5,000,000+
HTC Help : 10,000,000+
Moon+ Reader : 10,000,000+
English-Myanmar Dictionary : 1,000,000+
Golden Dictionary (EN-AR) : 1,000,000+
All Language Translator Free : 1,000,000+
Aldiko Book Reader : 10,000,000+
Dictionary - WordWeb : 5,000,000+
50000 Free eBooks & Free AudioBooks : 5,000,000+
Al-Quran (Free) : 10,000,000+
Al Quran Indonesia : 10,000,000+
Al'Quran Bahasa Indonesia : 10,000,000+
Al Quran Al karim : 1,000,000+
Al Quran : EAlim - Translations & MP3 Offline : 5,000,000+
Koran Read &MP3 30 Juz Offline : 1,000,000+
Hafizi Quran 15 lines per page : 1,000,000+
Quran for Android : 10,000,000+
Satellite AR : 1,000,000+
Oxford A-Z of English Usage : 1,000,000+
Dictionary.com: Find Definitions for English Words : 10,000,000+
English Dictionary - Offline : 10,000,000+
Bible KJV : 5,000,000+
NOOK: Read eBooks & Magazines : 10,000,000+
Brilliant Quotes: Life, Love, Family & Motivation : 1,000,000+
Stats Royale for *** Royale : 1,000,000+
Dictionary : 10,000,000+
wikiHow: how to do anything : 1,000,000+
EGW Writings : 1,000,000+
My Little Pony AR Guide : 1,000,000+
Spanish English Translator : 10,000,000+
Dictionary - Merriam-Webster : 10,000,000+
JW Library : 10,000,000+
Oxford Dictionary of English : Free : 10,000,000+
English Hindi Dictionary : 10,000,000+
English to Hindi Dictionary : 5,000,000+
这个利基市场似乎被处理和阅读电子书的软件以及各种图书馆和字典所主导,所以建立类似的应用程序可能不是一个好主意,因为会有一些激烈的竞争。我们还注意到,有相当多的应用是围绕《古兰经》开发的,这表明围绕一本受欢迎的书开发应用是有利可图的。对于 Google Play 和 App Store 市场来说,将一本受欢迎的书(也许是一本更近的书)转化成一款应用程序似乎是有利可图的。然而,看起来市场上已经充满了图书馆,所以我们需要在书的原始版本之外添加一些特殊功能。这可能包括书的每日引用、书的音频版本、关于书的测验、人们可以讨论书的论坛等等。
结论
在这个项目中,我们分析了 App Store 和 Google Play 移动应用程序的数据,目的是推荐一个对这两个市场都有利可图的应用程序配置文件。我们的结论是,把一本流行的书(也许是一本更近的书)转化成一个应用程序,对 Google Play 和应用商店市场都是有利可图的。当然,我们可以对这个数据集做进一步的分析,以收集进一步的见解,但是正如你所看到的,我们可以只使用基本的 Python 和我们免费的 Python 基础课程中涵盖的技术来发现一些非常有价值的趋势。(准备好进入下一关了吗?我们的中级 Python 编程课程也是免费的)。
教程:Python 中的基本统计—概率
原文:https://www.dataquest.io/blog/basic-statistics-in-python-probability/
July 18, 2018
在学习数据科学的统计学时,你不可避免地要学习概率。人们很容易迷失在概率背后的公式和理论中,但它在工作和日常生活中都有重要的用途。我们之前已经讨论过描述统计学中的一些基本概念;现在我们将探索统计学与概率的关系。
先决条件:
与上一篇文章类似,本文假设没有统计学的先验知识,但是至少需要 Python 和一般数据科学工作流的一般知识。如果你对 for 循环和列表感到不舒服,我建议在继续之前,在我们的 Python 入门课程中简要介绍一下它们。
概率是什么?
在最基本的层面上,概率试图回答这样一个问题,“一个事件发生的可能性有多大?”一个事件是一些感兴趣的结果。为了计算一个事件发生的几率,我们还需要考虑所有其他可能发生的事件。概率的典型表现是简单的抛硬币。在掷硬币游戏中,唯一可能发生的事件是:
- 翻转一个头
- 翻转尾巴
这两个事件形成了样本空间,所有可能发生的事件的集合。为了计算一个事件发生的概率,我们计算感兴趣的事件可能发生的次数(比如翻转头部)并用它除以样本空间。因此,概率会告诉我们,一个理想的硬币有 1/2 的机会是正面或反面。通过观察可能发生的事件,概率给了我们一个框架来对事件发生的频率做出预测。然而,即使看起来很明显,如果我们真的试着扔一些硬币,我们很可能每隔一段时间就会得到异常高或异常低的人头数。如果我们不想假设硬币是公平的,我们能做什么?我们可以收集数据!我们可以使用统计学来计算基于现实世界观察的概率,并检查它与理想情况相比如何。
从统计到概率
我们的数据将通过投掷硬币 10 次并计算我们得到多少次正面来生成。我们将一组 10 枚硬币的投掷称为试验。我们的数据点将是我们观察到的人头数。我们可能不会得到“理想的”5 个头,但我们不会太担心,因为一次试验只是一个数据点。如果我们进行很多很多的试验,我们期望所有试验中的平均头数接近 50%。下面的代码模拟 10、100、1000 和 1000000 次试验,然后计算观察到的头部的平均比例。下图也总结了我们的流程。

import random
def coin_trial():
heads = 0
for i in range(100):
if random.random() <= 0.5:
heads +=1
return heads
def simulate(n):
trials = []
for i in range(n):
trials.append(coin_trial())
return(sum(trials)/n)
simulate(10)
>>> 5.4
simulate(100)
>>> 4.83
simulate(1000)
>>> 5.055
simulate(1000000)
>>> 4.999781
coin_trial函数代表 10 次抛硬币的模拟。它使用random()函数生成一个介于 0 和 1 之间的浮点数,如果它在这个范围的一半以内,就增加我们的heads计数。然后,simulate根据您想要的次数重复这些试验,返回所有试验的平均人头数。抛硬币模拟给了我们一些有趣的结果。
首先,数据证实了我们的平均头数确实接近概率所建议的数量。此外,这个平均值随着更多的试验而提高。在 10 次试验中,会有一些微小的误差,但是在 1,000,000 次试验中,这个误差几乎完全消失。随着我们得到更多的试验,偏离平均值的偏差减小。听起来熟悉吗?当然,我们可以自己抛硬币,但是 Python 允许我们用代码对这个过程建模,从而节省了我们很多时间。随着我们获得越来越多的数据,现实世界开始与理想世界相似。
因此,给定足够的数据,统计学使我们能够使用真实世界的观察来计算概率。概率提供了理论,而统计学提供了用数据检验理论的工具。描述性统计,特别是均值和标准差,成为理论统计的替代物。你可能会问,“如果我可以计算理论概率本身,为什么我需要代理?”扔硬币是一个简单的玩具例子,但是更有趣的概率并不容易计算。
随着时间的推移,某人患病的几率有多大?当你在驾驶时,一个关键的汽车部件发生故障的概率是多少?没有简单的方法来计算概率,所以我们必须依靠数据和统计来计算它们。有了越来越多的数据,我们可以更加自信地认为,我们计算的数据代表了这些重要事件发生的真实概率。话虽如此,请记住我们之前在发布的统计数据,你是一名实习侍酒师。在你开始购买葡萄酒之前,你需要弄清楚哪些葡萄酒比其他的好。你手头有很多数据,所以我们将使用我们的统计数据来指导我们的决策。
数据和分布
在我们解决“哪种葡萄酒比平均水平更好”的问题之前,我们必须记住我们的数据的性质。直觉上,我们想用酒的分数来比较不同的组,但是有一个问题:分数通常在一个范围内。我们如何比较不同类型葡萄酒的分数,并在一定程度上确定其中一种比另一种更好?进入正态分布。正态分布是概率统计领域中一个特别重要的现象。正态分布是这样的:
关于正态分布要注意的最重要的性质是它的对称性和它的形状。我们一直称之为分配,但是到底分配的是什么呢?这要看上下文。在概率上,正态分布是所有事件概率的一种特殊分布。x 轴代表我们想要知道其概率的事件值。y 轴是与每个事件相关联的概率,从 0 到 1。
这里我们没有深入讨论概率分布,但是知道正态分布是一种特别重要的概率分布。在统计学中,分配的是我们数据的值。这里,x 轴是我们数据的值,y 轴是这些值的计数。这是正态分布的同一张图片,但是根据概率和统计上下文来标记:
在概率上下文中,正态分布的高点代表发生概率最高的事件。当你在任何一边离这个事件越来越远时,概率迅速下降,形成那个熟悉的钟形。统计意义上的高点实际上代表了平均值。就概率而言,当你离平均值越远,频率就越低。也就是说,与平均值的极高和极低偏差是存在的,但极其罕见。
如果你通过正态分布怀疑概率和统计之间还有另一种关系,那么你这么想是对的!我们将在本文后面探讨这种重要的关系,所以请抓紧时间。因为我们将使用分数分布来比较不同的葡萄酒,所以我们将做一些设置来捕捉我们感兴趣的一些葡萄酒。我们将引入葡萄酒数据,然后分离出我们感兴趣的一些葡萄酒的分数。为了取回数据,我们需要以下代码:
import csv
with open("wine-data.csv", "r", encoding="latin-1") as f:
wines = list(csv.reader(f))
数据以表格形式显示如下。我们需要points列,所以我们将它提取到自己的列表中。我们从一位葡萄酒专家那里听说匈牙利的托卡伊葡萄酒非常棒,而一位朋友建议我们从意大利的 Lambrusco 开始。我们有数据对比这些酒!如果你不记得数据是什么样子的,这里有一个快速的表格可以参考并重新熟悉。
| 指数 | 国家 | 描述 | 指定 | 点 | 价格 | 省 | 区域 _1 | 区域 _2 | 多样化 | 酿酒厂 |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 美国 | “这个惊人的 100%…” | 马撒葡萄园岛 | Ninety-six | Two hundred and thirty-five | 加利福尼亚 | 纳帕谷 | 英特尔迅驰双核移动计算技术 | 解百纳索维浓 | Heitz |
| one | 西班牙 | “无花果的成熟香气… | 特别储备胡萝卜 | Ninety-six | One hundred and ten | 西班牙北部 | 公牛 | 廷塔-德托罗 | 博德加卡门·罗德里格斯 | |
| Two | 美国 | “麦克·沃森荣誉…… | 特别精选晚熟收获 | Ninety-six | Ninety | 加利福尼亚 | 骑士谷 | 索诺马 | 白葡萄酒 | 麦考利 |
| three | 美国 | “这花了 20 个月…… | 保留 | Ninety-six | Sixty-five | 俄勒冈州 | 威拉米特山谷 | 威拉米特山谷 | 黑皮诺酒 | 庞氏骗局 |
| four | 法国 | “这是顶级葡萄酒… | 拉布雷拉德 | Ninety-five | Sixty-six | 普罗旺斯 | 班多尔 | 普罗旺斯红混合 | 米色区 |
# Extract the Tokaji scores
tokaji = []
non_tokaji = []
for wine in wines:
if points != '':
points = wine[4]
if wine[9] == "Tokaji":
tokaji.append(float(points))
else:
non_tokaji.append(points)
# Extract the Lambrusco scores
lambrusco = []
non_lambrusco = []
for wine in wines:
if points != '':
points = wine[4]
if wine[9] == "Lambrusco":
lambrusco.append(float(points))
else:
non_lambrusco.append(float(points))
如果我们将每组分数想象成正态分布,我们可以根据它们的位置立即判断两个分布是否不同。但是这种方法很快就会遇到问题,如下所示。我们假设分数将呈正态分布,因为我们有吨的数据。虽然这个假设在这里是可以的,但是我们将在后面讨论这样做实际上什么时候是危险的。
当两个分数分布重叠太多时,最好假设它们实际上来自同一个分布,没有什么不同。在另一个没有重叠的极端情况下,假设分布不相同是安全的。我们的问题在于有些重叠。考虑到一个分布的极端高点可能与另一个分布的极端低点相交,我们怎么能说这些组是不同的呢?在这里,我们必须再次呼吁正态分布给我们一个答案,并在统计和概率之间架起一座桥梁。
重温常态
正态分布对概率统计有重要意义得益于两个因素:中心极限定理和三适马法则。
中心极限定理
在上一节中,我们展示了如果我们重复 10 次投掷试验很多很多次,所有这些试验的平均人数将接近我们对理想硬币的预期的 50%。随着试验越来越多,这些试验的平均值就越接近真实概率,即使单个试验本身并不完美。这个想法是中心极限定理的一个关键原则。在我们掷硬币的例子中,10 次投掷的单次试验产生了一个单次的估计,该估计表明应该发生什么(5 次正面)。我们称之为估计,因为我们知道它不会是完美的(即,我们不会每次都得到 5 个头)。
如果我们做出许多估计,中心极限定理表明这些估计的分布将看起来像正态分布。这种分布的顶点将与估计值应该呈现的真实值一致。在统计学中,正态分布的峰值与平均值一致,这正是我们观察到的。因此,给定多个“试验”作为我们的数据,中心极限定理表明我们可以专注于由概率给出的理论理想,即使我们不知道真实的概率。中心极限定理让我们知道许多试验平均值将接近真实平均值,三适马法则将告诉我们有多少数据将围绕这个平均值分布。
三个适马法则
三适马法则,也称为经验法则或 68-95-99.7 法则,是一种表达我们有多少观察值落在平均值的一定距离内的方式。请记住,标准偏差(也称为“sigma”)是数据集中观察值与平均值的平均距离。三适马法则规定,给定一个正态分布,68%的观察值将落在平均值的一个标准差之间。95%会落在二内,99.7%会落在三内。这些值的推导过程中涉及到大量复杂的数学运算,因此超出了本文的范围。关键是要知道三适马法则使我们能够知道在正态分布的不同区间下包含了多少数据。下面的图片很好地总结了适马三法则的含义。
我们将把这些概念与我们的葡萄酒数据联系起来。作为一名侍酒师,我们非常自信地想知道霞多丽和黑皮诺比一般的葡萄酒更受欢迎。我们有数以千计的葡萄酒评论,所以根据中心极限定理,这些评论的平均分数应该与葡萄酒质量的所谓“真实”表现一致(由评论者判断)。虽然三适马法则是关于你的数据有多少属于已知值的陈述,但它也是关于极端值的稀有性的陈述。任何偏离平均值超过三个标准偏差的值都应谨慎处理。通过利用三适马法则和 Z 值,我们将最终能够为霞多丽和黑皮诺与普通葡萄酒的不同程度设定一个值。
z 分数
Z 得分是一个简单的计算,它回答了这样一个问题:“给定一个数据点,它离平均值有多少标准差?”下面的等式是 Z 分数等式。
Z 分数本身并不能给你提供多少信息。当与一个 Z 表比较时,它获得了最大的价值,该表列出了一个标准正态分布的累积概率,直到一个给定的 Z 分数。标准正态是平均值为 0、标准差为 1 的正态分布。即使我们的正态分布不是标准的,Z 得分也允许我们引用这个 Z 表。累积概率是到给定点为止所有值出现的概率的总和。
一个简单的例子是均值本身。平均值正好是正态分布的中间值,所以我们知道从左侧直到平均值为 50%的所有概率之和。如果你试图计算标准差之间的累积概率,三适马规则的值实际上会出现。下图提供了累积概率的可视化。 我们知道所有概率之和必须等于 100%,所以我们可以使用 Z 表来计算正态分布下 Z 得分两侧的概率。
我们知道所有概率之和必须等于 100%,所以我们可以使用 Z 表来计算正态分布下 Z 得分两侧的概率。 计算超过某个 Z 分数的概率对我们很有用。它让我们从“一个值离平均值有多远”到“一个离平均值这么远的值有多大可能来自同一组观察值?”因此,从 Z 得分和 Z 表得出的概率将回答我们基于葡萄酒的问题。
计算超过某个 Z 分数的概率对我们很有用。它让我们从“一个值离平均值有多远”到“一个离平均值这么远的值有多大可能来自同一组观察值?”因此,从 Z 得分和 Z 表得出的概率将回答我们基于葡萄酒的问题。
import numpy as np
tokaji_avg = np.average(tokaji)
lambrusco_avg = np.average(lambrusco)
tokaji_std = np.std(tokaji)
lambrusco = np.std(lambrusco)
# Let's see what the results are
print("Tokaji: ", tokaji_avg, tokaji_std)
print("Lambrusco: ", lambrusco_avg, lambrusco_std)
>>> Tokaji: 90.9 2.65015722804
>>> Lambrusco: 84.4047619048 1.61922267961
这个看起来不太适合我们朋友的推荐!出于本文的目的,我们将把 Tokaji 和 Lambrusco 分数都视为正态分布。因此,每种葡萄酒的平均分数将代表它们在质量方面的“真实”分数。我们将计算 Z 分数,并查看 Tokaji 平均值与 Lambrusco 的差距。
z = (tokaji_avg - lambrusco_avg) / lambrusco_std
>>> 4.0113309781438229
# We'll bring in scipy to do the calculation of probability from the Z-table
import scipy.stats as st
st.norm.cdf(z)
>>> 0.99996981130231266
# We need the probability from the right side, so we'll flip it!
1 - st.norm.cdf(z)
>>> 3.0188697687338895e-05
答案挺小的,但是到底是什么意思呢?这个概率极小,需要一些仔细的解释。假设我们相信我们朋友的 Lambrusco 和葡萄酒专家的 Tokaji 之间没有什么不同。也就是说,我们认为 Lambrusco 和 Tokaji 的质量差不多。同样,由于葡萄酒之间的个体差异,这些葡萄酒的得分会有一些差异。由于中心极限定理,如果我们制作托卡伊和兰布鲁斯科葡萄酒的直方图,这将产生正态分布的分数。
现在,我们有了一些数据,可以计算这两种葡萄酒的平均值和标准差。这些值允许我们实际测试我们的信念,即 Lambrusco 和 Tokaji 具有相似的质量。我们使用 Lambrusco 葡萄酒评分作为基础,并比较了 Tokaji 的平均值,但我们可以轻松地反过来做。唯一的区别是 Z 值为负。Z 值是 4.01!请记住,适马三定律告诉我们,假设托卡伊和兰布鲁斯科相似,99.7%的数据应该落在 T2 3 个标准差内。
在一个 Lambrusco 和 Tokaji 葡萄酒被认为是一样的世界里,像 Tokaji 这样极端的平均得分概率是非常非常小的。小到我们不得不考虑相反的情况:托卡伊葡萄酒不同于兰布鲁斯科葡萄酒,会产生不同的分数分布。我们小心翼翼地选择了措辞:我小心翼翼地不说,“托卡伊葡萄酒比兰布鲁斯科葡萄酒更好。”他们极有可能是。这是因为我们计算了一个概率,虽然从微观上看很小,但并不为零。为了准确起见,我们可以说 Lambrusco 和 Tokaji 葡萄酒肯定不是来自同一个分数分布,但我们不能说一个比另一个更好或更差。
这种类型的推理属于推理统计学的范畴,本文只是试图给你一个简单的介绍。我们在这篇文章中讨论了很多概念,所以如果你发现自己迷路了,回头慢慢来。拥有这种思维框架是非常强大的,但是容易被误用和误解。
结论
我们从描述性统计开始,然后将它们与概率联系起来。根据概率,我们开发了一种方法来定量显示两个组是否来自相同的分布。在这种情况下,我们比较了两个葡萄酒推荐,发现它们很可能不来自相同的分数分布。换句话说,一种葡萄酒很可能比另一种更好。统计学不一定是只属于统计学家的领域。作为一名数据科学家,对常用的统计方法有一个直观的理解将会让你在发展你自己的理论和随后测试这些理论的能力上占有优势。我们在这里仅仅触及了推论统计学的表面,但是这里同样的一般思想将有助于在你的统计之旅中引导你的直觉。我们的文章讨论了正态分布的优势,但是统计学家也开发了技术来调整非正态分布。
进一步阅读
本文围绕正态分布及其与统计学和概率的联系展开。如果您有兴趣阅读其他相关的分布或了解更多关于推断统计学的知识,请参考下面的参考资料。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
教程:Python 中的基本统计-描述性统计
原文:https://www.dataquest.io/blog/basic-statistics-with-python-descriptive-statistics/
July 3, 2018 The field of statistics is often misunderstood, but it plays an essential role in our everyday lives. Statistics, done correctly, allows us to extract knowledge from the vague, complex, and difficult real world. Wielded incorrectly, statistics can be used to harm and mislead. A clear understanding of statistics and the meanings of various statistical measures is important to distinguishing between truth and misdirection. We will cover the following in this article:
The field of statistics is often misunderstood, but it plays an essential role in our everyday lives. Statistics, done correctly, allows us to extract knowledge from the vague, complex, and difficult real world. Wielded incorrectly, statistics can be used to harm and mislead. A clear understanding of statistics and the meanings of various statistical measures is important to distinguishing between truth and misdirection. We will cover the following in this article:
- 定义统计数据
- 描述统计学
- 集中趋势测量
- 传播的量度
先决条件:
本文假设没有统计学的先验知识,但是至少需要 Python 的一般知识。如果你对 for 循环和列表感到不舒服,我建议你在继续学习之前先学习一下 Dataquest 的 Python 基础课程。
加载我们的数据
我们将基于真实世界的数据来讨论统计数据,这些数据来自 Kaggle 的葡萄酒评论数据集。数据本身来自一个搜索葡萄酒爱好者网站的刮刀。为了这篇文章,假设你是一个正在培训的品酒师,一个新的品酒师。你发现了这个有趣的葡萄酒数据集,你想比较和对比不同的葡萄酒。您将使用统计数据来描述数据集中的葡萄酒,并从中获得一些见解。也许我们可以从一套便宜的葡萄酒开始我们的训练,或者是评价最高的?下面的代码将数据集wine-data.csv作为列表列表加载到变量wines中。我们将在整篇文章中对wines进行统计。您可以在自己的计算机上使用这些代码。
import csv
with open("wine-data.csv", "r", encoding="latin-1") as f:
wines = list(csv.reader(f))
让我们简要地看一下 table 中的前五行数据,这样我们就可以看到我们正在处理哪种类型的值。
| 指数 | 国家 | 描述 | 指定 | 点 | 价格 | 省 | 区域 _1 | 区域 _2 | 多样化 | 酿酒厂 |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 美国 | “这个惊人的 100%…” | 马撒葡萄园岛 | Ninety-six | Two hundred and thirty-five | 加利福尼亚 | 纳帕谷 | 英特尔迅驰双核移动计算技术 | 解百纳索维浓 | Heitz |
| one | 西班牙 | “无花果的成熟香气… | 特别储备胡萝卜 | Ninety-six | One hundred and ten | 西班牙北部 | 公牛 | 廷塔-德托罗 | 博德加卡门·罗德里格斯 | |
| Two | 美国 | “麦克·沃森荣誉…… | 特别精选晚熟收获 | Ninety-six | Ninety | 加利福尼亚 | 骑士谷 | 索诺马 | 白葡萄酒 | 麦考利 |
| three | 美国 | “这花了 20 个月…… | 保留 | Ninety-six | Sixty-five | 俄勒冈州 | 威拉米特山谷 | 威拉米特山谷 | 黑皮诺酒 | 庞氏骗局 |
| four | 法国 | “这是顶级葡萄酒… | 拉布雷拉德 | Ninety-five | Sixty-six | 普罗旺斯 | 班多尔 | 普罗旺斯红混合 | 米色区 |
统计究竟是什么?
这个问题看起来很难。统计是非常非常多的事情,所以试图将其归类为一个简短的总结无疑会掩盖一些细节,但我们必须从某个地方开始。作为一个完整的领域,统计学可以被认为是处理数据的科学的 T2 框架。这个定义包括了所有与收集、分析和解释数据相关的任务。统计数据也可以指代表数据本身的摘要或方面的单个度量。在整篇文章中,我们将尽力区分现场测量和实际测量。
这自然让我们不禁要问:但数据是什么?幸运的是,数据更容易定义。数据是对世界观察的总体收集,其性质可能大不相同,从定性到定量都有。研究人员从实验中收集数据,企业家从他们的用户中收集数据,游戏公司从他们的玩家行为中收集数据。这些例子指出了数据的另一个重要方面:观察通常与感兴趣的人群有关。回到前面的例子,一个研究人员可能正在观察一组有特殊情况的病人。
对于我们的数据,有问题的人群是一组葡萄酒评论。人口这个术语非常模糊。通过清楚地定义我们的人口,我们能够对我们的数据进行统计,并从中提取知识。但是我们为什么要对人口感兴趣呢?能够比较和对比人群来测试我们对世界的想法是很有用的。我们想知道接受新疗法的患者实际上比接受安慰剂的患者更好,但我们也想从数量上证明这一点。这就是统计学的用武之地:给我们一种严谨的方法来处理数据,并根据世界上的真实事件而不是抽象的猜测做出决策。
关键要点:
- 统计学是数据的科学。
- 数据是对感兴趣的人群的观察的任何集合。
- 统计学给了我们一个具体的方法,用数字而不是模糊的描述来比较人口。
描述统计学
当我们有一组观察值时,将我们数据的特征总结成一个名为的描述性统计量是很有用的。顾名思义,描述性统计描述了他们总结的数据的特定质量。这些统计分为两大类:集中趋势的指标和扩散的指标。
集中趋势测量
集中趋势的测量是代表以下问题的答案的度量:“我们的数据的中间看起来像什么?”单词中间是模糊的,因为我们可以用多种定义来表示中间。我们将讨论每个新的测量方法如何改变我们对中间值的定义。
平均
平均值是一个描述性的统计数据,它着眼于一个数据集的平均值。虽然的意思是是一个专业术语,但大多数人会把它理解为仅仅是的平均值。这个平均数是怎么算出来的?下图采用了实际的等式,并将计算组件分解为更简单的术语。 在平均值的情况下,数据集的“中间”指的是这个典型值。平均值代表了我们数据集中典型的观察值。如果我们随机选择一个观察值,那么我们可能会得到一个接近平均值的值。在 Python 中,计算平均值是一项简单的任务。我们来算算数据集中的平均酒分是多少。
在平均值的情况下,数据集的“中间”指的是这个典型值。平均值代表了我们数据集中典型的观察值。如果我们随机选择一个观察值,那么我们可能会得到一个接近平均值的值。在 Python 中,计算平均值是一项简单的任务。我们来算算数据集中的平均酒分是多少。
# Extract all of the scores from the data set
scores = [float(w[4]) for w in wines]
# Sum up all of the scores
sum_score = sum(scores)
# Get the number of observations
num_score = len(scores)
# Now calculate the average
avg_score = sum_score / num_score
avg_score
>>> 87.8884184721394
葡萄酒数据集中的平均分数告诉我们,数据集中的“典型”分数在 87.8 左右。这告诉我们,数据集中的大多数葡萄酒都有很高的评级,假设从 0 到 100。然而,我们必须注意,葡萄酒爱好者网站选择不发布分数低于 80 的评论。有多种类型的手段,但这种形式是最常见的使用。这个平均值被称为算术平均值,因为我们对感兴趣的值求和。
中位数
我们将讨论的下一个集中趋势的度量是中位数。中位数也试图定义数据集中的典型值,但与平均值不同,它不需要计算。为了找到中间值,我们首先需要按升序重组我们的数据集。则中值是与数据集的中间相一致的值。如果有偶数个项目,那么我们取中间的两个值的平均值。
虽然 Python 的标准库不支持中位数函数,但我们仍然可以使用我们描述的过程找到中位数。让我们试着找出葡萄酒价格的中间值。
# Isolate prices from the data set
prices = [float(w[5]) for w in wines if w[5] != ""]
# Find the number of wine prices
num_wines = len(prices)
# We'll sort the wine prices into ascending order
sorted_prices = sorted(prices)
# We'll calculate the middle index
middle = (num_wines / 2) + 0.5
# Now we can return the median
sorted_prices[middle]
>>> 24
数据集中一瓶葡萄酒的中值价格是 24 美元。这一发现表明,数据集中至少有一半的葡萄酒售价为 24 美元或更低。那挺好的!如果我们试着找出平均值呢?鉴于它们都代表一个典型值,我们预计它们会大致相同。
sum(prices)/len(prices)
>>> 33.13
33.13 美元的平均价格肯定与我们的中值相差甚远,那么这里发生了什么呢?平均值和中值之间的差异是由于稳健性造成的。
离群值问题
请记住,平均值是通过将我们想要的所有值相加并除以项目数来计算的,而中位数是通过简单地重新排列项目来找到的。如果我们的数据中有异常值,比其他值高得多或低得多的项目,它会对平均值产生不利影响。也就是说,均值不是稳健地离群值。中位数,不必看离群值,对它们是稳健的。让我们看看我们在数据中看到的最高和最低价格。
min_price = min(prices)
max_price = max(prices)
print(min_price, max_price)
4.0, 2300.0
我们现在知道异常值存在于我们的数据中。离群值可以代表我们数据收集中有趣的事件或错误,因此能够识别它们何时出现在数据中非常重要。中位数和众数的比较只是检测异常值的许多方法之一,尽管可视化通常是检测它们的更快方法。
方式
我们将讨论的最后一个集中趋势的度量是模式。众数被定义为在我们的数据中出现最频繁的值。作为“中间”的模式的直觉不像 mean 或 median 那样直接,但是有一个清楚的基本原理。如果一个值在整个数据中重复出现,我们也知道它会影响平均值。一个值出现的越多,对均值的影响就越大。因此,一个模式代表了我们的均值的最高加权贡献因子。像 median 一样,Python 中没有内置的 mode 函数,但是我们可以通过统计我们的价格的外观并寻找最大值来找出它。
# Initialize an empty dictionary to count our price appearances
price_counts = {}
for p in prices:
if p not in price_counts:
counts[p] = 1
else:
counts[p] += 1
# Run through our new price_counts dictionary and log the highest value
maxp = 0
mode_price = None
for k, v in counts.items():
if maxp < v:
maxp = v
mode_price = kprint(mode_price, maxp)
>>> 20.0, 7860
众数相当接近中位数,所以我们可以有一定的信心,我们的中位数和众数都代表我们的葡萄酒价格的中间值。集中趋势的测量对于总结我们的数据中的平均观察是什么样的是有用的。然而,它们没有告诉我们如何分布数据。这些传播的概要就是传播测量帮助描述的。
传播的量度
传播的度量(也称为离差)回答了“我的数据变化有多大?”每当我们观察这个世界时,很少有事情是一成不变的。我们都知道有人曾感叹体重的轻微变化是由于自然波动而不是直接的体重增加。这种可变性使世界变得模糊和不确定,因此有一个度量标准来概括这种“模糊性”是很有用的。
极差和四分位差
我们将涉及的第一个传播度量是范围。Range 是我们将看到的最简单的计算方法:从数据的最大值中减去数据集的最小值。在调查中值时,我们发现了葡萄酒价格的最小值和最大值,因此我们将使用它们来找出范围。
price_range = max_price - min_price
print(price_range)
>>> 2296.0
我们发现了一个 2296 的范围,但是这到底意味着什么呢?当我们审视我们的各种衡量标准时,将所有这些信息放在您的数据的上下文中是很重要的。我们的中间价格是 24 美元,我们的范围是 2296 美元。这个范围比我们的中位数高两个数量级,所以这表明我们的数据非常分散。也许如果我们有另一个葡萄酒数据集,我们可以比较这两个数据集的范围,以了解它们之间的差异。否则,范围本身并不是超级有用的。更常见的是,我们希望看到我们的数据与典型值相差多少。该汇总由标准差和方差管辖。
标准偏差
标准差也是对观察值分布的度量,但它是对你的数据偏离典型数据点的多少的陈述。也就是说,标准差概括了你的数据与均值相差多少。这种与平均值的关系在标准差的计算中是显而易见的。方程的结构值得讨论。回想一下,平均值的计算方法是将所有观察值相加,然后除以观察次数。标准偏差方程与此类似,但除了额外的平方根运算之外,它还试图计算平均值偏差。你可能在别处看到n是分母而不是n-1。这个细节的细节超出了本文的范围,但是知道使用n-1通常被认为是更正确的。本文末尾有一个解释链接。
我们想要计算标准差,以更好地描述我们的葡萄酒价格和分数,因此我们将为此创建一个专用函数。手工计算数字的累积和很麻烦,但是 Python 的for循环让这变得很简单。我们正在制作自己的函数来演示 Python 使得执行这些统计变得容易,但是知道numpy库也在std下实现标准差也是很好的。
def stdev(nums):
diffs = 0
avg = sum(nums)/len(nums)
for n in nums:
diffs += (n - avg)**(2)
return (diffs/(len(nums)-1))**(0.5)
print(stdev(scores))
>>> 3.2223917589832167
print(stdev(prices))
>>> 36.32240385925089
这些结果是意料之中的。分数只在 80 到 100 之间,所以我们知道标准差会很小。相比之下,带有异常值的价格会产生更高的价值。标准差越大,越多,展开的数据越接近平均值,反之亦然。我们会看到方差与标准差密切相关。
差异
通常,标准偏差和方差被归为一类是有原因的。下面是方差的方程,看着眼熟吗?
 方差和标准差几乎是一模一样的东西!方差就是标准差的平方。同样,方差和标准差代表相同的东西,即分布的度量,但值得注意的是,单位是不同的。无论你的数据用什么单位,标准偏差都是一样的,变异也是这个单位的平方。许多统计学初学者问的一个问题是,“但是我们为什么要平方偏差呢?绝对值不会在和中去掉讨厌的负数吗?”虽然避免总和中的负值是平方运算的一个原因,但它不是唯一的原因。
方差和标准差几乎是一模一样的东西!方差就是标准差的平方。同样,方差和标准差代表相同的东西,即分布的度量,但值得注意的是,单位是不同的。无论你的数据用什么单位,标准偏差都是一样的,变异也是这个单位的平方。许多统计学初学者问的一个问题是,“但是我们为什么要平方偏差呢?绝对值不会在和中去掉讨厌的负数吗?”虽然避免总和中的负值是平方运算的一个原因,但它不是唯一的原因。
像平均值一样,方差和标准差也会受到异常值的影响。很多时候,异常值也是我们数据集中感兴趣的点,所以对平均值的差值求平方可以让我们指出这种重要性。如果你熟悉微积分,你会发现有一个指数项可以让我们找到最小偏差点在哪里。通常情况下,你做的任何统计分析都只需要均值和标准差,但方差在其他学术领域仍然有重要意义。集中趋势和扩散的度量允许我们总结数据集的关键方面,我们可以在这些总结的基础上从我们的数据中收集更多的见解。
关键要点
- 描述性统计为我们的数据提供了简单的总结。
- (算术)平均值计算数据集的典型值。它并不健壮。
- 中位数是我们数据集的精确中间值。它很健壮。
- 众数是出现最多的值。
- 该范围是数据集中最大值和最小值之间的差值。
- 方差和标准差是距平均值的平均距离。
结论
很容易陷入统计方程的方程和细节中,但理解这些概念代表什么很重要。在本文中,我们探讨了一些基本描述性统计数据背后的一些细节,同时查看了一些葡萄酒数据来为我们的概念奠定基础。在下一部分,我们将讨论统计和概率之间的关系。我们在这里学到的描述性统计在理解这种联系中起着关键作用,所以在继续之前记住这些概念代表什么是很重要的。
延伸阅读:
在本文的前面,我们解释了为什么标准差有一个n-1项而不是n。n-1术语的使用被称为*贝塞尔校正。"
六个月内从气象学家变成数据科学家
原文:https://www.dataquest.io/blog/become-data-scientist-six-months/
February 26, 2019
拥有强大的科学背景,但面临有限的职业选择,Isaac Pato 在六个月内放弃了一切,建立了一套技能,为他在数据科学领域找到了一份工作。
“我是学气象的,2012 年毕业。艾萨克说:“我在气象部门工作了大约一年,之后又在非营利管理部门工作了三年。“我也有航海背景,但我有很强的科学背景,我想找到一种方法来应用它,这种方法更有市场,会为我带来比气象学更多的机会。我对它充满热情,但它确实是一件小众的事情。”
在波士顿参加了一个免费的数据科学入门研讨会并决定继续深造后,一位家庭朋友建议他尝试 Dataquest 作为学习 Python、SQL 和应用统计学的一种方式。不久后,他和女友从东海岸搬到西海岸,一边找工作,一边专心学习。艾萨克通过 Dataquest 的课程,探索了普华永道和杜克大学教授的 Coursera 上的课程,以及微软的课程。
“对我来说,Dataquest 很棒,因为它都是动手项目——没有任何视频,所以我可以通读并按照自己的节奏进行,”他说。“我觉得从 Python 的基础开始是一个很好的起点。我有一点编程背景,因为我在大学里有一门非常基础的 C 语言课程,但那已经是五年前的事了。我觉得我可以用它来滚动地面。”
艾萨克制定了一个计划,安排好他的每一天,就好像他亲自去上课一样。他还将研究和补充阅读包括在内,学习公司如何在一个光谱中从领先和使用机器学习等最新工具到使用 SQL 等遗留系统。
申请数据科学工作
艾萨克说,当他觉得自己已经准备好开始申请工作时,他在 Dataquest 学到的技能就成了他简历的重点。
“我发现,实际上我收到的简历回复比我预期的要多得多,”他说。“部分原因可能是经济,但我曾和一位职业顾问一起工作,他和我就我的简历谈了很多。我把它保持得非常简短、非常甜蜜,并特别列出了我从 Dataquest 中获得的技能——Python、pandas、seaborn 等。”
经过六个月的在线学习和完善简历,Isaac 打下了坚实的技术基础,他在波特兰的一家数据分析公司 ciri um T1 找到了一份临时工作,该公司为航空航天业提供服务。他开始做基础分析,但四个月后,他的技能产生了如此大的影响,以至于他获得了一个全职职位,即数据科学质量工程师。
“我认为最能让我做好准备的技能是 SQL,其次是 Python,”他说。“这才是真正能够打动他们的地方。”
Isaac 将自己的角色描述为分析和质量保证(QA)的混合体。每天,他主要是运行数据库查询和执行分析,以确定该公司是否在交流高质量的数据。他还对业务的不同部分进行一些分析,包括对他所监控的指标的具体细节的特别请求。
艾萨克说,结合他从 Dataquest 获得的技术培训和他在 Coursera 上找到的一些商业知识,他能够在更大、更有洞察力的背景下构建 FlightGlobal 的数据。
“我能够传达可操作的见解,并尝试深入具体的业务问题,从而产生可衡量的影响,”他说。“我认为,这一点,加上我学到的硬技能,对我获得这份工作并在我真正喜欢的地方找到一份工作来说非常重要。我觉得自己的职业生涯正步入正轨。”
要成为一名成功的数据科学家,你不需要像 Isaac 那样有很强的科学背景。注册一个免费帐户,开始学习启动您新的数据科学职业生涯!
Dataquest 如何帮助 Mohammad 成为机器学习工程师
原文:https://www.dataquest.io/blog/become-machine-learning-engineer/
August 15, 2019
像大多数从事数据科学工作的人一样,Mohammad Minouneshan 在成长过程中并不想成为一名机器学习工程师。但在 2018 年参加了他的祖国伊朗的一些活动后,他对该领域的兴趣被激起了,他开始寻找学习数据科学的方法。
最近通过了一门 C 语言课程,他有了一些编程经验。但他说,他没有任何更广泛的计算机科学知识,也没有数据挖掘等技能方面的经验。除了基本的统计学理解,他还需要找到一个可以帮助他从头开始学习的平台。
“有勇气开始这样的挑战是关键,”他说。
所以他一头扎了进去,试图找出从哪里开始。“我只是在网上搜索‘如何成为数据科学家’之类的内容。”
他第一次登陆 DataCamp 的平台,但在 Quora 上寻找更多答案时,他看到了 Dataquest 创始人 Vik Paruchuri 对一个关于data quest 和 Datacamp 如何比较的问题的回答。读完之后,他说,“我决定测试 Dataquest,因为我可以尝试一个免费增值计划。”
“在我开始之后,我发现有非常非常大的不同,对我来说,Dataquest 要好得多,”Mohammad 说。" Dataquest 更加实用,我想要一门实用的课程."
他喜欢的另一件事是价格。“如果你看看 Coursera、EdX 等网站上的数据科学课程包。,它们比 Dataquest 贵,”他说。“给我们包月,让人们按照自己的进度学习,这对用户来说非常公平。对我来说,这样更好。”
成为机器学习工程师
在花了一些时间研究 Dataquest 之后,Mohammad 能够实现他进入数据科学行业的目标。他在一家位于伊朗的金融科技初创公司找到了一份机器学习工程实习生的工作。在继续他的传统教育的同时,他也在为他的教授做数据助理。“我每天都在以数据科学家的身份工作,”他说。“这是一项艰苦的工作。我每天都要学习。”
Dataquest 在工作中也帮了他不少忙。“当我在工作时,我使用 Dataquest 课程和项目来帮助我。例如,如果我有一些关于数据清理的问题,我会使用 Dataquest 提供的可下载 PDF 来回顾我所学到的内容。那些外卖非常非常有用,非常有帮助。”
Mohammad 将他的公司与 Intuit 进行了比较,并表示他希望该公司能够扩张。“我们可能很快就会来到欧洲,”他说,“因为我们想在那里和中东提供服务。”
他知道自己的技能也需要扩展。“我非常喜欢 Dataquest,”他说,“我想更多地使用它。我想做更多的项目。我想学习数据工程途径,我想学习R 途径,同时学习数据科学和数据工程。”

穆罕默德现在是一名机器学习工程实习生。
从任何地方学习数据科学
Mohammad 说,伊朗困难的经济形势使得伊朗的 it 专业人员处境艰难。很难找到国内对 It 技能的需求,而且与海外雇主合作因全球政治而变得复杂。然而,他说,对于那些愿意学习数据科学和机器学习等技能的人来说,机会是存在的,这些技能在全球范围内需求量很大。
尽管 Mohammad 计划最终搬到美国,他说他希望人们知道你的位置不应该成为学习数据科学和机器学习等有价值技能的障碍。“我在伊朗,”他说。“无论你从哪里开始学习,你都有可能成为一名数据科学家。”
Azure 给数据专业人员带来的好处(2023 年)
原文:https://www.dataquest.io/blog/benefits-of-azure-for-data-professionals/
November 28, 2022
如果你是一个有抱负的(或正在工作的)数据专家,那么你应该知道云是数据管理的未来。在云中管理数据的最强大的选择之一是 Microsoft Azure。
Azure 是微软创建的云计算平台和基础设施,用于通过微软管理的数据中心的全球网络来构建、部署和管理应用程序和服务。
在本文中,我们将分享 Microsoft Azure 的主要优势,以及您应该考虑学习如何使用它的原因。
微软 Azure 的优势
有了这么多优势,难怪 Azure 正成为各种规模的组织的首选平台。Azure 使组织很容易开始使用云计算,它为那些想要迁移到云的人提供了许多选择。
随着基于云的解决方案越来越受欢迎和使用,那些拥有管理这些复杂系统所需技能的人将成为越来越有价值的资产。
下面,你会发现微软 Azure 的主要优势。
可扩展性
Azure 提供了很大的灵活性,可以根据需要快速有效地扩大或缩小规模,这允许组织只为他们使用的资源付费。得益于自动扩展功能,计算、存储、联网和管理数据库等服务可以自动适应组织的需求。
灵活性
Azure 使组织能够从许多不同的部署模型中进行选择,包括公共、私有和混合云部署,并且它提供了管理和监控应用程序的工具,以最大限度地满足他们的需求。例如,一些组织可能希望将 Azure 仅用于开发和测试目的,而其他组织可能希望将其用于生产工作负载。
实时处理
借助 Azure 先进的实时数据处理和物联网(IoT)功能,数据科学家、机器学习工程师和解决方案架构师可以实时处理大量流数据,以前所未有的速度揭示见解。
综合分析工具
凭借 Power BI、Stream Analytics、Data Factory、HDInsight 等一系列内置分析工具,Azure 为数据专业人员提供了一套全面的工具来构建强大的分析应用程序。
安全性和合规性
Azure 提供了一套全面的安全功能,帮助保护静态和传输中的数据:
- 加密、访问控制和审计
- 保护传输中数据的工具,包括 VPN 和 SSL
- 与法规遵从性相关的服务,例如跟踪违规行为和生成报告的能力
数据专业人员的优势
随着许多组织将他们的数据管理转移到云,特别是微软 Azure,精通微软 Azure 的专业人员对他们的雇主来说非常有价值。
无论你是(或想成为)数据科学家、数据分析师、DevOps 工程师、解决方案架构师、数据工程师还是 AI 工程师,Azure 技能都可以帮助你在求职时从其他候选人中脱颖而出。
以下是数据专业人员学习 Azure 的主要好处:
-
Azure 技能在世界各地的雇主中需求量很大:雇主越来越重视 Azure 专业知识,他们正在寻找可以帮助他们构建、部署和管理基于云的解决方案的人。随着越来越多的公司过渡到混合或云计算环境,知道如何使用 Azure 可能是获得理想工作的关键因素。一个简单的 LinkedIn 搜索具有 Azure 技能的工作会显示超过 10 万个职位。
-
Azure 技能可以帮助你获得更高的薪水: Azure 专业人员可以期待看到他们的薪水飙升,因为他们帮助企业导航不断变化的云计算世界。美国 Azure 专业人员的平均年薪为 131,221 美元,入门级职位的起薪估计为每年 110,435 美元。
-
Azure 技能将使你更加多才多艺,更能适应你工作的组织的环境:知道如何使用 Azure 提供的服务组合来创建云解决方案会给你信心,并促进你的职业发展。由于您熟悉 Redis 缓存、物联网集线器、HDInsight 集群等概念,您将能够自信地处理涉及多个数据中心和远程位置的混合网络。
-
Azure 可以帮助你获得其他相关的、受欢迎的技能,这些技能将有助于推动你的职业发展:在与微软 Azure 合作时,你很可能还会从事当今需求量很大的技能——我们可以假设未来几十年对这些技能的需求将会增加,如开发运维、大数据分析、机器学习、容器和网络。这可以帮助你在一个组织内纵向或横向发展,或者在你的职业生涯中。
-
Azure 技能将帮助您使您工作的组织更加高效: Azure 通常可以帮助您改善组织的运营,包括降低基础设施成本、提高敏捷性、提高安全性、改进 IT 流程、推动数字化转型和提高盈利能力。
获得 Azure 认证
如果你想获得云技术给专业人士带来的好处,考虑获得微软 Azure 认证。Azure 的入门级认证“Microsoft Certified Azure Fundamentals”将测试你对云概念的基本知识,如 Azure 提供的服务以及价格。
根据皮尔森公司的一项调查,35%的受访者表示在完成认证后薪水有所增加。这个证书可能会让你得到一份工作或者升职。
第一步:熟悉微软 Azure
学习 Microsoft Azure 的第一步是创建一个帐户。
- 创建一个 Azure 帐户(注册后 30 天免费)
创建帐户后,请熟悉界面:
这里的目标是让自己熟悉这个界面。不要浪费太多时间去阅读所有的东西——你会想要开始用数据练习。
第二步:开始学习
您可以使用此参考来了解如何使用 Microsoft Azure:
- 使用 Microsoft Azure 的云数据使用 Dataquest 的路径
您将获得如何改进的反馈,Dataquest 提供了确保成功的指导!你不会有任何问题,因为所有的练习都是在 Dataquest 平台上进行的。
您也可以直接从微软学习中心学习:
第三步:用教程练习
下一步是开始学习微软 Azure 上最流行的服务:
您还可以按照项目演练在云中创建您的数据解决方案:
第四步:获得认证
一旦你熟悉了关键的 Azure 服务并完成了几个端到端项目,你就可以准备好参加微软认证:Azure 数据基础认证。
如果您完成了 Dataquest 的课程,您将获得 Azure 数据基础认证的 50%折扣。
结论
擅长管理 Azure 资源的数据专业人员可以帮助他们的组织节省资金,提高运营效率,并保护关键数据。随着云计算继续彻底改变商业世界,对 Azure 专家的需求肯定会增加,因此这对有抱负的数据专业人士来说是一项伟大的技能。
对于那些想要保持领先并从云技术的巨大潜力中受益的人来说,没有比 Azure 更好的起点了。
数据科学家访谈:本杰明·鲁特
November 2, 2015
在 Dataquest ,作为数据科学教育过程的一部分,我们努力帮助我们的用户更好地了解数据科学在行业中的工作方式。我们已经开始了一系列采访经验丰富的数据科学家的活动。我们重点介绍了他们的故事,他们对初露头角的数据科学家的建议,以及他们解决的各种问题。这是我们这个系列的第二篇文章,是对数据科学家和工程师 Benjamin Root 的采访。
Benjamin Root 是 Matplotlib 数据可视化库的贡献者,致力于改进 Matplotlib 中的文档和 mplot3d 工具包。Ben 以前是气象专业的研究生,他尝试使用 MATLAB 处理数据的经历促使他学习 Python,并进一步参与 SciPy 社区。
你参与 Matplotlib 项目有多久了,是什么推动你参与进来的?
Benjamin: 我在 2009 年初开始使用 Python,当时几个同事注意到我在使用 MATLAB 时遇到的一些问题,建议我尝试一下 Python。有了一些示例 pylab 脚本可以学习,我开始将我的一些.m文件转换成.py文件。我有一些非常复杂的 MATLAB 代码,所以我的同事向我推荐了 NumPy、SciPy 和 Matplotlib 的各种邮件列表。有了这些列表的反馈,我设法将我所有的 MATLAB 代码转换成 Python,声明我将“永远不再”使用 MATLAB。
好了,是时候进行新的开发和新的可视化了,我一直在 NumPy 和 Matplotlib 中遇到各种烦人的错误和边缘情况。我会用示例代码报告错误,开发人员通常会修复错误。最终,开发人员会开始引导我找到问题所在,我开始自己编写补丁。提交补丁大约一年后,John Hunter 给了我提交权限。他后来说,他把提交权给了任何一个“惹恼”他的人。所以,参与 Matplotlib 是因为惹恼了我的同事,然后惹恼了开发人员……
你和 Matplotlib 有什么关系?你在项目中扮演什么样的角色?
Benjamin: 最初,我在 Matplotlib 中关注的是文档,因为我有“新鲜的眼睛”,所以我更容易注意到错误和粗糙的边缘。现在我已经阅读文档很多次了,我甚至再也看不到错误了。顺便说一下,这就是为什么开发人员鼓励新人提交文档补丁的原因!我还试图打磨我不断遇到的粗糙边缘,特别是用 Matplotlib 打包的 mplot3d 工具包。我向 mplot3d 提交了足够多的补丁,以至于我成了它事实上的维护者。
目前,我的重点是审查 GitHub 上的 pull 请求,以及诊断/验证 bug 报告。我仍然不时地提交新特性(特别是,在即将到来的 1.5 版本中寻找新的“属性循环”和“经典风格”特性)。我参与设计讨论,试图确保我们在新功能的早期做出好的设计决策。我也将很快成为底图工具包的维护者。在邮件列表中,我倾向于回答新来者的大多数问题,尽管自从 StackOverflow 到来后,邮件列表流量大幅下降。
许多数据科学家和数据工程师依赖开源库,但不知道如何回报。对于那些想更多地参与开源的人,你有什么最好的建议?
本杰明:这类用户最适合像 Matplotlib 这样的库。他们通常是在图书馆能力的边界上工作的人。所以,对于那些用户来说,遇到错误和限制是很自然的。把那些错误报告归档!在邮件列表上提问,并给予反馈和批评!开发人员确实希望从他们的用户那里听到反馈,因为这意味着他们的工作正在被使用!参与开源不能用补丁数量来统计。开源开发不仅仅是代码和文档。
软件不会自发地从以太中“产生”。软件满足需求,是用户定义了需求。我个人认为,对开源项目最有价值的贡献者是那些向开发人员提供反馈和批评的人。没有他们,项目就会停滞不前,并因冷漠而死亡。所以,我对你的读者的挑战是找出他们直接使用最多的三个库和工具,并订阅他们的用户邮件列表。然后,下一次在使用这些工具时发生“奇怪的事情”或“意想不到的事情”,不要把它当作你自己的错误或你必须忍受的限制。给这个列表发一封电子邮件,询问是否有人认为这很奇怪或出乎意料。求解答。鼓励讨论。
最后,如果开发人员要求对某件事进行反馈,接受他们的要求。拜托,看在上帝的份上,请在测试版上试用你的软件,发布这些库的候选库,并报告问题!
你最近出版了一本名为使用 Matplotlib 的交互式应用的书。写这本书的目的是什么?你的目标读者是谁?
Benjamin: 主要是,我想提高自己在 Matplotlib 这方面的知识,同时也为它制作更好的文档。交互性是 Matplotlib 的一个非常重要的特性,但是它的文档却很少。我能在网上找到的所有例子和教程都只是展示了不同的方面,它们彼此之间是如此的脱节。没有任何叙述可以帮助用户从坚实的基础上建立他们的理解。在书中,我们不是让所有的示例代码完全相互独立,而是一点一点地构建一个应用程序。
我非常喜欢这种叙述方式的一点是,在 widgets 一章中,我有一种特别的满足感,我们添加了一个滑块,然后我向读者指出,新的滑块会自动绑定到键盘快捷键和其他一些按钮上,这是我们在上一章中所做的。这在典型的示例驱动文档中是不可能的,因为键盘快捷键的演示与小部件的演示完全无关。
本书的目标读者是那些对 Python 和面向对象编程有一定经验,并且需要用 Python 制作交互式可视化效果的人。您不需要任何 Matplotlib 或任何其他科学 Python 工具的经验,但我也不会花太多时间解释可能的可视化以及如何定制它们。有很多关于这方面的教程。我假设您已经可以按照您想要的方式显示一个图,但是需要构建与该图交互的工具。
你作为气象学研究生的经历如何影响了你现在的工作?
本杰明:气象学和许多其他科学一样,是一种非常直观的体验。将数据视为文本是理解数据的一种糟糕方式。所以,一个研究生必须能够创造他们自己的作品的可视化。有几个工具可以做到这一点,有些是非常具体的大气科学,如 NCL 和 GEMPAK,而其他人更普遍,如 MATLAB 语言。
作为一名研究生,我一直在尝试新的事物,并且我正在以一种前所未有的方式使用工具。因此,我一直在这些工具中遇到错误。真正将我从 MATLAB 世界推向 Python 的是修复这些错误的能力。此外,现在 Matplotlib 中有一些功能是从气象学的角度培养出来的。例如,我经常需要使用非常精确的地图来可视化我的数据,因此我对底图和制图等项目特别感兴趣,以确保它们满足我的需求。流图和风倒钩是我们在 Matplotlib 中为气象学家开发的另外两个功能。
你对新兴的数据可视化工具包 Vispy 有什么想法?
本杰明: Vispy 是一个令人惊叹的项目,显示了巨大的潜力。它的一个原始组件 glumpy 实际上是在我的鼓励下创建的,因为 Matplotlib 附带的 mplot3d 工具包存在局限性。Vispy 的几个原始组件是在 Matplotlib 开发人员的要求下创建的,因为我们看到了在 GPU 上执行可视化的价值,但我们没有足够的专业知识,也没有带宽在维护 Matplotlib 的同时进行这样的项目。
我们也不认为我们可以将这样的实验特性添加到 Matplotlib 中,而不会对我们的用户造成重大的干扰。因此,我们鼓励一些带着这些奇妙想法来到邮件列表的开发人员从头开始,将他们的想法变成现实,即使这只是一个概念证明。这些项目和其他一些项目合并到了 Vispy 中。
在 2015 年 SciPy 大会上,Matplotlib 开发团队有机会与一些 Vispy 开发人员深入讨论我们的项目在 Python 生态系统中的位置、我们各自的路线图以及我们两个项目的未来。这是一次非常激动人心的讨论。虽然我们还没有任何长期计划,但肯定有一些更直接的目标,例如 Vispy 使用 Matplotlib 的文本渲染代码来提高情节的视觉质量。我们还将与 Vispy 开发人员合作,为将 Vispy 作为后端连接到 Matplotlib 创建一些概念验证。的确,Python 中数据可视化的未来看起来非常光明!
10 大最佳数据工程课程(2023 版)
原文:https://www.dataquest.io/blog/best-data-engineering-courses/
December 14, 2022
我们已经编制了一份数据工程项目和课程的清单,可以让你很快从初学者变成专业人士。根据你现有的知识和对编程的熟悉程度,本指南将帮助你找到最好的数据工程课程。
我们分析了现有的顶级课程,并根据 14 个独特的变量得出了以下列表。
以下是 2023 年最佳数据工程课程的总结:
- 最佳数据工程职业: Dataquest 的数据工程师职业道路
- 最适合谷歌云: 准备谷歌云认证:云数据工程师职业证书
- Apache Spark 最佳课程: 用 Apache Spark 和 Python 驯服大数据——动手!
- 【PostgreSQL 最佳课程: 数据工程 PostgreSQL
- 机器学习最佳课程: 带 AWS 机器学习的数据工程
- 网页抓取最佳课程: 数据工程— ETL、网页抓取、大数据、SQL、Power BI
- 最佳免费课程: 数据工程动物园
**## 最适合从事数据工程的职业
Dataquest 的数据工程师职业道路
Dataquest 的职业道路包含了您开始从事数据工程职业所需的所有工具和知识。这条路线由 19 门课程和 16 个项目组成,旨在让您立即获得 Python 编程的实践经验。
您将学习如何构建复杂的数据架构、管理数据管道以及使用 pandas、NumPy 和 MapReduce 等工具。您将获得大量的 SQL 编程和数据库经验,这是任何数据工程职业的核心组成部分。
这条道路最好的部分是你将要从事的项目的广度。这些项目将是展示给潜在雇主的很好的作品集。一些项目包括:
- 分析股票价格数据
- 实现键值对数据存储
- 构建黑客新闻数据管道
这门课程为你提供了在数据工程领域开始职业生涯所需的确切知识,而费用只是传统训练营的一小部分。
以下是我们对该课程的详细分析:
| 价格:$ 399/年或$ 49/月(提供折扣) | 彻底性:获得工作所需的一切 |
| 前期费用:无 | 特长:Python 编程(熊猫、NumPy 等。)SQL 数据库数据管道 |
| 评分: 4.8 (359 条评论) | 所需先决条件:
Python 基础知识 |
| 预计持续时间: 5 个月,每周 10 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 16 |
| 注册学生人数:108,400 人 | 退款选项:完成后如果不满意可以使用 |
| 计划类型:职业道路 | 职业服务:完成认证和强大的社区支持 |
学生推荐信
你上小课,可以马上练习技能。太方便了。致力于 Dataquest 是一个简单的决定。
—呼延武
我真的很喜欢在 Dataquest 上学习。我研究了几个其他选项,发现与 Dataquest 的方法相比,它们太容易上手,太容易填空。Dataquest 上的项目是我得到这份工作的关键。我收入翻倍了!
—维多利亚·e·古齐克
IBM 数据工程专业证书
Coursera 上提供的 IBM specialization 提供了所有必要的课程和项目,让您为入门级数据工程职位做好准备。该证书是 Coursera 上最受欢迎的专业之一,并带有进入这一职业所需的所有资源。
你将和 16 名不同的教师一起工作,他们有着广泛的背景。你将完成总共 9 个项目,这将有助于建立你的投资组合,展示你的技能。
一些项目包括:
- 设计一个关系数据库来帮助咖啡连锁店改善经营
- 分析道路交通数据以执行 ETL,并使用 Airflow 和 Kafka 创建管道
- 通过创建 Apache Spark 应用程序来训练机器学习模型
总的来说,该课程将向您全面介绍数据工程中最相关的概念,并且在进入就业市场时,它还附带有补充性的职业服务。
以下是我们对该课程的详细分析:
| 价格:$ 49/月(EDx 上为$1,076.40) | 彻底性:获得工作所需的一切 |
| 前期费用: 7 天免费试用 | 特长: SQL 编程
Hadoop 和 Spark
ETL 数据管道(Kafka、Airflow 等。) |
| 评分: 4.6 (2,337 条评论) | 所需前提:基本编程 |
| 预计持续时间: 15 个月,每周 4 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 9 |
| 注册学生人数:28,713 人 | 退款选项:付款后 14 天内退款 |
| 项目类型:证书项目 | 职业服务:完成后获得证书,并获得职业资源以帮助招聘 |
|  | “Coursera 上的课程在我的职业转型中发挥了重要作用。在面试中,我学到了对我帮助很大的技能。”—乌吉瓦尔 J. |
| “Coursera 上的课程在我的职业转型中发挥了重要作用。在面试中,我学到了对我帮助很大的技能。”—乌吉瓦尔 J. |
Udacity 数据工程师纳米学位
正如 Udacity 所言,“数据工程是大数据新世界的基础”,对此我们深表赞同。数据工程纳米学位是一门为期 5 个月的课程,在这门课程中,你将学习如何管理大规模数据。具体来说,您将设计数据模型、构建数据仓库和湖泊,并实施 ETL,所有这些都是为了让您为使用大数据做好准备。
本课程以一个顶点项目结束,向潜在雇主展示你对数据工程的理解,并增加你的投资组合。该计划的其他好处包括沿途与技术导师合作,获得职业服务为就业市场做准备,以及非常灵活的时间表。
以下是我们对该课程的详细分析:
| 价格:$ 399/月,$ 1695 5 个月 | 彻底:为就业市场做好一切准备 |
| 前期费用:前期支付 | 特长:数据仓库和 LakesData 管道(气流)
Apache Spark |
| 评分:4.6(1786 条评论) | 所需先决条件:中级 Python & SQL 编程经验 |
| 预计持续时间: 5 个月,每周 5-10 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 6 |
| 注册学生:非公立 | 退款选项:在第一个月的订购日的前两天内退款 |
| 程序类型:纳米度 | 职业服务:包含在纳米学位项目中 |
到目前为止,我很惊讶这个项目教会了我这么多。这些练习对我理解和实际编写程序非常有帮助。这个项目的格式与我们通常得到的练习和演示有点不同,所以我对用什么格式写代码有点困惑。但是知识帮我做到了这一点,所以问题不大。
—戴荣
元数据库工程师职业证书
在脸书拥有超过 20 亿用户的情况下,Meta 当然对大数据略知一二。通过 Coursera 提供的 Meta 数据工程专业证书将为您提供设计、部署和管理大规模结构化和非结构化数据所需的工具。
您将向 Meta 的行业专家学习,并使用专注于 SQL 数据库管理系统、数据建模和使用 Python 的 ETL 框架的工具。证书课程还能帮助你准备技术面试和进入就业市场。
以下是我们对该课程的详细分析:
| 价格:$ 49/月 | 周全:为就业市场做好一切准备 |
| 前期费用: 7 天免费试用 | 特长: SQL 编程
Python 编程 |
| 评分: 4.6 (353 条评论) | 所需先决条件:
Python 基础知识 |
| 预计持续时间: 6 个月,每周 6 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 5 |
| 注册学生人数:11,786 人 | 退款选项:付款后 14 天内退款 |
| 项目类型:证书项目 | 职业服务:帮助准备简历和面试 |
我在学院是班上的尖子生,我对我所在领域的最新研究非常了解。多亏了 Coursera,这一切才成为可能。
—悉达多
最适合谷歌云
准备 Google 云认证:云数据工程师职业证书
如果你曾经想了解谷歌云平台(GCP),那么你会喜欢谷歌提供的数据工程专业证书。在这个证书课程中,您将学习大数据和机器学习的基础知识,同时使用 GCP 提供的许多服务。
除了完成作业和动手项目,本课程还将为您准备 Google Cloud 认证考试。这项考试是业内公认的,会在你进入就业市场时提升你的简历。
以下是我们对该课程的详细分析:
| 价格:$ 49/月 | 彻底性:关于谷歌云平台的深入课程为谷歌云认证考试做准备 |
| 前期费用: 7 天免费试用 | 特长:谷歌云平台谷歌的 BigQueryGCP 机器学习服务 |
| 评分:4.6(6516 条评论) | 所需先决条件:中级 SQL 编程知识 Python 基础知识 |
| 预计持续时间: 5 个月,每周 3 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量:多个 |
| 注册学生人数:71,978 人 | 退款选项:付款后 14 天内退款 |
| 项目类型:证书项目 | 职业服务:准备谷歌云认证考试 |
能够按照我自己的速度和节奏上课是一种很棒的经历。只要适合我的时间表和心情,我随时都可以学习。
——
阿帕奇火花的最佳路线
用 Apache Spark 和 Python 驯服大数据——动手吧!
Apache Spark 是从大型数据集中提取有意义见解的最佳框架之一,被亚马逊、Nasa 和易贝等公司使用。您将向一位前 Amazon 和 IMDB 员工学习,并将涵盖所有 Spark 基础知识,包括弹性分布式数据存储、使用 PySpark 进行 Python 编程,以及扩展您的程序以使用 AWS Elastic MapReduce。
该课程包括 7 个小时的视频和 20 多个真实世界的例子,帮助您入门。您将开发程序来构建和分析社交图,并使用大型数据集来确定 IMDB 等公司如何推荐推荐的电影。
以下是我们对该课程的详细分析:
| 价格: $24.99 | 彻底性:侧重于 Apache Spark 和相关框架的深入课程 |
| 前期费用:前期支付 | 特长:
Apache spark AWS Elastic MapReduce |
| 评分: 4.5 (13,959 条评论) | 所需先决条件:
中级 Python 编程经验
|
| 预计持续时间: 7 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 2 |
| 注册学生人数:83,761 人 | 退款选项:符合条件的课程在 30 天内退款 |
| 项目类型:个人课程 | 职业服务:未提供 |
让您了解 Apache Spark 和 Python 的绝佳课程!弗兰克的演讲非常透彻,但并不做作;他对自己引入的每个新概念的解释都很实际,也很容易理解。作为 Udacity 数据工程纳米学位项目的一部分,我参加了一个类似的课程,我很高兴我事先参加了 Frank 的课程,因为 Udacity 解释它的方式和他们提供的课程都不清楚,令人困惑。
—阿米里米
【PostgreSQL 最佳课程
用于数据工程的 PostgresSQL】
纯专注 SQL 的最好课程是 Dataquest 的数据工程 PostgreSQL。在本课程中,您将学习 SQL 数据库管理的所有知识,重点是 PostgreSQL,它是当今最流行的数据库平台之一。
您将直接投入到实际例子的工作中,包括建立一个用于分析犯罪报告的数据库。您将进一步提高 Python 编程技能,并学习如何使用 psycopg2 Python 包与 PostgreSQL 进行交互。本课程以一个顶点项目结束,在该项目中,您将分析风暴数据。
以下是我们对该课程的详细分析:
| 价格:$ 399/年或$ 49/月(提供折扣) | 彻底性:专注于 PostgreSQL 的深度课程 |
| 前期费用:无 | 特长:PostgreSQL
SQL 编程 Python 编程(重点是 psycopg2) |
| 评分: 4.8 (359 条评论) | 所需先决条件:Python 基础知识 |
| 预计持续时间: 9 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 3 |
| 注册学生人数:32200 人 | 退款选项:完成后如果不满意可以使用 |
| 项目类型:个人课程 | 职业服务:完成认证和强大的社区支持 |
很难找到这种理论和编码示例相结合的资源,这就是为什么当我被介绍给 Dataquest 时我如此兴奋。
—Patrick Nelli
机器学习的最佳课程
采用 AWS 机器学习的数据工程
没有对数据的访问,机器学习就无法存在。然而,处理和存储原始数据可能非常具有挑战性。这就是数据工程发挥作用的地方。
理解核心数据工程原理有助于实现成功的机器学习算法。因此,还有什么比将数据工程和机器学习结合到一门课程中更好的学习方法呢!
数据工程和 AWS 机器学习课程将带您了解亚马逊网络服务(AWS)。您将了解通过 AWS 提供的不同数据存储和机器学习服务,以及它们如何协同工作。
在课程结束时,你将知道如何建立完整的机器学习管道,从原始数据开始,到令人惊叹的预测和分类结束。
以下是我们对该课程的详细分析:
| 价格:$ 29/月 | 彻底性:AWS 数据存储和机器学习服务的高级概述 |
| 前期费用: 10 天免费试用 | 特长:
AWS 数据存储服务
AWS 机器学习服务 |
| 评分: 3.5 (26 条评论) | 所需先决条件:
熟悉 AWS 仪表板 |
| 预计持续时间: 3 小时 | 定速:自定速 |
| 认证项目:否 | 项目数量:未公开 |
| 注册学生:非公立 | 退款选项:不提供退款 |
| 项目类型:个人课程 | 职业服务:未提供 |
最佳网页抓取教程
数据工程——ETL、Web 抓取、大数据、SQL、Power BI
Web 抓取已经成为数据挖掘和聚合的一个重要组成部分。通过 Udemy 提供的这个课程介绍了在开发 ETL 管道的背景下的 web 抓取。除了 web 抓取之外,您还将学习如何将来自多个来源的数据聚合到一个数据库中。
该课程有 134 堂课,在 12 小时的运行时间里涵盖了大量的材料。但是你将会带走一个关于数据工程和新工具的很好的介绍,向潜在的雇主炫耀。
以下是我们对该课程的详细分析:
| 价格: $49.99 | 彻底性:入门级别核心数据工程概念的高级概述 |
| 前期费用:前期支付 | 特长:ETL pipelines web scraping
SQL 编程 |
| 评分: 3.8 (279 条评论) | 所需先决条件:SQL 基础知识 |
| 预计持续时间: 12 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 0 |
| 注册学生人数:25,011 人 | 退款选项:符合条件的课程在 30 天内退款 |
| 项目类型:个人课程 | 职业服务:未提供 |
最佳免费课程
数据工程动物园
阿列克谢·格里戈里耶夫教授的这门完全免费的课程因其独特的教学方法而榜上有名。该课程为期 9 周,所有材料都通过 GitHub 托管。你将成为一个高度参与的社区的一员,在这个社区中,学习者在整个课程期间就各种项目进行合作和竞争。
您将涉及的主题包括数据摄取、数据仓库、批处理和 ETL 管道。为了补充每一课,你将做每周的编程作业来帮助巩固你的知识。总的来说,这是一种有趣且经济的数据工程入门方式。
以下是我们对该课程的详细分析:
| 价格:免费 | 彻底性:入门级别核心数据工程概念的高级概述 |
| 前期费用:无 | 专业:数据摄取和 ETL 数据仓库(Google BigQuery)批处理和流式传输 |
| 评级:不公开 | 必要先决条件:
熟悉编码和命令行 SQL 基础知识 |
| 预计持续时间: 9 周,每周 5 小时 | 起搏:教师起搏 |
| 认证项目:是 | 项目数量: 1 |
| 注册学生:非公立 | 退款选项:不可用(免费课程) |
| 项目类型:个人课程 | 职业服务:不包括 |
**
适合各种场景的最佳数据科学课程(2023 版)
December 13, 2022
选择正确的数据科学课程对于实现您的目标至关重要。它可以执行以下操作:
- 为你省钱
- 尽量减少学习时间
- 提供一条通往令人兴奋的新职业的道路
- 让你的发现之旅尽可能愉快
谢天谢地,我们已经做了研究。我们比较了多门课程,并用 14 分制对它们进行了评分。这样,你就可以做出明智的决定,而不会浪费时间或金钱,同时准备开始一个有回报的新职业!
以下是 2023 年最佳数据科学课程的总结:
- 最佳综合数据科学课程: Dataquests 的职业道路
- 最适合基本面: 365 职业生涯完整数据科学训练营
- 最适合金融: 用 Python 火热的数据驱动投资|金融数据科学
- 最适合统计学: 365 职业统计学适合数据科学和商业分析
- 最佳在线数据科学训练营: 加州理工学院数据科学训练营
- 最佳现场数据科学训练营: 纽约数据科学学院
- 最佳免费数据科学课程: 哈佛数据科学:R 基础知识
最佳整体数据科学课程
Dataquest 的职业道路
如果你在寻找数据科学职业,那么 Dataquest 课程是你最好的选择。Dataquest 提供全面的职业发展道路,以极低的成本为您提供训练营的一体化结构。
以下是 Dataquest 目前的职业道路:
这些职业道路为你提供了胜任这份工作所需的一切。最棒的是,绝对没有前提条件!
另外,课程会让你从第一天就开始编程。不像其他大多数课程,你不会只是看几个小时的视频讲座。你将完成数百个练习和数十个项目。难怪 97%的学习者推荐 Dataquest 来获得职业发展。
在这篇综述中,我们将关注最受欢迎的职业道路:数据科学家。
| 价格:$ 399/年或$ 49/月(提供折扣) | 彻底性:获得工作所需的一切 |
| 前期费用:免费开始 | 特长: SQL 和数据库编程机器学习包罗万象的数据科学技能集 |
| 评分: 4.8 (359 条评论) | 所需先决条件:无 |
| 预计时长:全职:2-3 个月;兼职:6-9 个月 | 定速:自定速 |
| 认证项目:是 | 项目数量: 26 |
| 注册学生人数:25.9 万人 | 退款选项:完成后如果不满意可以使用 |
| 学习风格:编码模块和指导项目 | 职业服务:社区支持 |
学生推荐信
Dataquest 上的学习路径令人难以置信。你不用猜你接下来该学什么。
— 奥塔维奥·西尔维拉
我真的很喜欢在 Dataquest 上学习。我研究了几个其他选项,发现与 Dataquest 的方法相比,它们太容易上手,太容易填空。Dataquest 上的项目是我得到这份工作的关键。我收入翻倍了!
—维多利亚·e·古齐克
基本面最佳
365 职业数据科学课程:在 Udemy 上完成数据科学训练营
这门数据科学课程在 Udemy 上名列前茅。该课程有超过 100,000 条评论,纳斯达克、大众汽车和 Netapp 等公司向其员工提供了这些评论。
学生喜欢本课程,因为它是理解数据科学基础所需的所有概念的廉价介绍。
| 价格: $94.99 | 对主要话题的介绍,但是如果你想专攻其中任何一个,你需要更多的教育。 |
| 前期费用: 100%前期费用 | 专业:基础 |
| 评分: 4.6 (115,513 条评论) | 所需先决条件:无 |
| 预计时长: 32 小时授课 | 定速:自定速 |
| 认证项目:是 | 项目数量:无 |
| 注册学生人数:548,096 人 | 退款选择: 30 天全额退款保证。 |
| 学习方式:带小测验的视频讲座 | 职业服务:无 |
学生推荐信
这绝对是我迄今为止在数据科学领域所学的最好的课程。老师都很专业,什么都解释的很清楚。
—安东尼诺 n .
**> 这是一堂极好的课,也是对他们所教科目的解释。我会向任何想学这门课的人推荐这门课。如果你上这门课,你会学到新知识。
—阿扎马特 k .
最适合金融
用 Python 进行狂热的数据驱动投资|金融数据科学
如果你想利用数据进行财务预测或做出有统计数据支持的投资决策,这个由狂热的定性金融课程是给你的。
您将在本课程中学到的一些内容包括:
- 计算股票回报
- 估计预期收益
- 评估投资组合风险
- 获取财务数据
因为这是一门 Udemy 课程,所以有 30 天无条件退款保证。
| 价格: $84.99 | 彻底性:用 Python 实现金融数据科学 |
| 前期费用: 100%前期费用 | 专业:金融 |
| 评分: 4.9 /5 (73 条评论) | 必备条件:基本编码知识 |
| 预计时长: 13.5 小时的视频讲座 | 定速:自定速 |
| 认证项目:是 | 项目数量:无 |
| 注册学生人数:1,604 人 | 退款选项:如果您不满意,可在 30 天内退款 |
| 学习方式:带练习的视频讲座 | 职业服务:无 |
学生推荐信
伟大的格式,内容和讲师提供惊人的洞察力。
——
最适合统计:
365 数据科学和商业分析职业统计
如果你想成为一名数据科学家、商业分析师或数据工程师,如果你理解你所做的事情的基本数学概念,你将拥有优势。我们喜欢这门课程,因为它给了你理解复杂的统计分析的基本技能。
虽然本指南中的其他课程侧重于数据科学的应用,但本课程将让您了解它在数学层面上是如何工作的。不要让这吓到你——好评如潮,说课程材料以简单和吸引人的方式呈现。
即使你现在不是数据科学家,本课程也将帮助你在工作场所做出基于统计的决策。
| 价格: $84.99 | 彻底性:你在办公室需要的统计数据 |
| 前期费用: 100%前期费用 | 专业:统计 |
| 评分: 4.6 (159,883 条评论) | 所需先决条件:无 |
| 预计时长: 5 个小时的讲座 | 定速:自定速 |
| 认证项目:是 | 项目数量:无 |
| 注册学生: 49 人 | 退款选项:如果您不满意,可在 30 天内退款 |
| 学习方式:视频讲座,练习习题 | 职业服务:无 |
学生推荐信
我在读了一本与 Tensorflow 相关的书后选了这门课,书中使用了很多数学术语,但几乎没有解释,因为它们必须假设读者必须意识到这一点。上过这门课后,我对那些概念理解得更好了。我将把这门课程作为基础课程推荐给任何想进入任何分析领域的人。
—苏米特 c .
我从未见过任何人以如此简单而有逻辑的方式解释统计学。我相信如果我掌握了这些练习,我会很容易在统计方面出类拔萃。谢谢你创造了这么有趣的课程。
—塞萨尔 b .
最佳在线数据科学训练营
加州理工数据科学训练营
根据《泰晤士报高等教育版》的统计,2022 年,加州理工学院是美国第二好的大学。在本课程中,他们与 IBM 合作建立了一个一流的训练营。这个课程是为职业人士设计的,提供黑客马拉松和社交机会。
与其他一些数据科学训练营不同,它是专门为希望从另一个领域过渡到数据科学的专业人士设计的。
如果你正在寻找一所高排名学校的在线训练营,加州理工学院是一个不错的选择。
| 价格:8000 美元 | 彻底:过渡到数据科学所需的一切 |
| 前期费用: 100%,但有灵活的支付选项 | 专业:数据科学 |
| 评分: 4.6/5 (352 条评论) | 所需先决条件:高中文凭,18 岁以上,最好有 2 年以上正式工作经验 |
| 预计持续时间: 5 个月,每周 5-10 小时 | 调步:周结构 |
| 认证项目:是 | 项目数量: 1 个顶石项目 |
| 注册学生人数:2500 人 | 退款选项:购买七天内退款。 |
| 学习方式:在线讲座、编码模块、教程、项目、黑客马拉松 | 职业服务:一对一辅导&招聘合作伙伴 |
学生推荐信
优秀的课程设计。自学是一个很棒的方法。作为一名学生,我学到了很多以前没有的知识。我参加了一个项目,这个项目保证了我在数据科学领域的职业生涯。此外,该品牌在市场上也很有名。完全物有所值。
—阿克什特·普拉萨德
最佳现场数据科学训练营
纽约数据科学院
如果你正在寻找一个亲身的训练营体验,纽约数据科学学院是评价最高的学院之一。他们被认可的训练营和职业发展课程都在纽约市。
昂贵的价格标签对一些人来说可能是值得的——他们吹嘘他们的毕业生的平均年薪是 94280 美元。
与其他一些选择不同,纽约市数据科学院极具竞争力且严谨。你需要完成一次视频面试,讨论你的背景和职业目标。
| 价格:17600 美元 | 彻底性:获得工作所需的一切 |
| 前期费用: $5000 接受后的存款,以确保您的位置。 | 专业:数据科学与机器学习 |
| 评分: 4.89/5 (356 条评论) | 必要的先决条件:学士、硕士或博士 40 小时的在线课程,一旦你被录取。 |
| 预计持续时间: 12 周(全职),24 周(兼职) | 配速:每周 40 小时以上。 |
| 认证项目:是 | 项目数量:众多小项目贯穿始终;最后一个顶点项目 |
| 注册学生:非公立 | 退款选项:如果您在第一周之前或期间取消,将获得全额退款,之后将获得部分退款。 |
| 学习方式:面授;基于项目的 | 职业服务:职业顾问、简历审核和面试准备。 |
学生推荐信
你在这里会学到比你自己更有效率的东西。在这么短的时间内要学的东西实在太多了——如果没有知道如何计划和执行课程的知识渊博的教师,你将需要长得多的时间来掌握同样数量的材料。
—大卫·科里甘
。该课程涵盖了数据科学中的广泛主题,具有足够的深度可应用于现实世界,因此我现在觉得有能力在夏令营结束后进一步学习并解决更困难的数据/技术问题。
–迈克尔·庄
最佳免费数据分析课程
哈佛数据科学:R 基础知识
如果你想免费学习数据科学,可以从世界上最负盛名的大学之一哈佛大学的这门课程开始。
HarvardX 提供哈佛课程的免费在线版本,包括数据科学:R 基础。尽管是免费的,但这一基础课程具有巨大价值的三个主要原因是:
- 由合格的哈佛讲师授课。
- 如果你喜欢免费课程,可以选择继续学习更多的数据科学课程,以获得哈佛大学的数据科学专业证书。
- r 是一种专门为统计计算和数据科学设计的编程语言。
| 价格:免费* | 彻底性: R 基础 |
| 前期费用: $0 | 特长:使用 R 编程语言 |
| 等级:不可用 | 所需的先决条件:一个最新的浏览器,能够在基于浏览器的界面中直接编程。 |
| 预计持续时间: 8 周,每周 1-2 小时 | 定速:自定速 |
| 认证项目:否 | 项目数量: 1 |
| 注册学生人数:760,691 人 | 退款选项:不适用 |
| 学习方式:视频讲座、交互式编码练习和一个期末项目 | 职业服务:无 |
学生证明
虽然这是一个相对快速的课程,但它足以让你开始学习 r。
—丹尼尔 C 。**
7 大数据科学简讯,让您随时了解最新信息
原文:https://www.dataquest.io/blog/best-data-science-newsletters/
June 24, 2016In a fast-paced and rapidly growing industry like data science, keeping up is essential. Knowing what is trending is essential in helping you know what new tools to learn, to help you get a job, and much more. At the same time, there is so much content out there that it can be hard to know what to read and easy to be overwhelmed. The solution is to turn to email newsletters, which can help you keep a handle on the latest news, tools and tutorials. These great newsletters give you everything you need to know to keep up with the world of data science. Their creators put in the hard work so that you don’t have to. Here are my picks for the seven best data science newsletters.
1.数据药剂
 Data Elixir 每周由 Lon Reisberg 策划,这位自认是技术极客的人有着非常有声望的工作经历,包括为美国宇航局工作。自 2014 年以来,Data Elixir 每周五都会收到您的收件箱,一直在向数据爱好者发送最好的数据科学新闻和资源。Data Elixir 是一个很好的多面手,结合了新闻、观点和教程。Lon 还维护着一个数据科学工作委员会,并在每周的电子邮件中包含最新的工作列表。
Data Elixir 每周由 Lon Reisberg 策划,这位自认是技术极客的人有着非常有声望的工作经历,包括为美国宇航局工作。自 2014 年以来,Data Elixir 每周五都会收到您的收件箱,一直在向数据爱好者发送最好的数据科学新闻和资源。Data Elixir 是一个很好的多面手,结合了新闻、观点和教程。Lon 还维护着一个数据科学工作委员会,并在每周的电子邮件中包含最新的工作列表。
2.数据科学综述
 数据科学综述最早由 RJMetrics 推出。最近,随着 RJMetrics 被拆分成两家不同的公司并出售,“综述”已经独立出来,由 Fishtown Analytics 和 Stitch 赞助。每个星期天,数据科学综述都会在周末休息时间阅读的最佳时间到达你的收件箱。DS Roundup 通常只包括四到五篇好文章,而不是提供一个广泛的文章列表。《数据科学综述》由特里斯坦·哈迪编辑,我最喜欢的是他对每篇文章的摘要。它说得很直白,很容易读懂,也意味着即使我没有时间读完每一篇文章,我仍然可以获得关键的要点。
数据科学综述最早由 RJMetrics 推出。最近,随着 RJMetrics 被拆分成两家不同的公司并出售,“综述”已经独立出来,由 Fishtown Analytics 和 Stitch 赞助。每个星期天,数据科学综述都会在周末休息时间阅读的最佳时间到达你的收件箱。DS Roundup 通常只包括四到五篇好文章,而不是提供一个广泛的文章列表。《数据科学综述》由特里斯坦·哈迪编辑,我最喜欢的是他对每篇文章的摘要。它说得很直白,很容易读懂,也意味着即使我没有时间读完每一篇文章,我仍然可以获得关键的要点。
3.数据科学周刊
 自 2013 年以来,汉娜·布鲁克斯(商业战略专家)和塞巴斯蒂安·古提耶雷兹(数据即& D3.js 忍者)一直在编写《数据科学周刊》,亲手挑选最优秀的文章,并在每周四上午发出。DSW 还进行一些精彩的数据科学采访,并在 twitter 上维护一份真正完整的数据科学资源列表,包括书籍、聚会、数据集、博客和数据科学家。每期《数据科学周刊》都从编辑挑选的前一周的最佳文章开始,随后是更长的数据科学文章和教程列表,提供完美的平衡,帮助您掌握数据科学的脉搏。
自 2013 年以来,汉娜·布鲁克斯(商业战略专家)和塞巴斯蒂安·古提耶雷兹(数据即& D3.js 忍者)一直在编写《数据科学周刊》,亲手挑选最优秀的文章,并在每周四上午发出。DSW 还进行一些精彩的数据科学采访,并在 twitter 上维护一份真正完整的数据科学资源列表,包括书籍、聚会、数据集、博客和数据科学家。每期《数据科学周刊》都从编辑挑选的前一周的最佳文章开始,随后是更长的数据科学文章和教程列表,提供完美的平衡,帮助您掌握数据科学的脉搏。
4.KDnuggets 新闻
 KD nuggets 的淡黄色配色有一种美丽的安慰。KDnuggets 可能是所有数据科学网站中最全面的,由 Gregory Piatetsky-Shapiro 精心维护了 20 多年。超过 649 期可以追溯到 1993 年 8 月 20 日的第一期,这无疑是我们列表中最古老的时事通讯。最初一个月出版两次,但现在每周三出版,KDnuggets News 是每周发布到 KDnuggets 的 30 多篇文章的汇编。KDnuggets news 纯粹是一个没有任何摘要的链接列表,但即使如此,它仍然是前一周发生的事情的最全面的综述之一,这使得它非常值得订阅。
KD nuggets 的淡黄色配色有一种美丽的安慰。KDnuggets 可能是所有数据科学网站中最全面的,由 Gregory Piatetsky-Shapiro 精心维护了 20 多年。超过 649 期可以追溯到 1993 年 8 月 20 日的第一期,这无疑是我们列表中最古老的时事通讯。最初一个月出版两次,但现在每周三出版,KDnuggets News 是每周发布到 KDnuggets 的 30 多篇文章的汇编。KDnuggets news 纯粹是一个没有任何摘要的链接列表,但即使如此,它仍然是前一周发生的事情的最全面的综述之一,这使得它非常值得订阅。
5.奥莱利数据通讯
我记得我在 1996 年购买的第一本 O'Reilly 的书《Perl 编程》。许多数据科学家和软件工程师从 O'Reilly 出版物中学到了编程,它们独特的动物封面和质量被认为是首屈一指的。早在 20 世纪 80 年代,O'Reilly 就已经出版了关于数据的书籍,然而在过去的 6 年中,随着 Strata + Hadoop 世界大会的推出,O'Reilly 已经成为数据世界中的一个发电站。他们的每周数据简讯包含了来自 O'Reilly 自己和其他人的新闻、社论、操作方法和案例研究。我特别喜欢他们如何将一个特定新闻故事或专题的文章分组在一起,以提供一个平衡的视角。
- 订阅奥莱利数据简讯
- 没有可用的档案
6.分析调度
 自 2015 年 12 月起,分析派遣由模式分析策划。Mode 创建一个分析平台,允许您使用 SQL 和 Python 笔记本从几乎任何数据源创建报告和可视化。这是一款很棒的产品——我们在 Dataquest 中使用它进行我们自己的分析,并且非常喜欢它!(他们除了做出一个伟大的产品之外,没有做任何事情来获得这个褒奖)。每周一早上,分析调度会向你的收件箱发送大量关于数据的文章。由于他们所做的事情,这些文章往往涵盖更多的分析主题(包括大量的 SQL ),因此我发现它们非常实用——我总是从他们发布的文章中学到一些东西,可以改善我的日常工作。
自 2015 年 12 月起,分析派遣由模式分析策划。Mode 创建一个分析平台,允许您使用 SQL 和 Python 笔记本从几乎任何数据源创建报告和可视化。这是一款很棒的产品——我们在 Dataquest 中使用它进行我们自己的分析,并且非常喜欢它!(他们除了做出一个伟大的产品之外,没有做任何事情来获得这个褒奖)。每周一早上,分析调度会向你的收件箱发送大量关于数据的文章。由于他们所做的事情,这些文章往往涵盖更多的分析主题(包括大量的 SQL ),因此我发现它们非常实用——我总是从他们发布的文章中学到一些东西,可以改善我的日常工作。
7.数据请求下载

当然,我不能漏掉我们自己的时事通讯,即 Dataquest 下载。每周一我们都会重点报道一些头条新闻,传递一些很棒的职业建议,并尝试用一些很酷的项目和有用的学习资源来激励你。你可以通过注册一个免费的 Dataquest 账户来订阅。当然,我们也有博客,这有点像一个巨大的通迅链接目录。以下是一些我们最喜欢和阅读量最大的帖子:
要订阅,只需在页面底部的框中填写您的电子邮件。
我错过了什么吗?
你最喜欢的数据科学时事通讯是否不在列表中?
联系让我知道!
数据科学的 17 个最佳免费工具
原文:https://www.dataquest.io/blog/best-free-tools-data-science/
November 8, 2019
在数据科学行业工作的最大好处之一就是它充满了免费工具。总的来说,数据科学社区是相当开放和开放的,专业数据分析师和数据科学家每天使用的许多工具都是完全免费的。
但是,如果你刚刚开始,那么可供你使用的资源数量可能会多得令人不知所措。因此,我们没有把你埋在开源好东西的列表中,而是挑选了一些我们绝对喜欢的:使用 Python、R 和 SQL 的数据科学的最佳免费工具。
语言
很容易忘记,因为它们无处不在,但编程语言确实是数据科学工作的最佳免费工具。简单地学习这些语言中的一种,你就能获得巨大的分析能力。我们在这里列出的三种语言——数据科学中最常用的三种语言——都是完全免费使用的。
对于 post 人员来说,语言是他们在选择数据科学工具时做出的最大选择。三种最好的语言是:
- 稀有
- 计算机编程语言
- 结构化查询语言
您会发现数百篇文章试图区分 Python 和 R 哪个更适合数据科学。我们已经写了自己的文章比较 Python 和 R 在更客观的基础上——每种语言如何处理常见的数据科学任务。
事实上,它们都是很好的选择,各有各的优势,我们将在下面概述。如果你刚刚开始,最好选择其中任何一个并开始学习,而不是浪费时间试图找出哪个是最好的。
另一方面,SQL 是 Python 和 r 的补充。它可能不是你学习的第一门语言,但是你将需要学习它。
1.稀有
R 编程语言最初创建于 90 年代中期。r 是整个学术界选择的统计语言,以易学著称,尤其是对那些以前从未使用过编程语言的人来说。
R 语言的一个主要好处是它主要是为统计计算而设计的,所以数据科学家需要的许多关键特性都是内置的。
r 还有一个强大的软件包生态系统,允许扩展功能。有几个 R 包被许多人认为是处理数据的必备工具。我们将在后面的“R 包”部分概述这些内容。
2.计算机编程语言
和 R 一样,Python 也是在 90 年代创建的。但与 R 不同,Python 是一种通用编程语言。它通常用于 web 开发,是最流行的整体编程语言之一。
在 2000 年代中后期,使用 Python 进行数据科学工作开始变得流行起来,因为出现了专门的库(类似于 R 包),为处理数据提供了更好的功能。在过去的十年中,Python 作为数据科学语言的使用有了巨大的增长,从某些指标来看,它现在是数据科学最流行的语言。
Python 的主要优势之一是,因为它是一种通用语言,所以更容易执行与数据工作相关的一般任务。类似地,如果你学习 Python,后来发现软件开发比数据科学更适合你,你所学的很多东西都是可以转移的。
3.结构化查询语言
SQL 是 Python 和 R 的补充语言——如果有人想进入数据科学领域,它通常会是他们学习的第二种语言。SQL 是一种用于与存储在数据库中的数据进行交互的语言。
因为世界上大部分数据都存储在数据库中, SQL 是一种非常有价值的学习语言。数据科学家通常使用 SQL 来检索数据,然后使用 Python 或 r 来清理和分析这些数据。
许多公司还将 SQL 作为“一流”的分析语言,使用允许直接从 SQL 查询结果构建可视化和报告的工具。
R 包
R 有一个欣欣向荣的软件包生态系统,为核心 R 语言增加了功能。这些包由 CRAN 分发,可以使用 R 语法下载(与使用单独包管理器的 Python 相反)。我们下面列出的包是 r 中一些最常用和最流行的数据科学包。
4.Tidyverse
从技术上来说, tidyverse 是 R 包的集合,但我们在这里将它一起包含进来,因为它是 R 中数据科学最常用的一组包,集合中的关键包包括用于数据操作的 dplr、用于导入数据的 readr、用于数据可视化的 ggplot2 等等。

tidyverse 包有一个自以为是的设计哲学,围绕着“整齐的数据”——具有一致形式的数据,使得分析(特别是使用 tidyverse 包)更容易。
tidyverse 的流行程度已经达到了这样的程度,对许多人来说,“在 R 中工作”的想法实际上意味着在 R 中与 tidyverse 一起工作。
5.ggplot2
ggplot2 包允许你在 r 中创建数据可视化。尽管 ggplot2 是 tidyverse 集合的一部分,但它存在于集合之前,并且重要到足以提及它是自己的。
ggplot2 很受欢迎,因为它允许您使用易于理解的语法快速创建专业外观的可视化效果。
R 包括内置的绘图功能,但是 ggplot 包通常被认为是更好的和更容易使用的,并且是数据可视化的头号 R 包。
6.r 降价
R Markdown 包有助于使用 R. R Markdown 文档创建报告,R Markdown 文档是包含与 Markdown 文本交错的代码片段的文本文件。
R Markdown 文档通常在笔记本界面中编辑,该界面允许并排创建代码和文本。笔记本界面允许代码被执行,并且代码的输出与文本一起被看到。

行动中的 R Markdown 笔记本
R Markdown 文档可以呈现为多种多样的格式,包括 HTML、PDF、Microsoft Word、书籍等等!
7.发光的
这个闪亮的包允许你使用 r 构建交互式的 web 应用程序。你可以构建一些功能,允许人们以网页的形式与你的数据、分析和可视化进行交互。
Shiny 特别强大,因为它消除了创建应用程序时对 web 开发技能和知识的需求,并允许您专注于您的数据。
8.最低贷款利率(minimum lending rate)
mlr 包提供了一组标准的语法和功能,允许您在 R 中使用机器学习算法。虽然 R 具有内置的机器学习功能,但使用起来很麻烦。Mlr 提供了一个更简单的界面,因此您可以专注于训练您的模型。
mlr 包含分类、回归和聚类分析方法以及无数其他相关功能。
Python 库
和 R 一样,Python 也有蓬勃发展的包生态系统,虽然 Python 包通常被称为库。
与 R 不同,Python 的主要目的不是作为一种数据科学语言,所以使用像 pandas 这样的以数据为中心的库或多或少是在 Python 中处理数据所必须的。
可以使用 pip 从PyPI(Python 包索引)下载 Python 包,这是 Python 自带的一个工具,但在 Python 编码环境之外。
(pip 的补充选择是 conda 包管理器,我们将在后面讨论它。)
9.熊猫
pandas 库是为清理、操作、转换和可视化 Python 中的数据而构建的。虽然它是一个单独的包,但它在 R 中最接近的模拟是 tidyverse 集合。
除了提供很多便利之外,pandas 在处理数据方面通常比纯 Python 更快。和 R 一样,pandas 也利用了矢量化的优势,加快了代码的执行速度。
10.NumPy
NumPy 是一个为科学计算提供功能的基本 Python 库。NumPy 提供了构建 pandas 的一些核心逻辑。通常,大多数数据科学家将与 pandas 一起工作,但是了解 NumPy 很重要,因为它允许您在需要时访问一些核心功能。
11. Matplotlib
Matplotlib 库是一个强大的 Python 绘图库。数据科学家经常使用库中的 Pyplot 模块,它提供了绘制数据的标准接口。
pandas 中包含的绘图功能在幕后调用 matplotlib,因此理解 Matplotlib 有助于定制 pandas 中的绘图。
12. Scikit-Learn
Scikit-learn 是 Python 最流行的机器学习库。该库提供了一组基于 NumPy 和 Matplotlib 构建的工具,用于准备和训练机器学习模型。

用 scikit-learn 库创建的图
可用的模型类型包括分类、回归、聚类和降维。
13. Tensorflow
Tensorflow 是一个 Python 库,最初由 Google 开发,提供了与神经网络和深度学习合作的接口和框架。
Tensorflow 非常适合深度学习擅长的任务,如计算机视觉、自然语言处理、音频/视频识别等。
软件
到目前为止,我们已经了解了数据科学的最佳语言以及其中两种语言的最佳包。(作为一种查询语言,SQL 有点不同,不使用相同意义上的“包”)。
接下来,我们将了解一些对数据科学工作有用的软件工具。这些都不是开源的,但是任何人都可以免费使用,如果你经常处理数据,它们可以节省大量时间。
14.谷歌工作表
如果这不是一个免费工具的列表,那么毫无疑问微软 Excel 将会在这个列表的顶端。无处不在的电子表格软件使得以可视化的方式处理数据变得快速和容易,并且被全世界数百万人使用。
谷歌的 Excel 克隆版拥有 Excel 的核心功能,任何拥有谷歌账户的人都可以免费使用。
15.RStudio 桌面
RStudio 桌面是最流行的 R 工作环境,它包括代码编辑器、R 控制台、笔记本、绘图工具、调试工具等等。
此外,Rstudio(开发 Rstudio 桌面的公司)是现代 R 开发的核心,雇佣了 tidyverse、shiny 和其他重要 R 包的开发人员。
16.Jupyter 笔记型电脑

Jupyter Notebook 是使用 Python 进行数据科学研究的最流行的环境。与 R Markdown 类似,Jupyter 笔记本允许您将代码、文本和绘图合并到一个文档中,这使得数据工作变得容易。
像 RMarkdown 一样,Jupyter 笔记本可以导出为多种格式,包括 HTML、PDF 等。
Dataquest 的 guided Python 数据科学项目几乎所有的任务学生都在 Jupyter 笔记本上构建项目,因为这是工作数据分析师和科学家在现实世界工作中通常做的事情。
17.蟒蛇
Anaconda 是 Python 的一个发行版,专门用于帮助您安装科学的 Python 工具。在 Anaconda 之前,唯一的选择就是自己安装 Python,然后一个一个的安装类似 NumPy,pandas,Matplotlib 这样的包。这并不总是一个简单的过程,对于新的学习者来说也很困难。
Anaconda 在一个简单的安装中包含了数据科学所需的所有主要包,这节省了时间并允许您快速入门。它还内置了 Jupyter 笔记本电脑,可以从启动窗口轻松启动新的数据科学项目。这是开始使用 Python 进行数据科学的推荐方法。
Anaconda 还包括 conda 包管理器,它可以作为 pip 的替代来安装 Python 包(尽管如果您愿意,也可以使用 pip)。
免费学习数据科学
上面,我们列出了一些最好的数据科学免费工具。但是当然,这些工具中的大多数只有在你学会了有效使用它们所需的技能后才是真正有用的。
谢天谢地,也有很多学习数据科学的免费资源!我们重点介绍了一些关于数据科学的最佳免费书籍,我们还发布了许多免费的 Python 教程和 R 教程,让学习变得更加容易。
不过,最好的学习方法是实际编写代码。我们的交互式浏览器课程将帮助您快速编写真正的代码并使用真正的数据。我们每条学习路线的前两门完整课程都是免费的,这些课程花费了我们数小时的学习时间,涵盖了所有的基础知识等。
我们不用视频,不用选择题,也不用填空题。相反,我们要求你从一开始就在实际的功能代码中应用你所学的一切。我们会自动检查您的答案,以确保您回答正确。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
每种场景 12 毫升课程(初级到高级)
原文:https://www.dataquest.io/blog/best-machine-learning-courses/
December 5, 2022
在接近机器学习时,每个人都有不同的知识和技能水平。有几十个,如果不是几百个,机器学习课程,找到正确的一个可能是困难的。理想的课程应该做到以下几点:
- 尽量减少冗余知识的数量
- 最大限度地享受新话题
- 提供真实的编程示例
- 通过作品集项目提升你的简历
本指南将帮助您根据现有知识和对编程的熟悉程度找到最佳的机器学习课程。我们分析了基于 14 个独特变量的顶级课程,得出了以下列表。
以下是 2022 年最好的机器学习课程总结:
- 最适合初学者: Dataquest 的 Python 中的机器学习
- 最适合中级学习者: 机器学习专精
- 最适合高级学习者: 用 Python 进行机器学习:从线性模型到深度学习
- 最佳免费课程: 谷歌的机器学习速成班
- 最佳在线机器学习训练营: 编码道场的机器学习训练营
- 最佳现场机器学习训练营: 哥伦比亚工程数据分析训练营
- 最适合数据科学家: Dataquest 的数据科学家在 Python 途径
- 最适合音乐人和艺术家: 适合音乐人和艺术家的机器学习
最适合初学者
Dataquest 在 Python 中的机器学习
Dataquest 为希望在数据科学领域发展职业生涯的初学者提供了最佳课程。该课程为学习有监督和无监督的机器学习算法提供了基础。
涵盖的主题包括线性回归,逻辑回归,k-均值聚类,决策树,等等。每个主题都有必要的细节,为你解决现实世界的问题做好准备。
最重要的是,这门课程允许你直接开始写代码。每一课都配有一个真实世界的项目,让你建立自己的投资组合,向未来的雇主展示,并巩固你的知识基础。
您将参与的项目包括:
- 使用线性回归模型预测保险成本
- 使用逻辑回归对心脏病进行分类
- 使用就业数据确定生产率阈值
该课程包括一个最终的顶点项目,由专家评审,以完善你的作品集。
以下是我们对该课程的详细分析:
| 价格:$ 399/年,$ 49/月(提供折扣) | 彻底性:机器学习的完整介绍,包括简历制作的组合项目 |
| 前期费用:免费开始 | 特长:监督和非监督算法
Python 编程 |
| 评分: 4.8 (359 条评论) | 所需前提:Python 基础知识
基础数学概念 |
| 预计持续时间: 2 个月(每周 10 小时) | 定速:自定速 |
| 认证项目:是 | 项目数量: 7 |
| 注册学生: 400 人 | 退款选项:如果您在完成职业道路后不满意,可以退款 |
| 学习风格:编码模块和指导项目 | 职业服务:完成认证和强大的社区支持 |
学生推荐信
|  | “Dataquest 实际上让你思考并运用你的技能。你真的不需要在训练营上花 1 万美元。”—米格尔·库托 |
| “Dataquest 实际上让你思考并运用你的技能。你真的不需要在训练营上花 1 万美元。”—米格尔·库托 |
|  | “Dataquest 上的学习路径令人难以置信。你不用猜你接下来该学什么。”—奥特维奥·西尔韦拉 |
| “Dataquest 上的学习路径令人难以置信。你不用猜你接下来该学什么。”—奥特维奥·西尔韦拉 |
|  | "我无法相信复杂的材料在 Dataquest 上是如此简单明了."—维多利亚·乔拉耶娃 |
| "我无法相信复杂的材料在 Dataquest 上是如此简单明了."—维多利亚·乔拉耶娃 |
机器学习 A-Z:数据科学中的 Python&R
对于希望学习如何在 Python 或 r 中使用机器学习的初学者来说,这是一门非常棒的课程。该课程直接教授不同的机器学习算法和概念,包括支持向量回归、自然语言处理和深度学习。
该课程提供了视频和测验的组合形式,让您在学习过程中检查自己的理解情况。你将完成几个实践练习,这些练习与你将要学习的材料是高度互补的。
以下是我们对该课程的详细分析:
| 价格: $84.99 | 彻底:机器学习算法的彻底介绍 |
| 前期费用:全额支付 | 特长:监督和非监督算法
自然语言处理
Python 和 R 编程 |
| 评分: 4.5 (163,675 条评论) | 所需前提:Python 和 R 基础数学概念 |
| 预计持续时间: 42.5 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 0 |
| 注册学生人数:906,661 人 | 退款选项:30 天内退款 |
| 学习方式:视频讲座、文章和测验 | 职业服务:结业证书 |
对于想要了解机器学习所有内容的初学者来说,这是一门令人惊叹的课程。感谢导师(哈德林·德·庞特维斯和基里尔·叶列缅科)清晰地解释了它,并使它易于理解。我希望这些知识能帮助我发展自己的公司,推动技术进步,并造福他人。
—努曼阿姆里姆
最佳免费课程
谷歌的机器学习速成班,采用 tensor flow API
这个谷歌课程对于希望学习机器学习的初学者和希望复习的有经验的数据科学家来说都很棒。该课程首先询问您的经验水平,然后推荐特定资源以实现最大效率(智能机器学习课程!).
该课程包括 25 节课,需要 15 个小时完成,包括带有交互式可视化的真实案例研究。此外,你还将获得谷歌内部机器学习框架 Tensorflow 的实践经验。
本课程高度浓缩并消除了核心概念,因此需要进一步研究以更深入地理解所涵盖的主题。
课程亮点:
- 来自谷歌研究人员的讲座
- 访问现实世界应用的配套 Kaggle 数据集
- 洞察关键的机器学习概念,包括损失、梯度下降和神经网络
以下是我们对该课程的详细分析:
| 价格:免费 | 彻底性:核心机器学习概念的高级概述 |
| 前期费用:无 | 特长:用 Tensorflow神经网络进行 Python 编程 |
| 评级:不公开 | 所需前提:Python 基础
基础数学
微积分(针对高级题目) |
| 预计持续时间: 15 小时 | 定速:自定速 |
| 认证项目:否 | 项目数量:无 |
| 注册学生:非公立 | 退款选项:不可用(免费课程) |
| 学习风格: 25 节课,30+练习,来自谷歌研究人员的讲座 | 职业服务:无 |
Kaggle 的机器学习入门
Kaggle 是互联网上访问原始数据的最佳平台,并通过赞助的比赛来测试您的数据科学技能。
这门课程是 Kaggle 对一切数据科学的介绍,完全免费。该材料高度简洁,可以在 3 小时内完成,并将向您介绍如何使用 Kaggle 的平台。
本课程将介绍基本的数据探索、欠拟合和过拟合模型、随机森林,并最终让你为竞争做好准备。虽然不是很长,但该课程是对 Kaggle 平台的一个很好的介绍,对于任何有抱负的机器学习专家或数据科学家来说,这都是一个很好的资源。
以下是我们对该课程的详细分析:
| 价格:免费 | 彻底性:机器学习概念的高级概述 |
| 前期费用:无 | 特长:Kaggle 的编程平台 |
| 评级:不公开 | 必备先决条件:Python 基础基础数学概念 |
| 预计持续时间: 3 小时 | 定速:自定速 |
| 认证项目:否 | 项目数量: 0 |
| 注册学生:非公立 | 退款选项:不可用(免费课程) |
| 学习方式: 7 课 | 职业服务:无 |
中级学习者最佳
机器学习专业化
该计划由三门课程组成:
- 监督机器学习:回归和分类
- 高级学习算法
- 无监督学习、推荐器和强化学习
对于之前有机器学习知识的人来说,这是一门很棒的课程,它涵盖了广泛的主题,会让你感觉像个专家。
课程从监督机器学习开始,你将学习线性和逻辑回归。从那里,您将进入更高级的算法,并学习如何使用 Tensorflow 构建神经网络。最后,您将完成无监督学习,以执行聚类和异常检测,并构建深度强化学习模型。
Python 实践包括:
- 用 NumPy 和 scikit-learn 构建机器学习模型
- 用张量流训练神经网络
- 用协同过滤方法构建推荐系统
- 构建深度强化学习模型
Coursera 提供了这个项目的付费订阅版本,它允许你获得一个结业证书,等待项目的完成和及格分数。或者,你可以免费旁听课程,但你将没有资格获得证书。
以下是我们对该课程的详细分析:
| 价格:免费;Coursera Plus(每月 39 美元) | 透彻:对核心机器学习概念的透彻概述 |
| 前期费用:免费试用(7 天) | 特长:Python 编程用 Tensorflow监督和非监督算法 |
| 评分:4.9(6013 条评论) | 必备前提: Python 基础知识 |
| 预计持续时间: 3 个月(每周 9 小时) | 定速:自定速 |
| 认证项目:是 | 项目数量: 1 |
| 注册学生人数:98393 人 | 退款选项:付款后 14 天内退款 |
| 学习方式:视频讲座、交互式编码练习和一个期末项目 | 职业服务:技能展示证书 |
学生推荐信
|  | “我迷上了课程中的一切,从课程内容和助教反馈,到 meetup 活动和教授的 Twitter 信息。”—泽山大学 |
| “我迷上了课程中的一切,从课程内容和助教反馈,到 meetup 活动和教授的 Twitter 信息。”—泽山大学 |
|  | “事实是我热爱学习——我总是在寻找新的学习机会。Coursera 上的内容质量总是超出我的预期。”—娜塔莉·h . |
| “事实是我热爱学习——我总是在寻找新的学习机会。Coursera 上的内容质量总是超出我的预期。”—娜塔莉·h . |
|  | “能够尽可能多地学习对我来说很重要。我在 Coursera 上的课程让我对未来充满信心和希望。”—理查德·b . |
| “能够尽可能多地学习对我来说很重要。我在 Coursera 上的课程让我对未来充满信心和希望。”—理查德·b . |
佐治亚理工学院的机器学习
这门课程是乔治亚理工学院在线硕士课程的一部分,通过 Udacity 免费提供!该课程是研究生水平的课程,有一些崇高的先决条件,但提供了对几个核心机器学习概念的深入研究。
在导师 Michael Littman、Charles Isbell 和 Pushkar Kolhe 的带领下,您将通过视频讲座和作业探索有监督、无监督和强化学习的概念。此外,你还将获得马尔可夫决策过程和信息论的介绍。
这门课程也是 Udacity 的 NanoDegree 计划的一部分,该计划收集了数据科学和机器学习相关的课程,可以通过付费订阅来完成。
以下是我们对该课程的详细分析:
| 价格:免费;1077 美元(纳米学位课程) | 彻底性:详细的课程侧重于监督、非监督和强化学习 |
| 前期费用:免费开始 | 专业: Python 编程有监督、无监督和强化学习信息论 |
| 评级:不公开 | 所需先决条件:
概率论、线性代数和统计学
熟悉任何编程语言
熟悉神经网络 |
| 预计持续时间: 4 个月 | 定速:自定速 |
| 证书项目:否(带付费选项的纳米学位) | 项目数量: 0 |
| 注册学生:非公立 | 退款选项:在第一个月的订购日的前两天内退款 |
| 学习方式:视频讲座、作业、互动小测验 | 职业服务:未提供服务 |
最适合高级学习者
用 Python 进行机器学习:从线性模型到深度学习
本课程是统计和数据科学 MITx MicroMasters 项目的一部分,需要精通 Python 编程和大学水平的多变量微积分。
本课程提供从线性回归到神经网络和强化学习等主题的高级教学。本课程提供 Python 实践示例,学生将能够完成几个项目,包括:
- 自动评论分析器
- 基于神经网络的数字识别
- 强化学习
该课程由麻省理工学院的雷吉娜·巴兹莱教授、汤米·雅克拉教授和麦贝夷·朱教授授课,共 15 周。这门课和其他三门课组成了麻省理工学院完整的微硕士课程。要获得学位,你必须成功完成所有四门课程,并通过监考考试。不幸的是,这门课程要到 2023 年 2 月才开设,但开设时它的价格非常值得!
以下是我们对该课程的详细分析:
| 价格:免费(限制访问);300 美元(完全访问) | 彻底性:深度机器学习算法,用于精通 ML |
| 前期费用:免费开始 | 特长:Python 编程监督学习、深度学习、强化学习 |
| 评分:4.9(6013 条评论) | 必要先决条件:对 Python 编程和概率论有很好的理解大学水平的单变量/多变量微积分
向量和矩阵 |
| 预计工期:15 周,每周 10-14 小时
2023 年 2 月 1 日开工 | 起搏:教师起搏 |
| 认证项目:是 | 项目数量: 3 |
| 注册学生人数:174,710 人 | 退款选项:自购买之日起 14 天内退款 |
| 学习方式:视频授课、分级练习、考试(仅限付费版) | 职业服务:证书完成后付费订阅 |
生产中的机器学习简介
这个课程来自于 DeepLearning。人工智能,由斯坦福大学的吴恩达创立。本课程专为对机器学习有透彻理解的个人而设计,介绍了机器学习模型在生产环境中的实际部署。
该课程分为三周的增量,重点关注机器学习开发生命周期、选择和训练模型,以及使用具有现实世界约束的不同数据类型。
本课程与列表中的其他课程不同,它提供了作为数据科学家的日常操作的实际示例。你将学习机器学习的基本概念和现代软件开发的功能专业知识。
以下是我们对该课程的详细分析:
| 价格:$ 49/月,免费试用 | 彻底:为工作成功做好充分准备 |
| 前期费用:免费试用(7 天) | 专业:
生产质量代码 |
| 评分: 4.8 (2,155 条评论) | 所需先决条件:AI/深度学习的一些知识中级了解 Python 编程经验具备任何深度学习框架(PyTorch,Keras,或 TensorFlow) |
| 预计持续时间: 12 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 0 |
| 注册学生人数:66,698 人 | 退款选项:自购买之日起 14 天内退款 |
| 学习方式:视频讲座、交互式编码练习和一个期末项目 | 职业服务:结业证书(付费订阅) |
精品课程;你学习了 MLOps 的基本原理。如果你想了解机器学习算法在生产中的生命周期,这是一门推荐课程。
—DG
我喜欢对数据质量重要性的认可。机器学习不仅仅是训练模型。只有转移到现实生活中的数据,才能获得真正的好处
—萨
贯穿 ML 生命周期的实用且结构合理的建议。来自现实世界的问题和经验的例子使建议更加具体,并有助于反思你自己的问题。
—DC
最佳在线机器学习训练营
编码 Dojo 的数据科学训练营
Coding Dojo 提供了一个为期 16 周(或 20 周)的训练营,深入研究数据科学和 Python 机器学习的基础知识。该计划向您介绍数据准备,分析和可视化,以及如何正确地将机器学习算法应用于现实世界的例子。
这个项目的好处包括建立一个投资组合,向潜在的雇主展示你的新技能和一个结业证书。本课程是 Python 的实践课程,将带您了解各种主题,包括回归模型、数据库编程、无监督学习和数据可视化。
该课程价格不菲,但具有很大的灵活性,毕业后 180 天内的就业率高达 83.8%。
以下是我们对该课程的详细分析:
| 价格:11995 美元(16 周);13 995 美元(20 周) | 彻底性:获得工作所需的一切 |
| 前期费用:全额支付(提供奖学金和学费资助选项) | 特长:Python 编程
监督/非监督学习
数据操纵与可视化 |
| 评级:不公开 | 所需先决条件:Python 基础知识 |
| 预计持续时间: 16-20 周,每周 20 小时 | 起搏:教师起搏 |
| 认证项目:是 | 项目数量:几个 |
| 注册学生:非公立 | 退款选项:在第一天上课前退款(减去 100 美元管理费) |
| 学习方式:视频讲座、作业、项目 | 职业服务:
求职、简历准备和模拟面试 |
最佳面对面机器学习训练营
哥伦比亚工程数据分析训练营
哥伦比亚大学提供了一个完全沉浸式的 24 周数据分析训练营,为您在数据科学领域的职业生涯做准备。该课程涵盖广泛的主题,包括 SQL、中级 Excel、机器学习和软件开发最佳实践。
该计划要求每周工作 3 天,允许个人兼职完成所有要求。课程的亮点是项目演示日,学生可以向当地专业人士展示他们的顶点项目。
虽然出勤率很高,但你将受益于广泛的职业服务来帮助你被录用。你会被指派一名专门的蔻驰个人资料和职业指导,他们会帮你润色简历,为面试做准备。
以下是我们对该课程的详细分析:
| 价格:14745 美元 | 彻底性:获得工作所需的一切 |
| 前期费用:全额支付(提供学费融资选项) | 专业:Python 与 Javascript 编程
SQL 数据库与 ExcelMachine 学习 |
| 评级:不公开 | 必备条件:Python 基础基础数学技能
两年商业、管理、金融、统计或相关领域工作经验 |
| 预计持续时间: 24 周,每周 3 天 | 起搏:教师起搏 |
| 认证项目:是 | 项目数量:几个 |
| 注册学生:非公立 | 退款选项:在计划的第一个日历周内可用(初始存款不可退款) |
| 学习方式:现场讲座、编码作业、顶点项目 | 职业服务:专门的个人资料蔻驰和职业总监组合评论、简历和社交媒体个人资料支持、职业内容和实践课程。
|
最适合数据科学家
Dataquest 的数据科学家在 Python 途径
Dataquest 是进入数据科学职业的最佳选择。数据科学家途径提供了一个全面的课程,包括学习统计和机器学习框架,使用数据库,设计惊人的可视化。
职业道路包括一系列课程,将带您从初学者到完全胜任特定数据科学职位。这些职业道路就像一个价值 10,000 美元的训练营一样全面,但成本只是它的一小部分。完成课程后,您将有一个全面的项目组合展示给潜在的雇主,并访问 Dataquest 的专家和专业人士社区。
以下是我们对该课程的详细分析:
| 价格:$ 399/年,$ 49/月(提供折扣) | 彻底性:获得工作所需的一切 |
| 前期费用:免费开始 | 特长:Python 编程 SQL 和数据库编程机器学习包罗万象的数据科学技能集 |
| 评分: 4.8 (359 条评论) | 所需先决条件:无 |
| 预计持续时间: 9 个月(每周 10 小时) | 定速:自定速 |
| 认证项目:是 | 项目数量: 28 |
| 注册学生人数:271,400 人 | 退款选项:完成后如果不满意可以使用 |
| 学习风格: 36 门课程,28 个项目 | 职业服务:完成认证和强大的社区支持 |
它们就像真的一样。Dataquest 向您展示您需要学习的内容,然后帮助您应用这些内容。
——埃迪·柯克兰
最适合音乐家和艺术家
面向音乐家和艺术家的机器学习
我们列表中的最后一项是为音乐爱好者开设的课程。伦敦大学的机器学习课程与我们名单上的其他课程相比,采取了一种非常不同的角度,专注于可以用来理解人类手势、音乐音频和其他实时数据的机器学习技术。
除了教授传统的机器学习方法,如分类和回归,您还将学习如何将您的机器学习工具连接到常见的数字艺术工具,如 Max/MSP 和 Unity 3D。
以下是我们对该课程的详细分析:
| 价格:$ 20/月 | 彻底性:将机器学习应用于艺术问题的能力 |
| 前期费用: 1 次免费 | 专业:专注于数字艺术整合的机器学习 |
| 评分: 5.0 (89 条评论) | 所需先决条件:熟悉数字艺术工具(Wekinator)访问传感器(操纵杆、网络摄像头、麦克风等。) |
| 预计持续时间: 7 场,每场 8 小时 | 定速:自定速 |
| 认证项目:是 | 项目数量: 0 |
| 注册学生:非公立 | 退款选项:不提供退款 |
| 学习风格:视频和作业 | 职业服务:结业证书 |
对于任何对交互设计的未来感兴趣的人来说,这是一门很棒的课程。
—安东尼奥·里佐
2023 年最佳 Python 课程(带学生评价)
November 7, 2022
选择正确的 Python 课程对你的成功至关重要。它可以帮助您完成以下任务:
- 节省数千美元
- 减少学习所需的时间
- 降低故障率
- 最好让你为新的职业做好准备
- 最大限度享受
我们都有不同的目标和学习方式。学习 Python 没有放之四海而皆准的“最佳”方法。本指南将帮助您找到最适合您的情况的 Python 课程。我们分析了几十门课程,使用了 14 个变量,得出了下面的列表。
以下是 2023 年最好的 Python 课程汇总:
- 最适合数据科学: Dataquests 的职业道路
- 最适合 Web 开发: Nick Walter 的 Python Web 开发课程
- 最适合金融:365 Careers Python for Finance 投资基础课程
- 最适合软件工程: 授予 Klimaytys 的 Python 3 软件工程课程
- 最佳在线 Python 训练营: 乐 Wagon 数据科学训练营
- 最佳现场 Python 训练营: Codeup 在得克萨斯州的数据科学训练营
- 最佳免费 Python 课程: 谷歌的 Python 速成班
最适合数据科学
Dataquest 的职业道路
Dataquest 是数据科学的最佳选择。这是因为它全面的职业道路,实惠的价格,以及以项目为重点的课程。
职业道路包括一系列课程,将带您从初学者到完全胜任特定数据科学职位。这些职业道路就像一个价值 10,000 美元的训练营一样全面,但成本只是它的一小部分。
以下是 Dataquest 目前的职业道路:
另外,课程不是基于视频的。它会让你从第一天就开始编码。你将完成数百个练习和数十个项目。这是最好的学习方法。
为了这篇评论,我们将把重点放在最受欢迎的职业道路上:数据科学家。
- 价格:$ 24.50/月(当前促销)
- 前期费用:免费开始
- 评分: 4.8 (359 条评论)
- 预计时长:全职:2-3 个月;兼职:6-9 个月
- 类型:在线
- 注册学生人数:25.9 万人
- 学习风格:编码模块和指导项目
- 彻底性:获得工作所需的一切
- 专业:数据科学
- 所需先决条件:无
- 定速:自定速
- 项目数量: 26
- 退款选项:完成后如果不满意可以使用
- 职业服务:社区支持
学生推荐信
Dataquest 从最基础的水平开始,因此初学者可以理解这些概念。我之前尝试过学习编码,用 Codecademy 和 Coursera。我很挣扎,因为我没有编码的背景,而且我花了很多时间在谷歌上搜索。Dataquest 帮助我真正学会了。
—伦梅尔顿
我真的很喜欢在 Dataquest 上学习。我研究了几个其他选项,发现它们相对于 Dataquest 的方法来说太容易上手,太容易填空了。Dataquest 上的项目是我得到这份工作的关键。我收入翻倍了!
—维多利亚·e·古齐克
我上过 DataCamp 和 Dataquest 的课程,在我看来,Dataquest 要好得多,因为它让你付出努力。
—Jorge Varade
最适合网络开发
Nick Walter 在 Udemy 上举办的 Python Web 开发训练营
如果你想进入使用 Django 和 Python 的 web 开发领域,Nick Walter 的 Udemy 课程非常棒。Nick 在 Udemy 上总共教授了超过 270,000 名学生,获得了令人印象深刻的 55,000 条评论。
人们喜欢他的课程,因为他非常关注项目。一旦注册,你将能够从头开始建立三个完整的网站。
- 价格: $99
- 前期费用: 100%的前期价格
- 评分:4.7(5581 条评论)
- 预计时长: 10 小时讲座
- 类型:在线
- 注册学生人数:23,256 人
- 学习方式:视频讲座和项目
- 彻底性:很好的介绍,但在某些方面有所欠缺
- 专业:网页开发
- 所需先决条件:无
- 定速:自定速
- 项目数量: 3
- 退款选项:30 天内,如果您不满意
- 职业服务:无
学生推荐信
这种快速简洁的授课风格直击要害,同时确保核心概念不变。这家伙可以教任何东西,这很好,但这是一个特别令人兴奋的话题。我现在觉得和姜戈在一起很舒服。
— 强尼 W
尼克,谢谢你给我上了一堂精彩的课!我刚到姜戈,你的课程让学习变得既简单又有趣。我在对 Django 一无所知的情况下开始了这个课程,并满怀信心地完成了自己的网站建设。再次感谢!
—马杜米塔 P
最适合金融
365 Careers Python for Finance 投资基础课程
如果你想专攻金融,这个在线 Python 课程是你最好的选择。它从教你 Python 的基础开始。然后,深入探讨如何将 Python 知识应用于金融领域。
在财务部分,您将学习如下内容:
- 股票风险
- 股票投资组合的回报率
- 股票之间的相关性
- 多元回归分析
- 还有更多
另外,这是一门 Udemy 课程,所以它有 30 天无条件退款保证。你不会输的。
- 价格: $129.99
- 前期费用: 100%前期费用
- 评分: 4.6/5 (25,119 条评论)
- 预计时长:8 小时 45 分钟的视频讲座
- 类型:在线
- 注册学生人数:119,972 人
- 学习方式:带练习的视频讲座
- 彻底: Python 和金融基础
- 专业:金融
- 所需先决条件:无
- 定速:自定速
- 项目数量:无
- 退款选项:如果您不满意,可在 30 天内退款
- 职业服务:无
学生推荐信
这门课程充满了知识,无论是金融知识还是 Python 知识。视频被分成小的可消费的包,包里有容易理解的语言和动画。对于想把职业生涯转向金融领域的计算机科学学生来说,这是最好的课程之一。
—里特维克
课程中使用的方法论真的很棒。本课程从 Python 和 Anaconda 的介绍开始,在转向 Python 在金融中的应用之前,将转向 Python 的基本和高级技能。
——
最适合软件工程:
授予 Klimaytys 的 Python 3 软件工程课程
这个 Python 课程是新的,但是不要让它阻止你。该讲师开发了 28 门课程,收集了 18,831 条评论,并教授了超过 18,000 名学生。
如果你想成为一名使用 Python 的软件工程师,这是最好的选择。
为什么我们对这门课程评价如此之高?因为每个视频模块都包含一个小练习,让你从所学的知识中建立一些东西。此外,在在线课程结束时,您将学习如何为咖啡店构建一个会计应用程序。你好,真人技能!
- 价格: $84.99
- 前期费用: 100%前期费用
- 评分: 4.7 (8 条评论)
- 预计时长:6 小时 2 分钟讲座
- 类型:在线
- 注册学生: 49 人
- 学习方式:视频讲座、练习题、1 个项目
- 彻底性:只是基本面
- 专业:软件工程
- 所需先决条件:无
- 定速:自定速
- 项目数量: 1
- 退款选项:如果您不满意,可在 30 天内退款
- 职业服务:无
学生推荐信
导师对题目的讲解极其到位!最近很难找到好的教师。
—约翰 G
非常好的课程,很好的解释,耐心的老师,很好的教学能力,我学到了很多。对课程很满意。
—塞萨尔 B
最佳在线 Python 训练营
Le Wagon 数据科学训练营
如果你喜欢严格的结构,需要额外的求职支持,并且负担得起高昂的价格,Le Wagon 是学习数据科学 Python 的最佳途径。
近 9,000 美元的价格标签当然很贵,但你在整个过程中得到的支持是值得的。
不幸的是,Le Wagon 不提供工作保障。然而,他们确实拥有令人印象深刻的 93%的就业率。
- 价格:8850 美元
- 前期费用: 100%,但有灵活的支付选项
- 评分: 4.9 (1001 条评论)
- 预计时长:全职:2 个月;兼职:6 个月
- 类型:在线或离线
- 注册学生人数:17651 人
- 学习方式:视频讲座、编码模块、教程、项目
- 彻底性:获得工作所需的一切
- 专业:数据科学
- 所需前提:基础 Python 和数学
- 调步:周结构
- 项目数量: 1 个顶石项目
- 退款选项:无
- 职业服务:一对一辅导和雇佣合作伙伴
学生推荐信
在我看来,如果你正在寻找某种职业改变,加入阿乐旅行车训练营是最好的决定。一切都在现场,从训练营的强度到讲课的工作人员,还有助教。好友系统绝对是我最喜欢的功能之一,尤其是这样我就可以和我所有的新同学联系了。
—尼古拉斯桑托斯
辞去物流工作后,我决定加入乐旅行车,我从来没有后悔我的决定!我在短短 9 周内取得了令人难以置信的进步,并在训练营结束后的两周内找到了一份数据科学家的工作。不要犹豫!
—瓦伦丁
最佳现场 Python 训练营
Codeup 在德克萨斯州的数据科学训练营
对一些人来说,传统的面对面课堂环境是不可协商的。它可以让学生负起责任,提供最高水平的支持,并培养专业关系。
如果这是你正在寻找的东西,那么 Codeup 的数据科学训练营是最好的选择。尽管价格很高,但他们提供了工作保障。所以只有两种可能的结果:
- 你支付了 31,500 美元,却得到了一份数据科学的工作。
- 你拿回你的钱。
如果你问我,这是一个公平的交易。
当然,最大的好处也是最大的坏处:那就是面对面。目前,Codeup 只服务于德克萨斯州的几个城市。
- 价格:31500 美元
- 预付费用: 100%预付或毕业后 3 个月支付
- 评分: 4.6/5 (69 条评论)
- 预计持续时间: 20 周
- 类型:当面
- 注册学生:未知
- 学习方式:面授;基于项目
- 彻底性:获得工作所需的一切
- 专业:数据科学
- 所需前提:基础统计学和 Python 编程
- 调步:每日所需出勤
- 项目数量:小型项目贯穿始终;1 顶石项目
- 退款选项:没找到工作全额退款
- 职业服务:职业指导、面试准备、简历制作
学生推荐信
对于 Codeup 数据科学项目,我只有很棒的话要说。我喜欢老师、课程和就业安置团队。我们从“hello world”开始,一直到创建机器学习模型。学习并没有随着编程而停止。
编码只是这个项目让你做好准备的冰山一角。没有捷径,每天早上 9 点到下午 5 点。一路上,你会得到小组工作、家庭作业和大量的支持。
他们有一整个安置团队致力于帮助你找到一份职业。他们帮助我在甲骨文找到了职业,我热爱我的职业。这个项目真的改变了生活,任何人都可以做。
—约书亚·查韦斯
当然,也有其他学校,但是没有一所学校能比得上整个 Codeup 团队的服务和承诺。我花在教育上的最好的钱…
—尼克
最佳免费 Python 课程
谷歌的 Python 速成班
如果你想免费学习 Python,那么谷歌的 Python 速成班是最好的选择。
这是 Coursera Plus 课程,费用为 39 美元/月。然而,Coursera 有一个“审核功能”,允许你在没有正式订阅的情况下查看内容。唯一的缺点是,完成后你不会获得 Python 认证。
尽管是免费的,但 Python 速成班有巨大价值的三个主要原因是:
- 由合格的谷歌讲师授课。
- 它的评分为 4.8/5,评论超过 20,000 条。
- 它比大多数其他付费课程更全面。
详细信息:
- 价格:免费
- 前期费用: $0
- 评分: 4.8/5 (26,635 条评论)
- 预计持续时间: 29 小时
- 类型:在线
- 注册学生人数:691,433 人
- 学习方式:视频讲座,互动编码练习
- 彻底性: Python 基础知识
- 专业:普通
- 所需先决条件:一点 Python 知识是有帮助的
- 定步调:自定步调(有可重置的截止日期)
- 项目数量: 1
- 退款选项:不适用
- 职业服务:无
学生证明
课程设计和执行都很好。主题按照逻辑顺序清晰呈现。视频中嵌入的互动练习让概念变得实用而非抽象。实践练习进一步强化了这些概念。每个模块的分级评估清楚地解释了问题,并公平地评估学习。期末项目很有挑战性,但不是压倒性的。学生绝不会感到毫无准备或不确定期望和下一步是什么。这个演示文稿写得很好。主讲人很优秀。她清晰而生动地讲述了这些材料。
-彼得和T3
克服挑战的最佳策略
原文:https://www.dataquest.io/blog/best-strategies-overcoming-challenge/
January 22, 2019
学习数据科学是一场长跑。虽然你可能有飞行的日子,一切都很自然,你觉得自己像一个编码之神,但你也会有似乎什么都不工作的日子,你只是不能掌握你应该学习的概念。
你的长期成功取决于你度过那些艰难时刻的能力,那些人们最有可能放弃的时刻。
你能做些什么来保持头脑清醒,确保即使在困难和学习不开心的时候也能坚持下来?谢天谢地,科学给出了一些答案。
做自己不喜欢的事情,获得成功
由苏黎士大学的玛丽·亨内克领导的一个研究小组最近在欧洲人格杂志上发表了一篇论文,该论文讲述了他们进行的一系列实验,这些实验旨在调查人们用来成功推动自己做他们不喜欢的事情的策略。
他们首先对近 335 人进行了调查,询问受访者用于完成有时不愉快的任务(如在跑步机上跑步)的策略。然后,他们将受访者给出的近 2000 条具体策略归纳为几类:
改变环境策略包括减少分心、改变环境、喝咖啡、放一些音乐——这些策略不会改变任务本身,但旨在使任务变得更愉快,希望这将使他们更有可能完成活动。
注意力策略旨在集中注意力,通过专注于活动或有意将自己从活动中转移出来,以促进坚持。
认知改变策略是帮助人们以不同的方式思考活动的心理策略:比如关注完成跑步的积极结果,思考跳过跑步的消极结果,监控进度,思考他们如何接近终点,等等。
反应调节策略,其中研究人员仅引用了一条:抑制戒烟的冲动。
然后在随后的研究中,研究人员询问受试者最近完成的不愉快但必要的活动(如自学、听课、通勤等)。).回答者指出他们使用了上述哪种策略来完成这些任务,以及他们是否认为他们已经成功了。
最终,研究人员发现,其中一些策略比其他策略与成功更相关。具体来说,与自我报告的成功相关的策略有:
- 关注完成任务的积极结果
- 控制情绪
- 监测实现目标的进展
- 想着快到终点了
有趣的是,目标设定对应答者的成功率没有明显的影响。只有一种策略与成功负相关:分散自己对任务的注意力。
我们能从中学到什么
我们先来做一些说明:这项研究提出了一些有趣的建议,但是它们不应该被认为是板上钉钉的事实(任何单一研究的结果也不应该)。这项研究依赖于自我报告的成功,这一事实可能是一个特别薄弱的领域,因为受访者可能并不总是准确地评估自己的结果。当然,相关性并不能证明因果关系,所以这些策略与成功的相关性可能纯粹是巧合。
同样值得指出的是,如果你正在学习数据科学,你应该从中获得乐趣。这些建议可能有助于度过偶尔的低落时刻和那些真正具有挑战性的日子,但如果你觉得你必须每天打破这些,你可能会想后退一步,看看你是如何学习数据科学的。
也就是说,这项研究表明,当你度过艰难的一天时,尝试运用这些策略可能会让你更容易坚持下去,并真正完成你正在做的事情:
- 思考为什么完成这个任务或解决这个问题对你来说是有价值的。例如,如果你正在努力完成两个小时的学习,想想你学到了多少,或者结束时你得到了多少额外的练习。
- 尽最大努力控制消极的想法和情绪。这对于令人沮丧的时候可能特别有用,因为你的代码就是不工作,而你又不知道为什么。暂停片刻,深呼吸,试着积极思考你在做什么,或者当任务完成后你会有什么感觉,然后再投入进去。
- 通过你觉得不太有趣的学习部分来跟踪你的进展可能会有所帮助。(当然,Dataquest 平台会自动跟踪你在每节课、每门课程和每条道路上的进度,但你也可以跟踪其他指标,如学习时间,甚至更细粒度的指标,如编写的代码行,看看这是否有帮助。)
- 特别是当你试图结束一个更长的会议时,想想你是如何接近终点的可能会有所帮助。挣扎着完成两个小时的统计学学习?想想你只剩下 20 分钟了,这可能会帮助你坚持到底,而不是被诱惑提前打卡。
这些策略都不可能是灵丹妙药,但是如果你想最大化你的成功机会,它们都值得一试。
最好的学习习惯:给你的教中学增压
November 14, 2019
无论你是在学习数据科学还是学习其他东西,都很难记住你所学的一切。
此外,当你学习像编程这样复杂的东西时,很难评估自己。能够在代码中应用一个概念并不一定意味着你理解它。这些知识缺口可能很难发现。
令人欣慰的是,大量科学研究表明,任何人都可以采用的最佳学习习惯之一非常简单:教学。
科学是怎么说的?
几十年来,教育研究人员已经明白,教授一门学科可以帮助学生更彻底地掌握这门学科。
例如【1982 年的一项元研究观察了 65 项关于同伴辅导项目的不同研究,发现“导师们对辅导项目所涵盖的主题有了更好的理解,并形成了更积极的态度。”
换句话说:教授他们所学的东西不仅帮助学生更好地理解材料,还让他们更喜欢它!
在 2001 年对同伴辅导科学文献的回顾中,美国教育部也发现了同样的事情:当学生们互相教学时,双方都受益。同辈导师通常会看到理解和自尊两方面的收获。
最近更多的研究证实了这些效应,并扩展了我们对如何应用它们的理解。例如,2016 年的一项研究发现,在视频上解释一个概念比重新学习更能促进学生的学习,但书面解释却不能。
研究人员刚刚开始理解为什么通过教学学习如此有效。教学迫使你回忆你学过的材料的事实是当然是一个因素。事实上,你被迫用自己的语言表达事情,感同身受,并以其他人可以理解的方式呈现,这可能也有帮助。
但是值得庆幸的是,作为学生,我们不需要知道为什么这种方法行得通。几十年的研究已经证实了它的有效性,所以为了提高我们的学习效率,我们真正应该关心的是如何。

如何通过教学强化你的学习
我们可以用很多方法来教授一些东西。但由于 Dataquest 的学生正在学习数据科学技能,我们将重点关注在该领域可能最有效的方法。
现实生活中的教学。如果你有朋友或家人真的想学习数据科学,这是一个很好的选择。大多数关于教学的研究都集中在面对面的辅导上,所以你可以放心,这种方法有几十年非常坚实的科学支持。
然而,在现实世界中很难找到其他数据科学学生来授课。匹配适当的技能水平和协调时间表可能是一个真正的挑战,尤其是长期的挑战。
塑料鸭嘴兽学习/橡胶鸭子调试。这种方法包括“教导”一个无生命的物体(比如玩具鸭嘴兽或橡皮鸭),并假装它是一个同伴。当然,你不会从你的塑料朋友那里得到任何互动。但是这种模拟教学仍然可以帮助你更好地理解你正在学习的东西。
同样的原理也用于编程中的一种常见技术,称为橡皮鸭调试。假装向一只橡皮鸭解释你的代码在做什么,在这个过程中,你会经常发现错误和问题。

见见你的新学生。
用视频教学。在这个互联网时代,没有必要在你所在的地区寻找数据科学专业的学生。相反,您可以创建视频,向网络上成千上万的数据科学学生传授您所学的知识!
这是我们推荐大多数人采用的方法,它有一些主要优点:
- 这是有效的:如前所述,研究已经证实,通过视频教学似乎创造了类似于现实生活中的辅导效果。
- 它是互动的:来自在线观众的问题和评论可以帮助你发现你正在犯的错误,并突出你的理解可能没有你想象的那么完整的领域。获得你的视频帮助了某人的反馈也可以帮助你建立继续学习的动力和信心。
- 它很方便:与现实生活中的辅导不同,你不必担心协调时间表、交通或技能水平。有了现代的屏幕录制软件,整合一堂课变得非常快。
- 这是免费的:如果你有一台内置麦克风的电脑(或一部可以录制音频的智能手机,并且愿意做一点编辑)。
在下一节中,我们将通过介绍一些基本方法和强调一些免费工具,让视频教学变得更加简单。

视频编辑软件(别担心,你的视频课程可以比你在这里看到的要简单得多)。
如何通过视频或直播进行教学
虽然您当然可以创建更精细的视频产品,但为了增强您的学习,简单的屏幕录制可能就可以了。毕竟,我们在这里的目标是利用一个最好的学习习惯来提高我们自己的学习,而不是赢得奥斯卡奖!
所以不一定要复杂。例如,在我们的互动数据科学课程中,您可以在完成任务的过程中录制您的屏幕,解释您正在做什么以及为什么要做。
当然,要真正做到这一点,您仍然需要设置一些东西:
录像
你需要一些方法来记录你的屏幕,这样你就可以向人们展示你在做什么。
如果您需要免费的解决方案,Open Broadcaster Software(OBS)是一款免费的开源屏幕录制和流媒体程序,适用于 Windows、Mac 和 Linux。
它主要是为流媒体而设计的,所以当你第一次尝试时,要想知道如何用你想要的设置将你的屏幕录制成视频文件,有时可能需要一些摆弄。但是一旦你弄明白了,它应该可以完美地工作,而且不需要任何花费!
Screencast-o-matic 还为 Mac、Windows 和 Chromebook 提供了一个免费的屏幕录制器,设置起来更容易一些,尽管它不适用于直播,而且有些选项只对付费用户可用。
声音的
你还需要一些方法来记录你工作时所说的话。如果您的电脑有内置麦克风,或者您有一个插入式电脑麦克风,这可能就像打开麦克风并确保屏幕录制器中的音频输入设置正确一样简单。
如果你的电脑上没有麦克风,你仍然可以录制你的屏幕,并使用智能手机录音机来捕捉你说话时的音频,但你必须在完成后将音频和视频文件放入一些视频编辑软件中进行同步。
可选:视频编辑软件
如果你确实需要同步音频和视频,或者如果你想添加其他华丽的东西,呈现一个更精致的课程,你将需要某种视频编辑软件。
你的电脑可能带有一些基本的编辑软件来完成这个任务。如果你想更上一层楼, DaVinci Resolve 是一个专业级编辑程序,在 Windows、Mac 和 Linux 上完全免费。
一个平台
最后,你需要一个地方来发布你的视频。理想情况下,其他人可以找到它,并留下问题和评论,这样你就可以通过教学获得互动的好处。
当然,Youtube 是一个很好的选择,像脸书和推特这样支持视频的社交媒体平台也是。如果你在寻找实时互动,你可以在这些平台中的一个或像 Twitch 这样的特定流媒体平台上进行直播。
当你的视频准备分享时,很容易成为冒名顶替综合症的受害者。但是请记住:这里的目标是帮助你自己学得更好。科学表明,简单地制作和发布视频,你已经获得了教学的大部分好处。
(发布部分很重要,因为如果你知道你正在制作一个没有人会看到的视频,那么你可能不会以同样的标准来要求自己,或者以同样的方式呈现事情,如果视频是公开的话。)
因此,如果你想提高你的数据科学研究,当你学完一些东西后,开始教它吧!在 Dataquest 上,一个好的节奏可能是在你完成每个任务时制作一个小视频“教训”,解释你学到的概念以及你如何应用它们。指导性项目也可以制作出很棒的教学视频。
出去分享吧!除了是最好的学习习惯之一,如果你做得好,用视频教学也可以是建立你的“个人品牌”的好方法。
如果你根据你在 Dataquest 的研究制作了一个视频,请务必在社区和 Twitter 上与我们分享!
学习 SQL 的最佳方法(根据经验丰富的开发人员)
February 17, 2021
学习 SQL 最好的方法是什么?
有了所有可用的资源,以“正确的方式”学习 SQL 可能会很困难。找到学习 SQL 的最佳方法是很棘手的,因为每个人学习的东西都不一样。但是,在培训了成千上万的学生之后——看看哪些有效,哪些无效——我们想出了一些任何人都可以遵循的简单步骤。以下是学习 SQL 的最佳方法:
第一步:确定你为什么要学习 SQL
在你开始学习 SQL 课程之前,重要的是要确定你对“我为什么要学习 SQL”这个问题有一个好的答案
这是因为尽管 SQL 并不太难学,但没有一次学习之旅是完全一帆风顺的。你可能会面临挫折和困惑的时刻。如果你没有一个学习 SQL 的好理由,那么在那些时候你很容易就放弃了。
这个问题没有唯一的答案,但这里有一些人们想学习 SQL 的最常见的原因:
- 你感觉被 Excel 卡住了,厌倦了 VLOOKUP
- 您希望能够根据需要轻松访问您公司的数据
- 您希望能够快速处理更大的数据集
- 你想找一份数据分析师、数据科学家或数据工程师的工作(你知道 SQL 是这些工作最重要的技能)
- 您希望创建透明、可重复的数据流程来减少重复性任务
当然,这些只是几个广泛的原因。你需要找一个理由来说服你。它可能是非常具体的事情,比如您想要回答的关于客户的特定问题,或者您想要构建的特定仪表板。
(可以用 SQL 搭建仪表盘吗?算是吧。我们待会再谈!)
第二步:学习基本语法
这通常不是人们学习编程语言(或者在这种情况下,查询语言)最喜欢的部分。但这是无法避免的。如果不能看到这样的东西并知道发生了什么,你就不可能达到 SQL 的功能级别:
SELECT c.name capital_city, f.name country
FROM facts f
INNER JOIN (
SELECT * FROM cities
WHERE capital = 1
) c ON c.facts_id = f.id
LIMIT 10;
谢天谢地,学习这个可能比你想象的要容易。虽然乍一看这可能看起来复杂和混乱,但 SQL 的语法实际上非常简单。您实际上经常使用的 SQL 命令列表(上面代码中的 SELECT 之类的全大写单词)很短。
成功完成这一步的关键是尽快完成它。留出几个小时,一次性完成 Dataquest 的第一个 SQL 课程。或者选择另一种学习资源,留出足够的时间来完成基础知识。
这里最重要的是你不要把这个拖出来。你想尽快达到能够用 SQL 实际做事情的程度,因为能够深入研究实际问题并找到答案是一个强大的动力。这才是真正能让你保持动力和学习的东西,所以我们想让你尽快达到这一点。
步骤 3:开始指导项目的工作
一旦掌握了基础知识,就该开始使用 SQL 深入实际项目了。
如果您在 Dataquest 与我们一起学习,这将是课程的一部分,其中包含交互式指导项目,挑战您使用新的 SQL 技能来查询和分析真实数据库以获得答案。
如果您没有使用 Dataquest 学习,我们建议您退而求其次:指导项目和教程。
您需要找到一些能给您一些结构和指导的东西,因为在这个阶段,尝试从头构建一个完整的 SQL 项目的过程可能会令人沮丧。你想要一些你可以自己尝试去做的事情,但这也提供了一些指导,当你迷路或不确定下一步该做什么时,你可以参考。
例如,这里有一个关于 SQL 中连接的教程。这将是一个很好的实践,但是尝试自己完成它,只在编写完自己的查询后检查代码片段以确保正确。
请记住,这里的目标是以越来越大的独立性从事指导项目。如果你只是简单地复制粘贴教程中的代码,你不会学到很多东西,所以在检查答案之前,请确保你已经尽了最大努力。
步骤 4:熟悉有用的 SQL 资源
一旦你完成了一些有指导的项目,是时候自己走出去了。好消息是:你可以准确地处理你想要的数据,准确地回答你想要的问题。多么激励人心啊!
坏消息是:没有你可以检查的答案!因此,在开始第一个项目之前,标记一些有用的 SQL 资源是很有帮助的。请记住,在谷歌上搜索答案并不可耻——即使是最有经验的 SQL 开发人员和用户也经常这样做!
有用的 SQL 资源:
- 学习 SQL 第二版(PDF) —这本关于 SQL 基础知识的 O'Reilly 书籍,PDF 格式,免费提供,很好的参考。
- StackOverflow SQL 问题 —您可能会遇到的任何 SQL 问题都已经在这里得到了解答。但是,如果它还没有创建一个帐户,并要求它为自己!
- 如果 SQL 是您第一次涉足编程领域,您可能还没有一个帐户。如果是这样的话,设置一个并开始学习如何使用它!Github 非常适合与全世界(以及潜在雇主)分享您自己的 SQL 项目,它也是查看其他人代码的一个非常棒的资源。
- /r/SQL — Reddit 有一个庞大、活跃的 SQL 社区,并且(大部分)乐于回答问题。
- data quest 社区 —我们的社区积极友好,随时准备帮助您解决所有的 SQL 问题。最重要的是,它对所有人开放——你不必成为 Dataquest 的订户就可以在那里获得帮助。
步骤 5:构建您自己的 SQL 项目
既然您已经知道了一些在遇到困难时可以寻求帮助的好地方,那么是时候开始着手您自己的 SQL 项目了。
这就是你在第一步中想出的答案真正开始起作用的地方。知道你为什么想学习 SQL 可能会帮助你回答这个问题:我应该做什么项目?
简短的回答?做你关心的项目。如果您学习 SQL 是因为厌倦了 Excel 拖慢您的工作速度,那么您的第一个项目可能应该是弄清楚如何使用 SQL 更有效地完成这些工作任务。
如果你学习 SQL 是因为你想要一份特定的工作,你应该做一些 SQL 项目,这些项目应该尽可能地接近你得到这份工作后实际要做的事情。例如,如果你的激情是处理数据,以帮助减少碳排放和提高能源效率,那么你可能会想从事与该目标相关的项目。
我们应该注意:如果你不在一家公司工作,或者如果你不想在你的项目中使用公司数据,这一步可能会有点挑战性。根据您的目标,找到一个所有人都可以免费使用的、包含您想要使用的数据类型的 SQL 数据库可能会很困难。
但是不要害怕!虽然需要一点额外的努力,但是可以将你找到的任何 CSV 格式(或类似格式)的可下载数据转换成 SQL 数据库格式,比如一个 SQLite 表。甚至有网站可以让转换过程变得相当容易。
无论您想要处理什么数据,只要稍加挖掘,您应该能够找到一种使用 SQL 处理它的方法。
并且不要忘记:当你完成你的 SQL 项目时,在你的 Github 上分享它们。当你学到新的东西时,回去更新它们!
第六步:做更高级的项目
最后一步本质上是第五步的延续,你可以重复这个步骤,只要你愿意。在这里继续学习的关键是你必须迎接挑战。
一旦您学会了如何构建最初激励您的 SQL 项目(也许您已经编写了一个查询来替换您的旧 Excel 工作流),沿着这些相同的路线继续做项目会很有诱惑力。
一遍又一遍地做同样的事情对记忆有好处,但是会阻碍你的成长。最好确保每个新项目中,你都在学习或尝试至少一件新事物——一些你还不知道怎么做的事情。
这可能意味着你正在进行一个全新的项目,也可能意味着重新审视一个老项目,赋予它新的复杂性。
这也可能意味着接受你以前从未想过的挑战,例如:
- 您能否将您的 SQL 技能与类似于 Mode 的工具整合起来,以制作一个仪表板?
- 你能教别人如何使用 SQL 查询你公司的数据库吗?
此时,您将掌握使用 SQL 做您想做的或多或少任何事情的技能——不是因为您知道如何做所有事情,而是因为您的项目构建过程教会了您如何找到您不知道的任何事情的答案。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?

https://www.youtube.com/embed/JFlukJudHrk?feature=oembed
*## 关于 SQL 的常见问题:
SQL 难学吗?
这是一个非常私人的问题——对一个人来说非常容易的事情对另一个人来说可能非常困难,反之亦然。然而,大多数人发现 SQL 非常容易学习,尤其是与 Python 或 r 等全功能编程语言相比。
这是因为与“完整的”编程语言不同,SQL 是一种查询语言。它是专门为与关系数据库管理系统(如微软 SQL Server、Oracle、SQLite、MySQL 等)交互而构建的。由于这个原因,没有那么多要学的东西,一些在更全面的编程语言中必然存在的更复杂的概念在 SQL 中不是一个因素。
也就是说,大多数人发现 SQL 相对容易学习的事实并不意味着你会,或者如果你发现它具有挑战性,你应该感到羞耻!特别是如果这是你第一次涉足编程领域,你应该准备好迎接挑战。
(不过不用担心。不管你的背景是什么,你都可以完全学习 SQL。我们的社区随时为您提供帮助!)
SQL 和 Python:学哪个好?
这个问题的答案真的取决于你的目标。它们是非常不同的东西。
SQL 是一种查询语言。它实际上只对与数据库交互、过滤和轻微分析数据有用。它为在这些环境中处理数据提供了强大的功能,但它不能做像 Python 这样的完整编程语言所能做的所有事情。
Python 是一种编程语言。这使得学习起来有点复杂,但也意味着它可以做得更多。你可以用 Python 分析数据,但也可以用它来建立机器学习模型。或者制作电子游戏。或者给机器人编程。或者设计艺术。
如果你经常处理数据——如果你每天都在打开电子表格,并且你知道 VLOOKUP 是什么——学习这两种语言很有可能会让你受益匪浅。
在 Dataquest,我们教授 Python 和 SQL,作为我们数据分析师和数据科学家职业道路的一部分。这两种技能都是全职数据工作所需要的(虽然 R 可以代替 Python,但是学习 SQL 是没有商量余地的)。
可以自学 SQL 吗?
是的。我们已经看到成千上万的学生正是这样做的,他们利用自己的时间,按照自己的进度学习我们的 interactive SQL 课程。
即使您没有使用 Dataquest,也完全有可能自学 SQL。然而,拥有一个你可以求助的支持性社区肯定会让事情变得更容易!
你能多快学会 SQL?
简短的回答是:相当快。
更长的答案是,你可以很快学会基本知识——足以发挥作用。即使是兼职学习(例如,在全职工作后的晚上从事 SQL 工作),许多以前从未编写过代码的学习者也可以实现他们的目标,并能够在短短几个月内完成独立的 SQL 项目。
如果你有一些编程经验和/或你愿意每天多花一点时间学习,你可以学习足够的 SQL 来完成你的目标,甚至比这更快!
但是尽管如此,学习 SQL 就像学习任何语言一样——从来没有真正的终点。即使是每天都在工作中使用 SQL 的专业人士也仍然不时地学习新的东西。学习任何编程语言都应该被视为一个终生的旅程,而不是在几个月内开始和结束的事情。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
利用箱线图探索女性身高数据
April 25, 2018
我最近一直在从事数字全景监狱(Digital Panopticon)的工作,这是一个数字历史项目,收集(并创建)了大量关于 19 世纪英国囚犯和罪犯的数据,包括几个数据集,其中包括女性的 T2 高度。儿童时期的环境因素对成年人的身高影响很大,其中最重要的因素是营养。所以,
因此,过去人口的身高可以告诉历史学家很多关于个人在成长过程中遇到的情况。只要有足够的数据,就可以窥见家庭内部的情况,从而拼凑出工资下降、物价上涨、卫生条件改善和家庭规模缩小对成年人平均身高影响的历史。
然而,在 18 世纪和 19 世纪的英国,许多关于身高和营养的研究都集中在军事记录上,因此很少涉及女性。在 19 世纪的刑事记录中使用丰富的男性和女性(以及儿童)身高记录是最近的事情。
今天的帖子将着眼于四个数字全景视觉数据集的高度模式,主要使用一种许多历史学家不熟悉的可视化方法:箱线图。如果你看过它们,但没有真正理解它们,没关系——直到最近我也没有一点头绪!所以,在我开始研究实际数据之前,我会先解释一下我学到了什么。
箱线图,或称盒须图,是一种非常集中的可视化方式,统计学家称之为数据集的“五位数摘要”:
这里有一个图表:

中间的绿色粗条标记了中值值。与此平行的两条蓝线(又名“铰链”)显示了的上下四分位数。从盒子中延伸出来的粉红色水平线是胡须。在这个版本的方框图中,须不一定延伸到最小值和最大值。相反,它们被计算以排除离群值,这些离群值随后被绘制为胡须末端以外的单个点。
**那么这一切有什么意义呢?假设有两个数据集:一个包含值 4,4,4,4,4,4,4,4 ,另一个包含值 1,3,3,4,4,4,6,7 。这两个数据集具有相同的平均值,但是值的分布非常不同。箱线图有助于更仔细地观察数据集中的这种变化,或者比较不同的数据集,如果只考虑平均值,这些数据集可能看起来非常相似。
这是四个数据集:
- HCR,内政部犯罪记录 1790-1801,关押在纽盖特监狱等待审判的囚犯(总共 1226 人,1061 人年龄超过 19 岁)
- CIN ,囚犯契约 1820-1853,囚犯被运送到澳洲(17183 高地,14181 超过 19)
- PLF ,女性监狱执照 1853-1884,女性罪犯被判处劳役刑(571 高地,535 超过 19)
- RHC ,1881-1925 年惯犯登记册,出狱后受警方监管的惯犯(12599 高地,12118 超过 19)
对于每个数据集,我只包括有出生年份的女性,或者出生年份可以通过年龄和日期以及身高来计算的女性。(上面我说“高度”是因为我不能保证他们都是独一无二的个体;但几乎所有人都应该如此。)在下面所有的图表中,我只包括 19 岁以上的成年女性。
当你绘制 RHC 每个出生十年的身高时,会发生这样的情况。

(这是使用 R 包 ggplot2 生成的,它看起来与您将在网上看到的许多示例略有不同,因为 ggplot 有一个很好的功能,可以根据数据组的大小改变框的宽度。)
我首先寻找的是可能暗示数据有问题的不一致之处,总体来说看起来不错——这些方框基本上是对称的,没有一个异常值在可能性范围之外(最高的女性是 74.5 英寸,或 6 英尺 2 1/2,最短的是 48 英寸),尽管我有点怀疑这个数据集中是否有出生于 19 世纪的女性,这个数据开始于 19 世纪 80 年代;尽管如此,他们是一个非常小的数字,所以不太可能扭曲事情的整体。由于数据乍一看似乎还不错,有趣的是,从 19 世纪 50 年代开始,女性越来越高,19 世纪 90 年代出生的女性比 19 世纪 80 年代出生的女性高很多。这与 Deb Oxley 对相同数据的(更精细的)观察相当一致。
这是 CIN:

同样,我们有一个合理的身高分布,幸运的是有极少数轻微问题的早产。(碰巧的是,这些数据是手动转录的,而 RHC 是用光学字符识别创造的——但另一方面,RHC 的来源是打印的,比手写的凹痕清晰得多。)暂且忽略 18 世纪 70 年代之前的极小群体,该数据中最高的十年女性群体是那些出生于 18 世纪 90 年代的人,此后她们一直变矮。
让我们把所有四个数据集放在一起!(点击图片查看大图。)

我已经过滤掉了 1750 年之前和 1899 年之后出生的女性,因为这些数字非常小,还有一些极端的异常值(后面会有更多关于这些的……)。然后我在 19 世纪 20 年代的中间值(中点)添加了一个指南,因为我认为它有助于看到趋势。
乍一看,18 世纪晚期的 HCR 女性比 19 世纪 90 年代之前的任何一批女性都要高,这似乎令人惊讶。然而,这里的趋势与罗德里克·弗洛德等人对 1740 年至 1914 年间英国男人和男孩的开创性研究大体一致。他们认为“英国男性连续出生队列的平均身高在 1740 年至 1840 年间增加,在 1840 年至 1850 年间下降,从 19 世纪 50 年代起再次增加”(哈里斯,“健康、身高和历史”)。在 19 世纪的大部分时间里,英国人口吃得不太好(因为食物资源难以跟上人口的快速增长),结果人口变少了。然而,1850 年后,我们的女性增长可能比男性慢(直到 19 世纪 90 年代);也许女性比男性需要更长的时间才能重新开始生长。
不过,最后,我必须对 HCR 的数据提出一个重大警告。我提到我从上面的图表中排除了一些极端的异常值。HCR 是迄今为止最糟糕的罪犯,如果你仔细观察 HCR 所覆盖的 18 世纪人群,这些盒子并不像 19 世纪的盒子那样对称。如果我们使用直方图(另一种检查数据集中值的分布的简便方法)将其可视化,我们可以更清楚地看到有什么事情发生了。人口中的“正常”身高分布应该看起来像一条“钟形曲线”——非常紧密且对称地围绕平均值。CIN 和 RHC 很近:

但这就是 HCR 的样子。这可不好。

如果我们幸运的话,大部分问题可能是数据中的错误,这些错误是可以修复的。毕竟,它至少是大致正确的形状!然而,60 英寸(5 英尺)的高峰敲响了警钟。这看起来让人想起我们在数字全景监狱的大部分年龄数据中遇到的一个问题,称为“堆积”,倾向于将年龄四舍五入到最接近的 0 或 5(人们通常不知道他们的确切出生日期)。与这个峰值相比,年龄堆积是非常温和的,所以我认为这很可能是转录或用于提取高度的方法的另一个问题。但如果事实证明不是这样,这可能会很成问题。我们假设这些囚犯被适当地测量过,但是我们对所使用的设备一无所知。就我们所知,它可能经常在很大程度上是猜测工作。最终,我们可能会发现 HCR 根本不足以用于人口统计分析。18 世纪出生的女性身高数据很少,所以这是一个潜在的非常重要的来源。但是如果不能胜任工作呢?
进一步阅读
- 约翰·坎宁(John Canning),人文学科统计 (2014),尤其是第三章。
- 统计简介:箱线图
- 正态分布
- H Maxwell-Stewart ,K Inwood 和 M Cracknell,《高度、犯罪与殖民历史》,《法律、犯罪与历史》(2015)。
- 黛博拉·奥克斯利(Deborah Oxley)、大卫·梅雷迪思(David Meredith)和萨拉·霍雷尔(Sara Horrell),《19 世纪英国生活水平和性别不平等的人体测量》,当地人口研究,2007 年。
- 黛博拉·奥克斯利、生物识别、【https://www.digitalpanopticon.org】T2(2017)。
- 伯纳德·哈里斯,“健康、身高和历史:人体测量史近期发展综述”,医学社会史(1994)。
- Jessica M. Perkins 等人,《成人身高、营养和人群健康》,营养评论(2016 年)。
编者按:这最初是发布在早期现代笔记上,作为我们关注女性历史月的一部分,已经被 perlesson 转载。作者莎伦·霍华德在谢菲尔德大学担任数字历史项目的项目经理。**
让你得到工作的数据科学投资组合
原文:https://www.dataquest.io/blog/build-a-data-science-portfolio/
August 12, 2016
这是关于如何构建数据科学组合的系列文章中的第四篇。你可以在文章的底部找到本系列其他文章的链接。
雇主希望在新员工中看到强大的数据科学能力,但这种技能并不总是容易在面试中展示出来。这就是为什么我们创建了一个广泛的系列来讨论数据科学的重要性,以及如何通过培养这种技能来提高您的就业能力。在这里,您将学习如何建立一个强大的数据科学组合,展示您的技能并帮助您获得这份工作。
在本系列过去的几篇文章中,我们讨论了如何构建一个讲述故事的数据科学项目、如何构建一个端到端的机器学习项目,以及如何建立一个数据科学博客。在本帖中,我们将后退一步,从高层次上关注你的投资组合。我们将讨论雇主希望看到候选人展示哪些技能,以及如何建立一个能有效展示所有这些技能的作品集。我们将包括你的投资组合中的每个项目应该是什么样子的例子,并给你如何开始的建议。
读完这篇文章后,你应该很好地理解为什么你应该建立一个数据科学投资组合,以及如何着手去做。
雇主寻找什么
当雇主招聘时,他们寻找的是能为他们的企业增加价值的人。通常,这意味着某人拥有可以为企业创造收入和机会的技能。作为一名数据科学家,您可以通过以下四种主要方式之一为企业增加价值:
- 从原始数据中提取见解,并将这些见解呈现给其他人。
- 一个例子是分析广告点击率,并发现向 18 至 21 岁的人做广告比向 21 至 25 岁的人做广告更具成本效益,这通过允许企业优化其广告支出增加了商业价值。
- 构建为客户提供直接价值的系统。
- 例如,脸书的一名数据科学家优化了新闻订阅源,向用户展示了更好的结果——这为脸书带来了直接收入,因为更多的新闻订阅源参与意味着更多的广告参与。
- 构建为组织中的其他人提供直接价值的系统。
- 一个例子是构建一个脚本,该脚本自动聚合来自 3 个数据库的数据,并生成一个干净的数据集供其他人分析,这通过使其他人更快地完成他们的工作而增加了价值。
- 与组织中的其他人分享你的专业知识。
- 一个例子是与产品经理聊天,讨论如何建立一个需要机器学习算法的功能——这通过防止不切实际的时间表或半功能产品来增加价值。
不出所料,当雇主考虑要聘用的候选人时,他们会考虑能够做到上述四项中一项或多项的人(具体会考虑哪些取决于公司和职位)。为了证明你可以在上面列出的 4 个领域帮助企业,你需要展示这些技能的一些组合:
- 通讯能力
- 与他人合作的能力
- 技术能力
- 对数据进行推理的能力
- 主动的动机和能力
一份全面的投资组合应该展示你在上述每个领域的技能,并且相对容易被人浏览——投资组合的每个项目都应该有很好的记录和解释,这样招聘经理才能快速评估你的投资组合。
为什么是投资组合
如果你拥有顶级学校的机器学习或相关领域的学位,那么获得数据科学工作相对容易。雇主相信你能为他们的企业增加价值,因为给你颁发学位的机构很有声望,而且这个学位的主题与他们自己的工作相关。如果你没有顶级学校的相关学位,你必须自己建立这种信任。
可以这样想:雇主可以有多达 200 名申请人申请热门职位。假设招聘经理总共花了 10 个小时筛选申请,并决定与谁进行电话聊天。这意味着每个申请人平均只被评估 3 分钟。招聘经理一开始并不相信你能为公司增加价值,你有 3 分钟来建立他们的信任,直到他们决定做一次电话筛选。
数据科学的伟大之处在于,你在自己的建设项目中所做的工作往往与你被聘用后将要做的工作一模一样。作为一名在 Lending Club 的数据科学家,分析信用数据可能与分析发布的匿名贷款数据有很多相似之处。

借贷俱乐部匿名数据的前几行。
与招聘经理建立信任的首要方法是证明你能做他们需要你做的工作。对于数据科学,这归结为构建项目组合。项目越“真实”,招聘经理就越相信你会成为公司的资产,你出现在手机屏幕前的机会也就越大。
在您的数据科学投资组合中放入什么
现在我们知道我们需要建立一个投资组合,我们需要弄清楚该往里面放什么。至少,你应该在 Github 或者你的博客上有一些项目,那里的代码是可见的,并且有很好的文档记录。招聘经理越容易找到这些项目,他们就越容易评估你的技能。每个项目也应该尽可能地被很好地记录,带有一个自述文件,既解释如何设置它,又解释关于数据的任何奇怪现象。

Github 上一个结构良好的项目。
我们将介绍几个应该在你的投资组合中的项目类型。建议每种类型有多个项目,特别是如果你想要的角色类型与其中一个或另一个一致的话。例如,如果你申请需要大量机器学习的职位,建立更多使用机器学习的端到端项目可能会很有用。另一方面,如果你申请的是分析师职位,数据清理和讲故事的项目更为关键。
数据清理项目
一个数据清理项目向招聘经理展示了你可以获取完全不同的数据集并理解它们。这是数据科学家的大部分工作,也是一项需要展示的关键技能。这个项目包括获取杂乱的数据,然后清理并进行分析。一个数据清理项目展示了您可以对数据进行推理,可以从许多来源获取数据并将其合并到一个数据集中。数据清理是任何数据科学家工作的一个重要组成部分,展示你以前做过这方面的工作将是一个优势。
你会希望从原始数据到一个易于分析的版本。为此,您需要:
- 找到一个杂乱的数据集
- 尝试使用data.gov、 /r/datasets 或 Kaggle Datasets 来寻找一些东西。
- 避免选择任何已经干净的东西——您希望有多个数据文件,以及数据的一些细微差别。
- 如果可以的话,寻找任何补充数据集——例如,如果你下载了一个关于航班的数据集,你是否可以通过 Google 找到任何可以与之结合的数据集?
- 试着挑选一些你个人感兴趣的东西——如果你这样做了,你会做出一个好得多的最终项目
- 使用数据选择一个问题来回答
- 探索数据
- 确定一个有趣的角度去探索
- 清理数据
- 统一多个数据文件(如果有)
- 确保利用数据探索您想要的角度是可能的
- 做一些基本的分析
- 试着回答你最初选择的问题
- 展示您的结果
- 建议使用 Jupyter 笔记本或 R Markdown 进行数据清理和分析
- 确保你的代码和逻辑能够被遵循,并且尽可能多的添加注释和标记单元格来解释你的过程
- 将您的项目上传到 Github
- 由于许可问题,并不总是可能将原始数据包含在您的 git 存储库中,但是请确保您至少描述了源数据及其来源
本系列早期文章的第一部分“分析纽约市学校数据”将带您了解如何创建一个完整的数据清理项目。你可以在这里查看。

一些纽约市学校数据的数据字典。
如果你在寻找一个好的数据集时遇到困难,这里有一些例子:

辉煌的纽约地铁。
如果你需要一些灵感,这里有一些好的数据清理项目的例子:
数据故事项目
一个数据故事项目展示了你从数据中提取洞察力和说服他人的能力。这对你能交付的商业价值有很大的影响,并且是你的投资组合的重要部分。这个项目包括获取一组数据,并用它讲述一个令人信服的故事。例如,您可以使用航班数据来显示某些机场的严重延误,这可以通过更改路线来解决。
一个好的讲故事的项目将大量使用可视化,并将带读者走上一条让他们看到分析的每一步的道路。下面是构建一个好的数据故事项目需要遵循的步骤:
- 找到一个有趣的数据集
- 尝试使用data.gov、 /r/datasets 或 Kaggle Datasets 来寻找一些东西。
- 挑选一些与时事相关的东西会让读者感到兴奋。
- 试着挑选一些你个人感兴趣的东西——如果你这样做了,你会做出一个好得多的最终项目
- 探索数据中的几个角度
- 探索数据
- 识别数据中有趣的相关性
- 创建图表并逐步展示您的发现
- 写一篇引人注目的叙述
- 从你的探索中选择最有趣的角度
- 围绕从原始数据到你的发现写一个故事
- 创建引人注目的图表来增强故事
- 详细解释你在每一步的想法,以及代码在做什么
- 对每一步的结果写详细的分析,以及它们告诉读者什么
- 在你分析的过程中,教给读者一些东西
- 展示您的结果
- 建议使用 Jupyter 笔记本或 R Markdown 进行数据分析
- 确保你的代码和逻辑能够被遵循,并且尽可能多的添加注释和标记单元格来解释你的过程
- 将您的项目上传到 Github
本系列早期文章的第二部分,分析纽约市的学校数据,带你了解如何用数据讲述一个故事。你可以在这里查看。

纽约市各区 SAT 分数地图。
如果你在寻找一个好的数据集时遇到困难,这里有一些例子:
如果你需要一些灵感,这里有一些好的数据故事帖子的例子:

歌词中提到了 2016 年美国大选的每个初选候选人(来自上面的第一个项目)。
端到端项目
到目前为止,我们已经讨论了涉及探索性数据清理和分析的项目。这有助于招聘经理,他关心你如何能很好地提取见解并展示给别人。然而,这并不表明您有能力构建面向客户的系统。面向客户的系统包含高性能代码,这些代码可以用不同的数据运行多次,以生成不同的输出。一个例子是预测股票市场的系统——它会在每天早上下载新的市场数据,然后预测当天哪些股票会表现良好。
为了展示我们可以构建操作系统,我们需要构建一个端到端的项目。端到端项目接收并处理数据,然后生成一些输出。通常,这是机器学习算法的结果,但也可以是另一种输出,如匹配特定标准的总行数。
这里的关键是使系统足够灵活,能够处理新数据(比如我们的股票市场数据),并具有高性能。让代码易于设置和运行也很重要。以下是构建一个良好的端到端项目需要遵循的步骤:
- 找一个有趣的话题
- 导入和解析多个数据集
- 下载尽可能多的可用数据
- 读入数据
- 弄清楚你想预测什么
- 创建预测
- 计算任何需要的特征
- 收集培训和测试数据
- 做预测
- 清理并记录您的代码
- 将您的代码分成多个文件
- 添加一个自述文件,解释如何安装和运行项目
- 添加内嵌文档
- 使代码易于从命令行运行
- 将您的项目上传到 Github
我们在本系列中的早期文章“分析房利美贷款数据”将带您了解如何构建一个端到端的机器学习项目。你可以在这里查看。
如果你找不到好的话题,这里有一些例子:

标准普尔 500 数据。
如果你需要一些灵感,这里有一些好的端到端项目的例子:
解释性帖子
能够理解和解释复杂的数据科学概念很重要,比如机器学习算法。这有助于招聘经理了解你在向其他团队成员和客户传达复杂概念方面有多擅长。这是数据科学产品组合的关键部分,因为它涵盖了现实世界数据科学工作的很大一部分。这也表明你在深层次上理解概念和事物如何工作,而不仅仅是在语法层面。这种深刻的理解对于能够证明你的选择是正确的,并让其他人了解你的工作是很重要的。
为了建立一个解释性的帖子,我们需要选择一个数据科学主题来解释,然后写一篇博客帖子,从最基础的水平一直到有一个概念的工作示例。这里的关键是使用简单明了的语言——你越学术,招聘经理就越难判断你是否真正理解这个概念。
重要的步骤是选择一个你很了解的主题,向读者介绍这个概念,然后对最终的概念做一些有趣的事情。以下是您需要遵循的步骤:
- 找一个你很了解或者可以学习的概念
- 像k-neigbhors这样的机器学习算法是很好的选择。
- 统计概念也是很好的选择。
- 确保这个概念有足够的细微差别来花一些时间解释。
- 确保你完全理解这个概念,而且这个概念不会太复杂,解释不好。
- 选择一个数据集或“脚手架”来帮助你解释这个概念。
- 例如,如果你选择 k 个最近邻,你可以用 NBA 数据来解释 k 个最近邻(找到相似的球员)。
- 为你的文章创建一个大纲
- 假设读者不知道你正在解释的主题
- 将概念分解成小步骤
- 对于 k 近邻,这可能是:
- 使用相似度预测
- 相似性度量
- 欧几里得距离
- 使用 k=1 查找匹配
- 寻找 k > 1 的匹配
- 对于 k 近邻,这可能是:
- 写下你的帖子
- 用简单明了的语言解释一切
- 尽可能确保把所有东西都绑回你挑选的“脚手架”
- 试着让一个非技术人员阅读它,并评估他们的反应
- 分享你的帖子
- 最好在你自己的博客上发布
- 如果没有,上传到 Github
如果你很难找到一个好的概念,这里有一些例子:

可视化 kmeans 聚类。
如果你需要一些灵感,这里有一些很好的解释性博客帖子的例子:
可选组合件
虽然关键是在你的博客或 Github 上有一组项目,但在你的项目中添加其他组件也是有用的,如 Quora 答案、演讲和数据科学竞赛结果。对于招聘经理来说,这些通常是次要的,但它们可以是脱颖而出和证明你技能的好方法。
讨论
谈话是帮助教授他人的有效方式,也可以向招聘经理证明你对某个话题足够了解,可以教授他人。这有助于招聘经理了解你的沟通和表达能力。这些技能与投资组合的某些部分有些重叠,但仍然有助于展示。
最常见的演讲地点是当地的聚会。聚会都围绕特定的主题,比如“Python”,或者“使用 D3 的数据可视化”。
要做一场精彩的演讲,以下是一些好的步骤:
- 找一个你做过的有趣的项目或你知道的概念
- 一个很好的地方是你自己的投资项目和博客文章
- 无论你选择什么,都应该符合聚会的主题
- 将项目分解成幻灯片
- 你需要将项目分解成一系列幻灯片
- 每张幻灯片的文本应该尽可能少
- 练习几次你的演讲
- 说吧!
- 将您的幻灯片上传到 Github 或您的博客
如果你需要一些灵感,这里有一些好的谈话的例子:
数据科学竞赛
数据科学竞赛涉及尝试在一组数据上训练最准确的机器学习模型。这些比赛是学习的好方法。从招聘经理的角度来看,如果你表现出色,数据科学竞赛可以展示技术能力,如果你付出大量努力,可以展示主动性,如果你与他人合作,可以展示协作能力。这与其他一些投资组合项目有重叠,但是这是一个很好的脱颖而出的次要方法。
大多数数据科学竞赛都在 Kaggle 或 DrivenData 上举办。
要参加数据科学竞赛,您只需注册网站并开始!一个很好入门的比赛是这里,你可以在这里找到一套教程。

Kaggle 比赛的排行榜。
包扎
你现在应该很清楚在你的作品集里应该展示什么技能,以及如何着手建立你的作品集。现在是时候开始建设了!如果你想展示你的作品,请在评论中告诉我们!
在 Dataquest ,我们的互动指导项目旨在帮助您开始构建数据科学组合,向雇主展示您的技能,并获得一份数据方面的工作。如果你感兴趣,你可以注册并免费学习我们的第一个模块。
如果你喜欢这篇文章,你可能会喜欢阅读我们“构建数据科学组合”系列中的其他文章:
- 用数据讲故事。
- 如何建立数据科学博客。
- 打造机器学习项目。
- 寻找数据科学项目数据集的 17 个地方
- 如何在 Github 上展示您的数据科学作品集
商业分析和商业智能—解释!
原文:https://www.dataquest.io/blog/business-analysis-and-business-intelligence-explained/
February 23, 2022
数据是世界上最宝贵的资源。去吧:谷歌一下。一个组织成功(和生存)的秘密隐藏在由用户、消费者、平台、网站和几乎任何你能想到的有数字足迹的东西产生的 44z 字节的信息中——遍布世界各地。但是,就像钻石或石油一样,组织必须在使用数据之前对其进行提炼。然后,数据的质量将影响从商业战略到软件开发到办公室通信的一切。2022 年,说“数据就是生命”不为过。
业务分析师和商业智能专家是数据超级英雄
随着医疗保健、供应链管理、运输、金融和教育等行业和职能部门的数据量不断增加,组织需要越来越多能够产生有意义见解的数据超级英雄。那些超级英雄是谁?商业分析师、数据科学家、商业智能分析师,以及更多学习如何处理数据的人。
商业智能专家处理任何与数据及其应用相关的事情。这意味着报告、分析、创建仪表板、运行预测分析等等。这是一个非常重要的领域,已经从一个有趣的商业领域发展成为组织用来观察世界上正在发生什么以及他们如何适应这个世界的水晶球。你可以把它想象成潜艇上的潜望镜。如果你想知道发生了什么,你不能只看潜艇的窗外——你只能相信你的仪器和你通过潜望镜里的小透镜看到的东西。
但是商业分析师和商业智能专家并不是唯一争论数据的人。营销人员、财务人员、经理——组织中的每个人都需要 BI 技能。例如,LinkedIn 最近的一项调查表明,数据分析是销售、营销和信息技术领域最重要的技能之一。现在到处都是。
远程工作正在成为新常态,对数据和安全分析人才的需求只会增加,客户的旅程现在与数字生活交织在一起。这已经不仅仅是广告了。这是关于了解你的观众,他们去哪里,他们喜欢什么,他们在哪里度假,如果他们有宠物,他们开的车,他们在网飞看什么。任何东西的一切现在都是有价值的——只要你能在信息大海捞针。
你也可以发展商务智能技能
是的,你也可以成为潜望镜。无论你是数据专家还是在你的组织中的其他部门工作,BI 技能都是至关重要的(并且可以转移!).你从这浩如烟海的信息中过滤出一些即时的、可操作的东西——让你的组织看看潜艇外面有什么。一切基于数据。
随着业务本身的现代化,业务分析也在现代化,那么你对新的、更新的技能有什么期望呢?商业和技术不再分离,因此 BA 将不再是一家默默无闻的内部咨询公司,而更像是现代商业中人人都会说的一种语言。
用于强大商业智能的 Microsoft Power BI 技能
但是人需要什么技能来处理数据呢?他们使用许多应用程序,但世界上最受欢迎的平台之一是 Microsoft Power BI,全世界有超过 1.15 亿人使用它,而且这个数字还在增长。那是什么呢?
Microsoft Power BI 是行业领先的软件服务、应用和连接器集合,它们协同工作,将不相关的数据源转换为统一的、可操作的见解。因此,无论您使用的是 Excel 电子表格还是基于云的本地混合数据仓库集合,Microsoft Power BI 都可以帮助您连接数据源、发现见解并可视化您的发现。
根据知名 IT 研究公司 Gartner 的调查,微软 Power BI 已经连续 14 年成为全球领先的分析和商业智能平台。这意味着业务分析只会继续依赖于一流的洞察力,而这种洞察力可以通过这个多功能的平台来发现。
启动我们的 Power BI 路径
我们将推出自己的 分析数据,使用微软 Power BI 技能途径 !该技能路线是与微软合作开发的,将带您从完全初学者到完全精通,最终,您将准备好参加微软提供的 Microsoft Power BI(PL–300)认证考试,以及 Data quest Analyzing Data with Microsoft Power BI 技能路线证书。在这条道路上,您将学习如何建立数据模型、创建报告和构建交互式仪表板,以提高工作绩效—只需几个月的时间。
我们的课程是互动和动手的,这意味着您不仅仅是观看视频或阅读支持文档。在 Dataquest,我们相信真正学到东西的唯一方法就是去做。你将远离技能之路,知道如何浏览 Power BI 界面;如何清理、转换、加载和结构化数据;如何设计数据模型;如何利用有意义的视觉效果、仪表盘和报告创建引人注目的数据驱动的故事;如何管理工作区;以及如何进行商业分析。
使用 Microsoft Power BI 技能路径分析数据将于 2022 年 3 月 21 日推出。完成路径后,您将能够完成以下任务:
- 创建公司或客户数据的 360 度视图
- 识别业务弱点和机会
- 帮助做出更好的商业决策
- 创建有意义、可共享的仪表板
业务分析师岗位说明书(2022 年版)
原文:https://www.dataquest.io/blog/business-analyst-job-description-2022/
July 27, 2022
没有深刻的洞察力,企业就无法成功。句号。这就是商业分析的用武之地。
业务分析师帮助组织确定哪些策略可行,哪些不可行。广管局负责评估业务需求,并提出改善业务的建议。尽管这份工作的目的很明确,但要确定这份工作的日常活动、这份工作的必要技能以及这份工作需要的工具可能会很棘手。
在本文中,我们将详细介绍业务分析师的工作,以及他们需要哪些技能和工具来取得成功。
什么是商业分析师?
业务分析师既是调查员,又是战略家——同时还是演示者和监工。这份工作的各种要求是其诱人之处的一部分。
业务分析师生活中的每一天都可能与前一天不同,包括新的挑战,考验你的技能和知识。无论是收集数据,向高管演示,还是与利益相关者一起规划,这份工作的日常要求都不会令人厌烦。
如果新奇和挑战的承诺听起来很诱人,你不会失望的。然而,有各种各样的技能需要学习,所以你需要缩小你的兴趣和优势。毕竟,在你开始从事商业分析之前,你需要知道你将会从事什么。
业务分析师的主要职责
业务分析师的主要职责包括以下内容:
- 识别操作中的问题区域
- 开发有创意、有数据支持的解决方案
- 向高层决策者提出见解
业务分析师的实际日常经验因工作或部门而异。然而,所有的业务分析师都共享一组特定的技术,例如:
- 精通数据管理软件
- 能够将大型数据集提炼为可操作的策略
- 创建视觉辅助工具以改进演示
这只是高级业务分析师的工作描述。虽然你选择掌握的工具使你在业务分析的某些方面比其他方面更好,但了解从项目管理到沟通技巧的一切也很重要。
业务分析师预期
正如我们已经确定的,业务分析师的角色和职责是无限的,但归根结底是三件事:
- 分析数据
- 发现问题
- 推荐解决方案
要做到这一切,您需要从收集和整理大型数据集开始。数据支持的业务分析师职责是这份工作的核心。
无论您是在优化管理流程、揭露浪费行为,还是寻找增加收入的方法,您都需要首先收集所有相关数据。这可能包括以下内容:
- 发送定量调查
- 进行定性访谈
- 会见主要利益相关方
- 收集网站数据
- 收集平台行为数据
收集如此多的数据并不容易,但是精通数据库管理软件使得存储和组织这些数据变得容易得多。
然后你可以分析数据并把这些点联系起来。这是您确定操作是否正常运行的方式。如果你的数据表明在家工作的员工比在办公室工作的员工做得更多,那么你现在就有确凿的数据来支持任何在家工作的建议。这些发现的时刻需要很多艰苦的工作,但是你的发现会给整个公司带来变化。
查找数据和呈现数据是两种不同的技能。当与包括经理和高管在内的一群利益相关者交谈时,你不应该假设他们都和你一样理解相同的数据。你不能简单地扔出一个电子表格,然后说,“这是我发现的,这是我们应该做的。”
相反,你会以一种令人信服的方式展示信息,并寻求认同(或者,至少是强烈的理解)。你需要将你的数据综合成视觉辅助工具,让你的想法一目了然。这意味着你需要选择正确的图表,这样你才能以房间里每个人都能理解的方式传达你的故事。
一旦建议获得批准,业务分析师的职责就转向项目的管理和监控,这可能包括执行如下任务:
- 创建和实施项目计划
- 管理预算
- 管理跨职能团队
- 设置关键绩效指标(KPI)
- 使用数据和关键绩效指标来跟踪项目的有效性
- 向利益相关者报告
- 解决意外问题
贸易工具
Dataquest 的商业分析师职业道路教你如何管理数据库。此外,您将精通流行的业务分析应用程序,并学习如何使用 SQL 和 Python 等编码语言操作数据。你在整个课程中学到的技能是雇主非常想要的。
典型的业务分析师工作描述包括以下技能要求:
- 微软 Excel —精通 Excel 是常事。如果不知道如何使用电子表格,你就无法履行商业分析师的职责。
- Microsoft Access 由于其许多复杂的用途,可以说是所有 Microsoft Office 应用程序中最不为人所知的。大多数人不太可能在学校学习 Access 或在日常生活中使用它,但它是业务分析师工具箱中最大的工具之一。Access 是一个数据库应用程序,用于创建软件和管理数据库。用户可以在 Access 中输入和排序数据,或者将其用作其他数据库的前端。
- 微软 Power BI — Power BI 是一款将数字和数据转化为图形和图表等视觉效果的应用。Power BI 的最大特性之一是它能够创建带有许多不同小部件的仪表板,这些小部件跟踪各种数据集。这是一个信息的一站式商店,在这里人们可以获得一个项目的高级视图。
- Tableau —类似于 Power BI,它是一个非常流行的可视化应用程序,以其易用性而闻名。
- SiSense — SiSense 是另一个数据可视化应用。
- Qlik Sense —这是另一个数据可视化应用。
- SQL —(结构化查询语言)SQL 是一种用于管理数据库的编程语言。熟练掌握 SQL 后,用户可以创建自定义脚本,将多个数据库命令组合起来启动复杂的操作。
软技能很重要
除了了解所有必要的应用程序,业务分析师还依赖于各种软技能。业务分析师可能需要的软技能示例包括:
- 细节导向
- 清晰简洁的交流
- 有效倾听
- 敏锐的观察
- 合作
业务分析师必须与许多人交谈,因此他们需要适应社交互动。在某些方面,业务分析师是一个安静的观察者,他研究公司的内部运作,直到他们发现一些可操作的东西。在会议上谈论别人或做糟糕的笔记会让收集数据(和报告数据)变得更加困难。
公共演讲技巧会让你与众不同
正如我们之前提到的,演示是工作的一大部分。当你有良好的公开演讲技巧时,让人们认同你的想法就容易多了。带着暗淡的辅助设备站在那里,用几乎察觉不到的音量说话,不会说服任何人。你必须站起来,本质上讲道。你不需要在这方面出类拔萃(没人指望你像电视主持人一样游刃有余),但你必须相信自己的想法,让它听起来有趣。
质疑一切
除了人际交往技巧,商业分析师还需要敏锐的眼光。它有助于发现公司中其他人可能没有注意到的弱点和问题领域。从局外人的角度审视公司的做法,可以让你质疑为什么要以某种方式做某事。你的公司为什么使用某个供应商,或者营销在 swag 上的花费是多少?
光靠观察不能解决问题,但是它们会告诉你应该把注意力集中在哪里,以及如何利用公司资源来隔离问题区域。
在工作中,你会学到更多的硬技能和软技能,但是如果你从这篇文章中学到了什么,那应该是业务分析师的角色和职责是广泛的。这份工作是为喜欢多面手技能的人量身定做的。作为一名业务分析师,数据和分析是你的主要技能,而项目管理和编程等领域的经验将完善你的专业技能。
准备在工作中学习
没有任何学位、证书或课程可以教会你需要知道的一切。无论是职场礼仪、新的最佳实践,还是如何使用某个应用程序,总有一些你只能在工作中学习的新技能。
在你得到那份工作并开始学习那些专业技能之前,你需要理解那些能让你扩展技能的基本工具、流程和语言。
Dataquest 的业务分析师路径完全在线和异步,这意味着您可以按照自己的节奏学习。这个 15 部分的课程分为三个部分:每个部分集中在工作的一个关键方面和它需要的软件。Dataquest 的课程强调业务分析的 IT 方面,引导您了解数据库管理、数据分析和数据可视化等概念。
在此过程中,您将学习行业领先的应用程序和编程语言,例如:
- 微软优越试算表
- Microsoft Power BI
- 结构化查询语言
完成测试你勇气的项目后,你就可以开始工作了。尽管随着你在新岗位上掌握新技能,你的教育还会继续,但你总会有这些基本的商业分析技能可以依靠。
2022 年商业分析师的工作前景
原文:https://www.dataquest.io/blog/business-analyst-job-outlook/
June 21, 2022
随着组织转向数据来做出关键决策,对业务分析师的需求越来越大。这些就业增长预测证明了这一点。
未来并不是一成不变的,但就业前景分析师无论如何都会试图预测它。为此,各种来源报告良好,如果不是巨大的,在商业分析的增长。这也包括与业务分析师使用相同技能的相邻职位。
根据美国最权威的职业前景来源美国劳工统计局(BLS)的数据,到 2030 年,商业分析师的增长率有望达到 25%。这与该国预计到 2030 年 8%的平均增长率相去甚远。
对于计算机科学这个非常突出的领域之外的工作来说,这几乎是前所未有的增长。
越来越多的企业比以往任何时候都需要数据分析
为什么商业分析师职位会以两位数的百分比扩张,这并不神秘。如今,企业比以往任何时候都更依赖数据来做出关键决策。数据决定一切,从卖什么产品,卖多少钱,卖给谁。
从小型的本地企业到最大的公司,各种规模的组织都在寻找能够捕获、管理和解释大型数据集的业务分析师。随着信息时代的到来,公司可以获得 10 年前无法获得的数据。因此,他们需要能把数据放在商业战略背景下的人。
虽然大部分工作是管理数据库,以执行描述性和预测性统计分析,但工作的另一部分是以易于理解的方式向经理和主管人员展示。因此,精通数据可视化软件对于业务分析师来说至关重要。
业务分析师职位呈爆炸式增长
BLS 的工作清单中并没有专门追踪“商业分析师”。25%的增长预测指的是运营研究分析师,这是一个类似的职位,倾向于通过数据分析改善内部运营。25%的增长预测是总体预期的上限。
然而,BLS 也预测了其他与商业分析师分担责任的工作岗位的光明前景。例如,市场研究分析师是另一个类似的职位——它专注于使用数据来发现趋势,综合消费者数据,并提供销售策略建议。到 2030 年,这一职位的增长率将高达 22%。
最后,其他密切相关的职位,如预算和管理分析师,到 2030 年可能分别增长 5%和 14%。
和往常一样,对预测持保留态度是值得的。尽管如此,无论你选择销售和运营还是预算和管理分析,你都可以期待对商业分析师的需求保持上升趋势。
商业分析师的技能是可以转移的
BLS 没有“商业分析师”列表的原因之一是它可能有不同的含义。
正如您已经看到的,市场分析师和运筹学分析师等角色有不同的职责,但使用相同的基本技能。对于你这个未来的商业分析师来说,这意味着你并不局限于一个特定的职位。相反,你可以将商业分析技能应用到各种职位上,让你在商业分析师就业市场上拥有极大的灵活性。
看待这个问题的一个好方法是,你从像 Dataquest 的商业分析师之路这样的项目中学到的技能是一个坚实的基础。例如,营销经理的工作需要营销经验,但取决于雇主,这份工作可能会严重依赖于市场研究。一个可能的场景包括以下内容:
- 通过调查收集客户信息
- 从数据源中收集见解
- 分析数据以预测消费者意图
- 将信息呈现在视觉包中
如果这听起来像是商业分析师的工作,那是因为它确实是。唯一的例外是明确把营销放在其他业务部门之上。
当你能在其他工作中运用商业分析师的技能时,找到工作的机会对你非常有利。
在大约六个月内成为一名商业分析师
对业务分析师的需求很高,而且这种需求很可能会增加。随着商业分析师的前景在未来几年看起来非常有希望,现在是你迈出第一步的好时机。如何做到这一点取决于可用性和财务状况。
至少需要三年时间的大学学位课程是许多人选择的路线,但也有同样好的、更实惠的选择可以考虑。Dataquest 的业务分析师路径就是其中之一,你可以在短短六个月内完成,如果你需要的话,也可以更长。
在一个面对面的机构里,你每周要花 10 到 15 个小时去上课——如果算上家庭作业的话,时间会翻倍。然而,Dataquest 的业务分析师道路按照你自己的步伐前进,要求你每周不超过 10 小时的时间。这意味着你不必担心考试前的临时抱佛脚或从繁忙的日程中抽出额外的时间来完成作业。
无论您是否花时间或精力在六个月内完成,Business Analyst 数据路径都会根据您的计划进行调整。从来都不是反过来。
美国商业分析师工资(2022 年 7 月)
June 24, 2022
业务分析师是一个受欢迎的数据科学工作,工资范围极具竞争力。这是 2022 年的数字。
就业市场现在正处于一个关键时刻,许多人都在考虑换工作。输入业务分析师。。。
业务分析师是训练有素的数据专家,拥有数据库和商业智能软件技能,能够以直观的方式操纵、分析和呈现数据。
商业分析师是一份受欢迎的工作,位列 Glassdoor 的【2022 年全美 50 份最佳工作中,领先于项目经理、房地产经纪人、风险经理和前端工程师等重要职位。
除了充实的职业生涯,商业分析师还将享受远高于美国全国平均水平的薪水。
下面列出的美国业务分析师的薪酬以美元为单位,可能会因地区而异。
商业分析师的平均入门级工资是多少?
**除非你有另一份可以转化为业务分析师的工作经验,否则你可以期望从入门级业务分析师的薪水开始。
商业分析师的入门级工资范围从低端的 55,000 英镑到高端的 78,000 英镑(尽管,离群值可能会超出这个范围)。
初级业务分析师的工资差异如此之大的原因可以归结为地点、雇主和经验。此外,工作范围也会影响薪水。因为商业分析师需要很多技能来有效地完成他们的工作,所以需要更多特定技能经验的公司愿意为训练有素的候选人支付高价。
所以,为了更好地了解商业分析师的工资,最好看一下平均值。
商业分析师的平均工资是多少?
**商业分析师的平均工资更好地反映了你转行后的预期收入。根据 Glassdoor 的数据,商业分析师的平均工资为 74513 英镑。那一点也不差,但那只是开始。显然,这个数字接近 95,000。那是因为大约 20,000 英镑的奖金。现在,那是的一份薪水。
其他报告发现,商业分析师的平均工资在 8 万到 9 万英镑之间。
事实上,例如,列出的商业分析师平均工资为 79,987 英镑,但我们姑且称之为 80,000 英镑。然而,该网站显示,商业分析师的平均现金奖金为 3600 英镑,平均工资接近 80000 英镑左右。
而在薪资专家上,商业分析师平均薪资列在 9.6 万。这让只有几年经验的商业分析师离六位数俱乐部只有一步之遥。有经验的商业分析师的薪水可以高得多。
随着时间的推移,作为一名商业分析师,我能挣多少钱?
**对于受过良好教育、简历扎实、有几年工作经验的热门商业分析师来说,平均起薪在 10 万英镑左右。
在 Glassdoor 上,商业分析师的高端薪资范围最高为 23.2 万英镑。
类似地,在“的确”网站上,有一些工作在大致相同的地区列出,这意味着在作为一名商业分析师工作的五到十年内,20 万英镑的薪水不是不可能的。
高工资上限足以激励人们投身商业分析领域。当然,对于这样一个技术领域,雇主会寻找具备合适技能的高素质候选人。商业分析或相关领域的学位是最高要求,但不要气馁。
你不需要参加一个四年制的机构来开始你的商业分析师之旅。
以我的教育程度,我能期望多少薪水?
**雇主希望商业分析师候选人了解 SQL、Excel、微软 Power BI 和数据库软件。工作的另一半是经验。从本质上讲,雇主寻找的是不仅了解自己的专业知识,而且能够将这些知识运用到实际工作中的求职者。
诚然,这些技能可以通过参加学士或硕士学位课程来学习。这些传统的面对面的机构是一种选择,但它们可能会占用你太多的时间和金钱。参加三到五年的课程以获得学位是许多人无法负担的,尤其是考虑到高等教育费用的上涨。
此外,还有动手实践的问题,这在课堂上是无法保证的。虽然简历上的学位是加分项,但项目组合或一些现实世界的经验对雇主来说更重要。
新的 Dataquest 商业分析师路径将教你所有的技能,这些技能将使你成为未来雇主眼中的纸上和的顶级候选人。与你至少要花三年时间的现场机构不同,商业分析师之路按照你自己的节奏前进,每周只需要 7-10 个小时。15 门课程分为三个部分,业务分析师路径教授 Excel、SQL 和 Microsoft Power Bi 的熟练程度。
此外,随着课程的进行,你将把你的技能应用到指导项目中,这些项目将挑战你的知识并给你实践经验。最后,你将能够展示你作品集里的项目。最终,你将能够将大型数据集转化为可操作的商业战略,让你稳稳地走上年薪 10 万英镑或以上的道路。********
业务分析师与数据分析师:哪个适合你?(2022)
原文:https://www.dataquest.io/blog/business-analyst-vs-data-analyst/
July 1, 2022
商业分析师和数据分析师是两个非常时髦的数据职业。他们有许多共同点:都是最近才出现在劳动力市场上,都享受有竞争力的薪水,都处理大量数据,都在数据中寻找隐藏的见解和模式,以做出数据驱动的决策。
那么,这两个数据科学专业有什么区别,应该选择哪个呢?
很棒的问题!
为了回答这个问题,让我们看看业务分析师和数据分析师之间的异同,以便更好地理解每个角色的范围,并确定哪个角色最适合你。
他们做什么
直奔主题:业务分析师做业务分析,数据分析师做数据分析。我们知道:帮助不大。让我们看看我们在维基百科的朋友对商业分析和数据分析有什么看法:
商业分析是一门识别商业需求和确定商业问题解决方案的专业学科。解决方案通常包括软件系统开发组件,但也可能包括过程改进、组织变更或战略规划和策略开发。
数据分析是对数据进行检查、清理、转换和建模的过程,其目标是发现有用的信息、提供结论和支持决策。数据分析有多个方面和方法,包括各种名称下的不同技术,用于不同的商业、科学和社会科学领域。
比较责任和义务
商业分析师的职责如下:
- 使用各种数字和非数字数据来识别当前的业务问题和机会
- 决定关键的行业趋势
- 理解和分析业务需求
- 评估主要业务功能、IT 结构和流程的效率
- 构建财务模型
- 衡量业务绩效的关键指标
- 就最佳行动方案提出建议
- 提供战略性、数据驱动的解决方案来支持业务决策
相反,数据分析师的角色意味着主要关注数字数据本身。
数据分析师的职责如下:
- 从不同来源收集数据
- 数据清理
- 数据操作
- 数据可视化
- 统计分析
- 提出和验证假设
- 数据库管理
- 揭示数据中的模式和趋势
- 寻找初始业务问题的答案
- 以令人信服的形式向相应的部门、经理或股东传达可行的见解。
他们与谁一起工作
到目前为止,你可能已经知道你对这些数据科学工作中的哪一个更感兴趣。然而,让我们继续我们的比较——我们仍然有许多事情要讨论。例如,在每个角色中,你应该与哪些团队和专业人士一起工作?
业务分析师大多与销售、营销或产品团队以及客户服务密切互动。另一方面,数据分析师与数据科学家、数据工程师和数据管理团队合作。
业务分析师和数据分析师都与 IT 服务部门、经理、第三方股东沟通,当然也相互沟通。
一般来说,数据分析师的工作更加独立,而业务分析师通常与其他团队有更多的联系。
背景
另一件可以帮助你决定最适合你的选择的事情是你的教育(如果你想转行的话)。
虽然业务分析师和数据分析师可以来自不同的技术或业务背景,但业务分析师往往拥有与业务相关的专业学位,如工商管理、企业管理、金融、商业、项目管理等。
数据分析师通常是更多的技术专家,他们毕业于 STEM(科学、技术、工程和数学)学科,如数学、编程、计算机科学、IT、统计、医疗保健、自然科学、工程等。
然而,对于数据分析师来说,掌握所在行业的领域知识也很重要。例如,如果你有数学背景,并希望在医疗保健领域担任数据分析师,那么成为一名杰出的数学家是不够的:你还需要在医疗保健领域积累足够的知识,以便理解和分析医疗数据。
技能和工具
现在,让我们回顾一下你在业务分析师或数据分析师角色中取得成功所需的技能。虽然这些专家的一些技术数据科学技能和工具有所重叠,但他们的活动重点却有所不同。
对于业务分析师来说,关键能力如下:
- 强大的领域专业知识
- 数据分析
- 用 Excel 实现数据可视化
- 用 Power BI 和 Tableau 进行数据分析和数据建模
- 在 SQL 中使用数据库
- 熟练使用 SAP、SAS 或 Microsoft Visio 等工具
- 对项目管理流程有扎实的理解
此外,如果您正在考虑业务分析师的角色,您还需要 Python 及其数据分析库的基础知识。
至于数据分析师的角色,最基本的技能如下:
- 数据清理
- 数据争论
- 数据可视化
- 数据建模
- 数据库管理
- 概率与统计
- 假设检验
数据分析师在日常工作中使用的数据科学工具包括 Excel、Python 或 R(及其数据分析库)、SQL、Azure、命令行等等。如果你想了解更多数据分析的必要技巧,可以查看这篇文章。
两个角色的重要软技能是相似的。这里有一个方便的清单:
- 分析和数学思维
- 批判性思维
- 通讯技能
- 准确(性)
- 解决问题
- 积极主动性
- 对数据的好奇心
- 时间管理
- 能够独立和作为团队的一员高效工作
他们挣多少钱
最后但同样重要的是,关于业务分析师和数据分析师的工资的紧迫问题。
一般来说,业务分析师的工资往往高于数据分析师的工资。例如,根据实际上是,美国的商业分析师的当前(平均)基本工资是每年 82,327 美元(截至 2022 年 6 月 25 日),而数据分析师的基本工资是每年 65,520 美元。你可以在这篇文章中阅读更多关于商业分析师薪水的最新趋势。
然而,有许多因素决定了这两种工作的实际工资价值:公司简介、规模、地理位置、职位的确切要求、你的资历、合同类型等。
摘要
在本文中,我们分析了业务分析师和数据分析师之间的差异,以帮助您选择最适合您的分析师。
如果你选择商业分析师的职位,那么在 Dataquest 的商业分析师职业道路可以是一个完美的起点。要学习数据分析并成为数据分析师,您可以探索我们的Python 数据分析师或R职业道路数据分析师。
无论你选择哪种职业,我都祝你学习愉快,顺利过渡到新的领域。
有人能学会编码吗?是啊!(是科学)
原文:https://www.dataquest.io/blog/can-anyone-learn-to-code-yes-its-science/
August 14, 2020
学习编码可能感觉像是一个令人生畏的挑战。看门人让事情变得更糟——外面的程序员告诉你,只有“STEM 人”可以或者应该学习编程。
有些守门人可能是出于好意。每个人都应该成为软件工程师的想法和每个人都应该学习其他行业的想法一样愚蠢。做一个快速编码训练营并直接进入高薪程序员工作的梦想更多的是营销而不是现实。
但是“不要学习编码”的文章往往忽略了一个非常基本的要点:学习编码和成为一名全职软件工程师是两回事。
许多对学习编码感兴趣的人正在寻找其他职业,比如数据科学。其他人只是对向他们的技能集添加一些技能感兴趣,自动化他们的一些工作,或者追求一个有趣的爱好或副业。
显然,不是每个人都能成为软件工程师,但这并不是因为这是一门只有天才才能理解的神秘科学。只是因为这个世界不需要那么多软件工程师。
任何想学习编码的人都可以学习编码,并从中获得一些真正的好处。很多很多不是全职软件工程师的人每天都在使用编码技能。
尽管你可能听说过,你不必成为一个“数学人”或“STEM 人”来学习编程。
你不必是一个“数学人”
学习编程需要“擅长数学”的想法被一些人认为是常识。它甚至在我们的教育系统中被编纂——许多大学编程课程都将高等数学课程作为先决条件。
但是 2020 年 3 月科学报道发表的一项研究指出,现有的关于数学技能有助于学习编程的科学是“不一致的”在他们自己的研究中——对 36 名在线学习 Python 的人进行了 10 次 45 分钟的研究——发现学习人类语言的能力比数学能力更能预测成功。
表现最好的 Python 学习者往往有很强的语言学习和推理能力。工作记忆和静息状态下的大脑活动也是更高 Python 学习性能的预测因素。数学天资似乎确实有所帮助,但仅仅是勉强——它的影响没有其他任何因素那么强。
当然,这并不是说数学技能没有用。根据你希望用编码做什么,一定程度的数学知识是必要的。但这项研究表明,如果你不是一个“数学人”,你就不能或不应该学习编码的想法是无稽之谈。
正如这项研究的作者之一在接受科学日报采访时指出的那样,学习编码需要数学背景的想法已经成为一种自我实现的预言。“编程的许多障碍,从必修课到优秀程序员的刻板印象,都围绕着编程严重依赖数学能力的想法,而这种想法并没有在我们的数据中诞生,”首席研究作者 Chantel Prat 博士告诉该出版物。
任何人都可以学习编码,但是有一个问题
在 Dataquest 这里,我们向对学习数据科学感兴趣的人在线交互式地教授 Python 和 R 编程。我们已经看到成千上万的学习者,来自各种可以想象的背景,完成我们的课程,学习编码,并达到他们的学习目标。
问题是,虽然你不需要数学背景,但你需要动力。找到合适的学习平台可以让学习更顺利,但是学习编码很难。有时会令人沮丧。如果你没有一个好的理由去学习,说服自己退出就变得非常容易。
因此,具体一点会有帮助。如果你想学习编码,你绝对可以。但是为什么你要学习编码?
- 你是否正在尝试将工作中枯燥的任务自动化?
- 你有想要建立的网站或应用程序的想法吗?
- 你对制作游戏感兴趣吗?
- 您是否使用电子表格,并希望能够利用您的数据做更多的事情?
所有这些都是想要学习编码的好理由。重要的是,你选择一些对你来说特别的东西,让你保持兴趣。理想情况下,你的动机还会指向一个或多个项目,你可以将这些项目分解成更小的步骤,这样你就可以在学习的过程中逐步实现你的目标。
你可以在我们的文章中读到更多关于这种基于动机和项目的方法的内容,这些文章分别是如何学习数据科学、如何学习 Python 和如何学习 R 。
但是最重要的是,你需要一个个人的、真实的理由来学习。如果你只是因为有人说你应该学习编码,或者你读到一篇文章说编码是一项重要的技能,你可能会努力达到终点。
想学编码?要避免的陷阱
学习编程有很多方法,也有很多很好的地方可以学习(Dataquest 是其中之一,我们希望你能考虑我们)。
但是就像很多人有一个误区,认为你需要成为一个“数学人”才能学习编码一样,对于你应该如何学习编码,也有很多误区。这里有一些与平台无关的提示,适合任何出于任何原因而对学习用任何语言编码感兴趣的人:
- 先找到自己的目标/动力。弄清楚你想用编程技能做什么。这将帮助你确定你需要学习哪种语言,你应该专注于哪些具体技能,你必须选择哪些平台,等等。
- 不要花太多钱。那里有大量免费的学习编码的资源。像 Dataquest 和 Codecademy 这样的交互式学习平台和 Coursera 和 EdX 这样的基于讲座的平台收取少量费用,以换取不必自己规划课程和自己寻找资源的便利。训练营可能很棒,但它们非常昂贵——仔细想想你花了多少钱得到了什么,尤其是如果你正在考虑一个花费数千或数万美元的训练营或大学项目。
- 避开“最火科技”炒作。科技行业节奏很快,总有一些热门的新事物需要你去学习。试着避免这些时尚,在你跟随宣传列车之前,坚持学习你的目标的可靠的基本要素。(而且要提防 bootcamps 推最热的新鲜事物;有时他们会忽略一些基础知识来涵盖热门的新技术,因为这是最有市场的。例如,我们已经看到数据科学训练营浏览了 SQL — 数据工作的一项关键技能 —这样他们可以更快地进入机器学习。
- 建项目,弄脏自己的手。一些学习平台(包括 Dataquest)已经将这一点纳入课程,但如果你的平台没有,请确保你是自己做的。看视频讲座对你学习编码没有帮助;实际上写代码会。确保你花时间应用你正在学习的东西,或者选择一个像 Dataquest 这样的互动学习平台,在这个平台上写真正的代码是过程的一部分。
- (针对求职者)研究你的行业。你需要某种认证吗?我 n 数据科学,答案是没有,但是其他行业会不一样。
找到一个好的动机,遵循这些建议,你将在学习编码的道路上一帆风顺!不要让任何人告诉你,你不行,或者你需要成为某一类型的人。* 任何人都可以学习编码。*
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。

如何填写工作申请表以及何时申请
原文:https://www.dataquest.io/blog/career-guide-data-science-application-forms/
March 29, 2019
我们已经介绍了简历和项目组合,这是任何数据科学工作申请中最重要的两个方面。但是你可能会被要求提供一些其他的申请材料,以及在申请数据科学工作时需要考虑的其他事情。
( 本文是我们深入数据科学职业指南的一部分。要阅读其他文章,请参考 目录 或这篇文章后面的链接。 )
在线数据科学职位申请表
在你花了那么多时间制作一份看起来很酷的简历之后,为你申请的每家公司填写不同的在线表格可能会很烦人。
不幸的是,这往往是一个必要的邪恶。即使你已经亲自建立了联系,有时你也会被要求在线填写申请表,以便进入官方系统。
由于在求职过程中无法避免这些问题,所以在填写在线申请表时,你需要考虑以下几点:
如果可能的话,避免通过大型求职网站申请
如果你在 LinkedIn,或者 AngelList 等大型招聘网站上看到一份招聘信息。并且被要求在那里填写一份申请表,那么先花些时间看看这份工作是否在其他地方发布是值得的。
通常,你会发现在该公司的网站上有一种更直接的方式来申请这份工作,这种方式允许你直接提交 PDF 格式的简历,而不必在网上表格中输入所有内容。
即使你在公司网站上遇到另一个在线表格,填写公司网站上直接引用的申请几乎肯定是一个比使用 LinkedIn 上的“轻松申请”或大型求职网站上的任何“轻松”申请功能更好的主意。
这些功能确实让你很容易快速地向几十个不同的职位提交相同的申请材料,但从一份不是专门为该职位量身定制的申请中获得回应是不太可能的。
此外,一些招聘经理和招聘人员在通过大型网站提交的申请上花费的时间更少,因为对于技能型技术职位来说,这些网站通常比其他招聘渠道产生的申请人质量更低。
因此,即使你在 LinkedIn 上找到了一份工作,如果该公司的网站上有一份不同申请表格或流程的工作列表,那么最好还是通过该公司的网站申请。
根据工作量身定制你的答案,包括关键词
在典型的申请表上,你必须填写简历上的大部分或全部信息。
不要把这当成一个无聊的复制粘贴任务,而是以此为借口,重新审视你的简历,在你进入简历时,根据你申请的具体工作修改每一部分(当然,同时保持对你的资历的诚实,避免打字错误)。
尤其是那些会吸引大量申请者的初级职位,你的表格很有可能会在人看到之前被机器审查。
这也是许多公司需要这种表格输入工作申请的部分原因:机器扫描这些回复比扫描数百个不同大小和格式的 pdf 要容易得多。
你的简历和申请表的回复应该考虑到人类读者,但是也要考虑到机器人。从职位描述中找出重要的关键词,并确保在填写表格时包含这些关键词。
如果雇主在寻找一个特定的技能,他们可能会自动拒绝任何没有提到这个关键词的申请。
事实上,即使是招聘人员也会这么做。“在第一轮筛选中,”SharpestMinds 联合创始人爱德华·哈里斯(Edouard Harris)说,“看你简历的人几乎只是在做愚蠢的关键词匹配。你需要尽可能多的关键词重叠。”
不过,包含这些关键词应该不是什么难事。你在任何申请表格中所包含的内容都应该是你技能的真实体现。
如果你很难将职位描述中的关键词融入到申请材料中,这可能是一个信号,表明你不适合这份工作,你的时间可以更好地用在其他申请上。
分享和准备社交媒体账户
许多工作申请表会要求你分享社交媒体链接,如果你有的话。一般来说,是否分享取决于你自己,但对于许多数据科学职位来说,你可能需要分享两个网络,你可能需要做一些准备工作。
开源代码库
对于大多数数据科学和数据分析师的工作来说,这是必须的。这可能是你展示你的项目的地方,雇主无论如何都会想看一看,以确保你积极参与到数据科学的工作中。在分享你的 GitHub 之前,有几件事你需要仔细检查:
- 任何你不想让雇主看到的库都应该设为私有。
- 你应该有一张看起来相当专业的个人资料照片或图片。
- 你应该有一个听起来相当专业的用户名。
- 你的贡献活动应该表明你正在积极从事数据科学相关的工作。
商务化人际关系网
你没有绝对的权利分享一个 LinkedIn 账户,但是因为潜在的雇主可能会在 LinkedIn 上查找你,即使你没有在申请中分享你的链接,最好花一些时间来确保你的 LinkedIn 看起来是正确的(或者如果你没有账户,建立一个账户)。
具体来说,仔细检查:
- 你的技能、工作经历、教育经历和其他材料与你简历上所说的相符
- 你有一张相当专业的照片。照片不一定要专业质量——智能手机摄像头就可以——但你必须让看起来专业。LinkedIn 有一个快速视频指南,如果你需要的话,还会提供一些拍照建议。
- 您的个人资料标题和摘要与您的数据科学技能和职业规划相关。如果你要转行,你不希望雇主对你现在做什么感到困惑(数据分析、数据科学或数据工程)。
- 如果您没有专业的数据科学经验,您的项目将链接到您的“项目”部分(您可以使用个人资料页面上的“添加个人资料部分”按钮添加项目部分)。
- 你的课程证书(如 Dataquest 证书)和任何数据科学相关的技能认证或推荐都在页面上。如果你没有很多数据科学工作经验,因为你刚刚毕业或转行,你希望确保你的个人资料传达的信息是明确的:“我是一名数据科学家。”技能、认可、推荐和证书都有助于传达这一信息。
其他社交媒体网站
通常情况下,你是否向雇主提供你的其他社交账户取决于你自己。但是,即使你不提供链接,潜在雇主也很容易发现你的在线状态。
注意你的账户的隐私设置,并做好相应的计划。你可能会决定在求职期间最好将个人账户设为私人账户,或者你可能会决定让一切都开放(也许在提交申请之前做一点清理,以防万一)。
这两个决定都是正确的,但是你应该在做决定的时候知道,潜在的雇主可能会看到你公开的任何事情。
他们可能寻找的东西之一是对数据科学的真正兴趣。始终通过社交媒体与其他数据科学家合作并分享工作是个好主意,但这在你求职时可能尤为重要。
例如,浏览你的 Twitter 的潜在雇主可能会很高兴看到你是那里数据科学社区的积极参与者。
如果潜在雇主要求访问你的私人社交媒体账户,你必须决定是否愿意提供。
这种要求在美国的一些州是非法的,但即使法律保护你,向潜在雇主指出这一点也不太可能让你被雇佣。
在很多情况下,最好是拒绝请求,继续找工作——在招聘过程中不尊重你隐私的雇主在你被录用后也不太可能尊重你的隐私。
但是在某些情况下,这样的要求可能是合理的。例如,如果你申请的工作需要政府的高度安全许可,你可能必须愿意接受比平时更多的审查。
你应该附上求职信吗?
许多在线申请表会询问你是否想在申请中附上一封求职信。除非职位公告中特别要求附信,否则您应该认为这是可选的。
我们在制作这份职业指南时采访过的所有数据科学招聘人员都说求职信不常见。大多数数据科学职位申请人不包括他们。
至于你是否应该包括一个,意见不一。“简短的求职信,是的,的确很重要,” Gramener 的联合创始人兼分析主管 Ganes Kesari 说。
他发现,除了候选人的简历之外,他们还能提供一些信息,“比如他们为什么对这个行业感兴趣,是什么让他们进入这个行业,是什么驱使他们这样做。”但他警告说,任何求职信都不要超过两段。
Pramp 首席执行官 Refael Zikavashvili 有不同的看法:“我认为求职信已经过时了,”他说。“你不会经常见到他们,我也不会建议任何人这么做。”
Stephanie Leuck 是 84.51(T1)的大学招生人员,她看到了大量(T2)的入门级数据分析应用程序,她说,虽然求职信会有所帮助,但这是一个危险的游戏。“也许 20 个候选人中就有一个会有求职信,”她说,“我通常不会看它们。”
当她看着的时候,大多数求职者可能希望她没有看:“我经常看到这实际上伤害了求职者,因为这太模糊了,他们列出了错误的公司,或者这实际上让我问:‘你知道你想做什么吗?’"
简而言之:你可以附上一封求职信,它可以帮助你(与一些招聘人员)。但是你应该意识到它可能不会被发现,你也应该意识到它会伤害你。换句话说:如果你要附上一封求职信,最好是好的。
斯蒂芬妮对求职信的建议?“确保它是为公司量身定制的,”她说。“并且确保里面有一些有价值的信息。这个想法是,除了简历上的内容之外,求职信还应该为你说话。不用给我重复简历了。”
她说,对于初级申请人来说,一封好的求职信“可以解释你为什么想转行,或者你在大学主修英语,然后你攻读了数据科学的高级学位,或者通过不同的课程做了一些兼职,并解释你如何为自己在数据科学领域的职业生涯做准备。我认为这是求职信更有价值的用途。”
Ewa Zakrzewska 是波兰 Zety 公司的人力资源专家和招聘人员,她说,当她看求职信时,她在寻找“将你可衡量的成就与工作描述联系起来,并解释你能带来什么”的申请人
“说你没有经验,但你愿意在工作中学习,这可能不是一个好主意,”她补充道。
直接接触而不是求职信
Pramp 首席执行官 Refael Zikavashvili 推荐的另一种方法是通过电子邮件直接联系首席数据科学家、招聘经理或招聘人员,而不是发送求职信。
“如果候选人主动给我发电子邮件,告诉我,‘我相信你有这个业务挑战,这是我将如何着手解决的’,那将会给我留下非常深刻的印象,”Refael 说。
“如果有人能够根据公开信息发现问题,并能更进一步,提出解决问题的方法,那将让我大吃一惊。那个人得到了我的即时采访。不问任何问题。在这一点上,我甚至会跳过简历。”
这种方法在关于寻找数据科学工作的章节中有更详细的讨论,所以请参考那里的相关章节,了解如何正确执行这种方法的更多信息。
然而,我们要在这里重申,这是一个高风险、高回报的策略,你发送的内容必须非常仔细地为你的收件人和相关公司量身定制,否则很可能会损害你的机会,而不是帮助他们。
申请工作的日期和时间
作为一名数据分析师或数据科学家,当你得知数据显示你申请工作的时间很重要时,你不会感到惊讶。
同样的工作申请在周六晚上 11 点或周一早上 9 点发出,可能会产生完全不同的结果。
不同的数据集产生的结果略有不同,但大多数分析的一般信息是相同的:
你应该在周一到周四(T2)之间申请,最好是在周一。而且你应该在早上 6 点到 10 点之间在窗口敷。
如果你申请的工作在其他时区,考虑招聘人员的时区,以及他们什么时候会看到申请,而不是你什么时候发送申请。
甚至一年中的时间也可能很重要,尽管一年中的时间不是你总能控制的。也没有简单的规则可循——季节性招聘模式会因行业和当地假期等因素而异。
出于实用目的,这些差异可能没多大关系。如果你看到你感兴趣的工作,不管什么季节,你都应该去申请。但了解你所在地区的季节性招聘模式仍然是有帮助的,这样,如果你看到工作岗位短缺,你就能知道这是季节性放缓还是你所在地区没有多少工作。
我准备好申请了吗?
这是本指南的最后一节,讲述了在点击“申请”按钮之前应该做什么,所以让我们来回答一个许多申请人都在纠结的大问题:我真的准备好这份工作了吗?
很有可能你不够资格。如果一份工作需要 Python 和 SQL 技能,而你两者都不具备,那么在你花时间写简历或填写申请表之前,花更多时间学习可能是个好主意。
但是记住冒名顶替综合症是真实存在的也很重要。获得数据科学工作的 Dataquest 学生经常与我们分享的一条建议是,学生应该在感觉完全准备好之前申请。
例如,Carlos 在刚刚完成一半我们的数据科学家之路后,突发奇想决定申请工作。他并不认为自己真的准备好了。令他惊讶的是,他最终得到了三份不同的全职工作邀请。
当然,并不是每一份工作申请都以被录用而告终。从统计数据来看,即使是优秀的候选人,被拒的机会也可能比面试的机会多。
重要的是不要把这些拒绝放在心上,记住申请不会让你失去太多。最糟糕的情况是你得不到一份你已经没有的工作。
此外,即使你没有得到这份工作,你也会经常得到有价值的反馈,帮助你改进下一份工作申请,或者弄清楚你需要增加什么技能来使自己成为更有竞争力的申请人。
你发出的每一份申请,不管得到的回应如何,都会给你提供另一个数据点,帮助你更准确地评估自己在就业市场中的位置。
这就是为什么我们说: 有疑问的时候,套用 。你没什么可失去的,而且你可能会对你准备做的事情感到惊讶!
本文是我们深入的数据科学职业指南的一部分。
- 简介及目录
- 在你申请之前:考虑你的选项
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项— 你在这里。
- 准备数据科学的工作面试
- 评估和协商工作机会
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
准备数据科学工作面试
原文:https://www.dataquest.io/blog/career-guide-data-science-job-interview/
March 29, 2019
一旦你的申请材料都准备好了,就该开始考虑数据科学工作申请流程的下一个阶段了:工作面试。
( 本文是我们深入数据科学职业指南的一部分。要阅读其他文章,请参考 目录 或这篇文章后面的链接。)
如果你没有得到数据科学的工作面试会怎么样?
如果你已经具备了你申请的职位所需要的技能,并且你已经做好了准备申请材料的工作,最终你会开始收到有兴趣面试你的雇主的回复。
如果这需要一段时间或者你的回复率很低,不要气馁。这在申请入门级工作时很常见。这些职位竞争激烈,招聘过程也相当随意。坚持下去!
但是,如果你申请了数百份工作,却没有得到任何面试机会,那么很有可能出了什么问题。
这可能是因为你不适合你申请的工作,也可能是因为你的申请材料中的某些东西让招聘人员感到困扰。不管是哪种方式,都值得咨询一些知识渊博的人,他们可以评估你的应用程序,并给你一些错误的想法。
Dataquest Premium 订阅者可以从我们训练有素的职业服务社区版主那里获得个性化的职业建议(包括面试准备、作品集和简历评论)。你也可以请你数据科学网络中的朋友或联系人帮助你找出问题所在。
然而,一旦你开始接受面试,你就要为面试做好准备。你的申请材料给了你一次机会,但面试过程是你敲定交易,并向潜在雇主确认你是这份工作的合适人选。
期待什么,以及如何准备
先说坏消息:数据科学面试形式和问题相当多样,这让他们很难准备。
“老实说,面试过程千差万别,”SharpestMinds 的联合创始人爱德华·哈里斯说。“每家公司都认为自己找到了光明,他们有一种真正的面试方式,所以一旦你参加了面试,面试问题就会千差万别。你会看到 IBM 的面试过程,据我们所知,这是非常高层次的问题,比如“描述一下决策树是如何工作的”。描述这个或那个是如何工作的。另一方面是谷歌,它正在与工程师进行痛苦的白板编码会议。"
他说:“一些公司只是窃取了 leet code 上的问题。“差异太多了。这个行业实际上没有标准。这真是一团糟。没有足够多的公司真正对这些职位进行大规模面试,以收集有意义的数据,了解他们的招聘流程是否有效。所以面试只是一种巫毒仪式,没人知道怎么做。”
这是坏消息。好消息是,即使你可能不知道当你走进这扇门时会遇到什么,你仍然可以做很多事情来准备自己在数据科学工作面试中胜出(还有大量的免费工作面试资源在那里提供帮助)!
招聘经理想要什么
尽管每次面试都不一样,但招聘经理和招聘人员通常希望在面试过程中了解你的三个主要方面:
- 你对这家公司和这个职位有多感兴趣?他们希望看到你对公司的工作非常感兴趣,并且你已经开始思考如何在这个职位上为公司带来价值。
- 你的技能与工作要求有多匹配?他们希望看到你在技术上能够胜任这项工作。仅仅因为你的简历上说你知道 Python 并不意味着你擅长它,所以实际上每个面试过程都会包含一些旨在测试你技术能力的元素。雇主也希望看到你展示重要的软技能,比如沟通。
- 你会是一个优秀的“文化契合者”吗?他们希望看到你的个性能够融入他们的公司文化,并且你能够在他们的团队和系统中高效地工作。他们还希望看到你的个人职业目标与公司和相关职位保持一致。
如果你能在面试结束时让招聘经理和其他团队成员对这三件事都感到满意,你获得工作机会的机会就很大。
面试流程示例
尽管每个公司处理数据科学工作面试的方式不同,但我们还是来看看一些面试流程示例。
以下是几家不同公司入门级数据分析师职位的真实面试流程,基于过去几年 Glassdoor 上的受访者报告、我们自己对招聘人员的采访以及我们采访的 Dataquest 学生的经历。
我们已经删除了公司名称,因为公司经常改变他们的流程,我们不想误导任何人他们将面临的确切情况,因为我们无法总是确认受访者报告的准确性。
尽管如此,阅读这些过程仍然会让你对你在求职过程中可能经历的不同种类的过程有一个准确的概念。
第一大科技公司,美国办公室:两次电话面试,一次是数据科学家的技术面试,另一次是招聘经理的软技能和文化面试。四次现场面试侧重于工作的不同方面(如技术技能、沟通等。).整个过程耗时约三周。
第二大科技公司,印度办公室:一轮入门筛选,然后是两轮侧重于工作相关技能的在线测试,最后是一轮个人面试。整个过程花了几个星期。
第二大科技公司,新加坡办公室:与招聘经理进行一次电话筛选,然后是三轮现场面试,主要关注技术技能和挑战。整个过程花了大约三个星期,候选人称之为“有点累”
初创公司#1,美国办公室::电话筛选,然后是一个带回家的项目,做一些数据分析,并提交一个 Jupyter 笔记本文件供公司评估。随后是另外两次面试,一次技术面试和最后一次个人面试。这个过程大约需要三个星期。
主要电信公司,美国办公室:两次面试(电话或现场,取决于候选人的位置),一次侧重于个人问题,一次侧重于技术问题。面试是“轻松”和简短的;整个过程耗时约一周。
大型金融公司,美国办公室:一次快速电话筛选,然后是两次一对一的现场面试,令人惊讶的是,面试高度关注个人和行为问题,而不是技术问题。整个过程耗时约两周。
中型数据公司,美国办公室:通过电话进行技术筛选,然后是更深入的面试,重点是相关工作经验和解决与公司业务相关的技术挑战。第三次也是最后一次面试更侧重于个人和行为话题。整个过程大约需要三周时间。
中型软件公司,美国办公室:最初的电话筛选,随后是几轮现场面试,包括独自解决一个与工作相关的问题,以及在一天的大部分时间里与公司团队一起从事实际项目。这个过程需要几个星期。
第三大科技公司,美国办公室:筛选与招聘经理和他的一名员工的谈话,然后与人力资源部门的员工进行两次简短的面试,然后是包括五次单独面试的现场面试循环。整个过程用了一个多月。
如您所见,体验千差万别,但有一些共同点:
- 在这个过程的某个时刻,你将不得不回答一些技术问题或者完成一些与编码技能相关的项目。
- 通常至少会有一次面试关注软技能和文化。
- 大多数招聘流程都是从某种筛选(通常是通过电话)开始的,以快速淘汰不合格的候选人。
还要注意的是,你很有可能在网上找到你申请的公司面试流程的具体信息。Glassdoor 是一个很好的资源。点击“面试”选项卡,然后搜索公司名称。
一旦你进入该公司的“面试”页面,你可以在下方的搜索栏中筛选你的职位,然后点击“查找面试”,阅读与该职位相关的受访者经历。
这是一个非常有用的资源,只要你记住一些注意事项:
- 这些报告是由用户提交的,因此它们可能不准确、有偏见或完全不真实。
- 公司经常改变他们的面试程序,所以旧的报告可能不能反映公司当前的招聘实践。
- 面试流程可能因人而异:例如,一个被高层员工推荐的候选人可能比一个没有推荐人的候选人面临更宽松、更非正式的流程。
不幸的是,你申请的公司越小,你就越不可能在 Glassdoor 上找到有用的报告。对于许多公司(包括大多数初创公司)来说,你很可能什么也找不到。
不管怎样,不要担心!你要做好准备。方法如下:
如何准备
在本文的后面,我们将讨论具体的示例问题,但首先,让我们谈谈一般的面试准备。
你应该把面试过程想象成类似于学校的一次重要考试:如果你事先没有投入学习时间就去参加,你很可能会有麻烦。
具体来说,在每次面试之前,你应该回顾:
- 你提交给这家公司的简历。准备好回答关于你的背景、工作经历、技能的问题——简历上提到的任何事情都有可能出现,如果你在面试中给出的答案与简历上写的相矛盾,那就不太好了。
- 你的项目组合。特别是对于入门级的角色,你应该对自己的项目了如指掌。准备好回答关于你做了什么、你怎么做的、你为什么这样做的问题,以及关于你在项目中应用的编程和统计概念的更广泛的问题(面试官想知道你是否只是从 StackOverflow 中找到了一些很酷的代码来复制粘贴,或者你是否真正理解了幕后发生的事情)。
- 与职位描述相关的技术问题。没有办法确切地知道在面试中你会被要求回答什么技术问题或解决什么问题,但是如果工作描述中提到了具体的语言、技术或技能,你几乎可以肯定会遇到类似的问题。回顾你所知道的,确保你不仅知道如何做某事,还知道何时和为什么你可能想做这件事。我们有一些示例技术问题和更多资源的链接,您可以在本文稍后查看。
- 与工作、你的经历和求职相关的个人问题。不要以为你能即兴想出这些问题的好答案!尽管有些答案似乎显而易见,但在每次面试前,根据你的工作经历,为常见的工作面试问题和你预期的问题准备答案是值得的。
- 你打算在这次面试中问的问题。对于每次面试,如果有机会,你应该准备至少 3-5 个你可以问面试官的问题。我们将在本文后面更详细地讨论这一点,但准备好要问的问题意味着做一些研究,并对你在这家公司的角色做一些真正的思考。
为你的答案写下提纲是个好主意,但是练习大声说出来也是有帮助的。
编制一份“模拟面试”问题清单,请朋友或家人帮助你准备。即使他们对数据科学一无所知,你也很可能意识到是否还有技术概念需要你温习。
另外,非技术类的朋友仍然能够在面试的“软”方面提供有用的反馈,比如你听起来有多自信,你对个人问题的回答有多有说服力。
用视频记录自己回答模拟面试问题也是一种有益的(有时也是痛苦的)练习。把你的手机放在某个能捕捉你全身的地方,然后录下你对不同面试问题的回答。
你可能会对你的发现感到惊讶!
穿什么,如何展示自己:面试前的准备
在我们深入探讨示例问题之前,我们需要了解数据科学工作面试准备的另一个方面:展示自己。
喜欢与否,这很重要;你如何展示自己会影响面试官见到你的第一印象(无论是面对面还是视频聊天),第一印象很重要。
事实上,第一印象有多重要有点吓人。一些研究表明,人们会在最初的两秒钟内对你做出重要的、难以改变的判断(T2)。
在参加数据科学工作面试时,了解自己的能力是非常重要的,但同样重要的是,你要很好地展示自己。
这意味着什么呢?
服装:你应该穿干净的、适合你面试的任何工作场合的服装。因行业而异;在科技公司,你穿休闲装可能没问题,但在金融面试中,你可能需要穿西装。
如果你不确定公司的一般着装惯例,在面试前问一下这个完全没问题。有疑问时,谨慎为上。感觉自己穿得有点过了,肯定比穿着人字拖和短裤出现,发现别人都穿西装要好。
打扮:你需要看起来很专业。这对各种人来说意味着各种事情,在某种程度上,这因行业而异。但总的来说,你可能希望自己的头发整齐(并且远离脸部)。你想要干净整洁的指甲。等等。
卫生:这也很简单:你不应该闻起来很臭或者看起来不干净。在面试之前,确保你已经洗过澡,刷过牙,这可能是个好主意。手边放几片薄荷糖保持口气清新也不会有坏处。
视频面试的额外考虑:如果你在进行视频面试而不是现场面试,考虑一下面试官会看到什么。以下是一些需要考虑的事项:
- 有什么背景?空白的墙壁很好,干净整洁的房间也很好,墙壁艺术也很好,只要它看起来相当专业。你不希望出现在背景中的是像一张未整理的床、一堆脏衣服或者一堆奇怪的骷髅画。
- 你用什么聊天?如果可能的话,使用放在某个稳定地方的电脑、网络摄像头或手机。手里拿着手机或在膝盖上用电脑聊天会让面试官觉得视频很不稳定。
- 你长什么样?试着将你的电脑或相机设置在大致与眼睛齐平的位置,这样你就可以直视它,而不是俯视它或仰视它。这保证了你的面试官会以一个正常的角度看你。还要考虑照明——你的脸应该被清晰而均匀地照亮。如果你需要的话,不要害怕带上一两盏灯来确保你的脸被照亮。
- 你的设备是如何工作的?提前和朋友一起测试一切,确保他们能清楚地听到和看到你,并且没有不可预见的技术问题。
- 你在看哪里?视频聊天在这方面可能很困难,因为如果你看着某人出现在屏幕上的眼睛,他们通常会看到你看着他们视线下方的,因为大多数网络摄像头位于屏幕上方。如果可以的话,在你说话的时候,尽量记得看着你的相机而不是你的屏幕。这会让面试官觉得你正看着他们的眼睛。(但如果你觉得这太难了,不要太担心——给出好的答案更重要,大多数面试官会理解在视频聊天中很难“直视”某人的眼睛)。
*## 回答面试问题
现在你已经准备好了,是时候谈谈面试的实际经历了,看看你可能会面临的一些问题,并讨论一下面试者角色的一个重要方面:倾听。
倾听的重要性
获得数据科学工作面试的关键是什么?数据挖掘食谱 作者和 OliviaGroup 首席执行官奥利维亚·帕尔-鲁德说,“做一个好的倾听者”在求职面试中真的很有帮助。
“事实上,倾听,然后甚至可能重复对那个人说,‘好的,我只是想确保我明白你在寻找什么’,然后可能再深入一点,让他们感觉有人在听,这是非常重要的。”
“让我感到惊讶的是,有多少人感觉不到被倾听,而仅仅是倾听的行为就能真正地将你联系起来,”她说。“对我来说,这会给参加面试的人带来巨大的优势,即使是无意识的优势。”
Parr-Rud 建议你先听,然后重复问题,这背后有一些真正的科学依据。我们在最近的博客文章中更深入地讨论了这个话题,但是结论是:一项又一项的研究证实,简单地逐字重复一个人的问题往往会给他们留下更好的印象,并产生更好的结果。
在各种研究中,仅仅听和重复就能增加销售人员的销售额、女服务员的小费收入,甚至慈善捐款。
当然,你不必逐字复述每个问题。而且你还需要知道如何正确回答它们。但是科学表明,像这样一个简单的交换会有惊人的力量:
面试官:你能解释一下决策树算法吗?你:好的,这是我解释决策树算法的方式…
用面试官自己的措辞(或类似的措辞)重复这个问题,表明你在积极倾听他们在说什么。
它也可能对你有帮助——它迫使你思考你正在回答的问题,并给你一点时间来思考你想说什么。
因此,尽管你对问题的回答至关重要,但记住倾听也很重要。
回答问题的注意事项
在回答任何面试问题时,你都应该有三个目标:
- 明确一点。
- 简明扼要。
- 为你的听众做出恰当的回答。
掌握第一条要清楚,主要是关于准备。只有当你知道你在说什么的时候,你才能清楚地解释一些事情。
掌握第二条,言简意赅,就是要认真听,认真回答问题,仅此而已。避免陷入细节或离题,直接回答问题,如果需要的话,提供更多的细节。
如果你想知道为什么,这篇文章提供了一些很好的见解,但简而言之,提供太多细节会令人不快,并破坏你的可信度。
你可以说,如果面试官愿意,你很乐意提供更多的细节,你也可以要求面试官具体说明他们希望你的回答有多深入。
但是当有疑问时,保持相对简单。“为什么选择这个算法?”应该给出一个 1-2 分钟的答案,说明算法是做什么的,为什么对你的目的有用,而不是一个 20 分钟的讲座,讲述它的每一个复杂性和每一个可能的应用。
掌握第三点,恰当地回答你的听众,只需要你记住你在和谁说话。
你是在和一位拥有 15 年经验的数据科学家交谈吗?尽可能使用专业术语,尽可能多地使用术语!你是在和一个为公司每个团队招聘员工的人力资源代表说话吗?你可能需要给出更宏观的答案,并解释一些更复杂的技术问题。
你还应该避免使用“数据蒙混”这样的行话,而是说“我清理了数据”,这样任何人,不管他们的编程背景如何,都可以理解。
关于项目的示例问题
如果你没有太多的工作经验,你应该准备好被问到一些或所有你在简历、申请和 GitHub 上展示的项目。
这里有一些示例问题,你可以针对每个项目通过进行测试,以确保你得到了好的答案:
- 你为什么选择做这个项目?
- 这个项目对你来说意味着什么?
- 在这个项目中,你最喜欢的是什么?
- 在这个项目中,你最不喜欢的是什么?
- 在这个项目中,你遇到了哪些技术挑战,你是如何克服的?
- 你从哪里得到这个数据集的,你用了什么技术来清理数据?
- 你为什么选择使用你在这个项目中使用的统计技术?
- 你为什么选择使用你在这个项目中使用的编程技术?
- 你能解释一下这种算法/统计技术/代码段是如何工作的吗?
- 你在这个项目中使用了什么库、包或其他工具?
- 你花了多长时间完成这个项目?
- 如果有人问你,你会如何扩展这个项目?
- 如果让你再做一次,你会对这个项目做什么改变?
- 你在这个项目中使用的技能对我们的业务有什么价值?
- (如果是团队项目)你在这个项目中的工作是什么?
- (如果是团队项目)这个项目是如何组织和版本控制的?
- (如果是团队项目)你能谈谈你在这个项目中与队友发生的冲突或分歧,以及你是如何克服的吗?
根据您项目中的内容,您可能会被问到关于编程挑战、数据和您在分析中采用的统计方法的其他具体问题。
除了能够回答上面的问题之外,你应该回顾你所有的项目,以确保你理解你自己的代码在做什么,并且你能够清楚地解释你为什么做出所有的决定。
示例技术问题
你在工作面试中面临的技术问题会因你申请的职位、你申请的公司和随机机会而有很大不同。
如果能让你感到安慰的话,技术问题可能没有你想象的那么重要——当我们询问时,我们采访的大多数招聘人员和招聘经理都说,个人问题和关于项目的问题通常能让他们更深入地了解候选人是否“合适”。
当然,这并不意味着如果你所有的技术问题都答错了,你就会得到一份工作。
下面,我们列出了一些数据分析师和数据科学家职位可能会遇到的示例技术问题,但这些问题会有很大差异。
我们这里有的只是一些可能性的小样本,所以在这个列表下面我们还链接了更多的资源,在那里你可以找到更多的练习题。
数据分析师:
- 解释数据分析过程。
- 为什么数据清理很重要?
- 清理数据集时,您会寻找什么样的问题?
- 如何将网页中的数据表放入代码中进行分析?
- 如何使用 SQL/Python/R 将这两个表结合起来?
- 你如何估计旧金山的窗户数量?(像这样的“逻辑”问题数不胜数,意在测试你的逻辑和统计技能)。
- 如何使用 SQL/Python/R 对该表中的行进行数字排序?
- 您希望收集哪种数据来解决特定的业务问题?
- 你会用什么方法来分析两个不同产品搜索引擎的比较性能?
- 在 SQL 中,Union 和 Union All 有什么区别?联合 vs 加入?有 vs 哪里?
- 解释随机抽样、分层抽样和整群抽样。
- 谈谈你使用大型数据库或数据集的一次经历
- 什么是 Z 分数,它们有什么用处?
- 你会如何分析我们提高用户转化率的最佳方法?
- 可视化这些数据的最佳方式是什么?如何使用 Python/R 实现这一点?
- 如果你要分析我们的用户参与度,你会收集什么数据,如何分析?
- 结构化数据和非结构化数据有什么区别?
- 什么是 p 值?
- 如何处理数据集中缺失的值?
- 如果我们公司的一个重要指标不再出现在我们的数据源中,您将如何调查原因?
数据科学家:
- 如何为模型选择特征?你在寻找什么?
- logistic 回归和线性回归有什么区别?
- 解释决策树。
- 你如何测试一个新的信用风险评分模型是否有效?
- 解释 K-means 聚类和它什么时候有用。
- 如果你有不止一个训练过的模型,你如何评估哪一个是最好的?
- 解释偏差-方差权衡以及你如何驾驭它。
- 什么是中心极限定理?
- 线性模型(或任何其他类型的模型)的假设是什么?
- K 近邻和 K-means 聚类有什么区别?
- 你如何解决过度拟合的问题?
- 解释朴素贝叶斯算法。
- 你如何发现并纠正数据中的偏差?
- 什么是交叉验证?
- 什么是混杂变量?
技术问题资源
- Glassdoor 有用户报告的现实世界中的面试问题和数千家公司的建议答案,可以通过职位搜索。(此链接指向他们的数据分析师问题,但您可以搜索任何职位)。
- 在“数据库”部分,Leetcode 有一大堆按照难度组织的练习 SQL 问题。
- Data Science Interview 是 Quora 上一个大型的免费数据科学面试问答集,有些是技术性的,有些不是。
- DS 面试有数百个真实的面试问题,按难度排序。
- Dataquest 课程每节课结束时都有可下载的总结关键概念的 PDF 摘要,根据您完成的课程,它们可以成为测验您从 Python 到 SQL 到机器学习等一切内容的宝贵资源。
- Acing AI 面试定期发布文章,回答来自 Quora、Oracle、Twitch、Yelp 和 Spotify 等大公司的数据科学面试问题。
- 如果你注册了一个账户,你可以通过 HackerRank 解决一系列编码难题,其中一些可能与你在面试中遇到的问题类似。
- Codewars 允许你用 Python 和 SQL 挑战来测试你的技能(遗憾的是,没有 R)。
个人问题示例
- 谈谈你经历的一次职业失败,以及你是如何克服的。
- 你为什么想在这家公司工作?
- 你认为自己五年后会怎样?
- 你的职业规划是什么,这家公司如何融入其中?
- 你认为你在这个职位上会对我们公司产生什么影响?
- 谈谈你对数据科学的热情,以及为什么你对它感兴趣。
- 你认为我们应该收集和分析什么样的数据?
- (如果你没有接受过正规的数据科学教育)你能谈谈你是如何以及为什么学习数据科学的吗?
- 谈谈您如何跟上数据科学领域的发展,以及即将出现的哪些趋势让您激动。
- 你最大的优点和/或缺点是什么?
- 你为什么要转行/离开以前的工作?
- 谈谈你理想的工作环境。
- 谈谈你在工作中有分歧的一次,以及你是如何解决的。
- 到目前为止,你在数据科学领域最自豪的成就是什么?
- 你最佩服的数据科学家是哪些?
- 这份工作的哪一点吸引了你?
“期望薪资”问题
这里有一个面试问题值得特别提一下:“你现在的工资是多少?”或者“你对这个职位的期望薪资是多少?”
这些问题通常出现在面试过程的最后,那时公司正在考虑是否要提供一份工作,回答这些问题会很有挑战性。
不过,一般来说,你应该尽量避免提供你目前的薪水。在美国的一些州,问这个问题实际上是非法的,但即使这个问题在你居住的地方是合法的,最好礼貌地回避它。
像这样说“我不方便透露我目前的薪水,但根据我的经验,这是我期望的薪水范围,”应该没问题。
当然,关键是你需要知道一个合理的薪资范围,考虑到工作描述、你的技能和经验以及当地市场。
我们将在关于出价谈判的章节中更深入地讨论这个问题——了解你的市场价值,但简短的版本是这样的:
- 在类似于 Glassdoor 的网站上做一些调查,看看你所在地区的类似职位的人的工资是多少。
- 给出一个范围而不是一个具体数字;这给了你以后谈判的空间。
如果你在面试过程的早期就被问到这个问题,并且还没有做调查,那么最好简单地完全回避这个问题,比如说:“一旦我对这个职位有了更多的了解,我期待着讨论薪酬问题。”
你应该问的问题
面试过程不仅仅是回答个问题,还有问个问题。
大多数面试官会在每次面试结束时给你一个提问的机会,你不应该错过这个机会。
这是一个宝贵的机会,让你更多地了解公司,并进一步给你的谈话对象留下深刻印象。
要求留下深刻印象
我们采访过的大多数招聘人员和招聘经理都同意,他们对应聘者的印象会受到他们所提问题的影响,问正确的问题可以帮助应聘者。
他们建议问的问题类型包括:
关于做工作的详细问题:这里的关键是详细;不要只问你每天要做什么。问一些具体的问题,表明你已经在思考如何在这个职位上最有效地发挥作用,比如关于你将使用的具体工具或工作流程的问题,或者你将解决的具体业务问题。
例如,你可能会问一家公司是否可以灵活地使用一种工具或软件包/库,这种工具或软件包/库不在他们的技术堆栈中,但你认为可能对你申请的职位有帮助。
“我会被问到这样的问题,‘哦,你试过这个吗?你处理这种类型的数据吗?我想你会这样或那样做,”数据科学和分析经理 Michael Hupp 说。“我们还没有走上这条路,但他们正在考虑这一点这一事实非常突出。”
关于你在这个职位上将要解决的商业问题的详细问题:如上所述,问这种问题背后的想法是表明你已经在精神上参与解决这家公司的商业问题。
Kitware 的人力资源总监杰夫·霍尔说:“真正突出的问题是那些表明他们做了功课并且对 Kitware 特别感兴趣的问题。”。
首席技术官迈克·金(Mike Kim)表示同意:“我能想到的突出问题是,‘哇,这些问题令人印象深刻’,这些问题真正证明了候选人了解我们的问题,他们正在做什么,我们正在做什么,以及他们如何适应这些问题。”
我们在本指南中采访的许多其他招聘人员和招聘经理都有同感。
爱德华·哈里斯说,这种技巧在小公司面试时尤其有用。“几乎总是最好的问题是:‘目前你面临的最大瓶颈是什么?“作为一家公司,最阻碍你的是什么?”这个问题的作用是告诉面试官:这个人,一出门,就想知道他们如何尽可能地帮上忙。"
爱德华说,这个特殊的问题也是一个有价值的信息收集工具。“如果公司只有 20 人或不到 20 人,实际上公司里的每个人都应该能够回答这个问题。如果没有,就存在某种沟通问题,这本身就是一个危险信号。”
关于成长机会和培训的问题:这些问题表明你对不断提高技能和学习感兴趣,这是大多数雇主希望看到的。
(当然,这也是你日后评估工作机会时的宝贵信息;如果一家薪水较低的公司也能提供很好的培训机会,从长远来看对你的职业生涯有好处,那么它仍然是更好的选择。
关于与其他部门协作的问题:数据科学团队通常需要与许多其他部门协作。
沿着这些思路的问题表明你对这个职位的那个方面感兴趣,答案可能会让你对公司的文化有所了解,以及协作工作流程可能有多高效。
关于你将从事的长期计划和项目的问题“这些是我寻找的问题,”CiBo Technologies 人才招聘经理贾米森·瓦兹奎说,“人们想知道长期的未来是什么,想知道我们在哪里建设,但也想知道他们如何真正影响这些未来计划。”
什么不要问
什么都不问:这向面试官表明你根本没有参与,你也没有花太多时间考虑这个角色。你应该总是准备好至少几个问题。
询问报酬、带薪休假等事宜。:这种谈判的合适时间是在面试结束时,在你收到工作邀请之后。
如果你在那之前问这个问题,特别是如果你反复问这个问题,面试官会觉得你只是为了薪水而不是真的对工作感兴趣。
问一些容易找到答案的问题:例如,如果你问一些在公司网站上已经明确回答的问题,这只会让面试官看到你在面试前没有费心去做调查,而则表明你并不真正关心这份工作。
*#### 底线
你的问题需要表明你正在积极思考如何从这个角色中帮助这个公司,并且他们需要证明你在公司业务方面做了功课。
它们需要针对你面试的公司;没有一个问题清单可以让你在每次面试中使用,并给人留下好印象。
迈克·金说:“真正把最优秀的人和其他人区分开来的是他们提问的深度。我指的不是具体的技术问题。我的意思是,这些问题表明他们看到了事物的基础,并理解事物之间的联系。这才是真正令人印象深刻的地方。”
这意味着在面试之前,你需要花一些时间研究公司及其业务,并思考你的角色会如何影响它。
面谈后的跟进
在面试过程中,你可能会也可能不会被告知流程中接下来步骤的时间表。
当你希望得到一份工作或下一阶段面试的回复时,等待和查看你的电子邮件可能会很痛苦——特别是如果你被告知你会在周一得到回复,而现在已经是周二了!
那么,面试结束后,你应该什么时候伸出手去接触一下呢?
首先,在你面试的第二天给面试官发一封简短的邮件是个好主意。
不过,这封邮件的目的应该只是感谢他们的时间,并重申你的兴趣。可能是这样的:
非常感谢您昨天抽出时间与我谈论在[公司]从事数据科学工作。我真的很高兴见到这个团队,而且我对从事[与工作相关的特定业务问题]的前景感到兴奋。请让我知道我是否还能提供什么来帮助你评估我的候选资格。我期待着你的消息,
之后,你应该耐心等待,直到过了一段合理的时间再联系公司。
如果您被告知会在特定时间收到回复(例如,“您应该会在下周的某个时间收到我们关于后续步骤的回复。”),你应该在截止日期后至少等两个工作日再联系。
你不应该恐慌——事情被推迟几天是很常见的。
如果没有给你一个明确的截止日期,你应该至少等一周(五个工作日)再联系。
不管怎样,这条信息应该和前面的相似:简短、友好、热切但不急躁。
以一个问题结束也很好(这更有可能引起回应),但是你应该确保你的问题是提供一些东西而不是要求一些东西
“我还能提供其他信息吗?”总比“我什么时候能收到回复?”
想想这样的信息:
再次感谢您上周的宝贵时间!我只是想重申我对这个职位的热情。我相信我能给[公司]带来很多价值,我渴望有机会证明这一点。我期待着听到下一步措施。我还能提供什么信息来帮助我的申请进展吗?
发完类似上面的后续消息,再等一个星期。如果你仍然没有得到任何回复,最好假设你没有得到这个职位。
不要过河拆桥——有时公司会落后,或者在混乱中失去一些东西,所以你仍然有可能获得另一次面试或工作机会。你卑微的作者曾经在提交最初的工作申请六个月后得到一次面试机会。
不过,不要指望会有回音——最好是把你的时间和精力重新放在其他公司的申请上。
如果一家公司在面试过程中没有及时与你保持联系,这可能是一个信号,表明它不会是一个很好的工作场所。
从拒绝中学习
如果你确实听到了拒绝,重要的是不要灰心。
记住,你首先得到面试的事实意味着你做的事情是对的,公司在你的申请材料中看到了他们喜欢的东西。还会有更多的采访。
同样重要的是,你要把拒绝视为成长的机会。
反思自己的表现会有所帮助。面试中有什么问题让你纠结吗?想想下次如何更好地回答它们。
向你的面试官寻求一些见解也是可以的。他们不欠你一个回应(你也不会总是得到回应)。
但是如果你礼貌地用这样的话回复拒绝信息,你通常会得到有价值的反馈,可以用来确保下一次面试进行得更好:
谢谢你让我知道,并且花时间考虑我的申请。我一直在寻求进步,所以我在想:你认为我应该在哪些方面努力,让自己下次成为更强的候选人?
如果你收到回复,你的回复应该是简单的“谢谢!”或者类似的东西。
不要反驳或争辩,也不要试图说服招聘经理他们做出了错误的决定。这永远行不通。这是在浪费你的时间,如果你惹恼了招聘经理,让他们开始抱怨你,还会影响你获得其他工作的机会。
如果你没有收到回信,不要生气。一些公司的人力资源政策禁止提供这种反馈。
面试后得到好消息
当你在面试后听到好消息时(例如,被告知你将得到一份工作),你一定会很兴奋。但是值得记住一句古老的格言:“不结束,一切都不会结束”。"
口头承诺你会得到一份工作并不意味着你真的会得到。公司可能在财务上出了问题,或者面试官可能对他们自己无法做出的决定说了不该说的话。
这些情况并不常见(如果你被告知你得到了一份工作,你几乎肯定会得到一份工作)。
但是,在采取重大举措之前,比如撤回其他工作申请,还是明智的做法。
当然,庆祝你的胜利,但是在你正式接受邀请之前,保留你的选择权。不要未经协商就接受报价!更多细节参见我们的报价谈判章节。
本文是我们深入的数据科学职业指南的一部分。
- 简介及目录
- 在你申请之前:考虑你的选项
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学领域的工作面试— 你来了。
- 评估和协商工作机会
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
SIGN UP**
评估数据科学工作机会和谈判
原文:https://www.dataquest.io/blog/career-guide-data-science-job-offer-negotation/
March 29, 2019
所以你得到了一份工作,或者你现在公司的一份晋升机会!万岁!但是请记住,你还没有完全完成!还有薪水的讨论和出价的谈判。你需要有备而来。
这可能很有诱惑力,尤其是对于那些试图进入数据科学领域的人来说,抓住第一个给你的机会。但这并不总是一个好主意。
在这篇文章中,我们将深入探讨如何进行工作机会谈判(无论是新的工作机会还是当前工作的薪水讨论),以确保你得到你应得的!
(本文是我们深入数据科学职业指南的一部分。要阅读其他文章,请参考 目录 或这篇文章后面的链接。 )
要约谈判的基础
首先,这里有一个要约谈判要点的总体概述:
在去公司面试之前,一定要做好调查。
- 这是一家创业公司还是这家公司成立?这将决定你如何谈判一个潜在的提议。在这家公司,职业发展会是什么样的?在未来可能发生变化的团队/职能方面,是否有向上流动甚至灵活性的空间?
- 考虑他们使用的关键技术或平台。你对这些技术/平台感兴趣吗?你能看到自己快速学习它们或者真正享受使用它们吗?
- 考虑合同、全职、学徒和实习。
了解你参与报价谈判的价值。
- 调查一下你所在地区面试职位的平均工资。
- 永远谈判——谈论金钱总是有点不舒服,你不想低估自己或显得贪婪,但公司希望你谈判,所以要有所准备。
- 如果你在面试一家初创公司,那就开始研究股权吧。许多初创公司提供较低的工资,以换取较高的股权比例。
- 即使你在当前公司面临升职或即将到来的考核,你也可以协商薪资/职位/职责。
要约谈判不仅仅是为了钱。
- 在考虑报价时,请始终考虑“大局”。你能平衡工作与生活吗,比如远程工作的能力,等等。?通勤是什么样的?
- 在这家公司工作有任何额外的费用或津贴吗?他们的福利是什么样的,你会自掏腰包支付医疗费用吗,等等。?
- 公司文化是什么样子的?在多样性和包容性、慈善等方面,公司的价值观与你的一致吗??
现在,让我们更深入地探讨这些至关重要的话题。
在谈判之前做好调查
数据科学领域的职位现在需求量很大,可能在可预见的未来也是如此。
无论你的目标是数据科学家、数据分析师、数据工程师还是其他职位,重要的是要知道这些类型的职位需求明显高于供应。
此外,当你得到一份工作时,公司通常已经投入了相当多的时间和金钱来评估你的申请,进行面试等等。他们可能已经看过很多候选人,他们想雇用你。
这给了你一些谈判的筹码。
初创公司与老牌公司
知道你在和谁打交道。一般来说,大公司能够提供比一般初创公司更高的薪酬。这可能会使他们的报价更有吸引力。
然而,值得记住的是,创业工作有自己的额外津贴。他们可能不会付给你很高的薪水,但通常你会得到某种股权(公司的所有权份额,比如股票期权)作为你薪酬的一部分,并且在你的实际工作描述中会有更多创造性的灵活性。
当你试图在初创公司和成熟公司之间做出选择时要考虑的事情:
- 自己的财务:你目前的财务状况如何?初创公司可能是很棒的工作场所,但从统计数据来看,大多数初创公司都会失败,所以你在初创公司失业的几率比在老牌公司高。如果你没有任何存款或后备计划,在评估工作机会时,你需要仔细考虑失业的风险。
- 股权:大多数创业公司负担不起丰厚的薪酬福利待遇,但通常会用文化和股权来补偿。股权通常与你加入公司的时间成正比;你加入得越早,风险就越大,这通常意味着你将接受更低的薪酬,但获得更大的股权份额。这是你在得到工作机会时想要评估的事情——你得到了多少股权,考虑到你进入这家公司的阶段,这合理吗?
- 医疗保健:如果你在美国,有家庭甚至健康问题需要良好的保险,创业可能不是最好的选择。更成熟的公司通常能够提供更好的健康保险和更高的薪水。如果你所在的国家有负担得起的或普遍的医疗保健,这可能是一个不太重要的因素。
- 工作保障:没有一份工作是绝对安全的(裁员在任何地方都有可能发生),但通常来说,更成熟的公司更稳定,更不容易遇到突然的财务问题,因此,如果你在一家更大的公司工作,你不太可能发现你的工作在一夜之间突然被改变(或淘汰)。
- 成长和灵活性:在你的工作描述中能够有一些灵活性和成长性总是很有吸引力的,而对于一家初创公司来说,这通常会有更多的空间。很多时候,技术职位(包括数据职位)是初创公司聘用的第一个职位,因此你在这个职位上有更多的发展空间,可以更频繁地发挥你的创造力和想法。在大公司,成长空间通常较小,因为领导层的人可能已经在那里呆了一段时间,不会去任何地方。在一家成熟的公司,你可能没有足够的空间与不同的人和团队合作。
- 公司文化:这因公司而异,但通常情况下,初创公司有更自由、更宽松的公司文化,他们更容易接受灵活的工作时间、远程工作、无限假期政策等。规模较大的老牌公司往往没有灵活的文化,你需要愿意遵守已经制定好的规则。
了解所需的工具和技能
如果你得到了一份工作机会,很明显你拥有公司正在寻找的一些关键技能。但是许多人没有长远地考虑他们的新工作描述对他们的下一份工作意味着什么。
如果你决定离开,你在这个职位上使用的技能和工具对将来的其他工作有用吗?这个新角色是一个进步,还是在使用一些工具、技术和技巧方面迈出了一步,这将推进你的职业生涯?
显然,数据科学技能和编程技能非常受欢迎。但是你需要知道你将从事什么样的工作,并考虑它将如何影响你的长期职业生涯。你能获得新的技能和经验,对你未来的工作有所帮助吗?
与当前和未来的技术趋势保持联系是一个很好的举措,这样你就知道什么与你自己的成长相关。以下网站如 TechCrunch 、 Wired 和 Techradar 可以帮助你了解更多信息。
如果你真的对你将从事的主要工具或技术感兴趣,提前了解这一点也很重要。如果你真的想用 Python 做机器学习,但你得到了一个不涉及这方面的数据科学职位,这可能不适合你,即使这份工作本身很棒。
在接受一份工作之前,你可能想问这样的问题,以获得更多关于你将要做什么的信息(如果你还没有从面试过程中获得这些信息的话):
- 我的日常生活会是什么样子?
- 我将从事什么样的项目?
- 我是否会与业务部门(财务、人力资源、法律等)的其他团队合作?
- 我每天将使用什么样的工具/技术/平台?
- 我每天将和谁一起工作?
合同工与全职
你将要做的工作种类也会影响你获得报酬的方式。许多技术职位,包括一些数据科学相关的工作,都是基于合同的。这意味着你很可能会得到按小时计算的报酬,而不是年薪。
通常,作为承包商工作意味着你可以要求多一点,因为福利通常不包括在内,或者很贵。
在美国,合同报价可以是 W2 或 1099。大多数人更喜欢 W2,因为这意味着公司会为你减税。有了 1099,你将获得全额工资,没有税收减免,并负责自己支付季度估计税收。
纳税情况因人而异,你需要花一些时间研究你自己的个人情况,以确保你每个月留出足够的钱来支付你的税款,不要在纳税季节被大额账单缠身。
同样值得注意的是,许多人认为合同工并不总是得到与全职员工相同的待遇。例如,你可能不会被邀请参加公司活动。你也没有资格获得任何形式的晋升,如果出现财务问题,承包商往往是第一个被削减开支的人。
另一方面,作为一名承包商,你可能会赚更多的钱,而且你可能会在工作习惯和时间方面有更多的自由(只要你的合同工作按时完成)。
实习和学徒
另一件需要考虑的事情是,特别是如果你试图从一个不同的行业进入数据科学领域,要考虑学徒和实习。
这些职位可以让你在开始全职工作之前先尝试一下。如果你有资格申请,即使你已经得到了一份全职工作,也值得考虑。
一份好的实习可以帮助你快速地在简历中获得一些相关经验,让你更容易在几个月后实习结束时获得一份更好的全职工作。如果你能给雇主留下深刻印象,你也可以把实习变成一份全职工作。
实习通常是三个月,而学徒是六个月。学徒期通常还包括培训部分,如果你表现出色,你将在学徒期结束时成为全职员工。
实习和学徒的缺点是工资通常很低,没有商量的余地。然而,这并不意味着他们应该被忽视,因为他们可以让你在未来的三到六个月内获得比你目前全职工作更高的薪水。
了解你在报价中的价值,提高谈判水平
谈论金钱会让人不舒服。然而,当你在谈判工作机会的时候,你必须能够就金钱进行聪明而直接的对话。
知道你的市场价格和你的走开
为这次谈话做准备,你能做的最好的事情就是提前了解你的市场利率。
你的市场价是你希望得到的职位在你所在地区的平均工资。 Glassdoor 、 Indeed 和 LinkedIn 都有可以按国家或城市分类的薪资数据,看看所有这些应该会让你对在薪资谈判中可以要求什么有一个不错的想法。
请记住,这只是反映当地平均水平的参考点。你的市场价不一定是你应该确定的价格。这是一个工具,你可以用它来证明谈判的合理性,尤其是当你得到的工作机会低于你的职位和工作地点的平均水平时。
在头脑中有一个可以离开的薪水也将有助于谈判。为了维持你的平均生活成本(房租/抵押贷款、食品杂货、账单等),你的离开率基本上是你需要达到的最低水平。).
如果他们不能让你达到最低工资要求,做好“放弃”的准备,不要指望未来会加薪。假设书面工作邀请中的内容就是你想要的,并据此做出决定。
总是协商
立即接受或拒绝一个提议从来都不是好的做法。公司期待你去谈判;他们不会因为你没有马上接受就取消提议。通常情况下,首先会给出一个口头提议,然后你会收到一个书面提议(电子邮件),说明工资或合同费率。
一旦你看到了公司的最初报价,那就是你开始谈判的时候了。最好在 24 小时内回复报价,即使只是说你已经收到,正在审核。
当你看完了整个提议——福利、带薪休假(PTO)、津贴等。—你带着你提议的改变回去找他们。
请记住,你可以要求改变任何事情,不仅仅是你的工资。
不过,无论你想改变什么,都应该一起列出来,然后发送一次。不要先要求加薪,加薪获准后再要求更多的 PTO,之后再要求别的。
公司确实希望你做出让步,他们希望进行谈判,但他们不希望谈判过程拖得太久,也不喜欢一遍又一遍地修改报价,以应对每个阶段的新要求。这时,公司更有可能取消报价。
与初创公司的谈判可能会有所不同,因为在薪酬方面可能没有大公司那么灵活,但在薪酬待遇的其他方面有更多的灵活性,尤其是股权。
提前做好调查,不要害怕要求更多的公平、更好的职称或其他可能有助于补偿较低工资的额外待遇。
不过,请记住,初创公司的股权通常是受限制的,除非初创公司被出售或在公共证券交易所上市,否则你不太可能兑现你的股份。如果公司失败了——大多数早期创业公司都会失败——无论你谈判了多少次,你的股份都将价值 0 美元。
除非你真的相信创业公司的长期生存能力,否则不要用真金白银去交易股票。
提出谈判
如果你没有申请新的工作,由于你的新数据科学技能,你可能仍然有资格在当前的公司获得加薪或晋升!不管是哪种情况,上面提到的大部分都适用:你应该为谈判做好准备。
因为你的雇主知道你目前挣多少钱,所以在升职时谈判薪水可能会很棘手。
但是你确实有一些你可以利用的优势:你已经为公司工作了,你不需要接受培训,你的雇主会通过留住你来节省金钱和时间(寻找、雇用和培训一名新员工是昂贵的)。
否则,同样的规则适用。你仍然应该算出你的市场价格,你可以在薪资谈判中使用这个数字。如果你的公司有一个透明的工资级别(或者你的同事愿意和你谈钱),你也可以利用你所知道的公司如何支付你所晋升职位上的其他人的工资。
(注意:在美国,尽管雇主可能不鼓励员工分享他们的工资,但禁止或惩罚这些讨论通常是非法的,除非你签署了一份同意不讨论此事的 NDA。)
不要忘记,如果你经历了像 Dataquest 这样的项目,你已经获得了新的有价值的技能。你带来了比以前更多的东西,你肯定可以在谈判中提出来。
有时候经理不会在薪水上让步,即使你准备升职或者在你的评估中表现很好。请记住,你可以随时要求其他福利,如更好听的职称(职称在职业发展中非常重要),远程工作时间,或多或少的责任,更多的 PTO,或以后有保证的工资审查。
请记住,你可以在其他地方寻找选择。
如果你得到了一次晋升机会,或者在没有加薪的情况下获得了一次很好的评估,而你的薪酬似乎低于市场水平,这可能表明你目前的雇主没有支付你应得的薪酬,你应该去别处看看。
记住:这不仅仅是钱的问题
要约谈判不全是关于本杰明,甚至不全是关于利益。
你需要在你生活的大背景下看待这份工作和这份工作。
你如何评估一份工作将在很大程度上取决于你的个人偏好和生活状况,但这里有一些重要因素需要考虑:
- 你必须搬迁吗?搬迁可能既令人沮丧又昂贵,当然,搬到一个新的地方可能意味着远离(或朝向)家人和朋友。许多公司提供一次性费用来帮助支付搬迁费用,但是你可以自己做研究,看看实际上要花多少钱。这是你可以在谈判中提出的一个因素,但更广泛地说,当考虑一份工作时,花些时间想想如果你搬家,你的生活会有哪些不同。如果你喜欢爬山,在堪萨斯州的工作可能不值得,即使你得到了一份很好的薪水。
- 通勤是什么样的?即使你的收入比预期的多,你会每天花三个小时坐在车里与交通作斗争,或者挤在拥挤的地铁车厢里吗?就油钱和停车费而言,你的开支会是多少?您的通勤将如何影响您车辆的磨损?
- 这家公司允许人们远程工作吗?许多公司都在朝着这个方向努力,因为它可以降低成本,但如果他们不这样做,远程工作是你有时可以谈判的另一个好处(即每周一天或两天远程工作),特别是如果公司不会在工资上让步,或者如果你要升职或接受考核。你的论点是:你已经证明了自己是一名优秀、可靠的员工,所以现在在如何完成工作方面,你应该有一些灵活性。
- PTO(带薪休假)是你应该协商的一项福利,但它也是一个需要与工作和生活的其他细节一起考虑的因素。如果公司提供无限休假,你实际上可能休假多少时间?带薪休假天数最多的优惠可能不是最适合你的,这取决于你的工作习惯。
- 好处:你通常不能协商你的医疗/牙科/视力保险,因为公司已经有了预先打包的交易。但是你一定要问清楚这些福利,这样你才能在接受提议之前知道你的医疗保健会受到什么影响。此外,昂贵的健康福利也可以作为薪资谈判的筹码。你可以这样说:“看起来我通过这家公司购买保险的自付费用相当高;作为补偿,你能考虑提高我的基本工资吗?”
- 额外津贴:如果你的公司提供与保险无关的福利或额外津贴,如健身房会员资格、职业发展基金、免费按摩等。,你也应该在你的决定中考虑这些,你可能想把它们作为谈判的工具。如果你只想要比那些额外津贴更高的薪水,你可以简单地要求公司放弃那些津贴,把 x 加到你的薪水里。相反,如果他们不能在薪水上让步,你可以通过谈判来提高福利。
- 许多人忘记了一个职位是可以商量的。一个更好的职称会给你以后的职业生涯带来各种好处,所以现在考虑一下你正在考虑的职位的职称会如何影响你的职业生涯是很重要的。如果你想谈判你的职位,把你的成就技能拿出来作为论据。这个不要打折扣;即使你不能加薪,在这个职位上拥有一个更好的头衔可能意味着你在几年后的下一个职位上更容易获得更高的薪水。
- 公司文化:金钱之外,这家公司是什么样的?你认为你会喜欢在那里工作吗?你喜欢面试过程中遇到的人吗?你认为你在这家公司会感到被包容、舒适和安全吗?人们很容易被薪资数字迷惑,但从长远来看,如果另一种选择是在不愉快的工作场所获得更高的薪资,那么让工作生活变得有趣的愉快的公司文化往往值得接受更低的薪资。
- 公司价值观:你可能还需要考虑你的个人价值观,以及这家公司是否体现了这些价值观。例如,这家公司是否将多元化和包容性作为优先事项?这家公司参与志愿者工作/慈善事业吗?这家公司提供职业发展或同理心培训吗?这家公司环保吗?
- 到底是什么样子?在面试过程中,你会对每家公司有所了解,但是在 Glassdoor 上的公司评论也可以成为内部信息的启发来源。你也可以在 Twitter 或 LinkedIn 等社交媒体上联系现任和前任员工,询问问题。
你能行的!
如果你已经得到了一份工作机会(或任何其他薪资谈判),记住这意味着公司想要雇用你也很重要。
这是一个很好的迹象,这意味着即使这份工作不适合你,你也可以找到其他工作。不要害怕谈判,如果没有找到合适的人选,也不要害怕离开。
请记住:
- 做好准备!研究你的价值
- 尽可能多地了解这家公司以及在那里工作的感觉
- 不要只关注薪资待遇;看“大局”:福利、工作生活平衡、通勤、公司文化、头衔、工作职责、未来前景等。
- 你仍然可以就这些项目中的任何一个进行谈判,不仅仅是薪水,稍后在员工评估时(假设你做得很好)或者当你准备升职时
祝你好运!
本文是我们深入的数据科学职业指南的一部分。
- 简介及目录
- 在你申请之前:考虑你的选项
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学的工作面试
- 评估和协商工作机会——你在这里。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
开始你的数据科学职业生涯:你有什么选择?
原文:https://www.dataquest.io/blog/career-guide-data-science-options/
March 29, 2019
本文是我们深入的数据科学职业指南的一部分。要阅读其他文章,请参考目录或这篇文章后面的链接。
学习数据科学技能可以彻底改变你的职业生涯。但不幸的是,一旦你掌握了 Python 或 R、SQL 和其他必要的技术技能,伟大的工作不会从天而降。找工作需要时间和努力。找到适合 T2 的工作需要时间、努力和知识。
本职业指南的目标是用这些知识武装你,这样你就可以有效地利用你的时间,最终从事你想要的数据科学职业。
第一步是弄清楚你想要的职业到底是什么样的。你的新数据科学技能能为你的职业生涯带来哪些好处?哪条路适合你?
回答这些问题应该是你数据科学工作旅程的第一步。尽管答案似乎显而易见,但值得花时间深入探究,真正探索你所有的潜在选择。这就是我们在本文中要做的。
具体来说,我们将看看一些不同的职位名称和描述,如果你想转行,它们可能是你的选择。我们还将看看你可能没有想到的选择:成为自由职业者,在你目前的职位上使用数据科学。
转行:数据科学领域有哪些职称?
找工作的第一步是确定你应该寻找的工作类型。在数据科学领域,这很快变得复杂起来,原因有几个:
- “数据科学家”或“数据分析师”并没有每个公司都认同的统一定义,因此相同头衔的不同职位可能需要不同的技能组合
- 如果你只是在搜索“数据分析师”或“数据科学家”的角色,你可能找不到大量其他涉及数据科学工作的常用职位。
显然,我们无法涵盖公司可能使用的每一个潜在职位,但是我们可以谈论数据科学领域中的一些主要角色,它们之间的区别,以及如果你开始担任该角色,你在该领域的职业发展。
注意:下面,我们根据美国的数据,对每个职位使用实际上来自的平均工资数据。显然,薪水会因地点、公司和你自己的技能和经验水平而有所不同,所以最好把这些数字作为粗略的指导方针。它们最后一次更新是在 2020 年 9 月 9 日。
三巨头:数据分析师、数据科学家和数据工程师
数据分析师
平均工资::75068 美元(外加平均每年 2500 美元的现金奖金)
什么是数据分析师?这通常被认为是数据科学领域的“入门级”职位,尽管并非所有数据分析师都是初级职位,薪水也可能相差很大。
数据分析师的主要工作是查看公司或行业数据,并使用它来回答业务问题,然后将这些答案传达给公司的其他团队以采取行动。例如,可能会要求数据分析师查看最近营销活动的销售数据,以评估其有效性并确定优势和劣势。这将涉及访问数据,可能是清理数据,执行一些统计分析来回答相关的业务问题,然后可视化和交流结果。
随着时间的推移,数据分析师经常与一个公司内各种不同的团队合作;你可能一个月从事营销分析,然后帮助首席执行官利用数据找到公司下一个月增长的原因。通常会给你一些商业问题来回答,而不是像数据科学家经常做的那样,让你自己去发现有趣的趋势,你通常会被要求从数据中挖掘见解,而不是用机器学习来预测未来的结果。
所需技能:具体情况因职位而异,但总体而言,如果你在寻找数据分析师的职位,你会希望熟悉:
- Python 或 R 语言的中级数据科学编程,包括使用流行的软件包
- 中间 SQL 查询
- 数据清理
- 数据可视化
- 概率与统计
- 向没有统计学或编程背景的人清晰易懂地传达复杂的数据分析
职业前景:数据分析师是一个宽泛的术语,包含各种各样的职位,所以你的职业道路是相当开放的。一个常见的下一步是继续培养您的数据科学技能,通常侧重于机器学习,并努力成为一名数据科学家。或者,如果你对软件开发、数据基础设施和帮助建立完整的数据管道更感兴趣,你可以向数据工程师的职位努力。一些数据分析师也利用他们的编程技能过渡到更一般的开发人员角色。
如果你坚持做数据分析,许多公司会聘请高级数据分析师。在拥有数据团队的大公司,如果你对发展管理技能感兴趣,你也可以考虑向管理职位努力。
数据科学家
平均工资::121,674 美元(加上股票期权)
什么是数据科学家?数据科学家与数据分析师做许多相同的事情,但他们通常也会建立机器学习模型,根据过去的数据对未来做出准确的预测。数据科学家通常有更多的自由来追求自己的想法和实验,以在数据中找到管理层可能没有想到的有趣模式和趋势。
作为一名数据科学家,你可能会被要求评估营销策略的变化会如何影响公司的底线。这将需要大量的数据分析工作(获取、清理和可视化数据),但也可能需要建立和训练一个机器学习模型,该模型可以根据过去的数据做出可靠的未来预测。
所需技能:数据分析师所需的所有技能,加上:
- 对有监督和无监督的机器学习方法有扎实的理解
- 对统计学有很强的理解,能够评估统计模型
- Python 或 R 中更高级的数据科学相关编程技能,并且可能熟悉 Apache Spark 等其他工具
职业前景:如果你是一名数据科学家,你的下一个职位很可能是高级数据科学家,这个职位平均每年能让你多挣 2 万美元。你也可以选择进一步专攻机器学习,成为一名机器学习工程师,这也会带来加薪。或者,您可以更多地关注像首席数据科学家这样的管理角色。如果你想实现收入最大化,你的最终目标可能是数据行业的高管职位,比如首席数据官,尽管这些职位需要管理技能,可能不涉及大量实际的日常数据工作。
数据工程师
平均工资::129,609 美元(外加平均每年 5,000 美元的现金奖金)
什么是数据工程师?数据工程师管理公司的数据基础设施。他们的工作需要更少的统计分析和更多的软件开发和编程技能。在拥有数据团队的公司中,数据工程师可能负责构建数据管道,以便以可用的格式快速地将最新的销售、营销和收入数据提供给数据分析师和科学家。他们还可能负责构建和维护存储和快速访问过去数据所需的基础设施。
所需技能:数据工程师岗位所需技能往往更侧重于软件开发。根据你所关注的公司,他们也可能非常依赖于对公司现有技术的熟悉程度。但一般来说,数据工程师需要:
- 处理大型数据集和构建数据管道的高级编程技能(可能用 Python)
- 高级 SQL 技能,可能熟悉 Postgres 等系统
职业前景:数据工程师可以通过持续的经验进入更高级的工程岗位,或者利用他们的技能过渡到各种其他软件开发专业。在专业化之外,也有可能进入管理角色,或者作为工程或数据团队的领导者(或者两者兼而有之,尽管只有非常大的公司才有可能拥有相当规模的数据工程团队)。
了解有关数据工程师、数据分析师和数据科学家之间的差异的更多信息,或者参加下面的快速测试,找出哪种角色最适合你:
数据科学领域的其他职位
虽然数据分析师、数据科学家和数据工程师概括地描述了数据专家在公司中可以扮演的不同角色,但您会看到其他各种各样的职位,这些职位要么与这些角色直接相关,要么涉及数据科学技能的使用。下面,我们将快速浏览一下你在找工作时可能要考虑的职位名称。
机器学习工程师
平均工资:144813 美元
什么是机器学习工程师?机器学习工程师和数据科学家之间有很多重叠。在一些公司,这个头衔只是意味着专门从事机器学习的数据科学家。在其他公司,“机器学习工程师”更多的是一个软件工程角色,涉及将数据科学家的分析转化为可部署的软件。尽管具体情况有所不同,但几乎所有的机器学习工程师职位都至少需要数据科学编程技能和相当先进的机器学习技术知识。
你也可能会看到像这样的职位被列为“机器学习专家”,特别是如果公司正在寻找一名专门从事机器学习的数据科学家,而不是一名可以利用机器学习来构建可部署产品的软件工程师。
定量分析师
平均工资:127438 美元
什么是量化分析师?定量分析师,有时被称为“定量分析师”,使用高级统计分析来回答问题,并做出与金融和风险相关的预测。不用说,大多数数据科学编程技能对定量分析非常有用,扎实的统计学知识是该领域的基础。对机器学习模型以及如何应用它们来解决金融问题和预测市场的理解也越来越普遍。
数据仓库架构师
平均工资::134373 美元
什么是数据仓库架构师?本质上,这是数据工程中的一个专业或子领域,适合那些希望负责公司数据存储系统的人。SQL 技能对于这样一个角色来说肯定是很重要的,尽管你还需要对其他技术技能有扎实的掌握,这些技能会根据雇主的技术水平而有所不同。你不会仅仅因为你的数据科学技能而被聘为数据仓库架构师,但是如果你对业务的数据工程方面感兴趣,你将从学习数据科学中学到的 SQL 技能和数据管理知识使它成为你应该考虑的职位。
商业智能分析师
平均工资::95806 美元(外加平均每年 5000 美元的现金奖金)
什么是商业智能分析师?业务分析师本质上是专注于分析市场和业务趋势的数据分析师。该职位有时需要熟悉基于软件的数据分析工具(如微软 Power BI),但许多数据科学技能对于商业智能分析师职位也至关重要,其中许多职位还需要 Python 或 R 编程技能。
统计员
平均工资:99286 美元
什么是统计员?“统计学家”是在“数据科学家”一词出现之前对数据科学家的称呼。不同的工作所需的技能会有很大的不同,但是所有的技能都需要对概率和统计有扎实的理解。编程技能,尤其是在像 R 这样的以统计为中心的语言中,也很可能有用。与数据科学家不同,统计学家通常不需要知道如何建立和训练机器学习模型(尽管他们可能需要熟悉机器学习模型背后的数学原理)。
商业分析员
平均工资::80,025 美元(外加平均每年 4,000 美元的现金奖金)
什么是商业分析师?“业务分析师”是一个非常通用的职位头衔,适用于各种各样的角色,但从最广泛的角度来说,业务分析师帮助公司回答问题和解决问题。这不必然涉及数据科学技能的使用,一些业务分析师职位不需要它们。但许多业务分析师的工作确实需要分析师根据公司的数据来捕捉、分析和提出建议,拥有数据技能可能会让你成为几乎任何业务分析师职位的更有吸引力的候选人。
系统分析员
平均工资::79469 美元(外加平均 2600 美元的年度现金奖金)
什么是系统分析师?系统分析师的任务通常是识别组织问题,然后计划并监督解决这些问题所需的变更或新系统。这通常需要编程技能(尽管系统分析师并不总是直接参与开发他们推荐的系统),数据分析和统计技能对于识别有问题的趋势以及量化公司技术系统中哪些运行良好,哪些运行不良也经常是必要的。
营销分析师
平均工资::66379 美元
什么是营销分析师?营销分析师查看销售和营销数据,以评估和提高营销活动的有效性。在数字时代,这些分析师可以访问越来越多的数据,特别是在销售数字产品的公司,虽然有各种各样的软件解决方案,如谷歌分析,可以在没有编程技能的情况下进行体面的分析,但拥有数据科学和统计学知识的申请人可能会在许多其他申请人身上占有优势,如果他们在营销领域也有足够的领域知识。此外,其分析产生重大影响的营销分析师可以将目光放在首席营销官的职位上,这一职位的平均年薪为 157,960 美元。
运营分析师
平均工资::67254 美元(外加平均每年 2500 美元的现金奖金)
什么是运营分析师?运营分析师通常负责检查和简化企业的内部运营。具体的职责和工资可能会有很大的不同,并且不是所有的运营分析师职位都将利用数据技能,但在许多情况下,能够清理、分析和可视化数据对于确定哪些公司系统正在顺利工作以及哪些领域可能需要改进非常重要。
其他数据科学职位
如果你在求职网站上搜索(这可能不是最好的主意;请记住,公司使用各种各样的头衔,你可以根据自己的经验水平,加上“初级”、“助理”、“高级”、“领导”等词来调整上述头衔。在他们面前。
此外,这些只是一些传统的全职职业选择。如果你正在寻找数据科学工作,也有一些你可能没有考虑过的选择,我们现在就来看看。
数据科学实习
如果你正在寻找在职学习和入门级的角色,这通常是获得永久全职工作的途径,实习是一个很好的选择。它们并不适合——甚至不适合——所有人,但如果你认为自己可能对实习感兴趣,它们确实有一些优点值得考虑:
- 他们通常是有报酬的职位(美国的平均工资是每小时 20 美元)。
- 您可以与工作中的数据分析师和数据科学家一起工作(并向他们学习)。
- 实习很容易变成全职工作。
- 如果你没有数据科学方面的工作经验,实习会让相关经验很快进入你的简历。
Alyssa Columbus ,一位太平洋生命数据科学家,我们采访了关于获得初级职位的,她通过实习获得了工作,她建议你不要排除这条路。她说,关键是在实习期间努力工作,超越预期。如果你让自己成为团队中有价值的一员,并对学习和成长表现出强烈的兴趣,那么当你的实习时间结束时,你更有可能被录用。
当然,数据科学实习也有一些非常明显的缺点,使得一些人很难获得这些实习机会:
- 该领域的薪酬相对较低,一些实习是无薪的。
- 实习通常持续很短的时间(通常是三个月),最后也不能保证有工作。
- 实习往往只提供给学生,一些雇主可能会优先考虑大学年龄的申请人。
- 很难预先知道你会从实习中学到多少东西。出于所有这些原因,实习可能是一种风险,特别是对于那些没有经济自由来接受低薪工作,希望它可能在以后成为一份合适的数据科学工作的学生来说。但是如果不利的一面并没有影响你的交易,那么绝对值得考虑实习。
如果你没有实际工作经验,我们将在后面的章节中讨论很多在求职申请中展示你技能的方法,但是如果你能通过实习快速获得一些工作经验,那就更好了!
成为一名自由职业的数据科学家
尽管大多数学习数据科学的人都在寻找一家老牌公司或初创公司的全职工作,但值得记住的是,数据科学技能为你提供了作为自由职业者工作的机会。
公司有数据科学工作并不罕见,但还不足以证明雇佣全职数据科学家的合理性。对于对数据科学有新兴趣的公司来说,在承诺长期聘用数据科学顾问之前,聘请一名数据科学顾问并完成几个自由职业项目也并不少见。当然,即使拥有成熟数据科学团队的公司也可能不时需要额外的帮助。这些都是自由职业数据科学家或数据科学顾问的潜在客户。
自由职业的优势
你可以赚更多的钱。根据客户和项目的不同,一个拥有全套技能的数据科学家(就像一个经历了大部分我们的数据科学家之路的人可以向收取每小时 100 到 200 美元的费用——甚至更多。通常情况下,你可以在每周工作更少时间的情况下,比一个工薪阶层挣得更多。
它可以采用你想要的任何格式。作为全职自由职业者,你当然可以独自创业,但也有可能从事兼职自由数据科学工作,以补充你的常规收入,或者当你在寻找一点额外现金时,甚至只是偶尔做做自由职业者。任何自由职业者都可能需要一个包含项目、一些关于你的信息和一系列服务的组合网站,但除此之外,你投入多少真的取决于你自己——它可以是你喜欢的或大或小的承诺。
你决定你做什么。在你自由职业生涯的早期,你可能没有太多选择。但是一旦你确立了自己作为一个可靠的、有技能的自由职业者的地位,你很可能会发现你可以自由选择和你一起工作的项目或公司。
你决定什么时候做。通过远程自由工作,你可以按照自己认为合适的方式制定自己的时间表。现场自由职业在数据科学领域很常见,可能会有规定的工作时间,但由于你选择了你要做的工作,你通常会有自由做出受薪员工无法做出的生活选择——比如为了省钱而加班几个月,这样你就可以休一个月的假去旅行。
与不同的人一起做不同的项目。多样化是生活的调味品,作为一名自由职业者意味着你将一直和不同的人做不同的事情。许多自由职业者最终会发展出一个稳定的固定客户群,但是你可以在任何你认为合适的时候自由地改变它,接受一个完全不同的项目或者在一个不同的行业工作。
这种多样性对你的职业发展也非常有益。参与各种项目会迫使你学习和运用新的技术技能。为各种不同的客户工作也会帮助你建立一些真正有价值的“软”技能,比如沟通和客户管理。如果你在不同的行业工作,你也会学到有价值的领域知识,这些知识会让你在另一份自由职业(或者全职工作,如果你决定回去的话)中受益。
自由职业的缺点
你现在有两份工作:一份是数据科学家,一份是业务经理。人们很容易忘记,当你实际工作时,自由职业者的报酬很高,找工作,尤其是在最初需要付出大量无偿的努力。你必须建立并维护一个投资组合和网站,你必须找到潜在客户并与之建立关系网,你必须谈判项目费率,你必须仔细记录你已经赚了多少,欠了多少。
你必须既有能力推销自己,又愿意主动推销自己。仅仅建立一个投资组合网站并说“我有空”可能不足以维持生计,除非你在业内已经非常知名。
请记住,因为你不是正式员工,所以你通常是你的客户最不想见到的人。这意味着你必须付出额外的努力去寻找你可能需要的东西,比如账户或数据库访问。对于一些客户,你也必须追查你的工资(尽管这些客户你不应该再合作)。
你不能指望稳定的薪水。自由职业者的工作并不总是以稳定的速度流动,有些市场会有“季节性”变化,你可能很难预测,直到你从事自由职业一两年,并开始看到这种模式。例如,一家公司在今年前两个季度的自由职业者预算中有很多多余的脂肪,可能每个第三季度都有固定支出——这意味着他们会把你的工作时间减半。由于你无法预测自己每个月能挣多少钱,做自由职业者通常意味着你需要建立一个更大的储蓄安全网来保护自己。
在美国没有健康福利或扣缴税款自由职业者的情况因国家而异,但在美国,大多数自由职业者都是作为 1099 合同工获得报酬的——健康保险不是他们薪酬的一部分,税收也不会自动从工资中扣除。无论怎么想象,这都不是一个不可克服的问题,但这是一个需要仔细思考和预算的问题(并从每份薪水中留出一大块用于税收和医疗保险)。根据你的个人情况,如果你是全职的,把自己注册成一家公司可能是有意义的,比如 C-corp 或 S-corp ,以保护你的个人资产免受与工作相关的债务,在某些情况下也是出于税务原因。你可能会想和当地的注册会计师和律师谈谈,以彻底了解规章制度和自由职业咨询公司的法律和财务影响,无论你在哪里。
你不可能建立任何长期的东西。虽然自由职业者从事的项目种类繁多可能是一种优势,但如果你更喜欢从事长期项目,并帮助它们多年来发展壮大,这也可能是一种不利因素。雇佣自由职业者来做这种工作几乎没有任何意义,所以你很可能主要从事短期和一次性的项目。
一开始难度曲线陡峭。成为一名成功的自由职业者是很棒的,但是如果你还没有一份好的潜在客户名单,开始工作会非常困难。寻找可靠的客户可能是一场真正的斗争,尤其是如果你没有生活在一个良好的本地市场,并且不得不依赖在线远程工作,价格竞争非常激烈。如果你不确定你是否生活在一个主要的自由职业市场,最好先从兼职开始试水。
数据科学自由职业的技巧
如果你打算投身自由职业,这里有一些快速提示:
考虑自由职业网站的利弊。像 Upwork 、自由职业者和 Fiverr 这样的平台提供了获得自由职业者项目工作的便捷途径,它们可以成为快速完成大量项目的绝佳学习场所。
然而,重要的是要记住,它们提供的便利是以巨大的成本为代价的。首先,这是直接成本:这些平台会从你的收入中抽取很大一部分。例如,Upwork 目前从每个客户身上赚取的第一笔 500 美元中抽取 20%,之后抽取 10%。这是一大笔钱,尤其是当你记住你可能需要在后留出 30%的收入来支付税款。这意味着,举例来说,当你接受一个新的 Upwork 客户时,扣除 Upwork 的费用和支付的税款后,最终进入你口袋的金额很可能是你账单金额的一半,甚至更少。
使用这类平台也有间接成本。因为这些网站上的工作很容易获得,所以你在和全世界竞争每一个项目。你以合理的价格为你的位置和技能出价的每一份工作都有可能得到相当多的低价竞标,这些竞标承诺以五分之一的价格获得与你相同的结果。例如,Upwork 的一些员工自称是数据科学家,但每小时收费不到 10 美元。他们能提供和你一样的质量吗?可能不会,但你必须是一个相当熟练的销售人员,才能说服客户定期接受你高得多的出价。
此外,任何依赖第三方平台的自由职业者都存在固有的风险,因为平台可能会随时改变规则,暂停或删除你的账户,或者干脆停止运营。用户通常无法控制或影响平台范围的策略,对这些策略的更改会极大地影响您的业务。
记住:要成为一名成功的自由职业者,你不需要使用这些平台。虽然这需要更多的前期努力,但从长远来看,通过现实世界的网络发展本地和地区客户可能会带来更多的红利。这种方法可以让你建立更可靠的客户关系,并根据你的技能和你所在地区的生活成本开出账单。风险也更小,因为你的企业的存在并不取决于你无法控制的第三方平台的存在。
提供一份清晰的服务清单,并在此基础上开出账单。虽然你可以按小时计费,但你通常可以通过按服务收费获得更好的利润。这也有助于确保你不会因为你的客户购买了 10 个小时,而你在 8 个小时内完成了项目,而被迫去做与你提供的服务无关的繁忙或无聊的工作。拥有一份清晰的服务清单会让双方都有更好的期望:你清楚地知道你必须做什么,你会得到多少报酬,客户也清楚地知道他们会得到什么,会花多少钱。
从小处着手。如果你已经在做兼职,并且有固定客户,那么成为全职自由职业者的风险会小一些。开始做一些兼职或兼职自由职业者的工作也会帮助你发展组织技能和工作流程,你需要这些来管理全职自由职业者的业务。虽然没有任何自由职业经验也有可能从全职工作直接成为全职自由职业者,但你可以从小做起,避免很多压力和挣扎,这样做可以让你有机会在投身全职自由职业之前,测试你所在地区的市场,看看你有多喜欢自由职业。
利用数据科学提升你目前的工作
最后,值得指出的是,即使你没有兴趣成为一名全职或自由职业的数据科学家,数据科学也可能为你的当前职业提供帮助。确切地说,你能做什么在很大程度上取决于你的工作是什么,但如果你掌握了一些数据分析技能,你几乎总是能够以某种方式增加价值。如果你的数据分析技能可以降低公司的底线或提高你自己的生产力,那么它们可以帮助你在目前的职位上挣得更多。
例如,考虑一下 Dataquest 学生简略地评论道。我们采访他的时候,他在圭亚那牲畜发展局工作,他的部分工作包括处理电子表格(许多工作都是如此)。因为他的部门产生了大量数据,这个每月一次的 Excel 任务变成了长达一周的噩梦——直到 Curtly 学会了一些数据科学编程技巧,并能够将它变成一个只花了他几分钟的任务。
想象一下,每个月多一周你可以做多少事情!
并非每个例子都如此引人注目,但数据分析可以在几乎任何工作中提高效率。
如果您正在寻找目前职位上的数据科学机会,有两个简单的起点:
首先,通过应用数据科学技术,寻找可以节省时间或提高效率的地方。您的团队可能已经在 Excel 中进行了有效的数据分析,但是如果您应用 Python 或 R 编程技能,这个过程会变得更快、更容易重复吗?
第二,寻找公司中被忽视或未被充分利用的现有数据源。这种事情很常见,尤其是在没有数据科学团队的公司。可能是因为没人有时间用自己知道的低效的数据分析方法去深究,所以被忽略了。也许它没有被充分利用,因为没有足够的人知道如何做任何类型的数据分析。无论是哪种情况,应用一些真正的数据科学技能都可以为您的公司提供重要的(通常是意想不到的)价值。
第三,寻找优化自己表现的方法。在智能手表等个人数据追踪设备的时代,追踪和分析你自己的数据很有可能会让你更有效率和生产力。这里有几个的例子,你只需要一些基本的编程技巧(这篇文章关注的是 R,但是同样的事情也可以用 Python 来做)。如果你开始探索,你会发现你在生活和工作中使用的许多平台允许你导出数据,下载 CSV,或者访问你自己的数据进行一些个性化的数据处理。
我准备好接受数据科学工作了吗?
评估自己准备程度的最简单方法就是开始看看现实世界的工作和工作描述。你具备上面列出的技能吗?你觉得你能做(或学会做)所描述的任务吗?
你对这些问题的回答不一定要绝对肯定。冒名顶替综合症是真实存在的(这里有一些对抗它的技巧),特别是对于寻找第一份数据科学工作的入门级申请人来说,他们特别容易感受到这种症状。看着雇主列出的技能和资格清单,很容易让你害怕,甚至不敢申请。
当我们与在数据科学领域有全职工作的前 Dataquest 学生交谈时,他们经常建议其他学生申请工作,即使他们觉得自己没有准备好。例如,亚马逊数据科学家凯特琳·惠特洛克(Caitlin Whitlock)说,她在亚马逊面试的前景“令人害怕”但她仍然建议有抱负的数据科学家“申请任何工作,任何时期。如果你认为自己不会得到这份工作,那就去申请吧。”
米格尔·库托(Miguel Couto)在突发奇想申请工作后得到了三份工作邀请,在他认为自己真正准备好之前,他同意了。这并不意味着你应该毫无准备地去——这两个学生也说他们为工作面试做了充分的准备——但这确实意味着你可能在真正感觉到准备好之前就已经准备好得到一份数据科学的工作了。
我需要证书吗?
你是否需要某种认证来获得数据科学领域的工作,是刚刚开始考虑工作申请流程的学生经常问的另一个问题。这个问题的简短回答是:不,你没有。
事实上,在我们为该指南采访的招聘人员和招聘经理中,没有一个人提到证书的重要性,或谈到用它们来评估数据科学应用。我们询问了每一位受访者,是什么让数据科学申请者在简历和面试中脱颖而出,没有一个人提到过证书。
证书确实有一些用处,因为它们可以帮助证明你致力于学习,并积极努力提高自己的技能。但是数据科学没有必备的证书,任何证书都不太可能说服招聘人员雇佣你,甚至给你面试机会。在这方面,即使是名牌大学的证书也没有多大用处,因为招聘经理知道,这些项目通常与大学的常规业务分开管理,而且通过标准通常相当宽松。
所以当你在考虑是否准备好申请的时候,不要担心你有什么证书。如果你有证书,那很好,但是如果你没有,你当然不需要冲出去试着去弄一个。没有必备的数据科学证书。在数据科学领域找工作真正重要的是你的技能。
如果你需要那些技巧, Dataquest 可以教你!但是由于这个指南主要关注的是在数据科学领域找工作,让我们假设你们都熟练了,然后继续下一步。一旦你确定了你想要的类型的工作,你实际上能在哪里找到它呢?
本文是我们深入的数据科学职业指南的一部分。
- 简介和目录
- 申请之前:考虑你的选择——你来了。
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学的工作面试
- 评估和协商工作机会
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何为数据科学工作申请创建项目组合
原文:https://www.dataquest.io/blog/career-guide-data-science-projects-portfolio/
March 29, 2019
尽可能早地开始构建数据科学项目。
现在我们已经到了你工作申请的实质部分。对于入门级的职位,项目组合是橡胶遇到的道路。
事实上,如果你以前没有数据科学领域的经验,你的项目组合可能会决定你是否会得到那个非常重要的面试电话。项目通常在面试阶段也起着至关重要的作用。
首先,谈谈术语:你会听到数据科学世界中不同的人使用不同的术语,如项目和投资组合。对一些人来说,“投资组合”这个术语让人想起一个精心设计的项目包,就像一个定制的网站。
出于我们这里的目的,我们将把 portfolio 定义为你在工作申请中展示的一组项目,不管它们以何种形式展示(我们将在本文后面讨论展示)。
在我们深入探讨如何组合投资组合的之前,让我们先来看看为什么。
( 本文是我们深入数据科学职业指南的一部分。要阅读其他文章,请参考 目录 或这篇文章后面的链接。 )
为什么数据科学项目至关重要
雇主不会付钱给你去做你从未做过的事情。这是任何行业的劳动力市场的基本规则,数据科学也不例外。
这很符合逻辑,真的:你会去一个从未做过饭的厨师的餐馆吗?或者登上一架从未坐过飞机的飞行员驾驶的飞机?大概不会。
无论你是从全日制学习、其他职业过渡到数据科学,还是仅仅试图获得一份不同的数据科学工作,你都需要经验。
即使是初级职位,如果做一项工作需要技能,你需要在有人付钱给你之前向你展示可以做这件事。
但大多数入门级申请人很少或没有数据科学方面的专业经验。那么,你如何证明你已经掌握了工作所需的技能呢?投资组合项目。
在你的工作申请中,一系列的项目会取代你的工作经历。这向潜在雇主展示了你真的能够做你申请的那种数据科学工作。
事实上,项目可能是您的应用程序中最重要的部分,因为它们会在过程的每个阶段突然出现。他们将会在你的简历中被提及,在你的申请中被链接,你也可以期待他们在许多工作面试中发挥重要作用。
我们在创建本指南时采访的大多数招聘人员都说,他们在筛选候选人时会审查项目和投资组合,但他们也会在面试中谈论项目。
例如, G2 人群数据科学和分析经理 Michael Hupp 描述了其公司数据科学面试的第一阶段:“我们只是询问他们的项目。我们会试着测试他们的技术技能,但我们也想确保他们能够以一种可以理解的方式谈论这个项目和结果。”
你可能会被要求解释你在数据分析项目中做出的统计选择,或者通过你的代码与招聘经理交谈。你可能会被问及你与他人在一个团队项目中合作的经历,或者当你把一个特定的项目放在一起时所面临的挑战。
招聘人员告诉我们,他们有时会用项目来衡量一切,从候选人的技术能力到他们对主题的热情程度。
如果之前没有该领域的专业经验,你可能会在招聘过程的各个阶段严重依赖你的项目,所以把它们做好是至关重要的。
你的投资组合需要展示什么
确切地说,你需要用你的作品集展示什么,将取决于你申请的工作。
在市场营销中寻找数据分析师职位的人应该有一个突出市场营销相关分析技能的项目组合。
正在寻找机器学习工程师职位的人最好有一个令人印象深刻的机器学习项目组合。
但无论你在寻找什么样的角色,要记住的一句话是:你的投资组合应该证明你能胜任这项工作。
做这项工作并不仅仅意味着证明你有技能。对于大多数与数据相关的职位,您会希望您的投资组合证明您具有:
- 交流的能力
- 与他人合作的能力
- 技术能力
- 对数据进行推理的能力
- 采取主动的动机和能力
同样值得指出的是,“证明你能做这项工作”中的“你”这个词很重要。你的作品集应该是独一无二的。
“投资组合的意义,以及在很大程度上整个申请过程的指导原则,是能够证明你确实以一种容易被验证的方式工作,”联合创始人 Edouard Harris 解释道。
“如果你选择炫耀一些人们经常做的事情,而且已经有现成的教程,作为一名招聘经理,我很难评估你是否真的做了大量的工作和思考,或者你只是跟着一个通用的教程走。”
要包含在数据科学组合中的项目
数据科学作品集应该包含 3-5 个展示你工作相关技能的项目。同样,这里的目标是证明你能做这项工作,所以你的投资组合看起来越像你申请的工作的日常工作,它就越有说服力。
首席执行官兼联合创始人 Refael“Rafi”Zikavashvili 说:“不要随便挑选项目,然后把它添加到你的简历或投资组合中。”"解决一个与你感兴趣的公司相关的问题."
这适用于你在项目中承担的种任务,也适用于你的项目检查的主题领域,以及你正在处理的种数据集。让我们仔细看看这三个因素中的每一个:
任务种类:在你申请的工作中,你需要做哪些事情?您会做大量的数据清理工作吗?机器学习?数据可视化?自然语言处理?您会严格地进行分析,还是会为他人构建仪表板和其他分析工具?
不管这些问题的答案是什么,它们都应该被整合到你的投资组合中。
你在寻找市场营销方面的职位吗?你可能想突出那些旨在回答营销相关问题的项目。如果你正在寻找一份移动应用程序开发的数据工作,你会想要展示那些证明你可以从应用程序数据中提取有用的产品见解的项目。
用你的项目来表明你对与你申请的工作相关的主题和商业问题有所了解,或者至少是感兴趣,可以帮助你的申请脱颖而出。
数据集的类型:不同类型的数据可能在不同的行业中很常见,所以展示你有一些使用类似于你在工作中看到的数据集的经验有助于证明你已经具备了做这项工作的条件。
例如,如果你在目标工作中可能会看到大量的时间序列数据,在你的文件夹中展示一些时间序列分析技巧会很有帮助。
如有疑问,请包括以下项目:
你的投资组合越适合你申请的具体工作,你可能得到的结果就越好。
但是,如果你申请的是初级职位,你可能会广撒网,而且你也可能会寻找那些不论行业都需要大量相同技能的职位。
如果你在每个类别中至少有一个项目,那么你将会有一个很好的开始。
数据清理项目:数据准备、数据、管理、数据清理——不管你怎么称呼它,它占了大多数数据科学工作的 60-80%,所以你绝对需要一个展示你的数据清理技能的项目。
最起码,你会想要找到一个杂乱的数据集(不要选择任何已经清理过的),想出一些有趣的分析问题来检查,然后清理数据并执行一些基本的分析来回答这些问题。
如果您想提高难度,收集自己的数据(通过 API、web 抓取或其他方法)需要一些额外的技巧。处理某种非结构化数据(相对于杂乱但仍然结构化的数据集)看起来也不错。
数据讲述和可视化项目:讲述故事、提供真正的洞察力以及用数据说服他人是任何数据科学工作的关键部分。如果你不能让你的首席执行官理解或根据它采取行动,那么世界上最好的分析也是无用的。
这个项目应该带领读者踏上一个分析之旅,并让他们得出一个即使是没有多少编码或统计背景的外行也能理解的结论。
在这里,数据可视化和交流技巧对于展示和解释你的代码在做什么很重要。以 Jupyter 笔记本或 R Markdown 的形式展示这一点很好,但你可以通过额外的润色增加一些额外的难度,比如定制你的图表设计或包含一些交互元素。
团队项目:在团队中一起工作表明你已经掌握了沟通和协作技能,这两者对数据科学工作都很重要。
任何类型的项目都可以是团队项目;这里重要的是证明你可以在团队环境中工作,无论是在人际关系方面(清晰的沟通、公平的分工、真正的协作)还是在技术方面(用 Git 和 GitHub 管理项目)。
如果你想提高这里的难度,试着参与一个流行的开源项目,比如用你选择的语言为一个数据科学相关的开源库做贡献。
这可能相当困难,但如果你设法为一个受欢迎的图书馆或软件包做了贡献,这真的可以让你的申请在雇主面前脱颖而出。
例如,Spice IT recruiting的首席 IT 招聘人员 Alina Chistyakova 说,“对知名开源项目的成功承诺”是让数据科学投资组合脱颖而出的因素之一。
Kitware 的人力资源总监 Jeff Hall 说:“在这里申请的候选人当中,真正加分的是对我们具体的开源项目做出了贡献。”
要考虑的其他项目类型
端到端系统构建项目:许多数据科学工作可能包括构建能够有效分析常规数据集的系统,而不是分析单一的特定数据集。
例如,您可能负责为销售团队构建一个仪表板,该仪表板可视化公司的销售数据,并随着新数据的出现而定期更新。
这个项目应该表明,你有能力建立一个系统,可以对输入的新数据集执行相同的分析,也有能力建立一个系统,可以被其他人理解并相对容易地运行。
最简单的版本是注释良好的代码,它可以从公共的、定期更新的数据集中获取数据,并执行一些分析。它的 README 文件应该解释如何被其他人使用,并且该项目应该相对容易被其他程序员通过命令行运行。
如果你想增加这里的难度,天空是无限的:你可以构建成熟的交互式 web 仪表板,或者构建一个处理实时/流数据的系统。
这里的关键是展示你可以构建一个可重用的分析系统,并且其他人,或者至少其他程序员可以理解。
解释性的博文、文章或演讲:能够用简单易懂的术语解释复杂的技术概念对于任何数据科学家来说都是一项宝贵的技能,因此,如果做得好,在博文、文章或会议演讲中解释一些技术概念可以为你的投资组合增添一笔财富。
一定要选择一个适当复杂的主题,一个你能理解和解释的主题。
例如,一篇解释在你的目标行业中经常使用的机器学习算法的幕后发生的事情的博客帖子可能是投资组合的一个很好的选择。
组合项目格式和演示
现在你已经有了一些想法,你可能想在你的投资组合中包括什么,你应该如何介绍它?真正常见的途径只有两种: GitHub 和个人投资组合网站。
我们为这个项目采访的每个招聘人员都同意,申请人应该有展示他们项目的活跃 GitHub 账户,所以如果你的目标是广泛的吸引力,那绝对是你应该开始的地方。
一些招聘人员表示,他们对投资组合网站上更精心构建的项目展示印象深刻,但其他人表示,他们不太在乎单独的投资组合网站,只会查看候选人的 GitHub。
因此,从准备好 GitHub 开始是有意义的。
数据科学项目 GitHub
如果你还不知道 GitHub 的基础知识,看看这篇介绍性的博客文章或我们关于 Git 和版本控制的完整互动课程,让自己开始运行吧。如果你正在创建一个新的 GitHub 账户,确保你选择了一个听起来很专业的用户名(用户名是公开的,他们是潜在雇主找到你的方式)。
一旦你在 GitHub 上设置好了,好消息是你的项目演示不需要特别复杂:用 Jupyter Notebook 或 R Markdown 格式展示你的项目对大多数项目来说都很好。
在项目本身中,尽量保持代码块相对较短,并用文本块点缀它们,这些文本块清楚简明地解释代码在做什么以及为什么。
使用文本格式(标题和副标题、粗体、斜体、代码片段等。)来保持东西井井有条,便于阅读。
你应该总是假设你的代码会被那些知道他们在说什么的人阅读。这意味着你应该努力坚持你的语言中的命名约定,遵循你喜欢的风格,并努力保持你的代码高效和整洁。
这也意味着,只要您认为有帮助,就应该在代码中添加注释,这样很容易一眼就能看出发生了什么。
(当作为团队的一部分协同工作时,注释代码是一项特别重要的实践,因此包含好的注释使代码易于遵循也展示了良好的沟通和团队合作技能。)
在您的代码中,还有几个潜在的问题需要注意:
- 如果您在本地创建了一个项目,您可能已经对数据的文件路径进行了硬编码,这样您的代码就可以读取计算机上存储数据的一个非常具体的目录。对于公共项目,最好将数据保存在与您的笔记本相同的文件夹中(或子文件夹中),这样您就可以包含一个相对路径,该路径适用于下载您的存储库并运行您的代码的任何人。
- 您可能希望包含您所使用的外部包和库的任何包和版本详细信息,以便其他人更容易下载和运行您的代码。关于如何做到这一点的更多信息可以在这里找到。
- 如果您使用 API 密钥或其他访问凭证从某个地方提取数据,您不希望公开共享这些凭证!这篇文章包含了一个很好的演示,解释了如何在保持你的密钥私有的同时,让其他人也能很容易地使用你的代码。
- 如果您在项目的存储库中包含您使用的数据,您应该检查以确保您拥有重新分发它的合法权利。
您应该在每个项目中包含一个自述文件,通常采用 Markdown 格式,其中包含项目的简要说明。这是当有人查看您的项目存储库时,GitHub 默认显示的文件,因此它应该提供他们将要看到的内容的概述。
这可能包括一些细节,比如你的项目分析了什么,你的项目目标是什么,你使用了什么技术,以及你的结论摘要。它还应该包括其他人可能需要为自己安装和运行您的项目的任何信息。
使用 GitHub 要记住的一件重要事情是,它会向查看你的个人资料的任何人显示你的所有公共存储库,还会向 T2 显示你的所有贡献活动。
这意味着你需要保持你的帐户干净和活跃。如果潜在雇主点击你的个人资料,发现数百个被放弃的项目,这将是令人不快的,如果潜在雇主看到你在过去几个月里实际上什么也没做,这也将令人不快。
按照这些思路,请记住,一旦将项目添加到 GitHub 中,它们就不是一成不变的了。即使你在申请工作,你也可以并且应该继续重复这些问题。
如果你得到了有用的反馈(或者只是想出了一个好主意),在你已经发表的项目中实施这些改变并没有错。事实上,继续迭代你的项目是一个好主意——它向雇主展示你是积极的、有兴趣的,并且从事他们将雇佣你做的同类工作。
准备你的 GitHub 的最后一步?确保它与雇主可能找到你的所有地方都有关联。正如我们在简历章节中提到的,你的简历上应该有一个可点击的 GitHub 链接,但你也要确保在你使用的任何社交网站(LinkedIn、Twitter、Instagram、个人网站等)上包含一个。)并在您提交的任何在线申请表中附上该网址。
你要尽可能地让任何搜索你的人容易找到你的 GitHub。
下一级:专用项目或组合网站
一旦你启动并运行了一个活动的 GitHub,花些时间为你的一个或多个项目做一个更独特的展示可能是值得的。
不是每个招聘经理都会花时间去看一个专门的项目页面或者一个特别的投资组合网站,但是对一些人来说,多走一步就会引人注目。
“一般来说,你想要视觉上的东西,”SharpestMinds 的爱德华·哈里斯说。"理想情况下,是你在某个地方的服务器上运行的东西."
“最佳情况是:你在一个聚会上(与业内人士交谈),你巧妙地将谈话引向你打造的这个很酷的东西。然后你可以拿出你的手机,就像这样:看看这个。玩吧。就在这里。”
哈里斯说,拥有一个基于网络的可视或交互式数据项目“发出了一个非常好的信号”。“这发出了一个信号,这个人知道足够建立一个服务器。那是一笔不小的工作量。[这个人知道如何]使界面足够漂亮,人们可以使用它。这些都是真实的、有价值的东西。”
显然,为一个项目建立一个专门的网站,尤其是一个交互式的网站,比简单地把一个 Jupyter 笔记本扔到 GitHub 上需要更多的时间。虽然它需要更多的前期投资,但从长远来看,它真的会带来回报,特别是如果你在活动中亲自推销和建立关系网的话。
如果有人在拥挤的会议厅里用手机浏览你的 GitHub,眯着眼睛试图阅读你的代码,你很难给他们留下深刻印象。一个清晰、直观、基于数据的故事或互动项目能给人留下更深刻的印象。
为了激发灵感,这里有一个例子一个非常直观的数据故事还有一个例子一个很酷的互动数据项目。这些只是为了激发灵感——别担心,入门级的求职者不会有这种高质量的表现。
但是你可以看到为什么对于面对面的交流来说,拥有一个这样的项目来展示比试图带着某人浏览你最喜欢的 GitHub 库更有影响力。
项目资源
此时,你知道为什么你需要一个项目组合。你知道你的投资组合中应该包括哪些项目,以及你应该如何展示它们。现在,困难的部分来了:实际做项目。
根据你的个人兴趣和目标工作角色,你选择的项目会有很大的不同。但是如果你需要一个好的起点,实际上我们所有的数据科学课程都包括开放式指导项目。
您可能还会发现我们的 Python 初学者项目文章很有帮助。其中许多对于专业作品集来说太基础了,但是你可以把它们作为一个起点来构建一些更复杂的东西。(如果你学过 R,不用担心——这些项目思路大部分都适用于 R)。
如果你花些时间去适应它们并使它们成为你自己的,这些在作品集里会很有用,它们也会成为灵感的有用来源。例如,您可以在我们的网站上完成一个指导项目,然后找到一个新的数据集,并尝试对自己的投资组合项目进行类似的分析。
以下是一些额外的资源,当你在找工作之前组织新的项目或者回去改进和重复旧的项目时,这些资源可能会有所帮助:
数据源
在任何项目中,最重要的选择之一就是要分析哪些数据。如果你想使用现有的公共数据集,最好避免 Kaggle 等网站的热门数据——Kaggle 上的流行数据集将被用于数百个项目,雇主会厌倦看到它们。
幸运的是,网上有很多地方可以找到不太常用的数据。以下是我们最喜欢的几个:
- 数据门户——一个庞大的列表,包括来自世界各地的 551 个开放数据门户,每个门户都有自己的数据集库。您可以按地理位置(或字母顺序)浏览,也可以按关键字搜索。这里的大多数门户都是政府运营的开放数据门户。
- Data.gov——几乎所有美国政府数据的所在地,拥有近 25 万个数据集,涉及从工业到公共卫生再到金融的各个领域。
- AWS 开放数据(AWS Open Data)——亚马逊的门户网站有各种有趣和意想不到的东西,从网络抓取数据到来自太空的卫星监测数据。
- data . world——有点像数据的 GitHub。你会在这里找到各种各样的数据集,虽然其中一些会包括常见和流行的数据集,如泰坦尼克号乘客数据,因为它们是用户上传的,它们可能不总是准确或可靠的。
- /r/datasets–用于共享数据集的子编辑。多年的历史来浏览,每天都有新的东西,你甚至可以提出要求!
- academic torrents——科学家可以上传他们的研究和出版物数据集的网站。
当然,确保你在做完全独特的东西的最好方法是获取你自己的数据集,而不是下载别人编译的东西。两种最简单的方法是通过网络抓取或者访问 API。
Dataquest 提供了一门涵盖 API 和网页抓取的课程,我们也有一些免费的教程给 T2 使用 BeautifulSoup 和 T4 使用 API。例如,您可以访问 Twitter API,并使用它来实时分析推文(我们也有相关教程)。
如果你真的想走得更远,你也可以通过进行自己的调查或手动收集数据来收集数据。收集自己的数据非常耗时,但如果这是获得有趣且独特的数据集的唯一方法,那么你随后通过独特的分析所创造的“惊喜”因素将值得你预先付出的所有痛苦。
不要忘记,你可能会产生大量自己的数据——通过电脑和智能手机,你可以收集关于你自己的各种数据,从生产力水平到睡眠习惯。我们有教程可以帮助你分析你自己的亚马逊消费,或者你的脸书使用。
走这条路可能会有风险(你不想表现得以自我为中心,你的个人数据可能不会让别人像你自己一样感兴趣),但你肯定有办法将自己生活中的数据转化为有更广泛吸引力的有趣的数据科学项目。
设计资源
当一个项目完成时,让它脱颖而出的最简单的方法之一是升级可视化,这样它们就不会有招聘人员在许多其他数据科学组合中看到的“默认”外观。
有很多方法可以通过代码做到这一点——例如,看看我们的教程如何在 Python 中获得 FiveThirtyEight 图表外观。但更普遍的是,将一些基本设计原则应用到你的工作中会帮助你的图表脱颖而出,更清晰地讲述它们的故事。
以下是一些其他有用的数据可视化资源:
- Data Viz Project 的大型图表类型库非常适合提醒自己有各种各样的图表类型,并帮助您找到最适合您的数据的图表类型。
- Hubspot 的数据 viz design PDF 为特定类型的图表设计提供了一些非常有用的提示。
- 我们自己的《数据中的颜色指南》深入探讨了挑选颜色时应该考虑的问题。
- 如果你想要一些墙上的灵感和设计帮助,Geckoboard 提供了一张可打印的海报,你可以挂在办公室里。
- 加州大学伯克利分校有一个 30 分钟的视频,是关于数据背景下的平面设计的,如果你有时间深入了解的话,这个视频会很有帮助。
灵感来源
有时候,你只需要一点点火花来启动一个项目,或者给你一个让它从好变得伟大的想法。以下是一些您可以找到真正伟大的数据科学项目的地方:
- FiveThirtyEight——作为数据新闻的卫冕冠军,538 不断发布关于政治和体育的新数据作品。他们还公布了他们的大量数据,所以你可以尝试对他们的一些工作进行逆向工程。
- 信息是美丽的奖项–该网站每年为各种基于数据的项目类别颁发奖项,但他们也会定期发布全年伟大项目的亮点。
- 数据是美丽的——这个子区域承载着业余和专业的数据科学项目和可视化。你也可以在那里分享自己的项目,从其他 reddit 用户那里获得一些反馈。
- ka ggle–ka ggle 竞赛是寻找已完成的数据科学项目的好地方(寻找已完成的竞赛,然后浏览投票最多的“内核”)这里的美妙之处在于你可以看到整个项目,包括所有的代码。
- 全国性报纸的数据科学团队——主要的国内和国际报纸以及其他媒体机构通常都有“数据”版块,在那里您可以找到有趣的数据科学工作的结果。在某些情况下,他们也有 GitHub 账户,在那里分享项目和/或数据。
本文是我们深入的数据科学职业指南的一部分。
- 简介及目录
- 在你申请之前:考虑你的选项
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历
- 如何创建数据科学项目组合— 你在这里。
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学的工作面试
- 评估和协商工作机会
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何以及在哪里找到优秀的数据科学工作
原文:https://www.dataquest.io/blog/career-guide-find-data-science-jobs/
March 29, 2019
本文是我们深入的数据科学职业指南的一部分。要阅读其他文章,请参考 目录 或这篇文章后面的链接。
一旦你知道你希望申请的工作类型,你就面临下一个数据科学求职挑战:如何和在哪里你能找到数据科学工作?
最好的数据科学工作在哪里?
让我们来看看你可以寻找数据科学工作的一些地方,以及数据科学家和招聘经理对它们的看法。
大型在线招聘平台
像果然、领英、玻璃门等网站的招聘栏目。是首先想到的地方之一,与其他来源相比,它们有几个明显的优势:
- 他们列出了大量的工作。
- 他们通常有一个“简单应用”选项,允许您快速发送凭据。
然而,从求职者的角度来看,这些真的是优势吗?除非你真的得到了工作机会,否则最初的搜索和申请的便利性并没有特别的意义,在这方面,这些网站有一些巨大的劣势:
竞争是巨大的。由于这些热门网站上的工作很容易找到和申请,一个招聘启事会吸引成百上千的申请者,尤其是如果它有一份诱人的薪水。这意味着你要面对大量的竞争,也意味着潜在雇主必须从噪音中过滤信号。即使你真的是一个很好的候选人,你也很容易迷失在混乱中。
夏普斯明德公司的联合创始人爱德华·哈里斯说:“公司确实在所有这些巨大的地方张贴广告。然后,因为他们收到了大量的申请,“他们只是用喷灯根据几乎任意的标准进行筛选。”
许多公司都避免雇佣他们,尤其是技术类的工作。当然,有些公司会完全避开这些网站,但即使是在这些网站上发布信息的公司中,也往往倾向于选择通过其他渠道(尤其是个人推荐)获得信息的候选人。对于技术职位,LinkedIn 或实际上的发布可能会带来成千上万份并非真正合格的候选人的简历,这意味着招聘经理将花更多时间从其他渠道寻找候选人,他们通常会在其他渠道找到更高比例的合格候选人。
太平洋生命数据科学家艾丽莎·哥伦布说:“很多这样的地方变成了黑洞。”。"有时招聘人员甚至忘记检查他们."
他们鼓励不良行为。因为向任何职位提交申请都很容易,所以制作一份“通用数据科学”简历,然后在每一份看似毫不相关的工作岗位上大肆宣传,就变得很有诱惑力。这种方法可以帮助你每天发出几十份申请,但是回复率可能会很低。最起码,你应该根据你所申请的工作的要求来定制你的简历,突出特定的技能和项目(见我们的简历文章了解更多关于这个话题的信息)。
总的来说,我们建议避开大型求职网站。*当然有可能在那里找到工作,但考虑到你将面对一大堆其他申请人——招聘经理甚至可能看不到你的优秀申请——花大量时间在大型求职网站上申请并不是最有效的数据科学求职方式。
数据科学工作板和公司网站
相比像 Indeed 这样的全球招聘网站,较小的行业招聘板和公司网站上的招聘信息可能是更好的选择。但值得记住的是,在这里,你也面临着许多竞争。例如,在一个受欢迎的数据科学职位板上,你将与更少的申请人竞争,但你仍将面对许多入门级工作的竞争对手,而且每个申请人都更有可能是合格的。
数据科学工作板
如果你觉得自己与竞争对手不相上下,这里有一些很受欢迎的数据科学专业的求职板(注意:我们与这些网站没有任何专业关系,这只是一个资源列表):
- Kaggle Jobs :大量的数据科学和分析工作,通常在世界各地的知名公司工作。
- 每周都有一些新的工作,通常是在名牌公司,主要是在美国和欧洲。
- Outer Join–一个工作板,用于数据科学、数据分析、数据工程和机器学习领域的远程工作。
- 数据科学中心——分析人才:专注于美国的数据科学工作,有许多大型科技品牌,每周至少有几个新工作。
- 印度最大的数据科学就业委员会。
- 统计工作:数据科学和统计工作,主要在英国,但偶尔也会在欧洲和世界其他地方发布。
- I runcdata:各种与数据相关的工作,并不都与数据科学相关(但你可以根据所需技能进行筛选,这很好)。以美国为中心,但也包括一些全球性的工作。
- 数据工作:包括数据科学相关的工作和数据工程工作,主要在美国。
- 英国统计工作:英国的统计、数据科学家和数据分析师工作。
还有几个你可能想记下来的求职公告板:
- GitHub 的工作岗位:虽然 GitHub 规模更大,也不排斥数据科学,但它确实列出了一些业内最大的科技品牌的数据科学工作岗位。
- AngelList :一个为创业公司提供各种工作的通用平台。如果你有兴趣为一家初创公司工作,你经常可以在这里找到数据科学相关的职位。
公司网站
一家公司的网站可能是寻找和申请工作的好地方,但有时很难判断职位发布的时间有多近(并且不是所有公司都定期更新网站)。只要有可能,最好在申请前联系人力资源总监、招聘经理或数据科学团队负责人——这样,你可以建立稍微更私人的联系和你可以确认你没有浪费时间去申请一年前就有人应聘但从未从网站上撤下的工作。
建立工作关系网
许多求职者只是因为方便才看网上的求职公告板。但是如果你想增加成功的机会,你最好采取更加个人化的方法。
太平洋人寿的数据科学家艾丽莎·哥伦布说:“不要只看招聘广告来找工作。“在公司网站上寻找工作或查看特定的工作公告板可能很有诱惑力,但根据数据科学行业的从业人员(包括我)的说法,这些是最没有帮助的找工作方式。相反,你应该尝试联系招聘人员,或者建立自己的关系网,打入这个领域。”
那么你如何建立这些联系呢?让我们来看看一些最佳选择。
商务化人际关系网
你应该毫不犹豫地直接联系 LinkedIn 上的数据科学招聘人员或工作数据科学家,特别是如果他们在你所在的地区工作或为你特别感兴趣的公司工作。
例如,你可以在 LinkedIn 上搜索“数据科学招聘人员”。如果你发现任何二级关系,这意味着你认识一些相同的人,你可能会得到一个人介绍。联系和你有共同语言的人,看看是否有可能。
如果你们没有任何共同点,那也没关系。您仍然可以请求连接。不要发送默认的“加入社交网络”信息(或者直接询问工作),试着发送一些私人信息。请记住,你的目标是建立某种程度的关系,而不仅仅是利用这个人做工作。用一个与工作相关的问题寻求帮助可能比直接找工作更好。
例如,您可能会这样写:
嗨,我是一名有抱负的数据科学家。我看见你住在我的区域;我能请你喝杯咖啡吗?在我开始申请工作之前,我有几个简历问题想听听你的意见。
(不要到处复制粘贴——你要根据具体情况定制你的信息,更准确地反映你自己的声音。)
然而,请注意,它确实简洁地传达了你是一名正在寻找工作的数据科学家和你正试图在关系方面带来一些东西(即使只是一杯免费咖啡)。
“当你试图开启一段这样的新关系时,你应该尽可能地让它成为一条双行道,”艾丽莎说。
电子邮件
如果你在 LinkedIn 上找不到合适的人,你可以通过电子邮件做同样的事情。许多人,尤其是招聘人员,会将公司的电子邮件公开发布在公司网站或他们的社交账户上。
如果你找不到电子邮件地址,像 Hunter.io 和 VoilaNorbert 这样的工具对于找到员工的电子邮件账户非常有用,只要你知道这个人的名字和他们公司的网址。
在这里,就像在 LinkedIn 上一样,你应该保持你最初的信息简明扼要。在这里,就像在 LinkedIn 上一样,目标是建立关系。不要从推销自己或找工作开始。你应该问一个问题,建立一个真正的联系。
社会化媒体
社交媒体是与数据科学社区成员互动和建立联系的另一种好方法。尽管大肆宣传,数据科学仍然是一个非常小的领域,即使是最有影响力的帐户也往往得到脚踏实地的人的支持,他们乐于讨论数据科学主题,并向任何询问的人提供帮助和建议。特别是 Twitter 和 Quora,它们是数据科学非常活跃的网络,有着简单直接的互动。
如果你不确定从哪里开始,这个 Quora 问题的答案会很有帮助。Twitter 上的数据科学影响者列表和数据科学领域女性列表也是寻找关注对象的好地方。
和其他形式的社交一样,这里的关键是要真诚,努力建立真正的联系。不要伸手就马上向别人要工作。参与对话,寻求建议,询问关于他们工作的问题,并分享。成为社区的积极成员,随着时间的推移,你会建立真正的联系,这可能会带来机会。
即使你不喜欢参与社交媒体,也值得建立一个账户,关注你感兴趣的人。Twitter 的数据科学社区相当频繁地分享招聘信息,其中一些是你不太可能通过求职公告栏找到的工作。你会发现有用的职业建议和文章也经常在 Twitter 和 Quora 上分享。
聚会和活动
新冠肺炎更新:在疫情的时代,很少有面对面聚会的机会,但许多流行的数据科学活动和会议已经在线。虽然这些在线活动对社交没那么有用,但它们通常也更实惠,而且它们确实经常试图提供社交选项。
虽然目前你可能仅限于在线社交,但我们会留下以下信息,以便你在你所在的地区再次开放时做好准备。
数据科学和技术行业聚会和活动是与社区、网络中的其他人联系和寻找工作的好方法。通常,主持人甚至会问观众“谁在招聘?”这样你就可以很容易地找到你应该与之聊天的人。
事实上,meetups 可能是寻找数据科学工作的最佳地点之一。爱德华·哈里斯建议:“不要把你的简历和其他人堆在一起,去参加当地的数据科学和机器学习会议吧。”“就是这样。大多数组织实际上不会通过简历招聘很多人。他们通过秘密渠道雇人。进入一个人的暗道的方式是原始的:在各种设置中,把你的脸反复放在他们的面前,对他们微笑。”
首席技术官迈克·金(Mike Kim)对此表示赞同:“聚会、会议,任何你可以亲自与人见面并建立关系的地方,”他说。所有这些都是工作和工作机会的良好来源。
聚会通常是免费的,许多一次性的活动,如讲座和小组讨论,要么是免费的,要么相对便宜,所以除了几个小时的时间外,它们不需要太多的投资。在你所在地区的数据科学雇主面前露脸(最好是你的工作样本)的价值是值得投资的;你在聚会上花两个小时建立人际关系,可能会比花两个小时在大型求职网站上寻找和申请工作收获更多。
如果你正在积极寻找工作,你应该带着一些你可以展示给招聘人员、潜在雇主和其他任何可能帮你找到工作的人的东西去参加聚会。在本指南后面关于项目组合创建的文章中有更多的细节,但是这里有一个简短的版本:有一个可视的,可以在你的手机上访问的项目,甚至可能有一点互动。能够拿出你的手机,实际上向某人展示一个独特的数据科学项目,将比简单地告诉他们你的技能更有影响力。
即使你不是在找工作,参加这些活动也是值得的。当你真的想找工作时,现在结识人和建立关系会让你的生活变得更容易,而且你可以从与更有经验的数据分析师和数据科学家的交谈中学到很多东西。
记住:只有当你努力去结识人和建立关系网时,参加活动才是值得的。大多数活动都试图积极地促进这一点(在演讲之前或之后通常会安排社交时间),但你仍然必须愿意走出去,与你不认识的人交谈。这篇文章是在活动中建立关系网的有用提示的好来源。
那么在哪里可以找到聚会呢?如果你在大都市,这应该相对容易。在美国、欧洲和亚洲的主要城市,你只需在 Meetup.com 的搜索“数据科学”就能找到活动。根据你所在的国家,可能也有当地的【Meetup.com】的对等物;例如,中国的数据科学家可以在豆瓣上搜索事件。如果您在脸书,您还可以搜索脸书的数据科学活动(只需搜索“数据科学”,然后过滤结果,只包括您喜欢的城市或位置的活动。Eventbrite 也有活动搜索功能,尽管那里列出的活动可能需要付费。
如果你在一个人口较少的地区,并且没有发现太多与数据科学相关的东西,你可能需要变得更有创造力一些。搜索相关术语,如“机器学习”或“大数据”,并搜索与特定数据科学技能或语言(如 Python 或 r)相关的事件。这类事件可能是建立关系网的绝佳机会,即使它们并不专门关注数据科学主题。即使是一般的技术行业聚会也值得你花时间。
如果你真的找不到任何东西,考虑在你所在的地区开始你自己的数据科学聚会。这需要大量的跑腿工作,但并没有你想象的那么难。我们已经发布了如何做到这一点的指南,尽管这需要时间,但它也将你置于一个新的本地数据科学社区的中心。
会议
如果你想在很短的时间内建立大量有价值的人际网络,或者在你所在地区之外建立更广泛的人际网络,你应该考虑参加一些与数据科学相关的会议。奥利维亚集团首席执行官奥利维亚·帕尔-鲁德说,会议提供了双重职业机会,因为“你不仅可以学习,还可以与人交往。有时候,这是获得工作优势的最佳方式。”
会议的缺点是成本,而且通常很高。门票价格可能会有很大差异,但通常会花费数百或数千美元,而且与会者还需要考虑其他费用,如机票、住宿和餐饮费用。
不过,有一些方法可以规避这些成本!
让你的雇主为你买单。这是最常见的方法,也可能是最简单的。如果你在一个完全不相关的领域工作,这可能是一个艰难的推销,但如果你目前正在做一些与数据相关的事情,或者可以将会议作为一个有价值的社交或学习机会来推销,这对你目前的角色有帮助,你可能会让你的雇主支付你的成本,因为许多公司都有这种职业发展的预算。
事实上,这种参加会议的方式如此普遍,以至于许多会议实际上提供了“说服你的老板”的资源:你可以向你的经理展示的统计数据和论据,以帮助你参加会议,可下载的电子邮件请求模板等。值得花几分钟在你感兴趣的任何会议的网站上逛逛,看看他们是否提供类似的东西。
成为演示者或小组成员。这似乎遥不可及,但不要低估自己。有很多会议,它们都需要演讲者。如果你做了一些很酷或独特的事情,你就有机会成为一名演讲者,尤其是在小型或社区组织的会议上。这是免费参加会议的好方法和为你的简历增加了一个有吸引力的资格。
查看机票折扣选项。许多会议提供折扣,旨在帮助某些类型的与会者支付费用。像全日制学生、非营利员工和教师这样的群体往往能够获得更便宜的机票,而且群体折扣也经常出现。例如,你可以与我们会员 Slack 中其他感兴趣的 Dataquest 学生合作,一起获得团体折扣。
获得媒体通行证。如果你有写作或摄影的经验,并且你知道博客或新闻机构可能对报道会议感兴趣,不要犹豫,去接近他们,向他们推销你作为自由职业者报道会议的想法。他们能说的最坏的情况是不,如果他们同意,你通常可以从会议组织者那里得到一张免费或大幅折扣的会议门票。在会议网站上寻找关于“媒体通行证”或“记者通行证”的信息,看看这是否是一个可行的选择。
跳过会议,但获得人脉。如果你在开会的地方,但是没有票,你通常仍然可以通过在会议中心和/或酒店附近闲逛来建立一些有价值的关系网。早上,找最近的星巴克;晚上,找到最近的酒吧或去酒店酒吧。没有会议门票,花时间和金钱去另一个城市旅行可能不值得,但是如果一个会议要在你的城市举行,你可以在会议参与者(你的社交目标)可能去的公共场所获得大量的社交价值,而不需要花一分钱。
哪些特定的会议最能利用你的时间和金钱取决于你自己的目标,以及你的地点和你的日程安排。KDNuggets 保留了一份与数据科学相关的活动和会议的积极更新列表,您可以在这里找到,您也可以通过 Quora 查看关于参加美国或欧洲或印度的最佳会议的众包意见。
朋友和家人
最后,不要忘记你的个人关系网。不是每个人都能幸运地以这种方式找到工作,但至少,你应该确保朋友和家人都知道你正在积极寻找数据科学工作,以便他们可以传递他们遇到的任何机会。
如果你在这个领域没有家人或朋友,你可能不应该指望通过这个渠道有很多机会,但告诉朋友和家人你在找工作是快速、简单的,而且不可能有坏处。数据科学工作的竞争对手肯定会尽可能利用他们的个人网络,所以你也应该这样做。
创造你自己的工作:高风险、高回报的方法
Pramp 首席执行官 Refael Zikavashvili 提出了另一种寻找数据科学工作的方法,也值得考虑,尽管它有一些内在的风险:
“如果候选人主动给我发电子邮件,告诉我,‘看,我相信你有这个业务挑战,这是我将如何解决它’,那将会给我留下非常深刻的印象,”他说。“那些仅仅根据公开信息就能发现问题的人会更进一步,提出解决问题的方法,这将让我大吃一惊。”
“那个人基本上从我这里得到了即时采访,”他说。“没有问题问。在这一点上,我甚至会跳过简历。”
Refael 说,这种方法可以用来代替传统的工作申请,但他也建议申请人尝试他们热爱的公司,即使该公司没有开放的数据科学工作列表。
“找一家你真正喜欢的公司,你对它充满热情,”他建议道。“分析一下那家公司。找一个你认为你能帮助解决的挑战。想出解决办法。这是我能给别人的最好的建议。这是一种脱颖而出的方式。”
从理论上讲,这种方法(我们之前在这里写过)是可行的,因为它能快速传达雇主希望在求职者身上看到的三点:
- 你对他们的公司和解决问题充满热情。
- 你拥有解决这些问题并提出解决方案所需的商业意识和技术技能。
- 你积极主动,强烈的自我激励。
不用说,这是一个高风险的策略。这需要很多准备时间:你必须对有问题的公司进行广泛的研究,确定一个真正的问题,并做一个小小的数据科学项目,以某种方式解决这个问题。然后,你必须找到合适的人来联系他们,并迅速清晰地向他们传达你的工作。如果其中任何一个环节出错,你将在一份工作申请上花费大量时间,却得不到任何回报。
这是一种我们建议只考虑你真正想要的公司和工作的方法——那种如果你得到他们的工作邀请,你 100%肯定会加入的公司。
你也可以在你传统申请并获得面试机会的公司应用这种方法的低风险版本——我们将在关于工作面试的章节中更详细地讨论这一点。
TL;DR:哪里可以找到数据科学的工作
我们采访的招聘人员并不同意寻找和申请数据科学工作的单一最佳渠道,但他们确实几乎都同意,基于关系的申请通常比“冷”申请更有可能获得结果。一些人建议参加会议,一些聚会,一些在线网络和建立关系,但几乎每个人都觉得以某种方式“出名”会给申请者带来真正的优势。
当然,如果你正在尽快找工作,那会带来一点挑战,因为你不可能在一夜之间建立起一段关系,甚至没有必要安排任何个人互动。这就是为什么我们建议你现在就开始努力建立人脉和关系,不管你正处于职业旅程的哪个阶段。
本文是我们深入的数据科学职业指南的一部分。
- 简介和目录
- 在你申请之前:考虑你的选项
- 如何以及在哪里找到数据科学工作— 你在这里。
- 如何写一份数据科学简历
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学的工作面试
- 评估和协商工作机会
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
克里斯蒂安:“一致性是关键”
原文:# t0]https://www . dataquest . io/blog/Christian-lheures/
April 25, 2018
在商业智能领域工作后,Christian L'Heureux 暂时离开了数据科学领域。当他回来时,作为他 MBA 项目的一部分,他发现了一个变化的世界。他知道他需要快速适应新的环境——尤其是 Python。
在尝试了 DataCamp 和 CodeAcademy 之后,他找到了 Dataquest。“我喜欢它的结构,喜欢它如何分解每一章。项目的重点是巨大的——自己动手建造是让它深入人心的好方法。”他特别喜欢电影分级指导项目,甚至在他的一堂 MBA 课上使用了一个精简版。
到了找工作的时候,Christian 能够就一系列技术话题发表自己的见解。由于这种能力,加上投资组合和成功的 SQL 和业务测试,受欢迎的视频游戏公司暴雪聘请他为分析师。这些天,他在 Battle.net 平台工作,担任内部顾问。他构建业务问题,并与数据科学家、项目经理和其他分析师合作,寻找数据驱动的解决方案和策略。
他建议其他学生保持一致,并找到一个能让他们保持动力的项目。“每天做 30 分钟,你会走得更远,概念也会保持新鲜。”
“Dataquest 对于我发展数据分析师技能是一个非常有用的工具,我认为是它让我获得了今天的工作。”
在 Python 中生成气候温度螺旋
原文:https://www.dataquest.io/blog/climate-temperature-spirals-python/
May 21, 2018
气候科学家埃德·霍金斯(Ed Hawkins)在 2017 年发布了以下动画可视化效果,吸引了全世界的目光:

https://www.youtube.com/embed/wXrYvd-LBu0?feature=oembed
*这个图像显示了 1850 年到 1900 年间平均温度的偏差。这个视频在推特和脸书上被转发了数百万次,甚至在里约奥运会开幕式上展示了它的一个版本。这一可视化效果非常引人注目,因为它有助于观众了解过去 30 年中温度的变化波动以及平均温度的急剧上升。你可以在埃德·霍金斯的网站上阅读更多关于这一可视化背后的动机。在这篇博文中,我们将介绍如何用 Python 重新创建这个动画可视化。我们将特别使用 pandas(用于表示和管理数据)和 matplotlib(用于可视化数据)。如果你不熟悉 matplotlib,我们建议你参加探索性数据可视化和通过数据可视化讲述故事课程。在本文中,我们将使用以下库:
- Python 3.6
- 熊猫 0.22
- Matplotlib 2.2.2
数据清理
基础数据是由英国气象局发布的,该机构在天气和气候预报方面工作出色。数据集可以直接下载
此处。Github 上的 openclimatedata repo 在这个笔记本中包含了一些有用的数据清理代码。你需要向下滚动到标题为全球温度的部分。以下代码将文本文件读入 pandas 数据框:
hadcrut = pd.read_csv(
"HadCRUT.4.5.0.0.monthly_ns_avg.txt",
delim_whitespace=True,
usecols=[0, 1],
header=None)
然后,我们需要:
- 将第一列拆分为
month和year列 - 将
1列重命名为value - 选择并保存除第一列(
0)以外的所有列
hadcrut['year'] = hadcrut.iloc[:, 0].apply(lambda x: x.split("/")[0]).astype(int)
hadcrut['month'] = hadcrut.iloc[:, 0].apply(lambda x: x.split("/")[1]).astype(int)
hadcrut = hadcrut.rename(columns={1: "value"})hadcrut = hadcrut.iloc[:, 1:]
hadcrut.head()
| | 价值 | 年 | 月 |
| Zero | -0.700 | One thousand eight hundred and fifty | one |
| one | -0.286 | One thousand eight hundred and fifty | Two |
| Two | -0.732 | One thousand eight hundred and fifty | three |
| three | -0.563 | One thousand eight hundred and fifty | four |
| four | -0.327 | One thousand eight hundred and fifty | five |
来保存我们的数据
整理,让我们删除包含 2018 年数据的行(因为这是唯一一年有 3 个月的数据,而不是所有 12 个月)。
hadcrut = hadcrut.drop(hadcrut[hadcrut['year'] == 2018].index)
最后,让我们计算 1850 年至 1900 年全球气温的平均值,并从整个数据集中减去该值。为了简化这一过程,我们将创建一个
hadcrut = hadcrut.set_index(['year', 'month'])
这样,我们只修改
值栏(实际温度值)。最后,计算并减去 1850 年至 1900 年的平均温度,并将指数重置回之前的水平。
hadcrut -= hadcrut.loc[1850:1900].mean()
hadcrut = hadcrut.reset_index()
hadcrut.head()
| | 年 | 月 | 价值 |
| Zero | One thousand eight hundred and fifty | one | -0.386559 |
| one | One thousand eight hundred and fifty | Two | 0.027441 |
| Two | One thousand eight hundred and fifty | three | -0.418559 |
| three | One thousand eight hundred and fifty | four | -0.249559 |
| four | One thousand eight hundred and fifty | five | -0.013559 |
笛卡尔与极坐标系统
重建 Ed 的 GIF 有几个关键阶段:
- 学习如何在极坐标系统上绘图
- 为极坐标可视化转换数据
- 定制剧情的审美
- 一年一年地进行可视化,并将绘图转换成 GIF
我们将开始在一个
极坐标系统。你可能见过的大多数图(条形图、箱线图、散点图等。)住在笛卡尔坐标系中。在这个系统中:
x和y(以及z)的范围可以从负无穷大到正无穷大(如果我们坚持用实数的话)- 中心坐标是(0,0)
- 我们可以认为这个系统是矩形的
 相比之下,极坐标系统是圆形的,使用
相比之下,极坐标系统是圆形的,使用r和theta。r坐标指定了距中心的距离,范围从 0 到无穷大。theta坐标指定从原点的角度,范围从 0 到 2*pi。 要了解更多关于极坐标系统的信息,我建议进入以下链接:
要了解更多关于极坐标系统的信息,我建议进入以下链接:
为极坐标绘图准备数据
让我们先来了解一下这些数据是如何绘制在艾德·霍金斯的原始气候螺旋图中的。一年的温度值几乎跨越了一个完整的螺旋线/圆。您会注意到这条线是如何从 1 月跨越到 12 月,但又不连接到 1 月的。这是来自 GIF 的 1850 年的照片:
 这意味着我们需要按年份划分数据子集,并使用以下坐标:
这意味着我们需要按年份划分数据子集,并使用以下坐标:
r:给定月份的温度值,调整后不含负值。- Matplotlib 支持绘制负值,但不是以你想的方式。我们希望-0.1 比 0.1 更靠近中心,这不是默认的 matplotlib 行为。
- 我们还希望在绘图原点周围留出一些空间,以便将年份显示为文本。
theta:生成 12 个等间距的角度值,范围从 0 到 2*pi。
让我们深入了解如何在 matplotlib 中只绘制 1850 年的数据,然后扩展到所有年份。如果您不熟悉在 matplotlib 中创建图形和轴对象,我推荐我们的
探索性数据可视化课程。要生成使用极坐标系统的 matplotlib Axes 对象,我们需要在创建它时将参数projection设置为"polar"。
fig = plt.figure(figsize=(8,8))
ax1 = plt.subplot(111, projection='polar')
默认的极坐标图如下所示:
 要调整数据使其不包含负温度值,我们需要首先计算最低温度值:
要调整数据使其不包含负温度值,我们需要首先计算最低温度值:
hadcrut['value'].min()
-0.66055882352941175
让我们补充一下
1所有温度值,因此它们将是正的,但原点周围仍有一些空间用于显示文本:

让我们也生成从 0 到 2*pi 的 12 个均匀间隔的值,并将前 12 个用作theta值:
import numpy as np
hc_1850 = hadcrut[hadcrut['year'] == 1850]
fig = plt.figure(figsize=(8,8))
ax1 = plt.subplot(111, projection='polar')
r = hc_1850['value'] + 1
theta = np.linspace(0, 2*np.pi, 12)
为了在极轴投影上绘制数据,我们仍然使用
Axes.plot()方法,但是现在第一个值对应于theta值的列表,第二个值对应于 r 值的列表。
ax1.plot(theta, r)
这个图看起来是这样的:

调整美学
为了让我们的情节更接近艾德·霍金斯,让我们调整一下审美。在笛卡尔坐标系中正常绘图时,我们习惯使用的大多数其他 matplotlib 方法仍然有效。在内部,matplotlib 认为
theta为x,r为y。要查看实际情况,我们可以使用以下方法隐藏两个轴的所有刻度标签:
ax1.axes.get_yaxis().set_ticklabels([])
ax1.axes.get_xaxis().set_ticklabels([])
现在,让我们调整颜色。我们需要极坐标图中的背景颜色为黑色,极坐标图周围的颜色为灰色。我们实际上使用了一个图像编辑工具来找到准确的黑色和灰色值,如
- 格雷:#323331
- 黑色:#000100
我们可以使用
fig.set_facecolor()设置前景色,Axes.set_axis_bgcolor()设置绘图的背景色:
fig.set_facecolor("#323331")
ax1.set_axis_bgcolor('#000100')
接下来,让我们使用
Axes.set_title():
ax1.set_title("Global Temperature Change (1850-2017)", color='white', fontdict={'fontsize': 30})
最后,让我们在中心添加文本,指定当前显示的年份。我们希望这个文本在原点
(0,0),我们希望文本是白色的,有一个大的字体,并且水平居中对齐。
ax1.text(0,0,"1850", color='white', size=30, ha='center')
这是现在的情节(回想一下,这只是 1850 年的情况)。

绘制剩余年份
要绘制剩余年份的螺旋图,我们需要重复刚才的操作,但要针对数据集中的所有年份。这里我们应该做的一个调整是手动设置
r(或 matplotlib 中的y)。这是因为 matplotlib 会根据使用的数据自动缩放绘图的大小。这就是为什么在最后一步中,我们发现只有 1850 年的数据显示在绘图区域的边缘。让我们计算整个数据集中的最高温度值,并添加大量填充(以匹配 Ed 所做的)。
hadcrut['value'].max()
1.4244411764705882
我们可以使用手动设置 y 轴限值
Axes.set_ylim()
ax1.set_ylim(0, 3.25)
现在,我们可以使用 for 循环来生成其余的数据。让我们暂时忽略生成中心文本的代码(否则每年都会在同一点生成文本,这将非常混乱):
fig = plt.figure(figsize=(14,14))
ax1 = plt.subplot(111, projection='polar')
ax1.axes.get_yaxis().set_ticklabels([])
ax1.axes.get_xaxis().set_ticklabels([])
fig.set_facecolor("#323331")
ax1.set_ylim(0, 3.25)
theta = np.linspace(0, 2*np.pi, 12)
ax1.set_title("Global Temperature Change (1850-2017)", color='white', fontdict={'fontsize': 20})
ax1.set_axis_bgcolor('#000100')
years = hadcrut['year'].unique()
for year in years:
r = hadcrut[hadcrut['year'] == year]['value'] + 1
# ax1.text(0,0, str(year), color='white', size=30, ha='center')
ax1.plot(theta, r)
这个图看起来是这样的:

自定义颜色
现在,颜色感觉有点随机,与最初可视化传达的气候逐渐变暖不相符。在最初的视觉化中,颜色从蓝色/紫色过渡到绿色,再到黄色。
这种配色方案被称为顺序色图,因为颜色的渐变反映了数据的一些含义。虽然在 matplotlib 中创建散点图时很容易指定颜色图(使用来自Axes.scatter()的cm参数),但是在创建线图时没有直接的参数来指定颜色图。Tony Yu 有一篇关于如何在生成散点图时使用色图的精彩短文,我们将在这里使用。本质上,我们在调用Axes.plot()方法时使用color(或c)参数,并从plt.cm.(index)绘制颜色。下面是我们如何使用viridis颜色图:
ax1.plot(theta, r, c=plt.cm.viridis(index)) # Index is a counter variable
这将导致绘图具有从蓝色到绿色的连续颜色,但要得到黄色,我们实际上可以将计数器变量乘以
2:
ax1.plot(theta, r, c=plt.cm.viridis(index*2))
让我们重新格式化我们的代码来合并这个顺序色图。
fig = plt.figure(figsize=(14,14))
ax1 = plt.subplot(111, projection='polar')
ax1.axes.get_yaxis().set_ticklabels([])
ax1.axes.get_xaxis().set_ticklabels([])
fig.set_facecolor("#323331")
for index, year in enumerate(years):
r = hadcrut[hadcrut['year'] == year]['value'] + 1
theta = np.linspace(0, 2*np.pi, 12)
ax1.grid(False)
ax1.set_title("Global Temperature Change (1850-2017)", color='white', fontdict={'fontsize': 20})
ax1.set_ylim(0, 3.25)
ax1.set_axis_bgcolor('#000100')
# ax1.text(0,0, str(year), color='white', size=30, ha='center')
ax1.plot(theta, r, c=plt.cm.viridis(index*2))
下面是结果图的样子:

添加温度环
虽然我们现在的图很漂亮,但观众实际上根本无法理解底层数据。可视化中没有任何潜在温度值的指示。最初的可视化在 0.0、1.5 和 2.0 摄氏度下有完整、均匀的环来帮助实现这一点。因为我们添加了
对于每个温度值,我们在绘制这些均匀的环时也需要做同样的事情。蓝色的环最初是在 0.0 摄氏度,所以我们需要在r=1处生成一个环。第一个红圈原来在 1.5,所以我们需要在 2.5 出图。最后一个是 2.0,所以应该是 3.0。
full_circle_thetas = np.linspace(0, 2*np.pi, 1000)
blue_line_one_radii = [1.0]*1000
red_line_one_radii = [2.5]*1000
red_line_two_radii = [3.0]*1000
ax1.plot(full_circle_thetas, blue_line_one_radii, c='blue')
ax1.plot(full_circle_thetas, red_line_one_radii, c='red')
ax1.plot(full_circle_thetas, red_line_two_radii, c='red')
最后,我们可以添加指定环的温度值的文本。所有这 3 个文本值都位于 0.5 *π角度,距离值各不相同:
ax1.text(np.pi/2, 1.0, "0.0 C", color="blue", ha='center', fontdict={'fontsize': 20})
ax1.text(np.pi/2, 2.5, "1.5 C", color="red", ha='center', fontdict={'fontsize': 20})
ax1.text(np.pi/2, 3.0, "2.0 C", color="red", ha='center', fontdict={'fontsize': 20})
 因为“0.5°C”的文本被数据遮挡,我们可能要考虑在静态绘图版本中隐藏它。
因为“0.5°C”的文本被数据遮挡,我们可能要考虑在静态绘图版本中隐藏它。
生成 GIF 动画
现在我们准备从这个图生成一个 GIF 动画。动画是快速连续显示的一系列图像。我们将使用
matplotlib.animation.FuncAnimation 功能帮我们解决了这个问题。为了利用这个函数,我们需要编写代码:
- 定义基本地块的外观和特性
- 用新数据更新每帧之间的绘图
调用时,我们将使用以下必需的参数
FuncAnimation():
fig:matplotlib 图形对象func:每帧之间调用的更新函数frames:帧数(我们希望每年有一个)interval:每帧显示的毫秒数(一秒钟有 1000 毫秒)
该函数将返回一个
对象,它有一个我们可以用来将动画写到 GIF 文件的方法。下面是一些反映我们将使用的工作流的框架代码:
# To be able to write out the animation as a GIF file
import sysfrom matplotlib.animation import FuncAnimation
# Create the base plot
fig = plt.figure(figsize=(8,8))
ax1 = plt.subplot(111, projection='polar')
def update(i):
# Specify how we want the plot to change in each frame.
# We need to unravel the for loop we had earlier.
year = years[i]
r = hadcrut[hadcrut['year'] == year]['value'] + 1
ax1.plot(theta, r, c=plt.cm.viridis(i*2))
return ax1
anim = FuncAnimation(fig, update, frames=len(years), interval=50)
anim.save('climate_spiral.gif', dpi=120, writer='imagemagick', savefig_kwargs={'facecolor': '#323331'})
现在剩下的就是重新格式化我们之前的代码,并将其添加到上面的框架中。我们鼓励你自己去做,用 matplotlib 练习编程。
这里是最终动画在低分辨率下的样子(为了减少加载时间)。
后续步骤
在这篇文章中,我们探讨了:
- 如何在极坐标系统上绘图
- 如何自定义极坐标图中的文本
- 如何通过插值多个图来生成 GIF 动画
你可以在很大程度上重现 GIF Ed Hawkins 最初发布的优秀气候螺旋。以下是我们没有探究的几个关键问题,但我们强烈建议您自己去探究:
- 将月份值添加到极坐标图的外缘/
- 创建动画时,在绘图中心添加当前年份值。
- 如果您尝试使用
FuncAcnimation()方法来实现这一点,您会注意到年份值堆叠在彼此之上(而不是清除前一年的值并显示新的年份值)。
- 如果您尝试使用
- 将文本签名添加到图的左下角和右下角。
- 调整 0.0°C、1.5°C 和 2.0°C 的文本如何与静态温度环相交。*
使用 Matplotlib 在 Python 中实现有趣的数据可视化
原文:https://www.dataquest.io/blog/comical-data-visualization-in-python-using-matplotlib/
July 15, 2021

如何在 Matplotlib 中制作滑稽的可视化效果?使用网飞电影和电视节目数据集进行解释。
数据可视化是讲述一个故事的好方法。你可以很容易地吸收信息并识别数据中的模式。我们的一名学生决定使用 Matplotlib 创建 Python 中的数据可视化,以了解网飞上可用的不同类型的内容。
本文将重点介绍如何以有趣的方式使用 Matplotlib 进行数据可视化。阅读 Paridhi 整理的分步指南。尽情享受吧!
当你在网飞看完一场精彩的表演或 T2 的电影后,你有没有想过网飞是多么的棒,让你可以接触到如此丰富的内容?当然,我并不孤单,是吗?
一个想法引发另一个想法,在你知道之前,你已经下定决心做一个探索性的数据分析,以了解更多关于谁是最受欢迎的演员以及哪个国家更喜欢哪个流派的信息。
现在,我已经花了相当多的时间使用 Python 制作了常规的条形图和饼图,虽然它们在传达结果方面做得很好,但我想给这个项目添加一点有趣的元素。
我最近了解到,可以在 Python 最流行的数据可视化库 Matplotlib 中创建类似 xkcd 的图,并决定我应该在这个项目中合成我所有的 Matplotlib 可视化,只是为了让事情变得更有趣一些。
来看看数据都有什么说的吧!
数据
我用的是这个数据集,在 Kaggle 上有。截至 2020 年,它包含网飞上可用的 7,787 部电影和电视节目。
首先,我安装了所需的库并阅读了 CSV 文件。
import pandas as pd
pan class="token keyword">import matplotlib.pyplot as plt
t.rcParams['figure.dpi'] = 200
= pd.read_csv("../input/netflix-shows/netflix_titles.csv")
.head()

我还向数据集添加了新的特性,我将在项目的后面使用这些特性。
df["date_added"] = pd.to_datetime(df['date_added'])
['year_added'] = df['date_added'].dt.year.astype('Int64')
['month_added'] = df['date_added'].dt.month
['season_count'] = df.apply(lambda x : x['duration'].split(" ")[0] if "Season" in x['duration'] else "", axis = 1)
['duration'] = df.apply(lambda x : x['duration'].split(" ")[0] if "Season" not in x['duration'] else "", axis = 1)
.head()

现在我们可以开始有趣的东西了!
我还要补充一点,对于 matplotlib 中的 XKCDify 可视化,您只需将所有绘图代码放入以下块中,就万事俱备了:
with plt.xkcd():
pan class="token comment" spellcheck="true"># all your regular visualization code goes in here

1.这些年来的网飞
首先,我认为有必要看一下描绘网飞这些年发展的时间表。
from datetime import datetime
n class="token comment" spellcheck="true"># these go on the numbers below
ates = [
"1997\nFounded",
"1998\nMail Service",
"2003\nGoes Public",
"2007\nStreaming service",
"2016\nGoes Global",
"2021\nNetflix & Chill"
n class="token punctuation">]
= [1, 2, 4, 5.3, 8,9]
n class="token comment" spellcheck="true"># the numbers go on these
ub_x = [1.5,3,5,6.5,7]
ub_times = [
"1998","2000","2006","2010","2012"
n class="token punctuation">]
ext = [
"Netflix.com launched",
"Starts\nPersonal\nRecommendations","Billionth DVD Delivery","Canadian\nLaunch","UK Launch"]
n class="token keyword">with plt.xkcd():
n class="token comment" spellcheck="true"># Set figure & Axes
fig, ax = plt.subplots(figsize=(15, 4), constrained_layout=True)
ax.set_ylim(-2, 1.75)
ax.set_xlim(0, 10)
# Timeline : line
ax.axhline(0, xmin=0.1, xmax=0.9, c='deeppink', zorder=1)
# Timeline : Date Points
ax.scatter(tl_x, np.zeros(len(tl_x)), s=120, c='palevioletred', zorder=2)
ax.scatter(tl_x, np.zeros(len(tl_x)), s=30, c='darkmagenta', zorder=3)
# Timeline : Time Points
ax.scatter(tl_sub_x, np.zeros(len(tl_sub_x)), s=50, c='darkmagenta',zorder=4)
# Date Text
for x, date in zip(tl_x, tl_dates):
ax.text(x, -0.55, date, ha='center',
fontfamily='serif', fontweight='bold',
color='royalblue',fontsize=12)
# Stemplot : vertical line
levels = np.zeros(len(tl_sub_x))
levels[::2] = 0.3
levels[1::2] = -0.3
markerline, stemline, baseline = ax.stem(tl_sub_x, levels, use_line_collection=True)
plt.setp(baseline, zorder=0)
plt.setp(markerline, marker=',', color='darkmagenta')
plt.setp(stemline, color='darkmagenta')
# Text
for idx, x, time, txt in zip(range(1, len(tl_sub_x)+1), tl_sub_x, tl_sub_times, tl_text):
ax.text(x, 1.3*(idx%2)-0.5, time, ha='center',
fontfamily='serif', fontweight='bold',
color='royalblue', fontsize=11)
ax.text(x, 1.3*(idx%2)-0.6, txt, va='top', ha='center',
fontfamily='serif',color='royalblue')
# Spine
for spine in ["left", "top", "right", "bottom"]:
ax.spines[spine].set_visible(False)
# Ticks
ax.set_xticks([])
ax.set_yticks([])
# Title
ax.set_title("Netflix through the years", fontweight="bold", fontfamily='serif', fontsize=16, color='royalblue')
ax.text(2.4,1.57,"From DVD rentals to a global audience of over 150m people - is it time for Netflix to Chill?", fontfamily='serif', fontsize=12, color='mediumblue')
plt.show()

这个情节很好地描绘了网飞的旅程。此外,由于 plt.xkcd()函数,该图看起来像是手绘的。邪恶的东西。
2.电影与电视节目
接下来,我决定看看电影和电视剧的比例。
col = "type"
ped = df[col].value_counts().reset_index()
ped = grouped.rename(columns = {col : "count", "index" : col})
n class="token keyword">with plt.xkcd():
explode = (0, 0.1) # only "explode" the 2nd slice (i.e. 'TV Show')
fig1, ax1 = plt.subplots(figsize=(5, 5), dpi=100)
ax1.pie(grouped["count"], explode=explode, labels=grouped["type"], autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.show()

该平台上的电视节目数量不到总内容的三分之一。所以很可能,你和我都有更好的机会找到一部相对好的电影,而不是一部关于网飞的电视剧。叹气。
3.内容最多的国家
对于我使用 Matplotlib 的第三个可视化,我想制作一个水平条形图,代表内容最多的前 25 个国家。数据帧中的国家列有几行包含不止一个国家(用逗号分隔)。

为了处理这个问题,我用“,”作为分隔符将国家列中的数据分开,然后将所有国家放入一个名为 categories 的列表中:
from collections import Counter
= "country"
gories = ", ".join(df[col].fillna("")).split(", ")
ter_list = Counter(categories).most_common(25)
ter_list = [_ for _ in counter_list if _[0] != ""]
ls = [_[0] for _ in counter_list]
es = [_[1] for _ in counter_list]
n class="token keyword">with plt.xkcd():
fig, ax = plt.subplots(figsize=(10, 10), dpi=100)
y_pos = np.arange(len(labels))
ax.barh(y_pos, values, align='center')
ax.set_yticks(y_pos)
ax.set_yticklabels(labels)
ax.invert_yaxis() # labels read top-to-bottom
ax.set_xlabel('Content')
ax.set_title('Countries with most content')
plt.show()

看了上面的情节后的一些总体想法:
-
网飞上的绝大多数内容来自美国(相当明显)。
-
尽管网飞在印度起步较晚(2016 年),但它已经位居第二,仅次于美国。因此,印度是网飞的一个大市场。
-
我将在网飞上寻找来自泰国的内容,现在我知道它在平台上,brb。
4.受欢迎的导演和演员
为了看看受欢迎的导演和演员,我决定用来自内容最多的前六个国家的六个次要情节绘制一个图形(每个),并为每个次要情节制作水平条形图。看看下面的图,再读一遍第一行。
a.热门导演:
从集合导入计数器
from collections import Counter
n class="token keyword">from matplotlib.pyplot import figure
n class="token keyword">import math
urs = ["orangered", "mediumseagreen", "darkturquoise", "mediumpurple", "deeppink", "indianred"]
tries_list = ["United States", "India", "United Kingdom", "Japan", "France", "Canada"]
= "director"
n class="token keyword">with plt.xkcd():
figure(num=None, figsize=(20, 8))
x=1
for country in countries_list:
country_df = df[df["country"]==country]
categories = ", ".join(country_df[col].fillna("")).split(", ")
counter_list = Counter(categories).most_common(6)
counter_list = [_ for _ in counter_list if _[0] != ""]
labels = [_[0] for _ in counter_list][::-1]
values = [_[1] for _ in counter_list][::-1]
if max(values)<10:
values_int = range(0, math.ceil(max(values))+1)
else:
values_int = range(0, math.ceil(max(values))+1, 2)
plt.subplot(2, 3, x)
plt.barh(labels,values, color = colours[x-1])
plt.xticks(values_int)
plt.title(country)
x+=1
plt.suptitle('Popular Directors with the most content')
plt.tight_layout()
plt.show()

b.热门演员:
col = "cast"
n class="token keyword">with plt.xkcd():
figure(num=None, figsize=(20, 8))
x=1
for country in countries_list:
df["from_country"] = df['country'].fillna("").apply(lambda x : 1 if country.lower() in x.lower() else 0)
small = df[df["from_country"] == 1]
cast = ", ".join(small['cast'].fillna("")).split(", ")
tags = Counter(cast).most_common(11)
tags = [_ for _ in tags if "" != _[0]]
labels, values = [_[0]+" " for _ in tags][::-1], [_[1] for _ in tags][::-1]
if max(values)<10:
values_int = range(0, math.ceil(max(values))+1)
elif max(values)>=10 and max(values)<=20:
values_int = range(0, math.ceil(max(values))+1, 2)
else:
values_int = range(0, math.ceil(max(values))+1, 5)
plt.subplot(2, 3, x)
plt.barh(labels,values, color = colours[x-1])
plt.xticks(values_int)
plt.title(country)
x+=1
plt.suptitle('Popular Actors with the most content')
plt.tight_layout()
plt.show()

5.一些最古老的电影和电视节目
我觉得看看网飞最古老的电影和电视节目以及它们的历史会很有趣。
a.最老的电影:
small = df.sort_values("release_year", ascending = True)
all = small[small['duration'] != ""].reset_index()
all[['title', "release_year"]][:15]

b.最旧的电视节目:
small = df.sort_values("release_year", ascending = True)
all = small[small['season_count'] != ""].reset_index()
all = small[['title', "release_year"]][:15]
all

哦,网飞有一些非常老的电影和电视节目——有些甚至是 80 多年前发行的。你看过这些吗?
(有趣的事实:当他开始实施 Python 时,吉多·范·罗苏姆也在阅读来自 20 世纪 70 年代 BBC 喜剧系列《蒙蒂·Python 的飞行马戏团》(Monty Python ' s Flying Circus)(该系列于 2018 年在网飞播出)的已发布脚本。Van Rossum 认为他需要一个简短、独特且略带神秘的名字,所以他决定将这种语言称为 Python。)
6.网飞有最新的内容吗?
是的,网飞很酷,因为它有一个世纪以前的内容,但是它也有最新的电影和电视节目吗?为了找到答案,首先我计算了内容被添加到网飞的日期和内容发布年份之间的差异。
df["year_diff"] = df["year_added"]-df["release_year"]
然后,我创建了一个散点图,x 轴为年份差异,y 轴为电影/电视节目的数量:
col = "year_diff"
_movies = df[df["duration"]!=""]
_shows = df[df["season_count"]!=""]
ped1 = only_movies[col].value_counts().reset_index()
ped1 = grouped1.rename(columns = {col : "count", "index" : col})
ped1 = grouped1.dropna()
ped1 = grouped1.head(20)
ped2 = only_shows[col].value_counts().reset_index()
ped2 = grouped2.rename(columns = {col : "count", "index" : col})
ped2 = grouped2.dropna()
ped2 = grouped2.head(20)
n class="token keyword">with plt.xkcd():
figure(num=None, figsize=(8, 5))
plt.scatter(grouped1[col], grouped1["count"], color = "hotpink")
plt.scatter(grouped2[col], grouped2["count"], color = '#88c999')
values_int = range(0, math.ceil(max(grouped1[col]))+1, 2)
plt.xticks(values_int)
plt.xlabel("Difference between the year when the content has been\n added on Netflix and the realease year")
plt.ylabel("Number of Movies/TV Shows")
plt.legend(["Movies", "TV Shows"])
plt.tight_layout()
plt.show()

正如你在上面的图像中看到的,网飞上的大部分内容都是在发布后一年内添加的。所以,网飞大部分时间都有最新的内容!
如果你还在这里,这里有一个 xkcd 漫画给你。不客气

7.网飞关注什么样的内容?
我还想探索评级栏,比较网飞为儿童、青少年和成人制作的内容数量,以及这些年来他们的关注点是否从一个群体转移到了另一个群体。
为了做到这一点,我首先查看了数据框架中的独特评级:
print(df['rating'].unique())
输出:
['TV-MA' 'R' 'PG-13' 'TV-14' 'TV-PG' 'NR' 'TV-G' 'TV-Y' nan 'TV-Y7' 'PG' 'G' 'NC-17' 'TV-Y7-FV' 'UR']
然后,我根据他们所属的组(即小孩、大孩子、青少年和成年人)对评级进行分类,并将评级栏中的值更改为他们的组名。
ratings_list = ['TV-MA', 'R', 'PG-13', 'TV-14', 'TV-PG', 'TV-G', 'TV-Y', 'TV-Y7', 'PG', 'G', 'NC-17', 'TV-Y7-FV']
ngs_group_list = ['Little Kids', 'Older Kids', 'Teens', 'Mature']
ngs_dict={
'TV-G': 'Little Kids',
'TV-Y': 'Little Kids',
'G': 'Little Kids',
'TV-PG': 'Older Kids',
'TV-Y7': 'Older Kids',
'PG': 'Older Kids',
'TV-Y7-FV': 'Older Kids',
'PG-13': 'Teens',
'TV-14': 'Teens',
'TV-MA': 'Mature',
'R': 'Mature',
'NC-17': 'Mature'
n class="token punctuation">}
n class="token keyword">for rating_val, rating_group in ratings_dict.items():
df.loc[df.rating == rating_val, "rating"] = rating_group
最后,我用 x 轴上的年份和 y 轴上的内容计数做了线图。
df['rating_val']=1
an class="token operator">=0
ls=['kinda\nless', 'not so\nbad', 'holyshit\nthat\'s too\nmany']
n class="token keyword">with plt.xkcd():
for r in ratings_group_list:
grouped = df[df['rating']==r]
year_df = grouped.groupby(['year_added']).sum()
year_df.reset_index(level=0, inplace=True)
plt.plot(year_df['year_added'], year_df['rating_val'], color=colours[x], marker='o')
values_int = range(2008, math.ceil(max(year_df['year_added']))+1, 2)
plt.yticks([200, 600, 1000], labels)
plt.xticks(values_int)
plt.title('Count of shows and movies that Netflix\n has been producing for different audiences', fontsize=12)
plt.xlabel('Year', fontsize=14)
plt.ylabel('Content Count', fontsize=14)
x+=1
plt.legend(ratings_group_list)
plt.tight_layout()
plt.show()

好的,这个可视化的数据向我们展示了网飞成熟观众的内容数量远远高于其他群体。另一个有趣的观察结果是,从 2019 年到 2020 年,为小孩子制作的内容数量激增,而在此期间,为较大的孩子、青少年和成年观众制作的内容减少了。
8.热门流派(全国)
col = "listed_in"
urs = ["violet", "cornflowerblue", "darkseagreen", "mediumvioletred", "blue", "mediumseagreen", "darkmagenta", "darkslateblue", "seagreen"]
tries_list = ["United States", "India", "United Kingdom", "Japan", "France", "Canada", "Spain", "South Korea", "Germany"]
n class="token keyword">with plt.xkcd():
figure(num=None, figsize=(20, 8))
x=1
for country in countries_list:
df["from_country"] = df['country'].fillna("").apply(lambda x : 1 if country.lower() in x.lower() else 0)
small = df[df["from_country"] == 1]
genre = ", ".join(small['listed_in'].fillna("")).split(", ")
tags = Counter(genre).most_common(3)
tags = [_ for _ in tags if "" != _[0]]
labels, values = [_[0]+" " for _ in tags][::-1], [_[1] for _ in tags][::-1]
if max(values)>200:
values_int = range(0, math.ceil(max(values)), 100)
elif max(values)>100 and max(values)<=200:
values_int = range(0, math.ceil(max(values))+50, 50)
else:
values_int = range(0, math.ceil(max(values))+25, 25)
plt.subplot(3, 3, x)
plt.barh(labels,values, color = colours[x-1])
plt.xticks(values_int)
plt.title(country)
x+=1
plt.suptitle('Top Genres')
plt.tight_layout()
plt.show()

该地块的主要收获:
-
戏剧和喜剧几乎在每个国家都是最受欢迎的类型。
-
日本看很多动漫!
-
浪漫的电视节目和电视剧在韩国很受欢迎。(顺便说一句,我也迷上了 k 剧)
-
儿童和家庭电影是加拿大第三大流行类型。
9.单词云
我最终用两个单词云结束了这个项目——首先,一个单词云用于描述列,另一个用于标题列。
a.文字云描述:
from wordcloud import WordCloud
pan class="token keyword">import random
pan class="token keyword">from PIL import Image
pan class="token keyword">import matplotlib
pan class="token comment" spellcheck="true"># Custom colour map based on Netflix palette
ap = matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710'])
xt = str(list(df['description'])).replace(',', '').replace('[', '').replace("'", '').replace(']', '').replace('.', '')
sk = np.array(Image.open('../input/finallogo/New Note.png'))
rdcloud = WordCloud(background_color = 'white', width = 500, height = 200,colormap=cmap, max_words = 150, mask = mask).generate(text)
t.figure( figsize=(5,5))
t.imshow(wordcloud, interpolation = 'bilinear')
t.axis('off')
t.tight_layout(pad=0)
t.show()

生活、爱情、生活、朋友、家庭、世界和寻找是电影和电视剧描述中出现频率最高的几个词。另一个有趣的事情是,一、二、三、四这些词都出现在单词 cloud 中。
b.标题的文字云
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710'])
xt = str(list(df['title'])).replace(',', '').replace('[', '').replace("'", '').replace(']', '').replace('.', '')
sk = np.array(Image.open('../input/finallogo/New Note.png'))
rdcloud = WordCloud(background_color = 'white', width = 500, height = 200,colormap=cmap, max_words = 150, mask = mask).generate(text)
t.figure( figsize=(5,5))
t.imshow(wordcloud, interpolation = 'bilinear')
t.axis('off')
t.tight_layout(pad=0)
t.show()

你看到圣诞节就在这个词的中心吗?看起来网飞有很多圣诞电影。其他受欢迎的词有爱情、世界、男人、生活、故事、生活、秘密、女孩、男孩、美国人、游戏、夜晚、最后、时间和白天。
就是这样!
我只花了几个小时就完成了这个项目,现在我能以一种新的方式看到网飞的一切。我认为这是我迄今为止做过的最有趣的项目,接下来我肯定会通过建立一个推荐系统来扩展这个项目。从事这样的项目让我想到数据科学真的很酷。
我希望这个项目和所有使用 Matplotlib 的滑稽的数据可视化例子也能给你的项目带来灵感。
如果您有任何问题/反馈或只是想聊天,您可以通过 Twitter 或 LinkedIn 联系我。
如何学习使用 Matplotlib 进行数据可视化?
- 通过我们的数据可视化基础课程了解如何使用 Matplotlib
- 通过我们的讲故事、数据可视化和信息设计课程了解如何交流见解
您也可以查看以下课程:
- 了解如何使用 matplotlib 创建线图来分析数据。
- 了解如何使用 Matplotlib 生成散点图
- 了解如何使用 Matplotlib 生成条形图和直方图
本文由 Dataquest 社区的 Paridhi Agarwal 提供。你可以在 LinkedIn 和 Twitter 上找到帕里迪。
如何在 R 中使用 If-Else 语句和循环
原文:https://www.dataquest.io/blog/control-structures-in-r-using-loops-and-if-else-statements/
September 1, 2020
当我们用 R(或者其他语言)编程时,我们经常想要控制何时和如何执行我们代码的特定部分。我们可以使用控制结构来实现,比如 if-else 语句、for 循环和 while 循环。
控制结构是代码块,它根据指定的参数确定如何执行其他代码段。你可以认为这些有点像父母离家前给孩子的指示:
"如果我晚上 8 点还没回家,你就给自己做晚饭。"
控制结构设置一个条件,并告诉 R 当条件满足或不满足时做什么。不像有些孩子,R 会永远做我们让它做的事!如果你愿意,你可以在 R 文档中了解更多关于控制结构的信息。
在本教程中,我们假设您熟悉基本的数据结构和 r 中的算术运算。
还没到那一步?查看我们的介绍性 R 编程课程,这是我们的数据分析师在 R 路径中的一部分。开始学习是免费的,没有任何先决条件,也不需要安装任何东西—您现在就可以在浏览器中开始学习。
[thrive _ leads id = ' 21036 ']
(本教程是基于我们的中级 R 编程课程的,所以也来看看吧!它是交互式的,允许你在浏览器中编写和运行代码。)
R 中的比较运算符
为了使用控制结构,我们需要创建结果为TRUE或FALSE的语句。在上面的孩子的例子中,陈述“现在是晚上 8 点。我父母回来了吗?”产量TRUE(“是”)或FALSE(“否”)。在 R 中,将某物评估为TRUE或FALSE的最基本方式是通过比较运算符。
下面是在 R 中使用控制结构的六个基本比较运算符:
==意思是平等。被框成问题的语句x == a表示“x的值等于a的值吗?”!=意为“不相等”。语句x == b表示“x的值不等于b的值吗?”<意为“小于”。语句x < c的意思是“x的值小于c的值吗?”<=意为“小于或等于”。语句x <= d表示“x的值是否小于或等于d的值?”>意为“大于”。语句x >e 的意思是“T2 的值是否大于 T3 的值?”>=意为“大于或等于”。语句x >= f表示“x的值是否大于或等于f的值?”
理解 R 中的 If-Else
假设我们正在观看一场决定哪支球队进入季后赛的体育比赛。我们可以用这个树形图来想象可能的结果:

正如我们在树形图中看到的,只有两种可能的结果。如果 A 队赢了,他们就进入季后赛。如果 B 队赢了,他们就走。
让我们从尝试用 r 表示这个场景开始。我们可以使用一个 if 语句来编写一个程序,打印出获胜的团队。
如果条件返回TRUE,If 语句告诉 R 运行一行代码。if 语句在这里是一个很好的选择,因为它允许我们根据发生的结果来控制打印哪个语句。
下图显示了条件流程图和 if 语句的基本语法:

我们的 if 语句的条件应该是一个计算结果为TRUE或FALSE的表达式。如果表达式返回 TRUE,那么程序将执行括号{ }之间的所有代码。如果为 FALSE,则不会执行任何代码。
了解了这一点,让我们来看一个 if 语句的例子,它打印获胜队的名字。
team_A <- 3 # Number of goals scored by Team A
team_B <- 1 # Number of goals scored by Team B
if (team_A > team_B){
print ("Team A wins")
}
"Team A wins"
成功了!因为 A 队比 B 队有更多的进球,我们的条件语句(team_A > team_B)计算为TRUE,所以它下面的代码块运行,打印 A 队赢得比赛的消息。
在 R 中添加 else 语句
在前面的练习中,我们根据我们的表情打印了将进入季后赛的球队的名称。让我们来看一场新的比分对决。如果 A 队 1 球,B 队 3 球呢?我们的 team_A > team_B 条件将评估为FALSE。因此,如果我们运行我们的代码,什么都不会被打印出来。因为 if 语句的计算结果为 false,所以不执行 if 语句中的代码块:
team_A <- 1 # Number of goals scored by Team A
team_B <- 3 # Number of goals scored by Team B
if (team_A > team_B){
print ("Team A will make the playoffs")
}
如果我们回到最初的流程图,我们可以看到我们只为两种可能性中的一种编写了分支代码:

理想情况下,我们希望让我们的程序考虑到这两种可能性,并且如果表达式评估为 FALSE,则“B 队将进入季后赛”。换句话说,我们希望能够处理两个条件分支:

为此,我们将添加一个 else 语句,将它转换成通常所说的 if-else 语句。在 R 中,如果条件语句是TRUE,if-else 语句告诉程序运行一个代码块,如果条件语句是FALSE,则运行一个不同的代码块。下面以流程图的形式和 R 语法的形式直观地展示了这一过程:
-
-
-
![if-else-r-2]() * *
* *
-
-
 * *
* *概括来说,R 中的 if-else 需要三个参数:
- 评估为真或假的语句(例如比较运算符)。
- 如果比较运算符为 TRUE,R 应返回的值。
- 如果比较运算符为 FALSE,R 应返回的值。
因此,在我们的例子中,我们需要添加一段代码,如果我们的条件表达式team_A > team_B返回FALSE,这段代码就会运行。我们可以通过在 r 中添加一个else语句来做到这一点。如果我们的比较运算符评估为 FALSE,让我们打印“B 队将进入季后赛”
team_A <- 1 # Number of goals scored by Team A
team_B <- 3# Number of goals scored by Team B
if (team_A > team_B){
print ("Team A will make the playoffs")
} else {
print ("Team B will make the playoffs")
}
"Team B will make the playoffs"
概括一下:
- if 语句的本质特征是它帮助我们在代码中创建一个分支路径。
- R 中的关键字
if和else后面都是花括号{ },花括号定义了代码块。 - 每个代码块代表图中所示的一条路径。
- r 并不两者都运行,它使用比较运算符来决定运行哪个代码块。
超越两个分支
到目前为止,我们一直假设我们的控制结构中的每个决策只有两个分支:一个对应于TRUE,另一个对应于FALSE。很多时候,我们会有两个以上的选择,因为有些决定不能归结为“是”还是“不是”。
假设我们正在观看一场可能以平局收场的体育比赛。我们上一个例子中的控制结构没有考虑到这一点。幸运的是,R 提供了一种方法,可以用关键字else if在一个if语句中合并两个以上的分支。else if 关键字提供了另一个在if语句中使用的代码块,我们可以有任意多个合适的代码块。这看起来是这样的:
team_A <- 2 # Number of goals scored by Team A
team_B <- 2# Number of goals scored by Team B
if (team_A > team_B){
print ("Team A won")
} else if (team_A < team_B){
print ("Team B won")
} else {
"Team A & B tied"
}
"Team A & B tied"
每个潜在的游戏结果都有自己的分支。代码块有助于我们应对任何平局的情况。
在 R 中使用 for 循环
既然我们已经在 R 中使用 if-else 来显示一个匹配的结果,那么如果我们想要查找多个匹配的结果呢?假设我们有一个包含匹配结果的向量列表:matches <- list(c(2,1),c(5,2),c(6,3))。
记住,索引时我们必须使用[[]],因为我们想要返回列表中每个列表的单个值,而不是列表对象的值。用[]索引将返回一个列表对象,而不是值。
因此,例如,在我们上面的代码中,matches[[2]][1]正在调用第二列表的第一索引(即第二场比赛中 A 队的得分)。
假设团队 A 的目标列在第一位(向量的第一个索引),团队 B 的目标列在第二位,我们可以在 R 中使用 if-else 找到结果,如下所示:
if (matches[[1]][1] > matches[[1]][2]){
print ("Win")
} else {
print ("Loss")
}
if (matches[[2]][1] > matches[[2]][2]){
print ("Win")
} else {
print ("Loss")
}
if (matches[[3]][1] > matches[[3]][2]){
print ("Win")
} else {
print ("Loss")
}
这将打印:
"Win"
"Win"
"Win"
这段代码可以工作,但是如果我们观察这种方法,很容易发现问题。为三个游戏写出这个已经很麻烦了。如果我们有一个 100 或 1000 个游戏的列表来评估会怎么样?
我们可以通过使用 r 中的 for 循环执行相同的操作来改进我们的代码。for 循环为对象中的每个元素多次重复一段代码。这允许我们编写更少的代码(这意味着出错的可能性更小),并且可以更好地表达我们的意图。这里有一个流程图表示,以及 R 中的语法(看起来非常类似于 if 语法)。

在此图中,对于序列中的每个值,循环将执行代码块。当序列中没有更多的值时,这将返回FALSE并退出循环。
我们来分析一下这是怎么回事。
- 序列:这是一组对象。例如,这可能是数字 c(1,2,3,4,5)的向量。
- value :这是一个迭代器变量,用于引用序列中的每个值。有关有效的变量名,请参见第一课中的变量命名约定。
- 代码块:这是被求值的表达式。
我们来看一个具体的例子。我们将编写一个快速循环来打印列表中项目的值,我们将创建一个包含两个项目的短列表:Team A 和 Team B。
teams <- c("team_A","team_B")
for (value in teams){
print(value)
}
"team_A"
"team_B"
由于teams有两个值,我们的循环将运行两次。这是正在发生的事情的视觉表现

一旦循环显示了第一次迭代的结果,循环将查看该位置的下一个值。因此,它将经历另一次迭代。由于序列中没有更多的值,循环将在“team_B”之后退出。
总的来说,最终结果将如下所示:
"team_A"
"team_B"
将循环的结果添加到 R 中的对象
既然我们已经写出了我们的循环,我们将希望在我们的循环中存储每次迭代的每个结果。在本文中,我们将把我们的值存储在一个向量中,因为我们处理的是单一的数据类型。
从我们的 R 基础课程中你可能已经知道,我们可以使用c()函数组合向量。我们将使用相同的方法来存储 for 循环的结果。
我们从这个 for 循环开始:
for (match in matches){
print(match)
}
现在,假设我们想得到一场比赛中的总进球数,并将它们存储在 vector 中。我们需要做的第一步是将列表中的每个分数加在一起,这可以使用sum()函数来完成。我们将让代码循环通过matches来计算每场比赛的总进球数。
matches <- list(c(2,1),c(5,2),c(6,3))
for (match in matches){
sum(match)
}
但是我们实际上还没有在任何地方保存这些进球总数!如果我们想保存每场比赛的总目标,我们可以初始化一个新的向量,然后将每个额外的计算附加到该向量上,如下所示:
matches <- list(c(2,1),c(5,2),c(6,3))
total_goals <- c()
for (match in matches){
total_goals <- c(total_goals, sum(match))
}
在 R 中的 for 循环中使用 if-else 语句
现在我们已经学习了 R 中的 if-else 和 R 中的 for 循环,我们可以更进一步,在 for 循环中使用 if-else 语句来给出多个匹配的结果。
为了组合两个控制结构,我们将把一个控制结构放在另一个控制结构的括号{ }之间。
我们从 team_A 的比赛结果开始:
matches <- list(c(2,1),c(5,2),c(6,3))
然后我们将创建一个 for 循环来遍历它:
for (match in matches){
}
这一次,我们不打印结果,而是将 if-else 语句添加到 for 循环中。
在我们的场景中,我们希望程序打印出 A 队是赢了还是输了比赛。假设 A 队的目标是每对值中的第一个,对手是第二个指标,我们需要使用一个比较运算符来比较这些值。在我们进行这个比较之后,如果 team_A 的得分更高,我们将打印“Win”。如果没有,我们就印“输”。
当索引到 iterable 变量 match 时,我们可以使用[]或[[]],因为 iterable 是一个向量,而不是一个列表。
matches <- list(c(2,1),c(5,2),c(6,3))
for (match in matches){
if (match[1] > match[2]){
print("Win")
} else {
print ("Lose")
}
}
"Win"
"Win"
"Win"
打破 R 中的 for 循环
现在我们已经添加了一个 if-else 语句,让我们看看如何基于某个条件停止 R 中的 for 循环。在我们的例子中,我们可以使用一个break语句来停止循环,只要我们看到 A 队赢得了一场比赛。
使用我们上面写的 for 循环,我们可以在 if-else 语句中插入 break 语句。
matches <- list(c(2,1),c(5,2),c(6,3))
for (match in matches){
if (match[1] > match[2]){
print("Win")
break
} else {
print("Lose")
}
}
"Win"
[thrive _ leads id = ' 19015 ']
在 R 中使用 while 循环
在前面的练习中,我们在 R 中使用了一个 for 循环来重复一段代码,这段代码给出了匹配的结果。现在我们已经返回了每场比赛的结果,如果我们想计算胜利的数量来确定他们是否进入季后赛,会怎么样呢?返回前四个游戏结果的一种方法是在 r 中使用一个 while 循环。
R 中的 while 循环是 R 中 for 循环的近亲,然而,while 循环将检查逻辑条件,并且只要条件为真就继续运行循环。while 循环的语法如下所示:
while(condition){
expression
}
以流程图的形式:

如果 R 中 while 循环的条件是始终为真,那么 while 循环将是一个无限循环,我们的程序永远不会停止运行。这是我们绝对要避免的事情!在 R 中编写 while 循环时,我们希望确保在某个时刻条件为假,这样循环就可以停止运行。
让我们以一支赛季初零胜的球队为例。他们需要赢得 10 场比赛才能进入季后赛。我们可以编写一个 while 循环来告诉我们球队是否进入了季后赛:
wins <- 0
while (wins < 10){
print ("Does not make playoffs")
wins <- wins + 1
}
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
"Does not make playoffs"
当 wins 达到 10 时,我们的循环将停止运行。请注意,我们不断地给 win 总数加 1,所以最终,win < 10 的条件将返回FALSE。结果,循环退出。
如果整个过程看起来令人生畏,不要担心,虽然 R 中的循环需要时间来理解,但一旦掌握,它们就是强大的工具。有许多不同的变量需要处理,但是理解 while 循环的关键是要知道这些变量在每次循环运行时是如何变化的。
让我们在 R 中编写第一个 while 循环,计算 A 队获胜!
在 R 中的 while 循环中使用 if-else 语句
既然我们已经打印了球队没有足够胜利时的状态,我们将添加一个特性来指示他们何时进入季后赛。
为此,我们需要在 while 循环中添加一个 if-else 语句。将 if-else 语句添加到 while 循环中与将其添加到 R 中的 for 循环中是一样的,我们已经完成了这一步。回到我们的场景,10 场胜利允许 A 队进入季后赛,让我们添加一个 if-else 条件。
if-else 条件将放在 while 循环的括号之间,与我们之前将它放入 for 循环的位置相同。
wins <- 0
while (wins <= 10){
if (wins < 10){
print("does not make playoffs")
} else {
print ("makes playoffs")
}
wins <- wins + 1
}
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"makes playoffs"
打破 R 中的 while 循环
假设一支球队在一个赛季中最多能赢 15 场。为了进入季后赛,我们仍然需要 10 场胜利,所以一旦 A 队达到这个数字,我们就可以结束我们的循环。
为此,我们可以使用另一个break语句。同样,这在 while 循环中的作用与在 for 循环中的作用相同;一旦满足条件并执行break,循环结束。
wins <- 0
playoffs <- c()
while (wins <= 15){
if (wins < 10){
print("does not make playoffs")
playoffs <- c(playoffs, "does not make playoffs")
} else {
print ("makes playoffs")
playoffs <- c(playoffs, "makes playoffs")
break
}
wins <- wins + 1
}
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"does not make playoffs"
"makes playoffs"
while 循环背后的直觉
R 中的 for 循环可能是你最常处理的循环。但是了解 while 循环还是很有用的。
为了区分这两种类型的循环,将 for 循环视为处理家务清单是很有用的。这个想法是你有一定数量的杂务要完成,一旦你完成了所有的杂务,你就完成了。这里的关键是我们需要在 for 循环中循环一定数量的项。
另一方面,while 循环就像试图达到一个里程碑,就像为慈善活动筹集目标金额的资金。对于慈善活动,你通常会表演和做一些事情来为你的事业筹集资金,比如跑步或为人们提供服务。你做这些任务,直到你达到你的目标,从一开始就不清楚你需要做多少任务才能达到目标。这是 while 循环背后的关键思想:重复一些动作(读:一个代码块)直到满足一个条件或目标。

而循环在模拟和优化等繁重的分析任务中起着重要作用。优化是寻找一组参数的行为,这些参数可以最大化或最小化某个目标。
在其他数据分析任务中,如清理数据或计算统计数据,while 循环就不那么有用了。这些任务构成了你在 R 路径中遇到的数据分析师以及你的职业生涯的主要内容,但是作为一名程序员,知道什么工具对你是可用的总是好的。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
后续步骤
在本教程中,我们将一个基本的 if 语句开发成一个更复杂的程序,该程序根据逻辑条件执行代码块。
这些概念是 R 编程的重要方面,它们将帮助您编写更加强大的代码。但是我们仅仅触及了 R 力量的表面!
要学习编写更高效的 R 代码,请查看我们的 R 中级课程。您可以直接在浏览器中编写代码(并得到检查)!
在本课程中,您将学习:
- 如何以及为什么应该使用矢量化函数和泛函
- 如何编写自己的函数
tidyverse包dplyr和purrr如何帮助你写出更高效、更易读的代码- 如何使用
stringr包来操作字符串
简而言之,这些是帮助你将 R 代码从实用提升到美观的基本技能。准备好开始了吗?
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
在我们新的算法复杂性课程中学习优化算法
原文:https://www.dataquest.io/blog/course-optimize-algorithm-complexity-for-data-engineering/
March 24, 2020
算法是几乎所有编程工作的核心。尤其是在数据工程领域,使用有效的算法非常重要,以至于这是求职面试中经常被问到的话题。
这就是我们刚刚推出新课程的原因!
算法复杂度 是我们数据工程师职业道路的最新课程。它增加了五个全新的课程和一个全新的指导项目,旨在帮助您掌握高效算法的评估和实施,以适应您的用例。
该课程需要 Dataquest Premium 订阅(目前可享受 50%的折扣,尽管该优惠即将结束)。
我为什么要学算法?
简短的回答就在开篇:因为你很有可能会在求职申请中被问到这个问题。
然而,真正的答案是,虽然 Python 有很多内置函数,但它们并不总是适合您的用例。
例如,考虑一种排序算法:虽然 Python 有一些内置的解决方案,但您可能需要基于不同的参数进行排序。您可能还需要根据可用的资源优化性能,在更快的处理时间和更高的存储要求之间进行权衡。
算法优化在各种各样的编程相关学科中都很重要,但在数据工程中尤其重要,在数据工程中,您经常要处理大量的数据以及潜在的时间和存储限制。本课程将帮助您构建高效、可扩展的数据处理。
这道菜里有什么?
本课程主要关注算法复杂性的两个主要方面:
- 时间复杂度(即速度)
- 空间复杂性(即内存)
课程的前三节互动课集中在时间复杂度。从测量算法执行所需的时间等基础知识开始,您将很快进入更高级的主题,如建模执行时间、识别隐藏的函数调用和对数时间复杂度。
接下来的两节课集中在空间复杂度,以及基于你可能有的内存限制优化你的算法。您将学习如何评估算法的内存使用情况,以及学习和实现您自己的定制排序算法。
与所有 Dataquest 课程一样,您将在我们的交互式编码平台中完成这些课程,从您的浏览器中编写和运行真正的代码。

课程以一个指导的项目结束,该项目要求你将所有的新知识整合在一起,实现一个高效的算法来建立索引以查询 CSV 文件。
成为一名数据工程师!
现在就学习成为一名数据工程师所需的技能。注册一个免费帐户,访问我们的交互式 Python 数据工程课程内容。
(免费)

https://www.youtube.com/embed/ddM21fz1Tt0?rel=0
如何在 Tableau 中创建参数(简单指南)
原文:https://www.dataquest.io/blog/creating-parameters-in-tableau/
October 10, 2022
Tableau 中的参数是什么?
参数是 Tableau 中最通用和最有用的功能之一,尤其是在 2020 年添加了参数仪表板操作之后。就像 Tableau 中的任何东西一样,我们可以从小处着手,然后逐渐变得更复杂——Tableau 参数也不例外。
为什么要在 Tableau 中使用参数?
但是在我们开始之前,你可能想知道 tableau 中的参数是什么,我们为什么要使用它?匪夷所思的问题。tableau 参数类似于计算字段,因为它不是数据集的一部分,而是由 tableau 开发人员创建的。它也类似于过滤器,因为分析消费者通常会在仪表板上看到 Tableau 参数,他们可以单击该参数来自定义视图。它不同于计算字段和过滤器,因为一旦我们部署了它,它在创建和行为方面给了我们更多的灵活性。
在开始在 Tableau 中创建参数之前,下面是 Tableau 参数的一些最常见用法:
- 创建前 x 个过滤器
- 更改图表中显示的维或度量
- 选择要突出显示的单个值
如何在 Tableau 中创建参数
在 Tableau 中创建参数的方式与创建计算字段的方式相同。单击搜索栏右侧的下拉箭头。选择创建参数。然后我们将看到这个小部件。让我们过一遍。


名称:这将是参数的名称。
(提示—我喜欢以前缀“Para”或“@”开始我的所有参数,这样它们更容易识别。)
数据类型:我们在这里选择是浮点、整数、字符串(文本)还是日期类型。
显示格式:允许我们格式化数值(例如,将其改为货币)。
当前值:这是默认的起始值。
工作簿打开时的值:这里的默认值是当前值,在初学者教程中我们不会与此进行交互,但是随着我们获得更多关于参数的经验,这里有一些有用的功能。
允许值:缺省值为 all,这意味着任何浮点值(因此所有十进制数)都是有效的输入。一个列表意味着我们,作为开发者,给用户一个预定义的允许值列表来选择。范围(文本参数不可用)允许我们设置起点和终点,起点和终点之间的所有值都有效。
在 Tableau 中创建参数
让我们看两个例子,看看何时以及如何在 Tableau 中创建一个参数。我将使用超市销售数据集,这是内置于 Tableau。第一个示例是创建一个动态目标,用户可以控制它来快速查看哪些维度高于或低于目标。
在创建参数之前,让我们通过将子类别添加到列并将销售添加到行来构建一个快速图表。现在对于参数,让我们按照这些步骤。
- 点击字段搜索栏旁边的箭头,选择创建参数。
- 将参数命名为“Para 子类别目标”
- 将数据类型改为整数。
- 将当前值更改为 5000。
- 点击确定。

当我们单击 OK 时,计算字段窗格中会出现一个名为“Parameters”的新部分在该列表中,我们应该看到 Para 子类别目标。
如果我们右击参数并选择显示参数,参数控制部分出现在左侧。它将生成一个类似于过滤器的框,标题为“Para 子类别目标”,值为 5000。


参数本身是没有帮助的,所以我们必须采取第二步,将它们添加到我们的可视化或者计算字段中。例如,如果您在参数控件中键入 6000,我们的条形图不会发生任何变化。让我们将这个参数添加到图表中。
- 在字段列表的顶部,有一个将窗格更改为“分析”的选项
- 在“数据分析”面板中,将参考线拖到图表上。
- 对于数值,从参数中选择,并选择参数子类别目标。
- 点击下方的填充,选择红色。
这样,我们就有了一个动态目标,我们可以很容易地看到哪些子类别表现不佳。



参数的另一个常见用例是作为动态维度互换器,这是一个根据用户输入改变图表维度的参数。让我们创建第二个参数。这个将被称为“对位维度互换”
- 对于第二个参数,将类型设置为字符串。
- 把它做成一个列表。
- 在列表中,每一行输入以下内容:子类别、地区、州。
- 点击确定。
- 创建如下所示的计算字段:

现在,我们可以将新的计算字段拖到图表中的子类别维度上。如果我们右键单击我们的 Para Dimension Swap 参数并单击 Show Parameter ,我们可以让数据消费者选择他们如何查看该图表。当然,由于原始参数仍然存在,我们还可以在进行分析时调整目标参考线。

使用 Tableau 参数
我们刚刚探索了实现 Tableau 参数的两个介绍性示例,但是用例是无穷无尽的。掌握 Tableau 参数可以彻底改变 Tableau 开发体验,并在我们为用户创建定制的数据消费体验时打开一个充满可能性的世界。
随着我们获得参数方面的经验,我们可以尝试诸如测量交换、尺寸突出显示和页面交换等概念。一旦我们感到非常自信,我们就可以在仪表板上包含参数操作,这本身就非常强大。
现在,拿出你最喜欢的工作簿,尝试一些你自己的参数!
如果你想了解这个主题的更多信息,请查看 Dataquest 的 Tableau Path 中的交互式数据可视化,它将帮助你在大约 2 个月内掌握这些技能。
数据工程师、数据分析师、数据科学家—有什么区别?
原文:https://www.dataquest.io/blog/data-analyst-data-scientist-data-engineer/
April 12, 2021
数据工程师、数据分析师和数据科学家——当人们谈论快速发展的数据科学领域时,你会经常听到一起提到这些职位。
在数据科学和数据分析领域也有很多其他的头衔。但是在这里,我们要讨论的是:
- “三巨头”角色(数据分析师、数据科学家和数据工程师)
- 他们彼此如何不同
- 哪个角色最适合你
**尽管这些角色的确切定义因公司而异,但作为数据分析师、数据科学家或数据工程师,您每天可能要做的事情有很大的不同。
我们将更深入地探讨这些具体角色。
什么是数据分析师?
数据分析师通过获取数据、使用数据回答问题以及交流结果来帮助制定业务决策,从而为公司带来价值。
数据分析师完成的常见任务包括数据清理、执行分析和创建数据可视化。
根据行业的不同,数据分析师可能会有不同的头衔(例如,业务分析师、业务智能分析师、运营分析师、数据库分析师)。无论头衔如何,数据分析师都是多面手,能够适应多种角色和团队,帮助他人做出更好的数据驱动型决策。
数据分析师是做什么的?
数据分析师有潜力将传统业务转变为数据驱动型业务。他们的核心职责是帮助他人跟踪进度,并优化自己的工作重点。
营销人员如何利用分析数据来帮助开展下一次营销活动?销售代表如何更好地确定目标人群?首席执行官如何更好地理解最近公司增长背后的深层原因?这些 都是数据分析师通过执行分析和展示结果来提供答案的问题。
虽然通常数据分析师职位都是“入门级”职位,但在更广泛的数据领域, 并非所有分析师都是初级水平。作为掌握技术工具的有效沟通者,数据分析师对于技术和业务团队分离的公司至关重要。
一名高效的数据分析师将消除业务决策中的猜测,并帮助整个组织蓬勃发展。数据分析师必须成为不同团队之间的有效桥梁,分析新数据,组合不同的报告,并翻译结果。反过来,这使得组织能够保持对其增长的准确的脉搏检查。
所需技能的性质将取决于公司的具体需求,但这些是一些常见的任务:
- 清理和组织原始数据。
- 唱描述性统计来获得他们数据的大图。
- 分析数据中发现的有趣趋势。T3
- 创建可视化和仪表盘,帮助公司解读数据并做出决策。T3
- 向业务客户或内部团队展示技术分析的结果 l。
数据分析师为组织的技术和非技术层面都带来了巨大的价值。无论是运行探索性分析还是解释执行仪表板,分析师都在团队之间培养更好的联系。
数据分析师赚多少钱?
作为“三大”数据职位中最初级的职位,数据分析师的收入通常低于数据科学家或数据分析师。根据 Indeed.com 截至 2021 年 4 月 6 日的数据,美国数据分析师的平均工资为72,945 美元,外加 2500 美元的年度奖金。
然而,顶级公司中经验丰富的数据分析师可以赚得更多。脸书和 Target 等公司的高级数据分析师报告称,截至 2021 年 4 月,他们的薪酬约为 13 万美元。
数据角色,包括数据分析师角色,有时也会有股票期权和其他非工资报酬。
你觉得听起来有趣吗? 开始学习我们的数据分析师职业道路:
Data Analyst in PythonData Analyst in R **## 什么是数据科学家?
数据科学家是应用他们在统计和构建机器学习模型方面的专业知识来进行预测和回答关键业务问题的专家。
数据科学家仍然需要能够清理、分析和可视化数据,就像数据分析师一样。然而,数据科学家将在这些技能方面具有更多深度和专业知识,并且还将能够训练和优化机器学习模型。
数据科学家做什么?
数据科学家是一个可以通过解决更多开放式问题和利用他们的高级统计和算法知识来提供巨大价值的人。如果分析师专注于从过去和现在的角度理解数据,那么科学家专注于对未来做出可靠的预测。
数据科学家将通过对他们的机器学习模型利用监督(例如分类、回归)和非监督学习(例如聚类、神经网络、异常检测)方法来揭示隐藏的见解。他们本质上是在训练数学模型,这将使他们能够更好地识别模式并得出准确的预测。
以下是数据科学家的工作示例:
- 评估统计模型以确定分析的有效性。
- 利用机器学习建立更好的预测算法。
- 测试并不断提高机器学习模型的准确性。
- 构建数据可视化以总结高级分析的结论。
数据科学家带来了理解数据的全新方法和视角。虽然分析师可能能够描述趋势并将结果转化为商业术语,但科学家会提出新的问题,并能够基于新数据建立模型进行预测。
数据科学家赚多少钱?
数据科学的薪资差别很大,因为职位本身因公司而异。根据 Indeed.com 截至 2021 年 4 月 6 日的数据,美国数据科学家的平均工资为 121,050 美元(T2)。
顶级公司中经验丰富的数据科学家可以赚得更多。Twitter 等公司的高级数据分析师报告称,截至 2021 年 4 月,薪酬约为 17.8 万美元。
专注于建立机器学习技能的数据科学家也可以看看机器学习工程师角色,截至 2021 年 4 月,这些角色在美国的平均年薪为 149,924 美元。
你觉得怎么样?开始学习我们的数据科学家职业道路:
什么是数据工程师?
数据工程师构建并优化允许数据科学家和分析师执行其工作的系统。
每个公司都依赖于其数据的准确性,并且需要使用数据的个人可以访问这些数据。数据工程师确保任何数据都被正确地接收、转换、存储并可供其他用户访问。
数据工程师是做什么的?
数据工程师为数据分析师和科学家奠定基础。数据工程师负责构建数据管道,通常需要使用复杂的工具和技术来处理大规模数据。与前两条职业道路不同,数据工程更倾向于软件开发技能。
在大型组织中,数据工程师可能有不同的关注点,例如利用数据工具、维护数据库以及创建和管理数据管道。无论关注点是什么,好的数据工程师都允许数据科学家或分析师专注于解决分析问题,而不是将数据从一个来源转移到另一个来源。
数据工程师的思维方式通常更侧重于构建和优化。以下是数据工程师可能从事的任务示例:
- 构建用于数据消费的 API。
- 将外部或新数据集整合到现有数据管道中。
- 对新数据应用机器学习模型的特征变换。
- 持续监控和测试系统,以确保优化性能。
数据工程师挣多少钱?
数据工程师目前非常抢手,因此他们的平均工资是三个职位中最高的。根据 Indeed.com 截至 2021 年 4 月 7 日的数据,美国数据工程师的平均工资为130,287 美元,外加 5000 美元的年度奖金。
顶级公司的经验丰富的数据工程师可以赚得更多。例如,网飞公司的高级数据工程师报告说,截至 2021 年 4 月,他们的年薪超过 30 万美元。
开始在数据工程师职业道路上学习:
小测验:哪个角色最适合你?
下面,我们制作了一个包含四个问题的快速测验,帮助您了解哪种角色最适合您:
希望这个测验能让你知道你想从哪里开始你的数据科学行业之旅。
如果你没有得到你想要的答案,不要担心——这只是一个快速测验,三种工作角色所需的技能和任务之间有很多重叠!
数据分析师对数据科学家对数据工程师这个问题的真正答案只有你能回答。毕竟是你的事业!
你的数据驱动的职业道路
现在我们已经探索了这三个数据驱动的职业,问题仍然是-你适合哪里?你已经参加了我们的测验,但是让我们更深入地看看你如何真正决定什么是最适合你的。
关键是要理解这是三种根本不同的数据处理方式。
数据工程师在后端工作,不断改进数据管道,以确保组织所依赖的数据是准确和可用的。他们将利用各种不同的工具来确保数据得到正确处理,并且任何需要的人都可以获得正确的数据。
一个好的数据工程师可以为组织的其他人节省大量的时间和精力。
然后,数据分析师可以使用工程师构建的自定义 API 提取新的数据集,并开始识别该数据中有趣的趋势,并对异常进行分析。分析师将以清晰的方式总结和展示他们的结果,让非技术团队成员理解分析的含义。
最后,数据科学家可能会基于分析师的初步发现和研究来获得更深入的见解。无论是通过训练机器学习模型还是通过运行高级统计分析,数据科学家都将提供一个全新的视角,不仅可以了解过去发生的事情,还可以了解在不久的将来可能发生的事情。
不管你的具体道路是什么,好奇心是这三种职业的自然前提。利用数据提出更好的问题和进行更精确的实验的能力是数据驱动职业的全部目的。此外,数据科学领域在不断发展,因此非常需要不断学习更多知识。
在data quest处,我们为那些有兴趣追求 数据工程师 、d ata 分析师或数据科学家角色的人提供了教育途径。注册并开始免费了解更多关于这些职位的信息!
和 所有现在和未来的数据分析师、科学家和工程师——祝你们好运,继续学习!
知道你对哪份工作最感兴趣吗?
点击下面的按钮查看每个角色的完整学习路径,然后立即开始学习!
Data Analyst in PythonData Analyst in RData Scientist in PythonData Engineer******
2023 年面向初学者的 20 个有趣(且独特)的数据分析师项目
原文:https://www.dataquest.io/blog/data-analyst-projects-for-beginners/
December 5, 2022
如果说数据是新的石油,那么由此衍生的洞察就是提炼出来的产品!随着越来越多的组织愿意从他们的数据中提取见解,对合格数据分析师的需求也在持续增长——不仅是可用职位的数量,还包括现有的种数据分析师工作。
如果你曾经想过从事数据分析师的职业,如果你现在就获得必要的技能,未来会有很多机会。
在本文中,我们将与您分享 20 个面向初学者的数据分析项目,您可以用它们来构建自己的投资组合。您的数据分析组合将帮助您向潜在的招聘人员展示您的技能,并脱颖而出。
这些项目将涵盖最受欢迎的数据分析技能和最常用的数据分析工具。即:
- 微软优越试算表
- 结构化查询语言
- 计算机编程语言
- 稀有
- (舞台上由人扮的)静态画面
- 功率 BI
1.构建 Excel 呼叫中心仪表板
Microsoft Excel(或 Excel)电子表格已经存在了 30 多年,现在仍然是学习数据的一个很好的工具。许多组织继续使用 Excel 电子表格处理日常任务。由于 Excel 是一种广泛使用的数据分析工具,数据分析师应具备出色的 Excel 技能。Excel 可用于清理、存储、分析、建模、可视化和生成数据报告。Excel 的功能可以通过外接程序进行扩展,以执行更高级的分析。用于复杂统计和工程分析的分析工具箱插件只是一个例子。
在这个使用 Excel 的 data analyst 项目中,您将学习如何在 Excel 中预处理数据并将它们更改为您喜欢的数据类型。此外,您将学习如何创建数据透视表,并从它们构建图表和地图。此外,您将学习如何设计仪表板的结构和背景,以及如何将图表和地图插入仪表板。最后,您将学习如何使用过滤功能和切片器来使您的仪表板具有交互性。
以下是指向此项目的教程和数据集的链接:
Excel 是一个强大的工具,可用于高级数据分析。在我们的使用 Excel 分析数据技能路径中学习高级数据透视表技术、预测、建模、可视化等,并在 Excel 中从初学者迈向高级。
2.使用 SQL 回答业务问题
Excel 是一个很棒的应用程序,但它有局限性。它不能处理非常大的数据集,数据争论和分析很容易变成一项痛苦的工作。
结构化查询语言(SQL)克服了 Excel 的这些局限性。SQL 可以用来连接关系数据库中的几个表,以获得一个非常大的数据集。使用 SQL 执行数据争论和分析也非常容易和快速。
SQL 是最受欢迎的数据分析技能,出现在百分之六十一的数据分析师职位发布中。
在本项目中,您将通过回答在 Jupyter notebook 上运行 SQL 查询的几个业务问题来学习和练习 SQL 数据分析工作流。您将学习如何读取和使用数据库模式,以及如何查询数据库以连接表并从中返回特定信息。
奇努克唱片店正与一家唱片公司合作。通过分析确定美国最受欢迎的流派,帮助他们决定投资哪些艺术家。然后,通过按国家分析销售情况,帮助唱片店识别美国以外的机会。执行数据分析,以帮助 Chinook 唱片店了解其销售员工的表现,并帮助他们决定是否投资专辑或个人曲目。
以下是该项目的源代码、说明和数据库的链接:
您可以使用我们精选的 10 个有趣的 SQL 项目来帮助您获得更多实践。
SQL 知识是一项基本的数据分析技能,你可以在大多数数据分析师的招聘信息中找到。通过我们的 SQL 基础知识技能途径,深入学习 SQL 编程,获得作为数据分析师取得成功所需的技能。
3.使用 SQL 进行客户和产品分析
在前一个项目中,您在一个 Jupyter 笔记本上运行了 SQL 查询。Jupyter 笔记本在完成数据项目方面非常受欢迎,因为它们允许您在一个地方创建和共享包含代码、等式、文本和可视化的文档。其他时候,您可能会在 SQL 集成开发环境(IDE)中工作,如 DB Browser for SQLite 和 MySQL Workbench。
在这个数据分析项目中,您将学习如何使用 DB Browser for SQLite IDE 在您的机器上运行查询。您将探索比例模型汽车销售数据库。您将编写查询来分析产品性能并设计补货策略。你将分析你的客户的行为和消费习惯,并设计一个定制的营销和沟通策略,最大限度地提高客户的终身价值和最小化营销成本。
以下是该项目的源代码、说明和数据库的链接:
4.使用 PostgreSQL 建立犯罪报告数据库
您已经在以前的 SQL 项目中使用 SQLite 数据库引擎练习了 SQL 编程。SQLite 是世界上最常用的数据库引擎之一。它是轻量级的,不需要服务器来运行。这些特性使得它非常受移动应用程序的欢迎。
SQLite 是一个简单的数据库引擎,有并发限制。任何时候只有一个人可以对数据库进行更改,这限制了多次访问。PostgreSQL 解决了 SQLite 数据库引擎的并发写入限制。
在这个数据分析项目中,您将学习如何使用 PostgreSQL 构建存储数据的数据库。您将从设计数据库模式和表开始。此后,您将学习如何将数据从 CSV 文件加载到数据库表中。接下来,您将学习如何按照最小特权原则为每个用户组设置特权。最后,您将通过运行和分析 SQL 查询的输出来测试您的数据库设置。
以下是该项目的源代码、指令和数据的链接:
您可以在这里找到我们列出的其他 SQL 项目。探索并完成这些项目,让您的 SQL 技能更上一层楼。
5.分析维基百科页面
到目前为止,您已经使用了 Excel 和数据库文件。您的数据还可以以其他文件格式输入。让我们假设您的数据可以在互联网上的几个网页上找到。你可以从网站上获取数据,也可以将网页保存为 HTML 格式。
在这个项目中,你将学习如何使用从维基百科页面保存的数据分析 HTML 文档。您将了解如何通过删除页眉、页脚和无关的标记来清理数据。使用 BeautifulSoup 库,您将学习如何使用特定的标签从 HTML 页面中提取数据。最后,您将学习如何清理和分析从每个 HTML 文档中提取的数据。
以下是该项目的源代码和说明的链接:
6.Python 中的网络抓取 NBA 统计数据
没有数据,就没有数据分析。数据是数据分析项目的生命线。有时,我们项目所需的数据可能没有现成的。我们需要从互联网上的网站收集数据。
Web 抓取是从网页获取数据的过程。这是一项无价的数据收集技能,它将优秀的数据分析师与伟大的数据分析师区分开来。雇主会感到放心,你有必要的技能来收集你的项目所需的必要数据。
在这个数据分析项目中,您将学习如何从几个网页中抓取数据。您将学习如何使用 requests 和 selenium 库进行 web 抓取。接下来,您将学习如何检查网页上的元素,将 HTML 文档解析到 BeautifulSoup 库,以及从特定的标签中提取数据。您将把数据加载到 pandas 数据框架中,并将其保存为 CSV 文件,以便在分析中使用。
以下是该项目的源代码和视频教程的链接:
探索我们的英格兰超级联赛项目的网络抓取足球比赛以获得实践。
网络抓取是任何数据分析师工具箱中的一项重要技能。我们推荐我们的 API 和 Python 中的网络抓取课程来帮助您入门。
7.用 Python 和熊猫清理 NBA 统计数据
真实世界的数据和从互联网上搜集的数据并不干净。它们需要预处理,以便将它们转换成统计、机器学习和可视化库可以处理的格式。
这个项目是前一个项目的延续。在这里,您将使用 CSV 文件,其中包含您从几个网页中搜集的数据。使用 pandas 库,您将了解如何从数据中移除无关字符、处理缺失值、将要素转换为适当的数据类型、从每个数据框中选择所需的要素子集以及合并它们。在项目结束时,您将有准备好用于机器学习和统计分析的预处理数据。
以下是该项目的源代码和视频教程的链接:
作为数据分析师,您将花费大部分时间清理和预处理数据。参加我们的Python 中的数据清理技能课程,学习高效清理、转换和可视化数据的技能。
8.寻找最佳广告市场
掌握 Excel 和 SQL 之后,数据分析师必须添加到工具箱中的下一个最重要的工具是编程语言知识。Python 和 R 是最流行的数据分析编程语言。
编程语言只是完成数据分析工作的工具。我们在 Python 和 r 之间没有偏好,你可以在我们的平台上学习两者。这篇文章对 R 和 Python 进行了客观的比较,帮助你决定应该学习哪一个。
统计知识被列为雇主希望数据分析师展示的 8 项数据分析技能之一。因此,有抱负的数据分析师必须能够用一种或多种编程语言进行统计分析。
在这个数据分析项目中,您将使用 Python 编程语言来执行概率和统计分析,以帮助一家电子学习公司找到宣传其编程课程的最佳市场。
您将执行描述性统计-估计平均值、中值、众数、方差和频率分布-以更好地理解您的数据。
您还将通过调查公司的潜在客户的位置、密度和消费能力来进行说明性统计。在这个过程中,您将学习如何处理异常值,这些异常值会不成比例地影响和扭曲您的规范分析的结果。
不处理异常值会导致误导性的解释。如果有人根据你的误导性结果采取行动,结果通常是可怕的——例如,招致经济损失。你也损害了你作为一个称职的数据分析师的声誉。
最后,你将根据你的统计分析结果推荐这家电子学习公司应该做广告的市场。
以下是该项目的源代码、指令和数据的链接:
拓宽您的概率和统计知识,并在我们的概率和统计与 Python 技能路径中找到其他有趣的项目。
9.彩票瘾手机 App
许多统计和机器学习概念是使用一些概率的基础知识来实现的。概率和统计知识是数据分析师所需的核心技能,这并不奇怪。
在这个项目中,我们将通过调查彩票中奖的几率来深入了解概率世界。您将帮助一家专门治疗赌丨博成瘾的医疗机构开发其移动应用程序的逻辑。这个移动应用程序将帮助人们更好地估计他们赢得彩票的机会。您将使用概率论来估计一张或多张彩票赢得累积奖金的几率,以及匹配号码在 2 到 5 之间的小额奖金的几率。
以下是该项目的源代码和说明的链接:
10.用 Python 构建电影推荐系统
推荐系统在互联网上无处不在。当网飞推荐一个电视节目或者亚马逊建议你买一本书时,一个推荐系统正在幕后工作。它们属于自然语言处理领域(NLP)——机器学习的一个子领域。
作为一名数据分析师,你可能会发现自己在构建推荐系统,因为它们被广泛使用。从头开始构建这个系统以了解它们是如何工作的非常重要。
在这个数据分析项目中,您将使用 MovieLens 数据集构建一个电影推荐系统。您将把数据集加载到 pandas 数据框架中,并使用正则表达式执行元素清理操作。
机器学习算法不能很好地处理文本数据。我们必须找到一种用数字表示文本的方法。您将了解如何使用文本矢量化算法术语频率-逆密度频率(TF-IDF)来给出文本数据的数字表示。接下来,您将学习如何使用余弦相似性距离度量来评估相似性得分。最后,您将构建一个交互式仪表板来输出您的结果。
以下是源代码和视频教程的链接:
作为数据分析师,您的日常工作将涉及预测分析。机器学习的知识会让你更好地执行这些任务。我们推荐我们的 Python 中的中级机器学习技能路径,以提高您的预测建模技能。
11.预测 NBA MVP
预测分析是数据分析师日常工作的一部分。有多少预测分析任务,就有多少机器学习算法。我们将使用项目 7 的 NBA 统计数据探索更多用于预测分析任务的机器学习算法。
在这个项目中,我们将使用 NBA 统计数据来预测 NBA 中最有价值的球员(MVP)。我们将使用岭回归和随机森林回归算法。首先,我们将 CSV 文件加载到 pandas 数据框架中,清理并转换特征。接下来,我们将学习如何选择预测器来防止数据泄漏——机器学习中的主要问题之一。
接下来,我们将训练我们的回归算法,并选择适当的指标来评估模型性能。最后,我们将创建一个回溯测试来验证我们的模型在一段时间内的性能。
以下是该项目的源代码、视频教程和数据的链接:
12.用 R 分析电影分级
关于哪种编程语言最适合数据科学和分析,一直存在争论。尽管 Python 是最受欢迎的编程语言,但 R 针对统计分析、科学计算和可视化进行了优化。
为什么要学 R?R 编程语言在许多组织中都很流行。它还有许多经过严格测试的软件包来执行数据分析任务。今年早些时候,我的团队不得不使用 R 包来完成高级计量经济学建模任务的一部分,因为我们找不到一个好的 Python 等价物。
学习 R 是值得的。
在这个项目中,您将学习如何使用 rvest 包从网页中抓取和提取数据。您还将学习 r 中如何进行数据预处理。您将解析适当数据类型的数据,删除无关字符,并处理丢失的值。最后,您将使用 ggplot 包将数据加载到 dataframe 中并可视化它们的分布。
以下是这个项目要废弃的源代码、说明和网页:
无论 R 或 Python 是您的首选语言,我们都能满足您的需求。通过注册我们的API 和 R 技能途径来完善您的 R 技能网页抓取。
13.用 R 赢得危险
作为数据分析师,你的工作可能包括调查实验结果。一家公司最近改变了它的用户界面,注意到人们花更多的时间在它的网站上。您的任务可能是调查这是否是对用户界面进行更改的结果。为了进行你的调查,你得出了无效的和可供选择的假设。然后,您测试来自数据的观察结果是否具有统计显著性,或者是否出于偶然。
在这个项目中,你将学习如何制定假设并测试它们的统计显著性。您将使用热门电视节目《危险边缘》中的数据您将测试出现在节目中的参与者是否应该专注于特定的主题领域、特定类型的问题以及具有一定货币价值的问题。
以下是该项目的源代码、说明和数据:
在我们的概率和统计与 R 技能路径中了解更多关于假设检验的信息,并找到其他很酷的统计和概率项目。
14.用 R 预测公寓销售价格
数据分析师经常发现自己在从事预测分析任务。R 编程语言也非常适合预测分析。它有许多开发良好的机器学习包。
在这个数据分析项目中,您将学习如何使用 R 机器学习包进行预测。您将处理纽约市的房产销售数据。您将对数据进行预处理和探索,以加深对数据的理解。接下来,您将执行线性回归建模来预测纽约市每个区的公寓价格,并学习如何解释模型的汇总统计数据。
以下是该项目的源代码、指令和数据的链接:
参加我们在 R 的线性回归建模和 R 的机器学习基础课程,了解更多关于 R 的机器学习预测建模
15.用 R 分析森林火灾数据
数据可视化是一项非常重要的数据分析技能。当数据以可视化方式呈现时,我们可以很容易地识别数据中的模式和趋势。数据可视化也是交流分析结果的一种非常好的方式。
R 编程语言是一个非常强大的数据可视化工具。它有许多数据可视化包,只需几行代码,我们就可以创建任何类型的可视化。
在本项目中,您将使用 ggplot 包对森林火灾数据集执行探索性数据分析。您将创建单变量和双变量图来更好地理解数据。您将学习如何使用可视化图来识别异常值。您将创建图形图来回答一些问题,如一个月中什么时候发生最多的火灾以及什么因素导致了严重的森林火灾。
以下是该项目的源代码、说明和数据的链接:
一张图表抵得上一万字。通过我们的数据可视化与 R 技能路径,获得成为成功数据分析师所需的关键数据可视化技能。
16.带表格的客户分析仪表板
数据分析师必须与他们项目的利益相关者分享他们的发现。数据可视化工具有助于数据分析师有效地交流他们的分析结果。
虽然我们可以用 Excel、R 和 Python 来可视化数据,但 Tableau 和 Power BI 等商业智能(BI)工具有其优势。它们可扩展、快速且高度集成。这些 BI 工具可以轻松地与 Excel、数据库、云存储和其他文档格式集成。他们还可以用来创建托管在其服务器上的高度交互式仪表板。只需点击一下,您就可以访问这些仪表板。
在本教程中,您将使用客户数据用 Tableau 创建可视化效果。您将学习如何:格式化 Tableau 中的列;创建地图、条形图、直方图、散点图、圆环图和蝴蝶图。并构建一个交互式仪表板。
以下是该免费 data analyst 项目的视频教程、仪表盘和数据的链接:
17.包含 Tableau 1 的 Airbnb 仪表板
熟能生巧。我们将使用纽约市各区的 Airbnb 数据对 Tableau 进行更具描述性的分析。这个项目是双重的。在项目的这一部分,您将把列转换为适当的数据类型,并深入研究地理要素的可视化。
在项目结束时,你将根据 Airbnb 公寓的邮政编码,创建一个 Airbnb 公寓平均租赁价格的地图,以及评级和床位可用性最高的地区的水平条形图。
以下是该免费 data analyst 项目的视频教程、仪表盘和数据的链接:
18.Airbnb 仪表板和 Tableau 2
在项目的这一部分,我们将制作一个时间序列图来分析平均租赁价格的变化。您将学习图表格式化技术,这将使您能够创建准确传达结果的可视化效果。接下来,您将学习如何使用您创建的所有图表设计仪表板,以及如何使用过滤器使仪表板具有交互性。
以下是该免费 data analyst 项目的视频教程、仪表盘和数据的链接:
能够很好地交流您的结果是一项至关重要的数据分析技能。在我们的数据可视化与 Tableau 技能路径中,获得识别数据模式和趋势以及通过可视化交流分析结果所需的技能。
19.Domino's Pizza 的 Power BI 报告和仪表板
Power BI 是微软开发的商业智能工具。这是一个受欢迎的数据可视化工具,数据分析师使用它来交流他们对数据的见解。大多数组织都使用微软产品。使用 Power BI 的优势之一是易于与其他 Microsoft office 产品和服务集成。
在本项目中,您将使用 Domino's Pizza 销售数据创建一个 Power BI 报告和仪表板。您将学习如何将数据导入 Power BI,将列转换为适当的数据类型,并删除不需要的列。接下来,您将学习如何管理关系并使用 Power BI 的数据分析表达式(DAX)来执行计算。然后,您将学习如何在 Power BI 中创建仪表板和生成报告。
以下是 Power BI 免费 data analyst 项目的教程和数据链接:
20.Zomato 销售仪表板,带 Power BI
这是另一个加强你技能的 Power BI 项目。在本项目中,您将担任一名客户的数据分析师,该客户希望在班加罗尔市建立一家餐馆。您将创建一个交互式仪表板,使客户能够做出明智的决策,最大限度地提高盈利能力。您的仪表板将帮助客户选择餐厅类型、首选位置和菜肴。仪表板将告诉客户平均盈利能力和客户支出,并帮助他们识别潜在的竞争。
以下是该免费 data analyst 项目的视频教程和数据的链接:
通过参加我们的使用 Microsoft Power BI 分析数据技能途径,增强您在 Power BI 中的数据分析和可视化技能。本课程是与微软合作开发的,包含通过 PL-300 微软 Power BI 分析师认证考试所需的全部内容。
外卖食品
在本文中,我们讨论了 20 个有趣的数据分析师项目,涵盖了数据分析师应该具备的技能和工具。这些项目是您的数据分析师组合的必备项目,因为它们向招聘人员展示了您拥有成功成为数据分析师所需的技能。
数据分析职业正在扩展,有种不同的分析师角色。如果你是数据分析新手,还没有学习基础知识,我们推荐我们的用 Excel 分析数据、 SQL 技能、用于数据分析的 Python 基础知识,以及用 Tableau 实现数据可视化的技能路径。你将学到最受欢迎的技能,以获得你作为分析师的第一份工作。
学习实用的 Excel、SQL 和 Power BI 技能,并通过我们的业务分析师职业道路成为一名业务分析师。编程语言的知识将使你的数据分析技能更上一层楼。我们建议有抱负的数据分析师报名参加我们的Python 数据分析师和R职业道路数据分析师。
随着您在分析师职业生涯中的进步,您将担任不同的数据分析角色并使用不同的工具。在本文中,我们讨论了跨越数据分析师所需技能范围的数据分析项目。正如他们所说的,“运气就是当准备遇到机遇时发生的事情。”完成这些投资组合项目,加入我们的职业和技能计划,最大限度地提高您获得任何数据分析职位的机会。
2022 年雇主需要看到的 8 项数据分析师技能
June 27, 2022
什么是数据分析师?
数据分析师是使用技术技能来分析数据和报告见解的人。
在典型的一天中,数据分析师可能会使用以下技能:
- 从数据库中提取数据的 SQL 技能
- 分析这些数据的编程技巧
- 报告调查结果的沟通技巧
然而,哪种技能对获得数据分析工作最重要?为了回答这个问题,我们进行了许多小时的研究,包括采访数据分析师、数据科学家和招聘经理。
这是我们学到的。
数据分析师需要哪些技能?
因为您将使用的数据科学工具因角色、公司或行业而异,所以我们学会了关注技能而不是工具(如 Python、R、SQL、Excel、Tableau、Power BI 等)。).
以下是作为数据分析师你需要做的事情(不是如何做)。
以下是八项最重要的数据分析师技能:
- 数据清理和准备
- 数据分析和探索
- 统计知识
- 创建数据可视化
- 创建仪表板和报告
- 写作和交流
- 领域知识
- 问题解决
下面是对每一个问题的解释。。。
1:数据清理和准备
研究表明数据清理和准备将占大多数数据专业人员工作的 80%。这意味着这项技能至关重要。
数据分析师通常需要从一个或多个来源检索数据,并为数字和分类分析做准备。数据清理还包括解决可能影响分析的缺失和不一致的数据。
在数据分析中,数据清理并不总是令人兴奋的,但是当被视为解决问题的练习时,准备数据可能是有趣且具有挑战性的。
对这个技能感兴趣?查看我们对初学者友好的数据清理课程。
2:数据分析和探索
在一系列必需的数据分析师技能中提到“数据分析”可能听起来很奇怪,但是分析作为一项特定的技能是必要的。
从根本上来说,数据分析包括获取业务问题或需求,并分析相关数据以得出该问题的答案。
数据分析的另一种形式是探索。数据探索包括在数据中寻找可能给企业带来价值的有趣趋势或关系。
一个业务问题可能会引导探索,但它也可能是相对无指导的。通过寻找数据中的模式,您可能会偶然发现企业降低成本或加快增长的机会。
对这个技能感兴趣?查看我们的数据分析师课程列表。
3:统计知识
概率和统计是重要的数据分析师技能。这些知识将指导你的分析和探索,并帮助你破译数据。
此外,理解统计学也将帮助你确保你的分析是有效的,它将帮助你避免常见的谬误和逻辑错误。
所需的统计知识的确切水平将根据您特定角色的需求和您正在处理的数据而有所不同。
例如,如果你的公司依赖于概率分析,你会希望对这些领域有一个比你原本需要的更严格的理解。
对这种数据分析技能感兴趣?查看我们的概率和统计课程。
4:创建数据可视化
数据可视化阐明了数据趋势和模式。人类是视觉动物——这意味着大多数人理解图表或图形的速度要比理解电子表格的速度快。
这意味着创建干净、视觉上引人注目的图表,帮助他人理解你的发现。这也意味着要避免那些难以解释的东西(比如饼图)或者可能误导人的东西(比如操纵轴值)。
可视化也是数据探索的一个重要部分。有时候,当你只看数字时,你可以在数据中直观地看到隐藏的东西。

(图像来源
很难找到一个不需要数据可视化的数据科学角色,这使它成为一项关键的数据分析师技能。
对这个技能感兴趣?查看我们的数据可视化课程。
5:创建仪表板和报表
作为数据分析师,您需要授权他人使用数据做出关键决策。通过构建仪表板和报告,您可以消除技术障碍,让其他人访问重要数据。
这可能是一个简单的图表和带有日期过滤器的表格,也可能是一个包含数百个交互式数据点的复杂仪表板。
不同职位的工作描述和要求可能会有所不同,但几乎每个数据分析师的工作都将涉及到根据您的发现生成报告或构建仪表板来展示这些报告。
对这个技能感兴趣?通过我们的 Power BI 课程了解如何创建仪表盘和报告。
6:写作和交流
以多种格式交流的能力是数据分析师的另一项关键技能。写作、说话、解释和倾听都是沟通技巧,有助于你在任何数据分析工作中取得成功。
与同事合作时,沟通是关键。例如,在与业务利益相关者的动员会上,仔细的倾听技巧有助于你理解他们需要的分析。
同样,在你的项目中,你可能需要能够向非技术团队成员解释一个复杂的主题。
书面交流也非常重要——尤其是当你在写分析总结或解释数据探索中的发现时。
清晰而直接的沟通是一项技能,它将推动你在数据领域的职业发展。它可能是一种“软”技能,但不要低估它。
如果你不能解释它们的含义,如果你不能说服你的同事根据你的发现采取行动,那么世界上最好的分析技巧也是毫无价值的。
7:领域知识
领域知识是理解你工作的行业和公司的特定主题。
例如,如果你在一家有网上商店的公司工作,你可能需要了解电子商务的细微差别。
相比之下,如果你正在分析关于机械系统的数据,你可能需要理解那些特定的系统是如何工作的。
无论你在哪里工作,如果你不明白你在分析什么,这将使你的工作变得更加困难。
这当然是你可以在工作中学到的东西。然而,如果你知道你想从事的特定行业或领域,那么尽可能多地提前了解会让你成为一个更有吸引力的求职者——一旦你得到工作,也会成为一个更有效率的员工。
8:解决问题
作为一名数据分析师,你每天都会遇到问题、错误和障碍。作为一名数据分析师,能够解决问题是另一项很有价值的关键技能。
以下是一些潜在的场景:
-
你可能需要研究你正在使用的软件或编码语言的特点。
-
你的公司可能有资源限制,迫使你创新解决问题的方式。
-
您使用的数据可能不完整。
-
您可能需要执行一些“足够好”的分析来满足迫在眉睫的最后期限。
无论在什么情况下,强大的解决问题的技能对于任何数据分析师来说都是一笔不可思议的财富。
其他数据分析师技能
“数据分析师”的确切定义因你询问的对象而异,因此并非所有这些技能对每份数据分析师工作都是必要的。
同样,有些公司要求的技能可能不在这个清单上。我们在这里的重点是找到大多数数据分析师角色所需的一系列技能,以便为学生构建最佳的数据分析师学习路径。
被聘为数据分析师
如果你想建立成功获得数据分析师工作所需的技术技能,请查看我们的交互式在线数据分析课程。您将直接在浏览器中编写真实的代码来分析真实世界的数据。
Dataquest 独特的教学法和基于项目的学习方式将帮助您快速学习,保留概念,并增长信心。
具体来说,我们在本文中介绍的数据分析师技能是我们两条“数据分析师”学习路径的基础:
完成这些课程将改善您的数据分析师简历(和投资组合),这将有助于您作为候选人脱颖而出。您可以免费开始这两条道路,并立即开始成为数据分析师的旅程。
成为数据分析师!
立即学习成为数据分析师所需的技能。注册一个免费帐户,获得免费的交互式 Python、R 和 SQL 课程内容。
(不需要信用卡!)
11 份高薪数据分析职业(2022 年 12 月)
December 22, 2022
现在是学习数据分析并成为数据科学家的最佳时机。工作前景看好,机会横跨多个行业。工作的性质通常允许远程工作,灵活的时间表,甚至自营职业。
此外,许多数据分析专家的工资中位数很高,即使是在入门级的职位上!
劳工统计局认为数据科学是增长最快的前 20 个职业之一,并预测未来 10 年将增长 31%。
此外,数据科学领域的技能和工作机会超越了技术和数字领域。让我们看看作为一名分析师或数据科学家,你需要知道些什么,以及要达到这些目标,你需要学习些什么。
为什么选择数据分析职业?
数据分析职业之所以有吸引力,有很多实际原因。以下是几个例子:
- 高平均工资
- 技术工人的机会越来越多
- 职业发展的空间很大
然而,有几个不太明显的原因可以解释为什么从事数据分析是一个很好的选择:
- 基于解决问题的有趣的日常工作
- 技术工作和人际交流的良好结合
- 数据科学技能可以转移到许多其他职业中
- 典型的弹性工作时间和环境
- 几乎没有强制性的资格证书——技能比学位或证书更重要
- 丰富的学习资源——比以往任何时候都更容易了解到获得数据分析工作所需的一切
- 各种各样的可用机会
感兴趣吗?让我们先来看看这个领域中收入最高的工作,然后我们再来探究你需要哪些技能才能达到这个目标。
11 项使用数据分析的工作
在你开始学习一项新技能之前,你应该了解相关职位的收入潜力。
这里有几个值得研究的职位,以及它们的中值收入。
1.商业智能分析师
商业智能分析师的主要工作是从他们公司的数据中提取价值。
在大多数公司,BI 分析师需要熟练地分析数据、使用 SQL、创建数据可视化和模型。和大多数数据角色一样,这份工作也需要很强的沟通能力。
2022 年,商业智能分析师的平均年薪为 80,323 美元,外加平均 7,000 美元的现金奖励。
查看我们的 数据分析用异能匕技能路径 。
2.数据分析师
数据分析师的工作职能正如其职位所暗示的那样——分析公司和行业数据以提取价值。
数据分析师在每个行业都有工作,尽管职位名称可能会有所不同。有些角色会有特定的行业名称,如“医疗保健数据分析师”“业务分析师”、“情报分析师”和其他类似名称的角色通常与数据分析师角色重叠。
与数据科学家不同,数据分析师通常不需要精通机器学习。大多数数据分析师工作需要编程和 SQL 技能,以及统计知识、熟悉数据分析工作流程和数据可视化技能。
2022 年,数据分析师的平均工资为72443 美元/年,外加 2000 美元奖金。
如果你对数据分析师职业感兴趣,我们有一条 数据分析师职业道路 ,将带你从完全的初学者走向工作就绪。
3.数据科学家
与其他角色的分析师非常相似,数据科学家收集和分析数据,然后传达可行的见解。数据科学家通常比数据分析师高一个技术层次。他们可以从更明智的角度理解数据,以帮助做出预测。
这些职位需要很强的数据分析知识,包括软件工具、Python 或 R 等编程语言以及数据可视化技能,以交流他们的发现。
这些职位既有挑战性又有回报,平均工资为 145,145 美元。对具有技术背景的数据分析专家的需求空前高涨。
用我们的 数据科学家之路 开启你的数据科学家生涯。
4.数据工程师
数据工程师通常专注于更大的数据集,他们的工作是优化围绕不同数据分析流程的基础架构。
例如,数据工程师可能专注于捕获数据的过程,以提高采集管道的效率。他们可能还需要升级数据库基础设施以实现更快的查询。这些高级数据分析专业人员收入丰厚,平均工资与数据科学家相当,为 94,262 美元。
我们的 数据工程师之路 将带你了解开启数据工程师职业生涯所需的一切。
5.定量分析师
定量分析师是另一个非常抢手的职业,尤其是在金融公司。定量分析师使用数据分析来发现潜在的金融投资机会或风险管理问题。
他们也可能独自冒险,创建交易模型来预测股票、商品、汇率等的价格。这个行业的一些分析师甚至开始自己开公司。2022 年,量化分析师的工资中位数是 85995 美元。
想成为量化分析师?我们有 课程帮你学习数据分析 。
6.数据分析顾问
像许多这些职位一样,分析顾问的主要作用是为公司提供见解,帮助他们做出更好的决策。
虽然分析顾问可能专注于任何特定的行业或研究领域,但顾问与内部数据科学家或数据分析师之间的区别在于,顾问可能会短期为不同的公司工作。他们也可能同时为不止一家公司工作,专注于有明确目标的特定项目。
这些职位最适合那些喜欢改变的人,以及那些对某个特定研究领域有特殊兴趣的人。分析顾问经常远程工作,这是这一角色的另一个诱人之处。
不同行业的薪酬差异很大,但 87,068 美元是该职位在 2022 年的代表性薪酬。
通过我们的 数据分析 课程,开始成为数据分析顾问。
7.运营分析师
运营分析师通常在大公司内部工作,但他们也可能作为顾问工作。
运营分析师关注企业的内部流程。这可能包括内部报告系统、产品制造和分销以及一般业务运营。
对于担任这些角色的专业人员来说,具备一般的业务知识是很重要的,通常还需要具备他们正在使用的系统的技术知识。运营分析师在各种类型的企业中工作,从大型连锁杂货店到邮政服务提供商,甚至在军队中。
2022 年,运营分析师的平均年薪为 68,080 美元,平均额外现金奖励为 3,750 美元。由于数据分析工作的多面性,以及你可能找到工作的许多行业,工资可能会有很大差异。
下面是 一些课程 帮助你入门数据分析。
8.营销分析师
数字营销也依赖于数据分析。营销人员经常使用谷歌分析、定制报告工具和其他第三方网站等工具来分析网站和社交媒体广告的流量。
营销活动通常会涉及大量资金,因此营销专业人士依靠分析师做出如何利用现有资源的明智决策。
虽然数字营销人员的工资范围很广,但营销分析师的平均工资为 65,792 美元,对于高级和管理级别的职位,他们的工资可以超过六位数。
对营销分析感兴趣?我们有 课程,可以帮助 。
9.项目管理人
项目经理使用分析工具来跟踪团队的进度、效率和生产力。为此,他们至少需要对数据分析有一个实用的理解。
这些职位通常是大公司的内部职位,通常是管理咨询。
项目经理的另一个职业轨迹是产品和供应链管理,公司依靠它来保持利润率和高效运营。
在 2022 年,项目经理的典型薪资约为 73,495 美元。
想成为项目经理?我们有 课程 帮助你学习数据分析。
10.IT 系统分析师
系统分析员设计系统来解决信息技术中的问题。
这些职位所需的专业技术水平各不相同,这为行业和个人兴趣的专业化创造了机会。一些系统分析师使用现有的第三方工具来测试公司内部的软件,而其他人则通过结合数据分析和业务运营来开发新的专有工具。
2022 年,美国一名典型的 IT 系统分析师的收入约为 86,474 美元。
**### 11.运输物流专家
运输物流专家通常为亚马逊或 UPS 等大型航运公司以及海军运输公司、航空公司和城市规划办公室优化实物货物的运输。
数据分析背景对这项工作特别有帮助,因为运输物流专家需要可靠地确定产品和服务的最有效交付路径。他们必须查看大量数据,以帮助消除运输瓶颈,无论是在陆地、海上还是空中。
该行业经验丰富的专业人士年收入约为 53,653 美元,这使得运输物流成为注重细节、具有前瞻性思维的个人极具吸引力的职业道路。
想成为运输物流专员?通过我们关于数据分析的课程,了解在运输物流领域工作所需的一切。
**## 数据分析工作需要哪些技能?
这里列出的许多工作都需要同样的基本技能。在你开始找工作之前,确保你已经掌握了这些技能!
如果你发现一项你仍需要学习的技能,一门负担得起的、自定进度的数据科学课程可能正是你所需要的。从以下基础开始。
计算机编程语言
Python 是目前最常用的编程语言之一。
了解如何使用 Python 进行数据分析是许多数据科学职位的要求。但是,即使不是必需的,了解 Python 也会帮助你在潜在雇主面前脱颖而出。
如果您准备好提高您的编程语言水平,学习如何操作和分析数据,并开始 web 抓取和数据收集,当您注册我们的Python for Data Science:Fundamentals 课程时,您可以立即开始构建 web 应用程序。
结构化查询语言
使用数据源是数据分析的一个必要方面。
在职业生涯的早期,您至少需要对 SQL 有一个基本的了解。SQL 通常是这些职位的主要组成部分。当你面试时,许多招聘经理在询问你与数据库有关的工作时会提到 SQL。
您将在我们的 SQL 课程中获得的经验是一个良好的开端。像 Python 一样,SQL 是一种相对容易学习的语言。即使你是新手,一点 SQL 经验也大有帮助。
了解 SQL 的基础知识会让你有信心浏览大型数据库。一旦你有了第一份工作,你可以随时寻找机会学习更高级的 SQL 操作。
数据可视化技能
知道如何可视化数据和交流结果对求职者来说是一个巨大的优势。
在就业市场上,这些技能需求很大,而且报酬丰厚!不管你在考虑什么职业道路,能够可视化和交流与公司底线相关的见解是一项有价值的技能。
在 Dataquest,我们使用数据科学和可视化库,让学生掌握 Python 和 R 中的数据可视化技能,这将使你走上成为优秀的数据可视化者的道路。如果你想学习这个技能,可以看看我们的数据可视化技能路径。****
数据分析认证:2022 年你真的需要一个吗?
原文:https://www.dataquest.io/blog/data-analytics-certification/
September 7, 2022
我需要数据分析证书吗?如果你打算成为一名数据分析师,你无疑不止一次地问过自己这个问题。你并不孤单。
即便如此,得到一个关于数据分析师所需认证的直截了当的答案也很棘手。为什么?因为网上有几十家公司提供数据分析证书。你猜怎么着?他们都想说服你,你需要他们特定的证书项目。
见鬼,在 Dataquest,我们不仅有数据分析课程,还有授予证书的完整的数据分析师职业道路!
但是我们和其他公司的不同之处在于我们处理的是事实。所以,这就是:不,你不需要证书就能得到一份数据分析师的工作。
现在,这并不意味着数据分析认证项目没有价值。但这确实意味着你需要仔细考虑你的投资。这是因为证书本身——实际的一张纸和/或数字徽章——可能几乎没有价值。
在本文中,我们将讨论不同的数据分析证书计划以及如何评估它们。但首先,我们来解释一下为什么认证本身对你没有帮助。
为什么雇主不关心数据分析证书
当我为 Dataquest 的数据科学职业指南做研究时,我花了很多时间与业内人士交谈。我特别问他们,怎样才算是一名优秀的入门级数据分析师候选人。
事实上,我有将近 200 页的高级数据科学家、招聘经理和招聘人员的采访记录。
你知道什么词在那 200 页里从未出现过吗?认证。
原因很简单。
证书并不能很好地预测工作的成功
从雇主的角度来看,专业证书意义不大。它当然不能预测一个人在实际工作中的效率。
在数据分析领域尤其如此,因为很少有认证项目需要大量的实际数据工作。
以 MOOC 平台课程为例。它们通常由一系列视频讲座组成,中间穿插着选择题和填空题。他们最后可能会也可能不会有一个“顶点”项目。
最好的情况?简历上的专业证书意味着申请人完成了一个数据分析项目。这根本不够。
例如,这里有一个来自一个真实的 IBM/Coursera MOOC 的关于数据技能的样本问题:

Probably not.
从雇主的角度想象一下。能够回答这种问题是否证明申请人知道如何实际使用这个算法?肯定不是。
专业证书从哪里来很重要吗?
有些认证项目比其他项目更严格。但这对雇主来说无关紧要。
当招聘经理看你的简历时,你有大约 7 秒钟的时间来引起他们的注意。他们不会浪费时间去判断你选择的特定数据分析证书课程是否有用。
值得一提的是,品牌在这里也无关紧要。简历上的 T2 大学学位会给招聘人员留下深刻印象。但是一个大学认证?雇主们很清楚这是非常不同的事情。通常,大学品牌的证书课程甚至不是由学校运作的!
做什么雇主希望在数据分析师的简历上看到什么?
*如果一个证书项目不重要,那么什么才重要呢?说到数据科学和数据分析简历,要包含的最重要的是你能做实际工作的证明。
有相关工作经验者优先。
如果你正在寻找你在这个领域的第一份工作,你不会得到它。没关系!你可以用另一种方式证明你已经完成了工作:通过专业作品集展示你的数据分析项目。
有了 Dataquest ,学生们有机会在每门课程结束时创建有价值的项目组合。这样,你就有相关的工作可以向雇主炫耀。这比一周中任何一天的证书都要好!
例如,在我们的数据分析师路径中,学生将完成以下项目:
- 为彩票瘾打造手机 app
- 用朴素贝叶斯构建垃圾邮件过滤器
- 分析一组危险问题并发现获胜策略
- 使用可视化技术绘制欧元兑美元汇率的演变图
- 用 Jupyter 笔记本分析星战迷
- 分析 Fandango 电影评分的准确性
- 还有其他 14 个人!
这里可以免费报名。您将在几分钟内编写代码。
数据分析认证没用吗?
以上并不意味着认证项目对有抱负的数据分析师毫无用处。这只是意味着你需要评估他们,要知道你选择的证书品牌可能不会帮你找到工作。
对你找工作有帮助的是你在项目过程中学到的技能。所以,确保你选择了一个内容丰富的项目,你可以从中学习!
此外,重要的是要注意,虽然证书可能不会对你的求职有所帮助,但它们也不会对你的机会造成损害。大多数雇主会直接忽略它们。但也有一些招聘人员将证书视为求职者积极学习和进步的标志。
如何评估认证项目
你能从任何认证项目中获得的最重要的东西是你学到的技能。要问的重要问题包括:
- 这个项目是如何教学的?它使用视频讲座吗?互动编码课?面授课程?每个人学习的方式不同,但是科学表明实践越多的教学方法越好。
- 这个节目教什么?它是否足够深入地涵盖了最重要的数据分析师技能,比如数据可视化和 SQL?还是把时间浪费在非必需品上,比如机器学习?如果你还没有统计学知识,找一个涵盖基本统计学的程序也很重要。
4 选择认证计划时需要考虑的更多因素
做出决定时需要考虑的其他重要因素包括:
-
费用—认证项目的费用从几百美元到数万美元不等!你的投资能有什么样的回报?
-
时间要求 —有些认证项目,比如 Dataquest,是自助的。这意味着你可以在方便的时候开始学习,想多快就多快,想多慢就多慢。其他的是基于群体的和时间敏感的——例如,你可能只能在一年中的特定时间开始上课。或者,您可能只能在一天中的特定时间参加直播课程。
-
先决条件 —一些项目要求特定的学位、先前的经验和/或课程。
-
第三方评论 —任何一个还算过得去的营销团队都可以写满五星评论的登陆页面。但是,真正的学习者对数据分析认证计划有什么看法呢?像 Switchup 、 G2 和课程报告这样的第三方评论网站都是做一些研究的好地方。
如果有疑问,请尝试一下!许多平台提供免费试用和/或免费课程。例如,你可以通过 Dataquest 注册一个免费账户。然后,完成我们 60 多门免费课程中的任何一门,感受不同类型的内容和教学风格。如果一个平台或认证项目不给你任何机会去尝试他们的产品,那就是一个危险信号。在你确定它的教学风格适合你之前,花几百或几千美元在一个学习产品上是没有意义的!

One thing you definitely need to consider before choosing a certification program: what’s your budget? Costs can vary widely.
对比分析认证
有大量的数据分析师证书。下面,我们将比较几个认证计划,以便您更好地了解每个选项的优势。
数据请求
- 费用:49 美元/月
- 类型:在线、自助
- 平台:基于浏览器的实用编码界面
- 涵盖的主题:Python、SQL、统计、命令行/shell、Git
- 先决条件:无
- 时间限制:无(大多数学生在不到一年的非全日制学习中达到目标)。
Switchup.org 评论平均分:4.85 分(满分 5 分)
谷歌的数据分析证书
- 费用:每月 39 美元(可获得经济资助)
- 类型:在线
- 平台:Coursera
- 涵盖的主题:大数据介绍、数据可视化、R 编程
- 先决条件:高中数学
- 时间限制:无(按照自己的进度学习,非全日制或全日制)。
总装数据分析
- 成本:3,950 美元或更高(提供贷款选项)
- 类型:在线或面对面训练营
- 平台:面对面或在线虚拟教室
- 涵盖的主题:SQL,Excel,Tableau
- 先决条件:无
- 时间限制:必须参加特定的课程,在特定的时间参加课程。(但是,新的会话会频繁开始,所以您不必等很久就可以加入)。
Switchup.org 评论平均分:4.28 分(满分 5 分)
Thinkful 数据分析沉浸式
- 成本:12,250 美元或更高(提供贷款选项)
- 类型:在线
- 平台:在线虚拟教室
- 涵盖的主题:Python、SQL、机器学习
- 先决条件:无
- 时间限制:全职四个月,或者兼职(每周 20-30 小时)六个月
Switchup.org 评论平均分:4.65 分(满分 5 分)
跳板数据分析追踪
- 成本:5,500 美元或更高(提供贷款选项)
- 类型:在线
- 平台:在线虚拟教室
- 涵盖的主题:Python、SQL
- 先决条件:没有,虽然你必须申请并被接受。
- 时间限制:必须等待下一批开始,然后计划长度为六个月。
Switchup.org 评论平均分:4.67 分(满分 5 分)
比较外卖
正如你所看到的,这些程序之间有很大的不同。最明显的一个是成本—这里的成本从不到 300 美元到超过 12,000 美元不等!此外,还有其他有意义的差异。
以用户评论为例。尽管 Dataquest 是最实惠的选择,但它也拥有最高的平均评审分数。
时间限制也变化很大。有 Dataquest 或 General Assembly 之类的程序可以立即启动。相反,像跳板这样的项目需要一个申请过程。用户可能还需要等待队列开始。
最重要的是,实际涵盖的主题可能因项目而异。General Assembly 的程序对 SQL、Excel 和 Tableau 的关注有限。因此,它可能专注于技术要求较低的分析师角色。
另一方面,Thinkful 程序致力于机器学习,这通常不是数据分析师角色所需要的。Dataquest 似乎是这些选项中唯一一个对概率和统计有实质性覆盖的选项。
基于测试的认证怎么样?
如果你认为数据分析中基于测试的证书好得不像真的,那么 99%的情况下你都是对的。
有许多认证项目,如认证分析专家(CAP) 或 Cloudera 的 CCA 数据分析师,根本不需要任何教育。这些测试你只需要花几百美元就可以参加。一旦通过,您将立即获得认证。
这些是好的投资吗?通常不会。有一些特定的工作可能会青睐这些证书,但很少有人需要它们。也没有真正的证据表明雇主对他们感兴趣。
定量分析证实了这一理论。在撰写本文时,美国 Indeed.com 上大约有 39,000 个开放数据职位。其中,不到 100 要求 CAP 认证,不到 20 提到 CCA。
换句话说,大约 99.7%的数据工作不需要这些认证。这还是保守的估计。
事实上,只有 15%的数据工作包含“认证”这个词。其中许多是与公司特定技术体系相关的特定软件认证。这 15%中的一些还包括了“认证:无”的工作列表。
无论从哪个角度看,对通用数据分析认证的需求都很低。如果你确实需要一份工作的证书,它可能是特定于软件的东西:例如,一家做大量基于云的数据处理的公司的 AWS 证书。
选择证书课程(如果您决定获得一个)
还是那句话,不需要证书。但是如果你决定买一个,那就选一个合适的。
那么,对于你来说,最好的数据分析认证选项是什么?这将归结为基于以下因素的个人决定:
- 你的预算是多少?
- 你有多少空闲时间学习?
- 您已经具备哪些数据分析师技能(如果有)?
- 你希望完成的时间表是什么?
既然你知道具体的证书对于找工作来说并不重要,你就可以专注于*重要的事情了:学习正确的技能,建立伟大的项目,向潜在的雇主证明这些技能。别忘了看看 Dataquest 的数据分析课程。注册是免费的。此外,你将有多个机会建立你的相关投资组合,展示你将学到的所有就业技能!**
创业数据分析:你需要知道什么
原文:https://www.dataquest.io/blog/data-analytics-startups-what-you-need-to-know/
April 18, 2019
初创公司的数据分析——听起来很简单。而且收集和分析数据也确实不难。这是大多数创业公司已经在做的事情。然而,从数据中获得有价值的、可操作的洞察力要复杂一些。这里有六件事需要知道,它们将有助于你在成长和管理创业时做出正确的决定。
1.投资合适的分析团队
数据分析很复杂。曾经是 Excel 电子表格爱好者的领域,现在已经成为数据分析师和科学家的专业技能。虽然 Excel 仍然有它的位置,但如果你能雇佣一个拥有更高级技能的团队,你将能够从你的数据中获得更多。
一个好的数据分析团队将需要电子表格技能,但分析师还应该具备数据分析能力、 Python 或 R 编程技能、SQL 技能以及对统计学的良好掌握。
你需要知道什么对你的创业是现实的。一个拥有博士学位和 10 年自动驾驶深度学习经验的数据科学家在理论上可能看起来很棒,但你可能不需要这样的经验。在招聘数据分析师时,保持较高但合理的期望,并随着初创公司的发展寻找有发展空间的人才。
2.收集正确的数据
数据是数据分析的基础。如果没有好的数据,即使是世界上最好的分析师也帮不了你什么。确保您拥有进行准确而有意义的分析所需的数据。如果你不确定你需要什么,问问你的分析师——如果你招聘得好,他们会很清楚什么是需要的,什么是不需要的。
例如,如果你的初创公司从事电子商务,你几乎肯定已经安装了 Google Analytics 或其他一些分析工具。但是,您可能还需要一个扩展或包来处理 A/B 测试,以了解不同的页面布局或副本如何影响用户体验。
作为一家电子商务公司,你需要一张热图来了解点击模式是如何工作的吗?大概不会。然而,一个正在开发手机游戏的初创公司会喜欢这种类型的洞察力,并可以利用它通过根据玩家的动作做出特定的界面选择来改进产品。
你的创业公司需要什么取决于你的业务细节。决定收集哪些数据是您应该尽早研究和实现的事情,因为您收集的好数据越多,您的分析师在分析中就越有效。
3.尽早做出关键技术决策
同样,尽早选择技术组合也很重要。一家建立在糟糕基础上的公司不太可能蓬勃发展,并且不断更换您堆栈中的解决方案会对您的数据分析造成严重破坏。您现在做出的选择,包括像数据库这样的基础技术选择,甚至是防火墙最佳实践,都将影响您可以执行的分析类型。
糟糕的基础设施选择可能会造成严重后果。像 MongoDB 这样的 NoSQL 数据库近年来变得流行起来,因为它们允许快速扩展和构建产品。然而,这是以能够跨数据类型执行连接为代价的——传统的 SQL 数据库,如 MySQL 和 PostgreSQL 在这方面要好得多。虽然在早期你可能不需要这些特性(你也可能不需要),但是请记住,一旦系统启动并运行,对它的任何更改都可能是破坏性的和昂贵的。最好从一个技术栈和一个数据库解决方案开始,这样不会限制你的团队可以执行的分析类型。
4.衡量你的结果
对于您的数据分析团队来说,成功是什么样的?是否已经建立了具有度量标准的 ROI?例如,脸书有一个分析团队来衡量一篇文章与用户的相关性,它的成功依赖于这一衡量标准。能够衡量您的数据团队的效率是关键。
也就是说,不要走极端。一个常见的错误是有太多的指标。然后,您的数据分析团队必须平衡多个测量值,这将很难缩小关注范围。像任何其他团队一样,您的数据团队需要一个明确的方向,所以选择一两个 KPI 并坚持下去。
5.找到支持的投资者
正确的投资者可能是你创业公司数据分析的成败因素。一些投资者可能会嘲笑只专注于数据分析的团队的想法,认为只有在更大的规模下才需要。在你积累任何数据之前,其他投资者会要求提前雇佣一名有经验的分析师。
理想情况下,你希望找到这样的投资者,他们明白当有数据可供评估时,初创公司应该有一个数据分析团队。数据越旧,它提供的有用见解就越少,所以一旦你开始生成和收集数据,引入分析师或分析团队来帮助你赚钱是有意义的。
6.创业公司的成长黑客
创业公司数据分析的最大用途之一是增长黑客。通常,了解什么样的事情与用户注册你的网站或购买相关是很有价值的,这样你就可以双倍下注于促使用户做这些事情的策略。
例如,在其开发的早期,文件托管提供商 Dropbox 分析了其数据,并得出结论:在其平台上共享文件的用户更有可能成为重复用户。他们从来没有找出确切的原因,因为重要的是结果。Dropbox 重新安排了其网站,使分享更容易,并增加了提示,以提示用户分享。
由于平台的变化,他们的用户数量激增。但正是分析数据和发现份额与用户注册之间的联系,才使得 Dropbox 的井喷式增长成为可能。
你可能会希望一个数据团队在你的初创公司寻找类似的见解。确定导致用户增长的行动,看着你的创业腾飞!
使用 Dataquest 学习数据分析
数据分析是关于在我们的世界中寻找和探索解决问题的模式。它可以涉及任何事情,从分析全球变暖的速度到制造无人驾驶汽车。
数据科学使您的初创公司能够对世界产生影响,Dataquest 使您的团队成员能够高效、经济地学习有价值的数据技能。立即开始免费学习,了解数据分析如何帮助您和您的团队。
教程:使用命令行和 csvkit 清理 CSV 数据
原文:https://www.dataquest.io/blog/data-cleaning-command-line/
December 10, 2015The Museum of Modern Art is one of the most influential museums in the world and they have released a dataset on the artworks in their collection. The dataset has some data quality issues, however, and requires cleanup.
在之前的帖子中,我们讨论了如何使用 Python 和 Pandas 来清理数据集。在这篇文章中,我们将了解如何使用csvkit库来获取和探索表格数据。
为什么是命令行?
很棒的问题!当在云数据科学环境中工作时,您有时只能访问服务器的外壳。在这种情况下,精通命令行数据科学是真正的超能力。随着您越来越熟练,使用命令行完成一些数据科学任务比编写 Python 脚本或 Hadoop 作业要快得多。
最后,命令行拥有丰富的工具生态系统,并集成到文件系统中。这使得某些类型的任务,尤其是涉及多个文件的任务变得异常简单。这个职位需要一些在命令行工作的经验。如果你是命令行新手,我推荐你去看看我们的交互式命令行课程
csvkit
csvkit 是一个优化处理 CSV 文件的库。它是用 Python 写的,但是主要接口是命令行。您可以使用pip安装csvkit:
pip install csvkit
你需要这个库来跟进这篇文章。
数据采集
MOMA 艺术品数据集可以在博物馆的 Github repo 上找到。我们用 curl 从 Github 下载Artworks.csv吧。curl是一个内置于大多数 shell 环境中的工具,允许您在服务器之间传输数据。Github 为每个文件提供了直接的 URL,你可以通过点击Raw按钮找到它。
最后,我们将使用>操作符将来自curl的输出重定向到一个名为artworks.csv的文件。
curl https://raw.githubusercontent.com/MuseumofModernArt/collection/master/Artworks.csv > artworks.csv
数据探索
我们可以使用head命令显示文件的前n行(默认为 10 行)。要显示前 3 行,这两个命令都可以:
head -n 3 artworks.csv
head -3 artworks.csv
Title,Artist,ArtistBio,Date,Medium,Dimensions,CreditLine,MoMANumber,Classification,Department,DateAcquired,CuratorApproved,ObjectID,URL
"Ferdinandsbrücke Project, Vienna, Austria , Elevation, preliminary version",Otto Wagner,"(Austrian, 1841–1918)",1896,Ink and cut-and-pasted painted pages on paper,"19 1/8 x 66 1/2"" (48.6 x 168.9 cm)",Fractional and promised gift of Jo Carole and Ronald S. Lauder,885.1996,A&D Architectural Drawing,Architecture & Design,1996-04-09,Y,2,https://www.moma.org/collection/works/2
"City of Music, National Superior Conservatory of Music and Dance, Paris, France, View from interior courtyard",Christian de Portzamparc,"(French, born 1944)",1987,Paint and colored pencil on print,"16 x 11 3/4"" (40.6 x 29.8 cm)",Gift of the architect in honor of Lily Auchincloss,1.1995,A&D Architectural Drawing,Architecture & Design,1995-01-17,Y,3,https://www.moma.org/collection/works/3
与大多数数据集一样,看起来第一行包含列标题。除此之外,输出是混乱的,很难从默认输出中收集到任何其他信息。我们需要一个工具,知道如何以可读的方式显示 CSV 文件。
我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊!我的天啊
csvlook是csvkit中的一个工具,允许你以表格的形式显示和预览 CSV 文件。csvlook artworks.csv将显示整个数据集,这是繁琐的探索。让我们用管道将head -5 artworks.csv的stdout连接到csvlook来探索前 5 行:
head -5 artworks.csv | csvlook
| Title | Artist | ArtistBio | Date | Medium | Dimensions | CreditLine | MoMANumber | Classification | Department | DateAcquired | CuratorApproved | ObjectID | URL
| Ferdinandsbrücke Project, Vienna, Austria , Elevation, preliminary version | Otto Wagner | (Austrian, 1841–1918) | 1896 | Ink and cut-and-pasted painted pages on paper | 19 1/8 x 66 1/2" (48.6 x 168.9 cm) | Fractional and promised gift of Jo Carole and Ronald S. Lauder | 885.1996 | A&D Architectural Drawing | Architecture & Design | 1996-04-09 | Y | 2 | https://www.moma.org/collection/works/2 |
| City of Music, National Superior Conservatory of Music and Dance, Paris, France, View from interior courtyard | Christian de Portzamparc | (French, born 1944) | 1987 | Paint and colored pencil on print | 16 x 11 3/4" (40.6 x 29.8 cm) | Gift of the architect in honor of Lily Auchincloss | 1.1995 | A&D Architectural Drawing | Architecture & Design | 1995-01-17 | Y | 3 | https://www.moma.org/collection/works/3 |
| Villa near Vienna Project, Outside Vienna, Austria, Elevation | Emil Hoppe | (Austrian, 1876–1957) | 1903 | Graphite, pen, color pencil, ink, and gouache on tracing paper | 13 1/2 x 12 1/2" (34.3 x 31.8 cm) | Gift of Jo Carole and Ronald S. Lauder | 1.1997 | A&D Architectural Drawing | Architecture & Design | 1997-01-15 | Y | 4 | https://www.moma.org/collection/works/4 |
| The Manhattan Transcripts Project, New York, New York , Introductory panel to Episode 1: The Park | Bernard Tschumi | (French and Swiss, born Switzerland 1944) | 1980 | Photographic reproduction with colored synthetic laminate | 20 x 20" (50.8 x 50.8 cm) | Purchase and partial gift of the architect in honor of Lily Auchincloss | 2.1995 | A&D Architectural Drawing | Architecture & Design | 1995-01-17 | Y | 5 | https://www.moma.org/collection/works/5
以下是管道示意图:
 虽然输出现在更容易阅读,但探索起来还是有点困难。现在让我们学习如何使用
虽然输出现在更容易阅读,但探索起来还是有点困难。现在让我们学习如何使用csvcut来选择几列并显示它们。
csvcut〔t0〕
csvcut 是csvkit中的一个工具,被称为数据手术刀,因为它允许你分割和修改 CSV 中的列。让我们首先列出所有使用-n标志的列:
csvcut -n artworks.csv
1: Title
2: Artist
3: ArtistBio
4: Date
5: Medium
6: Dimensions
7: CreditLine
8: MoMANumber
9: Classification
10: Department
11: DateAcquired
12: CuratorApproved
13: ObjectID
14: URL
然后我们可以使用-c标志来指定我们想要的列。csvcut -c 1,2,3 artworks.csv | csvlook将返回前 3 列。您也可以使用列名本身:csvcut -c Artist,ArtistBio,Date。运行任一命令都将显示整个数据集的 3 列,因此我们需要利用管道来查看几行。
我们可以参考csvkit 文档来阅读csvkit公用设施之间的管道:
除了作为文件名之外,所有 csvkit 实用程序都接受输入文件作为“标准输入”。这意味着我们可以让一个 csvkit 实用程序的输出成为下一个的输入。
这意味着我们可以将csvcut的stdout通过管道传输到csvlook的stdin!我们可以构建以下管道:
- 使用
head仅提取前10行 - 使用
csvcut仅过滤前3列 - 使用
csvlook以简洁的方式显示
head -10 artworks.csv | csvcut -c 1,2,3 | csvlook
| Title | Artist | ArtistBio |
| Ferdinandsbrücke Project, Vienna, Austria , Elevation, preliminary version | Otto Wagner | (Austrian, 1841–1918) |
| City of Music, National Superior Conservatory of Music and Dance, Paris, France, View from interior courtyard | Christian de Portzamparc | (French, born 1944) |
| Villa near Vienna Project, Outside Vienna, Austria, Elevation | Emil Hoppe | (Austrian, 1876–1957) |
| The Manhattan Transcripts Project, New York, New York , Introductory panel to Episode 1: The Park | Bernard Tschumi | (French and Swiss, born Switzerland 1944) |
| Villa, project, outside Vienna, Austria, Exterior perspective | Emil Hoppe | (Austrian, 1876–1957) |
| The Manhattan Transcripts Project, New York, New York , Episode 1: The Park | Bernard Tschumi | (French and Swiss, born Switzerland 1944) |
| The Manhattan Transcripts Project, New York, New York , Episode 1: The Park | Bernard Tschumi | (French and Swiss, born Switzerland 1944) |
| The Manhattan Transcripts Project, New York, New York , Episode 1: The Park | Bernard Tschumi | (French and Swiss, born Switzerland 1944) |
| The Manhattan Transcripts Project, New York, New York, Episode 1: The Park | Bernard Tschumi | (French and Swiss, born Switzerland 1944)
csvgrep
在处理历史数据集时,我们需要确保日期和时间列的格式正确(否则即使是基本的时间序列图也无法工作)。让我们探索一下Date和DateAcquired列:
head -20 artworks.csv | csvcut -c Date,DateAcquired | csvlook
|----------+---------------|
| Date | DateAcquired |
|----------+---------------|
| 1896 | 1996-04-09 |
| 1987 | 1995-01-17 |
| 1903 | 1997-01-15 |
| 1980 | 1995-01-17 |
| 1903 | 1997-01-15 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
| 1976-77 | 1995-01-17 |
|----------+---------------|
虽然DateAcquired中的前 20 个值看起来不错,但是Date列中的一些值与大多数数据可视化工具如1976-77不太匹配。我们可以通过选择范围中的第一年(例如从范围1976-77中选择1976)来轻松处理这个问题。在我们这样做之前,让我们算出有多少行符合这个模式。
我们可以使用csvgrep工具提取一列(或多列)中匹配正则表达式的所有值。我们使用-c标志指定希望csvgrep匹配的列。我们使用-regex标志指定希望csvgrep使用的正则表达式。正则表达式^([0-9]*-[0-9]*)匹配由连字符(-)分隔的数值对。
因为我们正在搜索Date列上的模式实例,所以我们编写了以下代码:
csvgrep --c Date --regex "^([0-9]*-[0-9]*)"
让我们修改并运行我们构建的管道来合并csvgrep:
head -10 artworks.csv | csvcut -c Date | csvgrep --c Date --regex "^([0-9]*-[0-9]*)" | csvlook
|-----------|
| Date |
|-----------|
| 1976-77 |
| 1976-77 |
| 1976-77 |
| 1976-77 |
|-----------|
csvstart
精彩!既然我们知道它可以工作,让我们将正则表达式应用于整个Date列(而不仅仅是前 10 行),并确定有多少行匹配这个模式。csvstat工具将 CSV 作为输入(stdin)并计算汇总统计数据。我们可以使用--count标志来指定我们只需要行数。
我们也可以删除csvcut、head和csvlook,因为我们不需要显示输出。
csvgrep --c Date --regex "^([0-9]*-[0-9]*)" artworks.csv | csvstat --count
Row count: 18073
看起来有 18073 行符合这个模式。现在让我们来计算一下:
- 有多少行符合 4 位数的年份模式
- 数据集总共包含多少行
我们可以使用 regex ( ^[0-9]{4}$)来查找所有 4 位数的年份值,并将结果传送到csvstat:
csvgrep --c Date --regex "[0-9]{4}
Row count: 76263
最后,为了获得数据集的总行数,我们可以使用带有-l标志的 wc 命令(只显示行数):
wc -l artworks.csv
137382 artworks.csv
如果我们将匹配 4 位数年份正则表达式(76263)的行数与匹配年份范围正则表达式(18073)的行数相结合,我们得到(94336)行。考虑到总共有 137,382 行,这是我们分析的一个很好的起点!
接下来的步骤
如果您有兴趣了解更多关于使用 csvkit 的信息,您可以查看我们的交互式 csvkit 课程。
通过我们新的 Python 数据清理高级课程掌握数据清理
原文:https://www.dataquest.io/blog/data-cleaning-python-advanced/
June 13, 2019
数据清理。数据清理。数据管理。不管你怎么称呼它,不可否认的是,获取原始数据并将其转化为可供分析的数据集的过程是任何数据工作中最重要的任务之一。
事实上,这可能是数据科学中最重要的任务。在调查中,数据科学家报告说他们花了大部分时间清理和准备数据。调查还显示,“脏数据”是数据工作者在工作中面临的头号挑战。
数据清理可能不是“21 世纪最性感的工作”中“最性感”的部分,但它绝对是一项至关重要的技能,因为它是所有后续分析的基础。无论你的分析技能或机器学习算法有多好,如果你给它们提供的是肮脏的数据,它们都无法产生任何有价值的东西。俗话说:垃圾进来,垃圾出去。
即使你不从事数据科学,数据清理也是一项非常有价值的技能。例如,圭亚那的一名 Dataquest 学生的任务是处理几十个庞大而笨拙的 Excel 数据集。他说,学习用 Python 组合和清理这些数据改变了他的生活。它把曾经需要一周的任务变成了只需要几分钟的事情!
您可能已经掌握了一些 Python 数据清理技能。这是数据科学工作流程中如此重要的一部分,以至于我们的免费初级课程包含了一些数据清理。我们还提供关于数据清理和分析的更有针对性的课程。现在,为了帮助你在这一关键领域建立更多的技能,我们推出了一门新课程: 数据清理高级 。
准备好开始清理您的数据,直到它变得非常干净了吗?单击下面的按钮开始。
本课程需要基础或高级订阅,并假设熟悉在我们早期课程中介绍的概念,包括基本的数据科学 Python 编程技能,以及一些使用 pandas 和 matplotlib 等库的经验。
我为什么要选这门课?
数据清理对于任何数据分析师或数据科学家来说都是一项关键技能,您可以通过多种方式学习这些技能。然而,Dataquest 提供了一个独特的学习平台,将优秀的教学与动手编程实践相结合,使我们的课程非常有效。

简而言之,Dataquest 平台。
你不必相信我们的话。测试过这门课程的学生同意。100%的测试者认为在完成课程后,他们理解了正则表达式。100%的测试人员也同意,在完成课程后,他们可以使用他们学到的概念(如列表理解、lambda 函数、使用 JSON 数据等)。)在自己的项目里。
特别是,学生们称赞本课程的解释清晰而有思想,并报告说他们学到了宝贵的专业技能。“我将能够使用正则表达式改进我的工作,”一名学生在完成本课程中以正则表达式为中心的课程后写道。另一名学生说,这些高级技能“在实际工作环境中通常很有用”。
事实上,一名学生测试员告诉我们,这门课程包含“Dataquest 上最好的课程之一!”
在这个数据清理高级课程中,我将学到什么?
在数据清理高级课程中,您将深入研究并亲自动手,使用各种常用技术清理真实世界的数据集,以根除错误数据、处理缺失数据、合并数据集并准备用于分析的传入数据。使用我们的交互式浏览器内编码平台,您将编写 Python 代码,将有关黑客新闻标题和纽约市交通事故的肮脏数据转化为可供分析的干净数据。
为此,您将学习正则表达式(通常称为 regex),这是一种操作字符串的强大方法,以及如何利用 Python 中的 regex,通过 Python 的 regex 模块来清理脏文本数据。您将学习使用 json 格式的数据,这在使用 Python 的 JSON 模块处理来自 web APIs 的数据时很常见。您将学习使用 lambda 函数在函数中创建函数,以实现更快的工作流。
您还将学习使用列表理解更容易地处理类似列表的数据
一旦你掌握了这些清理和准备数据的重要技术,你将开始填补数据集中的漏洞,用各种方式处理丢失的数据。您将了解到:
- 如何使用表格和绘图查找缺失数据
- 如何使用各种统计方法估算缺失数据
- 如何使用其他来源的数据扩充不完整的数据集
在应对这些挑战的过程中,您还将获得使用您可能已经熟悉的流行 Python 数据科学库的额外实践,包括 pandas、matplotlib 和 seaborn。
本课程结束时,您将掌握从各种数据源中清理数据的技能,包括从 API 中提取的 JSON 数据。您将能够以多种不同的方式处理数据中缺失的值,这样您就不必再从数据集中删除行,从而减少其大小和值。您将掌握将源数据转换成分析所需格式的技能,使用 regex 的强大功能使混乱的文本字符串更容易处理。
谈到所有数据科学中最常用的技能,没有比现在更好的时机来开始磨练您的技能,并将您的数据清理能力升级到“高级”
教程:用 Python 清理 MoMA 艺术收藏的数据
August 13, 2015 Art is a messy business. Over centuries, artists have created everything from simple paintings to complex sculptures, and art historians have been cataloging everything they can along the way. The Museum of Modern Art, or MoMA for short, is considered one of the most influential museums in the world and recently released a dataset of all the artworks they’ve cataloged in their collection. This dataset contains basic information on metadata for each artwork and is part of MoMA’s push to make art more accessible to everyone. The museum has put out a disclaimer, however, that the dataset is still a work in progress – an evolving artwork in its own right perhaps. Because it’s still in progress, the dataset has data quality issues and needs some cleanup before we can analyze it. In this post, we’ll introduce a few tools for cleaning data (or munging data, as it’s sometimes called) in Python. and discuss how we can use them to diagnose data quality issues and correct them. You can download the dataset for yourself on Github.
Art is a messy business. Over centuries, artists have created everything from simple paintings to complex sculptures, and art historians have been cataloging everything they can along the way. The Museum of Modern Art, or MoMA for short, is considered one of the most influential museums in the world and recently released a dataset of all the artworks they’ve cataloged in their collection. This dataset contains basic information on metadata for each artwork and is part of MoMA’s push to make art more accessible to everyone. The museum has put out a disclaimer, however, that the dataset is still a work in progress – an evolving artwork in its own right perhaps. Because it’s still in progress, the dataset has data quality issues and needs some cleanup before we can analyze it. In this post, we’ll introduce a few tools for cleaning data (or munging data, as it’s sometimes called) in Python. and discuss how we can use them to diagnose data quality issues and correct them. You can download the dataset for yourself on Github.
为什么使用 Python 进行数据清理?
Python 是一种编程语言,从政府机构(如 SEC)到互联网公司(如 Dropbox),各种机构都用它来创建功能强大的软件。Python 已经成为大量处理数据的组织中用于数据分析的主要语言。虽然我们不会在这篇文章中深入太多关于 Python 如何工作的细节,但是如果你有兴趣了解更多,我们强烈推荐你阅读学习 Python 系列。
用熊猫探索数据
在这篇文章中,我们将只处理数据集的前 100 行。我们首先需要将 Pandas 库导入到我们的环境中,然后将数据集读入 Pandas 数据帧。DataFrame 是我们数据集的速度优化表示,内置于 Pandas 中,我们可以使用它来快速浏览和分析我们的数据。一旦我们将数据集读入 DataFrame 对象artworks_100,我们将:
import pandas
artworks_100 = pandas.read_csv("MOMA_Artworks.csv")
artworks_100.head(10)
| 标题 | 艺术家 | 艺术家简历 | 日期 | 中等 | 规模 | 作者姓名或来源附注 | MoMANumber | 分类 | 部门 | 获得日期 | 经监管机构批准 | ObjectID | 统一资源定位器 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 费迪南德布罗斯项目,奥地利维也纳 | 奥图·华格纳 | (奥地利人,1841 年至 1918 年) | One thousand eight hundred and ninety-six | 墨水和剪贴在纸上的画页 | 19 1/8 x 66 1/2 英寸(48.6 x 168.9 厘米) | 部分和承诺的礼物乔卡罗尔和… | 885.1996 | A&D 建筑制图 | 建筑与设计 | 1996-04-09 | Y | Two | https://www.moma.org/collection/works/2 |
| one | 音乐之城,国家高级音乐学院… | 克里斯蒂安·德·波扎姆帕克 | (法国人,生于 1944 年) | One thousand nine hundred and eighty-seven | 油漆和彩色铅笔打印 | 16 x 11 3/4 英寸(40.6 x 29.8 厘米) | 建筑师向莉莉·奥金奇致敬的礼物… | 1.1995 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | three | https://www.moma.org/collection/works/3 |
| Two | 澳大利亚维也纳郊外维也纳项目附近的别墅… | 埃米尔·霍普 | (奥地利人,1876 年至 1957 年) | One thousand nine hundred and three | 石墨、钢笔、彩色铅笔、墨水和水粉… | 13 1/2 x 12 1/2 英寸(34.3 x 31.8 厘米) | 乔·卡罗尔和罗纳德·s·劳德的礼物 | 1.1997 | A&D 建筑制图 | 建筑与设计 | 1997-01-15 | Y | four | https://www.moma.org/collection/works/4 |
| three | 纽约曼哈顿抄本项目… | 伯纳德·屈米 | (法国人和瑞士人,1944 年生于瑞士) | One thousand nine hundred and eighty | 彩色合成照相复制 | 20 x 20 英寸(50.8 x 50.8 厘米) | 购买和部分赠送的建筑师在… | 2.1995 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | five | https://www.moma.org/collection/works/5 |
| four | 奥地利维也纳郊外的别墅项目 | 埃米尔·霍普 | (奥地利人,1876 年至 1957 年) | One thousand nine hundred and three | 石墨,彩色铅笔,墨水,水粉在 tr… | 15 1/8 x 7 1/2 英寸(38.4 x 19.1 厘米) | 乔·卡罗尔和罗纳德·s·劳德的礼物 | 2.1997 | A&D 建筑制图 | 建筑与设计 | 1997-01-15 | Y | six | https://www.moma.org/collection/works/6 |
| five | 纽约曼哈顿抄本项目… | 伯纳德·屈米 | (法国人和瑞士人,1944 年生于瑞士) | 1976-77 | 明胶银照片 | 14 x 18 英寸(35.6 x 45.7 厘米) | 购买和部分赠送的建筑师在… | 3.1995.1 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | seven | https://www.moma.org/collection/works/7 |
| six | 纽约曼哈顿抄本项目… | 伯纳德·屈米 | (法国人和瑞士人,1944 年生于瑞士) | 1976-77 | 明胶银照片 | 每个:14 x 18 英寸(35.6 x 45.7 厘米) | 购买和部分赠送的建筑师在… | 3.1995.1-24 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | eight | https://www.moma.org/collection/works/8 |
| seven | 纽约曼哈顿抄本项目… | 伯纳德·屈米 | (法国人和瑞士人,1944 年生于瑞士) | 1976-77 | 明胶银照片 | 14 x 18 英寸(35.6 x 45.7 厘米) | 购买和部分赠送的建筑师在… | 3.1995.10 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | nine | https://www.moma.org/collection/works/9 |
| eight | 纽约曼哈顿抄本项目… | 伯纳德·屈米 | (法国人和瑞士人,1944 年生于瑞士) | 1976-77 | 明胶银照片 | 14 x 18 英寸(35.6 x 45.7 厘米) | 购买和部分赠送的建筑师在… | 3.1995.11 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | Ten | https://www.moma.org/collection/works/10 |
| nine | 纽约曼哈顿抄本项目… | 伯纳德·屈米 | (法国人和瑞士人,1944 年生于瑞士) | 1976-77 | 明胶银照片 | 14 x 18 英寸(35.6 x 45.7 厘米) | 购买和部分赠送的建筑师在… | 3.1995.12 | A&D 建筑制图 | 建筑与设计 | 1995-01-17 | Y | Eleven | https://www.moma.org/collection/works/11 |
在熊猫中处理日期
如果仔细观察Date列,您可能会注意到一些值是年份范围(1976-77),而不是个别年份(1976)。年份范围很难处理,我们不能像绘制单个年份那样简单地绘制它们。让我们利用熊猫的value_counts()功能来寻找任何其他奇怪之处。首先,要选择一个列,使用括号符号并在引号中指定列名artworks_100['Date'],然后附加.value_counts()以使用artworks_100['Date'].value_counts()获得值的分布。
artworks_100['Date'].value_counts()
1976-77 25
1980-81 15
1979 12
Unknown 7
1980 5
1917 5
1978 5
1923 4
1935 3
1987 2
1903 2
1970 1
1896 1
1975 1
1984 1
1918 1
1986 1
n.d. 1
1906 1
1905 1
1930 1
1974 1
1936 1
1968 1
1900 1
c. 1917 1
dtype: int64
清理数据模式
除了年份范围之外,我们还需要注意其他三种模式。下面是对Date列中不规则值类型的快速总结:
Pattern 1:“1976-77”(年份范围)Pattern 2:“约 1917 年”Pattern 3:“未知”Pattern 4:“未注明。”
如果我们想出处理每个模式的规则,我们可以用 Python 写出逻辑,并将所有不规则的值转换成适当的格式。一旦我们写出了我们的逻辑,我们就可以逐行迭代 DataFrame,并在必要时更改Date列的值。虽然模式 1 或 2 的行有日期值,但对我们来说格式很差,而模式 3 和 4 的行实际上没有关于艺术品制作时间的信息。因此,我们处理模式 1 和 2 的代码应该着重于将值重新格式化为干净的日期,而我们处理模式 3 和 4 的代码应该只将那些列标识为缺少日期信息。为了简单起见,我们可以保持模式 3 的行不变(如"Unknown"),并将模式 4 的行转换为模式 3。
模式 1
因为模式 1 的所有行都是仅跨越两年的年份范围(例如1980-81),所以我们可以选择一年并让它替换该范围。为了简单起见,让我们选择范围中的第一年,因为它包含所有四位数字(1980),而范围中的第二年只有最后两位数字(81)。我们还需要一种可靠的方法来识别哪些行实际上表现出模式 1,所以我们只更新那些行,而让其他行保持不变。我们需要让其他模式保持不变,要么是因为它们已经是正确的日期格式,要么是因为它们需要在以后使用我们为处理其他模式而编写的逻辑进行修改。
由于年份范围包含一个分隔两年的连字符-,我们可以在每一行的Date值中寻找-并将它分成两个独立的年份。核心 Python 库包含一个名为.split()的函数,在这种情况下,如果找到连字符,它将返回两年的列表,如果没有找到,则返回原始值。因为我们只寻找第一年,我们可以在每一行的Date上调用.split("-"),检查结果列表是否包含两个元素,如果包含,则返回第一个元素。让我们写一个函数clean_split_dates(row)来完成这个任务:
def clean_split_dates(row):
# Initial date contains the current value for the Date column
initial_date = str(row['Date'])
# Split initial_date into two elements if "-" is found
split_date = initial_date.split('-')
# If a "-" is found, split_date will contain a list with at least two items
if len(split_date) > 1:
final_date = split_date[0]
# If no "-" is found, split_date will just contain 1 item, the initial_date
else:
final_date = initial_date
return final_date
# Assign the results of "clean_split_dates" to the 'Date' column.
# We want Pandas to go row-wise so we set "axis=1". We would use "axis=0" for column-wise.
artworks_100['Date'] = artworks.apply(lambda row: clean_split_dates(row), axis=1)
artworks_100['Date'].value_counts()
1976 25
1980 20
1979 12
Unknown 7
1917 5
1978 5
1923 4
1935 3
1987 2
1903 2
c. 1917 1
1918 1
1975 1
1968 1
n.d. 1
1905 1
1896 1
1984 1
1930 1
1970 1
1974 1
1986 1
1936 1
1900 1
1906 1
dtype: int64
使用 Python 清理数据:后续步骤
我们在最后的Date列上运行.value_counts(),以验证所有年份范围都已从数据框架中删除。如果您有兴趣了解更多关于数据清理的信息,请查看 Dataquest 网站上我们的交互式数据清理课程。这个六部分的课程使用 Python 和 pandas 库来教你如何清理和处理数据。该课程包括两个指导项目,帮助你综合你的技能,并开始一个数据科学作品集,你可以用它来向雇主展示你的技能。最棒的是,无需安装!该课程完全在一个交互式环境中教授,您可以编写自己的代码,并立即在浏览器中看到结果。
教程:用 Python 构建分析数据管道
November 4, 2019
如果您曾经想在线学习 Python 处理流数据或快速变化的数据,那么您可能熟悉数据管道的概念。数据管道允许您通过一系列步骤将数据从一种表示形式转换为另一种表示形式。数据管道是数据工程的关键部分,我们在新的数据工程师路径中教授。在本教程中,我们将使用 Python 和 SQL 构建一个数据管道。
数据管道的一个常见用例是计算网站访问者的信息。如果你熟悉谷歌分析,你就会知道查看访客实时和历史信息的价值。在这篇博文中,我们将使用 web 服务器日志中的数据来回答关于访问者的问题。
如果你不熟悉的话,每次你访问一个网页,比如 Dataquest 博客,你的浏览器都会收到来自网络服务器的数据。为了托管这个博客,我们使用了一个名为 Nginx 的高性能网络服务器。下面是你输入一个网址并看到结果的过程:

从 web 浏览器向服务器发送请求的过程。
首先,客户机向 web 服务器发送一个请求,请求某个页面。然后,web 服务器从文件系统加载页面,并将其返回给客户机(web 服务器也可以动态生成页面,但我们现在不担心这种情况)。在处理请求时,web 服务器在文件系统的日志文件中写入一行,其中包含一些关于客户机和请求的元数据。该日志使某人能够在以后看到谁在什么时间访问了网站上的哪些页面,并执行其他分析。
以下是这篇博客的 Nginx 日志中的几行文字:
X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/css/jupyter.css HTTP/1.1" 200 30294 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)"
X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/js/jquery-1.11.1.min.js HTTP/1.1" 200 95786 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)
"X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/js/markdeep.min.js HTTP/1.1" 200 58713 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)"
X.X.X.X - - [09/Mar/2017:01:15:59 +0000] "GET /blog/assets/js/index.js HTTP/1.1" 200 3075 "https://www.dataquest.io/blog/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)"
X.X.X.X - - [09/Mar/2017:01:16:00 +0000] "GET /blog/atom.xml HTTP/1.1" 301 194 "-" "UniversalFeedParser/5.2.1 +https://code.google.com/p/feedparser/"
X.X.X.X - - [09/Mar/2017:01:16:01 +0000] "GET /blog/feed.xml HTTP/1.1" 200 48285 "-" "UniversalFeedParser/5.2.1 +https://code.google.com/p/feedparser/"
每个请求都是一行,当请求发送到服务器时,这些行按时间顺序附加。每一行的格式都是 Nginx combined格式,内部看起来是这样的:
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent"
请注意,日志格式使用类似于$remote_addr的变量,这些变量稍后会被替换为特定请求的正确值。以下是日志格式中每个变量的描述:
$remote_addr—向服务器发出请求的客户端的 ip 地址。对于日志中的第一行,这是X.X.X.X(为了保密,我们删除了 ips)。$remote_user—如果客户端使用基本认证进行认证,这是用户名。第一个日志行为空。$time_local—发出请求的当地时间。09/Mar/2017:01:15:59 +0000在第一线。$request—请求的类型,以及它被发送到的 URL。GET /blog/assets/css/jupyter.css HTTP/1.1在第一线。$status—来自服务器的响应状态码。200在第一线。$body_bytes_sent—响应正文中服务器发送给客户端的字节数。30294在第一线。$http_referrer—发送当前请求前客户端所在的页面。https://www.dataquest.io/blog/在第一线。$http_user_agent—客户端的浏览器和系统信息。Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +https://www.pingdom.com/)在第一线。
随着对日志文件的请求越来越多,web 服务器会不断地在日志文件中添加行。有时,web 服务器会轮换过大的日志文件,并存档旧数据。
你可以想象,公司从了解哪些访问者在他们的网站上,以及他们在做什么中获得了很多价值。例如,意识到使用谷歌 Chrome 浏览器的用户很少访问某个页面可能表明该页面在该浏览器中存在渲染问题。
另一个例子是了解每个国家每天有多少用户访问你的网站。它可以帮助你找出哪些国家是你营销努力的重点。在最简单的层面上,仅仅知道你每天有多少访问者就可以帮助你了解你的营销工作是否正常。
为了计算这些指标,我们需要解析日志文件并进行分析。为了做到这一点,我们需要构建一个数据管道。
思考数据管道
下面是一个简单的数据管道示例,它计算每天有多少访问者访问了网站:

从原始日志到每天的访问者数量。
正如你在上面看到的,我们从原始日志数据转到一个仪表板,在那里我们可以看到每天的访问者数量。请注意,这个管道是连续运行的——当新条目添加到服务器日志中时,它会获取并处理它们。关于我们如何构建渠道,您可能已经注意到了一些事情:
- 每个管道组件都与其他组件分离,接收定义的输入,并返回定义的输出。
- 虽然我们没有在这里展示它,但是这些输出可以被缓存或持久化以供进一步分析。
- 我们将原始日志数据存储到数据库中。这确保了如果我们想要运行不同的分析,我们可以访问所有的原始数据。
- 我们删除重复的记录。在分析过程中很容易引入重复数据,因此在通过管道传递数据之前进行重复数据删除至关重要。
- 每个管道组件都向另一个组件提供数据。我们希望每个组件尽可能小,以便我们可以单独放大管道组件,或者将输出用于不同类型的分析。
现在我们已经看到了这个管道的高级外观,让我们用 Python 来实现它。
处理和存储网络服务器日志
为了创建我们的数据管道,我们需要访问 web 服务器日志数据。我们创建了一个脚本,它将不断生成假的(但有些真实的)日志数据。下面是如何关注这篇文章的:
运行脚本后,您应该会看到新条目被写入到同一个文件夹中的log_a.txt。在100行被写到log_a.txt后,脚本会旋转到log_b.txt。它会每隔100行就在文件间来回切换。
一旦我们启动了脚本,我们只需要编写一些代码来接收(或读入)日志。该脚本需要:
- 打开日志文件并逐行读取。
- 将每一行解析成字段。
- 将每一行和解析后的字段写入数据库。
- 确保没有将重复的行写入数据库。
如果你想继续的话,代码在这个 repo 的 store_logs.py 文件中。
为了实现我们的第一个目标,我们可以打开文件,并不断尝试从其中读取行。
以下代码将:
- 以阅读模式打开两个日志文件。
- 永远循环。
- 找出两个文件中当前被读取的字符在哪里(使用
tell方法)。 - 尝试从两个文件中读取一行(使用
readline方法)。 - 如果两个文件都没有写入一行,请休眠一会儿,然后再试一次。
- 睡觉前把阅读点设回原来的位置(调用
readline前),这样就不会漏掉什么(用seek的方法)。
- 睡觉前把阅读点设回原来的位置(调用
- 如果其中一个文件写了一行,就抓取那一行。回想一下,一次只能写入一个文件,所以我们无法从两个文件中获取行。
- 找出两个文件中当前被读取的字符在哪里(使用
f_a = open(LOG_FILE_A, 'r')
f_b = open(LOG_FILE_B, 'r')
while True:
where_a = f_a.tell()
line_a = f_a.readline()
where_b = f_b.tell()
line_b = f_b.readline()
if not line_a and not line_b:
time.sleep(1)
f_a.seek(where_a)
f_b.seek(where_b)
continue
else:
if line_a:
line = line_a
else:
line = line_b
一旦我们读入了日志文件,我们需要做一些非常基本的解析,将它分成几个字段。我们不想在这里做任何太花哨的事情——我们可以把它留到以后的步骤中。您通常希望管道中的第一步(保存原始数据的那一步)尽可能地轻量级,这样失败的几率就低了。如果这一步在任何一点上失败了,您将会丢失一些原始数据,并且无法恢复!
为了保持解析简单,我们将只对空格()字符进行拆分,然后进行一些重组:
`
将日志文件解析为结构化字段。
在下面的代码中,我们:
- 取一个单独的日志行,在空格字符(
)上分割。
`* 从分割表示中提取所有字段。- 请注意,有些字段在这里看起来并不“完美”——例如,时间仍然用括号括起来。* 初始化一个存储数据库记录创建时间的
created变量。这将使未来的管道步骤能够查询数据。`
- 请注意,有些字段在这里看起来并不“完美”——例如,时间仍然用括号括起来。* 初始化一个存储数据库记录创建时间的
split_line = line.split(" ")
remote_addr = split_line[0]
time_local = split_line[3] + " " + split_line[4]
request_type = split_line[5]
request_path = split_line[6]
status = split_line[8]
body_bytes_sent = split_line[9]
http_referer = split_line[10]
http_user_agent = " ".join(split_line[11:])
created = datetime.now().strftime("%Y-%m-%dT%H:%M:%S")
我们还需要决定 SQLite 数据库表的模式,并运行所需的代码来创建它。因为我们希望这个组件简单,所以简单的模式是最好的。我们将使用以下查询来创建表:
CREATE TABLE IF NOT EXISTS logs (
raw_log TEXT NOT NULL UNIQUE,
remote_addr TEXT,
time_local TEXT,
request_type TEXT,
request_path TEXT,
status INTEGER,
body_bytes_sent INTEGER,
http_referer TEXT,
http_user_agent TEXT,
created DATETIME DEFAULT CURRENT_TIMESTAMP
)
请注意我们如何确保每个raw_log都是唯一的,因此我们避免了重复记录。另外,请注意我们是如何将所有经过解析的字段和原始日志一起插入数据库的。有一种观点认为我们不应该插入解析过的字段,因为我们可以很容易地再次计算它们。然而,将它们添加到字段中会使将来的查询更容易(例如,我们可以只选择time_local列),并且可以节省以后的计算工作量。
保留原始日志对我们有帮助,以防我们需要一些没有提取的信息,或者如果每一行中的字段顺序在以后变得重要。由于这些原因,存储原始数据总是一个好主意。
最后,我们需要将解析后的记录插入到一个 SQLite 数据库的logs表中。选择一个数据库来存储这类数据非常关键。在这种情况下,我们选择 SQLite,因为它简单,并且将所有数据存储在一个文件中。如果你更关心性能,你最好使用像 Postgres 这样的数据库。
在下面的代码中,我们:
- 连接到 SQLite 数据库。
- 实例化一个游标来执行查询。
- 将我们将插入到表中的所有值放在一起(
parsed是我们之前解析的值的列表) - 将值插入数据库。
- 提交事务,以便它写入数据库。
- 关闭与数据库的连接。
conn = sqlite3.connect(DB_NAME)
cur = conn.cursor()
args = [line] + parsed
cur.execute('INSERT INTO logs VALUES (?,?,?,?,?,?,?,?,?)', args)
conn.commit()
conn.close()
我们刚刚完成了管道的第一步!现在,我们已经存储了经过重复数据消除的数据,我们可以继续计算访问者数量了。
用数据管道统计访客数量
我们可以使用一些不同的机制在管道步骤之间共享数据:
- 文件
- 数据库
- 行列
在每种情况下,我们都需要一种方法将数据从当前步骤转移到下一个步骤。如果我们将下一步(按天计算 IP 数)指向数据库,它将能够通过基于时间的查询来提取添加的事件。虽然我们可以通过使用队列将数据传递到下一步来获得更高的性能,但性能目前并不重要。
我们将创建另一个文件, count_visitors.py ,并添加一些代码,从数据库中提取数据,并按天进行一些计数。
我们首先要从数据库中查询数据。在下面的代码中,我们:
- 连接到数据库。
- 查询在某个时间戳之后添加的任何行。
- 获取所有行。
def get_lines(time_obj):
conn = sqlite3.connect(DB_NAME)
cur = conn.cursor()
cur.execute("SELECT remote_addr,time_local FROM logs WHERE created > ?", [time_obj])
resp = cur.fetchall()
return resp
然后,我们需要一种方法从我们查询的每一行中提取 ip 和时间。以下代码将:
- 初始化两个空列表。
- 从查询响应中提取时间和 ip,并将它们添加到列表中。
def get_time_and_ip(lines):
ips = []
times = []
for line in lines:
ips.append(line[0])
times.append(parse_time(line[1]))
return ips, times
您可能会注意到,在上面的代码中,我们将字符串中的时间解析为一个 datetime 对象。用于解析的代码如下:
def parse_time(time_str):
time_obj = datetime.strptime(time_str, '[%d/%b/%Y:%H:%M:%S %z]')
return time_obj
一旦我们有了这些片段,我们只需要一种方法从数据库中提取新的行,并将它们添加到每天正在进行的访问者计数中。以下代码将:
- 基于给定的开始时间从数据库中获取要查询的行(我们获取在给定时间之后创建的任何行)。
- 从行中提取 ips 和
datetime对象。 - 如果我们有任何行,将开始时间指定为我们得到一行的最后时间。这可以防止我们多次查询同一行。
- 创建一个关键字
day,用于计算唯一 IP。 - 将每个 ip 添加到一个集合中,该集合将只包含每天的唯一 IP。
lines = get_lines(start_time)
ips, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for ip, time_obj in zip(ips, times):
day = time_obj.strftime("%d-%m-%Y")
if day not in unique_ips:
unique_ips[day] = set()
unique_ips[day].add(ip)
这段代码将确保unique_ips每天都有一个密钥,值将是包含当天访问该站点的所有唯一 IP 的集合。
按天整理 IP 后,我们只需要做一些清点。在下面的代码中,我们:
- 将每天的访客数量分配给
counts。 - 从
counts中提取元组列表。 - 将列表排序,使日期按顺序排列。
- 打印出每天的访客数量。
for k, v in unique_ips.items():
counts[k] = len(v)
count_list = counts.items()
count_list = sorted(count_list, key=lambda x: x[0])
for item in count_list:
print("{}: {}".format(*item))
然后我们可以从上面获取代码片段,这样它们每5秒运行一次:
unique_ips = {}
counts = {}
start_time = datetime(year=2017, month=3, day=9)
while True:
lines = get_lines(start_time)
ips, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for ip, time_obj in zip(ips, times):
day = time_obj.strftime("%d-%m-%Y")
if day not in unique_ips:
unique_ips[day] = set()
unique_ips[day].add(ip)
for k, v in unique_ips.items():
counts[k] = len(v)
count_list = counts.items()
count_list = sorted(count_list, key=lambda x: x[0])
for item in count_list:
print("{}: {}".format(*item))
time.sleep(5)
将管道拉在一起
我们现在已经浏览了生成日志的脚本,以及分析日志的两个管道步骤。为了使整个管道运行:
- 如果你还没有从 Github 克隆 analytics _ pipeline repo。
- 按照 README.md 文件进行设置。
- 执行
log_generator.py。 - 执行
store_logs.py。 - 执行
count_visitors.py。
运行count_visitors.py之后,您应该会看到每5秒钟打印出来的当天的访问者数量。如果您让脚本运行多天,您将开始看到多天的访问者计数。
恭喜你!您已经设置并运行了一个数据管道。现在让我们创建另一个从数据库中提取数据的管道步骤。
向数据管道添加另一个步骤
将管道分成独立的部分的主要好处之一是,很容易将一个步骤的输出用于另一个目的。与其计算访问者,不如让我们试着算出有多少访问我们网站的人使用每种浏览器。这将使我们的管道看起来像这样:

我们现在有一个管道步骤驱动两个下游步骤。
如您所见,一个步骤转换的数据可以是两个不同步骤的输入数据。如果您想继续这个管道步骤,您应该查看您克隆的 repo 中的count_browsers.py文件。
为了统计浏览者的数量,我们的代码与统计访问者数量的代码基本相同。主要区别在于我们解析用户代理来检索浏览器的名称。在下面的代码中,您会注意到我们查询的是http_user_agent列而不是remote_addr,我们解析用户代理来找出访问者使用的浏览器:
def get_lines(time_obj):
conn = sqlite3.connect(DB_NAME)
cur = conn.cursor()
cur.execute("SELECT time_local,http_user_agent FROM logs WHERE created > ?", [time_obj])
resp = cur.fetchall()
return resp
def get_time_and_ip(lines):
browsers = []
times = []
for line in lines:
times.append(parse_time(line[0]))
browsers.append(parse_user_agent(line[1]))
return browsers, times
def parse_user_agent(user_agent):
browsers = ["Firefox", "Chrome", "Opera", "Safari", "MSIE"]
for browser in browsers:
if browser in user_agent:
return browser
return "Other"
然后我们修改我们的循环来统计访问该站点的浏览器:
browsers, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for browser, time_obj in zip(browsers, times):
if browser not in browser_counts:
browser_counts[browser] = 0
browser_counts[browser] += 1
一旦我们做了这些改变,我们就可以运行python count_browsers.py来计算有多少浏览器访问了我们的网站。
我们现在已经创建了两个基本的数据管道,并演示了数据管道的一些关键原则:
- 使得每一步都相当小。
- 使用定义的接口在管道之间传递数据。
- 存储所有的原始数据用于以后的分析。
扩展数据管道
学完本数据管道教程后,您应该理解如何用 Python 创建一个基本的数据管道。但是现在不要停下来!请随意扩展我们实现的管道。以下是一些想法:
- 你能做一个能处理更多数据的管道吗?如果连续生成日志消息会怎样?
- 你能定位 IP 地址来找出访问者的位置吗?
- 你能找出哪些页面最常被点击吗?
如果您可以访问真实的 web 服务器日志数据,您可能还想对这些数据尝试一些脚本,看看是否可以计算出任何有趣的指标。
想要通过交互式、深入的数据工程课程将您的技能提升到一个新的水平吗?试试我们的数据工程师路径,它帮助你从头开始学习数据工程。 ### 成为一名数据工程师!
现在就学习成为一名数据工程师所需的技能。注册一个免费帐户,访问我们的交互式 Python 数据工程课程内容。
(免费)
https://www.youtube.com/embed/ddM21fz1Tt0?rel=0``
数据检索和清理:跟踪迁移模式
原文:https://www.dataquest.io/blog/data-retrieval-and-cleaning/
May 23, 2018
提升你的技能是成为数据科学家的重要组成部分。刚开始时,你主要集中在学习一门编程语言、正确使用第三方工具、显示可视化以及对统计算法的理论理解。下一步是在更难的数据集上测试你的技能。
有时,这些数据集需要大量清理,或者格式不良,或者很难找到。有很多关于理解我们周围数据的重要性的内容,但很少发现关于你如何实际获得数据的内容。
随着数据科学家的成长,最初的数据调查、探索和检索是最重要的学习步骤。不可否认,从各种来源中寻找和清理一个数据集会产生前期成本,但是一旦有了这个干净的、格式良好的、可理解的数据集,回答关于数据的多个问题的可能性就会大大增加。
在本帖中,我们将研究、检索和清理真实世界的数据集。为了纪念世界候鸟日,我们将使用候鸟数据。我们还将描述构建您自己的数据集所涉及的成本优势和必要工具。有了这些基础知识,你将能够到野外去找到你自己的数据集来使用。
研究现有的候鸟数据集
你应该从一个关键问题开始每项调查:我们想要了解什么?有了这个问题,就更容易找到合适的数据集。在我们的例子中,我们想了解北美鸟类的迁徙模式。为了理解这些模式,我们需要找到几年来准确的迁移数据。
像这样晦涩难懂的数据很难找到。可能会有业余爱好者在个人网站、论坛或其他渠道上存放自己的数据,但业余爱好者的数据集通常容易出错,并包含缺失的数据。相反,我们应该在政府或大学网站上寻找更专业的数据集。
用谷歌搜索关键词“鸟类迁徙”、“数据库”和“美国”,我们找到了几个有鸟类迁徙信息的网站。第一个名为 eBird ,包含康奈尔实验室托管的鸟类迁徙数据。第二个来自美国鱼类和野生动物服务 (USFWS)网站,该网站使用合作伙伴关系和公民研究数据来创建他们的报告。我们希望使用来自两个服务的数据集,这样我们就可以交叉检查数据并确定不一致的地方。
让我们从 eBirds 数据集开始。
导航到下载页面,您将被要求在康奈尔研究实验室创建一个帐户。登录后,您可以进入下载页面。但是在访问完整的数据集之前,您需要填写一张表格,描述您打算如何使用这些数据。我们成功地填写了表格,等了几天,才获得对数据集的完全访问权。需要时间,但不太难。

接下来,我们来看看 USFWS。乍一看,这个网站似乎比 eBirds 门户网站更容易使用。有一个清晰的链接,引导我们找到不同鸟类、地理数据点和迁徙路线的完整数据库列表。如果有有效的链接,这些有序分类的数据集将会非常有帮助并且易于分析。

不幸的是,从 USFWS 门户检索数据并不容易。有多个死链接,格式不良的数据集,HTML 按钮并不像宣传的那样工作。虽然这些问题大多是糟糕的接口设计,但所有 HTTP 端点似乎都工作正常,并且使用一点 Python 代码,我们会发现我们能够获得我们需要的数据。
寻找数据
由于 USFWS 网站提供了大量的链接,很难找到可能的数据集端点。当我们深入研究时,我们发现的第一个成功的数据集是通过链接到 USFWS 出版的水禽飞行路线模式的数据手册。这本数据手册应该包含了我们调查所需的所有信息,但有一个重大缺陷:它是以 PDF 格式存储的。由于 pdf 的结构不一致,很难对其进行解析,所以这应该是最后的手段。

致力于水禽飞行路线模式的数据集,我们决定遵循另一个链接路径到 USFWS 报告。这些报告被描述为 1995 年以来北美水禽飞行路线模式的调查数据;正是我们要找的。一旦我们点击报告的链接,就会看到一个服务条款和免责声明拦截器。接受它后,有一个报告生成表单,使研究人员能够限制水禽类型、状态或发现家禽的“地块”的数据。

我们没有限制数据,而是选择表单中的每一个值,然后点击 submit。最后,我们看到一个分页的表,其中包含完整数据集的样本。

滚动到页面底部还有一个下载整个数据集的按钮!不幸的是,按下按钮会将我们重定向到一个403 Unauthorized页面。
有点沮丧,但不是没有希望,我们寻找解决办法。首先,我们回顾检索数据的步骤。步骤是导航到下载页面,提交一个简单的表单 sublesson,解析一个 HTML 格式的表,并在每一页数据上运行解析器。想想这些步骤,我们意识到使用 Python web 抓取脚本可以很容易地实现自动化!
下载数据
我们将使用两个主要的包来收集数据。
- 请求(用于发出 HTTP 请求)
- beautifulsoup (用于解析 HTML)
我们从requests开始执行 HTTP 请求、表单提交和下载 HTML 表格文件。使用 Chrome 开发工具,我们将导航到调查表格页面,填写表格中的所有值,按下提交按钮,并检查请求的标题。

我们已经分别突出显示了请求类型、URL 和表单数据的字段。从屏幕截图来看,要生成报告,我们需要使用给定的表单数据向 URL 发送 POST 请求。为了使事情变得简单,我们将使用 URL 编码的表单数据源代码。然后,我们将使用下面的代码片段发出我们的 POST 请求,使用 requests.post() 和x-www-form-urlencoded内容类型头。
import requests
form_data = (
"txtYr=1993%2C1994%2C1995%2C1996%2C1997%2C1998%2C1999%2C2000%2C2001%2C2002%2C2003%2C2004%2C2005%2C2006%2C2007%2C2008%2C2009%2C2010%2C2011%2C2012%2C2013%2C2014%2C2015" "&txtSpecies=ABDU%2CAGWT%2CBWTE%2CCAGO%2CCOME%2CGADW%2CHOME%2CMALL%2CMUSW%2CWODU%2COTHER%2CTOTAL"
"&txtSpeciesName=American+black+duck%2CGreen-winged+teal%2CBlue-winged+teal%2CCanada+goose%2CCommon+merganser%2CGadwall%2CHooded+merganser%2CMallard%2CMute+swan%2CWood+duck%2C+Other+Species%2Cucks"
"&txtFlyway="
"&txtState=CT%2CDE%2CMA%2CMD%2CNH%2CNJ%2CNY%2CPA%2CRI%2CVA%2CVT"
"&txtPlots="
"&db=request%28%22db%22%29"
"&txtCurrPage=1"
"&LoadPage=query"
"&txtRows=55"
"&submit1=Submit"
)
re = requests.post('https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp', data=form_data, headers={'Content-Type': 'application/x-www-form-urlencoded'})
这个感觉是正确的,但是在我们发出请求之前,我们遗漏了一个关键部分。如果我们要运行这个代码片段,我们的请求将被 required terms and conditions 页面阻止,而不是返回报告。回想一下,USFWS 要求您在使用数据之前接受他们的免责声明。
要解决这个问题,请注意,当接受条款和条件时,您的浏览会话可以完全访问其余的报告。为了在 Python 脚本中重新创建这种行为,我们需要实例化一个持久的requests.Session对象。使用requests.Session对象,我们将通过导航到“accept”页面来接受免责声明,通过认证会话,我们将提交表单数据。
总的来说,它看起来像:
import requests
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = (
"txtYr=1993%2C1994%2C1995%2C1996%2C1997%2C1998%2C1999%2C2000%2C2001%2C2002%2C2003%2C2004%2C2005%2C2006%2C2007%2C2008%2C2009%2C2010%2C2011%2C2012%2C2013%2C2014%2C2015"
"&txtSpecies=ABDU%2CAGWT%2CBWTE%2CCAGO%2CCOME%2CGADW%2CHOME%2CMALL%2CMUSW%2CWODU%2COTHER%2CTOTAL"
"&txtSpeciesName=American+black+duck%2CGreen-winged+teal%2CBlue-winged+teal%2CCanada+goose%2CCommon+merganser%2CGadwall%2CHooded+merganser%2CMallard%2CMute+swan%2CWood+duck%2C+Other+Species%2Cucks"
"&txtFlyway="
"&txtState=CT%2CDE%2CMA%2CMD%2CNH%2CNJ%2CNY%2CPA%2CRI%2CVA%2CVT"
"&txtPlots="
"&db=request%28%22db%22%29"
"&txtCurrPage=1"
"&LoadPage=query"
"&txtRows=55"
"&submit1=Submit"
)
re = se.post('https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp', data=form_data, headers={'Content-Type': 'application/x-www-form-urlencoded'})
成功!我们得到了所需的报告表,但是注意有 616 页的数据需要解析。我们可以减少数量的一种方法是选择更大数量的textRows表单值。让我们将其更改为最大值,即每个表 99 行。
import requests
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = (
"txtYr=1993%2C1994%2C1995%2C1996%2C1997%2C1998%2C1999%2C2000%2C2001%2C2002%2C2003%2C2004%2C2005%2C2006%2C2007%2C2008%2C2009%2C2010%2C2011%2C2012%2C2013%2C2014%2C2015"
"&txtSpecies=ABDU%2CAGWT%2CBWTE%2CCAGO%2CCOME%2CGADW%2CHOME%2CMALL%2CMUSW%2CWODU%2COTHER%2CTOTAL"
"&txtSpeciesName=American+black+duck%2CGreen-winged+teal%2CBlue-winged+teal%2CCanada+goose%2CCommon+merganser%2CGadwall%2CHooded+merganser%2CMallard%2CMute+swan%2CWood+duck%2C+Other+Species%2Cucks"
"&txtFlyway="
"&txtState=CT%2CDE%2CMA%2CMD%2CNH%2CNJ%2CNY%2CPA%2CRI%2CVA%2CVT"
"&txtPlots="
"&db=request%28%22db%22%29"
"&txtCurrPage=1"
"&LoadPage=query"
"&txtRows=99" # Change from 55 to 99.
"&submit1=Submit"
)
re = se.post('https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp', data=form_data, headers={'Content-Type': 'application/x-www-form-urlencoded'})
现在我们已经有了每页的最大行数,我们可以进入 HTML 解析步骤了。
解析数据
为了解析数据,我们需要用报告响应 HTML 字符串创建一个BeautifulSoup对象。在底层,BeautifulSoup对象将 HTML 字符串转换成树状数据结构。这使得查询标签变得容易,比如包含报告数据的<table>标签。
import requests
from bs4 import BeautifulSoup
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = (
"txtYr=1993%2C1994%2C1995%2C1996%2C1997%2C1998%2C1999%2C2000%2C2001%2C2002%2C2003%2C2004%2C2005%2C2006%2C2007%2C2008%2C2009%2C2010%2C2011%2C2012%2C2013%2C2014%2C2015"
"&txtSpecies=ABDU%2CAGWT%2CBWTE%2CCAGO%2CCOME%2CGADW%2CHOME%2CMALL%2CMUSW%2CWODU%2COTHER%2CTOTAL"
"&txtSpeciesName=American+black+duck%2CGreen-winged+teal%2CBlue-winged+teal%2CCanada+goose%2CCommon+merganser%2CGadwall%2CHooded+merganser%2CMallard%2CMute+swan%2CWood+duck%2C+Other+Species%2Cucks"
"&txtFlyway="
"&txtState=CT%2CDE%2CMA%2CMD%2CNH%2CNJ%2CNY%2CPA%2CRI%2CVA%2CVT"
"&txtPlots="
"&db=request%28%22db%22%29"
"&txtCurrPage=1"
"&LoadPage=query"
"&txtRows=99"
"&submit1=Submit"
)
re = se.post('https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp', data=form_data, headers={'Content-Type': 'application/x-www-form-urlencoded'})
soup = BeautifulSoup(re.text, "lxml")
使用我们的可解析对象,我们现在可以在 HTML 文档中搜索<table>标签。在文档中,报表数据在第二个<table>中,所以我们将使用.findAll()方法并选择列表中的第二项。然后,我们将过滤表中的所有行,<tr>,并将它们设置为一个rows变量。
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
接下来,我们希望提取标题行并清理值。作为参考,HTML 表格的标题行使用<th>标签格式化,数据行使用<td>格式化。为了获得标签值,我们需要调用一个BeautifulSoup标签的.string属性。我们将从表的第一行获取标题值。
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string for col in rows[0].findAll('th') if col.string]
提取了标题后,就该从行中获取数据了。我们将遍历表中剩余的行,找到所有的<td>标记,并将其分配给一个新行。此外,我们将合并标题和行,然后清除值周围的一些空白,使其更容易解析。
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string.strip() for col in rows[0].findAll('th') if col.string]
modified_rows = []
for row in rows[1:]:
modified_row = [col.string.strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rows
使用unicodedata.normalize()进行更多的 unicode 清理,我们应该得到以下输出:
import unicodedata
soup = BeautifulSoup(re.text, "lxml")
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string.strip() for col in rows[0].findAll('th') if col.string]
modified_rows = []
for row in rows[1:]:
modified_row = [unicodedata.normalize('NFKD', col.string).strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rows
print(table[:3])
>> [['Year', 'State', 'Stratum', 'Plot', 'Type of check', 'Wet Habitat', 'AMERICAN BLACK DUCK TIP', 'AMERICAN BLACK DUCK TIB', 'GREEN-WINGED TEAL TIP', 'GREEN-WINGED TEAL TIB', 'BLUE-WINGED TEAL TIP', 'BLUE-WINGED TEAL TIB', 'CANADA GOOSE TIP', 'CANADA GOOSE TIB OLD', 'CANADA GOOSE TIB NEW', 'COMMON MERGANSER TIP', 'COMMON MERGANSER TIB', 'GADWALL TIP', 'GADWALL TIB', 'HOODED MERGANSER TIP', 'HOODED MERGANSER TIB', 'MALLARD TIP', 'MALLARD TIB', 'MUTE SWAN TIP', 'MUTE SWAN TIB', 'WOOD DUCK TIP', 'WOOD DUCK TIB', 'OTHER SPECIES TOTAL', 'TOTDUCKS'], ['1993', 'CT', '012', '0002', '2', 'Y', 'N', '0', '0', '', '0', '', '0', '', '0', '', '', '0', '', '', '', '0', '0', '0', '', '0', '1', '2', '', '2'], ['1993', 'CT', '012', '0004', '1', 'Y', 'Y', '0', '0', '', '0', '', '0', '', '2', '', '', '0', '', '', '', '0', '0', '0', '', '0', '0', '0', '', '0']]
通过解析我们的表,我们可以遍历数据集的每一页,并将值组合在一起。
把所有的放在一起
在构建完整的数据集之前,还有三个部分需要实现:
- 查找要分页的数据的总页数。
- 创建一个
form_data模板来动态修改表单数据。 - 遍历页面,合并所有行。
我们从第一点开始。查看报告页面的 HTML,我们看到总页数在标题中。从标题中提取总数的一种方法是从标题中分离出数字,然后将其转换为整数。这是可行的,但是依赖标题字符串的解决方案太脆弱了。
相反,如果我们仔细查看表单数据,会发现有一个隐藏的输入字段为我们工作。在标记的底部,有一个带有name=txtLastPage的输入值。使用BeautifulSoup,我们只需要搜索一个输入标签和匹配的名称,并将值转换成一个整数。这里有一个潜在的实现。
from bs4 import BeautifulSoup
import requests
import unicodedata
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data = (
"txtYr=1993%2C1994%2C1995%2C1996%2C1997%2C1998%2C1999%2C2000%2C2001%2C2002%2C2003%2C2004%2C2005%2C2006%2C2007%2C2008%2C2009%2C2010%2C2011%2C2012%2C2013%2C2014%2C2015"
"&txtSpecies=ABDU%2CAGWT%2CBWTE%2CCAGO%2CCOME%2CGADW%2CHOME%2CMALL%2CMUSW%2CWODU%2COTHER%2CTOTAL"
"&txtSpeciesName=American+black+duck%2CGreen-winged+teal%2CBlue-winged+teal%2CCanada+goose%2CCommon+merganser%2CGadwall%2CHooded+merganser%2CMallard%2CMute+swan%2CWood+duck%2C+Other+Species%2Cucks"
"&txtFlyway="
"&txtState=CT%2CDE%2CMA%2CMD%2CNH%2CNJ%2CNY%2CPA%2CRI%2CVA%2CVT"
"&txtPlots="
"&db=request%28%22db%22%29"
"&txtCurrPage=1"
"&LoadPage=query"
"&txtRows=99"
"&submit1=Submit"
)
re = se.post('https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp', data=form_data, headers={'Content-Type': 'application/x-www-form-urlencoded'})
soup = BeautifulSoup(re.text, "lxml")
# Find the last page value.
total_pages = soup.find('input', {'name': 'txtLastPage'}).get('value')
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = [col.string.strip() for col in rows[0].findAll('th') if col.string]
modified_rows = []
for row in rows[1:]:
modified_row = [unicodedata.normalize('NFKD', col.string).strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rows
现在,我们要将模板和分页一起添加进去。首先,我们将创建一个form_data的字符串模板,它使用字符串格式提交动态表单数据。在我们的例子中,我们希望动态修改当前页面值。接下来,我们将使用总页数值并继续循环,直到用完数据集。经过一点清理,我们得到了下面的最终实现:
from bs4 import BeautifulSoup
import requests
import unicodedata
# Set a url constant.
REPORT_URL = "https://migbirdapps.fws.gov/mbdc/databases/afbws/disp_plot.asp"
se = requests.Session()
se.get("https://migbirdapps.fws.gov/mbdc/databases/afbws/afbws.asp?opt=1")
form_data_template = (
"txtYr=1993%2C1994%2C1995%2C1996%2C1997%2C1998%2C1999%2C2000%2C2001%2C2002%2C2003%2C2004%2C2005%2C2006%2C2007%2C2008%2C2009%2C2010%2C2011%2C2012%2C2013%2C2014%2C2015"
"&txtSpecies=ABDU%2CAGWT%2CBWTE%2CCAGO%2CCOME%2CGADW%2CHOME%2CMALL%2CMUSW%2CWODU%2COTHER%2CTOTAL"
"&txtSpeciesName=American+black+duck%2CGreen-winged+teal%2CBlue-winged+teal%2CCanada+goose%2CCommon+merganser%2CGadwall%2CHooded+merganser%2CMallard%2CMute+swan%2CWood+duck%2C+Other+Species%2Cucks"
"&txtFlyway="
"&txtState=CT%2CDE%2CMA%2CMD%2CNH%2CNJ%2CNY%2CPA%2CRI%2CVA%2CVT"
"&txtPlots="
"&db=request%28%22db%22%29"
"&txtCurrPage={}" # Add format template.
"&LoadPage=query"
"&txtRows=99"
"&submit1=Submit"
)
# Find total pages.
re = se.post(REPORT_URL, data=form_data_template.format(1), headers={'Content-Type': 'application/x-www-form-urlencoded'})
soup = BeautifulSoup(re.text, "lxml")
total_pages = int(soup.find('input', {'name': 'txtLastPage'}).get('value', 1))
# Take out the header and modified rows out of the loop.
header = []
modified_rows = []
for current_page in range(1, total_pages + 1):
re = se.post(REPORT_URL, data=form_data_template.format(current_page), headers={'Content-Type': 'application/x-www-form-urlencoded'})
data_table = soup.findAll('table')[1]
rows = data_table.findAll('tr')
header = header or [col.string.strip() for col in rows[0].findAll('th') if col.string]
for row in rows[1:]:
modified_row = [unicodedata.normalize('NFKD', col.string).strip() for col in row.findAll('td')]
modified_rows.append(modified_row)
table = [header] + modified_rows
厉害!我们已经提取了完整的数据集,它也处于 Python 可读状态。从这里,我们可以添加更多的数据清理,将表保存到文件中,并对数据执行一些分析。
结论
使用一些基本的 Python web 抓取,我们能够:
- 使用会话访问仅经过身份验证的内容。
- 解析 HTML 表格数据并将数据映射到 Python 列表中。
- 跨多个 HTML 页面自动抓取数据集。
从这个例子中,我们能够展示 Python 对于数据调查、清理和检索的 web 抓取能力。正如本文开头所提到的,当问数据科学中更困难的问题时,你需要寻找你自己的数据集。网络上有大量的可用数据。一旦你有了工具和经验去寻找和收集这些数据,你将会在你的分析中得到很高的回报。
如果您想更新示例,可以添加以下内容:
- 用表格数据创建一个 CSV 文件。
- 使用协程或线程来加速网络调用的阻塞。
- 循环浏览页面,而不必两次请求第一页。
- 添加错误处理以提高代码的健壮性。
更新:自发布之日起,现在可以下载包含美国渔业署水禽飞行路线所有数据的 ASCII CSV 文件。尽管如此,这个例子很好地介绍了 web 抓取、数据检索以及长期维护这些类型的脚本的困难。
凯特琳是如何从宜家的零售到亚马逊的数据科学的
原文:https://www.dataquest.io/blog/data-science-amazon-dataquest-student/
April 3, 2019
不久前,凯特琳·惠特洛克还在宜家从事零售工作。她有一个运动科学的大学学位,但她并没有使用,她也不确定自己长期想做什么。现在,她在亚马逊担任数据科学家,教 Alexa 更好地理解人类语言。
她是怎么去的?很多艰苦的工作,包括在 Dataquest 上的大量时间。
凯特琳大学毕业后的职位实际上很普通。只有 27%的大学毕业生从事与其学位相关的领域。但对凯特琳来说幸运的是,她在宜家的工作包括偶尔在 Excel 中做一些数据工作,她很快发现自己喜欢这份工作。她决定转行,在南佛罗里达大学(USF)攻读第二个学士学位,重点是数据分析。
离线学习,在线学习数据科学
凯特琳相对较快地看到了成功。在 USF 学习期间,她从宜家跳槽到一家数据分析师的公司。但是后来,她在学校董事会面前做的学校演示非常成功,一名董事会成员向她提供了一份在科技数据公司担任初级数据科学家的工作。只有一个问题:凯特琳的学位更侧重于会计、财务分析和商业法等无关紧要的主题,实际上并没有让她做好从事数据科学工作的准备。
“USF 的程序真的没有进入任何类型的预测分析,或任何类似的东西,”她说。“我的工作是一名初级数据科学家,但我的学位根本没有让我为此做好准备。”
被迫学习,凯特琳去网上寻找数据科学学习材料。当她发现 Dataquest 时,她意识到它可能很有价值,并说服她在 Tech Data 的老板给她弄了一份订阅。
“我喜欢 Dataquest 的设置方式,”她说。在其他平台上,她会浪费大量时间来搜索她需要的特定信息,但由于 Dataquest 的路径,她可以很容易地按照逻辑顺序了解她需要的信息。“我发现了 Dataquest,它是预先策划的,超级棒,”她说。
她还喜欢 Dataquest 的答案检查如何在每一步提供即时反馈,这样学生就可以很容易地知道他们是否做对了。“其他平台,比如 EdX,甚至在某种程度上像 Coursera,他们什么都不评分,”她说。“他们不会告诉你你过得怎么样。你有点盲目。我喜欢 Dataquest 给你的反馈。”
转移到亚马逊
在 Tech Data,Caitlin 花了大量时间研究 Dataquest。“我做了很多,”她说。“实际上,我一天的大部分时间都花在了(数据探索)上。”这是一个很好的学习机会,但也反映了她工作中的一点问题:Tech Data 似乎不知道如何最好地利用她的数据科学技能。
认识到这个问题,凯特琳开始寻找新的职位。几个月后,她在亚马逊找到了一份 Alexa T1 的工作,并从佛罗里达州的坦帕搬到了马萨诸塞州的波士顿。
她说,申请亚马逊让她感到害怕。“经历面试是一次可怕的经历。我基本上事先尽可能多的在 Dataquest 上做了填充,这最终真的很有帮助。
由于亚马逊不喜欢分享其人工智能助手 Alexa 背后的秘密,凯特琳无法分享关于她目前角色的太多细节。但她说,从大的方面来看,她所做的是帮助教会 Alexa 如何更好地理解人。
“这有点像数据科学的利基领域,因为它与数字没有什么关系,”她说。“我们做了很多自然语言方面的工作。但我不能对我们的做事方式说太多。”
给有抱负的数据科学家的建议
凯特琳说,如果你在学习 Dataquest,重要的是既要完成指导项目,又要拓展自己的领域,寻找新的挑战。
“我肯定会说,要继续完成[Dataquest]安排的所有任务,”她说。但是她也鼓励学生们想出自己独特的项目来进行研究。“浏览策划好的作业并把它们做对是很棒的,”她说,“但你可以对任何怪异的事情进行预测分析,这种实践真的很有帮助。”
当你准备申请工作时,凯特琳说,不要低估自己!“老实说,申请任何工作,都行,”她说。“如果你认为自己不会得到这份工作,那就去申请吧。我见过很多人因为害怕而不去申请。”
她说,对搬迁持开放态度也很重要。“我确实从佛罗里达州的坦帕搬到了马萨诸塞州的波士顿(为了亚马逊的工作)。我认为有时有必要搬家,尤其是在像数据科学这样的新领域。”

https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
Stitch Fix 的数据科学:布拉德·克林根贝格访谈
原文:https://www.dataquest.io/blog/data-science-at-stitch-fix/
December 14, 2015
概述
布拉德·克林根伯格是旧金山 Stitch Fix 的造型算法总监。他的团队使用数据和算法来改善发送给客户的商品选择。在加入 Stitch Fix 之前,Brad 曾在金融和科技公司从事数据和预测分析工作。他在科罗拉多大学博尔德分校学习应用数学,并于 2012 年在斯坦福大学获得统计学博士学位。
缝补的教训是什么?
Brad: Stitch Fix 是一项针对女性的在线个人造型服务。我们的课程是帮助我们的客户看起来、感觉起来并成为最好的自己。当客户注册这项服务时,他们会告诉我们他们对合身和风格的偏好,然后我们会给他们发送五个项目的个性化选择,我们称之为“修复”。他们只保留自己喜欢的东西,其余的寄回去。我们通过结合推荐算法和人工监管来选择要发送的内容,为我们的客户挑选完美的库存。
你在 Stitch Fix 的角色是什么?
Brad: 我领导 Stitch Fix 的造型算法团队。概括地说,我们的目标是帮助挑选客户喜欢的商品。我们开发算法,利用我们对客户、库存和以往修复反馈的了解,向设计师推荐库存。我们还研究一些问题,比如为客户寻找最佳造型师,理解、衡量和优化推荐系统中人力选择的作用。
Dataquest: 人们把 Stitch Fix 称为服装界的网飞,你们显然有很多来自网飞的天才。
你们从网飞文化中引进了什么来修补针脚?
Stitch Fix 的几个人,包括首席算法官 Eric Colson,来自网飞。我在那里做研究生咨询时认识了埃里克。两家公司推荐的相似之处可能很明显。然而,缝合修复问题有许多不同的方式。例如,在 Stitch Fix,我们通过向客户实际交付商品来承诺我们的建议——犯错的代价很大。我们还利用人类造型师的专业判断来策划我们的建议。网飞文化有很多令人钦佩的地方。在 Stitch Fix,我们培养了对客户的热情关注。作为一名数据科学家,您有机会以各种方式直接改善我们客户的成果,从帮助我们做出购买库存的决策,到优化我们的运营,当然还有通过影响我们发送给客户的信息,这只是几个例子。以这种切实的方式影响业务的机会有助于吸引有才华的数据科学家和工程师。
Dataquest: Stitch Fix 在人机共生的方法上有些独特,因为实际上是人而不是计算机做出最终的建议。
你能谈谈 Stitch Fix 的人机共生方法吗?
Brad: 个人造型是个复杂的问题。为客户选择最佳项目取决于使用各种结构化和非结构化数据。在这个过程中,我们发现人类和机器是互补的。例如,统计模型非常适合从大型数据集中的细微模式做出预测,而这是人类永远无法做到的。另一方面,人类擅长处理非结构化数据,如图像和来自客户的书面请求,并擅长以整体方式考虑客户。我们的造型师还培养与客户的个人关系,例如,在每一次修复中添加个性化的注释。让人们参与进来非常有效,这对我们的客户非常有利。但也很复杂。我们的设计师的选择增加了另一个反馈回路,我们可以用它来改进我们的算法,同时也引入了偏见。例如,假设我们的设计师从不在炎热的气候下给客户送厚重的冬季毛衣。对于我们的客户来说,这很可能是正确的做法,但我们从来没有真正观察过毛衣是如何做的——这些数据会被我们的设计师有效地审查。当训练一个模型的时候,这可能是一个挑战。
Datquest: 使用推荐系统时,一个众所周知的问题是冷启动问题。
考虑到这一点,人们学习和实践构建推荐系统的最佳方式是什么?
Brad: 在真空中很难建立一个现实的推荐系统。有各种流行的方法(例如基于内容的方法、协作过滤方法和基于因子分解的方法)比其他方法更适合某些问题。这真的取决于你的数据。例如,数据的稀疏程度或同现程度可能会影响协同过滤或因式分解方法是否可行。对于有抱负的数据科学家,我建议尝试使用真实数据。有一些免费的数据集,如电影镜头。还值得记住的是,提出建议与其他监督学习问题有许多相似之处。建立统计模型的一般经验以及选择、实施和评估模型的周期将是有价值的,几乎与领域无关。
Dataquest: 你拥有统计学博士学位,并从事了几年的定量分析师工作。
对于没有你的背景和经验,却渴望在像 Stitch Fix 这样有才华的数据科学组织工作的人,你有什么建议?
布拉德:学习应用统计学的基础知识!构建模型时,实用很重要——从简单的东西开始。如果你还是一名学生,试着在一家公司找一份工业实习,在那里你将接触到有趣的数据。一个全面的数据科学家也将是一个足够好的工程师来完成工作。尝试获得使用 R 和 python 等语言的经验。了解凸优化的基础知识将有助于您在拟合模型时做出实际的选择。如果你以前没有写过,自己写一些优化代码是很有用的。框定问题的能力和技能一样重要。寻求经验会帮助你发展这项技能。尝试了解不同的问题,不同的工具是首选。它们有什么不同?在学术界,许多研究问题为构建商业问题提供了很好的经验。试着用模糊来发展一种安慰。
数据探索:数据科学非常广泛,这个领域吸引了各种背景的人。
Stitch Fix 的入职流程如何帮助新人融入公司文化?
Brad:Stitch Fix 的数据科学团队在过去两年中发展迅速。我们雇佣了各种背景的人——从物理学到心理学。在许多情况下,特定的背景不如处理数据的历史和建立并应用统计模型的坚实基础重要。我们在 Stitch Fix 的团队非常协作,我们的新员工在快速工作的同时,会与团队中的许多其他数据科学家一起工作。几位新员工写下了他们的经历:
- 亚历克斯·斯莫良斯卡娅
- 艾琳·博伊尔
您发现数据科学课程中经常缺少或不重视哪些技能?
Brad: 我认为人们很容易被复杂性所吸引,而像线性模型及其扩展和基本推理这样的基础工具往往不被重视。对于大多数数据科学来说,这些都是真正的主力。正如我在我们的科技博客上所说的,线性模型因其简单而具有许多优点——它们易于解释、易于扩展和缩放。虽然看起来很原始,但在大量的问题中,它们也是令人惊讶的有效工具。
Dataquest: Stitch Fix 已经在博客上写了一点关于 Julia 语言的内容,其中有一个大胆的教训,那就是从头开始构建技术计算的最佳语言。
Stitch Fix 在生产中使用 Julia 语言吗?
Julia 在 Stitch Fix 的生产中没有被广泛使用。我们确实有一些朱莉娅的爱好者,也有过像约翰·迈尔斯·怀特(T2)这样的人做的精彩客座演讲。虽然我个人并没有严肃地使用 Julia,但我认为这是一个令人兴奋的项目,我希望它继续为 R 和 Python 作为数据科学的主导语言提供更多的竞争。
人们在哪里可以了解更多关于 Stitch Fix 的文化?
Brad: 我们的科技博客多线程是一个很好的起点。您还会经常在 PyData、MLconf、HCOMP、Strata 等会议上看到。
最后,Stitch Fix 在招人吗?
布莱德:是的,我们在招人!https://www.stitchfix.com/careers
2022 年 54 本最佳数据科学书籍(由专家评审)
September 7, 2022

What are the best books for learning data science?
重要的事情先来:如果你想学习数据科学,你能做的最重要的事情就是获得一些真实世界的数据并开始编码。我们的学习平台旨在帮助您做到这一点。即使你没有使用 Dataquest,你学习数据技能的主要方法应该是动手,而不是被动。
但是当你不坐在电脑前的时候,你能做些什么来保持学习呢?看一些数据科学的书!
正如我们最近采访的一名学生所指出的,当你不能实际接触代码时,电子书是让你沉浸在数据科学中的一个很好的方式。例如,想象一下在乘坐公共汽车时阅读,或者在杂货店排队时阅读。
你也可以像听播客一样听书。只需使用带有“大声朗读”功能的电子书应用程序,或者选择付费购买有声读物。
不过,有很多不同的数据科学书籍可供选择。哪些值得花时间?我们在下面列出了一些最好的。好消息是什么?这些书很多都是完全免费的!
注意:下面的一些链接是 PDF 链接。在可能的情况下,我们尝试链接到免费版本的书籍。
非技术数据科学书籍
这些书籍可以帮助激励您开始或继续您的数据科学之旅。或者它们可以帮助您更好地理解数据科学领域的重要问题。你不会从它们中学到很多实用技能,但它们是很好的读物,有助于展示数据和统计在现实世界中是如何使用的。
1. 数学毁灭的武器(2016 年 9 月)
评分:4.5/5(3017)

最受欢迎的非虚构作品之一是关于“大数据”和机器学习如何不像它们可能出现的那样没有偏见。前华尔街量化分析师写的。
2. 大数据:一场将改变我们生活、工作和思考方式的革命(2014 年 3 月)
评级 : 4.3/5 (827)

一个好的“大图”阅读关于数据和机器学习如何改变现实世界的生活——以及未来还有什么可能改变。如果你听说过炒作,但不确定数据科学如何影响事物,这是一个好的起点。
3. 赤裸裸的统计:剥离数据中的恐惧(2014 年 1 月)
评分:4.6/5(2236)

外行人阅读的关于统计和数据的好读物。如果你对学习数据科学感兴趣,但距离你的第一门数学课已经有一段时间了,这本书适合你。理想情况下,它将帮助你建立信心和直觉,了解统计数据在现实世界中是如何有用的。
4. 《看不见的女人:为男人设计的世界里的数据偏差》(2019 年 3 月)
评分:4.7/5(8353)

理解数据中的偏差如何在现实世界中造成不平等对于任何处理数据的人来说都是至关重要的。这本书详细介绍了性别不平等的各个方面如何可以追溯到将男性视为“默认”的数据。
5. Numsense:外行人的数据科学(2017 年 3 月)
等级 : 4.5/5 (299)

这是一篇自诩为“温和”的数据科学和算法介绍,包含最少的数学知识。这是一些大学课程的教科书,如果你对数据感兴趣,但对数学有点恐惧,这是一个很好的起点。(对了,学编码不一定要数学好。其实连真的帮助都没有)。
6. 每个人都在撒谎:大数据、新数据,以及互联网能告诉我们关于我们到底是谁的东西(2017 年 5 月)
评分:4.4/5(2295)

这本书本质上是数据科学的魔鬼经济学。这是一本有趣的读物,它将帮助你学习如何使用数据回答不同类型的问题。
7. 【压迫的算法:搜索引擎如何强化种族主义(2018 年 2 月)
评级 : 4.7/5 (500)

另一本关于算法如何导致不平等的书;这一个集中在搜索引擎。理解算法偏差、其产生的方式以及如何避免算法偏差,对于任何想要处理数据的人来说都非常重要。
8.如何在数据科学领域领先(2021 年 12 月)
等级 : 4.9/5 (30)
如果你对成为数据科学领域领导者所必需的软技能感兴趣,这是一本很棒的手册。您将学习至关重要的行业概念,如管理复杂的数据项目、克服挫折以及促进团队间的多样性。

9. Ace 数据科学面试(2021 年 8 月)
评级 : 4.5/5 (577)
另一个伟大的职业资源,这本书破解了数据科学面试的代码。它不仅包括数百个来自数据科学巨头的实际面试问题,还包括简历和投资组合构建的提示。

10.经济和金融数据科学(2021 年 6 月)
评级 : 4.7/5 (39)
寻找数据科学成功案例的例子?这是给你的书。你会得到一个数据科学技术的速成班。然后,您将深入探究十几个数据科学如何改变经济和金融领域的详细例子。

通用数据科学书籍
1.【2015 年 3 月】数据分析风格的要素
*评级 : 3.9/5 (12)

这本书由约翰·霍普金斯大学教授杰夫·利克所著,对任何参与数据分析的人来说都是一本有用的指南。它涵盖了许多你在统计学课程和教科书中可能忽略的小细节。因为这是一本你想买就买的书,所以从技术上来说,你可以免费得到这本书。当然,如果可以的话,我们建议您做出贡献。
2. 数据科学的艺术(2016 年 6 月)
评级 : 4.6/5 (44)

这是另一本随你付多少钱的书。它从宏观角度看待如何进行数据科学,而不是专注于统计或编程技术的技术细节。
3. 数据科学概论(2017 年 9 月)
评级 : 4.4/5 (74)

这本入门教材是由锡拉丘兹大学的杰弗里·斯坦顿教授编写的。毫不奇怪,它涵盖了数据科学和统计学的许多基础知识。它还涵盖了一些 R 编程。尽管如此,有些章节甚至对于那些正在学习 Python 的人也是值得一读的。
4. 社交媒体挖掘(2014 年 4 月)
评级 : 4.8/5 (14)

剑桥大学出版社的这本教科书不会与每个数据科学项目都相关。但是如果你不得不从社交媒体平台搜集数据,这是一本评价很高的指南。请注意,该网站还包括相关主题的免费幻灯片演示的链接。
5. 《数据科学手册》(2021 年 3 月)
评级 : 4.4/5 (53)

这本书收集了对杰出数据科学家的采访。它没有提供技术或数学见解,但它是一个伟大的阅读。这对任何考虑将数据科学作为职业的人来说尤其重要。
6. 做数据科学:从一线直说(2013 年 10 月)
等级 : 4.3/5 (170)

这本书收集了在不同公司工作的数据科学家的演讲。它旨在消除宣传,并帮助您了解数据科学在现实世界中的工作方式。
7. 假人数据科学(2017 年 3 月)
等级 : 4.4/5 (204)

想笑就笑吧,但是这些书对很多重要的概念提供了很好的、清晰的介绍。还有一个 假人 的大数据值得一看。
8. 数据柔术:将数据转化为产品的艺术(2012 年 11 月)
等级 : 4.1/5 (141)

抛开吸引人的标题不谈,这本书是一本关于一般数据科学过程和数据科学问题解决方法的好书。另外,它是由 DJ Patil 撰写的,他可以说是美国最著名的数据科学家。
9. 挖掘海量数据集(2014 年 9 月)
评级 : 4.4/5 (54)

这是一本关于数据挖掘的免费教科书,正如你从标题中所期待的那样,它特别关注处理大型数据集。但是要注意,它侧重于数学和宏观理论。因此,它不是真正的编程教程。
10. 设计数据密集型应用(2017 年 5 月)
评分:4.8/5(3098)

这本书更多的是关于数据工程而不是数据科学。尽管如此,对于任何致力于创建生产就绪模型或数据工程工作的有抱负的数据科学家来说,这都是一本好书。注意:这在数据科学职位中并不少见,尤其是在较小的公司。
11. 数据科学工作:如何成为一名数据科学家(2020 年 1 月)
等级 : 4.0/5 (26)

一本关于学习数据科学的非技术方面的书——如何建立你的数据科学职业生涯。数据科学的世界变化很快,但这本书是在 2020 年自助出版的,所以它是相对最新的。另外,一些评论家说这是一本适合初学者的好书。(Dataquest 也有数据科学求职申请和职业指南,如果你对更短更免费的东西感兴趣。)
12.成为数据头(2021 年 5 月)
等级 : 4.6/5 (171)

这本书不仅仅是给数据科学家看的,这只会增加它的吸引力。对于这个领域的新人来说,它是完美的。为什么?它用外行人的术语讨论数据,同时也向读者介绍行业的行话和文化。
用于数据科学书籍的 Python
1. Python 数据科学手册(2017 年 1 月)
评分 : 4.6/5 (586)

这本书是 Jake VanderPlas 的奥莱利文本,也可以作为 Github 上的一系列 Jupyter 笔记本使用。它不适合完全的初学者,因为它假设你对 Python 编程有一定的了解。(但是不要担心——我们已经有了,你可以参加的互动 Python 课程。
2. 用 Python 自动化枯燥的东西(2019 年 11 月)
评分:4.7/5(2494)

这本完全是初学者的 Python 书籍并不专门关注数据科学。尽管如此,它教授的介绍性概念都与数据科学相关。此外,本书后面的一些特定技能(如网络抓取和使用 Excel 文件和 CSV)也将对数据科学家有用。
3. 一个字节的 Python(2013 年 9 月)
评级 : 3.9/5 (9)

像自动化枯燥的东西一样,这是一本广受欢迎的 Python 从头开始的电子书。它还向所有初学者教授语言的基础知识。它不是特定于数据科学的,但它涵盖的大多数概念都与数据科学家相关。它还被翻译成多种语言,因此全球各地的学习者都可以轻松阅读。
4. 学 Python,破 Python(2014 年 2 月)
等级 : 4.0/5 (11)

又一部深受初学者喜爱的 Python 巨著!这本书鼓励读者通过“破解”Python 并观察它如何处理错误来学习 Python。
5.从无到有的数据科学(2019 年 5 月)
等级 : 4.4/5 (589)

这本书通过引导你如何从头开始实现算法来完成用 Python 教授数据科学的任务。它涵盖了各种领域,包括深度学习、统计学、NLP 等等。
6.初学 Python(2021 年 8 月)
等级 : 4.1/5 (14)

这本书渴望做不可能的事——从零开始教你所有你需要知道的关于计算机编程的知识——都在一本书中。虽然它可能不会完全达到那个目标,但它肯定会在这个过程中教会你很多东西。请注意,本指南以 Python 3 指令为特色。
7.使用 Python 的数据科学项目(2021 年 7 月)
评级 : 4.6/5 (49)

一个独特的发现,这本书重新创造了在数据科学领域工作的经验。沉浸在这个基于项目的工作簿中的读者将获得新的技能——不仅仅是 Python,还有机器学习、数据可视化、逻辑回归等等。
R 为数据科学书籍
1. R 数据科学编程(2016 年 4 月)
等级 : 4.2/5 (20)

Roger D. Peng 的文字将从零开始教你 R 编程的基础知识。这是一条随你付的短信。请注意,只需 20 美元,您就可以获得所有提到的数据集和代码文件。
2. 数据科学概论(2017 年 9 月)
评级 : 4.4/5 (74)

上面已经列出了这些介绍性的文字,但是我们将它再次列在 R 部分,因为它确实涵盖了相当多的数据科学的 R 编程。
3. 高级 R(2019 年 5 月)
等级 : 4.8/5 (143)

这正是它听起来的样子:涵盖高级 R 主题的免费在线文本。这是哈德利·韦翰写的,他是 R 社区最有影响力的声音之一。
4. R 食谱(2019 年 7 月)
评级 : 4.6/5 (102)

确切地说,它听起来像是:数据分析和数据科学工作的 R“配方”的集合。
5. R 图文菜谱(2018 年 11 月)
评级 : 4.5/5 (77)

与上面类似,这是一本专门关注从 r 中获得更高质量的图形和图表的食谱。
6. R 为大家(2017 年 6 月)
等级 : 4.4/5 (235)

这是一本真正的 R 编程教材,重点是从零开始教 R。与许多其他 R 教科书不同,它在没有假定读者已经有很深的统计学知识的情况下接近主题。
机器学习书籍
1. 神经网络与深度学习(2018 年 8 月)
等级 :4.5/5 (164)

这本免费的在线书籍旨在教授机器学习原理。它不是学习任何特定库的复杂技术的地方,而且它是用现在已经过时的 Python 2.7 而不是 Python 3 编写的。尽管如此,这里还是有很多有价值的智慧。
2. 贝叶斯推理与机器学习(2012 年 3 月)
评级: 4.2/5 (83)

这是一个庞大的 680 页的 PDF,涵盖了许多重要的机器学习主题。它是为缺乏计算机科学或高等数学正式背景的学生编写的。欢迎所有新手!
3. 理解机器学习:从理论到算法(2014 年 5 月)
排名:4.4/5 (218)

想找一本机器学习的彻底复习,从基础,一直到高级机器学习理论?别再看了。
4.(2016 年 11 月)
*等级 : 4.3/5 (1850)

麻省理工出版社的这本教科书只有 HTML 格式。它涵盖了一切——从基础知识,通过当前的研究,到深度学习。
5. 机器学习向往(2018 年 11 月)

Ng 说教授技能的课程可以给你一把“锤子”这本书旨在教你如何正确使用那把锤子。
6. 用 Python 处理自然语言(2009 年 8 月)
等级 : 4.4/5 (179)

对于任何对 NLP 感兴趣的人来说,这都是一篇很棒的文章。网络版已经用 Python 3 更新了。
7. 用 Scikit-Learn、Keras、Tensorflow 动手机器学习(2019 年 10 月)
评分:4.8/5(3236)

这是一本以 Python 为中心的机器学习教材。它使用 scikit-learn 和 Tensorflow 框架来探索建模和构建不同类型的神经网络。
8.(2019 年 1 月)
*等级 : 4.4/5 (134)

Grokking 的意思是“理解”,这正是本书所关注的。它的目标是帮助您充分理解深度学习,以便从零开始构建神经网络!
9. 用 Python 深度学习(2017 年 12 月)
评级:4.5/5(1340)

另一个以 Python 为中心的深度学习和机器学习的文本。这一篇主要关注 Keras 库的使用。
10.谷歌云平台上的数据科学(2022 年 5 月)
等级 : 5/5 (10)

这是我们名单上的最新书籍之一,如果你想了解如何在 GCP 建立数据管道,这本书是必读书。我们尤其被它基于项目的方法所吸引,这种方法利用了真实世界的业务决策。
统计书籍
1. 概率简介(2008 年 1 月)
等级 : 4.5/5 (203)

不要想多了。这本书正是它听起来的样子:一本教授概率和统计的入门教材。
2. 思贝氏(2021 年 6 月)
评级 : 4.5/5 (41)

Allen Downey 的 O'Reilly 文本提供了贝叶斯统计的介绍。请注意,这里有本书的更新 Python 3 代码。
3. 贝叶斯黑客方法(2015 年 10 月)
等级 : 4.3/5 (128)

这是另一个关于贝叶斯统计和编程的免费阅读。这本书很酷的一点是,它的章节是以 Jupyter 笔记本的形式出现的,所以很容易运行、编辑和修改你遇到的所有代码。
4. 数据科学的统计推断(2016 年 5 月)

对统计推断的严格审视。这本书是为那些已经对基本的统计学主题和 r 编程比较熟悉的读者准备的。
5.(2021 年 7 月)统计学习概论
*评级 : 4.7/5 (132)

对数据科学相关的统计概念和 R 编程的极好介绍。
6. 统计学习的要素(2017 年 4 月)
评分:4.6/5(1002)

另一个有价值的统计文本,涵盖了你可能想知道的一切,然后一些。(长达 750 多页!)确保你在这里得到了这本书的最新版本。
7.(2020 年 1 月)
**评级 : 4.7/5 (18)

这本剑桥大学出版社的教科书将带你深入了解用于各种数据分析的统计学和算法。
8. 思考统计:探索性数据分析(2014 年 11 月)
等级 : 4.2/5 (132)

另一篇 stats 文本侧重于使用 Python 进行数据分析工作时的统计数据。
9.数据科学家实用统计(2020 年 6 月)
等级 : 4.6/5 (637)

一本专门为数据科学家编写的统计学书籍!这个第二版包括有价值的 Python 例子。
但是不要只是读书!
阅读(或聆听)书籍是增强您的数据科学知识的好方法。但学习任何东西(包括数据科学)的最佳方式是亲自动手,并实际去做。写下你正在阅读的代码。收集你自己的数据。建立自己的模型。边做边学。
Dataquest 的在线课程以动手实践、基于项目的形式教你成为数据科学家所需的一切。从你注册的那一刻起(这是免费的),你将会编写真正的代码并使用真正的数据集。
试一试吧,你会有什么损失呢?******
为什么数据科学训练营不理想(以及替代方案)
April 22, 2022
传统的数据科学训练营并不适合所有人
原因如下:
- 他们的学杂费可能超过 15,000 美元
- 有些学校像学校一样运作,需要冗长的申请表
- 申请之后,通常会有很长的等待期
- 如果你被录取了,还要等更长时间才能开始上课
- 根据它的位置,你可能需要支付差旅费
一些传统的数据科学训练营也要求在你开始他们的项目之前先完成课程或获得更高的学位。
例如,纽约数据科学院表示,它更喜欢“拥有硕士学位或博士学位的人”。没有背景的学习者应该提前六周申请,以便有时间做准备工作。
就好像他们不想让你申请一样!
为什么在线训练营是更好的选择
在线数据科学训练营可以提供所有的好处,没有任何麻烦。
像 Dataquest 这样的在线数据科学训练营可以让你在注册后的 5 分钟内编写第一个代码。
对你来说这就简单多了。
事实上,Switchup 是一个根据用户评论对编码训练营进行排名的平台,已经授予 data quest2021 年“最佳在线训练营”。
评级是基于诚实的学生评论。在撰写本文时,Dataquest 有超过 296 条学生评论,平均评分为 4.85 分(满分 5 分)。
速度像离线训练营,但具有灵活性
新兵训练营的名字来源于军事“新兵训练营”,旨在让新兵在短时间内快速上手的强化训练。
在线数据科学训练营训练不同的技能,但想法是一样的。如果你能承诺三个月,你将拥有基本的数据分析技能你将需要在数据科学领域找到一份工作。
Dataquest 可以定制,以完全相同的方式为您服务。只有更好。
因为你将有一个灵活的,按自己的步调工作的环境,你可以尽快完成你的训练。或者你可以慢慢来。
看看这个故事,一个学生在不到六个月的时间里从零相关经验变成了全职数据工程师。
教授你实际会用到的东西的课程
传统数据科学训练营有时间限制。
这迫使他们快速浏览课程,缩小他们的关注点,除了最重要的信息之外,什么都不要。
一个常见的抱怨是他们跳过了大量必要的信息。
有些学生没有学到多少 SQL 知识就完成了。但是 SQL 是现实世界数据科学工作的关键技能。
因为 Dataquest 的课程没有时间限制,他们可以提供两个世界的最佳选择:
职业道路涵盖了你需要学习的一切(包括 SQL 和统计),同时让你以舒适的节奏工作。
例如, Python 路径包括以下方面的培训:
- Python 编程
- 数据可视化
- 熊猫
- NumPy
- 数据清理
- 结构化查询语言
- 统计数字
- 机器学习
- 自然语言处理
- 火花
- 还有更多
Dataquest 路径包括指导现实世界的数据科学项目,您将使用这些项目来综合您的新技能并构建您的简历组合。

实践学习
传统的面对面训练营的另一个缺点是,他们的方法遵循传统的大学模式。在幻灯片前讲课的教授。
Dataquest 采用基于项目的方法。
学生获得基于真实世界数据的动手项目。你把大部分时间花在编码和实际学习如何使用你的知识上。项目将引导你通过真实的数据集,并使用有趣的问题,从事工作。
再也不用坐在演讲厅里看教授喋喋不休地讲无聊的理论了。
向同龄人学习
面对面训练营的好处之一是他们提供了同伴互动。
学生们发现能够互相提问和参与小组项目的价值。
由于 Dataquest 只在网上进行,所以你和你的同事之间没有物理距离。但是,你的课程中提供的数据科学社区让学生可以轻松获得技术问题的快速答案,建立网络,并为项目进行合作。
随着越来越多的团队转向远程工作环境,虚拟团队协作能力正成为一项越来越重要的技能。
职业帮助
这是一个大的。毕竟,这可能是你考虑参加数据科学训练营的首要原因——为了找份工作。
真实世界的训练营经常向学生推销他们的职业咨询服务。很难高估真正的数据科学专业人士、招聘人员和招聘经理的指导和建议的价值。
幸运的是,Dataquest Premium 用户也可以在我们的职业论坛中获得个性化职业帮助。在那里,你可以提出问题,查找简历评论,接收项目反馈,并从合格的数据科学家和职业专家团队那里获得面试技巧。
我们经过详尽研究的是另一个工具,每个人都可以使用,无需任何订阅。

学习获得理想工作所需的一切
传统的数据科学训练营通常会承诺结果,以帮助你在数据科学领域的公司找到工作。
然而,这并不是离线程序所独有的。
Dataquest 的学生已经在亚马逊、SpaceX 和花旗银行等公司以及 Noodle.ai 等初创公司获得了全职数据科学工作。
你可以在这里查阅一些最近的成功故事。
Dataquest 学生最常见的三种工作是:
- 数据科学家
- 软件工程师
- 数据分析师
此外,学生还被各种其他与分析相关的职位聘用。
在学习了 Dataquest 之后,看看这篇文章中更多你可能感兴趣的职位。
高质量的学习,实惠的价格
离线数据科学训练营绝对不便宜。
Switchup 排名第一的数据科学离线训练营(大会、Metis 和数据科学院)为期 12 周的数据科学训练营项目收费都超过 15,000 美元!
然而,与四年制学院和大学相比,这仍然是可以负担得起的,平均费用从:
- 40,000 加元(针对住在家里的州内公立大学学生)用于
- 187,000 美元(针对住校的私立大学学生)
这还不包括大多数大学生不得不花在书本、交通和其他杂费上的数千美元。
这当然是 Dataquest 的亮点。由于我们不必支付租赁、拥有或维护物理空间的费用,我们的成本远比一般的离线数据科学训练营更实惠。
只需 399 美元,你就可以在接下来的 37 年里学习 Dataquest 课程,并且仍然比大多数为期 12 周的训练营项目花费更少。
| 数据请求 | 传统训练营 | |
|---|---|---|
| 时间承诺 | 灵活 | 3 个月全日制 |
| 价格 | $399 或更少一年 | 5000 美元到20000 美元三个月 |
| 附加费用 | 无 | 旅行,食物,有时住宿 |
| 学生成绩 | 作为数据科学家、数据工程师、数据分析师 ( 阅读真实的学习者故事)的工作。 | 通常情况下,数据科学家或数据分析师的职位是 |
| 精心设计的课程序列 | ||
| 所需先决条件? | 无 | 经常需要“预备工作” |
| 职业咨询 | 是(个性化在线建议、答案、简历和项目评估) | 是(服务各不相同,有些提供工作保障) |
| 同伴互动 | 是(活跃、有益的社区论坛) | 是(各不相同) |
| 动手学习 | ||
| 科目涵盖 |
- 计算机编程语言或者稀有
- machine learning
- 结构化查询语言
- statistics
- command line
- 饭桶
|
- 计算机编程语言或者稀有
- machine learning
- SQL (sometimes)
- Statistics (sometimes)
|
Dataquest 的订阅模式提供了最佳性价比,但它还提供了更多内容:持续访问数据科学社区和不断扩展的课程库。
这胜过了线下训练营所能提供的。在你完成他们的课程后,你不能随时回去更新你的训练…
通过 Dataquest 订阅,您可以。
在 Dataquest,新的数据科学课程不断增加,旧的课程也频繁更新。这样,全年都可以得到最好的培训。
如果这听起来很有趣,看看 Dataquest 的学生在这些学生调查中说了些什么。或者,你可以在像 SwitchUp 和课程报告这样的网站上看到用户评论,看看学生们对 Dataquest 有多满意
如果你真的想学习数据科学,你会在一个顶级的数据科学训练营找到你想要的一切,而费用只是它的一小部分。
你准备好成为数据科学大师了吗?今天就开始吧!
数据科学职业指南
March 29, 2019
介绍
在 Dataquest,我们的目标是帮助每个学生,掌握从事数据科学所需的技能,并实现他们梦想的职业生涯,无论他们的背景是编码还是统计。
我们的交互式在线学习平台教授您从事数据科学所需的技术技能。但是,在数据科学领域找到一份工作,尤其是你在数据科学领域的第一份工作,并不总是那么容易,即使你已经具备了你需要的技术能力。
但是在我们开始谈论技术技能之前,让我们来看看为什么你可能想要学习数据科学。你可能会看到什么样的薪资变化?我们设计了一个小测验,可以帮助您快速做出评估:
(还不确定你对哪个角色感兴趣?本文将帮助您区分数据科学中的主要角色,以便您在下面的测验中做出正确的选择。
数据行业会如何改变你的薪水?
如果你得到了满意的结果,我们将随时提供帮助。
本指南旨在让数据科学求职变得更加容易。它基于与数据科学招聘人员和招聘经理、在职数据科学家、已获得数据科学全职工作的 Dataquest 学生以及我们自己的内部数据科学家和职业专家团队的数十次采访和对话。
准备好开始了吗?通过下面的目录直接阅读我们的文章,或者进一步向下滚动以了解更多关于本指南的信息。
我们希望本指南能为您提供成功寻找数据科学工作所需的一切!
(如果你想在求职过程中获得更多个人指导,我们的 Premium 订户可以访问我们学习社区中的特殊职业论坛,在那里你可以获得个性化反馈、简历评论、作品集和项目评论等。)
目录
点击下面的一个章节标题,以获取该主题的完整指南。
- 简介和目录— 你来了。
- 在你申请之前:考虑你的选项
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学的工作面试
- 评估和协商工作机会
关于本指南的更多信息
首先,也是最重要的:我们建议你在开始申请工作之前,通读本指南。
事实上,你越早意识到本指南中涵盖的一些内容(比如雇主希望在你的数据科学项目中看到什么),你就可以越早地开始勾选这些复选框,以加强你未来的应用。
本指南旨在为整个数据科学工作申请流程提供自上而下的指导,并旨在按顺序阅读(尽管如果您只在某些领域需要帮助,您当然可以跳过)。
这也是一份活的文档,随着行业的变化,随着我们与其他来源的交流和学习新事物,我们将不断扩充和更新。
如果你最近申请了工作或雇佣了数据分析师或数据科学家,并且有你想要分享的经验,请不要犹豫联系我们。如果有助于数据科学专业的学生更轻松地找到工作,我们一直希望在指南中添加更多信息。
信用
如上所述,本指南基于与数据科学招聘人员和招聘经理、在职数据科学家、已获得数据科学全职工作的 Dataquest 学生以及我们自己的内部数据科学家团队和职业顾问的数十次采访和非正式对话。
然而,我们想特别提到一些人,他们抽出相当多的时间与我们进行正式面试(在许多情况下还回答后续问题)。非常感谢:
alina Chistyakova—IT 招聘主管, Spice IT 招聘
Alyssa Columbus–太平洋人寿的数据科学家
clay McLeod——生物信息学软件开发经理,圣裘德儿童研究医院
爱德华·哈里斯——联合创始人,夏普明斯
ewa Zakrzewska——人力资源专家/招聘人员,Zety.com
ganes ke sari——联合创始人兼分析部主管, Gramener
贾米森·瓦兹奎——CiBo Technologies 人才招聘经理
杰夫·霍尔——Kitware 公司人力资源总监
Kristen Sosulski——副教授, NYU 商学院
Michael Hupp —数据科学和分析经理, G2 人群
迈克·金——首席技术官,离群人工智能
奥利维亚·帕尔-鲁德(Olivia Parr-Rud)首席执行官, OLIVIAGroup ,个人网站
refael“Rafi”Zikavashvili——联合创始人兼首席执行官,Pramp.com
Stephanie Leuck——大学招聘经理, 84.51
Stephen Yu-Willow Data Strategy总裁兼首席顾问
另外还要感谢所有与我们分享学生成功故事的学生。他们的求职经历和给其他学生的建议也对本指南有很大帮助。
数据科学职业指南更新日志
2019 年 4 月 4 日——在指南第一章的中增加了一小段,名为“我准备好接受数据科学工作了吗”。这包括如何知道你何时准备好申请的一些一般想法,以及对数据科学证书的简短讨论,以及它们为什么不是获得数据科学工作的必要条件。
2019 年 3 月 29 日—职业指南发布!
2019 年 8 月 20 日–增加了额外报价并更新了目录。
2019 年 9 月 12 日–ToC 中增加了职业测验,在“考虑你的选择”一章中增加了额外的内容和链接。
2020 年 9 月 9 日——各种更新,包括最新信息、工资等。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
2023 年数据科学证书?(15 个招聘人员告诉所有人)
December 20, 2022
想尽快得到一份数据科学的工作吗?那么你可能想知道你需要什么认证。事实上,Quora 上最常见的数据科学问题之一是:
“应该拿什么数据科学证书?”
但这是个不该问的问题。
我们与该领域的 15 名招聘经理进行了交谈,他们都淡化了数据科学领域对专业证书的需求。
你应该问的问题是:
“什么样的证书能为我提供数据科学招聘人员最看重的技能?”
没错——招聘人员对你的技能比对你的证书更感兴趣。在本文中,我们将解释证书对招聘经理的真正意义,并比较一些目前最好的行业证书。
额外收获:我们会让你知道一些招聘人员保守得最好的秘密,包括他们在筛选简历时最关注的是什么。
数据科学证书如何影响你的求职
当然,数据科学证书并非毫无价值,对吗?为了找到答案,我们采访了十几位数据科学领域的招聘经理和招聘人员,询问他们希望在申请人的简历上看到什么。
他们都没有提到证书。一个都没有。
以下是我们学到的:只要正确出示,证书肯定不会影响你的求职。但是他们也不太可能帮上什么忙,至少他们自己不会。
为什么数据科学证书达不到要求
你可能想知道为什么这些证书比不上印刷它们的纸张。
问题是没有普遍的标准,也没有普遍认可的认证机构。不同的网站,学校,在线学习平台都是自己出证。这意味着这些文件可能有任何意义,也可能毫无意义!
这就是为什么雇主在对候选人进行资格审查时,往往不会给他们一瞥。
那么认证有什么意义呢?
如果证书不能帮助你在数据科学领域找到工作,那么获得证书又有什么意义呢?
归根结底,数据科学家证书并不是完全无用的。在 Dataquest,当用户完成任何一门我们的数据科学课程时,我们会颁发证书。为什么?因为这是学生展示他们积极参与学习新技能的好方法。
招聘人员确实喜欢看到求职者不断努力提升自己。列出数据科学证书可以在那方面帮助你的工作申请。
有什么比数据科学证书更好?作品集!
对招聘人员来说,最重要的是你是否真的能胜任这份工作。证书不是真实技能的证明。
那么你能做些什么来证明你在数据科学领域的能力呢?完成一个项目组合!
投资组合就像数据科学技能的圣杯。这就是为什么招聘经理会先看他们。根据他们在你的投资组合中看到的,他们要么放弃你的申请,要么将它发送到下一轮招聘过程。
Dataquest 的大多数课程都包含互动项目,你可以完成这些项目来帮助你建立自己的投资组合。以下是其中的几个例子:
- 越狱——使用 Python 和 Jupyter Notebook 分析直升机越狱的数据集,享受其中的乐趣。
- 探索黑客新闻帖子——使用热门技术网站 Hacker News 的提交数据集。
- 探索易贝汽车销售数据——使用 Python 处理从德国易贝网站分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
可以免费报名!点击查看我们的课程。
在考虑拿哪个认证的时候,不要把重点放在“哪个数据科学证书最好。”相反,找到最有助于您学习基本数据科学技能的平台。这将有助于你在这个领域找到一份工作。
如何通过 5 个步骤选择数据科学证书课程
找到一个提供证书的数据科学项目很容易。在谷歌上快速搜索会找到几十个。难的是决定证书是否值得你花费时间和金钱。
让我们简化这个过程。在考虑数据科学认证时,需要考虑以下五个关键因素:
- 节目内容
- 项目成本
- 所需的先决条件或资格
- 需要时间承诺
- 往届学生的评论
请记住,除非数据科学证书能教会你雇主所需要的技能,否则它们一文不值。所以第一点是最重要的。想内容,想内容,想内容!
现在,我们来看一些现实生活中的例子进行比较。
顶级数据科学认证

数据请求
你将学到什么: Dataquest 为提供了四种不同的职业道路,涵盖了成为数据分析师、数据科学家和/或数据工程师所需的技能。涵盖的具体技能因您选择的道路而异。
主题包括:
- Python 和 R 编程
- SQL 和 PostgreSQL
- 概率与统计
- 机器学习
- 工作流技能,如 Git、命令行(bash/shell)
- 更多
费用:每年 399 美元的高级订阅费。也可以按月订阅。
先决条件:无。没有申请流程(任何人都可以报名,今天就开始学习)。不需要预先了解应用统计学或编程。
时间承诺:各不相同。Dataquest 是一个自助式互动学习平台。大多数学习者发现,如果每周学习少于十小时,他们可以在六个月内达到学习目标。更多的时间投入可以加速学习目标的实现。
点评:

Cloudera 大学数据分析师课程/考试
你将学到什么: 本课程关注使用 Apache 产品的数据分析:Hadoop、Hive 和 Impala。它涵盖了一些 SQL,但没有涉及 Python 或 R 编程。
费用:点播版费用 2235 美元(180 天访问)。认证考试需要额外的费用。
先决条件:需要有一些 SQL 和 Linux 命令行的前期知识。
时间承诺:各不相同。因为这是一门自定进度的课程,用户可以在 180 天内完成 15 个部分。每个部分预计需要 5-9 个小时。时间承诺在 75 到 135 小时之间。如果你每天承诺的时间少于一个小时,那么你可能会花掉整整 180 天。如果你每天能投入 9 个小时或更多的时间,你可能需要几个星期才能完成。
评论:很难找到该程序的第三方评论。

IBM 数据科学专业证书
你将学到什么:这个基于 Coursera 的项目涵盖了 Python 和 SQL。这包括一些使用 Python 的机器学习技巧。
费用:Coursera 订阅,需要。根据 Coursera 对 10 个月完成时间的估计,项目总成本约为 390 美元。一个类似的程序也可以在 EdX 上获得。
先决条件:无。
时间承诺:各不相同。Coursera 建议完成这个证书的平均时间是十个月。
点评:量化的第三方点评很难找到。
- Coursera 自己的网站平均得分为 4.6/5(57501 分)

哈佛/EdX 数据科学专业证书
你将学到什么:这个基于 EdX 的程序涵盖了 R,一些机器学习技能,以及一些统计和工作流技能。它似乎不包括 SQL。
费用:792.80 美元
先决条件:无。
时间承诺:一年零五个月。课程进度不会从一节课延续到另一节课,因此如果您无法在课程运行期间完成课程,可能需要更多时间。
点评:量化的第三方点评很难找到。
- 在级中央上的平均分为 4.6/5(11 次点评)

认证分析专家
你将学到什么:可能什么都没有——这只是一个认证考试。但是,备考课程是有的。
费用:认证考试费用为 695 美元,包括有限的准备材料。专门的预备课程需要额外付费。
先决条件:参加认证考试需要申请。因为没有包含任何课程,你需要自己学习所需的信息或单独注册一门课程。
时间承诺:考试本身比较短。专门的预备课程需要 1-2 个月,具体取决于选项。他们不需要参加考试。
点评:量化的第三方点评很难找到。以下是一些关于认证的独立意见:

通过谷歌云从数据到洞察
你将学到什么: 本课程涵盖 SQL 数据分析技能,重点是使用 BigQuery 和谷歌云的数据分析工具。
费用:Coursera 订阅费是必需的,每月 39 美元。Coursera 估计大多数学生需要两个月的时间来完成这个项目。
先决条件:课程页面上写着:“我们建议参与者熟练掌握 ANSI SQL。”不清楚需要什么水平的 SQL 熟练程度。
时间承诺: Coursera 估计大部分学生需要两个月的时间来完成这个项目,但是学生可以按照自己的进度工作。然而,课程确实在规定的日期开始。
评论:量化的第三方评论很难找到,但是:
- Coursera 本身的评分为 4.7/5(3712 分)
内幕提示:当心先决条件和资格!
在你开始寻找数据科学课程和证书之前,你需要知道一些事情。
虽然像 Dataquest、Coursera 和 Udemy 这样的一些项目不需要任何特定的背景或行业知识,但许多其他项目有具体的先决条件。
例如,DASCA 的高级数据科学家认证课程至少需要学士学位(有些课程需要硕士学位)。这还不包括至少 3-5 年的专业数据相关经验!
一些项目,特别是离线训练营,也需要特定的资格或者有广泛的申请过程。翻译?你不能马上投入并开始学习。当你做出选择时,你需要考虑这些项目的时间成本和申请费。
绝密:数据科学领域大学证书的神话
如果你正在考虑大学的数据科学证书,请三思。
名牌学校(甚至常春藤盟校)在网上提供的许多昂贵的认证项目对潜在雇主来说没有太大意义。
许多这样的项目甚至不是由学校自己管理的。相反,它们是由名为“在线项目经理”的第三方盈利公司运营的。
更糟糕的是,数据科学招聘人员知道这一点。是的,雇主们敏锐地意识到 EdX 的哈佛附属证书和哈佛大学学位是两回事。
此外,大多数数据科学招聘经理没有时间研究他们在简历上看到的每一项数据科学认证。大多数简历只有大约 30 秒的审阅时间。因此,即使你的大学文凭真的有价值,招聘人员也不会注意到它。
大学证书的贴纸冲击
大学证书往往很贵。考虑一下一些最受欢迎的选择的成本:
- 康奈尔大学为期三周的数据分析证书——3600 美元
- 杜克大学的大数据和数据科学证书——3195 美元
- 乔治敦大学数据科学专业证书——7496 美元
- 加州大学伯克利分校的数据科学家认证项目——5100 美元
- 哈佛的数据科学证书——11600 美元
如何获得雇主渴望的数据科学技能
我们已经确定,数据科学领域的招聘人员和招聘经理寻找的是现实世界的技能,而不一定是证书。那么获得所需技能的最佳途径是什么呢?
毫无疑问,获得令人信服的数据科学技能的最佳方式是深入研究并接触实际数据。
选择一门能让你边学边完成项目的数据科学课程。然后,展示你的数字作品集。这样,雇主在考虑你的申请时可以看到你掌握了什么技能。
在 Dataquest,我们的课程是互动的,并且是基于项目的。它们旨在让学生能够立即应用他们所学的知识,并记录他们的新技能,以引起招聘人员的注意。今天就免费注册,开始您在不断发展的数据科学领域的职业生涯!
提高数据科学沟通技巧的演示技巧
原文:https://www.dataquest.io/blog/data-science-communication-presentation/
May 9, 2019
在数据科学中,沟通至关重要。
当然,所有数据科学工作都需要获取数据、清理数据和执行分析的技术技能。但是当你这么做的时候,记住为什么也很重要。当你接到一个项目时,停下来问问自己它对公司有什么价值,它在大局中处于什么位置是值得的。
知道这些为什么问题的答案是与你的实际分析同样重要的过程的第一步:将你的发现传达给(通常)非数据科学家的听众。
数据科学交流是 Kristen Sosulski 非常了解的一个话题。她是纽约大学斯特恩商学院(New York University Stern School of Business)信息、运营和管理科学的临床副教授,她基本上是以教授如何在学术界和商界有效沟通为职业的。她甚至写了一本书, 数据可视化变得简单 ,讲述如何用可视化有效地交流数据科学的成果。
“在整个组织中展示和交流你的见解真的非常非常有力量,”Kristen 说。
那么,如何以有效的方式传达你的模型呢?
讲述这个问题
假设你已经建立了一个模型,并有机会在公司的主要决策者面前展示你的发现。你的工作是解释模型的含义以及它对业务的影响。
克里斯汀主张从识别你正在解决的问题或挑战开始。将问题与听众的兴趣联系起来,帮助他们理解更大的背景。为了让听众站在你这边,在提出你的解决方案之前先提问。例如:
你有过这种经历吗?
你在我们的生意中观察过吗?
这不仅仅是一种修辞技巧,也是一种衡量你的听众需要什么信息来理解你的推销的方式。“如果没有人认为这是一个问题,那么你必须开始介绍这个问题,然后为这个问题建立案例,”克里斯汀说,“你不想因为疏远他们而失去你的观众,因为他们认为这根本不是一个问题。”
请记住,对你来说似乎是显而易见的问题,对你的观众来说不一定是显而易见的,特别是如果你在过去几周一直埋头于别人还没有看到的数据集。您在数据中发现并试图用您的模型解决的问题可能是其他人还没有真正意识到的。
一旦你对问题本身进行了论证,你就可以提出常见的解决方案,以及为什么这些方案不是最好的、最有效的。
“你想制造某种类型的悬念,但你把这一切都植根于叙事之中,”克里斯汀说。“从一个问题开始,展示可供选择的解决方案,然后你最终会展示你的解决方案。”
与数据通信
尽管你的推销通常主要是基于语言的(无论是书面报告还是会议上的演讲),但可视化地展示你的数据对于与你的听众交流其意义是绝对重要的。很少有人能看着电子表格或表格,并对数据所表达的内容做出快速、清晰的结论。任何人都可以在条形图上比较条形的大小,或者在折线图上跟踪趋势。
当然,数据可视化在数据科学过程的每个阶段都是一项至关重要的技能。“你可以从很多角度来看待视觉化,以及看待它的方式,”克里斯汀说。“你可以纯粹从技术角度来看,也可以从探索的角度来看,比如将可视化作为一种工具来探索你的数据。”
但它对交流也很重要。
“我认为数据可视化是我们工具包中的一种工具,可以帮助人们更好地理解我们的见解和数据,”Kristen 说。
“就人类层面而言,如果设计得当,可视化可以让我们更加清晰地感知信息。”
当你为团队之外的交流设计视觉效果时,记住你的观众是很重要的。你的同事可能不像你的团队那样了解你的问题,他们也可能不具备技术知识。数据科学沟通的最大挑战之一是根据受众的技术水平定制您的演示文稿,并在不压倒他们(或以高人一等的态度对待他们)的情况下表达您的观点。
设身处地为非技术观众着想的一个好办法是,当你把车开进汽车修理厂时(假设你自己不是汽车修理工),想想你希望别人向你报告的信息。一般来说,最有说服力的机械师是那些能够:
- 用简单明了的语言解释你的问题。
- 向您展示问题存在的证据。
- 用简单明了的语言解释如何解决这个问题。
- 给你一个明确的时间表和修复费用的价格。
你不想听 30 分钟关于影响发动机效率的因素的讲座。你只是想确信你知道真正的问题是什么,并且机械师知道修理它的最好方法。
这也适用于数据科学中的交流,但现在你是机械师。当有疑问时,最好的方法是保持简单。留在所有的细节可能会令人困惑,使你的图表可读性更差,所以只包括传达你的观点所必需的内容。
“要知道,你不必一次展示每一个数据点,你可以放慢速度。你可以一次展示几个数据点来帮助构建你的故事和叙述,”克里斯汀说。
记住:如果你的同事觉得他们还没看够,你可以通过回答问题来提供更多的信息。但是如果你对他们抛出一系列复杂、难懂的图表,你就有完全失去它们的风险,而且很难撤销。
演示技巧
将可视化整合到演示文稿中是一种艺术形式,尤其是对于高度技术性的数据。为了让事情变得简单有效,克里斯汀建议牢记一些指导方针。
第一:不要强迫图表自己说话。确保你花时间清楚地解释屏幕上显示的内容。如果你在图表中显示数据,一次只显示一个图表,并解释它显示了什么,以及它在你所解决的问题的更广泛的上下文中意味着什么。您还可以显示哪里存在关系,哪里有异常值,以及您的模型与其他模型相比有多有效。
速度也很重要。
“不要走得太快,但整个演示不应该超过 10 或 15 分钟,”克里斯汀说。“你要确保你能在短时间内完成这种类型的推销,而不会用细节淹没观众,但也能清楚地展示数据,并将数据用作令人信服的证据。”
不要害怕谈论细节。虽然你不想让你的听众被技术细节淹没,但你确实需要确保你已经包括了理解你的演示所需要的细节,以及他们将要看到的图表。你说的是几个小时或几年内产生的新线索吗?为你的听众算一算。如果你在做预测,为他们量化它。
这也有助于将观众的注意力引向某些形象化的东西。很难将口语和视觉数据联系起来。如果你在谈论图表上的某个特定部分,指向它。从那里开始写你的故事。
最终,你需要记住沟通首先是一种人际互动。“你是坐在首席执行官面前的那个人,允许你自己提供有图形支持的解释,而不是相反。”
行业的数据科学通信工具
当然,创建任何像这样的演示的第一步实际上是创建数据可视化。你用来做什么取决于你选择的编程语言。“对我来说,我选择的工具是 R and R 工作室,以及随之而来的各种软件包,数量众多,”克里斯汀说。
Python 程序员也有大量的数据可视化选项。
如果你还不知道你有多喜欢可视化数据,Dataquest 有关于探索性数据可视化和用 Python 讲数据故事的互动在线课程,以及关于 R 数据可视化的免费课程。我们还有一个包含一些设计技巧的快速指南,可以帮助你让你的图表更容易阅读。
无论您使用什么工具,请记住这些数据科学交流的基本技巧,您将有更好的机会完成下一次演示:
- 先说问题。你的观众已经知道这个问题了吗?如果不是,你必须开始明确地确定是的问题。
- 对你的听众感同身受,用他们能理解的格式和语言向他们展示他们想要的信息。
- 用数据可视化来说明你的结论,但是让你自己的解释——而不是图表——来驱动你的陈述。
- 保持简单,在你的解释和图表中省去不必要的细节。整个演示不要超过 10 到 15 分钟。
您应该参加的数据科学竞赛
原文:https://www.dataquest.io/blog/data-science-competitions-you-should-participate-in/
November 15, 2021
众所周知,数据专业人员会花大量时间学习理论,然后自己实践所学。由于工作的性质,在寻找数据科学工作时,能够展示自己解决问题的能力至关重要。数据科学竞赛是获得真实世界经验、超越自身局限和发现新想法的最佳方式之一。
数据科学竞赛也打开了一个新的网络和就业机会的世界,它们是学习最佳实践的好方法。当你与他人合作和竞争来解决现实世界中的问题时,你会得到对你工作的即时反馈。在比赛结束时,您将提高您的数据科学技能。
为了让你的生活更轻松,我们列出了八个最喜欢的比赛。参加这些活动将有助于培养您的信心、技能和数据科学知识:
- 卡格尔
- 驱动数据
- 国际数据分析奥林匹克竞赛
- Codalab
- TopCoder
- 铁 Viz
- 天池大数据竞赛
Kaggle 为初学者提供了一些最好的数据科学竞赛。企业经常向 Kaggle 的大型社区提出他们的一些问题,试图找到解决方案。通过参加这些令人兴奋的比赛,崭露头角的数据科学家可以在获得学习乐趣和建立新联系的同时发展自己的技能。
这些竞赛提供了练习各种技术来解决数据科学问题的机会。你将有机会为医疗保健、金融和国防等领域的真正挑战贡献有价值的解决方案,从而有所作为。挑战越大,回报越大。一些 Kaggle 比赛的奖金高达 150 万美元。
驱动数据
DrivenData 提供的数据竞赛一般会持续两到三个月。它们的特点是数据科学家的全球社区,这些科学家竞相为困难的预测问题产生最佳的统计模型。DrivenData 有双重使命:它旨在帮助数据科学家获得经验和学习新技能,同时也为人道主义事业提供数据科学援助。DrivenData 主办的竞赛使数据科学家能够开发前沿的数据科学解决方案,并为非营利组织、非政府组织、政府和其他社会影响组织提供支持。
那些参加 DrivenData 比赛的人将受益于现实世界的经验,因为他们正在为一个更伟大的事业而努力。一旦数据问题得到解决,获胜者被选中,DrivenData 就会在开源许可下发布获胜代码。因此,即使您没有获得第一名,您仍然可以获得宝贵的经验和有用的代码!
国际数据分析奥林匹克
这是一项面向所有经验水平的数据科学专业人员的年度竞赛。IDAO 是一项团队活动,专注于解决复杂的机器学习问题。团队由两到三名成员组成。从初级到高级,任何想测试自己技术的人都可以参加这个比赛。
每场比赛分为两部分。第一部分是线上,所有队伍争夺进入第二轮的资格。第二部分只包括第一轮前 30 名的表演团队,通常在指定的地点离线进行,通常是在莫斯科的 Yandex 办公室。有价值的奖品通常授予获胜者。
Codalab
Codalab 是一个致力于促进计算研究的开源平台。Codalab 用户可以参加现有的比赛或创建自己的比赛。这些竞赛中的大多数都涉及机器学习和数据科学问题,尽管它们并不局限于这些领域。用户可以竞相提供任何问题的解决方案,只要他们能够以 zip 存档的形式交付解决方案。然后,组织者的评分程序会对文件进行量化评估。
Codalab 竞赛不提供有声望的奖品或奖励。相反,Codalabs 主要致力于促进协作研究和代码测试。主要目标是让数据科学家一起工作。Codalab 通过开发更高效和可复制的代码,创建了更有效的数据科学解决方案。报名参加 Codalab 竞赛是通过项目协作获得编程和代码构建经验的好方法。
TopCoder 寻求顶级数据科学专业人士的帮助,帮助各种规模的企业快速有效地解决复杂的数据问题。参与者可以获得奖励,并与世界上一些最伟大的数据科学家竞争。
TopCoder 提供了一个广泛的竞赛选择,集中在数据科学,编码和网页设计。他们最大的吸引力是一年一度的 TopCoder 公开赛,被称为“终极编程和设计锦标赛”这一赛事包括多个数据相关领域的众多比赛。比赛从网上开始,但是表现最好的选手可以获得额外的奖励和去美国参加 TCO 总决赛的机会。
TopCoder 的另一个优点是,除了大型活动,他们还有小型的地区性活动,以帮助更多的人参加比赛。
铁牍
Iron Viz 是世界上最大的数据可视化竞赛,由业内知名企业 Tableau 主办。比赛包括为期一个月的资格赛,然后是前三名决赛选手之间的冠军赛。决赛选手在 Tableau Conference 举办的拥挤竞技场中进行 20 分钟的闪电赛。他们可以赢得数千美元的现金奖励。这种兴奋使 Iron Viz 锦标赛成为每年最受期待的数据赛事之一。
当你注册了 Iron Viz,你将加入来自世界各地的数百名数据可视化专家。铁 Viz 的好处远远不止是幸运的赢家。即使您不是三名决赛选手之一,您也可以测试您的技能,并向数据可视化领域的佼佼者学习。我们都知道学习本身就是一种奖励!
天池大数据竞赛
天池是一个数据科学家的全球社区,举办跨越各种行业和技能水平的大数据竞赛。天池的目标是鼓励竞争对手通过应用数据科学和分布式计算来创建现实世界的解决方案。你将与世界上一些精英人工智能支持者竞争。现金池可能高达 100 万美元。
天池竞赛涉及大数据、人工智能操作、机器学习、对象检测和其他密切相关的数据领域。特别关注电子商务的消费者行为和预测分析。他们有几十个比赛可供选择,挑一个适合你的吧!
获得现实世界的数据科学经验 对于从事数据科学的职业来说是不可或缺的。竞争是获得这种体验的最好方式之一!除了获得丰富的知识,您还将开发一个具有竞争力的数据科学产品组合。您将在一些数据科学领导者面前展示您的工作,甚至可能在此过程中赢得一些奖项!
你将要克服的复杂挑战,以及友好的竞争精神,将帮助你超越自己的极限。竞赛也给你机会扩展你的数据技能。如果你已经有一段时间没有参加比赛了,或者你以前从未参加过比赛,我们建议你冒一次险,报名参加。
如何找到并选择最好的数据科学课程
December 3, 2019
选择数据科学课程有数百个选项,在迷宫般的选择中穿行可能会很困难。为方便起见,我们将数据科学课程指南分为五个主要类别:
- 大学/学院
- 数据科学训练营
- 数据科学书籍
- 在线视频课程(MOOCs)
- 在线互动课程(如我们在 Dataquest 提供的课程)
我们会查看每种方法的优缺点,以帮助您决定哪种方法最适合您。
在大学/学院学习数据科学
数据科学课程最传统的选择是高等教育机构,如大学或学院。课程包括三年或四年的本科学位,或者硕士或博士等研究生学位
在大学学习数据科学课程的一个有力论据是,你获得的学位证书得到了雇主的广泛认可,这将有助于你在该行业获得第一份工作。
此外,学习者选项的社交方面可以让你感觉你不是一个人在学习,并且可以让你的学习体验更加顺畅。
选择大学的一大不利因素是费用。研究生学位的费用在 10,000 美元到 50,000 美元之间,本科学位的费用要高出几倍。如果你足够幸运,生活在一个大学免费或有补贴的地方,那么这个因素就会减少,但对大多数人来说,上大学是一个不小的因素。

为了继续学习大学数据科学课程,你需要确保这是一个很好的选择。一旦你做了这个决定,你就要为你付出的代价负责。这可以被看作是积极的,因为你做出的坚定承诺将有助于你完成学业。
其他不利因素包括大量的时间投入、不灵活的学习计划和入学要求——尤其是在顶尖大学,入学竞争激烈。
如果你有时间和金钱花在大学学历上,这可能是进入这个行业的一个非常有效的方式,然而,还有几个更实惠的选择。
数据科学训练营
训练营提供浓缩的面对面数据科学课程,通常持续大约三个月的全日制学习。训练营有预定义的课程,因此您可以专注于学习。你会遇到其他人,并能够建立关系网和协作学习。
训练营可能很贵——短期训练营的费用从 3000 美元到整整三个月的 20000 美元不等。就像大学一样,这种成本是一把双刃剑。这是一个昂贵的选择,但另一方面,你可能会坚持到底,不会违背自己的承诺,因为有那么多钱在等着你。
为了充分利用你的训练营,你需要有一些经验。大多数训练营都有入学要求,否则几个月内要学的东西太多了。如果你没有这方面的经验,训练营可能不是一个好的选择,你可能需要考虑不同的数据科学课程(或者先考虑不同的选择)。
一些训练营会帮助你找到工作,或者至少在你找工作的时候给你支持,这是一个非常值得的好处。

有大量的数据科学训练营,而且质量很重要。出于这个原因,最好坚持那些已经建立并有很好声誉的学校,以确保你得到高质量的指导。虽然训练营是新的和/或小的并不意味着它不能提供,坚持与“大男孩”之一是一个低风险的策略。
如果你正在寻找一个更灵活的选择,并且不想要亲身体验,有许多在线训练营可供选择。
如果你能负担得起数据科学训练营,它们可能是快速获得找工作所需技能的有效方式。也就是说,在学习时间表方面,有一些选择更实惠,也更灵活。
数据科学书籍
虽然从技术上讲,这不是一门数据科学课程,但从书本中学习是一种屡试不爽的方法。即使您决定选择另一种方法来学习数据科学,书籍也是学习和参考的一个很好的补充来源。
当你不在电脑前的时候,它们也很棒——你可以在通勤或度假的时候学习!
书籍的一大优势是它们很便宜——大多数不到 40 美元,一些顶级数据科学书籍是免费的。
一般来说,如果您想要全面的数据科学教育,您至少需要使用一些书籍。有一些很棒的初学者教材,但是当你想更深入地挖掘时,你需要专门化你的阅读。
另一件要记住的事情是,为了从你的经历中获得最大的收获,你需要建立一个编码环境来将你学到的东西付诸实践。一些替代方案(如交互式在线课程)允许你推迟这个棘手的步骤,这样你就可以立即投入学习。
从书本中学习可能是学习数据科学的一种极其经济高效的方式。也就是说,您需要付出额外的努力将所学付诸实践,否则您将无法将您的知识转化为数据科学的实际应用。
在线视频课程(MOOCs)
2000 年代末出现的大规模开放在线课程(MOOCs)大多是在 Coursera 和 EdX 等平台上提供的大学课程的视频版本。
MOOCs 允许低摩擦地进入大学水平的数据科学课程——许多课程是免费提供的,如果你想要完成证书,只需收取少量费用。一些 MOOC 项目收取月订阅费。
一般来说,由于各种 mooc 的可用性,mooc 提供的数据科学证书不被认为是作为实际大学学位的一部分完成课程的权威。
也就是说,MOOCs 是数据科学课程最受欢迎的选择之一,尤其是在线课程。
像书籍一样,你需要建立自己的编码环境,将你学到的东西付诸实践,因为 MOOC 课程不是交互式的。
MOOCs 可能是学习数据科学的一个很好的选择——你可以以可承受的成本从世界上最好的大学学习。如果你决定追求这个选择,确保你付出额外的努力把你学到的东西付诸实践。
在线互动课程(Dataquest)
在线互动数据科学课程,如我们在 Dataquest 提供的课程,为大多数想要学习数据科学的人提供了我们认为的最佳选择。
Dataquest 每月收费 49 美元,尽管我们最受欢迎的模块是完全免费的。您可以按照自己的时间表学习,大多数学生在 6 个月内完成我们的数据科学学习路径,因此您的总成本约为 300 美元。这使得它比书籍或 MOOCs 更贵,但比大学或训练营便宜得多。
Dataquest 不使用任何视频。相反,我们的文本课程与交互式编码环境相结合。您可以直接在您的浏览器中完成我们的代码练习,因此您不必担心如何设置您的本地环境。当你运行你的代码时,你会得到关于你所写内容的即时反馈。
简而言之,Dataquest 平台。
MOOCs 和书籍等被动学习方法已被证明不如动手互动课程有效— 研究表明动手学习者的表现比通过被动方法学习的学生平均高出 20%。
与大学和训练营类似,Dataquest 的学习路径提供了一个整体课程,教你获得入门级数据科学或数据分析师工作所需的一切知识。我们的方法是经过验证的——在 2019 年对学生成果的调查中,96%的学生表示他们会向其他人推荐 Dataquest 以促进职业发展。
62.5%的学生表示,他们在目前的工作中使用了在 Dataquest 中学到的技能,并将 Dataquest 之前的工资与目前的工资进行比较时,工资中位数增加了 12,450 美元。
我们的学生对我们的教学方法赞不绝口。以下是他们的部分评价:

独立评级网站 Switchup 连续两年授予 Dataquest it 最佳在线训练营奖(尽管我们不是训练营),并连续三年授予其最佳数据科学训练营奖。学生对 Switchup 的平均评分为 4.9 分(满分 5 分)。
选择数据科学课程
下表便于比较不同类型的数据科学课程的属性:
| 页眉 |
大学/ 学院
| 训练营 |
书籍
|
MOOCs
|
数据请求
|
| --- | --- | --- | --- | --- | --- |
| 成本 | $10,000-$200,000 | $3,000-$20,000 | $0-$40 | $0-$50 | $0-$300 |
| 时间投入 | 1-4 岁 | 12 周 | 变化 | 变化 | 变化 |
| 灵活的学习时间表 | | | | | |
| 互动学习 | | | | | |
| 完成课程 | | | | | |
| 认可的凭证 | | | | | |
我们有一点偏见,但我们相信 Dataquest 的交互式学习路径提供了收益与成本的最佳平衡,可以根据您自己的时间表灵活地学习。
数据科学术语和行话:词汇表
February 20, 2018Getting started in data science can be overwhelming, especially when you consider the variety of concepts and techniques a data scienctist needs to master in order to do her job effectively. Even the term “data science” can be somewhat nebulous, and as the field gains popularity it seems to lose definition. To help those new to the field stay on top of industry jargon and terminology, we’ve put together this glossary of data science terms. We hope it will serve as your handy quick reference whenever you’re working on a project, or reading an article and find you can’t quite remember what “ETL” means. Are we missing a term? Get in touch.
基本原则
这些是在开始学习数据科学时有助于掌握的一些基本概念。虽然您可能不需要使用这里提到的每一个概念,但是在阅读文章或与其他数据爱好者讨论话题时,了解这些术语的含义会有所帮助。
算法
算法是我们给计算机的一组指令,因此它可以获取值并将其处理成可用的形式。这可能像找到并删除段落中的每个逗号一样简单,也可能像建立一个预测棒球运动员在 2018 年将打出多少个本垒打的方程一样复杂。
后端
后端是在幕后工作的所有代码和技术,用有用的信息填充前端。这包括数据库、服务器、认证过程等等。你可以把后端想象成一个公寓的框架、管道和电线。
大数据
大数据是一个因过于宽泛而无用的术语。将它理解为“如此多的数据,以至于您需要采取谨慎的措施来避免长达一周的脚本运行时间”会更有帮助大数据更多的是关于帮助计算机对非常大(阅读:1+ TB )的数据集进行复杂分析的策略和工具。我们必须用大数据解决的问题按 4 V 的分类:数量、多样性、准确性和速度。
分类
分类是一个有监督的机器学习问题。它根据数据点与其他数据点的相似性对数据点进行分类。你获取一组数据,其中每个项目都有一个类别,然后查看每个项目之间的共同特征。然后,您可以使用这些共同的特征作为新项目类别的指南。
数据库ˌ资料库
尽可能简单地说,这是一个数据存储空间。我们大多使用带有数据库管理系统(DBMS)的数据库,如 PostgreSQL 或 MySQL。这些是计算机应用程序,允许我们与数据库进行交互,以收集和分析其中的信息。
数据仓库
数据仓库是一个系统,用于使用来自许多来源的数据快速分析业务趋势。它们旨在让没有数据库架构博士学位的人也能轻松回答重要的统计问题。
前端
前端是客户或用户可以直接看到并与之交互的一切。这包括数据仪表板、网页和表单。
模糊算法
使用模糊逻辑来减少脚本运行时间的算法。模糊算法往往不如使用布尔逻辑的算法精确。它们往往更快,计算速度有时超过精度的损失。
模糊逻辑
布尔逻辑的一种抽象,代替通常的真和假,取值范围在 0 和 1 之间。也就是说,模糊逻辑允许像“有点正确”或“大部分错误”这样的陈述
贪婪算法
贪婪算法将一个问题分解成一系列步骤。然后,它将在每一步寻找可能的最佳解决方案,旨在找到可用的最佳整体解决方案。Dijkstra 算法就是一个很好的例子,它在图中寻找最短的可能路径。
机器学习
计算机使用算法来理解一组数据,然后根据其理解进行预测的过程。有许多类型的机器学习技术;大多数被归类为监督或非监督技术。
过度拟合
当模型考虑太多信息时,就会发生过度拟合。这就像让一个人一边读句子,一边通过显微镜看一页。有助于理解的模式迷失在噪音中。
回归
回归是另一个有监督的机器学习问题。它关注的是一个目标值如何随着数据集中其他值的变化而变化。回归问题通常处理连续变量,如平方英尺和位置如何影响房子的价格。
统计与统计
统计学(复数)是用来分析一组数据的整套工具和方法。统计数据(单数)是我们从数据中计算或推断出的值。我们通过使用统计学领域的技术得到一组数字的中间值(一个统计值)。
培训和测试
这是机器学习工作流程的一部分。在制作预测模型时,您首先要为它提供一组训练数据,以便它能够建立理解。然后,您向模型传递一个测试集,在那里它应用它的理解并试图预测一个目标值。
欠拟合
当你没有给模型提供足够的信息时,就会出现欠拟合。不适应的一个例子是让某人画出一天的温度变化图,并且只给出最高和最低温度。不是人们可能期望的平滑曲线,你只有足够的信息来画一条直线。
重点领域
随着企业越来越关注数据,各种技能的人都有机会成为数据社区的一员。这些是数据科学领域中存在的一些专业化领域。
人工智能
一门研究和开发能感知周围环境的机器的学科。人工智能的大多数工作都集中在使用机器意识来解决问题或完成一些任务。如果你不知道,人工智能已经在这里了:想想自动驾驶汽车、机器人外科医生和你最喜欢的视频游戏中的坏人。
商业智能(BI)
类似于数据分析,但更侧重于业务指标。BI 的技术方面包括学习如何有效地使用软件来生成报告和发现重要趋势。这是描述性的,而不是预测性的。
数据分析
这个学科是数据科学的小兄弟。数据分析更侧重于回答关于现在和过去的问题。它使用不太复杂的统计数据,通常试图识别可以改善组织的模式。
数据工程
数据工程是关于后端的。这些人构建系统,让数据科学家能够轻松地进行分析。在较小的团队中,数据科学家也可能是数据工程师。在更大的团队中,工程师能够专注于加速分析,并保持数据组织良好和易于访问。
数据新闻
这个学科是关于用数据聚焦的方法讲述有趣和重要的故事。随着越来越多的信息以数据的形式出现,这是自然而然的事情。故事可能是关于数据的,也可能是由数据提供信息的。如果你想了解更多,有一本完整的手册。
数据科学
鉴于该领域的快速扩张,数据科学的定义可能很难确定。基本上,它是使用数据和高级统计学进行预测的学科。数据科学也专注于在杂乱和不同的数据中创造理解。一个科学家正在研究的“什么”会因雇主而有很大不同。
数据可视化
视觉传达有意义数据的艺术。这可能涉及信息图、传统图表,甚至是完整的数据仪表板。
尼可拉斯·费尔顿是这一领域的先驱,爱德华·塔夫特毫不夸张地写了本书。
定量分析:
这个领域高度集中于使用算法在金融领域获得优势。这些算法要么根据大量数据推荐,要么做出交易决策,通常在皮秒的数量级。定量分析师通常被称为“定量分析师”
统计工具
数据专业人员使用许多统计数据来推理和交流有关其数据的信息。这些是帮助你开始的一些最基本和最重要的统计工具。
相互关系
相关性是衡量一组值对另一组值的依赖程度。如果值一起增加,它们是正相关的。如果一组中的一个值随着另一个值的减少而增加,它们就是负相关的。当一组中的变化与另一组中的变化无关时,就没有相关性。
平均值(平均值、期望值)
一种让我们对一组数字的“典型值”有所了解的计算。平均值是值列表的总和除以列表中值的数量。它本身可能具有欺骗性,在实践中,我们使用平均值和其他统计值来获得对数据的直觉。
中位数
在按顺序排列的一组值中,中值是位于中间的任何值。我们经常使用中位数和平均值来判断集合中是否有异常高或异常低的值。这是探索异常值的早期提示。
使标准化
当所有的值都被调整到一个共同的范围内时,就说一组数据被标准化了。我们将数据集标准化,以使比较更容易、更有意义。例如,从一堆不同的网站上获取电影评级,并对它们进行调整,使它们都在 0 到 100 的范围内。
局外人
离群值是被认为离其他点非常远的数据点。它们通常是异常情况或测量错误的结果,应该在数据分析工作流程的早期进行调查。
样品
样本是我们可以访问的数据点的集合。我们使用样本对更大的人群进行推断。例如,一项政治民意调查对 1000 名希腊公民进行抽样调查,以推断全希腊的意见。
标准偏差
一组值的标准差有助于我们了解这些值的分布情况。该统计比方差更有用,因为它与值本身用相同的单位表示。数学上,标准差是一个集合的方差的平方根。它通常用希腊符号σ来表示。
统计显著性
当我们判断一个结果可能不是由于偶然而发生时,它就具有统计意义。它在调查和统计研究中被大量使用,尽管并不总是实际价值的标志。统计学意义的数学细节超出了本文的范围,但是更全面的解释可以在这里找到。
汇总统计数据
汇总统计是我们用来以一种简单的方式交流对数据的见解的方法。汇总统计的例子有平均值、中值和标准差。
时间序列
时间序列是按每个数据点出现的时间排序的一组数据。想想一个月的股票市场价格,或者一天的温度。
残差(误差)
残差是对真实值与我们根据数据集计算出的统计值相差多少的度量。因此,给定一个预测,明天中午将是 20 华氏度,当中午到来时只有 18 度,我们有 2 度的误差。这经常与术语“误差”互换使用,尽管从技术上讲,误差是一个纯理论值。
差异
一组值的方差衡量这些值的分布程度。在数学上,它是单个值和一组值的平均值之间的平均差。集合方差的平方根给出了标准偏差,这更直观有用。
工作流的组成部分
虽然每个工作流都不同,但这些是数据专业人员用来从数据中获得洞察力的一些通用流程。
数据探索
数据科学过程中的一部分,科学家会问一些基本问题来帮助她理解数据集的上下文。您在探索阶段学到的东西将指导以后更深入的分析。此外,它有助于您认识到什么时候结果可能会令人惊讶,并需要进一步调查。
数据挖掘
从一组数据中提取切实可行的见解并加以充分利用的过程。这包括从清理和组织数据的一切;去分析它,找出有意义的模式和联系;以一种帮助决策者改善他们的产品或组织的方式沟通这些联系。
数据管道
一系列传递数据的脚本或函数的集合。第一个方法的输出成为第二个方法的输入。这种情况一直持续到数据被适当地清理和转换,以用于团队正在进行的任何任务。
数据争论(Munging)
以原始形式获取数据并“驯服”它直到它在更广泛的工作流或项目中更好地工作的过程。驯服意味着使值与更大的数据集一致,替换或删除可能影响以后的分析或性能的值,等等。争吵和蒙格可以互换使用。
ETL(提取、转换、加载)
这个过程是数据仓库的关键。它描述了将来自多个地方的数据以原始形式显示在屏幕上以供分析的三个阶段。ETL 系统通常是数据工程师送给我们的礼物,并且在幕后运行。
网页抓取
网络抓取是从网站源代码中提取数据的过程。它通常包括编写一个脚本来识别用户想要的信息,并将其放入一个新文件中供以后分析。
机器学习技术
机器学习领域已经发展得如此之大,以至于现在有机器学习工程师的职位。以下术语提供了机器学习中使用的一些常用技术的广泛概述。
使聚集
聚类技术试图将多组点收集并分类到彼此“足够相似”或“接近”的组中。“接近”取决于你选择如何测量距离。随着越来越多的特征被添加到问题空间,复杂性增加。
决策树
这种机器学习方法使用关于给定数据集的一系列分支问题或观察来预测目标值。随着数据集变大,它们往往会过度拟合模型。随机森林是一种决策树算法,旨在减少过度拟合。
深度学习
深度学习模型使用非常大的神经网络——称为深度网络——来解决复杂的问题,例如面部识别。模型中的层从识别非常简单的模式开始,然后逐渐增加复杂性。最终,网络(希望)会有一个细致入微的理解,可以准确地分类或预测值。
特征工程
将我们作为人类所拥有的知识转化为计算机可以理解的量化值的过程。例如,我们可以将我们对杯子图像的视觉理解转化为像素强度的表示。
特征选择
在建立模型时,确定数据集的哪些特征最有价值的过程。这对于大型数据集尤其有用,因为使用较少的特征将减少训练和测试模型所需的时间和复杂性。该过程从测量数据集中每个特征与预测目标变量的相关性开始。然后,您选择将导致高性能模型的特征子集。
神经网络
一种非常松散地基于大脑神经连接的机器学习方法。神经网络是一个由连接节点组成的系统,这些节点被分成几层,即输入层、输出层和隐藏层。隐藏层(可能有很多层)是用来做预测的重要工具。一层的值通过与下一层的连接进行过滤,直到给出最终的输出集并做出预测。一个很好的视频解释可以在这里找到。
监督机器学习
通过监督学习技术,数据科学家给计算机一组定义明确的数据。所有的列都有标签,计算机知道它在找什么。这就像一个教授给你一份教学大纲,告诉你在期末考试中会遇到什么。
无监督机器学习
在无监督学习技术中,计算机建立自己对一组未标记数据的理解。无监督的 ML 技术寻找数据中的模式,并且经常处理基于共享特征的分类项目。
准备好投身数据科学了吗?现在就免费报名。
Miguel 如何通过 Dataquest 快速获得 3 份数据科学工作
原文:https://www.dataquest.io/blog/data-science-job-offers-dataquest-review/
December 24, 2018
Miguel Couto 的数据科学故事始于拒绝。
“我收到了一封非常枯燥的电子邮件,上面写着,‘嗨,米格尔,只是想告诉你,我们不会给你奖学金。’”米格尔说。他申请了柏林一所著名但昂贵的数据科学训练营的奖学金。尽管他有资格,包括材料科学和工程的博士学位,他们并不感兴趣。他们告诉他,你的档案很好,但不够优秀。
“当我读到最后一行时,我想,‘好吧,这就是我要向你展示我可以靠自己做到的时候,不需要在你的学校花 8000 欧元。’“米格尔说。我做到了。"
来自葡萄牙的米格尔刚刚三十多岁,但他已经换过几次职业了。在经历了一段通往博士学位的学术生涯后,他决定搬到柏林学习音乐。但由于音乐人赚不了多少钱,他兼职为 ResearchGate 做广告运营。那份工作被证明是很棒的经历,但是随着时间的推移,米格尔意识到他并没有完全享受这份工作,但是他很享受他工作中与数据相关的部分。
“所以我辞掉了工作,开始自学,”他说。
基于项目的学习
由于他的博士学位,他对数据科学所需的数学和统计学有一点了解,对编码也有一点了解。但是他没有使用 Python 的经验,也没有真正的数据科学培训。
然后他找到了 Dataquest 。
“这真的对我帮助很大,”米格尔说。“尤其是这些项目,让我真正开始构建 Github 产品组合。而且社区很神奇;Dataquest 的 Slack 简直不可思议。我从那里的人那里学到了很多。不断有新的信息进来。”
“我也非常喜欢这个平台,”他说。“就像这种心理上的东西,你总是想增加你的分数,你的百分比,你的成就,这真的很好。”
但是他并没有把自己局限在数据探索上。Miguel 还在从媒体到 Youtube 的任何地方消费数据科学内容。他还尝试了其他学习平台,如 DataCamp 和 Codecademy,但他说他觉得 Dataquest 上的内容“解释得更好”
“有时候,比如说,在 Codecademy 上,你只是在打字。它不会让你思考,”他说。“Dataquest 实际上让你思考。”
但是他不仅仅是在做数据探索。米格尔也在承接他感兴趣的外部项目。他说,尤其是那些对他来说太大而无法完成的项目。
“那是我学到最多的时候,”他说,“因为我不得不实际做一个我不知道如何做的大项目。”
“你不应该害怕这一点,”米格尔谈到接受那些似乎超出你能力范围的项目时说。“有时候你只会想:‘哦,对我来说太多了,我做不到。’但只管去做吧。我认为这是人们学习的方式。你需要做的事情,而不是仅仅花一天时间阅读。阅读也很重要,但是你需要亲自动手。"
求职,毫无准备
经过几个月的学习,我们的数据科学家之路已经走了 50%,米格尔将他无所畏惧的态度提升到了一个新的高度。他决定开始申请数据科学的工作,尽管他觉得自己还没有准备好。“我有点厌倦了失业,”他说,“所以我决定,只是为了好玩,看看我和其他求职者相比处于什么位置,看看我是否能在这一点上找到工作。”
“令我惊讶的是,”他说,“我得到了很多肯定的答复。”
大多数回复都是从给他一个编码挑战开始面试的。因为他只是想测试自己的水平,Miguel 试图在不寻求任何人帮助的情况下完成这些挑战,看看他能用自己已经学会的技能做些什么。“事实上结果相当不错,”他说。“这些挑战对我来说相当容易,因为我在 Dataquest 中学到了一些东西。”
事实上,米格尔已经进入了四家不同公司面试的最后阶段。他最终取消了其中一个面试,但他收到了其他三家公司的工作邀请。他最终选择了一个数据分析师的角色,在公关巨头 WPP 的一个部门工作。
有趣的是,他说他不认为他的学术背景和博士学位对他得到这份工作有多大帮助。“这是一个很好的破冰方式,”他说,“谈论博士学位。在第一次面试中炫耀是件好事,但随后你会意识到你需要的不仅仅是一张纸。”
相反,他说他认为对他有帮助的是他的广告和营销知识以及数据科学的商业方面,这些都是他从以前的工作中获得的。“我认为,结合 DataQuest 的知识,是我得到这份工作的原因,”他说。
数据科学成功的建议
回想起来,米格尔并不后悔他从事数据分析师工作的道路,也不后悔被 bootcamp 奖学金拒绝。“最终我在 DataQuest 花了 250 欧元,而不是在这所学校花了 8000 欧元。我按照自己的节奏学习,”他说。
“你真的不需要在训练营上花一万美元。它不可能是你唯一的选择。但有些人认为:“这是我唯一的选择,因为我将获得人脉,我将与其他人一起工作。”“你也可以在网上学习,”他说,“你仍然可以找到工作。"
他给找工作的学生的建议是:为面试过度准备。“我会花两三天时间准备采访,”他说。“我有时会比他们更了解他们的商业模式。我真的很自豪,因为我不会让任何东西逃脱。比如,我会写自己的问题。”
“人们通常在最后的面试中问我的问题,我自己也问过,我知道答案。然后你假装,‘哦,这是个好问题。“让我想想,”但是你脑子里已经有答案了。"
对有抱负的数据科学家来说,另一个教训是:不要害怕把目标定得比你认为能达到的更高。米格尔说,他从接受看起来太难的项目中学到了很多东西,他通过申请他认为自己不胜任的工作获得了数据分析师的职位。
当然,他不打算就此罢休。
“这就是为什么我买了年度订阅,”他说。“尽管我将在 1 月份开始工作,但我仍将保持活跃,我将继续学习,因为显然我想达到其他途径。”
“我仍然认为 Dataquest 是最好的选择,”他补充道。“如果我只能选择一个,我会选择 Dataquest。”
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
今天开始收听数据科学播客
原文:https://www.dataquest.io/blog/data-science-podcasts-to-start-listening-today/
November 5, 2021
数据科学是一个复杂的领域。然而,数据科学播客向您介绍了发人深省的问题,并激发了信息科学领域专家之间的讨论。无论你是想 了解更多关于 Python探索 SQL 基础 ,甚至是 雇佣一个远程团队 ,播客都能帮上忙。作为学习新学科(课本和考试)的传统方法的替代,播客可以帮助你理解困难的概念,并让你跟上最新的发展。
你可以利用从他人那里学到的所有新思想和原则,为你面临的问题开发出创造性的解决方案。如果您是数据科学爱好者或专业数据科学家,数据科学播客可以为您提供该领域的不同观点和最新信息。
魔鬼经济学
《魔鬼经济学》一书的合著者斯蒂芬·j·杜布纳主持了 魔鬼经济学播客 。在杜布纳的节目中,他将带你踏上一段旅程,去揭开一切事物背后隐藏的意义,从你一直知道的事物到你从未想过的想法。如果你从事数据科学工作,发现数据的隐藏价值,拓宽你的视野不会有什么坏处。
跟我说说 Python
Python 多功能性的一个很好的例子是 “跟我说说 Python”播客 ,它已经录制了超过 320 集关于 Python 和类似技术的内容。它不仅仅面向数据科学家和软件开发人员;主持该节目的迈克尔·肯尼迪讨论了如何在其他领域使用 Python。
数据紧缩
data crunch 播客 面向对数据科学、人工智能、机器学习和 深度学习(DL) 感兴趣的人——以及希望更多了解这些学科对世界的影响的人。此外,企业家和专家经常出现在这个节目中,讨论他们处理这种独特技术的经验,包括他们的失败、成功和影响他人的能力。
数据怀疑论者
一周又一周, 数据怀疑论播客 带给你如何理解我们这个数据驱动的世界的故事。你还会获得关于 统计 、机器学习、大数据、人工智能和数据科学等主题的观点。
家庭数据科学
在本期 家庭数据科学 播客中,法国科学家弗朗切斯科·加达莱塔(Francesco Gadaleta)将带你了解一系列关于技术、机器学习和人工智能的重要对话和发人深省的问题。看一个关于人工智能黑暗的序列就是一个极好的例子。
数据科学的艺术家们
数据科学播客 的艺术家完全是为想要提高技能的数据科学家和分析师服务的。您将学习如何推进您的职业发展,保持信息灵通,并坚持最高的数据道德和完整性标准。该播客包括采访片段和“快乐时光”,在此期间,听众可以就任何与数据科学相关的问题提问。
留声机
会说话的机器播客 提供了对人工智能世界的洞察。每集都分享来自该领域专家的精彩信息,以及令人兴奋的讨论和对相关问题的回答。考虑到机器学习改变世界的速度有多快,我们必须开始学习如何提出正确的问题,以及如何处理答案。这些播客将帮助你做到这一点。
梯度异议
【Gradient dismission】,一个关于机器学习 的播客,提供了一个内部视角,让人们了解各种行业的领导者如何使用机器学习和深度学习模型来解决实际问题。OpenAI 联合创始人 Wojciech Zaremba、Lyft 数据科学家 Sean Taylor、OpenAI 基金会创始人 Chris Mattmann(美国宇航局喷气推进实验室首席技术和创新官)都曾在节目中亮相。
今日 AI
AI Today 播客 提供了关于人工智能采用、行业和在现实世界中的应用的优秀情报信息和市场研究。如果你想了解更多关于人工智能在工作场所的知识,请今天收听 AI。
香蕉数据播客
从有道德的人工智能(AI)到人性化的数据, 香蕉数据播客 都是关于数据科学的“最新和最伟大的”。聆听 Christopher Peter Makris 和 Corey Strausman 关于数据相关的最新趋势、新闻和热门话题。对于那些喜欢阅读的人,两人组还提供了一份时事通讯。
数据科学中的女性
在与数据科学领域的领先女性的多次会谈中,斯坦福大学教授 Margot Gerritsen 主持了一系列重要的讨论。 WiDS 播客 概述了数据科学在各个行业中的作用,从流媒体音乐到医疗保健,以及大量的职业建议。
数据未来学
在 数据未来学播客 系列中,数据科学执行网络(DSEN)的创始人兼首席执行官费利佩·弗洛雷斯采访了一些世界上最有成就的数据从业者。尽管它强调人工智能(AI)的领导地位,但该节目的内容经常包括如何在庞大的数据世界中起步并在其中脱颖而出的有用建议。
人类吗
HumAIn 是一个播客 ,由大卫·雅各布维奇主持,通过与行业思想领袖的讨论为客户揭示人工智能,目前已进入第二季。除了首席数据科学家和人工智能顾问以及推进人工智能的领导者,HumAIn 播客还涵盖了新的人工智能产品和行业趋势。它也弥合了第四次工业革命中人类与机器之间的鸿沟。
播客是学习新事物最有效的方式之一,可以培养听众的好奇心和激情。跟上数据科学的最新创新至关重要,因为该领域仍在以指数速度增长。
播客的伟大之处在于,你可以在旅行、排队、散步或做其他任何事情的时候听它们。这类似于参加一个会议,听 数据科学家和人工智能专家 发言,除了你可以随时暂停、播放、倒带。无论何时何地,您都可以访问技巧和新闻库。你可以在准备你最喜欢的苹果派的时候学习数据科学。太完美了!
构建数据科学投资组合:机器学习项目
原文:https://www.dataquest.io/blog/data-science-portfolio-machine-learning/
July 5, 2016Companies are increasingly looking at data science portfolios when making hiring decisions, and having a machine learning project in your portfolio is key.
(这是关于如何构建数据科学组合的系列文章的第三篇。你可以在文章的底部找到本系列其他文章的链接。)
制作高质量作品集的第一步是要知道要展示什么技能。公司希望数据科学家具备的主要技能,也就是他们希望投资组合展示的主要技能是:
- 通讯能力
- 与他人合作的能力
- 技术能力
- 对数据进行推理的能力
- 主动的动机和能力
任何好的投资组合都将由多个项目组成,每个项目都可能展示上述 1-2 点。这是一个系列的第三篇文章,将介绍如何制作一个全面的数据科学投资组合。
在这篇文章中,我们将讨论如何制作你的作品集中的第二个项目,以及如何构建一个端到端的机器学习项目。最后,你会有一个展示你数据推理能力和技术能力的项目。
如果你想看的话,这是已经完成的项目。
一个端到端的机器学习项目
作为一名数据科学家,有时你会被要求获取一个数据集,并想出如何用它来讲述一个故事。在这种时候,很重要的一点是要很好地沟通,并走完你的过程。像 Jupyter notebook 这样的工具,我们在之前的帖子中使用过,可以很好地帮助你做到这一点。这里的期望是,可交付成果是总结您的发现的演示文稿或文档。
然而,有时候你会被要求创建一个有操作价值的项目。一个有运营价值的项目直接影响着公司的日常运营,会被不止一次的使用,而且往往会被多人使用。像这样的任务可能是“创建一个算法来预测我们的流失率”,或者“创建一个可以自动标记我们的文章的模型”。
在这种情况下,讲故事不如技术能力重要。您需要能够获取一个数据集,理解它,然后创建一组可以处理该数据的脚本。这些脚本快速运行并使用最少的系统资源(如内存)通常很重要。这些脚本会被运行多次,这是很常见的,所以可交付的东西变成了脚本本身,而不是演示文稿。可交付成果通常被集成到操作流程中,甚至可能是面向用户的。构建端到端项目的主要组件包括:
- 理解上下文
- 探索数据,找出细微差别
- 创建一个结构良好的项目,使其易于集成到操作流程中
- 编写运行速度快且使用最少系统资源的高性能代码
- 很好地记录您的代码的安装和使用,这样其他人就可以使用它
为了有效地创建这种类型的项目,我们需要处理多个文件。强烈推荐使用像 Atom T1 这样的文本编辑器,或者像 T2 py charm T3 这样的 IDE。这些工具将允许您在文件之间跳转,并编辑不同类型的文件,如 markdown 文件、Python 文件和 csv 文件。
构建你的项目,使其易于版本控制和上传到协作编码工具,如 Github 也是有用的。 Github 上的这个项目。在这篇文章中,我们将使用我们的编辑工具以及像 Pandas 和 scikit-learn 这样的库。我们将广泛使用 Pandas DataFrames ,这使得在 Python 中读取和处理表格数据变得容易。
Github 上的这个项目。在这篇文章中,我们将使用我们的编辑工具以及像 Pandas 和 scikit-learn 这样的库。我们将广泛使用 Pandas DataFrames ,这使得在 Python 中读取和处理表格数据变得容易。
寻找好的数据集
端到端机器学习项目的良好数据集可能很难找到。数据集需要足够大,这样内存和性能限制才能发挥作用。它还需要具有潜在的可操作性。例如,这个数据集,包含美国大学 adlesson 标准、毕业率和毕业生未来收入的数据,将是一个用来讲述故事的很好的数据集。
然而,当您考虑数据集时,很明显没有足够的细微差别来用它构建一个好的端到端项目。例如,你可以告诉某人,如果他们去某个特定的大学,他们未来的潜在收入是多少,但这将是一个快速的查找,没有足够的细微差别来证明技术能力。你也可以弄清楚 adless 标准较高的大学是否倾向于让毕业生挣得更多,但这更多的是讲故事,而不是操作。
当您拥有超过 1gb 的数据时,以及当您对想要预测的内容有一些细微差别时,这些内存和性能约束往往会发挥作用,这涉及到在数据集上运行算法。一个好的操作数据集使您能够构建一组转换数据的脚本,并回答动态问题。
一个很好的例子是股票价格的数据集。您将能够预测第二天的价格,并在市场关闭时不断向算法输入新数据。这将使你能够进行交易,甚至有可能获利。这不是讲故事,而是增加直接价值。找到这样的数据集的一些好地方是:
- /r/datasets —拥有数百个有趣数据集的子编辑。
- Google 公共数据集 —可通过 Google BigQuery 获得的公共数据集。
- Awesome 数据集 —一个数据集列表,托管在 Github 上。
当您浏览这些数据集时,想想有人可能希望用这些数据集来回答什么问题,并想想这些问题是否是一次性的(“房价如何与标准普尔 500 相关联?”),或者正在进行(“你能预测股市吗?”).这里的关键是找到正在进行的问题,并要求相同的代码使用不同的输入(不同的数据)运行多次。
出于本文的目的,我们将看看房利美贷款数据。房利美是美国政府支持的企业,从其他贷方购买抵押贷款。然后,它将这些贷款打包成抵押贷款支持证券并转售。这使得贷款人可以发放更多的抵押贷款,并在市场上创造更多的流动性。这在理论上导致更多的房屋所有权,以及更好的贷款条件。
不过,从借款人的角度来看,情况基本没变。
房利美发布两种类型的数据——关于其收购的贷款的数据,以及这些贷款在一段时间内表现如何的数据。在理想的情况下,有人从贷款人那里借钱,然后偿还贷款,直到余额为零。然而,一些借款人错过了多次付款,这可能会导致取消抵押品赎回权。取消抵押品赎回权是指房子被银行没收,因为无法支付抵押贷款。
房利美跟踪哪些贷款已经逾期,哪些贷款需要取消抵押品赎回权。该数据每季度发布一次,比当前日期滞后1年。
在撰写本文时,最新的可用数据集来自于2015的第一季度。房利美收购贷款时公布的收购数据包含借款人的信息,包括信用评分以及他们的贷款和住房信息。获得贷款后,每季度公布一次的业绩数据包含借款人支付的款项以及止赎状况(如果有的话)的信息。
获得的贷款在绩效数据中可能有几十行。一个很好的方法是,收购数据告诉你房利美现在控制着贷款,业绩数据包含贷款的一系列状态更新。其中一个状态更新可能会告诉我们贷款在某个季度被取消赎回权。 被出售的止赎房屋。
被出售的止赎房屋。
挑选一个角度
我们可以从房利美数据集的几个方面入手。我们可以:
- 试着预测房子取消赎回权后的销售价格。
- 预测借款人的付款历史。
- 在收购时算出每笔贷款的分数。
重要的是坚持单一角度。试图同时关注太多的事情会让你很难做一个有效的项目。选择一个有足够细微差别的角度也很重要。以下是没有太多细微差别的角度示例:
- 找出哪些银行出售给房利美的贷款被取消抵押品赎回权最多。
- 弄清楚借款人信用评分的趋势。
- 探索哪种类型的房屋最常被取消赎回权。
- 探索贷款金额和止赎销售价格之间的关系
以上所有的角度都很有趣,如果我们专注于讲故事会很好,但是不太适合运营项目。有了房利美的数据集,我们将试图通过仅使用获得贷款时可用的信息来预测贷款在未来是否会被取消赎回权。实际上,我们将为任何抵押贷款创建一个“分数”,告诉我们房利美是否应该购买它。这将为我们提供一个很好的基础,也将是一个很好的投资组合。
理解数据
让我们快速看一下原始数据文件。以下是从第1季度到第2012季度的前几行采集数据:
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
这是第一季度的前几行性能数据
2012的1:
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
在深入编码之前,花些时间真正理解数据是有用的。这在运营项目中更为关键——因为我们不是以交互方式探索数据,除非我们提前发现,否则很难发现某些细微差别。
在这种情况下,第一步是阅读房利美网站上的资料:
通读这些文件后,我们知道一些对我们有帮助的关键事实:
- 从
2000年开始到现在,每个季度都有一个采集文件和一个性能文件。数据中有一个1年的滞后,所以在撰写本文时,最新的数据来自2015。 - 这些文件是文本格式的,以竖线(
|)作为分隔符。 - 这些文件没有标题,但是我们有一个每一列是什么的列表。
- 这些文件总共包含了 100 万笔贷款的数据。
- 因为绩效档案中包含了前几年获得的贷款的信息,所以前几年获得的贷款会有更多的绩效数据(即
2014年获得的贷款不会有太多的绩效历史)。
这些小信息将为我们节省大量时间,因为我们知道如何构建我们的项目和处理数据。
构建项目
在我们开始下载和研究数据之前,重要的是要考虑如何构建项目。构建端到端项目时,我们的主要目标是:
- 创造一个可行的解决方案
- 拥有运行速度快、使用资源最少的解决方案
- 让其他人能够轻松扩展我们的工作
- 让其他人更容易理解我们的代码
- 编写尽可能少的代码
为了实现这些目标,我们需要很好地组织我们的项目。一个结构良好的项目遵循几个原则:
- 将数据文件和代码文件分开。
- 将原始数据与生成的数据分开。
- 有一个
README.md文件,引导人们完成项目的安装和使用。 - 有一个
requirements.txt文件,其中包含运行项目所需的所有包。 - 有一个单独的
settings.py文件,包含其他文件中使用的任何设置。- 例如,如果您从多个 Python 脚本中读取同一个文件,让它们都导入
settings并从一个集中的地方获取文件名是很有用的。
- 例如,如果您从多个 Python 脚本中读取同一个文件,让它们都导入
- 有一个
.gitignore文件,防止提交大文件或机密文件。 - 将任务中的每个步骤分解成一个单独的文件,可以单独执行。
- 例如,我们可能有一个文件用于读入数据,一个用于创建要素,一个用于进行预测。
- 存储中间值。例如,一个脚本可能输出下一个脚本可以读取的文件。
- 这使我们能够在数据处理流程中进行更改,而无需重新计算一切。
我们的文件结构很快就会变成这样:
loan-prediction
├── data
├── processed
├── .gitignore
├── README.md
├── requirements.txt
├── settings.py
创建初始文件
首先,我们需要创建一个loan-prediction文件夹。在这个文件夹中,我们需要创建一个data文件夹和一个processed文件夹。第一个将存储我们的原始数据,第二个将存储任何中间计算值。
接下来,我们将制作一个.gitignore文件。一个.gitignore文件将确保某些文件被 git 忽略,而不是被推送到 Github。这种文件的一个很好的例子是 OSX 在每个文件夹中创建的.DS_Store文件。一个.gitignore文件的良好起点是这里的。
我们还想忽略数据文件,因为它们非常大,而且房利美条款禁止我们重新分发它们,所以我们应该在文件末尾添加两行:
data
processed
这里是这个项目的一个示例文件。接下来,我们需要创建README.md,这将帮助人们理解项目。.md表示文件为降价格式。Markdown 使您能够编写纯文本,但如果您愿意,也可以添加一些有趣的格式。这里有一个降价指南。如果你上传一个名为README.md的文件到 Github,Github 会自动处理 markdown,并显示给任何查看该项目的人。这里有一个例子。现在,我们只需要在README.md中放一个简单的描述:
Loan Prediction
-----------------------
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](https://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
现在,我们可以创建一个requirements.txt文件。这将使其他人很容易安装我们的项目。我们还不知道我们将使用什么样的库,但这里是一个很好的起点:
pandas
matplotlib
scikit-learn
numpy
ipython
scipy
上述库是 Python 中最常用的数据分析任务,可以合理地假设我们将使用其中的大部分。这里是这个项目的一个示例需求文件。创建requirements.txt之后,您应该安装软件包。在这篇文章中,我们将使用Python 3。
如果你没有安装 Python,你应该考虑使用 Anaconda ,这是一个 Python 安装程序,它也安装上面列出的所有包。最后,我们可以创建一个空白的settings.py文件,因为我们的项目还没有任何设置。
获取数据
一旦我们有了项目的框架,我们就可以得到原始数据。房利美在获取数据方面有一些限制,所以你需要注册一个账户。你可以在这里找到下载页面。创建帐户后,您可以下载任意数量的贷款数据文件。
这些文件是 zip 格式的,解压缩后相当大。为了这篇博文的目的,我们将下载从Q1 2012到Q1 2015的所有内容。然后我们需要解压缩所有的文件。解压文件后,删除原来的.zip文件。最后,loan-prediction文件夹应该是这样的:
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
├── .gitignore
├── README.md
├── requirements.txt
├── settings.py
下载完数据后,您可以使用head和tail shell 命令来查看文件中的行。您看到任何不需要的列了吗?在这样做的时候,参考列名的 pdf 可能会有帮助。
读入数据
目前有两个问题使我们的数据难以处理:
- 采集和性能数据集被分割成多个文件。
- 每个文件都缺少标题。
在我们开始处理数据之前,我们需要一个文件用于采集数据,一个文件用于性能数据。每个文件只需要包含我们关心的列,并有适当的标题。
这里的一个问题是性能数据非常大,所以如果可能的话,我们应该尝试修剪一些列。第一步是向settings.py添加一些变量,这些变量将包含我们的原始数据和处理后的数据的路径。我们还将添加一些其他设置,这些设置在以后会很有用:
DATA_DIR = "data"
PROCESSED_DIR = "processed"
MINIMUM_TRACKING_QUARTERS = 4
TARGET = "foreclosure_status"
NON_PREDICTORS = [TARGET, "id"]
CV_FOLDS = 3
将路径放在settings.py中会将它们放在一个集中的地方,并使它们易于修改。当在多个文件中引用相同的变量时,将它们放在一个中心位置比在每个文件中编辑它们更容易。这里是这个项目的示例settings.py文件。
第二步是创建一个名为assemble.py的文件,它将把所有的片段组装成2文件。当我们运行python assemble.py时,我们将在processed目录中获得2数据文件。然后我们将开始在assemble.py中编写代码。
我们首先需要定义每个文件的标题,因此我们需要查看列名的 pdf,并创建每个采集和性能文件中的列列表:
HEADERS = {
"Acquisition": [
"id",
"channel",
"seller",
"interest_rate",
"balance",
"loan_term",
"origination_date",
"first_payment_date",
"ltv",
"cltv",
"borrower_count",
"dti",
"borrower_credit_score",
"first_time_homebuyer",
"loan_purpose",
"property_type",
"unit_count",
"occupancy_status",
"property_state",
"zip",
"insurance_percentage",
"product_type",
"co_borrower_credit_score"
],
"Performance": [
"id",
"reporting_period",
"servicer_name",
"interest_rate",
"balance",
"loan_age",
"months_to_maturity",
"maturity_date",
"msa",
"delinquency_status",
"modification_flag",
"zero_balance_code",
"zero_balance_date",
"last_paid_installment_date",
"foreclosure_date",
"disposition_date",
"foreclosure_costs",
"property_repair_costs",
"recovery_costs",
"misc_costs",
"tax_costs",
"sale_proceeds",
"credit_enhancement_proceeds",
"repurchase_proceeds",
"other_foreclosure_proceeds",
"non_interest_bearing_balance",
"principal_forgiveness_balance"
]
}
下一步是定义我们想要保留的列。因为我们正在进行的关于贷款的测量是它是否曾经被取消抵押品赎回权,我们可以丢弃性能数据中的许多列。但是,我们需要保留收购数据中的所有列,因为我们希望最大化我们所拥有的关于贷款何时被收购的信息(毕竟,我们预测贷款在收购时是否会被取消赎回权)。丢弃列将使我们能够节省磁盘空间和内存,同时也加快我们的代码。
SELECT = {
"Acquisition": HEADERS["Acquisition"],
"Performance": [
"id",
"foreclosure_date"
]
}
接下来,我们将编写一个函数来连接数据集。以下代码将:
- 导入几个需要的库,包括
settings。 - 定义一个函数
concatenate,它:
import os
import settings
import pandas as pd
def concatenate(prefix="Acquisition"):
files = os.listdir(settings.DATA_DIR)
full = []
for f in files:
if not f.startswith(prefix):
continue
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
data = data[SELECT[prefix]]
full.append(data)
full = pd.concat(full, axis=0)
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
我们可以用参数调用上面的函数两次
Acquisition和Performance将所有采集和性能文件连接在一起。以下代码将:
- 只有从命令行用
python assemble.py调用脚本时才执行。 - 连接所有文件,生成两个文件:
processed/Acquisition.txtprocessed/Performance.txt
if __name__ == "__main__":
concatenate("Acquisition")
concatenate("Performance")
我们现在有了一个很好的、划分好的assemble.py,它很容易执行,也很容易构建。通过像这样将问题分解成几个部分,我们可以轻松地构建我们的项目。我们定义了将在脚本之间传递的数据,并使它们彼此完全分离,而不是一个混乱的脚本做所有的事情。
当您在处理较大的项目时,这样做是一个好主意,因为这样可以更容易地更改单个部分,而不会对项目的不相关部分产生意想不到的后果。一旦我们完成了assemble.py脚本,我们就可以运行python assemble.py。你可以在这里找到完整的assemble.py文件。这将在processed目录中产生两个文件:
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
│ ├── Acquisition.txt
│ ├── Performance.txt
├── .gitignore
├── assemble.py
├── README.md
├── requirements.txt
├── settings.py
根据性能数据计算值
下一步我们将从processed/Performance.txt开始计算一些值。我们想做的只是预测一处房产是否会被取消赎回权。为了解决这个问题,我们只需要检查与贷款相关的性能数据是否有一个foreclosure_date。如果foreclosure_date是None,那么该房产从未被取消赎回权。
为了避免在我们的样本中包括几乎没有业绩历史的贷款,我们还想计算每笔贷款在业绩文件中存在多少行。这将让我们从我们的培训数据中筛选出没有多少业绩历史的贷款。一种看待贷款数据和绩效数据的方式是这样的:
从上面可以看到,采集数据中的每一行都可以与绩效数据中的多行相关联。在性能数据中,foreclosure_date将出现在止赎发生的季度,因此在此之前应该为空。一些贷款从未被取消抵押品赎回权,因此在性能数据中与它们相关的所有行都有foreclosure_date空白。
我们需要计算foreclosure_status,这是一个布尔值,表明某笔贷款id是否被取消赎回权,以及performance_count,这是每笔贷款id的性能数据中的行数。有几种不同的方法来计算我们想要的计数:
- 我们可以读入所有性能数据,然后在数据帧上使用 Pandas groupby 方法计算出与每笔贷款
id相关的行数,以及foreclosure_date是否不是id的None。- 这种方法的好处是从语法角度来看很容易实现。
- 缺点是读取数据中的所有
129236094行将占用大量内存,并且非常慢。
- 我们可以读入所有性能数据,然后在采集数据帧上使用应用来查找每个
id的计数。- 好处是很容易概念化。
- 缺点是读取数据中的所有
129236094行将占用大量内存,并且非常慢。
- 我们可以迭代性能数据集中的每一行,并保存一个单独的计数字典。
- 好处是数据集不需要加载到内存中,所以速度极快,内存效率高。
- 缺点是概念化和实现需要稍长的时间,并且我们需要手动解析行。
加载所有的数据会占用相当多的内存,所以让我们使用上面的第三个选项。我们需要做的就是遍历性能数据中的所有行,同时保存每笔贷款的计数字典id。
在字典中,我们将记录id在性能数据中出现的次数,以及foreclosure_date是否不是None。这将给我们foreclosure_status和performance_count。我们将创建一个名为annotate.py的新文件,并添加代码来计算这些值。在下面的代码中,我们将:
- 导入所需的库。
- 定义一个名为
count_performance_rows的函数。- 打开
processed/Performance.txt。这不会将文件读入内存,而是打开一个文件处理程序,可以用它来逐行读入文件。 - 遍历文件中的每一行。
- 在分隔符(
|)上拆分行 - 检查
loan_id是否不在counts字典中。- 如果没有,添加到
counts。
- 如果没有,添加到
- 给定的
loan_id增加performance_count,因为我们在包含它的行上。 - 如果
date不是None,那么我们知道贷款被取消抵押品赎回权,所以适当地设置foreclosure_status。
- 在分隔符(
- 打开
import os
import settings
import pandas as pd
def count_performance_rows():
counts = {}
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
for i, line in enumerate(f):
if i == 0:
# Skip header row
continue
loan_id, date = line.split("|")
loan_id = int(loan_id)
if loan_id not in counts:
counts[loan_id] = {
"foreclosure_status": False,
"performance_count": 0
}
counts[loan_id]["performance_count"] += 1
if len(date.strip()) > 0:
counts[loan_id]["foreclosure_status"] = True
return counts
获取值
一旦我们创建了计数字典,我们就可以创建一个函数,如果传入了一个loan_id和一个key,该函数将从字典中提取值:
def get_performance_summary_value(loan_id, key, counts):
value = counts.get(loan_id, {
"foreclosure_status": False,
"performance_count": 0
})
return value[key]
上述函数将从counts字典中返回适当的值,并使我们能够为采集数据中的每一行分配一个foreclosure_status值和一个performance_count值。字典上的 get 方法在没有找到键的情况下返回一个默认值,所以这使我们能够在计数字典中没有找到键的情况下返回合理的默认值。
注释数据
我们已经给annotate.py添加了一些函数,但是现在我们可以进入文件的主体了。我们需要将采集数据转换成可用于机器学习算法的训练数据集。这涉及到几件事:
- 将所有列转换为数字。
- 填写任何缺失的值。
- 为每行分配一个
performance_count和一个foreclosure_status。 - 删除任何没有很多性能历史记录的行(其中
performance_count为低)。
我们的一些列是字符串,这对机器学习算法没有用。然而,它们实际上是分类变量,其中有一些不同的类别代码,如R、S等等。
我们可以通过给每个类别标签分配一个数字来将这些列转换为数字: 以这种方式转换列将允许我们在我们的机器学习算法中使用它们。一些列还包含日期(
以这种方式转换列将允许我们在我们的机器学习算法中使用它们。一些列还包含日期(first_payment_date和origination_date)。我们可以将这些日期拆分成2列,每列:
在下面的代码中,我们将转换采集的数据。我们将定义一个函数:
- 通过从
counts字典中获取值,在acquisition中创建一个foreclosure_status列。 - 通过从
counts字典中获取值,在acquisition中创建一个performance_count列。 - 将下列各列从字符串列转换为整数列:
channelsellerfirst_time_homebuyerloan_purposeproperty_typeoccupancy_statusproperty_stateproduct_type
- 将
first_payment_date和origination_date分别转换为2列:- 在正斜杠上拆分列。
- 将拆分列表的第一部分分配给
month列。 - 将拆分列表的第二部分分配给
year列。 - 删除列。
- 最后,我们将有
first_payment_month、first_payment_year、origination_month和origination_year。
- 用
-1填充acquisition中任何缺失的值。
def annotate(acquisition, counts):
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
for column in [
"channel",
"seller",
"first_time_homebuyer",
"loan_purpose",
"property_type",
"occupancy_status",
"property_state",
"product_type"
]:
acquisition `= acquisition``.astype('category').cat.codes
for start in ["first_payment", "origination"]:
column = "{}_date".format(start)
acquisition["{}_year".format(start)] = pd.to_numeric(acquisition``.str.split('/').str.get(1))
acquisition["{}_month".format(start)] = pd.to_numeric(acquisition``.str.split('/').str.get(0))
del acquisition` `acquisition = acquisition.fillna(-1)
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
return acquisition`
## 将所有东西整合在一起
我们几乎已经准备好把所有的东西都放在一起,我们只需要给`annotate.py`增加一点代码。在下面的代码中,我们:
* 定义读入采集数据的函数。
* 定义一个函数,将处理后的数据写入`processed/train.csv`
* 如果这个文件是从命令行调用的,比如`python annotate.py`:
* 读入采集数据。
* 计算性能数据的计数,并将其分配给`counts`。
* 注释`acquisition`数据帧。
* 将`acquisition`数据帧写入`train.csv`。
def read():
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
return acquisition
def write(acquisition):
acquisition.to_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"), index=False)
if name == "main":
acquisition = read()
counts = count_performance_rows()
acquisition = annotate(acquisition, counts)
write(acquisition)
一旦你完成了文件的更新,确保用`python annotate.py`运行它,生成`train.csv`文件。你可以在这里找到完整的`annotate.py`文件[。该文件夹现在应该如下所示:](https://github.com/dataquestio/loan-prediction/blob/master/annotate.py)
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
│ ├── Acquisition.txt
│ ├── Performance.txt
│ ├── train.csv
├── .gitignore
├── annotate.py
├── assemble.py
├── README.md
├── requirements.txt
├── settings.py
## 为我们的机器学习项目寻找一个误差度量
我们已经完成了生成训练数据集的工作,现在我们只需要做最后一步,生成预测。我们需要找出一个误差度量,以及我们希望如何评估我们的数据。
在这种情况下,没有止赎的贷款比止赎的多得多,所以典型的准确性测量没有多大意义。如果我们读入训练数据,并检查`foreclosure_status`列中的计数,我们会得到以下结果:
import pandas as pd
import settings
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
train["foreclosure_status"].value_counts()
False 4635982
True 1585
Name: foreclosure_status, dtype: int64
由于很少贷款被取消抵押品赎回权,仅仅检查正确预测的标签的百分比将意味着我们可以建立一个机器学习模型来预测每一行的`False`,并且仍然获得非常高的准确性。相反,我们希望使用一个考虑到阶级不平衡的指标,确保我们准确预测止赎。
我们不希望出现太多的误报,即我们预测某笔贷款将被取消抵押品赎回权,尽管它不会;我们也不希望出现太多的误报,即我们预测某笔贷款不会被取消抵押品赎回权,但它确实会被取消抵押品赎回权。在这两者中,假阴性对房利美来说代价更大,因为他们购买的贷款可能无法收回投资。
我们将假阴性率定义为模型预测没有止赎但实际上被止赎的贷款数量,除以实际上被止赎的贷款总数。这是模型“遗漏”的实际止赎的百分比。
这里有一个图表:

在上图中,`1`贷款被预测为不会被取消赎回权,但实际上是。如果我们用这个除以实际取消抵押品赎回权的贷款数量,`2`,我们就得到了假负利率,`50%`。我们将使用这个作为我们的误差度量,这样我们可以评估我们的模型的性能。
## 为机器学习设置分类器
我们将使用交叉验证来进行预测。通过交叉验证,我们将数据分成`3`组。然后,我们将执行以下操作:
* 在`1`和`2`组上训练一个模型,并使用该模型对`3`组进行预测。
* 在`1`和`3`组上训练一个模型,并使用该模型对`2`组进行预测。
* 在`2`和`3`组上训练一个模型,并使用该模型对`1`组进行预测。
以这种方式将其分组意味着我们永远不会使用与我们预测的数据相同的数据来训练模型。这避免了过度拟合。如果我们过度拟合,我们将得到一个错误的低假阴性率,这使得我们很难改进算法或在现实世界中使用它。 [Scikit-learn](https://scikit-learn.org/) 有一个名为 [cross_val_predict](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_predict.html) 的函数,它将使交叉验证变得容易。
我们还需要选择一种算法来进行预测。我们需要一个分类器,可以做[二元分类](https://en.wikipedia.org/wiki/Binary_classification)。目标变量`foreclosure_status`只有两个值,`True`和`False`。我们将使用[逻辑回归](https://en.wikipedia.org/wiki/Logistic_regression),因为它适用于二进制分类,运行速度极快,并且使用的内存很少。这是由于算法的工作方式——逻辑回归不像随机森林那样构建几十棵树,也不像支持向量机那样进行昂贵的转换,它的步骤少得多,涉及的矩阵运算也少得多。我们可以使用 scikit-learn 中实现的[逻辑回归分类器](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html)算法。
我们唯一需要注意的是每个类的权重。如果我们对这些类进行平均加权,该算法将为每一行预测`False`,因为它试图最小化错误。然而,我们更关心止赎,而不是没有止赎的贷款。因此,我们将把`balanced`传递给 [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) 类的`class_weight`关键字参数,让算法对止赎权进行更多加权,以考虑每个类的计数差异。这将确保算法不会对每一行都预测`False`,而是因为在预测任何一个类时出错而受到同等的惩罚。
## 做预测
既然我们已经做好了准备,我们就可以做预测了。我们将创建一个名为`predict.py`的新文件,它将使用我们在上一步中创建的`train.csv`文件。以下代码将:
* 导入所需的库。
* 创建一个名为`cross_validate`的函数:
* 使用正确的关键字参数创建逻辑回归分类器。
* 创建一个我们想要用来训练模型的列列表,删除`id`和`foreclosure_status`。
* 跨`train`数据框架运行交叉验证。
* 返回预测。
import os
import settings
import pandas as pd
from sklearn.model_selection import cross_validation
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
def cross_validate(train):
clf = LogisticRegression(random_state=1, class_weight="balanced")
predictors = train.columns.tolist()
predictors = [p for p in predictors if p not in settings.NON_PREDICTORS]
predictions = cross_validation.cross_val_predict(clf, train[predictors], train[settings.TARGET], cv=settings.CV_FOLDS)
return predictions
## 预测误差
现在,我们只需要写几个函数来计算误差。以下代码将:
* 创建一个名为`compute_error`的函数:
* 使用 scikit-learn 计算一个简单的准确度分数(与实际`foreclosure_status`值匹配的预测百分比)。
* 创建一个名为`compute_false_negatives`的函数:
* 为方便起见,将目标和预测组合成一个数据框架。
* 找出假阴性率。
* 创建一个名为`compute_false_positives`的函数:
* 为方便起见,将目标和预测组合成一个数据框架。
* 找出误报率。
* 查找模型预测会取消抵押品赎回权的未取消抵押品赎回权的贷款数量。
* 除以未被取消赎回权的贷款总数。
def compute_error(target, predictions):
return metrics.accuracy_score(target, predictions)
def compute_false_negatives(target, predictions):
df = pd.DataFrame({"target": target, "predictions": predictions})
return df[(df["target"] == 1) & (df["predictions"] == 0)].shape[0] / (df[(df["target"] == 1)].shape[0] + 1)
def compute_false_positives(target, predictions):
df = pd.DataFrame({"target": target, "predictions": predictions})
return df[(df["target"] == 0) & (df["predictions"] == 1)].shape[0] / (df[(df["target"] == 0)].shape[0] + 1)
## 把所有的放在一起
现在,我们只需将函数放在一起放在`predict.py`中。以下代码将:
* 读入数据集。
* 计算交叉验证的预测。
* 计算上面的`3`误差指标。
* 打印误差指标。
def read():
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
return train
if name == "main":
train = read()
predictions = cross_validate(train)
error = compute_error(train[settings.TARGET], predictions)
fn = compute_false_negatives(train[settings.TARGET], predictions)
fp = compute_false_positives(train[settings.TARGET], predictions)
print("Accuracy Score: {}".format(error))
print("False Negatives: {}".format(fn))
print("False Positives: {}".format(fp))
一旦添加了代码,就可以运行`python predict.py`来生成预测。运行一切显示我们的假阴性率是`.26`,这意味着在止赎贷款中,我们错过了预测它们的`26%`。
这是一个良好的开端,但可以用很多改进!你可以在这里找到完整的`predict.py`文件[。您的文件树现在应该如下所示:](https://github.com/dataquestio/loan-prediction/blob/master/predict.py)
loan-prediction
├── data
│ ├── Acquisition_2012Q1.txt
│ ├── Acquisition_2012Q2.txt
│ ├── Performance_2012Q1.txt
│ ├── Performance_2012Q2.txt
│ └── ...
├── processed
│ ├── Acquisition.txt
│ ├── Performance.txt
│ ├── train.csv
├── .gitignore
├── annotate.py
├── assemble.py
├── predict.py
├── README.md
├── requirements.txt
├── settings.py
## 撰写自述文件
现在我们已经完成了我们的端到端项目,我们只需要写一个`README.md`文件,这样其他人就知道我们做了什么,以及如何复制它。项目的典型`README.md`应包括以下部分:
* 项目的高层次概述,以及目标是什么。
* 从哪里下载任何需要的数据或材料。
* 安装说明。
* 如何安装需求。
* 使用说明。
* 如何运营项目?
* 每一步之后应该看到的内容。
* 如何为项目做贡献。
* 扩展项目的良好后续步骤。
这里是这个项目的样本`README.md`。
## 后续步骤
恭喜你,你已经完成了端到端机器学习项目!你可以在这里找到一个完整的示例项目[。](https://github.com/dataquestio/loan-prediction)
一旦你完成了你的项目,把它上传到 [Github](https://www.github.com) 是一个好主意,这样其他人就可以看到它作为你的作品集的一部分。这个数据还有相当多的角度可以探索。大体上,我们可以将它们分成`3`几类——扩展这个项目并使其更加准确,找到其他列进行预测,以及探索数据。以下是一些想法:
* 在`annotate.py`中生成更多特征。
* 切换`predict.py`中的算法。
* 试着使用比我们在这篇文章中使用的更多的房利美数据。
* 加入一种对未来数据进行预测的方法。如果我们添加更多的数据,我们编写的代码仍然可以工作,所以我们可以添加更多的过去或未来的数据。
* 试试看你能否预测一家银行最初是否应该发放贷款(相对于房利美是否应该获得贷款)。
* 删除`train`中银行在发放贷款时不知道的任何列。
* 有些栏目在房利美购买贷款时是已知的,但在此之前并不知道。
* 做预测。
* 探索是否可以预测除了`foreclosure_status`之外的列。
* 你能预测这份财产在出售时会值多少钱吗?
* 探索性能更新之间的细微差别。
* 你能预测借款人会拖欠多少次吗?
* 你能描绘出典型的贷款生命周期吗?
* 按州或按邮政编码级别绘制出一个州的数据。
* 你看到什么有趣的图案了吗?
如果您构建了任何有趣的东西,请[让我们知道](https://twitter.com/dataquestio)!在 [Dataquest](https://www.dataquest.io) ,我们的互动指导项目旨在帮助你开始建立一个数据科学组合,向雇主展示你的技能,并获得一份数据方面的工作。如果你感兴趣,你可以[注册并免费学习我们的第一个模块](https://www.dataquest.io)。
* * *
*如果你喜欢这篇文章,你可能会喜欢阅读我们“构建数据科学组合”系列中的其他文章:*
* *[用数据讲故事](https://www.dataquest.io/blog/data-science-portfolio-project/)。*
* *[如何建立数据科学博客](https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/)。*
* *[建立数据科学投资组合的关键是让你找到工作](https://www.dataquest.io/blog/build-a-data-science-portfolio/)。*
* *[ 17 个地方找数据科学项目的数据集](https://www.dataquest.io/blog/free-datasets-for-projects)*
* *[如何在 Github ](https://www.dataquest.io/blog/how-to-share-data-science-portfolio/)* 上展示您的数据科学作品集
数据科学组合项目:在哪里宣传电子学习产品
September 5, 2018
在 Dataquest,我们强烈主张将组合项目作为获得第一份数据科学工作的一种方式。在这篇博文中,我们将带你浏览一个投资组合项目的例子。
该项目是我们的统计中级:平均值和可变性课程的一部分,它假设熟悉:
- 抽样(总体、样本、样本代表性)
- 频率分布
- 箱线图和条形图
- 汇总指标(尤其是平均值)
pandas、matplotlib和seaborn
如果你认为你需要在前进之前填补任何空白,我们会在我们的统计基础和统计中级:平均值和可变性课程中深入讨论上述主题。本课程还将向您提供更深入的指导,说明如何构建这个项目,并在您的浏览器中对其进行编码。
我们还在我们的数据科学家路径中教授pandas、matplotlib和seaborn。
该项目遵循我们的数据科学项目的风格指南中提出的指导方针。
介绍
在这个项目中,我们的目标是找到两个最好的市场来宣传我们的产品——我们正在为一家提供编程课程的电子学习公司工作。我们的大部分课程都是关于网络和移动开发的,但是我们也涉及其他领域,比如数据科学、游戏开发等等。
我们将分析关于新编码者的现有数据,以找到投资广告的最佳市场。为了提出我们的建议,我们将尝试找出:
- 这些新的编码员在哪里?
- 哪些地方有最多的新编码员?
- 新程序员愿意花多少钱在学习上。
结果摘要
分析数据后,我们得出的唯一可靠结论是,美国将是一个很好的广告市场。对于第二好的市场,在印度和加拿大之间选择什么并不明确。我们决定将结果发送给营销团队,这样他们就可以利用他们的领域知识做出最佳决策。
有关更多详情,请参考下面的完整分析。
探索现有数据
为了避免花钱组织调查,我们将首先尝试利用现有的数据来确定我们是否能得出可靠的结果。
对于我们的目的来说,一个很好的候选人是 freeCodeCamp 的 2017 年新程序员调查。 freeCodeCamp 是一个提供网络开发课程的免费电子学习平台。因为他们经营着一个受欢迎的媒体出版物(超过 400,000 名追随者),他们的调查吸引了具有不同兴趣的新程序员(不仅仅是 web 开发),这对我们的分析是理想的。
调查数据在GitHub 知识库中公开。下面,我们将快速浏览一下存储在我们刚刚提到的存储库的clean-data文件夹中的2017-fCC-New-Coders-Survey-Data.csv文件。我们将使用直接链接在这里读取文件。
# Read in the dataimport pandas as pd
direct_link = 'https://raw.githubusercontent.com/freeCodeCamp/2017-new-coder-survey/master/clean-data/2017-fCC-New-Coders-Survey-Data.csv'
fcc = pd.read_csv(direct_link, low_memory = 0)
# low_memory = False to silence dtypes warning
# Quick exploration of the data
print(fcc.shape)
pd.options.display.max_columns = 150 # to avoid truncated output fcc.head()
(18175, 136)
| 年龄 | 参加训练营 | BootcampFinish | BootcampLoanYesNo | BootcampName | BootcampRecommend | 儿童数量 | 城市推广 | CodeEventConferences | CodeEventDjangoGirls | CodeEventFCC | CodeEventGameJam | CodeEventGirlDev | CodeEventHackathons | CodeEventMeetup | codeeventnodeeschool | CodeEventNone | CodeEventOther | CodeEventRailsBridge | CodeEventRailsGirls 女孩 | CodeEventStartUpWknd | CodeEventWkdBootcamps | CodeEventWomenCode | CodeEventWorkshops | 通勤时间 | 乡村公民 | 乡村生活 | 就业领域 | 就业领域其他 | 就业率 | 就业状况 | 预期学习 | 财政支持 | FirstDevJob | 性别 | 性别其他 | 哈斯儿童 | 有力的 | HasFinancialDependents | HasHighSpdInternet | 家庭抵押贷款 | HasServedInMilitary | HasStudentDebt | 家庭记忆 | 小时学习 | 身份证 | 身份证号码 | 收入 | IsEthnicMinority | isreceivedisabilityesbenefits 利益 | IsSoftwareDev | 我失业了 | JobApplyWhen | JobInterestBackEnd 后端 | JobInterestDataEngr | JobInterestDataSci | JobInterestDevOps | JobInterestFrontEnd | JobInterestFullStack | JobInterestGameDev | JobInterestInfoSec | JobInterestMobile | 工作兴趣其他 | JobInterestProjMngr | JobInterestQAEngr | JobInterestUX | JobPref | job relocation eyes no | 工作兴趣 | JobWherePref | 语言之家 | 婚姻状况 | 金钱促进学习 | 月份规划 | 网络 ID | Part1EndTime | 第 1 部分启动时间 | Part2EndTime | 第 2 部分启动时间 | 播客变更日志 | PodcastCodeNewbie | 播客代码笔 | 播客发展茶 | 播客网站 | 播客巨人机器人 | PodcastJSAir | PodcastJSJabber | 播客通 | 播客其他 | 播客节目下载 | 播客 RubyRogues | 播客每日 | 播客电台 | 播客商店谈话 | PodcastTalkPython | 播客 the bahead | 资源代码学院 | 资源代码战争 | 资源课程 a | 资源 | ResourceEdX | 资源 Egghead | 资源 FCC | ResourceHackerRank | 资源卡 | 资源琳达 | 资源 MDN | ResourceOdinProj | 资源其他 | ResourcePluralSight | ResourceSkillcrush | 资源 | 资源树屋 | 资源城市 | 资源数据库 | 资源 W3S | 学校学位 | 校长 | 学生俱乐部 | YouTube 视频教程 | YouTubeCodingTrain | YouTube 视频编码 360 | YouTube 电脑爱好者 | YouTubeDerekBanas | YouTube 视频提示 | YouTubeEngineeredTruth | YouTube efcc | YouTubeFunFunFunction | YouTubeGoogleDev | YouTubeLearnCode | youtubelieveluptuts | YouTube emit | YouTubeMozillaHacks | YouTubeOther | YouTubeSimplilearn | YouTube bethenewboston | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Twenty-seven | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 加拿大 | 加拿大 | 软件开发和信息技术 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 女性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | Zero | 圆盘烤饼 | Fifteen | 02d 9465 b 21e 8 BD 09374 b 0066 fb2d 5614 | EB 78 C1 C3 AC 6 CD 9052 AEC 557065070 fbf | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 开创自己的事业 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 英语 | 已婚或同居伴侣关系 | One hundred and fifty | Six | 6f1fbc6b2b | 2017-03-09 00:36:22 | 2017-03-09 00:32:59 | 2017-03-09 00:59:46 | 2017-03-09 00:36:26 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 一些大学学分,没有学位 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| one | Thirty-four | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 不到 10 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 美利坚合众国 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | Thirty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Ten | 5 bfef 9 ECB 211 EC 4 f 518 cf C1 D2 a6 F3 E0 c | 21 db 37 ADB 60 cdcafadfa 7 DCA 1 b 13 b 6 b 1 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 7 至 12 个月内 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为非营利组织工作 | One | 全栈 Web 开发人员 | 和其他开发人员在一个办公室里 | 英语 | 单身,从未结过婚 | Eighty | Six | f8f8be6910 | 2017-03-09 00:37:07 | 2017-03-09 00:33:26 | 2017-03-09 00:38:59 | 2017-03-09 00:37:10 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | 一些大学学分,没有学位 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| Two | Twenty-one | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 美利坚合众国 | 美利坚合众国 | 软件开发和信息技术 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Seventy thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | One | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Twenty-five | 14f 1863 AFA 9 C7 de 488050 b 82 EB 3 edd 96 | 21ba 173828 FBE 9 e 27 ccebaf 4d 5166 a 55 | Thirteen thousand | One | Zero | Zero | Zero | 7 至 12 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为一家中型公司工作 | One | 前端 Web 开发人员,后端 Web 开发人员… | 没有偏好 | 西班牙语 | 单身,从未结过婚 | One thousand | Five | 公元 189768 年 | 2017-03-09 00:37:58 | 2017-03-09 00:33:53 | 2017-03-09 00:40:14 | 2017-03-09 00:38:02 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Codenewbie | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 高中文凭或同等学历(GED) | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| three | Twenty-six | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 我在家工作 | 巴西 | 巴西 | 软件开发和信息技术 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Forty thousand | Zero | 圆盘烤饼 | 男性的 | 圆盘烤饼 | Zero | One | One | One | One | Zero | Zero | Forty thousand | Fourteen | 91756 EB 4d c 280062 a 541 c 25 a3 d 44 CFB 0 | 3be 37 b 558 f 02 daae 93 a6 da 10 f 83 f0c 77 | Twenty-four thousand | Zero | Zero | Zero | One | 在接下来的 6 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为一家中型公司工作 | 圆盘烤饼 | 前端 Web 开发人员,全栈 Web 开发… | 从家里 | 葡萄牙语 | 已婚或同居伴侣关系 | Zero | Five | db lic 0664 D1 | 2017-03-09 00:40:13 | 2017-03-09 00:37:45 | 2017-03-09 00:42:26 | 2017-03-09 00:40:18 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 一些大学学分,没有学位 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| four | Twenty | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 葡萄牙 | 葡萄牙 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | One hundred and forty thousand | 圆盘烤饼 | 圆盘烤饼 | 女性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | One | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Ten | aa3f 061 a 1949 a 90 b 27 bef 7411 ECD 193 f | d7c 56 bbf 2c 7 b 62096 be 9 db 010 e 86d 96d | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 7 至 12 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为一家跨国公司工作 | One | 全栈 Web 开发人员,信息安全… | 和其他开发人员在一个办公室里 | 葡萄牙语 | 单身,从未结过婚 | Zero | Twenty-four | 11b0f2d8a9 | 2017-03-09 00:42:45 | 2017-03-09 00:39:44 | 2017-03-09 00:45:42 | 2017-03-09 00:42:50 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 学士学位 | 信息技术 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
检查样本代表性
正如我们在介绍中提到的,我们的大多数课程都是关于 web 和移动开发的,但是我们也涵盖了许多其他领域,比如数据科学和游戏开发。出于我们分析的目的,我们想回答一些关于对我们教授的科目感兴趣的新程序员群体的问题。提醒一下,我们想知道:
- 这些新的编码员在哪里?
- 哪些地方有最多的新编码员?
- 他们愿意在学习上花多少钱。
我们首先需要澄清数据集是否有我们需要的类别。JobRoleInterest列描述了每个参与者感兴趣的角色。如果一个参与者对某个领域的工作感兴趣,我们可以假设他们也对学习那个领域感兴趣。所以让我们看看这个专栏的频率分布表,确定我们掌握的数据是否相关。
# Frequency distribution table for 'JobRoleInterest
'fcc['JobRoleInterest'].value_counts(normalize = True) * 100
Full-Stack Web Developer 11.770595
Front-End Web Developer 6.435927
Data Scientist 2.173913
Back-End Web Developer 2.030892
Mobile Developer 1.673341
Game Developer 1.630435
Information Security 1.315789
Full-Stack Web Developer, Front-End Web Developer 0.915332
Front-End Web Developer, Full-Stack Web Developer 0.800915
Product Manager 0.786613
Data Engineer 0.758009
User Experience Designer 0.743707
User Experience Designer, Front-End Web Developer 0.614989
Front-End Web Developer, Back-End Web Developer, Full-Stack Web Developer 0.557780
Back-End Web Developer, Full-Stack Web Developer, Front-End Web Developer 0.514874
Back-End Web Developer, Front-End Web Developer, Full-Stack Web Developer 0.514874
DevOps / SysAdmin 0.514874
Full-Stack Web Developer, Front-End Web Developer, Back-End Web Developer 0.443364
Front-End Web Developer, Full-Stack Web Developer, Back-End Web Developer 0.429062
Front-End Web Developer, User Experience Designer 0.414760
Full-Stack Web Developer, Mobile Developer 0.414760
Back-End Web Developer, Full-Stack Web Developer 0.386156
Full-Stack Web Developer, Back-End Web Developer 0.371854
Back-End Web Developer, Front-End Web Developer 0.286041
Full-Stack Web Developer, Back-End Web Developer, Front-End Web Developer 0.271739
Data Engineer, Data Scientist 0.271739
Front-End Web Developer, Mobile Developer 0.257437
Full-Stack Web Developer, Data Scientist 0.243135
Mobile Developer, Game Developer 0.228833
Data Scientist, Data Engineer 0.228833
...
Mobile Developer, User Experience Designer, Full-Stack Web Developer, DevOps / SysAdmin, Technical Writer 0.014302
Data Engineer, Data Scientist, Information Security 0.014302
Mobile Developer, Full-Stack Web Developer, Product Manager, Game Developer, Information Security, Front-End Web Developer, User Experience Designer, Data Scientist 0.014302
Back-End Web Developer, Game Developer, Data Engineer 0.014302
Full-Stack Web Developer, Information Security, Back-End Web Developer, Data Engineer, Mobile Developer, Data Scientist, DevOps / SysAdmin 0.014302
Software Specialist 0.014302
Game Developer, Information Security, Mobile Developer, DevOps / SysAdmin, Full-Stack Web Developer, Front-End Web Developer 0.014302
Back-End Web Developer, Game Developer, Full-Stack Web Developer, Front-End Web Developer, DevOps / SysAdmin 0.014302
Front-End Web Developer, Back-End Web Developer, Full-Stack Web Developer, Game Developer, Mobile Developer 0.014302
Game Developer, Information Security, Full-Stack Web Developer, Back-End Web Developer 0.014302
Front-End Web Developer, Data Scientist, Game Developer, Product Manager, Information Security 0.014302
Front-End Web Developer, Mobile Developer, Information Security, Full-Stack Web Developer, DevOps / SysAdmin, Back-End Web Developer, Game Developer 0.014302
Mobile Developer, Game Developer, Full-Stack Web Developer, Back-End Web Developer, Front-End Web Developer 0.014302
Data Engineer, Front-End Web Developer, Data Scientist, Full-Stack Web Developer 0.014302
Product Manager, Back-End Web Developer, Data Scientist, Full-Stack Web Developer, Game Developer, User Experience Designer, Information Security 0.014302
Mobile Developer, Back-End Web Developer, Front-End Web Developer, Full-Stack Web Developer 0.014302
User Experience Designer, Full-Stack Web Developer, Front-End Web Developer, Mobile Developer, User Interface Design 0.014302
Full-Stack Web Developer, Quality Assurance Engineer, Game Developer, Front-End Web Developer, User Experience Designer 0.014302
Quality Assurance Engineer, Front-End Web Developer, User Experience Designer, Game Developer 0.014302
DevOps / SysAdmin, Data Scientist, Full-Stack Web Developer, Information Security, Data Engineer, Back-End Web Developer 0.014302
Full-Stack Web Developer, Data Scientist, User Experience Designer, Mobile Developer, Front-End Web Developer 0.014302
Data Engineer, Product Manager, Data Scientist 0.014302
Full-Stack Web Developer, User Experience Designer, Back-End Web Developer, Data Scientist, Information Security, Criminal Defense Attorney-- focusing on cyber crimes 0.014302
Data Engineer, User Experience Designer, Front-End Web Developer, Game Developer, Data Scientist, Product Manager 0.014302
Front-End Web Developer, User Experience Designer, DevOps / SysAdmin, Back-End Web Developer, Data Scientist, Game Developer, Product Manager, Quality Assurance Engineer, Full-Stack Web Developer, Information Security, Mobile Developer 0.014302
Education 0.014302
DevOps / SysAdmin, Mobile Developer, Full-Stack Web Developer, Front-End Web Developer 0.014302
Back-End Web Developer, Data Scientist, Information Security, Front-End Web Developer, Quality Assurance Engineer, DevOps / SysAdmin, Data Engineer, Game Developer, Full-Stack Web Developer 0.014302
Data Scientist, Back-End Web Developer, Full-Stack Web Developer, Front-End Web Developer, User Experience Designer, Mobile Developer 0.014302
Game Developer, Mobile Developer, Back-End Web Developer, Front-End Web Developer, Information Security 0.014302
上表中的信息非常详细,但是快速浏览一下,看起来像是:
- 很多人对 web 开发感兴趣(全栈 web 开发,前端 web 开发,后端 web 开发)。
- 少数人(1.7%)对移动开发感兴趣。
- 除了 web 和移动开发,没有太多人对其他领域感兴趣。
有趣的是,许多受访者对不止一个主题感兴趣。更好地了解有多少人对一门学科感兴趣,有多少人对多门学科感兴趣,会很有帮助。因此,在下一个代码块中,我们将:
- 拆分
JobRoleInterest列中的每个字符串,找出每个参与者的选项数量。- 我们将首先删除空值,因为我们不能拆分
Nan值。
- 我们将首先删除空值,因为我们不能拆分
- 为描述选项数量的变量生成频率表。
# Split each string in the 'JobRoleInterest' column
interests_no_nulls = fcc['JobRoleInterest'].dropna()
splitted_interests = interests_no_nulls.str.split(',')
# Frequency table for the var describing the number of options
n_of_options = splitted_interests.apply(lambda x: len(x)) # x is a list of job options
n_of_options.value_counts(normalize = True).sort_index() * 100
1 31.650458
2 10.883867
3 15.889588
4 15.217391
5 12.042334
6 6.721968
7 3.861556
8 1.759153
9 0.986842
10 0.471968
11 0.185927
12 0.300343
13 0.028604
Name: JobRoleInterest, dtype: float64
只有 31.7%的参与者清楚地知道他们想从事什么样的编程工作,而绝大多数学生的兴趣不一。考虑到我们提供各种主题的课程,新程序员混合兴趣的事实实际上可能对我们有好处。
我们课程的重点是 web 和移动开发,所以让我们看看有多少受访者至少选择了这两个选项中的一个。
# Frequency table
web_or_mobile = interests_no_nulls.str.contains(
'Web Developer|Mobile Developer') # returns an array of booleans
freq_table = web_or_mobile.value_counts(normalize = True) * 100
print(freq_table)
# Graph for the frequency table above
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
freq_table.plot.bar()
plt.title('Most Participants are Interested in \nWeb or Mobile
Development", y = 1.08) # y pads the title upward
plt.ylabel('Percentage', fontsize = 12)
plt.xticks([0,1],['Web or mobile\ndevelopment', 'Other subject'],
rotation = 0) # the initial xtick labels were True and False
plt.ylim([0,100])
plt.show()
True 86.241419
False 13.758581
Name: JobRoleInterest, dtype: float64

本次调查中的大多数人(大约 86%)对 web 或移动开发感兴趣。这些数字为我们提供了一个强有力的理由来考虑这个样本代表我们感兴趣的人群。我们希望向对各种编程领域感兴趣的人宣传我们的课程,但主要是 web 和移动开发。
新编码员—位置和密度
让我们从找出这些新编码员的位置开始,以及每个位置的密度(有多少新编码员)。这应该是一个很好的开始,我们可以在这两个市场找到最好的广告投放市场。
该数据集提供了每个参与者在国家一级的位置信息。我们可以把每个国家想象成一个单独的市场,所以我们可以把目标定为找到两个最好的国家做广告。
我们可以从检查CountryLive变量的频率分布表开始,它描述了每个参与者居住在哪个国家(不是他们的原籍国)。我们将只考虑那些回答了他们对什么角色感兴趣的参与者,以确保我们的工作具有代表性。
# Isolate the participants that answered what role they'd be interested in
fcc_good = fcc[fcc['JobRoleInterest'].notnull()].copy()
# Frequency tables with absolute and relative frequencies
absolute_frequencies = fcc_good['CountryLive'].value_counts()
relative_frequencies = fcc_good['CountryLive'].value_counts(normalize = True) * 100
# Display the frequency tables in a more readable format
pd.DataFrame(data = {'Absolute frequency': absolute_frequencies,
'Percentage': relative_frequencies}
)
| 绝对频率 | 百分率 | |
|---|---|---|
| 美利坚合众国 | Three thousand one hundred and twenty-five | 45.700497 |
| 印度 | Five hundred and twenty-eight | 7.721556 |
| 联合王国 | Three hundred and fifteen | 4.606610 |
| 加拿大 | Two hundred and sixty | 3.802281 |
| 波兰 | One hundred and thirty-one | 1.915765 |
| 巴西 | One hundred and twenty-nine | 1.886517 |
| 德国 | One hundred and twenty-five | 1.828020 |
| 澳大利亚 | One hundred and twelve | 1.637906 |
| 俄罗斯 | One hundred and two | 1.491664 |
| 乌克兰 | eighty-nine | 1.301550 |
| 尼日利亚 | Eighty-four | 1.228429 |
| 西班牙 | Seventy-seven | 1.126060 |
| 法国 | Seventy-five | 1.096812 |
| 罗马尼亚 | Seventy-one | 1.038315 |
| 荷兰(荷兰,欧洲) | Sixty-five | 0.950570 |
| 意大利 | Sixty-two | 0.906698 |
| 塞尔维亚 | fifty-two | 0.760456 |
| 菲律宾 | fifty-two | 0.760456 |
| 希腊 | Forty-six | 0.672711 |
| 爱尔兰 | Forty-three | 0.628839 |
| 南非 | Thirty-nine | 0.570342 |
| 墨西哥 | Thirty-seven | 0.541094 |
| 火鸡 | Thirty-six | 0.526470 |
| 匈牙利 | Thirty-four | 0.497221 |
| 新加坡 | Thirty-four | 0.497221 |
| 新西兰 | Thirty-three | 0.482597 |
| 阿根廷 | Thirty-two | 0.467973 |
| 克罗地亚 | Thirty-two | 0.467973 |
| 瑞典 | Thirty-one | 0.453349 |
| 印度尼西亚 | Thirty-one | 0.453349 |
| … | … | … |
| 莫桑比克 | one | 0.014624 |
| 也门 | one | 0.014624 |
| 古巴 | one | 0.014624 |
| 苏丹 | one | 0.014624 |
| 危地马拉 | one | 0.014624 |
| 玻利维亚 | one | 0.014624 |
| 约旦 | one | 0.014624 |
| 缅甸(东南亚国家) | one | 0.014624 |
| 萨摩亚群岛 | one | 0.014624 |
| 冈比亚 | one | 0.014624 |
| 海峡群岛 | one | 0.014624 |
| 瓦努阿图 | one | 0.014624 |
| 特立尼达和多巴哥 | one | 0.014624 |
| 巴布亚新几内亚 | one | 0.014624 |
| 利比里亚 | one | 0.014624 |
| 巴拿马 | one | 0.014624 |
| 卢旺达 | one | 0.014624 |
| 喀麦隆 | one | 0.014624 |
| 阿鲁巴岛 | one | 0.014624 |
| 直布罗陀 | one | 0.014624 |
| 安圭拉 | one | 0.014624 |
| 博茨瓦纳 | one | 0.014624 |
| 土库曼斯坦 | one | 0.014624 |
| 吉尔吉斯斯坦 | one | 0.014624 |
| 卡塔尔 | one | 0.014624 |
| 安哥拉 | one | 0.014624 |
| Nambia | one | 0.014624 |
| 瓜德罗普岛 | one | 0.014624 |
| 尼加拉瓜 | one | 0.014624 |
| 开曼群岛 | one | 0.014624 |
137 行× 2 列
我们 45.7%的潜在客户位于美国,这无疑是最有趣的市场。印度拥有第二大客户密度,但它的客户密度仅为 7.7%,与英国(4.6%)或加拿大(3.8%)相差不远。
这是有用的信息,但我们需要比这更深入,并找出人们实际上愿意在学习上花多少钱。在大多数人只愿意免费学习的高密度市场做广告对我们来说是极不可能盈利的。
花钱学习
MoneyForLearning栏以美元描述了参与者从开始编码到完成调查的花费。我们公司以每月 59 美元的价格出售订阅,因此我们有兴趣了解每个学生每月花费多少钱。
我们将把分析范围缩小到四个国家:美国、印度、英国和加拿大。我们这样做有两个原因:
- 这些是上面频率表中出现频率最高的国家,这意味着我们对每个国家都有相当数量的数据。
- 我们的课程是用英语编写的,英语在这四个国家都是官方语言。懂英语的人越多,我们的广告就越有可能瞄准正确的人群。
让我们从创建一个新列开始,该列描述学生到目前为止每月花费的金额。为此,我们需要将MoneyForLearning列分成MonthsProgramming列。问题是有同学回答说学习编码 0 个月了(可能是刚开始)。为了避免被 0 除,我们将在MonthsProgramming列中用 1 替换 0。
# Replace 0s with 1s to avoid division by 0fcc_good['MonthsProgramming'].replace(0,1, inplace = True)
# New column for the amount of money each student spends each month
fcc_good['money_per_month'] = fcc_good['MoneyForLearning'] / fcc_good['MonthsProgramming']
fcc_good['money_per_month'].isnull().sum()
675
让我们只保留那些对于money_per_month列没有空值的行。
# Keep only the rows with non-nulls in the money_per_month column
fcc_good = fcc_good[fcc_good['money_per_month'].notnull()]
我们希望按国家对数据进行分组,然后测量每个国家学生每月花费的平均金额。首先,让我们删除对于CountryLive列为空值的行,并检查我们是否仍然有足够的关于我们感兴趣的四个国家的数据。
# Remove the rows with null values in 'CountryLive'
fcc_good = fcc_good[fcc_good['CountryLive'].notnull()]
# Frequency table to check if we still have enough data
fcc_good['CountryLive'].value_counts().head()
United States of America 2933
India 463
United Kingdom 279
Canada 240
Poland 122
Name: CountryLive, dtype: int64
这应该足够了,所以让我们来计算一个学生在每个国家每月花费的平均值。我们将使用平均值计算平均值。
# Mean sum of money spent by students each month
countries_mean = fcc_good.groupby('CountryLive').mean()
countries_mean['money_per_month'][['United States of America',
'India', 'United Kingdom',
'Canada']]
CountryLive
United States of America 227.997996
India 135.100982
United Kingdom 45.534443
Canada 113.510961
Name: money_per_month, dtype: float64
相对于我们在印度看到的数值,英国和加拿大的结果有点令人惊讶。如果我们考虑一些社会经济指标(如人均国内生产总值),我们会直觉地认为英国和加拿大人比印度人在学习上花费更多。
这可能是因为我们没有足够的英国和加拿大的代表性数据,或者我们有一些异常值(可能来自错误的调查答案),使得平均值对印度来说太大,或者对英国和加拿大来说太低。也有可能结果是正确的。
处理极端异常值
让我们用箱线图来形象化每个国家的money_per_month变量的分布。
# Isolate only the countries of interest
only_4 = fcc_good[fcc_good['CountryLive'].str.contains(
'United States of America|India|United Kingdom|Canada')]
# Box plots to visualize distributions
import seaborn as sns
sns.boxplot(y = 'money_per_month', x = 'CountryLive',
data = only_4)
plt.title('Money Spent Per Month Per Country\n(Distributions)', fontsize = 16)
plt.ylabel('Money per month (US dollars)')
plt.xlabel('Country')
plt.xticks(range(4), ['US', 'UK', 'India', 'Canada']) # avoids tick labels overlap
plt.show()

从上面的图表中很难看出英国、印度或加拿大的数据是否有问题,但我们可以立即看出美国确实有问题:图表显示,两个人每月花费 5 万美元或更多用于学习。这并非不可能,但似乎极不可能,因此我们将删除每月超过 20,000 美元的所有值。
# Isolate only those participants who spend less than 10000 per month
fcc_good = fcc_good[fcc_good['money_per_month'] < 20000]
现在让我们重新计算平均值,并再次绘制箱线图。
# Recompute mean sum of money spent by students each month
countries_mean = fcc_good.groupby('CountryLive').mean()
countries_mean['money_per_month'][['United States of America',
'India', 'United Kingdom',
'Canada']]
CountryLive
United States of America 183.800110
India 135.100982
United Kingdom 45.534443
Canada 113.510961
Name: money_per_month, dtype: float64
# Isolate again the countries of interest
only_4 = fcc_good[fcc_good['CountryLive'].str.contains(
'United States of America|India|United Kingdom|Canada')]
# Box plots to visualize distributions
sns.boxplot(y = 'money_per_month', x = 'CountryLive',
data = only_4)
plt.title('Money Spent Per Month Per Country\n(Distributions)',
fontsize = 16)
plt.ylabel('Money per month (US dollars)')
plt.xlabel('Country')
plt.xticks(range(4), ['US', 'UK', 'India', 'Canada'])
# avoids tick labels overlapplt.show()

我们可以看到印度的一些极端异常值(价值超过每月 2500 美元),但不清楚这是否是好数据。也许这些人参加了几个训练营,这往往非常昂贵。让我们检查这两个数据点,看看是否能找到相关的东西。
# Inspect the extreme outliers for India
india_outliers = only_4[
(only_4['CountryLive'] == 'India') &
(only_4['money_per_month'] >= 2500)]
india_outliers
| 年龄 | 参加训练营 | BootcampFinish | BootcampLoanYesNo | BootcampName | BootcampRecommend | 儿童数量 | 城市推广 | CodeEventConferences | CodeEventDjangoGirls | CodeEventFCC | CodeEventGameJam | CodeEventGirlDev | CodeEventHackathons | CodeEventMeetup | codeeventnodeeschool | CodeEventNone | CodeEventOther | CodeEventRailsBridge | CodeEventRailsGirls 女孩 | CodeEventStartUpWknd | CodeEventWkdBootcamps | CodeEventWomenCode | CodeEventWorkshops | 通勤时间 | 乡村公民 | 乡村生活 | 就业领域 | 就业领域其他 | 就业状况 | 就业状况 | 预期学习 | 财政支持 | FirstDevJob | 性别 | 性别其他 | 哈斯儿童 | 有力的 | HasFinancialDependents | HasHighSpdInternet | 哈希莫莱格 | HasServedInMilitary | HasStudentDebt | 家庭记忆 | 小时学习 | 身份证 | 身份证号码 | 收入 | IsEthnicMinority | isreceivedisabilityesbenefits 利益 | IsSoftwareDev | 我失业了 | JobApplyWhen | JobInterestBackEnd 后端 | JobInterestDataEngr | JobInterestDataSci | JobInterestDevOps | JobInterestFrontEnd | JobInterestFullStack | JobInterestGameDev | JobInterestInfoSec | JobInterestMobile | 工作兴趣其他 | JobInterestProjMngr | JobInterestQAEngr | JobInterestUX | JobPref | job relocation eyes no | 工作兴趣 | JobWherePref | 语言之家 | 婚姻状况 | 金钱促进学习 | 月份规划 | 网络 ID | Part1EndTime | 第 1 部分启动时间 | Part2EndTime | 第 2 部分启动时间 | 播客变更日志 | PodcastCodeNewbie | 播客代码笔 | 播客发展茶 | 播客网站 | 播客巨人机器人 | PodcastJSAir | PodcastJSJabber | 播客通 | 播客其他 | 播客节目下载 | 播客 RubyRogues | 播客每日 | 播客电台 | 播客商店谈话 | PodcastTalkPython | 播客 the bahead | 资源代码学院 | 资源代码战争 | 资源课程 a | 资源 | ResourceEdX | 资源 Egghead | 资源 FCC | ResourceHackerRank | 资源卡 | 资源琳达 | 资源 MDN | ResourceOdinProj | 资源其他 | ResourcePluralSight | ResourceSkillcrush | 资源 | 资源树屋 | 资源城市 | 资源数据库 | 资源 W3S | 学校学位 | 校长 | 学生俱乐部 | YouTube 视频教程 | YouTubeCodingTrain | YouTube 视频编码 360 | YouTube 电脑爱好者 | YouTubeDerekBanas | YouTube 视频提示 | YouTubeEngineeredTruth | YouTube efcc | YouTubeFunFunFunction | YouTubeGoogleDev | YouTubeLearnCode | youtubelieveluptuts | YouTube emit | YouTubeMozillaHacks | YouTubeOther | YouTubeSimplilearn | youtuberhenewboston | 每月收入 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One thousand seven hundred and twenty-eight | Twenty-four | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 印度 | 印度 | 圆盘烤饼 | 圆盘烤饼 | 全职父母或家庭主妇 | 圆盘烤饼 | Seventy thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | One | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Thirty | d 964 EC 629 FD 6d 85 a5 BF 27 f 7339 F4 fa 6d | 950 A8 cf 9 ce f1 AE 6 a 15 da 470 e 572 B1 b7a | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 在接下来的 6 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 为创业公司工作 | One | 用户体验设计师、移动开发者… | 和其他开发人员在一个办公室里 | 孟加拉语 | 单身,从未结过婚 | Twenty thousand | Four | 38d312a990 | 2017-03-10 10:22:34 | 2017-03-10 10:17:42 | 2017-03-10 10:24:38 | 2017-03-10 10:22:40 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 学士学位 | 计算机编程 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 5000.000000 |
| One thousand seven hundred and fifty-five | Twenty | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 印度 | 印度 | 圆盘烤饼 | 圆盘烤饼 | 不工作也不找工作 | 圆盘烤饼 | One hundred thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | One | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Ten | 811 BF 953 ef 546460 f 5436 fcf 2 baa 532d | 81e 2 a4 cab 0543 e 14746 C4 a20 ffda e17 c | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 我还没决定 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为一家跨国公司工作 | One | 信息安全,全栈 Web 开发人员… | 没有偏好 | 印地语 | 单身,从未结过婚 | Fifty thousand | Fifteen | 4611a76b60 | 2017-03-10 10:48:31 | 2017-03-10 10:42:29 | 2017-03-10 10:51:37 | 2017-03-10 10:48:38 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 学士学位 | 计算机科学 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 3333.333333 |
| Seven thousand nine hundred and eighty-nine | Twenty-eight | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 10 万到 100 万之间 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 15 到 29 分钟 | 印度 | 印度 | 软件开发和信息技术 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Five hundred thousand | One | 圆盘烤饼 | 男性的 | 圆盘烤饼 | Zero | One | One | One | Zero | Zero | One | 圆盘烤饼 | Twenty | a6a 5597 bbbc 2c 282386d 6675641 b 744 a | da 7 BBB 54 A8 b 26 a 379707 be 56 b 6 c 51 e 65 | Three hundred thousand | Zero | Zero | Zero | Zero | 从现在起超过 12 个月 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 为一家跨国公司工作 | One | 用户体验设计师,后端网络开发… | 和其他开发人员在一个办公室里 | 马拉地语 | 已婚或同居伴侣关系 | Five thousand | One | c47a447b5d | 2017-03-26 14:06:48 | 2017-03-26 14:02:41 | 2017-03-26 14:13:13 | 2017-03-26 14:07:17 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 还没听过任何东西。 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 学士学位 | 航空航天和航空工程 | Two thousand five hundred | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 5000.000000 |
| Eight thousand one hundred and twenty-six | Twenty-two | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 印度 | 印度 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | Eighty thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Eighty | 69e 8 ab 9126 BAE 49 f 66 e 3577 AEA 7 FD 3c | 9f 08092 e82f 709 e 63847 ba 88841247 c 0 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 我已经在申请了 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为创业公司工作 | One | 后端 Web 开发人员,全栈 Web 开发… | 和其他开发人员在一个办公室里 | 马拉雅拉姆语 | 单身,从未结过婚 | Five thousand | One | 0d3d1762a4 | 2017-03-27 07:10:17 | 2017-03-27 07:05:23 | 2017-03-27 07:12:21 | 2017-03-27 07:10:22 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 学士学位 | 电气和电子工程 | Ten thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 5000.000000 |
| Thirteen thousand three hundred and ninety-eight | Nineteen | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 印度 | 印度 | 圆盘烤饼 | 圆盘烤饼 | 无法工作 | 圆盘烤饼 | One hundred thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Thirty | b 7 Fe 7 BC 4 ede fc 3a 60 EB 48 f 977 e 4426 e 3 | 80ff 09859 AC 475 b 70 AC 19 b 7b 7369 e 953 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 我还没决定 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为一家跨国公司工作 | One | 移动开发者 | 没有偏好 | 印地语 | 单身,从未结过婚 | Twenty thousand | Two | 51a6f9a1a7 | 2017-04-01 00:31:25 | 2017-04-01 00:28:17 | 2017-04-01 00:33:44 | 2017-04-01 00:31:32 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 学士学位 | 计算机科学 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 10000.000000 |
| Fifteen thousand five hundred and eighty-seven | Twenty-seven | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 印度 | 印度 | 软件开发和信息技术 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Sixty-five thousand | Zero | 圆盘烤饼 | 男性的 | 圆盘烤饼 | Zero | One | One | One | Zero | Zero | One | 圆盘烤饼 | Thirty-six | 5a 7394 f 24292 CB 82 b 72 ADB 702886543 a | 8bc 7997217 D4 a57 b 22242471 cc8 d 89 ef | Sixty thousand | Zero | Zero | Zero | One | 我还没决定 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为创业公司工作 | 圆盘烤饼 | 全栈 Web 开发人员、数据科学家 | 从家里 | 印地语 | 单身,从未结过婚 | One hundred thousand | Twenty-four | 8af0c2b6da,请回答 | 2017-04-03 09:43:53 | 2017-04-03 09:39:38 | 2017-04-03 09:54:39 | 2017-04-03 09:43:57 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 学士学位 | 通信 | Twenty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 4166.666667 |
似乎两个参与者都没有参加训练营。总的来说,很难从数据中看出这些人是否真的在学习上花了那么多钱。调查的实际问题是“除了大学学费,到目前为止你在学习编程上花了多少钱(以美元计)?”,所以他们可能误会了,以为大学学费包含在内。去掉这两排似乎更安全。
# Remove the outliers for India
only_4 = only_4.drop(india_outliers.index) # using the row labels
回头看上面的方框图,我们还可以看到美国更多的极端异常值(每月超过 6000 美元的值)。让我们更详细地检查一下这些参与者。
# Examine the extreme outliers for the US
us_outliers = only_4[
(only_4['CountryLive'] == 'United States of America') &
(only_4['money_per_month'] >= 6000)]
us_outliers
| 年龄 | 参加训练营 | BootcampFinish | BootcampLoanYesNo | BootcampName | BootcampRecommend | 儿童数量 | 城市推广 | CodeEventConferences | CodeEventDjangoGirls | CodeEventFCC | CodeEventGameJam | CodeEventGirlDev | CodeEventHackathons | CodeEventMeetup | codeeventnodeeschool | CodeEventNone | CodeEventOther | CodeEventRailsBridge | CodeEventRailsGirls 女孩 | CodeEventStartUpWknd | CodeEventWkdBootcamps | CodeEventWomenCode | CodeEventWorkshops | 通勤时间 | 乡村公民 | 乡村生活 | 就业领域 | 就业领域其他 | 就业状况 | 就业状况 | 预期学习 | 财政支持 | FirstDevJob | 性别 | 性别其他 | 哈斯儿童 | 有力的 | HasFinancialDependents | HasHighSpdInternet | 哈希莫莱格 | HasServedInMilitary | HasStudentDebt | 家庭记忆 | 小时学习 | 身份证 | 身份证号码 | 收入 | IsEthnicMinority | isreceivedisabilityesbenefits 利益 | IsSoftwareDev | 我失业了 | JobApplyWhen | JobInterestBackEnd 后端 | JobInterestDataEngr | JobInterestDataSci | JobInterestDevOps | job 趣前端 | JobInterestFullStack | JobInterestGameDev | JobInterestInfoSec | JobInterestMobile | 工作兴趣其他 | JobInterestProjMngr | JobInterestQAEngr | JobInterestUX | JobPref | job relocation eyes no | 工作兴趣 | JobWherePref | 语言之家 | 海洋状态 | 金钱促进学习 | 月份规划 | 网络 ID | Part1EndTime | 第 1 部分启动时间 | Part2EndTime | 第 2 部分启动时间 | 播客变更日志 | PodcastCodeNewbie | 播客代码笔 | 播客发展茶 | 播客网站 | 播客巨人机器人 | PodcastJSAir | PodcastJSJabber | 播客通 | 播客其他 | 播客节目下载 | 播客 RubyRogues | 播客每日 | 播客电台 | 播客商店谈话 | PodcastTalkPython | 播客 the bahead | 资源代码学院 | 资源代码战争 | 资源课程 a | 资源 | ResourceEdX | 资源 Egghead | 资源 FCC | ResourceHackerRank | 资源卡 | 资源琳达 | 资源 MDN | ResourceOdinProj | 资源其他 | ResourcePluralSight | ResourceSkillcrush | 资源 o | 资源树屋 | 资源城市 | 资源数据库 | 资源 W3S | 学校学位 | 校长 | 学生俱乐部 | YouTube 视频教程 | YouTubeCodingTrain | YouTube 视频编码 360 | YouTube 电脑爱好者 | YouTubeDerekBanas | YouTube 视频提示 | YouTubeEngineeredTruth | YouTube efcc | YouTubeFunFunFunction | YouTubeGoogleDev | YouTubeLearnCode | youtubelieveluptuts | YouTube emit | YouTubeMozillaHacks | YouTubeOther | YouTubeSimplilearn | youtuberhenewboston | 每月收入 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Seven hundred and eighteen | Twenty-six | One | Zero | Zero | 加州大学洛杉矶分校的编码训练营 | One | 圆盘烤饼 | 超过 100 万 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 美利坚合众国 | 美利坚合众国 | 建筑或物理工程 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Fifty thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Thirty-five | 796 AE 14 C2 acdee 36 eebc 250 a 252 abdaf | d 9 e 44d 73057 fa 5d 322 a 071 ADC 744 BF 07 | Forty-four thousand five hundred | Zero | Zero | Zero | One | 在接下来的 6 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 为创业公司工作 | One | 用户体验设计师,全栈网络开发… | 和其他开发人员在一个办公室里 | 英语 | 单身,从未结过婚 | Eight thousand | One | 50dab3f716 | 2017-03-09 21:26:35 | 2017-03-09 21:21:58 | 2017-03-09 21:29:10 | 2017-03-09 21:26:39 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 学士学位 | 体系结构 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 8000.000000 |
| One thousand two hundred and twenty-two | Thirty-two | One | Zero | Zero | 铁场 | One | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 美利坚合众国 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作也不找工作 | 圆盘烤饼 | Fifty thousand | 圆盘烤饼 | 圆盘烤饼 | 女性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | Zero | 圆盘烤饼 | Fifty | BFA bebb 4293 AC 002d 26a 1397d 00 c 7443 | 590 f 0 be 70 e 80 f1 daf 5a 23 EB 7 F4 a 72 a 3d | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 在接下来的 6 个月内 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 为非营利组织工作 | One | 前端 Web 开发人员、移动开发人员…… | 和其他开发人员在一个办公室里 | 英语 | 单身,从未结过婚 | Thirteen thousand | Two | e512c4bdd0 | 2017-03-10 02:14:11 | 2017-03-10 02:10:07 | 2017-03-10 02:15:32 | 2017-03-10 02:14:16 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | One | One | One | One | 圆盘烤饼 | 学士学位 | 人类学 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 6500.000000 |
| Three thousand one hundred and eighty-four | Thirty-four | One | One | Zero | 我们可以编码它 | One | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 不到 15 分钟 | 圆盘烤饼 | 美利坚合众国 | 软件开发和信息技术 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Sixty thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | Zero | Zero | One | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | Ten | 5d 4889491 d9d 25 a 255 e 57 fd1c 0022458 | 585 E8 F8 B9 a 838 E1 abb E8 c6f 1891 c 048 | Forty thousand | Zero | Zero | Zero | Zero | 我还没决定 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 为一家中型公司工作 | Zero | 质量保证工程师,DevOps / SysAd… | 和其他开发人员在一个办公室里 | 英语 | 单身,从未结过婚 | Nine thousand | One | 和 7 bebaabd 4 | 2017-03-11 23:34:16 | 2017-03-11 23:31:17 | 2017-03-11 23:36:02 | 2017-03-11 23:34:21 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | One | 一些大学学分,没有学位 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 9000.000000 |
| Three thousand nine hundred and thirty | Thirty-one | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 美利坚合众国 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作也不找工作 | 圆盘烤饼 | One hundred thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Fifty | e1d 790033545934 FBE 5b b5 b 60 e 368 CD 9 | 7 cf1e 41682462 c 42 ce 48029 abf 77d 43 c | 圆盘烤饼 | One | Zero | Zero | 圆盘烤饼 | 在接下来的 6 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为创业公司工作 | One | DevOps / SysAdmin,前端 Web 开发人员… | 没有偏好 | 英语 | 已婚或同居伴侣关系 | Sixty-five thousand | Six | 75759e5a1c | 2017-03-13 10:06:46 | 2017-03-13 09:56:13 | 2017-03-13 10:10:00 | 2017-03-13 10:06:50 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | reactivex.io/learnrx/-贾法尔·侯赛因公司 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 学士学位 | 生物 | Forty thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | One | One | One | One | 圆盘烤饼 | 各种会议演示 | 圆盘烤饼 | 圆盘烤饼 | 10833.333333 |
| Six thousand eight hundred and five | Forty-six | One | One | One | Sabio.la | Zero | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 美利坚合众国 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | Seventy thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Forty-five | 69096 aacf 4245694303 cf 8f7 ce 68 至 63f | 4c 56 f82a 348836 e 76 DD 90d 18 a3 D5 ed 88 | 圆盘烤饼 | One | Zero | Zero | 圆盘烤饼 | 在接下来的 6 个月内 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 为一家跨国公司工作 | One | 全栈网络开发商,游戏开发商,公关… | 没有偏好 | 英语 | 已婚或同居伴侣关系 | Fifteen thousand | One | 53d13b58e9 | 2017-03-21 20:13:08 | 2017-03-21 20:10:25 | 2017-03-21 20:14:36 | 2017-03-21 20:13:11 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | One | One | 学士学位 | 商业行政与管理 | Forty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15000.000000 |
| Seven thousand one hundred and ninety-eight | Thirty-two | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 超过 100 万 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 美利坚合众国 | 美利坚合众国 | 教育 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Fifty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Four | CB 2754165344 e6be 79 da 8 a 4c 76 BF 3917 | 272219 FBD 28 a3 a 7562 CB 1d 778 e 482 E1 e | 圆盘烤饼 | One | Zero | Zero | Zero | 我已经在申请了 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为一家跨国公司工作 | Zero | 全栈 Web 开发人员,后端 Web 开发人员 | 没有偏好 | 西班牙语 | 单身,从未结过婚 | Seventy thousand | Five | 439a4adaf6 | 2017-03-23 01:37:46 | 2017-03-23 01:35:01 | 2017-03-23 01:39:37 | 2017-03-23 01:37:49 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 专业学位(MBA、MD、JD 等。) | 计算机科学 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 14000.000000 |
| Seven thousand five hundred and five | Twenty-six | One | Zero | One | 代码升级 | Zero | 圆盘烤饼 | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 美利坚合众国 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | Sixty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Forty | 657 FB 50800 bcc 99 a 07 caf 52387 f 67 fbb | ad1df 4669883 d8f 628 f0b 5598 a4 C5 c 45 | 圆盘烤饼 | Zero | Zero | Zero | 圆盘烤饼 | 在接下来的 6 个月内 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | 圆盘烤饼 | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为政府工作 | One | 移动开发人员、全栈 Web 开发人员…… | 和其他开发人员在一个办公室里 | 英语 | 单身,从未结过婚 | Twenty thousand | Three | 96e254de36 | 2017-03-24 03:26:09 | 2017-03-24 03:23:02 | 2017-03-24 03:27:47 | 2017-03-24 03:26:14 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | 学士学位 | 经济学 | Twenty thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 6666.666667 |
| Nine thousand seven hundred and seventy-eight | Thirty-three | One | Zero | One | 大马戏团 | One | 圆盘烤饼 | 10 万到 100 万之间 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 美利坚合众国 | 美利坚合众国 | 教育 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Fifty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | Zero | Zero | One | 圆盘烤饼 | Forty | 7a 62790 f 6 ded 15 e 26 D5 f 429 b 8 a 4d 1095 | 98 eee E1 aa 81 ba 70 B2 ab 288 bf4b 63d 703 | Twenty thousand | Zero | Zero | Zero | One | 在接下来的 6 个月内 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 为一家中型公司工作 | 圆盘烤饼 | 全栈网络开发人员,数据工程师,质量… | 从家里 | 英语 | 单身,从未结过婚 | Eight thousand | One | ea80a3b15e | 2017-04-05 19:48:12 | 2017-04-05 19:40:19 | 2017-04-05 19:49:44 | 2017-04-05 19:49:03 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 硕士学位(非专业) | 化学工程 | Forty-five thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 8000.000000 |
| Sixteen thousand six hundred and fifty | Twenty-nine | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Two | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 美利坚合众国 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 男性的 | 圆盘烤饼 | One | One | One | One | One | Zero | One | Four hundred thousand | Forty | e 1925d 408 c 973 b 91 cf 3 e 9 a 9285238796 | 7 e 9 e 3c 31 a 3d C2 cafe 3a 09269398 c4de 8 | 圆盘烤饼 | One | One | Zero | 圆盘烤饼 | 我已经在申请了 | One | One | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 为一家跨国公司工作 | One | 产品经理、数据工程师、全栈 W… | 和其他开发人员在一个办公室里 | 英语 | 已婚或同居伴侣关系 | Two hundred thousand | Twelve | 1a45f4a3ef | 2017-03-14 02:42:57 | 2017-03-14 02:40:10 | 2017-03-14 02:45:55 | 2017-03-14 02:43:05 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | One | 副学士学位 | 计算机编程 | Thirty thousand | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 16666.666667 |
| Sixteen thousand nine hundred and ninety-seven | Twenty-seven | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 超过 100 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15 到 29 分钟 | 美利坚合众国 | 美利坚合众国 | 卫生保健 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Sixty thousand | Zero | 圆盘烤饼 | 女性的 | 圆盘烤饼 | One | One | One | One | Zero | Zero | One | 圆盘烤饼 | Twelve | 624914 ce 07 c 296 c 866 c 9 e 16 a 14 DC 01 c 7 | 6384 a1 e 576 caf 4 b 6b 9339 Fe 496 a 51 f1f | Forty thousand | One | Zero | Zero | Zero | 7 至 12 个月内 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 为一家中型公司工作 | One | 移动开发者、游戏开发者、用户体验者… | 和其他开发人员在一个办公室里 | 英语 | 单身,从未结过婚 | Twelve thousand five hundred | One | ad1a21217c | 2017-03-20 05:43:28 | 2017-03-20 05:40:08 | 2017-03-20 05:45:28 | 2017-03-20 05:43:32 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | One | One | 一些大学学分,没有学位 | 圆盘烤饼 | Twelve thousand five hundred | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 12500.000000 |
| Seventeen thousand two hundred and thirty-one | Fifty | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Two | 不到 10 万 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 肯尼亚 | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 | 不工作但在找工作 | 圆盘烤饼 | Forty thousand | Zero | 圆盘烤饼 | 女性的 | 圆盘烤饼 | One | Zero | One | One | 圆盘烤饼 | Zero | 圆盘烤饼 | 圆盘烤饼 | One | d4bc 6 AE 775 b 20816 fcd 41048 ef 75417 c | 606749 CD 07 b 124234 ab 6 dff 81 b 324 c 02 | 圆盘烤饼 | One | Zero | Zero | 圆盘烤饼 | 在接下来的 6 个月内 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 为非营利组织工作 | Zero | 前端 Web 开发人员 | 和其他开发人员在一个办公室里 | 英语 | 已婚或同居伴侣关系 | Thirty thousand | Two | 38c1b478d0 | 2017-03-24 18:48:23 | 2017-03-24 18:46:01 | 2017-03-24 18:51:20 | 2017-03-24 18:48:27 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 学士学位 | 计算机编程 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 15000.000000 |
在这 11 个极端异常值中,有 6 个人参加了训练营,这证明了花在学习上的大笔钱是合理的。对于另外五个人来说,很难从数据中找出他们在学习上花了那么多钱的地方。因此,我们将删除那些参与者报告他们每月花费 6000 美元,但他们从未参加过训练营的行。
此外,数据显示,八名受访者在完成调查时,编程时间不超过三个月。他们很可能为一个持续几个月的训练营支付了一大笔钱,因此每月花费的金额是不现实的,应该明显更低(因为他们可能在调查后的几个月内没有花费任何东西)。因此,我们将移除这八个异常值。
在下一个代码块中,我们将删除以下回答:
- 没有参加训练营。
- 当他们完成调查时,已经编程三个月或更少。
# Remove the respondents who didn't attendent a bootcamp
no_bootcamp = only_4[
(only_4['CountryLive'] == 'United States of America') &
(only_4['money_per_month'] >= 6000) &
(only_4['AttendedBootcamp'] == 0)
]
only_4 = only_4.drop(no_bootcamp.index)
# Remove the respondents that had been programming for less than 3 months
less_than_3_months = only_4[
(only_4['CountryLive'] == 'United States of America') &
(only_4['money_per_month'] >= 6000) &
(only_4['MonthsProgramming'] <= 3)
]
only_4 = only_4.drop(less_than_3_months.index)
再次看上面的最后一个方框图,我们还可以看到加拿大的一个极端异常值——一个每月花费大约 5000 美元的人。让我们更深入地研究一下这个人。
# Examine the extreme outliers for Canada
canada_outliers = only_4[
(only_4['CountryLive'] == 'Canada') &
(only_4['money_per_month'] > 4500)]
canada_outliers
| 年龄 | 参加训练营 | BootcampFinish | BootcampLoanYesNo | BootcampName | BootcampRecommend | 儿童数量 | 城市推广 | CodeEventConferences | CodeEventDjangoGirls | CodeEventFCC | CodeEventGameJam | CodeEventGirlDev | CodeEventHackathons | CodeEventMeetup | codeeventnodeeschool | CodeEventNone | CodeEventOther | CodeEventRailsBridge | CodeEventRailsGirls 女孩 | CodeEventStartUpWknd | CodeEventWkdBootcamps | CodeEventWomenCode | CodeEventWorkshops | 通勤时间 | 乡村公民 | 乡村生活 | 就业领域 | 就业领域其他 | 就业率 | 就业状况 | 预期学习 | 财政支持 | FirstDevJob | 性别 | 性别其他 | 哈斯儿童 | 有力的 | HasFinancialDependents | HasHighSpdInternet | 哈希莫莱格 | HasServedInMilitary | HasStudentDebt | 家庭记忆 | 小时学习 | 身份证 | 身份证号码 | 收入 | IsEthnicMinority | isreceivedisabilityesbenefits 利益 | IsSoftwareDev | 我失业了 | JobApplyWhen | JobInterestBackEnd 后端 | JobInterestDataEngr | JobInterestDataSci | JobInterestDevOps | JobInterestFrontEnd | JobInterestFullStack | JobInterestGameDev | JobInterestInfoSec | JobInterestMobile | 工作兴趣其他 | JobInterestProjMngr | JobInterestQAEngr | JobInterestUX | JobPref | job relocation eyes no | 工作兴趣 | JobWherePref | 语言之家 | 婚姻状况 | 金钱促进学习 | 月份规划 | 网络 ID | Part1EndTime | 第 1 部分启动时间 | Part2EndTime | 第 2 部分启动时间 | 播客变更日志 | PodcastCodeNewbie | 播客代码笔 | 播客发展茶 | 播客网站 | 播客巨人机器人 | PodcastJSAir | PodcastJSJabber | 播客通 | 播客其他 | 播客节目下载 | 播客 RubyRogues | 播客每日 | 播客电台 | 播客商店谈话 | PodcastTalkPython | 播客 the bahead | 资源代码学院 | 资源代码战争 | 资源课程 a | 资源 | ResourceEdX | 资源 Egghead | 资源 FCC | ResourceHackerRank | 资源卡 | 资源琳达 | 资源 MDN | ResourceOdinProj | 资源其他 | ResourcePluralSight | ResourceSkillcrush | 资源 | 资源树屋 | 资源城市 | 资源数据库 | 资源 W3S | 学校学位 | 校长 | 学生俱乐部 | YouTube 视频教程 | YouTubeCodingTrain | YouTube 视频编码 360 | YouTube 电脑爱好者 | YouTubeDerekBanas | YouTube 视频提示 | YouTubeEngineeredTruth | YouTube efcc | YouTubeFunFunFunction | YouTubeGoogleDev | YouTubeLearnCode | youtubelieveluptuts | YouTube emit | YouTubeMozillaHacks | YouTubeOther | YouTubeSimplilearn | youtuberhenewboston | 每月收入 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Thirteen thousand six hundred and fifty-nine | Twenty-four | One | Zero | Zero | Bloc.io | One | 圆盘烤饼 | 超过 100 万 | One | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 30 到 44 分钟 | 加拿大 | 加拿大 | 金融 | 圆盘烤饼 | 为工资而受雇 | 圆盘烤饼 | Sixty thousand | 圆盘烤饼 | 圆盘烤饼 | 男性的 | 圆盘烤饼 | 圆盘烤饼 | One | Zero | One | One | Zero | Zero | Two hundred and fifty thousand | Ten | 739 b 584 AEF 0541450 c1f 713 b 82025181 | 28381 至 455ab25cc2a118d78af44d8749 | One hundred and forty thousand | One | One | Zero | Zero | 我还没决定 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | One | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 圆盘烤饼 | One | 为一家跨国公司工作 | 圆盘烤饼 | 移动开发人员、全栈 Web 开发人员…… | 从家里 | 粤(粤语)中文 | 单身,从未结过婚 | Ten thousand | Two | 41c26f2932 | 2017-03-25 23:23:03 | 2017-03-25 23:20:33 | 2017-03-25 23:24:34 | 2017-03-25 23:23:06 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | One | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 学士学位 | 金融 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Five thousand |
这里,情况类似于一些美国受访者——这位参与者在完成调查时,编程时间不超过两个月。他似乎在开始时花了一大笔钱参加训练营,然后在调查后的几个月里,他可能没有花任何钱。我们将采取与美国相同的方法,去除这个异常值。
# Remove the extreme outliers for Canada
only_4 = only_4.drop(canada_outliers.index)
让我们重新计算平均值并生成最终的箱线图。
# Recompute mean sum of money spent by students each month
only_4.groupby('CountryLive').mean()['money_per_month']
CountryLive
Canada 93.065400
India 65.758763
United Kingdom 45.534443
United States of America 142.654608
Name: money_per_month, dtype: float64
# Visualize the distributions again
sns.boxplot(y = 'money_per_month', x = 'CountryLive',
data = only_4)
plt.title('Money Spent Per Month Per Country\n(Distributions)',
fontsize = 16)
plt.ylabel('Money per month (US dollars)')
plt.xlabel('Country')
plt.xticks(range(4), ['US', 'UK', 'India', 'Canada']) # avoids tick labels overlap
plt.show()

选择两个最好的广告市场
显然,我们应该在美国做广告。许多新程序员住在那里,他们愿意每月支付一大笔钱(大约 143 美元)。
我们以每月 59 美元的价格出售订阅,加拿大似乎是最好的第二选择,因为那里的人愿意每月支付大约 93 美元,而印度为 66 美元,英国为 45 美元。
数据强烈表明,我们不应该在英国做广告,但在决定选择加拿大作为我们的第二个最佳选择之前,让我们再看看印度:
- \ ' 59 美元对印度人来说并不算贵,因为他们每月平均花费 66 美元。
- 我们在印度的潜在客户几乎是加拿大的两倍:
# Frequency table for the 'CountryLive' column
only_4['CountryLive'].value_counts(normalize = True) * 100
United States of America 74.967908
India 11.732991
United Kingdom 7.163030
Canada 6.136072
Name: CountryLive, dtype: float64
在加拿大和印度之间选择什么并不十分清楚。虽然选择加拿大似乎更有诱惑力,但印度也有可能是更好的选择,因为它有大量的潜在客户。
此时,我们似乎有几种选择:
- 在美国、印度和加拿大做广告,将广告预算分成不同的组合:
- 美国 60%,印度 25%,加拿大 15%。
- 美国 50%,印度 30%,加拿大 20%;等等。
- 仅在美国和印度或美国和加拿大做广告。同样,不平等地分割广告预算是有意义的。例如:
- 美国占 70%,印度占 30%。
- 美国为 65%,加拿大为 35%;等等。
- 仅在美国做广告。
最好把我们的分析发给营销团队,让他们用他们的领域知识来决定。他们可能想在印度和加拿大做一些额外的调查,然后回来分析新的调查数据。
结论
在这个项目中,我们分析了来自新编码者的调查数据,以找到最好的两个广告市场。我们得出的唯一可靠结论是,美国将是一个很好的广告市场。
对于第二好的市场,在印度和加拿大之间选择什么并不明确。我们决定将结果发送给营销团队,这样他们就可以利用他们的领域知识做出最佳决策。
构建数据科学组合:用数据讲故事
原文:https://www.dataquest.io/blog/data-science-portfolio-project/
June 2, 2016
这是关于如何构建数据科学组合的系列文章中的第一篇。你可以在文章的底部找到本系列其他文章的链接。
数据科学公司在做出招聘决定时,越来越多地考虑投资组合。其中一个原因是投资组合是判断一个人真实技能的最佳方式。对你来说,好消息是投资组合完全在你的掌控之中。如果你投入一些工作,你可以做出一个让公司印象深刻的优秀投资组合。
制作高质量作品集的第一步是要知道要展示什么技能。公司希望数据科学家具备的主要技能,也就是他们希望投资组合展示的主要技能是:
- 通讯能力
- 与他人合作的能力
- 技术能力
- 对数据进行推理的能力
- 主动的动机和能力
任何好的投资组合都将由多个项目组成,每个项目都可能展示上述 1-2 点。这是一个系列的第一篇文章,将介绍如何制作一个全面的数据科学投资组合。在本帖中,我们将介绍如何为数据科学作品集制作第一个项目,以及如何使用数据讲述一个有效的故事。最后,你会有一个项目来展示你的沟通能力,以及你对数据进行推理的能力。
用数据讲故事
数据科学从根本上讲是关于沟通的。你会在数据中发现一些见解,然后想出一种有效的方式将这种见解传达给其他人,然后向他们推销你提出的行动方案。数据科学中最关键的技能之一是能够使用数据讲述一个有效的故事。一个有效的故事可以让你的见解更有说服力,并帮助他人理解你的想法。
数据科学环境中的故事是围绕您发现了什么、如何发现以及它的意义的叙述。一个例子可能是发现你公司的收入在去年下降了 20%。仅仅陈述这一事实是不够的——你还必须传达收入下降的原因,以及如何潜在地解决这个问题。
用数据讲述故事的主要组成部分是:
- 理解和设置上下文
- 探索多个角度
- 使用引人注目的可视化
- 使用不同的数据源
- 有一致的叙述
有效用数据讲故事的最好工具是 Jupyter 笔记本。如果你不熟悉,这里有一个很好的教程。Jupyter notebook 允许您交互式地探索数据,然后在各种站点上共享您的结果,包括 Github。分享你的结果有助于合作,因此其他人可以扩展你的分析。
在本文中,我们将使用 Jupyter notebook,以及 Pandas 和 matplotlib 等 Python 库。
为您的数据科学项目选择主题
创建项目的第一步是确定你的主题。你希望话题是你感兴趣的,并且有动力去探索。很明显,当人们只是为了做项目而做项目,当人们做项目是因为他们真的对探索数据感兴趣。在这一步花费额外的时间是值得的,所以确保你找到了你真正感兴趣的东西。
找到主题的一个好方法是浏览不同的数据集,看看哪些看起来有趣。以下是一些不错的网站:
- Data.gov 包含政府数据。
- /r/datasets —拥有数百个有趣数据集的子编辑。
- Awesome datasets—Github 上托管的数据集列表。
- 寻找数据集的 17 个地方 —一篇包含 17 个数据源的博客文章,以及来自每个数据源的数据集示例。
在现实世界的数据科学中,您通常不会找到一个可以浏览的好的单一数据集。您可能必须聚合不同的数据源,或者进行大量的数据清理。如果一个话题是你非常感兴趣的,那么在这里做同样的事情是值得的,这样你可以更好地展示你的技能。
出于本文的目的,我们将使用纽约市公立学校的数据,这些数据可以在这里找到。
选择一个主题
能够将项目从头到尾进行下去是很重要的。为了做到这一点,限制项目的范围,让它成为我们知道自己能完成的事情,会很有帮助。在一个已经完成的项目中添加东西比完成一个你似乎永远没有足够动力去完成的项目更容易。
在这种情况下,我们将关注高中生的 SAT 分数,以及他们的各种人口统计和其他信息。SAT,即学术能力测试,是美国高中生在申请大学之前参加的一项考试。大学在做录取决定时会考虑考试成绩,所以在这方面做得好是相当重要的。考试分为 3 个部分,每个部分满分为 800 分。总分满分 2400(虽然这个来回换了几次,但是这个数据集中的分数都是满分 2400)。高中通常以平均 SAT 成绩排名,高 SAT 成绩被认为是一个学区有多好的标志。
有人指控 SAT 对美国的某些种族群体不公平,所以对纽约市的数据进行分析将有助于揭示 SAT 的公平性。
我们有一个 SAT 成绩数据集在这里,还有一个数据集包含每个高中的信息在这里。这些将构成我们项目的基础,但我们需要添加更多信息来创建令人信服的分析。
补充数据
一旦你有了一个好的主题,最好去寻找其他可以增强主题或者给你更多深度去探索的数据集。提前做这些是有好处的,这样在构建项目时,您就有尽可能多的数据可以探索。数据太少可能意味着你过早放弃你的项目。
在这种情况下,在同一网站上有几个相关的数据集,涵盖了人口统计信息和考试分数。
以下是我们将使用的所有数据集的链接:
- 学校 SAT 成绩 —纽约市每所高中的 SAT 成绩。
- 学校出勤 —纽约市每所学校的出勤信息。
- 数学测试结果 —纽约市每所学校的数学测试结果。
- 班级人数 —纽约市每所学校的班级人数信息。
- AP 考试成绩 —各高中跳级考试成绩。在美国,通过 AP 考试可以获得大学学分。
- 毕业结果 —毕业学生的百分比,以及其他结果信息。
- 人口统计 —每个学校的人口统计信息。
- 学校调查 —对每个学校的家长、老师和学生的调查。
- 学区地图 —包含学区的布局信息,以便我们绘制出它们的地图。
所有这些数据集都是相互关联的,我们可以在进行任何分析之前将它们结合起来。
获取背景信息
在开始分析数据之前,研究一些背景信息是有用的。在这种情况下,我们知道一些有用的事实:
- 纽约市被分成几个区,这些区本质上是不同的区域。
- 纽约市的学校分为几个学区,每个学区可以包含几十所学校。
- 并非所有数据集中的所有学校都是高中,因此我们需要进行一些数据清理。
- 纽约市的每所学校都有一个独特的代码,称为
DBN,或者区编号。 - 通过按地区汇总数据,我们可以使用地区绘图数据来绘制各区之间的差异。
理解数据
为了真正理解数据的上下文,您需要花时间探索和阅读数据。在这种情况下,上面的每个链接都有数据描述,以及相关的列。看起来我们有高中生 SAT 分数的数据,以及其他包含人口统计和其他信息的数据集。
我们可以运行一些代码来读入数据。我们将使用 Jupyter 笔记本来探索数据。以下代码将:
- 遍历我们下载的每个数据文件。
- 将文件读入熊猫数据帧。
- 将每个数据帧放入 Python 字典中。
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
一旦我们读入数据,我们就可以在数据帧上使用 方法来打印每个数据帧的前5行:
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())
math_test_results
DBN Grade Year Category Number Tested Mean Scale Score Level 1 # \
0 01M015 3 2006 All Students 39 667 21 01M015 3 2007 All Students 31 672 22 01M015 3 2008 All Students 37 668 03 01M015 3 2009 All Students 33 668 04 01M015 3 2010 All Students 26 677 6 Level 1 % Level 2 # Level 2 % Level 3 # Level 3 % Level 4 # Level 4 % \0 5.1% 11 28.2% 20 51.3% 6 15.4%1 6.5% 3 9.7% 22 71% 4 12.9%2 0% 6 16.2% 29 78.4% 2 5.4%3 0% 4 12.1% 28 84.8% 1 3%4 23.1% 12 46.2% 6 23.1% 2 7.7% Level 3+4 # Level 3+4 %0 26 66.7%1 26 83.9%2 31 83.8%3 29 87.9%4 8 30.8%ap_2010 DBN SchoolName AP Test Takers \0 01M448 UNIVERSITY NEIGHBORHOOD H.S. 391 01M450 EAST SIDE COMMUNITY HS 192 01M515 LOWER EASTSIDE PREP 243 01M539 NEW EXPLORATIONS SCI,TECH,MATH 2554 02M296 High School of Hospitality Management s Total Exams Taken Number of Exams with scores 3 4 or 50 49 101 21 s2 26 243 377 1914 s ssat_results DBN SCHOOL NAME \0 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES1 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL2 01M450 EAST SIDE COMMUNITY SCHOOL3 01M458 FORSYTH SATELLITE ACADEMY4 01M509 MARTA VALLE HIGH SCHOOL Num of SAT Test Takers SAT Critical Reading Avg. Score SAT Math Avg. Score \0 29 355 4041 91 383 4232 70 377 4023 7 414 4014 44 390 433 SAT Writing Avg. Score0 3631 3662 3703 3594 384class_size CSD BOROUGH SCHOOL CODE SCHOOL NAME GRADE PROGRAM TYPE \0 1 M M015 P.S. 015 Roberto Clemente 0K GEN ED1 1 M M015 P.S. 015 Roberto Clemente 0K CTT2 1 M M015 P.S. 015 Roberto Clemente 01 GEN ED3 1 M M015 P.S. 015 Roberto Clemente 01 CTT4 1 M M015 P.S. 015 Roberto Clemente 02 GEN ED CORE SUBJECT (MS CORE and 9-12 ONLY) CORE COURSE (MS CORE and 9-12 ONLY) \0 - -1 - -2 - -3 - -4 - - SERVICE CATEGORY(K-9* ONLY) NUMBER OF STUDENTS / SEATS FILLED \0 - 19.01 - 21.02 - 17.03 - 17.04 - 15.0 NUMBER OF SECTIONS AVERAGE CLASS SIZE SIZE OF SMALLEST CLASS \0 1.0 19.0 19.01 1.0 21.0 21.02 1.0 17.0 17.03 1.0 17.0 17.04 1.0 15.0 15.0 SIZE OF LARGEST CLASS DATA SOURCE SCHOOLWIDE PUPIL-TEACHER RATIO0 19.0 ATS NaN1 21.0 ATS NaN2 17.0 ATS NaN3 17.0 ATS NaN4 15.0 ATS NaNdemographics DBN Name schoolyear fl_percent frl_percent \0 01M015 P.S. 015 ROBERTO CLEMENTE 20052006 89.4 NaN1 01M015 P.S. 015 ROBERTO CLEMENTE 20062007 89.4 NaN2 01M015 P.S. 015 ROBERTO CLEMENTE 20072008 89.4 NaN3 01M015 P.S. 015 ROBERTO CLEMENTE 20082009 89.4 NaN4 01M015 P.S. 015 ROBERTO CLEMENTE 20092010 96.5 total_enrollment prek k grade1 grade2 ... black_num black_per \0 281 15 36 40 33 ... 74 26.31 243 15 29 39 38 ... 68 28.02 261 18 43 39 36 ... 77 29.53 252 17 37 44 32 ... 75 29.84 208 16 40 28 32 ... 67 32.2 hispanic_num hispanic_per white_num white_per male_num male_per female_num \0 189 67.3 5 1.8 158.0 56.2 123.01 153 63.0 4 1.6 140.0 57.6 103.02 157 60.2 7 2.7 143.0 54.8 118.03 149 59.1 7 2.8 149.0 59.1 103.04 118 56.7 6 2.9 124.0 59.6 84.0 female_per0 43.81 42.42 45.23 40.94 40.4[5 rows x 38 columns]graduation Demographic DBN School Name Cohort \0 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 20031 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 20042 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 20053 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 20064 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006 Aug Total Cohort Total Grads - n Total Grads - % of cohort Total Regents - n \0 5 s s s1 55 37 67.3% 172 64 43 67.2% 273 78 43 55.1% 364 78 44 56.4% 37 Total Regents - % of cohort Total Regents - % of grads \0 s s1 30.9% 45.9%2 42.2% 62.8%3 46.2% 83.7%4 47.4% 84.1% ... Regents w/o Advanced - n \0 ... s1 ... 172 ... 273 ... 364 ... 37 Regents w/o Advanced - % of cohort Regents w/o Advanced - % of grads \0 s s1 30.9% 45.9%2 42.2% 62.8%3 46.2% 83.7%4 47.4% 84.1% Local - n Local - % of cohort Local - % of grads Still Enrolled - n \0 s s s s1 20 36.4% 54.1% 152 16 25% 37.200000000000003% 93 7 9% 16.3% 164 7 9% 15.9% 15 Still Enrolled - % of cohort Dropped Out - n Dropped Out - % of cohort0 s s s1 27.3% 3 5.5%2 14.1% 9 14.1%3 20.5% 11 14.1%4 19.2% 11 14.1%[5 rows x 23 columns]hs_directory dbn school_name boro \0 17K548 Brooklyn School for Music & Theatre Brooklyn1 09X543 High School for Violin and Dance Bronx2 09X327 Comprehensive Model School Project M.S. 327 Bronx3 02M280 Manhattan Early College School for Advertising Manhattan4 28Q680 Queens Gateway to Health Sciences Secondary Sc... Queens building_code phone_number fax_number grade_span_min grade_span_max \0 K440 718-230-6250 718-230-6262 9 121 X400 718-842-0687 718-589-9849 9 122 X240 718-294-8111 718-294-8109 6 123 M520 718-935-3477 NaN 9 104 Q695 718-969-3155 718-969-3552 6 12 expgrade_span_min expgrade_span_max \0 NaN NaN1 NaN NaN2 NaN NaN3 9 14.04 NaN NaN ... \0 ...1 ...2 ...3 ...4 ... priority02 \0 Then to New York City residents1 Then to New York City residents who attend an ...2 Then to Bronx students or residents who attend...3 Then to New York City residents who attend an ...4 Then to Districts 28 and 29 students or residents priority03 \0 NaN1 Then to Bronx students or residents2 Then to New York City residents who attend an ...3 Then to Manhattan students or residents4 Then to Queens students or residents priority04 priority05 \0 NaN NaN1 Then to New York City residents NaN2 Then to Bronx students or residents Then to New York City residents3 Then to New York City residents NaN4 Then to New York City residents NaN priority06 priority07 priority08 priority09 priority10 \0 NaN NaN NaN NaN NaN1 NaN NaN NaN NaN NaN2 NaN NaN NaN NaN NaN3 NaN NaN NaN NaN NaN4 NaN NaN NaN NaN NaN Location 10 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67...1 1110 Boston Road\nBronx, NY 10456\n(40.8276026...2 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241...3 411 Pearl Street\nNew York, NY 10038\n(40.7106...4 160-20 Goethals Avenue\nJamaica, NY 11432\n(40...[5 rows x 58 columns]
我们可以开始在数据集中看到一些有用的模式:
- 大多数数据集包含一个
DBN列 - 一些字段看起来很适合映射,特别是
Location 1,它包含了一个更大的字符串中的坐标。 - 一些数据集似乎包含每个学校的多行(重复的 DBN 值),这意味着我们必须做一些预处理。
统一数据
为了更容易地处理数据,我们需要将所有单独的数据集统一成一个数据集。这将使我们能够快速比较数据集之间的列。为了做到这一点,我们首先需要找到一个公共列来统一它们。查看上面的输出,似乎DBN可能是那个公共列,因为它出现在多个数据集中。
如果我们用谷歌搜索DBN New York City Schools,我们会在这里找到,这解释了DBN是每个学校的唯一代码。当浏览数据集,尤其是政府数据集时,通常需要做一些检测工作来弄清楚每一列的含义,甚至每个数据集是什么。
现在的问题是,两个数据集class_size和hs_directory没有DBN字段。在hs_directory数据中,它只是被命名为dbn,所以我们可以重命名该列,或者将其复制到一个名为DBN的新列中。在class_size数据中,我们需要尝试不同的方法。
DBN列如下所示:
data["demographics"]["DBN"].head()
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: object
如果我们查看class_size数据,下面是我们在第一个5行中看到的内容:
data["class_size"].head()
| civil service department 文官部 | 自治的市镇 | 学校代码 | 学校名称 | 等级 | 程序类型 | 核心科目(仅限 MS CORE 和 9-12) | 核心课程(仅限 MS CORE 和 9-12) | 服务类别(仅限 K-9* | 学生人数/座位数 | 部分数量 | 平均班级人数 | 最小班级的规模 | 最大班级的规模 | 数据源 | 全校师生比率 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | M | M015 | 附言 015 罗伯托·克莱门特 | 0K | GEN ED | – | – | – | Nineteen | One | Nineteen | Nineteen | Nineteen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 |
| one | one | M | M015 | 附言 015 罗伯托·克莱门特 | 0K | 同CAPITAL TRANSFER TAX | – | – | – | Twenty-one | One | Twenty-one | Twenty-one | Twenty-one | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 |
| Two | one | M | M015 | 附言 015 罗伯托·克莱门特 | 01 | GEN ED | – | – | – | Seventeen | One | Seventeen | Seventeen | Seventeen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 |
| three | one | M | M015 | 附言 015 罗伯托·克莱门特 | 01 | 同CAPITAL TRANSFER TAX | – | – | – | Seventeen | One | Seventeen | Seventeen | Seventeen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 |
| four | one | M | M015 | 附言 015 罗伯托·克莱门特 | 02 | GEN ED | – | – | – | Fifteen | One | Fifteen | Fifteen | Fifteen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 |
正如你在上面看到的,看起来DBN实际上是CSD、BOROUGH和SCHOOL CODE的组合。对于那些不熟悉纽约市的人来说,纽约市是由5区组成的。每个行政区都是一个组织单位,大小相当于一个相当大的美国城市。DBN代表District Borough Number。看起来CSD是行政区,BOROUGH是行政区,当与SCHOOL CODE组合在一起时,就形成了DBN。没有系统化的方法在数据中找到这样的见解,这需要一些探索和尝试才能弄清楚。
现在我们知道如何构建DBN,我们可以将它添加到class_size和hs_directory数据集中:
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]
在调查中添加
最值得关注的潜在数据集之一是关于学校质量的学生、家长和教师调查数据集。这些调查包括每个学校的感知安全、学术标准等信息。在我们合并数据集之前,让我们添加调查数据。在现实世界的数据科学项目中,当您在分析中途时,您经常会遇到有趣的数据,并且会想要合并它。使用像 Jupyter notebook 这样的灵活工具,您可以快速添加一些额外的代码,并重新运行您的分析。
在这种情况下,我们将把调查数据添加到我们的data字典中,然后合并所有数据集。调查数据由2个文件组成,一个针对所有学校,一个针对学区75。我们需要编写一些代码来组合它们。在下面的代码中,我们将:
- 使用
windows-1252文件编码读取所有学校的调查。 - 使用
windows-1252文件编码阅读第 75 区学校的调查。 - 添加一个标志来指示每个数据集属于哪个学区。
- 在数据帧上使用 concat 方法将数据集合并成一个数据集。
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)
一旦我们把调查结合起来,还有一个额外的复杂因素。我们希望最大限度地减少组合数据集中的列数,这样我们就可以轻松地比较列并找出相关性。不幸的是,调查数据中有许多列对我们来说不是很有用:
survey.head()
| 名词短语 | 南加大 | N_t | aca_p_11 | 阿卡 _s_11 | aca_t_11 | aca_tot_11 | 十亿 | com_p_11 | com_s_11 | … | t_q8c_1 | t_q8c_2 | t_q8c_3 | t_q8c_4 | t_q9 | t_q9_1 | t_q9_2 | t_q9_3 | t_q9_4 | t_q9_5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Ninety | 圆盘烤饼 | Twenty-two | Seven point eight | 圆盘烤饼 | Seven point nine | Seven point nine | M015 | Seven point six | 圆盘烤饼 | … | Twenty-nine | Sixty-seven | Five | Zero | 圆盘烤饼 | Five | Fourteen | Fifty-two | Twenty-four | Five |
| one | One hundred and sixty-one | 圆盘烤饼 | Thirty-four | Seven point eight | 圆盘烤饼 | Nine point one | Eight point four | M019 | Seven point six | 圆盘烤饼 | … | Seventy-four | Twenty-one | Six | Zero | 圆盘烤饼 | Three | Six | Three | Seventy-eight | Nine |
| Two | Three hundred and sixty-seven | 圆盘烤饼 | Forty-two | Eight point six | 圆盘烤饼 | Seven point five | Eight | M020 | Eight point three | 圆盘烤饼 | … | Thirty-three | Thirty-five | Twenty | Thirteen | 圆盘烤饼 | Three | Five | Sixteen | Seventy | Five |
| three | One hundred and fifty-one | One hundred and forty-five | Twenty-nine | Eight point five | Seven point four | Seven point eight | Seven point nine | M034 | Eight point two | Five point nine | … | Twenty-one | Forty-five | Twenty-eight | Seven | 圆盘烤饼 | Zero | Eighteen | Thirty-two | Thirty-nine | Eleven |
| four | Ninety | 圆盘烤饼 | Twenty-three | Seven point nine | 圆盘烤饼 | Eight point one | Eight | M063 | Seven point nine | 圆盘烤饼 | … | Fifty-nine | Thirty-six | Five | Zero | 圆盘烤饼 | Ten | Five | Ten | Sixty | Fifteen |
5 行× 2773 列
我们可以通过查看随调查数据一起下载的数据字典文件来解决这个问题。该文件告诉我们数据中的重要字段:

然后我们可以删除survey中任何无关的列:
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
(1702, 23)
确保您了解每个数据集包含的内容,以及相关的列是什么,可以节省您以后的大量时间和精力。
压缩数据集
如果我们看一下一些数据集,包括class_size,我们会立即发现一个问题:
data["class_size"].head()
| civil service department 文官部 | 自治的市镇 | 学校代码 | 学校名称 | 等级 | 程序类型 | 核心科目(仅限 MS CORE 和 9-12) | 核心课程(仅限 MS CORE 和 9-12) | 服务类别(仅限 K-9* | 学生人数/座位数 | 部分数量 | 平均班级人数 | 最小班级的规模 | 最大班级的规模 | 数据源 | 全校师生比率 | DBN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | M | M015 | 附言 015 罗伯托·克莱门特 | 0K | GEN ED | – | – | – | Nineteen | One | Nineteen | Nineteen | Nineteen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 | 01M015 |
| one | one | M | M015 | 附言 015 罗伯托·克莱门特 | 0K | 同CAPITAL TRANSFER TAX | – | – | – | Twenty-one | One | Twenty-one | Twenty-one | Twenty-one | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 | 01M015 |
| Two | one | M | M015 | 附言 015 罗伯托·克莱门特 | 01 | GEN ED | – | – | – | Seventeen | One | Seventeen | Seventeen | Seventeen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 | 01M015 |
| three | one | M | M015 | 附言 015 罗伯托·克莱门特 | 01 | 同CAPITAL TRANSFER TAX | – | – | – | Seventeen | One | Seventeen | Seventeen | Seventeen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 | 01M015 |
| four | one | M | M015 | 附言 015 罗伯托·克莱门特 | 02 | GEN ED | – | – | – | Fifteen | One | Fifteen | Fifteen | Fifteen | 声音传输系统(Acoustic Transmission System) | 圆盘烤饼 | 01M015 |
每个高中都有几行(通过重复的DBN和SCHOOL NAME字段可以看到)。然而,如果我们看一下sat_results数据集,它只有每个高中一行:
data["sat_results"].head()
| DBN | 学校名称 | SAT 考生人数 | SAT 临界阅读平均值。得分 | SAT 数学平均成绩。得分 | SAT 写作平均成绩。得分 | |
|---|---|---|---|---|---|---|
| Zero | 01M292 | 亨利街国际研究学院 | Twenty-nine | Three hundred and fifty-five | Four hundred and four | Three hundred and sixty-three |
| one | 01M448 | 大学社区高中 | Ninety-one | Three hundred and eighty-three | Four hundred and twenty-three | Three hundred and sixty-six |
| Two | 01M450 | 东区社区学校 | Seventy | Three hundred and seventy-seven | Four hundred and two | Three hundred and seventy |
| three | 01M458 | 福塞斯卫星学院 | seven | Four hundred and fourteen | Four hundred and one | Three hundred and fifty-nine |
| four | 01M509 | 玛尔塔·瓦莱高中 | forty-four | Three hundred and ninety | Four hundred and thirty-three | Three hundred and eighty-four |
为了组合这些数据集,我们需要找到一种方法将像class_size这样的数据集压缩到每个高中只有一行。如果没有,就没有办法比较 SAT 成绩和班级规模。我们可以通过首先更好地理解数据,然后进行一些汇总来实现这一点。对于class_size数据集,看起来GRADE和PROGRAM TYPE对于每个学校都有多个值。通过将每个字段限制为单个值,我们可以过滤大多数重复的行。在下面的代码中,我们:
- 仅选择来自
class_size的值,其中GRADE字段为09-12。 - 仅选择来自
class_size的值,其中PROGRAM TYPE字段为GEN ED。 - 将
class_size数据集按DBN分组,取每列的平均值。本质上,我们会找到每个学校的平均class_size值。 - 重置索引,因此将
DBN作为一列添加回去。
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_size
浓缩其他数据集
接下来,我们需要压缩demographics数据集。这些数据是为同一所学校收集了多年的,因此每所学校都有重复的行。我们将只选择schoolyear字段最近可用的行:
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographics
我们需要压缩math_test_results数据集。该数据集由Grade和Year分割。我们只能从一年中选择一个级别:
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == '8']
最后,graduation需要浓缩:
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]
在进行项目的实质性工作之前,数据清理和探索是至关重要的。拥有良好、一致的数据集将有助于您更快地进行分析。
计算变量
计算变量有助于加快我们的分析速度,使我们能够更快地进行比较,并使我们能够进行我们否则无法进行的比较。我们可以做的第一件事是从各个列SAT Math Avg. Score、SAT Critical Reading Avg. Score和SAT Writing Avg. Score中计算出 SAT 总分。在下面的代码中,我们:
- 将每个 SAT 分数列从字符串转换为数字。
- 将所有列相加得到
sat_score列,这是 SAT 总分。
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True)
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]] + data['sat_results'][cols[2]]
接下来,我们需要解析出每所学校的坐标位置,这样我们就可以制作地图了。这将使我们能够画出每所学校的位置。在下面的代码中,我们:
- 解析来自
Location 1列的纬度和经度列。 - 将
lat和lon转换为数字。
data["hs_directory"]['lat'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[0])
data["hs_directory"]['lon'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[1])
for c in ['lat', 'lon']:
data["hs_directory"][c] = data["hs_directory"][c].convert_objects(convert_numeric=True)
现在,我们可以打印出每个数据集,看看我们有什么:
for k,v in data.items():
print(k)
print(v.head())
math_test_results DBN Grade Year Category Number Tested Mean Scale Score \111 01M034 8 2011 All Students 48 646280 01M140 8 2011 All Students 61 665346 01M184 8 2011 All Students 49 727388 01M188 8 2011 All Students 49 658411 01M292 8 2011 All Students 49 650 Level 1 # Level 1 % Level 2 # Level 2 % Level 3 # Level 3 % Level 4 # \111 15 31.3% 22 45.8% 11 22.9% 0280 1 1.6% 43 70.5% 17 27.9% 0346 0 0% 0 0% 5 10.2% 44388 10 20.4% 26 53.1% 10 20.4% 3411 15 30.6% 25 51% 7 14.3% 2 Level 4 % Level 3+4 # Level 3+4 %111 0% 11 22.9%280 0% 17 27.9%346 89.8% 49 100%388 6.1% 13 26.5%411 4.1% 9 18.4%survey DBN rr_s rr_t rr_p N_s N_t N_p saf_p_11 com_p_11 eng_p_11 \0 01M015 NaN 88 60 NaN 22.0 90.0 8.5 7.6 7.51 01M019 NaN 100 60 NaN 34.0 161.0 8.4 7.6 7.62 01M020 NaN 88 73 NaN 42.0 367.0 8.9 8.3 8.33 01M034 89.0 73 50 145.0 29.0 151.0 8.8 8.2 8.04 01M063 NaN 100 60 NaN 23.0 90.0 8.7 7.9 8.1 ... eng_t_10 aca_t_11 saf_s_11 com_s_11 eng_s_11 aca_s_11 \0 ... NaN 7.9 NaN NaN NaN NaN1 ... NaN 9.1 NaN NaN NaN NaN2 ... NaN 7.5 NaN NaN NaN NaN3 ... NaN 7.8 6.2 5.9 6.5 7.44 ... NaN 8.1 NaN NaN NaN NaN saf_tot_11 com_tot_11 eng_tot_11 aca_tot_110 8.0 7.7 7.5 7.91 8.5 8.1 8.2 8.42 8.2 7.3 7.5 8.03 7.3 6.7 7.1 7.94 8.5 7.6 7.9 8.0[5 rows x 23 columns]ap_2010 DBN SchoolName AP Test Takers \0 01M448 UNIVERSITY NEIGHBORHOOD H.S. 391 01M450 EAST SIDE COMMUNITY HS 192 01M515 LOWER EASTSIDE PREP 243 01M539 NEW EXPLORATIONS SCI,TECH,MATH 2554 02M296 High School of Hospitality Management s Total Exams Taken Number of Exams with scores 3 4 or 50 49 101 21 s2 26 243 377 1914 s ssat_results DBN SCHOOL NAME \0 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES1 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL2 01M450 EAST SIDE COMMUNITY SCHOOL3 01M458 FORSYTH SATELLITE ACADEMY4 01M509 MARTA VALLE HIGH SCHOOL Num of SAT Test Takers SAT Critical Reading Avg. Score \0 29 355.01 91 383.02 70 377.03 7 414.04 44 390.0 SAT Math Avg. Score SAT Writing Avg. Score sat_score0 404.0 363.0 1122.01 423.0 366.0 1172.02 402.0 370.0 1149.03 401.0 359.0 1174.04 433.0 384.0 1207.0class_size DBN CSD NUMBER OF STUDENTS / SEATS FILLED NUMBER OF SECTIONS \0 01M292 1 88.0000 4.0000001 01M332 1 46.0000 2.0000002 01M378 1 33.0000 1.0000003 01M448 1 105.6875 4.7500004 01M450 1 57.6000 2.733333 AVERAGE CLASS SIZE SIZE OF SMALLEST CLASS SIZE OF LARGEST CLASS \0 22.564286 18.50 26.5714291 22.000000 21.00 23.5000002 33.000000 33.00 33.0000003 22.231250 18.25 27.0625004 21.200000 19.40 22.866667 SCHOOLWIDE PUPIL-TEACHER RATIO0 NaN1 NaN2 NaN3 NaN4 NaNdemographics DBN Name schoolyear \6 01M015 P.S. 015 ROBERTO CLEMENTE 2011201213 01M019 P.S. 019 ASHER LEVY 2011201220 01M020 PS 020 ANNA SILVER 2011201227 01M034 PS 034 FRANKLIN D ROOSEVELT 2011201235 01M063 PS 063 WILLIAM MCKINLEY 20112012 fl_percent frl_percent total_enrollment prek k grade1 grade2 \6 NaN 89.4 189 13 31 35 2813 NaN 61.5 328 32 46 52 5420 NaN 92.5 626 52 102 121 8727 NaN 99.7 401 14 34 38 3635 NaN 78.9 176 18 20 30 21 ... black_num black_per hispanic_num hispanic_per white_num \6 ... 63 33.3 109 57.7 413 ... 81 24.7 158 48.2 2820 ... 55 8.8 357 57.0 1627 ... 90 22.4 275 68.6 835 ... 41 23.3 110 62.5 15 white_per male_num male_per female_num female_per6 2.1 97.0 51.3 92.0 48.713 8.5 147.0 44.8 181.0 55.220 2.6 330.0 52.7 296.0 47.327 2.0 204.0 50.9 197.0 49.135 8.5 97.0 55.1 79.0 44.9[5 rows x 38 columns]graduation Demographic DBN School Name Cohort \3 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 200610 Total Cohort 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL 200617 Total Cohort 01M450 EAST SIDE COMMUNITY SCHOOL 200624 Total Cohort 01M509 MARTA VALLE HIGH SCHOOL 200631 Total Cohort 01M515 LOWER EAST SIDE PREPARATORY HIGH SCHO 2006 Total Cohort Total Grads - n Total Grads - % of cohort Total Regents - n \3 78 43 55.1% 3610 124 53 42.7% 4217 90 70 77.8% 6724 84 47 56% 4031 193 105 54.4% 91 Total Regents - % of cohort Total Regents - % of grads \3 46.2% 83.7%10 33.9% 79.2%17 74.400000000000006% 95.7%24 47.6% 85.1%31 47.2% 86.7% ... Regents w/o Advanced - n \3 ... 3610 ... 3417 ... 6724 ... 2331 ... 22 Regents w/o Advanced - % of cohort Regents w/o Advanced - % of grads \3 46.2% 83.7%10 27.4% 64.2%17 74.400000000000006% 95.7%24 27.4% 48.9%31 11.4% 21% Local - n Local - % of cohort Local - % of grads Still Enrolled - n \3 7 9% 16.3% 1610 11 8.9% 20.8% 4617 3 3.3% 4.3% 1524 7 8.300000000000001% 14.9% 2531 14 7.3% 13.3% 53 Still Enrolled - % of cohort Dropped Out - n Dropped Out - % of cohort3 20.5% 11 14.1%10 37.1% 20 16.100000000000001%17 16.7% 5 5.6%24 29.8% 5 6%31 27.5% 35 18.100000000000001%[5 rows x 23 columns]hs_directory dbn school_name boro \0 17K548 Brooklyn School for Music & Theatre Brooklyn1 09X543 High School for Violin and Dance Bronx2 09X327 Comprehensive Model School Project M.S. 327 Bronx3 02M280 Manhattan Early College School for Advertising Manhattan4 28Q680 Queens Gateway to Health Sciences Secondary Sc... Queens building_code phone_number fax_number grade_span_min grade_span_max \0 K440 718-230-6250 718-230-6262 9 121 X400 718-842-0687 718-589-9849 9 122 X240 718-294-8111 718-294-8109 6 123 M520 718-935-3477 NaN 9 104 Q695 718-969-3155 718-969-3552 6 12 expgrade_span_min expgrade_span_max ... \0 NaN NaN ...1 NaN NaN ...2 NaN NaN ...3 9 14.0 ...4 NaN NaN ... priority05 priority06 priority07 priority08 \0 NaN NaN NaN NaN1 NaN NaN NaN NaN2 Then to New York City residents NaN NaN NaN3 NaN NaN NaN NaN4 NaN NaN NaN NaN priority09 priority10 Location 1 \0 NaN NaN 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67...1 NaN NaN 1110 Boston Road\nBronx, NY 10456\n(40.8276026...2 NaN NaN 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241...3 NaN NaN 411 Pearl Street\nNew York, NY 10038\n(40.7106...4 NaN NaN 160-20 Goethals Avenue\nJamaica, NY 11432\n(40... DBN lat lon0 17K548 40.670299 -73.9616481 09X543 40.827603 -73.9044752 09X327 40.842414 -73.9161623 02M280 40.710679 -74.0008074 28Q680 40.718810 -73.806500[5 rows x 61 columns]
组合数据集
现在我们已经完成了所有的准备工作,我们可以使用DBN列将数据集组合在一起。最后,我们将得到一个包含数百列的数据集,这些列来自每个原始数据集。当我们加入它们时,需要注意的是一些数据集缺少存在于sat_results数据集中的高中。为了解决这个问题,我们需要使用outer连接策略合并丢失行的数据集,这样我们就不会丢失数据。在现实世界的数据分析中,数据丢失是很常见的。能够证明推理和处理缺失数据的能力是构建投资组合的重要部分。
你可以在这里阅读不同类型的连接。
在下面的代码中,我们将:
- 遍历
data字典中的每个条目。 - 打印物料中非唯一 dbn 的数量。
- 决定加入策略—
inner或outer。 - 使用列
DBN将项目连接到数据框full。
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type = "inner"
if name in ["sat_results", "ap_2010", "graduation"]:
join_type = "outer"
if name not in ["math_test_results"]:
full = full.merge(f, on="DBN", how=join_type)full.shape
survey
0
ap_2010
1
sat_results
0
class_size
0
demographics
0
graduation
0
hs_directory
0
(374, 174)
添加值
现在我们有了数据框架,我们几乎拥有了进行分析所需的所有信息。不过,还是有一些缺失的部分。我们可能希望将跳级考试成绩与 SAT 成绩相关联,但是我们需要首先将这些列转换成数字,然后填入任何缺失的值:
cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5']
for col in cols:
full[col] = full[col].convert_objects(convert_numeric=True)
full[cols] = full[cols].fillna(value=0)
然后,我们需要计算一个school_dist列来表示学校的学区。这将使我们能够匹配学区,并使用我们之前下载的地区地图绘制地区级统计数据:
full["school_dist"] = full["DBN"].apply(lambda x: x[:2])
最后,我们需要用列的平均值填充full中任何缺失的值,这样我们就可以计算相关性:
full = full.fillna(full.mean())
计算相关性
浏览数据集并查看哪些列与您关心的列相关的一个好方法是计算相关性。这将告诉您哪些列与您感兴趣的列密切相关。我们可以通过熊猫数据帧上的 corr 方法来做到这一点。相关性越接近0,联系越弱。越靠近1,正相关越强,越靠近-1,负相关越强:
full.corr()['sat_score']
Year NaN
Number Tested 8.127817e-02
rr_s 8.484298e-02
rr_t -6.604290e-02
rr_p 3.432778e-02
N_s 1.399443e-01
N_t 9.654314e-03
N_p 1.397405e-01
saf_p_11 1.050653e-01
com_p_11 2.107343e-02
eng_p_11 5.094925e-02
aca_p_11 5.822715e-02
saf_t_11 1.206710e-01
com_t_11 3.875666e-02
eng_t_10 NaN
aca_t_11 5.250357e-02
saf_s_11 1.054050e-01
com_s_11 4.576521e-02
eng_s_11 6.303699e-02
aca_s_11 8.015700e-02
saf_tot_11 1.266955e-01
com_tot_11 4.340710e-02
eng_tot_11 5.028588e-02
aca_tot_11 7.229584e-02
AP Test Takers 5.687940e-01
Total Exams Taken 5.585421e-01
Number of Exams with scores 3 4 or 5 5.619043e-01
SAT Critical Reading Avg. Score 9.868201e-01
SAT Math Avg. Score 9.726430e-01
SAT Writing Avg. Score 9.877708e-01
...
SIZE OF SMALLEST CLASS 2.440690e-01
SIZE OF LARGEST CLASS 3.052551e-01
SCHOOLWIDE PUPIL-TEACHER RATIO NaN
schoolyear NaN
frl_percent -7.018217e-01
total_enrollment 3.668201e-01
ell_num -1.535745e-01
ell_percent -3.981643e-01
sped_num 3.486852e-02
sped_percent -4.413665e-01
asian_num 4.748801e-01
asian_per 5.686267e-01
black_num 2.788331e-02
black_per -2.827907e-01
hispanic_num 2.568811e-02
hispanic_per -3.926373e-01
white_num 4.490835e-01
white_per 6.100860e-01
male_num 3.245320e-01
male_per -1.101484e-01
female_num 3.876979e-01
female_per 1.101928e-01
Total Cohort 3.244785e-01
grade_span_max -2.495359e-17
expgrade_span_max NaN
zip -6.312962e-02
total_students 4.066081e-01
number_programs 1.166234e-01
lat -1.198662e-01
lon -1.315241e-01
Name: sat_score, dtype: float64
这给了我们一些需要探索的见解:
- 总入学人数与
sat_score密切相关,这令人惊讶,因为你会认为更关注学生的小学校会有更高的分数。 - 学校中女性的比例(
female_per)与 s at 成绩正相关,而男性的比例(male_per)与 SAT 成绩负相关。 - 没有一个调查回答与 SAT 成绩高度相关。
- SAT 成绩存在显著的种族不平等(
white_per、asian_per、black_per、hispanic_per)。 - 与 SAT 成绩显著负相关。
这些项目中的每一个都是探索和讲述使用数据的故事的潜在角度。
设置背景
在我们深入研究数据之前,我们需要为自己和阅读我们分析的其他人设置背景。一个很好的方法是使用探索性的图表或地图。在这种情况下,我们将标出学校的位置,这将有助于读者理解我们正在探索的问题。
在下面的代码中,我们:
- 设置以纽约市为中心的地图。
- 为城市中的每所高中在地图上添加标记。
- 显示地图。
import folium
from folium import plugins
schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
marker_cluster = folium.MarkerCluster().add_to(schools_map)
for name, row in full.iterrows():
folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster)
schools_map.create_map('schools.html')
schools_map
这张地图很有帮助,但是很难看出纽约市大多数学校在哪里。相反,我们将制作一个热图:
schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()]))
schools_heatmap.save("heatmap.html")
schools_heatmap
区级制图
热图有利于绘制梯度图,但我们需要更有结构的东西来绘制整个城市 SAT 分数的差异。学区是可视化这些信息的好方法,因为每个学区都有自己的管理机构。纽约市有几十个学区,每个学区是一个小的地理区域。
我们可以按学区计算 SAT 分数,然后在地图上画出来。在下面的代码中,我们将:
- 按学区分组。
- 计算每个学区每列的平均值。
- 转换
school_dist字段以删除前导的0,这样我们就可以匹配我们的地理区域数据。
district_data = full.groupby("school_dist").agg(np.mean)
district_data.reset_index(inplace=True)
district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x)))
我们现在可以绘制出每个学区的平均 SAT 分数。为此,我们将以 GeoJSON 格式读入数据,以获得每个地区的形状,然后使用school_dist列将每个地区的形状与 SAT 分数进行匹配,最后创建绘图:
def show_district_map(col):
geo_path = 'schools/districts.geojson'
districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
districts.geo_json(
geo_path=geo_path,
data=district_data,
columns=['school_dist', col],
key_on='feature.properties.school_dist',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
)
districts.save("districts.html")
return districts
show_district_map("sat_score")
探索注册和 SAT 分数
现在,我们已经通过绘制学校的位置设置了背景,并按地区设置了 SAT 分数,查看我们分析的人对数据集背后的背景有了更好的了解。现在我们已经搭建好了舞台,我们可以开始探索我们之前发现的角度,那时我们正在寻找相关性。第一个探讨的角度是一所学校的招生人数和 SAT 成绩之间的关系。
我们可以用散点图来探究这个问题,散点图比较了所有学校的总入学人数和所有学校的 SAT 分数。
full.plot.scatter(x='total_enrollment', y='sat_score')
<matplotlib.axes._subplots.AxesSubplot at 0x10fe79978>

如你所见,在左下方有一个低总入学率和低 SAT 分数的聚类。除此之外,SAT 成绩和总入学人数之间似乎只有轻微的正相关。绘制相关性图可以揭示意想不到的模式。
我们可以通过获取低入学率和低 SAT 分数的学校名称来进一步探究这个问题:
34 INTERNATIONAL SCHOOL FOR LIBERAL ARTS
143 NaN
148 KINGSBRIDGE INTERNATIONAL HIGH SCHOOL
203 MULTICULTURAL HIGH SCHOOL
294 INTERNATIONAL COMMUNITY HIGH SCHOOL
304 BRONX INTERNATIONAL HIGH SCHOOL
314 NaN
317 HIGH SCHOOL OF WORLD CULTURES
320 BROOKLYN INTERNATIONAL HIGH SCHOOL
329 INTERNATIONAL HIGH SCHOOL AT PROSPECT
331 IT TAKES A VILLAGE ACADEMY
351 PAN AMERICAN INTERNATIONAL HIGH SCHOO
Name: School Name, dtype: object
谷歌上的一些搜索显示,这些学校大多数是为学习英语的学生开设的,因此入学率很低。这项研究向我们表明,与 SAT 分数相关的不是总入学人数,而是学校的学生是否将英语作为第二语言学习。
探索英语语言学习者和 SAT 成绩
既然我们知道学校里英语语言学习者的比例与较低的 SAT 分数相关,我们可以探究这种关系。第ell_percent栏是每个学校学习英语的学生的百分比。我们可以对这种关系做一个散点图:
full.plot.scatter(x='ell_percent', y='sat_score')
<matplotlib.axes._subplots.AxesSubplot at 0x10fe824e0>

看起来有一群 SAT 分数高的学校也有低的平均分数。我们可以在地区一级对此进行调查,计算出每个地区英语学习者的百分比,并查看它是否与我们按地区划分的 s at 分数图相匹配:
show_district_map("ell_percent")
从两张地区地图中我们可以看出,英语学习者比例低的地区往往 SAT 分数高,反之亦然。
关联调查分数和 SAT 分数
假设学生、家长和老师的调查结果与 SAT 成绩有很大的相关性是公平的。例如,学术期望高的学校往往会有更高的 SAT 分数,这是有道理的。为了测试这一理论,让我们绘制出 SAT 分数和各种调查指标:
full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x114652400>

令人惊讶的是,最相关的两个因素是N_p和N_s,这是对调查做出回应的家长和学生的数量。两者都与总入学人数密切相关,因此很可能会被ell_learners所误导。另一个最相关的指标是saf_t_11。这就是学生、家长和老师对学校的看法。学校越安全,学生在环境中学习就越舒服,这是有道理的。然而,其他因素,如参与度、沟通和学术期望,都与 SAT 成绩无关。这可能表明 NYC 在调查中提出了错误的问题,或者考虑了错误的因素(如果他们的目标是提高 SAT 成绩,可能不是)。
探索种族和 SAT 分数
调查的另一个角度包括种族和 SAT 分数。有一个很大的相关差异,画出来将有助于我们理解发生了什么:
full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x108166ba8>

看起来白人和亚裔学生比例较高与 SAT 分数较高相关,但黑人和西班牙裔学生比例较高与 SAT 分数较低相关。对于西班牙裔学生,这可能是因为有更多的新移民是英语学习者。我们可以按地区绘制西班牙裔的比例图来观察这种相关性:
show_district_map("hispanic_per")
看起来与 ELL 百分比有一些关联,但是有必要对 SAT 分数中的这种和其他种族差异做更多的挖掘。
SAT 成绩的性别差异
最后要探讨的角度是性别和 SAT 成绩的关系。我们注意到,学校中女性比例较高往往与 SAT 分数较高相关。我们可以用一个条形图来形象地描述这一点:
full.corr()["sat_score"][["male_per", "female_per"]].plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x10774d0f0>

为了深入了解这种相关性,我们可以制作一个female_per和sat_score的散点图:
full.plot.scatter(x='female_per', y='sat_score')
<matplotlib.axes._subplots.AxesSubplot at 0x104715160>

看起来有一群学校的女生比例很高,SAT 分数也很高(在右上方)。我们可以得到这个集群中学校的名称:
full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"]
3 PROFESSIONAL PERFORMING ARTS HIGH SCH
92 ELEANOR ROOSEVELT HIGH SCHOOL
100 TALENT UNLIMITED HIGH SCHOOL
111 FIORELLO H. LAGUARDIA HIGH SCHOOL OF
229 TOWNSEND HARRIS HIGH SCHOOL
250 FRANK SINATRA SCHOOL OF THE ARTS HIGH SCHOOL
265 BARD HIGH SCHOOL EARLY COLLEGE
Name: School Name, dtype: object
搜索谷歌发现,这些都是专注于表演艺术的精英学校。这些学校的女生比例更高,SAT 分数也更高。这可能解释了较高的女性百分比和 SAT 分数之间的相关性,以及较高的男性百分比和较低的 SAT 分数之间的反向相关性。
AP 分数
到目前为止,我们已经从人口统计学的角度看了。我们有数据可以看的一个角度是更多的学生参加跳级考试和更高的 SAT 分数之间的关系。它们之间存在关联是有道理的,因为学业成绩优异的学生往往在 SAT 考试中表现更好。
full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"]
full.plot.scatter(x='ap_avg', y='sat_score')
<matplotlib.axes._subplots.AxesSubplot at 0x11463a908>

看起来这两者之间确实有很强的相关性。右上角的学校很有意思,它的 SAT 分数很高,参加 AP 考试的学生比例也很高:
full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"]
92 ELEANOR ROOSEVELT HIGH SCHOOL
98 STUYVESANT HIGH SCHOOL
157 BRONX HIGH SCHOOL OF SCIENCE
161 HIGH SCHOOL OF AMERICAN STUDIES AT LE
176 BROOKLYN TECHNICAL HIGH SCHOOL
229 TOWNSEND HARRIS HIGH SCHOOL
243 QUEENS HIGH SCHOOL FOR THE SCIENCES A
260 STATEN ISLAND TECHNICAL HIGH SCHOOL
Name: School Name, dtype: object
一些谷歌搜索显示,这些大多是高选择性的学校,你需要参加考试才能进入。这些学校有很高比例的 AP 考生是有道理的。
结束这个故事
对于数据科学,故事永远不会真正结束。通过向其他人发布分析,您可以让他们向他们感兴趣的任何方向扩展和塑造您的分析。例如,在这篇文章中,有相当多的角度,我们完全探索了,并可以深入更多。
开始使用数据讲述故事的最好方法之一是尝试扩展或复制别人已经完成的分析。如果你决定走这条路,欢迎你在这篇文章中扩展分析,看看你能找到什么。如果你这样做,请确保让我知道,这样我就可以看看了。
后续步骤
如果你已经做到这一步,希望你已经很好地理解了如何用数据讲述一个故事,以及如何构建你的第一个数据科学作品集。
在 Dataquest ,我们的互动指导项目旨在帮助您开始构建数据科学组合,向雇主展示您的技能,并获得一份数据方面的工作。如果你感兴趣,你可以注册并免费学习我们的第一个模块。
如果你喜欢这篇文章,你可能会喜欢阅读我们“构建数据科学组合”系列中的其他文章:
- 如何建立数据科学博客。
- 打造机器学习项目。
- 建立数据科学投资组合的关键是让你找到工作。
- 寻找数据科学项目数据集的 17 个地方
- 如何在 Github 上展示您的数据科学作品集
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
数据科学家常见的工作场所问题,以及如何解决这些问题
April 27, 2019
在数据科学领域工作有很多好处。但是像任何工作一样,成为一名数据科学家可能会令人沮丧,尤其是当你的公司没有采取正确的大数据方法时。
好消息是,其中一些问题是可以管理或避免的!让我们来看看数据科学家在工作场所的一些常见抱怨(来自网络),以及你如何可能能够避免或管理它们。
不合理的管理期望
人们常说,数据建模是 90%的数据收集/清理和 10%的模型构建。因此,当有人有一个在最后一刻插入的好主意时,这是一个巨大的头痛。
有时这是建模者的错误,但通常是优柔寡断的管理层在最后一秒钟决定他们刚刚想到的东西非常非常重要。等等,我们会把社交媒体历史纳入车祸频率的分析中吗?变量列表里没看到。让我们添加它!
数据建模人员对这类请求感到叹息,因为这通常意味着几天的额外数据收集和建模时间表的延迟(可能已经确定了)。数据建模师应该保持沟通渠道的畅通,并设置某种“不再调整”的日期,这样就不会发生这种情况。但不管怎样,它可能会。
在数据科学家中,抱怨管理层的不合理要求和期望是很常见的。值得庆幸的是,通过提高自己的沟通技巧、设定明确的期望和进行一点点教育,通常有可能改善这种情况。
在许多情况下,问题源于经理或团队成员不理解他们所提问题的含义。这是大多数技术领域中的常见问题,外行人看来微不足道的变化实际上可能需要更多的幕后工作。然而,假设你的经理或同事不是不讲道理的,在项目开始前设定明确的期望(包括分界点,在此之后做出改变或增加将会大大延迟结果)会大有帮助。
当你得到这种回应时,最好的方法是保持积极和以解决方案为导向,但也要清楚什么是可能的。考虑这样的回答:“是的,我们肯定可以加入那些社交媒体指标。我预计这将使我们的项目完成时间增加三到五天,因为我们需要捕获和清理这些数据,然后调整我们的模型来解决这些问题。”
我们有上周的数据,你能预测未来 6 个月吗?这是数据科学家最讨厌的事情。客户在电子表格中拼凑几行数据,并期望人工智能像水晶球一样凝视未来。有时这变得很奇怪,当客户承认没有任何数据,然后真正想知道机器学习是否可以填补空白。
*- * Ganes Kesari,联合创始人&Gramener 的分析主管,通过走向数据科学
期望数据科学家获取坏数据、少量数据或无数据,并将其转化为有意义、可操作的预测是数据科学家可能面临的另一个期望问题。经理们可能读过关于机器学习和人工智能的力量的文章,并得出结论说任何数据都可以被输入算法,并转化为有价值的商业情报。
当然,数据科学家知道这不是真的——你的分析和预测只能和你正在处理的数据一样好。当然,有统计技术可以帮助你填补数据集中的空白,但没有神奇的算法可以准确预测六个月的销售额,因为只有一周的数据可供学习。
解决这个问题的最好方法是在你的职位早期。加入一家已经在收集大量好数据的公司,或者一加入就开始努力改善公司的数据收集和存储。除此之外,你可以尽最大努力在每个项目开始时根据你所知道的可用数据设定现实的期望。
误解数据的重要性
不理解数据不是真理的人——它只是数据。除非有人对它进行了上下文包装,否则它甚至都不是信息!
*- * Alexander M Jackl,数据科学家、技术战略家和架构师,viaQuora
这是一个可能影响任何人的问题,包括数据科学家自己,所以如果不小心,你可能会在经理、队友甚至自己的心态中遇到这种情况。工作场所培养数据第一文化的尝试有时会误入数据崇拜的领域,并且很容易忘记数据只能通过上下文来正确理解。
提供这种环境是数据科学家工作的一部分。例如,如果数据收集的来源可能有偏差,那么您需要从一开始就将这种情况考虑到您的分析中。更广泛的背景,如市场趋势,也需要考虑在内。当同事和经理无论如何都倾向于相信这些数字时,你的工作就是去理解那些形成这些数字的弱点、偏见和背景。
因坏消息而受到责备
取决于工作中的文化如果你是一名数据科学家,并根据你提出的见解推荐行动,你可能会获得晋升、奖金或被解雇。
-**Hotels.com 产品经理阿马尔·贾瓦德,通过Quora
作为一名数据科学家的危险之一是,有时你不得不传递坏消息。如果你的分析揭示了公司的严重问题,或者描绘了一幅不太乐观的公司发展前景,向管理层展示这些信息可能会让人不舒服。尽管数据科学家几乎从来不是这些问题的原因,但一个糟糕的经理可能会把他们的不满发泄在你身上。
在某种程度上,这是一个问题,你可以通过更好的沟通和更好的期望设置来缓解。但最终,如果你的老板要求你挖掘公司数据,然后因为他们不喜欢你的发现而责备你,那么可能是时候更新你的简历了。在一个你会因为工作而受到攻击的环境中工作,不是你需要或者应该忍受的事情。
必须说服管理层
除非你在一家将数据科学放在决策前沿的公司工作,否则每个项目都将是为你所做的一切辩护的练习。你需要不断说服决策者,让他们相信你的工作能够产生真正的效果,而不仅仅是一些虚假的骗局[……]我宁愿花更少的时间说服人们应该启动一些数据科学项目,而花更多的时间在项目上。
-**h kon Hapnes Strand,Webstep 高级数据科学顾问,viaQuora
这是一个非常常见的抱怨,也是您在数据科学职业生涯中可能会遇到的事情。根据最近的一项研究,近三分之二的管理者不相信数据,宁愿依靠直觉。而那些信任数据的人往往是中层管理者,他们并不总是有很大的权力来影响大范围的战略决策。实际上,这意味着数据科学家在试图说服管理层相信新项目的价值时可能会面临挑战,他们也可能会面临让管理层根据他们的结果实际采取行动的挑战。
正是因为这个原因,沟通技巧对于任何与数据科学相关的角色都至关重要。你的分析结果不会对你公司的底线产生任何影响,除非你能让管理层真正采取行动。令人信服意味着清晰地交流,很好地可视化你的数据,并保持简单。如果你不确定自己在这方面做得如何,让一个没有技术或统计背景的朋友或亲戚来做你的演示。他们可能会告诉你这很棒,但要注意他们问了什么问题(这些是你没有说清楚的),以及他们从数据中得出了什么结论。这应该会让你知道你的演讲中哪些地方需要改进。
也就是说,同样重要的是要记住,管理层可能不得不根据数据的建议来权衡其他因素,而数据并不总是赢家。华尔街日报记录了去年这种的一个高调例子:网飞的数据团队发现格雷斯&弗兰基的宣传图片在不包括该节目的明星简·方达时效果最佳。然后,高管们不得不权衡这些信息的潜在好处(节目的点击率更高)和惹恼简·方达的潜在未来成本。
这里的好消息是,假设这些项目进展顺利,一旦你做了一两次,说服管理层应该会变得更容易。显示大多数经理不信任大数据的同一项研究还显示,根据该研究的作者 Nazim Taskin 博士的说法,“一旦经理体验到大数据的良好结果,就会建立更经常地应用分析工具的信心。”
沟通是关键
这里反复出现的主题是沟通。你的数据科学技能和你的出色的简历和投资组合可能是你获得这份工作的原因,但出色的沟通技能是保持这份工作的关键,也是让你作为数据科学家的日常生活更加愉快的关键。
以下是一些有助于提高数据科学家沟通技巧的资源:
- Dataquest 的 Python 和 R 的数据可视化课程,以及我们的 data viz 设计技巧。
- Kaggle 的数据科学作品展示指南
- Quora 的数据科学家如何提高沟通技巧?
数据科学组合项目:Fandango 还在膨胀收视率吗?
原文:https://www.dataquest.io/blog/data-science-project-fandango/
August 15, 2018
在 Dataquest,我们强烈提倡将组合项目作为获得第一份数据科学工作的一种方式。在这篇博文中,我们将带你浏览一个投资组合项目的例子。
该项目是我们的统计基础课程的一部分,它假设您对以下内容有所了解:
- 抽样(简单随机抽样、总体、样本、参数、统计)
- 变量
- 频率分布
pandas和matplotlib
如果您认为在继续前进之前需要填补任何空白,我们将在统计基础课程中深入探讨上述主题。本课程还将向您提供更深入的指导,说明如何构建这个项目,并在您的浏览器中对其进行编码。
要了解更多关于pandas和matplotlib的信息,请查看我们的数据科学家之路。
Fandango 还在膨胀收视率吗?
2015 年 10 月,来自 FiveThirtyEight 的 Walt Hickey 发表了一篇受欢迎的文章,其中他提出了强有力的证据,表明 Fandango 的电影评级系统是有偏见和不诚实的。在这个项目中,我们将分析更多最近的电影评级数据,以确定在 Hickey 的分析之后,Fandango 的评级系统是否有任何变化。
我们将使用两个电影评级样本:一个样本中的数据是在 Hickey 分析的之前收集的,另一个样本是在之后收集的。这将有助于我们比较分析前后的系统特性。幸运的是,我们有这两个时间段的现成数据:
- Walt Hickey 在 GitHub 上公开了他分析的数据。在他分析之前,我们将使用他收集的数据来分析 Fandango 评级系统的特征。
- Dataquest 的一名团队成员收集了 2016 年和 2017 年上映的电影的电影评分数据。这些数据在 GitHub 上是公开的,在 Hickey 的分析之后,我们将用它来分析评级系统的特征。
让我们从读入两个样本(分别存储为 CSV 文件:fandango_score_comparison.csv和movie_ratings_16_17.csv)开始,熟悉它们的结构。
import pandas as pd
pd.options.display.max_columns = 100 # Avoid having displayed truncated output
previous = pd.read_csv('fandango_score_comparison.csv')
after = pd.read_csv('movie_ratings_16_17.csv')
previous.head(3)
| 电影 | 腐烂的西红柿 | RottenTomatoes _ 用户 | 亚枝晶 | 元证书 _ 用户 | IMDB 中 | Fandango_Stars | Fandango_Ratingvalue | RT_norm | RT _ 用户 _ 定额 | Metacritic_norm | meta critic _ user _ name | IMDB_norm | RT_norm_round | RT _ 用户 _ 定额 _ 回合 | Metacritic_norm_round | Metacritic_user_norm_round | IMDB_norm_round | 元批评 _ 用户 _ 投票 _ 计数 | IMDB _ 用户 _ 投票 _ 计数 | Fandango_votes | Fandango_Difference | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 《复仇者联盟:奥创时代》(2015) | Seventy-four | Eighty-six | Sixty-six | Seven point one | Seven point eight | Five | Four point five | Three point seven | Four point three | Three point three | Three point five five | Three point nine | Three point five | Four point five | Three point five | Three point five | Four | One thousand three hundred and thirty | Two hundred and seventy-one thousand one hundred and seven | Fourteen thousand eight hundred and forty-six | Zero point five |
| one | 灰姑娘(2015) | eighty-five | Eighty | Sixty-seven | Seven point five | Seven point one | Five | Four point five | Four point two five | Four | Three point three five | Three point seven five | Three point five five | Four point five | Four | Three point five | Four | Three point five | Two hundred and forty-nine | Sixty-five thousand seven hundred and nine | Twelve thousand six hundred and forty | Zero point five |
| Two | Ant-Man (2015) | Eighty | Ninety | Sixty-four | Eight point one | Seven point eight | Five | Four point five | Four | Four point five | Three point two | Four point zero five | Three point nine | Four | Four point five | Three | Four | Four | Six hundred and twenty-seven | One hundred and three thousand six hundred and sixty | Twelve thousand and fifty-five | Zero point five |
after.head(3)
| 电影 | 年 | 金属芯 | imdb 中 | jmeter | 观众 | 方丹戈舞 | metascore | n_imdb | 电表 | n _ 观众 | nr_metascore | nr_imdb | netmeter | nr _ 观众 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 克洛弗菲尔德巷 10 号 | Two thousand and sixteen | Seventy-six | Seven point two | Ninety | Seventy-nine | Three point five | Three point eight | Three point six | Four point five | Three point nine five | Four | Three point five | Four point five | Four |
| one | 13 个小时 | Two thousand and sixteen | Forty-eight | Seven point three | Fifty | Eighty-three | Four point five | Two point four | Three point six five | Two point five | Four point one five | Two point five | Three point five | Two point five | Four |
| Two | 健康的良方 | Two thousand and sixteen | Forty-seven | Six point six | Forty | Forty-seven | Three | Two point three five | Three point three | Two | Two point three five | Two point five | Three point five | Two | Two point five |
下面,我们只分离出提供关于 Fandango 信息的列,以使相关数据更容易供以后使用。我们将复制以避免以后出现任何SettingWithCopyWarning 。
fandango_previous = previous[['FILM', 'Fandango_Stars', 'Fandango_Ratingvalue', 'Fandango_votes', 'Fandango_Difference']].copy()
fandango_after = after[['movie', 'year', 'fandango']].copy()
fandango_previous.head(3)
| 电影 | Fandango_Stars | Fandango_Ratingvalue | Fandango_votes | Fandango_Difference | |
|---|---|---|---|---|---|
| Zero | 《复仇者联盟:奥创时代》(2015) | Five | Four point five | Fourteen thousand eight hundred and forty-six | Zero point five |
| one | 灰姑娘(2015) | Five | Four point five | Twelve thousand six hundred and forty | Zero point five |
| Two | Ant-Man (2015) | Five | Four point five | Twelve thousand and fifty-five | Zero point five |
fandango_after.head(3)
| 电影 | 年 | 方丹戈舞 | |
|---|---|---|---|
| Zero | 克洛弗菲尔德巷 10 号 | Two thousand and sixteen | Three point five |
| one | 13 个小时 | Two thousand and sixteen | Four point five |
| Two | 健康的良方 | Two thousand and sixteen | Three |
我们的目标是确定在 Hickey 的分析之后,Fandango 的评级系统是否有任何变化。我们分析的感兴趣人群是由 Fandango 网站上存储的所有电影评级组成的,与上映年份无关。
因为我们想要找出在 Hickey 分析之后该群体的参数是否改变,我们感兴趣的是在 Hickey 分析之前和之后的两个不同时期对该群体进行采样,以便我们可以比较这两个状态。
我们正在处理的数据是在我们需要的时候采样的:一个样本是在分析之前采集的,另一个是在分析之后采集的。我们要描述总体,所以需要确保样本具有代表性。否则,我们将会有很大的抽样误差,最终得出错误的结论。
从 Hickey 的文章和数据集存储库的README.md中,我们可以看到他使用了以下采样标准:
- 在取样时(2015 年 8 月 24 日),这部电影在 Fandango 的网站上必须有至少 30 个粉丝评级。
- 这部电影 2015 年肯定有票卖。
这种抽样显然不是随机的,因为并非每部电影都有相同的机会被纳入样本——有些电影根本没有机会(比如那些粉丝评分低于 30 的电影或 2015 年没有售票的电影)。这个样本是否能代表我们感兴趣描述的整个人口是有疑问的。似乎更有可能不是这样,主要是因为这个样本受时间趋势的影响——例如,与其他年份相比,2015 年的电影可能非常好或非常差。
我们的另一个样本的采样条件是(可以在数据集的存储库的README.md中读取):
- 电影肯定是 2016 年或者更晚上映的。
- 这部电影一定有相当多的投票和评论(不清楚有多少来自
README.md或数据)。
第二个样本也受时间趋势的影响,它不太可能代表我们感兴趣的人群。
这两位作者在对数据进行采样时都有特定的研究问题,他们使用一套标准来获得符合他们问题的样本。他们的抽样方法被称为(或判断/选择/主观抽样)。虽然这些样本对他们的研究来说足够好,但对我们来说似乎不太有用。
**## 改变我们分析的目标
在这一点上,我们可以收集新的数据或改变我们的分析目标。让我们选择后者,并对我们最初的目标进行一些限制。
我们的新目标不是试图在 Hickey 的分析之后确定 Fandango 的评级系统是否有任何变化,而是确定 Fandango 在 2015 年对流行电影的评级和 Fandango 在 2016 年对流行电影的评级之间是否有任何差异。这个新目标也应该是我们最初目标的一个相当好的代理。
分离出我们需要的样本
有了这个新的研究目标,我们有了两个感兴趣的群体:
- 2015 年上映的热门电影的所有 Fandango 评分。
- 2016 年上映的热门电影的所有 Fandango 评分。
我们需要清楚什么是流行电影。我们将使用 Hickey 的 30 个粉丝评分的基准,只有当一部电影在 Fandango 的网站上有 30 个或更多的粉丝评分时,它才被视为受欢迎。
尽管我们的第二个示例中的一个采样标准是电影流行度,但是该示例并没有提供关于影迷评级数量的信息。我们应该再次持怀疑态度,并询问这个样本是否真正具有代表性,是否包含受欢迎的电影(粉丝评分超过 30 的电影)。
检查这个样本的代表性的一个快速方法是从中随机抽取 10 部电影,然后在 Fandango 的网站上自己检查粉丝评级的数量。理想情况下,10 部电影中至少有 8 部有 30 以上的粉丝评分。
fandango_after.sample(10, random_state = 1)
| 电影 | 年 | 方丹戈舞 | |
|---|---|---|---|
| One hundred and eight | 机械师:复活 | Two thousand and sixteen | Four |
| Two hundred and six | 军用飞机 | Two thousand and sixteen | Four |
| One hundred and six | 马克斯钢铁公司 | Two thousand and sixteen | Three point five |
| One hundred and seven | 我在你之前 | Two thousand and sixteen | Four point five |
| Fifty-one | 神奇的动物和在哪里可以找到它们 | Two thousand and sixteen | Four point five |
| Thirty-three | 细胞 | Two thousand and sixteen | Three |
| Fifty-nine | 天才捕手 | Two thousand and sixteen | Three point five |
| One hundred and fifty-two | 玷污 | Two thousand and sixteen | Four point five |
| four | 国王的全息图 | Two thousand and sixteen | Three |
| Thirty-one | 美国队长:内战 | Two thousand and sixteen | Four point five |
上面我们使用值 1 作为随机种子。这是一个很好的实践,因为它表明我们不是仅仅为了得到一个有利的样本而尝试各种随机的种子。
截至 2018 年 4 月,这些是我们发现的粉丝评分:
| 电影 | 粉丝评分 |
|---|---|
| 机械师:复活 | Two thousand two hundred and forty-seven |
| 军用飞机 | Seven thousand two hundred and seventy-one |
| 马克斯钢铁公司 | Four hundred and ninety-three |
| 我在你之前 | Five thousand two hundred and sixty-three |
| 神奇的动物和在哪里可以找到它们 | Thirteen thousand four hundred |
| 细胞 | Seventeen |
| 天才捕手 | One hundred and twenty-seven |
| 玷污 | Eleven thousand eight hundred and seventy-seven |
| 国王的全息图 | Five hundred |
| 美国队长:内战 | Thirty-five thousand and fifty-seven |
我们样本中 90%的电影都很受欢迎。这就足够了,我们带着更多的信心前进。
让我们也仔细检查一下流行电影的其他数据集。文档清楚地说明了只有至少 30 个粉丝的电影,但是在这里应该只需要几秒钟的时间来复查。
sum(fandango_previous['Fandango_votes'] < 30)
0
如果你探究这两组数据,你会注意到有些电影的上映年份不同于 2015 年或 2016 年。出于我们的目的,我们只需要分离出 2015 年和 2016 年上映的电影。
先从 Hickey 的数据集开始,只隔离出 2015 年上映的电影。没有发布年份的特殊列,但是我们应该能够从FILM列的字符串中提取出来。
fandango_previous.head(2)
| 电影 | Fandango_Stars | Fandango_Ratingvalue | Fandango_votes | Fandango_Difference | |
|---|---|---|---|---|---|
| Zero | 《复仇者联盟:奥创时代》(2015) | Five | Four point five | Fourteen thousand eight hundred and forty-six | Zero point five |
| one | 灰姑娘(2015) | Five | Four point five | Twelve thousand six hundred and forty | Zero point five |
fandango_previous['Year'] = fandango_previous['FILM'].str[-5:-1]
fandango_previous.head(2)
| 电影 | Fandango_Stars | Fandango_Ratingvalue | Fandango_votes | Fandango_Difference | 年 | |
|---|---|---|---|---|---|---|
| Zero | 《复仇者联盟:奥创时代》(2015) | Five | Four point five | Fourteen thousand eight hundred and forty-six | Zero point five | Two thousand and fifteen |
| one | 灰姑娘(2015) | Five | Four point five | Twelve thousand six hundred and forty | Zero point five | Two thousand and fifteen |
fandango_previous['Year'].value_counts()
2015 129
2014 17
Name: Year, dtype: int64
fandango_2015 = fandango_previous[fandango_previous['Year'] == '2015'].copy()
fandango_2015['Year'].value_counts()
2015 129
Name: Year, dtype: int64
很好,现在让我们把电影从另一个数据集中分离出来。
fandango_after.head(2)
| 电影 | 年 | 方丹戈舞 | |
|---|---|---|---|
| Zero | 克洛弗菲尔德巷 10 号 | Two thousand and sixteen | Three point five |
| one | 13 个小时 | Two thousand and sixteen | Four point five |
fandango_after['year'].value_counts()
2016 191
2017 23
Name: year, dtype: int64
fandango_2016 = fandango_after[fandango_after['year'] == 2016].copy()
fandango_2016['year'].value_counts()
2016 191
Name: year, dtype: int64
比较 2015 年和 2016 年的分布形状
我们的目的是找出 Fandango 在 2015 年和 2016 年的流行电影评分之间是否有任何差异。一种方法是分析和比较两个样本的电影评级分布。
我们将从使用核密度图比较两种分布的形状开始。我们将使用538 风格的情节。
import matplotlib.pyplot as plt
from numpy import arange
plt.style.use('fivethirtyeight')fandango_2015['Fandango_Stars'].plot.kde(label = '2015', legend = True, figsize = (8,5.5))
fandango_2016['fandango'].plot.kde(label = '2016', legend = True)
plt.title("Comparing distribution shapes for Fandango's ratings\n(2015 vs 2016)", y = 1.07)
# the `y` parameter pads the title upward
plt.xlabel('Stars')plt.xlim(0,5)
# because ratings start at 0 and end at 5
plt.xticks(arange(0,5.1,.5))
plt.show()

上图的两个方面引人注目:
- 两种分布都是强烈的左偏。
- 2016 年的分布相对于 2015 年的分布略微向左偏移。
左倾表明 Fandango 上的电影大多被给予很高和非常高的粉丝评级。再加上 Fandango 卖票,收视率高的有点半信半疑。进一步研究这一点真的很有趣——最好是在一个单独的项目中,因为这与我们当前的分析目标无关。
2016 年分布的轻微左移对我们的分析来说非常有趣。它显示,与 2015 年相比,2016 年的收视率略有下降。这表明,Fandango 在 2015 年对流行电影的评级和 Fandango 在 2016 年对流行电影的评级确实存在差异。我们也可以看到差异的方向:2016 年的收视率比 2015 年略有下降。
比较相对频率
目前看来,我们的思路不错,但我们需要分析更精细的信息。让我们检查两个分布的频率表来分析一些数字。因为数据集有不同数量的电影,所以我们对表格进行标准化,显示百分比。
print('2015' + '\n' + '-' * 16)
# To help us distinguish between the two tables immediately and avoid silly mistakes as we read to and from
fandango_2015['Fandango_Stars'].value_counts(normalize = True).sort_index() * 100
2015
----------------
3.0 8.527132
3.5 17.829457
4.0 28.682171
4.5 37.984496
5.0 6.976744
Name: Fandango_Stars, dtype: float64
print('2016' + '\n' + '-' * 16)
fandango_2016['fandango'].value_counts(normalize = True).sort_index() * 100
2016
----------------
2.5 3.141361
3.0 7.329843
3.5 24.083770
4.0 40.314136
4.5 24.607330
5.0 0.523560Name: fandango, dtype: float64
与 2015 年相比,2016 年非常高的评级(4.5 和 5 星)的百分比明显降低。2016 年,不到 1%的电影获得了 5 颗星的完美评级,而 2015 年这一比例接近 7%。4.5 的评分在 2015 年也更受欢迎——与 2016 年相比,2015 年评分为 4.5 的电影增加了约 13%。
2016 年的最低评级也更低——2.5 而不是 3 星,2015 年的最低。这两种频率分布之间显然存在差异。
对于其他一些评级,该百分比在 2016 年有所上升。与 2015 年相比,2016 年获得 3.5 星和 4 星的电影比例更高。3.5 和 4.0 是高评级,这挑战了我们在内核密度图上看到的变化方向。
确定变化的方向
让我们通过几个汇总指标来更准确地了解变化的方向。在接下来的内容中,我们将计算两个分布的平均值、中值和众数,然后使用条形图来绘制这些值。
mean_2015 = fandango_2015['Fandango_Stars'].mean()
mean_2016 = fandango_2016['fandango'].mean()
median_2015 = fandango_2015['Fandango_Stars'].median()
median_2016 = fandango_2016['fandango'].median()
mode_2015 = fandango_2015['Fandango_Stars'].mode()[0] # the output of Series.mode() is a bit uncommon
mode_2016 = fandango_2016['fandango'].mode()[0]
summary = pd.DataFrame()
summary['2015'] = [mean_2015, median_2015, mode_2015]
summary['2016'] = [mean_2016, median_2016, mode_2016]
summary.index = ['mean', 'median', 'mode']
summary
| Two thousand and fifteen | Two thousand and sixteen | |
|---|---|---|
| 意思是 | 4.085271 | 3.887435 |
| 中位数 | 4.000000 | 4.000000 |
| 方式 | 4.500000 | 4.000000 |
plt.style.use('fivethirtyeight')
summary['2015'].plot.bar(color = '#0066FF', align = 'center', label = '2015', width = .25)
summary['2016'].plot.bar(color = '#CC0000', align = 'edge', label = '2016', width = .25,
rot = 0, figsize = (8,5))
plt.title('Comparing summary statistics: 2015 vs 2016', y = 1.07)
plt.ylim(0,5.5)plt.yticks(arange(0,5.1,.5))
plt.ylabel('Stars')
plt.legend(framealpha = 0, loc = 'upper center')
plt.show()

2016 年的平均评分较低,约为 0.2。这意味着相对于 2015 年的平均评级下降了近 5%。
(summary.loc['mean'][0] - summary.loc['mean'][1]) / summary.loc['mean'][0]
0.048426835689519929
虽然两种分布的中值相同,但众数在 2016 年降低了 0.5。再加上我们看到的平均值,我们在内核密度图上看到的变化方向得到了证实:平均而言,2016 年上映的热门电影的评分略低于 2015 年上映的热门电影。
结论
我们的分析显示,Fandango 在 2015 年和 2016 年的热门电影评分之间确实存在轻微差异。我们还确定,平均而言,2016 年上映的热门电影在 Fandango 上的评分低于 2015 年上映的热门电影。
我们不能完全确定是什么导致了这种变化,但很有可能是由 Fandango 在 Hickey 的分析后修复了有偏见的评级系统引起的。
照片由 Jeepersmedia 提供
数据科学项目的深度风格指南
原文:https://www.dataquest.io/blog/data-science-project-style-guide/
July 9, 2018
当你申请与数据科学相关的职位时,你可能需要提交一个作品集或项目。虽然你的能力主要是潜在雇主在评估你的工作时所关注的,但风格方面也会发挥作用。
在招聘初级数据科学职位时,雇主通常会非常重视候选人的投资组合。虽然你可能有能力做一些技术上令人印象深刻的项目,但是如果你没有足够重视风格方面的话,你的求职就会受到影响。一个忙碌的雇主是不会审查糟糕的建设项目的。
在 Dataquest,我们帮助了许多数据科学学生进行项目组合评审。我们了解了学生们最常犯的错误,我们也思考了如何让雇主对一个项目感兴趣。
 Reviewing the project of a Dataquest student.
Reviewing the project of a Dataquest student.
基于我们的经验,我们创建了以下风格指南。我们还创建了一个示例项目,这样你就可以看到这些指导方针在起作用。
请注意,我们的指南主要针对笔记本风格的项目。这是学生发送给雇主的最常见的项目类型,它由在 Jupyter Notebook、Jupyter Lab、RStudio、nteract 等开发环境中编写的代码和叙述组成。
了解你的受众
在你开始建立你的作品集之前,要清楚地知道谁会去审阅它。
在本帖中,我们将把雇主作为我们项目的受众,因为这是我们最常见的用例。一般来说,雇主都是厌恶风险的——他们会寻找暗示你可能是一项风险投资的线索。让你的工作适应他们的标准有两大挑战:
- 受众是异质的,既有技术人员也有非技术人员。不同类型的雇主可能会阅读你的项目——例如,高级数据科学家可能会评估你的工作,但没有技术知识的人也可能会看一看。
- 有些雇主只会略读你的工作,而其他雇主会看得更详细。这通常取决于招聘阶段。最初,一个雇主要处理几十或几百份申请,也许他们会花五分钟在每个候选人身上。在一些较晚的阶段,他们通常会深入细节以选出合适的候选人。
为了解决这两个挑战,编写这样的项目:
- 让技术型和非技术型雇主都清楚你能为他们的公司带来价值。
- 做好一次快速扫描。
- 做好一篇通读。
接下来,我们将更详细地讨论上述三个行动项目中的每一个。
面向技术和非技术读者的写作
你能向技术和非技术雇主展示你能为他们公司带来价值的最快方式是拥有相关的项目主题。然而,什么是相关主题取决于你想从事的行业。
假设您有一个投资组合,其中有几个关于棒球和篮球数据的优秀项目。如果你申请的是金融行业的数据科学职位,雇主几乎肯定会发现你的项目无关紧要。你的工作可能很出色,但他们希望看到表明你很适合金融行业的东西:投资建议、股市预测、销售建议等。
另一方面,如果你在为一家每天写体育报道的出版物申请数据记者的职位,你的工作肯定是相关的。
因此,在投入大量工作来构建一些可能不相关的特殊项目之前,请尝试弄清楚您希望从事的数据科学行业和细分市场。
一旦你做出了决定,就开始构建相关的项目,并将它们包含在你的投资组合中。
理想情况下,你会找到一个既与你喜欢的行业相关,又能激发激情的项目。这应该是可行,因为你想在这个行业工作是有原因的。否则,至少要努力找到一个好的取舍。

在快速扫描中表现良好
这些是人们通常在快速浏览时考虑的数据科学组合项目的主要部分:
- 标题
- 介绍
- 副标题
- 结论
- 图形
- 密码
现在让我们来讨论如何改进这些部分,使其在快速浏览时表现良好。
Title
有可能雇主只会看到你的头衔。你选择的标题告诉他们:
- 你的项目是否与他们想要招聘的职位相关。
- 你的项目是否值得深入阅读。
你的教训是想出一个标题,立即告诉雇主你的工作既相关又有趣。我们已经讨论了相关的部分,所以这里有一些让你的头衔引起雇主注意的小技巧:
- 避免模糊的标题。例如,如果你正在分析纽约的房地产数据,不要把你的工作命名为“分析房地产数据”这是模糊的,你可以在这样的标题下写一整本书。不要去想那些能准确反映你的分析特点的东西。尽量选“寻找投资机会——分析纽约房价演变”之类的。
- 避免情感中立的头衔。在“分析纽约房价”和“寻找投资机会——分析纽约房价的演变”之间,你可能会选择后者,因为“投资”和“机会”这样的词会在读者的脑海中引发一些与收益相关的情绪。一般来说,人们更有可能点击情绪活跃的标题(无论标题引发积极还是消极的情绪)。
- 避免过长的标题。我们希望快速传达一个强烈的信息——长标题通常更难理解,所以你的目标是确保读者不需要再次阅读标题就能理解你想说的内容。作为一条规则,尽量把标题控制在 15 个字以内。例如,这似乎太多了:"在纽约寻找两个最好的社区进行投资,在房地产行业进行长期有利可图的投资。"
简介
你想出了一个好标题,并说服雇主看一看你的数据科学项目。介绍很可能是他们接下来要读的东西。同样,你想传达同样的信息:
- 你的项目与你被考虑的角色相关。
- 你的项目值得深入阅读。
以下是写一篇好的简介的一些主要注意事项:
- 有介绍。这里有必要说明一些显而易见的东西,因为我们已经看到了没有介绍的项目。
- 简洁地描述你的项目。用不超过三段的篇幅(每段最多 3-4 句话),简明扼要地讨论:
- 你分析的目标。
- 你实现目标的方法。
- 您发现的最重要的结果——我们在此提到这些结果是为了证明我们能够快速传达我们的发现。
- 不要使用目录(TOC) 。除非你正在写一个大项目,否则不要使用 TOC。目录很容易浏览,但是它通常占用大量的垂直空间,使得简介看起来很大。保持简介的简单和整洁会给人一种快速阅读的印象,这将鼓励雇主真正阅读它。
- 就事论事。不要夸夸其谈,也不要以引用(尤其是引用爱因斯坦的话)开始——只要坚持简明扼要地陈述你的分析目标、你将采取的实现目标的方法以及你发现的最重要的结果。
副标题
如果雇主想浏览你的整个项目,他们会发现副标题非常有用。再次强调,确保你发出的信息是你的工作是相关和有趣的。以下是一些关于写好副标题的建议:
- 有副标题。确保将项目分成几个逻辑部分,并为每个部分添加一个副标题。
- 使用标题的一些技巧。副标题只是项目不同逻辑部分的标题,这意味着我们可以使用我们学到的一些标题技巧:
- 避免模糊的字幕。
- 避免过长的字幕。
- 理想情况下,尽量避免情感中立的字幕。
结论
对于我们这里的目的,一个好的结论是:
- 提醒读者最初的目标是什么,以及达到这个目标的主要途径是什么。
- 总结了最重要的结果。
实际上,结论类似于根据正文中所做的事情重新措辞的导言。要写一个好的结论,试着:
- 简明扼要,不要使用超过两段(每段最多 3-4 句话)。
- 不要夸大你的最终主张。此外,最好不要试图以引用来结束,因为大多数读者不会阅读你的所有作品,因此,他们无法分享你的热情。
图表
如果您为您的项目生成图表(我们强烈建议您这样做),您可以相当确定每个图表都将被快速查看。我们的大脑似乎发现处理来自图像的信息比来自文本的信息更快更容易,所以我们更倾向于观看而不是阅读。因此,希望你的读者在看到图表时放慢滚动速度。
考虑到这一点,您需要确保您的图表快速清晰地传达信息,并且看起来专业。以下是实现这一点的一些建议:
- 给每张图起一个标题,清楚地解释图的内容。用加粗的字体写标题也是一个好主意。
- 标记每个轴。增加标签的字体大小,直到易于阅读。当你选择字体大小时,值得记住的是有些人可能会在小屏幕上阅读你的作品(小的笔记本电脑,平板电脑,手机等)。).
- 理想情况下,广泛定制您的图表。如果你在用 Python 编程,你可能想看看这个制作五个三十八度图的教程。
代码
在这个阶段,没有人会深入阅读您的代码,但是有经验的程序员可能会浏览您的代码,以评估如下元素:
- 代码可读性。
- 你用的算法。
- 您使用的库;等等。
在这篇文章的后面,我们将提供可读性方面的技巧。这些提示对快速浏览和全面阅读都有帮助,所以我们在下一节将它们归类在一起。
在全面阅读中表现出色
在招聘过程的后期,雇主通常会考虑更多细节来挑选合适的候选人。
在这一点上,你应该期待某个具有技术知识的人对你的项目进行深入的解读。在通读中做得好主要取决于项目的技术部分:
- 你用的算法。
- 你试图解决的问题。
- 你解决问题的方法。
- 你方法的深度;等等。
然而,风格元素也很重要,它们真的可以有所作为。你编写什么样的代码很重要,但是你如何编写代码也很重要。因此,我们接下来将重点学习一些技巧,它们可以帮助我们在风格方面更好地编码和编写。
代码
你如何写代码很重要,因为它向雇主展示了你是否能写出干净的代码,能被你未来的潜在同事阅读和理解。编写其他人能够容易理解的代码是相当具有挑战性的。
下面我们将讨论一些关于编写易于理解的代码的最佳实践。你可以从阅读编程语言的官方风格指南开始,在那里你可以找到很多提高代码可读性的技巧。
如果没有官方指南,可以搜索大多数人用该语言编写代码时使用的指南。对于 Python,你可以在这里找到官方风格指南,对于 R,你可以在这里找到指南。
下面我们探讨一些关于代码可读性的主要注意事项(我们将使用 Python 代码,但是这些准则也适用于其他语言):
- 使用块注释为每个具有不同功能的代码块添加简短描述。当你写代码的时候,大多数时候添加块注释是多余的。尽管如此,还是要添加它们,因为它们有助于读者,而且如果你几个月后阅读你的代码,它们也能帮助你容易地回忆起你试图做的事情。
否:
opened_file = open('Super_Bowl.csv')
read_file = opened_file.read()
super_bowl_split = read_file.split('\\n')
super_bowl = []
for row in super_bowl_split:
super_bowl.append(row.split(','))
是:
# Read in the data
opened_file = open('Super_Bowl.csv')
read_file = opened_file.read()
# Transform read_file into a list of lists
super_bowl_split = read_file.split('\n')
super_bowl = []
for row in super_bowl_split:
super_bowl.append(row.split(','))
- 垂直分隔具有不同功能的代码块。
否:
# Read in the data
opened_file = open('Super_Bowl.csv')
read_file = opened_file.read()
# Transform read_file into a list of lists
super_bowl_split = read_file.split('\n')
super_bowl = []
for row in super_bowl_split:
super_bowl.append(row.split(','))
是:
# Read in the data
opened_file = open('Super_Bowl.csv')
read_file = opened_file.read()
# Transform read_file into a list of listssuper_bowl_split = read_file.split('\n')
super_bowl = []
for row in super_bowl_split:
super_bowl.append(row.split(','))
- 添加行内注释,但是要确保它们是有用的,不要陈述显而易见的内容。
否:
for row in super_bowl[1:]: # Iterate through super_bowl[1:]
row[2] = int(row[2]) # Convert to integer
row[2] -= 5000 # Subtract 5000 from each row element in position 2
是:
for row in super_bowl[1:]: # Omit the first row - it contains the headers
row[2] = int(row[2])
row[2] -= 5000 # Values in the "Attendance" column are wrong - correct by subtracting 5000
- 清楚地命名变量 —不要为了节省几个按键而牺牲宝贵的代码可读性。
否:
o_f = open('Super_Bowl.csv')
r_f = opened_file.read()
是:
opened_file = open('Super_Bowl.csv')
read_file = opened_file.read()
正文
正如我们在介绍中提到的,学生可以发送给雇主的最常见类型的数据科学项目由代码和叙述的组合组成。
叙述部分很重要,因为它可以向雇主展示你是否有合适的沟通技巧。沟通是大多数数据科学角色的关键,因为数据科学家经常发现自己在跨职能团队中工作,与来自营销、产品、工程等部门的同事一起工作。团队成员一起工作在一个复杂的项目上,他们需要有效地相互沟通。
写一篇在通读中表现良好的记叙文取决于几个因素,比如:
- 可读性。
- 你的解释的深度和清晰度。
- 你所写的想法的流程。
- 叙事和代码之间的联系;等等。
下面,我们将探讨一些主要的注意事项,这些事项只与叙述的风格有关,旨在提高可读性:
- 不要使用长段落。文本墙会吓跑读者,而且会大大降低可读性。理想情况下,一个段落有三到四个句子,但如果你认为有意义,你甚至可以使用一句话的段落。这里有一个不要做的例子:
 Source: Wikipedia
Source: Wikipedia
-
Use the right sentence length. Long sentences (anything close to 40 words) are hard to understand on a first read and can make your writing feel heavy. Very short sentences (anything less than 5 words) are easy to understand and give a good flow to your writing, but they can also annoy some readers by fragmenting the narrative too much.
理想情况下,完全避免长句,稀疏地使用非常短的句子,大多数时候使用中等大小的句子。
-
其他小而重要的细节:
- 确保你的写作没有错别字。
- 遵守语法和拼写规则。
- 避免使用被动语态。
- 避免使用不必要的副词。
要在风格方面写一篇好的记叙文,你可以通过使用海明威应用来帮助自己。该应用程序可以帮助您:
- 浓缩你的句子和段落。
- 避免错别字。
- 避免被动语态和不必要的副词。
示例项目
我们在 Jupyter 实验室构建了一个示例项目,展示了如何实现我们在这里讨论的大部分指导方针。阅读项目时,请注意:
- 标题是具体的,情绪活跃的(它引发了与收益相关的情绪),不超过 15 个单词。
- 引言是就事论事的,它描述了分析的目标、我们将采取的实现目标的方法以及我们发现的最重要的结果。
- 这个项目有小标题。
- 结论重申了最初的目标,我们为实现这一目标所采取的主要方法,并总结了最重要的成果。
- 该项目有图表,每个图表有一个标题和轴标签。一个图形是使用 FiveThirtyEight 样式定制的。
- 代码和文本符合我们讨论过的指导原则。
还观察到:
- 我们将一个降价单元与一个代码单元交替。每个 markdown 单元格都介绍并解释了它下面的代码单元格中发生的事情(结论除外,它下面没有代码单元格)。通常,交替使用不同类型的单元格(换句话说,避免同一行中有两个相同类型的单元格)。
- 模块被优雅地导入到需要它们的代码单元中(而不是把所有东西都塞进第一个单元)。这样我们就避免了第一个代码单元不必要的拥挤。我们还防止了以后的混淆——想象一下,在最后一个代码单元中使用一个低级函数,这个函数是从一个不太知名的包中导入到第一个代码单元中的。读者不会记得你做的所有导入,他们会感到困惑。
- 我们告诉读者他们可以从哪里下载数据。
接下来的步骤
简而言之,数据科学组合项目应该:
- 做好快速扫描。
- 项目主题应该与雇主相关。
- 该项目在风格方面应该是精心打磨的。这些是快速浏览时通常会考虑的元素:标题、介绍、副标题、结论、图表和代码。
- 做好全面的阅读。
- 技术部分要强,要准。
- 就风格而言,代码和叙述应该是完美的。
以下是您可以采取的一些后续步骤:
如果您仍在努力构建一个完美而专业的数据科学项目,我们在 Dataquest 的团队可以提供帮助。您可以利用我们有用的数据科学课程或完成我们众多指导项目中的一个。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号