DataQuest-博客中文翻译-五-
DataQuest 博客中文翻译(五)
历史野火数据:R 中的探索性可视化
December 11, 2018
最近几周,席卷美国加利福尼亚州部分地区的毁灭性野火的消息在新闻中占据显著位置。虽然大多数野火是由人类意外引发的,但风和干旱等天气条件会加剧火灾的蔓延和强度。加深对历史野火趋势和原因的了解可以为火灾管理提供信息,并拯救生命和财产。在本练习中,我们将使用 R 来执行探索性数据可视化,因为我们了解了加利福尼亚州的历史野火数据。在决定对新数据集进行进一步分析时,探索性数据可视化是重要的第一步。如果您愿意,如果您安装了 R 或 RStudio,也可以在自己的机器上跟随。关于使用 R 和设置 RStudio 的初级读本,请查看我们的R课程简介。为了学习执行我们将在本练习中使用的一些更高级的数据争论技术,我们推荐中级 R 编程。

识别数据源
首先,我们需要找到要处理的数据。加州林业和消防部门(Cal Fire)提供了大量包含历史火灾数据的资源,包括 2000 年以来大规模野火(超过 300 英亩)的规模、持续时间和原因。
我们很高兴地发现拉扎罗·加米奥和吉尔·胡布里已经从 CAL FIRE 搜集了数据,并在这里发布。数据集包含以下变量:
- id :事件编号,用于唯一识别火灾的 id。
- 单位:Ranger 单位,Cal Fire 用来标识管理区域。* 名称:用来指代火的名称。
- 开始:火灾开始的日期。
- 结束:火势被控制的日期。
- 机构:提供数据的联邦机构。
- 英亩:大火烧毁的英亩数。该数据集包含大于 300 英亩的火灾的信息。
- 原因:火灾是什么引起的(如果知道的话)。
我们首先将数据作为名为ca_fires的数据帧导入 R:
library(readr)
ca_fires <- read_csv("axios-calfire-wildfire-data.csv")
让我们看看数据的前几行:
head(ca_fires)
| 身份证明(identification) | 单位 | 名字 | 开始 | 结束 | 代理 | 英亩 | 原因 |
| TGU-803 | 门多西诺 nfm nf–154 | 城镇 | 03-31-2000 | 04-05-2000 | 美国联邦调查局 | One thousand five hundred | 逃逸控制 |
| MNF-177 | 门多西诺 NF | 卷心菜 | 04-01-2000 | 04-01-2000 | 美国联邦调查局 | One thousand five hundred and forty | ? |
| TGU-851 | 门多西诺 NF MNF_178 | 富兰克林 | 04-02-2000 | 04-03-2000 | 美国联邦调查局 | four hundred | 钠 |
| LMU-630 | 拉森 NF | PNF 151(罗宾逊) | 04-04-2000 | 04-05-2000 | 美国联邦调查局 | Five hundred | 钠 |
| BDU-4016 | 莫诺县 | 协助(梓) | 05-29-2000 | 06-01-2000 | 美国联邦调查局 | Seven hundred and forty | 营火 |
| TUU-4863 | 图莱雷 | 大象 | 06-01-2000 | 06-01-2000 | 累积分布函数(Cumulative Distribution Function 的缩写) | Four hundred and ninety-seven | 控制烧伤 |
我们可以使用这些数据来回答各种问题,以帮助我们更好地了解过去 18 年来加州的野火:
- 它们有多大?
- 它们持续多长时间?
- 它们最有可能发生在什么时候?
- 随着时间的推移,它们的严重程度有变化吗?
准备用于分析的数据
我们将创建可视化来回答这些问题。数据相当干净,但是在我们开始探索性的可视化之前,我们需要执行一些操作:
start和end变量目前是字符数据,但是我们需要将它们改为日期。- 从
start和end中,我们可以计算出一个新的变量duration,来告诉我们每场火灾持续了多长时间。
为了将start和end变量日期从字符数据更改为日期数据,我们将使用包 lubridate 。我们还将使用来自dplyr包的数据争论工具。
library(lubridate)
library(dplyr)
使用dplyr函数mutate()和lubridate函数as.Date(),我们可以将start和end日期从字符改为数字:
ca_fires <- ca_fires %>% mutate(start = as.Date(start, "%m-%d-%Y"), end = as.Date(end, "%m-%d-%Y"))
由于按月或按年计算汇总统计数据可能很有用,所以让我们从start列中提取信息来创建新的month和year变量。我们可以使用lubridate功能month()和year()来完成这项工作:
ca_fires <- ca_fires %>% mutate(Month = month(start, label = TRUE),
Year = year(start))
从start和end日期,我们还可以计算出火灾发生的时间长度。我们将使用mutate()创建一个新变量duration:
ca_fires <- ca_fires %>% mutate(duration = end - start)
为了让我们能够直观地看到一段时间内被野火烧毁的英亩数的趋势,我们将使用mutate()和基数 R 函数cumsum()创建一个新变量acres_cumulative,包含被烧毁的英亩数的累积总和:
ca_fires <- ca_fires %>% mutate(acres_cumulative = cumsum(acres))
我们现在准备好开始通过创建可视化来探索数据。我们将使用 ggplot2 包,这是 r 中非常流行的数据可视化包
可视化数据分布
让我们首先考虑我们就 wildfire 数据提出的前两个问题:
- CA 野火的规模有多大?
- 它们持续多长时间?
当我们探索数据以试图理解我们对这个问题的答案时,一个好的第一步是创建直方图,以理解数据是如何分布的,或者大部分数据落在值范围的哪个位置。我们将使用 ggplot()函数创建直方图来可视化变量area和duration的分布:****
## area
ggplot(data = ca_fires) +
aes(x = acres) +
geom_histogram(bins = 30) +
theme_classic() +
scale_x_continuous(labels = scales::comma)
## duration
ggplot(data = ca_fires) +
aes(x = duration) +
geom_histogram(bins = 30) +
theme_classic() +
scale_x_continuous(labels = scales::comma)
让我们先来看看acres的直方图:

在直方图中,条形的高度对应于落入某个变量值范围(在 x 轴上)的观察值数量(在 y 轴上显示)。从这个直方图中可以清楚地看到,数据是高度倾斜的:也就是说,绝大多数火灾都小于几千英亩,但对于area,有一些非常大的值,接近 30 万英亩。直方图能告诉我们火灾持续了多长时间?
让我们看看duration :  的直方图,看看这个图上的 x 轴刻度。
的直方图,看看这个图上的 x 轴刻度。duration的所有值都应该是正数,但是直方图显示存在一些大的负值。让我们使用dplyr函数filter()来看看duration的值为负的观察值:
ca_fires %>% filter(duration < 0)
如果我们查看这些观察的start和end日期,我们可以看到它们似乎不正确,可能是由于数据输入错误:
id unit name start end <chr> <chr> <chr> <date> <date>
TUU-007233 Tulare Frazier 2003-07-08 2003-07-07
TCU-006534 TUOLUMNE EARLY 2004-08-11 2004-08-09
BTU-9805 BUTTE EMPIRE 2008-08-13 2008-08-03
BTU-7042 PLUMAS BOULDER COMPLEX 2016-06-25 2006-07-05
让我们从数据集中删除这些明显不准确的观察结果:
ca_fires <- ca_fires %>%
filter(duration >0)
如果我们重新运行创建直方图duration的代码,现在我们已经忽略了日期数据不准确的行,我们可以看到绝大多数火灾持续时间不到 100 天。
可视化年度模式
现在,我们已经使用直方图了解了野火最常见的规模和持续时间,让我们可视化数据来回答另一个问题:
- 什么时候最有可能发生火灾?
野火在一年中的特定时间更常见吗?因为我们有一个month变量,我们可以可视化野火发生的趋势和每月烧毁的英亩数。首先,让我们使用dplyr函数group_by()和summarize()来计算每个月发生的火灾数量:
month_summary <- ca_fires %>%
group_by(month) %>%
summarize(fires = n())
然后,我们将创建一个条形图来显示每月的火灾数量:
ggplot(data = month_summary) +
aes(x = month, y = fires) +
geom_bar(stat = "identity") +
theme_classic() +
scale_y_continuous(labels = scales::comma)
 这个条形图让我们清楚地看到,大多数火灾发生在春、夏、秋三季,这些季节的特点是炎热、干燥,有利于火势蔓延。然而,它并没有让我们看到不同年份中每月发生的火灾数量的变化。相反,让我们在
这个条形图让我们清楚地看到,大多数火灾发生在春、夏、秋三季,这些季节的特点是炎热、干燥,有利于火势蔓延。然而,它并没有让我们看到不同年份中每月发生的火灾数量的变化。相反,让我们在ca_fires数据框中按月和按年总结火灾发生次数,并创建一个箱线图,它将让我们直观地看到不同年份每月火灾次数的变化:
month_year_summary <- ca_fires %>%
group_by(month, year) %>%
summarize(fires = n())
ggplot(data = month_year_summary) +
aes(x = month, y = fires) +
geom_boxplot() +
theme_classic() +
scale_y_continuous(labels = scales::comma)
箱线图以图形方式描绘了数据的最小值、最大值和中值,因此是比较数据组而不模糊可变性的极佳可视化工具。让我们来看看每月野火数量的箱线图:
正如我们之前创建的条形图所表明的,野火在夏季最常见,在冬季通常很少发生。代表异常值的点的存在表明,虽然不常见,但野火全年都可能发生。
可视化随时间的变化
让我们继续讨论另一个我们可以利用这些数据回答的问题:
- 野火的严重程度是否随着时间的推移而改变?
为了回答这个问题,我们将创建一个随时间推移的累计燃烧英亩数的折线图:
ca_fires %>%
ggplot() +
aes(x = start, y = acres_cumulative) +
geom_line() +
theme_classic() +
scale_y_continuous(labels = scales::comma) +
ylab("Acres Burned (cumulative)") +
xlab("date") +
ggtitle("Cumulative Acres Burned Since 2000")
一条平滑的、向上的线将指示被野火烧毁的英亩数在一段时间内保持一致,而被烧毁的英亩数的任何增加或减少都将作为线斜率的变化而被注意到。
当我们看着累计烧毁的英亩数的线图时,我们可以看到一个看起来有点像楼梯的模式:烧毁的英亩数迅速增加,然后又趋于平稳。根据早期的探索,我们可以推断这种模式很可能是由于季节差异。在夏季的几个月里,更多的英亩被烧毁,而在较冷的几个月里,增加的面积较小。我们还可以看到一些“台阶”比其他的要高,这表明一次烧毁了大量的土地。
结论和后续步骤
在本练习中,我们的探索性数据可视化为我们提供了有关加州 300 英亩以上野火的信息:
- 虽然有一些大的异常值,但大多数野火都小于几百英亩,持续时间不到 50 天。
- 大多数野火发生在夏季,尽管它们可能在一年中的任何时候发生。
- 有些年份的特点是更具破坏性的野火。
探索性数据可视化的目的是让自己熟悉新的数据集,了解趋势,并计划未来的分析。一个有趣的下一步可能是探索气候和天气条件对森林火灾频率和严重程度的影响。此类数据有许多来源:
- 你可以从美国国家海洋和大气管理局(NOAA)的国家综合干旱信息系统(NIDIS)项目中获取加利福尼亚州的干旱数据。
- 历史天气和气候数据,如温度和降雨量可从 NOAA 获得。
- NIDIS 提供了土壤湿度的数据,这是干旱的一个指标,也是加剧野火的一个因素。

如果您有兴趣了解有关使用 R 进行探索性数据可视化的更多信息,包括调查环境变量和 wildfire 数据之间关系的方法,请务必查看我们在 R 课程中的数据可视化。
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
SIGN UP****
r 函数教程:编写、作用域、向量化等等!
June 11, 2019
当我们用 R 编程时,我们经常想要一个数据集,或者数据集的一部分,然后对它做一些事情。如果我们在电子表格中工作,这种任务可能会非常耗时。但是在 R 中,我们可以使用函数非常快速地对大型数据集执行非常复杂的操作。
什么是 R 函数?在本教程中,我们将仔细研究 R 中的一些不同类型的函数,它们是如何工作的,以及它们为什么对数据科学和数据分析任务有用。
r 函数:输入和输出
在编程中,函数描述了一些过程,这些过程接受一些输入,对其执行一些操作,并返回结果输出。
您可能会在数学课中想起这个概念,在数学课中,您可能学过平方函数,它接受一个输入数字,然后乘以该数字本身来产生输出答案。
在 R 中,函数做同样的事情:它们接受输入并运行一些 R 代码来产生并返回一个输出。如果你以前运行过任何 R 代码,你可能用过内置的 R 函数,比如print()或者summary()。这些函数接受一个输入,在编程中称为参数,并对其执行操作以产生一个输出。
我们将从加载一个来自 Kaggle 的很酷的数据集开始我们对函数的探索,这个数据集包含了将近 7000 个美国数据科学职位发布。想象一下,我们想要对这个数据集进行一些数据分析,以了解更多关于数据科学职位发布的信息。我们可能想做的第一件事是查看我们导入的数据,而summary()函数非常适合这一点。
这个函数和类似的head()函数在数据科学工作中非常有用,因为它们接受您导入的数据(您传递给函数的参数)并生成一个可视化表示,使您更容易看到您正在处理的内容(输出)。
在下面的代码片段中,我们将首先从 CSV 中导入数据作为数据帧。然后我们将调用head()函数,它接受我们的输入参数(我们刚刚创建的数据框)并返回前几行数据。
然后我们将运行summary()函数,将相同的数据帧作为参数传递给它,它将返回我们数据集中每个变量的摘要。例如,我们可以看到有 351 个职位的标题是“数据科学家”,56 个职位的标题是“机器学习工程师”。
注意,作为我们将传递给这些函数的参数的一部分,我们已经指定了我们希望看到的列。例如,summary()函数为我们提供了 position、company、reviews 和 location 列的摘要,因为这些是我们在参数中指定的列(我们传递给函数的输入,以便它执行操作)。
df <- read.csv("alldata.csv") #read in csv file as data.frame
df$description <- as.character(df$description) #change factor to character
head(df[,c(1,2,4,5)])
## position
## 1 Development Director
## 2 An Ostentatiously-Excitable Principal Research Assistant to Chief Scientist
## 3 Data Scientist
## 4 Data Analyst
## 5 Assistant Professor -TT - Signal Processing & Machine Learning
## 6 Manager of Data Engineering
## company reviews location
## 1 ALS TDI NA Atlanta, GA 30301
## 2 The Hexagon Lavish NA Atlanta, GA
## 3 Xpert Staffing NA Atlanta, GA
## 4 Operation HOPE 44 Atlanta, GA 30303
## 5 Emory University 550 Atlanta, GA
## 6 McKinsey & Company 385 Atlanta, GA 30318
summary(df[,c(1,2,4,5)])
## position
## Data Scientist : 351
## Senior Data Scientist : 96
## Research Analyst : 64
## Data Engineer : 60
## Machine Learning Engineer: 56
## Lead Data Scientist : 31
## (Other) :6306
## company reviews
## Amazon.com : 358 Min. : 2
## Ball Aerospace : 187 1st Qu.: 27
## Microsoft : 137 Median : 230
## Google : 134 Mean : 3179
## NYU Langone Health : 77 3rd Qu.: 1578
## Fred Hutchinson Cancer Research Center: 70 Max. :148114
## (Other) :6001 NA's :1638
## location
## Seattle, WA : 563
## New York, NY : 508
## Cambridge, MA : 487
## Boston, MA : 454
## San Francisco, CA: 425
## San Diego, CA : 294
## (Other) :4233
使用 R 矢量化节省时间
仅仅通过查看summary()函数生成的输出,我们就可以了解到一些有趣的东西,但是我们想知道更多!
虽然我们没有把它包括在我们上面的总结中,但是在这个数据集中有一个“描述”栏,包含了每个单独的工作描述。让我们通过使用nchar()函数来看看这些描述有多长,该函数接收一个字符串并返回字符数。在下面的代码中,我们将指定我们只想查看数据集第一行中的“description”列。
nchar(df[1,"description"])
## [1] 2208
我们可以看到数据集中的第一个职位描述有 2208 个字符长。
但是如果我们一个一个做差不多 7000 行的话,那就要花很长时间了!幸运的是,R 函数允许矢量化。矢量化指的是从一条指令中运行多个操作,它允许我们编写看起来更整洁、运行速度更快的代码。简单地说,它允许我们告诉 R 一次对大量数据(比如一个数据帧的整个列)执行相同的操作,而不是重复地告诉它对列中的每个条目执行该操作。

R 是为处理大型数据集而构建的,数据框中的每一列都是一个向量,这意味着我们可以很容易地告诉 R 对列中的每个值执行相同的操作。
许多处理单个值的 R 函数也被矢量化。我们可以给这些函数传递一个向量作为参数,这个函数将为向量中的每个值运行。
例如,我们可以使用矢量化来快速查看数据集中每个职位描述的长度,使用的是我们用来查看上面第一个职位描述的相同的nchar()函数。
为了存储我们的长度计数,我们将在df中创建一个名为symcount的新列,并将nchar(df$description)的输出分配给它。这告诉nchar()函数对整个描述列(向量)中的每个值进行操作。我们还将指定nchar()对每个值的输出应该存储在我们新的symcount列中。
df$symcount <- nchar(df$description)
head(df$symcount)
# symcount <- rep(NA, dim(df)[1])
# for (i in 1:length(symcount)){
# symcount[i] <- nchar(df[i,"description"])
# }
# all(symcount == df$symcount)
## [1] 2208 4412 2778 2959 3639 3920
正如我们在上面看到的,矢量化帮助我们的代码看起来漂亮——查看注释的 for 循环,注意如果我们不使用矢量化,它需要更多的代码来生成相同的结果。它也经常加速我们的代码。其原因有些技术性,你不需要理解它们就能有效地使用矢量化,但是如果你好奇的话,这篇文章提供了进一步的解释。
也就是说,请记住,作为数据科学家,我们的目标通常是让代码工作,而不是完美优雅和优化的代码。在我们有了工作代码之后,我们总是可以回去优化的!
R 中的一般函数
让我们更深入地挖掘我们的数据科学作业数据,探索 r 中的通用函数,通用函数是基于我们使用它的对象的类产生不同输出的函数。
plot()是内置通用函数的一个很好的例子,所以让我们用plot()来形象化我们刚刚测量的工作描述的长度。再次注意,我们可以将整个symcount列传递给plot(),它将绘制每个数据点。
plot(df$symcount)

We can see from the plot that most job descriptions have less than 10,000 symbols, but there’s some long ones! Note the points at the top near 25,000!
让我们看看数据集中排名前 4 位的公司的 symcount。我们将首先创建一个仅包含前四名公司的新数据框(可以从我们的summary()结果中获得),然后将该数据框传递给plot(),并将我们的 x 和 y 值(分别为 company 和 symcount)作为两个独立的参数。
top4 <- names(summary(df$company)[1:4]) #get names of top 4 companies
justtop4 <- df[df$company %in% top4,] #create a data frame with only jobs from the top 4
justtop4$company <- factor(justtop4$company) # make sure there are only 4 levels in our new factor
plot(justtop4$company, justtop4$symcount)

It looks like Amazon has shorter job descriptions than the other companies, though it does have quite the outlier at over 10,000 characters!
我们还可以运行方差分析(ANOVA) 来查看 4 家公司的 symcount 之间是否存在统计上的显著差异。r 对此也有一个内置函数!
我们将使用aov()函数创建 ANOVA 模型,然后在该模型上调用summary()和plot()。这些是我们一直在使用的相同函数,即使我们还没有掌握 ANOVA 是什么,我们也可以看到输出与我们之前看到的不同。
summary()和plot()(如前所述)是 r 中通用函数的例子,通用函数为对象的不同类创建不同的输出。当我们单独绘制 symcount(一个数字向量)时,plot()给了我们一个散点图。当我们绘制评论(一个数字向量)和公司(一个分类向量)时,plot()创建了一个箱线图。当我们绘制一个 aov 对象(由aov()函数创建)时,它给我们一系列的图来帮助我们评估我们的模型。
ANOVA <- aov(symcount ~ company, data = justtop4)
summary(ANOVA)
## Df Sum Sq Mean Sq F value Pr(>F)
## company 3 322841803 107613934 95.02 <2e-16 ***
## Residuals 812 919674198 1132604
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
par(mfrow = c(2,2)) #lets us see all 4 plots at once!
plot(ANOVA)

Similarly, when we called summary() on a dataframe, it provided a table of summary statistics for each column in the dataframe. When called on an aov object, summary() provides an ANOVA table.
像这样的通用函数非常有用,因为它们允许我们在 R 中对各种不同的对象使用具有相同语法的 same 函数,并根据对象类精确地定制输出。我们不必为不同的类记忆十几个略有不同的函数,我们可以依靠这些可靠的通用函数,它们适用于我们所有的类。
我们可以通过想象一个叫做feed()的函数来更好地理解泛型函数。由于通用函数基于作为参数输入的类提供不同的输出,我们可能期望feed(cat)产生猫粮,而feed(dog)产生狗粮。如果我们输入feed(Chelsea),我希望这个虚构的函数能让我做华夫饼。
编写 R 函数
虽然 R 有一些非常酷和复杂的通用函数,但并不总是有一个内置函数来生成我们想要的输出。编写自定义函数是编程的重要部分,包括用 r 编程。
与矢量化一样,编写我们自己的函数可以简化和加速我们的代码!一般来说,如果我们发现自己一遍又一遍地做着相同(或相似)的事情,可能是时候写一个函数了。
句法
要创建一个新的 R 函数,我们需要考虑 4 个主要因素:
- 函数的名
- 函数将采用的参数(输入)
- 该功能将运行代码
- 该函数的输出将返回给用户
为了看到这四件事在起作用,让我们编写自己的函数,看看我们的数据集中的工作描述是否提到了博士学位。
我们先给它一个明确的名字 : phdFinder()。我们将创建一个名为phdFinder的变量来存储我们的函数。为了创建一个函数,我们使用function(){}。
phdFinder <- function(){
}
上面的括号是空的,但是我们将在那里列出我们的函数需要运行的任何参数(输入)的名称。参数用于将 R 对象/变量从函数外部传递到函数中。
当选择我们的参数时,它有助于问:“每次运行这个函数时,哪些变量可能不同?”。如果一个变量可能会改变,那么它应该被指定为一个参数,而不是硬编码在函数将要运行的代码中。
在我们的函数中,唯一不同的是工作描述,所以我们将添加一个名为description的变量作为参数。
phdFinder <- function(description){
}
接下来,我们需要考虑函数将运行的代码。这就是我们想要函数对我们传递给它的一个或多个参数做的事情。现在,我们假设我们只寻找字符串“PHD ”,任何其他大写字母如“PhD”都不算,所以我们希望函数内部的代码查看每个传递的description,看它是否找到了那个字符串。
是一个内置的 R 函数,它在一个更大的字符串中寻找一个更小的字符串(比如“PhD”)。如果描述中有“PhD ”,它将返回TRUE,如果没有,则返回FALSE。让我们将它添加到我们的函数代码中,并将它的评估结果赋给一个名为mentioned的变量。
phdFinder <- function(description){
mentioned <- grepl("PhD",description)
}
我们需要考虑的最后一件事是我们希望我们的函数返回。这里,我们希望它返回mentioned,这将告诉用户每个描述是否包含“PhD”(在这种情况下mentioned将是TRUE)或不包含(在这种情况下mentioned将是FALSE)。
默认情况下,R 将返回我们运行的最后一条语句的值。phdFinder()只有一条语句,所以默认情况下我们的函数将返回mentioned,不需要额外的工作!但是如果我们想明确地告诉 R 返回什么,我们可以使用return()函数。
但是,如果我们使用return(),我们需要小心。return()函数告诉 R 该函数已经运行完毕。所以一旦代码运行,函数就会停止。
为了演示这一点,让我们添加一个return()行,然后在它后面添加几个打印语句。
phdFinder <- function(description){
print("checking...")
mentioned <- grepl("PhD",description)
return(mentioned)
print("YOU SEARCHED FOR A PHD!")
}
注意,运行这段代码不会产生输出 print 语句永远不会运行,因为 R 在return(mentioned)停止执行函数。
使用 R 函数
现在我们已经编写了自定义函数,让我们来试试吧!我们写它不仅仅是为了好玩和开心。让我们来看看原始数据集中的第一份工作描述(存储为数据框df),看看这份工作是否需要博士学位。
phdFinder(df[1,"description"])
## [1] "checking..."
## [1] FALSE
看起来那份工作描述里没有提到博士学位。如果我们想要一份不需要的工作,这是个好消息。
再次注意,只运行了第一个 print 语句,而不是第二个。如前所述,一旦调用了return()函数,下面的代码都不会运行。
我们也可以一次对整列描述使用我们的phdFinder()函数。是的,它是自动矢量化的!
让我们在df中创建一个名为phd的新列,并将在df$description上调用phdFinder()的结果存储在那里。
df$phd <- phdFinder(df$description)
head(df$phd)
print(sum(df$phd)/length(df$phd))
## [1] "checking..."
## [1] FALSE FALSE FALSE FALSE TRUE FALSE
## [1] 0.2415279
在我们的数据框架中,24%的职位描述提到了博士,这是非常有用的信息。如果我们知道一份工作需要一个拥有博士学位的人,它会告诉我们一些如何营销自己的信息,即使我们没有博士学位。
在现实世界中,我们可能会想写一些额外的代码来解释像“phd”、“Ph.D”、“PHD”等不同的拼写。,在我们从这些数据中得出任何严肃的结论之前。
我们在这里编写的代码中跳过了这一步,以使我们的函数更容易理解,但如果您想更多地练习编写函数,那么用更复杂的代码重写我们的函数来解释这些变量将是一个很好的下一步!提示:您可能想从研究名为tolower()和gsub()的函数开始。
编写好的 R 函数
现在我们知道了一点关于如何写 R 函数的知识,是时候让谈谈了。下面谈谈如何编写好的 R 函数。
首先,我们应该编写 R 函数,就像其他人将要使用它们一样,因为他们经常会被使用!但是,即使没有其他人会使用我们的代码,我们可能希望以后重用它,所以编写可读的代码总是一个好主意。
变量名和注释
编写可读代码意味着选择有意义的参数和变量名。不要只使用随机的字母(有时我可能会犯这种错误),使用一些有意义的东西。
例如,上面我们选择了变量名mentioned,因为这个变量告诉我们是否提到了“PhD”。我们可以称之为x或weljhf,但是通过称之为mentioned,我们帮助自己和他人更好地理解那个变量中存储了什么。
类似地,给我们的函数起一个类似于phdFinder()的描述性名称可以帮助传达函数做了什么。如果我们把这个函数叫做更神秘的东西,比如function_47()或者pf(),其他阅读我们代码的人会很难一眼就看出它是干什么的。
辖域

Another thing to think about is scope. We can think of our global R environment — our entire program — as a room that holds all the objects, variables, functions, etc. that we have used.
这包括我们在加载library()时加载的对象。当我们使用变量x时,R 将在我们所在的房间中寻找x的值(我们可以使用ls()检查我们的环境中有什么)。
当我们编写和运行一个函数时,R 为这个函数创建了一个新的临时环境。这有点像在我们的房间里有一个盒子。“盒子”保存了我们在函数中创建、更改和使用的所有对象。但是一旦函数运行完毕,这个框就消失了。
让我们看几个例子来更好地理解这是如何工作的。我们将运行一些不同的代码片段。在每种情况下,我们将创建一个对象(向量或数据框)并将其传递给我们的函数square,该函数返回我们传递给它的一个或多个数字的平方。
注意在下面的代码中,变量x的值是如何根据它是在函数之外(全局变量)还是在函数之内而变化的。x的值可以在函数内重新分配,但是由于函数环境是临时的,并且在函数运行后不再存在,所以x的全局值不变:
x <- 10
print(paste("Outside the function, x is...", x))
square <- function(y){
x <- y**2
print(paste("Inside the function, x is...", x))
}
square(x)
print(paste("Outside the function, x is...", x))
## [1] "Outside the function, x is... 10"
## [1] "Inside the function, x is... 100"
## [1] "Outside the function, x is... 10"
x <- c(1,2,3)
print(paste("Outside the function, x is...", x[1],x[2],x[3]))
square <- function(y){
x <- y**2
print(paste("Inside the function, x is...", x[1],x[2],x[3]))
}
square(x)
print(paste("Outside the function, x is...", x[1],x[2],x[3]))
## [1] "Outside the function, x is... 1 2 3"
## [1] "Inside the function, x is... 1 4 9"
## [1] "Outside the function, x is... 1 2 3"
x <- data.frame(a = c(1,2,3))
print("Outside the function, x is...")
print(x)
square <- function(y){
x$square <- x$a**2
print("Inside the function, x is...")
print(x)
}
square(x)
print("Outside the function, x is...")
print(x)
## [1] "Outside the function, x is..."
## a
## 1 1
## 2 2
## 3 3
## [1] "Inside the function, x is..."
## a square
## 1 1 1
## 2 2 4
## 3 3 9
## [1] "Outside the function, x is..."
## a
## 1 1
## 2 2
## 3 3
为了编写好的 R 函数,我们需要考虑我们正在处理的对象在哪里的 T2。如果在函数环境之外有什么,我们想在函数环境之内使用,我们可以通过将它作为参数传递给我们的函数来引入它。
如果我们不这样做,R 将在“盒子”之外寻找,并在全局环境(“房间”)中搜索变量。但是为了使我们的函数尽可能地一般化,并避免将两个变量命名为同一事物的任何问题,通过将它们作为参数传递来显式地给我们的 R 函数它需要运行的对象是一个好主意。
在函数中获取内容
让我们来看看当我们在函数内部调用一个全局变量而没有显式地将其作为参数传递时会发生什么。为此,我们将创建一个名为wordFinder()的新函数,类似于我们的phdFinder()。
我们将编写这个函数,让它在每个工作描述中查找变量my_test_word。但是my_test_word不存在于函数环境中,因为它不是作为参数传入的,也不是在函数中创建的。那么会发生什么呢?
一旦 R 搜索了这个本地环境并且没有结果,它将在全局环境中搜索my_test_word。由于my_test_word存在于全局环境中,R 将在函数中使用它。
my_test_word <- "python" #R uses "python" for my_test_word because it can't find my_test_word in the local function environment
wordFinder <- function(description){
print(paste("checking for...", my_test_word))
mentioned <- grepl(my_test_word,description)
return(mentioned)
}
wordFinder(df[1,"description"])
## [1] "checking for... python"
## [1] FALSE

What if we define my_test_word twice, both inside and outside the function? Let’s give it a shot!
在函数之外,在全局环境中,我们给my_test_word赋值'python'。在函数内部,我们将赋值给它'data'。
因为我们已经知道 R 在全局环境之前搜索函数环境,我们可能预测 R 将使用'data'作为my_test_word的值,因为这是在函数内部分配的值。事实上,事情就是这样:
my_test_word <- "python"
wordFinder <- function(description){
my_test_word <- "data" #R uses "data" for my_test_word because it searches the local environment first
print(paste("checking for...", my_test_word))
mentioned <- grepl(my_test_word,description)
return(mentioned)
}
wordFinder(df[1,"description"])
## [1] "checking for... data"
## [1] TRUE
当我们运行这个代码块时,我们可以看到 R 使用了'data'(函数内my_test_word 的值)而不是'python'。在grepl()中引用my_test_word时,R 首先搜索本地函数环境,找到了my_test_word。所以它根本不需要搜索全局环境。
在编写函数时,记住这一点很重要:如果 R 在函数环境中找不到变量(作为参数或函数本身定义的变量),它将只在全局环境中搜索该变量。
从函数中获取信息
R 通过在函数运行后移除局部函数环境为我们做了整理,这很好,但是如果我们想在函数运行后保留函数内部生成的值呢?
我们可以通过返回来保存函数中创建或更改的内容。当我们从函数中返回一个变量时,它允许我们将它存储在全局环境中(如果我们愿意的话)。
在wordFinder()中,我们返回mentioned。自从 R 去掉了局部函数环境,mentioned就不再存在了。当我们试图把它打印出来时,我们得到一个错误。
my_test_word <- "python"
wordFinder <- function(description){
my_test_word <- "data" #R uses "data" for my_test_word because it searches the local environment first
print(paste("checking for...", my_test_word))
mentioned <- grepl(my_test_word,description)
return(mentioned)
}
wordFinder(df[1,"description"])
print(mentioned)
## Error in print(mentioned): object 'mentioned' not found
## [1] "checking for... data"
## [1] TRUE
然而,由于wordFinder()返回mentioned的值,我们可以通过将函数的输出赋给一个变量,将它存储在全局环境中。现在我们可以在函数之外使用这个值。
my_test_word <- "python"
wordFinder <- function(description){
my_test_word <- "data" #R uses "data" for my_test_word because it searches the local environment first
print(paste("checking for...", my_test_word))
mentioned <- grepl(my_test_word,description)
return(mentioned)
}
mentioned2 <- wordFinder(df[1,"description"])
print(mentioned2)
## [1] "checking for... data"
## [1] TRUE
现在我们得到了保存在函数外部的函数内部的值。
回顾:
R 中的函数有很多用途,所以让我们总结几个要点:
- r 函数是几段代码,它们接受被称为参数的输入,并将它们转换成输出。
- 当我们定义函数和调用函数时,参数都放在函数的括号里。
- 输出是由函数返回的对象。
- 默认情况下,R 将返回函数中最后一条语句的值。一旦函数运行完毕,函数中可能已经更改或创建的所有其他内容都将消失,除非我们有意采取措施来保存它。
- r 函数是用来反复使用的。这为我们节省了时间和空间,并使我们的代码看起来更好。
- r 函数通常是矢量化,这意味着我们可以对向量中的每一项运行函数,就像数据框中的一列数据一样,一气呵成!这样往往会节省很多时间。
- 通用 R 函数是基于作为参数传递给它的对象的类而不同运行的函数。
- 编写好的 R 函数意味着为他人(和未来的自己)着想,并使我们的函数易于理解。
既然您已经对 R 函数的基础有了坚实的理解,那么就通过 Dataquest 的免费交互式 R 课程来增加您的技能吧。我们的中级课程将带你更深入地了解函数的世界,同时让你直接在浏览器中编写代码。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
r 基础:建立一个简单的分数计算器
March 15, 2018R is one of the most popular languages for statistical analysis, data science, and reporting. At Dataquest, we have been adding R courses (you can learn more in our recent update). For a comparison of R and Python, check out our analysis here. In this tutorial, we’ll teach you the basics of R by building a simple grade calculator. While we do not assume any R-specific knowledge, you should be familiar with general programming concepts. You’ll learn how to:
- 进行计算
- 储存你的价值观
- 使用特定功能回答问题
本教程基于我们新发布的 R 入门课程的一部分。该课程完全免费,包括结业证书。点击这里开始课程。
计算你的分数
假设你是一名高三学生,想要计算你的平均绩点(GPA)。GPA 代表你所有课程累积的最终分数的平均值。你选了七门课,考试、作业和项目的权重相等。我们假设 GPA 是在 0-100 的范围内测量的。在你的数学课上,你考试得了92,家庭作业得了87,项目得了85。为了计算平均数学分数,我们可以写如下:
# Math
(92 + 87 + 85)/3
我们可以执行任务,比如用手计算平均值。然而,如果我们必须计算 1000 名学生的平均值,手动计算将不会有效地利用我们的时间。相反,我们将使用编程来要求计算机执行计算。
执行计算
我们将从使用 R 作为基本计算器开始。我们之前写了以下内容来计算数学课的最终成绩:
(92 + 87 + 85)/3
这整行代码被称为一个表达式。我们在一个叫做脚本的文本文件中编写表达式。脚本是我们给计算机的一组指令。在脚本中编写完表达式后,解释器将运行代码,并在新窗口中显示表达式的结果。让我们运行print()语句,将我们的数学分数作为()之间的表达式:
print((92 + 87 + 85)/3)
运行表达式时,解释器将在新窗口中输出以下值:
[1] 88
注意:当你更深入地研究向量时,[1]将是有意义的,但是你不需要在本教程的上下文中理解它。在我们显示的结果中,计算和print()语句都有一对匹配的括号。为了更清楚,下面是同样的计算:
print((92 + 87 + 85)/3)
运行这个表达式将产生与在一行上写所有内容相同的结果。每个开始括号都需要一个结束括号。让我们试着去掉右括号:
print((92 + 87 + 85)/3
如果你的代码中有错误,解释器会告诉你有错误,以及错误是什么。在我们的例子中,解释器返回:Error in parse(text = x, srcfile = src): <text>:7:0: unexpected end of input。
文本unexpected end of input意味着 R 解释器(我们的代码)的输入缺少一个右括号)。您可以尝试使用上面的表达式,看看您还会得到哪些其他类型的错误。
执行多重计算
现在我们已经看到了使用print()语句的结果,让我们更深入地了解 R 解释器如何运行我们的代码。它:
- 扫描并查找语法错误。
- 解释并运行每一行代码,从上到下。
- 当最后一行代码运行时退出。
我们写了一个计算数学课最终分数的表达式。为了理解 R 代码被解释的顺序方式,让我们也添加一个计算你的化学分数的表达式。化学方面,你的分数是90、81和92。如果我们在不同的行上运行两个计算会发生什么?
print((92 + 87 + 85)/3)
print((90 + 81 + 92)/3)
运行这段代码,R 解释器将显示:
[1] 88
[1] 87.66667
如果我们写两行代码,R 总是显示两行吗?如果我们把代码分成多行呢?
print((92 + 87 + 85)/3)
print((90 + 81 + 92)/4)
R 解释器将仍然显示相同的值:
[1] 88
[1] 87.66667
注意 R 是如何解释我们的代码的。每个 print 语句对应于结果中它自己的行:

如果我们想计算写作和艺术的平均分,我们可以在随后的每一行写下这些表达式:
- 写作:
84、95、79 - 艺术:
95、86、93
print((92 + 87 + 85)/3) # Math
print((90 + 81 + 92)/3) # Chemistry
print((84 + 95 + 79)/3) # Writing
print((95 + 86 + 93)/3) # Art
运行这些表达式将显示以下结果:
[1] 88
[1] 87.66667
[1] 86
[1] 91.33333
使用算术运算符执行计算
+和/称为算术运算符。算术运算符用于执行数学运算。在下图中,您会发现一个最常见运算符的列表和一个使用每个运算符的简单表达式:
对于那些不熟悉取幂的人来说,取幂是一种用**或^运算符将一个数乘以自身特定次数的方法。如果我们想将值 4 乘以自身 3 次,使用乘法*运算符,结果如下所示:
4 * 4 * 4
虽然使用乘法运算符将 4 乘以自身三次并不太麻烦,但如果我们想将值 4 乘以自身 20 次,使用乘法运算符并不是最有效的方法。相反,我们可以将计算结果表示为指数:
4**20
运行4**20将返回:
[1] 1.099512e+12
现在我们已经了解了算术运算符,让我们来计算最后三门课的最终分数:历史、音乐和体育:
- 历史:77、85、90 年
- 音乐:92,90,91
- 体育:85,88,95
print((77 + 85 + 90)/3) # History
print((92 + 90 + 91)/3) # Music
print((85 + 88 + 95)/3) # Physical Education
然后解释器会显示:
[1] 84
[1] 91
[1] 89.33333
按照操作顺序执行计算
既然我们已经学会了如何使用算术运算符来计算每门课的平均分数,让我们回到数学的平均计算上来:
print((92 + 87 + 85)/3)
如果我们删除92 + 87 + 85周围的括号会怎么样?
print(92 + 87 + 85/3)
这将显示:
207.333
通过删除包围92 + 87 + 85的括号,R 解释器进行不同的计算。使用多个运算符时,有一些规则决定计算的执行顺序。确定计算顺序的一个简单方法是,在想要首先执行的计算周围加上一个括号和。这对于像这样更复杂的计算很有用:
print((92 + 87 + 85 + 67 + 92 + 84)/6 - (77 + 90 + 98)/3)
在这种情况下,我们在92 + 87 + 85 + 67 + 92 + 84和77 + 90 + 98两边加上了括号。我们告诉解释器在执行除法之前先执行加法运算符。R 解释器遵循数学中运算规则的顺序。记住这个的一个简单方法是 PEMDAS :
- 父母
- Ex onent
- M 乘法或 D 除法
- A 增加或 S 减少
让我们看一个没有括号的例子。对于92 + 87 + 85/3,R 解释器将按以下顺序计算表达式:

当你没有在92 + 87 + 85周围加上圆括号时,基于 PEMDAS,R 解释器将首先计算除法运算符。现在,让我们在表达式上重新加上括号。对于(92 + 87 + 85)/3。R 解释器将按照不同的顺序计算表达式:
以下是每个班级的最终分数:
- 数学:88 分
- 化学:87.66667
- 写作:86
- 艺术作品:91.33333
- 历史:84 年
- 音乐:91
- 体育:89.33333
让我们在考虑 PEMDAS 的情况下计算总体平均值。计算出总平均成绩后,在同一个表达式中,从数学成绩中减去总平均成绩:
print( 88 - ((88 + 87.66667 + 86 + 91.33333 + 84 + 91 + 89.33333)/7) )
[1] -0.1904757
创建注释
在前面的练习中,我们使用运算符进行了多次计算。稍后,当我们编写数百行代码时,组织我们的代码是一个很好的编程实践。我们可以通过插入注释来组织我们的代码。注释是帮助人们——包括你自己——理解代码的注释。R 解释器识别注释,将它们视为纯文本,不会试图执行它们。我们可以向代码中添加两种主要类型的注释:
- 内嵌注释
- 单行注释
内联注释每当我们想要对一个特定的语句进行注释或添加更多细节时,内联注释就非常有用。要在语句末尾添加行内注释,请以散列字符(#)开始,然后添加注释:
print( (92 + 87 + 85)/3 # Finding the math score)
虽然我们不需要在散列字符(#)后添加一个空格,但这被认为是一种好的风格,可以使我们的注释更加清晰易读。单行注释单行注释跨越整行,当我们想把代码分成几个部分时,这很有用。要指定我们希望将一行文本视为注释,请以散列字符(#)开始该行:
# Here, we're finding the average of our scores. Then, subtracting this average from the math score.
print(88 - ((88 + 87.66667 + 86 + 91.33333 + 84 + 91 + 89.33333)/7) )
让我们给代码添加注释吧!
# Adding some comments.
88 - ((88 + 87.66667 + 86 + 91.33333 + 84 + 91 + 89.33333)/7) ) # Adding more comments.
给变量赋值
用 R 进行简单的计算是有用的。然而,更可靠的方法是存储这些值以备后用。这个存储值的过程叫做变量赋值。R 中的一个变量就像一个命名的存储单元,可以保存值。分配变量的过程需要两个步骤:
- 给变量命名。
- 使用
<-为名称赋值。
命名变量时,有几条规则必须遵守:
- 变量名由字母、数字、点或下划线组成。
- 我们可以用一个字母或一个点开始一个变量。如果它是一个点,那么我们就不能在它后面跟着一个数字。
- 我们不能以数字开始变量。
- 不允许使用特殊字符。
关于更多细节,下面的表格详细说明了哪些变量名是允许的,哪些是不允许的:
 让我们回到我们的数学成绩计算:
让我们回到我们的数学成绩计算:(92 + 87 + 85)/3,这次计算的结果是88。为了将88存储在一个名为math的变量中,让我们编写以下表达式:
math <- 88
然后如果我们试着做数学运算,像这样:
print(math)
这将显示:[1] 88
变量,不仅可以保存我们计算的结果,我们还可以给一个表达式赋值:
math <- (92 + 87 + 85)/3
如果我们试着打印数学,像这样:
print(math)
这将显示与我们最初计算相同的结果[1] 88
我们把数学成绩储存在一个变量里。提醒一下,这里是班级:
- 化学:87.66667
- 写作:86
- 艺术作品:91.33333
- 历史:84 年
- 音乐:91
- 体育:89.33333
让我们将其他分数存储在变量中。
math <- 88
chemistry <- 87.66667
writing <- 86
art <- 91.33333
history <- 84
music <- 91
physical_education <- 89.33333
使用变量执行计算
既然我们已经将每个班级的分数存储在一个变量中,我们可以使用这些变量来计算平均绩点。让我们看看我们的数学和化学成绩:
math <- 88
chemistry <- 87.66667
执行计算时,变量和值被视为与相同。使用我们的math和chemistry变量,88 + 87.66667与math + chemistry相同。使用变量进行计算时,PEMDAS 法则仍然适用。如果我们想知道你的数学比化学好多少,我们可以使用减法-算术运算符来找出差异:
math <- 88chemistry <- 87.66667
print(math - chemistry)
这将显示:
[1] 0.33333
如果我们想找到数学和化学之间的平均分数,我们可以对这两个变量使用+、/、()运算符:
(math + chemistry)/2
这将显示:
[1] 87.83334
完成这些计算后,我们还可以将这些表达式的结果存储在一个变量中。如果我们想将数学和化学的平均值存储在一个名为average的变量中,它应该是这样的:
average <- (math + chemistry)/2
显示平均值将返回相同的值87.83334。
让我们使用以下变量来计算您的平均绩点:
math <- 88chemistry <- 87.66667writing <- 86art <- 91.33333history <- 84music <- 91physical_education <- 89.33333
## Classes
math <- 88
chemistry <- 87.66667
writing <- 86
art <- 91.33333
history <- 84
music <- 91
physical_education <- 89.33333
## Calculation
gpa <- (math + chemistry + writing + art + history + music + physical_education)/7
然后,让我们从历史中减去你的gpa,看看历史是否低于平均值。将该差值存储在history_difference中。
history_difference <- history - gpa
创建向量
从我们之前的例子来看,使用变量计算你的平均绩点是有用的。然而,在数据科学中,我们经常处理成千上万的数据点。如果你有每堂课的每项家庭作业、考试或项目的分数,我们的数据集会变得很大。回到我们的数学、化学示例,让我们看看当前变量:

我们需要一个可以存储多个值的存储单元,而不是将这两个值存储在两个变量中。在 R 中,我们可以使用一个向量来存储这些值。向量是一个存储容器,可以存储一系列值。然后我们可以用一个变量来命名一个矢量。像这样:

要创建一个向量,您将使用c()。在 R 中,c()被称为函数。类似于print()语句,c()函数接受多个输入并将这些值存储在一个地方。c()函数不对这些值执行任何算术运算,它只是存储这些值。你可以在这里阅读更多关于c()功能的内容。以下是创建向量的步骤:
- 确定您想要存储在向量中的值,并将这些值放在
c()函数中。使用逗号(,)分隔这些值。 - 使用
<-给矢量指定一个你选择的名称。
让我们创建一个包含您的数学和化学分数的向量。数学成绩88,化学成绩87.66667。
math_chemistry <- c(88,87.66667)
我们也可以使用变量名来创建向量:
math_chemistry <- c(math,chemistry)
如果我们去print(math_chemistry),它会是这样的:
[1] 88.00000 87.66667
另一方面,如果我们试图存储一系列值,就像这样:
math_chemistry <- 88, 87.66667
R 解释器只会尝试将 88 赋值给math_chemistry,但无法解释 88: Error: unexpected ',' in "math_chemistry <- 88,"之后的逗号
让我们使用以下变量将最终分数存储在一个向量中:
math <- 88
chemistry <- 87.66667
writing <- 86
art <- 91.33333
history <- 84
music <- 91
physical_education <- 89.33333
final_scores <- c(math, chemistry, writing, art, history, music, physical_education)
计算平均值
现在我们已经将你的分数存储在一个向量中,我们可以计算平均绩点。在之前的练习中,您使用了算术运算符来计算您的平均绩点:
(88 + 87.66667 + 86 + 91.33333 + 84 + 91 + 89.33333)/7
虽然这个解决方案可行,但是它不可扩展。现在你已经创建了一个向量,我们有一个更简单的方法来计算平均绩点。要使用向量计算平均绩点,请使用mean()功能。mean()函数将接受一个输入(向量)并计算该输入的平均值。然后解释器将显示结果。让我们将mean()函数应用于我们的math_chemistry向量:
math_chemistry <- c(88,87.66667)
mean(math_chemistry)
这将返回:
[1] 87.83334
然后我们可以将mean(math_chemistry)的结果存储在一个变量中以备后用:
average_score <- mean(math_chemistry)
让我们将mean()函数应用到你的最终分数向量上!
## Vector of Final Scores
final_scores <- c(math, chemistry, writing, art, history, music, physical_education)
## Calculating the mean
gpa <- mean(final_scores)
对向量执行运算
之前,你使用mean()函数和一个向量计算你的最终成绩。在数据科学中,总有多个问题可以用数据来回答。让我们更深入地研究我们的final_grades向量,并问它几个问题:
- 最高分是多少?
- 最低分是多少?
- 你上了多少课?
要回答这些问题,您还需要几个函数:
min():查找向量中的最小值max():查找向量中的最大值length():查找向量保存的值的总数sum()::取 vector 中所有值的和(注:本教程中不会用到。
您可以应用这个函数,类似于应用
mean()功能。为了找到我们的math_chemistry向量中的最大分数,我们将对这个向量应用max()函数:
math_chemistry <- c(88,87.66667)
max(math_chemistry)
这显示:[1] 88
再回答几个关于你成绩的问题吧!
- 你在哪个班得分最高?使用
max()。 - 你在哪个班得分最低?使用
min()。 - 你上了多少课?使用
length()。
final_scores <- c(math, chemistry, writing, art, history, music, physical_education)
## Highest Score
highest_score <- max(final_scores)print(highest_score)
## Lowest Score
lowest_score <- min(final_scores)print(lowest_score)
## Number of Classes
num_classes <- length(final_scores)
print(num_classes)
[1] 91.33333
[1] 84
[1] 7
后续步骤
如果您想了解更多,本教程基于我们的 R 基础知识课程,该课程是我们 R track 数据分析师的一部分。基于本教程中的概念,您将学习:
- 操纵向量的更复杂的方法:
- 索引到向量中
- 过滤掉向量中的不同值
- 向量的不同行为
- 使用矩阵推荐大学
- 创建您自己的矩阵
- 分割和重组矩阵
- 对矩阵排序
- 使用数据框架分析大学毕业生数据
- 进入数据帧的不同数据类型
- 选择并子集化数据帧中的特定值
- 将条件添加到数据框选择中
- 使用列表存储各种值
- 编入列表的索引
- 从列表中添加和减去值
- 合并列表
R Markdown 入门指南和备忘单
原文:https://www.dataquest.io/blog/r-markdown-guide-cheatsheet/
July 9, 2020
使用 R Markdown 将您的数据分析转化为漂亮的文档。
在这篇博文中,我们将看看如何使用 R Markdown。最后,你将拥有使用 R Markdown 从头开始制作文档或演示文稿所需的技能!
我们将向您展示如何将默认的 R Markdown 文档转换成您自己的有用参考指南。我们鼓励你建立你自己的 R Markdown 指南,但是如果你喜欢只是跟着读,那也是可行的!
R Markdown 是一个开源工具,用于在 r 中生成可重复的报告。它使您能够将所有的代码、结果、图表和文字保存在一个地方。当您为那些对您的分析结果感兴趣,而不是对您的代码感兴趣的读者制作文档时,R Markdown 特别有用。
R Markdown 功能强大,因为它可以用于数据分析和数据科学,与他人合作,并将结果传达给决策者。使用 R Markdown,您可以选择将您的作品导出为多种格式,包括 PDF、Microsoft Word、幻灯片或 HTML 文档,以便在网站中使用。
我们将使用 RStudio 集成开发环境(IDE)来制作我们的 R Markdown 参考指南。如果你想了解更多关于 RStudio 的信息,请查看我们的列表 23 个令人敬畏的 RStudio 提示和技巧!
在 Dataquest,我们喜欢使用 R Markdown 来编写 R 代码和创作内容。事实上,我们在 R Markdown 写了这篇博文!此外,Dataquest 平台上的学习者使用 R Markdown 来完成他们的 R 项目。
我们在这篇博文中包含了完全可复制的代码示例。当你掌握了这篇文章的内容后,看看我们的另一篇关于 R 降价技巧、诀窍和捷径的博客文章。
好了,让我们开始构建我们自己的 R Markdown 参考文档吧!
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
r 降价指南和备忘单:快速导航
- 1。安装 R 降价
- 2。默认输出格式
- 3。r 减价文件格式
- 4。章节标题
- 5。项目符号和编号列表
- 6。文本格式
- 7。链接
- 8。代码块
- 9。运行代码
- 10。用代码块选项控制行为
- 11。内嵌代码
- 12。导航部分和代码块
- 13。表格格式
- 14。输出格式选项
- 15。演示文稿
- 16。添加目录
- 17。使用 RStudio 云生成可再现的报告
- 更多降价技巧、窍门和快捷方式
- 奖励:R 降价备忘单
- 附加资源
1.安装 R 降价
R Markdown 是一个免费的开源工具,像其他 R 包一样安装。使用以下命令安装 R Markdown:
install.packages("rmarkdown")
既然已经安装了 R Markdown,导航到File > New File > R Markdown….R Markdown files have the file extension”,在 RStudio 中打开一个新的 R Markdown 文件。Rmd”。
2.默认输出格式
当您在 RStudio 中打开一个新的 R Markdown 文件时,会出现一个弹出窗口,提示您选择用于文档的输出格式。

默认的输出格式是 HTML。有了 HTML,你可以很容易地在网络浏览器中查看它。
我们建议现在选择默认的 HTML 设置——它可以节省您的时间!为什么?因为编译 HTML 文档通常比生成 PDF 或其他格式要快。当你接近一个成品时,你把输出转换成你选择的格式,然后进行最后的润色。
最后要注意的是,您在上面的弹出窗口中为文档指定的标题不是文件名!导航至File > Save As..命名并保存文档。
3.r 减价文件格式
一旦选择了所需的输出格式,R Markdown 文档就会出现在 RStudio 窗格中。但与空白的 R 脚本不同的是。Rmd 文档包括一些乍一看可能很奇怪的格式。我们来分解一下。
我们突出显示了 R Markdown 文档的六个不同部分,以了解正在发生的事情:
- YAML 页眉:控制应用于整个文档的某些输出设置。
- 代码块:包括要运行的代码,以及与代码相关的选项。
- 正文:用于向目标受众传达结果和发现。
- 生成一个表的代码:输出一个具有最小格式的表,就像您在控制台中看到的一样。
- 节头:用##指定。
- 生成图的代码:输出图。这里,不包括用于生成绘图的代码,因为指定了参数 echo=FALSE。这是一个块选项。我们将很快介绍大块选项!

此文档可以按原样输出。让我们“编织”或输出文档,看看这些格式规范在呈现的文档中是什么样子。在 RStudio 中,我们通过单击“针织”按钮来实现这一点。编织文档会生成一个 HTML 文档,因为这是我们指定的输出格式。
编织文档的快捷方式在 Mac 上是Command + Shift + K,在 Linux 和 Windows 上是Ctrl + Shift + K。“k”是“针织”的缩写!

上图展示了左边的 R Markdown 文档输出到右边的 HTML 时的样子。
注意默认的。RStudio 中的 Rmd 文件包括格式化 R Markdown 文档的有用指导。我们将把这个文档保存为RMarkdown_Guide.Rmd,这样我们就可以在本教程的过程中添加它。我们在 YAML 的标题中将该文档命名为“R Markdown Guide”。我们鼓励你也这样做,这样你就可以建立你自己的 R Markdown 参考指南!
注意:如果您在 RStudio 之外的 R Markdown 中工作,请使用函数rmarkdown::render()来编译您的文档。提供带引号的文档名作为函数参数。例如:
`rmarkdown::render("RMarkdown_Guide.Rmd")`
4.部分标题
接下来,我们将介绍。Rmd 文件。R Markdown 文件是用 Markdown 编写的纯文本文件,Markdown 是一种格式化语法。我们从章节标题开始。
注意在默认情况下。Rmd 文件,文件中有两个部分, R Markdown 和包括地块。这些是二级头,因为有双散列标记(##)。让我们在指南“文本格式基础”中创建新的二级标题,输入:
## Text Formatting Basics
接下来是第三级标题,称为标题,如下所示:
## Text Formatting Basics
### Headers
我们将用第一、第二和第三级标题的语法要求来构建我们的指南。我们希望我们的指南显示生成标题的代码。
因此,为了将标题的格式要求添加到我们的指南中,我们添加了以下内容:
# First Level Header
## Second Level Header
### Third Level Header
提示:在每行代码之间插入一个空行,以便在输出时将它们分开。并且在相邻但互不相同的格式元素(如节标题和正文)之间始终至少有一个空行。
的。Rmd 文档,输出如下所示:

在上图中,我们看到了第二层和第三层标题呈现时的样子。我们还指定了用#、##或###创建标题的语法。这是一个很好的例子,说明 R Markdown 中的格式化是多么简单而强大。
如果您不希望标题在最终输出中呈现为标题,请将代码用反斜杠括起来,如下所示,将文本格式化为代码:
`# First Level Header`
5.项目符号和编号列表
现在,我们将创建一个名为项目符号和编号列表的新的第三级标题,并在指南中键入以下内容以生成无序列表:
* List element 1
* List element 2
* List element 3
* List item 3a
* List item 3b
事实上,字符*、-和+都是为生成无序列表项而工作的。
以下是编号列表所需的语法:
1\. Numbered list 1
1\. Numbered list 2
1\. Numbered list 3.
数字会自动递增,所以我们只需输入“1”。如果我们添加或删除项目,这很好,因为我们不必担心重新编号!
也可以将有序列表和有序列表结合起来。按两次tab来缩进未排序的项目符号:
1\. Numbered list 1
1\. Numbered list 2
* Item 1
* Item 2
下面是这种格式在我们的指南和输出中的并排视图:

6.文本格式
我们将继续通过添加基本的文本格式来构建我们的 R Markdown 指南。创建一个名为文本格式的新的第三级标题,并复制或键入以下内容:
* Make text italic like *this* or _this_.
* Make text bold like **this** or __this__.
* Use `backticks` for code.
* Wrap a character to subscript in tildes (`~`). For example, `H~2~O` renders as H~2~O.
* Wrap a character to superscript in carets (`^`), like this: `R^2^` renders as R^2^.
这是渲染时的样子:

7.链接
R Markdown 使链接网站和图片变得容易。在我们指南中称为链接的这一部分,我们记录了以下内容:
Direct in-line links: <https://rmarkdown.rstudio.com/>.
Phrase links: RStudio's [R Markdown page](https://rmarkdown.rstudio.com/).

这是 HTML 输出:

8.代码块
要在 R Markdown 中运行代码块,请使用代码块。使用以下内容插入新代码块:
Command + Option + I在 Mac 上,或者Ctrl + Alt + I在 Linux 和 Windows 上。- 另一个选项是工具栏中的“插入”下拉图标并选择 r。
我们建议学习节省时间的捷径!我们将在 R Markdown 指南中插入一个新的代码块。
9.运行代码
RStudio 在工具栏的“运行”下拉选项卡中提供了许多运行代码块的选项:

在运行代码块之前,重启 R 会话并从一个干净的环境开始通常是一个好主意。在 Mac 上使用Command + Shift + F10或在 Linux 和 Windows 上使用Control + Shift + F10来完成此操作。
为了节省时间,有必要学习这些运行代码的快捷方式:
- 在 Mac 上使用
Command + Option + P运行当前块之上的所有块,或者在 Linux 和 Windows 上使用Ctrl + Alt + P。 - 在 Mac 上使用
Command + Option + C或Command + Shift + Enter运行当前块。在 Linux 和 Windows 上,使用Ctrl + Alt + C或Ctrl + Shift + Enter来运行当前块。 - 在 Mac 上使用
Command + Option + N运行下一个块,或者在 Linux 和 Windows 上使用Ctrl + Alt + N。 - 在 Mac 上使用
Command + Option + R或Command + A + Enter运行所有块。在 Linux 和 Windows 上,使用Ctrl + Alt + R或Ctrl + A + Enter来运行所有的块。
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
10.用代码块选项控制行为
R Markdown 的一个优点是,您有许多选项来控制如何评估和呈现每一段代码。这使您可以从头开始构建演示文稿和报告,包括代码、图表、表格和图像,同时只向目标受众展示必要的信息。例如,您可以包含一个结果图,而不显示用于生成它的代码。
掌握代码块选项是成为一个熟练的 R Markdown 用户的必要条件。学习组块选项的最好方法是在你的报告中需要时尝试它们,所以现在不要担心记住所有这些。以下是需要学习的关键块选项:
echo = FALSE:不在输出中显示代码,但运行代码并产生所有输出、绘图、警告和消息。下图中用于生成绘图的代码块就是一个例子。- 显示代码,但不评估它。
fig.show = "hide":隐藏情节。include = FALSE:运行代码,但抑制所有输出。这对设置代码很有帮助。你可以在下图的顶部代码块中看到这样的例子。message = FALSE:防止包加载时打印消息。这也抑制了函数生成的消息。results = "hide":隐藏打印输出。warning = FALSE:防止软件包和功能显示警告。
11.内嵌代码
用内联代码直接将 R 代码嵌入到 R Markdown 文档中。当您想要在书面摘要中包含有关数据的信息时,这很有用。我们将在 R Markdown 指南中添加几个内联代码的例子来说明它是如何工作的。
使用带r的内联代码,并在反勾号内添加要评估的代码。例如,下面是我们如何总结内置于 R 中的cars数据集中的行数和列数:
## Inline Code
The `cars` dataset contains `r nrow(cars)` rows and `r ncol(cars)` columns.
下面是比较 R Markdown 和 HTML 输出的并排视图:

上面的例子强调了如何通过有计划地总结信息来减少报告中的错误。如果我们改变数据集并改变行数和列数,我们只需要重新运行代码就能得到准确的结果。这比试图记住我们需要在文档中的什么地方更新结果、确定新的数字以及手动更改结果要好得多。R Markdown 功能强大,因为它可以节省时间,提高报告的质量和准确性。
12.导航部分和代码块
命名代码块对于包含许多代码块的长文档很有用。对于 R 代码块,这样命名块:{r my_boring_chunk_name}。
使用命名代码块,您可以在 R Markdown 窗口窗格底部包含的导航器中的代码块之间导航。这也可以使绘图易于按名称识别,以便在文档的其他部分使用。此导航器对于快速跳转到文档的另一部分也很有用。
以下是我们在 R Markdown 指南的导航器中看到的内容:

13.表格格式
正如本文前面提到的,默认情况下,R Markdown 中的表显示为您在 R 控制台中看到的样子。为了改善 R Markdown 文档中表格的美观,使用函数knitr::kable()。这里有一个例子:
knitr::kable(head(cars), caption = "The First Few Rows of the Cars Dataset")
这是我们指南中的样子,渲染时:

在 R Markdown 中有许多其他的用于创建表格的包。
提醒一句:格式化表格可能非常耗时。我们建议在学习 R Markdown 时首先坚持基础。随着技能的提高,表格格式的需求变得明显,如果需要,可以参考其他软件包。
14.输出格式选项
既然我们已经对如何格式化 R Markdown 文档有了很好的理解,那么让我们来讨论一下格式化选项。适用于整个文档的格式选项在 YAML 标题中指定。R Markdown 支持多种输出格式。
YAML 报头中指定的元数据控制输出。一个 R Markdown 文档可以支持多种输出格式。回想一下,呈现为 HTML 通常比 PDF 更快。如果您想以 HTML 格式预览文档,但最终会将文档输出为 PDF 格式,请注释掉 PDF 规范,直到需要为止,如下所示:
---
title: "R Markdown Guide"
author: "Dataquest"
date: "7/8/2020"
output: html_document
# output: pdf_document
# output: ioslides_presentation
---
正如您在这里看到的,我们还包含了将 R Markdown 指南作为演示文稿输出所需的元数据。
15.报告
rmarkdown包支持四种类型的演示。其他 R 包也是可用的,比如 revealjs、扩展了 R Markdown 的功能。我们将简要概述内置于 R Markdown 中的表示格式,然后我们将看一个例子。
四个演示选项及其输出格式如下:
- beamer_presentation : PDF
- io slides _ presentation:HTML
- powerpoint_presentation :微软 powerpoint
- slidy_presentation : HTML
让我们将 R Markdown 指南转换为一个幻灯片演示。ioslides 选项编译成 HTML,这对于在屏幕共享的远程会议中进行演示非常有用。我们用output: ioslides_presentation将指南转换成幻灯片演示。
---
title: "R Markdown Guide"
author: "Dataquest"
date: "7/8/2020"
# output: html_document
# output: pdf_document
output: ioslides_presentation
---
请注意,我们“注释掉”了 HTML 和 PDF 格式选项,以便在编译文档时忽略它们。这是一种保持其他输出选项可用的简便技术。
当我们编织时,R Markdown 指南和 HTML 演示出现,每个二级标题标记一个新幻灯片的开始。除了我们的“文本格式基础”部分有几个第三级标题部分之外,这一部分工作得很好:

为了通过手动换行符解决这种情况,我们根据需要在每个第三级标题前插入***,如下所示:
## Text Formatting Basics
### Headers`# First Level Header``## Second Level Header``### Third Level Header`***
### Bulleted or Numbered Lists
* List element 1
* List element 2
* List element 3
* List element 3a
* List element 3b
这将把“项目符号或编号列表”移到它自己的幻灯片中:

请参考以上每种演示文稿格式的链接,查看可用于自定义演示文稿外观的选项。
16.添加目录
你会注意到这篇博文包括一个目录。你可能记得我们在 R Markdown 写了这篇博客。我们在这篇博文中添加了目录,并在 YAML 标题中添加了一行代码toc: true。看起来是这样的:
output:
html_document:
toc: true
注意每一层使用的缩进,不要忘记在html_document后面加上:!
17.利用 RStudio 云生成可再现的报告
你在这里学到的一切都可以应用到名为 RStudio Cloud 的基于云的 RStudio 桌面版本上。RStudio Cloud 让您无需安装软件就能制作报告和演示 R Markdown,您只需要一个 web 浏览器。
RStudio Cloud 中的工作被组织到类似于桌面版本的项目中,但是 RStudio Cloud 使您能够指定您希望用于每个项目的 R 版本。
RStudio Cloud 还可以轻松安全地与同事共享项目,并确保每次访问项目时工作环境完全可再现。这对于在 R Markdown 中编写可重复的报告特别有用!
如您所见,RStudio Cloud 的布局非常类似于在 RStudio Desktop 中创作 R Markdown 文档:

在 RStudio Cloud 中使用 R Markdown 需要某些包。当您第一次在 RStudio Cloud 中打开一个新的 R Markdown 文档时,该程序会提示您是否要安装所需的软件包:

一旦软件包安装完毕,您就可以立即创建和编织 R Markdown 文档了!
奖金:R 降价备忘单
RStudio 发布了许多与 R 合作的备忘单,包括一份关于使用 R Markdown 的详细备忘单!通过选择Help > Cheatsheets > R Markdown Cheat Sheet,可以从 RStudio 中访问 R Markdown cheatsheet。
额外资源
RStudio 已经发表了几篇关于使用 R Markdown 的深入的 how to 文章。找到他们在这里。
R Markdown 食谱是一本全面的免费在线书籍,几乎包含了你需要知道的关于 R Markdown 的一切。
Hadley Wickham 在《数据科学的 R》一书中对 R Markdown 的创作做了很好的概述。
看看这个 R Markdown 创作快速导览,以及 RStudio 的这个综合在线课程。
RStudio 还出版了这本有用的 R Markdown 参考指南。
R Markdown 理解 Pandoc 的 Markdown,是 Markdown 的一个版本,有更多的功能。本 Pandoc 指南为格式化选项提供了丰富的资源。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
r 降价提示、技巧和快捷方式
原文:https://www.dataquest.io/blog/r-markdown-tips-tricks-and-shortcuts/
June 23, 2020
使用 R Markdown 将您的数据分析转化为漂亮的文档。
R Markdown 是一个开源工具,用于在 r 中生成可重复的报告。它可以帮助您将所有代码、结果和文字保存在一个地方,并以一种吸引人和易于理解的方式进行格式化。
它也是向他人展示您的数据工作的一个有价值的工具。使用 R Markdown,您可以选择将您的作品导出为多种格式,包括 PDF、Microsoft Word、幻灯片或 html 文档,以便在网站上使用。
R Markdown 是一个强大的工具,因为它可以用于数据分析和数据科学,与他人合作,并将结果传达给决策者。
在这篇博文中,我们将看看在 RStudio 中使用 R Markdown 的一些技巧、窍门和快捷方式。(如果您想了解 RStudio 的更多信息,请查看这篇 Dataquest 博客文章中的 RStudio 提示和技巧!)
我们喜欢使用 R Markdown 来编写 R 代码和创作内容。事实上,我们在 R Markdown 写了这篇博文!让我们来看看一些原因吧!
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
1.快捷键
知道 R Markdown 键盘快捷键会在创建报告时节省大量时间。
以下是一些基本的 R Markdown 快捷键:
- 在 Mac 上插入带有
Command + Option + I的新代码卡盘,或者在 Linux 和 Windows 上插入带有Ctrl + Alt + I的新代码卡盘。 - 在 Mac 上使用
Command + Shift + K,或者在 Linux 和 Windows 上使用Ctrl + Shift + K,以 YAML 头文件中指定的格式输出文档。“k”是“针织”的缩写!
接下来,我们将介绍运行代码块的快捷方式。但是在这样做之前,重启您的 R 会话并从一个干净的环境开始通常是一个好主意。在 Mac 上使用Command + Shift + F10或在 Linux 和 Windows 上使用Ctrl + Shift + F10来完成此操作。
- 在 Mac 上使用
Command + Option + P运行当前区块之上的所有区块;Ctrl + Alt + P在 Linux 和 Windows 上。 - 在 Mac 上使用
Command + Option + C或Command + Shift + Enter运行当前块;Linux 和 Windows 上的Ctrl + Alt + C或Ctrl + Shift + Enter。 - 在 Mac 上用
Command + Option + N运行下一个程序块;Ctrl + Alt + N在 Linux 和 Windows 上。 - 在 Mac 上运行带有
Command + Option + R或Command + A + Enter的所有块;Linux 和 Windows 上的Ctrl + Alt + R或Ctrl + A + Enter。
2.快速预览您的文档
R Markdown 为编译文档提供了许多格式选项。但是将你的作品转换成 PDF 或演示文稿比编译成 HTML 要花更长的时间。因此,在创作时将文档输出到 HTML 通常是有用的,因为这样可以快速迭代。
当您打开一个新的 R Markdown 文件时,默认的输出格式是 HTML —当您编译您的报告时,您可以很容易地在 web 浏览器中查看它。这个默认设置可以节省你的时间!当你接近一个完成的产品时,你改变输出到你选择的格式,然后做最后的润色。
3.了解您的代码块选项
R Markdown 的一个伟大之处在于,您有许多选项来控制如何评估和呈现每个代码块。这使您可以从头开始构建演示文稿和报告,包括代码、图表、表格和图像,同时只向目标受众展示必要的信息。例如,您可以包含一个结果图,而不显示用于生成它的代码。
掌握这些代码块选项对于成为熟练的 R Markdown 用户至关重要:
echo = FALSE:隐藏代码,但运行代码并产生所有输出、绘图、警告和消息。- 显示代码,但不评估它。
- fig.show = "hide ":隐藏绘图。
include = FALSE:运行代码,但禁止所有输出。这对设置代码很有帮助。当您打开一个新的 R Markdown 文档时,您可以在第一个代码块中看到这样的例子!message = FALSE:防止包加载时打印消息。这也抑制了函数生成的消息。results = "hide":隐藏打印输出。warning = FALSE:防止软件包和功能显示警告。
4.使用内联代码
用内联代码直接将 R 代码嵌入到 R Markdown 文档中。当您想要在书面摘要中包含有关数据的信息时,这很有用。
使用带r的内联代码,并在反勾号内添加要评估的代码。例如,我们在写这篇博文时使用了内联代码来自动对每一部分进行编号,这样我们就不必自己手动添加了。那么我们是怎么做到的呢?我们首先在setup代码块中创建了一个名为tip_number的变量,并将值设置为零,如下所示:
`tip_number <- 0`
然后,我们向每个部分添加以下内联代码,以在每次迭代中增加一个数字:
`r paste0(tip_number <- tip_number + 1, ". ")`
嘿,等一下!我们如何在不弄乱下面章节编号的情况下,将最后一行代码包含在这篇用 R Markdown 编写的博客文章中?带代码块选项!上面的代码示例是用选项eval = FALSE写在代码块中的,以防止代码运行。像这样:

正如你所看到的,R Markdown 是一个强大的工具,因为它给了你很多对文档输出的控制!
5.使用 TinyTex
通过 R Markdown,您可以使用 LaTeX 文档准备系统输出高质量的报告。当报告包含科学或数学符号和符号时,LaTeX 特别有用。例如,我们在 Dataquest 使用 LaTeX 来创作使用数学符号的统计数据内容。
但是像 TeX Live、MiKTeX 和 MacTeX 这样的 LaTeX 发行版需要大约 5g 的硬盘空间!相比之下, TinyTex 安装后仅使用大约 150 兆字节。
用install.packages('tinytex')或tinytex::install_tinytex()安装 TinyTex。用tinytex::uninstall_tinytex()卸载 TinyTex。
安装 TinyTex 后,如果您已经将 PDF 指定为输出格式,那么您不需要做任何其他事情就可以输出 PDF 文档!
要将 LaTeX 文档编译成 PDF,调用这些tinytex函数之一:pdflatex()、xelatex()和lualatex()。要使用的函数取决于您想要使用的 LaTeX 引擎。
TinyTex 开发者和 R Markdown 超级巨星谢一辉说,这是普通 R 用户需要了解的关于 TinyTex 的所有信息。为什么?因为上面提到的 LaTeX 功能会自动检测并安装任何需要的缺失 LaTeX 包!
6.用 R 脚本生成 R Markdown 文档
您知道可以从 R 脚本生成 R Markdown 文档吗?为此,用#'捕捉评论。您甚至可以用#+指定代码块选项。这里有一个例子:

该 R 脚本以文件名“r_script”保存。r”。为了将该文档呈现为 R Markdown 文档,我们从knitr中指定了spin()函数,如下所示:
knitr::spin("r_script.R", knit = FALSE, format = "Rmd")
这会生成一个 R Markdown 文档,如下所示:

当您编织这个文档时,会返回这个 HTML 输出:

7.用 R Markdown 文档生成 R 脚本
您可能想知道是否有办法将 R Markdown 文档转换成 R 脚本?有!knitr包也为此提供了一个名为purl()的函数。下面是将我们的 R Markdown 文档转换回 R 脚本的命令:
knitr::purl("r_script.Rmd", documentation = 2)
请注意,您必须在#'注释中指定documentation = 2来返回完整的文档。如果你的文档是纯代码,指定documentation = 0。
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
8.在 R Markdown 中添加分行符
在输出中添加换行符有多难?不是的。但是弄清楚这一点可能有点棘手!
要在 R Markdown 中换行并让它出现在你的输出中,使用两个尾随空格,然后点击return。让我们看一个例子。
这里,我们没有在第一组(顶部)的两个句子之间指定两个尾随空格。但是我们在第二组(底部)的两个句子之间指定了两个尾随空格。

我们编出文件后的结果?看看吧!

9.在 R Markdown 中添加空行
因为我们刚刚讨论了换行符,所以让我们也讨论一下如何在文档中添加空行。当您想要添加空白以减少文档中的混乱时,这很有用。
要在输出中显示一行或多行空行,请指定<br>。让我们看一个例子。
这里,我们没有在第一(顶部)组的两个句子之间指定两个<br>命令。但是我们在第二组(底部)的两个句子之间指定了两个<br>命令。

结果是这样的!

10.在 R Markdown 中查询 SQL
您可以通过创建一个{sql}代码块来查询 R Markdown 中的 SQL。
首先,您将生成一个内存中的 SQL 数据库,供本例使用。您将为著名的“mtcars”数据集生成一个 SQL 数据库。代码如下:

在新的代码块中,编写一个 SQL 查询,从数据库中选择所有四缸发动机的汽车。请务必将该块的类型更改为{sql}。该命令返回一个数据帧,您将把它保存为mt_cars_df:

指定output.var = "mt_cars_df"将查询结果保存到数据帧。数据帧看起来像这样:

您可以在 R 代码块中使用此数据帧来执行分析或生成 ggplot,例如:


11.使用块名
命名代码块对于包含许多代码块的长文档非常有用。以 R 代码组块为例,这样命名组块:{r my_boring_chunk_name}。
使用命名的代码块,您可以在 R Markdown 窗口窗格底部的代码块导航器中导航。这也可以使绘图易于按名称识别,以便在文档的其他部分使用。
我们已经在上面的 SQL 示例中添加了块名。以下是我们在导航器中看到的内容:

12.把它带到云端!
RStudio 现在提供一个基于云的 RStudio 桌面版本,名为 RStudio Cloud 。RStudio Cloud 让你不用安装软件就可以在 R Markdown 中创作,你只需要一个网页浏览器。
RStudio Cloud 中的工作被组织到类似于桌面版本的项目中,但是 RStudio Cloud 使您能够指定您希望用于每个项目的 R 版本。
RStudio Cloud 还可以轻松安全地与同事共享项目,并确保每次访问项目时工作环境完全可再现。这对于在 R Markdown 中编写可重复的报告非常有用!
如您所见,RStudio Cloud 的布局非常类似于在 RStudio Desktop 中创作 R Markdown 文档:
奖金:R 降价备忘单
RStudio 发布了许多与 R 合作的备忘单,包括一份关于使用 R Markdown 的详细备忘单!通过选择Help > Cheatsheets > R Markdown Cheat Sheet,可以从 RStudio 中访问 R Markdown cheatsheet。
额外资源
RStudio 已经发表了几篇关于使用 R Markdown 的深入的 how to 文章。找到他们在这里。
R Markdown 食谱是一本全面的免费在线书籍,几乎囊括了你需要知道的关于 R Markdown 的一切。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
教程:如何轻松读取 Python 中的文件(文本、CSV、JSON)
April 18, 2022
用 Python 读取文件
文件无处不在:在计算机上、移动设备上,以及在云中。无论您使用哪种编程语言,处理文件对每个程序员来说都是必不可少的。
文件处理是一种创建文件、写入数据和从中读取数据的机制。好消息是 Python 增加了处理不同文件类型的包。
在本教程中,我们将学习如何处理不同类型的文件。然而,我们将更加关注用 Python 读取文件的。
完成本教程后,您将知道如何执行以下操作:
- 打开文件并使用
with上下文管理器 - Python 中的文件模式
- 阅读文本
- 读取 CSV 文件
- 读取 JSON 文件
让我们开始吧。
打开文件
在访问文件内容之前,我们需要打开文件。Python 提供了一个内置函数,可以帮助我们以不同的模式打开文件。open()函数接受两个基本参数:文件名和模式;默认模式是'r',以只读方式打开文件。这些模式定义了我们如何访问一个文件以及如何操作它的内容。open()函数提供了一些不同的模式,我们将在本教程的后面讨论。
首先,让我们通过打开一个文本文件来尝试这个功能。下载包含 Python 之禅的文本文件,并将其存储在与您的代码相同的路径中。
f = open('zen_of_python.txt', 'r')
print(f.read())
f.close()
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
在上面的代码中,open()函数以阅读模式打开文本文件,允许我们从文件中获取信息,而不会意外地更改它。在第一行中,open()函数的输出被赋给了f变量,一个表示文本文件的对象。在上面代码的第二行,我们使用read()方法读取整个文件并打印其内容。close()方法关闭文件的最后一行。我们必须在使用完打开的文件后关闭它们,以释放我们的计算机资源并避免引发异常。
在 Python 中,我们可以使用with上下文管理器来确保程序在文件关闭后释放所使用的资源,即使发生了异常。让我们来试试:
with open('zen_of_python.txt') as f:
print(f.read())
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
上面的代码使用with语句创建了一个上下文,表明文件对象不再在上下文之外打开。绑定变量f表示文件对象,所有文件对象方法都可以通过该变量访问。read()方法在第二行读取整个文件,然后print()函数输出文件内容。
当程序到达with语句块上下文的末尾时,它会关闭文件以释放资源,并确保其他程序可以使用它们。一般来说,当您处理那些一旦不再需要就需要关闭的对象(比如文件、数据库和网络连接)时,强烈推荐使用with语句。
注意,即使在退出with上下文管理器块之后,我们仍然可以访问f变量;但是,该文件已关闭。让我们尝试一些文件对象属性,看看该变量是否仍然有效并且可以访问:
print("Filename is '{}'.".format(f.name))
if f.closed:
print("File is closed.")
else:
print("File isn't closed.")
Filename is 'zen_of_python.txt'.
File is closed.
然而,不可能从文件中读取或向文件中写入。当文件关闭时,任何访问其内容的尝试都会导致以下错误:
f.read()
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_9828/3059900045.py in <module>
----> 1 f.read()
ValueError: I/O operation on closed file.
Python 中的文件模式
正如我们在上一节中提到的,我们需要在打开文件时指定模式。下表显示了 Python 中不同的文件模式:
| 方式 | 描述 |
|---|---|
'r' |
它打开一个只读文件。 |
'w' |
它打开一个文件进行写入。如果文件存在,它会覆盖它,否则,它会创建一个新文件。 |
'a' |
它只打开一个附加文件。如果文件不存在,它会创建文件。 |
'x' |
它会创建一个新文件。如果文件存在,它将失败。 |
'+' |
它打开一个文件进行更新。 |
我们还可以指定以文本模式打开文件,默认模式是't',或者二进制模式是'b'。让我们看看如何使用简单的语句复制一个图像文件, dataquest_logo.png :
with open('dataquest_logo.png', 'rb') as rf:
with open('data_quest_logo_copy.png', 'wb') as wf:
for b in rf:
wf.write(b)
上面的代码复制了 Dataquest 徽标图像,并将其存储在相同的路径中。'rb'模式以二进制模式打开文件进行读取,'wb'模式以文本模式打开文件进行写入。
读取文本文件
阅读文本文件有不同的方法。本节将回顾一些阅读文本文件内容的有用方法。
到目前为止,我们已经了解了使用read()方法可以读取文件的全部内容。如果我们只想从文本文件中读取几个字节呢?为此,在read()方法中指定字节数。让我们来试试:
with open('zen_of_python.txt') as f:
print(f.read(17))
The Zen of Python
上面的简单代码读取 zen_of_python.txt 文件的前 17 个字节并打印出来。
有时,一次读取一行文本文件的内容更有意义。在这种情况下,我们可以使用readline()方法。让我们开始吧:
with open('zen_of_python.txt') as f:
print(f.readline())
The Zen of Python, by Tim Peters
上面的代码返回文件的第一行。如果我们再次调用该方法,它将返回文件中的第二行,等等。,如下所示:
with open('zen_of_python.txt') as f:
print(f.readline())
print(f.readline())
print(f.readline())
print(f.readline())
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
这种有用的方法帮助我们以增量方式读取整个文件。下面的代码通过逐行迭代输出整个文件,直到跟踪文件读写位置的文件指针到达文件末尾。当readline()方法到达文件末尾时,它返回一个空字符串''。用 open('zen_of_python.txt ')作为 f:
with open('zen_of_python.txt') as f:
line = f.readline()
while line:
print(line, end='')
line = f.readline()
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
上面的代码在 while 循环之外读取文件的第一行,并将其赋给line变量。在 while 循环中,它打印存储在line变量中的字符串,然后读取文件的下一行。while 循环迭代这个过程,直到readline()方法返回一个空字符串。在 while 循环中,空字符串的计算结果为False,因此迭代过程终止。
读取文本文件的另一个有用的方法是readlines()方法。对 file 对象应用此方法将返回包含文件每行的字符串列表。让我们看看它是如何工作的:
with open('zen_of_python.txt') as f:
lines = f.readlines()
让我们检查一下lines变量的数据类型,然后打印出来:
print(type(lines))
print(lines)
<class 'list'>
['The Zen of Python, by Tim Peters\n', '\n', 'Beautiful is better than ugly.\n', 'Explicit is better than implicit.\n', 'Simple is better than complex.\n', 'Complex is better than complicated.\n', 'Flat is better than nested.\n', 'Sparse is better than dense.\n', 'Readability counts.\n', "Special cases aren't special enough to break the rules.\n", 'Although practicality beats purity.\n', 'Errors should never pass silently.\n', 'Unless explicitly silenced.\n', 'In the face of ambiguity, refuse the temptation to guess.\n', 'There should be one-- and preferably only one --obvious way to do it.\n', "Although that way may not be obvious at first unless you're Dutch.\n", 'Now is better than never.\n', 'Although never is often better than *right* now.\n', "If the implementation is hard to explain, it's a bad idea.\n", 'If the implementation is easy to explain, it may be a good idea.\n', "Namespaces are one honking great idea -- let's do more of those!"]
这是一个字符串列表,列表中的每一项都是文本文件中的一行。\n转义字符代表文件中的新行。此外,我们可以通过索引或切片操作来访问列表中的每一项:
print(lines)
print(lines[3:5])
print(lines[-1])
['The Zen of Python, by Tim Peters\n', '\n', 'Beautiful is better than ugly.\n', 'Explicit is better than implicit.\n', 'Simple is better than complex.\n', 'Complex is better than complicated.\n', 'Flat is better than nested.\n', 'Sparse is better than dense.\n', 'Readability counts.\n', "Special cases aren't special enough to break the rules.\n", 'Although practicality beats purity.\n', 'Errors should never pass silently.\n', 'Unless explicitly silenced.\n', 'In the face of ambiguity, refuse the temptation to guess.\n', 'There should be one-- and preferably only one --obvious way to do it.\n', "Although that way may not be obvious at first unless you're Dutch.\n", 'Now is better than never.\n', 'Although never is often better than *right* now.\n', "If the implementation is hard to explain, it's a bad idea.\n", 'If the implementation is easy to explain, it may be a good idea.\n', "Namespaces are one honking great idea -- let's do more of those!"]
['Explicit is better than implicit.\n', 'Simple is better than complex.\n']
Namespaces are one honking great idea -- let's do more of those!
读取 CSV 文件
到目前为止,我们已经学习了如何处理常规文本文件。然而,有时数据以 CSV 格式出现,数据专业人员检索所需信息并处理 CSV 文件的内容是很常见的。
我们将在本节中使用 CSV 模块。CSV 模块提供了读取 CSV 文件中存储的逗号分隔值的有用方法。我们现在就尝试一下,但是首先,你需要下载 chocolate.csv 文件,并将其存储在当前工作目录中:
import csv
with open('chocolate.csv') as f:
reader = csv.reader(f, delimiter=',')
for row in reader:
print(row)
['Company', 'Bean Origin or Bar Name', 'REF', 'Review Date', 'Cocoa Percent', 'Company Location', 'Rating', 'Bean Type', 'Country of Origin']
['A. Morin', 'Agua Grande', '1876', '2016', '63%', 'France', '3.75', 'Â\xa0', 'Sao Tome']
['A. Morin', 'Kpime', '1676', '2015', '70%', 'France', '2.75', 'Â\xa0', 'Togo']
['A. Morin', 'Atsane', '1676', '2015', '70%', 'France', '3', 'Â\xa0', 'Togo']
['A. Morin', 'Akata', '1680', '2015', '70%', 'France', '3.5', 'Â\xa0', 'Togo']
['Acalli', 'Chulucanas, El Platanal', '1462', '2015', '70%', 'U.S.A.', '3.75', 'Â\xa0', 'Peru']
['Acalli', 'Tumbes, Norandino', '1470', '2015', '70%', 'U.S.A.', '3.75', 'Criollo', 'Peru']
['Adi', 'Vanua Levu', '705', '2011', '60%', 'Fiji', '2.75', 'Trinitario', 'Fiji']
['Adi', 'Vanua Levu, Toto-A', '705', '2011', '80%', 'Fiji', '3.25', 'Trinitario', 'Fiji']
['Adi', 'Vanua Levu', '705', '2011', '88%', 'Fiji', '3.5', 'Trinitario', 'Fiji']
['Adi', 'Vanua Levu, Ami-Ami-CA', '705', '2011', '72%', 'Fiji', '3.5', 'Trinitario', 'Fiji']
['Aequare (Gianduja)', 'Los Rios, Quevedo, Arriba', '370', '2009', '55%', 'Ecuador', '2.75', 'Forastero (Arriba)', 'Ecuador']
['Aequare (Gianduja)', 'Los Rios, Quevedo, Arriba', '370', '2009', '70%', 'Ecuador', '3', 'Forastero (Arriba)', 'Ecuador']
['Ah Cacao', 'Tabasco', '316', '2009', '70%', 'Mexico', '3', 'Criollo', 'Mexico']
["Akesson's (Pralus)", 'Bali (west), Sukrama Family, Melaya area', '636', '2011', '75%', 'Switzerland', '3.75', 'Trinitario', 'Indonesia']
["Akesson's (Pralus)", 'Madagascar, Ambolikapiky P.', '502', '2010', '75%', 'Switzerland', '2.75', 'Criollo', 'Madagascar']
["Akesson's (Pralus)", 'Monte Alegre, D. Badero', '508', '2010', '75%', 'Switzerland', '2.75', 'Forastero', 'Brazil']
['Alain Ducasse', 'Trinite', '1215', '2014', '65%', 'France', '2.75', 'Trinitario', 'Trinidad']
['Alain Ducasse', 'Vietnam', '1215', '2014', '75%', 'France', '2.75', 'Trinitario', 'Vietnam']
['Alain Ducasse', 'Madagascar', '1215', '2014', '75%', 'France', '3', 'Trinitario', 'Madagascar']
['Alain Ducasse', 'Chuao', '1061', '2013', '75%', 'France', '2.5', 'Trinitario', 'Venezuela']
['Alain Ducasse', 'Piura, Perou', '1173', '2013', '75%', 'France', '2.5', 'Â\xa0', 'Peru']
['Alexandre', 'Winak Coop, Napo', '1944', '2017', '70%', 'Netherlands', '3.5', 'Forastero (Nacional)', 'Ecuador']
['Alexandre', 'La Dalia, Matagalpa', '1944', '2017', '70%', 'Netherlands', '3.5', 'Criollo, Trinitario', 'Nicaragua']
['Alexandre', 'Tien Giang', '1944', '2017', '70%', 'Netherlands', '3.5', 'Trinitario', 'Vietnam']
['Alexandre', 'Makwale Village, Kyela', '1944', '2017', '70%', 'Netherlands', '3.5', 'Forastero', 'Tanzania']
['Altus aka Cao Artisan', 'Momotombo', '1728', '2016', '60%', 'U.S.A.', '2.75', 'Â\xa0', 'Nicaragua']
['Altus aka Cao Artisan', 'Bolivia', '1133', '2013', '60%', 'U.S.A.', '3', 'Â\xa0', 'Bolivia']
['Altus aka Cao Artisan', 'Peru', '1133', '2013', '60%', 'U.S.A.', '3.25', 'Â\xa0', 'Peru']
['Amano', 'Morobe', '725', '2011', '70%', 'U.S.A.', '4', 'Â\xa0', 'Papua New Guinea']
['Amano', 'Dos Rios', '470', '2010', '70%', 'U.S.A.', '3.75', 'Â\xa0', 'Dominican Republic']
['Amano', 'Guayas', '470', '2010', '70%', 'U.S.A.', '4', 'Â\xa0', 'Ecuador']
['Amano', 'Chuao', '544', '2010', '70%', 'U.S.A.', '3', 'Trinitario', 'Venezuela']
['Amano', 'Montanya', '363', '2009', '70%', 'U.S.A.', '3', 'Â\xa0', 'Venezuela']
['Amano', 'Bali, Jembrana', '304', '2008', '70%', 'U.S.A.', '2.75', 'Â\xa0', 'Indonesia']
['Amano', 'Madagascar', '129', '2007', '70%', 'U.S.A.', '3.5', 'Trinitario', 'Madagascar']
['Amano', 'Cuyagua', '147', '2007', '70%', 'U.S.A.', '3', 'Â\xa0', 'Venezuela']
['Amano', 'Ocumare', '175', '2007', '70%', 'U.S.A.', '3.75', 'Criollo', 'Venezuela']
['Amatller (Simon Coll)', 'Ghana', '322', '2009', '70%', 'Spain', '3', 'Forastero', 'Ghana']
['Amatller (Simon Coll)', 'Ecuador', '327', '2009', '70%', 'Spain', '2.75', 'Â\xa0', 'Ecuador']
['Amatller (Simon Coll)', 'Ecuador', '464', '2009', '85%', 'Spain', '2.75', 'Â\xa0', 'Ecuador']
['Amatller (Simon Coll)', 'Ghana', '464', '2009', '85%', 'Spain', '3', 'Forastero', 'Ghana']
['Amazona', 'LamasdelChanka, San Martin, Oro Verde coop', '1145', '2013', '72%', 'Peru', '3.25', 'Â\xa0', 'Peru']
['Ambrosia', 'Venezuela', '1498', '2015', '70%', 'Canada', '3.25', 'Â\xa0', 'Venezuela']
['Ambrosia', 'Peru', '1498', '2015', '68%', 'Canada', '3.5', 'Â\xa0', 'Peru']
['Amedei', 'Piura, Blanco de Criollo', '979', '2012', '70%', 'Italy', '3.75', 'Â\xa0', 'Peru']
['Amedei', 'Porcelana', '111', '2007', '70%', 'Italy', '4', 'Criollo (Porcelana)', 'Venezuela']
['Amedei', 'Nine', '111', '2007', '75%', 'Italy', '4', 'Blend', 'Â\xa0']
['Amedei', 'Chuao', '111', '2007', '70%', 'Italy', '5', 'Trinitario', 'Venezuela']
['Amedei', 'Ecuador', '123', '2007', '70%', 'Italy', '3', 'Trinitario', 'Ecuador']
['Amedei', 'Jamaica', '123', '2007', '70%', 'Italy', '3', 'Trinitario', 'Jamaica']
['Amedei', 'Grenada', '123', '2007', '70%', 'Italy', '3.5', 'Trinitario', 'Grenada']
['Amedei', 'Venezuela', '123', '2007', '70%', 'Italy', '3.75', 'Trinitario (85% Criollo)', 'Venezuela']
['Amedei', 'Madagascar', '123', '2007', '70%', 'Italy', '4', 'Trinitario (85% Criollo)', 'Madagascar']
['Amedei', 'Trinidad', '129', '2007', '70%', 'Italy', '3.5', 'Trinitario', 'Trinidad']
['Amedei', 'Toscano Black', '170', '2007', '63%', 'Italy', '3.5', 'Blend', 'Â\xa0']
['Amedei', 'Toscano Black', '40', '2006', '70%', 'Italy', '5', 'Blend', 'Â\xa0']
['Amedei', 'Toscano Black', '75', '2006', '66%', 'Italy', '4', 'Blend', 'Â\xa0']
['AMMA', 'Catongo', '1065', '2013', '75%', 'Brazil', '3.25', 'Forastero (Catongo)', 'Brazil']
['AMMA', 'Monte Alegre, 3 diff. plantations', '572', '2010', '85%', 'Brazil', '2.75', 'Forastero (Parazinho)', 'Brazil']
['AMMA', 'Monte Alegre, 3 diff. plantations', '572', '2010', '50%', 'Brazil', '3.75', 'Forastero (Parazinho)', 'Brazil']
['AMMA', 'Monte Alegre, 3 diff. plantations', '572', '2010', '75%', 'Brazil', '3.75', 'Forastero (Parazinho)', 'Brazil']
['AMMA', 'Monte Alegre, 3 diff. plantations', '572', '2010', '60%', 'Brazil', '4', 'Forastero (Parazinho)', 'Brazil']
['Anahata', 'Elvesia', '1259', '2014', '75%', 'U.S.A.', '3', 'Â\xa0', 'Dominican Republic']
['Animas', 'Alto Beni', '1852', '2016', '75%', 'U.S.A.', '3.5', 'Â\xa0', 'Bolivia']
['Ara', 'Madagascar', '1375', '2014', '75%', 'France', '3', 'Trinitario', 'Madagascar']
['Ara', 'Chiapas', '1379', '2014', '72%', 'France', '2.5', 'Â\xa0', 'Mexico']
['Arete', 'Camino Verde', '1602', '2015', '75%', 'U.S.A.', '3.5', 'Â\xa0', 'Ecuador']
['Artisan du Chocolat', 'Congo', '300', '2008', '72%', 'U.K.', '3.75', 'Forastero', 'Congo']
['Artisan du Chocolat (Casa Luker)', 'Orinoqua Region, Arauca', '1181', '2013', '72%', 'U.K.', '2.75', 'Trinitario', 'Colombia']
['Askinosie', 'Mababa', '1780', '2016', '68%', 'U.S.A.', '3.75', 'Trinitario', 'Tanzania']
['Askinosie', 'Tenende, Uwate', '647', '2011', '72%', 'U.S.A.', '3.75', 'Trinitario', 'Tanzania']
['Askinosie', 'Cortes', '661', '2011', '70%', 'U.S.A.', '3.75', 'Trinitario', 'Honduras']
['Askinosie', 'Davao', '331', '2009', '77%', 'U.S.A.', '3.75', 'Trinitario', 'Philippines']
['Askinosie', 'Xoconusco', '141', '2007', '75%', 'U.S.A.', '2.5', 'Trinitario', 'Mexico']
['Askinosie', 'San Jose del Tambo', '175', '2007', '70%', 'U.S.A.', '3', 'Forastero (Arriba)', 'Ecuador']
['Bahen & Co.', 'Houseblend', '999', '2012', '70%', 'Australia', '2.5', 'Blend', 'Â\xa0']
['Bakau', 'Bambamarca, 2015', '1454', '2015', '70%', 'Peru', '2.75', 'Â\xa0', 'Peru']
['Bakau', 'Huallabamba, 2015', '1454', '2015', '70%', 'Peru', '3.5', 'Â\xa0', 'Peru']
['Bar Au Chocolat', 'Bahia', '1554', '2015', '70%', 'U.S.A.', '3.5', 'Â\xa0', 'Brazil']
['Bar Au Chocolat', 'Maranon Canyon', '1295', '2014', '70%', 'U.S.A.', '4', 'Forastero (Nacional)', 'Peru']
['Bar Au Chocolat', 'Duarte Province', '983', '2012', '70%', 'U.S.A.', '3.25', 'Â\xa0', 'Dominican Republic']
['Bar Au Chocolat', 'Chiapas', '983', '2012', '70%', 'U.S.A.', '3.5', 'Â\xa0', 'Mexico']
['Bar Au Chocolat', 'Sambirano', '983', '2012', '70%', 'U.S.A.', '3.75', 'Trinitario', 'Madagascar']
["Baravelli's", 'single estate', '955', '2012', '80%', 'Wales', '2.75', 'Â\xa0', 'Costa Rica']
['Batch', 'Dominican Republic, Batch 3', '1840', '2016', '65%', 'U.S.A.', '3.5', 'Â\xa0', 'Domincan Republic']
['Batch', 'Brazil', '1868', '2016', '70%', 'U.S.A.', '3.75', 'Â\xa0', 'Brazil']
['Batch', 'Ecuador', '1880', '2016', '65%', 'U.S.A.', '3.25', 'Â\xa0', 'Ecuador']
['Beau Cacao', 'Asajaya E, NW Borneo, b. #132/4500', '1948', '2017', '73%', 'U.K.', '3', 'Â\xa0', 'Malaysia']
['Beau Cacao', 'Serian E., NW Borneo, b. #134/3800', '1948', '2017', '72%', 'U.K.', '3.25', 'Â\xa0', 'Malaysia']
['Beehive', 'Brazil, Batch 20316', '1784', '2016', '80%', 'U.S.A.', '2.75', 'Â\xa0', 'Brazil']
['Beehive', 'Dominican Republic, Batch 31616', '1784', '2016', '70%', 'U.S.A.', '2.75', 'Â\xa0', 'Domincan Republic']
['Beehive', 'Ecuador, Batch 31516', '1784', '2016', '70%', 'U.S.A.', '2.75', 'Â\xa0', 'Ecuador']
['Beehive', 'Ecuador', '1788', '2016', '90%', 'U.S.A.', '2.75', 'Â\xa0', 'Ecuador']
['Belcolade', 'Costa Rica', '586', '2010', '64%', 'Belgium', '2.75', 'Â\xa0', 'Costa Rica']
['Belcolade', 'Papua New Guinea', '586', '2010', '64%', 'Belgium', '2.75', 'Â\xa0', 'Papua New Guinea']
['Belcolade', 'Peru', '586', '2010', '64%', 'Belgium', '2.75', 'Â\xa0', 'Peru']
['Belcolade', 'Ecuador', '586', '2010', '71%', 'Belgium', '3.5', 'Â\xa0', 'Ecuador']
['Bellflower', 'Kakao Kamili, Kilombero Valley', '1800', '2016', '70%', 'U.S.A.', '3.5', 'Criollo, Trinitario', 'Tanzania']
['Bellflower', 'Alto Beni, Palos Blanco', '1804', '2016', '70%', 'U.S.A.', '3.25', 'Â\xa0', 'Bolivia']
['Vintage Plantations (Tulicorp)', 'Los Rios, Rancho Grande 2007', '153', '2007', '65%', 'U.S.A.', '3', 'Forastero (Arriba)', 'Ecuador']
['Violet Sky', 'Sambirano Valley', '1458', '2015', '77%', 'U.S.A.', '2.75', 'Trinitario', 'Madagascar']
['Wm', 'Wild Beniano, 2016, batch 128, Heirloom', '1912', '2016', '76%', 'U.S.A.', '3.5', 'Â\xa0', 'Bolivia']
['Wm', 'Ghana, 2013, batch 129', '1916', '2016', '75%', 'U.S.A.', '3.75', 'Â\xa0', 'Ghana']
['Woodblock', 'La Red', '769', '2011', '70%', 'U.S.A.', '3.5', 'Â\xa0', 'Dominican Republic']
['Xocolat', 'Hispaniola', '1057', '2013', '66%', 'Domincan Republic', '3', 'Â\xa0', 'Dominican Republic']
['Xocolla', 'Sambirano, batch 170102', '1948', '2017', '70%', 'U.S.A.', '2.75', 'Â\xa0', 'Madagascar']
['Xocolla', 'Hispaniola, batch 170104', '1948', '2017', '70%', 'U.S.A.', '2.5', 'Â\xa0', 'Dominican Republic']
['Zart Pralinen', 'UNOCACE', '1824', '2016', '70%', 'Austria', '2.75', 'Nacional (Arriba)', 'Ecuador']
['Zart Pralinen', 'San Juan Estate', '1824', '2016', '85%', 'Austria', '2.75', 'Trinitario', 'Trinidad']
['Zokoko', 'Guadalcanal', '1716', '2016', '78%', 'Australia', '3.75', 'Â\xa0', 'Solomon Islands']
CSV 文件的每一行都形成一个列表,其中的每一项都可以方便地访问,如下所示:
import csv
with open('chocolate.csv') as f:
reader = csv.reader(f, delimiter=',')
for row in reader:
print("The {} company is located in {}.".format(row[0], row[5]))
The Company company is located in Company Location.
The A. Morin company is located in France.
The A. Morin company is located in France.
The A. Morin company is located in France.
The A. Morin company is located in France.
The Acalli company is located in U.S.A..
The Acalli company is located in U.S.A..
The Adi company is located in Fiji.
The Adi company is located in Fiji.
The Adi company is located in Fiji.
The Adi company is located in Fiji.
The Aequare (Gianduja) company is located in Ecuador.
The Aequare (Gianduja) company is located in Ecuador.
The Ah Cacao company is located in Mexico.
The Akesson's (Pralus) company is located in Switzerland.
The Akesson's (Pralus) company is located in Switzerland.
The Akesson's (Pralus) company is located in Switzerland.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alexandre company is located in Netherlands.
The Alexandre company is located in Netherlands.
The Alexandre company is located in Netherlands.
The Alexandre company is located in Netherlands.
The Altus aka Cao Artisan company is located in U.S.A..
The Altus aka Cao Artisan company is located in U.S.A..
The Altus aka Cao Artisan company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amatller (Simon Coll) company is located in Spain.
The Amatller (Simon Coll) company is located in Spain.
The Amatller (Simon Coll) company is located in Spain.
The Amatller (Simon Coll) company is located in Spain.
The Amazona company is located in Peru.
The Ambrosia company is located in Canada.
The Ambrosia company is located in Canada.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The Anahata company is located in U.S.A..
The Animas company is located in U.S.A..
The Ara company is located in France.
The Ara company is located in France.
The Arete company is located in U.S.A..
The Artisan du Chocolat company is located in U.K..
The Artisan du Chocolat (Casa Luker) company is located in U.K..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Bahen & Co. company is located in Australia.
The Bakau company is located in Peru.
The Bakau company is located in Peru.
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Baravelli's company is located in Wales.
The Batch company is located in U.S.A..
The Batch company is located in U.S.A..
The Batch company is located in U.S.A..
The Beau Cacao company is located in U.K..
The Beau Cacao company is located in U.K..
The Beehive company is located in U.S.A..
The Beehive company is located in U.S.A..
The Beehive company is located in U.S.A..
The Beehive company is located in U.S.A..
The Belcolade company is located in Belgium.
The Belcolade company is located in Belgium.
The Belcolade company is located in Belgium.
The Belcolade company is located in Belgium.
The Bellflower company is located in U.S.A..
The Bellflower company is located in U.S.A..
The Vintage Plantations (Tulicorp) company is located in U.S.A..
The Violet Sky company is located in U.S.A..
The Wm company is located in U.S.A..
The Wm company is located in U.S.A..
The Woodblock company is located in U.S.A..
The Xocolat company is located in Domincan Republic.
The Xocolla company is located in U.S.A..
The Xocolla company is located in U.S.A..
The Zart Pralinen company is located in Austria.
The Zart Pralinen company is located in Austria.
The Zokoko company is located in Australia.
可以使用列名而不是使用它们的索引,这对开发人员来说通常更方便。在这种情况下,我们不使用reader()方法,而是使用返回字典对象集合的DictReader()方法。让我们来试试:
import csv
with open('chocolate.csv') as f:
dict_reader = csv.DictReader(f, delimiter=',')
for row in dict_reader:
print("The {} company is located in {}.".format(row['Company'], row['Company Location']))
The A. Morin company is located in France.
The A. Morin company is located in France.
The A. Morin company is located in France.
The A. Morin company is located in France.
The Acalli company is located in U.S.A..
The Acalli company is located in U.S.A..
The Adi company is located in Fiji.
The Adi company is located in Fiji.
The Adi company is located in Fiji.
The Adi company is located in Fiji.
The Aequare (Gianduja) company is located in Ecuador.
The Aequare (Gianduja) company is located in Ecuador.
The Ah Cacao company is located in Mexico.
The Akesson's (Pralus) company is located in Switzerland.
The Akesson's (Pralus) company is located in Switzerland.
The Akesson's (Pralus) company is located in Switzerland.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alain Ducasse company is located in France.
The Alexandre company is located in Netherlands.
The Alexandre company is located in Netherlands.
The Alexandre company is located in Netherlands.
The Alexandre company is located in Netherlands.
The Altus aka Cao Artisan company is located in U.S.A..
The Altus aka Cao Artisan company is located in U.S.A..
The Altus aka Cao Artisan company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amano company is located in U.S.A..
The Amatller (Simon Coll) company is located in Spain.
The Amatller (Simon Coll) company is located in Spain.
The Amatller (Simon Coll) company is located in Spain.
The Amatller (Simon Coll) company is located in Spain.
The Amazona company is located in Peru.
The Ambrosia company is located in Canada.
The Ambrosia company is located in Canada.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The Amedei company is located in Italy.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The AMMA company is located in Brazil.
The Anahata company is located in U.S.A..
The Animas company is located in U.S.A..
The Ara company is located in France.
The Ara company is located in France.
The Arete company is located in U.S.A..
The Artisan du Chocolat company is located in U.K..
The Artisan du Chocolat (Casa Luker) company is located in U.K..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Askinosie company is located in U.S.A..
The Bahen & Co. company is located in Australia.
The Bakau company is located in Peru.
The Bakau company is located in Peru.
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Bar Au Chocolat company is located in U.S.A..
The Baravelli's company is located in Wales.
The Batch company is located in U.S.A..
The Batch company is located in U.S.A..
The Batch company is located in U.S.A..
The Beau Cacao company is located in U.K..
The Beau Cacao company is located in U.K..
The Beehive company is located in U.S.A..
The Beehive company is located in U.S.A..
The Beehive company is located in U.S.A..
The Beehive company is located in U.S.A..
The Belcolade company is located in Belgium.
The Belcolade company is located in Belgium.
The Belcolade company is located in Belgium.
The Belcolade company is located in Belgium.
The Bellflower company is located in U.S.A..
The Bellflower company is located in U.S.A..
The Vintage Plantations (Tulicorp) company is located in U.S.A..
The Violet Sky company is located in U.S.A..
The Wm company is located in U.S.A..
The Wm company is located in U.S.A..
The Woodblock company is located in U.S.A..
The Xocolat company is located in Domincan Republic.
The Xocolla company is located in U.S.A..
The Xocolla company is located in U.S.A..
The Zart Pralinen company is located in Austria.
The Zart Pralinen company is located in Austria.
The Zokoko company is located in Australia.
读取 JSON 文件
我们主要用于存储和交换数据的另一种流行的文件格式是 JSON。JSON 代表 JavaScript 对象符号,它允许我们用逗号分隔的键值对来存储数据。
在这一节中,我们将加载一个 JSON 文件,并将其作为一个 JSON 对象使用,而不是作为一个文本文件。为此,我们需要导入 JSON 模块。然后,在with上下文管理器中,我们使用属于json对象的load()方法。它加载文件的内容,并将其作为字典存储在context变量中。让我们试一试,但是在运行代码之前,下载 movie.json 文件,放在当前工作目录下。
import json
with open('movie.json') as f:
content = json.load(f)
print(content)
{'Title': 'Bicentennial Man', 'Release Date': 'Dec 17 1999', 'MPAA Rating': 'PG', 'Running Time min': 132, 'Distributor': 'Walt Disney Pictures', 'Source': 'Based on Book/Short Story', 'Major Genre': 'Drama', 'Creative Type': 'Science Fiction', 'Director': 'Chris Columbus', 'Rotten Tomatoes Rating': 38, 'IMDB Rating': 6.4, 'IMDB Votes': 28827}
让我们检查一下content变量的数据类型:
print(type(content))
<class 'dict'>
它的数据类型是字典。所以我们可以用它的键访问存储在 JSON 文件中的每一条信息。让我们看看如何从中检索数据:
print('{} directed by {}'.format(content['Title'], content['Director']))
Bicentennial Man directed by Chris Columbus
结论
本教程讨论了 Python 中的文件处理,重点是读取文件的内容。您了解了 open()内置函数、带有上下文管理器的,以及如何读取常见的文件类型,如文本、CSV 和 JSON。
如何在 Python 中读取 Excel 文件(带有 21 个代码示例)
August 9, 2022
Microsoft Excel 是世界上最强大的电子表格软件应用程序之一,它已经成为所有业务流程中的关键。世界各地的公司,无论大小,都在使用 Microsoft Excel 来存储、组织、分析和可视化数据。
作为一名数据专业人员,当您将 Python 与 Excel 相结合时,您创建了一个独特的数据分析包,释放了企业数据的价值。
在本教程中,我们将学习如何在 Python 中读取和处理 Excel 文件。
完成本教程后,您将理解以下内容:
- 将 Excel 电子表格加载到 pandas 数据框架中
- 使用包含多个电子表格的 Excel 工作簿
- 组合多个电子表格
- 使用
xlrd包读取 Excel 文件
在本教程中,我们假设你知道熊猫数据框架的基本原理。如果你不熟悉熊猫图书馆,你可能想试试我们的熊猫和 NumPy 基础——data quest。
让我们开始吧。
和熊猫一起阅读电子表格
从技术上讲,多个包允许我们在 Python 中处理 Excel 文件。然而,在本教程中,我们将使用 pandas 和xlrd库与 Excel 工作簿进行交互。本质上,您可以将 pandas 数据帧视为一个电子表格,其中的行和列存储在 Series 对象中。作为可迭代对象的系列的可遍历性允许我们容易地获取特定的数据。一旦我们将 Excel 工作簿加载到 pandas 数据框架中,我们就可以对数据执行任何类型的数据分析。
在我们进行下一步之前,让我们先下载下面的电子表格:
Excel 工作簿由两张包含 2020 年和 2021 年文具销售数据的工作表组成。
注
虽然 Excel 电子表格可以包含公式,也支持格式,但 pandas 只将 Excel 电子表格作为平面文件导入,它不支持电子表格格式。
要将 Excel 电子表格导入 pandas 数据框架,首先,我们需要导入 pandas 包,然后使用read_excel()方法:
import pandas as pd
df = pd.read_excel('sales_data.xlsx')
display(df)
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | 铅笔 | Ninety-five | One point nine nine | One hundred and eighty-nine point zero five | 真实的 |
| one | 2020-02-09 | 中心的 | 怡和 | 铅笔 | Thirty-six | Four point nine nine | One hundred and seventy-nine point six four | 真实的 |
| Two | 2020-03-15 | 西 | 索尔维诺 | 铅笔 | fifty-six | Two point nine nine | One hundred and sixty-seven point four four | 真实的 |
| three | 2020-04-01 | 东方 | 琼斯 | 粘合剂 | Sixty | Four point nine nine | Two hundred and ninety-nine point four | 错误的 |
| four | 2020-05-05 | 中心的 | 怡和 | 铅笔 | Ninety | Four point nine nine | Four hundred and forty-nine point one | 真实的 |
| five | 2020-06-08 | 东方 | 琼斯 | 粘合剂 | Sixty | Eight point nine nine | Five hundred and thirty-nine point four | 真实的 |
| six | 2020-07-12 | 东方 | 霍华德 | 粘合剂 | Twenty-nine | One point nine nine | Fifty-seven point seven one | 错误的 |
| seven | 2020-08-15 | 东方 | 琼斯 | 铅笔 | Thirty-five | Four point nine nine | One hundred and seventy-four point six five | 真实的 |
| eight | 2020-09-01 | 中心的 | 史密斯(姓氏) | 书桌 | Thirty-two | One hundred and twenty-five | Two hundred and fifty | 真实的 |
| nine | 2020-10-05 | 中心的 | 摩根 | 粘合剂 | Twenty-eight | Eight point nine nine | Two hundred and fifty-one point seven two | 真实的 |
| Ten | 2020-11-08 | 东方 | 迈克 | 笔 | Fifteen | Nineteen point nine nine | Two hundred and ninety-nine point eight five | 错误的 |
| Eleven | 2020-12-12 | 中心的 | 史密斯(姓氏) | 铅笔 | Sixty-seven | One point two nine | Eighty-six point four three | 错误的 |
如果只想将有限数量的行加载到 DataFrame 中,可以使用nrows参数指定行数:
df = pd.read_excel('sales_data.xlsx', nrows=5)
display(df)
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | 铅笔 | Ninety-five | One point nine nine | One hundred and eighty-nine point zero five | 真实的 |
| one | 2020-02-09 | 中心的 | 怡和 | 铅笔 | Thirty-six | Four point nine nine | One hundred and seventy-nine point six four | 真实的 |
| Two | 2020-03-15 | 西 | 索尔维诺 | 铅笔 | fifty-six | Two point nine nine | One hundred and sixty-seven point four four | 真实的 |
| three | 2020-04-01 | 东方 | 琼斯 | 粘合剂 | Sixty | Four point nine nine | Two hundred and ninety-nine point four | 错误的 |
| four | 2020-05-05 | 中心的 | 怡和 | 铅笔 | Ninety | Four point nine nine | Four hundred and forty-nine point one | 真实的 |
通过skiprows参数可以从电子表格的开头跳过特定数量的行或跳过特定行的列表,如下所示:
df = pd.read_excel('sales_data.xlsx', skiprows=range(5))
display(df)
| 2020-05-05 00:00:00 | 中心的 | 怡和 | 铅笔 | Ninety | Four point nine nine | Four hundred and forty-nine point one | 真实的 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2020-06-08 | 东方 | 琼斯 | 粘合剂 | Sixty | Eight point nine nine | Five hundred and thirty-nine point four | 真实的 |
| one | 2020-07-12 | 东方 | 霍华德 | 粘合剂 | Twenty-nine | One point nine nine | Fifty-seven point seven one | 错误的 |
| Two | 2020-08-15 | 东方 | 琼斯 | 铅笔 | Thirty-five | Four point nine nine | One hundred and seventy-four point six five | 真实的 |
| three | 2020-09-01 | 中心的 | 史密斯(姓氏) | 书桌 | Thirty-two | One hundred and twenty-five | Two hundred and fifty | 真实的 |
| four | 2020-10-05 | 中心的 | 摩根 | 粘合剂 | Twenty-eight | Eight point nine nine | Two hundred and fifty-one point seven two | 真实的 |
| five | 2020-11-08 | 东方 | 迈克 | 笔 | Fifteen | Nineteen point nine nine | Two hundred and ninety-nine point eight five | 错误的 |
| six | 2020-12-12 | 中心的 | 史密斯(姓氏) | 铅笔 | Sixty-seven | One point two nine | Eighty-six point four three | 错误的 |
上面的代码跳过前五行,返回其余的数据。相反,下面的代码返回除具有上述索引的行之外的所有行:
df = pd.read_excel('sales_data.xlsx', skiprows=[1, 4,7,10])
display(df)
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2020-02-09 | 中心的 | 怡和 | 铅笔 | Thirty-six | Four point nine nine | One hundred and seventy-nine point six four | 真实的 |
| one | 2020-03-15 | 西 | 索尔维诺 | 铅笔 | fifty-six | Two point nine nine | One hundred and sixty-seven point four four | 真实的 |
| Two | 2020-05-05 | 中心的 | 怡和 | 铅笔 | Ninety | Four point nine nine | Four hundred and forty-nine point one | 真实的 |
| three | 2020-06-08 | 东方 | 琼斯 | 粘合剂 | Sixty | Eight point nine nine | Five hundred and thirty-nine point four | 真实的 |
| four | 2020-08-15 | 东方 | 琼斯 | 铅笔 | Thirty-five | Four point nine nine | One hundred and seventy-four point six five | 真实的 |
| five | 2020-09-01 | 中心的 | 史密斯(姓氏) | 书桌 | Thirty-two | One hundred and twenty-five | Two hundred and fifty | 真实的 |
| six | 2020-11-08 | 东方 | 迈克 | 笔 | Fifteen | Nineteen point nine nine | Two hundred and ninety-nine point eight five | 错误的 |
| seven | 2020-12-12 | 中心的 | 史密斯(姓氏) | 铅笔 | Sixty-seven | One point two nine | Eighty-six point four three | 错误的 |
另一个有用的参数是usecols,它允许我们选择带有字母、名称或位置数字的电子表格列。让我们看看它是如何工作的:
df = pd.read_excel('sales_data.xlsx', usecols='A:C,G')
display(df)
| 订单日期 | 地区 | 代表 | 总数 | |
|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | One hundred and eighty-nine point zero five |
| one | 2020-02-09 | 中心的 | 怡和 | One hundred and seventy-nine point six four |
| Two | 2020-03-15 | 西 | 索尔维诺 | One hundred and sixty-seven point four four |
| three | 2020-04-01 | 东方 | 琼斯 | Two hundred and ninety-nine point four |
| four | 2020-05-05 | 中心的 | 怡和 | Four hundred and forty-nine point one |
| five | 2020-06-08 | 东方 | 琼斯 | Five hundred and thirty-nine point four |
| six | 2020-07-12 | 东方 | 霍华德 | Fifty-seven point seven one |
| seven | 2020-08-15 | 东方 | 琼斯 | One hundred and seventy-four point six five |
| eight | 2020-09-01 | 中心的 | 史密斯(姓氏) | Two hundred and fifty |
| nine | 2020-10-05 | 中心的 | 摩根 | Two hundred and fifty-one point seven two |
| Ten | 2020-11-08 | 东方 | 迈克 | Two hundred and ninety-nine point eight five |
| Eleven | 2020-12-12 | 中心的 | 史密斯(姓氏) | Eighty-six point four three |
在上面的代码中,分配给参数usecols的字符串包含一系列列,其中:加上由逗号分隔的列 G。此外,我们能够提供一个列名列表,并将其分配给usecols参数,如下所示:
df = pd.read_excel('sales_data.xlsx', usecols=['OrderDate', 'Region', 'Rep', 'Total'])
display(df)
| 订单日期 | 地区 | 代表 | 总数 | |
|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | One hundred and eighty-nine point zero five |
| one | 2020-02-09 | 中心的 | 怡和 | One hundred and seventy-nine point six four |
| Two | 2020-03-15 | 西 | 索尔维诺 | One hundred and sixty-seven point four four |
| three | 2020-04-01 | 东方 | 琼斯 | Two hundred and ninety-nine point four |
| four | 2020-05-05 | 中心的 | 怡和 | Four hundred and forty-nine point one |
| five | 2020-06-08 | 东方 | 琼斯 | Five hundred and thirty-nine point four |
| six | 2020-07-12 | 东方 | 霍华德 | Fifty-seven point seven one |
| seven | 2020-08-15 | 东方 | 琼斯 | One hundred and seventy-four point six five |
| eight | 2020-09-01 | 中心的 | 史密斯(姓氏) | Two hundred and fifty |
| nine | 2020-10-05 | 中心的 | 摩根 | Two hundred and fifty-one point seven two |
| Ten | 2020-11-08 | 东方 | 迈克 | Two hundred and ninety-nine point eight five |
| Eleven | 2020-12-12 | 中心的 | 史密斯(姓氏) | Eighty-six point four three |
usecols参数也接受列号列表。以下代码显示了我们如何使用特定列的索引来选取它们:
df = pd.read_excel('sales_data.xlsx', usecols=[0, 1, 2, 6])
display(df)
| 订单日期 | 地区 | 代表 | 总数 | |
|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | One hundred and eighty-nine point zero five |
| one | 2020-02-09 | 中心的 | 怡和 | One hundred and seventy-nine point six four |
| Two | 2020-03-15 | 西 | 索尔维诺 | One hundred and sixty-seven point four four |
| three | 2020-04-01 | 东方 | 琼斯 | Two hundred and ninety-nine point four |
| four | 2020-05-05 | 中心的 | 怡和 | Four hundred and forty-nine point one |
| five | 2020-06-08 | 东方 | 琼斯 | Five hundred and thirty-nine point four |
| six | 2020-07-12 | 东方 | 霍华德 | Fifty-seven point seven one |
| seven | 2020-08-15 | 东方 | 琼斯 | One hundred and seventy-four point six five |
| eight | 2020-09-01 | 中心的 | 史密斯(姓氏) | Two hundred and fifty |
| nine | 2020-10-05 | 中心的 | 摩根 | Two hundred and fifty-one point seven two |
| Ten | 2020-11-08 | 东方 | 迈克 | Two hundred and ninety-nine point eight five |
| Eleven | 2020-12-12 | 中心的 | 史密斯(姓氏) | Eighty-six point four three |
使用多个电子表格
Excel 文件或工作簿通常包含多个电子表格。pandas 库允许我们从特定的工作表中加载数据,或者将多个电子表格合并成一个数据帧。在本节中,我们将探索如何使用这些有价值的功能。
默认情况下,read_excel()方法读取索引为0的第一个 Excel 工作表。然而,我们可以通过给sheet_name参数指定一个特定的工作表名称、工作表索引,甚至是工作表名称或索引的列表来选择其他工作表。让我们来试试:
df = pd.read_excel('sales_data.xlsx', sheet_name='2021')
display(df)
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2021-01-15 | 中心的 | 吉尔 | 粘合剂 | Forty-six | Eight point nine nine | Four hundred and thirteen point five four | 真实的 |
| one | 2021-02-01 | 中心的 | 史密斯(姓氏) | 粘合剂 | Eighty-seven | Fifteen | One thousand three hundred and five | 真实的 |
| Two | 2021-03-07 | 西 | 索尔维诺 | 粘合剂 | Twenty-seven | Nineteen point nine nine | One hundred and thirty-nine point nine three | 真实的 |
| three | 2021-04-10 | 中心的 | 安德鲁斯 | 铅笔 | Sixty-six | One point nine nine | One hundred and thirty-one point three four | 错误的 |
| four | 2021-05-14 | 中心的 | 吉尔 | 铅笔 | Fifty-three | One point two nine | Sixty-eight point three seven | 错误的 |
| five | 2021-06-17 | 中心的 | 汤姆(男子名) | 书桌 | Fifteen | One hundred and twenty-five | Six hundred and twenty-five | 真实的 |
| six | 2021-07-04 | 东方 | 琼斯 | 钢笔套装 | Sixty-two | Four point nine nine | Three hundred and nine point three eight | 真实的 |
| seven | 2021-08-07 | 中心的 | 汤姆(男子名) | 钢笔套装 | forty-two | Twenty-three point nine five | One thousand and five point nine | 真实的 |
| eight | 2021-09-10 | 中心的 | 吉尔 | 铅笔 | Forty-seven | One point two nine | Nine point zero three | 真实的 |
| nine | 2021-10-14 | 西 | 汤普森 | 粘合剂 | Fifty-seven | Nineteen point nine nine | One thousand one hundred and thirty-nine point four three | 错误的 |
| Ten | 2021-11-17 | 中心的 | 怡和 | 粘合剂 | Eleven | Four point nine nine | Fifty-four point eight nine | 错误的 |
| Eleven | 2021-12-04 | 中心的 | 怡和 | 粘合剂 | Ninety-four | Nineteen point nine nine | One thousand eight hundred and seventy-nine point zero six | 错误的 |
上面的代码读取工作簿中的第二个电子表格,其名称是2021。如前所述,我们还可以给sheet_name参数分配一个工作表位置号(零索引)。让我们看看它是如何工作的:
df = pd.read_excel('sales_data.xlsx', sheet_name=1)
display(df)
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2021-01-15 | 中心的 | 吉尔 | 粘合剂 | Forty-six | Eight point nine nine | Four hundred and thirteen point five four | 真实的 |
| one | 2021-02-01 | 中心的 | 史密斯(姓氏) | 粘合剂 | Eighty-seven | Fifteen | One thousand three hundred and five | 真实的 |
| Two | 2021-03-07 | 西 | 索尔维诺 | 粘合剂 | Twenty-seven | Nineteen point nine nine | One hundred and thirty-nine point nine three | 真实的 |
| three | 2021-04-10 | 中心的 | 安德鲁斯 | 铅笔 | Sixty-six | One point nine nine | One hundred and thirty-one point three four | 错误的 |
| four | 2021-05-14 | 中心的 | 吉尔 | 铅笔 | Fifty-three | One point two nine | Sixty-eight point three seven | 错误的 |
| five | 2021-06-17 | 中心的 | 汤姆(男子名) | 书桌 | Fifteen | One hundred and twenty-five | Six hundred and twenty-five | 真实的 |
| six | 2021-07-04 | 东方 | 琼斯 | 钢笔套装 | Sixty-two | Four point nine nine | Three hundred and nine point three eight | 真实的 |
| seven | 2021-08-07 | 中心的 | 汤姆(男子名) | 钢笔套装 | forty-two | Twenty-three point nine five | One thousand and five point nine | 真实的 |
| eight | 2021-09-10 | 中心的 | 吉尔 | 铅笔 | Forty-seven | One point two nine | Nine point zero three | 真实的 |
| nine | 2021-10-14 | 西 | 汤普森 | 粘合剂 | Fifty-seven | Nineteen point nine nine | One thousand one hundred and thirty-nine point four three | 错误的 |
| Ten | 2021-11-17 | 中心的 | 怡和 | 粘合剂 | Eleven | Four point nine nine | Fifty-four point eight nine | 错误的 |
| Eleven | 2021-12-04 | 中心的 | 怡和 | 粘合剂 | Ninety-four | Nineteen point nine nine | One thousand eight hundred and seventy-nine point zero six | 错误的 |
如您所见,这两条语句要么接受实际的工作表名称,要么接受工作表索引,以返回相同的结果。
有时,我们希望将存储在 Excel 文件中的所有电子表格同时导入到 pandas 数据框架中。好消息是read_excel()方法为我们提供了这个特性。为了做到这一点,我们可以给参数sheet_name分配一个工作表名称列表或它们的索引。但是有一个简单得多的方法可以做到这一点:将None赋给sheet_name参数。让我们来试试:
all_sheets = pd.read_excel('sales_data.xlsx', sheet_name=None)
在探索存储在all_sheets变量中的数据之前,让我们检查一下它的数据类型:
type(all_sheets)
dict
如您所见,该变量是一个字典。现在,让我们来揭示这本字典里储存了什么:
for key, value in all_sheets.items():
print(key, type(value))
2020 <class 'pandas.core.frame.DataFrame'>
2021 <class 'pandas.core.frame.DataFrame'>
上面的代码显示字典的键是 Excel 工作簿的工作表名称,它的值是每个电子表格的 pandas DataFrames。要打印出字典的内容,我们可以使用下面的代码:
for key, value in all_sheets.items():
print(key)
display(value)
2020
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | 铅笔 | Ninety-five | One point nine nine | One hundred and eighty-nine point zero five | 真实的 |
| one | 2020-02-09 | 中心的 | 怡和 | 铅笔 | Thirty-six | Four point nine nine | One hundred and seventy-nine point six four | 真实的 |
| Two | 2020-03-15 | 西 | 索尔维诺 | 铅笔 | fifty-six | Two point nine nine | One hundred and sixty-seven point four four | 真实的 |
| three | 2020-04-01 | 东方 | 琼斯 | 粘合剂 | Sixty | Four point nine nine | Two hundred and ninety-nine point four | 错误的 |
| four | 2020-05-05 | 中心的 | 怡和 | 铅笔 | Ninety | Four point nine nine | Four hundred and forty-nine point one | 真实的 |
| five | 2020-06-08 | 东方 | 琼斯 | 粘合剂 | Sixty | Eight point nine nine | Five hundred and thirty-nine point four | 真实的 |
| six | 2020-07-12 | 东方 | 霍华德 | 粘合剂 | Twenty-nine | One point nine nine | Fifty-seven point seven one | 错误的 |
| seven | 2020-08-15 | 东方 | 琼斯 | 铅笔 | Thirty-five | Four point nine nine | One hundred and seventy-four point six five | 真实的 |
| eight | 2020-09-01 | 中心的 | 史密斯(姓氏) | 书桌 | Thirty-two | One hundred and twenty-five | Two hundred and fifty | 真实的 |
| nine | 2020-10-05 | 中心的 | 摩根 | 粘合剂 | Twenty-eight | Eight point nine nine | Two hundred and fifty-one point seven two | 真实的 |
| Ten | 2020-11-08 | 东方 | 迈克 | 笔 | Fifteen | Nineteen point nine nine | Two hundred and ninety-nine point eight five | 错误的 |
| Eleven | 2020-12-12 | 中心的 | 史密斯(姓氏) | 铅笔 | Sixty-seven | One point two nine | Eighty-six point four three | 错误的 |
2021
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2021-01-15 | 中心的 | 吉尔 | 粘合剂 | Forty-six | Eight point nine nine | Four hundred and thirteen point five four | 真实的 |
| one | 2021-02-01 | 中心的 | 史密斯(姓氏) | 粘合剂 | Eighty-seven | Fifteen | One thousand three hundred and five | 真实的 |
| Two | 2021-03-07 | 西 | 索尔维诺 | 粘合剂 | Twenty-seven | Nineteen point nine nine | One hundred and thirty-nine point nine three | 真实的 |
| three | 2021-04-10 | 中心的 | 安德鲁斯 | 铅笔 | Sixty-six | One point nine nine | One hundred and thirty-one point three four | 错误的 |
| four | 2021-05-14 | 中心的 | 吉尔 | 铅笔 | Fifty-three | One point two nine | Sixty-eight point three seven | 错误的 |
| five | 2021-06-17 | 中心的 | 汤姆(男子名) | 书桌 | Fifteen | One hundred and twenty-five | Six hundred and twenty-five | 真实的 |
| six | 2021-07-04 | 东方 | 琼斯 | 钢笔套装 | Sixty-two | Four point nine nine | Three hundred and nine point three eight | 真实的 |
| seven | 2021-08-07 | 中心的 | 汤姆(男子名) | 钢笔套装 | forty-two | Twenty-three point nine five | One thousand and five point nine | 真实的 |
| eight | 2021-09-10 | 中心的 | 吉尔 | 铅笔 | Forty-seven | One point two nine | Nine point zero three | 真实的 |
| nine | 2021-10-14 | 西 | 汤普森 | 粘合剂 | Fifty-seven | Nineteen point nine nine | One thousand one hundred and thirty-nine point four three | 错误的 |
| Ten | 2021-11-17 | 中心的 | 怡和 | 粘合剂 | Eleven | Four point nine nine | Fifty-four point eight nine | 错误的 |
| Eleven | 2021-12-04 | 中心的 | 怡和 | 粘合剂 | Ninety-four | Nineteen point nine nine | One thousand eight hundred and seventy-nine point zero six | 错误的 |
将多个 Excel 电子表格合并成一个 Pandas 数据框架
每张表有一个数据帧,允许我们在不同的表中有不同的列或内容。
但是,如果我们更喜欢将所有电子表格的数据存储在一个数据帧中呢?在本教程中,工作簿电子表格具有相同的列,因此我们可以将它们与 pandas 的concat()方法结合起来。
如果运行下面的代码,您会看到存储在字典中的两个数据帧被连接起来:
combined_df = pd.concat(all_sheets.values(), ignore_index=True)
display(combined_df)
| 订单日期 | 地区 | 代表 | 项目 | 单位 | 单位成本 | 总数 | 装船 | |
|---|---|---|---|---|---|---|---|---|
| Zero | 2020-01-06 | 东方 | 琼斯 | 铅笔 | Ninety-five | One point nine nine | One hundred and eighty-nine point zero five | 真实的 |
| one | 2020-02-09 | 中心的 | 怡和 | 铅笔 | Thirty-six | Four point nine nine | One hundred and seventy-nine point six four | 真实的 |
| Two | 2020-03-15 | 西 | 索尔维诺 | 铅笔 | fifty-six | Two point nine nine | One hundred and sixty-seven point four four | 真实的 |
| three | 2020-04-01 | 东方 | 琼斯 | 粘合剂 | Sixty | Four point nine nine | Two hundred and ninety-nine point four | 错误的 |
| four | 2020-05-05 | 中心的 | 怡和 | 铅笔 | Ninety | Four point nine nine | Four hundred and forty-nine point one | 真实的 |
| five | 2020-06-08 | 东方 | 琼斯 | 粘合剂 | Sixty | Eight point nine nine | Five hundred and thirty-nine point four | 真实的 |
| six | 2020-07-12 | 东方 | 霍华德 | 粘合剂 | Twenty-nine | One point nine nine | Fifty-seven point seven one | 错误的 |
| seven | 2020-08-15 | 东方 | 琼斯 | 铅笔 | Thirty-five | Four point nine nine | One hundred and seventy-four point six five | 真实的 |
| eight | 2020-09-01 | 中心的 | 史密斯(姓氏) | 书桌 | Thirty-two | One hundred and twenty-five | Two hundred and fifty | 真实的 |
| nine | 2020-10-05 | 中心的 | 摩根 | 粘合剂 | Twenty-eight | Eight point nine nine | Two hundred and fifty-one point seven two | 真实的 |
| Ten | 2020-11-08 | 东方 | 迈克 | 笔 | Fifteen | Nineteen point nine nine | Two hundred and ninety-nine point eight five | 错误的 |
| Eleven | 2020-12-12 | 中心的 | 史密斯(姓氏) | 铅笔 | Sixty-seven | One point two nine | Eighty-six point four three | 错误的 |
| Twelve | 2021-01-15 | 中心的 | 吉尔 | 粘合剂 | Forty-six | Eight point nine nine | Four hundred and thirteen point five four | 真实的 |
| Thirteen | 2021-02-01 | 中心的 | 史密斯(姓氏) | 粘合剂 | Eighty-seven | Fifteen | One thousand three hundred and five | 真实的 |
| Fourteen | 2021-03-07 | 西 | 索尔维诺 | 粘合剂 | Twenty-seven | Nineteen point nine nine | One hundred and thirty-nine point nine three | 真实的 |
| Fifteen | 2021-04-10 | 中心的 | 安德鲁斯 | 铅笔 | Sixty-six | One point nine nine | One hundred and thirty-one point three four | 错误的 |
| Sixteen | 2021-05-14 | 中心的 | 吉尔 | 铅笔 | Fifty-three | One point two nine | Sixty-eight point three seven | 错误的 |
| Seventeen | 2021-06-17 | 中心的 | 汤姆(男子名) | 书桌 | Fifteen | One hundred and twenty-five | Six hundred and twenty-five | 真实的 |
| Eighteen | 2021-07-04 | 东方 | 琼斯 | 钢笔套装 | Sixty-two | Four point nine nine | Three hundred and nine point three eight | 真实的 |
| Nineteen | 2021-08-07 | 中心的 | 汤姆(男子名) | 钢笔套装 | forty-two | Twenty-three point nine five | One thousand and five point nine | 真实的 |
| Twenty | 2021-09-10 | 中心的 | 吉尔 | 铅笔 | Forty-seven | One point two nine | Nine point zero three | 真实的 |
| Twenty-one | 2021-10-14 | 西 | 汤普森 | 粘合剂 | Fifty-seven | Nineteen point nine nine | One thousand one hundred and thirty-nine point four three | 错误的 |
| Twenty-two | 2021-11-17 | 中心的 | 怡和 | 粘合剂 | Eleven | Four point nine nine | Fifty-four point eight nine | 错误的 |
| Twenty-three | 2021-12-04 | 中心的 | 怡和 | 粘合剂 | Ninety-four | Nineteen point nine nine | One thousand eight hundred and seventy-nine point zero six | 错误的 |
现在存储在combined_df数据帧中的数据已准备好进一步处理或可视化。在下面这段代码中,我们将创建一个简单的条形图,显示每个代表的总销售额。让我们运行它,看看输出图:
total_sales_amount = combined_df.groupby('Rep').Total.sum()
total_sales_amount.plot.bar(figsize=(10, 6))
<xlabel>

使用xlrd读取 Excel 文件
尽管将数据导入 pandas DataFrame 要常见得多,但另一个用 Python 读取 Excel 文件的有用包是xlrd。在这一节中,我们将简单介绍如何使用这个包读取 Excel 电子表格。
注
由于潜在的安全漏洞,xlrd 包不支持 xlsx 文件。所以,我们使用xls版本的销售数据。您可以从下面的链接下载xls版本:
销售数据 Excel 工作簿–xls ver。
让我们看看它是如何工作的:
import xlrd
excel_workbook = xlrd.open_workbook('sales_data.xls')
上面,第一行导入了xlrd包,然后open_workbook方法读取了sales_data.xls文件。
我们也可以打开包含实际数据的单个工作表。有两种方法可以做到这一点:按索引或按名称打开工作表。让我们按索引打开第一个工作表,按名称打开第二个工作表:
excel_worksheet_2020 = excel_workbook.sheet_by_index(0)
excel_worksheet_2021 = excel_workbook.sheet_by_name('2021')
现在,让我们看看如何打印一个单元格的值。xlrd包提供了一个名为cell_value()的方法,它接受两个参数:单元格的行索引和列索引。让我们来探索一下:
print(excel_worksheet_2020.cell_value(1, 3))
Pencil
我们可以看到,cell_value函数返回了位于行索引 1(第 2 行)和列索引 3(第 4 列)的单元格的值。

xlrd包提供了两个有用的属性:nrows和ncols,分别返回非空电子表格的行数和列数:
print('Columns#:', excel_worksheet_2020.ncols)
print('Rows#:', excel_worksheet_2020.nrows)
Columns#: 8
Rows#: 13
知道电子表格中非空行和列的数量有助于我们使用嵌套的for循环来迭代数据。这使得所有的 Excel 表格数据都可以通过cell_value()方法访问。
结论
本教程讨论了如何将 Excel 电子表格加载到 pandas 数据框架中,如何处理多个 Excel 表格,以及如何将它们合并到一个 pandas 数据框架中。我们还探索了作为访问 Excel 电子表格数据的最简单工具之一的xlrd包的主要方面。
Python 技能的 11 个真实应用
原文:https://www.dataquest.io/blog/real-world-python-use-cases/
April 12, 2021
Python 是最常被推荐的编程语言之一。你可能听人说过,那是因为它相对容易学——这是真的!但是 Python 实际上有用吗?一旦你掌握了 Python 技能,它们在现实世界中有哪些应用?
在本帖中,我们将看看 Python 的一些最常见的用例。我们还将看看 Python 可能不是最佳选择的几种情况。
也就是说,记住 Python 是一种非常通用的语言是很重要的。人们用它做各种事情。我们将在这里讨论的广泛的真实世界用例实际上只是冰山一角!
现在谁在用 Python?
简短的回答是:数百万开发人员,以及许多其他人。2019 年的一项估计认为 Python 开发者的数量为 820 万。StackOverflow 的 2020 年开发人员调查将 Python 列为开发人员中最流行和广泛使用的语言之一。截至 2021 年 4 月,【Indeed.com】列出了近 10 万个需要 Python 的空缺职位。
当然,也有相当多的使用 Python 的人不会被这些统计和调查所捕获。Python 不仅仅被开发者使用!它被营销人员、研究人员、数据科学家、儿童、业余爱好者、It 专业人员和其他各种各样的人使用。你不必靠写 Python 来谋生,也可以从学习 Python 中获得一些真正的好处!
不过,在专业层面上,Python 非常有用。例如:
有哪些公司用 Python?
这里只是使用 Python 的一些公司的简短列表:
- 谷歌和像 Youtube 这样的子公司使用 Python 做各种各样的事情。事实上,Youtube 主要是用 Python 构建的!
- 工业光魔公司(Industrial Light and Magic)是《T2》、《星球大战》、《T3》和数百部其他电影的特效制作公司,多年来一直在使用 Python 进行 CGI 和灯光工作。
- 脸书和像 T2 insta gram 这样的子公司在他们的基础设施中使用 Python。Instagram 完全使用 Python 及其 Django 框架构建。
- 制造 Roomba 真空吸尘器的 iRobot 公司使用 Python 为他们的机器人开发软件。
- 美国国家航空航天局和相关机构如 T2 喷气推进实验室将 Python 用于研究和科学目的。
- 网飞使用 Python 进行服务器端数据分析和各种后端应用,帮助保持大规模流媒体服务在线。
- Reddit 运行在 Python 及其 web.py 框架上。
- IBM 、英特尔以及其他各种硬件公司都使用 Python 进行硬件测试。
- 大通、高盛和许多其他金融公司使用 Python 进行金融分析和市场预测。
- Quora 是另一个使用大量 Python 构建的大型社交媒体平台。
而这还只是冰山一角!事实上,现在大多数大公司可能都在某种程度上使用 Python。检查的一个好方法是搜索像 LinkedIn 这样的工作网站,或者搜索公司名称+ python。通常,你会发现公司在寻找拥有 Python 技能的人。
所以,大家都在用 Python。他们用 Python 做什么?让我们深入一些 Python 的实际应用程序。
Python 在现实世界中是如何使用的?
1.数据分析
随着各行各业的公司收集越来越多的数据,他们需要能够理解这些数据的人。通常,这意味着雇佣具备 Python 技能的数据分析师。
Python 在数据分析工作中很受欢迎,因为像 numpy 和 pandas 这样强大的库使得数据清理和分析任务相对简单,即使在处理大量数据集时也是如此。还有 Python 库支持各种各样的其他数据分析任务,从用漂亮的汤抓取网页到用 Matplotlib 可视化数据。
像 Jupyter Notebook 这样的软件工具使数据分析师可以轻松地创建易于重复的分析,或者添加文本和可视化内容,使他们的工作即使对于没有编码技能的人也可以理解。
示例用例:一个电子商务网站希望更好地了解其用户。公司的数据分析师可以使用 Python 来分析公司的销售情况,突出可预测的趋势,并发现需要改进的地方。
2.数据科学/“人工智能”
Python 在机器学习领域更高级的数据工作中也非常受欢迎。像 scikit-learn 和 TensorFlow 这样的强大库使得实现流行的机器学习算法变得非常简单,并且存在更多专门的库来帮助完成从图像识别到内容生成的各种特定的机器学习任务。
几乎你在新闻中看到的任何被讨论为“AI”的东西都是某种机器学习实现。很多机器学习都是用 Python 完成的。
示例用例:某视频流媒体平台希望提高用户参与度和粘性。数据科学团队可以使用 Python 建立一个预测模型,根据用户的观看历史、收视习惯、具有类似习惯的其他用户观看的视频等因素向用户推荐视频。
3.Web 开发
从上面的公司列表中可以看出,Python 是一种非常流行的 web 应用程序开发语言。您每天使用的许多网站都是使用 Python 和流行的 Python web 框架(如 Django 和 Flask)构建的。虽然页面本身是用 HTML 和 CSS 呈现的,但 Python 是许多网站上这些视觉元素的基础,驱动功能、管理数据库、用户帐户等等。
示例用例:一家公司需要建立一个具有特定功能的新版本网站。web 开发人员可以使用 Python 和 Django 构建新网站,利用它们提供的灵活性和强大功能来支持公司需要的任何特定或定制功能。
4.游戏开发
Python 被用于独立视频游戏的开发,这要归功于 PyGame 等便捷库的存在。(注意到一个模式?无论您的用例是什么,可能已经有一些 Python 库可以帮助您了)。
Python 在高预算游戏的开发中并不经常使用——如果你的目标是建立一个逼真的 3D 世界,Python 相对较慢的速度和相对较高的内存使用率意味着它不是最理想的语言。然而,Python 有时被用于构建这些游戏背后的系统。包括战地 2* 、 Eve Online 、模拟人生 3 、文明四、坦克世界在内的游戏都使用了 Python,虽然没有一款是完全用 Python 编码的。*
示例用例:一个小团队想要构建一个有创意的独立侧滚游戏。开发人员可以选择使用 Python 来利用 PyGame 的便利性,以及学习如何用 Python 做新事情的相对容易性。
5.软件开发
Python 被广泛用于软件开发,跨越了各种各样的现实世界的应用程序。如今,软件开发和 web 开发之间的界限有点模糊,因为几乎所有的软件都是为在 web 上工作而构建的,即使有桌面应用程序也是如此。Dropbox 是现代软件开发公司双管齐下的一个很好的例子,Python 被用来构建 Dropbox 的桌面应用。类似地,Spotify 同时拥有网络和桌面应用程序,Python 被用来构建许多后台服务,使它们能够工作。
当然,Python 也被许多公司用来开发内部软件工具。
示例用例:一家公司计划构建一个新的电子邮件客户端。开发人员选择使用 Python,因为他们知道他们能够使用 Python 及其相关库创建 web 和桌面客户端。
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。

6.数据工程
许多 Python 库使其成为数据分析师和数据科学家的绝佳选择,也使 Python 成为数据工程师的重要语言。数据工程师使用 Python 来完成诸如构建管道、组合数据集、清理数据、使用 API、自动化各种数据处理等任务。
示例用例:一家公司拥有大量数据,但这些数据存储在各种格式和数据库中,这使得分析师查找和处理这些数据非常耗时。数据工程师可以利用他们的 Python 技能构建一个管道,自动从各种来源收集、连接和清理数据,并使分析师更容易访问和过滤。
7.机器人学
Python 是机器人领域的流行语言,无论是业余爱好者还是专业人士。对于业余爱好者来说,Python 经常与 Raspberry Pi 硬件平台一起使用,这允许进行灵活且负担得起的实验。在商业中,Python 是机器人过程自动化(RPA)常用的语言之一,它被用来做类似于编码工业机器人手臂的事情,这些手臂可以相互协作。
示例用例:一家公司为一家制造厂订购了许多机器人手臂。工程师可以使用 Python 来编写他们的行为,利用该语言的高级可读性,让每个人都更容易理解这些手臂要做什么。
8.自动化
Python 非常适合自动化重复的任务,并且 Python 自动化有几乎无穷无尽的真实世界用例。例如,Python 是 DevOps 中的一个流行工具,因为它使自动化系统和过程高效而透明。但在软件开发领域之外,它还被广泛用于自动化从复杂系统到简单的个人流程,如填写电子表格或回复电子邮件。
示例用例:一家公司在每个地区的每月 Excel 电子表格中报告其销售额,必须手动合并这些表格以构建公司范围的季度报告。员工不用手动完成这项耗时的任务,而是编写一个 Python 脚本,将所有电子表格结合起来,自动生成每份季度报告。
9.硬件接口和控制
Python 控制硬件的能力超越了机器人技术——事实上,它被用于各种现实世界的硬件控制应用。例如,这个方便的 Python 库使得将 Python 用于各种工业控制应用成为可能。
示例用例:一家公司的工程师需要编写软件来控制一个复杂的 HVAC 系统。他们可以用 Python 编写代码,向系统的传感器和硬件控制器发送命令,并从它们那里接收数据。
10.教育和培训
因为 Python 是一种非常高级的“可读”语言,而且有多种实际用途,所以对于想学习编程的人来说,Python 是一种非常受欢迎的第一语言。各种各样的 Python 教程、视频、互动课程以及其他可供 Python 使用的教育材料,使得 Python 可以说是最容易学习的编程语言。
示例用例:一家公司希望其数据分析团队能够超越 Excel 和 SQL 的限制。他们选择用 Python 进行团队培训,因为他们知道他们将有各种各样的学习资源可供选择。
11.个人便利
在本文中,我们主要关注 Python 的业务用例。但是 Python 的许多商业用例也适用于个人层面。Python 可以用来分析你自己的数据,自动化你工作中枯燥或重复的元素,甚至可以用来创作艺术!
示例用例:这里有一个非常个人化的例子——当我想阻止自己一口气坐很长时间时,我用我初学的 Python 技巧写了一个小脚本,它会在我想要的任何时间间隔弹出提醒,播放我选择的声音,并根据我可以调整的参数提示我做一些运动。
Python 不有什么用?
Python 是一种优秀的通用语言,但它并不是万能的最佳解决方案。这里有几个例子,在这些领域中,Python 可能不是现实世界商业应用程序的最佳选择或最常见的选择。
移动应用程序开发
虽然你当然可以为 Python 开发移动应用,但你需要利用第三方层来让它们在 Android 和 iOS 手机上工作。这些额外的层会降低 Python 应用程序的效率,这意味着 Python 并不总是移动应用程序开发的最佳选择(尽管取决于您特定应用程序的要求,它可能是好的)。
如果你对用 Python 开发移动应用感兴趣,有很多选择。其中最流行的是 Kivy 框架。
当然,你也可以将 Python 的 web 开发能力与 Django 这样的框架结合使用,来开发在移动浏览器中也能很好工作的 web 应用程序。
需要高速度或高内存使用率的东西
部分因为 Python 是一种高级语言,它并不总是最快或最有效的选择。对于许多用例来说,这种区别并不重要——您永远不会注意到使用 C++可能获得的额外的十分之一毫秒。但是,例如,如果你正在开发一个高速 3D 渲染的视频游戏,Python 的速度和内存限制可能会太有限。
类似地,如果你正在做一些事情,比如写一个操作系统,Python 并不是一个很好的选择,因为当用户在作为操作系统的主程序中运行程序时,它的低效率会层层叠加。
当高速和内存性能至关重要时,Python 可能不是最佳选择。然而,在许多情况下——包括上面描述的所有用例——我们使用 Python 在速度和效率上做出的微小牺牲远远超过了它提供的便利。
在哪里可以学习 Python 技巧?
- Youtube 。Youtube 上有成千上万的免费 Python 教程,几乎涵盖了所有可以想到的用例。
- 数据请求。交互式课程是一个很好的选择,它使入门变得更容易,因为你不必弄清楚如何在本地安装和运行 Python。
- Udemy 。如果你从视频讲座中学习得很好,这里有数百门 Python 课程可供学习。
- Coursera 。涵盖许多不同 Python 主题的大学品牌视频讲座课程可供选择。
- EdX 。这里也有大学品牌的 Python 视频讲座课程。
- 书籍。许多 Python 书籍,包括像本这样的热门书籍,如果你不介意在设备上阅读,都是免费的。
- 班级和训练营。Python 也有许多面对面的学习选择,尽管这些往往是最昂贵的学习方式。
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。
数据科学工作被拒的 17 个原因
原文:https://www.dataquest.io/blog/reasons-why-youre-getting-rejected-for-data-science-jobs/
October 7, 2021
数据科学工作机会很多,而且数量还在增长。尽管需求大量涌入,但一些数据专业人士仍然难以找到工作。如果你填写了许多你认为自己很容易胜任的工作申请,却遭到拒绝,你肯定不是唯一一个。
在这篇文章中,我们将回顾招聘经理可能会说“不”的一些最常见的原因,我们将为你提供开始听到“是”的解决方案
- 过于雄心勃勃的工作申请
- 找工作时没有利用过去的经验
- 不积极获取经验
- 公司不确定他们想要什么
- 忽略工作描述
- 忽略求职信
- 被 ATS 拒绝
- 你的简历太普通了
- 简历上的错误
- 简历上的跳槽和/或失业空白
- 你没有学位或“多年经验”
- 你缺乏一个强大的投资组合
- 你对自己的专业知识保持沉默
- 忽视网络
- 不推销自己
- 面试失败
- 文化不适应
过于雄心勃勃的求职申请
并非所有的数据科学工作都是平等的。虽然数据科学角色可能有很多重叠,但有些角色有完全不同的要求。
如果你的申请不断遭到拒绝,可能是你的资格和你申请的职位不匹配。了解你在职业生涯中所处的位置以及这与你申请的职位的期望值之间的关系是非常重要的。
解决办法
如果你似乎找不到你喜欢的职位,试着申请相关但不同的工作,这些工作可以作为你理想职位的垫脚石。
例如,“数据科学家”是一些广告最广的职位,他们拥有数据科学领域中最高的硕士和博士学位密度。
另一方面,数据分析师和数据工程师的教育背景更加多样化,对入门级申请者更加开放。如果你的目标是成为一名数据科学家,可以考虑从一个次要的角色开始,然后朝着目标努力。尤其是在你职业生涯的早期,迈出第一步比马上找到你梦想的工作更重要。
在数据科学中不同角色之间的转换是经常发生的事情,因此在数据科学职业生涯的开始阶段接受“初级”职位或实习可能是开启未来职业发展的关键。
在找工作时没有利用过去的经验和工作经历
几乎每个行业都在投资数据科学。这为拥有数据科学技能的人打开了一个充满机会的世界,他们中的许多人已经离开了他们以前的行业来获得这些技能。
虽然数据技能是重点,但记住你来自哪里可能是有利的。
解决办法
利用你过去的工作经验,并将其与你目前的数据科学技能相结合,以增加招聘经理同意的可能性
如果你有医疗领域的工作经验,考虑优先申请“生物技术分析师”而不是“金融分析师”不要忘记花时间去发现你以前职业中可以为你的新职业增加价值的方面!
不积极获取经验
在数据科学领域,你必须证明你有能力胜任你所追求的角色。即使获得一个入门级的职位,也需要基本的知识和经验。
如果你申请的工作很少或没有实际工作来支持你简历上列出的技能,你的申请很容易失败。
解决办法
不要坐等机会降临,要积极主动,抓住任何机会锻炼你的数据技能。招聘经理在潜在员工身上寻找的正是这种动机。
即使你是从零开始,也有一些事情你可以立即去做,开始获得有意义和有价值的经历。
- 联系非营利组织,小 businesses—you 甚至可以提供免费工作。这将为你提供解决现实世界数据问题的机会,并为你提供工作经验以供面试时讨论。
- 接受实习,带薪或不带薪。这将提供更有经验的专业人士的在职培训和指导。
- 如果可以的话,自由职业。如果你是企业家类型的人,你可以考虑作为自由职业者从事数据工作。你将发展你的技能,建立一个投资组合,收集参考和证明,并在此过程中赚一点钱!
- 做自己的项目。如果你找不到任何人来帮助,你可以进行你自己的酷数据科学项目!
公司不确定他们想要什么
尽管无数企业都明白数据科学的必要性,但并不是所有企业都知道它是如何工作的,他们需要什么,或者谁需要做这件事。由于这种混乱,公司通常会创建过于宽泛的职位列表。
例如,当他们实际上需要一个 Python 专家时,他们会要求一个“数据科学家”。这些工作列表可能会吸引许多申请,但大多数不会满足公司的需求。
解决办法
为了充分利用这种情况,你必须多做一点。首先,仔细阅读职位描述,确定公司需要什么。然后,如果不清楚,亲自去找工作列表,询问职位。
你不仅会发现更多关于这份工作的具体信息(让你创建更有针对性的申请),而且你还会在众多简历中脱颖而出,就像工作列表一样普通。
忽略工作描述
没有人喜欢找工作,在线申请和“一键式申请”按钮简单方便,很容易让人不假思索地填写几十份甚至几百份申请。不幸的是,如果你这样做,你会让自己被拒绝。
忽视对工作描述的适当关注,你会让自己陷入尴尬的错误。你可能会浪费时间去申请那些你不适合或者甚至不想要的工作。你也把自己局限于复制粘贴简历,招聘经理知道如何发现。
解决办法
注意你阅读的每一份工作描述。仔细记下这份工作需要的精确技能和能力,并在申请前使用这些精确的关键词来微调和 定制您的数据科学简历 。这种有针对性的为每份工作制作简历的方法会给你最好的机会得到一次回电。
忽略求职信
对于许多工作来说,求职信仍然是强制性的。然而,许多申请人认为这是一种不方便的手续。出于这个原因,求职者经常复制并粘贴相同的求职信到他们申请的每份工作中。
事实上,你的求职信是一个让你脱颖而出、给人留下深刻印象的独特机会。它提供了你的简历所没有的灵活性。如果你得到了这个千载难逢的机会,而你的求职信没有达到预期效果,你被拒绝的几率就会增加。
解决办法
充分利用求职信来解释你简历上的技能是如何在你的职业生涯中产生有利结果的。如果你要转行,这将是弥合你之前的行业和数据科学之间差距的绝佳机会。
不要只解释你做什么;解释它过去是如何帮助别人的,以及你将来如何提供价值。
Indeed 提供了 一份数据科学求职信的绝佳范例 ,可以作为你求职的参考点。
被 ATS 拒绝
如今,许多企业使用申请人跟踪系统(ATS)来审查和筛选工作申请。因此,一种算法可能会在招聘经理有机会看你的简历之前就拒绝你。
解决办法
ATS 被设计为寻找特定的目标关键词和短语,以确定哪些申请将通过过滤器进入招聘经理的手中。以下是一些帮助您通过 ATS 的数据科学应用的技巧:
- 利用在线工具帮助你找到简历中合适的关键词。ZipRecruiter 提供了大量数据科学关键词。
- 避免使用缩写。ATS 经常寻找被详细说明的术语。使用与工作描述中相同的术语永远不会出错。
- 确保您的简历以 Word 文档或 PDF 格式提交,以便 ATS 正确扫描
你的简历太普通了
大多数数据工作竞争激烈,尤其是初级职位。因此,过于宽泛和普通的简历在竞争激烈的就业市场上没有任何机会。
不要随大流。如果你要获得一个有竞争力的角色,你必须让自己脱颖而出。
解决办法
当你为求职申请准备简历时,要记住三点:特殊性、结果和成就。这三件事会让你和其他申请相同职位的人区分开来。
非常具体和直接地描述你对工作至关重要的技能。解释你如何在特定的公司、特定的项目中使用它们,并产生可衡量的结果。一定要包括招聘经理可以查看的任何现场项目,以进一步展示你的技能。
你还可以包括具体的、补充性的技能,表明你的数据专长,即使这些技能对相关工作并不重要。这会让你从其他申请者中脱颖而出。考虑提及以下高价值技能:
- 云计算
- 微软 Azure
- jupyter 笔记本
- 深度学习
细节将使你与其他申请人区分开来,他们中的许多人将停留在“普通”领域
简历上的错误
这一点很直接,适用于任何行业的任何工作申请。然而,数据专家的一个特征是关注微小的细节,所以判断会不那么宽容。
如果你在简历中犯了拼写、语法或连续性错误,说明你对细节不够关注,你的申请会被拒绝。
解决办法
每次提交简历时都要校对一下。你也应该使用类似于 语法 的工具来检查语法、拼写,甚至是你写作的语气。它应该简短、有力、真实、自信。你也可以把你的简历提交给另一群人,甚至雇佣一个专业的简历撰写人来帮助你。
跳槽和失业差距
许多公司认为,当他们收到的简历显示频繁更换工作或工作间隔时间长时,这是一个“危险信号”。虽然这不一定是一个交易破坏者,但如果这些都在你的简历上,你可以做一些事情来充分利用它——甚至让它成为你的优势。
解决办法
幸运的是,频繁的工作变动和就业缺口不再像过去那样带来耻辱。如果你能解释它们是如何帮助你适应当前的工作角色的,它们会是有益的!
如果你的简历包括频繁的工作变动或失业期,这里有一些事情需要考虑。
- 不要用“在这段时间里,我没有工作”来解决问题相反,讨论你在工作间隙获得了什么知识,发展了什么新技能。
- 强调你探索和尝试新事物的意愿,以及你快速适应和获得新技能的能力
- 关注当下。展示让你申请这份工作的愿望、知识和技能。
你没有学位/“多年经验”
现在可能是消除误解的时候了。数据科学工作确实在成倍增加,但合格劳动力却很短缺。然而,一个常见的误解是,由于劳动力短缺,一些刚从大学毕业的人可以简单地申请一份数据科学的工作,并期望获得一份工作。虽然这种情况是可能的(并且越来越普遍),但它仍然不是必然的。
绝大多数数据专业人士至少拥有相关领域的学士学位,在某些岗位上,硕士、博士学位更是家常便饭。
这并不是说你需要接受正规教育才能获得数据科学工作。事实上,许多继续从事数据工作的 Dataquest 学生并没有相关的学位。然而,这确实让事情变得更具挑战性。
解决办法
开始学习,永不停止。无论您的风格是通过在线课程 自学 、在职学习、训练营还是考虑正规教育,对于数据专业人员来说,不断学习、获得额外技能并跟上最新趋势和最佳实践都是至关重要的。
加入 GitHub 和 Kaggle 上的数据科学社区。向更有经验的专业人士学习,如果可能的话,找一个导师。关键是发展贸易知识,而不是名字后面有某些字母。
假设你能够展示出必要的知识,尽管你没有学位。在这种情况下,合适的公司会认识到你的价值和潜力,并愿意为你的未来投资。这个建议是学生们喜欢 Dataquest 的主要原因之一——它给了学生们一个完成真正的数据科学项目的机会,这有助于建立他们的投资组合,以展示给未来的雇主。
你缺乏一个强大的投资组合
一份出色的投资组合可能是你找工作时最大的财富,它可以帮助你克服许多许多障碍。相反,忽视建立一个合适的投资组合是有害的,尤其是对这个领域的新手来说。
即使你完全胜任某个角色,如果你没有展示你的技能和知识的作品集,你实际上是隐形的。
解决办法
这一点怎么强调都不为过:要想在数据科学领域找到一份工作并取得进展,你必须证明自己的资质。
如果你有技能,你必须在行动中表现出来。这与告诉招聘经理“我有一年的数据科学经验”和“这是我去年开发的 10 个实时项目,这是我的工作成果,这是我的客户对我的评价”是不同的
我们有一整篇文章是关于 建立你最好的数据科学项目组合 的。不仅仅是 Kaggle 项目,还有具有有意义的度量和可测量的结果的真实世界的数据项目。Kaggle 项目可以有所帮助,但不应该成为你的主要来源。
你应该在 GitHub 上有最新的投资组合,因为它是数据科学招聘经理的首选目的地。如果你没有自己品牌的网站,把你的 GitHub 个人资料当作你的广告牌,面向潜在的雇主。这应该是一个你派人展示你胜任数据科学职位的地方。
给他们看看你的本事!
你对自己的专业知识保持沉默
就像项目组合如何展示对硬技能的熟练程度一样,也有足够的机会来阐述你对知识的熟练程度以及对数据科学概念和理论的理解。
有许多数据专业人士拥有令人印象深刻的投资组合。然而,那些分享他们的作品和源源不断的有价值的评论和见解的人让自己与众不同。所以,如果你想让自己在招聘经理或招聘人员的眼中大放异彩,那就开始与世界分享你的知识和经验吧。
解决办法
考虑写关于数据科学的博客,积累一些文章,向雇主展示你的知识。您还可以撰写论文或创建演示文稿,记录您成功的项目,并给出评论、解释、教程或建议。这样做,你将不断成长、学习,并向招聘经理提供有力的证据,证明你拥有他们需要的技能和知识。
如果你想把你的专业知识展示出来,这里有一些你可能想考虑的话题:
- SQL/Python/R
- 数据挖掘技术
- 大数据平台
- 数据可视化
- 机器学习
忽视网络
人们很容易低估职业关系网的重要性,但也很难夸大它。
在竞争激烈的数据科学领域,您可能会被数百名申请相同职位的其他数据专业人员淹没。然而,一个有影响力的关系网的推荐是一个强大的资产。
解决办法
网络就像你的生活一样依赖于它,无论是离线还是在线。即使你目前没有在找工作,与数据科学领域的朋友和同事保持联系也是很有价值的。联系你感兴趣的公司里的其他专业人士。你甚至可以要求他们进行一次信息性的采访或者说一句好话。
加入数据科学对话,尤其是在 LinkedIn、Twitter、GitHub 和 Kaggle 上。对于一些招聘经理来说,你的 LinkedIn 个人资料相当于一份简历。有时候,拥有正确的关系会打开之前对你关闭的大门。
不要推销自己
无论是在求职信、简历还是面试中,目标都是一样的:向公司传达你的价值,说服他们选择你而不是其他人。不幸的是,这对许多人来说很难,因为我们有时会对自己做最坏的判断,并且经常对自己的工作过分挑剔。
解决办法
对于这个问题,你必须深入挖掘并发现销售艺术,有些人比其他人更自然。但这些是你可以在你的职业生涯中使用的关键原则,有助于在数据科学中获得新的角色和进步。
在考虑如何向潜在雇主展示自己时,有几个基本原则要记住:
- 准确描述你的技能以及这些技能如何给公司带来好处。
- 具体说说你的经历、成就和成就。
- 当讨论特定项目时,尽可能提供名称、日期和可衡量的结果。
- 不要只关注“你做的事情”相反,关注“你做什么”如何为雇主创造价值。因此,最终的问题不是“你能做什么?”而是“你将如何成为我们公司的优秀员工?”
面试中的不足
没有多少人喜欢面试,更没有人擅长面试。如果你有足够的动力和技能去获得期待已久的面试,你绝对必须做好准备。
搞定面试可能是你开始数据专家新角色的最后一道坎;让它有价值!
解决办法
这里有一些小技巧可以帮助你为重要的面试做好准备:
- 研究数据科学面试中最常见的问题并练习你的回答
- 略述向面试官提问的问题,以表明你对这份工作或公司的兴趣
- 要求家人和朋友进行模拟面试,并征求他们的反馈。在这些模拟面试中拍摄自己可能会有所帮助。虽然一开始看起来可能会很痛苦,但这会给你一个更广阔的视角,帮助你掌握面试的艺术!
- 最后,你只需要练习。学习经验和培养良好的沟通技巧是无可替代的。
不是一个好的文化适应
你可能得不到面试机会的最后一个原因可能与教育、经验、技能或任何资格无关。
越来越多的企业开始专注于创造他们的“公司文化”,以在特定的环境中保持士气。因为不是所有的公司和人都一样,不是每个人都适合。
虽然如果你被评价为“不太适合”公司文化,你也无能为力,但你仍然可以利用这一点。
解决办法
如果公司更加重视“公司文化”,你也应该如此!发现什么样的文化适合你,并寻找那些能传达恰当氛围的公司。如果很合适,你比其他申请人更有优势。
如果有公司渴望雇佣与你文化不同的人,其他公司也同样渴望雇佣像你这样的人。
你也可以尝试理解你申请的公司的文化,然后相应地调整自己。但是,你还是要对自己诚实,对自己想要的东西诚实。
结论
如果这篇文章有什么启示的话,那就是:如果你想要一份数据科学的工作,你必须展示你的数据科学专业知识。
如果你有硬技能,在行动中展示出来。如果你懂贸易,充分展示你的知识。我们已经提供了许多方法来帮助您做到这一点。当然,你可以全部或部分完成。然而,如果你什么都不做,当你拥有让你的应用程序大放异彩所需要的一切时,你的应用程序可能会表现不佳。
通过 Dataquest,您可以获得并发展作为数据专业人员迈出关键第一步所需的所有知识和技能。加入 100 多万名学习者的行列,他们使用 Dataquest 开发和磨练职业技能,平均工资增加了 30,000 美元。 今天开始免费 !
正则表达式备忘单:Python 正则表达式快速指南
April 2, 2018
学习数据科学的困难之处在于记住所有的语法。虽然在 Dataquest,我们提倡习惯于查阅 Python 文档,但有时有一个方便的 PDF 参考也不错,所以我们整理了这个 Python 正则表达式(regex)备忘单来帮助你!
这个正则表达式备忘单基于 Python 3 关于正则表达式的文档。
如果你对学习 Python 感兴趣,我们有免费的交互式初级和中级 Python 编程课程,你应该去看看。
数据科学的正则表达式(PDF)

特殊字符
^ |匹配字符串开头右侧的表达式。它匹配字符串中每个\n之前的每个这样的实例。
$ |匹配字符串末尾左侧的表达式。它匹配字符串中每个\n之前的每个这样的实例。
. |匹配任何字符,除了像\n这样的行终止符。
\ |转义特殊字符或表示字符类别。
A|B |匹配表达式A或B。如果先匹配到A,则不尝试B。
+ |贪婪地匹配表达式左侧 1 次或多次。
* |贪婪地匹配其左边的表达式 0 次或更多次。
? |贪婪地匹配其左边的表达式 0 或 1 次。但是如果将?添加到限定符(+、*和?本身)中,它将以非贪婪的方式执行匹配。
{m} |匹配其左侧的表达式m次,且不少于。
{m,n} |匹配其左边的表达式m到n次,并且不少于。
{m,n}? |匹配其左边的表达式m次,忽略n。参见上面的?。
字符类(又名特殊序列)
\w |匹配字母数字字符,表示a-z、A-Z和0-9。它也匹配下划线,_。
\d |匹配数字,表示0-9。
\D |匹配任何非数字。
\s |匹配空白字符,包括\t、\n、\r和空格字符。
\S |匹配非空白字符。
\b |匹配单词开头和结尾的边界(或空字符串),即\w和\W之间的边界。
\B |匹配\b不匹配的地方,即\w字符的边界。
\A |无论是在单行模式还是多行模式下,都在字符串的绝对起始处匹配其右侧的表达式。
\Z |无论是在单行模式还是多行模式下,都匹配位于字符串绝对末尾左侧的表达式。
设置
[ ] |包含一组要匹配的字符。
[amk] |匹配a、m或k。它与amk不符。
[a-z] |匹配从a到z的任意字母。
[a\-z] |匹配a、-或z。它匹配-,因为\转义了它。
[a-] |匹配a或-,因为-没有被用来表示一系列字符。
[-a] |同上,匹配a或-。
[a-z0-9] |匹配从a到z以及从0到9的字符。
[(+*)] |特殊字符在集合中变成文字,所以匹配(、+、*、)。
[^ab5] |添加^排除集合中的任何字符。这里,它匹配不是a、b或5的字符。
组
( ) |匹配括号内的表达式并对其进行分组。
(? ) |像这样的括号内,?作为扩展符号。它的含义取决于紧挨着它右边的字符。
(?PAB) |匹配表达式AB,可以用组名访问。
(?aiLmsux) |此处,a、i、L、m、s、u、x为标志:
a—仅匹配 ASCIIi—忽略大小写L—依赖于语言环境m—多行s—匹配所有u—匹配 unicodex—详细
(?:A) |匹配由A表示的表达式,但与(?PAB)不同,之后无法检索。
(?#...) |一个评论。内容是给我们看的,不是用来配的。
A(?=B) |前瞻断言。只有在表达式A后面跟有B时,它才与表达式A匹配。
A(?!B) |负前瞻断言。只有当表达式A后面没有B时,它才与表达式A匹配。
(?<=B)A |正向回顾断言。只有当B紧挨着它的左边时,它才与表达式A匹配。这只能匹配固定长度的表达式。
(?<!B)A |否定回顾断言。只有当B不在它的左边时,它才匹配表达式A。这只能匹配固定长度的表达式。
(?P=name) |匹配先前名为“name”的组所匹配的表达式。
(...)\1 |数字1对应第一个要匹配的组。如果我们想匹配同一个表达式的更多实例,只需使用它的编号,而不是再次写出整个表达式。我们可以使用从1到99这样的组和它们相应的编号。
流行的 Python re模块函数
re.findall(A, B) |匹配字符串B中表达式A的所有实例,并在列表中返回它们。
re.search(A, B) |匹配字符串B中表达式A的第一个实例,并将其作为 re match 对象返回。
re.split(A, B) |使用分隔符A将字符串 B 拆分成一个列表。
re.sub(A, B, C) |将A替换为C字符串中的B。
Python 的有用正则表达式资源:
成为数据分析师!
立即学习成为数据分析师所需的技能。注册一个免费帐户,获得免费的交互式 Python、R 和 SQL 课程内容。
(不需要信用卡!)
教程:面向数据科学家的 Python Regex(正则表达式)
原文:https://www.dataquest.io/blog/regular-expressions-data-scientists/
January 7, 2020
一头扎进数据集是任何从事数据科学工作的人都要上的一课。通常,这意味着数字运算,但是当我们的数据集主要是基于文本时,我们该怎么办呢?我们可以使用正则表达式。在本教程中,我们将仔细研究如何在 Python 中使用正则表达式(regex)。
正则表达式(regex)本质上是文本模式,可用于自动搜索和替换文本字符串中的元素。这使得清理和处理基于文本的数据集变得更加容易,省去了手动搜索大量文本的麻烦。
正则表达式可以在多种编程语言中使用,而且它们已经存在很长时间了!
不过,在本教程中,我们将学习 Python 中的正则表达式,因此基本熟悉一些关键的 Python 概念,如 if-else 语句、while 和 for 循环等。,是必需的。(如果您需要复习这些内容,我们的 Python 入门课程将在您的浏览器中以交互方式涵盖所有相关主题!)
本教程结束时,您将熟悉 Python regex 的工作方式,并能够使用 Python 的 regex 模块re中的基本模式和函数来分析文本字符串。您还将了解如何使用 regex 和 pandas 来处理大型文本语料库( corpus 表示文本数据集)。
(要完成本教程的熊猫部分,您需要安装熊猫库。最简单的方法是下载 Anaconda,并在 Jupyter 笔记本上完成本教程。对于其他选项,请查看熊猫安装指南。)

我们的任务:分析垃圾邮件
在本教程中,我们将使用来自 Kaggle 的欺诈性电子邮件语料库。它包含了 1998 年至 2007 年间发送的数千封钓鱼邮件。它们读起来很有趣。
你可以在这里找到完整的文集。但是我们将从使用几封电子邮件学习基本的 regex 命令开始。如果你愿意,你也可以使用我们的测试文件,或者你可以使用完整的语料库来尝试。
介绍 Python 的 Regex 模块
首先,我们将准备数据集,方法是打开测试文件,将其设置为只读,然后读取它。我们还将它赋给一个变量fh(表示“文件句柄”)。
fh = open(r"test_emails.txt", "r").read()
注意,我们在目录路径前面加了一个r。这种技术将字符串转换为原始字符串,这有助于避免由某些机器读取字符的方式引起的冲突,例如 Windows 上目录路径中的反斜杠。
现在,假设我们想找出邮件来自谁。我们可以单独尝试原始 Python:
for line in fh.split("n"):
if "From:" in line:
print(line)
der.com>
Message-Id: <[[email protected]](/cdn-cgi/l/email-protection)>
From: "Mr. Be
[[email protected]](/cdn-cgi/l/email-protection)>
Message-Id: <[[email protected]](/cdn-cgi/l/email-protection)>
From: "PRINCE OBONG ELEME" <obo
但这并没有给我们想要的。如果你看一下我们的测试文件,我们可以找出原因并修复它,但是,让我们使用 Python 的re模块并用正则表达式来做!
我们将从导入 Python 的re模块开始。然后,我们将使用一个名为re.findall()的函数,该函数返回我们在字符串中定义的模式的所有实例的列表。
它看起来是这样的:
import re
for line in re.findall("From:.*", fh):
print(line)
From: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>
From: "PRINCE OBONG ELEME" <[[email protected]](/cdn-cgi/l/email-protection)>
这基本上与我们的原始 Python 长度相同,但那是因为它是一个非常简单的例子。您尝试做的越多,Python regex 可能为您节省的精力就越多。
在我们继续之前,让我们仔细看看re.findall()。这个函数以re.findall(pattern, string)的形式接受两个参数。这里,pattern代表我们想要查找的子串,string代表我们想要在其中查找的主串。主字符串可以由多行组成。在这种情况下,我们让它搜索所有的fh,我们选择的电子邮件的文件。
.*是字符串模式的简写。正则表达式通过使用这些速记模式来查找文本中的特定模式,所以让我们看看其他一些常见的示例:
常见的 Python 正则表达式模式
我们在上面的re.findall()中使用的模式包含一个完整拼写的字符串"From:"。当我们精确地知道我们要找的是什么,精确到实际的字母以及它们是大写还是小写时,这是很有用的。如果我们不知道我们想要的字符串的确切格式,我们就会迷失方向。幸运的是,regex 有解决这种情况的基本模式。让我们看看我们在本教程中使用的:
w匹配字母数字字符,即 a-z、A-Z 和 0-9。它还匹配下划线、_ 和破折号-。d匹配数字,表示 0-9。s匹配空白字符,包括制表符、换行符、回车符和空格字符。S匹配非空白字符。.匹配除新行字符n之外的任何字符。
有了这些正则表达式模式,当我们继续解释它时,您将很快理解我们上面的代码。
使用正则表达式模式
我们现在可以解释上面的行re.findall("From:.*", text)中.*的用法。我们先来看.:
for line in re.findall("From:.", fh):
print(line)
From:
From:
通过在From:旁边添加一个.,我们在它旁边寻找一个额外的字符。因为.寻找除了n之外的任何字符,它捕捉空格字符,这是我们看不到的。我们可以尝试更多的点来验证这一点。
for line in re.findall("From:...........", fh):
print(line)
From: "Mr. Ben S
From: "PRINCE OB
看起来添加点确实为我们获得了线的其余部分。但是,这很乏味,我们不知道要添加多少点。这就是星号符号*出现的地方。
*匹配左侧模式的零个或多个实例。这意味着它寻找重复的模式。当我们寻找重复的模式时,我们说我们的搜索是“贪婪的”如果我们不寻找重复的模式,我们可以称我们的搜索为“非贪婪”或“懒惰”
让我们用*构造一个对.的贪婪搜索。
for line in re.findall("From:.*", fh):
print(line)
From: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>
From: "PRINCE OBONG ELEME" <[[email protected]](/cdn-cgi/l/email-protection)>
因为*匹配其左侧指示的模式的零个或多个实例,并且.在这里位于其左侧,所以我们能够获取From:字段中的所有字符,直到该行结束。这用非常简洁的代码打印出了完整的一行。
我们甚至可以更进一步,只分离出名字。像以前一样,让我们使用re.findall()返回包含模式"From:.*"的行列表。为了简洁起见,我们将它赋给变量match。接下来,我们将遍历列表。在每个循环中,我们将再次执行re.findall,匹配第一个引号以仅提取名称:
match = re.findall("From:.*", fh)
for line in match:
print(re.findall('\".*\"', line))
['"Mr. Ben Suleman"']
['"PRINCE OBONG ELEME"']
注意,我们在第一个引号旁边使用了反斜杠。反斜杠是用于转义其他特殊字符的特殊字符。例如,当我们想使用引号作为字符串文字而不是特殊字符时,我们用一个反斜杠来转义它,就像这样:\"。如果我们不使用反斜杠对上面的模式进行转义,它将变成"".*"",Python 解释器会将它解读为两个空字符串之间的句点和星号。它会产生一个错误并破坏脚本。因此,我们在这里用反斜杠来转义引号是至关重要的。
匹配第一个引号后,.*获取该行中的所有字符,直到下一个引号,也在模式中转义。这使我们得到的只是引号内的名称。名称也打印在方括号内,因为re.findall返回列表中的匹配项。
如果我们需要电子邮件地址呢?
match = re.findall("From:.*", fh)
for line in match:
print(re.findall("\w\S*@*.\w", line))
['[[email protected]](/cdn-cgi/l/email-protection)']
['[[email protected]](/cdn-cgi/l/email-protection)']
看起来很简单,不是吗?只是模式不同。让我们走一遍。
下面是我们如何匹配电子邮件地址的前部分:
for line in match:
print(re.findall("\w\S*@", line))
['[[email protected]](/cdn-cgi/l/email-protection)']
['[[email protected]](/cdn-cgi/l/email-protection)']
电子邮件总是包含一个@符号,所以我们从它开始。电子邮件中@符号之前的部分可能包含字母数字字符,这意味着w是必填项。然而,因为一些电子邮件包含句号或破折号,这是不够的。我们添加S来查找非空白字符。但是,w\S只会得到两个字。添加*寻找重复。图案的前部看起来是这样的:\w\S*@。
现在看看@符号背后的图案:
for line in match:
print(re.findall("@.*", line))
['@spinfinder.com>']
['@epatra.com>']
域名通常包含字母数字字符、句点,有时还包含破折号,因此使用.即可。为了使它变得贪婪,我们用一个*来扩展搜索。这允许我们匹配任何字符直到行尾。
如果我们仔细观察这一行,我们会看到每封电子邮件都被封装在尖括号内,< and >。我们的模式,.*,包括右括号,>。让我们补救一下:
for line in match:
print(re.findall("@.*\w", line))
['@spinfinder.com']
['@epatra.com']
电子邮件地址以字母数字字符结尾,所以我们用w作为模式的结尾。因此,在@符号后面有.*\w,这意味着我们想要的模式是一组以字母数字字符结尾的任意类型的字符。这不包括>。
因此,我们完整的电子邮件地址模式如下所示:\w\S*@.*\w。
唷!那是很难解决的。接下来,我们将运行一些常见的re函数,当我们开始重新组织我们的语料库时,这些函数会很有用。
常见 Python 正则表达式函数
re.findall()无疑是有用的,但它不是re中唯一可用的内置函数:
re.search()re.split()re.sub()
在使用它们给我们的数据集带来一些秩序之前,让我们一个接一个地看看它们。
重新搜索()
当re.findall()匹配一个字符串中一个模式的所有实例并在一个列表中返回它们时,re.search()匹配一个字符串中一个模式的第一个实例,并将其作为一个re匹配对象返回。
match = re.search("From:.*", fh)
print(type(match))
print(type(match.group()))
print(match)
print(match.group())
<class 're.Match'>
<class 'str'>
<re.Match object; span=(3590, 3644), match='From: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>
From: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>
和re.findall()一样,re.search()也是带两个自变量。第一个是要匹配的模式,第二个是要在其中查找的字符串。这里,为了整洁,我们将结果赋给了match变量。
因为re.search()返回的是一个re匹配对象,所以我们无法通过直接打印来显示姓名和邮箱地址。相反,我们必须先对它应用group()函数。我们已经在上面的代码中打印出了它们的类型。正如我们所看到的,group()将 match 对象转换成一个字符串。
我们还可以看到,打印match显示字符串本身以外的属性,而打印match.group()只显示字符串。
重新拆分()
假设我们需要一种快速的方法来获得电子邮件地址的域名。我们可以通过三个正则表达式操作来实现,如下所示:
address = re.findall("From:.*", fh)
for item in address:
for line in re.findall("\w\S*@.*\w", item):
username, domain_name = re.split("@", line)
print("{}, {}".format(username, domain_name))
bensul2004nng, spinfinder.com
obong_715, epatra.com
第一句台词很熟悉。我们返回一个字符串列表,每个字符串包含From:字段的内容,并将它赋给一个变量。接下来,我们遍历列表来查找电子邮件地址。同时,我们遍历电子邮件地址,并使用re模块的split()函数将每个地址剪成两半,用@符号作为分隔符。最后,我们打印它。
re.sub()
另一个方便的re功能是re.sub()。正如函数名所示,它替换字符串的一部分。一个例子:
sender = re.search("From:.*", fh)
address = sender.group()
email = re.sub("From", "Email", address)
print(address)
print(email)
From: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>
Email: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>
</[[email protected]](/cdn-cgi/l/email-protection)></[[email protected]](/cdn-cgi/l/email-protection)>
我们之前已经看过第一行和第二行的任务了。在第三行,我们将re.sub()应用于address,这是电子邮件标题中完整的From:字段。
re.sub()需要三个参数。第一个是要替换的子字符串,第二个是我们想要替换的字符串,第三个是主字符串本身。
熊猫的正则表达式
现在我们已经掌握了 Python 正则表达式的基础知识。但是通常对于数据任务,我们实际上并没有使用原始的 Python,而是使用 pandas 库。现在,让我们通过将正则表达式技术引入到 pandas 工作流中,使它们更上一层楼。
如果你以前没用过熊猫,也不用担心。我们将一步一步地检查代码,因此您永远不会感到迷失。但是如果你想更详细地了解熊猫,可以看看我们的熊猫教程或者我们提供的关于熊猫和熊猫的全互动课程。
用 Python 正则表达式和熊猫排序邮件
我们的语料库是一个包含数千封电子邮件的文本文件(不过,对于本教程,我们使用的是一个只有两封电子邮件的小得多的文件,因为在整个语料库上打印 regex 工作的结果会使这篇文章太长)。
我们将使用 regex 和 pandas 将每封电子邮件的各个部分分类到适当的类别中,以便可以更容易地阅读或分析语料库。
我们将每封电子邮件分为以下几类:
sender_namesender_addressrecipient_addressrecipient_namedate_sentsubjectemail_body
这些类别中的每一个都将成为我们的熊猫数据框架(即我们的表格)中的一列。这将使我们更容易分别处理和分析每一列。
我们将继续使用我们的小样本,但是值得重申的是,正则表达式允许我们编写更简洁的代码。简洁的代码减少了我们的机器必须做的操作数量,这加快了我们的分析过程。使用我们的两封电子邮件的小文件,没有太大的区别,但是如果您尝试使用和不使用 regex 处理整个语料库,您将开始看到优势!
准备脚本
首先,让我们导入我们需要的库并再次打开我们的文件。
除了re和pandas,我们还将导入 Python 的email包,这将有助于电子邮件的正文。单独使用正则表达式处理电子邮件的正文相当复杂。它甚至可能需要足够的清理来保证自己的教程。所以,我们将使用开发良好的email包来节省一些时间,让我们专注于学习 regex。
import re
import pandas as pd
import email
emails = []
fh = open(r"test_emails.txt", "r").read()
我们还创建了一个空列表emails,它将存储字典。每本词典都将包含每封电子邮件的详细信息。
现在,让我们开始应用正则表达式!
contents = re.split(r"From r", fh)
contents.pop(0)
[' Thu Oct 31 08:11:39 2002\nReturn-Path: <[[email protected]](/cdn-cgi/l/email-protection)>\nX-Sieve: cmu-sieve 2.0\nReturn-Path: <[[email protected]](/cdn-cgi/l/email-protection)>\nMessage-Id: <[[email protected]](/cdn-cgi/l/email-protection)>\nFrom: "Mr. Ben Suleman" <[[email protected]](/cdn-cgi/l/email-protection)>\nDate: Thu, 31 Oct 2002 05:10:00\nTo: [[email protected]](/cdn-cgi/l/email-protection)\nSubject: URGENT ASSISTANCE /RELATIONSHIP (P)\nMIME-Version: 1.0\nContent-Type: text/plain;charset="iso-8859-1"\nContent-Transfer-Encoding: 7bit\nStatus: O\n\nDear Friend,\n\nI am Mr. Ben Suleman a custom officer and work as Assistant controller of the Customs and Excise department Of the Federal Ministry of Internal Affairs stationed at the Murtala Mohammed International Airport...
注意:为了简洁起见,我们截掉了上面的打印输出。如果你在自己的机器上打印,它将显示包含在contents中的所有内容,而不是像上面那样以...结尾。
我们使用re模块的 split 函数将fh中的整个文本块分割成一个单独的电子邮件列表,我们将它赋给变量contents。这很重要,因为我们想通过 for 循环遍历列表,一封接一封地处理邮件。但是,我们怎么知道要被字符串"From r"分割呢?
我们之所以知道这一点,是因为我们在写脚本之前查看了文件。我们不必细读那里成千上万的电子邮件。只是前几个,看看数据的结构是什么样子。只要有可能,在开始处理代码之前先看看实际的数据是有好处的,因为您经常会发现像这样有用的特性。
我们截取了原始文本文件的屏幕截图:

电子邮件以“From r”开头
绿色块是第一封邮件。蓝色块是第二封邮件。正如我们所见,这两封邮件都以"From r"开头,用红框突出显示。
我们在本教程中使用欺诈性电子邮件语料库的一个原因是为了表明,当数据杂乱无章、不熟悉且没有文档记录时,我们不能仅仅依靠代码来对其进行分类。这需要一双人类的眼睛。正如我们刚才所展示的,我们不得不研究语料库本身来研究它的结构。
像这样杂乱无章的数据可能需要大量清理工作。例如,即使我们使用我们将要为本教程构建的完整脚本计算出这一组中有 3,977 封电子邮件,实际上还有更多。一些电子邮件实际上没有以"From r"开头,因此没有单独计算。(然而,为了简洁起见,我们将假设该问题已经解决,所有电子邮件都由"From r"分隔开。)
还要注意,我们使用contents.pop(0)来删除列表中的第一个元素。这是因为第一封电子邮件前面有一个"From r"字符串。当该字符串被拆分时,它在索引 0 处产生一个空字符串。我们将要写的脚本是为电子邮件设计的。如果我们试图在一个空字符串上使用它,它可能会抛出错误。去掉空字符串可以防止这些错误破坏我们的脚本。
用 For 循环获取每个名字和地址
接下来,我们将处理contents列表中的电子邮件。
for item in contents:
emails_dict = {}
在上面的代码中,我们使用了一个for循环来遍历contents,这样我们就可以依次处理每封邮件。我们创建了一个字典,emails_dict,它将保存每封电子邮件的所有细节,例如发件人的地址和姓名。事实上,这些是我们找到的第一批物品。
这是一个分三步走的过程。它从找到From:字段开始。
for item in contents:
# First two lines again so that Jupyter runs the code.
emails_dict = {}
# Find sender's email address and name.
# Step 1: find the whole line beginning with "From:".
sender = re.search(r"From:.*", item)
在步骤 1 中,我们使用re.search()函数找到整个From:字段。.表示除了n以外的任何字符,*将其延伸到行尾。然后我们将它赋给变量sender。
但是,数据并不总是简单明了的。它可以包含惊喜。例如,如果没有From:字段呢?脚本会抛出一个错误并中断。在步骤 2 中,我们先发制人地避免了这个场景中的错误。
# Step 2: find the email address and name.
if sender is not None:
s_email = re.search(r"\w\S*@.*\w", sender.group())
s_name = re.search(r":.*<", sender.group())
else:
s_email = None
s_name = None
为了避免由于缺少From:字段而导致的错误,我们使用一个if语句来检查sender不是None。如果是,我们给s_email和s_name分配None的值,这样脚本就可以继续运行,而不是意外中断。
如果您正在自己的文件中学习本教程,您可能已经意识到使用正则表达式会变得很麻烦。例如,这些 if-else 语句是在编写语料库时使用试错法的结果。编写代码是一个迭代的过程。值得注意的是,即使本教程看起来很简单,但实际操作需要更多的实验。
在第 2 步中,我们使用之前熟悉的正则表达式模式\w\S*@.*\w,它匹配电子邮件地址。
我们将对名称使用不同的策略。每个名字由左边的子字符串"From:"的冒号:和右边的电子邮件地址的左尖括号<限定。因此,我们使用:.*<来查找名称。我们马上从每个结果中去掉:和<。
现在,让我们打印出代码的结果,看看它们是什么样子。
print("sender type: " + str(type(sender)))
print("sender.group() type: " + str(type(sender.group())))
print("sender: " + str(sender))
print("sender.group(): " + str(sender.group()))
print("n")
sender type: <class 're.match'="">
sender.group() type: <class 'str'="">
sender: <re.match object="" span="(180," match="From: "PRINCE OBONG ELEME" <obong_715@epatra.com>>
sender.group(): From: "PRINCE OBONG ELEME" <obong_715@epatra.com>
请注意,我们没有在re.search()的每个应用程序中使用sender作为要搜索的字符串。我们已经打印出了sender和sender.group()的类型,这样我们就可以看出它们的区别。看起来sender是一个re.match对象,我们无法使用re.search()进行搜索。然而,sender.group()是一个字符串,这正是re.search()的用途。
让我们看看s_email和s_name是什么样子的。
print(s_email)
print(s_name)
<re.Match object; span=(28, 48), match='[[email protected]](/cdn-cgi/l/email-protection)'>
<re.Match object; span=(4, 28), match=': "PRINCE OBONG ELEME" <'>
同样,我们有匹配对象。每次我们将re.search()应用于字符串时,它都会产生匹配对象。我们必须把它们转换成字符串对象。
在我们这样做之前,回想一下,如果没有From:字段,sender将具有None的值,s_email和s_name也是如此。因此,我们必须再次检查这个场景,以便脚本不会意外中断。先来看看如何用s_email构造代码。
# Step 3A: assign email address as string to a variable.
if s_email is not None:
sender_email = s_email.group()
else:
sender_email = None
# Add email address to dictionary.
emails_dict["sender_email"] = sender_email
在步骤 3A 中,我们使用一个if语句来检查s_email不是None,否则它将抛出一个错误并中断脚本。
然后,我们简单地将s_email匹配对象转换成一个字符串,并将其赋给sender_email变量。我们把它添加到emails_dict字典中,这将使我们以后把细节变成熊猫的数据框架变得非常容易。
在 3B 步骤中,我们对s_name做了几乎完全相同的处理。
# Step 3B: remove unwanted substrings, assign to variable.
if s_name is not None:
sender_name = re.sub("s*<", "", re.sub(":s*", "", s_name.group()))
else:
sender_name = None
# Add sender's name to dictionary.
emails_dict["sender_name"] = sender_name
正如我们之前所做的,我们首先检查s_name不是 3B 步骤中的None。
然后,在将字符串赋给变量之前,我们使用了两次re模块的re.sub()函数。首先,我们删除冒号和名字之间的任何空白字符。我们通过用一个空字符串""替换:s*来做到这一点。然后,我们删除名称另一侧的空白字符和尖括号,再次用空字符串替换它。最后,在将字符串分配给sender_name之后,我们将它添加到字典中。
让我们看看我们的结果。
print(sender_email)
print(sender_name)
[[email protected]](/cdn-cgi/l/email-protection)
"PRINCE OBONG ELEME"
完美。我们分离出了电子邮件地址和发件人的名字。我们还将它们添加到了词典中,很快就会发挥作用。
现在我们已经找到了发件人的电子邮件地址和姓名,我们执行完全相同的步骤来为字典获取收件人的电子邮件地址和姓名。
首先,我们找到了To:字段。
recipient = re.search(r"To:.*", item)
接下来,我们先假设recipient是None的情况。
if recipient is not None:
r_email = re.search(r"wS*@.*w", recipient.group())
r_name = re.search(r":.*<", recipient.group())
else:
r_email = None
r_name = None
如果recipient不是None,我们使用re.search()来查找包含电子邮件地址和收件人姓名的匹配对象。否则,我们将None的值传递给r_email和r_name。
然后,我们将匹配对象转换成字符串,并将它们添加到字典中。
if r_email is not None:
recipient_email = r_email.group()
else:
recipient_email = None
emails_dict["recipient_email"] = recipient_email
if r_name is not None:
recipient_name = re.sub("\s*<", "", re.sub(":\s*", "", r_name.group()))
else:
recipient_name = None
emails_dict["recipient_name"] = recipient_name
因为From:和To:字段的结构是相同的,所以我们可以对两者使用相同的代码。我们需要为其他字段定制稍微不同的代码。
获取电子邮件的日期
现在是邮件发出的日期。
for item in contents:
# First two lines again so that Jupyter runs the code.
emails_dict = {}
date_field = re.search(r"Date:.*", item)
我们用与From:和To:字段相同的代码获取Date:字段。
就像我们对这两个字段所做的一样,我们检查分配给date_field变量的Date:字段不是None。
if date_field is not None:
date = re.search(r"\d+\s\w+\s\d+", date_field.group())
else:
date = None
print(date_field.group())
Date: Thu, 31 Oct 2002 22:17:55 +0100
我们把date_field.group()打印出来,这样我们可以更清楚地看到字符串的结构。它包括星期、DD MMM YYYY 格式的日期和时间。我们只想要日期。日期的代码与姓名和电子邮件地址的代码基本相同,但更简单。也许这里唯一的困惑是正则表达式模式,\d+\s\w+\s\d+。
日期以数字开头。因此,我们使用d来说明它。但是,作为日期的 DD 部分,它可以是一位数或两位数。这就是+变得重要的地方。在 Python 正则表达式中,+匹配其左侧的一个或多个模式实例。d+将匹配日期的 DD 部分,无论它是一位数还是两位数。
在那之后,有一个空间。这是由s解决的,它寻找空白字符。月份由三个字母组成,因此称为w+。然后它击中另一个空间,s。年份是由数字组成的,所以我们再次使用d+。
完整的模式\d+\s\w+\s\d+之所以有效,是因为它是一个精确的模式,两边都有空白字符。
接下来,我们像以前一样对值None进行同样的检查。
if date is not None:
date_sent = date.group()
date_star = date_star_test.group()
else:
date_sent = None
emails_dict["date_sent"] = date_sent
如果date不是None,我们就把它从一个匹配对象变成一个字符串,赋给变量date_sent。然后我们将它插入字典。
在我们继续之前,我们应该注意关键的一点。+和*看似相似,但它们可以产生非常不同的结果。让我们以这里的日期字符串为例。
date = re.search(r"\d+\s\w+\s\d+", date_field.group())
# What happens when we use * instead?
date_star_test = re.search(r"\d*\s\w*\s\d*", date_field.group())
date_sent = date.group()
date_star = date_star_test.group()
print(date_sent)
print(date_star)
31 Oct 2002
31
如果我们使用*,我们将匹配零个或多个事件。+匹配一个或多个事件。我们已经打印了两种场景的结果。差别很大。如您所见,+获得完整的日期,而*获得空格和数字31。
接下来,邮件的主题行。
获取电子邮件主题
和以前一样,我们使用相同的代码和代码结构来获取我们需要的信息。
for item in contents:
# First two lines again so that Jupyter runs the code.
emails_dict = {}
subject_field = re.search(r"Subject: .*", item)
if subject_field is not None:
subject = re.sub(r"Subject: ", "", subject_field.group())
else:
subject = None
emails_dict["subject"] = subject
我们现在越来越熟悉 Python 正则表达式的使用了,不是吗?除了我们用一个空字符串替换"Subject: "以仅获得主题本身之外,它与之前的代码基本相同。
获取电子邮件正文
最后一个插入字典的条目是电子邮件的正文。
full_email = email.message_from_string(item)
body = full_email.get_payload()
emails_dict["email_body"] = body
从电子邮件正文中分离出标题是一项非常复杂的任务,尤其是当许多标题在某种程度上不同的时候。在未经整理的原始数据中很少发现一致性。幸运的是,工作已经完成了。Python 的email包非常擅长这项任务。
请记住,我们之前已经导入了这个包。现在,我们将它的message_from_string()函数应用于item,将完整的电子邮件转换成一个email消息对象。消息对象由标题和有效载荷组成,它们对应于电子邮件的标题和正文。
接下来,我们在消息对象上应用它的get_payload()函数。该功能隔离电子邮件的正文。我们将它赋给变量body,然后将它插入到我们的emails_dict字典中的键"email_body"下。
为什么是邮件包而不是正文的正则表达式
你可能会问,为什么要用email Python 包而不是 regex?这是因为目前还没有用 Python regex 做这件事的好方法,它不需要大量的清理。这将意味着另一页代码可能值得自己的教程。
值得看看我们是如何做出这样的决定的。然而,在这样做之前,我们需要理解方括号[ ]在 regex 中是什么意思。
匹配其中的任何字符。例如,如果我们想在一个字符串中找到"a"、"b"或"c",我们可以使用[abc]作为模式。我们上面讨论的模式也适用。[\w\s]会查找字母数字或空白字符。例外是.,它变成了方括号内的文字句点。
现在,我们可以更好地理解我们是如何决定使用电子邮件包的。
对数据集的一瞥揭示了电子邮件标题在字符串"Status: 0"或"Status: R0"处停止,并在下一封电子邮件的字符串"From r"之前结束。因此,我们可以使用Status:\s*\w*\n*[\s\S]*From\sr*只获取邮件正文。[\s\S]*适用于大块文本、数字和标点符号,因为它搜索空白或非空白字符。
不幸的是,一些电子邮件有不止一个"Status:"字符串,而另一些不包含"From r",这意味着我们会将电子邮件分成多于或少于电子邮件列表中的字典数量。它们与我们现有的其他类别不匹配。这在和熊猫一起工作时会产生问题。因此,我们决定利用email方案。
创建词典列表
最后,将字典emails_dict添加到emails列表中:
emails.append(emails_dict)
我们可能希望在此时打印出emails列表,看看它看起来怎么样。如果您刚刚使用了我们的小样本文件,这将是非常反高潮的,但是通过整个语料库,您将看到正则表达式的威力!
我们还可以运行print(len(emails_dict))来查看列表中有多少字典,以及电子邮件。正如我们之前提到的,完整的语料库包含 3977 个。
下面是完整的代码:
import re
import pandas as pd
import email
emails = []
fh = open(r"test_emails.txt", "r").read()
contents = re.split(r"From r",fh)
contents.pop(0)
for item in contents:
emails_dict = {}
sender = re.search(r"From:.*", item)
if sender is not None:
s_email = re.search(r"\w\S*@.*\w", sender.group())
s_name = re.search(r":.*<", sender.group())
else:
s_email = None
s_name = None
if s_email is not None:
sender_email = s_email.group()
else:
sender_email = None
emails_dict["sender_email"] = sender_email
if s_name is not None:
sender_name = re.sub("\s*<", "", re.sub(":\s*", "", s_name.group()))
else:
sender_name = None
emails_dict["sender_name"] = sender_name
recipient = re.search(r"To:.*", item)
if recipient is not None:
r_email = re.search(r"\w\S*@.*\w", recipient.group())
r_name = re.search(r":.*<", recipient.group())
else:
r_email = None
r_name = None
if r_email is not None:
recipient_email = r_email.group()
else:
recipient_email = None
emails_dict["recipient_email"] = recipient_email
if r_name is not None:
recipient_name = re.sub("s*<", "", re.sub(":s*", "", r_name.group()))
else:
recipient_name = None
emails_dict["recipient_name"] = recipient_name
date_field = re.search(r"Date:.*", item)
if date_field is not None:
date = re.search(r"\d+\s\w+\s\d+", date_field.group())
else:
date = None
if date is not None:
date_sent = date.group()
else:
date_sent = None
emails_dict["date_sent"] = date_sent
subject_field = re.search(r"Subject: .*", item)
if subject_field is not None:
subject = re.sub(r"Subject: ", "", subject_field.group())
else:
subject = None
emails_dict["subject"] = subject
# "item" substituted with "email content here" so full email not
# displayed.
full_email = email.message_from_string(item)
body = full_email.get_payload()
emails_dict["email_body"] = "email body here"
emails.append(emails_dict)
# Print number of dictionaries, and hence, emails, in the list.
print("Number of emails: " + str(len(emails_dict)))
print("n")
# Print first item in the emails list to see how it looks.
for key, value in emails[0].items():
print(str(key) + ": " + str(emails[0][key]))
如果您使用我们的示例文本文件运行它,您会得到以下结果:
Number of emails: 7
n
sender_email: [[email protected]](/cdn-cgi/l/email-protection)
sender_name: "Mr. Ben Suleman"
recipient_email: [[email protected]](/cdn-cgi/l/email-protection)
recipient_name: None
date_sent: 31 Oct 2002
subject: URGENT ASSISTANCE /RELATIONSHIP (P)
email_body: email body here
我们已经打印出了emails列表中的第一项,这显然是一个包含键和值对的字典。因为我们使用了一个for循环,所以每个字典都有相同的键但是不同的值。
我们用"email content here"代替了item,这样我们就不会打印出整封邮件,堵塞我们的屏幕。如果你在家里用实际的数据集打印,你会看到整封邮件。
用熊猫操纵数据
有了字典列表,我们让熊猫图书馆的工作变得无比简单。每个键将成为一个列标题,每个值成为该列中的一行。
我们要做的就是应用下面的代码:
import pandas as pd
# Module imported above, imported again as reminder.
emails_df = pd.DataFrame(emails)
通过这一行代码,我们使用 pandas DataFrame()函数将字典列表emails转换成数据帧。我们也把它赋给一个变量。
就是这样。我们现在有一个复杂的熊猫数据框架。这基本上是一个整洁干净的表格,包含了我们从电子邮件中提取的所有信息。
让我们看看前几行。
pd.DataFrame.head(emails_df, n=3)
dataframe.head()函数只显示前几行,而不是整个数据集。这需要一个论证。一个可选参数允许我们指定想要显示多少行。这里,n=3让我们查看三行。
我们也能准确地找到我们想要的东西。例如,我们可以找到从一个特定域名发送的所有电子邮件。但是,让我们学习一个新的正则表达式模式,以提高查找所需项目的精确度。
竖线符号|在它自身的两边寻找字符。例如,a|b寻找a或者b。
|可能看起来和[ ]做的一样,但它们确实是不同的。假设我们想要匹配"crab"、"lobster"或"isopod"。使用crab|lobster|isopod会比[crablobsterisopod]更有意义,不是吗?前者会查找整个单词,而后者会查找每个字母。
现在,让我们使用|来查找从一个或另一个域名发送的所有电子邮件。
emails_df[emails_df["sender_email"].str.contains("epatra|spinfinder")]
我们在这里使用了相当长的一行代码。让我们从里到外开始。
emails_df['sender_email']选择标签为sender_email的列。接下来,如果在该列中找到子字符串"epatra"或"spinfinder",则str.contains(epatra|spinfinder)返回True。最后,外部的emails_df[]返回行的视图,其中sender_email列包含目标子字符串。俏皮!
我们也可以查看单个手机的电子邮件。为此,我们要经历四个步骤。在步骤 1 中,我们找到了行的索引,在该行中,"sender_email"列包含字符串"@spinfinder"。请注意我们是如何使用 regex 做到这一点的。
# Step 1: find the index where the "sender_email" column contains "@spinfinder.com".
index = emails_df[emails_df["sender_email"].str.contains(r"\w\S*@spinfinder.com")].index.values
在第 2 步中,我们使用索引来查找电子邮件地址,loc[]方法将该地址作为具有几个不同属性的 Series 对象返回。我们把它打印出来,看看它是什么样子。
# Step 2: use the index to find the value of the cell i the "sender_email" column.
# The result is returned as pandas Series object
address_Series = emails_df.loc[index]["sender_email"]
print(address_Series)
print(type(address_Series))
0 [[email protected]](/cdn-cgi/l/email-protection)
Name: sender_email, dtype: object
<class 'pandas.core.series.series'>
在第 3 步中,我们从 Series 对象中提取电子邮件地址,就像从列表中提取项目一样。你可以看到它的类型现在是 class。
# Step 3: extract the email address, which is at index 0 in the Series object.
address_string = address_Series[0]
print(address_string)
print(type(address_string))
[[email protected]](/cdn-cgi/l/email-protection)
<class 'str'>
第 4 步是我们提取电子邮件正文。
# Step 4: find the value of the "email_body" column where the "sender email" column is address_string.
print(emails_df[emails_df["sender_email"] == address_string]["email_body"].values)
['email body here']
在第 4 步中,emails_df['sender_email'] == "[[email protected]](/cdn-cgi/l/email-protection)"找到了sender_email列包含值"[[email protected]](/cdn-cgi/l/email-protection)"的行。接下来,['email_body'].values在同一行中查找email_body列的值。最后,我们打印出这个值。
正如你所看到的,我们可以在很多方面使用 regex,它也可以很好地处理熊猫。如果您的正则表达式工作包含大量的试错,不要气馁,尤其是在您刚刚开始的时候!
其他资源
自从多年前从生物学跳到工程学以来,Regex 已经有了巨大的发展。今天,正则表达式被用于不同的编程语言,除了它的基本模式之外还有一些变化。我们已经学习了很多 Python 正则表达式,如果你想更上一层楼,我们的 Python 数据清理高级课程可能是个不错的选择。
你也可以在官方参考资料中找到一些帮助,比如 Python 的文档中的re模块。谷歌有一个更快的参考。
如果你愿意,你也可以开始探索 Python regex 和其他形式的 regex 堆栈溢出 post 之间的区别。维基百科有一个表比较不同的正则表达式引擎。
如果你需要数据集来做实验,那么 Kaggle 和 StatsModels 会很有用。
最后,这里有一个我们制作的 Regex cheatsheet 也非常有用。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。


在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
机器学习中的正则化(附代码示例)
原文:https://www.dataquest.io/blog/regularization-in-machine-learning/
October 11, 2022
在本教程中,我们将学习什么是正则化以及我们为什么使用它。我们还将讨论正则化技术以及如何使用它们。
完成本教程后,您将理解以下内容:
- 机器学习中的正则化
- L1 正则化(套索回归)
- L2 正则化(岭回归)
- 弹性网
- 如何使用这些正则化技术
在本教程中,我们假设您了解机器学习的基础知识,包括线性回归的基本概念。如果你不熟悉机器学习或渴望更新你的机器学习技能,你可能会喜欢尝试我们的数据科学家在 Python 职业道路。
介绍
基本上,我们使用正则化技术来修复机器学习模型中的过度拟合。在更详细地讨论正则化之前,我们先讨论过拟合。
当机器学习模型与训练数据紧密拟合,并试图学习数据中的所有细节时,就会发生过度拟合;在这种情况下,模型不能很好地推广到看不见的数据。下图称为泛化曲线,显示了训练损失随着训练迭代次数的增加而不断减少:

虽然最小化训练损失是一件好事,但是验证损失在特定的迭代次数之后开始增加。验证损失的增加趋势意味着,当我们试图减少训练损失时,我们增加了模型的复杂性,因此它不能推广到新的数据点。
换句话说,高方差机器学习模型捕捉训练数据的所有细节以及数据中的现有噪声。因此,正如你在泛化曲线中看到的,训练损失和验证损失之间的差异变得越来越明显。相反,高偏差机器学习模型与训练数据松散耦合,这导致训练损失和验证损失之间的差异较小。
到目前为止,我们已经了解到,防止过度拟合对于提高我们的机器学习模型的性能至关重要。在接下来的部分中,我们将学习正则化及其技术。
什么是正规化?
正则化意味着通过将系数估计缩小到零来限制模型以避免过度拟合。当一个模型遭受过拟合时,我们应该控制模型的复杂性。从技术上讲,正则化通过向模型的损失函数添加惩罚来避免过度拟合:
$ $ \ text {正则化=损失函数+惩罚}$$
有三种常用的正则化技术来控制机器学习模型的复杂性,如下所示:
- L2 正则化
- L1 正则化
- 弹性网
让我们详细讨论这些标准技术。
L2 正则化
使用 L2 正则化技术的线性回归被称为岭回归。换句话说,在岭回归中,正则化项被添加到线性回归的成本函数中,这使得模型的权重(系数)的大小尽可能小。L2 正则化技术试图使模型的权重接近于零,但不是零,这意味着每个要素对输出的影响应该很小,而模型的精度应该尽可能高。
$ $ \ text {岭回归成本函数} = \ text {损失函数}+\ dfrac { 1 } { 2 } \lambda\sum_{j=1}^m w_j^2$$
其中\(\lambda\)控制正则化的强度,\(w_j\)是模型的权重(系数)。
通过增加\(\lambda\),模型变得受宠若惊且不合适。另一方面,通过减少\(\lambda\),模型变得更加过拟合,并且当\(\lambda\) = 0 时,正则化项将被消除。
L1 正则化
最小绝对收缩和选择算子(套索)回归是岭的替代方法,用于正则化线性回归。Lasso 回归也在成本函数中增加了一个惩罚项,但略有不同,称为 L1 正则化。L1 正则化使一些系数为零,这意味着模型将忽略这些特征。忽略最不重要的特性有助于强调模型的基本特性。
其中\(\lambda\)控制正则化的强度,\(w_j\)是模型的权重(系数)。
套索回归通过消除最不重要的要素来自动执行要素选择。
弹性网
弹性网是一种结合了脊和套索正则项的正则化回归技术。\(r\)参数控制组合比率。当\(r=1\)时,L2 项将被消除,当\(r=1\)时,L1 项将被消除。
$ $ \ text {弹性净成本函数} = \ text {损失函数}+r \ lambda \sum_{j=1}^m | wj |+\ dfrac {(1-r)} { 2 } \ lambda \ sum^m w_j^2$$
虽然将 lasso 和 ridge 的惩罚结合起来通常比只使用其中一种正则化技术效果更好,但调整两个参数\(\lambda\)和\(r\)有点棘手。
用 Python 演示正则化技术
在本节中,我们将对 Boston Housing 数据集应用 L2 和 L1 正则化技术,并比较使用这些技术前后的训练集得分和测试集得分。
首先,让我们加载数据集,并将其分为训练集和测试集,如下所示:
import mglearn as ml
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from numpy import genfromtxt
dataset = genfromtxt('https://raw.githubusercontent.com/m-mehdi/tutorials/main/boston_housing.csv', delimiter=',')
X = dataset[:,:-1]
y = dataset[:,-1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=0)
现在,我们可以训练线性回归模型,然后打印训练集分数和测试集分数:
lr = LinearRegression().fit(X_train, y_train)
print(f"Linear Regression-Training set score: {lr.score(X_train, y_train):.2f}")
print(f"Linear Regression-Test set score: {lr.score(X_test, y_test):.2f}")
Linear Regression-Training set score: 0.95
Linear Regression-Test set score: 0.61
比较训练集和测试集上的模型性能揭示了该模型遭受过拟合。
为了避免过度拟合并控制模型的复杂性,让我们使用岭回归(L2 正则化)并看看它在数据集上的表现如何:
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=0.7).fit(X_train, y_train)
print(f"Ridge Regression-Training set score: {ridge.score(X_train, y_train):.2f}")
print(f"Ridge Regression-Test set score: {ridge.score(X_test, y_test):.2f}")
Ridge Regression-Training set score: 0.90
Ridge Regression-Test set score: 0.76
虽然岭回归的训练集得分略低于线性回归的训练集得分,但岭的测试集得分显著高于线性回归的测试集得分。这些分数证实了岭回归降低了模型的复杂性,导致一个不太过度拟合但更通用的模型。
alpha参数指定了模型在训练集上的性能与其简单性之间的权衡。因此,增加alpha值(其默认值为 1.0)可以通过缩小系数来简化模型。
现在,让我们将套索回归应用于数据集并探究结果。
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=1.0).fit(X_train, y_train)
print(f"Lasso Regression-Training set score: {lasso.score(X_train, y_train):.2f}")
print(f"Lasso Regression-Test set score: {lasso.score(X_test, y_test):.2f}")
Lasso Regression-Training set score: 0.29
Lasso Regression-Test set score: 0.21
如图所示,拉索的表现相当令人失望,这是一个不适合的迹象。套索模型效果不好,因为大部分系数都变成了精确的零。如果我们想知道模型中已经使用的特性的确切数量,我们可以使用下面的代码:
print(f"Number of features: {sum(lasso.coef_ != 0)}")
Number of features: 4
这意味着训练集中的 104 个特征中只有 4 个用于 lasso 回归模型,而其余的被忽略。
让我们调整alpha,通过将其值降低到 0.01 来减少欠拟合:
lasso = Lasso(alpha=0.01).fit(X_train, y_train)
print("Lasso Regression-Training set score: {:.2f}".format(lasso.score(X_train, y_train)))
print("Lasso Regression-Test set score: {:.2f}".format(lasso.score(X_test, y_test)))
Lasso Regression-Training set score: 0.90
Lasso Regression-Test set score: 0.77
/Users/mohammadmehdi/opt/anaconda3/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 4.690e+01, tolerance: 3.233e+00
model = cd_fast.enet_coordinate_descent(
重新运行下面的代码显示,通过减少alpha,套索模型使用了 104 个特征中的 32 个:
print(f"Number of features: {sum(lasso.coef_ != 0)}")
Number of features: 32
虽然我们可以将alpha降低更多,但似乎它的最佳值是0.01。
我们要使用的最后一种技术是弹性网。让我们看看它做得有多好。
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.01, l1_ratio=0.01).fit(X_train, y_train)
print(f"Elastic Net-Training set score: {elastic_net.score(X_train, y_train):.2f}")
print(f"Elastic Net-Test set score: {elastic_net.score(X_test, y_test):.2f}")
Elastic Net-Training set score: 0.84
Elastic Net-Test set score: 0.70
/Users/mohammadmehdi/opt/anaconda3/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:647: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.474e+02, tolerance: 3.233e+00
model = cd_fast.enet_coordinate_descent(
注
一般来说,为了避免过度拟合,正则化模型优于简单的线性回归模型。在大多数情况下,ridge 工作得很好。但如果您不确定使用套索还是弹性网,弹性网是更好的选择,因为正如我们所见,套索移除了强相关的要素。
结论
本教程探讨了在线性机器学习模型中避免过拟合的不同方法。我们讨论了为什么会发生过度拟合,以及什么是脊、套索和弹性网回归方法。我们还将这些技术应用于波士顿住房数据集,并比较了结果。一些其他技术,如早期停止和退出,可用于正则化复杂模型,而后者主要用于正则化人工神经网络。
我希望你今天学到了一些新东西。请随时在 LinkedIn 或 Twitter 上与我联系。
23 RStudio 提示、技巧和快捷方式
原文:https://www.dataquest.io/blog/rstudio-tips-tricks-shortcuts/
June 10, 2020
RStudio 是一个用于 R 编程的开源工具。如果您对 R 编程感兴趣,那么有必要了解一下 RStudio 的功能。它是一个灵活的工具,帮助您创建可读的分析,并将您的代码、图像、注释和绘图放在一个地方。
在这篇博文中,我们将介绍 RStudio 免费版的一些最佳特性: RStudio 桌面。我们收集了一些顶级 RStudio 提示、技巧和快捷方式,帮助您快速成为 RStudio 高级用户!
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
1.在窗口窗格之间快速导航
RStudio 窗口窗格可让您随时访问有关项目的重要信息。知道如何在窗格之间切换而不用触摸鼠标来移动光标将节省时间并改进您的工作流程。使用这些快捷键可以在窗格之间即时移动:
Control/Ctrl + 1:源代码编辑器(您的脚本)Control/Ctrl + 2:控制台Control/Ctrl + 3:救命Control/Ctrl + 4:历史Control/Ctrl + 5:文件Control/Ctrl + 6:剧情Control/Ctrl + 7:包装Control/Ctrl + 8:环境Control/Ctrl + 9:查看器
如果你喜欢一次只查看一个窗格,添加Shift到上面的任何命令来最大化窗格。例如,输入Control/Ctrl + Shift + 1以最大化您正在处理的 R 脚本、笔记本或 R Markdown 文件。
(旁注:我们在快捷键中显示的+表示“和”,所以不需要实际键入+键。)
但是如果您想返回到标准的四窗格视图呢?没问题!输入Control/Ctrl + Shift + 0:

2.快捷键
知道 RStudio 键盘快捷键会在编程时节省很多时间。RStudio 提供了几十种有用的快捷方式,您可以通过顶部的菜单进入:Tools > Keyboard Shortcuts Help。
访问 RStudio 键盘快捷键的另一种方式是使用快捷键!要访问快捷方式,在 Mac 上键入Option + Shift + K,或者在 Linux 和 Windows 上键入Alt + Shift + K。
以下是我们最喜欢的 RStudio 快捷方式:
- 在 Mac 上插入带有
Option + -的 Alt + -。 - 在 Mac 上插入带有
Command + Shift + M的管道操作符%>%,或者在 Linux 和 Windows 上插入Ctrl + Shift + M。 - 在 Mac 上用
Command + Enter运行当前代码行,在 Linux 和 Windows 上用Control + Enter运行当前代码行。 - 在 Mac 上用
Command + A + Enter运行所有代码行,在 Linux 和 Windows 上用Control + A + Enter运行所有代码行。 - 重启当前的 R 会话,在 Mac 上用
Command + Shift + F10重新开始,在 Linux 和 Windows 上用Control + Shift + F10重新开始。 - 在 Mac 上用
Command + Shift + C注释或取消注释行,在 Linux 和 Windows 上用Control + Shift + C注释或取消注释行。 - 试图记住您之前提交的命令?在 Mac 上使用
Command + [up arrow]或在 Linux 和 Windows 上使用Control + [up arrow]从控制台搜索命令历史。
还有许多更有用的快捷方式,但是通过掌握上面的快捷方式,您将成为 RStudio 高级用户!
RStudio 快捷方式的另一个很好的资源是官方的 RStudio 备忘单,可从这里获得。
3.通过代码完成节省时间
在您开始输入之后,会弹出一个建议窗口,其中包含匹配的函数、对象和代码片段的名称。您可以使用向上或向下箭头在列表中切换,并点击return/Enter进行选择。
或者,你可以利用一个非常酷的功能,叫做模糊匹配,,它允许你通过输入你要匹配的项目的唯一字母来缩小你的搜索选项。只要您输入的内容与字符串的顺序匹配,就不需要输入所有的字母。
让我们看看这些代码完成方法是如何工作的。首先,我们将通过键入函数名的一部分来选择installed.packages()函数,然后使用箭头进行选择。接下来,我们将使用模糊匹配仅输入instd来进一步缩小选择范围:

4.快速查找文件和功能
在 RStudio 中,不需要在文件夹结构中摸索查找文件,也不需要挖掘功能!输入快捷键control/ctrl + .打开Go to File/Function窗口,然后使用模糊匹配技能缩小选择范围:

5.自定义外观
RStudio 提供了丰富的选项来根据您的喜好定制外观。在RStudio选项卡下,导航至Preferences > Appearance以探索许多可用选项。RStudio 的一个很好的特性是你可以快速点击Editor theme窗口来预览每个主题。

6.文档的简单链接
在右下窗口的Help选项卡下,您会找到 R 函数和 R 包的在线文档的链接。例如,如果我们使用搜索栏搜索关于install.packages()函数的信息,将返回官方文档:

我们也可以通过在?(例如?install.packages)前添加一个包或函数并在控制台中运行命令来访问Help选项卡中的文档。无论使用哪种方法,RStudio 都会在您键入时自动填充匹配的函数名!
7.预览并保存您的地块
RStudio 会话期间生成的图显示在右下窗口的Plots选项卡下。在此窗口中,您可以通过放大和缩小来检查您的绘图。如果要保存绘图,可以将绘图保存为 PDF 或图像文件。

8.导入和预览数据集
RStudio 使导入和预览数据集变得简单,无需编码!在右上方窗口的Environment选项卡下,有一个使您能够导入数据集的功能。此功能支持多种格式:

您甚至可以在加载数据集之前预览它:

数据集加载到 RStudio 后,您可以使用View()命令或通过单击数据集的名称来查看它:

9.一键查看命令历史记录
之前,我们从控制台学习了命令历史的快捷方式。RStudio 还允许您通过点击History选项卡,在右上角窗口中查看整个命令历史:

10.保存您的“真实”工作。其余删除。
实践良好的内务管理,以避免未来不可预见的挑战。如果您创建了一个值得保存的 R 对象,请在 R 脚本文件中捕获生成该对象的 R 代码。保存 R 脚本,但是不要保存创建对象的环境或工作空间。
要防止 RStudio 保存您的工作空间,请打开Preferences > General并取消选择启动时将.RData恢复到工作空间的选项。确保指定您永远不想保存您的工作区,如下所示:

现在,每次打开 RStudio 时,您都将从一个空会话开始。从您之前的会话中生成的任何代码都不会被记住。R 脚本和数据集可以用来从头开始重新创建环境。
11.用项目组织您的工作
RStudio 提供了一个强大的功能,让您保持条理;项目。当您进行多项分析时,保持条理是非常重要的。RStudio 的项目允许您将所有重要的工作放在一个地方,包括代码脚本、绘图、图表、结果和数据集。
通过导航到 RStudio 中的File选项卡并选择New Project...来创建一个新项目。您可以选择在新目录或现有目录中创建新项目。如果你正在开发一个 R 包,或者一个闪亮的 Web 应用程序,RStudio 提供了专门的项目类型。
当您需要与同事分享您的工作时,RStudio 项目非常有用。您可以发送您的项目文件(以.Rproj结尾)以及所有支持文件,这将使您的同事更容易重新创建工作环境并重现结果。
但是如果您想要无缝协作,您可能需要将包管理引入到您的工作流中。幸运的是,RStudio 提供了一个有用的包管理工具[renv](https://rstudio.github.io/renv/),它现在与 RStudio 项目兼容。接下来我们将讲述renv。
12.使用 renv 管理软件包版本
我们喜欢 Dataquest 的 R,但是管理软件包版本可能是一个挑战!幸运的是,由于 RStudio 的renv(“可再生环境”)包,R 包管理比以往任何时候都更容易。现在,RStudio 包含了对renv的内置支持。
我们不会在这篇博客中详细讨论如何将renv用于 RStudio 项目,因为 RStudio 在我们提供的链接和简介中为您提供了您需要的信息。但是将renv与 RStudio 一起使用可以使 R 包管理更加容易,所以我们想让您知道!
这个renv包取代了以前由 RStudio 维护的包Packrat包。
要在 RStudio 项目中使用renv包,请升级到 RStudio 的最新版本,然后安装带有library("renv")的renv包。在那里,您可以选择对所有新项目使用renv:

如果您想将renv用于现有项目,导航至Tools > Project Options > Environments并勾选复选框以启用renv:

13.在 RStudio 中使用 GitHub 管理版本控制
除了在 RStudio 中管理包之外,您还可以使用 GitHub 和 RStudio 来维护项目和 R 脚本的版本控制。查看来自 GitHub 的这篇文章和来自 RStudio 的这篇文章,了解将 Git 集成到 RStudio 工作流中所需的所有信息。
14.代码片段
RStudio 提供了一个非常有用的特性,可以插入常见的代码块,称为代码片段。我们最喜欢的一个是lib片段,它可以在调用library()函数加载 R 包时节省您的输入时间:

在您点击 return 键选择代码片段后,将加载library()函数,并且定位光标,这样您就可以立即开始输入您想要加载的包的名称:

我们的另一个最爱是有趣的代码片段,它提供了一个编写自定义函数的基本模板。您甚至可以添加自己的片段!要了解更多信息,请查看本文中来自 RStudio 的代码片段。
15.深入研究函数的源代码
如果您想研究某个函数的源代码,将光标移到感兴趣的函数上,然后输入F2(在 Mac 上,您可能需要输入fn + F2)。这个特性甚至适用于从您使用的任何 R 包中加载的函数。
16.功能提取
如果你已经写了一段代码,想把它变成一个函数,高亮显示这段代码,在 Mac 上输入control + option X,在 Linux/Windows 上输入Ctrl + Alt + X。将出现一个弹出窗口,要求您选择一个函数名。

选择函数名后,将代码转换成函数所需的输入和代码结构将自动添加。

如果您有一个想要提取的变量,突出显示该变量并在 Mac 上输入control + option V,在 Linux/Windows 上输入Ctrl + Alt + V。
17.在范围内重命名
在某些情况下,您可能需要更改函数名或函数中使用的变量名。但是使用“查找和替换”来做这件事是很伤脑筋的!幸运的是,RStudio 使得在作用域内重命名成为可能。这意味着您的更改将仅限于感兴趣的变量或函数。这将防止您意外替换代码脚本中其他地方的同名变量。要使用此功能,请选择您想要更改的函数或变量,并在 Mac 上输入control + shift + option + M,或在 Linux/Windows 上输入Ctrl + Shift + Alt + M。

18.多光标支持
RStudio 支持多个游标。在 Mac 上按住option,或者在 Windows/Linux 上按住Alt,只需点击并拖动鼠标。


19.将 Python 与 RStudio 和 reticulate 结合使用
RStudio 支持 python 中的编码。在 RStudio 中启动和运行 python 的过程包括以下几个一般步骤:
- 安装 Python 的基础版本
- 安装
pip和virtualenv - 在工作室项目中创建一个 python 环境
- 激活您的 Python 环境
- 在您的环境中安装所需的 Python 包
- 安装并配置 R
reticulate包以使用 Python
本文提供了上述步骤所需的代码。我们试用了一下,只用了几分钟就能在 RStudio 中运行 python:

要了解全部细节,请查看这个 RStudio 教程。
20.使用 DBI 包查询 SQL
在 RStudio 中运行 SQL 查询有很多种方式。这里有三个最流行的方法,从 r。
首先,您将生成一个内存中的 SQL 数据库,以便在所有 SQL 查询示例中使用。您将为著名的“mtcars”数据集生成一个 SQL 数据库。代码如下:
 现在编写一个 SQL 查询,从数据库中选择所有四缸发动机的汽车。该命令返回一个数据帧,您将把它保存为
现在编写一个 SQL 查询,从数据库中选择所有四缸发动机的汽车。该命令返回一个数据帧,您将把它保存为dbi_query:

数据帧看起来像这样:
21.在 R Markdown 中或使用 R 记事本查询 SQL
通过创建一个{sql}代码块,你可以在 R Notebook 或 R Markdown 中达到同样的效果。使用第一个示例中的连接和数据库,运行以下代码:
指定output.var = "mt_cars_df"将查询结果保存到数据帧。该数据帧是一个标准的 R 数据帧,与您在上一示例中生成的数据帧相同。您可以在 R 代码块中使用此数据帧来执行分析或生成 ggplot,例如:
22.用 dbplyr 查询 SQL
最后,您将使用dbplyr包来编写转换成 SQL 的标准dplyr命令!同样,使用第一个示例中的连接和数据库,您可以编写一个标准的filter()调用来查询四缸汽车,这将返回一个列表对象:

如果您想查看这个命令被转换成的 SQL 代码,您可以使用来自dbplyr的show_query()函数:
 当您对查询结果满意时,您可以使用
当您对查询结果满意时,您可以使用dbplyr中的collect()函数将结果保存为数据帧:

你有它!三种不同的查询 SQL 数据库的方法得到相似的结果。两个例子之间唯一的区别是,dbplyr方法返回一个 tibble,而前两个方法返回一个标准的 R 数据帧。
要了解更多关于使用 RStudio 查询 SQL 数据库的信息,请查看本文。
23.把它带到云端!
RStudio 现在提供一个基于云的 RStudio 桌面版本,名为,你猜对了… RStudio Cloud 。RStudio Cloud 让你不用安装软件就可以在 RStudio 中编码,你只需要一个网页浏览器。
RStudio Cloud 中的工作被组织到类似于桌面版本的项目中,但是 RStudio Cloud 使您能够指定您希望用于每个项目的 R 版本。
RStudio Cloud 还可以轻松安全地与同事共享项目,并确保每次访问项目时工作环境完全可再现。
可以看到,RStudio 云的布局与 RStudio 桌面非常相似:

奖励:备忘单
RStudio 发布了许多与 R 合作的备忘单,包括一份关于使用 RStudio 的详细备忘单!通过选择Help > Cheatsheets,可以从 RStudio 中访问选择备忘单。
额外资源
RStudio 发表了许多关于使用 RStudio 的深入的操作方法文章。找到他们在这里。
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
Scikit-learn 教程:Python 中的机器学习
November 15, 2018
Scikit-learn 是一个免费的 Python 机器学习库。它具有各种算法,如支持向量机、随机森林和 k 邻居,它还支持 Python 数值和科学库,如NumPy和SciPy。
在本教程中,我们将学习在 scikit-learn 库的帮助下编写 python 代码并应用机器学习,scikit-learn 库的创建是为了使在 Python 中进行机器学习变得更容易和更健壮。
为此,我们将使用来自 IBM Watson 存储库的 Sales_Win_Loss 数据。我们将使用 pandas 导入数据集,使用 pandas 方法如head()、tail()、dtypes()探索数据,然后尝试使用Seaborn中的绘图技术来可视化我们的数据。
然后我们将深入 scikit-learn 并使用 scikit-learn 中的preprocessing.LabelEncoder()来处理数据,并使用train_test_split()将数据集分成测试和训练样本。我们还将使用一个备忘单来帮助我们决定对数据集使用哪些算法。最后,我们将使用三种不同的算法(朴素贝叶斯、LinearSVC、K-Neighbors 分类器)进行预测,并使用 scikit-learn 库提供的accuracy_score()等方法比较它们的性能。我们还将使用 scikit-learn 和 Yellowbrick visualization 来可视化不同模型的性能得分。
为了从这篇文章中获得最大的收获,你可能已经熟悉了:
- 熊猫基础知识
- Seaborn 和 matplotlib 基础知识
如果你需要温习这些话题,看看这些熊猫和数据可视化的博客帖子。
数据集
在本教程中,我们将使用 IBM Watson 网站上提供的销售盈亏数据集。该数据集包含一家汽车零件批发供应商的销售活动数据。
我们将使用 scikit-learn 构建一个预测模型,告诉我们哪个销售活动会导致亏损,哪个会导致盈利。
让我们从导入数据集开始。
导入数据集
首先,我们将导入 pandas 模块,并使用一个变量url来存储要从中下载数据集的 url。
#import necessary modules
import pandas as pd
#store the url in a variable
url = "https://community.watsonanalytics.com/wp-content/uploads/2015/04/WA_Fn-UseC_-Sales-Win-Loss.csv"
接下来,我们将使用 pandas 模块提供的read_csv()方法来读取包含逗号分隔值的csv文件,并将其转换为 pandas 数据帧。
# Read in the data with `read_csv()`
sales_data = pd.read_csv(url)
上面的代码片段返回了一个变量sales_data,数据帧现在就存储在这个变量中。
对于不熟悉 pandas 的人来说,上面代码中的pd.read_csv()方法创建了一个称为Dataframe的表格数据结构,其中第一列包含唯一标记每行数据的索引,第一行包含每列的标签/名称,这是从数据集中保留的原始列名。上述代码片段中的sales_data变量的结构类似于下图。

来源:堆栈溢出
在上图中,row0、row1、row2 是数据集中每个记录的索引,col0、col1、col2 等是数据集中每个列(特征)的列名。
现在,我们已经从数据源下载了数据集,并将其转换为 pandas 数据帧,让我们显示这个数据帧中的一些记录。为此,我们将使用head()方法。
# Using .head() method to view the first few records of the data set
sales_data.head()
| 机会编号 | 供应分组 | 供应组 | 地区 | 通往市场的路线 | 销售阶段经过的天数 | 机会结果 | 销售阶段更改计数 | 通过结算确定的总天数 | 通过合格鉴定的总天数 | 机会金额美元 | 按收入划分的客户规模 | 按员工数量划分的客户规模 | 过去两年来自客户的收入 | 竞争对手类型 | 确定天数与总天数的比率 | 验证天数与总天数的比率 | 合格天数与总天数的比率 | 交易规模类别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | One million six hundred and forty-one thousand nine hundred and eighty-four | 外部配件 | 汽车配件 | 西北 | 现场销售 | Seventy-six | 获胜 | Thirteen | One hundred and four | One hundred and one | Zero | five | five | Zero | 未知的 | 0.69636 | 0.113985 | 0.154215 | one |
| one | One million six hundred and fifty-eight thousand and ten | 外部配件 | 汽车配件 | 太平洋 | 中间商 | Sixty-three | 失败 | Two | One hundred and sixty-three | One hundred and sixty-three | Zero | three | five | Zero | 未知的 | 0.00000 | 1.000000 | 0.000000 | one |
| Two | One million six hundred and seventy-four thousand seven hundred and thirty-seven | 摩托车零件 | 性能和非汽车 | 太平洋 | 中间商 | Twenty-four | 获胜 | seven | Eighty-two | Eighty-two | Seven thousand seven hundred and fifty | one | one | Zero | 未知的 | 1.00000 | 0.000000 | 0.000000 | one |
| three | One million six hundred and seventy-five thousand two hundred and twenty-four | 避难所和房车 | 性能和非汽车 | 中西部 | 中间商 | Sixteen | 失败 | five | One hundred and twenty-four | One hundred and twenty-four | Zero | one | one | Zero | 已知的 | 1.00000 | 0.000000 | 0.000000 | one |
| four | One million six hundred and eighty-nine thousand seven hundred and eighty-five | 外部配件 | 汽车配件 | 太平洋 | 中间商 | sixty-nine | 失败 | Eleven | Ninety-one | Thirteen | Sixty-nine thousand seven hundred and fifty-six | one | one | Zero | 未知的 | 0.00000 | 0.141125 | 0.000000 | four |
从上面的显示可以看出,head()方法向我们展示了数据集中的前几条记录。head()方法是 pandas 提供的一个非常漂亮的工具,可以帮助我们了解数据集的内容。我们将在下一节详细讨论head()方法。
数据探索
既然我们已经下载了数据集并将其转换成了熊猫数据框架,那么让我们快速浏览一下这些数据,看看这些数据能告诉我们什么,这样我们就可以计划我们的行动了。
数据探索是任何数据科学或机器学习项目中非常重要的一步。即使是对数据集的快速浏览也能给我们提供重要的信息,否则我们可能会错过这些信息,这些信息可以提示我们可以通过我们的项目尝试回答的重要问题。
为了探索数据集,我们将使用一些第三方 Python 库来帮助我们处理数据,以便它可以有效地用于 scikit-learn 的强大算法。但是我们可以从我们在上一节中使用的相同的head()方法开始查看导入的数据集的前几条记录,因为head()实际上能够做的远不止这些!我们可以定制head()方法,以便只显示特定数量的记录:
# Using head() method with an argument which helps us to restrict the number of initial records that should be displayed
sales_data.head(n=2)
| 机会编号 | 供应分组 | 供应组 | 地区 | 通往市场的路线 | 销售阶段经过的天数 | 机会结果 | 销售阶段更改计数 | 通过结算确定的总天数 | 通过合格鉴定的总天数 | 机会金额美元 | 按收入划分的客户规模 | 按员工数量划分的客户规模 | 过去两年来自客户的收入 | 竞争对手类型 | 确定天数与总天数的比率 | 验证天数与总天数的比率 | 合格天数与总天数的比率 | 交易规模类别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | One million six hundred and forty-one thousand nine hundred and eighty-four | 外部配件 | 汽车配件 | 西北 | 现场销售 | Seventy-six | 获胜 | Thirteen | One hundred and four | One hundred and one | Zero | five | five | Zero | 未知的 | 0.69636 | 0.113985 | 0.154215 | one |
| one | One million six hundred and fifty-eight thousand and ten | 外部配件 | 汽车配件 | 太平洋 | 中间商 | Sixty-three | 失败 | Two | One hundred and sixty-three | One hundred and sixty-three | Zero | three | five | Zero | 未知的 | 0.00000 | 1.000000 | 0.000000 | one |
在上面的代码片段中,我们在head()方法中使用了一个参数,只显示数据集中的前两条记录。自变量n=2中的整数‘2’实际上表示数据帧Sales_data的第二个index。使用它,我们可以快速查看我们必须处理的数据类型。例如,我们可以看到“供应商组”和“区域”等列包含字符串数据,而“机会结果”、“机会编号”等列包含字符串数据。包含整数。此外,我们可以看到“Opportunity Number”列包含每条记录的唯一标识符。
现在我们已经查看了数据帧的初始记录,让我们尝试查看数据集中的最后几条记录。这可以使用tail()方法来完成,该方法与head()方法的语法相似。让我们看看tail()方法能做什么:
# Using .tail() method to view the last few records from the dataframe
sales_data.tail()
| 机会编号 | 供应分组 | 供应组 | 地区 | 通往市场的路线 | 销售阶段经过的天数 | 机会结果 | 销售阶段更改计数 | 通过结算确定的总天数 | 通过合格鉴定的总天数 | 机会金额美元 | 按收入划分的客户规模 | 按员工数量划分的客户规模 | 过去两年来自客户的收入 | 竞争对手类型 | 确定天数与总天数的比率 | 验证天数与总天数的比率 | 合格天数与总天数的比率 | 交易规模类别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Seventy-eight thousand and twenty | Ten million eighty-nine thousand nine hundred and thirty-two | 电池和配件 | 汽车配件 | 东南 | 中间商 | Zero | 失败 | Two | Zero | Zero | Two hundred and fifty thousand | one | one | three | 未知的 | Zero | Zero | Zero | six |
| Seventy-eight thousand and twenty-one | Ten million eighty-nine thousand nine hundred and sixty-one | 避难所和房车 | 性能和非汽车 | 东北 | 中间商 | Zero | 获胜 | one | Zero | Zero | One hundred and eighty thousand | one | one | Zero | 未知的 | Zero | Zero | Zero | five |
| Seventy-eight thousand and twenty-two | Ten million ninety thousand one hundred and forty-five | 外部配件 | 汽车配件 | 东南 | 中间商 | Zero | 失败 | Two | Zero | Zero | Ninety thousand | one | one | Zero | 未知的 | Zero | Zero | Zero | four |
| Seventy-eight thousand and twenty-three | Ten million ninety thousand four hundred and thirty | 外部配件 | 汽车配件 | 东南 | 现场销售 | Zero | 失败 | Two | Zero | Zero | One hundred and twenty thousand | one | one | Zero | 未知的 | One | Zero | Zero | five |
| Seventy-eight thousand and twenty-four | Ten million ninety-four thousand two hundred and fifty-five | 内部配件 | 汽车配件 | 大西洋中部 | 中间商 | Zero | 失败 | one | Zero | Zero | Ninety thousand | one | one | Zero | 未知的 | Zero | Zero | Zero | four |
上面代码片段中的tail()方法返回数据帧sales_data中的最后几条记录。我们也可以向tail()方法传递一个参数,只查看数据帧中有限数量的记录:
# Using .tail() method with an argument which helps us to restrict the number of initial records that should be displayed
sales_data.tail(n=2)
| 机会编号 | 供应分组 | 供应组 | 地区 | 通往市场的路线 | 销售阶段经过的天数 | 机会结果 | 销售阶段更改计数 | 通过结算确定的总天数 | 通过合格鉴定的总天数 | 机会金额美元 | 按收入划分的客户规模 | 按员工数量划分的客户规模 | 过去两年来自客户的收入 | 竞争对手类型 | 确定天数与总天数的比率 | 验证天数与总天数的比率 | 合格天数与总天数的比率 | 交易规模类别 |
| Seventy-eight thousand and twenty-three | Ten million ninety thousand four hundred and thirty | 外部配件 | 汽车配件 | 东南 | 现场销售 | Zero | 失败 | Two | Zero | Zero | One hundred and twenty thousand | one | one | Zero | 未知的 | One | Zero | Zero | five |
| Seventy-eight thousand and twenty-four | Ten million ninety-four thousand two hundred and fifty-five | 内部配件 | 汽车配件 | 大西洋中部 | 中间商 | Zero | 失败 | one | Zero | Zero | Ninety thousand | one | one | Zero | 未知的 | Zero | Zero | Zero | four |
我们现在只能查看 dataframe 中的最后两条记录,如tail()方法中的参数n=2所示。与head()方法类似,tail()方法中参数n=2中的整数‘2’指向数据集sales_data中最后两条记录的第二个索引。
这最后两张唱片告诉了我们什么故事?查看数据框中拖车记录的“Opportunity Number”栏,我们清楚地看到总共有 78,024 条记录可用。从用tail()方法显示的记录的“索引”号可以明显看出这一点。
现在,如果我们能看到这个数据集中可用的不同数据类型,那就太好了;如果我们以后需要做一些转换,这些信息会很方便。我们可以在熊猫身上用dtypes()方法做到这一点:
# using the dtypes() method to display the different datatypes available
sales_data.dtypes
Opportunity Number int64
Supplies Subgroup object
Supplies Group object
Region object
Route To Market object
Elapsed Days In Sales Stage int64
Opportunity Result object
Sales Stage Change Count int64
Total Days Identified Through Closing int64
Total Days Identified Through Qualified int64
Opportunity Amount USD int64
Client Size By Revenue int64
Client Size By Employee Count int64
Revenue From Client Past Two Years int64
Competitor Type object
Ratio Days Identified To Total Days float64
Ratio Days Validated To Total Days float64
Ratio Days Qualified To Total Days float64
Deal Size Category int64
dtype: object
正如我们在上面的代码片段中看到的,使用dtypes方法,我们可以列出 Dataframe 中可用的不同列以及它们各自的数据类型。例如,我们可以看到 Supplies 子组列是一个object数据类型,而“按收入划分的客户规模”列是一个integer数据类型。所以,现在我们知道哪些列中有整数,哪些列中有字符串数据。
数据可视化
现在,我们已经完成了一些基本的数据探索,让我们尝试创建一些漂亮的图表来直观地表示数据,并揭示隐藏在数据集中的更多故事。
有许多 python 库提供了进行数据可视化的功能;一个这样的库是Seaborn。要使用 Seaborn plots,我们应该确保下载并安装了这个 python 模块。
让我们设置代码来使用Seaborn模块:
# import the seaborn module
import seaborn as sns
# import the matplotlib module
import matplotlib.pyplot as plt
# set the background colour of the plot to white
sns.set(style="whitegrid", color_codes=True)
# setting the plot size for all plots
sns.set(rc={'figure.figsize':(11.7,8.27)})
# create a countplot
sns.countplot('Route To Market',data=sales_data,hue = 'Opportunity Result')
# Remove the top and down margin
sns.despine(offset=10, trim=True)
# display the plotplt.show()

现在我们已经设置好了 Seaborn,让我们更深入地看看我们刚刚做了什么。
首先我们导入了 Seaborn 模块和 matplotlib 模块。下一行中的set()方法有助于为我们的绘图设置不同的属性,如“样式”、“颜色”等。使用sns.set(style="whitegrid", color_codes=True)代码片段,我们将绘图的背景设置为浅色。然后我们用sns.set(rc={'figure.figsize':(11.7,8.27)})代码片段设置绘图大小,它将绘图图形大小定义为 11.7px 和 8.27px
接下来,我们使用sns.countplot('Route To Market',data=sales_data,hue = 'Opportunity Result')创建情节。countplot()方法帮助我们创建一个计数图,它公开了几个参数来根据我们的需要定制计数图。在这里,在countplot()方法的第一个参数中,我们将 X 轴定义为数据集中的‘走向市场’列。第二个参数是数据源,在本例中是我们在本教程的第一部分中创建的 dataframe sales_data。第三个参数是条形图的颜色,我们从sales_data数据框架的“机会结果”列中为“赢得”标签分配了“蓝色”,为“失去”标签分配了“绿色”。
更多关于 Seaborn countplots 的细节可以在这里找到。
那么,关于这些数据,计数图告诉了我们什么呢?第一件事是,数据集中‘loss’类型的记录比‘won’类型的记录多,我们可以从条形的大小看出这一点。查看 x 轴和 x 轴上每个标签的相应条,我们可以看到数据集的大部分数据都集中在图的左侧:朝向“现场销售”和“经销商”类别。另一件需要注意的事情是,“现场销售”类别比“经销商”类别损失更多。
我们为我们的图选择了走向市场列,因为在我们对head()和tail()方法的输出进行初步研究后,它似乎会提供有用的信息。但其他字段,如“区域”、“供应组”等。也可以用于以同样的方式制作地块。
现在,我们已经对我们的整体数据有了一个很好的可视化,让我们看看在其他 Seaborn 图的帮助下,我们可以挖掘出更多的信息。另一个流行的选项是violinplots,所以让我们创建一个小提琴情节,看看这种风格的情节能告诉我们什么。
我们将使用 Seaborn 模块提供的violinplot()方法来创建小提琴情节。让我们首先导入seaborn模块,并使用set()方法定制我们的绘图大小。我们将看到图形的大小为 16.7 像素乘以 13.27 像素:
# import the seaborn module
import seaborn as sns
# import the matplotlib module
import matplotlib.pyplot as plt
# setting the plot size for all plots
sns.set(rc={'figure.figsize':(16.7,13.27)})
接下来,我们将使用violinplot()方法创建 violinplot,然后使用show()方法显示 plot
# plotting the violinplot
sns.violinplot(x="Opportunity Result",y="Client Size By Revenue", hue="Opportunity Result", data=sales_data);
plt.show()
现在,我们的情节已经创建,让我们看看它告诉我们什么。最简单的形式是,小提琴图显示数据在标签间的分布。在上图中,我们在 x 轴上标注了“赢得”和“损失”,在 y 轴上标注了“按收入划分的客户规模”的值。violin 图向我们展示了最大的数据分布在客户端大小“1”中,其余客户端大小标签具有较少的数据。
这个 violin plot 为我们提供了非常有价值的见解,让我们了解数据是如何分布的,以及哪些要素和标注具有最大的数据集中度,但在 violin plot 的情况下,不仅仅是看起来那么简单。你可以通过模块Seaborn的官方文档更深入地挖掘小提琴情节的额外用途
预处理数据
现在,我们已经很好地了解了我们的数据是什么样子的,我们可以使用 scikit-learn 来准备它以构建预测模型。
我们在最初的探索中看到,数据集中的大多数列都是字符串,但是 scikit-learn 中的算法只理解数字数据。幸运的是,scikit-learn 库为我们提供了许多将字符串数据转换成数字数据的方法。一种这样的方法是LabelEncoder()方法。我们将使用这种方法将数据集中的分类标签(如‘won’和‘loss ’)转换成数字标签。为了形象化我们试图用LabelEncoder()方法实现的目标,让我们看看下面的图片。
下图显示了一个数据帧,它有一个名为“颜色”的列和三条记录“红色”、“绿色”和“蓝色”。

由于 scikit-learn 中的机器学习算法只理解数字输入,我们希望将“红色”、“绿色”和“蓝色”等分类标签转换为数字标签。当我们转换完原始数据帧中的分类标签后,我们会得到如下结果:

现在,让我们开始实际的转换过程。我们将使用由LabelEncoder()提供的fit_transform()方法对分类列中的标签进行编码,例如sales_data数据帧中的‘市场路线’,并将它们转换成类似于我们在上面的图表中所看到的数字标签。fit_transform()函数将用户定义的标签作为输入,然后返回编码标签。让我们通过一个简单的例子来理解编码是如何完成的。在下面的代码示例中,我们有一个城市列表,即["paris", "paris", "tokyo", "amsterdam"],我们将尝试将这些字符串标签编码成类似于下面的内容—[2, 2, 1,3]。
#import the necessary module
from sklearn import preprocessing
# create the Labelencoder object
le = preprocessing.LabelEncoder()
#convert the categorical columns into numeric
encoded_value = le.fit_transform(["paris", "paris", "tokyo", "amsterdam"])
print(encoded_value)
[1 1 2 0]
瞧啊。我们已经成功地将字符串标签转换为数字标签。我们是怎么做到的?首先,我们导入了提供了LabelEncoder()方法的preprocessing模块。然后我们创建了一个代表LabelEncoder()类型的对象。接下来,我们使用这个对象的fit_transform()函数来区分列表["paris", "paris", "tokyo", "amsterdam"]的不同唯一类,然后返回一个具有各自编码值的列表,即[1 1 2 0]。
请注意LabelEncoder()方法是如何按照原始列表中类的第一个字母的顺序将数值分配给类的:“(a)msterdam”获得编码“0”,“p)aris 获得编码“1”,“t)okyo”获得编码“2”。
在各种编码需求下,LabelEncoder()提供了更多方便的功能。我们在这里不需要它们,但是要了解更多,一个很好的起点是sci kit-learn的官方页面,这里详细描述了LabelEncoder()及其相关功能。
既然我们现在对LabelEncoder()的工作原理有了一个很好的了解,我们可以继续使用这个方法对来自sales_data数据帧的分类标签进行编码,并将它们转换成数字标签。在前面的部分中,在数据集的初始探索过程中,我们看到以下列包含字符串值:“供应品子组”、“区域”、“市场路线”、“机会结果”、“竞争对手类型”和“供应品组”。在我们开始编码这些字符串标签之前,让我们快速地看一下这些列包含的不同标签:-
print("Supplies Subgroup' : ",sales_data['Supplies Subgroup'].unique())
print("Region : ",sales_data['Region'].unique())
print("Route To Market : ",sales_data['Route To Market'].unique())
print("Opportunity Result : ",sales_data['Opportunity Result'].unique())
print("Competitor Type : ",sales_data['Competitor Type'].unique())
print("'Supplies Group : ",sales_data['Supplies Group'].unique())
Supplies Subgroup' : ['Exterior Accessories' 'Motorcycle Parts' 'Shelters & RV'
'Garage & Car Care' 'Batteries & Accessories' 'Performance Parts'
'Towing & Hitches' 'Replacement Parts' 'Tires & Wheels'
'Interior Accessories' 'Car Electronics']
Region : ['Northwest' 'Pacific' 'Midwest' 'Southwest' 'Mid-Atlantic' 'Northeast'
'Southeast']
Route To Market : ['Fields Sales' 'Reseller' 'Other' 'Telesales' 'Telecoverage']
Opportunity Result : ['Won' 'Loss']
Competitor Type : ['Unknown' 'Known' 'None']
'Supplies Group : ['Car Accessories' 'Performance & Non-auto' 'Tires & Wheels'
'Car Electronics']
我们现在已经布置了来自sales_data数据框架的不同分类列以及这些列下的唯一类。现在,是时候将这些字符串编码成数字标签了。为此,我们将运行下面的代码,然后深入了解它的工作原理:
#import the necessary module
from sklearn import preprocessing
# create the Labelencoder object
le = preprocessing.LabelEncoder()
#convert the categorical columns into numeric
sales_data['Supplies Subgroup'] = le.fit_transform(sales_data['Supplies Subgroup'])
sales_data['Region'] = le.fit_transform(sales_data['Region'])
sales_data['Route To Market'] = le.fit_transform(sales_data['Route To Market'])
sales_data['Opportunity Result'] = le.fit_transform(sales_data['Opportunity Result'])
sales_data['Competitor Type'] = le.fit_transform(sales_data['Competitor Type'])
sales_data['Supplies Group'] = le.fit_transform(sales_data['Supplies Group'])
#display the initial records
sales_data.head()
| 机会编号 | 供应分组 | 供应组 | 地区 | 通往市场的路线 | 销售阶段经过的天数 | 机会结果 | 销售阶段更改计数 | 通过结算确定的总天数 | 通过合格鉴定的总天数 | 机会金额美元 | 按收入划分的客户规模 | 按员工数量划分的客户规模 | 过去两年来自客户的收入 | 竞争对手类型 | 确定天数与总天数的比率 | 验证天数与总天数的比率 | 合格天数与总天数的比率 | 交易规模类别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | One million six hundred and forty-one thousand nine hundred and eighty-four | Two | Zero | three | Zero | Seventy-six | one | Thirteen | One hundred and four | One hundred and one | Zero | five | five | Zero | Two | 0.69636 | 0.113985 | 0.154215 | one |
| one | One million six hundred and fifty-eight thousand and ten | Two | Zero | four | Two | Sixty-three | Zero | Two | One hundred and sixty-three | One hundred and sixty-three | Zero | three | five | Zero | Two | 0.00000 | 1.000000 | 0.000000 | one |
| Two | One million six hundred and seventy-four thousand seven hundred and thirty-seven | five | Two | four | Two | Twenty-four | one | seven | Eighty-two | Eighty-two | Seven thousand seven hundred and fifty | one | one | Zero | Two | 1.00000 | 0.000000 | 0.000000 | one |
| three | One million six hundred and seventy-five thousand two hundred and twenty-four | eight | Two | one | Two | Sixteen | Zero | five | One hundred and twenty-four | One hundred and twenty-four | Zero | one | one | Zero | Zero | 1.00000 | 0.000000 | 0.000000 | one |
| four | One million six hundred and eighty-nine thousand seven hundred and eighty-five | Two | Zero | four | Two | sixty-nine | Zero | Eleven | Ninety-one | Thirteen | Sixty-nine thousand seven hundred and fifty-six | one | one | Zero | Two | 0.00000 | 0.141125 | 0.000000 | four |
我们刚才做了什么?首先,我们导入了提供了LabelEncoder()方法的preprocessing模块。然后我们创建了一个类型为labelEncoder()的对象le。在接下来的几行中,我们使用了由LabelEncoder()提供的fit_transform()函数,并将不同列的分类标签(如“供应子组”、“区域”、“市场路线”)转换为数字标签。在此过程中,我们成功地将所有分类(字符串)列转换为数值。
既然我们已经准备好了数据并进行转换,那么几乎可以用于构建我们的预测模型了。但是我们仍然需要做一件重要的事情:
训练集和测试集
机器学习算法需要在一组数据上进行训练,以学习不同特征之间的关系以及这些特征如何影响目标变量。为此,我们需要将整个数据集分成两组。一个是训练集,我们将在其上训练我们的算法来建立一个模型。另一个是测试集,我们将在上面测试我们的模型,看看它的预测有多准确。
但是在进行所有这些拆分之前,让我们首先分离我们的特性和目标变量。与本教程之前一样,我们将首先运行下面的代码,然后仔细看看它做了什么:
# select columns other than 'Opportunity Number','Opportunity Result'cols = [col for col in sales_data.columns if col not in ['Opportunity Number','Opportunity Result']]
# dropping the 'Opportunity Number'and 'Opportunity Result' columns
data = sales_data[cols]
#assigning the Oppurtunity Result column as target
target = sales_data['Opportunity Result']
data.head(n=2)
| 供应分组 | 供应组 | 地区 | 通往市场的路线 | 销售阶段经过的天数 | 销售阶段更改计数 | 通过结算确定的总天数 | 通过合格鉴定的总天数 | 机会金额美元 | 按收入划分的客户规模 | 按员工数量划分的客户规模 | 过去两年来自客户的收入 | 竞争对手类型 | 确定天数与总天数的比率 | 验证天数与总天数的比率 | 合格天数与总天数的比率 | 交易规模类别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Two | Zero | three | Zero | Seventy-six | Thirteen | One hundred and four | One hundred and one | Zero | five | five | Zero | Two | 0.69636 | 0.113985 | 0.154215 | one |
| one | Two | Zero | four | Two | Sixty-three | Two | One hundred and sixty-three | One hundred and sixty-three | Zero | three | five | Zero | Two | 0.00000 | 1.000000 | 0.000000 | one |
好吧,那我们刚才做了什么?首先,我们不需要“Opportunity Number”列,因为它只是每个记录的唯一标识符。此外,我们希望预测“机会结果”,因此它应该是我们的“目标”而不是“数据”的一部分。因此,在上面代码的第一行,我们只选择了与“Opportunity Number”和“Opportunity Result”不匹配的列,并将它们分配给一个变量cols。接下来,我们用列表cols中的列创建了一个新的数据框架data。这将作为我们的功能集。然后,我们从数据框架sales_data中取出“机会结果”列,并创建了一个新的数据框架target。
就是这样!我们已经准备好将我们的功能和目标定义到两个独立的数据框架中。接下来,我们将把数据帧data和target分成训练集和测试集。分割数据集时,我们将保留 30%的数据作为测试数据,剩余的 70%作为训练数据。但是请记住,这些数字是任意的,最佳分割将取决于您正在处理的特定数据。如果您不确定如何分割数据,80/20 原则是一个不错的默认方法,即您将 80%的数据作为训练数据,将剩余的 20%作为测试数据。然而,对于本教程,我们将坚持我们先前的决定,保留 30%的数据作为测试数据。scikit-learn 中的train_test_split()方法可用于拆分数据:
#import the necessary module
from sklearn.model_selection import train_test_split
#split data set into train and test setsdata_train, data_test, target_train, target_test = train_test_split(data,target, test_size = 0.30, random_state = 10)
这样,我们现在已经成功地准备了一个测试集和一个训练集。在上面的代码中,我们首先导入了 train_test_split 模块。接下来我们使用train_test_split()方法将数据分为训练集(data_train,target_train)和测试集(data_test,data_train)。train_test_split()方法的第一个参数是我们在上一节中分离出来的特性,第二个参数是目标(“机会结果”)。第三个参数“test_size”是我们希望分离出来作为训练数据的数据的百分比。在我们的例子中是 30%,尽管这可以是任何数字。第四个参数“random_state”只是确保我们每次都能获得可重复的结果。
现在,我们已经准备好了一切,接下来是本教程最重要和最有趣的部分:使用 scikit-learn 提供的庞大算法库构建预测模型。
构建模型
在 scikit learn 的网站上有一个machine_learning_map可用,我们可以在选择算法时使用它作为快速参考。它看起来像这样:

我们可以使用该图作为备忘单,列出可以用来构建预测模型的算法。使用清单,让我们看看我们属于哪一类:
- 超过 50 个样本–检查
- 我们是在预测一个类别吗——检查
- 我们已经标记了数据?(商机金额等名称明确的数据。)–检查
- 少于 10 万个样本–检查
基于我们上面准备的清单,按照machine_learning_map我们可以尝试下面提到的算法。
- 朴素贝叶斯
- 线性 SVC
- k-邻居分类器
scikit-learn 库的真正魅力在于它为不同的算法公开了高级 API,使我们更容易尝试不同的算法,并比较模型的准确性,以了解什么最适合我们的数据集。
让我们开始一个接一个地尝试不同的算法。
朴素贝叶斯
Scikit-learn 提供了一组分类算法,这些算法“天真地”假设数据集中的每一对特征都是独立的。这个假设就是贝叶斯定理的底层原理。基于这一原理的算法被称为朴素贝叶斯算法。
在很高的层次上,朴素贝叶斯算法计算特征与目标变量的关联概率,然后选择概率最高的特征。让我们试着用一个非常简单的问题陈述来理解这一点:今天会下雨吗?假设我们有一组天气数据,这将是我们的特征集,而“下雨”的概率将是我们的目标。基于这个特性集,我们可以创建一个表来显示特定特性/目标对出现的次数。它看起来会像这样:

在上表中,特征(列)“天气”包含标签(“部分多云”和“多云”),列“雨”包含与特征“天气”一致的雨的出现(是/否)。每当一个特征与雨有关时,它被记录为“是”,而当该特征不导致雨时,它被记录为“否”。现在,我们可以使用事件表中的数据创建另一个称为“频率表”的表,在该表中,我们可以记录与每个功能相关的“是”和“否”答案的数量:

最后,我们将“发生表”和“频率表”中的数据结合起来,创建一个“可能性表”。该表列出了每个特征的“是”和“否”的数量,然后使用该数据计算每个特征对降雨发生的贡献概率:

请注意上表中的“个人概率”一栏。从“发生率表”和“可能性表”中,我们发现特征“部分多云”和“多云”出现了 6 次。很明显,特征“部分多云”出现了 4 次(2 次表示“否”,2 次表示“是”)。当我们用“出现表”中的“总数”除以特定特征的“否”和“是”的出现次数时,我们得到了该特定特征的概率。在我们的例子中,如果我们需要找出哪一个特征最有可能导致降雨的发生,那么我们将每个特征的“否”的总数加上“频率表”中它们各自的“是”数,然后将总和除以“发生率表”中的“总数”。这给了我们这些特征中的每一个与降雨相一致的概率。
我们将为销售数据使用的算法是Gaussian Naive Bayes,它基于一个类似于我们刚刚在上面探索的天气示例的概念,尽管在数学上要复杂得多。对‘朴素贝叶斯’算法的更详细的解释可以在这里找到给那些希望更深入研究的人。
现在让我们实现来自 scikit 的高斯朴素贝叶斯或GaussianNB算法——学习创建我们的预测模型:
# import the necessary module
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
#create an object of the type GaussianNB
gnb = GaussianNB()
#train the algorithm on training data and predict using the testing data
pred = gnb.fit(data_train, target_train).predict(data_test)
#print(pred.tolist())
#print the accuracy score of the model
print("Naive-Bayes accuracy : ",accuracy_score(target_test, pred, normalize = True))
Naive-Bayes accuracy : 0.759056732741
现在让我们仔细看看我们刚刚做了什么。首先,我们导入了GaussianNB方法和accuracy_score方法。然后我们创建了一个类型为GaussianNB的对象gnb。之后,我们使用fit()方法对测试数据(data_train)和测试目标(target_train)进行算法训练,然后使用predict()方法对测试数据中的目标进行预测。最后,我们使用accuracy_score()方法打印了分数,并成功应用了Naive-Bayes算法来构建预测模型。
现在让我们看看列表中的其他算法与朴素贝叶斯算法相比表现如何。
线性调频
LinearSVC 或线性支持向量分类是SVM(支持向量机)类的一个子类。我们不会深入这类算法所涉及的复杂数学,但在一个非常基本的层面上,LinearSVC 试图将数据划分到不同的平面,以便它可以找到不同类别的最佳可能分组。为了清楚地理解这个概念,让我们想象一个由“点”和“方块”组成的数据集,沿着两个轴分成两个二维空间,如下图所示:

来源: StackOverflow
在上图中,LinearSVC实现试图以这样一种方式划分二维空间,即两类数据即dots和squares被清晰地划分。这里的两行直观地表示了LinearSVC试图实现的不同划分,以区分两个可用的类。
对于那些想要更多细节的人来说,可以在这里找到一篇解释Support Vector Machine(SVM)的非常好的文章,但是现在,让我们开始动手做吧:
#import the necessary modules
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
#create an object of type LinearSVC
svc_model = LinearSVC(random_state=0)
#train the algorithm on training data and predict using the testing data
pred = svc_model.fit(data_train, target_train).predict(data_test)
#print the accuracy score of the model
print("LinearSVC accuracy : ",accuracy_score(target_test, pred, normalize = True))
LinearSVC accuracy : 0.777811004785
类似于我们在 GaussianNB 实现期间所做的,我们在前两行中导入了所需的模块。然后我们创建了一个 LinearSVC 类型的对象【with random _ state 为‘0’。坚持住!什么是“随机状态”?简单地说,random_state是一个给内置随机数发生器的指令,以特定的顺序打乱数据。
接下来,我们根据训练数据训练 LinearSVC,然后使用测试数据预测目标。最后,我们使用accuracy_score()方法检查了准确性分数。
既然我们已经尝试了GaussianNB和LinearSVC算法,我们将尝试列表中的最后一个算法,那就是K-nearest neighbours classifier
k 近邻分类器
与我们之前使用的两个算法相比,这个分类器稍微复杂一些。出于本教程的目的,我们最好使用 scikit-learn 提供的KNeighborsClassifier类,不用太担心算法是如何工作的。(但是如果你感兴趣,可以在这里找到关于这类算法的详细解释)
现在,让我们实现 K-Neighbors 分类器,看看它的得分情况:
#import necessary modules
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
#create object of the lassifier
neigh = KNeighborsClassifier(n_neighbors=3)
#Train the algorithm
neigh.fit(data_train, target_train)
# predict the response
pred = neigh.predict(data_test)
# evaluate accuracy
print ("KNeighbors accuracy score : ",accuracy_score(target_test, pred))
KNeighbors accuracy score : 0.814550580998
上面的代码可以像前面的实现一样进行解释。首先我们导入了必要的模块,然后我们创建了 KNeighborsClassifier 类型的对象neigh,邻居的数量是n_neighbors=3。然后我们使用fit()方法在训练集上训练我们的算法,然后我们在测试数据上测试模型。最后,我们打印出准确度分数。
现在我们已经实现了列表中的所有算法,我们可以简单地比较所有模型的得分,以选择得分最高的模型。但是,如果我们有办法直观地比较不同型号的性能,那不是很好吗?我们可以使用 scikit-learn 中的 yellowbrick 库,它提供了可视化表示不同评分方法的方法。
性能比较
在前面的章节中,我们使用了accuracy_score()方法来衡量不同算法的准确性。现在,我们将使用由Yellowbrick库提供的ClassificationReport类来给我们一个我们的模型如何执行的可视化报告。
高斯安 b
让我们从GaussianNB模型开始:
from yellowbrick.classifier import ClassificationReport
# Instantiate the classification model and visualizer
visualizer = ClassificationReport(gnb, classes=['Won','Loss'])
visualizer.fit(data_train, target_train) # Fit the training data to the visualizer
visualizer.score(data_test, target_test) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data

在上面的代码中,首先我们导入由yellowbrick.classifier模块提供的ClassificationReport类。接下来,创建一个类型为ClassificationReport的对象visualizer。这里的第一个参数是在‘朴素贝叶斯’部分实现Naive-Bayes算法时创建的GaussianNB对象gnb。第二个参数包含来自sales_data数据框架的“Opportunity Result”列的标签“Won”和“Loss”。
接下来,我们使用fit()方法来训练visualizer对象。接下来是score()方法,使用gnb对象按照GaussianNB算法进行预测,然后计算该算法所做预测的准确度分数。最后,我们使用poof()方法为GaussianNB算法绘制不同分数的图表。注意不同的分数是如何排列在“赢”和“输”的标签上的;这使我们能够可视化不同目标类别的分数。
线性调频
与我们在上一节中所做的类似,我们也可以绘制出LinearSVC算法的准确度分数:
from yellowbrick.classifier import ClassificationReport
# Instantiate the classification model and visualizer
visualizer = ClassificationReport(svc_model, classes=['Won','Loss'])
visualizer.fit(data_train, target_train) # Fit the training data to the visualizer
visualizer.score(data_test, target_test) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data

在上面的代码中,首先我们导入了由yellowbrick.classifier模块提供的ClassificationReport类。接下来,创建了一个类型为ClassificationReport的对象visualizer。这里第一个参数是LinearSVC对象svc_model,它是在实现“LinearSVC”部分的LinearSVC算法时创建的。第二个参数包含来自sales_data数据框架的“Opportunity Result”列的标签“Won”和“Loss”。
接下来,我们使用fit()方法来训练‘SVC _ model’对象。接下来是score()方法,该方法使用svc_model对象根据LinearSVC算法进行预测,然后计算该算法所做预测的准确度分数。最后,我们使用poof()方法画出了LinearSVC算法的不同分数。
近邻分类器
现在,让我们对 K 近邻分类器分数做同样的事情。
from yellowbrick.classifier import ClassificationReport
# Instantiate the classification model and visualizer
visualizer = ClassificationReport(neigh, classes=['Won','Loss'])
visualizer.fit(data_train, target_train) # Fit the training data to the visualizer
visualizer.score(data_test, target_test) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data

同样,我们首先导入由yellowbrick.classifier模块提供的ClassificationReport类。接下来,创建一个类型为ClassificationReport的对象visualizer。这里第一个参数是KNeighborsClassifier对象neigh,它是在实现‘KNeighborsClassifier’部分的KNeighborsClassifier算法时创建的。第二个参数包含来自sales_data数据框架的“Opportunity Result”列的标签“Won”和“Loss”。
接下来,我们使用fit()方法来训练“邻居”对象。接下来是score()方法,该方法使用neigh对象根据KNeighborsClassifier算法进行预测,然后计算该算法所做预测的准确度分数。最后,我们使用poof()方法画出KNeighborsClassifier算法的不同分数的曲线图。
现在我们已经可视化了结果,比较分数和选择最适合我们需求的算法就容易多了。
结论
scikit-learn 库提供了许多不同的算法,这些算法可以导入到代码中,然后用来构建模型,就像我们导入任何其他 Python 库一样。这使得快速构建不同的模型并比较这些模型以选择得分最高的模型变得更加容易。
在本教程中,我们仅仅触及了 scikit-learn 库的皮毛。为了最大限度地使用这个机器学习库,scikit-learn 的官方页面上有许多资源,其中包含详细的文档,您可以深入研究。scikit-learn 的快速入门指南可以在这里找到,对于刚刚开始探索机器学习世界的初学者来说,这是一个很好的切入点。
但是,要真正体会 scikit-learn 库的真正威力,您真正需要做的是开始在不同的开放数据集上使用它,并使用这些数据集构建预测模型。开放数据集的来源包括 Kaggle 和 Data.world 。两者都包含许多有趣的数据集,在这些数据集上,人们可以通过使用 scikit-learn 库提供的算法来练习构建预测模型。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
如何在谷歌云上建立一个免费的数据科学环境
原文:https://www.dataquest.io/blog/setting-up-a-free-data-science-environment-on-google-cloud/
January 4, 2018Whether you’re running out of memory on your local machine or simply want your code to run faster on a more powerful machine, there are many benefits to doing data science on a cloud server. A cloud server is really just a computer, like the one you’re using now, that’s located elsewhere.
在本帖中,我们将介绍如何在谷歌云平台 (GCP)上建立数据科学环境。谷歌购买数十万台个人电脑,使用定制软件在位于世界各地的数据中心管理它们,并提供这些电脑供出租。由于云托管公司提供的规模经济,个人或团队可以负担得起按需访问具有大量 CPU 和内存的强大计算机。
为什么用 GCP?
当从笔记本电脑/台式机环境迁移到云数据科学环境时,重要的是要考虑什么标准对您最重要。例如,为了在熊猫身上处理更大的数据集,拥有大量的内存是很重要的。为了使用 Spark 处理大型数据集,我们需要租用一个由许多计算机组成的池,这些计算机具有大量的总内存来分担负载。

为了能够自由地安装我们想要的任何库或工具,我们需要访问 GCP 上的一台虚拟计算机。这被称为虚拟机实例。租用虚拟机实例并不能让我们获得自己的专用计算机(云提供商对租用专用计算机收取更高的费用),而是只能获得我们想要的 CPU 和内存:

谷歌计算引擎(GCE)为高内存实例提供了合理的价格。下面是 2017 年 12 月定价的截图:

虽然这个价格乍一看似乎很高,但 GCP 有 12 个月的试用期,每个月可以用 300 美元的信用购买 GCP 的产品和服务。你可以在这里了解更多并报名。
这意味着你可以租一台 52g 内存的服务器,并持续运行一整月。因为租赁费用是按每分钟计算的,所以您可以在短时间内(几个小时)为特定任务租赁一台更强大的服务器(内存为 256)。
这种灵活性非常强大,使您能够执行大型计算工作流,而无需自己购买和管理硬件。
启动 GCE 实例
导航到虚拟机实例页面。您将被要求使用您的 Google 凭据登录并创建一个项目。完成后,您将进入虚拟机实例页面:

要创建新的虚拟实例,请单击创建实例。您将进入一个页面,在该页面中您可以自定义要租赁的实例的不同属性:
- 命名你的实例。我们只是使用了默认名称。
Zone:您的服务器位于哪个地理区域。我们使用了us-east1-b,但是您可以自由选择一个离您居住或工作的地方更近的实例。- 你想租一台多强大的机器。回想一下,你可以从本页中了解不同的机器类型。在你每月的预算内选择一个!
Boot Disk:您希望虚拟实例引导时使用的操作系统。我们用的是Ubuntu 16.04 LTS,这是一个流行的 Linux 版本。Firewall:应该允许哪些互联网流量进入。保留默认设置。
准备好之后,点击创建。
设置数据科学环境
在您启动了 Google 计算引擎实例之后,您实际上可以从 Google 计算引擎页面启动控制台:

我们将使用该控制台来设置数据科学环境的其余部分。如果你不熟悉命令行,我鼓励你去看看我们的命令行:初级和命令行:中级课程。
首先,让我们安装蟒蛇。从命令行,使用curl下载二进制安装文件的最简单方法。unix 工具 curl 从指定的 url 下载文件,并使用-O标志写入文件(而不是立即显示下载的内容):
curl -O https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh
下载完成后,您可以使用bash开始设置过程:
bash Anaconda3-5.0.1-Linux-x86_64.sh
有些时候你需要输入yes来接受许可。一旦安装完成,您需要将conda程序添加到您的路径中。该路径允许您指定希望操作系统在哪些目录中搜索程序。
现在我们已经安装了 anaconda,我们可以创建一个新的 anaconda 环境。我们在 Dataquest 教授使用 Python 3.5,所以我们在这里也将使用该版本:
conda create --name ds python=3.5
当您创建一个环境时,Anaconda 会为您安装许多流行的数据科学库(如numpy和jupyter notebook)。安装过程完成后,您可以像这样激活您的环境:
source activate ds
暴露朱庇特笔记本
现在,我们在这个实例中运行的 Jupyter 笔记本服务器不能从本地计算机通过 web 浏览器访问。为了理解为什么,让我们想想当我们在自己的计算机上本地运行 Jupyter Notebook 时会发生什么——只有我们的本地计算机才能通过 web 浏览器访问 Jupyter Notebook 服务器(通常在localhost:8888)。
然而,如果我们的 wifi(或以太网)网络上的其他人知道我们的 IP 地址和我们正在哪个端口运行 Jupyter Notebook(同样,通常在8888),他们可以通过导航到https://OUR_IP_ADDRESS:8888通过网络浏览器访问它。
通过做两个主要的调整,我们也可以为我们的云实例复制这种访问能力。默认情况下,我们的云实例的防火墙设置为阻止网络访问。此外,大多数云提供商经常更改我们实例的 IP 地址(真的,只要他们愿意!).这意味着如果我们实例的当前 IP 地址是35.227.18.17,我们不能指望它在几分钟内保持不变。
但是,我们可以将动态 IP 地址更改为静态 IP 地址。
设置静态 IP 地址
要将我们实例的 IP 地址更改为静态地址,请导航到左侧 Google 云平台菜单中的Networking > VPC network > External IP addresses。

也可以在这个网址直接跳转到页面。
请注意,如果您申请了一个静态 IP 地址,但没有与该静态 IP 地址相关联的正在运行的机器,Google 会收取少量费用。在爱荷华州地区,2017 年 12 月,这一成本为每小时 1 美分,如下图所示:

您可以通过导航到 GCE 定价页面并向下滚动到未使用 IP 地址定价来了解更多关于未使用静态 IP 定价的信息。
添加防火墙例外
现在我们有了一个静态 IP 地址,我们的本地计算机可以与我们的云实例对话。不幸的是,大多数云提供商都有防火墙来禁止对大多数端口的接入。幸运的是,我们可以为 Jupyter 笔记本服务器用来接受传入请求的端口8000手动添加一个例外。
现在,让我们自定义防火墙规则,以便传入的网络数据包可以通过特定端口访问我们的服务器。导航到防火墙规则页面,点击创建防火墙规则:

在出现的页面上,填写以下字段:
Name:为此防火墙规则添加一个名称Source IP ranges:0 . 0 . 0 . 0/0Allowed protocols and ports: tcp:8000
最后,我们需要配置 Jupyter Notebook 来使用我们之前为防火墙指定的 TCP 端口。
配置 jupiter 笔记本监听的端口
运行此命令以生成配置文件。
jupyter notebook --generate-config
现在我们已经设置好了一切,让我们使用以下标志启动 Jupyter 笔记本:
jupyter notebook --no-browser --port=8000
在您的本地计算机上,导航到 URL https://YOUR_STATIC_IP_ADDRESS:8000,您将看到欢迎 Jupyter 笔记本登录页面!

您甚至可以使用上传按钮将文件直接上传到您的 cloud Jupyter 笔记本中。
后续步骤
恭喜你!您刚刚在 Google Cloud 上设置了您的第一个环境!以下是您可能需要考虑的一些后续步骤:
- 设置从本地计算机到云实例的 SSH 访问
- 设置远程桌面以便您可以使用图形用户界面(GUI)与实例的操作系统进行交互
- 阅读更多关于 GCP 提供的其他数据科学产品的信息
SettingwithCopyWarning:如何在熊猫中修复此警告
July 5, 2017
是人们在学习熊猫时遇到的最常见的障碍之一。快速的网络搜索会发现大量的堆栈溢出问题、GitHub 问题和来自程序员的论坛帖子,他们试图理解这个警告在他们的特定情况下意味着什么。这并不奇怪,许多人都在为此挣扎;有很多方法来索引 pandas 数据结构,每种方法都有其独特的细微差别,甚至 pandas 本身也不能保证两行看起来相同的代码会有一个单一的结果。
本指南解释了产生警告的原因,并向您展示了解决方法。它还包括引擎盖下的细节,让您更好地了解正在发生的事情,并提供了一些关于该主题的历史,让您了解为什么它都是这样工作的。
为了探究SettingWithCopyWarning,我们将使用《建模在线拍卖一书中易贝 3 天拍卖中售出的 Xboxes 价格数据集。让我们来看看:
import pandas as pd
data = pd.read_csv('xbox-3-day-auctions.csv')
data.head()
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | |
|---|---|---|---|---|---|---|---|
| Zero | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | Ninety-five | 2.927373 | jake7870 | Zero | Ninety-five | One hundred and seventeen point five |
| one | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | One hundred and fifteen | 2.943484 | 大卫·布雷斯勒 2 | one | Ninety-five | One hundred and seventeen point five |
| Two | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | One hundred | 2.951285 | gladimacowgirl | Fifty-eight | Ninety-five | One hundred and seventeen point five |
| three | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | One hundred and seventeen point five | 2.998947 | 戴斯鲁斯 | Ten | Ninety-five | One hundred and seventeen point five |
| four | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Two | 0.065266 | 多尼 4814 | five | One | One hundred and twenty |
正如你所看到的,我们数据集的每一行都涉及到一次特定的易贝 Xbox 拍卖的单一出价。以下是对每列的简要描述:
auctionid—每个拍卖的唯一标识符。bid—投标的价值。bidtime—投标时的拍卖期限,以天为单位。bidder—投标人的易贝用户名。bidderrate–投标人的易贝用户评级。openbid—卖方为拍卖设定的开价。price—拍卖结束时胜出的出价。
什么是 SettingWithCopyWarning?
首先要明白的是SettingWithCopyWarning是一个警告,而不是一个错误。
虽然错误表明出现了问题,例如无效的语法或试图引用未定义的变量,但警告的作用是提醒程序员他们的代码中存在潜在的错误或问题,而这些错误或问题仍然是该语言中允许的操作。在这种情况下,警告很可能表示一个严重但不明显的错误。
SettingWithCopyWarning通知您您的操作可能没有按预期进行,您应该检查结果以确保没有出错。
如果您的代码仍然像预期的那样工作,忽略这个警告是很有诱惑力的。这是不好的做法,SettingWithCopyWarning应该永远不要被忽视。在采取行动之前,花些时间去理解为什么你会得到警告。
为了理解SettingWithCopyWarning是关于什么的,理解 pandas 中的一些动作可以返回你的数据的视图,而其他动作将返回一个副本是有帮助的。

正如你在上面看到的,左边的视图df2只是原始视图df1的子集,而右边的副本创建了一个新的、唯一的对象df2。
当我们试图进行更改时,这可能会导致问题:

根据我们正在做的事情,我们可能想要修改原始的df1(左图),或者我们可能想要只修改df2(右图)。警告是让我们知道我们的代码可能做了一件事,而我们希望它做了另一件事。
稍后我们将深入探讨这个问题,但是现在让我们先来解决这个警告的两个主要原因以及如何修复它们。
常见问题#1:链式分配
Pandas 在检测到一种叫做链式分配的东西时会发出警告。让我们定义几个我们将用来解释事情的术语:
- 赋值——设置值的操作,例如
data = pd.read_csv('xbox-3-day-auctions.csv')。通常被称为集。 - 访问—返回某个值的操作,例如下面的索引和链接示例。通常被称为 get 。
- 索引—引用数据子集的任何分配或访问方法;比如
data[1:5]。 - 链接——连续使用多个索引操作;比如
data[1:5][1:3]。
链式赋值是链接和赋值的组合。让我们快速看一个例子,它包含了我们之前加载的数据集。我们稍后将更详细地讨论这一点。为了这个例子,假设我们被告知用户'parakeet2004'的投标人评级不正确,我们必须更新它。让我们从当前值开始。
data[data.bidder == 'parakeet2004']
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | |
|---|---|---|---|---|---|---|---|
| six | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Three | 0.186539 | 鹦鹉 2004 | five | One | One hundred and twenty |
| seven | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Ten | 0.186690 | 鹦鹉 2004 | five | One | One hundred and twenty |
| eight | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Twenty-four point nine nine | 0.187049 | 鹦鹉 2004 | five | One | One hundred and twenty |
我们有三行来更新bidderrate字段;让我们继续做那件事。
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ipykernel/__main__.py:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy if __name__ == '__main__':
哦不!我们神秘地发现了SettingWithCopyWarning!
如果我们看一下,我们可以看到在这种情况下,值没有改变:
data[data.bidder == 'parakeet2004']
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | |
|---|---|---|---|---|---|---|---|
| six | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Three | 0.186539 | 鹦鹉 2004 | five | One | One hundred and twenty |
| seven | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Ten | 0.186690 | 鹦鹉 2004 | five | One | One hundred and twenty |
| eight | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | Twenty-four point nine nine | 0.187049 | 鹦鹉 2004 | five | One | One hundred and twenty |
生成该警告是因为我们将两个索引操作链接在一起。这更容易发现,因为我们已经使用了两次方括号,但是如果我们使用其他访问方法,如.bidderrate、.loc[]、.iloc[]、.ix[]等等,情况也是如此。我们的连锁经营包括:
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
这两个连锁操作一个接一个地独立执行。第一个是访问方法(get 操作),它将返回一个包含所有行的DataFrame,其中bidder等于'parakeet2004'。第二个是赋值操作(set 操作),在这个新的DataFrame上调用。我们根本没有在原版DataFrame上做手术。
解决方案很简单:使用loc将链接的操作组合成一个操作,这样 pandas 就可以确保原来的DataFrame被设置。熊猫将始终确保不被束缚的集合操作(如下所示)正常工作。
# Setting the new value
data.loc[data.bidder == 'parakeet2004', 'bidderrate'] = 100
# Taking a look at the result
data[data.bidder == 'parakeet2004']['bidderrate']
6 100
7 100
8 100
Name: bidderrate, dtype: int64
这是警告建议我们做的,并且在这种情况下非常有效。
常见问题#2:隐藏链接
接下来是人们遇到的第二种最常见的方式。让我们调查中标情况。我们将创建一个新的数据框架来处理它们,注意使用loc,因为我们已经学习了关于链式赋值的课程。
winners = data.loc[data.bid == data.price]
winners.head()
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | |
|---|---|---|---|---|---|---|---|
| three | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | One hundred and seventeen point five | 2.998947 | 戴斯鲁斯 | Ten | Ninety-five | One hundred and seventeen point five |
| Twenty-five | Eight billion two hundred and thirteen million sixty thousand four hundred and twenty | One hundred and twenty | 2.999722 | djnoeproductions | Seventeen | One | One hundred and twenty |
| forty-four | Eight billion two hundred and thirteen million sixty-seven thousand eight hundred and thirty-eight | One hundred and thirty-two point five | 2.996632 | 香槟泡泡 | Two hundred and two | Twenty-nine point nine nine | One hundred and thirty-two point five |
| Forty-five | Eight billion two hundred and thirteen million sixty-seven thousand eight hundred and thirty-eight | One hundred and thirty-two point five | 2.997789 | 香槟泡泡 | Two hundred and two | Twenty-nine point nine nine | One hundred and thirty-two point five |
| Sixty-six | Eight billion two hundred and thirteen million seventy-three thousand five hundred and nine | One hundred and fourteen point five | 2.999236 | rr6kids | four | One | One hundred and fourteen point five |
我们可能会用 winners 变量写几行后续代码。
mean_win_time = winners.bidtime.mean()
... # 20 lines of code
mode_open_bid = winners.openbid.mode()
一个偶然的机会,我们在DataFrame中遇到了另一个错误。这一次,标签为304的行中缺少了bidder值。
winners.loc[304, 'bidder']
nan
为了我们的例子,让我们说,我们知道这个投标人的真实用户名,并更新我们的数据。
winners.loc[304, 'bidder'] = 'therealname'
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/indexing.py:517: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy self.obj[item] = s
又一个SettingWithCopyWarning!但是我们用了loc,怎么又出现这种情况了?为了进行研究,让我们看看代码的结果:
print(winners.loc[304, 'bidder'])
therealname
这次成功了,那我们为什么会收到警告呢?
链式索引既可以出现在两行中,也可以出现在一行中。因为winners是作为 get 操作(data.loc[data.bid == data.price])的输出创建的,所以它可能是原始DataFrame的副本,也可能不是,但是在我们检查之前没有办法知道!当我们索引winners时,我们实际上使用的是链式索引。
这意味着当我们试图修改winners时,我们可能也修改了data。
在真正的代码库中,这些代码行可能相隔很远,因此追踪问题的根源可能更困难,但情况是一样的。
为了防止在这种情况下出现警告,解决方案是明确地告诉 pandas 在我们创建新的数据帧时制作一个副本:
winners = data.loc[data.bid == data.price].copy()
winners.loc[304, 'bidder'] = 'therealname'
print(winners.loc[304, 'bidder'])
print(data.loc[304, 'bidder'])
therealname
nan
就是这样!就这么简单。
诀窍是学会识别链式索引,并不惜一切代价避免它。如果你想改变原来的,使用单一的赋值操作。如果你想要一份拷贝,确保你强迫熊猫这么做。这将节省时间,并使您的代码滴水不漏。
还要注意的是,即使SettingWithCopyWarning只会在你设置的时候出现,也最好避免 gets 的链式索引。链式操作速度较慢,如果您决定稍后添加赋值操作,会导致问题。
处理设置 SettingWithCopyWarning 的提示和技巧
在我们下面做更深入的分析之前,让我们拿出显微镜,看看SettingWithCopyWarning的一些细微之处和本质细节。
关闭警告
首先,如果不讨论如何显式控制SettingWithCopy设置,这篇文章将是不完整的。熊猫mode.chained_assignment选项可以取其中一个值:
'raise'—引发异常而不是警告。'warn'—生成警告(默认)。None—完全关闭警告。
例如,让我们关闭警告:
pd.set_option('mode.chained_assignment', None)
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
因为这不会给我们任何警告,所以除非你完全明白自己在做什么,否则不推荐这样做。如果你感到一丝怀疑,这是不可取的。一些开发人员非常认真地对待SettingWithCopy,并选择将其提升为一个例外,就像这样:
pd.set_option('mode.chained_assignment', 'raise')
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
---------------------------------------------------------------------------SettingWithCopyError Traceback (most recent call last)<ipython-input-13-80e3669cab86> in <module>() 1 pd.set_option('mode.chained_assignment', 'raise')----> 2 data[data.bidder == 'parakeet2004']['bidderrate'] = 100/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/frame.py in __setitem__(self, key, value) 2427 else: 2428 # set column-> 2429 self._set_item(key, value) 2430 2431 def _setitem_slice(self, key, value):/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/frame.py in _set_item(self, key, value) 2500 # value exception to occur first 2501 if len(self):-> 2502 self._check_setitem_copy() 2503 2504 def insert(self, loc, column, value, allow_duplicates=False):/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/generic.py in _check_setitem_copy(self, stacklevel, t, force) 1758 1759 if value == 'raise':-> 1760 raise SettingWithCopyError(t) 1761 elif value == 'warn': 1762 warnings.warn(t, SettingWithCopyWarning, stacklevel=stacklevel)SettingWithCopyError: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
如果您的团队中有一个没有经验的 pandas 开发人员,或者一个需要高水平的严格性或完整性的确定性的项目,这可能特别有用。
使用这个设置的更精确的方法是使用一个上下文管理器。
# resets the option we set in the previous code segment
pd.reset_option('mode.chained_assignment')
with pd.option_context('mode.chained_assignment', None):
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
如您所见,这种方法支持细粒度的警告抑制,而不是不加区别地影响整个环境。
is_copy 属性
另一个可以用来避免警告的技巧是修改熊猫用来解释SettingWithCopy场景的工具之一。每个DataFrame都有一个默认为None的is_copy属性,但是如果是副本,则使用一个 weakref 来引用源DataFrame。通过将is_copy设置为None,可以避免生成警告。
winners = data.loc[data.bid == data.price]
winners.is_copy = None
winners.loc[304, 'bidder'] = 'therealname'
然而,请注意,这将而不是奇迹般地解决问题,但它确实使缺陷检测变得潜在非常困难。
单类型与多类型对象
值得强调的另一点是单数据类型和多数据类型对象之间的区别。如果一个DataFrame的所有列都是相同的数据类型,那么它就是单数据类型的;例如:
import numpy as np
single_dtype_df = pd.DataFrame(np.random.rand(5,2), columns=list('AB'))
print(single_dtype_df.dtypes)
single_dtype_df
A float64
B float64dtype: object
| A | B | |
|---|---|---|
| Zero | 0.383197 | 0.895652 |
| one | 0.077943 | 0.905245 |
| Two | 0.452151 | 0.677482 |
| three | 0.533288 | 0.768252 |
| four | 0.389799 | 0.674594 |
而如果一个DataFrame的列不具有相同的数据类型,那么它就是多数据类型的,例如:
multiple_dtype_df = pd.DataFrame({'A': np.random.rand(5),'B': list('abcde')})
print(multiple_dtype_df.dtypes)
multiple_dtype_df
A float64
B object
dtype: object
| A | B | |
|---|---|---|
| Zero | 0.615487 | a |
| one | 0.946149 | b |
| Two | 0.701231 | c |
| three | 0.756522 | d |
| four | 0.481719 | e |
由于下面历史部分解释的原因,在多数据类型对象上的索引器获取操作将总是返回一个副本。然而,主要为了提高效率,索引器对单数据类型对象的 get 操作几乎总是返回一个视图;这里需要注意的是,这取决于对象的内存布局,并且不能保证。
假阳性
假阳性,或无意中报告了连锁分配的情况,过去在早期版本的 pandas 中更常见,但后来基本上被消除了。为了完整起见,这里包括一些固定误报的例子是有用的。如果您在使用早期版本的 pandas 时遇到以下任何情况,那么可以安全地忽略或取消警告(或者通过升级来完全避免警告!)
使用用于的当前列的值向DataFrame添加一个新列会产生一个警告,但是这个问题已经被修复。
data['bidtime_hours'] = data.bidtime.map(lambda x: x * 24)
data.head(2)
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | 投标时间 _ 小时 | |
|---|---|---|---|---|---|---|---|---|
| Zero | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | Ninety-five | 2.927373 | jake7870 | Zero | Ninety-five | One hundred and seventeen point five | 70.256952 |
| one | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | One hundred and fifteen | 2.943484 | 大卫·布雷斯勒 2 | one | Ninety-five | One hundred and seventeen point five | 70.643616 |
直到最近,当在一个DataFrame的片上使用apply方法设置时,一个假阳性也发生了,尽管这个问题也已经被修复。
data.loc[:, 'bidtime_hours'] = data.bidtime.apply(lambda x: x * 24)
data.head(2)
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | 投标时间 _ 小时 | |
|---|---|---|---|---|---|---|---|---|
| Zero | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | Ninety-five | 2.927373 | jake7870 | Zero | Ninety-five | One hundred and seventeen point five | 70.256952 |
| one | Eight billion two hundred and thirteen million thirty-four thousand seven hundred and five | One hundred and fifteen | 2.943484 | 大卫·布雷斯勒 2 | one | Ninety-five | One hundred and seventeen point five | 70.643616 |
最后,直到版本 0.17.0,在 DataFrame.sample 方法中有一个导致虚假SettingWithCopy警告的 bug。sample方法现在每次都返回一个副本。
sample = data.sample(2)
sample.loc[:, 'price'] = 120
sample.head()
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | 投标时间 _ 小时 | |
|---|---|---|---|---|---|---|---|---|
| Four hundred and eighty-one | Eight billion two hundred and fifteen million four hundred and eight thousand and twenty-three | Ninety-one point zero one | 2.990741 | sailor4eva | one | Zero point nine nine | One hundred and twenty | 71.777784 |
| Five hundred and three | Eight billion two hundred and fifteen million five hundred and seventy-one thousand and thirty-nine | One hundred | 1.965463 | lambonius1 | Zero | Fifty | One hundred and twenty | 47.171112 |
深度链式赋值
让我们重新使用之前的例子,我们试图用'parakeet2004'的bidder值来更新data中每一行的bidderrate列。
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ipykernel/__main__.py:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy if __name__ == '__main__':
pandas 用这个SettingWithCopyWarning真正告诉我们的是,我们代码的行为是不明确的,但是要理解为什么是这样以及警告的措辞,回顾一些概念将是有帮助的。
我们之前简单地讨论了视图和副本。访问一个DataFrame的子集有两种可能的方法:要么在内存中创建一个对原始数据的引用(一个视图),要么将子集复制到一个新的、更小的DataFrame(一个副本)。视图是查看原始数据的特定部分的一种方式,而副本是该数据在内存中新位置的克隆。正如我们前面的图表所示,修改视图会修改原始变量,但修改副本不会。
由于我们将在后面讨论的原因,熊猫的“get”操作的输出不能保证。当您索引 pandas 数据结构时,可能会返回一个视图或一个副本,这意味着对一个DataFrame的 get 操作会返回一个新的DataFrame,它可以包含:
- 原始对象中数据的副本。
- 对原始对象数据的引用,但不制作副本。
因为我们不知道会发生什么,每种可能性都有非常不同的行为,忽视警告是在玩火。
为了更清楚地说明视图、副本和这种模糊性,让我们创建一个简单的DataFrame并将其编入索引:
df1 = pd.DataFrame(np.arange(6).reshape((3,2)), columns=list('AB'))
df1
| A | B | |
|---|---|---|
| Zero | Zero | one |
| one | Two | three |
| Two | four | five |
让我们将df1的子集分配给df2:
df2 = df1.loc[:1]
df2
| A | B | |
|---|---|---|
| Zero | Zero | one |
| one | Two | three |
根据我们所了解的,我们知道df2可能是df1上的一个视图,或者是df1的一个子集的副本。
在我们着手解决这个问题之前,我们还需要再看一看链式索引。用'parakeet2004'扩展我们的例子,我们将两个索引操作链接在一起:
data[data.bidder == 'parakeet2004']
__intermediate__['bidderrate'] = 100
其中__intermediate__代表第一次调用的输出,对我们完全隐藏。请记住,如果我们使用属性访问,也会得到同样有问题的结果:
data[data.bidder == 'parakeet2004'].bidderrate = 100
这同样适用于任何其他形式的链式调用,因为我们正在生成这个中间对象。
实际上,链式索引意味着不止一次调用__getitem__或__setitem__来完成一个操作。这些是特殊的 Python 方法,通过在实现它们的类的实例上使用方括号来调用,这是所谓的语法糖的一个例子。让我们看看 Python 解释器将在我们的例子中执行什么。
# Our code
data[data.bidder == 'parakeet2004']['bidderrate'] = 100
# Code executed
data.__getitem__(data.__getitem__('bidder') == 'parakeet2004').__setitem__('bidderrate', 100)
您可能已经意识到,SettingWithCopyWarning是这个链式__setitem__调用的结果。您可以自己尝试一下——上面几行的功能完全相同。为了清楚起见,请注意第二个__getitem__调用(针对bidder列)是嵌套的,根本不属于这里的链接问题。
一般来说,如前所述,pandas 不保证 get 操作将返回数据的视图还是副本。如果在我们的例子中返回了一个视图,那么我们的链式赋值中的第二个表达式将是对原始对象的调用__setitem__。但是,如果返回一个副本,将被修改的是该副本——原始对象不会被修改。
这就是警告所说的“试图在数据帧的切片副本上设置值”的含义。由于没有引用这个副本,它最终将被垃圾收集。SettingWithCopyWarning让我们知道 pandas 不能确定第一个__getitem__调用返回的是视图还是副本,因此不清楚赋值是否改变了原始对象。另一种思考熊猫为什么给我们这个警告的方式是因为“我们在修改原作吗?”是未知的。
我们确实想修改原始操作,警告建议的解决方案是使用loc将这两个独立的、链接的操作转换成一个赋值操作。这将从我们的代码中删除链式索引,我们将不再收到警告。我们的固定代码及其扩展版本将如下所示:
# Our code
data.loc[data.bidder == 'parakeet2004', 'bidderrate'] = 100
# Code executeddata.loc.__setitem__((data.__getitem__('bidder') == 'parakeet2004', 'bidderrate'), 100)
我们的 DataFrame 的loc属性保证是原始的DataFrame本身,但是具有扩展的索引功能。
假阴性
使用loc并不能解决我们的问题,因为使用loc的 get 操作仍然可以返回视图或副本。让我们快速检查一个有点复杂的例子。
data.loc[data.bidder == 'parakeet2004', ('bidderrate', 'bid')]
| 投标价格 | 出价 | |
|---|---|---|
| six | One hundred | Three |
| seven | One hundred | Ten |
| eight | One hundred | Twenty-four point nine nine |
这次我们抽出了两列,而不是一列。让我们尝试设置所有的bid值。
data.loc[data.bidder == 'parakeet2004', ('bidderrate', 'bid')]['bid'] = 5.0
data.loc[data.bidder == 'parakeet2004', ('bidderrate', 'bid')]
| 投标价格 | 出价 | |
|---|---|---|
| six | One hundred | Three |
| seven | One hundred | Ten |
| eight | One hundred | Twenty-four point nine nine |
没有效果也没有警告!我们在切片的副本上设置了一个值,但熊猫没有检测到它—这是一个假阴性。仅仅因为我们已经使用了loc并不意味着我们可以再次开始使用链式赋值。GitHub 上有一个关于这个特殊 bug 的旧的未解决的问题。
正确的做法如下:
data.loc[data.bidder == 'parakeet2004', 'bid'] = 5.0
data.loc[data.bidder == 'parakeet2004', ('bidderrate', 'bid')]
| 投标价格 | 出价 | |
|---|---|---|
| six | One hundred | Five |
| seven | One hundred | Five |
| eight | One hundred | Five |
您可能想知道在实践中怎么会有人遇到这样的问题,但是当我们在下一节中把DataFrame查询的结果赋给变量时,这比您想象的要容易。
隐藏链接
让我们再看看前面的隐藏链接示例,我们试图从我们的winners变量中标有304的行中设置bidder值。
winners = data.loc[data.bid == data.price]
winners.loc[304, 'bidder'] = 'therealname'
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/indexing.py:517: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy self.obj[item] = s
即使我们使用了loc,我们还是得到了另一个SettingWithCopyWarning。这个问题非常令人困惑,因为警告信息似乎在建议我们做我们已经做过的事情。
但是想想winners这个变量。到底是什么?假设我们通过data.loc[data.bid == data.price]实例化了它,我们无法知道它是视图还是原始dataT3 的副本(因为 get 操作要么返回视图,要么返回副本)。将实例化与生成警告的代码行结合起来,可以清楚地看出我们的错误。
data.loc[data.bid == data.price].loc[304, 'bidder'] = 'therealname'
/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/pandas/core/indexing.py:517: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy self.obj[item] = s
我们再次使用了链式赋值,但是这次它被分成了两行。思考这个问题的另一种方式是问这样一个问题“这是修改了一个还是两个东西?”在我们的例子中,答案是未知的:如果winners是一个副本,那么只有winners受到影响,但是如果它是一个视图,winners和data都将显示更新的值。这种情况可能发生在脚本或代码库中相距很远的代码行之间,使得问题的根源很难追踪。
这里警告的目的是防止我们认为我们的代码会修改原来的DataFrame,或者我们在修改一个副本而不是原来的。钻研熊猫 GitHub repo 的老问题,你可以阅读开发者自己对此的解释。
我们如何解决这个问题在很大程度上取决于我们自己的意图。如果我们乐于使用原始数据的副本,解决方案就是简单地强迫熊猫制作一个副本。
winners = data.loc[data.bid == data.price].copy()
winners.loc[304, 'bidder'] = 'therealname'
print(data.loc[304, 'bidder']) # Original
print(winners.loc[304, 'bidder']) # Copy
nan
therealname
另一方面,如果您要求更新原始的DataFrame,那么您应该使用原始的DataFrame,而不是实例化具有未知行为的其他变量。我们之前的代码会变成:
# Finding the winners
winner_mask = data.bid == data.price
# Taking a peek
data.loc[winner_mask].head()
# Doing analysis
mean_win_time = data.loc[winner_mask, 'bidtime'].mean()
... # 20 lines of code
mode_open_bid = data.loc[winner_mask, 'openbid'].mode()
# Updating the username
data.loc[304, 'bidder'] = 'therealname'
在更复杂的情况下,比如修改一个DataFrame子集的一个子集,而不是使用链式索引,你可以通过在原始DataFrame上的loc来修改你正在制作的切片。例如,您可以更改上面的新winner_mask变量,或者创建一个新变量来选择获胜者的子集,如下所示:
high_winner_mask = winner_mask & (data.price > 150)
data.loc[high_winner_mask].head()
| 拍卖 id | 出价 | 就寝时间 | 投标人 | 投标价格 | openid | 价格 | 投标时间 _ 小时 | |
|---|---|---|---|---|---|---|---|---|
| Two hundred and twenty-five | Eight billion two hundred and thirteen million three hundred and eighty-seven thousand four hundred and forty-four | One hundred and fifty-two | 2.919757 | uconnbabydoll1975 年 | Fifteen | Zero point nine nine | One hundred and fifty-two | 70.074168 |
| Three hundred and twenty-eight | Eight billion two hundred and thirteen million nine hundred and thirty-five thousand one hundred and thirty-four | Two hundred and seven point five | 2.983542 | toby2492 | Zero | Zero point one | Two hundred and seven point five | 71.605008 |
| Four hundred and sixteen | Eight billion two hundred and fourteen million four hundred and thirty thousand three hundred and ninety-six | One hundred and ninety-nine | 2.990463 | volpendesta | four | Nine point nine nine | One hundred and ninety-nine | 71.771112 |
| Five hundred and thirty-one | Eight billion two hundred and fifteen million five hundred and eighty-two thousand two hundred and twenty-seven | One hundred and fifty-two point five | 2.999664 | 最后通牒 _ 男人 | Two | Sixty | One hundred and fifty-two point five | 71.991936 |
这种技术对于未来的代码库维护和扩展更加健壮。
历史
您可能想知道为什么不能通过显式地指定返回视图或副本的索引方法来完全避免整个SettingWithCopy问题,而不是制造我们发现自己所处的混乱局面。为了理解这一点,我们必须了解熊猫的过去。
pandas 用来确定它是返回一个视图还是一个副本的逻辑源于它对 NumPy 库的使用,这是 pandas 操作的基础。观点实际上是通过 NumPy 进入熊猫词典的。事实上,视图在 NumPy 中非常有用,因为它们是可预测地返回的。因为 NumPy 数组是单一类型的,pandas 试图通过使用最合适的 dtype 来最小化空间和处理需求。因此,包含单个 dtype 的DataFrame片段可以作为单个 NumPy 数组上的视图返回,这是一种高效的操作处理方式。然而,在 NumPy 中,多数据类型片不能以同样的方式高效地存储。Pandas 将通用的索引功能与最有效地使用其 NumPy 内核的能力结合在一起。
最终,pandas 中的索引被设计成有用和通用的,其核心并不完全结合底层 NumPy 数组的功能。随着时间的推移,设计和功能的这些元素之间的相互作用导致了一组复杂的规则,这些规则决定了视图或副本是否可以被返回。有经验的 pandas 开发人员通常对 pandas 的行为感到满意,因为他们可以轻松地导航其索引行为。
不幸的是,对于库的新手来说,链式索引几乎是不可避免的,尽管这并不是想要的方法,因为 get 操作返回可索引的 pandas 对象。再者,用熊猫几年的核心开发者之一 Jeff Reback 的话来说,“从语言的角度来说,直接检测链式索引是根本不可能的;必须推断出来”。
因此,该警告在 2013 年底的版本 0.13.0 中被引入,作为许多开发人员遇到的链式分配的静默失败的解决方案。
在 0.12 版本之前, ix索引器是最流行的(在 pandas 命名法中,ix、loc和iloc等“索引器”是简单的构造,允许对象像数组一样用方括号索引,但具有特殊的行为)。但是大约在这个时候,也就是 2013 年年中,熊猫项目开始获得动力,迎合新用户变得越来越重要。从这个版本开始,loc和iloc索引器因其更清晰的本质和更容易解释的用法而更受青睐。

谷歌趋势:熊猫
在推出之后,SettingWithCopyWarning一直在继续发展,几年来在许多 GitHub 问题上被热议,甚至现在仍在更新,但它将继续存在,理解它对于成为熊猫专家仍然至关重要。
包扎
隐藏在SettingWithCopyWarning背后的复杂性是熊猫库中为数不多的粗糙边缘之一。它的根源深深植根于图书馆,不应该被忽视。用杰夫·雷巴克自己的话来说,“就我所知,没有任何情况下你真的应该忽略这个警告。…如果您执行某些类型的索引,它将永远不会工作,而其他类型的索引将会工作。你真是在玩火。”
幸运的是,解决这个警告只需要您识别链式赋值并修复它。如果说我们能从这一切中吸取什么的话,那就是。
如果你想了解更多关于这个话题的信息,请查看 Dataquest 的交互式 Pandas 和 NumPy Fundamentals 课程,以及我们的Python 数据分析师和Python 数据科学家路径,它们将帮助你在大约 6 个月内做好工作准备。

https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
数据故事:随着人类越来越多地影响海洋,鲨鱼袭击增加
原文:https://www.dataquest.io/blog/shark-attack-data-rise-humans-impact-oceans/
July 30, 2019
对一个多世纪以来报道的鲨鱼攻击数据的分析表明,攻击事件在增加。但它也暗示了一些原因:人类对海洋的影响和干涉越来越多。

自 1970 年以来报道的鲨鱼袭击事件。
鲨鱼袭击事件总体上呈上升趋势,而引发的袭击——鲨鱼遭遇某种人类干预的事件——也呈上升趋势。
攻击的模式也在变化。例如,随着气候变化使海水变暖,涉及虎鲨和牛鲨这两种最具攻击性的物种的攻击似乎正在向北移动。下面,我们可以看到发生在北纬 32 度线(蓝色)以北的年度攻击的百分比似乎在上升。


总的来说,虎鲨和牛鲨约占大多数年份所有报道的鲨鱼袭击事件的一半。这些物种在北方攻击的增加强化了海洋生物学家已经观察到的现象。例如,为了应对海水变暖,牛鲨正在更北的地方交配。许多其他种类的鲨鱼已经显示出相似的运动模式。
我们的分析没有发现涉及白鲨(包括著名的大白鲨)的“北方”鲨鱼袭击数量有任何显著变化。但是有一个有趣的生物学原因,为什么当其他物种明显向北移动时,白鲨可能没有向北移动以应对水温上升。
大多数鲨鱼,包括虎鲨和牛鲨都是冷血动物,这意味着它们的体温与周围的水相匹配。正因为如此,它们可能对水温的变化特别敏感。另一方面,白鲨是温血动物(吸热),因此不太可能根据周围水温的变化来改变它们的行为。
然而,由于大多数鲨鱼都是冷血动物,数据表明随着海洋温度的上升,游泳者、冲浪者和北方气候的划船者可能会预计他们的海洋中鲨鱼的数量会增加,从而导致鲨鱼袭击的数量增加。
当然,值得记住的是鲨鱼袭击仍然非常罕见。例如,你被闪电击中的可能性远远大于被鲨鱼攻击的可能性。致命事故更加罕见。我们分析的数据集包含 6000 多起人类报告的鲨鱼攻击事件的数据,其中只包括每年报告的几起死亡事件。鉴于据报道,人类每年杀死大约 1 亿条鲨鱼,很明显,鲨鱼对我们的恐惧超过了我们对它们的恐惧。
尽管如此,如果你想把撞上鲨鱼的几率降到最低,数据建议你应该把冲浪板存放起来。自 1980 年以来,冲浪一直是每年与鲨鱼袭击联系最紧密的单一活动。游泳和钓鱼分别是与报道的鲨鱼袭击相关的第二和第三大常见活动。

然而,冲浪和钓鱼鲨鱼袭击不太可能致命。游泳、沐浴和各种潜水活动(潜水、水肺潜水、浮潜、鱼叉捕鱼等。)有更高的致命攻击率。
学会做这种分析!
深入数据分析,开启一个激动人心的新职业——即使你之前没有编程或统计经验。如果你想自己做一个这样的项目,我们可以帮助你!查看我们的互动数据科学课程。
SQL 基础知识——分析自行车共享的实用初级 SQL 教程
February 1, 2021
在本教程中,我们将使用来自自行车共享服务 Hubway 的数据集,其中包括使用该服务进行的超过 150 万次旅行的数据。

在开始用 SQL 编写我们自己的查询之前,我们将从了解数据库、它们是什么以及我们为什么使用它们开始。
如果你想继续下去,你可以在这里下载hubway.db文件(130 MB)。
SQL 基础:关系数据库
关系数据库是一种跨多个表存储相关信息的数据库,允许您同时查询多个表中的信息。
通过思考一个例子,更容易理解这是如何工作的。假设你是一家企业,你想跟踪你的销售信息。您可以在 Excel 中设置一个电子表格,将所有要跟踪的信息作为单独的列:订单号、日期、到期金额、发货跟踪号、客户姓名、客户地址和客户电话号码。

这种设置可以很好地跟踪您需要的信息,但是当您开始从同一个客户那里获得重复订单时,您会发现他们的姓名、地址和电话号码存储在您的电子表格的多行中。
随着您的业务增长和您跟踪的订单数量增加,这些冗余数据将占用不必要的空间,通常会降低您的销售跟踪系统的效率。您可能还会遇到数据完整性的问题。例如,不能保证每个字段都填充了正确的数据类型,也不能保证每次都以完全相同的方式输入姓名和地址。

使用关系数据库,如上图所示,可以避免所有这些问题。您可以设置两个表,一个用于订单,一个用于客户。“客户”表将包括每个客户的唯一 ID 号,以及我们已经在跟踪的姓名、地址和电话号码。“订单”表将包括您的订单号、日期、到期金额、跟踪号,并且它将有一列用于客户 ID,而不是为每一项客户数据提供单独的字段。
这使我们能够调出任何给定订单的所有客户信息,但我们只需在数据库中存储一次,而不是为每一个订单列出一次。
我们的数据集
让我们先来看看我们的数据库。数据库有两个表,trips和stations。首先,我们只看一下trips表。它包含以下列:
id—作为每次行程参考的唯一整数duration—行程的持续时间,以秒为单位start_date—旅行开始的日期和时间start_station—一个整数,对应于行程开始站的stations表中的id列end_date—旅行结束的日期和时间end_station—旅程结束的车站的“id”bike_number— Hubway 在旅途中使用的自行车的唯一标识符sub_type—用户的订阅类型。"Registered"为会员用户,"Casual"为非会员用户zip_code—用户的邮政编码(仅适用于注册会员)birth_date—用户的出生年份(仅适用于注册会员)gender—用户的性别(仅适用于注册会员)
我们的分析
有了这些信息和我们很快会学到的 SQL 命令,下面是我们在这篇文章中试图回答的一些问题:
- 最长的一次旅行持续了多长时间?
- “注册”用户进行了多少次旅行?
- 平均旅行持续时间是多长?
- 注册用户或临时用户需要更长的行程吗?
- 哪辆自行车被用于最多的旅行?
- 30 岁以上用户的平均旅行时长是多少?
我们将使用以下 SQL 命令来回答这些问题:
SELECTWHERELIMITORDER BYGROUP BYANDORMINMAXAVGSUMCOUNT
安装和设置
出于本教程的目的,我们将使用名为 SQLite3 的数据库系统。从 2.5 版本开始,SQLite 就是 Python 的一部分,所以如果你安装了 Python,你几乎肯定也会安装 SQLite。如果你还没有 Python 和 SQLite3 库,可以很容易地用 Anaconda 安装和设置它们。
使用 Python 来运行我们的 SQL 代码允许我们将结果导入到 Pandas 数据框架中,从而更容易以易读的格式显示我们的结果。这也意味着我们可以对从数据库中提取的数据进行进一步的分析和可视化,尽管这超出了本教程的范围。
或者,如果我们不想使用或安装 Python,我们可以从命令行运行 SQLite3。只需从 SQLite3 网页下载“预编译二进制文件”并使用以下代码打开数据库:
~$ sqlite hubway.db SQLite version 3.14.0 2016-07-26 15:17:14Enter ".help" for usage hints.sqlite>
在这里,我们只需输入想要运行的查询,我们将在终端窗口中看到返回的数据。
使用终端的另一种方法是通过 Python 连接到 SQLite 数据库。这将允许我们使用 Jupyter 笔记本,这样我们就可以在一个整洁的表格中看到我们的查询结果。
为此,我们将定义一个函数,该函数将我们的查询(存储为字符串)作为输入,并将结果显示为格式化的数据帧:
import sqlite3
span class="token keyword">import pandas as pd
b = sqlite3.connect('hubway.db')
span class="token keyword">def run_query(query):
return pd.read_sql_query(query,db)
当然,我们不一定要用 Python 搭配 SQL。如果你已经是一名 R 程序员,我们的面向 R 用户的 SQL 基础课程将是一个很好的起点。
挑选
我们将使用的第一个命令是SELECT。SELECT将是我们编写的几乎每个查询的基础——它告诉数据库我们想要看到哪些列。我们可以通过名称(用逗号分隔)来指定列,或者使用通配符*来返回表中的每一列。
除了我们想要检索的列之外,我们还必须告诉数据库从哪个表中获取它们。为此,我们使用关键字FROM后跟表名。例如,如果我们希望在trips表中看到每次旅行的start_date和bike_number,我们可以使用以下查询:
SELECT start_date, bike_number FROM trips;
在这个例子中,我们从SELECT命令开始,这样数据库就知道我们希望它为我们找到一些数据。然后我们告诉数据库我们对start_date和bike_number列感兴趣。最后,我们使用FROM让数据库知道我们想要查看的列是trips表的一部分。
编写 SQL 查询时需要注意的一件重要事情是,我们希望用分号(;)结束每个查询。实际上并不是每个 SQL 数据库都需要这样,但有些确实需要,所以最好养成这个习惯。
限制
在开始对 Hubway 数据库运行查询之前,我们需要知道的下一个命令是LIMIT。LIMIT简单地告诉数据库您希望它返回多少行。
我们在上一节中看到的SELECT查询将为trips表中的每一行返回所请求的信息,但有时这可能意味着大量数据。我们可能不需要全部。相反,如果我们希望在数据库中看到前五次旅行的start_date和bike_number,我们可以将LIMIT添加到我们的查询中,如下所示:
SELECT start_date, bike_number FROM trips LIMIT 5;
我们简单地添加了LIMIT命令,然后添加了一个表示我们希望返回的行数的数字。在这种情况下,我们使用 5,但是您可以用任何数字来替换它,以便为您正在处理的项目获取适当的数据量。
在本教程中,我们将在对 Hubway 数据库的查询中大量使用LIMIT—trips表包含超过 150 万行数据,我们当然不需要显示所有这些数据!
让我们在 Hubway 数据库上运行第一个查询。首先,我们将查询存储为一个字符串,然后使用我们之前定义的函数在数据库上运行它。看一下下面的例子:
query = 'SELECT * FROM trips LIMIT 5;'
un_query(query)
| 身份证明(identification) | 期间 | 开始日期 | 起点站 | 结束日期 | 终点站 | 自行车 _ 号码 | 子类型 | 邮政编码 | 出生日期 | 性别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | nine | 2011-07-28 10:12:00 | Twenty-three | 2011-07-28 10:12:00 | Twenty-three | B00468 | 注册的 | ‘97217 | One thousand nine hundred and seventy-six | 男性的 |
| one | Two | Two hundred and twenty | 2011-07-28 10:21:00 | Twenty-three | 2011-07-28 10:25:00 | Twenty-three | B00554 | 注册的 | ‘02215 | One thousand nine hundred and sixty-six | 男性的 |
| Two | three | fifty-six | 2011-07-28 10:33:00 | Twenty-three | 2011-07-28 10:34:00 | Twenty-three | B00456 | 注册的 | ‘02108 | One thousand nine hundred and forty-three | 男性的 |
| three | four | Sixty-four | 2011-07-28 10:35:00 | Twenty-three | 2011-07-28 10:36:00 | Twenty-three | B00554 | 注册的 | ‘02116 | One thousand nine hundred and eighty-one | 女性的 |
| four | five | Twelve | 2011-07-28 10:37:00 | Twenty-three | 2011-07-28 10:37:00 | Twenty-three | B00554 | 注册的 | ‘97214 | One thousand nine hundred and eighty-three | 女性的 |
该查询使用*作为通配符,而不是指定要返回的列。这意味着SELECT命令已经给了我们trips表中的每一列。我们还使用了LIMIT函数将输出限制在表的前五行。
您会经常看到人们在查询中使用大写的 commmand 关键字(这是我们将在本教程中遵循的惯例),但这主要是个人偏好的问题。这种大写使代码更容易阅读,但它实际上不会以任何方式影响代码的功能。如果您更喜欢用小写命令编写查询,查询仍然会正确执行。
我们之前的例子返回了trips表中的每一列。如果我们只对duration和start_date列感兴趣,我们可以用列名替换通配符,如下所示:
query = 'SELECT duration, start_date FROM trips LIMIT 5'
un_query(query)
| 期间 | 开始日期 | |
|---|---|---|
| Zero | nine | 2011-07-28 10:12:00 |
| one | Two hundred and twenty | 2011-07-28 10:21:00 |
| Two | fifty-six | 2011-07-28 10:33:00 |
| three | Sixty-four | 2011-07-28 10:35:00 |
| four | Twelve | 2011-07-28 10:37:00 |
以...排序
在回答第一个问题之前,我们需要知道的最后一个命令是ORDER BY。这个命令允许我们根据给定的列对数据库进行排序。
要使用它,我们只需指定要排序的列的名称。默认情况下,ORDER BY按升序排序。如果我们想要指定数据库应该排序的顺序,我们可以添加关键字ASC进行升序排序,或者添加关键字DESC进行降序排序。
例如,如果我们想将trips表从最短的duration到最长的进行排序,我们可以在查询中添加下面一行:
ORDER BY duration ASC
有了我们的指令清单中的SELECT、LIMIT和ORDER BY命令,我们现在可以尝试回答我们的第一个问题:最长的旅行持续了多长时间?
要回答这个问题,将它分成几个部分并确定我们需要哪些命令来处理每个部分是很有帮助的。
首先,我们需要从trips表的duration列中提取信息。然后,为了找出哪一次旅行最长,我们可以按降序对duration列进行排序。下面是我们如何解决这个问题,提出一个查询来获取我们正在寻找的信息:
- 使用
SELECT检索duration列FROM和trips表 - 使用
ORDER BY对duration列进行排序,并使用DESC关键字指定您想要按降序排序 - 使用
LIMIT将输出限制为 1 行
以这种方式使用这些命令将返回持续时间最长的一行,这将为我们提供问题的答案。
还有一点需要注意——随着您的查询添加更多命令并变得更加复杂,您可能会发现如果您将它们分成多行,会更容易阅读。这和大写一样,是个人喜好问题。它不影响代码如何运行(系统只是从头开始读取代码,直到它到达分号),但它可以使您的查询更清晰,更容易理解。在 Python 中,我们可以使用三重引号将一个字符串分隔成多行。
让我们继续运行这个查询,找出最长的旅行持续了多长时间。
query = '''
ELECT duration FROM trips
RDER BY duration DESC
IMIT 1;
''
un_query(query)
| 期间 | |
|---|---|
| Zero | nine thousand nine hundred ninety nine |
现在我们知道最长的一次旅行持续了 9999 秒,也就是 166 分钟多一点。然而,最大值为 9999,我们不知道这是否真的是最长旅程的长度,或者数据库是否只允许四位数。
如果特别长的旅行真的被数据库缩短了,那么我们可能会看到很多旅行在 9999 秒达到极限。让我们尝试运行与之前相同的查询,但是调整LIMIT以返回 10 个最高的持续时间,看看情况是否如此:
query = '''
ELECT durationFROM trips
RDER BY duration DESC
IMIT 10
''
un_query(query)
| 期间 | |
|---|---|
| Zero | nine thousand nine hundred ninety nine |
| one | Nine thousand nine hundred and ninety-eight |
| Two | Nine thousand nine hundred and ninety-eight |
| three | Nine thousand nine hundred and ninety-seven |
| four | Nine thousand nine hundred and ninety-six |
| five | Nine thousand nine hundred and ninety-six |
| six | Nine thousand nine hundred and ninety-five |
| seven | Nine thousand nine hundred and ninety-five |
| eight | Nine thousand nine hundred and ninety-four |
| nine | Nine thousand nine hundred and ninety-four |
我们在这里看到的是,在 9999 没有一大堆旅行,所以看起来我们并没有切断我们的持续时间的顶端,但仍然很难判断这是旅行的真实长度还是只是最大允许值。
Hubway 对超过 30 分钟的骑行收取额外费用(有人骑自行车 9999 秒将不得不支付额外的 25 美元费用),所以他们决定 4 位数足以跟踪大多数骑行似乎是合理的。
在哪里
前面的命令对于提取特定列的排序信息非常有用,但是如果我们想要查看特定的数据子集呢?这就是WHERE的用武之地。WHERE命令允许我们使用逻辑运算符来指定应该返回哪些行。例如,您可以使用以下命令返回骑自行车B00400的每一次旅行:
WHERE bike_number = "B00400"
您还会注意到我们在这个查询中使用了引号。这是因为bike_number是以字符串的形式存储的。如果该列包含数字数据类型,则不需要引号。
让我们编写一个查询,使用WHERE返回trips表中的每一列,每一行的duration超过 9990 秒:
query = '''
ELECT * FROM trips
HERE duration > 9990;
''
un_query(query)
| 身份证明(identification) | 期间 | 开始日期 | 起点站 | 结束日期 | 终点站 | 自行车 _ 号码 | 子类型 | 邮政编码 | 出生日期 | 性别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Four thousand seven hundred and sixty-eight | Nine thousand nine hundred and ninety-four | 2011-08-03 17:16:00 | Twenty-two | 2011-08-03 20:03:00 | Twenty-four | B00002 | 非正式的 | |||
| one | Eight thousand four hundred and forty-eight | Nine thousand nine hundred and ninety-one | 2011-08-06 13:02:00 | fifty-two | 2011-08-06 15:48:00 | Twenty-four | B00174 | 非正式的 | |||
| Two | Eleven thousand three hundred and forty-one | Nine thousand nine hundred and ninety-eight | 2011-08-09 10:42:00 | Forty | 2011-08-09 13:29:00 | forty-two | B00513 | 非正式的 | |||
| three | Twenty-four thousand four hundred and fifty-five | Nine thousand nine hundred and ninety-five | 2011-08-20 12:20:00 | fifty-two | 2011-08-20 15:07:00 | Seventeen | B00552 | 非正式的 | |||
| four | Fifty-five thousand seven hundred and seventy-one | Nine thousand nine hundred and ninety-four | 2011-09-14 15:44:00 | Forty | 2011-09-14 18:30:00 | Forty | B00139 | 非正式的 | |||
| five | Eighty-one thousand one hundred and ninety-one | Nine thousand nine hundred and ninety-three | 2011-10-03 11:30:00 | Twenty-two | 2011-10-03 14:16:00 | Thirty-six | B00474 | 非正式的 | |||
| six | Eighty-nine thousand three hundred and thirty-five | Nine thousand nine hundred and ninety-seven | 2011-10-09 02:30:00 | Sixty | 2011-10-09 05:17:00 | Forty-five | B00047 | 非正式的 | |||
| seven | One hundred and twenty-four thousand five hundred | Nine thousand nine hundred and ninety-two | 2011-11-09 09:08:00 | Twenty-two | 2011-11-09 11:55:00 | Forty | B00387 | 非正式的 | |||
| eight | One hundred and thirty-three thousand nine hundred and sixty-seven | Nine thousand nine hundred and ninety-six | 2011-11-19 13:48:00 | four | 2011-11-19 16:35:00 | Fifty-eight | B00238 | 非正式的 | |||
| nine | One hundred and forty-seven thousand four hundred and fifty-one | Nine thousand nine hundred and ninety-six | 2012-03-23 14:48:00 | Thirty-five | 2012-03-23 17:35:00 | Thirty-three | B00550 | 非正式的 | |||
| Ten | Three hundred and fifteen thousand seven hundred and thirty-seven | Nine thousand nine hundred and ninety-five | 2012-07-03 18:28:00 | Twelve | 2012-07-03 21:15:00 | Twelve | B00250 | 注册的 | ‘02120 | One thousand nine hundred and sixty-four | 男性的 |
| Eleven | Three hundred and nineteen thousand five hundred and ninety-seven | Nine thousand nine hundred and ninety-four | 2012-07-05 11:49:00 | fifty-two | 2012-07-05 14:35:00 | Fifty-five | B00237 | 非正式的 | |||
| Twelve | Four hundred and sixteen thousand five hundred and twenty-three | Nine thousand nine hundred and ninety-eight | 2012-08-15 12:11:00 | Fifty-four | 2012-08-15 14:58:00 | Eighty | B00188 | 非正式的 | |||
| Thirteen | Five hundred and forty-one thousand two hundred and forty-seven | nine thousand nine hundred ninety nine | 2012-09-26 18:34:00 | Fifty-four | 2012-09-26 21:21:00 | Fifty-four | T01078 | 非正式的 |
正如我们所看到的,这个查询返回了 14 次不同的旅行,每次旅行持续时间为 9990 秒或更长。这个查询突出的一点是,除了一个结果之外,所有结果的sub_type都是"Casual"。也许这表明"Registered"的用户更清楚长途旅行的额外费用。也许 Hubway 可以更好地向临时用户传达他们的定价结构,帮助他们避免超额收费。
我们已经可以看到,即使是初级的 SQL 命令也可以帮助我们回答业务问题,并在我们的数据中找到洞察力。
回到WHERE,我们还可以使用AND或OR在WHERE子句中组合多个逻辑测试。例如,如果在我们之前的查询中,我们只想返回超过 9990 秒的duration行程,并且还注册了sub_type,我们可以使用AND来指定这两个条件。
这是另一个个人偏好建议:使用括号来分隔每个逻辑测试,如下面的代码块所示。这并不是代码运行的严格要求,但是随着复杂性的增加,括号会使查询更容易理解。
让我们现在运行该查询。我们已经知道它应该只返回一个结果,所以应该很容易检查我们是否得到了正确的结果:
query = '''
ELECT * FROM trips
HERE (duration >= 9990) AND (sub_type = "Registered")
RDER BY duration DESC;
''
un_query(query)
| 身份证明(identification) | 期间 | 开始日期 | 起点站 | 结束日期 | 终点站 | 自行车 _ 号码 | 子类型 | 邮政编码 | 出生日期 | 性别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Three hundred and fifteen thousand seven hundred and thirty-seven | Nine thousand nine hundred and ninety-five | 2012-07-03 18:28:00 | Twelve | 2012-07-03 21:15:00 | Twelve | B00250 | 注册的 | ‘02120 | One thousand nine hundred and sixty-four | 男性的 |
我们在帖子开头提出的下一个问题是“注册用户进行了多少次旅行?”要回答这个问题,我们可以运行与上面相同的查询,并修改WHERE表达式以返回所有sub_type等于'Registered'的行,然后对它们进行计数。
然而,SQL 实际上有一个内置的命令来为我们进行计算,COUNT。
允许我们将计算转移到数据库,省去了我们编写额外脚本来统计结果的麻烦。要使用它,我们只需包含COUNT(column_name)而不是(或除此之外)您想要SELECT的列,就像这样:
SELECT COUNT(id)
span class="token keyword">FROM trips
在这种情况下,我们选择计算哪一列并不重要,因为在我们的查询中,每一列都应该有每一行的数据。但是有时查询可能会丢失某些行的值(或“null”)。如果我们不确定一个列是否包含空值,我们可以在id列上运行我们的COUNT—id列从不为空,所以我们可以确定我们的计数不会遗漏任何东西。
我们还可以使用COUNT(1)或COUNT(*)对查询中的每一行进行计数。值得注意的是,有时我们实际上可能想要对一个包含空值的列运行COUNT。例如,我们可能想知道数据库中有多少行的某一列缺少值。
让我们看一个查询来回答我们的问题。我们可以使用SELECT COUNT(*)来计算返回的总行数,使用WHERE sub_type = "Registered"来确保我们只计算注册用户的旅行次数。
query = '''
ELECT COUNT(*)FROM trips
HERE sub_type = "Registered";
''
un_query(query)
| 计数(*) | |
|---|---|
| Zero | One million one hundred and five thousand one hundred and ninety-two |
这个查询成功了,并返回了我们问题的答案。但是列标题不是特别有描述性。如果其他人看到这张桌子,他们将无法理解它的含义。
如果我们想让我们的结果更易读,我们可以使用AS给我们的输出一个别名(或昵称)。让我们重新运行前面的查询,但是给我们的列标题一个别名Total Trips by Registered Users:
query = '''
ELECT COUNT(*) AS "Total Trips by Registered Users"
ROM trips
HERE sub_type = "Registered";
''
un_query(query)
| 注册用户的总行程 | |
|---|---|
| Zero | One million one hundred and five thousand one hundred and ninety-two |
聚合函数
这并不是 SQL 自有的唯一数学技巧。我们还可以使用SUM、AVG、MIN和MAX分别返回一列的总和、平均值、最小值和最大值。这些和COUNT一起被称为集合函数。
为了回答我们的第三个问题,“平均旅行持续时间是多少?”,我们可以在duration列上使用AVG函数(再一次,使用AS给我们的输出列一个更具描述性的名称):
query = '''
ELECT AVG(duration) AS "Average Duration"
ROM trips;
''
un_query(query)
| 平均持续时间 | |
|---|---|
| Zero | 912.409682 |
结果发现,平均行程时长为 912 秒,约为 15 分钟。这有点道理,因为我们知道 Hubway 对超过 30 分钟的行程收取额外费用。这项服务是为短途单程旅行的乘客设计的。
那么我们的下一个问题呢,注册用户还是临时用户会进行更长的旅行?我们已经知道了一种回答这个问题的方法——我们可以运行两个带有WHERE子句的SELECT AVG(duration) FROM trips查询,其中一个限制为"Registered"用户,另一个限制为"Casual"用户。
不过,我们换个方式吧。SQL 还包括一种在单个查询中回答这个问题的方法,使用GROUP BY命令。
分组依据
GROUP BY根据特定列的内容将行分成组,并允许我们对每个组执行聚合功能。
为了更好地理解这是如何工作的,让我们看一下gender栏。在gender列中,每行可以有三个可能的值之一:"Male"、"Female"或Null(缺少;我们没有针对临时用户的gender数据)。
当我们使用GROUP BY时,数据库会根据gender列中的值将每一行分成不同的组,就像我们将一副牌分成不同的花色一样。我们可以想象做两堆,一堆雄性,一堆雌性。
一旦我们有了两个独立的堆,数据库将依次对它们中的每一个执行任何聚合函数。例如,如果我们使用COUNT,查询将计算每一堆中的行数,并分别返回每一行的值。
让我们详细了解一下如何编写一个查询来回答我们的问题,即注册用户还是临时用户需要更长的旅程。
- 与我们到目前为止的每个查询一样,我们将从
SELECT开始,告诉数据库我们想要查看哪些信息。在这种情况下,我们需要sub_type和AVG(duration)。 - 我们还将包含
GROUP BY sub_type来按照订阅类型分离我们的数据,并分别计算注册用户和临时用户的平均值。
下面是我们将所有代码放在一起时的样子:
query = '''
ELECT sub_type, AVG(duration) AS "Average Duration"
ROM trips
ROUP BY sub_type;
''
un_query(query)
| 子类型 | 平均持续时间 | |
|---|---|---|
| Zero | 非正式的 | 1519.643897 |
| one | 注册的 | 657.026067 |
那是相当不同的!平均而言,注册用户的出行时间约为 11 分钟,而临时用户的每次出行时间约为 25 分钟。注册用户可能会进行更短、更频繁的旅行,这可能是他们上班通勤的一部分。另一方面,临时用户每次出行花费的时间是普通用户的两倍。
有可能临时用户倾向于来自更倾向于长途旅行的人群(例如游客),以确保他们到处走走,看看所有的景点。一旦我们发现了数据中的这种差异,公司可能会有许多方法来调查它,以更好地了解是什么导致了这种差异。
然而,出于本教程的目的,让我们继续。我们的下一个问题是哪辆自行车被用于最多的旅行?。我们可以用一个非常相似的查询来回答这个问题。看一下下面的例子,看看你是否能弄清楚每一行在做什么——我们以后会一步一步地检查,这样你就能检查你是否做对了:
query = '''
ELECT bike_number as "Bike Number", COUNT(*) AS "Number of Trips"
ROM trips
ROUP BY bike_number
RDER BY COUNT(*) DESC
IMIT 1;
''
un_query(query)
| 自行车号码 | 旅行次数 | |
|---|---|---|
| Zero | B00490 | Two thousand one hundred and twenty |
从输出中可以看到,自行车B00490行驶了最多的路程。让我们回顾一下我们是如何到达那里的:
- 第一行是一个
SELECT子句,告诉数据库我们希望看到bike_number列和每一行的计数。它还使用AS告诉数据库用一个更有用的名称显示每一列。 - 第二行使用
FROM指定我们正在寻找的数据在trips表中。 - 第三行是事情开始变得有点棘手的地方。我们使用
GROUP BY来告诉第 1 行的COUNT函数分别计算bike_number的每个值。 - 在第四行,我们有一个
ORDER BY子句以降序对表格进行排序,并确保我们最常用的自行车位于顶部。 - 最后,我们使用
LIMIT将输出限制在第一行,因为我们对第四行的数据进行了排序,所以我们知道这将是使用次数最多的自行车。
算术运算符
我们的最后一个问题比其他问题稍微复杂一点。我们想知道 30 岁以上的注册会员旅行的平均持续时间。
我们可以在脑子里算出 30 岁的人出生的年份,然后输入,但是更好的解决方案是直接在查询中使用算术运算。SQL 允许我们使用+、-、*和/一次对整个列执行算术运算。
query = '''
ELECT AVG(duration) FROM trips
HERE (2017 - birth_date) > 30;
''
un_query(query)
| AVG(期限) | |
|---|---|
| Zero | 923.014685 |
加入
到目前为止,我们一直在研究只从trips表中提取数据的查询。然而,SQL 如此强大的原因之一是它允许我们在同一个查询中从多个表中提取数据。
我们的自行车共享数据库包含第二个表stations。stations表包含关于 Hubway 网络中每个站点的信息,并包含一个被trips表引用的id列。
不过,在我们开始研究这个数据库中的一些真实例子之前,让我们先回顾一下前面的假设订单跟踪数据库。在那个数据库中,我们有两个表,orders和customers,它们通过customer_id列连接起来。
假设我们想要编写一个查询,为数据库中的每个订单返回order_number和name。如果它们都存储在同一个表中,我们可以使用以下查询:
SELECT order_number, name
span class="token keyword">FROM orders;
不幸的是,order_number列和name列存储在两个不同的表中,所以我们必须增加一些额外的步骤。让我们花点时间考虑一下数据库在返回我们想要的信息之前需要知道的其他事情:
order_number列在哪个表中?name列在哪个表中?orders表中的信息是如何连接到customers表中的信息的?
为了回答前两个问题,我们可以在我们的SELECT命令中包含每一列的表名。我们这样做的方法是简单地写出由一个.分隔的表名和列名。例如,我们可以写SELECT orders.order_number, customers.name,而不是SELECT order_number, name。在这里添加表名有助于数据库找到我们正在寻找的列,方法是告诉它在哪个表中查找每一列。
为了告诉数据库orders和customers表是如何连接的,我们使用了JOIN和ON。JOIN指定应该连接哪些表,而ON指定每个表中的哪些列是相关的。
我们将使用一个内部连接,这意味着只有在ON中指定的列匹配时,才会返回行。在这个例子中,我们将希望在任何没有包含在FROM命令中的表上使用JOIN。所以我们可以使用FROM orders INNER JOIN customers或者FROM customers INNER JOIN orders。
正如我们前面所讨论的,这些表在每个表的customer_id列上是相连的。因此,我们将使用ON告诉数据库这两列指的是同一个东西,如下所示:
ON orders.customer_ID = customers.customer_id
我们再次使用.来确保数据库知道这些列在哪个表中。因此,当我们将所有这些放在一起时,我们会得到如下所示的查询:
SELECT orders.order_number, customers.name
span class="token keyword">FROM orders
span class="token keyword">INNER JOIN customers
span class="token keyword">ON orders.customer_id = customers.customer_id
该查询将返回数据库中每个订单的订单号以及与每个订单相关联的客户名称。
回到我们的 Hubway 数据库,我们现在可以编写一些查询来查看JOIN的运行情况。
在开始之前,我们应该看一下stations表中的其余列。下面是一个显示前 5 行的查询,这样我们就可以看到stations表的样子:
query = '''
ELECT * FROM stations
IMIT 5;
''
un_query(query)
| 身份证明(identification) | 车站 | 自治市 | 拉脱维亚的货币单位 | 液化天然气 | |
|---|---|---|---|---|---|
| Zero | three | 芬威学院 | 波士顿 | 42.340021 | -71.100812 |
| one | four | 特里蒙特街在伯克利街。 | 波士顿 | 42.345392 | -71.069616 |
| Two | five | 东北大学/北停车场 | 波士顿 | 42.341814 | -71.090179 |
| three | six | 欢乐街的剑桥街。 | 波士顿 | 42.361284999999995 | -71.06514 |
| four | seven | 扇形码头 | 波士顿 | 42.353412 | -71.044624 |
id—每个站的唯一标识符(对应于trips表中的start_station和end_station列)station—车站名称- 车站所在的城市(波士顿、布鲁克林、剑桥或萨默维尔)
lat—测站的纬度lng—站点的经度- 哪些站是往返最常用的?
- 多少次旅行在不同的城市开始和结束?
和之前一样,我们试着回答一些数据中的问题,从哪个站是最频繁的起点开始?让我们一步一步地解决这个问题:
- 首先我们想使用
SELECT从stations表中返回station列和行数的COUNT。 - 接下来我们指定我们想要的表
JOIN,并告诉数据库将它们连接起来ON``trips表中的start_station列和stations表中的id列。 - 然后我们进入查询的实质——我们将
stations表中的station列设为GROUP BY,这样我们的COUNT将分别计算每个车站的旅行次数 - 最后我们可以
ORDER BY我们的COUNT和LIMIT输出可管理数量的结果
query = '''
ELECT stations.station AS "Station", COUNT(*) AS "Count"
ROM trips INNER JOIN stations
N trips.start_station = stations.idGROUP BY stations.stationORDER BY COUNT(*) DESC
IMIT 5;
''
un_query(query)
| 车站 | 数数 | |
|---|---|---|
| Zero | 南站-大西洋大道 700 号。 | Fifty-six thousand one hundred and twenty-three |
| one | 波士顿公共图书馆-博伊尔斯顿街 700 号。 | Forty-one thousand nine hundred and ninety-four |
| Two | 查尔斯环–剑桥街的查尔斯街。 | Thirty-five thousand nine hundred and eighty-four |
| three | 灯塔街/马斯大街 | Thirty-five thousand two hundred and seventy-five |
| four | 麻省理工学院位于马萨诸塞州大街/阿姆赫斯特街 | Thirty-three thousand six hundred and forty-four |
如果你熟悉波士顿,你就会明白为什么这些是最受欢迎的电台。南站是该市主要的通勤铁路站之一,查尔斯街沿河延伸,靠近一些美丽的风景线,博伊尔斯顿和灯塔街就在市中心,靠近一些办公楼。
我们接下来要看的问题是哪些车站是往返最常用的?我们可以使用和以前差不多的查询。我们将以同样的方式SELECT相同的输出列和JOIN表格,但是这一次我们将添加一个WHERE子句,以将我们的COUNT限制为start_station与end_station相同的旅行。
query = '''SELECT stations.station AS "Station", COUNT(*) AS "Count"
ROM trips INNER JOIN stations
N trips.start_station = stations.id
HERE trips.start_station = trips.end_station
ROUP BY stations.station
RDER BY COUNT(*) DESC
IMIT 5;
''
un_query(query)
| 车站 | 数数 | |
|---|---|---|
| Zero | 阿灵顿街的灯塔街。 | Three thousand and sixty-four |
| one | 查尔斯环–剑桥街的查尔斯街。 | Two thousand seven hundred and thirty-nine |
| Two | 波士顿公共图书馆-博伊尔斯顿街 700 号。 | Two thousand five hundred and forty-eight |
| three | 阿灵顿街的博伊尔斯顿街。 | Two thousand one hundred and sixty-three |
| four | 灯塔街/马斯大街 | Two thousand one hundred and forty-four |
正如我们所看到的,这些站点的数量与前一个问题相同,但数量要少得多。最繁忙的车站仍然是最繁忙的车站,但较低的整体数字表明,人们通常使用 Hubway 自行车从 A 点到达 B 点,而不是在返回起点之前骑自行车。
这里有一个显著的区别——从我们的第一个查询来看,Esplande 并不是最繁忙的站点之一,但它似乎是最繁忙的往返站点。为什么?一张图片胜过千言万语。这看起来的确是一个骑自行车的好地方:

继续下一个问题:有多少趟车在不同的城市开始和结束?这个问题更进了一步。我们想知道有多少次旅行在不同的municipality开始和结束。为了实现这一点,我们需要将trips表JOIN到stations表两次。一旦ON到start_station列,然后ON到end_station列。
为此,我们必须为stations表创建一个别名,以便我们能够区分与start_station相关的数据和与end_station相关的数据。我们可以使用AS为各个列创建别名,使它们以更直观的名称显示。
例如,我们可以使用下面的代码,通过别名“start”将stations表转换为trips表。然后,我们可以使用.将“start”与我们的列名结合起来,以引用来自这个特定的JOIN的数据(而不是第二个JOIN,我们将使用ON的end_station列):
INNER JOIN stations AS start ON trips.start_station = start.id
下面是我们运行最终查询时的样子。注意,我们使用了<>来表示“不等于”,但是!=也可以。
query =
span class="token triple-quoted-string string">'''
ELECT COUNT(trips.id) AS "Count"
ROM trips INNER JOIN stations AS start
N trips.start_station = start.id
NNER JOIN stations AS end
N trips.end_station = end.id
HERE start.municipality <> end.municipality;
''
un_query(query)
| 数数 | |
|---|---|
| Zero | Three hundred and nine thousand seven hundred and forty-eight |
这表明,在 150 万次旅行中,约有 30 万次(或 20%)在不同的城市结束,而不是开始-这进一步证明,人们大多在相对较短的旅程中使用 Hubway 自行车,而不是在城镇之间进行较长的旅行。
如果你已经走到这一步,恭喜你!您已经开始掌握 SQL 的基础知识。我们已经介绍了许多重要的命令,SELECT、LIMIT、WHERE、ORDER BY、GROUP BY和JOIN,以及聚合和算术函数。这些将为您继续 SQL 之旅打下坚实的基础。
您已经掌握了 SQL 基础知识。现在怎么办?
学完这篇初级 SQL 教程后,您应该能够选择一个感兴趣的数据库,并编写查询来提取信息。好的第一步可能是继续使用 Hubway 数据库,看看还能找到什么。以下是你可能想尝试回答的一些其他问题:
- 有多少次旅行产生了额外费用(持续时间超过 30 分钟)?
- 哪辆自行车总使用时间最长?
- 注册用户或临时用户往返次数多吗?
- 哪个城市的平均持续时间最长?
如果您想更进一步,请查看我们的交互式 SQL 课程,它涵盖了您需要了解的一切,从初级到数据分析师和数据科学家工作的高级 SQL。
你可能也想阅读我们关于将你的 SQL 查询数据导出到 Pandas 的帖子,或者看看我们的 SQL 备忘单和我们关于 SQL 认证的文章。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
2023 年的 SQL 认证?(我们询问了 15 位招聘经理)
December 21, 2022
获得 SQL 认证真的能帮你找到数据工作吗?
这个问题的答案可能会令人困惑,因为有很多相互矛盾的信息。但是别担心,我们会保护你的。
在这篇文章中,我们将消除一些关于 SQL 认证的神话,阐明招聘经理如何看待这些证书,并用实际数据支持我们的说法。
需要学习 SQL 吗?
在我们深入探讨认证问题之前,有一个问题值得一问:为了获得一份数据方面的工作,你甚至需要学习 SQL 吗?
简短的回答?是啊!SQL 是处理数据的一项关键技能。它可能是几十年前的语言,但不要被愚弄。它和以前一样重要。
事实上,我们最近做了一些数字计算,发现 SQL 仍然是数据科学中最常用的编程语言。甚至领先于 Python 或者 R!
所以你肯定需要学习 SQL。然而,这引发了更多的问题:
- 你需要某种 SQL 认证吗?
- 申请工作时认证有帮助吗?
现在让我们来解决这些问题。
工作需要 SQL 认证吗?看情况。
我们已经确定 SQL 知识是必须的。但是你需要一个实际的证书来证明这些知识吗?这取决于你想要在数据科学中扮演什么角色。
不需要证书时
你打算做数据分析师、数据工程师、统计学家或数据科学家吗?
那么,答案是:不,你不需要 SQL 证书。对于这些工作,你肯定需要 SQL 技能,但是不需要证书。事实上,它可能甚至没有帮助。
原因如下。。。
招聘经理对 SQL 证书有什么看法
我最近采访了数据科学招聘经理、招聘人员和其他专业人士,以获得数据科学职业指南。我问了他们希望在数据科学职位的优秀求职者身上看到的技能和资格。
在我长达 200 页的采访记录中,“SQL”这个词被提到了很多。这显然是大多数招聘经理希望看到的技能。但是“认证”和“证书”这两个术语呢?这些话根本不会出现在文字记录中。
我交谈过的人中,没有一个人认为证书重要到连提都不提的地步。
换句话说,雇佣数据分析师和数据科学家的人通常不关心证书。在简历中加入 SQL 证书不太可能影响他们的决定。
为什么数据科学招聘人员对证书不感兴趣?
行业内的证书随处可得,大力推广。但大多数数据科学雇主对此并不满意。为什么不呢?
简而言之,SQL 没有“标准”认证。此外,有如此多不同的在线和离线 SQL 认证选项,以至于雇主很难确定这些证书是否真的有意义。
雇主更容易简单地查看申请人的项目组合,而不是依赖一张可能等同于也可能不等同于实际技能的纸。与认证相比,业内真实经验的切实证明是 SQL 技能更可靠的体现。
这就是为什么 Dataquest 让学生在每门 interactive SQL 课程后完成综合项目。这创造了一个技能展示窗口,你可以在找工作时向雇主展示。你可以免费开始,注册后几分钟内你就可以编写真正的代码了。
异常
对于数据科学领域的大多数职位来说,SQL 证书并不是必需的。但是这个规则也有例外。
例如,如果你想从事数据库管理而不是数据科学,可能需要一个证书。同样,如果你正在寻找一个非常具体的公司或行业,SQL 认证可能会有所帮助。
有许多 SQL“风格”与不同的数据库系统和工具相关联。因此,可能会有与公司使用的特定 SQL 类型相关联的官方认证,这些认证是有价值的,甚至是强制性的。
例如,如果你申请一家使用微软 SQL Server 的公司的数据库工作,获得微软的 Azure 数据库管理员证书可能会有所帮助。如果你在一家使用甲骨文的公司申请工作,可能需要获得一个甲骨文数据库 SQL 认证。
大多数数据科学工作不需要认证
不过,让我们说清楚。对于绝大多数数据科学职位来说,通常不需要特定的认证。SQL 的不同变体很少与“基本”SQL 相差太多。因此,大多数雇主不会关心你是否掌握了某个特定品牌的专有技术。
一般来说,招聘人员只想看到你已经掌握了基本的 SQL 技能来访问和过滤你需要的数据的证据。证书并不能真正证明你有一项特殊的技能,所以在求职申请中展示你的 SQL 知识的最好方法是包含展示你精通 SQL 的项目。
为了数据科学,一个 SQL 认证值得吗?
看情况。问问你自己:认证项目是在教你有价值的技能,还是只是给你的 LinkedIn 一个要点?前者可以值得。后者?没有那么多。
认证价格也是一个重要的考虑因素。没有多少人有几千块花在 SQL 认证上。即使你这样做了,也没有理由付那么多钱。你可以在像 Dataquest 这样的平台上交互式地学习 SQL,并以低得多的价格获得认证。

https://www.youtube.com/embed/JFlukJudHrk?feature=oembed
*## 什么 SQL 证书最好?
如上所述,您很可能不需要 SQL 证书。但是,如果你觉得你需要一个,或者你只是想有一个,这里有一些最好的 SQL 认证:
Dataquest 的 SQL 课程
这些都是学习 SQL 进行数据科学和数据分析的绝佳选择。他们将带您实际操作真正的 SQL 数据库,并向您展示如何编写查询来提取、过滤和分析您需要的数据。我们所有的 SQL 课程都提供认证,你可以在完成后添加到你的 LinkedIn。它们还包括指导项目,您可以完成并添加到您的 GitHub 和简历中!
MTA:数据库基础
这是一项微软认证,涵盖了 SQL 数据库管理的一些基础知识。它侧重于微软的 SQL Server 产品,但是它涵盖的许多技能也与其他基于 SQL 的关系数据库系统相关。
微软的 Azure 数据库管理员证书
如果你申请使用微软 SQL 服务器的公司的数据库管理员职位,这是一个很好的选择。Azure 认证是与 Microsoft SQL Server 相关的最新和最相关的认证。
Oracle 数据库 SQL 认证
对于任何对使用 Oracle 的公司的数据库工作感兴趣的人来说,这可能是一个很好的证明。
Koenig SQL 认证
Koenig 提供各种与 SQL 相关的认证项目,尽管这些项目往往价格不菲(大多数项目超过 1000 美元)。这些认证中的大部分都是针对特定的数据库技术(比如微软的 SQL Server ),而不是为了建立一般的 SQL 知识。因此,它们最适合那些知道自己需要接受特定类型的数据库培训才能胜任数据库管理员工作的人。
SQL 方面的大学,edX,或者 Coursera 认证好到不真实吗?不幸的是,是的。
对更通用的 SQL 认证感兴趣吗?你可以通过大学附属项目获得认证。这些认证计划可以在线或亲自参加。例如,在 EdX 有一个斯坦福项目。在 Coursera 可以找到与加州大学戴维斯分校和密执安大学相关的项目。
这些项目似乎提供了一些大学学位的声望,而没有花费或时间。不幸的是,招聘经理通常不这么看他们。

This is Stanford University. Unfortunately, getting a Stanford certificate from EdX will not trick employers into thinking you went here.
为什么雇主对大学的 SQL 证书不感兴趣
例如,雇主知道斯坦福证书和斯坦福学位是完全不同的东西。即使这些证书课程使用真实课程的视频讲座,它们也很少包括严格的测试或基于项目的评估。
通常,他们甚至不做任何事情来验证学生身份!招聘人员非常清楚这些做法。
教授 SQL 的有缺陷的大学公式
大多数在线大学证书课程遵循一个基本公式:
- 观看视频讲座来学习材料。
- 参加选择题或填空题来测试你的知识。
- 如果你完成了任何形式的动手项目,它都不会被打分,或者由你同组的其他学习者打分。
这种形式非常受欢迎,因为这是大学将课程材料货币化的最佳方式。他们所要做的只是录制一些讲座,写一些小测验,然后成千上万的学生就可以通过这些课程,而不需要额外的努力或费用。
既轻松又有利可图。然而,这并不意味着它一定有效,雇主也知道这一点。
有了许多这样的认证提供商,无需编写或运行一行代码就可以完成在线编程认证!所以你可以理解为什么像这样的证书对招聘者来说没有多大的影响力。
如何才能学到雇主想要的 SQL 技能?
但是,获得编写和运行 SQL 查询的实践经验是必要的。处理真实数据也是如此。学习这些关键专业任务的最好方法是去做,而不是看教授谈论它们。
这就是为什么在 Dataquest,我们有一个交互式在线平台,让你可以直接从你的浏览器窗口编写和运行真实数据的真实 SQL 查询。当你学习新的 SQL 概念时,你将立即在现实世界中应用它们。这无疑是学习 SQL 的最佳方式。
每门课程结束后,你将被要求把你的新知识整合到一个更长的指导项目中。这是你可以定制的东西,一旦完成,你可以把它放在你的简历和 GitHub 上。我们也会给你一个证书,但这可能不是最有价值的东西。当然,确定一件事是否值得的最好方法总是自己去尝试。在 Dataquest,你可以注册一个免费账户并开始学习 SQL。

This is how we teach SQL at Dataquest
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
SQL 备忘单—用于数据分析的 SQL 参考指南
January 20, 2021
无论您是通过我们的交互式 SQL 课程学习 SQL,还是通过其他方式学习 SQL,拥有一份 SQL 备忘单都会非常有帮助。
将这篇文章加入书签,或者下载并打印 PDF 文件,并在下次编写 SQL 查询时方便地快速参考!

我们的 SQL 备忘单比这份手写的更深入一点!
在准备阅读备忘单之前,需要复习一下 SQL 吗?查看我们的交互式在线 SQL 基础课程,阅读为什么你应该学习 SQL ,或者做一些关于 SQL 认证和你是否需要一个的研究。
SQL 基础知识
SQL 代表结构化语言 Q 查询 L 。它是一个用于查询——请求、过滤和输出——来自关系数据库的数据的系统。
SQL 开发于 20 世纪 70 年代,最初被称为 SEQUEL。因此,今天这个词有时读作“Sequel”,有时读作“S.Q.L”。这两种发音都是可以接受的
尽管 SQL 有许多“风格”,但某种形式的 SQL 可以用于查询大多数关系数据库系统的数据,包括 MySQL、SQLite、Oracle、Microsoft SQL Server、PostgreSQL、IBM DB2、Microsoft Azure SQL 数据库、Apache Hive 等。数据库。
SQL 备忘单:基础
使用 SQL 执行计算
执行单一计算:
SELECT 1320+17;
执行多重计算:
SELECT 1320+17, 1340-3, 7*191, 8022/6;
使用多个数字进行计算:
SELECT 1*2*3, 1+2+3;
重命名结果:
SELECT 2*3 AS mult, 1+2+3 AS nice_sum;
选择表格、列和行:
记住:在 SQL 中,子句的顺序很重要。SQL 使用以下优先顺序:FROM、SELECT、LIMIT。
显示整个表格:
SELECT *
FROM table_name;
从表中选择特定列:
SELECT column_name_1, column_name_2
FROM table_name;
显示表格的前 10 行:
SELECT *
FROM table_name
LIMIT 10;
向 SQL 查询添加注释
添加单行注释:
-- First comment
SELECT column_1, column_2, column_3 -- Second comment
FROM table_name; -- Third comment
添加块注释:
/*
This comment
spans over
multiple lines
*/
SELECT column_1, column_2, column_3
FROM table_name;
SQL Intermediate:连接和复杂查询
这些示例中有许多使用了真实 SQL 数据库中的表名和列名,学员在我们的 interactive SQL 课程中会用到这些数据库。要了解更多信息,注册一个免费帐户并试用一个!
在 SQL 中联接数据:
使用内部联接联接表:
SELECT column_name_1, column_name_2 FROM table_name_1
INNER JOIN table_name_2 ON table_name_1.column_name_1 = table_name_2.column_name_1;
使用左连接来连接表:
SELECT * FROM facts
LEFT JOIN cities ON cities.facts_id = facts.id;
使用右连接来连接表:
SELECT f.name country, c.name city
FROM cities c
RIGHT JOIN facts f ON f.id = c.facts;
使用完全外部联接来联接表:
SELECT f.name country, c.name city
FROM cities c
FULL OUTER JOIN facts f ON f.id = c.facts_id;
在不指定列名的情况下对列排序:
SELECT name, migration_rate FROM FACTS
ORDER BY 2 desc; -- 2 refers to migration_rate column
在子查询中使用联接,但有一个限制:
SELECT c.name capital_city, f.name country
FROM facts f
INNER JOIN (
SELECT * FROM cities
WHERE capital = 1
) c ON c.facts_id = f.id
LIMIT 10;
连接两个以上表中的数据:
SELECT [column_names] FROM [table_name_one]
[join_type] JOIN [table_name_two] ON [join_constraint]
[join_type] JOIN [table_name_three] ON [join_constraint]
...
...
...
[join_type] JOIN [table_name_three] ON [join_constraint]
其他常见的 SQL 操作:
将列合并成一列:
SELECT
album_id,
artist_id,
"album id is " || album_id col_1,
"artist id is " || artist_id col2,
album_id || artist_id col3
FROM album LIMIT 3;
字符串的匹配部分:
SELECT
first_name,
last_name,
phone
FROM customer
WHERE first_name LIKE "%Jen%";
在带有 CASE 的 SQL 中使用 if/then 逻辑:
CASE
WHEN [comparison_1] THEN [value_1]
WHEN [comparison_2] THEN [value_2]
ELSE [value_3]
END
AS [new_column_name]
使用 WITH 子句:
WITH track_info AS
(
SELECT
t.name,
ar.name artist,
al.title album_name,
FROM track t
INNER JOIN album al ON al.album_id = t.album_id
INNER JOIN artist ar ON ar.artist_id = al.artist_id
)
SELECT * FROM track_info
WHERE album_name = "Jagged Little Pill";
创建视图:
CREATE VIEW chinook.customer_2 AS
SELECT * FROM chinook.customer;
删除视图:
DROP VIEW chinook.customer_2;
选择出现在一个或多个 SELECT 语句中的行:
[select_statement_one]
UNION
[select_statement_two];
选择在两个 SELECT 语句中都出现的行:
SELECT * from customer_usa
INTERSECT
SELECT * from customer_gt_90_dollars;
选择出现在第一个 SELECT 语句中但不出现在第二个 SELECT 语句中的行:
SELECT * from customer_usa
EXCEPT
SELECT * from customer_gt_90_dollars;
用语句链接:
WITH
usa AS
(
SELECT * FROM customer
WHERE country = "USA"
),
last_name_g AS
(
SELECT * FROM usa
WHERE last_name LIKE "G%"
),
state_ca AS
(
SELECT * FROM last_name_g
WHERE state = "CA"
)
SELECT
first_name,
last_name,
country,
state
FROM state_ca
重要概念和资源:
保留字
保留字是在编程语言中不能用作标识符的字(如变量名或函数名),因为它们在语言本身中有特定的含义。下面是 SQL 中的保留字列表。
https://www.youtube.com/embed/JFlukJudHrk?feature=oembed
*## 下载 SQL 备忘单 PDF
点击下面的按钮下载备忘单(PDF,3 MB,彩色)。
寻找不仅仅是一个快速参考?Dataquest 的交互式 SQL 课程将帮助您在学习构建您将需要为真实世界的数据工作编写的复杂查询时,亲自动手操作 SQL。
点击下面的按钮注册一个免费帐户并立即开始学习!
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
SQL 命令:完整列表(带示例)
February 17, 2021
为了在 2021 年得到一份数据工作,你需要学习 SQL 。与任何语言一样,尤其是当您是初学者时,在一个地方有一个常用 SQL 命令和操作符的列表是非常有用的,无论何时您需要它都可以参考——我们希望成为您的首选!
下面是 SQL 命令的完整列表,按每个命令的顶层组织(例如,SELECT TOP 在 SELECT 类别中)。
如果你正在学习 SQL,并且对缺乏结构或由谷歌搜索组成的枯燥课程感到沮丧,那么你可能会喜欢 Dataquest 的交互式 SQL 课程。无论您是一个试图做好工作准备的初学者,还是一个希望保持敏锐的经验丰富的开发人员,都有适合您的 SQL 课程。
以下是我们初学 SQL 的一些课程:
SQL 命令列表
挑选
SELECT 可能是最常用的 SQL 语句。每次用 SQL 查询数据时都会用到它。它允许您定义希望查询返回什么数据。
例如,在下面的代码中,我们从名为customers的表中选择名为name的列。
SELECT name
FROM customers;
选择*
带星号()的 SELECT 将返回我们正在查询的表中所有列的。*
SELECT * FROM customers;
选择不同
SELECT DISTINCT 仅返回不同的数据,换句话说,如果有重复的记录,它将只返回每条记录的一个副本。
下面的代码将只返回来自customers表的具有唯一name的行。
SELECT DISTINCT name
FROM customers;
选择进入
SELECT INTO 将指定数据从一个表复制到另一个表中。
SELECT * INTO customers
FROM customers_backup;
选择顶部
SELECT TOP only 返回表格中最上面的x数字或百分比。
下面的代码将从customers表中返回前 50 个结果:
SELECT TOP 50 * FROM customers;
下面的代码将返回 customers 表中前 50%的内容:
SELECT TOP 50 PERCENT * FROM customers;
如同
AS 用我们可以选择的别名重命名列或表。例如,在下面的代码中,我们将name列重命名为first_name:
SELECT name AS first_name
FROM customers;
从
FROM 指定从中提取数据的表:
SELECT name
FROM customers;
在哪里
WHERE 筛选您的查询,只返回符合设定条件的结果。我们可以将它与条件运算符一起使用,如=、>、<、>=、<=等。
SELECT name
FROM customers
WHERE name = ‘Bob’;
和
并在单个查询中组合两个或多个条件。要返回结果,必须满足所有条件。
SELECT name
FROM customers
WHERE name = ‘Bob’ AND age = 55;
运筹学
或者在单个查询中组合两个或多个条件。要返回结果,只需满足其中一个条件。
SELECT name
FROM customers
WHERE name = ‘Bob’ OR age = 55;
在...之间
BETWEEN 筛选您的查询以仅返回符合指定范围的结果。
SELECT name
FROM customers
WHERE age BETWEEN 45 AND 55;
喜欢
LIKE 在列中搜索指定的模式。在下面的示例代码中,将返回名称中包含字符 Bob 的任何行。
SELECT name
FROM customers
WHERE name LIKE ‘%Bob%’;
LIKE 的其他运算符:
%x—将选择所有以 x 开头的值%x%—将选择包含 x 的所有值x%—将选择所有以 x 结尾的值x%y—将选择所有以 x 开头以 y 结尾的值_x%—将选择第二个字符为 x 的所有值x_%—将选择所有以 x 开头且长度至少为两个字符的值。您可以添加附加 _ 字符来扩展长度要求,即x___%
在…里
IN 允许我们在使用 WHERE 命令时指定要选择的多个值。
SELECT name
FROM customers
WHERE name IN (‘Bob’, ‘Fred’, ‘Harry’);
为空
IS NULL 将只返回具有空值的行。
SELECT name
FROM customers
WHERE name IS NULL;
不为空
IS NOT NULL 的作用正好相反——它将只返回没有空值的行。
SELECT name
FROM customers
WHERE name IS NOT NULL;
创造
CREATE 可用于建立数据库、表、索引或视图。
创建数据库
CREATE DATABASE 创建一个新的数据库,假设运行该命令的用户具有正确的管理权限。
CREATE DATABASE dataquestDB;
创建表格
CREATE TABLE 在数据库中创建新表。本例中的术语 int 和 varchar(255) 指定了我们正在创建的列的数据类型。
CREATE TABLE customers (
customer_id int,
name varchar(255),
age int
);
创建索引
CREATE INDEX 为表生成索引。索引用于更快地从数据库中检索数据。
CREATE INDEX idx_name
ON customers (name);
创建视图
CREATE VIEW 基于 SQL 语句的结果集创建虚拟表。视图就像一个普通的表(可以像普通的表一样被查询),但是它是而不是作为一个永久的表保存在数据库中。
CREATE VIEW [Bob Customers] AS
SELECT name, age
FROM customers
WHERE name = ‘Bob’;
滴
DROP 语句可用于删除整个数据库、表或索引。
不用说,DROP 命令应该只在绝对必要的情况下使用。
删除数据库
DROP DATABASE 删除整个数据库,包括它的所有表、索引等以及其中的所有数据。
同样,这是一个我们希望非常小心使用的命令!
DROP DATABASE dataquestDB;
翻桌
DROP TABLE 删除一个表以及其中的数据。
DROP TABLE customers;
下降指数
DROP INDEX 删除数据库中的索引。
DROP INDEX idx_name;
更新
UPDATE 语句用于更新表中的数据。例如,下面的代码会将customers表中任何名为Bob的客户的年龄更新为56。
UPDATE customers
SET age = 56
WHERE name = ‘Bob’;
删除
DELETE 可以删除表中的所有行(使用),或者可以作为 WHERE 子句的一部分删除满足特定条件的行。
DELETE FROM customers
WHERE name = ‘Bob’;
更改表格
ALTER TABLE 允许您在表中添加或删除列。在下面的代码片段中,我们将为surname添加然后移除一列。文本varchar(255)指定了列的数据类型。
ALTER TABLE customers
ADD surname varchar(255);
ALTER TABLE customers
DROP COLUMN surname;
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
聚合函数(计数/总和/AVG/最小值/最大值)
聚合函数对一组值执行计算,并返回单个结果。
数数
COUNT 返回符合指定条件的行数。在下面的代码中,我们使用了*,因此将返回customers的总行数。
SELECT COUNT(*)
FROM customers;
总和
SUM 返回数值列的总和。
SELECT SUM(age)
FROM customers;
AVG
AVG 返回数值列的平均值。
SELECT AVG(age)
FROM customers;
部
MIN 返回数值列的最小值。
SELECT MIN(age)
FROM customers;
马克斯(男子名ˌ等于 Maximilian)
MAX 返回数值列的最大值。
SELECT MAX(age)
FROM customers;
分组依据
GROUP BY 语句将具有相同值的行分组到汇总行中。该语句通常与聚合函数一起使用。例如,下面的代码将显示出现在我们的customers表中的每个名字的平均年龄。
SELECT name, AVG(age)
FROM customers
GROUP BY name;
拥有
HAVING 执行与 WHERE 子句相同的操作。不同之处在于 HAVING 用于聚合函数,而 WHERE 不用于聚合函数。
下面的例子将返回每个名字的行数,但只返回超过 2 条记录的名字。
SELECT COUNT(customer_id), name
FROM customers
GROUP BY name
HAVING COUNT(customer_id) > 2;
以...排序
ORDER BY 设置返回结果的顺序。默认情况下,顺序是升序的。
SELECT name
FROM customers
ORDER BY age;
DESC
DESC 将按降序返回结果。
SELECT name
FROM customers
ORDER BY age DESC;
抵消
OFFSET 语句使用 ORDER BY,并指定在开始从查询返回行之前要跳过的行数。
SELECT name
FROM customers
ORDER BY age
OFFSET 10 ROWS;
取得
FETCH 指定处理 OFFSET 子句后要返回的行数。OFFSET 子句是必需的,而 FETCH 子句是可选的。
SELECT name
FROM customers
ORDER BY age
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY;
连接(内部、左侧、右侧、完全)
JOIN 子句用于合并两个或多个表中的行。四种类型的联接是内联接、左联接、右联接和全联接。
内部连接
内部联接选择在两个表中具有匹配值的记录。
SELECT name
FROM customers
INNER JOIN orders
ON customers.customer_id = orders.customer_id;
左连接
左连接从左表中选择与右表中的记录相匹配的记录。在下面的例子中,左边的表格是customers。
SELECT name
FROM customers
LEFT JOIN orders
ON customers.customer_id = orders.customer_id;
右连接
右联接从右表中选择与左表中的记录相匹配的记录。在下面的例子中,右边的表格是orders。
SELECT name
FROM customers
RIGHT JOIN orders
ON customers.customer_id = orders.customer_id;
完全连接
完全联接选择在左表或右表中有匹配项的记录。与“和”连接(内部连接)相比,可以将其视为“或”连接。
SELECT name
FROM customers
FULL OUTER JOIN orders
ON customers.customer_id = orders.customer_id;
存在
EXISTS 用于测试子查询中是否存在任何记录。
SELECT name
FROM customers
WHERE EXISTS
(SELECT order FROM ORDERS WHERE customer_id = 1);
同意
授予特定用户对数据库对象(如表、视图或数据库本身)的访问权限。下面的示例将向名为“usr_bob”的用户授予对 customers 表的选择和更新权限。
GRANT SELECT, UPDATE ON customers TO usr_bob;
取消
REVOKE 删除用户对特定数据库对象的权限。
REVOKE SELECT, UPDATE ON customers FROM usr_bob;
保存点
保存点允许您确定事务中的一个点,以后可以回滚到该点。类似于创建备份。
SAVEPOINT SAVEPOINT_NAME;
犯罪
提交用于将每个事务保存到数据库。COMMIT 语句将释放任何可能正在使用的现有保存点,一旦发出该语句,就不能回滚事务。
DELETE FROM customers
WHERE name = ‘Bob’;
COMMIT
反转
回滚用于撤消未保存到数据库的事务。这只能用于撤消自上次提交或回滚命令发出以来的事务。您还可以回滚到以前创建的保存点。
ROLLBACK TO SAVEPOINT_NAME;
缩短
TRUNCATE TABLE 从数据库的表中删除所有数据条目,但保留表和结构。类似于删除。
TRUNCATE TABLE customers;
联盟
UNION 使用两个或多个 SELECT 语句组合多个结果集,并消除重复行。
从客户工会中选择姓名从订单中选择姓名;
联合所有
UNION ALL 使用两个或多个 SELECT 语句组合多个结果集,并保留重复的行。
SELECT name FROM customers
UNION
SELECT name FROM orders;
我们希望这个页面可以作为 SQL 命令的快速参考指南。但是如果你真的想学习你的 SQL 技能,复制代码是不行的。查看我们的 interactive SQL 课程并开始边做边学!
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
SQL 基础教程:今天就开始学习 SQL!
February 11, 2020
无论您希望对数据做什么,拥有 SQL 技能可能是关键。
这是因为尽管事实上 SQL 已经很老了,但它的某个版本在地球上几乎每个公司的数据库中使用。无论您是对数据科学感兴趣,还是只是访问和分析公司的一点点数据,都有可能需要 SQL 基础知识。
什么是 SQL?
我们将以一个非常基本的问题开始这个 SQL 基础教程:到底什么是 SQL?SQL(通常读作“sequel”)是结构化查询语言的缩写。这是一种专门为查询和更新数据库而设计的编程语言。
这很有用,因为以电子表格或 CSV 等其他格式存储数据并不总是可行或可取的。例如,想象一下,一家公司拥有万亿字节的数据,这些数据由公司不同部门的人员定期更新。试图用电子表格来管理这将是一场后勤和安全噩梦!数据库允许安全存储大量数据,而 SQL 是我们用来访问和更改这些数据的工具,而不需要将它们全部存储在本地机器上的一个文件中。
在 SQL 中,我们将对数据库的请求表示为“查询”。例如,我们可能会向数据库发送一个查询(一条指令),以返回特定的数据子集,如特定的表,或者更新数据库中的特定值。
假设我们想从公司的数据库中获取一些工资数据。我们当然不想下载公司的所有数据,所以我们将编写一个 SQL 查询,只给出我们需要的特定数据。如果我们假设公司数据库中有一个名为salaries的表,该查询可能如下所示:
SELECT * FROM salaries
这里的*字符表示“一切”——从salaries表中选择每一列。通过这个简单的查询,我们将能够从我们公司的数据库中得到我们需要的表。
但是 SQL 可以比查询一个完整的表做更多的事情。它可以帮助我们有效地合并、过滤、更新和分析数据,以回答各种问题。因此,让我们开始深入学习如何编写 SQL 查询吧!
注意:对于许多学生来说,以交互方式学习 SQL 并在浏览器中编写查询可能比跟着教程学习更容易。您可以在我们的 interactive SQL 基础课程中免费完成这项工作:
通过做来学习 SQL
使用我们的交互式学习平台,立即动手操作 SQL。
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
(开始免费)
SQL 基础教程:简介
在本教程中,我们将探究美国社区调查中基于大学专业的工作结果统计数据。虽然最初的 CSV 版本可以在 FiveThirtyEight 的 Github 上找到,但我们将使用作为数据库存储的数据的稍加修改的版本。(记住,SQL 用于查询存储在数据库中的数据)。
具体来说,我们将只处理包含 2010-2012 年大学毕业生数据的数据。这些数据存储为 SQLite 数据库(SQLite 是最流行的基于 SQL 的数据库管理系统之一)。
如果您熟悉如何查询 SQLite 数据库,您可以在这里下载数据库文件。如果你不习惯在本地机器上建立并查询 SQLite 数据库,那么通过我们免费的 SQL 基础课程可能会更容易,该课程是交互式的,允许你只使用浏览器编写该数据库的真正 SQL 查询。
使用选择预览表格
每当我们处理一个新的数据集时,从预览我们实际处理的东西开始是很有帮助的。对于本教程,我们将使用数据库文件jobs.db,它包含一个名为recent_grads的表:
这是该结构的可视化表示:

让我们从只显示表格的前五行开始。这将使我们很好地了解我们正在处理什么,将查询限制在五行将确保它很快,我们不会被一个巨大的表淹没。
像其他编程语言一样,SQL 中的代码必须遵循定义的结构和词汇。要指定我们想要从recent_grads返回前 5 行,我们需要运行以下 SQL 查询:
SELECT * FROM recent_grads LIMIT 5
在此查询中,我们指定:
- 我们使用
SELECT *想要的列 - 我们想要使用
FROM recent_grads查询的表 - 使用
LIMIT 5得到我们想要的行数
下面是查询的不同组成部分的可视化分解:

现在,让我们看看这个查询返回什么!以下是运行该查询时我们将得到的结果:
| 指数 | 军阶 | 专业代码 | 重要的 | 专业 _ 类别 | 总数 | 样本大小 | 男人 | 女人 | 分享女性 | 被雇用的 | 全职 | 兼职 | 全年无休 | 失业的 | 失业率 | 中位数 | p25 | 第 75 页 | 大学 _ 工作 | 非大学工作 | 低工资工作 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Two thousand four hundred and nineteen | 石油钻采工程 | 工程 | Two thousand three hundred and thirty-nine | Thirty-six | Two thousand and fifty-seven | Two hundred and eighty-two | 0.120564 | One thousand nine hundred and seventy-six | One thousand eight hundred and forty-nine | Two hundred and seventy | One thousand two hundred and seven | Thirty-seven | 0.018381 | One hundred and ten thousand | Ninety-five thousand | One hundred and twenty-five thousand | One thousand five hundred and thirty-four | Three hundred and sixty-four | One hundred and ninety-three |
| one | Two | Two thousand four hundred and sixteen | 采矿和矿物工程 | 工程 | Seven hundred and fifty-six | seven | Six hundred and seventy-nine | Seventy-seven | 0.101852 | Six hundred and forty | Five hundred and fifty-six | One hundred and seventy | Three hundred and eighty-eight | eighty-five | 0.117241 | Seventy-five thousand | Fifty-five thousand | Ninety thousand | Three hundred and fifty | Two hundred and fifty-seven | Fifty |
| Two | three | Two thousand four hundred and fifteen | 冶金工程 | 工程 | Eight hundred and fifty-six | three | Seven hundred and twenty-five | One hundred and thirty-one | 0.153037 | Six hundred and forty-eight | Five hundred and fifty-eight | One hundred and thirty-three | Three hundred and forty | Sixteen | 0.024096 | Seventy-three thousand | Fifty thousand | One hundred and five thousand | Four hundred and fifty-six | One hundred and seventy-six | Zero |
| three | four | Two thousand four hundred and seventeen | 船舶建筑和海洋工程 | 工程 | One thousand two hundred and fifty-eight | Sixteen | One thousand one hundred and twenty-three | One hundred and thirty-five | 0.107313 | Seven hundred and fifty-eight | One thousand and sixty-nine | One hundred and fifty | Six hundred and ninety-two | Forty | 0.050125 | Seventy thousand | Forty-three thousand | Eighty thousand | Five hundred and twenty-nine | One hundred and two | Zero |
| four | five | Two thousand four hundred and five | 化学工程 | 工程 | Thirty-two thousand two hundred and sixty | Two hundred and eighty-nine | Twenty-one thousand two hundred and thirty-nine | Eleven thousand and twenty-one | 0.341631 | Twenty-five thousand six hundred and ninety-four | Twenty-three thousand one hundred and seventy | Five thousand one hundred and eighty | Sixteen thousand six hundred and ninety-seven | One thousand six hundred and seventy-two | 0.061098 | Sixty-five thousand | Fifty thousand | Seventy-five thousand | Eighteen thousand three hundred and fourteen | Four thousand four hundred and forty | Nine hundred and seventy-two |
正如我们所看到的,我们的查询返回了我们想要的结果:我们选择的表中的每一列,但只有前五行。如果我们将查询的结尾改为LIMIT 10,它将返回前十行。如果我们完全删除LIMIT命令,它将返回表中的每一行。
关于大写的快速注释
在我们继续之前,您可能已经注意到我们输入了一些东西,比如SELECT,全部用大写字母,而其他的东西比如表名是用小写字母写的。
根据您查询的特定数据库和它使用的数据库管理系统的类型,表名的大小写可能重要,也可能不重要。但是,为了确保您的查询在任何系统下都能正常工作并易于阅读,最好遵循以下约定:
- 语句或命令(如
SELECT、LIMIT等)。)应该全大写。 - 无论表名和列名存储在您查询的数据库中,它们都应该以小写形式书写(因此,如果数据库以小写形式存储它们,它们在您的查询中也应该以小写形式存储)。
现在,进入我们的下一个语句:WHERE!
使用 WHERE 筛选行
如果我们看一下这个数据集的细节,我们可以更好地了解这里有什么数据,以及我们可能能够回答什么类型的问题。花些时间熟悉每一列所代表的内容。
基于对每列所代表内容的理解,我们可能会有以下问题:
- 哪些专业女生居多?哪些学校男生居多?
- 哪些专业的起薪在 25%和 75%之间的差距最大?
- 哪些工程专业的全职就业率最高?
我们先来关注第一个问题。我们需要将这个问题翻译成 SQL,这样我们就可以从数据库中得到我们想要的答案。
为了确定哪些专业以女生为主,我们需要以下数据子集:
- 只有
Major列 - 只有
ShareWomen大于0.5的行(相当于 50%)
为了只返回Major列,我们需要将特定的列名添加到查询的SELECT语句部分(而不是使用*操作符返回所有列):
SELECT Major FROM recent_grads
这将返回Major列中所有值的。我们也可以用这种方式指定多个列,结果表将保持列的顺序:
SELECT Major, Major_category FROM recent_grads
为了只返回ShareWomen大于或等于0.5的值,我们需要添加一个WHERE 子句:
SELECT Major FROM recent_gradsWHERE ShareWomen >= 0.5
最后,我们可以使用LIMIT来限制返回的行数:
SELECT Major FROM recent_gradsWHERE ShareWomen >= 0.5 LIMIT 5
如果我们运行该查询,我们将看到以下内容:
| 重要的 |
|---|
| 保险统计计算科学 |
| 计算机科学 |
| 环境工程 |
| 护理 |
| 工业生产技术 |
下面是我们的查询的不同组成部分的分类:

而在查询的SELECT部分,我们表达我们想要的特定列。在WHERE部分,我们表达了我们想要的特定行。SQL 的美妙之处在于这些可以是独立的。
让我们编写一个 SQL 查询,返回女性占少数的专业。我们将只返回Major和ShareWomen列(按此顺序),我们不会限制返回的行数:
SELECT Major, ShareWomen FROM recent_grads WHERE ShareWomen < 0.5
| 重要的 | 分享女性 |
|---|---|
| 石油钻采工程 | 0.120564 |
| 采矿和矿物工程 | 0.101852 |
| 冶金工程 | 0.153037 |
| 船舶建筑和海洋工程 | 0.107313 |
| 化学工程 | 0.341631 |
| 核技术 | 0.144967 |
| 天文学和天体物理学 | 0.441356 |
| 机械工程 | 0.139793 |
| 电机工程 | 0.437847 |
| 计算机工程 | 0.199413 |
| 航空和航天工程 | 0.196450 |
| 生物医学工程 | 0.119559 |
| 材料科学 | 0.310820 |
| 工程力学物理和科学 | 0.183985 |
| 生物工程 | 0.320784 |
| 工业和制造工程 | 0.343473 |
| 普通工程 | 0.252960 |
| 建筑工程 | 0.350442 |
| 法庭记录 | 0.236063 |
| 营养学 | 0.222695 |
| 电气工程技术 | 0.325092 |
| 材料工程和材料科学 | 0.292607 |
| 管理信息系统和统计 | 0.278790 |
| 土木工程 | 0.227118 |
| 建筑服务 | 0.342229 |
| 运营物流和电子商务 | 0.322222 |
| 杂项工程 | 0.189970 |
| 国家政策 | 0.251389 |
| 工程技术 | 0.090713 |
| 杂项美术 | 0.410180 |
| 地质和地球物理工程 | 0.324838 |
| 金融 | 0.355469 |
| 经济学 | 0.340825 |
| 企业经济学 | 0.249190 |
| 核、工业放射和生物… | 0.430537 |
| 会计 | 0.253583 |
| 数学 | 0.244103 |
| 物理学 | 0.448099 |
| 医疗技术技术员 | 0.434298 |
| 统计和决策科学 | 0.281936 |
| 工程和工业管理 | 0.174123 |
| 医疗辅助服务 | 0.178982 |
| 计算机编程和数据处理 | 0.269194 |
| 一般业务 | 0.417925 |
| 体系结构 | 0.321770 |
| 国际商业 | 0.282903 |
| 药学药学科学与管理 | 0.451465 |
| 分子生物学 | 0.077453 |
| 杂项商业和医疗管理 | 0.200023 |
| 杂项工程技术 | 0.000000 |
| 机械工程相关技术 | 0.377437 |
| 工业和组织心理学 | 0.436302 |
| 自然科学 | 0.426924 |
| 军事技术 | 0.429685 |
| 电气、机械和精密技术… | 0.232444 |
| 营销和营销研究 | 0.382900 |
| 政治学与政府 | 0.485930 |
| 地理 | 0.473190 |
| 计算机管理和安全 | 0.180883 |
| 计算机网络和电信 | 0.305005 |
| 地质学和地球科学 | 0.470197 |
| 公共行政 | 0.476461 |
| 通信 | 0.305109 |
| 刑事司法和消防 | 0.125035 |
| 商业艺术和平面设计 | 0.374356 |
| 特殊需要教育 | 0.366177 |
| 交通科学与技术 | 0.321296 |
| 神经系统科学 | 0.475010 |
| 多学科/跨学科研究 | 0.495397 |
| 大气科学和气象学 | 0.124950 |
| 教育管理和监督 | 0.448732 |
| 哲学和宗教研究 | 0.416810 |
| 英语语言和文学 | 0.339671 |
| 科学和计算机教师教育 | 0.423209 |
| 音乐 | 0.444582 |
| 美容服务和烹饪艺术 | 0.383719 |
使用 AND 表示多个筛选条件
为了按照特定的标准过滤行,我们需要使用WHERE语句。一个简单的WHERE语句需要三样东西:
- 我们希望数据库过滤的列:
ShareWomen - 一个比较操作符,指定我们希望如何比较一个列中的值:
> - 我们希望数据库与每个值进行比较的值:
0.5
下面是我们可以使用的比较运算符:
- 小于:
< - 小于或等于:
<= - 大于:
> - 大于或等于:
>= - 等于:
= - 不等于:
!=
运算符后的比较值必须是文本或数字,具体取决于字段。因为ShareWomen是一个数字列,我们不需要用引号将数字0.5括起来。
最后,大多数数据库系统要求SELECT和FROM语句排在前面,在WHERE或任何其他语句之前。我们可以使用AND操作符来组合多个过滤标准。例如,要确定哪个工程专业女生占多数,我们需要指定 2 个过滤标准。
SELECT Major FROM recent_gradsWHERE Major_category = 'Engineering' AND ShareWomen > 0.5
| 重要的 |
|---|
| 环境工程 |
| 工业生产技术 |
看起来只有两个专业符合这个标准。如果我们想“缩小”回去查看这两个专业的所有列的“T2 ”( T3 ),看看它们是否有一些共同的属性,我们可以修改语句“T0 ”,使用符号“T1”来表示所有列
SELECT * FROM recent_gradsWHERE Major_category = 'Engineering' AND ShareWomen > 0.5
| 指数 | 军阶 | 专业代码 | 重要的 | 专业 _ 类别 | 总数 | 样本大小 | 男人 | 女人 | 分享女性 | 被雇用的 | 全职 | 兼职 | 全年无休 | 失业的 | 失业率 | 中位数 | p25 | 第 75 页 | 大学 _ 工作 | 非大学工作 | 低工资工作 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Thirty | Thirty-one | Two thousand four hundred and ten | 环境工程 | 工程 | Four thousand and forty-seven | Twenty-six | Two thousand six hundred and thirty-nine | Three thousand three hundred and thirty-nine | 0.558548 | Two thousand nine hundred and eighty-three | Two thousand three hundred and eighty-four | Nine hundred and thirty | One thousand nine hundred and fifty-one | Three hundred and eight | 0.093589 | Fifty thousand | Forty-two thousand | Fifty-six thousand | Two thousand and twenty-eight | Eight hundred and thirty | Two hundred and sixty |
| Thirty-eight | Thirty-nine | Two thousand five hundred and three | 工业生产技术 | 工程 | Four thousand six hundred and thirty-one | Seventy-three | Five hundred and twenty-eight | One thousand five hundred and eighty-eight | 0.750473 | Four thousand four hundred and twenty-eight | Three thousand nine hundred and eighty-eight | Five hundred and ninety-seven | Three thousand two hundred and forty-two | One hundred and twenty-nine | 0.028308 | Forty-six thousand | Thirty-five thousand | Sixty-five thousand | One thousand three hundred and ninety-four | Two thousand four hundred and fifty-four | Four hundred and eighty |
在考虑新问题时快速迭代查询的能力是 SQL 最强大的方面之一。SQL 工作流让数据专业人员专注于提问和回答问题,而不是担心底层编程概念。
现在,让我们编写一个 SQL 查询,返回所有女生占多数的专业和的平均工资高于50000。让我们也限制结果中显示的列,如下所示:
SELECT Major, Major_category, Median, ShareWomen FROM recent_grads WHERE ShareWomen > 0.5 AND Median > 50000
| 重要的 | 专业 _ 类别 | 中位数 | 分享女性 |
|---|---|---|---|
| 保险统计计算科学 | 商业 | Sixty-two thousand | 0.535714 |
| 计算机科学 | 计算机和数学 | Fifty-three thousand | 0.578766 |
似乎只有两个以女生为主的专业的平均工资高于 5 万美元。
用 OR 返回几个条件之一
我们使用了AND操作符来指定我们的过滤器需要符合两个布尔条件。这两个条件都必须评估为True,记录才会出现在结果中。
如果我们想指定一个过滤器满足或者的条件,我们可以使用OR操作符。
SELECT [column1, column2,...] FROM [table1]WHERE [condition1] OR [condition2]
让我们编写一个 SQL 查询,返回的前 20 个专业,其中或者的Median薪水大于或等于10,000,或者的人数小于或等于1,000 Unemployed。让我们只在结果中包括以下各列,并按顺序包括:
MajorMedianUnemployed
SELECT Major, Median, Unemployed FROM recent_grads WHERE Median >= 10000 OR Unemployed <= 1000 LIMIT 20
| 重要的 | 中位数 | 失业的 |
|---|---|---|
| 石油钻采工程 | One hundred and ten thousand | Thirty-seven |
| 采矿和矿物工程 | Seventy-five thousand | eighty-five |
| 冶金工程 | Seventy-three thousand | Sixteen |
| 船舶建筑和海洋工程 | Seventy thousand | Forty |
| 化学工程 | Sixty-five thousand | One thousand six hundred and seventy-two |
| 核技术 | Sixty-five thousand | four hundred |
| 保险统计计算科学 | Sixty-two thousand | Three hundred and eight |
| 天文学和天体物理学 | Sixty-two thousand | Thirty-three |
| 机械工程 | Sixty thousand | Four thousand six hundred and fifty |
| 电机工程 | Sixty thousand | Three thousand eight hundred and ninety-five |
| 计算机工程 | Sixty thousand | Two thousand two hundred and seventy-five |
| 航空和航天工程 | Sixty thousand | Seven hundred and ninety-four |
| 生物医学工程 | Sixty thousand | One thousand and nineteen |
| 材料科学 | Sixty thousand | seventy-eight |
| 工程力学物理和科学 | Fifty-eight thousand | Twenty-three |
| 生物工程 | Fifty-seven thousand one hundred | Five hundred and eighty-nine |
| 工业和制造工程 | Fifty-seven thousand | Six hundred and ninety-nine |
| 普通工程 | Fifty-six thousand | Two thousand eight hundred and fifty-nine |
| 建筑工程 | Fifty-four thousand | One hundred and seventy |
| 法庭记录 | Fifty-four thousand | Eleven |
现在,让我们开始使用更高级的 SQL 查询。
用括号将运算符分组
有一类问题仅靠我们目前所学的技术是无法回答的。例如,如果我们想编写一个查询,返回所有的专业,或者是 T2 的女毕业生居多,或者是 T4 的失业率低于 5.1%,我们需要用括号来表达这个更复杂的逻辑。
我们需要的三个原始条件是:
Major_category = 'Engineering'ShareWomen >= 0.5Unemployment_rate < 0.051
使用 parantheses 的 SQL 查询看起来像什么:
SELECT Major, Major_category, ShareWomen, Unemployment_rate FROM recent_grads
WHERE (Major_category = 'Engineering') AND (ShareWomen > 0.5 OR Unemployment_rate < 0.051);
请注意,我们将希望一起评估的逻辑括在括号中。这非常类似于我们如何使用括号将数学计算组合在一起,以定义首先评估哪些计算。括号清楚地向数据库表明,我们希望所有语句中表达式的和都等于True的行:
(Major_category = 'Engineering' AND ShareWomen > 0.5) -> True or False(ShareWomen > 0.5 OR Unemployment_rate < 0.051) -> True or False
如果我们编写了不带任何括号的where语句,数据库会猜测我们的意图,并实际执行以下查询:
WHERE (Major_category = 'Engineering' AND ShareWomen > 0.5) OR (Unemployment_rate < 0.051)
去掉括号意味着我们希望计算从左到右进行,按照编写逻辑的顺序,这样它就不会返回我们想要的数据。
现在让我们运行预期的查询并查看结果!我们将运行上面探索过的查询,它将返回所有的Engineering专业,这些专业要么是要么是的女性毕业生居多要么是的失业率低于 5.1% ,这是 2015 年 8 月的全国失业率。
让我们只在结果中包括以下各列,并按顺序包括:
MajorMajor_categoryShareWomenUnemployment_rate
我们的疑问是:
SELECT Major, Major_category, ShareWomen, Unemployment_rateFROM recent_gradsWHERE (Major_category = 'Engineering') AND (ShareWomen > 0.5 OR Unemployment_rate < 0.051)
| 重要的 | 专业 _ 类别 | 分享女性 | 失业率 |
|---|---|---|---|
| 石油钻采工程 | 工程 | 0.120564 | 0.018381 |
| 冶金工程 | 工程 | 0.153037 | 0.024096 |
| 船舶建筑和海洋工程 | 工程 | 0.107313 | 0.050125 |
| 材料科学 | 工程 | 0.310820 | 0.023043 |
| 工程力学物理和科学 | 工程 | 0.183985 | 0.006334 |
| 工业和制造工程 | 工程 | 0.343473 | 0.042876 |
| 材料工程和材料科学 | 工程 | 0.292607 | 0.027789 |
| 环境工程 | 工程 | 0.558548 | 0.093589 |
| 工业生产技术 | 工程 | 0.750473 | 0.028308 |
| 工程和工业管理 | 工程 | 0.174123 | 0.033652 |
这看起来很棒,但是如果我们想根据特定列的值对结果进行排序,以使它们更具可读性,该怎么办呢?
使用 ORDER BY 对结果进行排序
到目前为止,我们编写的每个查询的结果都是按照Rank列排序的。回想一下本文前面返回所有列的查询,您会看到 Rank 列:
SELECT * FROM recent_grads LIMIT 5
| 指数 | 军阶 | 专业代码 | 重要的 | 专业 _ 类别 | 总数 | 样本大小 | 男人 | 女人 | 分享女性 | 被雇用的 | 全职 | 兼职 | 全年无休 | 失业的 | 失业率 | 中位数 | p25 | 第 75 页 | 大学 _ 工作 | 非大学工作 | 低工资工作 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Two thousand four hundred and nineteen | 石油钻采工程 | 工程 | Two thousand three hundred and thirty-nine | Thirty-six | Two thousand and fifty-seven | Two hundred and eighty-two | 0.120564 | One thousand nine hundred and seventy-six | One thousand eight hundred and forty-nine | Two hundred and seventy | One thousand two hundred and seven | Thirty-seven | 0.018381 | One hundred and ten thousand | Ninety-five thousand | One hundred and twenty-five thousand | One thousand five hundred and thirty-four | Three hundred and sixty-four | One hundred and ninety-three |
| one | Two | Two thousand four hundred and sixteen | 采矿和矿物工程 | 工程 | Seven hundred and fifty-six | seven | Six hundred and seventy-nine | Seventy-seven | 0.101852 | Six hundred and forty | Five hundred and fifty-six | One hundred and seventy | Three hundred and eighty-eight | eighty-five | 0.117241 | Seventy-five thousand | Fifty-five thousand | Ninety thousand | Three hundred and fifty | Two hundred and fifty-seven | Fifty |
| Two | three | Two thousand four hundred and fifteen | 冶金工程 | 工程 | Eight hundred and fifty-six | three | Seven hundred and twenty-five | One hundred and thirty-one | 0.153037 | Six hundred and forty-eight | Five hundred and fifty-eight | One hundred and thirty-three | Three hundred and forty | Sixteen | 0.024096 | Seventy-three thousand | Fifty thousand | One hundred and five thousand | Four hundred and fifty-six | One hundred and seventy-six | Zero |
| three | four | Two thousand four hundred and seventeen | 船舶建筑和海洋工程 | 工程 | One thousand two hundred and fifty-eight | Sixteen | One thousand one hundred and twenty-three | One hundred and thirty-five | 0.107313 | Seven hundred and fifty-eight | One thousand and sixty-nine | One hundred and fifty | Six hundred and ninety-two | Forty | 0.050125 | Seventy thousand | Forty-three thousand | Eighty thousand | Five hundred and twenty-nine | One hundred and two | Zero |
| four | five | Two thousand four hundred and five | 化学工程 | 工程 | Thirty-two thousand two hundred and sixty | Two hundred and eighty-nine | Twenty-one thousand two hundred and thirty-nine | Eleven thousand and twenty-one | 0.341631 | Twenty-five thousand six hundred and ninety-four | Twenty-three thousand one hundred and seventy | Five thousand one hundred and eighty | Sixteen thousand six hundred and ninety-seven | One thousand six hundred and seventy-two | 0.061098 | Sixty-five thousand | Fifty thousand | Seventy-five thousand | Eighteen thousand three hundred and fourteen | Four thousand four hundred and forty | Nine hundred and seventy-two |
随着我们想要回答的问题变得越来越复杂,我们希望对结果的排序有更多的控制。我们可以使用 ORDER BY 子句指定顺序。
例如,我们可能想了解哪些符合WHERE陈述中标准的专业失业率最低。下面的查询将按照Unemployment_rate列的升序返回结果。
SELECT Rank, Major, Major_category, ShareWomen, Unemployment_rate
FROM recent_grads
WHERE (Major_category = 'Engineering') AND (ShareWomen > 0.5 OR Unemployment_rate < 0.051)
ORDER BY Unemployment_rate
| 军阶 | 重要的 | 专业 _ 类别 | 分享女性 | 失业率 |
|---|---|---|---|---|
| Fifteen | 工程力学物理和科学 | 工程 | 0.183985 | 0.006334 |
| one | 石油钻采工程 | 工程 | 0.120564 | 0.018381 |
| Fourteen | 材料科学 | 工程 | 0.310820 | 0.023043 |
| three | 冶金工程 | 工程 | 0.153037 | 0.024096 |
| Twenty-four | 材料工程和材料科学 | 工程 | 0.292607 | 0.027789 |
| Thirty-nine | 工业生产技术 | 工程 | 0.750473 | 0.028308 |
| Fifty-one | 工程和工业管理 | 工程 | 0.174123 | 0.033652 |
| Seventeen | 工业和制造工程 | 工程 | 0.343473 | 0.042876 |
| four | 船舶建筑和海洋工程 | 工程 | 0.107313 | 0.050125 |
| Thirty-one | 环境工程 | 工程 | 0.558548 | 0.093589 |
如果我们想让结果按同一列排序,但按降序排序,我们可以添加DESC关键字:
SELECT Rank, Major, Major_category, ShareWomen, Unemployment_rate
FROM recent_gradsWHERE (Major_category = 'Engineering') AND (ShareWomen > 0.5 OR Unemployment_rate < 0.051)
ORDER BY Unemployment_rate DESC
| 军阶 | 重要的 | 专业 _ 类别 | 分享女性 | 失业率 |
|---|---|---|---|---|
| Thirty-one | 环境工程 | 工程 | 0.558548 | 0.093589 |
| four | 船舶建筑和海洋工程 | 工程 | 0.107313 | 0.050125 |
| Seventeen | 工业和制造工程 | 工程 | 0.343473 | 0.042876 |
| Fifty-one | 工程和工业管理 | 工程 | 0.174123 | 0.033652 |
| Thirty-nine | 工业生产技术 | 工程 | 0.750473 | 0.028308 |
| Twenty-four | 材料工程和材料科学 | 工程 | 0.292607 | 0.027789 |
| three | 冶金工程 | 工程 | 0.153037 | 0.024096 |
| Fourteen | 材料科学 | 工程 | 0.310820 | 0.023043 |
| one | 石油钻采工程 | 工程 | 0.120564 | 0.018381 |
| Fifteen | 工程力学物理和科学 | 工程 | 0.183985 | 0.006334 |
让我们编写一个查询,返回所有专业,其中ShareWomen大于0.3,Unemployment_rate小于.1。让我们只在结果中包括以下各列,并按此顺序包括:
*** Major,
ShareWomen,Unemployment_rate
我们将按照ShareWomen列对结果进行降序排序。这将使我们能够很容易地比较女性比例较高或较低的专业的失业率。
SELECT Major, ShareWomen, Unemployment_rate FROM recent_grads
WHERE ShareWomen > 0.3 AND Unemployment_rate < .1O
RDER BY ShareWomen DESC
这是我们的结果!
| 重要的 | 分享女性 | 失业率 |
|---|---|---|
| 早期儿童教育 | 0.967998 | 0.040105 |
| 数学和计算机科学 | 0.927807 | 0.000000 |
| 初等教育 | 0.923745 | 0.046586 |
| 动物科学 | 0.910933 | 0.050862 |
| 生理学 | 0.906677 | 0.069163 |
| 杂项心理学 | 0.905590 | 0.051908 |
| 人类服务和社区组织 | 0.904075 | 0.037819 |
| 护理 | 0.896019 | 0.044863 |
| 地学 | 0.881294 | 0.024374 |
| 大众传媒 | 0.877228 | 0.089837 |
| 认知科学和生物心理学 | 0.854523 | 0.075236 |
| 艺术史和批评 | 0.845934 | 0.060298 |
| 教育心理学 | 0.817099 | 0.065112 |
| 普通教育 | 0.812877 | 0.057360 |
| 社会福利工作 | 0.810704 | 0.068828 |
| 教师教育:多层次 | 0.798920 | 0.036546 |
| 咨询心理学 | 0.798746 | 0.053621 |
| 数学教师教育 | 0.792095 | 0.016203 |
| 心理学 | 0.779933 | 0.083811 |
| 一般医疗卫生服务 | 0.774577 | 0.082102 |
| 卫生和医疗行政服务 | 0.770901 | 0.089626 |
| 土壤学 | 0.764427 | 0.000000 |
| 区域民族与文明研究 | 0.758060 | 0.063429 |
| 应用数学 | 0.753927 | 0.090823 |
| 家庭和消费者科学 | 0.752144 | 0.067128 |
| 工业生产技术 | 0.750473 | 0.028308 |
| 社会心理学 | 0.747561 | 0.029650 |
| 人文学科 | 0.745662 | 0.068584 |
| 酒店管理 | 0.733992 | 0.061169 |
| 社会科学或历史教师教育 | 0.733968 | 0.054083 |
| 神学和宗教职业 | 0.728495 | 0.062628 |
| 法语德语拉丁语和其他常见的外国语言… | 0.728033 | 0.075566 |
| 跨学科社会科学 | 0.721866 | 0.092306 |
| 杂项农业 | 0.719974 | 0.059767 |
| 新闻工作 | 0.719859 | 0.069176 |
| 杂项教育 | 0.718365 | 0.059212 |
| 计算机和信息系统 | 0.707719 | 0.093460 |
| 交流障碍科学与服务 | 0.707136 | 0.047584 |
| 杂项健康医疗职业 | 0.702020 | 0.081411 |
| 人文科学 | 0.700898 | 0.078268 |
| 林业 | 0.690365 | 0.096726 |
| 海洋学 | 0.688999 | 0.056995 |
| 艺术和音乐教育 | 0.686024 | 0.038638 |
| 体育健身公园休闲娱乐 | 0.683943 | 0.051467 |
| 广告和公共关系 | 0.673143 | 0.067961 |
| 人力资源和人事管理 | 0.672161 | 0.059570 |
| 多学科或普通科学 | 0.669999 | 0.055807 |
| 美术 | 0.667034 | 0.084186 |
| 作文和修辞 | 0.666119 | 0.081742 |
| 历史 | 0.651741 | 0.095667 |
| 生态学 | 0.651660 | 0.054475 |
| 遗传学 | 0.643331 | 0.034118 |
| 治疗专业 | 0.640000 | 0.059821 |
| 营养科学 | 0.638147 | 0.068701 |
| 动物学 | 0.637293 | 0.046320 |
| 国际关系 | 0.632987 | 0.096799 |
| 美国历史 | 0.630716 | 0.047179 |
| 戏剧和戏剧艺术 | 0.629505 | 0.077541 |
| 犯罪学 | 0.618223 | 0.097244 |
| 微生物学 | 0.615727 | 0.066776 |
| 植物科学和农学 | 0.606889 | 0.045455 |
| 生物 | 0.601858 | 0.070725 |
| 中等师范教育 | 0.601752 | 0.052229 |
| 农业生产与管理 | 0.594208 | 0.050031 |
| 法律预科和法律研究 | 0.591001 | 0.071965 |
| 农业经济学 | 0.589712 | 0.077250 |
| 工作室艺术 | 0.584776 | 0.089552 |
| 环境科学 | 0.584556 | 0.078585 |
| 商业管理和行政 | 0.580948 | 0.072218 |
| 计算机科学 | 0.578766 | 0.063173 |
| 语言和戏剧教育 | 0.576360 | 0.050306 |
| 杂项生物学 | 0.566641 | 0.058545 |
| 自然资源管理 | 0.564639 | 0.066619 |
| 环境工程 | 0.558548 | 0.093589 |
| 健康和医疗预备项目 | 0.556604 | 0.069780 |
| 杂项社会科学 | 0.543405 | 0.073080 |
| 保险统计计算科学 | 0.535714 | 0.095652 |
| 社会学 | 0.532334 | 0.084951 |
| 植物学 | 0.528969 | 0.000000 |
| 信息科学 | 0.526476 | 0.060741 |
| 药理学 | 0.524153 | 0.085532 |
| 普通农业 | 0.515543 | 0.019642 |
| 生物化学科学 | 0.515406 | 0.080531 |
| 跨文化和国际研究 | 0.507377 | 0.083634 |
| 体育与健康教学 | 0.506721 | 0.074667 |
| 化学 | 0.505141 | 0.053972 |
| 多学科/跨学科研究 | 0.495397 | 0.070861 |
| 神经系统科学 | 0.475010 | 0.048482 |
| 地质学和地球科学 | 0.470197 | 0.075449 |
| 药学药学科学与管理 | 0.451465 | 0.055521 |
| 教育管理和监督 | 0.448732 | 0.000000 |
| 物理学 | 0.448099 | 0.048224 |
| 音乐 | 0.444582 | 0.075960 |
| 天文学和天体物理学 | 0.441356 | 0.021167 |
| 电机工程 | 0.437847 | 0.059174 |
| 医疗技术技术员 | 0.434298 | 0.036983 |
| 核、工业放射和生物… | 0.430537 | 0.071540 |
| 自然科学 | 0.426924 | 0.035354 |
| 科学和计算机教师教育 | 0.423209 | 0.047264 |
| 一般业务 | 0.417925 | 0.072861 |
| 哲学和宗教研究 | 0.416810 | 0.096052 |
| 杂项美术 | 0.410180 | 0.089375 |
| 美容服务和烹饪艺术 | 0.383719 | 0.055677 |
| 营销和营销研究 | 0.382900 | 0.061215 |
| 机械工程相关技术 | 0.377437 | 0.056357 |
| 商业艺术和平面设计 | 0.374356 | 0.096798 |
| 特殊需要教育 | 0.366177 | 0.041508 |
| 金融 | 0.355469 | 0.060686 |
| 建筑工程 | 0.350442 | 0.061931 |
| 工业和制造工程 | 0.343473 | 0.042876 |
| 建筑服务 | 0.342229 | 0.060023 |
| 化学工程 | 0.341631 | 0.061098 |
| 经济学 | 0.340825 | 0.099092 |
| 英语语言和文学 | 0.339671 | 0.087724 |
| 电气工程技术 | 0.325092 | 0.087557 |
| 地质和地球物理工程 | 0.324838 | 0.075038 |
| 运营物流和电子商务 | 0.322222 | 0.047859 |
| 交通科学与技术 | 0.321296 | 0.072725 |
| 生物工程 | 0.320784 | 0.087143 |
| 材料科学 | 0.310820 | 0.023043 |
| 通信 | 0.305109 | 0.075177 |
掌握 SQL 的基础知识
如您所见,SQL 是一种强大的数据访问语言,这篇文章只是触及了皮毛。如果你想了解更多,我们鼓励你免费注册并开始我们的 interactive SQL 基础课程,这篇博文就是基于此。不过,本课程甚至更深入,将教您如何使用 SQL 做以下事情:
- 计算汇总统计数据
- 使用分组进一步细分数据
- 使用子查询编写更复杂的查询
在本课程中,您将继续使用最近大学毕业生的工资数据以及《中央情报局世界概况》中的数据。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
教程:将记录和数据帧插入 SQL 数据库
August 12, 2019
学会像专业人员一样将数据插入 SQL 数据库!
数据科学家的关键角色之一是从原始数据中提取模式和见解。由于世界上许多政府和企业数据都是在关系数据库中组织的,因此数据科学家需要知道如何使用这些数据库结构是有意义的。对于任何对数据分析或数据科学感兴趣的人来说,编写 SQL 查询来插入、提取和过滤数据库中的数据是一项关键技能。
SQL(结构化查询语言)基于 E. F. Codd 的关系模型和代数来管理关系数据库。它是一种数据库查询语言,用于创建、插入、查询和操作关系数据库,被大量应用程序使用。
虽然 SQL 已经存在了几十年,但对于现代数据科学家来说,学习 SQL 仍然是一项关键技能,实际上对于任何处理数据的人来说都是如此,因为 SQL 被用于各种关系数据库软件,包括 MySQL、SQL Server、Oracle 和 PostgreSQL。
在本教程中,我们将详细了解 SQL 插入操作。以下是我们将在本教程中学习的主题列表:
- SQL 插入
- 将记录插入数据库
- 使用 insert 命令将 Pandas 数据帧插入数据库
- 使用 to_sql()命令将 Pandas 数据帧插入数据库
- 从数据库中读取记录
- 更新数据库中的记录
想要达到更高水平的 SQL 技能?免费注册并查看 Dataquest 的 SQL 课程了解数据科学所需的所有 SQL 技能的全面互动课程。
SQL 插入
SQL 插入是数据工作者需要理解的基本操作。在大多数数据科学项目中,插入缺失数据或添加新数据是数据清理过程的主要部分。
插入也是大多数数据首先进入数据库的方式,因此它在您收集数据的任何时候都很重要。例如,当您的公司获得一个客户的新数据时,SQL insert 很有可能会将该数据插入到您现有的客户数据库中。
事实上,不管您是否意识到了这一点,数据一直在使用 SQL inserts 流入数据库!当您填写市场调查、完成交易、在线提交政府表格或做成千上万的其他事情时,您的数据可能会使用 SQL 插入到某个数据库中。
让我们深入了解如何使用 SQL 将数据插入数据库。我们可以逐行插入数据,或者一次添加多行。
将记录插入数据库
在 SQL 中,我们使用INSERT命令将记录/行添加到表数据中。这个命令不会修改我们要插入的表格的实际结构,它只是添加数据。
假设我们有一个如下所示的数据表,用来存储公司员工的一些信息。
现在,让我们想象一下,我们有新的员工需要输入到系统中。
这个employee表可以使用CREATE TABLE命令创建,所以我们可以使用该命令创建一个全新的表。但是每当我们想要添加数据时,创建一个全新的表是非常低效的!相反,让我们使用INSERT命令将新数据添加到现有的表中。
下面是在 SQL 中使用INSERT的基本语法:
我们从命令INSERT INTO开始,后跟我们想要插入数据的表的名称。在表名之后,我们在圆括号中列出我们要逐列插入的新数据的列。然后,在下一行,我们使用了命令VALUES以及我们想要插入的值(在括号内按顺序)。
因此,对于我们的employee表,如果我们添加一个名为 Kabir 的新雇员,我们的INSERT命令可能如下所示:
从 Python 向数据库中插入记录
因为我们在做数据科学时经常使用 Python 中的数据,所以让我们将 Python 中的数据插入到 MySQL 数据库中。这是一项常见任务,在数据科学中有多种应用。
我们可以通过在 Python 和 MySQL 之间建立连接来向 MySQL 数据库发送和接收数据。有各种方法可以建立这种联系;这里,我们将使用pymysql进行数据库连接。
下面是我们需要完成的大致步骤,以连接pymysql,插入我们的数据,然后从 MySQL 中提取数据:
让我们一步一步地完成这个过程。
第一步:导入 pymysql 模块。
# Import pymysql module
import pymysql
步骤 2: 创建到 MySQL 数据库的连接 a
使用带有参数 host、user、database name 和 password 的pymysql函数创建一个连接。
(以下参数仅用于演示目的;您需要填写您正在访问的 MySQL 数据库所需的特定访问细节。)
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='employee')
第三步:使用 cursor()函数创建一个游标。
这将允许我们在编写完 SQL 查询后执行它。
cursor = connection.cursor()
第四步:执行所需的 SQL 查询
使用commit()函数提交更改,并检查插入的记录。注意,我们可以创建一个名为sql的变量,将我们的查询语法赋给它,然后将 sql 和我们想要插入的特定数据作为参数传递给cursor.execute()。
然后,我们将使用commit()提交这些更改。
# Create a new record
sql = "INSERT INTO `employee` (`EmployeeID`, `Ename`, `DeptID`, `Salary`, `Dname`, `Dlocation`) VALUES (%s, %s, %s, %s, %s, %s)"
# Execute the query
cursor.execute(sql, (1008,'Kabir',2,5000,'IT','New Delhi'))
# the connection is not autocommited by default. So we must commit to save our changes.
connection.commit()
让我们快速检查一下,看看我们想要插入的记录是否已经被插入。
我们可以通过在数据库中查询employee的全部内容,然后获取并打印这些结果。
# Create a new query that selects the entire contents of `employee`
sql = "SELECT * FROM `employee`"
cursor.execute(sql)
# Fetch all the records and use a for loop to print them one line at a time
result = cursor.fetchall()
for i in result:
print(i)
(1001, 'John', 2, 4000, 'IT', 'New Delhi')
(1002, 'Anna', 1, 3500, 'HR', 'Mumbai')
(1003, 'James', 1, 2500, 'HR', 'Mumbai')
(1004, 'David', 2, 5000, 'IT', 'New Delhi')
(1005, 'Mark', 2, 3000, 'IT', 'New Delhi')
(1006, 'Steve', 3, 4500, 'Finance', 'Mumbai')
(1007, 'Alice', 3, 3500, 'Finance', 'Mumbai')
(1008, 'Kabir', 2, 5000, 'IT', 'New Delhi')
成功了!在上面,我们可以看到新记录已经被插入,现在是 MySQL 数据库中的最后一行。
第五步:关闭数据库连接
现在我们完成了,我们应该使用close()方法关闭数据库连接。
# Close the connection
connection.close()
当然,以一种能够更好地处理异常和错误的方式编写这段代码会更好。我们可以使用try来包含我们的代码体,并在出现错误时打印出来。然后,一旦完成,我们可以使用finally来关闭连接,不管try是成功还是失败。
这是所有这些看起来的样子:
import pymysql
try:
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='employee')
cursor=connection.cursor()
# Create a new record
sql = "INSERT INTO `employee` (`EmployeeID`, `Ename`, `DeptID`, `Salary`, `Dname`, `Dlocation`) VALUES (%s, %s, %s, %s, %s, %s)"
cursor.execute(sql, (1009,'Morgan',1,4000,'HR','Mumbai'))
# connection is not autocommit by default. So we must commit to save our changes.
connection.commit()
# Execute query
sql = "SELECT * FROM `employee`"
cursor.execute(sql)
# Fetch all the records
result = cursor.fetchall()
for i in result:
print(i)
except Error as e:
print(e)
finally:
# close the database connection using close() method.
connection.close()
((1001, 'John', 2, 4000, 'IT', 'New Delhi'), (1002, 'Anna', 1, 3500, 'HR', 'Mumbai'), (1003, 'James', 1, 2500, 'HR', 'Mumbai'), (1004, 'David', 2, 5000, 'IT', 'New Delhi'), (1005, 'Mark', 2, 3000, 'IT', 'New Delhi'), (1006, 'Steve', 3, 4500, 'Finance', 'Mumbai'), (1007, 'Alice', 3, 3500, 'Finance', 'Mumbai'), (1008, 'Kabir', 2, 5000, 'IT', 'New Delhi'), (1009, 'Morgan', 1, 4000, 'HR', 'Mumbai'), (1009, 'Morgan', 1, 4000, 'HR', 'Mumbai'))
使用 INSERT 将 Pandas 数据帧插入数据库
在 Python 中处理数据时,我们经常使用pandas,并且我们经常将数据存储为 pandas DataFrame。令人欣慰的是,如果我们想对数据帧使用 SQL,我们不需要做任何转换;我们可以使用INSERT将熊猫数据帧直接插入 MySQL 数据库。
同样,我们将一步一步来。
第一步:使用字典创建数据帧
我们还可以从 CSV 导入数据,或者以任何其他方式创建数据帧,但是对于本例,我们只是创建一个小的数据帧来保存一些数据科学教科书的标题和价格。
# Import pandas
import pandas as pd
# Create dataframe
data = pd.DataFrame({
'book_id':[12345, 12346, 12347],
'title':['Python Programming', 'Learn MySQL', 'Data Science Cookbook'],
'price':[29, 23, 27]
})
data
| 图书 id | 标题 | 价格 | |
|---|---|---|---|
| Zero | one two three four five | Python 编程 | Twenty-nine |
| one | Twelve thousand three hundred and forty-six | 学习 MySQL | Twenty-three |
| Two | Twelve thousand three hundred and forty-seven | 数据科学食谱 | Twenty-seven |
步骤 2: 在我们的 MySQL 数据库中创建一个表
在将数据插入 MySQL 之前,我们将在MySQL中创建一个book表来保存我们的数据。如果这样的表已经存在,我们可以跳过这一步。
我们将使用 CREATE TABLE 语句来创建我们的表,后跟我们的表名(在本例中为book_details),然后列出每一列及其对应的数据类型。

步骤 3: 创建一个到数据库的连接
一旦我们创建了这个表,我们就可以再次使用pymysql从 Python 创建一个到数据库的连接。
import pymysql
# Connect to the database
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='book')
# create cursor
cursor=connection.cursor()
步骤 4: 创建列列表并插入行
接下来,我们将创建一个列列表,通过遍历每一行并使用INSERT INTO将该行的值插入到数据库中,将我们的 dataframe 行一行一行地插入到数据库中。
(也可以一次插入整个数据帧,我们将在下一节中研究如何插入,但首先让我们看看如何逐行插入)。
# creating column list for insertion
cols = "`,`".join([str(i) for i in data.columns.tolist()])
# Insert DataFrame recrds one by one.
for i,row in data.iterrows():
sql = "INSERT INTO `book_details` (`" +cols + "`) VALUES (" + "%s,"*(len(row)-1) + "%s)"
cursor.execute(sql, tuple(row))
# the connection is not autocommitted by default, so we must commit to save our changes
connection.commit()
第五步:查询数据库检查我们的工作
同样,让我们查询数据库,以确保我们插入的数据已被正确保存。
# Execute query
sql = "SELECT * FROM `book_details`"
cursor.execute(sql)
# Fetch all the records
result = cursor.fetchall()
for i in result:
print(i)
(12345, 'Python Programming', 29)
(12346, 'Learn MySQL', 23)
(12347, 'Data Science Cookbook', 27)
一旦我们确信一切正常,我们就可以关闭连接。
connection.close()
使用 to_sql()函数将 Pandas 数据帧插入数据库
现在让我们尝试做同样的事情——将熊猫数据帧插入 MySQL 数据库——使用不同的技术。这一次,我们将使用模块sqlalchemy来创建连接,并使用to_sql()函数来插入数据。
这种方法以更直接的方式实现了相同的最终结果,并允许我们一次将整个数据帧添加到 MySQL 数据库中。
# Import modules
import pandas as pd
# Create dataframe
data=pd.DataFrame({
'book_id':[12345,12346,12347],
'title':['Python Programming','Learn MySQL','Data Science Cookbook'],
'price':[29,23,27]
})
data
| 图书 id | 标题 | 价格 | |
|---|---|---|---|
| Zero | one two three four five | Python 编程 | Twenty-nine |
| one | Twelve thousand three hundred and forty-six | 学习 MySQL | Twenty-three |
| Two | Twelve thousand three hundred and forty-seven | 数据科学食谱 | Twenty-seven |
导入模块sqlalchemy并使用参数 user、password 和 database name 创建一个引擎。这就是我们连接和登录 MySQL 数据库的方式。
# import the module
from sqlalchemy import create_engine
# create sqlalchemy engine
engine = create_engine("mysql+pymysql://{user}:{pw}@localhost/{db}"
.format(user="root",
pw="12345",
db="employee"))
一旦我们连接上了,我们就可以使用带有参数表名、引擎名、if_exists 和 chunksize 的to_sql()函数将整个数据帧导出到 MySQL。
我们一会儿将仔细看看这些参数分别指的是什么,但是首先,看看使用这种方法将 pandas 数据帧插入 MySQL 数据库有多简单。我们只用一行代码就可以做到:
# Insert whole DataFrame into MySQL
data.to_sql('book_details', con = engine, if_exists = 'append', chunksize = 1000)
现在让我们仔细看看这些参数在代码中的作用。
book_details是我们要插入数据帧的表的名称。con = engine提供连接细节(回想一下,我们在上一步中使用身份验证细节创建了引擎)。if_exists = 'append'检查我们指定的表格是否已经存在,然后追加新数据(如果存在)或创建新表格(如果不存在)。chunksize一次成批写入给定大小的记录。默认情况下,所有行都将一次写入。
从数据库中读取记录
一旦我们使用 SQL 插入将我们的数据放入数据库,我们将希望能够读回它!到目前为止,在本教程中,我们已经通过简单地打印整个数据库检查了我们的 SQL 插入,但是很明显,对于要打印数千行(甚至更多)的大型数据库来说,这不是一个可行的选择。因此,让我们更深入地看看如何回读我们已经创建或插入到 SQL 数据库中的记录。
我们可以使用SELECT命令从 SQL 数据库中读取记录。我们可以选择特定的列,或者使用*从给定的表中选择所有内容。我们还可以使用WHERE命令选择只返回满足特定条件的记录。
以下是这些命令的语法:

我们从一个SELECT子句开始,然后是列的列表,或者如果我们想要选择所有列,就从*开始。然后我们将使用一个FROM子句来命名我们想要查看的表。WHERE可以用来过滤记录,后面跟一个过滤条件,我们也可以用ORDER BY对记录进行排序。(条款WHERE和ORDER BY是可选的)。
对于较大的数据库,WHERE对于只返回我们想看的数据很有用。因此,例如,如果我们刚刚插入了一些关于特定部门的新数据,我们可以在查询中使用WHERE来指定部门ID,它将只返回部门 ID 与我们指定的部门 ID 相匹配的记录。
例如,使用前面的employee表比较这两个查询的结果。在第一个例子中,我们返回所有的行。在第二个例子中,我们只得到我们请求的行。当我们的表有 7 行时,这可能不会产生很大的差异,但是当您处理 7千行,甚至 7百万行时,使用WHERE只返回您想要的结果是非常重要的!
如果我们想在 Python 中这样做,我们可以使用本教程前面使用的相同脚本来查询这些记录。唯一的区别是,我们将告诉pymysql执行SELECT命令,而不是我们之前使用的INSERT命令。
# Import module
import pymysql
# create connection
connection = pymysql.connect(host='localhost',
user='root',
password='12345',
db='employee')
# Create cursor
my_cursor = connection.cursor()
# Execute Query
my_cursor.execute("SELECT * from employee")
# Fetch the records
result = my_cursor.fetchall()
for i in result:
print(i)
# Close the connection
connection.close()
(1001, 'John', 2, 4000, 'IT', 'New Delhi')
(1002, 'Anna', 1, 3500, 'HR', 'Mumbai')
(1003, 'James', 1, 2500, 'HR', 'Mumbai')
(1004, 'David', 2, 5000, 'IT', 'New Delhi')
(1005, 'Mark', 2, 3000, 'IT', 'New Delhi')
(1006, 'Steve', 3, 4500, 'Finance', 'Mumbai')
(1007, 'Alice', 3, 3500, 'Finance', 'Mumbai')
(1008, 'Kabir', 2, 5000, 'IT', 'New Delhi')
(1009, 'Morgan', 1, 4000, 'HR', 'Mumbai')
(1009, 'Morgan', 1, 4000, 'HR', 'Mumbai')
上面,我们已经选择并打印了整个数据库,但是如果我们想使用WHERE进行更仔细、有限的选择,方法是相同的:
my_cursor.execute("SELECT * FROM employee WHERE DeptID=2")
更新数据库中的记录
通常,我们需要在创建记录后修改表中的记录。
例如,假设我们的雇员表中的一名雇员获得了晋升。我们想更新他们的工资数据。这里,INSERT INTO命令帮不了我们,因为我们不想添加一个全新的行。
要修改表中的现有记录,我们需要使用UPDATE命令。UPDATE用于改变现有记录的内容。我们可以使用SET指定要更改的特定列和值,还可以使用WHERE进行有条件的更改,将这些更改仅应用于满足该条件的行。

现在,让我们更新 employee 表中的记录并显示结果。在这种情况下,假设大卫得到了提升——我们将使用UPDATE编写一个查询,仅在雇员 id 为 1004(大卫的 ID)的列中将Salary设置为6000。
小心——如果没有WHERE子句,这个查询将更新表中的每一条记录,所以不要忘记这一点!
执行上述查询后,更新后的表如下所示:
结论
在本教程中,我们已经了解了 SQL 插入以及如何从 Python 向 MySQL 数据库插入数据。我们还学习了使用两种不同的方法将 Pandas 数据帧插入 SQL 数据库,包括高效的to_sql()方法。
当然,这只是 SQL 查询的冰山一角。如果你真的想成为一名 SQL 大师,请免费注册,深入 Dataquest 的交互式 SQL 课程之一,获得交互式指导和编写高效、专业数据科学工作所需的所有查询的实践经验。
另外,请查看我们的其他免费 SQL 相关资源:
SQL Intermediate: PostgreSQL、子查询等等!
August 10, 2017
如果您正处于学习 SQL 的初级阶段,并且已经完成了一门或多门初级课程,那么您可能已经学习了大部分基础知识,甚至可能还学习了一些高级数据库概念。当您准备开始学习 SQL 的下一阶段时,重要的是不仅要理解 SQL 本身,还要理解使这一切成为可能的引擎:数据库。

在大多数入门课程中,您通常会使用某种嵌入式数据库(例如 SQLite)。
嵌入式数据库对于初学者来说是一个很好的选择,这样他们就可以专注于学习 SQL,而没有分配额外计算资源和减少安装配置软件时间的负担。但是,随着您的应用程序和/或数据的需求开始扩大,您可能需要更强大的解决方案。
概括地说,有两种主要类型的数据库:基于服务器的和基于文件的(也称为嵌入式)。
最流行的基于文件的数据库之一是 SQLite。它非常适合小规模的应用程序,但是随着您的需求变得越来越复杂,它会有很多限制。例如,它基于一个限制在 140 兆字节的大型二进制文件。
如果你认为这比你需要的任何东西都大(至少在不久的将来),你可能是对的。然而,许多文件系统将文件的最大大小限制为远远小于这个值。因此,如果你想开发一个大规模的 web 应用程序,这是不可行的。
此外,除其他外,还有安全问题。基于服务器的数据库为更大、更健壮的应用程序提供了关键功能,如高可用性/故障转移、更高且更灵活的安全性、可伸缩性、更高的性能等等。
今天,我们将使用 PostgreSQL (postgres)对来自消费者金融保护局(CFPB)的两个数据集进行数据发现和分析。这些数据包括消费者对两种金融服务的投诉:银行账户和信用卡。
通过做来学习 SQL
使用我们的交互式学习平台,立即动手操作 SQL。
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
(开始免费)
首先,我们将通过创建表、创建用户和从 CSV 文件加载数据来设置您的数据库。接下来,我们将深入探讨更高级的 SQL 概念,同时分析数据并发现有价值的见解!下面是我们今天要讲的一些 SQL 概念。
- 创建用户、数据库和表,
IS NULL/IS NOT NULL子句,- 观点,
- 子查询,
- Union/union all,
- 相交/例外,
- 字符串串联,和
- 转换数据类型。
如果您需要复习 SQL 基础知识,我们推荐您阅读我们的博客文章
我们的数据
我们将处理来自 CFPB 的两份不同的消费者投诉数据 CSV 文件:
Bank_Account_or_Service_Complaints.csvCredit_Card_Complaints.csv
这些文件最初是从 CFPB 网站下载的,但是我们已经上传了在本帖中用作的版本,你可以在这里下载,这样你就可以使用我们使用的确切文件版本,因为 CFPB 定期更新他们的数据。两个 CSV 文件具有相同的字段。下面是每个字段和数据类型下表包含数据集的字段和我们打算为它们使用的数据类型:
| 字段名 | 数据类型 |
|---|---|
complaint_id |
文本 |
date_received |
日期 |
product |
文本 |
sub_product |
文本 |
issue |
文本 |
sub_issue |
文本 |
consumer_complaint_narrative |
文本 |
company_public_response |
文本 |
company |
文本 |
state |
文本 |
zip_code |
文本 |
tags |
文本 |
consumer_consent_provided |
文本 |
submitted_via |
文本 |
date_sent |
日期 |
company_response_to_consumer |
文本 |
timely_response |
文本 |
consumer_disputed |
文本 |
您可能想知道为什么像zip_code和complaint_id这样的数字字段被存储为文本。一般的经验法则是始终将数字字符存储为文本,除非您计划对值本身进行某种类型的数学计算。下面是一个包含数字的字段示例,您希望将其存储为数字类型,但不希望存储为数字类型:
- 存储为数字类型——年龄字段存储人们的年龄,他们想做的事情包括查找居住在特定邮政编码的人的平均值。
- 存储为文本——某种不能进行任何数学运算的 ID 字段。一般来说,你不能对一个邮政编码进行加法、乘法或其他任何有意义的运算。
下载和安装 PostgreSQL
如果您还没有设置 PostgreSQL,那么您需要做的第一件事就是设置它。以下是主要操作系统的下载链接。
创建新的用户、数据库和表
我们需要创建两个新表来存储我们之前下载的文件中的数据。您可以通过几种不同的方式来实现这一点,但是在本教程中,我们将使用 psql shell。要打开 psql shell,可以通过打开命令提示符(Windows)或终端(Mac)窗口,键入psql并按 enter 键来实现。
这将启动 psql shell。如果这是您第一次使用 psql shell,您的用户可能没有必要的经验来启动该实用程序。首先,您需要使用一个具有管理员权限的帐户,然后使用psql -U postgres以postgres用户(在安装过程中自动创建)登录
~$ psql
sql (9.5.3)
ype "help" for help.postgres=#
您看到的postgres=#是 psql 提示符,而postgres将被您所连接的数据库所替换。我们将为我们的数据库创建一个新用户。
在本教程中,我们将称我们的用户为oracle,但是您可以使用任何名称,使用与您的操作系统相同的用户名也很方便,因为您不必担心密码或指定用户。要创建新用户,我们使用以下语法:
CREATE ROLE name WITH options_go_here;
点击
此处为关于CREATE ROLE声明的文档。在这里,您可以找到所有可用的选项和相关描述。我们将为这位新用户提供以下课程
- 用户将成为超级用户。
CREATEDB:用户将被允许创建数据库。CREATEROLE:用户将被允许创建新角色。LOGIN:用户将能够登录。INHERIT:用户将继承其所属角色的所有权限。
让我们创建新用户,
oracle,密码welcome1。
CREATE ROLE oracle password 'welcome1' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN;
我们的新用户现在应该已经创建好了。让我们检查一下,确保我们的新用户有足够的权限。输入命令
并按回车键。您的用户应该有以下经验。
postgres=# du
List of roles
ole name | Attributes | Member of
span class="token operator">----------+------------+-----------
racle | Superuser | {}
: Create role
: Create DB
ostgres | Superuser | {}
: Create role
: Create DB
这将允许您从现在开始使用 oracle 用户进行连接。现在,我们可以使用命令切换到 oracle 用户
SET ROLE oracle;
如果我们退出了 psql shell(使用q),我们可以在启动 psql shell 时连接:
~$ psql -U oracle postgres
sql (9.5.3)
ype "help" for help.
ostgres=#
-U标志允许我们指定用户,postgres指定 postgres 帐户数据库(如果我们不在这里指定数据库,我们将得到一个错误)。现在我们以 oracle 用户的身份登录,我们将创建一个新的数据库。要创建新的数据库,我们使用以下语法:
CREATE DATABASE database_name;
CREATE DATABASE语句有很多我们现在不需要的选项——如果你愿意,你可以在文档中读到它们。现在,让我们创建新的数据库consumer_complaints。
CREATE database consumer_complaints;
为了确认我们的数据库已经创建,使用
l(列表)命令。您应该会看到新的数据库,如下所示。
postgres=# l
List of databases
ame | Owner | Encoding | Collation | Ctype | Access privileges
span class="token operator">---------------------+----------+----------+-------------+-------------+-----------------------
onsumer_complaints | oracle | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
让我们通过使用
connect命令:
oracle=# connect consumer_complaints
ou are now connected to database "consumer_complaints" as user "oracle".
onsumer_complaints=#
您也可以从命令行启动直接连接到您的数据库的 psql。
~$ psql -U oracle consumer_complaints
sql (9.5.3)
ype "help" for help.
onsumer_complaints=#
为数据创建表格
接下来,我们可以创建表来存储 CSV 数据。表格名称如下:
credit_card_complaintsbank_account_complaints
两个表中的字段及其各自的数据类型将是相同的。要创建新表,我们使用以下语法:
CREATE TABLE name_of_table (
name_of_column data_type [PRIMARY KEY],
name_of_column data_type,
name_of_column data_type,
name_of_column data_type,
name_of_column data_type);
像CREATE DATABASE语句一样,CREATE TABLE有更多的选项,你可以在文档中找到。要创建我们的两个数据库,您需要在 psql shell 中运行以下两条语句。
CREATE TABLE bank_account_complaints (
complaint_id text PRIMARY KEY,
date_received date,
product text,
sub_product text,
issue text,
sub_issue text,
consumer_complaint_narrative text,
company_public_response text,
company text,
state text,
zip_code text,
tags text,
consumer_consent_provided text,
submitted_via text,
date_sent date,
company_response_to_consumer text,
timely_response text,
consumer_disputed text);;
CREATE TABLE credit_card_complaints (
complaint_id text PRIMARY KEY,
date_received date,
product text,
sub_product text,
issue text,
sub_issue text,
consumer_complaint_narrative text,
company_public_response text,
company text,
state text,
zip_code text,
tags text,
consumer_consent_provided text,
submitted_via text,
date_sent date,
company_response_to_consumer text,
timely_response text,
consumer_disputed text);;
您应该得到输出
'CREATE TABLE'让你知道它们是正确创建的。
将数据加载到数据库
有几种方法可以将外部数据加载到 postgres 表中。以下是加载 CSV 文件中现有数据的几种常用方法:
- 在 pgAdmin 客户端应用程序中导入实用程序。
- 通过 Python 、 Java 或其他编程语言读取文件、实例化数据库连接、加载数据。
- Postgres 复制实用程序。
今天,我们将通过 psql shell 使用 Postgres Copy 实用程序将两个 CSV 文件中的数据加载到两个新表中。Copy 允许您从 Postgres 数据库中导出数据或向其中导入数据。它支持以下格式:
- 二进制。
- 制表符分隔。
- 逗号分隔。
要使用 copy 语句将数据从文件复制到数据库表,我们使用以下语法:
COPY name_of_table (<name_of_column, name_of_column, name_of_column)
FROM 'filename'
WITH options_go_here
我们将使用
WITH CSV HEADER选项,但是和之前一样文档有完整的语法和解释。我们假设 CSV 文件与您启动 psql 会话的文件夹在同一个文件夹中。我们首先将数据从Credit_Card_Complaints.csv文件导入到credit_card_complaints postgres 表中。
consumer_complaints=# COPY credit_card_complaints (date_received, product, sub_product, issue, sub_issue, consumer_complaint_narrative, company_public_response, company, state, zip_code, tags, consumer_consent_provided, submitted_via, date_sent, company_response_to_consumer, timely_response, consumer_disputed, complaint_id)
FROM './Credit_Card_Complaints.csv'
WITH CSV HEADER
现在让我们对
Bank_Account_or_Service_Complaints.csv文件和bank_account_complaints postgres 表。
consumer_complaints=# COPY bank_account_complaints (date_received, product, sub_product, issue, sub_issue, consumer_complaint_narrative, company_public_response, company, state, zip_code, tags, consumer_consent_provided, submitted_via, date_sent, company_response_to_consumer, timely_response, consumer_disputed, complaint_id)
FROM './Bank_Account_or_Service_Complaints.csv'
WITH CSV HEADER
查询我们的 Postgres 数据库
我们可以直接从 psql shell 中运行查询,但是可能很难理解结果,尤其是有很多行和列的时候。在本教程中,我们将使用 Python 查询数据库。如果我们想返回查询结果,我们将使用 Pandas 模块,它允许我们将结果存储到 Dataframe 对象中。这将使可视化和分析结果变得更加容易。为此,我们必须首先导入 pandas、SQLAlchemy 和 psycopg2 模块。如果您没有这些软件,您可以使用
pip:
~$
ip install pandas sqlalchemy pscopg2
或者 conda(虽然都带有标准的 anaconda 包):
~$
onda install pandas sqlalchemy pscopg2
我们还需要创建两个助手函数——一个运行我们的查询,一个运行我们的命令(即创建/删除视图、表、序列等)。).如果您不理解这些函数是如何工作的,请不要担心,只要知道它们将帮助我们使用 Python 与数据库进行交互,并给我们更容易阅读的结果。
import pandas as pd
span class="token comment" spellcheck="true"># psycopg2 lets us easily run commands against our db
span class="token keyword">import psycopg2
onn = psycopg2.connect("dbname=consumer_complaints user=oracle")
onn.autocommit = True
ur = conn.cursor()
span class="token keyword">def run_command(command):
cur.execute(command)
return cur.statusmessage
span class="token comment" spellcheck="true"># sqlalchemy is needed to allow pandas to seemlessly connect to run queries
span class="token keyword">from sqlalchemy import create_engine
ngine = create_engine('postgresql://[[email protected]](/cdn-cgi/l/email-protection)/consumer_complaints')
span class="token keyword">def run_query(query):
return pd.read_sql_query(query,con=engine)
作为展示这些函数如何工作的测试查询,我们将验证表中的数据,以确保 CSV 文件中的所有数据都已加载。一种快速的方法是使用
count功能。
query = 'SELECT count(*) FROM credit_card_complaints;'
un_query(query)
| 数数 | |
|---|---|
| Zero | Eighty-seven thousand seven hundred and eighteen |
query = 'SELECT count(*) FROM bank_account_complaints;'
un_query(query)
| 数数 | |
|---|---|
| Zero | Eighty-four thousand eight hundred and eleven |
用条件句计数
将列与进行比较时
null(无值),不能使用=运算符。null表示未定义的值。由于未定义的值不能等于未定义的值,null不能等于null。
- 我们用
IS NULL代替= NULL。 - 我们用
IS NOT NULL代替<> NULL。
如果我们查看每个文件中的数据,我们可以看到有几个字段有大量的空值。该数据集最大的价值主张之一是消费者投诉叙述。这使我们能够了解和分析消费者投诉的情绪。让我们看看每个表中有多少记录的消费者投诉叙述字段为空值,从
credit_card_complaints表。
query = '''
ELECT count(*) FROM credit_card_complaints
HERE consumer_complaint_narrative IS NOT NULL;
''
un_query(query)
| 数数 | |
|---|---|
| Zero | Seventeen thousand four hundred and thirty-three |
中有 17,433 条消费者投诉记录
credit_card_complaints表。由于表 total 中有 87,718 条记录,因此肯定有 70,285 (87,718–17,433)条记录没有消费者投诉叙述(或者是null)。让我们手动检查一下:
query =
span class="token triple-quoted-string string">'''
ELECT count(*) FROM credit_card_complaints
HERE consumer_complaint_narrative IS NULL;
''
un_query(query)
| 数数 | |
|---|---|
| Zero | Seventy thousand two hundred and eighty-five |
看起来我们的人数排好队了!接下来,我们将看看
bank_account_complaints表的consumer_complaint_narrative列的null值。
query = '''
ELECT count(*) FROM bank_account_complaints
HERE consumer_complaint_narrative IS NOT NULL;
''
un_query(query)
| 数数 | |
|---|---|
| Zero | Thirteen thousand eight hundred and sixty |
在 credit_card_complaints 表中有 13,860 条消费者投诉叙述的记录。由于表 total 中有 84,811 条记录,因此肯定有 70,951 (84,811–13,860)条记录没有消费者投诉叙述。让我们看看:
query = '''
ELECT count(*) FROM bank_account_complaints
HERE consumer_complaint_narrative IS NULL;
''
un_query(query)
| 数数 | |
|---|---|
| Zero | Seventy thousand nine hundred and fifty-one |
再一次,数字排成一行。
使用视图
A
视图本质上是查询结果的逻辑表示。它的行为类似于传统的表,您可以在其中选择值,但不能插入、更新或删除值。以下是使用视图的一些好处:
- 可重用性——视图可以用来重用经常使用的复杂查询。
- 安全性——某些用户通常可以访问视图,这样他们就不能查看底层表,只能查看相关数据。
- 查询性能——有时,编写由几个子查询和聚合组成的复杂查询会占用大量资源。
更详细地考虑最后一点,即使我们有足够的资源,我们也可能降低机器上运行的进程的性能,或者这可能需要非常长的时间。我们可以使用视图提前过滤数据集,从而极大地降低复杂性和总的执行时间。临时视图(
TEMPORARY或TEMP)在当前会话结束时自动删除。根据使用情况,您可能希望使用临时视图,也可能不希望使用临时视图。例如,在验证或测试通过多个连接、表和计算创建的某些数据点时,使用临时视图非常有用。执行复杂的数据验证通常需要大量复杂的查询,这些查询不仅难以阅读和理解,而且执行起来也很糟糕。由多个子查询/内联视图组成的大型查询会利用大量的假脱机空间和计算资源,从而导致查询性能不佳和应用程序性能下降。在这些情况下,创建一个或多个视图通常是一个更好的主意。在上一节中,我们确定大量记录的消费者投诉叙述字段为空值。我们将创建视图供以后使用,而不是在以后过滤这个字段。我们将基于两个维度创建四个视图:按产品(例如信用卡与银行账户),以及它们是否包含消费者投诉叙述的空值。 我们的四个观点将被称为
我们的四个观点将被称为
credit_card_w_complaintscredit_card_wo_complaintsbank_account_w_complaintsbank_account_wo_complaints
创建视图的语法非常简单:
CREATE VIEW view_name AS
[query_to_generate_view_goes_here];
让我们创建我们的四个视图。
command =
span class="token triple-quoted-string string">'''
REATE VIEW credit_card_w_complaints AS
SELECT * FROM credit_card_complaints
WHERE consumer_complaint_narrative IS NOT NULL;
''
un_command(command)
'CREATE VIEW'
command = '''
REATE VIEW credit_card_wo_complaints as
SELECT * FROM credit_card_complaints
WHERE consumer_complaint_narrative IS NULL;
''
un_command(command)
'CREATE VIEW'
command = '''
REATE VIEW bank_account_w_complaints AS
SELECT * FROM bank_account_complaints
WHERE consumer_complaint_narrative IS NOT
NULL;
''
un_command(command)
'CREATE VIEW'
command = '''
REATE VIEW bank_account_wo_complaints AS
SELECT * FROM bank_account_complaints
WHERE consumer_complaint_narrative IS
NULL;
''
un_command(command)
'CREATE VIEW'
让我们快速地看一下我们新创建的视图,这样我们可以看到它就像一个表一样工作。
query =
span class="token triple-quoted-string string">'''
ELECT * FROM credit_card_w_complaints LIMIT 5;
''
un_query(query)
| 投诉 _id | 接收日期 | 产品 | 求和乘积 | 问题 | 子问题 | 消费者 _ 投诉 _ 叙述 | 公司 _ 公共 _ 响应 | 公司 | 状态 | 邮政编码 | 标签 | 消费者同意提供 | 提交 _ 通过 | 发送日期 | 公司回应消费者 | 及时 _ 响应 | 消费者 _ 有争议 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | One million two hundred and ninety-seven thousand nine hundred and thirty-nine | 2015-03-24 | 信用卡 | 没有人 | 其他的 | 没有人 | 收到 XXXX 首都一号签帐卡报价。一个… | 没有人 | 大写一 | 俄亥俄州 | 440XX | 没有人 | 提供同意 | 网 | 2015-03-30 | 以解释结束 | 是 | 不 |
| one | One million two hundred and ninety-six thousand six hundred and ninety-three | 2015-03-23 | 信用卡 | 没有人 | 奖励 | 没有人 | 我是 Charter One Bank/RBS 的长期会员… | 没有人 | 公民金融集团。 | 大调音阶的第三音 | 482XX | 没有人 | 提供同意 | 网 | 2015-03-23 | 以解释结束 | 是 | 是 |
| Two | One million two hundred and ninety-five thousand and fifty-six | 2015-03-23 | 信用卡 | 没有人 | 其他的 | 没有人 | 我尝试在网上申请探索卡… | 没有人 | 发现 | 医学博士 | 217XX | 没有人 | 提供同意 | 网 | 2015-03-23 | 以非货币救济结束 | 是 | 不 |
| three | One million two hundred and ninety-six thousand eight hundred and eighty | 2015-03-23 | 信用卡 | 没有人 | 滞纳金 | 没有人 | XXXX 信用卡服务公司被资本 O… | 没有人 | 大写一 | 大调音阶的第三音 | 488XX | 没有人 | 提供同意 | 网 | 2015-03-23 | 以货币救济结束 | 是 | 不 |
| four | One million two hundred and ninety-six thousand eight hundred and ninety | 2015-03-23 | 信用卡 | 没有人 | 账单纠纷 | 没有人 | 我被发现卡举报迟到了… | 没有人 | 发现 | 好 | 741XX | 服务成员 | 提供同意 | 网 | 2015-03-23 | 以解释结束 | 是 | 不 |
联合/联合所有
这
UNION运算符组合两个或多个查询的结果集。想象两块尺寸完全相同的乐高积木。由于它们具有相同的尺寸,因此可以完美地堆叠在一起。工会也以类似的方式行事。如果 select 语句具有相同的列数、数据类型,并且处于相同的顺序(根据数据类型),那么它们将“堆叠”在彼此之上,类似于我前面使用的乐高积木类比。联合有两种变体:
UNION ALL选择不同的(唯一的)值。UNION选择所有值(包括重复值)。
如果您还记得上一节,我们有四个视图。如果我们想一起查看这两种产品的数据,并且只通过它们的记录是否包含消费者投诉叙述的空值来区分,会怎么样?因为所有四个视图都有相同的列数和数据类型,这使它们成为 union 的完美候选。我们将创建两个新视图,通过对每个产品的视图执行联合,将当前的四个视图合并为两个。
command = '''
REATE VIEW with_complaints AS
SELECT * from credit_card_w_complaints
UNION ALL
SELECT * from bank_account_w_complaints;
''
un_command(command)
'CREATE VIEW'
command = '''
REATE VIEW without_complaints AS
SELECT * FROM credit_card_wo_complaints
UNION ALL
SELECT * FROM bank_account_wo_complaints;
''
un_command(command)
'CREATE VIEW'
相交/例外
这
INTERSECT操作符返回两个查询结果集中的所有记录,而EXCEPT操作符返回第一个查询结果集中的所有记录,但不返回第二个查询结果集中的所有记录。
INTERSECT/EXCEPT的语法很简单,我们只是使用命令连接两个 select 语句:
(SELECT * FROM name_of_table_one
span class="token keyword">INTERSECT [or EXCEPT]
span class="token keyword">SELECT * FROM name_of_table_two);
在上一节中,我们通过执行 union 将四个视图合并为两个新视图。如果我们想要验证以确保我们的新视图是正确创建的,我们可以通过使用这两者来实现
INTERSECT和EXCEPT运算符。首先,让我们检索credit_card_wo_complaints视图的记录数。
query = 'SELECT count(*) FROM credit_card_wo_complaints;'
un_query(query)
| 数数 | |
|---|---|
| Zero | Seventy thousand two hundred and eighty-five |
如果我们的逻辑在我们的联盟中是正确的,我们应该能够相交
without_complaints用credit_card_wo_complaints视图查看并返回相同数量的记录。
query = '''
ELECT count(*)FROM (SELECT * FROM without_complaints
INTERSECT
SELECT * FROM credit_card_wo_complaints)
ppg;
''
un_query(query)
| 数数 | |
|---|---|
| Zero | Seventy thousand two hundred and eighty-five |
相反,如果我们用 except 操作符替换 intersect 操作符,我们应该得到
without_complaints view以及先前返回的 70,285 条记录计数。差额应为 70,951 (141,236–70,285)。
query =
span class="token triple-quoted-string string">'''
ELECT count(*)FROM (SELECT * FROM without_complaints
EXCEPT
ELECT * FROM credit_card_wo_complaints) ppg;'''
un_query(query)
| 数数 | |
|---|---|
| Zero | Seventy thousand nine hundred and fifty-one |
串并置
字符串连接就是将两个或多个字符串(文本值)组合成一个字符串。在某些情况下,这是一个非常有用的工具。假设我们有一个“年”字段和一个“月”字段,但我们想将其显示为一个字段(即“2017-3 月”)。我们可以通过使用
||操作员。语法如下:
SELECT <string_1> || <string_2> FROM name_of_table;
让我们通过选择来尝试一下
complaint_id、product、company、zip_code,并连接所有这些字段,用连字符(-)从credit_card_complaints隔开。
query = '''
ELECT complaint_id, product, company, zip_code,
complaint_id || '-' || product || '-' || company || '-' ||
zip_code AS concat
ROM credit_card_complaints
IMIT 10
''
un_query(query)
| 投诉 _id | 产品 | 公司 | 邮政编码 | 串联 | |
|---|---|---|---|---|---|
| Zero | Four hundred and sixty-nine thousand and twenty-six | 信用卡 | 花旗银行 | Forty-five thousand two hundred and forty-seven | 469026-信用卡-花旗银行-45247 |
| one | Four hundred and sixty-nine thousand one hundred and thirty-one | 信用卡 | 同步金融 | Ninety-eight thousand five hundred and forty-eight | 469131-信用卡-同步金融-98548 |
| Two | Four hundred and seventy-nine thousand nine hundred and ninety | 信用卡 | 美国证券交易所 | Seventy-eight thousand two hundred and thirty-two | 479990-信用卡-美国运通-78232 |
| three | Four hundred and seventy-five thousand seven hundred and seventy-seven | 信用卡 | 大写一 | Thirty-two thousand two hundred and twenty-six | 475777-信用卡-资本一号-32226 |
| four | Four hundred and sixty-nine thousand four hundred and seventy-three | 信用卡 | 花旗银行 | Fifty-three thousand and sixty-six | 469473-信用卡-花旗银行-53066 |
| five | Four hundred and seventy thousand eight hundred and twenty-eight | 信用卡 | 富国银行公司 | Eighty-nine thousand one hundred and eight | 470828-信用卡-富国银行公司-89108 |
| six | Four hundred and seventy thousand eight hundred and fifty-two | 信用卡 | 花旗银行 | Seventy-eight thousand two hundred and forty-nine | 470852-信用卡-花旗银行-78249 |
| seven | Four hundred and seventy-nine thousand three hundred and thirty-eight | 信用卡 | 摩根大通公司。 | Nineteen thousand eight hundred and nine | 479338-信用卡-摩根大通公司-19809 |
| eight | Four hundred and eighty thousand nine hundred and thirty-five | 信用卡 | 花旗银行 | 07018 | 480935-信用卡-花旗银行-07018 |
| nine | Four hundred and sixty-nine thousand seven hundred and thirty-eight | 信用卡 | 富国银行公司 | Ninety-five thousand four hundred and nine | 469738-信用卡-富国银行公司-95409 |
子查询
子查询(技术上称为内嵌视图,也称为子选择语句、派生表)是
另一个 select 语句中的子句。它们在许多不同的场景中都非常有用。当我们在INTERSECT和EXCEPT的例子中使用COUNT(*)时,我们实际上已经看到了这样的例子。子查询有助于简化复杂的查询,并提供更大的灵活性,正如其专有名称(内嵌视图)所示,就像在单个查询中创建一个迷你视图一样。语法是:
SELECT [column_names_here]
FROM ( [subquery_goes_here] );
最初,子查询的概念可能有点困难,所以我们将向您展示一个实际的子查询,然后对它进行分解。
query = '''
ELECT ccd.complaint_id, ccd.product, ccd.company, ccd.zip_code
ROM (SELECT complaint_id, product, company, zip_code
FROM credit_card_complaints
WHERE zip_code = '91701') ccd LIMIT 10;
''
un_query(query)
| 投诉 _id | 产品 | 公司 | 邮政编码 | |
|---|---|---|---|---|
| Zero | Twenty-four thousand eight hundred and fifty-seven | 信用卡 | 巴克莱银行 | Ninety-one thousand seven hundred and one |
| one | Thirty-three thousand one hundred and fifty-seven | 信用卡 | 花旗银行 | Ninety-one thousand seven hundred and one |
| Two | Twelve thousand two hundred and forty-five | 信用卡 | 美洲银行 | Ninety-one thousand seven hundred and one |
| three | Three thousand one hundred and fifty-one | 信用卡 | 巴克莱银行 | Ninety-one thousand seven hundred and one |
| four | Three hundred and fifty-two thousand five hundred and thirty-four | 信用卡 | 花旗银行 | Ninety-one thousand seven hundred and one |
| five | One million nine hundred and sixty-three thousand eight hundred and thirty-six | 信用卡 | 摩根大通公司。 | Ninety-one thousand seven hundred and one |
| six | Two million one hundred and seventy-eight thousand and fifteen | 信用卡 | 发现 | Ninety-one thousand seven hundred and one |
| seven | Two million two hundred and thirty-four thousand seven hundred and fifty-four | 信用卡 | 发现 | Ninety-one thousand seven hundred and one |
| eight | Two million two hundred and thirty-five thousand nine hundred and fifteen | 信用卡 | 发现 | Ninety-one thousand seven hundred and one |
对于子查询,要认识到的最重要的事情是,您需要从里到外读取它们。
 首先执行最内层的查询(紫色部分),它根据特定的邮政编码过滤结果集。然后,最外层的查询对从最内层查询得到的结果集执行 select 语句。您会注意到,我们给子查询起了一个名字——
首先执行最内层的查询(紫色部分),它根据特定的邮政编码过滤结果集。然后,最外层的查询对从最内层查询得到的结果集执行 select 语句。您会注意到,我们给子查询起了一个名字——ccd——然后我们用它来引用外部SELECT语句中的列。这是 PostgreSQL 所要求的,但除此之外,它还使查询更容易阅读,并确保 SQL 引擎准确理解您的意图(这可以避免错误或意外的结果)。如果您认为上面的查询可以简化,并且在没有子查询的情况下也可以获得相同的结果,那么您是正确的。您实际上不需要使用内嵌视图。这仅仅是一个简单的例子,展示了内联视图是如何构造的。一种更有效、更简单的构造查询的方法如下。
query = '''
elect complaint_id, product, company, zip_codefrom credit_card_complaints
here zip_code = '91701'
imit 10
''
un_query(query)
| 投诉 _id | 产品 | 公司 | 邮政编码 | |
|---|---|---|---|---|
| Zero | Twenty-four thousand eight hundred and fifty-seven | 信用卡 | 巴克莱银行 | Ninety-one thousand seven hundred and one |
| one | Thirty-three thousand one hundred and fifty-seven | 信用卡 | 花旗银行 | Ninety-one thousand seven hundred and one |
| Two | Twelve thousand two hundred and forty-five | 信用卡 | 美洲银行 | Ninety-one thousand seven hundred and one |
| three | Three thousand one hundred and fifty-one | 信用卡 | 巴克莱银行 | Ninety-one thousand seven hundred and one |
| four | Three hundred and fifty-two thousand five hundred and thirty-four | 信用卡 | 花旗银行 | Ninety-one thousand seven hundred and one |
| five | One million nine hundred and sixty-three thousand eight hundred and thirty-six | 信用卡 | 摩根大通公司。 | Ninety-one thousand seven hundred and one |
| six | Two million one hundred and seventy-eight thousand and fifteen | 信用卡 | 发现 | Ninety-one thousand seven hundred and one |
| seven | Two million two hundred and thirty-four thousand seven hundred and fifty-four | 信用卡 | 发现 | Ninety-one thousand seven hundred and one |
| eight | Two million two hundred and thirty-five thousand nine hundred and fifteen | 信用卡 | 发现 | Ninety-one thousand seven hundred and one |
那么为什么内联视图/子查询有用呢?让我们看一个更复杂的例子。
正在运行的子查询
如果我们是一家金融服务公司,我们可能希望从这些数据中获得的一个见解是,最多的投诉来自哪里。此外,从我们的竞争对手那里看到相同的指标也可能是有用的。为了实现这一点,我们需要返回所有公司的不同列表,然后根据每个州找到与最高投诉数量相关的邮政编码。因此,对于每家公司,都应该有一个不同的州列表,以及该州投诉数量最多的邮政编码。让我们首先查询与投诉数量相关联的公司名称、州和邮政编码。让我们继续过滤州名为空的记录。现在,让我们从一家公司开始,花旗银行。
query = '''
ELECT company, state, zip_code, count(complaint_id) AS complaint_count
ROM credit_card_complaints
HERE company = 'Citibank' AND state IS NOT NULL
ROUP BY company, state, zip_code
RDER BY 4 DESC
IMIT 10;
''
un_query(query)
| 公司 | 状态 | 邮政编码 | 投诉 _ 计数 | |
|---|---|---|---|---|
| Zero | 花旗银行 | 纽约州 | 100XX | Eighty |
| one | 花旗银行 | 谢谢 | 750XX | Sixty-seven |
| Two | 花旗银行 | 加拿大 | 945XX | Fifty-eight |
| three | 花旗银行 | 纽约州 | 112XX | fifty-two |
| four | 花旗银行 | 加拿大 | 900XX | Fifty |
| five | 花旗银行 | 通用航空 | 300XX | Forty-six |
| six | 花旗银行 | 伊利诺伊 | 606XX | forty-four |
| seven | 花旗银行 | 新泽西州 | 070XX | forty-four |
| eight | 花旗银行 | 佛罗里达州 | 331XX | Thirty-nine |
| nine | 花旗银行 | 加拿大 | 926XX | Thirty-eight |
现在,我们已经有了一个按公司列出的州、邮政编码和投诉量的列表,并按投诉数量进行了排序,我们可以更进一步了。接下来,使用上面的查询作为子查询,我们可以返回每个州投诉数量最多的记录。目前,我们仍将使用花旗银行。
我们的第一个查询变成了子查询,用紫色突出显示,首先执行。然后,对我们的子查询的结果运行外部查询。让我们来看看结果。
query = '''
ELECT ppt.company, ppt.state, max(ppt.complaint_count) AS complaint_count
ROM (SELECT company, state, zip_code, count(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank'
AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC) ppt
ROUP BY ppt.company, ppt.state
RDER BY 3 DESC
IMIT 10;
''
un_query(query)
| 公司 | 状态 | 投诉 _ 计数 | |
|---|---|---|---|
| Zero | 花旗银行 | 纽约州 | Eighty |
| one | 花旗银行 | 谢谢 | Sixty-seven |
| Two | 花旗银行 | 加拿大 | Fifty-eight |
| three | 花旗银行 | 通用航空 | Forty-six |
| four | 花旗银行 | 伊利诺伊 | forty-four |
| five | 花旗银行 | 新泽西州 | forty-four |
| six | 花旗银行 | 佛罗里达州 | Thirty-nine |
| seven | 花旗银行 | 弗吉尼亚烟草 | Thirty-two |
| eight | 花旗银行 | 医学博士 | Thirty-two |
| nine | 花旗银行 | 直流电 | Thirty-one |
接下来,让我们继续扩展我们的查询,返回投诉数量最多的州和邮政编码。
这是一个复杂的查询,所以让我们一次看一个子查询。
- 我们从紫色中的第一个子查询开始,它统计按
company、state和zip_code分组的投诉数量。 - 接下来,我们将结果连接到包含另外两个子查询的子查询。记住我们需要从内向外读取子查询,让我们一次看一个:
- 我们之前见过的 orange 中最里面的子查询。这是该部分的第一个查询,它选择了花旗银行的投诉号码,并按
state和zip_code分组。 - 我们的下一个子查询在蓝色中,我们以前也见过,它是我们上一个例子中的外部查询,减去了
LIMIT语句。 - 我们最外层的红色子查询找到了所有州/邮政编码的最大投诉数量。
- 我们之前见过的 orange 中最里面的子查询。这是该部分的第一个查询,它选择了花旗银行的投诉号码,并按
query = '''
ELECT ens.company, ens.state, ens.zip_code, ens.complaint_count
ROM (select company, state, zip_code, count(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE state IS NOT NULL
GROUP BY company, state, zip_code) ens
NNER JOIN
(SELECT ppx.company, max(ppx.complaint_count) AS complaint_count
FROM (SELECT ppt.company, ppt.state, max(ppt.complaint_count) AS complaint_count
FROM (SELECT company, state, zip_code, count(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank'
AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC) ppt
GROUP BY ppt.company, ppt.state
ORDER BY 3 DESC) ppx
GROUP BY ppx.company) apx
N apx.company = ens.company
AND apx.complaint_count = ens.complaint_count
RDER BY 4 DESC;
''
un_query(query)
| 公司 | 状态 | 邮政编码 | 投诉 _ 计数 | |
|---|---|---|---|---|
| Zero | 花旗银行 | 纽约州 | 100XX | Eighty |
最后,我们可以从最里面的(橙色)子查询中删除公司过滤器,这样我们就可以看到每个公司收到最多投诉的州和邮政编码,以及他们收到了多少投诉。
query = '''
ELECT ens.company, ens.state, ens.zip_code, ens.complaint_count
ROM (select company, state, zip_code, count(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE state IS NOT NULL
GROUP BY company, state, zip_code) ens
NNER JOIN
(SELECT ppx.company, max(ppx.complaint_count) AS complaint_count
FROM (SELECT ppt.company, ppt.state, max(ppt.complaint_count) AS complaint_count
FROM (SELECT company, state, zip_code, count(complaint_id) AS complaint_count
FROM credit_card_complaints
WHERE company = 'Citibank'
AND state IS NOT NULL
GROUP BY company, state, zip_code
ORDER BY 4 DESC) ppt
GROUP BY ppt.company, ppt.state
ORDER BY 3 DESC) ppx
GROUP BY ppx.company) apx
N apx.company = ens.company
AND apx.complaint_count = ens.complaint_count
RDER BY 4 DESC;
''
un_query(query)
| 公司 | 状态 | 邮政编码 | 投诉 _ 计数 | |
|---|---|---|---|---|
| Zero | 花旗银行 | 纽约州 | 100XX | Eighty |
| one | 摩根大通公司。 | 纽约州 | 100XX | forty-four |
| Two | 美国证券交易所 | 纽约州 | 100XX | Forty-three |
| three | 美洲银行 | 纽约州 | Ten thousand and twenty-four | Thirty-four |
| four | 大写一 | 纽约州 | 112XX | Thirty |
| five | 大写一 | 通用航空 | 300XX | Thirty |
| six | 同步金融 | 纽约州 | 112XX | Twenty-nine |
| seven | 巴克莱银行 | 佛罗里达州 | 337XX | Twenty-eight |
| eight | 发现 | 全部商船 | 551XX | Nineteen |
| nine | 美国银行公司 | 直流电 | 200XX | Nineteen |
现在我们可以看到哪些公司收到的投诉最多,以及最多的投诉是从哪里产生的!
转换数据类型
有时,您需要动态更改字段的数据类型。例如,如果字段
Age是一个文本数据类型,但是你需要它是一个数字数据类型,这样你就可以对该数据执行计算,你可以简单地使用CAST()函数来临时适应你正在尝试执行的计算。要将字段转换为新的数据类型,我们使用以下语法:
CAST(source_column AS type);
每个数据类型可能有也可能没有额外的必需参数,所以请检查
为了确保您的 PostgreSQL 当前版本的文档。当我们之前创建表时,我们将complaint_id字段声明为主键。然而,我们将数据类型声明为text。让我们假设我们想要通过查询这个表来创建一个视图,但是想要在complaint_id上添加一个索引来提高性能。数字数据类型的索引比字符串(文本)数据类型更快,因为它们占用的空间更少。因此,让我们首先在bank_account_complaints表上运行一个简单的查询,将complaint_id作为float数据类型返回。
query = '''
ELECT CAST(complaint_id AS float) AS complaint_id
ROM bank_account_complaints LIMIT 10;
''
un_query(query)
| 投诉 _id | |
|---|---|
| Zero | Four hundred and sixty-eight thousand eight hundred and eighty-nine |
| one | Four hundred and sixty-eight thousand eight hundred and seventy-nine |
| Two | Four hundred and sixty-eight thousand nine hundred and forty-nine |
| three | Four hundred and sixty-eight thousand nine hundred and eighty-one |
| four | Four hundred and sixty-nine thousand one hundred and eighty-five |
| five | Four hundred and seventy-five thousand two hundred and seventy-three |
| six | Four hundred and sixty-nine thousand three hundred and nine |
| seven | Four hundred and sixty-nine thousand four hundred and fourteen |
| eight | Four hundred and sixty-nine thousand four hundred and forty-six |
| nine | Four hundred and sixty-nine thousand four hundred and forty-seven |
接下来,让我们测试我们将用来定义新视图的查询。我们的查询应该提取加利福尼亚州(state = 'CA ')的 Wells Fargo(Company = ' Wells Fargo & Company ')的所有字段值,其中消费者没有对公司的响应(consumer _ contracted = ' No ')提出异议。
query = '''
ELECT CAST(complaint_id AS int) AS complaint_id,
date_received, product, sub_product, issue, company,
state, zip_code, submitted_via, date_sent, company_response_to_consumer,
timely_response, consumer_disputed
ROM bank_account_complaints
HERE state = 'CA'
AND consumer_disputed = 'No'
AND company = 'Wells Fargo & Company'
IMIT 5;
''
un_query(query)
| 投诉 _id | 数据接收 | 产品 | 求和乘积 | 问题 | 公司 | 状态 | 邮政编码 | 提交 _ 通过 | 发送日期 | 公司回应消费者 | 及时 _ 响应 | 消费者 _ 有争议 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Four hundred and sixty-eight thousand eight hundred and eighty-nine | 2013-07-29 | 银行账户或服务 | 往来账户 | 使用借记卡或 ATM 卡 | 富国银行公司 | 加拿大 | Ninety-five thousand nine hundred and ninety-two | 网 | 2013-07-31 | 以解释结束 | 是 | 不 |
| one | Four hundred and sixty-nine thousand one hundred and eighty-five | 2013-07-29 | 银行账户或服务 | 其他银行产品/服务 | 存款和取款 | 富国银行公司 | 加拿大 | Ninety-six thousand and eighty-eight | 网 | 2013-08-01 | 以解释结束 | 是 | 不 |
| Two | Four hundred and sixty-nine thousand four hundred and forty-six | 2013-07-29 | 银行账户或服务 | 往来账户 | 存款和取款 | 富国银行公司 | 加拿大 | Ninety-two thousand two hundred and seventy-seven | 网 | 2013-08-05 | 以解释结束 | 是 | 不 |
| three | Four hundred and seventy-one thousand and seventy-five | 2013-07-31 | 银行账户或服务 | 储蓄账户 | 开户、销户或管理 | 富国银行公司 | 加拿大 | Ninety-one thousand two hundred and fourteen | 网 | 2013-08-02 | 以解释结束 | 是 | 不 |
| four | Four hundred and sixty-three thousand five hundred and twenty-five | 2013-07-22 | 银行账户或服务 | 其他银行产品/服务 | 开户、销户或管理 | 富国银行公司 | 加拿大 | Ninety-five thousand three hundred and seventy-six | 电话 | 2013-07-30 | 以解释结束 | 是 | 不 |
现在让我们创建名为
wells_complaints_v。
command = '''
REATE VIEW wells_complaints_v AS (
SELECT CAST(complaint_id AS int) AS complaint_id,
date_received, product, sub_product, issue, company,
state, zip_code, submitted_via, date_sent,
company_response_to_consumer,
timely_response, consumer_disputed
FROM bank_account_complaints
WHERE state = 'CA'
AND consumer_disputed = 'No'
AND company = 'Wells Fargo & Company')'''
un_command(command)
'CREATE VIEW'
SQL 挑战
学习 SQL 的基础知识相对简单。然而,学习语法和记忆 SQL 教程或数据库课程中教授的所有概念只是冰山一角。您应用到目前为止所学概念的能力,以及通过利用您的批判性思维和解决问题的技能来翻译一组需求的能力是拼图中最重要的一块。也就是说,随后的部分将由不同的场景组成,这些场景将包括一个简短的需求列表。所有场景都使用在本教程中创建的相同数据库表/视图。所有场景的解决方案都发布在本部分的末尾。
挑战 1
- 从
credit_card_complaints表中返回公司(company)的唯一列表,以及与不同公司名称(company_amt)相关的记录总数。 - 按
company_amt字段从大到小排序。 - 输出样本:
| 公司 | 公司 _ 金额 |
|---|---|
| 花旗银行 | Sixteen thousand five hundred and sixty-one |
| 大写一 | Twelve thousand seven hundred and forty |
| 摩根大通公司。 | Ten thousand two hundred and three |
| 美洲银行 | Eight thousand nine hundred and ninety-five |
| 同步金融 | Eight thousand six hundred and thirty-seven |
挑战 2
- 以挑战 1 中创建的查询为基础,添加第三列(
total)来反映credit_card_complaints表中的记录总数。每一行应该包含相同的数字。 - 输出样本:
| 公司 | 公司 _ 金额 | 总数 |
|---|---|---|
| 花旗银行 | Sixteen thousand five hundred and sixty-one | Eighty-seven thousand seven hundred and eighteen |
| 大写一 | Twelve thousand seven hundred and forty | Eighty-seven thousand seven hundred and eighteen |
| 摩根大通公司 | Ten thousand two hundred and three | Eighty-seven thousand seven hundred and eighteen |
| 美洲银行 | Eight thousand nine hundred and ninety-five | Eighty-seven thousand seven hundred and eighteen |
| 同步金融 | Eight thousand six hundred and thirty-seven | Eighty-seven thousand seven hundred and eighteen |
挑战 3
- 以挑战 2 中创建的查询为基础,添加第四列(
percent),反映与credit_card_complaints表中每个公司相关的记录的百分比。 - 输出样本:
| 公司 | 公司 _ 金额 | 总数 | 百分比 |
|---|---|---|---|
| 花旗银行 | Sixteen thousand five hundred and sixty-one | Eighty-seven thousand seven hundred and eighteen | 18.879819 |
| 大写一 | Twelve thousand seven hundred and forty | Eighty-seven thousand seven hundred and eighteen | 14.523815 |
| 摩根大通公司。 | Ten thousand two hundred and three | Eighty-seven thousand seven hundred and eighteen | 11.631592 |
| 美洲银行 | Eight thousand nine hundred and ninety-five | Eighty-seven thousand seven hundred and eighteen | 10.254452 |
| 同步金融 | Eight thousand six hundred and thirty-seven | Eighty-seven thousand seven hundred and eighteen | 9.846326 |
解决方案–SQL 挑战
以下是每个挑战的解决方案。
解决方案 1
SELECT company, COUNT(company) AS company_amt
span class="token keyword">FROM credit_card_complaints
span class="token keyword">GROUP BY company
span class="token keyword">ORDER BY 2 DESC;
解决方案 2
SELECT company, COUNT(company) as company_amt,
(SELECT COUNT(*) FROM credit_card_complaints) AS total
span class="token keyword">FROM credit_card_complaints
span class="token keyword">GROUP BY company
span class="token keyword">ORDER BY 2 DESC;
解决方案 3
SELECT ppg.company, ppg.company_amt, ppg.total,
((CAST(ppg.company_amt AS double precision) / CAST(ppg.total as double precision)) * 100) AS percent
span class="token keyword">FROM (SELECT company, COUNT(company) as company_amt, (SELECT COUNT(*) FROM credit_card_complaints) AS total
FROM credit_card_complaints
GROUP BY company
ORDER BY 2 DESC) ppg;
后续步骤
在本教程中,我们分析了金融服务消费者投诉数据,同时学习了 SQL 的中间概念,包括:
- 创建用户、数据库和表,
IS NULL/IS NOT NULL子句,- 观点,
- 子查询,
- Union/union all,
- 相交/例外,
- 字符串串联,和
- 转换数据类型。
尽管我们非常详细地介绍了每个概念,甚至用 SQL 场景问题测试了我们的知识,但是您自己实践每个概念是很重要的。为此,您可以使用这些数据提出自己的方案,然后编写查询来返回这些数据。如果你想更详细地研究 SQL,你可以免费注册,看看我们的互动课程 SQL &数据库:中级,它涵盖了本教程中教授的许多内容等等。
通过做来学习 SQL
使用我们的交互式学习平台,立即动手操作 SQL。
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
(开始免费)
SQL 面试问题——为工作面试做准备的真实问题
February 1, 2021
如果你想找一份数据方面的工作,很有可能你必须回答一些 SQL 面试问题,或者完成某种 SQL 测试。
这是因为大多数数据工作都需要 SQL 技能。我们在这篇文章中深入挖掘了关于为什么你应该学习 SQL 的数据,但简短的版本是这样的:2021 年超过一半的数据分析师、数据科学家和数据工程师工作将 SQL 列为一项要求。
SQL 对于数据分析师角色的重要性尤为突出:

SQL 无疑是数据分析师最需要的技能。数据来源:Indeed.com,2021 年 1 月 29 日。
准备工作面试中的 SQL 问题
我们已经写了一份关于数据科学领域工作面试的详尽指南。你应该意识到,SQL 几乎肯定会在你的面试过程中发挥作用,特别是如果你正在寻找数据分析师的角色。
每个公司都有不同的做法,但这里有一些公司测试 SQL 技能的更常见的方法:
- 面对面(或视频)面试,会问你一些 SQL 问题或给你一些要解决的 SQL 问题。
- 带回家的 SQL 任务。
- 现场(或视频)编码会议,要求您使用 SQL 技能实时回答问题。
- 白板编码会议,要求您通过在白板上勾画查询来展示您的 SQL 技能。
如果您还不习惯编写 SQL 查询,现在是最好的时机注册一个免费帐户,开始学习我们的交互式 SQL 课程。但是假设你已经是一个 SQL 高手了。你仍然需要一些练习!
这就是你可能会遇到问题的地方。
在线练习问题列表(大部分)很糟糕
如果你在谷歌上搜索“SQL 面试问题”,你会找到一堆列出类似问题的文章(这些都是从排名靠前的文章中提取的真实问题)
- 什么是 SQL?
- 什么是数据库?
- 什么是桌子?
- 什么是联接?
你明白了。我们认为在工作面试中你可能会被问到“什么是 SQL”。但绝对不可能是可能是。
更有可能的是:你将面临的 SQL 面试问题会要求你用 SQL 解决实际问题,或者要求你回答更棘手的问题来测试你的工作知识。
我们收集了下面的一些问题,并提供了可扩展的答案,这样你可以测试自己,然后检查以确保你是正确的。
用真实的 SQL 面试问题测试自己:
问题 1
根据下表,编写一个 SQL 查询来检索微积分考试中得分超过 16 分的校友的个人数据。
校友
| 学生 id | 名字 | 姓 | 出生日期 | 能力 |
|---|---|---|---|---|
| Three hundred and forty-seven | 丹妮拉(亦作 Danielle)(f.) | 洛佩斯 | 1991-04-26 | 医学院 |
| Three hundred and forty-eight | 罗伯特 | 费希尔 | 1991-03-09 | 数学 |
评估
| 学生 id | class_id | 考试日期 | 等级 |
|---|---|---|---|
| Three hundred and forty-seven | Seventy-four | 2015-06-19 | Sixteen |
| Three hundred and forty-seven | Eighty-seven | 2015-06-06 | Twenty |
| Three hundred and forty-eight | Seventy-four | 2015-06-19 | Thirteen |
课程设置
| class_id | 类别名称 | 教授 _id | 学期 |
|---|---|---|---|
| Seventy-four | 代数学 | Four hundred and thirty-five | 2015 _ 夏天 |
| Eighty-seven | 结石 | Five hundred and thirty-two | 2015 _ 夏天 |
| Forty-six | 统计数字 | Six hundred and twenty-five | 2015 _ 冬天 |
Click to reveal answer
有几种可能的答案。这里有一个:
SELECT a.name, a.surname, a.birth_date, a.faculty
FROM alumni AS a
INNER JOIN evaluation AS e
ON a.student_id=e.student_id
INNER JOIN curricula AS c
ON e.class_id = c.class_id
WHERE c.class_name = 'calculus' AND e.grade>16;
问题 2
我们将使用beverages表。下面给出了它的前几行。
| 身份证明(identification) | 名字 | 发布年份 | 水果 _ 百分比 | 供稿 _ 作者 |
|---|---|---|---|---|
| one | 嗡嗡声 | Two thousand and seven | Forty-five | 山姆·马龙 |
| Two | 令人愉快的 | Two thousand and eight | Forty-one | 山姆·马龙 |
| three | 尼斯(法国城市名) | Two thousand and fifteen | forty-two | 山姆·马龙 |
编写一个查询,只提取fruit_pct在35和40之间的饮料(包括两端)。
Click to reveal answer
有几种可能的答案。这里有一个:
SELECT *
FROM beverages
WHERE fruit_pct BETWEEN 35 AND 40;
问题 3
我们将再次使用饮料桌。下面给出了它的前几行。
| 身份证明(identification) | 名字 | 发布年份 | 水果 _ 百分比 | 供稿 _ 作者 |
|---|---|---|---|---|
| one | 嗡嗡声 | Two thousand and seven | Forty-five | 山姆·马龙 |
| Two | 令人愉快的 | Two thousand and eight | Forty-one | 山姆·马龙 |
| three | 尼斯(法国城市名) | Two thousand and fifteen | forty-two | 山姆·马龙 |
编写一个查询,只提取贡献者只有一个名字的饮料
Click to reveal answer
有几种可能的答案。这里有一个:
SELECT *
FROM beverages
WHERE contributed_by NOT LIKE '% %';
问题 4
我们将再次使用beverages表。下面给出了它的前几行。
| 身份证明(identification) | 名字 | 发布年份 | 水果 _ 百分比 | 供稿 _ 作者 |
|---|---|---|---|---|
| one | 嗡嗡声 | Two thousand and seven | Forty-five | 山姆·马龙 |
| Two | 令人愉快的 | Two thousand and eight | Forty-one | 山姆·马龙 |
| three | 尼斯(法国城市名) | Two thousand and fifteen | forty-two | 山姆·马龙 |
编写一个查询,按贡献者查找平均值fruit_pct,并按升序显示。
Click to reveal answer
有几种可能的答案。这里有一个:
SELECT contributed_by, AVG(fruit_pct) AS mean_fruit
FROM beverages
GROUP BY contributed_by
ORDER BY mean_fruit;
问题 5
看看下面给出的查询:
SELECT column, AGG_FUNC(column_or_expression), …
FROM a_table
INNER JOIN some_table
ON a_table.column = some_table.column
WHERE a_condition
GROUP BY column
HAVING some_condition
ORDER BY column
LIMIT 5;
SQL 以什么顺序运行子句?从下面的选项列表中选择正确的选项:
SELECT、FROM、WHERE、GROUP BYFROM、WHERE、HAVING、SELECT、LIMITSELECT、FROM、INNER JOIN,分组依据FROM、SELECT、LIMIT、WHERE
Click to reveal answer
正确选项是2。事情是这样的:
- SQL 引擎从表中获取数据(
FROM和INNER JOIN) - 过滤它(
WHERE) - 汇总数据(
GROUP BY) - 过滤汇总数据(
HAVING) - 选择要显示的列和表达式(
SELECT) - 订单剩余数据(
ORDER BY) - 限制结果(
LIMIT)
问题 6
数据库表中索引的用途是什么?
Click to reveal answer
数据库表中索引的目的是提高查看该表数据的速度。标准的类比是,通过查看索引在书中查找某样东西(通常)比翻阅每一页直到找到我们想要的东西要快得多。
问题 7
以下查询产生了my_table的哪些行?给个描述性的回答。
SELECT *
FROM my_table
WHERE 1 = 1.0;
Click to reveal answer
它返回整个表,因为1=1.0总是计算为真。
问题 8
以下查询产生了my_table的哪些行?给个描述性的回答。
SELECT *
FROM my_table
WHERE NULL = NULL;
Click to reveal answer
它不返回任何行,因为根据定义,NULL不等于自身。
SQL 面试准备的更多资源
随着时间的推移,我们会在列表中添加新的问题,但在此期间,这里有一些更有帮助的资源,供您在准备 SQL 面试问题时参考:
- 我们可下载的 SQL 备忘单
- 我们的 SQL 课程。我们的应用程序中还有交互式 SQL 练习题,可以让您进行更多的 SQL 练习。
- 破解 SQL 面试——Github 上一个很好的 SQL 面试问题和主题集合,比大多数列表有用得多。
- 另一个 Github repo 的面试问题表面上是从真实的 SQL 工作面试中提取的。
当然,不要忘了将这篇文章加入书签,因为我们会添加更多的 SQL 面试问题,供您随时测试自己!
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
布鲁诺·库尼亚写的 SQL 问题。
SQL 联接教程:使用数据库
January 18, 2021
SQL 连接不必如此具有挑战性!
当第一次学习 SQL 时,处理单个表中的数据是很常见的。在现实世界中,数据库通常在多个表中存储数据。如果我们希望能够处理这些数据,我们必须在一个查询中组合多个表。在这个 SQL 连接教程中,我们将学习如何使用连接从多个表中选择数据。
我们假设您了解使用 SQL 的基础知识,包括过滤、排序、聚合和子查询。如果你不知道,我们的 SQL 基础课程会教授所有这些概念,你可以注册并开始免费的课程。
**### 用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
事实手册数据库
我们将使用 CIA World Factbook (Factbook)数据库的一个版本,它有两个表。第一个表叫做facts,每行代表一个国家。以下是facts表格的前 5 行:
| 身份证明(identification) | 密码 | 名字 | 区域 | 面积 _ 土地 | 面积 _ 水 | 人口 | 人口增长 | 出生率 | 死亡率 | 迁移率 |
|---|---|---|---|---|---|---|---|---|---|---|
| one | 视频(同 audio frequency) | 阿富汗 | Six hundred and fifty-two thousand two hundred and thirty | Six hundred and fifty-two thousand two hundred and thirty | Zero | Thirty-two million five hundred and sixty-four thousand three hundred and forty-two | Two point three two | Thirty-eight point five seven | Thirteen point eight nine | One point five one |
| Two | -艾尔 | 阿尔巴尼亚 | Twenty-eight thousand seven hundred and forty-eight | Twenty-seven thousand three hundred and ninety-eight | One thousand three hundred and fifty | Three million twenty-nine thousand two hundred and seventy-eight | Zero point three | Twelve point nine two | Six point five eight | Three point three |
| three | (对他人的话作出反应或表示生气、恼怒)唔,啊,哎呀 | 阿尔及利亚 | Two million three hundred and eighty-one thousand seven hundred and forty-one | Two million three hundred and eighty-one thousand seven hundred and forty-one | Zero | Thirty-nine million five hundred and forty-two thousand one hundred and sixty-six | One point eight four | Twenty-three point six seven | Four point three one | Zero point nine two |
| four | 一;一个 | 安道尔 | Four hundred and sixty-eight | Four hundred and sixty-eight | Zero | Eighty-five thousand five hundred and eighty | Zero point one two | Eight point one three | Six point nine six | Zero |
| five | 安哥拉 | 安哥拉 | One million two hundred and forty-six thousand seven hundred | One million two hundred and forty-six thousand seven hundred | Zero | Nineteen million six hundred and twenty-five thousand three hundred and fifty-three | Two point seven eight | Thirty-eight point seven eight | Eleven point four nine | Zero point four six |
除了facts表之外,还有一个名为cities的表,它包含了来自 Factbook 中各个国家的主要城市区域的信息(在本教程的其余部分,我们将使用“城市”一词来表示“主要城市区域”)。让我们看一下该表的前几行以及对每一列所代表的内容的描述:
| 身份证明(identification) | 名字 | 人口 | 首都 | 事实 _id |
|---|---|---|---|---|
| one | 奥兰耶斯塔德 | Thirty-seven thousand | one | Two hundred and sixteen |
| Two | 圣约翰学院 | Twenty-seven thousand | one | six |
| three | 阿布扎比 | Nine hundred and forty-two thousand | one | One hundred and eighty-four |
| four | 迪拜 | One million nine hundred and seventy-eight thousand | Zero | One hundred and eighty-four |
| five | 沙迦 | Nine hundred and eighty-three thousand | Zero | One hundred and eighty-four |
id–每个城市的唯一 ID。name–城市的名字。- 城市的人口。
capital–该城市是否为首都:1 表示是,0 表示不是。facts_id–国家的 ID,来自事实表。
最后一列是我们特别感兴趣的,因为这一列数据也存在于我们的原始facts表中。表之间的这种链接很重要,因为它用于组合查询中的数据。下面是一个模式图,它显示了我们数据库中的两个表,其中的列以及这两个表是如何链接的。

模式图中的线条清楚地显示了facts表中的id列和城市表中的facts_id列之间的链接。
如果您想下载数据库以便在自己的计算机上使用,您可以将数据集下载为 SQLite 数据库。
我们的第一个 SQL 连接
使用 SQL 连接数据的最常见方式是使用一个内部连接。内部联接的语法是:
SELECT [column_names] FROM [table_name_one]
INNER JOIN [table_name_two] ON [join_constraint];
inner join 子句由两部分组成:
INNER JOIN,它告诉 SQL 引擎您希望在查询中连接的表的名称,以及您希望使用内部连接。ON,它告诉 SQL 引擎使用什么列来连接两个表。
连接通常用在查询中的FROM子句之后。让我们来看一个基本的内部连接,其中我们组合了来自两个表的数据。
SELECT * FROM facts
INNER JOIN cities ON cities.facts_id = facts.id
LIMIT 5;
让我们看看包含连接的查询行:
INNER JOIN cities:这告诉 SQL 引擎我们希望使用内部连接将城市表连接到我们的查询中。ON cities.facts_id = facts.id:这告诉 SQL 引擎在连接数据时使用哪些列,遵循语法 table_name.column_name。
您可能会认为SELECT * FROM facts意味着查询只返回来自facts表的列,但是*通配符在与连接一起使用时会给出来自两个表的所有列。以下是该查询的结果:
| 身份证明(identification) | 密码 | 名字 | 区域 | 面积 _ 土地 | 面积 _ 水 | 人口 | 人口增长 | 出生率 | 死亡率 | 迁移率 | 身份证明(identification) | 名字 | 人口 | 首都 | 事实 _id |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two hundred and sixteen | 嗜酒者互诫协会 | 阿鲁巴岛 | one hundred and eighty | one hundred and eighty | Zero | One hundred and twelve thousand one hundred and sixty-two | One point three three | Twelve point five six | Eight point one eight | Eight point nine two | one | 奥兰耶斯塔德 | Thirty-seven thousand | one | Two hundred and sixteen |
| six | 交流电 | 安提瓜和巴布达 | Four hundred and forty-two | Four hundred and forty-two | Zero | Ninety-two thousand four hundred and thirty-six | One point two four | Fifteen point eight five | Five point six nine | Two point two one | Two | 圣约翰学院 | Twenty-seven thousand | one | six |
| One hundred and eighty-four | 行政帐户(account executive) | 阿拉伯联合酋长国 | Eighty-three thousand six hundred | Eighty-three thousand six hundred | Zero | Five million seven hundred and seventy-nine thousand seven hundred and sixty | Two point five eight | Fifteen point four three | One point nine seven | Twelve point three six | three | 阿布扎比 | Nine hundred and forty-two thousand | one | One hundred and eighty-four |
| One hundred and eighty-four | 行政帐户(account executive) | 阿拉伯联合酋长国 | Eighty-three thousand six hundred | Eighty-three thousand six hundred | Zero | Five million seven hundred and seventy-nine thousand seven hundred and sixty | Two point five eight | Fifteen point four three | One point nine seven | Twelve point three six | four | 迪拜 | One million nine hundred and seventy-eight thousand | Zero | One hundred and eighty-four |
| One hundred and eighty-four | 行政帐户(account executive) | 阿拉伯联合酋长国 | Eighty-three thousand six hundred | Eighty-three thousand six hundred | Zero | Five million seven hundred and seventy-nine thousand seven hundred and sixty | Two point five eight | Fifteen point four three | One point nine seven | Twelve point three six | five | 沙迦 | Nine hundred and eighty-three thousand | Zero | One hundred and eighty-four |
这个查询给出了两个表中的所有列,以及来自facts的id列和来自cities的facts_id列匹配的每一行,仅限于前 5 行。
了解 SQL 内部连接
我们现在已经连接了两个表,为我们提供了关于cities中每一行的额外信息。让我们仔细看看这个内部连接是如何工作的。
内部连接的工作方式是只包含每个表中使用ON子句指定的匹配行。让我们看一下上一个屏幕中的连接是如何工作的。我们选择了一些最能说明这种连接的行:

我们的内部连接将包括:
- 来自
cities表中具有与来自facts的facts.id相匹配的cities.facts_id的行。
我们的内部联接不会包括:
- 来自
cities表的行,其cities.facts_id与事实中的任何facts.id都不匹配。 - 事实表中 facts.id 与城市中的任何
cities.facts_id都不匹配的行。
你可以看到这表现为一个文氏图:

我们已经知道如何使用别名来指定列的自定义名称,例如:
SELECT AVG(population) AS average_population
我们还可以为表名创建别名,这使得带有连接的查询更容易读写。而不是:
SELECT * FROM facts
INNER JOIN cities ON cities.facts_id = facts.id
我们可以写:
SELECT * FROM facts AS f
INNER JOIN cities AS c ON c.facts_id = f.id
就像列名一样,使用AS是可选的。我们可以通过书写得到相同的结果:
SELECT * FROM facts f
INNER JOIN cities c ON c.facts_id = f.id
我们还可以将别名和通配符结合起来——例如,使用上面创建的别名,c.*将给出表cities中的所有列。
虽然上一个屏幕中的查询包含了来自ON子句的两列,但是在最终的列列表中,我们不需要使用来自ON子句的任何一列。这很有用,因为这意味着我们可以只显示我们感兴趣的信息,而不是每次都必须包含两个连接列。
让我们使用我们所学的知识来构建我们的原始查询。我们将:
- 使用
INNER JOIN将cities连接到facts。 - 对表名使用别名。
- 依次包括:
- 从
cities开始的所有列。 - 从
facts到country_name的名称列别名。
- 从
- 只包括前 5 行。
SELECT
c.*,
f.name country_name
FROM facts f
INNER JOIN cities c ON c.facts_id = f.id
LIMIT 5;
| 身份证明(identification) | 名字 | 人口 | 首都 | 事实 _id | 国家名称 |
|---|---|---|---|---|---|
| one | 奥兰耶斯塔德 | Thirty-seven thousand | one | Two hundred and sixteen | 阿鲁巴岛 |
| Two | 圣约翰学院 | Twenty-seven thousand | one | six | 安提瓜和巴布达 |
| three | 阿布扎比 | Nine hundred and forty-two thousand | one | One hundred and eighty-four | 阿拉伯联合酋长国 |
| four | 迪拜 | One million nine hundred and seventy-eight thousand | Zero | One hundred and eighty-four | 阿拉伯联合酋长国 |
| five | 沙迦 | Nine hundred and eighty-three thousand | Zero | One hundred and eighty-four | 阿拉伯联合酋长国 |
在 SQL 中练习内部连接
让我们练习编写一个查询,使用内部连接来回答数据库中的一个问题。假设我们想利用我们目前所学的知识,从数据库中生成一个国家及其首都的表格。我们的第一步是考虑在最终查询中需要哪些列。我们需要:
- 来自
facts的name列 - 来自
cities的name列
假设我们已经确定需要来自两个表的数据,我们需要考虑如何连接它们。前面的模式图表明,每个表中只有一列将它们链接在一起,因此我们可以使用这些列的内部连接来连接数据。
到目前为止,通过思考我们的问题,我们已经可以编写我们的大部分查询(它几乎与我们编写的前一个查询相同):
SELECT
f.name,
c.name
FROM cities c
INNER JOIN facts f ON f.id = c.facts_id;
我们过程的最后一部分是确保我们有正确的行。从前面的两个屏幕中我们知道,这样的查询将返回来自cities的所有行,这些行在facts_id列中与来自facts的行有对应的匹配。我们只对城市表中的首都感兴趣,所以我们需要在capital列中使用一个WHERE子句,如果该城市是首都,则该子句的值为1,如果不是,则为0:
WHERE c.capital = 1
我们现在可以将这些放在一起,编写一个查询来回答我们的问题。我们将把它限制在前 10 行,这样输出的数量是可管理的。
SELECT
f.name country,
c.name capital_city
FROM cities c
INNER JOIN facts f ON f.id = c.facts_id
WHERE c.capital = 1
LIMIT 10;
| 国家 | 首都城市 |
|---|---|
| 阿鲁巴岛 | 奥兰耶斯塔德 |
| 安提瓜和巴布达 | 圣约翰学院 |
| 阿拉伯联合酋长国 | 阿布扎比 |
| 阿富汗 | 喀布尔 |
| 阿尔及利亚 | 阿尔及尔 |
| 阿塞拜疆 | 巴库 |
| 阿尔巴尼亚 | 地拉那 |
| 亚美尼亚 | 埃里温 |
| 安道尔 | Andorra La Vella |
| 安哥拉 | 罗安达 |
SQL 中的左连接
正如我们前面提到的,内部连接将不包括两个表中没有相互匹配的任何行。这意味着,在我们的查询中,可能存在行不匹配的信息。
我们可以使用 SQL 查询来探索这一点:
SELECT COUNT(DISTINCT(name)) FROM facts;
数数
| Two hundred and sixty-one |
SELECT COUNT(DISTINCT(facts_id)) FROM cities;
数数
| Two hundred and ten |
通过运行这两个查询,我们可以看到在facts表中有一些国家在cities表中没有相应的城市,这表明我们可能有一些不完整的数据。
让我们看看如何使用一种新的连接类型——左连接,创建一个查询来探索缺失的数据。
左联接包括内部联接将选择的所有行,加上第一个(或左)表中在第二个表中没有匹配项的所有行。我们可以用文氏图来表示。

让我们来看一个例子,用我们编写的第一个查询中的LEFT JOIN替换INNER JOIN,并从我们之前的图表中查看相同的行选择
SELECT * FROM facts
LEFT JOIN cities ON cities.facts_id = facts.id

这里我们可以看到,对于facts.id与cities.facts_id中的任何值都不匹配的行(237、238、240 和 244),这些行仍然包含在结果中。当这种情况发生时,cities表中的所有列都用空值填充。
我们可以使用这些空值过滤我们的结果,只过滤那些不存在于带有WHERE子句的cities中的国家。当在 SQL 中与 null 进行比较时,我们使用IS关键字,而不是=符号。如果我们想选择列为空的行,我们可以写:
WHERE column_name IS NULL
如果我们想选择列名不为空的行,我们使用:
WHERE column_name IS NOT NULL
让我们使用一个左连接来探索不存在于cities表中的国家。
SELECT
f.name country,
f.population
FROM facts f
LEFT JOIN cities c ON c.facts_id = f.id
WHERE c.name IS NULL;
| 国家 | 人口 |
|---|---|
| 科索沃 | One million eight hundred and seventy thousand nine hundred and eighty-one |
| 摩纳哥 | Thirty thousand five hundred and thirty-five |
| 瑙鲁 | Nine thousand five hundred and forty |
| 圣马力诺 | Thirty-three thousand and twenty |
| 新加坡 | Five million six hundred and seventy-four thousand four hundred and seventy-two |
| 罗马教廷(梵蒂冈城) | Eight hundred and forty-two |
| 台湾 | Twenty-three million four hundred and fifteen thousand one hundred and twenty-six |
| 欧洲联盟 | Five hundred and thirteen million nine hundred and forty-nine thousand four hundred and forty-five |
| 阿什莫尔-卡捷群岛 | |
| 圣诞岛 | One thousand five hundred and thirty |
| 科科斯(基林)群岛 | Five hundred and ninety-six |
| 珊瑚海群岛 | |
| 赫德岛和麦克唐纳群岛 | |
| 诺福克岛 | Two thousand two hundred and ten |
| 香港 | Seven million one hundred and forty-one thousand one hundred and six |
| 澳门 | Five hundred and ninety-two thousand seven hundred and thirty-one |
| 克利珀顿岛 | |
| 法国南部和南极地区 | |
| 圣巴特列米 | Seven thousand two hundred and thirty-seven |
| 圣马丁岛 | Thirty-one thousand seven hundred and fifty-four |
| 柑桂酒 | One hundred and forty-eight thousand four hundred and six |
| 你的尺寸 | Thirty-nine thousand six hundred and eighty-nine |
| 库克群岛 | Nine thousand eight hundred and thirty-eight |
| 纽埃 | One thousand one hundred and ninety |
| 托克劳群岛 | One thousand three hundred and thirty-seven |
| 布维岛 | |
| Jan Mayen | |
| 斯瓦尔巴群岛 | One thousand eight hundred and seventy-two |
| 阿克罗蒂里 | Fifteen thousand seven hundred |
| 英属印度洋领地 | |
| Dhekelia | Fifteen thousand seven hundred |
| 直布罗陀 | Twenty-nine thousand two hundred and fifty-eight |
| 根西岛 | Sixty-six thousand and eighty |
| 泽西岛 | Ninety-seven thousand two hundred and ninety-four |
| 蒙特塞拉特岛 | Five thousand two hundred and forty-one |
| 皮特凯恩群岛 | Forty-eight |
| 南乔治亚岛和南桑威奇群岛 | |
| 纳瓦拉岛 | |
| 威克岛 | |
| 美国太平洋岛屿野生动物保护区 | |
| 南极洲 | Zero |
| 加沙地带 | One million eight hundred and sixty-nine thousand and fifty-five |
| 帕拉塞尔群岛 | |
| “斯普拉特利群岛” | |
| 西岸 | Two million seven hundred and eighty-five thousand three hundred and sixty-six |
| 北冰洋 | |
| 大西洋 | |
| 印度洋 | |
| 太平洋 | |
| 南冰洋 | |
| 世界 | Seven billion two hundred and fifty-six million four hundred and ninety thousand and eleven |
浏览我们在上一个屏幕中编写的查询结果,我们可以看到国家/地区在cities中没有对应值的许多不同原因:
- 人口少和/或没有主要城市地区(定义为人口超过 750,000)的国家,如圣马力诺、科索沃和瑙鲁。
- 城邦,如摩纳哥和新加坡。
- 本身不是国家的领土,如香港、直布罗陀和库克群岛。
- 非国家的区域和海洋,如欧盟和太平洋。
- 真正缺失数据的案例,比如台湾。
无论何时使用内部联接,都要注意可能会排除重要的数据,尤其是当基于数据库模式中未链接的列进行联接时。
右连接和外连接
您应该知道 SQLite 不支持两种不太常见的连接类型。第一个是右连接。顾名思义,右连接与左连接正好相反。左连接包括表中在连接子句之前的所有行,而右连接包括新表中在连接子句中的所有行。我们可以在下面的文氏图中看到一个右连接:

下面两个查询,一个使用左连接,一个使用右连接,产生相同的结果。
SELECT f.name country, c.name city
FROM facts f
LEFT JOIN cities c ON c.facts_id = f.id
LIMIT 5;
SELECT f.name country, c.name city
FROM cities c
RIGHT JOIN facts f ON f.id = c.facts_id
LIMIT 5;
使用右连接的主要原因是当您连接两个以上的表时。在这些情况下,最好使用右连接,因为它可以避免为了连接一个表而重新构造整个查询。除此之外,右连接很少使用,所以对于简单连接,使用左连接比右连接更好,因为其他人更容易阅读和理解您的查询。
SQLite 不支持的另一种连接类型是完全外部连接。完整的外部联接将包括联接两侧表中的所有行。我们可以在下面的维恩图中看到一个完整的外部连接:

像右连接一样,完全外连接相当少见。完整外部连接的标准 SQL 语法是:
SELECT f.name country, c.name city
FROM cities c
FULL OUTER JOIN facts f ON f.id = c.facts_id
LIMIT 5;
当用一个完整的外部连接连接cities和facts时,结果将与上面的左右连接相同,因为cities.facts_id中没有不存在于facts.id中的值。
让我们一起来看看每种连接类型的文氏图,这将有助于您比较到目前为止我们讨论的四种连接的不同之处。

接下来,让我们练习使用连接来回答一些关于数据的问题。
寻找人口最多的首都城市
以前,我们在指定查询结果的顺序时使用了列名,如下所示:
SELECT
name,
migration_rate
FROM facts
ORDER BY migration_rate desc;
我们可以在查询中使用一个方便的快捷方式,让我们跳过列名,而是使用列在SELECT子句中出现的顺序。在这个实例中,migration_rate是我们的SELECT子句中的第二列,所以我们可以只使用2来代替列名:
SELECT
name,
migration_rate
FROM facts
ORDER BY 2 desc;
您可以在ORDER BY或GROUP BY子句中使用此快捷方式。请注意,您希望确保查询仍然可读,因此对于更复杂的查询,键入完整的列名可能更好。
让我们用我们所学的来列出人口最多的 10 个首都城市。因为我们对来自facts的在cities中没有对应城市的国家不感兴趣,所以我们应该使用一个INNER JOIN。
SELECT
c.name capital_city,
f.name country,
c.population
FROM facts f
INNER JOIN cities c ON c.facts_id = f.id
WHERE c.capital = 1
ORDER BY 3 DESC
LIMIT 10;
| 首都城市 | 国家 | 人口 |
|---|---|---|
| 东京 | 日本 | Thirty-seven million two hundred and seventeen thousand |
| 新德里 | 印度 | Twenty-two million six hundred and fifty-four thousand |
| 墨西哥城 | 墨西哥 | Twenty million four hundred and forty-six thousand |
| 北京 | 中国 | Fifteen million five hundred and ninety-four thousand |
| 达卡 | 孟加拉国 | Fifteen million three hundred and ninety-one thousand |
| 布宜诺斯艾利斯 | 阿根廷 | Thirteen million five hundred and twenty-eight thousand |
| 马尼拉 | 菲律宾 | Eleven million eight hundred and sixty-two thousand |
| 莫斯科 | 俄罗斯 | Eleven million six hundred and twenty-one thousand |
| 开罗 | 埃及 | Eleven million one hundred and sixty-nine thousand |
| 雅加达 | 印度尼西亚 | Nine million seven hundred and sixty-nine thousand |
将 SQL 连接与子查询相结合
子查询可以用来替代部分查询,使我们能够找到更复杂问题的答案。我们还可以连接到子查询的结果,就像我们连接表一样。
这是一个使用联接和子查询来生成国家及其首都的表的示例,就像我们在本课前面所做的那样。

起初,读取子查询可能会让人不知所措,所以我们将把本例中发生的事情分成几个步骤。要记住的重要一点是,任何子查询的结果总是首先计算的,所以我们从里到外读取。
- 首先计算红框中的子查询。这个简单的查询选择来自
cities的所有列,通过将capital的值设为 1 来过滤标记为首都城市的行。 INNER JOIN基于ON子句将别名为c的子查询结果连接到facts表。- 从连接的结果中选择了两列:
f.name,别名为country。c.name,别名为capital_city。
- 结果限于前 10 行。
以下是该查询的输出:
| 国家 | 首都城市 |
|---|---|
| 阿鲁巴岛 | 奥兰耶斯塔德 |
| 安提瓜和巴布达 | 圣约翰学院 |
| 阿拉伯联合酋长国 | 阿布扎比 |
| 阿富汗 | 喀布尔 |
| 阿尔及利亚 | 阿尔及尔 |
| 阿塞拜疆 | 巴库 |
| 阿尔巴尼亚 | 地拉那 |
| 亚美尼亚 | 埃里温 |
| 安道尔 | Andorra La Vella |
| 安哥拉 | 罗安达 |
使用这个示例作为模型,我们将编写一个类似的查询来查找人口超过 1000 万的非首都城市。
SELECT
c.name city,
f.name country,
c.population population
FROM facts f
INNER JOIN (
SELECT * FROM cities
WHERE capital = 0
AND population > 10000000
) c ON c.facts_id = f.id
ORDER BY 3 DESC;
| 城市 | 国家 | 人口 |
|---|---|---|
| 纽约-纽瓦克 | 美国 | Twenty million three hundred and fifty-two thousand |
| 上海 | 中国 | Twenty million two hundred and eight thousand |
| 圣保罗(葡萄牙) | 巴西 | Nineteen million nine hundred and twenty-four thousand |
| 孟买 | 印度 | Nineteen million seven hundred and forty-four thousand |
| 马赛-艾克斯-普罗旺斯 | 法国 | Fourteen million eight hundred and ninety thousand one hundred |
| 加尔各答 | 印度 | Fourteen million four hundred and two thousand |
| 卡拉奇 | 巴基斯坦 | Thirteen million eight hundred and seventy-six thousand |
| 洛杉矶-长滩-圣安娜 | 美国 | Thirteen million three hundred and ninety-five thousand |
| 大阪-神户 | 日本 | Eleven million four hundred and ninety-four thousand |
| 伊斯坦布尔 | 火鸡 | Eleven million two hundred and fifty-three thousand |
| 拉各斯 | 尼日利亚 | Eleven million two hundred and twenty-three thousand |
| 广州 | 中国 | Ten million eight hundred and forty-nine thousand |
SQL 挑战:包含连接和子查询的复杂查询
让我们把之前学过的东西拿来,用它来编写一个更复杂的查询。“用 SQL 思考”需要一点时间来适应,这并不罕见,所以如果这个查询一开始看起来很难理解,也不要气馁。通过练习会变得更容易!
当您编写包含连接和子查询的复杂查询时,遵循以下过程会有所帮助:
- 考虑在最终输出中需要哪些数据
- 确定需要连接哪些表,以及是否需要连接子查询。
- 如果需要联接到子查询,请先编写子查询。
- 然后开始编写 SELECT 子句,接着是 join 子句和您需要的任何其他子句。
- 不要害怕一步一步地编写查询,边编写边运行—例如,在编写外部查询之前,您可以先将子查询作为“独立”查询运行,以确保它看起来像您想要的那样。
我们将编写一个查询来查找城市中心(城市)人口超过国家总人口一半的国家。有多种方法可以编写这个查询,但是我们将逐步介绍一种方法。
我们可以从编写一个查询开始,对每个国家的所有城市人口进行求和。通过对facts_id进行分组,我们可以在没有连接的情况下做到这一点(在下面的例子中,我们将使用一个限制来使输出可管理):
SELECT
facts_id,
SUM(population) urban_pop
FROM cities
GROUP BY 1
LIMIT 5;
| 事实 _id | 都市流行 |
|---|---|
| one | Three million and ninety-seven thousand |
| Ten | One hundred and seventy-two thousand |
| One hundred | One million one hundred and twenty-seven thousand |
| One hundred and one | Five thousand |
| One hundred and two | Five hundred and forty-six thousand |
接下来,我们将把facts表连接到该子查询,选择国家名称、城市人口和总人口(同样,为了保持整洁,我们使用了一个限制):
SELECT
f.name country,
c.urban_pop,
f.population total_pop
FROM facts f
INNER JOIN (
SELECT
facts_id,
SUM(population) urban_pop
FROM cities
GROUP BY 1
) c ON c.facts_id = f.id
LIMIT 5;
| 国家 | 都市流行 | 总计 _pop |
|---|---|---|
| 阿富汗 | Three million and ninety-seven thousand | Thirty-two million five hundred and sixty-four thousand three hundred and forty-two |
| 奥地利 | One hundred and seventy-two thousand | Eight million six hundred and sixty-five thousand five hundred and fifty |
| 利比亚 | One million one hundred and twenty-seven thousand | Six million four hundred and eleven thousand seven hundred and seventy-six |
| 列支敦士登 | Five thousand | Thirty-seven thousand six hundred and twenty-four |
| 立陶宛 | Five hundred and forty-six thousand | Two million eight hundred and eighty-four thousand four hundred and thirty-three |
最后,我们将创建一个新列,将城市人口除以总人口,并使用WHERE和ORDER BY对结果进行过滤/排序:
SELECT
f.name country,
c.urban_pop,
f.population total_pop
FROM facts f
INNER JOIN (
SELECT
facts_id,
SUM(population) urban_pop
FROM cities
GROUP BY 1
) c ON c.facts_id = f.id
LIMIT 5;
| 国家 | 都市流行 | 总计 _pop | 城市百分比 |
|---|---|---|---|
| 乌拉圭 | One million six hundred and seventy-two thousand | Three million three hundred and forty-one thousand eight hundred and ninety-three | 0.500315 |
| 刚果共和国 | Two million four hundred and forty-five thousand | Four million seven hundred and fifty-five thousand and ninety-seven | 0.514185 |
| 文莱 | Two hundred and forty-one thousand | Four hundred and twenty-nine thousand six hundred and forty-six | 0.560927 |
| 新喀里多尼亚 | One hundred and fifty-seven thousand | Two hundred and seventy-one thousand six hundred and fifteen | 0.578024 |
| 维尔京群岛 | Sixty thousand | One hundred and three thousand five hundred and seventy-four | 0.579296 |
| 福克兰群岛(伊斯拉斯·福克兰) | Two thousand | Three thousand three hundred and sixty-one | 0.595061 |
| 吉布提 | Four hundred and ninety-six thousand | Eight hundred and twenty-eight thousand three hundred and twenty-four | 0.598800 |
| 澳大利亚 | Thirteen million seven hundred and eighty-nine thousand | Twenty-two million seven hundred and fifty-one thousand and fourteen | 0.606083 |
| 冰岛 | Two hundred and six thousand | Three hundred and thirty-one thousand nine hundred and eighteen | 0.620635 |
| 以色列 | Five million two hundred and twenty-six thousand | Eight million forty-nine thousand three hundred and fourteen | 0.649248 |
| 阿拉伯联合酋长国 | Three million nine hundred and three thousand | Five million seven hundred and seventy-nine thousand seven hundred and sixty | 0.675288 |
| 波多黎各 | Two million four hundred and seventy-five thousand | Three million five hundred and ninety-eight thousand three hundred and fifty-seven | 0.687814 |
| 巴哈马群岛 | Two hundred and fifty-four thousand | Three hundred and twenty-four thousand five hundred and ninety-seven | 0.782509 |
| 科威特 | Two million four hundred and six thousand | Two million seven hundred and eighty-eight thousand five hundred and thirty-four | 0.862819 |
| 圣皮埃尔和密克隆 | Five thousand | Five thousand six hundred and fifty-seven | 0.883861 |
| 关岛 | One hundred and sixty-nine thousand | One hundred and sixty-one thousand seven hundred and eighty-five | 1.044596 |
| 北马里亚纳群岛 | Fifty-six thousand | Fifty-two thousand three hundred and forty-four | 1.069846 |
| 美属萨摩亚群岛 | Sixty-four thousand | Fifty-four thousand three hundred and forty-three | 1.177705 |
您可以看到,虽然我们的最终查询很复杂,但是如果您一步一步地构建它,就会更容易理解。
SQL 连接教程:后续步骤
在本 sql 连接教程中,我们学习了:
- 内连接和左连接的区别。
- 右连接和外连接的作用
- 如何选择适合您的任务的联接。
- 使用带有子查询、聚合函数和其他 SQL 技术的连接。
您可能感兴趣的其他资源包括我们的 SQL 备忘单,我们的关于 SQL 认证的文章,我们的,当然还有我们的交互式 SQL 课程。点击下面注册并免费开始!
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
SQL 运算符:6 种不同的类型(带有 45 个代码示例)
September 24, 2022
本文将介绍什么是 SQL 操作符,各种类型的操作符,以及如何使用它们的许多不同的代码示例。
和任何新技能一样,人们喜欢以不同的方式学习。如果你不喜欢通过阅读博客文章来学习,你可能会喜欢我们的交互式 SQL 课程。在这里免费试用。
什么是 SQL 运算符?
SQL 运算符是用于执行任务的特殊单词或字符。这些任务可以是从复杂的比较到基本的算术运算。把 SQL 中的操作符想象成计算器功能上的不同按钮。
我们将讨论六种类型的 SQL 操作符:算术、按位、比较、复合、逻辑和字符串。
算术运算符
算术运算符用于对数值数据进行数学运算,如加或减。
+(加法)
+符号将两个数相加。
SELECT 10 + 10;
–(减法)
–符号从一个数字中减去另一个数字。
SELECT 10 - 10;
*(乘法)
*符号是两个数的倍数。
SELECT 10 * 10;
/(除法)
/符号将一个数除以另一个数。
SELECT 10 / 10;
%(余数/模数)
%符号(有时称为模数)返回一个数除以另一个数的余数。
SELECT 10 % 10;
按位运算符
位运算符在整数数据类型的两个表达式之间执行位操作。按位运算符将整数转换为二进制位,然后对每个单独的位执行和(&符号)、或(|、^) 或 NOT (~) 运算,最后将二进制结果转换回整数。
简单提醒一下:计算中的二进制数是由 0 和 1 组成的数字。
&(按位与)
&符号(按位 AND)将一个值中的每个位与另一个值中相应的位进行比较。在下面的例子中,我们只使用了一位。因为@BitOne 的值不同于@BitTwo,所以返回 0。
DECLARE @BitOne BIT = 1
DECLARE @BitTwo BIT = 0
SELECT @BitOne & @BitTwo;
但是如果我们让两者的价值相同呢?在这种情况下,它将返回 1。
DECLARE @BitOne BIT = 1
DECLARE @BitTwo BIT = 1
SELECT @BitOne & @BitTwo;
显然这只是针对 BIT 类型的变量。如果我们开始使用数字,会发生什么?以下面的例子为例:
DECLARE @BitOne INT = 230
DECLARE @BitTwo INT = 210
SELECT @BitOne & @BitTwo;
这里返回的答案将是 194 。
你可能会想,“怎么会是 194 呢?!"这完全可以理解。为了解释原因,我们首先需要将这两个数字转换成它们的二进制形式:
@BitOne (230) - 11100110
@BitTwo (210) - 11010010
现在,我们必须遍历每个位并进行比较(因此@BitOne 中的第 1 位和@BitTwo 中的第 1 位)。如果两个数字都是 1,我们记录 1。如果一个或两个都是 0,那么我们记录一个 0:
@BitOne (230) - 11100110
@BitTwo (210) - 11010010
Result - 11000000
我们剩下的二进制数是 11000000,如果你谷歌一下,它等于一个数值 194 。
困惑了吗?放心吧!按位运算符可能很难理解,但在实践中很少使用。
&=(按位 AND 赋值)
&=符号(按位 AND 赋值)的作用与按位 AND (&)运算符相同,但它将变量的值设置为返回的结果。
|(按位或)
|符号(按位或)在两个值之间执行按位逻辑或运算。让我们重温一下之前的例子:
DECLARE @BitOne INT = 230
DECLARE @BitTwo INT = 210
SELECT @BitOne | @BitTwo;
在这种情况下,我们必须再次检查每一位并进行比较,但这一次,如果任一数字为 1,则我们记录 1。如果两者都是 0,那么我们记录一个 0:
@BitOne (230) - 11100110
@BitTwo (210) - 11010010
Result - 11110110
我们剩下的二进制数是 11110110,等于数值 246 。
|=(按位或赋值)
|=符号(按位“或”赋值)的作用与按位“或”(|)运算符相同,但它将变量的值设置为返回的结果。
^(按位异或)
^符号(按位异或)在两个值之间执行按位逻辑或运算。
DECLARE @BitOne INT = 230
DECLARE @BitTwo INT = 210
SELECT @BitOne ^ @BitTwo;
在这个例子中,我们比较每个位,如果一个位等于 1,则返回 1,但不是两个位都等于 1。
@BitOne (230) - 11100110
@BitTwo (210) - 11010010
Result - 00110100
我们剩下的二进制数是 00110100,等于一个数值 34 。
^=(按位异或赋值)
=符号(按位异或赋值)的作用与按位异或()运算符相同,但它将变量的值设置为返回的结果。
比较运算符
比较运算符用于比较两个值并测试它们是否相同。
=(等于)
=符号用于过滤等于特定值的结果。在下面的示例中,该查询将返回年龄为 20 岁的所有客户。
SELECT * FROM customers
WHERE age = 20;
!=(不等于)
的!=符号用于过滤不等于特定值的结果。在下面的示例中,该查询将返回年龄不到 20 岁的所有客户。
SELECT * FROM customers
WHERE age != 20;
>(大于)
符号用于筛选列值大于查询值的结果。在下面的示例中,该查询将返回年龄在 20 岁以上的所有客户。
SELECT * FROM customers
WHERE age > 20;
!>(不大于)
的!>符号用于过滤列值不大于查询值的结果。在下面的示例中,该查询将返回年龄不超过 20 岁的所有客户。
SELECT * FROM customers
WHERE age !> 20;
SELECT * FROM customers
WHERE age < 20;
!
的!
SELECT * FROM customers
WHERE age !< 20;
> =(大于或等于)
=符号用于筛选列值大于或等于查询值的结果。在下面的示例中,该查询将返回年龄等于或大于 20 岁的所有客户。
SELECT * FROM customers
WHERE age >= 20;
< =(小于或等于)
< =符号用于筛选列值小于或等于查询值的结果。在下面的示例中,该查询将返回年龄等于或小于 20 岁的所有客户。
SELECT * FROM customers
WHERE age <= 20;
<>(不等于)
<>符号执行的操作与!=符号,用于过滤不等于特定值的结果。您可以使用任何一种,但是<>是 SQL-92 标准。
SELECT * FROM customers
WHERE age <> 20;
复合运算符
复合运算符对变量执行运算,然后将变量的结果设置为运算的结果。就当是做 a = a (+,-,*,等等)b。
+=(加等于)
+=运算符将在原始值上加一个值,并将结果存储在原始值中。以下示例将值设置为 10,然后将该值加 5 并打印结果(15)。
DECLARE @addValue int = 10
SET @addValue += 5
PRINT CAST(@addvalue AS VARCHAR);
这也可以用在字符串上。下面的例子将两个字符串连接在一起,并打印“dataquest”。
DECLARE @addString VARCHAR(50) = “data”
SET @addString += “quest”
PRINT @addString;
-=(减去等于)
-=运算符将从原始值中减去一个值,并将结果存储在原始值中。以下示例将值设置为 10,然后从该值中减去 5,并打印结果(5)。
DECLARE @addValue int = 10
SET @addValue -= 5
PRINT CAST(@addvalue AS VARCHAR);
*=(乘等于)
*=运算符将一个值乘以原始值,并将结果存储在原始值中。以下示例将值设置为 10,然后将其乘以 5 并打印结果(50)。
DECLARE @addValue int = 10
SET @addValue *= 5
PRINT CAST(@addvalue AS VARCHAR);
/=(除以等于)
/=运算符将一个值除以原始值,并将结果存储在原始值中。以下示例将值设置为 10,然后除以 5 并打印结果(2)。
DECLARE @addValue int = 10
SET @addValue /= 5
PRINT CAST(@addvalue AS VARCHAR);
%=(模等于)
%=运算符将一个值除以原始值,并将余数存储在原始值中。以下示例将值设置为 25,然后除以 5 并输出结果(0)。
DECLARE @addValue int = 10
SET @addValue %= 5
PRINT CAST(@addvalue AS VARCHAR);
逻辑运算符
逻辑运算符是那些返回 true 或 false 的运算符,例如 AND 运算符,当两个表达式都满足时返回 true。
全部
如果所有子查询值都满足指定的条件,ALL 运算符将返回 TRUE。在下面的例子中,我们过滤了年龄大于伦敦用户最高年龄的所有用户。
SELECT first_name, last_name, age, location
FROM users
WHERE age > ALL (SELECT age FROM users WHERE location = ‘London’);
任何/一些
如果任何子查询值满足指定的条件,ANY 运算符将返回 TRUE。在下面的例子中,我们过滤了在 orders 表中有任何记录的所有产品。SOME 操作符实现了相同的结果。
SELECT product_name
FROM products
WHERE product_id > ANY (SELECT product_id FROM orders);
和
如果由 AND 分隔的所有条件都为真,则 AND 运算符返回 TRUE。在下面的例子中,我们正在过滤年龄为 20 岁、地点为伦敦的用户。
SELECT *
FROM users
WHERE age = 20 AND location = ‘London’;
在...之间
BETWEEN 运算符筛选查询,只返回符合指定范围的结果。
SELECT *
FROM users
WHERE age BETWEEN 20 AND 30;
存在
EXISTS 运算符用于通过查找子查询中是否存在任何记录来筛选数据。
SELECT name
FROM customers
WHERE EXISTS
(SELECT order FROM ORDERS WHERE customer_id = 1);
在…里
IN 运算符包括设置在 WHERE 子句中的多个值。
SELECT *
FROM users
WHERE first_name IN (‘Bob’, ‘Fred’, ‘Harry’);
喜欢
LIKE 运算符在列中搜索指定的模式。(关于这里如何/为什么使用%的更多信息,参见关于通配符运算符的部分)。
SELECT *
FROM users
WHERE first_name LIKE ‘%Bob%’;
不
如果条件不为真,NOT 运算符将返回结果。
SELECT *
FROM users
WHERE first_name NOT IN (‘Bob’, ‘Fred’, ‘Harry’);
运筹学
如果由 or 分隔的任何条件为真,OR 运算符将返回 TRUE。在下面的例子中,我们正在过滤年龄为 20 岁或居住在伦敦的用户。
SELECT *
FROM users
WHERE age = 20 OR location = ‘London’;
为空
IS NULL 运算符用于筛选值为 NULL 的结果。
SELECT *
FROM users
WHERE age IS NULL;
字符串运算符
字符串运算符主要用于字符串连接(将两个或多个字符串组合在一起)和字符串模式匹配。
+(字符串连接)
+运算符可用于将两个或多个字符串组合在一起。以下示例将输出“dataquest”。
SELECT ‘data’ + ‘quest’;
+=(字符串串联赋值)
+=用于组合两个或多个字符串,并将结果存储在原始变量中。下面的示例设置了一个变量“data”,然后将“quest”添加到该变量中,给原始变量赋予值“dataquest”。
DECLARE @strVar VARCHAR(50)
SET @strVar = ‘data’
SET @strVar += ‘quest’
PRINT @strVar;
%(通配符)
%符号——有时称为通配符——用于匹配零个或多个字符的任何字符串。通配符可以用作前缀或后缀。在下面的示例中,查询将返回名字以“dan”开头的任何用户。
SELECT *
FROM users
WHERE first_name LIKE ‘dan%’;
[]用于匹配方括号中指定的特定范围或集合内的任何字符。在下面的例子中,我们搜索名字以 d 开头,第二个字符在 c 到 r 之间的任何用户。
SELECT *
FROM users
WHERE first_name LIKE ‘d[c-r]%’’;
^
[^]用于匹配不在方括号中指定的特定范围或集合内的任何字符。在下面的例子中,我们搜索名字以 d 开头,第二个字符不是 a 的用户。
SELECT *
FROM users
WHERE first_name LIKE ‘d[^a]%’’;
_(通配符匹配一个字符)
_ 符号——有时称为下划线字符——用于在字符串比较操作中匹配任何单个字符。在下面的示例中,我们搜索第一个字符以 d 开头,第三个字符是 n 的任何用户。第二个字符可以是任何字母。
SELECT *
FROM users
WHERE first_name LIKE ‘d_n%’;
更多有用的 SQL 资源:
或者,尝试一下最好的 SQL 学习资源:您可以在浏览器中直接学习的 interactive SQL 课程。注册一个免费帐户,开始学习吧!
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
给初学者的 10 个令人兴奋的 SQL 项目想法(2022)
September 28, 2022
为了向未来或当前的雇主展示您的 SQL 技能,您需要创建自己的项目。这就是你将如何学习在现实世界中应用你的知识。
所以,让我们来看看你现在可以做的 10 个很酷的 SQL 项目。其中大部分是初学者友好的,但是列表中最后的项目更复杂。一旦你获得了一些经验,你就可以进入更困难(也更有回报)的领域。)项目。
你现在就可以开始的 10 个很酷的 SQL 项目
开始 SQL 项目最简单的方法是使用内置的sqlite3 Python 包,它实现了一个轻量级数据库引擎:SQLite。但是不要担心——您不必了解 Python!只需几个命令,我们就可以创建数据库并在其上执行查询。
所有这些项目都标有三个难度等级中的一个:简单、中级和困难。
1.中情局数据
等级:容易
在创建自己的数据库之前,您可以使用 CIA factbook 分析一个简单的数据库,其中包含世界各国的数据,如人口、地区、出生率等。这个 Dataquest 指导项目将帮助你在现实世界中应用你的知识,并在这个过程中学习新的知识。比如水土比最高的国家是哪个?
2.银行营销
等级:容易
什么定义了一个好的营销策略?我们可以使用哪些指标来调整我们的下一个营销活动?我们如何为金融机构做到这一点?卡格尔有一个银行营销数据集,最初上传到 UCI 机器学习库,它包含了从一家葡萄牙金融机构的电话营销活动中收集的大量客户数据。
让我们看看如何使用sqlite3和 Python 创建一个单表数据库。要运行代码,你可以使用谷歌实验室,在那里我们也可以上传我们需要的数据。
import sqlite3
from pathlib import Path
# Create empty database
Path("bank.db").touch()
# Connect to database
conn = sqlite3.connect("bank.db")
c = conn.cursor()
# Create a table
c.execute(
"""CREATE TABLE bank (
age int, job text,
marital text, education text,
default_e text, balance int,
housing text, loan text,
contact text, day int,
month text, duration int,
campaign int, pdays text,
previous int, poutcome text,
deposit text
);"""
)
<sqlite3.Cursor at 0x7f917402ff40>
我们现在已经成功地创建了一个只有一个空表的数据库。注意,我将列名default更改为default_e,因为default是一个保留名称,而sqlite3在试图用这个列名创建一个表时抛出了一个错误。
现在我们必须用从 Kaggle 下载的数据填充这个表。我们使用pandas(Google Colab 上一个流行的数据分析包)打开csv文件,然后将其插入数据库。
# Import pandas to work with data sets
import pandas as pd
# Open csv file
bank = pd.read_csv("bank.csv")
# Add table to database
bank.to_sql("bank", conn, if_exists="append", index=False)
11162
让我们尝试从表中获取一个条目。我们可以通过使用.execute()函数来运行一个 SQL 查询,使用fetchone()方法来获得一个条目。您可以从课程从 Python 查询 SQLite 中了解更多关于如何集成 SQL 和 Python 的信息。很简单,你不到一个小时就能学会。
简而言之,我们使用:
fetchone()得到一个结果。fetchmany()得到n结果。fetchall()获得所有结果。
# Return one row from the 'bank' table
c.execute("""SELECT * FROM bank""").fetchone()
(59,
'admin.',
'married',
'secondary',
'no',
2343,
'yes',
'no',
'unknown',
5,
'may',
1042,
1,
'-1',
0,
'unknown',
'yes')
好,那么我们对这个数据集有什么疑问呢?
- 哪些职业最受 45 岁以上客户欢迎?
- 对于多少贷款人来说,营销活动成功了?
- 成功是靠余额,存款,还是贷款?
使用基本的 SQL 查询很容易回答这些问题。
3.超市销售
难度:简单
每天有成千上万的人去超市购买食物和住房用品。通过分析这些数据,我们可以更多地了解客户在支付方式、访问次数和忠诚度计划会员资格方面的偏好——基于地点或性别。然后,我们可以调整每一个超市,以提高顾客满意度和利润。
该数据集包含一家超市公司三个分支机构在三个月内收集的销售点和客户数据。通过分析该数据集,我们可以回答这些问题:
- 哪个分支机构在忠诚度计划中效果最好?
- 会员资格取决于客户评级吗?
- 总收入是否取决于忠诚计划中客户的比例?关于支付方式?
- 男女之间的指标有区别吗?
- 哪个产品类别产生的收入最高?
4.松鼠数据
难度:简单
现在我们来分析一些搞笑的数据。你知道纽约市收集人口普查数据。。。关于松鼠?是的,他们甚至有一个网站。
这个来自 2018 年的数据集包含了 3000+只松鼠目击事件的数据,比如年龄、皮毛颜色、活动、与人类的互动等。
我们可以想到许多问题:
- 目击次数最多的日期是哪一天?
- 成年人和青少年谁跑得多?
- 哪些松鼠更愿意接近人类,在哪些区域?
- 接近人类的松鼠会吃得更频繁吗?
- 我们还可以根据地点、皮毛颜色和年龄对松鼠进行分组,看看它们是否与松鼠的活动有关。
即使你没有发现任何相关性,分析起来仍然很有趣,甚至可能让未来的雇主微笑——而积极的反应正是我们希望从雇主那里得到的!
5.80 种谷物
难度:简单
下一步是什么?我们可以通过分析来自七家制造商的 80 种谷物类型的数据集来了解我们的饮食和健康,这些数据包含营养成分(如脂肪或蛋白质)和元素(如钾)的含量。我们能回答什么问题?
- 每个厂家每种营养素和元素的平均含量是多少?
- 每种产品每盎司的热量是多少?
- 每个制造商的平均评级是多少?这和平均营养含量有什么关系吗?
- 哪个制造商拥有最佳货架位置?
- 根据蛋白质、脂肪和碳水化合物的数据,每种谷物的营养价值是多少。
6.世界幸福报告
难度:中级
让我们从销售、财务和有趣的数据中分离出来,分析一些大家更感兴趣的数据。由联合国创建的一个名为可持续发展解决方案网络的非营利组织发布了一份年度世界幸福报告,其中包含了根据受访者的回答和生活质量指标(如教育、犯罪率、医疗保健等)进行的国民幸福排名。该页面包含 2015-2022 年的报告。请注意,2022 年的报告没有所有的列。
以下是我们可能会回答的一些问题:
- 每项指标排名前 10 的国家是哪些?
- 哪些国家最慷慨,社会支持度最好?
- 对慷慨的感知取决于人均 GDP 吗?
- 各地区的平均幸福得分是多少?
- 健康预期寿命和人均 GDP 最高的国家有哪些?有什么联系吗?
这个数据集需要你使用稍微复杂一点的子句,比如GROUP BY。
7.博物馆
难度:中级
在这一点上,我们可以开始处理更大更复杂的表,比如这个数据集包含了美国各地博物馆的数据。它有 25 列,数据范围从博物馆名称到位置和收入。有了这个数据集,我们就可以利用 SQL 的强大功能,向数据库中添加另一个表来关联不同的信息,就像在现实世界的数据库中一样。例如,通过使用关于美国各州人口的数据,我们可以连接(合并)两个表,并回答 Kaggle 页面上灵感部分的问题。此外,这里还有一些更有趣的问题:
- 哪个州的博物馆平均收入最高?最高费用?
- 有多少博物馆属于大学?
- 你也可以将各州划分为个标准的联邦区域,并回答灵感部分的问题,例如哪些区域拥有人均最多的博物馆。
这一次,您将不得不使用JOIN子句来合并表。
8.YouTube 统计
难度:中级
随着我们学习更多的 SQL 和获得更多的经验,让我们继续使用多个表。YouTube 包含大量数据,人们总是很容易就此提出问题。例如,这些数据集拥有大约 2000 个 YouTube 视频和评论的数据,比如观看和喜欢的数量。我们可以用这个来回答一些基本问题:
- 评论最多的视频有哪些?还是最喜欢的?
- 每个类别总共有多少次浏览?有几个赞?
- 最受欢迎的评论是什么?
- 每个视频的浏览量/点赞量的比例是多少?每个类别?
但是真正能扩展您对 SQL 的理解的是回答更复杂的问题:
- 每个关键词类别的平均情感分是多少?
- 公司名称(即苹果或三星)在每个关键词类别中出现多少次?
在这个项目中,你必须确定,例如,如何在一列的每个单元格中搜索特定的关键字。我这里没有条款建议。谷歌一下!
9.世界上 100 个最繁忙的机场
难度:中级
国际机场吸引了数百万人,从游客到商人。机场是一个主要的基础设施项目,可以给一个与世隔绝的地区带来新的生机。因此,分析关于他们的数据对许多专业人士来说是极其重要的,即使是在航空业之外。对于这个项目,我们可以使用关于全球 100 个最繁忙机场的数据集来练习以下与数据相关的技能:
- 搜索国家/城市人口数据集,并计算人均乘客数量
- 搜索 GDP 数据并将其与乘客数量相关联
- 下载关于国际旅游的数据集,对其进行预处理以进行分析,并将该数据与乘客数量相关联
你可以看到问题和程序变得不那么具体了。不要气馁;这是学习过程的一部分。当你独自处理一个数据集时,你将不得不根据很少的数据提出你自己的问题。在您的数据科学职业生涯中,您有时会遇到来自经理的非常模糊的请求,您必须自己确定确切的问题。它确实意味着这是正确的做事方式,但这是有时会发生的事情,我们必须处理它。
您可能需要使用子查询来调查不同的经济和人口因素与机场占用率之间的关系。
10.世界发展指标
难度:难
世界发展指标是世界银行收集的一组指标,用于评估世界各地区的发展情况。来自 Kaggle 的数据包括数千个数据点,涵盖从农业和工业到贸易和获得清洁水的领域。这些数据可以作为单独的csv文件或一个数据库文件(sqlite)使用,您可以使用sqlite3包来访问。你可以回答的问题的数量将足够一个以上的项目,你选择的问题将取决于你的个人兴趣。以下是一些例子:
- 在过去几十年里,世界不同地区的城市和农村人口获得清洁水的机会是增加了还是减少了?
- 耕地面积是如何变化的?这对农业中的童工有什么影响吗?
- 二氧化碳排放量会随着工业发展而增加吗?
这些数据中的项目可能会成为你与未来雇主分享的顶点项目。因此,做好准备,利用你的扩展技能来创造最好的项目!
结论
SQL 对于任何数据从业者来说都是一项基本技能,边做边学是获得必要技能的最佳方式之一,并且有更好的机会在数据领域开始职业生涯。在本文中,我们考虑了 SQL 项目,您可以从初学者开始,然后稳步前进到更复杂的数据库。这些项目涵盖了最基本的 SQL 查询以及可用于处理多个表的最高级查询。
为了开始您的 SQL 之旅,Dataquest 提供了一门关于 SQL 基础知识的课程,该课程将在一个月内使您掌握 SQL 的基本知识,您可以在课程结束时立即将这些知识应用到指导项目中,向您未来的雇主展示您的技能。
如果您有任何问题或疑问,请随时在 LinkedIn 或 GitHub 上问我。
SQL 子查询:初学者指南(带代码示例)
原文:https://www.dataquest.io/blog/sql-subqueries-for-beginners/
June 10, 2022
每个数据科学家都需要了解 SQL 数据库,包括子查询。下面介绍一下。
在本文中,我们将介绍 SQL 子查询的基础知识,它们的语法,它们如何有用,以及在查询数据库时何时以及如何使用它们。
本文假设您对使用 SQL 选择数据有一些基本的了解,比如数据分组、聚合函数、过滤和基本连接。
什么是子查询
子查询只不过是另一个查询中的一个查询。我们主要使用它们向主查询结果添加新列、创建过滤器或创建从中选择数据的统一源。
子查询将总是在括号中,并且它可以出现在主查询中的不同位置,这取决于目标—通常在SELECT、FROM或WHERE类中。此外,子查询的数量是无限的,这意味着您可以根据需要拥有任意多的嵌套查询。
数据库
为了编写一些真正的 SQL 代码,我们将使用 Chinook 数据库作为例子。这是一个示例数据库,可用于多种类型的数据库。
该数据库包含关于一个虚构的数字音乐商店的信息,例如关于该音乐商店的艺术家、歌曲、播放列表、音乐流派和专辑的数据,以及关于该商店的员工、客户和购买的信息。
这是数据库的模式,因此您可以更好地理解我们将要编写的查询是如何工作的:

创建新列的子查询
子查询的第一个用例包括使用它向主查询的输出中添加新列。语法看起来是这样的:
SELECT column_1,
columns_2,
(SELECT
...
FROM table_2
GROUP BY 1)
FROM table_1
GROUP BY 1
我们来看一个实际的例子。
在这里,我们希望看到应用程序中用户添加每首歌曲的播放列表的数量。
主查询返回两列:歌曲名称和用户添加的播放列表数量。需要子查询的是第二列。子查询在这里是必要的,因为我们必须将分配给播放列表的track_id与曲目表中的track_id进行匹配,然后对每个曲目进行计数。
SELECT t.name,
(SELECT
count(playlist_id)
FROM playlist_track pt
WHERE pt.track_id = t.track_id
) as number_of_playlists
FROM track t
GROUP BY 1
ORDER BY number_of_playlists DESC
LIMIT 50
然后我们得到这个输出:
| 名字 | 播放列表的数量 |
|---|---|
| 《仲夏夜之梦》,作品 61。配乐:第七首《夜曲》 | five |
| BWV 988“戈德堡变奏曲”:咏叹调 | five |
| 万福马利亚。亦称 HAIL MARY | five |
| 卡门:序曲 | five |
| 卡米娜·布拉纳:哦,福尔图娜 | five |
| 乡村骑士\行动\间奏曲 | five |
| F 小调第二钢琴协奏曲,作品 21: II。稍缓慢曲 | five |
| G 大调小提琴、弦乐和通奏低音协奏曲,作品 3,第 9 首:第一乐章:快板 | five |
| 来自地球的歌,来自于青春 | five |
| 死亡之旅:女武神之旅 | five |
| 魔笛 k 620 "地狱复仇在我心中沸腾" | five |
| 绿袖幻想曲 | five |
| 伊图斯:你们崇拜上帝 | five |
| 木星,欢乐的使者 | five |
| 卡累利阿组曲,作品 11: 2。叙事曲 | five |
| Koyaanisqatsi | five |
| 耶利米哀歌,第一集 | five |
| metopes,第 29 页:Calypso | five |
| 梅女士,德乌斯 | five |
做数学
创建新列时,子查询对于执行某些计算可能也很有用。当然,如果是这种情况,子查询的输出必须是一个数字。
在下一个查询中,我们想知道数据库中每种风格的曲目所占的百分比。语法与上一个示例基本相同,只是子查询是创建新列的一部分,而不是整个新列。
对于这个任务,我们需要将每个流派的歌曲数量除以曲目表中的歌曲总数。我们可以通过以下查询轻松访问曲目总数:
SELECT
count(*) as total_tracks
FROM track
| total_tracks |
|--------------|
| 3503 |
我们可以使用以下查询找到每个流派的曲目总数:
SELECT
g.name as genre,
count(t.track_id) as number_of_tracks
FROM genre g
INNER JOIN track t on g.genre_id = t.genre_id
GROUP BY 1
ORDER BY 2 DESC
| 类型 | 轨道数量 |
|---|---|
| 岩石 | One thousand two hundred and ninety-seven |
| 拉丁语 | Five hundred and seventy-nine |
| 金属 | Three hundred and seventy-four |
| 另类&朋克 | Three hundred and thirty-two |
| 爵士乐 | One hundred and thirty |
| 电视节目 | Ninety-three |
| 布鲁斯音乐 | Eighty-one |
| 经典的 | Seventy-four |
| 戏剧 | Sixty-four |
| R&B/灵魂 | Sixty-one |
| 瑞格舞(西印度群岛的一种舞蹈及舞曲) | Fifty-eight |
| 流行音乐 | Forty-eight |
| 配乐 | Forty-three |
| 供选择的 | Forty |
| 嘻哈/说唱 | Thirty-five |
| 电子/舞蹈 | Thirty |
| 重金属 | Twenty-eight |
| 世界 | Twenty-eight |
| 科幻与幻想 | Twenty-six |
| 轻松音乐 | Twenty-four |
| 喜剧 | Seventeen |
| 波沙·诺瓦 | Fifteen |
| 科幻小说 | Thirteen |
| 摇滚乐 | Twelve |
| 歌剧 | one |
如果我们将这两个查询组合起来,使第一个查询成为子查询,则输出是每个流派的歌曲百分比:
SELECT
g.name as genre,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
FROM genre g
INNER JOIN track t on g.genre_id = t.genre_id
GROUP BY 1
ORDER BY 2 DESC
| 类型 | 滤液(percolate 的简写) |
|---|---|
| 岩石 | Zero point three seven |
| 拉丁语 | Zero point one seven |
| 金属 | Zero point one one |
| 另类&朋克 | Zero point zero nine |
| 爵士乐 | Zero point zero four |
| 电视节目 | Zero point zero three |
| 布鲁斯音乐 | Zero point zero two |
| 经典的 | Zero point zero two |
| 戏剧 | Zero point zero two |
| R&B/灵魂 | Zero point zero two |
| 瑞格舞(西印度群岛的一种舞蹈及舞曲) | Zero point zero two |
| 供选择的 | Zero point zero one |
| 轻松音乐 | Zero point zero one |
| 电子/舞蹈 | Zero point zero one |
| 重金属 | Zero point zero one |
| 嘻哈/说唱 | Zero point zero one |
| 流行音乐 | Zero point zero one |
| 科幻与幻想 | Zero point zero one |
| 配乐 | Zero point zero one |
| 世界 | Zero point zero one |
| 波沙·诺瓦 | Zero |
| 喜剧 | Zero |
| 歌剧 | Zero |
| 摇滚乐 | Zero |
| 科幻小说 | Zero |
作为筛选的子查询
使用 SQL 子查询作为主查询的过滤器是我最喜欢的用例之一。在这个场景中,子查询将位于WHERE子句中,我们可以根据子查询的输出,使用IN、=、<>、>和<等操作符进行过滤。
这是语法:
SELECT
column_1,
columns_2
FROM table_1
WHERE column_1 in
(SELECT
...
FROM table_2)
在我们的例子中,假设我们想知道每个雇员被分配到多少个至少花费 100 美元的顾客。让我们分两步来做。
首先,让我们获得每个雇员的客户数量。这是一个简单的查询。
SELECT employee_id,
e.last_name,
count(distinct customer_id) as number_of_customers
FROM employee e
INNER JOIN customer c on e.employee_id = c.support_rep_id
GROUP BY 1,2
ORDER BY 3 DESC
这是输出:
| 员工 id | 姓氏 | 客户数量 |
|---|---|---|
| three | 雄孔雀 | Twenty-one |
| four | 公园 | Twenty |
| five | 约翰逊 | Eighteen |
现在,让我们看看哪些顾客在店里至少消费了 100 美元。这是查询:
SELECT
c.customer_id,
round(sum(i.total), 2) as total
FROM customer c
INNER JOIN invoice i on c.customer_id = i.customer_id
GROUP BY c.customer_id
HAVING sum(i.total) > 100
ORDER BY 2 DESC
这是输出:
| 客户标识 | 总数 |
|---|---|
| five | One hundred and forty-four point five four |
| six | One hundred and twenty-eight point seven |
| Forty-six | One hundred and fourteen point eight four |
| Fifty-eight | One hundred and eleven point eight seven |
| one | One hundred and eight point nine |
| Thirteen | One hundred and six point nine two |
| Thirty-four | One hundred and two point nine six |
现在,为了组合这两个查询,第一个将是主查询,第二个将在WHERE子句中过滤主查询。
它是这样工作的:
SELECT employee_id,
e.last_name,
count(distinct customer_id) as number_of_customers
FROM employee e
INNER JOIN customer c on e.employee_id = c.support_rep_id
WHERE customer_id in (
SELECT
c.customer_id
FROM customer c
INNER JOIN invoice i on c.customer_id = i.customer_id
GROUP BY c.customer_id
HAVING sum(i.total) > 100)
GROUP BY 1, 2
ORDER BY 3 DESC
这是最终输出:
| 员工 id | 姓氏 | 客户数量 |
|---|---|---|
| three | 雄孔雀 | three |
| four | 公园 | three |
| five | 约翰逊 | one |
请注意两点:
- 当将查询 2 放在主查询的
WHERE子句中时,我们删除了total_purchased列。这是因为我们希望这个查询只返回一列,也就是主查询用作过滤器的那一列。如果我们没有这样做,我们将会看到这样的错误消息(取决于 SQL 的版本):
sub-select returns 2 columns - expected 1
- 我们使用了
IN操作符。顾名思义,我们想要检查哪些客户在购买金额超过 100 美元的列的列表中。
要使用像=或<>这样的数学运算符,子查询应该返回一个数字,而不是一列。在这个例子中并不是这样的,但是我们可以在必要的时候轻松地修改代码。
作为新表的子查询
我们将在本文中看到的使用 SQL 子查询的最后一种方法是用它来创建一个新的统一数据源,您可以从中提取数据。
当主查询变得太复杂时,我们使用这种方法,我们希望保持代码的可读性和组织性——当我们为了不同的目的重复使用这种新的数据源时,我们也不希望一遍又一遍地重写它。
通常看起来是这样的:
SELECT
column_1,
column_2
FROM
(SELECT
...
FROM table_1
INNER JOIN table_2)
WHERE column_1 > 100
例如,这将是我们的子查询:
SELECT c.customer_id,
c.last_name,
c.country,
c.state,
count(i.customer_id) as number_of_purchases,
round(sum(i.total), 2) as total_purchased,
(SELECT
count(il.track_id) n_tracks
FROM invoice_line il
INNER JOIN invoice i on i.invoice_id = il.invoice_id
WHERE i.customer_id = c.customer_id
) as count_tracks
FROM customer c
INNER JOIN invoice i on i.customer_id = c.customer_id
GROUP BY 1, 2, 3, 4
ORDER BY 6 DESC
其结果是这个新表:
| 客户标识 | 姓氏 | 国家 | 状态 | 购买数量 | 总计 _ 已购买 | 计数 _ 曲目 |
|---|---|---|---|---|---|---|
| five | 威彻尔 | 捷克共和国 | 没有人 | Eighteen | One hundred and forty-four point five four | One hundred and forty-six |
| six | 光着身子 | 捷克共和国 | 没有人 | Twelve | One hundred and twenty-eight point seven | One hundred and thirty |
| Forty-six | 奥赖利 | 爱尔兰 | 都柏林 | Thirteen | One hundred and fourteen point eight four | One hundred and sixteen |
| Fifty-eight | Pareek | 印度 | 没有人 | Thirteen | One hundred and eleven point eight seven | One hundred and thirteen |
| one | 贡萨尔维斯 | 巴西 | 特殊卡 | Thirteen | One hundred and eight point nine | One hundred and ten |
| Thirteen | 拉莫斯 | 巴西 | DF | Fifteen | One hundred and six point nine two | One hundred and eight |
| Thirty-four | 费尔南德斯 | 葡萄牙 | 没有人 | Thirteen | One hundred and two point nine six | One hundred and four |
| three | 特里布莱 | 加拿大 | 质量控制 | nine | Ninety-nine point nine nine | One hundred and one |
| forty-two | 吉拉德 | 法国 | 没有人 | Eleven | Ninety-nine point nine nine | One hundred and one |
| Seventeen | 史密斯(姓氏) | 美利坚合众国 | 西澳大利亚州 | Twelve | Ninety-eight point zero one | Ninety-nine |
| Fifty | 穆尼奥斯 | 西班牙 | 没有人 | Eleven | Ninety-eight point zero one | Ninety-nine |
| Fifty-three | 休斯 | 联合王国 | 没有人 | Eleven | Ninety-eight point zero one | Ninety-nine |
| Fifty-seven | 罗哈斯 | 辣椒 | 没有人 | Thirteen | Ninety-seven point zero two | Ninety-eight |
| Twenty | 面粉厂主 | 美利坚合众国 | 加拿大 | Twelve | Ninety-five point zero four | Ninety-six |
| Thirty-seven | 齐默尔曼 | 德国 | 没有人 | Ten | Ninety-four point zero five | Ninety-five |
| Twenty-two | 李科克 | 美利坚合众国 | 佛罗里达州 | Twelve | Ninety-two point zero seven | Ninety-three |
| Twenty-one | 追赶 | 美利坚合众国 | 女士 | Eleven | Ninety-one point zero eight | Ninety-two |
| Thirty | 弗朗西斯 | 加拿大 | 在…上 | Thirteen | Ninety-one point zero eight | Ninety-two |
| Twenty-six | 坎宁安 | 美利坚合众国 | 谢谢 | Twelve | Eighty-six point one three | Eighty-seven |
| Thirty-six | 裁缝店 | 德国 | 没有人 | Eleven | Eighty-five point one four | Eighty-six |
| Twenty-seven | 灰色的 | 美利坚合众国 | 阿塞拜疆(Azerbaijan 的缩写) | nine | Eighty-four point one five | eighty-five |
| Two | 克勒 | 德国 | 没有人 | Eleven | Eighty-two point one seven | Eighty-three |
| Twelve | 阿尔梅达 | 巴西 | 交叉路口(road junction) | Eleven | Eighty-two point one seven | Eighty-three |
| Thirty-five | 桑帕约 | 葡萄牙 | 没有人 | Sixteen | Eighty-two point one seven | Eighty-three |
| Fifty-five | 泰勒 | 澳大利亚 | 新南威尔士 | Ten | Eighty-one point one eight | Eighty-two |
在这个新表中,我们整合了数据库中每个客户的 ID、姓氏、国家、州、购买次数、花费的总金额以及购买的曲目数量。
现在,我们可以看到美国哪些用户购买了至少 50 首歌曲:
SELECT
new_table.*
FROM
(SELECT c.customer_id,
c.last_name,
c.country,
c.state,
count(i.customer_id) as number_of_purchases,
round(sum(i.total), 2) as total_purchased,
(SELECT
count(il.track_id) n_tracks
FROM invoice_line il
INNER JOIN invoice i on i.invoice_id = il.invoice_id
WHERE i.customer_id = c.customer_id
) as count_tracks
FROM customer c
INNER JOIN invoice i on i.customer_id = c.customer_id
GROUP BY 1, 2, 3, 4
ORDER BY 6 DESC) as new_table
WHERE
new_table.count_tracks >= 50
AND new_table.country = 'USA'
请注意,我们只需要选择列,并在 SQL 子查询中应用我们想要的过滤器。
这是输出:
| 客户标识 | 姓氏 | 国家 | 状态 | 购买数量 | 总计 _ 已购买 | 计数 _ 曲目 |
|---|---|---|---|---|---|---|
| Seventeen | 史密斯(姓氏) | 美利坚合众国 | 西澳大利亚州 | Twelve | Ninety-eight point zero one | Ninety-nine |
| Twenty | 面粉厂主 | 美利坚合众国 | 加拿大 | Twelve | Ninety-five point zero four | Ninety-six |
| Twenty-two | 李科克 | 美利坚合众国 | 佛罗里达州 | Twelve | Ninety-two point zero seven | Ninety-three |
| Twenty-one | 追赶 | 美利坚合众国 | 女士 | Eleven | Ninety-one point zero eight | Ninety-two |
| Twenty-six | 坎宁安 | 美利坚合众国 | 谢谢 | Twelve | Eighty-six point one three | Eighty-seven |
| Twenty-seven | 灰色的 | 美利坚合众国 | 阿塞拜疆(Azerbaijan 的缩写) | nine | Eighty-four point one five | eighty-five |
| Eighteen | 布鲁克斯 | 美利坚合众国 | 纽约州 | eight | Seventy-nine point two | Eighty |
| Twenty-five | 斯蒂文斯 | 美利坚合众国 | WI | Ten | Seventy-six point two three | Seventy-seven |
| Sixteen | 哈里斯 | 美利坚合众国 | 加拿大 | eight | Seventy-four point two five | Seventy-five |
| Twenty-eight | 巴尼特 | 美利坚合众国 | 世界时 | Ten | Seventy-two point two seven | Seventy-three |
| Twenty-four | 罗尔斯顿 | 美利坚合众国 | 伊利诺伊 | eight | Seventy-one point two eight | seventy-two |
| Twenty-three | 戈登 | 美利坚合众国 | 马萨诸塞州 | Ten | Sixty-six point three three | Sixty-seven |
| Nineteen | 戈耶 | 美利坚合众国 | 加拿大 | nine | Fifty-four point four five | Fifty-five |
我们还可以看到每个州购买了至少 50 首歌曲的用户数量:
SELECT
state,
count(*)
FROM
(SELECT c.customer_id,
c.last_name,
c.country,
c.state,
count(i.customer_id) as number_of_purchases,
round(sum(i.total), 2) as total_purchased,
(SELECT
count(il.track_id) n_tracks
FROM invoice_line il
INNER JOIN invoice i on i.invoice_id = il.invoice_id
WHERE i.customer_id = c.customer_id
) as count_tracks
FROM customer c
INNER JOIN invoice i on i.customer_id = c.customer_id
GROUP BY 1, 2, 3, 4
ORDER BY 6 DESC) as new_table
WHERE
new_table.count_tracks >= 50
AND new_table.country = 'USA'
GROUP BY new_table.state
ORDER BY 2 desc
现在,我们只需要添加聚合函数count和GROUP BY子句。我们继续使用子查询,就好像它是一个新的数据源。
输出:
| 状态 | 计数(*) |
|---|---|
| 加拿大 | three |
| 阿塞拜疆(Azerbaijan 的缩写) | one |
| 佛罗里达州 | one |
| 伊利诺伊 | one |
| 马萨诸塞州 | one |
| 女士 | one |
| 纽约州 | one |
| 谢谢 | one |
| 世界时 | one |
| 西澳大利亚州 | one |
| WI | one |
还可以使用这个新的 SQL 表进行一些计算,并按订单选择平均花费最高的前 10 名用户:
SELECT
customer_id,
last_name,
round(total_purchased / number_of_purchases, 2) as avg_purchase
FROM
(SELECT c.customer_id,
c.last_name,
c.country,
c.state,
count(i.customer_id) as number_of_purchases,
round(sum(i.total), 2) as total_purchased,
(SELECT
count(il.track_id) n_tracks
FROM invoice_line il
INNER JOIN invoice i on i.invoice_id = il.invoice_id
WHERE i.customer_id = c.customer_id
) as count_tracks
FROM customer c
INNER JOIN invoice i on i.customer_id = c.customer_id
GROUP BY 1, 2, 3, 4
ORDER BY 6 DESC) as new_table
ORDER BY 3 DESC
LIMIT 10
我们使用子查询中的两列来执行计算,并得到以下结果:
| 客户标识 | 姓氏 | 平均购买量 |
|---|---|---|
| three | 特里布莱 | Eleven point one one |
| six | 光着身子 | Ten point seven two |
| Twenty-nine | 褐色的 | Ten point one five |
| Eighteen | 布鲁克斯 | Nine point nine |
| Thirty-seven | 齐默尔曼 | Nine point four |
| Twenty-seven | 灰色的 | Nine point three five |
| Sixteen | 哈里斯 | Nine point two eight |
| forty-two | 吉拉德 | Nine point zero nine |
| Fifty | 穆尼奥斯 | Eight point nine one |
| Fifty-three | 休斯 | Eight point nine one |
根据用户的需要,使用该子查询中的数据还有许多其他方法,甚至可以根据需要构建一个更大的子查询。
如果为此目的使用子查询过于频繁,那么根据数据库的体系结构,在数据库中创建一个视图,并使用这个新视图作为新的统一数据源可能会很有意思。请咨询您的数据工程团队!
结论
SQL 子查询是一个非常重要的工具,不仅对数据科学家来说如此,对任何经常使用 SQL 的人来说也是如此——花时间去理解它们绝对是值得的。
在本文中,我们介绍了以下内容:
- 如何以及何时使用子查询
- 使用子查询在主查询中创建新列
- 使用子查询作为过滤器
- 使用子查询作为新的数据源
SQL 教程:选择没有聚合函数的未分组列
原文:https://www.dataquest.io/blog/sql-tutorial-selecting-ungrouped-columns-without-aggregate-functions/
January 12, 2021
什么时候一个返回正确答案的 SQL 查询实际上是错误的?在本教程中,我们将仔细看看一个非常常见的错误。它实际上会返回正确的答案,但它仍然是一个必须避免的错误。
这听起来可能相当神秘,所以让我们开始吧。我们将举例说明您可能甚至不知道自己正在犯的 SQL 错误,并强调如何正确处理这个问题。
问题:正确的答案,但错误的 SQL 查询
在 Dataquest,我们最喜欢用来教授 SQL 的数据库之一是Chinook——一个虚拟在线音乐商店记录的数据库。在我们使用的一门课程中,学员们被要求从每个国家中找出花钱最多的顾客。
他们经常最终创造出下面的 CTE 。它包含每个客户的一行,其中包含他们的姓名、国家和消费总额:
| 国家 | 客户名称 | 总计 _ 已购买 |
|---|---|---|
| 阿根廷 | 迭戈·古铁雷斯 | Thirty-nine point six |
| 澳大利亚 | 马克·泰勒 | Eighty-one point one eight |
| 奥地利 | 阿斯特丽德·格鲁伯 | Sixty-nine point three |
| 比利时 | 好了,伙计们 | Sixty point three nine |
| 巴西 | 路易斯·贡萨尔维斯 | One hundred and eight point nine |
| 加拿大 | 弗朗索瓦·特伦布莱 | Ninety-nine point nine nine |
| 辣椒 | 路易斯·罗哈斯 | Ninety-seven point zero two |
| 捷克共和国 | 卫曲德人 | One hundred and forty-four point five four |
| 丹麦 | 卡拉·尼尔森 | Thirty-seven point six two |
| 芬兰 | 你好蜘蛛侠 | Seventy-nine point two |
| 法国 | 怀亚特吉拉德 | Ninety-nine point nine nine |
| 德国 | Fynn Zimmermann | Ninety-four point zero five |
| 匈牙利 | Ladislav Kovács | Seventy-eight point two one |
| 印度 | Manoj Pareek 先生 | One hundred and eleven point eight seven |
| 爱尔兰 | 休·奥莱利 | One hundred and fourteen point eight four |
| 意大利 | 卢卡斯·曼奇尼 | Fifty point four nine |
| 荷兰 | 约翰内斯·范德伯格 | Sixty-five point three four |
| 挪威 | Bjørn Hansen | Seventy-two point two seven |
| 波兰 | 我的天 | Seventy-six point two three |
| 葡萄牙 | 约翰·费尔南德斯 | One hundred and two point nine six |
| 西班牙 | 恩里克·穆尼奥斯 | Ninety-eight point zero one |
| 瑞典 | 乔金约翰森 | Seventy-five point two four |
| 美利坚合众国 | 杰克·史密斯 | Ninety-eight point zero one |
| 联合王国 | 菲尔·休斯 | Ninety-eight point zero one |
我们称之为 CTE。
通常,他们会使用以下查询获得正确的输出:
SELECT country, customer_name,
MAX(total_purchased)
FROM customer_country_purchases
GROUP BY country;
英文:选择国家,该国家的最高消费金额,并包括客户的姓名。
这是一个非常自然的尝试,它会产生正确的输出!然而,正如您可能已经从我的措辞中预料到的那样,这个解决方案并不像看上去那样简单。
这有什么不好?
这篇文章的目的是澄清什么是反对上述方法。为了更容易直观地看到正在发生的事情,我们将放弃 Chinook,使用一个更小的表。我们将使用elite_agent表。
(这也是虚构的数据库;可以把它想象成一个按城市、性别和年龄排列的特工表)。
| 身份证明(identification) | 城市 | 性别 | 年龄 |
| one | 里斯本 | M | Twenty-one |
| Two | 芝加哥 | F | Twenty |
| three | 纽约 | F | Twenty |
| four | 芝加哥 | M | Twenty-seven |
| five | 里斯本 | F | Twenty-seven |
| six | 里斯本 | M | Nineteen |
| seven | 里斯本 | F | Twenty-three |
| eight | 芝加哥 | F | Twenty-four |
| nine | 芝加哥 | M | Twenty-one |
如果你想尝试一下,这里有一个包含这个表的 SQLite 数据库。
如果我们将该表与我们使用的 Chinook 表进行比较,我们会发现它们在如何处理每列中的数据方面非常相似:
country在奇努克数据库中类似于城市name类似于性别total_purchased类似于年龄
考虑到这一点,我们可以为这个新表构造一个查询,这个查询本质上与我们在 Chinook 中看到的有问题的查询相同:
SELECT city, gender,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;
在代码方面,这些查询是等效的。
那么他们有什么问题呢?让我们开始回答这个问题。
据推测,这个查询的目标是确定最老的代理的年龄。如果我们不想要名字,我们将运行下面的查询。
SELECT city,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;
下面是使用 SQLite 引擎的输出:
| 城市 | 经营 |
|---|---|
| 芝加哥 | Twenty-seven |
| 里斯本 | Twenty-seven |
| 纽约 | Twenty |
因为我们是按city分组的,每行代表一个城市。我们还包括了每个组的最大年龄。
如果我们包括gender,我们将重现我们看到的这个表的第一个查询——不正确的那个。
为什么在这个查询中包含性别很重要?我们的结果是每组一行——在本例中,每个城市一行。城市没有性别,所以我们可以说在这个查询中包含性别在概念层面上没有意义。
但这不是这里的实际问题。******
**### 用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
“空列”问题
我们将调用在SELECT中的列/表达式,这些列/表达式不在聚合函数中,也不在GROUP BY、和、列中。换句话说,如果我们的结果包括一个我们没有分组的列,我们也没有对它执行任何类型的聚合或计算,这就是一个空列。
在上面的查询中,gender将生成一个空列——我们没有按性别分组,也没有对性别数据进行任何类型的聚合。这里的性别数据点本质上是“逢场作戏”
现在,在我们的课程中,我们使用的是 SQLite ,这在现实工作中也很常见。尽管空列不会给查询增加意义,但 SQLite 确实允许它们存在:
SELECT city, gender,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;
| 城市 | 性别 | 经营 |
|---|---|---|
| 芝加哥 | M | Twenty-seven |
| 里斯本 | F | Twenty-seven |
| 纽约 | F | Twenty |
有了这些结果,人们可能会认为这个查询是有意义的,因为包含gender意味着包含年龄等于max_age的代理的gender。
但是,当我们不用最大年龄来计算平均值这样的统计数据时,这种辩护就站不住脚了:
SELECT city, gender,
AVG(age) AS mean_age
FROM elite_agent
GROUP BY city;
| 城市 | 性别 | 平均年龄 |
|---|---|---|
| 芝加哥 | M | Twenty-three |
| 里斯本 | F | Twenty-two point five |
| 纽约 | F | Twenty |
在这里,我们看到一个城市,该城市中代理的平均年龄,以及性别。但是这个性别栏是什么意思呢?
检查表格,我们看到对于每个给定的城市,没有代理人的年龄等于他们城市的平均值。在这种情况下,输出完全是无意义的。
即使有年龄等于平均值的代理,也不会使输出正确。
我们还可以看到,这在电子表格的数据透视表世界中是不正确的。

在上面的数据透视表中,如果我们将gender作为一个值,我们将被迫选择一个聚合函数,如果我们将它作为一行,我们将得到下表:

它为每一个现有的城市和性别的组合创造了一个群体,这不是我们想要的。
那么,为什么下面的查询运行良好呢?
SELECT city, gender,
MAX(age) AS max_age
FROM elite_agent
GROUP BY city;
由于 SQLite 中的一个特殊特性,这个查询成功了(即,它输出了正确的结果)。来自文档:
避免 SQL 查询中的空列
虽然 SQLite 以这种方式处理问题,并因此输出正确的结果,尽管包含了空列,这种行为在不同的数据库中并没有标准化。因此,如果我们决定依赖它,我们应该小心——在 SQLite 之外的东西上运行相同的查询可能会产生不同的结果。
更广泛地说,这是 SQL 约定:查询不应该有空列。这个约定是在 SQL:1999 中引入的——一套关于 SQL 应该如何工作的规则。根据该标准:
此外,当
SELECT语句包含GROUP BY时,该语句的选择列表可能只包含对每个组都是单值的列的引用——这意味着选择列表不能包含对不包含在GROUP BY子句中的中间结果列的引用,除非该列是 set 函数之一的参数(AVG、COUNT、MAX、MIN、SUM、EVERY、ANY、SOME)。其中的每一个都将来自一列的值的集合缩减为单个值)。
避免裸露的色谱柱有以下好处:
- 它允许代码移植到其他数据库。一些 SQL 引擎不接受空列作为有效查询。运行它的人可能会表现出意想不到的行为。
- 它使代码更具可读性:如果不使用空列,没有 SQLite 经验的人会更容易理解代码。
- 它使代码更加直观——正如我们在上面看到的,空列通常没有意义,所以包含它们会使数据更难解释。
第一点可能是最重要的。例如, T-SQL 会对同一个查询产生以下错误:
Column 'elite_agent.gender' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
同样, Postgres 会给我们ERROR: column "elite_agent.gender" must appear in the GROUP BY clause or be used in an aggregate function Position: 14。
最后,甲骨文给了我们ORA-00979: not a GROUP BY expression。
这个错误信息并不特别详细,但是文档告诉我们:
GROUP BY 子句不包含 SELECT 子句中的所有表达式。GROUP BY 子句中必须列出未包含在组函数中的选择表达式,如 AVG、计数、最大值、最小值、总和、标准偏差或方差。
MySQL 是上述第一点的另一个很好的例子,因为这种查询的结果并不总是相同的(与 SQLite 相反)。另一个是 SAS ,它为每个结果重复性别值:
| 城市 | 性别 | 年龄 |
|---|---|---|
| 芝加哥 | F | Twenty-three |
| 芝加哥 | M | Twenty-three |
| 里斯本 | F | Twenty-two point five |
| 里斯本 | M | Twenty-two point five |
| 纽约 | F | Twenty |
我们如何解决它?
让我们回到最初的查询,回顾一下为什么它会有问题,尽管它确实产生了正确的输出(至少在使用 SQLite 时):
SELECT country, customer_name,
MAX(total_purchased)
FROM customer_country_purchases
GROUP BY country;
我们现在可以做如下观察:
- 当每行(组)代表一个国家时,包含
customer_name是没有意义的。 - 这种解决方案在技术上最终是正确的,但这只是因为 SQLite 处理这类查询的方式不同于标准方式。
- 主要的要点是:使用
GROUP BY子句的查询不应该有空列。
经过这一切,我们仍然没有提供一个适当的方法来解决这个问题。有一种方法可以从战略上分解如下:
- 创建一个表格,查找每个国家的最大花费金额。
- 将
customer_country_purchases与上面在 amount 列上创建的表连接起来。
SELECT ccp.country,
ccp.customer_name,
ccp.total_purchases AS total_purchased
FROM customer_country_purchases AS ccp
INNER JOIN (SELECT country,
MAX(total_purchases) AS max_purchase
FROM customer_country_purchases
GROUP BY 1) AS cmp
ON ccp.country = cmp.country
AND ccp.total_purchases = cmp.max_purchase
ORDER BY ccp.country;
在社区的这个帖子里可以找到这个练习的完整解决方案。虽然解决方案是由这篇博文的作者写的,但主要观点是由我们的一位学习者提出的!
您可能会发现另一个有用的资源:我们的 SQL 备忘单,可以在线获得,也可以下载 PDF。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
SQL 与 MySQL:区别的简单指南
February 11, 2021
SQL 和 MySQL 是世界上最流行的两种数据管理工具。但是对于一个初学者,或者甚至是更有经验的人来说,这两者之间的区别可能会令人困惑。
在这篇文章中,我们将定义什么是 SQL 和 MySQL,研究它们之间的区别,并深入研究一些可供选择的产品。
必备的 SQL 相关关键术语
在我们开始之前,让我们解释一下我们将在整个过程中使用的几个关键术语。如果您想直接进入文章或稍后返回以了解更多信息,请点击此处随意跳过这一部分。
数据库ˌ资料库
数据库是存储在计算机中的一组数据,它的结构通常使数据易于访问。
关系数据库管理系统
关系数据库是一种允许我们识别和访问与数据库中另一段数据相关的数据的数据库。它将数据存储在一系列表的行和列中,以提高处理和查询的效率。
一个简单的关系数据库示例:假设一家小企业 X 公司接受客户订单。它在其数据库中建立了两个表:
- 客户信息表(有
customer_id、address、phone_number等字段) - 客户订单表(有
customer_id、product、quantity等字段)
这两个表有关系(它们共享customer_id字段)。这就是为什么这是一个关系数据库。
在 X 公司的仓库中,他们通过检查客户订单表中的记录来处理订单。但是他们也可以使用 orders 表中的customer_id从 Customer information 表中获取关于客户的更多信息。
这不仅是一种更有效的数据存储方式,还意味着如果您需要更新客户信息,您可以在一个地方(客户信息表)完成,而不必使用冗余信息更新多个表。
我们关于 SQL 基础知识的文章更详细地介绍了关系数据库。大多数现代数据库都是这样建立的,因为它们更易于管理、灵活且可伸缩。
关系数据库有时被称为 RDBMS,即关系数据库管理系统。
存储引擎
存储引擎是数据库管理系统用来从数据库创建、读取和更新数据的一个软件。
开放源码
开源仅仅意味着软件的原始源代码对所有人免费开放,并且可以被重新分发和修改。
什么是 SQL?
SQL 代表结构化查询语言,发音为“S.Q.L .”或“Sequel”。它是一种特殊的编程语言,用于与数据库通信。
如果您想添加、检索或更新数据库中的数据,您可以使用 SQL 来完成。
这很重要,因为大多数公司都将数据存储在数据库中。数据库有很多种类型,其中大多数都使用 SQL。我们将在本文中讨论其中的两个(MySQL 和 SQL Server),但还有许多其他的,例如 PostgreSQL、IBM Db2 和 Amazon Aurora,这里仅举几例。
无论您或您的公司使用哪种数据库,学习 SQL 的基础知识都可能对您有所帮助。
有趣的事实:SQL 在 1986 年成为美国国家标准协会(ANSI)的官方标准,在 1987 年成为国际标准化组织(ISO)的官方标准。虽然它已经存在了几十年,但它在今天仍然被广泛使用并且非常受欢迎!
什么是 MySQL?
MySQL 是 Oracle 拥有的开源关系数据库管理系统(RDBMS)。
由于几个原因,它是一个非常受欢迎的工具。首先,它的开源状态意味着它可以完全免费使用。如果愿意,有经验的开发人员甚至可以直接进入并修改它的源代码来满足他们的需求。
尽管 MySQL 可以免费使用,但 Oracle 确实提供了卓越支持服务,您可以通过商业许可购买。
MySQL 也得到大力支持,用户可以在各种平台和操作系统上运行该软件,包括 Windows、Linux、UNIX 等。
MySQL 为其表提供了各种存储引擎:MyISAM、InnoDB、Merge、MEMORY (HEAP)、ARCHIVE、CSV 和 FEDERATED。
例如,CSV 引擎将以 CSV 文件格式存储数据。这可用于将数据迁移到替代的非 SQL 应用程序中,如电子表格软件。
这些存储引擎各有优缺点。在创建数据库之前,了解每一种方法并为您的表选择最合适的方法以最大限度地提高数据库的性能是很重要的。
我们仅仅触及了 MySQL 所能提供的皮毛。不过,了解一下 SQL 和 MySQL 的区别应该就够了。
有趣的事实:MySQL 的名字来源于创始人之一——Michael“Monty”wide nius——他以他女儿 My 的名字给它命名。
SQL 和 MySQL 有什么区别?
简而言之,SQL 是一种查询数据库的语言,MySQL 是一种开源数据库产品。
SQL 用于访问、更新和维护数据库中的数据,而 MySQL 是一种 RDBMS,允许用户对数据库中的数据进行组织。
SQL 变化不大,因为它是一种语言。MySQL 经常更新,因为它是一个软件。
通俗地说,SQL 可以被看作是银行出纳员,MySQL 可以被看作是银行。你需要银行出纳员(SQL)与银行(MySQL)通信,你需要银行管理钱(数据)。他们协同工作,但他们是完全不同的。
什么是 SQL Server?
和 MySQL 一样,SQL Server 也是一个关系数据库管理系统。但是,与 MySQL 不同,SQL Server 不是开源的。它归微软所有,根据用户的需求和预算,它有几个版本。
其中一个版本名为 SQL Server Express,可以免费下载和分发。它包括一个专门针对嵌入式和小规模应用的数据库
对于该领域的新手来说,一个常见的问题是“SQL 和 SQL Server 是一回事吗?”。一句话:不会。这两者之间的区别类似于我们在 SQL 和 MySQL 之间的区别。SQL 是一种查询数据库的语言,SQL Server 是一种管理关系数据库的系统。
就 MySQL 和 SQL Server 而言,没有适合每个组织的正确答案。
如果你是一家资金紧张的初创公司,你可能会选择 MySQL。
如果您是一家希望在数据库上运行大量活动的大公司,那么您可能会倾向于 SQL Server。
归根结底,每个系统都有自己的优缺点。
我为什么要使用 SQL?
如果你想要一份数据方面的工作,那么你需要学习 SQL 。它得到了很好的支持,是数据科学中最常用的语言,并且需求一直很高。
查看我们关于 SQL 认证的文章,了解为什么学习 SQL 认证是如此重要的技能。
我为什么要使用 MySQL?
如果你想建立一个便宜(或者免费)的数据库,你应该使用 MySQL。),安全可靠。您可以下载该软件,并在几分钟内开始运行。
然后,您需要学习 SQL 语言,开始有效地使用它。
结论
正如我们所见,很难实际比较 SQL 和 MySQL。虽然它们是相关的(并且有相似的名字),但是它们做完全不同的事情,并且可以单独使用或者串联使用,这取决于你想要实现的目标。
如果你想了解关于这个话题的更多信息,请查看 Dataquest 的交互式SQL 和数据库介绍课程,以及我们的 SQL 基础知识,它们将帮助你在大约 2 个月内掌握这些技能。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
SQL 与 T-SQL:了解差异
March 4, 2021
SQL 或 T-SQL——你需要学习哪一个?
SQL 和 T-SQL 在数据库和数据科学行业中都有大量的使用。但是它们到底是什么呢?这两种查询语言在名称和功能上都非常相似,因此很难理解它们之间的区别。
在这篇文章中,我们将:定义什么是标准 SQL 和 T-SQL,研究它们之间的区别,提供各自的例子,总结你应该学习哪一个以及为什么。
- 定义什么是标准 SQL 和 T-SQL
- 调查它们之间的差异
- 提供每个的示例
- 总结你应该学习哪些内容,为什么要学
什么是标准 SQL?
标准 SQL,通常简称为“SQL”,是一种称为查询语言的编程语言。查询语言用于与数据库通信。
SQL 用于添加、检索或更新存储在数据库中的数据。它被用于许多不同类型的数据库。也就是说,如果你学习了 SQL 的基础,你将在数据职业生涯中处于有利地位。
数据库和存储在其中的数据是许多公司运营的核心部分。一个简单的例子是,零售商可能会将订单或客户信息存储在数据库中。SQL 是一种允许公司处理这些数据的编程语言。
什么是 T-SQL?
T-SQL 代表 Transact-SQL,有时也称为 TSQL,是主要在 Microsoft SQL Server 中使用的 SQL 语言的扩展。这意味着它提供了 SQL 的所有功能,但增加了一些额外的功能。
你可以把它想象成一种 SQL 方言——它非常类似于常规的 SQL,但是它有一些额外的和不同的地方,使它独一无二。
尽管标准 SQL 有清晰而严格的规范,但它确实允许数据库公司添加自己的扩展,以使它们有别于其他产品。对于 Microsoft SQL Server 数据库来说,T-SQL 就是这样一个例子— T-SQL 是该软件的核心,并且在其中运行大多数操作。
大多数主要的数据库供应商都为自己的产品提供了自己的 SQL 语言扩展,T-SQL 就是其中使用最广泛的一个例子(因为 Microsoft SQL server 很流行)。
简而言之:当您在 Microsoft SQL Server 中编写查询时,您可以有效地使用 T-SQL。无论应用程序的用户界面如何,所有与 SQL Server 通信的应用程序都是通过向服务器发送 T-SQL 语句来进行通信的。
但是,除了 SQL Server,其他数据库管理系统(DBMS)也支持 T-SQL。另一款微软产品 Microsoft Azure SQL Database 支持 T-SQL 的大部分功能。
T-SQL 旨在使支持它的数据库的工作更容易、更高效。
SQL 和 T-SQL 有什么区别?
现在我们已经介绍了这两者的基础知识,让我们来看看它们的主要区别:
差异#1
明显的区别在于它们的设计目的:SQL 是一种用于操作存储在数据库中的数据的查询语言。T-SQL 也是一种查询语言,但它是 SQL 的扩展,主要用于 Microsoft SQL Server 数据库和软件。
差异#2
SQL 是开源的。T-SQL 由微软开发并拥有。
差异#3
SQL 语句一次执行一条,也称为“非过程化”T-SQL 以一种“过程化”的方式执行语句,这意味着代码将作为一个块,在逻辑上以结构化的顺序进行处理。
每种方法都有优点和缺点,但从学习者的角度来看,这种差异并不太重要。您将能够以任何一种语言获取和处理您想要的数据,只是根据您使用的语言和查询的具体情况,您处理数据的方式会有所不同。
差异#4
除了这些更普遍的差异之外,SQL 和 T-SQL 还有一些稍微不同的命令关键字。T-SQL 还具有不属于常规 SQL 的功能。
这方面的一个例子是我们如何选择最上面的 X 行。在标准 SQL 中,我们会使用 LIMIT 关键字。在 T-SQL 中,我们使用 TOP 关键字。
这两个命令做同样的事情,正如我们在下面的例子中看到的。这两个查询都将返回 users 表中按 age 列排序的前十行。
SQL 示例
SELECT *
FROM users
ORDER BY age
LIMIT 10;
T-SQL 示例
SELECT TOP 10 (*)
FROM users
ORDER BY age;
差异#5
最后,如前所述,T-SQL 提供了常规 SQL 中没有的功能。ISNULL 函数就是一个例子。这将替换来自特定列的空值。对于年龄列中值为 NULL 的任何行,下面的将返回年龄“0”。
SELECT ISNULL(0, age)
FROM users;
(当然,在标准 SQL 中也有这样做的种方式,但是命令略有不同。)
这些只是一些代码差异,让您对两者的比较有所了解,当然,还有更多。通过我们丰富的指南,您可以了解更多关于 SQL 命令的信息。当然,微软有与 T-SQL 一起工作的文档。
学哪个比较好?
如果你想以任何方式使用数据库,或者如果你正在寻找一份数据工作,学习 SQL 是必要的。
因为 T-SQL 是 SQL 的扩展,所以在开始之前,您需要学习 SQL 的基础知识。如果您首先学习 T-SQL,无论如何,您最终都会学到标准 SQL 的知识。
对于大多数事情来说,你选择学什么应该取决于你想要达到的目标。如果您打算使用 Microsoft SQL server,那么学习更多关于 T-SQL 的知识是值得的。如果你是一个初学使用数据库的人,那就从学习 SQL 开始吧。
如果你想了解关于这个话题的更多信息,请查看 Dataquest 的交互式SQL 和数据库介绍课程,以及我们的 SQL 基础知识,帮助你在大约 2 个月内掌握这些技能。
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
在 R 中使用线性回归进行预测建模
原文:https://www.dataquest.io/blog/statistical-learning-for-predictive-modeling-r/
May 16, 2018
在 R 编程中,预测模型对于预测未来的结果和估计那些不切实际的度量是非常有用的。例如,数据科学家可以使用预测模型根据降雨量和温度预测作物产量,或者确定具有某些特征的患者是否更有可能对新药产生不良反应。
在我们具体讨论线性回归之前,让我们提醒自己典型的数据科学工作流可能是什么样子。很多时候,我们会从一个我们想回答的问题开始,然后做如下的事情:
- 收集一些与问题相关的数据(越多越好)。
- 如果需要,将数据清理、扩充和预处理成方便的形式。
- 对数据进行探索性分析,以便更好地理解数据。
- 以你的发现为指导,构建数据的某个方面的模型。
- 使用该模型来回答您开始提出的问题,并验证您的结果。
线性回归是数据科学家用于预测建模的最简单、最常用的监督机器学习算法之一。在本帖中,我们将使用线性回归来构建一个模型,该模型可以根据研究树木的人更容易测量的指标来预测樱桃树的体积。
在这篇博文中,我们将使用 R 来探索这个数据集,并学习线性回归的基础知识。如果你是学习 R 语言的新手,我们推荐我们的 R 基础和 R 编程:中级课程,它们来自我们的 R 数据分析师路径。掌握一些非常基本的统计学知识也会有所帮助,但是如果你知道什么是均值和标准差,你就能理解了。如果您想自己练习构建模型和可视化,我们将使用下面的 R 包:
data sets这个包包含了各种各样的练习数据集。我们将使用其中的一个“树”来学习构建线性回归模型。ggplot2我们将使用这个流行的数据可视化包来构建我们的模型图。GGally这个包扩展了ggplot2的功能。我们将使用它来创建一个绘图矩阵,作为我们初始探索性数据可视化的一部分。scatterplot3d我们将使用这个软件包来可视化更复杂的具有多个预测因子的线性回归模型。
他们是如何测量树木体积的?
树数据集包含在 base R 的datasets包中,它将帮助我们回答这个问题。由于我们正在使用一个现有的(干净的)数据集,上面的步骤 1 和 2 已经完成,所以我们可以直接跳到步骤 3 中的一些初步探索性分析。这个数据集是什么样子的?
data(trees) ## access the data from R’s datasets package
head(trees) ## look at the first several rows of the data
| 肚带 | 高度 | 卷 |
| Eight point three | Seventy | Ten point three |
| Eight point six | Sixty-five | Ten point three |
| Eight point eight | Sixty-three | Ten point two |
| Ten point five | seventy-two | Sixteen point four |
| Ten point seven | Eighty-one | Eighteen point eight |
| Ten point eight | Eighty-three | Nineteen point seven |
str(trees) ## look at the structure of the variables
| $围长:数量 | 8.3 8.6 8.8 10.5 10.7 10.8 11 11 11.1 11.2 … |
| $高度:数字 | 70 65 63 72 81 83 66 75 80 75 … |
| $ Volume:一个 | 10.3 10.3 10.2 16.4 18.8 19.7 15.6 18.2 22.6 19.9 … |
该数据集由描述黑樱桃树的 3 个数值变量的 31 个观察值组成:
- 树干周长(英寸)
- 高度(英尺)
- 体积(英尺 ³
这些指标对于研究树木生态的森林学家和科学家来说是有用的信息。使用基本的林业工具来测量树的高度和周长是相当简单的,但是测量树的体积要困难得多。如果你不想真的砍倒和拆除这棵树,你不得不求助于一些技术上具有挑战性和耗时的活动,如爬树和进行精确测量。能够从高度和/或围长准确预测树木体积将是有用的。

为了决定我们是否可以建立一个预测模型,第一步是看看我们的预测变量和反应变量(在这种情况下是周长、高度和体积)之间是否存在关系。让我们做一些探索性的数据可视化。我们将使用GGally包中的 ggpairs() 函数来创建一个绘图矩阵,以查看变量之间的关系。
ggpairs(data=trees, columns=1:3, title="trees data")

ggpairs()函数为我们提供了每个变量组合的散点图,以及每个变量的密度图和变量之间的相关性强度。
如果你以前用过ggplot2,这个符号可能看起来很熟悉:GGally是ggplot2的扩展,它提供了一个简单的接口来创建一些复杂的图形,就像这个一样。当我们看这些图时,我们可以开始了解数据并提出问题。相关系数提供了关于变量有多接近某种关系的信息;相关系数越接近 1,关系越强。散点图让我们可以看到变量对之间的关系。散点图中的点具有清晰的视觉模式(与看起来像不成形的云相反),表明关系更强。
我们的问题:哪些预测变量似乎与响应变量相关?从查看ggpairs()输出来看,周长肯定似乎与体积相关:相关系数接近 1,并且点似乎具有线性模式。高度和体积之间可能存在关系,但似乎是一种较弱的关系:相关系数较小,散点图中的点更分散。变量之间的关系是什么形状?
这种关系似乎是线性的;从散点图中,我们可以看到,随着树围的增加,树的体积不断增加。是相关性强,还是数据中的噪音淹没了信号?身高和体积之间的关系不太清楚,但腰围和体积之间的关系似乎很强。现在,我们已经对数据有了相当全面的了解,我们可以进入第 4 步,进行一些预测建模。
形成一个假设
假设是关于我们认为数据发生了什么的有根据的猜测。在这种情况下,我们假设樱桃树的周长和体积是相关的。我们形成的每个假设都有一个对立面:“零假设”( H [0] )。这里,我们的无效假设是周长和体积不相关。在统计学中,零假设是我们用数据来支持或拒绝的假设;我们永远不能说我们“证明”了一个假设。我们称周长和体积相关的假设为“另类”假设( H [a] )。总结一下: H [0] :围长和体积没有关系 H [a] :围长和体积有一定的关系我们用线性回归模型来检验我们的假设。如果我们找到足够有力的证据来拒绝H[0],那么我们就可以用这个模型从围长来预测樱桃树的体积。
线性回归模型的构建模块
线性回归描述了感兴趣的响应变量(或因变量)和一个或多个预测变量(或自变量)之间的关系。它有助于我们将信号(我们可以从预测变量中了解到的响应变量)与噪声(我们无法从预测变量中了解到的响应变量)分开。随着我们的进展,我们将更深入地研究这个模型是如何做到这一点的。

让我们深入研究,建立一个树木体积和周长的线性模型。r 用基本函数lm()使这变得简单明了。
fit_1 <- lm(Volume ~ Girth, data = trees)
lm()函数为我们的数据拟合一条线,这条线尽可能接近我们的所有 31 个观察值。更具体地说,它以这样一种方式拟合直线,使得点和直线之间的平方差之和最小化;这种方法被称为“最小化最小二乘法”即使线性回归模型很好地拟合了数据,拟合也不是完美的。我们的观测值和它们的模型预测值之间的距离称为 残差 。

数学上,我们可以把线性回归的方程写成:Y≈β0+β1X+ε
- Y 和 X 变量是我们相互关联的数据中的响应和预测变量
- β0 是模型系数,代表模型截距,或与 y 轴相交的位置
- β1 是代表模型斜率的模型系数,该数字给出了关于直线的陡度及其方向(正或负)的信息
- ε 是误差项,包含了我们在模型中无法捕捉的可变性(X 无法告诉我们关于 Y 的事情)
以我们的例子为例:树量≈ 截距 + 斜率(树围)+ 误差 
lm()函数估计它拟合到我们的数据的线性模型的截距和斜率系数。有了模型,我们可以继续第 5 步,记住我们还有一些工作要做,以验证这个模型实际上是适合数据的。
我们可以用这个模型来做预测吗?
我们能否使用我们的模型进行预测将取决于:
- 我们是否可以拒绝变量之间没有关系的零假设。
- 模型是否适合我们的数据。
让我们使用summary()调用我们模型的输出。模型输出将为我们提供所需的信息,以测试我们的假设并评估模型与数据的吻合程度。
summary(fit_1)
 让我们浏览一下输出,回答每个问题。
让我们浏览一下输出,回答每个问题。
假设得到支持了吗?
系数:估计值和标准值。错误:
- 如果围长值为零,我们示例中的截距就是期望的树木体积。当然,我们不能有一棵负体积的树,但以后会有更多。
- 我们例子中的斜率是树围对树体积的影响。我们看到树围每增加一英寸,树的体积就增加 5.0659 英尺。
- 系数标准误差告诉我们估计系数与我们响应变量的实际平均值的平均偏差。
t 值:
Pr( > |t|) :
- 这个数字就是 p 值,定义为如果H[0]为真,观察到任何值等于或大于 t 的概率。t 统计值越大,p 值越小。通常,我们使用 0.05 作为显著性的临界值;当 p 值小于 0.05 时,我们拒绝 H [0] 。
我们可以拒绝零假设,而相信树的宽度和体积之间有关系。
模型与数据的吻合程度如何?
残差:
- 输出的这一部分为我们提供了残差的摘要(回想一下,这些是我们的观察值和模型之间的距离),它告诉我们一些关于我们的模型与我们的数据的拟合程度。残差应该在零附近有一个非常对称的分布。一般来说,我们希望残差在零附近呈正态分布(即钟形曲线分布),但重要的是,它们没有明显的视觉模式,这表明线性模型不适合数据。
我们可以使用ggplot2制作一个直方图来直观显示这一点。
ggplot(data=trees, aes(fit_1$residuals)) +
geom_histogram(binwidth = 1, color = "black", fill = "purple4") +
theme(panel.background = element_rect(fill = "white"),
axis.line.x=element_line(),
axis.line.y=element_line()) +
ggtitle("Histogram for Model Residuals")

我们的残差在 0 附近看起来非常对称,表明我们的模型很好地符合数据。残差标准误差:
- 这一项表示我们的响应变量测量值偏离拟合线性模型的平均量(模型误差项)。
自由度:
- 对自由度的讨论可能变得相当专业。就本文的目的而言,将它们视为用于计算估计值的独立信息片段的数量就足够了。自由度与测量次数有关,但并不相同。
多个 R 平方:
- R² 值是我们的数据与线性回归模型接近程度的度量。*R²值始终在 0 和 1 之间;接近 1 的数字表示模型非常合适。 R²*
F 统计:
- 这个测试统计量告诉我们在我们测试的因变量和自变量之间是否有关系。一般来说,一个大的 F 表示更强的关系。
p 值:
- 该 p 值与 F 统计相关,用于解释整个模型与我们的数据拟合的显著性。
让我们来看看适合我们的宽度和体积数据的模型。我们可以通过使用ggplot()将线性模型拟合到我们数据的散点图来做到这一点:
ggplot(data = trees, aes(x = Girth, y = Volume)) +
geom_point() +
stat_smooth(method = "lm", col = "dodgerblue3") +
theme(panel.background = element_rect(fill = "white"),
axis.line.x=element_line(),
axis.line.y=element_line()) +
ggtitle("Linear Model Fitted to Data")

线周围的灰色阴影表示置信区间为 0.95,这是 stat_smooth() 函数的默认值,它平滑数据以使模式更容易可视化。这个 0.95 的置信区间是所有黑樱桃树围长和体积的真实线性模型位于拟合我们数据的回归模型的置信区间内的概率。尽管这个模型非常符合我们的数据,但在我们的观察中仍然存在可变性。
这是因为这个世界普遍不整洁。在我们的模型中,树木体积不仅仅是树围的函数,也是我们不一定有数据可以量化的事物的函数(树干形状之间的个体差异,林业工作者树干围长测量技术的微小差异)。有时,这种可变性掩盖了反应变量和预测变量之间可能存在的任何关系。但在这里,我们的数据中的信号足够强,让我们开发出一个有用的模型来进行预测。
使用我们简单的线性模型进行预测
我们的模型适合做预测!各地的树木科学家欢欣鼓舞。假设我们有一棵树的围长、高度和体积数据,但这些数据被排除在数据集之外。我们可以用这棵树来测试我们的模型。
| 肚带 | 高度 | 卷 |
|---|---|---|
| 18.2 英寸 | 72 英尺 | 46.2 英尺 ³ |
我们的模型从树的周长预测树的体积会有多好?我们将使用predict()函数,这是一个通用的 R 函数,用于从模型拟合函数的模块中进行预测。predict()将我们的线性回归模型和我们需要响应变量值的预测变量的值作为参数。
predict(fit_1, data.frame(Girth = 18.2))
我们的体积预测是 55.2 英尺³。这接近我们的实际值,但有可能将我们的另一个预测变量高度添加到我们的模型中,可能会让我们做出更好的预测。
添加更多预测因子:多元线性回归
如果我们使用所有可用的信息(宽度和高度)来预测树木体积,也许我们可以提高模型的预测能力。重要的是,从帖子开始的五步过程实际上是一个迭代过程——在现实世界中,你会获得一些数据,建立一个模型,根据需要调整模型以改进它,然后可能会添加更多的数据并建立一个新的模型,等等,直到你对结果满意和/或确信你不能做得更好。我们可以建立两个独立的回归模型并对它们进行评估,但是这种方法存在一些问题。首先,想象一下,如果我们有 5 个、10 个甚至 50 个预测变量,那会有多麻烦。第二,两个预测模型将为我们提供两个独立的预测量,而不是我们追求的单一预测量。也许最重要的是,建立两个独立的模型并不能让我们在估计模型系数时考虑预测因子之间的关系。在我们的数据集中,基于我们最初的数据探索,我们怀疑树的高度和围长是相关的。正如我们将在本文中更清楚地看到的,忽略预测变量之间的这种相关性会导致关于它们与树木体积关系的误导性结论。更好的解决方案是建立一个包含多个预测变量的线性模型。我们可以通过为我们的模型中感兴趣的每个额外独立变量添加一个斜率系数来做到这一点。
树体≈ 截距 + 斜率 1 (树围)+ 斜率 2 (树高)+ 误差
使用lm()函数很容易做到这一点:我们只需要添加另一个预测变量。
fit_2 <- lm(Volume ~ Girth + Height, data = trees)
summary(fit_2)
 我们可以从模型输出中看到,围长和高与体积显著相关,并且模型很好地符合我们的数据。我们调整后的 R² 值也比我们调整后的 R² 型号
我们可以从模型输出中看到,围长和高与体积显著相关,并且模型很好地符合我们的数据。我们调整后的 R² 值也比我们调整后的 R² 型号fit_1高一点。因为我们在这个模型中有两个预测变量,我们需要一个第三维度来可视化它。我们可以使用包scatterplot3d创建一个漂亮的 3d 散点图:首先,我们为预测变量(在我们的数据范围内)制作一个网格。expand.grid()函数根据因子变量的所有组合创建一个数据框。
Girth <- seq(9,21, by=0.5) ## make a girth vector
Height <- seq(60,90, by=0.5) ## make a height vector
pred_grid <- expand.grid(Girth = Girth, Height = Height)
## make a grid using the vectors
接下来,我们基于预测变量网格对体积进行预测:
pred_grid$Volume2 <-predict(fit_2, new = pred_grid)
现在,我们可以根据预测网格和预测体积制作 3d 散点图:
fit_2_sp <- scatterplot3d(pred_grid$Girth, pred_grid$Height, pred_grid$Volume2, angle = 60, color = "dodgerblue", pch = 1, ylab = "Hight (ft)", xlab = "Girth (in)", zlab = "Volume (ft3)" )
最后叠加我们的实际观察结果,看看它们有多吻合:
fit_2_sp$points3d(trees$Girth, trees$Height, trees$Volume, pch=16)
让我们看看这个模型如何预测我们的树的体积。这一次,我们包括树的高度,因为我们的模型使用高度作为预测变量:
predict(fit_2, data.frame(Girth = 18.2, Height = 72))
这一次,我们得到的预测体积为 52.13 英尺 ³ 。这个预测比我们用简单的模型得到的预测更接近真实的树木体积,这个模型只用围长作为预测因子,但是,正如我们将要看到的,我们也许可以改进。
互动会计
虽然我们已经做出了改进,但我们刚刚构建的模型仍然不能说明全部情况。它假设树围对材积的影响独立于树高对材积的影响。这显然不是事实,因为树的高度和周长是相关的;更高的树往往更宽,我们的探索性数据可视化表明了这一点。换句话说,腰围的斜率应该随着身高斜率的增加而增加。为了说明我们模型中预测变量的这种非独立性,我们可以指定一个交互项,它被计算为预测变量的乘积。
树体≈ 截距 + 坡度 1 (树围)+ 坡度 2 (树高)+ 坡度 3 (树围 x 树高)+ 误差
同样,使用lm()很容易构建这个模型:
fit_3 <- lm(Volume ~ Girth * Height, data = trees)
summary(fit_3)
注意,在我们的模型中,“周长*高度”术语是“周长+高度+周长*高度”的简写。 正如我们所猜测的,树高和树围的交互作用是显著的,这表明我们应该在我们用来预测树木体积的模型中包括交互作用项。调整后的R²值接近 1,f 的大值和 p的小值也支持这一决定,表明我们的模型非常适合该数据。让我们来看一个散点图,用这个模型来直观地显示树木体积的预测值。我们可以使用为
正如我们所猜测的,树高和树围的交互作用是显著的,这表明我们应该在我们用来预测树木体积的模型中包括交互作用项。调整后的R²值接近 1,f 的大值和 p的小值也支持这一决定,表明我们的模型非常适合该数据。让我们来看一个散点图,用这个模型来直观地显示树木体积的预测值。我们可以使用为fit_2可视化生成的预测值的相同网格:
Girth <- seq(9,21, by=0.5)
Height <- seq(60,90, by=0.5)
pred_grid <- expand.grid(Girth = Girth, Height = Height)
类似于我们如何可视化fit_2模型,我们将使用带有交互项的fit_3模型来预测预测变量网格中的体积值:
pred_grid$Volume3 <-predict(fit_3, new = pred_grid)
现在我们制作预测网格和预测体积的散点图:
fit_3_sp <- scatterplot3d(pred_grid$Girth, pred_grid$Height, pred_grid$Volume3, angle = 60, color = "dodgerblue", pch = 1, ylab = "Hight (ft)", xlab = "Girth (in)", zlab = "Volume (ft3)")
最后,我们叠加我们观察到的数据:
fit_3_sp$points3d(trees$Girth, trees$Height, trees$Volume, pch=16)

在这幅图中有点难以看出,但这次我们的预测位于某个曲面上,而不是平面上。现在是关键时刻:让我们用这个模型来预测我们的树的体积。
predict(fit_3, data.frame(Girth = 18.2, Height = 72))
我们使用第三个模型的预测值是 45.89 ,最接近我们的真实值 46.2 英尺³。
关于预测模型的一些注意事项
请记住您的数据范围
使用模型进行预测时,最好避免试图外推至远远超出用于构建模型的值的范围。为了说明这一点,让我们试着估算一棵小树苗(幼树)的体积:
predict(fit_3, data.frame(Girth = 0.25, Height = 4))
我们得到的预测体积为 62.88 英尺(T1 3 T2 T3),比我们数据集中的大树还要大。这当然说不通。请记住,我们做出准确预测的能力受到我们用来构建模型的数据范围的限制。
避免制作过于特定于数据集的模型
在本帖中我们研究的简单示例数据集中,向我们的模型添加第二个变量似乎提高了我们的预测能力。然而,当尝试具有许多差异变量的多种多元线性回归模型时,选择最佳模型变得更具挑战性。如果添加了太多不能提高模型预测能力的项,我们就有可能使我们的模型“过度适应”我们的特定数据集。
过度适应特定数据集的模型会失去预测未来事件或适应不同数据集的功能,因此不是非常有用。虽然我们在本文中用于评估模型有效性的方法(调整后的 R² ,残差分布)有助于了解您的模型与您的数据的拟合程度,但将您的模型应用于数据集的不同子集可以提供有关您的模型在实践中表现如何的信息。
这种方法被称为“交叉验证”,通常用于测试预测模型。在我们的例子中,我们使用三个模型中的每一个来预测一棵树的体积。然而,如果我们在构建更复杂的模型,我们会希望保留一部分数据用于交叉验证。
后续步骤
我们使用线性回归来建立从两个连续预测变量预测连续响应变量的模型,但线性回归对于许多其他常见场景来说是一种有用的预测建模工具。
下一步,尝试建立线性回归模型,从两个以上的预测变量预测反应变量。考虑如何决定回归模型中包含哪些变量;你如何判断哪些是重要的预测因素?预测变量之间的关系如何影响这个决定?
R 中对处理多元线性回归问题有用的数据集包括:airquality、iris和mtcars。从数据中构建模型的另一个重要概念是用从现有数据中计算出的新预测值来扩充数据。这就是所谓的特征工程,在这里你可以运用你自己的专业知识来解决问题。
例如,如果您正在查看一个将时间戳作为变量之一的银行交易数据库,那么星期几可能与您想要回答的问题相关,因此您可以根据时间戳计算出该日期,并将其作为一个新变量添加到数据库中。这是一个复杂的主题,添加更多的预测变量并不总是一个好主意,但随着您对建模了解的深入,您应该记住这一点。在这篇文章使用的树木数据集中,你能想出任何额外的数量来计算周长和高度,这将有助于你预测体积吗?(提示:回想一下你学习各种几何形状体积公式的时候,想想一棵树是什么样子的。)
最后,虽然我们关注的是连续数据,但是线性回归也可以扩展到从分类变量进行预测。尝试使用线性回归模型从分类变量和连续预测变量中预测反应变量。R 中有几个数据集特别适合这个练习:ToothGrowth、PlantGrowth和npk。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
统计学新课程:R 中的条件概率
原文:https://www.dataquest.io/blog/statistics-course-conditional-probability-in-r/
January 14, 2020
借助我们快速发展的数据分析师 R 学习路径中的最新成员:R中的条件概率,让您的数据科学和统计知识更上一层楼。

在本课程中,您将学习条件概率的基础知识,然后深入探讨更高级的概念,如贝叶斯定理和朴素贝叶斯算法。随着你的学习,你将运用你的 R 技能将理论付诸实践,并建立这些关键统计概念的工作知识。
准备好开始学习了吗?单击下面的按钮深入研究 R 中的条件概率,或者向下滚动以了解关于这门新课程的更多信息。
## R 中的条件概率涵盖了哪些内容?*
条件概率是概率论的一个领域,顾名思义,它是根据特定条件来衡量特定事件发生的概率。
在本课程中,我们将从一些基础概念的课程开始,如条件概率公式、乘法法则、统计相关性和独立性等。本课程建立在中的概率基础课程的基础上。
从那里,我们将看看贝叶斯定理以及它如何被用来计算概率。我们将检查先验和后验概率分布。然后,我们将通过了解朴素贝叶斯算法(数据科学家使用的一种常用统计工具)来深入研究和应用这些统计概念。
最后,您将在一个新的指导项目中将所有新知识付诸实践,该项目要求您使用超过 5,000 条消息的数据集,采用朴素贝叶斯算法构建一个垃圾短信过滤器。
本课程结束时,你将能够运用条件概率的规则,根据条件为事件分配概率。你会知道这些事件何时对其他事件有(或没有)统计相关性。您将能够使用贝叶斯定理基于先验知识分配概率。
当然,您已经构建了一个很酷的垃圾短信过滤器,它利用了朴素贝叶斯算法(以及您在整个学习过程中构建的所有 R 编程技能)!
为什么我需要知道这些?
条件概率是统计学的一个重要领域,在数据分析和数据科学工作中经常出现。理解这一点对于确保你的分析建立在坚实的统计基础上是很重要的,并且你不会从你的数据中得出错误的结论。
实际上,关于贝叶斯定理和朴素贝叶斯算法的问题在数据科学工作面试中相当常见。例如,你可能会被要求解释朴素贝叶斯算法的“本质”是什么。理解它是如何工作的——我们将在本课程中介绍——有助于你证明你不仅仅是从 GitHub 复制粘贴,而且你真正理解你的分析背后的数学。
那么为什么要等呢?今天开始学习条件概率:
还没准备好投入进去吗?今天就开始学习 R 吧,你很快就会为这门新课程做好准备。另外,我们的前两门 R 课程完全免费😗
新 Python 统计教程:条件概率
原文:https://www.dataquest.io/blog/statistics-course-conditional-probability-python/
October 31, 2019
借助我们最新增加的数据科学课程: 条件概率 ,让您的数据科学和统计知识更上一层楼。
在本课程中,您将学习条件概率的基础知识,然后深入探讨更高级的概念,如贝叶斯定理和朴素贝叶斯算法。随着您的学习,您将使用 Python 技能将理论付诸实践,并构建这些关键统计概念的工作知识。
准备好开始学习了吗?点击下面的按钮深入了解条件概率,或者向下滚动以了解关于这门新课程的更多信息。
*## 条件概率涵盖了哪些内容?
条件概率是概率论的一个领域,顾名思义,它是根据特定条件来衡量特定事件发生的概率。
本课程建立在之前的概率基础课程的基础上,我们将从一些基础概念开始,如条件概率公式、乘法规则、统计相关性和独立性等。
从那里,我们将看看贝叶斯定理以及它如何被用来计算概率。我们将检查先验和后验概率分布。然后,我们将通过了解朴素贝叶斯算法(数据科学家使用的一种常用统计工具)来深入研究和应用这些统计概念。
最后,您将在一个新的指导项目中将所有新知识付诸实践,该项目要求您使用超过 5,000 条消息的数据集,采用朴素贝叶斯算法构建一个垃圾短信过滤器。
本课程结束时,你将能够运用条件概率的规则,根据条件为事件分配概率。你会知道这些事件何时对其他事件有(或没有)统计相关性。您将能够使用贝叶斯定理基于先验知识分配概率。
当然,您将构建一个很酷的垃圾短信过滤器,它利用了朴素贝叶斯算法(以及您的 Python 编程技能)!
为什么我需要知道这些?
条件概率是统计学的一个重要领域,在数据分析和数据科学工作中经常出现。理解这一点对于确保你的分析建立在坚实的统计基础上是很重要的,并且你不会从你的数据中得出错误的结论。
实际上,关于贝叶斯定理和朴素贝叶斯算法的问题在数据科学工作面试中相当常见。例如,你可能会被要求解释朴素贝叶斯算法的“本质”是什么。理解它是如何工作的——我们将在本课程中介绍——有助于你证明你不仅仅是从 GitHub 复制粘贴,而且你真正理解你的分析背后的数学。
那么为什么要等呢?今天开始学习条件概率:
停止拖延,开始用科学来学习
原文:https://www.dataquest.io/blog/stop-procrastinating-science-based/
May 2, 2019
我希望我能停止拖延。这可能是自古以来每个学生都说过的一句话。
拖延对于在线学生来说是一个特别的问题(就像你们这些在我们平台上学习数据科学的人一样),因为在线学习非常方便。如果你翘了一堂大学课,你就错过了,而且永远也补不回来。但是很容易告诉自己,你可以跳过今晚的学习课,明天再补上。
此外,对于在线学生来说,拖延的诱惑可能更强,他们经常试图将他们的学习融入已经忙碌的生活,其中可能包括全职工作或其他领域的学习。
那么如何停止拖延呢?有几十种理论(和大约一百万篇文章)声称拥有这个秘密,但是让我们来看看实际的科学是怎么说的。
什么是拖延症?
拖延症是一个适用于许多拖延工作的行为的术语,但重要的是要指出,并非所有这些都是真正的拖延症。举例来说,在试图解决问题之前花时间思考它并不是拖延症,尽管它有时被贴上拖延症的标签。当你有一张要做的事情的清单时,花时间去组织和排列优先次序也是一样。
约瑟夫·法拉利博士说,这些有益的拖延和有害的拖延的区别在于程度。任何人都可能在开始工作前花时间按优先顺序组织一份任务清单。但是如果你发现自己写下了清单,然后重写,然后开始一项任务,但又回去重新整理清单,然后复制一些……这就是拖延症。
拖延只是一种行为,它本身没有好坏之分。研究表明,它甚至有一些短期的心理好处。例如,在的一项研究 (PDF 链接)中,拖拉的学生在整个学期中报告了较低的压力水平,可能是因为他们在做更多有趣的事情,而不是做他们推迟的工作。
然而,从长远来看,对于那些关心有效学习成绩,甚至普遍快乐的人来说,拖延有一些非常明显的缺点。在那项研究中,拖延的学生报告说,随着截止日期的临近,他们的压力水平急剧上升,他们的成绩比那些没有拖延的同学“明显更低”。
从长远来看,很明显,如果学生们能够停止拖延,他们会过得更好。“拖延者最终比其他人遭受更多痛苦,表现更差,”该研究的作者总结道。
我们为什么拖延
如果拖延从长远来看对我们如此有害,我们为什么还要这样做呢?一种理论认为,这是一种自卫应对策略,旨在让他人(或我们自己)相信,我们所缺乏的只是努力而不是天生的能力。
一项表明这一点的研究将自称拖延者的人放入实验室,告诉他们在完成任务之前有 15 分钟的练习时间。所有受试者都被要求完成相同的任务,但对它的描述不同——对一些受试者来说,这被称为一项可以衡量他们认知技能的数学任务,而其他人则被告知这是一项“有趣的游戏”
在 15 分钟的练习期间,受试者可以玩电子游戏和其他有趣的活动。当拖延者被告知即将到来的任务是对他们技能的重要衡量时,他们比被告知这是一个“有趣的游戏”时花更多的时间拖延因此,该研究的作者得出结论,拖延可能是一种故意的“自我障碍”,一种在我们认为重要的任务没有做好的情况下给自己找借口的方式。
另一个理论是拖延症是关于用长期的不适换取短期的快乐和压力减轻。回想一下对拖延的大学生的研究:从长远来看,他们经历了更多的压力和更差的结果,但从短期来看,他们比那些跟上进度的学生压力更小。这种短期回报可能是导致许多拖延行为的原因。
当然,这些只是理论。还有其他原因,也有可能拖延症更多的是生理上的,而不是心理上的。最近的一项研究发现,自称拖延者的大脑往往有更大的杏仁核——这是大脑的一部分,它警告你做某事的潜在负面影响。他们的杏仁核和背侧前扣带皮层之间的连接也较少,这有助于你在决定是否实际做某事时处理来自杏仁核的信息。
当然,这并不意味着拖延者注定会被他们的大脑结构所左右(而且心理学和过去的行为会在多大程度上影响大脑结构还不清楚)。各种研究表明,各种各样的因素,从目前的情绪到任务的难度和不愉快程度,都会对我们拖延的程度产生影响。
无论如何,个人和情况变化如此之大,以至于你可能无法确定为什么你会拖延。谢天谢地,这并不意味着你无法阻止。
如何停止拖延(根据科学)
科学还没有找到治疗拖延症的灵丹妙药,这并不奇怪。没有什么灵丹妙药能让你专心学习,值得记住的是,科学研究不是科学定律,尤其是在心理学领域。这些结果可能是错误的,甚至那些正确的结果对你来说也可能是错误的。
也就是说,科学确实表明,如果你正在努力停止拖延,你可以做一些事情。具体来说,请尝试以下一种或多种方法:
分解任务,给自己奖励
将大任务分解成小任务有助于减轻大任务的压力。当你完成一项任务时,它也给你一个更快的途径去获得那种温暖的成就感。
对一些人来说,多巴胺的冲击已经足够奖励了,但对其他人来说,研究表明通过完成任务给自己奖励和改变奖励的种类可以对你成功的机会产生有意义的影响。
不同的类别很重要,因为虽然奖励可能是一个强大的动力,但为完成一个目标给自己一些奖励选项会让你感觉你错过了。想象一下,例如,你计划学习两个小时,然后奖励自己一块饼干或额外的半小时你最喜欢的电视节目。这看起来是给自己一些灵活性的好方法,但实际上这会让你觉得错过了你没有选择的奖励,这可能会打击你的积极性。
那么,更好的方法是把你的大任务分成小任务,每完成一项任务就给自己一个小奖励,同时保持奖励的多样性。例如,如果你想在一周内完成完整的 Dataquest 课程,最好是将任务分解为每个任务的单独部分,并在每个任务结束时给自己不同的奖励:完成任务 1 的额外游戏时间,完成任务 2 的美味甜点,完成任务 3 的长时间沐浴或淋浴,等等。
为了确保这种方法是可持续的,选择你感兴趣的奖励,小的,容易负担得起的或免费的。
设定最后期限(内部和外部)
研究表明,设定清晰、详细的截止日期对完成率有积极的影响。在之前的一篇文章中,我们已经讨论了制定关于何时、何地以及如何学习的真正具体计划的价值,但是这里值得补充的是,科学表明外部期限甚至比内部期限更有效。
对于使用灵活的在线自学平台的学生来说,这可能是一个问题,因为没有教授告诉他们在截止日期前上交任何作业。然而,订阅期可以作为一个很好的长期到期日——避免因为你没有完成工作而为额外的一年订阅支付更多费用的愿望可以是一个很好的激励因素。
外部分配的目标也是如此。例如,Dataquest 根据您的进度和长期目标,在您的仪表盘中分配每周目标。许多其他平台也提供了类似的功能,你可以用它来为自己设定外部期限。
让它有趣
如上所述,研究表明,当拖延者认为一项任务严肃或重要时,他们往往会拖延更多的时间。虽然你可能认为你的数据科学研究很重要,但你可以通过在心理上将你的研究课程重新定义为有趣的活动来减少你拖延的冲动。
当然,最简单的方法就是让它们变得有趣。这就是为什么我们一直提倡基于项目的方法,以及为什么我们提倡与真实世界的数据互动工作,而不是观看视频或通过假设的实践问题翻腾的很大一部分原因。
做真实的东西更有趣,更好玩。这将有助于你保持前进的动力,并使你不太可能开始拖延和寻找借口逃避学习。
改善其他影响拖延的因素
日常生活中的各种因素会影响你拖延的可能性,解决这些问题有时可能是唾手可得的果实,可以帮助你改善拖延症,而不会实际改变你的学习习惯。
例如,如果你是那种容易拖延的人,睡眠质量会影响第二天的拖延率。所以,如果你在改掉拖延的习惯上有困难,你可能会发现改善你的睡眠模式以获得更多(更好)的睡眠会有很大的不同。
还有其他因素你也可以看看。在之前的一篇文章中,我们写了智能手机的威胁和手机邻近效应——即使你的手机关机了,它也可能会让你分心!移除你的手机和其他环境干扰,改善你的工作空间,以及其他这种性质的调整可以通过增加自我干扰的难度来减少你拖延的机会。
(不过要小心,因为如果你花了本该花在学习、整理和完善学习空间上的两个小时,这种优化本身就是一种拖延。)
别自责了
有趣的是,治疗拖延症的最好方法可能是宽恕。2010 年的一项研究表明,能够原谅自己过去拖延行为的学生更有可能在将来做同样的事情时不再拖延。
当然,原谅自己过去的失败说起来容易做起来难。但有趣的是,实际上让自己休息一下可能是对抗拖延症最有效的方法之一。如果你想停止拖延,似乎最好的开始就是对自己好一点!
教程:在 Python 中使用流数据和 Twitter API
September 8, 2016
如果您做过任何数据科学或数据分析工作,您可能会读入 CSV 文件或连接到数据库并查询行。典型的数据分析工作流包括检索存储的数据,将其加载到分析工具中,然后对其进行研究。当您处理历史数据时,例如分析在线商店的客户最有可能购买什么产品,或者人们的饮食是否因广告而改变,这种方法非常有效。但是如果你想实时预测股票价格呢?或者弄清楚人们现在在看什么电视?
随着越来越多的数据生成,能够处理实时数据变得越来越重要。实时或流数据是连续生成的,在股票市场的情况下,每小时可以生成数百万行数据。由于大小和时间的限制,通常没有一个整洁的数据集可供您分析,您需要存储数据以供以后分析,或者在获得数据时进行实时分析。
对于任何有抱负的数据科学家来说,能够处理流数据是一项关键技能。在这个 Python API 教程中,我们将讨论处理流数据的策略,并通过一个例子来演示我们如何从 Twitter 中传输和存储数据。
推特
对于那些不熟悉 Twitter 的人来说,它是一个社交网络,人们在这里发布简短的 140 个字符的状态消息,称为 tweets。因为推文是不断发出的,Twitter 是一个很好的方式来了解人们对时事的感受。在本帖中,我们将创建一个工具,让我们能够了解人们对美国总统候选人唐纳德·川普和希拉里·克林顿的看法。为此,我们需要:
- 从 Twitter API 流推文。
- 过滤掉不相关的推文。
- 处理推文,找出他们对每个候选人表达了什么情绪。
- 存储推文以供进一步分析。
我们会在文章中构建代码,但是如果你想看最终版本,你可以看这里的。
事件驱动编程
如前所述,在典型的数据分析工作流程中,您将:
- 打开一个 csv 文件。
- 迭代这些行。
- 发现见解并创建可视化。
该流程可能涉及如下脚本:
import pandas
data = pandas.read_csv("products_sold.csv")
# Print out the mean selling price.
print(data["price"].mean())# Plot out the sale prices.data["price"].plot()
在上面的例子中,Python 解释器从我们程序的第一行开始,然后遍历它,直到完成。这被称为过程化编程,因为程序像过程一样以固定的顺序执行。
我们可以修改上面的程序来处理我们事先下载的一组推文:
import pandas
tweets = pandas.read_csv("tweets.csv")
# Get the emotion (sentiment) in each tweet.
# This is an example function that we'll assume is defined further up.
sentiment = tweets["text"].apply(get_sentiment)
# Plot out the sentiment in each tweet.sentiment.plot()
虽然处理一个 csv 格式的 tweets 文件很简单,但是我们如何修改这个程序来处理流媒体 tweets 还不清楚。对于流媒体推文,我们不会有一个好的 csv 文件——我们必须实时检索推文。要处理流媒体推文,我们需要:
- 打开到 Twitter API 的持久连接。
- 处理我们收到的每条微博。
- 存储处理后的推文。
为了实现这一点,我们需要使用一种叫做事件驱动编程的编程范式。在事件驱动编程中,程序根据外部输入执行动作。一个很好的例子是网络浏览器。网络浏览器可能由几个功能组成:
def go_to_site(url):
# Given a url, visit the site. ...
def go_back():
# Go back to the last site. ...
def go_forward():
# Go forward to the next site (if applicable) ...
def reload():
# Reload the current page. ...
当 web 浏览器加载时,它不做任何事情,而是等待用户采取行动。用户在地址栏中键入一个 URL 并按 enter 键将触发函数go_to_site,该函数将呈现该 URL 的内容。
在 web 浏览器中,一个函数可以被调用一次、多次,或者根本不被调用。这完全取决于用户做什么。该程序没有遵循一个过程,而是在等待外部操作。每个动作都可以被称为一个事件,这就是为什么这种编程风格是事件驱动的。功能可以绑定到事件(在这种情况下是用户按下按钮)。每个绑定到事件的函数都被称为该事件的回调函数。例如,在浏览器栏中输入一个 URL 被绑定到go_to_site 回调函数,然后该函数访问该站点。点击后退按钮与go_back 回调函数绑定,该函数访问上一个站点。

Chrome 浏览器的截图——你可以看到与每个回调函数相关的按钮。
在 web 浏览器的例子中,我们依靠用户来生成事件,但是我们也可以依靠其他程序来生成事件。比方说,我们有一个程序,它对 tweets 进行流式处理,然后调用我们的程序来处理它们。我们的程序中只需要几个函数:
def filter_tweet(tweet):
# Remove any tweets that don't match our criteria.
if not tweet_matches_criteria(tweet):
return
# Process the remaining tweets.
process_tweet(tweet)
def process_tweet(tweet):
# Annotate the tweet dictionary with any other information we need.
tweet["sentiment"] = get_sentiment(tweet)
# Store the tweet.
store_tweet(tweet)
def store_tweet(tweet):
# Saves a tweet for later processing. ...
我们设置了一个独立的程序来实时获取推文——我们称之为streamer。我们将filter_tweet注册为对streamer的回调,因此每次收到新的 tweet 时都会调用filter_tweet。我们可以决定是否要处理这条推文,然后调用process_tweet和store_tweet来处理这条推文。
Twitter 流媒体应用编程接口
为了使实时推文的工作变得容易,Twitter 提供了 Twitter 流 API 。关于如何从 Twitter 上传推文,有很多规则,但主要的有:
- 创建到 Twitter API 的持久连接,并增量读取每个连接。
- 快速处理推文,不要让你的程序出现备份。
- 正确处理错误和其他问题。
在所有主流编程语言中,Twitter 流 API 都有各种各样的客户端。对于 Python,有不少,你可以在这里找到。最受欢迎的是 tweepy ,它允许你连接到流式 API 并正确处理错误。
虽然 tweepy 为我们处理了处理流的大部分后勤工作,但我们还是要看一看幕后发生了什么。
打开连接
第一步是打开到 Twitter 流 API 的连接。这涉及到打开一个持久的 HTTP 连接。Tweepy 使用下面的代码段来实现这一点,您可以在这里找到:
resp = self.session.request('POST',
url,
data=self.body,
timeout=self.timeout,
stream=True,
auth=auth,
verify=self.verify)
上面的代码段使用 python requests 库发出请求,并传递了stream=True关键字参数以保持连接永远打开。每当 Twitter 上创建新的推文时,它都会通过连接将推文发送到我们的程序。
您可能会注意到上面的url参数。我们可以通过点击 firehose.json API 端点来收集 Twitter 上生成的所有推文。然而,一次收集所有的推文会让我们的电脑不堪重负,因为每分钟有几十万条推文。这种访问也受到限制,不是每个人都可以访问消防软管数据。我们将不得不访问 filter.json API 端点。这个 API 端点接受一个字符串列表,然后在 tweets 中搜索这些字符串。你得到的不是所有的 tweets,而是经过过滤的子集,这使得你的本地机器更容易处理它们。
您可能还注意到了上面的auth关键字参数。Twitter 流 API 需要认证。您需要创建一个开发者帐户,然后将您的凭据传递给 tweepy,这样 tweepy 就可以将它们传递给 Twitter。我们将在后面的小节中介绍如何做到这一点。
收听推文
一旦我们打开一个连接,我们将需要监听通过该连接传来的推文。Twitter 通过连接以纯文本形式发送数据,如下所示:
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
1953
{"retweet_count":0,"text":"Man I like me some @twitterapi","entities":{"urls":[],"hashtags":[],"user_mentions":[{"indices":[19,30],"name":"Twitter API","id":6253282,"screen_name":"twitterapi","id_str":"6253282"}]},"retweeted":false,"in_reply_to_status_id_str":null,"place":null,"in_reply_to_user_id_str":null,"coordinates":null,"source":"web","in_reply_to_screen_name":null,"in_reply_to_user_id":null,"in_reply_to_status_id":null,"favorited":false,"contributors":null,"geo":null,"truncated":false,"created_at":"Wed Feb 29 19:42:02 +0000 2012","user":{"is_translator":false,"follow_request_sent":null,"statuses_count":142,"profile_background_color":"C0DEED","default_profile":false,"lang":"en","notifications":null,"profile_background_tile":true,"location":"","profile_sidebar_fill_color":"ffffff","followers_count":8,"profile_image_url":"http:\/\/a1.twimg.com\/profile_images\/1540298033\/phatkicks_normal.jpg","contributors_enabled":false,"profile_background_image_url_https":"https:\/\/si0.twimg.com\/profile_background_images\/365782739\/doof.jpg","description":"I am just a testing account, following me probably won't gain you very much","following":null,"profile_sidebar_border_color":"C0DEED","profile_image_url_https":"https:\/\/si0.twimg.com\/profile_images\/1540298033\/phatkicks_normal.jpg","default_profile_image":false,"show_all_inline_media":false,"verified":false,"profile_use_background_image":true,"favourites_count":1,"friends_count":5,"profile_text_color":"333333","protected":false,"profile_background_image_url":"http:\/\/a3.twimg.com\/profile_background_images\/365782739\/doof.jpg","time_zone":"Pacific Time (US & Canada)","created_at":"Fri Sep 09 16:13:20 +0000 2011","name":"fakekurrik","geo_enabled":true,"profile_link_color":"0084B4","url":"http:\/\/blog.roomanna.com","id":370773112,"id_str":"370773112","listed_count":0,"utc_offset":-28800,"screen_name":"fakekurrik"},"id":174942523154894848,"id_str":"174942523154894848"}
前几行是 HTTP 连接头,我们可以忽略,因为它们只在建立连接时使用。一旦我们建立了连接,我们将得到一系列数字和 JSON 编码的推文。这些数字表明 tweet 数据正在通过连接发送,并告诉程序要从连接中读取多少字节才能获得 tweet 数据。在这种情况下,1953是在 tweet 结束之前从流中读取的字节数。读取下一个1953字节将为我们获取 tweet 的数据。
如您所见,数据不仅包含推文文本,还包含发送者、关注者数量和其他元数据的信息。这些数据是 JSON 格式的,可以使用 Python json库读取和处理。随着越来越多的 tweet 从 Twitter API 发送给我们,它们将遵循类似的格式,一行的长度以字节为单位,下一行是 tweet 的数据。所有的推文将通过相同的持久连接发送。
例如,随着我们处理更多的推文,我们可能会在我们的流中看到更多的推文,如下所示:
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
1953
{"retweet_count":0,"text":"Man I like me some @twitterapi","entities":{"urls":[],"hashtags":[],"user_mentions":[{"indices":[19,30],"name":"Twitter API","id":6253282,"screen_name":"twitterapi","id_str":"6253282"}]},"retweeted":false,"in_reply_to_status_id_str":null,"place":null,"in_reply_to_user_id_str":null,"coordinates":null,"source":"web","in_reply_to_screen_name":null,"in_reply_to_user_id":null,"in_reply_to_status_id":null,"favorited":false,"contributors":null,"geo":null,"truncated":false,"created_at":"Wed Feb 29 19:42:02 +0000 2012","user":{"is_translator":false,"follow_request_sent":null,"statuses_count":142,"profile_background_color":"C0DEED","default_profile":false,"lang":"en","notifications":null,"profile_background_tile":true,"location":"","profile_sidebar_fill_color":"ffffff","followers_count":8,"profile_image_url":"http:\/\/a1.twimg.com\/profile_images\/1540298033\/phatkicks_normal.jpg","contributors_enabled":false,"profile_background_image_url_https":"https:\/\/si0.twimg.com\/profile_background_images\/365782739\/doof.jpg","description":"I am just a testing account, following me probably won't gain you very much","following":null,"profile_sidebar_border_color":"C0DEED","profile_image_url_https":"https:\/\/si0.twimg.com\/profile_images\/1540298033\/phatkicks_normal.jpg","default_profile_image":false,"show_all_inline_media":false,"verified":false,"profile_use_background_image":true,"favourites_count":1,"friends_count":5,"profile_text_color":"333333","protected":false,"profile_background_image_url":"http:\/\/a3.twimg.com\/profile_background_images\/365782739\/doof.jpg","time_zone":"Pacific Time (US & Canada)","created_at":"Fri Sep 09 16:13:20 +0000 2011","name":"fakekurrik","geo_enabled":true,"profile_link_color":"0084B4","url":"http:\/\/blog.roomanna.com","id":370773112,"id_str":"370773112","listed_count":0,"utc_offset":-28800,"screen_name":"fakekurrik"},"id":174942523154894848,"id_str":"174942523154894848"}
2154
{"retweet_count":1,"text":"What's a tweet?","entities":{"urls":[],"hashtags":[],"user_mentions":[{"indices":[19,30],"name":"Twitter API","id":6253282,"screen_name":"twitterapi","id_str":"6253282"}]},"retweeted":false,"in_reply_to_status_id_str":null,"place":null,"in_reply_to_user_id_str":null,"coordinates":null,"source":"web","in_reply_to_screen_name":null,"in_reply_to_user_id":null,"in_reply_to_status_id":null,"favorited":false,"contributors":null,"geo":null,"truncated":false,"created_at":"Wed Feb 29 19:42:02 +0000 2012","user":{"is_translator":false,"follow_request_sent":null,"statuses_count":142,"profile_background_color":"C0DEED","default_profile":false,"lang":"en","notifications":null,"profile_background_tile":true,"location":"","profile_sidebar_fill_color":"ffffff","followers_count":8,"profile_image_url":"http:\/\/a1.twimg.com\/profile_images\/1540298033\/phatkicks_normal.jpg","contributors_enabled":false,"profile_background_image_url_https":"https:\/\/si0.twimg.com\/profile_background_images\/365782739\/doof.jpg","description":"I am just a testing account, following me probably won't gain you very much","following":null,"profile_sidebar_border_color":"C0DEED","profile_image_url_https":"https:\/\/si0.twimg.com\/profile_images\/1540298033\/phatkicks_normal.jpg","default_profile_image":false,"show_all_inline_media":false,"verified":false,"profile_use_background_image":true,"favourites_count":1,"friends_count":5,"profile_text_color":"333333","protected":false,"profile_background_image_url":"http:\/\/a3.twimg.com\/profile_background_images\/365782739\/doof.jpg","time_zone":"Pacific Time (US & Canada)","created_at":"Fri Sep 09 16:13:20 +0000 2011","name":"fakekurrik","geo_enabled":true,"profile_link_color":"0084B4","url":"http:\/\/blog.roomanna.com","id":370773112,"id_str":"370773112","listed_count":0,"utc_offset":-28800,"screen_name":"fakekurrik"},"id":174942523154894848,"id_str":"174942523154894848"}
呼叫回拨
一旦 tweepy 解码了 tweepy 数据,它就将数据传递给一个预先注册的回调函数。你可以在这里看到它的代码,我们将复制下面的一部分:
def _data(self, data):
if self.listener.on_data(data) is False:
self.running = False
self.listener实际上是一个用户定义类的实例,它有一个名为on_data的方法。on_data处理推文,然后返回True或False。如果on_data返回True,它处理了 tweet,一切正常。如果on_data返回False,连接将被关闭。
我们将在listener中放置我们的自定义代码来处理 tweet,然后返回适当的状态(True或False)。
速率限制和其他问题
Twitter 流媒体 API 有速率限制,禁止太多太快的连接尝试。它还防止使用相同的授权密钥建立太多的连接。谢天谢地,tweepy 为我们处理了这些细节,我们可以专注于我们的程序。
我们需要注意的主要事情是我们正在处理的推文队列。如果我们花太长时间处理推文,它们将开始排队,Twitter 可能会断开我们的连接。这意味着处理每条推文的速度必须非常快。
设置 Tweepy
既然我们已经了解了 Twitter 上的推文流是如何工作的,我们可以继续设置 tweepy 来开始流数据。我们需要做的第一件事是访问 Twitter 开发者中心并创建一个开发者账户。这个帐户将使我们能够创建凭据,让我们通过 Twitter 流 API 进行身份验证。
创建帐户后,我们可以转到应用程序控制台,创建一个新的 Twitter 应用程序。这将让我们获得特定于应用程序的凭证,这将让我们连接到 API。

填写所有的值来创建一个 Twitter 应用程序。
正如你在上面的截图中所看到的,你需要将“回拨 URL”字段留空。在“网站”字段中填写一个网站(如果有),否则您可以输入一个占位符值,如https://www.site.com。
创建应用程序后,您可以单击“密钥和访问令牌”选项卡来获取凭据。您需要从“应用程序设置”下获取以下信息:
Consumer Key (API Key)—我们称之为TWITTER_APP_KEY。Consumer Secret (API Secret)—我们称之为TWITTER_APP_SECRET。
您还需要在“您的访问令牌”下执行以下操作:
- 单击“创建我的访问令牌”
- 得到名为
Access Token的值—我们称之为TWITTER_KEY。 - 得到名为
Access Token Secret的值—我们称之为TWITTER_SECRET。
我们可以用下面的代码设置 tweepy 向 Twitter 认证:
auth = tweepy.OAuthHandler(TWITTER_APP_KEY, TWITTER_APP_SECRET)
auth.set_access_token(TWITTER_KEY, TWITTER_SECRET)
然后,我们可以创建一个 API 对象来从 Twitter 获取数据——我们将传递身份验证:
api = tweepy.API(auth)
设置监听器
正如我们上面提到的,使用 tweepy 打开 Twitter 流需要一个用户定义的listener类。我们需要子类化 StreamListener 类,并实现一些自定义逻辑。StreamListener类有一个叫做on_data的方法。这个方法会自动算出 Twitter 发送的是什么类型的数据,并调用合适的方法来处理具体的数据类型。它可以处理像用户发送直接消息、推文被删除等事件。目前,我们只关心用户何时发布推文。因此,我们需要覆盖 on_status 方法:
class StreamListener(tweepy.StreamListener):
def on_status(self, status):
print(status.text)
上面的代码将创建一个监听器,它打印来自 Twitter API 的任何 tweet 的文本。
我们还需要覆盖StreamListener的 on_error 方法,这样我们就可以正确处理来自 Twitter API 的错误。如果我们受到速率限制,Twitter API 将发送一个 420 状态码。如果发生这种情况,我们会想要断开连接。如果是其他错误,我们会继续:
class StreamListener(tweepy.StreamListener):
def on_status(self, status):
print(status.text)
def on_error(self, status_code):
if status_code == 420:
return False
启动监听器
一旦我们设置好监听器,我们就准备好连接所有东西,并传输提到Donald Trump或Hillary Clinton的 tweets。
在下面的代码段中,我们将:
- 创建我们的
StreamListener类的一个实例。 - 创建 tweepy Stream 类的一个实例,它将对 tweepy 进行流式传输。
- 我们传递我们的认证凭证(
api.auth),以便 Twitter 允许我们连接。 - 我们传入我们的
stream_listener,以便我们的回调函数被调用。
- 我们传递我们的认证凭证(
- 通过调用过滤器方法开始传输推文。这将开始从
filter.jsonAPI 端点传输推文,并将它们传递给我们的监听器回调。- 按照 API 的要求,我们传入一个要过滤的术语列表。
stream_listener = StreamListener()
stream = tweepy.Stream(auth=api.auth, listener=stream_listener)
stream.filter(track=["trump", "clinton", "hillary clinton", "donald trump"])
一旦我们设置好了,我们就有了一个简单的 Twitter 流!它不会做太多(只是打印出所有提到希拉里·克林顿或唐纳德·特朗普的推文的文本),但我们用很少的代码完成了很多工作。
过滤事件
我们想看看人们对每位总统候选人的看法。这意味着我们想忽略转发。转发出现在来自 Twitter API 的数据流中,但相同的文本可能会出现数百次或数千次。这将扭曲我们的结果,因为一个人的推文将在我们的分析中被有效地计数成千上万次。传递给on_status方法的 tweet 是状态类的一个实例。这个类有描述 tweet 的属性,包括属性retweeted_status,它告诉我们 tweet 是否是 retweet。我们可以通过检查retweeted_status属性来过滤掉转发。在下面的代码中,我们:
- 修改
on_status函数来过滤掉转发。- 如果
retweeted_status属性存在,那么不处理 tweet。 - 打印所有没有转发的推文。
- 如果
def on_status(self, status):
if status.retweeted_status:
return
print(status.text)
到目前为止,我们已经使用了 tweet 的text属性和retweeted_status属性。你可以在这里找到可用属性的完整列表。这些值来自 Twitter API,然后 tweepy 将它们设置为Status类实例的属性。我们可以通过使用以下字段来执行额外的过滤:
- 一条推文被转发的次数。
- 这条推文在某些国家被禁止发布。
favorite_count—该推文被其他用户收藏的次数。
例如,下面的代码将过滤掉收藏少于10的任何推文:
def on_status(self, status):
if status.favorite_count is None or status.favorite_count < 10:
return
print(status.text)
提取信息
因为我们必须快速处理推文,所以在保存之前,我们不想做任何太密集的事情。我们主要想提取和存储我们想要的属性。因为我们对分析支持Hillary Clinton或Donald Trump的人的情绪感兴趣,所以有几个领域会让我们感兴趣:
- 用户的描述(
status.user.description)。这是创建该推文的用户在他们的传记中写的描述。 - 用户的位置(
status.user.location)。这是创建推文的用户在他们的传记中写的位置。 - 用户的屏幕名称(
status.user.screen_name)。 - 创建用户帐户的时间(
status.user.created_at)。 - 用户有多少关注者(
status.user.followers_count)。 - 用户为其个人资料选择的背景颜色(
status.user.profile_background_color)。 - 推文的文本(
status.text)。 - Twitter 分配给 tweet 的唯一 id(
status.id_str)。 - 推文发送的时间(
status.created_at)。 - 该推文被转发了多少次(
status.retweet_count)。 - 推文的坐标(
status.coordinates)。推文发送的地理坐标。
这些属性将使我们能够分析有趣的事情,比如拥有更多追随者的用户是否支持Trump或Clinton。
我们可以用on_status方法提取这些信息:
description = status.user.description
loc = status.user.location
text = status.text
coords = status.coordinates
name = status.user.screen_name
user_created = status.user.created_at
followers = status.user.followers_count
id_str = status.id_str
created = status.created_at
retweets = status.retweet_count
bg_color = status.user.profile_background_color
处理推文
因为我们对支持两位总统候选人的人的情绪感兴趣,所以我们想分析每条推文的文本,以找出它表达的情绪。例如,这将告诉我们人们是否经常在推特上发布关于Hillary Clinton的正面消息。我们可以使用一种叫做情感分析的方法,给每条推文加上一个情感分数,从-1到1。一条-1意味着这条推文非常负面一条0是中性的,一条1意味着这条推文非常正面。情感分析工具通常通过查看字符串中是否出现已知表示消极和积极情感的单词来生成该分数。例如,如果单词hate出现在字符串中,它更有可能是负数。因为情感分析本质上是字符串匹配,所以它的工作速度非常快,这对我们来说很重要,因为我们处理的时间越长,我们就越有可能在处理推文时落后和断开连接。
为了执行情感分析,我们可以使用一个名为 TextBlob 的库,它允许我们在 Python 中进行情感分析,以及其他自然语言处理任务。
以下代码将:
- 在 tweet 的文本上初始化 TextBlob 类。
- 从班级中获取情绪得分。
blob = TextBlob(text)
sent = blob.sentiment
一旦我们有了sent对象,我们需要从中提取polarity和subjectivity。polarity是推文的负面或正面,用-1到1来衡量。subjectivity是指推文的客观或主观程度。0表示推文非常客观,1表示非常主观。为此,我们只需访问属性:
polarity = sent.polarity
subjectivity = sent.subjectivity
存储推文
一旦我们在每条 tweet 上获得了我们想要的所有数据,我们就准备存储这些数据以供以后处理。可以将我们的数据存储在 csv 文件中,但是 csv 文件使得查询数据变得困难。如果我们想从一个 csv 文件中读取,我们要么必须加载整个文件,要么通过一个复杂的过程来查询并只加载我们想要的部分。
存储数据的好地方是数据库。因为它们是常用的并且易于查询,所以我们将使用关系数据库。SQLite 是最容易使用的主要关系数据库,因为它不需要运行任何进程,所有东西都存储在一个文件中。
为了访问数据库,我们将使用数据集包,这使得访问数据库和存储数据变得极其简单。我们不是创建数据库和表,而是简单地存储数据,dataset包会自动创建数据库和我们需要的所有表。
我们必须首先使用连接字符串连接到我们的数据库:
import dataset
db = dataset.connect("sqlite:///tweets.db")
当使用 SQLite 时,如果数据库文件(在本例中为tweets.db)不存在,它将自动在当前文件夹中创建。
然后,我们必须将我们的坐标 json 字典转储到一个字符串中,这样我们就可以存储它:
if coords is not None:
coords = json.dumps(coords)
最后,我们可以在on_status方法中添加代码,将 tweet 写入数据库:
table = db["tweets"]
table.insert(dict(
user_description=description,
user_location=loc,
coordinates=coords,
text=text,
user_name=name,
user_created=user_created,
user_followers=followers,
id_str=id_str,
created=created,
retweet_count=retweets,
user_bg_color=bg_color,
polarity=sent.polarity,
subjectivity=sent.subjectivity,))
我们现在能够将我们处理过的每条推文写入数据库。一旦它们进入数据库,就可以很容易地被查询,或者转储到 csv 以供进一步分析。
将所有东西连接在一起
我们现在已经拥有了从 Twitter API 传输数据所需的所有部分!我们只需要将所有内容放在一个文件中,就可以从命令行运行了。这将使我们能够想看多久就看多久。你可以在这里看一下执行流的最终程序。这个程序可以通过输入python scraper.py来运行,之后它将永远运行,流式传输推文,处理它们,并保存到磁盘上。您可以使用Ctrl+C来停止程序。
我们希望将我们使用过的一些常量(比如数据库连接字符串、我们的数据库名称和我们的 Twitter 键)分离到一个单独的文件中,名为settings.py,这样它们就很容易更改。下面是settings.py的默认内容:
TRACK_TERMS = ["trump", "clinton", "hillary clinton", "donald trump"]
CONNECTION_STRING = "sqlite:///tweets.db"
CSV_NAME = "tweets.csv"
TABLE_NAME = "tweets"
这里可以看到设置文件。
你可以在这里阅读运行代码的完整说明。
分析推文
如果我们想在存储后分析推文,我们需要编写额外的代码来查询数据库。我们也可以使用datasets包来完成这项工作。
例如,下面的代码将从我们的数据库中查询所有的 tweets:
db = dataset.connect("sqlite:///tweets.db")
result = db["tweets"].all()
一旦我们有了一组结果,我们就可以处理它们,或者将它们存储到一个 csv 文件中,如下例所示:
dataset.freeze(result, format='csv', filename=settings.CSV_NAME)
你可以在这里看到一个程序的代码,该程序将所有现有的推文转储到一个 csv 文件。你可以用python dump.py从命令行运行这个程序。
后续步骤
我们在这篇文章中已经介绍了很多!我们开发了一个程序,可以从 Twitter 上传推文,对其进行注释,并将其存储到数据库中。既然您已经掌握了事件驱动编程,并且使用了流数据,我们就可以开始分析 tweets 了。这里有一个使用流媒体推特来描绘美国人对选举中每个候选人的感受的例子。
就你自己而言,这里有几个你可能想尝试使用 Twitter 流媒体工具的项目:
如果您有兴趣了解更多关于使用流数据和数据管道的信息,您可以查看我们的 Data questData Engineer Path。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何构建更好的 Tableau 项目(终极指南)
October 12, 2022
你想学 Tableau 吗?然后练习,练习,练习!这里有六个资源,将建立你的画面技巧和你的作品集!
Tableau 是一个非常强大的、包罗万象的数据可视化工具。它可以使用各种图表类型创建漂亮、清晰的数据可视化。它还有许多强大的内置计算功能。这为 Tableau 项目创造了无限的可能性,无论是自我指导还是作为更广泛社区的一部分,你都可以完成这些项目,从 Tableau 初学者到中级开发者,或者从中级到专业。
以下是一个资源列表,可以指导你通过 tableau 项目的想法,帮助你建立你的技能!
开始建造
盯着一张空白的画布是一种自由和挑战!我们会被所有的可能性压垮。然而,如果我们有一个有趣的数据源或分析,那么没有比简单地迎接挑战更好的学习方法了!
您可以运行从数据发现到仪表板设计和实施的整个范围的数据可视化项目。完成后,将其分享到 Tableau Public 个人资料上,并邀请朋友和同事对您的项目发表评论。
如果空白画布的前景让你兴奋,但你不确定在哪里可以找到数据,请查看 24 个免费数据集上的资源,以构建数据组合。你可以在 Kaggle.com 的或 data.world 的使用谷歌的数据集搜索找到额外的数据集。
改造星期一
如果你正在努力为你自己的 Tableau 项目想法寻找灵感,Tableau 社区会帮助你。
周一改头换面是八年来的传统。自 2016 年以来(2022 年有短暂中断),他们在自己的网站上发布了一张图表和一个附带的数据集。Tableau 用户可以利用数据集制作原始可视化的更好版本。这个群里分享的项目不会占用你太多时间,一周做一个当然是可行的。数据是经过筛选的,通常是干净的,因此您可以专注于可视化。
如果你在 Twitter 或 LinkedIn 上,你也可以使用标签#改头换面星期一与志同道合的数据专家分享你的结果。
周三锻炼
周三锻炼挑战我们探索利基 Tableau 功能,通常在计算或设计层。这些是很好的 Tableau 项目,用于练习我们可能不会每天使用的更高级的计算或图表类型。这是一个很好的工具,可以拓展我们的画面边界,发现有用的功能,否则我们可能发现不了。
结果会出现在网上,并附有一篇博文或操作视频。然后我们可以把我们学到的技术应用到另一个 Tableau 项目中。
真实世界的假日期
另一个由充满活力的 Tableau 社区创建的 Tableau 项目示例名为真实世界假数据(RWFD) 。我在提供 Tableau 培训中看到的一个主要问题是数据集通常是非概念性的。当然,我们可以想象《T2·宋飞正传》每一季的 IMDB 评分,但是这如何帮助发展业务呢?RWFD 试图通过提供反映真实商业环境的数据来纠正这一点。该分析更类似于在类似工作的情况下要求数据专业人员从事的工作类型。
类似于改造星期一和锻炼星期三,RWFD 有一个专门的用户组,分享,评论和鼓励彼此的数据可视化工作。
当天的画面
Tableau Public 有一个现象特征,叫做即今日。每周,Tableau 都会在 Tableau Public 的每日专题 Viz 中展示其他作者创建的 Tableau 项目示例。这些是典型的精细和专业的数据可视化,推动了 Tableau 功能的极限。虽然大多数日常生活可能与你无关,但它们仍然是灵感的绝佳来源。
大多数情况下,您可以下载《今日 Viz》工作簿。如果有我们感兴趣的特定设计元素或计算,我们可以下载 Tableau 文件并尝试对其进行逆向工程。然后,如果我们愿意,我们可以尝试将相同的方法和功能应用到我们已经在处理的项目或数据源中。
构建 Tableau 投资组合
一个 Tableau 作品集,通常在 Tableau Public 上,是我们作为 Tableau 专业人士进行交流和成长的最有价值的工具之一。填写一份生动的公开投资组合可能令人望而生畏。但是希望这篇文章已经给了你一些开始的方法。
无论你如何构建你的 Tableau 项目,请记住 Tableau 社区的价值。参与和分享你的 Tableau 项目将会带来参与和指导——两者都将有助于提高你的技能和职业生涯。
Tableau 培训:停止不正确的学习(改为这样做)
October 26, 2022
为什么要学 Tableau?
Tableau 是世界上最受欢迎的商业智能工具之一,根据 Gartner 的排名,它是该市场的前三大领导者之一。
2022 年,超过 3 万家机构使用 Tableau,LinkedIn 上超过 20 万个职位空缺至少需要一些关于它的知识。Tableau 不仅经常被数据专业人员使用,如业务分析师和数据分析师,还被广泛的其他人使用,如数字营销人员、消费者体验专家等。
通过学习 Tableau,你可以获得一项有价值的技能,这将有助于你的职业发展。向雇主证明你的技能并在面试中脱颖而出的最佳方式是获得 Tableau 专家认证并建立一个项目组合。
在本文中,我们将为您提供 5 个步骤来准备认证,给您掌握 Tableau 的经验,最后,帮助您建立一个项目组合。这 5 个步骤将促进你的职业发展。
如何学习 Tableau?
随着 Tableau 受欢迎程度的上升,培训的选择迅速增加。选择正确的方法来学习 Tableau 可能会很困难。
在 YouTube 上观看研讨会或在互联网上阅读专家博客似乎是很有吸引力的选择,但掌握 Tableau 需要深厚的知识和实践经验——其余的可以在工作中学习。
如果您想学习 Tableau,获得认证,并在短短几个月内建立您的投资组合,我们已经创建了一系列 Tableau 课程,将教你所需的一切。
第一步:下载 Tableau 并习惯它的界面
Tableau 有免费版和付费版可供下载。对于学生或只想试用 14 天的人来说,Tableau 可以在这里下载用于 PC 和 MAC 电脑。经过 14 天的试用,用户可以转换为付费许可证。对于那些想要长期免费访问的人,有 Tableau Public 。只要你不处理敏感数据,并且总是能够保存到云中,Tableau Public 就是一个极好的选择。
一旦 Tableau 安装完毕并准备就绪,我们就可以通过遵循入门指南来熟悉 Tableau 界面。在进入详细的 Tableau 在线培训之前学习界面是一个好主意,就像 Dataquest 的第一个 Tableau 课程。
步骤 2:开始构建图表和仪表板
跳转到数据源并构建图表和仪表板是 Tableau 最有趣的事情。但是说起来容易做起来难!在学习如何创建可视化分析时,一个干净的数据源是很重要的。Tableau 为数据清理和操作提供了很好的选择,但这可能不是我们想学的第一件事。相反,让我们找到一个干净的数据源来使用。在Kaggle.com上有很多选项,比如桌游排行榜上的这个数据集,或者多伦多 2017 年自行车份额使用情况的这个数据。Dataquest 在 Tableau track 中有一个关于塑造和设计仪表板的很棒的课程。
步骤 3:发布和共享您的仪表板
与他人分享我们的见解甚至比构建仪表板更有意义。共享仪表板有两种方式:静态或交互。
共享静态仪表板可以通过将其导出为 PDF、图像或 Powerpoint 来完成。这样做的时候,我们失去了所有的交互性,包括过滤器,点击动作和工具提示(悬停)。尽管如此,这仍然是一个很好的共享方法,因为它简单且与软件无关。所有这些选项都可以在顶部的仪表板菜单中找到。
如果我们希望我们的数据消费者具有交互性,我们需要将我们的工作簿发布到 Tableau Public、Online 或 Server。只有 Tableau Public 允许我们免费发布和分享,所以这是我们建立作品集的最佳选择。Tableau 有一个伟大的资源为分享你的仪表板的最佳方式,所以选择最适合你的路径。
第四步:建立你的投资组合
希望发布第一个仪表板的激动是一个积极的体验。是时候考虑扩大我们的 Tableau 投资组合了。为了让 Tableau 学习体验变得有吸引力和有价值,做一些令人愉快的事情是有帮助的。太多的在线 Tableau 课程使用完美的超市销售数据集,这既不现实,也不鼓舞人心。相反,尝试使用众多数据集聚合器中的一个来查找您感兴趣的数据。我们已经使用过几次 Kaggle 了。还有网站数据中的我们的世界和 Dataquest 文章 24 个免费数据集打造不可抗拒的投资组合(2022) 。无论是体育、政治、电影,还是任何其他激情,都很有可能存在一个关于这个主题的免费数据集。
第五步:获得认证
为了完成您的学习之旅,请考虑参加 Tableau 专业桌面认证。桌面认证的两个级别分别是桌面专员和认证数据分析师。专家考试是多项选择题,而认证数据分析师考试是多项选择题和解决问题的结合。两者都是很好的简历助推器,并提供了一个学习的里程碑,以建立对你的画面技巧的信心。这里有备考选项:来自 Tableau (guide)的备考文档。
外卖食品
获得 Tableau 技能并获得认证可能需要 1 到 6 个月甚至更长时间。有些人学得很快,而有些人可能需要更长的时间,因为其他的生活承诺。这完全取决于你的时间表和你的奉献精神,以你想要的速度学习 Tableau。
使用 Microsoft Power BI 技能路线分析数据现已上线!
原文:https://www.dataquest.io/blog/the-analyzing-data-with-microsoft-power-bi-skill-path-is-now-live/
March 21, 2022
这一天终于到来了—我们与微软合作开发的全新技能路线“使用微软 Power BI 分析数据”现已上线!在短短的几个月内,这条技能路线将帮助你获得在商业分析中找到工作所需的基本技能。您将学习使用数据分析来为更好的商业决策创造洞察力;您还将学习如何通过使用拖放界面来建模数据、创建报告和构建交互式仪表板。
响应市场需求的技能途径
我们推出这条技能之路有几个主要原因:
- 对商业分析和商业智能工作和技能的日益增长的市场需求
- 需要 Microsoft Power BI 的工作数量激增
- 与微软的共同愿望是将微软 Power BI 技能带给世界各地的学习者
- 构建一条业务分析师职业道路,该道路将教授以 Microsoft Excel 和 Microsoft Power BI 为基础开始职业生涯的基本技能
技能路径中的微软 Power BI 要素
通过我们的“使用 Microsoft Power BI 分析数据”技能路线,我们决定将重点放在您需要了解和使用该平台以做好工作准备的基本技能上。
你将学习如何做以下事情:
- 浏览 Power BI 界面
- 清理、转换、加载和结构化数据
- 设计数据模型
- 借助有意义的视觉效果、仪表盘和报告,创建引人注目的数据驱动型故事
- 管理工作区
- 执行业务分析
“我很高兴与微软合作推出我们新的 Power BI 技能路线。Power BI 被全球数以万计的公司使用,是当今最受欢迎的数据技能之一。我们的新路径将通过实践练习和项目帮助世界各地的学习者提高他们的 Power BI 技能。
我期待着继续与微软合作,为学习者创造更多的培训和认证机会。我们的创始人 Vik 说。
为什么您应该与我们一起学习 Microsoft Power BI
我们已经创建了一个技能途径,帮助技术和非技术用户开发他们需要的应用技能,以充分利用 Microsoft Power BI 您可以在工作中学习其他内容。
您不需要事先了解 Microsoft Power Bi —一些数学和电子表格的基本知识就足够了。完成课程后,你将具备向现有和未来的雇主展示必要知识和技能的能力。这不会像新兵训练营那样需要一年时间——只需要几个月。
当您完成这一过程时,您将为 Microsoft 认证考试 PL-300 做好准备,这是一项衡量您能力并证明您在 Power BI 方面技能的评估。而且,在我们的道路上完成 4 门课程,您将在考试中获得 50%的折扣。有了这个认证,您将让现有或未来的雇主知道,在涉及到 Power BI 时,您带有微软的认可印记。
学习 Dataquest
在 Dataquest,我们相信边做边学,而不仅仅是看视频或阅读支持文档。这意味着您将直接在浏览器中编写真实的代码,并且您将完成引导项目,您可以使用这些项目来构建您的文件夹。
Dataquest 的所有课程都是异步的,因此您可以在方便的时候按照自己的节奏学习。如果您遇到困难,我们积极支持的用户社区会为您解答每一个问题,我们只需点击一下鼠标。
这里有一些你在跟我们一起学习时可以期待的东西:
- 使用我们的浏览器内置编码界面轻松开始学习——安装软件时不会出现任何问题
- 通过我们基于实践和项目的学习方法,获得真实的实践经验,为您的工作做好准备
- 建立你的项目组合,向现有或未来的雇主展示你的技能
- 通过我们的结构化路径,只学习必要的东西,并走上实现目标的道路
- 在你的学习过程中,从同路的志趣相投的人那里获得支持
- 庆祝你的成就,展示你学习的证据
所以,现在技能之路已经开放,可以开始做生意了,来看看吧。您可以在短短几个月内掌握 Power BI。
Dataquest 的理念:构建完美的数据科学学习工具
原文:https://www.dataquest.io/blog/the-perfect-data-science-learning-tool/
August 6, 2019 When I launched Dataquest several ago, one of the first things I did was write a blog post about why. Here, I’d like to dig a bit deeper into Dataquest’s philosophy.
When I launched Dataquest several ago, one of the first things I did was write a blog post about why. Here, I’d like to dig a bit deeper into Dataquest’s philosophy.
在我创办 Dataquest 的时候,如果你想成为一名数据科学家,你会在 EdX 或 Coursera 等网站上遇到许多课程,找工作并不容易。我看到许多有前途的学生放弃学习数据科学,因为他们陷入了反复学习相同课程的循环中。
我试图用 Dataquest 解决学习数据科学的两个主要障碍:从理论到应用的挑战,以及知道下一步该学什么的挑战。
我坚信每个人都应该有机会做自己感兴趣的工作,Dataquest 是一种将这种信念付诸行动的方式,可以帮助其他人在一个困难的领域获得立足点。
多年来,我们一直努力让在一个地方学习数据科学职位所需的所有技能变得简单。从基本的 Python 和 R 到 SQL 再到机器学习,Dataquest 教你正确的技能,并帮助你建立一个项目组合。
当我们建立这个网站时,我们学到了很多如何最有效地帮助学生的经验。我们一直在逐步扩大我们最初设想的范围。在这篇文章中,我想概述一下我们现在关注的是什么,以及我们的前进方向。在这个过程中,我希望说明为什么 Dataquest 是您学习数据科学的好地方。
Dataquest 的哲学,基于多年的观察
人们常说,学习本身就是一种奖励。像前面提到的 edX 和 Coursera 这样的大规模开放在线课程(MOOC)网站就是基于这种智慧而创建的。
相反,我们发现我们的学生学习数据科学是因为他们喜欢它和因为他们想要更好的工作。这一观察促使我们变得更加专注于职业。学生们最希望的是一条通往数据科学职业生涯的更好的道路,我们认为这是我们能够努力的最高杠杆。
在我们帮助人们为新职业做好准备的同时,我们提出了四项重要观察:
- 专注对于保留知识至关重要,尤其是当你时间有限的时候。
- 动机是你能否找到工作的最重要的决定因素。
- 很容易陷入“困境”和沮丧——及时的帮助是关键。
- 没有太多好的职业建议和面试准备帮助。
让我们更深入地研究这些观察,看看它们是如何影响我们的思维的。
焦点
当您学习数据科学时,很容易迷失在工具的海洋中。有人告诉你,你必须学习 R、Python、Spark 和 Tensorflow。如果你不这样做,你就不是一个“真正的”数据科学家。这令人不快,但更重要的是,这实际上不是真的。
相反,我们发现最终找到工作的学生更关注概念而不是工具。如果你从零开始学习如何实现一个随机森林,并且知道训练它所涉及的权衡,那么你是使用 Python、Scala 还是 R 来做预测都没关系。
概念在工具之间泛化;如果你很好地学习了一个概念,你可以使用任何工具来实现它。如果你能在 R 中拟合一个决策树模型,你会有一些工作前景,但是如果你深刻理解这个模型及其工作原理,你会有一个数量级的提升。
一次专注于几个概念,在继续学习之前掌握它们是保留知识的关键。我们一直非常专注于 Dataquest,因此知识会深入人心。我们的互动平台不断挑战学生,让他们在进入下一步之前通过编写自己的代码来应用他们所学的知识,这样他们就可以一步一步地学习,并在他们没有理解某些内容时从我们的答案检查系统中获得即时反馈。
我们有一个线性课程,带你从没有编程知识一直到高级机器学习。因为我们开发了整个课程,所以我们能够按照逻辑顺序教学,并确保你永远不会迷路。我们一贯的风格和对概念的关注意味着你可以一次专注于学习一个概念。
例如,下面是我们的数据分析师在 Python 路径中的前几个步骤。每门课程都建立在前一门课程所学技能的基础上。
动机
学校里经常教导说,教师的工作是教学,而你的工作是激励学生。但是如果你没有动机,即使是一个非常了解材料的老师也不会有效。
我们发现动机是找到工作的学生和找不到工作的学生之间最大的区别。仅仅“打勾”领证是不够的。你必须建立项目来展示你的技能并建立一个投资组合。建立一个好的需要真正的兴趣和动力。
为了有动力建立有效的项目,你必须真正喜欢与数据打交道。正如我在一篇关于如何学习数据科学的博客文章中所写的,学习数据科学的先决条件是找到让你感兴趣和激励你的问题。
在 Dataquest,我们的理念是激励是我们的工作,我们围绕这一点来定位网站。
我们设计了我们的课程,将几十个有趣的数据集交织在一起,包括中情局干预和 NBA 球员统计数据。当你准备好了,我们包括几十个有趣的项目,探索如何赢得危险和股票价格预测等主题。通过专注于吸引和激励您,我们帮助您在获得数据科学工作的旅程中走得更远。
例如,这里有一个指导项目的屏幕,您使用 SQL 来分析电影评论网站上评分的一些差异:
被“卡住”
当涉及到更多开放式项目的工作时(这是所有有抱负的数据分析师和数据科学家都需要做的事情),我们发现学生需要帮助来“摆脱困境”。
被卡住的范围从不知道如何安装软件包到难以概念化数据的结构。学生们通常不需要大的帮助——只是朝着正确方向的一个小小的推动或者信心的提升都是非常宝贵的。
我们已经意识到,当你陷入困境时,这些小挫折累积起来,会降低你的动力,使你更有可能达不到你的目标。我们设计了一些系统,确保您可以从导师或同行那里获得帮助,以避免这种挫折,包括我们的数据科学学生社区。
职业建议
我们注意到,我们的许多学生都有职业问题,从想知道他们应该学习什么技能才能最受雇主欢迎,到面试中可能会问什么问题,到他们的投资组合应该是什么样子。
为了帮助回答这些问题,我们采访了数十位数据科学家、招聘人员和招聘经理,并制作了一份数据科学职业指南。对于高级订户,我们还提供职业咨询,在更直接、更私人的层面上帮助解决职业问题。当然,学生们也可以在学生社区向同龄人和导师寻求职业建议。
完美的数据科学学习工具
基于上述观察,Dataquest 的理念是,理想的数据科学学习工具应包括以下要素:
- 为您提供学习数据科学的路线图。
- 允许您通过在浏览器中编码来练习技能。
- 以应用的方式教授高级概念。
- 帮助您建立项目组合。
- 通过导师和社区帮助为您提供支持。
- 指导你的职业选择,并帮助你找到潜在的雇主。
我们认为我们正在处理所有这六个元素,尽管我们肯定还有很多可以改进的地方。我们一直在努力改进 Dataquest,所以让我们来看看这六个方面,我们提供了什么,我们正在努力改进什么。
1.数据科学路线图
数据科学路线图可以让您保持专注和按部就班,而不必考虑下一步该走哪条路。我们目前提供四种学习途径,旨在让学生从零经验到做好工作准备,成为数据分析师(Python 或 R)、数据科学家(Python)和数据工程师(Python)。
但是我们能做的还有很多。在不久的将来,我们计划重新推出我们的数据工程课程,使其对初学者更加友好,我们也在不断努力扩展我们的 R 课程,最终目标是培养一名 R 路径的数据科学家。
2.浏览器内编码
当你是一个初学者时,安装像熊猫这样的软件包或像 Spark 这样的工具要花很长时间,这是令人惊讶的。Dataquest 让您可以在浏览器中体验一下,编写真正的代码,而无需在本地进行任何设置。我们有自动化的答案检查,这使得在我们的网站上工作比在你的本地机器上工作更有利于学习。
不过,最终每个人都需要适应在本地工作,因此我们也帮助您在自己的计算机上设置一切,以便在自己的计算机上工作。
在过去的一年中,我们推出了一些令人兴奋的变化,如具有更好的浏览器内界面的大修命令行课程,以及使我们基于浏览器的系统更加可靠和快速的代码运行改进。我们一直在努力改进和优化我们的平台,因此在可预见的未来,我们将继续努力改进我们的交互式浏览器内编码。
3.应用概念
我们的课程通过让您使用有趣的数据集解决实际问题,向您传授决策树等数据科学概念。例如,您可能会处理有关航空事故或全球教育成就的数据。使用我们的浏览器内编码系统,您将一点一点地学习,在操作真实数据集的代码中应用每个概念。
一旦你学会了这些技能,你将能够在更大的指导项目中应用它们,这些项目仍然提供一些结构,同时挑战你综合你所学的新技能。
这种先学习后应用的循环有助于你快速发展和巩固你的技能。我们认为,我们的概念学习和应用的快速循环穿插着更大的指导项目是教授数据科学的最有效方式,我们的学生也同意这一点。
(查看我们的学生故事,看看有多少学生提到他们已经尝试了多种平台,但 Dataquest 是“迫使他们思考”并应用他们所学知识的平台)。
不过,总有改进的空间,我们会根据学生数据不断迭代和调整我们的课程。例如,如果我们发现学生在某个特定的屏幕上卡住了,我们可以也确实会做出调整。这是我们将继续做的事情,在未来的岁月里,我们将做得更多。
4.项目
我们帮助你建立一个项目组合。这不仅有助于你实践和学习概念,也有助于你获得工作面试!
招聘经理在决定面试谁时,越来越多地考虑投资组合。就连面试也越来越倾向于将项目作为一种评估手段——你可能会得到一个带回家的或亲自参与的项目作为面试的一部分。
我们知道 Dataquest 的引导式项目可以帮助人们找到工作— 这里有一个这样的例子。但是,我们希望提供更多的项目和更广泛的数据集,让学生在学习我们的课程时有更多的选择。
5.一路支持
现在,你可以在我们的学生社区从其他学习 Dataquest 的学生那里获得帮助,我们的数据科学家也经常在那里发帖。这种帮助对于保持你的注意力和积极性是至关重要的。今年,我们将努力扩大该社区,并引入工具,使其在遇到困难时更有效地快速找到您需要的帮助。
6.职业帮助
在过去的一年里,我们发布了一份超过 30,000 字的数据科学职业指南,这是基于对专家的几十次采访。它涵盖了工作申请过程的每个阶段。
我们还为 Dataquest Premium 用户提供职业咨询,以便他们可以获得更多个人职业问题的帮助。
在未来的一年里,我们计划引入更多的职业帮助,例如与职业专家举行社区网络研讨会,他们可以提供建议和回答问题。
Dataquest 的理念:展望未来
正如您所读到的,您可以期待 Dataquest 的许多改进。但是进步不会一蹴而就,它会定期发生,因为我们会不断调整 Dataquest 体验。
我们在不断迭代和改进平台体验,我们也在不断编写和发布新的课程来扩展我们的课程。如果您选择订阅,您将看到我们的课程目录随着您的学习而扩展,因此总会有新的东西添加到您的技能组合中。
祝你学习数据科学好运,希望我已经说服你试用 Dataquest !如有任何问题,请联系。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
这位艺术家将森林地面变成了数据可视化
原文:https://www.dataquest.io/blog/this-artist-turns-the-forest-floor-into-data-visualizations/
May 2, 2018
编者按:这篇文章是与营销情报公司 iDataLabs 合作的一部分。作者朱莉娅·库克在 iDataLabs 从事营销工作。
我们都熟悉数据可视化——文字云、饼图、数据透视表——但是如何将查询用绘画表现出来呢?来自华盛顿州西雅图的景观艺术家帕蒂·哈勒可能已经发现了这一点。她在华盛顿大学接受的金融培训和在盖奇艺术学院接受的传统油画培训提出的问题比回答的问题更多。在她的职业生涯中,从林务员到分析师再到艺术家,哈勒从未停止对她的工作提出问题。当每个形状都是一个数据点时,每个绿色空间就成了一个独特的群体,而她的工作就是找到模式。
在开始之前,你如何确定一个主题?
我喜欢真正复杂的森林,有很多不同层次的植物。如果我能在描绘我实际看到的东西和代表它的模式之间找到一个好的结合,我喜欢这样做。我喜欢用图案来表示沿横断面排列的事物。例如,我可以想象沿着这条线从这里到华盛顿湖的所有休耕植物。我可以运用数学或统计学的任何其他方法来帮助我自己理解这些意象。
我想了很多。如果所有这些叶子都占据笛卡尔坐标 x,y 和 z,我可以说,‘所有代表 y=x +5 的东西,不管在哪里,都是紫色的。’并不是我真的在做这些东西,而是我在思考它们。我把一点点应用到我正在画的任何画中。
那么当你开始创作时,你脑子里有完整的作品吗?
我主要有完整的骨架,我需要知道这将是一个很好的组成。这可以是一个快速的草图,或者有时是我提前做的非常详细的草图。一旦在面板上建立了这个,我就开始做其他的事情。如果我想加入一些很酷的叶子形状,我会把照片拿出来。一旦我有了骨架,我就填充中间的空间。

你在你的博客上谈到了对空间进行分组,你能谈谈吗?
如果我为自己选择一些规则来组织事物,我想这会让整体看起来更有凝聚力。所以我用一个叫做 Gesamkunstwerk 的概念来工作,这是德语,意思是“全部的艺术作品”,部分加起来就是整体,整体是有凝聚力的,艺术作品作为一个整体应该是有趣的,如果你想深入研究。
这就是我开始思考财务和我所有的电子表格的时候,你怎么能有一个汇总电子表格,但有所有这些东西在它后面,所有这些其他的表可以支持你的汇总数字。如果你给一位高管看‘这是我们的损益表’,他会说‘这个费用行是怎么回事,后面是什么?’你可以回答这个问题。当我画森林时,我必须考虑所有这些事情,因为它太复杂了。大多数艺术家只会简化事物,就像在一幅油画中,但这种方式对我来说更有趣。我试着不让自己觉得无聊。让别人感到厌烦已经够粗鲁的了…
如果我说,“前面需要一棵蕨类植物”,那就不是蕨类植物,它需要一些东西让你的眼睛跟随。它不是为了复杂而复杂,而是添加了一些东西,让它变得更有趣。
当你在一幅画中添加一些东西时,你是在绘画的同时为它创造一个功能吗?
我会一直为自己想规则,但我只会在对绘画有用的时候使用规则。总有一天它会变成一种直观的颜色。色彩真的是我知道我需要努力的最后一件事。所以唯一对我有用的功能就是让它和颜色有关。否则我想我会打破我的规则。
你也为大师们制作颜色图表。你能谈谈每个灯罩的位置吗?
挺随机化的。我学会了做彩色图表,网格中的每个矩形都是预先确定的,因为我在作品的顶部和侧面有一些东西。但是这些图表对我来说没有用,因为我更想知道,如果我选择这五管颜料,对我有用的所有可能的组合是什么,它们彼此看起来如何?所以对我来说,拿五管颜料会更好,这是最上面一排,下面是所有的混合物。所以这一切都是随机的,但对我来说,它非常有用。我已经做了很多年了,我有满满的彩色图表。我把它们拿出来,这就是我如何决定一件作品的颜色。

作为一名分析师,你会对庞大的数据集提出问题。在你开始工作之前,你会给你的项目分配一个问题吗?
有时候我就是这样,这是一个很好的例子:
我被要求画一些我通常不画的花卉,因为作为一名女画家,我不想被归类。所以如果你看我的画,有很多植物和树木,但实际上这些意象相当有男子气概。但是当我被要求画这些花卉时,我去了斯卡吉特山谷的冷杉岛,那里有成千上万的植物。所以我马上开始考虑巨型数据集。
事实上,我上周完成了一幅名为《冷杉岛数据集》的画。因为它让我想起了大数据中的概念,我们能不能把整个人口的数据保存为个体点,让数据自己说话?我一直在问自己,我是在让面板上的数据自己说话,还是我自己插入,特别是在过程的早期,总结和简化工厂,因为这是我唯一能处理的方式。我问自己的问题是扩展这个过程的方法,在这个过程中,我让各个数据点保持它们的特征。
有道理。没有人说过他们明白我在说什么!
我在一家数据科学公司工作,所以这对我很有意义!但是你用什么来表示每个数据点,是一朵花,还是花序?
通常是一个形状。一次想不出太多东西,就用形状。场景本身是绿色的,所以颜色对我来说并不太有趣。但是如果你看看这些形状,即使在这么小的区域,也有上百种。所以我认为每个形状都是一个数据点。我不太在意它,因为我只是用刷子做标记,但我确实试图做单独的标记来代表单独的叶子形状。再说一次,这和植物没有任何关系。这是关于保持复杂性。
那么,当你把目光吸引到一条线或一个图案上时,你关注的是像差还是相似点?
用我所谓的‘视线路径’,我用典型的艺术关注,在如何划分你的平面上。我没有考虑植物中的异常现象,除非有一个我想叫出来。如果有趣的话,我会把面板分成几部分,并把它放在特定的点上。我知道,从学习艺术,当这是有意义的。
我花了很多时间去想象,但是这幅画总是会接管,告诉你它想要什么。历史上有很多谈论——来自男人——关于对抗绘画,我对我的工作更温柔。我得到了我的电枢和图案,但后来它几乎感觉像一个对话,在那里我问它帮我看看它需要什么。如果没用就很明显了。
你有没有发现你画画的过程,比如让简单的事情变得更复杂,或者倾听数据告诉你的事情,会渗透到你生活的其他方面?
倒过来了!我很年轻的时候就获得了 MBA 学位,所以从 23 岁开始,我就每天阅读《华尔街日报》。所以对我来说,总结和深入研究的概念,或者发现一些细节并想知道关于一个群体的结论可能是什么,一直是显而易见的。那对我来说是自然的。我让这种态度贯穿于我的画中。

Madonna of the Back 40 oil on canvas, 60x40Smith and Vallee Gallery’s January 2017 show
As a painter, I’m trying to be more of myself. And myself is an analytical person. I get frustrated with people who don’t have the patience to drill down every once in awhile. Or people who try to change the characteristics of a data population because of some idea they have, some narrative. I find that very common with artists. They have this concept of ‘how the world works,’ and it’s a decision tree they only allow three branches to grow. You get to a more interesting truth if you’re patient, and acknowledge that there’s more complexity. I didn’t learn that in business school, though.
对于那些希望将数据科学和统计流程引入一个可能尚不适合这些方法的领域的人,你有什么建议吗?
不追求显而易见的东西。分形艺术,计算机生成的艺术,如果你对它不感兴趣,你就不应该做。我所说的一些东西,包括我的坐标,或者我的人口,一开始并不清楚如何把它们结合起来。但如果你只是拿着你的供给,不停地乱搞,你会找到某种方式来表达它。
我真的对我的实验很有条理,我做了很多笔记,我把它们储存起来,我考虑我以后要如何使用它们。只有当我发现自己真的对工作感到厌倦时,我才不得不问自己,“为什么我觉得它无聊,而其他人都觉得它很有趣?”我意识到这是因为我没有解决我对复杂性的兴趣。我对它有耐心,也有其他艺术家没有的兴趣。我不得不考虑了很久。
我读了肯尼斯·库基尔和维克托·迈尔·舍恩伯格的《大数据》( Big Data )( T1 ),他们谈到了大量的数据,以及我们过去如何需要统计抽样来观察这些数据。因为你永远没有预算去衡量一切。我以前也是做这个的,我在树林里做统计取样。有了更强大的计算机能力,你就可以在不使用这些样本的情况下处理更多的数据。在极端情况下,你的样本集可以包括每一个点。一切都可以被测量并保持其原有的特征。这是一个极端,也是理论上的,但阅读它对我产生了巨大的影响,因为我意识到我不必画每一片叶子,只要我保留视图的复杂性。这是授权,也是对主体的尊重。
帕蒂·哈勒最近在西雅图艺术博物馆画廊展出。她的下一个个展将于 2018 年 7 月在华盛顿州爱迪生市的史密斯和瓦利画廊举行。
你应该学习数据科学 R 的六个理由
原文:https://www.dataquest.io/blog/three-mighty-good-reasons-to-learn-r-for-data-science/
July 30, 2020
所以你想学数据技能。太好了!但是我们提供大量的数据科学课程。为什么要专门学 R 编程?学 Python 会不会更好?
*如果你真的想探究这个问题,我们已经展示了 Python 和 R 来展示每种语言如何处理常见的数据科学任务。虽然底线是每种语言都有自己的优势,并且都是数据科学的绝佳选择,但 R 确实有值得考虑的独特优势!
1。r 是为统计而建的。
r 最初是由统计学家为进行统计分析而设计的,现在它仍然是大多数统计学家的编程选择。r 的语法使得用几行代码创建复杂的统计模型变得很容易。既然这么多的统计学家使用 R 包并为之做出贡献,你很可能能够找到任何你需要执行的统计分析的支持。
出于相关的原因,R 是许多学术环境中的统计和数据分析语言。如果你渴望在学术界工作——或者如果你只是想阅读学术论文,然后能够挖掘它们背后的代码——拥有 R 编程技能可能是必须的。
2。r 是顶级科技公司 中数据科学的流行语言
几乎都是 雇佣使用 R .脸书的数据科学家,比如用 R 用用户帖子数据做行为分析。谷歌使用 R 来评估广告效果和进行经济预测。Twitter 使用 R 进行数据可视化和语义聚类。微软、优步、AirBnb、IBM、惠普——他们都雇佣了会用 r 语言编程的数据科学家
顺便说一下,不仅仅是科技公司:分析和咨询公司、银行和其他金融机构、学术机构和研究实验室都在使用 R,几乎所有其他需要分析和可视化数据的地方都在使用 R。连纽约时报都用 R!
3。在 r 中,学习数据科学基础知识无疑会更容易。
Python 可能是对初学者最友好的编程语言之一,但是一旦你掌握了语法,R 就有了一个很大的优势:它是专门为数据操作和分析而设计的。
正因为如此,一旦你掌握了基本的基础知识,学习数据科学的核心技能——数据操作、数据可视化和机器学习——实际上会变得更加容易。例如,看看在 R 中 创建这些常见的数据可视化样式有多简单。
当然,还有 tidyverse ,这是一组专门为使 R 中的数据工作更快、更容易、更易访问而构建的包。事实上,这本身就是一个优势:
4。令人惊叹的包装让您的生活更轻松。
因为 R 的设计考虑到了统计分析,所以它有一个奇妙的软件包和其他资源的生态系统,这对数据科学非常有用。例如,dplyr 包使数据操作变得轻而易举,而 ggplot2 是数据可视化的绝佳工具。
这些软件包是 tidyverse 的一部分,这是一个由 RStudio 维护的不断增长的软件包集合,R studio 是一家经过认证的 B-corp,它还创建了一个免费使用的同名 R 环境,非常适合数据工作。这些软件包功能强大,易于访问,并且有很好的文档。
RStudio 是一家生产一些令人惊叹的 R 软件包和最受欢迎的 R IDE 的公司。
这只是冰山一角——即使在 tidyverse 之外,也有很多 R 包做着很酷的事情。例如,看看这篇关于如何使用 R 和一个名为 googleAnalyticsR 的包来处理谷歌分析数据的博文。
5。包容的、不断壮大的数据科学家和统计学家社区。
随着数据科学领域的爆炸,R 也随之爆炸,成为世界上发展最快的语言之一( 用 StackOverflow 来衡量)。这意味着,当您在 R 中进行项目时,很容易找到问题的答案和社区指导。由于有如此多热情的 R 用户,您可以找到集成了几乎任何您能想到的应用程序的 R 包!
R 社区也特别热情和包容,有像 R 女士和少数民族 R 用户这样令人惊叹的团体,旨在帮助确保每个人学习和使用 R 技能。
6。在你的工具箱里再放一个工具。
即使你已经是一名 Python 专家,也没有一种语言是适合所有工作的工具。将 R 加入到你的技能清单中会让一些项目变得更容易——当然,当你在寻找数据科学领域的工作时,这也会让你成为一名更灵活、更有市场的员工。
即使你自己不想使用 R,如果你不得不接手一个同事的项目,学习这些基础知识会让你更容易遵循别人的 R 代码。能够查看 R 并将其翻译成 Python 意味着两种语言的惊人资源向你开放。
长话短说:有很多很好的理由说明你应该学习 R,因为它是数据科学的一门极好的语言。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
数据科学初学者的 10 个最佳机器学习算法
原文:https://www.dataquest.io/blog/top-10-machine-learning-algorithms-for-beginners/
June 26, 2019
自从哈佛商业评论 的文章将“数据科学家”命名为“21 世纪最性感的工作”以来,人们对机器学习的兴趣飙升。但如果你刚刚开始学习机器,可能会有点困难。这就是为什么我们重新启动我们非常受欢迎的关于初学者良好机器学习算法的帖子。
(这篇文章最初发表在 KDNuggets 上,名为机器学习工程师需要知道的 10 种算法。已经用 perlesson 转贴了,最后一次更新是在 2019 年)。
这篇文章是针对初学者的。如果你在数据科学和机器学习方面有一些经验,你可能会对这个更深入的关于用 Python 和scikit-learn进行机器学习的教程更感兴趣,或者对我们在这里开始的机器学习课程更感兴趣。如果你还不清楚“数据科学”和“机器学习”之间的区别,这篇文章提供了一个很好的解释:机器学习和数据科学——是什么让它们不同?
机器学习算法是可以从数据中学习并根据经验进行改进的程序,无需人工干预。学习任务可以包括学习将输入映射到输出的函数,学习未标记数据中的隐藏结构;或者“基于实例的学习”,其中通过将新实例(行)与存储在存储器中的来自训练数据的实例进行比较,为新实例产生类别标签。“基于实例的学习”并不从具体的实例中抽象出来。
机器学习算法的类型
有 3 种类型的机器学习(ML)算法:
监督学习算法:
监督学习使用带标签的训练数据来学习将输入变量(X)变成输出变量(Y)的映射函数。换句话说,它在下面的等式中求解 f :
Y = f (X)
这允许我们在给定新输入时准确地生成输出。
我们将讨论两种类型的监督学习:分类和回归。
分类用于当输出变量为类别形式时,预测给定样本的结果。分类模型可能会查看输入数据,并尝试预测“生病”或“健康”等标签
回归用于当输出变量为实值形式时,预测给定样本的结果。例如,回归模型可以处理输入数据来预测降雨量、人的身高等。
我们在这篇博客中介绍的前 5 种算法——线性回归、逻辑回归、CART、朴素贝叶斯和 K 近邻(KNN)——都是监督学习的例子。
集合是另一种监督学习。这意味着结合多个单独较弱的机器学习模型的预测,以对新样本产生更准确的预测。本文的算法 9 和 10——用随机森林打包,用 XGBoost 增强——是集成技术的例子。
无监督学习算法:
当我们只有输入变量(X)而没有相应的输出变量时,使用无监督学习模型。他们使用未标记的训练数据来建模数据的底层结构。
我们将讨论三种类型的无监督学习:
关联用于发现集合中项目同时出现的概率。它被广泛用于购物篮分析。例如,关联模型可能用于发现如果顾客购买面包,她/他有 80%的可能也购买鸡蛋。
聚类用于对样本进行分组,使得同一个聚类中的对象彼此之间的相似度高于另一个聚类中的对象。
降维用于减少数据集的变量数量,同时确保仍然传达重要信息。降维可以使用特征提取方法和特征选择方法来完成。特征选择选择原始变量的子集。特征提取执行从高维空间到低维空间的数据转换。示例:PCA 算法是一种特征提取方法。
我们在这里讨论的算法 6-8——Apriori、K-means、PCA——都是无监督学习的例子。
强化学习:
强化学习是一种机器学习算法,它允许代理根据其当前状态,通过学习将最大化奖励的行为来决定最佳的下一步行动。
强化算法通常通过试错来学习最优动作。例如,想象一个视频游戏,玩家需要在特定的时间移动到特定的地方来获得分数。玩这种游戏的强化算法一开始会随机移动,但随着时间的推移,通过反复试验,它会知道何时何地需要移动游戏中的角色,以最大化其总点数。
量化机器学习算法的流行程度
这篇文章中列出的 10 大算法是考虑到机器学习初学者而选择的。它们主要是我在孟买大学攻读计算机工程学士学位期间从“数据仓库和挖掘”(DWM)课程中学到的算法。我特别包括了最后两种算法(集成方法),因为它们经常被用来赢得游戏比赛。
事不宜迟,面向初学者的 10 大机器学习算法:
1.线性回归
在机器学习中,我们有一组输入变量(x ),用于确定输出变量(y)。输入变量和输出变量之间存在关系。ML 的目标是量化这种关系。

Figure 1: Linear Regression is represented as a line in the form of y = a + bx. Source
在线性回归中,输入变量(x)和输出变量(y)之间的关系表示为 y = a + bx 形式的方程。因此,线性回归的目标是找出系数 a 和 b 的值。这里,a 是直线的截距,b 是直线的斜率。
图 1 显示了一个数据集的 x 和 y 值。目标是拟合一条最接近大多数点的线。这将减少数据点的 y 值和直线之间的距离(“误差”)。
2.逻辑回归
线性回归预测是连续值(即以厘米为单位的降雨量),逻辑回归预测是应用变换函数后的离散值(即学生是否及格)。
逻辑回归最适合二元分类:y = 0 或 1 的数据集,其中 1 表示默认类别。例如,在预测一个事件是否会发生时,只有两种可能性:它会发生(我们用 1 表示)或不会发生(0)。因此,如果我们预测一个病人是否生病,我们将使用数据集中的值1来标记生病的病人。
逻辑回归因其使用的变换函数而得名,称为逻辑函数 h(x)= 1/ (1 + ex)。这就形成了一个 S 形曲线。
在逻辑回归中,输出采用默认类别概率的形式(与直接产生输出的线性回归不同)。因为是概率,所以输出在 0-1 的范围内。因此,举例来说,如果我们试图预测患者是否生病,我们已经知道生病的患者被表示为1,因此如果我们的算法给患者分配 0.98 的分数,它认为该患者很可能生病。
此输出(y 值)是通过使用逻辑函数 h(x)= 1/ (1 + e^ -x)对 x 值进行对数变换而生成的。然后应用一个阈值将这个概率强制转换成二进制分类。

图 2:确定肿瘤是恶性还是良性的逻辑回归。如果概率 h(x)>= 0.5,则分类为恶性。来源
在图 2 中,为了确定肿瘤是否是恶性的,默认变量是 y = 1(肿瘤=恶性)。x 变量可以是肿瘤的度量,例如肿瘤的大小。如图所示,逻辑函数将数据集各种实例的 x 值转换到 0 到 1 的范围内。如果概率越过阈值 0.5(由水平线显示),则肿瘤被分类为恶性。
logistic 回归方程p(x)= e ^(B0+b1x)/(1+e(B0+b1x))可以转化为 ln(p(x) / 1-p(x)) = b0 + b1x 。
逻辑回归的目标是使用训练数据来找到系数 b0 和 b1 的值,使得它将最小化预测结果和实际结果之间的误差。使用最大似然估计技术来估计这些系数。
3.手推车
分类和回归树(CART)是决策树的一种实现。
分类和回归树的非终端节点是根节点和内部节点。终端节点是叶节点。每个非终端节点代表单个输入变量(x)和该变量上的分裂点;叶节点代表输出变量(y)。该模型如下用于进行预测:遍历树的分裂以到达叶节点,并输出叶节点处存在的值。
下图 3 中的决策树根据一个人的年龄和婚姻状况对他是会买跑车还是小型货车进行了分类。如果这个人已经超过 30 岁了,还没有结婚,我们就像下面这样遍历树:“超过 30 岁?”->是-> '结婚了吗?'->否。因此,模型输出一辆跑车。

图 3:决策树的组成部分。来源
4.朴素贝叶斯
为了计算一个事件发生的概率,假设另一个事件已经发生,我们使用贝叶斯定理。为了计算假设(h)为真的概率,给定我们的先验知识(d),我们使用贝叶斯定理如下:
P(h|d)= (P(d|h) P(h)) / P(d)
其中:
- P(h|d) =后验概率。假设 h 为真的概率,给定数据 d,其中 P(h|d)= P(d1| h) P(d2| h)…P(dn| h)
- P(d|h) =可能性。假设假设 h 为真,数据 d 的概率。
- P(h) =类别先验概率。假设 h 为真的概率(不考虑数据)
- P(d) =预测值先验概率。数据的概率(不考虑假设)
这种算法被称为“天真的”,因为它假设所有的变量都是相互独立的,这是在现实世界的例子中做出的天真的假设。

图 4:使用朴素贝叶斯通过变量“天气”来预测“播放”的状态。
以图 4 为例,如果天气=晴朗,结果会是什么?
给定变量 weather = 'sunny '的值,计算 P(yes|sunny)和 P(no|sunny)并选择概率较高的结果,以确定结果 play = 'yes '或' no'。
->P(是|晴)= (P(晴|是)* P(是))/ P(晴)= (3/9 * 9/14 ) / (5/14) = 0.60
-> P(no | sunny)=(P(sunny | no)* P(no))/P(sunny)=(2/5 * 5/14)/(5/14)= 0.40
因此,如果天气= '晴朗',结果就是玩= '是'。
5.KNN
K-最近邻算法使用整个数据集作为训练集,而不是将数据集分成训练集和测试集。
当一个新的数据实例需要一个结果时,KNN 算法会遍历整个数据集,以找到与新实例最近的 k 个实例,或者与新记录最相似的 k 个实例,然后输出结果的平均值(对于回归问题)或者模式(最频繁的类)以解决分类问题。k 值由用户指定。
实例之间的相似性使用诸如欧几里德距离和汉明距离之类的度量来计算。
无监督学习算法
6.推测的
Apriori 算法用于事务数据库中挖掘频繁项目集,然后生成关联规则。它广泛用于市场购物篮分析,在这种分析中,人们检查数据库中频繁出现的产品组合。一般来说,我们把‘如果一个人购买了物品 X,那么他购买了物品 Y’的关联规则写成:X -> Y。
例如:如果一个人购买牛奶和糖,那么她可能会购买咖啡粉。这可以用关联规则的形式写成:{牛奶,糖} ->咖啡粉。关联规则是在跨越支持度和置信度的阈值之后生成的。

图 5:关联规则 X->Y 的支持度、置信度和提升度的公式。
支持度有助于减少在频繁项目集生成期间要考虑的候选项目集的数量。这项支持措施以先验原则为指导。先验原则指出,如果一个项目集是频繁的,那么它的所有子集也必须是频繁的。
7.k 均值
K-means 是一种迭代算法,它将相似的数据分组到聚类中。它计算 k 个聚类的质心,并将一个数据点分配给质心和该数据点之间距离最小的那个聚类。

图 6:K 均值算法的步骤。来源
它是这样工作的:
我们从选择 k 值开始,这里,假设 k = 3。然后,我们将每个数据点随机分配给 3 个集群中的任何一个。计算每个聚类的聚类质心。红色、蓝色和绿色的星星表示 3 个星团中每个星团的质心。
接下来,将每个点重新分配给最近的聚类质心。在上图中,上面的 5 个点被分配给了具有蓝色质心的簇。按照相同的步骤为包含红色和绿色质心的簇指定点。
然后,计算新簇的质心。旧的质心是灰色的星;新的质心是红色、绿色和蓝色的星。
最后,重复步骤 2-3,直到没有点从一个集群切换到另一个集群。一旦连续 2 步没有切换,退出 K-means 算法。
8.污染控制局(Pollution Control Agency)
主成分分析(PCA)用于通过减少变量的数量来使数据易于探索和可视化。这是通过将数据中的最大方差捕获到一个新的坐标系中来实现的,该坐标系具有称为“主分量”的轴。
每个分量都是原始变量的线性组合,并且彼此正交。分量之间的正交性表示这些分量之间的相关性为零。
第一个主成分捕获数据中最大可变性的方向。第二个主成分捕获数据中的剩余方差,但具有与第一个成分不相关的变量。类似地,所有连续的主成分(PC3、PC4 等)捕获剩余的方差,同时与前一个成分不相关。

图 7:3 个原始变量(基因)减少到 2 个新变量,称为主成分(PC 的)。来源
集成学习技术:
集成意味着通过投票或平均来组合多个学习者(分类器)的结果以获得改进的结果。在分类期间使用投票,在回归期间使用平均。这个想法是全体学习者比单个学习者表现更好。
有 3 种类型的组合算法:打包、提升和堆叠。我们不打算在这里讨论“堆叠”,但是如果你想要一个详细的解释,这里有一个来自 Kaggle 的可靠介绍。
9.用随机森林装袋
bagging 的第一步是用 Bootstrap 抽样方法创建的数据集创建多个模型。在 Bootstrap 采样中,每个生成的训练集都由原始数据集中的随机子样本组成。
这些训练集的大小都与原始数据集相同,但有些记录会重复多次,有些记录则根本不会出现。然后,整个原始数据集被用作测试集。因此,如果原始数据集的大小是 N,那么每个生成的训练集的大小也是 N,唯一记录的数量大约是(2N/3);测试集的大小也是 n。
bagging 的第二步是通过对不同生成的训练集使用相同的算法来创建多个模型。
这就是随机森林的由来。与决策树不同,在决策树中,每个节点根据最小化错误的最佳特征进行分割,在随机森林中,我们选择随机选择的特征来构建最佳分割。随机性的原因是:即使使用 bagging,当决策树选择最佳特征进行分割时,它们最终会得到相似的结构和相关的预测。但是在特征的随机子集上分裂后的 bagging 意味着来自子树的预测之间更少的相关性。
在每个分割点要搜索的特征数量被指定为随机森林算法的一个参数。
因此,在具有随机森林的 bagging 中,使用记录的随机样本来构建每棵树,并且使用预测因子的随机样本来构建每个分裂。
10.使用 AdaBoost 升压
Adaboost 代表自适应增压。Bagging 是一个并行集合,因为每个模型都是独立构建的。另一方面,boosting 是一个顺序集成,其中每个模型都是基于纠正前一个模型的错误分类而构建的。
Bagging 主要涉及“简单投票”,每个分类器投票以获得一个最终结果——一个由大多数平行模型决定的结果;提升涉及“加权投票”,其中每个分类器投票以获得由多数决定的最终结果——但顺序模型是通过给先前模型的错误分类实例分配更大的权重来建立的。

图 9:决策树的 Adaboost。来源
在图 9 中,步骤 1、2、3 涉及一个称为决策树桩的弱学习器(一个 1 级决策树仅基于一个输入特征的值进行预测;其根直接连接到其叶的决策树)。
构建弱学习者的过程继续,直到已经构建了用户定义数量的弱学习者,或者直到在训练时没有进一步的改进。步骤 4 组合了前面模型的 3 个决策树桩(因此在决策树中有 3 个分割规则)。
首先,从一个决策树开始,对一个输入变量进行决策。
数据点的大小表明我们已经应用了相等的权重来将它们分类为圆形或三角形。decision stump 在上半部分生成了一条水平线来对这些点进行分类。我们可以看到,有两个圆被错误地预测为三角形。因此,我们将为这两个圆分配更高的权重,并应用另一个决策树桩。
其次,移动到另一个决策树树桩,对另一个输入变量做出决策。
我们观察到上一步中两个错误分类的圆的大小大于其余的点。现在,第二个决策树桩将尝试正确预测这两个圆。
由于分配了较高的权重,这两个圆已被左边的垂直线正确分类。但这导致了顶部三个圆圈的错误分类。因此,我们将为顶部的这三个圆圈分配更高的权重,并应用另一个决策树桩。
第三,训练另一个决策树树桩对另一个输入变量做出决策。
上一步中的三个错误分类的圆大于其余的数据点。现在,已经生成了一条向右的垂直线来对圆和三角形进行分类。
第四,结合决策树桩。
我们结合了前面 3 个模型中的分隔符,并观察到与任何单个弱学习者相比,该模型中的复杂规则能够正确分类数据点。
结论:
概括地说,我们已经介绍了数据科学中一些最重要的机器学习算法:
- 5 监督学习技术——线性回归、逻辑回归、CART、朴素贝叶斯、KNN。
- 3 无监督学习技术——Apriori,K-means,PCA。
- 2 集合技术——用随机森林打包,用 XGBoost 增强。
编者按:这篇文章最初发布在 KDNuggets 上,并被 perlesson 转载。作者莉娜·肖是一名开发人员和数据科学记者。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
数据科学家必备的 12 个命令行工具
原文:https://www.dataquest.io/blog/top-12-essential-command-line-tools-for-data-scientists/
June 20, 2018This post is a short overview of a dozen Unix-like operating system command line tools which can be useful for data science tasks. The list does not include any general file management commands (pwd, ls, mkdir, rm, …) or remote session management tools (rsh, ssh, …), but is instead made up of utilities which would be useful from a data science perspective, generally those related to varying degrees of data inspection and processing. They are all included within a typical Unix-like operating system as well. It is admittedly elementary, but I encourage you to seek out additional command examples where appropriate. Tool names link to Wikipedia entries as opposed to man pages, as the former are generally more friendly to newcomers, in my view.
1.wget
wget 是一个文件检索实用程序,用于从远程位置下载文件。在其最基本的形式中,wget用于下载远程文件,如下所示:
~$ wget https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
--2018-03-20 18:27:21-- https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.20.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.20.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3716 (3.6K) [text/plain]
Saving to: ‘iris.csv’
iris.csv
100 [=======================================================================================================>] 3.63K --.-KB/s in 0s
2018-03-20 18:27:21 (19.9 MB/s) - ‘iris.csv’ saved [3716/3716]
2.cat
cat 是将文件内容输出到标准输出的工具。名字来源于串联。更复杂的用例包括将文件组合在一起(实际连接),将文件附加到另一个文件,给文件行编号,等等。
~$ cat iris.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
...
6.7,3,5.2,2.3,virginica
6.3,2.5,5,1.9,virginica
6.5,3,5.2,2,virginica
6.2,3.4,5.4,2.3,virginica
5.9,3,5.1,1.8,virginica
3.wc
wc 命令用于从文本文件中产生字数、行数、字节数和相关值。在不带选项的情况下运行时,wc 的默认输出是一行,从左到右包括行数、字数(注意每行不带分隔符的单个字符串算作一个单词)、字符数和文件名。
~$ wc iris.csv
151 151 3716 iris.csv
4.head
head 将文件的前 n 行(默认为 10 行)输出到标准输出。可以使用-n 选项设置显示的行数。
~$
head -n 5 iris.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5.tail
有人猜测 tail 是做什么的吗?
~$ tail -n 5 iris.csv
6.7,3,5.2,2.3,virginica
6.3,2.5,5,1.9,virginica
6.5,3,5.2,2,virginica
6.2,3.4,5.4,2.3,virginica
5.9,3,5.1,1.8,virginica

Working that command line sorcery.
6.find
find 是一个在文件系统中搜索特定文件的工具。以下代码从当前目录(" .)开始搜索树结构)对于任何以“iris”开头并以常规文件类型(“-type f”)的任何 dumber 字符(“-name‘iris *’”)结尾的文件:
~$ find . -name 'iris*' -type f
./iris.csv
./notebooks/kmeans-sharding-init/sharding/tests/results/iris_time_results.csv
./notebooks/ml-workflows-python-scratch/iris_raw.csv
./notebooks/ml-workflows-python-scratch/iris_clean.csv
...
7.cut
cut 用于从文件中切出一行文字的片段。虽然可以使用各种标准制作这些切片,但是 cut 对于从 CSV 文件中提取列数据非常有用。这将输出 iris.csv 文件的第五列("-f 5 "),使用逗号作为字段分隔符("-d ','"):
~$ cut -d ',' -f 5 iris.csv
species
setosa
setosa
setosa
...
8.uniq
uniq 通过将相同的连续行折叠成单个副本,将文本文件的输出修改为标准输出。就其本身而言,这可能看起来不太有趣,但是当用于在命令行构建管道(将一个命令的输出管道化到另一个命令的输入中,等等)时,这可能会变得有用。
下面给出了第五列中保存的 iris 数据集类名的唯一计数,以及它们的计数:
~$ tail -n 150 iris.csv | cut -d "," -f 5 | uniq -c
50 setosa
50 versicolor
50 virginica

What the cow say.
9.awk
awk 实际上并不是一种“命令”,而是一种完整的编程语言。它用于处理和提取文本,可以从命令行以单行命令的形式调用。
掌握 awk 需要一些时间,但在此之前,这里有一个它可以完成的示例。考虑到我们的示例文件— iris.csv —相当有限(尤其是当它涉及到文本的多样性时),这一行将调用 awk,在给定的文件(“iris.csv”)中搜索字符串“setosa”,并将遇到的项目(保存在$0 变量中)一个接一个地打印到标准输出中:
~$ awk '/setosa/ { print $0 }' iris.csv
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
10.grep
grep 是另一个文本处理工具,这个用于字符串和正则表达式的匹配。
~$ grep -i "vir" iris.csv
6.3,3.3,6,2.5,virginica
5.8,2.7,5.1,1.9,virginica
7.1,3,5.9,2.1,virginica
...
如果你花很多时间在命令行上做文本处理,grep 绝对是一个你会很熟悉的工具。更多有用的细节见这里。
11.sed
sed 是一个流编辑器,又一个文本处理和转换工具,类似于 awk。让我们使用下面的代码行将 iris.csv 文件中出现的“setosa”更改为“iris-setosa”。
~$
sed 's/setosa/iris-setosa/g' iris.csv > output.csv
~$ head output.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,iris-setosa
4.9,3,1.4,0.2,iris-setosa
4.7,3.2,1.3,0.2,iris-setosa
...
12.history
history 非常简单,但也非常有用,尤其是如果您依赖于复制您在命令行中完成的一些数据准备工作。
~$ history
547 tail iris.csv
548 tail -n 150 iris.csv
549 tail -n 150 iris.csv | cut -d "," -f 5 | uniq -c
550 clear
551 history
这是对 12 个方便的命令行工具的简单介绍。这只是对数据科学(或任何其他目标,就此而言)命令行可能实现的功能的一个尝试。把你从鼠标中解放出来,看着你的生产力提高。
编者按:这是最初发布在 KDNuggets 上的,已经被 perlesson 转载。作者马修·梅奥是机器学习研究员,也是 KDnuggets 的编辑。
商业分析师 20 大面试问答(2022)
原文:https://www.dataquest.io/blog/top-20-job-interview-questions-and-answers-for-business-analysts-2022/
September 21, 2022
在本文中,我们将分享你在求职面试中可能遇到的 20 个最常见的商业分析师面试问题和答案。为这些问题做好准备不仅可以帮助你为业务分析师职位的面试做好准备并感到更加舒适,还可以确定你在技术技能方面可能存在的差距。
我们从分享一般商业分析师面试问题开始。然后,我们将关注数据分析,探索您将面临的最常见的技术问题。
一般商业分析师面试问题
1.商业分析师的主要职责是什么?
业务分析师的主要目标是帮助组织解决问题,或者定义、推荐和实现最佳解决方案。
虽然业务分析师的一些活动可能因行业或组织而异,但以下是所有业务分析师共有的主要职责:
- 确定业务需求和目标
- 评估业务问题和市场机会
- 为企业提供数据驱动的建议
- 通过分析数据,协助制定战略性商业决策
- 定义关键和次要 KPI
- 创建项目计划以改善业务状况
- 提供相关数据报告以监控进度
如果您成为 IT 业务分析师,您的职责将包括 IT 项目的建议、设计、实现和变更管理。
延伸阅读
您可以在下面的文章中了解更多关于业务分析师的主要职责:
2.业务分析师和数据分析师的区别是什么?
虽然这两个角色有许多相似之处(都处理大量数据,做出数据驱动的决策,需要相同的软技能,等等。)有一些重要的区别:
| | 商业分析师 | 数据分析师 |
| 工作重点: | 通过数字和非数字数据确定业务需求 | 识别数字数据中的模式 |
| 与一起工作 | 营销、销售和产品团队 | 数据科学家和数据工程师 |
| 背景: | 商科专业 | 技术专业 |
| 技能: | 商业智能、项目管理、数据仓库 | 数据清理、数据争论、数据分析、统计 |
延伸阅读:
您可以在下面的文章中了解更多关于差异的信息:
- 商业分析师与数据分析师:哪个适合你?(2022)
3.商业分析师的基本技能是什么?
技术技能:
- 统计分析
- 商业智能软件(微软 Power BI、Tableau、Qlik Sense 等。)
- 数据分析和可视化
- 数据库管理
- 商业智能软件中的数据建模
- 使用数据库
- 领域专业知识
- 业务流程
- 项目管理
- 文件和报告
软技能:
- 分析思维
- 批判性思维
- 解决问题
- 决策
- 沟通和谈判技巧
- 时间管理
- 关注细节
- 协力
- 好奇心
4.商业项目的主要阶段是什么?
任何业务项目都包括以下全球阶段:
- 开始
- 分析
- 规划
- 履行
- 监测和控制
- 关闭
5.商业分析师使用哪些数字工具?
以下是业务分析师使用的一些工具:
- 商业智能工具:微软 Power BI、Tableau、Qlik Sense、SAP
- 办公工具:微软 Excel、Word、PowerPoint 或谷歌文档、谷歌工作表和谷歌幻灯片
- 项目管理工具:特雷罗,吉拉,汇合,阿萨纳
- 数据库语言(例如 SQL)
- 调查:调查猴子,类型表单,谷歌表单
- UX 线框:Balsamiq,UXPressia,Figma,Adobe XD
- 图表工具:MS Visio,draw.io
6.业务分析师处理哪些文档?
业务分析师使用不同类型的文档,这取决于他们工作的性质(例如 IT 业务分析师、具有领域专业知识的业务分析师等)。).
业务分析师在处理项目时最常用的一些文档包括:
- 商业案例
- 商业分析文件
- 业务需求文档(BRB)
- 用例文档
- 系统需求规格文件
- 功能需求
- 非功能性需求
- 数据映射要求
- 风险分析文件
- 征求建议书(RFP ),包括评估图
- 工程计划
- 线框
- 差距分析
- 用户验收测试(UAT)进度报告
- 测试案例
- 项目进度报告
- 移交文件
7.业务分析师使用什么样的图表?
业务分析中最常用的图表包括:
- 用例图——表示参与者与系统的所有可能的交互
- 活动图—显示跨不同业务单位的各种活动的流程
- 协作图—显示系统对象之间的交互
- 流程图—说明解决特定任务的操作工作流程
- 数据流图—显示进出系统的信息流
- 序列图——描述按时间顺序排列的系统各部分之间的相互作用
- 实体关系图(ERD) —描述系统中实体之间的关系
- 类图——展示系统的结构,包括其类、方法、属性和对象
8.什么是项目可交付成果?
项目可交付成果是指在项目的每个阶段产生的一系列有形或无形的成果,这些成果可以在内部交付,也可以交付给股东和客户。这些包括各种报告、文件、提案、图纸、战略以及最终产品和服务。
9.什么是需求,它和需求有什么不同?
需求是由股东制定的有针对性的陈述,并且代表了他们为了满足特定的业务需求和实现特定的业务目标而需要什么的良好记录的指示。需求代表了项目的核心;股东在项目开始前设定它们,然后业务分析师定义、分析、估计它们,并对它们进行优先级排序。我们可以说,虽然业务需求是期望的最终结果的高级规范,但是业务需求是该业务需求的可应用的、完整记录的表示。
10.定义需求获取,并列出其方法。
需求获取是从与股东、客户和最终用户的直接互动中收集与项目相关的需求的过程。需求获取的方法包括以下几种:
- 头脑风暴
- 面谈
- 车间
- 调查和问卷
- 观察
- 文件分析
- 小组讨论
- 界面分析
- 样机研究
11.业务分析师如何评估需求的质量?
为此,业务分析师可以使用智能规则。一个好的需求应该满足以下标准:
- 特定的:需求的描述应该是特定的、全面的和定义明确的。
- 可度量的:需求成功的标准可以使用提供的度量来度量。
- 可实现的:应该有所有必要的资源(时间、金钱和人员)来实现需求。
- 现实:在给定可用资源的情况下,需求应该是可行的。
- 有时间限制的:需求的满足应该被一个确定的时间间隔所限制。
12.什么是 BRD,它的主要组成部分是什么?
BRD 代表业务需求文档。这是一个重要的正式文档,它清楚地陈述了项目的目标并确定了项目的主要股东,包括他们的业务需求和要求、潜在的风险以及项目的预期结果。业务分析师负责在与股东沟通后创建此文档。
BRD 的主要内容包括:
- 行动纲要
- 项目概述、愿景和目标
- 项目范围
- 项目路线图
- 主要股东
- 业务需求陈述
- 业务需求
- 成本效益分析
- 项目风险
- 项目限制
- 基础设施要求
数据分析面试问题
数据分析是商业分析师最重要的部分之一。为了让你的建议得到关键利益相关者和企业领导的认可,你必须让他们相信你对形势做出了正确的诊断。您需要确定业务需求和问题,并有效地分享有意义的见解。为此,您将使用商业智能(BI)解决方案,如 Power BI 和 Tableau。以下是你在商业分析师面试中会遇到的一些最常见的问题。
13.商业分析师可用的顶级商业智能解决方案有哪些?
全球业务分析师最常用的商业智能解决方案包括:
- 微软 Power BI(世界领先的解决方案)
- (舞台上由人扮的)静态画面
- Qlik Sense
- 谷歌数据工作室
- 检查员
- 西森斯
延伸阅读
你可以在下面的文章中了解更多关于微软商务智能的顶级面试问题:
14.力量 BI 和 Tableau 有什么区别?
虽然 Power BI 和 Tableau 都是用于业务数据争论、数据分析和数据可视化的商业智能(BI)应用程序,但它们之间存在一些显著差异:
- Power BI 使用 DAX(数据分析表达式)进行计算,Tableau 使用 MDX(多维表达式)。
- Power BI 可以处理相对有限的数据量,而 Tableau 可以轻松处理海量数据。
- Power BI 有一个相对简单易学的界面,专业人士和初学者都可以使用。Tableau 界面更具挑战性;所以,不太适合新手。
- 与 Tableau 相比,Power BI 可连接的数据源范围较小。
- Power BI 比 Tableau 便宜很多。
- Power BI 是一个完美的报告工具,而 Tableau 擅长数据可视化。
15.商业智能解决方案的最大优势是什么?
作为业务分析师,您将使用业务分析或业务智能工具,如 Microsoft Power BI、Qlik Sense 或 Tableau。
以下是使用 BI 解决方案的主要优势:
- 无需深厚的技术技能即可分析数据
- 以结构化和一致的方式呈现数据和见解
- 使用相关 KPI 支持决策
- 在一个地方整合来自多个来源的数据
- 通过交互式仪表盘分享实时见解
- 提高公司对有意义数据的可见性
- 进行预测分析
- 提高生产力
16.商业智能解决方案的数据分析有哪些不同阶段?
商业智能解决方案的数据分析过程有四个主要阶段:
- 数据准备:这个阶段包括从多个数据源加载数据,格式化、清理和合并数据。
- 数据模型:这个阶段包括描述数据的结构,如何存储数据,以及各种数据集之间的关系和约束。
- 数据可视化:这个阶段包括选择正确的视觉效果和颜色来有效地传达你的故事。
- 数据分析:这个阶段包括分析数据、将数据分组、宁滨数据,以及准备表示 KPI 的仪表板
17.什么是数据清理,为什么它对您的分析很重要?
数据清理是数据分析过程中必要的准备(通常相当耗时)步骤,在收集数据之后,分析数据之前。该步骤包括以下内容:
- 删除重复数据
- 处理缺失值
- 纠正或删除不准确的数据
为了从输入数据中提取有意义的见解,它应该是可靠的、完整的、一致的和有代表性的-这正是数据清理的目的。
18.如果你有丢失的数据,你该怎么办?
处理缺失数据有多种方法:
- 删除任何缺少值的行
- 删除任何缺少值的列
- 用其他值填充缺失值,如该列的平均值、中值或众数;从另一列提取的值;从附加研究中获得的值;等等
- 保留丢失的值不变
19.数据建模涉及哪些关键活动?
- 识别用例及需求
- 检索、清理和转换数据
- 设计数据模型
- 定义不同表中数据之间的关系和层次结构
- 处理数据粒度
- 创建度量和扩充数据
- 调整和优化模型性能
- 验证数据模型
20.对于您的数据分析来说,什么是好的数据可视化?
良好的数据视觉效果应遵循的主要原则包括:
- 应该是干净易读。这意味着选择合适的字体,没有任何干扰元素(如不必要的颜色、线条、网格、多余的注释等)。)、所有必要元素(情节标题、轴名称和单位、关键特征的强调等。),并用最小的视觉效果传达最大的信息。
- 应该对目标受众清晰,有说服力,包括没有任何技术背景的人。
- 它应该讲述一个隐藏在原始数据中的故事,回答商业项目目标中陈述的主要问题或任何对回答主要问题很重要的中间问题。
外卖
现在,您已经看到了最常见的业务分析师面试问题和答案,您可以满怀信心地准备业务分析师技术面试了!
如果你想掌握或更新你的技能(并获得认证!)在申请商业分析师工作之前,在 Dataquest 探索独立的商业分析师职业道路。它将帮助您学习必要的技术技能,并在现实世界的项目中实践这些技能,您可以将它们包含在您的投资组合中。
有关业务分析的更多信息,请查看以下文章:
20 大 Python AI 和机器学习开源项目
原文:https://www.dataquest.io/blog/top-20-python-ai-and-machine-learning-open-source-projects/
July 23, 2018
进入机器学习和人工智能领域不是一件容易的事情,但却是数据科学项目的关键部分。许多有抱负的专业人士和爱好者发现很难建立一个合适的进入该领域的途径,因为今天有大量的资源可用。这个领域在不断发展,我们必须跟上这一快速发展的步伐。为了应对这种势不可挡的发展和创新速度,保持更新和了解 ML 进展的一个好方法是通过为许多高级专业人员日常使用的开源项目和工具做出贡献来参与社区。
在这里,我们更新了信息,并检查了自我们上一篇文章20 大 Python 机器学习开源项目(2016 年 11 月)以来的趋势。
Tensorflow 以三位数的贡献者增长率跃居第一。Scikit-learn 跌至第二位,但仍拥有大量的贡献者。
与 2016 年相比,贡献者数量增长最快的项目是
- TensorFlow 增长了 169%,从 493 人增加到 1324 人
- Deap 增长了 86%,从 21 人增加到 39 人
- Chainer 的贡献者从 84 人增加到 154 人,增加了 83%
- Gensim 增长了 81%,从 145 人增加到 262 人
- Neon,增长了 66%,从 47 人增加到 78 人
- Nilearn 增长了 50%,从 46 人增加到 69 人
2018 年还新增了:
- Keras,629 个贡献者
- PyTorch,399 个贡献者

图 Github 上排名前 20 的 Python AI 和机器学习项目。
大小与贡献者的数量成正比,颜色代表贡献者数量的变化——红色较高,蓝色较低。雪花形状用于深度学习项目,圆形用于其他项目。
我们看到像 TensorFlow、Theano 和 Caffe 这样的深度学习项目是最受欢迎的。
下面的列表根据 Github 上贡献者的数量以降序给出了项目。贡献者数量的变化是相对于 2016 KDnuggets 关于前 20 名 Python 机器学习开源项目的帖子。
我们希望您喜欢浏览这些文档页面,开始合作并学习使用 Python 进行机器学习的方法。
- TensorFlow 最初是由谷歌机器智能研究组织谷歌大脑团队的研究人员和工程师开发的。该系统旨在促进机器学习的研究,并使其快速而容易地从研究原型过渡到生产系统。投稿人数:1324(上升 168%),提交人数:28476,明星人数:92359。Github 网址: Tensorflow
- Scikit-learn 是用于数据挖掘和数据分析的简单高效的工具,每个人都可以访问,并可在各种上下文中重用,构建于 NumPy、SciPy 和 matplotlib 之上,开源,商业可用–BSD 许可证。投稿人数:1019(上升 39%),提交人数:22575,Github 网址: Scikit-learn
- Keras ,高级神经网络 API,用 Python 编写,能够运行在 TensorFlow、CNTK 或 Theano 之上。投稿人数:629(新),提交人数:4371,Github 网址: Keras
- PyTorch ,强 GPU 加速的 Python 中的张量和动态神经网络。投稿人数:399(新),提交人数:6458,Github 网址: pytorch
- Theano 允许您高效地定义、优化和评估涉及多维数组的数学表达式。投稿人数:327(上升 24%),提交人数:27931,Github 网址:theno
- Gensim 是一个免费的 Python 库,具有可扩展的统计语义、分析纯文本文档的语义结构、检索语义相似的文档等特性。贡献者:262 (81%以上),提交:3549,Github 网址: Gensim
- Caffe 是一个深度学习框架,考虑到了表达、速度和模块化。它是由伯克利视觉和学习中心()和社区贡献者开发的。投稿人数:260(上升 21%),提交人数:4099,Github 网址:咖啡馆
- Chainer 是一个基于 Python 的独立开源框架,用于深度学习模型。Chainer 提供了一种灵活、直观和高性能的方法来实现全方位的深度学习模型,包括最先进的模型,如递归神经网络和变分自动编码器。贡献者:154 (84%以上),提交:12613,Github 网址:链接者
- Statsmodels 是一个 Python 模块,允许用户探索数据、估计统计模型和执行统计测试。描述性统计、统计测试、绘图函数和结果统计的广泛列表可用于不同类型的数据和每个估计量。贡献者:144(上升了 33%),提交:9729,Github 网址: Statsmodels
- 幕府将军是一个机器学习工具箱,提供了广泛的统一高效的机器学习(ML)方法。工具箱无缝地允许轻松组合多种数据表示、算法类和通用工具。投稿人数:139(上升 32%),提交人数:16362,Github 网址:幕府
- Pylearn2 是一个机器学习库。它的大部分功能都建立在 Theano 之上。这意味着你可以使用数学表达式编写 Pylearn2 插件(新模型、算法等),Theano 将为你优化和稳定这些表达式,并将它们编译到你选择的后端(CPU 或 GPU)。贡献者:119(上升 3.5%),提交:7119,Github 网址:派拉恩 2
- NuPIC 是一个开源项目,基于一种叫做分级时间记忆(HTM)的大脑皮层理论。HTM 理论的一部分已经被实现,测试,并在应用中使用,而 HTM 理论的其他部分仍在发展中。投稿人数:85(上升 12%),提交人数:6588,Github 网址: NuPIC
- Neon 是 Nervana 的基于 Python 的深度学习库。它提供了易用性,同时提供了最高的性能。注意:英特尔不再支持 Neon,但是你仍然可以通过 Github 上的内容使用它。投稿人数:78(上升 66%),提交人数:1112,Github 网址:霓虹
- Nilearn 是一个 Python 模块,用于快速简单地对神经影像数据进行统计学习。它利用 scikit-learn Python 工具箱进行多变量统计,并应用于预测建模、分类、解码或连通性分析。投稿人数:69(上升 50%),提交人数:6198,Github 网址: Nilearn
- Orange3 是面向新手和专家的开源机器学习和数据可视化。带有大型工具箱的交互式数据分析工作流。贡献者:53 人(上升了 33%),提交数:8915,Github 网址: Orange3
- Pymc 是一个 python 模块,实现了贝叶斯统计模型和拟合算法,包括马尔可夫链蒙特卡罗。它的灵活性和可扩展性使它适用于大量的问题。贡献者:39(上升 5.4%),提交:2721,Github 网址: Pymc
- Deap 是一个新颖的进化计算框架,用于快速原型和想法测试。它试图使算法清晰,数据结构透明。它与多处理和 SCOOP 等并行化机制完美地协调工作。贡献者:39 人(86%以上),提交时间:1960 年,Github 网址: Deap
- aroy(近似最近邻哦耶)是一个 C++库,用 Python 绑定来搜索空间中靠近给定查询点的点。它还创建基于文件的大型只读数据结构,这些数据结构被映射到内存中,以便许多进程可以共享相同的数据。贡献者:35(上升 46%),提交:527,Github 网址:惹怒
- PyBrain 是 Python 的模块化机器学习库。它的目标是为机器学习任务提供灵活、易用但仍然强大的算法,并提供各种预定义的环境来测试和比较您的算法。贡献者:32(上升了 3%),提交:992,Github 网址: PyBrain
- Fuel 是一个数据管道框架,为你的机器学习模型提供它们需要的数据。计划由区块和派尔恩 2 神经网络库共同使用。投稿人数:32(上升 10%),提交人数:1116,Github 网址:燃料
贡献者和提交数记录于 2018 年 2 月。
编者按:这是最初发布在 KDNuggets 上的,已经被 perlesson 转载。作者 Ilan Reinstein 是一名物理学家和数据科学家。
准备好继续学习了吗?
永远不要想接下来我该学什么?又来了!
在我们的 Python for Data Science 路径中,您将了解到:
- 使用 matplotlib 和 pandas 进行数据清理、分析和可视化
- 假设检验、概率和统计
- 机器学习、深度学习和决策树
- ...还有更多!
立即开始学习我们的 60+免费任务:
面向数据专业人员的顶级会议
原文:https://www.dataquest.io/blog/top-conferences-for-data-professionals/
November 23, 2021
说到数据科学,我们都知道发展知识和技能的一个很好的方法就是一头扎进去做工作。然而,在数据科学领域,还有另一种方法可以让学习曲线变平,那就是向更有经验、更成功的数据专业人士学习,他们可以分享他们的专业知识,教你做生意的诀窍。获得这种机会的最佳方式之一是参加数据科学会议。
世界各地都有很多这样的会议,有面对面的,也有虚拟的。这些会议将行业领袖和杰出的数据专业人士聚集在一起,共同学习、分享想法和发展职业技能。如果您是任何类型的数据专业人员,参加数据科学会议可能是发展技术技能、扩展专业网络和保持数据科学最新发展前沿的最佳方式。
以下是您应该了解的七大即将召开的数据科学会议:
ODSC 西重新连接 2021
时间:2021 年 11 月 16 日至 18 日
地点:旧金山,虚拟的和真实的
定价::399 美元至 1699 美元
开放数据科学大会是机器学习和数据科学的领先会议之一。今年,OSDC 举办了有史以来第一次混合会议,将现场会议和实践培训与创新和有见地的虚拟会议相结合。1,700 家公司和 6,000 多名其他与会者参加了为期三天的会议,您将参加 80 场培训课程和研讨会,学习 300 个小时的内容。
TDWI 会议奥兰多
时间:2021 年 11 月 15 日至 18 日
地点:奥兰多,部分虚拟且真实
定价:1,535-3,535 美元
在四天的时间里,“用智能转变数据”将为您提供 40 门现场课程,其中 24 门也将通过虚拟方式提供。这些课程将增强您在 BI 和分析、数据科学和机器学习、数据素养和数据可视化、数据建模和数据治理、数据仓库和数据湖、架构等方面的技能。通过“选择您自己的培训议程”选项,无论您是新手还是经验丰富的专业人士,您都将从此次会议中受益。
Ai4
时间:2021 年 11 月 3 日至 4 日
其中:虚拟
定价:符合条件的申请人免费,普通注册 395 美元
Ai4 2021 企业人工智能峰会汇集了商业领袖和数据专业人士,以促进人工智能和机器学习技术的采用。在为期两天的会议中,您将听到来自积极参与企业人工智能和机器学习项目的领先组织的近 20 位发言者。这是一个“仅应用”的会议,它将允许您与企业人工智能计划的其他领导者联系,以获得专注于人工智能的企业级见解。
数据科学大会
时间:2022 年 5 月 12 日至 13 日
地点:芝加哥
定价:起价 900 美元
数据科学大会是一个没有赞助商和供应商的活动,它提供了一个空间,分析专业人员可以在这里交流和分享想法,而不会感觉自己被提议。它的“禁止拍照/录像/录音/广播”政策为它赢得了一个声誉,在这个活动中,数据专业人士可以分享他们否则可能不会广播的信息。这个会议集中于技能发展、知识分享和网络。是给专业人士的,由专业人士做的。
【icml 2022】
时间:2022 年 7 月 17 日至 23 日
地点:马里兰州巴尔的摩市
在机器学习国际会议上,你会发现关于机器学习的所有方面及其在人工智能、统计学、数据科学和其他相关领域中的作用的最新前沿研究。ICML 的参与者超越了广泛的背景来建立网络,分享想法,并了解机器学习及其现实世界应用中最令人兴奋的发展。
返工深度学习混合峰会
时间:2022 年 2 月 17 日至 18 日
地点:旧金山,虚拟的和真实的
定价:起价 595 美元
这次为期两天的峰会将有 90 名主要发言人出席。在这里,你将发现深度学习、企业人工智能和人工智能伦理的最新技术进步和现实应用。加入数百名其他参与者,了解人工智能的最新突破如何塑造未来,并对商业和社会产生深远影响。
ICLR 2022
时间:2022 年 4 月 25 日至 29 日
其中:虚拟
学习表征国际会议是世界上发展最快的人工智能会议之一。在这次会议上,你将涵盖广泛的人工智能主题,从度量学习和组合建模到结构化预测和强化学习,再到关于大规模学习和非凸优化的问题。在这个过程中,你将有机会扩大你的职业关系网。你会遇到研究人员、企业家、工程师、学生、博士后,以及介于两者之间的所有人!如果你对人工智能和深度学习的爆炸式增长感兴趣,这可能是适合你的会议。
结论
这些只是众多即将举行的数据科学会议中的一小部分,你可以从中选择来发展你的职业道路。如今有如此多的选择,尤其是随着虚拟活动的广泛使用,你有了前所未有的机会接触到业内的领军人物。利用这些会议获得有价值的见解并开启新的机会。如果你是一名有抱负的数据专家,我们强烈建议你考虑参与我们的七大选择之一。
向非洲 R 的 Shelmith Kariuki 学习 R 的技巧
原文:https://www.dataquest.io/blog/top-tips-for-learning-r-from-africa-rs-shelmith-kariuki/
August 20, 2020
如果你刚刚开始学习 R 编程,并且正在寻找技巧,那么你可以从 Shelmith Kariuki 那里学到很多东西。
Shel 在数据科学领域拥有多年的专业经验,并拥有多年向他人教授统计和数据技能的经验。她是一名数据分析师,RStudio 认证的 Tidyverse 讲师,也是一名社区领导者 NairobiR 的共同组织者,也是总部位于非洲的 R 用户组联盟 Africa R 的核心团队成员。
换句话说,她非常了解 R 的教与学。她最近从自己的日程安排中抽出一些时间与 Dataquest 谈论了她自己的 R 学习之旅以及她对当今 R 学习者的建议。
对 R 编程感兴趣
在获得精算学学士学位和应用统计学硕士学位的过程中,Shel 很早就接触了 R 语言编程的基础知识。在她攻读硕士学位期间,当她成为统计学的助教/讲师时,基数 R 成了她教授学生的课程的一部分。
但她说,这对她来说没有多大意义,直到一名学生来到她的办公室,问学习 R 将如何帮助他们的生活。
“作为一名讲师,你要勇敢面对,说,‘是的,这将对你的人生有所帮助,’”她说。“但实际上当我回到房间时,我想了很多。下一步是什么?我们会在哪里应用这些东西?”
所以她做了我们大多数人有问题时都会做的事情:“我谷歌了一下。我拿起手机,在谷歌上搜索‘我们如何用 R 来解决肯尼亚的问题?’我不知道该去谷歌搜索什么。所以我谷歌了一下,发现了很多东西。"
她发现其他的硕士生在他们的论文中使用 R 语言,她还在 Data Science Central 上发现了一些关于 R 编程的博客,这些博客让她看到了一个全新的世界。她发现了 RStudio,上了 Twitter,发现了那里的#rstats 社区。她很喜欢。
“在这一点上,过了一段时间后,我觉得学术界不适合我,”她说。“我真的想做一些不同的事情。”
完成硕士学位后,她仍在做讲师,但她开始寻找数据科学方面的工作。与此同时,她开始构建项目来自学更多关于 r 的知识,“我会登录互联网,获取一些数据,然后浏览一些资料。我会谷歌:我如何在 R 中创建一个表?我如何在 R 中创建一个图形?我如何改变颜色?诸如此类的事情。”
最终,她看到了一份数据分析工作的广告,申请了,然后就忘了这件事。她说,她对自己的机会并不乐观,因为她的背景是学术界,而不是数据科学。但令她惊讶的是,他们喜欢她的应用程序,并给她发送了一个数据任务来完成。
“我告诉你,我从一开始就在谷歌上搜索,”她笑着说。“我想我几乎谷歌了所有的东西……我甚至记得谷歌了 mutate 是什么。”

Google 是学习数据科学的好工具,但前提是你要正确使用它!
提示 1:不要盲目搜索——学习你搜索的内容
编程的行业秘密并不秘密,那就是每个人都使用谷歌。但谢尔的秘密是,她不只是在谷歌上寻找答案。“我不会盲目地搜索,”她说。“我试着去理解。”因此,当她完成工作申请的数据任务时,她在谷歌搜索,但她也在学习她搜索的内容。
她做得很好,所以她得到了第二个任务。“我当时想,‘哇,要是这些人知道我作弊就好了!’”她说因为对我来说,[谷歌搜索]是作弊。”但她坚持了下来,提交了第二份任务,并接到了亲自面试的电话。
这就是她的方法得到回报的地方。在采访中,她被要求解释她的一些代码。“记住,我不会盲目地搜索,”她说,“所以当我走进面试时,我知道我所有的代码都做了什么。”她解释得很好,这也是她获得第一份数据科学工作的原因。
“那时我开始意识到谷歌搜索并没有错,”谢尔说。“谷歌没关系,再优秀的人也谷歌。”关键是要像谢尔那样用谷歌搜索:不要只是找到答案然后复制粘贴;在你继续前进之前,努力去理解答案。
“我见过盲目搜索的人,”她说,“但当需要处理那个人的代码时,你会问,‘这个函数是做什么的?’他们会说,‘我其实不知道。我谷歌了一下。"
“特别是当我做自己的分析时,”她说,“我应该能够解释分析中的每一段代码。因为,第一,这是我们学习的方式,第二,你的代码可能会到达不同的人。当他们回来时,即使是两年后,问你某个功能,你应该能解释清楚,因为你拥有那件作品。”
技巧 2:了解 R 实际上是如何被使用的
Shel 说,帮助她学习 R 编程的另一件事是,当她开始在线参与 R 社区时,她看到了其他人在用 R 做什么,以及它在现实世界中是如何使用的。
“你需要知道 R 在这个领域是如何被使用的,”她说。“这是第一件事。你不能在不知道人们在这个领域到底在做什么的情况下盲目地去学习一门课程。”
了解人们是如何使用 R 的也将帮助你决定你自己的学习道路应该是怎样的。
“一旦你看到人们在做什么,你就会知道是什么让你心动。你想干嘛?你想成为数据分析师吗?你想成为一名机器学习工程师吗?对我来说,这是第一件事。”
技巧 3:参与全球 R 社区…
谢尔说,“关注业内人士”很重要,“因为这是我了解#rstats 的方式,也是我了解 Hadley(Wickham)的时候。他会发布令人惊叹的东西,我会在谷歌上搜索他和其他发布有趣东西的人。”
“我发现看他们的作品令人鼓舞,”她说。“只是跟踪他们,看看人们是如何进化的。开发人员在开发什么包,等等。”
“我的目标很高。我想成为一名 R 大师。”观察 R 大师们在做什么帮助 Shel 弄清楚她需要学习什么,以及什么样的 R 项目在现实世界中有用。
“让你尊敬的人给你指路真的真的很重要,”她说。

非洲 R 用户十六进制贴纸(图片来自@AfricaRUsers twitter)
技巧 4:…但是不要忘记在当地参与
“另一件非常重要的事情是见面,”谢尔说。“我真的,真的,真的感谢上帝的相遇,因为我在一次相遇中知道了什么是机器学习。”
“我从我的老师那里知道什么是回归,但我第一次听到机器学习时,我就想,‘哦,我的上帝,什么是机器学习?’然后我去参加了一个聚会,人们向我解释。我当时想,‘啊,所以我知道一点机器学习!’我从聚会中学到了很多。"
“我过去参加的第一次会议是内罗毕妇女在机器学习方面的会议。她说:“它们过去常常在周六上午举行,学习新东西总是令人惊叹。”。当时,她正处于数据分析师工作的第一年,她很快发现她在会面中学到的新东西可以应用到日常工作中。
“会面也是一种社交方式。她说:“你开始了解人们在做什么,这总能开阔你的思路。“尤其是如果你所有的同事都在同一个领域,有时认识其他人并看看他们在做什么是很好的。你可以从他们身上学到东西,这有助于建立你的投资组合。”
技巧 5:建立“宠物项目”
谢尔说,说到投资组合,构建项目来填补一个项目是至关重要的。她说这是新学员经常跳过的重要一步。
“例如,某人将在 Dataquest 注册一门课程,并获得证明他们成功完成课程的证书。太好了。但是接下来呢?我怎么知道你是熟练的?我怎么知道你真的理解了这门课程?最终并不总是证书的问题。”
“我总是建议新手,尤其是拥有像 GitHub 这样的公众形象真的很有帮助,因为这是你出售作品的唯一方式,”她说。“当你学了 100 门课程,却仍然失业,这是非常令人沮丧的。但是你为什么会失业呢?是课程没有帮到你吗?不完全是。可能是你不知道如何营销你的技能。”
(顺便说一下,这是我们 Dataquest 非常赞同的建议。我们已经写过数据科学证书以及为什么证书本身可能不会帮助你找到工作。我们的课程以指导的项目结束,以帮助学习者建立他们的文件夹,我们也鼓励学生在我们的社区的帮助下建立和分享个人项目。)
“任何时候我有一个短期培训,”Shel 说,“我告诉人们,‘创建一个 GitHub 个人资料和我在这个会议上要教的任何东西,做一些任务,并公开发布它们。’你永远不知道谁会看到它。有时这是向潜在雇主推销你技能的一种方式。"
谢尔说,事实上,公开项目可能是能否找到工作的关键。如果雇主有需要快速分析的数据,看到你的证书并不足以说服他们雇佣你做他们的分析。但是如果他们能在你的投资组合中看到你已经做过的类似项目,他们知道他们可以依靠你来做这项工作。
谢尔说,雇主“希望看到一些东西,让他们说,‘嗯,这正是我想让你为我做的,或者这正是我们想要的’”
秘诀 6:不要害怕从小处着手
“我给人们的一个建议是:我们并不完美,也不是超人,”谢尔说。“我们不是什么都知道。一周或一个月后你就不会好了。不能急。最好的学习方式是体验。”
“你不可能在一个月内一下子学会数据分析、数据科学、机器学习、人工智能。我想没有人这样做过。对我来说,为了得到我的第一份工作,我只需要知道如何在 R 中创建一个表和一个图。从那里,随着时间的推移,我学到了越来越多的东西:如何优化我的代码,如何在 R 中构建仪表板,如何做这做那。”
“我们总是必须一步一步来,”Shel 说,这在数据科学中尤其具有挑战性,因为炒作周期会让你觉得需要立即学习最新的热门技术。
“你不用什么都学。学一些能帮你找到第一份工作的东西。也就是说,如果你还没有工作的话。如果是这样,那就学习一些能帮助你提高技能的东西,因为归根结底,我们的目标是提高技能。”
这种从小做起的方法也适用于就业。虽然你的梦想可能是一份全职工作,但把你的作品集放到网上有时能让你得到一份短期工作。
“如果你能完成一项任务,并将其发布到网上,然后获得一份为期五六天的小合同,足以支付你未来两个月的租金,谁会讨厌这样呢?”谢尔说。
这也是拥有一个在线项目组合至关重要的另一个原因:“如果你的作品不在网上,别人将如何联系你?”

满座,2019 年在 NairobiR meetup 学习。(图片来自@AfricaRUsers Twitter)
技巧 7:教导他人
“你训练别人越多,你就越能消化你学到的所有信息,”谢尔说。
虽然 Shel 本人是 RStudio 认证的培训师,在不同的数据科学活动中为他人提供教育,但你不需要那种机会来通过教学开始学习。“只要找五个人并训练他们,”谢尔说。“在潮水上训练他们。如果你训练两次、三次,你就再也不需要回到书本或网络课程中去记住什么是 tidyverse,或者哪个功能用于什么任务。”
“训练可以和朋友一起进行,”她说。"坚持说你想向你的一个朋友解释一些事情."
“我过去也是这样,甚至在工作中也是这样,问‘我能向你解释一下这段代码是做什么的吗?’"
“你解释得越多,你就越意识到要么你知道,要么你不知道。当你解释时,你会想,‘顺便问一下,为什么会这样?’这意味着在某个地方有差距,你需要学习更多。"
换句话说,教学有助于强化你所知道的,突出你所不知道的。解释你的代码——即使是对那些可能没有要求解释的人——可以帮助你更好地学习它。
此外,培训他人是有益的。“当你教别人你知道的东西时,你是在给他们知识。你给了他们能力,让他们能够利用自己的技能找到工作。然后他们去教其他人,你的一次培训将导致五个人被雇用。”
“没有什么比这更令人惊讶了,”她说。“它实际上祝福你的心。”
秘诀 8:抓住机会(并给予机会)
正如谢尔所说的,把自己放在那里并“投出你的一球”,可以获得令人印象深刻的回报。这是她在帮助建立 Africa R 用户组时所看到的。在 R 社区,当你伸出手寻求帮助时,人们会有所回应。
例如,来自 RStudio 的许多人通过演讲和培训来帮助 Africa R。“这是巨大的,”谢尔说。
另一方面,虽然她说全球 R 社区一直非常支持非洲不断增长的 R 社区,但她希望看到更多的全球就业机会。“我知道有些国家对工作许可证有严格的限制,”她说,“但也有其他国家没有。拥有更加多样化的工作场所会让一些 Africa R 成员受益。我希望看到更多向所有人开放的机会。”
(尽管她很快补充道,这个问题与 R 社区的关系更小,而与整个世界的关系更大。她说,全球 R 社区“给了我们(非洲 R 用户)如此多的支持。我不认为我们可以说什么,他们没有帮助我们。”)
外卖食品
从 Shel 学习和教授 R 的经验中,我们可以学到很多东西,但这里有一个对新学习者来说最重要的事情的快速回顾:
- 不要盲目地搜索——想搜索多少就搜索多少,但要学习和理解你找到的答案,不要只是盲目地将它们复制粘贴到你的代码中,然后继续前进。
- 看看其他人在用 R 做什么——这将帮助你理解 R 在现实世界中是如何使用的,并帮助你找出你最热衷于用它做什么。
- 参与全球 R 社区,但要在当地结识同事——你应该跟踪全球领导者在 R 方面做了什么,但你也应该向周围的人学习并与他们建立联系。
- 建立项目——你需要展示你正在学习的技能,并公开分享。你永远不知道这会给你带来什么样的工作机会!
- 从小事做起——罗马不是一天建成的。不要被一个热门新技术的宣传,或者试图学习所有东西的诱惑分散注意力。
- 教导他人,解释你的代码——这有助于你学习,也有助于他人。双赢。
- 通过寻求帮助来抓住机会,当你可以的时候帮助别人——当你寻求帮助时,最坏的情况可能是有人说不。尝试一下,当别人和你一起尝试时,一旦你有了一些经验,就去帮助他们。
如果你想更多地了解谢尔和她的经历,你可以查看她的个人网站和关注她的推特。你也可以通过他们的网站或 Twitter 联系她帮助运营的 Africa R users 组织。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
数据科学领域的多伦多 Womxn 宣布 15 大 100 天代码获奖者
原文:https://www.dataquest.io/blog/toronto-womxn-in-data-science-announces-top-15-100daysofcode-winners/
July 5, 2022
我们很高兴地宣布 Dataquest &多伦多 Womxn 数据科学#100DaysofCode 挑战赛的获胜者。挑战中的尖子生完成了十多门课程,70%的参与者完成了 50 天或更长时间的挑战。
Dataquest 很高兴能与多伦多 Womxn 等致力于支持数据行业多样性和包容性的组织合作。了解更多关于 Dataquest 奖学金项目以及如何在此合作的信息。
这一联合倡议的构想是为妇女和女孩建立数据扫盲实践。凭借在挑战赛中学到的技能,参与者将参加一个独家的招聘会,与顶级招聘人员会面。
我们对获奖者的奉献表示祝贺,并感谢所有参与者充分利用这次学习机会。
恭喜 15 强
adekoya gbemiola
【adeola aki ntola】【aminah reimbo】
【evelin kanda】
【Farah abdou】【fatma kiraz】
【Lydia gaheri nturibi】
【inna Nicole sumalap】
【Jia Li】
Toronto Womxn in Data Science 是一个面向 Womxn in Data Science 的社区,为来自不同背景的成员提供了一个展示职业历程和知识分享的平台。
Dataquest 是一个在线学习平台,使用真实世界的挑战和项目来教授数据科学。它提供广泛的课程,是最全面的在线数据科学平台之一。
用我们的新方法从完全初学者变成数据工程师
原文:https://www.dataquest.io/blog/total-beginner-become-data-engineer/
October 16, 2019
我们得到了一些非常令人兴奋的消息:我们刚刚启动了对我们的 数据工程学习路径 的全面改造!
这条修改过的路线被设计成更像我们的其他路线。即使你没有以前的编码经验,你也可以开始,它会带你从完全的初学者到有经验的从业者,拥有成为数据工程师所需的所有核心技能。
如果你以前检查过路径,你会注意到我们已经改变了很多。我们增加了一些新课程。我们已经创建了现有课程的定制数据工程版本,并将其添加到该路径中。为了更有效的学习和更准确的答案检查,我们已经优化了所有课程的。
简而言之:DE 路径现在已经准备好带你从零开始一路到达你的目标。
哦,我们有没有提到你可以免费试用很多课程内容?

https://www.youtube.com/embed/DU1PirFI21A?feature=oembed
*## 数据工程之路有什么新内容?
新路径从三门 Python 课程开始,旨在让你从没有编程背景到精通 Python 基础。这些课程基于我们非常受欢迎的 Python 数据科学课程,但我们对它们进行了调整,以更准确地关注数据工程师需要的技能。
从那里,路径挖掘 SQL 技能,有两个 SQL 课程旨在让你开始和运行。虽然它不像其他技术技能那样“性感”,但 SQL 是任何数据角色的关键技能,对于经常与 SQL 数据库交互的数据工程师来说尤其重要。
有了这些基础知识,这条路就通向更高级的、特定于数据工程的技能。有几门关于 Postgres 的课程,还有一门关于优化大数据代码性能的课程。还有优化熊猫、递归和树、算法和数据结构、构建数据管道等课程。
有关具体内容的更多细节,请查看路径页面和课程列表。正如我们去年推出的改进后的 R 路径一样,我们也将随着时间的推移,用新的课程扩展这条路径,使之更加详尽。
此外,该路径中的 一切都经过了优化和返工,以改善学生体验。我们增加了新的内容,但我们也极大地改进了旧的内容,以使 DE 路径达到我们其他学习路径的标准。
成为一名数据工程师
数据科学家可能是“21 世纪最性感的工作”,但工程师是高效数据科学团队的关键成员。根据 2019 年 10 月来自实际上的数据,尽管这个角色背后的炒作较少,但数据工程师的平均工资实际上比数据科学家高。
准备好迈出成为数据工程师的第一步了吗?今天就来看看我们新推出的 DE path 吧!
成为一名数据工程师!
现在就学习成为一名数据工程师所需的技能。注册一个免费帐户,访问我们的交互式 Python 数据工程课程内容。
(免费)

https://www.youtube.com/embed/ddM21fz1Tt0?rel=0*
特雷·考西:数据科学家访谈
October 11, 2015
概述
在 Dataquest ,作为数据科学教育过程的一部分,我们努力帮助我们的用户更好地了解数据科学在行业中的工作方式。我们已经开始了一系列采访经验丰富的数据科学家的活动。我们重点介绍了他们的故事,他们对初露头角的数据科学家的建议,以及他们解决的各种问题。这一系列的第一篇文章是我们对特雷·考西的采访。
Trey Causey 是一名数据科学家,从事从电子商务到体育等领域的工作。在学术界短暂停留后,他进入了工业界,在西雅图的电子商务初创公司 Zulily 担任数据科学家。然后,他在数据科学团队工作了一段时间,分别在脸书和图瑞工作,后者是一家为数据科学家开发工具的公司。在他充裕的空闲时间里,他在他的个人网站上写关于数据科学的博客,并把他对足球分析的爱好变成了一个 NFL 球队的顾问。
你对数据科学的定义是什么?
很好的问题,当然也没有简单的答案。这里有一个尝试:数据科学是使用统计学、机器学习、软件工程和领域知识来 a)从数据中提取信息,b)使用该信息进行预测,以及 c)将这些预测用于一些应用设置。那是一个罗嗦的回答!我们可以争论如何给这些成分分配权重。
或者,我们可以链接到德鲁·康威著名的数据科学维恩图。我不认为数据科学只涉及大数据或者深度神经网络这样花哨的算法。但我确实认为使用统计学和机器学习是必要的组成部分。
你有很强的定量背景。你看到缺乏你严格量化训练的人犯了哪些错误?
实话告诉你,我有一个未完成的 UW 博士学位。我就是所谓的 ABD。我认为,在某种定量学科方面没有扎实训练的人经常陷入工具和编程语言的争论,比如,你应该学习 R 还是 Python?使用随机森林需要什么包?诸如此类。缺乏对你正在应用的算法的坚实理解可能是危险的,因为你不知道事情何时不以它们应该的方式工作。
我也看到很多人犯了基本的相关性/因果性错误,不管他们是有意还是无意,因为他们没有对自己的模型持健康的怀疑态度,而这种态度往往来自多年的教育。
在量化方面,填补知识空白的最佳方式是什么?
Trey: 为了填补这些空白,在获取信息方面,我们显然正处于一个前所未有的时期,有动力的自学者拥有丰富的选择。也就是说,我不认为有什么好的替代方法可以替代一门有很多重点作业、需要认真听讲和集中注意力的课程。我建议每个人至少上一门统计推断课——我指的是上一门课,而不仅仅是参加 MOOC。
我怀疑让成千上万人参加 MOOCs 的评估方法是否有利于真正学习和记住复杂材料所需的工作。不过,我很高兴被证明是错的!
你在学术界的经历是怎样的,是什么让你转行进入工业界?
Trey: 我从学术界过渡到工业界,部分是出于需要——当助理教授的就业市场随着经济的其他部分崩溃时,我还在读研——部分是因为数据科学开始成为像我这样的人的可行选择,他们想继续做统计和机器学习,但不一定想写没人会读并且需要几年才能发表的论文。我只是没有耐心。
从学术界到 Zulily 的转变是怎样的?
Trey: 我发现这种转变非常容易——我非常幸运地在 Zulily 遇到了一位出色的经理 Mike Errecart,他真正了解数据科学改善公司的潜力,知道什么是可能的,什么是不可能的,并且真正有兴趣帮助我成长为一名数据科学家。
你曾在电子商务、消费互联网和体育领域工作过。对于每个行业对数据的态度,您喜欢和不喜欢的是什么?
显然,像 zulily 和脸书这样的电子商务和社交媒体公司已经完全接受了数据,这不仅是为了做出更好的决策,也是为了利用数据改进和创造新产品。至于体育,我认为有很多有趣的新数据变得可用,但没有人使用。体育界的许多人,特别是 NFL,都很保守,喜欢“基于直觉”的决策,并且不相信数据可以帮助他们赢得比赛,而不会将比赛变成机械的机械练习。
你在行业中还见过哪些你觉得很少有人具备技能的角色?
在 Dataquest,我们非常怀疑数据科学家的独角兽主题,并认为数据专业角色的专业化将会发生,而且非常重要。我们已经有数据分析师和数据科学家跟踪,但希望增加更多。
Trey: 问得好——数据工程师对于任何使用数据的组织来说都是非常有价值的,我没有看到很多针对这些角色的培训。我同意许多其他人的观点,即在创业公司中,数据工程师应该先于数据科学家被聘用,以便建立可扩展的、强大的基础设施,使其能够从事数据科学家更擅长的工作。我不知道对它是否有很大的需求,或者在线培训是否是答案,但我也看到了关于领导数据科学团队或作为数据科学家在主管或执行级别工作的材料的真正缺乏。
我们刚刚开始了解数据科学家在大公司中已经上升到高级领导职位,但我还不知道我们对数据副总裁或数据科学总监的角色有什么好的想法。
除了填补技能缺口和做大量兼职项目,初级数据专业人员还可以通过哪些方式获得第一份工作?
Trey: 我总是建议尽可能多地建立关系网。去参加聚会,参加讲座,试着去认识那些你想扮演的角色的人。给人发邮件喝咖啡是很多人推荐的一种策略,但是我收到了很多这样的邮件,我可以告诉你这有点麻烦,我最终感觉自己像个混蛋,因为大多数时候我不得不忽略他们或者说不。
引人注目很重要——如果这意味着副业,那很好。这也可能意味着在聚会或会议上展示你的副业项目。不要指望在 GitHub 上扔些代码就能看到招聘人员的邮件蜂拥而至。
你在 NFL 的咨询经历对你观看足球比赛的体验有什么影响?
可能比你想象的要少。我一直是一个足球迷,就像一个普通人一样——我对重大比赛感到兴奋,对愚蠢的错误和决定大喊大叫,通常会被一场精彩的比赛所吸引。我仍然对足球赛季感到非常兴奋。一个小小的讽刺是,在多个与足球相关的项目中工作(包括与一支 NFL 球队合作,以及帮助构建《纽约时报》的第四个 Down Bot)通常意味着我在比赛期间工作,并关注我所构建的各种模型的表现如何,或者是否有任何东西需要紧急修复。
你对哪些新的数据科学技术和技巧最感兴趣?
我尽量不要过于热衷于对特定技术或技巧的炒作。观看 Spark 很有意思,因为围绕它有大量令人兴奋的东西,但我认为许多人发现当应用于实际项目时,有些难以争辩。当我在 Dato 时,我用迁移学习进行了一些实验,对与图像相似性等训练数据无关的新数据使用预训练的深度神经网络。
我对这在多个领域中的良好表现感到非常惊讶。我认为我最感兴趣的是无聊的事情,比如像 Scikit-learn 和 Pandas 这样的工具的持续改进,它们允许我在工作的同时“不碍事”。几乎一周的任何一天,我都会选择一个设计良好且稳定的 API,而不是一个华而不实的新工具。
结论
如果你喜欢这次采访或想了解更多关于数据科学的知识,请前往 Dataquest 并加入我们的社区。我们将定期采访数据科学家,并将通过我们的时事通讯宣布新的采访。您也可以通过在此请求邀请来加入我们的社区聊天。
教程:根据 If-Else 条件向 Pandas 数据框架添加一列
原文:https://www.dataquest.io/blog/tutorial-add-column-pandas-dataframe-based-on-if-else-condition/
July 1, 2020
当我们使用 Python 进行数据分析时,我们有时可能希望根据数据帧中其他列的值向 pandas 数据帧添加一列。
虽然这听起来很简单,但如果我们尝试使用一个 if-else 条件来做这件事,就会变得有点复杂。谢天谢地,使用 numpy 有一个简单的好方法来做到这一点!
要了解如何使用,我们来看一个具体的数据分析题。我们有超过 4000 条 Dataquest 推文的数据集。附有图片的推文会获得更多的赞和转发吗?下面我们来做一些分析来了解一下!
我们将从导入 pandas 和 numpy 开始,并加载我们的数据集来看看它是什么样子的。(如果你还不熟悉使用 pandas 和 numpy 进行数据分析,请查看我们的交互式 numpy 和 pandas 课程)。
import pandas as pd
import numpy as np
df = pd.read_csv('dataquest_tweets_csv.csv')
df.head()

我们可以看到,我们的数据集包含了每条推文的一些信息,包括:
date—推文发布的日期time—发布推文的时间tweet—推文的实际文本mentions—推文中提到的任何其他 twitter 用户photos—推文中包含的任何图片的 urlreplies_count—推文上的回复数量retweets_count—推文的转发次数likes_count—推文上的赞数
我们还可以看到photos数据的格式有点奇怪。
使用 np.where()添加具有真/假条件的熊猫列
对于我们的分析,我们只是想看看带有图片的 tweets 是否获得了更多的交互,所以我们实际上并不需要图片 URL。让我们尝试创建一个名为hasimage的新列,它将包含布尔值——如果推文包含图像,则为True,如果不包含图像,则为False。
为此,我们将使用 numpy 的内置where()函数。该函数按顺序接受三个参数:我们要测试的条件,如果条件为真,则分配给新列的值,如果条件为假,则分配的值。看起来是这样的:
np.where(condition, value if condition is true, value if condition is false)
在我们的数据中,我们可以看到没有图片的推文在photos列中总是有值[]。我们可以使用信息和np.where()来创建我们的新列hasimage,如下所示:
df['hasimage'] = np.where(df['photos']!= '[]', True, False)
df.head()

上面,我们可以看到我们的新列已经被追加到我们的数据集,并且它已经正确地将包含图像的推文标记为True,将其他推文标记为False。
现在我们已经有了我们的hasimage列,让我们快速制作几个新的数据帧,一个用于所有图片推文,一个用于所有非图片推文。我们将使用布尔过滤器:
image_tweets = df[df['hasimage'] == True]
no_image_tweets = df[df['hasimage'] == False]
现在我们已经创建了这些,我们可以使用内置的熊猫数学函数,如.mean()来快速比较每个数据帧中的推文。
我们将使用print()语句使结果更容易阅读。我们还需要记住使用str()将我们的.mean()计算结果转换成一个字符串,这样我们就可以在我们的打印语句中使用它:
## LIKES
print('Average likes, all tweets: ' + str(df['likes_count'].mean()))
print('Average likes, image tweets: ' + str(image_tweets['likes_count'].mean()))
print('Average likes, no image tweets: ' + str(no_image_tweets['likes_count'].mean()))
print('\n')
## RETWEETS
print('Average RTs, all tweets: ' + str(df['retweets_count'].mean()))
print('Average RTs, image tweets: ' + str(image_tweets['retweets_count'].mean()))
print('Average RTs, no image tweets: ' + str(no_image_tweets['retweets_count'].mean()))
Average likes, all tweets: 6.209759328770148
Average likes, image tweets: 14.21042471042471
Average likes, no image tweets: 5.176514584891549
Average RTs, all tweets: 1.5553102230072864
Average RTs, image tweets: 3.5386100386100385
Average RTs, no image tweets: 1.2991772625280478
基于这些结果,在 Dataquest 中加入图片似乎可以促进更多的 Twitter 互动。有图片的推文平均点赞和转发量是没有图片的推文的近三倍。
添加具有更复杂条件的熊猫列
这种方法工作得很好,但是如果我们想要添加一个具有更复杂条件的新列—一个超越真与假的列,该怎么办呢?
例如,为了更深入地研究这个问题,我们可能想要创建一些交互性“层”,并评估到达每个层的推文中包含图像的百分比。为了简单起见,让我们用喜欢来衡量交互性,并将推文分成四层:
tier_4— 2 个或更少的喜欢tier_3— 3-9 个赞tier_2— 10-15 个赞tier_1— 16+个赞
为了实现这一点,我们可以使用一个叫做np.select() 的函数。我们会给它两个参数:一个是我们的条件列表,另一个是我们希望分配给新列中每一行的相应值列表。
这意味着顺序很重要:如果满足我们的conditions列表中的第一个条件,我们的values列表中的第一个值将被分配给该行的新列。如果满足第二个条件,则将分配第二个值,依此类推。
让我们看看这在 Python 代码中是怎样的:
# create a list of our conditions
conditions = [
(df['likes_count'] <= 2),
(df['likes_count'] > 2) & (df['likes_count'] <= 9),
(df['likes_count'] > 9) & (df['likes_count'] <= 15),
(df['likes_count'] > 15)
]
# create a list of the values we want to assign for each condition
values = ['tier_4', 'tier_3', 'tier_2', 'tier_1']
# create a new column and use np.select to assign values to it using our lists as arguments
df['tier'] = np.select(conditions, values)
# display updated DataFrame
df.head()

厉害!我们创建了另一个新的专栏,根据我们的等级排名系统(诚然有些武断)对每条推文进行分类。
现在,我们可以用它来回答更多关于我们数据集的问题。例如:1 级和 4 级推文中有图片的比例是多少?
#tier 4 tweets
df[(df['tier'] == 'tier_4')]['hasimage'].value_counts(normalize=True)
False 0.948784
True 0.051216
Name: hasimage, dtype: float64
#tier 1 tweets
df[(df['tier'] == 'tier_1')]['hasimage'].value_counts(normalize=True)
False 0.836842
True 0.163158
Name: hasimage, dtype: float64
在这里,我们可以看到,虽然图像似乎有所帮助,但它们似乎不是成功的必要条件。超过 83%的 Dataquest“第一层”推文(赞数超过 15 的推文)没有附带图片。
虽然这是一个非常肤浅的分析,但是我们已经完成了我们真正的目标:根据关于现有列中的值的条件语句,向 pandas 数据帧添加列。
当然,这是一项可以通过多种方式完成的任务。np.where()和 np.select()只是许多潜在方法中的两种。如果你想了解更多这方面的知识,请查看 Dataquest 的交互式 Numpy 和 Pandas 课程,以及数据科学家在 Python 职业道路上的其他课程。
教程:Python 中的高级 For 循环
原文:https://www.dataquest.io/blog/tutorial-advanced-for-loops-python-pandas/
July 16, 2019
在之前的教程中,我们介绍了 Python for loops 的基础知识,看看如何遍历列表和列表列表。但是除了遍历列表之外,for 循环还有更多的内容,在现实世界的数据科学工作中,您可能希望对其他数据结构使用 for 循环,包括 numpy 数组和 pandas 数据帧。
本教程从如何使用 for 循环遍历除列表之外的常见 Python 数据结构(如元组和字典)开始。然后,我们将深入探讨与常见的 Python 数据科学库如numpy、pandas和matplotlib一起使用 for 循环。我们还将仔细看看range()函数,以及它在编写循环时是如何有用的。
快速回顾:Python For 循环
for 循环是一个编程语句,它告诉 Python 遍历一个对象集合,依次对每个对象执行相同的操作。基本语法是:
for object in collection_of_objects:
# code you want to execute on each object
每次 Python 遍历循环,变量object取我们序列中下一个对象collection_of_objects的值,Python 将按顺序执行我们在来自collection_of_objects的每个对象上编写的代码。
现在,让我们深入了解如何使用不同类型数据结构的 for 循环。我们将跳过列表,因为那些已经在前面的教程中讨论过了;如果你需要进一步的复习,请查看入门教程或 Dataquest 的关于列表和 for 循环的互动课程。
数据结构
元组
元组是序列,就像列表一样。元组和列表的区别在于元组是不可变的;也就是说,它们不能被改变(了解 Python 中可变和不可变对象的更多信息)。元组也使用圆括号代替方括号。
不考虑这些差异,遍历元组非常类似于列表。
x = (10,20,30,40,50)
for var in x:
print("index "+ str(x.index(var)) + ":",var)
index 0: 10
index 1: 20
index 2: 30
index 3: 40
index 4: 50
如果我们有一个元组列表,我们可以访问列表中每个元组的单个元素,方法是将它们作为变量包含在 for 循环中,如下所示:
x = [(1,2), (3,4), (5,6)]
for a, b in x:
print(a, "plus", b, "equals", a+b)
1 plus 2 equals 3
3 plus 4 equals 7
5 plus 6 equals 11
字典
除了列表和元组,字典是在处理数据时可能遇到的另一种常见的 Python 数据类型,for 循环也可以遍历字典。
Python 字典由键值对组成,因此在每个循环中,我们需要访问两个元素(键和值)。我们需要调用.items()方法,而不是像对待列表那样使用enumerate()来循环遍历每个键-值对的键和相应的值。
例如,假设我们有一个名为stocks的字典,其中包含股票代码和相应的股票价格。我们将使用字典上的.items()方法为每次迭代生成一个键和值:
stocks = {
'AAPL': 187.31,
'MSFT': 124.06,
'FB': 183.50
}
for key, value in stocks.items() :
print(key + " : " + str(value))
AAPL : 187.31
MSFT : 124.06
FB : 183.5
注意,名称、键和值是完全任意的;我们也可以把它们标为 k 和 v 或者 x 和 y。
字符串
正如介绍性教程中提到的,for 循环还可以遍历字符串中的每个字符。快速回顾一下,这是如何工作的:
print("data science")
for c in "data science":
print(c)
data science
d
a
t
a
s
c
i
e
n
c
e
Numpy 数组
现在,让我们看看如何将 for 循环用于常见的 Python 数据科学包及其数据类型。
我们将从如何使用带有numpy数组的 for 循环开始,所以让我们从创建一些随机数数组开始。
import numpy as np
np.random.seed(0) # seed for reproducibility
x = np.random.randint(10, size=6)
y = np.random.randint(10, size=6)
迭代一维 numpy 数组与迭代列表非常相似:
for val in x:
print(val)
5
0
3
3
7
9
现在,如果我们想遍历一个二维数组呢?如果我们像上面一样使用相同的语法来迭代二维数组,那么每次迭代只能迭代整个数组。
# creating our 2-dimensional array
z = np.array([x, y])
for val in z:
print(val)
[5 0 3 3 7 9]
[3 5 2 4 7 6]
二维数组是由一对一维数组构建而成的。为了访问每个元素而不是每个数组,我们可以使用 numpy 函数nditer(),这是一个多维迭代器对象,它将一个数组作为其参数。
在下面的代码中,我们将编写一个 for 循环,通过传递二维数组z作为nditer()的参数来遍历每个元素:
for val in np.nditer(z):
print(val)
5
0
3
3
7
9
3
5
2
4
7
6
正如我们所看到的,这首先列出了 x 中的所有元素,然后是 y 中的所有元素。
记住!当遍历这些不同的数据结构时,字典需要一个方法,numpy 数组需要一个函数。
熊猫数据帧
当我们在 Python 中处理数据时,我们经常使用pandas数据帧。幸运的是,我们也可以使用 for 循环来遍历它们。
让我们在使用一个小 CSV 文件时练习这样做,该文件记录了六个不同国家的 GDP、首都和人口。我们将在下面的熊猫数据框中读到这一点。
Pandas 的工作方式与 numpy 有点不同,所以我们不能简单地重复我们已经学过的 numpy 过程。如果我们像对 numpy 数组那样迭代 pandas DataFrame,这只会打印出列名:
import pandas as pd
df = pd.read_csv('gdp.csv', index_col=0)
for val in df:
print(val)
Capital
GDP ($US Trillion)
Population
相反,我们需要明确指出我们想要迭代数据帧的行。我们通过调用 DataFrame 上的iterrows()方法来实现这一点,并打印行标签和行数据,其中一行是整个 pandas 系列。
for label, row in df.iterrows():
print(label)
print(row)
Ireland
Capital Dublin
GDP ($US Trillion) 0.3337
Population 4784000
Name: Ireland, dtype: object
United Kingdom
Capital London
GDP ($US Trillion) 2.622
Population 66040000
Name: United Kingdom, dtype: object
United States
Capital Washington, D.C.
GDP ($US Trillion) 19.39
Population 327200000
Name: United States, dtype: object
China
Capital Beijing
GDP ($US Trillion) 12.24
Population 1386000000
Name: China, dtype: object
India
Capital New Delhi
GDP ($US Trillion) 2.597
Population 1339000000
Name: India, dtype: object
Germany
Capital Berlin
GDP ($US Trillion) 3.677
Population 82790000
Name: Germany, dtype: object
我们还可以访问熊猫系列中的特定值。假设我们只想打印出每个国家的首都。我们可以指定只需要“Capital”列的输出,如下所示:
for label, row in df.iterrows():
print(label + " : " + row["Capital"])
Ireland : Dublin
United Kingdom : London
United States : Washington, D.C.
China : Beijing
India : New Delhi
Germany : Berlin
为了比简单的打印输出更进一步,让我们使用 for 循环添加一列。我们再加一个人均 GDP 一栏。记住.loc[]是基于标签的。在下面的代码中,我们将添加列,并通过将每个国家的总 GDP 除以其人口,然后将结果乘以一万亿来计算其内容(因为 GDP 数字是以万亿为单位列出的)。
for label, row in df.iterrows():
df.loc[label,'gdp_per_cap'] = row['GDP ($US Trillion)']/row['Population '] * 1000000000000
print(df)
Capital GDP ($US Trillion) Population \
Country
Ireland Dublin 0.3337 4784000
United Kingdom London 2.6220 66040000
United States Washington, D.C. 19.3900 327200000
China Beijing 12.2400 1386000000
India New Delhi 2.5970 1339000000
Germany Berlin 3.6770 82790000
gdp_per_cap
Country
Ireland 69753.344482
United Kingdom 39703.210176
United States 59260.391198
China 8831.168831
India 1939.507095
Germany 44413.576519
对于我们的数据框架中的每一行,我们都创建了一个新标签,并将行数据设置为等于总 GDP 除以该国人口,再乘以 1T 美元(千美元)。
range()功能
我们已经看到了如何使用 for 循环来迭代任何序列或数据结构。但是,如果我们想以特定的顺序或者特定的次数来迭代这些序列呢?
这可以通过 Python 内置的range()函数来完成。根据传递给函数的参数数量,您可以决定一系列数字的开始和结束位置,以及一个数字和下一个数字之间的差异有多大。注意,与列表类似,range()函数的计数从 0 开始,而不是从 1 开始。
我们有三种方法可以调用range():
- 范围(停止)
- 范围(开始、停止)
- 范围(开始、停止、步进)
range(stop)
range(stop)有一个参数,当我们想要迭代一系列数字时使用,这些数字从 0 开始,包括所有数字,但不包括我们设置为停止的数字。
for i in range(3):
print(i)
0
1
2
range(start, stop)
range(start,stop)有两个参数,我们不仅可以设置系列的结束,还可以设置开始。您可以使用 range()生成从 A 到 B 的一系列数字,使用范围为(A,B)。
for i in range(1, 8):
print(i)
1
2
3
4
5
6
7
range(start, stop, step)
range(开始、停止、步进)有三个参数。除了最小值和最大值,我们还可以设置序列中一个数字与下一个数字之间的差值。如果没有提供步长值,则默认步长值为 1。
for i in range(3, 16, 3):
print(i)
3
6
9
12
15
注意,这对于非数字序列也是一样的。
我们也可以使用序列中元素的索引进行迭代。关键思想是首先计算列表的长度,然后在这个长度的范围内对序列进行迭代。让我们来看一个例子:
languages = ['Spanish', 'English', 'French', 'German', 'Irish', 'Chinese']
for index in range(len(languages)):
print('Language:', languages[index])
Language: Spanish
Language: English
Language: French
Language: German
Language: Irish
Language: Chinese
在上面的 for 循环中,我们看到了一个变量的索引和语言、关键字中的以及创建一个数字序列的range()函数。注意,我们在这种情况下也使用了len()函数,因为列表不是数字的。
对于每次迭代,我们都执行我们的 print 语句。因此,对于 len(languages)范围内的每个索引,我们希望打印一种语言。因为我们的语言序列的长度是 6(这是len(langauges)评估的值),我们可以将语句重写如下:
for index in range(6):
print('Language:', languages[index])
Language: Spanish
Language: English
Language: French
Language: German
Language: Irish
Language: Chinese
用 For 循环绘图
假设我们想要遍历一个集合,并使用每个元素来生成一个子情节,或者甚至是单个情节中的每个轨迹。例如,让我们以流行的虹膜数据集 ( 了解更多关于这个数据)为例,用 For 循环做一些绘图。考虑下图。
(如果你对 Matplotlib 或 Seaborn 不熟悉,可以查看一下 Kyso 的这些初学者指南: Matplotlib , Seaborn 。Dataquest 还提供关于 Python 数据可视化的互动课程。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('iris.csv')
# create a figure and axis
fig, ax = plt.subplots()
# scatter the sepal_length against the sepal_width
ax.scatter(df['sepal_length'], df['sepal_width'])
# set a title and labels
ax.set_title('Iris Dataset')
ax.set_xlabel('sepal_length')
ax.set_ylabel('sepal_width')
Text(0,0.5,'sepal_width')

上面,我们已经绘制了每个萼片的长度和宽度,但是我们可以通过每个花的种类在每个数据点上着色来赋予图表更多的意义。一种方法是使用 for 循环分散每个点,并传入各自的颜色。
# create color dictionary
colors = {'setosa':'r', 'versicolor':'g', 'virginica':'b'}
# create a figure and axis
fig, ax = plt.subplots()
# plot each data-point
for i in range(len(df['sepal_length'])):
ax.scatter(df['sepal_length'][i], df['sepal_width'][i], color=colors[df['species'][i]])
# set a title and labels
ax.set_title('Iris Dataset')
ax.set_xlabel('sepal_length')
ax.set_ylabel('sepal_width')
Text(0,0.5,'sepal_width')

如果我们想要可视化我们的虹膜数据集的某些特征的单变量分布呢?我们可以用plt.subplot()来做这件事,它在一个网格中创建一个单独的子情节,我们可以设置它的行数和列数。
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 6))
fig.subplots_adjust(hspace=0.8)
fig.suptitle('Distributions of Iris Features')
for ax, feature, name in zip(axes.flatten(), df.drop('species',axis=1).values.T, df.columns.values):
ax.hist(feature, bins=len(np.unique(df.drop('species',axis=1).values.T[0])//2))
ax.set(title=name[:-4].upper(), xlabel='cm')

暂时不要深入 matplotlib 语法,下面是我们图表的每个主要组成部分的简要描述:
- PLT . subplot()–用于创建 2 乘 2 的网格并设置整体大小。
- zip()–这是一个内置的 python 函数,它使得同时遍历多个相同长度的可迭代对象变得非常简单。
- axes.flatten(),其中 flatten()是一个 numpy 数组方法——这将返回数组(列)的展平版本。
- ax . set()–允许我们用一个方法设置我们的
axes对象的所有属性。
附加操作
嵌套循环
Python 允许我们在一个循环中使用另一个循环。这涉及到一个外部循环,在其命令内部有一个内部循环。
考虑以下结构:
for iterator_var in sequence:
for iterator_var in sequence:
# statements(s)
# statements(s)
嵌套的 for 循环对于遍历由列表组成的列表中的项非常有用。在由列表组成的列表中,如果我们只使用一个 for 循环,程序会将每个内部列表作为一个项目输出:
languages = [['Spanish', 'English', 'French', 'German'], ['Python', 'Java', 'Javascript', 'C++']]
for lang in languages:
print(lang)
['Spanish', 'English', 'French', 'German']
['Python', 'Java', 'Javascript', 'C++']
为了访问内部列表的每一项,我们定义了一个嵌套的 for 循环:
for x in languages:
print("------")
for lang in x:
print(lang)
------
Spanish
English
French
German
------
Python
Java
Javascript
C++
上面,外部的 for 循环遍历主列表列表(本例中包含两个列表),内部的 for 循环遍历单个列表本身。外部循环执行 2 次迭代(针对每个子列表),在每次迭代中,我们执行内部循环,打印各个子列表的所有元素。
这告诉我们,控件从最外面的循环开始,遍历内部循环,然后再次返回到外部 for 循环,直到控件覆盖了整个范围,在本例中是 2 次。
循环的继续和中断
循环控制语句改变了 for 循环的正常执行顺序。
如果我们想在我们的内部循环中过滤掉一种特定的语言呢?我们可以使用一个 continue 语句来做到这一点,这允许我们在外部条件被触发时跳过循环的特定部分。
for x in languages:
print("------")
for lang in x:
if lang == "German":
continue
print(lang)
------
Spanish
English
French
------
Python
Java
Javascript
C++
在上面的循环中,在内循环中,如果 langauge 等于“German ”,我们只跳过该迭代,继续循环的其余部分。循环没有终止。
让我们看看下面的一个数值例子:
from math import sqrt
number = 0
for i in range(10):
number = i ** 2
if i % 2 == 0:
continue # continue here
print(str(round(sqrt(number))) + ' squared is equal to ' + str(number))
1 squared is equal to 1
3 squared is equal to 9
5 squared is equal to 25
7 squared is equal to 49
9 squared is equal to 81
所以在这里,我们定义了一个循环,它遍历从 0 到 9 的所有数字,并对每个数字求平方。在我们的循环中,在每一次迭代中,我们都在检查这个数是否能被 2 整除,此时循环将继续执行,当 i 的计算结果为偶数时跳过迭代。
那么一个 break 语句呢?这允许我们在满足外部条件时完全退出循环。让我们使用与上面相同的示例来看看这是如何工作的简单演示:
number = 0
for i in range(10):
number = i ** 2
if i == 7:
break
print(str(round(sqrt(number))) + ' squared is equal to ' + str(number))
0 squared is equal to 0
1 squared is equal to 1
2 squared is equal to 4
3 squared is equal to 9
4 squared is equal to 16
5 squared is equal to 25
6 squared is equal to 36
在上面的例子中,我们的 if 语句给出了这样一个条件:如果我们的变量 i 的值为 7,我们的循环将会中断,所以我们的循环在完全退出循环之前会遍历整数 0 到 6。
想要更多吗?以下是一些可能有用的附加资源:
结论
在本教程中,我们了解了循环的的一些更高级的应用,以及如何在典型的 Python 数据科学工作流中使用它们。
我们学习了如何迭代不同类型的数据结构,以及如何使用循环和 pandas DataFrames 和 matplotlib 以编程方式创建多个轨迹或子图。
最后,我们研究了一些更高级的技术,这些技术使我们能够更好地控制 for 循环的操作和执行。
如果你想了解关于这个话题的更多信息,请查看 Dataquest 的 Python 路径中的数据科学家,它将帮助你在大约 6 个月内做好工作准备。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
教程:Python 请求库简介
原文:https://www.dataquest.io/blog/tutorial-an-introduction-to-python-requests-library/
February 9, 2022
请求库简化了向 web 服务器发出 HTTP 请求以及处理它们的响应。在本教程中,我们将学习如何安装和使用该库,并重点介绍其主要特性。
什么是 Python 请求库?
Requests 库提供了一个简单的 API 来与 HTTP 操作交互,比如GET、POST等。
在请求库中实现的方法针对由 URL 指定的特定 web 服务器执行 HTTP 操作。
它还支持通过参数和报头向 web 服务器发送额外的信息,对服务器响应进行编码,检测错误,以及处理重定向。
除了简化我们处理 HTTP 操作的方式,请求库还提供了一些高级特性,比如处理 HTTP 异常和认证,我们将在本教程中讨论。
什么是 HTTP?
超文本传输协议(HTTP)是一种基于客户端-服务器架构的请求/响应协议,它依靠 TCP/IP 连接来交换请求和响应消息。
HTTP 客户端(如 web 浏览器或移动应用程序)向 HTTP 服务器发送请求,服务器用包含状态行、标题和正文的消息来响应它们。
安装请求库
开始使用请求库的第一步是安装它。您可以使用pip或conda命令来安装库。为此,让我们首先创建一个新的 Python 虚拟环境,然后在其中安装库。
~ % mkdir req-prj
~ % python3 -m venv req-prj/venv
~ % source re q-prj/venv/bin/activate
(venv) ~ % python3 -m pip install requests
在终端窗口中键入以上命令,在 macOS 上创建环境。在上面的前三个命令中,我们在req-prj文件夹中创建了venv环境,然后激活该环境。最后,我们在环境中安装最新版本的请求包。
注
如果你不熟悉 Python 虚拟环境,Dataquest 博客上有一个很棒的教程,在Python 虚拟环境完全指南(2022)–data quest。
现在您可以导入这个库并编写您的第一个代码片段来试用它。
import requests
r = requests.get('https://www.dataquest.io/')
print(r)
运行上面的代码输出<Response [200]>,这意味着请求成功并且 URL 是可到达的。
让我们检查上面代码中r变量的数据类型:
print(type(r))
它返回<class 'requests.models.Response'>,这意味着它是响应类的一个实例。一个响应对象包含一个 HTTP 请求的结果。
注
在本教程中,我们使用httpbin.org网站。 httpbin 工具是一个免费且简单的 HTTP 请求-响应服务,它提供了一组 URL 端点。我们使用这些端点来测试使用 HTTP 操作的各种方式。我们将使用 httpbin 工具,因为它有助于我们专注于学习 Python 请求库,而无需设置真正的 web 服务器或使用在线 web 服务。
使用获取请求
我们使用get方法从特定的 web 服务器请求数据。让我们试一试:
url = 'http://httpbin.org/json'
r = requests.get(url)
print('Response Code:', r.status_code)
print('Response Headers:\n', r.headers)
print('Response Content:\n',r.text)
运行上面的代码会输出一个状态代码200,表示该 URL 是可访问的。然后,它返回页面的标题数据,后跟页面的内容。
headers属性返回一个专门针对 HTTP 头的特殊字典,因此您可以简单地使用它的键来访问每个项目:
print(r.headers['Content-Type'])
继续运行语句。它返回页面的内容类型 application/json。
在代码的最后一行,我们可以使用将页面内容作为一系列字节返回的content属性,但是我们更喜欢使用将页面内容作为 Unicode 格式的解码文本打印出来的text属性。
使用获取参数
我们使用 GET 参数通过 URL 将键值对格式的信息传递给 web 服务器。get方法允许我们使用params参数传递一个键值对字典。让我们试一试。
url = 'http://httpbin.org/get'
payload = {
'website':'dataquest.io',
'courses':['Python','SQL']
}
r = requests.get(url, params=payload)
print('Response Content:\n',r.text)
运行上面的代码。您将看到以下输出:
Response Content:
{
"args": {
"courses": [
"Python",
"SQL"
],
"website": "dataquest.io"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.27.1",
"X-Amzn-Trace-Id": "Root=1-61e7e066-5d0cacfb49c3c1c3465bbfb2"
},
"origin": "121.122.65.155",
"url": "http://httpbin.org/get?website=dataquest.io&courses=Python&courses=SQL"
}
响应内容是 JSON 格式的,我们通过params参数传递的键值对出现在响应的args部分。另外,url部分包含编码的 URL 以及传递给服务器的参数。
使用发布请求
我们使用 POST 请求将从 web 表单收集的数据提交到 web 服务器。要在请求库中做到这一点,您需要首先创建一个数据字典,并将其分配给post方法的data参数。让我们看一个使用post方法的例子:
url = 'http://httpbin.org/post'
payload = {
'website':'dataquest.io',
'courses':['Python','SQL']
}
r = requests.post(url, data=payload)
print('Response Content:\n',r.text)
运行上面的代码会返回以下响应:
Response Content:
{
"args": {},
"data": "",
"files": {},
"form": {
"courses": [
"Python",
"SQL"
],
"website": "dataquest.io"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "47",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.27.1",
"X-Amzn-Trace-Id": "Root=1-61e7ec9f-6333082d7f0b73d317acc1f6"
},
"json": null,
"origin": "121.122.65.155",
"url": "http://httpbin.org/post"
}
这一次,通过post方法提交的数据出现在响应的form部分,而不是在args中,因为我们没有将数据作为 URL 参数的一部分发送,而是将它们作为表单编码的数据发送。
处理异常
与远程服务器通信时可能会出现一些异常。例如,服务器可能无法访问,请求的 URL 在服务器上不存在,或者服务器没有在适当的时间范围内响应。在这一节中,我们将学习如何使用请求库的 HTTPError 类来检测和解决 HTTP 错误。
import requests
from requests import HTTPError
url = "http://httpbin.org/status/404"
try:
r = requests.get(url)
r.raise_for_status()
print('Response Code:', r.status_code)
except HTTPError as ex:
print(ex)
在上面的代码中,我们导入了 HTTPError 类,用于从请求库中捕获和解析 HTTP 异常。然后,我们尝试请求 httpbin.org 上的一个端点,这会生成一个404状态代码。每当 HTTP 响应包含错误状态代码(4XX 客户端错误或 5XX 服务器错误响应)时,raise_for_status()方法就会抛出异常。一旦出现错误,请求库不会自动引发异常。所以我们需要使用raise_for_status()方法来识别是否出现了错误状态代码。最后,异常处理程序块捕获错误并按如下方式打印出来:
404 Client Error: NOT FOUND for url: http://httpbin.org/status/404
```---
**NOTE**
If you try to access the <code>http://httpbin.org/status/200 endpoint, the code above outputs <code>Response Code: 200 because the status code is not in the range of error status codes. The <code>raise_for_status() method will return <code>None, which won't trigger the exception handler.
- - - -
In addition to the exception that we just discussed, let’s see how we can resolve server timeouts. It's crucial because we need to ensure our application doesn’t hang indefinitely. In the Requests library, if a request times out, a *Timeout* exception will occur. To specify the timeout of a request to a number of seconds, we can use the <code>timeout argument:
```pypy
import requests
from requests import Timeout
url = "http://httpbin.org/delay/10"
try:
r = requests.get(url, timeout=3)
print('Response Code:', r.status_code)
except Timeout as ex:
print(ex)
先说代码。我们导入了 Timeout 类来解决超时异常,并提供了一个 URL 来引用一个有 10 秒延迟的端点来测试我们的代码。然后,我们将超时参数设置为 3 秒,这意味着如果服务器在 3 秒内没有响应,get 请求将抛出一个异常。最后,异常处理程序捕获超时错误(如果有的话),并将其打印出来。所以运行上面的代码会输出下面的错误消息,因为服务器不会在给定的时间内响应。
HTTPConnectionPool(host='httpbin.org', port=80): Read timed out. (read timeout=3)
```## Authentication
The Requests library supports various web authentications, such as basic, digest, the two versions of OAuth, etc. We can use these authentication methods when we want to work with any data sources that require us to be logged in.
We will implement the basic authentication using HTTPBin service in the following example. The endpoint for Basic Auth is /basic-auth/{*user*}/{*password*}. For example, if you use the following endpoint . . .
http://httpbin.org/basic-auth/data/quest
. . . you can authenticate using the username *'data'* and the password *'quest'* by assigning them as a tuple to the <code>auth argument. Once you authenticate successfully, it responds with JSON data <code>{ "authenticated": true, "user": "data"}.
```pypy
import requests
r = requests.get('http://httpbin.org/basic-auth/data/quest', auth=('data', 'quest'))
print('Response Code:', r.status_code)
print('Response Content:\n', r.text)
运行上面的代码。它的输出如下:
Response Code: 200
Response Content:
{
"authenticated": true,
"user": "data"
}
如果我们使用户名或密码不正确,它的输出如下:
Response Code: 401
Response Content:
结论
我们了解了最强大和下载量最大的 Python 库之一。我们讨论了 HTTP 的基础知识和 Python 请求库的不同方面。我们还处理了 GET 和 POST 请求,并学习了如何解决请求的异常。最后,我们尝试通过 web 服务中的基本身份验证方法进行身份验证。
Azure SQL 数据库初学者教程(2023)
原文:https://www.dataquest.io/blog/tutorial-azure-sql-database/
November 17, 2022
介绍
您是否在寻找能够处理大量工作负载并快速扩展的数据库解决方案?如果是这样,Azure SQL 数据库可能是你的完美选择。Azure SQL Database 是一个基于云的数据库服务,它提供了 Microsoft SQL Server 的所有功能,并增加了可伸缩性和灵活性。Azure SQL 数据库基于 Microsoft SQL Server 数据库引擎的最新稳定版本,并提供了一个简化配置、修补、升级和监控的托管环境。Azure SQL 数据库可以通过多种方式部署,具体取决于应用程序的需求。在本文中,我们将讨论如何开始使用 Azure SQL 数据库。
Azure SQL 数据库的优势
Azure SQL 数据库提供了许多优于传统本地数据库的优势,包括成本节约、更高的灵活性和可伸缩性。也许 Azure SQL 数据库最大的优势是其现收现付的定价模式,它可以帮助组织节省数据库成本。此外,Azure SQL 数据库可以根据需要扩大或缩小,这使它成为比内部部署数据库更灵活的解决方案。最后,Azure SQL 数据库高度可用,并提供内置的灾难恢复功能,确保您的数据始终安全且可访问。
创建 Azure SQL 数据库的步骤
创建 Azure SQL 数据库是一个简单的过程,只需点击几下鼠标即可完成。第一步是导航到 Azure 门户并使用您的 Azure 帐户凭据登录。登录后,您将看到以下页面:

点击位于屏幕左侧的 +创建新资源按钮。这将开启创造资源刃。在数据库窗格下,可以看到 SQL 数据库。点击位于其下方的创建按钮。

这将打开创建 SQL 数据库刀片,在这里您将指定关于您的数据库的详细信息。首先,您将选择想要使用的订阅。之后,您需要选择要将数据库部署到的资源组。如果您没有资源组,您可以通过点击创建新的链接来创建一个。在本教程中,我们已经指定了 SQLResourceGroup 作为资源组的名称,但是您必须为它指定一个唯一的名称。

下一步是指定数据库的名称。在本教程中,我们已经指定了 SQLDB 作为数据库名称,但是您必须为它指定一个唯一的名称。

完成上述步骤后,单击服务器下拉菜单,选择要部署数据库的服务器。如果您没有服务器,您可以通过点击创建新的链接来创建一个,这将打开以下页面。按如下方式填写详细信息:
-
给一个唯一的服务器名,并选择您选择的位置。
-
在认证方式下,选择使用 SQL 认证选项,创建唯一的服务器管理员登录和密码配置。

填写完详细信息后,点击确定,将进入如下所示页面。对于想要使用 SQL 弹性池,保持默认设置 No ,对于工作负载环境设置保持默认设置 Development 。

使用下图所示的值完成创建 SQL 数据库刀片的剩余字段。

一旦完成上述步骤,点击下一步:联网,并配置如下所示的设置。


点击下一步:安全,将所有其他设置保留为默认,除了启用 Azure Defender for SQL ,为此你应该选择而不是现在。

保留其他选项卡的默认设置,并转到查看+创建。您可以查看您的配置,并根据需要返回进行编辑。您还可以查看以您的货币表示的每月估计费用。

一旦您对上面的配置感到满意,单击 Create 按钮来部署您的数据库。完成部署可能需要几分钟时间。部署窗格将显示状态。

点击转到资源,这将打开下面的页面,您可以在其中查看关于您的数据库的信息,例如它的服务器名称、状态和定价层。

删除资源
当您使用完 Azure SQL 数据库资源后,删除这些资源以避免不必要的成本是很重要的。这很容易做到。第一步是去 Azure 门户,在那里你可以看到资源组的列表。

单击您创建的 SQL 资源组,这将打开以下页面。

点击页面顶部的删除资源组按钮。最后,通过键入资源组的名称并单击 Delete 按钮来确认删除。删除资源可能需要几分钟时间。
结论
创建 Azure SQL 数据库是一个简单的过程,只需点击几下鼠标。按照上面的步骤,您可以很快建立并运行一个新的数据库。部署完数据库后,您可以通过在 Azure 门户中导航到 SQL 数据库刀片来管理它。从这里,您可以查看有关数据库的信息,并对其执行各种操作。
Azure Synapse 分析简单指南(2023 版)
原文:https://www.dataquest.io/blog/tutorial-azure-synapse-analytics/
December 12, 2022
如今,企业收集的数据比以往任何时候都多。挑战变成了管理和理解所有这些数据。这就是 Azure Synapse Analytics 的用武之地。Azure Synapse Analytics 是一个基于云的平台,允许您存储和管理数据,并在其上运行分析。这是一种完全托管的服务,具有可扩展性、高可用性和安全性。Azure Synapse Analytics 与其他 Azure 服务集成,如 HDInsight、Databricks 和 Power BI,以提供完整的数据平台解决方案。
在本教程中,我们将向您介绍 Azure Synapse Analytics,并讨论在 Azure 中创建平台的步骤。
Azure Synapse 分析的组件
Azure Synapse Analytics 首先从各种数据源获取数据,如社交媒体、物联网设备和 web 应用程序。然后,它使用大规模并行处理(MPP)架构在多个节点上并行处理数据。这使得它能够快速有效地处理非常大的数据集。然后,数据被转换并以优化的格式存储,以供分析。最后,对数据进行分析,以获得可用于改进业务运营的见解。
Azure Synapse 分析工作流的主要组件包括:
-
Azure Synapse Analytics Studio:这是一个基于网络的界面,允许用户开发和运行分析作业。
-
Azure Synapse 分析数据库:这些数据库用于存储由 Azure Synapse 分析服务处理的数据。
-
Azure Synapse 分析作业:这些是提交给 Azure Synapse 分析服务进行处理的作业。可以使用 Azure Synapse Analytics Studio 或 Azure Portal 来创建工作。
-
Azure Monitor:这是一个监控服务,帮助用户跟踪他们的 Azure Synapse Analytics 作业的性能。
-
Azure Active Directory:这用于对用户进行身份验证,并授权对 Azure Synapse 分析服务的访问。
Azure Synapse Analytics 的优势
使用 Azure Synapse Analytics 有很多好处,包括:
-
这是一项完全托管的服务,因此无需担心修补或升级软件。
-
它是可扩展的,因此可以随着您的业务增长而增长。
-
它与其他 Azure 服务集成,提供完整的数据平台解决方案。
-
根据您的需求,它提供两种不同的储物选择。
-
它是安全的,因此您可以放心,您的数据是安全和受保护的。
Azure Synapse Analytics 还支持实时分析,这使得在收集数据时对数据进行分析成为可能,这对于检测模式和趋势非常有用。
设置 Azure Snapse 分析
设置 Azure Synapse Analytics 是一个简单的过程,只需几次点击即可完成。第一步是导航到 Azure 门户并使用您的 Azure 帐户凭据登录。登录后,您将看到以下页面:

点击位于屏幕左侧的 +创建新资源按钮。这将开启创造资源刃。在搜索栏下,输入 synapse ,从选项中点击 Azure Synapse Analytics 。

在打开的页面上点击创建按钮。

这将打开 blade,您将在其中指定设置 Azure Synapse Analytics 的详细信息。首先,您将选择想要使用的订阅。之后,您需要选择您想要部署服务的资源组。如果您没有资源组,您可以通过点击创建新的链接来创建一个。在本教程中,我们已经指定 dqsynapserg 作为资源组的名称,但是您必须为它指定一个唯一的名称。

下一步是为您的工作区指定名称。在本教程中,我们已经指定了dqsyncapsews作为名称,但是您必须为它指定一个唯一的名称。对于地区,在教程中指定为东美,但是你可以选择离你最近的地区。在下选择 Data Lake Storage Gen 2 ,并在帐户名内提供一个唯一的名称。在本教程中,我们将其指定为 dqsynapsedatagen 。

下一步是指定文件系统名。在本教程中,我们已经指定了dqsyncapsefn作为文件名,但是您必须为它指定一个唯一的名称。

在 Data Lake Storage Gen2 account 框中,保留对**的默认检查选项,将自己指定为 Storage Blob Data Contributor 角色,并单击 Review + create**

这将打开页面,您将看到消息验证成功。如果需要,您可以检查您的配置并返回编辑。您还可以查看以您的货币表示的每月估计费用。

一旦您对上面的配置感到满意,单击 Create 按钮来部署您的数据库。完成部署可能需要几分钟时间,部署窗格将显示状态。
点击转到资源组打开以下页面,您可以在其中查看关于您刚刚创建的 synapse analytics 资源组的信息,例如 synapse workspace 和关联的存储帐户。

你现在可以通过点击 Synapse 工作区来打开 Synapse Studio,然后在打开 Synapse Studio 框中选择打开。

完成上述步骤将打开 Synapse Analytics Studio,如下所示。在左侧,您可以浏览用于数据、开发、整合、监控和管理的选项卡。

创建 Azure Synapse 分析工作区是一个简单的过程,只需几次点击。按照上面的步骤,你很快就能让它运行起来。
删除资源
当你用 Azure Synpase Analytics 完成工作后,删除资源以避免不必要的成本是很重要的。这很容易做到,第一步是去 Azure 门户,在那里你可以看到资源组的列表。

点击页面顶部的删除资源组按钮。通过键入资源组的名称并点击删除按钮来确认删除。删除资源组可能需要几分钟时间。

结论
在本教程中,您了解了 Azure Synapse Analytics、其组件及其优势。这是一个强大的工具,可以帮助企业将其数据转化为可操作的见解。它是完全托管的、可扩展的,并与其他 Azure 服务集成在一起,以提供一个完整的解决方案。如果你正在寻找一个基于云的数据仓库解决方案,那么 Azure Synapse Analytics 应该在你的考虑范围之内。
教程:使用 googleAnalyticsR 更好地分析博客文章
原文:https://www.dataquest.io/blog/tutorial-blog-post-analysis-with-r-googleanalyticsr/
July 21, 2020
我之前在一家博客公司担任营销数据分析师,我最重要的任务之一就是跟踪博客帖子的表现。
从表面上看,这是一个相当简单的目标。有了 Google Analytics,你可以快速获得任何日期范围内你的博客文章所需的任何指标。
但是当涉及到比较博客文章的性能时,事情就有点棘手了。
例如,假设我们想要比较六月份在 Dataquest 博客上发布的博文的性能(使用六月份作为我们的日期范围)。

但是等等……有两篇浏览量超过 1000 的博文是本月初发表的,还有两篇浏览量不足 500 的博文是月底发表的。这种比较很不公平!
我对这个问题的第一个解决方案是单独查看每篇文章,这样我就可以对每篇文章在第一天、第一周、第一个月等等的表现进行比较。
然而,这需要大量的手动复制和粘贴工作,如果我想一次比较多个帖子、日期范围或指标,这是非常乏味的。
但是后来,我学会了 R,意识到有一个更好的方法。
在这篇文章中,我们将介绍它是如何完成的,这样你就可以更好地分析我的博文了!
我们需要什么
要完成本教程,您需要 R 语法和 tidyverse 的基础知识,以及访问 Google Analytics 帐户的权限。
还不熟悉 R 的基础?我们可以帮你!我们的交互式在线课程从零开始教你 R,不需要以前的编程经验。报名从今天开始!
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
您还需要安装dyplr、lubridate和stringr包——提醒一下,您可以使用install.packages()命令来完成。
最后,你需要一个你想要分析的博客文章的 CSV 文件。以下是我的数据集中的内容:
post_url:博文的页面路径
post_date:博文发表的日期(格式为年月日)
category:博文发表的博客类别(可选)
title:博文的标题(可选)
根据您的内容管理系统,可能有一种方法可以自动收集这些数据——但这超出了本教程的范围!
对于本教程,我们将使用手动收集的过去十篇 Dataquest 博客文章的数据集。
设置 googleAnalyticsR 包
为了从 Google Analytics API 访问数据,我们将使用 Mark Edmonson 的优秀的googlenalyticsr包。
如文档中所述,googleAnalyticsR 包有两种“模式”。我们将在这里使用的第一种模式是“试用”模式,它使用一个共享的 Google 项目来授权您的 Google Analytics 帐户。
如果你想让这份报告成为你的博客或客户的常用工具,请确保创建你自己的 Google 项目,这将有助于将共享项目的流量保持在最低水平。要了解如何设置,请阅读包设置文档。
不过现在,我们将坚持“尝试”模式。
首先,我们将使用以下代码安装软件包:
install.packages('googleAnalyticsR', dependencies = TRUE)
这将安装软件包以及所需的依赖项。
接下来,我们将加载该库,并使用ga_auth()函数通过 Google Analytics 帐户对其进行授权。
library(googleAnalyticsR)
ga_auth()
当您第一次运行这段代码时,它会打开一个浏览器窗口,提示您登录到您的 Google 帐户。然后,它会给你一个代码粘贴到你的 R 控制台。之后,它将保存一个授权令牌,这样您只需这样做一次!
一旦你完成了 Google Analytics 授权,我们就可以设置剩下的库并加载我们的博客文章了。我们还将使用dplyr::mutate()将 post_date 更改为一个日期类!
library(dplyr)
library(lubridate)
library(stringr)
library(readr)
blog_posts <- read.csv("articles.csv") %>%
mutate(
post_date = as.Date(post_date, "%m/%d/%y") # changes the post_date column to a Date
)
以下是博客文章数据框的外观:

最后,要从您的 Google Analytics 帐户获取数据,您需要您想要访问的 Google Analytics 视图的 ID。ga_account_list()将返回您的可用帐户列表。
accounts <- ga_account_list()
# select the view ID by view and property name, and store it for ease of use
view_id <- accounts$viewId[which(accounts$viewName == "All Web Site Data" & accounts$webPropertyName == "Dataquest")]
# be sure to change this out with your own view and/or property name!
现在,我们准备好做我们的第一个谷歌分析 API 请求了!
使用 googleAnalyticsR 访问博客文章数据
在本教程中,我们的目标是收集每个帖子活跃的第一周的数据,并将其编译成数据帧进行分析。为此,我们将创建一个运行 for 循环的函数,并为我们的blog_posts dataframe 中的每个 post 请求该数据。
所以,让我们看看如何使用googleAnalyticsR向 Google Analytics API 发送请求。
google_analytics(view_id,
date_range = c(as.Date("2020-06-01"), as.Date("2020-06-30")),
metrics = c("pageviews"),
dimensions = c("pagePath")
)
这个请求有几个组成部分。首先,输入view_id,它已经存储在我们的ga_accounts()数据帧中。
接下来,指定日期范围,需要以日期列表的形式传入。
然后,我们输入指标(如页面浏览量、登录页面会话或页面停留时间)和维度(如页面路径、渠道或设备)。我们可以使用 Google Analytics UI 中可用的任何维度或指标——这里有一个有用的参考,用于查找任何 UI 指标或维度的 API 名称。
因此,上面的请求将按页面路径返回六月份所有页面浏览量的数据框架(默认情况下,googlenalyticsr 将只返回前 1000 个结果)。
但是,在我们的例子中,我们只想检索特定页面的浏览量,因此我们需要使用维度过滤器在 pagePath 维度上进行过滤,如下所示:
page_filter <- dim_filter(dimension = "pagePath",
operator = "REGEXP",
expressions = "^dataquestmarketingsite.kinsta.cloud/blog/r-markdown-guide-cheatsheet/$")
为了在我们的请求中使用这个过滤器,googleAnalyticsR 希望我们创建一个 filter 子句——如果您想使用多维过滤器,这就是如何组合过滤器。但是在我们的例子中,我们只需要一个:
page_filter_clause <- filter_clause_ga4(list(page_filter))
现在,让我们试着用这个过滤器发送一个响应:
google_analytics(view_id,
date_range = c(as.Date("2020-07-01"), Sys.Date()),
metrics = c("pageviews"),
dimensions = c("pagePath"),
dim_filters = page_filter_clause)

结果是 R Markdown 帖子的页面浏览量的数据框架!
创建 for 循环
既然我们可以收集数据并按维度进行过滤,我们就可以构建函数来运行 for 循环了!该功能的步骤如下:
- 设置数据框来保存结果
- 根据数据框中的行数开始循环
- 访问每篇文章的文章 URL 和文章日期
- 基于文章 URL 创建页面过滤器
- 向 Google Analytics 发送一个请求,将 post_date 作为开始日期,将一周后的日期作为结束日期
- 将帖子 URL 和浏览量数据添加到最终数据框中
我还添加了一个print()命令来让我们知道循环进行了多远(因为这可能需要一段时间),并添加了一个Sys.Sleep()命令来防止我们达到 Google Analytics API 速率限制。
这是所有东西放在一起的样子!
get_pageviews <- function(posts) {
# set up dataframe to be returned, using the same variable names as our original dataframe
final <- tibble(pageviews = numeric(),
post_url = character())
# begin the loop for each row in the posts dataframe
for (i in seq(1:nrow(posts))) {
# select the post URL and post date for this loop — also using the same variable names as our original dataframe
post_url <- posts$post_url[i]
post_date <- posts$post_date[i]
# set up the page filter and page filter clause with the current post URL
page_filter <- dim_filter(dimension = "pagePath",
operator = "REGEXP",
expressions = post_url)
page_filter_clause <- filter_clause_ga4(list(page_filter))
# send the request, and set the date range to the week following the date the post was shared
page_data <- google_analytics(view_id,
date_range = c(post_date, post_date %m+% weeks(1)),
metrics = c("pageviews"),
dim_filters = page_filter_clause)
# add the post url to the returned dataframe
page_data$post_url <- post_url
# add the returned data to the data frame we created outside the loop
final <- rbind(final, page_data)
# print loop status
print(paste("Completed row", nrow(final), "of", nrow(posts)))
# wait two seconds
Sys.sleep(2)
}
return(final)
}
我们可以用 R 中的“functional”来加速这个过程,比如purrr::map()。map()函数接受一个函数作为输入,返回一个向量作为输出。如果你想加深你的知识,请查看 Dataquest 的关于地图功能的互动在线课程!
不过,对于本教程,我们将使用 For 循环,因为它不太抽象。
现在,我们将在我们的blog_posts数据帧上运行循环,并将结果合并到我们的blog_posts数据中。
recent_posts_first_week <- get_pageviews(blog_posts)
recent_posts_first_week <- merge(blog_posts, recent_posts_first_week)
recent_posts_first_week

就是这样!现在,我们可以开始做好事了——分析和可视化数据。
博文数据,可视化!
为了进行演示,这里有一个 ggplot 条形图,显示了我们最近的 10 篇博文在发布后的第一周内的浏览量:
library(ggplot2)
library(scales)
recent_posts_first_week %>%
arrange(
post_date
) %>%
mutate(
pretty_title = str_c(str_extract(title, "^(\\S+\\s+\\n?){1,5}"), "..."),
pretty_title = factor(pretty_title, levels = pretty_title[order(post_date)])
) %>%
ggplot(aes(pretty_title, pageviews)) +
geom_bar(stat = "identity", fill = "#39cf90") +
coord_flip() +
theme_minimal() +
theme(axis.title = element_blank()) +
labs(title = "Recent Dataquest blog posts by first week pageviews") +
scale_y_continuous(labels = comma)

现在我们可以看到,能够在“平等的基础上”比较博客帖子是多么有用!
关于 googleAnalyticsR 包的更多信息以及你可以用它做什么,请查看它非常有用的资源页面。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
教程:通过聚类查找图像中的主色
原文:https://www.dataquest.io/blog/tutorial-colors-image-clustering-python/
February 21, 2019
用代码分析图像可能很困难。如何让你的代码“理解”图像的上下文?
一般来说,用 AI 分析图像的第一步是找到主色。在本教程中,我们将使用matplotlib的imageclass来寻找图像中的主色。使用第三方 API 也可以找到主色,但我们将为此构建自己的系统,这样我们就可以完全控制整个过程。
我们将首先以矩阵的形式将图像转换为其组成颜色,然后对其执行 k-means 聚类以找到主色。
先决条件
本教程假设您了解 Python 的基础知识,但是您不需要以前在 Python 中处理过图像。
本教程基于以下内容:
- Python 版本 3.6.5
- matplotlib 版本 2.2.3:解码图像和可视化主色
- scipy 版本 1.1.0:执行确定主色的聚类
软件包matplotlib和scipy可以通过软件包管理器pip安装。你可能希望在虚拟环境中安装特定版本的包,以确保不会与你正在处理的其他项目的依赖项发生冲突。
pip install matplotlib==2.2.3
pip install scipy==1.1.0
此外,我们在本教程中分析 JPG 图像,只有当你安装一个额外的软件包,枕头支持才可用。
pip install pillow==5.2.0
或者,你可以使用 Jupyter 笔记本。本教程的代码是在 Anaconda 版本 1.8.7 的 Jupyter 笔记本上运行的。以上这些包预装在 Anaconda 中。
import matplotlib
matplotlib.__version__
'3.0.2'
import PIL
PIL.__version__
'5.3.0'
import scipy
scipy.__version__
'1.1.0'
解码图像
图像可能有各种扩展名,JPG,PNG,TIFF 是常见的。这篇文章只关注 JPG 图像,但是其他图像格式的过程应该没有太大的不同。该过程的第一步是读取图像。
具有 JPG 扩展的图像在内存中存储为一系列点,称为像素。一个像素,或者一个图片元素,代表图像中的一个点。圆点的颜色由三个值的组合决定,即它的三种成分颜色(红色、蓝色和绿色)。像素的颜色本质上是这三种成分颜色的组合。

图片来源:数据遗传学
让我们使用 Dataquest 的徽标来寻找图像中的主色。你可以在这里下载图片。
要在 Python 中读取图像,需要导入 matplotlib 的 image 类(文档)。image 类的 imread()方法将图像解码为其 RGB 值。imread()方法的输出是一个尺寸为 M x N x 3 的数组,其中 M 和 N 是图像的尺寸。
from matplotlib import image as imgimage = img.imread('./dataquest.jpg')
image.shape(200, 200, 3)
您可以使用 matplotlib 的 pyplot 类的 imshow()方法来显示图像,该图像采用 RGB 值矩阵的形式。
%matplotlib inlinefrom matplotlib import pyplot as pltplt.imshow(image)
plt.show()

我们从 imread()方法中得到的矩阵依赖于正在读取的图像的类型。例如,PNG 图像还会包含一个测量像素透明度的元素。这篇文章将只涵盖 JPG 的图像。
在对图像进行聚类之前,我们需要执行一个额外的步骤。在找出图像主色的过程中,我们不关心像素的位置。因此,我们需要将 M x N x 3 矩阵转换成三个单独的列表,分别包含红色、蓝色和绿色值。以下代码片段将存储在 image 中的矩阵转换为三个单独的列表,每个列表的长度为 40,000 (200 x 200)。
r = []
g = []
b = []for line in image:
for pixel in line:
temp_r, temp_g, temp_b = pixel
r.append(temp_r)
g.append(temp_g)
b.append(temp_b)
上面的代码片段创建了三个空列表,然后遍历图像的每个像素,将 RGB 值分别追加到 r、g 和 b 列表中。如果操作正确,每个列表的长度将为 40,000 (200 x 200)。
聚类基础
现在我们已经存储了图像的所有颜色,是时候寻找主色了。现在让我们花一点时间来理解聚类的基础,以及它将如何帮助我们找到图像中的主色。
聚类是一种有助于根据特定属性将相似的项目分组在一起的技术。我们将对上面刚刚创建的三种颜色的列表应用 k 均值聚类。
每个聚类中心的颜色将反映一个聚类所有成员属性的平均值,这将帮助我们确定图像中的主色。
有多少主色?
在我们对像素数据点执行 k-means 聚类之前,弄清楚对于给定的图像有多少个聚类是理想的可能对我们有好处,因为不是所有的图像都具有相同数量的主色。
由于我们正在处理聚类的三个变量——像素的红色、蓝色和绿色值——我们可以在三维上可视化这些变量,以了解可能存在多少种主色。
为了在 matplotlib 中进行 3D 绘图,我们将使用 Axes3D()类(文档)。在使用 Axes3D()类初始化轴之后,我们使用 scatter 方法并使用三个颜色值列表作为参数。
from mpl_toolkits.mplot3d import Axes3Dfig = plt.figure()
ax = Axes3D(fig)
ax.scatter(r, g, b)
plt.show()

在结果图中,我们可以看到点的分布形成了两个拉长的集群。通过观察,我们可以看到图像主要由两种颜色组成,这一事实也支持了这一点。因此,我们将在下一节重点创建两个集群。
不过,首先,我们可能会猜测,3D 绘图可能不会为某些图像生成明显的聚类。此外,如果我们使用 PNG 图像,我们将有第四个参数(每个像素的透明度值),这将使三维绘图成为不可能。在这种情况下,您可能需要使用肘方法来确定理想的集群数量。
在 SciPy 中执行聚类
在上一步中,我们已经确定我们想要两个聚类,现在我们准备对数据执行 k-means 聚类。让我们创建一个 Pandas 数据框来轻松管理变量。
import pandas as pddf = pd.DataFrame({'red': r,
'blue': b,
'green': g})
使用 SciPy 进行 k-means 聚类的过程主要包括三个步骤:
- 通过将每个数据点除以其标准偏差来标准化变量。我们将使用
vq类的whiten()方法。 - 使用
kmeans()方法生成聚类中心。 - 使用
vq类的vq()方法为每个数据点生成分类标签。
上面的第一步确保每个变量的变化同等地影响聚类。想象一下两个尺度相差很大的变量。如果我们忽略上面的第一步,具有较大规模和变化的变量将对集群的形成产生较大影响,从而使过程有偏差。因此,我们使用 whiten()函数对变量进行标准化。whiten()函数接受一个参数,即变量值的列表或数组,并返回标准化的值。标准化后,我们打印数据框的样本。请注意,在标准化列中,列中的变化已经大大减少。
from scipy.cluster.vq import whitendf['scaled_red'] = whiten(df['red'])
df['scaled_blue'] = whiten(df['blue'])
df['scaled_green'] = whiten(df['green'])
df.sample(n = 10)
| 红色 | 蓝色 | 绿色的 | 缩放 _ 红色 | 缩放 _ 蓝色 | 缩放 _ 绿色 | |
|---|---|---|---|---|---|---|
| Twenty-four thousand eight hundred and eighty-eight | Two hundred and fifty-five | Two hundred and fifty-five | Two hundred and fifty-five | 3.068012 | 3.590282 | 3.170015 |
| Thirty-eight thousand five hundred and eighty-three | Two hundred and fifty-five | Two hundred and fifty-five | Two hundred and fifty-five | 3.068012 | 3.590282 | 3.170015 |
| Two thousand six hundred and fifty-nine | Sixty-seven | Ninety-one | seventy-two | 0.806105 | 1.281238 | 0.895063 |
| Thirty-six thousand nine hundred and fifty-four | Two hundred and fifty-five | Two hundred and fifty-five | Two hundred and fifty-five | 3.068012 | 3.590282 | 3.170015 |
| Thirty-nine thousand nine hundred and sixty-seven | Two hundred and fifty-five | Two hundred and fifty-five | Two hundred and fifty-five | 3.068012 | 3.590282 | 3.170015 |
| Thirteen thousand eight hundred and fifty-one | Seventy-five | One hundred and one | Eighty-two | 0.902357 | 1.422033 | 1.019377 |
| Fourteen thousand three hundred and fifty-four | Seventy-five | One hundred and one | Eighty-two | 0.902357 | 1.422033 | 1.019377 |
| Eighteen thousand six hundred and thirteen | Seventy-five | One hundred | Eighty-two | 0.902357 | 1.407954 | 1.019377 |
| Six thousand seven hundred and nineteen | Seventy-five | One hundred | Eighty-two | 0.902357 | 1.407954 | 1.019377 |
| Fourteen thousand two hundred and ninety-nine | Seventy-one | One hundred and four | Eighty-two | 0.854231 | 1.464272 | 1.019377 |
下一步是用标准化的列执行 k-means 聚类。我们将使用kmeans()函数来执行聚类。kmeans()函数(文档)有两个必需的参数——观察值和聚类数。它返回两个值-聚类中心和失真。失真是每个点与其最近的聚类中心之间距离的平方之和。我们将不会在本教程中使用失真。
from scipy.cluster.vq import kmeanscluster_centers, distortion = kmeans(df[['scaled_red', 'scaled_green', 'scaled_blue']], 2)
k-means 聚类的最后一步是生成聚类标签。但是,在本练习中,我们不需要这样做。我们只寻找由聚类中心表示的主色。
显示主色
我们已经执行了 k-means 聚类并生成了我们的聚类中心,所以让我们看看它们包含什么值。
print(cluster_centers)
[[2.94579782 3.1243935 3.52525635]
[0.91860119 1.05099931 1.4465091 ]]
如你所见,我们得到的结果是 RGB 值的标准化版本。为了得到原始的颜色值,我们需要将它们乘以它们的标准偏差。
我们将使用matplotlib的pyplot类的imshow()方法以调色板的形式显示颜色。然而,为了显示颜色,imshow()需要 0 到 1 范围内的 RGB 值,其中 1 表示我们原始 RGB 值的 255。因此,我们必须将聚类中心的每个 RGB 分量除以 255,以得到 0 到 1 之间的值,并通过imshow()方法显示它们。
最后,在使用imshow()函数(文档)绘制颜色之前,我们还有一个需要考虑的问题。聚类中心的维数是 N×3,其中 N 是聚类的数量。imshow()最初用于显示颜色的 A X B 矩阵,因此它需要一个维度为 A x B x 3 的 3D 数组(调色板中每个块有三个颜色元素)。因此,我们需要将 N×3 矩阵转换为 1×N×3 矩阵,方法是将聚类中心的颜色作为单个元素的列表进行传递。例如,如果我们将颜色存储在colors中,我们需要将[colors]作为参数传递给imshow()。
让我们探索一下图像中的主色。
colors = []r_std, g_std, b_std = df[['red', 'green', 'blue']].std()for cluster_center in cluster_centers:
scaled_r, scaled_g, scaled_b = cluster_center
colors.append((
scaled_r * r_std / 255,
scaled_g * g_std / 255,
scaled_b * b_std / 255
))
plt.imshow([colors])
plt.show()

正如所料,图像中看到的颜色与我们开始使用的图像中的突出颜色非常相似。也就是说,你可能已经注意到上面的浅蓝色实际上并没有出现在我们的源图像中。记住,聚类中心是每个聚类中所有像素的所有 RGB 值的平均值。因此,得到的聚类中心实际上可能不是原始图像中的颜色,它只是位于聚类中心的 RBG 值,所有相似的像素都来自我们的图像。
结论
在这篇文章中,我们看了使用matplotlib和scipy在 Python 中查找图像主色的逐步实现。我们从 JPG 图像开始,并使用matplotlib中图像类的imread()方法将其转换为 RGB 值。然后,我们使用scipy进行 k-means 聚类,以找到主色。最后,我们使用matplotlib中pyplot类的imshow()方法显示主色。
想学习更多 Python 技巧?Dataquest 提供了一系列完整的课程,可以带你从零到 Python 的数据科学家。报名开始免费学习!
教程:用 Python 连接、安装和查询 PostgreSQL
原文:https://www.dataquest.io/blog/tutorial-connect-install-and-query-postgresql-in-python/
February 21, 2022
数据库无处不在——在你的手机里,在你的电脑上,在你心爱的应用程序背后。但是,如果不能从数据库中查询数据,数据库又有什么价值呢?在本文中,我们将展示从 Python 代码中查询任何基于 PostgreSQL 的数据库的示例。首先,您将获得对 PostgreSQL 和数据库连接器的高级理解。在本文的后面,我们将深入研究实际的代码示例和其他关于如何使用 Python 查询数据库的技巧。我们开始吧!
PostgreSQL 是什么?
PostgreSQL 是最流行的开源关系数据库之一。全球各种规模的公司和开发人员都在使用它。根据 DB-Engines,PostgreSQL 在世界上最受欢迎的数据库中排名第四,并且有上升趋势。这并不奇怪,因为您可以在许多 web 和移动应用程序甚至分析软件背后找到 PostgreSQL 数据库。
PostgreSQL 也有一个丰富的生态系统,有大量的工具和扩展,可以很好地与核心数据库集成。由于这些原因,无论您是需要事务性数据库还是分析性数据库,或者希望构建自己的定制数据库解决方案,PostgreSQL 都是一个很好的选择。
现在您对 PostgreSQL 有了一个概念,让我们来看看如何使用 Python 来连接数据库。
如何从 Python 连接 PostgreSQL?
为了从 Python 脚本连接到 PostgreSQL 数据库实例,您需要使用数据库连接器库。在 Python 中,有几个选项可供选择。一些用纯 Python 编写的库包括 pg8000 和 py-postgresql 。但是最受欢迎和广为人知的是心理战 2 。
在本文的其余部分,您将看到使用 Psycopg2 连接到数据库并查询数据的示例。
但首先,什么是 Psycopg2?
什么是 Psycopg2?
Psycopg2 是 Python 中最广为人知和使用最多的 PostgreSQL 连接器库。Psycopg2 库实现了 Python DB API 2.0 规范,并且(在幕后)使用 C 编程语言作为对 libpq PostgreSQL 库的包装。由于它的 C 实现,Psycopg2 非常快速和高效。
您可以使用 Psycopg2 根据 SQL 查询从数据库中提取一行或多行。如果您想将一些数据插入数据库,这个库也是可行的——有多个选项可以进行单次或批量插入。
Python PostgreSQL 连接器的一个完全重写的实现目前正在积极开发中: Psycopg3 。Psycopg3 提供了与 Psycopg2 相同的功能,此外还有一些额外的功能,如异步通信、使用 COPY 的数据接收等等。它努力更好地利用新一代 Python 和 PostgreSQL 提供的功能。
如何安装 Psycopg2
要使用 Psycopg2,您需要先安装它。最简单的方法是使用 pip。与其他 Python 项目一样,建议使用虚拟环境来安装库:
virtualenv env && source env/bin/activate
pip install psycopg2-binary
这个代码片段将把 Psycopg2 库安装到您的 Python 虚拟环境及其所有依赖项中。之后,您可以将psycopg2模块导入到您的 Python 代码中并使用它。
应该用 Psycopg2 还是 Psycopg2-binary?
您可能已经注意到了,我们安装了psycopg2-binary包,这是 Psycopg2 的二进制版本。这意味着这个版本的库自带了自己版本的 C 库,即 liboq 和 libssl。对于 Psycopg2 初学者和大多数用户来说,这个版本非常好。另一方面,如果您希望 psycop 2 使用您系统的 C 库,您需要从源代码构建 psycop 2:
pip install psycopg2
作为一个数据库连接器库,Psycopg2 在许多基于无服务器架构的数据管道中是必不可少的。让我们快速介绍一下如何在无服务器环境中安装 Psycopg2。
如何在无服务器环境中安装 Psycopg2
Psycopg2 通常用于 AWS Lambda 函数或其他无服务器环境中。因为 Psycopg2 依赖于几个 PostgreSQL 库——它们在无服务器环境中不一定可用,或者不容易使用——所以建议使用预编译版本的库,例如, this one 。
您还可以通过搜索“Psycopg2 无服务器”或“psycopg2 aws lambda”关键字来查找 psycopg2 的其他预编译版本。
最后,在您的环境中安装了 Psycopg2 之后,这里有一个关于如何从数据库中查询数据的快速教程。
如何使用 Python 查询 PostgreSQL
为了查询您的数据库,您需要使用两个 Psycopg2 对象:
首先,您需要导入 Psycopg2 模块并创建一个连接对象:
import psycopg2
conn = psycopg2.connect(database="db_name",
host="db_host",
user="db_user",
password="db_pass",
port="db_port")
如您所见,为了连接到数据库,您需要定义相当多的参数。以下是对这些论点的含义的简要总结:
- 数据库:您要连接的数据库的名称(一个连接对象只能连接一个数据库)
- 主机:这可能是指向数据库服务器的 IP 地址或 URL(例如,xyz.example.com)
- 用户:PostgreSQL 用户的名称
- 密码:该用户的匹配密码
- 端口:PostgreSQL 服务器使用的端口(如果服务器位于本地,通常为 5432,但也可以是其他端口)
如果您提交了正确的数据库凭据,您将获得一个活动的数据库连接对象,可用于创建游标对象。
游标对象将帮助您在数据库上执行任何查询和检索数据。下面是创建光标对象的方法:
cursor = conn.cursor()
现在让我们使用刚刚创建的游标来查询数据库:
cursor.execute("SELECT * FROM example_table")
我们使用execute()函数并提交一个查询字符串作为它的参数。我们提交的这个查询将针对数据库运行。需要注意的是,在查询执行之后,您仍然需要使用 Psycopg2 函数之一来检索数据行:
让我们看看他们每个人是如何工作的!
示例:fetchone()
从数据库获取数据的最基本方法是使用fetchone()函数。在执行 SQL 查询后,该函数将恰好返回一行,即第一行。
这里有一个例子:
print(cursor.fetchone())
(1, 'Budapest', 'newly-built', 'after 2011', 30, 1)
在本例中,fetchone()以元组的形式返回数据库中的一行,其中数据在元组中的顺序将基于您在查询中指定的列的顺序。
因此,在创建查询字符串时,一定要确保正确指定列的顺序,这样才能知道元组中的数据。
示例:fetchall()
如果您需要数据库中不止一行数据,该怎么办?如果您需要 10、100、1000 或更多行呢?您可以使用fetchall() Psycopg2 函数,它的工作方式与fetchone()相同,只是它返回的结果不是一行,而是所有行。
print(cursor.fetchall())
[(1, 'Budapest', 'newly-built', 'after 2011', 30, 1),
(2, 'Budapest', 'newly-built', 'after 2011', 45, 2),
(3, 'Budapest', 'newly-built', 'after 2011', 32, 2),
(4, 'Budapest', 'newly-built', 'after 2011', 48, 2),
(5, 'Budapest', 'newly-built', 'after 2011', 49, 2),
(6, 'Budapest', 'newly-built', 'after 2011', 49, 2),
(7, 'Budapest', 'newly-built', 'after 2011', 71, 3),
(8, 'Budapest', 'newly-built', 'after 2011', 50, 2),
(9, 'Budapest', 'newly-built', 'after 2011', 50, 2),
(10, 'Budapest', 'newly-built', 'after 2011', 57, 3)]
[...]
注意我们如何获得更多的行,而不仅仅是一行。
示例:fetchmany()
使用fetchmany(),您可以从数据库中检索多条记录,并对检索的确切行数有更多的控制。
print(cursor.fetchmany(size=5))
[(1, 'Budapest', 'newly-built', 'after 2011', 30, 1),
(2, 'Budapest', 'newly-built', 'after 2011', 45, 2),
(3, 'Budapest', 'newly-built', 'after 2011', 32, 2),
(4, 'Budapest', 'newly-built', 'after 2011', 48, 2),
(5, 'Budapest', 'newly-built', 'after 2011', 49, 2)]
这里我们只收到 5 行,因为我们将参数size设置为 5。这个函数让您在代码级别上更好地控制从数据库表中返回多少行。
包扎
在查询完数据库并在 Python 代码中使用 connection 对象之后,确保总是使用conn.close()关闭连接。
我希望这篇文章有助于您开始使用 Python 和 PostgreSQL。我强烈建议阅读 Psycopg2 文档,了解更多关于不同的数据检索方法、游标类等等。
编码快乐!
机器学习中的决策树(从头开始构建)
原文:https://www.dataquest.io/blog/tutorial-decision-trees-in-machine-learning/
December 5, 2022
决策树代表了最流行的机器学习算法之一。在这里,我们将简要探讨它们的逻辑、内部结构,甚至如何用几行代码创建一个。
在本文中,我们将了解决策树的关键特征。有不同的算法生成它们,比如 ID3,C4.5,CART。在我们的例子中,我们将使用 CART,这是 Python 中最流行的机器学习库之一使用的算法:scikit-learn。
我们还将使用这个库来构建和可视化决策树。本文假设您至少具备使用 Python 语言的基本或中级编码知识。

决策树的结构和组件
在开始之前,让我们多了解您一点,看看 Dataquest 是否能提供您想要的。请用“是”或“否”回答下列问题:
- 你对学习数据科学感兴趣吗?
- 你更喜欢在线学习吗?
- 你更喜欢边做边学吗?
- 您对建立数据科学项目组合感兴趣吗?
如果你对所有这些问题的回答都是肯定的,那么这是一个极好的消息,因为在 Dataquest,我们有着相同的理念!但是,即使你回答“不”,仍然有一些好消息,因为你无意中使用了逻辑来构建决策树!
如果我们把这个过程翻译成 Python 代码,这样的逻辑可以理解为不同的 if/else 语句的总和,可以这样表示:
print("Are you interested in learning Data Science?")
if True:
print("Do you prefer to learn online?")
if True:
print("Do you prefer to learn by doing?")
if True:
print("Are you interested in building a portfolio with Data Science projects?")
if True:
print("Dataquest can give you what you want!")
if False:
print("Would you give it a chance?")
if False:
print("Would you give it a chance?")
if False:
print("Would you give it a chance?")
if False:
print("Would you give it a chance?")`
然而,虽然至少对 Python(以及一般的编码)有一些基本了解的人会熟悉这种逻辑,但对完全没有编码经验的人来说就不一样了,这是决策树的最大优势之一:在给他们一些关于如何解释它们的具体说明后,我们可以用一种普通观众可以理解的方式图形化地展示它们。
让我们用一个合适的决策树图形来展示前面的逻辑,然后我们将解释它的组件和一般结构。它看起来是这样的:

现在树已经被恰当地呈现了,我们可以继续探索它的结构。让我们关注我们看到的组件:
1)我们有四个正方形和五个圆圈,其中四个是负的(X),一个是正的(1000)。所有这些都被称为节点。

- 顶部的方形节点被称为根节点,因为它不源自任何其他节点,也因为它是最重要的节点。当我们构建决策树时,这是预测能力最强的节点。注意,它被称为根,指的是一棵树的根,这就是为什么我们在本文的开头使用了一个倒置的树图像:这意味着决策树被解释为倒置的树!

- 其余的方形节点被称为内部节点,它们的关键特征是它们总是源自前一个节点(它们是前一个节点的子节点)。同时,它们还生成后续节点(它们是那些后续节点的父节点)。

- 按照倒树的逻辑,我们将始终在圆形节点处结束,这些圆形节点被称为终端节点,或者最常见的是叶节点。因为它们是最终的,所以它们也总是子节点,因为它们不能生成更多的节点。这些叶子是至关重要的,因为它们告诉我们在这个过程中所做选择的结果。
2)对于每一个根节点和内部节点,都有两个箭头从其中出现,一个绿色,一个红色。除了根节点,我们在这个例子中有三个内部节点,所以我们总共得到八个箭头。这些箭头称为分支。

-
如果条件/问题的答案等于真,绿色箭头表示我们遵循的路径。例如,如果我们有一个问题“你喜欢边做边学吗?”而我们回答“是”,那么是真的,我们继续下面的左节点。
-
红色箭头代表相反的情况;所有等同于错误的条件/问题的答案继续到下面的正确节点。
记住这一点很重要,因为这对决策树来说是通用的: Left == True 。对==错。
现在我们已经描述了决策树的每个组成部分,我们可以再次回答这四个问题,看看我们的决策如何在图中流动。
其中一个问题是“你喜欢边做边学吗?“很明显,正如我们之前所表达的,我们遵循那个原则,所以在下一节中,我们将探索如何通过使用特定的数据集和强大的库scikit-learn,从头开始创建决策树!
数据集介绍
我们在这种情况下将使用的数据集是“基于饮食习惯和身体状况的肥胖水平估计”,可以在 UCI 机器学习库网站上找到,其中包括墨西哥、秘鲁和哥伦比亚的肥胖病例信息。
让我们加载它并检查第一个观察结果,以获得信息的一般概念:
import pandas as pd
df = pd.read_csv("ObesityDataSet_raw_and_data_sinthetic.csv")
df.iloc[:10, :11]
| 性别 | 年龄 | 高度 | 重量 | 超重的家庭历史 | FAVC | FCVC 的作用 | 新型冠状病毒肺炎(Novel coronavirus pneumonia) | CAEC | 烟 | CH2O | 单路调节器(single-channel controller) | FAF | TUE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 女性的 | Twenty-one | One point six two | Sixty-four | 是 | 不 | Two | Three | 有时 | 不 | Two | 不 | Zero | One |
| one | 女性的 | Twenty-one | One point five two | Fifty-six | 是 | 不 | Three | Three | 有时 | 是 | Three | 是 | Three | Zero |
| Two | 男性的 | Twenty-three | One point eight | Seventy-seven | 是 | 不 | Two | Three | 有时 | 不 | Two | 不 | Two | One |
| three | 男性的 | Twenty-seven | One point eight | Eighty-seven | 不 | 不 | Three | Three | 有时 | 不 | Two | 不 | Two | Zero |
| four | 男性的 | Twenty-two | One point seven eight | Eighty-nine point eight | 不 | 不 | Two | One | 有时 | 不 | Two | 不 | Zero | Zero |
| five | 男性的 | Twenty-nine | One point six two | Fifty-three | 不 | 是 | Two | Three | 有时 | 不 | Two | 不 | Zero | Zero |
| six | 女性的 | Twenty-three | One point five | Fifty-five | 是 | 是 | Three | Three | 有时 | 不 | Two | 不 | One | Zero |
| seven | 男性的 | Twenty-two | One point six four | Fifty-three | 不 | 不 | Two | Three | 有时 | 不 | Two | 不 | Three | Zero |
| eight | 男性的 | Twenty-four | One point seven eight | Sixty-four | 是 | 是 | Three | Three | 有时 | 不 | Two | 不 | One | One |
| nine | 男性的 | Twenty-two | One point seven two | Sixty-eight | 是 | 是 | Two | Three | 有时 | 不 | Two | 不 | One | One |
df.iloc[:10, 11:]
| 计算(calculation) | MTRANS | NObeyesdad | |
|---|---|---|---|
| Zero | 不 | 公共交通 | 正常体重 |
| one | 有时 | 公共交通 | 正常体重 |
| Two | 频繁地 | 公共交通 | 正常体重 |
| three | 频繁地 | 步行 | 超重 _ 一级 |
| four | 有时 | 公共交通 | 超重 _ 二级 |
| five | 有时 | 汽车 | 正常体重 |
| six | 有时 | 摩托车 | 正常体重 |
| seven | 有时 | 公共交通 | 正常体重 |
| eight | 频繁地 | 公共交通 | 正常体重 |
| nine | 不 | 公共交通 | 正常体重 |
我们还可以探索不同的栏目:
df.info()
<class>RangeIndex: 2111 entries, 0 to 2110
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Gender 2111 non-null object
1 Age 2111 non-null float64
2 Height 2111 non-null float64
3 Weight 2111 non-null float64
4 family_history_with_overweight 2111 non-null object
5 FAVC 2111 non-null object
6 FCVC 2111 non-null float64
7 NCP 2111 non-null float64
8 CAEC 2111 non-null object
9 SMOKE 2111 non-null object
10 CH2O 2111 non-null float64
11 SCC 2111 non-null object
12 FAF 2111 non-null float64
13 TUE 2111 non-null float64
14 CALC 2111 non-null object
15 MTRANS 2111 non-null object
16 NObeyesdad 2111 non-null object
dtypes: float64(8), object(9)
memory usage: 280.5+ KB
我们可以看到数据集包含 17 列和 2111 个观察值。虽然有些列名是不言自明的,如性别、年龄、身高、体重、家庭 _ 历史 _ 体重 _ 超重(二进制:是/否)和吸烟(二进制:是/否),但还有其他列名是缩写,因此我们需要澄清它们包含的信息:
-
FAVC :经常食用高热量食物(二元:是/否)。
-
FCVC :蔬菜消费频率(数字)
-
NCP :主餐数量(数字)
-
CAEC :两餐之间的食物消耗(序数:没有/有时/经常/总是)
-
CH20 :日用水量(数字)
-
CALC :饮酒量(序数:没有/有时/经常/总是)
-
SCC :卡路里消耗监测(二进制:是/否)
-
FAF :身体活动频率(数字)
-
TUE :使用科技设备的时间(数字)
-
MTRANS :使用的交通工具(分类:公共交通、汽车、步行、摩托车、自行车)
至于目标列,它是nobeeysdad(肥胖级别),以下是可能的类值,以及每个类的观察计数:
df["NObeyesdad"].value_counts()
Obesity_Type_I 351
Obesity_Type_III 324
Obesity_Type_II 297
Overweight_Level_I 290
Overweight_Level_II 290
Normal_Weight 287
Insufficient_Weight 272
Name: NObeyesdad, dtype: int64
由于scikit-learn要求我们只使用数字数据,我们需要预处理数据集,将特性列转换成数字。
准备数据集
如前所述,在本节中,我们将对数据集执行数据清理,为下一节构建机器学习模型做准备。
我们会经常用到。value_counts() 来自 pandas 库中的每个列,它返回每个特定列中所有不同值的计数。
在这种情况下,从我们的 2111 个总观察值中,我们看到对于“性别”列,我们有 1068 个男性和 1043 个女性。
# "GENDER" COLUMN
df["Gender"].value_counts()
Male 1068
Female 1043
Name: Gender, dtype: int64
由于该列是二进制的(它只包含两个可能的值),我们可以通过使它成为布尔值来将其转换为数值。
我们这样做是通过选择我们想要的任何性别(在这个例子中,我们选择了女性)并且如果它等于假(也就是说,如果它是男性),用 0 代替每个观察,如果观察等于真(观察是关于女性),用 1 代替。
最后,我们将重命名列 female 以反映这一变化并避免将来的混淆:
df["Gender"].replace({"Male": 0, "Female": 1}, inplace = True)
df.rename(columns = {"Gender": "female"}, inplace = True)
为了谨慎起见,我们将使用仔细检查数据转换是如何进行的。value_counts() 再次出现。请注意我们现在如何使用新的列名:
# Double Check
df["female"].value_counts()
0 1068
1 1043
Name: female, dtype: int64
我们可以确认转化是成功的。我们有 1068 个代表男性的假/0 观察值和 1043 个代表女性的真/1 观察值。这与转换前的原始值计数相匹配。
让我们将相同的步骤应用于下一列:
# "FAMILY HISTORY WITH OVERWEIGHT" COLUMN
df["family_history_with_overweight"].value_counts()
yes 1726
no 385
Name: family_history_with_overweight, dtype: int64
df["family_history_with_overweight"].replace({"no": 0, "yes": 1}, inplace = True)
df.rename(columns = {"family_history_with_overweight": "family_history_overweight"}, inplace = True)
# Double Check
df["family_history_overweight"].value_counts()
1 1726
0 385
Name: family_history_overweight, dtype: int64
我们将继续执行相同的步骤,但是在这种情况下,我们不需要重命名该列:
# "FREQUENT CONSUMPTION OF HIGH CALORIC FOOD" COLUMN
df["FAVC"].value_counts()
yes 1866
no 245
Name: FAVC, dtype: int64
df["FAVC"].replace({"no": 0, "yes": 1}, inplace = True)
# Double Check
df["FAVC"].value_counts()
1 1866
0 245
Name: FAVC, dtype: int64
下面的列是一个更复杂的情况,因为我们不仅有两个以上的唯一值(换句话说,它不再是二进制的),而且不同的值通过一个层次结构(在本例中是频率)相互关联:
不>有时>频繁>总是
这是一个序数列的明显例子。
# "CONSUMPTION OF FOOD BETWEEN MEALS" COLUMN
df["CAEC"].value_counts()
Sometimes 1765
Frequently 242
Always 53
no 51
Name: CAEC, dtype: int64
在这种情况下,当将数据转换为数值时,我们可以通过使用连续的数字来反映这种层次结构,从最低值 0 开始,以最高值的最高数字结束。
否== 0
有时== 1
频繁== 2
总是== 3
这是一个非常简单的解释,我们将在决策树课程中更详细地介绍这个主题。
from sklearn.preprocessing import OrdinalEncoder
ordinal_caec = [["no", "Sometimes", "Frequently", "Always"]]
df["CAEC"] = OrdinalEncoder(categories = ordinal_caec).fit_transform(df[["CAEC"]])
我们可以确认在转换为数值的过程中保留了层次结构:
# Double Check
df["CAEC"].value_counts()
1.0 1765
2.0 242
3.0 53
0.0 51
Name: CAEC, dtype: int64
下面的专栏是二进制的,所以暂时没有太多讨论。我们将简单地应用与上面相同的步骤:
# "SMOKE" COLUMN
df["SMOKE"].value_counts()
no 2067
yes 44
Name: SMOKE, dtype: int64
df["SMOKE"].replace({"no": 0, "yes": 1}, inplace = True)
# Double Check
df["SMOKE"].value_counts()
0 2067
1 44
Name: SMOKE, dtype: int64
# "CALORIES CONSUMPTION MONITORING" COLUMN
df["SCC"].value_counts()
no 2015
yes 96
Name: SCC, dtype: int64
df["SCC"].replace({"no": 0, "yes": 1}, inplace = True)
# Double Check
df["SCC"].value_counts()
0 2015
1 96
Name: SCC, dtype: int64
下一列也是有序的,因为它与前一列共享完全相同的层次结构(频率),所以我们将执行与前一列相同的步骤:
# "CONSUMPTION OF ALCOHOL" COLUMN
df["CALC"].value_counts()
Sometimes 1401
no 639
Frequently 70
Always 1
Name: CALC, dtype: int64
from sklearn.preprocessing import OrdinalEncoder
ordinal_calc = [["no", "Sometimes", "Frequently", "Always"]]
df["CALC"] = OrdinalEncoder(categories = ordinal_calc).fit_transform(df[["CALC"]])
# Double Check
df["CALC"].value_counts()
1.0 1401
0.0 639
2.0 70
3.0 1
Name: CALC, dtype: int64
在最后一篇专栏文章中,我们有另一个特例:虽然我们有两个以上不同的值,但是这里没有层次结构。不同的值代表不同的选项,这些选项通过层次结构彼此不相关。他们在这个意义上是独立的。因此,列是分类的。
# "TRANSPORTATION USED" COLUMN
df["MTRANS"].value_counts()
Public_Transportation 1580
Automobile 457
Walking 56
Motorbike 11
Bike 7
Name: MTRANS, dtype: int64
因为我们不能给每个值分配不同的数字,因为这将创建一个无意的层次结构,在这种情况下,我们必须为每个值创建一个新列;然后,我们将使用布尔方法:如果观察提到了某个交通工具,那么引用该交通工具类型的相应列将具有“1”,而其余的列将具有“0”。当我们再次检查时,我们将会看到这看起来如何。
这是执行操作的必要代码,由于其复杂性,将在决策树课程中详细分析。
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import make_column_transformer
col_trans = make_column_transformer((OneHotEncoder(), ["MTRANS"]),
remainder = "passthrough",
verbose_feature_names_out = False)
onehot_df = col_trans.fit_transform(df)
df = pd.DataFrame(onehot_df, columns = col_trans.get_feature_names_out())
值得注意的是,在这个转换过程中,包含所有不同值的列(“MTRANS”)将被删除,因为不再需要它了。
让我们检查转换。我们现在有五个不同的列,而不是“MTRANS”,每一列代表“MTRANS”的一个可能值: MTRANS_Automobile 、 MTRANS_Bike 、m trans _ 摩托车、m trans _ 公共交通和m trans _ 步行。
# Double Check
df.iloc[:10, :9]
| 汽车运输 | 自行车运输 | 摩托车运输 | MTRANS _ 公共交通 | MTRANS _ 步行 | 女性的 | 年龄 | 高度 | 重量 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | Zero | Zero | One | Zero | one | Twenty-one | One point six two | Sixty-four |
| one | Zero | Zero | Zero | One | Zero | one | Twenty-one | One point five two | Fifty-six |
| Two | Zero | Zero | Zero | One | Zero | Zero | Twenty-three | One point eight | Seventy-seven |
| three | Zero | Zero | Zero | Zero | One | Zero | Twenty-seven | One point eight | Eighty-seven |
| four | Zero | Zero | Zero | One | Zero | Zero | Twenty-two | One point seven eight | Eighty-nine point eight |
| five | One | Zero | Zero | Zero | Zero | Zero | Twenty-nine | One point six two | Fifty-three |
| six | Zero | Zero | One | Zero | Zero | one | Twenty-three | One point five | Fifty-five |
| seven | Zero | Zero | Zero | One | Zero | Zero | Twenty-two | One point six four | Fifty-three |
| eight | Zero | Zero | Zero | One | Zero | Zero | Twenty-four | One point seven eight | Sixty-four |
| nine | Zero | Zero | Zero | One | Zero | Zero | Twenty-two | One point seven two | Sixty-eight |
例如,对于第一次观察,由于那个人使用公共交通,相应的MTRANS _ Public _ Transportation列被标记为 1(“真”),其他四列被标记为 0(“假”)。
df.iloc[:10, 9:]
| 家族史超重 | FAVC | FCVC 的作用 | 新型冠状病毒肺炎(Novel coronavirus pneumonia) | CAEC | 烟 | CH2O | 单路调节器(single-channel controller) | FAF | TUE | 计算(calculation) | NObeyesdad | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Zero | Two | Three | One | Zero | Two | Zero | Zero | One | Zero | 正常体重 |
| one | one | Zero | Three | Three | One | one | Three | one | Three | Zero | One | 正常体重 |
| Two | one | Zero | Two | Three | One | Zero | Two | Zero | Two | One | Two | 正常体重 |
| three | Zero | Zero | Three | Three | One | Zero | Two | Zero | Two | Zero | Two | 超重 _ 一级 |
| four | Zero | Zero | Two | One | One | Zero | Two | Zero | Zero | Zero | One | 超重 _ 二级 |
| five | Zero | one | Two | Three | One | Zero | Two | Zero | Zero | Zero | One | 正常体重 |
| six | one | one | Three | Three | One | Zero | Two | Zero | One | Zero | One | 正常体重 |
| seven | Zero | Zero | Two | Three | One | Zero | Two | Zero | Three | Zero | One | 正常体重 |
| eight | one | one | Three | Three | One | Zero | Two | Zero | One | One | Two | 正常体重 |
| nine | one | one | Two | Three | One | Zero | Two | Zero | One | One | Zero | 正常体重 |
最后,我们不需要将目标列“NObeyesdad”转换为 numeric,因为它显示了决策树试图预测的可能的类。
构建我们自己的决策树
是一个非常标准化的库,这意味着它允许我们用几行代码实例化和训练我们的机器学习模型。这也适用于决策树。
提醒一下,scikit-learn使用 CART 算法,代表分类和回归树;因此,我们可以建立决策树来预测分类和回归问题!
简单回顾一下,当我们说分类时,我们指的是预测分类标签,它可以是二元的(例如,正/负、开/关、真/假等。)或有限数量的类别(例如,颜色、季节、月份等。),而回归指的是预测数字量(例如,价格、年龄、距离等)。).
在这种情况下,我们将坚持使用分类树,因为数据集在其目标列中包含类/类别。
df["NObeyesdad"].unique()
array(['Normal_Weight', 'Overweight_Level_I', 'Overweight_Level_II',
'Obesity_Type_I', 'Insufficient_Weight', 'Obesity_Type_II',
'Obesity_Type_III'], dtype=object)
scikit-learn创建机器学习模型的第一步是在特征列(X)和目标列(y)之间划分数据集。注意,我们从X中删除了“NObeyesdad”列,因为它包含目标值。
X = df.drop(["NObeyesdad"], axis = 1)
y = df["NObeyesdad"]
现在我们将导入决策树模型进行分类,以及train_test_split。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
train_test_split是一个工具,它允许我们将数据集分为四个部分,这些部分将存储在不同的变量中:X_train和y_train包含训练模型的观察值,而X_test和y_test包含测试模型准确性的观察值。
test_size参数设置用于测试目的的数据集观察值的百分比。在这种情况下,0.2是一个常用的比例,即总人数的 20%。
至于random_state,它只是一个确保结果可再现性的数字,因此你会经常看到它是不同函数的参数。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 14)
现在,我们的决策树诞生了!
需要考虑的一件重要事情是:虽然在其他机器学习算法中不包含任何参数可能很常见,但在决策树的情况下,我们需要为max_depth参数设置一个值。
此参数决定了树的深度。换句话说,它修剪几个内部节点,以避免一种叫做过度拟合的不良现象,当树适应数据集如此之近,以至于它无法对看不见的数据进行预测时,就会发生这种情况。
在这种情况下,max_depth = 4表示我们将把树限制在四个级别:根节点、两个中间级别和最后一个级别,即叶子所在的级别。
tree = DecisionTreeClassifier(max_depth = 4, random_state = 14)
太棒了。现在树已经存在,我们将使用存储在X_train和y_train中的训练数据来训练它:
tree.fit(X_train, y_train)
现在我们需要知道生成的树在准确性方面是否足够好(它预测看不见的数据有多好)。我们可以通过使用score方法快速确定这一点,决策树与其他机器学习算法共享该方法。
tree.score(X_test, y_test)
0.7848699763593381
注意生成和评估决策树所需的代码行很少:只有八行!绝对让这个过程变得非常简单!
关于分数:虽然完美值是 1.0,但在现实生活中它是不可能达到的(或者更糟:如果我们真的达到了,这意味着我们的机器学习模型过度拟合了!).尽管没有明确的标准,而且每个数据情况都不一样,但总的来说,我们可以确信,高于 0.7 的准确度分数表明该模型非常好,这就是我们在这里得到的结果!
但我们还必须考虑我们正在处理的主题:因为它与健康相关,所以“相当好”必须是进一步优化的起点,因为我们需要确保最高可能的准确性(即,理想情况下大约 0.95),因为对观察结果进行错误分类可能最终会在现实生活中产生真正不利的后果。在这种情况下,我们需要极其谨慎地行事。
在接下来的部分中,我们将探索这个小旅程的最后一个阶段,即可视化决策树并从中获得洞察力!
可视化树
一如既往,scikit-learn确保我们的机器学习任务变得直接和标准化,可视化决策树也不例外!
在这种情况下,我们将使用plot_tree工具,但是我们也将使用与数据可视化相关的附加库matplotlib。这将允许我们使用figure方法调整图像大小。
除了初始代码之外,下面是我们需要编写的参数,以便定制树的可视化:
-
decision_tree :决策树被实例化的变量。
-
feature_names :特性栏目的名称,可以通过
X.columns快速进入。 -
class_names :目标列中的类/类别的名称,可以通过
tree.classes_快速访问(如果您的决策树是用另一个变量名创建的,您可以相应地替换变量名)。 -
filled :如果设置为 True,这个参数给每个类分配一个不同的颜色,每个节点将被涂上主导类的颜色。此外,颜色可能更浓或更淡,取决于该类在该节点中的主导地位。
-
fontsize :节点内部的字体大小。
-
杂质:(我们将此设置为 False 以省略一条特定的信息;由于这是一篇介绍性文章,解释这个值将大大延长文章的长度。此外,我们需要深入研究更复杂的解释)。
关于_变量的一个重要澄清:虽然可以直接使用plot_tree而不用将函数赋给变量,但这将在可视化之前创建冗长的文本,这是我们希望避免的,以确保更清晰的显示。
一旦我们完成定制这些参数,我们就用plt.show()正式绘制决策树。
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize = [24.0, 12.0])
_ = plot_tree(
decision_tree = tree,
feature_names = X.columns,
class_names = tree.classes_,
impurity = False,
filled = True,
fontsize = 11)
plt.show()

每个节点显示的信息肯定比我们在文章开头使用的理论图更全面,所以让我们仔细分析一下我们在这里看到的内容,以澄清任何困惑:
- 每个节点中的最上面一行表示用于分割决策路径的条件。由于
scikit-learn只对数字信息起作用,这个条件将总是被转换成一个阈值。换句话说,你更喜欢通过做来学习,而不是像“这样的问题?”,我们将始终有一个列名和一个与特定数字的比较。
例如,如果我们的权重< = 76.063,那么权重低于或等于 76.063 的所有观察值都将被评估为真,因此我们将继续左边的子节点。另一方面,值高于 76.063 的所有观察值将评估为假,并且我们将继续到右边的子节点(即,78 <= 76.063 评估为假,因为 78 是高于 76.063 的数字)。
记住: Left == True。Right == False !
- 样本字段是指拆分信息后,在该节点下分类的观测值总数。
从这个意义上说,根节点中的“样本”字段将总是等于数据集的观察总数。(注意,这里我们只有 1688 个观察值,而不是 2111 个,因为我们出于测试目的隔离了一些观察值!)

如果我们检查下面级别中的两个节点,我们会看到左边的子节点有 1115 个观察值等于真,而右边的子节点有 573 个观察值等于假。如果我们对它们求和(1115 + 573 ),我们将得到 1688,即来自根节点的样本值。
-
值字段过滤来自样本的数字,以指示每个目标类的观察数量。例如,如果我们关注根节点,并且我们对来自值字段的所有数字求和,我们将得到样本数字。这个规则适用于的所有节点。
为了确定每个数字属于哪个目标类,我们必须将顺序与
classes_属性中的顺序进行匹配:
tree.classes_
array(['Insufficient_Weight', 'Normal_Weight', 'Obesity_Type_I',
'Obesity_Type_II', 'Obesity_Type_III', 'Overweight_Level_I',
'Overweight_Level_II'], dtype=object)
例如,如果我们有来自根节点的值[215, 227, 287, 246, 236, 234, 243],我们将像这样匹配它们:
values = [215, 227, 287, 246, 236, 234, 243]
classes = tree.classes_
list(zip(classes, values))
[('Insufficient_Weight', 215),
('Normal_Weight', 227),
('Obesity_Type_I', 287),
('Obesity_Type_II', 246),
('Obesity_Type_III', 236),
('Overweight_Level_I', 234),
('Overweight_Level_II', 243)]
-
最后,我们有类字段,它指示每个节点中的主要目标类。
请注意,正如我们之前所表达的,
scikit-learn为每个目标类分配了一种特定的颜色,因此,例如,权重不足的类具有深浅不同的棕色节点,这取决于该类在每个节点中的支配地位。![Insufficient Weight Node 1]()
例如,对于中间左侧的节点高度< = 1.66 ,尽管该类在那里有 209 个观察值(高于其他棕色节点),但因为下面的类(正常权重)也有大量的观察值(114),权重不足在那里并不占优势,并且它的颜色更浅,尽管与其他棕色节点相比,该目标类有更多的观察值。
![Insufficient Weight Node 1]()
另一方面,也是最重要的,如果我们想要预测我们自己的观察结果,我们需要到达一个叶节点并读取那里的类,以了解我们的观察结果属于哪个目标类。


既然我们已经看到了绘制的决策树的每个组件,我们将使用它来预测这些女性的体重分类:
- 瓜达卢佩,体重 75,身高 1.80

(在生成的图像此人不存在。)

首先我们有根节点,权重< = 99.536 。Guadalupe 权重为 75,因此阈值条件评估为 True,我们下降到左侧子节点。

在那里我们有一个阈值权重< = 60.059 ,所以 75 < = 60.059 评估为假,在这种情况下,我们下降到正确的子节点。

在第三个节点中,我们有权重< = 76.063 ,所以 75 < = 76.063 计算为真,我们下降到左边的子节点。

第四个节点的阈值是高度< = 1.735 ,所以 1.80 < = 1.735 求值为假,我们到达正确的子节点,也就是叶子,目标类是正常权重。

所以瓜达卢佩的体重很健康!
- 卡蜜拉,体重 111

(在生成的图像此人不存在。)
首先我们有根节点,权重< = 99.536 。卡蜜拉体重 111,因此阈值条件评估为假,我们下降到正确的子节点。

在这第二个节点中,阈值表示女< = 0.5 。考虑到当我们预处理数据时,我们改变了性别列使其为数字,现在该列被重命名为女性,而不是男性/女性,如果为假(男性)则值为 0,如果为真(女性)则值为 1。
所以,因为这个,女求值为 1,所以 1 < = 0.5 求值为假,我们下降到右边的子节点,也就是叶子,目标类是 Obesity_Type_III :

不幸的是,卡蜜拉没有一个最佳体重。
结论
决策树是最受欢迎的机器学习算法之一,这是因为与其他算法相比,它们相对更容易理解,因为我们可以构建它们洞察力的图形表示。
在这篇博文中,我们介绍了以下内容:
-
决策树的整体结构。
-
如何解读决策树?
-
如何用
scikit-learn创建自己的决策树? -
如何可视化我们自己的决策树?
然而,这只是一篇介绍性的文章;这些和其他方面将在我们专门针对决策树的课程中深入讨论。除了以上几点之外,这里还详细探讨了其他一些主题:
-
决策树是如何在表面下生成的。
-
训练决策树的数据预处理(包括一些不广为人知的有用的
scikit-learn工具!) -
创建分类和回归树。
-
决策树的优点和缺点。
-
决策树的效率评估,包括交叉验证的方法。
-
决策树的修剪和优化。
-
集合技术,包括随机森林和额外的树。
如果您有兴趣了解更多信息,您可以在下面的链接中找到更多信息。
教程:揭开 Python 中函数的神秘面纱
原文:https://www.dataquest.io/blog/tutorial-demystifying-functions-in-python/
January 10, 2022
在数据科学之旅中前进意味着遇到和处理越来越复杂的任务。为了做到这一点,您将需要一些东西来“接收”数据,以某种方式处理它,然后返回一些输出。我们可以通过使用函数来完成这个多阶段的过程。
什么是功能?
如果你需要给你的面试官留下深刻印象,总结一个功能的最好方法是“一个自包含的代码块,由用于完成某些特定任务的相关语句组成。”在 Python 中,这些函数以三种类型之一存在:
- Python 语言自带的内置函数
- 用户定义的函数,在使用它们的上下文和它们作用的数据中是特定的
- λ函数是未定义的,在短期内使用(即,不能在单一实例之外使用)
我们将在下面逐一分析这些类型。但在这之前,有必要问一个重要的问题。
为什么要使用函数?
函数因许多原因而受到高度重视。首先,使用函数主要使您能够避免在应用程序中的多个位置复制您经常使用的特定代码段。当然,您可以只进行复制和粘贴,但是如果您需要在任何时候修改代码段,您必须为每个实例重复这个过程。
这可以节省时间并消除潜在的错误。另外,如果你在一个协作元素中工作,这意味着避免任何混乱或复杂的代码。
 (一)
(一)

“做一些你能做得更少的事情来达到同样的结果会好得多”
除了减少一段代码的冗余,它还使我们在概念化和处理复杂任务时能够模块化(即,将复杂的过程分解成单独的步骤)。直觉上,我们在日常生活中这样做(比方说,准备一个大型晚宴),我们将活动的必要任务分解成所有必要的步骤。这使得我们更容易计划、扩展和调试。

(摘自安德烈娅·皮亚卡迪奥的《Pexel》
Python 中的函数是如何工作的?
在这种情况下,我们将讨论用户定义的函数。在最基本的层面上,这涉及几个组件:

| 成分 | 描述 |
| 定义
函数名
参数
自变量
:
语句* | 通知 Python 您正在定义一个函数的关键字
您正在调用什么函数满足命名约定在 Python 中
传递给函数的可选输入调整函数如何作用于参数
值传递给函数时分配给参数的值
表示函数头结束的标点符号
无论何时调用函数都将执行函数的语句块 |
*语句组成了函数的主体,用缩进
来表示。下面是一个我们如何定义函数的简单例子

注意:作为一个良好的实践,当创建一个用户定义的函数时,应用一个文档字符串来解释这个函数做什么。
在这种情况下,第一行使用“def”关键字向 Python 表明正在定义一个新函数(greeting ),它接受一个参数(name)和一个参数(大写)。缩进的下一行表示执行任务的函数体。在这里,我们看到参数调整了这个执行,如果它为真,它将打印出一个字符串,并对参数应用大写方法。否则,它不会。同样,在上面的例子中,我们有一个默认值附加到大写参数上,除非另有说明,否则它通常被设置为 True。
默认情况下,调用函数时必须使用正确数量的参数。这意味着如果一个函数需要一定数量的参数输入才能运行,那么你就需要这个数量的参数。否则,您将得到类似这样的结果:
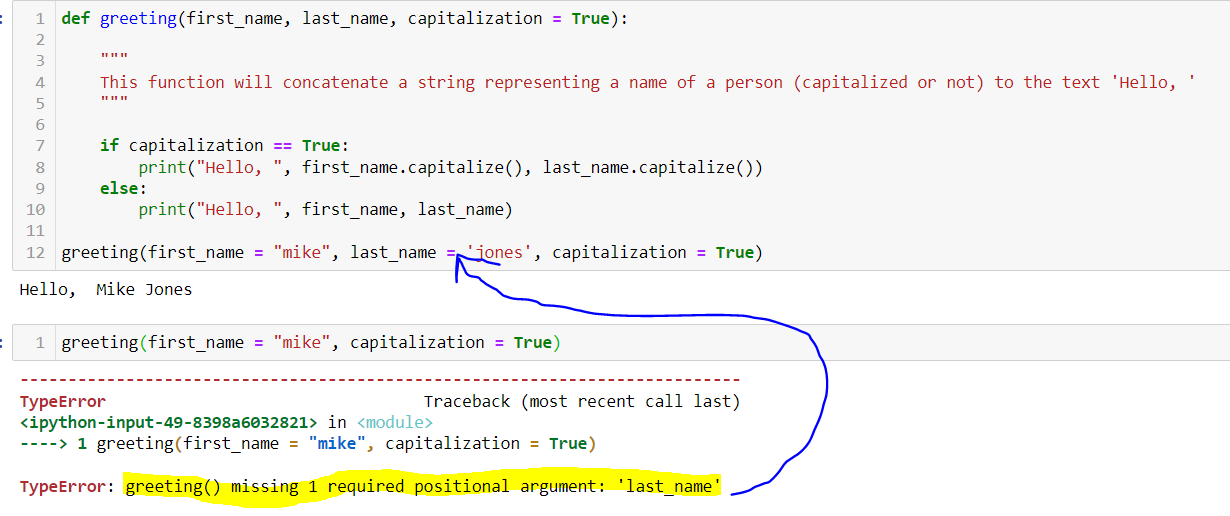
有时,在计划您希望函数做什么时,您可能不确定输出应该是什么。在这些情况下,运行该函数但不产生输出或错误消息可能是有用的。为此,我们使用如下所示的 pass 语句:

我们可能需要应用这一点的另一种情况是,当需要为特定输出创建一个条件时,我们也可以使用 pass 语句。

在上面的两个场景中,我们都有一个返回打印值的输出。有时,我们可能只需要返回值,以便在另一个上下文中使用(比如,进入另一个函数)。在这种情况下,我们可以使用 return 来代替。这里的 return 语句有两个目的:
- 它会立即终止函数,并将执行控制权返回给调用者
- 它为函数提供了一种将数据传递回调用者的机制
现在,由于 return 语句可以终止一个函数,我们可以在检查潜在错误的情况下应用它,在满足该条件的情况下,我们返回某种指示错误的输出。
有趣的是,对于函数,我们可以定义函数调用本身,这使得数据能够循环。但是,这应该小心进行,因为如果操作不当,可能会创建一个永远不会终止的函数。
注意函数将如何继续与后续值合并,直到最后一次输入。
关于争论
正如有不同类型的函数一样,有两种主要类型的参数:关键字参数和位置参数。在上面的例子中,输入到函数中的值可以通过特定的名称( first_name,last_name )来识别,该名称是关键字参数。对于关键字参数,关键字参数出现在函数中的什么位置并不重要,因为它已经用特定的名称“映射”出来了。

这里有三种方法来写出一个函数,它们都产生相同的输出。
另一种类型的参数是位置参数,它是根据函数定义过程中参数的排列顺序传递给函数的值。在这里,这些参数没有如上所示定义;相反,它们被输入到函数中,并根据函数中的参数进行操作。

请注意,在没有确定哪个值代表什么的情况下,我们会看到函数中的默认值。
到目前为止,我们一直在处理固定参数(即,预先知道输入到函数中的参数数量)。然而,有时我们可能不确定应该添加哪些参数。在某些情况下,这些值可能会超过先前设置的值。因此,为了解决这个问题,我们可以使用任意参数,这些参数是传递给函数的未定义的值。为了表示这些类型的参数,我们在参数前添加了一个“* ”(* args 表示非关键字/位置参数;*kwargs 用于关键字参数)。

什么是内置函数?
与任何其他编程语言一样,Python 语言内置了一组函数,用于执行与操作数据相关的常见任务,或者构建其他函数来执行更复杂的任务,例如某些模块中的任务。这些功能有很多,你可以在这里和这里和进行探索。

什么是 lambda 函数?
因此,lambda 函数(也称为匿名函数)与我们到目前为止所讨论的并没有太大的不同,因为它们为给定的参数执行一个表达式。唯一的区别是,与用户定义的函数不同,这些函数是未定义的(即,没有与此函数相关联的特定名称)。

注意用户定义的函数如何使用“def”作为关键字,而不是使用的匿名函数
在上面的例子中,我们看到参数( x )在通过 lambda 函数后被求值并返回。这与接受参数(名)的用户定义函数没有太大区别。然而,这个函数实际上并没有被设计成多次使用,因为没有办法再次调用它。
现在你可能会想,“为什么不总是使用用户定义的函数?”虽然你当然可以这样做,但它会产生低效的编码,其中单次使用的函数会使内容难以阅读——而且不必要的长。我们的想法是尽可能提高效率。使用匿名函数,您可以在执行简单的逻辑操作时替代这种需要,例如上面显示的,您知道输出只是将 x 参数连接到字符串的末尾。
例如,我们可以简单地将 lambda 函数应用于一个值,如下所示:

或者,我们可以使用 python 的一些内置函数(如 filter()或 map())将它应用于值列表,如下所示:
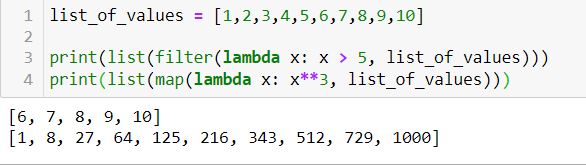
我们通常看到这些 lambda 函数用于系列对象或数据帧。例如,假设我们有一个即将到来的 NFL 选秀的几个顶级选秀候选人的列表:


如果您获得推荐,奖励积分
假设我们希望应用一个函数来计算每个潜在候选人的年龄;我们可以简单地使用 apply()函数或 map()函数:
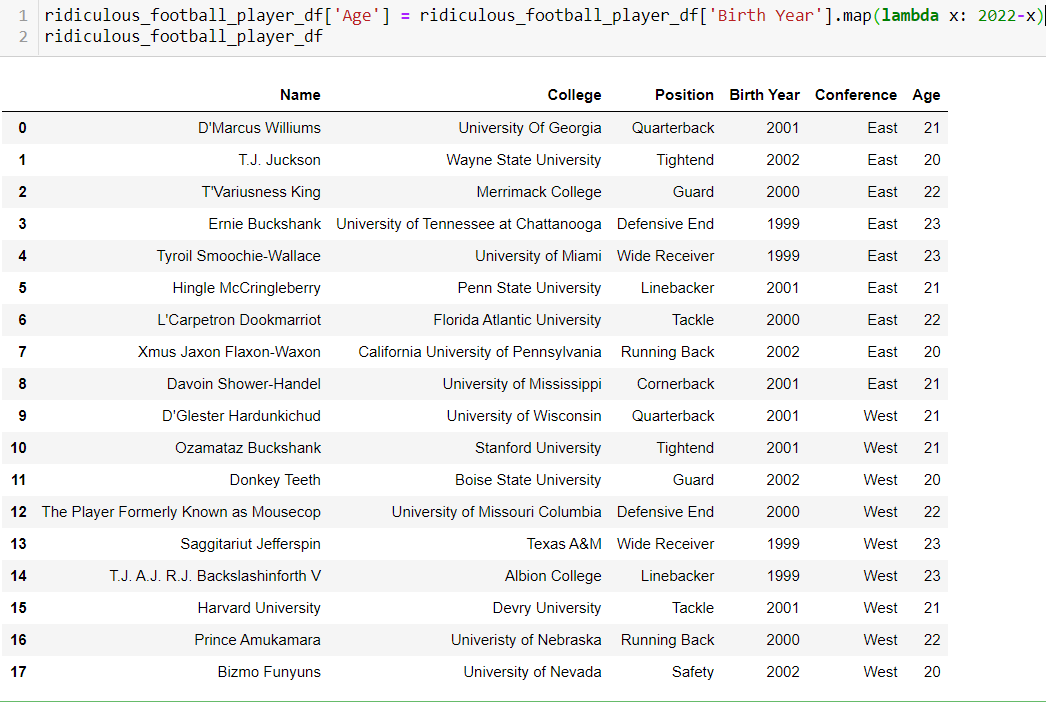
或者,我们也可以在有条件元素的情况下应用 lambda 函数。例如,假设我们希望为基于技能和非基于技能的职位(即四分卫、外接球手、跑卫和边锋)建立预计的第一年工资。我们可以将 if/else 语句与 lambda 函数结合使用:

lambda 函数的这些示例通常被认为是这些函数的“合理”使用。然而,有些情况下我们可以使用 lambda 函数,但是由于风格的原因,通常不鼓励这样做。
1.将名称应用于 lambda 函数,因为这将允许给定函数的可重用性。因为 lambda 函数通常是一次性使用的,所以更合适的用法是创建一个用户定义的函数。
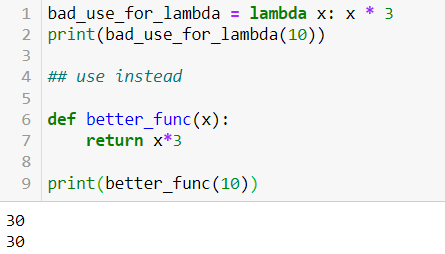
2.一个 lambda 函数对应多行代码——这可能会使事情变得过于复杂和难以阅读,每当需要修改或更正时,这都会成为问题。
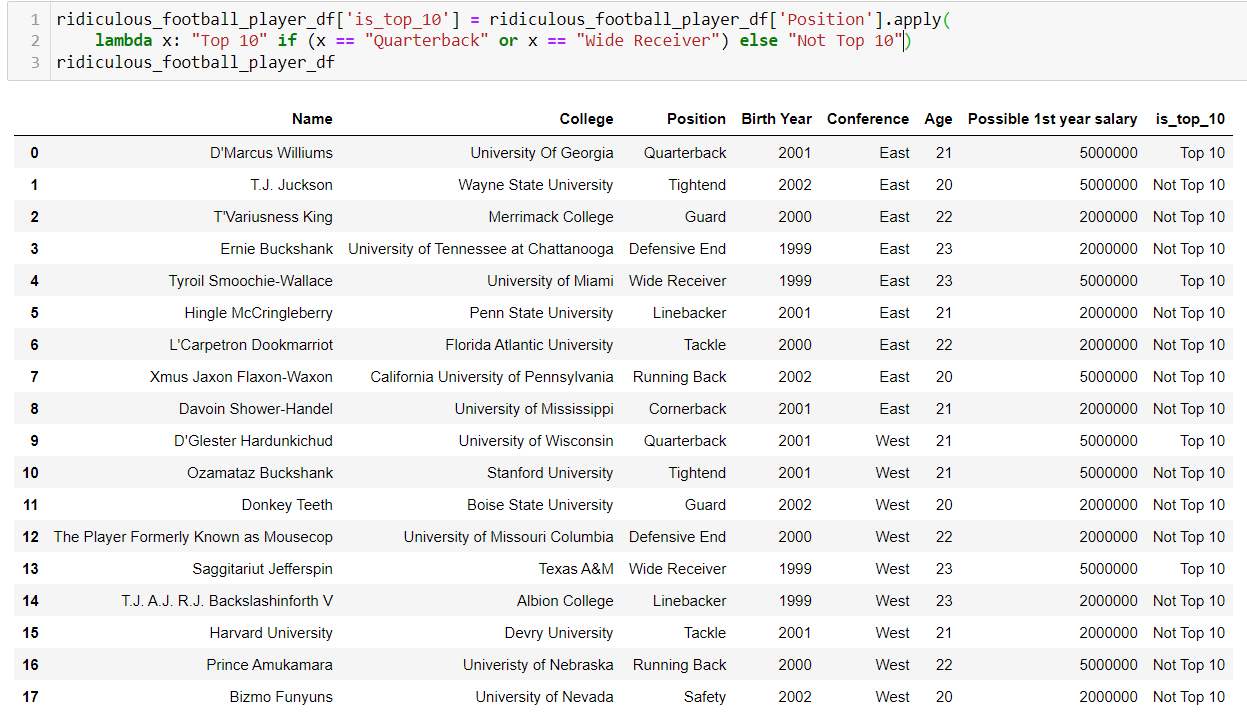
通过消除大块代码的重复输入来简化代码,使其更容易阅读和解释。虽然 Python 语言和其他模块中有各种内置函数,但我们也可以为给定的任务创建自己的函数,我们可以定义或不定义。根据手头的任务,制作这些可以相当简单或复杂。
每种功能都有其优点和缺点,了解如何以及何时应用每种功能将使您在数据科学的道路上走得更远。如果您想在实践环境中了解更多信息,请查看 Dataquest 的功能模块。
教程:揭秘 Python 列表
原文:https://www.dataquest.io/blog/tutorial-demystifying-python-lists/
January 28, 2022
在本教程中,您将学习如何使用 Python 列表,这是 Python 中最强大的数据类型之一。
完成本教程后,您将了解以下内容:
- 如何定义 Python 列表
- 如何创建 Python 列表以及访问或更改列表中的项目
- 如何创建列表列表
- 如何分割列表
- 如何在列表中添加或删除项目
- 如何使用 for 循环迭代列表中的项目
在本教程中,我们假设您了解 Python 的基础知识,包括变量、数据类型和基本结构。如果你不熟悉这些或者渴望提高你的 Python 技能,请在 Python 课程中尝试我们的变量、数据类型和列表。
什么是 Python 列表?
Python 列表是一个变量名下的异构元素(项目)的可变集合。在这个上下文中,可变性意味着当程序运行时,列表中的元素可以改变。我们还可以随时在列表中添加或删除元素。在 Python 中,我们通过将元素括在方括号中并用逗号分隔来定义列表。每个列表的元素都有一个索引,表示元素在列表中的位置,起始索引为零。
创建 Python 列表
要定义 Python 列表,需要使用以下语法:
variable_name = [item1, item2, item3, … , itemN]
作为一个例子,让我们创建我们的第一个 Python 列表。
shopping_list = ["eggs", "milk", "bread", "butter"]
上面的代码实现了一个包含四个元素的 Python 列表,这四个元素都是字符串。现在,让我们创建一个只保存购物清单上商品价格的列表。
price_list = [13.99, 8.50, 7.90, 12.50]
正如我们在 Python 列表的定义中提到的,列表项不必都是相同的数据类型。它们可以是任何对象,因为在 Python 中一切都是对象。
a_mixed_list = ["dataquest.io", 100, "python.org", 10.01, True, 'A']
现在,让我们检查这些列表的数据类型:
print(type(shopping_list))
print(type(price_list))
print(type(a_mixed_list))
继续,运行代码。无论列表中存储的是哪种数据类型,所有的type()函数都返回<class 'list'>,这是列表对象的数据类型。
访问 Python 列表中的项目
正如我们所看到的,列表中的每一项都有自己的索引,所以可以使用相关的索引来检索它们。让我们试试代码:
print(shopping_list[0])
print(price_list[2])
运行代码;它输出eggs和7.90。第一个值是eggs,因为它是购物列表中索引为 0 的第一个项目,第二个值是7.90,因为它是价格列表中索引为 2 的第三个项目。下图显示了一个包含六个整数元素及其从零开始的索引的列表。很高兴知道 Python 支持负索引,这意味着最后一个元素的索引是-1,倒数第二个元素的索引是-2,倒数第六个元素的索引是-k。

让我们首先定义num_list列表,然后看一些例子:
num_list = [21, 13, 17, 39, 17, 51]
print(num_list[-1])
print(num_list[0])
print(num_list[-6])
现在运行代码,并检查其输出。第一个print语句返回51,这是列表中的最后一个元素,最后两个print语句返回21,因为两个语句都引用了列表的第一个元素。有时候,我们需要知道一个列表中有多少个元素。为此,我们使用len()函数,就像这样:
print("The length of the list is {}.".format(len(num_list)))
运行代码输出The length of the list is 6,因为列表中的元素数量是 6。
更改列表中的值
修改列表中的项就像将变量重新声明为一个新值。让我们看下面的例子:
num_list = [21, 13, 17, 39, 17, 51]
print(num_list)
num_list[4] = 33
print(num_list)
在上面的代码中,在我们修改索引 4 处的值之前,它输出[21, 13, 17, 39, 17, 51],在将索引 4 处的值更改为 33 之后,它输出 [21, 13, 17, 39, 33, 51]。换句话说,我们的代码选择了位置 4 的项目,并将其值设置为 33。
创建列表的列表
在 Python 中,我们可以将列表存储在另一个列表中(嵌套列表)。为了检查我们如何创建嵌套列表,让我们尝试下面的代码,它使一个列表包含具有不同数据类型的其他列表和值。
data = [["Python", 100], ["Java", 101], "Hello", True]
print(data)
print(data[1])
运行代码,并检查其输出。
['Python', 100], ['Java', 101], 'Hello', True]
['Java', 101]
第一行显示了存储在 data变量中的整个列表,第二行显示了data的第二个元素,它本身是一个包含两个元素的列表。到目前为止,您已经学习了如何创建嵌套列表。但是如果我们想从内部列表中检索一个特定的元素呢?在 Python 中,为了访问列表中的一个条目,我们将条目的索引放在一对方括号中。但是,如果项目在内部列表中,我们必须在第一组方括号之后添加第二组方括号。让我们来看一个例子:
print(data[0][0])
inner_list = data[1]
print(inner_list[0])
运行上面的代码输出Python和Java。在第一行代码中,第一组方括号之间的第一个索引引用的是data列表中的第一项,它本身就是一个列表,第二组方括号之间的第二个索引引用的是内部列表的第一个值,这就产生了Python。下图显示了如何从data列表中检索到Python。

在第二行代码中,data列表的索引 1 处的值,它本身也是一个分配给inner_list变量的列表;然后在最后一行,我们正在访问存储在 inner_list变量中的内部列表的第一个元素,即Java。下图显示了如何从data列表中检索到Java。

切片列表
Python 允许我们使用切片技术创建列表子集。为了创建一个列表片,我们指定第一个和最后一个条目的索引。从第一个索引到最后一个索引(不包括最后一个索引)的项被复制到切片中,很明显,这种复制不会修改原始列表。分割列表有不同的方式;让我们来看看其中的一些。
使用起始索引进行切片
省略结束索引意味着切片包含从开始索引到列表结尾的列表元素。让我们来看看:
num_list = [21, 13, 17, 39, 17, 51]
print(num_list[3:])

使用结束索引切片
省略起始索引意味着切片包含从列表开头到结束索引的列表元素。让我们试试代码:
num_list = [21, 13, 17, 39, 17, 51]
print(num_list[:4])

注
省略起始和结束索引会导致整个列表。
print(num_list[:])
[21, 13, 17, 39, 17, 51]
分步切片
我们可以使用一个步骤在指定的时间间隔返回项目。步长是可选的,默认情况下为 1。以下代码返回num_list的每隔一项。
num_list = [21, 13, 17, 39, 17, 51]
print(num_list[ : :2])

用负步长反转列表
我们可以通过将步骤指定为-1 来反转列表。下面的代码以相反的顺序返回num_list项。
num_list = [21, 13, 17, 39, 17, 51]
print(num_list[ : :-1])

注
在上面的代码中,虽然我们没有指定开始和结束索引,但两者都被假定为负索引,如下所示:
print(num_list[-1:-9:-1])
[51, 17, 39, 17, 13, 21]
向列表中添加项目
向列表中添加新项目有两种方法,insert()和append()方法。新项目可以是一个字符串、一个数字,甚至是另一个列表。我们可以使用这两种方法来扩展列表。
。插入()
方法在列表中的指定位置添加一个条目。让我们看看它是如何工作的。
fruits = ["apple", "orange", "cherry"]
fruits.insert(1, "pineapple")
print(fruits)
上面的代码将pineapple插入到列表中的索引 1 处,并输出如下:['apple', 'pineapple', 'orange', 'cherry']
。追加()
方法在列表的末尾添加一个条目。我们去看看。
fruits = ["apple","orange","cherry"]
fruits.append("pineapple")
print(fruits)
上面的代码在列表的末尾添加了pineapple并将其打印出来。['apple', 'orange', 'cherry', 'pineapple']
注
您可以使用+=操作符在列表末尾添加一个对象列表。如果+=的左操作数是一个列表,那么右操作数必须是一个列表或者任何其他可迭代的对象。
students = ["Mary", "James","Patricia"]
students += ["Robert"]
students += ["Emma", "William"]
print(students)
['Mary', 'James', 'Patricia', 'Robert', 'Emma', 'William']
学生姓名两边的方括号在第二行创建了一个单元素列表,使用+=操作符将它附加到students列表中。同样,第三行将两个students的列表追加到学生列表中。我们还可以使用+操作符连接两个列表。结果是一个新的列表,包含 A 类的学生,后面跟着 b 类的学生。
classA = ["Mary", "James","Patricia"]
classB = ["Robert", "Emma", "William"]
students = classA + classB
print(students)
['Mary', 'James', 'Patricia', 'Robert', 'Emma', 'William']
从列表中删除项目
从列表中移除条目有两种主要的方法,pop()和remove()方法。
。流行()
pop()方法从列表中移除指定索引处的项目,并返回该项目,该项目可以被赋给一个变量供以后使用。索引的默认值是-1,这意味着如果没有提供索引值,它将删除最后一项。
fruits = ["apple", "orange", "cherry", "pineapple"]
second_fruit = fruits.pop(1) # removes the second item
last_fruit = fruits.pop() # removes the last item
print("Second Fruit is {}.".format(second_fruit))
print("Last Fruit is {}.".format(last_fruit))
print(fruits)
上面的代码删除了两项:第一项在索引 1 处,第二项在列表的末尾。此外,当从列表中弹出这些项目时,它将它们保存到second_fruit和last_fruit变量中,稍后将它们与修改后的fruits列表一起打印出来。
Second Fruit is orange.
Last Fruit is pineapple.
['apple', 'cherry']
。移除()
remove()方法删除具有指定值的元素的第一次出现。
fruits = ["apple", "orange", "cherry", "pineapple"]
fruits.remove('cherry')
print(fruits)
运行代码输出没有“cherry”的fruits列表,因为remove()方法成功地移除了它。
['apple', 'orange', 'pineapple']
但是如果我们要移除的项目不在列表中会发生什么呢?让我们运行下面的代码,看看结果:
fruits = ["apple", "orange", "cherry", "pineapple"]
fruits.remove('blueberry')
print(fruits)
代码会引发一个错误,指出该值不在列表中。让我们看看如何通过使用 try-except 块捕捉异常来修复它。
fruits = ["apple", "orange", "cherry", "pineapple"]
try:
fruits.remove('blueberry')
print(fruits)
except:
print("The fruit name does not exist in the list.")
运行代码。这一次我们的代码没有崩溃,它输出了一条正确的消息,表明列表中不存在该项目(水果名称)。
The fruit name does not exist in the list.
in和not in运算符
基本上,in操作符检查指定的值是否在列表中。当在一个条件中使用in运算符时,该语句返回一个布尔值,计算结果为True或False。当在列表中找到指定的值时,语句返回True;否则返回False。
num_list = []
if not num_list:
print(“The list is empty.”)
由于num_list为空,代码输出“列表为空”。
注
我们可以通过给变量分配空方括号来创建一个空列表。空列表的长度为零,我们总是可以使用append()或insert()方法向空列表添加元素。
for循环和列表
我们可以使用for循环来遍历一个项目列表,一次获取一个项目,直到没有其他项目需要处理。让我们看看代码。
fruits = ["apple", "orange", "cherry", "pineapple"]
for fruit in fruits:
print(fruit)
运行上面的代码将列表中的每一项打印在单独的一行上。换句话说,对于fruits列表中的每个水果,它打印水果的名称。
apple
orange
cherry
pineapple
结论
在本教程中,您学习了如何通过简单明了的代码片段使用 Python 列表。我们将在接下来的教程中探讨一些高级技术。
教程:关于 Python 集合你需要知道的一切
原文:https://www.dataquest.io/blog/tutorial-everything-you-need-to-know-about-python-sets/
January 21, 2022
在本教程中,我们将详细探讨 Python 集合:什么是 Python 集合,何时以及为何使用它,如何创建它,如何修改它,以及我们可以对 Python 集合执行哪些操作。
Python 中的集合是什么?
集合是一种内置的 Python 数据结构,用于在单个变量中存储唯一项的集合,可能是混合数据类型。Python 集包括:
- 无序–器械包中的物品没有任何已定义的顺序
- 未编入索引的–我们无法像访问列表一样访问带有
[i]的项目 - 可变–集合可以被修改为整数或元组
- 可迭代的(Iterable)——我们可以对集合中的项目进行循环
请注意,虽然 Python 集合本身是可变的(我们可以从中删除项目或添加新项目),但它的项目必须是不可变的数据类型,如整数、浮点、元组或字符串。
Python 集合的主要应用包括:
- 删除重复项
- 正在检查集合成员资格
- 执行数学集合运算,如并、交、差和对称差
创建 Python 集
我们可以通过两种方式创建 Python 集合:
- 通过使用内置的
set()函数和传入的 iterable 对象(比如列表、元组或字符串) - 通过将逗号分隔的所有项目放在一对花括号内
{}
在这两种情况下,重要的是要记住 Python 集合的未来项(即,可迭代对象的单个元素或放在花括号内的项)本身可以是可迭代的(例如,元组),但它们不能是可变类型,例如列表、字典或另一个集合。
让我们看看它是如何工作的:
# First way: using the set() function on an iterable object
set1 = set([1, 1, 1, 2, 2, 3]) # from a list
set2 = set(('a', 'a', 'b', 'b', 'c')) # from a tuple
set3 = set('anaconda') # from a string
# Second way: using curly braces
set4 = {1, 1, 'anaconda', 'anaconda', 8.6, (1, 2, 3), None}
print('Set1:', set1)
print('Set2:', set2)
print('Set3:', set3)
print('Set4:', set4)
# Incorrect way: trying to create a set with mutable items (a list and a set)
set5 = {1, 1, 'anaconda', 'anaconda', 8.6, [1, 2, 3], {1, 2, 3}}
print('Set5:', set5)
Set1: {1, 2, 3}
Set2: {'b', 'c', 'a'}
Set3: {'n', 'o', 'd', 'c', 'a'}
Set4: {1, 8.6, 'anaconda', (1, 2, 3), None}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_6832/1057027593.py in <module>
13
14 # Incorrect way: trying to create a set with mutable items (a list and a set)
---> 15 set5 = {1, 1, 'anaconda', 'anaconda', 8.6, [1, 2, 3], {1, 2, 3}}
16 print('Set5:', set5)
TypeError: unhashable type: 'list'
我们可以在这里作出以下观察:
- 在每种情况下,重复序列都已被删除
- 项目的初始顺序已更改
set4包含不同数据类型的元素- 试图用可变项目(一个列表和一个集合)创建一个 Python 集合导致了一个
TypeError
当我们需要创建一个空的 Python 集合时,会出现一种特殊的情况。因为空花括号{}创建了一个空的 Python 字典,所以我们不能用这种方法在 Python 中创建一个空集。在这种情况下,使用set()功能仍然有效:
empty1 = {}
empty2 = set()
print(type(empty1))
print(type(empty2))
<class><class>
正在检查集合成员资格
为了检查某个项目在 Python 集合中是否存在,我们使用操作符关键字in或关键字组合not in:
myset = {1, 2, 3}
print(1 in myset)
print(1 not in myset)
True
False
访问 Python 集中的值
由于 Python 集合是无序和无索引的,我们不能通过索引或切片来访问它的项目。一种方法是遍历集合:
myset = {'a', 'b', 'c', 'd'}
for item in myset:
print(item)
b
d
a
c
输出值的顺序可能与原始集合中显示的顺序不同。
修改 Python 集
向 Python 集添加项目
我们可以使用add()方法向 Python 集合添加单个不可变项,或者使用update()方法添加几个不可变项。后者以元组、列表、字符串或其他不可变项目的集合作为其参数,然后将它们中的每个单个唯一项目(或在字符串的情况下,每个单个唯一字符)添加到集合中:
# Initial set
myset = set()
# Adding a single immutable item
myset.add('a')
print(myset)
# Adding several items
myset.update({'b', 'c'}) # a set of immutable items
print(myset)
myset.update(['d', 'd', 'd']) # a list of immutable items
print(myset)
myset.update(['e'], ['f']) # several lists of immutable items
print(myset)
myset.update('fgh') # a string
print(myset)
myset.update([[1, 2], [3, 4]]) # an attempt to add a list of mutable items (lists)
print(myset)
{'a'}
{'b', 'c', 'a'}
{'b', 'd', 'c', 'a'}
{'e', 'f', 'b', 'd', 'c', 'a'}
{'e', 'f', 'b', 'h', 'd', 'c', 'a', 'g'}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_6832/2286239840.py in <module>
15 myset.update('fgh') # a string
16 print(myset)
---> 17 myset.update([[1, 2], [3, 4]]) # an attempt to add a list of mutable items (lists)
18 print(myset)
TypeError: unhashable type: 'list'
从 Python 集中移除项目
要从 Python 集合中移除一个或多个项目,我们可以选择以下四种方法之一:
discard()–删除特定的项目,如果该项目不在集合中,则不做任何操作remove()–删除特定的项目,如果该项目不在集合中,则引发KeyErrorpop()–移除并返回一个随机项目,或者如果集合为空,则引发KeyErrorclear()–清除集合(删除所有项目)
让我们看一些例子:
# Initial set
myset = {1, 2, 3, 4}
print(myset)
# Removing a particular item using the discard() method
myset.discard(1) # the item was present in the set
print(myset)
myset.discard(5) # the item was absent in the set
print(myset)
# Removing a particular item using the remove() method
myset.remove(4) # the item was present in the set
print(myset)
myset.remove(5) # the item was absent in the set
print(myset)
{1, 2, 3, 4}
{2, 3, 4}
{2, 3, 4}
{2, 3}
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_6832/2462592674.py in <module>
12 myset.remove(4) # the item was present in the set
13 print(myset)
---> 14 myset.remove(5) # the item was absent in the set
15 print(myset)
KeyError: 5
# Taking the set from the code above
myset = {2, 3}
# Removing and returning a random item
print(myset.pop()) # the removed and returned item
print(myset) # the updated set
# Removing all the items
myset.clear()
print(myset)
# An attempt to remove and return a random item from an empty set
myset.pop()
print(myset)
2
{3}
set()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_6832/901310087.py in <module>
11
12 # An attempt to remove and return a random item from an empty set
---> 13 myset.pop()
14 print(myset)
KeyError: 'pop from an empty set'
用于集合的内置 Python 函数
一些适用于列表和其他类似集合的数据结构的内置 Python 函数对于不同用途的 Python 集合也很有用。让我们考虑一下最有用的功能:
-
len()–返回集合大小(集合中的项目数) -
min()andmax()–return the small/large item in the set and are most used for the sets with numerical valuesNote: In the case of tuples or strings as set items, this becomes a bit complicated. For strings, the comparison follows the principle of lexicography (that is, the ASCII values of characters of two or more strings are compared from left to right). Instead, tuples are compared according to items with the same index, also from left to right. Using
min()andmax()functions on Python collections with mixed data type items will raiseTypeError. -
sum()–返回仅包含数值的集合中所有项目的总和
# A set with numeric items
myset = {5, 10, 15}
print('Set:', myset)
print('Size:', len(myset))
print('Min:', min(myset))
print('Max:', max(myset))
print('Sum:', sum(myset))
print('\n')
# A set with string items
myset = {'a', 'A', 'b', 'Bb'}
print('Set:', myset)
print('Min:', min(myset))
print('Max:', max(myset))
print('\n')
# A set with tuple items
myset = {(1, 2), (1, 0), (2, 3)}
print('Set:', myset)
print('Min:', min(myset))
print('Max:', max(myset))
Set: {10, 5, 15}
Size: 3
Min: 5
Max: 15
Sum: 30
Set: {'A', 'b', 'a', 'Bb'}
Min: A
Max: b
Set: {(1, 0), (1, 2), (2, 3)}
Min: (1, 0)
Max: (2, 3)
注意在集合{'b', 'a', 'A', 'Bb'}中,最小值是A,而不是a。发生这种情况是因为,从字典上看,所有的大写字母都比所有的小写字母低。
-
all()–如果集合中的所有项目都评估为True,或者集合为空,则返回True -
any()–如果集合中至少有一个项目评估为True,则返回True(对于空集,返回False)注:评估为
True的值是不评估为False的值。在计算机编程语言集合项的上下文中,评估为False的值是0``0.0``''``False``None和().
print(all({1, 2}))
print(all({1, False}))
print(any({1, False}))
print(any({False, False}))
True
False
True
False
sorted()–返回集合中项目的排序列表
myset = {4, 2, 5, 1, 3}
print(sorted(myset))
myset = {'c', 'b', 'e', 'a', 'd'}
print(sorted(myset))
[1, 2, 3, 4, 5]
['a', 'b', 'c', 'd', 'e']
对 Python 集合执行数学集合运算
这组运算包括并、交、差和对称差。它们中的每一个都可以由操作者或方法来执行。
让我们在以下两个 Python 集合上练习数学集合运算:
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7}
集合联合
两个(或更多)Python 集合的并集返回两个(所有)集合中所有唯一项目的新集合。可以使用|操作符或union()方法执行:
print(a | b)
print(b | a)
print(a.union(b))
print(b.union(a))
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7}
正如我们所看到的,对于 union 操作,集合的顺序并不重要:我们可以用相同的结果编写a | b或b | a,对于方法的使用也是如此。
两个以上 Python 集合上 union 操作的语法如下:a | b | c或a.union(b, c)。
请注意,在上面的示例(以及所有后续的示例)中,在操作符前后添加空格只是为了提高可读性。
设置交集
两个(或更多)Python 集合的交集返回两个(所有)集合共有的项目的新集合。可以使用&操作符或intersection()方法执行:
print(a & b)
print(b & a)
print(a.intersection(b))
print(b.intersection(a))
{4, 5}
{4, 5}
{4, 5}
{4, 5}
同样,在这种情况下,集合的顺序无关紧要:a & b或b & a将产生相同的结果,使用方法时也是如此。
两个以上 Python 集合的交集操作的语法如下:a & b & c或a.intersection(b, c)。
集合差异
两个(或更多)Python 集合的差返回一个新的集合,其中包含第一个(左)集合中第二个(右)集合中不存在的所有项目。在两组以上的情况下,操作从左向右进行。对于这个集合操作,我们可以使用-操作符或difference()方法:
print(a - b)
print(b - a)
print(a.difference(b))
print(b.difference(a))
{1, 2, 3}
{6, 7}
{1, 2, 3}
{6, 7}
这里集合的顺序很重要:a - b(或a.difference(b))返回所有在a但不在b的项目,而b - a(或b.difference(a))返回所有在b但不在a的项目。
对两个以上的 Python 集合进行差运算的语法如下:a - b - c或a.difference(b, c)。在这种情况下,我们首先计算a - b,然后找出得到的集合和右边下一个集合的差,也就是c,以此类推。
设置对称差
两个 Python 集合的对称差返回第一个或第二个集合中存在的一组新项目,但不是两个都存在。换句话说,两个集合的对称差是集合并和集合交之间的差,这对于多个集合的对称差也有意义。我们可以使用^操作符或symmetric_difference()方法来执行这个操作:
print(a ^ b)
print(b ^ a)
print(a.symmetric_difference(b))
print(b.symmetric_difference(a))
{1, 2, 3, 6, 7}
{1, 2, 3, 6, 7}
{1, 2, 3, 6, 7}
{1, 2, 3, 6, 7}
对于对称差分运算,集合的顺序无关紧要:a ^ b或b ^ a将产生相同的结果,我们可以说使用该方法也是如此。
对两个以上 Python 集合进行对称差分运算的语法如下:a ^ b ^ c。然而,这一次,我们不能使用symmetric_difference()方法,因为它只接受一个参数,否则会引发TypeError:
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7}
c = {7, 8, 9}
a.symmetric_difference(b, c)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_6832/4105073859.py in <module>
3 c = {7, 8, 9}
4
----> 5 a.symmetric_difference(b, c)
TypeError: set.symmetric_difference() takes exactly one argument (2 given)
Python 集合上的其他集合操作
还有一些其他有用的方法和运算符可用于处理两个或多个 Python 集:
intersection_update()(或&=运算符)—用当前集合与另一个(或多个)集合的交集重写当前集合difference_update()(或-=运算符)—用当前集合与另一个(或多个)集合的差异重写当前集合symmetric_difference_update()(或^=运算符)—用当前集合与另一个(或多个)集合的对称差重写当前集合isdisjoint()(没有对应的运算符)—如果两个集合没有任何公共项,则返回True,这意味着这些集合的交集是一个空集issubset()(或<=运算符)—如果另一个集合包含当前集合的每个项目,则返回True,包括两个集合相同的情况。如果要排除后一种情况,就不能用这种方法;相反,我们需要使用<(严格来说更小)操作符issuperset()(或>=运算符)—如果当前集合包含另一个集合的每个项目,包括两个集合相同的情况,则返回True。如果要排除后一种情况,就不能用这种方法;相反,我们需要使用>(严格更大)操作符
结论
最后,让我们回顾一下我们在本教程中学到的 Python 集合:
- Python 集的主要特征
- Python 集合的主要应用
- 创建 Python 集的两种方法
- 如何创建空 Python 集
- 如何检查某个项目在 Python 集合中是否存在
- 如何访问 Python 集中的值
- 向 Python 集合添加新项的两种方法
- 从 Python 集合中移除项目的四种方法
- 哪些内置 Python 函数适用于 Python 集合
- 如何通过方法或运算符对两个或更多 Python 集合执行主要数学集合运算
- 我们还可以在两个或更多 Python 集合上执行哪些操作
现在,您应该熟悉在 Python 中创建和使用集合的所有细微差别。
教程:为什么函数在 Python 中修改列表和字典
原文:https://www.dataquest.io/blog/tutorial-functions-modify-lists-dictionaries-python/
March 14, 2019
Python 的函数(包括内置函数和我们自己编写的自定义函数)是处理数据的重要工具。但是他们对我们的数据所做的事情可能会有点混乱,如果我们不知道发生了什么,这可能会在我们的分析中造成严重的错误。
在本教程中,我们将仔细研究 Python 如何处理在函数内部被操纵的不同数据类型,并学习如何确保我们的数据仅在我们希望改变时才被改变。
函数中的内存隔离
为了理解 Python 如何处理函数内部的全局变量,让我们做一个小实验。我们将创建两个全局变量 number_1 和 number_2,并将它们赋给整数 5 和 10。然后,我们将使用这些全局变量作为执行一些简单数学运算的函数的参数。我们还将使用变量名作为函数的参数名。然后,我们会看到函数中所有变量的使用是否影响了这些变量的全局值。
number_1 = 5
number_2 = 10
def multiply_and_add(number_1, number_2):
number_1 = number_1 * 10
number_2 = number_2 * 10
return number_1 + number_2
a_sum = multiply_and_add(number_1, number_2)
print(a_sum)
print(number_1)
print(number_2)
150
5
10
正如我们在上面看到的,函数工作正常,全局变量number_1和number_2的值没有改变,即使我们在函数中使用它们作为自变量和参数名。这是因为 Python 将函数中的变量存储在与全局变量不同的内存位置。他们被孤立了。因此,变量number_1可以在全局范围内有一个值(5 ),在函数内部有一个不同的值(50 ),在函数内部它是独立的。
(顺便说一句,如果你对参数和参数、之间的区别感到困惑,Python 关于这个主题的文档是很有帮助的。)
列表和字典呢?
列表
我们已经看到,我们在函数中对上面的number_1这样的变量所做的事情不会影响它的全局值。但是number_1是一个整数,这是一个非常基本的数据类型。如果我们用不同的数据类型(比如列表)进行相同的实验,会发生什么呢?下面,我们将创建一个名为duplicate_last()的函数,它将复制我们作为参数传递的任何列表中的最后一个条目。
initial_list = [1, 2, 3]
def duplicate_last(a_list):
last_element = a_list[-1]
a_list.append(last_element)
return a_list
new_list = duplicate_last(a_list = initial_list)
print(new_list)
print(initial_list)
[1, 2, 3, 3]
[1, 2, 3, 3]
正如我们所看到的,这里initial_list 的全局值被更新了,尽管它的值只是在函数内部被改变了!
字典
现在,让我们编写一个以字典作为参数的函数,看看在函数内部操作全局字典变量时,它是否会被修改。
为了让这个更真实一点,我们将使用在我们的 Python 基础课程中使用的AppleStore.csv数据集的数据(数据可以在这里下载)。
在下面的代码片段中,我们从一个字典开始,该字典包含数据集中每个年龄等级的应用程序的数量(因此有 4,433 个应用程序被评为“4+”,987 个应用程序被评为“9+”,等等)。).假设我们想要计算每个年龄分级的百分比,这样我们就可以了解 App Store 中哪些年龄分级是最常见的。
为此,我们将编写一个名为make_percentages()的函数,它将一个字典作为参数,并将计数转换为百分比。我们需要从零开始计数,然后遍历字典中的每个值,将它们添加到计数中,这样我们就可以得到评级的总数。然后我们将再次遍历字典,对每个值做一些数学运算来计算百分比。
content_ratings = {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}
def make_percentages(a_dictionary):
total = 0
for key in a_dictionary:
count = a_dictionary[key]
total += count
for key in a_dictionary:
a_dictionary[key] = (a_dictionary[key] / total) * 100
return a_dictionary
在我们查看输出之前,让我们快速回顾一下上面发生了什么。在将我们的应用年龄分级字典分配给变量content_ratings之后,我们创建了一个名为make_percentages()的新函数,它接受一个参数:a_dictionary。
为了计算属于每个年龄等级的应用程序的百分比,我们需要知道应用程序的总数,所以我们首先将一个名为total的新变量设置为0,然后遍历a_dictionary中的每个键,将其添加到total。
一旦完成,我们需要做的就是再次遍历a_dictionary,将每个条目除以总数,然后将结果乘以 100。这会给我们一个带有百分比的字典。
但是当我们使用全局变量content_ratings作为这个新函数的参数时会发生什么呢?
c_ratings_percentages = make_percentages(content_ratings)
print(c_ratings_percentages)
print(content_ratings)
{'4+': 61.595109073224954, '9+': 13.714047519799916, '12+': 16.04835348061692, '17+': 8.642489926358204}
{'4+': 61.595109073224954, '9+': 13.714047519799916, '12+': 16.04835348061692, '17+': 8.642489926358204}
正如我们在列表中看到的那样,我们的全局content_ratings变量已经被修改,尽管它只是在我们创建的make_percentages()函数中被修改。
这里到底发生了什么?我们碰到了可变和不可变数据类型之间的差异。
可变和不可变数据类型
在 Python 中,数据类型可以是可变的(可改变的)或不可变的(不可改变的)。虽然我们在 Python 入门中使用的大多数数据类型都是不可变的(包括整数、浮点、字符串、布尔和元组),但列表和字典是可变的。这意味着即使在函数内部使用,全局列表或字典也可以被更改,就像我们在上面的例子中看到的一样。
为了理解可变(可改变的)和不可变(不可改变的)之间的区别,看看 Python 实际上是如何处理这些变量的是有帮助的。
让我们从考虑一个简单的变量赋值开始:
a = 5
变量名a就像一个指向5的指针,它帮助我们在任何需要的时候检索5。

5是整数,整数是不可变的数据类型。如果一个数据类型是不可变的,这意味着它一旦被创建就不能被更新。如果我们做了a += 1,我们实际上并没有将5更新为6。在下面的动画中,我们可以看到:
a最初指向5。- 运行
a += 1,这将指针从5移动到6,它实际上并没有改变数字5。

列表和字典等可变数据类型的行为不同。他们 可以更新。例如,让我们列一个简单的清单:
list_1 = [1, 2]
如果我们将一个3追加到这个列表的末尾,我们不只是简单地将list_1指向一个不同的列表,我们是直接更新现有的列表:

即使我们创建了多个列表变量,只要它们指向同一个列表,当列表改变时,它们都会被更新,如下面的代码所示:
list_1 = [1, 2]
list_2 = list_1
list_1.append(3)
print(list_1)
print(list_2)
[1, 2, 3]
[1, 2, 3]
下面是上面代码中实际发生的事情的动画可视化:

这就解释了为什么我们在早期试验列表和字典时,我们的全局变量被改变了。因为列表和字典是可变的,所以改变它们(即使在函数内部)也会改变列表或字典本身,这对于不可变的数据类型来说不是这样。
保持可变数据类型不变
一般来说,我们不希望函数改变全局变量,即使它们包含可变的数据类型,比如列表或字典。这是因为在更复杂的分析和程序中,我们可能会频繁地使用许多不同的函数。如果他们都在改变他们正在工作的列表和字典,那么跟踪什么在改变什么会变得相当困难。
谢天谢地,有一个简单的方法可以解决这个问题:我们可以使用一个名为.copy()的内置 Python 方法来复制列表或字典。
如果你还没有学过方法,不要着急。它们包含在我们的中级 Python 课程中,但是对于本教程,你需要知道的是.copy()的工作方式类似于.append():
list.append() # adds something to a list
list.copy() # makes a copy of a list
让我们再来看看我们为列表编写的函数,并更新它,这样函数内部发生的事情不会改变initial_list。我们需要做的就是将传递给函数的参数从initial_list改为initial_list.copy()。
initial_list = [1, 2, 3]
def duplicate_last(a_list):
last_element = a_list[-1]
a_list.append(last_element)
return a_list
new_list = duplicate_last(a_list = initial_list.copy()) # making a copy of the list
print(new_list)
print(initial_list)
[1, 2, 3, 3]
[1, 2, 3]
如我们所见,这已经解决了我们的问题。原因如下:使用.copy()创建了一个单独的列表副本,因此a_list不是指向initial_list本身,而是指向一个以initial_list的副本开始的新列表。在那之后对a_list所做的任何改变都是针对那个单独的列表,而不是initial_list本身,因此initial_list的全局值是不变的。

然而,这个解决方案仍然不是完美的,因为我们必须记住在每次传递一个参数给我们的函数时添加.copy(),否则会有意外改变initial_list的全局值的风险。如果我们不想为此担心,我们实际上可以在函数本身内部创建列表副本:
initial_list = [1, 2, 3]
def duplicate_last(a_list):
copy_list = a_list.copy() # making a copy of the list
last_element = copy_list[-1]
copy_list.append(last_element)
return copy_list
new_list = duplicate_last(a_list = initial_list)
print(new_list)
print(initial_list)
[1, 2, 3, 3]
[1, 2, 3]
使用这种方法,我们可以安全地将像initial_list这样的可变全局变量传递给我们的函数,并且全局值不会被改变,因为函数本身制作了一个副本,然后在该副本上执行它的操作。
.copy()方法也适用于字典。与列表一样,我们可以简单地将.copy()添加到参数中,我们传递函数来创建一个将用于该函数的副本,而不改变原始变量:
content_ratings = {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}
def make_percentages(a_dictionary):
total = 0
for key in a_dictionary:
count = a_dictionary[key]
total += count
for key in a_dictionary:
a_dictionary[key] = (a_dictionary[key] / total) * 100
return a_dictionary
c_ratings_percentages = make_percentages(content_ratings.copy()) # making a copy of the dictionary
print(c_ratings_percentages)
print(content_ratings)
{'4+': 61.595109073224954, '9+': 13.714047519799916, '12+': 16.04835348061692, '17+': 8.642489926358204}
{'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}
但是同样,使用这种方法意味着我们需要记住在每次将字典传递给函数make_percentages()时添加.copy() 。如果我们要经常使用这个函数,那么最好将复制操作实现到函数本身中,这样我们就不必记住这样做了。
下面,我们将在函数内部使用.copy()。这将确保我们可以在不改变作为参数传递给它的全局变量的情况下使用它,并且我们不需要记住给我们传递的每个参数添加.copy()。
content_ratings = {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}
def make_percentages(a_dictionary):
copy_dict = a_dictionary.copy() # create a copy of the dictionary
total = 0
for key in a_dictionary:
count = a_dictionary[key]
total += count
for key in copy_dict: #use the copied table so original isn't changed
copy_dict[key] = (copy_dict[key] / total) * 100
return copy_dict
c_ratings_percentages = make_percentages(content_ratings)
print(c_ratings_percentages)
print(content_ratings)
{'4+': 61.595109073224954, '9+': 13.714047519799916, '12+': 16.04835348061692, '17+': 8.642489926358204}
{'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}
正如我们所看到的,修改我们的函数来创建我们的字典的副本,然后只在副本中将计数更改为百分比,这允许我们执行我们想要的操作,而不实际更改content_ratings。
结论
在本教程中,我们研究了可变数据类型(可以改变)和不可变数据类型(不能改变)之间的区别。我们学习了如何使用方法.copy()来复制可变数据类型,比如列表和字典,这样我们就可以在函数中使用它们,而不需要改变它们的全局值。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
教程:R 和 RStudio 入门
原文:https://www.dataquest.io/blog/tutorial-getting-started-with-r-and-rstudio/
August 5, 2020
在本教程中,我们将学习如何使用 RStudio 开始 R 编程。我们将安装 R 和 RStudio RStudio ,这是一个非常流行的 R 开发环境。我们将学习 RStudio 的关键特性,以便自己开始用 R 编程。
如果你已经知道如何使用 RStudio,并想学习一些技巧、诀窍和快捷方式,请查看这篇 Dataquest 博客文章。
目录
- 1。安装 R
- 2。安装 RStudio
- 3。先看 RStudio
- 4。控制台
- 5。全球环境
- 6。安装
tidyverse软件包 - 7。将
tidyverse包载入内存 - 8。识别加载的包
- 9。获得关于软件包的帮助
- 10。获取功能帮助
- 11。RStudio 项目
- 12。保存您的“真实”工作。其余删除。
- 13。r 脚本
- 14。运行代码
- 15。访问内置数据集
- 16。风格
- 17。可复制的报告,R 降价
- 18。使用 RStudio 云
- 19。把手弄脏!
- 附加资源
- 奖励:备忘单
RStudio 入门
RStudio 是一款用于 r 编程的开源工具。RStudio 是一款灵活的工具,可帮助您创建可读的分析,并将您的代码、图像、注释和绘图放在一个地方。有必要了解 RStudio 在数据分析和 r 编程方面的能力。

使用 RStudio 进行数据分析和 R 编程有很多好处。以下是 RStudio 提供的一些示例:
- 一个直观的界面,让我们跟踪保存的对象,脚本和图形
- 一个文本编辑器,具有颜色编码语法等功能,可以帮助我们编写简洁的脚本
- 自动完成功能节省时间
- 用于创建包含项目代码、注释和视觉效果的文档的工具
- 专用的项目文件夹,将所有内容保存在一个地方
RStudio 还可以用于其他语言的编程,包括 SQL、Python 和 Bash 等等。
但是在我们安装 RStudio 之前,我们需要在我们的计算机上安装一个最新版本的 R。
1.安装 R
R 可从官方 R 网站下载。查找网页的这一部分:

要下载的 R 版本取决于我们的操作系统。下面,我们提供了 Mac OS X、Windows 和 Linux (Ubuntu)的安装说明。
MAC OS X
- 选择
Download R for (Mac) OSX选项。 - 寻找 R 的最新版本(新版本经常发布,出现在页面顶部)并点击
.pkg文件下载。 - 打开
.pkg文件,按照标准说明在 MAC OS X 上安装应用程序。 - 将 R 应用程序拖放到
Applications文件夹中。
窗户
- 选择
Download R for Windows选项。 - 选择
base,因为这是我们第一次在计算机上安装 R。 - 遵循安装 Windows 程序的标准说明。如果要求我们选择
Customize Startup或Accept Default Startup Options,选择默认选项。
Linux/Ubuntu
- 选择
Download R for Linux选项。 - 选择
Ubuntu选项。 - 或者,如果您没有使用
Ubuntu,请选择与您相关的 Linux 包管理系统。
RStudio 兼容许多版本的 R (R 版本 3.0.1 或截至 2020 年 7 月的更新版本)。将 R 与 RStudio 分开安装,用户可以选择适合自己需求的 R 版本。
2.安装 RStudio
既然已经安装了 R,我们就可以安装 RStudio 了。导航至 RStudio 下载页面。
当我们到达 RStudio 下载页面时,让我们单击RStudio Desktop Open Source License Free选项的“下载”按钮:

我们的操作系统通常会被自动检测,因此我们可以通过单击“下载 RStudio”按钮直接下载适合我们计算机的正确版本。如果我们想为另一个操作系统(不是我们正在运行的操作系统)下载 RStudio,请向下导航到页面的“所有安装程序”部分。

3.先看 RStudio
当我们第一次打开 RStudio 时,我们可能会看到这样的布局:
 但是背景颜色会是白色的,所以不要指望第一次启动 RStudio 时会看到这种蓝色的背景。查看这个 Dataquest 博客,了解如何定制 RStudio 的外观。
但是背景颜色会是白色的,所以不要指望第一次启动 RStudio 时会看到这种蓝色的背景。查看这个 Dataquest 博客,了解如何定制 RStudio 的外观。
当我们打开 RStudio 时,R 也会启动。新用户的一个常见错误是打开 R 而不是 RStudio。要打开 RStudio,请在桌面上搜索 RStudio,并将 RStudio 图标固定到首选位置(如桌面或工具栏)。
4.控制台
让我们从介绍控制台的一些功能开始。Console是 RStudio 中的一个选项卡,我们可以在这里运行 R 代码。
请注意,控制台所在的窗格包含三个选项卡:Console、Terminal和Jobs(这可能因使用的 RStudio 版本而异)。我们现在将重点放在控制台上。
当我们打开 RStudio 时,控制台包含我们正在使用的 R 版本的信息。向下滚动,试着键入一些像这样的表达式。按回车键查看结果。
1 + 2
正如我们所看到的,我们可以使用控制台立即测试代码。当我们键入一个类似于1 + 2的表达式时,我们会在按下回车键后看到下面的输出。

我们可以将该命令的输出存储为一个变量。这里,我们将变量 result 命名为:
result <- 1 + 2
<-被称为赋值运算符。该运算符为变量赋值。上面的命令被翻译成一句话:
结果变量得到一加二的值。
RStudio 的一个很好的特性是输入赋值操作符<-的键盘快捷键:
- 麦克·OS X:
Option + - - Windows/Linux:
Alt + -
我们强烈建议您记住这个键盘快捷键,因为从长远来看,它可以节省很多时间!
当我们在控制台中键入result并按 enter 键时,我们会看到3的存储值:
> result <- 1 + 2
> result
[1] 3
当我们在 RStudio 中创建一个变量时,它会将其保存为 R 全局环境中的一个对象。我们将在下一节讨论环境以及如何查看存储在环境中的对象。
5.全球环境
我们可以将全球环境视为我们的工作空间。在 R 的编程会话中,我们定义的任何变量,或者我们导入并保存在 dataframe 中的数据,都存储在我们的全局环境中。在 RStudio 中,我们可以在界面右上角的Environment选项卡中看到全局环境中的对象:

我们将在Environment选项卡的值下看到我们创建的任何对象,比如result。注意,显示了存储在变量中的值3。
有时,在全局环境中有太多的命名对象会造成混乱。也许我们想要移除所有或一些对象。要移除所有对象,请单击窗口顶部的扫帚图标:

要从工作区中删除选定的对象,请从下拉菜单中选择网格视图:

在这里,我们可以勾选想要移除的对象的复选框,并使用扫帚图标将其从我们的Global Environment中清除。
6.安装 tidyverse 包
R 中的许多功能都来自于使用包。包是代码、数据和文档的可共享集合。软件包本质上是我们上面安装的 R 程序的扩展或附件。
R 中最流行的包集合之一被称为“tidyverse”。tidyverse 是为处理数据而设计的 R 包的集合。tidyverse 包拥有共同的设计理念、语法和数据结构。Tidyverse 包“一起玩好”。tidyverse 使您能够花更少的时间清理数据,以便您可以将更多的精力放在数据的分析、可视化和建模上。
让我们学习如何安装 tidyverse 包。最常见的“核心”tidyverse 包有:
readr,用于数据导入。ggplot2,用于数据可视化。dplyr,用于数据操作。tidyr,用于数据整理。purrr,用于功能编程。- 对于 tibbles 来说,这是对数据帧的现代重构。
stringr,用于字符串操作。forcats,用于处理因子(分类数据)。
为了在 R 中安装包,我们使用内置的install.packages()函数。我们可以一个接一个地安装上面列出的包,但是幸运的是 tidyverse 的创建者提供了一种从一个命令安装所有这些包的方法。在控制台中键入以下命令,然后按 enter 键。
install.packages("tidyverse")
第一次下载安装包只需要使用install.packages()命令。
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
7.将 tidyverse 包加载到内存中
将软件包安装到计算机硬盘上后,使用library()命令将软件包加载到内存中:
library(readr)
library(ggplot2)
用library()将包加载到内存中使得给定包的功能可以在当前 R 会话中使用。对于 R 用户来说,在他们的硬盘上安装数百个 R 包是很常见的,所以一次加载所有的包是没有效率的。相反,我们指定特定项目或任务所需的 R 包。
幸运的是,只需一个命令就可以将核心 tidyverse 包加载到内存中。控制台中的命令和输出如下所示:
library(tidyverse)## ── Attaching packages ───────────────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
## ✓ tibble 3.0.3 ✓ dplyr 1.0.0
## ✓ tidyr 1.1.0 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ──────────────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
输出的Attaching packages部分指定了加载到内存中的包及其版本。Conflicts部分指定了我们刚刚加载到内存中的包中包含的任何函数名,这些函数名与已经加载到内存中的函数名相同。使用上面的例子,现在如果我们调用filter()函数,R 将使用dplyr包中为这个函数指定的代码。这些冲突通常不是问题,但是值得阅读输出消息来确定。
8.识别加载的包
如果我们需要检查我们加载了哪些包,我们可以参考控制台右下角窗口中的包选项卡。

我们可以搜索包,选中包旁边的框就可以加载它(代码出现在控制台中)。
或者,将此代码输入控制台将显示当前加载到内存中的所有包:
(.packages())
它返回:
[1] "forcats" "stringr" "dplyr" "purrr" "tidyr" "tibble" "tidyverse"
[8] "ggplot2" "readr" "stats" "graphics" "grDevices" "utils" "datasets"
[15] "methods" "base"
另一个用于返回当前加载到内存中的包名的有用函数是search():
> search()
[1] ".GlobalEnv" "package:forcats" "package:stringr" "package:dplyr"
[5] "package:purrr" "package:readr" "package:tidyr" "package:tibble"
[9] "package:ggplot2" "package:tidyverse" "tools:rstudio" "package:stats"
[13] "package:graphics" "package:grDevices" "package:utils" "package:datasets"
[17] "package:methods" "Autoloads" "package:base"
9.获取关于软件包的帮助
我们已经学习了如何安装和加载软件包。但是如果我们想了解更多关于我们已经安装的包的信息呢?那很简单!点击Packages选项卡中的包名,我们将进入所选包的Help选项卡。如果我们点击tidyr包,我们会看到:

或者,我们可以在控制台中键入以下命令,并获得相同的结果:
help(package = "tidyr")
软件包的帮助页面提供了对软件包中包含的每个功能的文档的快速访问。在软件包的主帮助页面上,您还可以访问可用的“简介”。小插图提供关于软件包的简要介绍、教程或其他参考信息,或者如何使用软件包中的特定功能。
vignette(package = "tidyr")
这产生了可用选项的列表:
Vignettes in package ‘tidyr’:nest nest (source, html)
pivot Pivoting (source, html)
programming Programming with tidyr (source, html)
rectangle rectangling (source, html)
tidy-data Tidy data (source, html)
in-packages Usage and migration (source, html)
在那里,我们可以选择一个特定的插图进行查看:
vignette("pivot")
现在我们看到枢轴插图显示在Help选项卡中。这就是为什么 RStudio 是一个强大的 r 编程工具的一个例子。我们可以在不离开 RStudio 的情况下访问函数和软件包文档和教程!
10.获取函数的帮助
正如我们在上一节中所学的,我们可以通过点击Packages中的包名来获得关于函数的帮助,然后点击一个函数名来查看帮助文件。这里我们看到tidyr包中的pivot_longer()函数位于列表的顶部:

如果我们点击“pivot_longer”,我们会得到这个:
我们可以在Console中用这些函数调用中的任何一个获得相同的结果:
help("pivot_longer")
help(pivot_longer)
?pivot_longer
注意,如果包含函数的包还没有加载到内存中,那么pivot_longer()函数(或者我们感兴趣的任何函数)的特定Help选项卡可能不是默认结果。一般来说,在寻求某个函数的帮助之前,最好确保一个特定的包已经被加载。
11.RStudio 项目
RStudio 提供了一个强大的功能,让您保持条理;项目。当您进行多项分析时,保持条理是非常重要的。RStudio 的项目允许您将所有重要的工作放在一个地方,包括代码脚本、绘图、图表、结果和数据集。
通过导航到 RStudio 中的File选项卡并选择New Project...来创建一个新项目。然后指定是在新目录中还是在现有目录中创建项目。在这里我们选择“新建目录”:

如果你正在开发一个 R 包,或者一个闪亮的 Web 应用程序,RStudio 提供了专门的项目类型。在这里,我们选择“新建项目”,这将创建一个 R 项目:

接下来,我们给我们的项目命名。“将项目创建为的子目录:”显示该文件夹在计算机上的位置。如果我们同意该位置,请选择“创建项目”,如果我们不同意,请选择“浏览”并选择该项目文件夹在计算机上的位置。

现在,在 RStudio 中,我们看到项目的名称显示在屏幕的右上角。我们也看到了。文件选项卡中的 Rproj 文件。我们在该项目中添加或生成的任何文件都将出现在“文件”选项卡中。

当您需要与同事分享您的工作时,RStudio 项目非常有用。您可以发送您的项目文件(结尾为。Rproj)以及所有支持文件,这将使您的同事更容易重建工作环境并再现结果。
12.保存您的“真实”工作。其余删除。
这个技巧来自我们的博客文章 23 RStudio Tips,Tricks,and Shortcuts ,但是它非常重要,我们也在这里分享它!
实践良好的内务管理,以避免未来不可预见的挑战。如果您创建了一个值得保存的 R 对象,请在 R 脚本文件中捕获生成该对象的 R 代码。保存 R 脚本,但是不要保存创建对象的环境或工作空间。
要防止 RStudio 保存您的工作空间,请打开Preferences > General并取消选择启动时将.RData恢复到工作空间的选项。确保指定您永远不想保存您的工作区,如下所示:
现在,每次打开 RStudio 时,您都将从一个空会话开始。从您之前的会话中生成的任何代码都不会被记住。R 脚本和数据集可以用来从头开始重新创建环境。
其他专家同意T2 不保存你的工作空间是使用 RStudio 的最佳实践。
13.r 脚本
在学习本教程的过程中,我们在Console中编写了代码。随着我们的项目变得越来越复杂,我们编写更长的代码块。如果我们想保存我们的工作,有必要将我们的代码组织成一个脚本。这使我们能够跟踪我们在项目中的工作,用大量的注释编写干净的代码,复制我们的工作,并与他人分享。
在 RStudio 中,我们可以在界面左上角的文本编辑器窗口中编写脚本:
 要创建新的脚本,我们可以使用文件菜单中的命令:
要创建新的脚本,我们可以使用文件菜单中的命令:

我们也可以使用键盘快捷键 Ctrl + Shift + N。当我们保存一个脚本时,它的文件扩展名为. r。例如,我们将创建一个新的脚本,其中包含生成散点图的代码:
library(ggplot2)
ggplot(data = mpg,
aes(x = displ, y = hwy)) +
geom_point()
为了保存我们的脚本,我们导航到File菜单选项卡并选择Save。或者我们输入以下命令:
- 麦克·OS X:
Cmd + S - Windows/Linux:
Ctrl + S
14.运行代码
要运行我们在脚本中输入的一行代码,我们可以点击脚本右上角的Run,或者当光标位于我们想要运行的行上时,使用以下键盘命令:
- 麦克·OS X:
Cmd + Enter - Windows/Linux:
Ctrl + Enter
在这种情况下,我们需要突出显示多行代码来生成散点图。要突出显示并运行脚本中的所有代码行,请输入:
- 麦克·OS X:
Cmd + A + Enter - Windows/Linux:
Ctrl + A + Enter
让我们看看运行上面指定的代码行的结果:

附注:这个散点图是使用包含在ggplot2包中的mpg数据集的数据生成的。该数据集包含了从 1999 年到 2008 年的 38 种流行车型的燃油经济性数据。
在该曲线图中,发动机排量(即大小)描绘在 x 轴(水平轴)上。y 轴(纵轴)描绘了以英里每加仑为单位的燃料效率。一般来说,燃油经济性随着发动机尺寸的增加而降低。这个图是用 tidyverse 包ggplot2生成的。这个包对于 r 中的数据可视化非常流行。
15.访问内置数据集
想从我们在上一个例子中提到的ggplot2包中了解更多关于mpg数据集的信息吗?使用以下命令执行此操作:
data(mpg, package = "ggplot2")
从这里,您可以使用head()函数查看前六行数据:
head(mpg)
## # A tibble: 6 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
##
## 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
## 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
## 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
## 4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
## 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
## 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…
用summary()函数获取汇总统计数据:
summary(mpg)
## manufacturer model displ year
## Length:234 Length:234 Min. :1.600 Min. :1999
## Class :character Class :character 1st Qu.:2.400 1st Qu.:1999
## Mode :character Mode :character Median :3.300 Median :2004
## Mean :3.472 Mean :2004
## 3rd Qu.:4.600 3rd Qu.:2008
## Max. :7.000 Max. :2008
## cyl trans drv cty
## Min. :4.000 Length:234 Length:234 Min. : 9.00
## 1st Qu.:4.000 Class :character Class :character 1st Qu.:14.00
## Median :6.000 Mode :character Mode :character Median :17.00
## Mean :5.889 Mean :16.86
## 3rd Qu.:8.000 3rd Qu.:19.00
## Max. :8.000 Max. :35.00
## hwy fl class
## Min. :12.00 Length:234 Length:234
## 1st Qu.:18.00 Class :character Class :character
## Median :24.00 Mode :character Mode :character
## Mean :23.44
## 3rd Qu.:27.00
## Max. :44.00
或者在Help选项卡中打开帮助页面,如下所示:
help(mpg)
最后,有许多 R 内置的数据集可以使用。内置的数据集便于练习新的 R 技能,而无需搜索数据。使用以下命令查看可用数据集:
data()
16.风格
编写 R 脚本时,最好在脚本顶部指定要加载的包:
library(ggplot2)
当我们编写 R 脚本时,添加注释来解释我们的代码也是很好的做法(#就像这样)。r 忽略以#开头的代码行。与同事和合作者共享代码是很常见的。确保他们理解我们的方法非常重要。但更重要的是,透彻的笔记对你未来的自己是有帮助的,让你以后重温剧本的时候能明白自己的方法!
下面是我们的散点图代码的注释示例:
library(ggplot2)
# fuel economy data from 1999 to 2008, for 38 popular models of cars
# engine displacement (size) is depicted on the x-axis
# fuel efficiency is depicted on the y-axis
ggplot(data = mpg,
aes(x = displ, y = hwy)) +
geom_point()
17.可重复报告,带 R Markdown
上面例子中使用的注释可以为我们的 R 脚本提供简短的注释,但是这种格式不适合编写需要总结结果和发现的报告。我们可以使用 R Markdown 文件在 RStudio 中创建格式良好的报告。
R Markdown 是一个开源工具,用于在 R 中生成可重复的报告。R Markdown 使我们能够将所有的代码、结果和编写内容放在一个地方。使用 R Markdown,我们可以选择将我们的作品导出为多种格式,包括 PDF、Microsoft Word、幻灯片或 html 文档,以便在网站上使用。
如果你想学习 R Markdown,看看这些 Dataquest 博客帖子:
18.使用 RStudio 云
RStudio 现在提供一个基于云的 RStudio 桌面版本,名为 RStudio Cloud 。RStudio Cloud 让你不用安装软件就可以在 RStudio 中编码,你只需要一个网页浏览器。我们在本教程中学到的几乎所有内容都适用于 RStudio Cloud!
RStudio Cloud 中的工作被组织到类似于桌面版本的项目中。RStudio Cloud 使您能够指定您希望用于每个项目的 R 版本。如果您正在重新访问一个围绕以前版本的 r 构建的旧项目,这是非常好的。
RStudio Cloud 还可以轻松安全地与同事共享项目,并确保每次访问项目时工作环境完全可再现。
RStudio 云的布局与 RStudio 桌面非常相似:
19.把手弄脏!
学习 RStudio 的最佳方式是应用我们在本教程中介绍的内容。自己跳起来熟悉 RStudio 吧!创建您自己的项目,保存您的工作,并共享您的结果。我们再怎么强调这一点的重要性也不为过。
不确定从哪里开始?查看下面列出的其他资源!
额外资源
如果你喜欢这个教程,来 Dataquest 和我们一起学习吧!如果您不熟悉 R 和 RStudio,我们建议您从 R 课程中的 Dataquest 数据分析介绍开始。这是 R 路径中 Dataquest 数据分析师的第一门课程。
如需更多高级 RStudio 技巧,请查看 Dataquest 博客文章 23 RStudio 技巧、诀窍和快捷方式。
在这篇 Dataquest 博客文章的中,学习如何使用 tidyverse 工具加载和清理数据。
RStudio 发表了许多关于使用 RStudio 的深入的操作方法文章。找到他们在这里。
有一个官方的 RStudio 博客。
如果你想学习 R Markdown,看看这些 Dataquest 博客帖子:
学习 R 和数据科学的 tidyverse 与 R。通过完成 RStudio 中的练习巩固您的知识,并保存您的工作以供将来参考。
奖励:备忘单
RStudio 发布了许多与 R 合作的备忘单,包括一份关于使用 RStudio 的详细备忘单!通过选择Help > Cheatsheets,可以从 RStudio 中访问选择备忘单。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号