
DataQuest-博客中文翻译-四-
DataQuest 博客中文翻译(四)
熊猫备忘单—用于数据科学的 Python
March 4, 2020
如果你对用 Python 处理数据感兴趣,你几乎肯定会使用 pandas 库。但是,即使你已经学习了熊猫——也许是在我们的交互式熊猫课程中——也很容易忘记做某事的具体语法。这就是为什么我们创建了一个熊猫备忘单来帮助你容易地参考最常见的熊猫任务。
在我们开始阅读备忘单之前,值得一提的是,您不应该仅仅依赖于此。如果你还没有学过熊猫,我们强烈建议你完成我们的熊猫课程。这张小抄将帮助你快速找到并回忆起你已经知道的关于熊猫的事情;它不是为了从头开始教你熊猫而设计的!
不时查看官方的熊猫文档也是个好主意,即使你能在小抄里找到你需要的。阅读文档是每个数据专业人员都需要的技能,文档涉及的细节比我们在一张纸上所能描述的要多得多!
如果你想用熊猫来完成一个特定的任务,我们也推荐你查看一下我们的免费 Python 教程 的完整列表;他们中的许多人除了使用其他 Python 库之外,还使用 pandas。例如,在我们的 Python 日期时间教程中,您还将学习如何在 pandas 中处理日期和时间。
熊猫小抄:指南
首先,给这个页面加个书签可能是个好主意,当你要找某个特定的东西时,用 Ctrl+F 可以很容易地搜索到它。然而,我们也制作了一份 PDF 版本的备忘单,如果你想打印出来,你可以从这里下载。
在这个备忘单中,我们将使用下面的简写方式:
df |任意熊猫数据帧对象s |任意熊猫系列对象
向下滚动时,您会看到我们已经使用副标题组织了相关命令,以便您可以根据您要完成的任务快速搜索并找到正确的语法。
另外,快速提醒—要使用下面列出的命令,您需要首先导入相关的库,如下所示:
import pandas as pd
import numpy as np
导入数据
使用这些命令从各种不同的源和格式导入数据。
pd.read_csv(filename) |从 CSV 文件pd.read_table(filename) |从分隔文本文件(如 TSV) pd.read_excel(filename) |从 Excel 文件pd.read_sql(query, connection_object) |从 SQL 表/数据库pd.read_json(json_string)读取|从 JSON 格式的字符串、URL 或文件读取。pd.read_html(url) |解析 html URL、字符串或文件,并将表格提取到数据帧列表中pd.read_clipboard() |获取剪贴板中的内容,并将其传递给 read_table() pd.DataFrame(dict) |从 dict、列名关键字、数据值列表中##导出数据
使用这些命令将数据帧导出为 CSV 格式。xlsx、SQL 或 JSON。
df.to_csv(filename) |写入 CSV 文件df.to_excel(filename) |写入 Excel 文件df.to_sql(table_name, connection_object) |写入 SQL 表df.to_json(filename) |写入 JSON 格式的文件##创建测试对象
这些命令对于创建测试段非常有用。
pd.DataFrame(np.random.rand(20,5)) | 5 列 20 行随机浮动pd.Series(my_list) |从可迭代的 my_list 中创建一个序列df.index = pd.date_range('1900/1/30', periods=df.shape[0]) |添加一个日期索引##查看/检查数据
使用这些命令查看熊猫数据帧或系列的特定部分。
df.head(n) |数据帧的前 n 行df.tail(n) |数据帧的后 n 行df.shape |行数和列数df.info() |索引、数据类型和内存信息df.describe() |数字列的汇总统计信息s.value_counts(dropna=False) |查看唯一值和计数df.apply(pd.Series.value_counts) |所有列的唯一值和计数##选择
使用这些命令选择数据的特定子集。
df[col] |返回标签为 col 的列作为系列df[[col1, col2]] |返回列作为新的数据帧s.iloc[0] |按位置选择s.loc['index_one'] |按索引选择df.iloc[0,:] |第一行df.iloc[0,0] |第一列的第一个元素##数据清理
使用这些命令执行各种数据清理任务。
df.columns = ['a','b','c'] |重命名列pd.isnull() |检查空值, 返回布尔数组pd.notnull() |与 pd.isnull()相反df.dropna() |删除所有包含空值的行df.dropna(axis=1) |删除所有包含空值的列df.dropna(axis=1,thresh=n) |删除所有包含少于 n 个非空值的行df.fillna(x) |用 x 替换所有空值s.fillna(s.mean()) |用平均值替换所有空值(平均值可以用来自统计模块 ) s.astype(float) | 将序列的数据类型转换为浮点数s.replace(1,'one') |将所有等于 1 的值替换为“一”s.replace([1,3],['one','three']) |将所有 1 替换为“一”,将所有 3 替换为“三”df.rename(columns=lambda x: x + 1) |对列进行大规模重命名df.rename(columns={'old_name': 'new_ name'}) |选择性重命名df.set_index('column_one') |更改索引df.rename(index=lambda x: x + 1) |对索引进行大规模重命名##筛选、排序和分组依据
使用这些命令对数据进行筛选、排序和分组。
df[df[col] > 0.5] |列col大于0.5T3 的行】|列0.7 > col > 0.5T5 的行】|按列 1 升序排序df.sort_values(col2,ascending=False) |按col2降序排序df.sort_values([col1,col2],ascending=[True,False]) |按col1降序排序col2``df.groupby(col)|返回一列值的 groupby 对象df.groupby([col1,col2]) |返回多列值的 groupby 对象df.groupby(col1)[col2] |返回col2中值的平均值, 按col1中的值分组(平均值可以用统计模块中的几乎任何函数替换)df.pivot_table(index=col1,values=[col2,col3],aggfunc=mean) |创建一个按col1分组的数据透视表,并计算col2和col3的平均值df.groupby(col1).agg(np.mean) |求出每个唯一列 1 组的所有列的平均值df.apply(np.mean) |对每列应用函数np.mean()``nf.apply(np.max,axis=1)|对每行应用函数np.max()# #联接/组合
使用这些命令将多个数据帧合并成一个数据帧。
df1.append(df2) |将df1中的行添加到df2的末尾(列应该相同)pd.concat([df1, df2],axis=1) |将df1中的列添加到df2的末尾(行应该相同)df1.join(df2,on=col1,how='inner') | SQL 样式将df1中的列与df2中的列连接,其中col的行具有相同的值。'how'可以是'left'、'right'、'outer'、'inner' ##统计中的一种
使用这些命令执行各种统计测试。(这些都可以同样适用于一个系列。)
df.describe() |数字列的汇总统计数据df.mean() |返回所有列的平均值df.corr() |返回数据帧中列之间的相关性df.count() |返回每个数据帧列中非空值的数量df.max() |返回每列中的最高值df.min() |返回每列中的最低值df.median() |返回每列的中间值df.std() |返回每列的标准偏差##下载此备忘单的可打印版本
如果您想下载此备忘单的可打印版本,您可以在此处下载。
更多资源
如果你想了解关于这个话题的更多信息,请查看 Dataquest 的交互式 Pandas 和 NumPy Fundamentals 课程,以及我们的Python 数据分析师和Python 数据科学家路径,它们将帮助你在大约 6 个月内做好工作准备。

https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
教程:用 Pandas 和 Python 连接(组合数据表)
原文:https://www.dataquest.io/blog/pandas-concatenation-tutorial/
December 13, 2017
您很难找到不需要连接(将多个数据源组合在一起)的数据科学项目。很多时候,数据分析需要向表中追加新行,拉入额外的列,或者在更复杂的情况下,在一个公共键上合并不同的表。所有这些技巧都可以放在你的口袋里,这样不同的数据源就不会妨碍你的分析了!
在这个连接教程中,我们将介绍几种使用 pandas 合并数据的方法。它面向初级到中级水平,需要熊猫数据框架的基础知识。之前对 SQL 和关系数据库的一些了解也会派上用场,但不是必需的。我们将通过四种不同的技术(连接、追加、合并和连接)来分析几个国家的年平均劳动时间。我们还将在每一步之后创建一个图,以便直观地了解每种数据组合技术产生的不同结果。作为奖励,你将带着对全球劳动力趋势的深刻见解离开本教程,还有一组漂亮的图表可以添加到你的投资组合中!
我们将在经济合作与发展组织(经合组织)发挥宏观经济分析师的作用。我们试图回答的问题简单而有趣:哪些国家的公民工作时间最长,这些趋势如何随着时间的推移而变化?不幸的是,经合组织一直在分别收集不同大洲和不同时期的数据。我们的工作是首先将所有数据集中到一个地方,这样我们就可以进行必要的分析。
访问数据集
我们将使用来自经合组织就业和劳动力市场统计数据库的数据,该数据库提供了自 1950 年以来大多数发达国家的年均劳动时间数据。在整个教程中,我将交替使用数据帧和表格。我们将在 Python 3 中使用一个 Jupyter 笔记本(欢迎您使用任何 IDE(集成开发环境),但是本教程在 Jupyter 中是最容易理解的)。一旦启动,让我们导入pandas和matplotlib库,然后使用%matplotlb inline以便 Jupyter 知道在笔记本单元格内显示图形。如果我提到的任何工具听起来不熟悉,我建议看看 Dataquest 的入门指南。
import pandas as pd
import matplotlib.pyplot as plt
接下来,我们将使用pd.read_csv()函数打开前两个数据文件。我们将通过传递参数index_col=0来指定第一列应该用作行索引。最后,我们将展示我们的初始表的样子。
north_america = pd.read_csv('./north_america_2000_2010.csv', index_col=0)
south_america = pd.read_csv('./south_america_2000_2010.csv', index_col=0)
north_america
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | |||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 加拿大 | One thousand seven hundred and seventy-nine | One thousand seven hundred and seventy-one | One thousand seven hundred and fifty-four | One thousand seven hundred and forty | One thousand seven hundred and sixty | One thousand seven hundred and forty-seven | One thousand seven hundred and forty-five | One thousand seven hundred and forty-one | One thousand seven hundred and thirty-five | One thousand seven hundred and one | One thousand seven hundred and three |
| 墨西哥 | Two thousand three hundred and eleven point two | Two thousand two hundred and eighty-five point two | Two thousand two hundred and seventy-one point two | Two thousand two hundred and seventy-six point five | Two thousand two hundred and seventy point six | Two thousand two hundred and eighty-one | Two thousand two hundred and eighty point six | Two thousand two hundred and sixty-one point four | Two thousand two hundred and fifty-eight | Two thousand two hundred and fifty point two | Two thousand two hundred and forty-two point four |
| 美利坚合众国 | One thousand eight hundred and thirty-six | One thousand eight hundred and fourteen | One thousand eight hundred and ten | One thousand eight hundred | One thousand eight hundred and two | One thousand seven hundred and ninety-nine | One thousand eight hundred | One thousand seven hundred and ninety-eight | One thousand seven hundred and ninety-two | One thousand seven hundred and sixty-seven | One thousand seven hundred and seventy-eight |
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | |||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 辣椒 | Two thousand two hundred and sixty-three | Two thousand two hundred and forty-two | Two thousand two hundred and fifty | Two thousand two hundred and thirty-five | Two thousand two hundred and thirty-two | Two thousand one hundred and fifty-seven | Two thousand one hundred and sixty-five | Two thousand one hundred and twenty-eight | Two thousand and ninety-five | Two thousand and seventy-four | Two thousand and sixty-nine point six |
经过一些观察,我们发现行是国家,列是年份,单元格值是每个雇员的平均年工作时间。尽管数据框架如此辉煌,但它们仍然很难一眼看懂,所以我们将使用 matplotlib 的 DataFrame.plot()方法来绘制我们每年的劳动力趋势线图。
north_america.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x2fc51a80f0>

哇,这不是我们想要的!默认情况下,DataFrame.plot()方法将行视为 x 轴标签,将单元格值视为 y 轴标签,将列视为线条。这里的快速解决方案是使用DataFrame.transpose()方法在我们的数据框架上旋转轴。为了使我们的可视化完整,我们将使用 plot 方法中的title='string'参数添加一个标题。我们可以将这些方法链接在一起,然后使用plt.show()来整齐地显示我们的线图,而不在绘图上方显示 matplotlib 文本行。
north_america.transpose().plot(title='Average Labor Hours Per Year')
plt.show()

south_america.transpose().plot(title='Average Labor Hours Per Year')
plt.show()

串联美洲数据
看起来我们在north_america数据框架中有三个国家,在south_america数据框架中有一个国家。因为这是两个独立的地块,所以很难比较南美和北美的平均劳动时间。如果我们能把所有的国家都放在同一个数据框架中,这种比较就容易多了。
对于需要添加相同长度的行或列的简单操作, pd.concat()函数是完美的。我们所要做的就是传入一个 DataFrame 对象的列表,按照我们希望它们连接的顺序。
result = pd.concat([list of DataFrames], axis=0, join='outer', ignore_index=False)
- 轴:我们将沿着行(0)还是列(1)连接
- join:可设置为内、外、左或右。在本教程的后面会有更详细的解释
- ignore_index:是否应该保留的原始行标签
在我们的例子中,我们可以保留所有默认参数,只传入我们的north_america和south_america数据帧。
americas = pd.concat([north_america, south_america])
americas
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | |||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 加拿大 | One thousand seven hundred and seventy-nine | One thousand seven hundred and seventy-one | One thousand seven hundred and fifty-four | One thousand seven hundred and forty | One thousand seven hundred and sixty | One thousand seven hundred and forty-seven | One thousand seven hundred and forty-five | One thousand seven hundred and forty-one | One thousand seven hundred and thirty-five | One thousand seven hundred and one | One thousand seven hundred and three |
| 墨西哥 | Two thousand three hundred and eleven point two | Two thousand two hundred and eighty-five point two | Two thousand two hundred and seventy-one point two | Two thousand two hundred and seventy-six point five | Two thousand two hundred and seventy point six | Two thousand two hundred and eighty-one | Two thousand two hundred and eighty point six | Two thousand two hundred and sixty-one point four | Two thousand two hundred and fifty-eight | Two thousand two hundred and fifty point two | Two thousand two hundred and forty-two point four |
| 美利坚合众国 | One thousand eight hundred and thirty-six | One thousand eight hundred and fourteen | One thousand eight hundred and ten | One thousand eight hundred | One thousand eight hundred and two | One thousand seven hundred and ninety-nine | One thousand eight hundred | One thousand seven hundred and ninety-eight | One thousand seven hundred and ninety-two | One thousand seven hundred and sixty-seven | One thousand seven hundred and seventy-eight |
| 辣椒 | Two thousand two hundred and sixty-three | Two thousand two hundred and forty-two | Two thousand two hundred and fifty | Two thousand two hundred and thirty-five | Two thousand two hundred and thirty-two | Two thousand one hundred and fifty-seven | Two thousand one hundred and sixty-five | Two thousand one hundred and twenty-eight | Two thousand and ninety-five | Two thousand and seventy-four | Two thousand and sixty-nine point six |
这看起来是一个好的开始,但是我们希望我们的数据越新越好。从 2011 年到 2015 年,数据收集团队在要求提供这四个国家的数据后,每年都会向我们发送单独的 CSV 文件,如下所示:
[americas_2011.csv , americas_2012.csv, americas_2014.csv, americas_2015.csv]
让我们使用循环的和 string.format()方法加载新数据,使这个过程稍微自动化一些。我们将把前面的americas数据帧放到一个名为americas_dfs的列表中,并将这些新的数据帧添加到这个列表中。最后,我们将使用列表索引显示americas_2011数据帧。
americas_dfs = [americas]
for year in range(2011, 2016):
filename = "./americas_{}.csv".format(year)
df = pd.read_csv(filename, index_col=0)
americas_dfs.append(df)
americas_dfs[1]
| Two thousand and eleven | |
|---|---|
| 国家 | |
| --- | --- |
| 加拿大 | One thousand seven hundred |
| 辣椒 | Two thousand and forty-seven point four |
| 墨西哥 | Two thousand two hundred and fifty point two |
| 美利坚合众国 | One thousand seven hundred and eighty-six |
您可能会注意到,我们刚刚打印的americas_2011数据帧中的行与americas数据帧的顺序不同(pandas 自动按字母顺序排列它们)。幸运的是,pd.concat()函数连接的是索引标签上的数据(在我们的例子中是国家),而不是序列,所以这在拼接时不会造成问题。如果我们想按照当前的顺序连接这些行,我们可以传递参数ignore_index=True。这将导致索引被分配一个整数序列。同样重要的是要记住,我们必须按照我们希望它们连接的顺序来创建数据帧列表,否则我们的年份将会打乱时间顺序。
我们不能像上次一样使用pd.concat()函数,因为现在我们添加的是列而不是行。这就是轴发挥作用的地方。默认情况下,该参数被设置为axis=0,这意味着我们在连接行。这一次,我们需要传入axis=1来表明我们想要连接列。请记住,这只有在所有表格都具有相同高度(行数)的情况下才有效。

来源:堆栈溢出
沿着轴 1 连接时要记住的一个警告是,行索引的标题“Country”将被删除。这是因为 pandas 不确定这个标题是否适用于已经添加的新行标签。我们可以通过分配DataFrame.index.names属性轻松解决这个问题。之后,让我们做另一个图,看看我们在哪里。
americas = pd.concat(americas_dfs, axis=1)
americas.index.names = ['Country']
americas
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | Two thousand and eleven | Two thousand and twelve | Two thousand and thirteen | Two thousand and fourteen | Two thousand and fifteen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | ||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 加拿大 | One thousand seven hundred and seventy-nine | One thousand seven hundred and seventy-one | One thousand seven hundred and fifty-four | One thousand seven hundred and forty | One thousand seven hundred and sixty | One thousand seven hundred and forty-seven | One thousand seven hundred and forty-five | One thousand seven hundred and forty-one | One thousand seven hundred and thirty-five | One thousand seven hundred and one | One thousand seven hundred and three | One thousand seven hundred | One thousand seven hundred and thirteen | One thousand seven hundred and seven | One thousand seven hundred and three | One thousand seven hundred and six |
| 辣椒 | Two thousand two hundred and sixty-three | Two thousand two hundred and forty-two | Two thousand two hundred and fifty | Two thousand two hundred and thirty-five | Two thousand two hundred and thirty-two | Two thousand one hundred and fifty-seven | Two thousand one hundred and sixty-five | Two thousand one hundred and twenty-eight | Two thousand and ninety-five | Two thousand and seventy-four | Two thousand and sixty-nine point six | Two thousand and forty-seven point four | Two thousand and twenty-four | Two thousand and fifteen point three | One thousand nine hundred and ninety point one | One thousand nine hundred and eighty-seven point five |
| 墨西哥 | Two thousand three hundred and eleven point two | Two thousand two hundred and eighty-five point two | Two thousand two hundred and seventy-one point two | Two thousand two hundred and seventy-six point five | Two thousand two hundred and seventy point six | Two thousand two hundred and eighty-one | Two thousand two hundred and eighty point six | Two thousand two hundred and sixty-one point four | Two thousand two hundred and fifty-eight | Two thousand two hundred and fifty point two | Two thousand two hundred and forty-two point four | Two thousand two hundred and fifty point two | Two thousand two hundred and twenty-five point eight | Two thousand two hundred and thirty-six point six | Two thousand two hundred and twenty-eight point four | Two thousand two hundred and forty-six point four |
| 美利坚合众国 | One thousand eight hundred and thirty-six | One thousand eight hundred and fourteen | One thousand eight hundred and ten | One thousand eight hundred | One thousand eight hundred and two | One thousand seven hundred and ninety-nine | One thousand eight hundred | One thousand seven hundred and ninety-eight | One thousand seven hundred and ninety-two | One thousand seven hundred and sixty-seven | One thousand seven hundred and seventy-eight | One thousand seven hundred and eighty-six | One thousand seven hundred and eighty-nine | One thousand seven hundred and eighty-seven | One thousand seven hundred and eighty-nine | One thousand seven hundred and ninety |
americas.transpose().plot(title='Average Labor Hours Per Year')
plt.show()

追加来自其他大陆的数据
现在我们已经对美洲有了全面的了解,我们想看看与世界其他地方相比如何。数据收集团队提供了 2000 年至 2015 年亚洲、欧洲和南太平洋的 CSV 文件。让我们把这些文件放进去预览一下。由于europe是一个高得多的表,我们将利用DataFrame.head()方法通过只显示前 5 行来节省空间。
asia = pd.read_csv('./asia_2000_2015.csv', index_col=0)
asia
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | Two thousand and eleven | Two thousand and twelve | Two thousand and thirteen | Two thousand and fourteen | Two thousand and fifteen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | ||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 以色列 | Two thousand and seventeen | One thousand nine hundred and seventy-nine | One thousand nine hundred and ninety-three | One thousand nine hundred and seventy-four | One thousand nine hundred and forty-two | One thousand nine hundred and thirty-one | One thousand nine hundred and nineteen | One thousand nine hundred and thirty-one | One thousand nine hundred and twenty-nine | One thousand nine hundred and twenty-seven | One thousand nine hundred and eighteen | One thousand nine hundred and twenty | One thousand nine hundred and ten | One thousand eight hundred and sixty-seven | One thousand eight hundred and fifty-three | One thousand eight hundred and fifty-eight |
| 日本 | One thousand eight hundred and twenty-one | One thousand eight hundred and nine | One thousand seven hundred and ninety-eight | One thousand seven hundred and ninety-nine | One thousand seven hundred and eighty-seven | One thousand seven hundred and seventy-five | One thousand seven hundred and eighty-four | One thousand seven hundred and eighty-five | One thousand seven hundred and seventy-one | One thousand seven hundred and fourteen | One thousand seven hundred and thirty-three | One thousand seven hundred and twenty-eight | One thousand seven hundred and forty-five | One thousand seven hundred and thirty-four | One thousand seven hundred and twenty-nine | One thousand seven hundred and nineteen |
| 朝鲜;韩国 | Two thousand five hundred and twelve | Two thousand four hundred and ninety-nine | Two thousand four hundred and sixty-four | Two thousand four hundred and twenty-four | Two thousand three hundred and ninety-two | Two thousand three hundred and fifty-one | Two thousand three hundred and forty-six | Two thousand three hundred and six | Two thousand two hundred and forty-six | Two thousand two hundred and thirty-two | Two thousand one hundred and eighty-seven | Two thousand and ninety | Two thousand one hundred and sixty-three | Two thousand and seventy-nine | Two thousand one hundred and twenty-four | Two thousand one hundred and thirteen |
| 俄罗斯 | One thousand nine hundred and eighty-two | One thousand nine hundred and eighty | One thousand nine hundred and eighty-two | One thousand nine hundred and ninety-three | One thousand nine hundred and ninety-three | One thousand nine hundred and eighty-nine | One thousand nine hundred and ninety-eight | One thousand nine hundred and ninety-nine | One thousand nine hundred and ninety-seven | One thousand nine hundred and seventy-four | One thousand nine hundred and seventy-six | One thousand nine hundred and seventy-nine | One thousand nine hundred and eighty-two | One thousand nine hundred and eighty | One thousand nine hundred and eighty-five | One thousand nine hundred and seventy-eight |
europe = pd.read_csv('./europe_2000_2015.csv', index_col=0)
europe.head()
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | Two thousand and eleven | Two thousand and twelve | Two thousand and thirteen | Two thousand and fourteen | Two thousand and fifteen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | ||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 奥地利 | One thousand eight hundred and seven point four | One thousand seven hundred and ninety-four point six | One thousand seven hundred and ninety-two point two | One thousand seven hundred and eighty-three point eight | One thousand seven hundred and eighty-six point eight | One thousand seven hundred and sixty-four | One thousand seven hundred and forty-six point two | One thousand seven hundred and thirty-six | One thousand seven hundred and twenty-eight point five | One thousand six hundred and seventy-three | One thousand six hundred and sixty-eight point six | One thousand six hundred and seventy-five point nine | One thousand six hundred and fifty-two point nine | One thousand six hundred and thirty-six point seven | One thousand six hundred and twenty-nine point four | One thousand six hundred and twenty-four point nine |
| 比利时 | One thousand five hundred and ninety-five | One thousand five hundred and eighty-eight | One thousand five hundred and eighty-three | One thousand five hundred and seventy-eight | One thousand five hundred and seventy-three | One thousand five hundred and sixty-five | One thousand five hundred and seventy-two | One thousand five hundred and seventy-seven | One thousand five hundred and seventy | One thousand five hundred and forty-eight | One thousand five hundred and forty-six | One thousand five hundred and sixty | One thousand five hundred and sixty | One thousand five hundred and fifty-eight | One thousand five hundred and sixty | One thousand five hundred and forty-one |
| 瑞士 | One thousand six hundred and seventy-three point six | One thousand six hundred and thirty-five | One thousand six hundred and fourteen | One thousand six hundred and twenty-six point eight | One thousand six hundred and fifty-six point five | One thousand six hundred and fifty-one point seven | One thousand six hundred and forty-three point two | One thousand six hundred and thirty-two point seven | One thousand six hundred and twenty-three point one | One thousand six hundred and fourteen point nine | One thousand six hundred and twelve point four | One thousand six hundred and five point four | One thousand five hundred and ninety point nine | One thousand five hundred and seventy-two point nine | One thousand five hundred and sixty-eight point three | One thousand five hundred and eighty-nine point seven |
| 捷克共和国 | One thousand eight hundred and ninety-six | One thousand eight hundred and eighteen | One thousand eight hundred and sixteen | One thousand eight hundred and six | One thousand eight hundred and seventeen | One thousand eight hundred and seventeen | One thousand seven hundred and ninety-nine | One thousand seven hundred and eighty-four | One thousand seven hundred and ninety | One thousand seven hundred and seventy-nine | One thousand eight hundred | One thousand eight hundred and six | One thousand seven hundred and seventy-six | One thousand seven hundred and sixty-three | One thousand seven hundred and seventy-one | One thousand seven hundred and seventy-nine |
| 德国 | One thousand four hundred and fifty-two | One thousand four hundred and forty-one point nine | One thousand four hundred and thirty point nine | One thousand four hundred and twenty-four point eight | One thousand four hundred and twenty-two point two | One thousand four hundred and eleven point three | One thousand four hundred and twenty-four point seven | One thousand four hundred and twenty-four point four | One thousand four hundred and eighteen point four | One thousand three hundred and seventy-two point seven | One thousand three hundred and eighty-nine point nine | One thousand three hundred and ninety-two point eight | One thousand three hundred and seventy-five point three | One thousand three hundred and sixty-one point seven | One thousand three hundred and sixty-six point four | One thousand three hundred and seventy-one |
south_pacific = pd.read_csv('./south_pacific_2000_2015.csv', index_col=0)
south_pacific
| Two thousand | Two thousand and one | Two thousand and two | Two thousand and three | Two thousand and four | Two thousand and five | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | Two thousand and eleven | Two thousand and twelve | Two thousand and thirteen | Two thousand and fourteen | Two thousand and fifteen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | ||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 澳大利亚 | One thousand seven hundred and seventy-eight point seven | One thousand seven hundred and thirty-six point seven | One thousand seven hundred and thirty-one point seven | One thousand seven hundred and thirty-five point eight | One thousand seven hundred and thirty-four point five | One thousand seven hundred and twenty-nine point two | One thousand seven hundred and twenty point five | One thousand seven hundred and twelve point five | One thousand seven hundred and seventeen point two | One thousand six hundred and ninety | One thousand six hundred and ninety-one point five | One thousand six hundred and ninety-nine point five | One thousand six hundred and seventy-eight point six | One thousand six hundred and sixty-two point seven | One thousand six hundred and sixty-three point six | One thousand six hundred and sixty-five |
| 新西兰 | One thousand eight hundred and thirty-six | One thousand eight hundred and twenty-five | One thousand eight hundred and twenty-six | One thousand eight hundred and twenty-three | One thousand eight hundred and thirty | One thousand eight hundred and fifteen | One thousand seven hundred and ninety-five | One thousand seven hundred and seventy-four | One thousand seven hundred and sixty-one | One thousand seven hundred and forty | One thousand seven hundred and fifty-five | One thousand seven hundred and forty-six | One thousand seven hundred and thirty-four | One thousand seven hundred and fifty-two | One thousand seven hundred and sixty-two | One thousand seven hundred and fifty-seven |
当您只想添加新行时,Pandas 有一个快捷方式,称为 DataFrame.append()方法。语法略有不同——因为它是一个 DataFrame 方法,我们将使用点符号在我们的americas对象上调用它,然后将新对象作为参数传入。
result = DataFrame.append([DataFrame or list of DataFrames])
看起来这些新的数据框架把所有 16 年都作为它们的列。如果我们试图追加的数据中缺少任何列,它们将导致那些单元格中有NaN值的行落在缺少的年份列下。让我们运行 append 方法,并通过打印DataFrame.index来验证所有国家都已被成功追加。然后,我们可以绘制一个线图,看看新追加的数据是什么样子。
world = americas.append([asia, europe, south_pacific])
world.index
Index(['Canada', 'Chile', 'Mexico', 'USA', 'Israel', 'Japan', 'Korea', 'Russia', 'Austria', 'Belgium', 'Switzerland', 'Czech Republic', 'Germany', 'Denmark', 'Spain', 'Estonia', 'Finland', 'France', 'United Kingdom', 'Greece', 'Hungary', 'Ireland', 'Iceland', 'Italy', 'Lithuania', 'Luxembourg', 'Latvia', 'Netherlands', 'Norway', 'Poland', 'Portugal', 'Slovak Republic', 'Slovenia', 'Sweden', 'Australia', 'New Zealand'], dtype='object', name='Country')
world.transpose().plot(title='Average Labor Hours Per Year')
plt.show()

自定义可视化
包含 36 个国家的新数据框架很棒,但是天哪,它打乱了我们的计划!在继续之前,看看你是否能发现我们视觉化的三个错误。
首先,我们希望将我们的图放大很多,这样我们就能以更高的保真度看到所有这些新的数据点。如果我们传递figsize=(10,10)参数,这是一个非常简单的修复方法,元组指定了绘图图形的维度。你可能还注意到有 36 条线代表我们所有不同的国家,但是颜色是重复的。这是因为默认的色彩映射表只包含 10 种不同的颜色,但是我们需要更多的颜色。我查看了 matplotlib colormaps 文档,并决定使用彩虹贴图,这可以作为colormap='rainbow'传入。因为我们把图形变大了,我也想要更粗的线条,所以我设置了linewidth=2。
最后,我们将处理重叠到我们的阴谋传说。这可以通过plt.legend()功能完成。我们将传入loc='right'来表示我们希望图例框位于绘图的右侧。你可以测试一下,它并没有和图的边界完全一致。我们可以用bbox_to_anchor=(1.3,0.5)论点做一些微调;我们传入的元组是图例框相对于绘图的位置坐标。我摆弄了一下这些值,直到我找到一个匹配的,但是如果你喜欢不同的审美,请随意修改这四个参数中的任何一个。
world.transpose().plot(figsize=(10,10), colormap='rainbow', linewidth=2, title='Average Labor Hours Per Year')
plt.legend(loc='right', bbox_to_anchor=(1.3, 0.5))
plt.show()

连接入门
对于那些在 SQL 等关系数据库中有连接经验的人来说,这里有一些好消息:pandas 提供了高性能内存合并和连接选项。当我们需要组合非常大的数据帧时,连接是快速执行这些操作的强大方法。
需要记住几件重要的事情:一次只能在两个数据帧上进行连接,分别表示为左表和右表。键是两个数据框将要连接的公共列。使用在整个列中具有唯一值的键是一个很好的做法,这样可以避免无意中出现重复的行值。
根据哪些行必须保留它们的数据,有四种处理连接的基本方法(内连接、左连接、右连接和外连接)。下面的文氏图将帮助您直观地理解这些连接;请将蓝色区域视为最终表中将保留的键列部分。
一个内部连接是最简单的连接,它只保留两个表共享一个键值的行。

一个 left join 保存主(左)表中出现的所有行,右表只连接与左表共享键值的行。NaN没有匹配键值的单元格将被填入值。

一个右连接和一个左连接是相同的概念,但是保留了右表中出现的所有行。得到的数据帧将在左侧具有任何潜在的NaN值。

最后,全外连接保留两个表中出现的所有行,并且NaN值可以出现在结果数据帧的任何一侧。

合并历史劳动力数据
很高兴能够看到自 2000 年以来劳动时间是如何变化的,但是为了看到真正的趋势,我们希望能够看到尽可能多的历史数据。数据收集小组好心地发送了 1950 年到 2000 年的数据,让我们把它载入来看看。
historical = pd.read_csv('./historical.csv', index_col=0)
historical.head()
| One thousand nine hundred and fifty | One thousand nine hundred and fifty-one | One thousand nine hundred and fifty-two | One thousand nine hundred and fifty-three | One thousand nine hundred and fifty-four | One thousand nine hundred and fifty-five | One thousand nine hundred and fifty-six | One thousand nine hundred and fifty-seven | One thousand nine hundred and fifty-eight | One thousand nine hundred and fifty-nine | … | One thousand nine hundred and ninety | One thousand nine hundred and ninety-one | One thousand nine hundred and ninety-two | One thousand nine hundred and ninety-three | One thousand nine hundred and ninety-four | One thousand nine hundred and ninety-five | One thousand nine hundred and ninety-six | One thousand nine hundred and ninety-seven | One thousand nine hundred and ninety-eight | One thousand nine hundred and ninety-nine | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | |||||||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 澳大利亚 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand seven hundred and seventy-nine point five | One thousand seven hundred and seventy-four point nine | One thousand seven hundred and seventy-three point seven | One thousand seven hundred and eighty-six point five | One thousand seven hundred and ninety-seven point six | One thousand seven hundred and ninety-three point four | One thousand seven hundred and eighty-two point seven | One thousand seven hundred and eighty-three point six | One thousand seven hundred and sixty-eight point four | One thousand seven hundred and seventy-eight point eight |
| 奥地利 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | One thousand six hundred and nineteen point two | One thousand six hundred and thirty-seven point one five | One thousand six hundred and forty-eight point five | One thousand six hundred and forty-one point six five | One thousand six hundred and fifty-four |
| 比利时 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand six hundred and sixty-two point nine | One thousand six hundred and twenty-five point seven nine | One thousand six hundred and two point seven two | One thousand five hundred and fifty-eight point five nine | One thousand five hundred and fifty-eight point five nine | One thousand five hundred and fifteen point eight three five | One thousand five hundred point two nine five | One thousand five hundred and ten point three one five | One thousand five hundred and thirteen point three three | One thousand five hundred and fourteen point five |
| 加拿大 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand seven hundred and eighty-nine point five | One thousand seven hundred and sixty-seven point five | One thousand seven hundred and sixty-six | One thousand seven hundred and sixty-four point five | One thousand seven hundred and seventy-three | One thousand seven hundred and seventy-one point five | One thousand seven hundred and eighty-six point five | One thousand seven hundred and eighty-two point five | One thousand seven hundred and seventy-eight point five | One thousand seven hundred and seventy-eight point five |
| 瑞士 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | 圆盘烤饼 | One thousand six hundred and seventy-three point one | One thousand six hundred and eighty-four point eight | One thousand six hundred and eighty-five point eight | One thousand seven hundred and six point two | One thousand six hundred and eighty-five point five | One thousand six hundred and fifty-eight point nine | One thousand six hundred and forty-eight point six | One thousand six hundred and fifty-six point six | One thousand six hundred and seventy-eight point four |
5 行× 50 列
你会注意到有很多NaN值,尤其是在早些年。这仅仅意味着没有收集这些国家前几年的数据。在这些单元格中输入 0 会产生误导,因为这意味着那一年没有人花时间工作!相反,NaN表示空值,意思是“不是数字”。空值不会影响我们的数据帧合并,因为我们将使用行标签(索引)作为我们的键。
合并时,记住每个表中的哪些行将被保留是很重要的。我不确定我的表的完整尺寸是多少,所以我们可以只查看我们感兴趣的事实,而不是显示全部内容。让我们打印DataFrame.shape()属性来查看包含两个表的(总行数,总列数)的元组。
print("World rows & columns: ", world.shape)
print("Historical rows & columns: ", historical.shape)
World rows & columns: (36, 16)Historical rows & columns: (39, 50)
请注意,历史表有 39 行,尽管我们只分析了世界表中的 36 个国家。通过适当的数据帧合并,可以自动删除额外的三行。我们将把world作为主表,并希望它位于结果数据框的右侧,而 historical 位于左侧,因此年份(列)按时间顺序排列。这两个表中的列都是不同的,这意味着我们必须找到一个键来连接。在这种情况下,键将是行索引(国家)。
我们将使用 pd.merge()函数进行右连接,并使用索引作为键进行连接。
result = pd.merge(left DataFrame, right DataFrame, left_index=False, right_index=False, how='inner')
使用此函数时,前两个参数将始终分别是左侧和右侧数据帧。然后,我们希望设置left_index=True和right_index=True来指定索引将是我们的键值,这样我们就可以保留国家作为行标签(否则 pandas 会将行索引更改为整数序列。)最后,我们传入how='right'来指示一个右连接。
正确的连接将确保我们只保留正确表中的 36 行,而丢弃历史表中额外的 3 行。让我们打印生成的数据帧的形状,并显示头部,以确保一切结果正确。
world_historical = pd.merge(historical, world, left_index=True, right_index=True, how='right')
print(world_historical.shape)
world_historical.head()
(36, 66)
| One thousand nine hundred and fifty | One thousand nine hundred and fifty-one | One thousand nine hundred and fifty-two | One thousand nine hundred and fifty-three | One thousand nine hundred and fifty-four | One thousand nine hundred and fifty-five | One thousand nine hundred and fifty-six | One thousand nine hundred and fifty-seven | One thousand nine hundred and fifty-eight | One thousand nine hundred and fifty-nine | … | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | Two thousand and eleven | Two thousand and twelve | Two thousand and thirteen | Two thousand and fourteen | Two thousand and fifteen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | |||||||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 加拿大 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand seven hundred and forty-five | One thousand seven hundred and forty-one | One thousand seven hundred and thirty-five | One thousand seven hundred and one | One thousand seven hundred and three | One thousand seven hundred | One thousand seven hundred and thirteen | One thousand seven hundred and seven | One thousand seven hundred and three | One thousand seven hundred and six |
| 辣椒 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | Two thousand one hundred and sixty-five | Two thousand one hundred and twenty-eight | Two thousand and ninety-five | Two thousand and seventy-four | Two thousand and sixty-nine point six | Two thousand and forty-seven point four | Two thousand and twenty-four | Two thousand and fifteen point three | One thousand nine hundred and ninety point one | One thousand nine hundred and eighty-seven point five |
| 墨西哥 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | Two thousand two hundred and eighty point six | Two thousand two hundred and sixty-one point four | Two thousand two hundred and fifty-eight | Two thousand two hundred and fifty point two | Two thousand two hundred and forty-two point four | Two thousand two hundred and fifty point two | Two thousand two hundred and twenty-five point eight | Two thousand two hundred and thirty-six point six | Two thousand two hundred and twenty-eight point four | Two thousand two hundred and forty-six point four |
| 美利坚合众国 | One thousand nine hundred and sixty | One thousand nine hundred and seventy-five point five | One thousand nine hundred and seventy-eight | One thousand nine hundred and eighty | One thousand nine hundred and seventy point five | One thousand nine hundred and ninety-two point five | One thousand nine hundred and ninety | One thousand nine hundred and sixty-two | One thousand nine hundred and thirty-six point five | One thousand nine hundred and forty-seven | … | One thousand eight hundred | One thousand seven hundred and ninety-eight | One thousand seven hundred and ninety-two | One thousand seven hundred and sixty-seven | One thousand seven hundred and seventy-eight | One thousand seven hundred and eighty-six | One thousand seven hundred and eighty-nine | One thousand seven hundred and eighty-seven | One thousand seven hundred and eighty-nine | One thousand seven hundred and ninety |
| 以色列 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand nine hundred and nineteen | One thousand nine hundred and thirty-one | One thousand nine hundred and twenty-nine | One thousand nine hundred and twenty-seven | One thousand nine hundred and eighteen | One thousand nine hundred and twenty | One thousand nine hundred and ten | One thousand eight hundred and sixty-seven | One thousand eight hundred and fifty-three | One thousand eight hundred and fifty-eight |
5 行× 66 列
更快捷的加入方式
既然我们已经艰难地完成了,并且从概念上理解了表合并,那么让我们尝试一种更优雅的技术。熊猫有一个干净的方法来加入索引,这是完美的为我们的情况。
result = DataFrame.join([other DataFrame], how='inner', on=None)
DataFrame.join()方法让我们在左侧的表中使用点符号,然后传入右侧的表和how作为参数。这样就不需要像在前面的函数中那样指定右和左索引参数。如果是on=None,连接键将是行索引。让我们通过观察 DataFrame 头来观察空值是如何影响我们的分析的。
world_historical = historical.join(world, how='right')world_historical.head()
| One thousand nine hundred and fifty | One thousand nine hundred and fifty-one | One thousand nine hundred and fifty-two | One thousand nine hundred and fifty-three | One thousand nine hundred and fifty-four | One thousand nine hundred and fifty-five | One thousand nine hundred and fifty-six | One thousand nine hundred and fifty-seven | One thousand nine hundred and fifty-eight | One thousand nine hundred and fifty-nine | … | Two thousand and six | Two thousand and seven | Two thousand and eight | Two thousand and nine | Two thousand and ten | Two thousand and eleven | Two thousand and twelve | Two thousand and thirteen | Two thousand and fourteen | Two thousand and fifteen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 国家 | |||||||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 加拿大 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand seven hundred and forty-five | One thousand seven hundred and forty-one | One thousand seven hundred and thirty-five | One thousand seven hundred and one | One thousand seven hundred and three | One thousand seven hundred | One thousand seven hundred and thirteen | One thousand seven hundred and seven | One thousand seven hundred and three | One thousand seven hundred and six |
| 辣椒 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | Two thousand one hundred and sixty-five | Two thousand one hundred and twenty-eight | Two thousand and ninety-five | Two thousand and seventy-four | Two thousand and sixty-nine point six | Two thousand and forty-seven point four | Two thousand and twenty-four | Two thousand and fifteen point three | One thousand nine hundred and ninety point one | One thousand nine hundred and eighty-seven point five |
| 墨西哥 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | Two thousand two hundred and eighty point six | Two thousand two hundred and sixty-one point four | Two thousand two hundred and fifty-eight | Two thousand two hundred and fifty point two | Two thousand two hundred and forty-two point four | Two thousand two hundred and fifty point two | Two thousand two hundred and twenty-five point eight | Two thousand two hundred and thirty-six point six | Two thousand two hundred and twenty-eight point four | Two thousand two hundred and forty-six point four |
| 美利坚合众国 | One thousand nine hundred and sixty | One thousand nine hundred and seventy-five point five | One thousand nine hundred and seventy-eight | One thousand nine hundred and eighty | One thousand nine hundred and seventy point five | One thousand nine hundred and ninety-two point five | One thousand nine hundred and ninety | One thousand nine hundred and sixty-two | One thousand nine hundred and thirty-six point five | One thousand nine hundred and forty-seven | … | One thousand eight hundred | One thousand seven hundred and ninety-eight | One thousand seven hundred and ninety-two | One thousand seven hundred and sixty-seven | One thousand seven hundred and seventy-eight | One thousand seven hundred and eighty-six | One thousand seven hundred and eighty-nine | One thousand seven hundred and eighty-seven | One thousand seven hundred and eighty-nine | One thousand seven hundred and ninety |
| 以色列 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | One thousand nine hundred and nineteen | One thousand nine hundred and thirty-one | One thousand nine hundred and twenty-nine | One thousand nine hundred and twenty-seven | One thousand nine hundred and eighteen | One thousand nine hundred and twenty | One thousand nine hundred and ten | One thousand eight hundred and sixty-seven | One thousand eight hundred and fifty-three | One thousand eight hundred and fifty-eight |
5 行× 66 列
看起来很多行在数据帧的左侧有空值,正如我们对右连接的预期。在绘制最终的线形图之前,最好按照字母顺序对行进行排序,以便读者更容易阅读图例。这可以用 DataFrame.sort_index()方法来执行。我们可以传入参数inplace=True来避免重新分配我们的world_historical变量。然后简单地重用我们最近可视化的 matplotlib 代码来显示我们最终排序的数据帧。
world_historical.sort_index(inplace=True)
world_historical.transpose().plot(figsize=(15,10), colormap='rainbow', linewidth=2, title='Average Labor Hours Per Year')
plt.legend(loc='right', bbox_to_anchor=(1.15, 0.5))
plt.show()

将所有这些放在一起(双关语)
哇,我们的可视化看起来相当令人印象深刻,因为我们已经有了跨越半个多世纪的劳动力趋势的丰富多彩的视图。在 80 年代做一名韩国工人肯定会很累!
总结一下:
pd.concat()功能:最多功能,可用于沿任一轴组合多个数据帧。- 方法:向数据框架中添加行的快速方法,但不适用于添加列。
pd.merge()函数:当我们有一个包含公共值的列(键)时,很适合将两个数据帧连接在一起。- 方法:一种连接两个数据帧的快速方法,但只适用于索引标签而非列。
为了更深入地了解我们所使用的技术,请看一下 pandas 合并、加入和连接指南。
准备好继续学习了吗?
永远不要想接下来我该学什么?又来了!
在我们的 Python for Data Science 路径中,您将了解到:
- 使用 matplotlib 和 pandas 进行数据清理、分析和可视化
- 假设检验、概率和统计
- 机器学习、深度学习和决策树
- ...还有更多!
立即开始学习我们的 60+免费任务:
todorov . petar . p 的熊猫照片(自己的作品)
【CC BY-SA 4.0(【https://creativecommons.org/licenses/by-sa/4.0】)】
via Wikimedia Commons
使用 Python 数据透视表探索幸福数据
September 25, 2017
面对一个新的数据集时,最大的挑战之一是知道从哪里开始,关注什么。能够快速汇总数百行和列可以节省您大量的时间和挫折。您可以使用一个简单的工具来实现这一点,即数据透视表,它可以帮助您以查询的速度对数据进行切片、过滤和分组,并以视觉上吸引人的方式呈现信息。
数据透视表,有什么用?
您可能已经熟悉了 Excel 中数据透视表的概念,它们是在 1994 年由商标名 PivotTable 引入的。该工具使用户能够自动对存储在一个表中的数据进行排序、计数、合计或平均。在下图中,我们使用了数据透视表功能来快速汇总庞大的数据集。下面较大的表格显示了数据集的前 30 行,较小的表格是我们创建的数据透视表。

左边的数据透视表根据Sex和Survived列对数据进行分组。因此,该表显示了不同存活状态中每个性别的百分比(0:未存活,1:存活)。这让我们很快发现女性比男性有更好的生存机会。右边的表格也使用了Survived列,但是这次数据是按Class分组的。
介绍我们的数据集:世界幸福报告
我们在上面的例子中使用了 Excel,但是这篇文章将展示 pandas 内置函数 pivot_table 的优点。我们将使用世界幸福报告,这是一份关于全球幸福状况的调查。该报告根据幸福水平对 150 多个国家进行了排名,自 2012 年以来几乎每年发布一次。我们将使用 2015 年、2016 年和 2017 年收集的数据,如果你想跟进,可以从下载。我们运行的是 python 3.6 和 pandas 0.19。
我们可能想回答的一些有趣的问题是:
- 世界上最幸福和最不幸福的国家和地区有哪些?
- 幸福感受地域影响吗?
- 在过去的三年里,幸福指数有显著变化吗?
让我们导入我们的数据,快速浏览一下:
import pandas as pd
import numpy as np
# reading the data
data = pd.read_csv('data.csv', index_col=0)
# sort the df by ascending years and descending happiness scores
data.sort_values(['Year', "Happiness Score"], ascending=[True, False], inplace=True)
#diplay first 10 rows
data.head(10)
| 国家 | 地区 | 幸福等级 | 幸福分数 | 经济(人均国内生产总值) | 家庭的 | 健康(预期寿命) | 自由 | 信任(政府腐败) | 慷慨 | 反面乌托邦残余 | 年 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One hundred and forty-one | 瑞士 | 西欧 | One | Seven point five eight seven | 1.39651 | 1.34951 | 0.94143 | 0.66557 | 0.41978 | 0.29678 | 2.51738 | Two thousand and fifteen |
| Sixty | 冰岛 | 西欧 | Two | Seven point five six one | 1.30232 | 1.40223 | 0.94784 | 0.62877 | 0.14145 | 0.43630 | 2.70201 | Two thousand and fifteen |
| Thirty-eight | 丹麦 | 西欧 | Three | Seven point five two seven | 1.32548 | 1.36058 | 0.87464 | 0.64938 | 0.48357 | 0.34139 | 2.49204 | Two thousand and fifteen |
| One hundred and eight | 挪威 | 西欧 | Four | Seven point five two two | 1.45900 | 1.33095 | 0.88521 | 0.66973 | 0.36503 | 0.34699 | 2.46531 | Two thousand and fifteen |
| Twenty-five | 加拿大 | 北美洲 | Five | Seven point four two seven | 1.32629 | 1.32261 | 0.90563 | 0.63297 | 0.32957 | 0.45811 | 2.45176 | Two thousand and fifteen |
| Forty-six | 芬兰 | 西欧 | Six | Seven point four zero six | 1.29025 | 1.31826 | 0.88911 | 0.64169 | 0.41372 | 0.23351 | 2.61955 | Two thousand and fifteen |
| One hundred and two | 荷兰 | 西欧 | Seven | Seven point three seven eight | 1.32944 | 1.28017 | 0.89284 | 0.61576 | 0.31814 | 0.47610 | 2.46570 | Two thousand and fifteen |
| One hundred and forty | 瑞典 | 西欧 | Eight | Seven point three six four | 1.33171 | 1.28907 | 0.91087 | 0.65980 | 0.43844 | 0.36262 | 2.37119 | Two thousand and fifteen |
| One hundred and three | 新西兰 | 澳大利亚和新西兰 | Nine | Seven point two eight six | 1.25018 | 1.31967 | 0.90837 | 0.63938 | 0.42922 | 0.47501 | 2.26425 | Two thousand and fifteen |
| six | 澳大利亚 | 澳大利亚和新西兰 | Ten | Seven point two eight four | 1.33358 | 1.30923 | 0.93156 | 0.65124 | 0.35637 | 0.43562 | 2.26646 | Two thousand and fifteen |
每个国家的Happiness Score是通过将表中的其他七个变量相加计算出来的。这些变量中的每一个都显示了一个从 0 到 10 的人口加权平均分数,该分数随着时间的推移被跟踪并与其他国家进行比较。
这些变量是:
Economy:实际人均国内生产总值Family:社会支持Health:健康的预期寿命- 做出人生选择的自由
Trust:对腐败的看法- 慷慨的感觉
- 将每个国家与一个假设的国家进行比较,该假设的国家代表每个关键变量的最低国家平均值,并与剩余误差一起用作回归基准
每个国家的Happiness Score决定了它的Happiness Rank——这是它在特定年份在其他国家中的相对位置。例如,第一行表明瑞士以 7.587 的幸福指数被评为 2015 年最幸福的国家。瑞士排在冰岛之前,得分为 7.561。2015 年丹麦排名第三,以此类推。有趣的是,西欧在 2015 年的前八名中占据了七席。
我们将集中在最后的Happiness Score来演示数据透视表的技术方面。
# getting an overview of our data
print("Our data has {0} rows and {1} columns".format(data.shape[0], data.shape[1]))
# checking for missing values
print("Are there missing values? {}".format(data.isnull().any().any()))
data.describe()
Our data has 495 rows and 12 columns
Are there missing values? True
| 幸福等级 | 幸福分数 | 经济(人均国内生产总值) | 家庭的 | 健康(预期寿命) | 自由 | 信任(政府腐败) | 慷慨 | 反面乌托邦残余 | 年 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 数数 | 470.000000 | 470.000000 | 470.000000 | 470.000000 | 470.000000 | 470.000000 | 470.000000 | 470.000000 | 470.000000 | 495.000000 |
| 意思是 | 78.829787 | 5.370728 | 0.927830 | 0.990347 | 0.579968 | 0.402828 | 0.134790 | 0.242241 | 2.092717 | 2016.000000 |
| 标准 | 45.281408 | 1.136998 | 0.415584 | 0.318707 | 0.240161 | 0.150356 | 0.111313 | 0.131543 | 0.565772 | 0.817323 |
| 部 | 1.000000 | 2.693000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.328580 | 2015.000000 |
| 25% | 40.000000 | 4.509000 | 0.605292 | 0.793000 | 0.402301 | 0.297615 | 0.059777 | 0.152831 | 1.737975 | 2015.000000 |
| 50% | 79.000000 | 5.282500 | 0.995439 | 1.025665 | 0.630053 | 0.418347 | 0.099502 | 0.223140 | 2.094640 | 2016.000000 |
| 75% | 118.000000 | 6.233750 | 1.252443 | 1.228745 | 0.768298 | 0.516850 | 0.173161 | 0.315824 | 2.455575 | 2017.000000 |
| 最大 | 158.000000 | 7.587000 | 1.870766 | 1.610574 | 1.025250 | 0.669730 | 0.551910 | 0.838075 | 3.837720 | 2017.000000 |
describe() 方法显示Happiness Rank的范围从 1 到 158,这意味着某一年接受调查的国家最多为 158 个。值得注意的是,Happiness Rank最初是属于int类型的。事实上,它在这里显示为一个浮点数意味着我们在这一列中有NaN个值(我们也可以通过count行来确定这一点,在我们的数据集中只有 470 行,而不是 495 行)。
Year列没有任何缺失值。首先,因为它在数据集中显示为int,而且Year的计数达到 495,这是我们数据集中的行数。通过将Year的count值与其他列进行比较,似乎我们可以预计每列中有 25 个缺失值(495 在Year中,而其他列中有 470)。
通过Year和Region对数据进行分类
关于 pandas pivot_table的有趣之处在于,你只需要一行代码就可以从另一个角度来看待你的数据。大多数pivot_table参数使用默认值,所以您必须添加的唯一强制参数是data和index。虽然这不是强制性的,但在下一个例子中,我们也将使用value参数。
data是不言自明的——它是你想要使用的数据框架- 是用来对数据进行分组的列、分组器、数组(或前面的列表)。它将显示在索引列中(如果传递的是列表,则显示在多个列中)
values(可选)是要聚合的列。如果不指定此项,则该函数将聚合所有数值列。
让我们先看看输出,然后解释这个表是如何产生的:
pd.pivot_table(data, index= 'Year', values= "Happiness Score")
| 幸福分数 | |
|---|---|
| 年 | |
| --- | --- |
| Two thousand and fifteen | 5.375734 |
| Two thousand and sixteen | 5.382185 |
| Two thousand and seventeen | 5.354019 |
通过将Year作为index参数传递,我们选择按照Year对数据进行分组。输出是一个数据透视表,将Year的三个不同值显示为index,将Happiness Score显示为values。值得注意的是,聚合默认值是 mean(或 average ),因此显示在Happiness Score列中的值是所有国家的年平均值。该表显示,所有国家的平均水平在 2016 年最高,目前是过去三年中的最低水平。
下面是如何创建该数据透视表的详细示意图:

接下来,让我们将Region列用作index:
pd.pivot_table(data, index = 'Region', values="Happiness Score")
| 幸福分数 | |
|---|---|
| 地区 | |
| --- | --- |
| 澳大利亚和新西兰 | 7.302500 |
| 中欧和东欧 | 5.371184 |
| 东亚 | 5.632333 |
| 拉丁美洲和加勒比 | 6.069074 |
| 中东和北非 | 5.387879 |
| 北美洲 | 7.227167 |
| 东南亚 | 5.364077 |
| 南亚 | 4.590857 |
| 撒哈拉以南非洲 | 4.150957 |
| 西欧 | 6.693000 |
在上面的数据透视表的Happiness Score栏中显示的数字是平均值,和以前一样——但这次是每个地区所有记录年份(2015、2016、2017)的平均值。这种显示更容易看到Australia and New Zealand的平均得分最高,而North America紧随其后。有趣的是,尽管我们从阅读数据中得到的初步印象是Western Europe在大多数排名中名列前茅,但在计算过去三年的平均值时,Western Europe实际上排名第三。排名最低的地区是Sub-Saharan Africa,紧随其后的是Southern Asia。
创建多索引数据透视表
您可能已经使用了groupby()来实现数据透视表的一些功能(我们之前已经演示了如何使用 groupby() 来分析您的数据)。然而,pivot_table()内置函数提供了简单的参数名和默认值,可以帮助简化复杂的过程,比如多重索引。
为了按多个列对数据进行分组,我们所要做的就是传入一个列名列表。让我们按照Region和Year对数据进行分类。
pd.pivot_table(data, index = ['Region', 'Year'], values="Happiness Score")
| 幸福分数 | ||
|---|---|---|
| 地区 | 年 | |
| --- | --- | --- |
| 澳大利亚和新西兰 | Two thousand and fifteen | 7.285000 |
| Two thousand and sixteen | 7.323500 | |
| Two thousand and seventeen | 7.299000 | |
| 中欧和东欧 | Two thousand and fifteen | 5.332931 |
| Two thousand and sixteen | 5.370690 | |
| Two thousand and seventeen | 5.409931 | |
| 东亚 | Two thousand and fifteen | 5.626167 |
| Two thousand and sixteen | 5.624167 | |
| Two thousand and seventeen | 5.646667 | |
| 拉丁美洲和加勒比 | Two thousand and fifteen | 6.144682 |
| Two thousand and sixteen | 6.101750 | |
| Two thousand and seventeen | 5.957818 | |
| 中东和北非 | Two thousand and fifteen | 5.406900 |
| Two thousand and sixteen | 5.386053 | |
| Two thousand and seventeen | 5.369684 | |
| 北美洲 | Two thousand and fifteen | 7.273000 |
| Two thousand and sixteen | 7.254000 | |
| Two thousand and seventeen | 7.154500 | |
| 东南亚 | Two thousand and fifteen | 5.317444 |
| Two thousand and sixteen | 5.338889 | |
| Two thousand and seventeen | 5.444875 | |
| 南亚 | Two thousand and fifteen | 4.580857 |
| Two thousand and sixteen | 4.563286 | |
| Two thousand and seventeen | 4.628429 | |
| 撒哈拉以南非洲 | Two thousand and fifteen | 4.202800 |
| Two thousand and sixteen | 4.136421 | |
| Two thousand and seventeen | 4.111949 | |
| 西欧 | Two thousand and fifteen | 6.689619 |
| Two thousand and sixteen | 6.685667 | |
| Two thousand and seventeen | 6.703714 |
这些例子还揭示了 pivot table 的名称来源:它允许您旋转或透视汇总表,这种旋转为我们提供了不同的数据视角。这种观点可以很好地帮助你快速获得有价值的见解。
这是查看数据的一种方式,但是我们可以使用columns参数来获得更好的显示:
- 是用来对数据进行分组的前一列、分组器、数组或列表。使用它将水平分布不同的值。
使用Year作为Columns参数将显示year的不同值,并且会有更好的显示效果,如下所示:
pd.pivot_table(data, index= 'Region', columns='Year', values="Happiness Score")
| 年 | Two thousand and fifteen | Two thousand and sixteen | Two thousand and seventeen |
|---|---|---|---|
| 地区 | |||
| --- | --- | --- | --- |
| 澳大利亚和新西兰 | 7.285000 | 7.323500 | 7.299000 |
| 中欧和东欧 | 5.332931 | 5.370690 | 5.409931 |
| 东亚 | 5.626167 | 5.624167 | 5.646667 |
| 拉丁美洲和加勒比 | 6.144682 | 6.101750 | 5.957818 |
| 中东和北非 | 5.406900 | 5.386053 | 5.369684 |
| 北美洲 | 7.273000 | 7.254000 | 7.154500 |
| 东南亚 | 5.317444 | 5.338889 | 5.444875 |
| 南亚 | 4.580857 | 4.563286 | 4.628429 |
| 撒哈拉以南非洲 | 4.202800 | 4.136421 | 4.111949 |
| 西欧 | 6.689619 | 6.685667 | 6.703714 |
使用plot()可视化数据透视表
如果您想查看我们之前创建的数据透视表的可视化表示,您需要做的就是在pivot_table函数调用的末尾添加plot()(您还需要导入相关的绘图库)。
import matplotlib.pyplot as plt
import seaborn as sns
# use Seaborn styles
sns.set()
pd.pivot_table(data, index= 'Region', columns= 'Year', values= "Happiness Score").plot(kind= 'bar')
plt.ylabel("Happiness Rank")
<matplotlib.text.Text at 0x11b885630>

视觉表示有助于揭示差异是微小的。话虽如此,这也表明美国这两个地区的幸福指数都在持续下降。
使用aggfunc操作数据
到目前为止,我们一直使用平均值来了解数据,但还有其他重要的值需要考虑。使用aggfunc参数进行实验的时间:
aggfunc(可选)接受您希望在群组中使用的功能或功能列表(默认:numpy.mean)。如果传递了一个函数列表,结果透视表将具有分层列,其顶层是函数名。
让我们添加每个区域的中值、最小值、最大值和标准偏差。这可以帮助我们评估平均值的准确性,以及它是否真正代表真实的情况。
pd.pivot_table(data, index= 'Region', values= "Happiness Score", aggfunc= [np.mean, np.median, min, max, np.std])
| 意思是 | 中位数 | 部 | 最大 | 标准 | |
|---|---|---|---|---|---|
| 幸福分数 | 幸福分数 | 幸福分数 | 幸福分数 | 幸福分数 | |
| --- | --- | --- | --- | --- | --- |
| 地区 | |||||
| --- | --- | --- | --- | --- | --- |
| 澳大利亚和新西兰 | 7.302500 | 7.2995 | Seven point two eight four | Seven point three three four | 0.020936 |
| 中欧和东欧 | 5.371184 | 5.4010 | Four point zero nine six | Six point six zero nine | 0.578274 |
| 东亚 | 5.632333 | 5.6545 | Four point eight seven four | Six point four two two | 0.502100 |
| 拉丁美洲和加勒比 | 6.069074 | 6.1265 | Three point six zero three | Seven point two two six | 0.728157 |
| 中东和北非 | 5.387879 | 5.3175 | Three point zero zero six | Seven point two seven eight | 1.031656 |
| 北美洲 | 7.227167 | 7.2175 | Six point nine nine three | Seven point four two seven | 0.179331 |
| 东南亚 | 5.364077 | 5.2965 | Three point eight one nine | Six point seven nine eight | 0.882637 |
| 南亚 | 4.590857 | 4.6080 | Three point three six | Five point two six nine | 0.535978 |
| 撒哈拉以南非洲 | 4.150957 | 4.1390 | Two point six nine three | Five point six four eight | 0.584945 |
| 西欧 | 6.693000 | 6.9070 | Four point eight five seven | Seven point five eight seven | 0.777886 |
看起来一些地区有极端值,这可能比我们希望的更影响我们的平均值。例如,Middle East and Northern Africa区域有一个很高的标准偏差,所以我们可能要删除极值。让我们看看我们为每个区域计算了多少个值。这可能会影响我们看到的图像。例如,Australia and new Zealand标准差很低,三年都是排名最幸福的,但我们也可以假设他们只占两个国家。
应用自定义函数移除异常值
pivot_table允许您将自己的自定义聚合函数作为参数传递。您可以使用 lambda 函数,也可以创建一个函数。让我们计算一下给定年份每个地区的平均国家数量。我们可以使用 lambda 函数轻松做到这一点,如下所示:
pd.pivot_table(data, index = 'Region', values="Happiness Score", aggfunc= [np.mean, min, max, np.std, lambda x: x.count()/3])
| 意思是 | 部 | 最大 | 标准 | <lambda> |
|
|---|---|---|---|---|---|
| 幸福分数 | 幸福分数 | 幸福分数 | 幸福分数 | 幸福分数 | |
| --- | --- | --- | --- | --- | --- |
| 地区 | |||||
| --- | --- | --- | --- | --- | --- |
| 澳大利亚和新西兰 | 7.302500 | Seven point two eight four | Seven point three three four | 0.020936 | 2.000000 |
| 中欧和东欧 | 5.371184 | Four point zero nine six | Six point six zero nine | 0.578274 | 29.000000 |
| 东亚 | 5.632333 | Four point eight seven four | Six point four two two | 0.502100 | 6.000000 |
| 拉丁美洲和加勒比 | 6.069074 | Three point six zero three | Seven point two two six | 0.728157 | 22.666667 |
| 中东和北非 | 5.387879 | Three point zero zero six | Seven point two seven eight | 1.031656 | 19.333333 |
| 北美洲 | 7.227167 | Six point nine nine three | Seven point four two seven | 0.179331 | 2.000000 |
| 东南亚 | 5.364077 | Three point eight one nine | Six point seven nine eight | 0.882637 | 8.666667 |
| 南亚 | 4.590857 | Three point three six | Five point two six nine | 0.535978 | 7.000000 |
| 撒哈拉以南非洲 | 4.150957 | Two point six nine three | Five point six four eight | 0.584945 | 39.000000 |
| 西欧 | 6.693000 | Four point eight five seven | Seven point five eight seven | 0.777886 | 21.000000 |
标准偏差最低的两个排名最高的区域仅占两个国家。而Sub-Saharan Africa最低的Happiness score,却占了 43 个国家。一个有趣的下一步是从计算中去除极端值,看看排名是否有显著变化。让我们创建一个只计算 0.25 和 0.75 分位数之间的值的函数。我们将使用这个函数来计算每个地区的平均值,并检查排名是否保持不变。
def remove_outliers(values):
mid_quantiles = values.quantile([.25, .75])
return np.mean(mid_quantiles)
pd.pivot_table(data, index = 'Region', values="Happiness Score", aggfunc= [np.mean, remove_outliers, lambda x: x.count()/3])
| 意思是 | 移除离群值 | <lambda> |
|
|---|---|---|---|
| 幸福分数 | 幸福分数 | 幸福分数 | |
| --- | --- | --- | --- |
| 地区 | |||
| --- | --- | --- | --- |
| 澳大利亚和新西兰 | 7.302500 | 7.299125 | 2.000000 |
| 中欧和东欧 | 5.371184 | 5.449250 | 29.000000 |
| 东亚 | 5.632333 | 5.610125 | 6.000000 |
| 拉丁美洲和加勒比 | 6.069074 | 6.192750 | 22.666667 |
| 中东和北非 | 5.387879 | 5.508500 | 19.333333 |
| 北美洲 | 7.227167 | 7.244875 | 2.000000 |
| 东南亚 | 5.364077 | 5.470125 | 8.666667 |
| 南亚 | 4.590857 | 4.707500 | 7.000000 |
| 撒哈拉以南非洲 | 4.150957 | 4.128000 | 39.000000 |
| 西欧 | 6.693000 | 6.846500 | 21.000000 |
剔除异常值主要影响国家数量较多的地区,这是有道理的。我们可以看到Western Europe(每年调查的 21 个国家的平均值)排名提高了。不幸的是,Sub-Saharan Africa(每年调查的 39 个国家的平均值)在剔除异常值后排名更低。
使用字符串操作进行分类
到目前为止,我们已经根据原始表中的类别对数据进行了分组。然而,我们可以在类别中搜索字符串来创建我们自己的组。例如,按大洲查看结果会很有趣。我们可以通过查找包含Asia、Europe等的区域名称来做到这一点。为此,我们可以首先将数据透视表分配给一个变量,然后添加过滤器:
table = pd.pivot_table(data, index = 'Region', values="Happiness Score", aggfunc= [np.mean, remove_outliers])
table[table.index.str.contains('Asia')]
| 意思是 | 移除离群值 | |
|---|---|---|
| 幸福分数 | 幸福分数 | |
| --- | --- | --- |
| 地区 | ||
| --- | --- | --- |
| 东亚 | 5.632333 | 5.610125 |
| 东南亚 | 5.364077 | 5.470125 |
| 南亚 | 4.590857 | 4.707500 |
让我们看看Europe的结果:
table[table.index.str.contains('Europe')]
| 意思是 | 移除离群值 | |
|---|---|---|
| 幸福分数 | 幸福分数 | |
| --- | --- | --- |
| 地区 | ||
| --- | --- | --- |
| 中欧和东欧 | 5.371184 | 5.44925 |
| 西欧 | 6.693000 | 6.84650 |
差异显示,两个欧洲地区的幸福得分差异较大。在大多数情况下,剔除异常值会使得分更高,但在东亚并非如此。
如果您想从多个列中提取特定的值,那么最好使用df.query,因为前面的方法不适用于处理多索引。例如,我们可以选择查看非洲地区的特定年份和特定地区。
table = pd.pivot_table(data, index = ['Region', 'Year'], values='Happiness Score',aggfunc= [np.mean, remove_outliers])
table.query('Year == [2015, 2017] and Region == ["Sub-Saharan Africa", "Middle East and Northern Africa"]')
| 意思是 | 移除离群值 | ||
|---|---|---|---|
| 幸福分数 | 幸福分数 | ||
| --- | --- | --- | --- |
| 地区 | 年 | ||
| --- | --- | --- | --- |
| 中东和北非 | Two thousand and fifteen | 5.406900 | 5.515875 |
| Two thousand and seventeen | 5.369684 | 5.425500 | |
| 撒哈拉以南非洲 | Two thousand and fifteen | 4.202800 | 4.168375 |
| Two thousand and seventeen | 4.111949 | 4.118000 |
在本例中,差异很小,但一个有趣的练习是比较前几年的信息,因为该调查自 2012 年以来就有报告。
处理缺失数据
到目前为止,我们已经介绍了pivot_table最强大的参数,所以如果您在自己的项目中尝试使用这种方法,您已经可以从中获得很多。话虽如此,快速浏览一下剩余的参数(这些参数都是可选的,都有默认值)还是很有用的。首先要说的是缺失值。
dropna是 boolean 类型,用于表示不希望包含所有条目都是NaN的列(默认值:True)fill_value是标量类型,用于选择一个值来替换缺失的值(默认:无)。
我们没有所有条目都是NaN的列,但是值得一提的是,如果我们有了pivot_table,根据dropna的定义,默认情况下pivot_table会删除它们。
我们已经让pivot_table根据默认设置对待我们的NaN。fill_value的默认值是None,这意味着我们没有替换数据集中缺失的值。为了演示这一点,我们需要生成一个带有NaN值的数据透视表。我们可以将每个地区的Happiness Score分成三个分位数,并检查有多少国家属于这三个分位数中的每一个(希望至少有一个分位数有缺失值)。
为此,我们将使用 qcut() ,这是一个内置的 pandas 函数,允许您将数据分割成任意数量的分位数。例如,指定pd.qcut(data["Happiness Score"], 4)将产生四个分位数:
- 0-25%
- 25%-50%
- 50%-75%
- 75%-100%
# splitting the happiness score into 3 quantiles
score = pd.qcut(data["Happiness Score"], 4)
pd.pivot_table(data, index= ['Region', score], values= "Happiness Score", aggfunc= 'count').head(9)
| 幸福分数 | ||
|---|---|---|
| 地区 | 幸福分数 | |
| --- | --- | --- |
| 澳大利亚和新西兰 | (2.692, 4.509] | 圆盘烤饼 |
| (4.509, 5.283] | 圆盘烤饼 | |
| (5.283, 6.234] | 圆盘烤饼 | |
| (6.234, 7.587] | Six | |
| 中欧和东欧 | (2.692, 4.509] | Ten |
| (4.509, 5.283] | Twenty-eight | |
| (5.283, 6.234] | Forty-six | |
| (6.234, 7.587] | Three | |
| 东亚 | (2.692, 4.509] | 圆盘烤饼 |
特定分位数中没有国家的地区显示NaN。这并不理想,因为等于 NaN 的计数不会给我们任何有用的信息。为了减少显示0的混乱,让我们使用fill_value将NaN替换为零:
# splitting the happiness score into 3 quantiles
score = pd.qcut(data["Happiness Score"], 3)
pd.pivot_table(data, index= ['Region', score], values= "Happiness Score", aggfunc= 'count', fill_value= 0)
| 幸福分数 | ||
|---|---|---|
| 地区 | 幸福分数 | |
| --- | --- | --- |
| 澳大利亚和新西兰 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Zero | |
| (5.895, 7.587] | six | |
| 中欧和东欧 | (2.692, 4.79] | Fifteen |
| (4.79, 5.895] | Fifty-eight | |
| (5.895, 7.587] | Fourteen | |
| 东亚 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Eleven | |
| (5.895, 7.587] | seven | |
| 拉丁美洲和加勒比 | (2.692, 4.79] | four |
| (4.79, 5.895] | Nineteen | |
| (5.895, 7.587] | Forty-five | |
| 中东和北非 | (2.692, 4.79] | Eighteen |
| (4.79, 5.895] | Twenty | |
| (5.895, 7.587] | Twenty | |
| 北美洲 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Zero | |
| (5.895, 7.587] | six | |
| 东南亚 | (2.692, 4.79] | six |
| (4.79, 5.895] | Twelve | |
| (5.895, 7.587] | eight | |
| 南亚 | (2.692, 4.79] | Thirteen |
| (4.79, 5.895] | eight | |
| (5.895, 7.587] | Zero | |
| 撒哈拉以南非洲 | (2.692, 4.79] | One hundred and one |
| (4.79, 5.895] | Sixteen | |
| (5.895, 7.587] | Zero | |
| 西欧 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Twelve | |
| (5.895, 7.587] | Fifty-one |
添加总行数/列数
最后两个参数都是可选的,对改善显示非常有用:
margins为布尔类型,允许您添加一个all行/列,例如小计/总计(默认为假)margins_name这是一个字符串类型,当 margins 为真(默认为‘All’)时,它接受包含总计的行/列的名称
让我们用这些将总数加到最后一个表中。
# splitting the happiness score into 3 quantiles
score = pd.qcut(data['Happiness Score'], 3)
# creating a pivot table and only displaying the first 9 values
pd.pivot_table(data, index= ['Region', score], values= "Happiness Score", aggfunc= 'count', fill_value= 0, margins = True, margins_name= 'Total count')
| 幸福分数 | ||
|---|---|---|
| 地区 | 幸福分数 | |
| --- | --- | --- |
| 澳大利亚和新西兰 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Zero | |
| (5.895, 7.587] | Six | |
| 中欧和东欧 | (2.692, 4.79] | Fifteen |
| (4.79, 5.895] | Fifty-eight | |
| (5.895, 7.587] | Fourteen | |
| 东亚 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Eleven | |
| (5.895, 7.587] | Seven | |
| 拉丁美洲和加勒比 | (2.692, 4.79] | Four |
| (4.79, 5.895] | Nineteen | |
| (5.895, 7.587] | Forty-five | |
| 中东和北非 | (2.692, 4.79] | Eighteen |
| (4.79, 5.895] | Twenty | |
| (5.895, 7.587] | Twenty | |
| 北美洲 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Zero | |
| (5.895, 7.587] | Six | |
| 东南亚 | (2.692, 4.79] | Six |
| (4.79, 5.895] | Twelve | |
| (5.895, 7.587] | Eight | |
| 南亚 | (2.692, 4.79] | Thirteen |
| (4.79, 5.895] | Eight | |
| (5.895, 7.587] | Zero | |
| 撒哈拉以南非洲 | (2.692, 4.79] | One hundred and one |
| (4.79, 5.895] | Sixteen | |
| (5.895, 7.587] | Zero | |
| 西欧 | (2.692, 4.79] | Zero |
| (4.79, 5.895] | Twelve | |
| (5.895, 7.587] | Fifty-one | |
| 总菌数 | Four hundred and seventy |
让我们总结一下
如果您正在寻找一种从不同角度检查数据的方法,那么pivot_table就是答案。它很容易使用,对数值和分类值都有用,并且可以在一行代码中得到结果。
如果你喜欢挖掘这些数据,并有兴趣进一步调查,那么我们建议增加前几年的调查结果,和/或增加国家信息栏,如:贫困、恐怖、失业等。请随意分享您的笔记本,享受您的学习!
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。


在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
熊猫教程:用 Python 和熊猫分析视频游戏数据
August 26, 2019
Python 的 pandas 库是使 Python 成为数据分析的伟大编程语言的原因之一。熊猫使数据的导入、分析和可视化变得更加容易。它建立在像 NumPy 和 matplotlib 这样的软件包上,给你一个单一、方便的地方来完成你的大部分数据分析和可视化工作。
在这个 Python 数据科学教程中,我们将使用熊猫来分析来自 IGN 的视频游戏评论,这是一个流行的视频游戏评论网站,使用由 Eric Grinstein 收集的数据。哪一款主机正在赢得“主机大战”(从拥有评论更好的游戏的意义上来说)?这个数据集将帮助我们找到答案。
当我们分析视频游戏评论的时候,我们将学习像索引这样的关键熊猫概念。你可以继续下去,在我们众多的其他 Python 教程中,或者通过注册我们的 Python 熊猫课程来学习更多关于 Python 和熊猫的知识。我们的许多其他数据科学课程也使用熊猫。
注意,本教程是用 Python 3.5 编写的,用 Jupyter 笔记本构建的。您可能会使用更新版本的 Python、pandas 和 Jupyter,但是您的结果应该基本相同。
用熊猫导入数据
如果你正在学习本教程,你需要下载数据集,你可以在这里做。
我们要做的第一步是读入数据。数据存储为一个逗号分隔值,或 csv 文件,其中每行由一个新行分隔,每列由一个逗号(,)分隔。以下是ign.csv文件的前几行:
,score_phrase,title,url,platform,score,genre,editors_choice,release_year,release_month,release_day
0,Amazing,LittleBigPlanet PS Vita,/games/littlebigplanet-vita/vita-98907,PlayStation Vita,9.0,Platformer,Y,2012,9,12
1,Amazing,LittleBigPlanet PS Vita -- Marvel Super Hero Edition,/games/littlebigplanet-ps-vita-marvel-super-hero-edition/vita-20027059,PlayStation Vita,9.0,Platformer,Y,2012,9,12
2,Great,Splice: Tree of Life,/games/splice/ipad-141070,iPad,8.5,Puzzle,N,2012,9,12
3,Great,NHL 13,/games/nhl-13/xbox-360-128182,Xbox 360,8.5,Sports,N,2012,9,11
正如你在上面看到的,文件中的每一行都代表一个被 IGN 审查过的游戏。这些列包含关于该游戏的信息:
score_phrase—IGN 如何用一个词形容这款游戏。这与其收到的分数相关联。title—游戏的名称。url—您可以查看完整评论的 URL。platform—游戏被审查的平台(PC、PS4 等)。score—游戏的分数,从1.0到10.0。genre—游戏的流派。editors_choice——N如果游戏不是编辑的选择,那么Y如果是。这和分数挂钩。release_year—游戏发布的年份。release_month—游戏发布的月份。release_day—游戏发布的那一天。
还有一个包含行索引值的前导列。我们可以放心地忽略这一列,但是我们稍后将深入研究什么是索引值。
为了在 Python 和 pandas 中有效地处理数据,我们需要将 csv 文件读入一个 Pandas 数据帧。数据框是一种表示和处理表格数据的方式,即以表格形式出现的数据,如电子表格。表格数据有行和列,就像我们的 csv 文件一样,但是如果我们能以表格的形式查看它,我们会更容易阅读和排序。
为了读入数据,我们需要使用 pandas.read_csv 函数。这个函数将接受一个 csv 文件并返回一个数据帧。以下代码将:
- 导入
pandas库。我们将其重命名为pd,这样打字速度会更快。这是数据分析和数据科学中的标准约定,你会经常在别人的代码中看到熊猫被导入为pd。 - 将
ign.csv读入一个数据帧,并将结果赋给一个名为reviews的新变量,这样我们就可以使用reviews来引用我们的数据。
import pandas as pd
reviews = pd.read_csv("ign.csv")
一旦我们读入了一个数据框架,以一种更直观的方式看一看我们得到了什么是很有帮助的。Pandas 方便地为我们提供了两种方法,可以快速地打印出表格中的数据。这些功能是:
- DataFrame.head() —打印数据帧的前 N 行,其中 N 是作为参数传递给函数的数字,即
DataFrame.head(7)。如果不传递任何参数,默认为 5。 - data frame . tail()-打印数据帧的最后 N 行。同样,默认为
5。
我们将使用head方法来查看reviews中的内容:
reviews.head()
| 未命名:0 | 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | 令人惊异的 | LittleBigPlanet PS Vita | /games/little big planet-vita/vita-98907 | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| one | one | 令人惊异的 | 小小大星球 PS Vita——漫威超级英雄 E… | /games/little big planet-PS-vita-marvel-super-he… | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| Two | Two | 伟大的 | 拼接:生命之树 | /games/splice/ipad-141070 | 苹果平板电脑 | Eight point five | 难题 | 普通 | Two thousand and twelve | nine | Twelve |
| three | three | 伟大的 | NHL 13 | /games/nhl-13/xbox-360-128182 | xbox360 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
| four | four | 伟大的 | NHL 13 | /games/nhl-13/ps3-128181 | 游戏机 3 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
我们还可以参观熊猫。DataFrame.shape 属性查看多行多列在reviews:
reviews.shape
(18625, 11)
正如我们所看到的,一切都被正确地读入——我们有18,625行和11列。
与类似的 Python 包(如 NumPy)相比,使用 Pandas 的一大优势是 Pandas 允许我们拥有不同数据类型的列。在我们的数据集reviews中,我们有存储浮点值(如score)、字符串值(如score_phrase)和整数(如release_year)的列,所以在这里使用 NumPy 会很困难,但 Pandas 和 Python 处理得很好。
现在我们已经正确地读入了数据,让我们开始索引reviews以获得我们想要的行和列。
用熊猫
索引数据帧
之前,我们使用了head方法来打印reviews的前5行。我们可以用熊猫完成同样的事情。DataFrame.iloc 方法。iloc方法允许我们按位置检索行和列。为了做到这一点,我们需要指定我们想要的行的位置,以及我们想要的列的位置。下面的代码将通过选择数据集中的第 0 到第 5 行以及所有列来复制我们的reviews.head()的结果:
reviews.iloc[0:5,:]
| 未命名:0 | 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | 令人惊异的 | LittleBigPlanet PS Vita | /games/little big planet-vita/vita-98907 | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| one | one | 令人惊异的 | 小小大星球 PS Vita——漫威超级英雄 E… | /games/little big planet-PS-vita-marvel-super-he… | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| Two | Two | 伟大的 | 拼接:生命之树 | /games/splice/ipad-141070 | 苹果平板电脑 | Eight point five | 难题 | 普通 | Two thousand and twelve | nine | Twelve |
| three | three | 伟大的 | NHL 13 | /games/nhl-13/xbox-360-128182 | xbox360 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
| four | four | 伟大的 | NHL 13 | /games/nhl-13/ps3-128181 | 游戏机 3 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
让我们更深入地研究一下我们的代码:我们指定我们需要行0:5。这意味着我们想要从位置0到位置5的行,但不包括这些行。
第一行被认为是在位置0,所以选择行0:5给出了在位置0、1、2、3和4的行。我们也需要所有的列,我们使用快捷方式来选择它们。它是这样工作的:如果我们忽略第一个位置值,比如:5,就假设我们指的是0。如果我们忽略最后一个位置值,如0:,则假设我们指的是数据帧中的最后一行或最后一列。我们需要所有的列,所以我们只指定了一个冒号(:),没有任何位置。这给了我们从0到最后一列的列。以下是一些索引示例和结果:
reviews.iloc[:5,:]—前5行,以及这些行的所有列。reviews.iloc[:,:]—整个数据帧。reviews.iloc[5:,5:]—从位置5开始的行,从位置5开始的列。reviews.iloc[:,0]—第一列,以及该列的所有行。reviews.iloc[9,:]—第 10 行,以及该行的所有列。
按位置步进非常类似于 NumPy 步进。如果你想了解更多,可以阅读我们的 NumPy 教程。现在我们知道了如何按位置索引,让我们删除第一列,它没有任何有用的信息:
reviews = reviews.iloc[:,1:]
reviews.head()
| 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 令人惊异的 | LittleBigPlanet PS Vita | /games/little big planet-vita/vita-98907 | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| one | 令人惊异的 | 小小大星球 PS Vita——漫威超级英雄 E… | /games/little big planet-PS-vita-marvel-super-he… | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| Two | 伟大的 | 拼接:生命之树 | /games/splice/ipad-141070 | 苹果平板电脑 | Eight point five | 难题 | 普通 | Two thousand and twelve | nine | Twelve |
| three | 伟大的 | NHL 13 | /games/nhl-13/xbox-360-128182 | xbox360 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
| four | 伟大的 | NHL 13 | /games/nhl-13/ps3-128181 | 游戏机 3 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
在 Python 中使用标签索引熊猫
既然我们已经知道了如何按位置检索行和列,那么有必要研究一下使用数据帧的另一种主要方法,即按标签检索行和列。Pandas 相对于 NumPy 的一个主要优势是每一列和每一行都有一个标签。可以处理列位置,但是很难记住哪个数字对应于哪个列。
我们可以用熊猫做标签。DataFrame.loc 方法,它允许我们使用标签而不是位置进行索引。我们可以像这样使用loc方法显示reviews的前五行:
reviews.loc[0:5,:]
| 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 令人惊异的 | LittleBigPlanet PS Vita | /games/little big planet-vita/vita-98907 | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| one | 令人惊异的 | 小小大星球 PS Vita——漫威超级英雄 E… | /games/little big planet-PS-vita-marvel-super-he… | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| Two | 伟大的 | 拼接:生命之树 | /games/splice/ipad-141070 | 苹果平板电脑 | Eight point five | 难题 | 普通 | Two thousand and twelve | nine | Twelve |
| three | 伟大的 | NHL 13 | /games/nhl-13/xbox-360-128182 | xbox360 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
| four | 伟大的 | NHL 13 | /games/nhl-13/ps3-128181 | 游戏机 3 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
| five | 好的 | 全面战争战役:幕府将军 | /games/total-war-battles-幕府/mac-142565 | 麦金托什雨衣 | Seven | 战略 | 普通 | Two thousand and twelve | nine | Eleven |
以上其实看起来和reviews.iloc[0:5,:]没有太大区别。这是因为虽然行标签可以采用任何值,但是我们的行标签与位置完全匹配。您可以在上表的最左侧看到行标签(它们以粗体显示)。您也可以通过访问数据帧的索引属性来查看它们。我们将显示reviews的行索引:
reviews.index
Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, ...], dtype='int64')
不过,指数并不总是与头寸相匹配。在下面的代码单元格中,我们将:
- 获取
reviews的第10行到第20行,并将结果赋给some_reviews。 - 显示
some_reviews的前5行。
some_reviews = reviews.iloc[10:20,]
some_reviews.head()
| 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Ten | 好的 | 铁拳标记锦标赛 2 | /games/tekken-tag-锦标赛-2/ps3-124584 | 游戏机 3 | Seven point five | 战斗的 | 普通 | Two thousand and twelve | nine | Eleven |
| Eleven | 好的 | 铁拳标记锦标赛 2 | /games/tekken-tag-锦标赛-2/xbox-360-124581 | xbox360 | Seven point five | 战斗的 | 普通 | Two thousand and twelve | nine | Eleven |
| Twelve | 好的 | 狂野之血 | /games/wild-blood/iphone-139363 | 苹果手机 | Seven | 圆盘烤饼 | 普通 | Two thousand and twelve | nine | Ten |
| Thirteen | 令人惊异的 | 忍者的标记 | /games/mark-of-ninja-135615/Xbox-360-129276 | xbox360 | Nine | 动作,冒险 | Y | Two thousand and twelve | nine | seven |
| Fourteen | 令人惊异的 | 忍者的标记 | /游戏/忍者标记-135615/pc-143761 | 个人电脑 | Nine | 动作,冒险 | Y | Two thousand and twelve | nine | seven |
如上所述,在some_reviews中,行索引从10开始,到20结束。因此,尝试将loc与低于10或高于20的数字一起使用会导致错误:
some_reviews.loc[9:21,:]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython -input-76-5378b774c9a7> in <module>()
----> 1 some_reviews.loc[9:21,:]
/Users/vik/python_envs/dsserver/lib/python3.4/site-packages/pandas/core/indexing.py in __getitem__(self, key)
1198 def __getitem__(self, key):
1199 if type(key) is tuple:
-> 1200 return self._getitem_tuple(key)
1201 else:
1202 return self._getitem_axis(key, axis=0)
/Users/vik/python_envs/dsserver/lib/python3.4/site-packages/pandas/core/indexing.py in _getitem_tuple(self, tup)
702
703 # no multi-index, so validate all of the indexers
--> 704 self._has_valid_tuple(tup)
705
706 # ugly hack for GH #836
/Users/vik/python_envs/dsserver/lib/python3.4/site-packages/pandas/core/indexing.py in _has_valid_tuple(self, key)
129 if i >= self.obj.ndim:
130 raise IndexingError('Too many indexers')
--> 131 if not self._has_valid_type(k, i):
132 raise ValueError("Location based indexing can only have [%s] "
133 "types" % self._valid_types)
/Users/vik/python_envs/dsserver/lib/python3.4/site-packages/pandas/core/indexing.py in _has_valid_type(self, key, axis)
1258 raise KeyError(
1259 "start bound [%s] is not the [%s]" %
-> 1260 (key.start, self.obj._get_axis_name(axis))
1261 )
1262 if key.stop is not None:
KeyError: 'start bound [9] is not the [index]'
正如我们前面提到的,当您处理数据时,列标签可以使生活变得更加容易。我们可以在loc方法中指定列标签,通过标签而不是位置来检索列。
reviews.loc
[:5,"score"]
0 9.0
1 9.0
2 8.5
3 8.5
4 8.5
5 7.0
Name: score, dtype: float64
我们还可以通过传入一个列表来一次指定多个列:
reviews.loc[:5,["score", "release_year"]]
| 得分 | 发布年份 | |
|---|---|---|
| Zero | Nine | Two thousand and twelve |
| one | Nine | Two thousand and twelve |
| Two | Eight point five | Two thousand and twelve |
| three | Eight point five | Two thousand and twelve |
| four | Eight point five | Two thousand and twelve |
| five | Seven | Two thousand and twelve |
熊猫系列物件
我们可以用几种不同的方法在 Pandas 中检索一个单独的列。到目前为止,我们已经看到了两种类型的语法:
reviews.iloc[:,1]—将检索第二列。reviews.loc[:,"score_phrase"]—也将检索第二列。
还有第三种更简单的方法来检索整个列。我们可以在方括号中指定列名,就像字典一样:
reviews["score"]
0 9.0
1 9.0
2 8.5
3 8.5
4 8.5
5 7.0
6 3.0
7 9.0
8 3.0
9 7.0
10 7.5
11 7.5
12 7.0
13 9.0
14 9.0
...
18610 6.0
18611 5.8
18612 7.8
18613 8.0
18614 9.2
18615 9.2
18616 7.5
18617 8.4
18618 9.1
18619 7.9
18620 7.6
18621 9.0
18622 5.8
18623 10.0
18624 10.0
Name: score, Length: 18625, dtype: float64
我们也可以通过这种方法使用列列表:
reviews[["score", "release_year"]]
| 得分 | 发布年份 | |
|---|---|---|
| Zero | Nine | Two thousand and twelve |
| one | Nine | Two thousand and twelve |
| Two | Eight point five | Two thousand and twelve |
| three | Eight point five | Two thousand and twelve |
| four | Eight point five | Two thousand and twelve |
| five | Seven | Two thousand and twelve |
| six | Three | Two thousand and twelve |
| seven | Nine | Two thousand and twelve |
| eight | Three | Two thousand and twelve |
| nine | Seven | Two thousand and twelve |
| Ten | Seven point five | Two thousand and twelve |
| Eleven | Seven point five | Two thousand and twelve |
| Twelve | Seven | Two thousand and twelve |
| Thirteen | Nine | Two thousand and twelve |
| Fourteen | Nine | Two thousand and twelve |
| Fifteen | Six point five | Two thousand and twelve |
| Sixteen | Six point five | Two thousand and twelve |
| Seventeen | Eight | Two thousand and twelve |
| Eighteen | Five point five | Two thousand and twelve |
| Nineteen | Seven | Two thousand and twelve |
| Twenty | Seven | Two thousand and twelve |
| Twenty-one | Seven point five | Two thousand and twelve |
| Twenty-two | Seven point five | Two thousand and twelve |
| Twenty-three | Seven point five | Two thousand and twelve |
| Twenty-four | Nine | Two thousand and twelve |
| Twenty-five | Seven | Two thousand and twelve |
| Twenty-six | Nine | Two thousand and twelve |
| Twenty-seven | Seven point five | Two thousand and twelve |
| Twenty-eight | Eight | Two thousand and twelve |
| Twenty-nine | Six point five | Two thousand and twelve |
| … | … | … |
| Eighteen thousand five hundred and ninety-five | Four point four | Two thousand and sixteen |
| Eighteen thousand five hundred and ninety-six | Six point five | Two thousand and sixteen |
| Eighteen thousand five hundred and ninety-seven | Four point nine | Two thousand and sixteen |
| Eighteen thousand five hundred and ninety-eight | Six point eight | Two thousand and sixteen |
| Eighteen thousand five hundred and ninety-nine | Seven | Two thousand and sixteen |
| Eighteen thousand six hundred | Seven point four | Two thousand and sixteen |
| Eighteen thousand six hundred and one | Seven point four | Two thousand and sixteen |
| Eighteen thousand six hundred and two | Seven point four | Two thousand and sixteen |
| Eighteen thousand six hundred and three | Seven point eight | Two thousand and sixteen |
| Eighteen thousand six hundred and four | Eight point six | Two thousand and sixteen |
| Eighteen thousand six hundred and five | Six | Two thousand and sixteen |
| Eighteen thousand six hundred and six | Six point four | Two thousand and sixteen |
| Eighteen thousand six hundred and seven | Seven | Two thousand and sixteen |
| Eighteen thousand six hundred and eight | Five point four | Two thousand and sixteen |
| Eighteen thousand six hundred and nine | Eight | Two thousand and sixteen |
| Eighteen thousand six hundred and ten | Six | Two thousand and sixteen |
| Eighteen thousand six hundred and eleven | Five point eight | Two thousand and sixteen |
| Eighteen thousand six hundred and twelve | Seven point eight | Two thousand and sixteen |
| Eighteen thousand six hundred and thirteen | Eight | Two thousand and sixteen |
| Eighteen thousand six hundred and fourteen | Nine point two | Two thousand and sixteen |
| Eighteen thousand six hundred and fifteen | Nine point two | Two thousand and sixteen |
| Eighteen thousand six hundred and sixteen | Seven point five | Two thousand and sixteen |
| Eighteen thousand six hundred and seventeen | Eight point four | Two thousand and sixteen |
| Eighteen thousand six hundred and eighteen | Nine point one | Two thousand and sixteen |
| Eighteen thousand six hundred and nineteen | Seven point nine | Two thousand and sixteen |
| Eighteen thousand six hundred and twenty | Seven point six | Two thousand and sixteen |
| Eighteen thousand six hundred and twenty-one | Nine | Two thousand and sixteen |
| Eighteen thousand six hundred and twenty-two | Five point eight | Two thousand and sixteen |
| Eighteen thousand six hundred and twenty-three | Ten | Two thousand and sixteen |
| Eighteen thousand six hundred and twenty-four | Ten | Two thousand and sixteen |
18625 行× 2 列
当我们检索单个列时,我们实际上是在检索一个熊猫系列对象。DataFrame 存储表格数据,而 Series 存储单列或单行数据。
我们可以验证单个列是一个系列:
type(reviews["score"])
pandas.core.series.Series
我们可以手动创建一个系列来更好地理解它是如何工作的。为了创建一个系列,我们在实例化 Series 对象时将一个 list 或 NumPy 数组传递给它:
s1 = pd.Series([1,2])
s1
0 1
1 2
dtype: int64
系列可以包含任何类型的数据,包括混合类型的数据。在这里,我们创建一个包含字符串对象的系列:
s2 = pd.Series(["Boris Yeltsin", "Mikhail Gorbachev"])
s2
0 Boris Yeltsin
1 Mikhail Gorbachev
dtype: object
在 Pandas
中创建数据帧
我们可以通过将多个系列传递给 DataFrame 类来创建一个 DataFrame。这里,我们传入刚刚创建的两个系列对象,
s1为第一行,s2为第二行:
pd.DataFrame([s1,s2])
| Zero | one | |
|---|---|---|
| Zero | one | Two |
| one | 鲍里斯·叶利钦 | 米哈伊尔·戈尔巴乔夫 |
我们也可以用列表来完成同样的事情。每个内部列表都被视为结果数据帧中的一行:
pd.DataFrame(
[
[1,2],
["Boris Yeltsin", "Mikhail Gorbachev"]
]
)
| Zero | one | |
|---|---|---|
| Zero | one | Two |
| one | 鲍里斯·叶利钦 | 米哈伊尔·戈尔巴乔夫 |
我们可以在创建数据帧时指定列标签:
pd.DataFrame(
[
[1,2],
["Boris Yeltsin", "Mikhail Gorbachev"]
],
columns=["column1", "column2"]
)
| 列 1 | 列 2 | |
|---|---|---|
| Zero | one | Two |
| one | 鲍里斯·叶利钦 | 米哈伊尔·戈尔巴乔夫 |
以及行标签(索引):
frame = pd.DataFrame(
[
[1,2],
["Boris Yeltsin", "Mikhail Gorbachev"]
],
index=["row1", "row2"],
columns=["column1", "column2"]
)
frame
| 列 1 | 列 2 | |
|---|---|---|
| 行 1 | one | Two |
| 第 2 行 | 鲍里斯·叶利钦 | 米哈伊尔·戈尔巴乔夫 |
还要注意,缩进和分隔线不是必需的。我们以这种方式编写代码是为了让它更容易解析,但是您经常会遇到把它写成一行的情况。例如,下面的代码将产生与我们在本段上表中看到的完全相同的结果:
frame = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]],index=["row1", "row2"],columns=["column1", "column2"])
frame
无论如何,一旦我们添加了标签,我们就可以使用它们来索引数据帧:
frame.loc["row1":"row2", "column1"]
row1 1
row2 Boris Yeltsin
Name: column1, dtype: object
如果我们将字典传递给DataFrame构造函数,我们可以跳过指定columns关键字参数。这将自动设置列名:
frame = pd.DataFrame(
{
"column1": [1, "Boris Yeltsin"],
"column2": [2, "Mikhail Gorbachev"]
}
)
frame
| 列 1 | 列 2 | |
|---|---|---|
| Zero | one | Two |
| one | 鲍里斯·叶利钦 | 米哈伊尔·戈尔巴乔夫 |
熊猫数据帧方法
正如我们前面提到的,熊猫数据帧中的每一列都是一个系列对象:
type(reviews["title"])
pandas.core.series.Series
我们可以在一个系列对象上调用我们可以在一个数据帧上调用的大多数相同的方法,包括head:
reviews["title"].head()
0 LittleBigPlanet PS Vita
1 LittleBigPlanet PS Vita -- Marvel Super Hero E...
2 Splice: Tree of Life
3 NHL 13
4 NHL 13
Name: title, dtype: object
Pandas 系列和 DataFrames 也有其他方法使计算更简单。例如,我们可以用熊猫。Series.mean 求数列平均值的方法:
reviews["score"].mean()
6.950459060402685
我们也可以称类似的动物为熊猫。DataFrame.mean 方法,默认情况下,该方法将查找 DataFrame 中每个数值列的平均值:
reviews.mean()
score 6.950459
release_year 2006.515329
release_month 7.138470
release_day 15.603866
dtype: float64
我们可以将关键字参数axis修改为mean,以便计算每行或每列的平均值。默认情况下,axis等于0,将计算每列的平均值。我们也可以将它设置为1来计算每行的平均值。请注意,这将只计算每行中数值的平均值:
reviews.mean(axis=1)
0 510.500
1 510.500
2 510.375
3 510.125
4 510.125
5 509.750
6 508.750
7 510.250
8 508.750
9 509.750
10 509.875
11 509.875
12 509.500
13 509.250
14 509.250
...
18610 510.250
18611 508.700
18612 509.200
18613 508.000
18614 515.050
18615 515.050
18616 508.375
18617 508.600
18618 515.025
18619 514.725
18620 514.650
18621 515.000
18622 513.950
18623 515.000
18624 515.000
Length: 18625, dtype: float64
在序列和数据帧上有很多类似于mean的方法。以下是一些方便的例子:
- 熊猫。DataFrame.corr —查找数据帧中各列之间的相关性。
- 熊猫。DataFrame.count —计算每个 DataFrame 列中非空值的数量。
- 熊猫。DataFrame.max —查找每列中的最大值。
- 熊猫。DataFrame.min —查找每列中的最小值。
- 熊猫。DataFrame.median —查找每列的中间值。
- 熊猫。DataFrame.std —查找每列的标准偏差。
例如,我们可以使用corr方法来查看是否有任何列与score相关。这将告诉我们最近发布的游戏是否获得了更高的评论(release_year),或者接近年底发布的游戏是否得分更高(release_month):
reviews.corr()
| 得分 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|
| 得分 | 1.000000 | 0.062716 | 0.007632 | 0.020079 |
| 发布年份 | 0.062716 | 1.000000 | -0.115515 | 0.016867 |
| 发布 _ 月份 | 0.007632 | -0.115515 | 1.000000 | -0.067964 |
| 发布日期 | 0.020079 | 0.016867 | -0.067964 | 1.000000 |
正如我们在上面看到的,没有一个数字列与score相关,所以我们知道发布时间与评审分数没有线性关系。
与熊猫的数据帧数学
我们还可以用 pandas 对 Python 中的 Series 或 DataFrame 对象进行数学运算。例如,我们可以将score列中的每个值除以2来将刻度从0–10切换到0–5:
reviews["score"] / 2
0 4.50
1 4.50
2 4.25
3 4.25
4 4.25
5 3.50
6 1.50
7 4.50
8 1.50
9 3.50
10 3.75
11 3.75
12 3.50
13 4.50
14 4.50
...
18610 3.00
18611 2.90
18612 3.90
18613 4.00
18614 4.60
18615 4.60
18616 3.75
18617 4.20
18618 4.55
18619 3.95
18620 3.80
18621 4.50
18622 2.90
18623 5.00
18624 5.00
Name: score, Length: 18625, dtype: float64
在 Python 中工作的所有常见数学运算符,如+、-、*、/和^将在 pandas 中对系列或数据帧工作,并将应用于数据帧或系列中的每个元素。
熊猫
中的布尔索引
现在我们已经对熊猫有了一些基本的了解,让我们开始我们的分析。我们之前看到过,reviews的score列中所有值的平均值都在7附近。如果我们想找到所有得分高于平均水平的游戏呢?
我们可以从做一个比较开始。该比较将序列中的每个值与指定值进行比较,然后生成一个充满布尔值的序列,指示比较的状态。例如,我们可以看到哪些行的score值高于7:
score_filter = reviews["score"] > 7
score_filter
0 True
1 True
2 True
3 True
4 True
5 False
6 False
7 True
8 False
9 False
10 True
11 True
12 False
13 True
14 True...
18610 False
18611 False
18612 True
18613 True
18614 True
18615 True
18616 True
18617 True
18618 True
18619 True
18620 True
18621 True
18622 False
18623 True
18624 True
Name: score, Length: 18625, dtype: bool
一旦我们有了一个布尔序列,我们就可以用它来选择数据帧中包含值True的行。因此,我们只能在reviews中选择score大于7的行:
filtered_reviews = reviews[score_filter]
filtered_reviews.head()
| 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 令人惊异的 | LittleBigPlanet PS Vita | /games/little big planet-vita/vita-98907 | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| one | 令人惊异的 | 小小大星球 PS Vita——漫威超级英雄 E… | /games/little big planet-PS-vita-marvel-super-he… | PlayStation Vita | Nine | 平台游戏 | Y | Two thousand and twelve | nine | Twelve |
| Two | 伟大的 | 拼接:生命之树 | /games/splice/ipad-141070 | 苹果平板电脑 | Eight point five | 难题 | 普通 | Two thousand and twelve | nine | Twelve |
| three | 伟大的 | NHL 13 | /games/nhl-13/xbox-360-128182 | xbox360 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
| four | 伟大的 | NHL 13 | /games/nhl-13/ps3-128181 | 游戏机 3 | Eight point five | 运动 | 普通 | Two thousand and twelve | nine | Eleven |
可以使用多个条件进行过滤。假设我们想要找到为Xbox One发布的分数超过7的游戏。在下面的代码中,我们:
- 用两个条件设置过滤器:
- 检查
score是否大于7。 - 检查
platform是否等于Xbox One
- 检查
- 对
reviews应用过滤器,只获取我们想要的行。 - 使用
head方法打印filtered_reviews的前5行。
xbox_one_filter = (reviews["score"] > 7) & (reviews["platform"] == "Xbox One")
filtered_reviews = reviews[xbox_one_filter]
filtered_reviews.head()
| 分数 _ 短语 | 标题 | 全球资源定位器(Uniform Resource Locator) | 平台 | 得分 | 类型 | 编辑选择 | 发布年份 | 发布 _ 月份 | 发布日期 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Seventeen thousand one hundred and thirty-seven | 令人惊异的 | 回家了 | /games/gone-home/Xbox-one-2001 4 3 61 | Xbox One | Nine point five | 模拟 | Y | Two thousand and thirteen | eight | Fifteen |
| Seventeen thousand one hundred and ninety-seven | 令人惊异的 | 雷曼传奇 | /games/rayman-legends/Xbox-one-20008449 | Xbox One | Nine point five | 平台游戏 | Y | Two thousand and thirteen | eight | Twenty-six |
| Seventeen thousand two hundred and ninety-five | 令人惊异的 | 乐高漫威超级英雄 | /游戏/乐高-漫威-超级英雄/xbox-one-20000826 | Xbox One | Nine | 行动 | Y | Two thousand and thirteen | Ten | Twenty-two |
| Seventeen thousand three hundred and thirteen | 伟大的 | 死亡崛起 3 | /games/死亡崛起-3/xbox-one-124306 | Xbox One | Eight point three | 行动 | 普通 | Two thousand and thirteen | Eleven | Eighteen |
| Seventeen thousand three hundred and seventeen | 伟大的 | 杀手本能 | /games/killer-instinct-2013/Xbox-one-2000 05 38 | Xbox One | Eight point four | 战斗的 | 普通 | Two thousand and thirteen | Eleven | Eighteen |
当使用多个条件进行过滤时,将每个条件放在括号中,并用一个&符号(&)将它们分开,这一点很重要。
熊猫密谋
现在我们知道了如何过滤,我们可以创建图表来观察Xbox One的评论分布和PlayStation 4的评论分布。这将有助于我们找出哪个主机的游戏更好。
我们可以通过直方图来做到这一点,直方图将绘制不同得分范围的频率。我们可以使用熊猫为每个控制台制作一个直方图。DataFrame.plot 方法。该方法利用流行的 Python 绘图库 matplotlib 来生成好看的绘图。
plot方法默认画一个线图。我们需要传入关键字参数kind="hist"来绘制直方图。在下面的代码中,我们:
- 调用
%matplotlib inline在 Jupyter 笔记本中设置绘图。 - 过滤
reviews以仅包含关于Xbox One的数据。 - 绘制
score列。
reviews[reviews["platform"] == "Xbox One"]["score"].plot(kind="hist")
<matplotlib.axes._subplots.AxesSubplot at 0x10c9c5438>

我们也可以对PS4做同样的事情:
reviews[reviews["platform"] == "PlayStation 4"]["score"].plot(kind="hist")
<matplotlib.axes._subplots.AxesSubplot at 0x10c9e0e80>

从我们的直方图来看,PlayStation 4比Xbox One有更多的高评分游戏。
显然,这只是冰山一角,当谈到我们可以分析这个数据集的潜在方向时,但我们已经有了一个良好的开端:我们已经使用 Python 和 pandas 导入了一个数据集,学会了使用各种不同的索引方法选择我们想要的数据点,并做了一些快速的探索性数据分析来回答我们开始时提出的问题。
免费熊猫小抄
如果你有兴趣了解更多关于熊猫的知识,请查看我们关于 NumPy 和熊猫的互动课程。你可以注册并免费上第一课。你可能也想通过我们的免费熊猫小抄把你的熊猫技能提升到一个新的水平!
延伸阅读
希望这篇 Pandas 教程能够帮助您使用 Pandas 和 Python 来阅读、探索、分析和可视化数据。在下一篇文章中,我们将讨论数据分组和更高级的计算。这里可以找到。如果你想了解更多关于熊猫的信息,请查阅以下资源:
本文最后更新于 2019 年 9 月。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
熊猫教程:用 Python 进行数据分析:第 2 部分
December 2, 2016We covered a lot of ground in Part 1 of our pandas tutorial. We went from the basics of pandas DataFrames to indexing and computations. If you’re still not confident with Pandas, you might want to check out the Dataquest pandas Course. In this tutorial, we’ll dive into one of the most powerful aspects of pandas — its grouping and aggregation functionality. With this functionality, it’s dead simple to compute group summary statistics, discover patterns, and slice up your data in various ways. Since Thanksgiving was just last week, we’ll use a dataset on what Americans typically eat for Thanksgiving dinner as we explore the pandas library. You can download the dataset here. It contains 1058 online survey responses collected by FiveThirtyEight. Each survey respondent was asked questions about what they typically eat for Thanksgiving, along with some demographic questions, like their gender, income, and location. This dataset will allow us to discover regional and income-based patterns in what Americans eat for Thanksgiving dinner. As we explore the data and try to find patterns, we’ll be heavily using the grouping and aggregation functionality of pandas. 
我们非常喜欢美国的感恩节晚餐。请注意,我们将使用 Python 3.5 和 Jupyter Notebook 来做我们的分析。
读入并汇总数据
我们的第一步是读入数据,做一些初步的探索。这将帮助我们弄清楚我们想要如何创建群体和寻找模式。您可能还记得本教程的第一部分,我们可以使用
pandas.read_csv 功能。数据是使用Latin-1编码存储的,因此我们还需要指定encoding关键字参数。如果我们不这样做,pandas 将无法加载数据,我们将得到一个错误:
import pandas as pd
data = pd.read_csv("thanksgiving-2015-poll-data.csv", encoding="Latin-1")
data.head()
| 船货抵押借款 | 你庆祝感恩节吗? | 感恩节晚餐的典型主菜是什么? | 感恩节晚餐的典型主菜是什么?–其他(请具体说明) | 主菜通常是怎么做的? | 主菜通常是怎么做的?–其他(请具体说明) | 你通常有哪种馅料/调料? | 你通常有哪种馅料/调料?–其他(请具体说明) | 你通常吃哪种酸梅酱? | 你通常吃哪种酸梅酱?–其他(请具体说明) | … | 你有没有试过在感恩节晚上和家乡的朋友见面? | 你参加过“朋友聚会”吗? | 你会在感恩节购物吗? | 你在零售业工作吗? | 你的雇主会让你在黑色星期五工作吗? | 你会如何描述你住的地方? | 年龄 | 你的性别是? | 去年你家所有成员的总收入是多少? | 美国地区 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Four billion three hundred and thirty-seven million nine hundred and fifty-four thousand nine hundred and sixty | 是 | 火鸡 | 圆盘烤饼 | 烤的 | 圆盘烤饼 | 基于面包的 | 圆盘烤饼 | 没有人 | 圆盘烤饼 | … | 是 | 不 | 不 | 不 | 圆盘烤饼 | 郊区的 | 18 – 29 | 男性的 | 75000 美元至 99999 美元 | 大西洋中部 |
| one | Four billion three hundred and thirty-seven million nine hundred and fifty-one thousand nine hundred and forty-nine | 是 | 火鸡 | 圆盘烤饼 | 烤的 | 圆盘烤饼 | 基于面包的 | 圆盘烤饼 | 其他(请具体说明) | 自制蔓越莓明胶戒指 | … | 不 | 不 | 是 | 不 | 圆盘烤饼 | 农村的 | 18 – 29 | 女性的 | 50,000 美元至 74,999 美元 | 东南中心 |
| Two | Four billion three hundred and thirty-seven million nine hundred and thirty-five thousand six hundred and twenty-one | 是 | 火鸡 | 圆盘烤饼 | 烤 | 圆盘烤饼 | 以大米为基础 | 圆盘烤饼 | 自制的 | 圆盘烤饼 | … | 是 | 是 | 是 | 不 | 圆盘烤饼 | 郊区的 | 18 – 29 | 男性的 | 从 0 美元到 9999 美元 | 山 |
| three | Four billion three hundred and thirty-seven million nine hundred and thirty-three thousand and forty | 是 | 火鸡 | 圆盘烤饼 | 烤的 | 圆盘烤饼 | 基于面包的 | 圆盘烤饼 | 自制的 | 圆盘烤饼 | … | 是 | 不 | 不 | 不 | 圆盘烤饼 | 城市的 | 30 – 44 | 男性的 | 20 万美元及以上 | 太平洋 |
| four | Four billion three hundred and thirty-seven million nine hundred and thirty-one thousand nine hundred and eighty-three | 是 | 托富基 | 圆盘烤饼 | 烤的 | 圆盘烤饼 | 基于面包的 | 圆盘烤饼 | 罐装的 | 圆盘烤饼 | … | 是 | 不 | 不 | 不 | 圆盘烤饼 | 城市的 | 30 – 44 | 男性的 | 10 万美元至 124,999 美元 | 太平洋 |
5 行× 65 列
正如你在上面看到的,数据已经
大多数分类数据的列。例如,第一列似乎只允许Yes和No响应。让我们用熊猫来验证一下。Series.unique 方法查看data的Do you celebrate Thanksgiving?列中有哪些唯一值:
data["Do you celebrate Thanksgiving?"].unique()
array(['Yes', 'No'], dtype=object)
我们还可以查看所有的列名,以了解所有的调查问题。我们将截断下面的输出,以免您需要滚动:
data.columns[50:]
Index(['Which of these desserts do you typically have at Thanksgiving dinner? Please select all that apply. - Other (please specify).1', 'Do you typically pray before or after the Thanksgiving meal?','How far will you travel for Thanksgiving?','Will you watch any of the following programs on Thanksgiving? Please select all that apply. - Macy's Parade','What's the age cutoff at your "kids' table" at Thanksgiving?','Have you ever tried to meet up with hometown friends on Thanksgiving night?','Have you ever attended a "Friendsgiving?"','Will you shop any Black Friday sales on Thanksgiving Day?','Do you work in retail?','Will you employer make you work on Black Friday?', 'How would you describe where you live?', 'Age', 'What is your gender?', 'How much total combined money did all members of your HOUSEHOLD earn last year?', 'US Region'],
dtype='object')
利用感恩节调查数据,我们可以回答一些有趣的问题,比如:
- 住在郊区的人比住在农村的人吃更多的豆腐吗?
- 人们最常去哪里参加黑色星期五大甩卖?
- 感恩节祈祷和收入有关联吗?
- 什么收入群体最有可能自制蔓越莓酱?
为了回答这些问题和其他问题,我们首先需要熟悉熊猫的应用、分组和聚合。
将函数应用于 pandas 中的系列
当我们使用 pandas 时,有时我们希望对数据中的每一行或每一列应用一个函数。一个很好的例子是从我们
What is your gender?列为数值。我们将0分配给Male,将1分配给Female。在我们开始转换值之前,让我们确认列中的值是Male或Female。我们可以用熊猫。Series.value_counts 方法来帮助我们。我们将传递dropna=False关键字参数来计算缺失值:
data["What is your gender?"].value_counts(dropna=False)
Female 544
Male 481
NaN 33
Name: What is your gender?, dtype: int64
如您所见,并非所有的值都是
Male或Female。当我们转换列时,我们将在最终输出中保留任何丢失的值。下面是我们需要的输入和输出的图表: 我们需要对
我们需要对What is your gender?列中的每个值应用一个自定义函数,以获得我们想要的输出。这里有一个函数可以完成我们想要的转换:
import math
def gender_code(gender_string):
if isinstance(gender_string, float) and math.isnan(gender_string):
return gender_string
return int(gender_string == "Female")
为了将此函数应用于
What is your gender?列,我们可以编写一个 for 循环,循环遍历列中的每个元素,或者我们可以使用 pandas。法连载。该方法将接受一个函数作为输入,然后返回一个新的 pandas 系列,其中包含将该函数应用于该系列中每个项目的结果。我们可以将结果赋回data数据帧中的一列,然后使用value_counts验证结果:
data["gender"] = data["What is your gender?"].apply(gender_code)
data["gender"].value_counts(dropna=False)
1.0 544
0.0 481
NaN 33
Name: gender, dtype: int64
将函数应用于熊猫的数据帧
我们可以使用
apply数据帧和序列的方法。当我们使用熊猫时。DataFrame.apply 方法,整个行或列将被传递到我们指定的函数中。默认情况下,apply将跨数据帧中的每一列工作。如果我们传递axis=1关键字参数,它将跨每一行工作。在下面的例子中,我们使用一个 lambda 函数来检查data中每一列的数据类型。我们还对结果调用了head方法,以避免输出过多:
data.apply(lambda x: x.dtype).head()
RespondentID object
Do you celebrate Thanksgiving? object
What is typically the main dish at your Thanksgiving dinner? object
What is typically the main dish at your Thanksgiving dinner? - Other (please specify) object
How is the main dish typically cooked? object
dtype: object
使用 apply 方法清理收入
我们现在可以利用我们所知道的
apply清理How much total combined money did all members of your HOUSEHOLD earn last year?列的方法。清理收入列将允许我们从字符串值到数值。首先,让我们看看How much total combined money did all members of your HOUSEHOLD earn last year?列中的所有唯一值:
data["How much total combined money did all members of your HOUSEHOLD earn last year?"].value_counts(dropna=False)
$25,000 to $49,999 180
Prefer not to answer 136
$50,000 to $74,999 135
$75,000 to $99,999 133
$100,000 to $124,999 111
$200,000 and up 80
$10,000 to $24,999 68
$0 to $9,999 66
$125,000 to $149,999 49
$150,000 to $174,999 40
NaN 33
$175,000 to $199,999 27
Name: How much total combined money did all members of your HOUSEHOLD earn last year?, dtype: int64
看这个,有
4列中值的不同模式:
X to Y—一个例子是$25,000 to $49,999。- 我们可以通过提取数字并对其进行平均来将其转换为数值。
NaN- 我们将保留
NaN值,并且根本不转换它们。
- 我们将保留
X and up—一个例子是$200,000 and up。- 我们可以通过提取数字将其转换为数值。
Prefer not to answer- 我们将把它转换成一个
NaN值。
- 我们将把它转换成一个
下面是我们希望转换如何工作:
我们可以写一个涵盖所有这些情况的函数。在下面的函数中,我们:
- 取一个名为
value的字符串作为输入。 - 检查
value是否为$200,000 and up,如果是则返回200000。 - 检查
value是否为Prefer not to answer,如果是则返回NaN。 - 检查
value是否为NaN,如果是则返回NaN。 - 通过删除任何美元符号或逗号来清理
value。 - 拆分字符串以提取收入,然后进行平均。
import numpy as np
def clean_income(value):
if value == "$200,000 and up":
return 200000
elif value == "Prefer not to answer":
return np.nan
elif isinstance(value, float) and math.isnan(value):
return np.nan
value = value.replace(",", "").replace("
income_high, income_low = value.split(" to ")
return (int(income_high) + int(income_low)) / 2
创建函数后,我们可以将它应用到
How much total combined money did all members of your HOUSEHOLD earn last year?栏:
data["income"] = data["How much total combined money did all members of your HOUSEHOLD earn last year?"].apply(clean_income)
data["income"].head()
0 87499.5
1 62499.5
2 4999.5
3 200000.0
4 112499.5
Name: income, dtype: float64
与熊猫的分组数据
现在我们已经介绍了应用函数,我们可以继续使用 pandas 对数据进行分组。当执行数据分析时,只研究数据的子集通常是有用的。例如,如果我们想比较倾向于在感恩节吃自制蔓越莓酱的人和吃罐装蔓越莓酱的人之间的收入呢?首先,让我们看看列中的唯一值是什么:
data["What type of cranberry saucedo you typically have?"].value_counts()
Canned 502
Homemade 301
None 146
Other (please specify) 25
Name: What type of cranberry sauce do you typically have?, dtype: int64
我们现在可以过滤
data获得两个数据帧,它们分别只包含What type of cranberry saucedo you typically have?为Canned或Homemade的行:
homemade = data[data["What type of cranberry saucedo you typically have?"] == "Homemade"]
canned = data[data["What type of cranberry saucedo you typically have?"] == "Canned"]
最后,我们可以使用
熊猫。Series.mean 法求homemade和canned的平均收入:
print(homemade["income"].mean())
print(canned["income"].mean())
94878.1072874
83823.4034091
我们得到了我们的答案,但是它花费了比它应该的更多的代码行。如果我们现在想计算没有吃蔓越莓酱的人的平均收入呢?查找 pandas 的 groupwise 汇总统计数据的一个更简单的方法是使用
熊猫。DataFrame.groupby 方法。该方法将根据一列或一组列将数据帧分成多个组。然后我们将能够对每个组进行计算。下面是基于What type of cranberry saucedo you typically have?列拆分data的样子: 注意每个结果组在
注意每个结果组在What type of cranberry saucedo you typically have?列中只有一个唯一值。为我们选择作为分组依据的列中的每个唯一值创建一个组。让我们从What type of cranberry saucedo you typically have?列创建组:
grouped = data.groupby("What type of cranberry saucedo you typically have?")
grouped
<pandas.core.groupby.DataFrameGroupBy object at 0x10a22cc50>
正如您在上面看到的那样
groupby方法返回一个DataFrameGroupBy对象。我们可以称之为熊猫。GroupBy.groups 方法查看每个组中What type of cranberry sauce do you typically have?列的值:
grouped.groups
{'Canned': Int64Index([ 4, 6, 8, 11, 12, 15, 18, 19, 26, 27,
...
1040, 1041, 1042, 1044, 1045, 1046, 1047, 1051, 1054, 1057],
dtype='int64', length=502),
'Homemade': Int64Index([ 2, 3, 5, 7, 13, 14, 16, 20, 21, 23,
...
1016, 1017, 1025, 1027, 1030, 1034, 1048, 1049, 1053, 1056],
dtype='int64', length=301),
'None': Int64Index([ 0, 17, 24, 29, 34, 36, 40, 47, 49, 51,
...
980, 981, 997, 1015, 1018, 1031, 1037, 1043, 1050, 1055],
dtype='int64', length=146),
'Other (please specify)': Int64Index([ 1, 9, 154, 216, 221, 233, 249, 265, 301, 336, 380,
435, 444, 447, 513, 550, 749, 750, 784, 807, 860, 872,
905, 1000, 1007],
dtype='int64')}
我们可以给
熊猫。GroupBy.size 方法来查看每个组中有多少行。这相当于对一个系列使用value_counts方法:
grouped.size()
What type of cranberry sauce do you typically have?
Canned 502
Homemade 301
None 146
Other (please specify) 25
dtype: int64
我们还可以使用一个循环来手动遍历这些组:
for name, group in grouped:
print(name)
print(group.shape)
print(type(group))
Canned
(502, 67)
<class 'pandas.core.frame.DataFrame'>
Homemade
(301, 67)
<class 'pandas.core.frame.DataFrame'>
None
(146, 67)
<class 'pandas.core.frame.DataFrame'>
Other (please specify)
(25, 67)
<class 'pandas.core.frame.DataFrame'>
正如您在上面看到的,每个组都是一个数据帧,您可以对它使用任何普通的数据帧方法。我们也可以从一个组中提取一个单独的列。这将允许我们仅对该特定列执行进一步的计算:
grouped["income"]
<pandas.core.groupby.SeriesGroupBy object at 0x1081ef390>
正如你在上面看到的,这给了我们一个
SeriesGroupBy对象。然后我们可以调用我们可以在一个DataFrameGroupBy对象上调用的普通方法:
grouped["income"].size()
What type of cranberry sauce do you typically have?
Canned 502
Homemade 301
None 146
Other (please specify) 25
dtype: int64
分组汇总值
如果我们所能做的只是将一个数据帧分成组,那就没什么用了。组的真正力量在于我们在创建组后可以进行的计算。我们通过计算机进行这些计算
熊猫。GroupBy.aggregate 方法,我们可以简称为agg。这种方法允许我们对每个组执行相同的计算。例如,我们可以找到在感恩节提供每种酸果蔓酱的人的平均收入(Canned、Homemade、None等)。在下面的代码中,我们:
- 从
grouped中只提取income列,这样我们就不会找到每一列的平均值。 - 用
np.mean作为输入调用agg方法。- 这将计算每组的平均值,然后合并每组的结果。
grouped["income"].agg(np.mean)
What type of cranberry sauce do you typically have?
Canned 83823.403409
Homemade 94878.107287
None 78886.084034
Other (please specify) 86629.978261
Name: income, dtype: float64
如果我们只选择
income列,下面是我们得到的结果:
grouped.agg(np.mean)
| 船货抵押借款 | 性别 | 收入 | |
|---|---|---|---|
| 你通常吃哪种酸果沙司? | |||
| --- | --- | --- | --- |
| 罐装的 | Four billion three hundred and thirty-six million six hundred and ninety-nine thousand four hundred and sixteen | 0.552846 | 83823.403409 |
| 自制的 | Four billion three hundred and thirty-six million seven hundred and ninety-two thousand and forty | 0.533101 | 94878.107287 |
| 没有人 | Four billion three hundred and thirty-six million seven hundred and sixty-four thousand nine hundred and eighty-nine | 0.517483 | 78886.084034 |
| 其他(请具体说明) | Four billion three hundred and thirty-six million seven hundred and sixty-three thousand two hundred and fifty-three | 0.640000 | 86629.978261 |
上面的代码将查找中每一列的每一组的平均值
data。然而,大多数列是字符串列,而不是整数或浮点列,所以 pandas 没有处理它们,因为对它们调用np.mean会产生错误。
绘制汇总结果
我们可以利用我们的研究结果画一个图
agg法。这将创建一个条形图,显示每个类别的平均收入。在下面的代码中,我们:
sauce = grouped.agg(np.mean)
sauce["income"].plot(kind="bar")
<matplotlib.axes._subplots.AxesSubplot at 0x109ebacc0>

多列聚合
我们可以打电话
groupby用多个列作为输入来获得更细粒度的分组。如果我们使用What type of cranberry saucedo you typically have?和What is typically the main dish at your Thanksgiving dinner?列作为输入,我们将能够找到吃Homemade蔓越莓酱和Tofurkey的人的平均收入,例如:
grouped = data.groupby(["What type of cranberry sauce do you typically have?", "What is typically the main dish at your Thanksgiving dinner?"])
grouped.agg(np.mean)
| 船货抵押借款 | 性别 | 收入 | ||
|---|---|---|---|---|
| 你通常吃哪种酸果沙司? | 感恩节晚餐的典型主菜是什么? | |||
| --- | --- | --- | --- | --- |
| 罐装的 | 鸡肉 | Four billion three hundred and thirty-six million three hundred and fifty-four thousand four hundred and eighteen | 0.333333 | 80999.600000 |
| 火腿/猪肉 | Four billion three hundred and thirty-six million seven hundred and fifty-seven thousand four hundred and thirty-four | 0.642857 | 77499.535714 | |
| 我不知道 | Four billion three hundred and thirty-five million nine hundred and eighty-seven thousand four hundred and thirty | 0.000000 | 4999.500000 | |
| 其他(请具体说明) | Four billion three hundred and thirty-six million six hundred and eighty-two thousand and seventy-two | 1.000000 | 53213.785714 | |
| 烤牛肉 | Four billion three hundred and thirty-six million two hundred and fifty-four thousand four hundred and fourteen | 0.571429 | 25499.500000 | |
| 托富基 | Four billion three hundred and thirty-seven million one hundred and fifty-six thousand five hundred and forty-six | 0.714286 | 100713.857143 | |
| 火鸡 | Four billion three hundred and thirty-six million seven hundred and five thousand two hundred and twenty-five | 0.544444 | 85242.682045 | |
| 自制的 | 鸡肉 | Four billion three hundred and thirty-six million five hundred and thirty-nine thousand six hundred and ninety-three | 0.750000 | 19999.500000 |
| 火腿/猪肉 | Four billion three hundred and thirty-seven million two hundred and fifty-two thousand eight hundred and sixty-one | 0.250000 | 96874.625000 | |
| 我不知道 | Four billion three hundred and thirty-six million eighty-three thousand five hundred and sixty-one | 1.000000 | 圆盘烤饼 | |
| 其他(请具体说明) | Four billion three hundred and thirty-six million eight hundred and sixty-three thousand three hundred and six | 0.600000 | 55356.642857 | |
| 烤牛肉 | Four billion three hundred and thirty-six million one hundred and seventy-three thousand seven hundred and ninety | 0.000000 | 33749.500000 | |
| 托富基 | Four billion three hundred and thirty-six million seven hundred and eighty-nine thousand six hundred and seventy-six | 0.666667 | 57916.166667 | |
| 火鸭肯 | Four billion three hundred and thirty-seven million four hundred and seventy-five thousand three hundred and eight | 0.500000 | 200000.000000 | |
| 火鸡 | Four billion three hundred and thirty-six million seven hundred and ninety thousand eight hundred and two | 0.531008 | 97690.147982 | |
| 没有人 | 鸡肉 | Four billion three hundred and thirty-six million one hundred and fifty thousand six hundred and fifty-six | 0.500000 | 11249.500000 |
| 火腿/猪肉 | Four billion three hundred and thirty-six million six hundred and seventy-nine thousand eight hundred and ninety-six | 0.444444 | 61249.500000 | |
| 我不知道 | Four billion three hundred and thirty-six million four hundred and twelve thousand two hundred and sixty-one | 0.500000 | 33749.500000 | |
| 其他(请具体说明) | Four billion three hundred and thirty-six million six hundred and eighty-seven thousand seven hundred and ninety | 0.600000 | 119106.678571 | |
| 烤牛肉 | Four billion three hundred and thirty-seven million four hundred and twenty-three thousand seven hundred and forty | 0.000000 | 162499.500000 | |
| 托富基 | Four billion three hundred and thirty-six million nine hundred and fifty thousand and sixty-eight | 0.500000 | 112499.500000 | |
| 火鸭肯 | Four billion three hundred and thirty-six million seven hundred and thirty-eight thousand five hundred and ninety-one | 0.000000 | 圆盘烤饼 | |
| 火鸡 | Four billion three hundred and thirty-six million seven hundred and eighty-four thousand two hundred and eighteen | 0.523364 | 74606.275281 | |
| 其他(请具体说明) | 火腿/猪肉 | Four billion three hundred and thirty-six million four hundred and sixty-five thousand one hundred and four | 1.000000 | 87499.500000 |
| 其他(请具体说明) | Four billion three hundred and thirty-seven million three hundred and thirty-five thousand three hundred and ninety-five | 0.000000 | 124999.666667 | |
| 托富基 | Four billion three hundred and thirty-six million one hundred and twenty-one thousand six hundred and sixty-three | 1.000000 | 37499.500000 | |
| 火鸡 | Four billion three hundred and thirty-six million seven hundred and twenty-four thousand four hundred and eighteen | 0.700000 | 82916.194444 |
正如你在上面看到的,我们得到了一个漂亮的表格,显示了每一组每一列的平均值。这使我们能够发现一些有趣的模式,例如:
- 吃
Turducken和Homemade蔓越莓酱的人似乎家庭收入高。 - 吃蔓越莓酱的人往往收入较低,但吃蔓越莓酱的人收入最低。
- 看起来好像有一个人点了蔓越莓酱,却不知道他点的主菜是什么。
使用多种功能聚合
我们还可以使用多个函数执行聚合。例如,这使我们能够计算一个组的平均值和标准偏差。在下面的代码中,我们找到了
income栏:
grouped["income"].agg([np.mean, np.sum, np.std]).head(10)
| 意思是 | 总和 | 标准 | ||
|---|---|---|---|---|
| 你通常吃哪种酸果沙司? | 感恩节晚餐的典型主菜是什么? | |||
| --- | --- | --- | --- | --- |
| 罐装的 | 鸡肉 | 80999.600000 | Four hundred and four thousand nine hundred and ninety-eight | 75779.481062 |
| 火腿/猪肉 | 77499.535714 | One million eighty-four thousand nine hundred and ninety-three point five | 56645.063944 | |
| 我不知道 | 4999.500000 | Four thousand nine hundred and ninety-nine point five | 圆盘烤饼 | |
| 其他(请具体说明) | 53213.785714 | Three hundred and seventy-two thousand four hundred and ninety-six point five | 29780.946290 | |
| 烤牛肉 | 25499.500000 | One hundred and twenty-seven thousand four hundred and ninety-seven point five | 24584.039538 | |
| 托富基 | 100713.857143 | Seven hundred and four thousand nine hundred and ninety-seven | 61351.484439 | |
| 火鸡 | 85242.682045 | Thirty-four million one hundred and eighty-two thousand three hundred and fifteen point five | 55687.436102 | |
| 自制的 | 鸡肉 | 19999.500000 | Fifty-nine thousand nine hundred and ninety-eight point five | 16393.596311 |
| 火腿/猪肉 | 96874.625000 | Three hundred and eighty-seven thousand four hundred and ninety-eight point five | 77308.452805 | |
| 我不知道 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
在组上使用应用
聚合的限制之一是每个函数必须返回一个数字。虽然我们可以进行计算,比如求平均值,但是我们不能调用
得到一个类别的精确计数。我们可以用熊猫来做到这一点。GroupBy.apply 方法。该方法将对每个组应用一个函数,然后合并结果。在下面的代码中,我们将应用value_counts来查找每个地区类型(Rural、Suburban等)中在感恩节吃不同种类主菜的人数:
grouped = data.groupby("How would you describe where you live?")["What is typically the main dish at your Thanksgiving dinner?"]
grouped.apply(lambda x:x.value_counts())
How would you describe where you live? How would you describe where you live?
Rural Turkey 189
Other (please specify) 9
Ham/Pork 7
I don't know 3
Tofurkey 3
Turducken 2
Chicken 2
Roast beef 1
Suburban Turkey 449
Ham/Pork 17
Other (please specify) 13
Tofurkey 9
Roast beef 3
Chicken 3
Turducken 1
I don't know 1
Urban Turkey 198
Other (please specify) 13
Tofurkey 8
Chicken 7
Roast beef 6
Ham/Pork 4
Name: What is typically the main dish at your Thanksgiving dinner?, dtype: int64
上表告诉我们,生活在不同类型地区的人吃不同的感恩节主菜的比率大致相同。
免费熊猫小抄
如果你有兴趣了解更多关于熊猫的知识,请查看我们的互动课程
NumPy 和熊猫。你可以注册并免费上第一堂课。你可能也想通过我们的免费熊猫小抄把你的熊猫技能提升到一个新的水平!
延伸阅读
在本教程中,我们学习了如何使用熊猫来分组数据,并计算结果。我们学习了一些操纵群体和寻找模式的技巧。在下一个教程中,我们将更深入地组合和过滤数据帧。如果你想了解更多关于熊猫和本教程所涵盖的材料,这里有一些资源:
学习数据科学:Dataquest 教学理念
原文:https://www.dataquest.io/blog/philosophy-on-teaching-and-learning-data-science/
April 17, 2019
在 Dataquest,我们花了数年时间来完善我们的教学方法。我最初开始 Dataquest 的动机是因为我自己学习数据科学的经历,我们课程的主要目标仍然是帮助你在现实世界中应用你的数据科学技能。这可能是在工作中完成一个项目,能够做一个你以前不能做的分析,或者建立一个你一直想做的副业。
为了帮助你实现这一目标,我们花了数年时间制定了一套指导我们教学的原则。对于我们的许多学生来说,这些原则有助于引领他们进入数据科学的新职业。但是,我不相信一刀切的教育。对一个人来说很好的方法对另一个人来说可能根本不适用。
在这篇文章中,我将概述我们的教学原则,这样你就可以对 Dataquest 是否适合你做出明智的选择。因为最终,重要的是学习是否能帮助你实现目标。
关注学生
首先,我们坚信你是学习体验的中心。我们根据您的目标量身定制所有课程,并帮助您快速完成这些目标。我们首先定义你在完成一系列课程后能够实现的成果,我们称之为路径。
我们目前提供帮助你成为数据分析师、数据科学家或数据工程师的途径。为了开发这些路径,我们确定了在这些领域工作的人需要哪些技能才能成功,然后反向开发了教授这些技能的数据科学课程。
每门课程都建立在之前课程的基础上;我们的目标是帮助你花时间学习,而不是苦思冥想接下来要学哪门课程,或者你需要什么前提条件来填充一个阻碍你理解解释的关键知识。
我们的课程有一致的风格,所以你永远不需要花时间去适应一种新的解释方法。你可以把所有的精神能量花在理解概念上,而不是分析解释是如何传递的。
我们确保我们教授的所有课程都与您的目标相关。我们不希望你花时间去学习那些对我们来说很有趣,但对你来说没有意义的概念。我们花了大量时间对我们的课程进行测试,并获得您的反馈,以确保它们在我们推出之前是相关的。
帮助您过渡到现实世界的项目
第二,我们致力于帮助您从在浏览器中编码过渡到在真实项目中工作。这可能是一个很难跨越的障碍,我见过很多人陷入“学习模式”,他们不停地循环学习课程,而没有迈出构建自己的项目的一步(诚然这非常可怕)。我们在课程中挑战你,但也给你你需要的支持。
首先,我们着重解释概念,而不仅仅是语法(键入什么)。我们这样做是因为除非你理解一个命令在做什么以及为什么,否则你不能在现实世界中成功地使用它。例如,现在你可以用几行代码训练一个神经网络。然而,除非你知道如何解释预测和调整神经网络,否则你将无法在现实世界中应用它。
我们为我们教授的概念建立上下文,向您展示它们如何在真实数据集上工作。例如,我们教机器学习的基础知识,让你分析 AirBnB 租赁的数据。我们不希望你相信我们的话,为什么有些事情是相关的。相反,我们向您展示为什么它是相关的,因此您知道如何以及何时在现实世界中使用这个概念。
我们还要求你在每堂课中完成几个编码练习。这有助于您建立自己的能力,并在进入现实世界的项目之前更加熟悉编码。这些练习并不容易——你不能盲目地按照说明去做并获得成功——但是它们会给你关于代码的反馈,所以你能够不断地改进。
我们帮助您在每门数据科学课程结束时构建小项目,将您学到的概念结合在一起,并帮助您熟悉自己的编码。这些项目提供了指导,所以你不是完全靠自己,而是能够在自己投入更大的项目之前获得信心。
创造学习数据科学的真正动力
第三,我们明白动机在学习中有多重要。学习数据科学不仅仅是记忆事实或解决编码练习。它是关于当你终于学会一个新概念时你所感到的惊奇。它是关于你能从完成一个艰难的项目中获得的快乐。如果你正处于学习的最佳状态,这应该是令人愉快的;好像没有什么能阻挡你。
我们努力在我们教授的每一课中都包含引人入胜的故事情节和数据集。这意味着你不仅仅是在学习一系列命令。相反,你是在用数据创造一个故事,并在学习的过程中构建一个有趣的分析。这使得学习更有吸引力,并且比仅仅记忆大量语法更有可能成功。
我们帮助您建立令您兴奋的项目。随着您学习我们的课程,您将在越来越少的指导下构建越来越复杂的项目。这有助于创造一种随着时间的推移获得能力和进步的感觉。
我们在创作课程时不断思考动机,并随着时间的推移完善我们的课程以消除障碍。我们保持练习的挑战性,但我们不断调整我们的解释,使它们更有动力,更容易被你理解。
建设一个社区
第四,我们明白学习不仅仅是一项个人练习。拥有支持和社区可以让你的学习之旅变得不同。同行可以帮助你克服困难,了解整个行业的背景。导师可以帮助你跨越职业障碍,并快速识别和解决误解。如果没有强大的支持网络,小障碍很容易变得不可逾越。
我们有一个内部支持团队来回答技术问题,并帮助您在学习过程中摆脱困境。这在早期是非常宝贵的,因为有很多潜在的方法会陷入困境并放弃编码。我们讨厌看到有能力有魄力的人因为没有得到需要的支持而放弃。
我们还提供职业咨询,您可以在求职和招聘过程中获得支持。有时候你学习时需要的只是一点额外的动力。
总而言之,Dataquest 的教学原则是:
- 学生是数据科学学习体验的中心。
- 通过编码练习和项目建立真实世界的技能和能力。
- 教授概念,而不仅仅是输入什么。
- 有挑战性的练习,但也要提供帮助和支持来完成它们。
- 通过使用有趣的数据集建立动机。
- 帮助学生参与我们和社区的活动,以增加动力。
这些原则共同导致一种学习方法,帮助学生提升他们的职业和实现他们的梦想。如果您觉得我们的原则能引起您的共鸣,请尝试 Dataquest!您可以通过我们提供的 60 门免费课程感受我们的平台和风格。
手机邻近效应:你的手机可能会破坏你的学习
February 7, 2019
想知道你能做些什么来使你的学习时间更有效?科学表明,一个答案是让你和你的手机保持一定的距离。即使你确信你的手机没有让你分心,你也可能成为“手机邻近效应”的受害者。
什么是手机邻近效应?简而言之,这是一个想法,当你的手机离你很近时——当它触手可及时——你的认知表现会受到负面影响,即使你实际上并没有使用它。令人惊讶?也许吧,但最近一些非常有趣的科学证实了这一点:
例如,【2017 年,德克萨斯大学的一些学者对近 800 名智能手机用户进行了研究。研究人员有兴趣了解智能手机的存在对认知表现的影响,因此他们将受试者分为三组:
- 【desk】组把他们的手机带到测试区,正面朝下放在桌子上。
- “口袋/包”组将手机带入测试区,但放在口袋或包里。
- 【其他房间】组在进入测试区之前,将手机放在另一个房间。
这三组人都被要求将手机调成静音,并关掉震动,这样在测试过程中就不会有电话、短信或通知干扰他们。
一旦进入测试室,受试者就要完成几项旨在测量认知表现的测试。然后,他们回答了一份问卷,询问他们在测试中思考手机的频率,以及他们是否认为手机的位置会影响他们的表现。
智能手机带来的“人才流失”

每项认知测试的“书桌”、“口袋”和“其他房间”组的结果。
结果相当惊人。“书桌”组在两项认知测试中表现最差,“口袋/包”组位居第二。在两次测试中,“另一个房间”组表现最好。认知测试的结果强烈表明,我们的手机离我们越近,我们的表现就越差,即使它是静音的。
考虑到学生们可能一直在偷偷查看通知,研究人员进行了一项类似的实验,并要求一些学生完全关闭手机。但事实证明,这并不重要——认知能力表现最差的是“书桌”学生,最好的是“另一个房间”的学生,即使他们的手机是关着的。
也许更重要的是问卷调查的结果:绝大多数受试者认为他们的手机没有影响他们的表现,并报告说他们在测试期间没有考虑过他们的手机。
这项研究的意义相当重大:手机在身边会让我们表现更差,但我们没有意识到这有影响。
该研究的作者之一,Adrian Ward,解释说问题是即使不去想某件事也需要努力:“你的意识不会去想你的智能手机,但这个过程——要求你不去想某件事的过程——会耗尽你有限的认知资源。这是人才流失。”
换句话说,当你的手机触手可及时,你大脑的某个部分必须工作,以防止你被它分散注意力。当它在一个不同的房间,不容易接近时,这种影响明显减弱。
当然,这只是一项单独的研究,但是 一项更早的研究提出了完全相同的事情。在那项研究中,缅因大学的研究人员要求受试者完成旨在测量认知功能和注意力的任务,每项任务根据难度水平进一步细分。研究人员随后假装在测试时不小心将手机或笔记本落在了受试者的桌子上。
正如你所料,桌上有手机的学生表现明显比有笔记本的学生差。在接下来的实验中,研究人员证实,无论手机是谁的,这种效应都存在:被要求在考试时把自己的手机放在桌子上的学生比没有放的学生表现更差。这是手机邻近效应在起作用。
智能手机对学习和认知表现的负面影响也在最近的其他一些研究中得到了证明。
例如,2018 年发表在计算机和人类行为上的一项研究发现,被手机分散注意力的学生对简短讲座的记忆更少(在随后的测试中表现更差)。一项类似的研究发现,在课堂上使用手机的学生笔记更差,在后续评估中表现更差。另一项研究发现,禁止使用手机的学校在禁止后考试分数更高。日本的一项研究甚至发现,手机的物理位置可能会影响你工作时最关注的电脑屏幕部分。
你能做什么?
首先,永远值得记住的是,实验结果可能有偏差或完全错误,你应该做对你最有利的事情。在这种情况下,有相当多的研究表明类似的结论,但你在学习时如何对手机的存在做出反应不一定遵循这些研究人员在他们的研究中发现的结果模式。
也就是说,如果你想提高自己的表现,这些结果为你的数据科学学习课程(或你正在从事的任何类型的研究)提供了一些非常明显的建议:
首先:把手机放在不同的房间。正如得克萨斯州的一项研究表明的那样,即使手机静音或关机,即使你确信它不是而是在影响你,手机放在身边也会伤害你的认知能力。当你留出时间学习时,最好把手机放在另一个房间。
第二:关掉铃声(如果可以)。虽然德克萨斯的研究表明,即使在手机静音的情况下,手机邻近的负面认知影响也会持续存在,但其他研究表明,与手机的直接互动也会影响表现——如果你在另一个房间听到手机的嗡嗡声或铃声,这种情况仍然可能发生。
显然不是每个人都能做到这一点;如果你有家人需要你在紧急情况下提供帮助,那么学习期间认知能力的提高可能不值得失去联系。但是如果你能关掉手机,把它放在另一个房间里,你就能让你的大脑尽最大努力忘记你可能错过的通知,并专注于手头的任务。
还值得记住的是,这项研究仅适用于当你试图做其他事情时被手机分散注意力的情况(比如在你的数据科学研究中完成最新的 Dataquest 课程)。如果你正在用手机做一些的事情,比如阅读这些免费的数据科学电子书,你可能不会因为切换到在电脑上阅读并收起手机而获得任何性能提升。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何使用 Pandas 绘制数据帧(21 个代码示例)
June 8, 2022
Pandas 是一个数据分析工具,也为数据可视化提供了很好的选择。以下是如何开始在熊猫中绘图。
数据可视化是数据科学项目成功的重要一步——一个有效的图胜过千言万语。
数据可视化是捕捉趋势和分享从数据中获得的洞察力的强大方法。货架上有大量的数据可视化工具,具有许多突出的功能,但在本教程中,我们将学习用 Pandas 包绘图。
您可能已经知道,Pandas 是一个数据分析工具,但是它为数据可视化提供了一些很好的选项。在本教程的结尾,你会看到用熊猫绘图是多么简单和直接。
我们假设你知道熊猫数据框架的基本原理。如果你不熟悉熊猫图书馆,你可能想试试我们的熊猫和熊猫基础知识课程。
让我们开始吧。
熊猫plot()法
Pandas 附带了一些绘图功能,适用于使用 Matplotlib 库的 DataFrame 或 series 对象,这意味着 Pandas 库创建的任何绘图都是 Matplotlib 对象。
从技术上讲,Pandas plot()方法通过kind关键字参数提供了一组情节样式,以创建看起来不错的情节。kind参数的默认值是line字符串值。然而,有 11 个不同的字符串值可以分配给kind参数,它决定了我们将创建什么样的绘图。
.plot也是 Pandas DataFrame 和 series 对象的属性,提供了 Matplotlib 可用的一小部分绘图。事实上,Pandas 通过为我们自动化大部分数据可视化过程,使绘图变得简单,只需编写一行代码。
导入库和数据集
在本教程中,我们将研究过去几个月脸书、微软和苹果股票的周收盘价。以下代码导入可视化所需的必要库和数据集,然后在输出中显示 DataFrame 的内容。代码中还添加了%matplotlib inline magic 命令,以确保绘制的图形正确出现在笔记本单元格中:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset_url = ('https://raw.githubusercontent.com/m-mehdi/pandas_tutorials/main/weekly_stocks.csv')
df = pd.read_csv(dataset_url, parse_dates=['Date'], index_col='Date')
pd.set_option('display.max.columns', None)
print(df.head())
MSFT FB AAPL
Date
2021-05-24 249.679993 328.730011 124.610001
2021-05-31 250.789993 330.350006 125.889999
2021-06-07 257.890015 331.260010 127.349998
2021-06-14 259.429993 329.660004 130.460007
2021-06-21 265.019989 341.369995 133.110001
我们现在准备用熊猫来探索和可视化这些数据。
线形图
默认绘图是线形图,它在 x 轴上绘制索引,在 y 轴上绘制数据框中的其他数字列。
让我们绘制一个线图,看看微软在过去 12 个月的表现如何:
df.plot(y='MSFT', figsize=(9,6))
<xlabel>

注
figsize参数接受两个参数,以英寸为单位的宽度和高度,并允许我们改变输出图形的大小。宽度和高度的默认值分别为 6.4 和 4.8。
我们可以通过提供列名列表并将其分配给 y 轴,从数据中绘制多条线。例如,让我们看看这三家公司在过去一年的表现:
df.plot.line(y=['FB', 'AAPL', 'MSFT'], figsize=(10,6))
<xlabel>

我们可以使用由plot()方法提供的其他参数来为一个图添加更多的细节,就像这样:
df.plot(y='FB', figsize=(10,6), title='Facebook Stock', ylabel='USD')
<title stock="" xlabel="Date" ylabel="USD">

正如我们在图中看到的,title参数为绘图添加了一个标题,ylabel为绘图的 y 轴设置了一个标签。默认情况下会显示该图的图例,但是,我们可以将legend参数设置为false来隐藏图例。
条形图
条形图是比较数据组之间的值和用矩形条表示分类数据的基本可视化工具。该图可能包括特定类别的计数或任何定义的值,条形的长度对应于它们所代表的值。
在下面的示例中,我们将基于月平均股价创建一个条形图,以比较特定月份中每家公司与其他公司的平均股价。为此,首先,我们需要按月末对数据进行重新采样,然后使用mean()方法计算每个月的平均股价。我们还选择了最近三个月的数据,如下所示:
df_3Months = df.resample(rule='M').mean()[-3:]
print(df_3Months)
MSFT FB AAPL
Date
2022-03-31 298.400002 212.692505 166.934998
2022-04-30 282.087494 204.272499 163.704994
2022-05-31 262.803335 198.643331 147.326665
现在,我们准备好通过将bar字符串值赋给kind参数来创建一个基于聚合数据的条形图:
df_3Months.plot(kind='bar', figsize=(10,6), ylabel='Price')

我们可以通过将barh字符串值赋给kind参数来创建水平条形图。让我们开始吧:
df_3Months.plot(kind='barh', figsize=(9,6))

我们还可以在堆叠的垂直或水平条形图上绘制数据,这些条形图代表不同的组。结果栏的高度显示了各组的综合结果。要创建堆叠条形图,我们需要将True赋给stacked参数,如下所示:
df_3Months.plot(kind='bar', stacked=True, figsize=(9,6))

柱状图
直方图是一种条形图,表示数字数据的分布,其中 x 轴表示条柱范围,而 y 轴表示特定间隔内的数据频率。
df[['MSFT', 'FB']].plot(kind='hist', bins=25, alpha=0.6, figsize=(9,6))

在上面的例子中,bins参数指定 bin 间隔的数量,而alpha参数指定透明度。
直方图也可以堆叠。让我们试一试:
df[['MSFT', 'FB']].plot(kind='hist', bins=25, alpha=0.6, stacked=True, figsize=(9,6))

箱形图
箱线图由三个四分位数和两个须条组成,它们以一组指标概括数据:最小值、第一个四分位数、中值、第三个四分位数和最大值。箱线图传达了有用的信息,如每个数据组的四分位距(IQR)、中位数和异常值。让我们看看它是如何工作的:
df.plot(kind='box', figsize=(9,6))

我们可以通过将False赋给vert参数来创建水平盒图,就像水平条形图一样。像这样:
df.plot(kind='box', vert=False, figsize=(9,6))

面积图
面积图是折线图的扩展,它用颜色填充折线图和 x 轴之间的区域。如果在同一个绘图中显示多个面积图,不同的颜色会区分不同的面积图。让我们试一试:
df.plot(kind='area', figsize=(9,6))

默认情况下,Pandas plot()方法创建堆叠面积图。通过将False分配给stacked参数来拆分面积图是一个常见的任务:
df.plot(kind='area', stacked=False, figsize=(9,6))

饼图
如果我们对比率感兴趣,饼图是一列中数字数据的很好的比例表示。以下示例显示了苹果公司过去三个月的平均股价分布:
df_3Months.index=['March', 'April', 'May']
df_3Months.plot(kind='pie', y='AAPL', legend=False, autopct='%.f')

默认情况下,图例将显示在饼图上,因此我们将关键字legend指定为False来隐藏图例。
上面代码中的新关键字参数是autopct,它显示了饼图切片上的百分比值。
如果我们想将多个饼图中所有列的数据表示为子图,我们可以将True赋给subplots参数,如下所示:
df_3Months.plot(kind='pie', legend=False, autopct='%.f', subplots=True, figsize=(14,8))
array([, ,
], dtype=object)

散点图
散点图在 x 轴和 y 轴上绘制数据点,以显示两个变量之间的相关性。像这样:
df.plot(kind='scatter', x='MSFT', y='AAPL', figsize=(9,6), color='Green')

正如我们在上面的图中看到的,散点图显示了微软和苹果股价之间的关系。
赫克宾图
当数据非常密集时,六边形柱图(也称为六边形柱图)可以替代散点图。换句话说,当数据点的数量非常巨大,并且每个数据点无法单独绘制时,最好使用这种以蜂巢形式表示数据的绘图。此外,每个六边形的颜色定义了该范围内数据点的密度。
df.plot(kind='hexbin', x='MSFT', y='AAPL', gridsize=10, figsize=(10,6))

gridsize参数指定 x 方向上六边形的数量。更大的网格尺寸意味着更多和更小的箱。gridsize参数的默认值是 100。
KDE Plot
本教程中我们要讨论的最后一个图是核密度估计,也称为 KDE,它可视化了连续的非参数数据变量的概率密度。该图使用高斯核在内部估计概率密度函数(PDF)。让我们试一试:
df.plot(kind='kde')

我们还可以在 KDE 图中指定影响图平滑度的带宽,如下所示:
df.plot(kind='kde', bw_method=0.1)

df.plot(kind='kde', bw_method=1)

正如我们所见,选择小带宽会导致平滑不足,这意味着密度图显示为单个峰值的组合。相反,巨大的带宽会导致过度平滑,这意味着密度图显示为单峰分布。
摘要
在本教程中,我们讨论了 Pandas 库作为一个简单易学的数据可视化工具的功能。然后,我们用很少几行代码实现了一些例子,涵盖了《熊猫》中提供的所有情节。
请随时在 LinkedIn 和 Twitter 上与我联系。
Pol Brigneti 如何在 Belgrave Valley 使用 Dataquest 获得数据分析师的工作
原文:https://www.dataquest.io/blog/pol-brigneti-got-a-data-analyst-job-with-dataquest/
September 21, 2018
当 Pol Brigneti 在巴塞罗那 Pompeu Fabra 大学学习商业管理后开始职业生涯时,他根本不知道什么是数据分析。在 Ridelink 实习后,他很快发现了数据分析的重要性,并意识到要实现有一天成为产品经理的目标,他需要出色的数据分析技能。
2018 年 4 月,他前往伦敦参加贝尔格雷夫山谷的训练营。Belgrave 在他们的课程中使用 Dataquest 来帮助他们的学生学习 python 进行数据分析。在贝尔格雷夫山谷紧张地工作了两个月后,Pol 开始找工作。来自 Dataquest 和 Belgrave 的项目使他能够建立一个 GitHub 作品集,展示给潜在的雇主。几乎每次面试都需要进行编码测试,通常是 Python 或 SQL——幸运的是,他的学习为他做了充分的准备。
" Dataquest 是一个非常简单的平台,让学习数据分析变得非常容易."点击此处阅读 Pol 在贝尔格雷夫山谷的完整故事。
他在伦敦的在线支付和金融科技公司 Checkout.com 找到了一份数据分析师的工作。他是 BI 团队的一员,经常使用 Python,并将使用 SQL。他非常喜欢金融科技,并期待了解更多关于加密货币的知识,以及它如何扰乱金融科技。他还在贝尔格雷夫大学教书,喜欢向新学生介绍 Dataquest,并帮助他们学习。
Pol 给新学员的建议是不要气馁——以程序化的方式开始思考可能很难。“如果遇到困难,不要害怕。很正常。一旦你达到了一切都合二为一的地步,那一刻就会到来,这种感觉棒极了。”
投资组合项目:使用熊猫和 Scikit-learn 预测股票价格
December 16, 2021
在这个项目中,我们将学习如何使用 python、pandas 和 scikit-learn 预测股票价格。在这个过程中,我们将下载股票价格,创建一个机器学习模型,并开发一个回溯测试引擎。在此过程中,我们将讨论什么是数据科学投资组合的好项目,以及如何在您的投资组合中展示该项目。供您参考,您可以在这里看到已完成的项目。
首先,让我们把我们在这个项目中要做的事情和现实世界联系起来。当做一个项目时,即使是为了你的作品集,重要的是要考虑它在现实世界中会如何被使用。这是因为招聘经理希望你的项目尽可能接近实际的数据科学工作。所以花大量的时间考虑你想要什么样的误差指标,以及你的算法将如何被使用。
在这种情况下,假设我们在炒股。我们感兴趣的是以最小的风险进行有利可图的股票交易。因此,当我们购买一只股票时,我们希望相当确定价格会上涨。我们将在开市时买进股票,闭市时卖出。
机器学习设置
为了告诉我们何时交易,我们希望训练一个机器学习模型。这个模型需要使用今天的数据来预测明天的收盘价。如果模型预测价格会上涨,我们就买股票。如果模型说价格会下降,我们什么都不会做。
我们希望最大化我们的true positives——模型预测价格会上涨,而实际上价格会上涨的日子。因此,我们将使用 precision 作为模型的误差度量,即true positives / (false positives + true positives)。这将确保我们最大限度地减少误报(我们买入股票,但价格实际下跌)造成的损失。
这意味着我们将不得不接受许多false negatives天,当我们预测价格会下降,但它实际上是上升的。这没什么,因为我们宁愿最小化我们的潜在损失,而不是最大化我们的潜在收益。
所以我们的模型会有低的recall,但是高的precision。这里的更多的是在精度和召回上。
方法
我们将关注微软股票,其股票代码为MSFT。下面是我们预测MSFT股票价格的步骤:
- 从雅虎财经下载 MSFT 股票价格
- 探索数据
- 设置数据集以使用历史价格预测未来价格
- 测试机器学习模型
- 设置回溯测试引擎
- 提高模型的准确性
最后,我们将记录一些潜在的未来发展方向,以改进这项技术。
下载数据
首先,我们将从雅虎财经下载数据。为此,我们将使用yfinance python 包。我们可以通过在命令行中键入pip install yfinance来安装它(或者在 Jupyter 笔记本中键入!pip install yfinance)。
我们将使用一只股票(微软)从开始交易到现在的数据。
import yfinance as yf
msft = yf.Ticker("MSFT")
msft_hist = msft.history(period="max")
我们现在已经下载了数据!在现实世界中,我们希望将数据保存到磁盘,以便在需要时可以再次访问它,而无需反复调用 API。我们可以通过检查以前是否保存过数据来做到这一点。如果有的话,我们只需加载数据。否则,我们下载数据。
我们需要安装pandas来做到这一点。
import os
import pandas as pd
DATA_PATH = "msft_data.json"
if os.path.exists(DATA_PATH):
# Read from file if we've already downloaded the data.
with open(DATA_PATH) as f:
msft_hist = pd.read_json(DATA_PATH)
else:
msft = yf.Ticker("MSFT")
msft_hist = msft.history(period="max")
# Save file to json in case we need it later. This prevents us from having to re-download it every time.
msft_hist.to_json(DATA_PATH)
探索数据
接下来我们可以看一看msft_hist来看数据的结构。我们将在数据帧上使用.head方法来检查前 5 行数据。
正如我们在下面看到的,微软股票交易的每一天都有一行数据。以下是各列:
- 开盘——股票的开盘价
- 高–一天中的最高价格
- 低–一天中的最低价格
- 收盘——交易日的收盘价
- 成交量——交易了多少股票
数据帧的行索引是股票交易的日期。股票不是每天都交易(周末和节假日不交易),所以漏了一些日期。
msft_hist.head(5)
| 打开 | 高的 | 低的 | 关闭 | 卷 | 红利 | 股票分拆 | |
|---|---|---|---|---|---|---|---|
| 1986-03-13 | 0.055898 | 0.064119 | 0.055898 | 0.061378 | One billion thirty-one million seven hundred and eighty-eight thousand eight hundred | Zero | Zero |
| 1986-03-14 | 0.061378 | 0.064667 | 0.061378 | 0.063570 | Three hundred and eight million one hundred and sixty thousand | Zero | Zero |
| 1986-03-17 | 0.063570 | 0.065215 | 0.063570 | 0.064667 | One hundred and thirty-three million one hundred and seventy-one thousand two hundred | Zero | Zero |
| 1986-03-18 | 0.064667 | 0.065215 | 0.062474 | 0.063022 | Sixty-seven million seven hundred and sixty-six thousand four hundred | Zero | Zero |
| 1986-03-19 | 0.063022 | 0.063570 | 0.061378 | 0.061926 | Forty-seven million eight hundred and ninety-four thousand four hundred | Zero | Zero |
接下来,让我们绘制数据,这样我们就可以看到股票价格如何随着时间的推移而变化。这为我们提供了数据结构的另一个概览。我们可以在 DataFrames 上使用内置的 plot 方法来做到这一点。我们使用use_index参数,因为我们想要使用索引作为 x 轴值。
在我们可以绘图之前,请确保安装了matplotlib。
# Visualize microsoft stock prices
msft_hist.plot.line(y="Close", use_index=True)
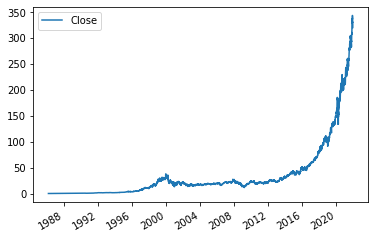
准备数据
好吧,希望你已经不再因为在过去的 30 年里没有买微软的股票而自责。
现在,让我们准备数据,这样我们就可以做预测。正如我们在引言中提到的,我们将根据今天的数据预测明天的价格是涨还是跌。
首先,我们将确定一个我们试图预测的目标。我们的目标是明天价格是涨是跌。如果价格上涨,目标是1,如果价格下跌,目标是0。
接下来,我们将把前几天的数据“前移”一天,这样我们就可以用它来预测目标价格。这确保了我们不会意外地使用同一天的数据进行预测!(很常见的错误)
然后,我们将两者结合起来,这样我们就有了我们的训练数据。
设定目标
首先,我们设置目标。
我们首先将Close列复制到一个名为data的新数据帧中,并将其重命名为actual_close。这确保了我们可以继续看到股票每天的实际收盘价。(我们稍后会改变一些东西,所以保留这一点很重要)。
然后,我们通过执行以下操作来设置我们的目标:
- 使用 pandas 滚动的方法,每隔 2 行数据帧。这将首先查看(' 1986-03-13 ',' 1986-03-14 '),然后(' 1986-03-14 ',' 1986-03-17 '),以此类推。
- 我们将比较第二行和第一行,看它是否更大。如果是,返回 1,否则返回 0。
- 然后,我们只需查看
Close列。
正如你在上面看到的,Target列现在显示价格在给定的一天是上涨还是下跌。如果Target是1,价格就上去了。如果Target是0,价格就下降了。
这是我们希望我们的机器学习模型预测的!
# Ensure we know the actual closing price
data = msft_hist[["Close"]]
data = data.rename(columns = {'Close':'Actual_Close'})
# Setup our target. This identifies if the price went up or down
data["Target"] = msft_hist.rolling(2).apply(lambda x: x.iloc[1] > x.iloc[0])["Close"]
data.head()
| 实际 _ 关闭 | 目标 | |
|---|---|---|
| 1986-03-13 | 0.061378 | 圆盘烤饼 |
| 1986-03-14 | 0.063570 | One |
| 1986-03-17 | 0.064667 | One |
| 1986-03-18 | 0.063022 | Zero |
| 1986-03-19 | 0.061926 | Zero |
将数据“前移”
接下来,我们将使用 DataFrame shift 方法将所有行“向前”移动一个交易日。
如您所见,1986-03-13的价格现在与1986-03-14相关联,其他价格上移一行。这是为了确保我们使用过去的数据预测未来的价格。
如果我们不这样做,我们将使用来自03-14的数据来预测03-14的价格。相反,我们需要使用来自03-13的数据来预测03-14的价格。如果我们不这样做,我们的模型在测试时会看起来很神奇,但在现实世界中根本不会工作。在现实世界中,我们实际上不知道明天的价格,所以我们不能用它来做预测。
# Shift stock prices forward one day, so we're predicting tomorrow's stock prices from today's prices.
msft_prev = msft_hist.copy()
msft_prev = msft_prev.shift(1)
msft_prev.head()
| 打开 | 高的 | 低的 | 关闭 | 卷 | 红利 | 股票分拆 | |
|---|---|---|---|---|---|---|---|
| 1986-03-13 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| 1986-03-14 | 0.055898 | 0.064119 | 0.055898 | 0.061378 | 1.031789e+09 | Zero | Zero |
| 1986-03-17 | 0.061378 | 0.064667 | 0.061378 | 0.063570 | 3.081600e+08 | Zero | Zero |
| 1986-03-18 | 0.063570 | 0.065215 | 0.063570 | 0.064667 | 1.331712e+08 | Zero | Zero |
| 1986-03-19 | 0.064667 | 0.065215 | 0.062474 | 0.063022 | 6.776640e+07 | Zero | Zero |
结合我们的数据
接下来,我们需要将我们的Target与我们想要用来预测目标的列结合起来。我们将在数据帧上使用这个方法和连接方法。
在我们加入数据后,我们看到我们将使用前一天的数据来预测目标。我们将用来预测目标的列是["Close", "Volume", "Open", "High", "Low"]。
最好明确地使用predictors来避免意外地使用你的目标来预测它自己。这将使你的模型在训练中看起来非常好,但在现实世界中根本行不通。
# Create our training data
predictors = ["Close", "Volume", "Open", "High", "Low"]
data = data.join(msft_prev[predictors]).iloc[1:]
data.head()
| 实际 _ 关闭 | 目标 | 关闭 | 卷 | 打开 | 高的 | 低的 | |
|---|---|---|---|---|---|---|---|
| 1986-03-14 | 0.063570 | One | 0.061378 | 1.031789e+09 | 0.055898 | 0.064119 | 0.055898 |
| 1986-03-17 | 0.064667 | One | 0.063570 | 3.081600e+08 | 0.061378 | 0.064667 | 0.061378 |
| 1986-03-18 | 0.063022 | Zero | 0.064667 | 1.331712e+08 | 0.063570 | 0.065215 | 0.063570 |
| 1986-03-19 | 0.061926 | Zero | 0.063022 | 6.776640e+07 | 0.064667 | 0.065215 | 0.062474 |
| 1986-03-20 | 0.060282 | Zero | 0.061926 | 4.789440e+07 | 0.063022 | 0.063570 | 0.061378 |
创建机器学习模型
接下来,我们将创建一个机器学习模型,看看我们预测股票价格的准确性如何。
因为我们处理的是时间序列数据,所以我们不能只使用交叉验证来为整个数据集创建预测。这将导致未来数据被用来预测过去价格的泄漏。这与现实世界不符,会让我们认为我们的算法比实际好得多。
相反,我们将按顺序拆分数据。我们将从使用其他行预测最后 100 行开始。
我们将使用随机森林分类器来生成我们的预测。对于许多应用程序来说,这是一个很好的“默认”模型,因为它可以提取数据中的非线性关系,并且对于使用正确的参数进行过度拟合具有一定的鲁棒性。
这只是为了设置我们的模型,并确保一切正常工作。为了获得准确的误差指标,我们需要对整个价格历史进行回溯测试。一旦我们建立了模型,这将是我们的下一步。
建立模型
首先,我们将从scikit-learn导入一个 RandomForestClassifier 。我们可以用pip install scikit-learn安装scikit-learn。
我们使用分类算法,因为我们的目标是二进制(0/1)。A 1表示价格上涨,a 0表示价格下跌。如果我们有不同类型的目标(如实际价格),我们可能会使用回归算法。
当我们初始化模型时,我们传递几个参数:
- n _ estimators–这是算法应该创建的独立决策树的数量。随机森林是决策树的集合,比单个树更能抵抗过度拟合。树越多,算法越健壮,但树越少意味着运行越快。
- min _ samples _ split–这是任何决策树应该分割的最小样本数。这个值越低,树木就越容易过度生长。将它设置得更高也会使它运行得更快。
- random _ state–这是一个很好的设置,这样对相同的数据运行两次算法会返回相同的结果。
from sklearn.ensemble import RandomForestClassifier
import numpy as np
# Create a random forest classification model. Set min_samples_split high to ensure we don't overfit.
model = RandomForestClassifier(n_estimators=100, min_samples_split=200, random_state=1)
训练模型
一旦我们建立了模型,我们就可以在数据集的最后100行上训练它。我们使用除最后的100行之外的所有数据来预测最后的100行。当您处理时间序列数据时,千万不要用未来的数据来预测过去,这一点很重要。
拟合方法将使用我们的预测器来训练模型,以预测Target。
# Create a train and test set
train = data.iloc[:-100]
test = data.iloc[-100:]
model.fit(train[predictors], train["Target"])
RandomForestClassifier(最小样本分割=200,随机状态=1)
测量误差
接下来,我们需要检查模型的准确性。前面,我们提到了使用precision来测量误差。我们可以通过使用 scikit-learn 中的precision_score函数来实现这一点。
Precision 将告诉我们算法预测价格会上涨的天数百分比,它实际上上涨了。因为我们想最小化风险,我们想有一个高精度。这意味着当我们购买股票时,我们对赚钱有很高的信心。
下面,我们做以下工作来计算精度:
- 导入 scikit-learn
precision_score功能 - 使用预测函数从我们的模型生成预测。这将为每行提供一个
0或一个1。 predict方法返回一个 numpy 数组。为了使它更容易使用,我们将把它变成一个熊猫系列。- 最后,我们执行
precision_score函数,传入预测和目标。
下面可以看到,我们的精度只有.51,不算很大。这意味着当模型预测价格会上涨时,它们只上涨了51%的时间。
from sklearn.metrics import precision_score
# Evaluate error of predictions
preds = model.predict(test[predictors])
preds = pd.Series(preds, index=test.index)
precision_score(test["Target"], preds)
Zero point five one
我们的模型有 51%的时间是方向准确的。这只比抛硬币好一点点!我们可以更深入地观察单个预测和实际情况,看看我们的差距在哪里。
我们可以通过对照预测标绘目标来做到这一点。我们首先使用 concat 函数将Target列和Predictions列组合成一个数据帧。这个函数连接两个熊猫对象。在这种情况下,每个对象都是一个系列,所以我们想在axis=1上将它们连接起来,这样每个对象都成为一列。
然后,我们可以绘制数据帧来可视化这两列。
正如我们所见,模型预测价格每天都会上涨。这并不理想,但是我们已经建立了模型,现在可以继续回溯测试了。
combined = pd.concat({"Target": test["Target"],"Predictions": preds}, axis=1)
combined.plot()
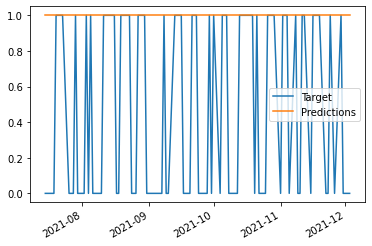
回溯测试
我们的模型不是很好,但幸运的是我们仍然可以改进它。在此之前,让我们弄清楚如何对整个数据集进行预测,而不仅仅是最后 100 行。这将为我们提供更可靠的误差估计。过去 100 天可能有非典型的市场条件或其他问题,使得这些天的误差指标对未来的预测不切实际(这是我们真正关心的)。
如果你只有 100 天的数据来测试,你不会想在现实世界中使用一个算法。
为了在更多的日子里进行测试,我们需要进行回溯测试。回溯测试确保我们只使用我们预测的那一天之前的数据。如果我们使用我们预测的那天之后的数据,这个算法是不现实的(在现实世界中,你不能用未来的数据来预测过去!).
我们的回溯测试方法将在数据集上循环,并且每750行训练一个模型。我们将使它成为一个函数,这样,如果我们想再次进行回溯测试,就可以避免重写代码。理想情况下,我们应该比每一个750行更频繁地训练一个模型,但是为了提高速度,我们将把这个数字设得更高。
在我们编写完整的回溯测试循环之前,让我们编写一次迭代的代码。在下面的代码中:
- 我们将把前 1000 行数据作为我们的训练集
- 我们将接下来的 750 行作为我们的测试集
- 我们将使我们的机器学习模型适合训练集
- 我们将在测试集上做预测
这与我们之前所做的类似,但是我们改变了我们正在查看的行:
i = 1000
step = 750
train = data.iloc[0:i].copy()
test = data.iloc[i:(i+step)].copy()
model.fit(train[predictors], train["Target"])
preds = model.predict(test[predictors])
预测概率
接下来,让我们增加一点精度。我们使用预测方法来生成预测。但是,这个方法并没有针对precision进行优化,这才是我们关心的。
默认情况下,如果模型认为价格有 50%或更高的可能性上涨,它会预测价格会上涨。我们来调整一下这个门槛,让模型只在更有把握的时候预测价格会涨。我们将这个阈值设置为.6。
为此,我们需要使用 predict_proba 方法。这种方法使我们能够得到原始概率,而不仅仅是 0/1。
在下面的代码中,我们:
- 使用
predict_proba方法获得价格上涨的概率,而不仅仅是0/1。 - 取结果的第二列,确保我们只得到价格上涨的概率。
- 将 numpy 数组的结果转换为 pandas 系列,以便于使用。
- 如果价格上涨的可能性大于 60%,那么就说价格会上涨。
如您所见,preds给出了模型每天的预测。
preds = model.predict_proba(test[predictors])[:,1]
preds = pd.Series(preds, index=test.index)
preds[preds > .6] = 1
preds[preds<=.6] = 0
preds.head()
1990-02-27 1.0
1990-02-28 1.0
1990-03-01 1.0
1990-03-02 1.0
1990-03-05 1.0
dtype:float 64
把它拉成一个圈
接下来,我们可以将我们所做的一切整合成一个循环。这个循环将使我们能够遍历整个数据集,生成预测,并将它们添加到predictions列表中。
除了数据集的前 1000 行,我们将获得所有行的预测。这是因为没有以前的数据可以用来预测这些行。
在这个循环中,我们:
- 在我们的训练和测试集上生成预测
- 将这些预测与实际目标结合起来
- 将所有预测添加到一个列表中
如您所见,查看predictions列表的第一个元素向我们展示了实际的Target和我们的模型制作的Predictions。
predictions = []
# Loop over the dataset in increments
for i in range(1000, data.shape[0], step):
# Split into train and test sets
train = data.iloc[0:i].copy()
test = data.iloc[i:(i+step)].copy()
# Fit the random forest model
model.fit(train[predictors], train["Target"])
# Make predictions
preds = model.predict_proba(test[predictors])[:,1]
preds = pd.Series(preds, index=test.index)
preds[preds > .6] = 1
preds[preds<=.6] = 0
# Combine predictions and test values
combined = pd.concat({"Target": test["Target"],"Predictions": preds}, axis=1)
predictions.append(combined)
predictions[0].head()
| 目标 | 预言 | |
|---|---|---|
| 1990-02-27 | Zero | One |
| 1990-02-28 | One | One |
| 1990-03-01 | One | One |
| 1990-03-02 | One | One |
| 1990-03-05 | One | One |
创建回溯测试函数
最后,我们将把循环封装在一个函数中,以便于使用。函数意味着我们以后可以很容易地调用它。该函数将数据、机器学习模型和预测器作为输入。我们还将 start 和 step 设置为可选参数。
在回溯测试功能中,我们将:
- 拆分训练和测试数据
- 训练模特
- 使用 predict_proba 对测试数据进行预测
- 将我们的预测与实际目标结合起来,这样我们就可以很容易地计算出误差
- 返回所有预测
该函数将使我们能够随时在整个数据集上创建预测。
def backtest(data, model, predictors, start=1000, step=750):
predictions = []
# Loop over the dataset in increments
for i in range(start, data.shape[0], step):
# Split into train and test sets
train = data.iloc[0:i].copy()
test = data.iloc[i:(i+step)].copy()
# Fit the random forest model
model.fit(train[predictors], train["Target"])
# Make predictions
preds = model.predict_proba(test[predictors])[:,1]
preds = pd.Series(preds, index=test.index)
preds[preds > .6] = 1
preds[preds<=.6] = 0
# Combine predictions and test values
combined = pd.concat({"Target": test["Target"],"Predictions": preds}, axis=1)
predictions.append(combined)
return pd.concat(predictions)
运行功能
既然我们已经创建了回溯测试函数,我们可以调用它来生成整个数据集的预测。
predictions = backtest(data, model, predictors)
接下来,让我们使用 value_counts 方法来确定算法预测价格上涨与下跌的次数。
如你所见,算法只预测价格会上涨739倍。在 Target中,你可以看到价格实际上涨了3945倍。因此,算法预测价格上涨的次数比实际上涨的次数要少得多。这意味着该算法的召回率较低,即找到价格上涨的所有日期的概率百分比。
这是因为我们使用.6作为价格是否上涨的阈值。如果我们使用较低的阈值,我们会增加recall,但精度会降低。因为我们想要最小化我们的风险,我们想要最大化精确度。所以如果算法只预测价格会在很少的几天内上涨也没关系。
predictions["Predictions"].value_counts()
0.0 7267
1.0 739
名称:预测,数据类型:int64
predictions["Target"].value_counts()
1.0 4061
0.0 3945
名称:目标,数据类型:int64
最后,再来看精度。我们可以用之前的同一个函数来计算。
看起来我们的精度也很低。这是因为算法限制了predictors来帮助它确定价格是上涨还是下跌。接下来,我们将添加更多的预测器,以帮助算法做出更好的决策。
precision_score(predictions["Target"], predictions["Predictions"])
0.503382949932341
提高准确性
这个模型不是很准确,但至少现在我们可以预测股票的整个历史。为了让这个模型有用,我们必须让它预测得更准确。
让我们再增加一些预测器,看看我们是否能提高准确性。
我们将添加一些滚动方法,因此模型可以根据最近的价格来评估当前价格。我们还会看看不同指标之间的比率。
滚动方式
滚动平均值非常有用,因为它们可以帮助算法根据本周、季度或年度的平均价格来评估当前价格。例如,如果现在的价格高于年度价格,这可能意味着股票处于上升趋势。
为了计算滚动平均值,我们将再次使用 pandas 滚动方法来寻找不同时间范围的Close列的滚动平均值。
weekly_mean = data.rolling(7).mean()["Close"]
quarterly_mean = data.rolling(90).mean()["Close"]
annual_mean = data.rolling(365).mean()["Close"]
我们还可以告诉算法上周价格上涨了多少天。我们可以通过使用 pandas shift和rolling方法来做到这一点:
我们将向前移动数据,所以我们不会将当天的信息合并到我们的预测中。如果我们不使用 shift,那么算法将知道实际的目标。
求目标的 7 天滚动总和。如果价格连续 7 天上涨,这将是 7。如果涨了 0 天,这就是0。
weekly_trend = data.shift(1).rolling(7).sum()["Target"]
现在,我们准备将我们的比率添加到预测数据框架中。
首先,我们将把周、季度和年平均值之间的比率加到收盘价上:
data["weekly_mean"] = weekly_mean / data["Close"]
data["quarterly_mean"] = quarterly_mean / data["Close"]
data["annual_mean"] = annual_mean / data["Close"]
接下来,我们将添加不同滚动方式之间的比率。这有助于算法理解相对于年度趋势的周趋势。
data["annual_weekly_mean"] = data["annual_mean"] / data["weekly_mean"]
data["annual_quarterly_mean"] = data["annual_mean"] / data["quarterly_mean"]
接下来,我们将把我们的周趋势添加到预测数据框架中。
data["weekly_trend"] = weekly_trend
然后,我们将添加一些日内开盘价、最低价和最高价与收盘价之间的比率。这有助于算法理解前一天的价格趋势。例如,如果高点比收盘价高得多,这可能意味着股票在一天结束时处于下降趋势。
data["open_close_ratio"] = data["Open"] / data["Close"]
data["high_close_ratio"] = data["High"] / data["Close"]
data["low_close_ratio"] = data["Low"] / data["Close"]
最后,我们将使用添加的所有新预测值来更新预测值列表。这确保我们在训练模型时使用所有新的预测器。
full_predictors = predictors + ["weekly_mean", "quarterly_mean", "annual_mean", "annual_weekly_mean", "annual_quarterly_mean", "open_close_ratio", "hig
更新我们的预测
我们现在可以用新的预测器更新我们的预测。我们必须截掉前 365 行,因为我们的滚动平均值将具有前 365 行的 NaN 值。我们希望确保我们预测的每一行都有一致的数据。
可以看到,我们的预测比以前准确多了!
predictions = backtest(data.iloc[365:], model, full_predictors)
precision_score(predictions["Target"], predictions["Predictions"])
0.5979381443298969
评估我们的预测
现在,我们可以看看我们已经做了多少交易。我们可以用value_counts.再做一次
如你所见,我们已经使用这个算法进行了194交易。当我们的算法认为价格上涨时,我们有接近于 T1 的机会。这是一个不错的开始,但是我们可以采取很多后续步骤来进一步改进算法!
# Show how many trades we would make
predictions["Predictions"].value_counts()
`0.0 7447
1.0 194
名称:预测,数据类型:int64
# Look at trades we would have made in the last 100 days
predictions.iloc[-100:].plot()
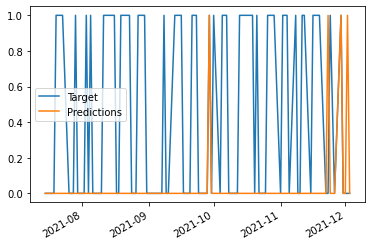
后续步骤
我们在这个项目上已经取得了很大进展!到目前为止,我们已经:
- 股票的下载数据
- 清理和探索数据
- 创造了一个机器学习模型
- 创建了回溯测试函数
- 改进了我们的预测
我们现在有一个模型,我们可以继续建立和调整。我们可以调整的最大领域是继续提高我们预测的准确性。
我们可以采取很多后续措施:
改进技术
- 计算如果你用这个算法交易,你会赚多少钱
改进算法
- 以较小的步长跑步!这将花费更长的时间,但提高准确性
- 尝试丢弃旧数据(仅保留特定窗口中的数据)
- 尝试不同的机器学习算法
- 调整随机森林参数或预测阈值
添加更多预测器
- 在当天交易日添加
- 看看你能否加入前一天的每小时趋势
- 交易结束后和交易开始前的活动账户
- 早期交易
- 在纽约证券交易所开盘前在其他交易所交易(观察全球情绪)
- 经济指标
- 利率
- 其他重要的经济新闻
- 关键日期
- 红利
- 选举等外部因素
- 公司里程碑
- 盈利电话
- 分析师评级
- 主要公告
- 相关股票的价格
- 同一行业的其他公司
- 主要合作伙伴、客户等。
希望这个项目是有帮助的,你现在有一些东西可以添加到你的投资组合。当你构建你的项目时,我建议你确保记录下你的关键选择,并向读者解释你为什么做出这些选择。你可以看到这个已完成项目的例子来获得灵感。
请继续关注更多的项目演练帖子!`
Postgres 内部:构建描述工具
January 10, 2018
在之前的博客 帖子中,我们已经描述了 Postgres 数据库以及使用 Python 与它交互的方式。这些帖子提供了基础知识,但是如果您想在生产系统中使用数据库,那么有必要知道如何使查询更快、更有效。要理解效率在 Postgres 中意味着什么,了解 Postgres 如何在幕后工作是很重要的。在这篇文章中,我们将关注 Postgres 和关系数据库的更高级的概念。首先,我们将学习 Postgres 如何存储自己的内部数据来描述、调试和识别系统中的瓶颈。然后,我们将使用我们对 Postgres 内部数据的了解来构建我们自己版本的 Python 数据库描述工具。像我们之前的博文一样,我们将使用以下工具:
- Postgres 的本地版本(v9.2 或更高版本)
- python3
- Postgres 的 Python 驱动程序,
psycopg2
我们将使用的数据集来自美国的住房和城市发展部——也被称为 HUD 。我们已经将文件打包到一个包含 CSV 格式数据的 zip 文件和一个 Python 3 脚本(load_hud_tables.py)中,该脚本将 CSV 复制到本地运行的 Postgres 中。如果您在没有默认连接的情况下运行 Postgres 服务器,您将需要更新脚本中的连接字符串。使用 HUD 的数据集,我们将使用每个 Postgres 引擎中可用的命令来处理真实世界的数据示例。从空白开始,我们将研究这些表及其数据类型。然后,我们将使用内部 Postgres 表来探索 HUD 表,以给我们关于数据库内容的详细描述。首先,下载并解压dq_postgres_internals.zip 文件。进入dq_postgres_internals/目录,更改load_hud_tables.py中的连接参数,然后运行脚本。这将把 CSV 文件加载到本地 Postgres 实例中。一旦您将文件加载到 Postgres 服务器上,我们就可以开始连接数据库了。如果本地 Postgres 实例不同于默认值,请更改连接值。在这篇文章中,任何未来对cur对象的引用都将是以下连接的光标:
import psyocpg2conn = psycopg2.connect(host="127.0.0.1", dbname="postgres", user="postgres", password="password")
cur = conn.cursor()
调查表格
现在我们已经连接好了,是时候开始探索我们有哪些可用的牌桌了。首先,我们将检查 Postgres 内部表,这些表为我们提供了关于数据库的详细信息。让我们从描述这些内部表开始。在每一个 Postgres 引擎中,都有一组 Postgres 用来管理其整个结构的内部表。这些表位于 Postgres 文档中,作为组 信息 _ 模式 和 系统目录 。这些包含了 Postgres 数据库中存储的关于数据、表名和类型的所有信息。例如,当我们使用属性cur.description时,它从内部表中提取信息显示给用户。不幸的是,没有数据集的详细模式。因此,我们需要对所包含的内容创建自己的详细描述。让我们使用来自information_schema的一个内部表来获得数据库中存储了哪些表的高级概述。内部表名为information _ schema . tables,从文档中我们可以看到有大量的列可供选择:
| 名字 | 数据类型 | 描述 |
| 表格 _ 目录 | sql _ 标识符 | 包含该表的数据库的名称(总是当前数据库) |
| 表模式 | sql _ 标识符 | 包含该表的架构的名称 |
| 表名 | sql _ 标识符 | 表的名称 |
| 表格类型 | 字符 _ 数据 | 表的类型:永久基表的基表(普通表类型)、视图的视图、外部表的外部表或临时表的本地临时表 |
| 自引用列名 | sql _ 标识符 | 适用于 PostgreSQL 中不可用的功能 |
| 参考 _ 生成 | 字符 _ 数据 | 适用于 PostgreSQL 中不可用的功能 |
| 用户定义的类型目录 | sql _ 标识符 | 如果该表是类型化表,则为包含基础数据类型的数据库的名称(始终为当前数据库),否则为 null。 |
| 用户定义类型模式 | sql _ 标识符 | 如果表是类型化表,则为包含基础数据类型的架构的名称,否则为 null。 |
| 用户定义类型名称 | sql _ 标识符 | 如果表是类型化表,则为基础数据类型的名称,否则为 null。 |
| is _ insertable _ into | 是或否 | 如果表是可插入的,则为“是”,否则为“否”(基表总是可插入的,视图不一定。) |
| 是类型化的 | 是或否 | 如果该表是类型化表,则为“是”,否则为“否” |
| 提交 _ 操作 | 字符 _ 数据 | 如果该表是临时表,则 PRESERVE,否则为 null。(SQL 标准为临时表定义了其他提交操作,PostgreSQL 不支持这些操作。) |
此时,我们只关心数据库中的表名。看一下上面的表描述,有一个列table_name公开了这些信息。让我们查询该列,看看我们在处理什么。
cur.execute("SELECT table_name FROM information_schema.tables ORDER BY table_name")
table_names = cur.fetchall()
for name in table_names:
print(name)
使用模式
当您运行前面的命令时,您会注意到输出包含了大量的表。这些表中的每一个都可以在postgres数据库中找到。问题是:我们在结果中包含了内部表。在输出中,您会注意到许多表格以前缀pg_*开始。这些表中的每一个都是内部表的pg_catalog组的一部分。这些是我们之前描述的系统目录表。然后,你可能已经猜到了,在information_schema名下还有一组其他的表。但是,这些表很难找到,因为它们没有明显的前缀模式。我们如何知道哪些表是内部的,哪些表是用户创建的?我们需要描述模式来解释上面的问题。在处理关系数据库时,模式这个词被概括为一个具有多重含义的术语。您可能听说过模式被用来描述表(它们的数据类型、名称、列等)。)或模式作为数据库的蓝图。图式的模糊含义只会使我们困惑。然而,对于 Postgres 来说,图式这个术语是为一个特定的目的而保留的。在 Postgres 中,模式被用作表的名称空间,其独特的目的是将它们分成单个数据库中的隔离组或集合。

让我们进一步分析一下。Postgres 使用数据库的概念来分离 Postgres 服务器中的用户和数据。当您创建数据库时,您正在创建一个隔离的环境,在该环境中,用户可以查询只能在该特定数据库中找到的表。这里有一个例子:假设国土安全部(DHS)和 HUD 共享同一个政府 Postgres 数据库,但是他们想要分离他们的用户和数据。然后,他们将使用数据库来分离他们的数据和用户,每个机构有一个单独的数据库。现在,当用户想要连接到他们的数据时,他们需要指定他们将连接到哪个数据库,并且只有在那里,他们才能使用他们的表。然而,假设有分析师想要对公民数据(citizens表)和城市住房开发(developments表)进行横截面分析。那么,他们会想要查询dhs数据库和hud数据库中的表。然而,在 Postgres 考试中,这是不可能的。
# Connect to the `dhs` database.
conn = psycopg2.connect(dbname='dhs')
cur = conn.cursor()
# This query works.
cur.execute('SELECT * FROM citizens')
# This query will fail because it is in the `hud` database.
cur.execute('SELECT * FROM developments')
如果我们想把表分成不同的组,但仍然允许跨表查询,那该怎么办?这是模式的完美用例。代替数据库,为每个机构使用不同的模式将使用名称空间来分隔表,但是仍然允许分析师查询两个表。
# Connect to the US Government database.
conn = psycopg2.connect(dbname='us_govt_data')
cur = conn.cursor()
# Using schemas, both queries work!
cur.execute('SELECT * FROM dhs.citizens')
cur.execute('SELECT * FROM hud.developments')
这就是 Postgres 如何划分内部表(以及用户创建的表!).当创建一个数据库时,有 3 个模式被实例化:pg_catalog(对于系统编目表)、information_schema(对于信息模式表)和public(对于用户创建的表的默认模式)。每次在数据库中发出CREATE TABLE命令时,默认情况下 Postgres 会将该表分配给public模式。现在,回到我们之前的问题,我们如何将用户创建的表与内部表分开?再看一下information_schema.tables的栏目。现在,检查是否存在可以将用户创建的表与内部表分开的列。
| 名字 | 数据类型 | 描述 |
| 表格 _ 目录 | sql _ 标识符 | 包含该表的数据库的名称(总是当前数据库) |
| 表模式 | sql _ 标识符 | 包含该表的架构的名称 |
| 表名 | sql _ 标识符 | 表的名称 |
| 表格类型 | 字符 _ 数据 | 表的类型:永久基表的基表(普通表类型)、视图的视图、外部表的外部表或临时表的本地临时表 |
| 自引用列名 | sql _ 标识符 | 适用于 PostgreSQL 中不可用的功能 |
| 参考 _ 生成 | 字符 _ 数据 | 适用于 PostgreSQL 中不可用的功能 |
| 用户定义的类型目录 | sql _ 标识符 | 如果该表是类型化表,则为包含基础数据类型的数据库的名称(始终为当前数据库),否则为 null。 |
| 用户定义类型模式 | sql _ 标识符 | 如果表是类型化表,则为包含基础数据类型的架构的名称,否则为 null。 |
| 用户定义类型名称 | sql _ 标识符 | 如果表是类型化表,则为基础数据类型的名称,否则为 null。 |
| is _ insertable _ into | 是或否 | 如果表是可插入的,则为“是”,否则为“否”(基表总是可插入的,视图不一定。) |
| 是类型化的 | 是或否 | 如果该表是类型化表,则为“是”,否则为“否” |
| 提交 _ 操作 | 字符 _ 数据 | 如果该表是临时表,则 PRESERVE,否则为 null。(SQL 标准为临时表定义了其他提交操作,PostgreSQL 不支持这些操作。) |
有一个名为table_schema的栏目符合我们的要求。我们可以对该列进行筛选,以选择所有公共表。我们可以这样编写查询:
conn = psycopg2.connect(dbname="dq", user="hud_admin", password="eRqg123EEkl")
cur = conn.cursor()
cur.execute("SELECT table_name FROM information_schema.tables WHERE table_schema='public' ORDER BY table_name")
for table_name in cur.fetchall():
name = table_name[0]
print(name)
描述表格
从输出来看,我们将只使用三个表。这些是:
homeless_by_coc
state_info
state_household_incomes
使用表名,我们可以调用cur.description属性来详细查看每个表的列、类型和任何其他元信息。之前,我们了解到可以发出一个SELECT查询,然后调用description属性来获取表信息。然而,如果我们想在for循环中为每个表做这件事呢?希望你的第一个想法是而不是使用.format()。在之前的帖子中,我们已经提到了关于使用.format()进行字符串插值的问题。答案是使用mogrify()方法或execute()方法中的第二个位置参数来 mogirfy 字符串。可惜事情没那么容易。试图插入表名(使用mogirfy())而不是列名、筛选键或分组键会导致错误。以下是此错误的一个示例:
table_name = "state_info"
bad_interpolation = cur.mogrify("SELECT * FROM %s LIMIT 0", [table_name])
# This will execute the query: SELECT * FROM 'state_info' LIMIT 0
# Notice the single quotation marks around state_info.
cur.execute(bad_interpolation)
# Throws an error
从代码片段中,您可能已经注意到,在表名"state_info"上使用mogrify()会将名称转换为 Postgres 字符串。这是列名或筛选查询所必需的行为,但不是表名。相反,你必须使用来自 psycopg2.extensions模块的一个名为AsIs 的类。
from psycopg2.extensions import AsIs
table_name = "state_info"
proper_interpolation = cur.mogrify("SELECT * FROM %s LIMIT 0", [AsIs(table_name)])
cur.execute(proper_interpolation)
# Executes!
SELECT查询中的表名不需要用字符串括起来。因此,AsIs将其保持为非字符串引用的有效 SQL 表示,而不是转换它。使用AsIs,我们可以检查每个表的描述,而不必写出每个请求!
from psycopg2.extensions import AsIs
cur.execute("SELECT table_name
FROM information_schema.tables WHERE table_schema='public'")
for table in cur.fetchall():
table = table[0]
cur.execute("SELECT * FROM %s LIMIT 0", [AsIs(table)])
print(cur.description, "\n")
类型代码映射
随着每个描述的打印出来,我们现在有了一个我们将要使用的表的详细视图。下面是来自homeless_by_coc描述的输出片段:
(Column(name='id', type_code=23, display_size=None, internal_size=4, precision=None, scale=None, null_ok=None), Column(name='year', type_code=1082, display_size=None, internal_size=4, precision=None, scale=None, null_ok=None), Column(name='state', type_code=1042, display_size=None, internal_size=2, precision=None, scale=None, null_ok=None), Column(name='coc_number', type_code=1042, display_size=None, internal_size=8, precision=None, scale=None, null_ok=None), Column(name='coc_name', type_code=1043, display_size=None, internal_size=128, precision=None, scale=None, null_ok=None), Column(name='measures', type_code=1043, display_size=None, internal_size=64, precision=None, scale=None, null_ok=None), Column(name='count', type_code=23, display_size=None, internal_size=4, precision=None, scale=None, null_ok=None))
理解了description属性,您应该对可用的元数据感到满意。然而,我们再次面对一个整数type_code,而不是人类可读的类型。当记住它们所代表的人类可读类型(即TEXT、INTEGER或BOOLEAN。您可以使用psycopg2类型值来查找每一列的近似类型,但是我们可以做得比近似这些值更好。使用内部表格,我们可以准确地映射 HUD 表格中每一列的类型。我们将使用的内部表来自系统编目模式pg_catalog,它被准确地命名为pg_type。我们建议查看文档中的表描述,因为本节中要添加的行太多了。你可以在这里找到表格描述。在这个表中,有许多已定义的列,其中许多您不需要关心。然而,关于这个表需要注意的一件有趣的事情是,它可以用来从头开始创建自己的 Postgres 类型。例如,使用这个表,您可以创建一个HEX类型,用于在您的列中只存储十六进制字符。让我们遍历返回的SELECT查询,并将整数类型代码映射到字符串。它应该看起来像这样:
type_mappings = {
16: 'bool',
18: 'char',
19: 'name',
...
}
利用字典理解,我们可以写出以下内容:
cur.execute("SELECT oid, typname
FROM pg_catalog.pg_type")
type_mappings = {
int(oid): typname
for oid, typname in cur.fetchall()}
可读描述类型
太好了!现在我们有了所有类型代码到它们的类型名的映射。使用type_mappings字典,无需在文档中查找就可以提供类型。让我们把所有这些放在一起,创建我们自己的表描述。我们希望将元组列表中的description属性重写为人类可读的内容。我们希望将之前练习的结果汇集到这本词典中:
{
"homeless_by_coc":
{
columns: [
{
name: "id",
type: "int4",
internal_size: 4
},
{
name: "year",
type: "date",
internal_size: 4
},
{
name: "state",
type: "char",
internal_size: 2
},
{
name: "coc_number",
type: "char",
internal_size: 128
},
{
name: "measures",
type: "varchar",
internal_size: 64
},
{
name: "count",
type: "int4",
internal_size: 4
}
]
}
...
}
使用type_mappings和table_names,我们将获得所需结果的步骤如下:
- 用
table变量循环通过table_names。 - 获取给定
table的description属性。 - 用一个
columns键将table的名称映射到一个字典。 - 通过遍历
description并映射适当的类型,从屏幕示例中重新创建columns列表。
cur.execute("SELECT oid, typname FROM pg_catalog.pg_type")
type_mappings = {
int(oid): typname
for oid, typname in cur.fetchall()}
cur.execute("SELECT table_name FROM information_schema.tables WHERE table_schema='public'")
table_names = [table[0] for table in cur.fetchall()]
readable_description = {}
for table in table_names:
cur.execute("SELECT * FROM %s LIMIT 0", [AsIs(table)])
readable_description[table] = dict(
columns=[
dict(
name=col.name,
type=type_mappings[col.type_code],
length=col.internal_size
)
for col in cur.description
] )print(readable_description)
行数
事情开始有头绪了。现在,为了完成我们的调查,我们想提供一些关于表中行的附加信息。让我们用表中的行数来提供我们的描述。我们可以使用COUNT()聚合函数找到行数。这与 SQLite 的 aggreggate 函数以及 SQL 语法的其他实现非常相似。如果你想进一步了解 Postgres 的聚合函数,它们都在 pg_catalog.pg_aggregate内部表中定义。提醒一下,下面是如何使用 Postgres 中的COUNT()函数:
SELECT COUNT(*) FROM example_table
我们希望描述表看起来像这样:
{
"homeless_by_coc":
{
columns: [
{
name: "id",
type: "int4",
internal_size: 4
},
...
{
name: "count",
type: "int4",
internal_size: 4
}
],
total: 86529
}
...
}
我们不再遍历table_names列表,而是遍历readable_description字典键:
for table in readable_description.keys():
cur.execute("SELECT COUNT(*) FROM %s", [AsIs(table)])
readable_description[table]["total"] = cur.fetchone()
样本行
最后,让我们在readable_description字典中添加一些示例行。由于homeless_by_coc表有很多行,我们应该为每个查询增加一个限制。即使您添加了比可用行数更高的限制,查询仍会执行。
SELECT * FROM example_table LIMIT 100
我们将在检索计数的同一个循环中添加限制查询。我们可以在同一个循环中执行这两个操作,而不是在键上迭代两次。不过要谨慎cur.fetchall()的调用顺序。如果我们不能立即获取查询结果,我们可以覆盖查询执行。cur.execute()命令不返回读取结果,请求结果是用户的责任。例如,下面的查询将只返回LIMIT的结果,而不返回COUNT的结果:
cur.execute("SELECT COUNT(*) FROM homeless_by_coc")
cur.execute("SELECT * FROM homless_by_coc LIMIT 100")
# Calling .fetchall() will only return the rows in the LIMIT query.
print(cur.fetchall())
让我们将这两个查询添加到一个代码块中:
for table in readable_description.keys():
cur.execute("SELECT COUNT(*) FROM %s", [AsIs(table)])
readable_description[table]["total"] = cur.fetchone()
cur.execute("SELECT * FROM %s LIMIT 100", [AsIs(table)])
readable_description[table]["sample_rows"] = cur.fetchall()
综上所述,我们现在有了一个通用脚本,它将返回一个人类可读的字典,其中包含数据库中所有用户创建的表。
import psyocpg2
from psyocpg2.extensions import AsIs
conn = psycopg2.connect(host="127.0.0.1", dbname="postgres", user="postgres", password="password")
cur = conn.cursor()
cur.execute("SELECT oid, typname FROM pg_catalog.pg_type")
type_mappings = {
int(oid): typname
for oid, typname in cur.fetchall()}
cur.execute("SELECT table_name FROM information_schema.tables WHERE table_schema='public'")
table_names = [table[0] for table in cur.fetchall()]
readable_description = {}
for table in table_names:
cur.execute("SELECT * FROM %s LIMIT 0", [AsIs(table)])
readable_description[table] = dict(
columns=[
dict(
name=col.name,
type=type_mappings[col.type_code],
length=col.internal_size
)
for col in cur.description
]
)
后续步骤
在这篇文章中,我们从对数据库及其表一无所知,到对我们将要使用的表进行人类可读的描述。首先,我们学习了 Postgres 的内部表和模式背后的概念。然后,我们应用我们的知识从零开始建立我们自己的描述字典。这篇文章改编自我们的数据工程课程。本课是课程优化 Postgres 数据库的一部分,我们将扩展 Postgres 内部表的知识,以优化 HUD 表及其查询。本课程侧重于解决您将在生产级数据分析系统中遇到的真实场景。
Dataquest 推出新的微软 Power BI 认证奖学金:改善数据表示
原文:https://www.dataquest.io/blog/power-bi-certification-scholarship/
April 25, 2022
Dataquest 很高兴地宣布,他们将与微软合作,为来自代表性不足的群体的寻求在数据领域开始职业生涯的申请人提供 500 个奖学金。
奖学金申请期从 2022 年 4 月 25 日至 6 月 25 日,对任何在数据领域代表性不足的人开放。性别、种族、教育水平和收入都是将被考虑的多样性的轴心。
完成 Dataquest Power BI 培训计划后,接受者将获得一次免费参加考试 PL-300 微软 Power BI 数据分析师的机会。
提高数据领域代表性的奖学金
数据角色中存在明显的公平差距。
- 2020 年,在数据科学相关职位的所有专业人员中,只有 15%至 22%是女性(BCG)。
- 2021 年,只有 5.2%的数据科学家是拉丁裔,只有 1%是非裔美国人(萨皮亚)。
- 2021 年 94%的数据科学家至少有大专学历(联大)。
“当我开始 Dataquest 时,我的目标是帮助数百万人进入数据领域。作为一名自学成才的数据科学家,我知道迈出这一步有多难。这就是为什么我很高兴与微软合作——Power BI 是帮助人们开始新的分析角色的一项关键技能。我们的奖学金计划帮助我们继续我们的使命,并改善受教育的机会。”—Vik Paruchuri,Dataquest 创始人
互动培训倡议
Dataquest 和微软合作提供了第一批交互式 Power BI 课程。这些课程通过基于项目的浏览器内方法教授 Power BI。这为学习者在现实世界中应用技能做准备,增加理解和信心。在完成为期 12 周的课程后,学员将为通过 PL-300 微软 Power BI 数据分析师考试做好充分准备,并继续推进他们的数据职业生涯。
Microsoft Power BI 是分析和商业智能平台的行业领导者。精通 Power BI 也是数据职位描述中最常见的要求之一。
“我们非常高兴能与 Dataquest 在这些奖学金上合作。这项计划支持我们的战略,帮助这个星球上的每个人和每个组织取得更大成就。通过将微软专业知识与交互式 Dataquest 学习平台相结合,学习者将获得通过 PL-300 考试所需的数字技能,并为数据科学职业生涯做好准备。”——微软高级主管杰夫·赫希。
点击此处了解更多关于奖学金以及如何申请的信息。
关于 Dataquest
Dataquest 成立于 2015 年,旨在帮助任何人学习数据科学并推进他们的职业生涯。有了 Dataquest 职业道路,学员可以在 3 到 9 个月内获得开始新工作所需的一切。学员可以随着课程的进展建立作品集,并通过完成顶点项目获得职业道路认证。
Dataquest 推出新的微软 Power BI 认证奖学金:改善数据表示
Dataquest 很高兴地宣布,他们将与微软合作,为来自代表性不足的群体的寻求在数据领域开始职业生涯的申请人提供 500 个奖学金。
奖学金申请期从 2022 年 4 月 25 日至 6 月 25 日,对任何在数据领域代表性不足的人开放。性别、种族、教育水平和收入都是将被考虑的多样性的轴心。
完成 Dataquest Power BI 培训计划后,接受者将获得一次免费参加考试 PL-300 微软 Power BI 数据分析师的机会。
提高数据领域代表性的奖学金
数据角色中存在明显的公平差距。
- 2020 年,在数据科学相关职位的所有专业人员中,只有 15%至 22%是女性(BCG)。
- 2021 年,只有 5.2%的数据科学家是拉丁裔,只有 1%是非裔美国人(萨皮亚)。
- 2021 年 94%的数据科学家至少有大专学历(联大)。
“当我开始 Dataquest 时,我的目标是帮助数百万人进入数据领域。作为一名自学成才的数据科学家,我知道迈出这一步有多难。这就是为什么我很高兴与微软合作——Power BI 是帮助人们开始新的分析角色的一项关键技能。我们的奖学金计划帮助我们继续我们的使命,并改善受教育的机会。”—Vik Paruchuri,Dataquest 创始人
互动培训倡议
Dataquest 和微软合作提供了第一批交互式 Power BI 课程。这些课程通过基于项目的浏览器内方法教授 Power BI。这为学习者在现实世界中应用技能做准备,增加理解和信心。在完成为期 12 周的课程后,学员将为通过 PL-300 微软 Power BI 数据分析师考试做好充分准备,并继续推进他们的数据职业生涯。
Microsoft Power BI 是分析和商业智能平台的行业领导者。精通 Power BI 也是数据职位描述中最常见的要求之一。
“我们非常高兴能与 Dataquest 在这些奖学金上合作。这项计划支持我们的战略,帮助这个星球上的每个人和每个组织取得更大成就。通过将微软专业知识与交互式 Dataquest 学习平台相结合,学习者将获得通过 PL-300 考试所需的数字技能,并为数据科学职业生涯做好准备。”——微软高级主管杰夫·赫希。
点击此处了解更多关于奖学金以及如何申请的信息。
关于 Dataquest
Dataquest 成立于 2015 年,旨在帮助任何人学习数据科学并推进他们的职业生涯。有了 Dataquest 职业道路,学员可以在 3 到 9 个月内获得开始新工作所需的一切。学员可以随着课程的进展建立作品集,并通过完成顶点项目获得职业道路认证。
25 个必知的权力 BI 面试问答(2022)
原文:https://www.dataquest.io/blog/power-bi-interview-questions-and-answers/
April 27, 2022
Power BI 面试问题:初级
先说最基本的问题。虽然这些问题对你来说可能很简单,但为每个问题准备一个自信、全面、简洁的答案总是一个好主意。

1。什么是 Power BI?
Power BI 是一款基于云的商业智能和数据可视化软件,由微软开发,用于从各种来源获取原始数据,对其进行转换和分析,从中提取有意义的见解,构建反映这些见解的交互式仪表盘和报告,并与相关的数据消费者群体(您的同事、经理或股东)共享结果,以做出明智的数据驱动型商业决策。

A visualization (sometimes also referred to as a visual) is a visual representation of data, like a chart, a color-coded map, or other interesting graphical displays you can create in Microsoft Power BI to represent your data.
2。Power BI 有什么优势?
Power BI 有许多使其成为优秀商业智能软件的优势特性:
- 它很容易使用,即使是非技术人员。
- 它有一个强大的工具包来执行 ETL(提取、转换和加载数据)。
- 它有助于与数据消费者分享来自数据的见解。
- 它可以快速更新数据源中正在使用的数据。
- 它配备了模板仪表板和 SaaS 解决方案报告。
- 它允许实时仪表板和报告更新。
- 它允许在各种设备(电脑、平板电脑和手机)上显示结果。
- 它确保快速安全地连接到云中或本地的数据源。
- 它支持使用自然语言处理的数据查询。
- 它提供混合配置和智能部署。
3。Power BI 有哪些缺点?
需要记住的 Power BI 的主要缺点包括:
- 这个软件对初学者来说不是很直观。
- 仪表板和报告共享受到限制:只有具有相同电子邮件域的用户才能访问结果。
- 大多数数据源不支持实时连接来支持 BI 交互式仪表板和报告。
- 免费用户的 Power BI 不能处理大于 1 GB 的数据集。
- 我们无法在节能 BI 可视报告筛选器中存储调整后的筛选器。此外,过滤器总是显示在报告上,这并不总是方便的
然而,Power Bi 正处于不断发展和改进的过程中,因此我们可以期待该软件能够克服它的一些或所有限制。

Power BI consists of three main elements: Power BI Desktop, the Power BI service, and Power BI Mobile. These work together to let you create, interact with, share, and consume your data however you want.
4。Power BI 中常见的工作流是什么?
标准的 Power BI 工作流程包括以下四个步骤:
- 将数据提取到 Power BI 桌面,清理和处理数据,并创建报告。
- 将报告发布到 Power BI 服务并构建仪表板。
- 与您的同事、经理或股东共享仪表板。
- 与 Power BI 移动应用中的最终仪表盘和报告进行交互,以获取业务洞察。
5。Power BI 的主要业务应用有哪些?
因为 Power BI 是一个商业智能应用程序,所以我们可以将它应用于一系列商业领域。其最重要的应用包括:
- 从可用的原始数据中提取有意义的商业见解
- 创建引人注目的实时报告和见解深刻的交互式仪表盘
- 识别不同部门或项目的当前状态
- 跟踪不同部门或项目的进度和关键绩效指标
- 从项目绩效的角度发现项目的优势和劣势
- 在团队内部分配角色
- 向相关团队成员授予对仪表板和报告的访问权限
- 在许多不同的应用程序和网站上以对潜在客户有利的方式显示特定业务的各种统计数据
6。什么样的专家通常使用 Power BI?
以下角色构成了大多数高级 BI 用户:
- 项目经理
- 商业分析员
- 数据分析师
- 数据科学家
- 信息技术专家
- 数据管理员
- 开发商
- 报告消费者

*Power BI Desktop allows you to retrieve data from many types of files. You can find a list of the available options when you use the Get data feature in Power BI Desktop. *
7 .。Power BI 中的仪表板是什么?
Power BI 中的仪表板也称为画布,是从报告中选取的最具洞察力的可视化内容的单页选择,这些内容共享了数据驱动的故事中最重要的亮点。Power BI 仪表板的最终用户可以从各种设备(包括移动电话)访问它们,与它们交互以提取有价值的业务见解,掌握业务或项目的全局(以及整体中不同部分之间的关系)。
8。什么是 Power BI 桌面?
Power BI Desktop 是一个免费的开源微软应用程序,它可以连接到各种数据源,获取数据,清理和转换数据,构建数据模型,并创建具有有意义的视觉效果的报告和仪表板。它还允许用户通过 Power BI 服务将最终报告和仪表板发布到云中,并与其他人共享。
9。什么是电力查询?
Power Query 是由 Microsoft Excel 开发的商业智能 ETL(提取-加载-转换)工具,可在 Power BI 桌面中通过 Power Query 编辑器获得。借助该工具,用户可以加载和组合来自不同数据源的数据,如 SQL、Oracle、Excel 或 CSV 文件、社交媒体等。,然后使用超级查询编辑器,用户可以清理、整形、转换和分析数据。Power Query 有一个直观的界面,它使用了 M 语言。我们也可以(尽管我们不需要)应用这种语言来自己编写和修改代码。

*The Power Query Editor ribbon contains many buttons you can use to select, view, and shape your data. *
10。什么是权力支点?
Power Pivot 是 Microsoft Excel 2010 的内置组件,旨在扩展应用程序的分析能力。我们可以使用它从多个数据源导入数据,在单个 Excel 电子表格中存储压缩数据,使用 DAX(数据分析表达式)语言构建表格数据模型,定义不同表格之间的关系,编写公式,计算新列,创建数据透视表和数据透视图,应用各种级别的筛选器,以及分析数据。
Power BI 面试问题:Power BI 结构
在本节中,我们将考虑一些与功率 BI 相关的典型问题。它们大多是基本的,但有时可能会产生误导。事实上,术语经常会混淆,比如 Power BI 的“构建模块”、“组件”、“视图”或“元素”。有些术语甚至可以互换使用,或者没有标准术语(例如,“格式”或“版本”)。幸运的是,问题本身通常会提供一些关于问题的背景。
11。Power BI 包的主要元素是什么?
Power BI 封装有三个主要元素:
- Power BI Desktop —一款微软 Windows 桌面应用程序,用于创建交互式仪表盘和报告,以便进一步共享
- Power BI Service —一种在线 SaaS(软件即服务),用于将报告发布到云
- Power BI 移动应用 —可在任何设备上使用,具有适用于 Windows、iOS 和 Android 的原生移动 BI 应用,因此 Power BI 的移动用户可以查看见解

On the Model tab, we can edit specific column and table properties by selecting a table or columns, and we can transform the data by using the Transform Data button, which takes us to Power Query Editor.
12。Power BI 的构建模块是什么?
我们在 Power BI 中所做的一切都可以分解为以下基本构件:
- 可视化。可视化是底层数据的可视化表示,旨在提供难以从原始表格或文本数据中辨别的业务上下文和洞察力。在 Power BI 中,我们有各种各样的可视化,比如条形图、饼图、折线图、渐变颜色图、气泡图等。
- 数据集。数据集是数据的集合,可能从不同的数据源获取,用于创建可视化和报告。数据集可以是 Excel 表、CSV 文件、Oracle 或 SQL server 表等。
- 报道。报告是在一个或多个页面上排列在一起的一组相互关联的可视化内容,用于展示从同一数据集中提取的各种业务洞察。一些例子是产品销售报告、营销活动报告和按公司分支机构的销售报告。
- 仪表盘。仪表板或画布是从一页报告中选择的最引人注目的视觉效果。它为我们将要向同事、经理或股东讲述的数据故事提供了见解。仪表板的消费者可以从各种设备上查看它,并与之交互以获得他们需要的信息。
- 瓷砖。平铺是报表或仪表板中被其他平铺包围的矩形块中包含的单个可视内容,例如,仪表板上的单个条形图或任何其他可视内容。
13。Power BI 工具包的主要组件是什么?
以下是 Power BI 工具包的主要组件,以及我们使用它们的目的:
- Power Query: 从各种来源收集数据并进行转换
- 动力中枢:建立数据模型
- Power View: 创建数据可视化
- Power Map: 创建 3D 地理空间数据可视化
- Power Q & A: 使用自然语言从最终报告中获取答案
14。Power BI 中有哪些不同的连接模式?
Power BI 中有三种连接模式:
- 导入方式,又名 SQL Server 导入。这是 Power BI 中的默认连接模式,因为它比其他两种使用得更频繁,而且它还提供了最快的性能。在这种模式下,我们可以将数据导入 Power BI 桌面以供进一步查询。但是,除非我们有 Power BI premium,否则我们无法导入大于 1 GB 的数据集。
- 直接查询模式。此模式连接到特定数据源的数据,在导入大型数据时特别有效。Power BI 本身并不存储数据;它存储其元数据并对数据执行直接查询。这种连接模式的缺点是,在这种情况下,我们可以执行哪些操作来操作数据是有限制的。
- 直播连接模式。在这种连接模式下,数据副本也不会存储在 Power BI 模型中。而是每次直接从 Power BI 查询数据源。我们只能使用这种模式访问三个数据源:SQL Server Analysis Services、Azure Analysis Services 和 Power BI 数据集

Every Power BI data analyst should understand the star schema. In a star schema, each table within your dataset is defined as a dimension or a fact table.
15。Power BI 可以连接哪些类型的数据源?
Power BI 可以连接的各种数据源分为以下几组:
- 文件。这些可以是 Excel、CSV、文本或 Power BI 桌面文件。
- 内容包。这些可以来自服务提供商或组织(即由我们公司的其他人共享)。
- 连接器。这些连接到数据库和数据集,如 Azure SQL 或 SQL Server Analysis Services。
16。Power BI 桌面中有哪些不同的视图?
- 报表视图。默认视图,显示报告的交互视觉效果。在这个视图中,我们可以添加和操作各种模板的报告页面,添加和调整可视化,以及发布最终报告。
- 数据视图。在该视图中,我们可以通过查询编辑器工具实现数据整形和转换,创建新的计算列,并在数据被馈送到模型后以表格格式查看数据。
- 关系视图,又名模型视图。我们使用它来探索、比较和管理数据模型或其子集之间的复杂关系。
Power BI 面试问题:中级
最后一套问题比较高级;如果你想找更高级的工作,这可能会有帮助。
17。Power BI 中的数据存储在哪里?
Power BI 中的数据以事实表(定量的,通常是非规范化的数据)或维度表(与事实表中的数据相关的属性和维度)的形式存储在以下两个云存储库中:
- 微软 Azure Blob 存储:包含用户上传的数据
- 微软 Azure SQL 数据库:包含系统的所有元数据和工件
对于这两者,加密和密码保护数据。

Power BI automatically detects relationships, but you can also go to Manage Relationships > New and create the relationship on the Date column. This will ensure that the granularity is the same between your different tables.
18。力量 BI 和 Tableau 有什么区别?
虽然 Power BI 和 Tableau 都是用于业务数据争论、数据分析和数据可视化的商业智能(BI)应用程序,但它们之间存在一些显著差异:
- Power BI 使用 DAX(数据分析表达式)进行计算,Tableau 使用 MDX(多维表达式)。
- Power BI 可以处理相对有限的数据量,而 Tableau 可以轻松处理海量数据。
- Power BI 有一个相对简单易学的界面,专业人士和初学者都可以使用。Tableau 界面更具挑战性,因此不太适合初学者。
- 与 Tableau 相比,Power BI 可连接的数据源范围较小。
- Power BI 比 Tableau 便宜很多。
- Power BI 是一个完美的报告工具,而 Tableau 擅长数据可视化。
19。Power BI 中的 M 语言是什么?
M 语言或 M 代码是一种功能性的、区分大小写的编程语言,在 Power BI 的 Power Query 编辑器中使用,通过查询过滤和组合数据。
20。Power BI 中的 DAX 是什么?
DAX 是数据分析表达式的缩写。它是 Power BI 的一种函数式编程语言,提供了一组函数、运算符和常数,我们可以在公式中使用它们来计算列、度量和表格,以及从可用数据中提取新信息。DAX 支持各种数据类型:整数和小数、布尔值、文本、日期、货币和 N/A。
21。自助商业智能(SSBI)是什么意思?
SSBI 是一套方法和工具,使最终用户——甚至是那些没有任何 BI 背景的人(例如,销售或营销团队、产品开发人员等)。)—以直观的方式访问、操作、分析和可视化数据,以做出战略性的、数据驱动的业务决策。

A smaller data model uses less memory and achieves faster data refreshing, calculations, and rendering of visuals in reports. Therefore, the performance optimization process involves minimizing the size of the data model and making the most efficient use of the data in the model.
22。Power BI 中的内容包是什么?
内容包是 Power BI 相关文档的包,例如仪表板、报告和数据集,它们存储为一个组。在 Power BI 中,有两种类型的包:来自 Google Analytics、Marketo、MailChimp 或 Twilio 等服务提供商的服务内容包,我们可以通过键入我们的帐户数据来访问;以及由我们公司的用户创建并与整个组织或选定的一组人共享的组织内容包。
23。在 Power BI Desktop 中,我们如何定义数据模型中两个表之间的关系?
有两种方法:
- 手动:使用主键和外键
- 自动:如果自动检测功能开启,则自动识别关系
要定义两个表之间的关系,数据中不应有任何空值或重复行。此外,表之间可能有多个关系(用虚线表示),但其中只有一个是活动的(用实线表示)。
24。Power BI 中有哪些不同的刷新选项?
Power BI 中有四个刷新选项:
- 包刷新:在 Power BI 服务和 OneDrive 或 SharePoint Online 之间同步 Power BI 桌面,而不从数据源获取数据。
- 模型刷新,又名数据刷新:用原始数据源中的数据刷新 Power BI 服务中可用的数据集。
- Tile refresh: 每次数据改变时,更新仪表板上 Power BI 中 Tile 的缓存(大约每 15 分钟一次,或者我们也可以强制更新)。
- 可视化容器刷新:一旦数据发生变化,刷新可视化容器并更新缓存的报表视图。
25。我们可以在 Power BI 报告中使用哪些类型的过滤器?
Power BI 中的过滤器可以是以下类型之一,根据其适用范围,按降序排列:
- 报表级过滤器:应用于整个报表
- 页面级过滤器:应用于报告的特定页面
- 可视化级别过滤器:应用于单个可视化
结论
在这篇文章中,我们讨论了在商务智能面试中最常见的问题,以及如何回答这些问题。希望这些信息能帮助你准备面试,让你更加自信。
觉得在开始找工作之前,你需要温习一下你的商务智能技能吗?想准备 PL-300 认证?或者也许你正在寻找从零开始发展力量 BI 技能?在所有这些情况下,我们的创新技能途径使用 Microsoft Power BI 分析数据,是开始您学习之旅的正确地方!
在这条道路上,我们提供了第一个交互式 Power BI 课程,您可以在浏览器中使用完整的 Power BI 界面,通过练习和完成练习来学习,并构建项目。在课程结束时,您将建立一个项目组合,并为 PL-300 认证考试做好准备,并在 Power BI 中找到您的第一份工作!
实用数据伦理——如何让您的数据工作更符合伦理
原文:https://www.dataquest.io/blog/practical-data-ethics-make-your-data-work-more-ethical/
September 22, 2020
作为一名初级数据专家,让你的公司实施道德方法可能会像爬山一样令人生畏。但是有一些方法可以让它变得更简单!
数据伦理很重要。从 为面部识别算法收集数据的侵入性方法 到 预测性警务模型中使用的有缺陷的犯罪数据,我们都见过数据工作中值得怀疑的方法的显著例子,以及它们可能引发的问题。
我们中的许多人都没有接触过这样的数据。但是,我们仍然担心我们从事的项目可能会处理得不好,或者我们的发现会被误解,这两种情况都会产生严重的道德影响。
令人欣慰的是,人们越来越关注数据科学和分析中的道德方法,多个 领域的专家正在开展出色的工作。
在这篇文章中,我将介绍初级数据专业人员如何围绕道德分析方法展开对话,尤其是当他们在更大的组织中几乎没有决策权时。
无论是试图解决现有项目的问题,还是主动寻求预防未来的灾难,这些方法在开始必要的对话时都被证明是有用的。
识别棘手问题
在您开始之前,有必要思考一下您、您的团队以及您的大型组织所使用和依赖的各种数据。您还应该考虑您的团队创建的报告和分析的类型。
从组织上来说,这种反思实践使对话个性化,防止人们将这些主题作为抽象概念来参与,并且更有可能激励可操作的步骤来将道德嵌入现有的工作流中。
为了说明这一点,让我们用与教育有关的数据作为例子。
在这一部分,您可能会分析学生表现或参与度的数据,在许多情况下,这些数据会与人口统计变量(如种族/民族、性别和收入)一起进行分析。
如果被问及的研究问题是关于弱势或边缘群体的,重要的是要问以下问题:
- 这些问题对所述群体有什么价值或支持?
- 对于那些被收集数据的人,有没有不言而喻但隐含的假设?
以调查的形式收集更多关于学生的数据也很常见,这引发了以下问题:
- 我们在问学生什么?为什么问?
** 我们会问特定的学生一些问题而不问其他人吗?* 这些问题本身是否隐含着对回答者有负面影响的假设?*
*不考虑这些问题会导致糟糕的研究。
例如,设想一个调查项目,旨在衡量低收入学生如何参与旨在支持他们的项目。
如果这项工作没有明确提出关于学生能力、兴趣和生活经历的假设,那么经常会看到调查问题明确询问学生逃课、欺负其他孩子的频率,甚至参与犯罪活动的频率。
不幸的是,这些都是在这类项目中被问到的真实问题。
这些问题不仅毫无意义(我们不应该期望回答者承认这些事情,即使是匿名的),它们还会削弱这个项目试图帮助的学生的信任。
这些问题会让学生觉得好像组织已经用一把大刷子刷过他们了。如果你的调查问题假设孩子行为不端,那么孩子有多大可能相信你真的在努力帮助他们?
获得盟友
无论你是试图解决一个正在进行的道德困境,还是在工作中先发制人,你都需要支持。
下一个关键步骤是邀请其他人参与关于这些话题的对话。当谈到争取盟友时,有两个关键点。首先,
- 从你自己的团队和那些与数据密切相关的人开始
**如果你是一个新的角色,一个新的视角在发现问题的盲点方面尤为重要,这些问题可能会被那些已经习惯了“这里的工作方式”的资深成员所忽视。
随着时间的推移,随着共识的增加,数据处理人员的统一战线确实有助于在向内部和外部利益相关者报告时提出新方向的建议。
这引出了第二个关键点:
- 邀请组织中的非技术专业人士,他们的项目严重依赖分析
虽然您的观点可以向团队中更高级的成员和其他熟悉数据的个人揭示盲点,但从不接触数据的人的外部观点可以揭示您自己在这些问题上可能存在的盲点。
在对话中包括更多的人也带来了在您的组织内解密数据的额外好处。
在任何公司,数据都应该被批判性地讨论和使用,而不是被当作只有专家才能使用的客观解决方案。
对你的听众讲话
在您进行这些对话时,为每个小组带来正确的框架非常重要。就技术专业人员而言,我发现最好将谈话集中在道德和方法的结合上:
- 就我们收集的问题和报告而言,我们的工作方式是否弊大于利?
- 我们的问题是否充满了需要认真思考的假设?
从方法论的角度来看,通过改进我们的伦理方法,我们无疑会更准确地研究我们的问题。我们也很可能在我们分析的数据中发现更有趣、更有影响力的故事。
我们近年来在数据科学中看到的许多伦理问题都会造成伤害,这是需要解决的最重要的问题。但它们也描绘了一幅非常不准确的真实世界图景。为了说服组织中的一些利益相关者,用准确性来组织讨论可能会有所帮助。
伦理和方法论的方法也可以为那些没有沉浸在数据中的人提供有用的框架。但如果这不起作用,对责任和形象的担忧可能会吸引那些不管出于什么原因,仍然不为伦理或方法论争论所动的人的注意力。
换句话说:即使团队成员不在乎你的方法会造成伤害或带来不准确结果的风险,他们可能会在乎这代表了潜在的法律或公共关系威胁。
我们距离追究滥用分析的责任还有很长的路要走,但例如数据泄露问题会带来现实世界的反响。
- 存储、报告和收集数据的方式在多大程度上让您的组织面临真实的法律后果?
- 如果有偏见和不道德的做法被曝光,组织的形象会受到多大程度的影响?
虽然重点应该始终放在良好的方法和道德问题上,但有时以这些方式构建对话可能是获得一些关注和至少开始对话的唯一方法。
当您以及希望与您一起投入这项工作的人就您的组织正在进行的数据工作进行更广泛的对话时,可以使用这些和其他框架观点的混合。
忍耐是一种“美德”?
最后,不言而喻,这种工作需要时间,随之而来的是利弊。先说坏消息。
- 你可能不得不看着一个有缺陷的项目在做出任何改变之前经历多次迭代
一旦你遇到了工作流程中的问题,并且有几个关键人物站在你这一边表示同意,进行必要的转变仍然会有障碍。
这可能是由于外部阻力或内部优先考虑不改变任何可能扰乱收入流或客户满意度的事情。
退一步说,这可能会令人沮丧,你需要在知道什么时候推动变革和什么时候已经达到了制度障碍所能做到的极限之间找到平衡。然而,即使在这些情况下,你的工作也不一定是徒劳的。
- 仅仅进行对话就能产生持久的积极成果
当涉及到改善数据工作流程中的道德框架时,真正的改变是可能的。
对于那些由于这样或那样的原因仍然以当前形式进行的有缺陷的项目,当涉及到它们固有的问题时,妖怪已经从瓶子里出来了。变化可能不会发生,但没人能说这些问题是未知的。
更重要的是,一旦道德问题被提出,人们更有可能在新项目的开发过程中嵌入道德方法,这对于防止新问题成为现状的一部分大有帮助。
坚持下去
对于这种工作,有得有失是游戏的名字。每个组织都是不同的,对解决这些问题有不同程度的热情。
然而,归根结底,将道德框架应用于数据工作并不一定是一个抽象的概念。
思考如何改进我们自己的工作,并产生认同,以共同实现这些目标是可能的。
这项工作至关重要,不幸的是,将会有一些障碍,使使用数据来讲述准确的故事和避免造成伤害具有挑战性。
但这就是利害所在,所以不要被吓住了!***
pre rit:“data quest 帮助我从一名软件开发人员转变为一名数据科学家。”
July 25, 2017
Prerit Anwekar 决定成为一名数据科学家。他在印第安纳大学攻读硕士学位。
“我意识到,要进行机器学习,我需要专注于 Python,但我只学到了 r。”
在尝试从一本书上学习 Python 之后,他气馁了。
“学习使用一本书真的很费力。这要花很多时间,而且代码示例经常会过时。”
当他开始在 Dataquest 上学习时,一切都变了。
“Dataquest 让一切变得简单。因为我可以在一个地方学习所有的东西,这帮助我学得更快。”
“Dataquest 不仅教你如何使用算法,还教你算法实际上是如何工作的。”
Dataquest 社区意味着 Prerit 总能解决问题。
Dataquest 帮助我从软件开发人员转型为数据科学家。
“我在那里交了很多朋友。我们会聊天,分享文章,一起解决问题。slack 社区是一个我总能在需要时得到帮助的地方。”
Prerit 认为 Dataquest 的指导项目是他成功找到工作的关键。
“当我完成课程后,引导式项目给了我一个挑战。他们给了我信心,让我知道自己可以做到。我创建了一个网站来展示我的项目,这在我开始找工作时派上了用场。”
"我面试的公司真的很喜欢我的项目."
Prerit 还认为 Dataquest 给了他面试的信心。
“他们问我关于 Python 的问题,我能够自信地回答。没有 Dataquest,我不可能做到这一点。”
他现在是一家数据和分析咨询公司的数据科学家,帮助公司解决数据方面的业务问题。
Prerit 给初露头角的数据科学家的建议很明确:“订阅 Dataquest。要是早点发现就好了。”
“如果没有 Dataquest,我就不会有今天。”
Priya:“data quest 帮助我去帮助别人”
January 10, 2018
Priya Iyer 决定学习数据科学,以便更好地帮助人们。她的初创公司 Tulalens 运营了两年,筹集了 10 万美元来帮助城市贫民窟的妇女。Tulelens 帮助这些妇女创办了销售富铁食品的小企业,并分享了有关缺铁性贫血的信息。
Priya 和她的合作伙伴意识到,如果他们采取一种更加数据驱动的方法来预测女性在铁摄入量方面属于哪一类,他们可能会更有效率。她试着用 Excel 处理数据,但是很麻烦。编程似乎是答案。
Codeacademy 和艰难地学习 Python 并没有坚持下来。“当人们只是告诉我该做什么而我不能问问题时,我学不好。”
Dataquest 给了她所需要的基础和动力。“即使我在硕士期间做了很多统计,我也没有真正保留它,直到我把它用在我关心的问题上。有了 Dataquest,我可以将这些概念应用到有趣的数据集上。”
Dataquest 还通过将项目分解成简单的术语,使学习编程变得不那么令人生畏。“编程似乎是一个很大的障碍——通常当你阅读 StackOverflow 的答案时,它看起来不像英语。”
Priya 现在是生物技术公司 Genentech 的高级分析主管,也是数据科学顾问的自由职业者。在基因泰克公司,她专注于改善患者获得药物的途径。她至少有 20%的时间用于使用 Python 来组合数据和执行预测分析(这对她的团队来说是新的)。
Dataquest 继续帮助她提高技能——“我仍然会回头参考我做过的指导项目。能够使用 Python 来帮助女性受益真的很有动力。”
数据科学编程最佳实践
原文:https://www.dataquest.io/blog/programming-best-practices-for-data-science/
June 8, 2018
数据科学生命周期通常由以下组件组成:
- 资料检索
- 数据清理
- 数据探索和可视化
- 统计或预测建模
虽然这些组件有助于理解不同的阶段,但它们并不能帮助我们思考我们的编程工作流程。
通常情况下,整个数据科学生命周期最终会成为任意混乱的笔记本单元,要么是 Jupyter 笔记本,要么是一个杂乱的脚本。此外,大多数数据科学问题需要我们在数据检索、数据清理、数据探索、数据可视化和统计/预测建模之间切换。
但是有更好的方法!在这篇文章中,我将回顾大多数人在进行专门针对数据科学的编程工作时会转换的两种心态:原型心态和生产心态。
| 原型思维优先: | 生产思维优先考虑: |
| 小段代码的迭代速度 | 整个管道上的迭代速度 |
| 更少的抽象(直接修改代码和数据对象) | 更抽象(改为修改参数值) |
| 更少的代码结构(更少的模块化) | 更多的代码结构(更多的模块化) |
| 帮助您和其他人理解代码和数据 | 帮助计算机自动运行代码 |
我个人在整个过程中都使用 JupyterLab (原型和生产)。我建议至少使用 JupyterLab 做原型。
租借俱乐部数据
为了帮助更具体地理解原型和生产思维模式之间的区别,让我们使用一些真实的数据。我们将使用来自点对点贷款网站 Lending Club 的贷款数据。与银行不同,Lending Club 本身并不放贷。相反,Lending Club 是一个市场,贷方向出于各种原因(房屋维修、婚礼费用等)寻求贷款的个人提供贷款。).我们可以使用这些数据来建立模型,预测给定的贷款申请是否会成功。在这篇文章中,我们不会深入构建一个机器学习管道来进行预测,但我们会在我们的机器学习项目演练课程中涉及到它。
Lending Club 提供有关已完成贷款(贷款申请得到 Lending Club 的批准,他们找到了贷款人)和已拒绝贷款(贷款申请被 Lending Club 拒绝,资金从未转手)的详细历史数据。导航到他们的数据下载页面,选择下的 2007-2011 。

原型思维
在原型思维中,我们对快速迭代感兴趣,并试图理解数据的一些属性和真相。创建一个新的 Jupyter 笔记本,并添加一个说明以下内容的减价单元格:
- 为了更好地了解 Lending Club 平台,您做了哪些研究
- 你下载的数据集有什么信息吗
首先,让我们将 CSV 文件读入 pandas。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv')
loans_2007.head(2)
我们得到两个输出,第一个是警告。
/home/srinify/anaconda3/envs/dq2/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (0,1,2,3,4,7,13,18,24,25,27,28,29,30,31,32,34,36,37,38,39,40,41,42,43,44,46,47,49,50,51,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,123,124,125,126,127,128,129,130,131,132,133,134,135,136,142,143,144) have mixed types. Specify dtype option on import or set low_memory=False. interactivity=interactivity, compiler=compiler, result=result)
然后是数据帧的前 5 行,我们将避免在这里显示(因为它很长)。
我们还获得了以下数据帧输出:
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 招股说明书发行的票据(https://www.lendingclub.com/info/prospectus.action) |
| d | 成员 id | 贷款金额 | 资助 _amnt | 资助 _amnt_inv | 学期 | 利息率 | 部分 | 等级 | 路基 | 员工 _ 职位 | 员工长度 | 房屋所有权 | 年度公司 | 验证 _ 状态 | 问题 _d | 贷款 _ 状态 | pymnt_plan | 全球资源定位器(Uniform Resource Locator) | desc | 目的 | 标题 | 邮政编码 | 地址状态 | 弥散张量成像 | delinq _ 年 | 最早 _cr_line | 最近 6 个月 | mths _ since _ last _ delinq | 月 _ 自 _ 最后 _ 记录 | open_acc | 发布 _ 记录 | 革命 _ 平衡 | 革命报 | 总计 _acc | 初始列表状态 | out_prncp | out_prncp_inv | total_pymnt | total_pymnt_inv | total_rec_prncp | total_rec_int | total_rec_late_fee | 追回款 | 收款 _ 回收 _ 费用 | last_pymnt_d | last_pymnt_amnt | 下一个 _pymnt_d | 最后一笔贷款 | 收藏 _ 12 _ 月 _ 月 _ 日 _ 医学 | 月 _ 自 _ 最后 _ 主要 _ 日志 | 策略代码 | 应用程序类型 | 年度 _ 公司 _ 联合 | dti _ 联合 | 验证 _ 状态 _ 联合 | acc _ now _ delinq | 总计 _ 合计 _ 金额 | tot_cur_bal | open_acc_6m | open_act_il | open_il_12m | open_il_24m | mths_since_rcnt_il | 总计 _bal_il | il_util | 开 _rv_12m | open_rv_24m | 最大余额 | all_util | 总计 _ 收入 _ 高收入 | inq_fi(消歧义) | 总计 _ 铜 _ 铊 | inq_last_12m | acc _ open _ past _ 月 | avg _ cur _ ball | bc_open_to_buy | bc_util | 12 个月内收费 | delinq _ amnt | 莫 _ 辛 _ 旧 _ 日 _ 账户 | mo_sin_old_rev_tl_op | mo_sin_rcnt_rev_tl_op | mo_sin_rcnt_tl | acc 死亡 | 月 _ 自 _ 最近 _ 公元前 | 月 _ 自 _ 最近 _bc_dlq | 月 _ 自 _ 最近 _ 入 q | mths _ since _ recent _ revol _ delinq | num_accts_ever_120_pd | 数字 _ 活动 _ 商业 _ 时间 | 数量 _ 活动 _ 版本 _tl | num _ bc _ 语句 | 数字 _bc_tl | 数字 il TL | S7-1200 可编程控制器 | num_rev_accts | 数量 _ 收益 _ tl _ 余额 _gt_0 | 数量 _ 饱和度 | num_tl_120dpd_2m | num_tl_30dpd | 数量 _tl_90g_dpd_24m | 数量 _tl_op_past_12m | pct_tl_nvr_dlq | percent_bc_gt_75 | pub _ rec _ 破产 | tax _ links-税捐连结 | tot_hi_cred_lim | total _ bal _ ex _ mort-总计 _ bal _ ex _ 死亡 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 _ 终止 | 总计 _ bc _ 限制 | total_il_high_credit_limit | 斜接 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 _ 边 | sec_app_earliest_cr_line | sec _ app _ inq _ last _ 个月 | 秒 _ 应用程序 _ 抵押 _ 帐户 | sec_app_open_acc | sec_app_revol_util | sec_app_open_act_il | 秒 _ 应用 _ 数量 _ 收入 _ 帐户 | sec _ app _ chargeoff _ within _ 12 _ 个月 | sec _ app _ collections _ 12 _ mths _ ex _ med | sec _ app _ mths _ since _ last _ major _ derog | 艰难 _ 标志 | 困难类型 | 困难 _ 原因 | 艰苦状况 | 延期 _ 期限 | 困难 _ 金额 | 艰难开始日期 | 困难 _ 结束 _ 日期 | 付款 _ 计划 _ 开始 _ 日期 | 艰辛 _ 长度 | 困难 _dpd | 困难 _ 贷款 _ 状态 | 原始 _ 预计 _ 附加 _ 应计 _ 利息 | 困难 _ 收益 _ 余额 _ 金额 | 困难 _ 最后 _ 付款 _ 金额 | 支付方式 | 债务 _ 结算 _ 标志 | 债务 _ 结算 _ 标志 _ 日期 | 结算 _ 状态 | 结算日期 | 结算 _ 金额 | 结算 _ 百分比 | 结算 _ 期限 |
这个警告让我们知道,如果我们在调用pandas.read_csv()时将low_memory参数设置为False,那么每一列的熊猫类型推断将会得到改进。
第二个输出更成问题,因为数据帧存储数据的方式有问题。JupyterLab 内置了一个终端环境,因此我们可以打开它并使用 bash 命令head来观察原始文件的前两行:
head -2 LoanStats3a.csv
虽然第二行包含了我们在 CSV 文件中期望的列名,但是当 pandas 试图解析该文件时,第一行似乎抛出了 DataFrame 的格式:
Notes offered by Prospectus (https://www.lendingclub.com/info/prospectus.action)
添加一个详述您的观察结果的 Markdown 单元格,并添加一个将观察结果考虑在内的 code 单元格。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv', skiprows=1, low_memory=False)
从 Lending Club 下载页面阅读数据字典,了解哪些栏目不包含有用的功能信息。desc和url列似乎很符合这个标准。
loans_2007 = loans_2007.drop(['desc', 'url'],axis=1)
下一步是删除丢失行超过 50%的任何列。使用一个单元格来研究哪些列符合该条件,使用另一个单元格来实际删除这些列。
loans_2007.isnull().sum()/len(loans_2007)
loans_2007 = loans_2007.dropna(thresh=half_count, axis=1)
因为我们使用 Jupyter 笔记本来跟踪我们的想法和代码,所以我们依靠环境(通过 IPython 内核)来跟踪状态的变化。这让我们可以自由行动,移动单元格,多次运行相同的代码,等等。
一般来说,原型思维中的代码应该关注:
- 易懂
- 来描述我们的观察和假设
- 实际逻辑的小段代码
- 大量的可视化和计数
- 最小抽象
- 大多数代码不应该在函数中(应该感觉更面向对象)
假设我们又花了一个小时探索数据,并编写描述我们所做的数据清理的 markdown 单元格。然后,我们可以切换到生产思维模式,使代码更加健壮。
生产思维
在生产思维中,我们希望专注于编写可以推广到更多情况的代码。在我们的例子中,我们希望我们的数据清理代码适用于来自 Lending Club(来自其他时间段)的任何数据集。概括我们代码的最好方法是把它变成一个数据管道。使用来自函数编程的原理设计了一条数据流水线,其中数据在函数内被修改,然后在函数间传递。
这是使用单个函数封装数据清理代码的管道的第一次迭代:
import pandas as pd
def import_clean(file_list):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
half_count = len(loans)/2
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv",
"grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp",
"out_prncp_inv", "total_pymnt", "total_pymnt_inv",
"total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee",
"recoveries", "collection_recovery_fee", "last_pymnt_d",
"last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'])
在上面的代码中,我们将前面的代码抽象为一个函数。这个函数的输入是文件名列表,输出是 DataFrame 对象列表。
总的来说,生产思维应该集中在:
- 健康的抽象概念
- 代码应该一般化以兼容相似的数据源
- 代码不应该太笼统,以至于难以理解
- 管道稳定性
- 可靠性应该与其运行频率相匹配(每天?周刊?每月?)
在思维模式之间切换
假设我们试图对 Lending Club 的所有数据集运行该函数,但 Python 返回了错误。一些潜在的错误来源:
- 某些文件中的列名不同
- 由于 50%缺失值阈值而被删除的列中的差异
- 基于该文件的熊猫类型推断的不同列类型
在这种情况下,我们实际上应该切换回我们的原型笔记本,并进一步研究。当我们确定希望我们的管道更加灵活,并考虑到数据中的特定变化时,我们可以将这些变化重新合并到管道逻辑中。
下面是一个例子,我们调整了函数以适应不同的跌落阈值:
import pandas as pd
def import_clean(file_list, threshold=0.5):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
threshold_count = len(loans)*threshold
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv",
"grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp",
"out_prncp_inv", "total_pymnt", "total_pymnt_inv",
"total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee",
"recoveries", "collection_recovery_fee", "last_pymnt_d",
"last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'], threshold=0.7)
默认值仍然是0.5,但是如果我们愿意,我们可以将其改写为0.7。
以下是一些使管道更灵活的方法,按优先级递减:
- 使用可选的、位置的和必需的参数
- 在函数中使用 if / then 语句和布尔输入值
- 使用新的数据结构(字典、列表等)。)来表示特定数据集的自定义操作
这个管道可以扩展到数据科学工作流的所有阶段。这里有一些框架代码,预览这是什么样子。
import pandas as pd
def import_clean(file_list, threshold=0.5):
## Code
def visualize(df_list):
# Find the most important features and generate pairwise scatter plots
# Display visualizations and write to file.
plt.savefig("scatter_plots.png")
def combine(df_list):
# Combine dataframes and generate train and test sets
# Drop features all dataframes don't share
# Return both train and test dataframes
return train,test
def train(train_df):
# Train model
return model
def validate(train_df, test-df):
# K-fold cross validation
# Return metrics dictionary
return metrics_dict
frames = import_clean(['LoanStats3a.csv', 'LoanStats2012.csv'],
threshold=0.7)
visualize(frames)
train_df, test_df = combine(frames)
model = train(train_df)
metrics = test(train_df, test_df)
print(metrics)
后续步骤
如果您有兴趣加深理解并进一步实践,我推荐以下步骤:
- 了解如何将您的管道变成一个独立的脚本,可以作为一个模块运行,也可以从命令行运行:https://docs.python.org/3/library/主。html
- 了解如何使用 Luigi 构建可以在云中运行的更复杂的管道:用 Python 和 Luigi 构建数据管道
- 了解更多关于数据工程的信息:Data quest 上的数据工程帖子
通过发布您的工作来帮助您的数据科学事业!(2022 指南)
原文:https://www.dataquest.io/blog/publish-data-science-work-2022/
May 22, 2020
本指南旨在涵盖数据科学学习者在互联网上撰写和发布文章所需的一切。它涵盖了为什么你应该写,为新作家写建议,以及邀请新作家投稿的地点列表。
我们开始吧!
为什么要写:
写作不仅仅是为了“作家”。写作的艺术是每个人都可以学习的——程序员、营销人员、经理和领导者都一样。是的,还有数据科学家和分析师!
你应该写文章,因为当你写的时候:
你学: 写作教你写作的艺术。这是一种循环,但它是真实的。不要搞错,写作的艺术不是关于语法(虽然,那很重要)和华丽的语言(肯定不重要)。而是用简单的语言清晰地传达你的想法。
**即使你完全知道你不想以写博客/文章为生,学习这门艺术也很重要。这很重要,因为所有的工作都涉及到某种形式的写作——信息、电子邮件、备忘录和所有的内容。所以基本上,写作是几乎任何工作的媒介。
除此之外,当你写作的时候,你学到了那些你以为你知道但实际上并不知道的东西。所以,写作是一个更好学习的机会。
你教:当你写作时,你与他人分享你的具体经历。
这也是为什么不管你的专业知识如何,你都有充分的理由相信你有重要的贡献。你有故事,你可以说出来。告诉他们你是怎么学的,学了什么,在哪里学的。告诉他们你艰难学到的所有课程。告诉他们你真正理解一个复杂概念的那些来之不易的时刻。
你可以写文章和博客来与他人分享这些经验,这样他们就可以比你过得更轻松。当然,当你知道你减轻了你的读者的学习之旅时,你得到了满足!
当你写下你的故事时,你有可能接触到成千上万的人。这是你建立自己的观众群的机会。一个建立自己追随者的机会。在这个领域“扬名立万”的机会。那是多么令人兴奋啊!
这不仅仅是刺激和兴奋。记住,职业人士也是学习者;在工作中学习是一件真实的事情。这意味着很多时候,阅读你文章的人将会是专业人士。帮助他们意味着你可以建立和发展你的职业网络!
写作对你的事业有帮助:
每次你发表你的一些作品,你就增加了潜在雇主或客户接触到它的机会。当你简单地把你的作品放在别人面前时,你可能会惊讶于会有什么意想不到的机会出现。
书面文章也可以很好地包含在你的简历中。毕竟,从事数据科学工作不仅仅是拥有编程技能!成为一名高效的数据科学家意味着能够清晰有效地交流数据。在简历上发表过作品证明了你的数据交流能力。
给新作家的写作建议:
希望最后几段已经激发了你写作的动力。
如果你已经决定开始写作,我有几条建议给你。这些是大多数新作家不知道的一些简单的提示。我花了很大的力气才学会其中一些,现在你可以轻松地学会它们了。
他们在这里:
- 注意你的写作风格。首先,所有面向学习者的内容都应该以热情、欢迎、包容、鼓励和友好的语气为特色。数据科学尤其复杂,可能会让人望而生畏。你写的东西越不吓人,就能接触到越多的人。
- 准备好扔掉你写的很多东西。作家键盘上最常用的键是删除/退格键。所以,如果有必要,不要害怕重写它。重读一遍。删除它。更换它。
- 检查拼写、标点和语法错误。拥有丰富的词汇并不重要,但使用正确的语法才重要。如果你的母语不是英语,你需要格外小心。语法上使用像这样的工具会有所帮助。
- 如果允许“规范的网址”,把你写的每一篇文章提交给多个来源/出版物。这叫做交叉过账。交叉发布有助于你的文章接触到多个受众——作为一名新作家,你需要接触到尽可能多的人。但是记住,交叉发布只能到允许你设置“规范网址”的网站。搜索引擎使用规范链接来确定内容的最终来源并对其进行优先排序,从而在不同位置存在同一文档的多个副本时消除混淆。发布过多重复内容而没有标明规范链接的网站可能会在搜索引擎排名中受到惩罚。
接受捐款的地点列表:
当你准备好一篇文章时,这里有一些非常受欢迎的地方,它们会接受你的文章,并与其庞大的粉丝群分享:
非常重要的一点是,你要仔细阅读并遵循你所提交的建议。
我们希望这个指南对你的写作之旅有所帮助!如果您发现 Dataquest 对您有所帮助,我们希望您能在文章中提及我们,以便其他学习者也能找到我们!🙂**
在 Windows 上设置 PyData 堆栈
November 22, 2017The speed of modern electronic devices allows us to crunch large amounts of data at home. However, these devices require the right software in order to reach peak performance. Luckily, it’s now easier than ever to set up your own data science environment. One of the most popular stacks for data science is PyData, a collection of software packages within Python. Python is one of the most common languages in data science, largely thanks to its wide selection of user-made packages.  In this tutorial, we’ll show you how to set up a fully functional PyData stack on your local Windows machine. This will give you full control over your installed environment and give you a first taste of what you’ll need to know when setting up more advanced configurations in the cloud. To install the stack, we’ll be making use of Anaconda, a popular Python distribution released by Continuum Analytics. It contains all the packages and tools to get started with data science, including Python packages and editors.
In this tutorial, we’ll show you how to set up a fully functional PyData stack on your local Windows machine. This will give you full control over your installed environment and give you a first taste of what you’ll need to know when setting up more advanced configurations in the cloud. To install the stack, we’ll be making use of Anaconda, a popular Python distribution released by Continuum Analytics. It contains all the packages and tools to get started with data science, including Python packages and editors. 
默认情况下,Anaconda 包含 100 多个包,还有 600 多个包可以通过包含的包管理器获得。一些最著名的软件包如下:
- NumPy:一个流行的线性代数包,极大地方便和加速了 Python 中的数值计算。
- SciPy :包含常用数学运算的函数,如积分、求导和数值优化,可用于 NumPy 对象。
- Pandas :构建于 NumPy 之上,可以灵活地处理带标签的数据,并提供对各种分析和可视化例程的轻松访问。
- Scikit-learn :最流行的 Python 机器学习库,包括许多流行的模型来执行预测分析,以及数据的预处理和后处理。
- StatsModels :类似于 scikit-learn,旨在执行经典的描述性统计。
- Matplotlib :一个流行的通用绘图库,包括线图、条形图和散点图。可以通过熊猫进入。
- 基于 matplotlib 的统计可视化库,包括分布图和热图的绘制。
- 底图:能够绘制地理数据(即在地图上绘制数据)的库;同样基于 matplotlib 构建。
可以在这里找到包含的软件包的完整列表。除了 Python 包,还包括各种桌面应用程序。其他的,比如 RStudio,只需点击一下就可以安装。当前预安装的程序有:
- Jupyter Notebook :一个 web 服务器应用程序,允许您交互式地运行 Python,并在浏览器中可视化您的数据。
- Jupyter Qt 控制台:类似于 jupyter notebook,允许您交互地运行 python 并可视化您的数据,但是是从命令行窗口。
- Spyder :一个更高级的 Python 编辑器,包括交互式测试、调试和自省等特性。
用 Anaconda 安装 PyData 堆栈
用 Anaconda 设置 PyData 通常是一个轻松的过程。标准发行版包含最常用的软件包,几乎不需要定制配置。使用包管理器可以很容易地添加其他包。在接下来的几节中,我们将带您完成安装过程。
选择您的安装程序
首先,您必须从他们的下载页面下载适当版本的 Anaconda。安装程序适用于 Windows、macOS 和 Linux。虽然我们将重点关注 Windows 上的安装过程,但本文中的许多信息也适用于其他操作系统。不同的 Python 版本也有不同的安装程序。在本教程中,我们将使用推荐的 Python 最新版本:3.6。 您还可以在 32 位和 64 位版本的发行版之间进行选择。通常建议使用 64 位,因为这将允许您使用超过 3.5 GB 的内存,这是处理大数据时通常会消耗的内存量。如果您运行的是不支持 64 位的旧计算机,您应该只下载 32 位软件包。
您还可以在 32 位和 64 位版本的发行版之间进行选择。通常建议使用 64 位,因为这将允许您使用超过 3.5 GB 的内存,这是处理大数据时通常会消耗的内存量。如果您运行的是不支持 64 位的旧计算机,您应该只下载 32 位软件包。
安装过程
- 一旦安装程序被下载,只需双击运行它。安装程序将打开下图所示的窗口;点击下一个。

- 将出现一个欢迎屏幕,显示 Anaconda 的许可协议。一旦你感到满意,点击我同意接受许可。

- 下一个窗口将让您选择是为自己安装还是为所有用户安装。选择前者,除非您计划从同一台计算机上的其他用户帐户访问 Anaconda。做出选择后,点击下一个。

- 现在您可以选择 Anaconda 的安装位置。在大多数情况下,默认路径就可以了。如果您居住在非英语国家,请确保路径不包含任何特殊字符。一旦选择了合适的路径,点击下一步的。

- 下一页允许您自定义与 Windows 的集成选项。正常情况下,默认选项应该没问题。如果您有另一个 Python 版本想要保留为默认版本,那么可以取消勾选底部的复选框。第一个单选按钮修改您的全局路径;除非你知道你在做什么,否则一般不推荐选择它。最后点击安装,安装过程开始。

使用 Anaconda Navigator 探索 Anaconda
一旦安装完成,在你的开始菜单中会有一个 Anaconda 文件夹。在里面你会找到一个到 Anaconda Navigator 的快捷方式,它是一个包含在发行版中的各种软件包和功能的入口。它将允许您快速方便地管理您的包、项目和环境。更高级的配置可以通过 Anaconda 提示符来执行,这是一个命令行界面,我们将在下一节讨论。 在左侧,您可以看到五个主要选项卡:主页、环境、项目、学习和社区。
在左侧,您可以看到五个主要选项卡:主页、环境、项目、学习和社区。
主页
home 选项卡列出了当前通过 Anaconda 安装的应用程序。默认情况下,它们是 Jupyter Notebook、Qt Console 和 Spyder。Home 还可以让你安装可视化软件 GlueViz 数据挖掘框架 Orange 对于那些对 R 感兴趣的人,RStudio。通过每个应用程序框右上角的设置图标,可以安装、更新或删除所有应用程序。出于兼容性原因,您也可以将应用程序更改为特定版本。
环境
Anaconda 使您能够通过环境管理您的 Python 安装。每个环境运行一个特定的 Python 版本,包的数量有限。可以在安装过程中选择软件包的具体版本,并且可以随时将更多的软件包添加到环境中。使用环境可以减少包之间的冲突,从而让您以安全的方式运行 Python 代码。它们也可以在计算机之间传输。默认情况下,只有根环境,运行包含所有 Anaconda 包的最新 Python 版本。关于使用 Anaconda 提示符进行高级环境管理的更多细节将在本文中给出。
项目
您想与其他用户共享您的个人项目吗?使用 Anaconda 项目,您可以在云中共享它们,并自动化部署过程。这包括下载文件、安装软件包、设置环境变量以及在您选择的平台上运行附加文件。
学问
获取有用的信息是很有价值的。在此选项卡中,您可以找到各种学习资源,包括文档、视频、培训课程和网络研讨会的链接。最重要的条目是 PyData 主要软件包的参考手册。
社区
“社区”选项卡可帮助您拓展业务。它提供了会议等未来活动的概述,以及各种开发人员论坛和博客的链接,您可以从其他 PyData 用户那里获得帮助。最后,在右上角,您可以登录 Anaconda Cloud,用户可以在这里共享包、笔记本、项目和环境。
使用 Anaconda 提示符进行高级管理
虽然 Navigator 提供了良好的基本功能,但是高级包管理最好通过命令行来执行。Anaconda 提供了一个特殊的命令提示符, Anaconda Prompt ,它确保正确设置所有必要的环境变量。我们将关注使用conda命令管理环境和包。如果你想了解更多关于 Windows 命令提示符的知识,网上有很多教程。
康达
Python 附带了一个内置的包管理器pip,能够自动安装 Python 包。然而,许多科学包具有 Python 包之外的依赖性。Anaconda 自带通用的包管理器:conda,可以处理包含依赖项和与 Python 无关的命令的复杂安装例程。与pip不同,它还具有处理环境的能力,取代了传统的 virtualenv。在一个conda环境中,你将能够精确地定义你想要安装的包和版本。在遗留包的情况下,您甚至可以更改在环境中使用的 Python 版本。通过使用环境,您可以大大减少软件包之间发生冲突的机会,并且可以测试各种配置,而不会影响您的全局安装。您可以通过在 Anaconda 提示符下键入以下命令来了解conda的命令行选项:
conda --help
这相当于:
conda -h
这将为您提供以下输出:
 如你所见,
如你所见,conda最重要的功能是管理环境和包。在接下来的几节中,我们将更详细地告诉您如何使用这些函数。注意,通过在末尾添加-h标志,您总是可以获得关于您想要执行的特定命令的更多信息。这将为您提供可用选项的完整概述,包括长格式和短格式。
康达环境
让我们首先创建一个没有任何特定包的名为 demo 的环境:
conda create --name demo
当要求确认时,键入y。
 如果你想在环境中使用一个特定的 Python 版本你可以在命令中添加它:
如果你想在环境中使用一个特定的 Python 版本你可以在命令中添加它:
conda create --name demo python=2.7
这将使用 Python 2.7 创建一个环境。类似地,如果您已经想将一些包添加到环境中,您可以简单地将它们添加到行尾:
conda create --name demo2 python=2.7 scikit-learn statsmodels
已安装的包可以在以后更改,我们将在本文的下一部分讨论。一旦创建了环境,它将出现在环境列表中。您可以使用以下任一方式访问该列表:
conda info --envs
或者
conda env list
这两个命令将给出相同的输出:环境的名称及其所在的路径。您当前活动的环境将标有星号。默认情况下,这将是“根”环境,对应于您的全局 Anaconda 安装。
 如图所示,我们仍处于根环境中。使用 activate 命令可以切换到新的演示环境:
如图所示,我们仍处于根环境中。使用 activate 命令可以切换到新的演示环境:
activate demo
您的命令行窗口现在将在该行的开头显示环境的名称。
完成后,您可以通过输入 deactivate 离开环境。现在想象你已经完全建立了你的完美环境,但是你决定做出改变。最安全的方法是对您当前的环境进行精确克隆。让我们创建一个名为 demo2 的环境,它将是演示环境的精确克隆:
conda create --name demo2 --clone demo
如果我们决定不再需要它,我们可以删除它:
conda remove --name demo2 --all
您还可以备份您的环境,供自己使用或与他人共享。为此,我们需要回到环境中去。
activate demo
然后,我们可以创建当前环境的环境文件:
conda env export > demo.yml
可用于从文件创建一个相同的环境,如下所示:
conda env create --file demo.yml
这在无法克隆环境的另一台计算机上尤其有用。当然,您必须确保 Anaconda 提示符位于包含您的环境文件的文件夹中。
管理包
现在我们已经学习了如何设置环境,让我们来看看如何在环境中管理包。我们已经看到,您可以在创建环境时提供要安装的软件包列表:
conda create --name demo scikit-learn statsmodels
这不仅会安装软件包本身,还会安装所有的依赖项。创建环境后,您可以使用以下任一方式查看已安装的软件包:
conda list
在环境中,或者在演示环境中:
conda list --name demo
在 Anaconda 主提示符下。
如果你想安装一个新的软件包,你可以先搜索它。例如,如果我们想寻找巴别塔包:
conda search babel
这将为您提供包含单词 babel 的软件包列表以及每个软件包的可用版本。
然后,您可以使用 install 命令在演示环境中安装该软件包:
conda install --name demo babel
省略-n demo 会将它安装在当前活动的环境中。稍后,您可以使用 update 命令更新软件包:
conda update --name demo babel
你甚至可以更新conda本身:
conda update conda
如果您决定不再需要某个软件包,同样可以将其从您的环境中删除:
conda remove --name demo babel
最后,如果您找不到您正在寻找的包(或包版本),您会怎么做?第一个选项是检查由Anaconda.org提供的附加包频道。前往 Anaconda.org,使用搜索框查找您的包裹。举个例子,让我们安装 cartopy。 Cartopy 是一个地理绘图包,用来替换 Anaconda 附带的不推荐使用的底图包。如果你在 Anaconda.org 上搜索,你会在康达-福吉频道找到它。 可以通过运行以下命令进行安装,其中
可以通过运行以下命令进行安装,其中-c标志表示通道名称:
conda install --name demo --channel conda-forge cartopy
然后,可以像管理任何其他包一样管理它。如果你找不到你的包裹怎么办?嗯,你可以试试其他的包管理器比如pip。后者实际上可以在conda环境中安装和使用:
conda install --name demo pip
然后,您可以在您的环境中正常使用 pip。例如,安装谷歌深度学习库 Tensorflow 的 CPU 版本将需要在您的环境中运行以下pip命令:
pip install --ignore-installed --upgrade tensorflow
如果conda和pip都不允许您添加所需的软件包,您将不得不查看附带的文档以获得手动安装说明。
下一步是什么?
现在您已经完成了本教程,您将能够使用 Anaconda 在您自己的 Windows 计算机上设置和使用 PyData 堆栈。您还可以使用图形化的 Anaconda Navigator 和从命令行使用conda包管理器来管理环境和包。现在您已经准备好开始编码了。寻找灵感?查看我们的课程和博客中的代码样本。
教程:用 Jupyter 笔记本安装和集成 PySpark
原文:https://www.dataquest.io/blog/pyspark-installation-guide/
October 26, 2015At Dataquest, we’ve released an interactive course on Spark, with a focus on PySpark. We explore the fundamentals of Map-Reduce and how to utilize PySpark to clean, transform, and munge data. In this post, we’ll dive into how to install PySpark locally on your own computer and how to integrate it into the Jupyter Notebbok workflow. Some familarity with the command line will be necessary to complete the installation.
概述
概括地说,以下是安装 PySpark 并将其与 Jupyter notebook 集成的步骤:
- 安装下面所需的软件包
- 下载并构建 Spark
- 设置您的环境变量
- 为 PySpark 创建一个 Jupyter 配置文件
必需的包
- Java SE 开发工具包
- Scala 构建工具
- Spark 1.5.1(撰写本文时)
- Python 2.6 或更高版本(我们更喜欢使用 Python 3.4+)
- Jupyter 笔记型电脑
Java
Spark 需要 Java 7+,可以从 Oracle 网站下载:
火花
前往
Spark 下载页面,保留步骤 1 到 3 中的默认选项,下载压缩版(。tgz 文件)的链接。一旦你下载了 Spark,我们建议解压文件夹,并将解压后的文件夹移动到你的主目录。
Scala 构建工具
- 要构建 Spark,您需要 Scala 构建工具,您可以安装:
- Mac:
brew install sbt - Linux: 指令
- 导航到 Spark 解压到的目录,并在该目录中运行
sbt assembly(这需要一段时间!).
测试
为了测试 Spark 构建是否正确,在同一个文件夹(Spark 所在的位置)中运行以下命令:
bin/pyspark
交互式 PySpark shell 应该会启动。这是交互式 PySpark shell,类似于 Jupyter,但是如果你运行
在 shell 中,您将看到已经初始化的 SparkContext 对象。您可以在这个 shell 中交互地编写和运行命令,就像使用 Jupyter 一样。
环境变量
环境变量是计算机上的任何程序都可以访问的全局变量,包含您希望所有程序都可以访问的特定设置和信息。在我们的例子中,我们需要指定 Spark 的位置,并添加一些特殊的参数,我们将在后面引用。使用
nano 或vim打开~/.bash_profile并在末尾添加以下几行:
export SPARK_HOME="$HOME/spark-1.5.1"
export PYSPARK_SUBMIT_ARGS="--master local[2]"
替换
将 Spark 解压缩到的文件夹的位置(还要确保版本号匹配!).
Jupyter 简介
最后一步是专门为 PySpark 创建一个 Jupyter 概要文件,并进行一些自定义设置。要创建此配置文件,请运行:
Jupyter profile create pyspark
使用
nano或vim在以下位置创建以下 Python 脚本:
~/.jupyter/profile_pyspark/startup/00-pyspark-setup.py
然后向其中添加以下内容:
import os
import sys
spark_home = os.environ.get('SPARK_HOME', None)
sys.path.insert(0, spark_home + "/python")
sys.path.insert(0, os.path.join(spark_home, 'python/lib/py4j-0.8.2.1-src.zip'))
filename = os.path.join(spark_home, 'python/pyspark/shell.py')
exec(compile(open(filename, "rb").read(), filename, 'exec'))
spark_release_file = spark_home + "/RELEASE"
if os.path.exists(spark_release_file) and "Spark 1.5" in open(spark_release_file).read():
pyspark_submit_args = os.environ.get("PYSPARK_SUBMIT_ARGS", "")
if not "pyspark-shell" in pyspark_submit_args:
pyspark_submit_args += " pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = pyspark_submit_args
如果您使用的是比 Spark 1.5 更高的版本,请在脚本中将“Spark 1.5”替换为您正在使用的版本。
运行
使用启动 Jupyter Notebook
pyspark配置文件,运行:
jupyter notebook --profile=pyspark
要测试 PySpark 是否正确加载,创建一个新的笔记本并运行
以确保 SparkContext 对象被正确初始化。
接下来的步骤
如果您想更详细地了解 spark,您可以访问我们的
Dataquest 上的互动火花课程。
我应该学 Python 2 还是 3?(以及为什么它很重要)
September 28, 2022
如果您想知道应该学习 Python 2 还是 Python 3,您并不孤单。
这是我们在 Dataquest 最常听到的问题之一,在那里,我们将 Python 作为数据科学课程的一部分来教授。
让我们解决这个问题。
剧透:在 Dataquest,我们只教 Python 3。如果您准备好现在就开始学习,请免费注册Python 简介课程!
如果你仍然犹豫不决,或者只是想了解更多信息,请继续阅读。这篇文章给出了问题背后的一些背景,解释了我们的立场,并告诉你应该学习哪个版本。
如果你想要简单的答案,这里就是:你应该学习 Python 3,因为它是与当今数据科学项目最相关的版本。另外,它很容易学习,很少需要担心兼容性问题。
需要更彻底的解释吗?让我们先简要回顾一下 Python 2 对 3 之争背后的历史。
2008 年:Python 3.0 的诞生
不,那不是印刷错误。Python 3 发布于 2008 年。
如果您是 Python 2-3 争论的新手,请注意这场争论已经酝酿了将近 15 年了!仅此一点就应该告诉你这是多么大的一件事。
2008 年的向后不兼容版本
Python 于 2008 年 12 月 3 日发布了 3.0 版本。这个版本的特别之处在于它是一个向后不兼容的版本。
作为这种向后不兼容的结果,将项目从 Python 2.x 迁移到 3.x 将需要很大的改变。这不仅包括单个项目和应用程序,还包括构成 Python 生态系统一部分的所有库。
Python 3 反冲
当时,这一变化被视为极具争议。因此,许多项目抵制了迁移的痛苦,尤其是在科学 Python 社区中。例如,主数字库 NumPy 花了整整两年时间才发布了它的第一个 3.x 版本!
在接下来的几年里,其他项目开始发布 3.x 兼容版本。到 2012 年,许多库已经支持 3.x,但大多数仍然是用 2.x 编写的。随着时间的推移,工具的发布使得移植代码更加容易,但仍然有很大的阻力。
在接下来的几年里,发布了几个工具来帮助旧代码库从 Python 2 过渡到 Python 3。
最初,Python 将 Python 2.x 的“生命终结”日期定在 2015 年。然而,在 2014 年,他们宣布将终止日期延长至 2020 年。这样做的部分原因是为了减轻那些还不能迁移到 Python 3 的用户的担忧。
然而,Python 2 的日子显然是有限的。2017 年,流行的网络框架 Django 宣布他们的新 2.0 版本将不支持 Python 2.x 。
此外,许多软件包开始宣布停止支持 2.x。甚至科学图书馆也承诺在 2020 年或更早之前停止支持 2.x。
快进到今天:为什么这还是一个问题?
今天,很少有库不支持 Python 3。
但是,如果 Python 2.x 不再受支持,那么为什么围绕 Python 2 对 3 的问题仍然存在混乱呢?
答案是双重的。
首先,网上有很多基于 Python 2 的旧的免费学习 Python 的资源。这包括来自 Coursera、Udemy 和 edX 等平台的大多数 MOOC 课程。
由于数据科学专业的学生总是希望省钱,这些免费资源很有吸引力。
另外,Zed Shaw 非常受欢迎的Learn Python Hard Way是用 Python 2.x 编写的。他直到 2017 年才写了一本关于 Python 3 的书——几乎是在它发布整整十年之后!
直到最近,我还以为这只是因为泽德这些年来太懒了,没有更新他的课程。但是后来我发现了他那篇有争议的文章:针对 Python 3 的案例。
尽管 Eevee 对 Python 3 进行了精彩的反驳,Zed 的抨击还是造成了损失。当然,今天赞同 Zed 的人数是极少数。但是整个争议减缓了从 Python 2 到 3 的过渡。这也给这个领域的许多新来者搅浑了水。
那么我应该学习哪种 Python 呢?
关于 Python 2 和 3 的所有争论,您可能会认为学习其中一个会是一个困难的决定。然而实际上,这很简单。
Python 3 是明显的赢家
Python 3.x 是未来,随着 Python 2.x 支持的减少,您应该花时间学习将会持续的版本。
如果您担心兼容性问题,不必担心。我只使用 Python 3.x,很少遇到兼容性问题。
偶尔(可能每 3-4 个月一次),我会发现我正在尝试运行一些需要 Python 2 支持的东西。在这些罕见的情况下,Python 的 virtualenv 允许我立即在我的机器上创建一个 2.x 环境来运行那部分遗留软件。
不要在 Python 2 上浪费时间
让我们明确一点:Python 2 已经过时了。Python 2.x 不会有未来的安全或 bug 修复,你的时间最好花在学习 3.x 上。
万一你最终使用的是一个遗留的 Python 2 代码库,像 Python-Future 这样的工具会让你在只学过 Python 3 的情况下轻松使用。
Dataquest 是学习成为使用 Python 的数据科学家的最佳在线平台(当然是 3.x!).我们有毕业生在 SpaceX、亚马逊等公司工作。如果您对此感兴趣,您可以在 Dataquest.io 注册并免费完成我们的第一门课程。
Python API 教程:API 入门
August 15, 2020
在这个 Python API 教程中,我们将学习如何为数据科学项目检索数据。网上有数百万个 API 提供数据访问。像 Reddit 、 Twitter 和脸书这样的网站都通过他们的 API 提供某些数据。
要使用 API,您需要向远程 web 服务器发出请求,并检索您需要的数据。
但是为什么要使用 API 而不是可以从网上下载的静态 CSV 数据集呢?API 在下列情况下很有用:
- 数据变化很快。股票价格数据就是一个例子。重新生成数据集并每分钟下载它实际上没有意义-这将占用大量带宽,并且非常慢。
- 你想要一个大得多的数据集的一小部分。Reddit 评论就是一个例子。如果你只想在 Reddit 上发布自己的评论呢?下载整个 Reddit 数据库,然后只过滤你自己的评论是没有意义的。
- 存在重复计算。Spotify 有一个 API 可以告诉你一段音乐的流派。理论上,你可以创建自己的分类器,并使用它来计算音乐类别,但你永远不会拥有像 Spotify 那样多的数据。
在上述情况下,API 是正确的解决方案。在这篇博文中,我们将查询一个简单的 API 来检索关于国际空间站的数据。
关于这个 Python API 教程
本教程是基于我们关于 Python 中的 API 和 Webscraping 的交互式课程的一部分,你可以免费开始。
对于本教程,我们假设您了解使用 Python 处理数据的一些基础知识。如果你没有,你可能想试试我们的免费 Python 基础课程。
如果你正在寻找更高级的东西,请查看我们的中级 API 教程。
什么是 API?
API 或应用程序编程接口是一种服务器,您可以使用代码来检索数据和向其发送数据。API 最常用于检索数据,这将是本初学者教程的重点。
当我们想从一个 API 接收数据时,我们需要发出一个请求。请求在网络上随处可见。例如,当您访问这篇博客文章时,您的 web 浏览器向 Dataquest web 服务器发出一个请求,它用这个 web 页面的内容作出响应。

API 请求的工作方式完全相同——您向 API 服务器发出数据请求,它会响应您的请求。
用 Python 制作 API 请求
为了使用 Python 中的 API,我们需要能够发出这些请求的工具。在 Python 中,最常见的发出请求和使用 API 的库是 请求库。请求库不是标准 Python 库的一部分,所以您需要安装它才能开始。
如果使用 pip 管理 Python 包,可以使用以下命令安装请求:
pip install requests
如果您使用 conda,您需要的命令是:
conda install requests
一旦你安装了库,你需要导入它。让我们从重要的一步开始:
import requests
现在我们已经安装并导入了请求库,让我们开始使用它。
发出我们的第一个 API 请求
有许多不同类型的请求。最常用的一个是 GET 请求,用于检索数据。因为我们只是检索数据,所以我们的重点是发出“get”请求。
当我们发出请求时,来自 API 的响应带有一个响应代码,它告诉我们我们的请求是否成功。响应代码很重要,因为它们会立即告诉我们是否出现了问题。
要发出一个“GET”请求,我们将使用 requests.get()函数,它需要一个参数——我们要向其发出请求的 URL。我们首先向一个不存在的 API 端点发出请求,这样我们就可以看到响应代码是什么样子。
response = requests.get("https://api.open-notify.org/this-api-doesnt-exist")
get()函数返回一个 response对象。我们可以使用[response.status_code](https://2.python-requests.org/en/master/user/quickstart/#response-status-codes)属性来接收请求的状态代码:
print(response.status_code)
404
“404”状态代码对您来说可能很熟悉——它是服务器在找不到我们请求的文件时返回的状态代码。在这种情况下,我们要求的this-api-doesnt-exist是(惊喜,惊喜)不存在的!
让我们再多了解一些常见的状态代码。
API 状态代码
向 web 服务器发出的每个请求都会返回状态代码。状态代码表示关于请求发生了什么的信息。以下是一些与 GET 请求相关的代码:
- 一切顺利,结果已经返回(如果有的话)。
301:服务器正在将您重定向到不同的端点。当公司切换域名或端点名称更改时,可能会发生这种情况。- 服务器认为你提出了一个错误的请求。当你没有发送正确的数据时,就会发生这种情况。
- 服务器认为你没有通过认证。许多 API 需要登录凭证,所以当您没有发送正确的凭证来访问 API 时,就会发生这种情况。
- 你试图访问的资源被禁止:你没有权限查看它。
404:在服务器上找不到您试图访问的资源。503:服务器未准备好处理请求。
您可能会注意到,所有以“4”开头的状态代码都表示某种错误。状态代码的第一个数字表示它们的类别。这很有用—您可以知道,如果您的状态代码以“2”开头,则表示成功,如果以“4”或“5”开头,则表示有错误。如果你感兴趣,你可以在这里阅读更多关于状态码的信息。
API 文档
为了确保我们发出成功的请求,当我们使用 API 时,参考文档是很重要的。文档一开始看起来很可怕,但是随着你越来越多地使用文档,你会发现它变得越来越容易。
我们将使用 Open Notify API,它提供对国际空间站数据的访问。这是一个很好的学习 API,因为它的设计非常简单,并且不需要认证。我们将在以后的文章中教你如何使用需要认证的 API。
通常在一个特定的服务器上会有多个可用的 API。这些 API 通常被称为端点。我们将使用的第一个端点是 http://api.open-notify.org/astros.json 的,它返回当前在太空中的宇航员的数据。
如果您点击上面的链接来查看这个端点的文档,您会看到它说这个 API 不接受任何输入。这使它成为我们开始使用的一个简单的 API。我们将从使用请求库向端点发出 GET 请求开始:
response = requests.get("https://api.open-notify.org/astros.json")
print(response.status_code)
200
我们收到一个“200”代码,告诉我们我们的请求是成功的。文档告诉我们,我们将得到的 API 响应是 JSON 格式的。在下一节中,我们将了解 JSON,但是首先让我们使用 response.json()方法来查看我们从 API 接收到的数据:
print(response.json())
{'message': 'success', 'people': [{'name': 'Alexey Ovchinin', 'craft': 'ISS'}, {'name': 'Nick Hague', 'craft': 'ISS'}, {'name': 'Christina Koch', 'craft': 'ISS'}, {'name': 'Alexander Skvortsov', 'craft': 'ISS'}, {'name': 'Luca Parmitano', 'craft': 'ISS'}, {'name': 'Andrew Morgan', 'craft': 'ISS'}], 'number': 6}
在 Python 中使用 JSON 数据
JSON (JavaScript 对象表示法)是 API 的语言。JSON 是一种对数据结构进行编码的方法,这种方法可以确保它们易于被机器读取。JSON 是数据在 API 之间来回传递的主要格式,大多数 API 服务器将以 JSON 格式发送响应。
您可能已经注意到,我们从 API 收到的 JSON 输出看起来包含 Python 字典、列表、字符串和整数。您可以将 JSON 看作是用字符串表示的这些对象的组合。让我们看一个简单的例子:

Python 的 json包提供了强大的 JSON 支持。json包是标准库的一部分,所以我们不需要安装任何东西来使用它。我们既可以将列表和字典转换为 JSON,也可以将字符串转换为列表和字典。在我们的 ISS Pass 数据中,它是一个以 JSON 格式编码为字符串的字典。
json 库有两个主要功能:
[json.dumps()](https://web.archive.org/web/20200107014409/https://docs.python.org/3/library/json.html#json.dumps)—接收 Python 对象,并将其转换(转储)为字符串。json.loads()—获取 JSON 字符串,并将其转换(加载)为 Python 对象。
dumps()函数特别有用,因为我们可以用它来打印一个格式化的字符串,这样更容易理解 JSON 输出,就像我们上面看到的图表一样:
import json
def jprint(obj):
# create a formatted string of the Python JSON object
text = json.dumps(obj, sort_keys=True, indent=4)
print(text)
jprint(response.json())
{
"message": "success",
"number": 6,
"people": [
{
"craft": "ISS",
"name": "Alexey Ovchinin"
},
{
"craft": "ISS",
"name": "Nick Hague"
},
{
"craft": "ISS",
"name": "Christina Koch"
},
{
"craft": "ISS",
"name": "Alexander Skvortsov"
},
{
"craft": "ISS",
"name": "Luca Parmitano"
},
{
"craft": "ISS",
"name": "Andrew Morgan"
}
]
}
我们可以立即更容易地理解数据的结构——我们可以看到他们目前在太空中有六个人,他们的名字作为字典存在于一个列表中。
如果我们将它与端点的文档进行比较,我们会看到它与端点的指定输出相匹配。
使用带有查询参数的 API
我们之前使用的 http://api.open-notify.org/astros.json 端点不带任何参数。我们只需发送一个 GET 请求,API 就会发回关于当前太空中人数的数据。
然而,拥有一个要求我们指定参数的 API 端点是很常见的。这样的一个例子是https://api.open-notify.org/iss-pass.json 端点。这个终点告诉我们下一次国际空间站将经过地球上一个给定位置的时间。
如果我们看一下文档,它指定了必需的lat(纬度)和long(经度)参数。
我们可以通过在请求中添加一个可选的关键字参数params来做到这一点。我们可以用这些参数做一个字典,然后把它们传入requests.get函数。使用纽约市的坐标,我们的字典看起来是这样的:
parameters = {
"lat": 40.71,
"lon": -74
}
我们也可以通过将参数直接添加到 URL 来做同样的事情。像这样:
https://api.open-notify.org/iss-pass.json?lat=40.71&lon;=-74
将参数设置为一个字典几乎总是更可取的,因为requests会处理出现的一些事情,比如正确格式化查询参数,并且我们不需要担心将值插入到 URL 字符串中。
让我们用这些坐标发出一个请求,看看会得到什么样的响应。
response = requests.get("https://api.open-notify.org/iss-pass.json", params=parameters)
jprint(response.json())
{
"message": "success",
"request": {
"altitude": 100,
"datetime": 1568062811,
"latitude": 40.71,
"longitude": -74.0,
"passes": 5
},
"response": [
{
"duration": 395,
"risetime": 1568082479
},
{
"duration": 640,
"risetime": 1568088118
},
{
"duration": 614,
"risetime": 1568093944
},
{
"duration": 555,
"risetime": 1568099831
},
{
"duration": 595,
"risetime": 1568105674
}
]
}
了解通行时间
JSON 响应与文档中指定的内容相匹配:
- 一本有三个键的字典
- 第三个键
response,包含通行时间列表 - 每个通过时间都是一个带有
risetime(通过开始时间)和duration键的字典。
让我们从 JSON 对象中提取通过时间:
pass_times = response.json()['response']
jprint(pass_times)
[
{
"duration": 395,
"risetime": 1568082479
},
{
"duration": 640,
"risetime": 1568088118
},
{
"duration": 614,
"risetime": 1568093944
},
{
"duration": 555,
"risetime": 1568099831
},
{
"duration": 595,
"risetime": 1568105674
}
]
接下来,我们将使用一个循环来提取五个risetime值:
risetimes = []
for d in pass_times:
time = d['risetime']
risetimes.append(time)
print(risetimes)
[1568082479, 1568088118, 1568093944, 1568099831, 1568105674]
这些时间很难理解——它们的格式被称为时间戳或纪元。从 1970 年 1 月 1 日开始,时间基本上是以秒数来计算的。我们可以使用 Python datetime.fromtimestamp()方法将这些转换成更容易理解的时间:
from datetime import datetime
times = []
for rt in risetimes:
time = datetime.fromtimestamp(rt)
times.append(time)
print(time)
2019-09-09 21:27:59
2019-09-09 23:01:58
2019-09-10 00:39:04
2019-09-10 02:17:11
2019-09-10 03:54:34
看起来国际空间站经常经过纽约市——接下来的五次发生在七个小时内!
Python API 教程:后续步骤
在本教程中,我们学习了:
- 什么是 API
- 请求和响应代码的类型
- 如何发出 get 请求
- 如何使用参数发出请求
- 如何从 API 中显示和提取 JSON 数据
这些基本步骤将帮助您开始使用 API。记住,我们每次使用 API 的关键是仔细阅读 API 文档,并利用它来理解要发出什么请求和提供什么参数。
现在您已经完成了我们的 Python API 教程,您可能希望:
- 完成我们的交互式 Dataquest APIs 和抓取课程,您可以免费开始学习。
- 尝试使用这个免费公共 API 列表中的一些数据——我们建议选择一个不需要认证的 API 作为良好的第一步。
- 试试我们的中级 API 教程,它涵盖了 API 认证、分页和速率限制
15 位招聘经理透露 Python 认证是否值得
December 19, 2022
“最好的 Python 证书是什么?”
这是编程和数据科学初学者的常见问题。如果你用谷歌搜索这个短语,结果可能会令人震惊。
Python 认证从免费的到 Python 课程的一部分,再到花费数千美元的。
本文回答了关于 Python 认证的三个非常重要的问题:
- 雇主实际上是怎么看待他们的?
- 他们在展示技能方面做得好吗?
- 哪些是最好的?
雇主如何看待认证
在整理 Dataquest 数据科学职业指南时,我们采访了十几位数据科学领域的招聘人员和招聘经理。
当我们问他们想从申请者身上看到什么时,没有人提到证书。一个都没有。
这可能令人困惑,因为大多数提供证书的 Python 课程或程序都称赞它们的重要性。不幸的是,这只是一个好的营销的例子。
为什么凭据的工作方式与您想象的不同
虽然有一些很好的 Python 认证项目,但是招聘人员需要跟踪的项目实在太多了。他们很难知道哪些证书是选择性的,哪些证书会授予愿意付费的人。
这意味着证书本身并不是一个非常有用的凭证,即使你从一个高度选择性的训练营项目中得到一个。
未来的雇主通常会花 15 秒钟来评估你的简历。他们不会花时间去谷歌你参加的 Python 训练营的课程细节,并试图确定它是否足够严格。
即使是大学证书课程也是如此。
许多大学提供 Python 和其他各种技能的在线认证。但是这些培训项目不像真正的学位项目那样有选择性或严格。通常,它们由外部教育公司管理,这些公司只是租用大学的“品牌”和一些视频讲座。
不管你怎么想,即使是“名牌大学”的证书对招聘人员和招聘经理来说也没什么分量。
雇主真正想要什么
所以,如果 Python 认证对雇主来说没有那么大的吸引力,他们到底想看到什么呢?
答案是技能。
展示你能做什么是给雇主留下深刻印象的关键,因为这表明你有做这份工作的技能和知识。
但是,如果你还没有这方面的经验,你怎么向雇主展示你的技能呢?这就是项目组合可以帮助你的地方。
仔细想想,这是有道理的——你的项目是你可能还没有的工作经验的替身。与招聘经理可能没听说过的在线项目证书不同,你的项目组合证明你有能力胜任这份工作。
有了项目,用人单位就不必信任或评估第三方发证机构;代码就在你的 GitHub 或 portfolio 网站上。
需要建立项目组合?我们可以帮忙
项目是我们 Dataquest 教学方法的关键。在我们基于浏览器的交互式课程中,您将在编写代码的同时学习数据科学技能。然后你将把这些技能放在我们的指导项目中。
引导式项目可以帮助您在刚刚学到的技能和现实世界中必须从事的数据科学工作之间架起一座桥梁。他们也会帮助你在申请工作时有一个良好的开端,因为你可以把你最好的作品放在你的项目文件夹里。
以下是我们指导的项目列表,完成后您可以立即将其添加到您的投资组合中:
- 越狱 —找点乐子,用 Python 和 Jupyter Notebook 分析一个直升机越狱的数据集。
- App Store 和 Google Play 市场的盈利应用简介 —在这个指导性项目中,你将在一家开发移动应用的公司担任数据分析师。您将使用 Python 通过实际的数据分析来提供价值。
- 探索黑客新闻帖子——使用热门技术网站 Hacker News 的提交数据集。
- 探索易贝汽车销售数据——使用 Python 处理从德国易贝网站分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
如果 Dataquest 方法听起来对你有吸引力,今天就开始参加我们的免费Python for Data Science:Fundamentals课程吧!
哪个 Python 认证最好?
如果你还在寻找学习 Python 的认证培训项目,那么这里是你的最佳选择。
Dataquest
在 Dataquest,我们为有抱负的数据分析师、数据科学家和数据工程师提供 Python 语言的特定职业认证。
这些认证是不同的——没有考试。相反,您可以通过完成 Dataquest 的在线学习模块来获得认证。每项认证都要求你完成一系列课程,这些课程旨在让你从初学者走向工作岗位。
与其他 Python 认证培训课程不同,这些课程专门侧重于使用 Python 处理数据——它们不是为有抱负的 Python 软件工程师或游戏开发人员设计的。
每条路径还包括 Python 之外的相关数据技能,包括 SQL、命令行和 Git。大多数课程还以项目结束,这些项目旨在帮助你应用你所学的知识并扩展你的项目组合。
Dataquest 的高级订阅费用为 399 美元/年(每月选项可用),这使您可以访问所有课程和教训。大多数学习者在不到一年的非全日制学习中达到他们的目标。
Python 研究所
Python 学院提供一些最知名的 Python 认证,包括四个初级证书等级考试:
- 认证入门级 Python 程序员(PCEP):59 美元(仅考试用)
- Python 编程认证助理(PCAP):295 美元(仅考试)
- Python 编程认证专家 1(PCPP-32-1):195 美元(仅考试用)
- Python 编程 2 认证专家(PCPP-32-2):195 美元(仅考试用)
这些认证是累进的,意味着你在获得 PCAP 之前获得 PCEP(等等)。在许多情况下,下一次认证考试需要之前的证书。
正如你所料,每门考试所涉及的内容越来越复杂。PCEP 考试涵盖了 Python 运算符、布尔值等基本主题..在序列的最后,PCPP-32-2 测试需要复杂的技能,如将 Python 与 SQL 数据库集成。
如果你通过了所有四个认证测试级别,你也可以称自己为 Python 编程(CEPP)的 Python 研究所认证专家。
这些认证只是考试。Python Institute 确实提供了一些免费的学习资源,但是你可以以任何你喜欢的方式学习这些材料,然后在你觉得准备好的时候报名参加考试。
在这方面,Python 研究所只提供认证——它不提供学习 Python 的课程。
微软
微软提供名为“使用 Python 编程入门”的入门级 Python 认证考试
这项考试的费用是 127 美元,和 Python 学院的认证一样,它不包括任何实际的课程。这只是一次考试。根据微软的说法,有兴趣参加考试的学习者应该至少有 100 小时的 Python 经验,并且应该能够自如地编写、调试和维护“格式良好、文档完备的 Python 代码”。
结论:项目组合> Python 项目
一些 Python 认证项目有其优点。但是不要把它们当成找工作的关键。相反,花时间学习现实世界的技能。然后,用一系列能给未来雇主留下深刻印象的项目展示你的技能。立即开始使用 Dataquest。
数据科学的 Python 备忘单:基础
July 20, 2017
第一次学习 Python 数据科学时,很难记住所有需要的语法,这是很常见的。虽然在 Dataquest,我们提倡习惯于查阅 Python 文档,但有时有一份方便的参考资料是很好的,所以我们整理了这份备忘单来帮助你!
这个备忘单是我们的 Python 中级数据科学备忘单的伴侣
如果你想学习 Python ,我们有一个 Python 编程:初学者课程,可以开始你的数据科学之旅。
关键基础知识,打印和获取帮助
x = 3 |给变量x
print(x)赋值 3】 |打印 x
type(x)的值|返回变量的类型x(在本例中,int为整数)
help(x) |显示数据类型
help(print)的文档|显示print()函数的文档
读取文件
f = open("my_file.txt", "r")
file_as_string = f.read()
打开文件my_file.txt并将其内容分配给string
import csv
f = open("my_dataset.csv", "r")
csvreader = csv.reader(f)
csv_as_list = list(csvreader)
打开 CSV 文件my_dataset.csv并将其数据分配给列表列表csv_as_list
用线串
s = "hello" |将字符串"hello"赋给变量s
s = """
She said,"there's a good idea.
""""
将多行字符串赋给变量s。也用于创建同时包含“和”字符的字符串。
len(s) |返回s
s.startswith("hel")中的字符个数|测试s是否以子串"hel"
s.endswith("lo")开头|测试s是否以子串"lo"
"{} plus {} is {}".format(3,1,4)结尾|返回值为3,1, 和4插入
s.replace("e","z") |返回一个基于s的新字符串,所有出现的"e"替换为"z"
s.strip() |返回一个基于s的新字符串,去掉字符串开头和结尾的任何空格
s.split(" ") |将字符串 s 拆分成一个字符串列表,在字符" "上进行分隔并返回该列表
数字类型和数学运算
i = int("5") |将字符串"5"转换为整数5并将结果赋给i
f = float("2.5") |将字符串"2.5"转换为浮点值2.5并将结果赋给f
5 + 5 |加法
5 - 5 |减法
10 / 2 |除法
5 * 2 |乘法
3 ** 2 |将3提升为2(或(3^{2})
27 ** (1/3)|第3根
列表
l = [100, 21, 88, 3] |分配一个包含整数100、21、88的列表, 并将3与变量l
l = list() |创建一个空列表并将结果赋给l
l[0] |返回列表中的第一个值l
l[-1] |返回列表中的最后一个值l
l[1:3] |返回包含l
len(l)的第二个和第三个值的切片(列表)】|返回l
sum(l)中元素的个数|返回l
的值之和 从l
max(l)返回最小值|从l
l.append(16)返回最大值|将值16追加到l
l.sort()的末尾|对l中的项目进行升序排序
" ".join(["A", "B", "C", "D"]) |将列表["A", "B", "C", "D"]转换为字符串"A B C D"
字典
d = {"CA": "Canada", "GB": "Great Britain", "IN": "India"} |创建一个带有"CA"、"GB"和"IN"关键字以及"Canada"、"Great Britain"和"India"
d["GB"]对应值的字典|从带有"GB"
d.get("AU","Sorry")关键字的字典d中返回值|从带有"AU"关键字的字典d中返回值, 如果在d
d.keys()中找不到关键字"AU"则返回字符串"Sorry"|从d
d.values()返回关键字列表|从d
d.items()返回值列表|从d返回(key, value)对列表
模块和功能
通过缩进定义函数体
import random |导入模块random
from random import random |从模块random导入函数random
def calculate(addition_one,addition_two,exponent=1,factor=1):
result = (value_one + value_two) ** exponent * factor
return result
用两个必需的和两个可选的命名参数定义一个新函数calculate,它计算并返回一个结果。
addition(3,5,factor=10) |用值3和5以及指定参数10运行加法函数
布尔比较
x == 5 |测试x是否等于5
x != 5 |测试x是否等于5
x > 5 |测试x是否大于5
x < 5 |测试x是否小于5
x >= 5 |测试x是否大于等于5
x <= 5 |测试x是否小于等于5
x == 5 or name == "alfred" | 测试x是否等于5或name是否等于"alfred"
x == 5 and name == "alfred" |测试x是否等于5``name是否等于"alfred"
5 in l |检查列表l
"GB" in d中是否有5的值|检查d的键中是否有"GB"的值
语句和循环
if 语句和循环体通过缩进定义
if x > 5:
print("{} is greater than five".format(x))
elif x < 0:
print("{} is negative".format(x))
else:
print("{} is between zero and five".format(x))
测试变量x的值,并根据该值运行代码体
for value in l:
print(value)
迭代l中的每个值,在每次迭代中运行循环体中的代码。
while x < 10:
x += 1
运行循环体中的代码,直到x的值不再小于10
准备好继续学习了吗?
永远不要想接下来我该学什么?又来了!
在我们的 Python for Data Science 路径中,您将了解到:
- 使用 matplotlib 和 pandas 进行数据清理、分析和可视化
- 假设检验、概率和统计
- 机器学习、深度学习和决策树
- ...还有更多!
立即开始学习我们的 60+免费任务:
如何在 Python 中复制列表(5 种技巧,包括示例)
September 14, 2022
列表是 Python 中常用的数据结构。我们经常会遇到需要复制列表的情况,您可能会问自己,“我如何用 Python 复制列表呢?”或者“哪种复制方法最符合我的要求?”
本教程将教你如何使用几种不同的技术来复制或克隆列表:
- 赋值运算符
- 切片语法
- list.copy()方法
- 函数的作用是
- copy.deepcopy()函数
我们还将详细讨论它们的用法和技术方面。
使用赋值运算符复制列表
假设您使用赋值操作符(=)通过将一个现有的列表变量赋给一个新的列表变量来复制一个列表。在这种情况下,您实际上并没有创建列表的副本;您只是创建了一个别名,它指向内存中原始列表对象所在的完全相同的位置。让我们展开细节,仔细看看。
假设我们有列表变量org_list,定义如下:
org_list = [1, 2, ['a', 'b', 'c'], 3]
然后,我们将它赋给一个新变量cpy_list,希望能复制一份供将来使用:
cpy_list = org_list
然而,您需要知道变量cpy_list不是原始列表的真实副本。你可能会问,“为什么它不是原始列表的真实副本?”这是一个很好的问题,因为正如您将在下面看到的,打印这两个变量将返回完全相同的值。
print('Original List:', org_list)
print('Copied List:', cpy_list)
Original List: [1, 2, ['a', 'b', 'c'], 3]
Copied List: [1, 2, ['a', 'b', 'c'], 3]
正如所料,这些列表包含相同的值。但是,让我们看看修改原始列表会发生什么。
org_list.append('Dataquest')
print('Original List:', org_list)
print('Copied List:', cpy_list)
Original List: [1, 2, ['a', 'b', 'c'], 3, 'Dataquest']
Copied List: [1, 2, ['a', 'b', 'c'], 3, 'Dataquest']
对原始列表的任何修改也会改变复制的列表。
下图显示了执行源代码后会发生什么。

事实上,当你将一个变量赋给另一个变量时,这两个变量引用的是内存中的同一个对象,而不是两个独立的对象。这意味着两个变量通过引用指向同一个对象。当一个以上的变量引用同一个对象时,它被称为共享引用或对象。
通过指向共享可变对象的一个变量对该对象的任何修改都会影响引用同一对象的另一个变量。
所以,使用赋值操作符并不能真正复制一个列表;它只是在内存中为同一个对象创建一个别名。
但是如果我们想制作一个列表的独立副本呢?在下一节中,我们将学习如何制作一个列表的浅层副本。
浅层复制技术
我们刚刚了解到,赋值总是存储对对象的引用,并不实际复制这些对象。然而,重要的是要知道改变一个可变的对象会影响代码中使用相同引用的其他对象。因此,如果我们想要的不仅仅是对象引用的副本,我们需要让 Python 明确知道要复制对象。一般来说,有两种方法可以制作一个独立的列表副本:浅层副本和深层副本。本节将讨论浅层拷贝以及实现它的不同方式。
简单地说,创建一个复合列表的浅层副本会创建一个新的复合列表,并使用对原始列表所使用的对象的引用。
注:复合对象是包含其他对象的对象,如列表或字典。
使用列表切片的浅层复制
为了理解浅层拷贝的概念,让我们从一个例子开始。假设我们有一个复合列表,如下所示:
org_list = [1, 2, ['a', 'b', 'c'], 3]
然后,我们可以使用列表切片语法创建它的浅层副本:
cpy_list = org_list[:]
如果我们运行下面的打印语句,我们可以看到,两者返回完全相同的值。
print('Original List:', org_list)
print('Copied List:', cpy_list)
Original List: [1, 2, ['a', 'b', 'c'], 3]
Copied List: [1, 2, ['a', 'b', 'c'], 3]
现在,让我们向原始列表添加一个新项目,并再次运行 print 语句:
org_list.append('Dataquest')
print('Original List:', org_list)
print('Copied List:', cpy_list)
Original List: [1, 2, ['a', 'b', 'c'], 3, 'Dataquest']
Copied List: [1, 2, ['a', 'b', 'c'], 3]
修改不会影响复制的列表。但是,这并不是故事的全部。让我们尝试另一个场景,更改嵌套列表中的一项,看看会发生什么:
org_list[2][0] = 'X'
print('Original List:', org_list)
print('Copied List:', cpy_list)
Original List: [1, 2, ['X', 'b', 'c'], 3, 'Dataquest']
Copied List: [1, 2, ['X', 'b', 'c'], 3]
虽然对列表进行浅层复制会产生原始列表的真实副本,但是对列表中嵌套元素的任何修改都会反映在两个列表中。原因是复制列表中的嵌套列表使用了与原始列表中相同的共享引用。换句话说,复制列表中的嵌套列表被绑定到原始列表中的嵌套列表。这就是为什么我们称之为浅拷贝——因为只有一个新的顶级对象被创建,而任何更深的对象使用与原始列表的共享引用。
现在,让我们看看其他一些制作列表浅层副本的方法。
Python list.copy()方法
前面,我们讨论了通过切片语法创建浅层副本。在这一节中,我们将了解 Python 程序员通常用来复制列表的内置方法。Python copy()方法返回列表的浅层副本,不带任何参数。让我们试一试:
org_list = [1, 2, ['a', 'b', 'c'], 3]
cpy_list = org_list.copy()
print('Original List: ', org_list, ' @', id(org_list))
print('Copied List: ', cpy_list, ' @', id(cpy_list))
Original List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024657920
Copied List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024657600
尽管org_list和cpy_list有相同的值,正如id()函数的输出所示,它们在内存中的不同位置结束。然而,在原始列表和复制列表中公开内部列表的内存地址会发现它们指向内存中的同一个位置,这意味着我们对原始列表进行了浅层复制。
org_list[2][0] = 'X'
print('Inner List in Original: ', org_list[2],' @', id(org_list[2]))
print('Inner List in Shallow Copied: ', cpy_list[2], ' @', id(cpy_list[2]))
Inner List in Original: ['X', 'b', 'c'] @ 140532024655936
Inner List in Shallow Copied: ['X', 'b', 'c'] @ 140532024655936
Python copy.copy()函数
另一个制作列表浅层副本的有用方法是copy.copy()函数。为了使用它,我们导入copy模块,然后将我们想要复制的列表传递给copy.copy()函数。让我们试一试:
import copy
org_list = [1, 2, ['a' ,'b' ,'c'], 3]
cpy_list = copy.copy(org_list)
print('Original List: ', org_list, ' @', id(org_list))
print('Copied List: ', cpy_list, ' @', id(cpy_list))
Original List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024760320
Copied List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024402048
现在,让我们向原始列表追加一个新项,再次打印两个列表,并检查输出;然而,我们可以在运行下面的代码之前预测输出。
org_list.append('Dataquest')
print('Original List: ', org_list, ' @', id(org_list))
print('Copied List: ', cpy_list, ' @', id(cpy_list))
Original List: [1, 2, ['a', 'b', 'c'], 3, 'Dataquest'] @ 140532024760320
Copied List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024402048
copy.copy()方法制作了原始列表的真实副本。然而,它仍然是一个浅层拷贝,嵌套列表指向完全相同的内存位置。换句话说,copy.copy()函数只制作顶层副本,不复制嵌套对象。因此,原始列表或复制列表的嵌套对象中的任何修改都会反映在另一个列表的嵌套对象中。
org_list[2][0] = 'X'
print('Inner List in Original: ', org_list[2], ' @', id(org_list[2]))
print('Inner List in Shallow Copied: ', cpy_list[2], ' @', id(cpy_list[2]))
Inner List in Original: ['X', 'b', 'c'] @ 140532024760128
Inner List in Shallow Copied: ['X', 'b', 'c'] @ 140532024760128
如果我们想要一个深度嵌套列表的完全独立的副本呢?在下一节中,我们将讨论如何在 Python 中执行深度复制。
Python copy.deepcopy()函数
copy.deepcopy()函数递归地遍历一个列表来复制它的每个嵌套对象。换句话说,它创建一个列表的顶层副本,然后递归地将原始列表中嵌套对象的副本添加到新副本中。这将从原始列表中产生一个完全独立的副本,对其中任何一个嵌套对象所做的任何更改都不会反映在另一个列表中。
和copy.copy()函数一样,copy.deepcopy()函数也属于copy模块。让我们试一试:
import copy
org_list = [1, 2, ['a', 'b', 'c'], 3]
cpy_list = copy.deepcopy(org_list)
print('Original List: ', org_list, ' @', id(org_list))
print('Copied List: ', cpy_list, ' @', id(cpy_list))
Original List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024761408
Copied List: [1, 2, ['a', 'b', 'c'], 3] @ 140532024405760
上面代码的输出清楚的显示了copy.deepcopy()对原列表做了真实的复制,即使我们修改了原列表的内部列表,也不会在深度复制的列表中体现出来。
org_list[2][0] = 'X'
print('Inner List in Original: ', org_list[2], ' @', id(org_list[2]))
print('Inner List in Deep Copied: ', cpy_list[2], ' @', id(cpy_list[2]))
Inner List in Original: ['X', 'b', 'c'] @ 140532024404736
Inner List in Deep Copied: ['a', 'b', 'c'] @ 140532024405248
上面的代码表明,当我们创建一个列表的深层副本时,它也会创建嵌套对象的真实副本。如前所述,递归深度复制产生了原始列表的真正独立的副本,这就是为什么原始列表和复制列表中的内部列表指向两个不同的内存位置。显然,对其中一个内部列表的任何更改都不会反映在另一个中。
结论
本教程讨论了在 Python 中复制列表的几种不同方式,比如赋值操作符、列表切片语法、list.copy()、copy.copy()和copy.deepcopy函数。此外,我们讨论了浅拷贝和深拷贝。我希望这篇教程能帮助你更好地理解 Python 中复制列表的不同方式,因为它们对成为 Python 爱好者至关重要。
教程:Python 的计数器类和概率质量函数
April 6, 2015
Python 计数器类
Python 中的 Counter 类是集合模块的一部分。计数器提供了一种快速计算列表中存在的唯一项的数量的方法。Counter 类也可以扩展为表示概率质量函数和贝叶斯假设集。计数器是从值到它们的频率的映射。如果你用一个字符串初始化一个计数器,你会得到一个从每个字母到它出现次数的映射。如果两个单词是字谜,它们会产生相等的计数器,因此您可以使用计数器在线性时间内测试字谜。这一课是根据艾伦·唐尼的小笔记本改编的。
from collections import Counter
def is_anagram(word1, word2):
"""
Checks whether the words are anagrams.
word1: string
word2: string
returns: boolean
"""
return Counter(word1) == Counter(word2)
print(is_anagram('tachymetric', 'mccarthyite'))
print(is_anagram('banana', 'peach'))
True
False
多重集
计数器是多重集的自然表示,多重集是指元素可以出现多次的集合。您可以使用 is_subset 之类的集合操作来扩展 Counter:您可以在 Scrabble 之类的游戏中使用is_subset,看看给定的一组瓷砖是否可以用来拼写给定的单词。
class Multiset(Counter):
"""A multiset is a set where elements can appear more than once."""
def is_subset(self, other):
"""Checks whether self is a subset of other.
other: Multiset
returns: boolean
"""
for char, count in self.items():
if other[char] < count:
return False
return True
# map the <= operator to is_subset
__le__ = is_subset
def can_spell(word, tiles):
"""Checks whether a set of tiles can spell a word.
word: string
tiles: string
returns: boolean
"""
return Multiset(word) <= Multiset(tiles)
print(can_spell('SYZYGY', 'AGSYYYZ'))
True
概率质量函数
你也可以扩展计数器来表示一个概率质量函数(PMF)。normalize计算频率的总和并除以,产生加到 1 的概率。__add__枚举所有值对,并返回一个新的 Pmf,它表示总和的分布。__hash__和__id__使 PMF 可散列;这不是最好的方法,因为它们是可变的。所以这个实现带有一个警告,如果您使用 Pmf 作为键,您不应该修改它。一个更好的选择是定义一个冻结的 Pmf。render以可用于绘图的形式返回数值和概率:
class Pmf(Counter):
"""A Counter with probabilities."""
def normalize(self):
"""Normalizes the PMF so the probabilities add to 1."""
total = float(sum(self.values()))
for key in self:
self[key] /= total
def __add__(self, other):
"""Adds two distributions.
The result is the distribution of sums of values from the
two distributions.
other: Pmf
returns: new Pmf
"""
pmf = Pmf()
for key1, prob1 in self.items():
for key2, prob2 in other.items():
pmf[key1 + key2] += prob1 * prob2
return pmf
def __hash__(self):
"""Returns an integer hash value."""
return id(self)
def __eq__(self, other):
return self is other
def render(self):
"""Returns values and their probabilities, suitable for plotting."""
return zip(*sorted(self.items()))
使用 Pmf 对象
例如,我们可以制作一个 Pmf 对象来表示一个 6 面骰子。
d6 = Pmf([1,2,3,4,5,6])
d6.normalize()
d6.name = 'one die'
print(d6)
Pmf({1: 0.16666666666666666, 2: 0.16666666666666666, 3: 0.16666666666666666, 4: 0.16666666666666666, 5: 0.16666666666666666, 6: 0.16666666666666666})
添加运算符
使用加法运算符,我们可以计算两个骰子之和的分布。
d6_twice = d6 + d6
d6_twice.name = 'two dice'
for key, prob in d6_twice.items():
print(key, prob)
2 0.027777777777777776
3 0.05555555555555555
4 0.08333333333333333
5 0.1111111111111111
6 0.1388888888888889
7 0.16666666666666669
8 0.1388888888888889
9 0.1111111111111111
10 0.08333333333333333
11 0.05555555555555555
12 0.027777777777777776
计算分布
使用 numpy.sum,我们可以计算三个骰子总和的分布。然后绘制结果(使用 Pmf.render)
pmf_ident = Pmf([0])
d6_thrice = sum([d6]*3, pmf_ident)
d6_thrice.name = 'three dice'
for die in [d6, d6_twice, d6_thrice]:
xs, ys = die.render()
plt.plot(xs, ys, label=die.name, linewidth=3, alpha=0.5)
plt.xlabel('Total')
plt.ylabel('Probability')
plt.legend()
plt.show()
贝叶斯统计
一个套件是一个 Pmf,它表示一组假设及其概率;它提供了bayesian_update,根据新数据更新假设的概率。Suite 是抽象的父类;子类应该提供一个可能性方法,在给定的假设下评估数据的可能性。bayesian_update遍历假设,评估每个假设下数据的可能性,并相应地更新概率。然后 PMF 恢复正常。
class Suite(Pmf):
"""Map from hypothesis to probability."""
def bayesian_update(self, data):
"""Performs a Bayesian update.
Note: called bayesian_update to avoid overriding dict.update
data: result of a die roll
"""
for hypo in self:
like = self.likelihood(data, hypo)
self[hypo] *= like
self.normalize()
套件示例
作为一个例子,我将使用 Suite 来解决“骰子问题”,来自第三章的 Think Bayes :
“假设我有一盒骰子,其中包含 4 面骰子、6 面骰子、8 面骰子、12 面骰子和 20 面骰子。如果你玩过龙与地下城,你知道我在说什么。假设我从盒子里随机选择一个骰子,掷骰子,得到一个 6。我掷出每个骰子的概率是多少?”
首先,我将列出代表骰子的 PMF 列表:
def make_die(num_sides):
die = Pmf(range(1, num_sides+1))
die.name = 'd%d' % num_sides
die.normalize()
return die
dice = [make_die(x) for x in [4, 6, 8, 12, 20]]
print(dice)
说〔t0〕
接下来我将定义 DiceSuite,它从 Suite 继承了bayesian_update,并提供了likelihood。data是观察到的掷骰子,例子中为 6。hypo是我可能掷出的假设骰子;为了得到数据的可能性,我从给定的骰子中选择给定值的概率。
class DiceSuite(Suite):
def likelihood(self, data, hypo):
"""Computes the likelihood of the data under the hypothesis.
data: result of a die roll
hypo: Die object
"""
return hypo[data]
更新分布
最后,我使用骰子列表来实例化一个套件,该套件从每个骰子映射到其先验概率。默认情况下,所有骰子都有相同的先验。然后我用给定的值更新分布并打印结果:
dice_suite = DiceSuite(dice)
dice_suite.bayesian_update(6)
for die, prob in dice_suite.items():
print(die.name)
print(prob)
又一更新
正如所料,4 面模具已被淘汰;它现在的概率是 0。6 面模具是最有可能的,但是 8 面模具还是很有可能的。现在假设我再次掷骰子,得到一个 8。我们可以用新数据再次更新套件。现在 6 面骰子已经被淘汰了,8 面骰子是最有可能的,我掷出 20 面骰子的几率不到 10%。这些例子展示了 Counter 类的多功能性,Counter 类是 Python 中未被充分利用的数据结构之一。
dice_suite.bayesian_update(8)
for die, prob in dice_suite.items():
print(die.name)
print(prob)
接下来的步骤
关于 Python 的计数器类的更多信息,你可以查看我们的互动教程
。
用于数据科学的 Python:入门
January 11, 2016Python is becoming an increasingly popular language for data science, and with good reason. It’s easy to learn, has powerful data science libraries, and integrates well with databases and tools like Hadoop and Spark. With Python, we can perform the full lifecycle of data science projects, including reading data in, analyzing data, visualizing data, and making predictions with machine learning. In this post, we’ll walk through getting started with Python for data science. If you want to dive more deeply into the topics we cover, visit Dataquest, where we teach every component of the Python data science lifecycle in depth. We’ll be working with a dataset of political contributions to candidates in the 2016 US presidential elections, which can be found here. The file is in csv format, and each row in the dataset represents a single donation to the campaign of a single candidate. The dataset has several interesting columns, including:
cand_nm—接受捐赠的候选人姓名。contbr_nm—投稿人姓名。contbr_state—说明贡献者的居住地。contbr_employer—投稿人工作的地方。contbr_occupation—投稿人的职业。contb_receipt_amount—贡献的大小,以美元为单位。contb_receipt_dt—收到捐款的日期。
安装 Python
分析这些数据的第一步是安装
Python 。使用 Anaconda 安装 Python 是一个简单的过程,Anaconda 是一个安装 Python 和几个流行的数据分析库的工具。你可以在这里下载蟒蛇。建议安装 Python 3.5 ,这是 Python 的最新版本。你可以在这里阅读更多关于 Python 2 vs Python 3 的内容。Anaconda 自动安装了我们将在本文中使用的几个库,包括 Jupyter 、 Pandas 、 scikit-learn 和 matplotlib 。
Jupyter 入门
现在我们已经安装了所有的东西,我们可以推出 Jupyter notebook(以前称为 IPython notebook)。Jupyter notebook 是一个强大的数据分析工具,使您能够快速浏览数据,可视化您的发现,并分享您的结果。它被 Google、IBM 和 Microsoft 等组织的数据科学家用来分析数据和进行协作。通过运行启动 Jupyter
ipython notebook在终端。如果你有困难,检查这里的。 您应该会看到一个允许您创建新笔记本的文件浏览器界面。创建一个 Python 3 笔记本,我们将在我们的分析中使用它。如果你需要更多的安装帮助,请点击这里查看我们的指南。
您应该会看到一个允许您创建新笔记本的文件浏览器界面。创建一个 Python 3 笔记本,我们将在我们的分析中使用它。如果你需要更多的安装帮助,请点击这里查看我们的指南。
笔记本电池
每个木星笔记本由多个
单元格,可以在其中运行代码或编写解释。您的笔记本最初只有一个单元,但是您可以添加更多:
# This is a code cell.
Any output we generate here will show up below.
print(10)
b = 10
# You can have multiple cells, and re-run each cell as many times as you want to refine your analysis.
# The power of Jupyter notebook is that the results of each cell you run are cached.
# So you can run code in cells that depends on other cells.
print(b * 10)
如果你想了解更多关于 Jupyter 的知识,请查看我们的深入教程
此处。
熊猫入门
Pandas 是 Python 的数据分析库。它使我们能够读入各种格式的数据,包括 csv,然后高效地分析这些数据。我们可以使用以下代码读入数据:
import pandas as pd
donations = pd.read_csv("political_donations.csv")
donations.shape
(384885, 18)
donations.head(2)
| cmte_id | 坎德 _id | cand_nm | contbr_nm | 控制城市 | 对比 | contbr_zip | contbr _ 雇主 | contbr _ 职业 | contb_receipt_amt | contb_receipt_dt | 收据 _desc | 备忘录 _ 光盘 | 备忘录 _ 文本 | 格式 | file_num | 交易标识 | 选举 _tp | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C00458844 | P60006723 | 红宝石马可 | 库马尔·基布尔 | DPO | 自动曝光装置 | 092131903 | 美国国土安全部 | 法律的实施 | Five hundred | 2015 年 8 月 27 日 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | SA17A | One million twenty-nine thousand four hundred and fifty-seven | SA17.813360 | P2016 | 圆盘烤饼 |
| C00458844 | P60006723 | 红宝石马可 | 迈克尔·赫弗南 | 陆军军邮局(Army Post Office) | 自动曝光装置 | 090960009 | 尽最大努力请求的信息 | 尽最大努力请求的信息 | Two hundred and ten | 2015 年 6 月 27 日 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | SA17A | One million twenty-nine thousand four hundred and thirty-six | SA17.796904 | P2016 | 圆盘烤饼 |
在上面的单元格中,我们使用
import pandas as pd,然后使用 read_csv() 方法将political_donations.csv读入donations变量。donations变量是一个 Pandas DataFrame ,它是一个矩阵的增强版本,具有内置的数据分析方法,并允许每列中有不同的数据类型。我们访问donations变量的shape属性来打印出它有多少行和多少列。当一个语句或变量放在笔记本单元格的最后一行时,它的值或输出会自动呈现!然后我们在数据帧上使用 head() 方法打印出前两行donations,这样我们就可以检查它们了。如果你想更深入地了解熊猫,请看我们的课程这里。
候选人捐款总额
我们可以使用熊猫来计算每个候选人的汇总统计数据
groupby() 法。我们可以首先使用 groupby 方法根据cand_nm将donations分割成子集。然后,我们可以分别计算每个候选人的统计数据。我们计算的第一个汇总统计数据是捐款总额。为了得到这个,我们只需要对每个候选人的contb_receipt_amount列求和。
donations.groupby("cand_nm").sum().sort("contb_receipt_amt")
| contb_receipt_amt | file_num | |
|---|---|---|
| cand_nm | ||
| --- | --- | --- |
| 乔治·帕塔基 | Three hundred and sixty-five thousand and ninety point nine eight | Two hundred and thirty-four million six hundred and ninety-five thousand four hundred and thirty |
| 小詹姆斯·亨利·韦伯 | Three hundred and ninety-eight thousand seven hundred and seventeen point two five | Seven hundred and nine million four hundred and nineteen thousand eight hundred and ninety-three |
| 劳伦斯·莱西格 | Six hundred and twenty-one thousand four hundred and ninety-four point five | One billion three hundred and seventy-eight million four hundred and eighty-eight thousand four hundred and forty-nine |
| 理查德·桑托勒姆 | Seven hundred and eighty-one thousand four hundred and one point zero three | Eight hundred and twenty-two million eighty-six thousand six hundred and thirty-eight |
| 唐纳德·特朗普 | One million nine thousand seven hundred and thirty point nine seven | Two billion three hundred and fifty-seven million three hundred and forty-seven thousand five hundred and seventy |
| 鲍比·金达尔 | One million thirteen thousand nine hundred and eighteen point one two | Five hundred and eighty-four million eight hundred and ninety-six thousand seven hundred and seventy-six |
| 詹姆斯·佩里(里克) | One million one hundred and twenty thousand three hundred and sixty-two point five nine | Nine hundred and twenty-five million seven hundred and thirty-two thousand one hundred and twenty-five |
| 迈克·哈克比 | One million eight hundred and ninety-five thousand five hundred and forty-nine point one five | Two billion seven hundred million eight hundred and ten thousand two hundred and fifty-five |
| 马丁·约瑟夫·欧玛利 | Two million nine hundred and twenty-one thousand nine hundred and ninety-one point six five | Two billion six hundred and sixty-four million one hundred and forty-eight thousand eight hundred and fifty |
| 林赛·格雷厄姆。 | Two million nine hundred and thirty-two thousand four hundred and two point six three | Three billion one hundred and thirty-one million one hundred and eighty thousand five hundred and thirty-three |
| 约翰·卡西奇 | Three million seven hundred and thirty-four thousand two hundred and forty-two point one two | Two billion six hundred and sixty-nine million nine hundred and forty-four thousand six hundred and eighty-two |
| 克里斯托弗·克里斯蒂 | Three million nine hundred and seventy-six thousand three hundred and twenty-nine point one three | Two billion four hundred and twenty-one million four hundred and seventy-three thousand three hundred and seventy-six |
| 保罗·兰德 | Four million three hundred and seventy-six thousand eight hundred and twenty-eight point one four | Sixteen billion fifty-six million six hundred and four thousand five hundred and seventy-seven |
| 卡莉·菲奥莉娜 | Four million five hundred and five thousand seven hundred and seven point zero six | Twelve billion five hundred and ninety-nine million six hundred and thirty-seven thousand seven hundred and seventy-seven |
| 斯科特·沃克 | Four million six hundred and fifty-four thousand eight hundred and ten point three | Five billion six hundred and thirty-six million seven hundred and forty-six thousand nine hundred and sixty-two |
| 伯纳德·桑德斯 | Nine million eighteen thousand five hundred and twenty-six | Seventy-one billion one hundred and thirty-nine million eight hundred and sixty-four thousand seven hundred and fourteen |
| 红宝石马可 | Ten million seven hundred and forty-six thousand two hundred and eighty-three point two four | Twenty-two billion seven hundred and thirty million one hundred and thirty-nine thousand five hundred and fifty-five |
| 本杰明·卡森 | Eleven million seven hundred and forty-six thousand three hundred and fifty-nine point seven four | Seventy-five billion six hundred and thirteen million six hundred and twenty-four thousand three hundred and sixty |
| 拉斐尔·爱德华·特德·克鲁兹 | Seventeen million eight thousand six hundred and twenty-two point one seven | Sixty-nine billion three hundred and seventy-five million six hundred and sixteen thousand five hundred and ninety-one |
| 布什,杰布 | Twenty-three million two hundred and forty-three thousand four hundred and seventy-two point eight five | Fourteen billion nine hundred and forty-six million ninety-seven thousand six hundred and seventy-three |
| 希拉里·罗德汉姆·克林顿 | Sixty-one million seven hundred and twenty-six thousand three hundred and seventy-four point zero nine | Eighty-six billion five hundred and sixty million two hundred and two thousand two hundred and ninety |
在上面的代码中,我们首先拆分
使用代码donations.groupby("cand_nm")根据cand_nm将donations分组。这将返回一个 GroupBy 对象,它有一些聚合数据的特殊方法。其中一个方法是sum(),我们用它来计算每组中每列的总和。当数据被读入时,Pandas 自动识别列的数据类型,并且只对数字列执行 sum 操作。我们最终得到一个数据帧,显示每个候选人的contb_receipt_amt和file_num列的总和。在最后一步中,我们对数据帧使用 sort() 方法,以升序对contb_receipt_amt进行排序。这向我们展示了每个候选人收集了多少捐款。
可视化捐赠总额
我们可以使用
matplotlib ,主要的 Python 数据可视化库,进行绘图。Jupyter notebook 甚至支持内联渲染 matplotlib 图。为此,我们需要激活 matplotlib 的内联模式。我们可以使用 Jupyter magics 让 matplotlib 数字显示在笔记本上。魔术是以%或%%开头的命令,影响 Jupyter notebook 的行为。它们是用来改变 Jupyter 配置的一种方式,不会将命令与 Python 代码混淆。为了使 matplotlib 的数字能够内联显示,我们需要在单元格中运行%matplotlib inline。点击阅读更多关于 Jupyter 绘图的信息。这里我们导入matplotlib库并激活内联模式:
import matplotlib.pyplot as plt
Pandas 数据框架有内置的可视化支持,您可以调用
plot() 方法从数据帧生成matplotlib图。这通常比直接使用matplotlib要快得多。首先,我们将前面的数据帧赋给一个变量total_donations。然后,我们使用索引来选择数据帧的单个列contb_receipt_amt。这就产生了熊猫系列。Pandas 系列的大多数方法与 DataFrames 相同,但它们存储一维数据,就像单行或单列一样。然后,我们可以调用序列上的 plot() 方法来生成每个候选人捐款总额的条形图。
total_donations = donations.groupby("cand_nm").sum().sort("contb_receipt_amt")
total_donations["contb_receipt_amt"].plot(kind="bar")
<matplotlib.axes._subplots.AxesSubplot at 0x108892208>

如果您想深入了解 matplotlib,请查看我们的课程
此处。
寻找平均捐赠规模
找到平均捐款额而不是总捐款额非常简单。我们只是交换了
sum()法为手段()法。
avg_donations = donations.groupby("cand_nm").mean().sort("contb_receipt_amt")
avg_donations["contb_receipt_amt"].plot(kind="bar")
<matplotlib.axes._subplots.AxesSubplot at 0x108d82c50>

预测捐赠规模
我们来做一个简单的算法,可以根据某人的状态计算出他会捐多少钱(
contbr_st)、职业(contbr_occupation)和首选候选人(cand_nm)。第一步是用这些列和我们想要预测的contb_receipt_amt列制作一个单独的数据框架。
pdonations = donations[["contbr_st", "contbr_occupation", "cand_nm", "contb_receipt_amt"]]
现在我们将检查
pdonations。当 Pandas 读入一个 csv 文件时,它会自动为每一列分配一个数据类型。我们只能使用数据类型为数字的列进行预测。
pdonations.dtypes
contbr_st object
contbr_occupation object
cand_nm object
contb_receipt_amt float64
dtype: object
不幸的是,我们想要用来预测的所有列都是
对象数据类型(字符串)。这是因为它们是分类数据。每列都有几个选项,但它们显示为文本,而不是使用数字代码。我们可以将每一列转换成数字数据,方法是先转换成分类数据类型,然后再转换成数字。下面是关于分类数据类型的更多内容。本质上,分类数据类型在后台为列中的每个唯一值分配一个数字代码。我们可以用这些代码替换列,完全转换成数字。
pdonations["contbr_st"] = pdonations["contbr_st"].astype('category')
pdonations["contbr_st"] = pdonations["contbr_st"].cat.codes
pdonations["contbr_st"]
0 1
1 1
2 1
3 2
4 2
5 2
6 2
7 2
8 2
9 2
10 2
11 2
12 2
13 2
14 2
...
384870 75
384871 75
384872 75
384873 75
384874 75
384875 75
384876 75
384877 75
384878 75
384879 75
384880 75
384881 75
384882 75
384883 77
384884 77
Name: contbr_st, Length: 384885, dtype: int8
如您所见,我们已经将
contbr_st列为数值。我们需要对contbr_occupation和cand_nm列重复相同的过程。
for column in ["contbr_st", "contbr_occupation", "cand_nm"]:
pdonations `= pdonations``.astype('category')
pdonations` `= pdonations``.cat.codes`
## 分成训练集和测试集
我们现在可以开始利用
[scikit-learn](https://scikit-learn.org/) ,主要的 Python 机器学习库,帮助我们完成剩余的预测工作流程。首先,我们将数据分成两组,一组用于训练我们的算法,称为训练集,另一组用于评估模型的性能,称为测试集。我们这样做是为了避免[过度拟合](https://en.wikipedia.org/wiki/Overfitting),从而得到一个误导性的误差值。我们可以使用 [train_test_split()](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html) 函数将`pdonations`拆分成一个训练集和一个测试集。
from sklearn.cross_validation import train_test_split
train, test, y_train, y_test = train_test_split(pdonations[["contbr_st", "contbr_occupation", "cand_nm"]], pdonations["contb_receipt_amt"], test_size=0.33, random_state=1)
上面的代码拆分了我们要用来为算法定型的列,以及我们要对其进行预测的列(
`contb_receipt_amt`)训练集和测试集各一套。我们获取测试集的数据的`33%`。这些行被随机分配给集合。
## 拟合模型
我们将使用
[随机森林](https://en.wikipedia.org/wiki/Random_forest)算法做出我们的预测。这是一个精确且通用的算法,由 scikit-learn 通过 [RandomForestRegressor](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html) 类实现。这个类使训练模型变得简单,然后用它进行预测。首先,我们将使用`train`和`y_train`来训练模型:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, min_samples_leaf=10)
model.fit(train, y_train)
RandomForestRegressor(bootstrap=True, compute_importances=None, criterion='mse', max_depth=None, max_features='auto', max_leaf_nodes=None, min_density=None, min_samples_leaf=10, min_samples_split=2, n_estimators=100, n_jobs=1, oob_score=False, random_state=None, verbose=0)
scikit-learn 的一个伟大之处在于,它对它实现的所有算法都有一个一致的 API。您可以像训练随机森林一样训练线性回归。我们现在有一个合适的模型,所以我们可以用它来做预测。
## 进行预测并发现错误
用 scikit-learn 进行预测非常容易。我们只是将测试数据传递给合适的模型。
predictions = model.predict(test)
现在我们有了预测,我们可以计算误差。我们的错误将让我们知道我们的模型执行得有多好,并在我们进行调整时给我们一个评估它的方法。我们将使用
[均方误差](https://en.wikipedia.org/wiki/Mean_squared_error),常见的误差度量。
from sklearn.metrics import mean_squared_error
import math
mean_squared_error(predictions, y_test)
756188.21680533944
如果你想了解更多关于 scikit-learn 的知识,请查看我们的教程
[此处](https://www.dataquest.io/course/python-for-data-science-fundamentals)。
## 接下来的步骤
取你得到的误差的平方根,会得到一个误差值,这个误差值更容易考虑捐赠的大小。如果你不求平方根,你会得到平均平方误差,这对我们的数据没有直接意义。无论哪种方式,误差都很大,你可以做很多事情来降低它。
* 添加更多列中的数据。
* 看看每个候选人的模型是否更准确。
* 试试其他算法。
以下是您可以进行的其他一些有趣的数据探索:
* 标出每个州哪个候选人得到的捐款最多。
* 画出每个候选人最喜欢的职业。
* 将候选人按共和党/民主党进行分类,看看是否有什么有趣的模式出现。
* 根据姓名分配性别,看看按性别划分数据是否能揭示出任何有趣的模式。
* 制作美国各地区捐款总额的热图。
如果您想更深入地了解这里提到的概念,请查看我们在
[用于数据科学的 Python](https://www.dataquest.io)。
教程:比较 Python 中的 7 种数据可视化工具
原文:https://www.dataquest.io/blog/python-data-visualization-libraries/
November 12, 2015The Python scientific stack is fairly mature, and there are libraries for a variety of use cases, including machine learning, and data analysis. Data visualization is an important part of being able to explore data and communicate results, but has lagged a bit behind other tools such as R in the past. Luckily, many new Python data visualization libraries have been created in the past few years to close the gap. matplotlib has emerged as the main data visualization library, but there are also libraries such as vispy, bokeh, seaborn, pygal, folium, and networkx that either build on matplotlib or have functionality that it doesn’t support. In this post, we’ll use a real-world dataset, and use each of these libraries to make visualizations. As we do that, we’ll discover what areas each library is best in, and how to leverage the Python data visualization ecosystem most effectively. At Dataquest, we’ve built interactive courses that teaches you about Python data visualization tools. If you want to learn in more depth, check out our data visualization courses.
探索数据集
在我们开始可视化数据之前,让我们快速浏览一下将要使用的数据集。我们将使用来自
开放航班。我们将使用航线、机场和航空公司的数据。路线数据中的每一行对应于两个机场之间的航线。机场数据中的每一行都对应于世界上的一个机场,并且有关于它的信息。航空公司数据中的每一行代表一家航空公司。我们首先读入数据:
# Import the pandas library.
import pandas
# Read in the airports data.
airports = pandas.read_csv("airports.csv", header=None, dtype=str)
airports.columns = ["id", "name", "city", "country", "code", "icao", "latitude", "longitude", "altitude", "offset", "dst", "timezone"]
# Read in the airlines data.airlines = pandas.read_csv("airlines.csv", header=None, dtype=str)
airlines.columns = ["id", "name", "alias", "iata", "icao", "callsign", "country", "active"]
# Read in the routes data.routes = pandas.read_csv("routes.csv", header=None, dtype=str)
routes.columns = ["airline", "airline_id", "source", "source_id", "dest", "dest_id", "codeshare", "stops", "equipment"]
数据没有列标题,所以我们通过将
columns属性。我们希望将每一列都作为一个字符串读入——这将使以后基于 id 匹配行时跨数据帧的比较更容易。我们通过在读入数据时设置dtype参数来实现这一点。我们可以快速浏览一下每个数据帧:
airports.head()
| 身份证明(identification) | 名字 | 城市 | 国家 | 密码 | 国际民航组织 | 纬度 | 经度 | 海拔 | 抵消 | 夏令时 | 时区 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Goroka | Goroka | 巴布亚新几内亚 | GKA | AYGA | -6.081689 | 145.391881 | Five thousand two hundred and eighty-two | Ten | U | 太平洋/莫尔兹比港 |
| one | Two | 马当 | 马当 | 巴布亚新几内亚 | 杂志 | 月,月 | -5.207083 | 145.788700 | Twenty | Ten | U | 太平洋/莫尔兹比港 |
| Two | three | 芒特哈根 | 芒特哈根 | 巴布亚新几内亚 | HGU | AYMH | -5.826789 | 144.295861 | Five thousand three hundred and eighty-eight | Ten | U | 太平洋/莫尔兹比港 |
| three | four | Nadzab | Nadzab | 巴布亚新几内亚 | 莱城 | AYNZ | -6.569828 | 146.726242 | Two hundred and thirty-nine | Ten | U | 太平洋/莫尔兹比港 |
| four | five | 莫尔斯比港杰克逊国际机场 | 莫尔兹比港 | 巴布亚新几内亚 | 砰的一声 | AYPY | -9.443383 | 147.220050 | One hundred and forty-six | Ten | U | 太平洋/莫尔兹比港 |
airlines.head()
| 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 | |
|---|---|---|---|---|---|---|---|---|
| Zero | one | 私人航班 | \N | – | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Y |
| one | Two | 135 航空公司 | \N | 圆盘烤饼 | GNL | 一般 | 美国 | 普通 |
| Two | three | 1 时代航空公司 | \N | 1T | RNX | 下次 | 南非 | Y |
| three | four | 2 Sqn 第一初级飞行训练学校 | \N | 圆盘烤饼 | WYT | 圆盘烤饼 | 联合王国 | 普通 |
| four | five | 213 飞行单位 | \N | 圆盘烤饼 | TFU | 圆盘烤饼 | 俄罗斯 | 普通 |
routes.head()
| 航空公司 | 航空公司 id | 来源 | 来源标识 | 建筑环境及 HVAC 系统模拟的软件平台 | 目的地标识 | 代码共享 | 停止 | 装备 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | 2B | Four hundred and ten | 年度等价利率 | Two thousand nine hundred and sixty-five | KZN | Two thousand nine hundred and ninety | 圆盘烤饼 | Zero | CR2 |
| one | 2B | Four hundred and ten | ASF | Two thousand nine hundred and sixty-six | KZN | Two thousand nine hundred and ninety | 圆盘烤饼 | Zero | CR2 |
| Two | 2B | Four hundred and ten | ASF | Two thousand nine hundred and sixty-six | MRV | Two thousand nine hundred and sixty-two | 圆盘烤饼 | Zero | CR2 |
| three | 2B | Four hundred and ten | CEK | Two thousand nine hundred and sixty-eight | KZN | Two thousand nine hundred and ninety | 圆盘烤饼 | Zero | CR2 |
| four | 2B | Four hundred and ten | CEK | Two thousand nine hundred and sixty-eight | OVB | Four thousand and seventy-eight | 圆盘烤饼 | Zero | CR2 |
我们可以单独对每个数据集进行各种有趣的探索,但只有将它们结合起来,我们才能看到最大的收获。Pandas 将在我们进行分析时为我们提供帮助,因为它可以轻松地过滤矩阵或对矩阵应用函数。我们将深入研究一些有趣的指标,比如分析航空公司和航线。在这样做之前,我们需要做一些数据清理工作:
routes = routes[routes["airline_id"] != "\\N"]
这一行确保我们在
airline_id列。
制作直方图
既然我们理解了数据的结构,我们就可以继续前进,开始绘制图表来探索它。对于我们的第一个图,我们将使用 matplotlib。matplotlib 是 Python 堆栈中一个相对低级的绘图库,因此与其他库相比,它通常需要更多的命令来制作好看的绘图。另一方面,你可以用 matplotlib 制作几乎任何类型的情节。它非常灵活,但是这种灵活性是以冗长为代价的。我们将首先制作一个直方图,按航空公司显示航线长度的分布。A
直方图将所有路线长度划分为范围(或“箱”),并计算每个范围内有多少条路线。这能告诉我们航空公司是飞更短的航线,还是更长的航线。为了做到这一点,我们需要首先计算路线长度。第一步是距离公式。我们将使用哈弗线距离,它计算纬度,经度对之间的距离。
import math
def haversine(lon1, lat1, lon2, lat2):
# Convert coordinates to floats.
lon1, lat1, lon2, lat2 = [float(lon1), float(lat1), float(lon2), float(lat2)]
# Convert to radians from degrees.
lon1, lat1, lon2, lat2 = map(math.radians, [lon1, lat1, lon2, lat2])
# Compute distance.
dlon = lon2 - lon1
dlat = lat2 - lat1
a = math.sin(dlat/2)**2 + math.cos(lat1) * math.cos(lat2) * math.sin(dlon/2)**2
c = 2 * math.asin(math.sqrt(a))
km = 6367 * c
return km
然后我们可以做一个函数来计算
source和dest机场为单条航线。为此,我们需要从 routes 数据帧中获取source_id和dest_id机场,然后将它们与airports数据帧中的id列进行匹配,以获取这些机场的纬度和经度。然后,就是做计算的问题了。函数如下:
def calc_dist(row):
dist = 0
try:
# Match source and destination to get coordinates.
source = airports[airports["id"] == row["source_id"]].iloc[0]
dest = airports[airports["id"] == row["dest_id"]].iloc[0]
# Use coordinates to compute distance.
dist = haversine(dest["longitude"], dest["latitude"], source["longitude"], source["latitude"])
except (ValueError, IndexError):
pass
return dist
如果中有无效的值,该函数可能会失败
source_id或dest_id列,所以我们将添加一个try/except块来捕捉这些。最后,我们将使用 pandas 在routes数据帧中应用距离计算功能。这将给我们一个包含所有路线长度的熊猫系列。路线长度均以千米为单位。
route_lengths = routes.apply(calc_dist, axis=1)
现在我们已经有了一系列的路径长度,我们可以创建一个直方图,它会将值绑定到范围内,并计算每个范围内有多少条路径:
import matplotlib.pyplot as plt
plt.hist(route_lengths, bins=20)
 我们用
我们用import matplotlib.pyplot as plt导入 matplotlib 绘图函数。然后我们用%matplotlib inline设置 matplotlib 来显示 ipython 笔记本中的图形。最后,我们可以用plt.hist(route_lengths, bins=20)做一个直方图。正如我们所看到的,航空公司飞行的短途航线比长途航线多。
使用 Seaborn
我们可以用 Python 的高级绘图库 seaborn 进行类似的绘图。Seaborn 建立在 matplotlib 的基础上,简化了通常与统计工作有关的某些类型的绘图。我们可以使用
distplot绘制一个直方图的函数,其顶部有一个核密度估计值。核密度估计是一条曲线——本质上是直方图的平滑版本,更容易看到其中的模式。
import seaborn
seaborn.distplot(route_lengths, bins=20)
如你所见,seaborn 也有比 matplotlib 更好的默认风格。Seaborn 没有自己版本的所有 matplotlib 图,但这是一种很好的方式,可以快速获得比默认 matplotlib 图更深入的好看的图。如果你需要更深入,做更多的统计工作,它也是一个很好的库。
条形图
直方图很棒,但也许我们想看看航空公司的平均航线长度。我们可以用柱状图来代替——每个航空公司都有一个单独的柱状图,告诉我们每个航空公司的平均长度。这将让我们看到哪些运营商是地区性的,哪些是国际性的。我们可以使用 python 数据分析库 pandas 来计算每家航空公司的平均航线长度。
import numpy
# Put relevant columns into a dataframe.
route_length_df = pandas.DataFrame({"length": route_lengths, "id": routes["airline_id"]})
# Compute the mean route length per airline.
airline_route_lengths = route_length_df.groupby("id").aggregate(numpy.mean)
# Sort by length so we can make a better chart.
airline_route_lengths = airline_route_lengths.sort("length", ascending=False)
我们首先用航线长度和航线 id 制作一个新的数据帧。我们分开了
route_length_df根据airline_id分组,基本上每个航空公司制作一个数据帧。然后,我们使用熊猫aggregate函数获取每个航空公司数据帧中length列的平均值,并将每个结果重新组合成一个新的数据帧。然后,我们对数据帧进行排序,使航线最多的航空公司排在最前面。然后我们可以用 matplotlib 来绘制:
plt.bar(range(airline_route_lengths.shape[0]), airline_route_lengths["length"])
 matplotlib
matplotlibplt.bar方法根据每家航空公司飞行的平均航线长度(airline_route_lengths["length"])来绘制每家航空公司。上面这个图的问题是,我们不能轻易看出哪个航空公司有什么航线长度。为了做到这一点,我们需要能够看到轴标签。这有点难,因为有这么多的航空公司。一种更简单的方法是让图具有交互性,这将允许我们放大和缩小来查看标签。我们可以使用散景库来实现这一点——它使得制作交互式、可缩放的绘图变得简单。要使用散景,我们首先需要预处理我们的数据:
def lookup_name(row):
try:
# Match the row id to the id in the airlines dataframe so we can get the name.
name = airlines["name"][airlines["id"] == row["id"]].iloc[0]
except (ValueError, IndexError):
name = ""
return name
# Add the index (the airline ids) as a column.
airline_route_lengths["id"] = airline_route_lengths.index.copy()
# Find all the airline names.
airline_route_lengths["name"] = airline_route_lengths.apply(lookup_name, axis=1)
# Remove duplicate values in the index.
airline_route_lengths.index = range(airline_route_lengths.shape[0])
上面的代码将获取
airline_route_lengths,并在name栏中添加,该栏包含各航空公司的名称。我们还添加了id列,这样我们就可以进行查找(apply 函数没有传入索引)。最后,我们重置索引列,使其包含所有唯一的值。如果没有这个,散景就不能正常工作。现在,我们可以进入图表部分了:
import numpy as np
from bokeh.io import output_notebook
from bokeh.charts import Bar, showoutput_notebook()
p = Bar(airline_route_lengths, 'name', values='length', title="Average airline route lengths")
show(p)
我们打电话
output_notebook设置散景以显示 ipython 笔记本中的图形。然后,我们使用我们的数据框架和某些列绘制一个柱状图。最后,show函数显示剧情。在您的笔记本中生成的图不是图像,它实际上是一个 javascript 小部件。因此,我们在下面显示了一个截图,而不是实际的图表。 有了这个图,我们可以放大看哪个航空公司飞的航线最长。上面的图像使标签看起来很紧凑,但是放大后更容易看到。
有了这个图,我们可以放大看哪个航空公司飞的航线最长。上面的图像使标签看起来很紧凑,但是放大后更容易看到。
水平条形图
Pygal 是一个 python 数据分析库,可以快速制作有吸引力的图表。我们可以用它来按长度划分路线。我们首先将路线分为短、中和长路线,并计算每条路线在我们的
route_lengths。
long_routes = len([k for k in route_lengths if k > 10000]) / len(route_lengths)
medium_routes = len([k for k in route_lengths if k < 10000 and k > 2000]) / len(route_lengths)
short_routes = len([k for k in route_lengths if k < 2000]) / len(route_lengths)
然后,我们可以在 pygal 水平条形图中将每个点绘制成一个条形:
import pygal
from IPython.display import SVG
chart = pygal.HorizontalBar()
chart.title = 'Long, medium, and short routes'
chart.add('Long', long_routes * 100)
chart.add('Medium', medium_routes * 100)
chart.add('Short', short_routes * 100)
chart.render_to_file('/blog/conteimg/routes.svg')
SVG(filename='/blog/conteimg/routes.svg')
 在上面,我们首先创建一个空图表。然后,我们添加元素,包括标题和栏。每个条形被传递一个百分比值(在
在上面,我们首先创建一个空图表。然后,我们添加元素,包括标题和栏。每个条形被传递一个百分比值(在100中),显示该类型的路线有多常见。最后,我们将图表呈现到一个文件中,并使用 IPython 的 SVG 显示功能来加载和显示该文件。这个图看起来比默认的 matplotlib 图表要好一些,但是我们确实需要编写更多的代码来创建它。Pygal 可能适用于小型演示质量的图形。
散点图
散点图使我们能够比较多列数据。我们可以做一个简单的散点图来比较航空公司 id 号和航空公司名称的长度:
name_lengths = airlines["name"].apply(lambda x: len(str(x)))
plt.scatter(airlines["id"].astype(int), name_lengths)
 首先,我们使用熊猫
首先,我们使用熊猫apply方法计算每个名字的长度。这将找到每个航空公司名称的字符长度。然后,我们使用 matplotlib 绘制一个散点图,比较航空公司 id 和名称长度。当我们绘图时,我们将airlines的id列转换为整数类型。如果我们不这样做,这个图就不会工作,因为它需要 x 轴上的数值。我们可以看到相当多的长名字出现在早期的 id 中。这可能意味着成立较早的航空公司往往名字更长。我们可以用 seaborn 来验证这种预感。Seaborn 有一个散点图的扩展版本,一个联合图,显示了两个变量的相关程度,以及每个变量的单独分布。
data = pandas.DataFrame({"lengths": name_lengths, "ids": airlines["id"].astype(int)})
seaborn.jointplot(x="ids", y="lengths", data=data)
上图显示这两个变量之间没有任何真正的相关性——r 的平方值很低。
静态地图
我们的数据天生非常适合地图绘制——我们有机场的纬度和经度对,也有出发地和目的地机场的纬度和经度对。我们能做的第一张地图是显示全世界所有机场的地图。我们可以用
matplotlib 的底图扩展。这使得绘制世界地图和添加点,是非常可定制的。
# Import the basemap package
from mpl_toolkits.basemap import Basemap
# Create a map on which to draw. We're using a mercator projection, and showing the whole world.
m = Basemap(projection='merc',llcrnrlat=-80,urcrnrlat=80,llcrnrlon=-180,urcrnrlon=180,lat_ts=20,resolution='c')
# Draw coastlines, and the edges of the map.
m.drawcoastlines()
m.drawmapboundary()
# Convert latitude and longitude to x and y coordinatesx, y = m(list(airports["longitude"].astype(float)), list(airports["latitude"].astype(float)))
# Use matplotlib to draw the points onto the map.
m.scatter(x,y,1,marker='o',color='red')
# Show the plot.
plt.show()
在上面的代码中,我们首先用一个
墨卡托投影。墨卡托投影是一种将整个世界投影到二维表面上的方法。然后,我们用红点在地图上画出机场。 上面地图的问题是很难看到每个机场的位置——它们只是在机场密度高的区域合并成一个红色的斑点。就像 bokeh 一样,有一个交互式地图库,我们可以使用它来放大地图,并帮助我们找到各个机场。
上面地图的问题是很难看到每个机场的位置——它们只是在机场密度高的区域合并成一个红色的斑点。就像 bokeh 一样,有一个交互式地图库,我们可以使用它来放大地图,并帮助我们找到各个机场。
import folium
# Get a basic world map.
airports_map = folium.Map(location=[30, 0], zoom_start=2)
# Draw markers on the map.
for name, row in airports.iterrows():
# For some reason, this one airport causes issues with the map.
if row["name"] != "South Pole Station":
airports_map.circle_marker(location=`, row["longitude"]], popup=row["name"])
# Create and show the map.airports_map.create_map('airports.html')
airports_map`
leave 使用 fleet . js 制作全交互地图。您可以点击每个机场,在弹出窗口中查看其名称。上面是截图,但是实际的图印象深刻得多。follow 还允许你广泛地修改选项,以制作更好的标记,或者在地图上添加更多的东西。
## 画大圆
在地图上看到所有的航线会很酷。幸运的是,我们可以使用底图来做到这一点。我们会抽签
[大圈](https://en.wikipedia.org/wiki/Great_circle)连接出发地和目的地机场。每个圆圈将显示一架飞机的航线。不幸的是,路线太多了,把它们都显示出来会很混乱。相反,我们将展示第一条`3000`路线。
Make a base map with a mercator projection.
Draw the coastlines.
m = Basemap(projection='merc',llcrnrlat=-80,urcrnrlat=80,llcrnrlon=-180,urcrnrlon=180,lat_ts=20,resolution='c')
m.drawcoastlines()
Iterate through the first 3000 rows.
for name, row in routes[:3000].iterrows():
try:
# Get the source and dest airports.
source = airports[airports["id"] == row["source_id"]].iloc[0]
dest = airports[airports["id"] == row["dest_id"]].iloc[0]
# Don't draw overly long routes.
if abs(float(source["longitude"]) - float(dest["longitude"])) < 90:
# Draw a great circle between source and dest airports.
m.drawgreatcircle(float(source["longitude"]), float(source["latitude"]), float(dest["longitude"]), float(dest["latitude"]),linewidth=1,color='b')
except (ValueError, IndexError):
pass
# Show the map.
plt.show()
上面的代码将绘制一张地图,然后在上面绘制路线。我们添加了一些过滤器,以防止过长的路线遮蔽其他路线。
## 绘制网络图
我们要做的最后一项探索是绘制机场网络图。每个机场将是网络中的一个节点,如果机场之间有路线,我们将在节点之间画边。如果有多条路线,我们将增加边权重,以显示机场之间的联系更加紧密。我们将使用 networkx 库来完成这项工作。首先,我们需要计算机场之间的边权重。
Initialize the weights dictionary.
weights = {}
Keep track of keys that have been added once -- we only want edges with a weight of more than 1 to keep our network size manageable.added_keys = []
Iterate through each route.
for name, row in routes.iterrows():
# Extract the source and dest airport ids.
source = row["source_id"]
dest = row["dest_id"]
# Create a key for the weights dictionary.
# This corresponds to one edge, and has the start and end of the route.
key = "{0}_{1}".format(source, dest)
# If the key is already in weights, increment the weight.
if key in weights:
weights[key] += 1
# If the key is in added keys, initialize the key in the weights dictionary, with a weight of 2.
elif key in added_keys:
weights[key] = 2
# If the key isn't in added_keys yet, append it.
# This ensures that we aren't adding edges with a weight of 1.
else:
added_keys.append(key)
一旦上述代码运行完毕,权重字典将包含两个机场之间权重大于 2 的每条边。因此,任何由两条或多条航线连接的机场都会出现。现在,我们需要绘制图表。
Import networkx and initialize the graph.
import networkx as nx
graph = nx.Graph()
Keep track of added nodes in this set so we don't add twice.
nodes = set()
Iterate through each edge.
for k, weight in weights.items():
try:
# Split the source and dest ids and convert to integers.
source, dest = k.split("_")
source, dest = [int(source), int(dest)]
# Add the source if it isn't in the nodes.
if source not in nodes:
graph.add_node(source)
# Add the dest if it isn't in the nodes.
if dest not in nodes:
graph.add_node(dest)
# Add both source and dest to the nodes set.
# Sets don't allow duplicates.
nodes.add(source)
nodes.add(dest)
# Add the edge to the graph.
graph.add_edge(source, dest, weight=weight)
except (ValueError, IndexError):
passpos=nx.spring_layout(graph)
Draw the nodes and edges.nx.draw_networkx_nodes(graph,pos, node_color='red', node_size=10, alpha=0.8)
nx.draw_networkx_edges(graph,pos,width=1.0,alpha=1)
Show the plot.
plt.show()

## 结论
用于数据可视化的 Python 库激增,几乎可以实现任何类型的可视化。大多数库都建立在 matplotlib 之上,并简化了某些用例。如果您想更深入地了解如何使用 matplotlib、seaborn 和其他工具可视化数据,请查看我们的交互式
[探索性数据可视化](https://www.dataquest.io/course/exploratory-data-visualization/)和[通过数据可视化讲故事](https://www.dataquest.io/course/storytelling-data-visualization/)课程。
Python 日期时间教程:操作时间、日期和时间跨度
October 31, 2019
在 Python 中处理日期和时间可能会很麻烦。幸运的是,有一个内置的方法可以让它变得更简单:Python datetime 模块。
帮助我们识别和处理与时间相关的元素,如日期、小时、分钟、秒、星期几、月、年等。它提供各种服务,如管理时区和夏令时。它可以处理时间戳数据。它可以从字符串中提取一周中的某一天、一个月中的某一天以及其他日期和时间格式。
简而言之,这是在 Python 中处理任何与日期和时间相关的事情的一种非常强大的方式。所以让我们开始吧!
在本教程中,我们将详细了解 python 日期时间函数,包括:
- 创建日期对象
- 从日期中获取年和月
- 从日期获取月日和工作日
- 从日期中获取小时和分钟
- 从日期获取一年中的第几周
- 将日期对象转换为时间戳
- 将 UNIX 时间戳字符串转换为日期对象
- 处理 timedelta 对象
- 获取两个日期和时间之间的差异
- 格式化日期:strftime()和 strptime()
- 处理时区
- 使用熊猫日期时间对象
- 获取年、月、日、小时和分钟
- 获取工作日和一年中的某一天
- 将日期对象转换为数据帧索引
当您学习本教程时,我们鼓励您在自己的机器上运行代码。或者,如果你想在浏览器中运行代码,并以互动的方式通过检查答案来学习,以确保你做对了,我们的 Python 中级课程有一节关于 Python 中的日期时间的课,我们推荐。你可以通过注册一个免费用户账户开始学习。
Python 日期时间类
在开始编写代码之前,有必要看一下在datetime模块中使用的五个主要对象类。根据我们要做的事情,我们可能需要使用一个或多个不同的类:
- datetime–允许我们一起操作时间和日期(月、日、年、小时、秒、微秒)。
- 日期–允许我们操纵独立于时间的日期(月、日、年)。
- 时间–允许我们操纵独立于日期的时间(小时、分钟、秒、微秒)。
- 时间增量 —用于操纵日期和测量的一段持续时间。
- tzinfo —处理时区的抽象类。
如果这些区别还没有意义,不要担心!让我们深入datetime并开始使用它来更好地理解这些是如何应用的。
创建日期对象
首先,让我们仔细看看一个datetime物体。由于datetime既是一个模块又是该模块中的一个类,我们将从从datetime模块导入datetime类开始。
然后,我们将打印当前的日期和时间,以便更仔细地看一看datetime对象中包含了什么。我们可以使用datetime的.now()功能来实现。我们将打印我们的 datetime 对象,然后使用type()打印它的类型,这样我们可以更仔细地查看。
# import datetime class from datetime module
from datetime import datetime
# get current date
datetime_object = datetime.now()
print(datetime_object)
print('Type :- ',type(datetime_object))
2019-10-25 10:24:01.521881
Type :- 'datetime.datetime'
从上面的结果我们可以看出,datetime_object确实是datetime类的一个datetime对象。这包括年、月、日、小时、分钟、秒和微秒。
从日期中提取年和月
现在我们已经看到了什么组成了一个datetime对象,我们大概可以猜测出date和time对象的样子,因为我们知道date对象就像没有时间数据的datetime,而time对象就像没有日期数据的datetime。
我们也可以解决一些问题。例如,在大多数数据集中,日期和时间信息以字符串格式存储!此外,我们可能不想要所有这些日期和时间数据——如果我们正在做类似每月销售分析的事情,按微秒细分不会非常有用。
所以现在,让我们开始深入研究数据科学中的一个常见任务:使用datetime从字符串中只提取我们真正想要的元素。
为此,我们需要做几件事。
用 strptime()和 strftime()处理日期和时间字符串
幸运的是,datetime包含了两个方法,strptime()和strftime(),用于将对象从字符串转换为datetime对象,反之亦然。strptime()可以读取带有日期和时间信息的字符串并将其转换成datetime对象,而strftime()将日期时间对象转换回字符串。
当然,strptime()不是魔术——它不能把任何字符串变成日期和时间,它需要我们的一点帮助来解释它所看到的!但是它能够读取日期和时间数据的最传统的字符串格式(更多细节参见文档)。我们给它一个 YYYY-MM-DD 格式的日期字符串,看看它能做什么!
my_string = '2019-10-31'
# Create date object in given time format yyyy-mm-dd
my_date = datetime.strptime(my_string, "%Y-%m-%d")
print(my_date)
print('Type: ',type(my_date))
2019-10-31 00:00:00 Type: 'datetime.datetime'
注意,strptime()有两个参数:字符串(my_string)和"%Y-%m-%d",另一个字符串告诉strptime()如何解释输入字符串my_string。例如,%Y告诉它字符串的前四个字符是年份。
这些模式的完整列表可以在文档中找到,我们将在本教程的后面更深入地研究这些方法。
您可能还注意到日期中添加了一个时间00:00:00。这是因为我们创建了一个datetime对象,它必须包含日期和时间。00:00:00是默认的时间,如果我们输入的字符串中没有指定时间,它就会被指定。
无论如何,我们希望分离出特定的日期元素来进行分析。一种方法是使用 datetime 对象的内置类属性,如.month或.year:
print('Month: ', my_date.month) # To Get month from date
print('Year: ', my_date.year) # To Get month from year
Month: 10 Year: 2019
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。

从日期中获取一个月中的某一天和一周中的某一天
让我们再做一些提取,因为这是一个非常常见的任务。这一次,我们将尝试从my_date中获取一个月中的某一天和一周中的某一天。Datetime 将使用它的.weekday()函数以数字的形式给出一周中的某一天,但是我们可以使用calendar模块和一个叫做day_name的方法将它转换成文本格式(即星期一、星期二、星期三……)。
我们先导入calendar,然后在my_date上使用.day和.weekday()。从那里,我们可以得到文本格式的星期几,如下所示:
# import calendar module
import calendar
print('Day of Month:', my_date.day)
# to get name of day(in number) from date
print('Day of Week (number): ', my_date.weekday())
# to get name of day from date
print('Day of Week (name): ', calendar.day_name[my_date.weekday()])
Day of Month: 31 Day of Week (number): 3 Day of Week (name): Thursday
等一下,这看起来有点奇怪!一周的第三天应该是星期三,而不是星期四,对吗?
让我们使用 for 循环仔细看看那个day_name变量:
j = 0
for i in calendar.day_name:
print(j,'-',i)
j+=1
0 - Monday 1 - Tuesday 2 - Wednesday 3 - Thursday 4 - Friday 5 - Saturday 6 - Sunday
现在我们可以看到 Python 从周一开始数周,从索引 0 开始计数,而不是从 1 开始。因此,正如我们在上面看到的,数字 3 被转换为“星期四”是有意义的。
从 Python Datetime 对象获取小时和分钟
现在让我们深入研究时间,从 datetime 对象中提取小时和分钟。就像我们在上面对月和年所做的一样,我们可以使用类属性.hour和.minute来获得一天中的小时和分钟。
让我们使用.now()功能设置一个新的日期和时间。截至本文写作时,时间是 2019 年 10 月 25 日上午 10:25。当然,根据您选择运行这段代码的时间,您会得到不同的结果!
from datetime import datetime todays_date = datetime.now()
# to get hour from datetime
print('Hour: ', todays_date.hour)
# to get minute from datetime
print('Minute: ', todays_date.minute)
Hour: 10 Minute: 25
从 Datetime 对象中获取一年中的星期
我们还可以用datetime做更奇妙的事情。例如,如果我们想知道这是一年中的第几周呢?
我们可以用.isocalendar()函数从一个datetime对象中获得年份、星期和星期几。
具体来说,isocalendar()返回一个包含 ISO 年、周数和工作日的元组。 ISO 日历是一种广泛使用的基于公历的标准日历。你可以在那个链接上读到更多的细节,但是为了我们的目的,我们需要知道的是它作为一个常规的日历工作,从每周的星期一开始。
# Return a 3-tuple, (ISO year, ISO week number, ISO weekday).
todays_date.isocalendar()
(2019, 43, 5)
注意,在 ISO 日历中,一周从 1 开始计数,所以这里的 5 代表一周中正确的一天:星期五。
从上面我们可以看到,这是一年中的第 43 周,但是如果我们想要隔离这个数字,我们可以像对任何其他 Python 列表或元组一样通过索引来实现:
todays_date.isocalendar()[1]
43
将日期对象转换成 Unix 时间戳,反之亦然
在编程中,经常会遇到将时间和日期数据存储为时间戳的情况,或者希望将自己的数据存储为 Unix 时间戳格式。
我们可以使用 datetime 的内置timestamp()函数来实现这一点,该函数将一个datetime对象作为参数,并以时间戳格式返回日期和时间:
#import datetime
from datetime import datetime
# get current date
now = datetime.now()
# convert current date into timestamp
timestamp = datetime.timestamp(now)
print("Date and Time :", now)
print("Timestamp:", timestamp)
Date and Time : 2019-10-25 10:36:32.827300 Timestamp: 1572014192.8273
同样,我们可以使用fromtimestamp()进行反向转换。这是一个datetime函数,它以时间戳(浮点格式)作为参数,并返回一个datetime对象,如下所示:
#import datetime
from datetime import datetime
timestamp = 1572014192.8273
#convert timestamp to datetime object
dt_object = datetime.fromtimestamp(timestamp)
print("dt_object:", dt_object)
print("type(dt_object): ", type(dt_object))
dt_object: 2019-10-25 10:36:32.827300 type(dt_object): <class 'datetime.datetime'>

使用 Timedelta 对象测量时间跨度
通常,我们可能希望使用 Python datetime 来度量一段时间,或者一个持续时间。我们可以用它内置的timedelta类来做到这一点。一个timedelta对象表示两个日期或时间之间的时间。我们可以用它来测量时间跨度,或者通过加减来操作日期或时间,等等。
默认情况下,timedelta 对象的所有参数都设置为零。让我们创建一个新的两周长的 timedelta 对象,看看它是什么样子:
#import datetime
from datetime import timedelta
# create timedelta object with difference of 2 weeks
d = timedelta(weeks=2)
print(d)
print(type(d))
print(d.days)
14 days, 0:00:00 <class 'datetime.timedelta'> 14
注意,我们可以通过使用timedelta类属性.days来获得以天为单位的持续时间。正如我们可以在的文档中看到的,我们也可以得到这个以秒或微秒为单位的持续时间。
让我们创建另一个时间增量持续时间来进行更多的练习:
year = timedelta(days=365)
print(year)
365 days, 0:00:00
现在让我们开始使用 timedelta 对象和 datetime 对象来做一些数学运算!具体来说,让我们给当前时间和日期加上几个不同的持续时间,看看 15 天后是什么日期,两周前是什么日期。
为此,我们可以使用+或-操作符将 timedelta 对象添加到 datetime 对象中,或者从其中减去 time delta 对象。结果将是 datetime 对象加上或减去在 timedelta 对象中指定的持续时间。很酷,对吧?
(注:下面的代码中,是 10 月 25 日上午 11:12;您的结果将根据您运行代码的时间而有所不同,因为我们正在使用.now()函数获取我们的datetime对象。
#import datetime
from datetime import datetime, timedelta
# get current time
now = datetime.now()
print ("Today's date: ", str(now))
#add 15 days to current date
future_date_after_15days = now + timedelta(days = 15)
print('Date after 15 days: ', future_date_after_15days)
#subtract 2 weeks from current date
two_weeks_ago = now - timedelta(weeks = 2)
print('Date two weeks ago: ', two_weeks_ago)
print('two_weeks_ago object type: ', type(two_weeks_ago))
Today's date: 2019-10-25 11:12:24.863308 Date after 15 days: 2019-11-09 11:12:24.863308 Date two weeks ago: 2019-10-11 11:12:24.863308 two_weeks_ago object type: <class 'datetime.datetime'>
注意,这些数学运算的输出仍然是一个datetime对象。
找出两个日期和时间之间的差异
类似于我们上面所做的,我们也可以使用 datetime 从一个日期减去另一个日期,以找到它们之间的时间跨度。
因为这个数学的结果是一个持续时间,当我们从一个日期中减去另一个日期时产生的对象将是一个timedelta对象。
这里,我们将创建两个date对象(请记住,这些对象的工作方式与datetime对象相同,只是它们不包含时间数据),并将其中一个减去另一个,以获得持续时间:
# import datetime
from datetime import date
# Create two dates
date1 = date(2008, 8, 18)
date2 = date(2008, 8, 10)
# Difference between two dates
delta = date2 - date1
print("Difference: ", delta.days)
print('delta object type: ', type(delta))
Difference: -8 delta object type: <class 'datetime.timedelta'>
上面,为了清楚起见,我们只使用了日期,但是我们可以对datetime对象做同样的事情来获得更精确的测量,包括小时、分钟和秒:
# import datetime
from datetime import datetime
# create two dates with year, month, day, hour, minute, and second
date1 = datetime(2017, 6, 21, 18, 25, 30)
date2 = datetime(2017, 5, 16, 8, 21, 10)
# Difference between two dates
diff = date1-date2
print("Difference: ", diff)
Difference: 36 days, 10:04:20

格式化日期:关于 strftime()和 strptime()的更多信息
我们之前简单地提到了strftime()和strptime(),但是让我们更仔细地看看这些方法,因为它们对于 Python 中的数据分析工作来说通常很重要。
strptime()是我们之前使用的方法,您应该还记得,它可以将文本字符串格式的日期和时间转换为 datetime 对象,格式如下:
time.strptime(string, format)
请注意,它需要两个参数:
- 字符串-我们要转换的字符串格式的时间
- format——字符串中时间的特定格式,以便 strptime()可以正确解析它
这次让我们尝试转换一种不同的日期字符串。这个网站对于寻找帮助strptime()解释我们的字符串输入所需的格式化代码是一个非常有用的参考。
# import datetime
from datetime import datetime
date_string = "1 August, 2019"
# format date
date_object = datetime.strptime(date_string, "%d %B, %Y")
print("date_object: ", date_object)
date_object: 2019-08-01 00:00:00
现在让我们做一些更高级的事情来练习到目前为止我们所学的一切!我们将从字符串格式的日期开始,将其转换为 datetime 对象,并研究几种不同的格式化方法(dd/mm 和 mm/dd)。
然后,坚持 mm/dd 格式,我们将把它转换成 Unix 时间戳。然后我们将它转换回一个datetime对象,并使用几个不同的 strftime 模式将那个转换回字符串,以控制输出:
# import datetime
from datetime import datetime
dt_string = "12/11/2018 09:15:32"
# Considering date is in dd/mm/yyyy format
dt_object1 = datetime.strptime(dt_string, "%d/%m/%Y %H:%M:%S")
print("dt_object1:", dt_object1)
# Considering date is in mm/dd/yyyy format
dt_object2 = datetime.strptime(dt_string, "%m/%d/%Y %H:%M:%S")
print("dt_object2:", dt_object2)
# Convert dt_object2 to Unix Timestamp
timestamp = datetime.timestamp(dt_object2)
print('Unix Timestamp: ', timestamp)
# Convert back into datetime
date_time = datetime.fromtimestamp(timestamp)
d = date_time.strftime("%c")
print("Output 1:", d)
d = date_time.strftime("%x")
print("Output 2:", d)
d = date_time.strftime("%X")
print("Output 3:", d)
dt_object1: 2018-11-12 09:15:32 dt_object2: 2018-12-11 09:15:32 Unix Timestamp: 1544537732.0 Output 1: Tue Dec 11 09:15:32 2018 Output 2: 12/11/18 Output 3: 09:15:32
这里有一个图像,您可以用一个备忘单保存,用于常见的、有用的 strptime 和 strftime 模式:
让我们多练习一下如何使用这些:
# current date and time
now = datetime.now()
# get year from date
year = now.strftime("%Y")
print("Year:", year)
# get month from date
month = now.strftime("%m")
print("Month;", month)
# get day from date
day = now.strftime("%d")
print("Day:", day)
# format time in HH:MM:SS
time = now.strftime("%H:%M:%S")
print("Time:", time)
# format date
date_time = now.strftime("%m/%d/%Y, %H:%M:%S")
print("Date and Time:",date_time)
Year: 2019 Month; 10 Day: 25 Time: 11:56:41 Date and Time: 10/25/2019, 11:56:41
处理时区
当涉及时区时,在 Pythin 中处理日期和时间会变得更加复杂。谢天谢地,pytz模块的存在是为了帮助我们处理跨时区转换。它还处理使用夏令时的地方的夏令时。
我们可以使用localize函数向 Python datetime 对象添加时区位置。然后我们可以使用函数astimezone()将现有的本地时区转换成我们指定的任何其他时区(它将我们想要转换成的时区作为一个参数)。
例如:
# import timezone from pytz module
from pytz import timezone
# Create timezone US/Eastern
east = timezone('US/Eastern')
# Localize date
loc_dt = east.localize(datetime(2011, 11, 2, 7, 27, 0))
print(loc_dt)
# Convert localized date into Asia/Kolkata timezone
kolkata = timezone("Asia/Kolkata")
print(loc_dt.astimezone(kolkata))
# Convert localized date into Australia/Sydney timezone
au_tz = timezone('Australia/Sydney')
print(loc_dt.astimezone(au_tz))
2011-11-02 07:27:00-04:00 2011-11-02 16:57:00+05:30 2011-11-02 22:27:00+11:00
当处理包含多个不同时区的数据集时,此模块有助于简化工作。
使用熊猫日期时间对象
数据科学家喜欢pandas有很多原因。其中之一是它包含了处理时间序列数据的大量功能和特性。很像datetime本身,pandas 有datetime和timedelta对象分别用于指定日期、时间和持续时间。
我们可以使用以下函数将日期、时间和持续时间文本字符串转换成 pandas Datetime 对象:
- to_datetime() :将字符串日期和时间转换为 Python datetime 对象。
- to_timedelta() :根据日、小时、分钟和秒查找时间差异。
正如我们将看到的,这些函数实际上非常擅长通过自动检测字符串的格式来将字符串转换为 Python datetime 对象,而不需要我们使用 strftime 模式来定义它。
让我们看一个简单的例子:
# import pandas module as pd
import pandas as pd
# create date object using to_datetime() function
date = pd.to_datetime("8th of sep, 2019")
print(date)
2019-09-08 00:00:00
请注意,即使我们给它一个带有一些复杂因素的字符串,如“th”和“Sep”而不是“sep .”或“junior”,pandas 也能够正确地解析该字符串并返回格式化的日期。
我们还可以使用 pandas(及其一些附属的 numpy 功能)自动创建日期范围作为 pandas 系列。例如,在下面,我们从上面定义的日期开始创建一系列 12 个日期。然后,我们使用pd.date_range()从预定义的日期开始创建一系列不同的日期:
# Create date series using numpy and to_timedelta() function
date_series = date + pd.to_timedelta(np.arange(12), 'D')
print(date_series)
# Create date series using date_range() function
date_series = pd.date_range('08/10/2019', periods = 12, freq ='D')
print(date_series)
DatetimeIndex(['2019-09-08', '2019-09-09', '2019-09-10', '2019-09-11', '2019-09-12', '2019-09-13', '2019-09-14', '2019-09-15', '2019-09-16', '2019-09-17', '2019-09-18', '2019-09-19'], dtype='datetime64[ns]', freq=None) DatetimeIndex(['2019-08-10', '2019-08-11', '2019-08-12', '2019-08-13', '2019-08-14', '2019-08-15', '2019-08-16', '2019-08-17', '2019-08-18', '2019-08-19', '2019-08-20', '2019-08-21'], dtype='datetime64[ns]', freq='D')
获得熊猫的年、月、日、小时、分钟
使用所有列的dt属性,我们可以很容易地从 pandas 数据帧的一列日期中获得年、月、日、小时或分钟。例如,我们可以使用df['date'].dt.year从包含完整日期的熊猫列中只提取年份。
为了探索这一点,让我们使用上面创建的一个系列制作一个快速数据框架:
# Create a DataFrame with one column date
df = pd.DataFrame()
df['date'] = date_series df.head()
| 日期 |
|---|
| Zero |
| one |
| Two |
| three |
| four |
现在,让我们使用相关的 Python datetime(通过dt访问)属性为日期的每个元素创建单独的列:
# Extract year, month, day, hour, and minute. Assign all these date component to new column.
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['hour'] = df['date'].dt.hour
df['minute'] = df['date'].dt.minute
df.head()
| 日期 | 年 | 月 | 天 | 小时 | 分钟 |
|---|---|---|---|---|---|
| Zero | 2019-08-10 | Two thousand and nineteen | eight | Ten | Zero |
| one | 2019-08-11 | Two thousand and nineteen | eight | Eleven | Zero |
| Two | 2019-08-12 | Two thousand and nineteen | eight | Twelve | Zero |
| three | 2019-08-13 | Two thousand and nineteen | eight | Thirteen | Zero |
| four | 2019-08-14 | Two thousand and nineteen | eight | Fourteen | Zero |
获取工作日和一年中的某一天
Pandas 还能够从其 datetime 对象中获取其他元素,如一周中的某一天和一年中的某一天。同样,我们可以使用dt属性来做到这一点。注意,在这里,通常在 Python 中,一周从索引 0 开始,所以一周的第 5 天是星期六。
# get Weekday and Day of Year. Assign all these date component to new column.
df['weekday'] = df['date'].dt.weekday
df['day_name'] = df['date'].dt.weekday_name
df['dayofyear'] = df['date'].dt.dayofyear
df.head()
| 日期 | 年 | 月 | 天 | 小时 | 分钟 | 工作日 | 日名 | dayofyear |
|---|---|---|---|---|---|---|---|---|
| Zero | 2019-08-10 | Two thousand and nineteen | eight | Ten | Zero | Zero | five | 星期六 |
| one | 2019-08-11 | Two thousand and nineteen | eight | Eleven | Zero | Zero | six | 星期日 |
| Two | 2019-08-12 | Two thousand and nineteen | eight | Twelve | Zero | Zero | Zero | 星期一 |
| three | 2019-08-13 | Two thousand and nineteen | eight | Thirteen | Zero | Zero | one | 星期二 |
| four | 2019-08-14 | Two thousand and nineteen | eight | Fourteen | Zero | Zero | Two | 星期三 |
将日期对象转换为数据帧索引
我们还可以使用 pandas 在数据帧的索引中创建一个 datetime 列。这对于探索性数据可视化等任务非常有帮助,因为 matplotlib 会识别 DataFrame 索引是一个时间序列,并相应地绘制数据。
为此,我们所要做的就是重新定义df.index:
# Assign date column to dataframe index
df.index = df.date
df.head()
| 日期 | 年 | 月 | 天 | 小时 | 分钟 | 工作日 | 日名 | dayofyear |
|---|---|---|---|---|---|---|---|---|
| 日期 | ||||||||
| --- | ||||||||
| 2019-08-10 | 2019-08-10 | Two thousand and nineteen | eight | Ten | Zero | Zero | five | 星期六 |
| 2019-08-11 | 2019-08-11 | Two thousand and nineteen | eight | Eleven | Zero | Zero | six | 星期日 |
| 2019-08-12 | 2019-08-12 | Two thousand and nineteen | eight | Twelve | Zero | Zero | Zero | 星期一 |
| 2019-08-13 | 2019-08-13 | Two thousand and nineteen | eight | Thirteen | Zero | Zero | one | 星期二 |
| 2019-08-14 | 2019-08-14 | Two thousand and nineteen | eight | Fourteen | Zero | Zero | Two | 星期三 |
结论
在本教程中,我们深入研究了 Python datetime,还使用 pandas 和日历模块做了一些工作。我们已经讲了很多,但是请记住:学习的最好方法是自己写代码!
如果你想练习编写带有交互式答案检查的datetime代码,请查看我们的 Python 中级课程的一节关于 Python 中的日期时间的课,带有交互式答案检查和浏览器内代码运行。
你能从培养新技能中获益吗?
下面挑一个技能点击免费报名即刻开始学习!
Advanced PandasData VisualizationProbability & Statistics**
Python Datetime:包含 39 个代码示例的简单指南(2022)
May 11, 2022
你可能已经熟悉了Python 中的各种数据类型,如整数、浮点数、字符串等。然而,有时当你开发一个脚本或机器学习算法时,你应该使用日期和时间。在日常生活中,我们可以用许多不同的格式来表示日期和时间,例如,July 4、March 8, 2022、22:00或31 December 2022, 23:59:59。它们使用整数和字符串的组合,或者您也可以使用浮点数来表示一天、一分钟等的分数。
但这不是唯一的复杂情况!此外,还列出了不同的时区、夏令时、不同的时间格式约定(在美国是 2022 年 7 月 23 日,在欧洲是 2023 年 7 月 23 日)等。
当我们告诉计算机做什么时,它们需要明确的精确度,但是日期和时间是一个挑战。幸运的是,Python 有datetime模块,允许我们轻松地操作表示日期和时间的对象。
在这个 Python datetime教程中,我们将学习以下内容:
- Python 中
datetime模块的使用 - 使用 Python
datetime函数将字符串转换为datetime对象,反之亦然 - 从
datetime对象中提取日期和时间 - 使用时间戳
- 对日期和时间执行算术运算
- 使用时区
- 最后,创建一个倒计时器来确定离 2023 年新年还有多久(在纽约市!)
让我们开始用 Python 处理日期和时间。
注意:如果一段代码没有import语句,假设代码中使用的类/函数已经被导入。
如何在 Python 中使用 datetime?
正如我们前面所说,在编程中表示日期和时间是一个挑战。首先,我们必须用一种标准的、普遍接受的格式来表示它们。幸运的是, 国际标准化组织 (ISO)开发了一个全球标准【ISO 8601】,它将与日期和时间相关的对象表示为YYYY-MM-DD HH:MM:SS,其信息范围从最重要的(年,YYYY)到最不重要的(秒,SS)。这种格式的每一部分都表示为一个四位数或两位数。
Python 中的datetime模块有 5 个主要类(模块的一部分):
date操纵日期对象time操纵时间物体datetime是date和time的组合timedelta允许我们用持续时间工作tzinfo允许我们使用时区
此外,我们将使用 zoneinfo模块,它为我们提供了一种处理时区的现代方式,以及 dateutil包,它包含了大量处理日期和时间的有用函数。
让我们导入datetime模块并创建我们的第一个日期和时间对象:
# From the datetime module import date
from datetime import date
# Create a date object of 2000-02-03
date(2000, 2, 3)
datetime.date(2000, 2, 3)
在上面的代码中,我们从模块中导入了date类,然后创建了一个 2000 年 2 月 3 日的datetime.date对象。我们可以注意到,我们用来创建这个对象的数字顺序与 ISO 8061 中的完全相同(但是我们省略了 0,只写了一位数的月和日)。
编码完全是实验,所以假设我们想要创建一个 2000-26-03 的对象:
# Create a date object of 2000-26-03
date(2000, 26, 3)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [2], in <module>
1 # Create a date object of 2000-26-03
----> 2 date(2000, 26, 3)
ValueError: month must be in 1..12
我们得到ValueError: month must be in 1..12,这是有意义的,因为日历中没有 26 月。这个函数严格遵循 ISO 8601 格式。实际上,向date函数添加更多的参数,并注意会发生什么。
让我们看看如何创建一个datetime.time对象:
# From the datetime module import time
from datetime import time
# Create a time object of 05:35:02
time(5, 35, 2)
datetime.time(5, 35, 2)
我们成功了,你可以猜到这个函数也遵循 ISO 8061 格式。你能像我们之前用date函数破解它吗?
现在,如果我们希望在一个对象中既有日期又有时间呢?我们应该使用datetime类:
# From the datetime module import datetime
from datetime import datetime
# Create a datetime object of 2000-02-03 05:35:02
datetime(2000, 2, 3, 5, 35, 2)
datetime.datetime(2000, 2, 3, 5, 35, 2)
太好了,我们有了目标。我们还可以更明确地将关键字参数传递给datetime构造函数:
datetime(year=2000, month=2, day=3, hour=5, minute=35, second=2)
datetime.datetime(2000, 2, 3, 5, 35, 2)
如果我们只传入三个参数(年、月和日)会怎么样?这会导致错误吗?
# Create a datetime object of 2000-02-03
datetime(2000, 2, 3)
datetime.datetime(2000, 2, 3, 0, 0)
我们可以看到,现在对象中有两个零分别代表小时和分钟。在这种情况下,秒被省略。
在很多情况下,我们希望知道此刻的准确时间。我们可以使用datetime类的now()方法:
# Time at the moment
now = datetime.now()
now
datetime.datetime(2022, 2, 14, 11, 33, 25, 516707)
我们得到一个datetime对象。这里最后一个数字是微秒。
如果我们只需要今天的日期,我们可以使用来自date类的today()方法:
today = date.today()
today
datetime.date(2022, 2, 14)
如果只是需要时间,我们可能会写time.now(),但是行不通。相反,我们必须访问datetime.now()对象的hour、minute和second属性,并将它们传递给time构造函数:
time(now.hour, now.minute, now.second)
datetime.time(11, 33, 25)
在实践中,从 Python 中的datetime对象获取日期(分配给now变量)。
我们还可以使用isocalendar()函数从datetime对象中提取星期数和日期。它将返回一个包含 ISO 年份、周数和工作日数的三项元组:
# isocalendar() returns a 3-item tuple with ISO year, week number, and weekday number
now.isocalendar()
datetime.IsoCalendarDate(year=2022, week=7, weekday=1)
在 ISO 格式中,一周从星期一开始,到星期日结束。一周中的每一天都用从 1(星期一)到 7(星期日)的数字编码。如果我们想要访问这些元组元素中的一个,我们使用括号符号:
# Access week number
week_number = now.isocalendar()[1]
week_number
7
从字符串中提取日期
在数据科学中,通常在编程中,我们主要处理日期和时间,这些日期和时间以数十种不同的格式存储为字符串,这取决于地区、公司或我们需要的信息的粒度。有时,我们需要日期和确切的时间,但在其他情况下,我们只需要年份和月份。如何从一个字符串中提取出我们需要的数据,方便地把它作为一个datetime ( date,time)对象来操作呢?
fromisoformat() 和 isoformat()
我们将学习的第一个将日期字符串转换成date对象的函数是fromisoformat。我们这样称呼它是因为它使用了 ISO 8601 格式(即YYYY-MM-DD)。让我们看一个例子:
# Convert a date string into a date object
date.fromisoformat("2022-12-31")
datetime.date(2022, 12, 31)
ISO 格式也包含时间,但是如果我们把它传递给函数,它就不起作用了:
date.fromisoformat("2022-12-31 00:00:00")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [13], in <module>
----> 1 date.fromisoformat("2022-12-31 00:00:00")
ValueError: Invalid isoformat string: '2022-12-31 00:00:00'
当然,我们也可以执行相反的操作,将一个datetime对象转换成 ISO 格式的日期字符串。为此,我们应该使用isoformat():
# Convert a datetime object into a string in the ISO format
date(2022, 12, 31).isoformat()
'2022-12-31'
strptime()
为了解决上面的ValueError问题,我们可以使用strptime()函数,该函数可以将一个任意的日期/时间字符串转换成一个datetime对象。我们的字符串不一定需要遵循 ISO 格式,但是我们应该指定字符串的哪一部分代表哪一个日期或时间单位(年、小时等)。).让我们看一个例子来阐明。首先,我们将使用严格的 ISO 格式将一个字符串转换成一个datetime对象:
# Date as a string
iso_date = "2022-12-31 23:59:58"
# ISO format
iso_format = "%Y-%m-%d %H:%M:%S"
# Convert the string into a datetime object
datetime.strptime(iso_date, iso_format)
datetime.datetime(2022, 12, 31, 23, 59, 58)
在的第一行,我们创建一个日期/时间字符串。在的第二行中,我们使用一个特殊的代码指定字符串的格式,该代码包含一个百分号,后跟一个编码日期或时间单位的字符。最后,在第三行中,我们使用strptime()函数将字符串转换为datetime对象。这个函数有两个参数:字符串和字符串的格式。
我们上面使用的代码也可以对其他日期和时间单位进行编码,如工作日、月份名称、周数等。
| 密码 | 例子 | 描述 |
|---|---|---|
| %A | 星期一 | 完整的工作日名称 |
| %B | 十二月 | 完整的月份名称 |
| %W | Two | 周数(星期一是一周的第一天) |
Python 中使用的其他代码可以参考这个网站。
让我们再看几个使用其他格式的例子:
# European date as a string
european_date = "31-12-2022"
# European format
european_format = "%d-%m-%Y"
# Convert the string into a datetime object
datetime.strptime(european_date, european_format)
datetime.datetime(2022, 12, 31, 0, 0)
正如我们在上面看到的,字符串被成功转换,但是我们有额外的零来表示时间。让我们看一个使用其他代码的示例:
# Full month name date
full_month_date = "12 September 2022"
# Full month format
full_month_format = "%d %B %Y"
# Convert the string into a datetime object
datetime.strptime(full_month_date, full_month_format)
datetime.datetime(2022, 9, 12, 0, 0)
再次成功!注意我们定义的格式应该匹配日期字符串的格式。因此,如果我们用空格、冒号、连字符或其他字符来分隔时间单位,它们应该在代码字符串中。否则,Python 会抛出一个ValueError:
# Full month name date
full_month_date = "12 September 2022"
# Wrong format (missing space)
full_month_format = "%d%B %Y"
# Convert the string into a datetime object
datetime.strptime(full_month_date, full_month_format)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [18], in <module>
5 full_month_format = "%d%B %Y"
7 # Convert the string into a datetime object
----> 8 datetime.strptime(full_month_date, full_month_format)
File ~/coding/dataquest/articles/using-the-datetime-package/env/lib/python3.10/_strptime.py:568, in _strptime_datetime(cls, data_string, format)
565 def _strptime_datetime(cls, data_string, format="%a %b %d %H:%M:%S %Y"):
566 """Return a class cls instance based on the input string and the
567 format string."""
--> 568 tt, fraction, gmtoff_fraction = _strptime(data_string, format)
569 tzname, gmtoff = tt[-2:]
570 args = tt[:6] + (fraction,)
File ~/coding/dataquest/articles/using-the-datetime-package/env/lib/python3.10/_strptime.py:349, in _strptime(data_string, format)
347 found = format_regex.match(data_string)
348 if not found:
--> 349 raise ValueError("time data %r does not match format %r" %
350 (data_string, format))
351 if len(data_string) != found.end():
352 raise ValueError("unconverted data remains: %s" %
353 data_string[found.end():])
ValueError: time data '12 September 2022' does not match format '%d%B %Y'
甚至一个空格都可能导致错误!
将日期时间对象转换为字符串
strftime()
在 Python 中,我们还可以使用strftime()函数将datetime对象转换成字符串。它有两个参数:一个datetime对象和输出字符串的格式。
# Create a datetime object
datetime_obj = datetime(2022, 12, 31)
# American date format
american_format = "%m-%d-%Y"
# European format
european_format = "%d-%m-%Y"
# American date string
print(f"American date string: {datetime.strftime(datetime_obj, american_format)}.")
# European date string
print(f"European date string: {datetime.strftime(datetime_obj, european_format)}.")
American date string: 12-31-2022.
European date string: 31-12-2022.
我们将同一个datetime对象转换成两种不同的格式。我们还可以指定其他格式,比如完整的月份名称后面跟着日期和年份。
full_month = "%B %d, %Y"
datetime.strftime(datetime_obj, full_month)
'December 31, 2022'
使用strftime的另一种方法是将其放在datetime对象之后:
datetime_obj = datetime(2022, 12, 31, 23, 59, 59)
full_datetime = "%B %d, %Y %H:%M:%S"
datetime_obj.strftime(full_datetime)
'December 31, 2022 23:59:59'
实际上,如果我们想要提取不同年份中 12 月 31 日的工作日名称,strftime()可能会很有用:
# Extract the weekday name of December 31
weekday_format = "%A"
for year in range(2022, 2026):
print(f"Weekday of December 31, {year} is {date(year, 12, 31).strftime(weekday_format)}.")
Weekday of December 31, 2022 is Saturday.
Weekday of December 31, 2023 is Sunday.
Weekday of December 31, 2024 is Tuesday.
Weekday of December 31, 2025 is Wednesday.
时间戳
在编程中,经常会看到日期和时间以 Unix 时间戳格式存储。这种格式用数字表示任何日期。基本上,时间戳是从 1970 年 1 月 1 日 00:00:00 UTC(协调世界时)开始的 Unix 纪元过去的秒数。我们可以使用timestamp()函数来计算这个数字:
new_year_2023 = datetime(2022, 12, 31)
datetime.timestamp(new_year_2023)
1672441200.0
1672441200 是 Unix 纪元开始到 2022 年 12 月 31 日之间的秒数。
我们可以通过使用fromtimestamp()功能来执行相反的操作:
datetime.fromtimestamp(1672441200)
datetime.datetime(2022, 12, 31, 0, 0)
带日期的算术运算
有时,我们可能希望计算两个日期之间的差值,或者对日期和时间执行其他算术运算。幸运的是,Python 的工具箱中有许多工具来执行这样的计算。
基本算术运算
我们可以执行的第一个操作是计算两个日期之间的差异。为此,我们使用减号:
# Instatiate two dates
first_date = date(2022, 1, 1)
second_date = date(2022, 12, 31)
# Difference between two dates
date_diff = second_date - first_date
# Function to convert datetime to string
def dt_string(date, date_format="%B %d, %Y"):
return date.strftime(date_format)
print(f"The number of days and hours between {dt_string(first_date)} and {dt_string(second_date)} is {date_diff}.")
The number of days and hours between January 01, 2022 and December 31, 2022 is 364 days, 0:00:00.
让我们看看first_date - second_date 返回什么类型的对象:
type(date_diff)
datetime.timedelta
这个对象的类型是datetime.timedelta。它的名字中有 delta ,它指的是一个绿色的字母 delta ,\(\Delta\),在科学和工程中,它描述了一种变化。的确,在这里它代表了时间的变化(差异)。
如果我们只对两次约会之间的天数感兴趣呢?我们可以访问timedelta对象的不同属性,其中一个叫做.days。
print(f"The number of days between {dt_string(first_date)} and {dt_string(second_date)} is {(date_diff).days}.")
The number of days between January 01, 2022 and December 31, 2022 is 364.
时间差()
现在我们已经知道了timedelta对象,是时候介绍一下timedelta()函数了。它允许我们对时间对象执行许多算术运算,通过加减时间单位,如日、年、周、秒等。例如,我们可能想知道 30 天后是星期几。为此,我们必须创建一个表示当前时间的对象和一个定义我们添加的时间量的timedelta对象:
# Import timedelta
from datetime import timedelta
# Current time
now = datetime.now()
# timedelta of 30 days
one_month = timedelta(days=30)
# Day in one month/using dt_string function defined above
print(f"The day in 30 days is {dt_string(now + one_month)}.")
The day in 30 days is March 16, 2022.
如果我们查看timedelta函数(help(timedelta))的帮助页面,我们会看到它有以下参数:days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0。所以,你可以练习给一个日期加上或减去其他时间单位。例如,我们可以计算 2030 年新年前 12 小时的时间:
# New year 2030
new_year_2030 = datetime(2030, 1, 1, 0, 0)
# timedelta of 12 hours
twelve_hours = timedelta(hours=12)
# Time string of 12 hours before New Year 2023
twelve_hours_before = (new_year_2030 - twelve_hours).strftime("%B %d, %Y, %H:%M:%S")
# Print the time 12 hours before New Year 2023
print(f"The time twelve hours before New Year 2030 will be {twelve_hours_before}.")
The time twelve hours before New Year 2030 will be December 31, 2029, 12:00:00.
我们还可以组合timedelta()函数的多个参数来计算一个更具体的时间。例如,从现在起 27 天 3 小时 45 分钟后的时间是什么?
# Current time
now = datetime.now()
# Timedelta of 27 days, 3 hours, and 45 minutes
specific_timedelta = timedelta(days=27, hours=3, minutes=45)
# Time in 27 days, 3 hours, and 45 minutes
twenty_seven_days = (now + specific_timedelta).strftime("%B %d, %Y, %H:%M:%S")
print(f"The time in 27 days, 3 hours, and 45 minutes will be {twenty_seven_days}.")
The time in 27 days, 3 hours, and 45 minutes will be March 13, 2022, 15:18:39.
相对的()
不幸的是,我们可以从帮助页面看到,该函数不允许我们使用月或年。为了克服这个限制,我们可以使用的 dateutil包中的relativedelta函数。这个功能与timedelta()非常相似,但是它扩展了它的功能。
例如,我们想从当前时间中减去 2 年 3 个月 4 天 5 小时:
# Import relativedelta
from dateutil.relativedelta import relativedelta
# Current time
now = datetime.now()
# relativedelta object
relative_delta = relativedelta(years=2, months=3, days=4, hours=5)
two_years = (now - relative_delta).strftime("%B %d, %Y, %H:%M:%S")
print(f"The time 2 years, 3 months, 4 days, and 5 hours ago was {two_years}.")
The time 2 years, 3 months, 4 days, and 5 hours ago was November 10, 2019, 06:33:40.
我们还可以使用relativedelta()来计算两个datetime对象之间的差异:
relativedelta(datetime(2030, 12, 31), now)
relativedelta(years=+8, months=+10, days=+16, hours=+12, minutes=+26, seconds=+19, microseconds=+728345)
这些算术运算可能看起来非常抽象和不切实际,但实际上,它们在许多应用中是有用的。一个这样的场景可能如下所示。
比如说,我们脚本中的某个操作应该在特定日期前 30 天执行。我们可以定义一个保存当前时间的变量,并向它添加一个 30 天的timedelta对象。如果今天是这一天,操作将被唤起!
否则,想象我们正在使用熊猫处理数据集,其中一列包含一些日期。假设我们有一个数据集,其中保存了公司一年中每天的利润。我们希望创建另一个数据集,该数据集将保存从当前日期算起正好一年的日期以及这些日期中每一天的预测利润。我们一定会在日期上使用算术计算!
迟早,你会在你的数据科学项目中遇到日期和时间。当你这样做的时候,回到这个教程。
使用时区
正如我们在介绍中提到的,在编程中使用时间的一个问题是处理时区。它们可以有不同的形状。我们还应该知道,有些地区实行夏令时(DST),而有些地区不实行。
Python 区分了两类日期时间对象: 天真的和觉察的 。简单对象不保存任何关于时区的信息,而感知对象保存这些信息。
首先,我们来看一个幼稚的时间对象:
# Import tzinfo
from datetime import tzinfo
# Naive datetime
naive_datetime = datetime.now()
# Naive datetime doesn't hold any timezone information
type(naive_datetime.tzinfo)
NoneType
从 Python 3.9 开始,我们有了一个使用 互联网号码分配机构 数据库的时区的具体实现。实现这个功能的模块叫做 zoneinfo 。注意,如果你使用的是以前版本的 Python,你可以使用 pytz 或者 dateutil 包。
让我们使用zoneinfo创建一个 aware datetime对象,特别是ZoneInfo类,它是datetime.tzinfo抽象类的一个实现:
# Import ZoneInfo
from zoneinfo import ZoneInfo
utc_tz = ZoneInfo("UTC")
# Aware datetime object with UTC timezone
dt_utc = datetime.now(tz=utc_tz)
# The type of an aware object implemented with ZoneInfo is zoneinfo.ZoneInfo
type(dt_utc.tzinfo)
zoneinfo.ZoneInfo
我们可以看到一个 aware datetime对象拥有关于时区的信息(实现为一个zoneinfo.ZoneInfo对象)。
我们来看几个例子。我们想确定中欧和加利福尼亚的当前时间。
首先,我们可以在zoneinfo中列出所有可用的时区:
import zoneinfo
# Will return a long list of timezones (opens many files!)
zoneinfo.available_timezones()
{'Africa/Abidjan',
'Africa/Accra',
'Africa/Addis_Ababa',
'Africa/Algiers',
'Africa/Asmara',
'Africa/Asmera',
'Africa/Bamako',
'Africa/Bangui',
'Africa/Banjul',
'Africa/Bissau',
'Africa/Blantyre',
'Africa/Brazzaville',
'Africa/Bujumbura',
'Africa/Cairo',
'Africa/Casablanca',
'Africa/Ceuta',
'Africa/Conakry',
'Africa/Dakar',
'Africa/Dar_es_Salaam',
'Africa/Djibouti',
'Africa/Douala',
'Africa/El_Aaiun',
'Africa/Freetown',
'Africa/Gaborone',
'Africa/Harare',
'Africa/Johannesburg',
'Africa/Juba',
'Africa/Kampala',
'Africa/Khartoum',
'Africa/Kigali',
'Africa/Kinshasa',
'Africa/Lagos',
'Africa/Libreville',
'Africa/Lome',
'Africa/Luanda',
'Africa/Lubumbashi',
'Africa/Lusaka',
'Africa/Malabo',
'Africa/Maputo',
'Africa/Maseru',
'Africa/Mbabane',
'Africa/Mogadishu',
'Africa/Monrovia',
'Africa/Nairobi',
'Africa/Ndjamena',
'Africa/Niamey',
'Africa/Nouakchott',
'Africa/Ouagadougou',
'Africa/Porto-Novo',
'Africa/Sao_Tome',
'Africa/Timbuktu',
'Africa/Tripoli',
'Africa/Tunis',
'Africa/Windhoek',
'America/Adak',
'America/Anchorage',
'America/Anguilla',
'America/Antigua',
'America/Araguaina',
'America/Argentina/Buenos_Aires',
'America/Argentina/Catamarca',
'America/Argentina/ComodRivadavia',
'America/Argentina/Cordoba',
'America/Argentina/Jujuy',
'America/Argentina/La_Rioja',
'America/Argentina/Mendoza',
'America/Argentina/Rio_Gallegos',
'America/Argentina/Salta',
'America/Argentina/San_Juan',
'America/Argentina/San_Luis',
'America/Argentina/Tucuman',
'America/Argentina/Ushuaia',
'America/Aruba',
'America/Asuncion',
'America/Atikokan',
'America/Atka',
'America/Bahia',
'America/Bahia_Banderas',
'America/Barbados',
'America/Belem',
'America/Belize',
'America/Blanc-Sablon',
'America/Boa_Vista',
'America/Bogota',
'America/Boise',
'America/Buenos_Aires',
'America/Cambridge_Bay',
'America/Campo_Grande',
'America/Cancun',
'America/Caracas',
'America/Catamarca',
'America/Cayenne',
'America/Cayman',
'America/Chicago',
'America/Chihuahua',
'America/Coral_Harbour',
'America/Cordoba',
'America/Costa_Rica',
'America/Creston',
'America/Cuiaba',
'America/Curacao',
'America/Danmarkshavn',
'America/Dawson',
'America/Dawson_Creek',
'America/Denver',
'America/Detroit',
'America/Dominica',
'America/Edmonton',
'America/Eirunepe',
'America/El_Salvador',
'America/Ensenada',
'America/Fort_Nelson',
'America/Fort_Wayne',
'America/Fortaleza',
'America/Glace_Bay',
'America/Godthab',
'America/Goose_Bay',
'America/Grand_Turk',
'America/Grenada',
'America/Guadeloupe',
'America/Guatemala',
'America/Guayaquil',
'America/Guyana',
'America/Halifax',
'America/Havana',
'America/Hermosillo',
'America/Indiana/Indianapolis',
'America/Indiana/Knox',
'America/Indiana/Marengo',
'America/Indiana/Petersburg',
'America/Indiana/Tell_City',
'America/Indiana/Vevay',
'America/Indiana/Vincennes',
'America/Indiana/Winamac',
'America/Indianapolis',
'America/Inuvik',
'America/Iqaluit',
'America/Jamaica',
'America/Jujuy',
'America/Juneau',
'America/Kentucky/Louisville',
'America/Kentucky/Monticello',
'America/Knox_IN',
'America/Kralendijk',
'America/La_Paz',
'America/Lima',
'America/Los_Angeles',
'America/Louisville',
'America/Lower_Princes',
'America/Maceio',
'America/Managua',
'America/Manaus',
'America/Marigot',
'America/Martinique',
'America/Matamoros',
'America/Mazatlan',
'America/Mendoza',
'America/Menominee',
'America/Merida',
'America/Metlakatla',
'America/Mexico_City',
'America/Miquelon',
'America/Moncton',
'America/Monterrey',
'America/Montevideo',
'America/Montreal',
'America/Montserrat',
'America/Nassau',
'America/New_York',
'America/Nipigon',
'America/Nome',
'America/Noronha',
'America/North_Dakota/Beulah',
'America/North_Dakota/Center',
'America/North_Dakota/New_Salem',
'America/Nuuk',
'America/Ojinaga',
'America/Panama',
'America/Pangnirtung',
'America/Paramaribo',
'America/Phoenix',
'America/Port-au-Prince',
'America/Port_of_Spain',
'America/Porto_Acre',
'America/Porto_Velho',
'America/Puerto_Rico',
'America/Punta_Arenas',
'America/Rainy_River',
'America/Rankin_Inlet',
'America/Recife',
'America/Regina',
'America/Resolute',
'America/Rio_Branco',
'America/Rosario',
'America/Santa_Isabel',
'America/Santarem',
'America/Santiago',
'America/Santo_Domingo',
'America/Sao_Paulo',
'America/Scoresbysund',
'America/Shiprock',
'America/Sitka',
'America/St_Barthelemy',
'America/St_Johns',
'America/St_Kitts',
'America/St_Lucia',
'America/St_Thomas',
'America/St_Vincent',
'America/Swift_Current',
'America/Tegucigalpa',
'America/Thule',
'America/Thunder_Bay',
'America/Tijuana',
'America/Toronto',
'America/Tortola',
'America/Vancouver',
'America/Virgin',
'America/Whitehorse',
'America/Winnipeg',
'America/Yakutat',
'America/Yellowknife',
'Antarctica/Casey',
'Antarctica/Davis',
'Antarctica/DumontDUrville',
'Antarctica/Macquarie',
'Antarctica/Mawson',
'Antarctica/McMurdo',
'Antarctica/Palmer',
'Antarctica/Rothera',
'Antarctica/South_Pole',
'Antarctica/Syowa',
'Antarctica/Troll',
'Antarctica/Vostok',
'Arctic/Longyearbyen',
'Asia/Aden',
'Asia/Almaty',
'Asia/Amman',
'Asia/Anadyr',
'Asia/Aqtau',
'Asia/Aqtobe',
'Asia/Ashgabat',
'Asia/Ashkhabad',
'Asia/Atyrau',
'Asia/Baghdad',
'Asia/Bahrain',
'Asia/Baku',
'Asia/Bangkok',
'Asia/Barnaul',
'Asia/Beirut',
'Asia/Bishkek',
'Asia/Brunei',
'Asia/Calcutta',
'Asia/Chita',
'Asia/Choibalsan',
'Asia/Chongqing',
'Asia/Chungking',
'Asia/Colombo',
'Asia/Dacca',
'Asia/Damascus',
'Asia/Dhaka',
'Asia/Dili',
'Asia/Dubai',
'Asia/Dushanbe',
'Asia/Famagusta',
'Asia/Gaza',
'Asia/Harbin',
'Asia/Hebron',
'Asia/Ho_Chi_Minh',
'Asia/Hong_Kong',
'Asia/Hovd',
'Asia/Irkutsk',
'Asia/Istanbul',
'Asia/Jakarta',
'Asia/Jayapura',
'Asia/Jerusalem',
'Asia/Kabul',
'Asia/Kamchatka',
'Asia/Karachi',
'Asia/Kashgar',
'Asia/Kathmandu',
'Asia/Katmandu',
'Asia/Khandyga',
'Asia/Kolkata',
'Asia/Krasnoyarsk',
'Asia/Kuala_Lumpur',
'Asia/Kuching',
'Asia/Kuwait',
'Asia/Macao',
'Asia/Macau',
'Asia/Magadan',
'Asia/Makassar',
'Asia/Manila',
'Asia/Muscat',
'Asia/Nicosia',
'Asia/Novokuznetsk',
'Asia/Novosibirsk',
'Asia/Omsk',
'Asia/Oral',
'Asia/Phnom_Penh',
'Asia/Pontianak',
'Asia/Pyongyang',
'Asia/Qatar',
'Asia/Qostanay',
'Asia/Qyzylorda',
'Asia/Rangoon',
'Asia/Riyadh',
'Asia/Saigon',
'Asia/Sakhalin',
'Asia/Samarkand',
'Asia/Seoul',
'Asia/Shanghai',
'Asia/Singapore',
'Asia/Srednekolymsk',
'Asia/Taipei',
'Asia/Tashkent',
'Asia/Tbilisi',
'Asia/Tehran',
'Asia/Tel_Aviv',
'Asia/Thimbu',
'Asia/Thimphu',
'Asia/Tokyo',
'Asia/Tomsk',
'Asia/Ujung_Pandang',
'Asia/Ulaanbaatar',
'Asia/Ulan_Bator',
'Asia/Urumqi',
'Asia/Ust-Nera',
'Asia/Vientiane',
'Asia/Vladivostok',
'Asia/Yakutsk',
'Asia/Yangon',
'Asia/Yekaterinburg',
'Asia/Yerevan',
'Atlantic/Azores',
'Atlantic/Bermuda',
'Atlantic/Canary',
'Atlantic/Cape_Verde',
'Atlantic/Faeroe',
'Atlantic/Faroe',
'Atlantic/Jan_Mayen',
'Atlantic/Madeira',
'Atlantic/Reykjavik',
'Atlantic/South_Georgia',
'Atlantic/St_Helena',
'Atlantic/Stanley',
'Australia/ACT',
'Australia/Adelaide',
'Australia/Brisbane',
'Australia/Broken_Hill',
'Australia/Canberra',
'Australia/Currie',
'Australia/Darwin',
'Australia/Eucla',
'Australia/Hobart',
'Australia/LHI',
'Australia/Lindeman',
'Australia/Lord_Howe',
'Australia/Melbourne',
'Australia/NSW',
'Australia/North',
'Australia/Perth',
'Australia/Queensland',
'Australia/South',
'Australia/Sydney',
'Australia/Tasmania',
'Australia/Victoria',
'Australia/West',
'Australia/Yancowinna',
'Brazil/Acre',
'Brazil/DeNoronha',
'Brazil/East',
'Brazil/West',
'CET',
'CST6CDT',
'Canada/Atlantic',
'Canada/Central',
'Canada/Eastern',
'Canada/Mountain',
'Canada/Newfoundland',
'Canada/Pacific',
'Canada/Saskatchewan',
'Canada/Yukon',
'Chile/Continental',
'Chile/EasterIsland',
'Cuba',
'EET',
'EST',
'EST5EDT',
'Egypt',
'Eire',
'Etc/GMT',
'Etc/GMT+0',
'Etc/GMT+1',
'Etc/GMT+10',
'Etc/GMT+11',
'Etc/GMT+12',
'Etc/GMT+2',
'Etc/GMT+3',
'Etc/GMT+4',
'Etc/GMT+5',
'Etc/GMT+6',
'Etc/GMT+7',
'Etc/GMT+8',
'Etc/GMT+9',
'Etc/GMT-0',
'Etc/GMT-1',
'Etc/GMT-10',
'Etc/GMT-11',
'Etc/GMT-12',
'Etc/GMT-13',
'Etc/GMT-14',
'Etc/GMT-2',
'Etc/GMT-3',
'Etc/GMT-4',
'Etc/GMT-5',
'Etc/GMT-6',
'Etc/GMT-7',
'Etc/GMT-8',
'Etc/GMT-9',
'Etc/GMT0',
'Etc/Greenwich',
'Etc/UCT',
'Etc/UTC',
'Etc/Universal',
'Etc/Zulu',
'Europe/Amsterdam',
'Europe/Andorra',
'Europe/Astrakhan',
'Europe/Athens',
'Europe/Belfast',
'Europe/Belgrade',
'Europe/Berlin',
'Europe/Bratislava',
'Europe/Brussels',
'Europe/Bucharest',
'Europe/Budapest',
'Europe/Busingen',
'Europe/Chisinau',
'Europe/Copenhagen',
'Europe/Dublin',
'Europe/Gibraltar',
'Europe/Guernsey',
'Europe/Helsinki',
'Europe/Isle_of_Man',
'Europe/Istanbul',
'Europe/Jersey',
'Europe/Kaliningrad',
'Europe/Kiev',
'Europe/Kirov',
'Europe/Lisbon',
'Europe/Ljubljana',
'Europe/London',
'Europe/Luxembourg',
'Europe/Madrid',
'Europe/Malta',
'Europe/Mariehamn',
'Europe/Minsk',
'Europe/Monaco',
'Europe/Moscow',
'Europe/Nicosia',
'Europe/Oslo',
'Europe/Paris',
'Europe/Podgorica',
'Europe/Prague',
'Europe/Riga',
'Europe/Rome',
'Europe/Samara',
'Europe/San_Marino',
'Europe/Sarajevo',
'Europe/Saratov',
'Europe/Simferopol',
'Europe/Skopje',
'Europe/Sofia',
'Europe/Stockholm',
'Europe/Tallinn',
'Europe/Tirane',
'Europe/Tiraspol',
'Europe/Ulyanovsk',
'Europe/Uzhgorod',
'Europe/Vaduz',
'Europe/Vatican',
'Europe/Vienna',
'Europe/Vilnius',
'Europe/Volgograd',
'Europe/Warsaw',
'Europe/Zagreb',
'Europe/Zaporozhye',
'Europe/Zurich',
'Factory',
'GB',
'GB-Eire',
'GMT',
'GMT+0',
'GMT-0',
'GMT0',
'Greenwich',
'HST',
'Hongkong',
'Iceland',
'Indian/Antananarivo',
'Indian/Chagos',
'Indian/Christmas',
'Indian/Cocos',
'Indian/Comoro',
'Indian/Kerguelen',
'Indian/Mahe',
'Indian/Maldives',
'Indian/Mauritius',
'Indian/Mayotte',
'Indian/Reunion',
'Iran',
'Israel',
'Jamaica',
'Japan',
'Kwajalein',
'Libya',
'MET',
'MST',
'MST7MDT',
'Mexico/BajaNorte',
'Mexico/BajaSur',
'Mexico/General',
'NZ',
'NZ-CHAT',
'Navajo',
'PRC',
'PST8PDT',
'Pacific/Apia',
'Pacific/Auckland',
'Pacific/Bougainville',
'Pacific/Chatham',
'Pacific/Chuuk',
'Pacific/Easter',
'Pacific/Efate',
'Pacific/Enderbury',
'Pacific/Fakaofo',
'Pacific/Fiji',
'Pacific/Funafuti',
'Pacific/Galapagos',
'Pacific/Gambier',
'Pacific/Guadalcanal',
'Pacific/Guam',
'Pacific/Honolulu',
'Pacific/Johnston',
'Pacific/Kanton',
'Pacific/Kiritimati',
'Pacific/Kosrae',
'Pacific/Kwajalein',
'Pacific/Majuro',
'Pacific/Marquesas',
'Pacific/Midway',
'Pacific/Nauru',
'Pacific/Niue',
'Pacific/Norfolk',
'Pacific/Noumea',
'Pacific/Pago_Pago',
'Pacific/Palau',
'Pacific/Pitcairn',
'Pacific/Pohnpei',
'Pacific/Ponape',
'Pacific/Port_Moresby',
'Pacific/Rarotonga',
'Pacific/Saipan',
'Pacific/Samoa',
'Pacific/Tahiti',
'Pacific/Tarawa',
'Pacific/Tongatapu',
'Pacific/Truk',
'Pacific/Wake',
'Pacific/Wallis',
'Pacific/Yap',
'Poland',
'Portugal',
'ROC',
'ROK',
'Singapore',
'Turkey',
'UCT',
'US/Alaska',
'US/Aleutian',
'US/Arizona',
'US/Central',
'US/East-Indiana',
'US/Eastern',
'US/Hawaii',
'US/Indiana-Starke',
'US/Michigan',
'US/Mountain',
'US/Pacific',
'US/Samoa',
'UTC',
'Universal',
'W-SU',
'WET',
'Zulu',
'build/etc/localtime'}
现在我们可以使用ZoneInfo来确定不同地区的当前时间:
# Function to convert datetime into ISO formatted time
def iso(time, time_format="%Y-%m-%d %H:%M:%S"):
return time.strftime(time_format)
# CET time zone
cet_tz = ZoneInfo("Europe/Paris")
# PST time zone
pst_tz = ZoneInfo("America/Los_Angeles")
# Current time in Central Europe
dt_cet = datetime.now(tz=cet_tz)
# Current time in California
dt_pst = datetime.now(tz=pst_tz)
print(f"Current time in Central Europe is {iso(dt_cet)}.")
print(f"Current time in California is {iso(dt_pst)}.")
Current time in Central Europe is 2022-02-14 11:33:42.
Current time in California is 2022-02-14 02:33:42.
让我们打印datetime.now(tz=cet_tz):
print(datetime.now(tz=cet_tz))
2022-02-14 11:33:43.048967+01:00
我们看到有+01:00,表示 UTC 偏移。事实上,欧洲中部时区比世界协调时早一个小时。
此外,ZoneInfo类处理夏令时。例如,我们可以在 DST 发生变化的一天中增加一天(24 小时)。在美国,2022 年,它将发生在 11 月 5 日(时钟向后)。
# Define timedelta
time_delta = timedelta(days=1)
# November 5, 2022, 3 PM
november_5_2022 = datetime(2022, 11, 5, 15, tzinfo=pst_tz) # Note that we should use tzinfo in the datetime construct
print(november_5_2022)
# Add 1 day to November 5, 2022
print(november_5_2022 + time_delta)
2022-11-05 15:00:00-07:00
2022-11-06 15:00:00-08:00
我们可以看到,偏移量从-07:00变为-08:00,但是时间保持不变(15:00)。
纽约市 2023 年新年倒计时
新年前夕,纽约的时代广场吸引了成千上万的人。让我们运用目前所学的一切知识,为时代广场新年前夜制作一个倒计时器!
这里我们将使用来自dateutil包的tz,它允许我们设置本地时区来展示dateutil包的效用。然而,我们也可以使用zoneinfo的build/etc/localtime时区来做同样的事情。
from zoneinfo import ZoneInfo
from dateutil import tz
from datetime import datetime
def main():
"""Main function."""
# Set current time in our local time zone
now = datetime.now(tz=tz.tzlocal())
# New York City time zone
nyc_tz = ZoneInfo("America/New_York")
# New Year 2023 in NYC
new_year_2023 = datetime(2023, 1, 1, 0, 0, tzinfo=nyc_tz)
# Compute the time left to New Year in NYC
countdown = relativedelta(new_year_2023, now)
# Print time left to New Year 2023
print(f"New Year in New Your City will come on: {new_year_2023.strftime('%B %-d, %Y %H:%M:%S')}.")
print(f"Time left to New Year 2023 in NYC is: {countdown.months} months, {countdown.days} days, {countdown.hours} hours, {countdown.minutes} minutes, {countdown.seconds} seconds.")
if __name__ == "__main__":
main()
New Year in New Your City will come on: January 1, 2023 00:00:00.
Time left to New Year 2023 in NYC is: 10 months, 17 days, 18 hours, 26 minutes, 16 seconds.
我们将代码包装在 main()函数中,现在我们可以在.py文件中使用它。在这个脚本中,我们使用时区,创建了一个datetime对象,使用strftime()将其转换为字符串,甚至访问了一个relativedelta对象的时间属性!
为了练习,你可以改进剧本。2022 年我在写这篇教程,所以对我来说,新年还没到。如果你在未来几年阅读它,你可以改进它,并考虑到 2023 年已经到来的事实。您还可以包括未来新年之前的剩余时间。或者你可以计算从前一个新年过去的时间。您还可以使用pytz包更新脚本,使其与 Python 的旧版本(3.9 之前)兼容。现在就看你的了。
结论
以下是我们在本教程中介绍的内容:
- 在计算机上表示日期和时间的问题
- 创建
date、time和datetime对象 - 标准日期格式,ISO 8061
- 使用
fromisoformat()和strptime()从字符串中提取日期 - 使用
strftime()将datetime对象转换成字符串 - 时间戳
- 日期和
timedelta对象的算术运算 - 用 Python 处理时区
- 在纽约市创建一个 2023 年新年倒计时器
现在,您的工具箱中有大量的工具,您可以开始用 Python 处理日期和时间了。
请随时在 LinkedIn 和 GitHub 上联系我。编码快乐!
Python 的 Deque:如何轻松实现队列和堆栈
原文:https://www.dataquest.io/blog/python-deque-queues-stacks/
September 8, 2022
如果您使用 Python,您可能对列表很熟悉,并且您可能也经常使用它们。它们是很棒的数据结构,有许多有用的方法,允许用户通过添加、删除和排序条目来修改列表。然而,在一些用例中,列表可能看起来是一个很好的选择,但它并不是。
在本文中,我们将介绍当您需要在 Python 中实现队列和堆栈时,collections模块中的deque()函数如何成为更好的选择。
为了阅读本文,我们假设您对 Python 编程有一定的经验,使用列表及其方法,因为它们中的大多数都可以推断出collections.deque的用法。
队列和堆栈
首先:在进入collections模块之前,让我们先理解队列和堆栈的概念。
行列
队列是一种以先进先出(FIFO)方式存储项目的数据结构。也就是说,添加到队列中的第一个项目将是从队列中移除的第一个项目。
比方说,你正在你最喜欢的音乐播放器中添加歌曲。你还没有开始,所以你的队列是空的。然后你添加三首歌曲:song_1、song_2和song_3,按照这个顺序。现在,您的队列如下所示:
queue = ['song_1', 'song_2', 'song_3']
然后,您开始播放队列中的歌曲。第一个出场并移出队列的就是第一个加入的:song_1 —这样,先进先出。根据这条规则,如果您播放了几首歌曲,然后又添加了三首,这将是您的队列:
queue = ['song_3', 'song_4', 'song_5', 'song_6']
大量
堆栈是一种以后进先出(LIFO)方式存储项目的数据结构。也就是说,添加到堆栈中的最后一项将是从堆栈中移除的第一项。
栈的一个经典例子是一堆盘子。假设你有几个朋友过来吃饭,用了五个盘子。晚饭后,你把那五个盘子堆在水槽里。所以你会有这个堆栈:
stack = ['plate_1', 'plate_2', 'plate_3', 'plate_4', 'plate_5']
当你开始洗碗时,你从最上面的一堆开始,plate_5,这意味着最后一个进来,先出去。所以在你洗完三个盘子后,一个朋友拿来另一个她用来做甜点的盘子,放在盘子堆的最上面。您的堆栈现在看起来像这样:
stack = ['plate_1', 'plate_2', 'plate_6']
这意味着plate_6将是下一个被清洗的。
为什么不是列表?
既然我们已经理解了队列和堆栈的概念,那么看起来用 Python 实现这些结构用列表就可以了。毕竟它们是用来代表歌曲的队列和上面的盘子堆的,对吧?嗯,没那么多。
列表不是 Python 中队列或堆栈的最佳数据结构,原因有两个。首先,列表不是线程安全的,这意味着如果一个列表被多个线程同时访问和修改,事情可能会变得不太顺利,最终可能会出现不一致的数据或错误消息。
此外,当您需要从列表的左端插入或删除元素时,列表也不是很有效。如果您使用list.append()在右端插入一个元素,或者使用list.pop()删除最右边的元素,列表将会很好地执行。但是,当您试图在左端执行这些操作时,列表需要将所有其他元素向右移动,这意味着列表的大小会影响执行此类操作所需的时间,从而导致性能下降。
使用collections.deque
来自collections的deque对象是一个类似列表的对象,支持快速追加,从两边弹出。它还支持线程安全、内存高效的操作,并且在用作队列和堆栈时,它被特别设计为比列表更高效。
名称 deque 是双端队列的缩写,发音像“deck”
创建一个deque对象
deque将一个 iterable 作为参数,它将成为一个deque对象。如果没有传递,它将为空:
from collections import deque
queue = deque()
print(queue)
deque([])
但是我们也可以将任何 iterable 传递给deque。下面,我们可以看到如何将字典中的列表、元组、集合、键和值转换成一个deque对象:
songs_list = ['song_1', 'song_2', 'song_3']
songs_tuple = ('song_1', 'song_2', 'song_3')
songs_set = {'song_1', 'song_2', 'song_3'}
songs_dict = {'1': 'song_1', '2': 'song_2', '3': 'song_3'}
deque_from_list = deque(songs_list)
deque_from_tuple = deque(songs_tuple)
deque_from_set = deque(songs_set)
deque_from_dict_keys = deque(songs_dict.keys())
deque_from_dict_values = deque(songs_dict.values())
print(deque_from_list)
print(deque_from_tuple)
print(deque_from_set)
print(deque_from_dict_keys)
print(deque_from_dict_values)
deque(['song_1', 'song_2', 'song_3'])
deque(['song_1', 'song_2', 'song_3'])
deque(['song_3', 'song_1', 'song_2'])
deque(['1', '2', '3'])
deque(['song_1', 'song_2', 'song_3'])
现在我们已经初始化了deque对象,我们可以使用 append 和 pop 方法从右端插入和删除项目:
queue = deque(songs_list)
print(queue)
queue.append('song_4')
print(queue)
queue.pop()
print(queue)
deque(['song_1', 'song_2', 'song_3'])
deque(['song_1', 'song_2', 'song_3', 'song_4'])
deque(['song_1', 'song_2', 'song_3'])
注意song_4 被插入到最右边的位置,然后被删除。
从左侧追加和删除
与列表相比,deque最大的优势之一是可以从左端添加和删除条目。
在列表中我们使用insert()方法,而对于deque,我们可以使用appendleft()方法。以下是每种方法的工作原理:
songs_list.insert(0, 'new_song')
print(songs_list)
queue.appendleft('new_song')
print(queue)
['new_song', 'song_2', 'song_3']
deque(['new_song', 'song_1', 'song_2', 'song_3'])
删除左端的项目也是一样。在一个列表中,我们使用索引为零的pop()方法作为参数,表示第一项应该被删除。在一个deque中,我们有popleft()方法来执行这个任务:
songs_list.pop(0)
print(songs_list)
queue.popleft()
print(queue)
['song_2', 'song_3']
deque(['song_1', 'song_2', 'song_3'])
如前所述,deque对象对于左端的这些操作更有效,尤其是当队列的大小增加时。
根据队列和堆栈的概念,我们使用popleft()方法从列表中删除第一个插入的条目。我们从右边追加,从左边移除:先进先出。
然而,如果队列为空,pop()和popleft()方法都会引发错误。在try和except子句中使用这些方法来防止错误是一个很好的实践。我们将在本文后面看到一个例子。
最后,我们还可以使用extendleft()方法将多个元素插入队列。此方法采用一个 iterable。这里有一个例子:
queue.extendleft(['new_song_1', 'new_song_2'])
print(queue)
deque(['new_song_2', 'new_song_1', 'song_1', 'song_2', 'song_3'])
队列上的内置函数和迭代
就像列表、元组和集合一样,deque对象也支持 Python 的内置函数。
例如,我们可以使用len()来检查一个队列的大小:
print(len(queue))
5
我们可以使用sorted()函数对一个队列进行排序:
print(sorted(queue))
['new_song_1', 'new_song_2', 'song_1', 'song_2', 'song_3']
我们使用reversed()函数来反转deque对象中项目的顺序:
print(deque(reversed(queue)))
deque(['song_3', 'song_2', 'song_1', 'new_song_1', 'new_song_2'])
还支持max()和min()功能:
new_queue = deque([1, 2, 3])
print(max(new_queue))
print(min(new_queue))
3
1
当然,我们可以遍历队列:
for song in queue:
print(song)
new_song_2
new_song_1
song_1
song_2
song_3
实现队列
现在,让我们将一个简化版本的队列付诸实践。我们将继续使用歌曲队列的例子,这意味着我们的队列将继续接收新的歌曲,同时播放队列中最老的歌曲,然后删除它们。虽然我们实现的是队列,但是我们可以使用相同的概念以非常相似的方式实现堆栈。
首先,我们将编写一个函数,将一个deque对象作为队列和歌曲列表。然后,该函数选择一首随机歌曲,并将其添加到队列中。该函数还打印出添加了哪首歌曲以及当前队列。这个过程会无限下去。
def add_song(queue, songs):
while True:
index = randint(0, len(songs))
song = songs[index]
queue.append(song)
print(f'Song Added: {song}, Queue: {queue}')
sleep(randint(0, 5))
我们现在需要一个功能来删除正在播放的歌曲。这个函数实际上不会播放一首歌曲,因为它的目标只是用 Python 来表示队列的功能。相反,这个函数接收一个队列,删除最左边的元素,并打印被删除的项和当前队列。如果队列为空,该函数将打印出来。
def play_song(queue):
while True:
try:
song = queue.popleft()
print(f'Song Played: {song}, Queue: {queue}')
except IndexError:
print('Queue is empty.')
sleep(randint(0, 5))
接下来,我们将创建一个歌曲列表并实例化一个deque对象。最后,我们将使用 Python 的threading模块同时运行这两个函数。这是最后的代码:
from threading import Thread
from collections import deque
from time import sleep
from random import randint
songs = [f'song_{i+1}' for i in range(100)]
def add_song(queue, songs):
while True:
index = randint(0, len(songs))
song = songs[index]
queue.append(song)
print(f'Song Added: {song}, Queue: {queue}')
sleep(randint(0, 5))
def play_song(queue):
while True:
try:
song = queue.popleft()
print(f'Song Played: {song}, Queue: {queue}')
except IndexError:
print('Queue is empty.')
sleep(randint(0, 5))
queue = deque()
Thread(target=add_song, args=(queue, songs)).start()
Thread(target=play_song, args=(queue,)).start()
如果我们运行上面的代码,我们将得到如下输出:
Song Added: song_60, Queue: deque(['song_60'])
Song Played: song_60, Queue: deque([])
Queue is empty.
Queue is empty.
Song Added: song_13, Queue: deque(['song_13'])
Song Played: song_13, Queue: deque([])
Queue is empty.
Song Added: song_59, Queue: deque(['song_59'])
Song Added: song_46, Queue: deque(['song_59', 'song_46'])
Song Added: song_48, Queue: deque(['song_59', 'song_46', 'song_48'])
Song Played: song_59, Queue: deque(['song_46', 'song_48'])
Song Added: song_3, Queue: deque(['song_46', 'song_48', 'song_3'])
Song Played: song_46, Queue: deque(['song_48', 'song_3'])
Song Added: song_98, Queue: deque(['song_48', 'song_3', 'song_98'])
Song Played: song_48, Queue: deque(['song_3', 'song_98'])
请注意,代码在队列的右端添加歌曲,并从左端删除它们,同时遵守用户定义的歌曲顺序。此外,由于deque支持多线程,我们对两个函数同时访问和修改同一个对象没有问题。
结论
在本文中,我们介绍了来自collections的deque对象如何成为在 Python 中实现队列和堆栈的绝佳选择。我们还介绍了以下内容:
-
队列和堆栈的概念
-
为什么在这种情况下列表不是最好的选择
-
如何使用
deque对象 -
实现在生产中工作的队列的简化版本
Python 字典:综合教程(包含 52 个代码示例)
April 1, 2022
Python 中的字典是什么?
Python 字典是一种数据结构,它允许我们轻松地编写非常高效的代码。在许多其他语言中,这种数据结构被称为哈希表,因为它的键是可哈希的。我们很快就会明白这意味着什么。
Python 字典是key:value对的集合。你可以把它们想象成单词,以及它们在普通字典中的意思。据说值被映射到键。例如,在一本物理词典中,使用计算机方法在复杂数据中搜索模式的定义科学被映射到关键字数据科学。
在这个 Python 教程中,你将学习如何创建一个 Python 字典,如何使用它的方法,以及字典理解,以及哪个更好:字典还是列表。为了充分利用本教程,您应该已经熟悉 Python 列表、for 循环、条件语句以及使用reader()方法读取数据集。如果你不是,你可以在 Dataquest 了解更多。
Python 字典是用来做什么的?
Python 字典允许我们将一个值与一个惟一的键相关联,然后通过快速访问这个值。每当我们想要找到(查找)某个 Python 对象时,使用它们是一个好主意。我们也可以在这个范围内使用列表,但是它们比字典慢得多。
这个速度是由于字典键是可散列的。Python 中的每个不可变的对象都是可散列的,所以我们可以将其传递给hash()函数,该函数将返回该对象的哈希值。然后,这些值用于查找与其唯一键相关联的值。参见下面的hash()功能使用示例:
print(hash("b"))
2132352943288137677
字符串b的哈希值为2132352943288137677。在您的情况下,该值可能有所不同。
如何创建字典?
但是,让我们停止理论,直接进入词典创作。我们有两种主要的方法来定义字典:用花括号{}或者使用dict()方法。我们将创建两个空字典:
# Create a dictionary
dictionary = {} # Curly braces method
another_dictionary = dict() # Dict method
# Are the above dictionaries equivalent?
print(type(dictionary))
print(type(another_dictionary))
print(dictionary == another_dictionary)
<class><class>True
我们可以看到,这两个字典具有相同的数据类型,并且是等效的。现在让我们用键和值填充一个字典。我们可以用方括号来做,就像这个dictionary[key] = value。然后,我们可以通过使用括号符号来访问该值,我们想要的值在括号之间:dictionary[key]。
# Populate the dictionary
dictionary["key1"] = "value1"
# Access key1
print(dictionary["key1"])
value1
返回key1的值。我们还可以使用下面的语法创建一个预填充的字典:
# Create a dictionary with preinserted keys/values
dictionary = {"key1": "value1"}
# Access key1
print(dictionary["key1"])
value1
最后,另一种方法是使用dict(),其中我们将键和值作为关键字参数列表或元组列表提供:
# Keyword argument list
dictionary = dict(key1="value1", key2="value2")
# Display the dictionary
print(dictionary)
{'key1': 'value1', 'key2': 'value2'}
# List of tuples
dictionary = dict([("key1", "value1"), ("key2", "value2")])
# Display the dictionary
print(dictionary)
{'key1': 'value1', 'key2': 'value2'}
我们对键和值使用了字符串数据类型,但是其他允许的数据类型是什么呢?在 Python 字典中,键应该是可散列的对象(即使技术上不正确,我们也可以说对象应该是不可变的)。因此,像列表这样的可变数据类型是不允许的。让我们尝试不同的数据类型,看看会发生什么:
# Hashing various data types
print(hash(1)) # Integer
print(hash(1.2)) # Float
print(hash("dataquest")) # String
print(hash((1, 2))) # Tuple
print(hash([1, 2, 3]))
1
461168601842738689
-3975257749889514375
-3550055125485641917
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_10024/758405818.py in <module>
4 print(hash("dataquest")) # String
5 print(hash((1, 2))) # Tuple
----> 6 print(hash([1, 2, 3]))
TypeError: unhashable type: 'list'
整数、浮点、字符串和元组是可散列的数据类型(它们也是不可变的)而列表是不可散列的数据类型(它们是可变的)。Python 使用哈希值来快速访问字典的值。
另一方面,值可以是任何类型。让我们使用不同的数据类型向字典添加更多的元素:
# Add more elements to the dictionary
dictionary[42] = "the answer to the ultimate question of life, the universe, and everything."
dictionary[1.2] = ["one point two"]
dictionary["list"] = ["just", "a", "list", "with", "an", "integer", 3]
# Display the dictionary
print(dictionary)
{'key1': 'value1', 'key2': 'value2', 42: 'the answer to the ultimate question of life, the universe, and everything.', 1.2: ['one point two'], 'list': ['just', 'a', 'list', 'with', 'an', 'integer', 3]}
此外,我们可以用我们用来填充字典的括号符号来修改一个键的值:
# Modify a value
dictionary["list"] = ["it's another", "list"]
# Display the dictionary
print(dictionary)
print()
# Access the value of "list"
print(dictionary["list"])
{'key1': 'value1', 'key2': 'value2', 42: 'the answer to the ultimate question of life, the universe, and everything.', 1.2: ['one point two'], 'list': ["it's another", 'list']}
["it's another", 'list']
最后,字典键应该是唯一的。让我们尝试创建一个具有重复键的字典:
# Dictionary with duplicate keys
duplicated_keys = {"key1": "value1", "key1": "value2", "key1": "value3"}
# Access key1
print(duplicated_keys["key1"])
value3
只返回最后一个键的值,所以技术上我们可以使用重复的键,但不建议这样做,因为字典的一个优点是快速检索与某个键相关联的值。如果有重复的,我们可能会返回一个我们不想要的值。想象一下,我们查找单词“data”的含义,并在字典中找到这个单词的 10 个不同的条目;可能会比较混乱。
Python 字典方法
现在让我们看看我们可以用什么方法来使用字典。
T2update()
每当我们想要合并字典或使用可迭代对象(例如,可迭代对象是列表或元组)添加新的key:value对时, update()方法就很有用。让我们用哈利波特世界中的人物和他们所属的房子来做个例子(剧透:我们稍后会用到哈利波特数据集!):
# Create a Harry Potter dictionary
harry_potter_dict = {
"Harry Potter": "Gryffindor",
"Ron Weasley": "Gryffindor",
"Hermione Granger": "Gryffindor"
}
# Display the dictionary
print(harry_potter_dict)
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor'}
现在让我们使用update()方法的不同选项添加其他角色和他们的房子:
# Characters to add to the Harry Potter dictionary
add_characters_1 = {
"Albus Dumbledore": "Gryffindor",
"Luna Lovegood": "Ravenclaw"
}
# Merge dictionaries
harry_potter_dict.update(add_characters_1)
# Display the dictionary
print(harry_potter_dict)
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw'}
我们可以看到字典现在包含了阿不思·邓布利多和卢娜。我们还可以使用 iterable 向字典中添加新元素:
# Use iterables to update a dictionary
add_characters_2 = [
["Draco Malfoy", "Slytherin"],
["Cedric Diggory", "Hufflepuff"]
]
harry_potter_dict.update(add_characters_2)
print(harry_potter_dict)
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff'}
我们使用了一个列表列表,其中每个列表的第一个元素是角色的名字,第二个元素是他们的房子。然后,update()方法会自动将第一个元素(键)与第二个元素(值)关联起来。出于实验的考虑,尝试用一个列表更新字典,但是每个嵌套列表中有三个元素。
我们也可以使用元组列表:
# Use iterables to update a dictionary
add_characters_3 = [
("Rubeus Hagrid", "Gryffindor"),
("Minerva McGonagall", "Gryffindor")
]
harry_potter_dict.update(add_characters_3)
print(harry_potter_dict)
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor', 'Minerva McGonagall': 'Gryffindor'}
T2del
如果我们想从字典中删除一个key:value对呢?我们可以用 del陈述。必须说明的是,del不是一个专有的字典方法,而是一个 Python 关键字,我们可以在多种情况下使用它来删除任何 Python 对象(如变量、函数、类、列表元素等)。).
# Delete a key:value pair
del harry_potter_dict["Minerva McGonagall"]
print(harry_potter_dict)
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor'}
如果我们试图删除字典中不存在的一对,我们将得到一个KeyError:
# Delete a key:value pair that doesn't exist in the dictionary
del harry_potter_dict["Voldemort"]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_10024/3860415884.py in <module>
1 # Delete a key:value pair that doesn't exist in the dictionary
----> 2 del harry_potter_dict["Voldemort"]
KeyError: 'Voldemort'
popitem() 和 pop()
有时,我们需要删除词典中插入的最后一个条目。 popitem()方法就是方法!注意在 Python 3.7 之前的,这个方法从字典中移除了一个随机元素:
# Insert Voldemort
harry_potter_dict["Voldemort"] = "Slytherin"
print("Dictionary with Voldemort:")
print(harry_potter_dict)
print()
# Remove the last inserted item (Voldemort)
harry_potter_dict.popitem()
print("Dictionary after popping the last inserted item (Voldemort):")
print(harry_potter_dict)
Dictionary with Voldemort:
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor', 'Voldemort': 'Slytherin'}
Dictionary after popping the last inserted item (Voldemort):
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor'}
我们还可以删除一个特定的key:value对,并使用 pop()方法返回值:
# Insert Voldemort
harry_potter_dict["Voldemort"] = "Slytherin"
print("Dictionary with Voldemort:")
print(harry_potter_dict)
print()
# Remove the last inserted item (Voldemort)
print("Remove Voldemort and return his house:")
print(harry_potter_dict.pop("Voldemort"))
print()
print("Dictionary after popping the last inserted item (Voldemort):")
print(harry_potter_dict)
Dictionary with Voldemort:
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor', 'Voldemort': 'Slytherin'}
Remove Voldemort and return his house:
Slytherin
Dictionary after popping the last inserted item (Voldemort):
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor'}
T2get()
如果我们试图访问字典中不存在的键值,Python 将返回一个KeyError。为了解决这个问题,我们可以使用 get()方法,如果它的键在字典中,它将返回值,或者它将返回我们设置的一些默认值:
# Return an existing value
print(harry_potter_dict.get("Harry Potter", "Key not found"))
# Return a default value if no key found in the dictionary
print(harry_potter_dict.get("Voldemort", "Key not found"))
# Try to retrieve a value of a non-existing key without get
print(harry_potter_dict["Voldemort"])
Gryffindor
Key not found
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_10024/3808675782.py in <module>
6
7 # Try to retrieve a value of a non-existing key without get
----> 8 print(harry_potter_dict["Voldemort"])
KeyError: 'Voldemort'
T2setdefault()
setdefault()法经常与get()法混淆。他们执行或多或少相同的任务。事实上,如果我们怀疑字典中有一个不存在的键,我们可以使用这个方法返回一个默认值。然而,与get()不同的是,这个方法在字典中插入这个键的默认值:
print("Dictionary without Voldemort.")
print(harry_potter_dict)
print()
print("Return the default value of Voldemort.")
print(harry_potter_dict.setdefault("Voldemort", "Slytherin"))
print()
print("Voldemort is now in the dictionary!")
print(harry_potter_dict)
Dictionary without Voldemort.
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor'}
Return the default value of Voldemort.
Slytherin
Voldemort is now in the dictionary!
{'Harry Potter': 'Gryffindor', 'Ron Weasley': 'Gryffindor', 'Hermione Granger': 'Gryffindor', 'Albus Dumbledore': 'Gryffindor', 'Luna Lovegood': 'Ravenclaw', 'Draco Malfoy': 'Slytherin', 'Cedric Diggory': 'Hufflepuff', 'Rubeus Hagrid': 'Gryffindor', 'Voldemort': 'Slytherin'}
items()keys()values()
如果我们想返回所有的key:value对呢?还是只有钥匙?价值观呢?
第一个问题的答案是 items()法。当在字典上使用时,它将返回一个dict_items对象,该对象本质上是一个元组列表,每个元组包含一个键和值。当我们遍历字典时,这个方法可能是有用的,我们将在后面看到。
print(harry_potter_dict.items())
dict_items([('Harry Potter', 'Gryffindor'), ('Ron Weasley', 'Gryffindor'), ('Hermione Granger', 'Gryffindor'), ('Albus Dumbledore', 'Gryffindor'), ('Luna Lovegood', 'Ravenclaw'), ('Draco Malfoy', 'Slytherin'), ('Cedric Diggory', 'Hufflepuff'), ('Rubeus Hagrid', 'Gryffindor'), ('Voldemort', 'Slytherin')])
如果我们只想得到密钥,我们应该使用 keys()方法。它将返回一个dict_keys对象:
print(harry_potter_dict.keys())
dict_keys(['Harry Potter', 'Ron Weasley', 'Hermione Granger', 'Albus Dumbledore', 'Luna Lovegood', 'Draco Malfoy', 'Cedric Diggory', 'Rubeus Hagrid', 'Voldemort'])
最后,我们有将值作为一个dict_values对象返回的values()方法:
print(harry_potter_dict.values())
dict_values(['Gryffindor', 'Gryffindor', 'Gryffindor', 'Gryffindor', 'Ravenclaw', 'Slytherin', 'Hufflepuff', 'Gryffindor', 'Slytherin'])
我什么时候使用所有这些方法?
在这个概述之后,你可能会被大量的信息淹没。确定何时应该使用 Python 字典方法也不容易。别担心——这完全没问题。你不应该试图记住每一个方法及其用例。当你面临一个现实世界的问题时(Dataquest 指导的项目可能是一个好的开始),你必须使用字典,只要回到这个 Python 教程,看看你能否用这些方法中的一个来解决你的问题。这是您获得宝贵经验并在未来项目中更快使用字典方法的唯一方法!
在字典中循环
正如我们能够遍历列表一样,我们也能够遍历字典。它们包含两种不同类型的元素,键和值,所以我们可以同时遍历这两种类型的元素,也可以只遍历其中一种。
首先,我们将使用items()方法,它产生键和值:
for key, value in harry_potter_dict.items():
print((key, value))
('Harry Potter', 'Gryffindor')
('Ron Weasley', 'Gryffindor')
('Hermione Granger', 'Gryffindor')
('Albus Dumbledore', 'Gryffindor')
('Luna Lovegood', 'Ravenclaw')
('Draco Malfoy', 'Slytherin')
('Cedric Diggory', 'Hufflepuff')
('Rubeus Hagrid', 'Gryffindor')
('Voldemort', 'Slytherin')
# Alternatively
for key_value in harry_potter_dict.items():
print(key_value)
('Harry Potter', 'Gryffindor')
('Ron Weasley', 'Gryffindor')
('Hermione Granger', 'Gryffindor')
('Albus Dumbledore', 'Gryffindor')
('Luna Lovegood', 'Ravenclaw')
('Draco Malfoy', 'Slytherin')
('Cedric Diggory', 'Hufflepuff')
('Rubeus Hagrid', 'Gryffindor')
('Voldemort', 'Slytherin')
for key, value in harry_potter_dict.items():
print(f"The current key is {key} and its value is {value}.")
The current key is Harry Potter and its value is Gryffindor.
The current key is Ron Weasley and its value is Gryffindor.
The current key is Hermione Granger and its value is Gryffindor.
The current key is Albus Dumbledore and its value is Gryffindor.
The current key is Luna Lovegood and its value is Ravenclaw.
The current key is Draco Malfoy and its value is Slytherin.
The current key is Cedric Diggory and its value is Hufflepuff.
The current key is Rubeus Hagrid and its value is Gryffindor.
The current key is Voldemort and its value is Slytherin.
我们可以看到,这个方法允许我们访问键和值。如果我们只对钥匙感兴趣呢?还是只在价值观上?
# Loop only through the keys
for key in harry_potter_dict.keys():
print(key)
Harry Potter
Ron Weasley
Hermione Granger
Albus Dumbledore
Luna Lovegood
Draco Malfoy
Cedric Diggory
Rubeus Hagrid
Voldemort
# Loop only through the values
for value in harry_potter_dict.values():
print(value)
Gryffindor
Gryffindor
Gryffindor
Gryffindor
Ravenclaw
Slytherin
Hufflepuff
Gryffindor
Slytherin
让我们更实际一点,也学一个稍微高级一点的方法。有时,我们需要计算字典中每个值的出现频率。我们可以使用来自collections的 Counter()方法,这是一个很棒的 Python 模块,它有很多有用的容器,使我们的编码工作变得更容易。
from collections import Counter
# Frequency of values
counter = Counter(harry_potter_dict.values())
print(counter)
Counter({'Gryffindor': 5, 'Slytherin': 2, 'Ravenclaw': 1, 'Hufflepuff': 1})
返回的对象Counter实际上非常类似于一个字典。我们可以在上面使用keys()、values()和items()方法!
# Items of Counter
for k, v in counter.items():
print((k, v))
('Gryffindor', 5)
('Ravenclaw', 1)
('Slytherin', 2)
('Hufflepuff', 1)
# Keys of Counter
for k in counter.keys():
print(k)
Gryffindor
Ravenclaw
Slytherin
Hufflepuff
# Values of Counter
for f in counter.values():
print(f)
5
1
2
1
频率表
当我们必须创建所谓的频率表时,Python 字典非常方便。简单来说,键就是我们要统计频率的对象,值就是频率。作为一个例子,我们将使用来自 Kaggle 的哈利波特电影数据集(Character.csv数据集)。假设我们想统计数据集中每栋房子出现的频率。为此,我们首先必须创建一个包含频率表的空字典。然后,我们必须遍历房屋列表,如果房屋的关键字已经出现在频率表中,我们就在它的值上加 1。否则,我们为当前的房子创建一个键,并将其映射到值 1(它是 one ,因为我们第一次遇到这个元素)。我们还必须考虑数据集中缺失的数据。
from csv import reader
# Open and read the dataset
opened_file_char = open("Characters.csv", encoding="utf-8-sig")
read_file_char = reader(opened_file_char)
hp_characters = list(read_file_char)
# Initialize an empty dictionary that will hold a frequency table
houses = {}
# Create a frequency table
for character in hp_characters[1:]: # Note that we should not include the header in the looping; therefore, we start from index 1
house = character[4]
if house in houses:
houses[house] += 1
elif house == "":
continue
else:
houses[house] = 1
print(houses)
{'Gryffindor': 31, 'Slytherin': 20, 'Ravenclaw': 12, 'Hufflepuff': 8, 'Beauxbatons Academy of Magic': 2, 'Durmstrang Institute': 2}
数据集中的大部分角色都来自格兰芬多。为了练习,尝试创建其他列的频率表。
嵌套词典
与列表类似,还有嵌套字典。换句话说,一个字典可以包含另一个字典!让我们使用同一套哈利波特数据集中的Movies.csv数据集。在您的职业生涯中,可能会同时处理多个数据集。组织它们的一种方法是使用字典:
opened_file_movies = open("Movies.csv", encoding="utf-8-sig")
read_file_movies = reader(opened_file_movies)
movies = list(read_file_movies)
# characters key contains Harry Potter characters dataset
# movies key contains movies dataset
hp_datasets = dict(characters=hp_characters, movies=movies)
现在,我们可以轻松地访问每个数据集或特定条目。为了说明这一点,让我们访问characters数据集的列:
# Columns of the characters dataset
print(hp_datasets["characters"][0])
['Character ID', 'Character Name', 'Species', 'Gender', 'House', 'Patronus', 'Wand (Wood)', 'Wand (Core)']
我们还可以用 for 循环访问两个数据集的列:
# Columns of both datasets
for v in hp_datasets.values():
print(v[0])
['Character ID', 'Character Name', 'Species', 'Gender', 'House', 'Patronus', 'Wand (Wood)', 'Wand (Core)']
['Movie ID', 'Movie Title', 'Release Year', 'Runtime', 'Budget', 'Box Office']
这种方法的替代方法(尤其是当我们没有几十个数据集时)是在字典中重新组织每个数据集。当我们必须访问不同的条目时,这将简化我们的工作:
# Create a dictionary from the characters dataset
characters_dict = dict(
columns = hp_characters[0],
data = hp_characters[1:]
)
# Create a dictionary from the movies dataset
movies_dict = dict(
columns = movies[0],
data = movies[1:]
)
# Access movies columns and their first entry
print("Movies columns:")
print(movies_dict["columns"])
print()
print("The first entry of movies:")
print(movies_dict["data"][0])
Movies columns:
['Movie ID', 'Movie Title', 'Release Year', 'Runtime', 'Budget', 'Box Office']
The first entry of movies:
['1', "Harry Potter and the Philosopher's Stone", '2001', '152', '$125,000,000 ', '$1,002,000,000 ']
词典理解
Python 中的是一种创建新字典的优雅而高效的方法。你可能已经学习了一些关于列表理解的知识。简单提醒一下:Python 中的理解意味着对 iterable 的每个元素(比如 list)应用相同的操作。让我们来说明这种技术是如何工作的。例如,我们想要一本保存每部哈利波特电影运行时间的字典。让我们从数据集的字典movies_dict中创建它:
# Dictionary of movies' runtimes
runtimes = {}
for movie in movies_dict["data"]:
name = movie[1]
runtime = int(movie[3])
runtimes[name] = runtime
# Display the runtimes
print(runtimes)
{"Harry Potter and the Philosopher's Stone": 152, 'Harry Potter and the Chamber of Secrets': 161, 'Harry Potter and the Prisoner of Azkaban': 142, 'Harry Potter and the Goblet of Fire': 157, 'Harry Potter and the Order of the Phoenix': 138, 'Harry Potter and the Half-Blood Prince': 153, 'Harry Potter and the Deathly Hallows Part 1': 146, 'Harry Potter and the Deathly Hallows Part 2': 130}
现在我们想将每次运行时间从几分钟转换成几小时。首先,我们可以用一个常规的 for 循环来实现:
# Dictionary to hold the runtimes in hours
runtimes_hours = {}
# Transform the runtimes into hours
for k, v in runtimes.items():
runtimes_hours[k] = round(v / 60, 2)
# Display the runtimes in hours
print(runtimes_hours)
{"Harry Potter and the Philosopher's Stone": 2.53, 'Harry Potter and the Chamber of Secrets': 2.68, 'Harry Potter and the Prisoner of Azkaban': 2.37, 'Harry Potter and the Goblet of Fire': 2.62, 'Harry Potter and the Order of the Phoenix': 2.3, 'Harry Potter and the Half-Blood Prince': 2.55, 'Harry Potter and the Deathly Hallows Part 1': 2.43, 'Harry Potter and the Deathly Hallows Part 2': 2.17}
但是,我们可以通过在一行代码中创建运行时字典来简化上面的代码:
print({k:round(v / 60, 2) for k, v in runtimes.items()})
{"Harry Potter and the Philosopher's Stone": 2.53, 'Harry Potter and the Chamber of Secrets': 2.68, 'Harry Potter and the Prisoner of Azkaban': 2.37, 'Harry Potter and the Goblet of Fire': 2.62, 'Harry Potter and the Order of the Phoenix': 2.3, 'Harry Potter and the Half-Blood Prince': 2.55, 'Harry Potter and the Deathly Hallows Part 1': 2.43, 'Harry Potter and the Deathly Hallows Part 2': 2.17}
我们来剖析一下上面的代码。首先,看看 for 循环现在在哪里:我们仍然在循环遍历runtimes字典的条目。现在注意花括号:我们在字典里写代码!k是我们 for 循环的当前键,冒号(:)后我们在v上直接执行四舍五入除以 60 的运算,这是 for 循环的值。
这段代码执行与前面完全相同的操作,但是它只用了一行而不是三行。
此外,我们还可以添加条件语句。假设我们要排除短于 2.5 小时的电影:
print({k:round(v / 60, 2) for k, v in runtimes.items() if (v / 60) >= 2.5})
{"Harry Potter and the Philosopher's Stone": 2.53, 'Harry Potter and the Chamber of Secrets': 2.68, 'Harry Potter and the Goblet of Fire': 2.62, 'Harry Potter and the Half-Blood Prince': 2.55}
我们只需要添加一个 if 语句,就可以了。
字典理解也以类似的方式与按键一起工作。你自己试试!
请注意,如果我们有多个条件语句或复杂的操作,最好使用常规的 for 循环,因为字典理解可能会成为一个难以理解的编码丛林,这会破坏 Python 可读性的好处。
Python 字典 vs List:哪个更好?
现在我们对 Python 字典有了更多的了解,是时候比较字典和列表了。哪个更好?两者都不比另一个好,但它们在不同的编码任务中有帮助。
选择这些数据结构之一的规则实际上非常简单:
- 当您只需要可以通过索引访问的一系列元素时,请选择列表。
- 如果您需要快速访问映射到特定唯一键的元素,请选择字典。
不止这些。如果我们想要访问一个特定的元素,字典会快得多,因为它们有一个常量运行时间,这意味着运行时间不依赖于输入对象的大小。相反,当我们想要查看一个元素是否存在于一个列表中时,运行时将取决于这个列表的大小(Python 遍历整个列表)。请看例子:
import time
# Create a list
lst = [ele for ele in range(10**7)]
now = time.time()
if 3 in lst:
print(True)
list_runtime = time.time() - now
print(f"\nList runtime: {list_runtime} seconds.")
True
List runtime: 0.00010442733764648438 seconds.
# Create a dictionary
d = {i:i*2 for i in range(10**7)}
now = time.time()
if 3 in d.keys():
print(True)
dict_runtime = time.time() - now
print(f"\nDictionary runtime: {dict_runtime} seconds.")
True
Dictionary runtime: 9.512901306152344e-05 seconds.
print(f"Runtime difference between dictionary and list: {list_runtime - dict_runtime} seconds.")
Runtime difference between dictionary and list: 9.298324584960938e-06 seconds.
这种差异看起来可以忽略不计,但是随着输入量的增加,这种差异会急剧增加。
我们来举一个更具体的例子。通常,我们想要访问列表或字典中的某个元素。为了在列表中找到这个元素,我们首先必须遍历整个列表,而在字典中,我们可以通过使用它的惟一键来快速访问同一个元素。让我们在列表和上面定义的字典中找到 9000000。
# Find 90000000 in the list
now = time.time()
for i in lst:
if i == 90000000:
break
list_runtime = time.time() - now
print(f"\nList runtime: {list_runtime} seconds.")
List runtime: 0.27323484420776367 seconds.
# Find the value of 90000000 in the dictionary
now = time.time()
num = d[9000000]
dict_runtime = time.time() - now
print(f"\nDictionary runtime: {dict_runtime} seconds.")
Dictionary runtime: 3.62396240234375e-05 seconds.
print(f"Runtime difference between dictionary and list: {list_runtime - dict_runtime} seconds.")
print(f"\nDictionary is faster by {(list_runtime / dict_runtime) * 100} times!")
Runtime difference between dictionary and list: 0.27319860458374023 seconds.
Dictionary is faster by 753967.1052631579 times!
字典几乎不用花多少时间就能找到这个号码,而列表执行同样的操作只需要 1 秒钟左右。这部字典几乎快了一百万倍!
奖励:使用 defaultdict() 处理丢失的按键
回想一下,我们使用了setdefault()方法在字典中插入一个默认键及其值。我们还使用了get()方法来返回一个不存在的键的默认值。执行类似操作的另一种方式是使用collections模块()中的 defaultdict()。我们可以用默认值数据类型初始化一个字典,方法是调用它并将我们想要的数据类型传递给方法。现在,如果我们试图访问一个丢失的键,字典将创建这个键并为它映射一个默认值:
# Import defaultdict
from collections import defaultdict
# Initialize a default dictionary with the list data type
default_d = defaultdict(list)
# Call a missing key
print(default_d["missing_key"])
[]
这里,该方法创建了一个键missing_key并为其分配了一个空列表,因为这是我们的字典的默认值。我们现在可以将一些值追加到这个列表中:
# Append values to missing_key
for i in range(1, 6):
default_d["missing_key"].append(f"value{i}")
# Call "missing_key"
print(default_d["missing_key"])
print()
# Display default_d
print(default_d)
['value1', 'value2', 'value3', 'value4', 'value5']
defaultdict(<class>, {'missing_key': ['value1', 'value2', 'value3', 'value4', 'value5']})
我们传递给defaultdict()的参数必须是 可调用 。如果我们传递一个不可调用的对象给defaultdict(),我们将得到一个TypeError:
default_d = defaultdict(0)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_10024/3911435701.py in <module>
----> 1 default_d = defaultdict(0)
TypeError: first argument must be callable or None
相反,我们可以将任何对象传递给setdefault()方法:
d = {}
d.setdefault(0, 0)
print(d)
{0: 0}
我们再来看看get()方法。当我们想要返回一个我们怀疑不存在的键值时,我们使用它。该方法将只返回值,但不会以任何方式更改字典:
# Return the default value of a missing key
print(d.get(3, "three"))
print()
# Display d
print(d)
three
{0: 0}
现在我们应该能够理解这三种方法的区别了。
结论
以下是我们在本教程中介绍的内容:
- Python 中的字典
- 字典如何让我们快速访问某个 Python 对象
- 用
dict()方法或花括号创建字典 - Python 字典方法
- 在字典中循环
- 创建频率表
- 嵌套词典
- 词典理解
- 何时使用列表或字典
- 使用
defaultdict()处理丢失的按键
请随时在 LinkedIn 或 T2 GitHub 上与我联系。编码快乐!
Python 字典理解教程(含 39 个代码示例)
原文:https://www.dataquest.io/blog/python-dictionary-comprehension-tutorial/
August 3, 2022
你可能已经掌握了 Python 中的字典,也学到了很多关于列表理解的知识。现在是时候结合这些技能,学习新的东西了:Python 中的字典理解。
Python 中的字典理解是什么?
不过,在此之前,让我们提醒自己什么是 Python 中的理解。它仅仅意味着对迭代器的每个元素(比如列表、字典或元组)应用特定种类的操作。当然,我们可以通过引入例如条件语句来使这个逻辑更加复杂。
让我们直截了当地做一个简单的例子!我们将创建一个字典,包含一些人的年龄。
d = {"Alex": 29, "Katherine": 24, "Jonathan": 22}
print(d)
{'Alex': 29, 'Katherine': 24, 'Jonathan': 22}
如果我们想给每个年龄加一年,然后把结果保存在一个新的字典里呢?我们可以用一个for循环来完成。
# Dictionary to store new ages
new_d = {}
# Add one year to each age in the dictionary
for name, age in d.items(): # .items() method displays dictionary keys and values as a list of tuple pairs (name and age in this case)
new_d[name] = age + 1
print(new_d)
{'Alex': 30, 'Katherine': 25, 'Jonathan': 23}
然而,for循环可以使用字典理解用一行代码重写。
# Add one year to each age in the dictionary using comprehension
new_d = {name: age + 1 for name, age in d.items()}
print(new_d)
{'Alex': 30, 'Katherine': 25, 'Jonathan': 23}
好看吗?如果你习惯于列出理解,你可能也会注意到代码非常相似。让我们把它分成几块。
我们用名字作为键,用年龄作为值。我们的新词典应该和旧词典有同样的结构。在这里,名字不变,但年龄变了。我们通过打开花括号创建一个新的字典new_d,并在里面写上name,后面跟着一个冒号、:和age。现在停下来,想一想name和age是从哪里来的,我们应该如何修改age。它们来自原始字典,所以我们可以使用items()方法和一个for关键字循环遍历它,其中第一个变量是一个键,第二个是一个值。因此,我们将这个for循环写在括号内。现在,唯一剩下的事情就是通过加 1 来修改新字典的age值。
这是我平时用字典理解时的思维过程。这个例子非常简单,如果有足够的经验,您几乎可以自动完成,但是一旦代码变得稍微复杂一点,最好仔细想想您的最终结果应该是什么样子,以及您如何实现它。
此外,最好先编写一个for循环,确保它按照您设计的方式运行,然后使用字典理解重写它。
更现实的例子
好了,简单不切实际的例子已经够多了。在现实生活中,我们可能需要出于测试目的创建一些随机字典,或者仅仅因为我们需要某种统计技术的随机性,但是现在我们将分析来自 Kaggle 的真实世界数据集,并应用这种 Python 字典技术。请注意,原始数据集是通过从user_review列中删除tbd字符串来修改的。
我们将使用一个包含 1995-2021 年在 Metacritic 上热门视频游戏的数据集。
from csv import reader
# Open and read the dataset
all_games = open("all_games.csv")
all_games = reader(all_games)
all_games = list(all_games)
该数据集包含以下信息:
- 名字
- 平台
- 出厂日期
- 故事概要
- 元分数
- 用户分数
比方说,我们有兴趣创建一个以名称为键、以平台为值的字典。
# Dictionary to store video game platforms
platform_dict = {}
# Create dictionary of platforms
for game in all_games[1:]: # Do not include the header
name = game[0]
platform = game[1]
platform_dict[name] = platform
# Print five items of the dictionary (need to transform it into a list before)
print(list(platform_dict.items())[:5])
[('The Legend of Zelda: Ocarina of Time', ' Nintendo 64'), ("Tony Hawk's Pro Skater 2", ' Nintendo 64'), ('Grand Theft Auto IV', ' PC'), ('SoulCalibur', ' Xbox 360'), ('Super Mario Galaxy', ' Wii')]
请注意,每个平台的名称前都有一个空格,所以让我们删除它。这可以通过for循环或字典理解来实现。
# Using a for loop
for name, platform in platform_dict.items():
platform_dict[name] = platform.strip()
以上是从值中删除空格的一种方法。我们使用了 str.strip 方法,如果没有给定参数,它会删除我们指定的前导和尾随字符或空格。现在,在阅读答案之前,尝试使用字典理解重写代码。
platform_dict = {name: platform.strip() for name, platform in platform_dict.items()}
这是编写相同代码的更好的方式!
有时我们可能需要提取数据集的每一列,将它们转换成列表,然后将一个列表中的每个元素用作字典键,将另一个列表中的每个元素用作字典值。这个过程允许以一种简单的方式访问字典元素,过滤和操作它们。这可能吗?是的,但是让我们先把每一列转换成一个单独的列表。
# Initialize empty lists to store column values
name = []
platform = []
date = []
summary = []
meta_score = []
user_score = []
# Iterate over columns and append values to lists
for game in all_games[1:]:
name.append(game[0])
platform.append(game[1].replace(" ", ""))
date.append(game[2])
summary.append(game[3])
meta_score.append(float(game[4]))
user_score.append(float(game[5]))
现在我们有了所有不同的列表,我们可以用其中的两个创建一个字典。我们已经有了一个平台字典,但是现在让我们提取发布年(不是日期!).我们将使用 zip() 函数,该函数允许同时迭代多个可迭代对象。
# Dictionary to store dates
year_dict = {}
# Populate dictionary with game's names and release years
for key, value in zip(name, date):
year_dict[key] = value[-4:]
# Print release year of Grand Theft Auto IV
print(f"Grand Theft Auto IV was released in {year_dict['Grand Theft Auto IV']}.")
Grand Theft Auto IV was released in 2008.
现在试着做同样的事情,但是在看答案之前用字典理解。
# Dictionary with game's names and release years using dictionary comprehension
year_dict = {key: value[-4:] for key, value in zip(name, date)}
# Print release year of Red Dead Redemption 2
print(f"Red Dead Redemption 2 was released in {year_dict['Red Dead Redemption 2']}.")
Red Dead Redemption 2 was released in 2019.
正如我们所看到的,Python 中的字典理解支持更短、更简单的代码。注意,我们使用字符串切片(即[-4:])从日期中提取年份。
词典理解中的条件语句
现在你应该能够理解 Python 中字典理解的基本逻辑了。因此,让我们把事情复杂化一点。
我们可以在创建字典之前使用条件语句过滤一些信息!让我们重新创建 2014 年后发布的电子游戏词典。
# Video games released after 2014
after_2014 = {key: value[-4:] for key, value in zip(name, date) if int(value[-4:]) > 2014}
# Print the first five items of the dictionary
print(list(after_2014.items())[:5])
[('Red Dead Redemption 2', '2019'), ('Disco Elysium: The Final Cut', '2021'), ('The Legend of Zelda: Breath of the Wild', '2017'), ('Super Mario Odyssey', '2017'), ('The House in Fata Morgana - Dreams of the Revenants Edition -', '2021')]
在上面的代码片段中,我们重用了相同的代码,但是添加了一个if条件语句来应用过滤器。我们希望按值进行过滤,因此我们提取了年份,将数字转换为整数,然后将其与整数 2014 进行比较。如果年份在 2014 年之前,则字典中不包含该字典元素。
当然,我们可以通过引入一个逻辑运算符(and、or、not)来使逻辑变得更加复杂。例如,如果我们想要 2012 年到 2018 年(含)之间发布的所有游戏,那么代码如下。
# Video games released between 2014 and 2018 (both inclusive)
y_2012_2018 = {
key: value[-4:]
for key, value in zip(name, date)
if int(value[-4:]) >= 2014 and int(value[-4:]) <= 2018
}
# Print the first five items of the dictionary
print(list(y_2012_2018.items())[:5])
[('Red Dead Redemption 2', '2018'), ('Grand Theft Auto V', '2015'), ('The Legend of Zelda: Breath of the Wild', '2017'), ('Super Mario Odyssey', '2017'), ('The Last of Us Remastered', '2014')]
此时,代码变得相当复杂难以理解,所以如果我们需要额外的逻辑操作符,最好求助于标准的for循环。
让我们再举一个例子,通过低于 25 或高于 97 的元分数进行过滤。
# Games with meta score below 25 or above 97
meta_25_or_97 = {
key: value
for key, value in zip(name, meta_score)
if float(value) < 25 or float(value) > 97
}
print(meta_25_or_97)
{'The Legend of Zelda: Ocarina of Time': 99.0, "Tony Hawk's Pro Skater 2": 98.0, 'Grand Theft Auto IV': 98.0, 'SoulCalibur': 98.0, 'NBA Unrivaled': 24.0, 'Terrawars: New York Invasion': 24.0, 'Gravity Games Bike: Street Vert Dirt': 24.0, 'Postal III': 24.0, 'Game Party Champions': 24.0, 'Legends of Wrestling II': 24.0, 'Pulse Racer': 24.0, 'Fighter Within': 23.0, 'FlatOut 3: Chaos & Destruction': 23.0, 'Homie Rollerz': 23.0, "Charlie's Angels": 23.0, 'Rambo: The Video Game': 23.0, 'Fast & Furious: Showdown': 22.0, 'Drake of the 99 Dragons': 22.0, 'Afro Samurai 2: Revenge of Kuma Volume One': 21.0, 'Infestation: Survivor Stories (The War Z)': 20.0, 'Leisure Suit Larry: Box Office Bust': 20.0}
为了练习,用用户分数在 6 到 8(包括 6 和 8)之间的游戏创建一个字典。另外,确保字典中的值是一个float数字。
用例
接下来的四个部分将演示字典理解的不同用例:
- 如何在嵌套字典中使用理解
- 如何对字典进行分类
- 如何展平字典
- 如何计算字符串中的词频
嵌套词典理解
有时,我们需要使用嵌套字典,也就是说,当一个字典在另一个字典中时。让我们首先创建一个嵌套字典。
# Create a nested dictionary
nested_d = {}
for n, p, dt in zip(name, platform, date):
nested_d[n] = {"platform": p, "date": dt}
# Print the first five items of the nested dictionary
print(list(nested_d.items())[:5])
[('The Legend of Zelda: Ocarina of Time', {'platform': 'Nintendo64', 'date': 'November 23, 1998'}), ("Tony Hawk's Pro Skater 2", {'platform': 'Nintendo64', 'date': 'August 21, 2001'}), ('Grand Theft Auto IV', {'platform': 'PC', 'date': 'December 2, 2008'}), ('SoulCalibur', {'platform': 'Xbox360', 'date': 'July 2, 2008'}), ('Super Mario Galaxy', {'platform': 'Wii', 'date': 'November 12, 2007'})]
有一种方法可以使用字典理解重写上面的for循环。为了练习而做。
为了不使事情复杂化,我们将只使用平台的内在价值。通常,这是数据通过 API 传递给我们的格式。
# Create another nested dictionary
nested_d = {}
for n, dt in zip(name, date):
nested_d[n] = {"date": dt}
# Print the first five items of the dictionary
print(list(nested_d.items())[:5])
[('The Legend of Zelda: Ocarina of Time', {'date': 'November 23, 1998'}), ("Tony Hawk's Pro Skater 2", {'date': 'August 21, 2001'}), ('Grand Theft Auto IV', {'date': 'December 2, 2008'}), ('SoulCalibur', {'date': 'July 2, 2008'}), ('Super Mario Galaxy', {'date': 'November 12, 2007'})]
假设我们想要提取年份并将其转换为整数,同时保持相同的嵌套字典格式。一种方法是使用一个for循环。
# Extract release years and transform them into integers inside the nested dictionary
for (title, outer_value) in nested_d.items():
for (inner_key, date) in outer_value.items():
try:
outer_value.update({inner_key: int(date[-4:])})
except:
print(date)
nested_d.update({title: outer_value})
# Print the first five items of the dictionary
print(list(nested_d.items())[:5])
[('The Legend of Zelda: Ocarina of Time', {'date': 1998}), ("Tony Hawk's Pro Skater 2", {'date': 2001}), ('Grand Theft Auto IV', {'date': 2008}), ('SoulCalibur', {'date': 2008}), ('Super Mario Galaxy', {'date': 2007})]
当然,使用字典理解重写上面的for循环是可能的。为了避免错误,下面的代码单元将在运行字典理解之前重新创建列表和嵌套字典。
# Initialize empty lists to store column values
name = []
platform = []
date = []
summary = []
meta_score = []
user_score = []
# Iterate over columns and append values to lists
for game in all_games[1:]:
name.append(game[0])
platform.append(game[1].replace(" ", ""))
date.append(game[2])
summary.append(game[3])
meta_score.append(float(game[4]))
user_score.append(float(game[5]))
# Create a nested dictionary
nested_d = {}
for n, dt in zip(name, date):
nested_d[n] = {"date": dt}
# The previous for loop using nested dictionary comprehension
dict_comprehension = {
title: {inner_key: int(date[-4:]) for (inner_key, date) in outer_value.items()}
for (title, outer_value) in nested_d.items()
}
# Print the first five items of the dictionary
print(list(dict_comprehension.items())[:5])
[('The Legend of Zelda: Ocarina of Time', {'date': 1998}), ("Tony Hawk's Pro Skater 2", {'date': 2001}), ('Grand Theft Auto IV', {'date': 2008}), ('SoulCalibur', {'date': 2008}), ('Super Mario Galaxy', {'date': 2007})]
这里的外for回路是第二for回路,而内for回路是第一for回路。此时代码变得相当复杂,所以在许多情况下,继续尝试使用字典理解是不值得的。记住 Python 的主要原则之一是可读性。
根据理解对词典进行分类
Python 中字典理解的另一个用途是字典排序。比如说我们要把字典按游戏标题和年份从第一年到最近一年排序?我们先把 years 从str数据类型转换成int数据类型(使用 comprehension!).
# Convert years from strings into intergers
year_dict_int = {key: int(value) for key, value in year_dict.items()}
# Sort by year
sorted_year = {key: value for key, value in sorted(year_dict_int.items(), key=lambda x: x[1])}
# Print the first five items of the dictionary sorted by year
print(list(sorted_year.items())[:5])
[('Full Throttle', 1995), ("Sid Meier's Civilization II", 1996), ('Diablo', 1996), ('Super Mario 64', 1996), ('Wipeout XL', 1996)]
我们使用了接受key参数的sorted函数,我们需要告诉函数我们想要对哪个元素进行排序。在这种情况下,我们有两个选择:按字典键或值排序。值排在第二位,所以索引应该是 1,而键应该是 0。密钥通常分配给 lambda函数,这些函数是 Python 中常用的匿名函数。你认为有可能应用一个for循环来达到同样的结果吗?
字典的扁平化列表
有时我们面对一系列字典,我们想要一本字典。也可以用字典理解来完成。
# Generate list of dictionaries
list_d = [
{"Full Throttle": 1995},
{"Sid Meier's Civilization II": 1996},
{"Diablo": 1996},
]
# Flatten list of dictionary
list_d_flat = {
title: year for dictionary in list_d for title, year in dictionary.items()
}
# Print flattened dictionary
print(list_d_flat)
{'Full Throttle': 1995, "Sid Meier's Civilization II": 1996, 'Diablo': 1996}
当然,我们也可以在上面的代码中添加一些条件语句,就像我们对前面的字典理解所做的那样。例如,在下面,我们过滤掉所有不是 1996 年的年份。
# Flatten list of dictionary
list_d_flat_1996 = {
title: year
for dictionary in list_d
for title, year in dictionary.items()
if year == 1996
}
# Print flattened dictionary with only the games released in 1996
print(list_d_flat_1996)
{"Sid Meier's Civilization II": 1996, 'Diablo': 1996}
你能用一个for循环重现上面的字典理解吗?相信我,这是理解词典理解背后逻辑的最好方法之一。
字频率
自然语言处理中的一个步骤是对文本中出现的单词进行计数。表示这些数据的一种自然方式是使用字典,其中的键是单词,值是这个单词在文本中出现的次数。也是字典理解的工作!
# Quote by Henry Van Dyke
quote = """time is too slow for those who wait too swift for those who fear too long for
those who grieve too short for those who rejoicebut for those who love, time is eternity"""
# Count frequency of words in the quote
frequency_dict = {word: quote.split(" ").count(word) for word in quote.split(" ")}
print(frequency_dict)
{'time': 2, 'is': 2, 'too': 4, 'slow': 1, 'for': 5, 'those': 4, 'who': 5, 'wait': 1, 'swift': 1, 'fear': 1, 'long': 1, '\nthose': 1, 'grieve': 1, 'short': 1, 'rejoicebut': 1, 'love,': 1, 'eternity': 1}
如果我们使用一个for循环(但是试着重新创建它),这将花费我们三行代码。
包扎
我们可以利用 Python 中的字典理解来改进代码的方法太多了,以至于要列出所有的方法需要太多的纸张。我建议你只要一看到可能性就马上开始使用它们(但是要记住可读性),并且阅读其他人的代码来获得关于代码用例的想法。
在某种程度上,直接写字典理解会变得很自然,但要达到这一点,你必须写代码,做项目。阅读教程和做代码练习有助于理解这个概念,但项目是你的数据科学或编码职业中真正的游戏规则改变者。
在本教程中,我们学习了:
- Python 中的字典理解是什么
- 如何使用这种技术创建词典
- 如何在词典理解中使用条件句
- 什么是嵌套式词典理解
- 如何对字典进行分类
- 如何展平字典
- 以及如何计算字符串中的单词出现次数
我希望你今天学到了一些新东西。请随时在 LinkedIn 或 T2 GitHub 上与我联系。编码快乐!
Python 字典教程:用字典分析精酿啤酒
原文:https://www.dataquest.io/blog/python-dictionary-tutorial/
October 3, 2018
Python 提供了多种数据结构来保存我们的信息——Python 字典是最有用的数据结构之一,因为它们快速、易用且灵活。
作为一名初级程序员,您可以使用本 Python 教程来熟悉字典及其常见用法,这样您就可以立即开始将它们合并到您自己的代码中。
在执行数据分析时,我们经常会遇到无法使用或难以使用的数据。Python 字典可以帮助我们更容易地阅读和修改数据。
在本教程中,我们将使用 Kaggle 的精酿啤酒数据集。一个数据集描述啤酒的特性,另一个数据集存储啤酒厂的地理信息。出于本文的目的,我们的数据将存储在 beers 和 breweries 变量中,每个变量都是一个列表的列表。
下表给出了数据的大概情况。该表包含 beers 数据集中的第一行。
| 酒精度 | 国际冬季两项联盟 | 身份证明(identification) | 名字 | 风格 | 啤酒厂 _id | 盎司 | |
|---|---|---|---|---|---|---|---|
| Zero | Zero point zero five | One thousand four hundred and thirty-six | 酒吧啤酒 | 美国淡啤酒 | Four hundred and eight | Twelve |
该表包含啤酒厂数据集的第一行。
| 名字 | 城市 | 状态 | |
|---|---|---|---|
| Zero | 诺斯盖特酿酒公司 | 明尼阿波利斯 | 全部商船 |
必备知识
本文假设您对 Python 有基本的了解。要完全理解这篇文章,你应该熟悉列表和for循环。如果你还没有,看看我们的互动 Python 基础课程,它涵盖了这些不需要经验的主题。
在本教程中,我们将涵盖:
- 与 Python 字典相关的关键术语和概念
- 词典规则
- 基本字典操作
- 创建和删除
- 访问和插入
- 成员资格检查
- 循环技术
- 词典释义
- 字典的优点和缺点
进入我们的角色
假设我们是一本啤酒爱好者杂志的评论员。我们希望在到达目的地进行评估之前,提前了解每家啤酒厂的产品,以便收集有用的背景信息。我们的数据集包含啤酒和啤酒厂的信息,但数据本身并不能立即访问。
数据目前以列表的列表的形式存在。若要访问单个数据行,必须使用编号索引。要获得breweries的第一个数据行,您需要查看第二个项目(列名在前)。
啤酒厂[1]
breweries[1]是一个列表,所以你也可以从它开始索引。获得该列表中的第三项看起来像:
啤酒厂[1][2]
如果你不知道breweries是关于啤酒厂的数据,你将很难理解索引试图做什么。想象一下,写下这段代码,6 个月后再看一遍。你很可能会忘记,所以以一种更易读的方式重新格式化数据对我们来说是有好处的。
关键术语和概念
Python 字典由键值对组成。在 Python 字典中查找键类似于在物理字典中查找特定的单词。值是与关键字相关联的相应数据,相当于物理词典中的单词定义。关键是我们查找什么,这是我们真正感兴趣的值。 当我们谈论 Python 字典时,我们说值被映射到键。在上面的例子中,如果我们在英语词典中查找“程序员”这个词,我们会看到:“编写计算机程序的人。”单词“程序员”是映射到该单词定义的关键。
当我们谈论 Python 字典时,我们说值被映射到键。在上面的例子中,如果我们在英语词典中查找“程序员”这个词,我们会看到:“编写计算机程序的人。”单词“程序员”是映射到该单词定义的关键。
键和值的 Python 字典规则
Python 字典非常灵活,因为它们允许将任何东西存储为值,从字符串和浮点等基本类型到对象等更复杂的类型,甚至其他字典(稍后将详细介绍)。
相比之下,什么可以被用作键是有限制的。在 Python 中,一个键必须是一个不可变的对象,这意味着它是不可变的。这个规则允许字符串、整数和元组作为键,但是排除了列表和字典,因为它们是可变的,或者能够被改变。基本原理很简单:如果一个键在您不知道的情况下发生了任何变化,您将无法再访问该值,从而使字典变得无用。因此,只允许不可变的对象作为键。
一个键在字典中也必须是唯一的。字典的键值结构使得它如此强大,在这篇文章中,我们将深入研究它的基本操作、用例以及它们的优缺点。
基本字典操作
创建和删除
先说如何创建词典。首先,我们将学习如何创建一个空字典,因为您经常会发现您希望从一个空字典开始,并根据需要填充数据。
要创建一个空字典,我们可以使用没有输入的dict()函数,或者给一个变量分配一对中间没有任何内容的花括号。我们可以确认这两种方法会产生相同的结果。
empty = {}
also_empty = dict()
empty == also_empty
>>> True
现在,一个空字典对任何人都没有多大用处,所以我们必须添加自己的键值对。我们将在本文的后面讨论这个问题,但是我们可以从空字典开始,在它们被创建后填充它们。这将允许我们在需要时添加更多的信息。
empty["First key"] = "First value"
empty["First key"]
>>> "First value"
或者,您也可以创建一个字典,并用键值对预先填充它。有两种方法可以做到这一点。第一种是使用包含键值对的括号。每个键和值由一个:分隔,而单独的键和值由逗号分隔。
虽然您可以将所有内容放在一行中,但是最好将键值对拆分到不同的行中,以提高可读性。
data = {
"beer_data": beers,
"brewery_data": breweries
}
上面的代码创建了一个字典data,其中我们的键是描述性的字符串,值是我们的数据集。这个字典允许我们通过名字访问两个数据集。
创建 Python 字典的第二种方法是通过dict()方法。您可以将键和值作为关键字参数或元组列表提供。我们将使用dict()方法重新创建data字典,并适当地提供键值对。
# Using keyword arguments
data2 = dict(beer_data=beers, brewery_data=breweries)
# Using a list of tuples
tuple_list = [("brewery_data", breweries), ("beer_data", beers)]
data3 = dict(tuple_list)
我们可以确认每一个data字典在 Python 的眼里都是等价的。
data == data2 == data3
>>> True
对于每个选项,键和值对必须以特定的方式格式化,因此很容易混淆。下图有助于理清键和值在每个中的位置。

我们现在有三本字典存储完全相同的信息,所以我们最好只保留一本。字典本身没有删除的方法,但是 Python 为此提供了del语句。
del data2
del data3
创建词典后,您几乎肯定需要添加和删除词典中的条目。Python 为这些操作提供了简单易读的语法。
数据访问和插入
我们的 beers and breweries 字典的当前状态仍然很糟糕——每个数据集最初都是列表的列表,这使得很难访问特定的数据行。
通过将每个数据集重新组织到它自己的字典中,并创建一些有用的键-值对来描述字典中的数据,我们可以实现更好的结构。原始数据本身是混杂的。每个列表中的第一行是包含列名的字符串列表,但其余部分包含实际数据。最好将列从数据中分离出来,这样我们可以更清楚。
因此,对于每个数据集,我们将创建一个字典,其中三个键映射到以下值:
- 原始数据本身
- 包含列名的列表
- 包含其余数据的列表列表
beer_details = {
"raw_data": beers,
"columns": beers[0],
"data": beers[1:]
}
brewery_details = {
"raw_data": breweries,
"columns": breweries[0],
"data": breweries[1:]
}
现在,我们可以显式引用columns键来列出数据的列名,而不是索引raw_data中的第一项。
类似地,我们现在能够明确地从data键请求只是数据。到目前为止,我们已经学会了如何创建空的和预填充的字典,但是我们不知道一旦它们被创建,如何从它们读取信息。
为了访问 Python 字典中的条目,我们需要括号符号。我们引用字典本身,后跟一对括号,括号中有我们要查找的关键字。例如下面,我们从brewery_details中读取列名。
brewery_details["columns"]
>>> ['', 'name', 'city', 'state']
这个动作感觉应该和我们在英语词典里查单词差不多。我们“查找”了一个键,并在映射值中获得了我们想要的信息。
除了查找键-值对,有时我们实际上想要改变与字典中的键相关的值。该操作也使用括号符号。要改变一个字典值,我们首先访问这个键,然后使用一个=表达式重新分配它。我们在上面的代码中看到,其中一个 brewery 列是一个空字符串,但是第一列实际上包含了每个 brewery 的惟一 ID!我们将把第一个列名重新分配给一个信息更丰富的名称。
# reassigning the first column of the breweries data set
brewery_details["columns"][0] = 'brewery_id'
# confirming that our reassignment worked
brewery_details["columns"][0]
>>> "brewery_id"
如果括号系列看起来令人困惑,不要烦恼。我们利用了筑巢的优势。我们知道brewery_details中的columns键被映射到一个列表,所以我们可以将brewery_details["columns"]视为一个列表(即我们可以使用列表索引)。
如果我们不知道每一层代表什么,嵌套会变得混乱,但是我们在下面可视化这个嵌套来澄清。在字典中嵌套字典也是一种常见的做法,因为这样会产生自文档化的代码。也就是说,仅仅通过阅读代码就可以清楚地知道代码在做什么,而不需要任何注释来帮助。
自文档化代码非常有用,因为在通读时理解起来更容易、更快。我们希望保持这种自我记录的品质,所以我们将把beer_details和brewery_details字典嵌套到一个集中的字典中。最终结果将是嵌套的 Python 字典,比原始数据本身更容易读取。
# datasets is now a dictionary whose values are other dictionaries
datasets = {
"beer": beer_details,
"breweries": brewery_details
}
# This structure allows us to make self-documenting inquiries to both data sets
datasets["beer"]["columns"]
>>> ['', 'abv', 'ibu', 'id', 'name', 'style', 'brewery_id', 'ounces']
# Compare the above to how our older data dictionary would have been written
data["beer_data"][0]
>>> ['', 'abv', 'ibu', 'id', 'name', 'style', 'brewery_id', 'ounces']
如果我们将字典嵌套在字典中,嵌入在代码中的信息就很清楚了。我们已经创建了一个容易描述程序员意图的结构。下图分解了字典嵌套。

从现在开始,我们将使用datasets来管理我们的数据集并执行更多的数据重组。我们制作的啤酒和啤酒厂词典是一个良好的开端,但我们可以做得更多。我们希望创建一个新的键-值对来包含每个数据集所包含内容的字符串描述,以防我们忘记。
我们可以创建字典,读取和更改现有键-值对的值,但是我们不知道如何插入新的键-值对。幸运的是,插入对类似于重新分配字典值。如果我们给一个字典中不存在的键赋值,Python 将获取新的键和值,并在字典中创建一对。
# The description key currently does not exist in either the inner dictionary
datasets["beer"]["description"] = "Contains data on beers and their qualities"
datasets["breweries"]["description"] = "Contains data on breweries and their locations"
虽然 Python 使得向字典中插入新的键对变得很容易,但是如果用户试图访问不存在的键,它就会阻止用户。如果你试图访问一个不存在的键,Python 将抛出一个错误并停止你的代码运行。
# The key best_beer doesn't currently exist, so we cannot access it
datasets["beer"]["best_beer"]
>>> KeyError: 'best_beer'
随着 Python 字典变得越来越复杂,越来越容易忘记存在哪些键。如果你把代码放了一个星期,却忘记了字典里有什么,你会不断地碰到KeyErrors。
谢天谢地,Python 为我们提供了一种简单的方法来检查字典中的当前键。这个过程被称为成员资格检查。
成员资格检查
如果我们想检查一个键是否存在于字典中,我们可以使用in操作符。您还可以使用not in来检查一个键是否不存在。生成的代码读起来几乎像自然英语,这也意味着乍看起来更容易理解。
"beer" in datasets
>>> True
"wine" in datasets
>>> False
"wine" not in datasets
>>> True
将 in 用于成员检查与if-else语句结合使用非常有用。这种组合允许您设置条件逻辑,这将阻止您获得KeyErrors,并使您能够编写更复杂的代码。我们不会深究这个概念,但结尾部分有一些资料可供好奇者参考。
章节摘要
至此,我们知道了如何创建、读取、更新和删除 Python 字典中的数据。我们将两个原始数据集转换成了具有更好可读性和易用性的字典。有了这些基本的字典操作,我们可以开始执行更复杂的操作。例如,想要循环访问键值对并在每一对上执行一些操作是非常常见的。
循环技术
当我们为每个数据集创建description键时,我们创建了两个单独的语句来创建每个键-值对。因为我们执行了相同的操作,所以使用循环会更有效。Python 提供了三种在循环中使用字典的主要方法:keys()、values()和items()。使用keys()和values()可以让我们遍历字典中的这些部分。
for key in datasets.keys():
print(key)
>>> beer
>>> breweries
for val in datasets.values():
print(type(val))
>>> <class 'dict'
>>>> <class 'dict'>
items()方法将两者合二为一。在循环中使用时,items()以元组的形式返回键值对。这个元组的第一个元素是键,第二个元素是值。我们可以使用析构将这些元素转化为适当的信息变量名称。第一个变量key将获取元组中的键,而val将获取映射的值。
for key, val in datasets.items():
print(f'The {key} data set has {len(val["data"])} rows.')
>>> The beer data set has 2410 rows.
>>> The breweries data set has 558 rows.
上面的循环告诉我们,啤酒数据集比啤酒厂数据集大得多。我们预计啤酒厂会出售多种类型的啤酒,所以啤酒的数量应该比啤酒厂的总体数量多。我们的循环证实了这个想法。
目前,每个数据行都是一个列表,因此不希望通过编号来引用这些元素。相反,我们将把每个数据行转换成它自己的字典,并将列名映射到它的实际值。从长远来看,这将使数据分析更加容易。我们应该在两个数据集上执行这个操作,所以我们将利用我们的循环技术。
# Perform this operation for both beers and breweries data setsfor k, v in datasets.items():
# Initialize a key-value pair to hold our reformatted data
v["data_as_dicts"] = []
# For every data row, create a new dictionary based on column names
for row in v["data"]:
data_row_dict = dict(zip(v["columns"], row))
v["data_as_dicts"].append(data_row_dict)
上面有很多,我们慢慢分解。
- 我们遍历
datasets以确保我们转换了啤酒和啤酒厂的数据。 - 然后,我们创建一个名为
data_as_dicts的新键,映射到一个空数组,该数组将保存我们的新字典。 - 然后我们开始迭代包含在
data键中的所有数据。zip()是一个函数,它接受两个或多个列表,并根据这些列表生成元组。 - 我们利用
zip()输出并使用dict()以我们喜欢的形式创建新数据:列名映射到它们的实际值。 - 最后,我们将它添加到
data_as_dicts列表中。最终结果是更好的格式化数据,更容易阅读和重复使用。
我们可以看看下面的最终结果。
# The first data row in the beers data set
datasets["beer"]["data_as_dicts"][0]
>>> {'': '0',
'abv': '0.05',
'brewery_id': '408',
'ibu': '',
'id': '1436',
'name': 'Pub Beer',
'ounces': '12.0',
'style': 'American Pale Lager'}
# The first data row in its original form
datasets["beer"]["raw_data"][0]
>>> ['0', '0.05', '408', '', '1436', 'Pub Beer', '12.0', 'American Pale Lager']
章节摘要
在本节中,我们学习了如何通过for循环使用字典。使用循环,我们将每个数据行重新格式化为字典,以增强可读性。当我们回头看自己写的代码时,未来的自己会感谢我们。
我们现在开始执行最后的操作:将所有的啤酒匹配到各自的酿酒厂。每种啤酒都有一个啤酒厂,由两个数据集中的brewery_id键给出。我们将创建一个全新的数据集,将所有啤酒与它们的酿酒厂匹配起来。
我们可以使用循环来实现这一点,但是我们可以使用高级的 Python 字典操作,将这种数据转换从多行循环变成单行代码。
词典释义
beers数据集中的每种啤酒都与一个brewery_id相关联,后者与breweries的一家啤酒厂相关联。使用这个 ID,我们可以将所有的啤酒与它们的酿酒厂配对。
通常,转换原始数据并将其放入一个新变量中比改变原始数据本身更好。因此,我们将在datasets中创建另一个字典来保存我们的配对。在这个新字典中,啤酒厂名称本身是关键,映射的值将是一个包含啤酒厂提供的所有啤酒名称的列表,我们将基于brewery_id数据元素匹配它们。
我们可以用之前学过的循环技术很好地执行这种匹配,但是还有最后一个字典方面要教。代替循环,我们可以使用字典理解简洁地执行匹配。
在计算机科学术语中,“理解”意味着对集合(如列表)中的所有项目执行一些任务或功能。就语法而言,字典理解类似于列表理解,但它是从基本列表创建字典的。
如果你需要复习单词理解,你可以在这里查看这个教程。举个简单的例子,我们将使用字典理解从数字列表中创建一个字典。
nums = [1, 2, 3, 4, 5]
dict_comprehension = {
str(n) : "The corresponding key is" + str(n) for n in nums}
for val in dict_comprehension.values():
print(val)
>>> The corresponding key is 1
The corresponding key is 2
The corresponding key is 3
The corresponding key is 4
The corresponding key is 5
我们将在下面剖析字典理解代码:

为了创建字典理解,我们将 3 个元素放在左右括号中:
- 基本列表
- 基本列表中每个项目的键应该是什么
- 基本列表中每个项目的值应该是多少
nums构成了dict_comprehension的键值对所基于的基本列表。键是每个数字的字符串版本(以区别于列表索引),而值是描述键是什么的字符串。
这个特别的例子本身是没有用的,但是用来说明理解字典的复杂语法。现在我们知道了字典理解是如何组成的,当我们将它应用到我们的啤酒和酿酒厂数据集时,我们将看到它的真正效用。我们只需要啤酒厂数据集的两个方面来执行匹配:
- 啤酒厂名称
- 啤酒厂 ID
首先,我们将创建一个元组列表,其中包含每个啤酒厂的名称和 ID。由于在data_as_dicts键中重新格式化的数据,这段代码很容易写成列表理解。
# This list comprehension captures all of the brewery IDs and names from store
brewery_id_name_pairs = [
(row["brewery_id"], row["name"]) for row in datasets["breweries"]["data_as_dicts"]]
brewery_id_name_pairs现在是元组列表,并将形成字典理解的基本列表。有了这个基本列表,我们将使用啤酒厂的名称作为我们的键,使用 list comprehension 作为值。
brewery_to_beers = {
pair[1] : [b["name"] for b in datasets["beer"]["data_as_dicts"] if b["brewery_id"] == pair[0]] for pair in brewery_id_name_pairs
}
在我们讨论这个怪物是如何工作的之前,有必要花一些时间来看看实际的结果是什么。
# Confirming that a dictionary comprehension creates a dictionary
type(brewery_to_beers)
>>> <class 'dict'>
# Let's see what the Angry Orchard Cider Company (a personal favorite) makes
brewery_to_beers["Angry Orchard Cider Company"]
>>> ["Angry Orchard Apple Ginger", "Angry Orchard Crisp Apple", "Angry Orchard Crisp Apple"]
正如我们对这个简单的例子所做的那样,我们将强调这个笨拙(尽管有趣)的字典理解的关键部分。

如果我们把代码拆开,突出特定的部分,代码背后的结构就会变得更加清晰。钥匙取自brewery_id_name_pair的适当部位。映射值占据了这里的大部分逻辑。值是用条件逻辑的列表理解。
简单地说,当啤酒的关联brewery_id与迭代中的当前啤酒厂匹配时,list comprehension 将存储啤酒数据中的任何啤酒。下面的另一幅插图展示了根据目的理解列表的代码。
因为我们的字典理解是基于所有 T2 啤酒厂的列表,所以最终结果是我们想要的:一个新的字典,它将啤酒厂的名称映射到它销售的所有啤酒!现在,当我们到达一家酿酒厂时,我们只需查阅brewery_to_beers就能立即了解他们有什么!
这一部分有一些复杂的代码,但它完全在你的掌握之中。如果您仍然有困难,请继续复习语法,并尝试创建您自己的 Python 字典理解。不久,您的编码库中就会有它们了。
在本教程中,我们已经讨论了很多关于如何使用词典的内容,但是重要的是后退一步,看看为什么我们可能想要使用(或不使用)它们。
Python 字典的优点和缺点
我们已经提到很多次字典增加了我们代码的可读性。能够写出我们自己的密钥给了我们灵活性,并增加了一层自我文档。理解代码所做的事情花费的时间越少,理解和调试就越容易,实现分析就越快。
除了以人为中心的优势,还有速度优势。在 Python 字典中查找关键字很快。计算机科学家可以通过查看完成一项计算机任务(即查找一个键或运行一个算法)需要多少操作来衡量它需要多长时间。他们用大 O 符号来描述这些时间。一些任务很快,在常数时间内完成,而更大的任务可能需要指数数量的运算,在多项式时间内完成。
在这种情况下,在恒定时间内完成查找键。将这与在大列表中搜索相同的项目进行比较。计算机必须检查列表中的每一项,所以所花的时间将与列表的长度成比例。我们称之为线性时间。如果你的列表特别大,那么寻找一个条目将花费比仅仅在字典中将它分配给一个键-值对并寻找键更长的时间。
在更深的层次上,字典是一个散列表的实现,对它的解释超出了本文的范围。重要的是要知道,我们字典的好处本质上是散列表本身的好处:快速的键查找和成员检查。
我们前面提到过,字典是无序的,这使得它们不适合于有序的数据结构,相对于其他 python 结构,占用了更多的空间,尤其是当你有大量的键时。考虑到内存非常便宜,这种缺点通常不会很明显,但是了解一下字典产生的开销是有好处的。
我们只讨论了普通的 Python 字典,但是 Python 中还有其他的实现来增加额外的功能。我在最后加入了进一步阅读的链接。我希望在读完这篇文章之后,你会更加自如地使用字典,并在你自己的编程中找到它们的用处。也许你已经找到了一种啤酒,你可能想在未来尝试!
进一步阅读
我们已经介绍了字典的基础知识,但是没有介绍所有可用的方法。
- Python 的字典文档
- Python 字典是哈希表的实现
- Python 中的增强词典
- Python 中的错误处理
- Python 教程 —我们不断扩充的数据科学 Python 教程列表。
- 数据科学课程 —通过完全交互式的编程、数据科学和统计课程,让您的学习更上一层楼,就在您的浏览器中。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
xlwings 教程:使用 Python 让 Excel 更快
原文:https://www.dataquest.io/blog/python-excel-xlwings-tutorial/
September 24, 2019
Excel 在当今企业中非常普遍。在 Dataquest,出于多种原因,我们通常建议使用代码,我们的许多数据科学课程旨在教授数据分析和数据科学的高效编码。但是,无论您多么喜欢使用 Python,在一天结束时,有时还是需要使用 Excel 展示您的发现或共享您的数据。
但这并不意味着不能享受 Python 的一些高效性!事实上,使用一个名为xlwings的库,您可以使用 Python 使在 Excel 中工作更快。
在本 xlwings 教程中,我们将介绍如何在 Excel 中使用 Python 来执行和使用一些常见操作,如基于特定标准删除行、使用 Excel 函数和公式、自动填充、创建表格、图表等。为了阅读这篇文章,你应该熟悉 Python 的基本概念(对象、方法、属性、函数)和 Python 的语法,并具备 Excel 和 VBA 的中级知识。
我们将使用一个数据集,该数据集包含一个名为 EuroMillions 的欧洲彩票的抽奖信息。这个数据集是从这个链接下载的,它包含了截至 9 月 20 日(含 9 月 20 日)的所有 EuroMillions 汇票。该链接上的可用数据应该会随着你阅读这篇文章时的最新信息而更新,但如果它不可用,这里有一个 CSV 文件,其中包含该链接截至 9 月 20 日的数据。
Euromillions 是一种在一些欧洲国家发行的跨国彩票,特别是在安道尔、奥地利、比利时、法国(包括海外地区和集体)、爱尔兰、马恩岛、列支敦士登、卢森堡、摩纳哥、葡萄牙、西班牙、瑞士和英国( source )。
截至本文撰写之时,抽奖由 50 个号码(编号为 1 至 50)中的 5 个号码和 12 个号码中的 2 个号码lucky stars组成。为了赢得头奖,参与者必须正确选择所有抽取的数字和幸运星。有史以来最大的累积奖金是 1.9 亿欧元。(不过,请注意,我们的数据集以英镑而不是欧元来命名奖金)。
在本教程中,我们将使用 Python 和 xlwings 以及 Excel 来清理数据集,然后生成一些图表来直观显示哪些号码最常赢得欧洲百万大奖。
import pandas as pd
import xlwings as xw
df = pd.read_csv('euromillions.csv')
df.sample(5)
| 号码 | 一天 | 直接伤害 | 嗯 | YYYY | N1 | N2 | N3 | N4 | N5 | 腰神经 2 | L2 | 头奖 | 视窗网际网路名称服务 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Six hundred and twenty-seven | Five hundred and fourteen | Fri | Twenty-four | 八月 | Two thousand and twelve | six | five | Nineteen | Thirty-seven | Twelve | seven | three | Thirty-seven million seven hundred and nine thousand and forty-seven | one |
| Two hundred and thirty | Nine hundred and eleven | 周二 | Fourteen | 六月 | Two thousand and sixteen | Thirteen | Fifty | forty-two | Thirty-nine | Thirty-four | Eleven | nine | Eleven million nine hundred and twenty-eight thousand | Zero |
| Nine hundred and ninety-eight | One hundred and forty-three | Fri | three | 十一月 | Two thousand and six | Thirteen | Eleven | forty-four | Twenty-four | forty-nine | nine | three | Eighty-eight million three hundred and forty-four thousand and ninety-nine | Zero |
| One thousand and seventy-one | Seventy | Fri | Ten | 六月 | Two thousand and five | Thirty-seven | Thirty-two | Forty-seven | seven | six | seven | one | Twenty-one million seven hundred and thirty-four thousand six hundred and ninety-nine | Zero |
| Five hundred and twenty-two | Six hundred and nineteen | 周二 | Twenty-seven | 八月 | Two thousand and thirteen | seven | Forty | Thirty-eight | Forty-three | Thirty | six | Two | Twelve million nine hundred and thirty-one thousand five hundred | Zero |
第一列是开奖号码,N1-L2列是开奖号码和幸运星(按照开奖的顺序),Jackpot列是以欧元为单位的头奖,Wins列告诉我们有多少赌注中了头奖。
见面xlwings
xlwings是一个 Python 库,它使得 Python 的一些数据分析特性在 Excel 实例中可用,包括对numpy数组和pandas系列和数据帧的支持。像任何其他 Python 库一样,它可以使用常见的方法安装,如pip或conda,但是如果您需要更多的细节,您可以在这里访问xlwings的文档。
请注意,您需要在用于学习 xlwings 教程的计算机上安装一个版本的 Microsoft Excel。
xlwings物体
在xlwings中,有四种主要的对象类型,按照层级递减的顺序依次为:App(代表一个 Excel 实例)、Book、Sheet和Range。除此之外,我们还将处理Chart和Shape对象。你可以在官方文档中找到关于这些和其他对象的有用信息,但是我们将一次一个地查看这些对象。
让我们首先创建一个Book实例,并将其命名为wb(工作簿)。
wb = xw.Book() # wb = xw.Book(filename) would open an existing file
当您运行该代码时,它应该看起来像这样。

请注意,当在 Jupyter 笔记本中运行代码单元格时,Excel 会自动启动。
通过实例化一个Book对象,一个属于我们的 book 对象的App对象被自动创建。下面是我们如何检查所有打开的 Excel 实例。
注意:我们不打算在本教程的每一步都包含 gif,因为我们不希望这个页面对于网速慢或者网络连接有限的人来说是一个加载的麻烦。然而,随后的代码运行步骤应该与我们上面看到的类似:当我们在 Juypter 中运行一个单元格时,Excel 电子表格会根据我们运行的代码进行更新。
print(xw.apps)
Apps([<Excel App 9536>])
对象xw.apps是可迭代的。要检查哪些工作簿属于这个 iterable 中的唯一实例,我们可以像这样调用它的books方法。
print(xw.apps[0].books)
Books([<Book [Book1]>])
正如所料,这个 iterable 的唯一实例是工作簿wb。我们在下面检查这个事实。
print(xw.apps[0].books[0] == wb)
True
同样,我们可以检查哪些工作表属于该工作簿:
print(wb.sheets)
Sheets([<Sheet [Book1]Sheet1>])
我们也可以通过名称来引用工作表:
#creates a worksheet object assigns it to ws
ws = wb.sheets["Sheet1"]
#checks that wb.sheets[0] equals ws
print(ws == wb.sheets[0])
True
Sheet对象有一个按预期工作的name属性。让我们更改我们唯一的工作表的名称。
ws.name = "EuroMillions"
我们可以将数据从某些 Python 对象(例如列表和元组)转移到 Excel 中。让我们将数据框中的数据移入工作表 EuroMillions 。为此,我们将利用range创建一个 range 对象,将数据框中的数据存储在 Excel 的一系列单元格中,在本例中从单元格 A1:
#ws.range("A1") is a Range object
ws.range("A1").value = df
这就是它的样子:

我们可以看到,df的索引列也被移到了 Excel 中。让我们清除此表的内容,复制不带索引的数据。
ws.clear_contents()
ws.range("A1").options(index=False).value = df
这将是有用的,能够告诉我们的表结束。更具体地说,我们需要最后一行数据。为此,我们可以使用end方法和Range对象的row属性。
毫不奇怪,row方法返回了Range对象的row。
方法end接受一个方向("up"(或1)、"right"(或2)、"left"(或3、"down"(或4))作为参数,并返回另一个 range 对象。它模仿了 Excel CTRL+Shift+Arrow中非常常见的动作。
last_row = ws.range(1,1).end('down').row
print("The last row is {row}.".format(row=last_row))
print("The DataFrame df has {rows} rows.".format(rows=df.shape[0]))
The last row is 1142.
The DataFrame df has 1141 rows.
核实过了。
API 属性
并非所有 Excel 功能都可以作为原生xlwings特性使用。有时我们不得不寻找变通方法来做我们想做的事情。幸运的是xlwings让我们很容易做到这一点。来自官方文档中的缺失功能部分:
变通方法:本质上,xlwings 只是 Windows 上的 pywin32 和 Mac 上的 appscript 的智能包装器。您可以通过调用 api 属性来访问基础对象。底层对象将为您提供几乎所有您可以用 VBA 做的事情,使用 pywin32(感觉很像 VBA)和 appscript(感觉不像 VBA)的语法。但是除了看起来难看之外,请记住它使您的代码平台特定(!)。Excel Visual Basic for Applications是各种现有 Excel 对象的丰富解释来源。
排序是xlwings中缺少的功能之一。您可能已经注意到,记录是按照从最近到最早的抽签顺序排列的。在接下来的几个步骤中,我们将颠倒顺序。
对象ws.range("A2:N{row}".format(row=last_row))是一个Range对象。将api属性附加到它会产生一个 VBA 范围对象,该对象反过来提供对其 VBA 特性的访问。
我们将使用这个 VBA 对象的排序属性。在其最简单的应用中,Sort接受两个参数:我们希望对表格进行排序所依据的列(作为一个 VBA 范围对象),以及排序类型(我们希望按升序还是降序排序)。第二个参数的文档可以在这里看到。我们将按升序排序。
将所有这些放在一起看起来像这样:
ws.range(
"A2:N{row}".format(row=last_row)
).api.Sort(Key1=ws.range("A:A").api, Order1=1)
True
下面是运行后它在屏幕上的样子(注意,第一列已经改变,现在它是按升序而不是降序排序的。

分析我们的数据
我们在试图分析这个数据集时会遇到的一个问题是,日期分散在三个不同的列中。我们需要把它压缩成一列。为此,我们将使用 Python 在 Excel 中适当地连接列。我们首先在相邻的空列中插入一个标题。
ws.range("O1").value = "Date"
接下来,我们可以插入想要用作字符串的 Excel 公式。注意:您应该使用什么参数分隔符取决于您的计算机的本地区域设置。在我的示例中,参数分隔符是逗号,这是我在本教程中使用的,但在你的示例中,它可能是分号。
ws.range("O2").value = "=C2&D2&RIGHT(E2, 2)"
在第一个单元格中插入公式后,在常规 Excel 工作流程中,自动填充表格末尾的其余单元格是第二天性。自动填充是VBA Range对象的一种方法。它将目标单元格作为一个VBA Range对象和填充类型作为参数。我们感兴趣的是枚举为0的缺省值。
ws.range("O2").api.AutoFill(
ws.range("O2:O{row}".format(row=last_row)).api,
0
)
True
这是完成这一步后屏幕的大致样子;注意最右边新的“日期”列。

我们也可以使用我们想要的填充类型的命名形式。为此,我们需要从模块xlwings.constants中检索它,该模块包含大多数 VBA 属性的枚举参数的命名版本。回想一下,您总是可以通过打印dir(xlwings.constants)来检查可用的属性。
(如果您不熟悉,dir是一个原生 Python 函数,可以接受多种参数(模块、类和常规对象(如列表和字符串))。例如,如果您打印dir(some_list),它将为您提供可以用于列表的所有方法和属性。)
我们上面所做的也可以通过下面的代码片段来实现。
from xlwings.constants import AutoFillType
ws.range("O2").api.AutoFill(
ws.range("O2:O{row}".format(row=last_row)).api,
AutoFillType.xlFillDefault
)
由于我们会经常使用这个函数,我们将创建一个应用默认填充的函数,给定:
- 工作表
- 表示工作表中单元格的字符串
- 要填充的最后一行。
为此,我们将引入一种新的Range方法,称为 get_address 。它接受四个布尔参数并返回一个字符串,该字符串标识具有不同细节级别的范围。下面是这种方法的一个很有启发性的例子。
for arg4 in (0, 1):
for arg3 in (0,1):
for arg2 in (0,1):
for arg1 in (0,1):
print(ws.range("O2").get_address(arg1, arg2, arg3, arg4))
O2
O$2
$O2
$O$2
EuroMillions!O2
EuroMillions!O$2
EuroMillions!$O2
EuroMillions!$O$2
[Book1]EuroMillions!O2
[Book1]EuroMillions!O$2
[Book1]EuroMillions!$O2
[Book1]EuroMillions!$O$2
[Book1]EuroMillions!O2
[Book1]EuroMillions!O$2
[Book1]EuroMillions!$O2
[Book1]EuroMillions!$O$2
现在我们定义我们的函数。
def autofill(worksheet, cell, last_row):
rg_cell = worksheet.range(cell)
to_fill = "{col}{top_row}:{col}{last_row}".format(
col=rg_cell.get_address(0,0)[0],
top_row=rg_cell.row,
last_row=last_row
)
rg_cell.api.Autofill(worksheet.range(to_fill).api, 0)
为了避免 Excel 进行不必要的计算,我们将用硬编码值替换刚刚插入到列O中的公式。在我们这样做之前,让我们花点时间想想当Range是一个数组时Range.value是什么类型的 Python 对象。
print(type(ws.range("O2:O{row}".format(row=last_row)).value))
<class 'list'>
这是一个列表!让我们看看它的前十个元素。
print(ws.range('O2:O{row}'.format(row=last_row)).value[:10])
['13Feb04', '20Feb04', '27Feb04', '5Mar04', '12Mar04', '19Mar04', '26Mar04', '2Apr04', '9Apr04', '16Apr04']
如果我们将这个列表插入任何区域,它将水平放置值,这不是我们想要的。为了垂直放置它们,我们需要使用带有选项transpose=True作为参数的Range对象的 options 方法,如下所示:
ws.range('O2').options(transpose=True).value\
= ws.range('O2:O{row}'.format(row=last_row)).value
我们现在可以删除列C到E。
ws.range('C:E').api.Delete()
True
EuroMillions 格式多年来经历了一些轻微的修改,最近一次发生在 2016 年 9 月 24 日。
从 2016 年 9 月 24 日起,幸运星的数量从 11 个变为 12 个。为了进行有意义的分析,我们将只考虑最后一次修改后发生的抽签。下一个代码片段找到修改前的最后一个游戏,并将其命名为to_delete。
import datetime
for day in ws.range('L2:L{}'.format(last_row)):
# checks if day is not prior to the change of the rules
if day.value <= datetime.datetime(2016, 9, 24, 0, 0):
# since day is past the modification date,
# the row we want is the previous one, hence minus 1
to_delete = int(day.get_address(0, 0)[1:])-1
# leave the for cycle
break
而且我们现在可以删除从第一场到to_delete的每一行。
ws.range('2:{}'.format(to_delete)).api.Delete()
True
在这一点上,我们的情况是这样的:

完成数据准备后,我们现在将格式化该表。我们首先将第一行的字体设置为粗体。
ws.range('1:1').api.Font.Bold = True
我们可以通过将Jackpot列格式化为百万来遵循这一点。请注意,下面的字符串格式取决于您的计算机的本地区域设置。如果你的格式看起来很奇怪,试着用点替换逗号。更多关于 Excel 自定义格式的信息请点击。
ws.range('J:J').number_format = "£##.##0,,' M'"
作为后续工作的辅助步骤,我们将找到对应于最后一列有数据的字母。
last_column = ws.range(1,1).end('right').get_address(0,0)[0]
现在让我们在标题单元格的底部添加一个边框。类似于我们一直在做的,我们将使用api属性。此外,我们还需要Range对象的 Border 属性、边框方向枚举和边框的样式。我们将只在标题单元格的底部设置一个双边边界(线条样式-4119)(方向9)。
ws.range('A1:{}1'.format(last_column)).api.Borders(9).LineStyle = -4119
现在让我们按行和列自动调整。
ws.autofit()

哎呀!这看起来有点挤,让我们将所有列的宽度设置为似乎最大的列J的宽度。这里是我们在下面使用的 ColumnWidth 文档。
ws.range('A:L').api.ColumnWidth = ws.range('J:J').api.ColumnWidth
那应该看起来更好。我们完成了这张床单!
让我们 add 一个名为Frequencies的新的空白表格,让我们将它分配给 Python 名称frequencies。
wb.sheets.add('Frequencies')
frequencies = wb.sheets['Frequencies']
我们将用我们刚刚在表EuroMillions中组织的数据集中每个数字和每个幸运星的绝对频率填充该表。
# add a header for the numbers
frequencies.range('A1').value = 'Number'
# populate the fifty cells immediately below with the numbers 1 through 50
# since we're starting from the second row, we'll want to substract 1 from the row
frequencies.range('A2:A51').value = '=ROW()-1'
下面我们将在单元格B1中插入一个频率标题,在单元格B2中我们将输入一个公式来计算A2中的值在范围C2:G201中出现的次数。换句话说,我们将计算N1-N5列中出现了多少次1。在此之后,我们将自动填充列B上的其余单元格,对它们各自的行进行同样的操作。
# add a header for the frequencies
frequencies.range('B1').value = 'Frequency'
# insert on B2 the result of a standard Excel formula
frequencies.range('B2').value = '=COUNTIF(Euromillions!$C$2:$G$201,Frequencies!A2)'
autofill(frequencies, 'B2', 51)
我们也为幸运星做同样的事情:
frequencies.range('D1').value = 'Lucky Star'
frequencies.range('E1').value = 'Frequency'
frequencies.range('D2:D13').value = '=ROW()-1'
frequencies.range('E2').value =\
'=COUNTIF(EuroMillions!$H$2:$I$201,Frequencies!D2)'
autofill(frequencies, 'E2', 13)
frequencies.autofit()
在这一点上,我们的新工作表应该是这样的:

我们正在接近我们的目标。让我们创建一个名为Graphs的工作表。
wb.sheets.add('Graphs')
graphs = wb.sheets['Graphs']
现在我们将创建一个 Chart 对象。这只会产生一个空白的白盒,但是不用担心!我们一会儿将使用那个盒子来绘制我们的数据。
nr_freq = xw.Chart()
我们可以 name 我们的图表类似于我们对工作表所做的。方法 set_source_data 允许我们通过传入一个 range 对象来定义图表的数据源。
nr_freq.name = 'Number Frequencies'
nr_freq.set_source_data(frequencies.range('Frequencies!B1:B51'))
Excel 会尝试猜测 x 轴应该是什么,但是我们可以通过使用VBA Chart方法 FullSeriesCollection 强制它是我们在Frequencies上创建的数字。我们可以使用nr_freq.api的索引 1 处的对象来编辑图表:
nr_freq.api[1].FullSeriesCollection(1).XValues = '=Frequencies!A2:A51'
Excel 很擅长猜测用户想要什么样的图表,但为了以防猜错,我们会强制它是柱形图。这里的列出了各种类型的图表。唉,将这些与 chart_type 属性的可能值联系起来的唯一文档是源代码本身。
nr_freq.chart_type = 'column_clustered'
我们现在将定义图表的高度和宽度。测量单位将是点。
nr_freq.height = 250
nr_freq.width = 750
在这一点上,我们应该看到以下内容:

SetElement方法和参数2一起设置图表上方的标题。其他论点见此处。
nr_freq.api[1].SetElement(2) # Place chart title at the top
nr_freq.api[1].ChartTitle.Text = 'Number Frequencies'
我们加上最后的润色。我们使用 HasLegend 属性移除图例。
nr_freq.api[1].HasLegend = 0
作为参数 1 传递给Axes方法的 xlCategory 类别,以及设置为1的属性 TickLabelSpacing ,确保轴的每个元素都被显示。
nr_freq.api[1].Axes(1).TickLabelSpacing = 1
为了完成该图表的格式化,我们通过将 Line 对象的属性 Visible 设置为0来移除轮廓。
graphs.shapes.api('Number Frequencies').Line.Visible = 0
这是我们将会看到的:

下面我们对幸运星做几乎同样的事情。
ls_freq = xw.Chart()
ls_freq.top = 250
ls_freq.name = 'Lucky Star Frequencies'
ls_freq.set_source_data(frequencies.range('Frequencies!E1:E13'))
ls_freq.api[1].FullSeriesCollection(1).XValues = '=Frequencies!D2:D13'
ls_freq.chart_type = 'column_clustered'
ls_freq.height = 250
ls_freq.width = 750
ls_freq.api[1].SetElement(2)
ls_freq.api[1].ChartTitle.Text = 'Lucky Star Frequencies'
ls_freq.api[1].HasLegend = 0
ls_freq.api[1].Axes(1).TickLabelSpacing = 1
graphs.shapes.api('Lucky Star Frequencies').Line.Visible = 0

最后,我们创建一个时间序列图来显示累积奖金的变化。
jackpot = xw.Chart()
jackpot.top = 500
jackpot.name = 'Jackpot'
last_row = ws.range(1,1).end('down').row
jackpot.set_source_data(ws.range('Euromillions!J2:J{}'.format(last_row)))
jackpot.api[1].FullSeriesCollection(1).XValues\
= 'Euromillions!L2:L{}'.format(last_row)
jackpot.chart_type = 'line'
jackpot.height = 250
jackpot.width = 750
jackpot.api[1].SetElement(2)
jackpot.api[1].ChartTitle.Text = 'Jackpot'
jackpot.api[1].HasLegend = 0
graphs.shapes.api('Jackpot').Line.Visible = 0
我们通过将 TickLabels 属性 NumberFormat 设置为所需的外观来固定纵轴“标签”格式。
jackpot.api[1].Axes(2).TickLabels.NumberFormat = "£0,,' M'"

我们完事了。现在,我们保存文件并退出 Excel 实例。
wb.save('EuroMillions.xlsx')
xw.apps[0].quit()
希望这篇 xlwings 教程有所帮助!
学习xlwings的一些有用资源是官方文档、这格式化备忘单、VBA Excel 文档和 xlwings: Python for Excel 由 Felix Zumstein 自己设计,他是xlwings的开发者。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
Python 异常:终极初学者指南(带示例)
June 7, 2022
本教程涵盖了 Python 中的异常,包括为什么会出现异常、如何识别异常以及如何解决异常。
在本教程中,我们将在 Python 中定义异常,我们将确定它们为什么重要以及它们与语法错误有何不同,我们将学习如何在 Python 中解决异常。
Python 中有哪些异常?
当运行 Python 代码时遇到意外情况时,程序会停止执行并抛出错误。Python 中基本上有两类错误:语法错误和异常。为了理解这两种类型之间的区别,让我们运行下面这段代码:
print(x
print(1)
File "C:\Users\Utente\AppData\Local\Temp/ipykernel_4732/4217672763.py", line 2
print(1)
^
SyntaxError: invalid syntax
由于我们忘记了关闭括号,引发了语法错误。当我们在 Python 中使用语法不正确的语句时,总是会出现这种错误。解析器通过一个小箭头^显示检测到语法错误的地方。还要注意,随后的行print(1)没有被执行,因为错误发生时 Python 解释器停止了工作。
让我们修复这个错误并重新运行代码:
print(x)
print(1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/971139432.py in <module>
----> 1 print(x)
2 print(1)
NameError: name 'x' is not defined
现在,当我们修复了错误的语法后,我们得到了另一种类型的错误:异常。换句话说,异常是当语法正确的 Python 代码产生错误时发生的一种错误。箭头指示发生异常的行,而错误信息的最后一行指定了异常的确切类型,并提供了其描述以方便调试。在我们的例子中,它是一个NameError,因为我们试图打印一个之前没有定义的变量x的值。同样在这种情况下,我们的第二行代码print(1)没有被执行,因为 Python 程序的正常流程被中断了。
为了防止程序突然崩溃,捕捉和处理异常非常重要。例如,当给定的异常发生时,提供代码执行的替代版本。这是我们接下来要学的。
标准内置类型的异常
Python 提供了在各种情况下抛出的多种类型的异常。让我们看看最常见的内置异常及其示例:
NameError–当名字不存在于局部或全局变量中时引发:
print(x)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/1353120783.py in <module>
----> 1 print(x)
NameError: name 'x' is not defined
TypeError–对不适用的数据类型运行操作时引发:
print(1+'1')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/218464413.py in <module>
----> 1 print(1+'1')
TypeError: unsupported operand type(s) for +: 'int' and 'str'
ValueError–当操作或函数接受无效的参数值时引发:
print(int('a'))
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/3219923713.py in <module>
----> 1 print(int('a'))
ValueError: invalid literal for int() with base 10: 'a'
IndexError–在 iterable 中不存在索引时引发:
print('dog'[3])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/2163152480.py in <module>
----> 1 print('dog'[3])
IndexError: string index out of range
IndentationError–缩进不正确时引发:
for i in range(3):
print(i)
File "C:\Users\Utente\AppData\Local\Temp/ipykernel_4732/3296739069.py", line 2
print(i)
^
IndentationError: expected an indented block
ZeroDivisionError–在试图将一个数除以零时引发:
print(1/0)
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/165659023.py in <module>
----> 1 print(1/0)
ZeroDivisionError: division by zero
ImportError–导入语句不正确时引发:
from numpy import pandas
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/3955928270.py in <module>
----> 1 from numpy import pandas
ImportError: cannot import name 'pandas' from 'numpy' (C:\Users\Utente\anaconda3\lib\site-packages\numpy\__init__.py)
AttributeError–在试图分配或引用不适用于给定 Python 对象的属性时引发:
print('a'.sum())
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/2316121794.py in <module>
----> 1 print('a'.sum())
AttributeError: 'str' object has no attribute 'sum'
KeyError–字典中没有该键时引发:
animals = {'koala': 1, 'panda': 2}
print(animals['rabbit'])
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/1340951462.py in <module>
1 animals = {'koala': 1, 'panda': 2}
----> 2 print(animals['rabbit'])
KeyError: 'rabbit'
关于 Python 内置异常的完整列表,请参考 Python 文档。
在 Python 中处理异常
由于引发异常会导致程序执行的中断,我们必须提前处理这个异常以避免这种不良情况。
try和except语句
Python 中用于检测和处理异常的最基本命令是try和except。
try语句用于运行一段容易出错的代码,并且必须始终跟有except语句。如果try块执行后没有出现异常,则except块被跳过,程序按预期运行。在相反的情况下,如果抛出异常,try块的执行会立即停止,程序通过运行except块中确定的替代代码来处理引发的异常。之后,Python 脚本继续工作并执行剩余的代码。
让我们通过我们最初的一小段代码print(x)的例子来看看它是如何工作的,它在前面提出了一个NameError:
try:
print(x)
except:
print('Please declare the variable x first')
print(1)
Please declare the variable x first
1
既然我们在except块中处理了异常,我们就收到了一条有意义的定制消息,告诉我们到底哪里出了问题以及如何修复。更何况这一次,程序并不是一遇到异常就停止工作,执行剩下的代码。
在上面的例子中,我们只预测和处理了一种类型的异常,更具体地说,是一个NameError。这种方法的缺点是,except子句中的这段代码将以相同的方式对待所有类型的异常,并输出相同的消息Please declare the variable x first。为了避免这种混淆,我们可以在except命令之后明确指出需要捕捉和处理的异常类型:
try:
print(x)
except NameError:
print('Please declare the variable x first')
Please declare the variable x first
处理多个异常
清楚地说明要捕获的异常类型不仅是为了代码的可读性。更重要的是,使用这种方法,我们可以预测各种特定的异常,并相应地处理它们。
为了理解这个概念,我们来看一个简单的函数,它总结了一个输入字典的值:
def print_dict_sum(dct):
print(sum(dct.values()))
my_dict = {'a': 1, 'b': 2, 'c': 3}
print_dict_sum(my_dict)
6
尝试运行这个函数时,如果我们不小心向它传递了一个错误的输入,我们可能会遇到不同的问题。例如,我们可以在字典名称中犯一个错误,导致一个不存在的变量:
print_dict_sum(mydict)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/2473187932.py in <module>
----> 1 print_dict_sum(mydict)
NameError: name 'mydict' is not defined
输入字典的某些值可以是字符串而不是数字:
my_dict = {'a': '1', 'b': 2, 'c': 3}
print_dict_sum(my_dict)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/2621846538.py in <module>
1 my_dict = {'a': '1', 'b': 2, 'c': 3}
----> 2 print_dict_sum(my_dict)
~\AppData\Local\Temp/ipykernel_4732/3241128871.py in print_dict_sum(dct)
1 def print_dict_sum(dct):
----> 2 print(sum(dct.values()))
3
4 my_dict = {'a': 1, 'b': 2, 'c': 3}
5 print_dict_sum(my_dict)
TypeError: unsupported operand type(s) for +: 'int' and 'str'
另一个选项允许我们为此函数传入一个不合适的数据类型的参数:
my_dict = 'a'
print_dict_sum(my_dict)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/1925769844.py in <module>
1 my_dict = 'a'
----> 2 print_dict_sum(my_dict)
~\AppData\Local\Temp/ipykernel_4732/3241128871.py in print_dict_sum(dct)
1 def print_dict_sum(dct):
----> 2 print(sum(dct.values()))
3
4 my_dict = {'a': 1, 'b': 2, 'c': 3}
5 print_dict_sum(my_dict)
AttributeError: 'str' object has no attribute 'values'
因此,我们至少有三种不同类型的异常应该被不同地处理:NameError、TypeError和AttributeError。为此,我们可以在单个try块之后添加多个except块(每个异常类型一个,在我们的例子中是三个):
try:
print_dict_sum(mydict)
except NameError:
print('Please check the spelling of the dictionary name')
except TypeError:
print('It seems that some of the dictionary values are not numeric')
except AttributeError:
print('You should provide a Python dictionary with numeric values')
Please check the spelling of the dictionary name
在上面的代码中,我们在try子句中提供了一个不存在的变量名作为函数的输入。代码应该抛出一个NameError,但是它在一个后续的except子句中被处理,相应的消息被输出。
我们也可以在函数定义中处理异常。重要:我们不能为任何函数参数处理NameError异常,因为在这种情况下,异常发生在函数体开始之前。例如,在下面的代码中:
def print_dict_sum(dct):
try:
print(sum(dct.values()))
except NameError:
print('Please check the spelling of the dictionary name')
except TypeError:
print('It seems that some of the dictionary values are not numeric')
except AttributeError:
print('You should provide a Python dictionary with numeric values')
print_dict_sum({'a': '1', 'b': 2, 'c': 3})
print_dict_sum('a')
print_dict_sum(mydict)
It seems that some of the dictionary values are not numeric
You should provide a Python dictionary with numeric values
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/3201242278.py in <module>
11 print_dict_sum({'a': '1', 'b': 2, 'c': 3})
12 print_dict_sum('a')
---> 13 print_dict_sum(mydict)
NameError: name 'mydict' is not defined
函数内部成功处理了TypeError和AttributeError,并输出了相应的消息。相反,由于上述原因,NameError尽管引入了单独的except条款,却没有得到妥善处理。因此,函数的任何参数的NameError都不能在函数体内部处理。
如果以相同的方式处理,可以将几个异常组合成一个元组放在一个except子句中:
def print_dict_sum(dct):
try:
print(sum(dct.values()))
except (TypeError, AttributeError):
print('You should provide a Python DICTIONARY with NUMERIC values')
print_dict_sum({'a': '1', 'b': 2, 'c': 3})
print_dict_sum('a')
You should provide a Python DICTIONARY with NUMERIC values
You should provide a Python DICTIONARY with NUMERIC values
else声明
除了try和except子句,我们可以使用可选的else命令。如果存在,else命令必须放在所有except子句之后,并且只有在try子句中没有出现异常时才执行。
例如,在下面的代码中,我们尝试除以零:
try:
print(3/0)
except ZeroDivisionError:
print('You cannot divide by zero')
else:
print('The division is successfully performed')
You cannot divide by zero
异常在except块中被捕获并处理,因此else子句被跳过。让我们看看如果我们提供一个非零数字会发生什么:
try:
print(3/2)
except ZeroDivisionError:
print('You cannot divide by zero')
else:
print('The division is successfully performed')
1.5
The division is successfully performed
因为没有出现异常,所以执行了else块并输出相应的消息。
finally声明
另一个可选语句是finally,如果提供,它必须放在包括else(如果存在)
在内的所有条款之后,并且在任何情况下都要执行,不管try条款中是否提出了例外。
让我们将finally块添加到前面的两段代码中,观察结果:
try:
print(3/0)
except ZeroDivisionError:
print('You cannot divide by zero')
else:
print('The division is successfully performed')
finally:
print('This message is always printed')
You cannot divide by zero
This message is always printed
try:
print(3/2)
except ZeroDivisionError:
print('You cannot divide by zero')
else:
print('The division is successfully performed')
finally:
print('This message is always printed')
1.5
The division is successfully performed
This message is always printed
在第一种情况下,出现了异常,在第二种情况下,没有出现异常。然而,在这两种情况下,finally子句输出相同的消息。
引发异常
有时,我们可能需要故意引发一个异常,并在某个条件发生时停止程序。为此,我们需要raise关键字和以下语法:
raise ExceptionClass(exception_value)
在上面,ExceptionClass是要引发的异常的类型(例如,TypeError),exception_value是可选的定制描述性消息,如果引发异常,将显示该消息。
让我们看看它是如何工作的:
x = 'blue'
if x not in ['red', 'yellow', 'green']:
raise ValueError
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/2843707178.py in <module>1 x = 'blue'
2 if x not in ['red', 'yellow', 'green']:
----> 3 raise ValueError
ValueError:
在上面这段代码中,我们没有为异常提供任何参数,因此代码没有输出任何消息(默认情况下,异常值为None)。
x = 'blue'
if x not in ['red', 'yellow', 'green']:
raise ValueError('The traffic light is broken')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4732/359420707.py in <module>
1 x = 'blue'
2 if x not in ['red', 'yellow', 'green']:
----> 3 raise ValueError('The traffic light is broken')
ValueError: The traffic light is broken
我们运行了相同的代码,但是这次我们提供了异常参数。在这种情况下,我们可以看到一条输出消息,该消息提供了更多的上下文信息,以说明发生该异常的确切原因。
结论
在本教程中,我们讨论了 Python 中异常的许多方面。特别是,我们了解到以下情况:
- 如何在 Python 中定义异常,以及它们与语法错误有何不同
- Python 中存在哪些内置异常,何时引发
- 为什么捕捉和处理异常很重要
- 如何在 Python 中处理一个或多个异常
- 捕捉和处理异常的不同子句如何协同工作
- 为什么指定要处理的异常类型很重要
- 为什么我们不能在函数定义中为函数的任何参数处理一个
NameError - 如何引发异常
- 如何向引发的异常添加描述性消息,以及为什么这是一种好的做法
有了这些技能,您就可以处理任何需要在 Python 中解决异常的真实世界的数据科学任务。
Python 初学者:为什么 Python 看起来是这样的?
原文:https://www.dataquest.io/blog/python-for-beginners-why-python-code-look/
February 4, 2020
Python 入门课程通常从编程基础开始,比如如何打印一串文本或者如何执行数学运算。但是他们并不经常解释为什么代码看起来是这个样子。
例如,考虑下面的代码片段。如果你是一个完全的初学者,你可能会感到有点困惑和害怕。为什么代码的某些部分用不同的颜色?为什么有些线之间有间断而其他的没有?为什么有些字符周围有空格,而其他字符周围没有?

让我们深入研究并回答其中的一些问题,这样当您开始编写第一行 Python 代码时,您会对所看到的内容有一个更好的了解!
为什么代码在不同的地方有不同的颜色?
你在大多数编码平台和程序上看到的不同颜色只是为了帮助我们区分代码的不同部分。它们实际上对代码的运行没有任何影响
在下面的 gif 图中,你可以看到带有颜色的代码被粘贴到一个没有突出显示颜色的记事本中。这两个代码片段将做完全相同的事情,并且计算机读取它们是相同的。这些颜色只是为了让我们人类的代码更易读。

随着您对编程了解的越来越多,您会发现颜色很有帮助,因为它们突出了代码的不同元素。例如,上面代码片段中的黄色突出显示数值(即数字)。
(注意:这些颜色不是通用的。根据您编写代码的位置,您可能会看到不同的代码元素有不同的颜色选择,或者根本没有颜色。本文中的例子都展示了 Dataquest 上的文本是如何着色的。
为什么有些字符(像+和=)周围有空格?
就像颜色一样,这些空间是给我们人类的,让代码更容易阅读。计算机会简单地忽略它们,所以不管你有没有空格,你的代码都会运行。
然而,添加空格会使代码看起来更容易。尽管代码正常运行并不需要,但你通常会看到 Python 是用这些空格编写的。
*
(这个约定有一些例外,但是如果你只是一个 Python 初学者,你现在不必担心它们!)
为什么有些行只是空白的?
就像颜色和空格一样,这些空行只是为了让代码更易读。
在下面的 gif 中,无论是否有空行,程序都将以完全相同的方式执行。然而,这些空白行让我们人类一眼就能发现代码的特定部分。

因此,再次强调,虽然空行不是绝对必要的,但是将代码中使用空行做不同事情的部分分开是一个很好的做法。这将使你(或其他人)以后更容易扫描和阅读你的代码。
为什么代码的不同部分被打在不同的行上?
代码中的每一行都代表一条编程语句。您可以将每条语句想象成指令列表中的一条指令。
例如,考虑如何喝水的说明:
- 拿一个杯子
- 把它装满水
- 喝点水
这里有一系列的步骤。为了喝水,我们需要按照正确的顺序一次喝一杯。
同样的概念也适用于编程。为了让计算机做我们想让它做的事情,我们需要一次给它一条指令(编程语句),按照逻辑顺序。
现在,考虑以下一组指令:
- 拿一个玻璃杯,装满水,把水喝了
虽然它没有被非常清楚地呈现出来,但是一个人可以阅读它,并且指出它实际上是三个连续的步骤。然而,电脑并没有那么聪明。他们需要按顺序一步一步来。
这就是换行符的作用。当我们将代码分成新的一行时,计算机理解每一行都是一个独特的步骤,它将按顺序执行它们。
- 拿一个杯子
- 把它装满水
- 喝点水
比如下面的 gif,我们先告诉 Python,变量 string 的值是‘Hello’。然后,在下一行,我们告诉 Python 打印该变量。我们必须用换行符分隔这两个步骤,否则 Python 会试图同时执行它们,从而导致错误。

Python 中大写重要吗?
是的。Python 是一种“区分大小写”的语言,这意味着大小写很重要。
例如,脸书、Facebook 和 facebook 与 Python 的区别就像脸书和谷歌的区别一样。因为大写的不同,Python 会把脸书、Facebook、facebook 读成三个完全不同的变量。
在下面的 gif 中,你可以看到,如果我们创建一个名为 Learn_DataScience 的变量,然后试图查看变量 learn_datascience,我们会得到一个错误。
那是因为大写的缘故——Learn_DataScience 和 Learn _ data science 被 Python 读成了不同的变量。

现在您已经准备好编写自己的代码了!
希望在这一点上,您对 Python 代码的外观有了更好的理解。现在,是时候开始编写自己的代码了!
点击下面的按钮注册一个免费的 Dataquest 帐户。我们的 Python 基础课程将教你从头开始编写 Python,即使你以前没有任何经验!
其他作者:Sahil Sunny 和 Nityesh Agarwal
导入 dataquest 作为 dq
开始免费学习我们的Python for Data Science:Fundamentals 课程。
Python For 循环的基础:教程
May 30, 2019
当您在 Python 中处理数据时, for loops 可能是一个强大的工具。但是当你刚开始的时候,它们也可能有点令人困惑。在本教程中,我们将一头扎进 for 循环,并了解当您在 Python 中进行数据清理或数据分析时,如何使用它们来做各种有趣的事情。
本教程是为 Python 初学者编写的,但是如果你以前从未写过一行代码,你可能想从我们免费的 Python 基础课程的开头开始,因为我们在这里不会涉及基本语法。
什么是循环?
在大多数数据科学工作的上下文中,Python for loops 用于遍历一个可迭代对象(如列表、元组、集合等)。)并对每个条目执行相同的操作。例如,For 循环允许我们遍历列表,对列表中的每一项执行相同的操作。
(顺便说一下,可交互对象是我们可以迭代或“循环”遍历的任何 Python 对象,每次返回一个元素。例如,列表是可迭代的,并且按照条目被列出的顺序,一次返回一个列表条目。字符串是可迭代的,按照字符出现的顺序,一次返回一个字符。等等。)
创建 for 循环的方法是,首先定义要循环的 iterable 对象,然后定义要对 iterable 对象中的每一项执行的操作。例如,当遍历一个列表时,首先指定想要遍历的列表,然后用和指定想要对每个列表项执行什么操作。
让我们看一个简单的例子:如果我们有一个用 Python 存储的名字列表,我们可以使用一个 for 循环来遍历这个列表,打印每个名字,直到它到达末尾。下面,我们将创建我们的名字列表,然后编写一个 for 循环来遍历它,按顺序打印列表中的每个条目。
our_list = ['Lily', 'Brad', 'Fatima', 'Zining']
for name in our_list:
print(name)
Lily
Brad
Fatima
Zining
这个简单循环中的代码提出了一个问题:变量name来自哪里?我们之前没有在代码中定义它!但是因为 for 循环遍历列表、元组等。按顺序,这个变量实际上可以被称为几乎任何东西。当循环执行时,Python 会将我们放在那个位置的任何变量名解释为按顺序引用每个列表条目。
所以,在上面的代码中:
name在循环的第一次迭代时指向'Lily'…- …然后
'Brad'在循环的第二次迭代中… - …等等。
不管我们怎么称呼这个变量,情况都会如此。因此,举例来说,如果我们重写代码,用x替换name,我们将得到完全相同的结果:
for x in our_list:
print(x)
Lily
Brad
Fatima
Zining
注意,这种技术适用于任何可迭代对象。例如,字符串是可迭代的,我们可以使用相同类型的 For 循环来迭代字符串中的每个字符:
for letter in 'Lily':
print(letter)
L
i
l
y
对列表的列表使用 For 循环
然而,在实际的数据分析工作中,我们不太可能使用如上所述的简短列表。一般来说,我们必须处理表格格式的数据集,有多行和多列。这种数据可以在 Python 中存储为列表的列表,其中表的每一行都存储为列表列表中的列表,我们也可以使用 for 循环来遍历这些列表。
为了了解如何做到这一点,让我们看看一个更现实的场景,并探索这个小数据表,其中包含一些美国价格和几款电动汽车的美国环保局范围估计值。
| 车辆 | 范围 | 价格 |
|---|---|---|
| 特斯拉 Model 3 LR | Three hundred and ten | Forty-nine thousand nine hundred |
| 现代离子 EV | One hundred and twenty-four | Thirty thousand three hundred and fifteen |
| 雪佛兰博尔特 | Two hundred and thirty-eight | Thirty-six thousand six hundred and twenty |
我们可以将相同的数据集表示为列表的列表,如下所示:
ev_data = [['vehicle', 'range', 'price'],
['Tesla Model 3 LR', '310', '49900'],
['Hyundai Ioniq EV', '124', '30315'],
['Chevy Bolt', '238', '36620']]
您可能已经注意到,在上面的列表中,我们的产品系列和价格数字实际上是以字符串而不是整数的形式存储的。以这种方式存储数据并不少见,但是为了便于分析,我们希望将这些字符串转换成整数,以便用它们进行一些计算。让我们使用一个 for 循环来遍历我们的列表,选择每个列表中的price条目,并将其从字符串更改为整数。
为此,我们需要做几件事。首先,我们需要跳过表中的第一行,因为它们是列名,如果我们试图将非数字字符串如'range'转换成整数,就会出现错误。我们可以使用列表切片来选择第一行之后的每一行。(如果你需要温习这一点,或者列表的任何其他方面,请查看我们关于 Python 编程基础的互动课程)。
然后,我们将遍历列表列表,对于每次迭代,我们将选择range列中的元素,这是表中的第二列。我们将把在该列中找到的值赋给一个名为'range'的变量。为此,我们将使用索引号1(在 Python 中,iterable 中的第一个条目位于索引0,第二个条目位于索引1,依此类推。).
最后,我们将使用 Python 内置的'int()函数将范围数转换成整数,并在我们的数据集中用这些整数替换原始字符串。
for row in ev_data[1:]: # loop through each row in ev_data starting with row 2 (index 1)
ev_range = row[1] # each car's range is found in column 2 (index 1)
ev_range = int(ev_range) # convert each range number from a string to an integer
row[1] = ev_range # assign range, which is now an integer, back to index 1 in each row
print(ev_data)
[['vehicle', 'range', 'price'], ['Tesla Model 3 LR', 310, '49900'], ['Hyundai Ioniq EV', 124, '30315'], ['Chevy Bolt', 238, '36620']]
既然我们已经将这些值存储为整数,我们还可以使用 for 循环来进行一些计算。比方说,我们想算出这个列表中一辆电动汽车的平均里程。我们需要将范围数加在一起,然后除以列表中的汽车总数。
同样,我们可以使用 for 循环来选择数据集中需要的特定列。我们将从创建一个名为total_range的变量开始,在这里我们可以存储范围的总和。然后,我们将编写另一个 for 循环,再次跳过标题行,再次将第二列(索引 1)标识为范围值。
之后,我们需要做的就是在我们的 for 循环中把这个值加到total_range上,然后在循环完成后用total_range除以汽车数量来计算这个值。
(注意,在下面的代码中,我们将通过计算列表的长度减去标题行来计算汽车的数量。对于像我们这样短的列表,我们也可以简单地除以 3,因为汽车的数量很容易计算,但是如果列表中添加了额外的汽车数据,就会破坏我们的计算。出于这个原因,最好使用len()来计算代码中汽车列表的长度,这样如果将来有额外的条目添加到我们的数据集中,我们可以重新运行这个代码,它仍然会产生正确的答案。)
total_range = 0 # create a variable to store the total range number
for row in ev_data[1:]: # loop through each row in ev_data starting with row 2 (index 1)
ev_range = row[1] # each car's range is found in column 2 (index 1)
total_range += ev_range # add this number to the number stored in total_range
number_of_cars = len(ev_data[1:]) # calculate the length of our list, minus the header row
print(total_range / number_of_cars) # print the average range
224.0
Python for 循环功能强大,可以在其中嵌套更复杂的指令。为了演示这一点,让我们对我们的'price'列重复上面的两个步骤,这次是在一个 for 循环中。
total_price = 0 # create a variable to store the total range number
for row in ev_data[1:]: # loop through each row in ev_data starting with row 2 (index 1)
price = row[2] # each car's price is found in column 3 (index 2)
price = int(price) # convert each price number from a string to an integer
row[2] = price # assign price, which is now an integer, back to index 2 in each row
total_price += price # add each car's price to total_price
number_of_cars = len(ev_data[1:]) # calculate the length of our list, minus the header row
print(total_price / number_of_cars) # print the average price
38945.0
我们还可以在 for 循环中嵌套其他元素,比如 If Else 语句,甚至其他 for 循环。
例如,假设我们希望在列表中找到每辆行驶里程超过 200 英里的汽车。我们可以从创建一个新的空列表来保存我们的长期汽车数据开始。然后,我们将使用 for 循环遍历前面创建的包含汽车数据的列表列表ev_data,仅当其范围值大于 200:
long_range_car_list = [] # creating a new list to store our long range car data
for row in ev_data[1:]: # iterate through ev_data, skipping the header row
ev_range = row[1] # assign the range number, which is at index 1 in the row, to the range variable
if ev_range > 200: # append the whole row to long-range list if range is higher than 200
long_range_car_list.append(row)
print(long_range_car_list)
[['Tesla Model 3 LR', 310, 49900], ['Chevy Bolt', 238, 36620]]
当然,对于如此小的数据集,手工执行这些操作也很简单。但是这些相同的技术将在具有成千上万行的数据集上工作,这可以使清理、排序和分析巨大的数据集成为非常快速的工作。
其他有用的技巧:范围、中断和继续
仅仅通过掌握上面描述的技术,您就可以从 for 循环中获得惊人的收益,但是让我们更深入地了解一些其他可能有帮助的东西,即使您在数据科学工作的上下文中不太经常使用它们。
范围
For 循环可以与 Python 的range()函数一起使用,遍历指定范围内的每个数字。例如:
for x in range(5, 9):
print(x)
5
6
7
8
请注意,Python 在范围计数中不包括范围的最大值,这就是为什么数字 9 没有出现在上面。如果我们想让这段代码从 5 数到 9,包括 9,我们需要将range(5, 9)改为range(5, 10):
for x in range(5, 10):
print(x)
5
6
7
8
9
如果在range()函数中只指定了一个数字,Python 会把它作为最大值,并指定一个缺省的最小值零:
for x in range(3):
print(x)
0
1
2
您甚至可以向range()函数添加第三个参数,以指定您希望以特定数字的增量进行计数。正如您在上面看到的,默认值是 1,但是如果您添加第三个参数 3,例如,您可以将range()与 for 循环一起使用,以三为单位向上计数:
for x in range(0, 9, 3):
print(x)
0
3
6
破裂
默认情况下,Python for 循环将遍历分配给它的可交互对象的每个可能的迭代。通常,当我们使用 for 循环时,这很好,因为我们希望对列表中的每一项执行相同的操作(例如)。
但是,有时,如果满足某个条件,我们可能希望停止循环。在这种情况下,break语句是有用的。当在 for 循环中与 if 语句一起使用时,break允许我们在循环结束前中断它。
让我们先来看一个简单的例子,使用我们之前创建的名为our_list的列表:
for name in our_list:
break
print(name)
当我们运行这段代码时,什么也没有打印出来。这是因为在我们的 for 循环中,break语句在print(name)之前。当 Python 看到break时,它会停止执行 for 循环,循环中 break后出现的代码不会运行。
让我们在这个循环中添加一个 if 语句,这样当 Python 到达紫凝这个名字时,我们就可以跳出这个循环了:
for name in our_list:
if name == 'Zining':
break
print(name)
Lily
Brad
Fatima
在这里,我们可以看到紫凝这个名字没有被印刷出来。下面是每次循环迭代发生的情况:
- Python 检查名字是否是“紫凝”。它不是,所以它继续执行 if 语句下面的代码,并输出名字。
- Python 检查第二个名字是否是“紫凝”。它不是,所以它继续执行 if 语句下面的代码,并打印第二个名字。
- Python 检查第三个名字是否是“紫凝”。它不是,所以它继续执行 if 语句下面的代码,并打印第三个名字。
- Python 检查第四个名字是否是“紫凝”。如果为,则
break被执行,for 循环结束。
让我们回到我们编写的用于收集电动汽车远程数据的代码,并再看一个例子。我们将插入一个 break 语句,一旦遇到字符串'Tesla'就停止查找:
long_range_car_list = [] # creating our empty long-range car list again
for row in ev_data[1:]: # iterate through ev_data as before looking for cars with a range > 200
ev_range = row[1]
if ev_range > 200:
long_range_car_list.append(row)
if 'Tesla' in row[0]: # but if 'Tesla' appears in the vehicle column, end the loop
break
print(long_range_car_list)
[['Tesla Model 3 LR', 310, 49900]]
在上面的代码中,我们可以看到特斯拉仍然被添加到了long_range_car_list,因为我们将它添加到了列表中,在使用break的 if 语句之前。Chevy Bolt 没有被添加到我们的列表中,因为尽管它的行驶里程超过 200 英里,break在 Python 到达 Chevy Bolt 行之前就结束了循环。
(记住,for 循环是按顺序执行的。如果在我们的原始数据集中,Bolt 列在 Tesla 之前,它将被包含在long_range_car_list中。
继续
当我们循环遍历一个像列表这样的可迭代对象时,我们也可能会遇到想要跳过特定的一行或多行的情况。对于像跳过标题行这样的简单情况,我们可以使用列表切片,但是如果我们想要基于更复杂的条件跳过行,这很快就变得不切实际了。相反,我们可以使用continue语句跳过 for 循环的一次迭代(“循环”),并进入下一次循环。
例如,当 Python 在列表上执行 for 循环时看到continue时,它将在该点停止,并移动到列表上的下一项。任何低于continue的代码都不会被执行。
让我们回到我们的名字列表(our_names)中,如果名字是“Brad”,那么在打印之前使用带有 if 语句的continue来结束循环迭代:
for name in our_list:
if name == 'Brad':
continue
print(name)
Lily
Fatima
Zining
上面,我们可以看到布拉德的名字被跳过了,我们列表中的其余名字是按顺序打印的。简而言之,这说明了break和continue的区别:
break完全结束循环。Python 执行break时,for 循环结束。
**continue结束循环的一个特定迭代并移动到列表中的下一项。当 Python 执行continue时,它会立即进入下一个循环迭代,但不会完全结束循环。*
为了对continue进行更多的练习,让我们列出一个短程电动车的列表,使用continue采取稍微不同的方法。我们将编写一个 for 循环,将每辆电动汽车的添加到我们的短程列表中,而不是识别行驶里程小于 200 英里的电动汽车,但是在之前有一个continue语句,如果行驶里程大于 200 英里,我们将添加到新列表中:*
short_range_car_list = [] # creating our empty short-range car list
for row in ev_data[1:]: # iterate through ev_data as before
ev_range = row[1]
if ev_range > 200: # if the car has a range of > 200
continue # end the loop here; do not execute the code below, continue to the next row
short_range_car_list.append(row) # append the row to our short-range car list
print(short_range_car_list)
[['Hyundai Ioniq EV', 124, 30315]]
这可能不是创建我们的短程汽车列表的最有效和可读的方式,但它确实演示了continue如何工作,所以让我们来看看这里到底发生了什么。
在第一次循环中,Python 正在查看特斯拉行。那辆车和确实有超过 200 英里的续航里程,所以 Python 看到 if 语句为真,并执行嵌套在 if 语句中的continue,这使得立即跳到下一行ev_data开始下一个循环。
在第二个循环中,Python 正在查看下一行,这是 Hyundai 行。那辆车的行驶里程不到 200 英里,因此 Python 发现条件 if 语句是而不是 met,并执行 for 循环中的其余代码,将 Hyundai 行追加到short_range_car_list。
在第三个也是最后一个循环中,Python 正在查看 Chevy 行。那辆车的行驶里程超过 200 英里,这意味着条件 if 语句为真。因此,Python 再次执行嵌套的continue,这结束了循环,并且由于我们的数据集中没有更多的数据行,因此完全结束了 for 循环。
额外资源
希望此时,您已经熟悉了 Python 中的 for 循环,并且了解了它们对于常见的数据科学任务(如数据清理、数据准备和数据分析)的用处。
准备好迈出下一步了吗?以下是一些可供查看的附加资源:
- 高级 Python For Loops 教程——在本教程的“续集”中,学习使用 For Loops 和 NumPy、Pandas 以及其他更高级的技术。
- Python 教程 —我们不断扩充的数据科学 Python 教程列表。
- 数据科学课程 —通过完全交互式的编程、数据科学和统计课程,让您的学习更上一层楼,就在您的浏览器中。
- Python 关于 For 循环的官方文档–官方文档没有本教程那么深入,但它回顾了 For 循环的基础知识,解释了一些相关概念,如 While 循环。
- Dataquest 的数据科学 Python 基础课程–我们的 Python 基础课程从头开始介绍数据科学的 Python 编码。它涵盖了列表、循环等等,你可以直接在浏览器中进行交互式编码。
- Dataquest 面向数据科学的中级 Python 课程——当你觉得自己已经掌握了 for 循环和其他核心 Python 概念时,这是另一个交互式课程,它将帮助你将 Python 技能提升到一个新的水平。
- 免费数据集练习–通过从这些来源中的一个获取免费数据集,并将您的新技能应用于大型真实数据集,自己练习循环。第一部分中的数据集(用于数据可视化)应该特别适合实践项目,因为它们应该已经相对干净了。
祝你好运,快乐循环!
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。*
Python 生成器
原文:https://www.dataquest.io/blog/python-generators-tutorial/
June 13, 2018Python generators are a powerful, but misunderstood tool. They’re often treated as too difficult a concept for beginning programmers to learn — creating the illusion that beginners should hold off on learning generators until they are ready. I think this assessment is unfair, and that you can use generators sooner than you think. In this tutorial, we’ll cover:
- 理解发电机所需的基本术语
- 什么是发电机
- 如何创建自己的发电机
- 如何使用生成器和生成器方法
- 何时使用发电机
先决条件
为了充分利用本教程,您应该熟悉以下概念:
- 基本 Python 数据结构
- 什么是列表
- 什么是字典
- 功能
- 什么是函数
- 如何创建和使用函数
- 列出理解
- 什么是列表理解
- 如何创建一个简单的列表理解
需要了解的基本术语
迭代和可迭代
迭代是某种过程一遍又一遍的重复。Python 的
for循环给了我们一个简单的方法来对不同的对象进行迭代。通常,您会迭代一个列表,但是我们也可以迭代其他 Python 对象,比如字符串和字典。
# Iterating over a list
ez_list = [1, 2, 3]
for i in ez_list:
print(i)
>>> 1
>>> 2
>>> 3
# Iterating over a string
ez_string = "Generators"
for s in ez_string:
print(s)
>>> "G"
>>> "e"
...
>>> "r"
>>> "s"
# Iterating over a dictionary
ez_dict = {1 : "First, 2 : "Second"}
for key, value in ez_dict.items():
print(k, v)
>>> 1 "First"
>>> 2 "Second"
在上面的每个示例中
循环在我们给定的序列上迭代。上面的代码使用了列表、字符串和字典,但是您也可以迭代元组和集合。在上面的每个循环中,我们按照出现的顺序对序列中的每个项目进行print。例如,您可以确认ez_list的顺序是按照其项目的打印顺序复制的。 我们将任何支持迭代的对象称为可迭代。
我们将任何支持迭代的对象称为可迭代。
什么定义了一个 iterable?
Iterables 支持一种叫做
迭代器协议迭代器协议的技术定义超出了本文的范围,但是它可以被认为是一组用于for循环的需求。也就是说:列表、字符串和字典都遵循迭代器协议,因此我们可以在 for 循环中使用它们。相反,不遵循协议的对象不能在for循环中使用。不遵循协议的对象的一个例子是整数。如果我们试图给一个for循环一个整数,Python 会抛出一个错误。
number = 12345
for n in number:
print(n)
>>> TypeError: 'int' object is not iterable
整数只是单数,不是序列。你可能会认为第一个数字
number为 1,但它不同于序列中的第一项。问“1 后面是什么”没有意义。因为 Python 只把整数理解为一个单独的实体。因此,成为可迭代的一个要求是能够向for循环描述下一个项要执行的操作是什么。例如,列表告诉for循环,下一个要迭代的条目在当前条目的索引+1 处(1 在 0 之后)。因此,当停止迭代时,iterable 也必须向for循环发出信号。这个信号通常在我们到达一个序列的末尾(即一个列表或字符串的末尾)时出现。我们将在本文的后面探索使某些东西可迭代的特定函数,重要的是要知道可迭代描述了一个循环应该如何遍历它的内容。生成器本身是可迭代的。稍后你会看到,for循环是我们使用生成器的主要方式之一,所以它们必须能够支持迭代。在下一节中,我们将深入研究如何创建我们自己的生成器。
要点:需要了解的基本术语
- 迭代是在一系列项目上重复一些过程的想法。在 Python 中,迭代通常与
for循环相关。 - iterable 是支持迭代的对象。
- 要成为可迭代的,它必须向一个
for循环描述两件事:- 迭代中的下一项是什么。
- 循环何时应该停止迭代。
- 发电机是可迭代的。
基于数据的方法
为了真正探索生成器,我们将使用
酿酒师的朋友啤酒食谱数据集来自 Kaggle。你可以在这里找到数据集,如果你想在你自己的电脑上跟随。该数据包含来自世界各地啤酒酿造商的重要啤酒特征,包括啤酒风格、酒精体积(ABV)和啤酒产量。就本文而言,假设我们对酿造自己的啤酒感兴趣。也许我们想卖我们的啤酒,所以我们想看看别人做了什么来通知我们的酿造选择和生产更受欢迎的啤酒风格。作者注:原始数据集中的“名称”列包含一些杂乱的值,干扰了我们的分析。你可以在这里找到一个符合我们目的的干净版本。
发电机和你
如果你以前从未遇到过发电机,那么现实生活中最常见的发电机例子就是备用发电机,它会产生—
产生——为你的房子或办公室供电。从概念上讲,Python 生成器从给定的序列中一次生成一个值,而不是一次给出整个序列。这种一次一个发生器的方式使得它们与for循环如此兼容。如果这听起来令人困惑,不要太担心。随着我们解释如何创建生成器,它将变得更加清晰。创建生成器有两种方法。它们的语法不同,但最终结果仍然是一个生成器。我们将通过介绍它们的语法并将其与一个类似的、但非生成器的等价概念进行比较来教授这些概念。
1. 一个生成器函数对一个常规函数
2. 生成器表达式*对列表理解
发电机功能
生成器函数就像一个常规函数,但是有一个关键的区别
yield关键字替换return。
# Regular function
def function_a():
return "a"
# Generator function
def generator_a():
yield "a"
上面的两个函数执行完全相同的操作(返回/产生相同的字符串)。但是,如果您尝试检查生成器函数,它不会与常规函数显示的内容相匹配。
function_a()
>>> "a"
generator_a()
>>> <generator object a at 0x000001565469DA98>
调用一个常规函数告诉 Python 返回函数在代码中的位置,执行代码块中的代码,并返回结果。为了让生成器函数产生它的值,您需要将它传递到
next()功能。next()是一个特殊的函数,它询问“迭代中的下一项是什么?”事实上,next()就是运行for循环时调用的精确函数!列表、字典、字符串等等都实现了next(),所以这就是为什么你可以首先将它们合并到循环中。
# Asking the generator what the next item is
next(a())
>>> "a"
# Do not do this
next(a)
注意,我们必须传入带括号的生成器函数,因为函数本身就是生成器。只提供函数名会抛出一个错误,因为你试图给出
next()一个功能名。正如所料,一旦我们调用next()函数,生成器函数将yield“a”。这个例子不能完全代表生成器的用途。请记住,生成器生成一个值流,所以使用单个值并不真正符合流的条件。为此,我们实际上可以将多个yield语句放入一个生成器函数中。这些yield语句构成了发生器将输出的序列。我们将创建一个生成器,并将其绑定到一个变量mg。然后,如果我们继续将mg传递到next(),我们将到达下一个yield。如果我们继续走过去,我们将得到一个StopIteration错误,告诉我们生成器没有更多的值可以给出。StopIteration错误实际上是for循环如何知道何时停止迭代。
def multi_generate():
yield "a"
yield "b"
yield "c"
mg = multi_generate()
next(mg)
>>> "a"
next(mg)
>>> "b"
next(mg)
>>> "c"
next(mg)
>>> StopIteration:
分配
multi_generate到mg是使用发生器功能的关键步骤。将生成器绑定到mg允许我们创建一个可以引用的生成器的单个实例。我们可以继续将mg传递给next(),并获得其他的yield语句。观察如果我们一直试图传入multi_generate本身会发生什么。
next(multi_generate())
>>> "a"
next(multi_generate())
>>> "a"
很容易把发生器想象成一台只等待一个命令的机器:
next()。一旦你在生成器上调用next(),它将按顺序分配下一个值。否则,你不能用发电机做更多的事情。下图将我们的生成器表示为一台简单的机器。 我们继续得到第一个
我们继续得到第一个yield语句的结果。这背后的原因很微妙。当我们将生成器函数本身传递给next()时,Python 假设你正在传递一个multi_generate的新实例给它,所以它总是给你第一个yield结果。通过将生成器绑定到一个变量,Python 知道当您将它传递给next()时,您正试图对同一事物进行操作。我们已经注意到,随着我们不断将mg传递给 next,我们会得到其他yield结果。只有当发电机以某种方式记得它最后做了什么,这才有可能。这个内存就是生成器函数区别于常规函数的地方!一旦你使用了一个函数,它就一劳永逸了。一旦你从函数中得到这个值。发电机将保持yield ing 值,直到它退出。这给我们带来了发电机的另一个重要性质。一旦我们完成了对它们的迭代,我们就不能再使用它们了。一旦我们通过了mg中的所有三个yield值,它就不能再为我们提供任何东西了。我们必须存储另一个multi_generate生成器的实例,以便再次开始查询它的next()语句。我们的数据还没有被读入,所以让我们用一个生成器函数来完成。该数据称为recipeData.csv,包含在一个 CSV 文件中。我们将使用open()函数来读取它,并且我们将开始使用next()函数来读取 CSV 的前几行。
# Creating a generator that will generate the data row by row
def beerDataGenerator():
file = "recipeData.csv"
for row in open(file, encoding="ISO-8859-1"):
yield row
我们将慢慢剖析上面的代码:
- 我们将
dataGenerator指定为生成器函数,它将逐行分发我们的 CSV 文件。该函数在file中包含文件名,这使我们能够使用open()函数来读取它。 - 虽然我们已经讨论了像列表和字典这样的 Python 对象可以被迭代,但是我们也可以迭代我们已经
open()过的文件。 encoding告诉 Python 它应该期望看到什么类型的字符;ISO-8859-1 特指拉丁语-1。for循环将从 CSV 文件中的第一行开始,yield该行,然后保存它在读取文件中的当前位置,直到再次调用生成器函数。
如果你在自己的电脑上跟踪数据,你需要替换
file用您电脑上文件所在的确切路径。这将使 Python 能够在您想要open()它时找到它。
# Remember to store an instance of the generator so we can refer back to it
beer = beerDataGenerator()
next(beer)
>>> 'BeerID,Name,URL,Style,StyleID,Size(L),OG,FG,ABV,IBU,Color,BoilSize,BoilTime,BoilGravity,Efficiency,MashThickness,SugarScale,BrewMethod,PitchRate,PrimaryTemp,PrimingMethod,PrimingAmount,UserId\n'next(beer
)
>>> '1,Vanilla Cream Ale,/homebrew/recipe/view/1633/vanilla-cream-ale,Cream Ale,45,21.77,1.055,1.013,5.48,17.65,4.83,28.39,75,1.038,70,N/A,Specific Gravity,All Grain,N/A,17.78,corn sugar,4.5 oz,116\n'
一旦我们创建了一个
beerDataGenerator在beer中,我们可以开始把它传入next()来查看数据本身。正如 CSV 文件所示,各列用逗号分隔。此外,每一行都以一个\n结尾,表示换行。我们发现recipeData.csv to 中的第一项是一个列名列表,第一行描述了一种美味的香草奶油麦酒。
自我施加的限制
你可能会问,“我们可以将数据存储在一个列表中理解!为什么要跳过一个额外的铁环,还要用发电机呢?”作为一名程序员,您可能会遇到
大数据。这是一个有点模糊的术语,因此我们不会在这里深入研究各种大数据定义。可以这么说,任何大数据文件都是太大而无法赋给变量。我们的数据文件不符合大数据的标准,但我们仍然可以通过限制自己重现这个难题来学习很多东西。我们现在假设我们的啤酒数据非常大,以至于我们无法将所有数据存储在一个列表列表中。由于读取数据的正常途径被阻断,我们被迫重新考虑我们的选择。这就是发电机的用武之地。稍后我们将解释为什么生成器在这里工作,但在此之前,我们可以放心,我们的生成器函数将使我们能够首先读取数据,尽管不是一次全部读取。除了生成器函数,我们还可以使用生成器表达式创建生成器。
发电机表达式
之前,我们将生成器函数与常规函数进行了比较,因为它们有许多相似之处。对于世代表达式,我们将使用
列举理解。
lc_example = [n**2 for n in [1, 2, 3, 4, 5]]
genex_example = (n**2 for n in [1, 2, 3, 4, 5])
lc_example是我们的列表理解,而genex_example是我们执行几乎相同任务的生成器表达式。请注意,两者之间的唯一区别是生成器表达式是用圆括号括起来的,而不是方括号。如果我们在一个for循环中使用这些迭代器中的任何一个,它们将产生相同的结果,并且无法区分。然而,如果我们试图在我们的解释器中检查这些变量,它们会产生不同的结果。
lc_example
>>> [1, 4, 9, 16, 25]
genex_example
>>> <generator object <genexpr> at 0x00000156547B4FC0>
这个结果类似于我们在研究一个常规函数和一个生成函数时看到的结果。Python 也认识到了这一点
genex_example是生成器表达式形式中的一个生成器(<genexpr>)。由于lc_example是一个列表,我们可以执行它们支持的所有操作:索引、切片、变异等。我们不能用生成器表达式做到这一点。生成器被专门化为一次容易产生一个输出,所以它们不支持这些操作。然而,像列表理解一样,如果需要的话,我们可以在生成器表达式中实现逻辑来形成过滤器。
genex_example2 = (n**2 for n in [1, 2, 3, 4, 5] if n >= 3)
next(genex_example2)
>>> 9
实际上,我们使用生成器函数或生成器表达式的方式没有区别。一旦我们有了生成器表达式,我们就可以调用
开始获取它将产生的价值。一旦我们遍历了生成器表达式可以生成的所有值,我们就不能再使用它了。这与列表理解形成了对比,我们可以尽可能多地重复使用列表理解。
next(genex_example)
>>> 1
# Repeat until we reach the end...
next(genex_example)
>>> 25
next(genex_example)
>>> StopIteration:
我们只能使用发电机的想法
一旦被捆绑到自己消费的想法。回想一下,当我们迭代一些迭代器时,我们对其中的每个值执行一些操作。然后我们使用这些处理过的值继续我们的分析,这意味着通常我们可能不需要原始的迭代器。生成器非常适合这种需求,它允许我们构造一个迭代器,我们可以使用一次,然后不用担心它在使用后会占用空间(例如,在一个for循环中)。我们谈到了用next()从生成器中获取值的方法,但是在for循环中使用生成器通常更好。使用next()迫使我们必须自己处理StopIteration,但是for循环使用这个来知道什么时候停止!
# Using a for loop to consume a generator is better than using next()
for ge in genex_example:
print(ge)
>>> 1
>>> 4
>>> 9
>>> 16
>>> 25
生成器表达式与函数的一个区别是它们的简洁。生成器函数占用多行,而我们可以将生成器表达式放在一行中。多行本身并不坏,但是它使函数变得更加复杂,可能会在以后引入错误。我们将把生成器函数重写为一个单行表达式,读入啤酒数据。这种简洁性在本文后面会派上用场。
beer_data = "recipeData.csv"
# This one line perfoms the same action as beerDataGenerator()!
lines = (line for line in open(beer_data, encoding="ISO-8859-1"))
关键要点:发电机和你
- 生成器一次产生一个值而不是一次给出所有值。
- 创建生成器有两种方法:生成器函数和生成器表达式。
- 发电机功能
yield,常规功能return。 - 生成器表达式需要
(),列表理解使用[]。 - 发电机只能用一次。
- 从生成器中获取值有两种方法:函数
next()和循环for。for循环通常是首选方法。 - 我们可以用生成器读取文件,一次给我们一行。
发电机:动机和用途
前面,我们讨论了对自己施加限制,迫使我们使用生成器来读取数据,而不是将数据读入一个列表的列表中。我们提到了大数据的问题,以及我们无法将其全部存储在一个变量中。虽然称之为大数据问题仍然是正确的,但您也可以称之为
记忆力问题。假设您有一台较旧的笔记本电脑,内存约为 4GB,随机存取存储器。我们的啤酒数据集的真实大小只与 3MB 有关,但是假设我们要求全球每个人给我们他们的食谱,结果数据集大约为 3GB。如果我们将整个数据集读入一个变量,它将占用 3GB 多一点的 RAM!这将使我们几乎没有空间进行其他操作,更不用说其他类似大小的变量了。将我们的数据存储在一个列表中会占用太多的内存,以至于我们所做的任何分析都要花费非常长的时间。
懒惰和发电机
我们现在知道生成器从一个定义的序列中产生一个单一的值,但是
只有当我们询问next()时才或者在for循环内。我们称之为懒评。生成器很懒,因为它们只在我们需要的时候才给我们一个值。另一方面,只有这个值占用内存。最终的结果是,生成器具有令人难以置信的内存效率,这使得它成为读取和使用大数据文件的完美候选。一旦我们请求一个生成器的下一个值,旧的值就被丢弃了。一旦我们遍历了整个生成器,它也会从内存中被丢弃。
给发电机供电的发电机
我们目前还没有从啤酒数据中学到任何东西。到目前为止,我们所做的就是获取原始的 CSV 文件,并创建一个生成器来生成 CSV 文件中的每一行,一次生成一个字符串。除非我们想做一些疯狂的字符串操作,否则我们需要想办法将数据转换成可读、可用的形式。下面是我们的代码当前所做的事情的表示:简单地从文件中读取并输出文件中的一行内容。
 发电机又来救援了!到目前为止,在本文中,我们已经向生成器传递了其他结构,特别是迭代器,以指示我们希望从哪个序列生成。然而,生成器本身也是迭代器——为什么我们不创建另一个生成器,将另一个生成器的输出?我们的
发电机又来救援了!到目前为止,在本文中,我们已经向生成器传递了其他结构,特别是迭代器,以指示我们希望从哪个序列生成。然而,生成器本身也是迭代器——为什么我们不创建另一个生成器,将另一个生成器的输出?我们的lines生成器输出完整的行,所以我们将制作第二个生成器来为我们做一些格式化。
beer_data = "recipeData.csv"
lines = (line for line in open(beer_data, encoding="ISO-8859-1"))
lists = (l.split(",") for l in lines)
我们的生成器的最终结果是一个列表流,每个列表包含 CSV 的一行中的数据。如果我们迭代通过
我们将能够轻松访问其中的数据元素,并执行我们需要的分析!我们已经有效地为我们的数据集制作了一个管道,从原始数据集开始,通过 2 个生成器将其发送到熟悉的形式。请记住,生成器本身并不是列表,它们只是生成序列中的一个元素,并且只占用该元素所需的数量。通过将生成器连接在一起,我们创建了一种快速、易读的方式来读取通过正常方式无法访问的数据。这种方法有一些真正的力量,它的重要性不可低估。在处理中间值时,我们不需要创建任何临时列表来保存它们。有了管道中的额外生成器,我们的代码可能看起来像这样: 在这个管道中,每个生成器负责一个操作,该操作最终将应用于数据集的所有行。虽然拥有每个列表是好的,但在我们进行任何有意义的分析之前,仍然有一些小问题需要解决。首先,我们希望获取列名,因为它们不是数据,然后将它们转换成一个字典,使任何进一步的代码更容易阅读。注意:如果你在自己的机器上运行这段代码,你必须记住你只能使用一次生成器。如果您在一个
在这个管道中,每个生成器负责一个操作,该操作最终将应用于数据集的所有行。虽然拥有每个列表是好的,但在我们进行任何有意义的分析之前,仍然有一些小问题需要解决。首先,我们希望获取列名,因为它们不是数据,然后将它们转换成一个字典,使任何进一步的代码更容易阅读。注意:如果你在自己的机器上运行这段代码,你必须记住你只能使用一次生成器。如果您在一个for循环中使用生成器来查看输出,您将需要再次运行数据和整个管道。谢天谢地,这里的发电机运转很快。
beer_data = "recipeData.csv"
lines = (line for line in open(beer_data, encoding="ISO-8859-1"))
lists = (l.split(",") for l in lines)
# Take the column names out of the generator and store them, leaving only data
columns = next(lists)
# Take these columns and use them to create an informative dictionary
beerdicts = (dict(zip(columns, data)) for data in lists)
这
做一些简单的格式化,这让我们的管道更加强大! 这是一个开始查询我们未来啤酒酿造选择数据的好地方。现在我们已经有了生成器管道,我们可以开始消费由生成器生成的数据并创建一些洞察。我们通常使用
这是一个开始查询我们未来啤酒酿造选择数据的好地方。现在我们已经有了生成器管道,我们可以开始消费由生成器生成的数据并创建一些洞察。我们通常使用for循环消耗发电机,所以我们将使用一个来计算最受欢迎的自制啤酒类型。
beer_counts = {}
for bd in beerdicts:
if bd["Style"] not in beer_counts:
beer_counts[bd["Style"]] = 1
else:
beer_counts[bd["Style"]] += 1
most_popular = 0
most_popular_type = None
for beer, count in beer_counts.items():
if count > most_popular:
most_popular = count
most_popular_type = beer
most_popular_type
>>> "American IPA"
这种操作在数据争论和处理中无处不在,您可能以前见过。这里唯一的新东西是,我们依赖于由生成器生成的字典,而不是引用包含我们数据的列表。有了生成器,我们能够从任何大数据集进行与常规大小数据集相同的查询。我们现在知道美国 IPA 是数据集中最受欢迎的自制啤酒,我们也知道它们在数据中有多少条目。我们可以试着算出我们的啤酒应该有多烈。这些数据包含在“ABV”(
酒精按体积键。既然我们使用字典作为生成器流的输出,我们为什么不添加另一个生成器来研究我们想要输出的确切值。
abv = (float(bd["ABV"]) for bd in beerdicts if bd["Style"] == "American IPA")
# Get the average ABV for an American IPAsum(abv)/most_popular
>>> 6.44429396984925
这最后一个生成器构成了我们的最后一个管道,如下图所示:
 我们应该特别注意将
我们应该特别注意将sum()与abv发生器一起使用。不太直观的是,sum()会对它收到的所有 ABV 值求和。你可能会认为sum()是将发电机的全部输出减少到一个值。用这个总数除以美国的 IPA 总数,我们得到了平均值。我们的数据表明,你的平均美国 IPA 约为 6.4%的酒精体积!我们的最后一个生成器abv获取beerdicts输出的字典,并输出ABV键,但是只输出如果啤酒是美国的 IPA。生成器表达式上的过滤器在我们的管道中形成了一个强大的工具。如果我们把每一个连续的发生器看作一个模块组件,那么我们就可以用其他可能有更好功能的发生器来替换它们。如果我们想改变我们想要研究的啤酒类型或查看另一种啤酒特性,我们唯一需要改变的是发电机的操作。下图展示了生成器管道方法的不同部分。它由您想要处理的一些原始数据、执行实际处理的管道以及该管道输出的最终消耗组成。遵循这种模式将使您能够重现我们对啤酒数据所做的工作。 如果您习惯于使用列表列表并利用所有列表方法进行分析的工作流,这种处理数据争论的新方法可能会很奇怪。然而,数据管道是一个强大的概念,可以立即集成到您的代码中,您应该尝试一下。
如果您习惯于使用列表列表并利用所有列表方法进行分析的工作流,这种处理数据争论的新方法可能会很奇怪。然而,数据管道是一个强大的概念,可以立即集成到您的代码中,您应该尝试一下。
无限代
假设您第一次对啤酒数据集进行分析已经有几年了。你用你的分析创造了一个成功的美国投资促进机构,你只能感谢发电机。您每天生产数千瓶啤酒,您需要一种方法来分析每批啤酒的质量。你回到你的旧笔记本电脑启动 Python 解释器。你开始编写一个函数来计算和检查你生产的啤酒批次的各种质量,但是你停下来了。你事先不知道你要做多少啤酒。按天分析批次可以为我们提供离散的点,但是如果我们想要连续的数据呢?常规函数在这里不起作用!它们需要一些参数,并且总是返回一个离散的对象。你不可能给一个常规函数一个数据流,然后返回一个连续的值流。但是你可以用发电机!发电机非常适合这种类型的任务。我们已经讨论了生成器如何一次产生一个值,直到它被告知停止。如果我们不给一个发生器一个停止信号,它将愉快地无限地产生这些值。以下面的例子为例。
function alwaysBeer():
while True:
yield "Beer"
这
while循环将始终为真,因此生成器函数将始终产生啤酒。我们没有做错任何事情,这是完全有效的代码(虽然不是你真正想要实现的代码)!这个“无限”的啤酒流如何符合我们的时间线?在我们最初查看啤酒数据集时,CSV 最初是一组行。如果您可以自动化酿造过程,将数据输出到类似的 CSV 并不断更新,那么您只需再次通过发生器运行数据即可进行分析!您可以在管道中创建一个生成器来捕捉任何不符合您期望的批处理,并实时标记它们!不幸的是,我们没有上述数据,但是这个思想实验应该为 Python 生成器提供另一个令人信服的用例。有了发电机,你甚至可以处理无穷大(在某些情况下)。
要点:发电机背后的动机和用途
- 生成器是内存高效的,因为它们只需要内存来存储它们产生的一个值。
- 生成器很懒:它们只有在被明确询问时才会产生值。
- 您可以将一个生成器的输出提供给另一个生成器的输入,以形成数据管道。
- 数据管道可以根据您的需求进行模块化和定制。
- 生成器对于无限地生成值非常有用。
结论
生成器不一定是复杂的主题,如果有足够的时间去理解,它们在任何 Python 程序员的全部技能中都有一席之地。即使在简单方法达不到要求的大数据情况下,基于生成器的分析仍然站得住脚。有很多关于生成器的内容我们没有在这里讨论,但是它仍然会给你一个很好的基础,让你在自己的分析生活中开始使用它们。
更多资源:
- Python 教程 —我们不断扩充的数据科学 Python 教程列表。
- 数据科学课程 —通过完全交互式的编程、数据科学和统计课程,让您的学习更上一层楼,就在您的浏览器中。
- 迭代器协议
- Python 的生成器文档
- PEP 289:生成器表达式
- PEP 342:高级发电机* *## 这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。*
Python if else 教程:控制代码流
October 23, 2019
编程时,控制在什么情况下运行什么代码的流程是极其重要的。Python if else命令的作用类似于数字交通警察,允许您定义在满足特定条件时运行的代码块。if else语法是您将要学习的最重要的 Python 语法之一。
在本教程中,你将学习如何使用 Python if else来控制你的代码。我们假设您已经了解一些 Python 基础知识,例如:
- 如何读取 CSV 文件
- 列表、字符串和整数等基本 Python 类型
- 使用 for 循环处理列表。
如果你对这些还不适应,我们推荐这个免费的交互式 Python 基础课程,它教授所有这些(以及 Python if else)!)
Taco 数据集
我们将学习如何使用 Python if else,同时使用一个数据集,该数据集总结了 Dataquest 在线聊天中特定月份使用的虚拟玉米卷。
在 Dataquest,我们在空闲时间提供虚拟玉米卷(使用 HeyTaco )作为一种感谢或奖励出色完成工作的同事的方式。你可以给某人一个玉米卷来表达你的感激之情,就像这样:

我们将对 HeyTaco 的数据进行分析,回答一些关于人们捐赠习惯的基本问题。数据集存储在 CSV 文件"tacos.csv"中,如果你想跟随本教程,你可以在这里下载它。(在此数据集中,我们更改了名称以保护 Dataquest 员工的隐私)。
让我们从读入 CSV 文件开始,查看文件的前几行:
import csv
f = open('tacos.csv')
tacos = list(csv.reader(f))
print(tacos[:5])
[['name', 'department', 'given', 'received'],
['Amanda', 'content', '4', '3'],
['Angela', 'engineering', '7', '20'],
['Brandon', 'marketing', '31', '26'],
['Brian', 'product', '13', '6']]
每行代表一个为公司工作的人。数据集有四列:
name:人员姓名(这些姓名是虚构的,但数据代表 Dataquest 的实际员工!)department:这个人在哪个部门(或团队)工作。given:那个人给别人的玉米饼的数量。- 这个人从其他人那里收到的玉米卷的数量
让我们删除第一行,因为它包括列名——我们的数据结构很简单,所以我们可以在进行过程中记住它们(或者如果您忘记了,可以参考文章的顶部!)
删除列名后,让我们再次查看数据的前五行:
tacos = tacos[1:]
print(tacos[:5])
[['Amanda', 'content', '4', '3'],
['Angela', 'engineering', '7', '20'],
['Brandon', 'marketing', '31', '26'],
['Brian', 'product', '13', '6'],
['Clinton', 'operations', '38', '9']]
准备数据
尽管第三列和第四列中的数据(代表每个人给予和接受的玉米饼数量)是数字,但它们被存储为字符串。我们可以看出它们是字符串,因为它们周围有引号:'4'而不是4。
为了对数据进行计算,我们需要将它们转换成整数,一种数字 Python 类型。
让我们使用一个for循环来遍历数据的每一行,并将第 3 列和第 4 列(位于索引 2 和 3 处)转换为整数类型:
for person in tacos:
person[2] = int(person[2])
person[3] = int(person[3])
print(tacos[:5])
[['Amanda', 'content', 4, 3],
['Angela', 'engineering', 7, 20],
['Brandon', 'marketing', 31, 26],
['Brian', 'product', 13, 6],
['Clinton', 'operations', 38, 9]]
您现在可以看到引号被移除了(例如4),表明这些值现在是整数而不是字符串。
在数据中寻找平均值
让我们从一些基本的分析开始——找出每个人给予和接受的玉米卷的平均数量。
为此,我们将把 given 和 received 列提取到单独的列表中,这样我们可以更容易地进行计算:
given = []
received = []
for person in tacos:
given.append(person[2])
received.append(person[3])
print(given[:5])
[4, 7, 31, 13, 38]
接下来,我们将这两个列表相加,然后除以长度(或值的数量)来求平均值:
given_avg = sum(given) / len(given)
received_avg = sum(received) / len(received)
print("Avg tacos given: ", given_avg)
print("Avg tacos received: ", received_avg)
Avg tacos given: 16.322580645161292
Avg tacos received: 16.322580645161292
平均数量的玉米卷给予和收到是相同的!当你想到这一点时,这是有道理的,因为某人给的每一个玉米卷都必须被其他人收到。
我们可能有兴趣回答的另一个问题是,公司不同部门的平均付出和收获相比如何。让我们从考察“内容”团队开始。
要做到这一点,我们需要像以前一样提取给定和收到的 tacos 的列表,但仅当行的部门是“content”时。我们刚刚描述的称为条件,我们将需要使用 Python if来检查该条件!
Python if
你可以把 Python if看作是一个决定。在我们的例子中,我们需要问一个问题:这个人属于“内容”团队吗?我们在代码中采取的行动取决于这个问题的答案或条件。这就是为什么 Python if有时也被称为条件表达式的原因。
下图显示了我们需要用来创建符合条件的值列表的逻辑:

让我们看看如何使用 Python if处理两个单独的行。首先,让我们打印第一行和第二行,这样我们可以提醒自己它们的值:
first_row = tacos[0]
print(first_row)
['Amanda', 'content', 4, 3]
second_row = tacos[1]
print(second_row)
['Angela', 'engineering', 7, 20]
第一行包含内容团队的 Amanda,而第二行包含工程团队的 Angela。让我们看看如何使用 Python if语法来打印一些输出,前提是这个人来自内容团队。
我们将使用==操作符来比较团队和字符串“content”。Python 中的==运算符的意思是“等于”。
我们可以在if条件中使用的其他一些常见运算符包括:
!=:不等于>:大于<:小于>=:大于或等于<=:小于或等于
team = first_row[1]
if team == 'content':
print("This person comes from the content team.")
This person comes from the content team.
因为 Amanda 来自内容团队,所以我们的print()函数被执行,我们看到了输出。让我们从之前的图表中追溯路径,以了解发生了什么:

让我们花一点时间仔细看看我们使用的语法,并标记不同的部分,以便我们可以理解发生了什么。

现在我们对代码有了更好的理解,让我们对第二行尝试同样的代码,看看会发生什么:
team = second_row[1]
if team == 'content':
print("This person comes from the content team.")
当我们运行上面的代码时,我们没有得到任何输出,因为 Angela 来自工程团队,而不是内容团队。让我们从之前的图表中追溯路径,以了解发生了什么。

使用 Python if 带 For 循环
现在我们已经了解了 Python if的基本工作原理,让我们在一个循环中使用它来获取内容团队的“给定”和“接收”值:
given_content = []
received_content = []
for person in tacos:
team = person[1]
if team == 'content':
given_content.append(person[2])
received_content.append(person[3])
print(given_content)
[4, 25, 10, 6, 0, 16, 8, 32]
我们打印了上面的given_content列表,我们可以看到内容团队的 8 名成员的值已经收集在一起。现在让我们来计算团队平均值:
given_content_avg = sum(given_content) / len(given_content)
received_content_avg = sum(received_content) / len(received_content)
print("Avg tacos given, content team: ", given_content_avg)
print("Avg tacos received, content team: ", received_content_avg)
Avg tacos given, content team: 12.625
Avg tacos received, content team: 6.0
我们可以看到,内容团队成员给予玉米卷的频率大约是他们收到的两倍。我们还可以将这些数字与总体平均值进行比较,发现:
- 内容团队成员给的玉米卷比总体平均少 25%
- 内容团队成员收到的玉米卷比总体平均水平少 60%
使用 Python if else 来改进我们的分析
当我们将内容团队成员与总体平均水平进行比较时,总体平均水平包括内容团队成员。将内容团队与内容团队中的每个人而不是进行比较可能会很有趣。
为此,我们需要使用 Python 的一个新部分if—else子句。else 子句在if之后,指定如果if 中的条件不匹配时要运行的一行或多行代码。
让我们看看前面的图表,看看添加的else子句是什么样子的:

让我们修改前面只查看第二行的代码,添加一个else子句。在我们开始之前,让我们快速提醒自己第二行的内容
print(second_row)
['Angela', 'engineering', 7, 20]
好,我们来添加else子句:
team = second_row[1]
if team == 'content':
print("This person comes from the content team.")
else:
print("This person doesn't come from the content team.")
This person doesn't come from the content team.
您可以看到我们的else子句中的代码被执行,因为 Angela 不属于内容团队。
让我们追溯之前图表中的路径:

最后,让我们在循环中添加一个else子句,并计算两组的平均值:
given_content = []
received_content = []
given_other = []
received_other = []
for person in tacos:
team = person[1]
if team == 'content':
given_content.append(person[2])
received_content.append(person[3])
else:
given_other.append(person[2])
received_other.append(person[3])
given_content_avg = sum(given_content) / len(given_content)
received_content_avg = sum(received_content) / len(received_content)
given_other_avg = sum(given_other) / len(given_other)
received_other_avg = sum(received_other) / len(received_other)
print("Avg tacos given, content team: ", given_content_avg)
print("Avg tacos given, other teams: ", given_other_avg)
print("Avg tacos received, content team: ", received_content_avg)
print("Avg tacos received, other teams: ", received_other_avg)
Avg tacos given, content team: 12.625
Avg tacos given, other teams: 17.608695652173914
Avg tacos received, content team: 6.0
Avg tacos received, other teams: 19.91304347826087
我们可以看到,内容团队给的玉米卷比其他团队少 30%左右,收到的玉米卷比其他团队少 70%左右。
Python elif
如果我们想计算在以下情况下赠送和收到的玉米卷会怎么样:
- 内容团队
- 工程团队
- 所有其他团队
为此,我们需要一个新工具:Python elif。与else子句一样,elif子句必须跟在if子句之后。它允许我们堆叠第二个条件,只有在第一个条件不满足时才进行评估。这一开始听起来可能会令人困惑,但是当你想到它的名字——else if——你就会明白这是在一个else内添加另一个if的捷径。
让我们看看前面的图表,看看添加的elif子句是什么样子的:

让我们在独立代码中添加一个elif来检查某人是在内容团队还是在工程团队。首先,让我们再次快速提醒自己第二行的内容:
print(second_row)
['Angela', 'engineering', 7, 20]
让我们添加elif子句:
team = second_row[1]
if team == 'content':
print("This person comes from the content team.")
elif team == 'engineering':
print("This person comes from the engineering team.")
else:
print("This person doesn't come from the content or engineering teams.")
This person comes from the engineering team.
您可以看到我们的elif子句中的代码被执行,因为 Angela 属于工程团队。
让我们追溯之前图表中的路径:

最后,让我们在循环中添加一个elif子句,并计算所有三组的平均值:
given_content = []
received_content = []
given_engineering = []
received_engineering = []
given_other = []
received_other = []
for person in tacos:
team = person[1]
if team == 'content':
given_content.append(person[2])
received_content.append(person[3])
elif team == 'engineering':
given_engineering.append(person[2])
received_engineering.append(person[3])
else:
given_other.append(person[2])
received_other.append(person[3])
given_content_avg = sum(given_content) / len(given_content)
received_content_avg = sum(received_content) / len(received_content)
given_engineering_avg = sum(given_engineering) / len(given_engineering)
received_engineering_avg = sum(received_engineering) / len(received_engineering)
given_other_avg = sum(given_other) / len(given_other)
received_other_avg = sum(received_other) / len(received_other)
print("Avg tacos given, content team: ", given_content_avg)
print("Avg tacos given, engineering team: ", given_engineering_avg)
print("Avg tacos given, other teams: ", given_other_avg)
print() # this prints an empty line
print("Avg tacos received, content team: ", received_content_avg)
print("Avg tacos received, engineering team: ", received_engineering_avg)
print("Avg tacos received, other teams: ", received_other_avg)
Avg tacos given, content team: 12.625
Avg tacos given, engineering team: 20.166666666666668
Avg tacos given, other teams: 16.705882352941178
Avg tacos received, content team: 6.0
Avg tacos received, engineering team: 26.166666666666668
Avg tacos received, other teams: 17.705882352941178
我们的分析表明,虽然内容团队给予和接受玉米卷的比率低于其他团队的平均水平,但工程团队给予和接受玉米卷的比率高于平均水平。
Python if else:后续步骤
在本教程中,我们学习了:
- Python
ifelse让我们可以根据条件控制代码流。 - 如何使用
if只在符合某个条件的情况下执行代码? - 如何在代码与不匹配的情况下使用
else来执行代码。
您可能希望扩展本教程,并通过计算数据集中每个团队的平均值来练习使用 Python if else。
如果你想在互动教程中学习 Python if else,你可以在我们免费的互动 Python 基础课程中学习如何分析应用数据。
教程:在 Python 中使用 Pandas 和 JSON 处理大型数据集
March 1, 2016
处理大型 JSON 数据集可能是一件痛苦的事情,尤其是当它们太大而无法放入内存时。在这种情况下,命令行工具和 Python 的结合可以提供一种有效的方式来探索和分析数据。在这篇关注学习 python 编程的文章中,我们将看看如何利用像 Pandas 这样的工具来探索和绘制马里兰州蒙哥马利县的警察活动。我们将从查看 JSON 数据开始,然后继续用 Python 探索和分析 JSON。
当数据存储在 SQL 数据库中时,它往往遵循一种看起来像表的严格结构。下面是一个来自 SQLite 数据库的示例:
id|code|name|area|area_land|area_water|population|population_growth|birth_rate|death_rate|migration_rate|created_at|updated_at1|af|Afghanistan|652230|652230|0|32564342|2.32|38.57|13.89|1.51|2015-11-01 13:19:49.461734|2015-11-01 13:19:49.4617342|al|Albania|28748|27398|1350|3029278|0.3|12.92|6.58|3.3|2015-11-01 13:19:54.431082|2015-11-01 13:19:54.4310823|ag|Algeria|2381741|2381741|0|39542166|1.84|23.67|4.31|0.92|2015-11-01 13:19:59.961286|2015-11-01 13:19:59.961286
如您所见,数据由行和列组成,其中每一列都映射到一个定义的属性,如id或code。在上面的数据集中,每行代表一个国家,每列代表该国的一些事实。
但是,随着我们捕获的数据量的增加,我们往往不知道数据在存储时的确切结构。这就是所谓的非结构化数据。一个很好的例子是网站上访问者的事件列表。以下是发送到服务器的事件列表示例:
{'event_type': 'started-lesson', 'keen': {'created_at': '2015-06-12T23:09:03.966Z', 'id': '557b668fd2eaaa2e7c5e916b', 'timestamp': '2015-06-12T23:09:07.971Z'}, 'sequence': 1} {'event_type': 'started-screen', 'keen': {'created_at': '2015-06-12T23:09:03.979Z', 'id': '557b668f90e4bd26c10b6ed6', 'timestamp': '2015-06-12T23:09:07.987Z'}, 'lesson': 1, 'sequence': 4, 'type': 'code'} {'event_type': 'started-screen', 'keen': {'created_at': '2015-06-12T23:09:22.517Z', 'id': '557b66a246f9a7239038b1e0', 'timestamp': '2015-06-12T23:09:24.246Z'}, 'lesson': 1, 'sequence': 3, 'type': 'code'},
如您所见,上面列出了三个独立的事件。每个事件都有不同的字段,一些字段嵌套在其他字段中。这种类型的数据很难存储在常规 SQL 数据库中。这种非结构化数据通常以一种叫做JavaScript Object Notation(JSON)的格式存储。JSON 是一种将列表和字典等数据结构编码成字符串的方法,可以确保它们易于被机器读取。尽管 JSON 以单词 Javascript 开头,但它实际上只是一种格式,可以被任何语言读取。
Python 有很好的 JSON 支持,有 json 库。我们既可以将列表和字典转换为 JSON,也可以将字符串转换为列表和字典。JSON 数据看起来很像 Python 中的字典,其中存储了键和值。
在这篇文章中,我们将在命令行上探索一个 JSON 文件,然后将它导入 Python 并使用 Pandas 来处理它。
数据集
我们将查看包含马里兰州蒙哥马利县交通违规信息的数据集。你可以在这里下载数据。该数据包含违规发生的地点、汽车类型、收到违规的人的人口统计信息以及其他一些有趣的信息。使用该数据集,我们可以回答很多问题,包括:
- 什么类型的车最有可能因为超速被拦下来?
- 警察一天中什么时候最活跃?
- “速度陷阱”有多普遍?还是说门票在地理上分布相当均匀?
- 人们被拦下来最常见的原因是什么?
不幸的是,我们事先不知道 JSON 文件的结构,所以我们需要做一些探索来弄清楚它。我们将使用 Jupyter 笔记本进行这次探索。
探索 JSON 数据
尽管 JSON 文件只有 600MB,但我们会把它当作大得多的文件来处理,这样我们就可以研究如何分析一个不适合内存的 JSON 文件。我们要做的第一件事是看一下md_traffic.json文件的前几行。JSON 文件只是一个普通的文本文件,因此我们可以使用所有标准的命令行工具与它进行交互:
%%bashhead md_traffic.json
<codeclass="language-bash">
{ "meta" : {
"view" : {
"id" : "4mse-ku6q",
"name" : "Traffic Violations",
"averageRating" : 0,
"category" : "Public Safety",
"createdAt" : 1403103517,
"description" : "This dataset contains traffic violation information from all electronic traffic violations issued in the County. Any information that can be used to uniquely identify the vehicle, the vehicle owner or the officer issuing the violation will not be published.\r\n\r\nUpdate Frequency: Daily",
"displayType" : "table",
由此,我们可以看出 JSON 数据是一个字典,并且格式良好。meta是顶级键,缩进两个空格。我们可以通过使用 grep 命令打印任何有两个前导空格的行来获得所有顶级密钥:
%%bashgrep -E '^ {2}"' md_traffic.json
"meta" : {"data" : [
[ 1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050", 1455876689, "498050", null, "2016-02-18T00:00:00", "09:05:00", "MCP", "2nd district, Bethesda", "DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION", "355/TUCKERMAN LN", "-77.105925", "39.03223", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "MD", "02 - Automobile", "2010", "JEEP", "CRISWELL", "BLUE", "Citation", "21-1124.2(d2)", "Transportation Article", "No", "WHITE", "F", "GERMANTOWN", "MD", "MD", "A - Marked Patrol", [ "{\"address\":\"\",\"city\":\"\",\"state\":\"\",\"zip\":\"\"}", "-77.105925", "39.03223", null, false ] ]
这表明meta和data是md_traffic.json数据中的顶级键。列表的列表似乎与data相关联,并且这可能包含我们的交通违规数据集中的每个记录。每个内部列表都是一条记录,第一条记录出现在grep命令的输出中。这与我们在操作 CSV 文件或 SQL 表时习惯使用的结构化数据非常相似。以下是数据的部分视图:
[ [1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050"], [1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050"], ...]
这看起来很像我们习惯使用的行和列。我们只是缺少了告诉我们每一列的含义的标题。我们也许能在meta键下找到这个信息。
meta通常指关于数据本身的信息。让我们更深入地研究一下meta,看看那里包含了什么信息。从head命令中,我们知道至少有3级按键,其中meta包含一个按键view,包含id、name、averageRating等按键。我们可以通过使用 grep 打印出任何带有2-6前导空格的行来打印出 JSON 文件的完整密钥结构:
%%bashgrep -E '^ {2,6}"' md_traffic.json
"meta" : { "view" : { "id" : "4mse-ku6q", "name" : "Traffic Violations", "averageRating" : 0, "category" : "Public Safety", "createdAt" : 1403103517, "description" : "This dataset contains traffic violation information from all electronic traffic violations issued in the County. Any information that can be used to uniquely identify the vehicle, the vehicle owner or the officer issuing the violation will not be published.\r\n\r\nUpdate Frequency: Daily", "displayType" : "table", "downloadCount" : 2851, "iconUrl" : "fileId:r41tDc239M1FL75LFwXFKzFCWqr8mzMeMTYXiA24USM", "indexUpdatedAt" : 1455885508, "newBackend" : false, "numberOfComments" : 0, "oid" : 8890705, "publicationAppendEnabled" : false, "publicationDate" : 1411040702, "publicationGroup" : 1620779, "publicationStage" : "published", "rowClass" : "", "rowsUpdatedAt" : 1455876727, "rowsUpdatedBy" : "ajn4-zy65", "state" : "normal", "tableId" : 1722160, "totalTimesRated" : 0, "viewCount" : 6910, "viewLastModified" : 1434558076, "viewType" : "tabular", "columns" : [ { "disabledFeatureFlags" : [ "allow_comments" ], "grants" : [ { "metadata" : { "owner" : { "query" : { "rights" : [ "read" ], "sortBys" : [ { "tableAuthor" : { "tags" : [ "traffic", "stop", "violations", "electronic issued." ], "flags" : [ "default" ]"data" : [ [ 1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050", 1455876689, "498050", null, "2016-02-18T00:00:00", "09:05:00", "MCP", "2nd district, Bethesda", "DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION", "355/TUCKERMAN LN", "-77.105925", "39.03223", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "MD", "02 - Automobile", "2010", "JEEP", "CRISWELL", "BLUE", "Citation", "21-1124.2(d2)", "Transportation Article", "No", "WHITE", "F", "GERMANTOWN", "MD", "MD", "A - Marked Patrol", [ "{\"address\":\"\",\"city\":\"\",\"state\":\"\",\"zip\":\"\"}", "-77.105925", "39.03223", null, false ] ]
这向我们展示了与md_traffic.json相关的完整密钥结构,并告诉我们 JSON 文件的哪些部分与我们相关。在这种情况下,columns键看起来很有趣,因为它可能包含关于data键中的列表的列表中的列的信息。
提取列上的信息
现在我们知道了哪个键包含列的信息,我们需要读入这些信息。因为我们假设 JSON 文件不适合内存,所以我们不能使用 json 库直接读取它。相反,我们需要以内存高效的方式迭代读取它。
我们可以使用 ijson 包来完成这个任务。ijson 将迭代解析 json 文件,而不是一次读入所有内容。这比直接读入整个文件要慢,但它使我们能够处理内存中容纳不下的大文件。要使用 ijson,我们指定一个要从中提取数据的文件,然后指定一个要提取的关键路径:
import ijson
filename = "md_traffic.json"
with open(filename, 'r') as f:
objects = ijson.items(f, 'meta.view.columns.item')
columns = list(objects)
在上面的代码中,我们打开了md_traffic.json文件,然后我们使用 ijson 中的items方法从文件中提取一个列表。我们使用meta.view.columns符号指定列表的路径。回想一下meta是一个顶级键,里面包含view,里面包含columns。然后,我们指定meta.view.columns.item来表示我们应该提取meta.view.columns列表中的每一项。items函数将返回一个生成器,所以我们使用 list 方法将生成器转换成一个 Python 列表。我们可以打印出清单中的第一项:
print(columns[0])
{'renderTypeName': 'meta_data', 'name': 'sid', 'fieldName': ':sid', 'position': 0, 'id': -1, 'format': {}, 'dataTypeName': 'meta_data'}
从上面的输出来看,columns中的每一项都是一个字典,包含了每一列的信息。为了得到我们的头,看起来fieldName是要提取的相关键。要获得我们的列名,我们只需从columns中的每一项提取fieldName键:
column_names = [col["fieldName"] for col in columns]column_names
[':sid', ':id', ':position', ':created_at', ':created_meta', ':updated_at', ':updated_meta', ':meta', 'date_of_stop', 'time_of_stop', 'agency', 'subagency', 'description', 'location', 'latitude', 'longitude', 'accident', 'belts', 'personal_injury', 'property_damage', 'fatal', 'commercial_license', 'hazmat', 'commercial_vehicle', 'alcohol', 'work_zone', 'state', 'vehicle_type', 'year', 'make', 'model', 'color', 'violation_type', 'charge', 'article', 'contributed_to_accident', 'race', 'gender', 'driver_city', 'driver_state', 'dl_state', 'arrest_type', 'geolocation']
太好了!现在我们已经有了列名,我们可以开始提取数据本身了。
提取数据
您可能还记得数据被锁在data键中的列表的列表中。我们需要将这些数据读入内存来操作它。幸运的是,我们可以使用刚刚提取的列名来只获取相关的列。这将节省大量空间。如果数据集更大,您可以迭代地处理成批的行。所以读取第一个10000000行,做一些处理,然后是下一个10000000,以此类推。在这种情况下,我们可以定义我们关心的列,并再次使用ijson迭代处理 JSON 文件:
good_columns = [
"date_of_stop",
"time_of_stop",
"agency",
"subagency",
"description",
"location",
"latitude",
"longitude",
"vehicle_type",
"year",
"make",
"model",
"color",
"violation_type",
"race",
"gender",
"driver_state",
"driver_city",
"dl_state",
"arrest_type"]
data = []
with open(filename, 'r') as f:
objects = ijson.items(f, 'data.item')
for row in objects:
selected_row = []
for item in good_columns:
selected_row.append(row[column_names.index(item)])
data.append(selected_row)
既然我们已经读入了数据,我们可以打印出data中的第一项:
data[0]
['2016-02-18T00:00:00', '09:05:00', 'MCP', '2nd district, Bethesda', 'DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION', '355/TUCKERMAN LN', '-77.105925', '39.03223', '02 - Automobile', '2010', 'JEEP', 'CRISWELL', 'BLUE', 'Citation', 'WHITE', 'F', 'MD', 'GERMANTOWN', 'MD', 'A - Marked Patrol']
将数据读入熊猫
现在我们有了作为列表的列表的数据,以及作为列表的列标题,我们可以创建一个熊猫数据框架来分析数据。如果您对 Pandas 不熟悉,它是一个数据分析库,使用一种称为 Dataframe 的高效表格数据结构来表示您的数据。Pandas 允许您将一个列表转换成一个数据框架,并单独指定列名。
import pandas as pd
stops = pd.DataFrame(data, columns=good_columns)
现在我们有了数据框架中的数据,我们可以做一些有趣的分析。这是一个根据汽车颜色划分的停靠站数量表:
stops["color"].value_counts()
BLACK 161319
SILVER 150650
WHITE 122887
GRAY 86322
RED 66282
BLUE 61867
GREEN 35802
GOLD 27808
TAN 18869
BLUE, DARK 17397
MAROON 15134
BLUE, LIGHT 11600
BEIGE 10522
GREEN, DK 10354
N/A 9594
GREEN, LGT 5214
BROWN 4041
YELLOW 3215
ORANGE 2967
BRONZE 1977
PURPLE 1725
MULTICOLOR 723
CREAM 608
COPPER 269
PINK 137
CHROME 21
CAMOUFLAGE 17
dtype: int64
迷彩似乎是一种非常流行的汽车颜色。下表列出了是哪种警察部门创造了这一记录:
stops["arrest_type"].value_counts()
A - Marked Patrol 671165
Q - Marked Laser 87929
B - Unmarked Patrol 25478
S - License Plate Recognition 11452
O - Foot Patrol 9604
L - Motorcycle 8559
E - Marked Stationary Radar 4854
R - Unmarked Laser 4331
G - Marked Moving Radar (Stationary) 2164
M - Marked (Off-Duty) 1301
I - Marked Moving Radar (Moving) 842
F - Unmarked Stationary Radar 420
C - Marked VASCAR 323
D - Unmarked VASCAR 210
P - Mounted Patrol 171
N - Unmarked (Off-Duty) 116
H - Unmarked Moving Radar (Stationary) 72
K - Aircraft Assist 41
J - Unmarked Moving Radar (Moving) 35
dtype: int64
随着闯红灯相机和高速激光的兴起,有趣的是,巡逻车仍然是迄今为止最主要的引用来源。
转换列
我们现在几乎准备好进行一些基于时间和位置的分析,但是我们需要首先将longitude、latitude和date列从字符串转换为浮点。我们可以使用下面的代码来转换latitude和longitude:
import numpy as np
def parse_float(x):
try:
x = float(x)
except Exception:
x = 0
return x
stops["longitude"] = stops["longitude"].apply(parse_float)
stops["latitude"] = stops["latitude"].apply(parse_float)
奇怪的是,一天中的时间和停止的日期存储在两个单独的列中,time_of_stop和date_of_stop。我们将对两者进行解析,并将它们转换成一个日期时间列:
import datetime
def parse_full_date(row):
date = datetime.datetime.strptime(row["date_of_stop"], "%Y-%m-%dT%H:%M:%S")
time = row["time_of_stop"].split(":")
date = date.replace(hour=int(time[0]), minute = int(time[1]), second = int(time[2]))
return date
stops["date"] = stops.apply(parse_full_date, axis=1)
我们现在可以画出哪一天的交通堵塞最多:
import matplotlib.pyplot as plt
%matplotlib inline plt.hist(stops["date"].dt.weekday, bins=6)
(array([ 112816., 142048., 133363., 127629., 131735., 181476.]), array([ 0., 1., 2., 3., 4., 5., 6.]), <a list of 6 Patch objects>)

在这个情节中,周一是0,周日是6。看起来周日停得最多,周一最少。这也可能是数据质量问题,因为某些原因导致无效日期出现在周日。你必须更深入地挖掘date_of_stop专栏才能最终找到答案(这超出了本文的范围)。
我们还可以绘制出最常见的交通停车时间:
plt.hist(stops["date"].dt.hour, bins=24)
(array([ 44125., 35866., 27274., 18048., 11271., 7796., 11959., 29853., 46306., 42799., 43775., 37101., 34424., 34493., 36006., 29634., 39024., 40988., 32511., 28715., 31983., 43957., 60734., 60425.]), array([ 0\. , 0.95833333, 1.91666667, 2.875 , 3.83333333, 4.79166667, 5.75 , 6.70833333, 7.66666667, 8.625 , 9.58333333, 10.54166667, 11.5 , 12.45833333, 13.41666667, 14.375 , 15.33333333, 16.29166667, 17.25 , 18.20833333, 19.16666667, 20.125 , 21.08333333, 22.04166667, 23\. ]), <a list of 24 Patch objects>)

看起来大多数停靠站发生在午夜左右,最少发生在凌晨 5 点左右。这可能是有道理的,因为人们在深夜从酒吧和晚宴开车回家,可能会受到损害。这也可能是一个数据质量问题,为了得到完整的答案,有必要浏览一下time_of_stop栏。
设置站点子集
现在我们已经转换了位置和日期列,我们可以绘制出交通站点。因为映射在 CPU 资源和内存方面非常密集,所以我们需要首先过滤掉从stops开始使用的行:
last_year = stops[stops["date"] > datetime.datetime(year=2015, month=2, day=18)]
在上面的代码中,我们选择了过去一年中出现的所有行。我们可以进一步缩小范围,只选择发生在高峰时间(每个人都去上班的早晨)的行:
morning_rush = last_year[(last_year["date"].dt.weekday < 5) & (last_year["date"].dt.hour > 5) & (last_year["date"].dt.hour < 10)]
print(morning_rush.shape)last_year.shape
(29824, 21)
(234582, 21)
使用优秀的叶子包,我们现在可以看到所有的停止发生在哪里。通过利用传单,Folium 允许你用 Python 轻松地创建交互式地图。为了保持性能,我们将只显示morning_rush的前1000行:
import folium
from folium import plugins
stops_map = folium.Map(location=[39.0836, -77.1483], zoom_start=11)
marker_cluster = folium.MarkerCluster().add_to(stops_map)
for name, row in morning_rush.iloc[:1000].iterrows():
folium.Marker([row["longitude"], row["latitude"]], popup=row["description"]).add_to(marker_cluster)
stops_map.create_map('stops.html')stops_map
https://www.dataquest.io/blog/large_files/json_folium.html
这说明很多交通站点都集中在县城右下方周围。我们可以通过热图进一步扩展我们的分析:
stops_heatmap = folium.Map(location=[39.0836, -77.1483], zoom_start=11)stops_heatmap.add_children(plugins.HeatMap([`, row["latitude"]] for name, row in morning_rush.iloc[:1000].iterrows()]))stops_heatmap.save("heatmap.html")stops_heatmap`
处理大型 JSON 数据集可能是一件痛苦的事情,尤其是当它们太大而无法放入内存时。在这种情况下,命令行工具和 Python 的结合可以提供一种有效的方式来探索和分析数据。在这篇关注学习 python 编程的文章中,我们将看看如何利用像 Pandas 这样的工具来探索和绘制马里兰州蒙哥马利县的警察活动。我们将从查看 JSON 数据开始,然后继续用 Python 探索和分析 JSON。
当数据存储在 SQL 数据库中时,它往往遵循一种看起来像表的严格结构。下面是一个来自 SQLite 数据库的示例:
id|code|name|area|area_land|area_water|population|population_growth|birth_rate|death_rate|migration_rate|created_at|updated_at1|af|Afghanistan|652230|652230|0|32564342|2.32|38.57|13.89|1.51|2015-11-01 13:19:49.461734|2015-11-01 13:19:49.4617342|al|Albania|28748|27398|1350|3029278|0.3|12.92|6.58|3.3|2015-11-01 13:19:54.431082|2015-11-01 13:19:54.4310823|ag|Algeria|2381741|2381741|0|39542166|1.84|23.67|4.31|0.92|2015-11-01 13:19:59.961286|2015-11-01 13:19:59.961286
如您所见,数据由行和列组成,其中每一列都映射到一个定义的属性,如`id`或`code`。在上面的数据集中,每行代表一个国家,每列代表该国的一些事实。
但是,随着我们捕获的数据量的增加,我们往往不知道数据在存储时的确切结构。这就是所谓的非结构化数据。一个很好的例子是网站上访问者的事件列表。以下是发送到服务器的事件列表示例:
{'event_type': 'started-lesson', 'keen': {'created_at': '2015-06-12T23:09:03.966Z', 'id': '557b668fd2eaaa2e7c5e916b', 'timestamp': '2015-06-12T23:09:07.971Z'}, 'sequence': 1} {'event_type': 'started-screen', 'keen': {'created_at': '2015-06-12T23:09:03.979Z', 'id': '557b668f90e4bd26c10b6ed6', 'timestamp': '2015-06-12T23:09:07.987Z'}, 'lesson': 1, 'sequence': 4, 'type': 'code'} {'event_type': 'started-screen', 'keen': {'created_at': '2015-06-12T23:09:22.517Z', 'id': '557b66a246f9a7239038b1e0', 'timestamp': '2015-06-12T23:09:24.246Z'}, 'lesson': 1, 'sequence': 3, 'type': 'code'},
如您所见,上面列出了三个独立的事件。每个事件都有不同的字段,一些字段*嵌套在其他字段*中。这种类型的数据很难存储在常规 SQL 数据库中。这种非结构化数据通常以一种叫做[JavaScript Object Notation](https://json.org/)(JSON)的格式存储。JSON 是一种将列表和字典等数据结构编码成字符串的方法,可以确保它们易于被机器读取。尽管 JSON 以单词 Javascript 开头,但它实际上只是一种格式,可以被任何语言读取。
Python 有很好的 JSON 支持,有 [json](https://docs.python.org/3/library/json.html) 库。我们既可以将*列表*和*字典*转换为 JSON,也可以将字符串转换为*列表*和*字典*。JSON 数据看起来很像 Python 中的*字典*,其中存储了键和值。
在这篇文章中,我们将在命令行上探索一个 JSON 文件,然后将它导入 Python 并使用 Pandas 来处理它。
## 数据集
我们将查看包含马里兰州蒙哥马利县交通违规信息的数据集。你可以在这里下载数据[。该数据包含违规发生的地点、汽车类型、收到违规的人的人口统计信息以及其他一些有趣的信息。使用该数据集,我们可以回答很多问题,包括:](https://catalog.data.gov/dataset/traffic-violations-56dda)
* 什么类型的车最有可能因为超速被拦下来?
* 警察一天中什么时候最活跃?
* “速度陷阱”有多普遍?还是说门票在地理上分布相当均匀?
* 人们被拦下来最常见的原因是什么?
不幸的是,我们事先不知道 JSON 文件的结构,所以我们需要做一些探索来弄清楚它。我们将使用 [Jupyter 笔记本](https://jupyter.org/)进行这次探索。
## 探索 JSON 数据
尽管 JSON 文件只有 600MB,但我们会把它当作大得多的文件来处理,这样我们就可以研究如何分析一个不适合内存的 JSON 文件。我们要做的第一件事是看一下`md_traffic.json`文件的前几行。JSON 文件只是一个普通的文本文件,因此我们可以使用所有标准的命令行工具与它进行交互:
%%bashhead md_traffic.json
<codeclass="language-bash">
{ "meta" : {
"view" : {
"id" : "4mse-ku6q",
"name" : "Traffic Violations",
"averageRating" : 0,
"category" : "Public Safety",
"createdAt" : 1403103517,
"description" : "This dataset contains traffic violation information from all electronic traffic violations issued in the County. Any information that can be used to uniquely identify the vehicle, the vehicle owner or the officer issuing the violation will not be published.\r\n\r\nUpdate Frequency: Daily",
"displayType" : "table",
由此,我们可以看出 JSON 数据是一个字典,并且格式良好。`meta`是顶级键,缩进两个空格。我们可以通过使用 [grep](https://en.wikipedia.org/wiki/Grep) 命令打印任何有两个前导空格的行来获得所有顶级密钥:
%%bashgrep -E '^ {2}"' md_traffic.json
"meta" : {"data" : [
[ 1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050", 1455876689, "498050", null, "2016-02-18T00:00:00", "09:05:00", "MCP", "2nd district, Bethesda", "DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION", "355/TUCKERMAN LN", "-77.105925", "39.03223", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "MD", "02 - Automobile", "2010", "JEEP", "CRISWELL", "BLUE", "Citation", "21-1124.2(d2)", "Transportation Article", "No", "WHITE", "F", "GERMANTOWN", "MD", "MD", "A - Marked Patrol", [ "{"address":"","city":"","state":"","zip":""}", "-77.105925", "39.03223", null, false ] ]
这表明`meta`和`data`是`md_traffic.json`数据中的顶级键。列表的列表*似乎与`data`相关联,并且这可能包含我们的交通违规数据集中的每个记录。每个内部*列表*都是一条记录,第一条记录出现在`grep`命令的输出中。这与我们在操作 CSV 文件或 SQL 表时习惯使用的结构化数据非常相似。以下是数据的部分视图:*
[ [1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050"], [1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050"], ...]
这看起来很像我们习惯使用的行和列。我们只是缺少了告诉我们每一列的含义的标题。我们也许能在`meta`键下找到这个信息。
`meta`通常指关于数据本身的信息。让我们更深入地研究一下`meta`,看看那里包含了什么信息。从`head`命令中,我们知道至少有`3`级按键,其中`meta`包含一个按键`view`,包含`id`、`name`、`averageRating`等按键。我们可以通过使用 grep 打印出任何带有`2-6`前导空格的行来打印出 JSON 文件的完整密钥结构:
%%bashgrep -E '^ {2,6}"' md_traffic.json
"meta" : { "view" : { "id" : "4mse-ku6q", "name" : "Traffic Violations", "averageRating" : 0, "category" : "Public Safety", "createdAt" : 1403103517, "description" : "This dataset contains traffic violation information from all electronic traffic violations issued in the County. Any information that can be used to uniquely identify the vehicle, the vehicle owner or the officer issuing the violation will not be published.\r\n\r\nUpdate Frequency: Daily", "displayType" : "table", "downloadCount" : 2851, "iconUrl" : "fileId:r41tDc239M1FL75LFwXFKzFCWqr8mzMeMTYXiA24USM", "indexUpdatedAt" : 1455885508, "newBackend" : false, "numberOfComments" : 0, "oid" : 8890705, "publicationAppendEnabled" : false, "publicationDate" : 1411040702, "publicationGroup" : 1620779, "publicationStage" : "published", "rowClass" : "", "rowsUpdatedAt" : 1455876727, "rowsUpdatedBy" : "ajn4-zy65", "state" : "normal", "tableId" : 1722160, "totalTimesRated" : 0, "viewCount" : 6910, "viewLastModified" : 1434558076, "viewType" : "tabular", "columns" : [ { "disabledFeatureFlags" : [ "allow_comments" ], "grants" : [ { "metadata" : { "owner" : { "query" : { "rights" : [ "read" ], "sortBys" : [ { "tableAuthor" : { "tags" : [ "traffic", "stop", "violations", "electronic issued." ], "flags" : [ "default" ]"data" : [ [ 1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050", 1455876689, "498050", null, "2016-02-18T00:00:00", "09:05:00", "MCP", "2nd district, Bethesda", "DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION", "355/TUCKERMAN LN", "-77.105925", "39.03223", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "MD", "02 - Automobile", "2010", "JEEP", "CRISWELL", "BLUE", "Citation", "21-1124.2(d2)", "Transportation Article", "No", "WHITE", "F", "GERMANTOWN", "MD", "MD", "A - Marked Patrol", [ "{"address":"","city":"","state":"","zip":""}", "-77.105925", "39.03223", null, false ] ]
这向我们展示了与`md_traffic.json`相关的完整密钥结构,并告诉我们 JSON 文件的哪些部分与我们相关。在这种情况下,`columns`键看起来很有趣,因为它可能包含关于`data`键中的列表的*列表中的列的信息。*
## 提取列上的信息
现在我们知道了哪个键包含列的信息,我们需要读入这些信息。因为我们假设 JSON 文件不适合内存,所以我们不能使用 [json](https://docs.python.org/3/library/json.html) 库直接读取它。相反,我们需要以内存高效的方式迭代读取它。
我们可以使用 [ijson](https://pypi.python.org/pypi/ijson/) 包来完成这个任务。ijson 将迭代解析 json 文件,而不是一次读入所有内容。这比直接读入整个文件要慢,但它使我们能够处理内存中容纳不下的大文件。要使用 ijson,我们指定一个要从中提取数据的文件,然后指定一个要提取的关键路径:
import ijson
filename = "md_traffic.json"
with open(filename, 'r') as f:
objects = ijson.items(f, 'meta.view.columns.item')
columns = list(objects)
在上面的代码中,我们打开了`md_traffic.json`文件,然后我们使用 ijson 中的`items`方法从文件中提取一个列表。我们使用`meta.view.columns`符号指定列表的路径。回想一下`meta`是一个顶级键,里面包含`view`,里面包含`columns`。然后,我们指定`meta.view.columns.item`来表示我们应该提取`meta.view.columns`列表中的每一项。`items`函数将返回一个[生成器](https://wiki.python.org/moin/Generators),所以我们使用 list 方法将生成器转换成一个 Python 列表。我们可以打印出清单中的第一项:
print(columns[0])
{'renderTypeName': 'meta_data', 'name': 'sid', 'fieldName': ':sid', 'position': 0, 'id': -1, 'format': {}, 'dataTypeName': 'meta_data'}
从上面的输出来看,`columns`中的每一项都是一个字典,包含了每一列的信息。为了得到我们的头,看起来`fieldName`是要提取的相关键。要获得我们的列名,我们只需从`columns`中的每一项提取`fieldName`键:
column_names = [col["fieldName"] for col in columns]column_names
[':sid', ':id', ':position', ':created_at', ':created_meta', ':updated_at', ':updated_meta', ':meta', 'date_of_stop', 'time_of_stop', 'agency', 'subagency', 'description', 'location', 'latitude', 'longitude', 'accident', 'belts', 'personal_injury', 'property_damage', 'fatal', 'commercial_license', 'hazmat', 'commercial_vehicle', 'alcohol', 'work_zone', 'state', 'vehicle_type', 'year', 'make', 'model', 'color', 'violation_type', 'charge', 'article', 'contributed_to_accident', 'race', 'gender', 'driver_city', 'driver_state', 'dl_state', 'arrest_type', 'geolocation']
太好了!现在我们已经有了列名,我们可以开始提取数据本身了。
## 提取数据
您可能还记得数据被锁在`data`键中的列表的*列表中。我们需要将这些数据读入内存来操作它。幸运的是,我们可以使用刚刚提取的列名来只获取相关的列。这将节省大量空间。如果数据集更大,您可以迭代地处理成批的行。所以读取第一个`10000000`行,做一些处理,然后是下一个`10000000`,以此类推。在这种情况下,我们可以定义我们关心的列,并再次使用`ijson`迭代处理 JSON 文件:*
good_columns = [
"date_of_stop",
"time_of_stop",
"agency",
"subagency",
"description",
"location",
"latitude",
"longitude",
"vehicle_type",
"year",
"make",
"model",
"color",
"violation_type",
"race",
"gender",
"driver_state",
"driver_city",
"dl_state",
"arrest_type"]
data = []
with open(filename, 'r') as f:
objects = ijson.items(f, 'data.item')
for row in objects:
selected_row = []
for item in good_columns:
selected_row.append(row[column_names.index(item)])
data.append(selected_row)
既然我们已经读入了数据,我们可以打印出`data`中的第一项:
data[0]
['2016-02-18T00:00:00', '09:05:00', 'MCP', '2nd district, Bethesda', 'DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION', '355/TUCKERMAN LN', '-77.105925', '39.03223', '02 - Automobile', '2010', 'JEEP', 'CRISWELL', 'BLUE', 'Citation', 'WHITE', 'F', 'MD', 'GERMANTOWN', 'MD', 'A - Marked Patrol']
## 将数据读入熊猫
现在我们有了作为列表的*列表的数据,以及作为*列表*的列标题,我们可以创建一个[熊猫](https://pandas.pydata.org/)数据框架来分析数据。如果您对 Pandas 不熟悉,它是一个数据分析库,使用一种称为 Dataframe 的高效表格数据结构来表示您的数据。Pandas 允许您将一个列表转换成一个数据框架,并单独指定列名。*
import pandas as pd
stops = pd.DataFrame(data, columns=good_columns)
现在我们有了数据框架中的数据,我们可以做一些有趣的分析。这是一个根据汽车颜色划分的停靠站数量表:
stops["color"].value_counts()
BLACK 161319
SILVER 150650
WHITE 122887
GRAY 86322
RED 66282
BLUE 61867
GREEN 35802
GOLD 27808
TAN 18869
BLUE, DARK 17397
MAROON 15134
BLUE, LIGHT 11600
BEIGE 10522
GREEN, DK 10354
N/A 9594
GREEN, LGT 5214
BROWN 4041
YELLOW 3215
ORANGE 2967
BRONZE 1977
PURPLE 1725
MULTICOLOR 723
CREAM 608
COPPER 269
PINK 137
CHROME 21
CAMOUFLAGE 17
dtype: int64
迷彩似乎是一种*非常*流行的汽车颜色。下表列出了是哪种警察部门创造了这一记录:
stops["arrest_type"].value_counts()
A - Marked Patrol 671165
Q - Marked Laser 87929
B - Unmarked Patrol 25478
S - License Plate Recognition 11452
O - Foot Patrol 9604
L - Motorcycle 8559
E - Marked Stationary Radar 4854
R - Unmarked Laser 4331
G - Marked Moving Radar (Stationary) 2164
M - Marked (Off-Duty) 1301
I - Marked Moving Radar (Moving) 842
F - Unmarked Stationary Radar 420
C - Marked VASCAR 323
D - Unmarked VASCAR 210
P - Mounted Patrol 171
N - Unmarked (Off-Duty) 116
H - Unmarked Moving Radar (Stationary) 72
K - Aircraft Assist 41
J - Unmarked Moving Radar (Moving) 35
dtype: int64
随着闯红灯相机和高速激光的兴起,有趣的是,巡逻车仍然是迄今为止最主要的引用来源。
## 转换列
我们现在几乎准备好进行一些基于时间和位置的分析,但是我们需要首先将`longitude`、`latitude`和`date`列从字符串转换为浮点。我们可以使用下面的代码来转换`latitude`和`longitude`:
import numpy as np
def parse_float(x):
try:
x = float(x)
except Exception:
x = 0
return x
stops["longitude"] = stops["longitude"].apply(parse_float)
stops["latitude"] = stops["latitude"].apply(parse_float)
奇怪的是,一天中的时间和停止的日期存储在两个单独的列中,`time_of_stop`和`date_of_stop`。我们将对两者进行解析,并将它们转换成一个日期时间列:
import datetime
def parse_full_date(row):
date = datetime.datetime.strptime(row["date_of_stop"], "%Y-%m-%dT%H:%M:%S")
time = row["time_of_stop"].split("😊
date = date.replace(hour=int(time[0]), minute = int(time[1]), second = int(time[2]))
return date
stops["date"] = stops.apply(parse_full_date, axis=1)
我们现在可以画出哪一天的交通堵塞最多:
import matplotlib.pyplot as plt
%matplotlib inline plt.hist(stops["date"].dt.weekday, bins=6)
(array([ 112816., 142048., 133363., 127629., 131735., 181476.]), array([ 0., 1., 2., 3., 4., 5., 6.]), <a list of 6 Patch objects>)

在这个情节中,周一是`0`,周日是`6`。看起来周日停得最多,周一最少。这也可能是数据质量问题,因为某些原因导致无效日期出现在周日。你必须更深入地挖掘`date_of_stop`专栏才能最终找到答案(这超出了本文的范围)。
我们还可以绘制出最常见的交通停车时间:
plt.hist(stops["date"].dt.hour, bins=24)
(array([ 44125., 35866., 27274., 18048., 11271., 7796., 11959., 29853., 46306., 42799., 43775., 37101., 34424., 34493., 36006., 29634., 39024., 40988., 32511., 28715., 31983., 43957., 60734., 60425.]), array([ 0. , 0.95833333, 1.91666667, 2.875 , 3.83333333, 4.79166667, 5.75 , 6.70833333, 7.66666667, 8.625 , 9.58333333, 10.54166667, 11.5 , 12.45833333, 13.41666667, 14.375 , 15.33333333, 16.29166667, 17.25 , 18.20833333, 19.16666667, 20.125 , 21.08333333, 22.04166667, 23. ]), <a list of 24 Patch objects>)

看起来大多数停靠站发生在午夜左右,最少发生在凌晨 5 点左右。这可能是有道理的,因为人们在深夜从酒吧和晚宴开车回家,可能会受到损害。这也可能是一个数据质量问题,为了得到完整的答案,有必要浏览一下`time_of_stop`栏。
## 设置站点子集
现在我们已经转换了位置和日期列,我们可以绘制出交通站点。因为映射在 CPU 资源和内存方面非常密集,所以我们需要首先过滤掉从`stops`开始使用的行:
last_year = stops[stops["date"] > datetime.datetime(year=2015, month=2, day=18)]
在上面的代码中,我们选择了过去一年中出现的所有行。我们可以进一步缩小范围,只选择发生在高峰时间(每个人都去上班的早晨)的行:
morning_rush = last_year[(last_year["date"].dt.weekday < 5) & (last_year["date"].dt.hour > 5) & (last_year["date"].dt.hour < 10)]
print(morning_rush.shape)last_year.shape
(29824, 21)
(234582, 21)
使用优秀的[叶子](https://github.com/python-visualization/folium)包,我们现在可以看到所有的停止发生在哪里。通过利用[传单](https://leafletjs.com/),Folium 允许你用 Python 轻松地创建交互式地图。为了保持性能,我们将只显示`morning_rush`的前`1000`行:
import folium
from folium import plugins
stops_map = folium.Map(location=[39.0836, -77.1483], zoom_start=11)
marker_cluster = folium.MarkerCluster().add_to(stops_map)
for name, row in morning_rush.iloc[:1000].iterrows():
folium.Marker([row["longitude"], row["latitude"]], popup=row["description"]).add_to(marker_cluster)
stops_map.create_map('stops.html')stops_map
[https://www.dataquest.io/blog/large_files/json_folium.html](https://www.dataquest.io/blog/large_files/json_folium.html)
这说明很多交通站点都集中在县城右下方周围。我们可以通过热图进一步扩展我们的分析:
stops_heatmap = folium.Map(location=[39.0836, -77.1483], zoom_start=11)stops_heatmap.add_children(plugins.HeatMap([, row["latitude"]] for name, row in morning_rush.iloc[:1000].iterrows()]))stops_heatmap.save("heatmap.html")stops_heatmap
[data:text/html;base64,CiAgICAgICAgPCFET0NUWVBFIGh0bWw+CiAgICAgICAgPGhlYWQ+CiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bWV0YSBodHRwLWVxdWl2PSJjb250ZW50LXR5cGUiIGNvbnRlbnQ9InRleHQvaHRtbDsgY2hhcnNldD1VVEYtOCIgLz4KICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL2NkbmpzLmNsb3VkZmxhcmUuY29tL2FqYXgvbGlicy9sZWFmbGV0LzAuNy4zL2xlYWZsZXQuanMiPjwvc2NyaXB0PgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPHNjcmlwdCBzcmM9Imh0dHBzOi8vYWpheC5nb29nbGVhcGlzLmNvbS9hamF4L2xpYnMvanF1ZXJ5LzEuMTEuMS9qcXVlcnkubWluLmpzIj48L3NjcmlwdD4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL21heGNkbi5ib290c3RyYXBjZG4uY29tL2Jvb3RzdHJhcC8zLjIuMC9qcy9ib290c3RyYXAubWluLmpzIj48L3NjcmlwdD4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL3Jhd2dpdGh1Yi5jb20vbHZvb2dkdC9MZWFmbGV0LmF3ZXNvbWUtbWFya2Vycy8yLjAvZGV2ZWxvcC9kaXN0L2xlYWZsZXQuYXdlc29tZS1tYXJrZXJzLmpzIj48L3NjcmlwdD4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL2NkbmpzLmNsb3VkZmxhcmUuY29tL2FqYXgvbGlicy9sZWFmbGV0Lm1hcmtlcmNsdXN0ZXIvMC40LjAvbGVhZmxldC5tYXJrZXJjbHVzdGVyLXNyYy5qcyI+PC9zY3JpcHQ+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8c2NyaXB0IHNyYz0iaHR0cHM6Ly9jZG5qcy5jbG91ZGZsYXJlLmNvbS9hamF4L2xpYnMvbGVhZmxldC5tYXJrZXJjbHVzdGVyLzAuNC4wL2xlYWZsZXQubWFya2VyY2x1c3Rlci5qcyI+PC9zY3JpcHQ+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bGluayByZWw9InN0eWxlc2hlZXQiIGhyZWY9Imh0dHBzOi8vY2RuanMuY2xvdWRmbGFyZS5jb20vYWpheC9saWJzL2xlYWZsZXQvMC43LjMvbGVhZmxldC5jc3MiIC8+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bGluayByZWw9InN0eWxlc2hlZXQiIGhyZWY9Imh0dHBzOi8vbWF4Y2RuLmJvb3RzdHJhcGNkbi5jb20vYm9vdHN0cmFwLzMuMi4wL2Nzcy9ib290c3RyYXAubWluLmNzcyIgLz4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxsaW5rIHJlbD0ic3R5bGVzaGVldCIgaHJlZj0iaHR0cHM6Ly9tYXhjZG4uYm9vdHN0cmFwY2RuLmNvbS9ib290c3RyYXAvMy4yLjAvY3NzL2Jvb3RzdHJhcC10aGVtZS5taW4uY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJodHRwczovL21heGNkbi5ib290c3RyYXBjZG4uY29tL2ZvbnQtYXdlc29tZS80LjEuMC9jc3MvZm9udC1hd2Vzb21lLm1pbi5jc3MiIC8+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bGluayByZWw9InN0eWxlc2hlZXQiIGhyZWY9Imh0dHBzOi8vcmF3Z2l0LmNvbS9sdm9vZ2R0L0xlYWZsZXQuYXdlc29tZS1tYXJrZXJzLzIuMC9kZXZlbG9wL2Rpc3QvbGVhZmxldC5hd2Vzb21lLW1hcmtlcnMuY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJodHRwczovL2NkbmpzLmNsb3VkZmxhcmUuY29tL2FqYXgvbGlicy9sZWFmbGV0Lm1hcmtlcmNsdXN0ZXIvMC40LjAvTWFya2VyQ2x1c3Rlci5EZWZhdWx0LmNzcyIgLz4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxsaW5rIHJlbD0ic3R5bGVzaGVldCIgaHJlZj0iaHR0cHM6Ly9jZG5qcy5jbG91ZGZsYXJlLmNvbS9hamF4L2xpYnMvbGVhZmxldC5tYXJrZXJjbHVzdGVyLzAuNC4wL01hcmtlckNsdXN0ZXIuY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJodHRwczovL3Jhdy5naXRodWJ1c2VyY29udGVudC5jb20vcHl0aG9uLXZpc3VhbGl6YXRpb24vZm9saXVtL21hc3Rlci9mb2xpdW0vdGVtcGxhdGVzL2xlYWZsZXQuYXdlc29tZS5yb3RhdGUuY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAgICAgPHN0eWxlPgoKICAgICAgICAgICAgaHRtbCwgYm9keSB7CiAgICAgICAgICAgICAgICB3aWR0aDogMTAwJTsKICAgICAgICAgICAgICAgIGhlaWdodDogMTAwJTsKICAgICAgICAgICAgICAgIG1hcmdpbjogMDsKICAgICAgICAgICAgICAgIHBhZGRpbmc6IDA7CiAgICAgICAgICAgICAgICB9CgogICAgICAgICAgICAjbWFwIHsKICAgICAgICAgICAgICAgIHBvc2l0aW9uOmFic29sdXRlOwogICAgICAgICAgICAgICAgdG9wOjA7CiAgICAgICAgICAgICAgICBib3R0b206MDsKICAgICAgICAgICAgICAgIHJpZ2h0OjA7CiAgICAgICAgICAgICAgICBsZWZ0OjA7CiAgICAgICAgICAgICAgICB9CiAgICAgICAgICAgIDwvc3R5bGU+CiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAgICAgPHN0eWxlPiAjbWFwX2EzMmQ2NzVlN2Y5MDQ5YTlhMTQzOTk4MjkwMzE0YTk4IHsKICAgICAgICAgICAgICAgIHBvc2l0aW9uIDogcmVsYXRpdmU7CiAgICAgICAgICAgICAgICB3aWR0aCA6IDEwMC4wJTsKICAgICAgICAgICAgICAgIGhlaWdodDogMTAwLjAlOwogICAgICAgICAgICAgICAgbGVmdDogMC4wJTsKICAgICAgICAgICAgICAgIHRvcDogMC4wJTsKICAgICAgICAgICAgICAgIH0KICAgICAgICAgICAgPC9zdHlsZT4KICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL2xlYWZsZXQuZ2l0aHViLmlvL0xlYWZsZXQuaGVhdC9kaXN0L2xlYWZsZXQtaGVhdC5qcyI+PC9zY3JpcHQ+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgPC9oZWFkPgogICAgICAgIDxib2R5PgogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgICAgIDxkaXYgY2xhc3M9ImZvbGl1bS1tYXAiIGlkPSJtYXBfYTMyZDY3NWU3ZjkwNDlhOWExNDM5OTgyOTAzMTRhOTgiID48L2Rpdj4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICA8L2JvZHk+CiAgICAgICAgPHNjcmlwdD4KICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAoKICAgICAgICAgICAgdmFyIHNvdXRoV2VzdCA9IEwubGF0TG5nKC05MCwgLTE4MCk7CiAgICAgICAgICAgIHZhciBub3J0aEVhc3QgPSBMLmxhdExuZyg5MCwgMTgwKTsKICAgICAgICAgICAgdmFyIGJvdW5kcyA9IEwubGF0TG5nQm91bmRzKHNvdXRoV2VzdCwgbm9ydGhFYXN0KTsKCiAgICAgICAgICAgIHZhciBtYXBfYTMyZDY3NWU3ZjkwNDlhOWExNDM5OTgyOTAzMTRhOTggPSBMLm1hcCgnbWFwX2EzMmQ2NzVlN2Y5MDQ5YTlhMTQzOTk4MjkwMzE0YTk4JywgewogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgY2VudGVyOlszOS4wODM2LC03Ny4xNDgzXSwKICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIHpvb206IDExLAogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgbWF4Qm91bmRzOiBib3VuZHMsCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICBsYXllcnM6IFtdLAogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgY3JzOiBMLkNSUy5FUFNHMzg1NwogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIH0pOwogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgICAgIHZhciB0aWxlX2xheWVyXzMxYjEzMTJiNmVhODQ0NWE4MmJiMGVlMDBjOTc2NjBjID0gTC50aWxlTGF5ZXIoCiAgICAgICAgICAgICAgICAnaHR0cHM6Ly97c30udGlsZS5vcGVuc3RyZWV0bWFwLm9yZy97en0ve3h9L3t5fS5wbmcnLAogICAgICAgICAgICAgICAgewogICAgICAgICAgICAgICAgICAgIG1heFpvb206IDE4LAogICAgICAgICAgICAgICAgICAgIG1pblpvb206IDEsCiAgICAgICAgICAgICAgICAgICAgYXR0cmlidXRpb246ICdEYXRhIGJ5IDxhIGhyZWY9Imh0dHA6Ly9vcGVuc3RyZWV0bWFwLm9yZyI+T3BlblN0cmVldE1hcDwvYT4sIHVuZGVyIDxhIGhyZWY9Imh0dHA6Ly93d3cub3BlbnN0cmVldG1hcC5vcmcvY29weXJpZ2h0Ij5PRGJMPC9hPi4nLAogICAgICAgICAgICAgICAgICAgIGRldGVjdFJldGluYTogZmFsc2UKICAgICAgICAgICAgICAgICAgICB9CiAgICAgICAgICAgICAgICApLmFkZFRvKG1hcF9hMzJkNjc1ZTdmOTA0OWE5YTE0Mzk5ODI5MDMxNGE5OCk7CgogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAgICAgdmFyIGhlYXRfbWFwX2I3OGIzMzNmZWMzMTQxY2U4ZDNiMGY1NzJiZTM0YjUwID0gTC5oZWF0TGF5ZXIoCiAgICAgICAgICAgICAgICBbWzM5LjAzMjIzLCAtNzcuMTA1OTI1XSwgWzAuMCwgMC4wXSwgWzM5LjA0MTM0NSwgLTc3LjA1MzkxNjY2NjY2NjddLCBbMzkuMDQwNTY1LCAtNzcuMDU2MjgxNjY2NjY2N10sIFszOS4wMTM0NDgzMzMzMzMzLCAtNzcuMTA2MTMzMzMzMzMzM10sIFszOS4wMTM1NjgzMzMzMzMzLCAtNzcuMTA2MjM4MzMzMzMzM10sIFszOS4wMTM2NCwgLTc3LjEwNjIyNjY2NjY2NjddLCBbMzkuMDIzMDA1LCAtNzcuMTAzMjAxNjY2NjY2N10sIFszOS4yNDA2NTMzMzMzMzMzLCAtNzcuMjM1MDIxNjY2NjY2N10sIFszOS4yNDA2NTMzMzMzMzMzLCAtNzcuMjM1MDIxNjY2NjY2N10sIFszOS4yNDA2NTMzMzMzMzMzLCAtNzcuMjM1MDIxNjY2NjY2N10sIFszOS4wMDE3OCwgLTc3LjAzODg1MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzguOTk4MTYsIC03Ni45OTUwODgzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjA0MTM0NSwgLTc3LjA1MzkxNjY2NjY2NjddLCBbMzkuMDQ3MDM4MzMzMzMzMywgLTc3LjA1MzE5XSwgWzM5LjA0NzAzODMzMzMzMzMsIC03Ny4wNTMxOV0sIFszOS4wNTcxODE2NjY2NjY3LCAtNzcuMDQ5NzE4MzMzMzMzM10sIFszOS4wNTcxODE2NjY2NjY3LCAtNzcuMDQ5NzE4MzMzMzMzM10sIFszOS4wNDA1NjUsIC03Ny4wNTYyODE2NjY2NjY3XSwgWzM4Ljk5OTE5MTY2NjY2NjcsIC03Ny4wMzM4MTY2NjY2NjY3XSwgWzM4Ljk5NzI3LCAtNzcuMDI3NDc2NjY2NjY2N10sIFszOS4wMTkxOTY2NjY2NjY3LCAtNzcuMDE0MjExNjY2NjY2N10sIFszOS4wOTYzMTE2NjY2NjY3LCAtNzcuMjA2NDRdLCBbMzkuMTAyMDA1LCAtNzcuMjEwODgzMzMzMzMzM10sIFszOS4xMDIwMDUsIC03Ny4yMTA4ODMzMzMzMzMzXSwgWzM5LjEwMjAwNSwgLTc3LjIxMDg4MzMzMzMzMzNdLCBbMzkuMDI5Mzk1LCAtNzcuMDYzODE1XSwgWzM5LjAyOTM5NSwgLTc3LjA2MzgxNV0sIFszOS4wMjkzOTUsIC03Ny4wNjM4MTVdLCBbMzkuMDI5Mzk1LCAtNzcuMDYzODE1XSwgWzM5LjAzMTIwNSwgLTc3LjA3MjQyODMzMzMzMzNdLCBbMzkuMDMxMzA1LCAtNzcuMDcyNTI1XSwgWzM4Ljk5MDE2MTY2NjY2NjcsIC03Ny4wMDE1NDgzMzMzMzMzXSwgWzM5LjExMzgyNSwgLTc3LjE5MzY1XSwgWzM5LjAwMzUwNjY2NjY2NjcsIC03Ny4wMzU2MDE2NjY2NjY3XSwgWzM5LjE2NDE3MzMzMzMzMzMsIC03Ny4xNTcyM10sIFszOS4xOTA2NjE2NjY2NjY3LCAtNzcuMjQyMDYzMzMzMzMzM10sIFszOS4xMTg4NCwgLTc3LjAyMTc1MTY2NjY2NjddLCBbMzkuMTI3NzA2NjY2NjY2NywgLTc3LjE2NzA4MzMzMzMzMzNdLCBbMzkuMTUxNzEsIC03Ny4yNzgyNF0sIFszOS4wNjUwMDUsIC03Ny4yNjU5NTVdLCBbMzkuMTAxODI1LCAtNzcuMTQxODRdLCBbMzguOTg1NjUzMzMzMzMzMywgLTc3LjIyNjU0NV0sIFszOS4wNzQ3OCwgLTc2Ljk5ODJdLCBbMzkuMDczOTMxNjY2NjY2NywgLTc3LjAwMDk5MzMzMzMzMzNdLCBbMzkuMTk4OTI4MzMzMzMzMywgLTc3LjI0NDgxMTY2NjY2NjddLCBbMzkuMjc4MTk1LCAtNzcuMzIyNjk2NjY2NjY2N10sIFszOS4yNzgxOTUsIC03Ny4zMjI2OTY2NjY2NjY3XSwgWzM5LjIyODQ4MzMzMzMzMzMsIC03Ny4yODI2MV0sIFszOS4xNzc4NzY2NjY2NjY3LCAtNzcuMjcwNjQ4MzMzMzMzM10sIFszOS4xNzgyNzY2NjY2NjY3LCAtNzcuMjcyNDcxNjY2NjY2N10sIFszOS4xNzgyMzUsIC03Ny4yNzIzMTMzMzMzMzMzXSwgWzM5LjE3NzQzNjY2NjY2NjcsIC03Ny4yNzEzMjY2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzM5LjE3MTE5ODMzMzMzMzMsIC03Ny4yNzc4MjY2NjY2NjY3XSwgWzM5LjE3MjA0NjY2NjY2NjcsIC03Ny4yNzY2ODgzMzMzMzMzXSwgWzM5LjE2ODg5NjY2NjY2NjcsIC03Ny4yNzk1N10sIFszOS4xNzEwNiwgLTc3LjI3NzkyNV0sIFszOS4xMTEyOTgzMzMzMzMzLCAtNzcuMTYxMjYxNjY2NjY2N10sIFszOS4wNjk1NTMzMzMzMzMzLCAtNzcuMTM4NDQzMzMzMzMzM10sIFszOS4wNDExMDgzMzMzMzMzLCAtNzcuMTYyMjYzMzMzMzMzM10sIFszOS4wOTU1NywgLTc3LjA0NDE5ODMzMzMzMzNdLCBbMzkuMjg3MTIsIC03Ny4yMDgwMV0sIFszOS4yNzU5NjUsIC03Ny4yMTQxNTVdLCBbMzkuMjc2NzI1LCAtNzcuMjEzNDY4MzMzMzMzM10sIFswLjAsIDAuMF0sIFszOC45OTg4MTUsIC03Ni45OTUxMDgzMzMzMzMzXSwgWzM4Ljk5Nzc0ODMzMzMzMzMsIC03Ni45OTQzM10sIFszOC45OTc3NDgzMzMzMzMzLCAtNzYuOTk0MzNdLCBbMzguOTk3NTY1LCAtNzYuOTk0MDkzMzMzMzMzM10sIFszOC45OTQ3OCwgLTc3LjAwNzgwMTY2NjY2NjddLCBbMzguOTk0NzgsIC03Ny4wMDc4MDE2NjY2NjY3XSwgWzM4Ljk5NDc4LCAtNzcuMDA3ODAxNjY2NjY2N10sIFszOC45OTQ3OCwgLTc3LjAwNzgwMTY2NjY2NjddLCBbMzkuMjIwMzEzMzMzMzMzMywgLTc3LjA2MDE2NjY2NjY2NjddLCBbMzkuMDc4NzMzMzMzMzMzMywgLTc3LjAwMTUyMzMzMzMzMzNdLCBbMzkuMDgxNjM4MzMzMzMzMywgLTc3LjAwMTEwMTY2NjY2NjddLCBbMzkuMTA1NzI4MzMzMzMzMywgLTc3LjA4NTIwMzMzMzMzMzNdLCBbMzkuMTA1NjQzMzMzMzMzMywgLTc3LjA4NTM4XSwgWzM5LjEwNzQ0LCAtNzcuMDgyNjNdLCBbMzkuMTA1MzcsIC03Ny4wODU2NzY2NjY2NjY3XSwgWzM5LjEwNTk1MTY2NjY2NjcsIC03Ny4wODUwMDE2NjY2NjY3XSwgWzM5LjEwNTA2MTY2NjY2NjcsIC03Ny4wODU4OF0sIFszOS4xMDQ0MDUsIC03Ny4wODY5NjY2NjY2NjY3XSwgWzM5LjI3ODE5NSwgLTc3LjMyMjY5NjY2NjY2NjddLCBbMzkuMjc4MTk1LCAtNzcuMzIyNjk2NjY2NjY2N10sIFszOS4yNzgxOTUsIC03Ny4zMjI2OTY2NjY2NjY3XSwgWzM5LjA4OTA2NjY2NjY2NjcsIC03Ny4yMTM5NV0sIFszOS4yMjg0ODMzMzMzMzMzLCAtNzcuMjgyNjFdLCBbMzkuMjA1ODA1LCAtNzcuMjQzMTkzMzMzMzMzM10sIFszOS4wMDk5NDY2NjY2NjY3LCAtNzcuMDk3MzMzMzMzMzMzM10sIFszOS4wMDk5NDY2NjY2NjY3LCAtNzcuMDk3MzMzMzMzMzMzM10sIFszOS4wMzAzMDgzMzMzMzMzLCAtNzcuMTA1MDldLCBbMzkuMDIwMjksIC03Ny4wNzcxNjgzMzMzMzMzXSwgWzM5LjAyMDI5LCAtNzcuMDc3MTY4MzMzMzMzM10sIFszOS4wNDc0MjE2NjY2NjY3LCAtNzcuMDc1ODkzMzMzMzMzM10sIFswLjAsIDAuMF0sIFszOS4wNDExMjMzMzMzMzMzLCAtNzcuMTU5MjgzMzMzMzMzM10sIFszOS4wMDc0OTE2NjY2NjY3LCAtNzcuMTEyNTkzMzMzMzMzM10sIFszOC45OTAxNjE2NjY2NjY3LCAtNzcuMDAxNTQ4MzMzMzMzM10sIFszOS4xMTM4MjUsIC03Ny4xOTM2NV0sIFszOS4xMTM4MjUsIC03Ny4xOTM2NV0sIFszOS4xNzE5OCwgLTc3LjI3NzAzODMzMzMzMzNdLCBbMzkuMDAzNTA2NjY2NjY2NywgLTc3LjAzNTYwMTY2NjY2NjddLCBbMzkuMDAzNTA2NjY2NjY2NywgLTc3LjAzNTYwMTY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDEzNDUsIC03Ny4wNTM5MTY2NjY2NjY3XSwgWzM5LjA0MTM0NSwgLTc3LjA1MzkxNjY2NjY2NjddLCBbMzkuMDQ3MDM4MzMzMzMzMywgLTc3LjA1MzE5XSwgWzM5LjA0NzAzODMzMzMzMzMsIC03Ny4wNTMxOV0sIFszOS4wNDcwMzgzMzMzMzMzLCAtNzcuMDUzMTldLCBbMzkuMDQ3Mjc1LCAtNzcuMDU0MDU1XSwgWzM5LjA2NjkyMTY2NjY2NjcsIC03Ny4wMTg4N10sIFszOS4wNjY5MjE2NjY2NjY3LCAtNzcuMDE4ODddLCBbMzkuMDY2OTIxNjY2NjY2NywgLTc3LjAxODg3XSwgWzM4Ljk4NzI4MzMzMzMzMzMsIC03Ny4wMjM0NjY2NjY2NjY3XSwgWzM4Ljk4Njk2MzMzMzMzMzMsIC03Ny4xMDc2MjMzMzMzMzMzXSwgWzM5LjA4Mzg2NSwgLTc3LjAwMDM0MzMzMzMzMzNdLCBbMzkuMTc2MjMsIC03Ny4yNzExMTE2NjY2NjY3XSwgWzM5LjEyMzkzMTY2NjY2NjcsIC03Ny4xNzk0MDY2NjY2NjY3XSwgWzM5LjEyMzkzMTY2NjY2NjcsIC03Ny4xNzk0MDY2NjY2NjY3XSwgWzM5LjAwNjY1MzMzMzMzMzMsIC03Ny4xOTEzN10sIFszOS4wMzk5MDgzMzMzMzMzLCAtNzcuMTIyMjhdLCBbMzkuMTE0MTk4MzMzMzMzMywgLTc3LjE2Mzg2ODMzMzMzMzNdLCBbMzkuMDI0Nzk4MzMzMzMzMywgLTc3LjA3NjQwNjY2NjY2NjddLCBbMzkuMDUzMTU4MzMzMzMzMywgLTc3LjExMjk1NjY2NjY2NjddLCBbMzkuMDUzMTU4MzMzMzMzMywgLTc3LjExMjk1NjY2NjY2NjddLCBbMzkuMDU0NDgzMzMzMzMzMywgLTc3LjExNzUxNV0sIFszOC45OTIxMjE2NjY2NjY3LCAtNzcuMDMzNzUzMzMzMzMzM10sIFszOC45ODgwMjY2NjY2NjY3LCAtNzcuMDI3XSwgWzM4Ljk4OTgxNjY2NjY2NjcsIC03Ny4wMjY0MjVdLCBbMzkuMDM4NDI1LCAtNzcuMDU4NTYzMzMzMzMzM10sIFszOS4wMzUwNjMzMzMzMzMzLCAtNzcuMTczOTgxNjY2NjY2N10sIFszOS4wMzUwNjMzMzMzMzMzLCAtNzcuMTczOTgxNjY2NjY2N10sIFszOS4wOTc3NzMzMzMzMzMzLCAtNzcuMjA3ODE1XSwgWzM5LjA5Nzc3MzMzMzMzMzMsIC03Ny4yMDc4MTVdLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDgyNjE1LCAtNzYuOTQ3MTAzMzMzMzMzM10sIFszOS4wODI2MTUsIC03Ni45NDcxMDMzMzMzMzMzXSwgWzM5LjA4MjYxNSwgLTc2Ljk0NzEwMzMzMzMzMzNdLCBbMzkuMDc3MzA1LCAtNzYuOTQyNzM4MzMzMzMzM10sIFszOS4wNzczMDUsIC03Ni45NDI3MzgzMzMzMzMzXSwgWzM5LjA4MzM5ODMzMzMzMzMsIC03Ni45MzkyMDVdLCBbMzkuMDgzMzk4MzMzMzMzMywgLTc2LjkzOTIwNV0sIFszOS4xMzkxNzE2NjY2NjY3LCAtNzcuMTkzNzI1XSwgWzM5LjEzOTE3MTY2NjY2NjcsIC03Ny4xOTM3MjVdLCBbMzkuMTkwNDAzMzMzMzMzMywgLTc3LjI2NzEyMTY2NjY2NjddLCBbMzkuMTkwNDAzMzMzMzMzMywgLTc3LjI2NzEyMTY2NjY2NjddLCBbMzkuMTY0MzgxNjY2NjY2NywgLTc3LjQ3Njk3NV0sIFszOS4xNjQzODE2NjY2NjY3LCAtNzcuNDc2OTc1XSwgWzM5LjE2NDM4MTY2NjY2NjcsIC03Ny40NzY5NzVdLCBbMzguOTg2NTgzMzMzMzMzMywgLTc3LjEwNzE3ODMzMzMzMzNdLCBbMzguOTg2Njc1LCAtNzcuMTA3Mjg2NjY2NjY2N10sIFszOC45ODY2NTY2NjY2NjY3LCAtNzcuMTA3MzFdLCBbMzguOTg2NjU2NjY2NjY2NywgLTc3LjEwNzMxXSwgWzM4Ljk4Njk2MzMzMzMzMzMsIC03Ny4xMDc2MjMzMzMzMzMzXSwgWzM4Ljk4NjYxNjY2NjY2NjcsIC03Ny4xMDcyMl0sIFszOC45ODY3MjUsIC03Ny4xMDczNDY2NjY2NjY3XSwgWzM5LjAxMTY1MTY2NjY2NjcsIC03Ny4xOTkwODMzMzMzMzMzXSwgWzM5LjA1NDA2NjY2NjY2NjcsIC03Ny4xMzk2ODVdLCBbMzkuMTU0OTI2NjY2NjY2NywgLTc3LjIxNDQ3MzMzMzMzMzNdLCBbMzkuMTU0OTI2NjY2NjY2NywgLTc3LjIxNDQ3MzMzMzMzMzNdLCBbMzkuMTc2NDMzMzMzMzMzMywgLTc3LjM1ODk0XSwgWzM5LjE3NjQzMzMzMzMzMzMsIC03Ny4zNTg5NF0sIFszOS4xMTg3MDMzMzMzMzMzLCAtNzcuMDc3NDA2NjY2NjY2N10sIFszOS4wMTMyMDUsIC03Ny4xMDY4MjVdLCBbMzkuMDEzMTYxNjY2NjY2NywgLTc3LjEwNjg3XSwgWzM5LjA3OTkwNSwgLTc3LjAwMTQwMzMzMzMzMzNdLCBbMzkuMTQ4MTgxNjY2NjY2NywgLTc3LjI3ODY3ODMzMzMzMzNdLCBbMzkuMTQ3NjI4MzMzMzMzMywgLTc3LjI3NTk4MTY2NjY2NjddLCBbMzkuMTcwNDg1LCAtNzcuMjc4Mzk1XSwgWzM5LjE3MjkzNSwgLTc3LjI2NDUxNjY2NjY2NjddLCBbMzkuMTcxODA2NjY2NjY2NywgLTc3LjI2MzQ5MzMzMzMzMzNdLCBbMzkuMDk2NjksIC03Ni45Mzc1NTE2NjY2NjY3XSwgWzM5LjA3NTU5LCAtNzYuOTk0NTI4MzMzMzMzM10sIFszOS4xNTc2MjE2NjY2NjY3LCAtNzcuMDQ4OTA4MzMzMzMzM10sIFszOS4wMTIwMjE2NjY2NjY3LCAtNzcuMTk5NzA4MzMzMzMzM10sIFszOS4wMTM0MzY2NjY2NjY3LCAtNzcuMjAzMTIzMzMzMzMzM10sIFszOS4wNzQ5MjE2NjY2NjY3LCAtNzcuMDkzOTJdLCBbMzkuMTg2Nzc1LCAtNzcuNDA1MzUzMzMzMzMzM10sIFszOS4xODY3NzUsIC03Ny40MDUzNTMzMzMzMzMzXSwgWzM5LjA5NjEwNjY2NjY2NjcsIC03Ny4xNzcxMzMzMzMzMzMzXSwgWzM5LjA5MTU5ODMzMzMzMzMsIC03Ny4xNzUyODE2NjY2NjY3XSwgWzM5LjA2NDQxNjY2NjY2NjcsIC03Ny4xNTYyNTY2NjY2NjY3XSwgWzM5LjA0NTUzNSwgLTc3LjE0OTIyMTY2NjY2NjddLCBbMzkuMDU2MzMsIC03Ny4xMTcyMTgzMzMzMzMzXSwgWzM5LjAzNDcwMTY2NjY2NjcsIC03Ny4wNzA4MTMzMzMzMzMzXSwgWzM5LjAzNDU5NjY2NjY2NjcsIC03Ny4wNzE2MTgzMzMzMzMzXSwgWzM5LjA4MzM5ODMzMzMzMzMsIC03Ni45MzkyMDVdLCBbMzkuMDY5MzY1LCAtNzcuMTA0OTE4MzMzMzMzM10sIFszOS4wNjkzNjUsIC03Ny4xMDQ5MTgzMzMzMzMzXSwgWzM5LjA2OTM2NSwgLTc3LjEwNDkxODMzMzMzMzNdLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTIyODM1LCAtNzcuMTc4MTI4MzMzMzMzM10sIFszOS4xMzkxNzE2NjY2NjY3LCAtNzcuMTkzNzI1XSwgWzM5LjAxMjE2NSwgLTc3LjE5OTg2ODMzMzMzMzNdLCBbMzkuMDA2NjUzMzMzMzMzMywgLTc3LjE5MTM3XSwgWzM5LjAxNDc3LCAtNzcuMjA0NDI1XSwgWzM5LjExODMxMTY2NjY2NjcsIC03Ny4zMTY1Ml0sIFszOS4wMTQ5NTMzMzMzMzMzLCAtNzcuMDAwNDMzMzMzMzMzM10sIFszOS4wMTQ5NTMzMzMzMzMzLCAtNzcuMDAwNDMzMzMzMzMzM10sIFszOS4wNTM3NjY2NjY2NjY3LCAtNzcuMDUwNzk4MzMzMzMzM10sIFszOC45ODgwMjY2NjY2NjY3LCAtNzcuMDI3XSwgWzM4Ljk4ODAyNjY2NjY2NjcsIC03Ny4wMjddLCBbMzguOTg5ODE2NjY2NjY2NywgLTc3LjAyNjQyNV0sIFszOS4wMDQ3MTUsIC03Ny4wNzc3NjY2NjY2NjY3XSwgWzM5LjAzMDI3LCAtNzcuMDg0ODU1XSwgWzM5LjAzMDI3LCAtNzcuMDg0ODU1XSwgWzM5LjE0NDk1NjY2NjY2NjcsIC03Ny4yMTg5OTgzMzMzMzMzXSwgWzM5LjE0NDk1NjY2NjY2NjcsIC03Ny4yMTg5OTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTgxODMzMzMzMzMsIC03Ny4wNzM3NzMzMzMzMzMzXSwgWzM5LjAyOTgxODMzMzMzMzMsIC03Ny4wNzM3NzMzMzMzMzMzXSwgWzM5LjAyOTgxODMzMzMzMzMsIC03Ny4wNzM3NzMzMzMzMzMzXSwgWzM5LjAyOTczNSwgLTc3LjA3NDY5MzMzMzMzMzNdLCBbMzkuMDI5NzM1LCAtNzcuMDc0NjkzMzMzMzMzM10sIFszOS4wMjk3MzUsIC03Ny4wNzQ2OTMzMzMzMzMzXSwgWzM5LjAyOTI3LCAtNzcuMDY4ODA4MzMzMzMzM10sIFszOS4wMjkyNywgLTc3LjA2ODgwODMzMzMzMzNdLCBbMzkuMDI5NDI2NjY2NjY2NywgLTc3LjA3NDg4MTY2NjY2NjddLCBbMzkuMDI5NDI2NjY2NjY2NywgLTc3LjA3NDg4MTY2NjY2NjddLCBbMzkuMDI5NDI2NjY2NjY2NywgLTc3LjA3NDg4MTY2NjY2NjddLCBbMzkuMTI3MDczMzMzMzMzMywgLTc3LjExODQyXSwgWzM5LjE4MDUzMTY2NjY2NjcsIC03Ny4yNjIzMl0sIFszOS4wMzgxNTMzMzMzMzMzLCAtNzYuOTk4OTU4MzMzMzMzM10sIFszOS4wMzgxNTMzMzMzMzMzLCAtNzYuOTk4OTU4MzMzMzMzM10sIFszOS4wMzgxNTMzMzMzMzMzLCAtNzYuOTk4OTU4MzMzMzMzM10sIFszOC45ODUxMjE2NjY2NjY3LCAtNzcuMDk0MDMzMzMzMzMzM10sIFszOS4wMDc4MiwgLTc2Ljk4NDM4XSwgWzM5LjE1ODA0LCAtNzcuMjI4MDQ2NjY2NjY2N10sIFszOS4wMDc5NzgzMzMzMzMzLCAtNzYuOTg0NDAxNjY2NjY2N10sIFszOS4wMDg2MTUsIC03Ni45ODQxOTY2NjY2NjY3XSwgWzM5LjAwODYxNSwgLTc2Ljk4NDE5NjY2NjY2NjddLCBbMzkuMDA4NzgsIC03Ni45ODQxODY2NjY2NjY3XSwgWzM5LjAwODc3MzMzMzMzMzMsIC03Ni45ODQyNDY2NjY2NjY3XSwgWzM5LjAwOTI5NjY2NjY2NjcsIC03Ni45ODQwMjE2NjY2NjY3XSwgWzM5LjAwOTE2MTY2NjY2NjcsIC03Ni45ODM5ODgzMzMzMzMzXSwgWzM5LjAwODk4NSwgLTc2Ljk4NDE4XSwgWzM5LjAwODM2MzMzMzMzMzMsIC03Ni45ODQyNzY2NjY2NjY3XSwgWzM5LjAwODEwMzMzMzMzMzMsIC03Ni45ODQzODE2NjY2NjY3XSwgWzM5LjAwNzk3NjY2NjY2NjcsIC03Ni45ODQ0MDMzMzMzMzMzXSwgWzM5LjAwNzk3NjY2NjY2NjcsIC03Ni45ODQ0MDMzMzMzMzMzXSwgWzM5LjAwNzgyLCAtNzYuOTg0MzhdLCBbMzguOTk5MDQ1LCAtNzYuOTk3ODZdLCBbMzguOTk5MDQ1LCAtNzYuOTk3ODZdLCBbMzguOTk5MDQ1LCAtNzYuOTk3ODZdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMTU4MDQsIC03Ny4yMjgwNDY2NjY2NjY3XSwgWzM5LjE3OTU1NjY2NjY2NjcsIC03Ny4yNjQ4ODVdLCBbMzkuMDMzMzI4MzMzMzMzMywgLTc3LjA0ODk3MzMzMzMzMzNdLCBbMzkuMDAxMzE2NjY2NjY2NywgLTc2Ljk5NTcwMTY2NjY2NjddLCBbMzkuMTE5NDYxNjY2NjY2NywgLTc3LjAxODg4XSwgWzM4Ljk4NjQzLCAtNzcuMDk0NzEzMzMzMzMzM10sIFszOS4wMjY4ODY2NjY2NjY3LCAtNzcuMDc3MDg1XSwgWzM4Ljk4MjAyNSwgLTc3LjA5OTg4MzMzMzMzMzNdLCBbMzguOTgyMDI1LCAtNzcuMDk5ODgzMzMzMzMzM10sIFszOS4wNDY3NjE2NjY2NjY3LCAtNzcuMTEyNV0sIFszOS4yNjYzNywgLTc3LjIwMTE5XSwgWzM5LjI2NjM3LCAtNzcuMjAxMTldLCBbMzkuMTcwODE1LCAtNzcuMjc4MDk2NjY2NjY2N10sIFszOS4xNzE2OTgzMzMzMzMzLCAtNzcuMjc3MzRdLCBbMzkuMTc5NTU2NjY2NjY2NywgLTc3LjI2NDg4NV0sIFszOS4wMDI3MiwgLTc3LjAwNjM3NV0sIFszOS4wMDYzNzY2NjY2NjY3LCAtNzcuMDA3MzQ2NjY2NjY2N10sIFszOS4wMDAxOSwgLTc3LjAxMjEzXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjAyNjcxODMzMzMzMzMsIC03Ny4wNDY4NjE2NjY2NjY3XSwgWzM5LjAzMzMyODMzMzMzMzMsIC03Ny4wNDg5NzMzMzMzMzMzXSwgWzM5LjE5MDU5MTY2NjY2NjcsIC03Ny4yNzMyMTMzMzMzMzMzXSwgWzM5LjE5MDU5MTY2NjY2NjcsIC03Ny4yNzMyMTMzMzMzMzMzXSwgWzM5LjE4MjgxLCAtNzcuMjc0MjNdLCBbMzkuMTgyODEsIC03Ny4yNzQyM10sIFszOS4xODI4MSwgLTc3LjI3NDIzXSwgWzM5LjAwMDczODMzMzMzMzMsIC03Ny4wMTA5N10sIFszOS4wMDQ1MywgLTc3LjAxNDgyNV0sIFszOS4wMDUwNSwgLTc3LjAyMjEzODMzMzMzMzNdLCBbMzkuMTgyMzcsIC03Ny4yNjQyNV0sIFszOS4xODIzNywgLTc3LjI2NDI1XSwgWzM5LjE4MjM3LCAtNzcuMjY0MjVdLCBbMzkuMTgyMzcsIC03Ny4yNjQyNV0sIFszOS4xODIzNywgLTc3LjI2NDI1XSwgWzM5LjE4MjM3LCAtNzcuMjY0MjVdLCBbMzkuMTgyMzcsIC03Ny4yNjQyNV0sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzguOTg0MjgxNjY2NjY2NywgLTc3LjA5NDEwNjY2NjY2NjddLCBbMzguOTgxOTM2NjY2NjY2NywgLTc3LjA5OTc1MzMzMzMzMzNdLCBbMzkuMDI2NTY2NjY2NjY2NywgLTc3LjAyMDIyNV0sIFszOS4wMjY1NjY2NjY2NjY3LCAtNzcuMDIwMjI1XSwgWzM5LjAyNjU2NjY2NjY2NjcsIC03Ny4wMjAyMjVdLCBbMzkuMDAxMzE2NjY2NjY2NywgLTc2Ljk5NTcwMTY2NjY2NjddLCBbMzkuMDI0Mzk4MzMzMzMzMywgLTc3LjAxODA3NV0sIFszOS4wMTgwMzMzMzMzMzMzLCAtNzcuMDA3MzY4MzMzMzMzM10sIFszOS4wMDIyMzMzMzMzMzMzLCAtNzcuMDA0ODY1XSwgWzM5LjAwMjUyODMzMzMzMzMsIC03Ny4wMDUxMDgzMzMzMzMzXSwgWzM5LjAwMTg0LCAtNzcuMDA0Nzc4MzMzMzMzM10sIFszOC45OTQzNjE2NjY2NjY3LCAtNzYuOTkyNzQxNjY2NjY2N10sIFszOS4wMzIwNDY2NjY2NjY3LCAtNzcuMDcyNDc1XSwgWzM5LjAzMjAxLCAtNzcuMDcyNDkzMzMzMzMzM10sIFszOS4wMzE5MjY2NjY2NjY3LCAtNzcuMDcyNDQ4MzMzMzMzM10sIFszOS4wMzE4NiwgLTc3LjA3MjI3NV0sIFszOS4wMzE5ODY2NjY2NjY3LCAtNzcuMDcyNDI2NjY2NjY2N10sIFszOS4xMzA3MTMzMzMzMzMzLCAtNzcuMTg3ODk2NjY2NjY2N10sIFszOS4xMzA3MTMzMzMzMzMzLCAtNzcuMTg3ODk2NjY2NjY2N10sIFszOS4xMzI4MTgzMzMzMzMzLCAtNzcuMTg5NTNdLCBbMzkuMTMyODE4MzMzMzMzMywgLTc3LjE4OTUzXSwgWzM5LjEzMDczLCAtNzcuMTg3OTddLCBbMzkuMTMwNzMsIC03Ny4xODc5N10sIFszOS4xMzA3MywgLTc3LjE4Nzk3XSwgWzM5LjEzMzg0ODMzMzMzMzMsIC03Ny4yNDQ3NjVdLCBbMzkuMTM2MTY4MzMzMzMzMywgLTc3LjI0Mjk5NV0sIFszOS4xMzIyNjgzMzMzMzMzLCAtNzcuMTY0ODkzMzMzMzMzM10sIFszOS4xMzIyNjgzMzMzMzMzLCAtNzcuMTY0ODkzMzMzMzMzM10sIFszOS4xODk3ODMzMzMzMzMzLCAtNzcuMjQ5NzAzMzMzMzMzM10sIFszOS4wMTIzODUsIC03Ny4wODA1OTVdLCBbMzkuMTI0NjcxNjY2NjY2NywgLTc3LjIwMDQ1MzMzMzMzMzNdLCBbMzkuMTAyMTg1LCAtNzcuMTc3OTUzMzMzMzMzM10sIFszOS4xMDIxODUsIC03Ny4xNzc5NTMzMzMzMzMzXSwgWzM5LjEwMjE4NSwgLTc3LjE3Nzk1MzMzMzMzMzNdLCBbMzguOTg1NzUxNjY2NjY2NywgLTc3LjA3NzAzNV0sIFszOC45ODU3NTE2NjY2NjY3LCAtNzcuMDc3MDM1XSwgWzM4Ljk4NjY3NSwgLTc3LjA3NDc4MTY2NjY2NjddLCBbMzguOTg2Njc1LCAtNzcuMDc0NzgxNjY2NjY2N10sIFszOC45ODY2NzUsIC03Ny4wNzQ3ODE2NjY2NjY3XSwgWzM4Ljk4NTc3ODMzMzMzMzMsIC03Ny4wNzY3MzE2NjY2NjY3XSwgWzM4Ljk4NTc3ODMzMzMzMzMsIC03Ny4wNzY3MzE2NjY2NjY3XSwgWzM5LjEzNDc4MzMzMzMzMzMsIC03Ny40MDA1NzY2NjY2NjY3XSwgWzM5LjEzNzc1MzMzMzMzMzMsIC03Ny4zOTc5NzMzMzMzMzMzXSwgWzM5LjE1NjY3NjY2NjY2NjcsIC03Ny40NDczNDVdLCBbMzkuMTcxNTI4MzMzMzMzMywgLTc3LjQ2NjM2NV0sIFszOS4xNzEzNzY2NjY2NjY3LCAtNzcuNDY1NTAxNjY2NjY2N10sIFszOS4xNzEzNzY2NjY2NjY3LCAtNzcuNDY1NTAxNjY2NjY2N10sIFszOS4xMjM5NzE2NjY2NjY3LCAtNzcuMTc1NTY1XSwgWzM5LjEyNDAxNSwgLTc3LjE3NTg0NjY2NjY2NjddLCBbMzkuMTI0MDE1LCAtNzcuMTc1ODQ2NjY2NjY2N10sIFszOS4xMjQwMTUsIC03Ny4xNzU4NDY2NjY2NjY3XSwgWzM5LjE5NDcyODMzMzMzMzMsIC03Ny4xNTQxNF0sIFszOS4xOTQ4MjY2NjY2NjY3LCAtNzcuMTU0MTI2NjY2NjY2N10sIFszOS4xOTQ3OTE2NjY2NjY3LCAtNzcuMTU0MDkzMzMzMzMzM10sIFszOS4xOTQ3OTE2NjY2NjY3LCAtNzcuMTU0MDkzMzMzMzMzM10sIFszOS4xNjM3NDUsIC03Ny4yMTQ2OTMzMzMzMzMzXSwgWzM5LjE2Mzc0NSwgLTc3LjIxNDY5MzMzMzMzMzNdLCBbMzkuMTYzNzQ1LCAtNzcuMjE0NjkzMzMzMzMzM10sIFszOS4xNjM3NDUsIC03Ny4yMTQ2OTMzMzMzMzMzXSwgWzM5LjExMjgxNjY2NjY2NjcsIC03Ny4xNjIxNjVdLCBbMzkuMTU5NTE4MzMzMzMzMywgLTc3LjI3Njg0NjY2NjY2NjddLCBbMzkuMTU5NTE4MzMzMzMzMywgLTc3LjI3Njg0NjY2NjY2NjddLCBbMzkuMTIwNzgsIC03Ny4wMTU3NjE2NjY2NjY3XSwgWzM5LjE5ODA0NSwgLTc3LjI2MzA2MzMzMzMzMzNdLCBbMzkuMTc4NDk4MzMzMzMzMywgLTc3LjI0MDc1XSwgWzM5LjE4MDQ1LCAtNzcuMjYyNDAzMzMzMzMzM10sIFszOS4xODA0NSwgLTc3LjI2MjQwMzMzMzMzMzNdLCBbMzkuMDIyNjQ4MzMzMzMzMywgLTc3LjA3MTc2NjY2NjY2NjddLCBbMzkuMDMyOTgxNjY2NjY2NywgLTc3LjA3MjczNjY2NjY2NjddLCBbMzkuMDMzMDIsIC03Ny4wNzI1MzMzMzMzMzMzXSwgWzM5LjE1MzUzLCAtNzcuMjEyNzIxNjY2NjY2N10sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjEzNDYyMTY2NjY2NjcsIC03Ny40MDEzNTVdLCBbMzkuMTM0NjIxNjY2NjY2NywgLTc3LjQwMTM1NV0sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjA4NDYyLCAtNzcuMDc5OTQ2NjY2NjY2N10sIFszOC45OTE5NzUsIC03Ny4wOTU3MzgzMzMzMzMzXSwgWzM4Ljk4NjY3MTY2NjY2NjcsIC03Ny4wOTQ3MzVdLCBbMzguOTg2NDMsIC03Ny4wOTQ3MTMzMzMzMzMzXSwgWzM4Ljk4NjQzLCAtNzcuMDk0NzEzMzMzMzMzM10sIFszOC45OTA4OSwgLTc3LjA5NTUxNV0sIFszOS4wMTAwMTE2NjY2NjY3LCAtNzcuMDkxNzU2NjY2NjY2N10sIFszOS4wMTIzODUsIC03Ny4wODA1OTVdLCBbMC4wLCAwLjBdLCBbMzkuMTM2MTgxNjY2NjY2NywgLTc3LjE1MjAzXSwgWzM5LjE4MzI0ODMzMzMzMzMsIC03Ny4yNzAzNTVdLCBbMzkuMDk4NTg4MzMzMzMzMywgLTc2LjkzNjQ3NV0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFszOS4xMTQ3NjMzMzMzMzMzLCAtNzcuMTk3MzkzMzMzMzMzM10sIFszOS4xMTQzMjY2NjY2NjY3LCAtNzcuMTk1NDMzMzMzMzMzM10sIFszOS4xNTM1MywgLTc3LjIxMjcyMTY2NjY2NjddLCBbMzkuMTM0NzczMzMzMzMzMywgLTc3LjQwMDYzMzMzMzMzMzNdLCBbMzkuMTM0NzczMzMzMzMzMywgLTc3LjQwMDYzMzMzMzMzMzNdLCBbMzkuMTM0NzczMzMzMzMzMywgLTc3LjQwMDYzMzMzMzMzMzNdLCBbMzkuMTM0Nzc2NjY2NjY2NywgLTc3LjQwMDU4NV0sIFszOS4xNTY2NzY2NjY2NjY3LCAtNzcuNDQ3MzQ1XSwgWzM5LjE3MTUyMzMzMzMzMzMsIC03Ny40NjYyMl0sIFszOS4xNzE1MTY2NjY2NjY3LCAtNzcuNDY2NzUxNjY2NjY2N10sIFszOS4xNzE1MjgzMzMzMzMzLCAtNzcuNDY2MzY1XSwgWzM5LjA0MzI1MTY2NjY2NjcsIC03Ni45ODMyNzVdLCBbMzkuMDQzMjUxNjY2NjY2NywgLTc2Ljk4MzI3NV0sIFszOS4wNDMyNTE2NjY2NjY3LCAtNzYuOTgzMjc1XSwgWzM5LjA0MzI1MTY2NjY2NjcsIC03Ni45ODMyNzVdLCBbMzkuMDQzMjUxNjY2NjY2NywgLTc2Ljk4MzI3NV0sIFszOS4xMTUyMTgzMzMzMzMzLCAtNzcuMDE2Nl0sIFszOS4xMTUyMTgzMzMzMzMzLCAtNzcuMDE2Nl0sIFszOS4xMTk0NjE2NjY2NjY3LCAtNzcuMDE4ODhdLCBbMzkuMTE5NDYxNjY2NjY2NywgLTc3LjAxODg4XSwgWzM5LjE5ODA0NSwgLTc3LjI2MzA2MzMzMzMzMzNdLCBbMzkuMDg2NzIzMzMzMzMzMywgLTc3LjE2NzQzMTY2NjY2NjddLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzguOTg1MDM1LCAtNzcuMDk0NDMzMzMzMzMzM10sIFszOC45ODQyODE2NjY2NjY3LCAtNzcuMDk0MTA2NjY2NjY2N10sIFszOC45ODE5MzY2NjY2NjY3LCAtNzcuMDk5NzUzMzMzMzMzM10sIFszOC45ODE5MzY2NjY2NjY3LCAtNzcuMDk5NzUzMzMzMzMzM10sIFszOC45ODIwOTE2NjY2NjY3LCAtNzcuMDk5MjYxNjY2NjY2N10sIFszOC45ODE5MzMzMzMzMzMzLCAtNzcuMTAwMTFdLCBbMzkuMDI5ODg4MzMzMzMzMywgLTc3LjA0ODc4NjY2NjY2NjddLCBbMzkuMDI5ODg4MzMzMzMzMywgLTc3LjA0ODc4NjY2NjY2NjddLCBbMzkuMTM0NjIxNjY2NjY2NywgLTc3LjQwMTM1NV0sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjEzNDYyMTY2NjY2NjcsIC03Ny40MDEzNTVdLCBbMzkuMTM0NjIxNjY2NjY2NywgLTc3LjQwMTM1NV0sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjA0MzI5NjY2NjY2NjcsIC03Ny4wNTIwNzY2NjY2NjY3XSwgWzM5LjA0MzI5NjY2NjY2NjcsIC03Ny4wNTIwNzY2NjY2NjY3XSwgWzM4Ljk5NDg1ODMzMzMzMzMsIC03Ny4wMjU3MTY2NjY2NjY3XSwgWzM5LjEzMTg0NSwgLTc3LjIwNjg0NjY2NjY2NjddLCBbMzkuMDk4NTc1LCAtNzcuMTM3NzM4MzMzMzMzM10sIFszOS4wMzEwOTgzMzMzMzMzLCAtNzcuMDc1NzI1XSwgWzM5LjAzMTI0LCAtNzcuMDc1MDI4MzMzMzMzM10sIFszOS4wMjY4ODY2NjY2NjY3LCAtNzcuMDc3MDg1XSwgWzM4Ljk4MjAyNSwgLTc3LjA5OTg4MzMzMzMzMzNdLCBbMzkuMDMyMDA1LCAtNzcuMDcyNDQxNjY2NjY2N10sIFszOS4wMzE5MjY2NjY2NjY3LCAtNzcuMDcyNDQ4MzMzMzMzM10sIFszOS4wMzE5NzY2NjY2NjY3LCAtNzcuMDcyNDM2NjY2NjY2N10sIFszOS4wMzE5NzY2NjY2NjY3LCAtNzcuMDcyNDM2NjY2NjY2N10sIFszOS4wMzE1OTUsIC03Ny4wNzE5OTE2NjY2NjY3XSwgWzM5LjAzMTk3MTY2NjY2NjcsIC03Ny4wNzIzMzMzMzMzMzMzXSwgWzM5LjAzMjA0NjY2NjY2NjcsIC03Ny4wNzI0OTgzMzMzMzMzXSwgWzM5LjAzMTk4NjY2NjY2NjcsIC03Ny4wNzI0MjY2NjY2NjY3XSwgWzM5LjA0ODc5MzMzMzMzMzMsIC03Ny4xMTk4NDY2NjY2NjY3XSwgWzM5LjA4NDY4LCAtNzcuMDgwMDIzMzMzMzMzM10sIFszOS4wODQ2NDY2NjY2NjY3LCAtNzcuMDgwMDAzMzMzMzMzM10sIFszOS4wODQ1NzgzMzMzMzMzLCAtNzcuMDc5OTA1XSwgWzM5LjA4NDY3NSwgLTc3LjA4MDAwMTY2NjY2NjddLCBbMzkuMDg0NjIsIC03Ny4wNzk5NDY2NjY2NjY3XSwgWzM5LjExOTYxLCAtNzcuMDk2OTg1XSwgWzM4Ljk5NDM2MTY2NjY2NjcsIC03Ni45OTI3NDE2NjY2NjY3XSwgWzM5LjEzNjE3ODMzMzMzMzMsIC03Ny4yNDMwOV0sIFszOC45OTY5MTMzMzMzMzMzLCAtNzYuOTkzNjRdLCBbMzguOTk2OTEzMzMzMzMzMywgLTc2Ljk5MzY0XSwgWzM5LjA0MDg4ODMzMzMzMzMsIC03Ny4wNTIxNDVdLCBbMzkuMDQwODg4MzMzMzMzMywgLTc3LjA1MjE0NV0sIFszOS4wNDA4ODgzMzMzMzMzLCAtNzcuMDUyMTQ1XSwgWzM5LjA0MDg4ODMzMzMzMzMsIC03Ny4wNTIxNDVdLCBbMzkuMTEyNjYsIC03Ni45MzI4MTMzMzMzMzMzXSwgWzM5LjE4OTc4MzMzMzMzMzMsIC03Ny4yNDk3MDMzMzMzMzMzXSwgWzM5LjEwNTM5MzMzMzMzMzMsIC03Ny4xOTc1ODE2NjY2NjY3XSwgWzM5LjE2NjQzNjY2NjY2NjcsIC03Ny4yODExODgzMzMzMzMzXSwgWzM5LjExOTAxNjY2NjY2NjcsIC03Ny4xODE5NzE2NjY2NjY3XSwgWzM5LjA5NzExLCAtNzcuMjI5NjEzMzMzMzMzM10sIFszOS4xMTA3NSwgLTc3LjI1MjQzMzMzMzMzMzNdLCBbMzkuMTEwNjM4MzMzMzMzMywgLTc3LjI1Mjc0NV0sIFszOS4xMTU1OTgzMzMzMzMzLCAtNzcuMjUyODg1XSwgWzM5LjExNTU5ODMzMzMzMzMsIC03Ny4yNTI4ODVdLCBbMzkuMTE1NzM2NjY2NjY2NywgLTc3LjI1MjkxMzMzMzMzMzNdLCBbMzkuMTE0NSwgLTc3LjI1MzM4MzMzMzMzMzNdLCBbMzkuMDk2NzY1LCAtNzcuMjY1NzMzMzMzMzMzM10sIFszOS4wOTY3NjUsIC03Ny4yNjU3MzMzMzMzMzMzXSwgWzM5LjA5NDQ2NjY2NjY2NjcsIC03Ny4yNjU3NDY2NjY2NjY3XSwgWzM5LjA5NDQ2NjY2NjY2NjcsIC03Ny4yNjU3NDY2NjY2NjY3XSwgWzM5LjE0NTgxMTY2NjY2NjcsIC03Ny4xOTIyNDVdLCBbMzkuMTMwMTgzMzMzMzMzMywgLTc3LjEyMzM3NjY2NjY2NjddLCBbMzkuMTMwMTgzMzMzMzMzMywgLTc3LjEyMzM3NjY2NjY2NjddLCBbMzkuMTIyMzUsIC03Ny4wNzM5NTMzMzMzMzMzXSwgWzM5LjE1ODQ3ODMzMzMzMzMsIC03Ny4wNjQ3NDgzMzMzMzMzXSwgWzM5LjA3NDc2ODMzMzMzMzMsIC03Ni45OTgyMzY2NjY2NjY3XSwgWzM5LjA3NDc2ODMzMzMzMzMsIC03Ni45OTgyMzY2NjY2NjY3XSwgWzM5LjA3NDc2ODMzMzMzMzMsIC03Ni45OTgyMzY2NjY2NjY3XSwgWzM5LjA3NTAyODMzMzMzMzMsIC03Ni45OTkwMl0sIFszOS4wNzg0NDE2NjY2NjY3LCAtNzcuMDcyMjczMzMzMzMzM10sIFszOS4wMTg5NiwgLTc3LjA1MDFdLCBbMzkuMTI0MTU2NjY2NjY2NywgLTc3LjIwMDAzMzMzMzMzMzNdLCBbMzkuMTgzMDk1LCAtNzcuMjU3NTg1XSwgWzM5LjE2OTMwMTY2NjY2NjcsIC03Ny4yNzkzMTE2NjY2NjY3XSwgWzM5LjE2OTMwMTY2NjY2NjcsIC03Ny4yNzkzMTE2NjY2NjY3XSwgWzM5LjE3MDA0MTY2NjY2NjcsIC03Ny4yNzg4NTMzMzMzMzMzXSwgWzM5LjE2ODg5ODMzMzMzMzMsIC03Ny4yNzk2MDgzMzMzMzMzXSwgWzM5LjE3MDU1LCAtNzcuMjc4Mzg1XSwgWzM5LjE3MDI2NSwgLTc3LjI3ODYwODMzMzMzMzNdLCBbMzkuMTAxODcsIC03Ny4yMTkzMTE2NjY2NjY3XSwgWzM5LjEwMTg3LCAtNzcuMjE5MzExNjY2NjY2N10sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFszOS4wNzQ2MDgzMzMzMzMzLCAtNzYuOTk4MDYxNjY2NjY2N10sIFszOS4wNzQ2MDgzMzMzMzMzLCAtNzYuOTk4MjE4MzMzMzMzM10sIFszOS4wNzQ5MSwgLTc2Ljk5ODM1NV0sIFszOS4wNDE2MywgLTc3LjE0NzUzNV0sIFszOS4wNDQ0MTY2NjY2NjY3LCAtNzcuMTExOTExNjY2NjY2N10sIFszOS4xMTcwMzMzMzMzMzMzLCAtNzcuMjUxOTAzMzMzMzMzM10sIFszOS4xMTc1NzE2NjY2NjY3LCAtNzcuMjUxMjM2NjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMTcwMTE2NjY2NjY3LCAtNzcuMjUyNzFdLCBbMzkuMTE4Mzg2NjY2NjY2NywgLTc3LjI1MTE2NV0sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4xODk5MTUsIC03Ny4yNDE5MTVdLCBbMzkuMDg3NDI2NjY2NjY2NywgLTc3LjE3Mzk1MTY2NjY2NjddLCBbMzkuMTE1Njc4MzMzMzMzMywgLTc3LjI1Mjk2MTY2NjY2NjddLCBbMzkuMTA4NiwgLTc3LjE4NTQyNjY2NjY2NjddLCBbMzkuMTEzNTYxNjY2NjY2NywgLTc3LjI0MjgyMzMzMzMzMzNdLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDMyMjYxNjY2NjY2NywgLTc3LjA3NDI3MTY2NjY2NjddLCBbMzkuMDMzNTkxNjY2NjY2NywgLTc3LjA3Mjg4NV0sIFszOS4wMzM5NCwgLTc3LjA3MjIzNjY2NjY2NjddLCBbMzkuMDMzNjk2NjY2NjY2NywgLTc3LjA3MzAzMzMzMzMzMzNdLCBbMzkuMDMzNDkzMzMzMzMzMywgLTc3LjA3MzM1NV0sIFszOS4wMzQ1OTE2NjY2NjY3LCAtNzcuMDcxMzQ1XSwgWzM5LjAzMzkyNjY2NjY2NjcsIC03Ny4wNzIyNjE2NjY2NjY3XSwgWzM5LjEwMTg3LCAtNzcuMjE5MzExNjY2NjY2N10sIFszOS4xMDE4NywgLTc3LjIxOTMxMTY2NjY2NjddLCBbMzkuMTQ1ODExNjY2NjY2NywgLTc3LjE5MjI0NV0sIFszOS4xNDU4MTE2NjY2NjY3LCAtNzcuMTkyMjQ1XSwgWzM5LjE0NTgxMTY2NjY2NjcsIC03Ny4xOTIyNDVdLCBbMzkuMTE1ODEsIC03Ny4xODU5NTgzMzMzMzMzXSwgWzM5LjExNTgxLCAtNzcuMTg1OTU4MzMzMzMzM10sIFszOS4xMTU4MSwgLTc3LjE4NTk1ODMzMzMzMzNdLCBbMzkuMTE1ODEsIC03Ny4xODU5NTgzMzMzMzMzXSwgWzM5LjEyMTMxNjY2NjY2NjcsIC03Ny4xNjE2MTVdLCBbMzkuMTAxMTE1LCAtNzcuMDQ1MjQ2NjY2NjY2N10sIFszOS4wNzQ2MDgzMzMzMzMzLCAtNzYuOTk4MDYxNjY2NjY2N10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOC45OTk5OSwgLTc3LjAyNTcwNV0sIFszOC45OTk5OSwgLTc3LjAyNTcwNV0sIFszOS4xNTc1NDgzMzMzMzMzLCAtNzcuMTg4NzJdLCBbMzkuMTU3NTg1LCAtNzcuMTg5MTIzMzMzMzMzM10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjEzOTk3LCAtNzcuMTgyNzFdLCBbMzkuMTM5OTcsIC03Ny4xODI3MV0sIFszOS4xMzk5NywgLTc3LjE4MjcxXSwgWzM5LjEzOTk3LCAtNzcuMTgyNzFdLCBbMzkuMTM5OTcsIC03Ny4xODI3MV0sIFszOS4xMzk5NywgLTc3LjE4MjcxXSwgWzM5LjEzOTk3LCAtNzcuMTgyNzFdLCBbMzkuMDMxNTE2NjY2NjY2NywgLTc3LjA0ODM3NV0sIFszOS4wNDQ0MTY2NjY2NjY3LCAtNzcuMTExOTExNjY2NjY2N10sIFszOS4wMzE1MTY2NjY2NjY3LCAtNzcuMDQ4Mzc1XSwgWzM5LjAzMTUxNjY2NjY2NjcsIC03Ny4wNDgzNzVdLCBbMzkuMDAxMTcsIC03Ni45ODU1NjVdLCBbMzkuMDAxMTcsIC03Ni45ODU1NjVdLCBbMzkuMDQxNzE1LCAtNzYuOTk0OTI2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA2NzQxMTY2NjY2NjcsIC03Ni45MzcyNV0sIFszOS4wOTA4NTE2NjY2NjY3LCAtNzcuMDc5NzQ4MzMzMzMzM10sIFszOS4wMDg0NDUsIC03Ni45OTg0NTMzMzMzMzMzXSwgWzM5LjAwODQ0NSwgLTc2Ljk5ODQ1MzMzMzMzMzNdLCBbMzguOTk5OTksIC03Ny4wMjU3MDVdLCBbMzkuMjg4NTA1LCAtNzcuMjAxOV0sIFszOS4wNTY1NTUsIC03Ny4wNTAwNDVdLCBbMzguOTg3NjA4MzMzMzMzMywgLTc3LjA5ODYwNjY2NjY2NjddLCBbMzguOTkzNDI2NjY2NjY2NywgLTc3LjAyNjg5MzMzMzMzMzNdLCBbMzguOTkzNDI2NjY2NjY2NywgLTc3LjAyNjg5MzMzMzMzMzNdLCBbMzkuMTE0NDgzMzMzMzMzMywgLTc3LjI2NjQyODMzMzMzMzNdLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4xMzY2NzE2NjY2NjY3LCAtNzcuMzk1MDg1XSwgWzM5LjE2NzYsIC03Ny4yODAzNTgzMzMzMzMzXSwgWzM4Ljk5NjcxNjY2NjY2NjcsIC03Ny4wMTMwMTE2NjY2NjY3XSwgWzM4Ljk5NjcxNjY2NjY2NjcsIC03Ny4wMTMwMTE2NjY2NjY3XSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjA0ODUxODMzMzMzMzMsIC03Ny4wNTY3ODMzMzMzMzMzXSwgWzM5LjE1MDkyODMzMzMzMzMsIC03Ny4yMDU1NzVdLCBbMzkuMTcwMTc2NjY2NjY2NywgLTc3LjI3ODcyODMzMzMzMzNdLCBbMzkuMDE1NjcxNjY2NjY2NywgLTc3LjA0MzAzODMzMzMzMzNdLCBbMzkuMDE1NjcxNjY2NjY2NywgLTc3LjA0MzAzODMzMzMzMzNdLCBbMzkuMDE1NjcxNjY2NjY2NywgLTc3LjA0MzAzODMzMzMzMzNdLCBbMzguOTkxODE4MzMzMzMzMywgLTc3LjAzMDgxMzMzMzMzMzNdLCBbMzguOTkxODE4MzMzMzMzMywgLTc3LjAzMDgxMzMzMzMzMzNdLCBbMzkuMTQ5NDM4MzMzMzMzMywgLTc3LjE4OTEyXSwgWzM5LjE0OTQzODMzMzMzMzMsIC03Ny4xODkxMl0sIFszOS4xNDk0MzgzMzMzMzMzLCAtNzcuMTg5MTJdLCBbMzkuMTcwMzQxNjY2NjY2NywgLTc3LjI3ODUzMzMzMzMzMzNdLCBbMzguOTgyMDUxNjY2NjY2NywgLTc3LjA5OTgxMzMzMzMzMzNdLCBbMzkuMjA1MDc1LCAtNzcuMjcxMzU1XSwgWzM4Ljk4MjA1MTY2NjY2NjcsIC03Ny4wOTk4MTMzMzMzMzMzXSwgWzM5LjE3MjE4ODMzMzMzMzMsIC03Ny4yMDM4NTVdLCBbMzkuMDIwODMsIC03Ny4wNzM0NTE2NjY2NjY3XSwgWzM5LjAyMDgzLCAtNzcuMDczNDUxNjY2NjY2N10sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOS4xNTAzODgzMzMzMzMzLCAtNzcuMDYwODc2NjY2NjY2N10sIFszOS4xNTAzODgzMzMzMzMzLCAtNzcuMDYwODc2NjY2NjY2N10sIFszOS4yMTc1MDgzMzMzMzMzLCAtNzcuMjc3ODA4MzMzMzMzM10sIFszOS4xNjk4ODgzMzMzMzMzLCAtNzcuMjc5MDA2NjY2NjY2N10sIFszOS4yMTc1MDgzMzMzMzMzLCAtNzcuMjc3ODA4MzMzMzMzM10sIFszOS4xNTAzNzE2NjY2NjY3LCAtNzcuMTkwODY1XSwgWzM5LjE1MDM3MTY2NjY2NjcsIC03Ny4xOTA4NjVdLCBbMzkuMTUwMzcxNjY2NjY2NywgLTc3LjE5MDg2NV0sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOS4yMjkwOTY2NjY2NjY3LCAtNzcuMjY3MzY2NjY2NjY2N10sIFszOC45OTQ3MjY2NjY2NjY3LCAtNzcuMDI0MjAzMzMzMzMzM10sIFszOS4xMTA4MzgzMzMzMzMzLCAtNzcuMTg3ODU2NjY2NjY2N10sIFszOS4xNzAyNTE2NjY2NjY3LCAtNzcuMjc4NjA2NjY2NjY2N10sIFszOS4xMDU1MTY2NjY2NjY3LCAtNzcuMTgyMzg1XSwgWzM5LjEwNTUxNjY2NjY2NjcsIC03Ny4xODIzODVdLCBbMzkuMTAxNzkxNjY2NjY2NywgLTc3LjMwNzUyNV0sIFszOS4xNjc5NDMzMzMzMzMzLCAtNzcuMjgwMjI1XSwgWzM5LjE0ODQ5LCAtNzcuMTkyMTRdLCBbMzkuMTQ4NDksIC03Ny4xOTIxNF0sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOS4wOTUzMzE2NjY2NjY3LCAtNzcuMTc2ODkxNjY2NjY2N10sIFszOS4xMDE3OTE2NjY2NjY3LCAtNzcuMzA3NTI1XSwgWzM5LjE0MzUxLCAtNzcuNDA2MjUxNjY2NjY2N10sIFszOS4wNDEzMDgzMzMzMzMzLCAtNzcuMTEzMTc4MzMzMzMzM10sIFszOS4xNTk3MDgzMzMzMzMzLCAtNzcuMjg5OTI1XSwgWzM5LjEwMTY5NjY2NjY2NjcsIC03Ny4zMDc0NTVdLCBbMzkuMTAxNjk2NjY2NjY2NywgLTc3LjMwNzQ1NV0sIFszOS4wNzcxNCwgLTc3LjE2ODM4MTY2NjY2NjddLCBbMzguOTgyMDUxNjY2NjY2NywgLTc3LjA5OTgxMzMzMzMzMzNdLCBbMzkuMTQ1ODIzMzMzMzMzMywgLTc3LjE4NDQ2MzMzMzMzMzNdLCBbMzkuMDg0NjM4MzMzMzMzMywgLTc3LjA3OTkxXSwgWzM5LjE3MDI3NSwgLTc3LjI3ODYyXSwgWzM5LjA0MTc3LCAtNzcuMTEzMjFdLCBbMzkuMDQxNzcsIC03Ny4xMTMyMV0sIFszOS4xMDE3ODY2NjY2NjY3LCAtNzcuMzA3NTI2NjY2NjY2N10sIFszOS4wNzUxNiwgLTc3LjE2MTkyMTY2NjY2NjddLCBbMzkuMDc1MTYsIC03Ny4xNjE5MjE2NjY2NjY3XSwgWzM4Ljk4MTk4NSwgLTc3LjA5OTc5MzMzMzMzMzNdLCBbMzkuMDc1MTYsIC03Ny4xNjE5MjE2NjY2NjY3XSwgWzM4Ljk4MTk4NSwgLTc3LjA5OTc5MzMzMzMzMzNdLCBbMzkuMTU5NzAxNjY2NjY2NywgLTc3LjI4OTk0XSwgWzAuMCwgMC4wXSwgWzM5LjE0NTQ0ODMzMzMzMzMsIC03Ny4xODQ0MDgzMzMzMzMzXSwgWzM5LjEwMTc4NjY2NjY2NjcsIC03Ny4zMDc1MjY2NjY2NjY3XSwgWzM5LjEwMTc4NjY2NjY2NjcsIC03Ny4zMDc1MjY2NjY2NjY3XSwgWzM5LjA3MTc3NSwgLTc3LjE2MTk0MzMzMzMzMzNdLCBbMzkuMDcxNzc1LCAtNzcuMTYxOTQzMzMzMzMzM10sIFszOS4wODQ1OCwgLTc3LjA3OTg1ODMzMzMzMzNdLCBbMzkuMDg0NTgsIC03Ny4wNzk4NTgzMzMzMzMzXSwgWzM5LjA0MTQwMzMzMzMzMzMsIC03Ny4xMTMxNl0sIFszOS4wMzY5NywgLTc3LjA1Mjk0ODMzMzMzMzNdLCBbMzkuMDQxNzE1LCAtNzYuOTk0OTI2NjY2NjY2N10sIFszOS4xMDE3MTE2NjY2NjY3LCAtNzcuMzA3NDY1XSwgWzM4Ljk5Nzc4ODMzMzMzMzMsIC03Ni45OTE2Nl0sIFszOS4wODQ2MzgzMzMzMzMzLCAtNzcuMDc5OTFdLCBbMzkuMDQxMjg1LCAtNzcuMTEzMTY1XSwgWzAuMCwgMC4wXSwgWzM5LjE1MTIyODMzMzMzMzMsIC03Ny4xODg3MjY2NjY2NjY3XSwgWzM5LjE1MTIyODMzMzMzMzMsIC03Ny4xODg3MjY2NjY2NjY3XSwgWzM5LjE1MTIyODMzMzMzMzMsIC03Ny4xODg3MjY2NjY2NjY3XSwgWzM5LjIwNjczLCAtNzcuMjQxNzM4MzMzMzMzM10sIFszOS4wNTM4ODE2NjY2NjY3LCAtNzcuMTUzNTA1XSwgWzM5LjA1Mzg4MTY2NjY2NjcsIC03Ny4xNTM1MDVdLCBbMzkuMjIwMzI2NjY2NjY2NywgLTc3LjA2MDE2NjY2NjY2NjddLCBbMzkuMDQxNDk1LCAtNzcuMDUwODQxNjY2NjY2N10sIFszOS4wNDE0OTUsIC03Ny4wNTA4NDE2NjY2NjY3XSwgWzM5LjA0MTQ5NSwgLTc3LjA1MDg0MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzkuMDQxNzE1LCAtNzYuOTk0OTI2NjY2NjY2N10sIFszOS4wNDE3MTUsIC03Ni45OTQ5MjY2NjY2NjY3XSwgWzM5LjExNTg1NSwgLTc2Ljk2MTc3MTY2NjY2NjddLCBbMzkuMTczNDE4MzMzMzMzMywgLTc3LjE4OTMyXSwgWzM5LjE3MzQxODMzMzMzMzMsIC03Ny4xODkzMl0sIFszOS4wNDE0MzUsIC03Ny4xMTMxMzgzMzMzMzMzXSwgWzM5LjIyMDMyNjY2NjY2NjcsIC03Ny4wNjAxNjY2NjY2NjY3XSwgWzM4Ljk5NzQ0NSwgLTc2Ljk5MjAxXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzM5LjAyMTQ5ODMzMzMzMzMsIC03Ny4wMTQ0NDE2NjY2NjY3XSwgWzM5LjA0NzQyMTY2NjY2NjcsIC03Ny4xNTA1MzgzMzMzMzMzXSwgWzM4Ljk5NzUwMTY2NjY2NjcsIC03Ni45ODc4OTE2NjY2NjY3XSwgWzM5LjEyMTc3LCAtNzcuMTU5NTg1XSwgWzM5LjA1MDk4NSwgLTc3LjEwOTUwODMzMzMzMzNdLCBbMzkuMDA3MDI4MzMzMzMzMywgLTc3LjAyMTE1NjY2NjY2NjddLCBbMzkuMDA3MDI4MzMzMzMzMywgLTc3LjAyMTE1NjY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMjIwMzI2NjY2NjY2NywgLTc3LjA2MDE2NjY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzkuMTUwNzM2NjY2NjY2NywgLTc3LjE5MTQxNV0sIFszOS4xNTA3MzY2NjY2NjY3LCAtNzcuMTkxNDE1XSwgWzM5LjE2ODcyMTY2NjY2NjcsIC03Ny4yNzk3MDgzMzMzMzMzXSwgWzM5LjE2ODcyMTY2NjY2NjcsIC03Ny4yNzk3MDgzMzMzMzMzXSwgWzM5LjExNTc3MTY2NjY2NjcsIC03Ni45NjE1ODY2NjY2NjY3XSwgWzM5LjEwMTY2ODMzMzMzMzMsIC03Ny4zMDc0NTVdLCBbMzkuMTAxNjY4MzMzMzMzMywgLTc3LjMwNzQ1NV0sIFszOS4wMzc4MzE2NjY2NjY3LCAtNzcuMDUzNDExNjY2NjY2N10sIFszOS4wMzc4MzE2NjY2NjY3LCAtNzcuMDUzNDExNjY2NjY2N10sIFszOS4xMDk5MDUsIC03Ny4xNTM5NV0sIFszOC45OTY3NTMzMzMzMzMzLCAtNzYuOTkxNTA1XSwgWzM5LjAzMTAxLCAtNzcuMDA0OTgxNjY2NjY2N10sIFszOS4wMzEwMSwgLTc3LjAwNDk4MTY2NjY2NjddLCBbMzkuMDM1NjcxNjY2NjY2NywgLTc3LjEyNDIzNV0sIFszOS4wMzU2NzE2NjY2NjY3LCAtNzcuMTI0MjM1XSwgWzM5LjIyMDMyNjY2NjY2NjcsIC03Ny4wNjAxNjY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4yNjYxLCAtNzcuMjAxMDY1XSwgWzM4Ljk5MDYyLCAtNzcuMDAxODFdLCBbMzguOTkwNjIsIC03Ny4wMDE4MV0sIFszOS4xMTU4NTMzMzMzMzMzLCAtNzcuMDc1NDQxNjY2NjY2N10sIFszOS4xMTU4NTMzMzMzMzMzLCAtNzcuMDc1NDQxNjY2NjY2N10sIFszOS4wNzgzMTE2NjY2NjY3LCAtNzcuMTI5MDQ1XSwgWzM5LjA3ODMxMTY2NjY2NjcsIC03Ny4xMjkwNDVdLCBbMzkuMDM5NjcxNjY2NjY2NywgLTc3LjA1NDU1MTY2NjY2NjddLCBbMzkuMjI1ODY1LCAtNzcuMjYzNDU1XSwgWzM5LjIyNTg2NSwgLTc3LjI2MzQ1NV0sIFszOS4yMjAzMjY2NjY2NjY3LCAtNzcuMDYwMTY2NjY2NjY2N10sIFszOS4yMjAzMjY2NjY2NjY3LCAtNzcuMDYwMTY2NjY2NjY2N10sIFszOS4xNjI0MDY2NjY2NjY3LCAtNzcuMjUwNjEzMzMzMzMzM10sIFszOS4xNjI0MDY2NjY2NjY3LCAtNzcuMjUwNjEzMzMzMzMzM10sIFszOS4wMzEwMzgzMzMzMzMzLCAtNzcuMDA0ODRdLCBbMzguOTk3MjgxNjY2NjY2NywgLTc2Ljk5NDAwODMzMzMzMzNdLCBbMzguOTk3MjgxNjY2NjY2NywgLTc2Ljk5NDAwODMzMzMzMzNdLCBbMzkuMTUwMzc4MzMzMzMzMywgLTc3LjE5MDk1XSwgWzM5LjE1MDM3ODMzMzMzMzMsIC03Ny4xOTA5NV0sIFszOS4xNTAzNzgzMzMzMzMzLCAtNzcuMTkwOTVdLCBbMzkuMDc3NzAxNjY2NjY2NywgLTc3LjEyNTk3NjY2NjY2NjddLCBbMzkuMDc3NzAxNjY2NjY2NywgLTc3LjEyNTk3NjY2NjY2NjddLCBbMzkuMDQ5NDg1LCAtNzcuMDY4MDk1XSwgWzM5LjA0OTQ4NSwgLTc3LjA2ODA5NV0sIFszOS4wNDk0ODUsIC03Ny4wNjgwOTVdLCBbMzkuMDQ5NDg1LCAtNzcuMDY4MDk1XSwgWzM5LjA0OTQ4NSwgLTc3LjA2ODA5NV0sIFszOC45OTY3NSwgLTc2Ljk5MTcyNV0sIFszOC45OTcxOCwgLTc3LjAyNjAyMzMzMzMzMzNdLCBbMzguOTk3MTgsIC03Ny4wMjYwMjMzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjA5NjY5ODMzMzMzMzMsIC03Ny4yNjU2NDVdLCBbMzkuMDk2Njk4MzMzMzMzMywgLTc3LjI2NTY0NV0sIFszOS4wOTc1MSwgLTc2Ljk0ODE2ODMzMzMzMzNdLCBbMzkuMjIwMjY2NjY2NjY2NywgLTc3LjA2MDE5MzMzMzMzMzNdLCBbMzguOTk5NjQsIC03Ni45OTMyNjVdLCBbMzguOTk5NjQsIC03Ni45OTMyNjVdLCBbMzkuMDI0NzIzMzMzMzMzMywgLTc3LjAxMTIzMzMzMzMzMzNdLCBbMzguOTk5ODAxNjY2NjY2NywgLTc2Ljk5MjMyNjY2NjY2NjddLCBbMzkuMTA3NzU1LCAtNzYuOTk4OTk4MzMzMzMzM10sIFszOS4wOTAwOCwgLTc3LjA1MzYzODMzMzMzMzNdLCBbMzkuMTA3NzU1LCAtNzYuOTk4OTk4MzMzMzMzM10sIFszOS4xMDc3NTUsIC03Ni45OTg5OTgzMzMzMzMzXSwgWzM5LjEwNzc1NSwgLTc2Ljk5ODk5ODMzMzMzMzNdLCBbMzkuMTA3NzU1LCAtNzYuOTk4OTk4MzMzMzMzM10sIFszOS4xNTA0MTE2NjY2NjY3LCAtNzcuMTkwOTZdLCBbMzkuMTI4NDk1LCAtNzcuMTg2NDVdLCBbMzkuMTI4NDk1LCAtNzcuMTg2NDVdLCBbMzkuMTI4NDk1LCAtNzcuMTg2NDVdLCBbMzkuMDY3NjcxNjY2NjY2NywgLTc3LjAwMTY0ODMzMzMzMzNdLCBbMzkuMDkwMTMsIC03Ny4wNTM3Nl0sIFszOS4wOTAxMywgLTc3LjA1Mzc2XSwgWzM5LjA5MDEzLCAtNzcuMDUzNzZdLCBbMzkuMDc1MzAxNjY2NjY2NywgLTc3LjExNTE4NjY2NjY2NjddLCBbMzkuMTM2NjcxNjY2NjY2NywgLTc3LjM5NTA4NV0sIFszOS4wNDM3MSwgLTc3LjA2MjQ2MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzkuMTM2NjcxNjY2NjY2NywgLTc3LjM5NTA4NV0sIFszOS4wNzQ0ODgzMzMzMzMzLCAtNzcuMTY1MjY2NjY2NjY2N10sIFszOS4yNjYxLCAtNzcuMjAxMDY1XSwgWzM5LjAwOTQ3NSwgLTc2Ljk5OTQwMzMzMzMzMzNdLCBbMzkuMDA5NDc1LCAtNzYuOTk5NDAzMzMzMzMzM10sIFszOS4wNzU0NzUsIC03Ny4xMTUwNzMzMzMzMzMzXSwgWzM5LjA3NTQ3NSwgLTc3LjExNTA3MzMzMzMzMzNdLCBbMzkuMDc1NDc1LCAtNzcuMTE1MDczMzMzMzMzM10sIFszOS4wNzU0NzUsIC03Ny4xMTUwNzMzMzMzMzMzXSwgWzM5LjA3NTQ3NSwgLTc3LjExNTA3MzMzMzMzMzNdLCBbMzkuMDkxMjIzMzMzMzMzMywgLTc3LjIwNDgwODMzMzMzMzNdLCBbMzkuMDc1NzM1LCAtNzcuMDAxODc4MzMzMzMzM10sIFszOS4wNzU3MzUsIC03Ny4wMDE4NzgzMzMzMzMzXSwgWzM5LjA3NTczNSwgLTc3LjAwMTg3ODMzMzMzMzNdLCBbMzkuMDc1NzM1LCAtNzcuMDAxODc4MzMzMzMzM10sIFszOS4wNzU3MzUsIC03Ny4wMDE4NzgzMzMzMzMzXSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzguOTk0NDAzMzMzMzMzMywgLTc3LjAyODMzMzMzMzMzMzNdLCBbMzkuMDMyMjQzMzMzMzMzMywgLTc3LjA3NTA0NV0sIFszOS4wNTI1MzgzMzMzMzMzLCAtNzcuMTY2MzU4MzMzMzMzM10sIFszOS4wMzIyNDMzMzMzMzMzLCAtNzcuMDc1MDQ1XSwgWzM5LjA2NjEzMzMzMzMzMzMsIC03Ny4wMDA1MzMzMzMzMzMzXSwgWzM5LjI2NjEsIC03Ny4yMDEwNjVdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMTIxMTIsIC03Ny4wMTE1MjY2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjAzMTEwNSwgLTc3LjAwNDkzNjY2NjY2NjddLCBbMzkuMTg0NjMsIC03Ny4yMTA5OTMzMzMzMzMzXSwgWzM5LjE4NDYzLCAtNzcuMjEwOTkzMzMzMzMzM10sIFszOS4wODM4MDY2NjY2NjY3LCAtNzYuOTUwMTczMzMzMzMzM10sIFszOS4xODczNTY2NjY2NjY3LCAtNzcuMjU3MzRdLCBbMzkuMTg3MzU2NjY2NjY2NywgLTc3LjI1NzM0XSwgWzM5LjE4NzM1NjY2NjY2NjcsIC03Ny4yNTczNF0sIFszOS4xODczNTY2NjY2NjY3LCAtNzcuMjU3MzRdLCBbMzkuMTg3MzU2NjY2NjY2NywgLTc3LjI1NzM0XSwgWzM5LjE4NzM1NjY2NjY2NjcsIC03Ny4yNTczNF0sIFszOC45OTkzNjMzMzMzMzMzLCAtNzcuMDE3Nzg1XSwgWzM4Ljk5MDcsIC03Ny4wMjE5MTVdLCBbMzkuMTQ5Mjc4MzMzMzMzMywgLTc3LjA2NjYyXSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOS4xNDkyNzgzMzMzMzMzLCAtNzcuMDY2NjJdLCBbMzkuMTQ5Mjc4MzMzMzMzMywgLTc3LjA2NjYyXSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOS4xNDkyNzgzMzMzMzMzLCAtNzcuMDY2NjJdLCBbMzkuMTYwMTk1LCAtNzcuMjg5NDcxNjY2NjY2N10sIFszOS4xNDgyODMzMzMzMzMzLCAtNzcuMjc2OTc2NjY2NjY2N10sIFszOS4wODk5NTMzMzMzMzMzLCAtNzcuMDI3NzZdLCBbMzkuMDg5OTUzMzMzMzMzMywgLTc3LjAyNzc2XSwgWzAuMCwgMC4wXSwgWzM5LjE0ODU4MTY2NjY2NjcsIC03Ny4yNzkwOV0sIFszOC45OTY3ODY2NjY2NjY3LCAtNzcuMDI3NjIxNjY2NjY2N10sIFszOC45ODIzMTE2NjY2NjY3LCAtNzcuMDc1MzI2NjY2NjY2N10sIFszOC45OTc5NTgzMzMzMzMzLCAtNzcuMDI2NzU2NjY2NjY2N10sIFszOC45OTc5NTgzMzMzMzMzLCAtNzcuMDI2NzU2NjY2NjY2N10sIFszOS4xNTk3MDE2NjY2NjY3LCAtNzcuMjg5OTczMzMzMzMzM10sIFszOS4xNDg1MzE2NjY2NjY3LCAtNzcuMjc2NzczMzMzMzMzM10sIFszOS4wNjcwOTMzMzMzMzMzLCAtNzcuMDAxMzY4MzMzMzMzM10sIFszOS4xNTk3NjY2NjY2NjY3LCAtNzcuMjg5OTE4MzMzMzMzM10sIFszOS4xNDgyNjUsIC03Ny4yNzc0XSwgWzM5LjAxMjYwNjY2NjY2NjcsIC03Ny4xMDc5NTY2NjY2NjY3XSwgWzM5LjIyMDM0LCAtNzcuMDYwMTZdLCBbMC4wLCAwLjBdLCBbMzkuMTU5ODAzMzMzMzMzMywgLTc3LjI4OTgyMzMzMzMzMzNdLCBbMzkuMTEzODYsIC03Ny4xOTYzMzY2NjY2NjY3XSwgWzM5LjE0ODM3MTY2NjY2NjcsIC03Ny4yNzY5MV0sIFszOC45ODIxNjMzMzMzMzMzLCAtNzcuMDc2NDMzMzMzMzMzM10sIFszOC45ODIxNjMzMzMzMzMzLCAtNzcuMDc2NDMzMzMzMzMzM10sIFszOS4wNjY3MDgzMzMzMzMzLCAtNzcuMDAxMDgxNjY2NjY2N10sIFszOS4xMjM5NDUsIC03Ny4xNzU1NjY2NjY2NjY3XSwgWzM5LjEyMzk0NSwgLTc3LjE3NTU2NjY2NjY2NjddLCBbMzkuMjIwMzQsIC03Ny4wNjAxNl0sIFszOS4wMDIxNDE2NjY2NjY3LCAtNzcuMDM5MDU2NjY2NjY2N10sIFswLjAsIDAuMF0sIFszOS4xMjM5NDUsIC03Ny4xNzU1NjY2NjY2NjY3XSwgWzM5LjE1OTU5NjY2NjY2NjcsIC03Ny4yODk4OTE2NjY2NjY3XSwgWzM5LjExMzAzLCAtNzcuMTkyNjYxNjY2NjY2N10sIFszOS4wMTI3MjE2NjY2NjY3LCAtNzcuMTA3OTk1XSwgWzM5LjEyMzY2MTY2NjY2NjcsIC03Ny4xNzUxM10sIFszOS4xMjM2NjE2NjY2NjY3LCAtNzcuMTc1MTNdLCBbMzkuMjIwMzQsIC03Ny4wNjAxNl0sIFszOS4wNjEwNDUsIC03Ni45OTg3MzMzMzMzMzMzXSwgWzM4Ljk5MDE5MzMzMzMzMzMsIC03Ny4wOTUzNTMzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzM4Ljk5MDA2MzMzMzMzMzMsIC03Ny4wOTUxMTVdLCBbMzkuMDY5NDUxNjY2NjY2NywgLTc3LjE2OTQ5MzMzMzMzMzNdLCBbMzkuMDEzMTA4MzMzMzMzMywgLTc3LjEwNzYzODMzMzMzMzNdLCBbMzkuMjIwMzQsIC03Ny4wNjAxNl0sIFszOS4yMjAzNCwgLTc3LjA2MDE2XSwgWzM5LjA1MjQ1ODMzMzMzMzMsIC03Ny4xNjU3NjVdLCBbMzkuMTU5Njk4MzMzMzMzMywgLTc3LjI4OTk0XSwgWzAuMCwgMC4wXSwgWzM5LjA1MjQ1NjY2NjY2NjcsIC03Ny4xNjU4MzMzMzMzMzMzXSwgWzM5LjAxMjA1NSwgLTc3LjEwODMzNjY2NjY2NjddLCBbMzkuMTI2MDc1LCAtNzcuMTczOTVdLCBbMzkuMTI2MDc1LCAtNzcuMTczOTVdLCBbMzkuMTU5Njk4MzMzMzMzMywgLTc3LjI4OTkxXSwgWzM5LjAxMTQ3ODMzMzMzMzMsIC03Ni45Nzk1NDE2NjY2NjY3XSwgWzM5LjE1MTg1ODMzMzMzMzMsIC03Ny4yODM1XSwgWzAuMCwgMC4wXSwgWzM5LjAwMDE0ODMzMzMzMzMsIC03Ni45OTA4NF0sIFszOS4wMDAxNDgzMzMzMzMzLCAtNzYuOTkwODRdLCBbMzguOTk0NjY4MzMzMzMzMywgLTc3LjAyNzYyNjY2NjY2NjddLCBbMzkuMTE5MTY4MzMzMzMzMywgLTc3LjAxOTg1XSwgWzM5LjExNjA1MzMzMzMzMzMsIC03Ny4wMTc3NjE2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOS4xMTkwMywgLTc3LjAyMDM0MzMzMzMzMzNdLCBbMzkuMDg3MjcxNjY2NjY2NywgLTc3LjIxMTU1NjY2NjY2NjddLCBbMzkuMDg4Nzk4MzMzMzMzMywgLTc3LjIxMDI1MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzguOTY4NjU4MzMzMzMzMywgLTc3LjEwOTEyNV0sIFszOS4xMjE3MzE2NjY2NjY3LCAtNzYuOTkyNTldLCBbMzkuMTE5MDE2NjY2NjY2NywgLTc3LjAyMDM2NjY2NjY2NjddLCBbMzkuMTIxNzMxNjY2NjY2NywgLTc2Ljk5MjU5XSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOC45OTk1LCAtNzcuMDk3NzkxNjY2NjY2N10sIFszOS4xMDYzNSwgLTc3LjE4OTUyMzMzMzMzMzNdLCBbMzkuMTI4MTM1LCAtNzcuMTYxMzhdLCBbMzkuMTE4ODg1LCAtNzcuMDIwOTddLCBbMzkuMDE1NzcsIC03Ny4wNDMyODY2NjY2NjY3XSwgWzM5LjAyODA5MTY2NjY2NjcsIC03Ny4wMTMzODVdLCBbMzkuMTI4MTM1LCAtNzcuMTYxMzhdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMDg2Mzc4MzMzMzMzMywgLTc2Ljk5OTUzMTY2NjY2NjddLCBbMzkuMTE1ODQsIC03Ny4wNzM2NV0sIFswLjAsIDAuMF0sIFszOS4xMjgxNjUsIC03Ny4xNjEyNzgzMzMzMzMzXSwgWzM5LjE1MTc1MTY2NjY2NjcsIC03Ny4yMTEwNTY2NjY2NjY3XSwgWzM5LjE1MTc1MTY2NjY2NjcsIC03Ny4yMTEwNTY2NjY2NjY3XSwgWzM5LjAxNDk0ODMzMzMzMzMsIC03Ny4wOTk2NDY2NjY2NjY3XSwgWzM5LjI0MTU4LCAtNzcuMTQzNjMzMzMzMzMzM10sIFszOS4wMzQzMzMzMzMzMzMzLCAtNzcuMDcxNjU4MzMzMzMzM10sIFszOS4wMTM3OTgzMzMzMzMzLCAtNzcuMDk5MzJdLCBbMzkuMDMyMjEsIC03Ny4wNzQzNzE2NjY2NjY3XSwgWzM5LjA5OTQ0MTY2NjY2NjcsIC03Ny4yMTIxNl0sIFszOS4wOTk0NDE2NjY2NjY3LCAtNzcuMjEyMTZdLCBbMzguOTg1NTkxNjY2NjY2NywgLTc3LjA5MzcyNV0sIFszOS4wOTk0NDE2NjY2NjY3LCAtNzcuMjEyMTZdLCBbMzguOTg0MzQ1LCAtNzcuMDk0MjkxNjY2NjY2N10sIFszOS4wNTI1NDUsIC03Ni45NzY5MDMzMzMzMzMzXSwgWzM5LjA1MjU0NSwgLTc2Ljk3NjkwMzMzMzMzMzNdLCBbMzkuMDUyNTQ1LCAtNzYuOTc2OTAzMzMzMzMzM10sIFszOS4wMTg1NzgzMzMzMzMzLCAtNzcuMDE0NzEzMzMzMzMzM10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzM5LjAyMDQzODMzMzMzMzMsIC03Ny4xMDMxMzMzMzMzMzMzXSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDg5NzkxNjY2NjY2NywgLTc3LjEzMDI5MTY2NjY2NjddLCBbMzkuMDg5NzkxNjY2NjY2NywgLTc3LjEzMDI5MTY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOC45OTE3NjMzMzMzMzMzLCAtNzcuMDk1NzI4MzMzMzMzM10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM4Ljk5MTE2MTY2NjY2NjcsIC03Ny4wOTQwMzE2NjY2NjY3XSwgWzM4Ljk5NDMyLCAtNzcuMDI4MDFdLCBbMzkuMTQwMDcsIC03Ny4xNTIxMzE2NjY2NjY3XSwgWzM5LjEyOTMxNjY2NjY2NjcsIC03Ny4yMzI0MTgzMzMzMzMzXSwgWzM5LjEyOTMxNjY2NjY2NjcsIC03Ny4yMzI0MTgzMzMzMzMzXSwgWzM5LjE5NzM3ODMzMzMzMzMsIC03Ny4yODI0MjVdLCBbMzkuMTk3Mzc4MzMzMzMzMywgLTc3LjI4MjQyNV0sIFszOS4xOTczNzgzMzMzMzMzLCAtNzcuMjgyNDI1XSwgWzM5LjEwOTU5NjY2NjY2NjcsIC03Ny4wNzc0NzY2NjY2NjY3XSwgWzM5LjAxMDE5NjY2NjY2NjcsIC03Ny4wMDA2NTVdLCBbMzguOTkwMywgLTc3LjA5NTM2XSwgWzM4Ljk5MDM2ODMzMzMzMzMsIC03Ny4wMDE4MjE2NjY2NjY3XSwgWzM4Ljk5MDM2ODMzMzMzMzMsIC03Ny4wMDE4MjE2NjY2NjY3XSwgWzM5LjAwMDUwMzMzMzMzMzMsIC03Ni45ODk4OTVdLCBbMzkuMjYwMzMxNjY2NjY2NywgLTc3LjIyMzExMTY2NjY2NjddLCBbMzkuMjYwMzMxNjY2NjY2NywgLTc3LjIyMzExMTY2NjY2NjddLCBbMzguOTkwMzIxNjY2NjY2NywgLTc3LjA5NTI1ODMzMzMzMzNdLCBbMzkuMjY2MDA4MzMzMzMzMywgLTc3LjIwMTQ3NjY2NjY2NjddXSwKICAgICAgICAgICAgICAgIHsKICAgICAgICAgICAgICAgICAgICBtaW5PcGFjaXR5OiAwLjUsCiAgICAgICAgICAgICAgICAgICAgbWF4Wm9vbTogMTgsCiAgICAgICAgICAgICAgICAgICAgbWF4OiAxLjAsCiAgICAgICAgICAgICAgICAgICAgcmFkaXVzOiAyNSwKICAgICAgICAgICAgICAgICAgICBibHVyOiAxNSwKICAgICAgICAgICAgICAgICAgICBncmFkaWVudDogbnVsbAogICAgICAgICAgICAgICAgICAgIH0pCiAgICAgICAgICAgICAgICAuYWRkVG8obWFwX2EzMmQ2NzVlN2Y5MDQ5YTlhMTQzOTk4MjkwMzE0YTk4KTsKICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICA8L3NjcmlwdD4KICAgICAgICA=](data:text/html;base64,CiAgICAgICAgPCFET0NUWVBFIGh0bWw+CiAgICAgICAgPGhlYWQ+CiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bWV0YSBodHRwLWVxdWl2PSJjb250ZW50LXR5cGUiIGNvbnRlbnQ9InRleHQvaHRtbDsgY2hhcnNldD1VVEYtOCIgLz4KICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL2NkbmpzLmNsb3VkZmxhcmUuY29tL2FqYXgvbGlicy9sZWFmbGV0LzAuNy4zL2xlYWZsZXQuanMiPjwvc2NyaXB0PgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPHNjcmlwdCBzcmM9Imh0dHBzOi8vYWpheC5nb29nbGVhcGlzLmNvbS9hamF4L2xpYnMvanF1ZXJ5LzEuMTEuMS9qcXVlcnkubWluLmpzIj48L3NjcmlwdD4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL21heGNkbi5ib290c3RyYXBjZG4uY29tL2Jvb3RzdHJhcC8zLjIuMC9qcy9ib290c3RyYXAubWluLmpzIj48L3NjcmlwdD4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL3Jhd2dpdGh1Yi5jb20vbHZvb2dkdC9MZWFmbGV0LmF3ZXNvbWUtbWFya2Vycy8yLjAvZGV2ZWxvcC9kaXN0L2xlYWZsZXQuYXdlc29tZS1tYXJrZXJzLmpzIj48L3NjcmlwdD4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL2NkbmpzLmNsb3VkZmxhcmUuY29tL2FqYXgvbGlicy9sZWFmbGV0Lm1hcmtlcmNsdXN0ZXIvMC40LjAvbGVhZmxldC5tYXJrZXJjbHVzdGVyLXNyYy5qcyI+PC9zY3JpcHQ+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8c2NyaXB0IHNyYz0iaHR0cHM6Ly9jZG5qcy5jbG91ZGZsYXJlLmNvbS9hamF4L2xpYnMvbGVhZmxldC5tYXJrZXJjbHVzdGVyLzAuNC4wL2xlYWZsZXQubWFya2VyY2x1c3Rlci5qcyI+PC9zY3JpcHQ+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bGluayByZWw9InN0eWxlc2hlZXQiIGhyZWY9Imh0dHBzOi8vY2RuanMuY2xvdWRmbGFyZS5jb20vYWpheC9saWJzL2xlYWZsZXQvMC43LjMvbGVhZmxldC5jc3MiIC8+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bGluayByZWw9InN0eWxlc2hlZXQiIGhyZWY9Imh0dHBzOi8vbWF4Y2RuLmJvb3RzdHJhcGNkbi5jb20vYm9vdHN0cmFwLzMuMi4wL2Nzcy9ib290c3RyYXAubWluLmNzcyIgLz4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxsaW5rIHJlbD0ic3R5bGVzaGVldCIgaHJlZj0iaHR0cHM6Ly9tYXhjZG4uYm9vdHN0cmFwY2RuLmNvbS9ib290c3RyYXAvMy4yLjAvY3NzL2Jvb3RzdHJhcC10aGVtZS5taW4uY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJodHRwczovL21heGNkbi5ib290c3RyYXBjZG4uY29tL2ZvbnQtYXdlc29tZS80LjEuMC9jc3MvZm9udC1hd2Vzb21lLm1pbi5jc3MiIC8+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICA8bGluayByZWw9InN0eWxlc2hlZXQiIGhyZWY9Imh0dHBzOi8vcmF3Z2l0LmNvbS9sdm9vZ2R0L0xlYWZsZXQuYXdlc29tZS1tYXJrZXJzLzIuMC9kZXZlbG9wL2Rpc3QvbGVhZmxldC5hd2Vzb21lLW1hcmtlcnMuY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJodHRwczovL2NkbmpzLmNsb3VkZmxhcmUuY29tL2FqYXgvbGlicy9sZWFmbGV0Lm1hcmtlcmNsdXN0ZXIvMC40LjAvTWFya2VyQ2x1c3Rlci5EZWZhdWx0LmNzcyIgLz4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxsaW5rIHJlbD0ic3R5bGVzaGVldCIgaHJlZj0iaHR0cHM6Ly9jZG5qcy5jbG91ZGZsYXJlLmNvbS9hamF4L2xpYnMvbGVhZmxldC5tYXJrZXJjbHVzdGVyLzAuNC4wL01hcmtlckNsdXN0ZXIuY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgPGxpbmsgcmVsPSJzdHlsZXNoZWV0IiBocmVmPSJodHRwczovL3Jhdy5naXRodWJ1c2VyY29udGVudC5jb20vcHl0aG9uLXZpc3VhbGl6YXRpb24vZm9saXVtL21hc3Rlci9mb2xpdW0vdGVtcGxhdGVzL2xlYWZsZXQuYXdlc29tZS5yb3RhdGUuY3NzIiAvPgogICAgICAgIAogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAgICAgPHN0eWxlPgoKICAgICAgICAgICAgaHRtbCwgYm9keSB7CiAgICAgICAgICAgICAgICB3aWR0aDogMTAwJTsKICAgICAgICAgICAgICAgIGhlaWdodDogMTAwJTsKICAgICAgICAgICAgICAgIG1hcmdpbjogMDsKICAgICAgICAgICAgICAgIHBhZGRpbmc6IDA7CiAgICAgICAgICAgICAgICB9CgogICAgICAgICAgICAjbWFwIHsKICAgICAgICAgICAgICAgIHBvc2l0aW9uOmFic29sdXRlOwogICAgICAgICAgICAgICAgdG9wOjA7CiAgICAgICAgICAgICAgICBib3R0b206MDsKICAgICAgICAgICAgICAgIHJpZ2h0OjA7CiAgICAgICAgICAgICAgICBsZWZ0OjA7CiAgICAgICAgICAgICAgICB9CiAgICAgICAgICAgIDwvc3R5bGU+CiAgICAgICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAgICAgPHN0eWxlPiAjbWFwX2EzMmQ2NzVlN2Y5MDQ5YTlhMTQzOTk4MjkwMzE0YTk4IHsKICAgICAgICAgICAgICAgIHBvc2l0aW9uIDogcmVsYXRpdmU7CiAgICAgICAgICAgICAgICB3aWR0aCA6IDEwMC4wJTsKICAgICAgICAgICAgICAgIGhlaWdodDogMTAwLjAlOwogICAgICAgICAgICAgICAgbGVmdDogMC4wJTsKICAgICAgICAgICAgICAgIHRvcDogMC4wJTsKICAgICAgICAgICAgICAgIH0KICAgICAgICAgICAgPC9zdHlsZT4KICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIDxzY3JpcHQgc3JjPSJodHRwczovL2xlYWZsZXQuZ2l0aHViLmlvL0xlYWZsZXQuaGVhdC9kaXN0L2xlYWZsZXQtaGVhdC5qcyI+PC9zY3JpcHQ+CiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgCiAgICAgICAgPC9oZWFkPgogICAgICAgIDxib2R5PgogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgICAgIDxkaXYgY2xhc3M9ImZvbGl1bS1tYXAiIGlkPSJtYXBfYTMyZDY3NWU3ZjkwNDlhOWExNDM5OTgyOTAzMTRhOTgiID48L2Rpdj4KICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICA8L2JvZHk+CiAgICAgICAgPHNjcmlwdD4KICAgICAgICAgICAgCiAgICAgICAgCiAgICAgICAgICAgIAoKICAgICAgICAgICAgdmFyIHNvdXRoV2VzdCA9IEwubGF0TG5nKC05MCwgLTE4MCk7CiAgICAgICAgICAgIHZhciBub3J0aEVhc3QgPSBMLmxhdExuZyg5MCwgMTgwKTsKICAgICAgICAgICAgdmFyIGJvdW5kcyA9IEwubGF0TG5nQm91bmRzKHNvdXRoV2VzdCwgbm9ydGhFYXN0KTsKCiAgICAgICAgICAgIHZhciBtYXBfYTMyZDY3NWU3ZjkwNDlhOWExNDM5OTgyOTAzMTRhOTggPSBMLm1hcCgnbWFwX2EzMmQ2NzVlN2Y5MDQ5YTlhMTQzOTk4MjkwMzE0YTk4JywgewogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgY2VudGVyOlszOS4wODM2LC03Ny4xNDgzXSwKICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIHpvb206IDExLAogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgbWF4Qm91bmRzOiBib3VuZHMsCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICBsYXllcnM6IFtdLAogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgY3JzOiBMLkNSUy5FUFNHMzg1NwogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIH0pOwogICAgICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICAgICAgCiAgICAgICAgICAgIHZhciB0aWxlX2xheWVyXzMxYjEzMTJiNmVhODQ0NWE4MmJiMGVlMDBjOTc2NjBjID0gTC50aWxlTGF5ZXIoCiAgICAgICAgICAgICAgICAnaHR0cHM6Ly97c30udGlsZS5vcGVuc3RyZWV0bWFwLm9yZy97en0ve3h9L3t5fS5wbmcnLAogICAgICAgICAgICAgICAgewogICAgICAgICAgICAgICAgICAgIG1heFpvb206IDE4LAogICAgICAgICAgICAgICAgICAgIG1pblpvb206IDEsCiAgICAgICAgICAgICAgICAgICAgYXR0cmlidXRpb246ICdEYXRhIGJ5IDxhIGhyZWY9Imh0dHA6Ly9vcGVuc3RyZWV0bWFwLm9yZyI+T3BlblN0cmVldE1hcDwvYT4sIHVuZGVyIDxhIGhyZWY9Imh0dHA6Ly93d3cub3BlbnN0cmVldG1hcC5vcmcvY29weXJpZ2h0Ij5PRGJMPC9hPi4nLAogICAgICAgICAgICAgICAgICAgIGRldGVjdFJldGluYTogZmFsc2UKICAgICAgICAgICAgICAgICAgICB9CiAgICAgICAgICAgICAgICApLmFkZFRvKG1hcF9hMzJkNjc1ZTdmOTA0OWE5YTE0Mzk5ODI5MDMxNGE5OCk7CgogICAgICAgIAogICAgICAgIAogICAgICAgICAgICAKICAgICAgICAgICAgdmFyIGhlYXRfbWFwX2I3OGIzMzNmZWMzMTQxY2U4ZDNiMGY1NzJiZTM0YjUwID0gTC5oZWF0TGF5ZXIoCiAgICAgICAgICAgICAgICBbWzM5LjAzMjIzLCAtNzcuMTA1OTI1XSwgWzAuMCwgMC4wXSwgWzM5LjA0MTM0NSwgLTc3LjA1MzkxNjY2NjY2NjddLCBbMzkuMDQwNTY1LCAtNzcuMDU2MjgxNjY2NjY2N10sIFszOS4wMTM0NDgzMzMzMzMzLCAtNzcuMTA2MTMzMzMzMzMzM10sIFszOS4wMTM1NjgzMzMzMzMzLCAtNzcuMTA2MjM4MzMzMzMzM10sIFszOS4wMTM2NCwgLTc3LjEwNjIyNjY2NjY2NjddLCBbMzkuMDIzMDA1LCAtNzcuMTAzMjAxNjY2NjY2N10sIFszOS4yNDA2NTMzMzMzMzMzLCAtNzcuMjM1MDIxNjY2NjY2N10sIFszOS4yNDA2NTMzMzMzMzMzLCAtNzcuMjM1MDIxNjY2NjY2N10sIFszOS4yNDA2NTMzMzMzMzMzLCAtNzcuMjM1MDIxNjY2NjY2N10sIFszOS4wMDE3OCwgLTc3LjAzODg1MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzguOTk4MTYsIC03Ni45OTUwODgzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjA0MTM0NSwgLTc3LjA1MzkxNjY2NjY2NjddLCBbMzkuMDQ3MDM4MzMzMzMzMywgLTc3LjA1MzE5XSwgWzM5LjA0NzAzODMzMzMzMzMsIC03Ny4wNTMxOV0sIFszOS4wNTcxODE2NjY2NjY3LCAtNzcuMDQ5NzE4MzMzMzMzM10sIFszOS4wNTcxODE2NjY2NjY3LCAtNzcuMDQ5NzE4MzMzMzMzM10sIFszOS4wNDA1NjUsIC03Ny4wNTYyODE2NjY2NjY3XSwgWzM4Ljk5OTE5MTY2NjY2NjcsIC03Ny4wMzM4MTY2NjY2NjY3XSwgWzM4Ljk5NzI3LCAtNzcuMDI3NDc2NjY2NjY2N10sIFszOS4wMTkxOTY2NjY2NjY3LCAtNzcuMDE0MjExNjY2NjY2N10sIFszOS4wOTYzMTE2NjY2NjY3LCAtNzcuMjA2NDRdLCBbMzkuMTAyMDA1LCAtNzcuMjEwODgzMzMzMzMzM10sIFszOS4xMDIwMDUsIC03Ny4yMTA4ODMzMzMzMzMzXSwgWzM5LjEwMjAwNSwgLTc3LjIxMDg4MzMzMzMzMzNdLCBbMzkuMDI5Mzk1LCAtNzcuMDYzODE1XSwgWzM5LjAyOTM5NSwgLTc3LjA2MzgxNV0sIFszOS4wMjkzOTUsIC03Ny4wNjM4MTVdLCBbMzkuMDI5Mzk1LCAtNzcuMDYzODE1XSwgWzM5LjAzMTIwNSwgLTc3LjA3MjQyODMzMzMzMzNdLCBbMzkuMDMxMzA1LCAtNzcuMDcyNTI1XSwgWzM4Ljk5MDE2MTY2NjY2NjcsIC03Ny4wMDE1NDgzMzMzMzMzXSwgWzM5LjExMzgyNSwgLTc3LjE5MzY1XSwgWzM5LjAwMzUwNjY2NjY2NjcsIC03Ny4wMzU2MDE2NjY2NjY3XSwgWzM5LjE2NDE3MzMzMzMzMzMsIC03Ny4xNTcyM10sIFszOS4xOTA2NjE2NjY2NjY3LCAtNzcuMjQyMDYzMzMzMzMzM10sIFszOS4xMTg4NCwgLTc3LjAyMTc1MTY2NjY2NjddLCBbMzkuMTI3NzA2NjY2NjY2NywgLTc3LjE2NzA4MzMzMzMzMzNdLCBbMzkuMTUxNzEsIC03Ny4yNzgyNF0sIFszOS4wNjUwMDUsIC03Ny4yNjU5NTVdLCBbMzkuMTAxODI1LCAtNzcuMTQxODRdLCBbMzguOTg1NjUzMzMzMzMzMywgLTc3LjIyNjU0NV0sIFszOS4wNzQ3OCwgLTc2Ljk5ODJdLCBbMzkuMDczOTMxNjY2NjY2NywgLTc3LjAwMDk5MzMzMzMzMzNdLCBbMzkuMTk4OTI4MzMzMzMzMywgLTc3LjI0NDgxMTY2NjY2NjddLCBbMzkuMjc4MTk1LCAtNzcuMzIyNjk2NjY2NjY2N10sIFszOS4yNzgxOTUsIC03Ny4zMjI2OTY2NjY2NjY3XSwgWzM5LjIyODQ4MzMzMzMzMzMsIC03Ny4yODI2MV0sIFszOS4xNzc4NzY2NjY2NjY3LCAtNzcuMjcwNjQ4MzMzMzMzM10sIFszOS4xNzgyNzY2NjY2NjY3LCAtNzcuMjcyNDcxNjY2NjY2N10sIFszOS4xNzgyMzUsIC03Ny4yNzIzMTMzMzMzMzMzXSwgWzM5LjE3NzQzNjY2NjY2NjcsIC03Ny4yNzEzMjY2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzM5LjE3MTE5ODMzMzMzMzMsIC03Ny4yNzc4MjY2NjY2NjY3XSwgWzM5LjE3MjA0NjY2NjY2NjcsIC03Ny4yNzY2ODgzMzMzMzMzXSwgWzM5LjE2ODg5NjY2NjY2NjcsIC03Ny4yNzk1N10sIFszOS4xNzEwNiwgLTc3LjI3NzkyNV0sIFszOS4xMTEyOTgzMzMzMzMzLCAtNzcuMTYxMjYxNjY2NjY2N10sIFszOS4wNjk1NTMzMzMzMzMzLCAtNzcuMTM4NDQzMzMzMzMzM10sIFszOS4wNDExMDgzMzMzMzMzLCAtNzcuMTYyMjYzMzMzMzMzM10sIFszOS4wOTU1NywgLTc3LjA0NDE5ODMzMzMzMzNdLCBbMzkuMjg3MTIsIC03Ny4yMDgwMV0sIFszOS4yNzU5NjUsIC03Ny4yMTQxNTVdLCBbMzkuMjc2NzI1LCAtNzcuMjEzNDY4MzMzMzMzM10sIFswLjAsIDAuMF0sIFszOC45OTg4MTUsIC03Ni45OTUxMDgzMzMzMzMzXSwgWzM4Ljk5Nzc0ODMzMzMzMzMsIC03Ni45OTQzM10sIFszOC45OTc3NDgzMzMzMzMzLCAtNzYuOTk0MzNdLCBbMzguOTk3NTY1LCAtNzYuOTk0MDkzMzMzMzMzM10sIFszOC45OTQ3OCwgLTc3LjAwNzgwMTY2NjY2NjddLCBbMzguOTk0NzgsIC03Ny4wMDc4MDE2NjY2NjY3XSwgWzM4Ljk5NDc4LCAtNzcuMDA3ODAxNjY2NjY2N10sIFszOC45OTQ3OCwgLTc3LjAwNzgwMTY2NjY2NjddLCBbMzkuMjIwMzEzMzMzMzMzMywgLTc3LjA2MDE2NjY2NjY2NjddLCBbMzkuMDc4NzMzMzMzMzMzMywgLTc3LjAwMTUyMzMzMzMzMzNdLCBbMzkuMDgxNjM4MzMzMzMzMywgLTc3LjAwMTEwMTY2NjY2NjddLCBbMzkuMTA1NzI4MzMzMzMzMywgLTc3LjA4NTIwMzMzMzMzMzNdLCBbMzkuMTA1NjQzMzMzMzMzMywgLTc3LjA4NTM4XSwgWzM5LjEwNzQ0LCAtNzcuMDgyNjNdLCBbMzkuMTA1MzcsIC03Ny4wODU2NzY2NjY2NjY3XSwgWzM5LjEwNTk1MTY2NjY2NjcsIC03Ny4wODUwMDE2NjY2NjY3XSwgWzM5LjEwNTA2MTY2NjY2NjcsIC03Ny4wODU4OF0sIFszOS4xMDQ0MDUsIC03Ny4wODY5NjY2NjY2NjY3XSwgWzM5LjI3ODE5NSwgLTc3LjMyMjY5NjY2NjY2NjddLCBbMzkuMjc4MTk1LCAtNzcuMzIyNjk2NjY2NjY2N10sIFszOS4yNzgxOTUsIC03Ny4zMjI2OTY2NjY2NjY3XSwgWzM5LjA4OTA2NjY2NjY2NjcsIC03Ny4yMTM5NV0sIFszOS4yMjg0ODMzMzMzMzMzLCAtNzcuMjgyNjFdLCBbMzkuMjA1ODA1LCAtNzcuMjQzMTkzMzMzMzMzM10sIFszOS4wMDk5NDY2NjY2NjY3LCAtNzcuMDk3MzMzMzMzMzMzM10sIFszOS4wMDk5NDY2NjY2NjY3LCAtNzcuMDk3MzMzMzMzMzMzM10sIFszOS4wMzAzMDgzMzMzMzMzLCAtNzcuMTA1MDldLCBbMzkuMDIwMjksIC03Ny4wNzcxNjgzMzMzMzMzXSwgWzM5LjAyMDI5LCAtNzcuMDc3MTY4MzMzMzMzM10sIFszOS4wNDc0MjE2NjY2NjY3LCAtNzcuMDc1ODkzMzMzMzMzM10sIFswLjAsIDAuMF0sIFszOS4wNDExMjMzMzMzMzMzLCAtNzcuMTU5MjgzMzMzMzMzM10sIFszOS4wMDc0OTE2NjY2NjY3LCAtNzcuMTEyNTkzMzMzMzMzM10sIFszOC45OTAxNjE2NjY2NjY3LCAtNzcuMDAxNTQ4MzMzMzMzM10sIFszOS4xMTM4MjUsIC03Ny4xOTM2NV0sIFszOS4xMTM4MjUsIC03Ny4xOTM2NV0sIFszOS4xNzE5OCwgLTc3LjI3NzAzODMzMzMzMzNdLCBbMzkuMDAzNTA2NjY2NjY2NywgLTc3LjAzNTYwMTY2NjY2NjddLCBbMzkuMDAzNTA2NjY2NjY2NywgLTc3LjAzNTYwMTY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDEzNDUsIC03Ny4wNTM5MTY2NjY2NjY3XSwgWzM5LjA0MTM0NSwgLTc3LjA1MzkxNjY2NjY2NjddLCBbMzkuMDQ3MDM4MzMzMzMzMywgLTc3LjA1MzE5XSwgWzM5LjA0NzAzODMzMzMzMzMsIC03Ny4wNTMxOV0sIFszOS4wNDcwMzgzMzMzMzMzLCAtNzcuMDUzMTldLCBbMzkuMDQ3Mjc1LCAtNzcuMDU0MDU1XSwgWzM5LjA2NjkyMTY2NjY2NjcsIC03Ny4wMTg4N10sIFszOS4wNjY5MjE2NjY2NjY3LCAtNzcuMDE4ODddLCBbMzkuMDY2OTIxNjY2NjY2NywgLTc3LjAxODg3XSwgWzM4Ljk4NzI4MzMzMzMzMzMsIC03Ny4wMjM0NjY2NjY2NjY3XSwgWzM4Ljk4Njk2MzMzMzMzMzMsIC03Ny4xMDc2MjMzMzMzMzMzXSwgWzM5LjA4Mzg2NSwgLTc3LjAwMDM0MzMzMzMzMzNdLCBbMzkuMTc2MjMsIC03Ny4yNzExMTE2NjY2NjY3XSwgWzM5LjEyMzkzMTY2NjY2NjcsIC03Ny4xNzk0MDY2NjY2NjY3XSwgWzM5LjEyMzkzMTY2NjY2NjcsIC03Ny4xNzk0MDY2NjY2NjY3XSwgWzM5LjAwNjY1MzMzMzMzMzMsIC03Ny4xOTEzN10sIFszOS4wMzk5MDgzMzMzMzMzLCAtNzcuMTIyMjhdLCBbMzkuMTE0MTk4MzMzMzMzMywgLTc3LjE2Mzg2ODMzMzMzMzNdLCBbMzkuMDI0Nzk4MzMzMzMzMywgLTc3LjA3NjQwNjY2NjY2NjddLCBbMzkuMDUzMTU4MzMzMzMzMywgLTc3LjExMjk1NjY2NjY2NjddLCBbMzkuMDUzMTU4MzMzMzMzMywgLTc3LjExMjk1NjY2NjY2NjddLCBbMzkuMDU0NDgzMzMzMzMzMywgLTc3LjExNzUxNV0sIFszOC45OTIxMjE2NjY2NjY3LCAtNzcuMDMzNzUzMzMzMzMzM10sIFszOC45ODgwMjY2NjY2NjY3LCAtNzcuMDI3XSwgWzM4Ljk4OTgxNjY2NjY2NjcsIC03Ny4wMjY0MjVdLCBbMzkuMDM4NDI1LCAtNzcuMDU4NTYzMzMzMzMzM10sIFszOS4wMzUwNjMzMzMzMzMzLCAtNzcuMTczOTgxNjY2NjY2N10sIFszOS4wMzUwNjMzMzMzMzMzLCAtNzcuMTczOTgxNjY2NjY2N10sIFszOS4wOTc3NzMzMzMzMzMzLCAtNzcuMjA3ODE1XSwgWzM5LjA5Nzc3MzMzMzMzMzMsIC03Ny4yMDc4MTVdLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDgyNjE1LCAtNzYuOTQ3MTAzMzMzMzMzM10sIFszOS4wODI2MTUsIC03Ni45NDcxMDMzMzMzMzMzXSwgWzM5LjA4MjYxNSwgLTc2Ljk0NzEwMzMzMzMzMzNdLCBbMzkuMDc3MzA1LCAtNzYuOTQyNzM4MzMzMzMzM10sIFszOS4wNzczMDUsIC03Ni45NDI3MzgzMzMzMzMzXSwgWzM5LjA4MzM5ODMzMzMzMzMsIC03Ni45MzkyMDVdLCBbMzkuMDgzMzk4MzMzMzMzMywgLTc2LjkzOTIwNV0sIFszOS4xMzkxNzE2NjY2NjY3LCAtNzcuMTkzNzI1XSwgWzM5LjEzOTE3MTY2NjY2NjcsIC03Ny4xOTM3MjVdLCBbMzkuMTkwNDAzMzMzMzMzMywgLTc3LjI2NzEyMTY2NjY2NjddLCBbMzkuMTkwNDAzMzMzMzMzMywgLTc3LjI2NzEyMTY2NjY2NjddLCBbMzkuMTY0MzgxNjY2NjY2NywgLTc3LjQ3Njk3NV0sIFszOS4xNjQzODE2NjY2NjY3LCAtNzcuNDc2OTc1XSwgWzM5LjE2NDM4MTY2NjY2NjcsIC03Ny40NzY5NzVdLCBbMzguOTg2NTgzMzMzMzMzMywgLTc3LjEwNzE3ODMzMzMzMzNdLCBbMzguOTg2Njc1LCAtNzcuMTA3Mjg2NjY2NjY2N10sIFszOC45ODY2NTY2NjY2NjY3LCAtNzcuMTA3MzFdLCBbMzguOTg2NjU2NjY2NjY2NywgLTc3LjEwNzMxXSwgWzM4Ljk4Njk2MzMzMzMzMzMsIC03Ny4xMDc2MjMzMzMzMzMzXSwgWzM4Ljk4NjYxNjY2NjY2NjcsIC03Ny4xMDcyMl0sIFszOC45ODY3MjUsIC03Ny4xMDczNDY2NjY2NjY3XSwgWzM5LjAxMTY1MTY2NjY2NjcsIC03Ny4xOTkwODMzMzMzMzMzXSwgWzM5LjA1NDA2NjY2NjY2NjcsIC03Ny4xMzk2ODVdLCBbMzkuMTU0OTI2NjY2NjY2NywgLTc3LjIxNDQ3MzMzMzMzMzNdLCBbMzkuMTU0OTI2NjY2NjY2NywgLTc3LjIxNDQ3MzMzMzMzMzNdLCBbMzkuMTc2NDMzMzMzMzMzMywgLTc3LjM1ODk0XSwgWzM5LjE3NjQzMzMzMzMzMzMsIC03Ny4zNTg5NF0sIFszOS4xMTg3MDMzMzMzMzMzLCAtNzcuMDc3NDA2NjY2NjY2N10sIFszOS4wMTMyMDUsIC03Ny4xMDY4MjVdLCBbMzkuMDEzMTYxNjY2NjY2NywgLTc3LjEwNjg3XSwgWzM5LjA3OTkwNSwgLTc3LjAwMTQwMzMzMzMzMzNdLCBbMzkuMTQ4MTgxNjY2NjY2NywgLTc3LjI3ODY3ODMzMzMzMzNdLCBbMzkuMTQ3NjI4MzMzMzMzMywgLTc3LjI3NTk4MTY2NjY2NjddLCBbMzkuMTcwNDg1LCAtNzcuMjc4Mzk1XSwgWzM5LjE3MjkzNSwgLTc3LjI2NDUxNjY2NjY2NjddLCBbMzkuMTcxODA2NjY2NjY2NywgLTc3LjI2MzQ5MzMzMzMzMzNdLCBbMzkuMDk2NjksIC03Ni45Mzc1NTE2NjY2NjY3XSwgWzM5LjA3NTU5LCAtNzYuOTk0NTI4MzMzMzMzM10sIFszOS4xNTc2MjE2NjY2NjY3LCAtNzcuMDQ4OTA4MzMzMzMzM10sIFszOS4wMTIwMjE2NjY2NjY3LCAtNzcuMTk5NzA4MzMzMzMzM10sIFszOS4wMTM0MzY2NjY2NjY3LCAtNzcuMjAzMTIzMzMzMzMzM10sIFszOS4wNzQ5MjE2NjY2NjY3LCAtNzcuMDkzOTJdLCBbMzkuMTg2Nzc1LCAtNzcuNDA1MzUzMzMzMzMzM10sIFszOS4xODY3NzUsIC03Ny40MDUzNTMzMzMzMzMzXSwgWzM5LjA5NjEwNjY2NjY2NjcsIC03Ny4xNzcxMzMzMzMzMzMzXSwgWzM5LjA5MTU5ODMzMzMzMzMsIC03Ny4xNzUyODE2NjY2NjY3XSwgWzM5LjA2NDQxNjY2NjY2NjcsIC03Ny4xNTYyNTY2NjY2NjY3XSwgWzM5LjA0NTUzNSwgLTc3LjE0OTIyMTY2NjY2NjddLCBbMzkuMDU2MzMsIC03Ny4xMTcyMTgzMzMzMzMzXSwgWzM5LjAzNDcwMTY2NjY2NjcsIC03Ny4wNzA4MTMzMzMzMzMzXSwgWzM5LjAzNDU5NjY2NjY2NjcsIC03Ny4wNzE2MTgzMzMzMzMzXSwgWzM5LjA4MzM5ODMzMzMzMzMsIC03Ni45MzkyMDVdLCBbMzkuMDY5MzY1LCAtNzcuMTA0OTE4MzMzMzMzM10sIFszOS4wNjkzNjUsIC03Ny4xMDQ5MTgzMzMzMzMzXSwgWzM5LjA2OTM2NSwgLTc3LjEwNDkxODMzMzMzMzNdLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTI1MDkzMzMzMzMzMywgLTc3LjE4MTg3MTY2NjY2NjddLCBbMzkuMTIyODM1LCAtNzcuMTc4MTI4MzMzMzMzM10sIFszOS4xMzkxNzE2NjY2NjY3LCAtNzcuMTkzNzI1XSwgWzM5LjAxMjE2NSwgLTc3LjE5OTg2ODMzMzMzMzNdLCBbMzkuMDA2NjUzMzMzMzMzMywgLTc3LjE5MTM3XSwgWzM5LjAxNDc3LCAtNzcuMjA0NDI1XSwgWzM5LjExODMxMTY2NjY2NjcsIC03Ny4zMTY1Ml0sIFszOS4wMTQ5NTMzMzMzMzMzLCAtNzcuMDAwNDMzMzMzMzMzM10sIFszOS4wMTQ5NTMzMzMzMzMzLCAtNzcuMDAwNDMzMzMzMzMzM10sIFszOS4wNTM3NjY2NjY2NjY3LCAtNzcuMDUwNzk4MzMzMzMzM10sIFszOC45ODgwMjY2NjY2NjY3LCAtNzcuMDI3XSwgWzM4Ljk4ODAyNjY2NjY2NjcsIC03Ny4wMjddLCBbMzguOTg5ODE2NjY2NjY2NywgLTc3LjAyNjQyNV0sIFszOS4wMDQ3MTUsIC03Ny4wNzc3NjY2NjY2NjY3XSwgWzM5LjAzMDI3LCAtNzcuMDg0ODU1XSwgWzM5LjAzMDI3LCAtNzcuMDg0ODU1XSwgWzM5LjE0NDk1NjY2NjY2NjcsIC03Ny4yMTg5OTgzMzMzMzMzXSwgWzM5LjE0NDk1NjY2NjY2NjcsIC03Ny4yMTg5OTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTc5MzMzMzMzMzMsIC03Ny4wNzQ1NTgzMzMzMzMzXSwgWzM5LjAyOTgxODMzMzMzMzMsIC03Ny4wNzM3NzMzMzMzMzMzXSwgWzM5LjAyOTgxODMzMzMzMzMsIC03Ny4wNzM3NzMzMzMzMzMzXSwgWzM5LjAyOTgxODMzMzMzMzMsIC03Ny4wNzM3NzMzMzMzMzMzXSwgWzM5LjAyOTczNSwgLTc3LjA3NDY5MzMzMzMzMzNdLCBbMzkuMDI5NzM1LCAtNzcuMDc0NjkzMzMzMzMzM10sIFszOS4wMjk3MzUsIC03Ny4wNzQ2OTMzMzMzMzMzXSwgWzM5LjAyOTI3LCAtNzcuMDY4ODA4MzMzMzMzM10sIFszOS4wMjkyNywgLTc3LjA2ODgwODMzMzMzMzNdLCBbMzkuMDI5NDI2NjY2NjY2NywgLTc3LjA3NDg4MTY2NjY2NjddLCBbMzkuMDI5NDI2NjY2NjY2NywgLTc3LjA3NDg4MTY2NjY2NjddLCBbMzkuMDI5NDI2NjY2NjY2NywgLTc3LjA3NDg4MTY2NjY2NjddLCBbMzkuMTI3MDczMzMzMzMzMywgLTc3LjExODQyXSwgWzM5LjE4MDUzMTY2NjY2NjcsIC03Ny4yNjIzMl0sIFszOS4wMzgxNTMzMzMzMzMzLCAtNzYuOTk4OTU4MzMzMzMzM10sIFszOS4wMzgxNTMzMzMzMzMzLCAtNzYuOTk4OTU4MzMzMzMzM10sIFszOS4wMzgxNTMzMzMzMzMzLCAtNzYuOTk4OTU4MzMzMzMzM10sIFszOC45ODUxMjE2NjY2NjY3LCAtNzcuMDk0MDMzMzMzMzMzM10sIFszOS4wMDc4MiwgLTc2Ljk4NDM4XSwgWzM5LjE1ODA0LCAtNzcuMjI4MDQ2NjY2NjY2N10sIFszOS4wMDc5NzgzMzMzMzMzLCAtNzYuOTg0NDAxNjY2NjY2N10sIFszOS4wMDg2MTUsIC03Ni45ODQxOTY2NjY2NjY3XSwgWzM5LjAwODYxNSwgLTc2Ljk4NDE5NjY2NjY2NjddLCBbMzkuMDA4NzgsIC03Ni45ODQxODY2NjY2NjY3XSwgWzM5LjAwODc3MzMzMzMzMzMsIC03Ni45ODQyNDY2NjY2NjY3XSwgWzM5LjAwOTI5NjY2NjY2NjcsIC03Ni45ODQwMjE2NjY2NjY3XSwgWzM5LjAwOTE2MTY2NjY2NjcsIC03Ni45ODM5ODgzMzMzMzMzXSwgWzM5LjAwODk4NSwgLTc2Ljk4NDE4XSwgWzM5LjAwODM2MzMzMzMzMzMsIC03Ni45ODQyNzY2NjY2NjY3XSwgWzM5LjAwODEwMzMzMzMzMzMsIC03Ni45ODQzODE2NjY2NjY3XSwgWzM5LjAwNzk3NjY2NjY2NjcsIC03Ni45ODQ0MDMzMzMzMzMzXSwgWzM5LjAwNzk3NjY2NjY2NjcsIC03Ni45ODQ0MDMzMzMzMzMzXSwgWzM5LjAwNzgyLCAtNzYuOTg0MzhdLCBbMzguOTk5MDQ1LCAtNzYuOTk3ODZdLCBbMzguOTk5MDQ1LCAtNzYuOTk3ODZdLCBbMzguOTk5MDQ1LCAtNzYuOTk3ODZdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMTU4MDQsIC03Ny4yMjgwNDY2NjY2NjY3XSwgWzM5LjE3OTU1NjY2NjY2NjcsIC03Ny4yNjQ4ODVdLCBbMzkuMDMzMzI4MzMzMzMzMywgLTc3LjA0ODk3MzMzMzMzMzNdLCBbMzkuMDAxMzE2NjY2NjY2NywgLTc2Ljk5NTcwMTY2NjY2NjddLCBbMzkuMTE5NDYxNjY2NjY2NywgLTc3LjAxODg4XSwgWzM4Ljk4NjQzLCAtNzcuMDk0NzEzMzMzMzMzM10sIFszOS4wMjY4ODY2NjY2NjY3LCAtNzcuMDc3MDg1XSwgWzM4Ljk4MjAyNSwgLTc3LjA5OTg4MzMzMzMzMzNdLCBbMzguOTgyMDI1LCAtNzcuMDk5ODgzMzMzMzMzM10sIFszOS4wNDY3NjE2NjY2NjY3LCAtNzcuMTEyNV0sIFszOS4yNjYzNywgLTc3LjIwMTE5XSwgWzM5LjI2NjM3LCAtNzcuMjAxMTldLCBbMzkuMTcwODE1LCAtNzcuMjc4MDk2NjY2NjY2N10sIFszOS4xNzE2OTgzMzMzMzMzLCAtNzcuMjc3MzRdLCBbMzkuMTc5NTU2NjY2NjY2NywgLTc3LjI2NDg4NV0sIFszOS4wMDI3MiwgLTc3LjAwNjM3NV0sIFszOS4wMDYzNzY2NjY2NjY3LCAtNzcuMDA3MzQ2NjY2NjY2N10sIFszOS4wMDAxOSwgLTc3LjAxMjEzXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjAyNjcxODMzMzMzMzMsIC03Ny4wNDY4NjE2NjY2NjY3XSwgWzM5LjAzMzMyODMzMzMzMzMsIC03Ny4wNDg5NzMzMzMzMzMzXSwgWzM5LjE5MDU5MTY2NjY2NjcsIC03Ny4yNzMyMTMzMzMzMzMzXSwgWzM5LjE5MDU5MTY2NjY2NjcsIC03Ny4yNzMyMTMzMzMzMzMzXSwgWzM5LjE4MjgxLCAtNzcuMjc0MjNdLCBbMzkuMTgyODEsIC03Ny4yNzQyM10sIFszOS4xODI4MSwgLTc3LjI3NDIzXSwgWzM5LjAwMDczODMzMzMzMzMsIC03Ny4wMTA5N10sIFszOS4wMDQ1MywgLTc3LjAxNDgyNV0sIFszOS4wMDUwNSwgLTc3LjAyMjEzODMzMzMzMzNdLCBbMzkuMTgyMzcsIC03Ny4yNjQyNV0sIFszOS4xODIzNywgLTc3LjI2NDI1XSwgWzM5LjE4MjM3LCAtNzcuMjY0MjVdLCBbMzkuMTgyMzcsIC03Ny4yNjQyNV0sIFszOS4xODIzNywgLTc3LjI2NDI1XSwgWzM5LjE4MjM3LCAtNzcuMjY0MjVdLCBbMzkuMTgyMzcsIC03Ny4yNjQyNV0sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzguOTg0MjgxNjY2NjY2NywgLTc3LjA5NDEwNjY2NjY2NjddLCBbMzguOTgxOTM2NjY2NjY2NywgLTc3LjA5OTc1MzMzMzMzMzNdLCBbMzkuMDI2NTY2NjY2NjY2NywgLTc3LjAyMDIyNV0sIFszOS4wMjY1NjY2NjY2NjY3LCAtNzcuMDIwMjI1XSwgWzM5LjAyNjU2NjY2NjY2NjcsIC03Ny4wMjAyMjVdLCBbMzkuMDAxMzE2NjY2NjY2NywgLTc2Ljk5NTcwMTY2NjY2NjddLCBbMzkuMDI0Mzk4MzMzMzMzMywgLTc3LjAxODA3NV0sIFszOS4wMTgwMzMzMzMzMzMzLCAtNzcuMDA3MzY4MzMzMzMzM10sIFszOS4wMDIyMzMzMzMzMzMzLCAtNzcuMDA0ODY1XSwgWzM5LjAwMjUyODMzMzMzMzMsIC03Ny4wMDUxMDgzMzMzMzMzXSwgWzM5LjAwMTg0LCAtNzcuMDA0Nzc4MzMzMzMzM10sIFszOC45OTQzNjE2NjY2NjY3LCAtNzYuOTkyNzQxNjY2NjY2N10sIFszOS4wMzIwNDY2NjY2NjY3LCAtNzcuMDcyNDc1XSwgWzM5LjAzMjAxLCAtNzcuMDcyNDkzMzMzMzMzM10sIFszOS4wMzE5MjY2NjY2NjY3LCAtNzcuMDcyNDQ4MzMzMzMzM10sIFszOS4wMzE4NiwgLTc3LjA3MjI3NV0sIFszOS4wMzE5ODY2NjY2NjY3LCAtNzcuMDcyNDI2NjY2NjY2N10sIFszOS4xMzA3MTMzMzMzMzMzLCAtNzcuMTg3ODk2NjY2NjY2N10sIFszOS4xMzA3MTMzMzMzMzMzLCAtNzcuMTg3ODk2NjY2NjY2N10sIFszOS4xMzI4MTgzMzMzMzMzLCAtNzcuMTg5NTNdLCBbMzkuMTMyODE4MzMzMzMzMywgLTc3LjE4OTUzXSwgWzM5LjEzMDczLCAtNzcuMTg3OTddLCBbMzkuMTMwNzMsIC03Ny4xODc5N10sIFszOS4xMzA3MywgLTc3LjE4Nzk3XSwgWzM5LjEzMzg0ODMzMzMzMzMsIC03Ny4yNDQ3NjVdLCBbMzkuMTM2MTY4MzMzMzMzMywgLTc3LjI0Mjk5NV0sIFszOS4xMzIyNjgzMzMzMzMzLCAtNzcuMTY0ODkzMzMzMzMzM10sIFszOS4xMzIyNjgzMzMzMzMzLCAtNzcuMTY0ODkzMzMzMzMzM10sIFszOS4xODk3ODMzMzMzMzMzLCAtNzcuMjQ5NzAzMzMzMzMzM10sIFszOS4wMTIzODUsIC03Ny4wODA1OTVdLCBbMzkuMTI0NjcxNjY2NjY2NywgLTc3LjIwMDQ1MzMzMzMzMzNdLCBbMzkuMTAyMTg1LCAtNzcuMTc3OTUzMzMzMzMzM10sIFszOS4xMDIxODUsIC03Ny4xNzc5NTMzMzMzMzMzXSwgWzM5LjEwMjE4NSwgLTc3LjE3Nzk1MzMzMzMzMzNdLCBbMzguOTg1NzUxNjY2NjY2NywgLTc3LjA3NzAzNV0sIFszOC45ODU3NTE2NjY2NjY3LCAtNzcuMDc3MDM1XSwgWzM4Ljk4NjY3NSwgLTc3LjA3NDc4MTY2NjY2NjddLCBbMzguOTg2Njc1LCAtNzcuMDc0NzgxNjY2NjY2N10sIFszOC45ODY2NzUsIC03Ny4wNzQ3ODE2NjY2NjY3XSwgWzM4Ljk4NTc3ODMzMzMzMzMsIC03Ny4wNzY3MzE2NjY2NjY3XSwgWzM4Ljk4NTc3ODMzMzMzMzMsIC03Ny4wNzY3MzE2NjY2NjY3XSwgWzM5LjEzNDc4MzMzMzMzMzMsIC03Ny40MDA1NzY2NjY2NjY3XSwgWzM5LjEzNzc1MzMzMzMzMzMsIC03Ny4zOTc5NzMzMzMzMzMzXSwgWzM5LjE1NjY3NjY2NjY2NjcsIC03Ny40NDczNDVdLCBbMzkuMTcxNTI4MzMzMzMzMywgLTc3LjQ2NjM2NV0sIFszOS4xNzEzNzY2NjY2NjY3LCAtNzcuNDY1NTAxNjY2NjY2N10sIFszOS4xNzEzNzY2NjY2NjY3LCAtNzcuNDY1NTAxNjY2NjY2N10sIFszOS4xMjM5NzE2NjY2NjY3LCAtNzcuMTc1NTY1XSwgWzM5LjEyNDAxNSwgLTc3LjE3NTg0NjY2NjY2NjddLCBbMzkuMTI0MDE1LCAtNzcuMTc1ODQ2NjY2NjY2N10sIFszOS4xMjQwMTUsIC03Ny4xNzU4NDY2NjY2NjY3XSwgWzM5LjE5NDcyODMzMzMzMzMsIC03Ny4xNTQxNF0sIFszOS4xOTQ4MjY2NjY2NjY3LCAtNzcuMTU0MTI2NjY2NjY2N10sIFszOS4xOTQ3OTE2NjY2NjY3LCAtNzcuMTU0MDkzMzMzMzMzM10sIFszOS4xOTQ3OTE2NjY2NjY3LCAtNzcuMTU0MDkzMzMzMzMzM10sIFszOS4xNjM3NDUsIC03Ny4yMTQ2OTMzMzMzMzMzXSwgWzM5LjE2Mzc0NSwgLTc3LjIxNDY5MzMzMzMzMzNdLCBbMzkuMTYzNzQ1LCAtNzcuMjE0NjkzMzMzMzMzM10sIFszOS4xNjM3NDUsIC03Ny4yMTQ2OTMzMzMzMzMzXSwgWzM5LjExMjgxNjY2NjY2NjcsIC03Ny4xNjIxNjVdLCBbMzkuMTU5NTE4MzMzMzMzMywgLTc3LjI3Njg0NjY2NjY2NjddLCBbMzkuMTU5NTE4MzMzMzMzMywgLTc3LjI3Njg0NjY2NjY2NjddLCBbMzkuMTIwNzgsIC03Ny4wMTU3NjE2NjY2NjY3XSwgWzM5LjE5ODA0NSwgLTc3LjI2MzA2MzMzMzMzMzNdLCBbMzkuMTc4NDk4MzMzMzMzMywgLTc3LjI0MDc1XSwgWzM5LjE4MDQ1LCAtNzcuMjYyNDAzMzMzMzMzM10sIFszOS4xODA0NSwgLTc3LjI2MjQwMzMzMzMzMzNdLCBbMzkuMDIyNjQ4MzMzMzMzMywgLTc3LjA3MTc2NjY2NjY2NjddLCBbMzkuMDMyOTgxNjY2NjY2NywgLTc3LjA3MjczNjY2NjY2NjddLCBbMzkuMDMzMDIsIC03Ny4wNzI1MzMzMzMzMzMzXSwgWzM5LjE1MzUzLCAtNzcuMjEyNzIxNjY2NjY2N10sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjEzNDYyMTY2NjY2NjcsIC03Ny40MDEzNTVdLCBbMzkuMTM0NjIxNjY2NjY2NywgLTc3LjQwMTM1NV0sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjA4NDYyLCAtNzcuMDc5OTQ2NjY2NjY2N10sIFszOC45OTE5NzUsIC03Ny4wOTU3MzgzMzMzMzMzXSwgWzM4Ljk4NjY3MTY2NjY2NjcsIC03Ny4wOTQ3MzVdLCBbMzguOTg2NDMsIC03Ny4wOTQ3MTMzMzMzMzMzXSwgWzM4Ljk4NjQzLCAtNzcuMDk0NzEzMzMzMzMzM10sIFszOC45OTA4OSwgLTc3LjA5NTUxNV0sIFszOS4wMTAwMTE2NjY2NjY3LCAtNzcuMDkxNzU2NjY2NjY2N10sIFszOS4wMTIzODUsIC03Ny4wODA1OTVdLCBbMC4wLCAwLjBdLCBbMzkuMTM2MTgxNjY2NjY2NywgLTc3LjE1MjAzXSwgWzM5LjE4MzI0ODMzMzMzMzMsIC03Ny4yNzAzNTVdLCBbMzkuMDk4NTg4MzMzMzMzMywgLTc2LjkzNjQ3NV0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFszOS4xMTQ3NjMzMzMzMzMzLCAtNzcuMTk3MzkzMzMzMzMzM10sIFszOS4xMTQzMjY2NjY2NjY3LCAtNzcuMTk1NDMzMzMzMzMzM10sIFszOS4xNTM1MywgLTc3LjIxMjcyMTY2NjY2NjddLCBbMzkuMTM0NzczMzMzMzMzMywgLTc3LjQwMDYzMzMzMzMzMzNdLCBbMzkuMTM0NzczMzMzMzMzMywgLTc3LjQwMDYzMzMzMzMzMzNdLCBbMzkuMTM0NzczMzMzMzMzMywgLTc3LjQwMDYzMzMzMzMzMzNdLCBbMzkuMTM0Nzc2NjY2NjY2NywgLTc3LjQwMDU4NV0sIFszOS4xNTY2NzY2NjY2NjY3LCAtNzcuNDQ3MzQ1XSwgWzM5LjE3MTUyMzMzMzMzMzMsIC03Ny40NjYyMl0sIFszOS4xNzE1MTY2NjY2NjY3LCAtNzcuNDY2NzUxNjY2NjY2N10sIFszOS4xNzE1MjgzMzMzMzMzLCAtNzcuNDY2MzY1XSwgWzM5LjA0MzI1MTY2NjY2NjcsIC03Ni45ODMyNzVdLCBbMzkuMDQzMjUxNjY2NjY2NywgLTc2Ljk4MzI3NV0sIFszOS4wNDMyNTE2NjY2NjY3LCAtNzYuOTgzMjc1XSwgWzM5LjA0MzI1MTY2NjY2NjcsIC03Ni45ODMyNzVdLCBbMzkuMDQzMjUxNjY2NjY2NywgLTc2Ljk4MzI3NV0sIFszOS4xMTUyMTgzMzMzMzMzLCAtNzcuMDE2Nl0sIFszOS4xMTUyMTgzMzMzMzMzLCAtNzcuMDE2Nl0sIFszOS4xMTk0NjE2NjY2NjY3LCAtNzcuMDE4ODhdLCBbMzkuMTE5NDYxNjY2NjY2NywgLTc3LjAxODg4XSwgWzM5LjE5ODA0NSwgLTc3LjI2MzA2MzMzMzMzMzNdLCBbMzkuMDg2NzIzMzMzMzMzMywgLTc3LjE2NzQzMTY2NjY2NjddLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzkuMDg1ODE4MzMzMzMzMywgLTc2Ljk0NTQzODMzMzMzMzNdLCBbMzguOTg1MDM1LCAtNzcuMDk0NDMzMzMzMzMzM10sIFszOC45ODQyODE2NjY2NjY3LCAtNzcuMDk0MTA2NjY2NjY2N10sIFszOC45ODE5MzY2NjY2NjY3LCAtNzcuMDk5NzUzMzMzMzMzM10sIFszOC45ODE5MzY2NjY2NjY3LCAtNzcuMDk5NzUzMzMzMzMzM10sIFszOC45ODIwOTE2NjY2NjY3LCAtNzcuMDk5MjYxNjY2NjY2N10sIFszOC45ODE5MzMzMzMzMzMzLCAtNzcuMTAwMTFdLCBbMzkuMDI5ODg4MzMzMzMzMywgLTc3LjA0ODc4NjY2NjY2NjddLCBbMzkuMDI5ODg4MzMzMzMzMywgLTc3LjA0ODc4NjY2NjY2NjddLCBbMzkuMTM0NjIxNjY2NjY2NywgLTc3LjQwMTM1NV0sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjEzNDYyMTY2NjY2NjcsIC03Ny40MDEzNTVdLCBbMzkuMTM0NjIxNjY2NjY2NywgLTc3LjQwMTM1NV0sIFszOS4xMzQ2MjE2NjY2NjY3LCAtNzcuNDAxMzU1XSwgWzM5LjA0MzI5NjY2NjY2NjcsIC03Ny4wNTIwNzY2NjY2NjY3XSwgWzM5LjA0MzI5NjY2NjY2NjcsIC03Ny4wNTIwNzY2NjY2NjY3XSwgWzM4Ljk5NDg1ODMzMzMzMzMsIC03Ny4wMjU3MTY2NjY2NjY3XSwgWzM5LjEzMTg0NSwgLTc3LjIwNjg0NjY2NjY2NjddLCBbMzkuMDk4NTc1LCAtNzcuMTM3NzM4MzMzMzMzM10sIFszOS4wMzEwOTgzMzMzMzMzLCAtNzcuMDc1NzI1XSwgWzM5LjAzMTI0LCAtNzcuMDc1MDI4MzMzMzMzM10sIFszOS4wMjY4ODY2NjY2NjY3LCAtNzcuMDc3MDg1XSwgWzM4Ljk4MjAyNSwgLTc3LjA5OTg4MzMzMzMzMzNdLCBbMzkuMDMyMDA1LCAtNzcuMDcyNDQxNjY2NjY2N10sIFszOS4wMzE5MjY2NjY2NjY3LCAtNzcuMDcyNDQ4MzMzMzMzM10sIFszOS4wMzE5NzY2NjY2NjY3LCAtNzcuMDcyNDM2NjY2NjY2N10sIFszOS4wMzE5NzY2NjY2NjY3LCAtNzcuMDcyNDM2NjY2NjY2N10sIFszOS4wMzE1OTUsIC03Ny4wNzE5OTE2NjY2NjY3XSwgWzM5LjAzMTk3MTY2NjY2NjcsIC03Ny4wNzIzMzMzMzMzMzMzXSwgWzM5LjAzMjA0NjY2NjY2NjcsIC03Ny4wNzI0OTgzMzMzMzMzXSwgWzM5LjAzMTk4NjY2NjY2NjcsIC03Ny4wNzI0MjY2NjY2NjY3XSwgWzM5LjA0ODc5MzMzMzMzMzMsIC03Ny4xMTk4NDY2NjY2NjY3XSwgWzM5LjA4NDY4LCAtNzcuMDgwMDIzMzMzMzMzM10sIFszOS4wODQ2NDY2NjY2NjY3LCAtNzcuMDgwMDAzMzMzMzMzM10sIFszOS4wODQ1NzgzMzMzMzMzLCAtNzcuMDc5OTA1XSwgWzM5LjA4NDY3NSwgLTc3LjA4MDAwMTY2NjY2NjddLCBbMzkuMDg0NjIsIC03Ny4wNzk5NDY2NjY2NjY3XSwgWzM5LjExOTYxLCAtNzcuMDk2OTg1XSwgWzM4Ljk5NDM2MTY2NjY2NjcsIC03Ni45OTI3NDE2NjY2NjY3XSwgWzM5LjEzNjE3ODMzMzMzMzMsIC03Ny4yNDMwOV0sIFszOC45OTY5MTMzMzMzMzMzLCAtNzYuOTkzNjRdLCBbMzguOTk2OTEzMzMzMzMzMywgLTc2Ljk5MzY0XSwgWzM5LjA0MDg4ODMzMzMzMzMsIC03Ny4wNTIxNDVdLCBbMzkuMDQwODg4MzMzMzMzMywgLTc3LjA1MjE0NV0sIFszOS4wNDA4ODgzMzMzMzMzLCAtNzcuMDUyMTQ1XSwgWzM5LjA0MDg4ODMzMzMzMzMsIC03Ny4wNTIxNDVdLCBbMzkuMTEyNjYsIC03Ni45MzI4MTMzMzMzMzMzXSwgWzM5LjE4OTc4MzMzMzMzMzMsIC03Ny4yNDk3MDMzMzMzMzMzXSwgWzM5LjEwNTM5MzMzMzMzMzMsIC03Ny4xOTc1ODE2NjY2NjY3XSwgWzM5LjE2NjQzNjY2NjY2NjcsIC03Ny4yODExODgzMzMzMzMzXSwgWzM5LjExOTAxNjY2NjY2NjcsIC03Ny4xODE5NzE2NjY2NjY3XSwgWzM5LjA5NzExLCAtNzcuMjI5NjEzMzMzMzMzM10sIFszOS4xMTA3NSwgLTc3LjI1MjQzMzMzMzMzMzNdLCBbMzkuMTEwNjM4MzMzMzMzMywgLTc3LjI1Mjc0NV0sIFszOS4xMTU1OTgzMzMzMzMzLCAtNzcuMjUyODg1XSwgWzM5LjExNTU5ODMzMzMzMzMsIC03Ny4yNTI4ODVdLCBbMzkuMTE1NzM2NjY2NjY2NywgLTc3LjI1MjkxMzMzMzMzMzNdLCBbMzkuMTE0NSwgLTc3LjI1MzM4MzMzMzMzMzNdLCBbMzkuMDk2NzY1LCAtNzcuMjY1NzMzMzMzMzMzM10sIFszOS4wOTY3NjUsIC03Ny4yNjU3MzMzMzMzMzMzXSwgWzM5LjA5NDQ2NjY2NjY2NjcsIC03Ny4yNjU3NDY2NjY2NjY3XSwgWzM5LjA5NDQ2NjY2NjY2NjcsIC03Ny4yNjU3NDY2NjY2NjY3XSwgWzM5LjE0NTgxMTY2NjY2NjcsIC03Ny4xOTIyNDVdLCBbMzkuMTMwMTgzMzMzMzMzMywgLTc3LjEyMzM3NjY2NjY2NjddLCBbMzkuMTMwMTgzMzMzMzMzMywgLTc3LjEyMzM3NjY2NjY2NjddLCBbMzkuMTIyMzUsIC03Ny4wNzM5NTMzMzMzMzMzXSwgWzM5LjE1ODQ3ODMzMzMzMzMsIC03Ny4wNjQ3NDgzMzMzMzMzXSwgWzM5LjA3NDc2ODMzMzMzMzMsIC03Ni45OTgyMzY2NjY2NjY3XSwgWzM5LjA3NDc2ODMzMzMzMzMsIC03Ni45OTgyMzY2NjY2NjY3XSwgWzM5LjA3NDc2ODMzMzMzMzMsIC03Ni45OTgyMzY2NjY2NjY3XSwgWzM5LjA3NTAyODMzMzMzMzMsIC03Ni45OTkwMl0sIFszOS4wNzg0NDE2NjY2NjY3LCAtNzcuMDcyMjczMzMzMzMzM10sIFszOS4wMTg5NiwgLTc3LjA1MDFdLCBbMzkuMTI0MTU2NjY2NjY2NywgLTc3LjIwMDAzMzMzMzMzMzNdLCBbMzkuMTgzMDk1LCAtNzcuMjU3NTg1XSwgWzM5LjE2OTMwMTY2NjY2NjcsIC03Ny4yNzkzMTE2NjY2NjY3XSwgWzM5LjE2OTMwMTY2NjY2NjcsIC03Ny4yNzkzMTE2NjY2NjY3XSwgWzM5LjE3MDA0MTY2NjY2NjcsIC03Ny4yNzg4NTMzMzMzMzMzXSwgWzM5LjE2ODg5ODMzMzMzMzMsIC03Ny4yNzk2MDgzMzMzMzMzXSwgWzM5LjE3MDU1LCAtNzcuMjc4Mzg1XSwgWzM5LjE3MDI2NSwgLTc3LjI3ODYwODMzMzMzMzNdLCBbMzkuMTAxODcsIC03Ny4yMTkzMTE2NjY2NjY3XSwgWzM5LjEwMTg3LCAtNzcuMjE5MzExNjY2NjY2N10sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFswLjAsIDAuMF0sIFszOS4wNzQ2MDgzMzMzMzMzLCAtNzYuOTk4MDYxNjY2NjY2N10sIFszOS4wNzQ2MDgzMzMzMzMzLCAtNzYuOTk4MjE4MzMzMzMzM10sIFszOS4wNzQ5MSwgLTc2Ljk5ODM1NV0sIFszOS4wNDE2MywgLTc3LjE0NzUzNV0sIFszOS4wNDQ0MTY2NjY2NjY3LCAtNzcuMTExOTExNjY2NjY2N10sIFszOS4xMTcwMzMzMzMzMzMzLCAtNzcuMjUxOTAzMzMzMzMzM10sIFszOS4xMTc1NzE2NjY2NjY3LCAtNzcuMjUxMjM2NjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMjA5NzgzMzMzMzMzLCAtNzcuMTU4MTQxNjY2NjY2N10sIFszOS4xMTcwMTE2NjY2NjY3LCAtNzcuMjUyNzFdLCBbMzkuMTE4Mzg2NjY2NjY2NywgLTc3LjI1MTE2NV0sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4wNTkwMzMzMzMzMzMzLCAtNzcuMTYxMzY2NjY2NjY2N10sIFszOS4xODk5MTUsIC03Ny4yNDE5MTVdLCBbMzkuMDg3NDI2NjY2NjY2NywgLTc3LjE3Mzk1MTY2NjY2NjddLCBbMzkuMTE1Njc4MzMzMzMzMywgLTc3LjI1Mjk2MTY2NjY2NjddLCBbMzkuMTA4NiwgLTc3LjE4NTQyNjY2NjY2NjddLCBbMzkuMTEzNTYxNjY2NjY2NywgLTc3LjI0MjgyMzMzMzMzMzNdLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDc0NzY4MzMzMzMzMywgLTc2Ljk5ODIzNjY2NjY2NjddLCBbMzkuMDMyMjYxNjY2NjY2NywgLTc3LjA3NDI3MTY2NjY2NjddLCBbMzkuMDMzNTkxNjY2NjY2NywgLTc3LjA3Mjg4NV0sIFszOS4wMzM5NCwgLTc3LjA3MjIzNjY2NjY2NjddLCBbMzkuMDMzNjk2NjY2NjY2NywgLTc3LjA3MzAzMzMzMzMzMzNdLCBbMzkuMDMzNDkzMzMzMzMzMywgLTc3LjA3MzM1NV0sIFszOS4wMzQ1OTE2NjY2NjY3LCAtNzcuMDcxMzQ1XSwgWzM5LjAzMzkyNjY2NjY2NjcsIC03Ny4wNzIyNjE2NjY2NjY3XSwgWzM5LjEwMTg3LCAtNzcuMjE5MzExNjY2NjY2N10sIFszOS4xMDE4NywgLTc3LjIxOTMxMTY2NjY2NjddLCBbMzkuMTQ1ODExNjY2NjY2NywgLTc3LjE5MjI0NV0sIFszOS4xNDU4MTE2NjY2NjY3LCAtNzcuMTkyMjQ1XSwgWzM5LjE0NTgxMTY2NjY2NjcsIC03Ny4xOTIyNDVdLCBbMzkuMTE1ODEsIC03Ny4xODU5NTgzMzMzMzMzXSwgWzM5LjExNTgxLCAtNzcuMTg1OTU4MzMzMzMzM10sIFszOS4xMTU4MSwgLTc3LjE4NTk1ODMzMzMzMzNdLCBbMzkuMTE1ODEsIC03Ny4xODU5NTgzMzMzMzMzXSwgWzM5LjEyMTMxNjY2NjY2NjcsIC03Ny4xNjE2MTVdLCBbMzkuMTAxMTE1LCAtNzcuMDQ1MjQ2NjY2NjY2N10sIFszOS4wNzQ2MDgzMzMzMzMzLCAtNzYuOTk4MDYxNjY2NjY2N10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wMjQzNTE2NjY2NjY3LCAtNzcuMDQ1MDMzMzMzMzMzM10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOS4wNTcxMjE2NjY2NjY3LCAtNzcuMDQ5NjU2NjY2NjY2N10sIFszOC45OTk5OSwgLTc3LjAyNTcwNV0sIFszOC45OTk5OSwgLTc3LjAyNTcwNV0sIFszOS4xNTc1NDgzMzMzMzMzLCAtNzcuMTg4NzJdLCBbMzkuMTU3NTg1LCAtNzcuMTg5MTIzMzMzMzMzM10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjEzOTk3LCAtNzcuMTgyNzFdLCBbMzkuMTM5OTcsIC03Ny4xODI3MV0sIFszOS4xMzk5NywgLTc3LjE4MjcxXSwgWzM5LjEzOTk3LCAtNzcuMTgyNzFdLCBbMzkuMTM5OTcsIC03Ny4xODI3MV0sIFszOS4xMzk5NywgLTc3LjE4MjcxXSwgWzM5LjEzOTk3LCAtNzcuMTgyNzFdLCBbMzkuMDMxNTE2NjY2NjY2NywgLTc3LjA0ODM3NV0sIFszOS4wNDQ0MTY2NjY2NjY3LCAtNzcuMTExOTExNjY2NjY2N10sIFszOS4wMzE1MTY2NjY2NjY3LCAtNzcuMDQ4Mzc1XSwgWzM5LjAzMTUxNjY2NjY2NjcsIC03Ny4wNDgzNzVdLCBbMzkuMDAxMTcsIC03Ni45ODU1NjVdLCBbMzkuMDAxMTcsIC03Ni45ODU1NjVdLCBbMzkuMDQxNzE1LCAtNzYuOTk0OTI2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM5LjA2NzQxMTY2NjY2NjcsIC03Ni45MzcyNV0sIFszOS4wOTA4NTE2NjY2NjY3LCAtNzcuMDc5NzQ4MzMzMzMzM10sIFszOS4wMDg0NDUsIC03Ni45OTg0NTMzMzMzMzMzXSwgWzM5LjAwODQ0NSwgLTc2Ljk5ODQ1MzMzMzMzMzNdLCBbMzguOTk5OTksIC03Ny4wMjU3MDVdLCBbMzkuMjg4NTA1LCAtNzcuMjAxOV0sIFszOS4wNTY1NTUsIC03Ny4wNTAwNDVdLCBbMzguOTg3NjA4MzMzMzMzMywgLTc3LjA5ODYwNjY2NjY2NjddLCBbMzguOTkzNDI2NjY2NjY2NywgLTc3LjAyNjg5MzMzMzMzMzNdLCBbMzguOTkzNDI2NjY2NjY2NywgLTc3LjAyNjg5MzMzMzMzMzNdLCBbMzkuMTE0NDgzMzMzMzMzMywgLTc3LjI2NjQyODMzMzMzMzNdLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4xMzY2NzE2NjY2NjY3LCAtNzcuMzk1MDg1XSwgWzM5LjE2NzYsIC03Ny4yODAzNTgzMzMzMzMzXSwgWzM4Ljk5NjcxNjY2NjY2NjcsIC03Ny4wMTMwMTE2NjY2NjY3XSwgWzM4Ljk5NjcxNjY2NjY2NjcsIC03Ny4wMTMwMTE2NjY2NjY3XSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjExNjc1ODMzMzMzMzMsIC03Ny4yNjExODMzMzMzMzMzXSwgWzM5LjA0ODUxODMzMzMzMzMsIC03Ny4wNTY3ODMzMzMzMzMzXSwgWzM5LjE1MDkyODMzMzMzMzMsIC03Ny4yMDU1NzVdLCBbMzkuMTcwMTc2NjY2NjY2NywgLTc3LjI3ODcyODMzMzMzMzNdLCBbMzkuMDE1NjcxNjY2NjY2NywgLTc3LjA0MzAzODMzMzMzMzNdLCBbMzkuMDE1NjcxNjY2NjY2NywgLTc3LjA0MzAzODMzMzMzMzNdLCBbMzkuMDE1NjcxNjY2NjY2NywgLTc3LjA0MzAzODMzMzMzMzNdLCBbMzguOTkxODE4MzMzMzMzMywgLTc3LjAzMDgxMzMzMzMzMzNdLCBbMzguOTkxODE4MzMzMzMzMywgLTc3LjAzMDgxMzMzMzMzMzNdLCBbMzkuMTQ5NDM4MzMzMzMzMywgLTc3LjE4OTEyXSwgWzM5LjE0OTQzODMzMzMzMzMsIC03Ny4xODkxMl0sIFszOS4xNDk0MzgzMzMzMzMzLCAtNzcuMTg5MTJdLCBbMzkuMTcwMzQxNjY2NjY2NywgLTc3LjI3ODUzMzMzMzMzMzNdLCBbMzguOTgyMDUxNjY2NjY2NywgLTc3LjA5OTgxMzMzMzMzMzNdLCBbMzkuMjA1MDc1LCAtNzcuMjcxMzU1XSwgWzM4Ljk4MjA1MTY2NjY2NjcsIC03Ny4wOTk4MTMzMzMzMzMzXSwgWzM5LjE3MjE4ODMzMzMzMzMsIC03Ny4yMDM4NTVdLCBbMzkuMDIwODMsIC03Ny4wNzM0NTE2NjY2NjY3XSwgWzM5LjAyMDgzLCAtNzcuMDczNDUxNjY2NjY2N10sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOS4xNTAzODgzMzMzMzMzLCAtNzcuMDYwODc2NjY2NjY2N10sIFszOS4xNTAzODgzMzMzMzMzLCAtNzcuMDYwODc2NjY2NjY2N10sIFszOS4yMTc1MDgzMzMzMzMzLCAtNzcuMjc3ODA4MzMzMzMzM10sIFszOS4xNjk4ODgzMzMzMzMzLCAtNzcuMjc5MDA2NjY2NjY2N10sIFszOS4yMTc1MDgzMzMzMzMzLCAtNzcuMjc3ODA4MzMzMzMzM10sIFszOS4xNTAzNzE2NjY2NjY3LCAtNzcuMTkwODY1XSwgWzM5LjE1MDM3MTY2NjY2NjcsIC03Ny4xOTA4NjVdLCBbMzkuMTUwMzcxNjY2NjY2NywgLTc3LjE5MDg2NV0sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOS4yMjkwOTY2NjY2NjY3LCAtNzcuMjY3MzY2NjY2NjY2N10sIFszOC45OTQ3MjY2NjY2NjY3LCAtNzcuMDI0MjAzMzMzMzMzM10sIFszOS4xMTA4MzgzMzMzMzMzLCAtNzcuMTg3ODU2NjY2NjY2N10sIFszOS4xNzAyNTE2NjY2NjY3LCAtNzcuMjc4NjA2NjY2NjY2N10sIFszOS4xMDU1MTY2NjY2NjY3LCAtNzcuMTgyMzg1XSwgWzM5LjEwNTUxNjY2NjY2NjcsIC03Ny4xODIzODVdLCBbMzkuMTAxNzkxNjY2NjY2NywgLTc3LjMwNzUyNV0sIFszOS4xNjc5NDMzMzMzMzMzLCAtNzcuMjgwMjI1XSwgWzM5LjE0ODQ5LCAtNzcuMTkyMTRdLCBbMzkuMTQ4NDksIC03Ny4xOTIxNF0sIFszOC45ODIwNTE2NjY2NjY3LCAtNzcuMDk5ODEzMzMzMzMzM10sIFszOS4wOTUzMzE2NjY2NjY3LCAtNzcuMTc2ODkxNjY2NjY2N10sIFszOS4xMDE3OTE2NjY2NjY3LCAtNzcuMzA3NTI1XSwgWzM5LjE0MzUxLCAtNzcuNDA2MjUxNjY2NjY2N10sIFszOS4wNDEzMDgzMzMzMzMzLCAtNzcuMTEzMTc4MzMzMzMzM10sIFszOS4xNTk3MDgzMzMzMzMzLCAtNzcuMjg5OTI1XSwgWzM5LjEwMTY5NjY2NjY2NjcsIC03Ny4zMDc0NTVdLCBbMzkuMTAxNjk2NjY2NjY2NywgLTc3LjMwNzQ1NV0sIFszOS4wNzcxNCwgLTc3LjE2ODM4MTY2NjY2NjddLCBbMzguOTgyMDUxNjY2NjY2NywgLTc3LjA5OTgxMzMzMzMzMzNdLCBbMzkuMTQ1ODIzMzMzMzMzMywgLTc3LjE4NDQ2MzMzMzMzMzNdLCBbMzkuMDg0NjM4MzMzMzMzMywgLTc3LjA3OTkxXSwgWzM5LjE3MDI3NSwgLTc3LjI3ODYyXSwgWzM5LjA0MTc3LCAtNzcuMTEzMjFdLCBbMzkuMDQxNzcsIC03Ny4xMTMyMV0sIFszOS4xMDE3ODY2NjY2NjY3LCAtNzcuMzA3NTI2NjY2NjY2N10sIFszOS4wNzUxNiwgLTc3LjE2MTkyMTY2NjY2NjddLCBbMzkuMDc1MTYsIC03Ny4xNjE5MjE2NjY2NjY3XSwgWzM4Ljk4MTk4NSwgLTc3LjA5OTc5MzMzMzMzMzNdLCBbMzkuMDc1MTYsIC03Ny4xNjE5MjE2NjY2NjY3XSwgWzM4Ljk4MTk4NSwgLTc3LjA5OTc5MzMzMzMzMzNdLCBbMzkuMTU5NzAxNjY2NjY2NywgLTc3LjI4OTk0XSwgWzAuMCwgMC4wXSwgWzM5LjE0NTQ0ODMzMzMzMzMsIC03Ny4xODQ0MDgzMzMzMzMzXSwgWzM5LjEwMTc4NjY2NjY2NjcsIC03Ny4zMDc1MjY2NjY2NjY3XSwgWzM5LjEwMTc4NjY2NjY2NjcsIC03Ny4zMDc1MjY2NjY2NjY3XSwgWzM5LjA3MTc3NSwgLTc3LjE2MTk0MzMzMzMzMzNdLCBbMzkuMDcxNzc1LCAtNzcuMTYxOTQzMzMzMzMzM10sIFszOS4wODQ1OCwgLTc3LjA3OTg1ODMzMzMzMzNdLCBbMzkuMDg0NTgsIC03Ny4wNzk4NTgzMzMzMzMzXSwgWzM5LjA0MTQwMzMzMzMzMzMsIC03Ny4xMTMxNl0sIFszOS4wMzY5NywgLTc3LjA1Mjk0ODMzMzMzMzNdLCBbMzkuMDQxNzE1LCAtNzYuOTk0OTI2NjY2NjY2N10sIFszOS4xMDE3MTE2NjY2NjY3LCAtNzcuMzA3NDY1XSwgWzM4Ljk5Nzc4ODMzMzMzMzMsIC03Ni45OTE2Nl0sIFszOS4wODQ2MzgzMzMzMzMzLCAtNzcuMDc5OTFdLCBbMzkuMDQxMjg1LCAtNzcuMTEzMTY1XSwgWzAuMCwgMC4wXSwgWzM5LjE1MTIyODMzMzMzMzMsIC03Ny4xODg3MjY2NjY2NjY3XSwgWzM5LjE1MTIyODMzMzMzMzMsIC03Ny4xODg3MjY2NjY2NjY3XSwgWzM5LjE1MTIyODMzMzMzMzMsIC03Ny4xODg3MjY2NjY2NjY3XSwgWzM5LjIwNjczLCAtNzcuMjQxNzM4MzMzMzMzM10sIFszOS4wNTM4ODE2NjY2NjY3LCAtNzcuMTUzNTA1XSwgWzM5LjA1Mzg4MTY2NjY2NjcsIC03Ny4xNTM1MDVdLCBbMzkuMjIwMzI2NjY2NjY2NywgLTc3LjA2MDE2NjY2NjY2NjddLCBbMzkuMDQxNDk1LCAtNzcuMDUwODQxNjY2NjY2N10sIFszOS4wNDE0OTUsIC03Ny4wNTA4NDE2NjY2NjY3XSwgWzM5LjA0MTQ5NSwgLTc3LjA1MDg0MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzkuMDQxNzE1LCAtNzYuOTk0OTI2NjY2NjY2N10sIFszOS4wNDE3MTUsIC03Ni45OTQ5MjY2NjY2NjY3XSwgWzM5LjExNTg1NSwgLTc2Ljk2MTc3MTY2NjY2NjddLCBbMzkuMTczNDE4MzMzMzMzMywgLTc3LjE4OTMyXSwgWzM5LjE3MzQxODMzMzMzMzMsIC03Ny4xODkzMl0sIFszOS4wNDE0MzUsIC03Ny4xMTMxMzgzMzMzMzMzXSwgWzM5LjIyMDMyNjY2NjY2NjcsIC03Ny4wNjAxNjY2NjY2NjY3XSwgWzM4Ljk5NzQ0NSwgLTc2Ljk5MjAxXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzM5LjEyMzExMzMzMzMzMzMsIC03Ny4yMjk5NDgzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzM5LjAyMTQ5ODMzMzMzMzMsIC03Ny4wMTQ0NDE2NjY2NjY3XSwgWzM5LjA0NzQyMTY2NjY2NjcsIC03Ny4xNTA1MzgzMzMzMzMzXSwgWzM4Ljk5NzUwMTY2NjY2NjcsIC03Ni45ODc4OTE2NjY2NjY3XSwgWzM5LjEyMTc3LCAtNzcuMTU5NTg1XSwgWzM5LjA1MDk4NSwgLTc3LjEwOTUwODMzMzMzMzNdLCBbMzkuMDA3MDI4MzMzMzMzMywgLTc3LjAyMTE1NjY2NjY2NjddLCBbMzkuMDA3MDI4MzMzMzMzMywgLTc3LjAyMTE1NjY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMjIwMzI2NjY2NjY2NywgLTc3LjA2MDE2NjY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzkuMTUwNzM2NjY2NjY2NywgLTc3LjE5MTQxNV0sIFszOS4xNTA3MzY2NjY2NjY3LCAtNzcuMTkxNDE1XSwgWzM5LjE2ODcyMTY2NjY2NjcsIC03Ny4yNzk3MDgzMzMzMzMzXSwgWzM5LjE2ODcyMTY2NjY2NjcsIC03Ny4yNzk3MDgzMzMzMzMzXSwgWzM5LjExNTc3MTY2NjY2NjcsIC03Ni45NjE1ODY2NjY2NjY3XSwgWzM5LjEwMTY2ODMzMzMzMzMsIC03Ny4zMDc0NTVdLCBbMzkuMTAxNjY4MzMzMzMzMywgLTc3LjMwNzQ1NV0sIFszOS4wMzc4MzE2NjY2NjY3LCAtNzcuMDUzNDExNjY2NjY2N10sIFszOS4wMzc4MzE2NjY2NjY3LCAtNzcuMDUzNDExNjY2NjY2N10sIFszOS4xMDk5MDUsIC03Ny4xNTM5NV0sIFszOC45OTY3NTMzMzMzMzMzLCAtNzYuOTkxNTA1XSwgWzM5LjAzMTAxLCAtNzcuMDA0OTgxNjY2NjY2N10sIFszOS4wMzEwMSwgLTc3LjAwNDk4MTY2NjY2NjddLCBbMzkuMDM1NjcxNjY2NjY2NywgLTc3LjEyNDIzNV0sIFszOS4wMzU2NzE2NjY2NjY3LCAtNzcuMTI0MjM1XSwgWzM5LjIyMDMyNjY2NjY2NjcsIC03Ny4wNjAxNjY2NjY2NjY3XSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOS4yNjYxLCAtNzcuMjAxMDY1XSwgWzM4Ljk5MDYyLCAtNzcuMDAxODFdLCBbMzguOTkwNjIsIC03Ny4wMDE4MV0sIFszOS4xMTU4NTMzMzMzMzMzLCAtNzcuMDc1NDQxNjY2NjY2N10sIFszOS4xMTU4NTMzMzMzMzMzLCAtNzcuMDc1NDQxNjY2NjY2N10sIFszOS4wNzgzMTE2NjY2NjY3LCAtNzcuMTI5MDQ1XSwgWzM5LjA3ODMxMTY2NjY2NjcsIC03Ny4xMjkwNDVdLCBbMzkuMDM5NjcxNjY2NjY2NywgLTc3LjA1NDU1MTY2NjY2NjddLCBbMzkuMjI1ODY1LCAtNzcuMjYzNDU1XSwgWzM5LjIyNTg2NSwgLTc3LjI2MzQ1NV0sIFszOS4yMjAzMjY2NjY2NjY3LCAtNzcuMDYwMTY2NjY2NjY2N10sIFszOS4yMjAzMjY2NjY2NjY3LCAtNzcuMDYwMTY2NjY2NjY2N10sIFszOS4xNjI0MDY2NjY2NjY3LCAtNzcuMjUwNjEzMzMzMzMzM10sIFszOS4xNjI0MDY2NjY2NjY3LCAtNzcuMjUwNjEzMzMzMzMzM10sIFszOS4wMzEwMzgzMzMzMzMzLCAtNzcuMDA0ODRdLCBbMzguOTk3MjgxNjY2NjY2NywgLTc2Ljk5NDAwODMzMzMzMzNdLCBbMzguOTk3MjgxNjY2NjY2NywgLTc2Ljk5NDAwODMzMzMzMzNdLCBbMzkuMTUwMzc4MzMzMzMzMywgLTc3LjE5MDk1XSwgWzM5LjE1MDM3ODMzMzMzMzMsIC03Ny4xOTA5NV0sIFszOS4xNTAzNzgzMzMzMzMzLCAtNzcuMTkwOTVdLCBbMzkuMDc3NzAxNjY2NjY2NywgLTc3LjEyNTk3NjY2NjY2NjddLCBbMzkuMDc3NzAxNjY2NjY2NywgLTc3LjEyNTk3NjY2NjY2NjddLCBbMzkuMDQ5NDg1LCAtNzcuMDY4MDk1XSwgWzM5LjA0OTQ4NSwgLTc3LjA2ODA5NV0sIFszOS4wNDk0ODUsIC03Ny4wNjgwOTVdLCBbMzkuMDQ5NDg1LCAtNzcuMDY4MDk1XSwgWzM5LjA0OTQ4NSwgLTc3LjA2ODA5NV0sIFszOC45OTY3NSwgLTc2Ljk5MTcyNV0sIFszOC45OTcxOCwgLTc3LjAyNjAyMzMzMzMzMzNdLCBbMzguOTk3MTgsIC03Ny4wMjYwMjMzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjA5NjY5ODMzMzMzMzMsIC03Ny4yNjU2NDVdLCBbMzkuMDk2Njk4MzMzMzMzMywgLTc3LjI2NTY0NV0sIFszOS4wOTc1MSwgLTc2Ljk0ODE2ODMzMzMzMzNdLCBbMzkuMjIwMjY2NjY2NjY2NywgLTc3LjA2MDE5MzMzMzMzMzNdLCBbMzguOTk5NjQsIC03Ni45OTMyNjVdLCBbMzguOTk5NjQsIC03Ni45OTMyNjVdLCBbMzkuMDI0NzIzMzMzMzMzMywgLTc3LjAxMTIzMzMzMzMzMzNdLCBbMzguOTk5ODAxNjY2NjY2NywgLTc2Ljk5MjMyNjY2NjY2NjddLCBbMzkuMTA3NzU1LCAtNzYuOTk4OTk4MzMzMzMzM10sIFszOS4wOTAwOCwgLTc3LjA1MzYzODMzMzMzMzNdLCBbMzkuMTA3NzU1LCAtNzYuOTk4OTk4MzMzMzMzM10sIFszOS4xMDc3NTUsIC03Ni45OTg5OTgzMzMzMzMzXSwgWzM5LjEwNzc1NSwgLTc2Ljk5ODk5ODMzMzMzMzNdLCBbMzkuMTA3NzU1LCAtNzYuOTk4OTk4MzMzMzMzM10sIFszOS4xNTA0MTE2NjY2NjY3LCAtNzcuMTkwOTZdLCBbMzkuMTI4NDk1LCAtNzcuMTg2NDVdLCBbMzkuMTI4NDk1LCAtNzcuMTg2NDVdLCBbMzkuMTI4NDk1LCAtNzcuMTg2NDVdLCBbMzkuMDY3NjcxNjY2NjY2NywgLTc3LjAwMTY0ODMzMzMzMzNdLCBbMzkuMDkwMTMsIC03Ny4wNTM3Nl0sIFszOS4wOTAxMywgLTc3LjA1Mzc2XSwgWzM5LjA5MDEzLCAtNzcuMDUzNzZdLCBbMzkuMDc1MzAxNjY2NjY2NywgLTc3LjExNTE4NjY2NjY2NjddLCBbMzkuMTM2NjcxNjY2NjY2NywgLTc3LjM5NTA4NV0sIFszOS4wNDM3MSwgLTc3LjA2MjQ2MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzkuMTM2NjcxNjY2NjY2NywgLTc3LjM5NTA4NV0sIFszOS4wNzQ0ODgzMzMzMzMzLCAtNzcuMTY1MjY2NjY2NjY2N10sIFszOS4yNjYxLCAtNzcuMjAxMDY1XSwgWzM5LjAwOTQ3NSwgLTc2Ljk5OTQwMzMzMzMzMzNdLCBbMzkuMDA5NDc1LCAtNzYuOTk5NDAzMzMzMzMzM10sIFszOS4wNzU0NzUsIC03Ny4xMTUwNzMzMzMzMzMzXSwgWzM5LjA3NTQ3NSwgLTc3LjExNTA3MzMzMzMzMzNdLCBbMzkuMDc1NDc1LCAtNzcuMTE1MDczMzMzMzMzM10sIFszOS4wNzU0NzUsIC03Ny4xMTUwNzMzMzMzMzMzXSwgWzM5LjA3NTQ3NSwgLTc3LjExNTA3MzMzMzMzMzNdLCBbMzkuMDkxMjIzMzMzMzMzMywgLTc3LjIwNDgwODMzMzMzMzNdLCBbMzkuMDc1NzM1LCAtNzcuMDAxODc4MzMzMzMzM10sIFszOS4wNzU3MzUsIC03Ny4wMDE4NzgzMzMzMzMzXSwgWzM5LjA3NTczNSwgLTc3LjAwMTg3ODMzMzMzMzNdLCBbMzkuMDc1NzM1LCAtNzcuMDAxODc4MzMzMzMzM10sIFszOS4wNzU3MzUsIC03Ny4wMDE4NzgzMzMzMzMzXSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzguOTk0NDAzMzMzMzMzMywgLTc3LjAyODMzMzMzMzMzMzNdLCBbMzkuMDMyMjQzMzMzMzMzMywgLTc3LjA3NTA0NV0sIFszOS4wNTI1MzgzMzMzMzMzLCAtNzcuMTY2MzU4MzMzMzMzM10sIFszOS4wMzIyNDMzMzMzMzMzLCAtNzcuMDc1MDQ1XSwgWzM5LjA2NjEzMzMzMzMzMzMsIC03Ny4wMDA1MzMzMzMzMzMzXSwgWzM5LjI2NjEsIC03Ny4yMDEwNjVdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMTIxMTIsIC03Ny4wMTE1MjY2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzAuMCwgMC4wXSwgWzM5LjAzMTEwNSwgLTc3LjAwNDkzNjY2NjY2NjddLCBbMzkuMTg0NjMsIC03Ny4yMTA5OTMzMzMzMzMzXSwgWzM5LjE4NDYzLCAtNzcuMjEwOTkzMzMzMzMzM10sIFszOS4wODM4MDY2NjY2NjY3LCAtNzYuOTUwMTczMzMzMzMzM10sIFszOS4xODczNTY2NjY2NjY3LCAtNzcuMjU3MzRdLCBbMzkuMTg3MzU2NjY2NjY2NywgLTc3LjI1NzM0XSwgWzM5LjE4NzM1NjY2NjY2NjcsIC03Ny4yNTczNF0sIFszOS4xODczNTY2NjY2NjY3LCAtNzcuMjU3MzRdLCBbMzkuMTg3MzU2NjY2NjY2NywgLTc3LjI1NzM0XSwgWzM5LjE4NzM1NjY2NjY2NjcsIC03Ny4yNTczNF0sIFszOC45OTkzNjMzMzMzMzMzLCAtNzcuMDE3Nzg1XSwgWzM4Ljk5MDcsIC03Ny4wMjE5MTVdLCBbMzkuMTQ5Mjc4MzMzMzMzMywgLTc3LjA2NjYyXSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOS4xNDkyNzgzMzMzMzMzLCAtNzcuMDY2NjJdLCBbMzkuMTQ5Mjc4MzMzMzMzMywgLTc3LjA2NjYyXSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOS4xNDkyNzgzMzMzMzMzLCAtNzcuMDY2NjJdLCBbMzkuMTYwMTk1LCAtNzcuMjg5NDcxNjY2NjY2N10sIFszOS4xNDgyODMzMzMzMzMzLCAtNzcuMjc2OTc2NjY2NjY2N10sIFszOS4wODk5NTMzMzMzMzMzLCAtNzcuMDI3NzZdLCBbMzkuMDg5OTUzMzMzMzMzMywgLTc3LjAyNzc2XSwgWzAuMCwgMC4wXSwgWzM5LjE0ODU4MTY2NjY2NjcsIC03Ny4yNzkwOV0sIFszOC45OTY3ODY2NjY2NjY3LCAtNzcuMDI3NjIxNjY2NjY2N10sIFszOC45ODIzMTE2NjY2NjY3LCAtNzcuMDc1MzI2NjY2NjY2N10sIFszOC45OTc5NTgzMzMzMzMzLCAtNzcuMDI2NzU2NjY2NjY2N10sIFszOC45OTc5NTgzMzMzMzMzLCAtNzcuMDI2NzU2NjY2NjY2N10sIFszOS4xNTk3MDE2NjY2NjY3LCAtNzcuMjg5OTczMzMzMzMzM10sIFszOS4xNDg1MzE2NjY2NjY3LCAtNzcuMjc2NzczMzMzMzMzM10sIFszOS4wNjcwOTMzMzMzMzMzLCAtNzcuMDAxMzY4MzMzMzMzM10sIFszOS4xNTk3NjY2NjY2NjY3LCAtNzcuMjg5OTE4MzMzMzMzM10sIFszOS4xNDgyNjUsIC03Ny4yNzc0XSwgWzM5LjAxMjYwNjY2NjY2NjcsIC03Ny4xMDc5NTY2NjY2NjY3XSwgWzM5LjIyMDM0LCAtNzcuMDYwMTZdLCBbMC4wLCAwLjBdLCBbMzkuMTU5ODAzMzMzMzMzMywgLTc3LjI4OTgyMzMzMzMzMzNdLCBbMzkuMTEzODYsIC03Ny4xOTYzMzY2NjY2NjY3XSwgWzM5LjE0ODM3MTY2NjY2NjcsIC03Ny4yNzY5MV0sIFszOC45ODIxNjMzMzMzMzMzLCAtNzcuMDc2NDMzMzMzMzMzM10sIFszOC45ODIxNjMzMzMzMzMzLCAtNzcuMDc2NDMzMzMzMzMzM10sIFszOS4wNjY3MDgzMzMzMzMzLCAtNzcuMDAxMDgxNjY2NjY2N10sIFszOS4xMjM5NDUsIC03Ny4xNzU1NjY2NjY2NjY3XSwgWzM5LjEyMzk0NSwgLTc3LjE3NTU2NjY2NjY2NjddLCBbMzkuMjIwMzQsIC03Ny4wNjAxNl0sIFszOS4wMDIxNDE2NjY2NjY3LCAtNzcuMDM5MDU2NjY2NjY2N10sIFswLjAsIDAuMF0sIFszOS4xMjM5NDUsIC03Ny4xNzU1NjY2NjY2NjY3XSwgWzM5LjE1OTU5NjY2NjY2NjcsIC03Ny4yODk4OTE2NjY2NjY3XSwgWzM5LjExMzAzLCAtNzcuMTkyNjYxNjY2NjY2N10sIFszOS4wMTI3MjE2NjY2NjY3LCAtNzcuMTA3OTk1XSwgWzM5LjEyMzY2MTY2NjY2NjcsIC03Ny4xNzUxM10sIFszOS4xMjM2NjE2NjY2NjY3LCAtNzcuMTc1MTNdLCBbMzkuMjIwMzQsIC03Ny4wNjAxNl0sIFszOS4wNjEwNDUsIC03Ni45OTg3MzMzMzMzMzMzXSwgWzM4Ljk5MDE5MzMzMzMzMzMsIC03Ny4wOTUzNTMzMzMzMzMzXSwgWzAuMCwgMC4wXSwgWzM4Ljk5MDA2MzMzMzMzMzMsIC03Ny4wOTUxMTVdLCBbMzkuMDY5NDUxNjY2NjY2NywgLTc3LjE2OTQ5MzMzMzMzMzNdLCBbMzkuMDEzMTA4MzMzMzMzMywgLTc3LjEwNzYzODMzMzMzMzNdLCBbMzkuMjIwMzQsIC03Ny4wNjAxNl0sIFszOS4yMjAzNCwgLTc3LjA2MDE2XSwgWzM5LjA1MjQ1ODMzMzMzMzMsIC03Ny4xNjU3NjVdLCBbMzkuMTU5Njk4MzMzMzMzMywgLTc3LjI4OTk0XSwgWzAuMCwgMC4wXSwgWzM5LjA1MjQ1NjY2NjY2NjcsIC03Ny4xNjU4MzMzMzMzMzMzXSwgWzM5LjAxMjA1NSwgLTc3LjEwODMzNjY2NjY2NjddLCBbMzkuMTI2MDc1LCAtNzcuMTczOTVdLCBbMzkuMTI2MDc1LCAtNzcuMTczOTVdLCBbMzkuMTU5Njk4MzMzMzMzMywgLTc3LjI4OTkxXSwgWzM5LjAxMTQ3ODMzMzMzMzMsIC03Ni45Nzk1NDE2NjY2NjY3XSwgWzM5LjE1MTg1ODMzMzMzMzMsIC03Ny4yODM1XSwgWzAuMCwgMC4wXSwgWzM5LjAwMDE0ODMzMzMzMzMsIC03Ni45OTA4NF0sIFszOS4wMDAxNDgzMzMzMzMzLCAtNzYuOTkwODRdLCBbMzguOTk0NjY4MzMzMzMzMywgLTc3LjAyNzYyNjY2NjY2NjddLCBbMzkuMTE5MTY4MzMzMzMzMywgLTc3LjAxOTg1XSwgWzM5LjExNjA1MzMzMzMzMzMsIC03Ny4wMTc3NjE2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOS4xMTkwMywgLTc3LjAyMDM0MzMzMzMzMzNdLCBbMzkuMDg3MjcxNjY2NjY2NywgLTc3LjIxMTU1NjY2NjY2NjddLCBbMzkuMDg4Nzk4MzMzMzMzMywgLTc3LjIxMDI1MTY2NjY2NjddLCBbMC4wLCAwLjBdLCBbMzguOTY4NjU4MzMzMzMzMywgLTc3LjEwOTEyNV0sIFszOS4xMjE3MzE2NjY2NjY3LCAtNzYuOTkyNTldLCBbMzkuMTE5MDE2NjY2NjY2NywgLTc3LjAyMDM2NjY2NjY2NjddLCBbMzkuMTIxNzMxNjY2NjY2NywgLTc2Ljk5MjU5XSwgWzM5LjE0OTI3ODMzMzMzMzMsIC03Ny4wNjY2Ml0sIFszOC45OTk1LCAtNzcuMDk3NzkxNjY2NjY2N10sIFszOS4xMDYzNSwgLTc3LjE4OTUyMzMzMzMzMzNdLCBbMzkuMTI4MTM1LCAtNzcuMTYxMzhdLCBbMzkuMTE4ODg1LCAtNzcuMDIwOTddLCBbMzkuMDE1NzcsIC03Ny4wNDMyODY2NjY2NjY3XSwgWzM5LjAyODA5MTY2NjY2NjcsIC03Ny4wMTMzODVdLCBbMzkuMTI4MTM1LCAtNzcuMTYxMzhdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMC4wLCAwLjBdLCBbMzkuMDg2Mzc4MzMzMzMzMywgLTc2Ljk5OTUzMTY2NjY2NjddLCBbMzkuMTE1ODQsIC03Ny4wNzM2NV0sIFswLjAsIDAuMF0sIFszOS4xMjgxNjUsIC03Ny4xNjEyNzgzMzMzMzMzXSwgWzM5LjE1MTc1MTY2NjY2NjcsIC03Ny4yMTEwNTY2NjY2NjY3XSwgWzM5LjE1MTc1MTY2NjY2NjcsIC03Ny4yMTEwNTY2NjY2NjY3XSwgWzM5LjAxNDk0ODMzMzMzMzMsIC03Ny4wOTk2NDY2NjY2NjY3XSwgWzM5LjI0MTU4LCAtNzcuMTQzNjMzMzMzMzMzM10sIFszOS4wMzQzMzMzMzMzMzMzLCAtNzcuMDcxNjU4MzMzMzMzM10sIFszOS4wMTM3OTgzMzMzMzMzLCAtNzcuMDk5MzJdLCBbMzkuMDMyMjEsIC03Ny4wNzQzNzE2NjY2NjY3XSwgWzM5LjA5OTQ0MTY2NjY2NjcsIC03Ny4yMTIxNl0sIFszOS4wOTk0NDE2NjY2NjY3LCAtNzcuMjEyMTZdLCBbMzguOTg1NTkxNjY2NjY2NywgLTc3LjA5MzcyNV0sIFszOS4wOTk0NDE2NjY2NjY3LCAtNzcuMjEyMTZdLCBbMzguOTg0MzQ1LCAtNzcuMDk0MjkxNjY2NjY2N10sIFszOS4wNTI1NDUsIC03Ni45NzY5MDMzMzMzMzMzXSwgWzM5LjA1MjU0NSwgLTc2Ljk3NjkwMzMzMzMzMzNdLCBbMzkuMDUyNTQ1LCAtNzYuOTc2OTAzMzMzMzMzM10sIFszOS4wMTg1NzgzMzMzMzMzLCAtNzcuMDE0NzEzMzMzMzMzM10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzAuMCwgMC4wXSwgWzM5LjAyMDQzODMzMzMzMzMsIC03Ny4xMDMxMzMzMzMzMzMzXSwgWzM5LjA0NTQyNSwgLTc2Ljk5MDczNjY2NjY2NjddLCBbMzkuMDg5NzkxNjY2NjY2NywgLTc3LjEzMDI5MTY2NjY2NjddLCBbMzkuMDg5NzkxNjY2NjY2NywgLTc3LjEzMDI5MTY2NjY2NjddLCBbMzkuMDQ1NDI1LCAtNzYuOTkwNzM2NjY2NjY2N10sIFszOC45OTE3NjMzMzMzMzMzLCAtNzcuMDk1NzI4MzMzMzMzM10sIFszOS4wNDU0MjUsIC03Ni45OTA3MzY2NjY2NjY3XSwgWzM4Ljk5MTE2MTY2NjY2NjcsIC03Ny4wOTQwMzE2NjY2NjY3XSwgWzM4Ljk5NDMyLCAtNzcuMDI4MDFdLCBbMzkuMTQwMDcsIC03Ny4xNTIxMzE2NjY2NjY3XSwgWzM5LjEyOTMxNjY2NjY2NjcsIC03Ny4yMzI0MTgzMzMzMzMzXSwgWzM5LjEyOTMxNjY2NjY2NjcsIC03Ny4yMzI0MTgzMzMzMzMzXSwgWzM5LjE5NzM3ODMzMzMzMzMsIC03Ny4yODI0MjVdLCBbMzkuMTk3Mzc4MzMzMzMzMywgLTc3LjI4MjQyNV0sIFszOS4xOTczNzgzMzMzMzMzLCAtNzcuMjgyNDI1XSwgWzM5LjEwOTU5NjY2NjY2NjcsIC03Ny4wNzc0NzY2NjY2NjY3XSwgWzM5LjAxMDE5NjY2NjY2NjcsIC03Ny4wMDA2NTVdLCBbMzguOTkwMywgLTc3LjA5NTM2XSwgWzM4Ljk5MDM2ODMzMzMzMzMsIC03Ny4wMDE4MjE2NjY2NjY3XSwgWzM4Ljk5MDM2ODMzMzMzMzMsIC03Ny4wMDE4MjE2NjY2NjY3XSwgWzM5LjAwMDUwMzMzMzMzMzMsIC03Ni45ODk4OTVdLCBbMzkuMjYwMzMxNjY2NjY2NywgLTc3LjIyMzExMTY2NjY2NjddLCBbMzkuMjYwMzMxNjY2NjY2NywgLTc3LjIyMzExMTY2NjY2NjddLCBbMzguOTkwMzIxNjY2NjY2NywgLTc3LjA5NTI1ODMzMzMzMzNdLCBbMzkuMjY2MDA4MzMzMzMzMywgLTc3LjIwMTQ3NjY2NjY2NjddXSwKICAgICAgICAgICAgICAgIHsKICAgICAgICAgICAgICAgICAgICBtaW5PcGFjaXR5OiAwLjUsCiAgICAgICAgICAgICAgICAgICAgbWF4Wm9vbTogMTgsCiAgICAgICAgICAgICAgICAgICAgbWF4OiAxLjAsCiAgICAgICAgICAgICAgICAgICAgcmFkaXVzOiAyNSwKICAgICAgICAgICAgICAgICAgICBibHVyOiAxNSwKICAgICAgICAgICAgICAgICAgICBncmFkaWVudDogbnVsbAogICAgICAgICAgICAgICAgICAgIH0pCiAgICAgICAgICAgICAgICAuYWRkVG8obWFwX2EzMmQ2NzVlN2Y5MDQ5YTlhMTQzOTk4MjkwMzE0YTk4KTsKICAgICAgICAKICAgICAgICAKICAgICAgICAKICAgICAgICA8L3NjcmlwdD4KICAgICAgICA=)
后续步骤
在这篇关注学习 python 编程的文章中,我们学习了如何使用 Python 从原始 JSON 数据到使用命令行工具、ijson、Pandas、matplotlib 和 folium 的全功能地图。如果你想了解关于这些工具的更多信息,请查看我们在 Dataquest 上的数据分析、数据可视化和命令行课程。
如果您想进一步探索这个数据集,这里有一些有趣的问题需要回答:
- 车站的类型因地点而异吗?
- 收入和停留次数有什么关系?
- 人口密度如何与停靠点数量相关联?
- 午夜前后什么类型的停车最常见?
## 后续步骤
在这篇关注学习 python 编程的文章中,我们学习了如何使用 Python 从原始 JSON 数据到使用命令行工具、ijson、Pandas、matplotlib 和 folium 的全功能地图。如果你想了解关于这些工具的更多信息,请查看我们在 [Dataquest](https://www.dataquest.io) 上的[数据分析](https://www.dataquest.io/subject/data-analysis)、[数据可视化](https://www.dataquest.io/subject/data-visualization)和[命令行](https://www.dataquest.io/subject/the-command-line)课程。
如果您想进一步探索这个数据集,这里有一些有趣的问题需要回答:
* 车站的类型因地点而异吗?
* 收入和停留次数有什么关系?
* 人口密度如何与停靠点数量相关联?
* 午夜前后什么类型的停车最常见?
## 这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
  [ Python Tutorials ](/python-tutorials-for-data-science/)
在我们的免费教程中练习 Python 编程技能。
[ Data science courses ](/data-science-courses/)
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
Python 列表教程:列表、循环等等!
November 15, 2019
列表是 Python 中最强大的数据类型之一。在本 Python 列表教程中,您将了解如何在分析移动应用程序数据时使用列表。
在本教程中,我们假设您了解 Python 的基础知识,包括使用字符串、整数和浮点数。如果你不熟悉这些,你可能想试试我们的免费 Python 基础课程。
我们将使用这张数据表,它取自移动应用商店数据集(Ramanathan Perumal) :
| 名字 | 价格 | 货币 | 评级 _ 计数 | 等级 |
|---|---|---|---|---|
| 脸谱网 | Zero | 美元 | Two million nine hundred and seventy-four thousand six hundred and seventy-six | Three point five |
| 照片墙 | Zero | 美元 | Two million one hundred and sixty-one thousand five hundred and fifty-eight | Four point five |
| 部族冲突 | Zero | 美元 | Two million one hundred and thirty thousand eight hundred and five | Four point five |
| 神庙逃亡 | Zero | 美元 | One million seven hundred and twenty-four thousand five hundred and forty-six | Four point five |
| 潘多拉——音乐和广播 | Zero | 美元 | One million one hundred and twenty-six thousand eight hundred and seventy-nine | Four |
表格中的每个值都是一个数据点。例如,第一行(列标题之后)有五个数据点:
Facebook0.0USD29746763.5
数据点的集合构成了一个数据集。我们可以将上面的整个表理解为数据点的集合,因此我们将整个表称为数据集。我们可以看到我们的数据集有五行和五列。
利用我们对 Python 类型的理解,我们可能会认为可以将每个数据点存储在它自己的变量中——例如,我们可以这样存储第一行的数据点:

上面,我们存储了:
- 字符串形式的文本“脸书”
- 价格 0.0 为浮动
- 字符串形式的文本“USD”
- 评级将 2,974,676 计为整数
- 用户将 3.5 评级为浮动
为数据集中的每个数据点创建一个变量将是一个繁琐的过程。幸运的是,我们可以使用列表更有效地存储数据。这就是我们如何为第一行创建数据点列表:

为了创建上面的列表,我们:
- 输入一系列数据点,并用逗号分隔:
'Facebook', 0.0, 'USD', 2974676, 3.5 - 用括号将序列括起来:
['Facebook', 0.0, 'USD', 2974676, 3.5]
在我们创建了这个列表之后,我们通过将它赋给一个名为row_1的变量来将它存储在计算机的内存中。
要创建数据点列表,我们只需:
- 用逗号分隔数据点。
- 用括号将数据点序列括起来。
现在让我们创建五个列表,数据集中的每一行都有一个列表:
row_1 = ['Facebook', 0.0, 'USD', 2974676, 3.5]
row_2 = ['Instagram', 0.0, 'USD', 2161558, 4.5]
row_3 = ['*** of Clans', 0.0, 'USD', 2130805, 4.5]
row_4 = ['Temple Run', 0.0, 'USD', 1724546, 4.5]
row_5 = ['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0]
索引 Python 列表
列表可以包含各种数据类型。像[4, 5, 6]这样的列表有相同的数据类型(只有整数),而列表['Facebook', 0.0, 'USD', 2974676, 3.5]有混合的数据类型:
- 两根弦(
'Facebook', 'USD') - 两个浮动(
0.0、3.5) - 一个整数(
2974676)
['Facebook', 0.0, 'USD', 2974676, 3.5]列表有五个数据点。要找到一个列表的长度,我们可以使用len()命令:

对于小列表,我们可以只计算屏幕上的数据点来确定长度,但是无论何时当你处理包含许多元素的列表,或者需要为事先不知道长度的数据编写代码时,len()命令将会非常有用。
列表中的每个元素(数据点)都有一个与之相关的特定数字,称为索引号。索引总是从 0 开始,因此第一个元素的索引号为 0,第二个元素的索引号为 1,依此类推。

要快速找到列表元素的索引,请确定它在列表中的位置号,然后减去 1。例如,字符串'USD'是列表的第三个元素(位置号 3),因此它的索引号必须是 2,因为 3–1 = 2。
索引号帮助我们从列表中检索单个元素。回头看看上面代码示例中的列表row_1,我们可以通过运行代码row_1[0]来检索索引号为 0 的第一个元素(字符串'Facebook')。

检索单个列表元素的语法遵循模型list_name[index_number]。例如,上面列表的名称是row_1,第一个元素的索引号是0——按照list_name[index_number]模型,我们得到row_1[0],其中索引号0在变量名row_1后面的方括号中。

这就是我们如何检索row_1中的每个元素:

检索列表元素使得执行操作更加容易。例如,我们可以选择脸书和 Instagram 的评分,并找出两者之间的平均值或差异:

让我们使用列表索引从前三行中提取评级数量,然后对它们进行平均:
ratings_1 = row_1[3]
ratings_2 = row_2[3]
ratings_3 = row_3[3]
total = ratings_1 + ratings_2 + ratings_3
average = total / 3
print(average)
2422346.3333333335
对列表使用负索引
在 Python 中,我们有两个列表索引系统:
- 正索引:第一个元素的索引号为 0,第二个元素的索引号为 1,依此类推。
- 负索引:最后一个元素的索引号为-1,倒数第二个元素的索引号为-2,依此类推。

在实践中,我们几乎总是使用正索引来检索列表元素。当我们想要选择列表的最后一个元素时,负索引非常有用——尤其是当列表很长,并且我们无法通过计数来判断长度时。

注意,如果我们使用两个索引系统范围之外的索引号,我们将得到一个IndexError。

让我们使用负索引从前三行的每一行中提取用户评级(最后一个值),然后对它们进行平均。
rating_1 = row_1[-1]
rating_2 = row_2[-1]
rating_3 = row_3[-1]
total_rating = rating_1 + rating_2 + rating_3
average_rating = total_rating / 3
print(average)
2422346.3333333335
切片 Python 列表
我们可以使用语法快捷方式来选择两个或多个连续的元素,而不是单独选择列表元素:

当我们从名为a_list的列表中选择第一个n元素(n代表一个数字)时,我们可以使用语法快捷键a_list[0:n]。在上面的例子中,我们需要从列表row_3中选择前三个元素,所以我们使用了row_3[0:3]。
当我们选择前三个元素时,我们对列表的一部分进行了切片。因此,选择列表的一部分的过程被称为列表切片。
我们可能有很多方法来分割列表:

要检索我们想要的任何列表片段:
- 我们首先需要识别切片的第一个和最后一个元素。
- 然后,我们需要确定切片的第一个和最后一个元素的索引号。
- 最后,我们可以通过使用语法
a_list[m:n]来检索我们想要的列表片,其中:m表示切片第一个元素的索引号;和n代表切片最后一个元素加一个的索引号(如果最后一个元素的索引号为 2,那么我们n将为 3,如果最后一个元素的索引号为 4,那么n将为 5,以此类推)。

当我们需要选择第一个或最后一个x元素(x代表一个数字)时,我们可以使用更简单的语法快捷方式:
a_list[:x]当我们要选择第一个x元素时。a_list[-x:]当我们想要选择最后一个x元素时。

让我们看看如何从第一行中提取前四个元素(带有关于脸书的数据):
first_4_fb = row_1[:4]
print(first_4_fb)
['Facebook', 0.0, 'USD', 2974676]
同一行的最后三个元素:
last_3_fb = row_1[-3:]
print(last_3_fb)
['USD', 2974676, 3.5]
第五行的第三和第四个元素(关于潘多拉的数据):
pandora_3_4 = row_5[2:4]
print(pandora_3_4)
['USD', 1126879]
Python 列表列表
以前,我们引入了列表作为每个数据点使用一个变量的更好的替代方法。我们可以将数据点捆绑到一个列表中,然后将该列表存储在一个单独的变量中,而不是为五个数据点'Facebook', 0.0, 'USD', 2974676, 3.5中的每一个都有一个单独的变量。
到目前为止,我们一直在处理一个有 5 行的数据集,并且我们一直将每一行作为一个列表存储在一个单独的变量中(变量row_1、row_2、row_3、row_4和row_5)。然而,如果我们有一个有 5000 行的数据集,我们最终会有 5000 个变量,这将使我们的代码混乱不堪,几乎无法使用。
为了解决这个问题,我们可以将五个变量存储在一个列表中:

正如我们所看到的,data_set是一个存储其他五个列表(row_1、row_2、row_3、row_4和row_5)的列表。包含其他列表的列表称为列表列表。
data_set变量仍然是一个列表,这意味着我们可以检索单个列表元素,并使用我们所学的语法执行列表切片。下面,我们:
- 使用
data_set[0]检索第一个列表元素(row_1)。 - 使用
data_set[-1]检索最后一个列表元素(row_5)。 - 通过使用
data_set[:2]执行列表切片来检索前两个列表元素(row_1和row_2)。

我们经常需要从列表的列表中检索单个元素——例如,我们可能想从列表的data_set列表中的['Facebook', 0.0, 'USD', 2974676, 3.5]中检索值3.5。下面,我们用我们所学的从data_set中提取3.5:
- 我们使用
data_set[0]检索row_1,并将结果赋给一个名为fb_row的变量。 - 我们打印
fb_row,它输出['Facebook', 0.0, 'USD', 2974676, 3.5]。 - 我们使用
fb_row[-1]从fb_row中检索最后一个元素(因为fb_row是一个列表),并将结果赋给一个名为fb_rating的变量。 - 打印
fb_rating,输出3.5

上面,我们分两步检索3.5:首先检索data_set[0],然后检索fb_row[-1]。然而,通过链接两个索引([0]和[-1]),有一种更简单的方法来检索3.5的相同值——代码data_set[0][-1]检索3.5:

上面,我们已经看到了两种检索值3.5的方法。这两种方法都产生相同的输出(3.5),但是第二种方法包含的输入更少,因为它很好地结合了我们在第一种情况下看到的步骤。虽然你可以选择任何一个选项,但人们通常会选择第二个。
让我们将五个单独的列表转换成一个列表列表:
app_data_set = [row_1, row_2, row_3, row_4, row_5]
print(app_data_set)
[['Facebook', 0.0, 'USD', 2974676, 3.5],
['Instagram', 0.0, 'USD', 2161558, 4.5],
['*** of Clans', 0.0, 'USD', 2130805, 4.5],
['Temple Run', 0.0, 'USD', 1724546, 4.5],
['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0]]
重复列表过程
在本课之前,我们对计算应用程序的平均评分感兴趣。当我们只处理三行时,这是一个可行的任务,但是我们添加的行数越多,它就变得越困难。使用我们之前的策略,我们将:
- 检索每个单独的评分。
- 总结收视率。
- 除以收视率。

如你所见,有了五个等级,这就变得复杂了。如果我们正在处理包含 1000 行的数据,这将需要大量不切实际的代码!我们需要找到一种简单的方法来检索许多评级。
查看上面的代码示例,我们看到一个过程一直在重复:我们为app_data_set中的每个列表选择最后一个列表元素。app_data_set存储五个列表,所以我们重复相同的过程五次。如果我们可以直接告诉 Python 我们想对app_data_set中的每个列表重复这个过程,会怎么样?
幸运的是,我们可以做到这一点——Python 为我们提供了一种简单的方法来重复一个过程,当我们需要重复一个过程数百次、数千次甚至数百万次时,这给了我们巨大的帮助。
假设我们有一个列表[3, 5, 1, 2]赋给了一个变量ratings,我们想要重复下面的过程:对于 ratings中的每个元素,打印那个元素。这就是我们如何将它翻译成 Python 语法:

在上面的第一个例子中,我们想要重复的过程是 _“提取 app_data_set中每个列表的最后一个元素”。这就是我们如何将该过程转换成 Python 语法:****

让我们试着更好地理解上面发生的事情。Python 一次一个地从app_data_set中分离出每个列表元素,并将其分配给each_list(它基本上变成了一个存储列表的变量——我们将在下一个屏幕中对此进行更多讨论):

上图中的代码是下面代码的一个更加简化和抽象的版本:

使用上面的技术需要我们为数据集中的每一行写一行代码。但是使用for each_list in app_data_set技术只需要我们写两行代码,而不管数据集中有多少行——数据集可以有五行或一百万行。
我们的中期目标是使用这种新技术来计算上述 5 行的平均评级,我们的最终目标是计算 7,197 行数据集的平均评级。在本课接下来的几个屏幕中,我们将完全做到这一点,但现在,我们将专注于练习这一技巧,以便很好地掌握它。
在编写任何代码之前,我们需要将我们想要重复的代码向右缩进四个空格字符:

从技术上讲,我们只需要将代码向右缩进至少一个空格,但是 Python 社区的惯例是使用四个空格。这有助于提高可读性——遵循这一约定的其他人更容易阅读您的代码,您也更容易阅读他们的代码。
让我们使用这种技术来打印每个应用程序的名称和评级:
for each_list in app_data_set:
name = each_list[0]
rating = each_list[-1]
print(name, rating)
Facebook 3.5
Instagram 4.5
*** of Clans 4.5
Temple Run 4.5
Pandora - Music & Radio 4.0
Python 中的列表和 For 循环
我们刚刚学习的技术叫做循环。循环是一个非常有用的工具,用于执行 Python 列表的重复过程。因为我们总是从for(像在for some_variable in some_list:中)开始,这种技术被称为循环的。
这些是循环的的结构部分:

主体中的缩进代码与可迭代变量中的元素执行相同的次数。如果 iterable 变量是一个包含三个元素的列表,那么主体中的缩进代码将被执行三次。我们称每一次代码执行为一次迭代,因此对于一个包含三个元素的列表将有三次迭代。对于每次迭代,迭代变量将采用不同的值,遵循以下模式:
- 对于第一次迭代,值是 iterable 的第一个元素(来自上面的例子,
1)。 - 对于第二次迭代,值是 iterable 的第二个元素(来自上面的例子,
3)。 - 对于第三次迭代,该值是 iterable 的第三个元素(来自上面的示例,
5)。

交互变量的名称可以是您喜欢的任何名称——如果您将上面代码中的value替换为dog,代码将以完全相同的方式工作。也就是说,使用有助于传达数据内容的东西是一种惯例。
循环体外的代码可以与循环体内的代码交互。例如,在下面的代码中,我们:
- 在循环体之外,用零值初始化变量
a_sum。 - 我们在
a_list上循环(或者迭代)。对于循环的每次迭代,我们:- 在迭代变量
value的当前值和a_sum中存储的当前值之间执行加法(在循环体内)(a_sum在循环体外定义)。 - 将加法的结果赋回
a_sum(循环体内)。 - 打印
a_sum变量的值(在循环体内)。请注意,a_sum的值在每次添加后都会发生变化。在循环结束时,a_sum的值为9,它相当于a_list(1 + 3 + 5)中数字的总和。
- 在迭代变量

上图中,我们创建了一种对列表中的数字求和的方法。我们可以使用这种技术来总结数据集中的评分。一旦我们有了总和,我们只需要除以收视率的数量就可以得到平均值。
rating_sum = 0
for row in app_data_set:
rating = row[-1]
rating_sum = rating_sum + rating
avg_rating = rating_sum / len(app_data_set)
print(avg_rating)
4.2
我们已经在这里介绍了 for 循环的基础知识,但是如果你想要更多的练习,我们也有关于 for 循环基础知识和for 循环高级知识的教程,你可以看看。
计算列表平均值的替代方法
现在,我们将学习另一种计算平均评分值的方法。一旦我们创建了一个列表,我们可以使用append()命令向它添加(或追加值)。

与我们所学的其他命令不同,请注意append()有一个特殊的语法用法,遵循模式list_name.append()而不是简单地用作append()。
既然我们知道了如何将值追加到列表中,我们可以采取以下步骤来计算平均应用评级:
- 我们初始化一个空列表。
- 我们开始循环我们的数据集,并提取评级。
- 我们将评级追加到我们在第一步创建的空列表中。
- 一旦我们有了所有的评级,我们:
- 使用
sum()命令对所有评级进行求和(为了能够使用sum(),我们需要将评级存储为浮点数或整数);然后 - 我们将总和除以评级数量(可以使用
len()命令获得)。
- 使用
下面,我们可以看到为我们的五行数据集实现的上述步骤:

我们还可以使用append()通过将数据作为列表追加来将另一行添加到我们的列表中。让我们看看它是如何工作的:
row_6 = ['Pinterest', 0.0, 'USD', 1061624, 4]
app_data_set.append(row_6)
print(app_data_set)
[['Facebook', 0.0, 'USD', 2974676, 3.5],
['Instagram', 0.0, 'USD', 2161558, 4.5],
['*** of Clans', 0.0, 'USD', 2130805, 4.5],
['Temple Run', 0.0, 'USD', 1724546, 4.5],
['Pandora - Music & Radio', 0.0, 'USD', 1126879, 4.0],
['Pinterest', 0.0, 'USD', 1061624, 4],
['Pinterest', 0.0, 'USD', 1061624, 4]]
现在,让我们使用上面学到的技术来计算所有六款应用的平均评分:
all_ratings = []
for row in app_data_set:
rating = float(row[-1])
all_ratings.append(rating)
avg_rating = sum(all_ratings) / len(all_ratings)
print(avg_rating)
4.166666666666667
接下来的步骤
在本教程中,我们学习了如何:
- 使用 Python 列表存储和处理数据
- 使用正负索引访问存储在列表中的值
- 使用列表列表来处理表格数据
- 使用 for 循环来自动执行重复性任务
- 向列表追加值
如果你想练习使用 Python 列表,这个教程是基于我们免费的 Python 基础课程的一部分。该课程可以在您的网络浏览器上进行,您将编写代码来分析超过 7,000 个移动应用程序的完整数据集!
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
Python 数学模块指南(22 个示例和 18 个函数)
原文:https://www.dataquest.io/blog/python-math-module-and-functions/
May 10, 2022
使用 Python 中的math模块
math是 Python 3 标准库中的内置模块,提供标准的数学常数和函数。您可以使用math模块执行各种数学计算,如数值、三角函数、对数和指数计算。
本教程将探索在math模块中实现的常用常量和函数——以及如何使用它们。
math模块常数
math模块中有几个内置常量。我们将在这一节中讨论一些最重要的常数。
math.pi
𝜋是一个数学常数,大约等于 3.14159。导入math模块后,只需要写math.pi就可以访问𝜋号:
import math
print(math.pi)
3.141592653589793
让我们用𝜋数来计算圆的面积。计算圆面积的公式如下:
\(Area = \pi r^2\)
import math
def circle_area(r):
return math.pi*r**2
radius = 3
print("Area =", circle_area(radius))
Area = 28.274333882308138
math.tau
τ常量返回几乎精确的值\(2\pi\)。让我们打印它的值:
print(math.tau)
6.283185307179586
math.e
我们可以简单地通过使用math.e常数来访问数字 e (或欧拉数):
print(math.e)
2.718281828459045
math.nan
math.nan常量代表而不是数字,它可以初始化那些不是数字的变量。从技术上讲,math.nan常量的数据类型是浮点;但是,这不是一个有效的数字。
print(math.nan)
print(type(math.nan))
nan
<class 'float'>
math.inf
math.inf常数代表浮点正无穷大。它可以表示正无穷大和负无穷大常数,如下所示:
print(math.inf)
print(-math.inf)
inf
-inf
math模块功能
math模块为许多不同的科学和工程应用提供了广泛的数学函数,包括:
- 数字函数
- 幂函数和对数函数
- 三角函数
- 角度转换函数
- 双曲函数
- 和一些特殊功能
然而,我们在这一节中将只讨论最重要的几个。让我们来探索它们。
数字函数
math.ceil()
math.ceil()方法将一个浮点数映射到最小的后续整数:
p = 10.1
print(math.ceil(p))
11
math.floor()
math.floor()方法将一个浮点数映射到前面最大的整数:
q = 9.99
print(math.floor(q))
9
math.factorial()
如果n是正整数,math.factorial(n)方法返回所有小于或等于n的自然数的乘积。然而,如果n = 0,它返回1。下面的代码使用math.factorial()来计算\(5!\):
n = 5
print("{}! = {}".format(n, math.factorial(n)))
5! = 120
math.gcd()
math.gcd()方法返回两个数的最大公分母;我们可以用它来减少分数。
例如,25 和 120 的 GCD 是 5,因此我们可以将分子和分母除以 5,得到一个缩减的分数(例如\ frac { 25 } { 120 } = \ frac { 5 } { 24 })。让我们看看它是如何工作的:
gcd = math.gcd(25, 120)
print(gcd)
5
math.fabs()
math.fabs()方法删除给定数字的负号(如果有的话),并以浮点形式返回其绝对值:
print(math.fabs(-25))
25.0
幂函数和对数函数
math.pow()
math.pow()方法返回一个浮点值,表示 x 值的 y \((x^y)\).次方让我们通过预测一项投资来尝试一下math.pow()方法。为了做到这一点,我们需要知道初始存款,年利率,以及你把钱投资到投资账户的年数。最后,通过使用下面的公式,我们可以计算出投资的最终金额:
$ { amount } = deposit(1+interest)^{years}$
例如,考虑以下值:
- 初始存款:10,000 美元
- 年利率:4%
- 年数:5 年
该代码计算五年后存入投资账户的最终金额:
deposit = 10000
interest_rate = 0.04
number_years = 5
final_amount = deposit * math.pow(1 + interest_rate, number_years)
print("The final amount after five years is", final_amount)
The final amount after five years is 12166.529024000001
math.pow(x, y)方法总是返回浮点值,让我们检查函数返回值的数据类型:
print(type(math.pow(2, 4)))
<class 'float'>
math.exp()
math.exp(x)方法等于\(e^x\),其中\(e\)是欧拉数。我们可以说math.exp(x)方法等价于下面的语句:
math.pow(math.e, x)
print(math.exp(3))
print(math.pow(math.e, 3))
20.085536923187668
20.085536923187664
math.sqrt()
math.sqrt()方法返回一个数的平方根。让我们来试试:
print(math.sqrt(16))
4.0
math.log()
math.log()方法接受两个参数,x和base,其中 base 的缺省值是\(e\)。因此,如果我们只传递一个参数,该方法将返回自然对数 x \((\log_e x)\)的值。另一方面,如果我们提供两个参数,它计算 x 对给定底数的对数(\(\log_b x\))。让我们计算不同的对数:
print(math.log(10))
print(math.log(10, 3))
2.302585092994046
2.095903274289385
第一行返回 10 的自然对数,第二行返回 10 的以 3 为底的对数。
尽管我们能够使用math.log(x, 10)计算任何以 10 为底的数的对数,但是math模块提供了一种更精确的方法来执行同样的计算。让我们来看看:
print(math.log10(1000))
3.0
三角函数
math模块也提供了一些做三角学的有用方法。在本节中,我们将学习如何使用math模块中提供的以下方法计算给定值的正弦、余弦和正切值。
math.sin()
math.sin()方法返回给定值的正弦值,该值必须以弧度为单位。返回值是介于-1 和 1 之间的浮点数:
print(math.sin(math.pi/4))
0.7071067811865476
math.cos()
math.cos()方法返回给定值的余弦值,和math.sin()方法一样,该值必须以弧度为单位。返回值是介于-1 和 1 之间的浮点数:
print(math.cos(math.pi/2))
6.123233995736766e-17
math.tan()
math.tan()方法返回一个浮点值,表示给定值的正切值。该值必须以弧度为单位。让我们找出不同角度的切线:
print(math.tan(math.pi/4))
print(math.tan(math.pi/6))
print(math.tan(0))
0.9999999999999999
0.5773502691896257
0.0
注
math模块提供了两种有用的角度转换方法。使用math.degrees()将给定的角度从弧度转换成角度,使用math.radians(x)将给定的角度从角度转换成弧度。
双曲函数
双曲函数与三角函数非常相似;但是,还是有区别的。math模块提供了科学和工程应用中出现的所有双曲线函数,如下所示:
| 功能 | 描述 |
|---|---|
math.cosh(x) |
计算 x 的双曲余弦。 |
math.sinh(x) |
计算 x 的双曲正弦。 |
math.tanh(x) |
计算 x 的双曲正切。 |
math.acosh(x) |
计算 x 的反双曲余弦值。 |
math.asinh(x) |
计算 x 的反双曲正弦值。 |
math.atanh(x) |
计算 x 的反双曲正切。 |
让我们使用双曲函数进行一些计算:
x = 0.5
print(math.cosh(x))
print(math.sinh(x))
print(math.tanh(x))
1.1276259652063807
0.5210953054937474
0.46211715726000974
结论
math内置模块包括许多常量和方法,支持从基础到高级的数学运算。我们探讨了一些最重要和最广泛使用的常数和方法,包括数字、幂和对数、三角函数等等。
使用 Python 和 Pandas 处理 SQLite 数据库
October 3, 2016
SQLite 是一个数据库引擎,可以简化关系数据的存储和处理。与 csv 格式非常相似,SQLite 将数据存储在一个文件中,可以很容易地与他人共享。大多数编程语言和环境都很好地支持使用 SQLite 数据库。Python 也不例外,从版本2.5开始,Python 中就包含了一个用于访问 SQLite 数据库的库sqlite3。
在这篇文章中,我们将介绍如何使用sqlite3来创建、查询和更新数据库。我们还将介绍如何使用 pandas 包简化 SQLite 数据库的工作。我们将使用 Python 3.5,但是同样的方法也应该适用于 Python 2。
如果你想学习 SQL 的基础知识,你可能想先看看我们的 SQL 基础博客。
在我们开始之前,让我们快速浏览一下我们将要处理的数据。我们将查看航空公司的航班数据,其中包含有关航空公司、机场和机场间航线的信息。每条航线代表一家航空公司在出发地和目的地机场之间的重复飞行。
所有数据都在一个名为flights.db的 SQLite 数据库中,该数据库包含三个表— airports、airlines和routes。你可以在这里下载数据。
下面是来自airlines表的两行:
| 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 | |
|---|---|---|---|---|---|---|---|---|
| Ten | Eleven | 4D 航空公司 | \N | 圆盘烤饼 | QRT | 四重奏 | 泰国 | 普通 |
| Eleven | Twelve | 611897 艾伯塔有限公司 | \N | 圆盘烤饼 | 带螺纹的(threaded 的简写) | 甜甜圈 | 加拿大 | 普通 |
正如您在上面看到的,每一行都是不同的航空公司,每一列都是该航空公司的属性,例如name和country。每个航空公司也有一个独特的id,所以当我们需要的时候,我们可以很容易地找到它。
下面是来自airports表的两行:
| 身份证明(identification) | 名字 | 城市 | 国家 | 密码 | 国际民航组织 | 纬度 | 经度 | 海拔 | 抵消 | 夏令时 | 时区 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Goroka | Goroka | 巴布亚新几内亚 | GKA | AYGA | -6.081689 | 145.391881 | Five thousand two hundred and eighty-two | Ten | U | 太平洋/莫尔兹比港 |
| one | Two | 马当 | 马当 | 巴布亚新几内亚 | 杂志 | 月,月 | -5.207083 | 145.7887 | Twenty | Ten | U | 太平洋/莫尔兹比港 |
如您所见,每一行都对应一个机场,并且包含机场位置的信息。每个机场也有一个独特的id,所以我们可以很容易地找到它。
下面是来自routes表的两行:
| 航空公司 | 航空公司 id | 来源 | 来源标识 | 建筑环境及 HVAC 系统模拟的软件平台 | 目的地标识 | 代码共享 | 停止 | 装备 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | 2B | Four hundred and ten | 年度等价利率 | Two thousand nine hundred and sixty-five | KZN | Two thousand nine hundred and ninety | 圆盘烤饼 | Zero | CR2 |
| one | 2B | Four hundred and ten | ASF | Two thousand nine hundred and sixty-six | KZN | Two thousand nine hundred and ninety | 圆盘烤饼 | Zero | CR2 |
每条航线都包含一个airline_id,即飞行该航线的航空公司的id,以及source_id,即该航线始发机场的 id,以及dest_id,即该航班的目的地机场的 id。
现在我们知道了我们正在处理哪种数据,让我们从连接到数据库并运行查询开始。
在 Python 中查询数据库行
为了使用 Python 中的 SQLite 数据库,我们首先必须连接到它。我们可以使用 connect 函数来实现,该函数返回一个连接对象:
import sqlite3
conn = sqlite3.connect("flights.db")
一旦我们有了一个连接对象,我们就可以创建一个光标对象。游标允许我们对数据库执行 SQL 查询:
cur = conn.cursor()
一旦我们有了一个游标对象,我们就可以用它来执行一个针对数据库的查询,这个查询有一个恰当的名字 execute 方法。以下代码将从airlines表中获取前5行:
cur.execute("select * from airlines limit 5;")
您可能已经注意到,我们没有将上述查询的结果赋给一个变量。这是因为我们需要运行另一个命令来实际获取结果。我们可以使用 fetchall 方法获取一个查询的所有结果:
results = cur.fetchall()
print(results)
[(0, '1', 'Private flight', '\\N', '-', None, None, None, 'Y'), (1, '2', '135 Airways', '\\N', None, 'GNL', 'GENERAL', 'United States', 'N'), (2, '3', '1Time Airline', '\\N', '1T', 'RNX', 'NEXTIME', 'South Africa', 'Y'), (3, '4', '2 Sqn No 1 Elementary Flying Training School', '\\N', None, 'WYT', None, 'United Kingdom', 'N'), (4, '5', '213 Flight Unit', '\\N', None, 'TFU', None, 'Russia', 'N')]
如您所见,结果被格式化为一个由元组组成的列表。每个元组对应于我们访问的数据库中的一行。用这种方式处理数据是相当痛苦的。我们需要手动添加列标题,并手动解析数据。幸运的是,熊猫图书馆有一个更简单的方法,我们将在下一节看到。
在我们继续之前,最好关闭打开的连接对象和光标对象。这可以防止 SQLite 数据库被锁定。当 SQLite 数据库被锁定时,您可能无法更新该数据库,并且可能会出现错误。我们可以像这样关闭光标和连接:
cur.close()
conn.close()
绘制机场地图
使用我们新发现的查询知识,我们可以创建一个图表,显示世界上所有机场的位置。首先,我们查询纬度和经度:
import sqlite3
conn = sqlite3.connect("flights.db")
cur = conn.cursor()
coords = cur.execute("""
select cast(longitude as float),
cast(latitude as float)
from airports;""").fetchall()
上面的查询将从airports中检索latitude和longitude列,并将它们都转换成浮点数。然后我们调用fetchall方法来检索它们。
然后我们需要通过导入 Python 的主要绘图库 matplotlib 来设置我们的绘图。结合底图包,这允许我们仅使用 Python 创建地图。
我们首先需要导入库:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
然后,我们设置我们的地图,并绘制将形成地图背景的大陆和海岸线:
m = Basemap(
projection='merc',
llcrnrlat=-80,
urcrnrlat=80,
llcrnrlon=-180,
urcrnrlon=180,
lat_ts=20,
resolution='c')
m.drawcoastlines()
m.drawmapboundary()
最后,我们在地图上标出每个机场的坐标。我们从 SQLite 数据库中检索了一个元组列表。每个元组中的第一个元素是机场的经度,第二个元素是纬度。我们将把经度和纬度转换成它们自己的列表,然后把它们标在地图上:
x, y = m(
[l[0] for l in coords],
[l[1] for l in coords])
m.scatter(
x,
y,
1, marker='o',
color='red')
我们最终得到了一张显示世界上每个机场的地图:
您可能已经注意到,处理数据库中的数据有点痛苦。我们需要记住每个元组中的哪个位置对应于哪个数据库列,并手动解析出每个列的单独列表。幸运的是,pandas 库为我们提供了一种更简单的方法来处理 SQL 查询的结果。
将结果读入熊猫数据帧
我们可以使用 pandas read_sql_query 函数将 sql 查询的结果直接读入 pandas 数据帧。下面的代码将执行我们刚才执行的相同查询,但是它将返回一个 DataFrame。与我们上面的查询相比,它有几个优点:
- 它不需要我们创建一个光标对象或者在最后调用
fetchall。 - 它会自动从表格中读入标题的名称。
- 它创建了一个数据框架,因此我们可以快速浏览数据。
import pandas as pd
import sqlite3
conn = sqlite3.connect("flights.db")
df = pd.read_sql_query("select * from airlines limit 5;", conn)
df
| 指数 | 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | one | 私人航班 | \N | – | 没有人 | 没有人 | 没有人 | Y |
| one | one | Two | 135 航空公司 | \N | 没有人 | GNL | 一般 | 美国 | 普通 |
| Two | Two | three | 1 时代航空公司 | \N | 1T | RNX | 下次 | 南非 | Y |
| three | three | four | 2 Sqn 第一初级飞行训练学校 | \N | 没有人 | WYT | 没有人 | 联合王国 | 普通 |
| four | four | five | 213 飞行单位 | \N | 没有人 | TFU | 没有人 | 俄罗斯 | 普通 |
如您所见,我们得到了一个格式良好的数据帧。我们可以很容易地操纵柱子:
df["country"]
0 None
1 United States
2 South Africa
3 United Kingdom
4 Russia
Name: country, dtype: object
强烈建议尽可能使用read_sql_query功能。
映射路线
既然我们知道如何将查询读入熊猫数据帧,我们就可以创建世界上每条航线的地图。我们首先从查询数据开始。以下查询将:
- 获取每条路线的源机场的纬度和经度。
- 获取每条路线的目的地机场的纬度和经度。
- 将所有坐标值转换为浮点数。
- 将结果读入数据帧,并存储到变量
routes。
routes = pd.read_sql_query("""
select cast(sa.longitude as float) as source_lon,
cast(sa.latitude as float) as source_lat,
cast(da.longitude as float) as dest_lon,
cast(da.latitude as float) as dest_lat
from routes
inner join airports sa on sa.id = routes.source_id
inner join airports da on da.id = routes.dest_id;
""",
conn)
然后我们设置我们的地图:
m = Basemap(
projection='merc',
llcrnrlat=-80,
urcrnrlat=80,
llcrnrlon=-180,
urcrnrlon=180,
lat_ts=20,
resolution='c'
)
m.drawcoastlines()
我们遍历第一个3000行,并绘制它们。以下代码将:
- 循环通过
routes中的前3000行。 - 弄清楚路线是否过长。
- 如果路线不太长:
- 在起点和终点之间画一个圆。
for name, row in routes[:3000].iterrows():
if abs(row["source_lon"] - row["dest_lon"]) < 90:
# Draw a great circle between source and dest airports.
m.drawgreatcircle(
row["source_lon"],
row["source_lat"],
row["dest_lon"],
row["dest_lat"],
linewidth=1,
color='b'
)
我们最终得到了下面的地图:

当我们使用 pandas 将 SQL 查询的结果转换成 DataFrame,而不是处理来自sqlite3的原始结果时,上面的效率要高得多。
现在我们知道了如何查询数据库行,让我们继续修改它们。
修改数据库行
我们可以使用sqlite3包通过插入、更新或删除行来修改 SQLite 数据库。创建连接与查询表是一样的,所以我们将跳过这一部分。
使用 Python 插入行
要插入一行,我们需要编写一个INSERT查询。下面的代码将向airlines表中添加一个新行。我们指定要插入的9值,在airlines中每列一个。这将向表中添加一个新行。
cur = conn.cursor()
cur.execute("insert into airlines values (6048, 19846, 'Test flight', '', '', null, null, null, 'Y')")
如果现在尝试查询该表,实际上还看不到新行。相反,您会看到创建了一个名为flights.db-journal的文件。flights.db-journal存储新行,直到您准备好将它commit到主数据库,flights.db。
SQLite 不会写入数据库,直到您提交一个事务。一个事务由一个或多个查询组成,这些查询同时对数据库进行更改。这是为了更容易从意外更改或错误中恢复。事务允许您运行几个查询,然后最终用所有查询的结果修改数据库。这确保了如果其中一个查询失败,数据库不会被部分更新。
一个很好的例子是,如果您有两个表,其中一个包含对人们的银行账户的收费(charges),另一个包含银行账户中的美元金额(balances)。假设银行客户 Roberto 想给他的妹妹 Luisa 汇去 50 美元。为了做到这一点,世行需要:
- 在
charges中创建一行,说明从 Roberto 的账户中取出 50 美元并发送给 Luisa。 - 更新
balances表中 Roberto 的行并删除$50。 - 更新 Luisa 在
balances表中的行,并添加$50。
这将需要三个单独的 SQL 查询来更新所有的表。如果一个查询失败了,我们将被数据库中的坏数据困住。例如,如果前两个查询成功,那么第三个查询失败,Roberto 将失去他的钱,但 Luisa 不会得到它。事务意味着除非所有查询都成功,否则主数据库不会更新。这可以防止系统进入不良状态,导致客户损失金钱。
默认情况下,当您执行任何修改数据库的查询时,sqlite3会打开一个事务。你可以在这里了解更多关于的信息。我们可以提交事务,并使用提交方法将我们的新行添加到airlines表中:
conn.commit()
现在,当我们查询flights.db时,我们将看到包含我们测试飞行的额外行:
pd.read_sql_query("select * from airlines where id=19846;", conn)
| 指数 | 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Nineteen thousand eight hundred and forty-six | 试飞 | 没有人 | 没有人 | 没有人 | Y |
向查询传递参数
在上一个查询中,我们硬编码了想要插入到数据库中的值。大多数情况下,当您将数据插入数据库时,它不会被硬编码,而是您希望传入的动态值。这些动态值可能来自下载的数据,也可能来自用户输入。
处理动态数据时,使用 Python 字符串格式插入值可能很有诱惑力:
cur = conn.cursor()
name = "Test Flight"
cur.execute("insert into airlines values (6049, 19847, {0}, '', '', null, null, null, 'Y')".format(name))
conn.commit()
你想避免这样做!使用 Python 字符串格式插入值会使您的程序容易受到 SQL 注入攻击。幸运的是,sqlite3有一种直接的方法来注入动态值,而不依赖于字符串格式:
cur = conn.cursor()
values = ('Test Flight', 'Y')
cur.execute("insert into airlines values (6049, 19847, ?, '', '', null, null, null, ?)", values)
conn.commit()
查询中的任何?值都将被values中的值替换。第一个?会被values中的第一个项目替换,第二个会被第二个替换,以此类推。这适用于任何类型的查询。这创建了一个 SQLite 参数化查询,避免了 SQL 注入问题。
更新行
我们可以使用execute方法修改 SQLite 表中的行:
cur = conn.cursor()
values = ('USA', 19847)
cur.execute("update airlines set country=? where id=?", values)
conn.commit()
然后,我们可以验证更新发生了:
pd.read_sql_query("select * from airlines where id=19847;", conn)
| 指数 | 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | Six thousand and forty-nine | Nineteen thousand eight hundred and forty-seven | 试飞 | 没有人 | 没有人 | 美利坚合众国 | Y |
删除行
最后,我们可以使用execute方法删除数据库中的行:
cur = conn.cursor()values = (19847, )
cur.execute("delete from airlines where id=?", values)conn.commit()
然后,我们可以通过确保没有行与我们的查询相匹配来验证是否发生了删除:
pd.read_sql_query("select * from airlines where id=19847;", conn)
| 指数 | 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 |
|---|
创建表格
我们可以通过执行 SQL 查询来创建表。我们可以创建一个表来表示某条路线上的每个每日航班,该表包含以下各列:
id—整数departure—航班离开机场的日期arrival—航班到达目的地的日期number—文本,航班号route_id—整数,航班飞行路线的 id
cur = conn.cursor()
cur.execute("create table daily_flights (id integer, departure date, arrival date, number text, route_id integer)")conn.commit()
一旦我们创建了一个表,我们就可以正常地向其中插入数据:
cur.execute("insert into daily_flights values (1, '2016-09-28 0:00', '2016-09-28 12:00', 'T1', 1)")
conn.commit()
当我们查询该表时,我们现在将看到该行:
pd.read_sql_query("select * from daily_flights;", conn)
| 身份证明(identification) | 离开 | 到达 | 数字 | 路线标识 | |
|---|---|---|---|---|---|
| Zero | one | 2016-09-28 0:00 | 2016-09-28 12:00 | 一种网络的名称(传输率可达 1.54mbps) | one |
用熊猫制作桌子
pandas 包为我们提供了一种更快的创建表格的方法。我们只需首先创建一个数据帧,然后将其导出到 SQL 表中。首先,我们将创建一个数据帧:
from datetime import datetime
df = pd.DataFrame(
[[1, datetime(2016, 9, 29, 0, 0) ,
datetime(2016, 9, 29, 12, 0), 'T1', 1]],
columns=["id", "departure", "arrival", "number", "route_id"])
然后,我们将能够调用 to_sql 方法将df转换成数据库中的一个表。我们将keep_exists参数设置为replace,以删除和替换任何名为daily_flights的现有表:
df.to_sql("daily_flights", conn, if_exists="replace")
然后,我们可以通过查询数据库来验证一切正常:
pd.read_sql_query("select * from daily_flights;", conn)
| 指数 | 身份证明(identification) | 离开 | 到达 | 数字 | 路线标识 | |
|---|---|---|---|---|---|---|
| Zero | Zero | one | 2016-09-29 00:00:00 | 2016-09-29 12:00:00 | 一种网络的名称(传输率可达 1.54mbps) | one |
用熊猫改变桌子
使用真实世界的数据科学最困难的部分之一是每条记录中的数据经常变化。以我们的航空公司为例,我们可以决定在airlines表中添加一个airplanes字段,指示每家航空公司拥有多少架飞机。幸运的是,有一种方法可以在 SQLite 中修改表来添加列:
cur.execute("alter table airlines add column airplanes integer;")
注意,我们不需要调用 commit — alter table查询会被立即执行,并且不会被放入事务中。我们现在可以查询并查看额外的列:
pd.read_sql_query("select * from airlines limit 1;", conn)
| 指数 | 身份证明(identification) | 名字 | 别名 | international air transport association 国际航空运输协会 | 国际民航组织 | callsign | 国家 | 活跃的 | 飞机 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | one | 私人航班 | \N | – | 没有人 | 没有人 | 没有人 | Y | 没有人 |
注意,在 SQLite 中所有的列都被设置为null(在 Python 中转换为None),因为该列还没有任何值。
用熊猫改变桌子
还可以使用 Pandas 修改表格,方法是将表格导出到数据帧,对数据帧进行修改,然后将数据帧导出到表格:
df = pd.read_sql("select * from daily_flights", conn)
df["delay_minutes"] = None
df.to_sql("daily_flights", conn, if_exists="replace")
上面的代码将向daily_flights表中添加一个名为delay_minutes的列。
后续步骤
现在,您应该已经很好地掌握了如何使用 Python 和 pandas 处理 SQLite 数据库中的数据。我们讨论了查询数据库、更新行、插入行、删除行、创建表和修改表。这涵盖了所有主要的 SQL 操作,以及几乎所有您日常使用的东西。
如果你有兴趣了解更多关于如何使用 Python 和 SQL 的知识,你可以在 Dataquest 查看我们的 interactive SQL 课程。
如果您想深入了解,这里有一些补充资源:
最后,如果你想继续练习,你可以在这里下载我们在这篇博文中使用的文件flights.db、。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
Python 在线实践:提高技能的 74 种方法(2023)
December 19, 2022
无论您是刚刚开始学习之旅,还是想在工作面试前温习一番,掌握正确的 Python 实践都会带来很大的不同。
关于学习的研究一再表明,人们通过做 T1 学习得最好。这里有 74 种通过编写实际代码在线练习 Python 的方法。
免费的 Python 编码练习
点击这些链接中的任何一个,注册一个免费账户并投入到互动的在线实践练习中,在那里你将编写真正的代码!这些练习对初学者很有帮助。
-
【Matplotlib 线图
这些只是冰山一角。我们有更多免费的 Python 练习题。
使用在线 Python 课程进行练习
如果您正在寻找更多的结构,那么在线练习 Python 课程可能是您所喜欢的。以下是一些推荐的课程。
Python 简介
数据分析和可视化
数据清理
机器学习
在这些课程中,会给你一些问题和作业来测试你的技能。此外,其中一些课程包含一个指导项目,允许您应用您所学的一切。
Python 项目实践
在线实践 Python 的最有效方法之一是使用项目。这里有几个项目,你可以马上开始练习。下面的链接将带你去一个包含你正在寻找的项目的课程。
-
越狱 —找点乐子,用 Python 和 Jupyter Notebook 分析一个直升机越狱的数据集。
-
App Store 和 Google Play 市场的盈利应用简介 —在这个指导性项目中,你将在一家开发移动应用的公司担任数据分析师。您将使用 Python 通过实际的数据分析来提供价值。
-
探索黑客新闻帖子——使用热门技术网站 Hacker News 的提交数据集。
-
探索易贝汽车销售数据——使用 Python 处理从德国易贝网站分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
-
在 94 号州际公路上寻找繁忙的交通指示器 —探索如何使用 pandas 绘图功能和 Jupyter 笔记本界面,让我们通过可视化快速浏览数据。
-
讲述汇率数据可视化 —使用一个或多个条件快速创建多个子集图。
-
清理和分析员工离职调查 —处理澳大利亚昆士兰州教育部员工的离职调查。扮演数据分析师的角色,假装利益相关者想要重要数据问题的答案。
-
星球大战调查 —在这个项目中,你将使用 Jupyter Notebook 分析星球大战电影的数据。
-
分析纽约高中数据 —使用散点图和地图发现不同人口统计的 SAT 成绩。
如果这些没有激发你的兴趣,这里有很多其他的在线 Python 项目可以尝试。
使用在线 Python 教程进行练习
如果在线练习、课程和项目对你没有吸引力,这里有一些博客风格的教程,可以帮助你学习 Python。
网络上也有成千上万的其他初级 Python 教程。只要你在 Python 基础上有坚实的基础,你就可以通过它们找到很好的实践。
常见问题
哪里可以练习 Python 编程?
-
Dataquest.io 有几十个免费的互动练习题,还有免费的互动课、项目创意、教程等等。
-
HackerRank 是一个很好的互动实践网站。
-
CodingGame 是一个有趣的练习平台,支持 Python。
-
Edabit 有 Python 挑战,这对练习或自测很有好处。
你也可以使用上面列出的所有互动课程练习 Python
在家怎么练 Python?
-
在你的机器上安装 Python。你可以在这里直接下载,或者下载一个像 Anaconda 个人版这样的程序,让这个过程更容易。或者你可以找一个像 Dataquest 这样的交互式在线平台,在你的浏览器中编写代码,不需要安装任何东西。
-
制定详细的计划。安排你的练习会让你更有可能坚持到底。
-
加入一个在线社区。从真人那里得到帮助总是很棒的。Reddit 有很棒的 Python 社区,如果你正在学习 Python 数据技能,Dataquest 的社区也很棒。
30 天能学会 Python 吗?
在 30 天内,你绝对可以学会足够多的 Python,从而能够构建一些很酷的东西。你不可能那么快就掌握 Python,但是你可以学习完成一个特定的项目或者做一些事情,比如自动化你工作的某些方面。
了解更多关于学习 Python 需要多长时间。
可以在手机上练习 Python 吗?
是的,有许多应用程序可以让你在 iOS 和 Android 上练习 Python。然而,如果您渴望在职业生涯中使用 Python,这不应该是您的主要练习形式——在台式机和笔记本电脑上练习安装和使用 Python 是很好的,因为这是大多数专业编程工作的完成方式。
多快能学会 Python?
一个周末就能学会 Python 的基础知识。如果你很勤奋,你可以学到足够的东西来完成小项目,并在一个月左右的时间内真正影响你的工作。掌握 Python 需要的时间要长得多,但是你不需要成为大师就能把事情做好!
了解更多关于学习 Python 需要多长时间。
2022 年给初学者的 55 个有趣(且独特)的 Python 项目创意
原文:https://www.dataquest.io/blog/python-projects-for-beginners/
October 23, 2022
如果我可以在我作为初学者努力学习 Python 的时候给以前的自己一个建议,那就是:创建更多的 Python 项目。
学习 Python 可能很难。你可以花时间阅读教科书或观看视频,但却很难将所学付诸实践。
或者你可能花了大量时间学习语法,但最终会感到厌倦或失去动力。(我也是这样。很多)。
为了增加成功的机会,你必须构建 Python 项目。为什么?因为建立有趣的项目会加速你的学习,让你的动力保持在空前的高度。这是终极学习工具。
这里列出了超过 50 个令人难以置信的 Python 项目,您可以亲自尝试或用作灵感。有针对初级、中级和高级学习者的项目。
在构建第一个 Python 项目之前
如果你有一些编程经验,你也许可以直接开始构建一个项目。然而,如果你刚刚开始,首先学习 Python 基础知识是很重要的(我们在这里推荐我们的初级 Python 课程)。
这个想法是尽快学习基础知识,这样你就可以开始做一些真正有趣的事情,比如 Python 项目!
在 Dataquest,我们几乎在每门课程中都包含指导项目。这样,你就可以立即实施你所学到的东西。点击查看我们的完整课程列表。入门免费!
初级 Python 项目示例
现在,让我们看几个 Python 项目示例。看看你是否能找到一个让你感兴趣的。
帮助构建投资组合的指导性 Python 项目(推荐):
以上是 Dataquest 的指导项目,推荐给初学者。他们提供完成项目所需的课程,以及万一你遇到困难时的结构。
下面的链接将带你到包含你正在寻找的项目的课程。今天就免费注册!
-
越狱 —找点乐子,用 Python 和 Jupyter Notebook 分析一个直升机越狱的数据集。
-
App Store 和 Google Play 市场的盈利应用简介 —在这个指导性项目中,你将在一家开发移动应用的公司担任数据分析师。您将使用 Python 通过实际的数据分析来提供价值。
-
探索黑客新闻帖子——使用热门技术网站 Hacker News 的提交数据集。
-
探索易贝汽车销售数据——使用 Python 处理从德国易贝网站分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
-
在 94 号州际公路上寻找繁忙的交通指示器 —探索如何使用 pandas 绘图功能和 Jupyter 笔记本界面,让我们通过可视化快速浏览数据。
-
讲述汇率数据可视化 —使用一个或多个条件快速创建多个子集图。
-
清理和分析员工离职调查 —处理澳大利亚昆士兰州教育部员工的离职调查。扮演数据分析师的角色,假装利益相关者想要重要数据问题的答案。
-
星球大战调查 —在这个项目中,你将使用 Jupyter Notebook 分析星球大战电影的数据。
-
分析纽约高中数据 —使用散点图和地图发现不同人口统计的 SAT 成绩。
构建数据技能的有趣 Python 项目想法:
-
找出你在亚马逊上花了多少钱——用这个初级教程挖掘你自己的消费习惯!
-
分析你自己的网飞数据——另一个让你使用自己的个人数据集的初级到中级教程。
-
分析你个人的脸书发帖习惯——你是否在脸书上花了太多时间?数字不会说谎,您可以在这个初级到中级的 Python 数据项目中找到它们。
-
分析调查数据 —本演练将向您展示如何设置 Python 以及如何从任何数据集中过滤调查数据(或者只使用本文中链接的样本数据)。
-
Dataquest 的指导项目 —这些指导项目引导您构建日益复杂的真实世界数据项目,并提供如何扩展每个项目的建议。
-
分析一切——抓住一个让你感兴趣的免费数据集,然后开始探索!如果你遇到困难或者不知道从哪里开始,我们的 Python 课程随时可以提供帮助,你可以免费试用!
游戏开发者的酷 Python 项目:
-
石头、剪子、布 —从一个大家都知道的简单而有趣的游戏开始您的 Python 学习之旅。
-
构建一个文本冒险游戏——这是一个经典的 Python 初学者项目(它也出现在这本书中),它将教你许多基本的游戏设置概念,这些概念对于更高级的游戏是有用的。
-
猜谜游戏 —这是另一个帮助你学习和练习基础知识的初级项目。
-
Mad Libs —了解如何制作交互式 Python Mad Libs!
-
Hangman——另一个你可以用 Python 制作的童年经典,以拓展你的技能。
-
这是一个有点复杂的游戏,但是这是一个经典的(而且非常有趣的)游戏。
面向初级 Web 开发人员的简单 Python 项目:
-
这个免费的视频课程将向你展示如何使用 Python 和 Django 构建你自己的 URL shorter,比如 Bit.ly。
-
用 Django 构建一个简单的网页——这是一个非常深入的、从头开始的教程,用 Python 和 Django 构建一个网站,甚至还有卡通插图!
面向有抱负的开发人员的简单 Python 项目:
-
密码生成器 —用 Python 构建一个安全的密码生成器。
-
使用 Tweepy 创建一个 Twitter 机器人——这更高级一点,因为你需要使用 Twitter API,但这绝对很有趣!
-
用 Python 创建一个加密应用 —这个免费的视频课程将带你使用一些 API 和 Python 来构建带有加密货币数据的应用。
其他 Python 项目想法
还没有找到一个吸引你的项目创意?这里还有很多,按经验水平分。
这些不是教程;这些想法需要你自己去挖掘和研究,但这也是乐趣的一部分!这是学习编码和作为程序员工作的自然过程的一部分。
专业人士总是使用谷歌来寻找答案——所以不要害怕一头扎进去弄脏你的手!
Python 项目理念:初级水平
-
创建代码生成器。这个 can 以文本作为输入,用另一个字母替换每个字母,并输出“编码的”消息。
-
构建一个倒计时计算器。写一些可以把两个日期作为输入的代码,然后计算它们之间的时间量。这将是熟悉 Python 的 datetime 模块的好方法。
-
写一个排序方法。给定一个列表,你能写一些代码按字母或数字排序吗?是的,Python 内置了这个功能,但是看看你能不能不用 sort()就能做到!
-
建立一个互动测验。你是哪个复仇者?构建一个个性化或推荐性测验,询问用户一些问题,存储他们的答案,然后执行某种计算,根据他们的答案给用户一个个性化的结果
-
文字井字游戏。构建一个像文本冒险一样可玩的井字游戏。你能让它在每次移动后打印一个基于文本的棋盘图形吗?
-
制作温度/测量转换器。写一个脚本,可以将华氏温度转换成摄氏温度,或者将英寸转换成厘米,等等。你能走多远?
-
搭建专柜 app。通过构建一个非常简单的应用程序,用户每次点击一个按钮,这个应用程序就会递增 1,从而迈出你进入 UI 世界的第一步。
-
构建一个猜数字游戏。把这想成有点像文字冒险,但是有数字。你能走多远?
-
造一个闹钟。这只是初级/中级水平,但值得尝试为自己打造一个闹钟。你能创建不同的警报吗?贪睡功能?
Python 项目理念:中级
-
构建升级的代码生成器。从初学者部分提到的项目开始,看看你能做些什么来使它变得更复杂。你能让它产生不同种类的代码吗?如果用户输入一个密钥,你能创建一个“解码器”程序来读取编码信息吗?你能创建一个比简单的字母替换更复杂的代码吗?
-
让你的井字游戏变得可点击。在初学者项目的基础上,现在制作一个井字游戏版本,它有一个实际的用户界面,你可以通过点击开放的方块来使用。挑战:你能写一个简单的“AI”对手让人类玩家对战吗?
-
刮一些数据来分析。这真的可以是任何东西,来自你喜欢的任何网站。网络上充满了有趣的数据,如果你了解一点网络搜集,你可以收集一些真正独特的数据集。
-
建一个时钟网站。你能让它多接近实时?你能实现不同的时区选择器,并添加“倒计时计算器”功能来计算时间长度吗?
-
让你的一些工作自动化。这可能会有所不同,但许多工作都有某种重复的流程,您可以将其自动化!
-
自动化你的个人习惯。上班期间要不要记得每小时站一次?编写一些代码,根据你的目标和喜好生成独特的锻炼计划,怎么样?你可以为自己开发各种简单的应用程序来自动化或增强你生活的不同方面。
-
创建一个简单的网络浏览器。构建一个简单的 UI,接受 URL 并加载网页。PyWt 在这里会很有帮助!你能添加一个“后退”按钮、书签和其他很酷的功能吗?
-
写一个笔记 app。创建一个帮助人们书写和存储笔记的应用程序。你能想出一些有趣和独特的功能来添加吗?
-
建立一个打字测试器。这应该向用户显示一些文本,然后要求他们键入文本——同时计时并对准确性评分。
-
创建一个“网站更新”通知系统。当你不得不刷新一个网站来查看一个脱销的产品是否重新上市,或者查看是否有任何新闻发布时,你是否感到恼火?编写一个 Python 脚本,自动检查给定 URL 的更新,并在发现更新时通知您。(不过,注意不要让你正在检查的任何网站的服务器过载——保持每次检查之间的合理时间间隔)。
-
用 Python 重现你最喜欢的桌游。这里有大量的选项,从简单的跳棋到冒险,甚至是更现代、更先进的游戏,如“骑票”或“卡坦的定居者”。你能多接近真实的东西?
-
建立一个维基百科浏览器。构建一个显示随机维基百科页面的应用程序。这里的挑战在于细节:你能添加用户选择的类别吗?你能尝试一个不同的“兔子洞”版本的应用程序吗,其中每篇文章都是从上一篇文章链接的文章中随机选择的?这看似简单,但实际上需要一些严肃的网络搜集技巧。
Python 项目思想:高级水平
-
搭建一个股市预测 app。对于这一点,你需要一个股票市场数据源和一些机器学习技能,但许多人已经尝试过了,所以有大量的源代码可供使用。
-
构建一个聊天机器人。这里的挑战与其说是制造聊天机器人,不如说是让它变得更好。比如,你能不能实现一些自然语言处理技术,让它听起来更自然、更自然?
-
给机器人编程。这需要一些硬件(通常不是免费的),但有许多负担得起的选择,也有许多学习资源。如果你还没有沿着这些思路思考的话,一定要去看看覆盆子酱。
-
搭建图像识别 app。从手写识别开始是一个好主意——data quest 甚至有一个指导项目来帮助它!但是一旦你学会了,你就可以更上一层楼。
-
制作价格预测模型。选择一个你感兴趣的行业或产品,建立一个预测价格变化的机器学习模型。
-
创建自己的情感分析模型。当然,有许多预构建的工具可用,但您能收集大量文本数据并构建自己的工具吗?(或者,挑战性更小:针对你正在分析的特定文本,优化现有的情感分析模型。)
-
创建互动地图。这将需要数据技能和 UI 创建技能的结合。你的地图可以显示任何你想显示的信息——鸟类迁徙、交通数据、犯罪报告——但它应该以某种方式互动。你能走多远?
后续步骤
上一节中的每个例子都是基于为初学者选择一个优秀的 Python 项目的实践。接下来,您可以进行以下操作:
-
想想自己对什么感兴趣,选择和自己兴趣重合的项目。
-
思考您的 Python 学习目标,并确保您的项目使您更接近实现这些目标。
-
从小处着手。一旦您构建了一个小项目,您可以扩展它或者构建另一个项目。
现在您已经准备好开始了。如果你还没有学习 Python 的基础知识,我推荐你参加 Dataquest 的 Python 基础课程。
如果你已经知道了基本知识,就没有理由犹豫了!现在是时候开始寻找您的完美 Python 项目了。
Python 范围教程:学习使用这个有用的内置函数
October 24, 2019
循环是任何编程语言不可或缺的一部分。在 Python 中,循环的一个重要组成部分是内置的range函数。
在这份详细的指南中,我们将通过示例带您了解range函数的工作方式,并讨论它的局限性及其解决方法。尽管range对于各种各样的 Python 编程任务都很有用,但本指南将以几个关于range函数的数据科学用例来结束。
出于本教程的目的,我们假设您至少了解一些 Python 语法。如果你以前从未使用过 Python,我们建议你先从这个交互式 Python 基础课程开始。
Python 中范围的简史
本教程主要关注 Python 3,但是如果你以前使用过 Python 2,就需要做一些解释,因为range的含义在这两个版本之间发生了变化。
Python 2 中的range函数生成了一个可以迭代的数字列表。因此,对于较大的列表,这个过程占用了大量内存。Python 2 中的xrange函数通过惰性求值返回项目,这意味着只有在需要时才生成数字,这样使用的内存更少。
Python 2 中的xrange函数在 Python 3 中被重命名为range,而 Python 2 中的range则被弃用。在本教程中,我们正在使用 Python 3 的range函数,所以它没有曾经与 Python 2 中的range相关的性能问题。
Python 范围:基本用途
让我们首先看看 Python 中for循环和range函数的基本用法。让我们打印前五个整数。
for i in range(5):
print(i)
0
1
2
3
4
上面的代码片段在数字 0 到 4 之间循环。请注意,五没有包含在循环中。因此,range的基本用途是遍历一系列数字。我们将很快重新审视range的范围。
对于range,我们可以使用三个参数:开始、停止和步进。我们可以将这三者说明如下:
- range(stop):这将创建一个从零到比停止号小 1 的数字范围,增量为 1。
- range(start,stop):这将创建一个数字范围,从起始数字到比终止数字小 1 的数字,增量为 1。
- range(start,stop,step):这将创建一个数字范围,从起始数字到小于终止数字的数字,按步长递增。
上面的简单例子使用了声明range函数的第一种方式。让我们探索另外两种方法。
# range(start, stop)
for i in range(3, 8):
print(i)
3
4
5
6
7
请注意,开始编号包含在范围内,而停止编号不包含在范围内。
# range (start, stop, step)
for i in range(1, 10, 3):
print(i)
1
4
7
在声明range的第三种方式中,我们从开始数开始,然后向上数三(步数),直到到达停止数。
范围:数据类型
让我们检查由range函数返回的对象的类型。
print(type(range(5)))
<class 'range'>
注意range是 Python 中的一种类型。类的默认打印方法打印 range 对象将迭代的数字范围。请注意,仍然没有生成数字—这是由于前面提到的节省内存的“惰性评估”。这些数字只有在它们以某种方式被实际使用时才会生成(比如在上面的 print 函数中被调用)。
print(range(5))
range(0, 5)
范围对象:高级使用
有趣的是,我们可以通过索引访问 range 对象中的项目,就像我们访问列表一样。我们范围内的第三个对象是 2。
range(5)[2]
2
像列表一样,我们也可以分割一个范围对象。这将返回一个新的 range 对象!
range(5)[:3]
range(0, 3)
我们也可以反转一个范围对象,使用同样适用于列表的reversed()函数。
# reversed
for i in reversed(range(5)):
print(i)
4
3
2
1
0
Range 可用于生成负数。
# show negative numbers
for i in range(-10, 5, 3):
print(i)
-10
-7
-4
-1
2
我们也可以定义一个负的阶跃函数来生成递减顺序的数字,而不是使用reversed函数。
# show negative iteration
for i in range(-10, -17, -2):
print(i)
-10
-12
-14
-16
注意,如果您使用带有range的 step 参数,它不能为零(这将导致无限循环,从而抛出 ValueError)。
此外,如果从开始参数开始计数不会到达结束参数,range不会返回任何内容。请注意,当我们运行下面的代码时,不会打印任何内容,因为如果我们从 17 开始计数,我们将永远无法达到指定的 end 参数 10:
# What if no numbers are in range?
for i in range(17, 10):
print(i)
带浮点数的范围对象
range 函数不适用于浮点数。只能将整数值指定为 start、stop 和 step 参数。
# floats with python range
for i in range(0.1, 0.5, 0.1):
print(i)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-a83306d87fcd> in <module>
1 # floats with python range
----> 2 for i in range(0.1, 0.5, 0.1):
3 print(i)
TypeError: 'float' object cannot be interpreted as an integer
但是,如果我们需要用 floats 生成类似 range 的返回,有几个变通办法。
首先,我们可以定义一个带有三个参数的简单函数,它逐步增加起始数字,直到到达停止:
# floats with python range
def range_with_floats(start, stop, step):
# Works only with positive float numbers!
while stop > start:
yield start
start += step
for i in range_with_floats(0.1, 0.5, 0.1):
print(i)
0.1
0.2
0.30000000000000004
0.4
我们也可以使用 NumPy 从 NumPy 的arange()函数中获得相同的结果。
import numpy as np
for i in np.arange(0.1, 0.5, 0.1):
print(i)
0.1
0.2
0.30000000000000004
0.4
数字0.30000000000000004从何而来?系统中只存储浮点数的近似值。因此,如果我们想生成一个更清晰的输出,我们可能需要在处理浮点数时使用 round()函数。
def range_with_floats(start, stop, step):
while stop > start:
yield round(start, 2) # adding round() to our function and rounding to 2 digits
start += step
for i in range_with_floats(0.1, 0.5, 0.1):
print(i)
0.1
0.2
0.3
0.4
在数据科学中使用 Python 的 Range 函数
读取大文件
Python 的 range 函数在数据科学环境中的一个用途是当我们读取大文件时。
例如,考虑 UCI 提供的【1985 年的汽车进口数据集。该文件采用 CSV 格式,其中的值用逗号分隔。下载文件并用open()功能打开。让我们使用.readline()方法打印前五行。
data_file = open('imports-85.data')
for i in range(5):
print(data_file.readline())
3,?,alfa-romero,gas,std,two,convertible,rwd,front,88.60,168.80,64.10,48.80,2548,dohc,four,130,mpfi,3.47,2.68,9.00,111,5000,21,27,13495
3,?,alfa-romero,gas,std,two,convertible,rwd,front,88.60,168.80,64.10,48.80,2548,dohc,four,130,mpfi,3.47,2.68,9.00,111,5000,21,27,16500
1,?,alfa-romero,gas,std,two,hatchback,rwd,front,94.50,171.20,65.50,52.40,2823,ohcv,six,152,mpfi,2.68,3.47,9.00,154,5000,19,26,16500
2,164,audi,gas,std,four,sedan,fwd,front,99.80,176.60,66.20,54.30,2337,ohc,four,109,mpfi,3.19,3.40,10.00,102,5500,24,30,13950
2,164,audi,gas,std,four,sedan,4wd,front,99.40,176.60,66.40,54.30,2824,ohc,five,136,mpfi,3.19,3.40,8.00,115,5500,18,22,17450
头文件描述了列名。最后一列包含汽车进口的价格。如果我们研究文件的前几行,我们会注意到缺失的项目被存储为一个问号(?).
每一行之间都有一个空行,因为它们以换行符(n)结束。我们需要在下面的分析中考虑这一点。让我们检查一下文件中有多少行。在 UNIX 终端中,您可以使用带有文件名的命令 wc -l 作为参数来计算行数。如果您正在使用 Jupyter 笔记本,您可以在命令前使用感叹号来从单元格内运行终端命令。
!wc -l imports-85.data
205 imports-85.data
有了 205 行数据,让我们试着找到价格最高的汽车进口和汽车在数据集中的行号。首先,我们将在文件长度的范围内循环。接下来,用.readline()方法读取该行,去掉每行末尾的换行符,并使用split()函数将该行转换成一个条目列表。
单子上的最后一项是进口汽车的价格。如果缺少价格,我们就循环下一个项目。如果价格比我们的max_price高,我们改变max_price的值并更新行号,存储在变量max_price_loc中。
# basic looping in Python
# reading lines in a file (time with a magic function)
data_file = open('imports-85.data')
max_price = 0
max_price_loc = 0
for i in range(205):
row = data_file.readline().rstrip('\n').split(",")
price = row[-1]
# Missing price
if price == '?':
continue
if (max_price < int(price)):
max_price = int(price)
max_price_loc = i + 1
print("Maximum Price: ", max_price)
print("Maximum Price Location: Row number ", max_price_loc)
Maximum Price: 45400
Maximum Price Location: Row number 75
最贵的汽车在 1985 年的价格是 45400 美元,根据 2019 年的价格扣除通货膨胀大约是 108000 美元。
网页抓取时迭代页面
range 函数在数据科学环境中的另一个用途是从某些网站抓取信息。
例如,假设我们想从一个 BBS 论坛中提取数据。通常,文章分布在大量的页面上,在 URL 的某个地方包含一个页码。我们可以只输入一次 URL,而不是一个接一个地输入每个页面的 URL,通过用一个range函数产生的每个数字替换 URL 中的页码来交互每个页面。
例如,如果我们想发送一个请求到一个 URL 格式:https://www.website.com/?p=page_number的页面,我们可以使用 range 按顺序生成每个 URL。在下面的例子中,我们获得了前十个页面的 URL,但是这种技术可以用来快速生成成百上千个 URL,然后您可以从这些 URL 中一个一个地抓取内容,而实际上不必在代码中放入多个 URL。
for i in range(1, 11):
current_url = 'https://www.website.com/?p={page_num}'.format(page_num = i)
print(current_url)
# Make a request to the URL
https://www.website.com/?p=1
https://www.website.com/?p=2
https://www.website.com/?p=3
https://www.website.com/?p=4
https://www.website.com/?p=5
https://www.website.com/?p=6
https://www.website.com/?p=7
https://www.website.com/?p=8
https://www.website.com/?p=9
https://www.website.com/?p=10
最终想法
在本教程中,我们学习了使用 range()函数的一些不同方法,并看到了它如何在数据科学工作中特别有用的一些示例。
如果您处理数据,range()不太可能是您每天都要使用的函数,但是在某些情况下,对它的工作原理有一个扎实的了解可以节省大量的时间和精力。
想要为数据科学打下更坚实的 Python 基础吗?注册一个免费账户并查看我们的 Python 基础和中级课程。它们是深入的,互动的,完全免费的!
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。
Python 字符串:深入教程(55+代码示例)
April 21, 2022
数据类型帮助我们对数据项进行分类。它们决定了我们可以对数据项执行的操作种类。在 Python 中,常见的标准数据类型包括数字、字符串、列表、元组、布尔、集合、字典。
在本教程中,我们将重点关注字符串数据类型。我们将讨论如何声明字符串数据类型,字符串数据类型与 ASCII 表之间的关系,字符串数据类型的属性,以及一些重要的字符串方法和操作。
什么是 Python 字符串?
一个字符串是一个包含字符序列的对象。字符是长度为 1 的字符串。在 Python 中,单个字符也是字符串。具有讽刺意味的是,Python 编程语言中没有字符数据类型。然而,我们在其他编程语言中发现了字符数据类型,如 C、Kotlin 和 Java。
我们可以使用单引号、双引号、三引号或str()函数来声明 Python 字符串。以下代码片段显示了如何在 Python 中声明字符串:
# A single quote string
single_quote = 'a' # This is an example of a character in other programming languages. It is a string in Python
# Another single quote string
another_single_quote = 'Programming teaches you patience.'
# A double quote string
double_quote = "aa"
# Another double-quote string
another_double_quote = "It is impossible until it is done!"
# A triple quote string
triple_quote = '''aaa'''
# Also a triple quote string
another_triple_quote = """Welcome to the Python programming language. Ready, 1, 2, 3, Go!"""
# Using the str() function
string_function = str(123.45) # str() converts float data type to string data type
# Another str() function
another_string_function = str(True) # str() converts a boolean data type to string data type
# An empty string
empty_string = ''
# Also an empty string
second_empty_string = ""
# We are not done yet
third_empty_string = """""" # This is also an empty string: ''''''
在 Python 中获取字符串的另一种方法是使用input()函数。input()功能允许我们用键盘向程序中插入数值。插入的值作为字符串读取,但是我们可以将它们转换成其他数据类型:
# Inputs into a Python program
input_float = input() # Type in: 3.142
input_boolean = input() # Type in: True
# Convert inputs into other data types
convert_float = float(input_float) # converts the string data type to a float
convert_boolean = bool(input_boolean) # converts the string data type to a bool
我们使用type()函数来确定 Python 中对象的数据类型。它返回对象的类。当对象是字符串时,它返回str类。同样,当对象是字典、整数、浮点、元组或布尔时,它分别返回dict、int、float、tuple、bool类。现在让我们使用type()函数来确定前面代码片段中声明的变量的数据类型:
# Data types/ classes with type()
print(type(single_quote))
print(type(another_triple_quote))
print(type(empty_string))
print(type(input_float))
print(type(input_boolean))
print(type(convert_float))
print(type(convert_boolean))
<class><class><class><class><class><class><class>
我们已经讨论了如何声明字符串。现在让我们来看看字符串和 ASCII 表之间的关系。
ASCII 表与 Python 字符串字符
开发美国信息交换标准代码( ASCII )是为了帮助我们将字符或文本映射到数字,因为数字组比文本更容易存储在计算机内存中。ASCII 编码 128 个字符,主要在英语中,用于在计算机和编程中处理信息。ASCII 编码的英文字符包括小写字母(a-z)、大写字母(A-Z)、数字(0-9)和标点符号等符号。
ord()函数将长度为 1(一个字符)的 Python 字符串转换成 ASCII 表上的十进制表示,而chr()函数将十进制表示转换回字符串。例如:
import string
# Convert uppercase characters to their ASCII decimal numbers
ascii_upper_case = string.ascii_uppercase # Output: ABCDEFGHIJKLMNOPQRSTUVWXYZ
for one_letter in ascii_upper_case[:5]: # Loop through ABCDE
print(ord(one_letter))
65
66
67
68
69
# Convert digit characters to their ASCII decimal numbers
ascii_digits = string.digits # Output: 0123456789
for one_digit in ascii_digits[:5]: # Loop through 01234
print(ord(one_digit))
48
49
50
51
52
在上面的代码片段中,我们遍历了字符串ABCDE和01234,并将每个字符转换成它们在 ASCII 表中的十进制表示。我们也可以用chr()函数执行相反的操作,将 ASCII 表上的十进制数转换成 Python 字符串。例如:
decimal_rep_ascii = [37, 44, 63, 82, 100]
for one_decimal in decimal_rep_ascii:
print(chr(one_decimal))
%
,
?
R
d
在 ASCII 表上,上述程序输出中的字符串字符映射到它们各自的十进制数。到目前为止,我们已经讨论了如何声明 Python 字符串以及字符串字符如何映射到 ASCII 表。接下来,我们来讨论一个字符串的属性。
字符串属性
零索引:字符串中第一个元素的索引为零,而最后一个元素的索引为len(string) - 1。例如:
immutable_string = "Accountability"
print(len(immutable_string))
print(immutable_string.index('A'))
print(immutable_string.index('y'))
14
0
13
不变性。这意味着我们不能更新字符串中的字符。例如,我们不能从一个字符串中删除一个元素,或者试图在它的任何索引位置分配一个新元素。如果我们试图更新字符串,它会抛出一个TypeError:
immutable_string = "Accountability"
# Assign a new element at index 0
immutable_string[0] = 'B'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_11336/2351953155.py in <module>
2
3 # Assign a new element at index 0
----> 4 immutable_string[0] = 'B'
TypeError: 'str' object does not support item assignment
然而,我们可以将一个字符串重新分配给immutable_string变量,但是我们应该注意到它们不是同一个字符串,因为它们没有指向内存中的同一个对象。Python 不更新旧的字符串对象;它创建了一个新的,正如我们在 ids 中看到的:
immutable_string = "Accountability"
print(id(immutable_string))
immutable_string = "Bccountability"
print(id(immutable_string)
test_immutable = immutable_string
print(id(test_immutable))
2693751670576
2693751671024
2693751671024
你会得到和例子中不同的 id,因为我们在不同的计算机上运行程序,所以我们的内存地址是不同的。但是,在同一台计算机上,这两个 id 也应该是不同的。这意味着两个immutable_string变量指向内存中不同的地址。我们将最后一个immutable_string变量赋给了test_immutable变量。可以看到test_immutable变量和最后一个immutable_string变量指向同一个地址。
串联:将两个或多个字符串连接在一起,得到一个带有+符号的新字符串。例如:
first_string = "Data"
second_string = "quest"
third_string = "Data Science Path"
fourth_string = first_string + second_string
print(fourth_string)
fifth_string = fourth_string + " " + third_string
print(fifth_string)
Dataquest
Dataquest Data Science Path
重复:一个字符串可以用*符号重复。例如:
print("Ha" * 3)
HaHaHa
索引和切片:我们已经知道字符串是零索引的。我们可以用它的索引值访问字符串中的任何元素。我们也可以通过在两个索引值之间切片来获取字符串的子集。例如:
main_string = "I learned R and Python on Dataquest. You can do it too!"
# Index 0
print(main_string[0])
# Index 1
print(main_string[1])
# Check if Index 1 is whitespace
print(main_string[1].isspace())
# Slicing 1
print(main_string[0:11])
# Slicing 2:
print(main_string[-18:])
# Slicing and concatenation
print(main_string[0:11] + ". " + main_string[-18:])
I
True
I learned R
You can do it too!
I learned R. You can do it too!
字符串方法
str.split(sep=None, maxsplit=-1): 字符串拆分方法包含两个属性:sep和maxsplit。当使用默认值调用该方法时,它会在有空格的地方拆分字符串。此方法返回字符串列表:
string = "Apple, Banana, Orange, Blueberry"
print(string.split())
['Apple,', 'Banana,', 'Orange,', 'Blueberry']
我们可以看到字符串没有被很好地分割,因为分割后的字符串包含,。我们可以使用sep=','来拆分任何有,的地方:
print(string.split(sep=','))
['Apple', ' Banana', ' Orange', ' Blueberry']
这比之前的分裂要好。然而,我们可以在一些分割的字符串前看到空白。我们可以用(sep=', ')删除它:
# Notice the whitespace after the comma
print(string.split(sep=', '))
['Apple', 'Banana', 'Orange', 'Blueberry']
现在,绳子被很好地分开了。有时候,我们不想分最大次数。我们可以使用maxsplit属性来指定我们想要分割的次数:
print(string.split(sep=', ', maxsplit=1))
print(string.split(sep=', ', maxsplit=2))
['Apple', 'Banana, Orange, Blueberry']
['Apple', 'Banana', 'Orange, Blueberry']
str.splitlines(keepends=False): 有时候我们想处理一个边界处有不同换行符('\n'、\n\n'、'\r'、'\r\n')的语料库。我们想分成句子,而不是单个的单词。我们将使用splitline方法来做到这一点。当keepends=True时,文本中包含换行符;否则,他们将被排除在外。让我们看看莎士比亚的《麦克白》是如何做到这一点的:
import nltk # You may have to `pip install nltk` to use this library.
macbeth = nltk.corpus.gutenberg.raw('shakespeare-macbeth.txt')
print(macbeth.splitlines(keepends=True)[:5])
['[The Tragedie of Macbeth by William Shakespeare 1603]\n', '\n', '\n', 'Actus Primus. Scoena Prima.\n', '\n']
str.strip([chars]): 我们用strip的方法去除字符串两边的尾随空格或字符。例如:
string = " Apple Apple Apple no apple in the box apple apple "
stripped_string = string.strip()
print(stripped_string)
left_stripped_string = (
stripped_string
.lstrip('Apple')
.lstrip()
.lstrip('Apple')
.lstrip()
.lstrip('Apple')
.lstrip()
)
print(left_stripped_string)
capitalized_string = left_stripped_string.capitalize()
print(capitalized_string)
right_stripped_string = (
capitalized_string
.rstrip('apple')
.rstrip()
.rstrip('apple')
.rstrip()
)
print(right_stripped_string)
Apple Apple Apple no apple in the box apple apple
no apple in the box apple apple
No apple in the box apple apple
No apple in the box
在上面的代码片段中,我们使用了lstrip和rstrip方法,分别从字符串的左侧和右侧删除尾随空格或字符。我们还使用了capitalize方法,它将字符串转换成句子的大小写。
str.zfill(width):zfill方法用0前缀填充一个字符串,得到指定的width。例如:
example = "0.8" # len(example) is 3
example_zfill = example.zfill(5) # len(example_zfill) is 5
print(example_zfill)
000.8
str.isalpha(): 如果字符串中的所有字符都是字母,该方法返回True;否则,返回False:
# Alphabet string
alphabet_one = "Learning"
print(alphabet_one.isalpha())
# Contains whitspace
alphabet_two = "Learning Python"
print(alphabet_two.isalpha())
# Contains comma symbols
alphabet_three = "Learning,"
print(alphabet_three.isalpha())
True
False
False
类似地,如果字符串字符是字母数字,则str.isalnum()返回True;如果字符串字符为十进制,则str.isdecimal()返回True;如果字符串字符是数字,str.isdigit()返回True;如果字符串字符是数字,则str.isnumeric()返回True。
如果字符串中的所有字符都是小写,则 str.islower() 返回True。如果字符串中的所有字符都是大写的,str.isupper()返回True,如果每个单词的首字母都是大写的,str.istitle()返回True:
# islower() example
string_one = "Artificial Neural Network"
print(string_one.islower())
string_two = string_one.lower() # converts string to lowercase
print(string_two.islower())
# isupper() example
string_three = string_one.upper() # converts string to uppercase
print(string_three.isupper())
# istitle() example
print(string_one.istitle())
False
True
True
True
str.endswith(suffix) 返回的True是以指定后缀结尾的字符串。如果字符串以指定的前缀开始,则str.startswith(prefix)返回True:
sentences = ['Time to master data science', 'I love statistical computing', 'Eat, sleep, code']
# endswith() example
for one_sentence in sentences:
print(one_sentence.endswith(('science', 'computing', 'Code')))
True
True
False
# startswith() example
for one_sentence in sentences:
print(one_sentence.startswith(('Time', 'I ', 'Ea')))
True
True
True
str.find(substring) 如果字符串中存在子串,则返回最低索引;否则,它返回-1。str.rfind(substring)返回最高指数。如果找到子串,str.index(substring)和str.rindex(substring)也分别返回子串的最低和最高索引。如果子串不在字符串中,他们抛出ValueError。
string = "programming"
# find() and rfind() examples
print(string.find('m'))
print(string.find('pro'))
print(string.rfind('m'))
print(string.rfind('game'))
# index() and rindex() examples
print(string.index('m'))
print(string.index('pro'))
print(string.rindex('m'))
print(string.rindex('game'))
6
0
7
-1
6
0
7
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_11336/3954098241.py in <module>
11 print(string.index('pro')) # Output: 0
12 print(string.rindex('m')) # Output: 7
---> 13 print(string.rindex('game')) # Output: ValueError: substring not found
ValueError: substring not found
str.maketrans(dict_map) 从字典映射创建翻译表,str.translate(maketrans)用新值替换翻译中的元素。例如:
example = "abcde"
mapped = {'a':'1', 'b':'2', 'c':'3', 'd':'4', 'e':'5'}
print(example.translate(example.maketrans(mapped)))
12345
字符串操作
通过一根绳子循环。字符串是可迭代的。因此,它们支持使用for loop和enumerate的循环操作:
# For-loop example
word = "bank"
for letter in word:
print(letter)
b
a
n
k
# Enumerate example
for idx, value in enumerate(word):
print(idx, value)
0 b
1 a
2 n
3 k
字符串和关系运算符:当使用关系运算符(>、<、==等)比较两个字符串时。),两个字符串的元素通过它们的 ASCII 十进制数逐个索引地进行比较。例如:
print('a' > 'b')
print('abc' > 'b')
False
False
两种情况下,输出都是False。关系运算符首先比较两个字符串的索引0中元素的 ASCII 十进制数。由于b大于a,所以返回False;在这种情况下,其他元素的 ASCII 十进制数以及字符串的长度都无关紧要。
当字符串长度相同时,它会比较索引0中每个元素的 ASCII 十进制数,直到找到 ASCII 十进制数不同的元素。例如:
print('abd' > 'abc')
True
在上面的代码片段中,前两个元素具有相同的 ASCII 十进制数;但是,在第三个元素中有一个不匹配,因为d大于c,所以它返回True。在元素的所有 ASCII 数字都匹配的情况下,较长的字符串大于较短的字符串。例如:
print('abcd' > 'abc')
True
检查字符串的成员资格。in操作符用于检查一个子串是否是一个字符串的成员:
print('data' in 'dataquest')
print('gram' in 'programming')
True
True
另一种检查字符串成员、替换子串或匹配模式的方法是使用正则表达式
import re
substring = 'gram'
string = 'programming'
replacement = '1234'
# Check membership
print(re.search(substring, string))
# Replace string
print(re.sub(substring, replacement, string))
<re.match object="" span="(3," match="gram">pro1234ming</re.match>
字符串格式化。 f-string和str.format()方法用于格式化字符串。两者都使用花括号{}占位符。例如:
monday, tuesday, wednesday = "Monday", "Tuesday", "Wednesday"
format_string_one = "{} {} {}".format(monday, tuesday, wednesday)
print(format_string_one)
format_string_two = "{2} {1} {0}".format(monday, tuesday, wednesday)
print(format_string_two)
format_string_three = "{one} {two} {three}".format(one=tuesday, two=wednesday, three=monday)
print(format_string_three)
format_string_four = f"{monday} {tuesday} {wednesday}"
print(format_string_four)
Monday Tuesday Wednesday
Wednesday Tuesday Monday
Tuesday Wednesday Monday
Monday Tuesday Wednesday
f-strings可读性更好,并且比str.format()方法实现得更快。因此,f-string是字符串格式化的首选方法。
处理引号和撇号:撇号(')代表 Python 中的一个字符串。为了让 Python 知道我们不是在处理一个字符串,我们必须使用 Python 转义字符(\)。因此,在 Python 中,撇号被表示为\'。与处理撇号不同,Python 中有许多处理引号的方法。它们包括以下内容:
# 1\. Represent string with single quote (`""`) and quoted statement with double quote (`""`)
quotes_one = '"Friends don\'t let friends use minibatches larger than 32" - Yann LeCun'
print(quotes_one)
# 2\. Represent string with double quote `("")` and quoted statement with escape and double quote `(\"statement\")`
quotes_two = "\"Friends don\'t let friends use minibatches larger than 32\" - Yann LeCun"
print(quotes_two)
# 3\. Represent string with triple quote `("""""")` and quoted statment with double quote ("")
quote_three = """"Friends don\'t let friends use minibatches larger than 32" - Yann LeCun"""
print(quote_three)
"Friends don't let friends use minibatches larger than 32" - Yann LeCun
"Friends don't let friends use minibatches larger than 32" - Yann LeCun
"Friends don't let friends use minibatches larger than 32" - Yann LeCun
结论
Python 字符串是不可变的,它们是基本的数据类型之一。我们可以使用单引号、双引号或三引号,或者使用str()函数来声明它们。
我们可以将字符串的每个元素映射到 ASCII 表上的一个数字。这是我们在使用关系运算符比较字符串时使用的属性。有许多方法可用于处理字符串。
本文讨论最常用的方法,包括拆分字符串、检查开始和结束字符、填充、检查字符串大小写以及替换字符串中的元素的方法。我们还讨论了用于遍历字符串成员、检查字符串成员资格、格式化字符串以及处理引号和撇号的字符串操作。
Python 子过程:简单的初学者教程(2022)
September 6, 2022
简单来说,计算机中发生的一切都是一个过程。当您打开应用程序或运行命令行命令或 Python 脚本时,您正在启动一个新的进程。从打开菜单栏到启动一个复杂的应用程序,一切都是在你的机器上运行的进程。
例如,当您从命令行调用 Python 脚本时,一个进程正在创建另一个进程。这两个进程现在有了相互关系:创建另一个进程的进程是父进程,而创建的进程是子进程。
同样,Python 脚本也可以启动一个新进程,然后它将成为这个新进程的父进程。在本文中,我们将看到如何使用 python 中的subprocess模块在常规 python 脚本的过程中运行不同的子流程。
虽然这不是一篇高级文章,但是为了理解示例和概念,Python 的基础知识可能是必要的。
subprocess模块
subprocess是一个标准的 Python 模块,旨在从 Python 脚本中启动新的进程。它非常有用,事实上,当您需要并行运行多个进程或者从 Python 代码内部调用外部程序或外部命令时,它是推荐的选项。
subprocess模块的优点之一是它允许用户管理输入、输出,甚至是 Python 代码中的子进程产生的错误。这种可能性使得调用子流程更加强大和灵活——例如,它允许在 Python 脚本的其余部分将子流程的输出作为变量使用。
该模块最初是在 Python 2.4 中实现的,目标是作为其他函数的替代,比如os.system。另外,从 Python 3.5 开始,这个模块的推荐用法是通过run()函数,这将是本文的重点。
使用 subprocess.run()
Python 中的subprocess模块的run函数是在后台运行命令的好方法,不用担心打开新的终端或手动运行命令。该功能对于自动化任务或运行不想手动运行的命令也非常有用。
该函数接收的主参数是*args,它是一个 iterable,包含运行子流程的指令。为了执行另一个 Python 代码,args应该包含 Python 可执行文件和 Python 脚本的路径。
所以它看起来像这样:
import subprocess
subprocess.run(["python", "my_script.py"])
也可以将 Python 代码直接写到函数中,而不是传递一个.py文件。下面是运行此类子流程的一个示例:
result = subprocess.run(["/usr/local/bin/python", "-c", "print('This is a subprocess')"])
在args内部,我们有以下内容:
"/usr/local/bin/python":本地 Python 可执行文件的路径。"-c":Python 标签,允许用户将 Python 代码作为文本写入命令行。"print('This is a subprocess')":实际要运行的代码。
其实这和把/usr/local/bin/python -c print('This is a subprocess')传到命令行是一样的。本文中的大部分代码将采用这种格式,因为这样更容易展示run函数的特性。但是,您总是可以调用包含相同代码的另一个 Python 脚本。
同样,在上面的例子中,我们两次都使用了run函数,args中的第一个字符串指的是 Python 可执行文件的路径。第一个例子使用了一个更通用的路径,我们将在整篇文章中保持这样。
然而,如果您在机器上找不到 Python 可执行文件的路径,您可以让sys模块帮您找到。这个模块与subprocess交互得很好,一个很好的用例是替换可执行文件的路径,如下所示:
import sys
result = subprocess.run([sys.executable, "-c", "print('This is a subprocess')"])
run 函数然后返回一个CompletedProcess类的对象,它代表一个完成的流程。
如果我们打印result,我们会得到这样的结果:
CompletedProcess(args=['/usr/bin/python3', '-c', "print('This is a subprocess')"], returncode=0)
正如我们所期望的,它是显示命令的CompletedProcess类的实例,而returncode=0表明它运行成功。
更多参数
既然我们已经了解了如何使用run函数运行子流程,我们应该探索能够更好地利用该函数的选项。
控制输出
注意,上面代码返回的对象只显示了命令和返回代码,但是没有关于子流程的其他信息。然而,如果我们将capture_output参数设置为True,它会返回更多的信息,让用户对他们的代码有更多的控制。
所以如果我们运行这个。。。
result = subprocess.run(["python", "-c", "print('This is a subprocess')"], capture_output=True)
我们会得到这个。。。
CompletedProcess(args=['/usr/bin/python3', '-c', "print('This is a subprocess')"], returncode=0, stdout=b'This is a subprocess\n', stderr=b'')
现在我们在返回的对象中也有了stdout和stderr。如果我们将它们都打印出来,我们会得到以下结果:
print(result.stdout)
print(result.stderr)
b'This is a subprocess\n'
b''
它们都是表示子流程输出的字节序列。但是,我们也可以将文本参数设置为True,然后将这些输出作为字符串。
但是,如果脚本中有错误,stdout将为空,stderr将包含错误消息,如下所示:
result = subprocess.run(["python", "-c", "print(subprocess)"], capture_output=True, text=True)
print('output: ', result.stdout)
print('error: ', result.stderr)
output:
error: Traceback (most recent call last): File "<string>", line 1, in <module> NameError: name 'subprocess' is not defined
因此,这使得您可以根据子流程的输出来调整代码的其余部分,在整个代码中使用该输出作为变量,甚至可以跟踪子流程并存储它们(如果它们都运行无误)及其输出。
引发错误
尽管我们能够在上面的代码中生成一条错误消息,但重要的是要注意它没有停止父进程,这意味着即使子进程中发生了错误,代码仍然会运行。
如果我们想让代码在子流程出错时继续执行,我们可以使用run函数的check参数。通过将该参数设置为True,子进程中的任何错误都将在父进程中引发,并导致整个代码停止。
下面,我们使用与上一节相同的例子,但是使用了check=True:
result = subprocess.run(["pyhon", "-c", "print(subprocess)"], capture_output=True, text=True, check=True)
print('output: ', result.stdout)
print('error: ', result.stderr)
---------------------------------------------------------------------------
CalledProcessError Traceback (most recent call last)
<ipython-input-7-5b9e69e8fef6> in <module>()
----> 1 result = subprocess.run(["python", "-c", "print(subprocess)"], capture_output=True, text=True, check=True)
2 print('output: ', result.stdout)
3 print('error: ', result.stderr)
/usr/lib/python3.7/subprocess.py in run(input, capture_output, timeout, check, *popenargs, **kwargs)
510 if check and retcode:
511 raise CalledProcessError(retcode, process.args,
--> 512 output=stdout, stderr=stderr)
513 return CompletedProcess(process.args, retcode, stdout, stderr)
514
CalledProcessError: Command '['python', '-c', 'print(subprocess)']' returned non-zero exit status 1.
代码引发了一个错误,指出子流程返回了状态 1。
引发错误的另一种方式是使用timeout参数。顾名思义,使用该参数将停止子进程,如果运行时间比预期的长,将引发错误。
例如,下面子流程中的代码需要五秒钟来运行:
subprocess.run(["python", "-c", "import time; time.sleep(5)"], capture_output=True, text=True)
但是如果我们将timeout参数设置为小于 5,我们会有一个异常:
subprocess.run(["python", "-c", "import time; time.sleep(5)"], capture_output=True, text=True, timeout=2)
---------------------------------------------------------------------------
TimeoutExpired Traceback (most recent call last)
<ipython-input-9-93e2b7acaf10> in <module>()
----> 1 subprocess.run(["python", "-c", "import time; time.sleep(5)"], capture_output=True, text=True, timeout=2)
/usr/lib/python3.7/subprocess.py in _check_timeout(self, endtime, orig_timeout, stdout_seq, stderr_seq, skip_check_and_raise)
1009 self.args, orig_timeout,
1010 output=b''.join(stdout_seq) if stdout_seq else None,
-> 1011 stderr=b''.join(stderr_seq) if stderr_seq else None)
1012
1013
TimeoutExpired: Command '['python', '-c', 'import time; time.sleep(5)']' timed out after 2 seconds
在子流程中输入
我们前面看到,在父代码的其余部分使用子进程的输出是可能的,但是反过来也是正确的:我们可以使用input参数将父进程的值输入到子进程。
我们使用该参数将任何字节或字符串序列(如果是text=True)发送给子流程,子流程将通过sys模块接收该信息。sys.stdin.read()函数将读取子进程中的input参数,在子进程中,它可以被赋给一个变量,并像代码中的任何其他变量一样使用。
这里有一个例子:
result = subprocess.run(["python", "-c", "import sys; my_input=sys.stdin.read(); print(my_input)"], capture_output=True, text=True, input='my_text')
print(result.stdout)
my_text
上面子流程中的代码导入模块,并使用sys.stdin.read()将输入分配给一个变量,然后打印该变量。
但是,我们也可以通过args输入值,并使用sys.argv在子代码内部读取它们。例如,假设我们在一个名为my_script.py的脚本中有以下代码:
# ../subprocess/my_script.py
import sys
my_input = sys.argv
def sum_two_values(a=int(my_input[1]), b=int(my_input[2])):
return a + b
if __name__=="__main__":
print(sum_two_values())
下面的run函数中的args位于将成为上面的子进程的父进程的脚本中,它包含另外两个值,这两个值将由sys.argv访问,然后在my_script.py中累加。
# ../subprocess/main.py
result = subprocess.run(["python", "my_script.py", "2", "4"], capture_output=True, text=True)
print(result.stdout)
6
结论
Python 子流程模块和 subprocess.run()函数是非常强大的工具,用于在运行 Python 脚本时与其他流程进行交互。
在本文中,我们介绍了以下内容:
-
流程和子流程
-
如何使用
run()功能运行子流程 -
如何访问子流程生成的输出和错误
-
如果子进程中有错误,如何在父进程中引发错误
-
如何为子进程设置超时
-
如何向子流程发送输入
Python 三元组:如何使用它以及它为什么有用(有例子)
August 10, 2022
什么是 Python 三元运算符,什么时候有用?本教程将带你了解你需要知道的一切。
Python 三元运算符(或条件运算符)测试条件是真还是假,并根据结果返回相应的值——所有这些都在一行代码中完成。换句话说,在我们只需要在两个值之间“切换”的情况下,它是常见的多行 if-else 控制流语句的一个紧凑替代方案。Python 2.5 中引入了三元运算符。
该语法由三个操作数组成,因此称为“三元”:
a if condition else b
以下是这些操作数:
condition—测试真或假的布尔表达式a—如果条件被评估为真,将返回的值b—如果条件被评估为假,将返回的值
在这种情况下,普通 if-else 语句的等效语句如下:
if condition:
a
else:
b
让我们看一个简单的例子:
"Is true" if True else "Is false"
'Is true'
虽然三元运算符是重写经典 if-else 块的一种方式,但在某种意义上,它的行为就像一个函数,因为它返回一个值。事实上,我们可以将这个操作的结果赋给一个变量:
my_var = a if condition else b
例如:
x = "Is true" if True else "Is false"
print(x)
Is true
在我们有三元运算符之前,我们将使用condition and a or b而不是a if condition else b。例如,不运行下面的。。。
True if 2 > 1 else False
True
。。。我们将运行这个:
2 > 1 and True or False
True
然而,如果语法condition and a or b中a的值计算为False(例如,如果a等于0,或者None,或者False,我们将会收到不准确的结果。下面这个三元运算符的例子看起来逻辑上有争议(我们想返回Falseif 2>1;否则,我们希望返回True),但这在技术上是正确的,因为如果条件评估为True,则由我们决定返回哪个值,如果条件评估为False,则由我们决定返回哪个值。在这种情况下,我们期待False,我们得到了它:
False if 2 > 1 else True
False
出于同样的目的,使用“旧式”语法而不是三元运算符,我们仍然会期待False。然而,我们收到了一个意想不到的结果:
2 > 1 and False or True
True
为了避免这样的问题,在类似的情况下最好使用三元运算符。
Python 三元运算符的局限性
注意,Python 三元运算符的每个操作数都是一个表达式,而不是一个语句,这意味着我们不能在它们中的任何一个内部使用赋值语句。否则,程序会抛出一个错误:
1 if True else x = 0
File "C:\Users\Utente\AppData\Local\Temp/ipykernel_13352/3435735244.py", line 1
1 if True else x=0
^
SyntaxError: cannot assign to conditional expression
如果我们需要使用语句,我们必须编写一个完整的 if-else 块,而不是三元运算符:
if True:
1
else:
x=0
Python 三元运算符的另一个限制是,我们不应该使用它来测试多个表达式(即,if-else 块包含两个以上的情况)。从技术上讲,我们仍然可以这样做。例如,以下面这段代码为例:
x = -1
if x < 0:
print('x is less than zero')
elif x > 0:
print('x is greater than zero')
else:
print('x is equal to 0')
x is less than zero
我们可以使用嵌套的三元运算符重写这段代码:
x = -1
'x is less than zero' if x < 0 else 'x is greater than zero' if x > 0 else 'x is equal to 0'
'x is less than zero'
(边注:在上面这段代码中,我们省略了print()语句,因为 Python 三元运算符总是返回值。)
虽然第二段代码看起来比第一段更紧凑,但可读性也差得多。为了避免可读性问题,我们应该选择只在有简单的 if-else 语句时使用 Python 三元运算符。
如何使用 Python 三元运算符
现在,我们将讨论应用 Python 三元运算符的各种方法。假设我们想检查某个温度的水是否在沸腾。在标准大气压下,水在 100 摄氏度沸腾。假设我们想知道水壶里的水是否在沸腾,因为它的温度达到了 90 摄氏度。在这种情况下,我们可以简单地使用 if-else 块:
t = 90
if t >= 100:
print('Water is boiling')
else:
print('Water is not boiling')
Water is not boiling
我们可以使用一个简单的 Python 三元运算符重写这段代码:
t = 90
'Water is boiling' if t >= 100 else 'Water is not boiling'
'Water is not boiling'
(边注:上面,我们省略了print()语句,因为 Python 三元运算符总是返回值。)
上面两段代码的语法已经很熟悉了。然而,还有一些我们还没有考虑的实现 Python 三元运算符的其他方法。
使用元组
重新组织 Python 三元运算符的第一种方法是编写其元组形式。如果 Python 三元运算符的标准语法是a if condition else b,这里我们将把它重写为(b, a)[condition],如下所示:
t = 90
('Water is not boiling', 'Water is boiling')[t >= 100]
'Water is not boiling'
在上面的语法中,元组的第一项是如果条件评估为False(自False==0)将返回的值,而第二项是如果条件评估为True(自True==1)将返回的值。
与 Python 三元运算符的常见语法相比,这种使用方式并不流行,因为在这种情况下,元组的两个元素都被计算,因为程序首先创建元组,然后才检查索引。此外,确定在哪里放置真值和在哪里放置假值可能是违反直觉的。
使用字典
除了元组,我们还可以使用 Python 字典,如下所示:
t = 90
{True: 'Water is boiling', False: 'Water is not boiling'}[t >= 100]
'Water is not boiling'
现在,我们没有区分真假值的问题。但是,与前一种情况一样,在返回正确的表达式之前,两个表达式都会被计算。
使用 Lambdas
最后,实现 Python 三元运算符的最后一种方法是应用 Lambda 函数。为此,我们应该按照下面的形式重写初始语法a if condition else b:(lambda: b, lambda: a)[condition]()
t = 90
(lambda: 'Water is not boiling', lambda: 'Water is boiling')[t >= 100]()
'Water is not boiling'
请注意,在这种情况下,我们可能会对在哪里放置真值和假值感到困惑。但是,与前两种方法相比,这种方法的优势在于它的执行效率更高,因为只计算一个表达式。
结论
让我们总结一下我们在本教程中学到的关于 Python 三元运算符的知识:
- Python 三元运算符的工作原理
- 当它优于普通的 if-else 块时
- Python 三元运算符的语法
- 相当于在普通 if-else 块中编写的 Python 三元运算符
- Python 三元运算符的旧版本及其问题
- Python 三元运算符的局限性
- 嵌套 Python 三元运算符及其对代码可读性的影响
- 如何使用元组、字典和 Lambda 函数应用 Python 三元运算符,包括每种方法的优缺点
Python 元组:一步一步的教程(包含 14 个代码示例)
March 28, 2022
在处理数据集合时,我们偶尔会遇到这样的情况,我们希望确保在创建后无法更改对象的顺序。
例如,当用 Python 从数据库中读取数据时,我们可以将每个表记录表示为有序且不可改变的对象序列,因为我们不需要在以后改变该序列。Python 有一个内置的序列数据类型来将数据存储在一个不可改变的对象中,称为元组。
完成本 Python 教程后,您将了解以下内容:
- 如何在 Python 中使用元组
- Python 中元组和列表的区别
- 元组的基本用途
在本教程中,我们假设您了解 Python 的基础知识,包括变量、数据类型和基本结构。如果你不熟悉这些或者想复习一下,你可能想试试我们的 Python 数据分析基础——Data quest。
让我们开始吧。
什么是 Python 元组?
元组表示由逗号分隔并括在括号中的任何对象的序列。tuple 是一个不可变的对象,这意味着它不能被改变,我们用它来表示项目的固定集合。
让我们来看一些 Python 元组的例子:
()—空元组(1.0, 9.9, 10)—包含三个数字对象的元组('Casey', 'Darin', 'Bella', 'Mehdi')—包含四个字符串对象的元组('10', 101, True)—包含字符串、整数和布尔对象的元组
此外,列表和元组等其他对象可以组成一个元组,如下所示:
a_tuple = (0, [1, 2, 3], (4, 5, 6), 7.0)
上面的代码创建了一个包含整数、列表、元组和浮点数的元组。下面的代码返回整个元组及其数据类型。
print(a_tuple)
print(type(a_tuple))
(0, [1, 2, 3], (4, 5, 6), 7.0)
<class>
但是,('A')不是元组。让我们看看它的数据类型:
print(type(('A')))
<class>
那么,怎样才能声明一个单值元组呢?答案很简单。我们需要在右括号前加一个额外的逗号,就像这样:
('A',)
后面的逗号是指括号中保存的是一个单值元组,不是为了增加一个数学运算的优先级。
对元组进行索引和切片
如前所述,因为元组是一个对象序列,所以我们可以通过索引来访问这些对象。与字符串一样,第一个元素的索引是 0,第二个元素的索引是 1,依此类推。让我们尝试索引一个元组:
print('The first element:', a_tuple[0])
print('The last element:', a_tuple[-1])
print('The data type of the second element:', type(a_tuple[1]))
The first element: 0
The last element: 7.0
The data type of the second element: <class>
在上面的代码中,第一个和第二个语句返回元组的第一个和最后一个元素的值。最后一条语句打印出元组的第二个元素的数据类型,它是一个列表对象。
此外,下面这段代码显示了如何在索引 2 处检索内部元组的第二个元素。
print(a_tuple[2][1])
5
这意味着我们可以通过一系列索引操作来访问存储在内部元组(存储在另一个元组中的元组)中的元素。
对元组进行切片就像用相同的规则对 Python 字符串或列表进行切片一样简单。为了获得元组中的元素范围,我们可以通过选择范围的开始(包含)和结束(不包含)来指定要检索的索引范围。
让我们来看一些例子:
num_tuple = 2, 4, 5, 7, 8, 10
print(num_tuple[:3])
print(num_tuple[4:])
print(num_tuple[-3:])
print(num_tuple[2:5])
(2, 4, 5)
(8, 10)
(7, 8, 10)
(5, 7, 8)
代码的第一行声明了一个整数值元组。虽然这不常见,但这是声明元组的另一种方式,即提供一系列用逗号分隔的对象,而不用圆括号将它们括起来。后续语句打印出元组的不同部分,如图所示。
注
如果你不熟悉用 Python 对序列对象进行索引和切片,或者想复习一下,Dataquest 博客上有一个很好的教程:教程:揭开 Python 列表的神秘面纱。
要连接两个或更多元组,我们可以像字符串一样使用+符号。例如,以下代码连接两个元组:
tuple_1 = (1, 2)
tuple_2 = (3, 4)
print(tuple_1 + tuple_2)
(1, 2, 3, 4)
此外,将一个元组乘以一个整数会产生一个包含重复多次的原始元组的元组。让我们来试试:
my_tuple = (1, 7, 9, 8)
print(my_tuple * 2)
(1, 7, 9, 8, 1, 7, 9, 8)
压缩元组
zip()方法接受多个序列对象,并通过匹配它们的元素返回一个 iterable 对象。要了解关于压缩元组的更多信息,请考虑以下示例。
假设我们有三个不同的元组,包含四个客户的个人详细信息。我们希望创建一个元组,以单独元组的形式保存每个客户的相应数据,包括他们的名字、姓氏和年龄:
first_names = ('Simon', 'Sarah', 'Mehdi', 'Fatime')
last_names = ('Sinek', 'Smith', 'Lotfinejad', 'Lopes')
ages = (49, 55, 39, 33)
zipped = zip(first_names, last_names,ages)
print(zipped)
我们在上面的代码中声明了first_name、last_name和ages元组。zip()方法接受三元组并返回一个 zip 对象,这是一个迭代器。要使用迭代器对象,我们需要将它转换为列表或元组,如下所示:
customers = tuple(zipped)
print(customers)
(('Simon', 'Sinek', 49), ('Sarah', 'Smith', 55), ('Mehdi', 'Lotfinejad', 39), ('Fatime', 'Lopes', 33))
customers tuple 由四个 tuple 对象组成,每个对象属于一个客户。
解包元组
解包元组允许我们提取元组元素并将它们分配给命名变量。让我们来试试:
first_name, last_name, age = customers[2]
print(first_name, last_name, ',', age, 'years old')
Mehdi Lotfinejad , 39 years old
上面的代码检索存储在customers元组的索引 2 处的元组元素,并将它们分配给first_name、last_name和age变量。
Python 中元组和列表的区别
除了元组和列表之间的直观差异,如前所述,元组是不可变的,因此与列表不同,元组不能被修改。然而,一些技术差异使得元组成为 Python 编程中不可否认的资产。
列表比元组更适合作为可迭代对象的第一个区别是列表对象提供了更多的方法。但是额外的功能是有代价的。让我们先看看下面代码中每个对象占用内存的大小,然后讨论为什么元组在某些情况下是更好的选择。
import sys
a_list = ['abc', 'xyz', 123, 231, 13.31, 0.1312]
a_tuple = ('abc', 'xyz', 123, 231, 13.31, 0.1312)
print('The list size:', sys.getsizeof(a_list), 'bytes')
print('The tuple size:', sys.getsizeof(a_tuple), 'bytes')
The list size: 104 Bytes
The tuple size: 88 Bytes
我们可以看到列表对象比元组对象占用更多的内存。当我们处理大数据时,占用更少内存的重要性变得更加明显,这意味着在处理大量数据时,不变性会带来显著的优化。除了占用更少的内存之外,处理元组对象比列表要快得多,尤其是在处理数以百万计的序列对象时。
Python 元组的使用
本节将讨论在实践中使用元组的两种令人兴奋的方式。让我们来探索它们。
元组元素交换
只有当变量是元组元素时,我们才能使用元组来交换与变量相关联的值。让我们试一试:
x = 19
y = 91
print('Before swapping:')
print(f'x = {x}, y = {y}')
(x, y) = (y, x)
print('After swapping:')
print(f'x = {x}, y = {y}')
Before swapping:
x = 19, y = 91
After swapping:
x = 91, y = 19
y的值赋给x变量,x的值同时赋给y。这是一种更为 Pythonic 式的交换值的方式。
从函数中返回多个值
函数只能返回一个值。然而,我们可以使用一个 tuple,并在其中放入我们需要的任意多的值,然后返回 tuple 对象作为函数的返回值。让我们看看如何使用元组从下面的代码中的函数返回多个值:
def sum_and_avg(x, y, z):
s = x + y + z
a = s/3
return(s, a)
(S, A) = sum_and_avg(3, 8, 5)
print('Sum =', S)
print('Avg =', A)
Sum = 16
Avg = 5.333333333333333
sum_and_avg()函数计算三个数值的和与平均值。该函数返回s和a,这是它在元组对象的上下文中计算的两个值。实际上,函数只返回单个值,这是一个包含多个值的元组对象。我们还使用了元组解包技术来提取返回的元组对象中的值,然后将它们打印出来。
结论
本教程讲述了如何创建元组对象,以及 Python 元组的许多方面,如索引、切片、压缩、解包等。我们还讨论了元组和列表之间的区别。正确使用 Python 元组肯定会使我们的代码更加高效和健壮。
Python 初学者教程:分析您的个人网飞数据
原文:https://www.dataquest.io/blog/python-tutorial-analyze-personal-netflix-data/
November 5, 2020
我花了多少时间看办公室?
这是我多年来反复思考的问题。很长一段时间以来,这部受人喜爱的情景喜剧一直是我首选的“舒适秀/背景噪音”。
这曾经是一个我无法回答的问题,因为网飞允许用户下载的关于他们活动的数据极其有限。
不过,现在网飞允许你下载一个名副其实的账户数据宝库。通过一点 Python 和 pandas 编程,我们现在可以得到这个问题的具体答案:我花了多少时间看办公室?
想知道你花了多少时间看《办公室》或网飞的其他节目吗?
在本教程中,我们将带你一步一步地了解如何去做!
有一点 Python 和熊猫的经验对本教程会有帮助,但不是绝对必要的。你可以注册并免费试用我们面向初学者的交互式 Python 课程。
但首先,让我们回答一个简单的问题。。。
我就不能用 Excel 吗?为什么我需要写代码?
根据你看《网飞》的时间和你使用这项服务的时间长短,你可能能够使用 Excel 或其他电子表格软件来分析你的数据。
但是很有可能会很艰难。
你将从网飞获得的数据集包括每隔时间播放的的任意长度的视频——这包括当你浏览你的列表时自动播放的那些预告片。
因此,如果你经常使用网飞或者已经使用流媒体服务很长时间了,你正在处理的文件可能会非常大。例如,我自己的观看活动数据超过 27,000 行。
在 Excel 中打开那么大的文件没问题。但是为了进行分析,我们需要进行一系列的过滤和计算。有了这么多的数据,Excel 可能会陷入严重的停顿,尤其是如果您的计算机不是特别强大的话。
在如此庞大的数据集中滚动,试图找到特定的单元格和公式也会很快变得令人困惑。
Python 可以更流畅地处理像这样的大型数据集和计算,因为它不必可视化地呈现一切。因为我们只用几行代码就可以做所有的事情,所以看到我们正在做的一切真的很容易,而不必滚动一个大的电子表格来寻找带有公式的单元格。
步骤 1:下载你的网飞数据
出于本教程的目的,我将使用我自己的网飞数据。要获取您自己的,请确保您已登录网飞,然后访问此页面。在网飞主屏幕上,您也可以通过点击右上角的您的帐户图标,点击“帐户”,然后在加载的页面上点击“下载您的个人信息”来找到此页面。
在下一页,您应该会看到:

点击红色按钮提交您的数据下载请求。
单击“提交请求”网飞将向您发送一封确认电子邮件,您需要点击该邮件。
那么,不幸的是,你必须等待。网飞说准备你的数据报告可能需要 30 天。我曾经在 24 小时内收到一份报告,但另一份报告需要几周时间。考虑给这个页面添加书签,这样一旦你得到了你的数据,你就可以回来了。
如果你愿意,我还从我自己的数据中制作了一个小样本,可以在这里下载。如果你愿意,你可以下载这个文件并在这个项目中使用它。然后,当您自己的数据变得可用时,只需用您的文件替换相同的数据,再次运行您的代码,您将几乎立即得到您的答案!

当网飞说可能需要一个月才能得到你的数据时。
当你的报告可供下载时,网飞会发电子邮件给你。如果是这样的话,赶快行动吧,因为下载会在几个星期后“过期”并再次消失!
下载文件将以. zip 文件的形式到达,该文件包含大约十几个文件夹,其中大部分包含。csv 格式。此外,还有两个 pdf 文件,其中包含有关数据的附加信息。
第二步:熟悉数据
这是数据分析过程中的一个关键步骤。我们对数据理解得越好,产生有意义的分析的机会就越大。
让我们看看我们有什么。当我们解压缩文件时,我们将看到以下内容:

我们的目标是计算出我花了多少时间看网飞。似乎是最有可能包含这些数据的文件夹。如果我们打开它,我们会发现一个名为ViewingActivity.csv的文件,看起来正是我们想要的——记录了我们在帐户历史中查看的所有内容。

数据看起来像电子表格的一个例子。
看着这些数据,我们可以很快发现一个潜在的挑战。有一个单独的列Title,它包含了节目和的剧集标题,所以我们需要做一些额外的工作,只过滤掉办公室的剧集。
在这一点上,使用这些数据进行分析是很诱人的,但是让我们先确保我们理解了这些数据!在下载的 zip 文件中,有一个名为Cover sheet.pdf的文件,其中包含所有。csv 文件,包括ViewingActivity.csv。
这个数据字典可以帮助我们回答问题,避免错误。例如,查询字典中的ViewingActivity.csv,我们可以看到列Start Time使用了的 UTC 时区。例如,如果我们想分析一天中我们最常观看网飞的时间,我们需要将该列转换为我们的本地时区。
在进入下一步之前,花些时间查看一下ViewingActivity.csv中的数据和Cover sheet.pdf中的数据字典!
第三步:将你的数据载入 Jupyter 笔记本
在本教程中,我们将在 Jupyter 笔记本中使用 Python 和 pandas 来分析我们的数据。如果你还没有设置好,你可以在本教程的开头找到一个快速的、对初学者友好的指南,或者查看为初学者提供的更深入的 Jupyter 笔记本帖子。
打开笔记本后,我们将导入 pandas 库,并将我们的网飞数据 CSV 读入 pandas 数据帧,我们称之为df:
import pandas as pd
df = pd.read_csv('ViewingActivity.csv')
现在,让我们快速预览一下数据,确保一切正常。我们将从df.shape开始,它将告诉我们刚刚创建的数据帧中的行数和列数。
df.shape
(27354, 10)
这个结果意味着我们有 27,353 行和 10 列。现在,让我们通过使用df.head()预览前几行数据来看看它是什么样子的。
为了保护隐私,我将在.head()括号内添加额外的参数1,这样在这篇博文中只有一行打印出来。然而,在您自己的分析中,您可以使用默认的.head()来打印前五行。
df.head(1)
| 配置文件名称 | 开始时间 | 持续时间 | 属性 | 标题 | 补充视频类型 | 设备类型 | 书签 | 最新书签 | 国家 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 傻瓜 | 2020-10-29 3:27:48 | 0:00:02 | 圆盘烤饼 | 办公室(美国):第七季:最后通牒(Episod… | 圆盘烤饼 | 索尼 PS4 | 0:00:02 | 0:00:02 | 美国(美国) |
完美!
步骤 4:准备用于分析的数据
在我们进行数字运算之前,让我们稍微整理一下这些数据,使其更容易处理。
删除不必要的列(可选)
首先,我们将从删除不打算使用的列开始。这完全是可选的,对于大规模或正在进行的项目来说,这可能不是一个好主意。但是对于像这样的小规模个人项目,使用只包含我们实际使用的列的 dataframe 可能会更好。
在这种情况下,我们计划在观察完办公室后,分析有多少和,因此我们需要保留Start Time、Duration和Title列。其他的都可以去。
为此,我们将使用df.drop()并向它传递两个参数:
- 我们要删除的列的列表
axis=1,告诉熊猫放下柱子
它看起来是这样的:
df = df.drop(['Profile Name', 'Attributes', 'Supplemental Video Type', 'Device Type', 'Bookmark', 'Latest Bookmark', 'Country'], axis=1)
df.head(1)
| 开始时间 | 持续时间 | 标题 | |
|---|---|---|---|
| Zero | 2020-10-29 3:27:48 | 0:00:02 | 办公室(美国):第七季:最后通牒(Episod… |
太好了!接下来,让我们处理时间数据。
在 Pandas 中将字符串转换为日期时间和时间增量
我们的两个与时间相关的列中的数据看起来当然是正确的,但是这些数据实际上是以什么格式存储的呢?我们可以使用df.dtypes获得数据帧中每一列的数据类型的快速列表:
df.dtypes
Start Time object
Duration object
Title object
dtype: object
正如我们在这里看到的,所有三列都存储为object,这意味着它们是字符串。这对于Title列来说没问题,但是我们需要将这两个与时间相关的列转换成正确的数据类型,然后才能使用它们。
具体来说,我们需要做到以下几点:
- 将
Start Time转换为日期时间(一种熊猫可以理解并执行计算的数据和时间格式) - 将
Start Time从 UTC 转换为我们的本地时区 - 将
Duration转换为时间增量(一种熊猫可以理解并执行计算的持续时间格式)
所以,让我们按照这个顺序来处理这些任务,首先使用 pandas 的pd.to_datetime()将Start Time转换成 datetime。
我们还将添加可选参数utc=True,以便我们的日期时间数据附加了 UTC 时区。这很重要,因为我们需要在下一步将它转换成不同的时区。
然后,我们将再次运行df.dtypes来确认这是否如预期的那样工作。
df['Start Time'] = pd.to_datetime(df['Start Time'], utc=True)
df.dtypes
Start Time datetime64[ns, UTC]
Duration object
Title object
dtype: object
现在我们已经得到了正确格式的列,是时候改变时区了,这样当我们进行分析时,我们将看到当地时间的所有内容。
我们可以使用.tz_convert()将日期时间转换为任何时区,并向它传递一个参数,该参数包含我们要转换到的时区的字符串。在这种情况下,那就是'US/Eastern'。为了找到你的具体时区,这里有一个方便的参考 TZ 时区选项。
这里比较棘手的一点是,我们只能在 DatetimeIndex 上使用.tz_convert(),所以在执行转换之前,我们需要使用set_index()将我们的Start Time列设置为索引。
在本教程中,我们随后将使用reset_index()将其转换回常规列。根据您的偏好和目标,这可能不是必需的,但是为了简单起见,我们将尝试使用列中的所有数据进行分析,而不是将其中的一些数据作为索引。
将所有这些放在一起看起来像这样:
# change the Start Time column into the dataframe's index
df = df.set_index('Start Time')
# convert from UTC timezone to eastern time
df.index = df.index.tz_convert('US/Eastern')
# reset the index so that Start Time becomes a column again
df = df.reset_index()
#double-check that it worked
df.head(1)
| 开始时间 | 持续时间 | 标题 | |
|---|---|---|---|
| Zero | 2020-10-28 23:27:48-04:00 | 0:00:02 | 办公室(美国):第七季:最后通牒(Episod… |
我们可以看到这是正确的,因为我们的数据集中先前的第一行有一个2020-10-29 03:27:48的Start Time。在夏令时期间,美国东部时区比 UTC 晚四个小时,因此我们可以看到我们的转换是正确的!
现在,让我们来处理我们的Duration专栏。顾名思义,这是一个持续时间——一个对时间长度的度量。因此,我们需要将其转换为 timedelta,而不是将其转换为 datetime,time delta 是熊猫能够理解的持续时间的度量。
这与我们在转换Start Time列时所做的非常相似。我们只需要使用pd.to_timedelta()并将我们想要转换的列作为参数传递给它。
我们将再次使用df.dtypes来快速检查我们的工作。
df['Duration'] = pd.to_timedelta(df['Duration'])
df.dtypes
Start Time datetime64[ns, US/Eastern]
Duration timedelta64[ns]
Title object
dtype: object
完美!但是我们还有一个数据准备任务要处理:过滤Title列,这样我们就可以只分析办公室的视图。
使用 str.contains 在 pandas 中按子串过滤字符串
我们有很多方法可以过滤办公室的观点。不过,出于我们的目的,我们将创建一个名为office的新数据帧,并只在其中的Title列包含'The Office (U.S.)'的行中填充数据。
我们可以使用 str.contains() 来做到这一点,给它两个参数:
'The Office (U.S.)',这是我们用来挑选《办公室剧集的子字符串。regex=False,告诉函数前面的参数是字符串,不是正则表达式。
实际情况是这样的:
# create a new dataframe called office that that takes from df
# only the rows in which the Title column contains 'The Office (U.S.)'
office = df[df['Title'].str.contains('The Office (U.S.)', regex=False)]
一旦我们做到了这一点,有几种方法可以让我们复查我们的工作。例如,我们可以使用office.sample(20)来检查新的office数据帧的随机十行。如果所有 20 行都包含 Office 剧集,我们可以非常自信地认为事情会按预期进行。
不过,为了在本教程中保留一点隐私,我将运行office.shape来检查新数据帧的大小。由于这个数据帧应该只包含的我对办公室的看法,我们应该期望它的行数比 27,000+行df的数据集少得多。
office.shape
(5479, 3)
使用时间增量 过滤掉短持续时间
在我们真正深入研究和分析之前,我们可能应该采取最后一个步骤。我们在数据探索中注意到,当像剧集预览这样的东西在主页上自动播放时,它在我们的数据中算作一个视图。
然而,当你滚动过去的时候看两秒钟的预告片和实际看一集是不一样的!因此,让我们进一步过滤我们的office数据帧,将它限制为仅包含Duration值大于一分钟的行。这应该有效地计算部分观看剧集的观看时间,同时过滤掉那些短暂的、不可避免的“预览”视图。
同样,office.head()或office.sample()是检查我们工作的好方法,但是为了保持一些隐私,我将再次使用df.shape来确认一些行已经从数据帧中删除。
office = office[(office['Duration'] > '0 days 00:01:00')]
office.shape
(5005, 3)
这看起来不错,所以让我们继续有趣的东西!
分析数据

当你意识到你花了多少时间看同一个节目时。
我花了多少时间看办公室?
首先,我们来回答一个大问题:我花了多少时间看办公室?
因为我们已经有了熊猫可以计算的格式的Duration栏,回答这个问题相当简单。我们可以使用.sum()来合计总持续时间:
office['Duration'].sum()
Timedelta('58 days 14:03:33')
所以,我总共花了 58 天 14 小时 3 分 33 秒看《网飞的办公室》。那就是。。。很多。
在我看来,那是在十年的过程中,其中很大一部分时间没有花在积极观看上!当我在做脑力劳动、健身、玩旧电子游戏等的时候。我会经常打开办公室的背景噪音,这样我就可以进出办公室了。我也曾经在睡着的时候把它当作一种白噪音。
但我们不是来为我糟糕的生活方式找借口的!既然我们已经回答了这个大问题,让我们更深入地挖掘一下我的办公室——观看习惯:
我什么时候看办公室?
让我们用两种不同的方式来回答这个问题:
- 我在一周的哪几天看了最多的 Office 集?
- 我在一天中的哪几个小时最常开始看办公室集?
我们将从一点准备工作开始,这将使这些任务更加简单:为“工作日”和“小时”创建新列。
我们可以使用Start Time列上的.dt.weekday和.dt.hour方法来实现这一点,并将结果分配给名为weekday和hour的新列:
office['weekday'] = office['Start Time'].dt.weekday
office['hour'] = office['Start Time'].dt.hour
# check to make sure the columns were added correctly
office.head(1)
| 开始时间 | 持续时间 | 标题 | 工作日 | 小时 | |
|---|---|---|---|---|---|
| one | 2020-10-28 23:09:43-04:00 | 0 天 00:18:04 | 办公室(美国):第七季:优雅的圣诞节:… | Two | Twenty-three |
现在,我们来做一点分析!这些结果在视觉上更容易理解,所以我们将开始使用%matplotlib inline魔法让我们的图表显示在我们的 Jupyter 笔记本上。然后,我们再导入matplotlib。
%matplotlib inline
import matplotlib
现在,让我们按一周中的每一天来绘制我的观看习惯的图表。为此,我们需要完成几个步骤:
- 告诉 pandas 我们希望使用
pd.Categorical来绘制日期的顺序——默认情况下,它会根据每天观看的剧集数量以降序绘制它们,但当查看图表时,以周一至周日的顺序查看数据会更直观。 - 统计我每天观看的剧集总数
- 对数据进行分类和绘图
(当然,我们还有许多其他方法来分析和可视化这些数据。)
让我们一步一步来看看它是怎样的:
# set our categorical and define the order so the days are plotted Monday-Sunday
office['weekday'] = pd.Categorical(office['weekday'], categories=
[0,1,2,3,4,5,6],
ordered=True)
# create office_by_day and count the rows for each weekday, assigning the result to that variable
office_by_day = office['weekday'].value_counts()
# sort the index using our categorical, so that Monday (0) is first, Tuesday (1) is second, etc.
office_by_day = office_by_day.sort_index()
# optional: update the font size to make it a bit larger and easier to read
matplotlib.rcParams.update({'font.size': 22})
# plot office_by_day as a bar chart with the listed size and title
office_by_day.plot(kind='bar', figsize=(20,10), title='Office Episodes Watched by Day')

办公室白天看风景,周一至周日。
正如我们所看到的,我实际上在工作日比周末更倾向于观察办公室。根据我的习惯,这是有意义的,因为它经常是晚上工作、锻炼时的背景噪音。
现在,让我们按小时来看一下同样的数据。这里的过程与我们刚才所做的非常相似:
# set our categorical and define the order so the hours are plotted 0-23
office['hour'] = pd.Categorical(office['hour'], categories=
[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23],
ordered=True)
# create office_by_hour and count the rows for each hour, assigning the result to that variable
office_by_hour = office['hour'].value_counts()
# sort the index using our categorical, so that midnight (0) is first, 1 a.m. (1) is second, etc.
office_by_hour = office_by_hour.sort_index()
# plot office_by_hour as a bar chart with the listed size and title
office_by_hour.plot(kind='bar', figsize=(20,10), title='Office Episodes Watched by Hour')

办公室查看时间,上午-下午
从数据来看,看起来 12 点和 1 点是我最常开始看《办公室里的 T1》的时间。这是由于我睡觉时把节目当作白噪音的(不健康)习惯——这些剧集中的许多可能是在我已经睡着的时候自动播放的!
除此之外,毫不奇怪,我的大部分观看都发生在晚上。
(注意:这个数据实际上可能没有很好地反映我的真实习惯,因为我在网飞账户所有权的很大一部分时间里都住在中国。我们在本教程中没有考虑这一点,因为这是一种独特的情况,不适用于大多数人。如果您在使用网飞期间花费了大量时间在不同的时区,那么您可能需要在分析之前的数据清理阶段进行一些额外的日期过滤和时区转换。)
下一步是什么?
在本教程中,我们快速浏览了一些网飞的个人数据,并了解到——除了别的以外——我看了太多的《办公室》。但是从这里你可以去很多地方!以下是为你自己扩展这个项目的一些想法:
- 为另一个节目做相同或相似的分析。
- 看看您是否可以使用正则表达式为节目标题和剧集标题创建单独的列[在我们的高级数据清理课程中学习使用它们]
- 找出你看得最多和最少的特定剧集
- 创建更漂亮的图表(我们的数据可视化讲故事课程可以在这方面提供帮助)

当你意识到你在网飞的观看习惯让你完成了一个很酷的项目。
你也可以用自己的个人数据尝试一些其他有趣的项目。例如:
- 使用 Python 找出你在亚马逊上花了多少钱
- 使用 Python 来分析你的脸书发帖习惯
想学着自己做这种项目,什么时候都行?我们的交互式数据科学课程将教你做所有这些事情,甚至更多!—就在您的浏览器窗口中。
https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
Python 与 Anaconda——有什么区别?
July 7, 2022
Python 和 Anaconda 的主要区别是什么?以下是你需要知道的。
Python 是一种多用途编程语言,从机器学习到网页设计,无所不包。它使用pip(“Pip Installs Packages”或“Pip Installs Python”的递归首字母缩写)作为其包管理器来自动安装、更新和删除包。
Anaconda 是 Python、R 和其他语言的发行版(捆绑包),以及为数据科学量身定制的工具(即 Jupyter Notebook 和 RStudio)。它还提供了另一个名为conda的包管理器。
因此,当您安装 Python 时,您会得到一种编程语言和pip(在 Python 3.4+和 Python 2.7.9+中可用),这使用户能够安装在 Python 包索引(或 PyPi)上可用的附加包。
相比之下,使用 Anaconda 可以获得 Python、R、250+预装包、数据科学工具和图形用户界面 Anaconda Navigator。
因此,Python 和 Anaconda 的主要区别在于,前者是一种编程语言,后者是安装和管理 Python 和其他编程语言(如 R)的软件。
在本文中,我们将讨论如何使用 Anaconda 来管理和安装软件包,以及何时使用pip或conda。此外,我们将讨论conda品种(即miniconda和mamba)之间的差异。
包和环境经理
请注意,我使用 Linux 作为我的主要系统,因为它非常方便编程项目(和 macOS 一起),所以在 Windows 上,以下命令可能会有所不同。我建议安装 Anaconda 并使用 Anaconda 命令提示符在 Windows 上运行命令。
在数据科学中,通常在编程中,我们使用虚拟环境来隔离不同项目中使用的包依赖关系,以便它们不会相互冲突。例如,您可能有两个项目:一个使用 pandas 0.25,另一个使用 pandas 1.5。您不能在系统范围内安装这两个版本,但是您可以为每个项目创建独立的环境,激活它们,并开始编码。
但是,请注意可以在系统范围内安装多个版本的 Python和 pyenv ,并使用其插件 pyenv-virtualenv 来管理 Unix 上的虚拟环境。
Python 和 Anaconda 都为虚拟环境创建和包管理提供了解决方案。
计算机编程语言
Python 整合了一个内置模块venv(来自“虚拟环境”),可以创建 Python 版本和附属包的孤立集合。
- 运行
python3 -m venv /path/to/dir创建一个环境。例如,命令python3 -m venv ./venv_dir将在当前工作目录下的目录venv_dir中创建一个虚拟环境。 - 通过运行
source venv_dir/bin/activate将其激活。 - 您将看到括号中的环境名称出现在您的用户名之前。
- 通过运行
pip list列出该环境中安装的软件包。目前没有那么多,因为这是一个新鲜的环境。 - 使用
deactivate命令将其禁用。
python3 -m venv ./venv_dir
source venv_dir/bin/activate
pip list
Package Version
------------- -------
pip 20.0.2
pkg-resources 0.0.0
setuptools 44.0.0
现在,让我们在这个环境中安装几个包。我们可以用pip来做到这一点,但首先,我们必须再次激活环境。接下来,运行命令pip install pandas==1.2.5 seaborn。这将安装自2021 年 6 月起的pandas版本和seaborn的最新可用版本(自 2021 年 8 月起为 0.11.2)。
注意pip收集并安装这些包的依赖项,比如numpy(pandas需要的)和matplotlib(seaborn需要的)。
pip install pandas==1.2.5 seaborn
蟒蛇
Anaconda 提供了自己的开源包管理器conda。它与pip非常相似,尽管它并不总是拥有最新的软件包,并且比pip慢一些。然而,conda允许我们在 Python 生态系统之外安装软件包。conda提供了不同的安装包的渠道。pip有一个中央公共存储库 PyPi ,但是也可以创建和托管您自己的存储库。
要使用 Anaconda 创建虚拟环境,我们可以使用 GUI Anaconda Navigator 或命令行。让我们从 Anaconda Navigator 开始。
- 首先,打开 Anaconda Navigator 并单击左侧窗格中的“Environments ”( 1)。然后,点击底部的
Create(2),写下你的环境名称(3),选择 Python(或 R)版本,点击绿色按钮“创建”(4):

- 现在,单击环境将其激活(5):

- 我们已经在环境中安装了一些软件包,但要安装更多,请在顶部的下拉菜单中选择“未安装”(6),并使用搜索栏搜索软件包(7)。我们现在必须找到所需的软件包,选择它,单击底部的“应用”(8),并在它要求我们确认时再次单击“应用”(9):


最后,返回到“Home”页面,选择环境,并运行所需的应用程序(例如,JupyterLab)。
虽然与命令行相比,使用 GUI 对初学者来说是友好的,但它确实很慢而且更复杂。我强烈建议学习命令行基础知识,以显著提高您的工作速度。
现在让我们用命令行创建一个虚拟环境。
- 类型
conda create -n test_env_v2。这将创建一个名为test_env_v2的环境。它会问你是否要在一个目录下创建一个环境,键入y,按回车键确认。注意,我正在miniconda3目录中创建环境。牢记在心;稍后我会解释什么是miniconda。 - 要激活环境,运行
conda activate test_env_v2。注意,环境名出现在您的用户名和计算机名之前(在我的例子中是[[email protected]](/cdn-cgi/l/email-protection))。 - 现在通过运行
conda install pandas=1.2.5 seaborn jupyterlab安装pandas、seaborn和jupyterlab。 - 您现在可以通过运行
jupyterlab命令来运行 JupyterLab。
conda create -n test_env_v2
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: /home/artur/miniconda3/envs/test_env_v2
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate test_env_v2
#
# To deactivate an active environment, use
#
# $ conda deactivate
conda activate test_env_v2
(test_env_v2) [[email protected]](/cdn-cgi/l/email-protection):~$
(test_env_v2) [[email protected]](/cdn-cgi/l/email-protection):~$ conda install pandas=1.2.5 seaborn jupyterlab
(test_env_v2) [[email protected]](/cdn-cgi/l/email-protection):~$ jupyterlab
注意,用conda安装比用pip安装花费的时间长,但是语法有点类似,而且更简单。
conda的一个显著优点是它提供了多个通道来安装不同用途的包。默认使用的主包通道由 Anaconda Inc .管理,可能包含过时的包。另一方面,频道conda-forge ( 他们的网站)是由社区维护的,通常提供大量最新的软件包。
运行conda config --add channel conda-forge添加该频道。现在,无论何时你想从conda-forge安装包,只需在conda install上添加-c conda-forge选项——例如,conda install -c conda-forge pandas seaborn从conda-forge通道安装pandas和seaborn。
(test_env_v2) [[email protected]](/cdn-cgi/l/email-protection):~$ conda config --add channel conda-forge
(test_env_v2) [[email protected]](/cdn-cgi/l/email-protection):~$ conda install -c conda-forge pandas seaborn
当然,还有许多其他渠道是为了不同的目的而创建的。例如,我是一名生物信息学家,为我的工作安装了许多只在 bioconda 频道上可用的工具。另一个例子是机器学习框架 PyTorch 提供的pytorch通道。
何时使用 Python 或 Anaconda?
但是我们什么时候用pip或者conda?看情况。
PyPi 包含 350,000 多个专门为 Python 设计的包,而 Anaconda 在主通道和conda-forge中只提供了大约 20,000 个包。然而,Anaconda 包并不是特定于 Python 的!也就是说,也可能有同时使用 Python、R 和 Perl 的 R 包甚至整个软件发行版。
此外,Anaconda 主要包含用于数据科学的包,而 PyPi 可以安装用于任何用例(即联网或网站建设)的包。此外,Anaconda 有一个初学者友好的 GUI。
因此,此时您可能已经决定了何时使用其中一个。如果您是数据科学的初学者,请使用 Anaconda 如果您对命令行更有经验,并且找不到您项目的包(这可能在数据科学领域之外),那么使用 Python 的pip和 PyPi。
现在我们来讨论 Anaconda 和 Miniconda 的区别。
腰果 vs .迷你穹顶
Miniconda 是另一个 Python 发行版,但是与 Anaconda 不同,它只包含几个预安装的包(而不是 Anaconda 中的 250 多个)。当然也融入了包管理器conda。
换句话说,Miniconda 是 Anaconda 的轻量级版本。如果您想使用命令行自己安装所有必需的软件包,并且不想为您不使用的软件包浪费磁盘空间,那么您应该使用它。您可以按照您的平台的说明在这里安装它。
但是,如果您对命令行不太熟悉,但想马上开始编码,那么可以选择 Anaconda 及其图形用户界面 Anaconda Navigator。
曼巴
还记得我跟你说过conda包管理器比pip慢一点吗?好吧,我们有更好的选择来加快速度。
Mamba 是用 C++重写的 Miniconda,所以速度更快,使用的计算资源更少。它使用完全相同的语法:您只需在命令中将conda改为mamba。
要安装 Mamba,请运行conda install -c conda-forge mamba。
我确定在我的机器上,有了已经建立的环境和大量缓存的包(以及添加的频道),conda实际上稍微快了一点!然而,我总是在我的 Amazon EC2 实例(一个由 Amazon Web Services提供的微型服务器)上使用mamba,只有 1gb 的 RAM,因为conda进程因为内存耗尽而被终止。此外,mamba在新机器上的运行速度比conda快得多。最后,由您来为您的项目选择包管理器。
结论
在本文中,我讨论了 Python、Anaconda、Miniconda 和 Mamba 之间的区别。我们总结一下:
- 如果您只想将 Python 包用于数据科学和其他领域,请使用 Python 的
pip包管理器。 - 如果您是数据科学的初学者,并且希望立即开始创建优秀的项目,那么可以使用 Anaconda 和 GUI Anaconda Navigator。
- 如果你对命令行有更多的了解,又不想浪费存储空间,就用
miniconda。 - 如果你想加快速度或者在慢机器上运行
miniconda,使用mamba。
现在您知道了如何选择 Python 项目所需的工具。编码快乐!
如果您有任何问题或疑问,请通过 LinkedIn 和 GitHub 联系我。
用于数据分析的 r 与 Python 客观的比较
October 21, 2020

r vs Python——观点 vs 事实
有几十篇文章从主观的、基于观点的角度比较了 R 和 Python。对于数据分析或数据科学领域的任何工作,Python 和 R 都是很好的选择。
但是如果你的目标是找出哪种语言适合你,阅读别人的意见可能没有帮助。一个人的“容易”是另一个人的“困难”,反之亦然。
在这篇文章中,我们将做一些不同的事情。我们将客观地看看这两种语言是如何处理日常数据科学任务的,这样你就可以并列地看它们,看看哪一种对你来说更好。
请记住,您不需要真正理解所有这些代码来做出判断!我们将为您提供每个任务的 R 和 Python 代码片段——只需浏览代码,并考虑哪一个对您来说更“可读”。阅读解释,看看一种语言是否比另一种更有吸引力。
好消息是什么?这里没有错误答案!如果你想学习一些处理数据的编程技巧,参加 Python 课程或 R 课程都是不错的选择。
为什么您应该信任我们
因为我们将在本文中并排展示代码,所以您真的不需要“信任”任何东西——您可以简单地查看代码并做出自己的判断。
不过,为了记录在案,在 R 与 Python 的争论中,我们不支持任何一方!这两种语言都非常适合处理数据,并且各有优缺点。我们两个都教,所以我们没有兴趣指导你选择哪一个。
R vs Python:导入 CSV
让我们直接进入现实世界的比较,从 R 和 Python 如何处理导入 CSV 开始!
(当我们比较代码时,我们还将分析 NBA 球员的数据集以及他们在 2013-2014 赛季的表现。如果你想亲自尝试,你可以在这里下载文件。)
稀有
library(readr)
ba <- read_csv("nba_2013.csv")
计算机编程语言
import pandas
ba = pandas.read_csv("nba_2013.csv")
在这两种语言中,这段代码都会将包含 2013-2014 赛季 NBA 球员数据的 CSV 文件nba_2013.csv加载到变量nba中。
唯一真正的区别是,在 Python 中,我们需要导入熊猫库来访问数据帧。在 R 中,虽然我们可以使用基本的 R 函数read.csv()导入数据,但是使用readr库函数read_csv()具有更快的速度和一致的数据类型解释的优势。
数据帧在 R 和 Python 中都可用——它们是二维数组(矩阵),其中每一列可以是不同的数据类型。你可以把它们想象成数据表或电子表格的编程版本。在这一步结束时,CSV 文件已经由两种语言加载到数据帧中。
查找行数
稀有
dim(nba)
[1] 481 31
/code>
计算机编程语言
nba.shape
(481, 31)
/code>
尽管语法和格式略有不同,但我们可以看到,在这两种语言中,我们可以非常容易地获得相同的信息。
上面的输出告诉我们这个数据集有 481 行和 31 列。
检查数据的第一行
稀有
head(nba, 1)
player pos age bref_team_id
Quincy Acy SF 23 TOT[output truncated]
/code>
计算机编程语言
nba.head(1)
player pos age bref_team_id
Quincy Acy SF 23 TOT[output truncated]
/code>
同样,我们可以看到,虽然有一些细微的语法差异,但这两种语言非常相似。
值得注意的是,Python 在这里更加面向对象——head是 dataframe 对象上的一个方法,而 R 有一个单独的head函数。
这是我们开始分析这些语言时会看到的一个常见主题。Python 更面向对象,R 更函数化。
如果您不理解其中的区别,请不要担心——这只是两种不同的编程方法,在处理数据的环境中,这两种方法都可以很好地工作!
r 与 Python:寻找每个统计数据的平均值
现在让我们找出数据集中每个统计数据的平均值!
正如我们所见,这些列有类似于fg(射门得分)和ast(助攻)的名称。这些是整个赛季的统计数据,我们的数据集跟踪每一行(每一行代表一个单独的球员)。
如果你想更全面地了解这些数据,请看这里。让我们看看 R 和 Python 如何通过查找数据中每个 stat 的平均值来处理汇总统计数据:
稀有
library(purrr)
ibrary(dplyr)
ba %>%
select_if(is.numeric) %>%
map_dbl(mean, na.rm = TRUE)
player NA
os NA
ge 26.5093555093555
ref_team_id NA
output truncated]
计算机编程语言
nba.mean()
age 26.509356
53.253638
s 25.571726
output truncated]
/code>
现在我们可以看到 R 和 Python 在方法上的一些主要区别。
在这两种情况下,我们都跨数据帧列应用了一个函数。在 Python 中,默认情况下,对数据帧使用 mean 方法将得到每列的平均值。
在 R 中,要复杂一点。我们可以使用两个流行包中的函数来选择我们想要平均的列,并对它们应用mean函数。称为“管道”的%>%操作符将一个函数的输出作为输入传递给下一个函数。
取字符串值的平均值(换句话说,不能被平均的文本数据)只会导致NA —不可用。我们可以通过使用select_if只取数字列的平均值。
然而,当我们取平均值时,我们确实需要忽略NA值(要求我们将na.rm=TRUE传递给mean函数)。如果我们不这样做,我们最终用NA来表示像x3p.这样的列的平均值。这一栏是百分之三点。有些球员没有投三分球,所以他们的命中率是缺失的。如果我们尝试 R 中的mean函数,我们会得到NA作为响应,除非我们指定na.rm=TRUE,这在取平均值时会忽略NA值。
相比之下,Python 中的.mean()方法已经默认忽略了这些值。
制作成对散点图
浏览数据集的一种常见方法是查看不同的列如何相互关联。让我们比较一下ast、fg和trb列。
稀有
library(GGally)
ba %>%
elect(ast, fg, trb) %>%
gpairs()

计算机编程语言
import seaborn as sns
span class="token keyword">import matplotlib.pyplot as plt
ns.pairplot(nba[["ast", "fg", "trb"]])
lt.show()

最后,两种语言产生了非常相似的情节。但在代码中,我们可以看到 R 数据科学生态系统有许多更小的包( GGally 是最常用的 R 绘图包 ggplot2 的助手包),以及更多的可视化包。
在 Python 中, matplotlib 是主要的绘图包, seaborn 是 matplotlib 上广泛使用的层。
使用 Python 中的可视化,通常有一种主要的方法来做某事,而在 R 中,有许多包支持不同的做事方法(例如,至少有六个包可以做结对图)。
同样,这两种方法都不是“更好”,但是 R 可能提供了更多的灵活性,能够挑选出最适合你的包。
将玩家聚集在一起
探索这类数据的另一个好方法是生成聚类图。这些将显示哪些球员最相似。
(现在,我们只是要制作集群;我们将在下一步中直观地绘制它们。)
稀有
library(cluster)
et.seed(1)
sGoodCol <- function(col){
sum(is.na(col)) == 0 && is.numeric(col)
span class="token punctuation">}
oodCols <- sapply(nba, isGoodCol)
lusters <- kmeans(nba[,goodCols], centers=5)
abels <- clusters$cluster
计算机编程语言
from sklearn.cluster import KMeans
means_model = KMeans(n_clusters=5, random_state=1)
ood_columns = nba._get_numeric_data().dropna(axis=1)
means_model.fit(good_columns)
abels = kmeans_model.labels_
为了正确地进行集群,我们需要删除任何非数字列和缺少值的列(NA、Nan等)。
在 R 中,我们通过对每一列应用一个函数来做到这一点,如果该列有任何缺失值或者不是数字,就删除该列。然后,我们使用集群包来执行 k 均值,并在我们的数据中找到5集群。我们使用set.seed设置一个随机种子,以便能够重现我们的结果。
在 Python 中,我们使用主要的 Python 机器学习包 scikit-learn ,来拟合 k-means 聚类模型并获得我们的聚类标签。我们执行非常类似的方法来准备我们在 R 中使用的数据,除了我们使用get_numeric_data和dropna方法来删除非数字列和缺少值的列。
按集群绘制玩家
我们现在可以通过聚类划分玩家来发现模式。一种方法是先用 PCA 把我们的数据做成二维的,然后画出来,根据聚类关联给每个点加阴影。
稀有
nba2d <- prcomp(nba[,goodCols], center=TRUE)
woColumns <- nba2d$x[,1:2]
lusplot(twoColumns, labels)

计算机编程语言
from sklearn.decomposition import PCA
ca_2 = PCA(2)
lot_columns = pca_2.fit_transform(good_columns)
lt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=labels)
lt.show()

上面,我们制作了一个数据散点图,并根据聚类对每个数据点的图标进行了着色或更改。
在 R 中,我们使用了clusplot函数,它是集群库的一部分。我们通过 r 中内置的pccomp函数执行 PCA。
对于 Python,我们使用了 scikit-learn 库中的 PCA 类。我们使用 matplotlib 来创建情节。
我们再次看到,虽然两种语言采用的方法略有不同,但最终结果和获得结果所需的代码量是非常相似的。
将数据分成训练集和测试集
如果我们想使用 R 或 Python 进行监督机器学习,将数据分成训练集和测试集是一个好主意,这样我们就不会过拟合。
让我们比较一下每种语言是如何处理这种常见的机器学习任务的:
稀有
trainRowCount <- floor(0.8 * nrow(nba))
et.seed(1)
rainIndex <- sample(1:nrow(nba), trainRowCount)
rain <- nba[trainIndex,]
est <- nba[-trainIndex,]
计算机编程语言
train = nba.sample(frac=0.8, random_state=1)
est = nba.loc[~nba.index.isin(train.index)]
对比 Python 和 R,我们可以看到 R 内置了更多的数据分析能力,像floor、sample和set.seed,而在 Python 中这些是通过包调用的(math.floor、random.sample、random.seed)。
在 Python 中,pandas 的最新版本带有一个sample方法,该方法返回从源数据帧中随机抽取的一定比例的行——这使得代码更加简洁。
在 R 中,有一些包可以使采样更简单,但是它们并不比使用内置的sample函数更简洁。在这两种情况下,我们设置了一个随机种子以使结果可重复。
R vs Python:一元线性回归
继续常见的机器学习任务,假设我们想要从每个球员的投篮命中率预测每个球员的助攻数:
稀有
fit <- lm(ast ~ fg, data=train)
redictions <- predict(fit, test)
计算机编程语言
from sklearn.linear_model import LinearRegression
r = LinearRegression()
r.fit(train[["fg"]], train["ast"])
redictions = lr.predict(test[["fg"]])
Python 在我们之前的步骤中更简洁一点,但是现在 R 在这里更简洁了!
Python 的 Scikit-learn 包有一个线性回归模型,我们可以根据它进行拟合并生成预测。
r 依赖于内置的lm和predict函数。predict将根据传递给它的拟合模型的种类表现不同——它可以与各种拟合模型一起使用。
计算模型的汇总统计数据
另一个常见的机器学习任务:
稀有
summary(fit)
Call:
m(formula = ast ~ fg, data = train)
esiduals:Min 1Q Median 3Q Max
228.26 -35.38 -11.45 11.99 559.61
output truncated]
计算机编程语言
import statsmodels.formula.api as sm
odel = sm.ols(formula='ast ~ fga', data=train)
itted = model.fit()
itted.summary()
Dep. Variable: ast
-squared: 0.568
odel: OLS
dj. R-squared: 0.567
output truncated]
正如我们在上面看到的,如果我们想要得到关于拟合的统计数据,比如 r 的平方值,我们需要在 Python 中做的比在 R 中多一点。
有了 R,我们可以使用内置的summary函数立即获得模型的信息。对于 Python,我们需要使用 statsmodels 包,这使得许多统计方法可以在 Python 中使用。
我们得到了类似的结果,尽管一般来说用 Python 做统计分析有点困难,而且一些 R 中存在的统计方法在 Python 中并不存在。
符合随机森林模型
我们的线性回归在单变量的情况下工作得很好,但是假设我们怀疑数据中可能存在非线性。因此,我们想拟合一个随机森林模型。
以下是我们在每种语言中的做法:
稀有
library(randomForest)
redictorColumns <- c("age", "mp", "fg", "trb", "stl", "blk")
f <- randomForest(train[predictorColumns], train$ast, ntree=100)
redictions <- predict(rf, test[predictorColumns])
计算机编程语言
from sklearn.ensemble import RandomForestRegressor
redictor_columns = ["age", "mp", "fg", "trb", "stl", "blk"]
f = RandomForestRegressor(n_estimators=100, min_samples_leaf=3)
f.fit(train[predictor_columns], train["ast"])
redictions = rf.predict(test[predictor_columns])
这里的主要区别是,我们需要使用 R 中的 randomForest 库来使用该算法,而这已经内置在 Python 中的 scikit-learn 中了。
Scikit-learn 有一个统一的接口,可以在 Python 中使用许多不同的机器学习算法。每个算法通常只有一个主要的实现。
在 R 中,有许多包含单个算法的更小的包,通常以不一致的方式访问它们。这导致了算法的更大多样性(许多有几个实现,有些是刚从研究实验室出来的),但是可用性有点问题。
换句话说,Python 在这里可能更容易使用,但 R 可能更灵活。
计算误差
现在我们已经拟合了两个模型,让我们计算一下 R 和 Python 中的误差。我们将使用 MSE 。
稀有
mean((test["ast"] - predictions)^2)
4573.86778567462
计算机编程语言
from sklearn.metrics import mean_squared_error
an_squared_error(test["ast"], predictions)
4166.9202475632374
在 Python 中,scikit-learn 库有各种我们可以使用的错误度量。在 R 中,可能有一些较小的库来计算 MSE,但是手动计算在任何一种语言中都很容易。
您可能会注意到这里的结果有一点小差异——这几乎肯定是由于参数调整造成的,没什么大不了的。
(如果您自己运行这个代码,您也可能得到稍微不同的数字,这取决于每个包的版本和您使用的语言)。
R vs Python: Web 抓取,第 1 部分
我们有 2013-2014 年 NBA 球员的数据,但让我们通过网络搜集一些额外的数据来补充它。
为了节省时间,我们只看 NBA 总决赛的一个比分。
稀有
library(RCurl)
rl <- "https://www.basketball-reference.com/boxscores/201506140GSW.html"
ata <- readLines(url)
计算机编程语言
import requests
rl = "https://www.basketball-reference.com/boxscores/201506140GSW.html"
ata = requests.get(url).content
在 Python 中, requests 包使得下载网页变得简单明了,所有请求类型都有一致的 API。
在 R 中, RCurl 提供了一种类似的简单方法来发出请求。
两者都将网页下载到字符数据类型。
注意:这一步对于 R 中的下一步来说是不必要的,只是为了比较而显示出来。
Web 抓取,第 2 部分
现在我们已经下载了包含 Python 和 R 的网页,我们需要解析它来提取玩家的分数。
稀有
library(rvest)
age <- read_html(url)
able <- html_nodes(page, ".stats_table")[3]
ows <- html_nodes(table, "tr")
ells <- html_nodes(rows, "td a")
eams <- html_text(cells)
xtractRow <- function(rows, i){
if(i == 1){
return
}
row <- rows[i]
tag <- "td"
if(i == 2){
tag <- "th"
}
items <- html_nodes(row, tag)
html_text(items)
span class="token punctuation">}
crapeData <- function(team){
teamData <- html_nodes(page, paste("#",team,"_basic", sep=""))
rows <- html_nodes(teamData, "tr")
lapply(seq_along(rows), extractRow, rows=rows)
span class="token punctuation">}
ata <- lapply(teams, scrapeData)
计算机编程语言
from bs4 import BeautifulSoup
span class="token keyword">import re
oup = BeautifulSoup(data, 'html.parser')
ox_scores = []
span class="token keyword">for tag in soup.find_all(id=re.compile("[A-Z]{3,}_basic")):
rows = []
for i, row in enumerate(tag.find_all("tr")):
if i == 0:
continue
elif i == 1:
tag = "th"
else:
tag = "td"
row_data = [item.get_text() for item in row.find_all(tag)]
rows.append(row_data)
box_scores.append(rows)
在这两种语言中,这段代码将创建一个包含两个列表的列表
CLE的方块分数GSW的方块分数
两个列表都包含标题,以及每个玩家和他们在游戏中的状态。我们现在不会将它转化为更多的训练数据,但它可以很容易地转化为一种可以添加到我们的nba数据框架中的格式。
R 代码比 Python 代码更复杂,因为没有方便的方法使用正则表达式来选择项目,所以我们必须进行额外的解析来从 HTML 中获取球队名称。
r 也不鼓励使用for循环,而是支持沿着向量应用函数。我们使用lapply来做这件事,但是因为我们需要根据每一行是否是标题来区别对待,所以我们将我们想要的项目的索引和整个rows列表传递到函数中。
在 R 中,我们使用rvest,一个广泛使用的 R web 抓取包来提取我们需要的数据。注意,我们可以将一个 url 直接传递给 rvest,所以在 r 中实际上不需要前面的步骤。
在 Python 中,我们使用最常用的 web 抓取包 BeautifulSoup 。它使我们能够遍历标签并以一种简单的方式构造一个列表。
R vs Python:哪个更好?看情况!
我们现在已经了解了如何使用 R 和 Python 来分析数据集。正如我们所看到的,尽管它们做事情的方式略有不同,但两种语言都倾向于需要大约相同数量的代码来实现相同的输出。
当然,有许多任务我们没有深入研究,比如持久化我们的分析结果,与他人共享结果,测试并使事情生产就绪,以及进行更多的可视化。
关于这个主题还有很多要讨论的,但是仅仅基于我们上面所做的,我们可以得出一些有意义的结论,关于这两者有什么不同。
(至于哪个其实更好,那是个人喜好问题。)
R 更函数化,Python 更面向对象。
正如我们从lm、predict等函数中看到的,R 让函数完成大部分工作。与 Python 中的LinearRegression类和 Dataframes 上的sample方法形成对比。
就数据分析和数据科学而言,这两种方法都可行。
R 内置更多数据分析功能,Python 依赖包。
当我们查看汇总统计数据时,我们可以使用 R 中的summary内置函数,但是必须导入 Python 中的statsmodels包。Dataframe 是 R 中的内置构造,但是必须通过 Python 中的pandas包导入。
Python 有用于数据分析任务的“主”包,R 有由小包组成的更大的生态系统。
有了 Python,我们可以用 scikit-learn 包做线性回归、随机森林等等。它提供了一致的 API,并且维护良好。
在 R 中,我们有更多不同的包,但也有更多的碎片和更少的一致性(线性回归是内置的,lm,randomForest是一个单独的包,等等)。
一般来说,R 有更多的统计支持。
r 是作为一种统计语言建立的,它显示了。Python 和其他包为统计方法提供了不错的覆盖面,但是 R 生态系统要大得多。
在 Python 中执行非统计任务通常更简单。
有了 BeautifulSoup 和 requests 这样维护良好的库,Python 中的 web 抓取比 r 中的更简单。
这也适用于我们没有仔细研究的其他任务,如保存到数据库、部署 web 服务器或运行复杂的工作流。
由于 Python 被广泛用于各种行业和编程领域,如果您将数据工作与其他类型的编程任务相结合,那么它可能是更好的选择。
另一方面,如果您专注于数据和统计,R 提供了一些优势,因为它是以统计为重点开发的。
两者的数据分析工作流程有很多相似之处。
R 和 Python 之间有明显的相似之处(熊猫数据帧的灵感来自于 R 数据帧, rvest 包的灵感来自于 BeautifulSoup ),而且两个生态系统都在不断发展壮大。
事实上,对于两种语言中的许多常见任务来说,语法和方法是如此的相似,这是非常值得注意的。
R vs Python:应该学哪个?
在 Dataquest ,我们最出名的是我们的 Python 课程,但是我们在 R path 完全重新制作并重新推出了我们的数据分析师,因为我们觉得 R 是另一种优秀的数据科学语言。
我们认为这两种语言是互补的,每种语言都有它的长处和短处。正如本演练所证明的,这两种语言都可以用作唯一的数据分析工具。这两种语言在语法和方法上有很多相似之处,任何一种都不会错。
最终,您可能会想要学习 Python 和 R,这样您就可以利用这两种语言的优势,根据您的需要在每个项目的基础上选择一种或另一种。
当然,如果你想在数据科学领域谋得一个职位,了解这两方面也会让你成为一个更灵活的求职者。
PyTorch 初学者入门(2022)
November 14, 2022
当使用 Python 进行机器学习时,对于使用哪个库或框架,您有多种选择。然而,如果你正在走向深度学习,你可能应该使用 TensorFlow 或 PyTorch,这两个最著名的深度学习框架。
在本文中,我们将快速介绍 PyTorch 框架,从最初的概念一直到第一个图像分类模型的训练和测试。
我们不会深入学习复杂的概念和数学,因为本文旨在成为一种更具实践性的方法,介绍如何将 PyTorch 作为一种工具开始,而不是将深度学习作为一种概念。
因此,我们假设你有一些中级 Python 知识——包括类和面向对象编程——并且你熟悉深度学习的主要概念。
PyTorch
PyTorch 是一个强大而易用的 Python 深度学习库,主要用于计算机视觉和自然语言处理等应用。
TensorFlow 是由谷歌开发的,PyTorch 是由脸书的人工智能研究小组开发的,该小组最近将该框架的管理工作移交给了新成立的 PyTorch 基金会,该基金会受 Linux 基金会的监管。
PyTorch 的灵活性允许轻松集成新的数据类型和算法,并且该框架也是高效的和可伸缩的,因为它被设计为最小化所需的计算量并与各种硬件架构兼容。
张量
在深度学习中,张量是一种非常类似于数组和矩阵的基本数据结构,利用它我们可以高效地对大数据集进行数学运算。张量可以表示为矩阵,也可以表示为向量、标量或更高维的数组。
为了更容易形象化,可以把张量想象成一个包含标量或其他数组的简单数组。在 PyTorch 上,张量是一种非常类似于ndarray的结构,不同之处在于它们能够在 GPU 上运行,这大大加快了计算过程。
从一个数字创建一个张量很简单:
import torch
import numpy as np
ndarray = np.array([0, 1, 2])
t = torch.from_numpy(ndarray)
print(t)
tensor([0, 1, 2])
PyTorch 上的张量有三个属性:
- 形状:张量的大小
- 数据类型:存储在张量中的数据类型
- 设备:存储张量的设备
如果我们打印我们创建的张量的属性,我们将得到如下结果:
print(t.shape)
print(t.dtype)
print(t.device)
torch.Size([3])
torch.int64
cpu
这意味着我们有一个大小为 3 的一维张量,包含存储在 CPU 中的整数。
我们也可以从 Python 列表中实例化张量:
t = torch.tensor([0, 1, 2])
print(t)
tensor([0, 1, 2])
张量也可以是多维的:
ndarray = np.array([[0, 1, 2], [3, 4, 5]])
t = torch.from_numpy(ndarray)
print(t)
tensor([[0, 1, 2],
[3, 4, 5]])
也有可能从另一个张量创建一个张量。在这种情况下,新张量继承了初始张量的特征。以下示例基于之前创建的张量创建了一个包含随机数的张量:
new_t = torch.rand_like(t, dtype=torch.float)
print(new_t)
tensor([[0.1366, 0.5994, 0.3963],
[0.1126, 0.8860, 0.8233]])
请注意,rand_like()函数创建了一个形状为(2,2)的新张量。然而,由于函数返回值从 0 到 1,我们不得不覆盖数据类型为 float。
我们也可以简单地从我们期望的形状创建一个随机张量:
my_shape = (3, 3)
rand_t = torch.rand(my_shape)
print(rand_t)
tensor([[0.8099, 0.8816, 0.3071],
[0.1003, 0.3190, 0.3503],
[0.9088, 0.0844, 0.0547]])
张量运算
就像在 NumPy 中一样,我们可以对张量执行多种可能的操作,比如切片、转置、矩阵相乘等等。
张量的切片与 Python 中的任何其他数组结构完全一样。考虑下面的张量:
zeros_tensor = torch.zeros((2, 3))
print(zeros_tensor)
tensor([[0., 0., 0.],
[0., 0., 0.]])
我们可以很容易地索引第一行或第一列:
print(zeros_tensor[1])
print(zeros_tensor[:, 0])
tensor([0., 0., 0.])
tensor([0., 0.])
我们也可以把这个张量转置:
transposed = zeros_tensor.T
print(transposed)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
最后,我们可以将张量相乘:
ones_tensor = torch.ones(3, 3)
product = torch.matmul(zeros_tensor, ones_tensor)
print(product)
tensor([[0., 0., 0.],
[0., 0., 0.]])
请注意,我们使用了zeros和ones函数来创建一个只包含 0 和 1 的张量,它带有我们传递的形状。
这些操作只是 PyTorch 所能做的一小部分。然而,本文的目的并不是要涵盖它们中的每一个,而是给出它们如何工作的一般概念。如果你想了解更多,PyTorch 有完整的文档。
加载数据
PyTorch 自带一个内置模块,为许多深度学习应用程序提供现成的数据集,如计算机视觉、语音识别和自然语言处理。这意味着有可能建立自己的神经网络,而不需要自己收集和处理数据。
例如,我们将下载 MNIST 数据集。MNIST 是手写数字图像的数据集,包含 6 万个样本和 1 万个图像的测试集。
我们将使用来自torchvision的datasets模块下载数据:
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.MNIST(root=".", train=True, download=True, transform=ToTensor())
test_data = datasets.MNIST(root=".", train=False, download=True, transform=ToTensor())
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./MNIST/raw/train-images-idx3-ubyte.gz
0%| | 0/9912422 [00:00<?, ?it/s]
Extracting ./MNIST/raw/train-images-idx3-ubyte.gz to ./MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./MNIST/raw/train-labels-idx1-ubyte.gz
0%| | 0/28881 [00:00<?, ?it/s]
Extracting ./MNIST/raw/train-labels-idx1-ubyte.gz to ./MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./MNIST/raw/t10k-images-idx3-ubyte.gz
0%| | 0/1648877 [00:00<?, ?it/s]
Extracting ./MNIST/raw/t10k-images-idx3-ubyte.gz to ./MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./MNIST/raw/t10k-labels-idx1-ubyte.gz
0%| | 0/4542 [00:00<?, ?it/s]
Extracting ./MNIST/raw/t10k-labels-idx1-ubyte.gz to ./MNIST/raw
在下载函数中,我们有以下参数:
-
root :保存数据的目录。您可以传递带有目录路径的字符串。一个点(如示例中所示)将文件保存在您所在的目录中。
-
train :用于通知 PyTorch 你正在下载 train 还是测试集。
-
下载:如果您指定的路径已经没有数据,是否下载。
-
转换:对数据进行转换。在我们的代码中,我们选择张量。
如果我们打印训练集的第一个元素,我们将看到以下内容:
training_data[0]
(tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0118, 0.0706, 0.0706, 0.0706,
0.4941, 0.5333, 0.6863, 0.1020, 0.6510, 1.0000, 0.9686, 0.4980,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.1176, 0.1412, 0.3686, 0.6039, 0.6667, 0.9922, 0.9922, 0.9922,
0.9922, 0.9922, 0.8824, 0.6745, 0.9922, 0.9490, 0.7647, 0.2510,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1922,
0.9333, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922,
0.9922, 0.9843, 0.3647, 0.3216, 0.3216, 0.2196, 0.1529, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0706,
0.8588, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922, 0.7765, 0.7137,
0.9686, 0.9451, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.3137, 0.6118, 0.4196, 0.9922, 0.9922, 0.8039, 0.0431, 0.0000,
0.1686, 0.6039, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0549, 0.0039, 0.6039, 0.9922, 0.3529, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.5451, 0.9922, 0.7451, 0.0078, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0431, 0.7451, 0.9922, 0.2745, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.1373, 0.9451, 0.8824, 0.6275,
0.4235, 0.0039, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3176, 0.9412, 0.9922,
0.9922, 0.4667, 0.0980, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1765, 0.7294,
0.9922, 0.9922, 0.5882, 0.1059, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0627,
0.3647, 0.9882, 0.9922, 0.7333, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.9765, 0.9922, 0.9765, 0.2510, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1804, 0.5098,
0.7176, 0.9922, 0.9922, 0.8118, 0.0078, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.1529, 0.5804, 0.8980, 0.9922,
0.9922, 0.9922, 0.9804, 0.7137, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0941, 0.4471, 0.8667, 0.9922, 0.9922, 0.9922,
0.9922, 0.7882, 0.3059, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0902, 0.2588, 0.8353, 0.9922, 0.9922, 0.9922, 0.9922, 0.7765,
0.3176, 0.0078, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0706, 0.6706,
0.8588, 0.9922, 0.9922, 0.9922, 0.9922, 0.7647, 0.3137, 0.0353,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.2157, 0.6745, 0.8863, 0.9922,
0.9922, 0.9922, 0.9922, 0.9569, 0.5216, 0.0431, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.5333, 0.9922, 0.9922, 0.9922,
0.8314, 0.5294, 0.5176, 0.0627, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]]), 5)
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1765, 0.7294,
0.9922, 0.9922, 0.5882, 0.1059, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0627,
0.3647, 0.9882, 0.9922, 0.7333, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.9765, 0.9922, 0.9765, 0.2510, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1804, 0.5098,
0.7176, 0.9922, 0.9922, 0.8118, 0.0078, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.1529, 0.5804, 0.8980, 0.9922,
0.9922, 0.9922, 0.9804, 0.7137, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0941, 0.4471, 0.8667, 0.9922, 0.9922, 0.9922,
0.9922, 0.7882, 0.3059, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0902, 0.2588, 0.8353, 0.9922, 0.9922, 0.9922, 0.9922, 0.7765,
0.3176, 0.0078, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
上面的张量只是整个元素的一小部分,因为它太大而无法显示。
这一串数字对我们来说可能没有任何意义,因为它们代表图像,所以我们可以使用 matplotlib 将它们可视化为实际图像:
figure = plt.figure(figsize=(8, 8))
cols, rows = 5, 5
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

我们还可以使用classes属性来查看数据中的类:
training_data.classes
['0 - zero',
'1 - one',
'2 - two',
'3 - three',
'4 - four',
'5 - five',
'6 - six',
'7 - seven',
'8 - eight',
'9 - nine']
当模型被训练时,它可以接收新的输入,然后分类为这些类别之一。
现在我们已经下载了数据,我们将使用DataLoader。这使我们能够以小批量迭代数据集,而不是一次一个观察,并在训练模型的同时洗牌数据。代码如下:
from torch.utils.data import DataLoader
loaded_train = DataLoader(training_data, batch_size=64, shuffle=True)
loaded_test = DataLoader(test_data, batch_size=64, shuffle=True)
神经网络
在深度学习中,神经网络是一种用于以复杂模式对数据进行建模的算法。神经网络试图通过由处理节点连接的多个层来模拟人脑的功能,其行为类似于人类神经元。通过节点连接的这些层创建了一个能够处理和理解大量复杂数据的复杂网络。
在 PyTorch 中,与神经网络相关的一切都是使用torch.nn模块构建的。网络本身被写成一个继承自nn.Module的类,在这个类中,我们将使用nn来构建层。以下是 PyTorch 文档中的一个简单实现:
from torch import nn
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
尽管深入研究这些层是什么、它们是如何工作的以及如何实现它们已经超出了本文的范围,但是让我们快速探究一下上面的代码是做什么的。
-
nn.Flaten负责将多维数据转换为一维数据。 -
nn.Sequential容器在网络内部创建一系列层。 -
在容器内部,我们有几层。每种类型的层都以不同的方式转换数据,在神经网络中有多种方式来实现这些层。
-
前进函数是模型执行时调用的函数;但是,我们不应该直接调用它。
下面一行实例化了我们的模型:
model = NeuralNetwork()
print(model)
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
训练神经网络
现在我们已经定义了我们的神经网络,我们可以把它投入使用。在开始训练之前,我们应该首先设置一个损失函数。损失函数衡量我们的模型离正确结果有多远,这也是我们在网络训练期间试图最小化的。交叉熵是用于分类任务的常见损失函数,也是我们将要使用的函数。我们应该初始化函数:
loss_function = nn.CrossEntropyLoss()
训练前的最后一步是设置一个优化算法。这种算法将负责在训练过程中调整模型,以便最小化由我们上面选择的损失函数测量的误差。这种任务的常见选择是随机梯度下降算法。然而,PyTorch 有其他几种可能性,你可以在这里熟悉。下面是代码:
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
lr参数是学习率,它代表了在训练的每次迭代中模型参数更新的速度。
最后,是训练和测试网络的时候了。对于这些任务中的每一个,我们将实现一个函数。训练函数包括一次遍历一批数据,使用优化器调整模型,以及计算预测和损失。这是 PyTorch 的标准实现:
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 1000 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
注意,对于每一次迭代,我们都获得数据来为模型提供数据,而且还要跟踪批次号,这样我们就可以每 100 次迭代打印一次损耗和当前批次。
然后是测试函数,它计算精度和损耗,这次使用测试集:
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
然后,我们设置历元数来训练我们的模型。一个历元由数据集上的一次迭代组成。例如,如果我们设置epochs=5 ,这意味着我们将对整个数据集进行 5 次神经网络训练和测试。我们训练得越多,结果就越好。
这是 PyTorch 的实现和这样一个循环的输出:
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(loaded_train, model, loss_function, optimizer)
test(loaded_test, model, loss_function)
print("Done!")
Epoch 1
-------------------------------
loss: 2.296232 [ 0/60000]
Test Error:
Accuracy: 47.3%, Avg loss: 2.254638
Epoch 2
-------------------------------
loss: 2.260034 [ 0/60000]
Test Error:
Accuracy: 63.2%, Avg loss: 2.183432
Epoch 3
-------------------------------
loss: 2.173747 [ 0/60000]
Test Error:
Accuracy: 66.9%, Avg loss: 2.062604
Epoch 4
-------------------------------
loss: 2.078938 [ 0/60000]
Test Error:
Accuracy: 72.4%, Avg loss: 1.859960
Epoch 5
-------------------------------
loss: 1.871736 [ 0/60000]
Test Error:
Accuracy: 75.8%, Avg loss: 1.562622
Done!
请注意,在每个时期,我们在训练循环中每 100 批打印一次损失函数,它一直变得越来越低。此外,在每个时期之后,我们可以看到,随着平均损耗的降低,精度越来越高。
如果我们设置更多的纪元——比如说 10 个、50 个甚至 100 个——我们可能会看到更好的结果,但输出会更长,更难可视化和理解。
随着我们的模型最终定型,保存它并在必要时加载它变得很容易:
torch.save(model, "model.pth")
model = torch.load("model.pth")
结论
在本文中,我们介绍了使用 PyTorch 进行深度学习的基础知识,包括:
-
张量及其使用方法
-
如何加载和准备数据
-
神经网络以及如何在 PyTorch 上定义它们
-
如何训练你的第一个图像分类模型
-
在 PyTorch 上保存和加载模型
R API 教程:R 中的 API 入门
February 13, 2020
有趣的数据集是好的数据科学项目的燃料。虽然 Kaggle 等网站向感兴趣的数据科学家提供免费数据集,但 API 是访问和获取有趣数据的另一种非常常见的方式。
API 允许程序员通过所谓的应用编程接口(因此称为“API”)直接从某些网站请求数据,而不是下载数据集。许多大型网站,如 Reddit、Twitter 和脸书,都提供 API,以便数据分析师和数据科学家可以访问有趣的数据。
在本教程中,我们将讲述使用 R 编程语言访问 API 的基础知识。您不需要任何 API 经验,但是您需要熟悉 R 的基础知识。
如果你对自己的研发能力还不自信,你可以看看我们免费的互动研发基础课程和研发中级课程:
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
已经具备了你需要的 R 编程技能?太好了!让我们深入研究用 r 访问 API。
带 R 的 API 简介
“API”是一个通用术语,指一个计算机程序与另一个程序或其自身交互的地方。在本教程中,我们将具体使用 web APIs,其中两台不同的计算机—客户机和服务器—将相互交互,分别请求和提供数据。
API 为数据科学家提供了一种从网站请求干净有序的数据的完美方式。当像脸书这样的网站建立一个 API 时,他们实际上是在建立一台等待数据请求的计算机。
一旦这台计算机收到数据请求,它将自己处理数据,并将其发送到请求它的计算机。从我们作为请求者的角度来看,我们需要用 R 编写代码来创建请求,并告诉运行 API 的计算机我们需要什么。然后,该计算机将读取我们的代码,处理请求,并返回格式良好的数据,这些数据很容易被现有的 R 库解析。
这为什么有价值?将 API 方法与纯 web 抓取进行对比。当一个程序员抓取一个网页时,他们收到的数据是一大堆杂乱的 HTML。虽然确实有一些库可以使解析 HTML 文本变得容易,但这些都是在我们得到我们想要的数据之前需要采取的清理步骤!
通常,我们可以立即使用从 API 中获得的数据,这节省了我们的时间和挫折。
在 R 中发出 API 请求
为了在 R 中使用 API,我们需要引入一些库。这些库包含了 API 请求的所有复杂性,并将它们封装在我们可以在单行代码中使用的函数中。我们将使用的 R 库是httr和jsonlite。它们在我们的 API 介绍中扮演不同的角色,但都是必不可少的。
如果您的 R 控制台或 RStudio 中没有这两个库,您需要先下载它们。使用install.packages()功能引入这些包。
install.packages(c("httr", "jsonlite"))
下载完这些库之后,我们将能够在 R 脚本或 RMarkdown 文件中使用它们。
library(httr)
library(jsonlite)
发出我们的第一个 API 请求
从 API 获取数据的第一步是在 r 中发出实际的请求。这个请求将被发送到拥有 API 的计算机服务器,假设一切顺利,它将发回一个响应。下图说明了这一点:
可以向 API 服务器发出几种类型的请求。这些类型的请求对应于您希望服务器执行的不同操作。
出于我们的目的,我们将只要求数据,这对应于一个GET请求。其他类型的请求有POST和PUT,但是在这篇以数据科学为中心的 R API 教程中,我们不需要担心它们。
为了创建一个GET请求,我们需要使用httr库中的 GET()函数。GET()函数需要一个 URL,它指定请求需要发送到的服务器的地址。
GET()函数封装了一个GET请求的所有复杂性。对于我们的例子,我们将使用开放的 Notify API,它开放了各种 NASA 项目的数据。使用 Open Notify API,我们可以了解国际空间站的位置以及目前有多少人在太空中。
我们将首先使用后一个 API。我们首先使用GET()函数发出请求,并指定 API 的 URL:
>> res = GET("https://api.open-notify.org/astros.json")
GET()函数的输出是一个列表,其中包含 API 服务器返回的所有信息。换句话说,res变量包含 API 服务器对我们的请求的响应
检查GET()输出
让我们看看res变量在 R 控制台中是什么样子的:
>> res
Response [https://api.open-notify.org/astros.json]
Date: 2020-01-30 18:07
Status: 200
Content-Type: application/json
Size: 314 B
研究 res 变量给我们一个结果响应的概要。首先要注意的是,它包含了GET请求被发送到的 URL。我们还可以看到发出请求的日期和时间,以及响应的大小。
内容类型让我们了解数据的形式。这个特定的响应表示数据采用 json 格式,这暗示了我们为什么需要jsonlite库。
这一地位值得特别关注。“状态”是指 API 请求的成功或失败,它以数字的形式出现。返回的数字告诉您请求是否成功,还可以详细说明失败的原因。
200 这个数字是我们想看到的;它对应于一个成功的请求,这就是我们这里所拥有的。这里有更多关于我们可能遇到的其他状态代码的信息。由于我们有一个成功的 200 状态响应,我们知道我们手头有数据,我们可以开始使用它。
处理 JSON 数据
JSON 代表 JavaScript 对象符号。虽然 JavaScript 是另一种编程语言,但我们对 JSON 的关注点是它的结构。JSON 很有用,因为它很容易被计算机读取,正因为如此,它已经成为通过 API 传输数据的主要方式。大多数 API 将以 JSON 格式发送它们的响应。
JSON 被格式化为一系列的键值对,其中一个特定的单词(“key”)与一个特定的值相关联。这种键值结构的一个示例如下所示:
{
“name”: “Jane Doe”,
“number_of_skills”: 2
}
在当前状态下,res变量中的数据不可用。实际数据作为原始 Unicode 包含在res列表中,最终需要转换成 JSON 格式。
要做到这一点,我们首先需要将原始的 Unicode 转换成一个类似于上面显示的 JSON 格式的字符向量。rawToChar()函数只执行这项任务,如下所示:
>> rawToChar(res$content)
[1] "{\"people\": [{\"name\": \"Christina Koch\", \"craft\": \"ISS\"}, {\"name\": \"Alexander Skvortsov\", \"craft\": \"ISS\"}, {\"name\": \"Luca Parmitano\", \"craft\": \"ISS\"}, {\"name\": \"Andrew Morgan\", \"craft\": \"ISS\"}, {\"name\": \"Oleg Skripochka\", \"craft\": \"ISS\"}, {\"name\": \"Jessica Meir\", \"craft\": \"ISS\"}], \"number\": 6, \"message\": \"success\"}"
虽然得到的字符串看起来很混乱,但它确实是字符格式的 JSON 结构。
从一个字符向量,我们可以使用jsonlite库中的fromJSON()函数将其转换成list数据结构。
fromJSON()函数需要一个包含 JSON 结构的字符向量,这是我们从 rawToChar()输出中得到的。所以,如果我们把这两个函数串在一起,我们将得到我们想要的数据,其格式在 r 中更容易操作。
>> data = fromJSON(rawToChar(res$content))
>> names(data)
[1] "people" "number" "message"
在我们的data变量中,我们感兴趣的数据集包含在people数据框中。我们可以使用$运算符直接查看这个数据框:
>> data$people
name craft
1 Christina Koch ISS
2 Alexander Skvortsov ISS
3 Luca Parmitano ISS
4 Andrew Morgan ISS
5 Oleg Skripochka ISS
6 Jessica Meir ISS
所以,这就是我们的答案:在写这篇博文的时候,太空中有 6 个人。但是如果你自己尝试,你可能会得到不同的名字和不同的数字。这是 API 的优势之一——与可下载的数据集不同,它们通常是实时或接近实时更新的,因此它们是访问最新数据的一种很好的方式。
一个数据框,就像我们上面看到的,是我们在 Dataquest 课程中学到的典型的存储结构化数据的方式,以便在tidyverse库中进行进一步的分析。(如果有兴趣,您可以在我们位于 R Path 的数据分析师那里了解更多信息。)
上面,我们已经走过了一个非常简单的 API 工作流程。大多数 API 会要求你遵循同样的通用模式,但是它们可能更复杂。
我们上面使用的 API URL 只是要求我们从它发出一个请求,没有任何额外的细节。有些 API 需要用户提供更多信息。在本教程的最后一部分,我们将介绍如何根据您的请求向 API 提供附加信息。
API 和查询参数
如果我们想知道国际空间站什么时候会经过地球上一个给定的位置呢?与 People in Space API 不同,Open Notify 的 ISS Pass Times API 要求我们提供额外的参数,然后它才能返回我们想要的数据。
具体来说,我们需要在我们的GET()请求中指定我们要询问的地点的纬度和经度。一旦纬度和经度被指定,它们就与原始 URL 组合成查询参数。
让我们使用这个 API 来找出国际空间站何时会经过布鲁克林大桥(大约在纬度 40.7,经度:-74):
res = GET(“http://api.open-notify.org/iss-pass.json",
query = list(lat = 40.7, lon = -74))
# Checking the URL that gets used in the API request yields
# https://api.open-notify.org/iss-pass.json?lat=40.7&lon=-74
我们传递给GET()中的query参数的列表的不同元素被正确地格式化成 URL,所以你不必自己做这些。
您需要查看正在使用的 API 的文档,看看是否有任何必需的查询参数。这里的是国际空间站通过时间的 API 文件。
您可能想要访问的绝大多数 API 都有文档,您可以(也应该)阅读这些文档,以便清楚地了解您的请求需要哪些参数。许多 API 都需要一个公共参数,尽管不是我们在本教程中使用的参数,那就是 API 密钥或其他形式的身份验证。查看 API 的文档,了解如何获取 API 密钥以及如何将其插入到您的请求中。
无论如何,现在我们已经发出了请求,包括位置参数,我们可以使用前面使用的相同函数来检查响应。让我们从回答中提取数据:
>> res = GET("https://api.open-notify.org/iss-pass.json",
query = list(lat = 40.7, lon = -74))
>> data = fromJSON(rawToChar(res$content))
>> data$response
duration risetime
1 623 1580439398
2 101 1580445412
3 541 1580493826
4 658 1580499550
5 601 1580505413
这个 API 以 Unix time 的形式向我们返回时间。Unix 时间只是自 1970 年 1 月 1 日以来经过的时间量。有许多函数可以实现从 Unix 到熟悉的时间形式的轻松转换——我们不会在本教程中讨论日期和时间,但会在我们的 R interactive learning path 中的数据分析师中讨论。
我们还可以在像这样的网站上快速地将 Unix 时间转换成可读性更好的格式。
您已经掌握了 R 中 API 的基础知识!
在本教程中,我们学习了什么是 API,以及它们如何对数据分析师和数据科学家有用。
使用我们的 R 编程技能以及httr和jsonlite库,我们从 API 中获取数据,并将其转换成熟悉的格式以供分析。
在这里,我们只是触及了使用 API 的表面,但是希望这篇介绍已经给了你信心去研究一些更复杂和更强大的 API,并且帮助你打开一个全新的数据世界,让你去探索!
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号