
DataQuest-博客中文翻译-三-
DataQuest 博客中文翻译(三)
在您的机器上安装 R
原文:https://www.dataquest.io/blog/installing-r-on-your-computer/
February 7, 2022
2020 年初,全球数据量估计为 44 zettabytes 。到 2025 年,每天生成的数据量预计将达到 463。这些数据的主要来源如下:
- 社交数据来自脸书的帖子、推文、谷歌趋势
- 来自医疗设备、卫星、网络日志的机器数据
- 来自发票、付款单、付款方式、折扣的交易数据
企业和组织可以通过分析大量数据(“大数据”)来揭示模式并获得洞察力,从而获得竞争优势。数据分析研究我们如何收集、处理和解释数据。数据科学应用数学分析、统计技术和机器学习算法从数据中提取洞察力。
商业智能 (BI)应用程序,如 Power BI 和 Tableau,有助于分析和可视化数据。然而,大多数时候,数据以非结构化格式出现,需要预处理和转换。商业智能应用程序无法执行这样的转换。数学或统计分析也不能使用它们。执行这些任务需要强大的编程语言。 R 、 Python 和 Julia 是数据分析和数据科学领域流行的编程语言。
R 是什么?
R 是 Ross Ihaka 和 Robert Gentleman 在 1993 年开发的免费开源脚本语言。它是 S 编程语言的替代实现,后者在 20 世纪 80 年代被广泛用于统计计算。R 环境设计用于执行复杂的统计分析,并使用许多可视化图形显示结果。 R 编程语言是用 C、Fortran 和 R 本身编写的。大多数 R 包是用 R 编程语言编写的,但是繁重的计算任务是用 C、C++和 Fortran 编写的。r 允许与 Python、C、C++、.Net 和 Fortran。
r 既是一种编程语言,也是一种软件开发环境。换句话说,R 这个名字描述了 R 编程语言和用于运行 R 代码的 R 软件开发环境。r 是的词汇范围。词法范围是静态范围的另一个名称。这意味着程序的词法结构决定了变量的范围,而不是最近赋值的变量。下面是 R 中词法范围的一个例子:
x <- 5
y <- 2
multiple <- function(y) y * x
func <- function() {
x <- 3
multiple(y)
}
func()
Output:
10
变量x <- 5和y <- 2是全局变量,我们可以在 R 函数内部和外部使用它们。然而,当一个变量在函数(func())中声明为(x <- 3),而另一个函数(multiple())在函数(func())中被调用时,声明的变量(x <- 3)只有当且仅当声明的变量是被调用函数(multiple())的输入时才会被引用。据说声明变量(x <- 3)的范围没有扩展到被调用函数(multiple())中。
在上面的代码片段中,func()函数返回multiple()函数。multiple()函数只接受一个输入参数y;然而,它使用两个变量x和y来执行乘法。它会全局搜索x变量,因为它不是函数的输入参数。变量y是multiple()函数的输入参数,所以它先在本地搜索y(称为本地推理)。如果它找不到本地声明的y变量,它会进行全局搜索。在上面的代码片段中,multiple()函数是用全局值x、(x <-2)和全局值y、(y <-2)来计算的。它返回值 10。
在下一个例子中,multiple()函数查找本地声明的y,(y <- 10)。它使用这个本地值y,而不是全局值(y <-2)。因为变量x不是multiple()函数的输入,所以它会全局搜索它的值(x <- 5)。该函数返回值 50
x <- 5
y <- 2
multiple <- function(y) y * x
func <- function() {
x <- 3
y <- 10
multiple(y)
}
func()
Output:
50
可以在 Windows 、 macOS X 和 Linux 操作系统上编译运行 R。它还带有一个命令行接口。>字符代表命令行提示符。下面是一个与 R 命令行的简单交互:
> a <- 5
> b <- 6
> a * b
[1] 30
R 编程语言的特性被组织成包。R 编程语言的标准安装附带了 25 个这样的包。可以从综合 R 档案网 ( CRAN )下载附加包。R 项目目前正在由 R 开发核心团队开发和支持。
为什么用 R
r 是用于统计计算、数据分析和机器学习的最先进的编程语言。它已经存在了近三十年,CRAN 上有超过 12,000 个软件包可供下载。这意味着有一个 R 包支持您想要执行的任何类型的分析。以下是一些你应该学习和使用 R 的理由:
-
免费开源:
R 编程语言是开源的,是在通用公共许可证(GNU)下发布的。这意味着您可以免费使用 R 的所有功能,没有任何限制或许可要求。因为 R 是开源的,所以欢迎每个人对这个项目做出贡献,而且因为它是免费的,所以开源社区很容易发现并修复错误。 -
受欢迎程度:
R 编程语言在 2021 年顶级编程语言IEEE spectrum 排名中排名第 7,在 2022 年 1 月的 TIOBE 指数排名中排名第 12。根据 edX 的说法,它是仅次于 Python 的第二大最流行的数据科学编程语言,也是最流行的统计分析编程语言。r 的流行也意味着在 Stackoverflow 这样的平台上有广泛的社区支持。R 也有一个详细的在线文档,R 用户可以参考以寻求帮助。 -
高质量可视化:
R 编程语言以高质量可视化而闻名。r 的ggplot2是图形语法的详细实现——一个简明描述图形组成部分的系统。借助 R 的高质量图形,您可以轻松实现直观的交互式图形。 -
一种用于数据分析和数据科学的语言:
R 编程语言不是一种通用编程语言。这是一种专门用于统计计算的编程语言。因此,R 的大多数函数都执行向量化操作,这意味着您不需要遍历每个元素。这使得运行 R 代码非常快。分布式计算可以在 R 中执行,因此任务可以在多个处理计算机中进行分配,以减少执行时间。r 集成了 Hadoop 和 Apache Spark,可以用来处理大数据量。r 可以连接各种数据库,它有进行机器学习和深度学习操作的包。 -
在学术界和工业界从事令人兴奋的职业的机会:
R 编程语言在学术界被广泛信任和用于研究。r 越来越多地被政府机构、社交媒体、电信、金融、电子商务、制造和制药公司所使用。使用 R 的顶级公司包括亚马逊、谷歌、ANZ 银行、Twitter、LinkedIn、托马斯·库克、脸书、埃森哲、Wipro、纽约时报等等。对 R 编程语言的良好掌握在学术界和工业界打开了各种各样的机会。
在 Windows 操作系统上安装 R
要在 Windows 操作系统上安装 R:
-
进入 CRAN 网站。
-
点击“下载 R for Windows”。
-
点击“首次安装 R”链接下载 R 可执行文件(。exe)文件。
-
运行 R 可执行文件开始安装,并允许应用程序对您的设备进行更改。
-
选择安装语言。

- 遵循安装说明。
- 点击“完成”退出安装设置。
r 现已成功安装在您的 Windows 操作系统上。打开 R GUI,开始编写 R 代码。

在 MacOS X 上安装 R
在 MacOS X 上安装 R 与在 Window OS 上安装 R 非常相似。区别在于你必须下载的文件格式。该过程如下:
- 进入 CRAN 网站。
- 点击“下载 R for MAC OS”。
- 下载最新版本的 R GUI。pkg 文件)下【最新发布】。你可以通过“旧目录”或“克兰档案”链接下载更老的版本。
- 运行。pkg 文件,并按照安装说明进行操作。
附加 R 接口
除了 R GUI,其他与 R 接口的方式还包括 RStudio 集成开发环境( RStudio IDE )和 Jupyter Notebook 。要在 RStudio 上运行 R,首先需要在电脑上安装 R,而要在 Jupyter Notebook 上运行 R,则需要安装一个 R 内核。RStudio 和 Jupyter Notebook 为 R 提供了一个交互式友好图形界面,极大地改善了用户体验。
安装 RStudio 桌面
要在您的计算机上安装 RStudio Desktop,请执行以下操作:
- 访问 RStudio 网站。
- 点击右上角的“下载”。
- 点击【r studio 开源许可证】下的【下载】。
- 下载适合您电脑的 RStudio Desktop。
- 运行 RStudio 可执行文件(。exe)或 Apple Image Disk 文件(。dmg)用于 macOS X。
- 按照安装说明完成 RStudio 桌面安装。
RStudio 现已成功安装在您的计算机上。RStudio 桌面 IDE 界面如下图所示:
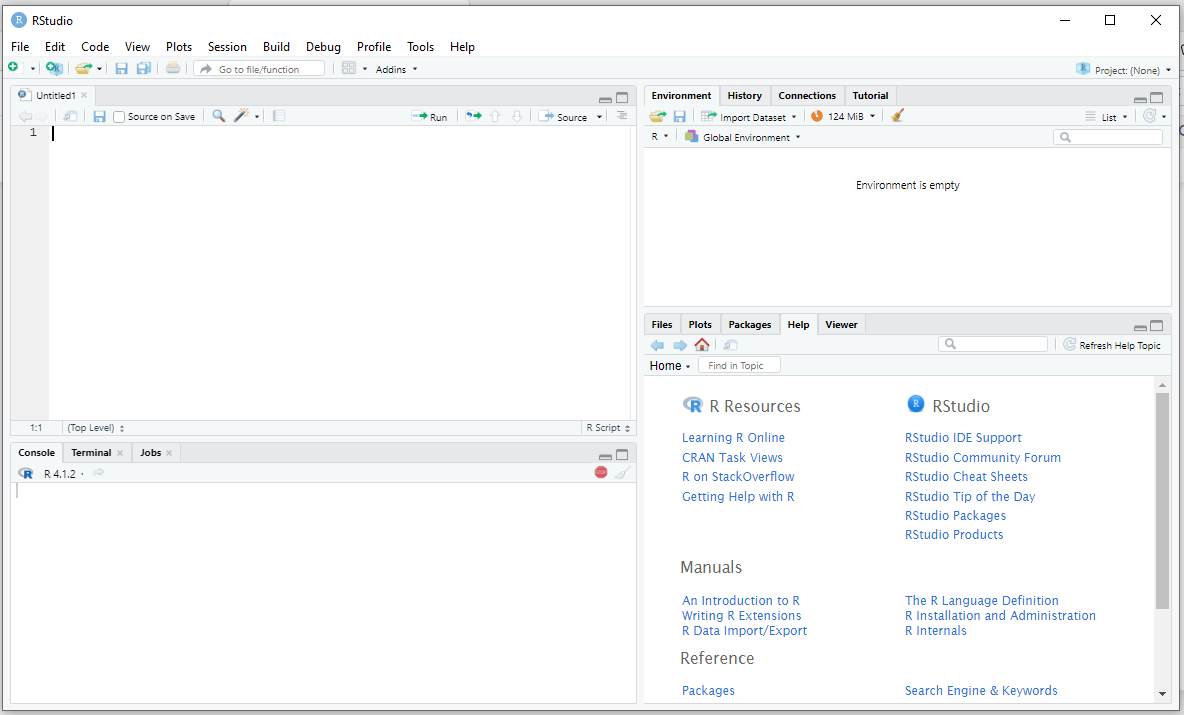
使用 RStudio 与 R 交互的另一种方式是使用 RStudio 服务器。RStudio 服务器提供了基于浏览器的 R 接口。
在 Jupyter 笔记本电脑上安装 R 内核
要在您的电脑上安装 Jupyter Notebook 上的 R kernel,请执行以下操作:
- 下载蟒蛇。
- 运行下载的文件。
- 按照安装说明完成 Anaconda 发行版的安装。
- 以管理员身份打开 Anaconda 提示符。
-
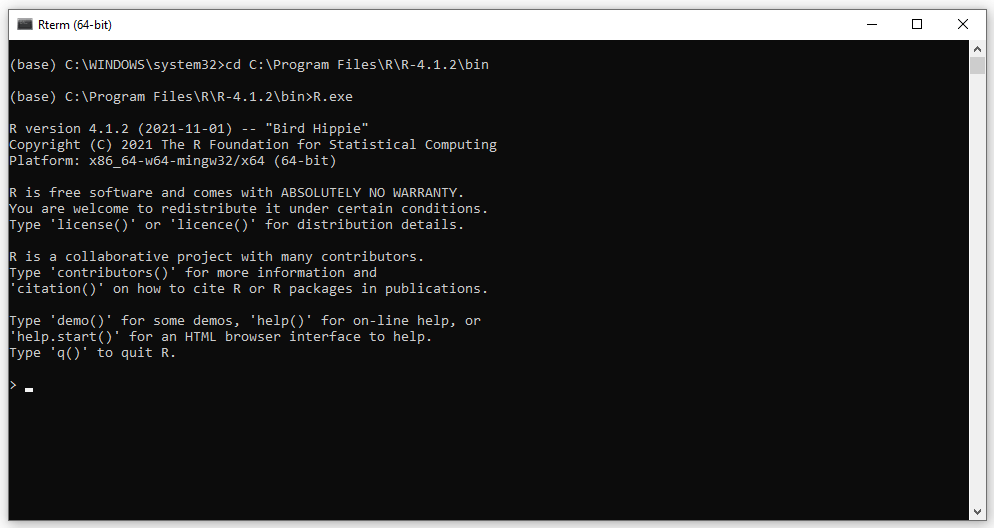
将目录更改为 where 文件在计算机上的位置。(我电脑上的目录是
C:\Program Files\R\R-4.1.2\bin。)然后在 Anaconda 提示符下运行 R>cd C:\Program Files\R\R-4.1.2\bin >R.exe
-
使用以下代码安装
devtool包,以启用install_github()功能> install.packages("devtools") -
使用以下代码从 GitHub 安装 R 的
IRkernel:devtools::install_github("IRkernel/IRkernel") -
使用以下代码指示 Jupyter Notebook 查找 IRkernel:
IRkernel::installspec() -
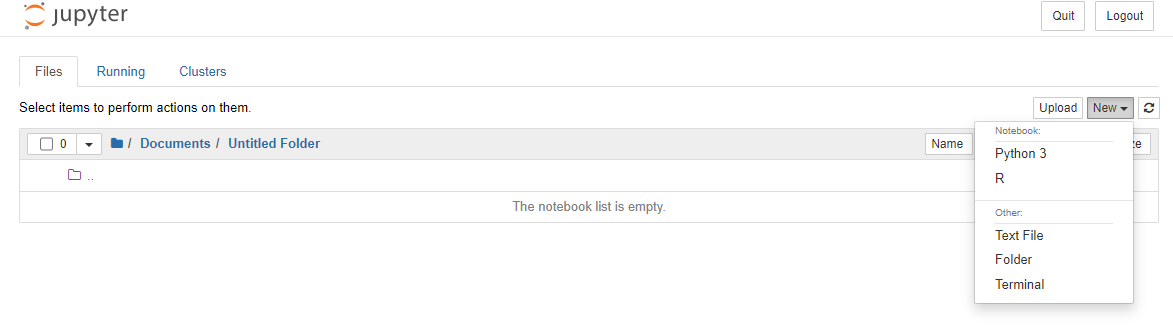
打开 Jupyter 笔记本,打开一个 R 内核的新笔记本
MAC OS 的步骤类似,除了:
-
如果尚未安装,安装以下软件包和
devtoolsinstall.packages(c('repr', 'IRdisplay', 'evaluate', 'crayon', 'pbdZMQ', 'devtools', 'uuid', 'digest'))
结论
R 是数据分析和数据科学的重要脚本语言。它为统计分析和输出漂亮的图形而优化。它也是一种非常快速的编程语言,因为它的大多数函数都执行向量化操作。r 可以用于分布式计算处理大数据,可以连接不同的数据库。可以在 R GUI,Jupyter Notebook,或者 RStudio 上写 R 代码。R 知识对于在学术界和工业界的成功职业生涯是很重要的。
新课程:R 中的统计学:平均值和可变性
原文:https://www.dataquest.io/blog/intermediate-r-statistics-course-averages-variability/
November 19, 2019
不管你在数据科学领域(或任何其他行业)扮演什么角色,数据很少会以易于理解的格式出现在你面前。
统计学是一门数学学科,旨在帮助我们从数据中收集准确的见解,因此统计方法可能有助于分析您遇到的几乎任何数据集。
在 R 课程的第一次统计中,我们关注的是组织频率。现在,我们将推出一门新课程,旨在帮助您使用平均值和可变性测量来理解您的数据。
这门新课程,R 中的统计中级,是我们 R 路径中数据分析师的最新成员。如果您已经订阅了 Dataquest,请单击下面的按钮直接进入新课程并开始学习!
*(如果你还没有订阅,你可以注册一个免费账户并学习我们免费的交互式 R 编程课程。)
我将从这门课程中学到什么?
本课程旨在利用您在 R 课程中的统计基础知识,并将平均值和可变性测量添加到您的统计武库中。
本课程从检验平均值开始,以及如何用平均值来概括一个变量的分布。
从那里,它进入相关测量,如加权平均值、中位值和模式。您将学习如何,更重要的是何时使用这些替代测量值来代替或补充平均值,以更好地理解您的数据。
然后,本课程深入研究可变性测量,如范围、平均绝对偏差、方差和标准差。您将学习使用这些工具来测量任何分布的可变性。
最后,您将了解 z 分数以及如何使用它们来标准化分布,并且您将练习使用 z 分数来定位和比较值。
一旦你完成了所有的学习课程,你将面临在一个指导项目中测试你的新统计技能的挑战,在这个项目中,你将分析房地产市场,为一家公司找到一个理想的广告。
在整个过程中,您将使用我们的交互式浏览器编码界面。这意味着您将在学习这些概念的同时,使用 R 代码亲自动手应用这些概念。

简而言之,Dataquest 平台。
在本课程中,我们的平台将帮助您使用流行的 R 包,如 purrr、readr、stringr、dplyr、DescTools 和 ggplot2。这反映了真实世界的 R 数据科学工作流。
本课程结束时,你将能够运用均值和标准差等概念准确地总结数据。您将能够可视化数据,并确定变量是如何分布或聚集的。并且,在给定您正在处理的数据类型的情况下,您将确信可以选择正确的平均度量值来使用。
我为什么要研究这个?
理解数据的结构是几乎所有分析项目的关键,您在本课程中学到的概念将帮助您更全面、更准确地理解数据结构。
即使您分析的最终目标是更复杂的东西,平均值和方差测量通常也是分析过程中的一个重要步骤。能够使用这些方法可视化您的数据可以快速揭示模式,即使是在大规模、复杂的数据集中。
虽然你可能已经知道均值、中值和标准差等概念,但知道何时以及如何正确应用这些概念来确保你的结果准确是至关重要的。
当然,即使你已经掌握了这些概念,本课程结束时的指导项目也提供了一个很好的方法,让你在实际应用的环境中复习这些概念。你建立的项目可以进入你的项目组合,帮助你获得下一份工作,或者帮助你证明你的技能,这样你就可以获得下一次加薪。
*刚刚开始您的 R 编程之旅?
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
SIGN UP**
教程:Python 函数和函数式编程
原文:https://www.dataquest.io/blog/introduction-functional-programming-python/
January 25, 2018
我们大多数人都是作为一种面向对象的语言被介绍给 Python 的,但是 Python 函数对于数据科学家和程序员来说也是有用的工具。虽然开始使用类和对象很容易,但是还有其他方法来编写 Python 代码。像 Java 这样的语言很难摆脱面向对象的思维,但是 Python 让这变得很容易。
鉴于 Python 为不同的代码编写方法提供了便利,一个合乎逻辑的后续问题是:什么是不同的代码编写方法?虽然这个问题有几个答案,但最常见的替代代码编写风格被称为函数式编程。函数式编程因编写函数而得名,函数是程序中逻辑的主要来源。
在本帖中,我们将:
- 通过比较函数式编程和面向对象编程来解释函数式编程的基础。
- 解释为什么你想在你自己的代码中加入函数式编程。
- 向您展示 Python 如何允许您在两者之间切换。
比较面向对象和函数式
介绍函数式编程最简单的方法是将其与我们已经知道的东西进行比较:面向对象编程。假设我们想要创建一个行计数器类,它接收一个文件,读取每一行,然后计算文件中的总行数。使用一个类,它可能看起来像下面这样:
class LineCounter:
def __init__(self, filename):
self.file = open(filename, 'r')
self.lines = []
def read(self):
self.lines = [line for line in self.file]
def count(self):
return len(self.lines)
虽然不是最好的实现,但它确实提供了对面向对象设计的洞察。在类中,有熟悉的方法和属性的概念。属性设置并检索对象的状态,方法操作该状态。
为了让这两个概念都起作用,对象的状态必须随着时间而改变。在调用了read()方法之后,这种状态变化在lines属性中很明显。作为一个例子,下面是我们如何使用这个类:
# example_file.txt contains 100 lines.
lc = LineCounter('example_file.txt')
print(lc.lines)
>> []
print(lc.count())
>> 0
# The lc object must read the file to
# set the lines property.
lc.read()
# The `lc.lines` property has been changed.
# This is called changing the state of the lc
# object.
print(lc.lines)
>> [['Hello world!', ...]]
print(lc.count())
>> 100
一个物体不断变化的状态既是它的福也是它的祸。为了理解为什么一个变化的状态可以被看作是负面的,我们必须引入一个替代。另一种方法是将行计数器构建为一系列独立的函数。
def read(filename):
with open(filename, 'r') as f:
return [line for line in f]
def count(lines):
return len(lines)
example_lines = read('example_log.txt')
lines_count = count(example_lines)
使用纯函数
在前面的例子中,我们只能通过使用函数来计算行数。当我们只使用函数时,我们正在应用一种函数式编程方法,毫无疑问,这种方法叫做 函数式编程 。函数式编程背后的概念要求函数是无状态的,并且仅依靠给定的输入来产生输出。
满足上述准则的函数称为纯函数。这里有一个例子来突出纯函数和非纯函数之间的区别:
# Create a global variable `A`.
A = 5
def impure_sum(b):
# Adds two numbers, but uses the
# global `A` variable.
return b + A
def pure_sum(a, b):
# Adds two numbers, using
# ONLY the local function inputs.
return a + b
print(impure_sum(6))
>> 11
print(pure_sum(4, 6))
>> 10
使用纯函数优于不纯(非纯)函数的好处是减少了副作用。当在函数的操作中执行了超出其范围的更改时,就会产生副作用。例如,当我们改变一个对象的状态,执行任何 I/O 操作,甚至调用print():
def read_and_print(filename):
with open(filename) as f:
# Side effect of opening a
# file outside of function.
data = [line for line in f]
for line in data:
# Call out to the operating system
# "println" method (side effect).
print(line)
程序员减少代码中的副作用,使代码更容易跟踪、测试和调试。代码库的副作用越多,就越难逐步完成一个程序并理解它的执行顺序。
虽然尝试和消除所有副作用很方便,但它们通常用于简化编程。如果我们禁止所有的副作用,那么你将不能读入一个文件,调用 print,甚至不能在一个函数中赋值一个变量。函数式编程的倡导者理解这种权衡,并试图在不牺牲开发实现时间的情况下尽可能消除副作用。
λ表达式
代替函数声明的def语法,我们可以使用一个 lambda表达式来编写 Python 函数。lambda 语法严格遵循def语法,但它不是一对一的映射。下面是一个构建两个整数相加的函数的示例:
# Using `def` (old way).
def old_add(a, b):
return a + b
# Using `lambda` (new way).
new_add = lambda a, b: a + bold_add(10, 5) == new_add(10, 5)
>> True
lambda表达式接受逗号分隔的输入序列(像def)。然后,紧跟在冒号后面,不使用显式 return 语句返回表达式。最后,当将lambda表达式赋给一个变量时,它的行为就像一个 Python 函数,并且可以使用函数调用语法:new_add()来调用。
如果我们不把lambda赋给一个变量名,它将被称为一个匿名函数。这些匿名函数非常有用,尤其是在将它们用作另一个函数的输入时。例如,sorted() 函数接受一个可选的key参数(一个函数),描述列表中的项目应该如何排序。
unsorted = [('b', 6), ('a', 10), ('d', 0), ('c', 4)]
# Sort on the second tuple value (the integer).
print(sorted(unsorted, key=lambda x: x[1]))
>> [('d', 0), ('c', 4), ('b', 6), ('a', 10)]
地图功能
虽然将函数作为参数传递的能力并不是 Python 所独有的,但这是编程语言的一项最新发展。允许这种行为的函数被称为一级函数。任何包含一级函数的语言都可以用函数式风格编写。
在函数范式中有一组常用的重要的一级函数。这些函数接受一个 Python iterable ,并且像sorted()一样,为列表中的每个元素应用一个函数。在接下来的几节中,我们将检查这些函数中的每一个,但是它们都遵循function_name(function_to_apply, iterable_of_elements)的一般形式。
我们将使用的第一个函数是map()函数。map()函数接受一个 iterable(即。list),并创建一个新的可迭代对象,一个特殊的地图对象。新对象将一级函数应用于每个元素。
# Pseudocode for map.
def map(func, seq):
# Return `Map` object with
# the function applied to every
# element.
return Map(
func(x)
for x in seq
)
下面是我们如何使用 map 将10或20添加到列表中的每个元素:
values = [1, 2, 3, 4, 5]
# Note: We convert the returned map object to
# a list data structure.
add_10 = list(map(lambda x: x + 10, values))
add_20 = list(map(lambda x: x + 20, values))
print(add_10)
>> [11, 12, 13, 14, 15]
print(add_20)
>> [21, 22, 23, 24, 25]
注意,将来自map()的返回值转换为一个list对象是很重要的。如果你希望返回的map对象像list一样工作,那么使用它是很困难的。首先,打印它不会显示它的每一项,其次,您只能迭代它一次。
过滤功能
我们要使用的第二个函数是filter()函数。filter()函数接受一个 iterable,创建一个新的 iterable 对象(同样是一个特殊的map对象),以及一个必须返回一个bool值的一级函数。新的map对象是所有返回True的元素的过滤后的 iterable。
# Pseudocode for filter.
def filter(evaluate, seq):
# Return `Map` object with
# the evaluate function applied to every
# element.
return Map(
x for x in seq
if evaluate(x) is True
)
下面是我们如何从列表中过滤奇数或偶数值:
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Note: We convert the returned filter object to
# a list data structure.
even = list(filter(lambda x: x % 2 == 0, values))
odd = list(filter(lambda x: x % 2 == 1, values))
print(even)
>> [2, 4, 6, 8, 10]
print(odd)
>> [1, 3, 5, 7, 9]
Reduce 函数
我们要看的最后一个函数是 functools包中的reduce()函数。reduce()函数接受一个可迭代对象,然后将该可迭代对象简化为一个值。Reduce 不同于filter()和map(),因为reduce()接受一个有两个输入值的函数。
这里有一个例子,说明我们如何使用reduce()对列表中的所有元素求和。
from functools import reduce
values = [1, 2, 3, 4]
summed = reduce(lambda a, b: a + b, values)
print(summed)
>> 10

一个有趣的注意事项是,你不需要而不是去操作lambda表达式的第二个值。例如,您可以编写一个总是返回 iterable 的第一个值的函数:
from functools import reduce
values = [1, 2, 3, 4, 5]
# By convention, we add `_` as a placeholder for an input
# we do not use.
first_value = reduce(lambda a, _: a, values)
print(first_value)
>> 1
用列表理解重写
因为我们最终会转换成列表,所以我们应该使用列表理解来重写map()和filter()函数。这是编写列表的更为Python 化的方式,因为我们利用了 Python 的语法来制作列表。以下是你如何将前面的map()和filter()的例子翻译成列表理解:
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Map.
add_10 = [x + 10 for x in values]
print(add_10)
>> [11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
# Filter.
even = [x for x in values if x % 2 == 0]
print(even)
>> [2, 4, 6, 8, 10]
从例子中,你可以看到我们不需要添加 lambda 表达式。如果您希望在自己的代码中添加map()或filter()函数,这通常是推荐的方式。然而,在下一节中,我们将提供一个仍然使用map()和filter()函数的案例。
书写函数分部
有时,我们希望使用函数的行为,但减少它的参数数量。目的是“保存”其中一个输入,并使用保存的输入创建一个默认行为的新函数。假设我们想写一个函数,它总是将 2 加到任何数上:
def add_two(b):
return 2 + b
print(add_two(4))
>> 6
add_two函数类似于一般的函数,\(f(a,b) = a + b\),只是它默认了其中一个参数(\(a = 2\))。在 Python 中,我们可以使用functools包中的模块来设置这些参数默认值。partial模块接收一个函数,并从第一个参数开始“冻结”任意数量的参数(或 kwargs ),然后返回一个带有默认输入的新函数。
from functools import partialdef add(a, b):
return a + b
add_two = partial(add, 2)
add_ten = partial(add, 10)
print(add_two(4))
>> 6
print(add_ten(4))
>> 14
分部可以接受任何函数,包括标准库中的函数。
# A partial that grabs IP addresses using
# the `map` function from the standard library.
extract_ips = partial(
map,
lambda x: x.split(' ')[0]
)
lines = read('example_log.txt')
ip_addresses = list(extract_ip(lines))
后续步骤
在这篇文章中,我们介绍了函数式编程的范例。我们学习了 Python 中的 lambda 表达式、重要的函数以及偏导数的概念。总之,我们展示了 Python 为程序员提供了在函数式编程和面向对象编程之间轻松切换的工具。
查看其他一些可能对您有帮助的资源:
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。


在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
面向数据科学家的 AWS 简介
原文:https://www.dataquest.io/blog/introduction-to-aws-for-data-scientists/
January 30, 2018
如今,许多企业使用基于云的服务;因此,各种各样的公司已经开始建立和提供这种服务。亚马逊以亚马逊网络服务(AWS)开始了这一趋势。虽然 AWS 在 2006 年开始作为一项副业,但它现在每年为带来 145 亿美元的收入。
该领域的其他领导者包括:
- 谷歌——谷歌云平台(GCP)
- 微软—Azure 云服务
- IBM—IBM 云
云服务对各种规模的企业都很有用,与购买服务器相比,小公司受益于低成本。较大的公司以较低的成本获得了可靠性和生产力,因为服务运行在最佳的能量和维护上。
这些服务也是您可以用来减轻工作负担的强大工具。如果您是第一次使用 Spark,手动设置 Hadoop 集群可能需要几天时间,但 AWS 可以在几分钟内为您设置好。
这里我们将重点关注 AWS,因为它附带了更多与数据科学家相关的产品。总的来说,我们可以说熟悉 AWS 有助于数据科学家:
- 轻松准备他们工作所需的基础架构(例如 Hadoop 集群)
- 轻松设置必要的工具(如 Spark)
- 大幅降低开支,例如仅在需要时才购买大型 Hadoop 集群
- 减少维护时间,因为不需要手动备份数据等任务
- 开发不需要工程师帮助(或者至少需要很少的帮助)就可以发布的产品和功能
在这篇文章中,我将概述对数据科学家有用的 AWS 服务——它们是什么,为什么有用,以及它们的价格。
弹性计算云(EC2)
许多其他 AWS 服务都是围绕 EC2 构建的,使其成为 AWS 的核心部分。ec2 实际上是(虚拟)服务器,你可以从 Amazon 上租用,并在上面安装或运行任何程序/应用程序。这些服务器采用不同的操作系统,亚马逊根据服务器的计算能力和容量(即硬盘容量、CPU、内存等)向您收费。)和服务器启动的持续时间。
EC2 优势
例如,您可以租用一台计算能力和存储容量符合您特定需求的 Linux 或 Windows 服务器,亚马逊会根据这些规格和您使用服务器的时间向您收费。请注意,以前 AWS 对您运行的每个实例至少收费一个小时,但是他们最近将他们的政策改为每秒收费。
EC2 的优点之一是它的可伸缩性——通过改变内存、vCPUs 数量、带宽等,您可以轻松地扩展或缩小您的系统。因此,如果您认为系统没有足够的能力来运行特定任务,或者项目中的计算耗时太长,您可以扩大规模来完成您的工作,稍后再缩小规模来降低成本。EC2 也非常可靠,因为 Amazon 会负责维护。
EC2 成本
EC2 实例的成本相对较低,不同的用例有不同类型的实例。例如,有些实例针对计算进行了优化,而那些实例的 CPU 使用成本相对较低。或者那些针对内存优化的应用程序的内存使用成本较低。
为了让您了解 EC2 的成本,一个具有 2 个 vCPUs 和 4gb 内存的通用中型实例(在撰写本文时)的 linux 服务器每小时成本为 0.0464 美元,有关价格和更多信息,请参见 Amazon EC2 Pricing 。AWS 现在也有现货实例定价,它根据当时的供应/需求计算价格,并根据您想要使用实例的时间,为短期使用提供高达 90%的折扣。例如,在现货定价方案中,上述相同的实例每小时的成本为 0.0173 美元。
请注意,您还必须将存储成本添加到上述成本中。大多数 EC2 实例使用弹性块存储(EBS)系统,其成本约为 0.1 美元/千兆/月;点击查看价格。存储优化实例使用更贵的固态硬盘(SSD)系统。

EBS 就像一个外部硬盘驱动器。您可以将其附加到实例,取消附加,然后重新附加到另一个实例。您还可以在工作完成后停止或终止实例,并且在实例空闲时不为其付费。
如果您停止一个实例,AWS 仍将保持 EBS 活动,因此您在硬盘上的数据将保持不变(就像关闭您的计算机一样)。稍后,您可以重新启动停止的实例,并访问您生成的数据,甚至是您在之前的会话中安装的工具。然而,当您停止一个实例而不是终止它时,Amazon 仍然会向您收取附加的 EBS 费用(约 0.1 美元/GIG/月)。如果您终止实例,EBS 将被清理,因此您将丢失该实例上的所有数据,但您不再需要为 EBS 付费。
如果您需要将数据保存在 EBS 上以备将来使用(假设您在该实例上安装了定制工具,并且您不希望以后再次重做您的工作),您可以制作 EBS 的快照,以后可以将其恢复到新的 EBS 中,并将其附加到新的实例。
快照存储在 S3(亚马逊的廉价存储系统;我们稍后会谈到它),所以像这样在 EBS 中保存数据会花费您更少的成本(0.05 美元/GB 月)。但是,获取快照并恢复它需要时间(取决于 EBS 的大小)。此外,将恢复的 EBS 重新附加到 EC2 实例并不是那么简单,所以只有在您知道暂时不会使用该 EBS 的情况下,使用这样的快照才有意义。
请注意,要放大或缩小实例,您必须首先停止实例,然后更改实例规范。你不能减少 EBS 的大小,只能增加它,这更困难。你必须:
- 停止实例
- 为 EBS 制作快照
- 使用新大小在 EBS 中恢复快照
- 取消附加以前的 EBS
- 附上新的。
简单存储服务(S3)
S3 是 AWS 对象(文件)存储服务。S3 就像 Dropbox 或 Google drive,但更具可扩展性,特别适合处理代码和应用程序。
S3 没有提供一个用户友好的界面,因为它是为在线应用程序而设计的,而不是为最终用户设计的。因此,通过 API 使用 S3 比通过其 web 控制台更容易,并且有许多库和 API(用各种语言)被开发来使用该服务。例如, Boto3 是一个用 Python 编写的 S3 库(事实上 Boto3 也适用于许多其他 AWS 服务)。
S3 基于bucket s 和key s 存储文件,桶类似于根文件夹,键类似于子文件夹和文件。因此,如果你在 s3 上存储一个名为my_file.txt的文件,比如myproject/mytextfiles/my_file.txt,那么“我的项目”就是你正在使用的桶,那么mytextfiles/my_file.txt就是那个文件的密钥。了解这一点很重要,因为当您想从 s3 中检索文件时,API 会分别要求 bucket 和 key。
S3 福利
你可以在 S3 上存储的数据大小没有限制——你只需要根据你每月需要的大小来支付存储费用。
S3 也非常可靠,其设计具有 99.999999999%的耐用性。但是,该服务可能不会一直运行。2017 年 2 月 28 日,s3 的一些服务器宕机了几个小时,这中断了许多应用程序,如 Slack、Trello 等。见这些 文章了解更多关于这一事件的信息。
S3 成本
如果您希望定期访问这些文件,成本很低,标准访问每月每 GB 0.023 美元起。如果您不需要过于频繁地加载数据,它可能会更低。查看亚马逊 S3 定价了解更多信息。
AWS 可能会对其他与 S3 相关的操作(如通过 API 的请求)收费,但这些费用微不足道(大多数情况下每 1000 个请求不到 0.05 美元)。
关系数据库服务
AWS RDS 是云中的关系数据库服务。RDS 目前支持 SQL Server、MySQL、PostgreSQL、ORACLE 和一些其他基于 SQL 的框架。AWS 设置您需要的系统并配置参数,这样您可以在几分钟内建立并运行一个关系数据库。RDS 还自行处理备份、恢复、软件修补、故障检测和修复,因此您无需维护系统。
RDS 优势
RDS 是可扩展的,计算能力和存储容量都可以很容易地扩大或缩小。RDS 系统运行在 EC2 服务器上(正如我提到的,EC2 服务器是大多数 AWS 服务的核心,包括 RDS 服务),因此这里的计算能力指的是运行 RDS 服务的 EC2 服务器的计算能力,您可以将该系统的计算能力扩展到 32 个 vCPUs 和 244 GiB RAM,更改扩展不会超过几分钟。
也可以提高或降低存储要求。 Amazon Aurora 是 MySQL 和 PostgreSQL 的一个版本,具有一些附加功能,并且可以在需要更多存储空间时自动扩展(您可以定义最大值)。MySQL、MariaDB、Oracle 和 PostgreSQL 引擎允许您在不停机的情况下动态扩展。
RDS 成本
RDS 服务器的成本基于三个因素:计算能力、存储和数据传输。

例如,一个中等计算能力(2 个 vCPUs 和 8g 内存)的 PostgreSQL 系统每小时的成本为 0.182 美元;如果你签一年或三年的合同,你可以少付钱。
储物方面,有多种选择和价格。如果您选择单可用性区域通用 SSD 存储(gp2),这是数据科学家的一个好选择,在撰写本文时,北弗吉尼亚的服务器成本为 0.115 美元/GB 月,您可以选择 5 GB 至 16 TB 的 SSD。
对于数据传输,成本会根据数据的来源和目的地(其中之一是 RDS)而有所不同。例如,所有从互联网传输到 RDS 的数据都是免费的。从 RDS 传输到互联网的第一个千兆字节的数据也是免费的,一个月内接下来的 10 兆字节的数据每千兆字节收费 0.09 美元;传输更多数据的成本会降低。
红移
Redshift 是亚马逊的数据仓库服务;它是一个分布式系统(有点像 Hadoop 框架),允许你存储大量的数据和进行查询。该服务与 RDS 的区别在于其高容量和处理大数据的能力(TB 和 Pb)。您也可以对红移使用简单的 SQL 查询。
Redshift 在分布式框架上工作,数据分布在集群上连接的不同节点(服务器)上。简单地说,分布式系统上的查询在所有节点上并行运行,然后从每个节点收集结果并进行汇总。
红移的好处
Redshift 是高度可扩展的,这意味着在理论上(取决于查询、网络结构和设计、服务规范等。)从 1tb 的数据和 1tb 的数据中获取查询的速度可以通过纵向扩展(添加更多集群)系统来匹配。
创建红移表时,可以选择三种分布样式之一:均匀、关键或全部。
- EVEN 意味着表行将平均分布在所有节点上。然后,涉及该表的查询分布在集群中,并行运行,最后进行总结。根据 Amazon 的文档,“当一个表不参与连接时,平均分布是合适的”。
- ALL 意味着在每个节点上都有这个表的一个副本,所以如果您查询那个表上的一个连接,这个表已经在所有节点上了,不需要通过网络从一个节点到另一个节点复制所需的数据。问题是"所有的分布都将集群中节点的数量乘以所需的存储,因此将数据加载、更新或插入到多个表中需要更长的时间。
- 在键样式中,表的分布行基于一列中的值进行分布,试图将该列中具有相同值的行保留在同一节点中。在相同的节点上物理地存储匹配的值使得在并行系统中连接特定的列更快,参见更多信息这里。
红移成本
红移有两种类型的实例:密集计算或密集存储。密集计算针对快速查询进行了优化,并且对于小于 500GB 的数据具有成本效益(三年期部分预付合同约为 5,500 美元/TB/年)。
密集存储针对大容量存储进行了优化(三年期合同,部分预付约 1,000 美元/TB/年),并且对于+500GB 具有成本效益,但速度较慢。您可以在此找到更多一般定价。
您还可以在 S3 上保存大量数据,并使用 Amazon Redshift Spectrum 对这些数据运行 SQL 查询。对于红移谱,AWS 按每次查询红移谱扫描的字节数向你收费;扫描每兆字节数据 5 美元(每次查询至少 10 兆字节)。
弹性 MapReduce
EMR 适合使用 Spark 和其他分布式应用程序设置 Hadoop 集群。Hadoop 集群可以用作计算引擎或(分布式)存储系统。然而,如果数据太大,需要一个分布式系统来处理,红移比存储在 EMR 中更合适,也更便宜。
集群上有三种类型的节点:
- 主节点(您只有一个)负责管理集群。它将工作负载分配给核心和任务节点,跟踪任务状态,并监控集群的健康状况。
- 核心节点运行任务并存储数据。
- 任务节点只能运行任务。
EMR 优势
由于您可以设置 EMR 安装 Apache Spark,因此该服务非常适合清理、重新格式化和分析大数据。您可以按需使用 EMR,这意味着您可以将其设置为从一个源获取代码和数据(例如,s3 获取代码,S3 或 RDS 获取数据),在集群上运行任务,并将结果存储在某个位置(同样是 S3、RDS 或 Redshift)并终止集群。
通过以这种方式使用服务,您可以显著降低集群的成本。在我看来,EMR 是对数据科学家最有用的 AWS 服务之一。
要设置 EMR 集群,您需要首先配置要在集群上安装的应用程序。请注意,不同版本的 EMR 带有不同版本的应用程序。例如,如果您将 EMR 版本 5.10.0 配置为安装 Spark,则该版本的 Spark 默认版本是 2.2.0。所以如果你的代码只在 Spark 1.6 上运行,你需要在 4.x 版本上运行 EMR。EMR 将设置网络并配置集群上的所有节点以及所需的工具。
EMR 集群有一个主实例和许多核心节点(从实例)。您可以选择核心节点的数量,甚至可以选择没有核心节点,只使用主服务器进行工作。像其他服务一样,您可以选择服务器的计算能力和每个节点上可用的存储大小。您可以为核心节点使用 autoscale 选项,这意味着您可以向系统添加规则,以便在运行代码时根据需要添加/删除核心节点(最多可达您选择的最大数量)。有关自动缩放的更多信息,请参见在 Amazon EMR 中使用自动缩放。
EMR 定价
EMR 定价基于您为不同实例(主节点、核心节点和任务节点)选择的计算能力。基本上,它是 EC2 服务器的成本加上 EMR 的成本。你可以在这里找到详细的定价。

结论
我在 AWS 上使用 Python 和 Spark 为我们公司开发了许多端到端的数据驱动产品(包括报告、机器学习模型和产品健康检查系统),这些产品后来成为公司的良好收入来源。
使用云服务的经验,尤其是像 AWS 这样的知名服务,对你的数据科学家职业生涯是一个巨大的加分。许多公司现在依赖于这些服务,并不断地使用它们,所以你熟悉这些服务会给他们信心,你需要更少的培训就可以加入。随着越来越多的人进入数据科学领域,你希望你的简历尽可能突出。
你有云小贴士可以补充吗?让我们了解一下。
Azure 中 Databricks 的温和介绍(2022 版)
原文:https://www.dataquest.io/blog/introduction-to-databricks-in-azure/
October 14, 2022
Azure Databricks 是一个强大的数据科学和机器学习平台。它为您提供了快速、轻松地清理、准备和处理数据的能力。此外,它还提供可扩展的计算资源,允许您大规模地训练和部署您的模型。Azure Databricks 不仅限于数据科学和机器学习,它还提供强大的数据工程功能。
其基于云的数据处理平台包括构建和运行数据管道所需的所有组件。它是完全托管的,并提供各种功能,如与 Azure Active Directory 和基于角色的访问控制集成,以帮助您保护您的数据。
Databricks 还提供了一个交互式的工作空间,使得在数据项目上的协作变得容易。此外,它还提供了多种工具来帮助您优化管道和提高性能。总的来说,Azure Databricks 是任何希望在云中构建或运行数据管道的人的绝佳选择。
在这篇文章中,你将学习如何在 Azure Databricks 中构建、训练和评估机器学习模型。
登录 Azure Databricks
第一步是用 Azure 创建一个帐户。可以去这个 Azure 门户链接。

创建帐户并登录后,您将看到以下页面:

您可以看到订阅,在本例中是现收现付。你还可以看到选项创建资源,将在 Azure 中创建数据块资源。点击它,在搜索栏中输入 Azure Databricks ,你会看到以下内容:

点击数据块的创建按钮。

填写必填字段,如订阅、区域、资源组等。然后,点击审核+创建。您必须为资源组和数据块工作区指定一个唯一的名称。

最后,单击 Create 开始创建您的数据块资源!请注意,这可能需要几分钟才能完成。

创建资源后,您可以点击转到资源以转到该资源。

数据块页面将如下所示:

点击启动工作区进入 Azure Databricks 环境。
创建集群
下一步是创建一个新的 Databricks 集群。为此,点击 Create,,然后选择 Azure Databricks 工作区左侧面板中的集群按钮。

在下一页上,指定新集群的配置。例如,您可以指定访问模式中的用户数量,还可以定义节点类型和运行时版本。注意,在本教程中,我们指定了单节点,,但是您也可以自由接受默认设置。

为新集群指定配置后,单击创建集群按钮。这将创建集群,并将显示以下页面。请注意,这可能需要几分钟才能完成。

启动笔记本
您将在 Databricks 工作区内的 Python 笔记本中运行您的机器学习代码。要启动笔记本,请点击 Create,,然后在您的 Databricks 工作区内选择左侧边栏中的笔记本图标。

现在,系统会提示您为新笔记本命名并选择语言。出于我们的目的,为您的笔记本取一个唯一的名称,并选择 Python 作为语言。

点击创建,,您将能够看到您刚刚创建的笔记本。

创建笔记本后,您将进入笔记本的编辑器页面,在这里您可以开始编写和运行代码!现在让我们开始一些机器学习!
加载数据
在建立机器学习模型之前,我们需要加载数据。我们将使用由seaborn库提供的一个内置数据集。Seaborn 的库中有许多重要的数据集。安装后,这些软件会自动下载并随时可用!以下命令导入库并提供从 seaborn 库中可用的数据集列表。
import pandas as pd
import seaborn as sns
sns.get_dataset_names()
这将返回 seaborn 中可用数据集的列表,如下所示:
Out[1]: ['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'dowjones', 'exercise', 'flights', 'fmri', 'geyser', 'glue', 'healthexp', 'iris', 'mpg', 'penguins', 'planets', 'seaice', 'taxis', 'tips',...]
我们可以用load_dataset()函数加载数据集。在本文中,我们将使用Iris数据集。这个数据集包含了不同种类的花的信息。您可以根据需要,通过单击向下箭头,然后单击下面的“添加单元”或上面的“添加单元”,轻松创建新的代码块。

在新代码块中,加载数据集并使用以下命令查看前五行:
df = sns.load_dataset('iris')
df.head()
这将产生以下输出:
| |萼片 _ 长度|萼片 _ 宽度|花瓣 _ 长度|花瓣 _ 宽度|种类|
| |–😐——————😐————😐————😐————😐
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4

下载数据集后,我们需要将其分成训练集和测试集。训练集用于训练我们的机器学习模型,而测试集用于评估我们的模型的性能。我们可以使用“scikit-learn”中的“train_test_split()”函数将数据集分成训练集和测试集。这也是导入所有必需库的合适时机。
重现上述结果的代码如下:
# Import other required libraries
import sklearn
import numpy as np
# Import necessary modules
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
# Create arrays for the features and the response variable
y = df['species'].values
X = df.drop('species', axis=1).values
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state=10)
X_train.shape, X_test.shape
Out[3]: ((90, 4), (60, 4))
建立和评估机器学习模型
现在我们有了训练和测试集,我们可以开始构建我们的机器学习模型了。我们将使用“scikit-learn”中的“LogisticRegression”类来构建我们的模型。
为了训练我们的模型,我们将调用 LogisticRegression 对象上的 fit 函数,并将我们的训练集作为参数传入。在训练我们的模型之后,我们现在可以使用我们的测试集进行预测。为此,我们将调用 LogisticRegression 对象上的 predict 函数,并将测试集作为参数传入。该函数将返回测试集中每个样本的预测列表。
评估你的机器学习模型的性能对于确保你的模型按预期工作很重要。有许多不同的指标可以用来评估机器学习模型的性能。在本文中,我们将使用准确性作为我们的衡量标准。
为了计算我们模型的准确性,我们需要将我们的预测与测试集中的实际标签进行比较。我们可以使用“混淆矩阵”函数来计算我们预测的准确性。
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
上述命令将产生以下输出:
precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 1.00 0.96 0.98 24
virginica 0.95 1.00 0.97 18
accuracy 0.98 60
macro avg 0.98 0.99 0.98 60
weighted avg 0.98 0.98 0.98 60

上面的输出显示,模型准确率为 98%,这是一个很好的结果。
结论
在本教程中,您了解了流行的数据科学和机器学习统一分析平台 Azure Databricks。您学习了如何启动 Databricks 工作空间,以及如何使用 Databricks 笔记本构建和评估机器学习模型。您现在已经准备好使用 Azure Databricks 开始您的机器学习之旅了!
最后一步是删除你已经创建的资源,如果你不打算在将来使用它们。这很容易做到。第一步是去 Azure 门户,在那里你可以看到资源组的列表。

找到要删除的资源组,然后单击它。

点击页面顶部的删除资源组按钮。
最后,通过键入资源组的名称并点击删除按钮来确认删除。
Python 合集简介
January 11, 2018
在 Python 中高效地堆叠模型
集成已经迅速成为应用机器学习中最热门和最流行的方法之一。几乎每一个获奖的 Kaggle 解决方案都有它们的特色,许多数据科学管道都有它们的组合。简而言之,集成将来自不同模型的预测结合起来生成最终预测,我们包含的模型越多,它的性能就越好。更好的是,由于集成结合了基线预测,它们的表现至少和最好的基线模型一样好。合奏几乎免费为我们带来性能提升! 一部系综的示例示意图。输入数组(X)通过两个预处理管道,然后送到一组基础学习器(f^{(i)}).集成将所有基本学习者预测组合成最终预测数组(P)。来源 在本帖中,我们将带你了解合奏的基础——它们是什么,为什么它们工作得这么好——并提供构建基本合奏的实践指南。在这篇文章结束时,你将:
一部系综的示例示意图。输入数组(X)通过两个预处理管道,然后送到一组基础学习器(f^{(i)}).集成将所有基本学习者预测组合成最终预测数组(P)。来源 在本帖中,我们将带你了解合奏的基础——它们是什么,为什么它们工作得这么好——并提供构建基本合奏的实践指南。在这篇文章结束时,你将:
- 理解合奏的基础
- 知道如何编码它们
- 理解合奏的主要陷阱和缺点
预测共和党和民主党的捐款
为了说明集合是如何工作的,我们将使用美国政治捐款的数据集。原始数据集是由fivethirtyeeight的 Ben Wieder 准备的,他研究了美国政府的政治捐款登记册,发现当科学家向政客捐款时,通常是给民主党人。这种说法是基于对共和党和民主党捐款份额的观察。然而,还有很多可以说的:例如,哪个科学学科最有可能为共和党捐款,哪个州最有可能为民主党捐款?我们将更进一步,预测捐款最有可能是给共和党还是民主党。我们在这里使用的数据略有改动。除了民主党或共和党,我们删除了对其他党派的任何捐赠,以使我们的阐述更加清晰,并删除一些重复和不太有趣的功能。数据脚本可以在这里找到。数据如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
### Import data
# Always good to set a seed for reproducibility
SEED = 222
np.random.seed(SEED)
df = pd.read_csv('input.csv')
### Training and test set
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
def get_train_test(test_size=0.95):
"""Split Data into train and test sets."""
y = 1 * (df.cand_pty_affiliation == "REP")
X = df.drop(["cand_pty_affiliation"], axis=1)
X = pd.get_dummies(X, sparse=True)
X.drop(X.columns[X.std() == 0], axis=1, inplace=True)
return train_test_split(X, y, test_size=test_size, random_state=SEED)
xtrain, xtest, ytrain, ytest = get_train_test()
# A look at the data
print("\nExample data:")
df.head()
| cand_pty_affiliation | 加拿大办公室街 | cand_office | 坎德 _status | rpt_tp | 交易 _tp | 实体 _tp | 状态 | 分类 | 循环 | 交易 _ 金额 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 代表 | 美国 | P | C | Q3 | Fifteen | 印度 | 纽约州 | 工程师 | Two thousand and sixteen | Five hundred |
| one | 那个人 | 美国 | P | C | M5 | 15E | 印度 | 运筹学 | Math-Stat | Two thousand and sixteen | Fifty |
| Two | 那个人 | 美国 | P | C | M3 | Fifteen | 印度 | 谢谢 | 科学家 | Two thousand and eight | Two hundred and fifty |
| three | 那个人 | 美国 | P | C | Q2 | 15E | 印度 | 在…里 | Math-Stat | Two thousand and sixteen | Two hundred and fifty |
| four | 代表 | 美国 | P | C | 12G | Fifteen | 印度 | 马萨诸塞州 | 工程师 | Two thousand and sixteen | One hundred and eighty-four |
df.cand_pty_affiliation.value_counts(normalize=True).plot( kind="bar", title="Share of No. donations")
plt.show()
上图是支持本索赔的数据。事实上,在民主党和共和党之间,大约 75%的捐款都给了民主党。让我们浏览一下我们可以使用的特性。我们有关于捐赠者、交易和接受者的数据: 为了衡量我们的模型表现如何,我们使用 ROC-AUC 分数,该分数以高精确度和高召回率为代价(如果这些概念对你来说是新的,请参见维基百科关于精确度和召回率的条目以获得快速介绍)。如果您以前没有使用过这个指标,随机猜测的得分为 0.5,完全回忆和精确率为 1.0。
为了衡量我们的模型表现如何,我们使用 ROC-AUC 分数,该分数以高精确度和高召回率为代价(如果这些概念对你来说是新的,请参见维基百科关于精确度和召回率的条目以获得快速介绍)。如果您以前没有使用过这个指标,随机猜测的得分为 0.5,完全回忆和精确率为 1.0。
什么是合奏?
想象你在玩琐碎的追求。当你一个人玩的时候,可能会有一些你擅长的话题,而一些你几乎一无所知。如果我们想最大化我们琐碎的追求分数,我们需要建立一个涵盖所有主题的团队。这是集合的基本思想:将几个模型的预测结合起来,可以消除特殊的误差,产生更好的整体预测。一个重要的问题是如何组合预测。在我们琐碎的追踪例子中,很容易想象团队成员可能会提出他们的案例,多数投票决定选择哪一个。机器学习在分类问题上非常相似:采用最常见的类别标签预测相当于多数投票规则。但是有许多其他方法来组合预测,更普遍的是,我们可以使用一个模型来学习如何最好地组合预测。 基本系综结构。数据被输入到一组模型中,元学习器组合模型预测。来源
基本系综结构。数据被输入到一组模型中,元学习器组合模型预测。来源
通过组合决策树来理解集成
为了说明集成的机制,我们将从一个简单的可解释模型开始:决策树,它是一个由if-then规则组成的树。如果你对决策树不熟悉,或者想更深入地学习,请查看 Dataquest 网站上的决策树课程。树越深,它能捕捉的模式越复杂,但越容易过度拟合。正因为如此,我们需要一种替代的方法来构建复杂的决策树模型,不同决策树的集合就是这样一种方法。我们将使用下面的帮助器函数来可视化我们的决策规则:
import pydotplus # you can install pydotplus with: pip install pydotplus
from IPython.display import Image
from sklearn.metrics import roc_auc_score
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def print_graph(clf, feature_names):
"""Print decision tree."""
graph = export_graphviz(
clf,
label="root",
proportion=True,
impurity=False,
out_file=None,
feature_names=feature_names,
class_names={0: "D", 1: "R"},
filled=True,
rounded=True
)
graph = pydotplus.graph_from_dot_data(graph)
return Image(graph.create_png())
让我们在训练数据上拟合一个具有单个节点(决策规则)的决策树,并看看它在测试集上的表现如何:
t1 = DecisionTreeClassifier(max_depth=1, random_state=SEED)
t1.fit(xtrain, ytrain)
p = t1.predict_proba(xtest)[:, 1]
print("Decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
print_graph(t1, xtrain.columns)

决策树 ROC-AUC 得分:0.672
两个叶子中的每一个都记录它们的训练样本份额、它们份额内的类别分布以及类别标签预测。我们的决策树基于贡献大小是否大于 101.5 来进行预测:但是不管怎样,它都会做出相同的预测!考虑到 75%的捐款都给了民主党,这并不奇怪。但是它没有利用我们现有的数据。让我们使用三个级别的决策规则,看看我们能得到什么:
t2 = DecisionTreeClassifier(max_depth=3, random_state=SEED)
t2.fit(xtrain, ytrain)
p = t2.predict_proba(xtest)[:, 1]
print("Decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
print_graph(t2, xtrain.columns)
 决策树 ROC-AUC 得分:0.751
决策树 ROC-AUC 得分:0.751
这个模型比简单的决策树好不了多少:所有捐款中只有少得可怜的 5%预计会流向共和党——远远低于我们预期的 25%。仔细观察我们会发现决策树使用了一些可疑的分裂规则。多达 47.3%的观察结果出现在最左边的叶子,而另外 35.9%出现在右边第二个叶子。因此,绝大多数叶子是不相关的。让模型变得更深只会让它过度拟合。在固定深度的情况下,可以通过增加“宽度”来使一棵决策树变得更加复杂,也就是创建几棵决策树,并将它们组合起来。换句话说,就是决策树的集合。为了理解为什么这样的模型会有所帮助,考虑一下我们如何强迫一个决策树去调查除了上面的树之外的其他模式。最简单的解决方案是删除树中出现较早的特征。例如,假设我们移除了交易金额特征(transaction_amt),即树的根。我们的新决策树将如下所示:
drop = ["transaction_amt"]
xtrain_slim = xtrain.drop(drop, 1)
xtest_slim = xtest.drop(drop, 1)
t3 = DecisionTreeClassifier(max_depth=3, random_state=SEED)
t3.fit(xtrain_slim, ytrain)p = t3.predict_proba(xtest_slim)[:, 1]
print("Decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
print_graph(t3, xtrain_slim.columns)
 决策树 ROC-AUC 得分:0.740 。
决策树 ROC-AUC 得分:0.740 。
ROC-AUC 得分相似,但共和党捐款份额增加到 7.3%。还是太低,但是比以前高了。重要的是,与第一棵树不同,在第一棵树中,大多数规则与交易本身相关,这棵树更关注候选人的居住地。我们现在有两个模型,它们本身具有相似的预测能力,但根据不同的规则运行。正因为如此,它们很可能会产生不同的预测误差,我们可以用集合来平均这些误差。
插曲:为什么平均预测有效
为什么我们会期望平均预测有效呢?考虑一个玩具示例,它有两个我们想要生成预测的观察值。第一个观察的真正标签是共和党,第二个观察的真正标签是民主党。在这个玩具示例中,假设模型 1 倾向于预测民主党,而模型 2 倾向于预测共和党,如下表所示:
| 模型 | 意见 1 | 意见 2 |
|---|---|---|
| 真实标签 | 稀有 | D |
| 模型预测:(P(R)) | ||
| 模型 1 | Zero point four | Zero point two |
| 模型 2 | Zero point eight | Zero point six |
如果我们使用标准的 50%截止规则来进行分类预测,每个决策树都会得到一个正确的观察结果和一个错误的观察结果。我们通过平均模型的类别概率来创建集成,这是由模型预测的强度(概率)加权的多数投票。在我们的玩具例子中,模型 2 对观察 1 的预测是确定的,而模型 1 相对不确定。权衡他们的预测,集合支持模型 2,并正确预测共和党。对于第二个观察结果,形势发生了逆转,总体正确地预测了民主党:
| 模型 | 意见 1 | 意见 2 |
|---|---|---|
| 真实标签 | 稀有 | D |
| 全体 | Zero point six | Zero point four |
对于两个以上的决策树,集合根据多数进行预测。出于这个原因,平均分类器预测的集成被称为多数投票分类器。当集合基于概率进行平均时(如上所述),我们称之为软投票,平均最终类别标签预测被称为硬投票。当然,合奏不是灵丹妙药。你可能已经注意到,在我们的玩具例子中,为了平均,预测误差必须是不相关的。如果两个模型都做出不正确的预测,集合就不能做出任何修正。此外,在软投票方案中,如果一个模型以高概率值做出不正确的预测,则集合将被淹没。一般来说,集成不会得到所有正确的观察结果,但是预期会比基础模型做得更好。
森林是树木的集合体
回到我们的预测问题,让我们看看是否可以从我们的两个决策树中构建一个集合。我们首先检查误差相关性:高度相关的误差导致较差的集成。
p1 = t2.predict_proba(xtest)[:, 1]
p2 = t3.predict_proba(xtest_slim)[:, 1]
pd.DataFrame({"full_data": p1,
"red_data": p2}).corr()
| 完整数据 | 红色 _ 数据 | |
|---|---|---|
| 完整数据 | 1.000000 | 0.669128 |
| 红色 _ 数据 | 0.669128 | 1.000000 |
有一些相关性,但并不过分:仍然有大量的预测方差可以利用。为了建立我们的第一个集合,我们简单地平均两个模型的预测。
p1 = t2.predict_proba(xtest)[:, 1]
p2 = t3.predict_proba(xtest_slim)[:, 1]
p = np.mean([p1, p2], axis=0)
print("Average of decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
决策树 ROC-AUC 得分平均值:0.783
事实上,合奏程序导致分数增加。但是如果我们有更多不同的树,我们可能会有更大的收获。在设计决策树时,我们应该如何选择排除哪些特征?一种在实践中行之有效的快速方法是随机选择一个特征子集,在每个绘图上拟合一个决策树,并对它们的预测进行平均。这个过程被称为自举平均(通常缩写为装袋),当应用于决策树时,得到的模型是一个随机森林。让我们看看随机森林能为我们做什么。我们使用 Scikit-learn 实现并构建了一个由 10 个决策树组成的集合,每个决策树包含 3 个特征。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=10,
max_features=3,
random_state=SEED)
rf.fit(xtrain, ytrain)
p = rf.predict_proba(xtest)[:, 1]
print("Average of decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
决策树 ROC-AUC 得分平均值:0.844
随机森林对我们以前的模型产生了显著的改进。我们有所发现了!但是你只能用决策树做这么多。是我们扩展视野的时候了。
作为平均预测的集合
到目前为止,我们对合奏的尝试向我们展示了合奏的两个重要方面:
- 预测误差的相关性越小越好
- 模型越多越好
出于这个原因,尽可能使用不同的模型是一个好主意(只要它们表现得体面)。到目前为止,我们一直依赖于简单的平均,但稍后我们将看到如何使用更复杂的组合。为了跟踪我们的进展,将我们的系综形式化为(n)模型(f_i)平均成系综(e ):(e(x)= \ frac 1n \sum_{i=1}^n f _ I(x)是有帮助的。)对包含什么模型没有限制:决策树、线性模型、基于内核的模型、非参数模型、神经网络甚至其他集合!请记住,我们包含的模型越多,整体速度就越慢。为了构建各种模型的集成,我们首先在数据集上对一组 Scikit-learn 分类器进行基准测试。为了避免重复代码,我们使用下面的帮助函数:
# A host of Scikit-learn models
from sklearn.svm import SVC, LinearSVC
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.kernel_approximation import Nystroem
from sklearn.kernel_approximation import RBFSampler
from sklearn.pipeline import make_pipeline
def get_models():
"""Generate a library of base learners."""
nb = GaussianNB()
svc = SVC(C=100, probability=True)
knn = KNeighborsClassifier(n_neighbors=3)
lr = LogisticRegression(C=100, random_state=SEED)
nn = MLPClassifier((80, 10), early_stopping=False, random_state=SEED)
gb = GradientBoostingClassifier(n_estimators=100, random_state=SEED)
rf = RandomForestClassifier(n_estimators=10, max_features=3, random_state=SEED)
models = {'svm': svc,
'knn': knn,
'naive bayes': nb,
'mlp-nn': nn,
'random forest': rf,
'gbm': gb,
'logistic': lr,
}
return models
def train_predict(model_list):
"""Fit models in list on training set and return preds"""
P = np.zeros((ytest.shape[0], len(model_list)))
P = pd.DataFrame(P)
print("Fitting models.")
cols = list()
for i, (name, m) in enumerate(models.items()):
print("%s..." % name, end=" ", flush=False)
m.fit(xtrain, ytrain)
P.iloc[:, i] = m.predict_proba(xtest)[:, 1]
cols.append(name)
print("done")
P.columns = cols
print("Done.\n")
return P
def score_models(P, y):
"""Score model in prediction DF"""
print("Scoring models.")
for m in P.columns:
score = roc_auc_score(y, P.loc[:, m])
print("%-26s: %.3f" % (m, score))
print("Done.\n")
我们现在准备创建预测矩阵(P),其中每个特征对应于给定模型做出的预测,并根据测试集对每个模型进行评分:
models = get_models()
P = train_predict(models)
score_models(P, ytest)
| 模型 | 得分 |
|---|---|
| 支持向量机 | Zero point eight five |
| knn | Zero point seven seven nine |
| 朴素贝叶斯 | Zero point eight zero three |
| 多层前馈神经网络 | Zero point eight five one |
| 随机森林 | Zero point eight four four |
| 恶性胶质瘤 | Zero point eight seven eight |
| 物流的 | Zero point eight five four |
这是我们的底线。梯度推进机(GBM)效果最好,其次是简单的逻辑回归。为了使我们的集合策略有效,预测误差必须是相对不相关的。确认这一点是我们的首要任务:
# You need ML-Ensemble for this figure: you can install it with: pip install mlens
from mlens.visualization import corrmat
corrmat(P.corr(), inflate=False)
plt.show()
误差是显著相关的,这对于表现良好的模型来说是意料之中的,因为通常是离群值很难得到正确的结果。然而,大多数相关性都在 50-80%的区间内,因此还有相当大的改进空间。事实上,如果我们在类预测的基础上看误差相关性,事情看起来更有希望:
corrmat(P.apply(lambda pred: 1*(pred >= 0.5) - ytest.values).corr(), inflate=False)
plt.show()

为了创建集合,我们像以前一样进行并平均预测,正如我们可能期望的那样,集合优于基线。平均是一个简单的过程,如果我们存储模型预测,我们可以从一个简单的集合开始,并在训练新模型时动态增加它的大小。
print("Ensemble ROC-AUC score: %.3f" % roc_auc_score(ytest, P.mean(axis=1)))
总体 ROC-AUC 评分:0.884
想象合奏是如何工作的
我们已经理解了集合作为纠错机制的力量。这意味着集成通过消除不规则性来平滑决策边界。判定边界向我们展示了估计器如何将特征空间分割成邻域,在该邻域内,所有观察值被预测为具有相同的类别标签。通过平均基本学习者决策边界,集成被赋予更平滑的边界,从而更自然地概括。下图显示了这一点。这里的例子是 iris 数据集,评估者试图对三种类型的花进行分类。基本学习器在它们的边界中都有一些不期望的属性,但是集成具有相对平滑的决策边界,与观察值一致。令人惊讶的是,系综既增加了模型的复杂性,又起到了正则化的作用!
 示例判定边界为三个模型和这三个模型的合集。来源
示例判定边界为三个模型和这三个模型的合集。来源
当任务是分类时,理解集合中正在发生什么的另一种方法是检查接收算子曲线(ROC)。这条曲线向我们展示了评估者如何权衡精确度和召回率。通常,不同的基础学习者做出不同的权衡:一些人通过牺牲回忆来获得更高的精确度,而另一些人通过牺牲精确度来获得更高的回忆。另一方面,非线性元学习者能够针对每个训练点调整它所依赖的模型。这意味着它可以显著减少必要的牺牲,并在提高召回率的同时保持高精度(反之亦然)。在下图中,为了提高召回率,集合在精确度上做了更小的牺牲(ROC 在“东北”角)。
from sklearn.metrics import roc_curve
def plot_roc_curve(ytest, P_base_learners, P_ensemble, labels, ens_label):
"""Plot the roc curve for base learners and ensemble."""
plt.figure(figsize=(10, 8))
plt.plot([0, 1], [0, 1], 'k--')
cm = [plt.cm.rainbow(i)
for i in np.linspace(0, 1.0, P_base_learners.shape[1] + 1)]
for i in range(P_base_learners.shape[1]):
p = P_base_learners[:, i]
fpr, tpr, _ = roc_curve(ytest, p)
plt.plot(fpr, tpr, label=labels[i], c=cm[i + 1])
fpr, tpr, _ = roc_curve(ytest, P_ensemble)
plt.plot(fpr, tpr, label=ens_label, c=cm[0])
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(frameon=False)
plt.show()
plot_roc_curve(ytest, P.values, P.mean(axis=1), list(P.columns), "ensemble")

超越作为简单平均值的总体
但是,考虑到预测误差的变化,你难道不会期待更多的提升吗?嗯,有一件事有点烦。有些模型的表现比其他模型差得多,但它们的影响与表现更好的模型一样大。这对于不平衡的数据集来说可能是毁灭性的:回想一下软投票,如果一个模型做出极端的预测(即接近 0 或 1),该预测对预测平均值有很大的影响。对我们来说,一个重要的因素是模型是否能够捕捉到共和党的全部内涵。一个简单的检查表明,所有的模型都没有充分代表共和党的捐款,但有些模型比其他模型要差得多。
p = P.apply(lambda x: 1*(x >= 0.5).value_counts(normalize=True))
p.index = ["DEM", "REP"]
p.loc["REP", :].sort_values().plot(kind="bar")
plt.axhline(0.25, color="k", linewidth=0.5)plt.text(0., 0.23, "True share republicans")
plt.show()

我们可以尝试通过移除最坏的罪犯来改善集成,比如说多层感知器(MLP):
include = [c for c in P.columns if c not in ["mlp-nn"]]
print("Truncated ensemble ROC-AUC score: %.3f" % roc_auc_score(ytest, P.loc[:, include].mean(axis=1)))
截断集合 ROC-AUC 得分:0.883
这算不上什么进步:我们需要一种更智能的方式来区分模型之间的优先级。显然,从集合中移除模型是相当激烈的,因为可能存在被移除的模型携带重要信息的情况。我们真正想要的是学习一组合理的权重,在平均预测时使用。这将集合变成需要训练的参数模型。
学习组合预测
学习加权平均意味着对于每个模型(f_i),我们有一个权重参数(\omega_i \in (0,1))将我们的权重分配给该模型的预测。加权平均要求所有权重总和为 1。系综现在定义为(e(x)= \sum_{i=1}^n \ω_ I \ f _ I(x)。)这与我们之前的定义相比是一个微小的变化,但很有趣,因为一旦模型生成了预测(p_i = f_i(x)\,学习权重就等同于对这些预测拟合线性回归:( e(p_1,…,p _ n)= \ omega _ 1 p _ 1+…+\ \ omega _ n p _ n,),并对权重进行一些约束。再说一次,没有理由限制我们自己去拟合一个线性模型。相反,假设我们符合最近邻模型。然后,集成将基于给定观测值的最近邻取局部平均值,使集成能够适应输入变化时模型性能的变化。
实现合奏
为了建立这种类型的合奏,我们需要三样东西:
- 生成预测的基础学习者库
- 学习如何最好地组合这些预测的元学习者
- 一种在基础学习者和元学习者之间分割训练数据的方法。
基础学习者是输入模型,它接受原始输入并生成一组预测。如果我们有一个按形状为(n_samples, n_features)的矩阵(X)排序的原始数据集,则基础学习者库输出一个大小为(n_samples, n_base_learners)的新预测矩阵(P_{\text{base}}\ ),其中每一列代表一个基础学习者做出的预测。元学习者在(P_{\text{base}})上接受训练。这意味着以适当的方式处理训练集(X)是绝对重要的。特别是,如果我们都在(X)上训练基础学习者,并让他们预测(X),元学习者将在基础学习者的训练错误上训练,但在测试时间它将面对他们的测试错误。我们需要一种策略来生成反映测试误差的预测矩阵(P)。最简单的策略是将整个数据集(X)一分为二:在一半上训练基础学习者,让他们预测另一半,然后这一半成为元学习者的输入。虽然简单且相对较快,但我们丢失了相当多的数据。对于小型和中型数据集,信息丢失可能很严重,导致基础学习者和元学习者表现不佳。为了确保覆盖完整的数据集,我们可以使用交叉验证,这是一种最初为在模型选择期间验证测试集性能而开发的方法。有许多方法可以执行交叉验证,在我们深入研究之前,让我们通过自己一步一步地实现一个来感受一下这种类型的集成。
步骤 1:定义基础学习者库
这些模型获取原始输入数据并生成预测,可以是从线性回归到神经网络再到另一个集成的任何东西。一如既往,多样性蕴含着力量!唯一要考虑的是,我们添加的模型越多,合奏的速度就越慢。这里,我们将使用之前的一组模型:
base_learners = get_models()
步骤 2:定义元学习者
使用哪种元学习器并不明显,但流行的选择是线性模型、基于核的模型(SVM 和 KNNS)和基于决策树的模型。但是你也可以使用另一个集成作为“元学习者”:在这种特殊情况下,你最终得到一个两层集成,类似于一个前馈神经网络。在这里,我们将使用梯度推进机。为了确保 GBM 探索局部模式,我们限制 1000 个决策树中的每一个在 4 个基础学习者和 50%输入数据的随机子集上训练。这样,GBM 将在输入空间的不同邻域中暴露给每个基础学习者的力量。
meta_learner = GradientBoostingClassifier(
n_estimators=1000,
loss="exponential",
max_features=4,
max_depth=3,
subsample=0.5,
learning_rate=0.005,
random_state=SEED)
步骤 3:定义生成训练集和测试集的过程
为了简单起见,我们将完整的训练集分成基础学习者的训练和预测集。这种方法有时被称为混合。不幸的是,不同的社区有不同的术语,所以并不总是很容易知道集成使用的是什么类型的交叉验证。
xtrain_base, xpred_base, ytrain_base, ypred_base = train_test_split(
xtrain, ytrain, test_size=0.5, random_state=SEED)
我们现在有一个基础学习者的训练集((X_{\text{train_base}},y_{\text{train_base}}))和一个预测集((X_{\text{pred_base}},y_{\text{pred_base}})),并准备好为元学习者生成预测矩阵。
步骤 4:在训练集上训练基础学习者
为了根据基础学习者训练数据训练基础学习者库,我们照常进行:
def train_base_learners(base_learners, inp, out, verbose=True):
"""
Train all base learners in the library.
"""
if verbose: print("Fitting models.")
for i, (name, m) in enumerate(base_learners.items()):
if verbose: print("%s..." % name, end=" ", flush=False)
m.fit(inp, out)
if verbose: print("done")
要培训基础学员,请执行
train_base_learners(base_learners, xtrain_base, ytrain_base)
步骤 5:生成基础学习者预测
有了合适的基础学习者,我们现在可以为元学习者生成一组预测来训练。注意,我们为用于训练基础学习者的观察值而不是生成预测。对于基础学习者预测集中的每个观察(x_{\text{pred}}{(i)},我们生成一组基础学习者预测:(p_{\text{base}} = \左(\ f_1(x_{\text{pred}}^{(i)}) \,…,\ f_n(x_{\text{pred}}^{(i)})\ \右)。)如果您实现自己的集成,请特别注意如何索引预测矩阵的行和列。当我们将数据一分为二时,这并不困难,但是对于交叉验证,事情就更有挑战性了。
def predict_base_learners(pred_base_learners, inp, verbose=True):
"""
Generate a prediction matrix.
"""
P = np.zeros((inp.shape[0], len(pred_base_learners)))
if verbose: print("Generating base learner predictions.")
for i, (name, m) in enumerate(pred_base_learners.items()):
if verbose: print("%s..." % name, end=" ", flush=False)
p = m.predict_proba(inp)
# With two classes, need only predictions for one class
P[:, i] = p[:, 1]
if verbose: print("done")
return P
要生成预测,请执行
P_base = predict_base_learners(base_learners, xpred_base)
6.训练元学习者
预测矩阵(P_{\text{base}})反映了测试时的表现,可以用来训练元学习者:
meta_learner.fit(P_base, ypred_base)
就是这样!我们现在有了一个训练有素的集合,可以用来预测新的数据。为了生成对某些观察值的预测((x{(j)}),我们首先将其提供给基础学习者。这些输出一组我们提供给元学习者的预测(p_{\text{base}} = \左(\ f_1(x^{(j)}) \,…,\ f_n(x{(j)}) \右))。元学习者然后给我们集合的最终预测(p = m\left(p_{\text{base}}^{(j)} \右)。)现在,我们对集成学习有了一个明确的理解,是时候看看它能做些什么来提高我们在政治捐款数据集上的预测性能了:
def ensemble_predict(base_learners, meta_learner, inp, verbose=True):
"""
Generate predictions from the ensemble.
"""
P_pred = predict_base_learners(base_learners, inp, verbose=verbose)
return P_pred, meta_learner.predict_proba(P_pred)[:, 1]
要生成预测,请执行
P_pred, p = ensemble_predict(base_learners, meta_learner, xtest)
print("\nEnsemble ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
总体 ROC-AUC 评分:0.881
正如预期的那样,总体优于我们之前基准测试中的最佳估计量,但它优于简单平均总体。这是因为我们只在一半的数据上训练了基础学习者和元学习者,所以很多信息都丢失了。为了防止这种情况,我们需要使用交叉验证策略。
交叉验证培训
在对基础学习者进行交叉验证训练的过程中,每个基础学习者的一个副本被拟合在(K-1)个折叠上,并预测被遗漏的折叠。重复这个过程,直到每个折叠都被预测。我们指定的折叠越多,每次训练中遗漏的数据就越少。这使得交叉验证的预测噪音更小,更好地反映了测试期间的性能。成本是培训时间明显增加。用交叉验证来拟合一个集合通常被称为叠加,而集合本身被称为超级学习者。为了理解交叉验证是如何工作的,我们可以把它看作是我们之前的系综的外部循环。外部循环迭代(K)个不同的测试折叠,剩余的数据用于训练。内部循环训练基础学习器,并为保留的数据生成预测。下面是一个简单的堆栈实现:
from sklearn.base import clone
def stacking(base_learners, meta_learner, X, y, generator):
"""Simple training routine for stacking."""
# Train final base learners for test time
print("Fitting final base learners...", end="")
train_base_learners(base_learners, X, y, verbose=False)
print("done")
# Generate predictions for training meta learners
# Outer loop:
print("Generating cross-validated predictions...")
cv_preds, cv_y = [], []
for i, (train_idx, test_idx) in enumerate(generator.split(X)):
fold_xtrain, fold_ytrain = X[train_idx, :], y[train_idx]
fold_xtest, fold_ytest = X[test_idx, :], y[test_idx]
# Inner loop: step 4 and 5
fold_base_learners = {name: clone(model)
for name, model in base_learners.items()}
train_base_learners(
fold_base_learners, fold_xtrain, fold_ytrain, verbose=False)
fold_P_base = predict_base_learners(
fold_base_learners, fold_xtest, verbose=False)
cv_preds.append(fold_P_base)
cv_y.append(fold_ytest)
print("Fold %i done" % (i + 1))
print("CV-predictions done")
# Be careful to get rows in the right order
cv_preds = np.vstack(cv_preds)
cv_y = np.hstack(cv_y)
# Train meta learner
print("Fitting meta learner...", end="")
meta_learner.fit(cv_preds, cv_y)
print("done")
return base_learners, meta_learner
让我们回顾一下这里涉及的步骤。首先,我们使我们的最终基础学习者适合所有数据:与我们之前的混合集合相比,在测试时使用的基础学习者是在所有可用数据上训练的。然后,我们循环所有折叠,然后循环所有基础学习器,以生成交叉验证的预测。这些预测叠加起来,为元学习者建立训练集,元学习者也能看到所有数据。因此,混合和堆叠之间的基本区别在于,堆叠允许基础学习者和元学习者在整个数据集上进行训练。使用双重交叉验证,我们可以衡量这在我们的案例中产生的差异:
from sklearn.model_selection import KFold
# Train with stacking
cv_base_learners, cv_meta_learner = stacking(
get_models(), clone(meta_learner), xtrain.values, ytrain.values, KFold(2))
P_pred, p = ensemble_predict(cv_base_learners, cv_meta_learner, xtest, verbose=False)
print("\nEnsemble ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
总体 ROC-AUC 评分:0.889
堆叠产生了相当大的性能提升:事实上,它给了我们迄今为止最好的分数。这种结果对于中小型数据集来说是典型的,在这种情况下,混合的影响可能会很严重。随着数据集大小的增加,混合和堆叠的表现类似。堆叠有其自身的缺点,尤其是速度。一般来说,当涉及到实现交叉验证的集成时,我们需要注意以下重要问题:
- 计算的复杂性
- 结构复杂性(信息泄露的风险)
- 内存消耗
理解这些对于有效地使用合奏是很重要的,所以让我们依次来看一下。
1.计算的复杂性
假设我们要使用 10 个折叠进行堆叠。这需要对 90%的数据对所有基础学习者进行 10 次训练,对所有数据进行一次训练。有了 4 个基础学习者,集成大约比使用最好的基础学习者慢 40 倍。但是每个 cv-fit 都是独立的,所以我们不需要依次拟合模型。如果我们可以并行地适应所有的折叠,那么这个整体将只比最好的基础学习者慢大约 4 倍,这是一个巨大的进步。集成是并行化的主要候选,最大限度地利用这种能力至关重要。并行拟合所有模型的所有折叠,集合的时间损失可以忽略不计。为了更好地理解这一点,下面是来自 ML-Ensemble 的一个基准测试,它显示了通过在 4 个线程上顺序或并行堆叠或混合来适应一个 Ensemble 所需的时间。

即使有这种适度的并行度,我们也可以实现计算时间的显著减少。但是并行化伴随着一系列潜在的棘手问题,比如竞争条件、死锁和内存爆炸。
2.结构复杂性
一旦我们决定使用整个训练集来元学习者,我们必须担心信息泄露。当我们错误地预测训练中使用的样本时,就会出现这种现象,例如,通过混淆我们的折叠或使用在错误子集上训练的模型。当元学习者的训练集中存在信息泄漏时,它将不会学习正确地纠正基本学习者预测错误:垃圾输入,垃圾输出。然而发现这样的漏洞是极其困难的。
3.内存消耗
最后一个问题是并行化,尤其是在 Python 中经常出现的多处理。在这种情况下,每个子进程都有自己的内存,因此需要从父进程复制所有数据。因此,天真的实现会将所有数据复制到所有进程,耗尽内存并在数据序列化上浪费时间。防止这种情况需要共享数据内存,这反过来容易导致数据损坏。
结果:使用包
结论是,你应该使用一个经过单元测试的包,并专注于构建你的机器学习管道。事实上,一旦你选定了一个集成包,构建集成就变得非常简单:你需要做的就是指定基础学习者、元学习者和训练集成的方法。幸运的是,在所有流行的编程语言中都有许多可用的包,尽管它们有不同的风格。在本帖的最后,我们列举了一些作为参考。现在,让我们选择一个,看看堆叠系综在我们的政治捐款数据集上表现如何。这里,我们使用 ML-Ensemble 并构建我们之前的广义系综,但是现在使用 10 重交叉验证:
from mlens.ensemble import SuperLearner
# Instantiate the ensemble with 10 folds
sl = SuperLearner(
folds=10,
random_state=SEED,
verbose=2,
backend="multiprocessing"
)
# Add the base learners and the meta learner
sl.add(list(base_learners.values()), proba=True)
sl.add_meta(meta_learner, proba=True)
# Train the ensemble
sl.fit(xtrain, ytrain)
# Predict the test set
p_sl = sl.predict_proba(xtest)
print("\nSuper Learner ROC-AUC score: %.3f" % roc_auc_score(ytest, p_sl[:, 1]))
Fitting 2 layers
Processing layer-1 done | 00:02:03
Processing layer-2 done | 00:00:03
Fit complete | 00:02:08
Predicting 2 layers
Processing layer-1 done | 00:00:50
Processing layer-2 done | 00:00:02
Predict complete | 00:00:54
Super Learner ROC-AUC score: 0.890
就这么简单!对照简单平均系综检查超级学习者的 ROC 曲线揭示了如何利用全部数据使超级学习者在给定精度水平下牺牲较少的回忆。
plot_roc_curve(ytest, p.reshape(-1, 1), P.mean(axis=1), ["Simple average"], "Super Learner")

从这里去哪里
除了这里介绍的,还有许多其他类型的合奏。然而,基本要素总是相同的:基础学习者库、元学习者和训练过程。通过摆弄这些组件,可以创建各种特殊形式的合奏。mlware 的这篇出色的帖子是一个很好的起点,可以用来学习更高级的集成学习材料。说到软件,那就是品味的问题了。随着合奏越来越受欢迎,可用的套装数量也在增加。传统上,集成是在统计社区中开发的,所以 R 在专门构建的库方面处于领先地位。最近用 Python 和其他语言开发了几个包,更多的包正在开发中。每个包都迎合不同的需求,处于不同的成熟阶段,所以我们建议货比三家,直到你找到你要找的东西。这里有几个软件包供您使用:
| 语言 | 名字 | 评论 |
|---|---|---|
| 计算机编程语言 | ml-组合 | 通用集成学习 |
| 计算机编程语言 | Scikit-learn | Bagging,多数投票分类器。用于开发中堆叠的 API |
| 计算机编程语言 | mlxe tend | 回归和分类集成 |
| 稀有 | 超级赢家 | 超级学习者合奏 |
| 稀有 | 子集合 | 子进程 |
| 稀有 | caretenemble | 插入估计的集合 |
| 多个的 | H20 | 分布式堆叠集成学习。仅限于 H20 库中的估计器 |
| Java 语言(一种计算机语言,尤用于创建网站) | 堆栈网 | 由 H20 支持 |
| 基于网络的 | xcessive | 基于网络的集成学习 |
一个 Power BI 认证值得吗(2022 年)?
原文:https://www.dataquest.io/blog/is-a-power-bi-certification-worth-it-in-2022/
August 22, 2022
Microsoft Power BI 是进行业务分析的首选应用程序。那么,从事这个领域的工作需要认证吗?
Microsoft Power BI 是世界上顶级的商业智能和数据分析平台之一。如果您是一名有抱负的业务分析师,您几乎肯定会很快遇到这个工具。出于这个原因,组织不介意以竞争性的方式补偿合格的 Power BI 专家。
如果你打算找一份业务分析师的工作,或者你对其他数据科学职业感兴趣,你可能会问自己,我如何才能脱颖而出?我需要一个证书来增加我的简历的价值并得到雇主的注意吗?
在本文中,我们将分享为什么我们认为 Power BI 认证是值得的,以及如何准备考试。
Power BI 微软认证
Power BI 是一款微软数据可视化应用,可将各种来源的不相关数据转换为连贯的交互式见解,帮助企业做出数据驱动的决策。微软有能力在这个市场提供有知识的认证。
微软 Power BI 认证名为“考试 PL-300:微软 Power BI 数据分析师”,原名为“考试 DA-100:用微软 Power BI 分析数据。”考试持续 90 分钟,费用为 165 美元,有多种语言版本,如英语、日语、德语和阿拉伯语。
该认证衡量您完成以下技术任务的能力:
- 准备数据
- 建模数据
- 可视化和分析数据
- 部署和维护资产
为什么 Power BI 认证很有用
那么,为什么 Power BI 需要 PL-300 微软认证呢?该认证非常重要,因为它确认您知道如何使用 Power BI 来管理报告和仪表板。它还证明您知道如何共享和分发内容、创建分页报告以及将报告发布到 Power BI 工作区。最后,Microsoft certified stamp 让您在市场上获得了信誉,因为您已经获得了构建 Power BI 的公司的认可!
获得 PL-300 Power BI 认证可以在几个方面帮助您:
- 能力证明和工作准备
- 在竞争激烈的就业市场中展现价值
- 增加职业机会
你需要学习什么来通过考试
为了通过 PL-300 考试,您需要能够将以下所有技能纳入端到端工作流程:
1.在 Power BI 中准备数据
- 使用 Power BI 接口和构建模块
- 从各种数据源导入数据
- 清理、转换和加载数据
2.Power BI 中的模型数据
- 设计数据模型
- 使用数据分析表达式-DAX 创建度量
- 优化数据模型
3.在 Power BI 中可视化数据
- 创建电力 BI 数据可视化
- 用报告构建数据驱动的故事
- 创建交互式仪表板
4.电力商业智能中的数据分析
- 执行数据分析
- 使用人工智能视觉
5.在 Power BI 中管理工作空间和数据集
- 创建工作区
- 管理数据集
- 实现行级安全性
准备考试
有许多在线资源可以帮助你免费准备这个认证考试,但它们不一定能帮助你掌握技能。你可能会学习如何回答问题,但你无法从头到尾交付一个 Power BI 项目。
如果你想在求职时脱颖而出,你需要准备考试,建立一个项目组合来展示你进行数据分析的能力。
我们与微软合作设计的交互式使用 Microsoft Power BI 分析数据技能路径,可帮助您在短时间内学会如何使用 Microsoft Power BI 分析和可视化数据,并开始构建您需要给雇主留下深刻印象的项目组合。通过完成此路径中的所有 Power BI 培训课程,您将获得 PL-300 认证的 50%折扣。
准备好转行了吗——或者开始一份新的工作?看看这条用户友好的道路,准备好迎接一个充满就业机会的新世界。
Dataquest 值得吗?这是我们的学习者在 2020 年说的话
原文:https://www.dataquest.io/blog/is-dataquest-worth-it-2020/
May 4, 2020
许多报名参加在线学习项目的人都在寻找一些方法来让他们的生活变得更好。
也许你正在寻找一份更有成就感的职业。也许你想去赚更多的钱。也许你想建立一些信心或者做一个你目前不具备技能的项目。
当你评估一个像 Dataquest 这样的平台时,可能会遇到的问题是:这真的有帮助吗?data quest 值得吗?我在教育上的投资能帮助我实现目标吗?
在 Dataquest,我们希望我们所有的学员都能达到他们的目标。因此,在我们的 2020 年结果调查 (n=656) 中,我们决定直接提问:【Dataquest 对你的生活产生了什么影响?
结果是压倒性的。为了确保学习者认为他们可以安全地提供诚实的反馈,我们的调查是匿名的,但我们确实询问了我们是否可以引用他们提供的一些答案。以下是其中几个答案的集合。
如果愿意,您可以滚动浏览整个列表,或者使用下面的按钮跳转到与特定目标相关的反馈:
注意:我们编辑了其中一些引文的拼写、语法和长度,并在某些情况下用 Dataquest 替换了单词“it ”,以使学习者评论的上下文更加清晰。
我想在数据科学领域开创一个新的职业生涯!

在完成 Dataquest 后,我能够转行,这改变了我的生活,也给了我力量。
–德国的 Dataquest 学员
我从来没有想到一个人可以在这么短的时间内改变自己的职业生涯。但是我真的做到了!我非常感谢 DQ 的教学方法。感觉就像是为我设计的。
–巴西的 Dataquest 学员
Dataquest 帮助我找到了一份我真正喜欢的工作,并发现有价值和挑战性。
–英国的 Dataquest 学员
我的收入在一年内翻了一番。
–加拿大 Dataquest 学员
有趣的是,上面提到的学习者并不是最近唯一一个使用“收入翻倍”这句话的 Dataquest 学习者。查看维多利亚如何利用她在 Dataquest 学到的数据技能在一夜之间使工资翻了一番的故事。
Dataquest 通过教我新技能和帮助我转向更好的职业,让我的生活变得更好。
–美国的 Dataquest 学员
我找到了一份数据科学家的工作。现在我很开心,工作也很开心。
–土耳其的 Dataquest 学员
能够转行,而且不减薪——我实际上获得了加薪——真是太棒了。
–美国的 Dataquest 学员
从 15000 到 170000 的薪水…没有可比性!
–荷兰的 Dataquest 学员
Dataquest 真的帮助我顺利地从教书转向了数据科学。
–美国的 Dataquest 学员
我能够过渡到一个令人满意的职业,做一些我几年前就应该学会的事情
–美国的 Dataquest 学员
我换了一份新工作,我对我的工作感到兴奋。从那以后,我得到了几次晋升,现在我觉得更轻松了,因为我的工作很有成就感。
–捷克共和国的 Dataquest 学员
我现在赚更多的钱,也有更多的自由。
–荷兰的 Dataquest 学员
Dataquest skills 让我得到了一份我想要的分析工作。
–美国的 Dataquest 学员
我现在作为一名数据分析师做着100%的远程工作。偏远以难以形容和无价的方式改变了我的生活。"
–美国的 Dataquest 学员
在 Dataquest 获得 Python 技能是在一个非常好的研究所获得学生研究助理职位的关键因素。
–德国的 Dataquest 学员
Dataquest 让我能够找到一份工作,做更多我喜欢的工作并获得更多报酬,这对我生活的其他部分也有好处。
–美国的 Dataquest 学员
我现在有了更高的薪水和更好的工作前景。
–荷兰的 Dataquest 学员
立即订阅 Dataquest 】,按照您自己的进度开始交互式学习数据技能。
(或者报名免费试用!)
我想改善我现在的工作!

我被视为组织中的重要成员,肩负着更多的责任。我得到了我一直希望雇主给予我的关注和信任。
–卡塔尔的 Dataquest 学员
作为一名女性, Dataquest 给了一些男同事更多的自信来挑战性别刻板印象。现在,我是一个妈妈,我觉得我学得和在大学时一样快。
–巴西的 Dataquest 学员
Dataquest 之后,我能够更快地完成工作并更好地指导我的团队。
–美国的 Dataquest 学员
Dataquest 让我能够改进增加销售额的流程,例如过滤大型数据集,并让我对自己的新技能更有信心。后者更容易与同事交流并获得他们的反馈。
–美国的 Dataquest 学员
Dataquest 给了我一个在职业生涯中成长的机会。
–委内瑞拉的 Dataquest 学员
我几乎能够在学习后立即在工作中应用新技能。
–捷克共和国的 Dataquest 学员
我觉得使用数据更舒服,这让我能够在工作中做出更好的决定。
–美国的 Dataquest 学员
我自动化了一些任务,花更少的时间做更多的事。此外,由于我的新技能,我获得了加薪。
–美国的 Dataquest 学员
开始接触编程帮助我改进了处理数据的方法,如何组织数据,如何清理数据。我在工作中获得了更多的乐趣。
–卢森堡的 Dataquest 学员
每天在工作中使用我从 Dataquest 中学到的知识,这让我受益匪浅。我已经编写了新的分析程序,更新和简化了旧的程序,并接触了 Jupyter(这是一个游戏改变者)之类的东西。
–美国的 Dataquest 学员
人们经常依靠我来解决编程问题。我认为 Dataquest 给了我很多关于熊猫和熊猫的知识。
–丹麦的 Dataquest 学员
我现在是工作中的关键人物!
–美国的 Dataquest 学员
立即订阅 Dataquest 】,按照您自己的进度开始交互式学习数据技能。
(或者报名免费试用!)
我想学编码!

我没有计算机科学背景,但是现在我可以用 Python 来简化我的 Excel 工作,这很有趣!
–印度尼西亚的 Dataquest 学员
Dataquest 让我认为遥不可及的事情——编码并将 Python 应用于数据分析——成为现实。
–印度尼西亚的 Dataquest 学员
数据科学以前从未感到如此容易,我 再也不害怕编程了!
–印度的 Dataquest 学员
现在感觉可以写代码了。这在 Dataquest 之前对我来说是不可想象的。
–西班牙的 Dataquest 学员
Dataquest 让我明白了学习编程永远不晚!
–卢旺达的 Dataquest 学员
我害怕编码、统计和数学。但是 Dataquest 通过它的学习方法,让我意识到我擅长以前害怕的东西。我现在可以超越阅读和了解更多,这是我前进了一步
职业
–尼日利亚的 Dataquest 学员
有了 Dataquest,我可以在我的教育机构参加高级编程课程的考试。
–美国的 Dataquest 学员
在加入 Dataquest 之前,我曾经做过一些研究工作。但是我在写代码的时候绊倒了。现在我能够流利地用 Python 编写与数据科学相关的代码。
–孟加拉国的 Dataquest 学员
我无法想象在我的一生中,我会学会如何编程,而我现在就在这里。
–瑞士的 Dataquest 学员
立即订阅 Dataquest 】,按照您自己的进度开始交互式学习数据技能。
(或者报名免费试用!)
我要改善我的生活!

我对自己的未来更有安全感。
–新加坡的 Dataquest 学员
使用 Dataquest 进行学习改变了我的学习模式,培养了一种安静的自信感,这也在生活的其他领域帮助了我。
–印度的 Dataquest 学员
信心是一个在很多回答中出现的主题,包括很多我们在这里没有引用的类似问题。Dataquest 在帮助建立自信方面如此有效的原因之一是我们专注于通过做来学习。当你以前已经做过某件事的时候,你很容易对自己能够做这件事充满信心!
我能够在 T2【Kaggle】参加更多的比赛,并感到更加自信。
–美国的 Dataquest 学员
我真的从 Dataquest 中学到了比大数据硕士学位更多的东西。
–西班牙的 Dataquest 学员
我暂停工作来帮助抚养一个孩子。 Dataquest 让我感觉我仍在学习和发展我的技能,而不是仅仅坐在一旁。
–美国的 Dataquest 学员
Dataquest 真的让我的生活变得更美好。我是在课程打折时购买的,但现在我很乐意再付一年的全价。
–日本的 Dataquest 学员
我仍在学习 Dataquest 课程,这是我一生中最好的投资!
–俄罗斯的 Dataquest 学员
这些只是我们收到的许多类似回复的简短摘录。当然,我们只分享那些表示我们可以发表他们的语录的学习者的语录。尽管如此,我们认为这很好地回答了这个问题:Dataquest 值得吗?
但你不必相信我们的话!从我们的调查中查看一些定量数据,或者在第三方网站上阅读我们的学习者评论,如 SwitchUp 和课程报告,你会发现很多相同的主题。
Dataquest 会对你的生活产生什么影响?

https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
Ishango.ai 和 Dataquest 合作伙伴支持非洲数据科学家
原文:https://www.dataquest.io/blog/ishango-ai-and-dataquest-scholarship-partnership/
May 24, 2022
Dataquest 和 Ishango.ai 自豪地宣布建立新的合作伙伴关系,以提高数据科学领域的包容性和多样性。
Dataquest 将向 Ishango.ai 提供四百份奖学金,支持非洲数据科学人才的成长。来自非洲各地的奖学金获得者将获得 Dataquest 数据科学课程,为他们在数据行业的职业生涯做准备。与 Dataquest 的合作将有助于推进 Ishango.ai 的使命,即在全球地图上展示非洲数据科学人才,并在该地区创造数据就业机会。
当我开始 Dataquest 时,我的目标是帮助数百万人进入数据领域。我很高兴与 Ishango.ai 合作,建立培训非洲数据科学家的基础设施,并将他们与全球远程工作机会联系起来。这项奖学金计划有助于我们继续完成改善数据教育的使命。—Vik Paruchuri,Dataquest 创始人
我们对与 Dataquest 的合作感到非常兴奋。在 Ishango.ai,我们直接了解到,由于缺乏技能提升和就业机会,非洲有大量人才尚未开发。Dataquest 奖学金将进一步推动我们建立非洲数据科学人才管道的工作,这些人才已准备好在国际层面工作并产生全球影响。——Eunice Baguma Ball, Ishango.ai 联合创始人
关于 Ishango
Ishango.ai 是一家创新的社会企业,为非洲带来高技能的数据科学工作,并展示了非洲大陆丰富的人才资源。通过我们为期两个月的数据科学奖学金,研究员获得了为全球主机组织远程开展增值项目的实际经验。自 2021 年推出以来,Ishango.ai 已经为七个非洲国家的数据科学人才提供了支持,并将他们与欧洲、美国和澳大利亚的全球公司联系起来。
关于 Dataquest
Dataquest 成立于 2015 年,旨在帮助学习者建立现实世界的技能,并推进他们在数据方面的职业生涯。Dataquest 是排名第一的基于浏览器的自主数据科学学习平台。用户直接在浏览器中学习概念、编写代码和构建真实世界的项目。Dataquest 专业设计的学习路径可以帮助学习者高效地实现他们的数据职业目标,无论他们的经验水平如何。Dataquest 已经帮助成千上万的学习者在亚马逊、SpaceX 和特斯拉等公司开始或推进他们的职业生涯。
Jennifer:“我使用 Dataquest 帮助我管理数据科学项目”
July 25, 2017
詹妮弗·托马斯是美国“四大”银行之一的办公室主任。她支持开发银行家使用的所有软件的团队。
“我做任何需要做的事情,这样我们的程序员就可以坐下来尽可能多地编码。我负责财务、预算、报告、签证工作——什么都做一点。”
“我的大老板负责领导每个资产类别的数据战略。全球大约有 40,000 人,这是一个很大的数据。”
结果,Jennifer 发现自己在会议中充当数据项目的项目经理。“我正和系统架构师开会,我发誓,我们没有共同语言。我知道他们在说英语,但他们说的话我一句也听不懂。”
“人们在谈论 Python 和 R,我听不懂。我不知道从何说起。”
这是你想要的所有信息中最令人惊奇的一个。我自己要花好几年来收集这些信息。
Jennifer 意识到,要做好自己的工作,她需要更深入地了解数据科学。她在网上寻找资源:“我找到的所有网站都不在我的水平上,它们超出了我的理解范围。”
“我团队中负责数据的一名开发人员向我推荐了 Dataquest。他形容这是你想要的所有信息中最令人惊奇的一个。他说这真的很清楚,我自己要花好几年才能收集到这些信息。”
有了这个建议,Jennifer 订阅了 Dataquest,并发现这正是她所需要的。
“我喜欢浏览器中的 IDE,它让一切变得非常简单。一切都布置得很好。”
之前的教学经验让 Jennifer 对 Dataquest 的教学风格十分欣赏。“我在巴塞罗那教了一年半的英语,所以我了解你教学方式的重要性。它的设置方式是完美的。我在 Codecademy 做了一些事情,但它不能与之相比。”
“先教我基础知识,然后在数字、熊猫和 Matplotlib 的基础上进行构建,这意味着我了解幕后发生的事情。”
Jennifer 还将 Dataquest 的项目描述为关键。“它们非常有帮助,能给你一些真实的世界来整合你所学的东西。”
她毫不犹豫地推荐 Dataquest:“这是一项投资,完全值得。”
想要一份数据科学方面的工作?这就是你应该专攻的原因
原文:https://www.dataquest.io/blog/job-data-science-specialize/
March 8, 2019
如果你正在读这篇文章,很可能你正在寻找“一份数据科学的工作”但这实际上意味着什么呢?数据科学领域不仅仅由数据科学家组成。一家公司可能会招聘分析师、算法开发人员、机器学习工程师或数据工程师等职位。你是哪一个?
“我都能做到!”是一个常见的答案,但它可能不是最好的答案。如果你加入的是一个非常小的团队,你将是员工中唯一的“数据人”,那么成为一名多面手可能是必要的。但是,当你在寻找数据科学工作时,拥有一项专长通常会有所帮助。
为什么专家会被雇佣
说到在数据科学领域工作,很少有人像 Mike Kim 一样有如此丰富的经验。他是 Outlier.ai 的联合创始人兼首席技术官,他领导了谷歌、土豚和 AltSchool 的数据科学和机器学习项目。作为一个积极招聘数据科学领域职位的人,Kim 说他通常会寻找具有特定技能的申请人,而不是数据科学通才。
“这通常会使数据科学领域的招聘和求职变得非常困难。“数据科学家这个术语包含了许多不同种类的技能和各种各样的人,”Mike 说。“这完全取决于我在寻找什么。”
例如,让我们看看他最近聘用的一名员工:一名机器学习工程师。虽然工作描述肯定属于数据科学领域,但如果有可能找到具备 Mike 所需的特定机器学习技能的候选人,那么雇用数据分析师甚至数据科学通才就没有太大意义。
这些特殊技能影响了 Mike 评估申请人简历的方式。“我需要看到围绕大规模机器学习平台的流行语,或者不管这些东西是什么。如果你列出的都是‘哦,是的。我写 SQL,我写报告,我可以在 Tableau 中建立仪表板,“你不是我要找的人。”
他说,反之亦然。“如果我真正寻找的是一名分析师,那么我不想要已经建立了一个大规模 Spark 集群并在这些专门模型上运行它的人。”
金的方法并不独特。招聘经理都必须学会如何在一个有很多技术重叠和大量多面手的行业中为正确的角色找到正确的候选人,尤其是在入门级别的行业。
为有抱负的数据科学家提供指导的公司 SharpestMinds 的联合创始人 Jeremie Harris 在他的最新文章中重申了这一点:
哈里斯写道:“想象一下,你是一家试图招聘数据科学家的公司。“几乎可以肯定,你心中有一个相当明确的问题需要帮助,而这个问题需要一些相当具体的技术知识和专业知识。”那么,如果有专家,为什么还要雇佣多面手呢?
另一方面,值得记住的是,公司并不总是知道他们需要一个专家,或者知道他们需要什么样的专家。在数据科学这样一个新兴且快速发展的领域,这是一个相当普遍的问题。申请数据科学工作的挑战之一是评估公司是否真的需要它所说的东西,以及你的技能在多大程度上实际上可以帮助解决它的问题。
如果你是一名机器学习工程师,你不会想要一个“机器学习工程师”的职位,因为公司实际上并不需要机器学习。不幸的是,对此没有简单的解决方案;这是求职者在申请过程中必须自己评估的事情。
强调你的专业
如果你已经到了申请数据科学工作的时候,你可能已经意识到了自己的一些优势和劣势,以及你喜欢做的项目类型。这可以暗示一个很好的专业方向。
但是,即使你的目标是成为一名专家,你也可能已经掌握了一些通用的数据科学技能,而且试图把自己推销成一名多面手可能会很有诱惑力,以防寻找机器学习工程师的公司可能也会看重会构建仪表盘的人。
战胜这种冲动。仔细看看你感兴趣的职位描述,定制你的简历和作品集,提供与职位直接相关的技能和项目的例子。招聘经理可能会浏览数以千计的求职者资料——你的相关技能应该一目了然,不要被无关的工作包围,那样会让你不清楚自己是谁,做什么。
“如果你的所有投资组合都是‘看看我构建的这些很酷的仪表板’,那么我知道你是一种数据科学家,”Mike 说。“如果你所有的投资组合项目都是‘我建立了这个非常粗糙的分类器,或者这个数据集’,那么我知道你是一个不同类型的数据科学家。”
需要明确的是,没有什么错误的数据科学家。但是仪表板生成器并不适合设计机器学习模型的工作,反之亦然。此外,如果雇主不能通过浏览你的简历很快判断出你就是需要的那种特定的数据科学家,那么你很可能得不到回复。
还有什么能让你与众不同?
迈克说,一旦清楚你已经具备了这个职位所要求的特定技能,他就会继续评估其他素质。
一个重要的因素是勇气。“许多数据科学都是令人讨厌的数据收集和清理、测试和验证——远没有那么迷人、有趣或令人兴奋的工作,但却非常重要,”迈克说。“我肯定会寻找了解这一现实的候选人,更好的是,有第一手经验或证据,能够以正确的态度处理好这件事。”
又一个?“我更喜欢有严格量化背景的候选人。我不在乎是什么领域——但我更喜欢有定量背景的人,”他说。他说,如果做不到这一点,他希望看到“他们的经历中有一些东西向我表明,他们在实践中拥有定量技能。”
这并不意味着你不能从事具有人文背景的数据科学(我们已经看到这是非常可能的)。但这确实意味着,如果你没有正式的量化背景,你必须尽你所能证明你拥有这些技能,并能将其付诸实践,即使你没有上过学。
Mike 还寻找那些不仅仅是与技术人员和非技术人员合作,还具有沟通技巧的申请人。他在寻找韧性和灵活性的结合。
“你进来并拥有我需要你拥有的一切的几率基本为零,对吗?”迈克说。“所以,灵活、务实、接受反馈、适应反馈以及成长的能力……真的是我寻找的关键。”
28 Jupyter 笔记本提示、技巧和快捷方式
原文:https://www.dataquest.io/blog/jupyter-notebook-tips-tricks-shortcuts/
October 12, 2016
Jupyter 笔记型电脑
Jupyter notebook,以前称为 IPython notebook,是一个灵活的工具,可以帮助您创建可读的分析,因为您可以将代码、图像、注释、公式和图表放在一起。在本帖中,我们收集了一些最好的 Jupyter 笔记本技巧,帮助你快速成为 Jupyter 超级用户!
(这篇文章基于最初出现在阿历克斯·罗戈日尼科夫的博客“绝妙的错误”上的一篇文章。我们已经扩展了帖子,并将继续这样做——如果您有建议,请让我们知道。感谢亚历克斯让我们在这里重新发布他的作品。)
Jupyter 是相当可扩展的,支持许多编程语言,并且很容易在您的计算机或几乎任何服务器上托管——您只需要 ssh 或 http 访问。最棒的是,它是完全免费的。现在让我们来看看我们的 28 人名单(还在继续!)Jupyter 笔记本小技巧!

Jupyter 接口。
Project Jupyter 诞生于 IPython 项目,该项目发展成为一个可以支持多种语言的笔记本,因此其历史名称为 IPython 笔记本。Jupyter 这个名字是它设计的三种核心语言的间接组合: JU lia、 PYT hon 和 R ,灵感来自木星。
在 Jupyter 中使用 Python 时,使用了 IPython 内核,这使我们可以从我们的 Jupyter 笔记本中方便地访问 IPython 特性(稍后将详细介绍!)
我们将向您展示 28 个提示和技巧,让您更轻松地使用 Jupyter。
1.快捷键
任何高级用户都知道,键盘快捷键会节省你很多时间。Jupyter 在顶部的菜单下存储了一个快捷键列表:Help > Keyboard Shortcuts,或者在命令模式下按下H(后面会有更多介绍)。每次更新 Jupyter 时都值得检查一下,因为更多的快捷方式一直在添加。
访问键盘快捷键的另一种方法,也是学习它们的一种简便方法是使用命令面板:Cmd + Shift + P(或者 Linux 和 Windows 上的Ctrl + Shift + P)。此对话框帮助您按名称运行任何命令-如果您不知道某个操作的键盘快捷键,或者如果您想要执行的操作没有键盘快捷键,则此对话框非常有用。该功能类似于 Mac 上的 Spotlight search,一旦你开始使用它,你会想知道没有它你是怎么生活的!

命令调色板。
我最喜欢的一些:
Esc将带您进入命令模式,您可以使用箭头键在笔记本中导航。- 在命令模式下:
A在当前单元格上方插入新单元格,B在下方插入新单元格。M将当前单元格改为降价,Y改回编码D + D(按两次键)删除当前单元格
Enter会将您从命令模式带回到给定单元格的编辑模式。Shift + Tab将向您显示您刚刚在代码单元格中键入的对象的文档字符串(文档)——您可以持续按此快捷键在文档的几种模式之间循环。Ctrl + Shift + -将从光标所在的位置将当前单元格一分为二。- 在您的代码中查找并替换,而不是在输出中。
Esc + O切换单元格输出。- 选择多个单元格:
Shift + J或Shift + Down选择向下方向的下一次卖出。您也可以使用Shift + K或Shift + Up选择向上销售。- 选择单元格后,您可以批量删除/复制/剪切/粘贴/运行它们。当您需要移动笔记本的部件时,这很有帮助。
- 你也可以使用
Shift + M来合并多个单元格。

合并多个单元格。
2.变量的漂亮展示
第一部分是众所周知的。通过用变量名或语句的未赋值输出来结束 Jupyter 单元格,Jupyter 将显示该变量,而不需要打印语句。这在处理 Pandas 数据帧时特别有用,因为输出被整齐地格式化成表格。
不太为人所知的是,您可以修改一个 modifyast_note_interactivity内核选项,让 Jupyter 在它自己的行上为任何变量或语句做这件事,因此您可以一次看到多个语句的值。
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
from pydataset import data
quakes = data('quakes')
quakes.head()
quakes.tail()
| 【T0 年】 | 龙
| 深度
| 弹匣
| 车站
|
| --- | --- | --- | --- | --- |
| 1
| -20.42
| 181.62
| 562
| 4.8
| 41
|
| 2
| -20.62
| 181.03
| 650
| 4.2
| 15
|
| 3
| -26.00
| 184.10
| 42
| 5.4
| 43
|
| 4
| -17.97
| 181.66
| 626
| 4.1
| 19
|
| 5
| -20.42
| 181.96
| 649
| 4.0
| 11
|
| 【T0 年】 | 龙
| 深度
| 弹匣
| 车站
|
| --- | --- | --- | --- | --- |
| 996
| -25.93
| 179.54
| 470
| 4.4
| 22
|
| 997
| -12.28
| 167.06
| 248
| 4.7
| 35
|
| 998
| -20.13
| 184.20
| 244
| 4.5
| 34
|
| 999
| -17.40
| 187.80
| 40
| 4.5
| 14
|
| 1000
| -21.59
| 170.56
| 165
| 6.0
| 119
|
如果您想为 Jupyter(笔记本和控制台)的所有实例设置这种行为,只需用下面几行创建一个文件~/.ipython/profile_default/ipython_config.py。
c = get_config()
# Run all nodes interactively
c.InteractiveShell.ast_node_interactivity = "all"
3.文档的简单链接
在Help菜单中,你会找到常用库的在线文档链接,包括 NumPy、Pandas、SciPy 和 Matplotlib。
也不要忘记,通过在库、方法或变量前面加上?,你可以访问 Docstring 来快速参考语法。
?str.replace()
Docstring:
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
Type: method_descriptor
4.在笔记本中绘图
在您的笔记本中有许多生成图的选项。
- matplotlib (事实上的标准),用
%matplotlib inline激活——这里有一个 Dataquest Matplotlib 教程。 - 提供交互性,但可能会有点慢,因为渲染是在服务器端完成的。
- Seaborn 建立在 Matplotlib 之上,使建立更有吸引力的地块变得更加容易。仅仅通过导入 Seaborn,你的 matplotlib 图就变得“更漂亮”,而不需要修改任何代码。
- mpld3 为 matplotlib 代码提供替代渲染器(使用 d3)。相当不错,虽然不完整。
- 散景是构建互动情节的更好选择。
- plot.ly 可以生成漂亮的图——这曾经只是一项付费服务,但最近被开源了。
- Altair 是一个相对较新的用于 Python 的声明式可视化库。它很容易使用,并且可以做出很好看的图,但是定制这些图的能力远不如 Matplotlib 强大。

Jupyter 接口。
https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
5.IPython 魔法命令
*你在上面看到的%matplotlib inline是一个 IPython Magic 命令的例子。基于 IPython 内核,Jupyter 可以访问来自 IPython 内核的所有魔法,它们可以让您的生活变得更加轻松!
# This will list all magic commands
%lsmagic
Available line magics:
%alias %alias_magic %autocall %automagic %autosave %bookmark %cat %cd %clear %colors %config %connect_info %cp %debug %dhist %dirs %doctest_mode %ed %edit %env %gui %hist %history %killbgscripts %ldir %less %lf %lk %ll %load %load_ext %loadpy %logoff %logon %logstart %logstate %logstop %ls %lsmagic %lx %macro %magic %man %matplotlib %mkdir %more %mv %notebook %page %pastebin %pdb %pdef %pdoc %pfile %pinfo %pinfo2 %popd %pprint %precision %profile %prun %psearch %psource %pushd %pwd %pycat %pylab %qtconsole %quickref %recall %rehashx %reload_ext %rep %rerun %reset %reset_selective %rm %rmdir %run %save %sc %set_env %store %sx %system %tb %time %timeit %unalias %unload_ext %who %who_ls %whos %xdel %xmode
Available cell magics:%%! %%HTML %%SVG %%bash %%capture %%debug %%file %%html %%javascript %%js %%latex %%perl %%prun %%pypy %%python %%python2 %%python3 %%ruby %%script %%sh %%svg %%sx %%system %%time %%timeit %%writefile
Automagic is ON, % prefix IS NOT needed for line magics.
我推荐浏览所有 IPython 神奇命令的文档,因为你肯定会找到一些对你有用的。下面是我最喜欢的几个:
6.IPython Magic –% env:设置环境变量
您可以管理笔记本的环境变量,而无需重新启动 jupyter 服务器进程。一些库(比如 theano)使用环境变量来控制行为,%env 是最方便的方法。
# Running %env without any arguments
# lists all environment variables# The line below sets the environment
# variable
%env OMP_NUM_THREADS%env OMP_NUM_THREADS=4
env: OMP_NUM_THREADS=4
7.IPython Magic –% run:执行 Python 代码
%run可以从执行 python 代码。py 文件——这是有据可查的行为。鲜为人知的是,它还可以执行其他 jupyter 笔记本,这可能非常有用。
注意,使用%run并不等同于导入 python 模块。
# this will execute and show the output from
# all code cells of the specified notebook
%run ./two-histograms.ipynb

8.IPython Magic –% load:插入来自外部脚本的代码
这将用外部脚本替换单元格的内容。您可以使用计算机上的文件作为源,也可以使用 URL 作为源。
# Before Running
%load ./hello_world.py
# After Running
# %load ./hello_world.py
if __name__ == "__main__":
print("Hello World!")
Hello World!
9.IPython Magic –% store:在笔记本之间传递变量。
%store命令允许你在两个不同的笔记本之间传递变量。
data = 'this is the string I want to pass to different notebook'
%store data
del data # This has deleted the variable
Stored 'data' (str)
现在,在一个新的笔记本中…
%store -r data
print(data)
this is the string I want to pass to different notebook
10.IPython Magic-% who:列出全局范围的所有变量。
不带任何参数的%who命令将列出全局范围内存在的所有变量。传递类似于str的参数将只列出该类型的变量。
one = "for the money"
two = "for the show"
three = "to get ready now go cat go"
%who str
one three two
11.IPython Magic–计时
有两个 IPython 神奇的命令对计时很有用—%%time和%timeit。当您有一些运行缓慢的代码,并且您试图确定问题出在哪里时,这些工具尤其方便。
%%time将为您提供单元格中代码的单次运行信息。
%%time
import time
for _ in range(1000):
time.sleep(0.01) # sleep for 0.01 seconds
CPU times: user 21.5 ms, sys: 14.8 ms, total: 36.3 ms Wall time: 11.6 s
%%timeit使用 Python timeit 模块,该模块运行一条语句 100,000 次(默认情况下),然后提供最快三次的平均值。
import numpy
%timeit numpy.random.normal(size=100)
The slowest run took 7.29 times longer than the fastest. This could mean that an intermediate result is being cached.
100000 loops, best of 3: 5.5 µs per loop
12.IPython Magic –% % writefile 和%pycat:导出单元格的内容/显示外部脚本的内容
使用%%writefile魔法将该单元格的内容保存到外部文件中。%pycat做相反的事情,向您显示(在弹出窗口中)外部文件的语法高亮内容。
%%writefile pythoncode.py
import numpy
def append_if_not_exists(arr, x):
if x not in arr:
arr.append(x)def some_useless_slow_function():
arr = list()
for i in range(10000):
x = numpy.random.randint(0, 10000)
append_if_not_exists(arr, x)
Writing pythoncode.py
%pycat pythoncode.py
import numpy
def append_if_not_exists(arr, x):
if x not in arr:
arr.append(x)def some_useless_slow_function():
arr = list()
for i in range(10000):
x = numpy.random.randint(0, 10000)
append_if_not_exists(arr, x)
13.IPython Magic –% prun:显示你的程序在每个函数上花费了多少时间。
使用“%prun statement_name”将为您提供一个有序的表格,显示每个内部函数在语句中被调用的次数、每次调用所用的时间以及该函数所有运行的累计时间。
%prun some_useless_slow_function()
26324 function calls in 0.556 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
10000 0.527 0.000 0.528 0.000 :2(append_if_not_exists)
10000 0.022 0.000 0.022 0.000 {method 'randint' of 'mtrand.RandomState' objects}
1 0.006 0.006 0.556 0.556 :6(some_useless_slow_function)
6320 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.556 0.556 :1()
1 0.000 0.000 0.556 0.556 {built-in method exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
14.IPython Magic–使用%pdb 进行调试
Jupyter 有自己的接口用于Python 调试器(pdb ) 。这使得进入函数内部并研究那里发生的事情成为可能。
你可以在这里查看pdb接受的命令列表。
%pdb
def pick_and_take():
picked = numpy.random.randint(0, 1000)
raise NotImplementedError()
pick_and_take()
Automatic pdb calling has been turned ON
--------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
in ()
5 raise NotImplementedError()
6
----> 7 pick_and_take()
in pick_and_take()
3 def pick_and_take():
4 picked = numpy.random.randint(0, 1000)
----> 5 raise NotImplementedError()
6
7 pick_and_take()
NotImplementedError:
> (5)pick_and_take()
3 def pick_and_take():
4 picked = numpy.random.randint(0, 1000)
----> 5 raise NotImplementedError()
6
7 pick_and_take()
ipdb>
15.IPython Magic–Retina 笔记本电脑的高分辨率绘图输出
IPython magic 的一条线将为 Retina 屏幕提供双倍分辨率的绘图输出,例如最近的 Macbooks。注意:下面的例子不会在非视网膜屏幕上渲染
x = range(1000)
y = [i ** 2 for i in x]
plt.plot(x,y)
plt.show();
%config InlineBackend.figure_format ='retina'
plt.plot(x,y)
plt.show();


16.抑制最终函数的输出。
有时在最后一行隐藏函数的输出是很方便的,例如在绘图时。为此,您只需在末尾添加一个分号。
%matplotlib inline
from matplotlib import pyplot as plt
import numpyx = numpy.linspace(0, 1, 1000)**1.5
# Here you get the output of the function
plt.hist(x)
(array([ 216., 126., 106., 95., 87., 81., 77., 73., 71., 68.]), array([ 0\. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1\. ]),
<a list of 10 Patch objects>)
# By adding a semicolon at the end, the output is suppressed.plt.hist(x);

17.执行 Shell 命令
从笔记本内部执行 shell 命令很容易。您可以使用它来检查工作文件夹中有哪些数据集可用:
!ls *.csv
nba_2016.csv titanic.csv pixar_movies.csv whitehouse_employees.csv
或者检查和管理包。
!pip install numpy !pip list | grep pandas
Requirement already satisfied (use --upgrade to upgrade): numpy in /Library/Frameworks/Python.framework/Versions/3.4/lib/python3.4/site-packages pandas (0.18.1)
18.将胶乳用于论坛
当您在 Markdown 单元格中写入 LaTeX 时,它将使用 MathJax 呈现为一个公式。
这个:
$P(A \mid B) = \frac{P(B \mid A)P(A)}{P(B)}$
变成了这样:

Markdown 是笔记本的重要组成部分,别忘了利用它的表现力!
19.在笔记本中运行不同内核的代码
如果你愿意,你可以将多个内核的代码合并到一个笔记本中。
只需在每个要使用内核的单元格的开头使用 IPython Magics 和内核的名称:
%%bash%%HTML%%python2%%python3%%ruby%%perl
%%bash
for i in {1..5}
do echo "i is $i"
done
i is 1
i is 2
i is 3
i is 4
i is 5
20.为 Jupyter 安装其他内核
Jupyter 的一个很好的特性是能够运行不同语言的内核。作为一个例子,下面是如何让和 R 内核运行。
简单的选择:使用 Anaconda 安装 R 内核
如果您使用 Anaconda 来设置您的环境,让 R 工作是非常容易的。只需在您的终端中运行以下命令:
conda install -c r r-essentials
不太容易的选择:手动安装 R 内核
如果您没有使用 Anaconda,这个过程会稍微复杂一些。首先,如果你还没有安装 R,你需要从曲柄安装 R。
完成后,启动一个 R 控制台并运行以下命令:
install.packages(c('repr', 'IRdisplay', 'crayon', 'pbdZMQ', 'devtools'))
devtools::install_github('IRkernel/IRkernel')
IRkernel::installspec() # to register the kernel in the current R installation
21.在同一个笔记本上运行 R 和 Python。
最好的解决方案是安装 rpy2 (也需要一个 R 的工作版本),这可以用pip轻松完成:
pip install rpy2
然后,您可以一起使用这两种语言,甚至在它们之间传递变量:
%load_ext rpy2.ipython
%R require(ggplot2)
array([1], dtype=int32)
import pandas as pd df = pd.DataFrame({
'Letter': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c'],
'X': [4, 3, 5, 2, 1, 7, 7, 5, 9],
'Y': [0, 4, 3, 6, 7, 10, 11, 9, 13],
'Z': [1, 2, 3, 1, 2, 3, 1, 2, 3]
})
%%R -i df ggplot(data = df) + geom_point(aes(x = X, y= Y, color = Letter, size = Z))

示例礼貌革命博客
22.其他语言的书写功能
有时候 numpy 的速度不够,我需要写一些快速代码。原则上,你可以在动态库中编译函数,并编写 python 包装器…
但是当这个无聊的部分为你做的时候会好很多,对吗?
您可以用 cython 或 fortran 编写函数,并直接从 python 代码中使用它们。
首先,您需要安装:
!pip install cython fortran-magic
%load_ext Cython
%%cython
def myltiply_by_2(float x):
return 2.0 * x
myltiply_by_2(23.)
就我个人而言,我更喜欢使用 fortran,我发现它对于编写数字运算函数非常方便。更多使用细节可以在这里找到。
%load_ext fortranmagic
%%fortran subroutine compute_fortran(x, y, z)
real, intent(in) :: x(:), y(:)
real, intent(out) :: z(size(x, 1))
z = sin(x + y)
end subroutine compute_fortran
compute_fortran([1, 2, 3], [4, 5, 6])
还有不同的抖动系统可以加快 python 代码的速度。更多的例子可以在这里找到。
23.多光标支持
Jupyter 支持多光标,类似于 Sublime 文本。按住Alt,点击并拖动鼠标即可。

多光标支持。
24. Jupyter-contrib extensions
Jupyter-contrib 扩展是一个扩展家族,为 Jupyter 提供了更多的功能,包括jupyter spell-checker和code-formatter。
以下命令将安装扩展,以及基于菜单的配置器,该配置器将帮助您从 Jupyter 笔记本主屏幕浏览和启用扩展。
!pip install https://github.com/ipython-contrib/jupyter_contrib_nbextensions/tarball/master !pip install jupyter_nbextensions_configurator !jupyter contrib nbextension install --user !jupyter nbextensions_configurator enable --user

nbextension 配置器。
25.从 Jupyter 笔记本创建演示文稿。
Damian Avila 的 RISE 允许你从现有的笔记本上创建一个 powerpoint 风格的演示文稿。
您可以使用 conda 安装 RISE:
conda install -c damianavila82 rise
或者 pip:
pip install RISE
然后运行以下代码来安装并启用该扩展:
jupyter-nbextension install rise --py --sys-prefix jupyter-nbextension enable rise --py --sys-prefix
26.木星输出系统
笔记本显示为 HTML,单元格输出可以是 HTML,因此您可以返回几乎任何内容:视频/音频/图像。
在本例中,我扫描了存储库中包含图像的文件夹,并显示了前 5:
import os
from IPython.display import display, Image names = [f for f in os.listdir('img/ml_demonstrations/') if f.endswith('.png')]
for name in names[:5]:
display(Image('img/ml_demonstrations/' + name, width=100))





我们可以用 bash 命令创建相同的列表,因为 magics 和 bash 调用返回 python 变量:
names = !ls img/ml_demonstrations/*.png names[:5]
['img/ml_demonstrations/colah_embeddings.png',
'img/ml_demonstrations/convnetjs.png',
'img/ml_demonstrations/decision_tree.png',
'img/ml_demonstrations/decision_tree_in_course.png',
'img/ml_demonstrations/dream_mnist.png']
27.大数据分析
许多解决方案可用于查询/处理大型数据样本:
- ipyparallel(以前的 ipython cluster) 对于 python 中的简单 map-reduce 操作来说是一个很好的选择。我们在 rep 中使用它来并行训练许多机器学习模型
- pyspark
- spark-sql magic %%sql
28.共享笔记本
共享笔记本最简单的方法就是使用笔记本文件(。ipynb),但是对于那些不使用 Jupyter 的人,您有几个选择:
- 使用
File > Download as > HTML菜单选项将笔记本转换为 html 文件。 - 上传您的。ipynb 文件到 Google Colab 。
- 与 gists 或在 github 上共享您的笔记本文件,这两者都会渲染笔记本。参见这个例子。
- 如果你上传你的笔记本到 github 库,你可以使用方便的 mybinder 服务,允许某人用半个小时的交互式 Jupyter 访问你的库。
- 用 jupyterhub 设置你自己的系统,这在你组织小型课程或研讨会而没有时间关心学生机器时非常方便。
- 将您的笔记本存放在 dropbox 中,并将链接放入 nbviewer 中。nbviewer 将从您托管笔记本的任何源呈现笔记本。
- 使用
File > Download as > PDF菜单将笔记本保存为 PDF 格式。如果你正在走这条路,我强烈推荐阅读朱利叶斯·舒尔茨的优秀文章制作出版就绪的 Python 笔记本。 - 从你的 Jupyter 笔记本上用 Pelican 创建一个博客。
你最喜欢的是什么?
让我知道你最喜欢的 Jupyter 笔记本小贴士是什么。
在 Dataquest ,我们的互动指导项目使用 Jupyter 笔记本来构建数据科学项目,并获得一份数据方面的工作。如果你感兴趣,你可以注册并免费学习我们的第一个模块。
我还推荐以下链接供进一步阅读:
- IPython 内置魔法
- Ben Zaitlen 关于 jupyter 的精彩互动演示
- 高级笔记本第一部分:魔法
和第二部分:小工具 - 使用 jupyter 在 python 中进行剖析
- 扩展笔记本的 4 种方式
- IPython 笔记本招数
- Jupyter vs Zeppelin 争夺大数据
- 制作发布就绪的 Python 笔记本。*
如何使用 Jupyter 笔记本:初学者教程
August 24, 2020
Jupyter 笔记本是什么?
Jupyter Notebook 是一个非常强大的交互式开发和展示数据科学项目的工具。本文将带您了解如何使用 Jupyter 笔记本进行数据科学项目,以及如何在您的本地机器上设置它。
首先,什么是“笔记本”?
笔记本将代码及其输出集成到一个文档中,该文档结合了可视化、叙述性文本、数学公式和其他富媒体。换句话说:这是一个单一的文档,你可以在其中运行代码,显示输出,还可以添加解释,公式,图表,并使你的工作更加透明,可理解,可重复和可共享。
使用笔记本电脑现在是全球公司数据科学工作流程的主要部分。如果您的目标是处理数据,使用笔记本将加快您的工作流程,并使交流和共享您的结果变得更加容易。
最棒的是,作为开源项目 Jupyter 的一部分,Jupyter 笔记本是完全免费的。你可以下载软件本身,或者作为 Anaconda 数据科学工具包的一部分。
尽管在 Jupyter 笔记本中可以使用许多不同的编程语言,但本文将重点讨论 Python,因为它是最常见的用例。(在 R 用户中, R Studio 往往是更受欢迎的选择)。
如何遵循本教程
为了从本教程中获得最大收益,你应该熟悉编程——特别是 Python 和 pandas 。也就是说,如果你有使用另一种语言的经验,本文中的 Python 应该不会太晦涩难懂,仍然可以帮助你在本地设置 Jupyter 笔记本。
Jupyter 笔记本也可以作为一个灵活的平台来学习熊猫甚至 Python,这在本教程中会变得很明显。
我们将:
- 涵盖安装 Jupyter 和创建您的第一台笔记本的基础知识
- 深入钻研,学习所有重要的术语
- 探索在线共享和发布笔记本有多容易。
(其实这篇文章是作为 Jupyter 笔记本写的!它以只读形式发布在这里,但这是一个很好的例子,说明笔记本可以多么多功能。事实上,我们大多数的编程教程甚至我们的 Python 课程都是用 Jupyter 笔记本创建的。
Jupyter 笔记本中的示例数据分析
首先,我们将通过设置和样本分析来回答一个实际问题。这将展示笔记本流程如何在我们工作时让数据科学任务变得更加直观,以及在需要分享我们的工作时让其他人更加直观。
假设你是一名数据分析师,你的任务是找出美国最大公司的利润历史变化。你会发现一组财富 500 强公司的数据,从 1955 年第一次发布到现在已经超过 50 年了,这些数据是从财富的公共档案中收集的。我们已经创建了一个 CSV 格式的数据,您可以在这里使用。
正如我们将要展示的,Jupyter 笔记本非常适合这项调查。首先,让我们继续安装 Jupyter。
装置
初学者开始使用 Jupyter 笔记本最简单的方法是安装 Anaconda 。
Anaconda 是数据科学中使用最广泛的 Python 发行版,预装了所有最流行的库和工具。
Anaconda 中包含的一些最大的 Python 库包括 NumPy 、 pandas 和 Matplotlib ,尽管完整的 1000+列表是详尽的。
因此,Anaconda 让我们可以立即开始运行一个库存充足的数据科学研讨会,而不会有管理无数安装的麻烦,也不用担心依赖关系和特定于操作系统(即特定于 Windows)的安装问题。
要得到 Anaconda,很简单:
- 下载Python 3.8 的 Anaconda 最新版本。
- 按照下载页面和/或可执行文件中的说明安装 Anaconda。
如果你是一个已经安装了 Python 的高级用户,并且喜欢手动管理你的包,你可以使用 pip :
pip3 install jupyter
创建您的第一个笔记本
在本节中,我们将学习运行和保存笔记本,熟悉它们的结构,并理解界面。我们将熟悉一些核心术语,引导您实际理解如何自己使用 Jupyter 笔记本,并为下一部分做好准备,下一部分将介绍一个数据分析示例,并将我们在此学到的一切融入生活。
跑步 Jupyter
在 Windows 上,您可以通过 Anaconda 添加到开始菜单的快捷方式来运行 Jupyter,这将在您的默认 web 浏览器中打开一个新的选项卡,看起来应该类似于下面的截图。

这还不是一个笔记本,但不要惊慌!没什么大不了的。这是笔记本仪表盘,专门用于管理您的 Jupyter 笔记本。将它视为探索、编辑和创建笔记本的发射台。
请注意,仪表板将只允许您访问 Jupyter 的启动目录(即 Jupyter 或 Anaconda 的安装位置)中包含的文件和子文件夹。但是,启动目录可以更改。
也可以在任何系统上通过命令提示符(或 Unix 系统上的终端)输入命令jupyter notebook来启动仪表板;在这种情况下,当前工作目录将是启动目录。
在浏览器中打开 Jupyter Notebook 时,您可能已经注意到仪表板的 URL 类似于[https://localhost:8888/tree](https://localhost:8888/tree)。Localhost 不是一个网站,但它表明内容是从你的本地机器:你自己的电脑上提供的。
Jupyter 的笔记本和仪表板是 web 应用程序,Jupyter 启动一个本地 Python 服务器来为您的 web 浏览器提供这些应用程序,使其基本上独立于平台,并打开了更容易在 web 上共享的大门。
(如果你还不明白这一点,不要担心,重要的是,虽然 Jupyter 笔记本可以在你的浏览器中打开,但它是在你的本地机器上托管和运行的。在你决定分享它们之前,你的笔记本实际上并不在网上。)
仪表板的界面基本上是不言自明的——尽管我们稍后会简单地回到它。那么我们还在等什么呢?浏览到您想要创建第一个笔记本的文件夹,单击右上角的“新建”下拉按钮,然后选择“Python 3”:

嘿,很快,我们到了!您的第一个 Jupyter 笔记本将在新选项卡中打开,每个笔记本都使用自己的选项卡,因为您可以同时打开多个笔记本。
如果您切换回仪表板,您将会看到新文件Untitled.ipynb,并且您应该会看到一些绿色文本,告诉您您的笔记本正在运行。
什么是 ipynb 文件?
简而言之:每个.ipynb文件都是一个笔记本,所以每次创建新笔记本时,都会创建一个新的.ipynb文件。
更长的答案是:每个.ipynb文件都是一个文本文件,以一种叫做 JSON 的格式描述你笔记本的内容。每个单元格及其内容,包括已经转换成文本字符串的图像附件,与一些元数据一起列在其中。
如果你知道你在做什么,你可以自己编辑它!—从笔记本的菜单栏中选择“编辑>编辑笔记本元数据”。您还可以通过从仪表板上的控件中选择“编辑”来查看笔记本文件的内容
但是,这里的关键词是可以。在大多数情况下,您没有理由需要手动编辑笔记本元数据。
笔记本界面
现在你面前有一个打开的笔记本,希望它的界面不会看起来完全陌生。毕竟,Jupyter 本质上只是一个高级的文字处理器。
为什么不四处看看呢?检查一下菜单,感受一下,特别是花一些时间向下滚动命令面板中的命令列表,命令面板是带有键盘图标的小按钮(或Ctrl + Shift + P)。

你应该注意到两个相当突出的术语,它们可能对你来说是新的:细胞和内核是理解 Jupyter 的关键,也是它不仅仅是一个文字处理器的关键。好在这些概念并不难理解。
- 一个内核是一个“计算引擎”,它执行笔记本文档中包含的代码。
- 一个单元是一个容器,用于显示笔记本中的文本或者由笔记本内核执行的代码。
细胞
稍后我们将回到内核,但首先让我们来了解一下细胞。细胞构成了笔记本的主体。在上一节中新笔记本的屏幕截图中,带有绿色轮廓的框是一个空单元格。我们将介绍两种主要的细胞类型:
- 一个代码单元包含要在内核中执行的代码。当代码运行时,笔记本在生成它的代码单元格下面显示输出。
- 一个降价单元格包含使用降价格式化的文本,并在降价单元格运行时就地显示其输出。
新笔记本中的第一个单元格总是代码单元格。
让我们用一个经典的 hello world 例子来测试一下:在单元格中键入print('Hello World!'),然后点击上面工具栏中的运行按钮 或者按下
或者按下Ctrl + Enter。
结果应该是这样的:
print('Hello World!')
Hello World!
当我们运行该单元时,其输出显示在下方,其左侧的标签将从In [ ]变为In [1]。
代码单元的输出也构成了文档的一部分,这就是为什么您可以在本文中看到它。您总是可以区分代码单元格和降价单元格,因为代码单元格的标签在左边,而降价单元格没有。
标签的“In”部分是“Input”的简称,而标签号表示当单元在内核上被执行时的——在这种情况下,单元首先被执行。
再次运行该单元,标签将变为In [2],因为现在该单元是第二个在内核上运行的单元。当我们更仔细地研究内核时,会更清楚为什么这是如此有用。
从菜单栏中,点击插入并选择在下面插入单元格,在你的第一个下面创建一个新的代码单元格,并尝试下面的代码看看会发生什么。你注意到什么不同了吗?
import time
time.sleep(3)
这个单元格不产生任何输出,但是它确实需要三秒钟来执行。注意 Jupyter 如何通过将标签更改为In [*]来表示单元当前正在运行。
一般来说,单元格的输出来自于在单元格执行期间专门打印的任何文本数据,以及单元格中最后一行的值,无论是单独的变量、函数调用还是其他内容。例如:
def say_hello(recipient):
return 'Hello, {}!'.format(recipient)
say_hello('Tim')
'Hello, Tim!'
您会发现自己在自己的项目中几乎经常使用这种方法,以后我们会看到更多。
快捷键
运行单元格时,您可能观察到的最后一件事是,它们的边框变成了蓝色,而在您编辑时它是绿色的。在 Jupyter 笔记本中,总有一个“活跃”单元格用边框高亮显示,边框的颜色表示其当前模式:
- 绿色轮廓 —单元格处于“编辑模式”
- 蓝色轮廓 —单元格处于“命令模式”
那么,当细胞处于命令模式时,我们能对它做什么呢?到目前为止,我们已经看到了如何使用Ctrl + Enter运行单元格,但是我们还可以使用许多其他命令。使用它们的最佳方式是使用键盘快捷键
键盘快捷键是 Jupyter 环境中非常流行的一个方面,因为它们促进了基于单元格的快速工作流。其中许多操作是您可以在活动单元格处于命令模式时执行的。
下面,你会发现一些 Jupyter 的键盘快捷键列表。你不需要马上记住它们,但是这个列表会给你一个很好的主意,什么是可能的。
- 分别用
Esc和Enter在编辑和命令模式之间切换。 - 一旦进入命令模式:
- 用
Up和Down键上下滚动单元格。 - 按
A或B在当前单元格的上方或下方插入一个新单元格。 M将活动单元格转换为减价单元格。Y将当前单元格设置为代码单元格。D + D(D两次)将删除当前单元格。Z将撤消单元格删除。- 按住
Shift并按下Up或Down一次选择多个单元格。选中多个单元格,Shift + M会合并你的选择。
- 用
Ctrl + Shift + -,在编辑模式下,将光标处的活动单元格拆分。- 您也可以点击单元格左边的空白处的和
Shift + Click来选择它们。
继续在你自己的笔记本上尝试这些。准备好之后,创建一个新的减价单元格,我们将学习如何设置笔记本中文本的格式。
降价
Markdown 是一种轻量级的、易于学习的标记语言,用于格式化纯文本。它的语法与 HTML 标记一一对应,所以这里的一些先验知识会有帮助,但绝对不是先决条件。
请记住,这篇文章是在 Jupyter 笔记本上写的,所以到目前为止你看到的所有叙述性文本和图像都是用 Markdown 写的。让我们用一个简单的例子来介绍一下基础知识:
# This is a level 1 heading
## This is a level 2 heading
This is some plain text that forms a paragraph. Add emphasis via **bold** and __bold__, or *italic* and _italic_.
Paragraphs must be separated by an empty line.
* Sometimes we want to include lists.
* Which can be bulleted using asterisks.
1\. Lists can also be numbered.
2\. If we want an ordered list.
[It is possible to include hyperlinks](https://www.example.com)
Inline code uses single backticks: `foo()`, and code blocks use triple backticks:
bar()
Or can be indented by 4 spaces:
foo()
And finally, adding images is easy: 
以下是运行单元格进行渲染后的降价效果:

(注意,此处显示了图像的替代文本,因为在我们的示例中,我们实际上没有使用有效的图像 URL)
附加图像时,您有三种选择:
- 使用网络上图像的 URL。
- 使用一个本地 URL 链接到您将与笔记本一起保存的图像,比如在同一个 git repo 中。
- 通过“编辑>插入图像”添加附件;这将把图像转换成一个字符串并存储在你的笔记本
.ipynb文件中。请注意,这将使您的.ipynb文件更大!
还有更多的东西需要削减,尤其是超链接,也可以简单地包含普通的 HTML。一旦你发现自己正在挑战上述基础知识的极限,你可以参考 Markdown 的创始人约翰·格鲁伯在其网站上发布的官方指南。
核心
每台笔记本背后都运行着一个内核。当您运行代码单元时,该代码在内核中执行。任何输出都返回到单元格中进行显示。内核的状态会随着时间的推移在单元格之间持续存在——它属于整个文档,而不是单个单元格。
例如,如果您在一个单元格中导入库或声明变量,它们将在另一个单元格中可用。让我们试试这个来感受一下。首先,我们将导入一个 Python 包并定义一个函数:
import numpy as np
def square(x):
return x * x
一旦我们执行了上面的单元格,我们就可以在任何其他单元格中引用np和square。
x = np.random.randint(1, 10)
y = square(x)
print('%d squared is %d' % (x, y))
1 squared is 1
不管笔记本中单元格的顺序如何,这都将有效。只要一个单元已经运行,您声明的任何变量或您导入的库将在其他单元中可用。
你可以自己试试,我们再把变量打印出来。
print('Is %d squared %d?' % (x, y))
Is 1 squared 1?
这里没有惊喜!但是如果我们改变y?的值会发生什么
y = 10
print('Is %d squared is %d?' % (x, y))
如果我们运行上面的单元,你认为会发生什么?
我们将得到类似于Is 4 squared 10?的输出。这是因为一旦我们运行了y = 10代码单元,y不再等于内核中 x 的平方。
大多数时候,当你创建一个笔记本时,流程是自上而下的。但是回去做改动是常有的事。当我们确实需要对一个更早的单元进行更改时,我们可以在每个单元的左侧看到的执行顺序,比如In [6],可以通过查看单元的运行顺序来帮助我们诊断问题。
如果我们希望重新设置,内核菜单中有几个非常有用的选项:
- 重启:重启内核,从而清除所有已定义的变量等。
- 重新启动并清除输出:同上,但也会清除代码单元格下方显示的输出。
- 重启并运行全部:同上,但也将从第一个到最后一个顺序运行所有单元格。
如果您的内核在某个计算上停滞不前,并且您希望停止它,您可以选择中断选项。
选择内核
你可能注意到了,Jupyter 给了你改变内核的选项,事实上有很多不同的选项可供选择。当您通过选择 Python 版本从仪表板创建新笔记本时,您实际上是在选择使用哪个内核。
有不同版本 Python 的内核,也有超过 100 种语言的内核,包括 Java,C,甚至 Fortran。数据科学家可能会对 R 和 Julia 的内核,以及 imatlab 和 Calysto MATLAB 的内核特别感兴趣。
SoS 内核在一台笔记本电脑中提供多语言支持。
每个内核都有自己的安装说明,但可能需要您在计算机上运行一些命令。
实例分析
现在我们已经了解了什么是 Jupyter 笔记本,是时候看看如何在实践中使用它们了,这将让我们更清楚地了解为什么它们如此受欢迎。
终于到了开始使用前面提到的财富 500 强数据集的时候了。请记住,我们的目标是找出美国最大公司的利润是如何发生历史性变化的。
值得注意的是,每个人都会发展自己的喜好和风格,但总的原则仍然适用。如果您愿意,可以在自己的笔记本上跟随这一部分,或者将它作为创建自己的方法的指南。
命名您的笔记本
在开始编写项目之前,您可能希望给它起一个有意义的名称。文件名Untitled在屏幕左上角输入一个新的文件名,点击其下方的保存图标(看起来像软盘)进行保存。
请注意,关闭浏览器中的“笔记本”选项卡将而不是“关闭”笔记本,就像在传统应用程序中关闭文档一样。笔记本的内核将继续在后台运行,并且需要在它真正“关闭”之前关闭——尽管如果你不小心关闭了标签或浏览器,这是非常方便的!
如果内核关闭,您可以关闭标签页,而不用担心它是否还在运行。
最简单的方法是从笔记本菜单中选择“文件>关闭并暂停”。但是,您也可以关闭内核,方法是在笔记本应用程序中进入“内核>关闭”,或者在仪表板中选择笔记本,然后单击“关闭”(见下图)。

设置
通常从专门用于导入和设置的代码单元开始,这样,如果您选择添加或更改任何内容,您可以简单地编辑并重新运行该单元,而不会导致任何副作用。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns sns.set(style="darkgrid")
我们将导入 pandas 来处理我们的数据,导入 Matplotlib 来绘制图表,导入 Seaborn 来使我们的图表更漂亮。进口 NumPy 也很常见,但在这种情况下,熊猫为我们进口。
第一行不是 Python 命令,而是使用一种叫做 line magic 的东西来指示 Jupyter 捕获 Matplotlib 图并在单元格输出中呈现它们。我们稍后会谈到更多的线魔法,它们也包含在我们的高级 Jupyter 笔记本教程中。
现在,让我们继续加载我们的数据。
df = pd.read_csv('fortune500.csv')
明智的做法是在单个单元格中也这样做,以防我们需要在任何时候重新加载它。
保存和检查点
现在我们已经开始了,定期储蓄是最好的做法。按Ctrl + S会通过调用“保存和检查点”命令来保存我们的笔记本,但是这个检查点是什么东西呢?
每当我们创建一个新的笔记本时,检查点文件会随笔记本文件一起创建。它位于保存位置的隐藏子目录.ipynb_checkpoints中,也是一个.ipynb文件。
默认情况下,Jupyter 会每隔 120 秒自动将您的笔记本保存到该检查点文件,而不会改变您的主笔记本文件。当您“保存并检查”时,笔记本和检查点文件都会更新。因此,检查点使您能够在出现意外问题时恢复未保存的工作。
您可以通过“文件”>“恢复到检查点”从菜单中恢复到检查点
调查我们的数据集
现在我们真的开始了!我们的笔记本被安全保存,我们已经将数据集df加载到最常用的 pandas 数据结构中,该数据结构被称为DataFrame,基本上看起来像一个表。我们的看起来像什么?
df.head()
| 年 | 军阶 | 公司 | 收入(百万) | 利润(百万) |
|---|---|---|---|---|
| Zero | One thousand nine hundred and fifty-five | one | 通用汽车 | Nine thousand eight hundred and twenty-three point five |
| one | One thousand nine hundred and fifty-five | Two | 埃克森美孚 | Five thousand six hundred and sixty-one point four |
| Two | One thousand nine hundred and fifty-five | three | 美国钢铁 | Three thousand two hundred and fifty point four |
| three | One thousand nine hundred and fifty-five | four | 通用电气 | Two thousand nine hundred and fifty-nine point one |
| four | One thousand nine hundred and fifty-five | five | 埃斯马特 | Two thousand five hundred and ten point eight |
df.tail()
| 年 | 军阶 | 公司 | 收入(百万) | 利润(百万) |
|---|---|---|---|---|
| Twenty-five thousand four hundred and ninety-five | Two thousand and five | Four hundred and ninety-six | Wm。小箭牌 | Three thousand six hundred and forty-eight point six |
| Twenty-five thousand four hundred and ninety-six | Two thousand and five | Four hundred and ninety-seven | 皮博迪能源公司 | Three thousand six hundred and thirty-one point six |
| Twenty-five thousand four hundred and ninety-seven | Two thousand and five | Four hundred and ninety-eight | 温迪国际 | Three thousand six hundred and thirty point four |
| Twenty-five thousand four hundred and ninety-eight | Two thousand and five | Four hundred and ninety-nine | 亲属保健 | Three thousand six hundred and sixteen point six |
| Twenty-five thousand four hundred and ninety-nine | Two thousand and five | Five hundred | 辛辛那提金融公司 | Three thousand six hundred and fourteen |
看起来不错。我们有我们需要的列,每一行对应于一年中的一家公司。
让我们重新命名这些列,以便以后引用它们。
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']
接下来,我们需要探索我们的数据集。完成了吗?熊猫如预期的读了吗?是否缺少任何值?
len(df)
25500
好的,看起来不错——从 1955 年到 2005 年,每年都有 500 行。
让我们检查一下我们的数据集是否像我们期望的那样被导入了。一个简单的检查是查看数据类型(或 dtypes)是否被正确解释。
df.dtypes
year int64 rank int64 company object revenue float64 profit object dtype: object
啊哦。看起来利润栏有问题——我们认为它会像收入栏一样。这表明它很可能包含一些非整数值,所以我们来看看。
non_numberic_profits = df.profit.str.contains('[^0-9.-]')
df.loc[non_numberic_profits].head()
| 年 | 等级 | 公司 | 税收 | 利润 |
|---|---|---|---|---|
| Two hundred and twenty-eight | One thousand nine hundred and fifty-five | Two hundred and twenty-nine | 诺顿(男子名) | One hundred and thirty-five |
| Two hundred and ninety | One thousand nine hundred and fifty-five | Two hundred and ninety-one | 施利茨酿酒公司 | One hundred |
| Two hundred and ninety-four | One thousand nine hundred and fifty-five | Two hundred and ninety-five | 太平洋植物油 | Ninety-seven point nine |
| Two hundred and ninety-six | One thousand nine hundred and fifty-five | Two hundred and ninety-seven | 利伯曼啤酒厂 | Ninety-six |
| Three hundred and fifty-two | One thousand nine hundred and fifty-five | Three hundred and fifty-three | 明尼阿波利斯-魔线 | Seventy-seven point four |
正如我们所怀疑的!有些值是字符串,用于指示丢失的数据。有没有其他的价值观已经悄然进入?
set(df.profit[non_numberic_profits])
{'N.A.'}
这很容易解释,但是我们应该怎么做呢?嗯,那要看少了多少个值。
len(df.profit[non_numberic_profits])
369
这只是我们数据集的一小部分,尽管并非完全无关紧要,因为它仍然在 1.5%左右。
如果包含N.A.的行在这些年中大致均匀分布,最简单的解决方法就是删除它们。所以让我们快速看一下分布情况。
bin_sizes, _, _ = plt.hist(df.year[non_numberic_profits], bins=range(1955, 2006))

一眼看去,我们可以看到一年中最无效的值少于 25,并且由于每年有 500 个数据点,删除这些值将占最差年份数据的不到 4%。事实上,除了 90 年代左右的飙升,大多数年份都不到峰值的一半。
出于我们的目的,假设这是可以接受的,并继续删除这些行。
df = df.loc[~non_numberic_profits]
df.profit = df.profit.apply(pd.to_numeric)
我们应该检查一下是否有效。
len(df)
25131
df.dtypes
year int64 rank int64 company object revenue float64 profit float64 dtype: object
太好了!我们已经完成了数据集设置。
如果我们要将您的笔记本显示为一个报告,我们可以去掉我们创建的调查单元格,这些单元格在这里是作为笔记本工作流程的演示,并合并相关的单元格(有关这方面的更多信息,请参见下面的高级功能部分)来创建一个单独的数据集设置单元格。
这意味着,如果我们在其他地方弄乱了数据集,我们可以重新运行 setup 单元来恢复它。
使用 matplotlib 绘图
接下来,我们可以通过绘制每年的平均利润来解决手头的问题。我们也可以绘制收入图,所以首先我们可以定义一些变量和一个减少代码的方法。
group_by_year = df.loc[:, ['year', 'revenue', 'profit']].groupby('year')
avgs = group_by_year.mean()
x = avgs.index
y1 = avgs.profit
def plot(x, y, ax, title, y_label):
ax.set_title(title)
ax.set_ylabel(y_label)
ax.plot(x, y)
ax.margins(x=0, y=0)
现在我们来策划!
fig, ax = plt.subplots()
plot(x, y1, ax, 'Increase in mean Fortune 500 company profits from 1955 to 2005', 'Profit (millions)')

哇,这看起来像一个指数,但它有一些巨大的下降。它们必须与 20 世纪 90 年代初的衰退和 T2 的网络泡沫相对应。在数据中看到这一点很有趣。但是,每次衰退之后,利润是如何恢复到更高水平的呢?
也许收入能告诉我们更多。
y2 = avgs.revenue
fig, ax = plt.subplots()
plot(x, y2, ax, 'Increase in mean Fortune 500 company revenues from 1955 to 2005', 'Revenue (millions)')

这增加了故事的另一面。收入没有受到那么严重的打击——这是财务部门的一些出色的会计工作。
在栈溢出的一点帮助下,我们可以用+/-它们的标准偏差叠加这些图。
def plot_with_std(x, y, stds, ax, title, y_label):
ax.fill_between(x, y - stds, y + stds, alpha=0.2)
plot(x, y, ax, title, y_label)
fig, (ax1, ax2) = plt.subplots(ncols=2)
title = 'Increase in mean and std Fortune 500 company %s from 1955 to 2005'
stds1 = group_by_year.std().profit.values
stds2 = group_by_year.std().revenue.values
plot_with_std(x, y1.values, stds1, ax1, title % 'profits', 'Profit (millions)')
plot_with_std(x, y2.values, stds2, ax2, title % 'revenues', 'Revenue (millions)')
fig.set_size_inches(14, 4)
fig.tight_layout()

这是惊人的,标准差是巨大的!一些财富 500 强公司赚了数十亿美元,而另一些公司却损失了数十亿美元,而且随着这些年利润的增加,风险也在增加。
也许有些公司比其他公司表现更好;前 10%的利润比后 10%的利润波动更大还是更小?
接下来我们可以研究很多问题,很容易看出在笔记本上工作的流程如何与一个人自己的思维过程相匹配。出于本教程的目的,我们将在这里停止我们的分析,但是您可以自由地自己继续挖掘数据!
这个流程帮助我们轻松地在一个地方调查我们的数据集,而无需在应用程序之间切换上下文,并且我们的工作可以立即共享和复制。如果我们希望为特定的受众创建更简洁的报告,我们可以通过合并单元格和删除中间代码来快速重构我们的工作。
共享您的笔记本
当人们谈论共享他们的笔记本时,他们通常会考虑两种模式。
大多数情况下,个人分享他们工作的最终结果,就像这篇文章本身一样,这意味着分享他们笔记本的非交互式、预渲染版本。然而,借助于版本控制系统,如 Git 或在线平台如 Google Colab ,在笔记本上进行合作也是可能的。
在分享之前
共享笔记本将完全按照导出或保存时的状态显示,包括任何代码单元格的输出。因此,为了确保您的笔记本可以共享,您应该在共享前采取以下几个步骤:
- 单击“单元格>所有输出>清除”
- 点击“内核>重启并全部运行”
- 等待您的代码单元完成执行,并按预期检查运行情况
这将确保您的笔记本不包含中间输出,没有过时的状态,并在共享时按顺序执行。
导出您的笔记本
Jupyter 内置了对导出为 HTML 和 PDF 以及其他几种格式的支持,你可以在“文件>下载为”下的菜单中找到
如果您希望与一个小型私人团体共享您的笔记本电脑,此功能可能正是您所需要的。事实上,由于学术机构中的许多研究人员都获得了一些公共或内部网络空间,并且因为您可以将笔记本导出为 HTML 文件,所以 Jupyter 笔记本对于研究人员来说是一种与同行共享他们的成果的特别方便的方式。
但是如果共享导出的文件对你来说还不够,还有一些非常流行的方法可以更直接地在网上共享.ipynb文件。
开源代码库
随着 GitHub 上的公共笔记本数量在 2018 年初超过 180 万,它无疑是最受欢迎的与世界分享 Jupyter 项目的独立平台。GitHub 已经集成了对直接在存储库和网站上的 gists 中呈现.ipynb文件的支持。如果你还不知道的话, GitHub 是一个代码托管平台,为用 Git 创建的存储库提供版本控制和协作。你需要一个帐户来使用他们的服务,但标准帐户是免费的。
一旦你有了 GitHub 账户,在 GitHub 上分享笔记本最简单的方法实际上根本不需要 Git。自 2008 年以来,GitHub 提供了 Gist 服务来托管和共享代码片段,每个代码片段都有自己的存储库。要使用 Gists 共享笔记本:
- 登录并导航至gist.github.com。
- 在一个文本编辑器中打开您的
.ipynb文件,选择 all 并将 JSON 复制到里面。 - 将笔记本 JSON 粘贴到要点中。
- 给你的要点一个文件名,记住要加上
.iypnb,否则就没用了。 - 点按“创建秘密要点”或“创建公开要点”
这应该类似于以下内容:

如果你创建了一个公共 Gist,你现在可以和任何人分享它的 URL,其他人也可以派生和克隆你的作品。
创建自己的 Git 库并在 GitHub 上共享超出了本教程的范围,但是 GitHub 提供了大量的指南让你自己开始。
对于那些使用 git 的人来说,一个额外的提示是为 Jupyter 创建的那些隐藏的.ipynb_checkpoints目录添加一个例外到你的.gitignore中,这样就不会不必要地提交检查点文件到你的 repo 中。
abviewer
到 2015 年,NBViewer 已经发展到每周渲染数十万台笔记本,是网络上最受欢迎的笔记本渲染器。如果你已经有一个地方可以在线存放你的 Jupyter 笔记本,无论是 GitHub 还是其他地方,NBViewer 都会呈现你的笔记本并提供一个可共享的 URL。作为 Jupyter 项目的一部分,它是免费提供的,可在 nbviewer.jupyter.org的获得。
NBViewer 最初是在 GitHub 的 Jupyter 笔记本集成之前开发的,它允许任何人输入 URL、Gist ID 或 GitHub 用户名/repo/file,它会将笔记本呈现为网页。Gist 的 ID 是其 URL 末尾的唯一数字;比如[https://gist.github.com/username/50896401c23e0bf417e89cd57e89e1de](https://gist.github.com/username/50896401c23e0bf417e89cd57e89e1de)中最后一个反斜杠后的字符串。如果您输入 GitHub 用户名或用户名/回购,您将看到一个最小的文件浏览器,让您浏览用户的回购及其内容。
显示笔记本时,NBViewer 显示的 URL 是一个常数,基于它所渲染的笔记本的 URL,因此您可以与任何人共享它,只要原始文件保持在线,它就可以工作-nb viewer 不会缓存文件很长时间。
如果你不喜欢 Nbviewer,还有其他类似的选择— 这里有一个帖子,有一些来自我们社区的可以考虑。
附加功能:Jupyter 笔记本扩展
我们已经涵盖了您在 Jupyter 笔记本上开始工作所需的一切。
什么是扩展?
扩展正是它们听起来的样子——扩展 Jupyter 笔记本功能的附加功能。虽然基本的 Jupyter 笔记本可以做很多事情,但扩展提供了一些额外的功能,这些功能可能有助于特定的工作流程,或者只是改善用户体验。
例如,一个名为“目录”的扩展为你的笔记本生成一个目录,使大笔记本更容易可视化和导航。
另一个叫做变量检查器,可以显示笔记本中每个变量的值、类型、大小和形状,便于快速参考和调试。
另一个叫做 ExecuteTime,让您知道每个单元何时运行以及运行了多长时间——如果您试图加快代码片段的速度,这可能特别方便。
这些只是冰山一角;有许多扩展可用。
你能在哪里得到延长?
要获得扩展,您需要安装 Nbextensions。您可以使用 pip 和命令行来实现这一点。如果您有 Anaconda,那么通过 Anaconda 提示符而不是常规的命令行来完成可能更好。
关闭 Jupyter 笔记本,打开 Anaconda 提示符,运行以下命令:pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install。
一旦你这样做了,启动一个笔记本,你应该看到一个 Nbextensions 标签。单击此选项卡将显示可用扩展的列表。只需勾选您想要启用的扩展的复选框,您就可以开始比赛了!
安装扩展
一旦安装了 Nbextensions 本身,就不需要额外安装每个扩展。然而,如果你已经安装了 Nbextensons,但是没有看到这个标签,你并不孤单。Github上的这个帖子详细介绍了一些常见问题和解决方案。
临时演员:朱庇特的线条魔术
当我们使用%matplotlib inline使 Matplotlib 图表在我们的笔记本中正确呈现时,我们前面提到了神奇的命令。我们也可以使用许多其他的魔法。
如何在 Jupyter 中使用魔法
好的第一步是打开一个 Jupyter 笔记本,在单元格中键入%lsmagic,然后运行单元格。这将输出一个可用的线条魔术和单元格魔术的列表,它还会告诉你“自动魔术”是否打开。
- 线条魔术在代码单元的单行上操作
- 单元魔法作用于调用它们的整个代码单元
如果 automagic 是打开的,你可以简单地运行一个魔术,只需在代码单元中键入它自己的行,然后运行这个单元。如果关闭,你需要将%放在线魔法之前,将%%放在单元魔法之前来使用它们。
许多魔法需要额外的输入(就像函数需要参数一样)来告诉它们如何操作。我们将在下一节中查看一个示例,但是您可以通过带问号运行它来查看任何魔术的文档,就像这样:
%matplotlib?
当你在笔记本上运行上述单元格时,屏幕上会弹出一个很长的文档字符串,详细说明如何使用这个魔法。
一些有用的魔法命令
我们将在高级 Jupyter 教程中介绍更多内容,但这里有一些可以帮助您入门:
| 魔法命令 | 它的作用 |
|---|---|
| %运行 | Runs an external script file as part of the cell being executed.例如,如果 %run myscript.py 出现在代码单元格中,myscript.py 将作为该单元格的一部分由内核执行。 |
| %timeit | 计算循环次数,测量并报告代码单元执行所需的时间。 |
| %writefile | Save the contents of a cell to a file.例如, %savefile myscript.py 会将代码单元格保存为名为 myscript.py 的外部文件。 |
| %商店 | 保存变量以在不同的笔记本中使用。 |
| % n-d | 打印当前工作的目录路径。 |
| %%javascript | 将单元格作为 JavaScript 代码运行。 |
从那里来的还有很多。跳进 Jupyter 笔记本,开始使用%lsmagic探索吧!
最后的想法
从零开始,我们已经掌握了 Jupyter 笔记本的自然工作流程,深入研究了 IPython 更高级的功能,并最终学会了如何与朋友、同事和世界分享我们的工作。我们从一台笔记本电脑上完成了这一切!
应该清楚笔记本如何通过减少上下文切换和模仿项目过程中思维的自然发展来促进高效的工作体验。使用 Jupyter 笔记本的力量也应该是显而易见的,我们涵盖了大量线索,让您开始在自己的项目中探索更多的高级功能。
如果你想为你自己的笔记本寻找更多的灵感,Jupyter 已经收集了一系列有趣的 Jupyter 笔记本,你可能会觉得有帮助,并且 Nbviewer 主页链接到一些真正精美的优质笔记本。
如果你想了解更多关于这个话题的信息,请查看 Dataquest 的交互式 Python 函数,学习 Jupyter 笔记本课程,以及我们的Python 数据分析师和Python 数据科学家路径,它们将帮助你在大约 6 个月内做好工作准备。
更多优秀的 Jupyter 笔记本资源
- 高级 Jupyter 笔记本教程–现在您已经掌握了基础知识,通过本高级教程成为 Jupyter 笔记本专业版!
- 28 个 Jupyter 笔记本提示、技巧和快捷方式——用这些提示和技巧让自己成为超级用户并提高效率!
- 引导式项目——安装并学习 Jupyter 笔记本电脑—通过完成这个交互式引导式项目,为自己使用 Jupyter 笔记本电脑打下良好的基础,该项目将帮助您进行设置并教会您使用技巧。
教程:K-Means 聚类美国参议员
原文:https://www.dataquest.io/blog/k-means-clustering-us-senators/
February 15, 2015 Clustering is a powerful way to split up datasets into groups based on similarity. A very popular clustering algorithm is K-means clustering. In K-means clustering, we divide data up into a fixed number of clusters while trying to ensure that the items in each cluster are as similar as possible. In this post, we’ll explore cluster US Senators using an interactive Python environment. We’ll use the voting history from the 114th Congress to split Senators into clusters.
Clustering is a powerful way to split up datasets into groups based on similarity. A very popular clustering algorithm is K-means clustering. In K-means clustering, we divide data up into a fixed number of clusters while trying to ensure that the items in each cluster are as similar as possible. In this post, we’ll explore cluster US Senators using an interactive Python environment. We’ll use the voting history from the 114th Congress to split Senators into clusters.
载入数据
我们有一个包含第 114 届参议院所有投票的 csv 文件。你可以在这里下载文件。每行包含一位参议员的投票。投票以0表示“反对”,1表示“赞成”,0.5表示“弃权”。以下是前三行数据:
name,party,state,00001,00004,00005,00006,00007,00008,00009,00010,00020,00026,00032,00038,00039,00044,00047
Alexander,R,TN,0,1,1,1,1,0,0,1,1,1,0,0,0,0,0
Ayotte,R,NH,0,1,1,1,1,0,0,1,0,1,0,1,0,1,0
我们可以使用pandas将 csv 文件读入 Python。
import pandas as pd
# Read in the csv file
votes = pd.read_csv("114_congress.csv")
# As you can see, there are 100 senators, and they voted on 15 bills (we subtract 3 because the first 3 columns aren't bills).
print(votes.shape)
# We have more "Yes" votes than "No" votes overall
print(pd.value_counts(votes.iloc[:,3:].values.ravel()))
(100, 18)
1.0 803
0.0 669
0.5 28
dtype: int64
初始 k 均值聚类
K-means 聚类将尝试从参议员中进行聚类。每个集群将包含投票尽可能相似的参议员。我们需要预先指定我们想要的集群数量。让我们试试2看看看起来怎么样。
import pandas as pd
# The kmeans algorithm is implemented in the scikits-learn library
from sklearn.cluster import KMeans
# Create a kmeans model on our data, using 2 clusters. random_state helps ensure that the algorithm returns the same results each time.
kmeans_model = KMeans(n_clusters=2, random_state=1).fit(votes.iloc[:, 3:])
# These are our fitted labels for clusters -- the first cluster has label 0, and the second has label 1.
labels = kmeans_model.labels_
# The clustering looks pretty good!
# It's separated everyone into parties just based on voting history
print(pd.crosstab(labels, votes["party"]))
party D I R
row_0
0 41 2 0
1 3 0 54
探索错误群组中的人
我们现在可以找出哪些参议员属于“错误的”群体。这些参议员属于与对方有关联的群体。
# Let's call these types of voters "oddballs" (why not?)
# There aren't any republican oddballs
democratic_oddballs = votes[(labels == 1) & (votes["party"] == "D")]
# It looks like Reid has abstained a lot, which changed his cluster.
# Manchin seems like a genuine oddball voter.
print(democratic_oddballs["name"])
42 Heitkamp
56 Manchin
74 Reid
Name: name, dtype: object
绘制群集图
让我们通过绘制它们来更深入地探索我们的集群。每一列数据都是图上的一个维度,我们无法可视化 15 个维度。我们将使用主成分分析将投票列压缩成两列。然后,我们可以根据他们的投票划分出我们所有的参议员,并根据他们的 K 均值聚类对他们进行着色。
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca_2 = PCA(2)
# Turn the vote data into two columns with PCA
plot_columns = pca_2.fit_transform(votes.iloc[:,3:18])
# Plot senators based on the two dimensions, and shade by cluster label
# You can see the plot by clicking "plots" to the bottom right
plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=votes["label"])
plt.show()
尝试更多群集
虽然两个集群很有趣,但它没有告诉我们任何我们不知道的事情。更多的集群可以显示每个政党的翅膀,或跨党派团体。让我们尝试使用 5 个集群来看看会发生什么。
import pandas as pdfrom sklearn.cluster
import KMeanskmeans_model = KMeans(n_clusters=5, random_state=1).fit(votes.iloc[:, 3:])
labels = kmeans_model.labels_
# The republicans are still pretty solid, but it looks like there are two democratic "factions"
print(pd.crosstab(labels, votes["party"]))
party D I R
row_0 6 0 0
1 0 0 52
2 31 1 0
3 0 0 2
4 7 1 0
关于 k 均值聚类的更多信息
关于 K-means 聚类的更多信息,你可以查看我们关于 K-means 聚类的 Dataquest 课程。
教程:Python 中的 K 近邻
原文:https://www.dataquest.io/blog/k-nearest-neighbors-in-python/
July 27, 2015
在本帖中,我们将使用 K 近邻算法来预测 2013-2014 赛季 NBA 球员的得分。一路上,我们将了解欧几里德距离,并找出哪些 NBA 球员与勒布朗詹姆斯最相似。如果您想跟进,您可以在这里获取 csv 格式的数据集。
看一看数据
在我们深入研究算法之前,让我们看一下我们的数据。数据中的每一行都包含一名球员在 2013-2014 赛季的表现信息。
以下是从数据中选择的一些列:
player—玩家的名字pos—玩家的位置g—玩家参与的游戏数量gs—玩家开始的游戏次数pts—玩家的总得分
数据中有更多的列,主要包含赛季中平均玩家游戏表现的信息。其余的解释见本网站。
我们可以读入数据集,并确定存在哪些列:
import pandas
with open("nba_2013.csv", 'r') as csvfile:
nba = pandas.read_csv(csvfile)
print(nba.columns.values) # The names of all the columns in the data.
['player' 'pos' 'age' 'bref_team_id' 'g' 'gs' 'mp' 'fg' 'fga' 'fg.' 'x3p' 'x3pa' 'x3p.' 'x2p' 'x2pa' 'x2p.' 'efg.' 'ft' 'fta' 'ft.' 'orb' 'drb' 'trb' 'ast' 'stl' 'blk' 'tov' 'pf' 'pts' 'season' 'season_end']
KNN 概述
k-最近邻算法基于通过将未知值与最相似的已知值进行匹配来预测未知值的简单思想。
假设我们有三种不同类型的汽车。我们知道车的名字,马力,是否有赛车条纹,是否很快。:
car,horsepower,racing_stripes,is_fast
Honda Accord,180,False,False
Yugo,500,True,True
Delorean DMC-12,200,True,True
假设我们现在有另一辆车,但我们不知道它有多快:
car,horsepower,racing_stripes,is_fast
Chevrolet Camaro,400,True,Unknown
我们想弄清楚这车到底快不快。为了预测它是否与 k 最近邻,我们首先找到最相似的已知汽车。在这种情况下,我们将比较horsepower和racing_stripes的值,以找到最相似的汽车,即Yugo。由于 Yugo 很快,我们可以预测 Camaro 也很快。这是一个 1-最近邻的例子,我们只查看了最相似的汽车,给出了 1 的 k 值。
如果我们执行 2-最近邻,我们将得到 2 个True值(对于 Delorean 和 Yugo ),平均为True。Delorean 和 Yugo 是最相似的两辆车,我们的 k 值为 2。
如果我们做 3 个最近邻,我们将得到 2 个True值和一个False值,平均到True。
我们用于 k-最近邻的邻居数量(k)可以是小于数据集中行数的任何值。在实践中,只查看几个邻居会使算法执行得更好,因为邻居与我们的数据越不相似,预测就越差。
欧几里得距离
在使用 KNN 进行预测之前,我们需要找到一些方法来计算出哪些数据行“最接近”我们试图预测的行。
一个简单的方法是使用欧几里德距离。公式是(\sqrt{(q_1-p_1)2+(q_2-p_2)2+\ cdots+(q_n-p_n)^2})
假设我们有这两行(True/False 已转换为 1/0),我们希望找到它们之间的距离:
car,horsepower,is_fast
Honda Accord,180,0
Chevrolet Camaro,400,1
我们将首先只选择数字列。那么距离就变成了(\sqrt{(180-400)^2 + (0-1)^2}),大约等于220。
我们可以利用欧几里德距离原理,找出与勒布朗詹姆斯最相似的 NBA 球员。
# Select Lebron James from our dataset
selected_player = nba[nba["player"] == "LeBron James"].iloc[0]
# Choose only the numeric columns (we'll use these to compute euclidean distance)
distance_columns = ['age', 'g', 'gs', 'mp', 'fg', 'fga', 'fg.', 'x3p', 'x3pa', 'x3p.', 'x2p', 'x2pa', 'x2p.', 'efg.', 'ft', 'fta', 'ft.', 'orb', 'drb', 'trb', 'ast', 'stl', 'blk', 'tov', 'pf', 'pts']
def euclidean_distance(row):
"""
A simple euclidean distance function
"""
inner_value = 0
for k in distance_columns:
inner_value += (row[k] - selected_player[k]) ** 2
return math.sqrt(inner_value)
# Find the distance from each player in the dataset to lebron.
lebron_distance = nba.apply(euclidean_distance, axis=1)
规范化列
您可能已经注意到,汽车示例中的horsepower对最终距离的影响比racing_stripes大得多。这是因为horsepower值的绝对值要大得多,从而使racing_stripes值在欧几里德距离计算中的影响相形见绌。
这可能不好,因为具有较大值的变量不一定能更好地预测哪些行是相似的。
处理这个问题的一个简单方法是将所有列标准化,使其平均值为 0,标准差为 1。这将确保没有单个列对欧几里德距离计算有显著影响。
要将平均值设置为 0,我们必须找到一列的平均值,然后从该列的每个值中减去该平均值。为了将标准差设置为 1,我们将列中的每个值除以标准差。公式为(x=\frac{x-\mu}{\sigma})。
# Select only the numeric columns from the NBA dataset
nba_numeric = nba[distance_columns]
# Normalize all of the numeric columns
nba_normalized = (nba_numeric - nba_numeric.mean()) / nba_numeric.std()
寻找最近的邻居
我们现在已经知道了足够的信息,可以在 NBA 数据集中找到给定行的最近邻。我们可以使用scipy.spatial中的distance.euclidean函数,这是一种计算欧几里德距离更快的方法。
from scipy.spatial import distance
# Fill in NA values in nba_normalized
nba_normalized.fillna(0, inplace=True)
# Find the normalized vector for lebron james.
lebron_normalized = nba_normalized[nba["player"] == "LeBron James"]
# Find the distance between lebron james and everyone else.
euclidean_distances = nba_normalized.apply(lambda row: distance.euclidean(row, lebron_normalized), axis=1)
# Create a new dataframe with distances.
distance_frame = pandas.DataFrame(data={"dist": euclidean_distances, "idx": euclidean_distances.index})
distance_frame.sort("dist", inplace=True)
# Find the most similar player to lebron (the lowest distance to lebron is lebron, the second smallest is the most similar non-lebron player)
second_smallest = distance_frame.iloc[1]["idx"]
most_similar_to_lebron = nba.loc[int(second_smallest)]["player"]
生成训练集和测试集
既然我们知道如何找到最近的邻居,我们可以在测试集上进行预测。我们将尝试使用5最近的邻居来预测一个玩家得了多少分。我们将通过使用数据集中的所有数字列生成相似性得分来查找邻居。
首先,我们必须生成测试和训练集。为了做到这一点,我们将使用随机抽样。我们将随机打乱nba数据帧的索引,然后使用随机打乱的值选择行。
如果我们不这样做,我们最终会在相同的数据集上进行预测和训练,这将会过度拟合。我们也可以做交叉验证,这样会稍微好一点,但是稍微复杂一点。
import random
from numpy.random import permutation
# Randomly shuffle the index of nba.
random_indices = permutation(nba.index)
# Set a cutoff for how many items we want in the test set (in this case 1/3 of the items)
test_cutoff = math.floor(len(nba)/3)
# Generate the test set by taking the first 1/3 of the randomly shuffled indices.
test = nba.loc[random_indices[1:test_cutoff]]
# Generate the train set with the rest of the data.
train = nba.loc[random_indices[test_cutoff:]]
使用 sklearn 查找 k 个最近邻
我们可以使用 scikit-learn 中的 k-nearest neighbors 实现,而不必自己去做。这是文件。有一个回归变量和一个分类器可用,但我们将使用回归变量,因为我们有连续的值要预测。
Sklearn 自动执行标准化和距离查找,并让我们指定想要查看多少个邻居。
# The columns that we will be making predictions with.
x_columns = ['age', 'g', 'gs', 'mp', 'fg', 'fga', 'fg.', 'x3p', 'x3pa', 'x3p.', 'x2p', 'x2pa', 'x2p.', 'efg.', 'ft', 'fta', 'ft.', 'orb', 'drb', 'trb', 'ast', 'stl', 'blk', 'tov', 'pf']
# The column that we want to predict.
y_column = ["pts"]
from sklearn.neighbors import KNeighborsRegressor
# Create the knn model.
# Look at the five closest neighbors.
knn = KNeighborsRegressor(n_neighbors=5)
# Fit the model on the training data.
knn.fit(train[x_columns], train[y_column])
# Make point predictions on the test set using the fit model.
predictions = knn.predict(test[x_columns])
计算误差
现在我们知道了我们的点预测,我们可以计算我们预测的误差。我们可以计算出均方误差。公式是(\frac{1}{n}\sum_{i=1}{n}(\hat{y_{i}}-y_{i})).
# Get the actual values for the test set.
actual = test[y_column]
# Compute the mean squared error of our predictions.
mse = (((predictions - actual) ** 2).sum()) / len(predictions)
后续步骤
有关 k 近邻的更多信息,您可以查看我们的六部分交互式机器学习基础课程,该课程使用 k 近邻算法教授机器学习的基础知识。
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。
卡格尔基础:泰坦尼克号竞赛
October 25, 2017
Kaggle 是一个人们创造算法并与世界各地的机器学习从业者竞争的网站。如果你的算法在一个特定的数据集上是最准确的,你就赢得了比赛。Kaggle 是一种练习机器学习技能的有趣方式。
本教程基于我们免费的四节课的一部分: Kaggle 基础知识。这个互动课程是有史以来对 Kaggle 的泰坦尼克号比赛最全面的介绍。这门课程包括结业证书。使用下面的按钮开始课程:
在本教程中,我们将学习如何:
- 接近一场纸牌游戏比赛
- 探索比赛数据,了解比赛主题
- 为机器学习准备数据
- 训练模特
- 衡量你的模型的准确性
- 准备并制作您的第一个 Kaggle sublesson
本教程假设您对 Python 和 pandas 库有所了解。如果你需要了解这些,我们推荐我们的熊猫教程博文。
泰坦尼克号比赛
Kaggle 创建了许多为初学者设计的比赛。这些竞赛中最受欢迎的,也是我们将要关注的,是关于预测哪些乘客在泰坦尼克号沉没中幸存。
在这个比赛中,我们有一个关于泰坦尼克号上乘客的不同信息的数据集,我们看看是否可以用这些信息来预测那些人是否幸存。在我们开始看这个具体的比赛之前,让我们花一点时间来理解 Kaggle 比赛是如何工作的。
每场 Kaggle 比赛都有两个你将使用的关键数据文件——一个训练集和一个测试集。
训练集包含我们可以用来训练模型的数据。它有许多包含各种描述性数据的特性列,以及一列我们试图预测的目标值:在本例中是Survival。
测试集包含所有相同的功能列,但缺少目标值列。此外,测试集的观察值(行)通常比训练集少。

这很有用,因为我们需要尽可能多的数据来训练我们的模型。一旦我们在训练集上训练了我们的模型,我们将使用该模型对来自测试集的数据进行预测,并将这些预测提交给 Kaggle。
本次比赛中,两档分别命名为test.csv和train.csv。我们首先使用 pandas.read_csv() 库来读取这两个文件,然后检查它们的大小。
import pandas as pd
test = pd.read_csv("test.csv")
train = pd.read_csv("train.csv")
print("Dimensions of train: {}".format(train.shape))
print("Dimensions of test: {}".format(test.shape))
Dimensions of train: (891, 12)
Dimensions of test: (418, 11)
探索数据
我们刚刚打开的文件可以在 Kaggle 上的泰坦尼克号比赛的数据页面上找到。该页面还有一个数据字典,它解释了组成数据集的各个列。以下是该数据字典中包含的描述:
PassengerID—由 Kaggle 添加的列,用于标识每一行并使子分类更容易Survived—乘客是否生还,以及我们预测的值(0 =否,1 =是)Pclass—乘客购买的机票等级(1 = 1 号,2 = 2 号,3 = 3 号)Sex—乘客的性别Age—乘客的年龄,以年为单位- 乘客在泰坦尼克号上的兄弟姐妹或配偶的数量
- 乘客在泰坦尼克号上的父母或孩子的数量
Ticket—乘客的机票号码Fare—乘客支付的车费Cabin—乘客的客舱号Embarked—乘客上船的港口(C =瑟堡,Q =皇后镇,S =南安普顿)
Kaggle 上的数据页面有一些关于一些列的附加说明。为了对数据有一个全面的了解,详细地探究这一点总是值得的。
让我们看看train数据帧的前几行。
train.head()
| 乘客 Id | 幸存 | Pclass | 名字 | 性 | 年龄 | SibSp | 烤 | 票 | 票价 | 小木屋 | 从事 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Zero | three | 布劳恩,欧文·哈里斯先生 | 男性的 | Twenty-two | one | Zero | A/5 21171 | 7.2500 | 圆盘烤饼 | S |
| one | Two | one | one | 卡明斯,约翰·布莱德利夫人(佛罗伦萨布里格斯 Th… | 女性的 | Thirty-eight | one | Zero | PC 17599 | 71.2833 | C85 | C |
| Two | three | one | three | 很虚弱,小姐。借我用用 | 女性的 | Twenty-six | Zero | Zero | STON/氧气。3101282 | 7.9250 | 圆盘烤饼 | S |
| three | four | one | one | Futrelle,夫人雅克希思(莉莉可能皮) | 女性的 | Thirty-five | one | Zero | One hundred and thirteen thousand eight hundred and three | 53.1000 | C123 | S |
| four | five | Zero | three | 威廉·亨利先生,艾伦 | 男性的 | Thirty-five | Zero | Zero | Three hundred and seventy-three thousand four hundred and fifty | 8.0500 | 圆盘烤饼 | S |
我们将进行的机器学习类型被称为分类,因为当我们进行预测时,我们会将每个乘客分类为“幸存”与否。更具体地说,我们正在执行二元分类,这意味着我们正在分类的只有两种不同的状态。
在任何机器学习练习中,思考你所预测的主题是非常重要的。我们称这一步为获取领域知识,这是机器学习成功的最重要的决定因素之一。
在这种情况下,理解泰坦尼克号的灾难,特别是哪些变量可能会影响生存的结果是很重要的。任何看过电影《泰坦尼克号》的人都会记得妇女和儿童优先选择救生艇(就像他们在现实生活中一样)。你也会记得乘客的巨大阶级差异。
这表明Age、Sex和PClass可能是存活的良好预测因子。我们将从通过可视化数据来探索Sex和Pclass开始。
因为Survived列包含乘客是否幸存的0和乘客是否幸存的1,我们可以按性别对数据进行分段,并计算这一列的平均值。我们可以使用DataFrame.pivot_table()轻松做到这一点:
import matplotlib.pyplot as plt
sex_pivot = train.pivot_table(index="Sex",values="Survived")
sex_pivot.plot.bar()
plt.show()

我们可以立即看到女性的存活率比男性高得多。让我们对Pclass列做同样的操作。
class_pivot = train.pivot_table(index="Pclass",values="Survived")
class_pivot.plot.bar()
plt.show()

浏览和转换年龄列
Sex和PClass列是我们所说的分类特征。这意味着这些值代表几个独立的选项(例如,乘客是男是女)。
让我们用 Series.describe() 来看看Age栏。
train["Age"].describe()
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
Age列包含从0.42到80.0的数字(如果你查看 Kaggle 的数据页面,它会通知我们,如果乘客少于 1,则Age是小数)。这里要注意的另一件事是,该列中有 714 个值,少于我们在本课前面发现的train数据集的 814 行,这表明我们有一些丢失的值。
所有这些都意味着需要稍微不同地对待Age列,因为这是一个连续的数字列。查看连续数值集中值的分布的一种方法是使用直方图。我们可以创建两个直方图来直观地比较不同年龄范围内的幸存者和死亡者:
survived = train[train["Survived"] == 1]
died = train[train["Survived"] == 0]
survived["Age"].plot.hist(alpha=0.5,color='red',bins=50)
died["Age"].plot.hist(alpha=0.5,color='blue',bins=50)
plt.legend(['Survived','Died'])
plt.show()

这里的关系并不简单,但我们可以看到,在一些年龄范围内,有更多的乘客幸存下来——红柱高于蓝柱。
为了让这一点对我们的机器学习模型有用,我们可以通过将这一连续特征划分为多个范围,将其分离为一个分类特征。我们可以使用 pandas.cut()函数来帮助我们。
pandas.cut()函数有两个必需的参数——我们希望剪切的列,以及定义剪切边界的数字列表。我们还将使用可选参数labels,该参数为生成的 bin 获取一个标签列表。这将使我们更容易理解我们的结果。
在修改本专栏之前,我们必须了解两件事。首先,我们对train数据进行的任何更改,我们也需要对test数据进行更改,否则我们将无法使用我们的模型对我们的子契约进行预测。其次,我们需要记住处理我们上面观察到的缺失值。
我们将创建一个函数:
- 使用
pandas.fillna()方法用-0.5填充所有缺失的值 - 将
Age列切割成六段:Missing,从-1到0Infant,从0到5Child,从5到12Teenager,从12到18Young Adult,从18到35Adult,从35到60Senior,从60到100
然后我们将在train和test数据帧上使用该函数。
下图显示了该函数如何转换数据:

注意,cut_points列表比label_names列表多了一个元素,因为它需要定义最后一段的上边界。
def process_age(df,cut_points,label_names):
df["Age"] = df["Age"].fillna(-0.5)
df["Age_categories"] = pd.cut(df["Age"],cut_points,labels=label_names)
return df
cut_points = [-1,0,5,12,18,35,60,100]
label_names = ["Missing","Infant","Child","Teenager","Young Adult","Adult","Senior"]
train = process_age(train,cut_points,label_names)
test = process_age(test,cut_points,label_names)
pivot = train.pivot_table(index="Age_categories",values='Survived')
pivot.plot.bar()
plt.show()

为机器学习准备数据
到目前为止,我们已经确定了可能对预测存活率有用的三列:
SexPclassAge,或者更确切地说是我们新创建的Age_categories
在我们建立模型之前,我们需要为机器学习准备这些列。大多数机器学习算法无法理解文本标签,所以我们必须将我们的值转换为数字。
此外,我们需要注意不要在没有数字关系的地方暗示任何数字关系。数据字典告诉我们,Pclass列中的值是1、2和3。我们可以用熊猫来证实这一点:
train["Pclass"].value_counts()
3 491
1 216
2 184
Name: Pclass, dtype: int64
虽然每个乘客的等级肯定具有某种有序关系,但是每个等级之间的关系与数字1、2和3之间的关系不同。例如,等级2的“价值”不是等级1的两倍,等级3的“价值”不是等级1的三倍。
为了消除这种关系,我们可以为Pclass中的每个唯一值创建虚拟列:

我们可以使用 pandas.get_dummies()函数来生成如上图所示的列,而不是手工操作。
我们将创建一个函数来为Pclass列创建虚拟列,并将其添加回原始数据帧。然后,我们将对每个Pclass、Sex和Age_categories列的train和test数据帧应用该函数。
def create_dummies(df,column_name):
dummies = pd.get_dummies(df[column_name],prefix=column_name)
df = pd.concat([df,dummies],axis=1)
return df
for column in ["Pclass","Sex","Age_categories"]:
train = create_dummies(train,column)
test = create_dummies(test,column)
创建我们的第一个机器学习模型
现在我们的数据已经准备好了,我们准备训练我们的第一个模型。我们将使用的第一个模型称为逻辑回归,这通常是您在执行分类时将训练的第一个模型。
我们将使用 scikit-learn 库,因为它有许多工具可以使机器学习变得更容易。scikit-learn 工作流程包括四个主要步骤:
- 实例化(或创建)您想要使用的特定机器学习模型
- 使模型符合训练数据
- 使用模型进行预测
- 评估预测的准确性
scikit-learn 中的每个模型都是作为一个单独的类实现的,第一步是确定我们想要创建其实例的类。在我们的例子中,我们想要使用 LogisticRegression 类。
我们将从前两步开始。首先,我们需要导入这个类:
from sklearn.linear_model import LogisticRegression
接下来,我们创建一个LogisticRegression对象:
lr = LogisticRegression()
最后,我们使用 LogisticRegression.fit()方法来训练我们的模型。.fit()方法接受两个参数:X和y。X必须是我们希望训练模型的二维特征数组(如数据帧),而y必须是我们目标的一维数组(如序列),或我们希望预测的列。
columns = ['Pclass_2', 'Pclass_3', 'Sex_male']
lr.fit(train[columns], train['Survived'])
上面的代码适合(或训练)我们的LogisticRegression模型,使用三列:Pclass_2、Pclass_3和Sex_male。
让我们使用我们用create_dummies()函数创建的所有列来训练我们的模型。
from sklearn.linear_model import LogisticRegression
columns = ['Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex_female', 'Sex_male',
'Age_categories_Missing','Age_categories_Infant',
'Age_categories_Child', 'Age_categories_Teenager',
'Age_categories_Young Adult', 'Age_categories_Adult',
'Age_categories_Senior']
lr = LogisticRegression()
lr.fit(train[columns], train["Survived"])
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
分割我们的训练数据
恭喜你,你已经训练了你的第一个机器学习模型!我们的下一步是找出我们的模型有多精确,为了做到这一点,我们必须做一些预测。
如果你还记得之前的内容,我们确实有一个test数据框架,可以用来做预测。我们可以对该数据集进行预测,但是因为它没有Survived列,所以我们必须将它提交给 Kaggle 来确定我们的准确性。如果我们每次优化我们的模型时都必须提交来找出准确性,这将很快成为一种痛苦。
我们还可以在我们的train数据框架上拟合和预测,但是如果我们这样做,我们的模型很可能会过度拟合,这意味着它将表现良好,因为我们正在对我们已经训练过的相同数据进行测试,但是在新的、看不见的数据上表现差得多。
相反,我们可以将train数据帧一分为二:
- 一部分用来训练我们的模型(通常是 80%的观察值)
- 一部分用于预测和测试我们的模型(通常占观察值的 20%)
机器学习中的约定是把这两部分叫做train和test。这可能会变得令人困惑,因为我们已经有了我们的test数据框架,我们最终将使用它来进行预测并提交给 Kaggle。为了避免混淆,从现在开始,我们将把这种 Kaggle“测试”数据称为保持数据,这是对用于最终预测的这类数据的技术名称。
scikit-learn 库有一个方便的 model_selection.train_test_split()函数,我们可以用它来拆分我们的数据。train_test_split()接受两个参数,X和y,它们包含我们想要训练和测试的所有数据,并返回四个对象:train_X、train_y、test_X、test_y:

您会注意到我们使用了一些额外的参数:test_size,它让我们控制我们的数据被分割成什么比例,以及random_state。train_test_split()函数在划分观察值之前将它们随机化,设置一个随机种子意味着我们的结果将是可重复的,所以你可以跟着做,得到和我们一样的结果。
holdout = test # from now on we will refer to this
# dataframe as the holdout data
from sklearn.model_selection import train_test_split
all_X = train[columns]
all_y = train['Survived']
train_X, test_X, train_y, test_y = train_test_split(
all_X, all_y, test_size=0.20,random_state=0)
做出预测并测量其准确性
现在我们已经将数据分为训练集和测试集,我们可以在训练集上再次拟合我们的模型,然后使用该模型在测试集上进行预测。
一旦我们拟合了我们的模型,我们可以使用 LogisticRegression.predict()方法进行预测。
predict()方法采用单个参数X,这是我们希望预测的观测值的二维特征数组。X必须具有与我们用来拟合模型的阵列完全相同的特征。该方法返回预测的一维数组。
lr = LogisticRegression()
lr.fit(train_X, train_y)
predictions = lr.predict(test_X)
有多种方法可以衡量机器学习模型的准确性,但当参加 Kaggle 比赛时,你需要确保使用 Kaggle 用于计算特定比赛准确性的相同方法。
在这种情况下,ka ggle上泰坦尼克号比赛的评估部分告诉我们,我们的分数计算为“正确预测的乘客百分比”。到目前为止,这是二进制分类最常见的精度形式。
作为一个例子,假设我们正在预测一个由五个观察值组成的小数据集。
| 我们模型的预测 | 实际价值 | 正确的 |
|---|---|---|
| Zero | Zero | 是 |
| one | Zero | 不 |
| Zero | one | 不 |
| one | one | 是 |
| one | one | 是 |
在这种情况下,我们的模型正确预测了五个值中的三个,因此基于该预测集的准确性将为 60%。
同样,scikit-learn 有一个方便的函数,我们可以使用它来计算精度: metrics.accuracy_score() 。该函数接受两个参数,y_true和y_pred,它们分别是实际值和我们的预测值,并返回我们的准确度分数。
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(test_y, predictions)
让我们把所有这些步骤放在一起,得到我们的第一个准确度分数。
from sklearn.metrics import accuracy_score
lr = LogisticRegression()
lr.fit(train_X, train_y)
predictions = lr.predict(test_X)
accuracy = accuracy_score(test_y, predictions)
print(accuracy)
0.810055865922
使用交叉验证进行更精确的误差测量
我们的模型在对 20%的测试集进行测试时,准确率为 81.0%。考虑到这个数据集非常小,我们的模型很有可能过度拟合,在完全看不到的数据上表现不佳。
为了让我们更好地了解我们模型的真实性能,我们可以使用一种称为交叉验证的技术,在我们数据的不同分割上训练和测试我们的模型,然后平均准确度分数。

交叉验证最常见的形式,也是我们将要使用的形式,叫做 k 倍交叉验证。“折叠”是指我们训练模型的每个不同的迭代,“k”只是指折叠的次数。在上图中,我们展示了 k 倍验证,其中 k 为 5。
我们将使用 scikit-learn 的 model_selection.cross_val_score()函数来自动化这个过程。cross_val_score()的基本语法是:
cross_val_score(estimator, X, y, cv=None)
estimator是一个 scikit-learn 估计器对象,就像我们一直在创建的LogisticRegression()对象一样。X是我们数据集中的所有特征。y是目标变量。cv指定折叠的次数。
该函数返回每个折叠的准确度分数的 numpy 数组。值得注意的是,cross_val_score()函数可以使用多种交叉验证技术和评分类型,但是它默认为我们的输入类型提供 k 倍验证和准确性评分。
在计算产生的
分数的平均值之前,我们将使用model_selection.cross_val_score()对我们的数据进行交叉验证:
from sklearn.model_selection import cross_val_score
lr = LogisticRegression()
scores = cross_val_score(lr, all_X, all_y, cv=10)
scores.sort()
accuracy = scores.mean()
print(scores)
print(accuracy)
[ 0.76404494 0.76404494 0.7752809 0.78651685 0.8 0.80681818 0.80898876 0.81111111 0.83146067 0.87640449]
0.802467086596
根据看不见的数据做出预测
从我们的 k-fold 验证结果中,您可以看到准确性数字随着每个折叠而变化,范围在 76.4%和 87.6%之间。这说明了为什么交叉验证很重要。
碰巧的是,我们的平均准确率为 80.2%,这与我们从简单的训练/测试分割中获得的 81.0%相差不远;然而,情况并不总是这样,您应该总是使用交叉验证来确保您从模型中获得的误差度量是准确的。
我们现在准备使用我们建立的模型来训练我们的最终模型,然后根据我们看不见的坚持数据,或 Kaggle 所谓的“测试”数据集进行预测。
lr = LogisticRegression()
lr.fit(all_X,all_y)
holdout_predictions = lr.predict(holdout[columns])
创建子文件夹文件
我们需要做的最后一件事是创建一个 sublesson 文件。每个 Kaggle 竞赛对 sublesson 文件的要求可能略有不同。以下是泰坦尼克号竞赛评估页面上的具体内容:
您应该提交一个包含 418 个条目和一个标题行的 csv 文件。如果您有额外的列(超出 PassengerId 和 Survived)或行,您的子分类将显示错误。
该文件应该正好有两列:
- PassengerId(按任意顺序排序)
- 存活(包含您的二元预测:1 表示存活,0 表示死亡)
下表以一种稍微容易理解的格式显示了这一点,因此我们可以想象我们的目标是什么。
| 乘客 Id | 幸存 |
|---|---|
| Eight hundred and ninety-two | Zero |
| Eight hundred and ninety-three | one |
| Eight hundred and ninety-four | Zero |
我们需要创建一个新的数据框架,它包含我们在前面的屏幕中创建的holdout_predictions和来自holdout数据框架的PassengerId列。我们不需要担心匹配数据的问题,因为这两个数据都保持原来的顺序。
为此,我们可以将字典传递给 pandas.DataFrame()函数:
holdout_ids = holdout["PassengerId"]
sublesson_df = {"PassengerId": holdout_ids,
"Survived": holdout_predictions}
sublesson = pd.DataFrame(sublesson_df)
最后,我们将使用 DataFrame.to_csv()方法将数据帧保存到一个 CSV 文件。我们需要确保将index参数设置为False,否则我们将在 CSV 中添加一个额外的列。
sublesson.to_csv("sublesson.csv",index=False)
我们第一次转租给卡格尔
你可以从我们的免费 Kaggle 基础课程中下载上面创建的 sublesson 文件。在自己的电脑上工作时,它会和你的笔记本在同一个目录下。
现在我们已经有了我们的子订阅文件,我们可以通过点击竞赛页面上的蓝色“提交预测”按钮开始我们的子订阅。

然后会提示您上传您的 CSV 文件,并添加您的分包商的简要说明。当你进行转租时,Kaggle 会处理你的预测,并给出你的拒绝数据和排名的准确性。处理完成后,您将看到我们的第一个 sublesson 获得了 0.75598 的准确度分数,即 75.6%。
与我们通过交叉验证获得的 80.2%的准确率相比,我们对维持数据的准确率为 75.6%,这一事实表明我们的模型对我们的训练数据略有过度拟合。
在撰写本文时,75.6%的准确率给出了 7,954 中的 6,663。在第一次转租后,很容易看到 Kaggle 排行榜并感到气馁,但请记住,这只是一个起点。
看到泰坦尼克排行榜第一的一小部分分数是 100%,认为自己任重道远,这也是很常见的。事实上,任何在这场比赛中得分 90%的人都有可能作弊(很容易在网上找到抵制者的名字,看看他们是否幸存)。
Kaggle 上有一个很好的分析,我的分数如何,它使用了一些不同的策略,并建议这场比赛的最低分数为 62.7%(假设每个乘客都死了),最高分数约为 82%。我们正处于最小值和最大值的中间,这是一个很好的起点。
继续了解 Kaggle
我们可以做很多事情来提高模型的准确性。以下是你将在剩下的 Kaggle 基础课程中学到的一些东西:
- 特征准备、选择和工程
- 如何确定模型中哪些要素与您的预测最相关
- 减少用于训练模型的特征数量并避免过度拟合的方法
- 创建新要素以提高模型精度的技术
- 模型选择和调整
- k-最近邻和随机森林算法的工作原理
- 关于超参数,以及如何选择给出最佳预测的超参数
- 如何比较不同的算法来提高预测的准确性
- 创建 Kaggle 工作流
- 如何使用木星笔记本,同时与 kaggle 竞争
- 为什么工作流对于机器学习和创建 Kaggle 工作流很重要
- 如何使用函数来自动化和简化重复性的机器学习任务
Kaggle 入门:房价竞争
May 5, 2017
成立于 2010 年的 Kaggle 是一个数据科学平台,用户可以在这里分享、合作和竞争。Kaggle 的一个关键功能是“竞赛”,它为用户提供了在真实世界数据上练习的能力,并与国际社会一起测试他们的技能。
本指南将教你如何接近并参加 Kaggle 竞赛,包括探索数据、创建和设计特征、构建模型以及提交预测。我们将使用 Python 3 和 Jupyter 笔记本。

竞争
我们将完成房价:高级回归技术竞赛。
我们将按照以下步骤成功完成 Kaggle 竞赛分包:
- 获取数据
- 探索数据
- 设计和转换特征和目标变量
- 建立一个模型
- 做出并提交预测
步骤 1:获取数据并创建我们的环境
我们需要为比赛获取数据。特性的描述和其他一些有用的信息包含在一个文件中,这个文件有一个明显的名字data_description.txt。
下载数据并将其保存到一个文件夹中,您可以在其中保存比赛所需的一切。
我们先来看一下train.csv的数据。在我们训练了一个模型之后,我们将使用test.csv数据进行预测。
首先,导入 Pandas ,这是一个用 Python 处理数据的极好的库。接下来我们将导入 Numpy 。
import pandas as pd
import numpy as np
我们可以用熊猫读入 csv 文件。pd.read_csv()方法从一个 csv 文件创建一个数据帧。
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
让我们检查一下数据的大小。
print ("Train data shape:", train.shape)
print ("Test data shape:", test.shape)
Train data shape: (1460, 81)
Test data shape: (1459, 80)
我们看到test只有 80 列,而train有 81 列。当然,这是因为测试数据不包括最终销售价格信息!
接下来,我们将使用DataFrame.head()方法查看几行。
train.head()
| 身份 | MSSubClass | MSZoning | 地段临街 | 地段面积 | 街道 | 胡同 | LotShape | 陆地等高线 | 公用事业 | 日志配置 | 风景 | 附近 | 情况 | 情况 | 建筑类型 | HouseStyle | 总体平等 | 总体代码 | 年造的 | YearRemodAdd | 屋顶样式 | 室友 | 外部 1st | 外部第二 | MasVnrType | 马斯夫纳雷亚 | exteequal | 外部 | 基础 | BsmtQual | BsmtCond | bsm 曝光 | BsmtFinType1 | BsmtFinSF1 | BsmtFinType2 | BsmtFinSF2 | BsmtUnfSF | 总计 BsmtSF | 加热 | 加热 QC | 中央空气 | 与电有关的 | 1stFlrSF | 2ndFlrSF | 低质量 FinSF | GrLivArea | BsmtFullBath | 半沐浴 | 全浴 | 半浴 | BedroomAbvGr | KitchenAbvGr | KitchenQual | TotRmsAbvGrd | 功能的 | 壁炉 | 壁炉曲 | GarageType | 车库 | 车库整理 | 车库汽车 | 车库区域 | GarageQual | GarageCond | 铺面车道 | WoodDeckSF | OpenPorchSF | 封闭门廊 | 3SsnPorch | 纱窗阳台 | 游泳池区域 | PoolQC | 栅栏 | 杂项功能 | 米沙尔 | mos old | YrSold | 标度类型 | 销售条件 | 销售价格 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | Sixty | RL | Sixty-five | Eight thousand four hundred and fifty | 安排 | 圆盘烤饼 | 车辆注册号 | 单板层积材 | AllPub | 里面的 | Gtl | CollgCr | 标准 | 标准 | 1Fam | 2 历史 | seven | five | Two thousand and three | Two thousand and three | 三角形建筑部分 | 康普什 | 乙烯树脂 | 乙烯树脂 | BrkFace | One hundred and ninety-six | 钆 | 钽 | PConc | 钆 | 钽 | 不 | GLQ | Seven hundred and six | 未溶化的 | Zero | One hundred and fifty | Eight hundred and fifty-six | 加萨 | 前夫;前妻;前男友;前女友 | Y | SBrkr | Eight hundred and fifty-six | Eight hundred and fifty-four | Zero | One thousand seven hundred and ten | one | Zero | Two | one | three | one | 钆 | eight | 典型 | Zero | 圆盘烤饼 | 附上 | Two thousand and three | RFn | Two | Five hundred and forty-eight | 钽 | 钽 | Y | Zero | Sixty-one | Zero | Zero | Zero | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | Two | Two thousand and eight | 陆军部(War Department) | 常态 | Two hundred and eight thousand five hundred |
| one | Two | Twenty | RL | Eighty | Nine thousand six hundred | 安排 | 圆盘烤饼 | 车辆注册号 | 单板层积材 | AllPub | FR2 | Gtl | 维肯 | Feedr | 标准 | 1Fam | 1 历史 | six | eight | One thousand nine hundred and seventy-six | One thousand nine hundred and seventy-six | 三角形建筑部分 | 康普什 | 金属 | 金属 | 没有人 | Zero | 钽 | 钽 | CBlock | 钆 | 钽 | 钆 | ALQ | Nine hundred and seventy-eight | 未溶化的 | Zero | Two hundred and eighty-four | One thousand two hundred and sixty-two | 加萨 | 前夫;前妻;前男友;前女友 | Y | SBrkr | One thousand two hundred and sixty-two | Zero | Zero | One thousand two hundred and sixty-two | Zero | one | Two | Zero | three | one | 钽 | six | 典型 | one | 钽 | 附上 | One thousand nine hundred and seventy-six | RFn | Two | Four hundred and sixty | 钽 | 钽 | Y | Two hundred and ninety-eight | Zero | Zero | Zero | Zero | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | five | Two thousand and seven | 陆军部(War Department) | 常态 | One hundred and eighty-one thousand five hundred |
| Two | three | Sixty | RL | Sixty-eight | Eleven thousand two hundred and fifty | 安排 | 圆盘烤饼 | IR1 | 单板层积材 | AllPub | 里面的 | Gtl | CollgCr | 标准 | 标准 | 1Fam | 2 历史 | seven | five | Two thousand and one | Two thousand and two | 三角形建筑部分 | 康普什 | 乙烯树脂 | 乙烯树脂 | BrkFace | One hundred and sixty-two | 钆 | 钽 | PConc | 钆 | 钽 | 锰 | GLQ | Four hundred and eighty-six | 未溶化的 | Zero | Four hundred and thirty-four | Nine hundred and twenty | 加萨 | 前夫;前妻;前男友;前女友 | Y | SBrkr | Nine hundred and twenty | Eight hundred and sixty-six | Zero | One thousand seven hundred and eighty-six | one | Zero | Two | one | three | one | 钆 | six | 典型 | one | 钽 | 附上 | Two thousand and one | RFn | Two | Six hundred and eight | 钽 | 钽 | Y | Zero | forty-two | Zero | Zero | Zero | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | nine | Two thousand and eight | 陆军部(War Department) | 常态 | Two hundred and twenty-three thousand five hundred |
| three | four | Seventy | RL | Sixty | Nine thousand five hundred and fifty | 安排 | 圆盘烤饼 | IR1 | 单板层积材 | AllPub | 角落 | Gtl | 克劳福德 | 标准 | 标准 | 1Fam | 2 历史 | seven | five | One thousand nine hundred and fifteen | One thousand nine hundred and seventy | 三角形建筑部分 | 康普什 | Wd Sdng | Wd Shng | 没有人 | Zero | 钽 | 钽 | 贝尔蒂尔 | 钽 | 钆 | 不 | ALQ | Two hundred and sixteen | 未溶化的 | Zero | Five hundred and forty | Seven hundred and fifty-six | 加萨 | 钆 | Y | SBrkr | Nine hundred and sixty-one | Seven hundred and fifty-six | Zero | One thousand seven hundred and seventeen | one | Zero | one | Zero | three | one | 钆 | seven | 典型 | one | 钆 | 荷兰的 | One thousand nine hundred and ninety-eight | 未溶化的 | three | Six hundred and forty-two | 钽 | 钽 | Y | Zero | Thirty-five | Two hundred and seventy-two | Zero | Zero | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | Two | Two thousand and six | 陆军部(War Department) | 反常的 | One hundred and forty thousand |
| four | five | Sixty | RL | Eighty-four | Fourteen thousand two hundred and sixty | 安排 | 圆盘烤饼 | IR1 | 单板层积材 | AllPub | FR2 | Gtl | 诺里奇 | 标准 | 标准 | 1Fam | 2 历史 | eight | five | Two thousand | Two thousand | 三角形建筑部分 | 康普什 | 乙烯树脂 | 乙烯树脂 | BrkFace | Three hundred and fifty | 钆 | 钽 | PConc | 钆 | 钽 | 音像的 | GLQ | Six hundred and fifty-five | 未溶化的 | Zero | Four hundred and ninety | One thousand one hundred and forty-five | 加萨 | 前夫;前妻;前男友;前女友 | Y | SBrkr | One thousand one hundred and forty-five | One thousand and fifty-three | Zero | Two thousand one hundred and ninety-eight | one | Zero | Two | one | four | one | 钆 | nine | 典型 | one | 钽 | 附上 | Two thousand | RFn | three | Eight hundred and thirty-six | 钽 | 钽 | Y | One hundred and ninety-two | Eighty-four | Zero | Zero | Zero | Zero | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | Twelve | Two thousand and eight | 陆军部(War Department) | 常态 | Two hundred and fifty thousand |
我们的文件夹中应该有data dictionary可供比赛使用。你也可以在这里找到它。
以下是您将在数据描述文件中找到的内容的简要版本:
SalePrice—以美元为单位的房产销售价格。这是你试图预测的目标变量。MSSubClass—建筑类MSZoning—一般分区分类LotFrontage—与物业相连的街道的线性英尺数LotArea—以平方英尺为单位的批量Street—道路通道的类型Alley—小巷通道的类型LotShape—物业的总体形状LandContour—财产的平坦度Utilities—可用的公用设施类型LotConfig—批次配置
诸如此类。
比赛要求你预测每套房子的最终价格。
在这一点上,我们应该开始思考我们对房价的了解,艾姆斯,爱荷华,以及我们可能期望在这个数据集中看到什么。
查看数据,我们看到了我们预期的特征,比如YrSold(房屋最后出售的年份)和SalePrice。其他的我们可能没有预料到,比如LandSlope(房屋所在土地的坡度)和RoofMatl(用于建造屋顶的材料)。稍后,我们将不得不决定如何处理这些和其他特性。
我们希望在项目的探索阶段进行一些绘图,并且我们也需要将该功能导入到我们的环境中。绘图使我们能够可视化数据的分布,检查异常值,并看到我们可能会忽略的其他模式。我们将使用 Matplotlib ,一个流行的可视化库。
import matplotlib.pyplot as plt
plt.style.use(style='ggplot')
plt.rcParams['figure.figsize'] = (10, 6)
步骤 2:探索数据和工程特征
挑战在于预测房屋的最终售价。该信息存储在SalePrice栏中。我们试图预测的值通常被称为目标变量。
我们可以使用Series.describe()来获取更多信息。
train.SalePrice.describe()
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.00000
0max 755000.000000
Name: SalePrice, dtype: float64
给你任何系列的更多信息。count显示系列中的总行数。对于数值数据,Series.describe()也给出了mean、std、min和max的值。
在我们的数据集中,房屋的平均销售价格接近于$180,000,大部分价格都在$130,000到$215,000的范围内。
接下来,我们将检查偏斜度,这是对值分布形状的度量。
执行回归时,当目标变量有偏差时,有时对其进行对数变换是有意义的。这样做的一个原因是为了提高数据的线性度。虽然论证超出了本教程的范围,但是更多信息可以在这里找到。
重要的是,最终模型生成的预测也将进行对数转换,因此我们需要稍后将这些预测转换回原始形式。
np.log()将转换变量,np.exp()将反转转换。
我们使用plt.hist()来绘制SalePrice的直方图。请注意,右边的分布有一个较长的尾部。分布是正偏的。
print ("Skew is:", train.SalePrice.skew())
plt.hist(train.SalePrice, color='blue')
plt.show()
Skew is: 1.88287575977

现在我们使用np.log()来转换train.SalePric并再次计算偏斜度,同时重新绘制数据。更接近 0 的值意味着我们已经改善了数据的偏斜度。我们可以直观地看到,数据将更像一个正态分布。
target = np.log(train.SalePrice)
print ("Skew is:", target.skew())
plt.hist(target, color='blue')
plt.show()
Skew is: 0.121335062205

现在我们已经转换了目标变量,让我们考虑一下我们的特性。首先,我们将检查数字特征并绘制一些图表。.select_dtypes()方法将返回匹配指定数据类型的列的子集。
使用数字要素
numeric_features = train.select_dtypes(include=[np.number])
numeric_features.dtypes
Id int64
MSSubClass int64
LotFrontage float64
LotArea int64
OverallQual int64
OverallCond int64
YearBuilt int64
YearRemodAdd int64
MasVnrArea float64
BsmtFinSF1 int64
BsmtFinSF2 int64
BsmtUnfSF int64
TotalBsmtSF int64
1stFlrSF int64
2ndFlrSF int64
LowQualFinSF int64
GrLivArea int64
BsmtFullBath int64
BsmtHalfBath int64
FullBath int64
HalfBath int64
BedroomAbvGr int64
KitchenAbvGr int64
TotRmsAbvGrd int64
Fireplaces int64
GarageYrBlt float64
GarageCars int64
GarageArea int64
WoodDeckSF int64
OpenPorchSF int64
EnclosedPorch int64
3SsnPorch int64
ScreenPorch int64
PoolArea int64
MiscVal int64
MoSold int64
YrSold int64
SalePrice int64
dtype: object
DataFrame.corr()方法显示列之间的相关性(或关系)。我们将检查特征和目标之间的相关性。
corr = numeric_features.corr()
print (corr['SalePrice'].sort_values(ascending=False)[:5], '\n')
print (corr['SalePrice'].sort_values(ascending=False)[-5:])
SalePrice 1.000000
OverallQual 0.790982
GrLivArea 0.708624
GarageCars 0.640409
GarageArea 0.623431
Name: SalePrice, dtype: float64
YrSold -0.028923
OverallCond -0.077856
MSSubClass -0.084284
EnclosedPorch -0.128578
KitchenAbvGr -0.135907
Name: SalePrice, dtype: float64
前五个特征是最正相关的和SalePrice,而接下来的五个是最负相关的。
让我们更深入地了解一下OverallQual。我们可以使用.unique()方法来获得唯一值。
train.OverallQual.unique()
array([ 7, 6, 8, 5, 9, 4, 10, 3, 1, 2])
OverallQual数据是 1 到 10 区间内的整数值。
我们可以创建一个数据透视表来进一步研究OverallQual和SalePrice之间的关系。熊猫医生展示了如何完成这项任务。我们设定了index='OverallQual'和values='SalePrice'。我们选择看这里的median。
quality_pivot = train.pivot_table(index='OverallQual',
values='SalePrice', aggfunc=np.median)
quality_pivot
OverallQual
1 50150
2 60000
3 86250
4 108000
5 133000
6 160000
7 200141
8 269750
9 345000
10 432390
Name: SalePrice, dtype: int64
为了帮助我们更容易地可视化这个数据透视表,我们可以使用Series.plot()方法创建一个条形图。
quality_pivot.plot(kind='bar', color='blue')
plt.xlabel('Overall Quality')
plt.ylabel('Median Sale Price')
plt.xticks(rotation=0)plt.show()

请注意,中间销售价格随着整体质量的提高而严格提高。
接下来,让我们使用plt.scatter()生成一些散点图,并可视化地面生活区GrLivArea和SalePrice之间的关系。
plt.scatter(x=train['GrLivArea'], y=target)
plt.ylabel('Sale Price')
plt.xlabel('Above grade (ground) living area square feet')
plt.show()

乍一看,我们发现居住面积的增加对应着价格的上涨。我们将为GarageArea做同样的事情。
plt.scatter(x=train['GarageArea'], y=target)
plt.ylabel('Sale Price')
plt.xlabel('Garage Area')
plt.show()

注意有很多家的Garage Area用0表示,表示没有车库。我们稍后将转换其他特性来反映这一假设。也有一些离群值。异常值会影响回归模型,使我们的估计回归线远离真实的总体回归线。因此,我们将从数据中删除这些观察值。剔除异常值是一门艺术,也是一门科学。有许多处理异常值的技术。
我们将创建一个删除了一些离群值的新数据帧。
train = train[train['GarageArea'] < 1200]
让我们再看一看。
plt.scatter(x=train['GarageArea'], y=np.log(train.SalePrice))
plt.xlim(-200,1600) # This forces the same scale as before
plt.ylabel('Sale Price')
plt.xlabel('Garage Area')
plt.show()

处理空值
接下来,我们将检查空值或缺失值。
我们将创建一个数据框架来查看顶部的空列。将train.isnull().sum()方法链接在一起,我们返回每一列中 null 值的一系列计数。
nulls = pd.DataFrame(train.isnull().sum().sort_values(ascending=False)[:25])
nulls.columns = ['Null Count']
nulls.index.name = 'Feature'
nulls
| 空计数 | |
|---|---|
| 特征 | |
| --- | --- |
| PoolQC | One thousand four hundred and forty-nine |
| 杂项功能 | One thousand four hundred and two |
| 胡同 | One thousand three hundred and sixty-four |
| 栅栏 | One thousand one hundred and seventy-four |
| 壁炉曲 | Six hundred and eighty-nine |
| 地段临街 | Two hundred and fifty-eight |
| GarageCond | Eighty-one |
| 车库类型 | Eighty-one |
| 车库 | Eighty-one |
| 车库整理 | Eighty-one |
| GarageQual | Eighty-one |
| bsm 曝光 | Thirty-eight |
| BsmtFinType2 | Thirty-eight |
| BsmtFinType1 | Thirty-seven |
| BsmtCond | Thirty-seven |
| BsmtQual | Thirty-seven |
| 马斯夫纳雷亚 | eight |
| MasVnrType | eight |
| 与电有关的 | one |
| 公用事业 | Zero |
| YearRemodAdd | Zero |
| MSSubClass | Zero |
| 基础 | Zero |
| 外部 | Zero |
| exteequal | Zero |
文档可以帮助我们理解缺失的值。在PoolQC的情况下,该列指的是池质量。当PoolArea为0时,池质量为NaN,否则没有池。我们可以在许多与车库相关的栏目中找到类似的关系。
让我们来看看另一个专栏,MiscFeature。我们将使用Series.unique()方法返回唯一值的列表。
print ("Unique values are:", train.MiscFeature.unique())
Unique values are: [nan 'Shed' 'Gar2' 'Othr' 'TenC']
我们可以使用文档来找出这些值的含义:
MiscFeature: Miscellaneous feature not covered in other categories
Elev Elevator
Gar2 2nd Garage (if not described in garage section)
Othr Other
Shed Shed (over 100 SF)
TenC Tennis Court
NA None
这些值描述了房子是否有超过 100 平方英尺的小屋、第二个车库等等。我们以后可能会用到这些信息。为了在处理缺失数据时做出最佳决策,收集领域知识非常重要。
争论非数字特征
现在让我们考虑非数字特性。
categoricals = train.select_dtypes(exclude=[np.number])
categoricals.describe()
| MSZoning | 街道 | 胡同 | LotShape | 陆地等高线 | 公用事业 | 日志配置 | 风景 | 附近 | 情况 | 情况 | 建筑类型 | HouseStyle | 屋顶样式 | 室友 | 外部 1st | 外部第二 | MasVnrType | exteequal | 外部 | 基础 | BsmtQual | BsmtCond | bsm 曝光 | BsmtFinType1 | BsmtFinType2 | 加热 | 加热 QC | 中央空气 | 与电有关的 | KitchenQual | 功能的 | 壁炉曲 | 车库类型 | 车库整理 | GarageQual | GarageCond | 铺面车道 | PoolQC | 栅栏 | 杂项功能 | 标度类型 | 销售条件 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数数 | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | Ninety-one | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and forty-seven | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and eighteen | One thousand four hundred and eighteen | One thousand four hundred and seventeen | One thousand four hundred and eighteen | One thousand four hundred and seventeen | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | One thousand four hundred and fifty-four | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five | Seven hundred and sixty-six | One thousand three hundred and seventy-four | One thousand three hundred and seventy-four | One thousand three hundred and seventy-four | One thousand three hundred and seventy-four | One thousand four hundred and fifty-five | six | Two hundred and eighty-one | Fifty-three | One thousand four hundred and fifty-five | One thousand four hundred and fifty-five |
| 独一无二的 | five | Two | Two | four | four | Two | five | three | Twenty-five | nine | eight | five | eight | six | seven | Fifteen | Sixteen | four | four | five | six | four | four | four | six | six | six | five | Two | five | four | seven | five | six | three | five | five | three | three | four | four | nine | six |
| 顶端 | RL | 安排 | Grvl | 车辆注册号 | 单板层积材 | AllPub | 里面的 | Gtl | 名称 | 标准 | 标准 | 1Fam | 1 历史 | 三角形建筑部分 | 康普什 | 乙烯基 | 乙烯树脂 | 没有人 | 钽 | 钽 | PConc | 钽 | 钽 | 不 | 未溶化的 | 未溶化的 | 加萨 | 前夫;前妻;前男友;前女友 | Y | SBrkr | 钽 | 典型 | 钆 | 附上 | 未溶化的 | 钽 | 钽 | Y | 前夫;前妻;前男友;前女友 | MnPrv | 棚 | 陆军部(War Department) | 常态 |
| 频率 | One thousand one hundred and forty-seven | One thousand four hundred and fifty | Fifty | Nine hundred and twenty-one | One thousand three hundred and nine | One thousand four hundred and fifty-four | One thousand and forty-eight | One thousand three hundred and seventy-eight | Two hundred and twenty-five | One thousand two hundred and fifty-seven | One thousand four hundred and forty-one | One thousand two hundred and sixteen | Seven hundred and twenty-two | One thousand one hundred and thirty-nine | One thousand four hundred and thirty | Five hundred and fourteen | Five hundred and three | Eight hundred and sixty-three | Nine hundred and five | One thousand two hundred and seventy-eight | Six hundred and forty-four | Six hundred and forty-seven | One thousand three hundred and six | Nine hundred and fifty-one | Four hundred and twenty-eight | One thousand two hundred and fifty-one | One thousand four hundred and twenty-three | Seven hundred and thirty-seven | One thousand three hundred and sixty | One thousand three hundred and twenty-nine | Seven hundred and thirty-three | One thousand three hundred and fifty-five | Three hundred and seventy-seven | Eight hundred and sixty-seven | Six hundred and five | One thousand three hundred and six | One thousand three hundred and twenty-one | One thousand three hundred and thirty-five | Two | One hundred and fifty-seven | Forty-eight | One thousand two hundred and sixty-six | One thousand one hundred and ninety-six |
count列表示非空观察值的数量,而unique表示唯一值的数量。top是最常出现的值,顶部值的频率由freq显示。
对于其中的许多特性,我们可能想要使用一键编码来利用信息进行建模。
One-hot 编码是一种将分类数据转换为数字的技术,因此模型可以理解某个特定的观察值是否属于某个类别。
转换和工程特征
在转换特征时,重要的是要记住,在拟合模型之前应用于训练数据的任何转换都必须应用于测试数据。
我们的模型期望来自train集合的特征的形状与来自test集合的特征的形状相匹配。这意味着在处理train数据时发生的任何特征工程应再次应用于test器械组。
为了演示这是如何工作的,考虑一下Street数据,它表明是否有Gravel或Paved道路通往该地产。
print ("Original: \n")
print (train.Street.value_counts(), "\n")
Original:
Pave 1450
Grvl 5
Name: Street, dtype: int64
在Street列中,唯一值是Pave和Grvl,它们描述了通往该地产的道路类型。在训练组中,只有 5 个家庭有砾石通道。我们的模型需要数字数据,所以我们将使用一键编码将数据转换为布尔列。
我们创建一个名为enc_street的新列。pd.get_dummies()方法将为我们处理这个问题。
如前所述,我们需要对train和test数据都这样做。
train['enc_street'] = pd.get_dummies(train.Street, drop_first=True)
test['enc_street'] = pd.get_dummies(train.Street, drop_first=True)
print ('Encoded: \n')
print (train.enc_street.value_counts())
Encoded:
1 1450
0 5
Name: enc_street, dtype: int64
价值观一致。我们设计了我们的第一个功能!特征工程是使数据的特征适用于机器学习和建模的过程。当我们将Street特征编码成一列布尔值时,我们设计了一个特征。
让我们尝试设计另一个功能。我们将通过构建和绘制一个数据透视表来查看SaleCondition,就像我们对OverallQual所做的那样。
condition_pivot = train.pivot_table(index='SaleCondition', values='SalePrice', aggfunc=np.median)
condition_pivot.plot(kind='bar', color='blue')
plt.xlabel('Sale Condition')
plt.ylabel('Median Sale Price')
plt.xticks(rotation=0)
plt.show()

请注意,Partial的销售价格中值明显高于其他产品。我们将把它编码为一个新特性。我们选择所有SaleCondition等于Patrial的房子,并赋值1,否则赋值0。
遵循我们在上面Street中使用的类似方法。
def encode(x):
return 1 if x == 'Partial' else 0
train['enc_condition'] = train.SaleCondition.apply(encode)
test['enc_condition'] = test.SaleCondition.apply(encode)
让我们探索一下这个新特性的剧情。
condition_pivot = train.pivot_table(index='enc_condition', values='SalePrice', aggfunc=np.median)
condition_pivot.plot(kind='bar', color='blue')
plt.xlabel('Encoded Sale Condition')
plt.ylabel('Median Sale Price')
plt.xticks(rotation=0)
plt.show()

这看起来很棒。您可以继续使用更多功能来提高模型的最终性能。
在为建模准备数据之前,我们需要处理缺失的数据。我们将用平均值填充缺失值,然后将结果赋给data。这是一种插补的方法。DataFrame.interpolate()方法使这变得简单。
这是处理缺失值的一种快速而简单的方法,并且可能不会使模型在新数据上达到最佳性能。处理丢失的值是建模过程的重要部分,在这里创造力和洞察力可以发挥很大的作用。这是本教程中您可以扩展的另一个领域。
data = train.select_dtypes(include=[np.number]).interpolate().dropna()
检查是否所有列都有 0 空值。
sum(data.isnull().sum() != 0)
0
第三步:建立一个线性模型
让我们执行最后的步骤,为建模准备数据。我们将特性和目标变量分开建模。我们将特性分配给X,目标变量分配给y。我们使用如上所述的np.log()来转换模型的 y 变量。data.drop([features], axis=1)告诉熊猫我们想要排除哪些列。出于显而易见的原因,我们不会将SalePrice包括在内,而Id只是一个与SalePrice没有关系的指标。
y = np.log(train.SalePrice)
X = data.drop(['SalePrice', 'Id'], axis=1)
让我们对数据进行分区并开始建模。
我们将使用 scikit-learn 中的train_test_split()函数来创建一个训练集和一个拒绝集。以这种方式划分数据允许我们评估我们的模型在以前从未见过的数据上可能如何执行。如果我们根据所有测试数据训练模型,将很难判断是否发生了过度拟合。
train_test_split()返回四个对象:
X_train是我们用于训练的特征子集。X_test是将成为我们“坚持”集的子集,我们将用它来测试模型。y_train是对应于X_train的目标变量SalePrice。y_test是对应于X_test的目标变量SalePrice。
第一参数值X表示预测器数据集,而y是目标变量。接下来,我们设定random_state=42。这提供了可重复的结果,因为 sci-kit learn 的train_test_split将随机划分数据。test_size参数告诉该函数在test分区中应该有多大比例的数据。在本例中,大约 33%的数据专用于拒绝集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=42, test_size=.33)
开始建模
我们将首先创建一个线性回归模型。首先,我们实例化模型。
from sklearn import linear_model
lr = linear_model.LinearRegression()
接下来,我们需要拟合模型。首先实例化模型,然后拟合模型。模型拟合是一个因不同类型的模型而异的过程。简而言之,我们正在估计预测值和目标变量之间的关系,这样我们就可以根据新数据做出准确的预测。
我们用X_train和y_train拟合模型,用X_test和y_test评分。lr.fit()方法将对我们传递的特征和目标变量进行线性回归拟合。
model = lr.fit(X_train, y_train)
评估性能并可视化结果
现在,我们要评估模型的性能。每个竞赛可能会对分包商的评价有所不同。在这次竞赛中,Kaggle 将使用均方根误差(RMSE) 来评估我们的分包合同。我们还会看看的 r 平方值。r 平方值衡量数据与拟合回归线的接近程度。它取 0 到 1 之间的值,1 表示目标中的所有差异都可以用数据来解释。一般来说,较高的 r 平方值意味着更好的拟合。
默认情况下,model.score()方法返回 r 平方值。
print ("R^2 is: \n", model.score(X_test, y_test))
R^2 is:
0.888247770926
这意味着我们的特征解释了目标变量中大约 89%的方差。点击上面的链接了解更多信息。
接下来,我们来考虑rmse。为此,使用我们建立的模型对测试数据集进行预测。
predictions = model.predict(X_test)
给定一组预测值,model.predict()方法将返回一个预测列表。拟合模型后使用model.predict()。
mean_squared_error函数接受两个数组并计算rmse。
from sklearn.metrics import mean_squared_error
print ('RMSE is: \n', mean_squared_error(y_test, predictions))
RMSE is:
0.0178417945196
解释这个值比 r 平方值更直观。RMSE 测量我们的预测值和实际值之间的距离。
我们可以用散点图来直观地观察这种关系。
actual_values = y_test
plt.scatter(predictions, actual_values, alpha=.7,
color='b') #alpha helps to show overlapping data
plt.xlabel('Predicted Price')
plt.ylabel('Actual Price')
plt.title('Linear Regression Model')
plt.show()

如果我们的预测值与实际值相同,这个图将是直线y=x,因为每个预测值x将等于每个实际值y。
尝试改进模型
接下来,我们将尝试使用脊正则化来减少不太重要的特征的影响。岭正则化是缩小不太重要的特征的回归系数的过程。
我们将再次实例化该模型。脊正则化模型采用参数alpha,该参数控制正则化的强度。
我们将通过循环几个不同的 alpha 值进行实验,看看这会如何改变我们的结果。
for i in range (-2, 3):
alpha = 10**i
rm = linear_model.Ridge(alpha=alpha)
ridge_model = rm.fit(X_train, y_train)
preds_ridge = ridge_model.predict(X_test)
plt.scatter(preds_ridge, actual_values, alpha=.75, color='b')
plt.xlabel('Predicted Price')
plt.ylabel('Actual Price')
plt.title('Ridge Regularization with alpha = {}'.format(alpha))
overlay = 'R^2 is: {}\nRMSE is: {}'.format(
ridge_model.score(X_test, y_test),
mean_squared_error(y_test, preds_ridge))
plt.annotate(s=overlay,xy=(12.1,10.6),size='x-large')
plt.show()





这些型号的性能几乎与第一种型号相同。在我们的例子中,调整 alpha 并没有实质性地改进我们的模型。当您添加更多功能时,规范化会很有帮助。添加更多功能后,重复此步骤。
第四步:转租
我们需要为test.csv数据集中的每个观察值创建一个包含预测的SalePrice的csv。
我们将登录我们的 Kaggle 帐户,并前往转租页面进行转租。
我们将使用DataFrame.to_csv()创建一个 csv 来提交。
第一列必须包含测试数据中的 ID。
sublesson = pd.DataFrame()
sublesson['Id'] = test.Id
现在,像我们上面所做的那样,从模型的测试数据中选择特性。
feats = test.select_dtypes(
include=[np.number]).drop(['Id'], axis=1).interpolate()
接下来,我们生成我们的预测。
predictions = model.predict(feats)
现在我们将把预测转换成正确的形式。记住,要反转log(),我们要做exp()。
所以我们将把np.exp()应用到我们的预测中,因为我们之前已经取了对数。
final_predictions = np.exp(predictions)
看区别。
print ("Original predictions are: \n", predictions[:5], "\n")
print ("Final predictions are: \n", final_predictions[:5])
Original predictions are:
[ 11.76725362 11.71929504 12.07656074 12.20632678 12.11217655]
Final predictions are:
[ 128959.49172586 122920.74024358 175704.82598102 200050.83263756 182075.46986405]
让我们分配这些预测,并检查一切看起来都很好。
sublesson['SalePrice'] = final_predictions
sublesson.head()
| 身份 | 销售价格 | |
|---|---|---|
| Zero | One thousand four hundred and sixty-one | 128959.491726 |
| one | One thousand four hundred and sixty-two | 122920.740244 |
| Two | One thousand four hundred and sixty-three | 175704.825981 |
| three | One thousand four hundred and sixty-four | 200050.832638 |
| four | One thousand four hundred and sixty-five | 182075.469864 |
一旦我们确信已经以正确的格式安排了数据,我们就可以像 Kaggle 期望的那样导出到.csv file中。我们通过了index=False,因为熊猫会为我们创建一个新的索引。
sublesson.to_csv('sublesson1.csv', index=False)
提交我们的结果
我们在工作目录中创建了一个名为sublesson1.csv的文件,它符合正确的格式。进入转租页面进行转租。
我们从大约 2400 名竞争者中挑选了 1602 名。差不多是中游水平,还不错!注意我们这里的分数是.15097,比我们在测试数据上观察到的分数要好。这是一个好结果,但不会总是如此。
后续步骤
您可以通过以下方式扩展本教程并改进您的结果:
- 使用和转换训练集中的其他功能
- 尝试不同的建模技术,如随机森林回归或梯度推进
- 使用集合模型
我们创建了一组名为categoricals的分类特征,它们并没有全部包含在最终的模型中。请返回并尝试包含这些功能。还有其他方法可能有助于分类数据,特别是pd.get_dummies()方法。在处理完这些特性之后,重复测试数据的转换,并创建另一个子分类。
研究模型和参加 Kaggle 竞赛可能是一个反复的过程——尝试新想法、了解数据和测试更新的模型和技术非常重要。
有了这些工具,您可以在工作的基础上改进结果。
祝你好运!
我在 Kaggle 上成功使用的技巧和诀窍
June 22, 2017I learned machine learning through competing in Kaggle competitions. I entered my first competitions in 2011, with almost no data science knowledge. I soon ended up in fifth place out of a hundred or so in a stock trading competition. Over the next year, I won several competitions on automated essay scoring and bond price prediction, and placed well in others.
卡格尔比赛需要技巧、运气和团队合作的独特结合才能获胜。确切的混合因比赛而异,并且经常会令人惊讶。
例如,在个性预测竞赛进行的大部分时间里,我都是第一和/或第二名,但由于在特征选择阶段过度拟合,我最终获得了第 18 名,这是我使用的方法从未遇到过的情况。在 Kaggle 博客上可以找到一篇关于比赛结束时发生的一些看似半随机的变化的好文章。
在这篇文章中,我将分享我的成功秘诀。
坚持不懈
在 Kaggle 比赛中取得成功的首要因素是坚持不懈。看到自己第一次分包的排名很容易就气馁,但是继续努力绝对值得。在一次比赛中,我想我真的尝试了每一种发表的方法。
在我的第一次 Kaggle 比赛中,即照片质量预测比赛中,我获得了第 50 名,并且不知道顶级竞争者与我有什么不同。
然而,我设法从这次经历中吸取了教训,并在我的第二次比赛中做得更好,即算法交易挑战。
让结果从照片质量比赛变成算法交易比赛的,是学习和坚持。我并没有在第一场比赛上花太多时间,这在结果中有所体现。
预计会出现许多得分不高的糟糕的分包。在比赛进行期间,你绝对应该尽可能多地阅读相关文献(和博客帖子等)。只要你学到了一些新的东西,可以在以后的竞争中应用,或者你从失败的分包中学到了一些东西(也许某个特定的算法或方法不适合数据),你就在正确的轨道上。
然而,这种坚持需要来自内心。为了让自己愿意这样做,你必须问自己为什么要参加一场特殊的比赛。你想学吗?你想通过高度放置来获得机会吗?你只是想证明自己吗?在大多数 Kaggle 比赛中,金钱奖励不足以激励大量的时间投资,所以除非你清楚地知道自己想要什么以及如何激励自己,否则很难坚持下去。等级对你重要吗?如果没有,你有机会了解一些有趣的事情,这些事情可能会也可能不会影响分数,但如果你想获得第一名,你就不会这样做。
花时间在数据准备和特征工程上
最重要的与数据相关的因素(对我来说)是你如何准备数据,以及你设计了什么特性。算法选择很重要,但远没有那么重要。
你真的只需要运用直觉和常识,找出有效的方法,抛弃无效的方法。真正有帮助的是创建一个好的交叉验证框架,这样你可以得到一个可靠的误差估计。
特征工程是数据科学如此有趣/有创造力的真正原因,也是它与某些类型的编程如此不同的原因,在某些类型的编程中,有一种“最佳”的方法来做某事。
不要忽视特定领域的知识
因为特征工程是非常特定于问题的领域知识帮助很大。
我发现你通常可以在竞争中通过学习获得特定领域的知识。例如,我在参加休利特基金会 ASAP 竞赛时学习了 NLP 方法。也就是说,你肯定需要快速学习你不知道的相关领域特定元素,否则你将无法真正参与大多数比赛。
明智地选择你的比赛
选择一个竞争不那么激烈的竞争在一开始肯定是有用的。研究竞赛的竞争者往往少于大奖竞赛。后来,我发现在更激烈的竞争中竞争是有用的,因为它迫使你学习更多,走出你的舒适区。
找一个好的团队
组建一支优秀的团队至关重要。我很幸运地在两个不同的比赛中与伟大的人一起工作(ASAP 和 Bond),我从他们身上学到了很多。人们往往会被分为几乎总是独自工作的人和几乎总是团队工作的人,但尝试两者都做是有用的。你可以从团队工作中学到很多东西,但是独立工作可以让你学到一些你可能要依靠队友才能学到的东西。
其他哲学
有几件事不太重要,但在继续时要记住。
运气会起到一定作用
我之前提到过,但是运气也是一个因素。例如,在一些比赛中,0.001%的人会获得第三名和第四名。此时,很难说谁的方法“更好”,但只有一种方法被公认为赢家。我想这是事实。
不要因为你不了解的话题而被竞赛吓跑
机器学习的伟大之处在于,你可以将类似的技术应用于几乎任何问题。我不认为你需要挑选你有特别见解或特别知识的问题,因为坦率地说,做一些新的事情并在进行中学习会更有趣。即使你在第一天就有了很好的洞察力,其他人也可能会想到,但他们可能会在第 20 天或第 60 天才想到。
不要再担心你的个人资料了
不要害怕得到一个低等级。有时你看到一个有趣的比赛,但认为你不会花太多时间,可能不会得到一个体面的排名。这个不用担心。没人会评判你!
对你来说,埋头苦干,从准备任何一次分包中获得经验和知识,比担心你个人资料上的排名更重要。
一个成功的参赛作品是由许多小步骤组成的
每一个获奖的 Kaggle 条目都是几十个小见解的组合。很少有一个重大的顿悟时刻能让你赢得一切。如果你做到了以上所有,确保你不断学习,不断迭代你的解决方案,你会做得很好。
永远不要停止学习
现在有成百上千的 Kaggle 教程和文章,还有成千上万的机器学习文章、书籍和资源。永远不要停止学习,不要害怕使用谷歌来回答你的问题。
此外,Kaggle 论坛是一个极好的资源,KaggleNoobs slack 社区也是如此。
最后,令人惊叹的埃利奥特·安德烈斯维护了一个可搜索和可排序的 Kaggle 过去解决方案的汇编。一旦你开始,这是一个很好的方式来了解竞赛获胜者是如何做的: Kaggle 过去的解决方案
总之:坚持和学习
我认为我在这里强调的两个主要因素是坚持和学习。我认为这两个概念很好地概括了我的 Kaggle 经历,即使你没有赢得比赛,只要你学到了一些东西,你就明智地度过了你的时间。
如果你对 Kaggle 入门感兴趣,我强烈推荐这本 Kaggle 教程。
如果你对学习数据科学感兴趣,Dataquest 是学习 Python 和数据科学的最佳在线平台。我们有毕业生在 SpaceX、亚马逊等公司工作。如果您对此感兴趣,您可以在 Dataquest.io 注册并免费完成我们的第一门课程
这篇博文基于我的 Quora 回答
如何使用 Python 进入 Kaggle 比赛的前 15 名
May 3, 2016
Kaggle 竞赛是学习数据科学和建立投资组合的绝佳方式。我个人用 Kaggle 学习了很多数据科学概念。学编程几个月就开始和 Kaggle 一起了,后来赢了几次比赛。在 Kaggle 比赛中取得好成绩需要的不仅仅是知道机器学习算法。它需要正确的心态、学习的意愿和大量的数据探索。不过,在 Kaggle 入门教程中,这些方面通常都不会被强调。在这篇文章中,我将讲述如何开始参加 Kaggle Expedia 酒店推荐竞赛,包括建立正确的思维模式,建立测试基础设施,探索数据,创建特征,以及做出预测。最后,我们将使用本文中的技术生成一个 sublesson 文件。在撰写本文时,sublesson 将排在第一位。
截至本文撰写时,该分契的排名。
Expedia Kaggle 竞赛
Expedia 竞赛的挑战是,根据用户在 Expedia 上进行搜索的一些属性,预测用户将预订哪家酒店。在我们开始任何编码之前,我们需要花时间去理解问题和数据。
对这些列的快速浏览
第一步是查看数据集列的描述。你可以在这里找到。在页面底部,您会看到数据中每一列的描述。看一下这个,我们似乎有相当多的关于用户在 Expedia 上进行搜索的数据,以及他们最终在test.csv和train.csv预订的酒店集群的数据。destinations.csv包含用户搜索酒店的地区信息。我们不会担心我们现在预测什么,我们会专注于理解这些列。
Expedia
由于竞争包括来自 Expedia 上预订酒店的用户的活动数据,我们需要花一些时间来了解 Expedia 网站。查看预订流程将有助于我们了解数据中的字段,以及它们如何与 Expedia 结合使用。

预订酒店时最初看到的页面。
标有Going To的方框映射到数据中的srch_destination_type_id、hotel_continent、hotel_country和hotel_market字段。标有Check-in的方框映射到数据中的srch_ci字段,标有Check out的方框映射到数据中的srch_co字段。标有Guests的框映射到数据中的srch_adults_cnt、srch_children_cnt和srch_rm_cnt字段。标有Add a Flight的方框映射到数据中的is_package字段。site_name是您访问的站点的名称,无论它是主Expedia.com站点还是其他站点。user_location_country、user_location_region、user_location_city、is_mobile、channel、is_booking和cnt都是由用户在哪里、他们的设备是什么或者他们在 Expedia 站点上的会话所决定的属性。只要看一个屏幕,我们就可以立即将所有的变量联系起来。摆弄屏幕、填充值和浏览预订流程可以帮助进一步了解上下文。
探索 Python 中的 Kaggle 数据
现在我们已经在高层次上处理了数据,我们可以做一些探索来更深入地了解。
下载数据
你可以在这里下载的资料。数据集相当大,因此您需要大量的磁盘空间。您需要解压缩文件以获得原始的.csv文件,而不是.csv.gz。
用熊猫探索数据
考虑到系统的内存容量,读取所有数据可能可行,也可能不可行。如果不是,您应该考虑在 EC2 或 DigitalOcean 上创建一台机器来处理数据。
这里有一个关于如何开始的教程。一旦我们下载了数据,我们就可以用熊猫来读取它:
import pandas as pd
destinations = pd.read_csv("destinations.csv")
test = pd.read_csv("test.csv")
train = pd.read_csv("train.csv")
我们先来看看有多少数据:
train.shape
(37670293, 24)
test.shape
(2528243, 22)
我们有大约37百万训练集行,和2百万测试集行,这将使这个问题变得有点挑战性。我们可以研究数据的前几行:
train.head(5)
| 日期时间 | 站点名称 | 波萨大陆 | 用户 _ 位置 _ 国家 | 用户 _ 位置 _ 区域 | 用户 _ 位置 _ 城市 | 起点 _ 终点 _ 距离 | 用户标识 | 不变的 | is _ 包 | … | srch_children_cnt | srch _ rm _ cnt | 目的地标识 | 目的地类型标识 | is _ 预订 | (cannot)不能 | 大陆酒店 | 国家酒店 | 酒店 _ 市场 | 酒店 _ 集群 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 2014-08-11 07:46:59 | Two | three | Sixty-six | Three hundred and forty-eight | Forty-eight thousand eight hundred and sixty-two | 2234.2641 | Twelve | Zero | one | … | Zero | one | Eight thousand two hundred and fifty | one | Zero | three | Two | Fifty | Six hundred and twenty-eight | one |
| one | 2014-08-11 08:22:12 | Two | three | Sixty-six | Three hundred and forty-eight | Forty-eight thousand eight hundred and sixty-two | 2234.2641 | Twelve | Zero | one | … | Zero | one | Eight thousand two hundred and fifty | one | one | one | Two | Fifty | Six hundred and twenty-eight | one |
| Two | 2014-08-11 08:24:33 | Two | three | Sixty-six | Three hundred and forty-eight | Forty-eight thousand eight hundred and sixty-two | 2234.2641 | Twelve | Zero | Zero | … | Zero | one | Eight thousand two hundred and fifty | one | Zero | one | Two | Fifty | Six hundred and twenty-eight | one |
| three | 2014-08-09 18:05:16 | Two | three | Sixty-six | Four hundred and forty-two | Thirty-five thousand three hundred and ninety | 913.1932 | Ninety-three | Zero | Zero | … | Zero | one | Fourteen thousand nine hundred and eighty-four | one | Zero | one | Two | Fifty | One thousand four hundred and fifty-seven | Eighty |
| four | 2014-08-09 18:08:18 | Two | three | Sixty-six | Four hundred and forty-two | Thirty-five thousand three hundred and ninety | 913.6259 | Ninety-three | Zero | Zero | … | Zero | one | Fourteen thousand nine hundred and eighty-four | one | Zero | one | Two | Fifty | One thousand four hundred and fifty-seven | Twenty-one |
有几件事马上就凸显出来了:
- 可能对我们的预测有用,所以我们需要转换它。
- 大多数列都是整数或浮点数,所以我们不能做很多特性工程。比如,
user_location_country不是一个国家的名字,是一个整数。这使得创建新功能更加困难,因为我们不知道每个值的确切含义。
test.head(5)
| 身份证明(identification) | 日期时间 | 站点名称 | 波萨大陆 | 用户 _ 位置 _ 国家 | 用户 _ 位置 _ 区域 | 用户 _ 位置 _ 城市 | 起点 _ 终点 _ 距离 | 用户标识 | 不变的 | … | srch_ci | srch 怎么了 | srch _ 成人 _ 计数 | srch_children_cnt | srch _ rm _ cnt | 目的地标识 | 目的地类型标识 | 大陆酒店 | 国家酒店 | 酒店 _ 市场 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | 2015-09-03 17:09:54 | Two | three | Sixty-six | One hundred and seventy-four | Thirty-seven thousand four hundred and forty-nine | 5539.0567 | one | one | … | 2016-05-19 | 2016-05-23 | Two | Zero | one | Twelve thousand two hundred and forty-three | six | six | Two hundred and four | Twenty-seven |
| one | one | 2015-09-24 17:38:35 | Two | three | Sixty-six | One hundred and seventy-four | Thirty-seven thousand four hundred and forty-nine | 5873.2923 | one | one | … | 2016-05-12 | 2016-05-15 | Two | Zero | one | Fourteen thousand four hundred and seventy-four | seven | six | Two hundred and four | One thousand five hundred and forty |
| Two | Two | 2015-06-07 15:53:02 | Two | three | Sixty-six | One hundred and forty-two | Seventeen thousand four hundred and forty | 3975.9776 | Twenty | Zero | … | 2015-07-26 | 2015-07-27 | four | Zero | one | Eleven thousand three hundred and fifty-three | one | Two | Fifty | Six hundred and ninety-nine |
| three | three | 2015-09-14 14:49:10 | Two | three | Sixty-six | Two hundred and fifty-eight | Thirty-four thousand one hundred and fifty-six | 1508.5975 | Twenty-eight | Zero | … | 2015-09-14 | 2015-09-16 | Two | Zero | one | Eight thousand two hundred and fifty | one | Two | Fifty | Six hundred and twenty-eight |
| four | four | 2015-07-17 09:32:04 | Two | three | Sixty-six | Four hundred and sixty-seven | Thirty-six thousand three hundred and forty-five | 66.7913 | Fifty | Zero | … | 2015-07-22 | 2015-07-23 | Two | Zero | one | Eleven thousand eight hundred and twelve | one | Two | Fifty | Five hundred and thirty-eight |
我们可以从看test.csv中学到一些东西:
- 看起来
test.csv中的所有日期都晚于train.csv中的日期,并且数据页证实了这一点。测试集包含来自2015的数据,训练集包含来自2013和2014的数据。 - 考虑到重叠的整数范围,
test.csv中的用户 id 似乎是train.csv中用户 id 的子集。我们稍后可以证实这一点。 - 在
test.csv中,is_booking列总是看起来像是1。数据页证实了这一点。
弄清楚要预测什么
我们预测的是
我们将预测用户在给定搜索后会预订哪本hotel_cluster。根据描述,总共有100个星团。
我们将如何得分
评估页面说我们将使用平均精度 @ 5 进行评分,这意味着我们需要对每一行进行5聚类预测,并将根据正确的预测是否出现在我们的列表中进行评分。如果正确的预测出现在列表的前面,我们会得到更多的分数。例如,如果“正确的”聚类是3,并且我们预测了4, 43, 60, 3, 20,那么我们的得分将低于我们预测的3, 4, 43, 60, 20。我们应该把更有把握的预测放在预测列表的前面。
探索酒店集群
现在我们知道了我们预测的是什么,是时候投入进去探索了。我们可以对序列使用 value_counts 方法来做到这一点:
train["hotel_cluster"].value_counts()
91 1043720
41 772743
48 754033
64 704734
65 670960
5 620194
...
53 134812
88 107784
27 105040
74 48355
上面的输出被截断了,但是它显示了每个集群中的酒店数量分布相当均匀。聚类数和项目数之间似乎没有任何关系。
探索培训和测试用户 id
最后,我们将确认我们的假设,即所有的test用户 id 都在train数据帧中找到。我们可以通过在test中找到user_id的唯一值,并查看它们是否都存在于train中。在下面的代码中,我们将:
- 创建一组唯一的
test用户 id。 - 创建一组唯一的
train用户 id。 - 计算出
train用户 id 中有多少个test用户 id。 - 查看计数是否与
test用户 id 的总数相匹配。
test_ids = set(test.user_id.unique())
train_ids = set(train.user_id.unique())
intersection_count = len(test_ids & train_ids)
intersection_count == len(test_ids)
True
看起来我们的假设是正确的,这将使处理这些数据更加容易!
缩减采样我们的 Kaggle 数据
整个train.csv数据集包含37百万行,这使得很难试验不同的技术。理想情况下,我们需要一个足够小的数据集,让我们能够快速迭代不同的方法,但仍能代表整个训练数据。我们可以这样做,首先从我们的数据中随机抽取行,然后从train.csv中选择新的训练和测试数据集。通过从train.csv中选择两个集合,我们将拥有每一行的真正的hotel_cluster标签,并且我们将能够在测试技术时计算我们的准确度。
添加时间和日期
第一步是给train添加month和year字段。因为train和test数据是按日期区分的,所以我们需要添加日期字段,以允许我们以同样的方式将数据分成两组。如果我们添加year和month字段,我们可以使用它们将数据分成训练集和测试集。下面的代码将:
- 将
train中的date_time列从object转换为datetime值。这使得约会时更容易相处。 - 从
date_time中提取year和month,并将它们分配到各自的列中。
train["date_time"] = pd.to_datetime(train["date_time"])
train["year"] = train["date_time"].dt.year
train["month"] = train["date_time"].dt.month
挑选 10000 名用户
因为test中的用户 id 是train中用户 id 的子集,所以我们需要以保留每个用户的完整数据的方式进行随机采样。我们可以通过随机选择一定数量的用户来实现这一点,然后只从train中选择行,其中user_id在我们的用户 id 随机样本中。
import random
unique_users = train.user_id.unique()
sel_user_id = random.sample(unique_user_id,10000)
sel_train = train[train.user_id.isin(sel_user_ids)]
上面的代码创建了一个名为sel_train的 DataFrame,它只包含来自10000用户的数据。
选择新的训练和测试集
我们现在需要从sel_train中挑选新的训练和测试集。我们将这些集合称为t1和t2。
t1 = sel_train[((sel_train.year == 2013) | ((sel_train.year == 2014) & (sel_train.month < 8)))]
t2 = sel_train[((sel_train.year == 2014) & (sel_train.month >= 8))]
在原始的train和test数据帧中,test包含来自2015的数据,train包含来自2013和2014的数据。我们分割这些数据,使July 2014之后的数据在t2中,之前的数据在t1中。这为我们提供了具有与train和test相似特征的更小的训练和测试集。
移除点击事件
如果is_booking是0,代表点击,1代表预订。test只包含预订事件,所以我们需要对t2进行采样,使其也只包含预订。
t2 = t2[t2.is_booking == True]
简单的算法
我们可以对这些数据尝试的最简单的技术是找出数据中最常见的聚类,然后将它们用作预测。我们可以再次使用 value_counts 方法来帮助我们:
most_common_clusters = list(train.hotel_cluster.value_counts().head().index)
上面的代码会给我们一个在train中最常见的5集群的列表。这是因为 head 方法默认返回第一个5行, index 属性将返回 DataFrame 的索引,data frame 是运行 value_counts 方法后的酒店集群。
生成预测
我们可以通过对每一行进行相同的预测,将most_common_clusters变成一个预测列表。
predictions = [most_common_clusters for i in range(t2.shape[0])]
这将创建一个包含与t2中的行数一样多的元素的列表。每个元素将等于most_common_clusters。
评估误差
为了评估误差,我们首先需要弄清楚如何计算平均精度。幸运的是, Ben Hamner 写了一个实现,可以在这里找到。它可以作为ml_metrics包的一部分安装,你可以在这里找到如何安装它的安装说明。我们可以用ml_metrics中的mapk方法计算我们的误差度量:
import ml_metrics as metrics
target = [[l] for l in t2["hotel_cluster"]]
metrics.mapk(target, predictions, k=5)
0.058020770920711007
我们的目标需要列表格式的列表才能让mapk工作,所以我们将t2的hotel_cluster列转换成列表的列表。然后,我们用我们的目标、我们的预测和我们想要评估的预测数量来调用mapk方法(5)。我们的结果不是很好,但我们刚刚生成了第一组预测,并评估了我们的误差!我们构建的框架将允许我们快速测试各种技术,并查看它们的得分情况。我们正在为排行榜构建一个性能良好的解决方案。
寻找相关性
在我们继续创建一个更好的算法之前,让我们看看是否有什么东西与hotel_cluster有很好的关联。这将告诉我们是否应该更深入地研究任何特定的列。我们可以使用 corr 方法在训练集中找到线性相关性:
train.corr()["hotel_cluster"]
site_name -0.022408
posa_continent 0.014938
user_location_country -0.010477
user_location_region 0.007453
user_location_city 0.000831
orig_destination_distance 0.007260
user_id 0.001052
is_mobile 0.008412
is_package 0.038733
channel 0.000707
这告诉我们没有列与hotel_cluster线性相关。这是有意义的,因为对hotel_cluster没有线性排序。例如,拥有更高的集群编号并不意味着拥有更高的srch_destination_id。不幸的是,这意味着像线性回归和逻辑回归这样的技术对我们的数据不起作用,因为它们依赖于预测者和目标之间的线性相关性。
为我们的 Kaggle 入口创造更好的预测
这个比赛的数据很难对使用机器学习进行预测,原因如下:
- 有数百万行,这增加了算法的运行时间和内存使用。
- 有不同的组别,根据竞赛管理人员的说法,界限相当模糊,因此很难做出预测。随着聚类数量的增加,分类器的准确性通常会降低。
- 没有什么是与目标(
hotel_clusters)线性相关的,这意味着我们不能使用像线性回归这样的快速机器学习技术。
出于这些原因,机器学习可能不会很好地处理我们的数据,但我们可以尝试一种算法来找出答案。
生成特征
应用机器学习的第一步是生成特征。我们可以利用训练数据中的可用信息和destinations中的可用信息生成特征。我们还没有看到destinations,所以让我们快速浏览一下。
从目的地生成要素
Destinations 包含一个对应于srch_destination_id的 id,以及关于该目的地的潜在信息的149列。这里有一个例子:
| 目的地标识 | d1 | d2 | d3 | d4 | d5 | d6 | d7 | d8 | d9 | … | d140 | d141 | d142 | d143 | d144 | d145 | d146 | d147 | d148 | d149 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Zero | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -1.897627 | -2.198657 | -2.198657 | -1.897627 | … | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 | -2.198657 |
| one | one | -2.181690 | -2.181690 | -2.181690 | -2.082564 | -2.181690 | -2.165028 | -2.181690 | -2.181690 | -2.031597 | … | -2.165028 | -2.181690 | -2.165028 | -2.181690 | -2.181690 | -2.165028 | -2.181690 | -2.181690 | -2.181690 | -2.181690 |
| Two | Two | -2.183490 | -2.224164 | -2.224164 | -2.189562 | -2.105819 | -2.075407 | -2.224164 | -2.118483 | -2.140393 | … | -2.224164 | -2.224164 | -2.196379 | -2.224164 | -2.192009 | -2.224164 | -2.224164 | -2.224164 | -2.224164 | -2.057548 |
| three | three | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.115485 | -2.177409 | -2.177409 | -2.177409 | … | -2.161081 | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.177409 | -2.177409 |
| four | four | -2.189562 | -2.187783 | -2.194008 | -2.171153 | -2.152303 | -2.056618 | -2.194008 | -2.194008 | -2.145911 | … | -2.187356 | -2.194008 | -2.191779 | -2.194008 | -2.194008 | -2.185161 | -2.194008 | -2.194008 | -2.194008 | -2.188037 |
竞争并没有告诉我们每个潜在的特征是什么,但可以肯定的是,它是一些目的地特征的组合,如名称、描述等等。这些潜在的特征被转换成数字,因此可以匿名。我们可以使用目的地信息作为机器学习算法中的特征,但是我们需要首先压缩列数,以最小化运行时间。
我们可以使用 PCA 来做到这一点。PCA 将减少矩阵中的列数,同时试图保持每行的方差不变。理想情况下,PCA 会将所有列中包含的所有信息压缩到更少,但实际上,一些信息会丢失。在下面的代码中,我们:
- 使用 scikit-learn 初始化 PCA 模型。
- 指定我们希望数据中只有
3列。 - 将列
d1-d149转换为3列。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
dest_small = pca.fit_transform(destinations[["d{0}".format(i + 1) for i in range(149)]])
dest_small = pd.DataFrame(dest_small)
dest_small["srch_destination_id"] = destinations["srch_destination_id"]
上面的代码将destinations中的149列压缩为3列,并创建一个名为dest_small的新数据帧。在这样做的时候,我们保留了destinations中的大部分方差,所以我们不会丢失很多信息,但是为机器学习算法节省了很多运行时间。
生成特征
既然预备工作已经完成,我们可以生成我们的特征。我们将执行以下操作:
- 基于
date_time、srch_ci和srch_co生成新的日期特征。 - 删除非数字列,如
date_time。 - 添加来自
dest_small的功能。 - 用
-1替换任何缺失值。
def calc_fast_features(df):
df["date_time"] = pd.to_datetime(df["date_time"])
df["srch_ci"] = pd.to_datetime(df["srch_ci"], format='%Y-%m-%d', errors="coerce")
df["srch_co"] = pd.to_datetime(df["srch_co"], format='%Y-%m-%d', errors="coerce")
props = {}
for prop in ["month", "day", "hour", "minute", "dayofweek", "quarter"]:
props[prop] = getattr(df["date_time"].dt, prop)
carryover = [p for p in df.columns if p not in ["date_time", "srch_ci", "srch_co"]]
for prop in carryover:
props[prop] = df[prop]
date_props = ["month", "day", "dayofweek", "quarter"]
for prop in date_props:
props["ci_{0}".format(prop)] = getattr(df["srch_ci"].dt, prop)
props["co_{0}".format(prop)] = getattr(df["srch_co"].dt, prop)
props["stay_span"] = (df["srch_co"] - df["srch_ci"]).astype('timedelta64[h]')
ret = pd.DataFrame(props)
ret = ret.join(dest_small, on="srch_destination_id", how='left', rsuffix="dest")
ret = ret.drop("srch_destination_iddest", axis=1)
return ret
df = calc_fast_features(t1)
df.fillna(-1, inplace=True)
上面将计算诸如停留时间、入住日和退房月等特征。这些特征将帮助我们稍后训练机器学习算法。用-1替换丢失的值并不是最好的选择,但是目前来说它工作得很好,并且我们总是可以在以后优化行为。
机器学习
现在我们有了训练数据的特征,我们可以尝试机器学习。我们将在训练集中使用3-fold 交叉验证来生成可靠的误差估计。交叉验证将训练设置分割成3个部分,然后使用其他部分预测每个部分的hotel_cluster进行训练。我们将使用随机森林算法生成预测。随机森林建立树,可以适应数据中的非线性趋势。这将使我们能够做出预测,即使我们的列没有线性相关。我们将首先初始化模型并计算交叉验证分数:
predictors = [c for c in df.columns if c not in ["hotel_cluster"]]
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=10, min_weight_fraction_leaf=0.1)
scores = cross_validation.cross_val_score(clf, df[predictors], df['hotel_cluster'], cv=3)
scores
array([ 0.06203556, 0.06233452, 0.06392277])
上面的代码没有给我们很好的准确性,并且证实了我们最初的怀疑,即机器学习不是解决这个问题的好方法。然而,当存在高聚类计数时,分类器往往具有较低的准确性。我们可以试着训练二进制分类器。每个分类器将只确定一行是否在它的簇中。这将需要在hotel_cluster中为每个标签训练一个分类器。
二元分类器
我们将再次训练随机森林,但每个森林将只预测一个酒店集群。我们将使用2折叠交叉验证来提高速度,并且每个标签只训练10棵树。在下面的代码中,我们:
- 循环遍历每个唯一的
hotel_cluster。- 使用双重交叉验证训练随机森林分类器。
- 从分类器中提取该行在唯一
hotel_cluster中的概率
- 综合所有的可能性。
- 对于每一行,找出最大的
5个概率,并将这些hotel_cluster个值指定为预测值。 - 使用
mapk计算精度。
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import KFold
from itertools import chain
all_probs = []
unique_clusters = df["hotel_cluster"].unique()
for cluster in unique_clusters:
df["target"] = 1
df["target"][df["hotel_cluster"] != cluster] = 0
predictors = [col for col in df if col not in ['hotel_cluster', "target"]]
probs = []
cv = KFold(len(df["target"]), n_folds=2)
clf = RandomForestClassifier(n_estimators=10, min_weight_fraction_leaf=0.1)
for i, (tr, te) in enumerate(cv):
clf.fit(df[predictors].iloc[tr], df["target"].iloc[tr])
preds = clf.predict_proba(df[predictors].iloc[te])
probs.append([p[1] for p in preds])
full_probs = chain.from_iterable(probs)
all_probs.append(list(full_probs))
prediction_frame = pd.DataFrame(all_probs).T
prediction_frame.columns = unique_clusters
def find_top_5(row):
return list(row.nlargest(5).index)
preds = []
for index, row in prediction_frame.iterrows():
preds.append(find_top_5(row))
metrics.mapk([[l] for l in t2.iloc["hotel_cluster"]], preds, k=5)
0.041083333333333326
我们这里的准确率比以前差了,排行榜上的人准确率分数好了很多。为了竞争,我们需要放弃机器学习,转向下一种技术。机器学习可能是一种强大的技术,但它并不总是解决所有问题的正确方法。
基于 hotel_cluster 的顶级分类
竞争中有一些 Kaggle 内核,涉及基于orig_destination_distance或srch_destination_id聚合hotel_cluster。在orig_destination_distance上聚合将利用竞争中的数据泄漏,并试图将同一用户匹配在一起。聚集在srch_destination_id上可以找到每个目的地最受欢迎的酒店群。然后,我们将能够预测搜索目的地的用户将前往该目的地最受欢迎的酒店集群之一。可以把这看作是我们之前使用的最常见的集群技术的一个更细粒度的版本。我们可以首先在每个srch_destination_id中为每个hotel_cluster生成分数。我们会把预订看得比点击更重要。这是因为测试数据都是预订数据,这是我们要预测的。我们希望包含点击信息,但是要降低权重以反映这一点。一步一步来,我们将:
- 通过
srch_destination_id和hotel_cluster将t1分组。 - 遍历每个组,并且:
- 在
is_booking为真的情况下,给每个酒店群分配 1 分。 - 将
.15点分配给is_booking为假的每个酒店群。 - 将分数分配给字典中的
srch_destination_id/hotel_cluster组合。
- 在
下面是完成上述步骤的代码:
def make_key(items):
return "_".join([str(i) for i in items])
match_cols = ["srch_destination_id"]
cluster_cols = match_cols + ['hotel_cluster']
groups = t1.groupby(cluster_cols)
top_clusters = {}
for name, group in groups:
clicks = len(group.is_booking[group.is_booking == False])
bookings = len(group.is_booking[group.is_booking == True])
score = bookings + .15 * clicks
clus_name = make_key(name[:len(match_cols)])
if clus_name not in top_clusters:
top_clusters[clus_name] = {}
top_clusters[clus_name][name[-1]] = score
最后,我们将有一个字典,其中每个键都是一个srch_destination_id。字典中的每个值都是另一个字典,包含酒店集群作为键,分数作为值。它看起来是这样的:
{'39331': {20: 1.15, 30: 0.15, 81: 0.3},
'511': {17: 0.15, 34: 0.15, 55: 0.15, 70: 0.15}}
接下来,我们想要转换这个字典,为每个srch_destination_id找到前 5 个酒店集群。为此,我们将:
- 在
top_clusters中循环每个键。 - 找到该关键字的前
5个簇。 - 将顶部的
5聚类分配给新字典cluster_dict。
代码如下:
import operator
cluster_dict = {}
for n in top_clusters:
tc = top_clusters[n]
top = [l[0] for l in sorted(tc.items(), key=operator.itemgetter(1), reverse=True)[:5]]
cluster_dict[n] = top
根据目的地进行预测
一旦我们知道了每个srch_destination_id的顶级集群,我们就可以快速地做出预测。要做预测,我们要做的就是:
- 遍历
t2中的每一行。- 提取该行的
srch_destination_id。 - 查找该目标 id 的顶级集群。
- 将顶部集群附加到
preds。
- 提取该行的
代码如下:
preds = []
for index, row in t2.iterrows():
key = make_key( `for m in match_cols])
if key in cluster_dict:
preds.append(cluster_dict[key])
else:
preds.append([])`
在循环结束时,`preds`将是一个包含我们预测的列表列表。它看起来会像这样:
[
[2, 25, 28, 10, 64],
[25, 78, 64, 90, 60],
...
]
### 计算误差
一旦我们有了我们的预测,我们可以使用前面的`mapk`函数来计算我们的准确度:
metrics.mapk([[l] for l in t2["hotel_cluster"]], preds, k=5)
0.22388136288998359
我们做得很好!与最好的机器学习方法相比,我们的准确率提高了 4 倍,而且我们采用了一种更快、更简单的方法。您可能已经注意到,这个值比排行榜上的准确度低很多。本地测试比提交测试的准确度低,所以这种方法在排行榜上表现相当好。排行榜分数和本地分数的差异可以归结为几个因素:
* 计算排行榜分数的本地和隐藏集中的不同数据。例如,我们在训练集的样本中计算误差,而排行榜分数是在测试集上计算的。
* 通过更多的训练数据获得更高准确度的技术。我们只使用一小部分数据进行训练,当我们使用完整的训练集时,可能会更准确。
* 不同的随机化。在某些算法中,会涉及到随机数,但我们不会用到这些。
## 为您的 Kaggle sublesson 生成更好的预测
论坛在 Kaggle 中非常重要,通常可以帮助你找到有助于提高分数的信息。Expedia 竞赛也不例外。
[这篇文章](https://www.kaggle.com/c/expedia-hotel-recommendations/forums/t/20345/data-leak)详细描述了一个数据泄露,它允许你使用一组包括`user_location_country`和`user_location_region`的列来匹配来自测试集的训练集中的用户。我们将使用帖子中的信息将测试集中的用户匹配到训练集中,这将提高我们的分数。根据论坛的帖子,这样做是可以的,比赛不会因为泄露而更新。
### 查找匹配用户
第一步是在训练集中找到与测试集中的用户相匹配的用户。为此,我们需要:
* 根据匹配列将训练数据分成不同的组。
* 循环测试数据。
* 基于匹配列创建索引。
* 使用组获取测试数据和训练数据之间的任何匹配。
下面是实现这一点的代码:
match_cols = ['user_location_country', 'user_location_region', 'user_location_city', 'hotel_market', 'orig_destination_distance']
groups = t1.groupby(match_cols)
def generate_exact_matches(row, match_cols):
index = tuple( `for t in match_cols])
try:
group = groups.get_group(index)
except Exception:
return []
clus = list(set(group.hotel_cluster))
return clus
exact_matches = []
for i in range(t2.shape[0]):
exact_matches.append(generate_exact_matches(t2.iloc[i], match_cols))`
在这个循环结束时,我们将得到一个列表,其中包含训练集和测试集之间的任何精确匹配。但是,匹配的没有那么多。为了准确评估误差,我们必须将这些预测与我们早期的预测结合起来。否则,我们将得到一个非常低的精度值,因为大多数行都有空的预测列表。
组合预测
我们可以结合不同的预测列表来提高准确性。这样做还可以帮助我们了解我们的精确匹配策略有多好。为此,我们必须:
-
组合
exact_matches、preds和most_common_clusters。 -
从这里的使用
f5函数,按顺序只取唯一的预测。 -
确保测试集中的每一行最多有
5个预测。
我们可以这样做:
def f5(seq, idfun=None):
if idfun is None:
def idfun(x): return x
seen = {}
result = []
for item in seq:
marker = idfun(item)
if marker in seen: continue
seen[marker] = 1
result.append(item)
return result
full_preds = [f5(exact_matches[p] + preds[p] + most_common_clusters)[:5] for p in range(len(preds))]
mapk([[l] for l in t2["hotel_cluster"]], full_preds, k=5)
0.28400041050903119
就误差而言,这看起来相当不错——我们比之前有了显著的改进!我们可以继续下去,做更多的小改进,但我们现在可能准备提交。
制作 Kaggle 子文件夹文件
幸运的是,由于我们编写代码的方式,我们所要做的就是将train赋给变量t1,将test赋给变量t2。然后,我们只需重新运行代码来进行预测。在train和test场景中重新运行代码应该不到一个小时。一旦我们有了预测,我们只需要把它们写到一个文件中:
write_p = [" ".join([str(l) for l in p]) for p in full_preds]
write_frame = ["{0},{1}".format(t2["id"][i], write_p[i]) for i in range(len(full_preds))]
write_frame = ["id,hotel_clusters"] + write_frame
with open("predictions.csv", "w+") as f:
f.write("\n".join(write_frame))
然后我们将有一个正确格式的 sublesson 文件来提交。在写这篇文章的时候,做这个分包会让你进入顶级15。
摘要
我们在这篇文章中走了很长的路!我们从只看数据一路发展到创建子分类并登上排行榜。一路走来,我们采取的一些关键步骤包括:
-
探索数据和理解问题。
-
建立一种快速迭代不同技术的方法。
-
创造了一种在本地计算精确度的方法。
-
仔细阅读论坛、脚本和比赛的描述,以便更好地理解数据的结构。
-
尝试各种技术,不怕不用机器学习。
这些步骤将在任何卡格尔比赛中很好地为你服务。
后续步骤
为了快速迭代和探索技术,速度是关键。这在这场比赛中很难做到,但有一些策略可以尝试:
-
对数据进行更多的采样。
-
跨多个内核并行化操作。
-
使用 Spark 或其他可以在并行工作机上运行任务的工具。
-
探索编写代码的各种方法,并进行基准测试以找到最有效的方法。
-
避免迭代完整的训练集和测试集,而是使用组。
编写快速、高效的代码是这场竞争中的巨大优势。一旦有了运行代码的稳定基础,就可以探索一些提高准确性的方法:
-
找出用户之间的相似性,然后根据相似性调整酒店聚类分数。
-
使用目的地之间的相似性将多个目的地分组在一起。
-
在数据子集内应用机器学习。
-
以一种不那么幼稚的方式结合不同的预测策略。
-
探索酒店集群和区域之间的联系。
我希望你在这次比赛中玩得开心!我很乐意听到您的任何反馈。如果你想在参加比赛之前了解更多,请查看我们在 Dataquest 上的课程,了解数据操作、统计学、机器学习、如何使用 Spark 等。
凯尔:“Dataquest 帮助我进入了科技行业”
April 9, 2017
在职业生涯的前四年,Kyle Stewart 在工业自动化领域担任产品经理。“我在一家财富 500 强公司工作。我管理有助于工业流程的产品,比如在炼油厂。”
他想进入更有活力的科技行业。“在工业产品管理中,很难做出改变。我们制造的工具很贵,所以一旦制造出来就进行修改是不切实际的。软件是另一个极端,它更令人兴奋。
Kyle 听说过数据科学,但并不完全了解该行业。但在日本度假时,一切都变了。
凯尔参观了致力于新兴科学和创新的 Miraikan 博物馆。“他们在博物馆里有一整块区域专门用于数据科学。
“我一进入房间,传感器就开始捕捉关于我的数据。当我接近车站时,他们会分享我的数据,比如我走了多少步。这太神奇了,它向我展示了数据的力量。”
在离开日本之前,Kyle 决定学习数据科学。
在开始 Dataquest 之前我什么都不知道。这是我进入这个复杂世界的第一步。
回家后,他在 Udemy 上尝试了一些在线课程。“我在用视频讲座学习,但没有效果。我意识到,看视频时,你似乎在学习,但实际上你只是在娱乐。我发现你只有通过做才能学到东西。”
当凯尔找到 Dataquest 时,他知道自己找到了更好的方法。“布局简洁,易于学习,交互式编码意味着我在实践中学习。
Dataquest 以职业为重点的学习路径给了 Kyle 信心。“他们给了我学习的概述;我不需要担心失去技能。Dataquest 帮助我在不知所措的情况下学习。”
经过大约六个月的学习,凯尔开始申请工作。他获得了航天公司 SpaceX 的面试机会。
在第一次面试中,他意识到他要提高自己的 SQL 技能。“Dataquest 在这里非常棒。转向一个新话题很容易,我直接去 SQL 模块做准备。”
他的努力得到了回报,凯尔现在是 SpaceX 的一名商业系统分析师。
“这是一家令人兴奋的公司。它将帮助我开始获得进入科技产品管理领域所需的知识。”
“在开始 Dataquest 之前,我一无所知。这是我进入这个复杂世界的第一步。Dataquest 改变了我的职业生涯。”
教程:使用 Python 通过 Last.fm API 获取音乐数据
October 7, 2019
API 允许我们从服务器请求检索数据。API 在很多方面都很有用,但其中之一是能够为数据科学项目创建唯一的数据集。在本教程中,我们将学习一些使用 Last.fm API 的高级技术。
在我们的初级 Python API 教程中,我们使用了一个非常适合教授基础知识的简单 API:
- 它有几个容易理解的端点。
- 因为它不需要认证,所以我们不必担心如何告诉 API 我们有 perlesson 来使用它。
- 每个端点响应的数据都很小,并且具有易于理解的结构。
实际上,大多数 API 比这更复杂,所以要使用它们,您需要理解一些更高级的概念。具体来说,我们将学习:
- 如何用 API 密钥认证自己?
- 如何使用速率限制和其他技术在 API 的指导下工作。
- 如何使用分页处理大型响应?
本教程假设您了解 Python 中使用 API 的基础知识。如果没有,我们推荐我们的初学者 API 教程开始。我们还假设您对 Python 和熊猫有一定的了解。如果你没有,你可以开始免费学习我们的 Python 基础课程。
使用 Last.fm API
我们将使用 Last.fm API。Last.fm 是一项音乐服务,它通过连接到 iTunes、Spotify 和其他类似的音乐流媒体应用程序来建立个人档案,并跟踪你所听的音乐。
他们提供对 API 的免费访问,以便音乐服务可以向他们发送数据,但也提供总结 Last.fm 关于各种艺术家、歌曲和流派的所有数据的端点。我们将使用他们的 API 建立一个流行艺术家的数据集。
遵循 API 指南
使用 API 时,遵循它们的指导方针很重要。如果您不这样做,您可能会被禁止使用该 API。除此之外,特别是当公司免费提供 API 时,尊重他们的局限性和指导方针是很好的,因为他们免费提供了一些东西。
查看 API 文档中的介绍页面,我们可以注意到一些重要的指导原则:
请在所有请求中使用可识别的用户代理标题。这有助于我们的记录,并减少你被禁止的风险。
当向 last.fm API 发出请求时,可以使用头来标识自己。Last.fm 希望我们在标题中指定一个用户代理,这样他们就知道我们是谁了。当我们一会儿提出第一个请求时,我们会学习如何去做。
在决定打多少个电话时,运用常识。例如,如果您正在开发一个 web 应用程序,尽量不要在页面加载时使用 API。如果您的应用程序每秒钟连续进行几次调用,您的帐户可能会被暂停。
为了构建数据集,我们需要向 Last.fm API 发出数千个请求。虽然他们没有在文档中提供具体的限制,但他们建议我们不应该每秒钟连续打很多电话。在本教程中,我们将学习一些限制速率的策略,或者确保我们不会过多地攻击他们的 API,这样我们就可以避免被禁止。
在我们发出第一个请求之前,我们需要学习如何使用 Last.fm API 进行认证
使用 API 密钥认证
大多数 API 都要求你验证自己,这样他们就知道你有足够的时间来使用它们。最常见的认证形式之一是使用一个 API 密钥,它就像是使用他们的 API 的密码。如果在发出请求时没有提供 API 键,将会得到一个错误。
使用 API 密钥的过程如下:
- 您向 API 的提供商创建一个帐户。
- 您请求一个 API 键,它通常是一个像
54686973206973206d7920415049204b6579这样的长字符串。 - 你把你的 API 密匙记录在某个安全的地方,就像一个密码保管员。如果有人得到了你的 API 密匙,他们就可以用 API 冒充你。
- 每次发出请求时,您都需要提供 API 密钥来验证自己的身份。
要获得 Last.fm 的 API 密钥,首先需要创建一个账户。创建帐户后,您应该看到以下表格:

在每个字段中填写您计划如何使用 API 的信息。您可以将“回调 URL”字段留空,因为这仅在您构建 web 应用程序以作为特定 Last.fm 用户进行身份验证时使用。
提交表单后,您将获得 API 密钥和共享密钥的详细信息:

请将它们记在安全的地方——在本教程中,我们不需要使用共享秘密,但最好将它记下来,以防您想要做一些需要您作为特定用户进行身份验证的事情。
制作我们的第一个 API 请求
为了创建一个流行艺术家的数据集,我们将使用 chart.getTopArtists端点。
查看 Last.fm API 文档,我们可以观察到一些情况:
- 看起来只有一个真正的端点,每个“端点”实际上都是使用
method参数指定的。 - 文档说这个服务不需要认证。虽然这乍一看可能有点令人困惑,但它告诉我们的是,我们不需要作为特定的 Last.fm 用户进行身份验证。如果你看上面,你会发现我们确实需要提供我们的 API 密匙。
- API 可以以多种格式返回结果——我们将指定 JSON,这样我们就可以利用我们已经知道的使用 Python 中的 API 的知识
在我们开始之前,请记住,我们需要提供一个用户代理头,以便在发出请求时标识我们自己。对于 Python 请求库,我们使用 headers参数和如下所示的头字典来指定头:
headers = {
'user-agent': 'Dataquest'
}
r = requests.get('https://my-api-url', headers=headers)
我们将从定义 API 键和用户代理开始(本教程中显示的 API 键不是真正的 API 键!)
API_KEY = '54686973206973206d7920415049204b6579'
USER_AGENT = 'Dataquest'
接下来,我们将导入请求库,为我们的头和参数创建一个字典,并发出我们的第一个请求!
import requests
headers = {
'user-agent': USER_AGENT
}
payload = {
'api_key': API_KEY,
'method': 'chart.gettopartists',
'format': 'json'
}
r = requests.get('https://ws.audioscrobbler.com/2.0/', headers=headers, params=payload)
r.status_code
200
我们的请求返回了状态代码“200”,所以我们知道它是成功的。
在我们查看我们的请求返回的数据之前,让我们考虑一下在本教程中我们将发出许多请求的事实。在这些请求中,许多功能都是相同的:
- 我们将使用相同的 URL
- 我们将使用相同的 API 键
- 我们将指定 JSON 作为我们的格式。
- 我们将使用相同的标题。
为了节省时间,我们将创建一个函数来完成大量的工作。我们将为该函数提供一个有效载荷字典,然后我们将向该字典添加额外的键,并将其与我们的其他选项一起传递以发出请求。
让我们看看这个函数是什么样子的:
def lastfm_get(payload):
# define headers and URL
headers = {'user-agent': USER_AGENT}
url = 'https://ws.audioscrobbler.com/2.0/'
# Add API key and format to the payload
payload['api_key'] = API_KEY
payload['format'] = 'json'
response = requests.get(url, headers=headers, params=payload)
return response
让我们看看它简化了我们之前的请求:
r = lastfm_get({
'method': 'chart.gettopartists'
})
r.status_code
200
正如我们在初级 Python API 教程中了解到的,大多数 API 以 JSON 格式返回数据,我们可以使用 Python json模块以更容易理解的格式打印 JSON 数据。
让我们重新使用我们在该教程中创建的jprint()函数,并从 API 中打印我们的响应:
import json
def jprint(obj):
# create a formatted string of the Python JSON object
text = json.dumps(obj, sort_keys=True, indent=4)
print(text)
jprint(r.json())
{
"artists": {
"@attr": {
"page": "1",
"perPage": "50",
"total": "2901036",
"totalPages": "58021"
},
"artist": [
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1957174",
"mbid": "b7539c32-53e7-4908-bda3-81449c367da6",
"name": "Lana Del Rey",
"playcount": "232808939",
"streamable": "0",
"url": "https://www.last.fm/music/Lana+Del+Rey"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "588883",
"mbid": "",
"name": "Billie Eilish",
"playcount": "35520548",
"streamable": "0",
"url": "https://www.last.fm/music/Billie+Eilish"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "655052",
"mbid": "",
"name": "Post Malone",
"playcount": "34942708",
"streamable": "0",
"url": "https://www.last.fm/music/Post+Malone"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "2290993",
"mbid": "20244d07-534f-4eff-b4d4-930878889970",
"name": "Taylor Swift",
"playcount": "196907702",
"streamable": "0",
"url": "https://www.last.fm/music/Taylor+Swift"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1166180",
"mbid": "f4fdbb4c-e4b7-47a0-b83b-d91bbfcfa387",
"name": "Ariana Grande",
"playcount": "124251766",
"streamable": "0",
"url": "https://www.last.fm/music/Ariana+Grande"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1716587",
"mbid": "b8a7c51f-362c-4dcb-a259-bc6e0095f0a6",
"name": "Ed Sheeran",
"playcount": "92646726",
"streamable": "0",
"url": "https://www.last.fm/music/Ed+Sheeran"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4084524",
"mbid": "420ca290-76c5-41af-999e-564d7c71f1a7",
"name": "Queen",
"playcount": "197850122",
"streamable": "0",
"url": "https://www.last.fm/music/Queen"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4449534",
"mbid": "164f0d73-1234-4e2c-8743-d77bf2191051",
"name": "Kanye West",
"playcount": "250533444",
"streamable": "0",
"url": "https://www.last.fm/music/Kanye+West"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3732023",
"mbid": "b10bbbfc-cf9e-42e0-be17-e2c3e1d2600d",
"name": "The Beatles",
"playcount": "526866107",
"streamable": "0",
"url": "https://www.last.fm/music/The+Beatles"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3441963",
"mbid": "b49b81cc-d5b7-4bdd-aadb-385df8de69a6",
"name": "Drake",
"playcount": "147881092",
"streamable": "0",
"url": "https://www.last.fm/music/Drake"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4778856",
"mbid": "a74b1b7f-71a5-4011-9441-d0b5e4122711",
"name": "Radiohead",
"playcount": "507682999",
"streamable": "0",
"url": "https://www.last.fm/music/Radiohead"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1528378",
"mbid": "381086ea-f511-4aba-bdf9-71c753dc5077",
"name": "Kendrick Lamar",
"playcount": "109541321",
"streamable": "0",
"url": "https://www.last.fm/music/Kendrick+Lamar"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4618838",
"mbid": "db36a76f-4cdf-43ac-8cd0-5e48092d2bae",
"name": "Rihanna",
"playcount": "204114198",
"streamable": "0",
"url": "https://www.last.fm/music/Rihanna"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3550620",
"mbid": "ada7a83c-e3e1-40f1-93f9-3e73dbc9298a",
"name": "Arctic Monkeys",
"playcount": "339370140",
"streamable": "0",
"url": "https://www.last.fm/music/Arctic+Monkeys"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3401872",
"mbid": "5441c29d-3602-4898-b1a1-b77fa23b8e50",
"name": "David Bowie",
"playcount": "197606611",
"streamable": "0",
"url": "https://www.last.fm/music/David+Bowie"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "680102",
"mbid": "b7d92248-97e3-4450-8057-6fe06738f735",
"name": "Shawn Mendes",
"playcount": "28807659",
"streamable": "0",
"url": "https://www.last.fm/music/Shawn+Mendes"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "2093863",
"mbid": "7e9bd05a-117f-4cce-87bc-e011527a8b18",
"name": "Miley Cyrus",
"playcount": "70227591",
"streamable": "0",
"url": "https://www.last.fm/music/Miley+Cyrus"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3631084",
"mbid": "859d0860-d480-4efd-970c-c05d5f1776b8",
"name": "Beyonc\u00e9",
"playcount": "165422358",
"streamable": "0",
"url": "https://www.last.fm/music/Beyonc%C3%A9"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "314392",
"mbid": "",
"name": "Lil Nas X",
"playcount": "6086745",
"streamable": "0",
"url": "https://www.last.fm/music/Lil+Nas+X"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3800669",
"mbid": "122d63fc-8671-43e4-9752-34e846d62a9c",
"name": "Katy Perry",
"playcount": "151925781",
"streamable": "0",
"url": "https://www.last.fm/music/Katy+Perry"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1184440",
"mbid": "63aa26c3-d59b-4da4-84ac-716b54f1ef4d",
"name": "Tame Impala",
"playcount": "78074910",
"streamable": "0",
"url": "https://www.last.fm/music/Tame+Impala"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3877144",
"mbid": "650e7db6-b795-4eb5-a702-5ea2fc46c848",
"name": "Lady Gaga",
"playcount": "292105109",
"streamable": "0",
"url": "https://www.last.fm/music/Lady+Gaga"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "840762",
"mbid": "f6beac20-5dfe-4d1f-ae02-0b0a740aafd6",
"name": "Tyler, the Creator",
"playcount": "56318705",
"streamable": "0",
"url": "https://www.last.fm/music/Tyler,+the+Creator"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "5429555",
"mbid": "cc197bad-dc9c-440d-a5b5-d52ba2e14234",
"name": "Coldplay",
"playcount": "364107739",
"streamable": "0",
"url": "https://www.last.fm/music/Coldplay"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4665823",
"mbid": "8bfac288-ccc5-448d-9573-c33ea2aa5c30",
"name": "Red Hot Chili Peppers",
"playcount": "298043491",
"streamable": "0",
"url": "https://www.last.fm/music/Red+Hot+Chili+Peppers"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "269116",
"mbid": "50d06c43-5392-4393-ba2d-f091d8167227",
"name": "Lizzo",
"playcount": "6953283",
"streamable": "0",
"url": "https://www.last.fm/music/Lizzo"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "823024",
"mbid": "260b6184-8828-48eb-945c-bc4cb6fc34ca",
"name": "Charli XCX",
"playcount": "34914186",
"streamable": "0",
"url": "https://www.last.fm/music/Charli+XCX"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "2246723",
"mbid": "8dd98bdc-80ec-4e93-8509-2f46bafc09a7",
"name": "Calvin Harris",
"playcount": "75778154",
"streamable": "0",
"url": "https://www.last.fm/music/Calvin+Harris"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4320593",
"mbid": "9282c8b4-ca0b-4c6b-b7e3-4f7762dfc4d6",
"name": "Nirvana",
"playcount": "226060468",
"streamable": "0",
"url": "https://www.last.fm/music/Nirvana"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1646166",
"mbid": "bbfa1e12-8b61-4ed8-bc6e-52d2298f41a2",
"name": "Tool",
"playcount": "122824468",
"streamable": "0",
"url": "https://www.last.fm/music/Tool"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1008791",
"mbid": "5a85c140-dcf9-4dd2-b2c8-aff0471549f3",
"name": "Sam Smith",
"playcount": "30910342",
"streamable": "0",
"url": "https://www.last.fm/music/Sam+Smith"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "2204118",
"mbid": "bd13909f-1c29-4c27-a874-d4aaf27c5b1a",
"name": "Fleetwood Mac",
"playcount": "70574855",
"streamable": "0",
"url": "https://www.last.fm/music/Fleetwood+Mac"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3125893",
"mbid": "83d91898-7763-47d7-b03b-b92132375c47",
"name": "Pink Floyd",
"playcount": "318740438",
"streamable": "0",
"url": "https://www.last.fm/music/Pink+Floyd"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "273449",
"mbid": "",
"name": "BROCKHAMPTON",
"playcount": "36180740",
"streamable": "0",
"url": "https://www.last.fm/music/BROCKHAMPTON"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1326470",
"mbid": "c8b03190-306c-4120-bb0b-6f2ebfc06ea9",
"name": "The Weeknd",
"playcount": "81295303",
"streamable": "0",
"url": "https://www.last.fm/music/The+Weeknd"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4569194",
"mbid": "b95ce3ff-3d05-4e87-9e01-c97b66af13d4",
"name": "Eminem",
"playcount": "204081058",
"streamable": "0",
"url": "https://www.last.fm/music/Eminem"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3842009",
"mbid": "b071f9fa-14b0-4217-8e97-eb41da73f598",
"name": "The Rolling Stones",
"playcount": "157067654",
"streamable": "0",
"url": "https://www.last.fm/music/The+Rolling+Stones"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1257764",
"mbid": "e520459c-dff4-491d-a6e4-c97be35e0044",
"name": "Frank Ocean",
"playcount": "87152244",
"streamable": "0",
"url": "https://www.last.fm/music/Frank+Ocean"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3622199",
"mbid": "e21857d5-3256-4547-afb3-4b6ded592596",
"name": "Gorillaz",
"playcount": "173334985",
"streamable": "0",
"url": "https://www.last.fm/music/Gorillaz"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "982956",
"mbid": "7fb57fba-a6ef-44c2-abab-2fa3bdee607e",
"name": "Childish Gambino",
"playcount": "54111939",
"streamable": "0",
"url": "https://www.last.fm/music/Childish+Gambino"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3784477",
"mbid": "084308bd-1654-436f-ba03-df6697104e19",
"name": "Green Day",
"playcount": "191486003",
"streamable": "0",
"url": "https://www.last.fm/music/Green+Day"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1710145",
"mbid": "012151a8-0f9a-44c9-997f-ebd68b5389f9",
"name": "Imagine Dragons",
"playcount": "85440640",
"streamable": "0",
"url": "https://www.last.fm/music/Imagine+Dragons"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "1297869",
"mbid": "8e494408-8620-4c6a-82c2-c2ca4a1e4f12",
"name": "Lorde",
"playcount": "76314107",
"streamable": "0",
"url": "https://www.last.fm/music/Lorde"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "997026",
"mbid": "25b7b584-d952-4662-a8b9-dd8cdfbfeb64",
"name": "A$AP Rocky",
"playcount": "48732470",
"streamable": "0",
"url": "https://www.last.fm/music/A$AP+Rocky"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "2976178",
"mbid": "69ee3720-a7cb-4402-b48d-a02c366f2bcf",
"name": "The Cure",
"playcount": "160080692",
"streamable": "0",
"url": "https://www.last.fm/music/The+Cure"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4472323",
"mbid": "95e1ead9-4d31-4808-a7ac-32c3614c116b",
"name": "The Killers",
"playcount": "211585596",
"streamable": "0",
"url": "https://www.last.fm/music/The+Killers"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "2974470",
"mbid": "d6e0e274-8e19-44ce-b5b2-52c12f8a674a",
"name": "Led Zeppelin",
"playcount": "191578475",
"streamable": "0",
"url": "https://www.last.fm/music/Led+Zeppelin"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "3825396",
"mbid": "056e4f3e-d505-4dad-8ec1-d04f521cbb56",
"name": "Daft Punk",
"playcount": "212334330",
"streamable": "0",
"url": "https://www.last.fm/music/Daft+Punk"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "4019451",
"mbid": "f59c5520-5f46-4d2c-b2c4-822eabf53419",
"name": "Linkin Park",
"playcount": "299550825",
"streamable": "0",
"url": "https://www.last.fm/music/Linkin+Park"
},
{
"image": [
{
"#text": "https://lastfm-img2.akamaized.net/i/u/34s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "small"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/64s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "medium"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/174s/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "large"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "extralarge"
},
{
"#text": "https://lastfm-img2.akamaized.net/i/u/300x300/2a96cbd8b46e442fc41c2b86b821562f.png",
"size": "mega"
}
],
"listeners": "487567",
"mbid": "c6bfb05d-f570-46c8-98e1-e25441189770",
"name": "Khalid",
"playcount": "15759258",
"streamable": "0",
"url": "https://www.last.fm/music/Khalid"
}
]
}
}
JSON 响应的结构是:
- 只有一个
artists键的字典,包含:- 一个包含许多关于响应的属性的
@attr键。 - 包含艺术家对象列表的
artist键。
- 一个包含许多关于响应的属性的
让我们看一下'@attr'(属性)键本身:
jprint(r.json()['artists']['@attr'])
{
"page": "1",
"perPage": "50",
"total": "2901036",
"totalPages": "58021"
}
在这个 API 端点的结果中,总共有将近 300 万个艺术家,我们在一个“页面”中显示前 50 个艺术家。这种将结果分布在多个页面上的技术被称为分页。
使用分页数据
为了建立一个包含许多艺术家的数据集,我们需要为每个页面发出一个 API 请求,然后将它们放在一起。我们可以使用文档中指定的两个可选参数来控制结果的分页:
limit:每页提取的结果数(默认为 50)。page:我们要取结果的哪一页。
因为'@attrs'键给出了总页数,所以我们可以使用一个while循环来遍历页面,直到页码等于最后一个页码。
我们还可以使用limit参数在每个页面获取更多的结果——我们将在每个页面获取 500 个结果,因此我们只需要进行大约 6000 次调用,而不是大约 60000 次。
让我们看一个如何构建代码的例子:
# initialize list for results
results = []
# set initial page and a high total number
page = 1
total_pages = 99999
while page > total_pages:
# simplified request code for this example
r = request.get("endpoint_url", params={"page": page})
# append results to list
results.append(r.json())
# increment page
page += 1
正如我们刚才提到的,我们需要对这个端点进行近 6000 次调用,这意味着我们需要考虑速率限制,以符合 Last.fm API 的服务条款。让我们来看看几种方法。
速率限制
速率限制是使用代码来限制我们每秒钟访问特定 API 的次数。速率限制会让你的代码变慢,但这总比完全禁止使用 API 要好。
执行速率限制最简单的方法是使用 Python time.sleep()函数。该函数接受一个浮点数,指定在继续之前等待的秒数。
例如,以下代码将在两个 print 语句之间等待四分之一秒:
import time
print("one")
time.sleep(0.25)
print("two")
因为进行 API 调用本身需要一些时间,我们可能每秒进行两到三次调用,而不是睡眠 0.25 秒可能暗示的每秒四次调用。这应该足以让我们保持在 Last.fm 的阈值之下(如果我们要在几个小时内达到他们的 API,我们可能会选择更低的速率)。
另一种对速率限制有用的技术是使用本地数据库来缓存任何 API 调用的结果,这样,如果我们两次进行相同的调用,第二次它就从本地缓存中读取它。想象一下,当您正在编写代码时,您发现了语法错误,并且您的循环失败了,您必须重新开始。使用本地缓存有两个好处:
- 不需要进行额外的 API 调用。
- 当从缓存中读取重复调用时,您不需要等待额外的时间来限制速率。
我们可以用来将等待与缓存结合起来的逻辑如下所示:

为本地缓存创建逻辑是一项相当复杂的任务,但是有一个名为 requests-cache 的强大库,它只需要几行代码就可以为您完成所有的工作。
您可以使用 pip 安装请求缓存:
pip install requests-cache
然后我们需要做的就是导入这个库,调用 requests_cache.install_cache()函数,这个库就会透明地缓存新的 API 请求,每当我们重复调用的时候就使用缓存。
import requests_cache
requests_cache.install_cache()
我们应该考虑的最后一件事是,我们的 6,000 个请求可能需要大约 30 分钟才能完成,因此我们将在每个循环中打印一些输出,这样我们就可以看到所有内容的位置。我们将使用一个 IPython 显示技巧在每次运行后清除输出,这样我们的笔记本看起来更整洁。
我们开始吧!
import time
from IPython.core.display import clear_output
responses = []
page = 1
total_pages = 99999 # this is just a dummy number so the loop starts
while page < = total_pages:
payload = {
'method': 'chart.gettopartists',
'limit': 500,
'page': page
}
# print some output so we can see the status
print("Requesting page {}/{}".format(page, total_pages))
# clear the output to make things neater
clear_output(wait = True)
# make the API call
response = lastfm_get(payload)
# if we get an error, print the response and halt the loop
if response.status_code != 200:
print(response.text)
break
# extract pagination info
page = int(response.json()['artists']['@attr']['page'])
total_pages = int(response.json()['artists']['@attr']['totalPages'])
# append response
responses.append(response)
# if it's not a cached result, sleep
if not getattr(response, 'from_cache', False):
time.sleep(0.25)
# increment the page number
page += 1
Requesting page 5803/5803
第一次运行该代码时,大约需要半个小时。因为有缓存,第二次会快很多(可能不到一分钟!)
处理数据
让我们用熊猫来看看我们的responses列表中第一个响应的数据:
import pandas as pd
r0 = responses[0]
r0_json = r0.json()
r0_artists = r0_json['artists']['artist']
r0_df = pd.DataFrame(r0_artists)
r0_df.head()
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | 图像 | |
|---|---|---|---|---|---|---|---|
| Zero | 国王的羊毛 | Two hundred and thirty-two million eight hundred and eight thousand nine hundred and thirty-nine | One million nine hundred and fifty-seven thousand one hundred and seventy-four | b 7539 c 32-53e 7-4908-BD a3-81449 c 367 da 6 | https://www.last.fm/music/Lana+Del+Rey | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… |
| one | 比莉·艾利什 | Thirty-five million five hundred and twenty thousand five hundred and forty-eight | Five hundred and eighty-eight thousand eight hundred and eighty-three | https://www.last.fm/music/Billie+Eilish | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… | |
| Two | 波兹·马龙 | Thirty-four million nine hundred and forty-two thousand seven hundred and eight | Six hundred and fifty-five thousand and fifty-two | https://www.last.fm/music/Post+Malone | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… | |
| three | 泰勒·斯威夫特 | One hundred and ninety-six million nine hundred and seven thousand seven hundred and two | Two million two hundred and ninety thousand nine hundred and ninety-three | 20244 d07-534 f-4 eff-b4d 4-930878889970 | https://www.last.fm/music/Taylor+Swift | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… |
| four | 爱莉安娜·格兰德 | One hundred and twenty-four million two hundred and fifty-one thousand seven hundred and sixty-six | One million one hundred and sixty-six thousand one hundred and eighty | f 4 FD bb4c-e4b 7-47a 0-b83b-d 91 bbf CFA 387 | https://www.last.fm/music/Ariana+Grande | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… |
我们可以使用 list comprehension 对来自responses的每个响应执行这个操作,给我们一个数据帧列表,然后使用 pandas.concat()函数将数据帧列表转换成一个数据帧。

frames = [pd.DataFrame(r.json()['artists']['artist']) for r in responses]
artists = pd.concat(frames)
artists.head()
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | 图像 | |
|---|---|---|---|---|---|---|---|
| Zero | 国王的羊毛 | Two hundred and thirty-two million eight hundred and eight thousand nine hundred and thirty-nine | One million nine hundred and fifty-seven thousand one hundred and seventy-four | b 7539 c 32-53e 7-4908-BD a3-81449 c 367 da 6 | https://www.last.fm/music/Lana+Del+Rey | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… |
| one | 比莉·艾利什 | Thirty-five million five hundred and twenty thousand five hundred and forty-eight | Five hundred and eighty-eight thousand eight hundred and eighty-three | https://www.last.fm/music/Billie+Eilish | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… | |
| Two | 波兹·马龙 | Thirty-four million nine hundred and forty-two thousand seven hundred and eight | Six hundred and fifty-five thousand and fifty-two | https://www.last.fm/music/Post+Malone | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… | |
| three | 泰勒·斯威夫特 | One hundred and ninety-six million nine hundred and seven thousand seven hundred and two | Two million two hundred and ninety thousand nine hundred and ninety-three | 20244 d07-534 f-4 eff-b4d 4-930878889970 | https://www.last.fm/music/Taylor+Swift | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… |
| four | 爱莉安娜·格兰德 | One hundred and twenty-four million two hundred and fifty-one thousand seven hundred and sixty-six | One million one hundred and sixty-six thousand one hundred and eighty | f 4 FD bb4c-e4b 7-47a 0-b83b-d 91 bbf CFA 387 | https://www.last.fm/music/Ariana+Grande | Zero | [{ ' # text ':' https://last FM-img 2 . akamaized . net/… |
我们的下一步将是删除 image 列,它包含艺术家图像的 URL,从分析的角度来看,这些图像对我们并没有真正的帮助。
artists = artists.drop('image', axis=1)
artists.head()
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | |
|---|---|---|---|---|---|---|
| Zero | 国王的羊毛 | Two hundred and thirty-two million eight hundred and eight thousand nine hundred and thirty-nine | One million nine hundred and fifty-seven thousand one hundred and seventy-four | b 7539 c 32-53e 7-4908-BD a3-81449 c 367 da 6 | https://www.last.fm/music/Lana+Del+Rey | Zero |
| one | 比莉·艾利什 | Thirty-five million five hundred and twenty thousand five hundred and forty-eight | Five hundred and eighty-eight thousand eight hundred and eighty-three | https://www.last.fm/music/Billie+Eilish | Zero | |
| Two | 波兹·马龙 | Thirty-four million nine hundred and forty-two thousand seven hundred and eight | Six hundred and fifty-five thousand and fifty-two | https://www.last.fm/music/Post+Malone | Zero | |
| three | 泰勒·斯威夫特 | One hundred and ninety-six million nine hundred and seven thousand seven hundred and two | Two million two hundred and ninety thousand nine hundred and ninety-three | 20244 d07-534 f-4 eff-b4d 4-930878889970 | https://www.last.fm/music/Taylor+Swift | Zero |
| four | 爱莉安娜·格兰德 | One hundred and twenty-four million two hundred and fifty-one thousand seven hundred and sixty-six | One million one hundred and sixty-six thousand one hundred and eighty | f 4 FD bb4c-e4b 7-47a 0-b83b-d 91 bbf CFA 387 | https://www.last.fm/music/Ariana+Grande | Zero |
现在,让我们用 和 来稍微了解一下数据:
artists.info()
artists.describe()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 10500 entries, 0 to 499
Data columns (total 6 columns):
name 10500 non-null object
playcount 10500 non-null object
listeners 10500 non-null object
mbid 10500 non-null object
url 10500 non-null object
streamable 10500 non-null object
dtypes: object(6)
memory usage: 574.2+ KB
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | |
|---|---|---|---|---|---|---|
| 数数 | Ten thousand five hundred | Ten thousand five hundred | Ten thousand five hundred | Ten thousand five hundred | Ten thousand five hundred | Ten thousand five hundred |
| 独一无二的 | ten thousand | Nine thousand nine hundred and ninety | Nine thousand eight hundred and eighty-two | Seven thousand two hundred and twenty-three | ten thousand | one |
| 顶端 | 克莱尔罗 | Four million five hundred and ninety-one thousand seven hundred and eighty-nine | Two million ninety-six thousand nine hundred and eighty-five | https://www.last.fm/music/alt-J | Zero | |
| 频率 | Two | Two | four | Two thousand eight hundred and thirteen | Two | Ten thousand five hundred |
我们预计大约有 300 万名艺术家,但我们只有 10500 名。其中,只有 10,000 个是唯一的(如有重复)。
让我们看看我们的响应对象列表中艺术家列表的长度,看看我们是否能更好地理解哪里出了问题。
artist_counts = [len(r.json()['artists']['artist']) for r in responses]
pd.Series(artist_counts).value_counts()
0 5783
500 19
1000 1
dtype: int64
看起来我们的请求中只有 20 个有回应列表——让我们按顺序看看前 50 个,看看是否有某种模式。
print(artist_counts[:50])
[500, 1000, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 500, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
看起来在前二十次响应之后,这个 API 没有返回任何数据——这是一个未记录的限制。
这不是世界末日,因为 10,000 名艺术家仍然是一个很大的数据量。让我们去掉之前检测到的重复项。
artists = artists.drop_duplicates().reset_index(drop=True)
artists.describe()
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | |
|---|---|---|---|---|---|---|
| 数数 | ten thousand | ten thousand | ten thousand | ten thousand | ten thousand | ten thousand |
| 独一无二的 | ten thousand | Nine thousand nine hundred and ninety | Nine thousand eight hundred and eighty-two | Seven thousand two hundred and twenty-three | ten thousand | one |
| 顶端 | 你确定? | Five hundred and eight thousand five hundred and sixty-six | Thirty thousand one hundred and seventy-six | https://www.last.fm/music/Heinz+Goldblatt | Zero | |
| 频率 | one | Two | three | Two thousand seven hundred and fifty | one | ten thousand |
使用第二个 Last.fm API 端点扩充数据
为了让我们的数据更有趣,让我们使用另一个 last.fm API 端点来添加一些关于每个艺术家的额外数据。
Last.fm 允许其用户创建“标签”来对艺术家进行分类。通过使用 artist.getTopTags 端点,我们可以从单个艺术家那里获得顶级标签。
让我们以我们的一位艺术家为例,看看来自该端点的响应:
r = lastfm_get({
'method': 'artist.getTopTags',
'artist': 'Lana Del Rey'
})
jprint(r.json())
{
"toptags": {
"@attr": {
"artist": "Lana Del Rey"
},
"tag": [
{
"count": 100,
"name": "female vocalists",
"url": "https://www.last.fm/tag/female+vocalists"
},
{
"count": 93,
"name": "indie",
"url": "https://www.last.fm/tag/indie"
},
{
"count": 88,
"name": "indie pop",
"url": "https://www.last.fm/tag/indie+pop"
},
{
"count": 80,
"name": "pop",
"url": "https://www.last.fm/tag/pop"
},
{
"count": 67,
"name": "alternative",
"url": "https://www.last.fm/tag/alternative"
},
{
"count": 14,
"name": "american",
"url": "https://www.last.fm/tag/american"
},
{
"count": 13,
"name": "dream pop",
"url": "https://www.last.fm/tag/dream+pop"
},
{
"count": 12,
"name": "seen live",
"url": "https://www.last.fm/tag/seen+live"
},
{
"count": 10,
"name": "singer-songwriter",
"url": "https://www.last.fm/tag/singer-songwriter"
},
{
"count": 10,
"name": "trip-hop",
"url": "https://www.last.fm/tag/trip-hop"
},
{
"count": 7,
"name": "cult",
"url": "https://www.last.fm/tag/cult"
},
{
"count": 7,
"name": "sadcore",
"url": "https://www.last.fm/tag/sadcore"
},
{
"count": 7,
"name": "legend",
"url": "https://www.last.fm/tag/legend"
},
{
"count": 6,
"name": "Lana Del Rey",
"url": "https://www.last.fm/tag/Lana+Del+Rey"
},
{
"count": 6,
"name": "chamber pop",
"url": "https://www.last.fm/tag/chamber+pop"
},
{
"count": 5,
"name": "baroque pop",
"url": "https://www.last.fm/tag/baroque+pop"
},
{
"count": 4,
"name": "female vocalist",
"url": "https://www.last.fm/tag/female+vocalist"
},
{
"count": 4,
"name": "alternative pop",
"url": "https://www.last.fm/tag/alternative+pop"
},
{
"count": 4,
"name": "Retro",
"url": "https://www.last.fm/tag/Retro"
},
{
"count": 3,
"name": "art pop",
"url": "https://www.last.fm/tag/art+pop"
},
{
"count": 3,
"name": "chillout",
"url": "https://www.last.fm/tag/chillout"
},
{
"count": 3,
"name": "soul",
"url": "https://www.last.fm/tag/soul"
},
{
"count": 3,
"name": "USA",
"url": "https://www.last.fm/tag/USA"
},
{
"count": 3,
"name": "sexy",
"url": "https://www.last.fm/tag/sexy"
},
{
"count": 2,
"name": "new york",
"url": "https://www.last.fm/tag/new+york"
},
{
"count": 2,
"name": "rock",
"url": "https://www.last.fm/tag/rock"
},
{
"count": 2,
"name": "hollywood sadcore",
"url": "https://www.last.fm/tag/hollywood+sadcore"
},
{
"count": 2,
"name": "indie rock",
"url": "https://www.last.fm/tag/indie+rock"
},
{
"count": 2,
"name": "trip hop",
"url": "https://www.last.fm/tag/trip+hop"
},
{
"count": 2,
"name": "female",
"url": "https://www.last.fm/tag/female"
},
{
"count": 2,
"name": "jazz",
"url": "https://www.last.fm/tag/jazz"
},
{
"count": 2,
"name": "10s",
"url": "https://www.last.fm/tag/10s"
},
{
"count": 2,
"name": "folk",
"url": "https://www.last.fm/tag/folk"
},
{
"count": 2,
"name": "lana",
"url": "https://www.last.fm/tag/lana"
},
{
"count": 2,
"name": "electronic",
"url": "https://www.last.fm/tag/electronic"
},
{
"count": 2,
"name": "blues",
"url": "https://www.last.fm/tag/blues"
},
{
"count": 2,
"name": "2010s",
"url": "https://www.last.fm/tag/2010s"
},
{
"count": 2,
"name": "vintage",
"url": "https://www.last.fm/tag/vintage"
},
{
"count": 2,
"name": "alternative rock",
"url": "https://www.last.fm/tag/alternative+rock"
},
{
"count": 2,
"name": "overrated",
"url": "https://www.last.fm/tag/overrated"
},
{
"count": 2,
"name": "retro pop",
"url": "https://www.last.fm/tag/retro+pop"
},
{
"count": 2,
"name": "beautiful",
"url": "https://www.last.fm/tag/beautiful"
},
{
"count": 2,
"name": "melancholic",
"url": "https://www.last.fm/tag/melancholic"
},
{
"count": 2,
"name": "dark pop",
"url": "https://www.last.fm/tag/dark+pop"
},
{
"count": 1,
"name": "Hollywood Pop",
"url": "https://www.last.fm/tag/Hollywood+Pop"
},
{
"count": 1,
"name": "chill",
"url": "https://www.last.fm/tag/chill"
},
{
"count": 1,
"name": "americana",
"url": "https://www.last.fm/tag/americana"
},
{
"count": 1,
"name": "diva",
"url": "https://www.last.fm/tag/diva"
},
{
"count": 1,
"name": "sad",
"url": "https://www.last.fm/tag/sad"
}
]
}
}
我们只对标签名感兴趣,而且只对最流行的标签感兴趣。让我们使用列表理解来创建前三个标签名的列表:
tags = [t['name'] for t in r.json()['toptags']['tag'][:3]]
tags
['female vocalists', 'indie', 'indie pop']
然后我们可以用 str.join()方法把这个列表变成一个字符串:
', '.join(tags)
'female vocalists, indie, indie pop'
让我们创建一个函数,使用这个逻辑来返回任何艺术家的最流行标签的字符串,稍后我们将使用它来应用到我们的数据帧中的每一行。
请记住,这个函数会被连续使用很多次,所以我们将重用前面的time.sleep()逻辑。
def lookup_tags(artist):
response = lastfm_get({
'method': 'artist.getTopTags',
'artist': artist
})
# if there's an error, just return nothing
if response.status_code != 200:
return None
# extract the top three tags and turn them into a string
tags = [t['name'] for t in response.json()['toptags']['tag'][:3]]
tags_str = ', '.join(tags)
# rate limiting
if not getattr(response, 'from_cache', False):
time.sleep(0.25)
return tags_str
让我们在另一位艺术家身上测试我们的功能:
lookup_tags("Billie Eilish")
'pop, indie pop, indie'
将这个函数应用到我们的 10,000 行只需要不到一个小时。因此,我们知道事情实际上正在进展,我们将像以前一样用输出来监视操作。
不幸的是,当用熊猫 应用一个函数时,手动打印输出不是我们可以使用的方法。取而代之的是,我们将使用 tqdm 包来自动完成这项工作。
from tqdm import tqdm
tqdm.pandas()
artists['tags'] = artists['name'].progress_apply(lookup_tags)
100%|██████████| 10000/10000 [00:33<00:00, 295.25it/s]
让我们看看我们操作的结果:
artists.head()
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | 标签 | |
|---|---|---|---|---|---|---|---|
| Zero | 国王的羊毛 | Two hundred and thirty-two million eight hundred and eight thousand nine hundred and thirty-nine | One million nine hundred and fifty-seven thousand one hundred and seventy-four | b 7539 c 32-53e 7-4908-BD a3-81449 c 367 da 6 | https://www.last.fm/music/Lana+Del+Rey | Zero | 女歌手、独立歌手、独立流行歌手 |
| one | 比莉·艾利什 | Thirty-five million five hundred and twenty thousand five hundred and forty-eight | Five hundred and eighty-eight thousand eight hundred and eighty-three | https://www.last.fm/music/Billie+Eilish | Zero | 流行,独立流行,独立 | |
| Two | 波兹·马龙 | Thirty-four million nine hundred and forty-two thousand seven hundred and eight | Six hundred and fifty-five thousand and fifty-two | https://www.last.fm/music/Post+Malone | Zero | 嘻哈,说唱,陷阱 | |
| three | 泰勒·斯威夫特 | One hundred and ninety-six million nine hundred and seven thousand seven hundred and two | Two million two hundred and ninety thousand nine hundred and ninety-three | 20244 d07-534 f-4 eff-b4d 4-930878889970 | https://www.last.fm/music/Taylor+Swift | Zero | 乡村、流行、女歌手 |
| four | 爱莉安娜·格兰德 | One hundred and twenty-four million two hundred and fifty-one thousand seven hundred and sixty-six | One million one hundred and sixty-six thousand one hundred and eighty | f 4 FD bb4c-e4b 7-47a 0-b83b-d 91 bbf CFA 387 | https://www.last.fm/music/Ariana+Grande | Zero | 流行音乐,女歌手,rnb |
最终确定并导出数据
在导出数据之前,我们可能希望对数据进行排序,使最受欢迎的艺术家位于顶部。到目前为止,我们只是将数据存储为文本,而没有转换任何类型:
artists.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 7 columns):
name 10000 non-null object
playcount 10000 non-null object
listeners 10000 non-null object
mbid 10000 non-null object
url 10000 non-null object
streamable 10000 non-null object
tags 10000 non-null object
dtypes: object(7)
memory usage: 547.0+ KB
让我们从将 listeners 和 playcount 列转换成数字开始。
artists[["playcount", "listeners"]] = artists[["playcount", "listeners"]].astype(int)
现在,让我们按听众人数排序
artists = artists.sort_values("listeners", ascending=False)
artists.head(10)
| 名字 | 播放计数 | 听众 | mbid | 全球资源定位器(Uniform Resource Locator) | 可流式传输 | 标签 | |
|---|---|---|---|---|---|---|---|
| Twenty-three | 酷玩乐队 | Three hundred and sixty-four million one hundred and seven thousand seven hundred and thirty-nine | Five million four hundred and twenty-nine thousand five hundred and fifty-five | cc 197 bad-dc9c-440d-a5 b5-d 52 ba 2e 14234 | https://www.last.fm/music/Coldplay | Zero | 摇滚,另类,英国流行 |
| Ten | 电台司令 | Five hundred and seven million six hundred and eighty-two thousand nine hundred and ninety-nine | Four million seven hundred and seventy-eight thousand eight hundred and fifty-six | a 74 B1 b 7 f-71 a5-4011-9441-d0b5 e 4122711 | https://www.last.fm/music/Radiohead | Zero | 另类,另类摇滚,摇滚 |
| Twenty-four | 红辣椒乐队 | Two hundred and ninety-eight million forty-three thousand four hundred and ninety-one | Four million six hundred and sixty-five thousand eight hundred and twenty-three | 8 bfac 288-cc C5-448d-9573-c 33 ea 2 aa 5c 30 | https://www.last.fm/music/Red+Hot+Chili+Peppers | Zero | 摇滚,另类摇滚,另类 |
| Twelve | 蕾哈娜 | Two hundred and four million one hundred and fourteen thousand one hundred and ninety-eight | Four million six hundred and eighteen thousand eight hundred and thirty-eight | db 36 a 76 f-4c df-43ac-8cd 0-5e 48092 D2 BAE | https://www.last.fm/music/Rihanna | Zero | 流行,rnb,女歌手 |
| Thirty-five | 埃米纳姆 | Two hundred and four million eighty-one thousand and fifty-eight | Four million five hundred and sixty-nine thousand one hundred and ninety-four | b 95 ce 3 ff-3d 05-4 e87-9e 01-c 97 b 66 af 13d 4 | https://www.last.fm/music/Eminem | Zero | 说唱,嘻哈,阿姆 |
| Forty-five | 杀手们 | Two hundred and eleven million five hundred and eighty-five thousand five hundred and ninety-six | Four million four hundred and seventy-two thousand three hundred and twenty-three | 95 E1 EAD 9-4d 31-4808-a7ac-32c 3614 c 116 b | https://www.last.fm/music/The+Killers | Zero | 独立,摇滚,独立摇滚 |
| seven | 坎耶·维斯特 | Two hundred and fifty million five hundred and thirty-three thousand four hundred and forty-four | Four million four hundred and forty-nine thousand five hundred and thirty-four | 164 f0d 73-1234-4e2c-8743-d77bf 2191051 | https://www.last.fm/music/Kanye+West | Zero | 嘻哈,说唱,嘻哈 |
| Twenty-eight | 天堂 | Two hundred and twenty-six million sixty thousand four hundred and sixty-eight | Four million three hundred and twenty thousand five hundred and ninety-three | 9282 c8 B4-ca0b-4c6b-b7e 3-4f 7762 DFC 4d 6 | https://www.last.fm/music/Nirvana | Zero | 垃圾,摇滚,另类 |
| Fifty-seven | 司文艺、音乐、美术的女神缪斯 | Three hundred and forty-nine million two hundred and sixty-four thousand one hundred and sixty-four | Four million one hundred and twenty-three thousand one hundred and forty-eight | FD 857293-5ab 8-40de-b29e-5a 69d 4 e 4d 0f | https://www.last.fm/music/Muse | Zero | 另类摇滚,摇滚,另类 |
| six | 女王 | One hundred and ninety-seven million eight hundred and fifty thousand one hundred and twenty-two | Four million eighty-four thousand five hundred and twenty-four | 420 ca 290-76 C5-41af-999 e-564 D7 c71 f1a 7 | https://www.last.fm/music/Queen | Zero | 经典摇滚,摇滚,80 年代 |
最后,我们可以将数据集导出为 CSV 文件。
artists.to_csv('artists.csv', index=False)
接下来的步骤
在本教程中,我们使用 Last.fm API 构建了一个数据集,同时学习了如何使用 Python 来:
- 如何使用 API 密钥通过 API 进行身份验证
- 如何使用分页从 API 端点收集更大的响应
- 如何使用速率限制来遵守 API 的准则。
如果你想扩展你的学习范围,你可以:
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
通过做更好的笔记来记住更多你学到的东西
原文:https://www.dataquest.io/blog/learn-better-taking-notes-study/
March 9, 2019
如果你正试图学习数据科学(或其他任何东西,就此而言),手写笔记真的有帮助吗?
至少从 17 世纪开始,甚至可能更早,做笔记就已经成为典型学习过程的一部分。几个世纪以来,记笔记看起来几乎总是一样的:学生们在演讲厅或图书馆里,用笔和纸做笔记。
今天,学习的选择更加多样化。你可以用传统的方式记笔记,但你也可以在笔记本电脑上数字化地输入,在电话上为自己记录解释,或者将你最大的收获输入到抽认卡学习应用程序中,以供将来阅读。
许多在线学习平台提供预先写好的笔记,方便学生复习。在 Dataquest ,我们使用可下载的“外卖”pdf 文件来完成这项工作,您可以在每节交互式编码课的末尾找到这些文件。但是自己做笔记也有一些真正的价值。那么你应该如何做笔记呢?让我们看看科学是怎么说的。
穆勒和奥本海默的研究
普林斯顿大学学者帕姆·穆勒和加州大学洛杉矶分校学者丹尼尔·奥本海默在 2014 年撰写的这项研究是第一个,也是唯一一个,你会在讨论什么最适合做笔记时找到的科学参考。但是他们的结果的意义经常被误解。
在这项研究中,穆勒和奥本海默要求学生用笔记本电脑(与互联网断开连接)或纸笔在 TED talk 视频讲座上做笔记。视频结束大约 30 分钟后,学生们接受了两项测试,一是对讲座中具体事实的回忆,二是对与讲座主题相关的更广泛的概念性问题的评估能力。
在回忆具体事实时,用笔记本电脑记笔记的学生比用手写(用笔和纸)的学生表现稍好。但是当涉及到概念理解时,用手记笔记的学生表现得更好。

图片来源:穆勒和奥本海默研究
这个结果产生了过多的标题,宣称用手记笔记天生就优于用电脑记笔记。但是这种解释存在一些问题。
首先,正如穆勒和奥本海默自己指出的,学生记笔记的方式可能不如 T2 的方式重要。注意到使用笔记本电脑的学生打出的单词比手写笔记者写的多,他们推断,因为打字比写字快,所以学生在通过笔记本电脑记笔记时可能会做更多的死记硬背逐字记录(因此不会积极参与到所提出的想法中)。在接下来的实验中,他们明确指示笔记本电脑笔记员而不是逐字记录,这在一定程度上提高了他们的概念分数,尽管还不足以赶上手写笔记员。
另一项后续实验允许两组学生在接受评估前研究他们的笔记。和之前的实验一样,手写笔记者的表现优于笔记本笔记者。
那么,手写笔记真的比数字笔记好吗?也许吧。但这是一项单独的研究,穆勒和奥本海默的每个实验都只测试了一小部分学生(第一次实验中有 67 人,后续实验中大约有 110 人)。尽管大量的新闻文章提出了相反的观点,但仅凭这项研究的结果就得出手写笔记比用电脑做笔记更好的结论可能是不合理的。
记笔记时真正重要的是什么
也许更有助于评估有效笔记策略证据的是哈佛学者 Michael C. Friedman 的工作,他对现有的研究进行了更广泛的回顾,T2 在《高等教育》的《T4》中总结了他对学生的建议。尽管大多数关于这一主题的研究都集中在正式的学术背景上,但弗里德曼的建议也很容易适用于自我导向的学习(如在线学习数据科学)。
具体来说,弗里德曼建议:
- 避免抄录或复制/粘贴。写笔记时用你自己的话表达事情,因为这迫使你思考如何理解和如何最好地解释一个概念。(如果你不能用自己的话表达出来,这是一个好迹象,表明你还没有理解它)。
- 定期回顾你的笔记,包括你写笔记的当天和之后的重复。
- 自我测试。在数据科学的背景下,这可能意味着在检查您的笔记以查看您是否正确记忆之前尝试编写一些代码。
弗里德曼还建议对数字笔记和手写笔记哪个更适合你进行深思熟虑的评估。这是个人决定,但以下是每种方法最有可能的优势:
| 数字笔记 | 手写笔记 | |
|---|---|---|
| 易接近 | 可以存储在云中,以便随时随地访问 | 只能在纸上获得 |
| 可兑换 | 易于编辑,或复制粘贴到其他应用程序中进行研究 | 难以编辑或转换成其他格式 |
| 事实回忆 | 大概是为了更好地记住特定的事实 | 大概是因为记不住具体的事实 |
| 概念理解 | 可能在理解和应用概念方面更差 | 可能更好地理解和应用概念 |
在一天结束时,似乎最重要的是,无论你如何记笔记,你都要用自己的话来表达它们,并在你写下它们时,花时间真正参与并评估你对概念的理解,而不是简单地逐字逐句地抄录你正在学习的一切。
**当然,记笔记并不是一切。其他因素如你选择的学习材料甚至你的手机是否在附近也会影响你学习数据科学的效率。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
SIGN UP**
新课程:用 Python 和熊猫学习数据清理
原文:https://www.dataquest.io/blog/learn-data-cleaning-python-pandas/
February 19, 2019
数据清理可能不是你对数据科学感兴趣的原因,但如果你想成为一名数据科学家,没有什么技能比这更重要了。工作数据科学家花费至少 60%的时间清理数据,而脏数据通常被认为是数据科学家在工作中面临的最大障碍。
这就是为什么我们刚刚在 Python 数据分析师和数据科学家的道路上增加了一门全新的课程,名为 数据清理和分析 。如果你是 Dataquest 高级用户,你可以现在就开始学习。

为什么要学习数据清理?
数据科学家最终可能会从事各种行业的各种工作,但几乎所有数据科学工作都至少有一个共同点:数据清理。毕竟,现实世界是混乱的,这意味着现实世界的数据集也往往是混乱的。不完整的输入、不一致的格式、输入错误——这些都是你在几乎每个数据集中都会遇到的事情。
即使你正在处理完美的数据,数据清理技能仍然是必要的。您几乎总是希望对数据及其格式进行更改,以方便您的分析,这意味着对杂乱的数据做同样的事情:删除不相关的条目、重新格式化列等。
如果你渴望从事任何类型的机器学习,学习数据清理就显得尤为重要。正如《哈佛商业评论》所说:
*> 糟糕的数据质量是机器学习广泛、有益使用的头号敌人。[……]机器学习的质量要求很高,坏数据可能会出现两次,第一次是用于训练预测模型的历史数据,第二次是该模型用于未来决策的新数据。
简单地说,没有数据清理就没有数据科学。
这门课程包括什么?
在数据清理和分析中,你将使用流行的 pandas 数据分析库学习 Python 中的关键数据清理技术(如果你想学习 R 中的数据清理,我们有一个单独的 R 数据清理课程)。在整个课程中,您将使用《世界幸福报告》中的真实数据,清理和分析一个大型数据集,该数据集包括世界各国的各种指标,如 GDP 和平均预期寿命。
在数据清理的前三课中,您将学习使用 pandas 有效地聚合、组合和转换数据,以便为分析做好准备。然后,您将深入探讨稍微复杂一些的主题,比如如何在 pandas 中处理字符串,如何使用正则表达式,以及如何处理缺失和重复的数据。
完成教学课程后,您将面临一项挑战,即通过一个新的指导项目来测试您所有的新数据清理技能,在您清理和分析来自两个澳大利亚政府部门的员工离职调查的真实数据集时,该项目还会教您一些新的熊猫技能和数据演示技能。
当然,所有的材料都是以 Dataquest 的分屏显示方式呈现的,这样您就可以马上动手编写代码了。
拿起你的拖把
数据清理听起来可能没有机器学习那么性感,但数据科学经常被忽视的现实是你的分析只能和你的数据一样好。如果你的数据一团糟,你的分析也会一团糟。
谢天谢地,有了 Python 和pandas的力量,你不必让这种情况发生,所以现在就拿起你的拖把,投入我们新的 数据清理和分析 课程吧!
正确的内部动机可以提高你的学习
原文:https://www.dataquest.io/blog/learn-data-science-motivation-success/
January 8, 2019
你可能已经知道内部动机比外部动机更强大。但是你知道内部动机的类型在释放更好的表现时很重要吗?
学习数据科学可能是一件苦差事。在 Dataquest,我们试图让它尽可能简单有趣,但没有魔杖。成为一名数据科学家需要持续努力,而持续努力需要动力。
动机的类型
我们都感受过来自外部的灵感的小爆发。听完一首特定的歌曲,或者读到一段鼓舞人心的引语,你可能会感到兴奋。
但是这些外在或外在的动机都是转瞬即逝的。没有哪首歌能让你在几周或几个月的学习中保持正轨。
内部动机——发自内心的动机——在产生绩效时更有效。一次又一次的实验发现,当谈到积极的结果和心理幸福时,内部动机每次都胜过外部动机。
但是内部动机可以进一步分为两个不同的子类:
- 内在动机,指的是我们自然想要做的事情,因为我们喜欢这些事情,例如,“我正在学习数据科学,因为学习操纵数据很有趣!”
- 确定的动机,指的是我们正在做的事情,因为我们已经确定这些事情对实现我们想要实现的目标很重要,例如,“我学习数据科学是因为我想成为一名数据科学家。”
虽然内部动机和外部动机之间的结果差异已经得到了广泛的研究,但内部动机和识别动机之间的差异却没有得到广泛的讨论。然而,【2006 年一项引人入胜的研究对此进行了仔细研究,得出了一些有意义的结果。
这项研究
这项研究的主要部分着眼于加拿大的 241 名学龄儿童。在学年开始时,每个孩子都被要求回答一份调查问卷,评估他们在学校行为的原因,包括关于内在动机和确定动机的问题。他们还填写了关于他们情绪的问卷。
在第一组成绩公布后,研究人员回到教室,让学生再次评估他们的情绪,然后进行一些分层多元回归分析,看看内在动机和确定的动机如何影响心理健康和学业成绩。
结果呢
研究人员发现,学生的内在动机水平(即“学习是乐趣”)在看到他们的成绩后,积极预测他们的心理健康。
换句话说,更喜欢学习的孩子往往更快乐,不管他们的成绩如何。
有更多明确动机的学生受他们成绩的影响更大,对那些成绩好的学生有积极的情绪影响,对那些成绩不好的学生有消极的情绪影响。
更有趣的是,研究人员还发现,确定的动机(即“我想学习新东西,因为我认为这是一件重要的事情”)是学业成功的一个强有力的预测因素。换句话说,学生的动机越明确,他们在学校的表现就越好。
在对少数大学年龄学生的后续实验中,研究人员证实了这些发现,并做出了另一个重要的发现:在测量学习时间后,他们发现花更多时间学习的学生也往往报告他们的生活满意度有积极的变化。
我们如何将此应用于学习数据科学
显然,这只是一项单独的研究,还需要对这个主题进行更多的研究。但这并不意味着我们不能从现有的数据中得出一些基本结论。
这项研究表明,拥有内在动机有助于让我们保持快乐(这将使我们更容易应对挫折和陷入困境的时刻),并且确定动机与更成功的结果相关。因此,当谈到学习数据科学时,我们真的希望两者都健康。
至于内在动机,培养这种动机的最好方法是做你真正感兴趣的项目。或者,正如 Dataquest 创始人 Vik Paruchuri 在他的“如何真正学习数据科学”博客文章中所说,你应该“根据你想做的事情来控制你的学习,而不是相反。”
例如,如果你真的喜欢电影,找一些与电影相关的数据集来处理。尝试用数据分析来回答关于电影的问题会帮助你保持努力,即使事情变得艰难,因为你对这个主题真正感兴趣。
在 Dataquest,我们试图通过有趣的数据科学项目来巩固每一门主要课程,还有许多其他基于项目的数据科学学习资源。
但是,如果你能以一种让你更感兴趣的方式修改它,或者简单地创建你自己的项目,不要觉得你需要严格地坚持任何“分配”的项目!
Kaggle 有许多正在进行的和已经完成的竞赛,你可以从中寻找你感兴趣的主题项目。
你的目标应该是找到你关心并喜欢做的项目,而不是强迫自己完成一系列你不感兴趣的项目。
好消息是:与提高绩效相关的明确动机可能是你已经有的。
你明确的动机是你阅读这篇文章的原因。是你对“为什么要学数据科学”这个问题的回答
这个答案因人而异,但是你的答案越有说服力,它就越有可能成为一个激励因素。不管你的答案是什么,不时地强化它并反思它可能会有所帮助。
如果你没有这个问题的答案,这项研究建议你最好在钻研数据科学之前找到一个答案。即使你喜欢与数据打交道(一种内在动机),有一个更切实的学习理由似乎与更好的表现相关,而内在动机则不然。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
在 Dataquest 学习数据科学一年
原文:https://www.dataquest.io/blog/learn-data-science-online-dataquest/
October 28, 2019
一年的 Dataquest 实际上给你带来了什么?在 Dataquest 上学习数据科学需要多长时间?这些是我们经常被问到的问题。
每个学生都是不同的,所以这些问题可能很难回答。Dataquest 上的学习是自定进度的,一些学生比其他人移动得快得多。但是在本文中,我们将概述一个“典型的”学习过程。
具体来说,当你在我们这里学习数据科学一年的时候,这篇文章将让你知道你可以期望学到什么,以及你可以申请什么样的工作。
当然,像 Dataquest 这样的在线课程的优势之一是,你可以按照自己的节奏学习,根据自己的背景量身定制学习,跳过那些你已经熟悉的内容。出于本文的目的,我们将做一些保守的假设:
- 你很忙,每周只能花大约五个小时在学习上。
- 你以前没有编程经验。
- 你没有接受过数学训练(除了高中代数)。
- 您已经注册了的高级订阅(它让您可以访问所有 Dataquest 课程和项目、高级支持等等)。
我们的许多学生每周花五个多小时学习,所以这是对你一年所能完成的事情的一个相当保守的估计。
但是,如果你每周至少投入 5 个小时,我们预计在一年内,你可以完成数据分析师路径,或者完成超过一半的数据科学家路径,并且将成为合格的各种入门级数据分析和数据科学工作。
让我们仔细看看那一年是什么样子,您将从 Python path 中的 Data Scientist 学到什么,以及您如何在这一年中最好地利用您的订阅。(然而,您在 Python 或 R 中的数据分析师道路上的经历将非常相似)。
一年的数据探索
- 1 月-2 月(第 1-8 周):学习 Python
- 3 月-5 月(第 9-20 周):数据清理、数据分析和数据可视化
- 5 月-7 月(第 21-28 周):命令行、版本控制和 Git
- 7 月至 10 月(第 29-40 周):学习 SQL、API 和网络抓取
- 10 月-12 月(第 41-50 周):数据科学统计
- 继续您的数据科学之旅
1 月-2 月:学习 Python
你一年中的前八周可能会花在学习 Python 上。如果你赶时间的话,你或许可以更快地完成我们的初级和中级 Python 课程,但是建立一个坚实的 Python 基础对于接下来的几乎所有事情都很重要。在这里花一点额外的时间来确保你能理解和应用所有的概念是值得的。
好消息是,即使你从零编码经验开始这八周,你也会以程序员的身份结束。完成这些课程后,您将能够自信地应用 Python 编程的大多数重要概念(从函数和 for 循环等基础概念到正则表达式和列表理解等更高级的概念),并且您还将能够轻松使用 Jupyter 笔记本,这是使用 Python 的数据科学家的一个重要工具。
随着您学习这些技能和技术,您也将对 Python 中的数据分析基础有一个很好的介绍。我们所有的课程都让你处理真实世界的数据,作为这些课程的一部分,你将在指导项目中应用你所学到的东西,分析什么样的应用商店档案会导致更多的应用下载,以及成功的黑客新闻帖子彼此之间有什么共同点。
仅仅这两门课不足以让你在数据科学领域找到一份工作,但在八周结束时,你会发现你已经学到了足够的知识,可以自己进行一些基本的数据分析,可能还会编写一些其他的东西!仅仅这八周就足够给你一些技能,帮助你在目前的工作中节省一些分析任务的时间。
这前八周也是您在我们的数据科学学习社区中建立自己形象的好时机。在那里,你可以从你的同学那里得到帮助,也可以从我们的数据科学家和职业顾问那里得到帮助。如果你陷入困境,这个社区是让你快速摆脱困境的好方法,这很重要,尤其是在学习过程的早期。
这些课程是构建其余数据科学“房子”的基础,因此在这里做得格外彻底将在以后带来回报。有不懂的地方就问!
3 月至 5 月:数据清理、数据分析和数据可视化
这 12 周是应用您的新 Python 技能来完成典型的数据科学任务的真正开始。在这里,您将学习四门课程,每门课程对于从事数据科学都至关重要。
在第一门课程 Pandas 和 NumPy Fundamentals 中,您将学习如何使用 Pandas 库,这是一个用于现实世界数据分析任务的重要工具。您还将了解另一个有用的 Python 包 NumPy,并且您将学习如何让它们很好地配合工作。然后,您将在一个分析真实世界的易贝汽车销售数据的指导项目中应用这些知识。
从那里,您将进入关于数据可视化的两个课程。第一个, 探索性数据可视化 ,将教你如何使用 matplotlib 包和 pandas 来做探索性可视化,这将帮助你理解你的数据并指导你的分析。
第二个, 通过数据可视化讲述故事 ,将教你更多如何使用 Seaborn 制作美观、可读的图表,以确保你知道如何向他人清楚地传达你的数据(任何数据科学工作中的一项关键技能)。在这些课程中,你将综合你在指导性项目中所学到的东西,分析诸如大学学位中的性别差距和地理飞行模式等主题(当然,所有这些都使用真实世界的数据)。
最后,你将进入两门关于数据清理的课程,数据清理是任何数据科学家工具箱中最不性感但又必不可少的技能之一。你将学习探索和清理数据集,如何将多个数据集合并成一个单一、干净的源,并通过一些指导性项目分析来自纽约高中的数据和一项关于星球大战的调查。
到 5 月中旬(你的第 20 周),你将掌握许多基本的数据科学技能,你应该准备好开始承担自己的数据科学项目。你可能还没有为全职数据科学工作做好准备,但你将知道足够多的知识,能够以可能影响你当前工作的方式解决数据科学的现实问题。
例如, Dataquest 的学生 curtty Critchlow在完成了我们的 Pandas and NumPy 课程后,每个月花一整周的时间完成了一个 Excel 数据分析的噩梦,而只花了几分钟就完成了这个项目。
不过,在这几周里,你可能会遇到一种有时被称为“低谷”的心理现象。这经常发生在学习新技能的过程中;一旦你超越了初级阶段,大的收获就会来得慢一些,学习新事物的新鲜感也会消失。结果可能会使你的自然动力水平有所下降。
但是不要担心:我们会帮助你战胜衰退!我们所有的课程都使用有趣的真实世界的数据,通过让你对分析保持兴趣来对抗这种影响,你将在每门课程中解决不同的有趣问题。
5 月-7 月:学习命令行和 SQL
随着我们进入数据科学年的中期,是时候介绍一些对数据科学工作非常重要的技能了:使用命令行和使用 SQL。
在前两门课程中,您将学习如何使用命令行。您将能够轻松地在不使用 GUI 的情况下进行导航,并从命令行使用 Python 脚本和包。然后您将继续讨论更高级的主题,重点是在命令行中处理文本。
从那里,你将开始钻研我们的三门 SQL 课程。首先,您将学习一些基础知识,比如如何在 SQL 中探索和分析数据,以及如何在 Python 中使用 SQLite。然后,您将进入更中级的主题,如跨多个表查询,并开始练习使用 SQL 回答业务问题。最后,您将深入了解高级内容,如 PostgreSQL 和使用数据库索引来加速 SQL 查询。
虽然您的新 SQL 技能对于使用大多数数据库至关重要,但您还会想要使用大量其他数据源,因此在 SQL 课程之后,您将进入关于API 和 web 抓取的课程,该课程将教您如何查询 API 并从没有 API 的网站抓取数据。
为了巩固这些技能,您将使用 SQL 回答一些更真实的业务问题,并深入研究 CIA World Factbook 中的数据。
在你学习的这个阶段,是开始考虑投资组合项目的好时机。拥有一个 GitHub 或其他包含引人注目的项目的项目组合页面是在数据科学领域找到工作的关键,Dataquest 充满了指导项目,您绝对可以将其用于项目组合。你已经完成了其中的一些,所以这是一个回顾过去并考虑给你的最爱添加一些润色的好时机,这样当你开始申请工作时,你已经准备好了一些很酷的项目。
7 月-10 月:学习统计学
至此,您已经具备了进行大量数据分析的编程技能,但是您仍然需要对统计学和概率有一个扎实的理解,以便能够充分利用它们,所以在 Dataquest 这一年的最后一部分,您将参加一系列四门课程,旨在为您提供一个坚实的统计基础,并帮助您在 Python 中应用这些概念。
您将从基础的开始,比如学习不同的采样技术,以便从您的数据中获取好的样本。然后,您将开始查看分布、测量可变性以及定位和比较值与 z 分数。最后,您将了解更多关于概率的知识,并深入探讨高级主题,如显著性测试和卡方检验。
像往常一样,在学习这些课程时,您将使用真实世界的数据来回答有趣的问题,例如自行车共享公司如何预测租赁模式。你将能够把你的新技能应用到很酷的指导项目中,比如计算出获胜的危险的策略,以及确定一个电影评级网站的评级是否有偏见。
在不到三个月的时间内完成这些课程是有可能的,但是我们建议你在这里花点时间,并且确信你理解了所有的东西。虽然如果你忘记了如何用 Python 或 SQL 做一些事情,很容易检查引用,但误解你分析的数学基础可能会有更严重的后果,而且更难发现。
这是一个很好的时机,可以拓展更多的领域,开始在数据科学社区中建立一些联系。如果你还不活跃,我们自己的社区是一个很好的起点。你可能还想通过其他方式来建立自己作为数据科学家的品牌,比如为 Dataquest 博客写一篇教程。
如果你对数据分析师的职位感兴趣,你可以在这几个月的任何时候开始申请工作。拥有 Python、SQL 和统计技能将使你有资格胜任大多数数据分析师职位。
10 月-12 月:深入研究机器学习
至此,您已经掌握了进行大量数据分析的编程技能,以及理解幕后发生的事情的统计技能。但如果你想成为一名数据科学家,你需要在你的技能组合中增加一项大技能:机器学习。
在这几个月中,您将开始深入了解我们的机器学习课程。你将从机器学习的基础开始,然后你将学习一些重要的微积分和线性代数概念,它们支撑着关键的机器学习算法。
你可能会通过我们的线性回归课程,根据你的速度,你可能会通过后续课程,如机器学习中级、决策树和深度学习。
以这种相对缓慢的速度学习,你不太可能在这个时间框架内一直走到我们数据科学家之路的尽头,而且在你的未来仍有相当多的课程涉及自然语言处理和 Adobe Spark 等酷主题。
但是一旦你到了这一步,你应该准备好开始申请入门级的数据科学工作。你有编程技能,统计知识,并且在机器学习方面有很强的基础。尽管你应该永远计划继续学习,这些技能——以及你在获得这些技能时建立的项目组合——已经让你成为一个令人信服的候选人。
如果你不确定如何开始找工作,通读我们的数据科学职业指南将是一个很好的开始!
这只是您数据科学之旅的开始
假设你坚持每周只工作五个小时,到第一年学习结束时,你很可能已经完成了数据分析师道路,并在数据科学家道路的机器学习部分获得了坚实的立足点。
在这一点上,你完全有资格申请数据分析师的职位。我们有许多像 Pol Brigneti 这样的学生,他们已经完成了我们的数据分析师之路,并找到了全职数据分析师的职位。如果这是你的选择,那么你不需要太担心机器学习技能,你可以花额外的三个月时间来建立很酷的项目,申请工作,并向你的技能集添加新技能。(例如,既然你一直在学习 Python,那么学习 R 的基础知识也无妨,以防你遇到更喜欢它的工作)。
你也可以开始申请入门级的数据科学职位和实习,尽管在机器学习领域还有很多东西要学,在我们的数据科学道路上还有更高级的主题。
请记住,这是一个非常保守的估计。每周多花一点时间学习会让你走得更远、更快。每周大约 10 个小时,我们估计你可以在一年内完成整个数据科学家之路。
即使你不渴望走完数据科学这条路,在你找工作的时候,甚至在你找到工作之后,继续学习也是值得的。这是 Miguel 在我们的数据科学道路中途找到全职工作后告诉我们的。“尽管我将在 1 月份开始工作,但我仍将保持活跃,我将继续学习,因为显然我想达到其他途径。”
“我仍然认为 Dataquest 是最好的选择,”他告诉我们。“如果我只能选择一个,我会选择 Dataquest。”
2022 年如何学习数据科学(正确的方法)
October 17, 2022

对数据科学家的需求空前高涨。如果你正在考虑从事数据科学,现在是进入这个领域的好时机。
然而,不幸的现实是,大多数试图学习数据科学的人都失败了。他们失败是因为他们的方法充满了阻碍他们进步的缺陷。别担心:失败是 100%可以避免的。
快速有效地学习数据科学的关键是找到正确的方法。
这篇文章将展示大多数学习方法导致人们失败的 5 个原因。我将揭示正确的学习方法,这是我 10 年前从历史老师转型为机器学习工程师后发现的。
为什么大部分数据科学学习者会失败?
高准入门槛
许多想要学习数据科学的人放弃了,因为他们认为学习数据科学太昂贵了。训练营和认证项目可能会带来巨大的价格标签,把人吓跑。许多学习者没有意识到有更多负担得起的学习方式。
枯燥的课程
负担得起的课程并不能保证成功。许多在线课程由干视频讲座或其他人编写代码的录音组成。这并不吸引人,所以学习者最终会听之任之。
因此,这些类型的课程的完成率为 5%至15%。可能性不大。
生活阻碍了我们
许多数据科学课程都有严格的时间表。课程在特定的一周开始,在另一周结束,并且可能需要在特定的时间进行实时课程。
在线学习的人通常有工作、家庭或其他义务。这可能会使保持这些时间表成为一个挑战。
难度曲线偏离了
如果课程太容易或太难,大多数学习者最终会放弃。在线数据科学项目中的一个常见问题是,它们是由预先存在的课程拼凑而成的。一门课程可能看起来太简单,但下一门太难了。发生这种情况是因为这些课程不是一起构建的。
课程感觉不相关
当人们感觉自己朝着目标前进时,他们往往会坚持学习。但许多数据科学课程侧重于讲座和演练,而不是做真实世界的数据科学工作。这会让学习者感觉像是在踩水。
学习数据科学的正确方法
在我创建 Dataquest 之前,我自学了从从事非技术性工作到担任机器学习工程师所需的技能。
通过那次经历,以及过去八年来通过 Dataquest 获得数据科学技能的成千上万名学习者的经历,我开始了解到很多关于学习数据科学时什么可行,什么不可行。
这一切都内置于 Dataquest 体验中。
Dataquest 的“学习循环”
为了让学习者成功,我们需要感觉到自己在进步。这一点的重要性不能低估。我们需要感觉到我们可以立即使用我们正在学习的技能。
这就是 Dataquest 亲力亲为的原因。从第一天开始,你就要编写和运行真正的代码,使用真正的数据集。
在我们的并排学习平台中,您将在屏幕左侧阅读一个概念,然后挑战编写并运行实际代码,以在屏幕右侧应用您所学的内容。

这个简单的学习循环会在我们的每一门课程中重复。你学到一些新东西,然后立即将其应用到一个真实的数据科学问题中。每个屏幕都建立在前一个屏幕的基础上,并通向下一个屏幕。
这意味着随着你的学习,你会知道你已经真正掌握了材料,因为你正在使用它来做真正的数据科学工作。
你不是在看讲座。你不是在填空或者回答选择题。您正在编写和运行代码,就像在真正的数据科学工作中一样。
量身定制的课程路径
这种方法的一个重要部分是我们的课程被仔细排序,以确保没有空白。一门课程总会引出下一门课程,每门课程都有一个明确的目标。
例如,以下是我们的一些职业道路:
我们的许多学生喜欢这些途径,因为它们包含了他们获得一个职位所需要知道的一切。是啊,真的!如果你想成为一名数据分析师,你需要的每一点信息都在数据分析师职业道路之内。
另外,没有先决条件。任何人都能做到!
你可以点击上面的任何链接免费开始。
有趣的真实项目
虽然我们的所有课程都让您亲身体验真实数据,但我们也知道,在您学习的过程中综合这些技能至关重要。
这就是为什么我们的大多数课程都以引导式项目结束,这些项目挑战您使用您在之前的课程中学到的技能来回答真正的数据科学问题。
这些项目是有趣的学习工具,有助于巩固你的新知识,但当你找工作时,它们也会对你有所帮助,因为你可以将它们包含在你的项目组合中。(顺便说一句,招聘经理喜欢你这样做。)
数据科学路径中的示例项目包括:
- 越狱 —使用 Python 和 Jupyter Notebook 分析直升机越狱的数据集,玩得开心。
- App Store 和 Google Play 市场的盈利应用简介——在一家开发移动应用的公司担任假装的数据分析师。您将使用 Python 通过实际的数据分析来提供价值。
- 探索黑客新闻帖子——使用提交给黑客新闻的数据集,这是一个流行的技术网站。
- 探索易贝汽车销售数据——使用 Python 处理从德国易贝网站的分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
- 在 94 号州际公路 上寻找繁忙的交通指示器——探索如何通过 Jupyter 笔记本界面使用 pandas 绘图功能,使我们能够通过可视化快速浏览数据。
- 清理和分析员工离职调查 —处理澳大利亚昆士兰州教育部员工的离职调查。扮演数据分析师的角色,假装利益相关者想要重要数据问题的答案。
- 《星球大战》调查——配合 Jupyter 笔记本分析有关《星球大战》电影的数据。
成功原因:真正的成功故事
这种方法对我有效,对 Dataquest 的学生也有效!不过,你不必相信我的话。以下是一些新学员对他们的 Dataquest 体验的看法:
Perfist 的数据科学家 Dilara :“在我完成 Dataquest 课程后,我决定应该开始找工作或实习。我在**十天* *被聘为数据科学培训生,四个月就升职了。”
Clinfocus 的技术数据科学家 Rahila:Data quest 的浏览器内编码体验绝对赢得了我的心。我接触过很多平台,也和其他人一起尝试过免费的编码体验,但 Dataquest […]是更好的学习方式。”
分形分析公司的数据科学家维克多利亚说:“像统计学和编程这样的东西不容易学。但是 Dataquest 对它们的解释比所有其他资源都更清楚,即使是没有受过专业教育的人也能理解。”
你也不必相信他们的话!Dataquest 是免费的,所以开始吧,开始学习,看看 Dataquest 的不同之处能为您提供什么帮助。
学习做数据即在 R
原文:https://www.dataquest.io/blog/learn-data-visualization-r/
December 5, 2018One of the reasons that R is a top language for data science is that it’s great for data visualization. R users can take advantage of the wildly popular ggplot2 package to turn massive data sets into easily-readable charts in just a few lines of code. That can be incredibly valuable for presenting your data, but more importantly, when it’s done right, data viz is a tool for helping you understand what the data is telling you. That’s why we just launched a new course dedicated to teaching you how to do data visualization in R.
在本课程中,您将学习使用真实世界数据的ggplot2来构建五种不同的流行图表类型(包括您在上面看到的图表版本)。但更重要的是,你将学会何时使用不同的图表,以及如何正确解读它们。当然,除了学习一些新的编码技巧之外,你还会得到一些练习,使用你在我们的介绍性 R 课程中学到的基础知识编写干净、高效的 R 代码!这门课程包括四门全新的课程和一个新的指导项目。在学习过程中,您将构建并分析折线图来评估美国各种人群的预期寿命,使用直方图、条形图、箱线图和散点图来调查电影评论中的偏见,然后使用您的新技能来回答有关野火原因的问题(当然,使用真实世界的数据)。就像我们上个月推出的 R 课程一样,这门课程是由 R 母语的 Rose Martin 博士编写的,这意味着你将学习现代的、生产就绪的 R 代码。
为什么要学习 R 中的数据
这对发现洞察力至关重要
对数据进行可视化应该是几乎所有数据科学项目中的重要一步,因为查看数据可以揭示趋势、模式和问题,而通过其他方式可能不会注意到这些。特别是,一旦您了解了为什么以及如何使用本课程中介绍的流行图表格式,您将能够使用它们从数据中收集见解,这些见解在没有可视化(或可视化类型错误)的情况下很容易被忽略。
这也是交流的关键
然而,学习做数据 viz 不仅仅是为了你自己的利益。在大多数数据科学工作中,你必须向他人展示你的发现(包括不是数据科学家或统计学家的人)。在这些演示中,你的数据只有在可以理解的情况下才有价值,如果你的观众看不到你在说什么,你发现的见解可能会被当成耳旁风。数据可视化是你最好的交流工具之一,因为对于普通人来说,图表比数字和表格更容易理解,特别是如果它设计得很好的话(这里有一些快速而肮脏的图表设计技巧)。管理职位上的人可能不具备理解你的代码的技术知识,但他们通常非常熟悉阅读图表和图形,所以擅长数据 viz 有助于你说他们的语言。
深入研究数据,即
如果你准备好了,请点击这里开始学习课程。前三节课免费!如果你还没有完全准备好,我们的 R 入门课程是完全免费的,一旦你完成了这些课程,它们将为你打下基础,让你满怀信心地投入到这个数据即课程中去。
新课程:面向数据工程师的数字课程
原文:https://www.dataquest.io/blog/learn-numpy-for-data-engineering/
May 21, 2020
Python 编程是数据工程师的一项关键技能。当涉及到处理数据时,有一个强大的库可以显著提高代码的效率,尤其是在处理大型数据集时: NumPy 。
这就是为什么我们为数据工程师课程 增加了一个 号到我们的数据工程路径!

目前,这是我们数据工程道路上 14 门课程中的第九门——我们最近还增加了一门关于算法复杂性的课程。
完成数据工程路径需要高级订阅,但您可以使用免费帐户试用新课程的第一课或路径中的任何其他课程,无需信用卡!
我将从这门课程中学到什么?
本课程为数据工程师提供了关于 NumPy 的从头开始的教育。这意味着您不需要有任何使用 NumPy 的经验,并且您不会浪费任何时间去学习与数据工程工作无关的东西。
在浏览了基础知识之后,您将很快开始使用 NumPy 构建和操作二维和三维数组。控制数组将允许您一次对大量数据执行计算,而不是逐行循环,从而节省您的时间和处理能力。
随着课程深入到 NumPy 的更高级应用,您还将学习如何评估内存使用情况,并了解 NumPy 的局限性。这为我们的数据工程师之路的下一个课程提供了一个很好的引导:在 Pandas 中处理大型数据集。
在这两个课程结束时,你将能够使用你的 Python 技能和你的新 NumPy 和 Pandas 知识来处理和处理巨大的数据集,比使用普通的 Python 要有效得多。
当然,您将在我们的交互式浏览器平台上完成所有这些工作。您将处理真实数据,编写和运行真实代码,而不必担心下载数据集、安装库或任何其他麻烦。
为什么数据工程师需要学习 NumPy?
NumPy 是 Python 中最流行也是最强大的数据工作库之一。事实上,它非常强大,以至于最流行的 Python 数据科学库 pandas 依赖并利用了一些 NumPy 功能。
从数据工程师的角度来看,NumPy 的主要优势是它允许您使用数组进行矢量化数学运算。这种方法比一次遍历数据集的每一行来执行计算要高效得多。
与“普通”Python 相比,NumPy 中的数组操作所提供的效率对于数据工程师来说尤为重要,因为他们经常要处理大量的数据,并且需要尽可能快地处理这些数据。
准备好开始学习 NumPy 了吗?免费尝试新课程(不需要信用卡!)
或者,从头开始我们的数据工程职业道路(免费试用,不需要任何经验)。
成为一名数据工程师!
现在就学习成为一名数据工程师所需的技能。注册一个免费帐户,访问我们的交互式 Python 数据工程课程内容。
(免费)

https://www.youtube.com/embed/ddM21fz1Tt0?rel=0
一位首席执行官解释如何在 2022 年学习 Power BI(循序渐进)
April 11, 2022
为什么要学 Power BI?
微软 Power BI 是全球使用最广泛的数据工具之一。全球有 50,000 家公司使用 Power BI 来清理、转换、建模和可视化他们的数据。
Power BI 的使用一直在快速增长,LinkedIn 上有超过 80,000 个空缺职位。大多数业务分析师和数据分析师定期使用 Power BI。通过学习 Power BI,您可以加速您的职业发展,成为一名数据专家。
向雇主证明您的 Power BI 技能的最佳方式是获得微软 Power BI 数据分析师认证。获得认证让雇主知道你可以使用像 DAX、M 语言和 Power 查询编辑器这样的 Power BI 特性。
要获得认证,你需要参加 PL-300 考试(DA-100 考试的更新版本)。要通过 PL-300 考试,您需要具备使用 Power BI 界面的所有方面的经验。
如果你想在求职面试中脱颖而出,你还应该建立一个项目组合。投资组合将表明你可以在现实世界中进行复杂的分析。
在本帖中,我们将通过 5 个步骤获得真实世界的 Power BI 经验,获得认证,并建立产品组合。这需要工作和努力,但如果你遵循这些步骤,你将能够开始一个新的数据职业生涯。
如何学习 Power BI 并获得认证
Power BI 有一个友好的图形界面,但在表面之下有很多复杂性。看视频或者看教程,很容易假设自己学过 Power BI。但是要通过考试并为工作做好准备,你需要实践技能。
培养动手能力 BI 技能的最佳方式是创建项目。项目反映了真实世界的数据分析,并将帮助您获得从加载数据到清理数据再到可视化的经验。
在我们的 5 个步骤中,我们将向您展示如何通过构建项目来实际学习 Power BI 技能。有了实践技能,你将为 PL-300 考试和工作面试做好准备。
如果你想更快地学习,我们还与微软合作了一系列 Power BI 课程,将教你通过 PL-300 考试所需的一切。
第一步:熟悉界面
学习 Power BI 的第一步是安装,熟悉界面。
幸运的是,Power BI 是从微软免费下载的。Power BI 仅在 Windows 上运行,因此如果您不使用 Windows,您将需要在虚拟机中运行 Power BI。
安装 Power BI 后,您应该熟悉界面的主要部分。这里有一些资源可以帮助你:
- 动手能力商务智能入门课程–这一互动课程将在让您动手实践的同时,教会您基础的商务智能
- Microsoft Power BI 快速入门指南-帮助您导航 Power BI 的指南
不要在界面上花太多时间。你的目标应该是尽快开始使用真实数据。
第二步:建立一些可视化!
您的下一步应该是使用干净的数据集在报告视图中开发一些可视化。您希望数据集不需要做太多建模或数据清理工作。
这将为您提供导入数据和创建报告的经验。以下是一些可用于创建可视化效果的数据集:
这些数据集不需要太多的数据清理就可以做出一些有趣的可视化效果。
您还可以使用这些参考资料来学习如何在 Power BI 中构建可视化:
- 动手能力商务智能可视化课程-这一互动课程将教你如何创建和分享商务智能可视化
- 微软 Power BI 可视化指南–Power BI 中不同可视化的概述
- Power BI 示例报告–该示例报告将帮助您了解报告的主要功能
步骤 3:建模和清理数据
一旦您理解了如何构建可视化,您就可以使用 Power BI 进行更复杂的分析。这涉及到构建数据模型、使用 DAX 计算值以及使用 Power Query 编辑器清理数据。
这些特性起初看起来很复杂,但是你可以通过构建项目一个一个地学习它们。
以下是一些数据集,您可以使用它们来探索数据建模和数据清理:
- 奥运选手——这里有从 1896 年至今的奥运选手信息。您可以对两个文件—
noc_regions.csv和olympic_athletes.csv之间的关系进行建模。您还可以将这些数据集与其他数据集相结合,例如国家人口。 - 国际足联数据(FIFA data)–这包含了流行的足球视频游戏 FIFA 的球员评分。你可以把这个数据集和其他数据集结合起来,比如国家人口,或者 gdp 。
如果您想要了解如何分析这些数据集,我们制作了视频演示来帮助您:
您还可以使用这些参考资料来了解如何在 Power BI 中建模和清理数据:
- 动手操作 Power BI 建模课程–本互动课程将教您如何在 Power BI 中建模和清理数据
- 微软 Power BI 数据建模指南—Power BI 中的数据关系概述
- Power BI 示例报告–这些报告将帮助您了解如何在 Power BI 中清理和建模数据
步骤 4:发布您的报告
当您在工作环境中使用 Power BI 时,您需要能够在整个团队中共享您的分析。这是通过使用电源 BI 服务完成的。
在 Power BI desktop 中创建报告后,您可以将它们发布到 Power BI 服务并与其他人共享。
要练习发布您的结果,您需要注册 Power BI 服务,并熟悉该界面。这些资源可以帮助:
- Dataquest Power BI 技能途径–本实践课程将教您如何管理工作空间和 Power BI 服务
- 开始使用 Power BI 服务–本文将帮助您注册 Power BI 服务并迈出第一步
- 微软工作区指南–该指南将帮助您在 Power BI 服务中使用工作区
步骤 5:建立项目组合
一旦您理解了 Power BI 的所有主要特性,您将需要能够将所有这些技能整合到一个端到端的工作流中。
该工作流程包括:
- 查找数据集并将其加载到 Power BI 中
- 使用超级查询编辑器清理数据
- 数据建模和建立关系
- 使用 DAX 计算任何需要的列
- 创建可视化和报告
- 发布这些报告
确保您使用几个数据集完成了这个端到端的过程,以便您可以完全理解如何使用 Power BI 和所有功能。
你也可以利用你为这些项目所做的工作来创建一个作品集。作品集是你已经完成的项目的汇编,你可以在你的 Github 个人资料、简历或个人网站上向雇主强调这些项目。
以下是查找可用于投资组合的数据集的一些地方:
- Data.gov——查找美国政府数据的好地方
- 美国国家海洋和大气管理局(NOAA)——你可以从这个网站下载天气数据进行分析
- 你可以在这里找到大量的市场调查和经济数据
获得认证
一旦您熟悉了所有关键的 Power BI 特性并完成了几个端到端项目,您就可以准备好参加 PL-300 认证考试了!
考试需要的主要技能是:
- 准备数据(导入、清理、转换数据)
- 数据建模(设计数据模型、使用 DAX、优化性能)
- 可视化和分析数据(创建报告、增强报告和识别趋势)
- 部署资产(管理文件和工作区)
你可以在这里看到关于考试将评估的技能的更多细节。
如果你遵循了上面的步骤,你应该具备通过考试所需的所有主要技能!
学动力 BI 要多久?
读完这些步骤后,人们问我们的最常见的问题是:“所有这些需要多长时间?”
学习 Power BI 并获得认证可能需要 1 到 6 个多月的时间。
我们看到人们以闪电般的速度通过我们的课程,而其他人则慢得多。这完全取决于你想要的时间表、你可以用来学习 Power BI 的空闲时间以及你学习的速度。
幸运的是,我们的互动 Power BI 课程是为您创建的,您可以按照自己的速度进行。我们与微软合作,以确保你学会通过 PL-300 考试所需的一切,并为工作做好准备。
Javier:在 Dataquest 在线学习编程比在大学学习要好
原文:https://www.dataquest.io/blog/learn-programming-online-university/
May 10, 2019
哈维尔·费尔南德斯·苏亚雷斯(Javier Fernández Suárez)在大学毕业时遇到了许多毕业生都有的问题:他真的不知道自己想做什么。
作为一名学生,哈维尔已经爱上了物理,这就是他在学校追求的。一路上,他学习了一些 Matlab、C++编程,然后寻找 Python 课程,因为他喜欢编码工作。
“我真的很喜欢学位的这一部分,”他说。“但在获得学位后,老实说,我不清楚该做些什么。”
Javier 知道数据科学是一个选择,但他并没有仔细研究过,直到一个研究数据科学的朋友在伦敦拜访他,并向他展示了他如何使用 Dataquest 在线学习编程。“我看到这正是我在寻找的,”哈维尔说。
“混合数学、编程、统计的机会,同时像逻辑或一点商业一样,能够给出见解——这真的很吸引我,”他说。
哈维尔最终报名参加了位于伦敦的贝尔格雷夫谷训练营,该训练营将 Dataquest 的在线编程和统计课程与职业支持和指导相结合。随着他深入研究 Dataquest,他很快发现这与他在学校接受的编程培训不同。
在线学习编程与在校学习编程
Javier 说:“我不得不说,我在大学时的老师真是不可思议,但即使从这个角度考虑,我也相信 Dataquest 是一种更好的学习编程的方式。”
毕竟,即使是一个伟大的老师,也不得不应对大学的大班额——哈维尔说他的班级有 50-80 人。在讲堂里教授动手编程是困难的,而在 Dataquest,Javier 可以学习一个新概念,然后在同一个浏览器窗口中立即实践应用它。

他还发现 Dataquest 教授的是他大学编程课程中没有涉及的重要专业技能。例如,他的大学 Python 培训没有包含任何pandas,尽管这个包对于 Python 中的日常数据科学工作至关重要。他没有接触过 SQL,这是数据科学家的另一种重要语言。
Dataquest 提供了这两种技能的全面培训,以及更多的培训。
所有这些对哈维尔来说都有点意外。“在我的国家西班牙,我们对在线课程的声誉有一个非常糟糕的想法。我们倾向于认为它们并不是真的好。但对我来说,Dataquest 是一种比学校更好的学习方式。”
学习和找到工作
Javier 在 Belgrave 几乎全职研究 Dataquest,仅用了两个月的时间就掌握了就业所需的所有技能。“我从 9 点到 5 点和 Dataquest 在一起,只有一个小时的午餐时间,”他说。几个月后——他的求职确实因寒假而有所延迟——他发现自己处于令人羡慕的境地,有两份竞争性的工作机会可供选择。
“我选择了一个名为 SportPursuit 的网站,总部设在英国,销售运动器材,”他说。作为初级 Data Insight 分析师,他负责分析客户和销售数据,以帮助公司更有效地锁定客户。他还帮助公司的其他团队提供他们需要的数据。
“我现在的角色很完美,”他说。"我正在同时学习编程、统计和商业."
如果你希望有一天能站在 Javier 的立场上,他确实有一些建议可以传授,至少对那些像他一样决定用 Dataquest 在线学习编程的学生来说是这样。首先,他建议尽可能多的花时间在 Dataquest 上。“如果你有机会只专注于做 Dataquest,我推荐它,”他说。"也许休息一个月,每天只做数据查询."
他还建议 Dataquest 的学生尽量避免看答案,即使这很痛苦。“你可能会花四个小时寻找一个愚蠢的错误,可能只是删除一个逗号,”他说,“但你永远不会再犯同样的错误。”
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何为数据科学(或其他)从零开始学习 Python
January 9, 2019
大约有一百万个网站承诺帮助你从头开始学习 Python。但是,如果你曾经尝试过学习 Python,你可能会注意到它可以是 extr
开始很难,进步更难。你可能曾经尝试过学习编码并放弃了,认为这不是你擅长的事情。
如果这听起来像你,我们有一些好消息:你绝对可以从零开始学习 Python,没有任何编程经验。如果你以前尝试过但失败了,那可能不是你的错。
有三个主要原因导致新的 Python 程序员在取得任何重大进展之前就放弃学习。
原因 1:好的程序员,坏的老师
大多数“学习代码”资源都是由真心希望帮助他人学习的程序员创建的。但遗憾的是,做一个好的编码者和做一个好的老师并不一定有太多的重合。对于使用 Python 多年的有经验的程序员来说,很难把自己放回初学者的位置。
现实是,如果你第一次遇到许多编程概念,你很难理解它们。例如,考虑 Python 索引列表等数据类型的方式。如果你来自一个编程背景,把列表中的第一项算作第 0 项是完全有意义的。但是普通人是从一开始计数的,不是零!
当然,Python 使用零索引有很好的理由。但是编程充满了这样的概念。对于有经验的程序员来说,它们是有意义的,但是对于试图从头开始学习编程的人来说,它们可能显得非常不直观。
有经验的程序员通常很难记住和理解这些早期的斗争,所以在他们创建的学习材料中,他们希望你“理解就好”这对一些学生有用,但也让很多人感到沮丧和失望。
在我们真正掌握具有挑战性的新概念之前,我们大多数人都需要良好的解释、背景和实践。许多 Python 学习资源,包括那些承诺帮助您“从零开始学习 Python”的资源,提供了对那些已经被训练成像程序员一样思考的人来说完全有意义的解释,但是对我们其他人来说很难解析。这导致人们辍学。
原因 2:缺少动力

试图从头开始学习 Python 的人经常停下来的另一个原因是因为他们已经失去了动力。在传统教育中,这通常被认为是学生的失败。在 Dataquest,我们认为这是一次教学失败。
没有足够的动机是很难学习任何东西的。最强的激励因素之一实际上是能够使用你正在学习的技能。这是很多 Python 学习资源失败的地方。他们让你通过死记硬背的练习来学习语法,或者编写与你想要学习 Python 的原因毫无关系的无意义的程序。
如果你已经开始学习,很容易就掉链子,停止学习,因为你想学习 Python 来进行数据科学,但是你在学习的时候并没有真正地处理数据。
原因 3:“学习”但不应用
应用你所学的东西对于长期记忆来说是绝对重要的。研究经过研究证明。
这很重要,因为许多学生试图利用书籍或视频讲座等流行资源从头开始学习 Python。虽然这些资源通常很好,但它们不能强迫你去应用你所学的东西。即使你真的留出一些时间来写你自己的代码,例如,在读完教科书的一章之后,书也没有办法给你提供任何反馈,或者让你知道什么时候你做错了。
这并不是说你不应该从书本或视频中学习——两者都是无价的资源!但是如果你不小心的话,他们也会欺骗你,让你觉得你理解了一个概念,而实际上你并不理解。可能只有几天或几周后,当你去写你自己的代码时,你才意识到你并没有像你想象的那样理解事情。

在 Python 中有很多东西要学,但是你不需要知道所有的东西来做有意义的工作。
解决方案:如何从头开始学习 Python
如果您想最大限度地提高成功学习 Python 的机会,显然您需要采取一种方法来帮助您避免这三个陷阱。你不只是想学 Python,你还想用正确的方式学习 Python。
第步是弄清楚你为什么要学习 Python。其他的一切都源于此,您所采用的方法将会根据您是想学习 Python 用于数据科学还是机器人技术还是游戏开发还是其他什么而有所不同!
第二步是学习 Python 的基本语法。这里重要的词是基本。不需要什么都学,也不应该学。学习语法是必要的,但它可能会有点无聊,并且您希望最大限度地减少花在学习语法上的时间。你的目标应该是了解你开始从事对你重要的项目所需的最起码的知识。
如果你能找到适合你想学习 Python 的原因的学习资源,你可以使这一步变得容易一些。例如,如果你想为数据科学学习 Python,我们的初级和中级 Python 课程都是免费的,将教你从头开始构建数据科学项目所需的所有语法,同时让你处理真实世界的数据,这使得学习语法的过程对有兴趣学习数据技能的人来说更有吸引力。
第三步是构建结构化项目。给找一个可以跟随的教程可能是个不错的方法。对数据科学感兴趣的学生可以尝试一些我们的指导项目,这些项目旨在鼓励实验和创造力,同时仍然提供结构和指导。
这篇文章提供了许多其他资源,用于寻找跨越各种编程学科的结构化项目想法,包括游戏开发、机器人技术等。例如,如果你想开发移动应用,这个 Kivy 教程是一个很好的第一个项目。如果你想做游戏,看看这些 Pygame 教程。关键是尽快开始你真正感兴趣的项目。
第四步是随着你继续发展自己的能力,建立越来越复杂的独特项目。在完成一些指导性项目后,你可能会有一些自己想尝试的想法。尽管你认为自己不具备成功所需的所有技能,也要努力去做。当你需要的时候,你会在过程中学习这些新技能。
关键是将每个项目分解成小的、可管理的部分。例如,假设您想要分析 Twitter 上的情绪。这是一个令人生畏的大项目,但是你可以把它分解成更小的任务,然后一个接一个地学习。首先,你可能需要学习如何访问和使用 Twitter 的 API。一旦你明白了这一点,继续学习如何过滤和存储你想要分析的推文。然后,您可以继续清理数据,之后您可以研究情感分析的方法。
您可以对各种项目采取类似的方法。你不需要知道所有关于如何做一个项目来开始一个项目!将项目分成几个部分,一部分一部分地学习。
你会花很多时间去搜索 Google、StackOverflow、 Python 的官方文档,也没问题!关于编程,一个不那么秘密的行业秘密是,即使是专业人士也会花大量的时间在谷歌上搜索问题。
第五步实际上只是继续第四步,但是会增加你所承担的每个项目的难度。如果你在一开始就知道如何实现项目的每个部分,这是一个好的迹象,表明它对你来说可能太容易了,你不会从中学到什么。
关键是让事情充满挑战,但不是不可能。如果你正试图学习用 Python 制作游戏,并且你已经制作了一个简单的游戏,比如 Snake ,你的下一个项目不应该是一个沉浸式开放世界 3D RPG。这太快增加了太多的难度。但是应该开发一个比贪吃蛇稍微复杂一点的游戏。
去哪里学 Python
显然,有很多地方可以学习基本的 Python 编码技能,我们鼓励学生寻找最适合他们的资源。如果您对学习 Python 进行数据科学感兴趣,Dataquest 有一些您在别处可能找不到的独特优势:

简而言之,Dataquest 平台。
- 独一无二的平台,以动手学习为主 。我们想让你尽可能快地处理代码并尝试每个新概念。你永远不会超过一两分钟而没有机会应用你所学的东西,有了我们的平台,你可以在浏览器窗口中编写和检查 Python 代码。
- 易于搜索的、基于文本的内容。视频可以很有趣,但是如果你必须在有机会应用你所学的任何东西之前观看 30 分钟的视频,你将浪费大量的时间来浏览视频,试图找到正确的时刻来复习你已经忘记的概念。Dataquest 基于文本的学习内容更准确地反映了作为一名数据科学家的工作现实(在这种情况下,您经常需要查阅书面文档),并且搜索以前的课程并找到您想要的内容非常容易。
- 真实数据和有趣项目。如果你在没有任何意义的项目中处理无聊的、虚假的数据,很难有学习的灵感。这就是为什么我们使用真实世界的数据来回答真实世界的问题,并帮助您在申请工作时建立可以在您的数据科学投资组合中使用的项目。
如果你想为数据科学从零开始学习 Python,我们认为
我们免费的 Python 入门课程是理想的起点。
如果你因为其他原因想要学习 Python,你会想要寻找特定于你的目标的学习资源。
如果你找不到,一般的“学习 Python”资源也可以——只要记得尽快开始构建项目和从事激发你的事情。最终,这将使你坚持下去,并确保你真的成为新的程序员,他们可以真正声称你是从零开始学习 Python 的。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
2023 年如何学习 Python(循序渐进)
原文:https://www.dataquest.io/blog/learn-python-the-right-way/
December 23, 2022
学习 Python 对我来说极其困难,但也不尽然。
十多年前,我是一名大学毕业生,拥有历史学位,前途渺茫。然后,我成为了一名成功的机器学习工程师、数据科学顾问,现在是 Dataquest 的 CEO。
然而,这并不是一夜成功的故事。我学习 Python 的旅程漫长、低效,而且经常令人沮丧。
如果我能再做一次,我会按照我将在这篇文章中与你分享的步骤去做。它会加速我的职业生涯,节省数千小时的浪费时间,并避免很多压力。
本指南将向您展示如何以正确的方式学习 Python。
第一步:了解大多数人失败的原因
学习 Python 并不一定很难。事实上,如果你使用正确的资源,这实际上很容易(也很有趣)。
大多数学习资源的问题是
很多课程让学习 Python 变得更加困难。为了说明我的观点,我给你举一个个人的例子。
当我刚开始学习 Python 时,我想做让我兴奋的事情,比如制作网站。不幸的是,我所学的课程迫使我在语法上花了几个月的时间。太痛苦了。
在整个课程中,Python 代码看起来仍然很陌生,令人困惑。它就像一种外星语言。毫不奇怪,我很快失去了兴趣。
遗憾的是,大多数 Python 教程都与此非常相似。他们假设在开始做任何有趣的事情之前,您需要学习所有的 Python 语法。大多数人放弃有什么奇怪的吗?
与其在这些平凡的任务上浪费时间,不如体验一下 Python 真正的刺激。想想分析数据,建立一个网站,或者创造一个具有人工智能的自主无人机!
更简单的方法
经过多次失败的尝试,我找到了一种更适合我的方法。事实上,我相信这是学习 Python 编程的最好方法。
首先,我花尽可能少的时间去记忆 Python 语法。然后,我带着我学到的东西,立即一头扎进一个我真正感兴趣的项目。
遵循下面列出的步骤不仅更有趣,还能让你以惊人的速度学习!
事实上,这种更好的学习方式是我创建 Dataquest 的原因。我们的数据科学课程将让您用最少的时间做枯燥的事情,立即构建项目。点击这里查看我们的课程。报名免费。
第二步:确定你的动力
好消息是:只要有正确的动机,任何人都可以熟练掌握 Python。
作为一个初学者,当我试图记忆语法时,我努力让自己保持清醒。然而,当我需要应用 Python 基础知识来构建一个有趣的项目时,我高兴地熬了一整夜来完成它。
这里的教训是什么?你需要找到激励你的东西,并为此感到兴奋!首先,找到一两个你感兴趣的领域:
- 数据科学/机器学习
- 移动应用
- 网站
- 计算机科学
- 比赛
- 数据处理和分析
- 硬件/传感器/机器人
- 自动化工作任务

Yes, you can make robots using the Python programming language! From the Raspberry Pi Cookbook.
第三步:快速学习基本语法
我知道,我知道。我说过我们会在语法上花尽可能少的时间。不幸的是,这一步不能完全跳过。
这里有一些很好的资源,可以帮助您学习 Python 基础知识,而不会扼杀您的学习动力:
- Dataquest——Python for Data Science 基础课程 —我创办 Data quest 是为了让学习 Python 和数据科学更容易。Dataquest 在学习数据科学的背景下教授 Python 语法。例如,您将在分析天气数据时学习基本的 Python 命令。
- 艰难地学习 Python——这本书教授从基础到更深入程序的 Python 概念。
- Python 教程 —主要 Python 站点上的教程。
我怎么强调都不为过:尽你所能学习语法,然后继续前进。理想情况下,你会在这个阶段花上几周时间,但不会超过一个月。
你越早开始做项目,你学得就越快。如有必要,您可以随时回头参考该语法。
快速说明:学 Python 3,不学 Python 2 。不幸的是,网上很多“学习 Python”的资源还是教 Python 2。但是 Python 2 是不再支持,所以 bug 和安全漏洞不会被修复!
第四步:制作结构化项目
一旦你学会了基本的 Python 语法,就开始做项目吧。马上应用你的知识会帮助你记住你所学的一切。
最好从结构化的项目开始,直到你觉得足够舒服可以自己做项目。在 Dataquest,我们战略性地将结构化项目纳入了几乎所有的 Python 课程。这样,你可以立即应用你所学到的东西。
下面是一些实际 Dataquest 项目的例子。哪个点燃了你的好奇心?
- 越狱:大多数直升机越狱发生在何时何地?通过这个针对 Python 初学者的指导性项目来寻找答案。
- 员工离职调查:该结构化项目专为具备中级技能的 Python 用户设计,让您清理数据集,为澳大利亚昆士兰州教育部的利益相关者找到答案。
- 数据清理和可视化星球大战风格:星球大战的粉丝们不会想错过这个使用电影中真实数据的结构化项目。
结构化项目的灵感
说到结构化项目,没有一个合适的起点。对你来说最好的资源将取决于你的动机以及你对 Python 编程的目标。
你对通用数据科学还是机器学习感兴趣?你想建立一个特定的应用程序或网站吗?以下是一些推荐的灵感资源,按类别分类:
数据科学/机器学习
- Dataquest —以互动方式教你 Python 和数据科学。您分析了一系列有趣的数据集,从中情局文件到 NBA 球员数据。你最终会构建复杂的算法,包括神经网络和决策树。
- Scikit-learn 文档 — Scikit-learn 是主要的 Python 机器学习库。它有一些很棒的文档和教程。
- 这是哈佛大学教授 Python 数据科学的课程。他们在网上有一些他们的项目和其他材料。
手机应用
- Kivy 是一个让你用 Python 制作移动应用的工具。他们有入门指南。
网站
- Bottle 教程 — Bottle 是 Python 的另一个 web 框架。以下是入门指南。
- 如何与 Django 合作——Django 使用指南,一个复杂的 Python web 框架。
游戏
- Pygame 教程 —这是 Pygame 的教程列表,这是一个流行的制作游戏的 Python 库。
- 用 Pygame 制作游戏——一本教如何用 Python 制作游戏的书。
用 Python 发明你自己的电脑游戏——这本书将带你了解如何用 Python 制作几个游戏。

An example of a game you can make with Pygame. This is Barbie Seahorse Adventures 1.0, by Phil Hassey.
硬件/传感器/机器人
- 使用 Python 和 Arduino —了解如何使用 Python 控制连接到 Arduino 的传感器。
- 使用 Raspberry Pi 学习 Python—使用 Python 和 Raspberry Pi 构建硬件项目。
- 使用 Python 学习机器人学 —学习如何使用 Python 建造机器人。
- 树莓派食谱 —了解如何使用树莓派和 Python 制作机器人。
自动化工作的脚本
- 使用 Python 自动化枯燥的工作 —了解如何使用 Python 自动化日常任务。
项目至关重要。它们拓展你的能力,帮助你学习新的 Python 概念,并允许你向潜在雇主展示你的能力。一旦你完成了一些结构化的项目,你就可以继续做你自己的项目了。
第五步:独立完成 Python 项目
在你完成几个结构化的项目后,是时候加快进度了。你可以通过从事独立的 Python 项目来加速你的学习。
这里是关键:从小项目开始。完成一个小项目比着手一个永远无法完成的大项目要好。
发现迷人 Python 项目的 8 个技巧
我知道找到一个好的 Python 项目可能会令人望而生畏。以下是找到有趣项目的一些提示:
- 扩展您之前正在处理的项目,并添加更多功能。
- 查看我们为初学者准备的 Python 项目列表。
- 去你所在地区的 Python meetups 网站,寻找从事有趣项目的人。
- 寻找开源软件包来为之做出贡献。
- 看看当地是否有非营利组织在寻找志愿者开发者。
- 找到其他人已经完成的项目,看看你是否可以扩展或修改它们。Github 是一个很好的起点。
- 浏览别人的博客文章,找到感兴趣的项目创意。
- 想想能让你的日常生活变得更轻松的工具。然后,建造它们。
17 Python 项目创意
需要更多灵感?这里有一些额外的想法来激发你的创造力:
数据科学/机器学习项目创意
- 按州显示选举投票的地图
- 预测当地天气的算法
- 预测股票市场的工具
- 自动总结新闻文章的算法

Try making a more interactive version of this map from RealClearPolitics.
手机 App 项目创意
- 追踪你每天行走距离的应用程序
- 向你发送天气通知的应用程序
- 基于位置的实时聊天
网站项目创意
- 一个帮助你计划每周膳食的网站
- 允许用户评论视频游戏的网站
- 笔记平台
Python 游戏项目创意
- 一款基于地理位置的手机游戏,你可以在其中占领领地
- 一种通过编程解决谜题的游戏
硬件/传感器/机器人项目创意
- 远程监控你房子的传感器
- 更智能的闹钟
- 探测障碍物的自动驾驶机器人
工作自动化项目创意
- 自动化数据输入的脚本
- 从网络上抓取数据的工具
关键是挑一件事去做。如果你太执着于寻找完美的项目,你就有可能永远不会开始一个项目。
我的第一个独立项目包括将我的自动论文评分算法从 R 移植到 Python。它最终看起来并不漂亮,但它给了我一种成就感,并让我开始了建设技能的道路。
记住:障碍是不可避免的。当你构建你的项目时,你会在你的代码中遇到问题和错误。这里有一些资源可以帮助你。
3 个摆脱困境的最佳 Python 资源
不要让挫折使你气馁。相反,请查看以下资源:
- StackOverflow —一个社区问答网站,人们在这里讨论编程问题。你可以在这里找到 Python 特有的问题。
- 任何有经验的程序员最常用的工具。在尝试解决错误时非常有用。这里有一个的例子。
- Python 文档 —查找 Python 参考资料的好地方。
第六步:继续做更难的项目
当你在独立项目中获得成功时,不断增加项目的难度和范围。学习 Python 是一个过程,你需要动力来完成它。
一旦你对你正在构建的东西完全满意了,是时候尝试更难的东西了。继续寻找挑战你的技能并推动你成长的新项目。
5 个掌握 Python 的提示
当那个时刻到来时,这里有一些想法:
- 试着教一个新手如何构建你的项目。
- 问问你自己:你能扩展你的工具吗?它能处理更多的数据吗,或者它能处理更多的流量吗?
- 试着让你的程序运行得更快。
- 想象一下如何让你的工具对更多的人有用。
- 想象一下如何把你做的东西商业化。
与 Python 一起前进
记住,Python 是不断发展的。世界上只有少数人能声称完全理解 Python。而这些就是创造它的人!
那会给你留下什么?在不断的学习和新项目的工作中磨练你的技能。
六个月后,你会发现自己回头看你的代码时会想到它有多糟糕。不要绝望!当你到了这一步,你就知道你走对了。
如果你是那种依靠最小的结构而茁壮成长的人,那么你就拥有了开始你的旅程所需要的一切。然而,如果你需要更多的指导,那么我们的课程可能会有所帮助。
我创建 Dataquest 是为了帮助人们快速学习,避免那些通常会让人放弃的事情。您将在几分钟内编写实际代码,并在几小时内完成真正的项目。
如果你想学习 Python 成为一名商业分析师、数据分析师、数据工程师或数据科学家,我们为你设计了职业道路,让你在几个月内从完全的初学者到工作就绪。或者,您可以先尝试一下,在这里试驾一下我们的Python 入门课程。
常见 Python 问题
学 Python 难吗?
学习 Python 肯定会很有挑战性。然而,如果你采取我在这里概述的一步一步的方法,你会发现这比你想象的要容易得多。
可以免费学习 Python 吗?
有很多免费的 Python 学习资源。例如,在 Dataquest,我们有几十个免费的 Python 教程。你可以免费注册我们的互动数据科学学习平台。
免费学习有一个缺点:为了有效地学习,你需要拼凑几个免费资源。这意味着你要花额外的时间研究下一步需要学什么以及如何学。
优质平台可能会提供更好的教学方法(如交互式浏览器内编码 Dataquest 提供的)。它们也节省了你寻找和建立自己的课程的时间。
可以从零开始学习 Python 吗(没有编码经验)?
是的。Python 对于编程初学者来说是一门很棒的语言,因为你不需要有代码方面的经验就能掌握它。Dataquest 帮助没有编程经验的学生找到数据分析师、数据科学家和数据工程师的工作。
学习 Python 需要多长时间?
学习一门编程语言有点像学习一门口语——你永远不会真正完成!那是因为语言在进化,所以总是有更多的东西要学!不过,你可以很快掌握编写简单但功能强大的 Python 代码。
做好工作准备需要多长时间?这取决于你的目标,你正在寻找的具体工作,以及你能投入多少时间来学习。
我们在 2020 年调查的 Dataquest 学习者报告称,他们在不到一年的时间内达到了学习目标。许多人在不到六个月的时间里就做到了。这还不包括每周不超过 10 小时的学习。
怎样才能更快的学习 Python?
找一个专门针对你想学习的技能(例如,游戏开发的 Python 或数据科学的 Python)教授 Python 的平台(或者为自己建立一个课程)。
这样,您就不会浪费时间去学习与日常 Python 工作无关的东西。
找工作需要 Python 认证吗?
大概不会。在数据科学中,证书没有多大分量。雇主关心的是技能,而不是纸文凭。
翻译?一个充满 Python 代码的 GitHub 比一张证书重要得多。
应该学 Python 2 还是 3?
Python 3,手到擒来。几年前,这还是一个争论的话题。一些极端分子甚至声称 Python 3 将“杀死 Python”这还没有发生。今天,Python 3 无处不在。
Python 与数据科学/机器学习之外的相关吗?
是的。Python 是一种流行且灵活的语言,在各种各样的环境中被专业地使用。
我们为数据科学和机器学习教授 Python。不过,您可以将 Python 技能应用到另一个领域。你会发现它被用于金融、网络开发、软件工程、游戏开发等等。
掌握一些 Python 的数据分析技能对于各种各样的其他工作也很有用。例如,如果您处理电子表格,那么使用 Python 有可能会做得更快更好。
Python 的影响力真的是无止境的。成为革命的一部分。准备好开始了吗?了解更多关于 Dataquest 如何帮助您在线学习 Python的信息,并立即注册,没有任何风险。
通过我们新的 R 课程学习 R 进行数据分析!
原文:https://www.dataquest.io/blog/learn-r-data-analysis-data-science/
July 15, 2020
激动人心的消息!我们知道,对于任何想学习数据分析和数据科学的人来说,R 是最重要的编程语言之一。这就是为什么我们刚刚推出了四门新的 R 课程——对我们的数据分析师 R 职业道路的第一步进行了全面改造!

这四门新课程旨在让你更容易从零开始学习 R,帮助你建立更好的 R 编程基础。
与我们所有的课程一样,它们也旨在通过让您从第一天开始就动手工作、编写真实代码和使用真实数据来保持您的动力。
这四门新课程是:
新课程还引入了新的指导项目,通过在学习的同时构建真实的数据分析项目来帮助你综合新的 R 技能。
我们将帮助您在您的机器上设置一个本地 R 环境,然后指导您完成分析新冠肺炎趋势数据和查看图书销售数据的项目,以收集关于营销活动和评论对销售的影响的见解。
我需要一个初学者的资源;一些带着清晰、详细的说明带我走过基础的东西。这正是我在 Dataquest 的 R 课程介绍中得到的信息。
因为 Dataquest,我开始读研,在 R 方面有很强的基础,每天在处理数据的时候都会用到。
瑞安·奎因——波士顿大学博士生
我需要一个初学者的资源;一些带着清晰、详细的说明带我走过基础的东西。这正是我在 Dataquest 的 R 课程介绍中得到的信息。
因为 Dataquest,我开始读研,在 R 方面有很强的基础,每天在处理数据的时候都会用到。
瑞恩奎因–波士顿大学博士生
我们如何教学
Dataquest 不同于你可能尝试过的其他在线教育平台。你会注意到的最大区别之一是我们不用视频教学。
我们之前已经写了一些这背后的科学,但这里有一个简短的版本:学习动手的学生比通过视频学习的学生表现得更好。

我们所有的课程,包括我们的 R 课程,都是这样呈现的:一边是一个介绍新概念的文本窗口,另一边是一个编码窗口,在那里你可以立即试验并应用你所学到的东西。
这个学习一点点,应用它,增加一点点,应用它,等等的短反馈循环是我们学习平台的核心部分,我们相信这是教和学 r 的最有效的方法。
我们希望教授学生现实世界的工作技能,这就是为什么我们的目标是教授数据分析师在现实世界中实际使用的工具。在我们的 R 课程中,这意味着让学生们熟悉 RStudio,这是使用 R 的行业标准工具。
我们知道动机也很重要,这就是为什么我们所有的课程都会让你在第一堂课中几乎立即接触到真实世界的数据并完成真实的数据科学任务。
后续课程都利用了新的有趣的数据集,并要求您在学习编程技能的同时解决现实世界的数据分析问题。
当你完成每门课程时,你将被要求通过进行我们的一个指导项目来综合你所学到的东西。
这些数据科学项目旨在帮助您实践新技能,即使您刚开始构建数据科学组合。
虽然如果你迷路了,我们的说明会帮助你指出正确的方向,但指导性项目是开放式的,所以你可以完全属于自己,想走多远就走多远。
为什么要学 R?
虽然 Python 是一种流行的数据科学语言, R 也越来越流行。对于学习数据科学来说,这两种语言都是一个很好的选择(这里的是对他们如何处理数据科学任务的面对面比较,但是学习 R 将为你打开各种数据科学职位,不管你是否已经学习了一些 Python。
几乎所有的顶级科技公司都雇佣 R 用户从事数据分析和数据科学。因为 R 最初设计时考虑了高级统计,所以 R 中的一些基本数据分析和统计操作比 Python 中的简单。r 还有一个非常友好和有用的在线社区(在 Twitter 上使用#rstats),以及一些非常棒的数据科学开源包和库(包括 tidyverse 包,如ggplot2和dplyr)。
每个从事数据工作的人都可以从学习一些 R 中受益,有了我们的 R path 数据分析师,现在比以往任何时候都更容易入门。现在就开始学习数据科学中发展最快的语言之一,五分钟后你就可以编写出你的第一个 R 代码,并开始学习 R。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
学习 R 中的数据清理
January 23, 2019
没有人报名参加数据科学的职业生涯,因为他们真的对清理数据充满热情。但事实是,数据清理是几乎每一项数据科学工作的一大部分。这是你几乎需要为你承担的每个项目做的事情。
这就是为什么我们刚刚在 R 路径为我们的数据分析师增加了一门全新的课程,名为 RT5数据清理。它是完全免费的,你现在就可以开始学习。
什么是数据清洗?
在学习数据科学的早期阶段,您经常会收到原始的数据集,您无需花费任何时间进行准备就可以深入研究、操作和分析这些数据集。但在现实世界中,数据集几乎从来没有这么整齐。
数据清理的确切内容在很大程度上取决于您获得的数据是什么样的,以及您试图用它做什么。但通常情况下,您需要浏览它来删除不相关的或错误的数据点。您可能需要创建新的变量,或者将多个数据集连接在一起,以获得分析所需的数据。您还必须确定如何处理缺失值,因为很少有真实世界的数据集是 100%完整的。
有效地完成这些任务需要专业技能和良好的专业判断。
你将从这门课程中学到什么?
在R中的数据清理中,我们将通过学习分析和清理来自纽约市学校系统的一些杂乱的测试和人口统计数据来建立我们的 R 技能。
我们将学习识别和删除不相关的数据,并创建新的变量来帮助我们的分析。我们将使用 R 来连接相关的数据框并重塑数据,以便进行更有效和高效的分析。当然,我们将学习如何处理缺失值和数据集中的缺口。
然而,这门课程不仅仅是关于编程技能。数据清理的一部分是学习确定需要做什么,在某些情况下,做一些主题领域的研究以更好地理解数据集。我们还将深入数据清理的这些方面,这样当您完成课程时,您不仅会知道如何使用 R 清理数据,还会知道如何在开始分析之前识别给定数据集需要哪种清理。
在课程的最后,我们将深入到一个指导项目中,该项目允许您将新的数据清理技能应用于一些杂乱的调查数据,并且还可以让您使用 R 笔记本开始运行,这是一个受使用 R 的数据科学家欢迎的工具。
该开始打扫了
很难夸大数据清理技能的重要性。你会经常听到“80%”这个数字,它不仅仅是一种比喻:对数据科学家的调查表明,数据科学家平均花费大约 80%的工作时间来准备数据(收集和清理数据)。
因此,虽然这不太可能是你最喜欢的数据科学工作流程的一部分(近 60%的数据科学家说数据清理是他们最不喜欢的任务),但这是你绝对需要知道的事情。当然,如果你知道如何用我们在新的 R 课程中教授的现代的、生产就绪的 R 快速有效地做事,清理脏数据的痛苦可以减轻一些。
如果你认为你已经准备好开始擦洗了,拿起你的拖把点击这里免费学习 R 中的数据清理。
(如果你需要先温习基础知识,我们也为你准备了免费课程。)
用 5 个步骤学会正确的方法
April 14, 2021
r 是一种日益流行的编程语言,尤其是在数据分析和数据科学领域。你甚至可能听人说过,学 R 很容易!但是容易是相对的。如果你不确定如何学习,学习 R 会是一个令人沮丧的挑战。
如果你过去曾努力学习 R 或另一种编程语言,你肯定不是唯一一个这样的人。这不是你的失败,也不是语言本身的问题。
通常,这是你学习的动机和你实际学习的方式不匹配的结果。
当你学习任何编程语言时,这种不匹配都会导致大问题,因为它会直接把你带到一个我们喜欢称之为无聊的悬崖的地方。
无聊的悬崖是什么?这是枯燥的编码语法和枯燥的实践问题的堆积如山,你通常被要求在得到好的东西——你真正想做的东西——之前完成。

无聊的悬崖是一种隐喻,但有时你真的会觉得你正在看着它。
obody 报名学习一门编程语言,因为他们喜欢语法。然而,许多学习资源,从教科书到在线课程,都是基于这样的想法编写的,即学生需要掌握 R 语法的所有关键领域,然后才能真正使用它。
这是导致新学员成群结队离开的过程:
- 你对学习编程语言感到兴奋,因为你想用它做些事情。
- 你试着开始学习,但很快就被带到了这面复杂、无聊的墙前。
- 你纠结于一些无聊的事情,却不知道它们与你真正想做的事情有什么关系。
当这个是默认的学习体验时,许多人退出,这有什么奇怪的吗?
不要误解我——在 R 或任何其他编程语言中,学习语法是没有出路的。
但是有是一种避免无聊悬崖的方法。
这么多学生掉悬崖真是可惜,因为 R 绝对值得学习!事实上,对于任何对学习数据科学感兴趣的人来说,R 比其他语言有一些很大的优势:
- R tidyverse 生态系统使得各种日常数据科学任务变得非常简单。
- R 中的数据可视化既简单又非常强大。
- r 是用来执行统计计算的。
- 在线 R 社区是所有编程社区中最友好、最包容的社区之一。
- RStudio 集成开发环境(IDE)是用 R 编程的强大工具,因为你所有的代码、结果和可视化都在一个地方。有了 RStudio Cloud 你就可以在网页浏览器上使用 RStudio 进行编程。
当然,学习 R 对你的职业生涯大有裨益。数据科学是一个快速发展的领域,平均工资很高(查看你的工资能增加多少)。
并且吨的公司和组织使用 R 进行数据科学工作!以下是一些使用 R(截至 2021 年 4 月来自 Hired.com 的)的公司的简短示例:
- SpaceX
- 谷歌
- 星巴克
- Fitbit
- 力啊
- 葫芦
- 亚马孙
- iRobot
- 育碧
- 好事达
- 推趣
- 美国电话电报公司(American Telephone and Telegraph Company)
- 销售力量
- 辉瑞
- 通用汽车
- 诺斯罗普·格鲁曼公司
- 拉尔夫·劳伦
- 高盛
这份名单只是冰山一角——全球成千上万的公司雇佣拥有研发技能的人,研发在学术界和政府中也非常受欢迎。即使从这份简短的名单来看,很明显,拥有 R 技能的人几乎可以从事任何他们想从事的行业。
大型科技、金融、视频游戏、大型制药、保险、时尚——每个行业都需要能够处理数据的人,这意味着每个行业都需要 R 编程技能。
那么如何才能得到它们呢?
第一步。找到你学习的动力
在你破解一本教科书,注册一个学习平台,或者在你的第一个教程视频上点击播放之前,花一些时间认真思考一下为什么你想学习 R,你想用它做什么。
- 您对处理哪些数据感兴趣?
- 你喜欢做什么项目?
- 你想回答什么问题?
在过程中找到激励你的东西。这将有助于你定义你的最终目标,它将有助于你达到最终目标而不会感到厌倦。
尝试深入了解“成为数据科学家”之外的内容有各种各样的数据科学家在处理各种各样的问题和项目。你对分析语言感兴趣吗?预测股市?深入挖掘体育统计数据?你想用你的新技能做什么事情,让你在学习 R 的过程中保持动力?
选择一两件你感兴趣并且愿意坚持的事情。让你的学习面向他们,在头脑中建立你感兴趣的项目。
弄清楚你的动机会帮助你找到一个最终目标,以及一条不会让你厌倦的道路。你不必想出一个确切的项目,只要在你准备学习 r 的时候有一个你感兴趣的领域就可以了。
选择您感兴趣的领域,例如:
- 数据科学/数据分析
- 数据可视化
- 预测建模/机器学习
- 统计数字
- 可复制的报告
- 仪表板报告

用光线着色器 在 R 中创建三维数据可视化
第二步。学习基本语法
不幸的是,没有办法完全避免这一步。语法是一种编程语言,甚至比人类语言中的语法更重要。如果有人说“我要去的商店”,他们的英语语法是错误的,但你仍然可以理解他们的意思。不幸的是,计算机在解释你的代码时远没有这么宽容。
但是,学习语法是枯燥的,所以你的目标一定是花尽可能少的时间做语法学习。相反,在解决你感兴趣的现实世界问题 时,尽可能多地学习语法,这样即使语法本身并不那么令人兴奋,也能让你保持动力。
这里有一些学习 R 基础知识的资源:
- Codecademy —在教授基本语法方面做得很好。
- Dataquest:R 编程简介 —我们构建了 data quest,通过整合真实世界的数据和真实的数据科学问题,帮助数据科学学生避免枯燥的悬崖。我们认为在解决实际问题的背景下学习语法会使它变得更有趣,我们的互动平台会让你真正地应用你所学的东西,并在进行中检查你的工作。
- R for Data Science —学习 R 和 tidyverse 工具最有用的资源之一。可从 O'Reilly 获得印刷版或在线免费下载。
- r studio Education–r studio 是最受欢迎的 r 编程集成开发环境(IDE),其面向初学者的教育页面包含有用的资源,包括教程、书籍和网络研讨会。
- RStudio Cloud Primers–使用 R 开始编码,无需安装任何软件,使用 R studio 基于云的教程。
你越快投入到项目中,你学习 r 的速度就越快。如果你后来遇到困难,你可以参考各种资源来学习和仔细检查语法。但是你的目标应该是在这个阶段最多花几周时间。
RStudio 备忘单是 R 语法的绝佳参考指南:

第三步。从事结构化项目
一旦你掌握了足够的语法,你就可以更独立地进行结构化项目了。项目是一种很好的学习方式,因为它们能让你应用你已经学到的东西,同时也能激发你去学习新的东西和解决问题。此外,建筑项目将帮助你建立一个投资组合,你可以展示给未来的雇主。
你可能还不想一头扎进完全独特的项目。你会遇到很多困难,这个过程可能会令人沮丧。相反,寻找结构化的项目,直到你可以积累更多的经验,提高你的舒适度。
如果你选择通过 Dataquest 学习 R,这是我们课程的一部分——几乎我们的每一门数据科学课程都以一个指导项目结束,该项目要求你综合并应用你所学的知识。这些项目提供了一些结构,所以你不是完全靠自己,但它们比常规的课程内容更开放,允许你实验,以新的方式综合你的技能,并犯错误。
如果你没有学习 Dataquest,那么还有很多其他的结构化项目等着你去做。让我们来看看每个领域的一些好的项目资源:
数据科学/数据分析
- Dataquest —交互式教你 R 和数据科学。你分析了一系列有趣的数据集,从中情局文件到 WNBA 球员数据。
- 由 Hadley Wickham 和 Garrett Grolemund 撰写的《数据科学的 R》,是一个极好的 R 资源,具有激励性和挑战性。
- tidy Tuesday——R 的一个半结构化的每周社交数据项目,初露头角的 R 从业者每周二都会清理、争论、整理和绘制一个新的数据集。新的数据集每周在发布。结果通过标签 #tidytuesday 在推特上分享。
数据可视化
- ggplot2–R 中最流行的数据可视化工具之一是 gg plot 2 包。R for Data Science 的数据可视化章节是学习 ggplot2 数据可视化基础知识的好地方。关于用于交流的图形的章节是让图形看起来更专业的一个很好的资源。
- rayshader–用 ray shader 包在 R 中构建二维和三维贴图。还可以使用 rayshader 将使用 ggplot2 开发的图形转换为 3D 图形。
预测建模/机器学习
- 从 Tidymodels 开始——一系列教授 Tidymodels 的文章,这是一个使用 tidyverse 原理进行建模和机器学习的软件包集合。
- 用 Tidymodels 创建稳健的模型——用这一系列项目建立和训练预测模型。
- 调整、比较和使用模型–使用网格搜索、嵌套重采样和贝叶斯方法等方法,使用 tidymodel 工具。
- 开发定制建模工具–通过这些教程增强和定制您的模型。
统计数字
- 使用 Tidymodels 进行统计分析——这是一系列使用 Tidymodels 进行统计分析的更高级的文章。
可复制的报告
- R Markdown 入门指南–使用 Dataquest 的免费教程,创建您自己的 R Markdown 参考指南。通过用 R Markdown 记录这里描述的任何项目来提高你的 R Markdown 技能。
- R Markdown Cookbook-是一本全面的免费在线书籍,几乎包含了你需要知道的关于 R Markdown 的一切。
- R Markdown:权威指南-学习 R Markdown 的另一个伟大的免费资源。
仪表板报告
第四步。自己构建项目
一旦你完成了一些结构化的项目,你可能就准备好进入下一个学习阶段了:做你自己独特的数据科学项目。很难知道你真正学到了多少,直到你走出去,尝试自己做一些事情。从事你感兴趣的独特项目会给你一个很好的主意,不仅知道你已经走了多远,还知道你下一步想学什么。
尽管您将构建自己的项目,但您不会独自工作。在工作中,你仍然需要参考资源来寻求帮助,学习新的技术和方法。特别是 R,你可能会发现有一个软件包专门帮助你正在做的项目,所以承担一个新项目有时也意味着你正在学习一个新的 R 软件包。
如果你卡住了,你会怎么做?做专业人士做的事,寻求帮助!这里有一些很好的资源可以帮助你找到 R 项目:
- StackOverflow —不管你的问题是什么,很可能以前有人在这里问过,如果没有,你可以自己问。你可以在这里找到标有 R 的问题。
- Google —信不信由你,这可能是每个有经验的程序员最常用的工具。当你遇到一个你不理解的错误时,在谷歌上快速搜索错误信息通常会给你指出答案。
- 推特(Twitter)——这可能令人惊讶,但推特是获得 R 相关问题帮助的绝佳资源。Twitter 也是一个很好的资源,可以获得来自世界领先的 R 从业者的 R 相关新闻和更新。Twitter 上的 R 社区围绕着#rstats 标签。
- Dataquest 的学习社区 —通过的免费学生账户,你可以加入我们的学习社区,提出你的同学或 Dataquest 的数据科学家可以回答的技术问题。
你应该建立什么样的项目?与结构化项目一样,这些项目应该以您在步骤 1 中得出的答案为指导。做你感兴趣的项目和问题。例如,如果你对气候变化感兴趣,就去找一些气候数据来研究,并开始挖掘见解。
最好从小处着手,而不是试图承担一个永远无法完成的大项目。如果你最感兴趣的是一个大项目,试着把它分成小块,一次解决一个。
以下是您可以考虑的一些项目想法:
- 扩展您之前构建的结构化项目之一,以添加新功能或更深入的分析。
- 参加聚会或与其他 R 程序员在线交流,加入一个已经在进行的项目。
- 找一个开源包来做贡献(R 有很多很棒的开源包!)
- 在 Github 上找一个别人用 R 做的有趣的项目,试着对它进行扩展或扩充。或者,找一个别人用另一种语言做的项目,试着用 r 重新创建它。
- 阅读新闻,寻找有趣的故事,这些故事可能有你可以为一个项目挖掘的可用数据。
- 查看我们为数据科学项目提供的免费数据集列表,看看哪些可用数据会激励您开始构建!
以下是我们讨论过的主题领域中的一些项目想法:
数据科学/数据分析
- 自动化数据输入的脚本。
- 一个从网上抓取数据的工具。
数据可视化
- 按州或地区显示选举投票的地图。
- 描述您所在地区房地产销售或租赁趋势的地块集合。
预测建模/机器学习
- 预测你居住地天气的算法。
- 预测股市的工具。
- 自动总结新闻文章的算法。
统计数字
- 预测您所在地区优步旅行费用的模型。
可复制的报告
- 在 R Markdown 报告中报告您所在地区的新冠肺炎趋势,当有新数据时可以更新。
- 您最喜欢的运动队的成绩数据汇总报告。
仪表板报告
- 您所在区域的公交车实时位置地图。
- 股票市场摘要。
- 一个新冠肺炎追踪器,就像这个一样。
- 你个人消费习惯的总结。

把项目想象成一系列的步骤——每一步都应该把标准设得高一点,比前一步更有挑战性。
第五步。增加难度
从事项目是很棒的,但是如果你想学习 R,那么你需要确保你继续学习。例如,您可以仅使用数据可视化做很多事情,但这并不意味着您应该连续构建 20 个仅使用您的数据可视化技能的项目。每个项目都应该比前一个更难一点,更复杂一点。每个项目都应该挑战你去学习一些你以前不知道的东西。
如果你不确定如何做到这一点,你可以问自己一些问题,让你考虑的项目变得更加复杂和困难:
- 可以通过(比如)写教程的方式教一个新手怎么做这个项目吗?尝试教别人一些东西会很快让你知道你对它的理解有多好,而且这可能是一个令人惊讶的挑战!
- 你能扩大你的项目,使它能处理更多的数据吗?更多的数据?
- 你能提高它的性能吗?它能跑得更快吗?
- 你能改善视觉效果吗?你能说得更清楚吗?你能让它互动吗?
- 你能让它具有预测性吗?
永远不要停止学习
学习编程语言有点像学习第二种口语——你会达到舒适和流畅的程度,但你永远不会真正完成学习。即使是与 R 一起工作多年的经验丰富的数据科学家也仍然在学习新的东西,因为语言本身也在发展,新的包一直在使新事物成为可能。
保持好奇心和不断学习是很重要的,但是不要忘记不时地回头看看和欣赏你已经走了多远。
即使采用这种方法,学习 R 也绝对是一个挑战。但是如果你能找到正确的动机,让自己参与到很酷的项目中,我认为任何人都可以达到很高的水平。
我们希望这份指南对你的旅行有用。如果您有任何其他资源建议,请告诉我们!
如果你正在寻找一个将这些课程直接整合到课程中的学习平台,你很幸运,因为我们已经建立了一个。我们的 R path 中的数据分析师是一个互动的课程序列,旨在让任何人从完全的初学者到 R 和 SQL 方面的合格工作人员。
我们所有的课程都旨在通过挑战您使用真实世界的数据解决数据科学问题来让您保持参与。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
常见的 R 问题:
学 R 难吗?
学习 R 当然很有挑战性,你可能会有沮丧的时候。保持不断学习的动力是最大的挑战之一。
然而,如果你采取我们在这里概述的一步一步的方法,你会发现很容易度过沮丧的时刻,因为你将会从事真正让你感兴趣的项目。
可以免费学 R 吗?
有很多免费的 R 学习资源——在 Dataquest,我们有一系列免费的 R 教程,我们的交互式数据科学学习平台教授 R,是免费注册的,包括许多免费课程。
网上到处都是免费的 R 学习资源!免费学习的缺点是,为了学习你想要的东西,你可能需要拼凑一堆不同的免费资源。你会花额外的时间研究下一步你需要学什么,然后寻找免费的资源来教授它。花钱搭建的平台可能会提供更好的教学方法(比如 Dataquest 提供的交互式浏览器内编码),而且还能节省你寻找和建立自己课程的时间。
可以从零开始学 R 吗(没有编码经验)?
是的。在 Dataquest,我们有许多初学者从没有编码经验开始,然后成为数据分析师、数据科学家和数据工程师。对于编程初学者来说,r 是一种很好的学习语言,你不需要任何代码方面的经验就可以掌握它。
如今,R 比以往任何时候都更容易学习,这要感谢包的集合。tidyverse 是一个强大的工具集合,用于访问、清理、操作、分析和可视化 R. 这个 Dataquest 教程对 tidyverse 进行了很好的介绍。
学习 R 需要多长时间?
学习一门编程语言有点像学习一门口语——你永远不会真的完成,因为编程语言在进化,永远有更多的东西要学!然而,你可以很快地写出简单而实用的 R 代码。
做好工作准备需要多长时间取决于你的目标、你正在寻找的工作以及你能投入多少时间来学习。但在某些情况下,我们在 2020 年调查的data quest 学习者报告称,他们在不到一年的时间内达到了学习目标——许多人不到六个月——每周学习时间不到十个小时。
找工作需要 R 认证吗?
我们已经深入地写了关于证书的文章,但是简短的回答是:可能不会。不同的公司和行业有不同的标准,但是在数据科学中,证书并没有多大的分量。雇主关心你拥有的技能——能够向他们展示一个充满优秀 R 代码的 GitHub 比能够向他们展示一张证书更重要。
*#### 2021 年学习 R 语言好吗?
是的。r 是一种流行而灵活的语言,在各种各样的环境中被专业地使用。例如,我们为数据分析和机器学习教授 R,但是如果你想在其他领域应用你的 R 技能,R 被用于金融、学术和商业,仅举几例。
此外,即使你没有成为全职数据科学家或程序员的愿望,R 数据技能也会非常有用。掌握一些 R 方面的数据分析技能对各种工作都很有用——如果你处理电子表格,有可能有些事情你用一点 R 知识就能做得更快更好。
R 程序员赚多少钱?
这很难回答,因为大多数拥有 R 技能的人从事研究或数据科学工作,他们还拥有其他技术技能,如 SQL 。 Ziprecruiter 列出的美国研发人员平均薪资为13 万美元(截至 2021 年 4 月)。
数据科学家的平均工资也非常相似——根据 Indeed.com 的数据,截至 2021 年 4 月,平均工资为12.1 万美元。
**#### 我应该先学 base R 还是 tidyverse?
这是 R 社区流行的辩论话题。在 Dataquest,我们在 R 课程的数据分析介绍中混合教授 base R 和 tidyverse 方法。我们是 tidyverse 的忠实粉丝,因为它功能强大,直观,使用起来很有趣。
但是要完全理解 tidyverse 工具,您需要理解一些 base R 语法,并理解 R 中的数据类型。由于这些原因,我们发现在我们的入门 R 课程中混合教授 base R 和 tidyverse 方法是最有效的。
我需要一个初学者的资源;一些带着清晰、详细的说明带我走过基础的东西。这正是我在 Dataquest 的 R 课程介绍中得到的信息。
因为 Dataquest,我开始读研,在 R 方面有很强的基础,每天在处理数据的时候都会用到。
瑞恩奎因–波士顿大学博士生***
免费学习 R——我们的互动 R 课程本周全部免费!
July 20, 2020

激动人心的消息:下周,我们所有的 R 编程课程都是免费的。事实上,从 7 月 20 日到 27 日,我们的数据分析师职业道路中的每一门课程都是免费的。
这个免费周包括我们所有的 R 编程课程和R 路径中包含的所有 SQL 和统计课程。
我们为什么要这么做?上周,我们推出了四门新的 R 课程,并彻底修改了我们的数据分析师在 R 学习路径的开头。这些课程从零开始教授数据科学的现代、生产就绪的 R(包括 tidyverse 包)——不需要任何先决条件。
现在,使用 Dataquest,从完全的初学者到合格的工作人员比以往任何时候都更容易。付费墙倒了!
(无需信用卡。)
我们的交互式 R 编程课程是如何工作的
在 Dataquest,我们的做法略有不同。你在这里找不到任何讲座视频。你也找不到任何选择题或填空题。
相反,我们要求你编写真正的 R 代码并使用真正的数据集。从第一课的第一课开始,你将使用我们的交互式代码运行平台编写和运行你自己的 R 代码。当您的代码正确时,您将获得实时反馈,提示和答案,并在您需要帮助时访问我们令人惊叹的学习者社区。
在课程结束时,您通常会面临通过构建一个真正的数据科学项目来整合新技能的挑战。即使你正在为 Github 构建一个很酷的项目组合,我们的指导项目也会帮助你建立使用 R 的技能和信心。
为什么要尝试 Dataquest 的 R 课程?学生们是这样说的:
课程中最精彩的部分是当他们接受一个看起来令人畏惧和抽象的概念,然后让它变得相关和容易理解。
—新的 R 课程 beta 测试器
这些课程以一种简单的方式向我介绍了 R,不需要任何语言知识。但它并不太简单,所以它让我保持了很高的兴趣。
—新的 R 课程 beta 测试器
现在的新课程对初学者非常友好。tidyverse 上的工作流程非常有用。
—新 R 课程 beta 测试者
常见问题解答
要进入免费课程,我需要做些什么?
只需注册一个免费的 Dataquest 帐户(或登录您现有的帐户),您就可以访问 R 学习路径中的数据分析师的所有课程。
你可以从头开始,也可以从你喜欢的任何一点开始。如果您有一个现有帐户,并且已经在 Python 路径上取得了进展,请不要担心,您的 Python 进度已经保存,并且您可以随时从您的仪表盘来回切换路径。
从世界协调时 7 月 20 日 0:00到世界协调时 7 月 28 日 0:00R 路径的所有课程都将免费。
我需要信用卡来注册吗?
不!您可以免费创建 Dataquest 账户,无需信用卡。即使在免费周结束后,您仍可以使用您的免费帐户访问我们数十门免费课程中的任何一门。
在这一周里,我能学到多少东西有限制吗?
没有。我们的平台是自助式的,允许您按照自己的节奏工作。在免费的一周内,你可以完成你想完成的所有课程,并且你将获得你完成的所有课程的证书。
免费周结束后,没有付费订阅的用户将不再能够访问 R path 的付费部分,但您在免费周的进度将被保存,并且您仍可以访问每门课程的免费课程。
免费周结束后,我如何访问完整的 R 路径?
一旦免费周结束,将需要 Dataquest 订阅才能访问完整的 R 路径。
在 2020 年对 600 多名 Dataquest 学习者的调查中,91%的学生认为 Dataquest 订阅服务是一项很好或很棒的投资,97%的学生表示他们推荐 Dataquest 以促进职业发展。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
如何在线学习 SQL
October 25, 2019
如果你想在数据科学领域取得成功,SQL 是 学习 最重要的语言之一。几乎世界上所有的数据都存在于数据库中,而 SQL 是您需要用来访问和分析这些数据的语言。但是学习 SQL 有时会是一种令人沮丧的经历。在本文中,我们将分享帮助您在线学习 SQL 的提示和技巧。
了解 SQL
为了了解如何有效地在线学习 SQL,让我们花一点时间来了解 SQL 的几个关键点。
SQL 数据是结构化的
结构化查询语言 SQL 标准。当你在使用 SQL 时,你几乎总是在使用数据库中的数据,这些数据被结构化到多个表中。您编写查询,以便选择特定的数据并将其转换为您需要的数据。

SQL 数据被组织到多个相互连接的表中。(图片:Pixabay)
许多 SQL 工作涉及到使用连接来连接不同表中的特定数据,以便您可以对其进行分析。
SQL 有许多不同的“风格”
SQL 有不同的版本(或风格)。其中最著名的是 SQL Server、PostgreSQL、Oracle、MySQL 和 SQLite。这可能会给即将开始学习的人带来问题——我该选择哪一个?
简短的回答是没关系。每种 SQL 风格使用的绝大多数语法都是相同的——“风格”之间的区别主要是添加了可选功能。此外,您作为初学者将要学习的几乎所有 SQL 语法对于所有 SQL 风格都是通用的。
作为初学者,假装所有这些不同的味道都不存在,只专注于学习 SQL 基础知识。对他们一视同仁,直到你达到更高的水平,需要担心差异。
上述建议的一个例外是 NoSQL 数据库。顾名思义,NoSQL 数据库并不是传统意义上的 SQL 数据库。虽然 NoSQL 数据库最近越来越受欢迎,并且似乎是一个“性感”的学习对象,但与“真正的”SQL 风格相比,它们的使用是微不足道的,并且您最好将时间花在学习 SQL 上,从中您将获得更多的价值。
通过做 SQL 来学习 SQL
为了有效地学习 SQL,你将不得不编写大量的查询。这意味着,要想成功地学习 SQL online,你不能仅仅依靠视频或基于文本的课程,并认为这就足够了。你必须将你所学到的东西运用到实践中去。您将需要某种设置,在那里您可以编写查询并处理真实的数据。
找到学习 SQL 的结构化数据极其困难。虽然网上有成千上万对学习有用的数据集,但几乎所有的数据集都是“平面文件”,这是对非结构化的一个时髦说法。
为了学习 SQL,您需要找到感兴趣的数据,然后在练习之前通过将数据拆分到多个表中来准备这些数据。这就造成了很高的入门门槛。
此外,在你的计算机上安装数据库软件可能会非常麻烦和耗时。当你可以深入研究并开始编写查询时,更容易保持动力,而不是花几个小时准备开始。
解决办法?找到一门课程,通过在浏览器中编写 SQL 查询,您可以在线学习 SQL。这不仅节省了您在计算机上进行设置的时间和精力,您还能够使用反映真实世界 SQL 用例的结构化数据。
有少数网站提供这种在线学习 SQL 的快速入门环境。其中之一就是我们的产品— Dataquest —我们专门设计了学习界面,为学习 SQL 提供理想的环境。
但是无论你选择在哪里学习,记住尽早和经常地把它付诸实践的重要性。如果您正在“学习 SQL ”,但没有实际编写和运行 SQL 查询来应用您所学的内容,那么在现实世界中使用 SQL 时,您可能会遇到困难。
通过做来学习 SQL
使用我们的交互式学习平台,立即动手操作 SQL。
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
(开始免费)
为艰难的、真实的 SQL 做好准备
在线学习 SQL 时要记住的下一件事是,在现实世界中编写 SQL 是复杂的。我们之前简单地讨论了如何使用连接来连接多个数据库表中的数据。
大多数课程没有让你准备好使用许多连接编写查询的复杂性,所以你会想要找到一门超出基础的课程。你想找一门能让你发挥潜能的课程,教你做艰难的事情(或者为自己创造这样的课程)。

真实世界的 SQL 查询。
您还需要足够复杂的数据来实践这一点——许多 SQL 课程会教您使用具有两个或三个表的数据库进行连接。但是在现实世界中编写 SQL 时,您经常需要连接四个或更多的表,所以最好在学习时就开始面对这种复杂性,而不是在工作中第一次处理它。
在 Dataquest,我们的 SQL 课程从零开始,但它们将带您超越基础知识,让您准备好在现实世界中编写 SQL。上图显示了一个 SQL 查询,一旦你学习了我们的中级 SQL 课程,你将能够编写这个查询。
练习使用 SQL 回答问题
使用 SQL 时,您会反复看到一个常见的工作流:
- 理解你需要用数据回答的问题。
- 制定将回答你的问题的数据结构。
- 编写一个 SQL 查询来转换数据库表中的数据,以回答您的问题。
做这些步骤需要大量的练习。获得实践的理想方法是构建项目,但是正如我们前面讨论的,自己构建 SQL 项目有很多障碍。这并不意味着你做不到,但这绝对会是一个挑战!
在 Dataquest,我们的每门 SQL 课程都有一个或多个指导项目,在这些项目中,您可以分析我们为您准备的数据,以练习真实世界的分析工作流程。
后续步骤:开始在线学习 SQL
如果你想在数据世界中取得成功,你必须熟悉 SQL。如果您已经准备好开始,您可以开始 Dataquest 的 SQL 基础课程,今天免费 ,无需离开您的浏览器:
通过做来学习 SQL
使用我们的交互式学习平台,立即动手操作 SQL。
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
(开始免费)
新课程:R 中的统计基础和 R 中的概率基础
August 27, 2019
我们在 R path 的不断扩大的数据分析师今天有两门新课程,它们都是关于帮助你使用 R 学习统计学。
R中的统计基础知识和R中的概率基础知识是全新的互动课程,它们将建立在您在之前课程中开发的 R 编程技能的基础上,同时教授您统计和概率中的关键概念。

学习这种数学对于有效的数据科学工作至关重要,因为能够用代码执行某些东西并不等同于理解它是如何工作的。为了做出正确的决策,并确保您的分析测量的是您希望它测量的东西,您需要牢固地掌握统计数据,以及在您的代码“引擎盖”下您的数据发生了什么。
但是不要担心——仅仅因为它是数学并不意味着它一定是痛苦的!像所有 Dataquest 课程一样,这些新课程是交互式的,当您分析真实世界的数据集以解决现实的数据科学问题时,它们将通过 R 编程教您统计学和概率。
statistics in r courseprobability in R course
在 R 中我将从统计学基础中学到什么?
在 R 的统计学基础课程中,你将学会提出更好的问题,并就如何分析数据做出更明智的决定。您将学习使用统计方法来发现隐藏的模式,并且您将学习如何通过 R 编程来实现一切,以便它适合您现有的数据科学工作流。
具体来说,您将从学习抽样开始,并进一步了解如何执行分层抽样和整群抽样。然后你将学习统计学中的变量,并了解用于测量变量的不同尺度。
接下来是频率分布、绝对和相对频率、分组频率分布和百分位数。您将了解这些概念,并练习使用它们来识别数据中的模式,进行跨类别的比较,并使大量数据集更易于管理。您还将学习使用各种可视化工具,如分组条形图、阶跃直方图、内核密度图等,来比较频率分布并更好地理解数据中的模式。
在整个课程中,您将分析来自 WNBA 的真实世界体育数据。然后,一旦你完成了所有的主要概念,你将面临的挑战是把所有新的 R 统计技能放在一起,建立一个分析 Fandango 上电影评级的指导性项目。
完成本课程后,您将对使用各种方法进行数据采样感到舒适。您将对数据结构有更好的理解,并且能够轻松地创建、可视化和比较频率分布表。
R 中的概率基础我会学到什么?
在 R 的概率基础课程中,你将通过分析彩票数据时钻研概率来加深你的统计技能。
在整个课程中,你将使用你的 R 编程技能和你所学的统计学知识来估计经验和理论概率。你将学习概率的基本规则,然后解决日益复杂的概率问题。
您还将了解概率的独立性,对于某些类型的数据科学建模来说,这是一个需要理解的重要概念。
最后,你将面临一项挑战,即测试你所有的新技能和 R 编程,设计一个移动应用程序的功能,通过向人们提供各种不同情况下中奖概率的准确信息,帮助他们戒掉赌丨博瘾。
课程结束时,你将能够计算随机实验的概率,并使用组合和排列公式来计算潜在结果的数量。您还将能够设置基本的模拟,并使用这些来计算概率。
为什么要用 Dataquest 学习?
有很多地方可以学习统计和概率,但是使用 Dataquest 学习有一些特殊的优势。
首先,我们进行交互式教学,要求你运用你的 R 编码技能应用新概念,并在每个屏幕上检查你的工作。这意味着你将获得关于你是否真正理解你所学内容的即时反馈,同时你也将在建立你的统计学专业知识的同时强化你的 R 技能。

简而言之,Dataquest 平台。
我们还使用真实世界的数据,并通过要求您解决现实的数据科学问题来进行教学。对于许多学生来说,这使得在 Dataquest 上学习比解决抽象的样本问题或阅读教科书中的公式更有趣、更有吸引力。你对你正在做的事情越感兴趣,你就越有可能坚持下去。这就是为什么我们努力让我们的课程变得有趣并与您的数据分析目标相关。
如果你已经是 Dataquest 的订阅者,现在就开始在 R 中建立统计专业知识吧!如果你还不是订户,查看我们的计划,看看你错过了什么。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
新课程:学习数据科学的概率基础
原文:https://www.dataquest.io/blog/learn-statistics-probability-data-science-course/
July 9, 2019
学习概率和统计并不是大多数有抱负的数据分析师和科学家要解决的第一件事。但是不要搞错:理解数学和理解编程一样重要!
数学可能令人生畏,尤其是如果你以前没有花太多时间学习概率和统计的话。今天,我们很高兴地宣布,我们正在通过推出一门新的 概率基础 课程,让学习数据科学的概率和统计变得更加容易,这门课程将成为学习数据科学工作所需数学的一个更加平易近人的切入点。

本课程已作为统计学课程系列的第三部分添加到我们的 Python 数据分析师和 Python 路径数据科学家中,但您无需完成之前的课程即可深入学习并开始学习概率。
它确实假设中级 Python 知识,包括熟悉 pandas 库。如果你正在学习我们的某一条道路,你已经完成了你需要的所有先决条件,但是如果你正在学习点菜课程,你可以通过我们的 Python 和 pandas 入门课程这里来填补这些空白。像我们的其他统计课程一样,它至少需要一个基本订阅。
你将在概率基础中学到什么
正如您可能已经从标题中猜到的那样,概率基础知识旨在让您对概率中与数据分析和数据科学日常工作相关的关键概念有一个实用的理解。
像所有 Dataquest 课程一样,您将在网络浏览器中完成本课程,编写代码以应用您在过程中的每一步所学。
简而言之,Dataquest 平台。
在整个课程中,您将使用 Python 编程技能和所学的统计学知识来估计经验和理论概率。你将学习概率的基本规则,然后解决日益复杂的概率问题。
最后,您将学习像排列和组合这样的计数技术,然后在一个指导项目中综合您的所有新知识,为一个移动应用程序构建逻辑,帮助赌丨博成瘾者更准确地估计彩票赔率,以帮助他们克服毒瘾。
在课程结束时,你将理解理论概率和实验概率之间的区别。你将有计算各种不同事件的概率的经验,你将能够计算实验结果中可能的排列和组合的数量。
为什么要学概率统计?
尽管许多数据科学工作都是作为编程来体验的,但数据科学家所做的几乎所有事情都涉及到统计工作。当数据科学家做出预测时,他们是在处理概率。概率的概念似乎很基本,但它是最先进的预测模型的基础。
虽然实际的数学运算经常被放入流行的数据科学库中以便快速应用,但这种便利可能是一把双刃剑。毕竟,仅仅因为一项技术容易应用,并不意味着在每种情况下应用都是正确的。
这就是为什么学习概率和统计概念,包括本课程中涉及的概念,对于数据科学家来说如此重要。当你理解了为什么的时候,你就更容易为你试图解决的问题找到正确的统计技术或计算方法。
当你牢牢掌握了为什么使用你选择的技术时,向别人解释你的分析也变得更容易。
准备好开始学习数据科学的概率了吗?如果您已经拥有帐户和基本订阅,请点击此处开始学习课程。
否则,你会想从注册一个免费账户和阅读我们的订阅选项和我们的其他数据科学课程开始。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
学员聚焦–Ashray Adappa
原文:https://www.dataquest.io/blog/learner-spotlight-ashray-adappa/
February 17, 2022
Ashray 在化学工程领域开始了他的职业生涯,但当他感觉自己迷失了方向时,他发现了数据科学,在 Dataquest 平台上自学,并找到了一份数据分析顾问的工作。这是一个关于他如何一步一步决定改变生活的故事。
1。第一,你首选的代词是什么?
他/他
2。好了阿什蕾。你能告诉我们你住在哪里吗?
我住在印度古雅而阳光明媚的果阿邦,在它的首府帕纳吉。
3。告诉我们一些你的背景。您从哪里来?你在哪里学的什么?
从小到大,我的祖父鼓励我阅读报纸、短篇小说和文章。阅读帮助我建立了英语交流技能,正如我们所知,这是在数据分析中取得成功的工具。这也开始了我对问答和琐事的兴趣。我的母亲(她是家里第一个研究生)帮助我理解了小学教我的基础数学。这开启了一个良性循环,我尝到了数学成功的滋味,然后开始自学数学,并在学校的课堂上取得了好成绩。我在公立学校也有一些很棒的老师(向 Mushtifund 高中大喊!).因此,密切的指导和积极的影响可以帮助一个人对自己的定量能力建立信心。
我对科学和技术的兴趣也来自于从借来的百科全书和叮当杂志上阅读科学文章,以及在电视上观看比克曼的世界。小时候,我想成为一名生物医学工程师(一部分是因为我喜欢科学,一部分是因为生物医学工程是医生和工程师的结合)。我决心为入学考试努力学习,以便被印度最好的大学录取。准备工科入学考试是一次变革性的经历,因为只有那时我才能真正理解数学和科学包罗万象的本质。许多现象都可以用科学方法来解释。我还认为我的工程入学考试辅导课(Aryaan 辅导课)让我清楚地了解了概念学习(以前我依赖死记硬背的学习)。我在入学考试中确实表现得相当好,但我只能做得足够好以获得化学工程课程的录取。
有一次在工科院校,我在内在动力方面迷失了方向(我这么做是为了自己吗?还是我做了社会似乎希望我做的事情?),我变得对工程学中教授的数学特别失望。它似乎非常狭窄和模糊。此时,我也对更多的人类事务产生了兴趣,比如经济、商业、社会科学和人文科学。尽管如此,我真的希望能够将数学应用于现实世界的现象。应用数学中有一部分可以用于此,即应用统计学和概率(尽管这是数学中最薄弱的环节之一)。随着我对如何应用统计学的了解越来越多,我发现了一个新兴领域——数据科学。它完全符合我的愿望和世界的需求。
在大学里,我学习了一些与数据分析相关的课程,但由于我自己的原因,我没有应用急需的定量严谨性。大学毕业后,我决定尝试从网上学习分析的基础知识。我在那里找到了 Dataquest.io,它的结构和对统计、微积分和代数概念的清晰阐述,以及 Python 编程和软件工程的介绍给了我很大的帮助。在完成了数据分析师和数据科学家的道路后,我在申请数据分析职位时有了更多的信心,并最终以数据分析顾问的身份加入了分形分析,我在那里一直工作到今天。
4。你能分享更多关于你在分形分析中的位置吗?
我是数据分析顾问(类似于高级数据分析师),从事分形分析。我帮助企业利用他们的数据来研究他们的市场表现。它主要涉及数据清理、数据协调和数据可视化,以及一些机器学习。
5。你能描述一下这个职位的招聘流程吗?
大学毕业后,我回到家中,通过 Dataquest.io 学习分析。我花了大约三个月的时间完成了 Python 中的数据分析师和 Python 中的数据科学家课程。获得完成徽章对我来说非常有益,因为我可以将它们附加到我的 LinkedIn 个人资料中,这增加了非常需要的合法性。此外,我在 Dataquest 课程中获得的关于在 GitHub 上建立我的作品集的指导对我向更广泛的公众展示我的动机非常有帮助。
我通过 LinkedIn 的一个帖子申请了现在的工作,我有机会在两周内面试它。面试包括四轮。第一轮是对 Python 和 SQL 的在线技术评估。我必须在一个小时内编写代码来回答 Python 中的五个问题和 SQL 中的五个问题。Python 问题难度很高,SQL 问题难度中等。我记得我不能通过三个 Python 问题的所有用例,但是我可以正确地回答所有的 SQL 问题。Dataquest 的编码环境确实有助于我在技术评估中将代码输入到基于网络的编辑器中。
我通过了第二轮面试,那是分形公司数据分析经理的电话面试。她通过问一些猜测性的问题来测试我的定量能力。她还问我如何提高实体玩具店的销售额(例如,我可以运用什么样的分析技术来帮助商店提高销售额?).然后,她问了几个与 SQL 相关的问题(例如,“如何在 SQL 中显示文本记录的子集,如何使用 SQL 查询输出某一列中第二高的数量?”).我能够很好地回答这些问题,从而进入第三轮,即与分形的数据科学家进行视频电话采访。
在这里,他问我关于我的投资组合项目,关于我如何以及为什么以我的方式准备数据(标准化,插补,删除非常空的行或列,等等)。),以及我使用的准确度分数的真正含义。然后,他问了我一个案例研究问题,涉及在给定香水香水销售人员的销售数据(有和没有这些销售人员的商场)和地理数据的情况下,决定哪种最大似然算法最适用于决定将香水香水销售人员安排在全国各地的一组商场中。我不记得我如何回答这个问题的具体细节,除了说这将是一个清晰的分类练习,并推荐了一个K-最近邻算法。这不是最好的答案,因为他希望我提到 SVM 算法,但我认为他相信我的思考过程,并确定我适合进入下一轮。
最后一轮是对一位来自分形的人力资本经理的直接个人采访,她问了我一些与我在数据分析方面的动机有关的问题,并让我描述我的旅程。一周后,我收到一封电子邮件,说我通过了面试,于是我开始了我在孟买分形分析公司的第一份数据分析工作。
6。你的工作让你兴奋的是什么?
我很兴奋地发现了其他人以前可能没有注意到的模式——无论是数据是如何被接受的,还是从汇总分析中得出什么结论。我也喜欢和我的队友一起工作,和他们一起集思广益。
7。这份工作有你非常擅长的地方吗?
与分析师用于个人项目的 Anaconda 发行版的流行技术堆栈相反,公司为公司开发了许多与数据相关的应用程序,我很擅长即时获取这些应用程序。通常,我发现我可以帮助我的同事学习它们。
8。在开始您的 Dataquest 之旅之前,您感觉如何?
在开始我的数据探索之旅之前,我百感交集。最重要的是,我很兴奋,因为我迷恋上了课程文本的分屏界面和编码窗口,我认为它们非常漂亮。我没有像在任何其他数据分析课程之前那样焦虑,因为 a)我有机会查看每一课的主题,并觉得难度的分级节奏很好,b)我在大学时确实有一些使用 Python 和 C 语言编码的经验。
9。你喜欢 Dataquest 学习平台的哪些方面?
Dataquest 的数学教学给我留下了深刻的印象。只教授最重要的概念;它们被分解得如此之好,以至于我认为任何有基本算术技能的人都可以开始学习。此外,在那个时候,浏览器内编码是最先进的。它帮助我更加自信地继续使用代码编辑器。
10。你和我们的旅行怎么样?
我的 Dataquest 之旅开始得非常顺利。由于我以前在大学的技术经验,我能够轻松地完成分析师之路。一旦我在数据科学家的道路上前进了一半,事情就变得(不出所料地)棘手了。
11。你和我们一起学到了什么新技能?
我学会了如何找到数据源,清理和准备数据,决定最适合所应用的 ML 算法的数据操作策略,可视化数据以找到相关性和其他关系,然后使用 sklearn 库来应用机器学习。我还学会了如何以一种容易理解的方式来交流我的发现。一旦我用 Dataquest 掌握了这些技能,我真的觉得我是一个真正的数据分析师——好像我不再是一个局外人了。
12。你的学习过程是怎样的?
它带走了我。。。我想大约三个月的时间来完成数据分析师和数据科学家的道路。我每天早上都会登录,就像上学一样,晚上,大约下午 5 点左右,我会注销。我会记笔记,把它们写下来,这样就能真正把学到的东西牢牢记在脑子里。
13。你对考虑 Dataquest 的人有什么建议吗?
做大量的笔记,并定期检查。在本地机器上尽可能多地练习编码。试着理解课程中的每一行代码。耐心点。
14。说说你用 Dataquest 学习后最自豪的是什么?
我为自己用 Dataquest 完成的个人项目感到自豪。我为我能够应用于启动数据分析项目或应用于我在企业分析领域的工作的真实技能感到自豪。
15。最后,人们在网上哪里能找到你?
我的 LinkedIn-https://www.linkedin.com/in/ashray-adappa/My Github-https://github.com/ash-adappa
学员聚焦:大卫·拉什顿
原文:https://www.dataquest.io/blog/learner-spotlight-david-rushton/
August 20, 2021
见见 David Rushton,他曾是一名体育教师,后来转行从事数据工作。在做了一些研究后,他发现了编码,并决定用 Dataquest 学习他的新技能。
下面是他的故事…
问:首先,你的首选代词是什么?
答:他/他
好吧,大卫!你现在的职称是什么?在哪家公司?
答:我是一家初创公司的解决方案工程师。
问:你能告诉我们一些你目前工作的情况吗?
答:我向潜在客户完成我们能力的技术演示,开发供内部和客户使用的 Python 脚本,并帮助原始设备制造商和企业客户集成我们的产品。
问:现在你能告诉我们一些你的背景吗?
我在英国北威尔士长大。我完成了体育发展学士学位,然后我学习了体育教师。五年来,我在五个国家生活和教学。我曾经从事过教育领域的领导工作,但是我觉得我想要一个新的挑战。这是我决定学习编码的地方!
问:是什么让你进入了数据行业?
答:研究!我从前端、后端、UX 等各方面考虑了所有选项。我发现数据技能显示出需求,我在大学完成了绩效分析课程。这让我觉得挑选数据很舒服。我只是觉得数据被用在了所有的事情上。
问:【Dataquest 的教学方法(无视频、浏览器内编码)对你有什么作用?
答:这种方法效果很好。但是,它更适合我的生活方式。我很容易分心,会开始另一项任务,任务进行到一半。因此,当我尝试视频时,我发现自己没有听,不得不重新观看视频,而阅读和编码却很有效,因为我必须集中注意力。
问:你在 Dataquest 做了哪些工作,为什么?
答:这个比较难!我从数据分析师路径开始,打算接着做数据科学路径。但是,我还是决定转行数据工程,我喜欢!现在专业地使用 Python 代码,由于这个课程,我更好地优化了我的代码。
问:你最喜欢 Dataquest 的哪一点,为什么?
我喜欢你在最后提供的摘要 PDFs 它们对我尝试完成任务很有帮助。我没有去查看堆栈溢出,只是看着它们,因为它们通常会回答我的问题。
问:你是如何开始找工作的?
答:我首先研究了有哪些工作,以及我有什么资格。我看了多个提供建议的 Reddit 论坛,等等。我注意到了趋势建议,并遵循了它。我基本上申请了我想要的工作,即使我有点不合格。求反馈!
问:你在 Dataquest 学到的哪些技能对你的工作有帮助?
答: Python 脚本、 Git 、GitHub、熊猫、API、数据类型、优化数据管道、 NumPy (类)、机器学习课程、 Postgres (使用 MongoDB)、 Jupyter 笔记本!!!(大的一个),可视化,清理(类),命令行。
问:你会给刚刚开始学习 Dataquest 的人什么建议?
A: 要有耐心——而且,你不需要知道所有的事情。我有一个朋友是工程师,他不知道我在 Dataquest 学到的任何技能,但我对他的工作一无所知。不要一开始就试图学习所有的东西,让自己负担过重
问:最后,人们在网上哪里可以找到你?
答:https://www.linkedin.com/in/rushton93/
大卫还在 Dataquest 社区发布了更多关于他在一家初创公司从体育老师到销售工程师的转变。
学员聚焦— Dilara Karabey
原文:https://www.dataquest.io/blog/learner-spotlight-dilara-karabey/
April 12, 2022
认识一下 Dilara,她只想通过学习“Python 中的数据分析师”职业道路来提高她的 Python 技能,但最终却在 Perfist 找到了一份数据科学家、Web & CRO 分析师的工作!对于一个在开始之前就焦虑并与冒名顶替综合征作斗争的人来说,事情变得相当好。
1。第一,你首选的代词是什么?
她/她
2。你能告诉我们你住在哪里吗?
土耳其伊斯坦布尔。
3。告诉我们一些你的背景。
我是学语言学出身的。我于 2017 年开始在博阿齐奇大学语言学系学习。我从高中开始就一直对编程感兴趣,也参加过黑客马拉松等。主要是做机器人,但我不能说这是我的激情。然后,在我搬到伊斯坦布尔学习后,我完全停止了编码,说我们会再见面的。
在疫情大受欢迎之后,我被一个冷酷的事实所震撼,那就是我还没有真正决定在语言学领域寻找什么样的未来。因此,我试着看看我是否有其他的兴趣,我想更深入地挖掘并在此基础上建立我的未来。然后我来到 Dataquest 的奖学金项目,决定尝试一下,并爱上了它。我可以说我个人与 Dataquest 关系密切。后来,事情像滚雪球一样越滚越大,现在我正在一家数字营销机构建立分析和 CRO 部门,处理大量的营销数据。
4。你现在的职称是什么?
我目前的职位是“数据科学家,Web & CRO 分析师”,在 Perfist 工作。
5。请告诉我们更多关于获得当前工作的信息。完成 Dataquest 课程后,我决定开始找工作或实习。我在 10 天内被另一家数字营销机构聘为数据科学实习生,4 个月后获得晋升。晋升之后,我也进入了数字营销分析领域,并更好地了解了我一直在处理的数据。
6。你的工作让你兴奋的是什么?
市场营销是一个充满有趣动态的非常有趣的领域。在一家机构工作实际上是真正驱动我的原因,因为当你在一家机构工作时,你有来自不同领域的广泛客户,他们中的每一个人都有自己的秘密需要探索和分析。
7。这份工作有你非常擅长的地方吗?
我很擅长发现问题并提供最佳解决方案。我也很擅长 Python 中的熊猫库。
8。在开始旅程之前,你感觉如何?
实际上,我感到非常焦虑,因为我因为冒名顶替综合症已经停止编程一段时间了。
9。你喜欢 Dataquest 学习平台的哪些方面?
我真的很喜欢。叙述的很干净,引导的项目都是金。在我看来,没有视频的概念实际上更好,因为我有时很容易分心,当视频中出现这种情况时,我必须倒带,这样我就不会错过主题。我也在社区里呆了一段时间,这真的很有帮助。我第一次面试时全副武装!
10。你和我们的旅行怎么样?
其实对我来说真的很简单。就像,自然的。我确实创造了很多很酷的项目;我喜欢指导项目部分。当我走完这条路的时候,我已经掌握了很多有用的数据技能。
11。你学到了什么新技能?
我已经学会了大部分关于处理数据的基础知识和一些其他有用的东西,比如 Git 或 Bash。
**12。你的学习过程是怎样的?
我记得我几乎每天都在学习,已经完全走完了这条路!我花了大约三个月的时间才完成。
**13。你对正在考虑进入 Dataquest 的人有什么建议?
我的建议是努力去做,真正进入社区部分。还有,引导式项目真的很有用,要好好利用。
14。说说你用 Dataquest 学习后最自豪的是什么?
我为编写指导项目的人感到骄傲!此外,社区经理真的很擅长保持社区的培育和安全。
15。最后,人们在网上哪里能找到你?
这是链接到我的 LinkedIn 个人资料;请随时发送连接请求!****
学员聚焦:吉诺·帕拉吉斯
原文:https://www.dataquest.io/blog/learner-spotlight-gino-parages/
September 3, 2021
见见 Gino Parages,一位没有编程技能的前销售和 IT 业务分析师,他决定是时候学习编程来促进他的职业生涯了。他选择 Dataquest 来帮助他实现学习目标,并获得他想要的
工作。
下面是他的故事…
问:首先,你首选的代词是什么?
答:他/他
问:好吧,吉诺!你现在的职称是什么?在哪家公司?
答:我是一名数据工程师,负责客户报告。
问:你能告诉我们一些你目前工作的情况吗?
答:数据工程:Python,SQL,熊猫清洗,PySpark。数据科学:机器
学习、Tableau、谷歌数据工作室、Dash/Plotly、视觉、数据聚合。解决方案交付:需求收集、需求澄清、策略。
问:现在你能告诉我们一些你的背景吗?
答:我在辉瑞工作了七年。我总是呆在医疗保健/生物技术行业。我想让
编码,并把我的职业生涯推向一个更具技术性/实践性/个人贡献的方向。
我在辉瑞的工作经历是:3.5 年销售,3.5 年 IT,业务分析师/数据分析师/数据工程师混合角色,但零编码。去年变成了所有的编码和数据争论/准备等。Dataquest 的技能
让这变得非常可行。
问:是什么让你进入了数据行业?
答:未来业务的潜力,但也只是有趣而已。我喜欢
电子表格。为什么不学习处理大量的“电子表格”呢?
问:Dataquest 的教学方法(无视频、浏览器内编码)对你来说如何?
对我来说太棒了。我其实更喜欢这种方法。这对我来说非常重要,因为
我喜欢在一边的 Jupyter 笔记本上做实验,因为我通过课程理解
我读到的一切。这很辛苦,但它确保了我在材料上是可靠的。
问:你在 Dataquest 做了哪些工作,为什么?
答: 数据科学家和部分数据
工程师。我喜欢学习数据科学道路背后的数学的想法。我还想确保我得到了关于机器学习的像样的介绍,我可以用我喜欢的其他资源来构建。
问:你最喜欢 Dataquest 的哪一点,为什么?
答:在我用过的平台中,Dataquest 是最难的。我认为《T2》这部电影非常具有挑战性,在其他电影中,他们基本上是握着你的手。牵手很容易陷入
的“冷眼旁观”模式。如果你想得到这份工作,你必须尊重学习曲线!
问:现在你能告诉我们你是如何开始求职过程的吗?
在我完成了大约八个端到端的项目后,我开始找工作。我
想确保我有一个 GitHub 回购协议,这不仅是为了展示,也是为了让我觉得我能胜任这份工作。我
为自己创造了富有挑战性的项目,并以许多
的工作简历为基准,试图涵盖我想象中雇主想要的一切。
我花了大概三四个月的时间在我的主要项目上,同时吸收内容。我认为对我来说最好的想法是习惯于这样一种想法,即我不会到达一个内容摄取会停止的点。在那之后,我把目光放在完成我强加给自己的挑战上,给自己时间去阅读、观看和倾听尽可能多的信息,以创造出酷的东西。
一旦这样做了,我就觉得在工作中接手项目很舒服。我向团队伸出援手。我所在的团队有一个来自公司外部 API 的完整 ETL 请求。我接受了对
的请求,提取数据,转换,然后准备加载。这是对“是的,我能做到这一点”的最后鼓励
从那里我使用了 skillsyncer.com。我为每一份
工作定制了简历。我把自己的标准设定在我想要的可行性/薪水/技能上。提交给每一个简单的申请工作,然后
提交给更多的工作。。。大概做了四次。我至少经历了 15-20 次面试。然后我
找到了我想要的工作,接受了这个角色🙂
问:你在 Dataquest 学到的哪些技能对你的工作有帮助?
答:蟒蛇,熊猫
问:你对刚刚开始学习 Dataquest 的人有什么建议?
答:你需要明白,如果你像风一样吹过材料,完成 Dataquest 的想法不会给你足够的
来得到一份工作。这需要思考、责任和对材料的尊重。你必须花时间回顾这些表格,写笔记,练习,让你自己被信息包围
,以确保你在继续前进之前不会感到困惑。做书面笔记。用 JUPYTER 笔记本!
问:最后,人们在网上哪里可以找到你?
学员聚焦–奥塔维奥·西尔维拉
原文:https://www.dataquest.io/blog/learner-spotlight-otavio-silveira/
January 15, 2022
认识一下经济学毕业生奥塔维奥·西尔韦拉,他在 YouTube 上学习 Python 和 SQL 以增加他在数据领域获得第一份工作的机会时发现了 Python 和数据科学。
他加入了 Dataquest,后来获得了奖学金,并以此完成了他的学习之路。下面是他的故事…
1。第一,你首选的代词是什么?
他/他
2。好吧,奥塔维奥!你现在的职称是什么?在哪家公司?
小数据科学分析师 Hortifruti Natural da Terra(巴西)
3。你能告诉我们一些你目前工作的情况吗?
目前,我使用 python 和 SQL:自动化任务和流程,执行探索性数据分析,web 爬行,创建集群化、回归和分类的算法。
4。现在你能告诉我们一些你的背景吗?
我上大学是学经济的,但当我终于拿到学位的时候,2018 年,我很难找到工作,也不确定是否申请硕士。尽管我上了一所好大学,但我觉得自己没有足够的工具去找到一份好工作。
幸运的是,我在美国找到了一份临时的交换工作,做一名足球教练。这 4 个月的时间对我在简历中增加国际经验很重要。也是在这个时期,我开始对数据和编程产生了兴趣。当我开始阅读迈克尔·刘易斯的《金钱球:赢得不公平游戏的艺术》这本书时,我已经在学习如何在股票市场申请一份工作了(尽管我不确定这是我真正想要的)。这是一个来自耶鲁大学的经济学家的真实故事,他用数据科学帮助改变了棒球世界(事情发生时还没有这个名字)。
5。是什么让你进入数据行业的?
我做了大量的研究,这些研究帮助我理解了这是一个不断发展、充满希望的领域,对我来说还有很大的发展空间和职业生涯。
6。Dataquest 的教学方法(无视频、浏览器内编码)对你有什么帮助?
这招很管用。我用视频学习从来没有问题,所以我不会说我更喜欢文本课程,但它对我来说也很好。然而,浏览器内编码是游戏规则的改变者。能够在阅读完文本后立即编写代码,而无需进行任何设置,这非常有帮助。它让你只关注代码。
此外,Dataquest 让您编写完整的代码,而不仅仅是填充空白。这可能会让你在某些时候觉得有点困难,但我相信,这些时候正是你真正发展自己的时候。
7。你在 Dataquest 做了哪条路径(/s),为什么?
数据科学与 Python 路径。我感兴趣的只是学习领域和语言。
8。你最喜欢的指导项目是什么,它们对你找工作有什么帮助?
我真的不确定我有一个最喜欢的指导项目,但我认为它们是 Dataquest 的一个重要部分。这是你做更多实际工作的地方。你不仅要写代码片段,而且要从头开始编写所有代码。这非常有助于让学生全面了解数据科学项目到底是什么。
我还想谈谈无指导的项目。对开发自己的东西感兴趣对我的学习非常重要。虽然我喜欢 Dataquest 方法,它也很有帮助,但当你为自己做一些事情时,当你在研究一个你相信并且充满热情的主题时,追求答案和学习新事物的动力会更大。我确实相信这是学生更需要激发的东西。
9。现在你能告诉我们你是如何开始找工作的吗?
我是一名经济学家,我热爱运动,我意识到我在大学里学过一点数据科学,只知道他们称之为计量经济学。我不确定身在不同的国家对这有什么影响,或者如果我从未旅行过,情况是否会一样,但当我回到巴西时,我决定放弃股票市场,专心学习编程和数据科学。Python、SQL 和数据科学是我添加到简历中的最重要的工具,这让我相信,与大学毕业时相比,我为找工作做了更充分的准备。
在我得到这份工作后,我很确定这不是我想要的,但这是一个不容错过的机会。我不得不搬到一个大城市,对此并不完全满意,但我知道这是必须的。虽然我不是数据科学家,但这份工作确实给了我一些使用 Python 和 SQL 的实际经验,并让我接触到了大都市更大的就业市场。
在那里呆了大约 6 个月后,我终于得到了我一直在寻找的数据科学工作。我现在为巴西最大的零售公司工作,专营水果、蔬菜、肉、鱼等新鲜产品。我们是一家在美国东南部地区拥有近 100 家门店的快速增长的连锁店,最棒的是我在家工作,在我家乡所在州的一个小城市,离我的家人和朋友很近,不需要远离大城市的家。
10。你在 Dataquest 学到的哪些技能对你的工作有帮助?
Python、SQL、统计学和机器学习概念的来源路径。来自社区的写作和沟通技巧。
11。你最喜欢 Dataquest 的哪一点,为什么?
学习路径。因为它们在整个学习过程中给你指明了方向,你不必总是东张西望地寻找下一步要学的东西。
12。你会给刚刚开始学习 Dataquest 的人什么建议?
遵循正道。键入每一行代码,不要复制粘贴。在有指导和无指导的项目上投入一些时间和精力。加入并积极参与社区活动。要有耐心,坚持不懈。这通常不容易,而且你学的也不是简单的东西。这需要时间。确保以正确的方式去做,并坚持下去。
13。最后,人们在网上哪里能找到你?
https://Twitter . com/_ otaviosshttps://github . com/OTA VIO-s-shttps://www . LinkedIn . com/in/OTA VIOS 28/https://medium . com/@ OTA VIOS . s
在这里阅读奥塔维奥的旅程。
学员聚焦–拉希拉·哈希姆
原文:https://www.dataquest.io/blog/learner-spotlight-rahila-hashim/
December 6, 2021
认识一下 Rahil Hashim,他是一名动物学毕业生,之前没有编程经验,在获得我们的一项奖学金后,他加入了 Dataquest 的 SQL path 。
请继续阅读,了解 Rahila 如何利用 Dataquest 的课程找到一份技术数据科学家的工作。
1。第一,你首选的代词是什么?
她/她
2。好吧,拉希拉!你现在的职称是什么?在哪家公司?
Clinfocus 的技术数据科学家(临床数据管理)。
3。你能告诉我们一些你目前工作的情况吗?
作为 Clinfocus 的一名数据科学家,我利用 SAS 编程语言来创建 SAS 输出,从我们的输出中得出见解,并呈现给客户,以便他们可以做出决策。
4。现在你能告诉我们一些你的背景吗?
作为一名动物学毕业生,我对编程一窍不通。我过去的工作经验和志愿工作清楚地表明,掌握数据技能非常重要。2020 年 11 月,通过学习 Excel、SQL 和 python,我开始了向科技转型的旅程。在我研究提高技术技能和知识的最佳方法时,我遇到了 Dataquest。
5。是什么让你进入数据行业的?
作为一名志愿者(以及我过去的工作经验),我看到了使用数据做出有影响力的决策的重要性,我注意到了使用数据做出战略决策的重要性。我立即开始学习 Excel、SQL 和 Python 等重要技能。
6。Dataquest 的教学方法(无视频、浏览器内编码)对你有什么帮助?
Dataquest 的浏览器内编码体验绝对赢得了我的心。我遇到过很多平台,并和其他人一起尝试过免费的编码体验,但是我注意到 Dataquest 使它更容易理解,所以这是一个更好的学习方法。
7。你在 Dataquest 做了哪条路径(/s),为什么?
我获得了 Dataquest 的奖学金,并加入了 SQL path。我报名参加 SQL 之路是因为我刚刚结束了在另一家组织的 SQL 学习,该组织使用基于视频的课程,但我需要一种更实用的方法来提高我的技能。
8。你最喜欢的指导性项目是什么,它对你有什么帮助?
我需要在来自安卓和苹果的数据集上工作的指导性项目——在这些项目中,洞察力可以决定公司关于创建哪个应用程序来产生最多收入的下一步决策。这个项目在我目前工作的面试中有所帮助,我被要求解释我执行的一个项目,我解释了这个指导项目。
9。现在你能告诉我们你是如何开始找工作的吗?
我看到一个招聘广告,要求没有或很少需要数据科学方面的经验,只要是愿意在工作中学习的终身学习者,并具备其他软技能和优势。有人问我学过什么编程语言,以及我是否愿意在工作中学习。我在 Dataquest 方面的经验是我获得这份工作的额外优势。
10。你在 Dataquest 学到的哪些技能对你的工作有帮助?
在 Dataquest 学习 SQL 帮助很大。在我目前的工作中,我们使用 SAS,但 SAS 也嵌入了 SQL 语言,这使得它更容易理解和使用。
11。你最喜欢 Dataquest 的哪一点,为什么?
Dataquest 是我最喜欢的学习平台,因为当你编写代码时,你不仅会立即得到答案,相反,你会绞尽脑汁去理解代码。阅读笔记和浏览器内编码让它变得超级实用和易于理解
12。你会给刚刚开始学习 Dataquest 的人什么建议?
我的建议是,每天抽出几分钟到一个小时的时间来学习会更容易——而且不会让人不知所措。有时候,当我迷上了一个代码,然后休息一下,回来,我发现错误更容易,并继续工作。
13。最后,人们在网上哪里能找到你?
www.linkedin.com/in/rahilahashim
学员聚焦:Solange Van Der Kolff
原文:https://www.dataquest.io/blog/learner-spotlight-solange-van-der-kolff/
October 1, 2021
认识一下 Solange,她是一名软件工程师,进入数据科学领域是因为她想为社会做贡献。她选择 Dataquest 来帮助她准备数据库迁移。
下面是她的故事…
1。第一,你首选的代词是什么?
她/她
2。好吧,索兰吉!你现在的职称是什么?在哪家公司?
我是 Livit Orthopedie 的软件工程师。
3。你能告诉我们一些你目前工作的情况吗?
目前,我负责数据库迁移,并构建应用程序。
4。现在你能告诉我们一些你的背景吗?
2018 年我读完硕士后,我参加了一个编程学校(Codam)的考试,因为我不喜欢在我学习的领域工作。在我完成了为期一个月的测试后,我被 Codam 录取了。我已经在那里编程两年了,之后开始了我的职业生涯。
5。是什么让你迷上了编程?
职业自由、创造力和编程有用的众多应用吸引了我。我想以一种实用的方式为社会做贡献,有了编程技能,你可以在任何领域创造有用的东西。
6。Dataquest 的教学方法(无视频、浏览器内编码)对你有什么帮助?
对我来说,它完美的工作!任务所需的精确信息以视觉愉悦的方式提供。在项目中不仅有理论,还有大量的例子,这帮助我真正理解了不同的主题——并自己编写代码。
7。Dataquest 对你目前的工作有什么帮助?
如果没有 Dataquest,我不会学得这么快,也许我会忽略处理数据库迁移的不同选项。它极大地帮助了我很好地了解我需要哪些知识,以及哪种函数和库对设置数据库迁移有用。
我学习了 Python、SQL、设置数据库、清理和处理数据——所以基本上所有执行数据库迁移所需的技能都是我以前没有做过的。所以对我来说,Dataquest 为我提供了一个完美的学习途径,让我可以学到我需要的所有技能,并可以立即应用到我的工作中,这让我松了一口气。每次我遇到数据分析师的问题时,我都会查看课程寻求帮助,我总能在那里找到我的答案!
因此,我非常高兴能够访问 Dataquest,因为我的编程团队没有时间或所有技能来帮助我进行数据库迁移的实习。而我就这样因为通过这个平台学习而解决了问题!
8。你最喜欢 Dataquest 的哪一点,为什么?
我想我最喜欢在浏览器中用适量的信息循序渐进地学习编程。我最喜欢这种学习方式,因为你很快就变得实用,而且你可以一头扎进你想学的材料,而不会被过多的信息所困扰。
9。你在 Dataquest 学到的哪些技能对你的工作有帮助?
数据角力,数据清洗,Python,数据分析,数据可视化,数据聚合,SQL。
10。你会给刚刚开始学习 Dataquest 的人什么建议?
坚持不懈,每周花时间完成课程,这样你学到的新技能就有时间消化。有很多材料和项目需要你去完成,有些项目你需要更多的时间去练习和学习。
11。最后,人们在网上哪里能找到你?
人们可以在 LinkedIn:https://www.linkedin.com/in/solangevdkolff/和 GitHub:https://github.com/svan-der上找到我
学员聚焦:数据工程师学生 Veena Sanjeeve
原文:https://www.dataquest.io/blog/learner-spotlight-veena-sanjeeve/
August 4, 2021
认识一下 Veena Sanjeeve,她是 data quest数据工程职业道路的毕业生。两个月前,Veena 开始了她的新工作,在一家私人 IT 公司
担任数据工程师。在这里,她在 AWS 上从事分布式系统的工作。
下面是她的故事。。。
问:嘿,Veena,给我们介绍一下你的背景……
我扎根于 CS。我有一些学分,SQL 是我的核心优势,我在技术工作上做得很好。但是后来,生活发生了。
我的孩子和我的职业差距一样大——8 岁。我享受其中的每一点。
问:您是如何了解 Dataquest 的?
2020 年初,我试图重新开始我的科技生涯,但却是在数据行业。当我发现 Dataquest 并从 Python path 中的数据分析师开始时,我正在研究顶级
质量课程。
问:你是如何进入数据工程的?
随着我沿着数据分析师的道路前进,我开始对 Python 变得超级熟悉。这时候我对后端越来越好奇。我想知道以下问题的答案:
- 数据有多真实?
- 数据是如何获得的?
- 是什么让他们快速?
- 系统如何获得实时/接近实时的数据?
当我发现 Dataquest 允许我查看他们所有的数据工程课程时,真是一个惊喜!我所要做的只是切换路径偷看一眼,然后回到我原来的路径。
这时我明白了数据工程是真正解渴的东西。
问:你最喜欢 Dataquest 的哪一点,为什么?
我有很多最爱:
- 无视频,浏览器内编码太棒了!我不需要暂停,倒带,前进。此外,我很感激
我不必挂在耳机上。 - 许多令人敬畏的项目尝试!边做边学能建立坚实的信心。这些不仅仅是项目;他们使用真实世界的数据源和趋势。
- 社区中乐于助人且充满活力的用户。
- 帮助别人的机会也会帮助你自己。(千万不要小看这个!这是一个很棒的
功能,它帮助我建立了我的在线数据足迹,一家公司的部门主管发现我的 SQL 很有帮助
并通过 DQ 的个人资料页面在 GitHub 上找到了我)直到那时,我都不知道它是可以谷歌的!想象一下这可能带来的
机会?我不得不问,你是怎么找到我的?
问:你甚至在完成数据工程课程之前就获得了目前的工作机会。你能分享一下你是如何寻找工作的吗?
当我还在积极学习的时候,我在 Dataquest 博客上读到一篇文章,鼓励学习者在他们还在上课的时候分发他们的简历。这对我来说很有意义。
因此,我分发了三个版本的简历——一个是 Python 程序员,另一个是数据分析师,还有一个是数据工程师。
起初,我只是在 LinkedIn 上分享,看看会怎么样。但后来我也在 Dice 上分享了它。就在那时,机会开始滚滚而来,我的招聘人员找到了我。我的招聘人员找到了我的数据分析师简历,但当我提到我目前在 Dataquest 从事数据工程工作时,我得到了一个数据工程师的职位。
我不需要寻求任何推荐。
问:加入 Dataquest 社区对你的求职有何帮助?
Dataquest 社区给了我
帮助他人的机会。这帮助我建立了我的在线足迹。
因此,当一名招聘人员找到我,说我只有一年的工作经验时,我可以说,“看看我的 GitHub 和我在 Dataquest 的在线足迹。”
有相当多的招聘人员知道如何根据应聘者的工作质量而不是工作经验来发现人才。
问:你在 Dataquest 学到的哪些东西对你的
工作有帮助?
- 对 DQ 的大部分 DE 材料有了很好的理解,让我在理解分布式系统是如何运行的方面有了优势。其中的一个重要步骤是多重处理模块。对我来说,这是一座金矿,现在依然如此。
- 除此之外——Git、命令行、时间&算法的空间复杂性(这让我对使用
嵌套循环和额外变量三思而行)、递归、SQL 漏洞、最小特权原则以及数据帧的概念。 - 仅仅通过思考如何回复 Dataquest 社区中的查询,我也学到了很多。
问:你会给刚开始学习的人什么建议?
- 勇气有回报!学习和找工作时会有起伏。耐心和勇气是最好的朋友。
- 保持高质量的投资组合。Jupyter 笔记本是你真正的证书。你不必做世界上的每一个项目。选择那些很多人没有尝试过的,并个性化他们。
- 此外,我怎么强调质量代码和有意义的注释都不为过,包括命名约定。这些应该成为一种习惯。
- 最后,求职要有创意;说出真相,脱颖而出。没有放之四海而皆准的方法。
学员聚焦–维多利亚·乔拉耶娃
原文:https://www.dataquest.io/blog/learner-spotlight-viktoria-jorayeva/
November 8, 2021
认识一下 Viktoria Jorayeva,她是一名乌克兰学生,使用 Dataquest 仅用了几个月时间就完成了从语文学到数据科学的转变。作为一个来自非技术、非数学背景的人,进入数据科学领域是可能的,这要感谢 Dataquest 的数据科学职业道路。
她的故事对全世界梦想获得“21 世纪最性感工作”的人来说是一个真正的鼓舞通过分享 Viktoria 的经验,我们希望努力实现转变的非传统途径的学习者能够找到开始数据科学之旅所需的动力。
以下是她的故事:
问:首先,你首选的代词是什么?
她/她
问:你现在的职位是什么?在哪家公司?
我是分形分析的初级数据科学家。
问:你能告诉我们一些你目前工作的情况吗?
已经工作快两个月了。我为业务需求、项目文档和解决方案架构图编写伪代码。
现在你能告诉我们一些你的背景吗?
我来自乌克兰(基辅)。事实上,通过教育,我是一个语言学家(波斯语),我根本没有数学背景。但是 Dataquest 帮助我实现了我的梦想,即使我没有接受过技术教育。我发现了这个超级棒的资源。这是我试过最好的(我试了五道菜)。在 Dataquest,我选择了“数据科学家”的道路,并开始学习 Python 和 SQL ,数据分析和可视化,在我开始机器学习之前,我得到了一份工作。
问:是什么让你进入了数据行业?
我想做一些进步的,科学的事情。当我在学习成为一名翻译时,我意识到在线翻译也在和我一起“学习”,将机器翻译推向了完美。所以,我需要选择一个更现代的职业。
问:Dataquest 的教学方法(无视频、浏览器内编码)对你有什么作用?
对我来说太完美了。视频内容的缺失节省了时间。这篇课文是用最通俗易懂的方式写的。但我最喜欢的是每张幻灯片上的练习!你阅读,然后立刻用一个小的实际任务巩固你的知识。
问:你在 Dataquest 做了哪一项工作,为什么?
数据科学家。这是目前最进步、收入最高的职业之一。
问:你最喜欢的指导项目是什么,它们对你找工作有什么帮助?
我喜欢所有的项目,因为它们提供了新的知识,巩固了我所学到的东西。在 Jupyter 工作对我来说也是一种乐趣🙂
现在你能告诉我们你是如何开始求职过程的吗?
我的朋友在 https://dou.ua/的上发现了一个空缺,并与我分享了它。它是乌克兰主要的 It 工作资源。
问:你在 Dataquest 学到的哪些技能对你的工作有帮助?
Python、SQL、数据分析、数据可视化、统计
问:你最喜欢 Dataquest 的哪一点,为什么?
如此复杂的材料是如何简单明了地呈现出来的。统计、编程之类的东西不好学。但是 Dataquest 对它们的解释比所有其他资源都要清楚。也就是说,即使对于一个没有受过专门教育的人来说,这也是可以理解的。
问:你对刚刚开始学习 Dataquest 的人有什么建议?
世界上没有你学不到的东西!简而言之,一切都很简单——你每天花大约三个小时学习,瞧,你得到了你梦想的工作。我在 Dataquest 上只学了四个月,然后公司就带我去实习了。你只需要勤奋;Dataquest 已经为您做了所有其他事情。
问:最后,人们在网上哪里可以找到你
领英:https://www.linkedin.com/in/viktoria-jorayeva-0b6951205
教程:Python 中机器学习的学习曲线
原文:https://www.dataquest.io/blog/learning-curves-machine-learning/
January 3, 2018
当建立机器学习模型时,我们希望尽可能降低误差。对于任何打算学习 Python 进行数据科学研究的人来说,这是一项关键技能。误差的两个主要来源是偏差和方差。如果我们设法减少这两个,那么我们可以建立更准确的模型。但是我们如何首先诊断偏差和方差呢?一旦我们发现了什么,我们应该采取什么行动?
在本帖中,我们将学习如何使用学习曲线来回答这两个问题。我们将使用真实世界的数据集,并尝试预测发电厂的电能输出。
假设您对 scikit-learn 和机器学习理论有所了解。如果我说交叉验证或监督学习时你不皱眉,那么你就可以开始了。如果你是机器学习的新手,并且从未尝试过 scikit,那么这篇博客文章是一个很好的起点。
我们先简要介绍一下偏差和方差。
偏差-方差权衡
在监督学习中,我们假设特征和目标之间存在真实的关系,并用模型估计这种未知的关系。假设假设为真,那么就真的存在一个模型,我们称之为(f\ ),它完美地描述了特征和目标之间的关系。
在实践中,(f)几乎总是完全未知的,我们尝试用模型(\hat{f})(注意(f)和(\hat{f})之间的符号略有不同)。我们用一个确定的训练集,得到一个确定的 (\hat{f})。如果我们使用不同的训练集,我们很可能会得到不同的(\hat{f})。随着我们不断改变训练集,我们得到了(\hat{f})的不同输出。当我们改变训练集时,变化的量称为方差。
为了估计真值,我们使用不同的方法,如线性回归或随机森林。例如,线性回归假设特征和目标之间是线性的。然而,对于大多数真实场景,特征和目标之间的真实关系是复杂的,远非线性的。简化假设会给模型带来偏差。关于真实关系的假设越错误,偏差就越大,反之亦然。
通常,模型(\hat{f})在用一些测试数据进行测试时会有一些误差。数学上可以证明偏差和方差只会增加模型的误差。我们需要低误差,因此我们需要将偏差和方差保持在最小。然而,那不太可能。偏差和方差之间有一个权衡。
低偏差方法非常适合训练数据。如果我们改变训练集,我们将得到明显不同的模型(\hat{f})。

您可以看到,低偏差方法捕捉到了不同训练集之间的大多数差异(甚至是微小的差异)。(\hat{f}) 随着我们改变训练集,变化很大,这表明方差很大。
一种方法的偏差越小,它对数据的拟合能力就越强。这种能力越大,方差就越高。因此,偏差越低,方差越大。
反之亦然:偏差越大,方差越小。高偏差方法建立的模型过于简单,通常不适合训练数据。当我们改变训练集时,我们从高偏差算法得到的模型(\hat{f})通常彼此没有很大的不同。

如果(\hat{f})没有随着我们改变训练集而改变太多,那么方差就低,这就证明了我们的观点:偏差越大,方差越低。
从数学上来说,我们为什么想要低偏差和低方差是很清楚的。如上所述,偏差和方差只会增加模型的误差。然而,从更直观的角度来看,我们希望低偏差,以避免构建过于简单的模型。在大多数情况下,一个简单的模型在训练数据上表现很差,并且极有可能在测试数据上重复这种差的表现。
同样,我们希望低方差,以避免构建过于复杂的模型。这种模型几乎完全符合训练集中的所有数据点。然而,训练数据通常包含噪声,并且只是来自大得多的人群的样本。一个过于复杂的模型捕捉到了这种噪音。并且在的样本外数据上测试时,性能通常很差。那是因为模型学习样本训练数据太好了。它对某件事知道很多,但对其他事却知之甚少。
然而,在实践中,我们需要接受一个权衡。我们不能既有低偏差又有低方差,所以我们想把目标定在中间。

在我们生成和解释下面的学习曲线时,我们将尝试为这种权衡建立一些实用的直觉。
学习曲线——基本理念
假设我们有一些数据,并将其分成训练集和验证集。我们举一个例子(没错,一个!)并使用它来估计模型。然后,我们在验证集和单个训练实例上测量模型的误差。训练实例上的误差将为 0,因为完全适合单个数据点是非常容易的。然而,验证集上的误差将非常大。
这是因为该模型是围绕单个实例构建的,它几乎肯定无法对以前没有见过的数据进行准确概括。现在让我们假设不是一个训练实例,而是十个并重复误差测量。然后,我们采取五十,一百,五百,直到我们使用我们的整个训练集。当我们改变训练集时,错误分数会或多或少地变化。因此,我们需要监控两个错误分数:一个用于验证集,一个用于训练集。如果我们绘制两个错误分数随着训练集变化的演变,我们最终得到两条曲线。这些被称为学习曲线。简而言之,学习曲线显示了随着训练集大小的增加,误差是如何变化的。
下面的图表应该有助于你想象到目前为止所描述的过程。在“训练集”列中,您可以看到我们不断增加训练集的大小。这导致我们的模型发生了微小的变化(\hat{f})。在第一行中,其中 n = 1 ( n 是训练实例的数量),该模型完全符合该单个训练数据点。然而,完全相同的模型非常不适合 20 个不同数据点的验证集。因此,模型在训练集上的误差为 0,但在验证集上的误差要高得多。随着训练集大小的增加,模型不再完全适合训练集。所以训练误差变大。但是,该模型是在更多数据上训练的,因此它能够更好地适应验证集。因此,验证误差减少。提醒您,验证集在所有三种情况下保持不变。 如果我们为每个训练规模绘制误差分数,我们会得到两条类似的学习曲线:
如果我们为每个训练规模绘制误差分数,我们会得到两条类似的学习曲线: 学习曲线给我们一个机会来诊断监督学习模型中的偏差和方差。我们将在接下来的内容中看到这是如何实现的。
学习曲线给我们一个机会来诊断监督学习模型中的偏差和方差。我们将在接下来的内容中看到这是如何实现的。
介绍数据
上面绘制的学习曲线是出于教学目的而理想化的。然而,在实践中,它们通常看起来非常不同。因此,让我们通过使用一些真实世界的数据将讨论转移到实际环境中。我们将尝试建立回归模型来预测发电厂每小时的电能输出。我们使用的数据来自土耳其研究人员 pnar tüfek ci 和 Heysem Kaya,可以从这里下载。由于数据存储在一个.xlsx文件中,我们使用 pandas 的read_excel() 函数将其读入:
import pandas as pd
electricity = pd.read_excel('Folds5x2_pp.xlsx')
print(electricity.info())
electricity.head(3)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9568 entries, 0 to 9567
Data columns (total 5 columns):
AT 9568 non-null float64
V 9568 non-null float64
AP 9568 non-null float64
RH 9568 non-null float64
PE 9568 non-null float64
dtypes: float64(5)
memory usage: 373.8 KB
None
| 在(某时间或时刻);在(学习或工作地点);在(某处) | V | 美国联合通讯社(Associated Press) | 右手 | 体育课 | |
|---|---|---|---|---|---|
| Zero | Fourteen point nine six | Forty-one point seven six | One thousand and twenty-four point zero seven | Seventy-three point one seven | Four hundred and sixty-three point two six |
| one | Twenty-five point one eight | Sixty-two point nine six | One thousand and twenty point zero four | Fifty-nine point zero eight | Four hundred and forty-four point three seven |
| Two | Five point one one | Thirty-nine point four | One thousand and twelve point one six | Ninety-two point one four | Four hundred and eighty-eight point five six |
让我们快速破译每个列名:
| 缩写 | 全名 |
|---|---|
| 在(某时间或时刻);在(学习或工作地点);在(某处) | 环境温度 |
| V | 排气真空 |
| 美国联合通讯社(Associated Press) | 环境压力 |
| 右手 | 相对湿度 |
| 体育课 | 电能输出 |
PE列是目标变量,它描述了每小时净电能输出。所有其他变量都是潜在的特性,每个变量的值实际上都是每小时的平均值(不是净值,就像PE)。电力由燃气轮机、蒸汽轮机和热回收蒸汽发生器产生。根据数据集的文件,真空水平对汽轮机有影响,而其他三个变量影响燃气轮机。因此,我们将在回归模型中使用所有的特征列。在这一步,我们通常会将测试集放在一边,彻底探索训练数据,移除任何异常值,测量相关性等。然而,出于教学目的,我们将假设这已经完成,并直接生成一些学习曲线。在我们开始之前,值得注意的是没有丢失值。此外,这些数字是未缩放的,但是我们将避免使用有未缩放数据问题的模型。
决定训练集的大小
让我们首先决定我们想要使用什么样的训练集大小来生成学习曲线。最小值为 1。最大值由训练集中的实例数给出。我们的训练集有 9568 个实例,所以最大值是 9568。然而,我们还没有抛开验证集。我们将使用 80:20 的比例,最终得到 7654 个实例(80%)的训练集和 1914 个实例(20%)的验证集。假设我们的训练集将有 7654 个实例,我们可以用来生成学习曲线的最大值是 7654。在我们的例子中,我们使用这六种尺寸:
train_sizes = [1, 100, 500, 2000, 5000, 7654]
需要注意的一件重要事情是,对于每个指定的大小,都会训练一个新的模型。如果你正在使用交叉验证,我们将在这篇文章中进行,将为每个训练规模训练 k 个模型(其中 k 由用于交叉验证的折叠数给出)。为了节省代码运行时间,最好将自己的训练规模限制在 5-10 个。
scikit-learn 中的 learning_curve()函数
我们将使用 scikit-learn 库中的learning_curve() 函数来生成回归模型的学习曲线。我们没有必要搁置验证集,因为learning_curve()会处理好的。在下面的代码单元格中,我们:
- 从
sklearn进行所需的导入。 - 声明特性和目标。
- 使用
learning_curve()生成绘制学习曲线所需的数据。该函数返回一个包含三个元素的元组:训练集大小,以及验证集和训练集的错误分数。在函数内部,我们使用以下参数:estimator—表示我们用来估计真实模型的学习算法;X—包含特征的数据;y—包含目标的数据;train_sizes—指定要使用的训练集大小;cv—确定交叉验证分割策略(我们将立即讨论这一点);scoring—表示要使用的误差度量;目的是使用均方差(MSE)度量,但这不是scoring的可能参数;我们将使用最近的代理,负的 MSE,我们稍后将不得不翻转符号。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import learning_curve
features = ['AT', 'V', 'AP', 'RH']
target = 'PE'
train_sizes, train_scores, validation_scores = learning_curve(
estimator = LinearRegression(),
X = electricity[features],
y = electricity[target], train_sizes = train_sizes, cv = 5,
scoring = 'neg_mean_squared_error')
我们已经知道train_sizes里有什么了。让我们检查另外两个变量,看看learning_curve()返回了什么:
print('Training scores:\n\n', train_scores)
print('\n', '-' * 70) # separator to make the output easy to read
print('\nValidation scores:\n\n', validation_scores)
Training scores:
[[ -0\. -0\. -0\. -0\. -0\. ] [-19.71230701 -18.31492642 -18.31492642 -18.31492642 -18.31492642] [-18.14420459 -19.63885072 -19.63885072 -19.63885072 -19.63885072] [-21.53603444 -20.18568787 -19.98317419 -19.98317419 -19.98317419] [-20.47708899 -19.93364211 -20.56091569 -20.4150839 -20.4150839 ] [-20.98565335 -20.63006094 -21.04384703 -20.63526811 -20.52955609]] --------------------------------------------------------------------Validation scores:
[[-619.30514723 -379.81090366 -374.4107861 370.03037109 -373.30597982]
[ -21.80224219 -23.01103419 20.81350389 -22.88459236 -23.44955492]
[ -19.96005238 -21.2771561 19.75136596 -21.4325615 -21.89067652]
[ -19.92863783 21.35440062 19.62974239 -21.38631648 -21.811031 ]
[ -19.88806264 -21.3183303 19.68228562 -21.35019525 -21.75949097]
[ -19.9046791 21.33448781 19.67831137 -21.31935146 -21.73778949]]
因为我们指定了六个训练集大小,所以您可能期望每种分数有六个值。取而代之的是,每一行有六行,每行有五个错误分数。这是因为learning_curve()运行了一个k折叠交叉验证,其中k的值由我们为cv参数指定的值给出。在我们这里,cv = 5,所以会有五个分裂。对于每个分裂,为每个指定的训练集大小训练一个估计器。上面两个数组中的每一列表示一个分割,每一行对应一个测试大小。下表列出了培训错误分数,有助于您更好地理解流程:
| 训练集大小(索引) | 拆分 1 | 拆分 2 | 拆分 3 | 拆分 4 | 拆分 5 |
|---|---|---|---|---|---|
| one | Zero | Zero | Zero | Zero | Zero |
| One hundred | -19.71230701 | -18.31492642 | -18.31492642 | -18.31492642 | -18.31492642 |
| Five hundred | -18.14420459 | -19.63885072 | -19.63885072 | -19.63885072 | -19.63885072 |
| Two thousand | -21.53603444 | -20.18568787 | -19.98317419 | -19.98317419 | -19.98317419 |
| Five thousand | -20.47708899 | -19.93364211 | -20.56091569 | -20.4150839 | -20.4150839 |
| Seven thousand six hundred and fifty-four | -20.98565335 | -20.63006094 | -21.04384703 | -20.63526811 | -20.52955609 |
为了绘制学习曲线,我们只需要每个训练集大小的一个错误分数,而不是 5。为此,在下一个代码单元中,我们取每行的平均值,并翻转错误分数的符号(如上所述)。
train_scores_mean = -train_scores.mean(axis = 1)
validation_scores_mean = -validation_scores.mean(axis = )
print('Mean training scores\n\n', pd.Series(train_scores_mean, index = train_sizes))
print('\n', '-' * 20) # separator
print('\nMean validation scores\n\n',pd.Series(validation_scores_mean, index = train_sizes))
Mean training scores
1 -0.000000
100 18.594403
500 19.339921
2000 20.334249
5000 20.360363
7654 20.764877
dtype: float64
--------------------
Mean validation scores
1 423.372638
100 22.392186
500 20.862362
2000 20.822026
5000 20.799673
7654 20.794924
dtype: float64
现在我们有了绘制学习曲线所需的所有数据。然而,在绘制之前,我们需要停下来做一个重要的观察。你可能已经注意到在训练集合上的一些错误分数是相同的。对于对应于训练集大小为 1 的行,这是意料之中的,但是其他行呢?除了最后一行,我们有很多相同的值。例如,以第二行为例,从第二次分割开始,我们有相同的值。为什么会这样呢?这是因为没有对每次分割的训练数据进行随机化。让我们借助下图来看一个例子。当训练大小为 500 时,将选择训练集中的前 500 个实例。
对于第一次分割,这 500 个实例将从第二个块中取出。从第二次分割开始,这 500 个实例将取自第一个块。因为我们不随机化训练集,所以用于训练的 500 个实例对于第二次分割是相同的。这解释了从 500 个训练实例案例的第二次分割开始的相同值。相同的推理适用于 100 个实例的情况,类似的推理适用于其他情况。 为了停止这种行为,我们需要在
为了停止这种行为,我们需要在learning_curve()函数中将shuffle参数设置为True。这将使每次分割的训练数据的指数随机化。我们没有随机化有两个原因:
- 数据被预混洗了五次(正如在文档中提到的),所以没有必要再随机化了。
- 我想让你意识到这个怪癖,以防你在实践中偶然发现它。
最后,让我们进行绘图。
学习曲线——高偏差和低方差
我们使用常规的 matplotlib 工作流程绘制学习曲线:
import matplotlib.pyplot as plt
plt.style.use('seaborn')
plt.plot(train_sizes, train_scores_mean, label = 'Training error')
plt.plot(train_sizes, validation_scores_mean, label = 'Validation error')
plt.ylabel('MSE', fontsize = 14)
plt.xlabel('Training set size', fontsize = 14)
plt.title('Learning curves for a linear regression model', fontsize = 18, y = 1.03)
plt.legend()
plt.ylim(0,40)
(0, 40)

我们可以从这个图中提取很多信息。让我们继续细化。当训练集大小为 1 时,我们可以看到训练集的 MSE 为 0。这是正常的行为,因为模型可以完美地拟合单个数据点。因此,当在相同的数据点上测试时,预测是完美的。但是当在验证集(有 1914 个实例)上测试时,MSE 上升到大约 423.4。这个相对较高的值是我们将 y 轴范围限制在 0 到 40 之间的原因。这使我们能够精确读取大多数 MSE 值。如此高的值是意料之中的,因为基于单个数据点训练的模型极不可能准确地推广到它在训练中没有见过的 1914 个新实例。当训练集大小增加到 100 时,训练 MSE 急剧增加,而验证 MSE 同样减少。
线性回归模型不能完美地预测所有 100 个训练点,因此训练 MSE 大于 0。然而,该模型现在在验证集上表现得更好,因为它是用更多的数据估计的。从 500 个训练数据点开始,验证 MSE 大致保持不变。这告诉我们一些极其重要的事情:添加更多的训练数据点不会导致明显更好的模型。因此,与其浪费时间(可能还有金钱)来收集更多数据,我们需要尝试其他东西,比如转换到可以建立更复杂模型的算法。
为了避免这里的误解,需要注意的是,向训练数据中添加更多的实例(行)并没有什么帮助。然而,添加更多的功能是另一回事,并且很可能有所帮助,因为这将增加我们当前模型的复杂性。现在让我们来诊断偏差和方差。偏倚问题的主要指标是高验证误差。在我们的例子中,验证 MSE 停滞在大约 20 的值。但是这有多好呢?我们将受益于一些领域知识(在这种情况下可能是物理学或工程学)来回答这个问题,但是让我们试一试。
从技术上来说,值 20 以 MW(^2(兆瓦平方)为单位(当我们计算 MSE 时,单位也得到平方)。但是我们的目标栏中的值是以 MW 为单位的(根据文档)。取 20 MW(^2\的平方根)得到大约 4.5 MW。每个目标值代表每小时净电能输出。因此,每小时我们的模型平均下降 4.5 MW。根据这个 Quora 回答,4.5 MW 相当于 4500 个手持吹风机产生的热功率。如果我们试图预测一天或更长时间的总能量输出,这将会增加。我们可以得出结论,20 MW(^2\的均方差是相当大的。所以我们的模型有一个偏差问题。
但是是低偏置问题还是高偏置问题呢?要找到答案,我们需要看看训练误差。如果训练误差非常低,这意味着估计模型非常好地拟合了训练数据。如果模型非常适合训练数据,这意味着它相对于那组数据具有低偏差。如果训练误差很高,这意味着估计模型对训练数据的拟合不够好。如果模型未能很好地拟合训练数据,这意味着它相对于该组数据具有高偏差。
在我们的特殊情况下,训练 MSE 稳定在大约 20 MW(^2).的值正如我们已经确定的,这是一个很高的错误分数。因为验证 MSE 很高,训练 MSE 也很高,所以我们的模型存在高偏差问题。现在让我们继续诊断最终的方差问题。估计方差至少有两种方法:
- 通过检查验证学习曲线和训练学习曲线之间的差距。
- 通过检查训练误差:随着训练集大小的增加,其值及其演变。

较窄的差距表明方差较低。一般来说,差距越小,方差越低。反之亦然:差距越大,方差越大。现在我们来解释一下为什么会这样。正如我们之前所讨论的,如果方差很高,那么模型就太适合训练数据了。当训练数据拟合得太好时,模型将很难对训练中未见过的数据进行归纳。当这样的模型在其训练集上被测试,然后在验证集上被测试时,训练误差将是低的,而验证误差通常将是高的。当我们改变训练集的大小时,这种模式继续,训练和验证错误之间的差异将决定两条学习曲线之间的差距。
训练与验证错误之间的关系,以及差距可以这样概括:( gap =验证\错误-训练\错误)所以两个错误之间的差异越大,差距就越大。差距越大,方差越大。就我们的情况而言,差距非常小,因此我们可以有把握地得出结论,方差很低。高训练均方误差分数也是检测低方差的一种快速方法。如果学习算法的方差较低,那么当我们改变训练集时,该算法会产生简单和相似的模型。由于模型过于简化,它们甚至不能很好地拟合训练数据(它们将置于数据之下)。所以我们应该期待高水平的培训 MSE。因此,高训练均方误差可用作低方差的指标。
在我们的例子中,训练 MSE 稳定在 20 左右,我们已经得出结论,这是一个很高的值。因此,除了差距缩小之外,我们现在有了另一个确认,即我们有一个低方差问题。到目前为止,我们可以断定:
- 我们的学习算法受到高偏差和低方差的影响,对训练数据拟合不足。
- 在当前的学习算法下,向训练数据添加更多的实例(行)极不可能产生更好的模型。
在这一点上,一个解决方案是改为更复杂的学习算法。这将减少偏差,增加方差。一个错误是试图增加训练实例的数量。一般来说,当处理高偏差和低方差问题时,这另外两个修正也是有效的:
- 在更多的特征上训练当前的学习算法(为了避免收集新数据,你可以很容易地生成多项式特征)。这将通过增加模型的复杂性来降低偏差。
- 减少当前学习算法的正则化,如果是这样的话。简而言之,正则化会阻止算法太好地拟合训练数据。如果我们减少正则化,模型将更好地拟合训练数据,因此,方差将增加,偏差将减少。
学习曲线——低偏差和高方差
让我们看看一个非正则化的随机森林回归子在这里的表现。我们将使用与上面相同的工作流程来生成学习曲线。这一次,我们将把所有东西都打包到一个函数中,以便以后使用。为了比较,我们还将显示上面的线性回归模型的学习曲线。
### Bundling our previous work into a function ###
def learning_curves(estimator, data, features, target, train_sizes, cv):
train_sizes, train_scores, validation_scores = learning_curve(
estimator, data[features], data[target], train_sizes =
train_sizes,
cv = cv, scoring = 'neg_mean_squared_error')
train_scores_mean = -train_scores.mean(axis = 1)
validation_scores_mean = -validation_scores.mean(axis = 1)
plt.plot(train_sizes, train_scores_mean, label = 'Training error')
plt.plot(train_sizes, validation_scores_mean, label = 'Validation error')
plt.ylabel('MSE', fontsize = 14)
plt.xlabel('Training set size', fontsize = 14)
title = 'Learning curves for a ' + str(estimator).split('(')[0] + ' model'
plt.title(title, fontsize = 18, y = 1.03)
plt.legend()
plt.ylim(0,40)
### Plotting the two learning curves ###
from sklearn.ensemble import RandomForestRegressor
plt.figure(figsize = (16,5))
for model, i in [(RandomForestRegressor(), 1), (LinearRegression(),2)]:
plt.subplot(1,2,i)
learning_curves(model, electricity, features, target, train_sizes, 5)

现在让我们试着应用我们刚刚学到的东西。在这一点上暂停阅读并尝试自己解释新的学习曲线是一个好主意。查看验证曲线,我们可以看到我们已经设法减少了偏差。仍然有一些明显的偏见,但没有以前那么多了。查看训练曲线,我们可以推断这次有一个低偏差问题。
两条学习曲线之间的新差距表明方差大幅增加。低训练 MSEs 证实了这种高方差的诊断。较大的间隙和较低的训练误差也表明存在过拟合问题。当模型在训练集上表现良好,但在测试(或验证)集上表现较差时,就会发生过度拟合。这里我们可以做的一个更重要的观察是添加新的训练实例很可能会产生更好的模型。验证曲线不会在使用的最大训练集大小时保持平稳。它仍然有可能减少并向训练曲线收敛,类似于我们在线性回归案例中看到的收敛。到目前为止,我们可以断定:
- 我们的学习算法(随机森林)遭受高方差和相当低的偏差,过度拟合训练数据。
- 在当前的学习算法下,添加更多的训练实例极有可能导致更好的模型。
此时,我们可以做一些事情来改进我们的模型:
- 添加更多培训实例。
- 为我们当前的学习算法增加正则化。这应该会减少方差并增加偏差。
- 减少我们目前使用的训练数据中的特征数量。该算法仍将非常适合训练数据,但由于特征数量的减少,它将构建不太复杂的模型。这应该会增加偏差并减少方差。
在我们的情况下,我们没有任何其他现成的数据。我们可以进入电厂进行一些测量,但我们将把这个留到另一篇文章中(开玩笑)。让我们试着规范我们的随机森林算法。一种方法是调整每个决策树中叶子节点的最大数量。这可以通过使用RandomForestRegressor()的max_leaf_nodes参数来完成。你不一定要理解这个正则化技术。对于我们这里的目的,你需要关注的是这种正则化对学习曲线的影响。
learning_curves(RandomForestRegressor(max_leaf_nodes = 350), electricity, features, target, train_sizes, 5)

还不错!差距现在更小了,所以差异更小了。偏差似乎增加了一点,这正是我们想要的。但是我们的工作还远远没有结束!验证 MSE 仍然显示出很大的下降潜力。为实现这一目标,您可以采取以下步骤:
- 添加更多培训实例。
- 添加更多功能。
- 特征选择。
- 超参数优化。
理想学习曲线和不可约误差
学习曲线是一个很好的工具,可以在机器学习工作流程的每一点快速检查我们的模型。但是我们怎么知道什么时候停止呢?我们如何识别完美的学习曲线?对于我们之前的回归案例,您可能认为完美的场景是两条曲线都收敛到 MSE 为 0。这的确是一个完美的场景,但不幸的是,这是不可能的。实践中没有,理论上也没有。这是因为一种叫做的不可约误差。当我们建立一个模型来映射特征(X)和目标(Y)之间的关系时,我们首先假设存在这样的关系。
假设假设为真,则有一个真实的模型(f)完美地描述了(X)和(Y)之间的关系,如下所示:
但是为什么会有误差呢?!我们刚才不是说过(f)完美地描述了 X 和 Y 的关系吗?!这里有一个错误,因为(Y)不仅仅是我们有限数量的特征(X)的函数。可能有许多其他特征影响(Y)的值。我们没有的功能。也可能是(X)包含测量误差的情况。所以,除了(X),(Y)也是(不可约\误差)的函数。现在我们来解释为什么这个误差是不可约的。当我们用模型(\hat{f}(X))估计(f(X))时,我们引入了另一种误差,称为可约误差:
$ \( f(X)= \ hat { f }(X)+reducable \ error \ tag { 2 } \) $
将((1))中的(f(X))替换,我们得到:
可减少的误差可以通过建立更好的模型来减少。看方程((2))我们可以看到,如果(可约\误差)为 0,我们的估计模型(\hat{f}(X))等于真实模型(f(X))。
然而,从((3))我们可以看到,即使(可约\误差)为 0,但(不可约\误差)仍然存在于方程中。从这里我们可以推断,无论我们的模型估计有多好,通常还是会有一些我们无法减少的误差。这就是为什么这个误差被认为是不可约的。这告诉我们,在实践中,我们所能看到的最好的学习曲线是那些收敛到某个不可约误差值的曲线,而不是朝着某个理想误差值的曲线(对于 MSE,理想误差分数是 0;我们将立即看到其他误差度量具有不同的理想误差值)。
实际上,不可约误差的精确值几乎总是未知的。我们还假设不可约误差与(X)无关。这意味着我们不能用(X)来寻找真正的不可约误差。用更精确的数学语言表达同样的事情,没有函数(g)将(X)映射到不可约误差的真实值:
因此,根据我们现有的数据,无法知道不可约误差的真实值。在实践中,一个好的解决方法是尽可能降低错误分数,同时记住,限制是由一些不可约的错误给出的。
分类呢?
到目前为止,我们已经了解了回归设置中的学习曲线。对于分类任务,工作流几乎是相同的。主要的区别是我们必须选择另一个误差度量——一个适合评估分类器性能的度量。我们来看一个例子: 
与我们目前所看到的不同,请注意,训练错误的学习曲线高于验证错误的学习曲线。这是因为所使用的分数准确性描述了模型有多好。精确度越高越好。另一方面,MSE 描述了一个模型有多差。MSE 越低越好。这对不可约误差也有影响。对于描述模型有多差的误差度量,不可约误差给出了一个下限:你不能比它更低。对于描述一个模型有多好的误差度量,不可约误差给出了一个上限:你不能得到比这个更高的。作为一个旁注,在更多的技术著作中,术语 贝叶斯错误率 通常用来指分类器的最佳可能错误分数。这个概念类似于不可约误差。
后续步骤
在任何监督学习算法中,学习曲线都是诊断偏差和方差的重要工具。我们已经学习了如何使用 scikit-learn 和 matplotlib 生成它们,以及如何使用它们来诊断模型中的偏差和方差。为了巩固您所学到的知识,以下是一些需要考虑的后续步骤:
- 使用不同的数据集为回归任务生成学习曲线。
- 为分类任务生成学习曲线。
- 通过从头开始对所有内容进行编码,为监督学习任务生成学习曲线(不要使用 scikit-learn 中的
learning_curve())。使用交叉验证是可选的。 - 将没有交叉验证获得的学习曲线与使用交叉验证获得的曲线进行比较。这两种曲线应该用于相同的学习算法。
准备好继续学习了吗?
永远不要想接下来我该学什么?又来了!
在我们的 Python for Data Science 路径中,您将了解到:
- 使用 matplotlib 和 pandas 进行数据清理、分析和可视化
- 假设检验、概率和统计
- 机器学习、深度学习和决策树
- ...还有更多!
立即开始学习我们的 60+免费任务:
学习数据科学:更好的方法
February 9, 2015
How do I learn more about data science?
What can I do to start analyzing data?
Where do I get started with machine learning?
我不断听到这些问题和其他变化。问他们的人和他们的背景就像问题本身一样多种多样。从想要拓展业务的应届大学毕业生,到寻求更量化的营销人员,再到想要开发算法的初创公司创始人,似乎如今每个人都对数据感兴趣。
为什么不应该呢?从数据中进行推断可能是半神奇的,甚至在你进入机器学习之前。这些年来,我一直在努力回答这些问题。在进一步了解这个人的背景和兴趣后,我会说“从可汗学院的这些视频开始,然后读这本书,再看这些视频,然后试着自己解决这些问题。”目光会很快变得呆滞——我失去了帮助别人的机会,并有可能把他们推得更远,远离这个领域。
我把这句话演变成“嗯, Kaggle 有一些很棒的比赛——试试看吧”。这对大约 5%的人来说非常有效。甚至像安装 Python 和scikit-learn这样看似简单的事情也可能成为巨大的进入障碍(尽管 Anaconda 在这里提供了帮助)。
更不用说开始哪怕是最简单的 Kaggle 竞赛的基线是“非常了解编程,知道一些基本的统计数据,并且能够合理地管理数据”。在 edx 工作后,我还尝试了其他变化,比如“先上这个 MOOC,再上这个 MOOC”——这给了人们一个清晰的起点和结构,但 MOOC 通常非常理论化,当它们不直接适用于他们的目标时,许多人无法鼓起动力坚持到底。
学习数据科学的障碍
随着时间的推移,我越来越清楚障碍是:
- “数据科学”正成为许多人的愿望。很多不懂编码的人都想学数据科学。这里的障碍是,许多侧重于数据科学的课程都假定学生具备非常好的编程知识,并且通常具备良好的数学知识,如线性代数。
- “数据科学”涵盖了广泛的主题,如自然语言处理、map/reduce、机器学习、时间序列分析等。这些话题很多都是相互依存的——比如,要学习机器学习(足够合理地调优参数,知道发生了什么),就要学习统计学、线性代数、编程、机器学习。然而,这些主题中的每一个通常都是独立呈现的,这些链接并没有很好地呈现出来。想要学习机器学习的人要么在面对 10 门不同的课程时感到气馁,要么在试图跳过所有的构建模块并直接应用算法时感到困惑。
- “小范围学习”——不是每个想学习数据科学的人都想成为数据科学家。也许他们想在工作中做一些文本分析。或者,他们可能想构建一个包含数据组件的附带项目。或者他们只是想学习基础知识。对于这群人来说,没有真正的资源(这比想要成为数据科学家的人多得多)。向这个阵营中的人推荐数据科学课程是很困难的,因为数据科学课程每周需要几个小时,并且通常面向那些希望成为专业人士的人。
- 术语!有时候,我觉得学习机器学习或统计学等主题的 75%的战斗是术语的密度。通常,当你“理解”这个概念时,你会发现它简单而优雅。学习术语很重要,因为它能让你与该领域的人交流,但这在第一遍中并不是必要的,而且会让很多人失去兴趣。
- MOOC 提供商,尤其是 Udacity,在关注应用而非理论方面取得了很大进展。但是我们仍然停留在“课程”的概念上,它按照固定的时间表运行,不允许在固定的轨道之外进行探索。这本身就可能成为一个巨大的障碍,因为当人们无法改变自己的生活来满足固定的时间表时,他们就会退出。
- 最后但同样重要的是成本。一个数据科学学位,如加州大学伯克利分校提供的硕士学位,是 6 万美元。就学位而言,这相对便宜。即使是较新的“新兵训练营”也经常是几个月 10k+。在线课程的费用大约在 2000 美元左右。
Dataquest 简介
几年来,我一直在考虑开发一个工具,让人们能够更有效地在线学习数据科学。2014 年 11 月,我发现自己有了空闲时间,于是我开始创建一个网站。一开始我把它叫做“LearnDS ”,一周后给几个朋友看。我得到了一些很好的反馈(当时这个网站还不是很好),并花了一些时间对它进行迭代,使它变得更好。
最终, Dataquest 来了。它还没有我们想要的所有内容,但它正在出现。Dataquest 通过以下方式解决学习数据科学的问题:
- 每个“课程”(lesson)都围绕一个数据集,因此您总是在直接分析数据。
- 学习分为多个主题领域,每个主题领域之间都有链接。
- 欢迎你想怎么跳就怎么跳,尽管是有顺序的。
- 很少视频。95%的时间,你都在编写代码来解决问题。
- 从基础开始——不需要任何编程知识(如果你懂 Python,可以跳过介绍部分)
- 关注全局,而不仅仅是算法——例如,你需要了解 unicode 和字符编码来进行文本分析,所以会教授 unicode。
- 我们根据学习者的反馈不断改进网站。
到目前为止,成千上万的人已经在 data quest 上迈出了学习数据科学的第一步。为什么不是下一个?
从银行数据中学习:世界各地的妇女
April 11, 2018This post looks at the World Bank World Development Indicators (WDI). This massive collection has data in several categories: demographic, education, work, poverty, health. It includes both country-level data and various aggregates by different criteria: geographical regions, income levels, etc. The UK Data Service has a useful guide as well as access to the data. You can also download it directly from the World Bank website (and it has an API which I haven’t tried), and there are tools like R packages.
许多数据与女性和性别历史相关,以至于性别有了自己的数据门户。我只选择了少数几个覆盖面最广的重要指标(预期寿命、生育率、教育),并绘制了两个系列的图表:第一个使用了世界银行的收入水平分组,第二个选择了六个国家(选择这些国家是因为它们在地理、文化、收入和数据模式方面各不相同,还因为它们具有良好的数据覆盖面,而不是任何类型的代表性)。
我敢肯定,对于研究全球发展的人来说,这并不奇怪,但对我来说,这至少是一次教育经历。这个数据中似乎有相当多对女性有利的消息。坏消息是,在许多指标中,收入地区之间的不平等程度非常严重。
男性和女性的预期寿命
预期寿命是数据中运行时间最长的序列之一;大多数国家从 1960 年起就有了。这是一个“多面”图表,比较了五个收入群体(以及整个世界)中女性和男性的出生时预期寿命。众所周知,女性比男性长寿不仅仅是“西方”的现象,尽管国家越富裕,差距越大。最富裕国家和最贫穷国家之间持续存在的差距水平没有太大变化。

第二张图使用相同的格式来看这六个国家,在国家一级有更多的变化——甚至是与总体上升趋势相反的下降或停滞期。

(哎呀。我忘记给 y 轴做漂亮的标签了。那应该是“从出生开始的岁月”。)
这张图表以不同的方式显示了六个国家的数据。我认为它在某些方面不太清晰,但它有助于比较特定时期的国家,以及它们的轨迹如何变化。

生育率
自 1960 年以来,生育率也可以广泛获得。与 60 年前相比,世界各地的女性生育数量都在减少,但下降最快的是中等收入国家。这六个国家再次显示出更多的差异。


女孩的教育
世界银行最早的教育数据开始得比人口指标稍晚,从 1970 年开始。这方面最显著的特征是小学阶段各收入群体的趋同,除了最贫穷的国家,中等教育也没有落后太多。(注意两个图表的 y 轴刻度和透视的差异…)
在国家数据中,尤其是在中学数据中,出现了一些差距。当然,差距可能会令人沮丧,但它们对于突出我需要问的问题很重要,这些问题涉及数据是如何收集的,以及总量的计算。
初等教育


中等教育


教师
大多数情况下,WDI 的就业数据直到 20 世纪 90 年代才开始出现。但是教育数据确实包含了一些关于小学教师性别的信息。(国家数据中最奇怪的差距之一是,挪威没有这方面的记录。中学教师的数据甚至更少,我决定不包括在内。)
我已经知道,在英国,小学教师是一个以女性为主的职业,但我并不十分了解这种现象在高收入国家普遍存在的程度。全球趋势似乎是同一个方向,但在低收入国家群体中要慢得多。


编者按:这最初是发布在早期现代笔记上,作为我们关注女性历史月的一部分,已经被 perlesson 转载。作者莎伦·霍华德在谢菲尔德大学担任数字历史项目的项目经理。
新课程:学习 R 中的线性建模
December 19, 2019
对于任何对使用数据进行预测或对变量之间的关系进行推断感兴趣的人来说,线性建模是一项基本的数据技能。
对于数据科学家来说,能够制作线性模型是绝对的要求,但数据分析师甚至爱好者也可以从线性建模的强大功能中受益匪浅。

R中的线性建模,我们 R 路径中数据分析师的最新课程,将从头教你这个技巧。你准备好动手并开始建模了吗?
(如果你还没有订阅,你可以注册一个免费账户并完成我们免费的交互式 R 编程课程,或者点击这里查看我们的订阅计划。)
我将从这门课程中学到什么?
R 中的线性建模将教你如何通过使用模型进行预测和推断来从数据中获取更多信息。同样重要的是,它将教你如何评估这些预测和推断的准确性,因为你积累了制作、评估和选择不同类型模型的经验。
在整个过程中,您将使用我们的交互式浏览器编码界面。这意味着您将在学习这些概念的同时,使用 R 代码亲自动手应用这些概念。
简而言之,Dataquest 平台。
您将通过学习构建和选择模型的基础知识开始本课程,这些技能不仅在线性建模中会用到,而且在您未来的机器学习中也会用到。我们将详细介绍预测模型和可以帮助您做出推断的模型,以确定哪些变量会影响您的结果。
接下来,您将逐步完成在 R 中实际构建线性模型的过程,并了解更多关于如何选择输入变量来做出准确的预测或推断。
有了你的初始模型,你就可以开始安装它了。在 R 中拟合一个模型很简单,但是理解输出的意义就有点复杂了。在这一课中,你将学会有效地解释你的结果,从而得出有用的结论。
然后,我们将更深入地评估您的模型。您将学习如何计算残差标准差和 R 平方,如何可视化残差,以及如何使用这些方法来更好地了解模型的优缺点。
从头到尾构建了一个模型之后,您将开始创建多个模型,使用 Broom 包快速有效地拟合、分析和可视化多个线性模型。
最后,您的任务是将所有这些新知识整合到一个指导性项目中,该项目要求您分析真实的纽约房地产价格,并使用线性模型进行预测。
本课程结束时,您将对建模的基础有一个坚实的理解,并且您将有信心在 r 中构建、拟合和评估线性模型。您还将获得一个课程完成证书和一个使用真实世界的房地产数据来突出您在工作申请中的新技能的优秀作品集项目。
为什么要学线性建模?
线性建模是预测和推理的可靠方法。如果你一直在 R path 中通过我们的数据分析师工作,你已经学会了分析数据。学习线性建模让你更进一步,使你能够对未来做出预测。
如果你的目标是从事数据科学,那么了解线性建模是理所当然的。即使您的目标是将大部分时间用于更高级的机器学习应用程序,您在本课程中学习的基础知识对于理解各种机器学习模型类型也是至关重要的。
但是,即使您根本不打算从事数据科学家的工作或全职处理数据,线性建模也是一项有用的技能,它使您能够释放数据的预测能力,同时即使是数据爱好者也相对容易理解。无论你是一名分析师,还是想从数据中获取更多信息的人,学习线性建模都是实现这一目标的好方法,同时也为未来的机器学习学习打下基础,如果你对此感兴趣的话。
现实生活中的线性回归
原文:https://www.dataquest.io/blog/linear-regression-in-real-life/
November 5, 2018
这篇文章是由卡罗莱纳便当写的。她领导数据分析团队,帮助公司做出数据驱动的决策,目前在 eero 管理产品分析团队。这篇文章最初发布在媒体上,并被 perlesson 转载。
我们在学校里学到了很多有趣和有用的概念,但有时我们并不清楚如何在现实生活中运用它们。
一个可能被广泛低估的概念/工具是线性回归。
(你也可能对一个相关的话题感兴趣:回归 vs 相关性)。
假设你正计划和你的两个好朋友去拉斯维加斯旅行。你从旧金山出发,知道要开大约 9 个小时的车。你的朋友负责聚会的运作,而你负责所有相关的后勤工作。你必须计划好每一个细节:时间表,什么时候停下来,在哪里,确保你准时到达那里…
那么,你做的第一件事是什么?你悄悄地从地球上消失,不再回你朋友的电话,因为他们会在你当派对警察的时候玩得很开心?!不,你给自己一张白纸,开始计划吧!
你清单上的第一项是什么?预算!这是一次 9 小时(约 1200 英里)的有趣旅程,所以路上总共有 18 小时。后续问题:我应该花多少钱买汽油?
这是一个非常重要的问题。你不会想在高速公路中间停下来,可能只是因为没油而走了几英里!
你应该为汽油拨多少钱?
你带着以科学为导向的心态来处理这个问题,认为必须有一种方法根据你旅行的距离来估计所需的钱数。
首先,你看一些数据。
在过去的一年里,你一直在努力跟踪你的汽车的效率——因为谁没有呢!—所以在你电脑的某个地方有这个电子表格

在这一点上,这些只是数字。从这个电子表格中获取任何有价值的信息都不太容易。

然而,像这样绘图,很明显,在没有加满油箱的情况下,你能开多远之间有某种“联系”。不是说你以前不知道,但是现在有了数据,事情就变得很清楚了。
你真正想弄清楚的是:如果我开 1200 英里,我要付多少油钱?
为了回答这个问题,你将使用到目前为止你已经收集的数据,并用它来预测你将花费多少。这个想法是,你可以根据过去的数据——你辛辛苦苦记录的数据点——对未来——你的拉斯维加斯之旅——进行估计性的猜测。
你最终会得到一个数学模型来描述行驶里程和加油费用之间的关系。
一旦这个模型被定义,你可以向它提供新的信息——你从旧金山开车到拉斯维加斯有多少英里——这个模型将预测你需要多少钱。

该模型将使用来自过去的数据来了解行驶的总里程和支付的汽油总金额之间的关系。
当呈现给它一个新的数据点时——你从旧金山开车到拉斯维加斯有多少英里——该模型将利用它从所有过去的数据中获得的知识,并提供它的最佳猜测——一个预测,即你来自未来的数据点。
回头看看你的数据,你会发现,通常,你在汽油上花的越多,在汽油耗尽之前你能开的时间就越长——假设汽油价格保持不变。
如果您要最好地描述——或“解释”——上面图中的关系,它看起来会有点像这样:

很明显,行驶里程和汽油总费用之间有一个线性关系。因为这种关系是线性的,如果你花更少/更多的钱——例如,油箱加满一半——你就能开更少/更多的里程。
因为这种关系是线性的,而且你知道从三藩市到拉斯韦加斯的车程有多长,使用线性模型将帮助预测你在汽油上的预算。
线性回归模型
最能描述总行驶里程和总油费之间关系的模型类型是线性回归模型。这里有“回归”的意思,因为你试图预测的是一个数值。
这里有几个概念需要解释:
- 因变量
- 独立变量
- 拦截
- 系数
你要为汽油预算的金额取决于你要开多少英里,在这种情况下,从旧金山到拉斯维加斯。因此,为天然气支付的总费用是模型中的因变量。
另一方面,拉斯维加斯不会去任何地方,所以从旧金山到拉斯维加斯你需要行驶多少英里与你在加油站支付的费用无关-行驶英里数是模型中的独立变量。让我们暂时假设油价保持不变。
由于我们只处理一个独立变量,该模型可以指定为:

这是线性组合的简单版本,其中只有一个变量。如果你想在计算中更加严谨,你也可以在这个模型中加入每桶石油的价格作为独立变量,因为它会影响天然气的价格。

模型的所有必要部分都准备好了,剩下的唯一问题是:B0、B1 和 B2 呢?
B0,读作“Beta 0”,是模型的截距,意味着如果每个因变量都等于零,它就是自变量取的值。你可以把它想象成一条穿过轴的原点的直线。
 线性模型的不同截距值:y =β0+2x
线性模型的不同截距值:y =β0+2x
“β1”和“β2”是被调用的系数。模型中的每个独立变量都有一个系数。它们决定了描述模型的回归线的斜率。
如果我们以上面的例子为例,一个由 y= Beta0 + Beta1x 指定的模型,并使用不同的 Beta 1 值,我们得到类似 的线性模型的不同系数值:y = 1 + Beta1x
的线性模型的不同系数值:y = 1 + Beta1x
这些系数解释了因变量的变化率,即当每个自变量变化一个单位时,你要支付的汽油价格。
所以,在上面蓝线的情况下,自变量 x 每改变一个单位,因变量 y 就改变 1 倍。
对于绿线,这种影响是因变量 x 单位变化的 4 倍。
普通最小二乘法
至此,我们已经讨论了线性模型,甚至对截距和系数插入不同的值进行了实验。
然而,为了计算出你去拉斯维加斯旅行要付多少油钱,我们需要一种机制来估算这些价值。
有不同的技术来估计模型的参数。其中最流行的是普通最小二乘法(OLS) 。
普通最小二乘法的前提是最小化模型的残差的平方和。即数据集中预测值和实际值之间的差异,即距离。
通过这种方式,模型计算出最佳参数,因此回归线中的每个点都尽可能地接近数据集。

在预算练习的最后,有了模型参数,你就可以输入你期望驾驶的总里程,并估计你需要为汽油分配多少。

太好了,现在你知道你应该为汽油预算 114.5 美元!
(你会注意到我们的模型中没有参数β0。在我们的用例中,有一个截距——或者当因变量等于零时有一个常数值——没有多大意义。对于这个特定的模型,我们强迫它通过原点,因为如果你不开车,你就不会花任何油钱。)
下一次,当你发现自己需要根据一系列可以用直线描述的因素来估算一个数量时——你知道你可以使用线性回归模型。
这篇文章是由卡罗莱纳便当写的。她领导数据分析团队,帮助公司做出数据驱动的决策,目前在 eero 管理产品分析团队。这篇文章最初发布在媒体上,并被 perlesson 转载。
Tidyverse 基础知识:使用 R tidyverse 工具加载和清理数据
原文:https://www.dataquest.io/blog/load-clean-data-r-tidyverse/
July 24, 2020
我们将使用 R 和 tidyverse 加载、清理和准备一些布鲁克林房地产数据以供分析!
杂乱的数据集无处不在。如果您想要分析数据,不可避免地需要清理数据。在本教程中,我们将看看如何使用 R 和一些漂亮的 tidyverse 工具来实现这一点。
tidyverse 工具提供了强大的方法来诊断和清理 r 中杂乱的数据集。虽然我们可以使用 tidy verse 做更多的事情,但在本教程中,我们将重点学习如何:
- 将逗号分隔值(CSV)和 Microsoft Excel 平面文件导入 R
- 组合数据帧
- 清除列名
- 还有更多!
tidyverse 是为处理数据而设计的 R 包的集合。tidyverse 包拥有共同的设计理念、语法和数据结构。Tidyverse 包“一起玩好”。tidyverse 使您能够花更少的时间清理数据,以便您可以将更多的精力放在数据的分析、可视化和建模上。
install.packages("Dataquest ")
从我们的R 课程简介开始学习 R——不需要信用卡!
1.干净数据和杂乱数据的特征
干净数据到底是什么?干净的数据是准确、完整的,并且其格式便于分析。干净数据的特征包括以下数据:
- 没有重复的行/值
- 无错误(例如,无拼写错误)
- 相关(例如没有特殊字符)
- 用于分析的适当数据类型
- 无异常值(或仅包含已识别/了解的异常值),以及
- 遵循“整齐的数据”结构
杂乱数据的常见症状包括包含以下内容的数据:
- 特殊字符(如数值中的逗号)
- 存储为文本/字符数据类型的数值
- 重复行
- 拼写错误
- 不准确
- 空格
- 缺失数据
- 零而不是空值
2.动机
在这篇博文中,我们将使用纽约市财政局滚动销售数据网站上公开的五个房产销售数据集。我们鼓励您下载数据集并跟进!每个文件包含纽约市五个区之一的一年的房地产销售数据。我们将使用以下 Microsoft Excel 文件:
- rollingsales_bronx.xls
- rollingsales_brooklyn.xls
- rollingsales_manhattan.xls
- rollingsales_queens.xls
- rollingalsales _ stationland . xls
当我们阅读这篇博文时,想象一下你正在帮助一个朋友在纽约市开展他们的房屋检查业务。你主动提出通过分析数据来帮助他们更好地了解房地产市场。但是您意识到,在您可以分析 R 中的数据之前,您需要首先诊断和清理它。在您可以诊断数据之前,您需要将它加载到 R!
3.用 readxl 将数据载入 R
在数据加载过程中,使用 tidyverse 工具的好处是显而易见的。在许多情况下,当 Microsoft Excel 数据被加载到 r 中时,tidyverse 包readxl将为您清理一些数据。如果您正在处理 CSV 数据,则 tidyverse readr包函数read_csv()是要使用的函数(我们将在后面介绍)。
让我们看一个例子。布鲁克林区的 Excel 文件如下所示:

布鲁克林 Excel 文件
现在让我们将布鲁克林数据集从一个 Excel 文件加载到 R 中。我们将使用readxl包。我们指定函数参数skip = 4,因为我们想要用作标题的行(即列名)实际上是第 5 行。我们可以完全忽略前四行,从第 5 行开始将数据加载到 R 中。代码如下:
library(readxl) # Load Excel files
brooklyn <- read_excel("rollingsales_brooklyn.xls", skip = 4)
注意我们用变量名brooklyn保存了这个数据集以备将来使用。
4.用 tidyr::glimpse()查看数据
tidyverse 提供了一种用户友好的方式,通过作为tibble包一部分的glimpse()函数来查看这些数据。要使用这个包,我们需要加载它以便在当前会话中使用。但是我们可以一次加载许多 tidyverse 包,而不是单独加载这个包。如果没有包的 tidyverse 集合,请在 R 或 R Studio 会话中使用以下命令将其安装到您的计算机上:
install.packages("tidyverse")
软件包安装完成后,将其加载到内存中:
library(tidyverse)
既然 tidyverse 已经加载到内存中,那么就来“一瞥”一下 Brooklyn 数据集:
glimpse(brooklyn)
## Observations: 20,185
## Variables: 21
## $ BOROUGH <chr> "3", "3", "3", "3", "3", "3", "…
## $ NEIGHBORHOOD <chr> "BATH BEACH", "BATH BEACH", "BA…
## $ `BUILDING CLASS CATEGORY` <chr> "01 ONE FAMILY DWELLINGS", "01 …
## $ `TAX CLASS AT PRESENT` <chr> "1", "1", "1", "1", "1", "1", "…
## $ BLOCK <dbl> 6359, 6360, 6364, 6367, 6371, 6…
## $ LOT <dbl> 70, 48, 74, 24, 19, 32, 65, 20,…
## $ `EASE-MENT` <lgl> NA, NA, NA, NA, NA, NA, NA, NA,…
## $ `BUILDING CLASS AT PRESENT` <chr> "S1", "A5", "A5", "A9", "A9", "…
## $ ADDRESS <chr> "8684 15TH AVENUE", "14 BAY 10T…
## $ `APARTMENT NUMBER` <chr> NA, NA, NA, NA, NA, NA, NA, NA,…
## $ `ZIP CODE` <dbl> 11228, 11228, 11214, 11214, 112…
## $ `RESIDENTIAL UNITS` <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1…
## $ `COMMERCIAL UNITS` <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ `TOTAL UNITS` <dbl> 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1…
## $ `LAND SQUARE FEET` <dbl> 1933, 2513, 2492, 1571, 2320, 3…
## $ `GROSS SQUARE FEET` <dbl> 4080, 1428, 972, 1456, 1566, 22…
## $ `YEAR BUILT` <dbl> 1930, 1930, 1950, 1935, 1930, 1…
## $ `TAX CLASS AT TIME OF SALE` <chr> "1", "1", "1", "1", "1", "1", "…
## $ `BUILDING CLASS AT TIME OF SALE` <chr> "S1", "A5", "A5", "A9", "A9", "…
## $ `SALE PRICE` <dbl> 1300000, 849000, 0, 830000, 0, …
## $ `SALE DATE` <dttm> 2020-04-28, 2020-03-18, 2019-0…
glimpse()函数提供了一种用户友好的方式来查看数据框中所有列或变量的列名和数据类型。使用此功能,我们还可以查看数据框中的前几个观察值。这个数据框有 20,185 个观察值,即房产销售记录。有 21 个变量或列。
5.数据类型
查看每一列的数据类型,我们会发现,一般来说,数据是以随时可用的格式存储的!例如:
NEIGHBORHOOD是“字符”型,也称为字符串。GROSS SQUARE FEET(即属性的大小)属于“double”类型,属于 r 中“numeric”类的哪一部分。SALE PRICE也是数字。SALE DATE以表示日历日期和时间的格式存储。
那么,为什么这很重要呢?因为GROSS SQUARE FEET和SALE PRICE是数值,我们可以马上对数据进行算术运算。例如,我们可以计算所有房产的平均销售价格:
mean(brooklyn$`SALE PRICE`)
## [1] 1098644
6.准备剧情!
SALE DATE以表示日历日期和时间的格式存储是很有用的,因为这使我们能够使用一行代码按日期制作房地产销售直方图:
qplot(`SALE DATE`, data = brooklyn)

2020 年 4 月房产销售大幅下滑
请注意 2020 年 4 月房地产销售的急剧下降。这可能与新冠肺炎·疫情有关吗?如您所见,只需几行代码,我们就可以开始探索我们的数据并提出一些有趣的问题!
注意,用于制作直方图的 qplot()函数来自 ggplot2 包,是一个核心tidyverse包。
7.与 read.csv()进行比较
readxl()功能帮了我们多大的忙?让我们将它与 r 内置的 read.csv()函数进行比较。为此,我们下载了原始的 Excel 文件,在 Mac 上的 Numbers 程序中打开它,并将文件转换为 CSV 格式。当然,这种工作流程并不理想,但是分析师更喜欢以 CSV 格式读取表格数据的情况并不少见。
下面是我们用read.csv()加载 CSV 格式的相同数据时看到的情况:
brooklyn_csv <- read.csv("rollingsales_brooklyn.csv", skip = 4)
glimpse(brooklyn_csv)
## Observations: 20,185
## Variables: 21
## $ BOROUGH <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ NEIGHBORHOOD <fct> BATH BEACH, BATH BEACH, BATH BEAC…
## $ BUILDING.CLASS.CATEGORY <fct> 01 ONE FAMILY DWELLINGS, 01 ONE F…
## $ TAX.CLASS.AT.PRESENT <fct> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ BLOCK <int> 6359, 6360, 6364, 6367, 6371, 637…
## $ LOT <int> 70, 48, 74, 24, 19, 32, 65, 20, 1…
## $ EASE.MENT <lgl> NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ BUILDING.CLASS.AT.PRESENT <fct> S1, A5, A5, A9, A9, A9, A2, A5, B…
## $ ADDRESS <fct> 8684 15TH AVENUE, 14 BAY 10TH STR…
## $ APARTMENT.NUMBER <fct> , , , , , , , , , , , , , , , , ,…
## $ ZIP.CODE <int> 11228, 11228, 11214, 11214, 11214…
## $ RESIDENTIAL.UNITS <int> 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, …
## $ COMMERCIAL.UNITS <int> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ TOTAL.UNITS <int> 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, …
## $ LAND.SQUARE.FEET <fct> "1,933", "2,513", "2,492", "1,571…
## $ GROSS.SQUARE.FEET <fct> "4,080", "1,428", "972", "1,456",…
## $ YEAR.BUILT <int> 1930, 1930, 1950, 1935, 1930, 189…
## $ TAX.CLASS.AT.TIME.OF.SALE <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ BUILDING.CLASS.AT.TIME.OF.SALE <fct> S1, A5, A5, A9, A9, A9, A2, A5, A…
## $ SALE.PRICE <fct> "1,300,000", "849,000", "0", "830…
## $ SALE.DATE <fct> 4/28/20, 3/18/20, 8/15/19, 6/26/2…
这个数据比较乱!以下是方法:
- 字符(字符串)数据,如
ADDRESS,已被存储为类“因子”。将因素视为类别或桶。 GROSS.SQUARE.FEET和SALE.PRICE也被存储为因子。我们不能对一个因子执行算术运算,比如计算平均值!SALE.DATE不是以表示日历日期和时间的格式存储的。所以我们无法构建上面看到的直方图。(我们可以做一个直方图,但是很乱,没有意义)。GROSS.SQUARE.FEET和SALE.PRICE列包含一个特殊字符,逗号(,)。
但是如果我们用来自readr包的 read_csv()函数加载同一个数据集,它是 tidyverse 的一部分,我们会看到类似于我们用readxl()的原始方法的结果:
brooklyn_csv <- read_csv("rollingsales_brooklyn.csv", skip = 4)
glimpse(brooklyn_csv)
## Observations: 20,185
## Variables: 21
## $ BOROUGH <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
## $ NEIGHBORHOOD <chr> "BATH BEACH", "BATH BEACH", "BA…
## $ `BUILDING CLASS CATEGORY` <chr> "01 ONE FAMILY DWELLINGS", "01 …
## $ `TAX CLASS AT PRESENT` <chr> "1", "1", "1", "1", "1", "1", "…
## $ BLOCK <dbl> 6359, 6360, 6364, 6367, 6371, 6…
## $ LOT <dbl> 70, 48, 74, 24, 19, 32, 65, 20,…
## $ `EASE-MENT` <lgl> NA, NA, NA, NA, NA, NA, NA, NA,…
## $ `BUILDING CLASS AT PRESENT` <chr> "S1", "A5", "A5", "A9", "A9", "…
## $ ADDRESS <chr> "8684 15TH AVENUE", "14 BAY 10T…
## $ `APARTMENT NUMBER` <chr> NA, NA, NA, NA, NA, NA, NA, NA,…
## $ `ZIP CODE` <dbl> 11228, 11228, 11214, 11214, 112…
## $ `RESIDENTIAL UNITS` <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1…
## $ `COMMERCIAL UNITS` <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ `TOTAL UNITS` <dbl> 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1…
## $ `LAND SQUARE FEET` <dbl> 1933, 2513, 2492, 1571, 2320, 3…
## $ `GROSS SQUARE FEET` <dbl> 4080, 1428, 972, 1456, 1566, 22…
## $ `YEAR BUILT` <dbl> 1930, 1930, 1950, 1935, 1930, 1…
## $ `TAX CLASS AT TIME OF SALE` <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ `BUILDING CLASS AT TIME OF SALE` <chr> "S1", "A5", "A5", "A9", "A9", "…
## $ `SALE PRICE` <dbl> 1300000, 849000, 0, 830000, 0, …
## $ `SALE DATE` <chr> "4/28/20", "3/18/20", "8/15/19"…
总而言之,使用readxl()或read_csv()将数据加载到 R 中的关键区别在于,没有任何变量被强制转换为factor数据类型。相反。许多变量是作为字符或字符串数据类型加载的。
另外,请注意,Sale Price列中缺少特殊字符,该列已经作为double或数字数据类型加载。这意味着我们可以立即执行与销售价格相关的计算,而无需采取额外的步骤将列转换为数字!
8.组合数据集
如果我们想对纽约市的所有五个区进行数据分析,那么合并数据集将会很有帮助。此外,如果数据需要任何额外的清理,最好是只在一个地方清理数据,而不是在五个地方!我们已经验证了五个 Excel 文件中的列名是相同的。所以我们可以将数据帧与来自dplyr包(另一个 tidyverse 包)的 bind_rows()函数组合起来。):
brooklyn <- read_excel("rollingsales_brooklyn.xls", skip = 4)
bronx <- read_excel("rollingsales_bronx.xls", skip = 4)
manhattan <- read_excel("rollingsales_manhattan.xls", skip = 4)
staten_island <- read_excel("rollingsales_statenisland.xls", skip = 4)
queens <- read_excel("rollingsales_queens.xls", skip = 4)
# Bind all dataframes into one, save as "NYC_property_sales"
NYC_property_sales <- bind_rows(brooklyn, bronx, manhattan, staten_island, queens)
glimpse(NYC_property_sales)
## Observations: 70,870
## Variables: 21
## $ BOROUGH <chr> "3", "3", "3", "3", "3", "3", "…
## $ NEIGHBORHOOD <chr> "BATH BEACH", "BATH BEACH", "BA…
## $ `BUILDING CLASS CATEGORY` <chr> "01 ONE FAMILY DWELLINGS", "01 …
## $ `TAX CLASS AT PRESENT` <chr> "1", "1", "1", "1", "1", "1", "…
## $ BLOCK <dbl> 6359, 6360, 6364, 6367, 6371, 6…
## $ LOT <dbl> 70, 48, 74, 24, 19, 32, 65, 20,…
## $ `EASE-MENT` <lgl> NA, NA, NA, NA, NA, NA, NA, NA,…
## $ `BUILDING CLASS AT PRESENT` <chr> "S1", "A5", "A5", "A9", "A9", "…
## $ ADDRESS <chr> "8684 15TH AVENUE", "14 BAY 10T…
## $ `APARTMENT NUMBER` <chr> NA, NA, NA, NA, NA, NA, NA, NA,…
## $ `ZIP CODE` <dbl> 11228, 11228, 11214, 11214, 112…
## $ `RESIDENTIAL UNITS` <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1…
## $ `COMMERCIAL UNITS` <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ `TOTAL UNITS` <dbl> 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1…
## $ `LAND SQUARE FEET` <dbl> 1933, 2513, 2492, 1571, 2320, 3…
## $ `GROSS SQUARE FEET` <dbl> 4080, 1428, 972, 1456, 1566, 22…
## $ `YEAR BUILT` <dbl> 1930, 1930, 1950, 1935, 1930, 1…
## $ `TAX CLASS AT TIME OF SALE` <chr> "1", "1", "1", "1", "1", "1", "…
## $ `BUILDING CLASS AT TIME OF SALE` <chr> "S1", "A5", "A5", "A9", "A9", "…
## $ `SALE PRICE` <dbl> 1300000, 849000, 0, 830000, 0, …
## $ `SALE DATE` <dttm> 2020-04-28, 2020-03-18, 2019-0…
这个NYC_property_sales数据帧也包含 21 个变量,就像brooklyn数据帧一样。这很好,因为它确认了所有五个数据集具有完全相同的列名,所以我们能够将它们组合在一起,而无需任何更正!bind_rows()函数实际上是将五个数据帧堆叠在一起,形成一个数据帧。
如果我们合并这些数据帧,最终得到的列数比brooklyn数据帧中的多,这可能表明存在问题,比如某个数据集中的列名错误。但是这里没有发生这种情况,所以我们可以继续清理列名。
9.用马格里特魔法清理列名!
现在是 Dataquest 中我们最喜欢的数据清理技巧之一的时候了!
列名包含空格,这在 tidyverse 中可能更难处理。此外,列名包含大写字母。在我们的分析过程中,我们不想担心空格或记住大写变量名!让我们使用 magrittr包中的一种简便方法快速清理列名。首先将包加载到内存中。如果需要,安装软件包。tidyverse 中使用了“magrittr”包,但是我们需要显式地加载它来访问它的一个内置函数。
library(magrittr)
我们将使用magrittr包中的“赋值管道”函数来有效地更新所有变量名。管道是强大的工具,允许 R 用户一次链接多个操作。管道也使 R 代码更易读,更容易理解。在使用 tidyverse 工具时,管道被广泛使用。
让我们将赋值管道操作符与 tidyverse stringr包中的str_replace_all()函数结合起来,用下划线替换所有空格。NYC_property_sales数据帧的代码如下所示:
colnames(NYC_property_sales) %<>% str_replace_all("\\s", "_") %<>% tolower()
这是怎么回事?!把%<>%想成是“然后更新”的意思。让我们把这个放在上下文中。上面一行代码实际上意味着:
从
NYC_property_sales数据框中取出列名,然后更新所有列名,将所有空格替换为下划线,然后将所有列名更新为小写。
好长的一句话!但是这展示了管道操作符将多个命令链接在一起的价值。让我们看看更新后的列名:
colnames(NYC_property_sales)
## [1] "borough" "neighborhood"
## [3] "building_class_category" "tax_class_at_present"
## [5] "block" "lot"
## [7] "ease-ment" "building_class_at_present"
## [9] "address" "apartment_number"
## [11] "zip_code" "residential_units"
## [13] "commercial_units" "total_units"
## [15] "land_square_feet" "gross_square_feet"
## [17] "year_built" "tax_class_at_time_of_sale"
## [19] "building_class_at_time_of_sale" "sale_price"
## [21] "sale_date"
这样看起来更好!
10.管道操作
通常,当使用 tidyverse 工具时,我们将使用来自magrittr的单管道(%>%)。管道是将多个命令链接在一起的一种方式。回想一下上面我们是如何把%<>%想成“然后更新”的?好吧,单管可以简单的认为是“然后”。下面是一个使用我们到目前为止所学命令的示例:
NYC_property_sales %>% glimpse()
这大致可以解释为:
让我们抓住 NYC_property_sales 数据框架,然后浏览一下数据。
概述
哇,看看我们在这篇博文中涵盖的所有内容:
- 用
readxl包中的read_excel()函数将 Microsoft Excel 平面文件加载到 R 中 - 从
readr包导入带有read_csv()功能的 CSV 文件 - 使用
tibble包中的glimpse()功能查看数据帧特征 - 使用
ggplot2包中的qplot()函数生成直方图 - 用
dplyr包中的bind_rows()函数组合数据帧 - 使用
magrittr包和stringr包中的函数清理列名 - 用来自
magrittr的单管道(%>%)将命令连接在一起
正如您所看到的,tidyverse 包是加载、清理和检查数据的非常强大的工具,因此您可以立即开始分析您的数据!请记住,您可以使用library(tidyverse)一次性加载所有这些包。
额外资源
如果您是 R 和 tidyverse 的新手,我们建议您从 R 课程中的 Dataquest 数据分析介绍开始。这是 R 路径中 Dataquest 数据分析师的第一门课程。
Hadley Wickham 和 Garrett Grolemund 的《数据科学》的书 R 涵盖了我们在这里讨论的很多内容(甚至更多!).我们向任何正在学习 r 的人推荐这本书。
奖励:备忘单
RStudio 已经发布了许多关于使用 R 和 tidyverse 工具的备忘单。与本文相关的备忘单包括:
通过选择Help > Cheatsheets,可以从 RStudio 中访问选择备忘单。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
教程:使用 Python 和 CSV 将数据加载到 Postgres
原文:https://www.dataquest.io/blog/loading-data-into-postgres/
September 30, 2017
Python Postgres 简介
数据存储是数据系统最重要的组成部分之一。你会在网上找到数百个 SQL 教程,详细介绍如何编写疯狂的 SQL 分析查询,如何在数 Pb 的训练数据上运行复杂的机器学习算法,以及如何在数据库的数千行上建立统计模型。唯一的问题是:没有人首先提到你如何获得存储的数据。
无论您是数据分析师、数据科学家、数据工程师,甚至是 web 开发人员,知道如何存储和访问您的数据都是非常重要的。在这篇博客文章中,我们将关注一种叫做关系数据库的数据存储。关系数据库是用于 web 内容、大型商业存储以及最相关的数据平台的最常见存储。
具体来说,我们将重点关注 Postgres (或 PostgreSQL) ,最大的开源关系数据库之一。我们喜欢 Postgres 是因为它的高稳定性,在云提供商(AWS,Google Cloud 等)中的易用性,以及它是开源的事实!使用 Python 库psycopg2,我们将通过一个例子演示如何从头开始创建自己的表,然后将数据集加载到本地运行的 Postgres 服务器中。
在我们开始之前,您应该确保已经安装了必要的工具。最重要的是在你的电脑上安装一个 Postgres 的本地版本。Postgres wiki 有一个安装页面,上面有关于最流行的操作系统的指南。
接下来,您应该确保安装了psycopg2库。如果没有,您可以运行:
pip install psycopg2
在我们的代码示例中,我们将在 Mac 或 Linux 操作系统上使用 Python 版。如果您运行的是 2.7 版或在 Windows 机器上,命令应该仍然是相似的。设置好一切后,让我们开始连接本地 Postgres 服务器吧!
Postgres 和客户机-服务器模型
如果您过去曾经使用过 SQL 引擎,那么您很可能已经了解过 SQLite ,因为它是最常见的数据库引擎之一。您的所有数据都保存在一个文件中,使其易于移植和开发。此外,SQLite 包含大部分用于大型引擎的 SQL 命令——因此,如果您了解 SQLite,那么您就会了解所有其他 SQL 数据库的基础知识
然而,在数据生产系统中使用 SQLite 也有缺点。由于其简单的用例,SQLite 不是为多连接而构建的。SQLite 只允许单个进程写入数据库,因此很难与多个用户和服务共享。
另一方面,Postgres 是一个更加健壮的引擎,它被实现为一个服务器,而不是一个单独的文件。作为服务器,Postgres 接受来自客户端的连接,客户端可以请求SELECT、INSERT或任何其他类型的 SQL 查询。这种类型的设计被称为 客户机-服务器模型 ,其中客户机可以与服务器交互。
这种模式不是偶然出现的,它实际上是一种非常常见的模式,你现在用它来连接 dq-staging.t79ae38x-liquidwebsites.com/blog.,你的电脑,笔记本电脑,或者任何你用来阅读这篇文章的设备就是从 dq-staging.t79ae38x-liquidwebsites.comserver请求信息的client。每当您访问一个网站时,您的浏览器(客户端)将不断向服务器请求网站数据。
然而,在 Postgres 的例子中,连接到 Postgres 服务的客户机将使用 database=specific 请求,而不是请求网站数据。这些类型的请求是根据定义的协议实现的,协议是客户机和服务器都同意的一组规则。你可以把协议想象成当客户端请求时,服务器用数据响应时,客户端和服务器都会使用的语言。
使用这个模型,Postgres 可以处理到数据库的多个连接,解决了将多个用户连接到一个数据库的难题。此外,作为一个服务器,Postgres 可以通过适当的安全措施实现更高级的查询功能。所有这些原因使得 Postgres 成为数据分析的绝佳选择。
连接到 Postgres
如果我们希望与 Postgres 服务器通信,我们需要使用一种使用前面描述的数据库协议的客户机。我们将使用 psycopg2 ,这是一个实现 Postgres 协议的开源库。你可以把 psycopg2 想象成类似于使用 sqlite3 连接到 SQLite 数据库。
以下面的例子为例,使用 psycopg2 连接到 Postgres 数据库
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
让我们描述一下传递给psycopg2.connect()方法的这三个参数。首先,需要指定一个主机名host,描述 Postgres 服务器在哪里运行。因为我们运行的是 Postgres 的本地版本,所以我们使用默认的主机名localhost。
然后,我们需要传入数据库名称dbname和用户user。由于存在多个连接,Postgres 使用多个用户和数据库作为提高安全性和数据分割的方法。我们对这两个值都使用postgres,因为这是 Postgres 安装时的默认值。
如果没有psycopg2中的这些值,Postgres 将不知道您想要连接到哪里,并且会失败。请记住,无论何时您想要连接到 Postgres 服务器,无论是在 web 上还是在本地,您都必须传递适当的连接参数。现在我们已经连接上了,是时候利用 Postgres 的特性了!
与数据库交互
在前面的例子中,我们通过使用psycopg2模块的connect()方法打开了一个到 Postgres 的连接。connect()方法接受一系列参数,库使用这些参数连接到 Postgres 服务器。connect()方法的返回值是一个连接对象。
连接对象创建了一个与数据库服务器的客户端会话,该会话实例化了一个持久客户端进行对话。为了对数据库发出命令,您还需要创建另一个名为 Cursor 对象的对象。Cursor是由Connection对象创建的,使用Cursor对象我们将能够执行我们的命令。
要在 Postgres 数据库上执行命令,可以用一个字符串化的 SQL 命令调用Cursor对象上的execute方法。下面是一个如何在假的notes表上运行的例子:
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
cur.execute('SELECT * FROM notes')
在这个例子中,cur对象调用execute方法,如果成功,将返回None。要从查询中获得返回值,需要调用两个方法之一:fetchone()或fetchall()。fetchone()方法返回第一行结果或None,而fetchall()方法返回表中每一行的列表,如果没有行,则返回空列表[]。
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
cur.execute('SELECT * FROM notes')
one = cur.fetchone()
all = cur.fetchall()
遗憾的是,对于我们当前的数据库,我们没有创建任何表。没有任何表,就没有什么有趣的查询。为了解决这个问题,让我们继续创建我们的第一个表!
创建表格
现在我们已经对如何连接和执行数据库查询有了基本的了解,是时候创建您的第一个 Postgres 表了。从 Postgres 文档中,可以看到如何在 Postgres 中创建表格:
CREATE TABLE tableName(
column1 dataType1 PRIMARY KEY,
column2 dataType2,
column3 dataType3,
...
);
每个column[n]都是列名的占位符,dataType[n]是要为该列存储的数据类型,PRIMARY KEY是要添加到表中的可选参数的示例。在 Postgres 中,每个表至少需要一个包含一组唯一值的PRIMARY KEY列。现在让我们看看我们希望加载到数据库中的 CSV 文件(注意,CSV 文件不包含真实用户,而是使用名为 faker 的 Python 库随机生成的用户)。
| 身份证明(identification) | 电子邮件 | 名字 | 地址 |
| Zero | 【电子邮件保护】 | 安娜·杰克逊 | 22871 东北 30037 汉纳营阿姆斯壮顿 |
| one | 【电子邮件保护】 | 娜塔莉·霍洛韦 | 7357 芭芭拉课穆尔茅斯,你好 03826 |
| Two | 【电子邮件保护】' | 亚伦·赫尔 | 362 考克斯旁路套房 052 新达伦茅斯,爱荷华州 67749-2829 |
您可以从 Dataquest 服务器下载这个 CSV 文件,。在您刚刚下载的 CSV 文件中,user_accounts.csv,看起来我们基本上有两种不同的数据类型需要考虑。第一个是每个 id 的整数类型,其余的是字符串类型。像其他关系数据库一样,Postgres 是类型敏感的——这意味着您必须为您创建的表的每一列声明类型。你可以在 Postgres 文档中找到所有类型的列表。
为了创建一个适合我们数据集的表,我们必须运行CREATE TABLE命令,其中的列与 CSV 文件的顺序以及它们各自的类型相同。类似于运行一个SELECT查询,我们将把命令写成一个字符串,并把它传递给execute()方法。下面是该表的外观:
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
cur.execute("""
CREATE TABLE users(
id integer PRIMARY KEY,
email text,
name text,
address text
)
""")
SQL 事务
如果您现在检查postgres数据库,您会注意到其中实际上没有一个users表。这不是一个错误——这是因为一个叫做 SQL 事务的概念。与 SQLite 相比,在该引擎中执行的每个查询都会立即反映为数据库的变化。
使用 Postgres,我们要处理的是可能同时更改数据库的多个用户。让我们想象一个简单的场景,我们跟踪一家银行不同客户的账户。我们可以编写一个简单的查询来为此创建一个表:
CREATE TABLE accounts(
id integer PRIMARY KEY,
name text,
balance float
);
我们的表在表中有以下两行:
id name balance
1 Jim 100
2 Sue 200
假设Sue给100美元给Jim。我们可以用两个查询对此建模:
UPDATE accounts SET balance=200 WHERE name="Jim";
UPDATE accounts SET balance=100 WHERE name="Sue";
在上面的例子中,我们从Sue中删除了100美元,并将100美元添加到Jim中。如果第二个UPDATE语句有错误,数据库失败,或者另一个用户有冲突的查询,该怎么办?第一个查询可以正常运行,但是第二个查询会失败。这将导致以下结果:
id name balance
1 Jim 100
2 Sue 200
Jim将被记入100美元,但100美元不会从Sue中移除。这将导致银行亏损。
事务通过确保事务块中的所有查询同时执行来防止这种行为。如果任何事务失败,整个组都会失败,并且不会对数据库进行任何更改。
每当我们在 psycopg2 中打开一个连接,就会自动创建一个新的事务。在调用提交方法之前运行的所有查询都将被放入同一个事务块中。当调用 commit 时,PostgreSQL 引擎将立即运行所有查询。
如果我们不想在事务块中应用更改,我们可以调用 rollback 方法来删除事务。不调用提交或回滚将导致事务停留在未决状态,并将导致更改不会应用到数据库。
为了提交我们的更改并从前面创建users表,我们需要做的就是在事务结束时运行commit()方法。现在应该是这样的:
conn = psycopg2.connect("dbname=dq user=dq")
cur = conn.cursor()
cur.execute("""CREATE TABLE users(
id integer PRIMARY KEY,
email text,
name text,
address text
)
""")
conn.commit()
插入数据
创建并提交了我们的表之后,是时候将 CSV 文件加载到数据库中了!
将数据加载到 Postgres 表中的一种常见方式是在表上发出一个INSERT命令。insert 命令需要插入的表名和插入的值序列。下面是一个对users表进行插入查询的示例:
INSERT INTO users VALUES (10, "[[email protected]](/cdn-cgi/l/email-protection)", "Some Name", "123 Fake St.")
使用INSERT命令,我们可以使用pyscopg2将插入到users表中。首先,为execute()方法编写一个字符串INSERT SQL 命令。然后,用所有值格式化字符串:
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
insert_query = "INSERT INTO users VALUES {}".format("(10, '[[email protected]](/cdn-cgi/l/email-protection)', 'Some Name', '123 Fake St.')")
cur.execute(insert_query)
conn.commit()
不幸的是,format()字符串方法有一个问题。问题是你必须手动格式化类型,比如字符串转义"'[[email protected]](/cdn-cgi/l/email-protection)'"。使用这种插入方式很可能会出错。
幸运的是,psycopg2提供了另一种无需format()就能执行字符串插值的方法。这是使用psycopg2呼叫INSERT的推荐方式:
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
cur.execute("INSERT INTO users VALUES (%s, %s, %s, %s)", (10, '[[email protected]](/cdn-cgi/l/email-protection)', 'Some Name', '123 Fake St.'))
conn.commit()
这种类型的插入会自动将每种类型转换成表所期望的正确数据类型。另一个好处是您的插入查询实际上加快了,因为数据库中的INSERT语句是准备好的。在我们的 Postgres 课程中,如果你感兴趣的话,我们会介绍这种优化,但是现在让我们先插入 CSV 文件。
我们首先使用 csv模块加载 Python 中的 CSV 文件。然后,我们将为每一行运行INSERT查询,然后提交事务:
import csv
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
with open('user_accounts.csv', 'r') as f:
reader = csv.reader(f)
next(reader) # Skip the header row.
for row in reader:
cur.execute(
"INSERT INTO users VALUES (%s, %s, %s, %s)",
row
)
conn.commit()
虽然这完成了加载数据的任务,但实际上并不是最有效的方式。如您所见,我们必须遍历文件中的每一行,才能将它们插入到数据库中!幸运的是,Postgres 有一个专门用于将文件加载到表中的命令。
复制数据
将文件直接加载到表格中的 Postgres 命令称为 COPY 。它接收一个文件(类似于 CSV ),并自动将文件加载到 Postgres 表中。不同于创建查询,然后像INSERT一样通过execute()运行它,psycopg2有一个专门为这个查询编写的方法。
将文件加载到表格中的方法称为 copy_from 。像execute()方法一样,它被附加到Cursor对象上。然而,由于其参数的原因,它与execute()方法有很大的不同。
copy_from参数需要加载一个文件(没有头文件),它应该加载的表名,以及一个分隔符(关键参数sep)。然后,运行commit(),文件被传输到 ths 中,这是将 CSV 文件加载到 Postgres 表中的最有效的方法,也是推荐的方法。
这就是我们如何使用copy_from()来加载我们的文件,而不是循环使用INSERT命令:
import psycopg2
conn = psycopg2.connect("host=localhost dbname=postgres user=postgres")
cur = conn.cursor()
with open('user_accounts.csv', 'r') as f:
# Notice that we don't need the `csv` module.
next(f) # Skip the header row.
cur.copy_from(f, 'users', sep=',')
conn.commit()
就这么简单!最后,我们使用最优 Postgres 方式成功地将user_accounts.csv文件加载到我们的表中。让我们花一点时间回顾一下到目前为止我们所学的内容。
摘要
- Postgres 使用客户机-服务器模型来支持到数据库的多个连接。
- 使用流行的
psycopg2库,我们可以使用 Python 连接 Postgres。 - Postgres 是类型敏感的,所以我们必须在每一列中声明类型。
- Postgres 使用 SQL 事务来保存数据库的状态。
- 插入数据时,使用
psycopg2字符串插值代替.format()。 - 将文件加载到 Postgres 表中最有效的方法是使用
COPY或psycopg2.copy_from()方法。
后续步骤
如果您想了解更多,本教程基于我们的 Data questPostgres课程简介,这是我们数据工程学习路径的一部分。该课程扩展了本文中的模型,并在您编写代码的过程中提供实践学习。
如果您想继续使用此表格,您还可以做以下几件事:
- 删除数据,然后使用
DELETE命令重新加载。 - 对正在加载的数据使用更有效的类型。例如,对于字符串数据,Postgres 有比
TEXT更多的类型。如果你感兴趣的话,我们会在一节课中详细介绍 Postgres 的类型。 - 尝试使用
COPY ... TO或cur.copy_to()方法将表格导出到另一个文件中。在本课程中,我们将介绍这一点以及加载数据的其他INSERT和COPY选项。
成为一名数据工程师!
现在就学习成为一名数据工程师所需的技能。注册一个免费帐户,访问我们的交互式 Python 数据工程课程内容。
(免费)
https://www.youtube.com/embed/ddM21fz1Tt0?rel=0
Python 中的逻辑回归介绍(有 100 多个代码示例)
原文:https://www.dataquest.io/blog/logistic-regression-in-python/
November 21, 2022
逻辑回归算法是一种用于分类任务的概率机器学习算法。这通常是您尝试分类任务的第一个分类算法。与许多似乎是黑箱的机器学习算法不同,logisitc 回归算法很容易理解。
在本教程中,您将了解到关于逻辑回归算法的所有知识。首先,您将创建一个定制的逻辑回归算法。这将有助于你理解幕后发生的一切,以及如何调试你的逻辑回归模型的问题。接下来,您将学习如何训练和优化逻辑回归算法的 Scikit-Learn 实现。最后,您将学习如何使用该算法处理多类分类任务。
本教程涵盖了L1和L2正则化、使用网格搜索的超参数调整、使用管道的自动化机器学习工作流、one vs rest 分类器、面向对象编程、模块化编程以及使用 docstring 记录 Python 模块。
构建您自己的定制逻辑回归模型
在本节中,您将使用随机梯度下降构建自己的自定义逻辑回归模型。这种逻辑回归算法可以用批量、小批量或随机梯度下降来训练。
在批量梯度下降中,整个训练集用于在一个时期后更新模型参数。对于非常大的训练集,最好用数据的随机子集来更新模型参数,因为用整个集合来训练模型在计算上将是昂贵的。这就是小批量梯度下降背后的想法。在随机梯度下降中,在对训练集中的每个单个数据点进行训练之后,更新模型参数。当列车组很小时,可以使用这种方法。
总而言之,假设我们有一个包含m行的训练集。批量大小n,用于训练和更新以下模型参数:
- 批量梯度下降:\(n = m\)
- 小批量梯度下降:\(1 < n < m\)
- 随机梯度下降:\(n = 1\)
我们的列车组中的行数m很少。在我们的例子中,使用随机梯度下降是可以的。接下来,让我们讨论我们的自定义逻辑回归模型中的方法。
__init__法
要创建一个对象的实例,您需要初始化或分配一些初始值。这些起始值通过__init__方法传递。为了创建随机逻辑回归(SLR)类的实例,我们必须传递learning_rate、n_epochs和cutoff参数。
此外,我们还初始化了截距、b和系数w值。这些是我们希望使用梯度下降优化的值。
class SLR(object):
"""
This is the SLR class
"""
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
"""
The __init__ method
Params:
learning_rate
n_epochs
cutoff
"""
self.learning_rate = learning_rate
self.n_epochs = n_epochs
self.cutoff = cutoff
self.w = None
self.b = 0.0
__repr__法
方法帮助我们制作自己的对象的可打印表示。为了理解这是如何工作的,让我们打印没有__repr__方法的SLR类:
创建 SLR 类的一个实例
slr0 = SLR()
打印 slr0 对象
print(slr0)
当我们在没有__repr__方法的情况下打印SLR类的实例时,输出的是对象在内存中的地址。使用__repr__方法,我们定义我们想要如何打印对象,如下所示:
class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
self.learning_rate = learning_rate
self.n_epochs = n_epochs
self.cutoff = cutoff
...
def __repr__(self):
params = {
'learning_rate': self.learning_rate,
'n_epochs': self.n_epochs,
'cutoff': self.cutoff
}
return "SLR({0}={3}, {1}={4}, {2}={5})".format(*params.keys(), *params.values())
创建 SLR 类的一个实例
slr1 = SLR()
打印 slr1 对象
print(slr1)
我们的SLR类的新实例准确地打印了我们在__repr__方法中定义的内容。为了简洁起见,我们从 SLR 类中排除了一些东西。我们将使用省略号...来表示项目被排除的部分。
sigmoid法
sigmoid 方法是逻辑回归算法的核心。它将线性函数\(z = {w^T}x + b\)映射到开区间\((0,1)\)。sigmod 方法输出的概率值将与预测的临界值进行比较。它在数学上表示为:$ { \ large { 1 } over { 1+e^{-z}}}}$
sigmoid 函数的形状如下图所示。sigmoid 函数的渐近线在\(z\)变为\(+\infty\)时接近值\(1\),在\(z\)变为\(-\infty\)时接近值\(0\)。

class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
def __repr__(self):
...
def sigmoid(self, z):
"""
The sigmoid method:
Param:
z
Return:
1.0 / (1.0 + exp(-z))
"""
return 1.0 / (1.0 + np.exp(-z))
predict_proba法
此方法预测每一行的概率值。使用截距b和系数w参数计算线性函数值z。z的值被传递给sigmoid方法以获得一个概率值。
class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
def __repr__(self):
...
def sigmoid(self, z):
...
def predict_proba(self, row):
"""
The predict_proba
Param:
row
Return:
sigmoid(z)
"""
z = np.dot(row, self.w) + self.b
return self.sigmoid(z)
fit法
该方法采用随机梯度下降来更新w和b参数。首先要做的事情之一是初始化w和b的参数。b的值被设置为0.0,而w中的值被设置为zeros,如下图所示:
class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
self.w = None
self.b = 0.0
...
def fit(self, X, y):
...
self.w = np.zeros(X.shape[1])
...
接下来的重要步骤是使用b和w的值来计算概率值,并计算相对于w和b的梯度。这些用数学方法表示如下:
- 计算一个概率值,
yhat😒 \ hat { y _ I } $ = $ { \ large { 1 \ over { 1+e^{-z_i}}}}$ - 计算梯度 w.r.t
b,grad_b😒 \ nabla _ b = \ hat { y _ I }–y _ I $ - 计算梯度 w.r.t
w,grad_w😒 \ nab la _ w = x _ I(\ hat { y _ I }–y _ I)$
class SLR(object):
...
def fit(self, X, y):
...
for n_epoch in range(1, self.n_epochs + 1):
losses = []
for i in range(self.m):
# Calculate the probability value for a row
yhat = self.predict_proba(X[i])
# Calculate the gradient w.r.t b
grad_b = yhat - y[i]
# Calculate the gradient w.r.t w
grad_w = X[i] * (yhat - y[i])
最后的步骤是使用学习率\(\alpha\)更新b和w的值,并计算损失函数:
- 更新
b的值:$ b = b –\ alpha \ nab la _ b $ - 更新
w的值:$ w = w –\ alpha \ nab la _ w $ - 计算对数损失:\(-(y _ I \ log(\ hat { y } _ I+(1–y _ I)\ log((1 –\ hat { y } _ I))\)
class SLR(object):
...
def fit(self, X, y):
...
for n_epoch in range(1, self.n_epochs + 1):
losses = []
for i in range(self.m):
...
# Update the value of w
self.w -= self.learning_rate * grad_w / self.m
# Update the value of b
self.b -= self.learning_rate * grad_b / self.m
# Calculate the log-loss
loss = -1/self.m * (y[i] * np.log(yhat) + (1 - y[i]) * np.log(1 - yhat))
losses.append(loss)
# Calculate the cost fuction
self.cost.append(sum(losses))
在一个时期的训练之后,为该时期计算成本函数。成本函数是损失函数的平均值。如果你想了解更多关于梯度下降和参数是如何得出的,请阅读 DataQuest 上的这篇文章。
将fit方法中的所有内容放在一起,我们得到:
class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
def __repr__(self):
...
def sigmoid(self, z):
...
def predict_proba(self, row):
...
def fit(self, X, y):
"""
The fit method implement stochastic gradient descent
Param
X, y
Return
None
"""
if not isinstance(X, np.ndarray):
X = X.to_numpy()
if not isinstance(y, np.ndarray):
y = y.to_numpy()
self.w = np.zeros(X.shape[1])
self.cost = []
self.m = X.shape[0]
self.log_loss = {}
self.cost = []
for n_epoch in range(1, self.n_epochs + 1):
losses = []
for i in range(self.m):
yhat = self.predict_proba(X[i])
grad_b = yhat - y[i]
grad_w = X[i] * (yhat - y[i])
self.w -= self.learning_rate * grad_w / self.m
self.b -= self.learning_rate * grad_b / self.m
loss = -1/self.m * (y[i] * np.log(yhat) + (1 - y[i]) * np.log(1 - yhat))
losses.append(loss)
self.cost.append(sum(losses))
predict法
这种方法用于进行离散预测。它使用predict_proba方法获得概率值,然后将这些概率值与临界值进行比较。低于临界值的概率值属于一个类,大于或等于临界值的概率值属于另一个类。
class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
def __repr__(self):
...
def sigmoid(self, z):
...
def predict_proba(self, row):
...
def fit(self, X, y):
...
def predict(self, X):
if not isinstance(X, np.ndarray):
X = X.to_numpy()
self.predict_probas = []
for i in range(X.shape[0]):
ypred = self.predict_proba(X[i])
self.predict_probas.append(ypred)
return (np.array(self.predict_probas) >= self.cutoff) * 1.0
score法
该方法用于使用模型的训练参数来计算准确度分数。它使用predict方法进行离散预测,并将这些值与实际值进行比较。
class SLR(object):
...
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
...
def __repr__(self):
...
def sigmoid(self, z):
...
def predict_proba(self, row):
...
def fit(self, X, y):
...
def predict(self, X):
...
def score(self, X, y):
"""
The score method
Param
X, y
Return
accuracy_score(y, ypred)
"""
ypred = self.predict(X)
y = y.to_numpy()
return accuracy_score(y, ypred)
逻辑回归模块
将所有内容放入 python 脚本(.py文件)并保存(slr.py)为我们提供了一个定制的逻辑回归模块。通过导入,您可以在逻辑回归模块中重用代码。您可以在多个 Python 脚本和 Jupyter 笔记本中使用您的自定义逻辑回归模块。
请务必将模块与您将要使用的脚本或笔记本保存在同一个目录中。让我们假设我们的slr.py文件保存在logreg目录中。在下一节中,我们将使用自定义模块。
../logreg/slr.py
"""
# slr.py
This is stochastic logistic regression module
To use:
from slr import SLR
# Import the SLR class from the module and use its methods
log_reg = SLR() # Initialization with default params
log_reg.fit(X, y) # Fit with train set
log_reg.predict(X) # Make predictions with test set
log_reg.score(X,y) # Get accuracy score
Method:
__init__
__repr__
sigmoid
predict
predict_proba
fit
score
"""
import numpy as np
from sklearn.metrics import accuracy_score
class SLR(object):
"""
This is the SLR class
"""
def __init__(self, learning_rate=10e-3, n_epochs=10_000, cutoff=0.5):
"""
The __init__ method
Params:
learning_rate
n_epochs
cutoff
"""
self.learning_rate = learning_rate
self.n_epochs = n_epochs
self.cutoff = cutoff
self.w = None
self.b = 0.0
def __repr__(self):
params = {
'learning_rate': self.learning_rate,
'n_epochs': self.n_epochs,
'cutoff': self.cutoff
}
return "SLR({0}={3}, {1}={4}, {2}={5})".format(*params.keys(), *params.values())
def sigmoid(self, z):
"""
The sigmoid method:
Param:
z
Return:
1.0 / (1.0 + exp(-z))
"""
return 1.0 / (1.0 + np.exp(-z))
def predict_proba(self, row):
"""
The predict_proba
Param:
row
Return:
sigmoid(z)
"""
z = np.dot(row, self.w) + self.b
return self.sigmoid(z)
def predict(self, X):
if not isinstance(X, np.ndarray):
X = X.to_numpy()
self.predict_probas = []
for i in range(X.shape[0]):
ypred = self.predict_proba(X[i])
self.predict_probas.append(ypred)
return (np.array(self.predict_probas) >= self.cutoff) * 1.0
def score(self, X, y):
"""
The score method
Param
X, y
Return
accuracy_score(y, ypred)
"""
ypred = self.predict(X)
y = y.to_numpy()
return accuracy_score(y, ypred)
def fit(self, X, y):
"""
The fit method implement stochastic gradient descent
Param
X, y
Return
None
"""
if not isinstance(X, np.ndarray):
X = X.to_numpy()
if not isinstance(y, np.ndarray):
y = y.to_numpy()
self.w = np.zeros(X.shape[1])
self.cost = []
self.m = X.shape[0]
self.log_loss = {}
self.cost = []
for n_epoch in range(1, self.n_epochs + 1):
losses = []
for i in range(self.m):
yhat = self.predict_proba(X[i])
grad_b = yhat - y[i]
grad_w = X[i] * (yhat - y[i])
self.w -= self.learning_rate * grad_w / self.m
self.b -= self.learning_rate * grad_b / self.m
loss = -1/self.m * (y[i] * np.log(yhat) + (1 - y[i]) * np.log(1 - yhat))
losses.append(loss)
self.cost.append(sum(losses))
使用slr模块
../log reg/random . ipynb
import slr
from slr import SLR
我们已经在这个模块中导入了slr模块和SLR类。这一步看着眼熟吗?是啊!您过去一定已经导入了几个 Python 库——numpy、pandas 和 matplotlib 被广泛使用。
您可以从它们的文档中了解 Python 库、模块、类、方法和函数。文档字符串是记录 Python 工作原理的一种极好的方式。要查看不熟悉的模块或函数的文档,可以使用__doc__属性。您可以使用dir()函数查看 Python 对象的方法和属性。
slr 模块的属性和方法
dir(slr)
SLR 类的属性和方法
dir(SLR)
slr模块和SLR类都有__doc__属性。我们可以查看他们的文档字符串中写了什么:
slr.py 模块中的 Docstring
print(slr.__doc__)
print(SLR.__doc__)
让我们也查看一下sigmoid和fit方法中的文档字符串:
print(SLR.sigmoid.__doc__)
print(SLR.fit.__doc__)
或者,您可以使用help()功能查看所有文档字符串:
help(SLR)
用slr理解逻辑回归
../log reg/random . ipynb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')
加载和拆分数据
../log reg/random . ipynb
加载数据
bin_data = load_breast_cancer()
X = bin_data.data
y = bin_data.target
将数据存储为熊猫对象
X = pd.DataFrame(X, columns=bin_data.feature_names)
y = pd.Series(y, name='diagnosis', dtype=np.int8)
pd.options.display.max_columns = X.shape[1]
X.head()
目标有两类——二元分类任务
y.value_counts()
将数据分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=47)
逻辑回归的损失和成本函数
线性回归算法使用均方误差成本函数。对于线性函数\(z = {w^T}x + b\)来说,这个代价函数总是凸的。换句话说,在训练期间,成本函数总是接近其全局最小值。
逻辑回归算法使用 sigmoid 函数,它是指数函数。对于均方误差成本函数,此函数并不总是凸的。因此,我们的逻辑回归可能陷入局部最小值。我们必须随机初始化我们的模型并训练几个以确保我们得到最好的结果。
我们在构建SLR时将权重初始化为零,因为我们使用的成本函数总是与 sigmoid 函数成凸关系。否则,如果我们使用均方误差成本函数,我们应该随机初始化我们的权重。
用于训练逻辑回归算法的损失函数被称为对数损失。它在数学上表示为:
- log-loss= \(-y _ I \ cdot \ log \ hat { y }–(1–y _ I)\ cdot \ log(1–hat { y })\)。
成本函数\(J(w,b)\)就是一个历元的对数损失函数的平均值:
- \(J(w,b)=-{ 1 \ over m}\sum^m_{i=1}y_i \ cdot \ log \ hat { y }+(1–y _ I)\ cdot \ log(1–hat { y })\)
下图显示了第 1 个、第 2 个、第 100 个、第 999 个和第 1000 个时期的训练集中每一行的对数损失图。在第一个历元中有许多对数损失值的尖峰。随着我们继续训练,峰值减少,在第 1000 个纪元中,我们有许多接近于零的对数损失值。

当我们平均每个历元的对数损失值时,我们得到成本函数。我们期望成本函数值随着历元数的增加而减少。当我们对上述示例的对数损失值进行平均时,成本函数图如下所示:

上面的成本函数图是凸的。成本函数值继续接近全局最小值。如果你有兴趣了解更多关于凸性和对数损失函数的知识,这篇文章解释了为什么对数损失函数适用于逻辑回归,而均方误差却不适用。而这个交易所试图证明对数损失函数总是凸的。
接下来,让我们看看学习率如何影响成本函数的形状。
成本函数和学习率
学习率是我们的 SLR 模型中的一个重要参数。这里,我们用不同的学习速率创建了 SLR 类的五个实例。当学习率很小时,成本函数\(Cost (J)\)是一条水平直线。
随着我们增加从\({10^{-4}}\)到\(10^{-0}\)的学习率,我们得到了 u 形曲线的前半部分。学习率越大,代价函数越快接近全局最小值。

你认为我们应该继续提高学习率吗?当学习率大于 1 时,模型会出现问题。当我们创建一个学习率为 4 的SLR类的实例时,我们得到了下图中的部分 A 的图:

500 个纪元后的代价函数发生了什么变化?predict_proba方法开始输出非常接近于零的概率。对数损失(以及延伸的成本函数)值变成正无穷大。对于np.inf日志损失值,您将得到np.nan。这是 500 个纪元后发生的事情。在这一点之后,我们无法绘制成本函数图。如果你想观察这些np.inf值,你可以在你的对数损耗:np.nan_to_num(log-loss)上使用np.nan_to_num功能。该功能用非常大的值替换np.inf。
在学习率非常大的情况下,成本函数会从 A 部分跳到更大的值(如 b 部分),从而错过全局最小值。因此,选择适当的学习率非常重要。
slr的表现
在本节中,我们将使用自定义逻辑回归模型进行训练和预测。首先,让我们为我们的模型确定一个基线。
基线模型
y_train.value_counts(normalize='True')
y_test.value_counts(normalize='True')
如果我们预测训练集和测试集中的所有条目的1,我们将分别获得 63%和 61%的准确率。因此,63%是我们的训练集的基线。对于测试集是 61%。我们希望我们的定制模型能够超越基线。
比例特征
X_train.describe()
X_train.info()
describe()和info()方法告诉我们,数据中的特征是不同尺度上的连续变量。在训练之前,我们将首先用StandardScaler()函数缩放特征。我们不想手动操作,所以我们将使用Pipeline连接缩放和配件:
训练SLR
用管道连接 StandardScaler()和 SLR()
pipe0 = Pipeline([
('scaler', StandardScaler()),
('lr', SLR(learning_rate=1e-2, n_epochs=1000, cutoff=0.5))
])
训练模型
pipe0.fit(X_train, y_train)
获得训练集和测试集的准确性
检查他们是否击败了基线模型
accuracies = {
'train accuracy': pipe0.score(X_train, y_train),
'test accuracy': pipe0.score(X_test, y_test)
}
print(*accuracies.items())
检查测试集的其他分类指标
print(classification_report(y_test, pipe0.predict(X_test)))
检查训练集的其他分类指标
print(classification_report(y_train, pipe0.predict(X_train)))
我们的定制slr模型在训练和测试集上的表现超过了基线。这太酷了。
接下来,让我们研究一下临界值是否会显著影响预测精度。
用slr预测
我们将在本节中使用pipe0进行预测。然后我们将使用 0.5 的临界值来绘制预测概率。截止点以上的点属于一个类,截止点以下的点属于单独的类。
import matplotlib
matplotlib.rcParams['font.family'] = 'monospace'
使用管道 0 预测
predictions = pipe0.predict(X_test)
predict_probas = pipe0['lr'].predict_probas
cutoff = pipe0['lr'].cutoff
绘制预测概率
fig = plt.figure(figsize=(15, 5), constrained_layout=True)
x = range(1, len(predict_probas) + 1)
plt.scatter(x, predict_probas, c=predictions, label='predicted probabilities')
plt.plot(x, [cutoff] * len(predictions), color='red', label='cutoff=0.5')
plt.ylabel('Predicted probabilites', fontsize=12)
plt.xlabel('test data', fontsize=12)
plt.legend(loc=7);
使用 pipe0 调用精度值
print(*accuracies.items())
我们可以从上面的图中看到,有接近截止点的值。让我们假设这些值属于错误分类。让我们将截止值降低到 0.35,并观察改进情况:
创建新实例 pipe1,截断值为 0.35
pipe1 = Pipeline([
('scaler', StandardScaler()),
('lr', SLR(learning_rate=1e-2, n_epochs=1000, cutoff=0.35))
])
拟合管道 1 实例
pipe1.fit(X_train, y_train)
获取管道 1 的预测概率
predictions = pipe1.predict(X_test)
predict_probas = pipe1['lr'].predict_probas
cutoff = pipe1['lr'].cutoff
绘制预测的概率
fig = plt.figure(figsize=(15, 5), constrained_layout=True)
x = range(1, len(predict_probas) + 1)
plt.scatter(x, predict_probas, c=predictions, label='predicted probabilities')
plt.plot(x, [cutoff] * len(predictions), color='red', label='cutoff=0.35')
plt.ylabel('Predicted probabilites', fontsize=12)
plt.xlabel('test data', fontsize=12)
plt.legend(loc=5);
获取管道 1 精度
accuracies1 = {
'train accuracy': pipe1.score(X_train, y_train),
'test accuracy': pipe1.score(X_test, y_test)
}
print(*accuracies1.items())
虽然我们的精度没有提高,但我们已经知道,根据我们面临的问题类型,我们可以增加或减少默认值的临界值。
我们的定制逻辑回归模型表现不差。但是我们可以用逻辑回归算法的 Scikit-Learn 实现做更多的事情。这个机器学习框架有更多的功能,并且经过了严格的测试。我们将继续使用 Scikit-Learn。
Scikit-Learn 逻辑回归模型
在本节中,我们将使用 Scikit-Learn 逻辑回归模型的特性。首先,我们将训练一个没有正则化的逻辑回归模型。然后我们将使用L1、L2和L1 and L2正则化来训练模型。
让我们从 Scikit-Learn 导入这个模型:
from sklearn.linear_model import LogisticRegression
没有正规化
没有调整的训练仅仅意味着将penalty参数设置为none:
不使用正则化训练 sklearn 逻辑回归模型:pipe2
pipe2 = Pipeline([
('scaler', StandardScaler()),
('lr', LogisticRegression(penalty='none'))
])
符合模型
pipe2.fit(X_train, y_train)
Fet 模型精度
accuracies2 = {
'train accuracy': pipe2.score(X_train, y_train),
'test accuracy': pipe2.score(X_test, y_test)
}
print(*accuracies2.items())
我们可以看到模型过度拟合了列车组。训练和测试精度之间的差异为 12%。正则化的目的是防止过度拟合。
接下来,让我们使用L1正则化。
随着 L1 正规化
正则化是我们对机器学习算法进行的修改,以减少它们的泛化错误。换句话说,正则化有助于我们提高机器学习模型在它以前没有见过/没有训练过的数据上的性能。
逻辑回归中的正则化仅仅意味着将正则化参数添加到我们的成本函数中:
- \(J(w,b)=-{ 1 \ over m}\sum^m_{i=1}y_i \ cdot \ log \ hat { y }+(1–y _ I)\ cdot \ log(1–hat { y })+{ \ lambda \ over m } r(w _ I)\)
参数\(\lambda\)和\(R(w_i)\)分别是正则化参数和正则化函数。对于逻辑回归,正则化参数\(C\)给出为:$ C = { 1 \ over \ lambda } $ 1。对于L1正则化,\(R(w *i)\)被给定为\(\sum* {j=1}^p|w_i|\).
使用L1正则化的逻辑回归成本函数变为:
- \(J(w,b)=-{ 1 \ over m}\sum^m_{i=1}y_i \ cdot \ log \ hat { y }+(1–y*I)\ cdot \ log(1–hat { y })+{ 1 \ over m \ cdot c } \ sum*{j=1}^p|w_i|\)
回想一下\(w\)是我们模型的系数。因此\(|w_i|\)是系数的绝对值。
接下来,我们将使用L1正则化实现 Scikit-Learn 逻辑回归模型。在此之前,我们先讨论一下L1正规化的利弊。L1正则化的主要优点是它用于特征选择。不重要特征的权重被设置为零。只留下重要特征的系数。L1正则化的缺点是不使用统计技术移除共线的要素。它可以从模型中移除两个共线特征中最具预测性的特征。
我们将使用solver='saga',因为saga求解器适用于所有类型的惩罚或正则化。
正则化参数 C=1e-1 的 L1 正则化逻辑回归
pipe3 = Pipeline([
('scaler', StandardScaler()),
('lr', LogisticRegression(penalty='l1', C=1e-1, solver='saga'))
])
安装管道
pipe3.fit(X_train, y_train)
获得精确度
accuracies3 = {
'train accuracy': pipe3.score(X_train, y_train),
'test accuracy': pipe3.score(X_test, y_test)
}
print(*accuracies3.items())
回想一下,逻辑回归将系数设置为零。让我们从下面的模型中检查这些系数:
df_coefficients = pd.DataFrame(
{
'feature': X_train.columns,
'coefficient': pipe3['lr'].coef_[0]
}
)
df_coefficients
让我们只检查下面的重要特性:
(
df_coefficients[df_coefficients.coefficient != 0]
.sort_values(by=['coefficient'])
)
在我们数据中的 30 个特征中,只有少数被 L1 正则化认为是重要的。接下来,让我们看看 L2 正则化如何与逻辑回归一起工作。
随着 L2 正规化
对于L2正则化,\(R(w *i)\)被给定为$ { 1 \除以 2 } \总和* {j=1}pw_i2$.
使用L2正则化的逻辑回归成本函数变为:
- \(J(w,b)=-{ 1 \ over m}\sum^m_{i=1}y_i \ cdot \ log \ hat { y }+(1–y*I)\ cdot \ log(1–hat { y })+{ 1 \ over 2 \ cdot m \ cdot c } \ sum*{j=1}^pw_i^2\)
其中,\(w_i^2\)是模型系数的平方。
L2正则化不能执行特征选择,但它用于防止过度拟合。使用L2正则化的逻辑回归实现如下:
具有正则化参数 C=1e-1 的 L2 正则化的逻辑回归
pipe4 = Pipeline([
('scaler', StandardScaler()),
('lr', LogisticRegression(penalty='l2', C=1e-1, solver='saga'))
])
安装管道
pipe4.fit(X_train, y_train)
获得精确度
accuracies4 = {
'train accuracy': pipe4.score(X_train, y_train),
'test accuracy': pipe4.score(X_test, y_test)
}
print(*accuracies4.items())
我们可以从下面的数据框架中观察到,没有任何特征的系数为零。如果我们想要一个具有更少特征的更简单的模型,L2 正则化不是很有帮助。
pd.DataFrame(
{
'feature': X_train.columns,
'coefficient': pipe4['lr'].coef_[0]
}
).sort_values(by=['coefficient'])
随着 L1 和 L2 正规化
使用L1和L2正则化的逻辑回归使用L1和L2正则化函数。这种正则化被称为elasticnet,数学上给出如下:
- \(J(w,b)=-{ 1 \ over m}\sum^m_{i=1}y_i \ cdot \ log \ hat { y }+(1–y*I)\ cdot \ log(1 –\ hat { y })+{ 1 \ over m \ cdot c } \ sum*{j=1}^p(\beta \ cdot | w _ I |+{ 1 \ over 2 } \ cdot(1 –\ beta)\ cdot w_i^2)\)
参数\(\beta\)被称为 L1 比率。这是L1和L2正则化对模型系数的混合效果。当这个参数设置为零时,它的L2正则化。设置为 1 时,为L1正则化。
这种正则化实现如下:
使用 L1 和 L2 正则化的逻辑回归,正则化参数 C=1e-1,L1 比率=0.5
pipe5 = Pipeline([
('scaler', StandardScaler()),
('lr', LogisticRegression(penalty='elasticnet', l1_ratio=0.5, C=1e-1, solver='saga'))
])
安装管道
pipe5.fit(X_train, y_train)
获得精确度
accuracies5 = {
'train accuracy': pipe5.score(X_train, y_train),
'test accuracy': pipe5.score(X_test, y_test)
}
print(*accuracies5.items())
获取特征系数
pd.DataFrame(
{
'feature': X_train.columns,
'coefficient': pipe5['lr'].coef_[0]
}
)
系数设置为零和未设置为零的百分比特征
(
pd.DataFrame(
{
'feature': X_train.columns,
'coefficient': pipe5['lr'].coef_[0]
})
.coefficient
.apply(lambda x: x == 0)
.value_counts(normalize=True)
)
我们使用了 50% L1 比率的正则化。L1 和 L2 正则化对模型系数具有相同的影响。有了这个正则化,我们得到了比单独使用 L1 正则化更重要的特性。
我们还没有尝试调整我们模型的超参数。让我们在下一节看看如何优化模型超参数。
使用 GridSearch 进行超参数调整
超参数是我们为了控制学习过程而明确做出的假设。如果我们假设学习率和正则化常数取特定的值,我们不太确定这些值是否实际上是最优的。
为了找到我们模型的最佳超参数,我们可以列出它们的一系列值。网格搜索创建这些参数的组合,并将它们绘制到网格中。我们的评估人员在每个网格上进行训练,并记录所选指标的得分。如果精度是所选的度量,网格搜索从给出最高精度的网格中选择参数作为最佳估计值。
让我们假设我们想要优化一个具有C和LR超参数的模型。列出的C值为[1e-1, 1e-3],LR值为[2e-1, 2e-3]。网格搜索将训练和评估下面显示的每个网格的准确性。具有最高精确度的一个被选为最佳估计器。

您可以对超参数中的两个以上条目以及两个以上的超参数使用网格搜索。如果使用三个超参数,我们会得到一个立方体形状,而不是一个平面。
让我们使用网格搜索来优化我们的逻辑回归模型。
import gridsearchcv
from sklearn.model_selection import GridSearchCV
创建管道评估器
pipe6 = Pipeline([
('scaler', StandardScaler()),
('lr', LogisticRegression(solver='saga'))
])
指定超参数及其值
params = {
'lr__C': [1.0, 1e-1, 1e-2, 1e-3],
'lr__penalty': ['l1', 'l2', 'elasticnet'],
'lr__l1_ratio': [0.25, 0.5, 0.75]
}
将管道作为估计器来拟合网格搜索
grid_pipe6 = GridSearchCV(
pipe6,
params,
cv=5
)
grid_pipe6.fit(X_train, y_train)
获得最佳超参数值
print(grid_pipe6.best_params_)
获得最佳评估者/模型
print(grid_pipe6.best_estimator_)
探索最佳估计参数字典
grid_pipe6.best_estimator_.get_params()
获得最佳估计精度
accuracies6 = {
'train accuracy': grid_pipe6.score(X_train, y_train),
'test accuracy': grid_pipe6.score(X_test, y_test)
}
print(*accuracies6.items())
在本教程中,我们调整了超参数以获得训练集和测试集的最高精度。如果我们在当前列出的值之外进行搜索,也许我们可以获得更好的精确度。例如,如果我们列出的最高参数是最好的,我们可能希望列出更多的参数值,最好的参数在列表的中心。通过这样做,我们可以探索更好的参数的优势。
接下来,我们将看到如何用逻辑回归模型处理多类分类。
用逻辑回归进行多类分类
加载多类数据
from sklearn.datasets import load_wine
mult_data = load_wine()
X = mult_data.data
y = mult_data.target
X = pd.DataFrame(X, columns=mult_data.feature_names)
y = pd.Series(y, name='class', dtype=np.int8)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=47)
X_train.head()
基线模型
获取训练集的基线
y_train.value_counts(normalize=True)
获取测试集的基线
y_test.value_counts(normalize=True)
训练和优化您自己的 OneVsRestClassifier
在这一部分,我们将训练我们自己的多类分类器。我们将使用 One-Vs-Rest 方法,在该方法中,我们将多类分类任务分成多个二进制分类任务。然后,我们将训练分类器,可以将特定的类与其他类区分开来。
让我们通过转换标签将多类任务分成多个二进制分类任务:
class_0 与 rest 分类器的目标变量
y0_train = (y_train == 0)
class_1 与 rest 分类器的目标变量
y1_train = (y_train == 1)
class_2 与 rest 分类器的目标变量
y2_train = (y_train == 2)
创建 class_0 vs rest 分类器
mult_pipe0 = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga'))
])
要优化的超参数
params = {
'mult_lr__C': [1.0, 1e-1, 1e-2, 1e-3],
'mult_lr__penalty': ['l1', 'l2', 'elasticnet'],
'mult_lr__l1_ratio': [0.10, 0.25, 0.5, 0.75]
}
使用 gridsearch 执行优化
grid_mult_pipe0 = GridSearchCV(
mult_pipe0,
params,
cv=3
)
grid_mult_pipe0.fit(X_train, y0_train)
创建 class_1 vs rest 分类器
mult_pipe1 = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga'))
])
要优化的超参数
params = {
'mult_lr__C': [1.0, 1e-1, 1e-2, 1e-3],
'mult_lr__penalty': ['l1', 'l2', 'elasticnet'],
'mult_lr__l1_ratio': [0.10, 0.25, 0.5, 0.75]
}
使用 gridsearch 执行优化
grid_mult_pipe1 = GridSearchCV(
mult_pipe1,
params,
cv=3
)
grid_mult_pipe1.fit(X_train, y1_train)
创建 class_2 vs rest 分类器
mult_pipe2 = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga'))
])
要优化的超参数
params = {
'mult_lr__C': [1.0, 1e-1, 1e-2, 1e-3],
'mult_lr__penalty': ['l1', 'l2', 'elasticnet'],
'mult_lr__l1_ratio': [0.10, 0.25, 0.5, 0.75]
}
使用 gridsearch 执行优化
grid_mult_pipe2 = GridSearchCV(
mult_pipe2,
params,
cv=3
)
grid_mult_pipe2.fit(X_train, y2_train)
获取测试集上 class_0 与 rest 分类器的预测概率值
predict_proba_pipe0 = grid_mult_pipe0.best_estimator_.predict_proba(X_test)
获取测试集上 class_1 与 rest 分类器的预测概率值
predict_proba_pipe1 = grid_mult_pipe1.best_estimator_.predict_proba(X_test)
获取测试集上 class_2 与 rest 分类器的预测概率值
predict_proba_pipe2 = grid_mult_pipe2.best_estimator_.predict_proba(X_test)
创建他们结果的数据框架
df_result_proba_test = pd.DataFrame(
{
'class_0': predict_proba_pipe0[:, 1],
'class_1': predict_proba_pipe1[:, 1],
'class_2': predict_proba_pipe2[:, 1]
}
)
df_result_proba_test.head()
使用概率值获得每个测试集的分类结果
一行被赋予具有最高概率值的类
df_result_proba_test.idxmax(axis=1).head()
将字符串输出转换为整数
y_mult_pred_test = (
df_result_proba_test.idxmax(axis=1)
.replace({
'class_0': 0,
'class_1': 1,
'class_2': 2
})
)
y_mult_pred_test.head()
获取测试多类分类报告
print(classification_report(y_test, y_mult_pred_test))
我们的多类分类器工作出色。让我们看看它在火车布景上的表现。我们可以通过用训练集而不是测试集运行前面代码的后半部分来做到这一点。我们也可以通过为三标签多类分类创建一个模块来做到这一点。
让我们复制下面的代码,并将其作为onevsall3.py保存在我们的工作目录中。
../logreg/onevsall3.py
"""
####onevsall3.py
This is a custom one vs all classifier for making predictions
for multiclass problems with 3 classes
"""
import numpy as np
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
def onevsall3(X_train, y_train, X_test, y_test):
y0_train = (y_train == 0)
y1_train = (y_train == 1)
y2_train = (y_train == 2)
mult_pipe0 = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga'))
])
params = {
'mult_lr__C': [1.0, 1e-1, 1e-2, 1e-3],
'mult_lr__penalty': ['l1', 'l2', 'elasticnet'],
'mult_lr__l1_ratio': [0.10, 0.25, 0.5, 0.75]
}
grid_mult_pipe0 = GridSearchCV(
mult_pipe0,
params,
cv=3
)
mult_pipe1 = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga'))
])
grid_mult_pipe1 = GridSearchCV(
mult_pipe1,
params,
cv=3
)
mult_pipe2 = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga'))
])
grid_mult_pipe2 = GridSearchCV(
mult_pipe2,
params,
cv=3
)
grid_mult_pipe0.fit(X_train, y0_train)
grid_mult_pipe1.fit(X_train, y1_train)
grid_mult_pipe2.fit(X_train, y2_train)
predict_proba_pipe0 = grid_mult_pipe0.best_estimator_.predict_proba(X_test)
predict_proba_pipe1 = grid_mult_pipe1.best_estimator_.predict_proba(X_test)
predict_proba_pipe2 = grid_mult_pipe2.best_estimator_.predict_proba(X_test)
df_result_proba_test = pd.DataFrame(
{
'class_0': predict_proba_pipe0[:, 1],
'class_1': predict_proba_pipe1[:, 1],
'class_2': predict_proba_pipe2[:, 1]
})
return (
df_result_proba_test.idxmax(axis=1)
.replace({
'class_0': 0,
'class_1': 1,
'class_2': 2
}))
从 onevsall3.py 模块导入 onevsall3 函数
从 onevsall3 导入 onevsall3
将测试集数据传递给 valid,以确保其正常工作
test_predict_onevsall = onevsall3(X_train, y_train, X_test, y_test)
获取测试集分类报告
print(classification_report(y_test, test_predict_onevsall))
一切看起来都很好!我们的onevsall3功能工作正常。让我们看看它在火车布景上的表现。
使用 onevsall3 模块的列车组分类报告
train_predict_onevsall = onevsall3(X_train, y_train, X_train, y_train)
print(classification_report(y_train, train_predict_onevsall))
我们的多类分类器在训练集和测试集上都表现良好。与其从头开始构建我们自己的 One-Vs-Rest 分类器,不如让我们学习如何使用 Scikit-Learn 实现它。
sci kit-学习 OneVsRestClassifier
在本节中,我们将对多类数据使用 Scikit-Learn 的 OneVsRestClassifier。为了确保我们获得优异的性能,我们将使用网格搜索来优化超参数。
导入 OneVsRestClassifier
from sklearn.multiclass import OneVsRestClassifier
创建 OneVsRestClassifier 的实例
onevsrest = OneVsRestClassifier(LogisticRegression(solver='saga'))
创建连接缩放和训练的管道
onevsrest_pipe = Pipeline([
('scaler', StandardScaler()),
('mult_lr', onevsrest)
])
指定要优化的超参数
params = {
'mult_lr__estimator__C': [1.0, 1e-1, 1e-2, 1e-3],
'mult_lr__estimator__penalty': ['l1', 'l2', 'elasticnet'],
'mult_lr__estimator__l1_ratio': [0.10, 0.25, 0.5, 0.75]
}
火车上休息
grid_onevsrest = GridSearchCV(
onevsrest_pipe,
params,
cv=3
)
grid_onevsrest.fit(X_train, y_train)
获取模型精确度
print(*{
'test accuracy': grid_onevsrest.best_estimator_.score(X_test, y_test),
'train accuracy': grid_onevsrest.best_estimator_.score(X_train, y_train)}
.items()
)
这是很好的性能,但不如我们的onevsrest3分类器。Scikit 中有一个multi_class参数——学习逻辑回归。其默认值设置为auto。当解析多类分类任务时,此参数会检测到它。然后,逻辑回归使用默认的多类分类设置来执行多类分类。
让我们在下一节看看它是如何处理我们的多类分类任务的。
逻辑回归multi_class参数
为 Scikit-Learn 的逻辑回归多类分类器创建一个管道
mult_class_pipe = Pipeline([
('scaler', StandardScaler()),
('mult_lr', LogisticRegression(solver='saga', multi_class='auto'))
])
指定要优化的超参数
params = {
'mult_lr__C': [1.0, 1e-1, 1e-2, 1e-3],
'mult_lr__penalty': ['l1', 'l2', 'elasticnet'],
'mult_lr__l1_ratio': [0.10, 0.25, 0.5, 0.75]
}
训练管子
grid_mult_class = GridSearchCV(
mult_class_pipe,
params,
cv=3
)
grid_mult_class.fit(X_train, y_train)
获取模型精确度
print(*{
'test accuracy': grid_mult_class.score(X_test, y_test),
'train accuracy': grid_mult_class.score(X_train, y_train)}
.items())
这是对OneVsRestClassifier的改进。然而,它的性能达不到我们定制的onevsall3分类器。
结论
在本教程中,我们深入探讨了逻辑回归算法的工作原理。我们从零开始构建自己的逻辑回归模型。我们使用我们的自定义回归模型来了解凸性和选择适当学习率的重要性。最后,我们使用逻辑回归算法的 Scikit-Learn 实现来了解正则化、超参数调整和多类分类。
在接下来的步骤中,如果您对使用和调试逻辑回归模型感到满意,您可能希望开始学习其他常用的分类器,如支持向量机和决策树分类器。
Luiz:“data quest 帮助我按照自己的时间表学习”
January 10, 2018
当路易斯·萨尼尼决定彻底改变职业时,他是一名机电一体化工程师。他对公司生活感到沮丧,并且知道作为一名程序员他会更快乐。在研究新的职业道路时,数据科学家脱颖而出——他真的很喜欢 Python,并梦想着数字游牧生活方式。
“我列出了尽快成为数据科学家必须掌握的基本技能,以及学习这些技能的最快方法。”
他尝试了 Udacity,但很快意识到这是行不通的——他白天没有时间观看完整的视频,晚上他想和妻子呆在一起。
Dataquest 的课程完全符合 Luiz 创建的列表,其格式允许他在有几分钟空闲时一点一点地前进。“我过去总是让 Dataquest 的标签保持打开,它可以帮助我按照自己的时间表学习,随时随地快速学习。”
在完成数据分析师的道路后,他开始申请工作,同时追求数据科学家的道路。
他在找工作时很小心,想在这个新领域做出正确的选择。手机游戏公司 About Fun 向他发送了一份用户数据样本,要求他进行分析并得出结论。Luiz 使用他们熟悉的工具给他们留下了深刻的印象——Jupyter 笔记本、熊猫和 seaborn。
“起初我不知道从哪里开始,然后我浏览了指导项目,它们帮助我知道该怎么做。”
Luiz 现在是 About Fun 的数据分析师。大部分时间都在编写 SQL 系列、Python 代码和机器学习模型——他探索这些数据,以发现用户跳过一步或停止播放的原因。“我每天做的大部分工作是数据清理,这些都是我在 Dataquest 学到的。”
他给其他学员的建议是赶快行动:“不要等太久才开始找工作,有很多公司准备帮助你进一步发展技能。”
M-Kopa 案例研究:“Dataquest 正在改变我们的工作方式”
原文:https://www.dataquest.io/blog/m-kopa-case-study-dataquest-is-changing-the-way-we-work/
July 25, 2019
“我们是一家拥有万亿字节数据的企业,我们应该利用这些数据来帮助非洲农村地区获得电力和金融服务,但我们并没有像我们需要的那样有效地利用这些数据。 。 “正是这个问题让 M-Kopa 的首席数据官大卫·丹伯格(David Damberger)来到 Dataquest。
用社会企业改变生活
M-Kopa 是一家总部位于肯尼亚的绿色能源和金融公司,为东非那些可能会断电的客户提供小型太阳能系统和贷款。
“这很难衡量,但我们可能是最大、最成功的社会企业之一,”丹伯格说。自 2012 年成立以来,M-Kopa 已经向离网客户提供了超过 100 万笔贷款,将他们与清洁太阳能连接起来,并为他们提供资金支持,如学费和农业项目。
M-Kopa 的贷款可以帮助客户获得改变生活的服务。但为了能够继续提供贷款和其他服务,它需要能够理解不断增长的客户群所产生的海量数据。这就是 Dataquest 的用武之地。
向数据团队添加关键的新技能
M-Kopa 的数据团队包括几位数据科学家和各种数据技能不太先进的分析师,他们很难从正在处理的庞大数据集获得所需的见解。
“仅仅使用 Excel 和一些 SQL 的技能不足以处理我们现有的数据,”Damberger 说。
因此,该公司开始寻找提高数据团队集体技能的方法。因为该公司主要位于肯尼亚,所以必须找到一个在线平台,让学生可以根据自己的时间和进度学习。
“我们中的一些人正在使用[另一个数据科学学习平台],”Damberger 说,但在一些成员转向 Dataquest 后,他们很快意识到他们更喜欢它。他们还意识到 Dataquest 提供了真正有用的 团队功能 用于团队培训,也可以帮助他们的同事。
“所以我们开始让越来越多的数据团队加入 Dataquest,”Damberger 说。“现在我们有三个不同团队的 15 名成员在使用 Dataquest 平台。”

M-Kopa 团队(照片由 M-Kopa 提供)。
由于 Dataquest 提供各种各样的数据科学课程,学生可以注册他们喜欢的任何课程,该平台对技能水平差异很大的员工都有好处。“在我们的团队中,我们有非常资深的数据科学家,他们非常精通 R、Python 和构建数据科学模型,”Damberger 说。“但我们有一大群其他数据分析师和信用分析师,他们基本上没有编码背景,基本上他们只是使用 Excel 进行大量分析。”
“现在团队都在上课,”他说。"我们在培养他们所有的技能。数据世界中的每个人都看到,未来更有可能用 R、Python 编写代码,构建模型并理解不同的算法。所以这一直是我们的动力。”
Dataquest 平台本身也有助于激励,因为团队成员可以看到其他团队成员的进展。“我们真的很喜欢团队的功能,它允许每个人对彼此负责,”丹伯格说。“在平台上看到人们的进步,有点竞争的感觉真的很好。事实上,我们已经将此与奖项配对,认可人们通过该平台进行的改进和工作。”
“ 我们一直在聘用顶尖的数据科学家,他们希望解决对世界产生社会影响的有趣问题,但我们也需要确保他们的技能跟上最新趋势。”
“data quest 正在从根本上改变我们的工作方式,”他说。“我们正试图让我们团队的大部分成员从简单的数据报告和商业智能转向更高级的分析和更数据驱动的洞察。”
“那就是我们想去的地方。所以,Dataquest 完全改变了我们做生意的方式。我们对能够继续提升团队感到非常兴奋。”
提升你的团队
了解 Dataquest 如何帮助您的团队提高效率。
提升你的团队
了解 Dataquest 如何帮助您的团队提高效率。
机器学习的数据清理和准备
原文:https://www.dataquest.io/blog/machine-learning-preparing-data/
June 19, 2019
数据清理和准备是任何机器学习项目中关键的第一步。虽然我们经常认为数据科学家花费大量时间修补算法和机器学习模型,但现实是大多数数据科学家花费大部分时间清理数据。
在这篇博客文章中(最初由 Dataquest 学生 Daniel Osei 撰写,Dataquest 于 2019 年 6 月更新),我们将浏览 Python 中的数据清理过程,检查数据集,选择要素列,可视化探索数据,然后为机器学习编码要素。
我们建议使用 Jupyter 笔记本来跟随本教程。
要了解有关数据清理的更多信息,请查看我们的交互式数据清理课程:
理解数据
在我们开始为机器学习项目清理数据之前,了解数据是什么以及我们想要实现什么是至关重要的。不了解这一点,我们就没有基础来决定在清理和准备数据时哪些数据是相关的。
我们将使用来自 Lending Club 的一些数据,这是一个个人贷款市场,为寻求贷款的借款人和希望放贷并获得回报的投资者牵线搭桥。每个借款人都要填写一份全面的申请表,提供他们过去的财务历史、贷款原因等等。Lending Club 使用过去的历史数据(以及他们自己的数据科学流程)评估每个借款人的信用评分!)并为借款人指定一个利率。

批准的贷款列在 Lending Club 网站上,合格投资者可以在这里浏览最近批准的贷款、借款人的信用评分、贷款目的以及申请中的其他信息。
一旦投资者决定提供贷款,借款人每月向 Lending Club 还款。Lending Club 将这些款项重新分配给投资者。这意味着投资者不必等到全额付清才开始看到回报。如果贷款按时全部还清,投资者将获得回报,该回报相当于借款人在要求的金额之外必须支付的利率。
然而,许多贷款没有完全按时还清,一些借款人拖欠贷款。这是我们在从 Lending Club 清理一些数据以进行机器学习时将试图解决的问题。让我们想象一下,我们的任务是建立一个模型来预测借款人是否有可能偿还或拖欠贷款。
步骤 1:检查数据集
Lending Club 定期在其网站上发布其所有批准和拒绝的贷款申请的数据。为了确保我们使用的是同一组数据,我们在 data.world 上镜像了我们将在本教程中使用的数据。
在 LendingClub 的网站上,您可以选择不同的年份范围来下载已批准和已拒绝贷款的数据集(CSV 格式)。你还可以在 LendingClub 页面的底部找到一个数据字典(XLS 格式),其中包含了不同列名的信息。这个数据字典有助于理解数据集中每一列代表什么。数据字典包含两张表:
- LoanStats 表:描述批准的贷款数据集
- RejectStats 表:描述被拒绝的贷款数据集
我们将使用 LoanStats 表,因为我们对批准的贷款数据集感兴趣。
批准的贷款数据集包含当前贷款、已完成贷款和违约贷款的信息。在本教程中,我们将使用 2007 年到 2011 年的已批准贷款数据,但是发布到 LendingClub 网站的任何数据都需要类似的清理步骤。
首先,让我们导入一些我们将使用的库,并设置一些参数以使输出更容易阅读。出于本教程的目的,我们假设您已经牢固掌握了使用 Python 处理数据的基础知识,包括使用 pandas、numpy 等。因此,如果你需要温习这些技能,你可以浏览我们的课程列表。
import pandas as pd
import numpy as np
pd.set_option('max_columns', 120)
pd.set_option('max_colwidth', 5000)
import matplotlib.pyplot as plt
import seaborn as sns
*%matplotlib inline
plt.rcParams['figure.figsize'] = (12,8)*
*#### 将数据加载到 Pandas
我们已经下载了我们的数据集,并将其命名为lending_club_loans.csv,但是现在我们需要将它加载到一个 pandas 数据框架中来研究它。一旦它被加载,我们将需要做一些基本的清理工作来删除一些我们不需要的信息,这会使我们的数据处理速度变慢。
具体来说,我们将:
- 删除第一行:它包含无关的文本,而不是列标题。这个文本阻止数据集被 pandas 库正确解析。
- 删除“desc”列:它包含一个我们不需要的贷款的长文本解释。
- 删除“url”栏:它包含每个 on Lending Club 的链接,只有投资者帐户才能访问。
- 删除丢失值超过 50%的所有列:这将使我们工作得更快(并且我们的数据集足够大,即使没有它们也仍然有意义。
我们还将把过滤后的数据集命名为loans_2007,在这一节的最后,我们将把它保存为loans_2007.csv,以使它与原始数据分开。这是一种很好的做法,可以确保我们拥有原始数据,以防我们需要返回并检索任何要删除的内容。
现在,让我们继续执行这些步骤:
# skip row 1 so pandas can parse the data properly.
loans_2007 = pd.read_csv('data/lending_club_loans.csv', skiprows=1, low_memory=False)
half_count = len(loans_2007) / 2
loans_2007 = loans_2007.dropna(thresh=half_count,axis=1) # Drop any column with more than 50% missing values
loans_2007 = loans_2007.drop(['url','desc'],axis=1) # These columns are not useful for our purposes
让我们使用 pandas head()方法来显示 loans_2007 数据帧的前三行,以确保我们能够正确地加载数据集:
loans_2007.head(3)
| 身份证明(identification) | 成员 id | 贷款金额 | 资助 _amnt | 资助 _amnt_inv | 学期 | 利息率 | 部分 | 等级 | 路基 | 员工 _ 职位 | 员工长度 | 房屋所有权 | 年度公司 | 验证 _ 状态 | 问题 _d | 贷款 _ 状态 | pymnt_plan | 目的 | 标题 | 邮政编码 | 地址 _ 状态 | 弥散张量成像 | delinq _ 年 | 最早 _cr_line | fico_range_low | fico _ range _ 高 | 最近 6 个月 | open_acc | 发布 _ 记录 | 革命 _ 平衡 | 革命报 | 总计 _acc | 初始列表状态 | out_prncp | out_prncp_inv | total_pymnt | total_pymnt_inv | total_rec_prncp | total_rec_int | total_rec_late_fee | 追回款 | 收款 _ 回收 _ 费用 | last_pymnt_d | last_pymnt_amnt | 最后一笔贷款 | last _ fico _ range _ 高 | last_fico_range_low | 收藏 _ 12 _ 月 _ 月 _ 日 _ 医学 | 策略代码 | 应用程序类型 | acc _ now _ delinq | 12 个月内收费 | delinq _ amnt | pub _ rec _ 破产 | tax _ links-税捐连结 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | One million seventy-seven thousand five hundred and one | One million two hundred and ninety-six thousand five hundred and ninety-nine | Five thousand | Five thousand | Four thousand nine hundred and seventy-five | 36 个月 | 10.65% | One hundred and sixty-two point eight seven | B | B2 | 圆盘烤饼 | 10 年以上 | 租金 | Twenty-four thousand | 已证实的 | 2011 年 12 月 | 全部付讫 | n | 信用卡 | 计算机 | 860xx | 阿塞拜疆(Azerbaijan 的缩写) | Twenty-seven point six five | Zero | 1985 年 1 月 | Seven hundred and thirty-five | Seven hundred and thirty-nine | One | Three | Zero | Thirteen thousand six hundred and forty-eight | 83.7% | Nine | f | Zero | Zero | 5863.155187 | Five thousand eight hundred and thirty-three point eight four | Five thousand | Eight hundred and sixty-three point one six | Zero | Zero | Zero | 2015 年 1 月 | One hundred and seventy-one point six two | 2016 年 9 月 | Seven hundred and forty-four | Seven hundred and forty | Zero | One | 个人 | Zero | Zero | Zero | Zero | Zero |
| one | One million seventy-seven thousand four hundred and thirty | One million three hundred and fourteen thousand one hundred and sixty-seven | Two thousand five hundred | Two thousand five hundred | Two thousand five hundred | 60 个月 | 15.27% | Fifty-nine point eight three | C | 补体第四成份缺乏 | 赖德 | 不到 1 年 | 租金 | Thirty thousand | 来源已核实 | 2011 年 12 月 | 注销 | n | 汽车 | 自行车 | 309xx | 通用航空 | One | Zero | 1999 年 4 月 | Seven hundred and forty | Seven hundred and forty-four | Five | Three | Zero | One thousand six hundred and eighty-seven | 9.4% | Four | f | Zero | Zero | 1008.710000 | One thousand and eight point seven one | Four hundred and fifty-six point four six | Four hundred and thirty-five point one seven | Zero | One hundred and seventeen point zero eight | One point one one | 2013 年 4 月 | One hundred and nineteen point six six | 2016 年 9 月 | Four hundred and ninety-nine | Zero | Zero | One | 个人 | Zero | Zero | Zero | Zero | Zero |
| Two | One million seventy-seven thousand one hundred and seventy-five | One million three hundred and thirteen thousand five hundred and twenty-four | Two thousand four hundred | Two thousand four hundred | Two thousand four hundred | 36 个月 | 15.96% | Eighty-four point three three | C | 溴化五烃季胺 | 圆盘烤饼 | 10 年以上 | 租金 | Twelve thousand two hundred and fifty-two | 未验证 | 2011 年 12 月 | 全部付讫 | n | 小企业 | 房地产业务 | 606xx | 伊利诺伊 | Eight point seven two | Zero | 2001 年 11 月 | Seven hundred and thirty-five | Seven hundred and thirty-nine | Two | Two | Zero | Two thousand nine hundred and fifty-six | 98.5% | Ten | f | Zero | Zero | 3005.666844 | Three thousand and five point six seven | Two thousand four hundred | Six hundred and five point six seven | Zero | Zero | Zero | 2014 年 6 月 | Six hundred and forty-nine point nine one | 2016 年 9 月 | Seven hundred and nineteen | Seven hundred and fifteen | Zero | One | 个人 | Zero | Zero | Zero | Zero | Zero |
让我们也使用 pandas .shape属性来查看我们在此阶段处理的样本和特性的数量:
loans_2007.shape
(42538, 56)
步骤 2:缩小要清理的列的范围
既然我们已经建立了数据,我们应该花一些时间来研究它,并理解每一列代表什么特性。这一点很重要,因为对特性的理解不足会导致我们在数据分析和建模过程中出错。
我们将使用 LendingClub 提供的数据字典来帮助我们熟悉数据集中的列以及每个列所代表的内容。为了简化这个过程,我们将创建一个 DataFrame 来包含列名、数据类型、第一行的值和数据字典中的描述。为了使这更容易,我们已经将数据字典从 Excel 格式预先转换为 CSV 格式。
让我们打开字典看一看。
data_dictionary = pd.read_csv('LCDataDictionary.csv') # Loading in the data dictionary
print(data_dictionary.shape[0])
print(data_dictionary.columns.tolist())
117
['LoanStatNew', 'Description']
data_dictionary.head()
data_dictionary = data_dictionary.rename(columns={'LoanStatNew': 'name', 'Description': 'description'})
| LoanStatNew | 描述 | |
|---|---|---|
| Zero | acc _ now _ delinq | 借款人现在拖欠的账户数量。 |
| one | acc _ open _ past _ 月 | 过去 24 个月中的开仓交易数量。 |
| Two | 地址状态 | 借款人在贷款申请中提供的状态 |
| three | all_util | 所有交易的信贷限额余额 |
| four | 年度公司 | 借款人在登记时提供的自报年收入。 |
现在我们已经加载了数据字典,让我们将第一行loans_2007连接到data_dictionary数据帧,以给出一个包含以下各列的预览数据帧:
name—包含loans_2007的列名。dtypes—包含loans_2007列的数据类型。first value—包含第一行loans_2007的值。description—解释loans_2007中每一列的含义。
loans_2007_dtypes = pd.DataFrame(loans_2007.dtypes,columns=['dtypes'])
loans_2007_dtypes = loans_2007_dtypes.reset_index()
loans_2007_dtypes['name'] = loans_2007_dtypes['index']
loans_2007_dtypes = loans_2007_dtypes[['name','dtypes']]
loans_2007_dtypes['first value'] = loans_2007.loc[0].values
preview = loans_2007_dtypes.merge(data_dictionary, on='name',how='left')
preview.head()
| 名字 | dtypes(类型) | 第一个值 | 描述 | |
|---|---|---|---|---|
| Zero | 身份证明(identification) | 目标 | One million seventy-seven thousand five hundred and one | 贷款列表的唯一 LC 分配 ID。 |
| one | 成员 id | float64 | 1.2966e+06 | 借款人成员的唯一 LC 分配 Id。 |
| Two | 贷款金额 | float64 | Five thousand | 借款人申请的贷款金额。如果在某个时间点,信贷部门减少了贷款金额,那么它将反映在这个值中。 |
| three | 资助 _amnt | float64 | Five thousand | 当时承诺的贷款总额。 |
| four | 资助 _amnt_inv | float64 | Four thousand nine hundred and seventy-five | 投资者在该时间点承诺的贷款总额。 |
当我们之前打印loans_2007的形状时,我们注意到它有 56 列,所以我们知道这个预览数据帧有 56 行(一行解释loans_2007中的每一列)。
尝试一次浏览预览的所有行可能会很麻烦,因此我们将把它分成三个部分,每次查看较小的功能选择。当我们探索这些特性以更好地理解它们时,我们希望关注任何具有以下特征的专栏:
- 从未来泄露信息(在贷款已经被资助之后),
- 不影响借款人偿还贷款的能力(如 Lending Club 随机生成的 ID 值),
- 格式很差,
- 需要更多数据或大量预处理才能变成有用的功能,或者
- 包含冗余信息。
这些都是我们需要小心的事情,因为从长远来看,处理不当会损害我们的分析。
我们需要特别关注数据泄露,它会导致模型过拟合。这是因为该模型还会从我们使用它时无法获得的功能中学习,从而预测未来的贷款。我们需要确保我们的模型仅使用贷款申请时的数据进行训练。
第一组列
让我们显示preview的前 19 行并进行分析:
preview[:19]
| 名字 | dtypes(类型) | 第一个值 | 描述 | |
|---|---|---|---|---|
| Zero | 身份证明(identification) | 目标 | One million seventy-seven thousand five hundred and one | 贷款列表的唯一 LC 分配 ID。 |
| one | 成员 id | float64 | 1.2966e+06 | 借款人成员的唯一 LC 分配 Id。 |
| Two | 贷款金额 | float64 | Five thousand | 借款人申请的贷款金额。如果在某个时间点,信贷部门减少了贷款金额,那么它将反映在这个值中。 |
| three | 资助 _amnt | float64 | Five thousand | 当时承诺的贷款总额。 |
| four | 资助 _amnt_inv | float64 | Four thousand nine hundred and seventy-five | 投资者在该时间点承诺的贷款总额。 |
| five | 学期 | 目标 | 36 个月 | 贷款的付款次数。值以月为单位,可以是 36 或 60。 |
| six | 利息率 | 目标 | 10.65% | 贷款利率 |
| seven | 部分 | float64 | One hundred and sixty-two point eight seven | 如果贷款来源,借款人所欠的每月付款。 |
| eight | 等级 | 目标 | B | LC 分配的贷款等级 |
| nine | 路基 | 目标 | B2 | LC 指定贷款路基 |
| Ten | 员工 _ 职位 | 目标 | 圆盘烤饼 | 借款人在申请贷款时提供的职位名称。* |
| Eleven | 员工长度 | 目标 | 10 年以上 | 雇佣年限。可能的值介于 0 和 10 之间,其中 0 表示不到一年,10 表示十年或更长时间。 |
| Twelve | 房屋所有权 | 目标 | 租金 | 借款人在登记时提供的房屋所有权状况。我们的价值观是:租金、自有、抵押、其他。 |
| Thirteen | 年度公司 | float64 | Twenty-four thousand | 借款人在登记时提供的自报年收入。 |
| Fourteen | 验证 _ 状态 | 目标 | 已证实的 | 指示收入是否已由信用证核实、未核实或收入来源是否已核实 |
| Fifteen | 问题 _d | 目标 | 2011 年 12 月 | 为贷款提供资金的月份 |
| Sixteen | 贷款 _ 状态 | 目标 | 全部付讫 | 贷款的当前状态 |
| Seventeen | pymnt_plan | 目标 | n | 指明贷款的付款计划是否已经到位 |
| Eighteen | 目的 | 目标 | 信用卡 | 借款人为贷款请求提供的类别。 |
在分析了这些列并考虑了我们试图构建的模型之后,我们可以得出结论,可以删除以下特性:
id—由 LendingClub 随机生成的字段,仅用于唯一识别目的。member_id—也是由 LendingClub 随机生成的字段,仅用于识别目的。funded_amnt—从未来泄露信息(在贷款已经开始融资之后)。funded_amnt_inv—也泄露未来的数据。sub_grade—包含已经在grade列中的冗余信息(更多信息见下文)。int_rate—也包括在grade列中。emp_title—需要其他数据和大量处理才能变得潜在有用issued_d—泄露未来的数据。
注意:Lending Club 使用借款人的等级和付款期限(30 或 30 个月)来分配利率(你可以阅读更多关于利率和费用)。这导致给定等级内的利率变化。
对我们的模型有用的是关注借款人群体而不是个人。这正是评级的作用——它根据借款人的信用评分和其他行为对借款人进行细分,这就是为什么我们将保留grade列,并降低利息int_rate和sub_grade。在移动到下一组列之前,让我们从数据框架中删除这些列。
drop_list = ['id','member_id','funded_amnt','funded_amnt_inv',
'int_rate','sub_grade','emp_title','issue_d']
loans_2007 = loans_2007.drop(drop_list,axis=1)
现在我们准备继续下一组专栏(特性)。
第二组列
让我们继续下面的 19 个专栏:
preview[19:38]
| 名字 | dtypes(类型) | 第一个值 | 描述 | |
|---|---|---|---|---|
| Nineteen | 标题 | 目标 | 计算机 | 借款人提供的贷款名称 |
| Twenty | 邮政编码 | 目标 | 860xx | 借款人在贷款申请中提供的邮政编码的前 3 个数字。 |
| Twenty-one | 地址状态 | 目标 | 阿塞拜疆(Azerbaijan 的缩写) | 借款人在贷款申请中提供的状态 |
| Twenty-two | 弥散张量成像 | float64 | Twenty-seven point six five | 使用借款人每月总债务付款对总债务(不包括抵押贷款和要求的 LC 贷款)除以借款人自我报告的月收入计算的比率。 |
| Twenty-three | delinq _ 年 | float64 | Zero | 在过去 2 年中,借款人信用档案中逾期 30 天以上的拖欠事件的数量 |
| Twenty-four | 最早 _cr_line | 目标 | 1985 年 1 月 | 借款人最早报告的信用额度开立的月份 |
| Twenty-five | fico_range_low | float64 | Seven hundred and thirty-five | 贷款发放时借款人 FICO 所属的下限范围。 |
| Twenty-six | fico _ range _ 高 | float64 | Seven hundred and thirty-nine | 贷款发放时借款人 FICO 所属的上限范围。 |
| Twenty-seven | 最近 6 个月 | float64 | one | 过去 6 个月的查询次数(不包括汽车和抵押贷款查询) |
| Twenty-eight | open_acc | float64 | three | 借款人信用档案中未结信用额度的数量。 |
| Twenty-nine | 发布 _ 记录 | float64 | Zero | 贬损公共记录的数量 |
| Thirty | 革命 _ 平衡 | float64 | Thirteen thousand six hundred and forty-eight | 贷方循环余额合计 |
| Thirty-one | 革命报 | 目标 | 83.7% | 循环额度利用率,或借款人相对于所有可用循环信贷使用的信贷金额。 |
| Thirty-two | 总计 _acc | float64 | nine | 借款人信用档案中当前的信用额度总数 |
| Thirty-three | 初始列表状态 | 目标 | f | 贷款的初始上市状态。可能的值为–W,F |
| Thirty-four | out_prncp | float64 | Zero | 资金总额的剩余未偿本金 |
| Thirty-five | out_prncp_inv | float64 | Zero | 投资者出资总额部分的剩余未偿本金 |
| Thirty-six | total_pymnt | float64 | Five thousand eight hundred and sixty-three point one six | 迄今收到的资金总额付款 |
| Thirty-seven | total_pymnt_inv | float64 | Five thousand eight hundred and thirty-three point eight four | 迄今收到的投资者出资总额部分的付款 |
在该组中,请注意fico_range_low和fico_range_high列。虽然两者都在上表中,但我们将在看完最后一组专栏后进一步讨论它们。另请注意,如果您正在处理较新的 LendingClub 数据,它可能不包括 FICO 分数的数据。
现在,查看我们的第二组列,我们可以通过删除以下列来进一步细化我们的数据集:
zip_code–addr _ state 列大部分是冗余的,因为只有 5 位邮政编码的前 3 位是可见的。out_prncp–泄露未来的数据。out_prncp_inv–也泄露未来的数据。total_pymnt–也泄露未来的数据。total_pymnt_inv–也泄露未来的数据。
让我们继续从数据框中删除这 5 列:
drop_cols = [ 'zip_code','out_prncp','out_prncp_inv',
'total_pymnt','total_pymnt_inv']
loans_2007 = loans_2007.drop(drop_cols, axis=1)
第三组列
让我们来分析最后一组特性:
preview[38:]
| 名字 | dtypes(类型) | 第一个值 | 描述 | |
|---|---|---|---|---|
| Thirty-eight | total_rec_prncp | float64 | Five thousand | 迄今收到的本金 |
| Thirty-nine | total_rec_int | float64 | Eight hundred and sixty-three point one six | 迄今收到的利息 |
| Forty | total_rec_late_fee | float64 | Zero | 迄今收到的滞纳金 |
| Forty-one | 追回款 | float64 | Zero | 冲销总回收 |
| forty-two | 收款 _ 回收 _ 费用 | float64 | Zero | 邮政冲减托收费用 |
| Forty-three | last_pymnt_d | 目标 | 2015 年 1 月 | 上个月的付款已经收到 |
| forty-four | last_pymnt_amnt | float64 | One hundred and seventy-one point six two | 上次收到的总付款金额 |
| Forty-five | 最后一笔贷款 | 目标 | 2016 年 9 月 | 最近一个月的信用证提取了这笔贷款的信用 |
| Forty-six | last _ fico _ range _ 高 | float64 | Seven hundred and forty-four | 借款人最后一笔 FICO 贷款所属的上限范围。 |
| Forty-seven | last_fico_range_low | float64 | Seven hundred and forty | 借款人最后一笔 FICO 贷款所属的下限范围。 |
| Forty-eight | 收藏 _ 12 _ 月 _ 月 _ 日 _ 医学 | float64 | Zero | 12 个月内的收集次数,不包括医疗收集 |
| forty-nine | 策略代码 | float64 | one | 公开提供的 policy _ code = 1 \新产品不公开提供的 policy_code=2 |
| Fifty | 应用程序类型 | 目标 | 个人 | 指明贷款是个人申请还是两个共同借款人的联合申请 |
| Fifty-one | acc _ now _ delinq | float64 | Zero | 借款人现在拖欠的账户数量。 |
| fifty-two | 12 个月内收费 | float64 | Zero | 12 个月内的销账次数 |
| Fifty-three | delinq _ amnt | float64 | Zero | 借款人现在拖欠的帐户的过期欠款。 |
| Fifty-four | pub _ rec _ 破产 | float64 | Zero | 公开记录的破产数量 |
| Fifty-five | tax _ links-税捐连结 | float64 | Zero | 税收留置权的数量 |
在最后一组列中,我们需要删除以下内容,所有的都泄露了未来的数据:
total_rec_prncptotal_rec_inttotal_rec_late_feerecoveriescollection_recovery_feelast_pymnt_dlast_pymnt_amnt
让我们删除最后一组列:
drop_cols = ['total_rec_prncp','total_rec_int',
'total_rec_late_fee','recoveries',
'collection_recovery_fee', 'last_pymnt_d'
'last_pymnt_amnt']
loans_2007 = loans_2007.drop(drop_cols, axis=1)
太好了!我们现在有了一个数据集,它将对构建我们的模型更加有用,因为它不必浪费时间处理不相关的数据,也不会通过分析泄露贷款结果的未来信息来“欺骗”。
调查 FICO 分数列
值得花点时间来讨论一下fico_range_low、fico_range_high、last_fico_range_low和last_fico_range_high列。
FICO 分数是一种信用分数:银行和信用卡用来表示一个人的信用程度的数字。虽然有几种类型的信用评分在美国使用,FICO 评分是最有名的和最广泛使用的。
当借款人申请贷款时,LendingClub 从 FICO 获得借款人的信用评分——他们获得借款人评分所属范围的下限和上限,并将这些值存储为fico_range_low、fico_range_high。在那之后,对借款者分数的任何更新都被记录为last_fico_range_low和last_fico_range_high。
任何数据科学项目的一个关键部分是尽一切努力理解数据。在研究这个特定的数据集时,我发现了斯坦福大学的一群学生在 2014 年做的一个项目。在项目的报告中,该小组将滞纳金和恢复费中的当前信用评分(last_fico_range)列为他们错误添加到功能中的字段,但声明他们后来知道这些列都泄露了未来的信息。
然而,在这个小组的项目之后,来自斯坦福的另一个小组研究了这个相同的 Lending Club 数据集。他们在建模中使用了 FICO 分数栏,只去掉了last_fico_range_low。第二组的报告将last_fico_range_high描述为预测准确结果的更重要特征之一。
有了这些信息,我们必须回答的问题是:FICO 信用评分会泄露未来的信息吗?回想一下,当我们使用我们的模型进行预测时,如果列中包含的数据不可用,则该列被视为泄漏信息,在这种情况下,当我们在未来的贷款申请中使用我们的模型来预测借款人是否会违约时。
这篇博客文章(不再提供)深入研究了 LendingClub 贷款的 FICO 分数,并指出,虽然观察 FICO 分数的趋势可以很好地预测贷款是否会违约,但在贷款获得资金后,FICO 分数会继续由 LendingClub 更新。换句话说,虽然我们可以使用初始 FICO 分数(fico_range_low和fico_range_high)——这些分数将作为借款人申请的一部分提供——但我们不能使用last_fico_range_low和last_fico_range_high,因为 LendingClub 可能会在借款人申请后更新这些分数。
让我们看看我们可以使用的两列中的值:
print(loans_2007['fico_range_low'].unique())
print(loans_2007['fico_range_high'].unique())
[ 735\. 740\. 690\. 695\. 730\. 660\. 675\. 725\. 710\. 705\. 720\. 665\. 670\. 760\. 685\. 755\. 680\. 700\. 790\. 750\. 715\. 765\. 745\. 770\. 780\. 775\. 795\. 810\. 800\. 815\. 785\. 805\. 825\. 820\. 630\. 625\. nan 650\. 655\. 645\. 640\. 635\. 610\. 620\. 615.]
[ 739\. 744\. 694\. 699\. 734\. 664\. 679\. 729\. 714\. 709\. 724\. 669\. 674\. 764\. 689\. 759\. 684\. 704\. 794\. 754\. 719\. 769\. 749\. 774\. 784\. 779\. 799\. 814\. 804\. 819\. 789\. 809\. 829\. 824\. 634\. 629\. nan 654\. 659\. 649\. 644\. 639\. 614\. 624\. 619.]
让我们去掉缺失的值,然后绘制直方图来查看两列的范围:
fico_columns = ['fico_range_high','fico_range_low']
print(loans_2007.shape[0])
loans_2007.dropna(subset=fico_columns,inplace=True)
print(loans_2007.shape[0])
loans_2007[fico_columns].plot.hist(alpha=0.5,bins=20);
42538
42535

现在让我们继续为fico_range_low和fico_range_high列的平均值创建一个列,并将其命名为fico_average。请注意,这不是每个借款人的平均 FICO 分数,而是我们知道的借款人所处的最高和最低范围的平均值。
loans_2007['fico_average'] = (loans_2007['fico_range_high'] + loans_2007['fico_range_low']) / 2
让我们检查一下我们刚才做了什么。
cols = ['fico_range_low','fico_range_high','fico_average']
loans_2007[cols].head()
| fico_range_low | fico _ range _ 高 | fico _ 平均 | |
|---|---|---|---|
| Zero | Seven hundred and thirty-five | Seven hundred and thirty-nine | Seven hundred and thirty-seven |
| one | Seven hundred and forty | Seven hundred and forty-four | Seven hundred and forty-two |
| Two | Seven hundred and thirty-five | Seven hundred and thirty-nine | Seven hundred and thirty-seven |
| three | Six hundred and ninety | Six hundred and ninety-four | Six hundred and ninety-two |
| four | Six hundred and ninety-five | Six hundred and ninety-nine | Six hundred and ninety-seven |
很好!我们得到了平均计算和一切权利。现在,我们可以删除fico_range_low、fico_range_high、last_fico_range_low和last_fico_range_high列。
drop_cols = ['fico_range_low','fico_range_high','last_fico_range_low', 'last_fico_range_high']
loans_2007 = loans_2007.drop(drop_cols, axis=1)
loans_2007.shape
(42535, 33)
请注意,通过熟悉数据集中的列,我们已经能够将列数从 56 减少到 33,而不会丢失任何对我们的模型有意义的数据。我们还通过删除泄露未来信息的数据来避免问题,这些数据会打乱我们模型的结果。这就是数据清理如此重要的原因!
决定目标列
现在,我们将决定使用哪一列作为建模的目标列。
我们的主要目标是预测谁将偿还贷款,谁将违约,我们需要找到一个反映这一点的栏目。我们从预览数据帧中的列描述中了解到,loan_status是主数据集中描述贷款状态的唯一字段,因此让我们将该列用作目标列。
preview[preview.name == 'loan_status']
| 名字 | dtypes(类型) | 第一个值 | 描述 | |
|---|---|---|---|---|
| Sixteen | 贷款 _ 状态 | 目标 | 全部付讫 | 贷款的当前状态 |
目前,此列包含需要转换为数值的文本值,以便能够用于训练模型。让我们在本专栏中探讨不同的价值观,并想出一个转换它们的策略。我们将使用 DataFrame 方法 value_counts() 返回loan_status列中唯一值的频率。
loans_2007["loan_status"].value_counts()
Fully Paid 33586
Charged Off 5653
Does not meet the credit policy. Status:Fully Paid 1988
Does not meet the credit policy. Status:Charged Off 761
Current 513
In Grace Period 16
Late (31-120 days) 12
Late (16-30 days) 5
Default 1
Name: loan_status, dtype: int64
贷款状态有九种不同的可能值!让我们了解这些独特的值,以确定最能描述贷款最终结果的值,以及我们将要处理的分类问题。
我们可以在 LendingClub 网站上看到大多数不同的贷款状态,也可以在 Lend Academy 和 Orchard 论坛上看到这些帖子。
下面,我们将这些数据汇总到下表中,这样我们就可以看到唯一的值、它们在数据集中的出现频率,并更清楚地了解每个值的含义:
meaning = [
"Loan has been fully paid off.",
"Loan for which there is no longer a reasonable expectation of further payments.",
"While the loan was paid off, the loan application today would no longer meet the credit policy and wouldn't be approved on to the marketplace.",
"While the loan was charged off, the loan application today would no longer meet the credit policy and wouldn't be approved on to the marketplace.",
"Loan is up to date on current payments.",
"The loan is past due but still in the grace period of 15 days.",
"Loan hasn't been paid in 31 to 120 days (late on the current payment).",
"Loan hasn't been paid in 16 to 30 days (late on the current payment).",
"Loan is defaulted on and no payment has been made for more than 121 days."]
status, count = loans_2007["loan_status"].value_counts().index, loans_2007["loan_status"].value_counts().values
loan_statuses_explanation = pd.DataFrame({'Loan Status': status,'Count': count,'Meaning': meaning})[['Loan Status','Count','Meaning']]
loan_statuses_explanation
| 贷款状态 | 数数 | 意义 | |
|---|---|---|---|
| Zero | 全部付讫 | Thirty-three thousand five hundred and eighty-six | 贷款已全部还清。 |
| one | 注销 | Five thousand six hundred and fifty-three | 不再有进一步还款的合理预期的贷款。 |
| Two | 不符合信贷政策。状况:全额支付 | One thousand nine hundred and eighty-eight | 虽然贷款已经还清,但今天的贷款申请不再符合信贷政策,不会被批准上市。 |
| three | 不符合信贷政策。状态:已关闭 | Seven hundred and sixty-one | 当贷款被取消时,今天的贷款申请将不再符合信贷政策,不会被批准上市。 |
| four | 目前的 | Five hundred and thirteen | 当前付款的贷款是最新的。 |
| five | 在宽限期内 | Sixteen | 贷款已经过期,但仍在 15 天的宽限期内。 |
| six | 后期(31-120 天) | Twelve | 贷款在 31 到 120 天内没有支付(当前付款的延迟)。 |
| seven | 后期(16-30 天) | five | 贷款已有 16 到 30 天没有支付(当前付款的延迟)。 |
| eight | 默认 | one | 贷款违约,超过 121 天没有付款。 |
请记住,我们的目标是建立一个机器学习模型,它可以从过去的贷款中学习,试图预测哪些贷款将被还清,哪些不会。从上表中可以看出,只有完全支付和冲销的价值描述了贷款的最终结果。其他值描述的是仍在进行的贷款,即使有些贷款逾期未还,我们也不能过早将它们归类为已冲销贷款。
此外,虽然违约状态类似于已冲销状态,但在 LendingClub 看来,已冲销的贷款基本上没有偿还的机会,而违约贷款的机会很小。因此,我们应该只使用loan_status栏为'Fully Paid'或'Charged Off'的样本。
我们对任何表明贷款正在进行或正在进行的状态不感兴趣,因为预测某事正在进行并不能告诉我们任何事情。
我们感兴趣的是能够预测贷款将属于'Fully Paid'还是'Charged Off'中的哪一个,因此我们可以将问题视为二元分类。让我们删除所有不包含'Fully Paid'或'Charged Off'作为贷款状态的贷款,然后将'Fully Paid'值转换为1表示正例,将'Charged Off'值转换为0表示负例。
这意味着在我们拥有的大约 42,000 行中,我们将删除 3,000 多行。
有几种不同的方法来转换一列中的所有值,我们将使用 DataFrame 方法replace() 。
loans_2007 = loans_2007[(loans_2007["loan_status"] == "Fully Paid") |
(loans_2007["loan_status"] == "Charged Off")]
mapping_dictionary = {"loan_status":{ "Fully Paid": 1, "Charged Off": 0}}
loans_2007 = loans_2007.replace(mapping_dictionary)
可视化目标列结果
fig, axs = plt.subplots(1,2,figsize=(14,7))
sns.countplot(x='loan_status',data=filtered_loans,ax=axs[0])
axs[0].set_title("Frequency of each Loan Status")
filtered_loans.loan_status.value_counts().plot(x=None,y=None, kind='pie', ax=axs[1],autopct='%1.2f%%')
axs[1].set_title("Percentage of each Loan status")
plt.show()

这些图表明,在我们的数据集中,相当数量的借款人还清了贷款——85.62%的借款人还清了借款金额,而 14.38%的借款人不幸违约。我们更感兴趣的是识别这些“违约者”,因为为了我们模型的目的,我们试图找到一种最大化投资回报的方法。
不向这些违约者贷款将有助于增加我们的回报,因此我们将继续清理我们的数据,着眼于建立一个可以在应用时识别可能违约者的模型。
删除只有一个值的列
为了总结这一节,让我们查找只包含一个唯一值的任何列,并删除它们。这些列对模型没有用,因为它们没有向每个贷款申请添加任何信息。此外,删除这些列将减少我们在下一阶段需要进一步探索的列的数量。
熊猫系列方法nunique() 返回唯一值的个数,不包括任何空值。我们可以在数据集上应用这个方法,通过一个简单的步骤来删除这些列。
loans_2007 = loans_2007.loc[:,loans_2007.apply(pd.Series.nunique) != 1]
同样,有些列可能有多个唯一值,但其中一个值在数据集中出现的频率很低。让我们查找并删除任何唯一值出现次数少于四次的列:
for col in loans_2007.columns:
if (len(loans_2007[col].unique()) < 4):
print(loans_2007[col].value_counts())
print()
36 months 29096
60 months 10143
Name: term, dtype: int64
Not Verified 16845
Verified 12526
Source Verified 9868
Name: verification_status, dtype: int64
1 33586
0 5653
Name: loan_status, dtype: int64
n 39238
y 1
Name: pymnt_plan, dtype: int64
付款计划列(pymnt_plan)有两个唯一值,'y'和'n',其中'y'只出现一次。让我们放弃这个专栏:
print(loans_2007.shape[1])
loans_2007 = loans_2007.drop('pymnt_plan', axis=1)
print("We've been able to reduce the features to => {}".format(loans_2007.shape[1]))
25
We've been able to reduce the features to => 24
最后,让我们使用 pandas 将我们新清理的数据帧保存为 CSV 文件:
loans_2007.to_csv("processed_data/filtered_loans_2007.csv",index=False)
现在我们有了一个更好的数据集。但是我们仍然没有完成我们的数据清理工作,所以让我们继续努力吧!
步骤 3:为机器学习准备特征
在这一部分,我们将为机器学习准备filtered_loans_2007.csv数据。我们将着重于处理缺失值,将分类列转换为数字列,并删除任何其他无关的列。
在将数据输入机器学习算法之前,我们需要处理缺失值和分类特征,因为大多数机器学习模型的数学基础假设数据是数值型的,不包含缺失值。为了强化这一要求,如果您在处理线性回归和逻辑回归等模型时,试图使用包含缺失值或非数值的数据来训练模型,scikit-learn 将返回错误。
这是我们在这一阶段要做的事情的概要:
- 处理缺失值
- 调查分类列
- 将分类列转换为数字特征
- 将序数值映射到整数
- 将标称值编码为虚拟变量
- 将分类列转换为数字特征
首先,让我们加载上一节最终输出的数据:
filtered_loans = pd.read_csv('processed_data/filtered_loans_2007.csv')
print(filtered_loans.shape)
filtered_loans.head()
(39239, 24)
| 贷款金额 | 学期 | 部分 | 等级 | 员工长度 | 房屋所有权 | 年度公司 | 验证 _ 状态 | 贷款 _ 状态 | 目的 | 标题 | 地址状态 | 弥散张量成像 | delinq _ 年 | 最早 _cr_line | 最近 6 个月 | open_acc | 发布 _ 记录 | 革命 _ 平衡 | 革命报 | 总计 _acc | 最后一笔贷款 | pub _ rec _ 破产 | fico _ 平均 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Five thousand | 36 个月 | One hundred and sixty-two point eight seven | B | 10 年以上 | 租金 | Twenty-four thousand | 已证实的 | one | 信用卡 | 计算机 | 阿塞拜疆(Azerbaijan 的缩写) | Twenty-seven point six five | Zero | 1985 年 1 月 | One | Three | Zero | Thirteen thousand six hundred and forty-eight | 83.7% | Nine | 2016 年 9 月 | Zero | Seven hundred and thirty-seven |
| one | Two thousand five hundred | 60 个月 | Fifty-nine point eight three | C | 不到 1 年 | 租金 | Thirty thousand | 来源已核实 | Zero | 汽车 | 自行车 | 通用航空 | One | Zero | 1999 年 4 月 | Five | Three | Zero | One thousand six hundred and eighty-seven | 9.4% | Four | 2016 年 9 月 | Zero | Seven hundred and forty-two |
| Two | Two thousand four hundred | 36 个月 | Eighty-four point three three | C | 10 年以上 | 租金 | Twelve thousand two hundred and fifty-two | 未验证 | one | 小企业 | 房地产业务 | 伊利诺伊 | Eight point seven two | Zero | 2001 年 11 月 | Two | Two | Zero | Two thousand nine hundred and fifty-six | 98.5% | Ten | 2016 年 9 月 | Zero | Seven hundred and thirty-seven |
| three | Ten thousand | 36 个月 | Three hundred and thirty-nine point three one | C | 10 年以上 | 租金 | Forty-nine thousand two hundred | 来源已核实 | one | 其他的 | 个人的 | 加拿大 | Twenty | Zero | 1996 年 2 月 | One | Ten | Zero | Five thousand five hundred and ninety-eight | 21% | Thirty-seven | 2016 年 4 月 | Zero | Six hundred and ninety-two |
| four | Five thousand | 36 个月 | One hundred and fifty-six point four six | A | 3 年 | 租金 | Thirty-six thousand | 来源已核实 | one | 婚礼 | 我的结婚贷款我保证会还的 | 阿塞拜疆(Azerbaijan 的缩写) | Eleven point two | Zero | 2004 年 11 月 | Three | Nine | Zero | Seven thousand nine hundred and sixty-three | 28.3% | Twelve | 2016 年 1 月 | Zero | Seven hundred and thirty-two |
处理缺失值
让我们计算缺失值的数量,并确定如何处理它们。我们可以返回数据帧中缺失值的数量,如下所示:
- 首先,使用 Pandas DataFrame 方法
isnull()返回一个包含布尔值的 DataFrame:True如果原始值为空False如果原始值不为空
- 然后,使用 Pandas DataFrame 方法
sum()来计算每一列中空值的数量。
null_counts = filtered_loans.isnull().sum()
print("Number of null values in each column:\n{}".format(null_counts))
Number of null values in each column:
loan_amnt 0
term 0
installment 0
grade 0
emp_length 0
home_ownership 0
annual_inc 0
verification_status 0
loan_status 0
purpose 0
title 10
addr_state 0
dti 0
delinq_2yrs 0
earliest_cr_line 0
inq_last_6mths 0
open_acc 0
pub_rec 0
revol_bal 0
revol_util 50
total_acc 0
last_credit_pull_d 2
pub_rec_bankruptcies 697
fico_average 0
dtype: int64
请注意,虽然大多数列有 0 个缺失值,title有 9 个缺失值,revol_util有 48 个,而pub_rec_bankruptcies包含 675 行缺失值。
让我们完全删除那些超过 1% (392)的行包含空值的列。此外,我们将删除剩余的包含空值的行。这意味着我们会丢失一些数据,但作为回报,我们会保留一些额外的特征用于预测(因为我们不必删除那些列)。
我们将保留title和revol_util列,只删除包含缺失值的行,但是完全删除pub_rec_bankruptcies列,因为超过 1%的行在该列中有缺失值。
具体来说,我们要做的是:
这是它在代码中的样子。
filtered_loans = filtered_loans.drop("pub_rec_bankruptcies",axis=1)
filtered_loans = filtered_loans.dropna()
请注意,有多种方法可以处理缺失值,这是机器学习数据清理中最重要的步骤之一。我们的Python 数据清理高级课程更深入地探讨了在清理数据时处理缺失值的问题,这将是深入学习该主题的绝佳资源。
但是,对于我们的目的来说,我们已经完成了这一步,所以让我们继续处理分类列。
调查分类列
我们在这里的目标是最终得到一个可用于机器学习的数据集,这意味着它不包含缺失值,并且列中的所有值都是数值(float 或 int 数据类型)。
我们已经处理了丢失的值,所以现在让我们找出属于对象数据类型的列的数量,并弄清楚如何将这些值变成数字。
print("Data types and their frequency\n{}".format(filtered_loans.dtypes.value_counts()))
Data types and their frequency
float64 11
object 11
int64 1
dtype: int64
我们有 11 个对象列,包含需要转换成数字特征的文本。让我们使用 DataFrame 方法 select_dtype 只选择对象列,然后显示一个示例行,以便更好地理解每列中的值是如何格式化的。
object_columns_df = filtered_loans.select_dtypes(include=['object'])
print(object_columns_df.iloc[0])
term 36 months
grade B
emp_length 10+ years
home_ownership RENT
verification_status Verified
purpose credit_card
title Computer
addr_state AZ
earliest_cr_line Jan-1985
revol_util 83.7%
last_credit_pull_d Sep-2016
Name: 0, dtype: object
注意revol_util列包含数值,但是被格式化为 object。我们从前面对preview数据框架中各列的描述中了解到,revol_util是一个“循环额度使用率或借款人相对于所有可用信贷的信贷额”(在此阅读更多信息)。我们需要将revol_util格式化为一个数值。我们可以这样做:
- 使用
str.rstrip()字符串方法去掉右边的尾随百分号(%)。 - 在生成的 Series 对象上,使用
astype()方法转换为类型float。 - 将新的浮点值序列赋回
filtered_loans中的revol_util列。
filtered_loans['revol_util'] = filtered_loans['revol_util'].str.rstrip('%').astype('float')
继续,这些列似乎代表分类值:
home_ownership—根据数据字典,房屋所有权状态只能是 4 个分类值中的一个。verification_status—表示收入是否被 LendingClub 核实。emp_length—申请时借款人受雇的年数。term—贷款的支付次数,36 或 60。addr_state—借款人的居住国。grade— LC 根据信用评分分配的贷款等级。purpose—借款人为贷款申请提供的类别。title—借款人提供的贷款名称。
为了确保万无一失,让我们通过检查每个字段中唯一值的数量来进行确认。
此外,基于第一行的purpose和title的值,这两列似乎反映了相同的信息。我们将分别探究它们的唯一值计数,以确认这是否属实。
最后,请注意第一行中的earliest_cr_line和last_credit_pull_d列的值都包含日期值,这些值需要大量的功能工程才能发挥作用:
earliest_cr_line—借款人最早报告的信用额度被开立的月份。last_credit_pull_d—最近一个月 LendingClub 为此贷款提取信用。
对于某些分析,进行这种特性工程可能是值得的,但是出于本教程的目的,我们将只从数据帧中删除这些日期列。
首先,让我们研究一下六个列的唯一值计数,这些列似乎包含分类值:
cols = ['home_ownership', 'grade','verification_status', 'emp_length', 'term', 'addr_state']
for name in cols:
print(name,':')
print(object_columns_df[name].value_counts(),'\n')
home_ownership :
RENT 18677
MORTGAGE 17381
OWN 3020
OTHER 96
NONE 3
Name: home_ownership, dtype: int64
grade :
B 11873
A 10062
C 7970
D 5194
E 2760
F 1009
G 309
Name: grade, dtype: int64
verification_status :
Not Verified 16809
Verified 12515
Source Verified 9853
Name: verification_status, dtype: int64
emp_length :
10+ years 8715
< 1 year 4542
2 years 4344
3 years 4050
4 years 3385
5 years 3243
1 year 3207
6 years 2198
7 years 1738
8 years 1457
9 years 1245
n/a 1053
Name: emp_length, dtype: int64
term :
36 months 29041
60 months 10136
Name: term, dtype: int64
addr_state :
CA 7019
NY 3757
FL 2831
TX 2693
NJ 1825
IL 1513
PA 1493
VA 1388
GA 1381
MA 1322
OH 1197
MD 1039
AZ 863
WA 830
CO 777
NC 772
CT 738
MI 718
MO 677
MN 608
NV 488
SC 469
WI 447
OR 441
AL 441
LA 432
KY 319
OK 294
KS 264
UT 255
AR 241
DC 211
RI 197
NM 187
WV 174
HI 170
NH 169
DE 113
MT 84
WY 83
AK 79
SD 61
VT 53
MS 19
TN 17
IN 9
ID 6
IA 5
NE 5
ME 3
Name: addr_state, dtype: int64
这些列中的大多数包含离散的分类值,我们可以将其编码为虚拟变量并保留。然而,addr_state列包含太多的唯一值,所以最好删除它。
接下来,让我们看看purpose和title列的唯一值计数,以了解我们想要保留哪些列。
for name in ['purpose','title']:
print("Unique Values in column: {}\n".format(name))
print(filtered_loans[name].value_counts(),'\n')
Unique Values in column: purpose
debt_consolidation 18355
credit_card 5073
other 3921
home_improvement 2944
major_purchase 2178
small_business 1792
car 1534
wedding 940
medical 688
moving 580
vacation 377
house 372
educational 320
renewable_energy 103
Name: purpose, dtype: int64
Unique Values in column: title
Debt Consolidation 2142
Debt Consolidation Loan 1670
Personal Loan 650
Consolidation 501
debt consolidation 495
Credit Card Consolidation 354
Home Improvement 350
Debt consolidation 331
Small Business Loan 317
Credit Card Loan 310
Personal 306
Consolidation Loan 255
Home Improvement Loan 243
personal loan 231
personal 217
Loan 210
Wedding Loan 206
Car Loan 198
consolidation 197
Other Loan 187
Credit Card Payoff 153
Wedding 152
Major Purchase Loan 144
Credit Card Refinance 143
Consolidate 126
Medical 120
Credit Card 115
home improvement 109
My Loan 94
Credit Cards 92
...
toddandkim4ever 1
Remainder of down payment 1
Building a Financial Future 1
Higher interest payoff 1
Chase Home Improvement Loan 1
Sprinter Purchase 1
Refi credit card-great payment record 1
Karen's Freedom Loan 1
Business relocation and partner buyout 1
Update My New House 1
tito 1
florida vacation 1
Back to 0 1
Bye Bye credit card 1
britschool 1
Consolidation 16X60 1
Last Call 1
Want to be debt free in "3" 1
for excellent credit 1
loaney 1
jamal's loan 1
Refying Lending Club-I LOVE THIS PLACE! 1
Consoliation Loan 1
Personal/ Consolidation 1
Pauls Car 1
Road to freedom loan 1
Pay it off FINALLY! 1
MASH consolidation 1
Destination Wedding 1
Store Charge Card 1
Name: title, dtype: int64
看来purpose和title列确实包含重叠的信息,但是purpose列包含的离散值更少,也更清晰,所以我们将保留它并删除title。
让我们删除到目前为止已经决定不保留的列:
drop_cols = ['last_credit_pull_d','addr_state','title','earliest_cr_line']
filtered_loans = filtered_loans.drop(drop_cols,axis=1)
将分类列转换为数字特征
首先,让我们了解数据集中的两种类型的分类特征,以及如何将它们转换为数值特征:
- 序数值:这些分类值按自然顺序排列。我们可以按升序或降序对它们进行排序。例如,我们之前了解到 LendingClub 将贷款申请人分为 A 到 G 级,并为每个申请人分配相应的利率——A 级风险最小,B 级风险大于 A 级,依此类推:
A < B < C < D < E < F < G ; 其中<意味着比风险小
- 名义值:这些是常规分类值。不能点名义值。例如,虽然我们可以根据工作年限对就业年限列(
emp_length)中的贷款申请人进行排序:
第 1 年
我们不能对列purpose这样做。没有道理说:
汽车
这些是我们数据集中现有的列:
- 序数值
gradeemp_length
- 标称值 _
home_ownershipverification_statuspurposeterm
有不同的方法来处理这两种类型。为了将顺序值映射到整数,我们可以使用 pandas DataFrame 方法replace()将grade和emp_length映射到适当的数值:
mapping_dict = {
"emp_length": {
"10+ years": 10,
"9 years": 9,
"8 years": 8,
"7 years": 7,
"6 years": 6,
"5 years": 5,
"4 years": 4,
"3 years": 3,
"2 years": 2,
"1 year": 1,
"< 1 year": 0,
"n/a": 0
},
"grade":{
"A": 1,
"B": 2,
"C": 3,
"D": 4,
"E": 5,
"F": 6,
"G": 7
}
}
filtered_loans = filtered_loans.replace(mapping_dict)
filtered_loans[['emp_length','grade']].head()
| 员工长度 | 等级 | |
|---|---|---|
| Zero | Ten | Two |
| one | Zero | three |
| Two | Ten | three |
| three | Ten | three |
| four | three | one |
完美!让我们继续讨论名义价值。将名义特征转换为数字特征需要将它们编码为虚拟变量。这一过程将是:
- 使用 pandas 的
get_dummies()方法返回一个新的 DataFrame,其中包含每个虚拟变量的一个新列。 - 使用
concat()方法将这些虚拟列添加回原始数据帧。 - 使用 Drop 方法完全删除原始列。
让我们继续对数据集中的名义列进行编码:
nominal_columns = ["home_ownership", "verification_status", "purpose", "term"]
dummy_df = pd.get_dummies(filtered_loans[nominal_columns])
filtered_loans = pd.concat([filtered_loans, dummy_df], axis=1)
filtered_loans = filtered_loans.drop(nominal_columns, axis=1)
filtered_loans.head()
| 贷款金额 | 部分 | 等级 | 员工长度 | 年度公司 | 贷款 _ 状态 | 弥散张量成像 | delinq _ 年 | 最近 6 个月 | open_acc | 发布 _ 记录 | 革命 _ 平衡 | 革命报 | 总计 _acc | fico _ 平均 | 房屋所有权抵押贷款 | 首页 _ 所有权 _ 无 | 首页 _ 所有权 _ 其他 | 家 _ 所有权 _ 拥有 | 房屋 _ 所有权 _ 租金 | 验证 _ 状态 _ 未验证 | 验证 _ 状态 _ 来源已验证 | 验证 _ 状态 _ 已验证 | 目的 _ 汽车 | 目的 _ 信用卡 _ 信用卡 | 目的 _ 债务 _ 合并 | 目的 _ 教育 | 目的 _ 家居 _ 改善 | 目的 _ 房屋 | 目的 _ 专业 _ 购买 | 目的 _ 医疗 | 目的 _ 移动 | 目的 _ 其他 | 目的 _ 可再生能源 | 目的 _ 小型企业 | 目的 _ 假期 | 目的 _ 婚礼 | 期限 _ 36 个月 | 期限 _ 60 个月 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Five thousand | One hundred and sixty-two point eight seven | Two | Ten | Twenty-four thousand | one | Twenty-seven point six five | Zero | One | Three | Zero | Thirteen thousand six hundred and forty-eight | Eighty-three point seven | Nine | Seven hundred and thirty-seven | Zero | Zero | Zero | Zero | one | Zero | Zero | one | Zero | one | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | one | Zero |
| one | Two thousand five hundred | Fifty-nine point eight three | three | Zero | Thirty thousand | Zero | One | Zero | Five | Three | Zero | One thousand six hundred and eighty-seven | Nine point four | Four | Seven hundred and forty-two | Zero | Zero | Zero | Zero | one | Zero | one | Zero | one | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | one |
| Two | Two thousand four hundred | Eighty-four point three three | three | Ten | Twelve thousand two hundred and fifty-two | one | Eight point seven two | Zero | Two | Two | Zero | Two thousand nine hundred and fifty-six | Ninety-eight point five | Ten | Seven hundred and thirty-seven | Zero | Zero | Zero | Zero | one | one | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | one | Zero | Zero | one | Zero |
| three | Ten thousand | Three hundred and thirty-nine point three one | three | Ten | Forty-nine thousand two hundred | one | Twenty | Zero | One | Ten | Zero | Five thousand five hundred and ninety-eight | Twenty-one | Thirty-seven | Six hundred and ninety-two | Zero | Zero | Zero | Zero | one | Zero | one | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | one | Zero | Zero | Zero | Zero | one | Zero |
| four | Five thousand | One hundred and fifty-six point four six | one | three | Thirty-six thousand | one | Eleven point two | Zero | Three | Nine | Zero | Seven thousand nine hundred and sixty-three | Twenty-eight point three | Twelve | Seven hundred and thirty-two | Zero | Zero | Zero | Zero | one | Zero | one | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | Zero | one | one | Zero |
最后,让我们检查一下这个部分的最终输出,以确保所有的特征长度相同,不包含空值,并且是数字的。我们将使用 pandas 的信息方法来检查filtered_loans数据帧:
filtered_loans.info()
<class 'pandas.core.frame.dataframe'="">
Int64Index: 39177 entries, 0 to 39238
Data columns (total 39 columns):
loan_amnt 39177 non-null float64
installment 39177 non-null float64
grade 39177 non-null int64
emp_length 39177 non-null int64
annual_inc 39177 non-null float64
loan_status 39177 non-null int64
dti 39177 non-null float64
delinq_2yrs 39177 non-null float64
inq_last_6mths 39177 non-null float64
open_acc 39177 non-null float64
pub_rec 39177 non-null float64
revol_bal 39177 non-null float64
revol_util 39177 non-null float64
total_acc 39177 non-null float64
fico_average 39177 non-null float64
home_ownership_MORTGAGE 39177 non-null uint8
home_ownership_NONE 39177 non-null uint8
home_ownership_OTHER 39177 non-null uint8
home_ownership_OWN 39177 non-null uint8
home_ownership_RENT 39177 non-null uint8
verification_status_Not Verified 39177 non-null uint8
verification_status_Source Verified 39177 non-null uint8
verification_status_Verified 39177 non-null uint8
purpose_car 39177 non-null uint8
purpose_credit_card 39177 non-null uint8
purpose_debt_consolidation 39177 non-null uint8
purpose_educational 39177 non-null uint8
purpose_home_improvement 39177 non-null uint8
purpose_house 39177 non-null uint8
purpose_major_purchase 39177 non-null uint8
purpose_medical 39177 non-null uint8
purpose_moving 39177 non-null uint8
purpose_other 39177 non-null uint8
purpose_renewable_energy 39177 non-null uint8
purpose_small_business 39177 non-null uint8
purpose_vacation 39177 non-null uint8
purpose_wedding 39177 non-null uint8
term_ 36 months 39177 non-null uint8
term_ 60 months 39177 non-null uint8
dtypes: float64(12), int64(3), uint8(24)
memory usage: 5.7 MB
这一切看起来很好!恭喜你,我们刚刚清理了一个用于机器学习的大型数据集,并在这个过程中向我们的剧目添加了一些有价值的数据清理技能。
不过,我们还有一项重要的最终任务需要完成!
保存到 CSV
将工作流程中每个部分或阶段的最终输出存储在单独的 csv 文件中是一种很好的做法。这种做法的好处之一是,它帮助我们在数据处理流程中做出改变,而不必重新计算一切。
正如我们之前所做的,我们可以使用方便的 pandas to_csv()函数将数据帧存储为 CSV。
filtered_loans.to_csv("processed_data/cleaned_loans_2007.csv",index=False)
后续步骤
在这篇文章中,我们已经介绍了处理大型数据集所需的基本步骤,为机器学习项目清理和准备数据。但是还有更多的东西要学,从这里你可以选择很多不同的方向。
如果您对自己的数据清理技能感到满意,并且希望更多地使用这个数据集,请查看我们的交互式机器学习演练课程,它涵盖了使用这个 Lending Club 数据的后续步骤。
如果您想继续学习您的数据清理技能,请查看我们的一个(或多个)交互式数据清理课程,深入了解这一至关重要的数据科学技能:
关于原作者丹尼尔·奥塞:2015 年在 Quora 上第一次读到关于机器学习的内容后,丹尼尔开始对一个可以将他对数学和编程的热爱结合起来的领域的前景感到兴奋。在阅读了这篇关于如何学习数据科学的文章后,Daniel 开始按照步骤学习,最终在 2016 年 4 月加入了 Dataquest,与我们一起学习数据科学。我们要感谢丹尼尔的辛勤工作,并慷慨地让我们发表这篇文章。这篇文章是由 Dataquest 编辑在 2019 年 6 月更新的。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
教程:学习 Python 编程和机器学习
October 21, 2015As you learn Python programming, you’ll become aware of a growing number of opportunities for analyzing and utilizing collections of data. Machine learning is one of the areas that you’ll want to master. With machine learning, you can make predictions by feeding data into complex algorithms. The uses for machine learning are seemingly endless, making this a powerful skill to add to your resume. In this tutorial, we’ll guide you through the basic principles of machine learning, and how to get started with machine learning with Python. Luckily for us, Python has an amazing ecosystem of libraries that make machine learning easy to get started with. We’ll be using the excellent Scikit-learn, Pandas, and Matplotlib libraries in this tutorial. If you want to dive more deeply into machine learning, and apply algorithms in your browser, check out our interactive machine learning fundamentals course. The first lesson is totally free!
数据集
在我们深入机器学习之前,我们将探索一个数据集,并找出什么可能是有趣的预测。数据集来自
BoardGameGeek ,并包含80000棋盘游戏的数据。这里是网站上的一款单人桌游。这些信息被 Sean Beck 友好地整理成了CSV格式,可以在这里 T10 下载。数据集包含关于每个棋盘游戏的几个数据点。以下是一些有趣的例子:
name—棋盘游戏的名称。playingtime—播放时间(厂家给定)。minplaytime—最小播放时间(厂家给定)。maxplaytime—最大播放时间(厂家给定)。minage—建议的最小游戏年龄。users_rated—给游戏评分的用户数量。average_rating—用户给游戏的平均评分。(0-10)total_weights—用户给定的重量数。Weight是 BoardGameGeek 编造的主观衡量标准。这是一个游戏有多“深入”或有多复杂。这里有一个完整的解释。average_weight—所有主观权重的平均值(0-5)。
学习 Python 编程:熊猫入门
我们探索的第一步是读入数据并打印一些快速汇总统计数据。为了做到这一点,我们将使用熊猫图书馆。Pandas 提供了数据结构和数据分析工具,使得在 Python 中操作数据更快更有效。最常见的数据结构被称为
数据帧。数据帧是矩阵的扩展,所以在回到数据帧之前,我们将讨论什么是矩阵。我们的数据文件如下所示(为了便于查看,我们删除了一些列):
id,type,name,yearpublished,minplayers,maxplayers,playingtime
12333,boardgame,Twilight Struggle,2005,2,2,180
120677,boardgame,Terra Mystica,2012,2,5,150
这是一种叫做
csv ,或者逗号分隔的值,你可以在这里阅读更多关于的内容。数据的每一行都是一个不同的棋盘游戏,每一个棋盘游戏的不同数据点都用逗号分隔。第一行是标题行,描述每个数据点是什么。一个数据点的整个集合向下是一列。我们可以很容易地将 csv 文件概念化为矩阵:
_ 1 2 3 4
1 id type name yearpublished
2 12333 boardgame Twilight Struggle 2005
3 120677 boardgame Terra Mystica 2012
出于显示目的,我们在这里删除了一些列,但是您仍然可以直观地感受到数据的外观。矩阵是由行和列组成的二维数据结构。我们可以通过位置来访问矩阵中的元素。第一行开始于
id,第二排从12333开始,第三排从120677开始。第一列是id,第二列是type,以此类推。Python 中的矩阵可以通过 NumPy 库使用。然而,矩阵也有一些缺点。不能简单地通过名称访问列和行,并且每一列都必须具有相同的数据类型。这意味着我们无法在一个矩阵中有效地存储我们的棋盘游戏数据——name列包含字符串,而yearpublished列包含整数,这意味着我们无法将它们都存储在同一个矩阵中。另一方面,dataframe 在每一列中可以有不同的数据类型。它还有很多分析数据的内置细节,比如按名称查找列。Pandas 让我们可以访问这些功能,并且通常使数据处理更加简单。
读入我们的数据
现在,我们将把 csv 文件中的数据读入 Pandas 数据帧,使用
read_csv法。
# Import the pandas library.
import pandas
# Read in the data.
games = pandas.read_csv("board_games.csv")
# Print the names of the columns in games.
print(games.columns)
Index(['id', 'type', 'name', 'yearpublished', 'minplayers', 'maxplayers','playingtime', 'minplaytime', 'maxplaytime', 'minage', 'users_rated', 'average_rating', 'bayes_average_rating', 'total_owners', 'total_traders', 'total_wanters', 'total_wishers', 'total_comments', 'total_weights', 'average_weight'],
dtype='object')
上面的代码读入数据,并向我们显示所有的列名。数据中没有在上面列出的列应该是不言自明的。
print(games.shape)
(81312, 20)
我们还可以看到数据的形状,这表明它已经
81312行或游戏,以及20列或描述每个游戏的数据点。
绘制我们的目标变量
预测一个人给一个新的、未发行的棋盘游戏的平均分数可能是有趣的。这存储在
average_rating列,这是一个棋盘游戏的所有用户评级的平均值。举例来说,预测这个专栏可能对那些正在考虑下一步该做什么游戏的桌游制造商有用。我们可以使用games["average_rating"]来访问一个包含熊猫的数据帧。这将从数据帧中提取一个单独的列。让我们绘制这个栏目的直方图,这样我们就可以直观地看到收视率的分布。我们将使用 Matplotlib 来生成可视化。当你学习 Python 编程时,你会发现 Matplotlib 是主要的绘图基础设施,大多数其他绘图库,如 seaborn 和 ggplot2 都是建立在 Matplotlib 之上的。我们用import matplotlib.pyplot as plt导入 Matplotlib 的绘图函数。然后我们可以画出并展示图表。
# Import matplotlib
import matplotlib.pyplot as plt
# Make a histogram of all the ratings in the average_rating column.
plt.hist(games["average_rating"])
# Show the plot.plt.show()
 我们在这里看到的是,有相当多的游戏有
我们在这里看到的是,有相当多的游戏有0评级。有一个相当正常的评分分布,有些偏右,平均评分在6左右(如果你去掉零)。
探索 0 评级
真的有这么多可怕的游戏被赋予了
0评级?还是发生了其他事情?我们需要更深入地研究数据来检查这一点。对于 Pandas,我们可以使用布尔序列选择数据子集(向量,或一列/一行数据,在 Pandas 中称为序列)。这里有一个例子:
games[games["average_rating"] == 0]
上面的代码将创建一个新的 dataframe,只包含
games其中average_rating列的值等于0。然后我们可以索引得到的数据帧来得到我们想要的值。在 Pandas 中有两种索引方式——我们可以根据行或列的名称进行索引,也可以根据位置进行索引。按名称索引看起来像games["average_rating"]——这将返回整个games的average_rating列。按位置索引看起来像games.iloc[0] —这将返回数据帧的整个第一行。我们也可以一次传入多个索引值— games.iloc[0,0]将返回games第一行的第一列。点击阅读更多关于熊猫索引的信息。
# Print the first row of all the games with zero scores.
# The .iloc method on dataframes allows us to index by position.
print(games[games["average_rating"] == 0].iloc[0])
# Print the first row of all the games with scores greater than 0.
print(games[games["average_rating"] > 0].iloc[0])
id 318
type boardgame
name Looney Leo
users_rated 0
average_rating 0
bayes_average_rating 0
Name: 13048, dtype: object
id 12333
type boardgame
name Twilight Struggle
users_rated 20113
average_rating 8.33774
bayes_average_rating 8.22186
Name: 0, dtype: object
这向我们展示了一个游戏与
0评级和一个评级在0以上的游戏就是0评级的游戏没有评论。users_rated栏是0。通过过滤掉任何带有0评论的桌游,我们可以去除很多噪音。
移除没有评论的游戏
# Remove any rows without user reviews.
games = games[games["users_rated"] > 0]
# Remove any rows with missing values.
games = games.dropna(axis=0)
我们只是过滤掉了所有没有用户评论的行。在此过程中,我们还删除了所有缺少值的行。许多机器学习算法无法处理缺失值,因此我们需要一些方法来处理它们。过滤掉它们是一种常见的技术,但这意味着我们可能会丢失有价值的数据。列出了处理缺失数据的其他技术
此处。
集群游戏
我们已经看到可能有不同的博弈。一组(我们刚刚删除)是没有评论的游戏。另一组可以是一组高评级的游戏。了解这些游戏的一种方法是一种叫做
聚类。聚类通过将相似的行(在本例中为游戏)组合在一起,使您能够轻松地找到数据中的模式。我们将使用一种叫做的特殊类型的聚类,k-means 聚类。Scikit-learn 有一个很好的 k 均值聚类实现,我们可以使用它。Scikit-learn 是 Python 中主要的机器学习库,包含最常见算法的实现,包括随机森林、支持向量机和逻辑回归。Scikit-learn 有一个一致的 API 来访问这些算法。
# Import the kmeans clustering model.
from sklearn.cluster import KMeans
# Initialize the model with 2 parameters -- number of clusters and random state.
kmeans_model = KMeans(n_clusters=5, random_state=1)
# Get only the numeric columns from games.
good_columns = games._get_numeric_data()
# Fit the model using the good columns.
kmeans_model.fit(good_columns)
# Get the cluster assignments.
labels = kmeans_model.labels_
为了在 Scikit-learn 中使用聚类算法,我们将首先使用两个参数初始化它——
n_clusters定义了我们想要多少个游戏集群,而random_state是我们设置的一个随机种子,以便稍后重现我们的结果。这里是关于实施的更多信息。然后,我们只从数据帧中获取数字列。大多数机器学习算法不能直接对文本数据进行操作,只能以数字作为输入。仅获取数字列会删除type和name,这对于聚类算法是不可用的。最后,我们将 kmeans 模型与我们的数据进行拟合,并获得每一行的集群分配标签。
绘制集群
现在我们有了集群标签,让我们绘制集群。一个症结是我们的数据有许多列——这超出了人类理解和物理学的领域,无法以超过 3 维的方式可视化事物。所以我们必须在不损失太多信息的情况下降低数据的维度。实现这一点的一种方法是一种叫做
主成分分析,或称 PCA。PCA 采用多列,将它们变成较少的列,同时试图保留每列中的唯一信息。为了简化,假设我们有两列,total_owners和total_traders。这两列之间有一些关联,并且有一些重叠的信息。PCA 会将这些信息压缩到一个包含新数字的列中,同时尽量不丢失任何信息。我们将尝试把我们的棋盘游戏数据转换成二维或列,这样我们就可以很容易地绘制出来。
# Import the PCA model.
from sklearn.decomposition import PCA
# Create a PCA model.
pca_2 = PCA(2)
# Fit the PCA model on the numeric columns from earlier.
plot_columns = pca_2.fit_transform(good_columns)
# Make a scatter plot of each game, shaded according to cluster assignment.
plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=labels)
# Show the plot.
plt.show()
 我们首先从 Scikit-learn 初始化一个 PCA 模型。PCA 不是一种机器学习技术,但 Scikit-learn 还包含其他对执行机器学习有用的模型。在为机器学习算法预处理数据时,像 PCA 这样的降维技术被广泛使用。然后,我们将数据转换成
我们首先从 Scikit-learn 初始化一个 PCA 模型。PCA 不是一种机器学习技术,但 Scikit-learn 还包含其他对执行机器学习有用的模型。在为机器学习算法预处理数据时,像 PCA 这样的降维技术被广泛使用。然后,我们将数据转换成2列,并绘制这些列。当我们绘制列时,我们根据它们的簇分配给它们着色。该图向我们展示了 5 个不同的集群。我们可以更深入地了解每个集群中有哪些游戏,从而更多地了解是什么因素导致了游戏的集群化。
弄清楚预测什么
在进入机器学习之前,我们需要确定两件事——我们将如何测量误差,以及我们将预测什么。我们之前认为
预测可能是好的,我们的探索强化了这一观念。测量误差的方法有很多种(这里列出了许多)。一般来说,当我们进行回归并预测连续变量时,我们将需要一个不同于我们进行分类并预测离散值时的误差度量。为此,我们将使用均方误差 —这很容易计算,也很容易理解。它告诉我们,平均来说,我们的预测与实际值有多远。
寻找相关性
既然我们想预测
让我们看看哪些列可能对我们的预测感兴趣。一种方法是找出average_rating和其他每一列之间的相关性。这将向我们展示哪些其他栏目可能预测average_rating最好。我们可以在熊猫数据框架上使用 corr 方法来轻松找到相关性。这将为我们提供每列和其他列之间的相关性。因为这样做的结果是一个数据帧,所以我们可以对它进行索引,并且只获得average_rating列的相关性。
games.corr()["average_rating"]
id 0.304201
yearpublished 0.108461
minplayers -0.032701
maxplayers -0.008335
playingtime 0.048994
minplaytime 0.043985
maxplaytime 0.048994
minage 0.210049
users_rated 0.112564
average_rating 1.000000
bayes_average_rating 0.231563
total_owners 0.137478
total_traders 0.119452
total_wanters 0.196566
total_wishers 0.171375
total_comments 0.123714
total_weights 0.109691
average_weight 0.351081
Name: average_rating, dtype: float64
我们看到
average_weight和id栏与评分的相关性最好。ids可能是在游戏被添加到数据库时被分配的,所以这可能表明后来创建的游戏在评级中得分更高。也许在 BoardGameGeek 早期,评论者没有这么好,或者更老的游戏质量更低。average_weight表示一款游戏的“深度”或复杂程度,所以可能是越复杂的游戏复习的越好。
选择预测列
在我们开始学习 Python 编程时进行预测之前,让我们只选择与训练我们的算法相关的列。我们希望删除某些非数字列。我们还希望删除那些只有在您已经知道平均评级的情况下才能计算的列。包含这些列将破坏分类器的目的,即在没有任何先前知识的情况下预测评级。使用只能在知道目标的情况下计算的列会导致
过度拟合,你的模型在训练集中表现良好,但不能很好地推广到未来数据。在某种程度上,bayes_average_rating列似乎是从average_rating派生出来的,所以让我们删除它。
# Get all the columns from the dataframe.
columns = games.columns.tolist()
# Filter the columns to remove ones we don't want.
columns = [c for c in columns if c not in ["bayes_average_rating", "average_rating", "type", "name"]]
# Store the variable we'll be predicting on.
target = "average_rating"
分成训练集和测试集
我们希望能够使用我们的误差度量来计算出一个算法有多精确。然而,在该算法已经被训练的相同数据上评估该算法将导致过度拟合。我们希望算法学习一般化的规则来进行预测,而不是记住如何进行特定的预测。一个例子是学习数学。如果你记住了
1+1=2和2+2=4,你将能够完美地回答任何关于1+1和2+2的问题。你会有0错误。然而,一旦有人问你一些你知道答案的训练之外的问题,比如3+3,你将无法解答。另一方面,如果你能够归纳和学习加法,你会偶尔犯错误,因为你没有记住答案——也许你会得到一个3453 + 353535,但你将能够解决任何抛给你的加法问题。如果你在训练机器学习算法时,你的错误看起来出奇地低,你应该总是检查一下,看看你是否过度拟合了。为了防止过度拟合,我们将在由数据的80%组成的集合上训练我们的算法,并在由数据的20%组成的另一个集合上测试它。为此,我们首先随机抽取80%行放入训练集中,然后将所有其他的放入测试集中。
# Import a convenience function to split the sets.
from sklearn.cross_validation import train_test_split
# Generate the training set. Set random_state to be able to replicate results.
train = games.sample(frac=0.8, random_state=1)
# Select anything not in the training set and put it in the testing set.
test = games.loc[~games.index.isin(train.index)]
# Print the shapes of both sets.
print(train.shape)
print(test.shape)
(45515, 20)
(11379, 20)
上面,我们利用了这样一个事实,即每一个 Pandas 行都有一个惟一的索引来选择不在训练集中的任何一行到测试集中。
拟合线性回归
线性回归是一种强大且常用的机器学习算法。它使用预测变量的线性组合来预测目标变量。假设我们有两个值,3和4。线性组合将是3 * .5 + 4 * .5。线性组合包括将每个数字乘以一个常数,然后将结果相加。这里可以阅读更多。只有当预测变量和目标变量线性相关时,线性回归才有效。正如我们前面看到的,一些预测因素与目标相关,所以线性回归对我们来说应该很好。我们可以在 Scikit-learn 中使用线性回归实现,就像我们之前使用 k-means 实现一样。
# Import the linearregression model.
from sklearn.linear_model import LinearRegression
# Initialize the model class.
model = LinearRegression()
# Fit the model to the training data.
model.fit(train[columns], train[target])
当我们拟合模型时,我们传递预测矩阵,该矩阵由我们之前选取的数据帧中的所有列组成。如果在索引时将一个列表传递给 Pandas 数据帧,它将生成一个包含列表中所有列的新数据帧。我们还传入目标变量,我们希望对其进行预测。该模型学习以最小误差将预测值映射到目标值的方程。
预测误差
训练完模型后,我们可以用它对新数据进行预测。这些新数据必须与训练数据的格式完全相同,否则模型不会做出准确的预测。我们的测试集与训练集相同(除了各行包含不同的棋盘游戏)。我们从测试集中选择相同的列子集,然后对其进行预测。
# Import the scikit-learn function to compute error.
from sklearn.metrics import mean_squared_error
# Generate our predictions for the test set.
predictions = model.predict(test[columns])
# Compute error between our test predictions and the actual values.
mean_squared_error(predictions, test[target])
1.8239281903519875
一旦我们有了预测,我们就能够计算测试集预测和实际值之间的误差。均方差的公式为(\frac{1}{n}\sum_{i=1}{n}(y_i–\hat{y}_i)\。基本上,我们从实际值中减去每个预测值,求差值的平方,然后将它们加在一起。然后我们将结果除以预测值的总数。这将给出每次预测的平均误差。
尝试不同的模式
Scikit-learn 的一个好处是,它使我们能够非常容易地尝试更强大的算法。一种这样的算法叫做
随机森林。随机森林算法可以发现线性回归无法发现的数据非线性。比方说,如果一个游戏的minage,小于 5,则等级低,如果是5-10,则等级高,如果在10-15之间,则等级低。线性回归算法无法发现这一点,因为预测值和目标值之间没有线性关系。用随机森林做出的预测通常比用线性回归做出的预测误差更小。
# Import the random forest model.
from sklearn.ensemble import RandomForestRegressor
# Initialize the model with some parameters.
model = RandomForestRegressor(n_estimators=100, min_samples_leaf=10, random_state=1)
# Fit the model to the data.
model.fit(train[columns], train[target])
# Make predictions.
predictions = model.predict(test[columns])
# Compute the error.
mean_squared_error(predictions, test[target])
1.4144905030983794
进一步探索
我们已经成功地从 csv 格式的数据转向预测。以下是进一步探索的一些想法:
想了解更多关于机器学习的知识?
在
Dataquest ,我们提供关于机器学习和数据科学的互动课程。我们相信边做边学,通过分析真实数据和构建项目,您可以在浏览器中进行交互式学习。今天学习 Python 编程,并查看我们所有的机器学习课程。
Python 机器学习教程:预测 Airbnb 价格
July 10, 2019
不可否认,机器学习是目前数据科学领域最热门的话题。这也是支撑一些最令人兴奋的技术领域的基本概念,如自动驾驶汽车和预测分析。2019 年 4 月,谷歌上机器学习的搜索量创下历史新高,此后人们的兴趣并没有下降多少。但实际上学习机器学习可能很难。你要么使用像“黑盒”一样的预建包,在那里你传递数据,魔法从另一端出来,要么你必须处理高级数学和线性代数。这两种方法都使机器学习变得具有挑战性和令人生畏。
本教程旨在向您介绍机器学习的基本概念。随着您的继续,您将从头开始构建您的第一个模型来进行预测,同时准确理解您的模型是如何工作的。
(本教程基于我们的机器学习基础课程,该课程是我们数据科学学习路径的一部分。本课程将深入介绍更多细节,并允许您以交互方式编写代码,这样您就可以边做边学。如果你对掌握机器学习非常感兴趣,我们建议你参加该课程以及我们的数据科学家之路中的其他机器学习课程。)
什么是机器学习?
简而言之,机器学习是建立系统的实践,称为模型,可以使用数据对其进行训练,以找到可以用于对新数据进行预测的模式。
与许多其他编程不同,机器学习模型是而不是一个基于规则的系统,其中一系列“if/then”语句用于确定结果(例如,“如果学生错过超过 50%的课程,则自动不及格”)。
相反,机器学习模型检查具有定义结果的数据集中的数据点之间的统计关系,然后应用它对这些关系的了解来分析和预测新数据集的结果。
机器学习是如何工作的
为了更好地理解机器学习的基础知识,我们来看一个例子。假设我们要出售一栋房子,我们想确定一个合适的挂牌价格。我们可能做的——也是房地产经纪人实际做的——是查看我们地区已经售出的类似房屋。用机器学习的术语来说,我们观察的每栋房子都被称为一次观察。
对于每栋房子,我们都要考虑一些因素,比如房子的大小,有多少间卧室和浴室,离杂货店等便利设施有多远等等。在机器学习术语中,这些属性中的每一个都被称为特征。
一旦我们找到了一些相似的房子,我们就可以看看它们的售价,平均这些价格,并对我们自己的房子的价值做出一个相当合理的预测。

看看类似的房子可以帮你决定自己房子的价格。
在这个例子中,我们建立的“模型”是根据我们所在地区其他房屋的数据(观察数据)训练的,然后用来预测我们房子的价值。我们预测的价值,即价格,被称为目标变量。
当然,这个例子并不是真正的“机器学习”,因为我们根据自己房子的特点精心挑选了“观察”房屋进行研究。试图在更大范围内做这种事情——比如根据大量房地产数据预测城市中任何房屋的价格——对人类来说都是极其困难的。观察和特征越多,手动进行这种分析就越困难,也就越容易遗漏数据中重要但不明显的模式。
这就是机器学习的用武之地。一个真正的机器学习模型可以在更大的规模上做一些与我们的小房子预测模型非常相似的事情:
- 检查过去房屋销售的大型数据集(观察)
- 寻找房子的特征和价格(目标变量)之间的模式和统计关系,包括对查看数据的人来说可能不明显的模式
- 使用这些统计关系和模式来预测我们提供数据的任何新房的价格。
我们将在本教程中建立的模型类似于我们上面概述的。我们将通过使用 Python 构建一个简单的模型来提供 Airbnb 公寓租赁价格建议。
(这篇文章假设你熟悉 Python 的pandas库——如果你需要温习熊猫,我们推荐我们的两篇熊猫教程博文或我们的互动 Python 和熊猫课程。)
预测 Airbnb 租赁价格
对于外行人来说,Airbnb 是一个短期房屋和公寓租赁的互联网市场。例如,它允许你在外出时将房子出租一周,或者将多余的卧室出租给旅行者。该公司自 2008 年成立以来发展迅速,估值接近 400 亿美元,目前市值超过世界上任何一家连锁酒店。
Airbnb 房东面临的一个挑战是确定最佳的每夜租金价格。在许多地区,潜在的租房者都有很好的房源可供选择,他们可以根据价格、卧室数量、房间类型等标准进行筛选。由于 Airbnb 是一个市场,房东每晚收取的费用与市场动态密切相关。以下是 Airbnb 上的搜索体验截图:

Airbnb 搜索结果
假设我们想在 Airbnb 上租一个房间。作为房东,如果我们试图收取高于市场价的价格,租房者会选择更实惠的替代品,我们就赚不到钱了。另一方面,如果我们把每晚的租金定得太低,我们就会错过潜在的收入。
如何才能击中中间的“甜蜜点”?我们可以使用的一个策略是:
- 找几个和我们相似的列表,
- 将与我们最相似的产品的标价平均一下,
- 并将我们的标价设置为这个计算出的平均价格。
但是一遍又一遍地手动操作会非常耗时,而我们是数据科学家!我们将建立一个机器学习模型来自动完成这一过程,而不是手动完成,该模型使用了一种叫做k-最近邻的技术。
我们首先来看看将要使用的数据集。
我们的 Airbnb 数据
Airbnb 不在其市场上发布任何房源数据,但 Airbnb 内部一个名为的独立小组提取了该网站上许多主要城市的房源样本数据。在本帖中,我们将使用他们从 2015 年 10 月 3 日开始的数据集,处理来自美国首都华盛顿特区的房源。这里有一个到数据集的直接链接。
数据集中的每一行都是华盛顿特区 Airbnb 上可供租赁的特定房源。用机器学习的术语来说,每一行都是一个观察。这些列描述了每个列表的不同特征(机器学习术语中的特征)。
为了使数据集不那么麻烦,我们删除了原始数据集中的许多列,并将文件重命名为dc_airbnb.csv。
以下是我们希望使用的一些更重要的栏目(功能),因为这些都是租赁者可能用来评估他们将选择哪个房源的特征:
- 租赁可以容纳的客人数量
bedrooms:租金中包含的卧室数量bathrooms:租金中包含的浴室数量beds:租金中包含的床位数price:租金的夜间价格minimum_nights:租赁期间客人可入住的最少天数maximum_nights:租赁期间客人可入住的最大天数number_of_reviews:之前客人留下的评论数量
我们首先将清理后的数据集读入 pandas,打印其大小并查看前几行。(如果你不确定如何自己从原始数据集中删除多余的列,看看我们的一些熊猫和数据清理课程)。
import pandas as pd
dc_listings = pd.read_csv('dc_airbnb.csv')
print(dc_listings.shape)
dc_listings.head()
(3723, 19)
| 主机响应速率 | 主机接受率 | 主机列表计数 | 容纳 | 房间类型 | 卧室 | 浴室 | 床 | 价格 | 清洁 _ 费用 | 保证金 _ 押金 | 最少 _ 晚 | 最多 _ 晚 | 评论数量 | 纬度 | 经度 | 城市 | 邮政编码 | 状态 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 92% | 91% | Twenty-six | four | 整个住宅/公寓 | One | One | Two | $160.00 | $115.00 | $100.00 | one | One thousand one hundred and twenty-five | Zero | 38.890046 | -77.002808 | 华盛顿 | Twenty thousand and three | 直流电 | |
| one | 90% | 100% | one | six | 整个住宅/公寓 | Three | Three | Three | $350.00 | $100.00 | 圆盘烤饼 | Two | Thirty | Sixty-five | 38.880413 | -76.990485 | 华盛顿 | Twenty thousand and three | 直流电 | |
| Two | 90% | 100% | Two | one | 私室 | One | Two | One | $50.00 | 圆盘烤饼 | 圆盘烤饼 | Two | One thousand one hundred and twenty-five | one | 38.955291 | -76.986006 | 海兹维尔 | Twenty thousand seven hundred and eighty-two | 医学博士 |
| three | 100% | 圆盘烤饼 | one | Two | 私室 | One | One | One | $95.00 | 圆盘烤饼 | 圆盘烤饼 | one | One thousand one hundred and twenty-five | Zero | 38.872134 | -77.019639 | 华盛顿 | Twenty thousand and twenty-four | 直流电 |
| four | 92% | 67% | one | four | 整个住宅/公寓 | One | One | One | $50.00 | $15.00 | $450.00 | seven | One thousand one hundred and twenty-five | Zero | 38.996382 | -77.041541 | 银泉 | Twenty thousand nine hundred and ten | 医学博士 |
看起来不错!现在,让我们继续讨论我们将用于机器学习模型的算法。
K-最近邻算法
K-最近邻(KNN)算法的工作方式类似于我们之前概述的三步过程,将我们的列表与类似的列表进行比较,并获取平均价格。让我们更详细地看一下:
首先是,我们选择想要比较的相似列表的数量k。
其次,我们需要使用相似性度量来计算每个列表与我们的列表有多相似。

第三个,我们使用相似性度量对每个列表进行排名,并选择第一个k列表。

最后是,我们计算了k个相似列表的平均价格,并将其作为我们的标价。
虽然为了简单起见,上面的图像只使用每个观察的两个特征(卧室和价格)来与我们的列表进行比较,但机器学习的妙处在于,我们可以通过评估每个观察的更多特征来进行更复杂的比较。
让我们通过定义将要使用的相似性度量来开始构建我们的真实模型。然后,我们将实现 k-nearest neighbors 算法,并使用它来建议新列表的价格。出于本教程的目的,我们将使用固定的5值k,但是一旦您熟悉了算法的工作流程,您就可以用这个值进行实验,看看是否使用更低或更高的k值可以获得更好的结果。
欧几里得距离
当试图预测像价格这样的连续值时,使用的主要相似性度量是欧几里德距离。欧几里德距离的一般公式是这样的:(d = \sqrt{(q_1-p_1)2+(q_2-p_2)2+\ cdots+(q_n-p_n)^2})其中(Q1 )到(qn )表示一个观察值的特征值,而(P1 )到(p n )表示另一个观察值的特征值。
如果你的头爆炸了,不要担心!我们要把它分解成更小的部分。我们将从…开始
建立一个基本的 KNN 模型
让我们从分解事物开始,只看我们数据集中的一列。下面是一个特征的公式:(d = \ sqrt {(Q1–p_1)^2} )
平方根和平方幂抵消,公式简化为:(d = | q _ 1–p _ 1 | )
用文字来表达,我们希望找到观测值和数据点之间的差异的绝对值来预测我们正在使用的特性。
就我们目前的目的而言,假设我们想租的居住空间可以容纳三个人。
我们将首先使用accommodates特征计算数据集中第一个居住空间和我们自己居住空间之间的距离。我们可以使用 NumPy 函数np.abs()来获得绝对值。
import numpy as np
our_acc_value = 3
first_living_space_value = dc_listings.loc[0,'accommodates']
first_distance = np.abs(first_living_space_value - our_acc_value)
print(first_distance)
1
最小的欧几里德距离是零,这意味着我们要比较的观察结果和我们的是一样的,所以我们在这里得到的结果是有意义的。然而,孤立地看,这个值没有多大意义,除非我们知道它与其他值相比如何。让我们计算数据集中每个观察值的欧几里德距离,并使用pd.value_counts()查看我们拥有的值的范围。
dc_listings['distance'] = np.abs(dc_listings.accommodates - our_acc_value)
dc_listings.distance.value_counts().sort_index()
0 461
1 2294
2 503
3 279
4 35
5 73
6 17
7 22
8 7
9 12
10 2
11 4
12 6
13 8
Name: distance, dtype: int64
有 461 个列表的距离为0,因此容纳的人数与我们的列表相同。这些清单可能是一个很好的起点。
如果我们只使用距离为0的前五个值,我们的预测将偏向数据集的现有排序。相反,我们将随机排列观察值,然后选择距离为0的前五行。我们将使用DataFrame.sample()来随机化这些行。该方法通常用于选择数据帧的随机部分,但我们将告诉它随机选择 100%,这将为我们随机洗牌。
我们还将使用random_state参数,它只是给我们一个可重复的随机顺序,因此任何人都可以跟随并得到完全相同的结果。
dc_listings = dc_listings.sample(frac=1,random_state=0)
dc_listings = dc_listings.sort_values('distance')
dc_listings.price.head()
$75.002825
$120.002145
$90.002541
$50.003349
$105.00
Name: price, dtype: object
在我们计算价格的平均值之前,您会注意到我们的价格列具有object类型,因为价格有美元符号和逗号(我们上面的示例没有显示逗号,因为所有的值都小于 1000 美元)。
在计算前五个值的平均值之前,让我们通过删除这些字符并将其转换为float类型来清理该列。我们将使用熊猫的Series.str.replace()来删除杂散字符,并通过正则表达式\$|,来匹配<center或,`。
dc_listings['price'] = dc_listings.price.str.replace("\$|,",'').astype(float)
mean_price = dc_listings.price.iloc[:5].mean()
mean_price
88.0
我们现在做出了第一个预测——我们的 KNN 模型告诉我们,当我们只使用accommodates功能为我们的三人列表找到一个合适的价格时,我们应该将我们的公寓列为 88.00 美元。
这是一个好的开始!问题是,我们没有任何办法知道这个模型有多精确,这就无法优化和改进。在没有评估其准确性的情况下,跟随任何机器学习模型的预测都不是一个好主意!
评估我们的模型
测试模型质量的一个简单方法是:
- 将数据集分成 2 个分区:
- 一个训练集合:包含大多数行(75%)
- 一个测试集合:包含剩余的少数行(25%)
- 使用训练集中的行来预测测试集中的行的
price值 - 将预测值与测试集中的实际
price值进行比较,看看预测值有多准确。
我们将遵循这种方法,将 3723 行数据集分成两部分:train_df和test_df,比例为 75%-25%。

分割成训练和测试数据帧
我们还将删除之前创建第一个模型时添加的列。
dc_listings.drop('distance',axis=1)
train_df = dc_listings.copy().iloc[:2792]
test_df = dc_listings.copy().iloc[2792:]
为了在查看指标时让事情变得更简单,我们将把之前制作的模型合并到一个函数中。我们不需要担心随机化这些行,因为它们仍然是之前随机化的。
def predict_price(new_listing_value,feature_column):
temp_df = train_df
temp_df['distance'] = np.abs(dc_listings[feature_column] - new_listing_value)
temp_df = temp_df.sort_values('distance')
knn_5 = temp_df.price.iloc[:5]
predicted_price = knn_5.mean()
return(predicted_price)
我们现在可以使用这个函数来预测使用accommodates列的测试数据集的值。
test_df['predicted_price'] = test_df.accommodates.apply(predict_price,feature_column='accommodates')
用 RMSE 来评估我们的模型
对于许多预测任务,我们希望更多地惩罚远离实际值的预测值,而不是更接近实际值的预测值。
为此,我们可以取平方误差值的平均值,这被称为均方根误差 (RMSE)。下面是 RMSE 的公式:(RMSE = \ sqrt { \ dfrac {(actual_1-predicted_1)2+(actual_2-predicted_2)2+\ cdots+(actual_n-predicted_n)^2 } { n } } )其中n表示测试集中的行数。这个公式一开始可能看起来让人不知所措,但是我们所做的就是:
- 取每个预测值和实际值(或误差)之间的差,
- 将这个差值平方(平方),
- 取所有平方差的平均值(平均值),以及
- 取该平均值的平方根(根)。
因此,从下往上读:均方根误差。让我们计算我们在测试集上所做预测的 RMSE 值。
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1/2)
rmse
212.98927967051529
我们的 RMSE 大约是 213 美元。关于 RMSE 的一个方便的事情是,因为我们平方然后取平方根,RMSE 的单位与我们预测的值相同,这使得我们很容易理解我们的误差范围。
在这种情况下,规模相当大——我们离准确预测还相当远。
比较不同的模型
有了可以用来查看模型准确性的误差指标,让我们使用不同的列创建一些预测,并看看误差是如何变化的。
for feature in ['accommodates','bedrooms','bathrooms','number_of_reviews']:
test_df['predicted_price'] = test_df.accommodates.apply(predict_price,feature_column=feature)
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1/2)
print("RMSE for the {} column: {}".format(feature,rmse))
RMSE for the accommodates column: 212.9892796705153
RMSE for the bedrooms column: 216.49048609414766
RMSE for the bathrooms column: 216.89419042215704
RMSE for the number_of_reviews column: 240.2152831433485
我们可以看到,我们训练的四个模型中最好的模型是使用accomodates列的模型。
然而,相对于我们数据集中列表的价格范围,我们得到的错误率相当高。这种错误率的预测不会有很大帮助。
谢天谢地,我们还能做点什么!到目前为止,我们一直只用一个特征来训练我们的模型,这就是所谓的单变量模型。为了更准确,我们可以让它同时评估多个特征,这就是所谓的多变量模型。
我们将读入这个数据集的一个干净版本,以便我们可以专注于评估模型。在我们清理过的数据集中:
- 所有列都已转换为数值,因为我们无法计算带有非数字字符的值的欧几里德距离。
- 为简单起见,删除了非数字列。
- 任何缺少值的列表都已被删除。
- 我们已经对列进行了规范化,这将为我们提供更准确的结果。
如果你想阅读更多关于数据清理和为机器学习准备数据的内容,你可以阅读优秀的帖子为机器学习准备和清理数据。
让我们读入这个被清理的版本,它被称为dc_airbnb.normalized.csv,并预览前几行:
normalized_listings = pd.read_csv('dc_airbnb_normalized.csv')
print(normalized_listings.shape)
normalized_listings.head()
(3671, 8)
| 容纳 | 卧室 | 浴室 | 床 | 价格 | 最少 _ 晚 | 最多 _ 晚 | 评论数量 | |
|---|---|---|---|---|---|---|---|---|
| Zero | -0.596544 | -0.249467 | -0.439151 | -0.546858 | One hundred and twenty-five | -0.341375 | -0.016604 | 4.579650 |
| one | -0.596544 | -0.249467 | 0.412923 | -0.546858 | Eighty-five | -0.341375 | -0.016603 | 1.159275 |
| Two | -1.095499 | -0.249467 | -1.291226 | -0.546858 | Fifty | -0.341375 | -0.016573 | -0.482505 |
| three | -0.596544 | -0.249467 | -0.439151 | -0.546858 | Two hundred and nine | 0.487635 | -0.016584 | -0.448301 |
| four | 4.393004 | 4.507903 | 1.264998 | 2.829956 | Two hundred and fifteen | -0.065038 | -0.016553 | 0.646219 |
然后,我们将随机化这些行,并将其分成训练和测试数据集。
normalized_listings = normalized_listings.sample(frac=1,random_state=0)
norm_train_df = normalized_listings.copy().iloc[0:2792]
norm_test_df = normalized_listings.copy().iloc[2792:]
计算具有多个特征的欧氏距离
让我们再次提醒自己,最初的欧几里德距离方程是什么样子的:(d = \sqrt{(q_1-p_1)2+(q_2-p_2)2+\ cdots+(q_n-p_n)^2})
我们将从构建一个使用accommodates和bathrooms特性的模型开始。在这种情况下,我们的欧几里得方程看起来像是:(d = \sqrt{(accommodates_1-accommodates_2)2+(bathrooms_1-bathrooms_2)2 } )
为了找到两个生活空间之间的距离,我们需要计算两个accommodates值之间的平方差,两个bathrooms值之间的平方差,将它们加在一起,然后取所得和的平方根。
下面是normalized_listings中前两行之间的欧几里德距离:

到目前为止,我们一直通过自己编写方程的逻辑来计算欧几里得距离。我们可以使用来自scipy.spatial的 distance.euclidean()函数,它接受两个向量作为参数,并计算它们之间的欧氏距离。euclidean()函数期望:
- 两个向量都使用类似于列表的对象来表示(Python 列表、NumPy 数组或 pandas 系列)
- 这两个向量必须是一维的,并且具有相同数量的元素
让我们使用euclidean()函数来计算我们要练习的数据集中第一行和第五行之间的欧几里德距离。
from scipy.spatial import distance
first_listing = normalized_listings.iloc[0][['accommodates', 'bathrooms']]
fifth_listing = normalized_listings.iloc[20][['accommodates', 'bathrooms']]
first_fifth_distance = distance.euclidean(first_listing, fifth_listing)
first_fifth_distance
0.9979095531766813
创建多元 KNN 模型
我们可以扩展之前的函数,使用两个特征和整个数据集。我们将使用 distance.cdist() 而不是distance.euclidean(),因为它允许我们一次传递多行。
(cdist()方法可用于使用多种方法计算距离,但它默认为欧几里得。)
def predict_price_multivariate(new_listing_value,feature_columns):
temp_df = norm_train_df
temp_df['distance'] = distance.cdist(temp_df[feature_columns],[new_listing_value[feature_columns]])
temp_df = temp_df.sort_values('distance')
knn_5 = temp_df.price.iloc[:5]
predicted_price = knn_5.mean()
return(predicted_price)cols = ['accommodates', 'bathrooms']
norm_test_df['predicted_price'] = norm_test_df[cols].apply(predict_price_multivariate,feature_columns=cols,axis=1)
norm_test_df['squared_error'] = (norm_test_df['predicted_price'] - norm_test_df['price'])**(2)
mse = norm_test_df['squared_error'].mean()
rmse = mse ** (1/2)
print(rmse)
122.702007943
你可以看到,当使用两个特性而不是仅仅使用accommodates时,我们的 RMSE 从 212 提高到了 122。这是一个巨大的进步,尽管它仍然不像我们希望的那样准确。
scikit 简介-了解
我们一直在从头开始编写函数来训练我们的 k 近邻模型。这有助于理解机制是如何工作的,但是现在我们理解了底层的基本原理,我们可以使用 Python 的scikit-learn库更快更有效地工作。
Scikit-learn 是 Python 中最流行的机器学习库。它内置了所有主要机器学习算法的功能和一个简单、统一的工作流程。这两个属性都允许数据科学家在新数据集上训练和测试不同模型时具有难以置信的生产力。
scikit-learn 工作流程包括四个主要步骤:
- 实例化您想要使用的特定机器学习模型。
- 使模型符合训练数据。
- 使用模型进行预测。
- 评估预测的准确性。
scikit-learn 中的每个模型都是作为一个单独的类实现的,第一步是确定我们想要创建的类的实例。
任何帮助我们预测数值的模型,比如我们模型中的标价,都被称为回归模型。机器学习模型的另一个主要类别叫做分类。当我们试图从一组固定的标签(例如,血型或性别)中预测一个标签时,会使用分类模型。
在我们的例子中,我们想要使用 KNeighborsRegressor 类。来自类名KNeighborsRegressor的单词 regressor 指的是我们刚刚讨论过的回归模型类,而“KNeighbors”来自我们正在构建的 k-nearest neighbors 模型。
Scikit-learn 使用类似于 Matplotlib 的面向对象风格。我们需要通过调用构造函数在做任何事情之前实例化一个空模型。
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor()
如果我们参考文档,我们会注意到默认情况下:
n_neighbors:邻居数量,设置为5algorithm:计算最近邻,设为autop:设置为2,对应欧几里德距离
让我们将algorithm参数设置为brute,并将n_neighbors值保留为5,这与我们构建的手动实现相匹配。
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(algorithm='brute')
拟合模型并进行预测
现在,我们可以使用拟合方法来拟合模型和数据。对于所有模型,fit方法接受两个必需的参数:
- 一个类似矩阵的对象,包含我们要从训练集中使用的特征列。
- 一个类似列表的对象,包含正确的目标值。
“类矩阵对象”意味着该方法是灵活的,可以接受熊猫数据帧或 NumPy 2D 数组。这意味着我们可以从 DataFrame 中选择想要使用的列,并将其用作fit方法的第一个参数。
对于第二个参数,回想一下前面的内容,以下所有内容都是可接受的类似列表的对象:
- 数字阵列
- Python 列表
- 熊猫系列对象(如圆柱)
让我们从数据帧中选择目标列,并将其用作fit方法的第二个参数:
knn.fit(train_features, train_target)
当调用fit()方法时,scikit-learn 将我们指定的训练数据存储在 KNearestNeighbors 实例(knn)中。如果我们试图将包含缺失值或非数值的数据传入fit方法,scikit-learn 将返回一个错误。这是这个库的奇妙之处之一——它包含许多这样的功能来防止我们犯错误。
现在我们已经指定了我们想要用来进行预测的训练数据,我们可以使用预测方法来对测试集进行预测。predict方法只有一个必需的参数:
- 一个类似矩阵的对象,包含我们要对其进行预测的数据集的特征列
我们在训练和测试期间使用的特性列数需要匹配,否则 scikit-learn 将返回错误。
predictions = knn.predict(test_features)
predict()方法返回一个 NumPy 数组,包含测试集的预测值price。
我们现在拥有了练习整个 scikit-learn 工作流程所需的一切:
knn.fit(norm_train_df[cols], norm_train_df['price'])
two_features_predictions = knn.predict(norm_test_df[cols])
当然,仅仅因为我们使用 scikit-learn 而不是手动编写函数,并不意味着我们可以跳过评估步骤来看看我们的模型的预测实际上有多准确!
使用 Scikit-Learn 计算 MSE
到目前为止,我们一直使用 NumPy 和 SciPy 函数来帮助我们手动计算 RMSE 值。或者,我们可以使用sk learn . metrics . mean _ squared _ error 函数()。
mean_squared_error()函数接受两个输入:
- 一个类似列表的对象,代表测试集中的真实值。
- 第二个类似列表的对象,表示由模型生成的预测值。
from sklearn.metrics import mean_squared_error
two_features_mse = mean_squared_error(norm_test_df['price'], two_features_predictions)
two_features_rmse = two_features_mse ** (1/2)
print(two_features_rmse)
124.834722314
这不仅从语法角度来看要简单得多,而且由于 scikit-learn 已经针对速度进行了大量优化,因此模型运行所需的时间也更少。
请注意,我们的 RMSE 与我们手动实现的算法略有不同——这可能是由于我们的“手动”KNN 算法与 scikit-learn 版本在随机化方面的差异以及实现方面的细微差异。
请注意,对 scikit-learn 库本身的更改也会在一定程度上影响这些值。如果您按照本教程学习并得到了稍微不同的结果,很可能是因为您使用了 scikit-learn 的新版本。
使用更多功能
scikit-learn 最棒的一点是它允许我们更快地迭代。让我们通过创建一个使用四个特征而不是两个特征的模型来尝试一下,看看这是否会改善我们的结果。
knn = KNeighborsRegressor(algorithm='brute')
cols = ['accommodates','bedrooms','bathrooms','beds']
knn.fit(norm_train_df[cols], norm_train_df['price'])
four_features_predictions = knn.predict(norm_test_df[cols])
four_features_mse = mean_squared_error(norm_test_df['price'], four_features_predictions)
four_features_rmse = four_features_mse ** (1/2)
four_features_rmse
120.92729413345498
在这种情况下,我们的误差略有下降。不过,当你添加新功能时,可能并不总是这样。需要注意的一件重要事情是:添加更多的特性并不一定会产生更精确的模型。
这是因为添加一个不能准确预测目标变量的特征会给模型增加“噪音”。
摘要
让我们来看看我们学到了什么:
- 我们学习了什么是机器学习,并通过一个非常基本的手动“模型”来预测房屋的销售价格。
- 我们学习了 k-最近邻算法,在 Python 中从头开始构建了一个单变量模型(只有一个要素),并使用它进行预测。
- 我们了解到,RMSE 可以用来计算我们模型的误差,然后我们可以用它来迭代并尝试改进我们的预测。
- 然后,我们从头开始创建了一个多变量(不止一个特征)模型,并使用它来进行更好的预测。
- 最后,我们学习了 scikit-learn 库,并使用了
KNeighborsRegressor类来进行预测。
后续步骤
如果你想了解更多,本教程基于我们的 Dataquest 机器学习基础课程,这是我们数据科学学习路径的一部分。该课程更为详细,并对本文中构建的模型进行了改进,同时允许您在浏览器中编写代码,每一步都由我们的答案检查系统进行检查,以确保您做的一切都是正确的。
如果您想自己继续研究这个模型,您可以做以下几件事来提高准确性:
- 尝试用不同的值代替
k。 - 回到原始数据集,将我们移除的一些列转换为数字(我们的准备和清理机器学习数据帖子将在这里帮助你),并尝试添加不同的功能组合。
- 尝试一些功能工程,在那里你基于现有数据创建新的专栏:我们的开始使用 Kaggle:房价竞争文章有一个简单的例子。
本帖更新于 2019 年 7 月。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何用 Python 生成 FiveThirtyEight 图
September 5, 2017
如果你阅读数据科学的文章,你可能已经偶然发现了 FiveThirtyEight 的内容。自然,你会被他们令人敬畏的可视化效果所打动。你想做出自己的令人敬畏的可视化效果,于是问 Quora 和 Reddit 如何做到这一点。你收到了一些答案,但它们相当模糊。你还是不能自己完成图表。在这篇文章中,我们将帮助你。使用 Python 的 matplotlib 和 pandas ,我们将看到复制任何 FiveThirtyEight (FTE)可视化的核心部分是相当容易的。我们将从这里开始: ,在本教程结束时,到达这里:
,在本教程结束时,到达这里: 要继续学习,您至少需要一些 Python 的基础知识。如果您知道方法和属性之间的区别,那么您就可以开始了。
要继续学习,您至少需要一些 Python 的基础知识。如果您知道方法和属性之间的区别,那么您就可以开始了。
数据集介绍
我们将使用描述 1970 年至 2011 年美国女性获得学士学位的比例的数据。我们将使用由数据科学家编辑的数据集
兰德尔·奥尔森,他从国家教育统计中心收集数据。如果你想继续自己写代码,你可以从 Randal 的博客下载数据。为了节省您的时间,您可以跳过下载文件,直接传递到 pandas 的read_csv() 函数中。在下面的代码单元格中,我们:
- 导入熊猫模块。
- 将指向数据集的直接链接作为
string分配给名为direct_link的变量。 - 使用
read_csv()读入数据,并将内容分配给women_majors。 - 使用
info()方法打印关于数据集的信息。我们寻找行数和列数,同时检查空值。 - 通过使用
head()方法,显示前五行以更好地理解数据集的结构。
import pandas as pd
direct_link = 'https://www.randalolson.com/wp-content/uploads/percent-bachelors-degrees-women-usa.csv'
women_majors = pd.read_csv(direct_link)
print(women_majors.info())
women_majors.head()
RangeIndex: 42 entries, 0 to 41
Data columns (total 18 columns):
Year 42 non-null int64
Agriculture 42 non-null float64
Architecture 42 non-null float64
Art and Performance 42 non-null float64
Biology 42 non-null float64
Business 42 non-null float64
Communications and Journalism 42 non-null float64
Computer Science 42 non-null float64
Education 42 non-null float64
Engineering 42 non-null float64
English 42 non-null float64
Foreign Languages 42 non-null float64
Health Professions 42 non-null float64
Math and Statistics 42 non-null float64
Physical Sciences 42 non-null float64
Psychology 42 non-null float64
Public Administration 42 non-null float64
Social Sciences and History 42 non-null float64
dtypes: float64(17), int64(1)
memory usage: 6.0 KB
None
| 年 | 农业 | 体系结构 | 艺术和表演 | 生物 | 商业 | 通信和新闻 | 计算机科学 | 教育 | 工程 | 英语 | 外语 | 健康职业 | 数学和统计学 | 自然科学 | 心理学 | 公共行政 | 社会科学和历史 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | One thousand nine hundred and seventy | 4.229798 | 11.921005 | Fifty-nine point seven | 29.088363 | 9.064439 | Thirty-five point three | Thirteen point six | 74.535328 | Zero point eight | 65.570923 | Seventy-three point eight | Seventy-seven point one | Thirty-eight | Thirteen point eight | Forty-four point four | Sixty-eight point four | Thirty-six point eight |
| one | One thousand nine hundred and seventy-one | 5.452797 | 12.003106 | Fifty-nine point nine | 29.394403 | 9.503187 | Thirty-five point five | Thirteen point six | 74.149204 | One | 64.556485 | Seventy-three point nine | Seventy-five point five | Thirty-nine | Fourteen point nine | Forty-six point two | Sixty-five point five | Thirty-six point two |
| Two | One thousand nine hundred and seventy-two | 7.420710 | 13.214594 | Sixty point four | 29.810221 | 10.558962 | Thirty-six point six | Fourteen point nine | 73.554520 | One point two | 63.664263 | Seventy-four point six | Seventy-six point nine | Forty point two | Fourteen point eight | Forty-seven point six | Sixty-two point six | Thirty-six point one |
| three | One thousand nine hundred and seventy-three | 9.653602 | 14.791613 | Sixty point two | 31.147915 | 12.804602 | Thirty-eight point four | Sixteen point four | 73.501814 | one point six | 62.941502 | Seventy-four point nine | Seventy-seven point four | Forty point nine | Sixteen point five | Fifty point four | Sixty-four point three | Thirty-six point four |
| four | One thousand nine hundred and seventy-four | 14.074623 | 17.444688 | Sixty-one point nine | 32.996183 | 16.204850 | Forty point five | Eighteen point nine | 73.336811 | Two point two | 62.413412 | Seventy-five point three | Seventy-seven point nine | Forty-one point eight | Eighteen point two | Fifty-two point six | Sixty-six point one | Thirty-seven point three |
除了
Year栏,每隔一栏的名称表示该科目的学士学位。学士栏中的每个数据点代表授予女性学士学位的百分比。因此,每一行都描述了某一年授予妇女的各种学士的百分比。如前所述,我们有 1970 年至 2011 年的数据。为了确认后一个限制,让我们使用tail() 方法打印数据集的最后五行:
women_majors.tail()
| 年 | 农业 | 体系结构 | 艺术和表演 | 生物 | 商业 | 通信和新闻 | 计算机科学 | 教育 | 工程 | 英语 | 外语 | 健康职业 | 数学和统计学 | 自然科学 | 心理学 | 公共行政 | 社会科学和历史 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Thirty-seven | Two thousand and seven | 47.605026 | 43.100459 | Sixty-one point four | 59.411993 | 49.000459 | Sixty-two point five | Seventeen point six | 78.721413 | Sixteen point eight | 67.874923 | Seventy point two | Eighty-five point four | Forty-four point one | Forty point seven | Seventy-seven point one | Eighty-two point one | Forty-nine point three |
| Thirty-eight | Two thousand and eight | 47.570834 | 42.711730 | Sixty point seven | 59.305765 | 48.888027 | Sixty-two point four | Seventeen point eight | 79.196327 | Sixteen point five | 67.594028 | Seventy point two | Eighty-five point two | Forty-three point three | Forty point seven | Seventy-seven point two | Eighty-one point seven | Forty-nine point four |
| Thirty-nine | Two thousand and nine | 48.667224 | 43.348921 | Sixty-one | 58.489583 | 48.840474 | Sixty-two point eight | Eighteen point one | 79.532909 | Sixteen point eight | 67.969792 | Sixty-nine point three | Eighty-five point one | Forty-three point three | Forty point seven | Seventy-seven point one | Eighty-two | Forty-nine point four |
| Forty | Two thousand and ten | 48.730042 | 42.066721 | Sixty-one point three | 59.010255 | 48.757988 | Sixty-two point five | Seventeen point six | 79.618625 | Seventeen point two | 67.928106 | Sixty-nine | Eighty-five | Forty-three point one | Forty point two | Seventy-seven | Eighty-one point seven | Forty-nine point three |
| Forty-one | Two thousand and eleven | 50.037182 | 42.773438 | Sixty-one point two | 58.742397 | 48.180418 | Sixty-two point two | Eighteen point two | 79.432812 | Seventeen point five | 68.426730 | Sixty-nine point five | Eighty-four point eight | Forty-three point one | Forty point one | Seventy-six point seven | Eighty-one point nine | Forty-nine point two |
我们的 538 图的上下文
几乎每个 FTE 图都是一篇文章的一部分。图表通过说明一个小故事或一个有趣的想法来补充正文。在复制我们的 FTE 图表时,我们需要注意这一点。为了避免偏离本教程的主要任务,让我们假设我们已经写了一篇关于美国教育中性别差异演变的文章的大部分。我们现在需要创建一个图表来帮助读者形象化单身汉性别差异的演变,在 1970 年,这种情况对女性来说非常糟糕。我们已经设定了 20%的门槛,现在我们想绘制出 1970 年女性毕业生比例低于 20%的每个单身汉的变化图。我们先来识别一下那些具体的光棍。在下面的代码单元格中,我们将:
- 使用
.loc,一个基于标签的索引器,来:- 选择第一行(对应于 1970 年的那一行);
- 仅选择第一行中值小于 20 的项目;字段
Year也将被检查,但显然不会被包括在内,因为 1970 年比 20 年大得多。
- 将结果内容分配给
under_20。
under_20 = women_majors.loc[0, women_majors.loc[0] < 20]
under_20
Agriculture 4.229798
Architecture 11.921005
Business 9.064439
Computer Science 13.600000
Engineering 0.800000
Physical Sciences 13.800000
Name: 0, dtype: float64
使用 matplotlib 的默认样式
让我们开始制作图表。我们将首先看一下默认情况下我们可以构建什么。在下面的代码块中,我们将:
- 运行 Jupyter magic
%matplotlib到使 Jupyter 和 matplotlib 有效地协同工作,并添加inline使我们的图形显示在笔记本内。 - 在
women_majors上使用plot()方法绘制图形。我们向plot()传递以下参数:x–从women_majors中指定用于 x 轴的列;y–从women_majors中指定用于 y 轴的列;我们将使用存储在该对象的.index属性中的under_20的索引标签;figsize–将图形尺寸设置为tuple,格式为(width, height),单位为英寸。
- 将 plot 对象分配给一个名为
under_20_graph的变量,并打印其类型以显示 pandas 在遮光罩下使用了matplotlib对象。
under_20_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
print('Type:', type(under_20_graph))
Type: <class 'matplotlib.axes._subplots.AxesSubplot'>

使用 matplotlib 的 fivethirtyeight 样式
上图有一些特定的特征,比如书脊的宽度和颜色,y 轴标签的字体大小,没有网格等等。所有这些特征构成了 matplotlib 的默认风格。作为一个简短的插入语,值得一提的是,在这篇文章中,我们将使用一些关于图形部分的技术术语。如果你在任何一点上感到迷茫,可以参考下面的图例。

资料来源: Matplotlib.org
除了默认样式之外,matplotlib 还附带了几个我们可以随时使用的内置样式。要查看可用样式的列表,我们将:
- 以
style的名字导入matplotlib.style模块。 - 探索
matplotlib.style.available(该模块的预定义变量)的内容,它包含所有可用内置样式的列表。
import matplotlib.style as style
style.available
['seaborn-deep',
'seaborn-muted',
'bmh',
'seaborn-white',
'dark_background',
'seaborn-notebook',
'seaborn-darkgrid',
'grayscale',
'seaborn-paper',
'seaborn-talk',
'seaborn-bright',
'classic',
'seaborn-colorblind',
'seaborn-ticks',
'ggplot',
'seaborn',
'_classic_test',
'fivethirtyeight',
'seaborn-dark-palette',
'seaborn-dark',
'seaborn-whitegrid',
'seaborn-pastel',
'seaborn-poster']
你可能已经注意到有一种内置的风格叫做
fivethirtyeight。让我们使用这种风格,看看会有什么结果。为此,我们将使用来自同一个matplotlib.style模块(我们以名称style导入该模块)的恰当命名的use() 函数。然后,我们将使用与前面相同的代码来生成我们的图表。
style.use('fivethirtyeight')
women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
 哇,这是一个重大变化!关于我们的第一个图表,我们可以看到这个有不同的背景颜色,它有网格线,没有任何刺,主要刻度标签的粗细和字体大小不同,等等。你可以在这里阅读
哇,这是一个重大变化!关于我们的第一个图表,我们可以看到这个有不同的背景颜色,它有网格线,没有任何刺,主要刻度标签的粗细和字体大小不同,等等。你可以在这里阅读fivethirtyeight风格的技术描述——它也应该让你很好地了解当我们使用这种风格时,什么代码在幕后运行。样式表的作者卡梅隆大卫-皮隆,在这里讨论了一些特征。
matplotlib 的 fivethirtyeight 风格的局限性
总而言之,使用
很明显,风格让我们离目标更近了。尽管如此,仍有许多工作要做。让我们检查一个简单的 FTE 图,看看我们还需要添加什么。
来源:538
通过将上面的图表与我们到目前为止所做的比较,我们可以看到我们仍然需要:
- 添加标题和副标题。
- 删除块样式图例,并在相关地块线附近添加标签。我们还必须使这些标签周围的网格线透明。
- 添加一个签名栏,注明图表作者和数据来源。
- 添加一些其他的小调整:
- 增加刻度标签的字体大小;
- 将“%”符号添加到 y 轴的一个主要刻度标签上;
- 移除 x 轴标签;
- 在 y = 0 处加粗水平网格线;
- 在 y 轴刻度标签旁边添加一条额外的网格线;
- 增加图的横向边距。

来源:538
为了最大限度地减少生成图表所花费的时间,避免开始添加标题、副标题或任何其他文本片段是很重要的。在 matplotlib 中,通过指定 x 和 y 坐标来定位文本片段,我们将在下面的一些章节中看到。要详细复制上面的 FTE 图,请注意,我们必须将 y 轴的刻度标签与标题和副标题垂直对齐。我们希望避免这样的情况:我们得到了想要的垂直对齐方式,但由于增加了刻度标签的字体大小而丢失了它,然后不得不再次更改标题和副标题的位置。

来源:538
出于教学目的,我们现在将逐步调整我们的 FTE 图。因此,我们的代码将跨越多个代码单元。然而,在实践中,将需要不超过一个代码单元。
自定义刻度标签
我们将从增加刻度标签的字体大小开始。在下面的代码单元格中,我们:
- 使用与前面相同的代码绘制图形,并将结果对象分配给
fte_graph。给一个变量赋值允许我们重复而容易地在对象上应用方法,或者访问它的属性。 - 使用带有以下参数的
tick_params()方法增加所有主要刻度标签的字体大小:axis–指定我们要修改的刻度标签所属的轴;这里我们要修改两个轴的刻度标签;which–指示受影响的刻度标签(主要标签或次要标签;不知道区别的见前面展示的图例);labelsize–设置刻度标签的字体大小。
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
 你可能注意到了,这次我们没有用
你可能注意到了,这次我们没有用style.use('fivethirtyeight')。这是因为对任何 matplotlib 样式的偏好一旦在我们的代码中第一次声明就会变成全局的。我们之前已经将样式设置为fivethirtyeight,从那以后所有的图形都继承了这个样式。如果出于某种原因你想回到默认状态,只需运行style.use('default')。现在,我们将在前面更改的基础上,对 y 轴的刻度标签进行一些调整:
- 我们在 y 轴的最高可见刻度标签 50 上添加一个“%”符号。
- 我们还在其他可见标签后添加了一些空白字符,以使它们与新的“50%”标签优雅地对齐。
为了对 y 轴的刻度标签进行这些更改,我们将使用
set_yticklabels() 方法连同label参数。从下面的代码可以推断,这个参数可以接受一个混合数据类型的列表,并且不需要传递任何固定数量的标签。
# The previous code
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
# Customizing the tick labels of the y-axis fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
print('The tick labels of the y-axis:', fte_graph.get_yticks()) # -10 and 60 are not visible on the graph
The tick labels of the y-axis: [-10\. 0\. 10\. 20\. 30\. 40\. 50\. 60.]

将 y = 0 处的水平线加粗
我们现在将 y 坐标为 0 的水平线加粗。为此,我们将使用
axhline() 方法添加一条新的水平网格线,并覆盖现有的一条。我们用于axhline()的参数是:
y–指定水平线的 y 坐标;color–表示线条的颜色;linewidth–设置线条的宽度;alpha–调节线条的透明度,但我们在这里用它来调节黑色的强度;alpha的值范围从 0(完全透明)到 1(完全不透明)。
#
# The previous code
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
# Generate a bolded horizontal line at y = 0
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)

添加额外的垂直线
正如我们前面提到的,我们必须在 y 轴的刻度标签附近添加另一条垂直网格线。为此,我们只需调整 x 轴值的范围。增加范围的左边界限将会产生我们想要的额外的垂直网格线。下面,我们使用
set_xlim() 方法带有自明参数left和right。
# The previous code
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)
# Add an extra vertical line by tweaking the range of the x-axis
fte_graph.set_xlim(left = 1969, right = 2011)

生成签名栏
上面给出的示例 FTE 图的特征条具有几个明显的特征:
- 它位于图表的底部。
- 作者的名字位于签名栏的左侧。
- 签名栏的右侧提到了数据的来源。
- 文本具有浅灰色(与图形的背景颜色相同)和深灰色背景。
- 作者姓名和来源名称之间的区域也有深灰色背景。

该图像会再次发布,因此您不必向后滚动。来源:538
添加这样一个签名栏似乎很难,但是只要有一点点独创性,我们就可以很容易地完成。我们将添加一个文本片段,给它一个浅灰色,背景色为深灰色。我们将在一个文本片段中写下作者的名字和来源,但是我们将这两个分开,这样一个在最左边,另一个在最右边。好的方面是空白字符也将得到深灰色的背景,这将产生一个签名栏的效果。我们还将使用一些空白字符来对齐作者的姓名和来源的名称,您将在下一个代码块中看到这一点。这也是去掉 x 轴标签的好时机。通过这种方式,我们可以更好地了解签名栏在整个图表中的位置。在下一个代码单元中,我们将在目前所做的基础上进行构建,我们将:
- 通过向我们应用于对象
fte_graph.xaxis.label的set_visible()方法传递一个False值来移除 x 轴的标签。可以这样想:我们访问fte_graph的xaxis属性,然后我们访问fte_graph.xaxis的label属性。然后我们最后把set_visible()应用到fte_graph.xaxis.label。 - 按照上面讨论的方式在图上添加一段文本。我们将使用带有以下参数的
text()方法:x–指定文本的 x 坐标;y–指定文本的 y 坐标;s–表示要添加的文本;fontsize–设置文本的大小;color–指定文本的颜色;下面我们用的值的格式是十六进制;我们使用这种格式来精确匹配整个图形的背景颜色(如中指定的fivethirtyeight样式的代码);backgroundcolor–设置文本片段的背景颜色。
# The previous code
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)
fte_graph.set_xlim(left = 1969, right = 2011)
# Remove the label of the x-axis
fte_graph.xaxis.label.set_visible(False)
# The signature bar
fte_graph.text(x = 1965.8, y = -7,
s = ' ©DATAQUEST Source: National Center for Education Statistics',fontsize = 14, color = '#f0f0f0', backgroundcolor = 'grey')
 添加的文本片段的 x 和 y 坐标是通过反复试验的过程找到的。您可以将
添加的文本片段的 x 和 y 坐标是通过反复试验的过程找到的。您可以将floats传递给x和y参数,这样您就能够高精度地控制文本的位置。同样值得一提的是,我们调整了签名栏的位置,添加了一些视觉上令人耳目一新的侧边空白(我们之前讨论过这种调整)。为了增加左边距,我们简单地降低了 x 坐标的值。为了增加右边的空格,我们在作者的名字和来源的名字之间添加了更多的空白字符——这将来源的名字推到右边,从而导致添加所需的边距。
另一种签名酒吧
您还会遇到一种略有不同的签名栏:
来源: FiveThirtyEight 这种签名酒吧也很容易复制。我们只是添加一些灰色的文本,并在它的正上方加一条线。我们将通过添加多个下划线字符(“_”)的文本片段来创建一行的视觉效果。你可能想知道为什么我们不使用axhline()简单地在我们想要的 y 坐标上画一条水平线。我们没有这样做,因为新的线条会拖下整个图表的网格,这不会产生预期的效果。我们也可以尝试添加一个箭头,然后移除指针,这样我们就得到一条线。然而,“下划线”解决方案要简单得多。在下一个代码块中,我们实现了我们刚刚讨论过的内容。我们在这里使用的方法和参数应该已经在前面的章节中熟悉了。
# The previous code
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)
fte_graph.xaxis.label.set_visible(False)
fte_graph.set_xlim(left = 1969, right = 2011)
# The other signature bar
fte_graph.text(x = 1967.1, y = -6.5,
s = '________________________________________________________________________________________________________________',
color = 'grey', alpha = .7)
fte_graph.text(x = 1966.1, y = -9,
s = ' ©DATAQUEST Source: National Center for Education Statistics ',
fontsize = 14, color = 'grey', alpha = .7)

添加标题和副标题
如果你检查
几张 FTE 图表,你可能会注意到标题和副标题的这些模式:
- 标题几乎总是有副标题作为补充。
- 标题给出了一个上下文角度来看一个特定的图表。标题几乎从来都不是技术性的,它通常表达一个简单的想法。它也几乎从来不是情感中立的。在上面的 Fandango 图中,我们可以看到一个简单的,“情感活跃”的标题(“Fandango 爱电影”),而不是平淡无奇的“各种电影评级类型的分布”。
- 副标题提供了有关图表的技术信息。这些信息使得轴标签经常变得多余。因为我们已经去掉了 x 轴标签,所以我们应该小心地相应定制我们的副标题。
- 从视觉上看,标题和副标题的字体粗细不同,它们是左对齐的(不像大多数标题那样居中)。此外,它们与 y 轴的主要刻度标签垂直对齐,如我们前面所示。
现在让我们在注意上述观察的同时,给我们的图表添加一个标题和副标题。在下面的代码块中,我们将基于我们目前已经编写的代码,我们将:
- 使用与我们在签名栏中添加文本相同的
text()方法添加标题和副标题。如果你已经有了一些使用 matplotlib 的经验,你可能会想为什么我们不使用title()和suptitle()方法。这是因为这两种方法在精确移动文本方面有着可怕的功能。text()的唯一新参数是weight。我们用它来加粗标题。
# The previous code
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)
fte_graph.xaxis.label.set_visible(False)
fte_graph.set_xlim(left = 1969, right = 2011)
fte_graph.text(x = 1965.8, y = -7,
s = ' ©DATAQUEST Source: National Center for Education Statistics ',
fontsize = 14, color = '#f0f0f0', backgroundcolor = 'grey')
# Adding a title and a subtitle
fte_graph.text(x = 1966.65, y = 62.7, s = "The gender gap is transitory - even for extreme cases",
fontsize = 26, weight = 'bold', alpha = .75)
fte_graph.text(x = 1966.65, y = 57,
s = 'Percentage of Bachelors conferred to women from 1970 to 2011 in the US for\nextreme cases where the percentage was less than 20% in 1970',
fontsize = 19, alpha = .85)
如果你想知道,最初 FTE 图表中使用的字体是 Decima Mono,一种付费字体。出于这个原因,我们将坚持使用 Matplotlib 的默认字体,它看起来非常相似。
添加色盲友好的颜色
现在,我们有那个笨重的矩形图例。我们将去掉它,并在每条情节线附近添加彩色标签。每条线都有一种特定的颜色,一个相同颜色的单词将命名该线对应的单身汉。但是,首先,我们将修改地块线的默认颜色,并添加
色盲友好颜色: 来源:观点:Bang Wong 的色盲我们将使用上图中的值来编辑色盲友好颜色的 RGB 参数列表。顺便提一句,我们避免使用黄色,因为用这种颜色的文本片段在图形的深灰色背景上不容易阅读。编译完这个 RGB 参数列表后,我们将把它传递给我们在前面的代码中使用的
来源:观点:Bang Wong 的色盲我们将使用上图中的值来编辑色盲友好颜色的 RGB 参数列表。顺便提一句,我们避免使用黄色,因为用这种颜色的文本片段在图形的深灰色背景上不容易阅读。编译完这个 RGB 参数列表后,我们将把它传递给我们在前面的代码中使用的plot()方法的color参数。请注意,matplotlib 将要求 RGB 参数在 0-1 的范围内,因此我们将每个值除以 255,这是最大的 RGB 值。因为 0/255 = 0,所以我们不会费心去划分 0。
# Colorblind-friendly colors
colors = [[0,0,0], [230/255,159/255,0], [86/255,180/255,233/255], [0,158/255,115/255],
[213/255,94/255,0], [0,114/255,178/255]]
# The previous code we modify
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8), color = colors)
# The previous code that remains the same
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)
fte_graph.xaxis.label.set_visible(False)
fte_graph.set_xlim(left = 1969, right = 2011)
fte_graph.text(x = 1965.8, y = -7,
s = ' ©DATAQUEST Source: National Center for Education Statistics ',
fontsize = 14, color = '#f0f0f0', backgroundcolor = 'grey')
fte_graph.text(x = 1966.65, y = 62.7, s = "The gender gap is transitory - even for extreme cases",
fontsize = 26, weight = 'bold', alpha = .75)
fte_graph.text(x = 1966.65, y = 57,
s = 'Percentage of Bachelors conferred to women from 1970 to 2011 in the US for\nextreme cases where the percentage was less than 20% in 1970',
fontsize = 19, alpha = .85)

通过添加彩色标签来更改图例样式
最后,我们通过使用
text()早期使用的方法。唯一的新参数是rotation,我们用它来旋转每个标签,使其优雅地适合图表。我们还将在这里做一点小技巧,通过简单地修改标签的背景颜色来匹配图表的颜色,使标签周围的网格线变得透明。在我们之前的代码中,我们只通过将legend参数设置为False来修改plot()方法。这将使我们摆脱默认的图例。我们也跳过了重新声明colors列表,因为它已经存储在前一个单元格的内存中。
# The previous code we modify
fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8), color = colors, legend = False)
# The previous code that remains unchanged
fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)
fte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])
fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)
fte_graph.xaxis.label.set_visible(False)
fte_graph.set_xlim(left = 1969, right = 2011)
fte_graph.text(x = 1965.8, y = -7,
s = ' ©DATAQUEST Source: National Center for Education Statistics ',
fontsize = 14, color = '#f0f0f0', backgroundcolor = 'grey')
fte_graph.text(x = 1966.65, y = 62.7, s = "The gender gap is transitory - even for extreme cases",
fontsize = 26, weight = 'bold', alpha = .75)
fte_graph.text(x = 1966.65, y = 57,
s = 'Percentage of Bachelors conferred to women from 1970 to 2011 in the US for\nextreme cases where the percentage was less than 20% in 1970',
fontsize = 19, alpha = .85)
# Add colored labels
fte_graph.text(x = 1994, y = 44, s = 'Agriculture', color = colors[0], weight = 'bold', rotation = 33,
backgroundcolor = '#f0f0f0')
fte_graph.text(x = 1985, y = 42.2, s = 'Architecture', color = colors[1], weight = 'bold', rotation = 18,
backgroundcolor = '#f0f0f0')
fte_graph.text(x = 2004, y = 51, s = 'Business', color = colors[2], weight = 'bold', rotation = -5,
backgroundcolor = '#f0f0f0')
fte_graph.text(x = 2001, y = 30, s = 'Computer Science', color = colors[3], weight = 'bold', rotation = -42.5,
backgroundcolor = '#f0f0f0')
fte_graph.text(x = 1987, y = 11.5, s = 'Engineering', color = colors[4], weight = 'bold',
backgroundcolor = '#f0f0f0')
fte_graph.text(x = 1976, y = 25, s = 'Physical Sciences', color = colors[5], weight = 'bold', rotation = 27,
backgroundcolor = '#f0f0f0')

后续步骤
就这样,我们的图表现在可以发布了!简单回顾一下,我们已经开始用 matplotlib 的默认样式生成一个图表。然后,我们通过一系列步骤将该图提升到“FTE 水平”:
- 我们使用了 matplotlib 的内置
fivethirtyeight样式。 - 我们添加了一个标题和一个副标题,并分别进行了定制。
- 我们增加了一个签名栏。
- 我们移除了默认图例,并添加了彩色标签。
- 我们做了一系列其他的小调整:定制记号标签,在 y = 0 处加粗水平线,在记号标签附近添加垂直网格线,移除 x 轴的标签,增加 y 轴的横向边距。
为了建立在你所学的基础上,下面是几个可以考虑的后续步骤:
- 为其他单身汉生成一个类似的图表。
- 生成不同种类的 FTE 图:直方图,散点图等。
- 探索 matplotlib 的图库,寻找潜在的元素来丰富你的 FTE 图(如插入图片,或添加箭头等)。).添加图像可以将您的 FTE 图表提升到一个全新的水平:

来源:538
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。
用艺术让学习编码更友好——艾莉森·霍斯特博士访谈录
原文:https://www.dataquest.io/blog/making-learning-to-code-friendlier-with-art-allison-horst-interview/
September 16, 2020
模糊怪物的鼓励能帮助你学习编码吗?(来源: 艾利森霍斯特的 Github )
当你想到数据科学和编程时,你可能不会想到艺术。你可能不会把代码中的函数描绘成可爱的、模糊的怪物,或者把你的数据描绘成彩色的宝石。但艾莉森·霍斯特医生知道。
如果你以前考虑过学习 R,很有可能你熟悉 Allison 的工作。她是加州大学圣巴巴拉分校布伦环境科学与管理学院的数据科学、统计学和科学传播助理教授,但她也是 RStudio 的常驻艺术家,在那里她制作了如下插图:
说明 dplyr::mutate
展示扫帚包装。
展示数据科学社区!
(顺便说一下,这些图片来自 Allison 的 Github ,在那里它们和更多图片可以在 CC4.0 许可下获得)。
如果看着那些可爱的绒毛球让你的脸上有片刻的微笑,那么,这就是重点。Allison 的 R art 有一个非常具体的目的,它有力地反映了 R 社区的一些特殊之处。
将艺术带入数据科学
艾莉森的学术背景是工程和环境科学——她攻读的博士学位是关于纳米粒子如何与细菌相互作用的。
“从我很小的时候起,我就一直在做艺术品,”她说,“作为一名普莱恩空中风景画家,我有美术方面的背景。我只是喜欢能够走到大自然中,画出我所看到的东西。”
“当我开始教学时,我注意到当我在许多其他领域如生态学和海洋科学中寻找时,他们会有这些他们在野外工作的美丽照片和他们正在工作的有机体的非常酷的插图。”
霍斯特博士
“与此同时,当我教授数据科学时,我会尝试制作代表数据科学和统计学的引人入胜的幻灯片,但我对自己的发现并不感到兴奋。”
“在某一点上,我意识到我正在试图教一个班级,我正在从 dplyr 引入 mutate 函数,”她说。"在我身后的屏幕上是这个包的 R 文档的截图."
“我想:这是一个严重的不匹配!我站在这里说,“这太酷了!“Mutate 太棒了,看看你能做的这些很酷的事情!”然后在我身后的屏幕上就是这些密集的文本,上面有他们不理解的论点。"
她就是这样开始做 R 插画的。“我想,‘第一次向学生介绍一项功能时,肯定会有更好的视觉入口。’"
“我真的希望学生们对某个功能的第一印象是友好和丰富多彩的。他们以后会用它做很多困难的事情。但我想,如果他们的第一印象和互动真的很吸引人,那不是很酷吗?"
虽然使用模糊 R 字符学习数据科学的长期影响尚未得到评估,但 Allison 说她肯定注意到了差异。“当我(现在)介绍某样东西时,我会在背景上放一张幻灯片(上面有那些人物),然后一教室的学生都在微笑,”她说。
“那对我来说,是最好的事情。人们可能是第一次被介绍一些关于编码的东西,他们对此很开心。”
多年以后,这仍然是驱使她把 R 函数变成可爱的、模糊的生物的原因。“所有这一切都是为了实现一个目标,即努力让 R 和数据科学在总体上变得更加平易近人,更受欢迎,并吸引不同的学习者。”
加入#rstats 社区和 RStudio
起初,虽然,艾莉森的插图是严格为她的课堂上的学生。“我多年来一直拒绝加入 Twitter,”艾莉森说,“直到我为 Openscapes 做艺术工作,我亲爱的朋友和令人敬畏的海洋数据科学家Julia Lowndes博士最终说服我【在那里分享一些艺术作品】”
“我想我分享的第一个可能是 dplyr 牧马人。社区的反应如此积极,如此支持,这让我想做更多的艺术作品。”
“我从社区中获益良多,不仅从艺术技能和数据科学技能方面学到了东西,还鼓励我做出创造性贡献。我开始创作更多的作品,仍然专注于为我的研究生创作艺术品,但似乎有更广泛的观众欣赏这些插图。”
2018 年,当艾莉森在国家生态分析中心&综合担任常驻艺术家时,RStudio 联系了她,为 2019 年 RStudio 大会上的“一丘之貉”会议提供一些工作。那次合作变成了更多的合作,并最终成为 RStudio 的驻场艺术家。
“我和 Hadley(Wickham)谈过我想做什么,主要是继续以降低学习障碍和欢迎更多 R 用户的方式贡献艺术作品,”她说。
“从那时起,我就一直在为教育和宣传做艺术作品,只是因为我认为这对人们来说很有趣[……]从去年秋天开始,我一直很高兴成为 RStudio 的常驻艺术家,并且非常兴奋能与他们合作。”
R 社区和包容性的重要性
如果你搜索大多数数据科学公司的工作列表,你不太可能找到一个“驻场艺术家”的职位。那么 RStudio 为什么不一样呢?
“RStudio 如此投入,证明了他们重视友善,欢迎并支持不同的学习者,”Allison 说。“我认为,支持有助于实现这一目标的艺术品是他们这样做的众多方式之一,是让社区变得更加包容的广泛努力的一部分。”
包容性是整个 R 社区显而易见的价值观。你只需浏览 Twitter 上的#rstats 标签就能明白这一点。艾莉森说,部分原因是良好的领导力:“我认为看到那些价值观从最高层的人那里可见并被表达出来是非常令人惊讶的。”
“R 社区的领导者(RStudio 和其他团体的领导者)对这些价值和优先事项的了解,鼓励其他人知道这些是这个社区重视的事情。”
这些价值观在 R 社区中根深蒂固。这一点从有影响力的、包容性的和注重多样性的组织的存在中显而易见,如 RLadies 、 R-Forwards 、 Minority R Users 、 Africa R Users 、 LatinR 等等。
“我认为 R 社区感到如此包容的另一个最大原因是因为 RLadies,”Allison 说。“我真的很高兴看到其他倡议开始启动,如 Minority R Users ,这是由 Dorris Scott 和 Danielle Smalls-Perkins 启动的。并使社区更加多样化和包容。”
(我们最近采访了 Shelmith Kariuki,他是 Africa R 用户的领导者之一— 点击此处阅读采访。 )
Hadley Wickham 讲座“函数式编程的乐趣(数据科学)”系列插图之一
给 R 初学者的建议
凭借多年的 R 教学经验,Allison 也有一些关于 R 初学者如何帮助自己实现目标的想法。
她的第一条建议并不令人惊讶:“尽早加入社区。这是支持和鼓励以及分享新工具的重要来源。”
“这看起来很可怕,”她说,“因为你会说,‘这些人我一个都不认识!’我认为新用户会对 R 社区的支持程度感到惊讶,特别是在 Twitter 上,但也在会议和 R-Ladies 上。"
“对于各个层次的用户和学习者来说都是如此。每个人都很兴奋你想学习 R 并加入这个社区。我希望几年前我就能说服自己,这有多么重要,有多么激励人心。”
第二,她说,是利用 R 社区提供的惊人的免费资源。“这个社区也真的致力于开放大量学习材料,”她说。“这包括视频课程和 bookdown 中的书籍、数据科学在线学习社区的R,以及教程和博客帖子。”
“我认为自从我使用 R 以来,我从博客帖子中学到了比任何其他学习方式都多的新技能,”她说,“所以拥抱那些人们一直在 R 社区中自由创建和分享的非传统和惊人的资源和教程。”
(Dataquest 提供了免费的交互式 R 课程以及不断增加的免费 R 教程库,在这篇文章的最后还有一个其他有用 R 资源的列表。)
另一个建议?“不要觉得每次都要做一个大项目才能学到东西,”艾莉森说。“每周尝试一项新功能。参与整理星期二。经常做一些无关紧要的事情。我认为这是开始感到舒适的最好方式。”
她说,这是她在自己的教室里采用的方法。“我试图以这种方式推动我的任务,朝着高频率、低风险、高多样性、小任务的方向发展,以培养更多技能,创造重复的舒适感。”
“我认为,重复对学习者来说真的很有价值。”
Allison 还鼓励新的学习者尝试一些东西,并在网上分享他们的工作,即使他们已经尝试的东西不起作用。“我喜欢看到人们发布不完美的东西,”她说。“这不是比赛。不一定要完美。关键是你尝试了一些东西,你做了一些练习,然后你与人分享。这就是整洁星期二的精神。”
她还为希望转行从事数据科学的人提供了一些建议:接受你已经拥有的学科领域知识,并将其与你的数据技能相结合。“这种组合真的很强大,”她说。当你有领域专业知识时,你可以说,“我不仅有领域专业知识,而且最重要的是,我有回答这个领域问题所需的技能。"
“有这样一个人真的很强大,他可以进来说,‘我可以做所有这些数据分析,但我也足够了解如何负责任地做这件事,并与不同的利益相关者沟通。’"
更多 R 和数据科学艺术:
- 阿米莉亚·麦克纳马拉制作酷酷的 R/tidyverse 布料,包括 R 面具
- 生成艺术由托马斯·林·彼得森用 R 和 tidyverse 包装创作
- 生成艺术由丹妮尔·纳瓦罗制作
- 茶杯,长颈鹿,&统计数据德西里·德莱昂和哈塞·瓦勒姆
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
数据科学中的数学
November 30, 2018
数学就像一只章鱼:它的触角可以触及几乎所有的学科。虽然有些受试者只是轻轻一刷,但其他受试者却像蛤蜊一样被触手紧紧抓住。数据科学属于后一类。如果你想从事数据科学,你将不得不与数学打交道。如果你已经完成了一个数学学位或其他一些强调定量技能的学位,你可能想知道你为获得学位所学的一切是否是必要的。我知道我做到了。如果你没有那样的背景,你可能会想:做数据科学真的需要多少数学知识?
在本帖中,我们将探讨数据科学的含义,并讨论开始时需要了解多少数学知识。先说“数据科学”实际上是什么意思。你可能会问十几个人,得到十几个不同的答案!在 Dataquest,我们将数据科学定义为使用数据和高级统计学进行预测的学科。这是一门专业学科,专注于从有时杂乱和分散的数据中创造理解(尽管数据科学家处理的具体内容因雇主而异)。统计学是我们在那个定义中提到的唯一的数学学科,但是数据科学也经常涉及数学中的其他领域。学习统计学是一个很好的开始,但数据科学也使用算法来进行预测。这些算法被称为机器学习算法,实际上有数百种。深入讨论每种算法需要多少数学知识不在这篇文章的范围之内,我将讨论你需要了解以下每种常用算法的多少数学知识:
- 朴素贝叶斯
- 线性回归
- 逻辑回归
- 神经网络
- k 均值聚类
- 决策树
现在让我们来看看每一个都需要多少数学知识!
朴素贝叶斯分类器
它们是什么:朴素贝叶斯分类器是一系列算法,基于一个共同的原则,即特定特征的值独立于任何其他特征的值。它们使我们能够根据我们所知道的有关事件的情况来预测事件发生的概率。名字来源于 贝叶斯定理 ,数学上可以这样写:$ $ P(A \ mid B)= \ frac { P(B \ mid A)P(A)} { P(B)} $ $其中(A)和(B)是事件且(P(B))不等于 0。这看起来很复杂,但是我们可以把它分解成很容易管理的部分:
- (P(A|B))是条件概率。具体来说,假设(B)为真,事件 A 发生的可能性。
- (P(B|A))也是条件概率。具体来说,给定(A)的情况下,事件(B)发生的可能性为真。
- (P(A))和(P(B))是相互独立地观察到(A)和(B)的概率。
数学我们需要:如果你想了解朴素贝叶斯分类器是如何工作的,你需要了解概率和条件概率的基本原理。为了获得概率的介绍,你可以查看我们的概率的课程。你也可以看看我们关于条件概率的课程,以彻底理解贝叶斯定理,以及如何从头开始编写朴素贝叶斯。
线性回归
什么是:线性回归是最基本的回归类型。它允许我们理解两个连续变量之间的关系。在简单线性回归的情况下,这意味着获取一组数据点并绘制一条趋势线,可用于预测未来。线性回归就是参数化机器学习的一个例子。在参数机器学习中,训练过程最终使机器学习算法成为一个数学函数,它最接近在训练集中找到的模式。这个数学函数可以用来预测未来的预期结果。在机器学习中,数学函数被称为模型。在线性回归的情况下,模型可以表示为:$ $ y = a _ 0+a _ 1 x _ 1+a _ 2 x _ 2+\ ldots+a _ I x _ I $ \(其中\(a_1\),\(a_2\),\(\ldots\),\(a_n\)表示特定于数据集的参数值,\(x_1\),\(x_2\),\(\ldots\),\(x_n\)表示我们选择的特征列线性回归的目标是找到最能描述功能列和目标列之间关系的最佳参数值。换句话说:找到数据的最佳拟合线,以便可以外推趋势线来预测未来的结果。为了找到线性回归模型的最佳参数,我们希望最小化模型的残差平方和。残差通常被称为误差,它描述了预测值和真实值之间的差异。残差平方和的公式可以表示为:\) $ RSS =(y _ 1–\hat{y_1})^{2}+(y _ 2–\hat{y_2})^{2}+\ ldots+(y _ n–\hat{y_n})^{2} $ $(其中(\hat{y})是目标列的预测值,y 是真实值。)我们需要的数学:如果你想浅尝辄止,一门初级统计学课程就可以了。如果你想在概念上有更深的理解,你可能想知道残差平方和的公式是如何推导出来的,你可以在大多数高级统计的课程中学到。
逻辑回归
什么是:逻辑回归侧重于估计因变量为二元(即只有两个值 0 和 1 代表结果)的情况下事件发生的概率。像线性回归一样,逻辑回归是参数化机器学习的一个例子。因此,这些机器学习算法的训练过程的结果是最接近训练集中的模式的数学函数。但是线性回归模型输出实数,逻辑回归模型输出概率值。正如线性回归算法生成线性函数模型一样,逻辑回归算法生成逻辑函数模型。你也可能听说过它被称为 sigmoid 函数,它压缩所有的值以产生一个介于 0 和 1 之间的概率结果。sigmoid 函数可以表示如下:$$ y = \frac{1}{1+e^{-x}} $$那么为什么 sigmoid 函数总是返回 0 到 1 之间的值呢?请记住,从代数的角度来看,将任何一个数提升到负指数就等于将该数的倒数提升到相应的正指数。我们需要的数学:我们已经在这里讨论了指数和概率,你会希望对代数和概率有一个坚实的理解,以获得逻辑算法中正在发生的工作知识。如果你想得到深入的概念理解,我会推荐你学习概率论以及离散数学或者实分析。
神经网络
它们是什么:神经网络是机器学习模型,非常松散地受到人脑中神经元结构的启发。这些模型是通过使用一系列被称为神经元的激活单元来预测某些结果而构建的。神经元接受一些输入,应用一个转换函数,然后返回一个输出。神经网络擅长捕捉数据中的非线性关系,并在音频和图像处理等任务中帮助我们。虽然有许多不同种类的神经网络(递归神经网络、前馈神经网络、递归神经网络等。),它们都依赖于将输入转换为输出的基本概念。 当观察任何一种神经网络时,我们会注意到到处都是线条,将每个圈与另一个圈连接起来。在数学中,这就是所谓的图,一种由边(表示为线)连接的节点(表示为圆)组成的数据结构。)请记住,我们这里所指的图表不同于线性模型或其他方程的图表。如果你熟悉旅行推销员问题,你可能也熟悉图的概念。在其核心,神经网络是一个系统,接受一些数据,执行一些线性代数,然后输出一些答案。线性代数是理解神经网络幕后发生的事情的关键。线性代数是数学的一个分支,它涉及诸如(y=mx+b)的线性方程及其通过矩阵和向量空间的表示。因为线性代数涉及通过矩阵来表示线性方程,所以矩阵是你开始理解神经网络核心部分时需要知道的基本概念。矩阵是由按行或列排列的数字、符号或表达式组成的矩形数组。矩阵以下列方式描述:一行一列。例如,下面的矩阵:
当观察任何一种神经网络时,我们会注意到到处都是线条,将每个圈与另一个圈连接起来。在数学中,这就是所谓的图,一种由边(表示为线)连接的节点(表示为圆)组成的数据结构。)请记住,我们这里所指的图表不同于线性模型或其他方程的图表。如果你熟悉旅行推销员问题,你可能也熟悉图的概念。在其核心,神经网络是一个系统,接受一些数据,执行一些线性代数,然后输出一些答案。线性代数是理解神经网络幕后发生的事情的关键。线性代数是数学的一个分支,它涉及诸如(y=mx+b)的线性方程及其通过矩阵和向量空间的表示。因为线性代数涉及通过矩阵来表示线性方程,所以矩阵是你开始理解神经网络核心部分时需要知道的基本概念。矩阵是由按行或列排列的数字、符号或表达式组成的矩形数组。矩阵以下列方式描述:一行一列。例如,下面的矩阵:

is called a 3 by 3 matrix because it has three rows and three columns. With dealing with neural networks, each feature is represented as an input neuron. Each numerical value of the feature column multiples to a weight vector that represents your output neuron. Mathematically, the process is written like this: $$ \hat{y} = Xa^{T} + b$$ where (X) is an (m x n) matrix where (m) is the number of input neurons there are and (n) is the number of neurons in the next layer. Our weights vector is denoted as (a), and (a^{T}) is the transpose of (a). Our bias unit is represented as (b). Bias units are units that influence the output of neural networls by shifting the sigmoid function to the left or right to give better predictions on some data set. Transpose is a Linear Algebra term and all it means is the rows become columns and columns become rows. We need to take the transpose of (a) because the number columns of the first matrix must equal the number of rows in the second matrix when multiplying matrices. For example, if we have a (3×3) matrix and a weights vector that is a (1×3) vector, we can’t multiply outright because three does not equal one. However, if we take the transpose of the (1×3) vector, we get a (3×1) vector and we can successfully multiply our matrix with the vector. After all of the feature columns and weights are multiplied, an activation function is called that determines whether the neuron is activated. There are three main types of activation functions: the RELU function, the sigmoid function, and the hyperbolic tangent function. We’re already familiar with the sigmoid function. The RELU function is a neat function that takes an input x and outputs the same number if it is greater than 0; however, it’s equal to 0 if the input is less than 0. The hyperbolic tangent function is essentially the same as the sigmoid function except that it constrains any value between -1 and 1.

我们需要的数学:我们已经在概念方面讨论了很多!如果你想对这里介绍的数学有一个基本的理解,离散数学课程和线性代数课程是一个很好的起点。对于深入的概念理解,我推荐图论、矩阵理论、多元微积分和实分析的课程。如果你对学习线性代数基础感兴趣,你可以从我们的线性代数机器学习课程开始。
k-均值聚类
什么是:K 均值聚类算法是一种无监督的机器学习,用于对未标记的数据进行分类,即没有定义类别或组的数据。该算法的工作原理是在数据中查找组,组的数量由变量 k 表示。然后,它遍历数据,根据提供的特征将每个数据点分配到 k 个组中的一个组。K-means 聚类依靠算法中的距离概念将数据点“分配”给一个聚类。如果你不熟悉距离的概念,它指的是两个给定物品之间的距离。在数学中,任何描述集合中任意两个元素之间距离的函数都称为距离函数或度量。有两种度量:欧几里德度量和出租车度量。欧几里德度量定义如下:$$ d( (x_1,y_1),(x_2,y _ 2))= \ sqrt {(x _ 2–x_1)^{2}+(y _ 2–y_1)^{2}} $ \(其中\((x_1,y_1)\)和\((x_2,y_2)\)是笛卡尔平面上的坐标点。虽然欧几里德度量是足够的,但在某些情况下它不起作用。假设你正在一个大城市散步;如果有一座巨大的建筑挡住了你的去路,说“我离目的地还有 6.5 个单位”是没有意义的。为了解决这个问题,我们可以使用出租车度量标准。出租车度量如下:\)$ d( (x_1,y_1),(x_2,y _ 2))= | x _ 1–x _ 2 |+| y _ 1–y _ 2 | $ $其中((x_1,y_1))和((x_2,y_2))是笛卡尔平面上的坐标点。我们需要的数学:这个有点复杂;实际上,你只需要知道加减法,理解代数的基础,这样你就能掌握距离公式。但是,为了更好地理解每一种度量所存在的基本几何类型,我推荐一门几何课,它涵盖了欧几里德和非欧几里德几何。为了深入理解度量和度量空间的含义,我会阅读数学分析并参加一个真正的分析课程。
决策树
什么是:决策树是一种类似流程图的树形结构,使用分支方法来说明决策的每一种可能结果。树中的每个节点代表一个特定变量的测试——每个分支都是该测试的结果。决策树依靠一种叫做信息论的理论来决定它们是如何构建的。在信息论中,一个人对一个话题了解得越多,他能知道的新信息就越少。信息论中的一个关键指标是熵。熵是对给定变量的不确定性进行量化的一种度量。熵可以这样写:$ $ \ hbox { entropy } = -\sum_{i=1}^{n}p(x_i)\log_b p(x _ I)$ \(在上面的等式中,\(P(x)\)是特征出现在数据集中的概率。应该注意,任何底数 b 都可以用于对数;但是,常见的值是 2、(e\) (2.71)和 10。你可能已经注意到了这个看起来像“S”的奇特符号。这是求和符号,它意味着尽可能多次地连续相加求和之外的函数。你相加的次数由总和的上限和下限决定。在计算熵之后,我们可以使用信息增益开始构造决策树,它告诉我们哪个分裂将最大程度地减少熵。信息增益的公式写为:\)$ IG(T,A)= \ hbox { Entropy }(T)–\ sum _ { v \ in A } \ frac { | T _ v | } { | T | } \ cdot \ hbox { Entropy }(T _ v)$ $信息增益衡量一个人可以获得多少“比特”的信息。在决策树的情况下,我们可以计算数据集中每一列的信息增益,以便找到哪一列将为我们提供最大的信息增益,然后在该列上进行拆分。我们需要的数学:基本的代数和概率是你真正需要的,来了解决策树的表面。如果你想对概率和对数有深刻的概念理解,我会推荐概率论和代数课程。
最终想法
如果你还在上学,我强烈推荐你选修一些纯数学和应用数学的课程。它们有时肯定会令人生畏,但你可以感到安慰的是,当你遇到这些算法并知道如何最好地应用它们时,你会有更好的准备。如果你现在不在学校,我建议你去最近的书店,阅读这篇文章中强调的主题。如果你能找到涉及概率、统计和线性代数的书籍,我强烈建议你挑选那些深入涵盖这些主题的书籍,以便真正感受一下这篇文章中涉及的和这篇文章中没有涉及的机器算法背后发生的事情。
数学在数据科学中无处不在。虽然一些数据科学算法有时感觉像魔术一样,但我们可以理解许多算法的来龙去脉,而不需要比代数和基本概率统计更多的东西。不想学什么数学?从技术上来说,你
可以依靠 scikit 这样的机器学习库——学会为你做这一切。但是,对于数据科学家来说,对这些算法背后的数学和统计学有一个坚实的理解是非常有帮助的,这样他们就可以为他们的问题和数据集选择最佳算法,从而做出更准确的预测。所以拥抱痛苦,投入到数学中去吧!这并不像您想象的那么难,我们甚至针对其中几个主题开设了课程来帮助您入门:
** 概率与统计
Matplotlib 教程:策划提及特朗普、克林顿和桑德斯的推文
May 12, 2016
用熊猫和 Matplotlib 分析推文
Python 有多种可视化库,包括 seaborn 、 networkx 、 vispy 。大多数 Python 可视化库全部或部分基于 matplotlib ,这通常使它成为制作简单绘图的首选,也是制作复杂到无法在其他库中创建的绘图的最后手段。在这个 matplotlib 教程中,我们将介绍这个库的基础知识,并演示一些中间可视化。我们将处理大约 240,000 条关于希拉里·克林顿、唐纳德·特朗普和伯尼·桑德斯的推文数据集,他们都是当前的美国总统候选人。数据来自 Twitter 流媒体 API,所有 240,000 条推文的 csv 可以在这里下载。如果你想自己刮更多的数据,可以在这里找刮码。
探索熊猫的微博
在开始绘图之前,让我们加载数据并做一些基本的探索。我们可以使用用于数据分析的 Python 库 Pandas 来帮助我们。在下面的代码中,我们将:
- 导入熊猫库。
- 将
tweets.csv读入一个熊猫数据帧。 - 打印数据帧的前
5行。
import pandas as pd
tweets = pd.read_csv("tweets.csv")
tweets.head()
| 身份证明(identification) | 标识字符串 | 用户位置 | 用户背景颜色 | 转发次数 | 用户名 | 极性 | 创造 | 长狭潮道 | 用户 _ 描述 | 用户 _ 创建的 | 用户 _ 追随者 | 协调 | 主观性 | 文本 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | 729828033092149248 | 惠灵 WV | 022330 | Zero | Jaybo26003 | Zero | 2016-05-10T00:18:57 | 圆盘烤饼 | 圆盘烤饼 | 2011-11-17T02:45:42 | Thirty-nine | 圆盘烤饼 | Zero | 投出不同的一票!伯尼·桑德斯大学… |
| one | Two | 729828033092161537 | 圆盘烤饼 | 好吧 | Zero | 英国人 | Zero point one five | 2016-05-10T00:18:57 | 圆盘烤饼 | 18 // PSJAN | 2012 年 12 月 24 日 17 时 33 分 12 秒 | One thousand one hundred and seventy-five | 圆盘烤饼 | Zero point one | RT @HlPHOPNEWS: T.I .说如果唐纳德·特朗普赢了… |
| Two | three | 729828033566224384 | 圆盘烤饼 | 好吧 | Zero | 杰弗里斯洛里 | Zero | 2016-05-10T00:18:57 | 圆盘烤饼 | 圆盘烤饼 | 2012-10-11T14:29:59 | forty-two | 圆盘烤饼 | Zero | 如果是真的,你只能怪你自己 |
| three | four | 729828033893302272 | 全球的 | 好吧 | Zero | WhorunsGOVs | Zero | 2016-05-10T00:18:57 | 圆盘烤饼 | 了解最新的全球政治新闻 | 2014-02-16T07:34:24 | Two hundred and ninety | 圆盘烤饼 | Zero | “毁掉他们的余生”:唐纳德·特朗普 c… |
| four | five | 729828034178482177 | 美国加州 | One hundred and thirty-one thousand five hundred and sixteen | Zero | BJCG0830 | Zero | 2016-05-10T00:18:57 | 圆盘烤饼 | 拉丁同性恋援引他的第一修正案特权… | 2009 年 3 月 21 日 | Three hundred and fifty-four | 圆盘烤饼 | Zero | RT @elianayjohnson:根据来源,共和党大捐助者… |
以下是对数据中重要列的快速解释:
id—数据库中行的 id(这并不重要)。id_str—推特上推文的 id。user_location—推特用户在其推特简历中指定的地点。user_bg_color—高音扬声器轮廓的背景颜色。user_name—推特用户的推特用户名。polarity—推文的情绪,从-1到1。1表示强阳性,-1表示强阴性。created—推文发出的时间。user_description—tweeter 在其简历中指定的描述。user_created—当 tweeter 创建他们的账户时。user_follower—高音喇叭拥有的关注者数量。text—推文的文本。subjectivity—推文的主观性或客观性。0很客观,1很主观。
生成候选人列
我们可以用这个数据集做的大多数有趣的事情包括比较一个候选人的推文和另一个候选人的推文。例如,我们可以比较关于唐纳德·川普的推特和关于伯尼·桑德斯的推特的客观程度。为了实现这一点,我们首先需要生成一个列,告诉我们每条推文中提到了哪些候选人。在下面的代码中,我们将:
- 创建一个函数,查找在一段文本中出现的候选名称。
- 在 DataFrames 上使用 apply 方法生成一个名为
candidate的新列,其中包含推文提到的候选人。
def get_candidate(row):
candidates = []
text = row["text"].lower()
if "clinton" in text or "hillary" in text:
candidates.append("clinton")
if "trump" in text or "donald" in text:
candidates.append("trump")
if "sanders" in text or "bernie" in text:
candidates.append("sanders")
return ",".join(candidates)
tweets["candidate"] = tweets.apply(get_candidate,axis=1)
制作第一个情节
现在我们已经有了初步的准备,我们准备使用 matplotlib 绘制我们的第一个图。在 matplotlib 中,绘制绘图包括:
由于其灵活的结构,您可以在 matplotlib 中将多个地块绘制成单个图像。每个轴对象代表一个单独的图,就像条形图或直方图。这听起来可能很复杂,但是 matplotlib 有方便的方法来为我们完成设置图形和轴对象的所有工作。
导入 matplotlib
为了使用 matplotlib,您需要首先使用import matplotlib.pyplot as plt导入库。如果你正在使用 Jupyter 笔记本,你可以使用%matplotlib inline设置 matplotlib 在笔记本内部工作。
import matplotlib.pyplot as plt
import numpy as np
我们导入matplotlib.pyplot是因为它包含了 matplotlib 的绘图函数。为了方便起见我们改名为plt,这样出图更快。
制作条形图
一旦我们导入了 matplotlib,我们就可以绘制一个柱状图,显示有多少条推文提到了每个候选人。为此,我们将:
- 对熊猫系列使用 value_counts 方法来统计有多少条推文提到了每个候选人。
- 使用
plt.bar创建条形图。我们将把从0到candidate列中唯一值的数量的数字列表作为 x 轴输入,计数作为 y 轴输入。 - 显示计数,以便我们对每个条形代表的内容有更多的了解。
counts = tweets["candidate"].value_counts()
plt.bar(range(len(counts)), counts)
plt.show()
print(counts)
trump 119998
clinton,trump 30521
25429
sanders 25351
clinton 22746
clinton,sanders 6044
clinton,trump,sanders 4219
trump,sanders 3172
Name: candidate, dtype: int64

关于川普的推文比关于桑德斯或希拉里的多得多,这真令人惊讶!您可能会注意到,我们没有创建图形或任何轴对象。这是因为调用plt.bar将自动设置一个图形和一个单轴对象,代表条形图。调用 plt.show 方法将显示当前图形中的任何内容。在本例中,它显示了一个包含条形图的图像。matplotlib 在 pyplot 模块中有一些方法,这些方法使得创建普通类型的绘图更快更方便,因为它们自动创建图形和轴对象。最广泛使用的是:
- 柱状图 —创建一个柱状图。
- plt.boxplot —绘制一个盒须图。
- plt.hist —制作直方图。
- PLT . plot-创建一个线形图。
- plt.scatter —制作散点图。
调用这些方法中的任何一个都会自动设置图形和轴对象,并绘制绘图。每种方法都有不同的参数,可以传入这些参数来修改结果图。
自定义地块
现在,我们已经制作了基本的第一个图,我们可以继续创建一个更加定制的第二个图。我们将制作一个基本的直方图,然后修改它以添加标签和其他信息。我们可以关注的事情之一是发微博的用户账户的年龄。我们将能够发现在推特上发布关于特朗普的用户账户和在推特上发布关于克林顿的用户账户的创建时间是否有差异。一个候选人最近创建了更多的用户账户,这可能意味着有人用假账户操纵 Twitter。在下面的代码中,我们将:
- 将
created和user_created列转换为熊猫日期时间类型。 - 创建一个
user_age列,表示自帐户创建以来的天数。 - 创建用户年龄直方图。
- 显示直方图。
from datetime import datetime
tweets["created"] = pd.to_datetime(tweets["created"])
tweets["user_created"] = pd.to_datetime(tweets["user_created"])
tweets["user_age"] = tweets["user_created"].apply(lambda x: (datetime.now() - x).total_seconds() / 3600 / 24 / 365)
plt.hist(tweets["user_age"])
plt.show()

添加标签
我们可以给 matplotlib 图添加标题和轴标签。实现这一点的常用方法有:
- PLT . title-为绘图添加标题。
- plt.xlabel —添加一个 x 轴标签。
- plt.ylabel —添加一个 y 轴标签。
由于我们之前讨论的所有方法,如bar和hist,都自动创建一个图形和图形中的单个 Axes 对象,当调用该方法时,这些标签将被添加到 Axes 对象中。我们可以使用上述方法将标签添加到先前的直方图中。在下面的代码中,我们将:
- 生成与之前相同的直方图。
- 在直方图上绘制一个标题。
- 在直方图上绘制一个 x 轴标签。
- 在直方图上绘制一个 y 轴标签。
- 展示剧情。
plt.hist(tweets["user_age"])
plt.title("Tweets mentioning candidates")
plt.xlabel("Twitter account age in years")
plt.ylabel("# of tweets")
plt.show()

制作堆积直方图
当前的直方图很好地告诉了我们所有推特用户的账户年龄,但它没有按候选人进行细分,这可能更有趣。我们可以利用hist方法中的附加选项来创建堆叠直方图。在下面的代码中,我们将:
- 生成三个熊猫系列,每个系列只包含关于某个候选人的推文的
user_age数据。 - 通过调用带有额外选项的
hist方法制作一个堆积直方图。- 指定一个列表作为输入将绘制三组柱状图。
- 指定
stacked=True将堆叠三组棒线。 - 添加
label选项将为图例生成正确的标签。
- 调用 plt.legend 方法在右上角绘制图例。
- 添加标题、x 轴和 y 轴标签。
- 展示剧情。
cl_tweets = tweets["user_age"][tweets["candidate"] == "clinton"]
sa_tweets = tweets["user_age"][tweets["candidate"] == "sanders"]
tr_tweets = tweets["user_age"][tweets["candidate"] == "trump"]
plt.hist([
cl_tweets,
sa_tweets,
tr_tweets
],
stacked=True,
label=["clinton", "sanders", "trump"])
plt.legend()
plt.title("Tweets mentioning each candidate")plt.xlabel("Twitter account age in years")
plt.ylabel("# of tweets")
plt.show()

注释直方图
我们可以利用 matplotlibs 在绘图上绘制文本的能力来添加注释。注释指向图表的特定部分,让我们添加一个片段来描述要查看的内容。在下面的代码中,我们将制作与上面相同的直方图,但是我们将调用 plt.annotate 方法向绘图添加注释。
plt.hist([
cl_tweets,
sa_tweets,
tr_tweets
],
stacked=True,
label=["clinton", "sanders", "trump"])
plt.legend()
plt.title("Tweets mentioning each candidate")
plt.xlabel("Twitter account age in years")
plt.ylabel("# of tweets")
plt.annotate('More Trump tweets', xy=(1, 35000), xytext=(2, 35000),
arrowprops=dict(facecolor='black'))
plt.show()

下面描述一下传递给annotate的选项是做什么的:
xy—确定箭头应该开始的x和y坐标。xytext—确定文本应该开始的x和y坐标。arrowprops—指定关于箭头的选项,如颜色。
正如你所看到的,关于特朗普的推文明显比关于其他候选人的多,但看起来账户年龄没有明显差异。
多个支线剧情
到目前为止,我们一直在使用像plt.bar和plt.hist这样的方法,它们自动创建一个图形对象和一个轴对象。然而,当我们想要更多地控制我们的地块时,我们可以显式地创建这些对象。我们想要更多控制的一种情况是当我们想要在同一个图像中并排放置多个图时。我们可以通过调用 plt.subplots 方法来生成一个图形和多个轴对象。我们传入两个参数,nrows和ncols,它们定义了图中 Axes 对象的布局。例如,plt.subplots(nrows=2, ncols=2)会生成2x2坐标轴对象的网格。plt.subplots(nrows=2, ncols=1)将生成一个轴对象的2x1网格,并垂直堆叠两个轴。每个轴对象支持pyplot中的大多数方法。例如,我们可以调用 Axes 对象上的bar方法来生成条形图。
提取颜色
我们将生成4图,显示用户关于特朗普的推特背景色中红色和蓝色的数量。这可能表明,如果推特上的人认为自己是共和党人,他们更有可能在个人资料中添加红色。首先,我们将生成两列,red和blue,这两列告诉我们从0到1,每种颜色在每个高音喇叭的轮廓背景中所占的比例。在下面的代码中,我们将:
- 使用
apply方法遍历user_bg_color列中的每一行,并提取其中有多少红色。 - 使用
apply方法遍历user_bg_color列中的每一行,并提取其中有多少蓝色。
import matplotlib.colors as colors
tweets["red"] = tweets["user_bg_color"].apply(lambda x: colors.hex2color('#{0}'.format(x))[0])
tweets["blue"] = tweets["user_bg_color"].apply(lambda x: colors.hex2color('#{0}'.format(x))[2])
创造情节
一旦我们有了数据设置,我们就可以创建图。每个图将是一个直方图,显示有多少推特用户的个人背景包含一定量的蓝色或红色。在下面的代码中,我们:
- 用
subplots方法生成一个图形和多个轴。轴将作为数组返回。 - 这些轴以 2×2 NumPy 数组的形式返回。我们通过使用数组的平坦属性来提取每个单独的轴对象。这给了我们可以使用的轴对象。
- 使用 hist 方法在第一个轴上绘制直方图。
- 使用 set_title 方法将第一个轴的标题设置为
Red in all backgrounds。这执行与plt.title相同的功能。 - 使用 hist 方法在第二个轴上绘制直方图。
- 使用 set_title 方法将第二个轴的标题设置为
Red in Trump tweeters。 - 使用 hist 方法在第三轴绘制直方图。
- 使用 set_title 方法将第三个轴的标题设置为
Blue in all backgrounds。这执行与plt.title相同的功能。 - 使用 hist 方法在第四轴绘制直方图。
- 使用 set_title 方法将第四个轴的标题设置为
Blue in Trump tweeters。 - 调用 plt.tight_layout 方法来减少图形中的填充并适合所有元素。
- 展示剧情。
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flat
ax0.hist(tweets["red"])
ax0.set_title('Red in backgrounds')
ax1.hist(tweets["red"][tweets["candidate"] == "trump"].values)
ax1.set_title('Red in Trump tweeters')
ax2.hist(tweets["blue"])
ax2.set_title('Blue in backgrounds')
ax3.hist(tweets["blue"][tweets["candidate"] == "trump"].values)
ax3.set_title('Blue in Trump tweeters')
plt.tight_layout()
plt.show()

移除常见背景颜色
Twitter 有默认的背景颜色,我们可能应该删除,这样我们就可以减少噪音,生成一个更准确的图。颜色采用十六进制格式,其中 code>#000000 为黑色,#ffffff为白色。以下是如何在背景色中找到最常见的颜色:
tweets["user_bg_color"].value_counts()
C0DEED 108977
000000 31119
F5F8FA 25597
131516 7731
1A1B1F 5059
022330 4300
0099B9 3958
现在,我们可以删除三种最常见的颜色,只标出具有独特背景颜色的用户。下面的代码大部分是我们之前做的,但是我们将:
- 从
user_bg_color中移除C0DEED、000000和F5F8FA。 - 创建一个函数,不包含内部最后一个图表的绘图逻辑。
- 绘制与之前相同的
4图,但不使用user_bg_color中最常见的颜色。
tc = tweets[~tweets["user_bg_color"].isin(["C0DEED", "000000", "F5F8FA"])]
def create_plot(data):
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flat
ax0.hist(data["red"])
ax0.set_title('Red in backgrounds')
ax1.hist(data["red"][data["candidate"] == "trump"].values)
ax1.set_title('Red in Trump tweets')
ax2.hist(data["blue"])
ax2.set_title('Blue in backgrounds')
ax3.hist(data["blue"][data["candidate"] == "trump"].values)
ax3.set_title('Blue in Trump tweeters')
plt.tight_layout()
plt.show()
create_plot(tc)

正如你所看到的,发关于特朗普的推文的用户的背景颜色中蓝色和红色的分布几乎与所有推文的分布相同。
策划情绪
我们使用 TextBlob 为每条推文生成情感分数,这些分数存储在polarity列中。我们可以画出每个候选人的平均值,以及标准偏差。标准差将告诉我们所有推文之间的差异有多大,而平均值将告诉我们平均推文有多大。为了做到这一点,我们可以将两个轴添加到一个图形中,并在一个图形中绘制出polarity的平均值,在另一个图形中绘制出标准偏差。因为在这些图中有许多文本标签,我们需要增加生成图形的大小来匹配。我们可以通过plt.subplots方法中的figsize选项来实现这一点。下面的代码将:
- 根据候选人对推文进行分组,并计算每个数字列的平均值和标准偏差(包括
polarity)。 - 创建一个尺寸为
7英寸乘7英寸的图形,带有两个垂直排列的轴对象。 - 创建第一个轴对象的标准偏差条形图。
- 使用 set_xticklabels 方法设置刻度标签,并使用
rotation参数旋转标签45度。 - 设置标题。
- 使用 set_xticklabels 方法设置刻度标签,并使用
- 在第二个轴对象上创建平均值条形图。
- 设置刻度标签。
- 设置标题。
- 展示剧情。
gr = tweets.groupby("candidate").agg([np.mean, np.std])
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(7, 7))
ax0, ax1 = axes.flat
std = gr["polarity"]["std"].iloc[1:]
mean = gr["polarity"]["mean"].iloc[1:]
ax0.bar(range(len(std)), std)
ax0.set_xticklabels(std.index, rotation=45)
ax0.set_title('Standard deviation of tweet sentiment')
ax1.bar(range(len(mean)), mean)
ax1.set_xticklabels(mean.index, rotation=45)
ax1.set_title('Mean tweet sentiment')
plt.tight_layout()
plt.show()

生成并排条形图
我们可以用柱状图绘制候选人的推文长度。我们首先将推文分成short、medium和long推文。然后,我们将统计每组中有多少条提及每位候选人的推文。然后,我们将生成一个条形图,并排显示每个候选人的条形图。
生成推文长度
为了绘制推文长度,我们首先要对推文进行分类,然后计算每个候选人有多少推文落入每个箱子。在下面的代码中,我们将:
- 定义一个函数,如果 tweet 少于
100个字符,则标记为short,如果是100到135个字符,则标记为medium,如果超过135个字符,则标记为long。 - 使用
apply生成一个新列tweet_length。 - 算出每个候选人有多少条推文归入每个组。
def tweet_lengths(text):
if len(text) < 100:
return "short"
elif 100 <= len(text) <= 135:
return "medium"
else:
return "long"
tweets["tweet_length"] = tweets["text"].apply(tweet_lengths)
tl = {}
for candidate in ["clinton", "sanders", "trump"]:
tl[candidate] = tweets["tweet_length"][tweets["candidate"] == candidate].value_counts()
测绘
现在我们有了想要绘制的数据,我们可以生成并排条形图。我们将使用bar方法在同一轴上绘制每个候选人的 tweet 长度。然而,我们将使用一个偏移量来将我们绘制的第二个和第三个候选项的条形向右移动。这将为我们提供三个类别区域,short、medium和long,每个区域中的每个候选人都有一个条形。在下面的代码中,我们:
- 创建一个图形和一个单轴对象。
- 定义每根棒线的
width,.5。 - 生成一个数值序列,
x,即0、2、4。每个值都是一个类别的开始,例如short、medium和long。我们在每个类别之间放置了一个2的距离,这样我们就有空间放置多个条形。 - 在 Axes 对象上绘制
clintontweets,并在x定义的位置绘制条。 - 在 Axes 对象上绘制
sanderstweets,但是将width添加到x中以向右移动条。 - 在 Axes 对象上绘制
trumptweets,但是将width * 2添加到x以将条移动到最右边。 - 设置轴标签和标题。
- 使用
set_xticks将刻度标签移动到每个类别区域的中心。 - 设置刻度标签。
fig, ax = plt.subplots()
width = .5
x = np.array(range(0, 6, 2))
ax.bar(x, tl["clinton"], width, color='g')
ax.bar(x + width, tl["sanders"], width, color='b')
ax.bar(x + (width * 2), tl["trump"], width, color='r')
ax.set_ylabel('# of tweets')
ax.set_title('Number of Tweets per candidate by length')
ax.set_xticks(x + (width * 1.5))
ax.set_xticklabels(('long', 'medium', 'short'))
ax.set_xlabel('Tweet length')
plt.show()

后续步骤
接下来你可以制作几个情节:
- 分析用户描述,并查看描述长度如何因候选人而异。
- 探索一天中的时间——某个候选人的支持者在特定时间会发更多的微博吗?
- 探索用户位置,并查看哪些州关于哪些候选人的推文最多。
- 看看什么样的用户名会发更多关于什么样的候选人的微博。
- 用户名中的数字越多,对候选人的支持就越大吗?
- 哪位候选人拥有最多的全大写支持者?
- 收集更多的数据,看看模式是否会改变。
我们已经学习了很多关于 matplotlib 如何生成图的知识,并且浏览了很多数据集。如果你想了解更多关于 matplotlib 和数据可视化的知识,你可以查看我们的交互式数据可视化课程。每门课的第一课都是免费的!希望这个 matplotlib 教程对你有帮助,如果你对这些数据做了什么有趣的分析,请联系——我们很想知道!
微软 Azure 和云计算简介
原文:https://www.dataquest.io/blog/microsoft-azure-and-cloud-computing/
October 9, 2022
云计算是当代最重要的技术进步之一,它改变了我们生活和工作的本质。微软 Azure 是云计算服务的领先提供商之一,它提供了广泛的功能和优势。在本文中,我们将向您介绍 Azure 云计算,并且我们将讨论您应该考虑学习和使用 Azure 来满足您的云计算需求的一些关键原因。
什么是云计算?
云计算是通过互联网(“云”)交付计算服务,包括服务器、存储、数据库、网络、软件、分析和智能,以提供更快的创新、灵活的资源和规模经济。
国家标准与技术研究院 (NIST)对云计算的定义如下:
[A]支持对可配置计算资源(例如,网络、服务器、存储、应用程序和服务)共享池进行无处不在、方便、按需的网络访问的模型,这些资源可以通过最少的管理工作或服务提供商交互来快速调配和释放。
换句话说,云计算是通过互联网访问技术服务(如数据存储或计算机能力)的能力,而无需自己购买或维护技术基础设施。这可以节省您的时间和金钱,因为您只在需要的时候使用您需要的资源。
为什么要使用云计算?
使用云计算的原因有很多,但最重要的一个是它省钱。借助云计算,您可以避免购买和维护硬件和软件的前期成本。取而代之的是,您可以按使用量付费。这可以帮助您降低 IT 成本,并腾出现金用于其他业务开支。
使用云计算的另一个原因是,它让您可以访问可扩展的资源。例如,如果您的网站流量突然激增,您可以快速扩大服务器容量以满足需求,而无需投资新硬件。当流量恢复到正常水平时,您可以再次缩减流量,这又一次节省了资金。
云计算还可以帮助你更好地应对变化。当您可以快速供应和部署新服务时,您就可以快速响应市场机遇和客户需求。这可以让你在当今快速发展的商业世界中获得竞争优势。
所以有很多很好的理由使用云计算。但是在你做出改变之前,了解你的选择是很重要的。
云计算服务的类型
在过去十年中,云计算变得越来越受欢迎,因为各种规模的企业都开始依赖基于云的服务的灵活性和可扩展性。云计算服务主要有三种类型:基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。这三者之间的区别主要在于您管理了多少,而云供应商管理了多少
基础设施即服务(IaaS): IaaS 是一种云计算模式,允许您按需供应和使用处理能力、存储和网络资源。
平台即服务(PaaS): PaaS 是一种云计算模式,允许您开发、运行和管理应用程序,而无需担心底层基础架构—服务器、存储和网络。第三方提供商管理基础设施,而开发人员管理应用程序。
软件即服务(SaaS): SaaS 是一种云计算模式,通过互联网交付软件,并通过网络浏览器或移动应用程序提供软件。供应商管理一切;你只需付费就能享受服务。
云计算部署模型
云计算有四种主要的部署模式:公共、私有、混合和社区。
公共云由第三方服务提供商拥有和运营,该提供商通过互联网提供服务。在这里,供应商向公共云中的众多客户端提供云服务,这些客户端在后端共享相同的硬件。私有云由单一组织拥有和运营,该组织可以是企业,也可以是服务提供商。
混合云是使用 VPN 或数据加密等技术连接的公共云和私有云的组合。社区云由一组具有相似需求的组织共享。当许多国家的政府建立一个共享服务部门来容纳政府的所有 IT 时,我们经常会看到社区云的例子。
您选择的部署模型类型将取决于您的特定需求和要求。例如,如果您需要高级别的安全性和隐私性,那么您可能会选择私有云或混合云部署模式。如果成本是主要考虑因素,那么您可能会选择公共云部署模式。
云供应商
三大云厂商分别是微软 Azure、AWS 和谷歌云平台。每一款都提供不同的功能和服务,因此选择适合您需求的产品非常重要。
微软 Azure 是微软创建的云计算服务,用于通过微软管理的数据中心的全球网络构建、测试、部署和管理应用和服务。Azure 于 2008 年 10 月发布,2010 年 2 月 1 日发布,名为 Windows Azure,2014 年 3 月 25 日更名为微软 Azure。
另一方面,AWS 是亚马逊的子公司,在付费订阅的基础上向个人、公司和政府提供按需云计算平台,提供 12 个月的免费层选项。AWS 的服务包括计算、存储、数据库、安全和身份管理等。
最后, Google Cloud Platform 是云计算的提供商,提供平台即服务(PaaS)和基础设施即服务(IaaS)。他们的一些 IaaS 产品包括预配置的虚拟机、存储选项(如 SQL 或 NoSQL 数据库)、DNS 服务和内容交付。
三大云供应商拥有不相上下的优势和产品;然而,对于已经在使用微软产品的大型组织来说,Azure 是完美的选择。
Azure 还允许公司通过与 Office 365 和 Active Directory 的完全集成,从现有的微软投资中获得更多价值。对于将 Windows 服务器迁移到云的公司,微软提供了扩展的安全更新。因此,对于任何在内部使用 Windows 服务器和微软堆栈的公司来说,迁移到 Azure 是有意义的。一旦你开始行动,集成的环境也使它变得非常用户友好。虽然 Azure 比 AWS 拥有更多的功能,但它使用起来更简单。
AWS 很复杂,涉及大量文档,而 Azure 依赖于你和你的用户已经知道的工具,如 Windows、Active Directory 和 Linux,所以向云的过渡不那么痛苦。
如果你正在寻找一个比 AWS 和谷歌云提供更多优势的云平台,那么 Azure 是明确的选择。
如果我们深入研究一下,只关注微软,在基础设施即服务方面,我们有 Azure Compute,这是其虚拟机的名称,还有 Azure Storage。在平台即服务中,我们有 Azure 逻辑应用、Azure 功能、Azure Web 作业和 Azure 自动化。对于软件即服务,我们有 SharePoint Online、OneDrive for Business、Microsoft Teams 和 Power Platform 等服务。这些只是几个例子。微软在每个类别中都有十几项服务。
云计算的未来是光明的,这就是为什么对拥有 Azure 云计算专业知识的专业人士有巨大的需求。
结论
在本文中,我们讨论了云计算的基础知识,并探索了主要的云供应商之一——Microsoft Azure。我们了解了云计算是如何工作的,我们了解了不同类型的服务和可用的部署选项,我们还了解了 Azure 的云服务及其一些主要优势。
现在,你可以开始下一步了。首先,你可以专攻特定的微软云认证或课程。微软对 Azure 的入门级认证被称为微软认证:Azure 基础,它测试你对云概念的基本知识,如他们提供的服务以及定价。
网上有许多学习云计算的资源,该列表将很快包括 Dataquest 的最新学习路径“Microsoft Azure 云数据基础”当你通过 Dataquest 完成这条道路时,你将获得 Azure Fundamentals 认证的 50%折扣。您可以点击查看认证详情。
我们为想要学习、提升或提高 Azure 云计算技能的学习者设计了“Microsoft Azure 云数据基础”路径。我们将提供一个面向行业的项目,将概念和练习恰当地结合在一起,帮助您练习技能。所有的练习都在我们的平台上,所以你不需要安装任何东西。我们还会对您的进步提供反馈,这样您就能看到自己的进步。
我们相信,我们的课程将是提高您在 Microsoft Azure 中的云计算技能的最佳方式!请关注我们的博客,了解这条激动人心的新道路的发布消息。
迈克:“我想提高我的技能”
April 25, 2018
Mike Roberts 并没有打算成为一名数据科学家。在获得物理学学位后,他在成为 BI 分析师之前尝试了艺术管理和职业扑克。他加入 Dataquest 是为了加强这些 BI 技能,但很快发现他可以在数据科学领域转换到一个更有趣的角色。他第一次对自己的职业机会感到兴奋。
Python 是一门伟大的语言,非常受欢迎的社区
直观的学习过程很有帮助——Mike 喜欢 read/code 平台,以及课程的逻辑进展。“我从来没有因为技术问题而沮丧过,也没有浪费时间在编码前看视频。”
如果他碰壁了,Slack 社区会帮助他。他的同学和 Dataquest 的老师都很快做出反应,伸出了援助之手。他建议他的同学们不止一次地复习课程——“简单地勾掉一些东西很有诱惑力,但如果你回去重做那些困难的东西,它会更好地嵌入你的大脑。”
到了找工作的时候,他在 Dataquest 建立的项目就完全不同了——直到他把这些项目放在 GitHub 上让潜在雇主审查,他才开始得到回电。
Mike 现在是一名数据工程师,与数据科学家密切合作。“面试的时候星火课程真的帮了大忙。”他的雇主向他承诺了很多变化,所以他期待着在他的工程知识的基础上继续学习数据科学。
2021 年对数据清理最有帮助的 Python 库
原文:https://www.dataquest.io/blog/most-helpful-python-libraries-for-data-cleaning/
September 23, 2021
大多数调查表明,数据科学家和数据分析师花费 70-80%的时间清理和准备用于分析的数据。对于许多数据工作者来说,数据的清理和准备也是他们工作中最不喜欢的部分,因此他们将其余 20-30%的时间用于抱怨。。。这个笑话大概是这样的。。。
不幸的是,数据总是会有某些不一致、遗漏的输入、不相关的信息、重复的信息或彻头彻尾的错误;这是无法回避的。尤其是当数据来自不同来源时,每一个都有自己的怪癖、挑战和不规则性。杂乱的数据是无用的数据,这就是为什么数据科学家花费大部分时间来理解所有的废话。
毫无疑问,清理和准备数据既繁琐又辛苦,而且很重要。你的数据越干净、越有条理,一切都会变得更快、更容易、更高效。在 Dataquest,我们知道这种斗争,所以我们很高兴分享我们的 15 个最有助于数据清理的 Python 库。
- NumPy
- 熊猫
- Matplotlib
- 数据清洁器
- 动力操作研究机构(dynamic operators research apparatus 的缩写)
- 希伯恩
- 箭
- Scrubadub
- 有平面的
- 缺少编号
- 摩丁
- Ftfy
- 我的天啊
- Dabl
- Imblearn
NumPy
NumPy 是一个快速易用的开源科学计算 Python 库。它也是数据科学生态系统的基础库,因为许多最受欢迎的 Python 库,如 Pandas 和 Matplotlib,都是基于 NumPy 构建的。
除了作为其他强大库的基础之外,NumPy 还有许多特性,这些特性使得它对于用于数据分析的Python 来说是不可或缺的。由于其速度和多功能性,NumPy 的向量化、索引和广播概念代表了数组计算的事实上的标准;然而,NumPy 在处理多维数组时确实大放异彩。它还提供了一个数字计算工具的综合工具箱,如线性代数例程、傅立叶变换等。
NumPy 可以为很多人做很多事情。其高级语法允许任何背景或经验水平的程序员使用其强大的数据处理能力。例如,NumPy 使事件视界太空望远镜产生了有史以来第一张黑洞图像。它还证实了引力波的存在,目前它正在加速各种科学研究和体育分析。
一个涵盖从体育到太空的所有内容的程序也可以帮助你管理和清理数据,这是不是很令人惊讶?
熊猫
熊猫是 NumPy 支持的图书馆之一。它是 Python 中使用最广泛的数据分析和操作库,不难看出其中的原因。
Pandas 快速且易于使用,其语法非常用户友好,再加上它在操作数据帧方面令人难以置信的灵活性,使它成为分析、操作和清理数据不可或缺的工具。
这个强大的 Python 库不仅处理数字数据,还处理文本数据和日期。它允许您连接、合并、连接或复制数据帧,并使用 drop()函数轻松添加或删除列或行。
简而言之,pandas 结合了速度、易用性和灵活的功能,创建了一个非常强大的工具,使数据操作和分析变得快速而简单。
Matplotlib
了解您的数据是清理过程的关键部分。清理数据的全部目的是让数据变得可以理解。但是在你拥有漂亮干净的数据之前,你需要了解你的杂乱数据中的问题,比如它们的种类和程度,然后你才能清理它。该操作的很大一部分依赖于准确而直观的数据呈现。
Matplotlib 以其令人印象深刻的数据可视化而闻名,这使得它成为数据清理的一个有价值的工具。它是使用 Python 生成图形、图表和其他 2D 数据可视化的首选库。
您可以在数据清理中使用 Matplotlib,通过生成分布图来帮助您了解数据的不足之处。你可以让它处理数据中的问题和异常的识别和可视化。这意味着您可以集中精力解决这些数据问题。
数据清洁器
Datacleaner 是一个基于熊猫数据框架的第三方库。Datacleaner 相当新,没有熊猫受欢迎,因为 Datacleaner 能做的许多事情在熊猫身上也是可能的。然而,Datacleaner 有一个独特的方法,它结合了一些典型的数据清理功能,并使它们自动化,从而节省您宝贵的时间和精力。
使用 Datacleaner,您可以在逐列的基础上用众数或中位数轻松替换缺失值,对分类变量进行编码,并删除缺失值的行。
动力操作研究机构(dynamic operators research apparatus 的缩写)
Dora 库使用 scikit-learn、pandas 和 Matplotlib 进行探索性分析,或者更具体地说,用于自动化探索性分析中最不理想的方面。除了负责特征选择、提取和可视化,Dora 还优化和自动化数据清理。
Dora 将通过许多数据清理功能为您节省宝贵的时间和精力,如输入缺失值、读取缺失值和缩放不当值的数据以及缩放输入变量的值。
此外,Dora 还提供了一个简单的接口,用于在转换数据时为数据拍摄快照,并且它以其独特的数据版本控制功能与其他 Python 包区别开来。
希伯恩
在本文的前面,我们讨论了可视化数据以揭示数据缺陷和不一致性的重要性。在解决数据中的问题之前,您需要知道它们是什么以及它们在哪里:数据可视化就是答案。对于许多 Python 用户来说,Matplotlib 是数据可视化的首选库。然而,一些用户发现 Matplotlib 在定制数据可视化选项方面的局限性令人沮丧。这就是为什么我们现在有了 seaborn。
Seaborn 是一个数据可视化包,它建立在 Matplotlib 的基础上,在提供可定制的数据可视化的同时,生成有吸引力的、信息丰富的统计图形。
虽然许多用户更喜欢 seaborn,因为它的定制功能,但它也改进了其前身的一个功能问题:即,seaborn 在 pandas 的数据框架内工作更流畅,使探索性分析和数据清理更令人愉快。
箭
提高数据质量的一个重要方面是在整个数据框架中创建统一性和一致性。对于试图在处理日期和时间时创建这种一致性的 Python 开发人员来说,这可能会令人沮丧。数小时和数行代码之后,日期和时间格式化的特殊困难仍然存在。
Arrow 是一个 Python 库,专门用来处理这些困难并创建数据一致性。它的省时功能包括时区转换;自动字符串格式化和解析;支持 pytz、dateutil 对象、ZoneInfo tzinfo 以及生成从微秒到年的时间范围的范围、下限、时间跨度和上限。
Arrow 是时区敏感的(与标准 Python 库不同),默认情况下是 UTC。它让用户可以用更少的代码和更少的输入更熟练地控制日期和时间。这意味着您可以提高数据的一致性,同时减少争分夺秒的时间。
Scrubadub
Scrubadub 是金融和医疗保健数据科学家的最爱,是一个专门从自由文本中消除个人身份信息(PII)的 Python 库。
这个简单、免费的开源软件包可以轻松地从您的数据中删除敏感的个人信息,并保护信任您的人的隐私和安全。
Scrubadub 目前允许用户清除其数据中的以下信息:
- 电子邮件地址
- 资源定位符
- 名称
- Skype 用户名
- 电话号码
- 密码/用户名组合
- 社会安全号码
有平面的
只需一个函数调用,制表将使用您的数据来创建小而有吸引力的表格,这些表格可读性很强,这要归功于许多功能,如数字格式、标题和按小数点对齐的列。
这个 开源库 还允许用户使用其他工具和语言处理表格数据,使用户能够以其他流行格式输出数据,如 HTML、PHP 或 Markdown Extra。
缺少编号
处理缺失值是数据清理的主要方面之一。Missingno 图书馆就是这么做的。它逐列识别并可视化数据帧中缺失的值,以便用户可以看到他们的数据所处的状态。
可视化问题是解决问题的第一步,Missingno 是一个简单方便的库,可以完成这项工作。
摩丁
熊猫已经是一个快速库了,正如我们上面提到的。但是摩丁把熊猫带到了一个全新的水平。摩丁通过分配数据和计算速度来提高熊猫的性能。
Modin 用户将受益于与 pandas 语法的平滑和不引人注目的集成,这可以将 pandas 的速度提高 400%!
Ftfy
另一个专门的库,Ftfy 非常简单并且擅长它所做的事情。这一切都在名称中,Ftfy,或“为您修复文本。”Ftfy 的诞生是为了一个简单的任务:将不好的 Unicode 和无用的字符转换成相关的可读文本数据。
例子:
“quoteâ€\x9d = "quote"
ü = ü
lt;3 = <3
如果你花很多时间处理文本数据,Ftfy 是一个方便的小工具,可以快速理解无意义的内容。
我的天啊
与这个列表中的其他提到的不同,SciPy 不仅仅是一个库;这是一个完整的数据科学生态系统,提供了这个列表中已经提到的一系列开源库,包括 NumPy、Matplotlib 和 pandas。
此外,SciPy 还提供了许多专门的工具,其中之一是 Scikit-learn,它的“预处理”包可用于数据清理和数据集标准化。
Dabl
scikit-learn 的核心工程师之一开发了 Dabl 作为数据分析库,以简化 数据探索 和预处理。
Dabl 有一个完整的流程来检测数据集中的某些数据类型和质量问题,并自动应用适当的预处理程序。
它可以处理缺失值,将分类变量转换为数值,它甚至有内置的可视化选项来促进快速数据探索。
Imblearn
我们倒计时的最后一个库是 unbalanced-learn(缩写为 Imblearn),它依赖于 Scikit-learn,并为面临分类和不平衡类的 Python 用户提供工具。
使用称为“欠采样”的预处理技术,Imblearn 将梳理您的数据,并删除数据集中缺失、不一致或不规则的值。
结论
当涉及到数据科学时,你会得到你投入的东西。数据分析模型的好坏取决于输入的数据,数据越干净,处理、分析和可视化就越简单。正是因为这个原因,我们专门为用 Python 清理 数据开辟了一条完整的技能之路。
这个库列表绝不是详尽的。Python 生态系统中有许多强大的工具,可以极大地改善数据科学家的日常工作流程。虽然你可能不会使用所有这些工具,但我们希望通过采用其中一些,你会看到日常效率、生产力和乐趣的显著提高。
如果您认为这篇文章有帮助或有见地,我们鼓励您加入我们由成千上万的学生和数据专业人员组成的蓬勃发展的社区,寻求了解更多关于不断扩展的数据科学世界的信息。今天就免费报名吧!
忘记动机,加倍你学习成功的机会
原文:https://www.dataquest.io/blog/motivation-double-chances-of-learning-success/
November 20, 2018
学习任何东西(包括数据科学)最困难的部分之一是保持动力。起初,我们对我们的新研究感到兴奋,我们通过基础知识进步很快。但随着时间的推移,随着工作变得更具挑战性,以及生活中出现的其他问题和压力,我们越来越容易摆脱这种状态。
这是一个非常普遍的现象。这就是为什么健身房通常在 1 月初挤满了新客户,但到了 2 月下旬,他们又变成了常客。
想要改变你的生活,很容易让人兴奋。很难让保持兴奋,尤其是当这种改变——比如健身或学习数据科学——很难,而且收效甚微的时候。
我们如何克服这一点?可悲的是,我们真的不能。我们可以用励志名言和海报包围自己,并试图伪装,但从长远来看,研究表明这并不真正有效。事实上,这可能会损害我们成功的机会!
但是有一种方法是我们可以确保我们更有可能坚持我们的目标:忽略动机,专注于科学家所说的实现意图。
动机和实施意图是什么?
在学习数据科学的背景下,我们都有自己的动机。我们中的一些人只是喜欢与数据打交道,其他人可能在寻找更有成就感的职业,或者更高的薪水。
这些动机是我们数据科学研究的“为什么”,是驱使我们首先进行研究的东西。“你为什么学数据科学?”这个问题的答案是你的动机。
如果动机是“为什么”,那么实施意图就是“如何”这是我们为实现目标而制定的具体计划。例如,如果我们的目标是学习数据科学,我们的实施意图可能是每天五点钟开始学习一个小时,或者每天晚上睡觉前学习一堂 Dataquest 课。
“你打算怎么学数据科学?”这个问题的答案应该是您的实现意图,并且应该明确您具体要做什么以及何时要做。
为什么这很重要?因为在心理学文献中,设定一个实现的意图对你是否真的实现它有相当大的影响。
各种研究已经证实的基本观点是,设定具体的环境触发的目标,如“我要在每天下午 5 点做这件事”,比思考我们做某事的动机(如作为数据科学家,我们最终可能获得更高的工资)有更高的成功率。
一个例子:健身
为了看到这种效果,让我们来看看一项真实的研究发表在 2002 年英国健康心理学杂志上。
在这项研究中,研究人员希望评估动机和实施意图如何影响那些希望坚持锻炼(至少每周一次)的人的成功率。因此,他们将 248 名想要更多锻炼的成人研究对象分成三组。
所有三个小组都被要求在两周内跟踪他们的锻炼情况,但是每个小组还被分配了一些其他任务:

结果相当惊人。在对照组中,只有 38%的人按照计划每周锻炼一次。在“动机”组中,只有 34%的人成功了。
但是“意图”组,得到激励,然后制定具体的执行计划,有令人难以置信的 91%的成功率。
这里有两个主要的教训,它们在类似的研究中反复出现:
- 动力本身并不特别有效
- 设定具体的时间和地点目标——实施意图——确实有效。
这到底是怎么回事?
实现一个目标几乎总是意味着我们需要定期执行某种行为。想成为一名伟大的吉他手吗?你需要让自己长期坚持练习。
我们需要一个“触发器”来让自己执行那个行为。动机作为行为触发器的问题是它不是特别可靠。我们没有足够的动力去每天执行任何行为。
在使用实现意图来制定具体的何时何地计划时,我们为行为设置了不同的外部触发器。如果我计划每天晚上 9 点在我的房间里学习,我学习行为的触发器不再是我的动机水平,而是晚上 9 点的钟声。
显然,这还涉及到某种程度的意志力。敲九点的钟本身不会迫使你开始学习。但是正如上面的研究表明的那样,简单地制定一个具体的、有意的计划会让你更有可能对时钟敲九下的外部触发做出反应。
如何制定你的计划
让我们回到学习数据科学的世界。如何利用这些知识让自己的学习更有成效?
首先,我们可以制定一个具体的计划,什么时候去学习,去哪里学习,每周学习多少。选择一个你很有可能有空的时间,一个可能支持你学习目标的地方,以及一个合理的时间段(每天学习六个小时是很好的,但是大多数人不能坚持很久)。
接下来,我们需要考虑意外情况。无论我们计划得多好,生活都是不可预测的,我们肯定会不时遇到干扰我们计划的中断和最后一分钟的计划变更。
处理这些问题的关键是预测它们,并计划如果-这个-那么-规则来解决可能出现的问题。例如:“如果发生了一些事情,我错过了晚上 9 点的学习时间,我会在周日下午 2 点多学习一个小时来弥补。”或者:如果我不在家,我会去咖啡店,晚上 9 点戴着耳机学习一个小时。"
外卖食品
如果你想提高你达到数据科学学习目标的机会,你不能只依靠动机。你需要做的是:
- 制定一个关于如何实现目标的具体计划,包括每周学习的地点、时间和方式等细节。确保这个计划是现实的,并能适应你的日常安排。
- 当你的计划出错时,制定“如果-这个-那么-那个”规则。“如果我错过了晚上 9 点的学习时间,我会在第二天早上提前一个小时醒来学习。”
当然,这不足以保证你成功,但是科学表明,简单地做这两件事将会大大增加你成功的机会。你会失去什么?
进入一个相关的问题 : 分享你的目标有助于还是有损于你成功的机会?
Python 中的多线程:终极指南(带编码示例)
July 14, 2022
在本教程中,我们将向您展示如何通过使用 Python 中的多线程技术在代码中实现并行性。
“并行”、“多线程”——这些术语是什么意思,它们之间有什么联系?我们将在本教程中回答您的所有问题,包括以下内容:
- 什么是并发?
- 并发和并行有什么区别?
- 进程和线程有什么区别?
- Python 中的多线程是什么?
- 什么是全局解释器锁?
这里我们假设您了解 Python 的基础知识,包括基本的结构和功能。如果你对这些不熟悉(或者急于复习),试试我们的 Python 数据分析基础——Data quest。
什么是并发?
在我们进入多线程细节之前,让我们比较一下并发编程和顺序编程。
在顺序计算中,程序的组成部分是逐步执行的,以产生正确的结果;然而,在并发计算中,不同的程序组件是独立或半独立的。因此,处理器可以独立地同时运行不同状态的组件。并发的主要优势在于改善程序的运行时间,这意味着由于处理器同时运行独立的任务,因此处理器运行整个程序并完成主要任务所需的时间更少。
并发和并行有什么区别?
并发是指在一个处理器和内核上,两个或多个任务可以在重叠的时间段内启动和完成。并行性是指多个任务或任务的分布式部分在多个处理器上同时独立运行。因此,在只有一个处理器和一个内核的机器上,并行是不可能的。
想象两个排队的顾客;并发意味着单个收银员通过在两个队列之间切换来服务客户。并行意味着两个收银员同时为两个顾客队列服务。
进程和线程有什么区别?
进程是一个正在执行的程序,它有自己的地址空间、内存、数据堆栈等。操作系统根据任何调度策略将资源分配给进程,并通过将 CPU 时间分配给不同的执行进程来管理进程的执行。
线程类似于进程。但是,它们在相同的进程中执行,并共享相同的上下文。因此,与其他线程共享信息或通信比它们是单独的进程更容易访问。
Python 中的多线程
Python 虚拟机不是线程安全的解释器,这意味着解释器在任何给定时刻只能执行一个线程。这个限制是由 Python 全局解释器锁(GIL)强制实施的,它本质上限制了一次只能运行一个 Python 线程。换句话说,GIL 确保在同一时间,在单个处理器上,只有一个线程在同一个进程中运行。
基本上,线程化可能不会加快所有任务的速度。与 CPU 绑定任务相比,花费大量时间等待外部事件的 I/O 绑定任务更有可能利用线程。
注
Python 附带了两个用于实现多线程程序的内置模块,包括thread和threading模块。thread和threading模块为创建和管理线程提供了有用的特性。然而,在本教程中,我们将把重点放在threading模块上,这是一个改进很多的高级模块,用于实现严肃的多线程程序。此外,Python 提供了Queue模块,允许我们创建一个队列数据结构来跨多个线程安全地交换信息。
让我们从一个简单的例子开始,来理解使用多线程编程的好处。
假设我们有一个整数列表,我们要计算每个数字的平方和立方,然后在屏幕上打印出来。
该程序包括如下两个独立的任务(功能):
import time
def calc_square(numbers):
for n in numbers:
print(f'\n{n} ^ 2 = {n*n}')
time.sleep(0.1)
def calc_cube(numbers):
for n in numbers:
print(f'\n{n} ^ 3 = {n*n*n}')
time.sleep(0.1)
上面的代码实现了两个功能,calc_square()和calc_cube()。calc_square()函数计算列表中每个数字的平方,calc_cube()计算列表中每个数字的立方。函数体中的time.sleep(0.1)语句在每次迭代结束时暂停代码执行 0.1 秒。我们将这个语句添加到函数中,使 CPU 空闲一会儿,并模拟一个 I/O 绑定的任务。在真实的场景中,I/O 绑定的任务可能会等待外围设备或 web 服务响应。
numbers = [2, 3, 5, 8]
start = time.time()
calc_square(numbers)
calc_cube(numbers)
end = time.time()
print('Execution Time: {}'.format(end-start))
如您所见,程序的顺序执行几乎需要一秒钟。现在让我们利用 CPU 的空闲时间,利用多线程技术,减少总的执行时间。多线程技术通过在其他任务等待 I/O 响应的同时将 CPU 时间分配给一个任务来减少运行时间。让我们看看它是如何工作的:
import threading
start = time.time()
square_thread = threading.Thread(target=calc_square, args=(numbers,))
cube_thread = threading.Thread(target=calc_cube, args=(numbers,))
square_thread.start()
cube_thread.start()
square_thread.join()
cube_thread.join()
end = time.time()
print('Execution Time: {}'.format(end-start))
2 ^ 2 = 4
2 ^ 3 = 8
3 ^ 3 = 27
3 ^ 2 = 9
5 ^ 3 = 125
5 ^ 2 = 25
8 ^ 2 = 64
8 ^ 3 = 512
Execution Time: 0.4172379970550537
太棒了,执行时间不到半秒,这是一个相当大的改进,这要归功于多线程。让我们一行一行地研究代码。
首先,我们需要导入“线程”模块,这是一个具有各种有用特性的高级线程模块。
我们使用“Thread”构造方法来创建一个线程实例。在此示例中,“Thread”方法以元组的形式接受两个输入,即函数名(target)及其参数(args)。当一个线程开始执行时,这个函数将被执行。当我们实例化“Thread”类时,将自动调用“Thread”构造方法,它将创建一个新线程。但是新线程不会立即开始执行,这是一个很有价值的同步特性,一旦所有线程都被分配,我们就可以启动线程。
要开始线程执行,我们需要分别调用每个线程实例的“start”方法。因此,这两行同时执行 square 和 cube 线程:
square_thread.start()
cube_thread.start()
我们需要做的最后一件事是调用“join”方法,它告诉一个线程等待,直到另一个线程的执行完成:
square_thread.join()
cube_thread.join()
当sleep方法暂停执行calc_square()函数 0.1 秒时,calc_cube()函数被执行并打印出列表中某个值的立方,然后进入休眠状态,calc_square()函数将被执行。换句话说,操作系统在线程之间来回切换,每次运行一点点,这导致了整个进程运行时间的改进。
threading方法
Python threading模块提供了一些有用的函数,帮助您高效地管理我们的多线程程序:
| * 方法名* | * 描述* | 方法的结果 |
|---|---|---|
| threading.active_count() | 返回当前活动线程的数量 | 8 |
| threading . current _ thread() | 返回当前线程,对应于调用者的控制线程 | < _MainThread(主线程,已启动 4303996288) > |
| threading.enumerate() | 返回当前所有活动线程的列表,包括主线程;被终止的线程和尚未启动的线程被排除在外 | [ < MainThread(MainThread,已启动 4303996288) >,<Thread(Thread-4( Thread _ main),已启动守护进程 6182760448) >,<heart(Thread-5,已启动守护进程 6199586816) >,<Thread(Thread-6(_ watch _ pipe _ FD),已启动守护进程 6217560064) >,】 |
| threading.main_thread() | 返回主线程 | < _MainThread(主线程,已启动 4303996288) > |
结论
多线程是高级编程中实现高性能应用程序的一个广泛概念,本教程涉及 Python 中多线程的基础知识。我们讨论了并发和并行计算的基本术语,然后实现了一个基本的多线程程序来计算数字列表的平方和立方。我们将在以后讨论一些更高级的多线程技术。
教程:用朴素贝叶斯预测电影评论情绪
March 17, 2015Sentiment analysis is a field dedicated to extracting subjective emotions and feelings from text. One common use of sentiment analysis is to figure out if a text expresses negative or positive feelings. Written reviews are great datasets for doing sentiment analysis because they often come with a score that can be used to train an algorithm. Naive Bayes is a popular algorithm for classifying text. Although it is fairly simple, it often performs as well as much more complicated solutions. In this post, we’ll use the naive Bayes algorithm to predict the sentiment of movie reviews. We’ll also do some natural language processing to extract features to train the algorithm from the text of the reviews.
在我们分类之前
我们有一个包含电影评论的 csv 文件。数据集中的每一行包含评论的文本,以及评论的语气是否被分类为正面(
1),或者负(-1)。我们希望在给定文本的情况下,预测评论是负面的还是正面的。为了做到这一点,我们将使用train.csv中的评论和分类来训练一个算法,然后对test.csv中的评论进行预测。然后我们将能够使用test.csv中的实际分类来计算我们的误差,并看看我们的预测有多好。对于我们的分类算法,我们将使用朴素贝叶斯。朴素贝叶斯分类器的工作原理是计算出数据的不同属性与某个类相关联的概率。这是基于贝叶斯定理。定理为(P(A \mid B) = \frac{P(B \mid A),P(A)}{P(B)})。这基本上说明了“给定 B 为真的概率等于给定 A 为真的概率乘以 A 为真的概率,除以 B 为真的概率。”让我们做一个快速练习来更好地理解这条规则。
# Here's a running history for the past week.
# For each day, it contains whether or not the person ran, and whether or not they were tired.
days = [["ran", "was tired"], ["ran", "was not tired"], ["didn't run", "was tired"], ["ran", "was tired"], ["didn't run", "was not tired"], ["ran", "was not tired"], ["ran", "was tired"]]
# Let's say we want to calculate the odds that someone was tired given that they ran, using bayes' theorem.
# This is P(A).
prob_tired = len([d for d in days if d[1] == "was tired"]) / len(days)
# This is P(B).
prob_ran = len([d for d in days if d[0] == "ran"]) / len(days)
# This is P(B|A).
prob_ran_given_tired = len([d for d in days if d[0] == "ran" and d[1] == "was tired"]) / len([d for d in days if d[1] == "was tired"])
# Now we can calculate P(A|B).
prob_tired_given_ran = (prob_ran_given_tired * prob_tired) / prob_ran
print("Probability of being tired given that you ran: {0}".format(prob_tired_given_ran))
Probability of being tired given that you ran: 0.6
朴素贝叶斯简介
让我们尝试一个稍微不同的例子。假设我们还有一个分类——你是否累了。假设我们有两个数据点——你是否跑步,以及你是否早起。贝叶斯定理在这种情况下不适用,因为我们有两个数据点,而不是一个。这就是朴素贝叶斯可以帮忙的地方。朴素贝叶斯通过假设每个数据点都是独立的,扩展了贝叶斯定理来处理这种情况。公式看起来是这样的:(P(y \mid x_1,\dots,x _ n)= \ frac { p(y)\prod_{i=1}^{n} p(x _ I \ mid y)} { p(x _ 1,\dots,x_n)}\。也就是说“给定特征(x1 )、(x2 )等,分类 y 正确的概率等于 y 乘以给定 y 的每个 x 特征的乘积,再除以 x 特征的概率”。要找到“正确的”分类,我们只需用公式找出哪个分类( (P(y \mid x_1,\dots,x_n)))的概率最高。
# Here's our data, but with "woke up early" or "didn't wake up early" added.
days = [["ran", "was tired", "woke up early"], ["ran", "was not tired", "didn't wake up early"], ["didn't run", "was tired", "woke up early"], ["ran", "was tired", "didn't wake up early"], ["didn't run", "was tired", "woke up early"], ["ran", "was not tired", "didn't wake up early"], ["ran", "was tired", "woke up early"]]
# We're trying to predict whether or not the person was tired on this day.new_day = ["ran", "didn't wake up early"]
def calc_y_probability(y_label, days):
return len([d for d in days if d[1] == y_label]) / len(days)
def calc_ran_probability_given_y(ran_label, y_label, days):
return len([d for d in days if d[1] == y_label and d[0] == ran_label]) / len(days)
def calc_woke_early_probability_given_y(woke_label, y_label, days):
return len([d for d in days if d[1] == y_label and d[2] == woke_label]) / len(days)
denominator = len([d for d in days if d[0] == new_day[0] and d[2] == new_day[1]]) / len(days)
# Plug all the values into our formula. Multiply the class (y) probability, and the probability of the x-values occuring given that class.
prob_tired = (calc_y_probability("was tired", days) * calc_ran_probability_given_y(new_day[0], "was tired", days) * calc_woke_early_probability_given_y(new_day[1], "was tired", days)) / denominator
prob_not_tired = (calc_y_probability("was not tired", days) * calc_ran_probability_given_y(new_day[0], "was not tired", days) * calc_woke_early_probability_given_y(new_day[1], "was not tired", days)) / denominator
# Make a classification decision based on the probabilities.
classification = "was tired"
if prob_not_tired > prob_tired:
classification = "was not tired"
print("Final classification for new day: {0}. Tired probability: {1}. Not tired probability: {2}.".format(classification, prob_tired, prob_not_tired))
Final classification for new day: was tired. Tired probability: 0.10204081632653061\. Not tired probability: 0.054421768707482984.
查找字数
我们试图确定一个数据行应该归类为负数还是正数。正因为如此,我们可以忽略分母。正如您在最后一个代码示例中看到的,它在每个可能的类中都是一个常数,因此对每个概率的影响是相等的,所以它不会改变哪个是最大的(用 5 除以 2 和用 10 除以 2 不会改变第二个数字更大的事实)。因此,我们必须计算每个分类的概率,以及每个特征落入每个分类的概率。在上一个例子中,我们使用了几个独立的特性。这里,我们只有一根长绳子。从文本生成要素的最简单方法是将文本分割成单词。评论中的每个单词都将成为我们可以使用的功能。为了做到这一点,我们将根据空白分割评论。然后,我们将统计每个词在负面评价中出现的次数,以及每个词在正面评价中出现的次数。这将允许我们最终计算属于每个类的新评论的概率。
# A nice python class that lets you count how many times items occur in a list
from collections import Counter
import csv
import re
# Read in the training data.
with open("train.csv", 'r') as file:
reviews = list(csv.reader(file))
def get_text(reviews, score):
# Join together the text in the reviews for a particular tone.
# We lowercase to avoid "Not" and "not" being seen as different words, for example.
return " ".join([r[0].lower() for r in reviews if r[1] == str(score)])
def count_text(text):
# Split text into words based on whitespace. Simple but effective.
words = re.split("\s+", text)
# Count up the occurence of each word.
return Counter(words)
negative_text = get_text(reviews, -1)
positive_text = get_text(reviews, 1)
# Generate word counts for negative tone.
negative_counts = count_text(negative_text)
# Generate word counts for positive tone.
positive_counts = count_text(positive_text)
print("Negative text sample: {0}".format(negative_text[:100]))
print("Positive text sample: {0}".format(positive_text[:100]))
Negative text sample: plot : two teen couples go to a church party drink and then drive . they get into an accident . one
Positive text sample: films adapted from comic books have had plenty of success whether they're about superheroes ( batman
做出预测
现在我们有了字数,我们只需要将它们转换成概率,然后乘以它们就可以得到预测的分类。假设我们想找出评论
didn't like it表示消极的情绪。我们将找到单词didn't在负面评论中出现的总次数,并用它除以负面评论中的单词总数,得到给定 y 时 x 的概率。然后我们将对like和it做同样的事情。我们将所有三个概率相乘,然后乘以任何表达负面情绪的文档的概率,以获得句子表达负面情绪的最终概率。对于积极情绪,我们也会这样做,然后无论哪个概率更大,都将是该评论被分配到的类别。要做到这一点,我们需要计算数据中每个类出现的概率,然后创建一个函数来计算分类。
import re
from collections import Counter
def get_y_count(score):
# Compute the count of each classification occuring in the data.
return len([r for r in reviews if r[1] == str(score)])
# We need these counts to use for smoothing when computing the prediction.
positive_review_count = get_y_count(1)
negative_review_count = get_y_count(-1)
# These are the class probabilities (we saw them in the formula as P(y)).
prob_positive = positive_review_count / len(reviews)
prob_negative = negative_review_count / len(reviews)
def make_class_prediction(text, counts, class_prob, class_count):
prediction = 1
text_counts = Counter(re.split("\s+", text))
for word in text_counts:
# For every word in the text, we get the number of times that word occured in the reviews for a given class, add 1 to smooth the value, and divide by the total number of words in the class (plus the class_count to also smooth the denominator).
# Smoothing ensures that we don't multiply the prediction by 0 if the word didn't exist in the training data.
# We also smooth the denominator counts to keep things even.
prediction *= text_counts.get(word) * ((counts.get(word, 0) + 1) / (sum(counts.values()) + class_count))
# Now we multiply by the probability of the class existing in the documents.
return prediction * class_prob
# As you can see, we can now generate probabilities for which class a given review is part of.
# The probabilities themselves aren't very useful -- we make our classification decision based on which value is greater.
print("Review: {0}".format(reviews[0][0]))
print("Negative prediction: {0}".format(make_class_prediction(reviews[0][0], negative_counts, prob_negative, negative_review_count)))
print("Positive prediction: {0}".format(make_class_prediction(reviews[0][0], positive_counts, prob_positive, positive_review_count)))
Review: plot : two teen couples go to a church party drink and then drive . they get into an accident . one of the guys dies but his girlfriend continues to see him in her life and has nightmares . what's the deal ? watch the movie and " sorta " find out . . . critique : a mind-fuck movie for the teen generation that touches on a very cool idea but presents it in a very bad package . which is what makes this review an even harder one to write since i generally applaud films which attempt
Negative prediction: 3.0050530362356505e-221
Positive prediction: 1.3071705466906793e-226
预测测试集
现在我们可以预测了,让我们来预测
test.csv。如果你对train.csv中的评论进行预测,你会得到误导性的好结果,因为概率是从中产生的(而且,算法对它预测的数据有先验知识)。在训练集上获得好的结果可能意味着你的模型是过度拟合,并且只是拾取随机噪声。只有在模型未被训练的集合上进行测试,才能告诉你它是否正常运行。
import csv
def make_decision(text, make_class_prediction):
# Compute the negative and positive probabilities.
negative_prediction = make_class_prediction(text, negative_counts, prob_negative, negative_review_count)
positive_prediction = make_class_prediction(text, positive_counts, prob_positive, positive_review_count)
# We assign a classification based on which probability is greater.
if negative_prediction > positive_prediction:
return -1
return 1
with open("test.csv", 'r') as file:
test = list(csv.reader(file))
predictions = [make_decision(r[0], make_class_prediction) for r in test]
计算错误
现在我们知道了预测,我们将使用下面的面积来计算误差
ROC 曲线。这将告诉我们模型有多“好”——越接近 1 意味着模型越好。计算误差对于知道你的模型什么时候是“好的”,什么时候变得更好或更差非常重要。
actual = [int(r[1]) for r in test]
from sklearn import metrics
# Generate the roc curve using scikit-learn.
fpr, tpr, thresholds = metrics.roc_curve(actual, predictions, pos_label=1)
# Measure the area under the curve. The closer to 1, the "better" the predictions.
print("AUC of the predictions: {0}".format(metrics.auc(fpr, tpr)))
AUC of the predictions: 0.680701754385965
一种更快的预测方法
我们可以对这个算法进行许多扩展,使它的性能更好。我们可以看看
n-grams 而不是 unigrams。我们可以删除标点符号和其他非字符。我们可以移除停用词。我们也可以执行词干或词条化。但是,我们不希望每次都必须将整个算法编码出来。使用朴素贝叶斯的一个更简单的方法是使用 scikit-learn 中的实现。Scikit-learn 是一个 python 机器学习库,包含了所有常见机器学习算法的实现。
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import metrics
# Generate counts from text using a vectorizer. There are other vectorizers available, and lots of options you can set.
# This performs our step of computing word counts.
vectorizer = CountVectorizer(stop_words='english')
train_features = vectorizer.fit_transform([r[0] for r in reviews])
test_features = vectorizer.transform([r[0] for r in test])
# Fit a naive bayes model to the training data.
# This will train the model using the word counts we computer, and the existing classifications in the training set.
nb = MultinomialNB()
nb.fit(train_features, [int(r[1]) for r in reviews])
# Now we can use the model to predict classifications for our test features.
predictions = nb.predict(test_features)
# Compute the error. It is slightly different from our model because the internals of this process work differently from our implementation.
fpr, tpr, thresholds = metrics.roc_curve(actual, predictions, pos_label=1)
print("Multinomial naive bayes AUC: {0}".format(metrics.auc(fpr, tpr)))
Multinomial naive bayes AUC: 0.6509287925696594
接下来的步骤
要了解更多信息,请查看我们的 Dataquest 课程
教程:使用 Python 进行自然语言处理
原文:https://www.dataquest.io/blog/natural-language-processing-with-python/
June 9, 2015
Python 有一些强大的工具,可以让你做自然语言处理 (NLP)。在本教程中,我们将学习如何用 Python 做一些基本的自然语言处理。
看着数据
我们将看到一个由 2006 年至 2015 年《黑客新闻》的子新闻组成的数据集。数据取自这里的。Arnaud Drizard 用黑客新闻 API 刮出来的。我们从数据中随机抽取了10000行,并删除了所有无关的列。我们的数据只有四列:
sublesson_time—故事提交的时间。url—子订阅的基本 url。upvotes—分包商获得的支持票数。headline—分包合同的标题。
我们将利用头条来预测投票数。数据存储在sublessons变量中。
自然语言处理—第一步
我们希望最终训练一个机器学习算法来接受一个标题,并告诉我们它将获得多少赞成票。但是,机器学习算法只理解数字,不理解文字。我们如何将我们的标题翻译成算法可以理解的东西?
第一步是创建一个叫做单词包矩阵的东西。一包单词矩阵给了我们哪个单词在哪个标题中的数字表示。为了构建一个单词包矩阵,我们首先在整个标题集中找到唯一的单词。然后,我们建立一个矩阵,其中每行是一个标题,每列是一个独特的单词。然后,我们在每个单元格中填入该词在标题中出现的次数。这将产生一个矩阵,其中许多单元格的值为零,除非词汇表主要在标题之间共享。
from collections import Counter
headlines = [
"PretzelBros, airbnb for people who like pretzels, raises $2 million",
"Top 10 reasons why Go is better than whatever language you use.",
"Why working at apple stole my soul (I still love it though)",
"80 things I think you should do immediately if you use python.",
"Show HN: carjack.me -- Uber meets GTA"
]
# Find all the unique words in the headlines.
unique_words = list(set(" ".join(headlines).split(" ")))
def make_matrix(headlines, vocab):
matrix = []
for headline in headlines:
# Count each word in the headline, and make a dictionary.
counter = Counter(headline)
# Turn the dictionary into a matrix row using the vocab.
row = [counter.get(w, 0) for w in vocab]
matrix.append(row)
df = pandas.DataFrame(matrix)
df.columns = unique_words
return df
print(make_matrix(headlines, unique_words))
why HN: for people immediately like I Go 80 meets ... my who
0 0 0 0 0 0 0 0 0 0 0 ... 0 0
1 0 0 0 0 0 0 0 0 0 0 ... 0 0
2 0 0 0 0 0 0 1 0 0 0 ... 0 0
3 0 0 0 0 0 0 1 0 0 0 ... 0 0
4 0 0 0 0 0 0 0 0 0 0 ... 0 0
PretzelBros, whatever language do $2 still than soul
0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0
[5 rows x 51 columns]
删除标点符号
我们刚刚制作的矩阵非常稀疏,这意味着许多值为零。这在某种程度上是不可避免的,因为标题没有太多的共享词汇。不过,我们可以采取一些措施来改善这个问题。现在Why和why,以及use和use.被视为不同的实体,但是我们知道它们指的是同一个词。我们可以通过降低每个单词的大小写并删除所有标点符号来帮助解析器识别出这些事实上是相同的。
import re
# Lowercase, then replace any non-letter, space, or digit character in the headlines.
new_headlines = [re.sub(r'[^wsd]','',h.lower()) for h in headlines]
# Replace sequences of whitespace with a space character.
new_headlines = [re.sub("s+", " ", h) for h in new_headlines]
unique_words = list(set(" ".join(new_headlines).split(" ")))
# We've reduced the number of columns in the matrix a bit.
print(make_matrix(new_headlines, unique_words))
2 why top hn for people immediately like python 80 ... should
0 1 0 0 0 0 0 0 0 0 0 ... 0
1 0 0 0 0 0 0 0 0 0 0 ... 0
2 0 0 0 0 0 0 0 0 0 0 ... 0
3 0 0 0 0 0 0 0 0 0 0 ... 0
4 0 0 0 0 0 0 0 0 0 0 ... 0
my who go whatever language do still than soul
0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0
[5 rows x 47 columns]
移除停用字词
某些词不能帮助你区分好的和坏的标题。像the、a和also这样的词在所有的上下文中出现得足够频繁,以至于它们并不能真正告诉我们什么东西是好是坏。它们通常同样可能出现在好的和坏的标题中。通过删除这些,我们可以减少矩阵的大小,并使训练算法更快。
# Read in and split the stopwords file.
with open("stop_words.txt", 'r') as f:
stopwords = f.read().split("n")
# Do the same punctuation replacement that we did for the headlines, # so we're comparing the right things.
stopwords = [re.sub(r'[^wsd]','',s.lower()) for s in stopwords]
unique_words = list(set(" ".join(new_headlines).split(" ")))
# Remove stopwords from the vocabulary.unique_words = [w for w in unique_words if w not in stopwords]
# We're down to 34 columns, which is way better!
print(make_matrix(new_headlines, unique_words))
2 top hn people immediately like python 80 meets pretzels ... \
0 1 0 0 0 0 0 0 0 0 0 ...
1 0 0 0 0 0 0 0 0 0 0 ...
2 0 0 0 0 0 0 0 0 0 0 ...
3 0 0 0 0 0 0 0 0 0 0 ...
4 0 0 0 0 0 0 0 0 0 0 ...
gta 10 uber raises pretzelbros go whatever language still soul
0 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0
[5 rows x 34 columns]
为所有标题生成矩阵
现在我们知道了基础知识,我们可以为整套标题制作一个单词包矩阵。我们不希望每次都必须手工编写代码,所以我们将使用来自 scikit-learn 的一个类来自动完成。使用 scikit-learn 的矢量器来构建你的单词矩阵包将会使这个过程变得更加容易和快速。
from sklearn.feature_extraction.text import CountVectorizer
# Construct a bag of words matrix.
# This will lowercase everything, and ignore all punctuation by default.
# It will also remove stop words.
vectorizer = CountVectorizer(lowercase=True, stop_words="english")
matrix = vectorizer.fit_transform(headlines)
# We created our bag of words matrix with far fewer commands.
print(matrix.todense())
# Let's apply the same method to all the headlines in all 100000 sublessons.
# We'll also add the url of the sublesson to the end of the headline so we can take it into account.
sublessons['full_test'] = sublessons["headline"] + " " + sublessons["url"]
full_matrix = vectorizer.fit_transform(sublessons["headline"])
print(full_matrix.shape)
[[0 0 1 0 0 0 0 0 0 0 1 0 0 1 1 1 1 0 1 0 0 0 0 0 0 0 0]
[1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0]
[0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 1]
[0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 1 0]
[0 0 0 0 0 1 1 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0]]
(9356, 13631)
降维
我们已经构建了一个矩阵,但是它现在有13631个唯一的单词,或者列。这将需要很长时间来进行预测。我们想加快速度,所以我们需要以某种方式减少列数。一种方法是选择信息最丰富的列的子集,即最能区分好标题和坏标题的列。
找出信息量最大的列的一个好方法是使用一种叫做卡方测试的东西。卡方检验发现,在高投票率的帖子和没有高投票率的帖子之间,区别最大的词。这可以是在高投票的帖子中出现很多的词,而在没有投票的帖子中根本不会出现,或者是在没有投票的帖子中出现很多的词,但在投票的帖子中不会出现。卡方检验只对二进制值起作用,因此我们将通过将任何比平均值多的投票数设置为1并将任何比平均值少的投票数设置为0来使我们的 upvotes 列为二进制。这样做的一个缺点是,我们使用来自数据集的知识来选择特征,因此引入了一些过度拟合。我们可以通过使用数据的子集进行特征选择,并使用不同的子集来训练算法,来避免“现实世界”中的过度拟合。我们现在让事情简单一点,跳过这一步。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# Convert the upvotes variable to binary so it works with a chi-squared test.
col = sublessons["upvotes"].copy(deep=True)
col_mean = col.mean()
col[col < col_mean] = 0
col[(col > 0) & (col > col_mean)] = 1
# Find the 1000 most informative columns
selector = SelectKBest(chi2, k=1000)
selector.fit(full_matrix, col)
top_words = selector.get_support().nonzero()
# Pick only the most informative columns in the data.
chi_matrix = full_matrix[:,top_words[0]]
添加元特征
如果我们忽略了标题的“元”特征,我们就会错过很多好的信息。这些特征包括长度、标点符号数量、平均单词长度和其他句子特定的特征。添加这些可以大大提高预测的准确性。为了添加它们,我们将遍历标题,并对每个标题应用一个函数。一些函数将计算标题的字符长度,其他函数将做更高级的事情,比如计算数字的个数。
# Our list of functions to apply.
transform_functions = [
lambda x: len(x),
lambda x: x.count(" "),
lambda x: x.count("."),
lambda x: x.count("!"),
lambda x: x.count("?"),
lambda x: len(x) / (x.count(" ") + 1),
lambda x: x.count(" ") / (x.count(".") + 1),
lambda x: len(re.findall("d", x)),
lambda x: len(re.findall("[A-Z]", x)),
]
# Apply each function and put the results into a list.
columns = []
for func in transform_functions:
columns.append(sublessons["headline"].apply(func))
# Convert the meta features to a numpy array.
meta = numpy.asarray(columns).T
添加更多功能
我们可以使用的功能不仅仅是文本功能。我们有一个名为sublesson_time的专栏,告诉我们一个故事是何时提交的,并且可以添加更多信息。通常,在进行 NLP 工作时,您可以添加外部特征,使您的预测更好。一些机器学习算法可以计算出这些特征如何与你的文本特征进行交互(即“在午夜发布标题中带有‘tacos’一词的帖子会导致高分帖子”)。
columns = []
# Convert the sublesson dates column to datetime.
sublesson_dates = pandas.to_datetime(sublessons["sublesson_time"])
# Transform functions for the datetime column.
transform_functions = [
lambda x: x.year,
lambda x: x.month,
lambda x: x.day,
lambda x: x.hour,
lambda x: x.minute
]
# Apply all functions to the datetime column.
for func in transform_functions:
columns.append(sublesson_dates.apply(func))
# Convert the meta features to a numpy array.
non_nlp = numpy.asarray(columns).T
# Concatenate the features together.
features = numpy.hstack([non_nlp, meta, chi_matrix.todense()])
做出预测
既然我们可以将单词翻译成数字,我们就可以使用算法进行预测。我们将随机选取7500个标题作为训练集,然后在2500个标题的测试集上评估算法的性能。在我们训练的同一个集合上预测结果将导致过度拟合,此时你的算法对训练集过度优化——我们会认为错误率很好,但实际上在新数据上它可能会高得多。对于算法,我们将使用岭回归。与普通的线性回归相比,岭回归引入了对系数的惩罚,防止它们变得太大。这可以帮助它处理大量相互关联的预测值(列),就像我们所做的那样。
from sklearn.linear_model
import Ridge
import numpy
import random
train_rows = 7500
# Set a seed to get the same "random" shuffle every time.
random.seed(1)
# Shuffle the indices for the matrix.
indices = list(range(features.shape[0]))
random.shuffle(indices)
# Create train and test sets.
train = features[indices[:train_rows], :]
test = features[indices[train_rows:], :]
train_upvotes = sublessons["upvotes"].iloc[indices[:train_rows]]
test_upvotes = sublessons["upvotes"].iloc[indices[train_rows:]]
train = numpy.nan_to_num(train)
# Run the regression and generate predictions for the test set.
reg = Ridge(alpha=.1)
reg.fit(train, train_upvotes)
predictions = reg.predict(test)
评估错误
我们现在有预测,但我们如何确定它们有多好?一种方法是计算测试集上的预测和测试集的实际向上投票计数之间的错误率。我们还需要一个巴塞尔协议来比较误差,看看结果是否好。我们可以通过使用一个简单的方法来对测试集进行基线估计,并将我们预测的错误率与基线估计的错误率进行比较。
一个非常简单的基线是获取训练集中每个子成员的平均投票数,并将其用作每个子成员的预测。我们将使用平均绝对误差作为误差度量。非常简单——只需从预测值中减去实际值,取差值的绝对值,然后求所有差值的平均值。
# We're going to use mean absolute error as an error metric.
# Our error is about 13.6 upvotes, which means that, on average,
# our prediction is 13.6 upvotes away from the actual number of upvotes.
print(sum(abs(predictions - test_upvotes)) / len(predictions))
# As a baseline, we'll use the average number of upvotes# across all sublessons.
# The error here is 17.2 -- our estimate is better, but not hugely so.
# There either isn't a ton of predictive value encoded in the
# data we have, or we aren't extracting it well.
average_upvotes = sum(test_upvotes)/len(test_upvotes)
print(sum(abs(average_upvotes - test_upvotes)) / len(predictions))
13.6606593988
17.2759421912
接下来的步骤
这种方法在这个数据集上工作得相当好,但不是非常好。我们发现标题和其他栏目有一定的预测价值。我们可以通过使用不同的预测算法来改进这种方法,比如随机森林或神经网络。当我们生成单词包矩阵时,我们也可以使用 ngrams,比如二元模型和三元模型。
在矩阵上尝试一个 tf-idf 变换也会有所帮助——sci kit-learn 有一个类可以自动完成这项工作。我们还可以考虑其他数据,如提交文章的用户,并生成指示用户因果报应和用户最近活动的特征。提交的 url 上的其他统计数据,如收到的来自该 url 的平均 upvotes sublessons 数也可能是有用的。
在执行这些操作时要小心,只考虑在您预测的分包完成之前就存在的信息。所有这些添加将比我们目前所做的花费更长的时间,但是会减少错误。希望你有时间尝试一下!如果你想更多地使用 NLP,你可以看看我们的交互式自然语言编程课程。
新课程:R 语言中的机器学习导论
原文:https://www.dataquest.io/blog/new-course-learn-machine-learning-in-r/
April 17, 2020
机器学习可能是任何数据专业人员工具箱中的一个强大工具。无论你的目标是成为一名数据科学家,还是仅仅希望从有趣的数据集中获得更多,学习使用 R 进行机器学习都可以帮助你打开一个全新的洞察力世界。
这就是为什么我们很高兴地宣布,我们将在 R 职业道路中为我们的数据分析师推出另一门课程:R机器学习简介。

在我们的 R 课程路径中,本课程遵循另一个最近发布的版本R 中的线性建模。它包括五个新的教训,并以一个新的指导项目结束。
这门课程包括什么?
《机器学习简介》涵盖了机器学习工作流的基础知识,这是一种无论使用何种算法都可以用来构建和调整模型的方法。
由于 Dataquest 侧重于实践学习,而不仅仅是告诉您工作流程,因此我们将在您使用 k-nearest neighbors 算法构建和优化模型时一步一步地指导您
为了做到这一点,您将使用您的 R 编程技能和脱字符包在 R 中进行机器学习。
本课程首先引导您使用误差度量和简单验证来构建和评估单变量模型。然后,您将深入更高级的主题,如多元模型、交叉验证和超参数优化。
与所有 Dataquest 课程一样,在通过编写自己的代码立即应用每门新课之前,您将通过它学习一点点文本块。

概括地说,Dataquest 平台。
在课程结束时,你将把它们与一个更开放的引导项目结合起来,该项目将挑战你建立一个准确的模型,从头开始预测汽车价格。
为什么我需要学习这个?
对于任何有兴趣从事数据科学家工作的人来说,机器学习是一项关键技能。如果 R 是你选择的语言,那么你至少需要扎实掌握大多数数据科学家工作的基础知识。
这意味着能够将机器学习应用于现实世界的数据问题,也意味着了解引擎盖下实际发生的事情,以便在遇到新问题时知道应用什么样的解决方案。
像所有的 Dataquest 课程一样,R 语言的机器学习导论涵盖了基础理论和实际应用。你需要通过技术面试,并成功地将机器学习模型应用于现实世界的问题。
即使你对数据科学家的工作不感兴趣,机器学习技能也可以解锁有价值的见解,并帮助你发现你自己永远无法看到的模式。
坦率地说,构建 ML 模型也很有趣!
这门课的第一课是免费的,为什么不试试呢?你可能会惊讶于你学得有多快!
成为数据分析师!
立即学习成为数据分析师所需的技能。注册一个免费帐户,获得免费的交互式 Python、R 和 SQL 课程内容。
(不需要信用卡!)
NLP 项目第 1 部分:搜集网络数据
原文:https://www.dataquest.io/blog/nlp-project-scraping-the-web-to-gather-data/
December 20, 2021
这是描述我的自然语言处理(NLP)项目的系列文章中的第一篇。要真正从这篇 NLP 文章中受益,您应该了解 pandas 库并了解用于清理数据的 regex。我们还将关注网络抓取,因此 HTML(用于创建网站的语言)的基础知识非常有帮助,但不是必不可少的。
这个 NLP 项目是关于收集和分析来自 Dataquest 社区的帖子!如果您不熟悉 Dataquest 社区,这是一个获得项目反馈的好地方。我在社区中分享我的项目,人们分享他们对我工作的见解让我受益匪浅。随着我的进步,我开始回馈并向其他人展示在他们的笔记本上我本可以做得不同的地方。
我甚至开始写一篇关于如何建设好项目的来自社区的建议的普通帖子。为了在我的帖子中包含更多有趣的内容,我开始查看其他用户对指导项目的反馈。然后,我有了主意!等一下。。。如果我们将每个指导项目的所有反馈数据合并到一个数据集中会怎么样?
基于此,我决定从 Dataquest 社区收集所有的项目反馈,并对其进行分析,以找到最常见的项目反馈。
结构
我把这个项目分为三个阶段。这些阶段本身并不复杂,但是将它们结合在一起可能会让人感觉有些力不从心。我将在单独的文章中介绍每个阶段:
- 第一部分:收集数据。我们将使用 BeautifulSoup 库从网站上抓取所有必要的字符串值,并将它们存储在 pandas 数据帧中。我们将在下面的文章中讨论这一部分。
- 第二部分:清理和分析数据。网页抓取经常产生“脏”文本值。在这个过程中,scraper 获得一些额外的符号或 HTML 行是正常的。我们将使用正则表达式技术将数据转换成更有用的格式,然后进行分析。
- 第三部分:对数据使用机器学习模型。当您可以让机器为您分析时,为什么要自己进行分析呢?在第 2 部分工作的基础上,我们将测试不同的机器学习方法来分析文本数据。
你可以访问我的 GitHub 上的所有项目文件。在我发表下一篇文章时,我会添加更多的文件并对现有的文件进行微调。
准备好了吗?我们开始工作吧。。。
第 1 部分—自然语言处理项目的网络搜集
如果你还没有用过 BeautifulSoup,那么我鼓励你去看看我的介绍笔记本。它遵循一条类似于我们将要走的路:抓取不是一个而是许多网站。另外,Dataquest 上有一篇更深入的文章向我们介绍网络抓取。
让我们看看实际的指导项目帖子类别是什么样子的,以便更好地了解我们想要实现的目标:

这是引导项目的主线。它包含了我们决定发布的所有指导项目。他们中的大多数人都收到了带有一些评论的回复——我们对回复的内容很感兴趣。下面是一个示例帖子:

在这篇文章中,Michael 发表了他的项目,Elena 对他的工作做了一些评论。我们感兴趣的只是搜集埃琳娜的言论内容。这不会像清理一个网站那么简单。我们想刮很多网站的特定部分,我们没有链接。。。还没有。攻击计划如下:
- 我们没有所有引导式项目帖子的链接——我们需要提取它们,这意味着我们必须抓住引导式项目的主线。
- 抓取主线程后,我们将创建一个包含帖子、标题、链接、浏览量和回复数量的数据框架(我们将过滤掉没有回复的帖子)。
- 剩下的数据集应该只包含收到反馈的帖子和这些帖子的链接——我们可以开始抓取实际的单个帖子
非常基本的 HTML 介绍
在我们开始之前,你见过 HTML 代码吗?它不同于 Python。如果你从未体验过 HTML 代码,这里有一个非常基本的 HTML 表格示例:
<html>
<body>
<table border=1>
<tr>
<td>Emil</td>
<td>Tobias</td>
<td><a href="https://www.dataquest.io/">dataquest</a></td>
</tr>
</table>
</body>
</html>
| 电子邮件 | 托拜厄斯(男子名) | 数据请求 |
在 HTML 中,我们使用标签来定义元素。许多元素都有一个开始标签和一个结束标签,例如。。。
<table>
。。。打开表的构建,在表编码的最后,我们写。。。
</table>
。。。关闭它。此表格有一行,该行有 3 个单元格。在第三个单元格中,我们使用了一个链接
<a href=...>
HTML 标签可以有属性(我们在“table”标签中使用了“border”属性,在“a”标签中使用了“href”属性)。
The concept behind web scraping is to extract (scrape) specific elements of a website.
第一步:网页抓取引导项目的主线
检查网站
我们将从检查整个网站的内容开始:https://community.dataquest.io/c/share/guided-project/55
我们可以用我们的浏览器来做这件事;我用 Chrome。将鼠标悬停在文章标题上方,点击右键,选择 Inspect 即可。(注意,我选择了一个比顶部低几个帖子的帖子——以防第一个帖子有不同的类别。)
现在我们可以看看网站的代码。当您将鼠标悬停在右窗口中的某些代码元素上时,浏览器会在左窗口中突出显示该元素。在下面的示例中,我的光标悬停在以下内容上:
<tr data-topic-id=...>
在左侧,我们可以看到网站的一大块突出部分:

首次尝试抓取网页
对于我们的第一次尝试,我们将尝试只获得每个帖子的链接。请注意,实际的链接在下面代码的第二行中有一个类——“title raw-link raw-topic-link”:
<a href="https://www.dataquest.io/t/predicting-bike-rentals-with-machine-learning-optimization-of-the-linear-model/558618/3" role="heading" level="2" class="title raw-link raw-topic-link" data-topic-id="558618"><span dir="ltr">Predicting Bike Rentals
With Machine Learning, Optimization of the Linear Model</span></a>
我们将使用以下代码将该类的所有链接收集到一个列表中,并查看我们成功提取了多少链接:
# imports:
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
# step 1 lets scrape the guided project website with all the posts:
url = "https://community.dataquest.io/c/share/guided-project/55"
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
# look for every 'a' tag with 'class' title raw-link raw-topic-link:
list_all = soup.find_all("a", class_="title raw-link raw-topic-link")
# check how many elements we've extracted:
len(list_all) [Output]: 30
我们的列表只有 30 个元素!我们期待一个更大的数字,所以发生了什么?不幸的是,我们正试图构建一个动态网站。当我们的浏览器打开论坛页面时,Dataquest 只加载前 30 个帖子;如果我们想看到更多,我们必须向下滚动。但是我们如何编程我们的刮刀向下滚动? Selenium 是该问题的首选解决方案,但我们将使用一种更简单的方法:
- 向下滚动到网站的底部。
- 当我们到达终点时,将网站保存为一个文件。
- 我们将处理那个文件,而不是用 BeautifulSoup 处理一个链接。
让我们开始向下滚动:

是的,这是一个真正的叉子,推动键盘上的向下箭头,用一个空咖啡杯压着(这篇文章的作者不鼓励在你的电子设备周围使用任何不寻常的餐具或餐具)。向下滚动到最底部后,我们可以使用文件>将页面另存为……来保存网站。现在我们可以将该文件加载到我们的笔记本中并开始抓取;这次我们将瞄准每一个新行:
<tr>。因为最终,我们不感兴趣的只是抓取链接——我们想要提取尽可能多的数据。不仅是标题,带链接,还有回复数,浏览量等。
import codecs
# this is the file of the website, after scrolling all the way down:
file = codecs.open("../input/dq-projects/projects.html", "r", "utf-8")
# parse the file:
parser = BeautifulSoup(file, 'html.parser')
# look for every 'tr' tag, scrape its contents and create a pandas series from the list:
list_all = parser.find_all('tr')
series_4_df = pd.Series(list_all)
# create a dataframe from pandas series:
df = pd.DataFrame(series_4_df, columns=['content'])
df['content'] = df['content'].astype(str)
df.head()
| | 内容 |
| Zero | <tr><th class="default" data-sort-order="defau... | |
| one | <tr class="topic-list-item category-share-guid... |
| Two | <tr class="topic-list-item category-share-guid... |
| three | <tr class="topic-list-item category-share-guid... |
| four | <tr class="topic-list-item category-share-guid... |
步骤 2:从 HTML 中提取数据
我们已经创建了一个充满 HTML 代码的数据框架。让我们检查一个单元格的内容:
df.loc[2,'content']
<tr class="topic-list-item category-share-guided-project tag-257 tag-sql-fundamentals tag-257-8 has-excerpt
unseen-topic ember-view" data-topic-id="558357" id="ember71">\n<td class="main-link clearfix" colspan="">\n
<div class="topic-details">\n<div class="topic-title">\n<span class="link-top-line">\n<a class="title raw-link
raw-topic-link" data-topic-id="558357" href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357"
level="2" role="heading"><span dir="ltr">Analyzing CIA Factbook with SQL - Full Project</span></a>\n<span
class="topic-post-badges">\xa0<a class="badge badge-notification new-topic"
href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357"
title="new topic"></a></span>\n</span>\n</div>\n<div class="discourse-tags"><a class="discourse-tag bullet"
data-tag-name="257" href="https://community.dataquest.io/tag/257">257</a> <a class="discourse-tag bullet"
data-tag-name="sql-fundamentals" href="https://community.dataquest.io/tag/sql-fundamentals">sql-fundamentals</a>
<a class="discourse-tag bullet" data-tag-name="257-8" href="https://community.dataquest.io/tag/257-8">257-8</a>
</div>\n<div class="actions-and-meta-data">\n</div>\n</div></td>\n<td class="posters">\n<a class="latest single"
data-user-card="noah.gampe" href="https://community.dataquest.io/u/noah.gampe"><img alt=""
aria-label="noah.gampe - Original Poster, Most Recent Poster" class="avatar latest single" height="25"
src="./Latest Share_Guided Project topics - Dataquest Community_files/12175_2.png"
title="noah.gampe - Original Poster, Most Recent Poster" width="25"/></a>\n</td>\n<td class="num posts-map posts"
title="This topic has 0 replies">\n<button class="btn-link posts-map badge-posts">\n<span
aria-label="This topic has 0 replies" class="number">0</span>\n</button>\n</td>\n<td class="num
likes">\n</td>\n<td class="num views"><span class="number" title="this topic has been viewed 9 times">9</span>
</td>\n<td class="num age activity" title="First post: Nov 20, 2021 9:25 am\nPosted: Nov 20, 2021 9:27 am">\n
<a class="post-activity" href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357/1">
<span class="relative-date" data-format="tiny" data-time="1637360860367">1d</span></a>\n</td>\n</tr>
从 HTML 中提取数据:
如何在这一片混乱中找到秩序?我们只需要上面代码中的两个元素(但是我们会尝试提取更多)。上面代码块的标题是“用 SQL 分析 CIA 事实手册——整个项目”我们可以在 span 元素中找到标题:
<span dir="ltr">Analyzing CIA Factbook with SQL - Full Project</span>
前一个元素是我们想要的链接:
<a class="title raw-link raw-topic-link" data-topic-id="558357" href="https://community.dataquest.io/t/analyzing-cia-factbook-with-sql-full-project/558357" level="2" role="heading">
视图的数量应该是有用的:
<span class="number" title="this topic has been viewed 9 times">9</span>
我们想要的最后一点信息是每个帖子的回复数量:
<span aria-label="This topic has 0 replies" class="number">0</span>
我们可以使用 BeautifulSoup 来定位这些特定的元素并提取它们的内容,但是这个数据集并不大,直接从同一行的单元格中提取我们需要的信息似乎是一个更安全的选择。我们将遵循这个计划:
- 删除第一行(不是 post 元素)。
- 使用正则表达式技术提取标题、链接、回复数和浏览量。这里有一张正则表达式的备忘单。)
- 删除回复为 0 的行。
# remove 1st row:
df = df.iloc[1:,:]
# extract title, link and number of replies:
df['title'] = df['content'].str.extract('<span dir="ltr">(.*?)</span>')
df['link'] = df['content'].str.extract('href=(.*?)level="2"')
df['replies'] = df['content'].str.extract("This topic has (.*?) re").astype(int)
df['views'] = df['content'].str.extract("this topic has been viewed (.*?) times")
df['views'] = df['views'].str.replace(',','').astype(int)
# remove 1 generic post and posts with 0 replies:
df = df[df['replies']>0]
df = df[df['replies']<100]
df.head()
| 内容 | 标题 | 环 | 答复 | 视图 | |
|---|---|---|---|---|---|
| four | < tr class= "主题-列表-项目类别-共享-guid… | 预测房价 | https://community.dataquest.io/t/predicting-ho… | one | Twenty-six |
| five | < tr class= "主题-列表-项目类别-共享-guid… | [重新上传]项目反馈-流行数据科学… | https://community.dataquest.io/t/re-upload-pro… | three | Forty-seven |
| seven | < tr class= "主题-列表-项目类别-共享-guid… | GP:清理和分析员工离职调查++ | https://community.dataquest.io/t/gp-clean-and-… | Two | Fifty-three |
| Ten | < tr class= "主题-列表-项目类别-共享-guid… | 项目反馈—流行的数据科学问题 | https://community.dataquest.io/t/project-feedb… | five | Seventy-one |
| Twelve | < tr class= "主题-列表-项目类别-共享-guid… | 指导项目:专辑与单曲 w 的答案… | https://community.dataquest.io/t/guided-projec… | five | Three hundred and seventy |
第三步:删除单个帖子
这最后一步和第一步没什么不同。我们必须检查单个帖子,并推断哪个页面元素负责帖子的第一个回复的内容。我们假设最有价值的内容将存储在对已发布项目的第一个回复中。我们会忽略所有其他回复。
为了处理如此大量的文本数据,我们将创建一个函数。所有繁重的数据处理都在函数中,我们不用担心一些变量在处理完之后会占用内存。
# create a function for scraping the actual posts website:
def get_reply(one_link):
response = requests.get(one_link)
content = response.content
parser = BeautifulSoup(content, 'html.parser')
tag_numbers = parser.find_all("div", class_="post")
# we're only going to scrape the content of the first reply (that's usually the feedback)
feedback = tag_numbers[1].text
return feedback
测试刮刀
这里有一个非常重要的规则,每当我进行网络搜集时,我都会遵循这个规则:从小处着手!
You don’t want to scrape a few thousand websites just to learn that your last line of code didn’t work and you have to redo everything and wait again. That is why we’ll start with a very small dataset, check if everything is clicking, then move on.
# create a test dataframe to test scraping on 5 rows:
df_test = df[:5].copy()
# we'll use a loop on all the elements of pd.Series (faster than using 'apply')
feedback_list = []
for el in df_test['link2']:
feedback_list.append(get_reply(el))
df_test['feedback'] = feedback_list
df_test
看起来很有希望——让我们检查整个细胞:
df_test['feedback'][4]
在函数中处理数据可以节省内存(当您使用完函数时,您创建的变量会保留在函数中,而不会存储在内存中)。当你在处理更大的数据集时,这一点很重要——如果你有兴趣进行实验,尝试在 Kaggle 笔记本上清理 1 个月的数据集(并查看你的 RAM 使用情况),包括函数外部和函数内部。比较两个示例中的 RAM 使用情况。
全回复,准备清洗。
收集所有的反馈
现在让我们继续(这需要一段时间):
# this lets scrape all the posts, not just 5 of them:
def scrape_replies(df):
feedback_list = []
for el in df['link']:
feedback_list.append(get_reply(el))
df['feedback'] = feedback_list
return df
df = scrape_replies(df)
就这样,我们已经从 Dataquest 的网站上提取了我们想要的所有原始数据。在下一篇文章中,我们将重点关注使用自然语言处理技术清理和分析这些数据。我们将尝试在项目反馈的内容中找到最常见的模式。但在你离开之前,有几件事需要考虑:
刮削工具
BeautifulSoup is a great library to start with, but you’ve probably noticed that we came across its limitations, to perform web scraping on complex dynamic websites we should use a more advanced tool (We’ll try to cover Selenium library in the future)
考虑服务器
如果你不断地从一个网站上请求大量内容,大多数服务器会接收到它,并经常切断你的联系。记得从小处着手。在我们的具体示例中,我们请求了一大块数据,并毫无问题地收到了它。但是遇到一些问题是很常见的,比如这个问题:
ConnectionError: HTTPSConnectionPool(host='en.wikipedia.orghttps', port=443): Max retries exceeded with url:[...]
重要的部分是最大重试次数超过。这意味着我们已经请求数据太多次了。偶尔停止抓取网页来模仿人类的自然行为是一个好习惯。我们如何做到这一点?我们需要偷偷输入这行代码:
time.sleep(np.random.randint(1,20))
这将使我们的算法暂停一个随机数(1-20)秒,自然,这延长了提取数据所需的时间,但也使它成为可能。请记住,我们需要将这个一行程序放在代码中的适当位置:
# this lets scrape all the posts, not just 5 of them:
def scrape_replies(df):
feedback_list = []
for el in df['link']:
# go to sleep first, then do your work:
time.sleep(np.random.randint(1,20))
feedback_list.append(get_reply(el))
df['feedback'] = feedback_list
return df
df = scrape_replies(df)
如果你对其他网页抓取技巧感兴趣,请阅读这篇文章。
互联网连接
Assuming that the server will let us extract all of that data, can your service provider handle it? Our DataFrame is fairly small, but imagine performing this task on much bigger datasets. Hotspotting wifi from an iphone may not be an ideal solution. Maybe that data has already been extracted and the dataset is available online? I encourage you to post the dataset after you’ve scraped it. Some people may not have as good a connection as you do. Alternatively, you could use an environment with a better connection. While working on this project, I’ve used Kaggle. I didn’t have to worry about my slow connection; it was fast enough to connect to and work on Kaggle. All the web scraping went through their servers.
内存使用
Ok, so your connection can handle it, but can your laptop? Our DataFrame is small, but always be prepared! If the size of the DataFrame is close to your RAM size, then you have to start considering doing it in stages. Check your disk space, and make sure that you need all that data.
合法吗?
There are several articles relating to this topic, and the answer doesn’t seem to be very clear. You should thoroughly research and be aware of what you’re doing. It’s very important, especially when web scraping for business activities.
有什么问题吗?
Feel free to reach out and ask me anything:
Adam at Dataquest, LinkedIn, GitHub
Huyen Vu 如何通过 Dataquest 从零编码技能成为数据分析师
原文:https://www.dataquest.io/blog/no-coding-skills-data-science-job/
March 22, 2019
Huyen Vu 非常实际地寻找职业。她看到芬兰对数据科学领域的人才有需求,她接受过一些培训,对商业分析感兴趣。这看起来很合适,但是有一个问题。
Huyen 的教育背景是经商。“我甚至没有学习技术或计算机科学,”她说。当她开始查看职位描述时,她发现像 Python 和 SQL 这样的数据科学编程技能非常受欢迎。她知道她需要加强自己的技术和编程技能,使自己成为更有吸引力的求职者。
她就是这样找到 Dataquest 的。
钻研数据科学
在寻找在线学习数据科学的方法时,Huyen 遇到了一些其他资源,但似乎没有一个适合她需要学习的内容。
“我想我发现了脸书的 Dataquest,”她说。“我的一些朋友在关注 Dataquest,所以我去看看。我看到你们有 Python 和 SQL 的课程,正是我要找的,就这么简单。”
在尝试了一门免费的入门课程后,Huyen 跳了进去,开始通过数据分析师途径工作。
她说,加入 Dataquest 是一个简单的决定,因为这个平台正在为她工作。“在这个平台上,你可以马上学到一些小课程、实践和技能。太方便了。”
“此外,我真的很喜欢网站上的文字说明。这非常非常容易理解。她说:“我更喜欢阅读,而不是听或看视频教程,所以[Dataquest]满足了我的需求。”
在完成一些课程并获得 Python 和 SQL 证书后,Huyen 开始在数据科学行业寻找工作,特别是需要她最近学习的数据科学技能的工作。
Huyen 说:“我把我的新技能放在了简历上,我觉得我有了更多的兴趣,因为芬兰的许多公司都在寻找 Python 和 SQL。”
她最终在一家采购分析公司找到了一份数据管理专员的工作。在这个职位上,她负责分类、整合和验证数据,她说她从 Dataquest 中学到的技能非常有用。
“SQL 技能对我的工作非常有用,”她说,“所以我的 Dataquest 经验很有帮助。”
也许更重要的是,Huyen 对未来感到兴奋。虽然她目前的职位是入门级的,但她的数据科学技能让她走上了一条充满希望的道路,她说在她的公司,她将“有很多机会成长,并转移到其他负责更高级职责的团队。”
根据你想要的工作学习技能
作为一个成功地在求职领域导航并涉足数据科学的人,Huyen 向其他寻找工作的学习者推荐了她的方法。
她说:“我会看看我感兴趣的公司,找到工作描述,记下他们需要的技能清单。”“然后,我会去 Dataquest 或其他类似的学习网站,参加课程,获得证书,并向正在寻找该领域人才的公司展示这些证书。”
“真的,自学市场需要的技能,”她建议道。
当然,Huyen 推荐使用 Dataquest 学习!“事实上,我已经把它推荐给了我的两个年长的室友,”她说。"现在,他们正在用 Dataquest 研究这个网站."
NumPy 备忘单—用于数据科学的 Python
April 13, 2017NumPy is the library that gives Python its ability to work with data at speed. Originally, launched in 1995 as ‘Numeric,’ NumPy is the foundation on which many important Python data science libraries are built, including Pandas, SciPy and scikit-learn. It’s common when first learning NumPy to have trouble remembering all the functions and methods that you need, and while at Dataquest we advocate getting used to consulting the NumPy documentation, sometimes it’s nice to have a handy reference, so we’ve put together this cheat sheet to help you out! If you’re interested in learning NumPy, you can consult our NumPy tutorial blog post, or you can signup for free and start learning NumPy through our interactive Python data science course. Download a Printable PDF of this Cheat Sheet
密钥和导入
在本备忘单中,我们使用以下简写方式:
arr |一个 numpy 数组对象你还需要导入 NumPy 来开始:
import numpy as np
导入/导出
np.loadtxt('file.txt') |从文本文件np.genfromtxt('file.csv',delimiter=',') |从 CSV 文件np.savetxt('file.txt',arr,delimiter=' ') |写入文本文件np.savetxt('file.csv',arr,delimiter=',') |写入 CSV 文件
创建数组
np.array([1,2,3]) |一维数组np.array([(1,2,3),(4,5,6)]) |二维数组np.zeros(3) |长度为3的 1D 数组0 np.ones((3,4)) | 3 x 4数组1 np.eye(5) | 5 x 5数组0对角线上有1的数组【单位矩阵】np.linspace(0,100,6) |从0到100 np.arange(0,10,3)的6数组|从0到小于10的值数组3 2 x 3数组包含所有值8 np.random.rand(4,5) | 4 x 5数组包含0–1``np.random.rand(6,7)*100|6x7数组包含0–100–np.random.randint(5,size=(2,3))|2x3数组包含0–4之间的随机整数
检查属性
arr.size |返回arr arr.shape中的元素个数】|返回arr(行、列)arr.dtype的尺寸|返回arr arr.astype(dtype)中的元素类型|将arr元素转换为类型dtype arr.tolist() |将arr转换为 Python 列表np.info(np.eye) |查看np.eye的文档
复制/分类/整形
np.copy(arr) |将arr复制到新内存arr.view(dtype) |创建类型为dtype arr.sort()的arr元素的视图|排序arr arr.sort(axis=0) |排序arr two_d_arr.flatten()的特定轴|将 2D 数组two_d_arr变平为 1D arr.T |转置arr(行变成列,反之亦然)arr.reshape(3,4) |将arr重新整形为3行,4列不改变数据arr.resize((5,6)) |将arr形状更改为5 x 6和
添加/删除元素
np.append(arr,values) |将值追加到arr np.insert(arr,2,values)的末尾|将值插入到索引2 np.delete(arr,3,axis=0)之前的arr|删除arr np.delete(arr,4,axis=1)的索引3上的行|删除arr的索引4上的列
合并/拆分
np.concatenate((arr1,arr2),axis=0) |将arr2作为行添加到arr1的末尾np.concatenate((arr1,arr2),axis=1) |将arr2作为列添加到arr1的末尾np.split(arr,3) |将arr拆分成3子数组np.hsplit(arr,5) |在第5个索引上水平拆分arr
索引/切片/子集化
arr[5] |返回索引5 arr[2,5]处的元素。|返回索引[2][5] arr[1]=4处的 2D 数组元素。|给索引1处的数组元素赋值4 arr[1,3]=10 |给索引[1][3]处的数组元素赋值10 arr[0:3] |返回索引0,1,2处的元素(在 2D 数组中:返回行0,1,2 ) arr[0:3,4] |返回行0,1,2处列4 arr[:2]处的元素。| 返回索引0,1处的元素(在 2D 数组中:返回行0,1 ) arr[:,1] |返回所有行arr<5中索引1处的元素|返回布尔值数组(arr1<3) & (arr2>5) |返回布尔值数组~arr |反转布尔值数组arr[arr<5] |返回小于5的数组元素
标量数学
np.add(arr,1) |每个数组元素加1``np.subtract(arr,2)|每个数组元素减2``np.multiply(arr,3)|每个数组元素乘3 np.divide(arr,4) |每个数组元素除4(返回np.nan除以零)np.power(arr,5) |每个数组元素的5次幂
向量数学
np.add(arr1,arr2) |逐元素地将arr2加到arr1 np.subtract(arr1,arr2) |逐元素地从arr1 np.multiply(arr1,arr2)中减去arr2|逐元素地将arr1乘以arr2 np.divide(arr1,arr2) |逐元素地将arr1除以arr2 np.power(arr1,arr2) |逐元素地提升arr1到arr2 np.array_equal(arr1,arr2)的幂|如果数组具有相同的元素和形状则返回True``np.sqrt(arr)|数组中每个元素的平方根np.sin(arr) |数组中每个元素的正弦np.log(arr) | 数组中每个元素的自然对数np.abs(arr) |数组中每个元素的绝对值np.ceil(arr) |上舍入到最近的整数np.floor(arr) |下舍入到最近的整数np.round(arr) |上舍入到最近的整数
统计数据
np.mean(arr,axis=0) |返回特定轴的平均值arr.sum() |返回arr和arr.min() |返回arr的最小值arr.max(axis=0) |返回特定轴的最大值np.var(arr) |返回数组的方差np.std(arr,axis=1) |返回特定轴的标准差arr.corrcoef() |返回数组的相关系数
下载此备忘单的可打印版本
如果你想下载这个备忘单的打印版本,你可以在下面做。
NumPy 教程:使用 Python 进行数据分析
October 18, 2016
不要错过这篇文章底部的免费数字备忘单
NumPy 是一个常用的 Python 数据分析包。通过使用 NumPy,您可以加快工作流程,并与 Python 生态系统中的其他包进行交互,比如使用 NumPy 的 scikit-learn 。NumPy 最初是在 2000 年代中期开发的,起源于一个更古老的名为 Numeric 的包。这种长寿意味着几乎每一个 Python 的数据分析或机器学习包都以某种方式利用了 NumPy。
在本教程中,我们将使用 NumPy 来分析葡萄酒质量的数据。该数据包含葡萄酒各种属性的信息,如pH和fixed acidity,以及每种葡萄酒在0和10之间的质量分数。质量分数至少是3人类味觉测试者的平均值。当我们学习如何与 NumPy 合作时,我们将尝试了解更多关于葡萄酒的感知质量。

我们将要分析的葡萄酒来自葡萄牙的米尼奥地区。
数据是从 UCI 机器学习库下载的,在这里可以得到。这里是winequality-red.csv文件的前几行,我们将在整个教程中使用:
"fixed acidity";"volatile acidity";"citric acid";"residual sugar";"chlorides";"free sulfur dioxide";"total sulfur dioxide";"density";"pH";"sulphates";"alcohol";"quality"
7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4;5
7.8;0.88;0;2.6;0.098;25;67;0.9968;3.2;0.68;9.8;5
数据是我称之为 ssv (分号分隔值)的格式——每条记录由分号(;)分隔,行由新行分隔。文件中有1600行,包括一个标题行和12列。
在我们开始之前,一个简短的版本说明——我们将使用 Python 3.5 。我们的代码示例将使用 Jupyter 笔记本来完成。
CSV 数据列表的列表
在使用 NumPy 之前,我们将首先尝试使用 Python 和 csv 包来处理数据。我们可以使用 csv.reader 对象读入文件,这将允许我们从 ssv 文件中读入并拆分所有内容。
在下面的代码中,我们:
- 导入
csv库。 - 打开
winequality-red.csv文件。- 打开文件,创建一个新的
csv.reader对象。- 传入关键字参数
delimiter=";"以确保记录在分号字符而不是默认的逗号字符上分割。
- 传入关键字参数
- 调用 list 类型从文件中获取所有行。
- 将结果分配给
wines。
- 打开文件,创建一个新的
import csv
with open('winequality-red.csv', 'r') as f:
wines = list(csv.reader(f, delimiter=';'))
一旦我们读入了数据,我们就可以打印出前3行:
print(wines[:3])
[['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar', 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol', 'quality'], ['7.4', '0.7', '0', '1.9', '0.076', '11', '34', '0.9978', '3.51', '0.56', '9.4', '5'], ['7.8', '0.88', '0', '2.6', '0.098', '25', '67', '0.9968', '3.2', '0.68', '9.8', '5']]
数据已被读入一个列表列表。每个内部列表都是来自 ssv 文件的一行。您可能已经注意到,整个列表中的每一项都表示为一个字符串,这使得计算更加困难。
我们将数据格式化成表格,以便于查看:
| 固定酸度 | 挥发性酸度 | 柠檬酸 | 残糖 | 氯化物 | 游离二氧化硫 | 二氧化硫总量 | 密度 | pH 值 | 硫酸盐 | 酒精 | 质量 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Seven point four | Zero point seven | Zero | One point nine | Zero point zero seven six | Eleven | Thirty-four | 0.9978 | Three point five one | Zero point five six | Nine point four | five |
| Seven point eight | Zero point eight eight | Zero | Two point six | Zero point zero nine eight | Twenty-five | Sixty-seven | 0.9968 | Three point two | Zero point six eight | Nine point eight | five |
从上表可以看出,我们已经读入了三行,第一行包含列标题。标题行之后的每一行代表一种葡萄酒。每一行的第一个元素是fixed acidity,第二个是volatile acidity,依此类推。我们可以找到葡萄酒的平均 T2。以下代码将:
- 从标题行之后的每一行中提取最后一个元素。
- 将每个提取的元素转换为浮点型。
- 将所有提取的元素分配到列表
qualities。 - 将
qualities中所有元素的总和除以qualities中的元素总数,得到平均值。
qualities =
[float(item[-1]) for item in wines[1:]]
sum(qualities) / len(qualities)
5.6360225140712945
虽然我们能够进行我们想要的计算,但是代码相当复杂,而且每次我们想要计算一个量时都必须做类似的事情,这并不有趣。幸运的是,我们可以使用 NumPy 来简化数据处理。
Numpy 二维数组
使用 NumPy,我们可以处理多维数组。稍后我们将深入探讨所有可能的多维数组类型,但是现在,我们将把重点放在二维数组上。二维数组也称为矩阵,是您应该熟悉的东西。事实上,这只是对列表列表的不同思考方式。矩阵有行和列。通过指定行号和列号,我们能够从矩阵中提取元素。
在下面的矩阵中,第一行是标题行,第一列是fixed acidity列:
| 固定酸度 | 挥发性酸度 | 柠檬酸 | 残糖 | 氯化物 | 游离二氧化硫 | 二氧化硫总量 | 密度 | pH 值 | 硫酸盐 | 酒精 | 质量 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Seven point four | Zero point seven | Zero | One point nine | Zero point zero seven six | Eleven | Thirty-four | 0.9978 | Three point five one | Zero point five six | Nine point four | five |
| Seven point eight | Zero point eight eight | Zero | Two point six | Zero point zero nine eight | Twenty-five | Sixty-seven | 0.9968 | Three point two | Zero point six eight | Nine point eight | five |
如果我们选择第一行第二列的元素,我们会得到volatile acidity。如果我们选择第三行第二列的元素,我们会得到0.88。
在 NumPy 数组中,维数称为秩,每个维称为一个轴。所以行是第一个轴,列是第二个轴。
现在你已经理解了矩阵的基础知识,让我们看看如何从我们的列表中得到一个 NumPy 数组。
创建 NumPy 数组
我们可以使用 numpy.array 函数创建一个 NumPy 数组。如果我们传入一个列表的列表,它将自动创建一个具有相同行数和列数的 NumPy 数组。因为我们希望数组中的所有元素都是易于计算的浮点元素,所以我们将省略包含字符串的标题行。NumPy 的限制之一是数组中的所有元素必须是同一类型,所以如果我们包含标题行,数组中的所有元素都将作为字符串读入。因为我们希望能够计算出葡萄酒的平均值,所以我们需要所有的元素都是浮点数。
在下面的代码中,我们:
- 导入
numpy包。 - 将列表列表
wines传递给array函数,该函数将其转换成一个 NumPy 数组。- 使用列表切片排除标题行。
- 指定关键字参数
dtype以确保每个元素都被转换成浮点数。稍后我们将深入探讨dtype是什么。
import csv
with open("winequality-red.csv", 'r') as f:
wines = list(csv.reader(f, delimiter=";"))
import numpy as np
wines = np.array(wines[1:], dtype=np.float)
试着运行上面的代码,看看会发生什么!
如果我们显示wines,我们将得到一个 NumPy 数组:
wines
array([[ 7.4 , 0.7 , 0\. , ..., 0.56 , 9.4 , 5\. ],
[ 7.8 , 0.88 , 0\. , ..., 0.68 , 9.8 , 5\. ],
[ 7.8 , 0.76 , 0.04 , ..., 0.65 , 9.8 , 5\. ],
...,
[ 6.3 , 0.51 , 0.13 , ..., 0.75 , 11\. , 6\. ],
[ 5.9 , 0.645, 0.12 , ..., 0.71 , 10.2 , 5\. ],
[ 6\. , 0.31 , 0.47 , ..., 0.66 , 11\. , 6\. ]])
我们可以使用 NumPy 数组的 shape 属性来检查数据中的行数和列数:
wines.shape
(1599, 12)
可选的 NumPy 数组创建方法
有多种方法可以用来创建 NumPy 数组。首先,您可以创建一个数组,其中每个元素都是零。下面的代码将创建一个具有3行和4列的数组,其中每个元素都是0,使用 numpy.zeros :
import numpy as np
empty_array = np.zeros((3,4))
empty_array
当你需要一个固定大小的数组,但是还没有任何值的时候,创建一个全零元素的数组是很有用的。
您还可以使用numpy . rand . rand创建一个数组,其中每个元素都是一个随机数。这里有一个例子:
np.random.rand(3,4)
array([[ 0.2247223 , 0.92240549, 0.14541893, 0.61731257],
[ 0.00154957, 0.82342197, 0.74044906, 0.11466845],
[ 0.6152478 , 0.14433138, 0.13009583, 0.22981301]])
当您希望使用示例数组快速测试代码时,创建充满随机数的数组会很有用。
使用 NumPy 读入文件
可以使用 NumPy 直接将 csv 或其他文件读入数组。我们可以使用 numpy.genfromtxt 函数来实现这一点。我们可以用它来读取红酒的初始数据。
在下面的代码中,我们:
- 使用
genfromtxt功能读入winequality-red.csv文件。 - 指定关键字参数
delimiter=";",以便正确解析字段。 - 指定关键字参数
skip_header=1,以便跳过标题行。
wines = np.genfromtxt("winequality-red.csv", delimiter=";", skip_header=1)
看起来和我们把它读入一个列表,然后把它转换成一个浮点数组一样。NumPy 将根据元素的格式自动为数组中的元素选择数据类型。
索引数字数组
我们现在知道了如何创建数组,但是除非我们可以从数组中检索结果,否则我们无法使用 NumPy 做很多事情。我们可以使用数组索引来选择单个元素、元素组或整行整列。需要记住的重要一点是,就像 Python 列表一样,NumPy 是零索引的,这意味着第一行的索引是0,第一列的索引是0。如果我们想要处理第四行,我们将使用索引3,如果我们想要处理第二行,我们将使用索引1,等等。我们将再次使用wines数组:
| Seven point four | Zero point seven | Zero | One point nine | Zero point zero seven six | Eleven | Thirty-four | 0.9978 | Three point five one | Zero point five six | Nine point four | five |
| Seven point eight | Zero point eight eight | Zero | Two point six | Zero point zero nine eight | Twenty-five | Sixty-seven | 0.9968 | Three point two | Zero point six eight | Nine point eight | five |
| Seven point eight | Zero point seven six | Zero point zero four | Two point three | Zero point zero nine two | Fifteen | Fifty-four | 0.9970 | Three point two six | Zero point six five | Nine point eight | five |
| Eleven point two | Zero point two eight | Zero point five six | One point nine | Zero point zero seven five | Seventeen | Sixty | 0.9980 | Three point one six | Zero point five eight | Nine point eight | six |
| Seven point four | Zero point seven | Zero | One point nine | Zero point zero seven six | Eleven | Thirty-four | 0.9978 | Three point five one | Zero point five six | Nine point four | five |
让我们选择位于行3和列4的元素。在下面的代码中,我们传入索引2作为行索引,传入索引3作为列索引。这将从第三行的第四列中检索值:
wines[2,3]
2.2999999999999998
因为我们在 NumPy 中使用的是二维数组,所以我们指定了两个索引来检索一个元素。第一个索引是行或轴1的索引,第二个索引是列或轴2的索引。使用2索引可以检索wines中的任何元素。
切片 NumPy 数组
如果我们想从第四列中选择前三项,我们可以使用冒号(:)来实现。冒号表示我们想要选择从起始索引到结束索引的所有元素,但不包括结束索引。这也称为切片:
wines[0:3,3]
array([ 1.9, 2.6, 2.3])
就像列表切片一样,可以省略0来检索从开始到元素3的所有元素:
wines[:3,3]
array([ 1.9, 2.6, 2.3])
我们可以通过指定想要的所有元素来选择整个列,从第一个到最后一个。我们仅使用冒号(:)来指定,没有起始或结束索引。下面的代码将选择整个第四列:
wines[:,3]
array([ 1.9, 2.6, 2.3, ..., 2.3, 2\. , 3.6])
我们在上面选择了整个列,但是我们也可以提取整个行:
wines[3,:]
array([ 11.2 , 0.28 , 0.56 , 1.9 , 0.075, 17\. , 60.,
0.998, 3.16 , 0.58 , 9.8 , 6\. ])
如果我们将索引发挥到极致,我们可以使用两个冒号来选择整个数组,以选择wines中的所有行和列。这是一个很棒的聚会小把戏,但是没有太多好的应用:
wines[:,:]
array([[ 7.4 , 0.7 , 0\. , ..., 0.56 , 9.4 , 5\. ],
[ 7.8 , 0.88 , 0\. , ..., 0.68 , 9.8 , 5\. ],<br />
[ 7.8 , 0.76 , 0.04 , ..., 0.65 , 9.8 , 5\. ],<br />
...,
[ 6.3 , 0.51 , 0.13 , ..., 0.75 , 11\. , 6\. ],
[ 5.9 , 0.645, 0.12 , ..., 0.71 , 10.2 , 5\. ],<br />
[ 6\. , 0.31 , 0.47 , ..., 0.66 , 11\. , 6\. ]])
给 NumPy 数组赋值
我们还可以使用索引为数组中的某些元素赋值。我们可以通过直接给索引值赋值来做到这一点:
wines[1,5] = 10
我们可以对切片做同样的事情。要覆盖整个列,我们可以这样做:
wines[:,10] = 50
上面的代码用50覆盖了第 11 列中的所有值。
一维 NumPy 数组
到目前为止,我们已经使用了二维数组,比如wines。然而,NumPy 是一个用于处理多维数组的包。最常见的多维数组类型之一是一维数组或向量。正如你可能已经注意到的,当我们切片wines时,我们获得了一个一维数组。一维数组只需要一个索引来检索一个元素。二维数组中的每一行和每一列都是一维数组。就像列表的列表类似于二维数组一样,单个列表类似于一维数组。如果我们对葡萄酒进行切片,只检索第三行,我们会得到一个一维数组:
third_wine = wines[3,:]
下面是third_wine的样子:
11.200
0.280
0.560
1.900
0.075
17.000
60.000
0.998
3.160
0.580
9.800
6.000
我们可以使用单个索引从third_wine中检索单个元素。以下代码将显示third_wine中的第二项:
third_wine[1]
0.28000000000000003
我们使用过的大多数 NumPy 函数,比如NumPy . rand . rand,都可以用于多维数组。下面是我们如何使用numpy.random.rand生成一个随机向量:
np.random.rand(3)
array([ 0.88588862, 0.85693478, 0.19496774])
以前,当我们调用np.random.rand时,我们为一个二维数组传入了一个形状,所以结果是一个二维数组。这一次,我们为一维数组传入了一个形状。该形状指定维度的数量以及每个维度中数组的大小。(10,10)的形状将是一个具有10行和10列的二维数组。(10,)的形状将是一个包含10个元素的一维数组。
NumPy 变得更复杂的地方是当我们开始处理超过2维的数组时。
n 维 NumPy 数组
这种情况并不经常发生,但是在某些情况下,您会希望处理维度大于3的数组。一种理解方式是把它看作列表的列表。假设我们希望存储一家商店的月收入,但是我们希望能够快速查找一个季度和一年的结果。一年的收益可能是这样的:
[500, 505, 490, 810, 450, 678, 234, 897, 430, 560, 1023, 640]
店铺一月赚$500,二月赚$505,以此类推。我们可以按季度将这些收益分成一系列的列表:
year_one = [
[500,505,490],
[810,450,678],
[234,897,430],
[560,1023,640]
]
我们可以通过调用year_one[0][0]来检索 1 月份的收益。如果我们想要整个季度的结果,我们可以打电话给year_one[0]或year_one[1]。我们现在有了一个二维数组或矩阵。但是如果我们现在想添加另一年的结果呢?我们必须增加第三维度:
earnings = [
[
[500,505,490],
[810,450,678],
[234,897,430],
[560,1023,640]
],
[
[600,605,490],
[345,900,1000],
[780,730,710],
[670,540,324]
]
]
我们可以通过调用earnings[0][0][0]来检索第一年 1 月的收益。我们现在需要三个索引来检索单个元素。NumPy 中的三维数组也差不多。事实上,我们可以将earnings转换成一个数组,然后获得第一年 1 月的收益:
earnings = np.array(earnings)
earnings[0,0,0]
500
我们还可以找到数组的形状:
earnings.shape
(2, 4, 3)
索引和切片的工作方式与三维数组完全相同,但是现在我们有了一个额外的轴可以传入。如果我们想得到所有年份中一月份的收益,我们可以这样做:
earnings[:,0,0]
array([500, 600])
如果我们想获得两年的第一季度收益,我们可以这样做:
earnings[:,0,:]
array([[500, 505, 490],
[600, 605, 490]])
如果数据是以某种方式组织的,添加更多的维度可以使查询数据变得更加容易。当我们从 3 维数组发展到 4 维和更大的数组时,同样的属性也适用,它们可以用同样的方式进行索引和切片。
NumPy 数据类型
正如我们前面提到的,每个 NumPy 数组可以存储单一数据类型的元素。例如,wines只包含浮点值。NumPy 使用自己的数据类型存储值,这与 Python 类型如float和str截然不同。这是因为 NumPy 的核心是用一种叫做 C 的编程语言编写的,它存储数据的方式不同于 Python 数据类型。NumPy 数据类型在 Python 和 C 之间映射,允许我们使用 NumPy 数组而没有任何转换障碍。
您可以通过访问 dtype 属性来查找 NumPy 数组的数据类型:
wines.dtype
dtype('float64')
NumPy 有几种不同的数据类型,它们大多映射到 Python 数据类型,比如float和str。您可以在这里找到 NumPy 数据类型的完整列表,但这里有几个重要的:
float—数字浮点数据。int—整数数据。string—字符数据。object— Python 对象。
数据类型还以一个后缀结尾,表明它们占用了多少位内存。所以int32是 32 位整数数据类型,float64是64位浮点数据类型。
转换数据类型
您可以使用 numpy.ndarray.astype 方法将数组转换为不同的类型。该方法将实际复制数组,并返回具有指定数据类型的新数组。例如,我们可以将wines转换为int数据类型:
wines.astype(int)
array([[ 7, 0, 0, ..., 0, 9, 5],
[ 7, 0, 0, ..., 0, 9, 5],
[ 7, 0, 0, ..., 0, 9, 5],
...,
[ 6, 0, 0, ..., 0, 11, 6],
[ 5, 0, 0, ..., 0, 10, 5],
[ 6, 0, 0, ..., 0, 11, 6]])
正如您在上面看到的,结果数组中的所有项都是整数。注意,在转换wines时,我们使用 Python int类型而不是 NumPy 数据类型。这是因为几种 Python 数据类型,包括float、int和string,都可以与 NumPy 一起使用,并自动转换成 NumPy 数据类型。
我们可以检查结果数组的 dtype 的 name 属性,以查看结果数组映射到了什么数据类型 NumPy:
int_wines = wines.astype(int)
int_wines.dtype.name
'int64'
该数组已被转换为 64 位整数数据类型。这允许很长的整数值,但是比将值存储为 32 位整数占用更多的内存空间。
如果您想要更多地控制数组在内存中的存储方式,您可以直接创建 NumPy dtype 对象,如 numpy.int32 :
np.int32
numpy.int32
您可以直接使用这些在类型之间转换:
wines.astype(np.int32)
array([[ 7, 0, 0, ..., 0, 9, 5],
[ 7, 0, 0, ..., 0, 9, 5],
[ 7, 0, 0, ..., 0, 9, 5],
...,
[ 6, 0, 0, ..., 0, 11, 6],
[ 5, 0, 0, ..., 0, 10, 5],
[ 6, 0, 0, ..., 0, 11, 6]], dtype=int32)
NumPy 数组操作
NumPy 使得对数组执行数学运算变得简单。这是 NumPy 的主要优点之一,它使计算变得非常容易。
单数组数学
如果您对一个数组和一个值进行任何基本的数学运算(/、*、-、+、^),它会将运算应用于数组中的每个元素。
假设我们想给每个质量分数加上10分,因为我们喝醉了,感觉很慷慨。我们是这样做的:
wines[:,11] + 10
array([ 15., 15., 15., ..., 16., 15., 16.])
注意,上面的操作不会改变wines数组——它将返回一个新的一维数组,其中10已被添加到葡萄酒质量列的每个元素中。
如果我们改为使用+=,我们将就地修改数组:
wines[:,11] += 10
wines[:,11]
array([ 15., 15., 15., ..., 16., 15., 16.])
所有其他操作都以同样的方式工作。例如,如果我们想将每个质量分数乘以2,我们可以这样做:
wines[:,11] * 2
array([ 30., 30., 30., ..., 32., 30., 32.])
多重数组数学
也可以在数组之间进行数学运算。这将把操作应用于元素对。例如,如果我们将quality列添加到自身,我们会得到以下结果:
wines[:,11] + wines[:,11]
array([ 10., 10., 10., ..., 12., 10., 12.])
注意,这相当于wines[11] * 2 —这是因为 NumPy 将每对元素相加。第一个数组中的第一个元素与第二个数组中的第一个元素相加,第二个元素与第二个元素相加,依此类推。
我们也可以用这个来乘数组。假设我们想挑选一款酒精含量和质量最大化的葡萄酒(我们想喝醉,但我们很优雅)。我们将alcohol乘以quality,选择得分最高的葡萄酒:
wines[:,10] * wines[:,11]
array([ 47., 49., 49., ..., 66., 51., 66.])
所有常见操作(/、*、-、+、^)都将在阵列之间工作。
广播
除非你操作的数组大小完全相同,否则不可能进行元素操作。在这种情况下,NumPy 执行广播来尝试匹配元素。本质上,广播包括几个步骤:
- 比较每个数组的最后一个维度。
- 如果维度长度相等,或者其中一个维度的长度为
1,那么我们继续前进。 - 如果尺寸长度不相等,并且没有一个尺寸有长度
1,那么就有一个错误。
- 如果维度长度相等,或者其中一个维度的长度为
- 继续检查尺寸,直到最短的数组超出尺寸。
例如,以下两种形状是兼容的:
A: (50,3)
B (3,)
这是因为数组A的尾维长度是3,数组B的尾维长度是3。它们是相等的,所以量纲没问题。然后,数组B没有元素了,所以我们没事了,数组对于数学运算是兼容的。
以下两种形状也是兼容的:
A: (1,2)
B (50,2)
最后一个维度匹配,A的长度为第一维度的1。
这两个数组不匹配:
A: (50,50)
B: (49,49)
维度的长度不相等,并且没有一个数组的维度长度等于1。
这里有一个广播的详细解释,但是我们将通过几个例子来说明这个原理:
wines * np.array([1,2])
------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython -input-40-821086ccaf65> in <module>()
----> 1 wines * np.array([1,2])
ValueError: operands could not be broadcast together with shapes (1599,12) (2,)
上面的例子不起作用,因为两个数组没有匹配的尾部维度。以下是最后一个维度匹配的示例:
array_one = np.array(
[
[1,2],
[3,4]
]
)
array_two = np.array([4,5])
array_one + array_two
array([[5, 7],
[7, 9]])
大家可以看到,array_two已经跨array_one的每一行播出了。下面是我们的wines数据的一个例子:
rand_array = np.random.rand(12)
wines + rand_array
array([[ 8.08375389, 0.89047394, 0.77022918, ..., 0.94917479,
10.34668852, 5.34569289],
[ 8.48375389, 1.07047394, 0.77022918, ..., 1.06917479,
10.74668852, 5.34569289],
[ 8.48375389, 0.95047394, 0.81022918, ..., 1.03917479,
10.74668852, 5.34569289],
...,
[ 6.98375389, 0.70047394, 0.90022918, ..., 1.13917479,
11.94668852, 6.34569289],
[ 6.58375389, 0.83547394, 0.89022918, ..., 1.09917479,
11.14668852, 5.34569289],
[ 6.68375389, 0.50047394, 1.24022918, ..., 1.04917479,
11.94668852, 6.34569289]])
rand_array的元素在wines的每一行中传播,所以wines的第一列加上了rand_array中的第一个值,依此类推。
NumPy 数组方法
除了常见的数学运算之外,NumPy 还有几个方法可以用于更复杂的数组计算。这方面的一个例子是 numpy.ndarray.sum 方法。默认情况下,这将查找数组中所有元素的总和:
wines[:,11].sum()
9012.0
我们所有质量评级的总和是154.1788。我们可以将axis关键字参数传递到sum方法中,以计算一个轴上的总和。如果我们通过wines矩阵调用sum,并传入axis=0,我们将找到数组第一个轴上的总和。这将给出每一列中所有值的总和。第一个轴上的总和会给出每一列的总和,这看起来似乎是反过来的,但考虑这个问题的一种方式是,指定的轴是“离开”的轴。因此,如果我们指定axis=0,我们希望这些行消失,并且我们希望找到每一行中剩余轴的总和:
wines.sum(axis=0)
array([ 13303.1 , 843.985 , 433.29 , 4059.55 ,
139.859 , 25384\. , 74302\. , 1593.79794,
5294.47 , 1052.38 , 16666.35 , 9012\. ])
我们可以通过检查形状来验证我们做的加法是否正确。形状应为12,对应列数:
wines.sum(axis=0).shape
(12,)
如果我们传入axis=1,我们将在数组的第二个轴上找到总和。这将给我们每一行的总和:
wines.sum(axis=1)
array([ 74.5438 , 123.0548 , 99.699 , ...,<br />
100.48174, 105.21547,
92.49249])
还有其他几种方法的行为类似于sum方法,包括:
- numpy.ndarray.mean —计算数组的平均值。
- numpy.ndarray.std —查找数组的标准偏差。
- numpy.ndarray.min —查找数组中的最小值。
- numpy.ndarray.max —查找数组中的最大值。
你可以在这里找到数组方法的完整列表。
NumPy 数组比较
NumPy 可以使用数学比较操作,如<、>、>=、<=和==,来测试行是否匹配某些值。例如,如果我们想查看哪些葡萄酒的质量等级高于5,我们可以这样做:
wines[:,11] > 5
array([False, False, False, ..., True, False, True], dtype=bool)
我们得到一个布尔数组,告诉我们哪些葡萄酒的质量等级高于5。我们可以对其他运营商做类似的事情。例如,我们可以查看是否有葡萄酒的质量等级等于10:
wines[:,11] == 10
array([False, False, False, ..., False, False, False], dtype=bool)
sb 设置
我们可以用布尔数组和 NumPy 数组做的一件强大的事情是只选择 NumPy 数组中的某些行或列。例如,下面的代码将只选择质量超过7的wines中的行:
high_quality = wines[:,11] > 7
wines[high_quality,:][:3,:]
array([[ 7.90000000e+00, 3.50000000e-01, 4.60000000e-01,
3.60000000e+00, 7.80000000e-02, 1.50000000e+01,
3.70000000e+01, 9.97300000e-01, 3.35000000e+00,
8.60000000e-01, 1.28000000e+01, 8.00000000e+00],
[ 1.03000000e+01, 3.20000000e-01, 4.50000000e-01,
6.40000000e+00, 7.30000000e-02, 5.00000000e+00,
1.30000000e+01, 9.97600000e-01, 3.23000000e+00,
8.20000000e-01, 1.26000000e+01, 8.00000000e+00],
[ 5.60000000e+00, 8.50000000e-01, 5.00000000e-02,
1.40000000e+00, 4.50000000e-02, 1.20000000e+01,
8.80000000e+01, 9.92400000e-01, 3.56000000e+00,
8.20000000e-01, 1.29000000e+01, 8.00000000e+00]])
我们只选择那些high_quality包含一个True值的行,以及所有的列。这种子集化使得根据特定标准过滤数组变得简单。例如,我们可以寻找酒精含量高、质量好的葡萄酒。为了指定多个条件,我们必须将每个条件放在括号中,并用一个&符号(&)分隔条件:
high_quality_and_alcohol = (wines[:,10] > 10) & (wines[:,11] > 7)
wines[high_quality_and_alcohol,10:]
array([[ 12.8, 8\. ],
[ 12.6, 8\. ],
[ 12.9, 8\. ],
[ 13.4, 8\. ],
[ 11.7, 8\. ],
[ 11\. , 8\. ],
[ 11\. , 8\. ],
[ 14\. , 8\. ],
[ 12.7, 8\. ],
[ 12.5, 8\. ],
[ 11.8, 8\. ],
[ 13.1, 8\. ],
[ 11.7, 8\. ],
[ 14\. , 8\. ],
[ 11.3, 8\. ],
[ 11.4, 8\. ]])
我们可以结合子集化和赋值来覆盖数组中的某些值:
high_quality_and_alcohol = (wines[:,10] > 10) & (wines[:,11] > 7)
wines[high_quality_and_alcohol,10:] = 20
重塑 NumPy 数组
我们可以改变数组的形状,同时仍然保留所有的元素。这通常会使访问数组元素变得更容易。最简单的整形是翻转轴,这样行就变成了列,反之亦然。我们可以用 numpy.transpose 函数来实现这一点:
np.transpose(wines).shape
(12, 1599)
我们可以使用 numpy.ravel 函数将数组转换成一维表示。它实际上将一个数组展平成一长串值:
wines.ravel()
array([ 7.4 , 0.7 , 0\. , ..., 0.66, 11\. , 6\. ])
这里有一个例子,我们可以看到numpy.ravel的排序:
array_one = np.array(
[
[1, 2, 3, 4],
[5, 6, 7, 8]
]
)
array_one.ravel()
array([1, 2, 3, 4, 5, 6, 7, 8])
最后,我们可以使用numpy . shape函数将数组整形为我们指定的形状。下面的代码将把第二行wines变成一个有2行和6列的二维数组:
wines[1,:].reshape((2,6))
array([[ 7.8 , 0.88 , 0\. , 2.6 , 0.098 , 25\. ],
[ 67\. , 0.9968, 3.2 , 0.68 , 9.8 , 5\. ]])
组合 NumPy 数组
使用 NumPy,将多个阵列组合成一个统一阵列是非常常见的。我们可以使用 numpy.vstack 来垂直堆叠多个数组。想象一下,第二个数组的项目作为新行添加到第一个数组中。我们可以读入包含白葡萄酒质量信息的winequality-white.csv数据集,然后将其与包含红葡萄酒信息的现有数据集wines相结合。
在下面的代码中,我们:
- 读入
winequality-white.csv。 - 显示
white_wines的形状。
white_wines = np.genfromtxt("winequality-white.csv", delimiter=";", skip_header=1)
white_wines.shape
(4898, 12)
正如你所看到的,我们有葡萄酒的属性。现在我们有了白葡萄酒的数据,我们可以合并所有的葡萄酒数据。
在下面的代码中,我们:
- 使用
vstack功能组合wines和white_wines。 - 显示结果的形状。
all_wines = np.vstack((wines, white_wines))
all_wines.shape
(6497, 12)
可以看到,结果有6497行,这是wines中的行数和red_wines中的行数之和。
如果我们想要水平组合数组,其中行数保持不变,但列是连接的,那么我们可以使用 numpy.hstack 函数。我们组合的数组需要有相同的行数才能工作。
最后,我们可以使用 numpy.concatenate 作为hstack和vstack的通用版本。如果我们想要连接两个数组,我们将它们传递给concatenate,然后指定我们想要连接的axis关键字参数。沿第一轴串联类似于vstack,沿第二轴串联类似于hstack:
np.concatenate((wines, white_wines), axis=0)
array([[ 7.4 , 0.7 , 0\. , ..., 0.56, 9.4 , 5\. ],
[ 7.8 , 0.88, 0\. , ..., 0.68, 9.8 , 5\. ],
[ 7.8 , 0.76, 0.04, ..., 0.65, 9.8 , 5\. ],
...,
[ 6.5 , 0.24, 0.19, ..., 0.46, 9.4 , 6\. ],
[ 5.5 , 0.29, 0.3 , ..., 0.38, 12.8 , 7\. ],
[ 6\. , 0.21, 0.38, ..., 0.32, 11.8 , 6\. ]])
免费数字备忘单
如果你有兴趣了解更多关于 NumPy 的信息,请查看我们关于 NumPy 和熊猫的互动课程。你可以注册并免费上第一堂课。
你也可以通过我们的免费数字小抄将你的数字技能提升到一个新的水平!
进一步阅读
您现在应该很好地掌握了 NumPy,以及如何将它应用到数据集。
如果您想深入了解,这里有一些资源可能会有所帮助:
- NumPy 快速入门 —有很好的代码示例,涵盖了最基本的 NumPy 功能。
- Python NumPy 教程 —关于 NumPy 和其他 Python 库的优秀教程。
- 视觉数字简介 —用生活游戏来说明数字概念的指南。
在我们的下一个教程中,我们将更深入地研究 Pandas ,这是一个基于 NumPy 构建的库,它使数据分析变得更加容易。它解决了两个最大的难题:
- 不能在一个数组中混合多种数据类型。
- 你必须记住每一列包含什么类型的数据。
用正确的方法学习 Python。
从第一天开始,就在你的浏览器窗口中通过编写 Python 代码来学习 Python。这是学习 Python 的最佳方式——亲自看看我们 60 多门免费课程中的一门。
教程:在 Python 中使用带有大型数据集的 Pandas
August 4, 2017
您是否知道当您处理大数据集时,Python 和 pandas 可以减少多达 90%的内存使用?
当使用 pandas 处理小数据(小于 100 兆字节)的 Python 时,性能很少成为问题。当我们转移到更大的数据(100 兆字节到数千兆字节)时,性能问题会使运行时间变得更长,并导致代码由于内存不足而完全失败。
虽然 Spark 等工具可以处理大型数据集(100 到数 TB),但充分利用它们的能力通常需要更昂贵的硬件。与熊猫不同,它们缺乏丰富的功能集来进行高质量的数据清理、探索和分析。对于中等大小的数据,我们最好尝试从 pandas 中获得更多,而不是切换到不同的工具。
在这篇文章中,我们将了解 Python 对 pandas 的内存使用,如何通过为列选择适当的数据类型,将数据帧的内存占用减少近 90%。

使用棒球比赛日志
我们将研究 130 年来美国职业棒球大联盟比赛的数据,这些数据最初来自于回顾表。
最初,数据在 127 个单独的 CSV 文件中,但是我们使用了 csvkit 来合并文件,并在第一行中添加了列名。如果你想下载我们的数据版本来跟进这篇文章,我们已经在这里提供了。
让我们从在 Python 中导入熊猫和我们的数据开始,看看前五行。
import pandas as pd
gl = pd.read_csv('game_logs.csv')
gl.head()
| 日期 | 游戏的数量 | 星期几 | 虚拟姓名 | v _ 联赛 | v _ 游戏 _ 号码 | hgame | h _ 联赛 | h _ 游戏 _ 号码 | v _ 分数 | h 分数 | 长度 _ 超时 | 白天夜晚 | 完成 | 丧失 | 抗议 | 公园 id | 出席 | 长度 _ 分钟 | v _ 线 _ 分数 | h_line_score | 蝙蝠 | v_hits | v _ 双打 | v_triples | v _ 本垒打 | 虚拟银行 | v _ 牺牲 _ 命中 | v _ 牺牲 _ 苍蝇 | 垂直命中间距 | v_walks | v _ 有意行走 | v _ 删除线 | 五 _ 被盗 _ 基地 | 偷窃被抓 | v _ 接地 _ 进 _ 双 | v _ 优先 _ 捕捉器 _ 干扰 | v _ 左 _ 上 _ 下 | v _ 投手 _ 已用 | 个人获得的跑步记录 | v _ team _ earned _ runs | v _ wild _ pitches | v_balks | v _ 输出 | vassistx | v _ 错误 | v _ 传球 _ 球 | 双人游戏 | 三重播放 | 蝙蝠 | 点击次数 | h _ 双打 | h_triples | h _ 本垒打 | h_rbi | h _ 牺牲 _ 命中 | h _ 祭祀 _ 苍蝇 | h _ hit _ by _ 音高 | h _ 行走 | h _ 有意行走 | h _ 删除线 | h _ 被盗 _ 基地 | 偷东西被抓 | h _ 接地 _ 进 _ 双 | h _ 优先 _ 捕捉器 _ 干扰 | 左满垒 | h_pitchers_used | 个人获得的跑步记录 | h _ team _ earned _ runs | h _ wild _ pitches | h_balks | h _ 输出 | h _ 助攻 | h _ 错误 | h _ 传球 _ 球 | 双人游戏 | 三重播放 | 惠普 _ 裁判 _id | 惠普裁判姓名 | 1b _ 裁判 _id | 1b _ 裁判员 _ 姓名 | 2b _ 裁判 _id | 2b _ 裁判员 _ 姓名 | 3b _ 裁判 _id | 3b _ 裁判员 _ 姓名 | lf _ 裁判员 _id | lf _ 裁判员 _ 姓名 | rf _ 裁判员 _id | rf _ 裁判员 _ 姓名 | 虚拟经理 id | 虚拟经理姓名 | h _ 经理 _id | 经理姓名 | winning _ pitcher _ id | 获胜投手姓名 | losing_pitcher_id | 失去投手姓名 | 正在保存 _pitcher_id | 保存 _pitcher_name | 中奖 _ 打点 _ 击球手 _id | 获奖 _rbi_batter_id_name | v_starting_pitcher_id | v_starting_pitcher_name | h_starting_pitcher_id | h_starting_pitcher_name | 虚拟玩家 1 号 | v _ 玩家 _ 1 _ 姓名 | 虚拟玩家 1 定义位置 | v _ 玩家 _2_id | v _ 玩家 _ 2 _ 姓名 | 虚拟玩家 2 定义位置 | 虚拟玩家 3 号 id | v _ 玩家 _ 3 _ 姓名 | 虚拟玩家 3 定义位置 | v _ 玩家 _4_id | v _ 玩家 _ 4 _ 姓名 | 虚拟玩家 4 定义位置 | v _ 玩家 _5_id | v_player_5_name | 虚拟玩家 5 定义位置 | v_player_6_id | v_player_6_name | 虚拟玩家 6 定义位置 | v _ 玩家 _7_id | v_player_7_name | 虚拟玩家 7 定义位置 | v_player_8_id | v_player_8_name | 虚拟玩家 8 定义位置 | v _ 玩家 _9_id | v_player_9_name | 虚拟玩家 9 定义位置 | h_player_1_id | h_player_1_name | h _ 播放器 _1_def_pos | h_player_2_id | h_player_2_name | h _ 播放器 _2_def_pos | h_player_3_id | h_player_3_name | h _ 播放器 _3_def_pos | h_player_4_id | h_player_4_name | h _ 播放器 _4_def_pos | h_player_5_id | h_player_5_name | h _ 播放器 _5_def_pos | h_player_6_id | h_player_6_name | h _ 播放器 _6_def_pos | h_player_7_id | h_player_7_name | h _ 播放器 _7_def_pos | h_player_8_id | h_player_8_name | h _ 播放器 _8_def_pos | h_player_9_id | h_player_9_name | h _ 播放器 _9_def_pos | 附加信息 | 收购信息 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Eighteen million seven hundred and ten thousand five hundred and four | Zero | 星期四 | CL1 | 钠 | one | FW1 | 钠 | one | Zero | Two | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 对于 01 | Two hundred | One hundred and twenty | 000000000 | 010010000 | Thirty | Four | One | Zero | Zero | Zero | Zero | Zero | Zero | One | -1.0 | Six | One | -1.0 | -1.0 | -1.0 | Four | One | One | One | Zero | Zero | Twenty-seven | Nine | Zero | Three | Zero | Zero | Thirty-one | Four | One | Zero | Zero | Two | Zero | Zero | Zero | One | -1.0 | Zero | Zero | -1.0 | -1.0 | -1.0 | Three | One | Zero | Zero | Zero | Zero | Twenty-seven | Three | Three | One | One | Zero | boakj901 | 约翰·布莱克 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | paboc101 | 查理·帕博尔 | lennb101 | 比尔·列侬 | mathb101 | 鲍比·马修斯 | 普拉塔 101 | 艾尔·普拉特 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 普拉塔 101 | 艾尔·普拉特 | mathb101 | 鲍比·马修斯 | whitd102 | 迪肯·怀特 | Two | kimbg101 | 吉恩·金博尔 | Four | paboc101 | 查理·帕博尔 | Seven | allia101 | 阿特·艾利森 | Eight | 白色 104 | 埃尔默·怀特 | Nine | 普拉塔 101 | 艾尔·普拉特 | One | 萨图特 101 | 以斯拉·萨顿 | Five | 卡莱 102 | 吉姆·卡尔顿 | Three | bassj101 | 约翰·巴斯 | Six | selmf101 | 弗兰克·塞尔曼 | Five | mathb101 | 鲍比·马修斯 | One | 福尔马林 101 | Jim Foran | Three | goldw101 | 沃利·戈德史密斯 | Six | lennb101 | 比尔·列侬 | Two | 职业 101 | 汤姆·凯里 | Four | 碎肉 101 | 埃德·明彻 | Seven | mcdej101 | 詹姆斯·麦克德莫特 | Eight | kellb105 | 比尔·凯利 | Nine | 圆盘烤饼 | Y |
| one | Eighteen million seven hundred and ten thousand five hundred and five | Zero | Fri | BS1 | 钠 | one | WS3 | 钠 | one | Twenty | Eighteen | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | WAS01 | Five thousand | One hundred and forty-five | One hundred and seven million four hundred and thirty-five | Six hundred and forty million one hundred and thirteen thousand and thirty | Forty-one | Thirteen | One | Two | Zero | Thirteen | Zero | Zero | Zero | Eighteen | -1.0 | Five | Three | -1.0 | -1.0 | -1.0 | Twelve | One | Six | Six | One | Zero | Twenty-seven | Thirteen | Ten | One | Two | Zero | Forty-nine | Fourteen | Two | Zero | Zero | Eleven | Zero | Zero | Zero | Ten | -1.0 | Two | One | -1.0 | -1.0 | -1.0 | Fourteen | One | Seven | Seven | Zero | Zero | Twenty-seven | Twenty | Ten | Two | Three | Zero | 多布斯 901 | 亨利·多布森 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | wrigh101 | 哈里·赖特 | younn801 | 尼克·杨 | spala101 | 阿尔·斯伯丁 | 巴西 102 | 阿萨·布雷纳德 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | spala101 | 阿尔·斯伯丁 | 巴西 102 | 阿萨·布雷纳德 | 箭牌 101 | 乔治·赖特 | Six | 巴恩斯 102 | 罗斯·巴恩斯 | Four | birdd102 | 戴夫·伯索尔 | Nine | mcvec101 | 卡尔·麦克维 | Two | wrigh101 | 哈里·赖特 | Eight | goulc101 | 查理·古尔德 | Three | 沙赫 101 | 哈里·斯查费 | Five | conef101 | 弗雷德·科恩 | Seven | spala101 | 阿尔·斯伯丁 | One | watef102 | 弗雷德·沃特曼 | Five | forcd101 | 戴维力量 | Six | mille105 | 埃弗里特·米尔斯 | Three | allid101 | 道格·艾利森 | Two | hallg101 | 乔治·霍尔 | Seven | 利昂娜 101 | 安迪·伦纳德 | Four | 巴西 102 | 阿萨·布雷纳德 | One | burrh101 | 亨利·巴勒斯 | Nine | berth101 | 亨利·贝思龙 | Eight | HTBF | Y |
| Two | Eighteen million seven hundred and ten thousand five hundred and six | Zero | 坐 | CL1 | 钠 | Two | RC1 | 钠 | one | Twelve | four | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | RCK01 | One thousand | One hundred and forty | Six hundred and ten million twenty thousand and three | 010020100 | Forty-nine | Eleven | One | One | Zero | Eight | Zero | Zero | Zero | Zero | -1.0 | One | Zero | -1.0 | -1.0 | -1.0 | Ten | One | Zero | Zero | Two | Zero | Twenty-seven | Twelve | Eight | Five | Zero | Zero | Thirty-six | Seven | Two | One | Zero | Two | Zero | Zero | Zero | Zero | -1.0 | Three | Five | -1.0 | -1.0 | -1.0 | Five | One | Three | Three | One | Zero | Twenty-seven | Twelve | Thirteen | Three | Zero | Zero | mawnj901 | J.H .曼尼 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | paboc101 | 查理·帕博尔 | hasts101 | 斯科特·黑斯廷斯 | 普拉塔 101 | 艾尔·普拉特 | 鱼 c102 | 切诺基费希尔 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 普拉塔 101 | 艾尔·普拉特 | 鱼 c102 | 切诺基费希尔 | whitd102 | 迪肯·怀特 | Two | kimbg101 | 吉恩·金博尔 | Four | paboc101 | 查理·帕博尔 | Seven | allia101 | 阿特·艾利森 | Eight | 白色 104 | 埃尔默·怀特 | Nine | 普拉塔 101 | 艾尔·普拉特 | One | 萨图特 101 | 以斯拉·萨顿 | Five | 卡莱 102 | 吉姆·卡尔顿 | Three | bassj101 | 约翰·巴斯 | Six | mackd101 | 丹尼·麦克 | Three | addyb101 | 鲍勃·艾迪 | Four | 鱼 c102 | 切诺基费希尔 | One | hasts101 | 斯科特·黑斯廷斯 | Eight | ham-r101 | Ralph Ham | Five | ansoc101 | 安森角 | Two | sagep101 | 小马的事 | Six | birdg101 | 乔治·伯德 | Seven | 搅拌 101 | Gat Stires | Nine | 圆盘烤饼 | Y |
| three | Eighteen million seven hundred and ten thousand five hundred and eight | Zero | 孟人 | CL1 | 钠 | three | CH1 | 钠 | one | Twelve | Fourteen | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | CHI01 | Five thousand | One hundred and fifty | One hundred and one million four hundred and three thousand one hundred and eleven | 077000000 | Forty-six | Fifteen | Two | One | Two | Ten | Zero | Zero | Zero | Zero | -1.0 | One | Zero | -1.0 | -1.0 | -1.0 | Seven | One | Six | Six | Zero | Zero | Twenty-seven | Fifteen | Eleven | Six | Zero | Zero | Forty-three | Eleven | Two | Zero | Zero | Eight | Zero | Zero | Zero | Four | -1.0 | Two | One | -1.0 | -1.0 | -1.0 | Six | One | Four | Four | Zero | Zero | Twenty-seven | Fourteen | Seven | Two | Zero | Zero | willg901 | 加德纳·威拉德 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | paboc101 | 查理·帕博尔 | woodj106 | 吉米·伍德 | zettg101 | 乔治·蔡特林 | 普拉塔 101 | 艾尔·普拉特 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 普拉塔 101 | 艾尔·普拉特 | zettg101 | 乔治·蔡特林 | whitd102 | 迪肯·怀特 | Two | kimbg101 | 吉恩·金博尔 | Four | paboc101 | 查理·帕博尔 | Seven | allia101 | 阿特·艾利森 | Eight | 白色 104 | 埃尔默·怀特 | Nine | 普拉塔 101 | 艾尔·普拉特 | One | 萨图特 101 | 以斯拉·萨顿 | Five | 卡莱 102 | 吉姆·卡尔顿 | Three | bassj101 | 约翰·巴斯 | Six | mcatb101 | 布·麦卡蒂 | Three | kingm101 | 马歇尔·金 | Eight | hodec101 | 查理·霍兹 | Two | woodj106 | 吉米·伍德 | Four | simmj101 | 乔·西蒙斯 | Nine | 小精灵 101 | 汤姆·福利 | Seven | 粗呢 101 | 艾德·达菲 | Six | pinke101 | 艾德平克曼 | Five | zettg101 | 乔治·蔡特林 | One | 圆盘烤饼 | Y |
| four | Eighteen million seven hundred and ten thousand five hundred and nine | Zero | 周二 | BS1 | 钠 | Two | TRO | 钠 | one | nine | five | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | TRO01 | Three thousand two hundred and fifty | One hundred and forty-five | 000002232 | One hundred and one million and three thousand | Forty-six | Seventeen | Four | One | Zero | Six | Zero | Zero | Zero | Two | -1.0 | Zero | One | -1.0 | -1.0 | -1.0 | Twelve | One | Two | Two | Zero | Zero | Twenty-seven | Twelve | Five | Zero | One | Zero | Thirty-six | Nine | Zero | Zero | Zero | Two | Zero | Zero | Zero | Three | -1.0 | Zero | Two | -1.0 | -1.0 | -1.0 | Seven | One | Three | Three | One | Zero | Twenty-seven | Eleven | Seven | Three | Zero | Zero | leroi901 | 艾萨克·勒罗伊 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | wrigh101 | 哈里·赖特 | pikel101 | 唇矛 | spala101 | 阿尔·斯伯丁 | 麦克莫吉 101 | 约翰·麦克穆林 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | spala101 | 阿尔·斯伯丁 | 麦克莫吉 101 | 约翰·麦克穆林 | 箭牌 101 | 乔治·赖特 | Six | 巴恩斯 102 | 罗斯·巴恩斯 | Four | birdd102 | 戴夫·伯索尔 | Nine | mcvec101 | 卡尔·麦克维 | Two | wrigh101 | 哈里·赖特 | Eight | goulc101 | 查理·古尔德 | Three | 沙赫 101 | 哈里·斯查费 | Five | conef101 | 弗雷德·科恩 | Seven | spala101 | 阿尔·斯伯丁 | One | flync101 | 快船弗林 | Nine | mcgem101 | 迈克·麦吉瑞 | Two | yorkt101 | 汤姆·约克 | Eight | 麦克莫吉 101 | 约翰·麦克穆林 | One | 金斯 101 | 史蒂夫·金 | Seven | beave101 | 爱德华·比弗斯 | Four | 贝尔 s101 | 史蒂夫·贝伦 | Five | pikel101 | 唇矛 | Three | cravb101 | 比尔·克雷默 | Six | HTBF | Y |
我们在下面总结了一些重要的列,但是如果您想查看所有列的指南,我们为整个数据集创建了一个数据字典:
date—比赛日期。v_name—客队名称。v_league—客队联赛。h_name—主队名称。h_league—主队联赛。v_score—客队得分。h_score—主队得分。v_line_score—客队线路得分,如010000(10)00。h_line_score—主队线路得分,如010000(10)0X。park_id—举办比赛的公园的 ID。attendance—游戏出席率。
我们可以使用 DataFrame.info() 方法来给出一些关于数据帧的高级信息,包括它的大小、数据类型和内存使用的信息。
默认情况下,pandas 大约使用数据帧的内存来节省时间。因为我们对准确性感兴趣,所以我们将把memory_usage参数设置为'deep'来获得一个准确的数字。
gl.info(memory_usage='deep')
<class 'pandas.core.frame.DataFrame'>RangeIndex: 171907 entries, 0 to 171906
Columns: 161 entries, date to acquisition_infodtypes: float64(77), int64(6), object(78)
memory usage: 861.6 MB
我们可以看到有 171,907 行和 161 列。Pandas 已经为我们自动检测了类型,有 83 个数字列和 78 个对象列。对象列用于字符串或包含混合数据类型的列。
因此,我们可以更好地了解我们可以在哪里减少这种内存使用,让我们看看 Python 和 pandas 如何在内存中存储数据。
数据帧的内部表示
在底层,pandas 将列分组为相同类型的值块。下面是 pandas 如何存储我们的数据帧的前 12 列的预览。

您会注意到这些块没有维护对列名的引用。这是因为块是为存储数据帧中的实际值而优化的。 BlockManager 类负责维护行和列索引与实际块之间的映射。它充当一个 API,提供对底层数据的访问。每当我们选择、编辑或删除值时,dataframe 类都会与 BlockManager 类接口,将我们的请求转换为函数和方法调用。
每种类型在 pandas.core.internals 模块中都有专门的类。Pandas 使用 ObjectBlock 类表示包含 string 列的块,使用 FloatBlock 类表示包含 float 列的块。对于表示数字值(如整数和浮点数)的块,pandas 合并列并将其存储为 NumPy ndarray。NumPy ndarray 是围绕 C 数组构建的,值存储在连续的内存块中。由于这种存储方案,访问一部分值的速度非常快。
因为每种数据类型都是单独存储的,所以我们将按数据类型检查内存使用情况。让我们从查看数据类型的平均内存使用量开始。
for dtype in ['float','int','object']:
selected_dtype = gl.select_dtypes(include=[dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b / 1024 ** 2
print("Average memory usage for {} columns: {:03.2f} MB".format(dtype,mean_usage_mb))
Average memory usage for float columns: 1.29 MB
Average memory usage for int columns: 1.12 MB
Average memory usage for object columns: 9.53 MB
我们可以立即看到,我们的 78 个object列使用了大部分内存。我们将在后面讨论这些,但首先让我们看看是否可以改善数字列的内存使用。
了解子类型
正如我们之前简单提到的,pandas 将数值表示为 NumPy ndarrays,并将它们存储在连续的内存块中。这种存储模型占用更少的空间,并允许我们快速访问值本身。因为 pandas 使用相同数量的字节表示相同类型的每个值,并且 NumPy ndarray 存储值的数量,pandas 可以快速准确地返回数字列消耗的字节数。
pandas 中的许多类型有多个子类型,可以使用较少的字节来表示每个值。例如,float类型有float16、float32和float64子类型。类型名的数字部分表示类型用来表示值的位数。例如,我们刚刚列出的子类型分别使用2、4、8和16字节。下表显示了最常见熊猫类型的子类型:
| 内存使用 | 漂浮物 | (同 Internationalorganizations)国际组织 | uint | 日期时间 | 弯曲件 | 目标 |
|---|---|---|---|---|---|---|
| 1 字节 | int8 | uint8 | 弯曲件 | |||
| 2 字节 | 浮动 16 | int16 | uint16 | |||
| 4 字节 | float32 | int32 | uint32 | |||
| 8 字节 | float64 | int64 | uint64 | 日期时间 64 | ||
| 可变的 | 目标 |
一个int8值用1字节(或8位)存储一个值,可以用二进制表示256值(2^8)。这意味着我们可以用这个子类型来表示从-128到127(包括0)的值。
我们可以使用 numpy.iinfo 类来验证每个整数子类型的最小值和最大值。让我们看一个例子:
import numpy as np
int_types = ["uint8", "int8", "int16"]
for it in int_types:
print(np.iinfo(it))
Machine parameters for uint8----------------------------------------
min = 0
max = 255
Machine parameters for int8-----------------------------------------
min = -128
max = 127
Machine parameters for int16----------------------------------------
min = -32768
max = 32767
我们在这里可以看到uint(无符号整数)和int(有符号整数)的区别。这两种类型具有相同的存储容量,但是通过只存储正值,无符号整数允许我们更有效地存储只包含正值的列。
使用子类型优化数字列
我们可以使用函数pd.to_numeric()来向下转换我们的数值类型。我们将使用DataFrame.select_dtypes只选择整数列,然后我们将优化类型并比较内存使用情况。
# We're going to be calculating memory usage a lot,
# so we'll create a function to save us some time!
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # we assume if not a df it's a series
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # convert bytes to megabytes
return "{:03.2f} MB".format(usage_mb)
gl_int = gl.select_dtypes(include=['int'])
converted_int = gl_int.apply(pd.to_numeric,downcast='unsigned')
print(mem_usage(gl_int))
print(mem_usage(converted_int))
compare_ints = pd.concat([gl_int.dtypes,converted_int.dtypes],axis=1)
compare_ints.columns = ['before','after']
compare_ints.apply(pd.Series.value_counts)
7.87 MB
1.48 MB
| 以前 | 在...之后 | |
|---|---|---|
| uint8 | 圆盘烤饼 | Five |
| uint32 | 圆盘烤饼 | One |
| int64 | Six | 圆盘烤饼 |
我们可以看到内存使用量从 7.9 兆字节下降到 1.5 兆字节,降幅超过 80%。尽管对原始数据帧的整体影响并不大,因为整数列很少。
让我们对浮动列做同样的事情。
gl_float = gl.select_dtypes(include=['float'])
converted_float = gl_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(gl_float))
print(mem_usage(converted_float))
compare_floats = pd.concat([gl_float.dtypes,converted_float.dtypes],axis=1)
compare_floats.columns = ['before','after']
compare_floats.apply(pd.Series.value_counts)
100.99 MB
50.49 MB
| 以前 | 在...之后 | |
|---|---|---|
| float32 | 圆盘烤饼 | Seventy-seven |
| float64 | Seventy-seven | 圆盘烤饼 |
我们可以看到,所有的浮动列都从float64转换成了float32,从而减少了 50%的内存使用。
让我们创建原始数据帧的副本,将这些优化的数字列分配到原始数据帧的位置,并查看我们现在的整体内存使用情况。
optimized_gl = gl.copy()
optimized_gl[converted_int.columns] = converted_int
optimized_gl[converted_float.columns] = converted_float
print(mem_usage(gl))
print(mem_usage(optimized_gl))
861.57 MB
804.69 MB
虽然我们已经极大地减少了数字列的内存使用,但总的来说,我们只将数据帧的内存使用减少了 7%。我们的大部分收益将来自优化对象类型。
在此之前,让我们仔细看看 pandas 中字符串是如何存储的,与数字类型相比
比较数字存储和字符串存储
object类型使用 Python 字符串对象表示值,部分原因是 NumPy 中缺少对缺失字符串值的支持。因为 Python 是一种高级的解释型语言,所以它对值在内存中的存储方式没有细粒度的控制。
这种限制导致字符串以碎片的方式存储,从而消耗更多的内存,并且访问速度较慢。对象列中的每个元素实际上是一个指针,包含实际值在内存中位置的“地址”。
下图显示了数字数据如何存储在 NumPy 数据类型中,以及字符串如何使用 Python 的内置类型存储。

图改编自优帖Python 为什么慢。
您可能已经注意到,我们之前的图表将object类型描述为使用可变数量的内存。虽然每个指针占用 1 个字节的内存,但是每个实际的字符串值使用的内存量与单独存储在 Python 中的字符串使用的内存量相同。让我们使用sys.getsizeof()来证明这一点,首先查看单个字符串,然后查看熊猫系列中的项目。
from sys import getsizeof
s1 = 'working out'
s2 = 'memory usage for'
s3 = 'strings in python is fun!'
s4 = 'strings in python is fun!'
for s in [s1, s2, s3, s4]:
print(getsizeof(s))
60
65
74
74
obj_series = pd.Series(['working out',
'memory usage for',
'strings in python is fun!',
'strings in python is fun!'])
obj_series.apply(getsizeof)
0 60
1 65
2 74
3 74
dtype: int64
您可以看到,存储在 pandas 系列中的字符串的大小与它们在 Python 中作为单独字符串的用法相同。
使用范畴优化对象类型
熊猫在 0.15 版本中引入了种类。category类型使用整数值来表示列中的值,而不是原始值。Pandas 使用单独的映射字典将整数值映射到原始值。每当一列包含有限的一组值时,这种安排就很有用。当我们将一个列转换为category dtype 时,pandas 使用空间效率最高的int子类型,它可以表示一个列中的所有唯一值。

为了了解我们可以在哪里使用这种类型来减少内存,让我们来看看每个对象类型的唯一值的数量。
gl_obj = gl.select_dtypes(include=['object']).copy()
gl_obj.describe()
| 星期几 | 虚拟姓名 | v _ 联赛 | hgame | h _ 联赛 | 白天夜晚 | 完成 | 丧失 | 抗议 | 公园 id | v _ 线 _ 分数 | h_line_score | 惠普 _ 裁判 _id | 惠普裁判姓名 | 1b _ 裁判 _id | 1b _ 裁判员 _ 姓名 | 2b _ 裁判 _id | 2b _ 裁判员 _ 姓名 | 3b _ 裁判 _id | 3b _ 裁判员 _ 姓名 | lf _ 裁判员 _id | lf _ 裁判员 _ 姓名 | rf _ 裁判员 _id | rf _ 裁判员 _ 姓名 | 虚拟经理 id | 虚拟经理姓名 | h _ 经理 _id | 经理姓名 | winning _ pitcher _ id | 获胜投手姓名 | losing_pitcher_id | 失去投手姓名 | 正在保存 _pitcher_id | 保存 _pitcher_name | 中奖 _ 打点 _ 击球手 _id | 获奖 _rbi_batter_id_name | v_starting_pitcher_id | v_starting_pitcher_name | h_starting_pitcher_id | h_starting_pitcher_name | 虚拟玩家 1 号 | v _ 玩家 _ 1 _ 姓名 | v _ 玩家 _2_id | v _ 玩家 _ 2 _ 姓名 | 虚拟玩家 3 号 id | v _ 玩家 _ 3 _ 姓名 | v _ 玩家 _4_id | v _ 玩家 _ 4 _ 姓名 | v _ 玩家 _5_id | v_player_5_name | v_player_6_id | v_player_6_name | v _ 玩家 _7_id | v_player_7_name | v_player_8_id | v_player_8_name | v _ 玩家 _9_id | v_player_9_name | h_player_1_id | h_player_1_name | h_player_2_id | h_player_2_name | h_player_3_id | h_player_3_name | h_player_4_id | h_player_4_name | h_player_5_id | h_player_5_name | h_player_6_id | h_player_6_name | h_player_7_id | h_player_7_name | h_player_8_id | h_player_8_name | h_player_9_id | h_player_9_name | 附加信息 | 收购信息 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数数 | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and forty thousand one hundred and fifty | One hundred and sixteen | One hundred and forty-five | one hundred and eighty | One hundred and seventy-one thousand nine hundred and seven | One hundred and forty-seven thousand two hundred and seventy-one | One hundred and forty-seven thousand two hundred and seventy-one | One hundred and seventy-one thousand eight hundred and eighty-eight | One hundred and seventy-one thousand eight hundred and ninety-one | One hundred and forty-seven thousand and forty | One hundred and seventy-one thousand eight hundred and ninety-one | Eighty-eight thousand five hundred and forty | One hundred and seventy-one thousand one hundred and twenty-seven | One hundred and sixteen thousand seven hundred and twenty-three | One hundred and seventy-one thousand one hundred and thirty-five | Two hundred and three | One hundred and seventy-one thousand nine hundred and two | nine | One hundred and seventy-one thousand nine hundred and two | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and seventy-one thousand nine hundred and seven | One hundred and forty thousand two hundred and twenty-nine | One hundred and forty thousand two hundred and twenty-nine | One hundred and forty thousand two hundred and twenty-nine | One hundred and forty thousand two hundred and twenty-nine | Forty-eight thousand and eighteen | One hundred and forty thousand eight hundred and thirty-eight | One hundred and five thousand six hundred and ninety-nine | One hundred and forty thousand eight hundred and thirty-eight | One hundred and seventy-one thousand eight hundred and sixty-three | One hundred and seventy-one thousand eight hundred and sixty-three | One hundred and seventy-one thousand eight hundred and sixty-three | One hundred and seventy-one thousand eight hundred and sixty-three | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-five | One hundred and forty thousand eight hundred and thirty-five | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One hundred and forty thousand eight hundred and thirty-eight | One thousand four hundred and fifty-six | One hundred and forty thousand eight hundred and forty-one |
| 独一无二的 | seven | One hundred and forty-eight | seven | One hundred and forty-eight | seven | Two | One hundred and sixteen | three | five | Two hundred and forty-five | Thirty-six thousand three hundred and sixty-seven | Thirty-seven thousand eight hundred and fifty-nine | One thousand one hundred and forty-nine | One thousand one hundred and forty-six | Six hundred and seventy-eight | Six hundred and seventy-eight | Three hundred and twenty-four | Three hundred and twenty-five | Three hundred and sixty-two | Three hundred and sixty-three | Thirty-one | Thirty-two | eight | nine | Six hundred and forty-eight | Six hundred and forty-eight | Six hundred and fifty-nine | Six hundred and fifty-nine | Five thousand one hundred and twenty-three | Five thousand and eighty-four | Five thousand six hundred and fifty-three | Five thousand six hundred and six | Three thousand one hundred and thirty-three | Three thousand one hundred and seventeen | Five thousand seven hundred and thirty-nine | Five thousand six hundred and seventy-four | Five thousand one hundred and ninety-three | Five thousand one hundred and twenty-nine | Five thousand one hundred and seventy | Five thousand one hundred and twenty-five | Two thousand eight hundred and seventy | Two thousand eight hundred and forty-seven | Three thousand seven hundred and nine | Three thousand six hundred and seventy-three | Two thousand nine hundred and eighty-nine | Two thousand nine hundred and sixty-four | Two thousand five hundred and eighty-one | Two thousand five hundred and sixty-three | Three thousand seven hundred and fifty-seven | Three thousand seven hundred and twenty-two | Four thousand seven hundred and ninety-four | Four thousand seven hundred and thirty-six | Five thousand three hundred and one | Five thousand two hundred and forty-one | Four thousand eight hundred and twelve | Four thousand seven hundred and sixty-three | Five thousand six hundred and forty-three | Five thousand five hundred and eighty-five | Two thousand eight hundred and two | Two thousand seven hundred and eighty-two | Three thousand six hundred and forty-eight | Three thousand six hundred and fourteen | Two thousand eight hundred and eighty-one | Two thousand eight hundred and fifty-eight | Two thousand five hundred and thirty-three | Two thousand five hundred and seventeen | Three thousand six hundred and ninety-six | Three thousand six hundred and sixty | Four thousand seven hundred and seventy-four | Four thousand seven hundred and twenty | Five thousand two hundred and fifty-three | Five thousand one hundred and ninety-seven | Four thousand seven hundred and sixty | Four thousand seven hundred and ten | Five thousand one hundred and ninety-three | Five thousand one hundred and forty-two | Three hundred and thirty-two | one |
| 顶端 | 坐 | 测链 | 荷兰 | 测链 | 荷兰 | D | 19510725,,6,6,46 | H | V | STL07 | 000000000 | 000000000 | klemb901 | 比尔挤压 | 康恩 901 | (无) | westj901 | (无) | mcgob901 | (无) | sudoe901 | (无) | gormt101 | (无) | mackc101 | 康妮·麦克 | mackc101 | 康妮·麦克 | johnw102 | 华特·强森 | rixee101 | 荷兰人伦纳德 | rivem002 | (无) | pujoa001 | (无) | younc102 | 年纪轻的 | younc102 | 年纪轻的 | suzui001 | 铃木一朗 | 福克斯 n101 | 内莉·福克斯 | speat101 | Tris 扬声器 | bottj101 | 吉姆·博顿利 | 海尔 101 | 哈里·赫尔曼 | grimc101 | 查理·格林 | grimc101 | 查理·格林 | 洛普亚 102 | 阿尔·洛佩兹 | grifa001 | 阿尔弗雷多·格里芬 | suzui001 | 铃木一朗 | 福克斯 n101 | 内莉·福克斯 | speat101 | Tris 扬声器 | gehrl101 | 卢·格里克 | 海尔 101 | 哈里·赫尔曼 | grimc101 | 查理·格林 | grimc101 | 查理·格林 | 洛普亚 102 | 阿尔·洛佩兹 | spahw101 | 沃伦·斯帕恩 | HTBF | Y |
| 频率 | Twenty-eight thousand eight hundred and ninety-one | Eight thousand eight hundred and seventy | Eighty-eight thousand eight hundred and sixty-six | Nine thousand and twenty-four | Eighty-eight thousand eight hundred and sixty-seven | Eighty-two thousand seven hundred and twenty-four | one | sixty-nine | Ninety | Seven thousand and twenty-two | Ten thousand one hundred and two | Eight thousand and twenty-eight | Three thousand five hundred and forty-five | Three thousand five hundred and forty-five | Two thousand and twenty-nine | Twenty-four thousand eight hundred and fifty-one | Eight hundred and fifteen | Eighty-two thousand five hundred and eighty-seven | One thousand one hundred and twenty-nine | Fifty-four thousand four hundred and twelve | Thirty | One hundred and seventy-one thousand six hundred and ninety-nine | Two | One hundred and seventy-one thousand eight hundred and ninety-three | Three thousand nine hundred and one | Three thousand nine hundred and one | Three thousand eight hundred and forty-eight | Three thousand eight hundred and forty-eight | Three hundred and eighty-five | Three hundred and eighty-five | Two hundred and fifty-one | Two hundred and ninety-five | Five hundred and twenty-three | Ninety-two thousand eight hundred and twenty | Two hundred and eighty-eight | Thirty-five thousand one hundred and thirty-nine | Four hundred and three | Four hundred and forty-one | Four hundred and twelve | Four hundred and fifty-one | Eight hundred and ninety-three | Eight hundred and ninety-three | Eight hundred and fifty-two | Eight hundred and fifty-two | One thousand two hundred and twenty-four | One thousand two hundred and twenty-four | Eight hundred and sixteen | Eight hundred and sixteen | Six hundred and sixty-three | Six hundred and sixty-three | Four hundred and sixty-five | Four hundred and sixty-five | Four hundred and eighty-five | Four hundred and eighty-five | Six hundred and eighty-seven | Six hundred and eighty-seven | Three hundred and thirty-three | Three hundred and thirty-three | Nine hundred and twenty-seven | Nine hundred and twenty-seven | Eight hundred and fifty-nine | Eight hundred and fifty-nine | One thousand one hundred and sixty-five | One thousand one hundred and sixty-five | Seven hundred and fifty-two | Seven hundred and fifty-two | Six hundred and twelve | Six hundred and twelve | Four hundred and twenty-seven | Four hundred and twenty-seven | Four hundred and ninety-one | Four hundred and ninety-one | Six hundred and seventy-six | Six hundred and seventy-six | Three hundred and thirty-nine | Three hundred and thirty-nine | One thousand one hundred and twelve | One hundred and forty thousand eight hundred and forty-one |
快速浏览一下就会发现,在我们的数据集中,相对于大约 172,000 个游戏,许多列几乎没有唯一值。
在我们深入研究之前,我们将从选择一个对象列开始,看看当我们将它转换为分类类型时,幕后发生了什么。我们将使用数据集的第二列day_of_week。
看着上面的桌子。我们可以看到它只包含七个唯一值。我们将使用.astype()方法将其转换为分类。
dow = gl_obj.day_of_week
print(dow.head())
dow_cat = dow.astype('category')
print(dow_cat.head())
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: object
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: category
Categories (7, object): [Fri, Mon, Sat, Sun, Thu, Tue, Wed]
如您所见,除了列的类型发生了变化之外,数据看起来完全相同。让我们来看看到底发生了什么。
在下面的代码中,我们使用Series.cat.codes属性返回整数值,category类型使用这些整数值来表示每个值。
dow_cat.head().cat.codes
0 4
1 0
2 2
3 1
4 5
dtype: int8
您可以看到每个惟一值都被赋予了一个整数,该列的底层数据类型现在是int8。该列没有任何丢失的值,但是如果有,category子类型通过将它们设置为-1来处理丢失的值。
最后,让我们看看这个列在转换为category类型之前和之后的内存使用情况。
print(mem_usage(dow))
print(mem_usage(dow_cat))
9.84 MB
0.16 MB
我们的内存使用量从 9.8MB 减少到了 0.16MB,减少了 98%!请注意,这个特定的列可能代表了我们的最佳情况之一——一个包含大约 172,000 个条目的列,其中只有 7 个唯一值。
虽然将所有列都转换成这种类型听起来很吸引人,但是了解其中的利弊也很重要。最大的问题是无法进行数值计算。如果不先转换成真正的数字数据类型,我们就不能对category列进行算术运算,也不能使用像Series.min()和Series.max()这样的方法。
我们应该坚持将category类型主要用于object列,其中不到 50%的值是唯一的。如果一列中的所有值都是唯一的,那么category类型将会使用更多的内存。这是因为除了整数类别代码之外,该列还存储所有的原始字符串值。你可以在 pandas 文档中阅读更多关于category类型的限制。
我们将编写一个循环来迭代每个object列,检查唯一值的数量是否小于 50%,如果是,则将其转换为 category 类型。
converted_obj = pd.DataFrame()
for col in gl_obj.columns:
num_unique_values = len(gl_obj[col].unique())
num_total_values = len(gl_obj[col])
if num_unique_values / num_total_values < 0.5:
converted_obj.loc[:,col] = gl_obj[col].astype('category')
else:
converted_obj.loc[:,col] = gl_obj[col]
和以前一样,
print(mem_usage(gl_obj))
print(mem_usage(converted_obj))
compare_obj = pd.concat([gl_obj.dtypes,converted_obj.dtypes],axis=1)
compare_obj.columns = ['before','after']
compare_obj.apply(pd.Series.value_counts)
752.72 MB
51.67 MB
| 以前 | 在...之后 | |
|---|---|---|
| 目标 | Seventy-eight | 圆盘烤饼 |
| 种类 | 圆盘烤饼 | Seventy-eight |
在这种情况下,我们所有的对象列都被转换为category类型,然而这并不是所有数据集的情况,所以您应该确保使用上面的过程进行检查。
此外,我们的object列的内存使用从 752MB 减少到 52MB,减少了 93%。让我们将这一点与数据帧的其余部分结合起来,看看我们相对于开始时的 861MB 内存使用量处于什么位置。
optimized_gl[converted_obj.columns] = converted_obj
mem_usage(optimized_gl)
'103.64 MB'
哇,我们真的取得了一些进展!我们还可以做一个优化——如果你还记得我们的类型表,有一个datetime类型可以用于我们数据集的第一列。
date = optimized_gl.date
print(mem_usage(date))
date.head()
0.66 MB
0 18710504
1 18710505
2 18710506
3 18710508
4 18710509
Name: date, dtype: uint32
您可能记得这是作为整数类型读入的,并且已经优化到了unint32。因此,将它转换成datetime实际上会使它的内存使用加倍,因为datetime类型是 64 位类型。无论如何,将它转换成datetime是有价值的,因为它将允许我们更容易地进行时间序列分析。
我们将使用pandas.to_datetime()函数进行转换,使用format参数告诉它我们的日期数据存储在YYYY-MM-DD中。
optimized_gl['date'] = pd.to_datetime(date,format='%Y%m%d')
print(mem_usage(optimized_gl))
optimized_gl.date.head()
104.29 MB
0 1871-05-04
1 1871-05-05
2 1871-05-06
3 1871-05-08
4 1871-05-09
Name: date, dtype: datetime64[ns]
读取数据时选择类型
到目前为止,我们已经探索了减少现有数据帧的内存占用的方法。通过首先读取数据帧,然后迭代节省内存的方法,我们能够更好地了解每次优化可以节省的内存量。但是,正如我们在本课前面提到的,我们通常没有足够的内存来表示数据集中的所有值。当我们甚至不能首先创建数据帧时,我们如何应用节省内存的技术呢?
幸运的是,当我们读取。 pandas.read_csv() 函数有几个不同的参数允许我们这样做。dtype参数接受以(string)列名作为键、以 NumPy 类型对象作为值的字典。
首先,我们将把每一列的最终类型存储在一个包含列名键的字典中,首先删除日期列,因为它需要单独处理。
dtypes = optimized_gl.drop('date',axis=1).dtypes
dtypes_col = dtypes.index
dtypes_type = [i.name for i in dtypes.values]
column_types = dict(zip(dtypes_col, dtypes_type))
# rather than print all 161 items, we'll
# sample 10 key/value pairs from the dict
# and print it nicely using prettyprint
preview = first2pairs = {key:value for key,value in list(column_types.items())[:10]}
import pprintpp
pp = pp = pprint.PrettyPrinter(indent=4)
pp.pprint(preview)
{
'acquisition_info': 'category',
'h_caught_stealing': 'float32',
'h_player_1_name': 'category',
'h_player_9_name': 'category',
'v_assists': 'float32',
'v_first_catcher_interference': 'float32',
'v_grounded_into_double': 'float32',
'v_player_1_id': 'category',
'v_player_3_id': 'category',
'v_player_5_id': 'category'
}
现在,我们可以使用字典和几个日期参数,用几行代码读入正确类型的数据:
read_and_optimized = pd.read_csv('game_logs.csv',dtype=column_types,parse_dates=['date'],infer_datetime_format=True)
print(mem_usage(read_and_optimized))
read_and_optimized.head()
104.28 MB
| 日期 | 游戏的数量 | 星期几 | 虚拟姓名 | v _ 联赛 | v _ 游戏 _ 号码 | hgame | h _ 联赛 | h _ 游戏 _ 号码 | v _ 分数 | h 分数 | 长度 _ 超时 | 白天夜晚 | 完成 | 丧失 | 抗议 | 公园 id | 出席 | 长度 _ 分钟 | v _ 线 _ 分数 | h_line_score | 蝙蝠 | v_hits | v _ 双打 | v_triples | v _ 本垒打 | 虚拟银行 | v _ 牺牲 _ 命中 | v _ 牺牲 _ 苍蝇 | 垂直命中间距 | v_walks | v _ 有意行走 | v _ 删除线 | 五 _ 被盗 _ 基地 | 偷窃被抓 | v _ 接地 _ 进 _ 双 | v _ 优先 _ 捕捉器 _ 干扰 | v _ 左 _ 上 _ 下 | v _ 投手 _ 已用 | 个人获得的跑步记录 | v _ team _ earned _ runs | v _ wild _ pitches | v_balks | v _ 输出 | vassistx | v _ 错误 | v _ 传球 _ 球 | 双人游戏 | 三重播放 | 蝙蝠 | 点击次数 | h _ 双打 | h_triples | h _ 本垒打 | h_rbi | h _ 牺牲 _ 命中 | h _ 祭祀 _ 苍蝇 | h _ hit _ by _ 音高 | h _ 行走 | h _ 有意行走 | h _ 删除线 | h _ 被盗 _ 基地 | 偷东西被抓 | h _ 接地 _ 进 _ 双 | h _ 优先 _ 捕捉器 _ 干扰 | 左满垒 | h_pitchers_used | 个人获得的跑步记录 | h _ team _ earned _ runs | h _ wild _ pitches | h_balks | h _ 输出 | h _ 助攻 | h _ 错误 | h _ 传球 _ 球 | 双人游戏 | 三重播放 | 惠普 _ 裁判 _id | 惠普裁判姓名 | 1b _ 裁判 _id | 1b _ 裁判员 _ 姓名 | 2b _ 裁判 _id | 2b _ 裁判员 _ 姓名 | 3b _ 裁判 _id | 3b _ 裁判员 _ 姓名 | lf _ 裁判员 _id | lf _ 裁判员 _ 姓名 | rf _ 裁判员 _id | rf _ 裁判员 _ 姓名 | 虚拟经理 id | 虚拟经理姓名 | h _ 经理 _id | 经理姓名 | winning _ pitcher _ id | 获胜投手姓名 | losing_pitcher_id | 失去投手姓名 | 正在保存 _pitcher_id | 保存 _pitcher_name | 中奖 _ 打点 _ 击球手 _id | 获奖 _rbi_batter_id_name | v_starting_pitcher_id | v_starting_pitcher_name | h_starting_pitcher_id | h_starting_pitcher_name | 虚拟玩家 1 号 | v _ 玩家 _ 1 _ 姓名 | 虚拟玩家 1 定义位置 | v _ 玩家 _2_id | v _ 玩家 _ 2 _ 姓名 | 虚拟玩家 2 定义位置 | 虚拟玩家 3 号 id | v _ 玩家 _ 3 _ 姓名 | 虚拟玩家 3 定义位置 | v _ 玩家 _4_id | v _ 玩家 _ 4 _ 姓名 | 虚拟玩家 4 定义位置 | v _ 玩家 _5_id | v_player_5_name | 虚拟玩家 5 定义位置 | v_player_6_id | v_player_6_name | 虚拟玩家 6 定义位置 | v _ 玩家 _7_id | v_player_7_name | 虚拟玩家 7 定义位置 | v_player_8_id | v_player_8_name | 虚拟玩家 8 定义位置 | v _ 玩家 _9_id | v_player_9_name | 虚拟玩家 9 定义位置 | h_player_1_id | h_player_1_name | h _ 播放器 _1_def_pos | h_player_2_id | h_player_2_name | h _ 播放器 _2_def_pos | h_player_3_id | h_player_3_name | h _ 播放器 _3_def_pos | h_player_4_id | h_player_4_name | h _ 播放器 _4_def_pos | h_player_5_id | h_player_5_name | h _ 播放器 _5_def_pos | h_player_6_id | h_player_6_name | h _ 播放器 _6_def_pos | h_player_7_id | h_player_7_name | h _ 播放器 _7_def_pos | h_player_8_id | h_player_8_name | h _ 播放器 _8_def_pos | h_player_9_id | h_player_9_name | h _ 播放器 _9_def_pos | 附加信息 | 收购信息 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 1871-05-04 | Zero | 星期四 | CL1 | 钠 | one | FW1 | 钠 | one | Zero | Two | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | 对于 01 | Two hundred | One hundred and twenty | 000000000 | 010010000 | Thirty | Four | One | Zero | Zero | Zero | Zero | Zero | Zero | One | -1.0 | Six | One | -1.0 | -1.0 | -1.0 | Four | One | One | One | Zero | Zero | Twenty-seven | Nine | Zero | Three | Zero | Zero | Thirty-one | Four | One | Zero | Zero | Two | Zero | Zero | Zero | One | -1.0 | Zero | Zero | -1.0 | -1.0 | -1.0 | Three | One | Zero | Zero | Zero | Zero | Twenty-seven | Three | Three | One | One | Zero | boakj901 | 约翰·布莱克 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | paboc101 | 查理·帕博尔 | lennb101 | 比尔·列侬 | mathb101 | 鲍比·马修斯 | 普拉塔 101 | 艾尔·普拉特 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 普拉塔 101 | 艾尔·普拉特 | mathb101 | 鲍比·马修斯 | whitd102 | 迪肯·怀特 | Two | kimbg101 | 吉恩·金博尔 | Four | paboc101 | 查理·帕博尔 | Seven | allia101 | 阿特·艾利森 | Eight | 白色 104 | 埃尔默·怀特 | Nine | 普拉塔 101 | 艾尔·普拉特 | One | 萨图特 101 | 以斯拉·萨顿 | Five | 卡莱 102 | 吉姆·卡尔顿 | Three | bassj101 | 约翰·巴斯 | Six | selmf101 | 弗兰克·塞尔曼 | Five | mathb101 | 鲍比·马修斯 | One | 福尔马林 101 | Jim Foran | Three | goldw101 | 沃利·戈德史密斯 | Six | lennb101 | 比尔·列侬 | Two | 职业 101 | 汤姆·凯里 | Four | 碎肉 101 | 埃德·明彻 | Seven | mcdej101 | 詹姆斯·麦克德莫特 | Eight | kellb105 | 比尔·凯利 | Nine | 圆盘烤饼 | Y |
| one | 1871-05-05 | Zero | Fri | BS1 | 钠 | one | WS3 | 钠 | one | Twenty | Eighteen | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | WAS01 | Five thousand | One hundred and forty-five | One hundred and seven million four hundred and thirty-five | Six hundred and forty million one hundred and thirteen thousand and thirty | Forty-one | Thirteen | One | Two | Zero | Thirteen | Zero | Zero | Zero | Eighteen | -1.0 | Five | Three | -1.0 | -1.0 | -1.0 | Twelve | One | Six | Six | One | Zero | Twenty-seven | Thirteen | Ten | One | Two | Zero | Forty-nine | Fourteen | Two | Zero | Zero | Eleven | Zero | Zero | Zero | Ten | -1.0 | Two | One | -1.0 | -1.0 | -1.0 | Fourteen | One | Seven | Seven | Zero | Zero | Twenty-seven | Twenty | Ten | Two | Three | Zero | 多布斯 901 | 亨利·多布森 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | wrigh101 | 哈里·赖特 | younn801 | 尼克·杨 | spala101 | 阿尔·斯伯丁 | 巴西 102 | 阿萨·布雷纳德 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | spala101 | 阿尔·斯伯丁 | 巴西 102 | 阿萨·布雷纳德 | 箭牌 101 | 乔治·赖特 | Six | 巴恩斯 102 | 罗斯·巴恩斯 | Four | birdd102 | 戴夫·伯索尔 | Nine | mcvec101 | 卡尔·麦克维 | Two | wrigh101 | 哈里·赖特 | Eight | goulc101 | 查理·古尔德 | Three | 沙赫 101 | 哈里·斯查费 | Five | conef101 | 弗雷德·科恩 | Seven | spala101 | 阿尔·斯伯丁 | One | watef102 | 弗雷德·沃特曼 | Five | forcd101 | 戴维力量 | Six | mille105 | 埃弗里特·米尔斯 | Three | allid101 | 道格·艾利森 | Two | hallg101 | 乔治·霍尔 | Seven | 利昂娜 101 | 安迪·伦纳德 | Four | 巴西 102 | 阿萨·布雷纳德 | One | burrh101 | 亨利·巴勒斯 | Nine | berth101 | 亨利·贝思龙 | Eight | HTBF | Y |
| Two | 1871-05-06 | Zero | 坐 | CL1 | 钠 | Two | RC1 | 钠 | one | Twelve | four | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | RCK01 | One thousand | One hundred and forty | Six hundred and ten million twenty thousand and three | 010020100 | Forty-nine | Eleven | One | One | Zero | Eight | Zero | Zero | Zero | Zero | -1.0 | One | Zero | -1.0 | -1.0 | -1.0 | Ten | One | Zero | Zero | Two | Zero | Twenty-seven | Twelve | Eight | Five | Zero | Zero | Thirty-six | Seven | Two | One | Zero | Two | Zero | Zero | Zero | Zero | -1.0 | Three | Five | -1.0 | -1.0 | -1.0 | Five | One | Three | Three | One | Zero | Twenty-seven | Twelve | Thirteen | Three | Zero | Zero | mawnj901 | J.H .曼尼 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | paboc101 | 查理·帕博尔 | hasts101 | 斯科特·黑斯廷斯 | 普拉塔 101 | 艾尔·普拉特 | 鱼 c102 | 切诺基费希尔 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 普拉塔 101 | 艾尔·普拉特 | 鱼 c102 | 切诺基费希尔 | whitd102 | 迪肯·怀特 | Two | kimbg101 | 吉恩·金博尔 | Four | paboc101 | 查理·帕博尔 | Seven | allia101 | 阿特·艾利森 | Eight | 白色 104 | 埃尔默·怀特 | Nine | 普拉塔 101 | 艾尔·普拉特 | One | 萨图特 101 | 以斯拉·萨顿 | Five | 卡莱 102 | 吉姆·卡尔顿 | Three | bassj101 | 约翰·巴斯 | Six | mackd101 | 丹尼·麦克 | Three | addyb101 | 鲍勃·艾迪 | Four | 鱼 c102 | 切诺基费希尔 | One | hasts101 | 斯科特·黑斯廷斯 | Eight | ham-r101 | Ralph Ham | Five | ansoc101 | 安森角 | Two | sagep101 | 小马的事 | Six | birdg101 | 乔治·伯德 | Seven | 搅拌 101 | Gat Stires | Nine | 圆盘烤饼 | Y |
| three | 1871-05-08 | Zero | 孟人 | CL1 | 钠 | three | CH1 | 钠 | one | Twelve | Fourteen | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | CHI01 | Five thousand | One hundred and fifty | One hundred and one million four hundred and three thousand one hundred and eleven | 077000000 | Forty-six | Fifteen | Two | One | Two | Ten | Zero | Zero | Zero | Zero | -1.0 | One | Zero | -1.0 | -1.0 | -1.0 | Seven | One | Six | Six | Zero | Zero | Twenty-seven | Fifteen | Eleven | Six | Zero | Zero | Forty-three | Eleven | Two | Zero | Zero | Eight | Zero | Zero | Zero | Four | -1.0 | Two | One | -1.0 | -1.0 | -1.0 | Six | One | Four | Four | Zero | Zero | Twenty-seven | Fourteen | Seven | Two | Zero | Zero | willg901 | 加德纳·威拉德 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | paboc101 | 查理·帕博尔 | woodj106 | 吉米·伍德 | zettg101 | 乔治·蔡特林 | 普拉塔 101 | 艾尔·普拉特 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 普拉塔 101 | 艾尔·普拉特 | zettg101 | 乔治·蔡特林 | whitd102 | 迪肯·怀特 | Two | kimbg101 | 吉恩·金博尔 | Four | paboc101 | 查理·帕博尔 | Seven | allia101 | 阿特·艾利森 | Eight | 白色 104 | 埃尔默·怀特 | Nine | 普拉塔 101 | 艾尔·普拉特 | One | 萨图特 101 | 以斯拉·萨顿 | Five | 卡莱 102 | 吉姆·卡尔顿 | Three | bassj101 | 约翰·巴斯 | Six | mcatb101 | 布·麦卡蒂 | Three | kingm101 | 马歇尔·金 | Eight | hodec101 | 查理·霍兹 | Two | woodj106 | 吉米·伍德 | Four | simmj101 | 乔·西蒙斯 | Nine | 小精灵 101 | 汤姆·福利 | Seven | 粗呢 101 | 艾德·达菲 | Six | pinke101 | 艾德平克曼 | Five | zettg101 | 乔治·蔡特林 | One | 圆盘烤饼 | Y |
| four | 1871-05-09 | Zero | 周二 | BS1 | 钠 | Two | TRO | 钠 | one | nine | five | Fifty-four | D | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | TRO01 | Three thousand two hundred and fifty | One hundred and forty-five | 000002232 | One hundred and one million and three thousand | Forty-six | Seventeen | Four | One | Zero | Six | Zero | Zero | Zero | Two | -1.0 | Zero | One | -1.0 | -1.0 | -1.0 | Twelve | One | Two | Two | Zero | Zero | Twenty-seven | Twelve | Five | Zero | One | Zero | Thirty-six | Nine | Zero | Zero | Zero | Two | Zero | Zero | Zero | Three | -1.0 | Zero | Two | -1.0 | -1.0 | -1.0 | Seven | One | Three | Three | One | Zero | Twenty-seven | Eleven | Seven | Three | Zero | Zero | leroi901 | 艾萨克·勒罗伊 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | wrigh101 | 哈里·赖特 | pikel101 | 唇矛 | spala101 | 阿尔·斯伯丁 | 麦克莫吉 101 | 约翰·麦克穆林 | 圆盘烤饼 | (无) | 圆盘烤饼 | (无) | spala101 | 阿尔·斯伯丁 | 麦克莫吉 101 | 约翰·麦克穆林 | 箭牌 101 | 乔治·赖特 | Six | 巴恩斯 102 | 罗斯·巴恩斯 | Four | birdd102 | 戴夫·伯索尔 | Nine | mcvec101 | 卡尔·麦克维 | Two | wrigh101 | 哈里·赖特 | Eight | goulc101 | 查理·古尔德 | Three | 沙赫 101 | 哈里·斯查费 | Five | conef101 | 弗雷德·科恩 | Seven | spala101 | 阿尔·斯伯丁 | One | flync101 | 快船弗林 | Nine | mcgem101 | 迈克·麦吉瑞 | Two | yorkt101 | 汤姆·约克 | Eight | 麦克莫吉 101 | 约翰·麦克穆林 | One | 金斯 101 | 史蒂夫·金 | Seven | beave101 | 爱德华·比弗斯 | Four | 贝尔 s101 | 史蒂夫·贝伦 | Five | pikel101 | 唇矛 | Three | cravb101 | 比尔·克雷默 | Six | HTBF | Y |
通过优化列,我们成功地将 pandas 的内存使用量从 861.6 MB 减少到 104.28 MB,降幅高达 88%。
分析棒球比赛
现在我们已经优化了我们的数据,我们可以执行一些分析。我们先来看一下游戏天数的分布。
optimized_gl['year'] = optimized_gl.date.dt.year
games_per_day = optimized_gl.pivot_table(index='year',columns='day_of_week',values='date',aggfunc=len)
games_per_day = games_per_day.divide(games_per_day.sum(axis=1),axis=0)
ax = games_per_day.plot(kind='area',stacked='true')
ax.legend(loc='upper right')
ax.set_ylim(0,1)
plt.show()

我们可以看到,在 20 世纪 20 年代以前,星期天的棒球比赛很少,直到上世纪下半叶才逐渐流行起来。
我们也可以很清楚地看到,在过去的 50 年里,游戏日的分布相对稳定。
让我们也来看看游戏长度在这些年里是如何变化的。
game_lengths = optimized_gl.pivot_table(index='year', values='length_minutes')
game_lengths.reset_index().plot.scatter('year','length_minutes')
plt.show()

看起来棒球比赛从 20 世纪 40 年代开始持续变长。
总结和后续步骤
我们已经了解了 pandas 如何使用不同类型存储数据,然后我们利用这些知识,通过使用一些简单的技术,将 pandas 数据帧的内存使用量减少了近 90%:
- 将数字列向下转换为更有效的类型。
- 将字符串列转换为分类类型。
如果你想更深入地研究熊猫中更大的数据,这篇博文中的许多内容都可以在我们的互动课程处理熊猫课程中的大数据集中找到,你可以免费开始。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号