DataQuest-博客中文翻译-二-
DataQuest 博客中文翻译(二)
数据科学 Python 备忘单:中级
原文:https://www.dataquest.io/blog/data-science-python-cheat-sheet/
August 29, 2017

本备忘单的可打印版本
学习数据的困难之处在于记住所有的语法。虽然在 Dataquest,我们提倡习惯于查阅 Python 文档,但有时有一份方便的参考资料是很好的,所以我们整理了这份备忘单来帮助你!
该备忘单是我们的 Python 基础数据科学备忘单的配套
如果你想学习 Python ,我们有一个 Python 编程:初学者课程,可以开始你的数据科学之旅。
关键基础知识,打印和获取帮助
本备忘单假设您熟悉我们的 Python 基础备忘单的内容。
s |一个 Python 字符串变量
i |一个 Python 整数变量
f |一个 Python 浮点变量
l |一个 Python 列表变量
d |一个 Python 字典变量
列表
l.pop(3) |从l返回第四个项目并将其从列表
l.remove(x)中删除】|删除l中等于x
l.reverse()的第一个项目|颠倒l
l[1::2]中项目的顺序|从l返回第二个项目,从第一个项目
l[-5:]开始。|从l返回最后一个5项目
用线串
s.lower() |返回小写版本的s
s.title() |返回每个单词的第一个字母都大写的s
"23".zfill(4)|返回"0023"用0的左填充字符串使其长度为4。
s.splitlines() |通过在任何换行符上拆分字符串返回一个列表。
Python 字符串与列表 |
s[:5] |返回s
"fri" + "end"的第一个5字符|返回"friend"
"end" in s |如果在s中找到子串"end"则返回True
范围
Range 对象对于创建循环整数序列很有用。
range(5) |返回从0到4
range(2000,2018)的序列。|返回从2000到2017
range(0,11,2)的序列。|返回从0到10的序列,每项递增2
range(0,-10,-1) |返回从0到-9
list(range(5))的序列。|返回从0到4的列表
字典
max(d, key=d.get) |返回d
min(d, key=d.get)中最大值对应的键d中最小值对应的键
设置
my_set = set(l) |从l
len(my_set)返回包含唯一值的集合对象|返回my_set中对象的个数(或者,l
a in my_set中唯一值的个数)
|如果my_set中存在a值,则返回True
正则表达式
import re |导入正则表达式模块
re.search("abc",s) |如果在s中找到正则表达式"abc",则返回一个match对象,否则None
re.sub("abc","xyz",s) |返回一个字符串,其中所有匹配正则表达式"abc"的实例都被替换为"xyz"
列表理解
for 循环的单行表达式
[i ** 2 for i in range(10)] |返回从0到9
[s.lower() for s in l_strings]的值的平方列表。|返回列表l_strings,其中每一项都应用了.lower()方法
[i for i in l_floats if i < 0.5] |返回小于0.5的l_floats项
循环功能
for i, value in enumerate(l):
print("The value of item {} is {}".format(i,value))
遍历列表 l,打印每一项的索引位置及其值
for one, two in zip(l_one,l_two):
print("one: {}, two: {}".format(one,two))
遍历两个列表l_one和l_two,并打印每个值
while x < 10:
x += 1
运行循环体中的代码,直到x的值不再小于10
日期时间
import datetime as dt |导入datetime模块
now = dt.datetime.now() |将代表当前时间的datetime对象赋给now
wks4 = dt.datetime.timedelta(weeks=4) |将代表 4 周时间跨度的timedelta对象赋给wks4
now - wks4 |返回一个代表now
newyear_2020 = dt.datetime(year=2020, month=12, day=31)前 4 周时间的datetime对象|将代表 2020 年 12 月 25 日的datetime对象赋给newyear_2020
newyear_2020.strftime("%A, %b %d, %Y") |返回"Thursday, Dec 31, 2020"
dt.datetime.strptime('Dec 31, 2020',"%b %d, %Y") |返回一个
随意
import random |导入random模块
random.random() |返回一个介于0.0和1.0
random.randint(0,10)之间的随机浮点数|返回一个介于0和10
random.choice(l)之间的随机整数|从列表中返回一个随机项l
计数器
from collections import Counter |导入Counter类
c = Counter(l) |分配一个Counter(类似字典的)对象,该对象具有来自l的每个唯一项目的计数,to c
c.most_common(3) |返回来自l的 3 个最常见的项目
尝试/例外
捕捉并处理错误
l_ints = [1, 2, 3, "", 5]
将一组缺少一个值的整数赋给l_ints
l_floats = []
for i in l_ints:
try:
l_floats.append(float(i))
except:
l_floats.append(i)
将l_ints的每个值转换成一个浮点数,捕捉并处理ValueError: could not convert string to float:其中缺少值。
下载此备忘单的可打印版本
如果你想下载这个备忘单的打印版本,你可以在下面做。
数据科学家的五个基本特征
October 17, 2017
已经部署了数万亿像素来回答“怎样才能成为一名优秀的数据科学家?”这些文章中的大部分都集中在数据科学的技能和工具上,而几乎没有一篇讨论了成为优秀甚至伟大的数据科学家的个性。谷歌搜索“数据科学技能”会返回 3800 万个结果;“数据科学家特质”产生的结果少得可怜,只有 93.8 万条。
鉴于互联网上免费、几乎免费和付费培训的范围,几乎任何人都可以掌握数据科学实践中的工具和技能。但是获得这些工具并很好地应用它们需要一系列难以识别和更难掌握的特征。
什么是特质?
技能是一套适用于有限环境的技术或实践知识。编程是一门技能,统计分析也是。就此而言,烘焙也是如此。但是,知道蛋糕中液体和干燥成分的正确比例不太可能对构建排序算法有用。高斯分布的特征不会让你的饼干变得又轻又脆。
另一方面,特质是一种精神习惯,广泛应用于处理生活、宇宙和一切事物。在古代或宗教意义上,我们可能会认为品质是美德。回到我们的烘焙例子,Python 不会帮助面团发酵,但耐心会阻止我们在它不发酵时将搅拌碗扔到房间的另一边。与普遍的看法相反,特质不是一成不变的,我们可以随着时间的推移发展我们所缺乏的。
当我开始确定一个伟大的数据科学家的 k-特质时,我与我个人认识的数据科学家和我在 Twitter 上关注的数据科学家进行了交谈,并阅读了许多更聪明的人就此主题撰写的文章。这产生了大约 15 个特征,太多了。
我对这 15 个人运行了一个原始的聚类算法——我的记者大脑——得出了一个伟大的数据科学家的五个基本特征:
- 好奇心
- 清楚
- 创造力
- 怀疑论
- 谦逊
好奇心
在许多方面,好奇心——对知识和理解永不满足的渴望——是数据科学家的首要特征。我们的工作是询问数据和人的问题。大多数人不知道也不关心数据的局限性,所以我们一定要好奇他们在做什么,想达到什么目的。我们的领域发展如此之快,以至于我们必须保持兴趣来保持我们的优势。
为了培养帮助我们建立和保持技能的好奇心,我们会问一些我们“应该”已经知道答案的问题。这是一个具有挑战性的特质,需要一个坚定的典范来证明:艾尔·伍兹。
《律政俏佳人》(Legally Blonde)中永远活泼的女主角(如果你还没有看过这部杰作,请停止阅读,立即这样做)有一种天赋,出于对人和主题的真正好奇,她会毫不掩饰地问一些完全初级的问题,即使是在她自己的专业领域。她似乎天生就有这种天赋,所以如果我们想发展这种天赋,我们应该抛开自我,不要害怕自己不是房间里最聪明的人。
清楚
清晰是好奇心的基本产物。无论我们是在编写代码、执行分析,还是仅仅清理杂乱的数据,我们都应该理解我们在做什么以及为什么要这样做。毕竟,这是“数据科学”,而不是“数据随机尝试的东西。”我们可以把数据科学想象成趴在一只大乌龟背上,大乌龟反过来又趴在另一只乌龟身上。一直以来都是海龟,我们应该能够解释每一只海龟,就好像我们的对话者是五个,或者拥有五个博士学位。
我们通过不断问自己两个问题来发展清晰:“为什么?”以及“那又怎样?”对于你在分析中采取的每一步,问问你自己你为什么要这么做,以及这对你正在做的具体项目和更大的背景意味着什么。就像一个好奇的蹒跚学步的孩子或乖戾的青少年,不断地问这些问题,直到你得到一个不可简化的答案。换句话说,用“为什么”和“那又怎样”来看海龟们一路下跌。
创造力
创造力可能是这个列表中最有争议的元素,主要是因为它被误解了。总的来说,人们把它看作是二元的:要么有人拥有它,要么没有。例如,人们普遍认为莫扎特已经将他的音乐从以太中分离出来,在他八岁的时候出版了完整的歌剧,完全是基于天生的创造力。当你了解到沃尔夫冈的父亲列奥波尔得·莫扎特是一位成功的音乐教师,几乎从沃尔夫冈一出生就把他作为教学方法的实验品时,这个故事就变得不那么浪漫了。
恕我直言,莫扎特当然有天生的音乐天才,但创造力是可以学习和发展的,就像运动员为他们的运动发展技能一样。
尝试这些常规的创造性追求:
- 头脑风暴
- 未经编辑的意识流写作(如【晨页】)
- 阅读你所知之外的文章
也试着对你的生活做一些小的自发的改变,比如改变你的上班路线,或者用不同的方式解决一个熟悉的问题,这些都会帮助你发展你的创造力。我应该指出,比我聪明得多的人把他们的一生都奉献给了研究创造力(谷歌返回 1.67 亿万的“开发创造力”点击量),所以有一整个世界来帮助你提高你的创造力。(就我个人而言,我非常喜欢刘易斯·卡罗尔(Lewis Carroll)关于早餐前相信三件不可能的事情的训令。)
怀疑论
即使我们想变得更有创造力,我们也必须至少脚踏实地,而健康的怀疑精神恰恰有助于我们做到这一点。怀疑主义控制着我们的创造力,让我们置身于现实世界,而不是掉进兔子洞。
但是,你如何在保持乐观的好奇心的同时培养怀疑精神,从而推动你不断学习呢?首先要记住,虽然你可能会问像 Elle Woods 这样的问题,但这并不意味着你会从表面上接受每一个答案。保持好奇心,探索你的数据,但要记住,数据的好坏取决于收集数据的方法。找出答案,然后检查给你数据的人的假设和期望。当你建立你的模型时,看看你自己的假设,它们是否映射到模型的假设,它们是否实际上符合数据所说的。
正如著名的统计学家乔治·e·p·博克斯(George E. P. Box)所说,“所有的模型都是错的,但有些是有用的。”通过保持这种怀疑态度,我们可以在数据科学固有的乐观主义中建立自我监管。
谦逊
博克斯教授向我们展示了数据科学家的最后一个统一特征:谦逊。数据科学不是魔法,我们也不是巫师。好奇的数据科学家知道他并不知道所有的事情,并且总是在寻找新的东西来学习。这位目光敏锐的数据科学家咽下了她的骄傲,调整了她的演示文稿以适应她的观众,即使这意味着放弃她建立的一些巧妙的技术。这位创造性的数据科学家会“跳出框框”思考,即使这听起来很傻。当然,持怀疑态度的数据科学家知道不信任她的数据和模型,清晰地评估所有数据和模型,并提出所有必要的警告。
TL;dr:数据科学家的五个特质是
- 好奇心:培养你的内心世界
- 清晰:能够解释你正在做的事情,就像我五岁或者有五个博士学位一样
- 创造力:以不同的方式,横向的,更好的方式思考
- 怀疑:所有的模型都是错的,有些是有用的
- 谦逊:你不是巫师,哈里特
这就是数据科学家的基本特征。正如我在开头所说的,我最初的名单是 15 个,所以我确信还有改进的空间。你们都怎么看?我错过了什么重要的东西吗?甚至这个简短的列表也太长了吗?
Dataquest 如何帮助 SEO 专家节省大量时间
原文:https://www.dataquest.io/blog/data-skills-python-for-seo/
April 21, 2021
Antoine Eripret 是 Liligo.com 的 SEO 主管,他决定为 SEO 学习 Python,因为 T2 意识到他在浪费时间。
他在学生时代就对搜索引擎优化产生了兴趣,并在 2016 年获得硕士学位后全职进入该行业。
随着他在该领域积累经验,他说,“我意识到我有时会一遍又一遍地做同样的工作。像将一个值从一个文件复制粘贴到另一个文件这样的事情——重复的机械步骤。我开始意识到,也许有更聪明的方法可以做到这一点。”
同时,他与一些客户的合作涉及处理大型数据集。Excel 和大型数据集并不总是能很好地协同工作,Antoine 意识到他还想找到一种方法来“处理大量数据,而不必在电脑前祈祷 Excel 不会崩溃。”
所以他做了任何 SEO 专家都会做的事情。他谷歌了一下。

https://www.youtube.com/embed/3KgRFtgDczg?feature=oembed
*## 以错误的方式学习 Python
Antoine 很快发现学习一些 Python 编程可能会解决他的两个问题。“有了 Python,你就有了自动化任务的能力,它对数据分析也非常有用,”他说。
于是他开始尝试学习 Python。并没有持续多久。“我基本上放弃了,”他说,“因为我开始用错误的方式学习。”
他买了 用 Python 把枯燥的东西自动化,这是一本 Python 初学者很喜欢的书,但对他来说就是不行。
“问题是当我试图应用书中解释的东西时,”他说。“我经历了一段非常艰难的时间,从理论(这在书中解释得非常清楚)到能够将其应用于我自己的问题的实践。所以我放弃了。”
我有一个每周使用的脚本,可以节省我一个小时。Python 是一个巨大的省时工具。
【安托万·埃里克森】【SEO lead,Lili go . com】
过了一段时间,Antoine 决定再试一次学习 Python。这时他发现了 Dataquest。
为什么 Dataquest 为 Antoine 工作
对于他的第二次尝试,Antoine 知道他想通过在线平台学习。这样,他就可以直接应用他所学的东西,并且当他需要帮助时,他可以进入一个熟悉他所学内容的内置社区。
一旦他知道他需要一个平台,他就开始查找评论、意见,并尝试不同的平台。他说,最终,“我在 DataCamp 和 Dataquest 之间做出了选择。我选择 Dataquest 是因为你解释事情的方式更有利于从理论走向实践,至少对我来说是这样。”
因为他不是一个完全的 Python 初学者,Antoine 想跳过一些介绍性的课程材料。但他发现,像 DataCamp 这样基于视频的平台很难做到这一点。除非他观看,否则他无法知道他们的视频是否包含对他来说新的信息。
这给他留下了一个不舒服的选择:浪费时间看他已经知道的东西的视频,或者跳过视频,冒着错过重要信息的风险。
有了 Dataquest 基于文本的方法,他就不必做出这样的选择。对他来说,浏览课程很容易,跳过他知道的概念部分,每当他的眼睛捕捉到新的东西时就放慢速度。
他还喜欢 Dataquest 没有遗漏视觉学习者。它是基于文本的,但不仅仅是文本,概念也用插图和动画来解释。“例如,对于布尔索引,”他说,“我第一次读到这个概念时,我就想,‘这到底是什么?’但是你有一个红色和蓝色的动画来展示它是如何工作的。"
“这是我真正喜欢 Dataquest 的地方,”他说。“这是书面的,是的,但你也有一些非常非常好的视觉解释。”
“data quest 是一个令人惊叹的平台,”他说,即使对于那些不渴望在数据科学领域拥有全职工作的人来说也是如此。“这不是以 SEO 为重点,而是以数据科学为重点,但我不介意,因为当你从事 SEO 工作时,你必须处理和转换大量数据。”
Antoine 在 Python 课程中学习了我们的数据分析师,跳过了他已经知道的或者与他的工作无关的内容。现在他已经走完了这条路,他更加确信自己做出了正确的选择。
“Dataquest 对我来说是最好的选择,因为它的教学方式和解释方式,”他说。
使用 Python 进行 SEO
那么学习 Python 技能有助于 Antoine 解决他认为会解决的问题吗?
“现在,”他说,“我基本上使用 Python 进行数据处理、数据混合,并且能够做我想做的任何事情,因为我有 Python 社区做我的后盾。”
他不再祈求 Excel 不要崩溃,他已经编写了 Python 脚本来自动化他的一些常规任务。
例如,他说,“我有一个每周使用的脚本,每周三可以为我节省一个小时。我大概花了三个小时来创作它。”
仅这一个脚本现在每年就为他节省了 40 多个小时的工作时间,相当于他现在拥有的一个完整工作周的时间。这不是他写的唯一一个自动化脚本。
“说到底,Python 节省了大量时间,”他说。“它对于一些特定的搜索引擎优化任务也很有帮助,在这些任务中,你无法使用像尖叫青蛙这样的商业工具。”
“对于 95%的任务来说,这些商业工具是好的,”他说。“但有时你需要一些更高级的工具,一些真正定制的东西。Python 让我能够构建这些工具,并更有效地工作。
Dataquest 是我的最佳选择因为它的教学方式和解释方式。
【安托万·埃里克森】【SEO lead,Lili go . com】
安托万的建议
Antoine 说,尽管业界大肆宣传,Python 技能并不是从事 SEO 工作的必要条件,尽管它们肯定会有所帮助。Antoine 建议从你试图解决的具体问题开始,而不是仅仅为了学习 Python(或任何其他语言)而学习。
(我们同意,顺便说一句——从一个你想解决的真实问题开始 如何 Dataquest 推荐你学习 Python 或者 学习 R 或者学习其他任何语言也行!)
考虑其他因素也是一个好主意,比如学习者群体的规模,以及该语言的语法是否适合你。
他还回应了我们从许多成功的学习者那里听到的一些建议:不要害怕搜索答案,但是也不要复制粘贴你不理解的代码。
安东尼说,每个人都在谷歌上搜索。关键是试图理解你在搜索结果中找到的解决方案,这样下次你遇到问题时,你就能自己解决了。
“你不会因为谷歌搜索东西而得到更少或更多的报酬,”他说。"说到底,你的客户或雇主关心的是最终结果."*
你需要数据技能来保证你的职业生涯不会过时
原文:https://www.dataquest.io/blog/data-skills-to-future-proof-your-career/
April 5, 2021
无论你在哪个行业,你都需要数据技能来为你的职业生涯做好准备。
你可能会想: Vik 是一家教授数据科学的公司的首席执行官,他当然会这么说!但请继续关注我的文章,我将带您了解数据是如何成为我所有工作的关键。
在我开始 Dataquest 之前,我做过很多不同的工作。我曾是 UPS 的装卸工,百事可乐的物流主管,美国外交官,数据科学顾问,edX 的机器学习工程师。
(如果这听起来像一个奇怪的职业道路,你可以在这里阅读更多我的故事:我勉强大学毕业,没关系。)
回过头来看,我的每一项工作都有一个数据部分。为了出类拔萃,无论我是把箱子装到卡车上,还是创建论文评分算法,我都需要能够使用数据。
随着时间的推移,这些角色变得越来越以数据为中心。今天走进这些工作岗位的人会比我有更多的机会将数据融入到他们的角色中。
在 UPS 使用数据
您可能会惊讶地发现,UPS 的装载员需要一些数据技能。为了解释原因,我需要讨论一下 UPS 是如何工作的。
你可能熟悉标志性的棕色 UPS 送货卡车。这些卡车在一条路线上装载包裹,然后回到一个集散地卸货。

在那里,包裹被分类并装入拖拉机拖车,运往目的地。
但是从芝加哥到旧金山的包裹不会直接送到那里。它在到达目的地之前要经过中间枢纽。

我的工作是在一个中心把包裹装进拖车里。为了将正确的包裹装上正确的卡车,我会在装货时扫描包裹。这使得 UPS 能够跟踪我的工作效率。它还使 UPS 能够通过其枢纽跟踪包裹。

我使用扫描数据来跟踪我和团队中的其他人每晚装载了多少包裹。我根据这些数据优化了我的团队成员工作的卡车。我还利用这些数据来决定何时要求更多的雇员。
数据还使 UPS 能够优化他们的路线,为他们的枢纽配备人员,并预测未来的需求(尤其是季节性需求)。
例如:你可能听说过著名的 UPS没有让它的送货卡车左转。这是由于优化路线的算法。UPS 还通过使用数据预测需求,在每年的旺季雇佣员工。
随着 UPS 向自动化枢纽转移,数据技能对员工来说越来越重要。现在可以准确地跟踪在任何给定时间有多少包裹流经一个枢纽,以及它们的去向。
即使一个枢纽的效率有一点点的提高,也能让 UPS 获利数百万美元。随着时间的推移,数据技能实际上对 UPS 越来越重要,并且是他们战略的核心部分。
在百事可乐使用数据
在百事可乐,我在一家生产汽水的工厂工作。这项工作需要使用的数据比我在 UPS 使用的还要多。
汽水制成后,我们要么把它储存在我们的仓库里,要么把它运到其他仓库。在仓库里,我们会将苏打装上卡车或拖拉机拖车,运送给顾客(超市、便利店等)。

我们不想生产太多或太少的任何种类的汽水,所以我们必须预测顾客的需求。我们还必须知道我们的仓库里有多少苏打水,这样我们就不会有太多的库存。
我的工作是计算出我们仓库里有多少苏打水,然后把它输入到我们的生产计划中。
令人惊讶的是,我们计算仓库里有多少苏打水的方法是每天数几次。我们知道我们生产了多少苏打,流出了多少,但当我加入时,没有办法结合这些数据做出更好的估计。我通过组合这些信号改进了我们的估计。
这种类型的数据工作对百事来说越来越重要。喝太多或太少任何一种汽水都会花费数百万,而数据可以提高利润。百事在投入巨资 数据培训全公司也不足为奇。
作为外交官使用数据
我在国务院担任美国外交官的工作是我与数据打交道最少的地方。但是数据仍然是我工作的一部分。
我面试了移民和非移民签证的申请者。鉴于有多少人通过了面试资格预审,我知道我和其他外交官每天要面试多少人。

我们还跟踪了每个人每天面试多少人,以及我们的签证批准率。批准率很重要,因为你不想拒绝合格的申请人,或者批准不合格的申请人。这帮助我们优化了工作方式,尽管我们承认没有尽可能多地使用数据。
根据我的经验,政府是数据使用最不复杂的部门。但是这种情况正在改变。国务院正在任命一名 T2 首席数据官。数千名外交官正在接受如何有效使用数据的培训。
这样做的原因是,数据可以帮助外交官更有效——它可以帮助他们批准签证的合适人选。我甚至可以想象未来,签证审批是一个自动化的过程,没有人在循环中。
数据也有助于对单个国家的经济和政治进行更细致入微的报道。这方面的一个例子是国务院已经公布的人道主义数据。
数据技能在国务院刚刚开始变得重要,但在不久的将来,它们将成为外交的重要组成部分。
你需要数据技能
我自己的职业经历表明,无论你是在航运业、制造业还是政府部门,数据都很重要。而这只是冰山一角。
数据正在改变几乎每个行业的角色,包括医疗、金融和旅游。像 UPS 和百事可乐这样的公司正在利用数据作为竞争优势。未来几年,这些公司将需要越来越多具备数据技能的人。
开放数据角色比拥有合适技能的人多得多。因此,企业需要在内部培养数据技能,而不是通过招聘。在精通数据的公司中获得成功和晋升的人将是能够理解和有效使用数据的人。
现在是学习数据技能的最佳时机。我在国务院结束工作后就完成了转变,数据技能将我的职业生涯带到了我从未想象过的地方。如果你准备好迈出下一步, Dataquest 是一个很好的起点。
Python 数据结构:列表、字典、集合、元组(2022)
September 19, 2022
阅读完本教程后,您将了解 Python 中存在哪些数据结构,何时应用它们,以及它们的优缺点。我们将从总体上讨论数据结构,然后深入 Python 数据结构:列表、字典、集合和元组。
什么是数据结构?
数据结构是在计算机内存中组织数据的一种方式,用编程语言实现。这种组织是高效存储、检索和修改数据所必需的。这是一个基本概念,因为数据结构是任何现代软件的主要构件之一。学习存在什么样的数据结构以及如何在不同的情况下有效地使用它们是学习任何编程语言的第一步。
Python 中的数据结构
Python 中的内置数据结构可以分为两大类:可变和不可变。可变的(来自拉丁语 mutabilis ,“可变的”)数据结构是我们可以修改的——例如,通过添加、删除或改变它们的元素。Python 有三种可变的数据结构:列表、字典和集合。另一方面,不可变的数据结构是那些我们在创建后不能修改的数据结构。Python 中唯一基本的内置不可变数据结构是一个元组。
Python 还有一些高级的数据结构,比如栈或者队列,可以用基本的数据结构实现。但是,这些在数据科学中很少使用,在软件工程和复杂算法的实现领域更常见,所以在本教程中我们不讨论它们。
不同的 Python 第三方包实现了自己的数据结构,比如pandas中的数据帧和系列或者NumPy中的数组。然而,我们也不会在这里谈论它们,因为这些是更具体的教程的主题(例如如何创建和使用 Pandas DataFrame 或 NumPy 教程:用 Python 进行数据分析)。
让我们从可变数据结构开始:列表、字典和集合。
列表
Python 中的列表被实现为动态可变数组,它保存了一个有序的条目集合。
首先,在许多编程语言中,数组是包含相同数据类型的元素集合的数据结构(例如,所有元素都是整数)。然而,在 Python 中,列表可以包含不同的数据类型和对象。例如,整数、字符串甚至函数都可以存储在同一个列表中。列表的不同元素可以通过整数索引来访问,其中列表的第一个元素的索引为 0。这个属性来源于这样一个事实,即在 Python 中,列表是有序的,这意味着它们保留了将元素插入列表的顺序。
接下来,我们可以任意添加、删除和更改列表中的元素。例如,.append()方法向列表中添加新元素,而.remove()方法从列表中删除元素。此外,通过索引访问列表的元素,我们可以将它更改为另一个元素。有关不同列表方法的更多详细信息,请参考文档。
最后,当创建一个列表时,我们不必预先指定它将包含的元素数量;所以可以随心所欲的扩展,让它充满活力。
当我们想要存储不同数据类型的集合,并随后添加、移除或对列表的每个元素执行操作(通过循环遍历它们)时,列表是有用的。此外,通过创建例如字典列表、元组列表或列表,列表对于存储其他数据结构(甚至其他列表)是有用的。将表存储为列表的列表(其中每个内部列表代表一个表的列)以供后续数据分析是非常常见的。
因此,列表的优点是:
- 它们代表了存储相关对象集合的最简单方法。
- 它们很容易通过删除、添加和更改元素来修改。
- 它们对于创建嵌套数据结构很有用,比如列表/字典列表。
然而,它们也有缺点:
- 在对元素执行算术运算时,它们可能会非常慢。(为了提高速度,请使用 NumPy 的数组。)
- 由于其隐蔽的实现,它们使用更多的磁盘空间。
例子
最后,我们来看几个例子。
我们可以使用方括号([])创建一个列表,用逗号分隔零个或多个元素,或者使用构造函数list() 。后者也可以用于将某些其他数据结构转换成列表。
# Create an empty list using square brackets
l1 = []
# Create a four-element list using square brackets
l2 = [1, 2, "3", 4] # Note that this lists contains two different data types: integers and strings
# Create an empty list using the list() constructor
l3 = list()
# Create a three-element list from a tuple using the list() constructor
# We will talk about tuples later in the tutorial
l4 = list((1, 2, 3))
# Print out lists
print(f"List l1: {l1}")
print(f"List l2: {l2}")
print(f"List l3: {l3}")
print(f"List l4: {l4}")
List l1: []
List l2: [1, 2, '3', 4]
List l3: []
List l4: [1, 2, 3]
我们可以使用索引来访问列表的元素,其中列表的第一个元素的索引为 0:
# Print out the first element of list l2
print(f"The first element of the list l2 is {l2[0]}.")
print()
# Print out the third element of list l4
print(f"The third element of the list l4 is {l4[2]}.")
The first element of the list l2 is 1.
The third element of the list l4 is 3.
我们还可以分割列表并同时访问多个元素:
# Assign the third and the fourth elements of l2 to a new list
l5 = l2[2:]
# Print out the resulting list
print(l5)
['3', 4]
注意,如果我们想要从索引 2(包括)到列表末尾的所有元素,我们不必指定我们想要访问的最后一个元素的索引。一般来说,列表分片的工作方式如下:
- 左方括号。
- 写入我们要访问的第一个元素的第一个索引。该元素将包含在输出中。将冒号放在该索引后面。
- 写索引,加上我们想要访问的最后一个元素。这里需要加 1,因为我们写的索引下的元素不会包含在输出中。
让我们用一个例子来展示这种行为:
print(f"List l2: {l2}")
# Access the second and the third elements of list l2 (these are the indices 1 and 2)
print(f"Second and third elements of list l2: {l2[1:3]}")
List l2: [1, 2, '3', 4]
Second and third elements of list l2: [2, '3']
注意,我们指定的最后一个索引是 3,而不是 2,尽管我们想访问索引 2 下的元素。因此,我们写的最后一个索引不包括在内。
您可以尝试不同的索引和更大的列表,以了解索引是如何工作的。
现在让我们证明列表是可变的。例如,我们可以将一个新元素添加到列表中,或者从列表中添加一个特定的元素:
# Append a new element to the list l1
l1.append(5)
# Print the modified list
print("Appended 5 to the list l1:")
print(l1)
# Remove element 5 from the list l1
l1.remove(5)
# Print the modified list
print("Removed element 5 from the list l1:")
print(l1)
Appended 5 to list l1:
[5]
Removed element 5 from the list l1:
[]
此外,我们可以通过访问所需的索引并为该索引分配一个新值来修改列表中已经存在的元素:
# Print the original list l2
print("Original l2:")
print(l2)
# Change value at index 2 (third element) in l2
l2[2] = 5
# Print the modified list l2
print("Modified l2:")
print(l2)
Original l2:
[1, 2, '3', 4]
Modified l2:
[1, 2, 5, 4]
当然,我们只是触及了 Python 列表的皮毛。你可以从这门课中学到更多,或者看看的 Python 文档。
字典
Python 中的字典与现实世界中的字典非常相似。这些是可变的数据结构,包含一组键和与之相关的值。这种结构使它们非常类似于单词定义词典。例如,单词 dictionary (我们的关键字)与其在牛津在线词典中的定义(值)相关联:按字母顺序给出一种语言的单词列表并解释其含义的书或电子资源,或者给出一种外语的单词。
字典用于快速访问与唯一键相关的某些数据。唯一性是必不可少的,因为我们只需要访问特定的信息,不要与其他条目混淆。想象一下,我们想要阅读数据科学的定义,但是一本字典将我们重定向到两个不同的页面:哪一个是正确的?请注意,从技术上讲,我们可以创建一个具有两个或更多相同键的字典,尽管由于字典的性质,这是不可取的。
# Create dictionary with duplicate keys
d1 = {"1": 1, "1": 2}
print(d1)
# It will only print one key, although no error was thrown
# If we try to access this key, then it'll return 2, so the value of the second key
print(d1["1"])
# It is technically possible to create a dictionary, although this dictionary will not support them,
# and will contain only one of the key
当我们能够关联(用技术术语来说,映射)特定数据的唯一键,并且我们希望非常快速地访问该数据(在恒定时间内,不管字典大小如何)时,我们就使用字典。此外,字典值可能相当复杂。例如,我们的关键字可以是客户的名字,他们的个人数据(值)可以是带有关键字的字典,如“年龄”、“家乡”等。
因此,字典的优点是:
- 如果我们需要生成
key:value对,它们使得代码更容易阅读。我们也可以对列表的列表做同样的事情(其中内部列表是成对的“键”和“值”),但是这看起来更加复杂和混乱。 - 我们可以很快地在字典中查找某个值。相反,对于一个列表,我们必须在命中所需元素之前读取列表。如果我们增加元素的数量,这种差异会急剧增加。
然而,他们的缺点是:
- 它们占据了很大的空间。如果我们需要处理大量的数据,这不是最合适的数据结构。
- 在 Python 3.6.0 和更高版本中,字典记住元素插入的顺序。请记住这一点,以避免在不同版本的 Python 中使用相同代码时出现兼容性问题。
例子
现在让我们来看几个例子。首先,我们可以用花括号({})或dict()构造函数创建一个字典:
# Create an empty dictionary using curly brackets
d1 = {}
# Create a two-element dictionary using curly brackets
d2 = {"John": {"Age": 27, "Hometown": "Boston"}, "Rebecca": {"Age": 31, "Hometown": "Chicago"}}
# Note that the above dictionary has a more complex structure as its values are dictionaries themselves!
# Create an empty dictionary using the dict() constructor
d3 = dict()
# Create a two-element dictionary using the dict() constructor
d4 = dict([["one", 1], ["two", 2]]) # Note that we created the dictionary from a list of lists
# Print out dictionaries
print(f"Dictionary d1: {d1}")
print(f"Dictionary d2: {d2}")
print(f"Dictionary d3: {d3}")
print(f"Dictionary d4: {d4}")
Dictionary d1: {}
Dictionary d2: {'John': {'Age': 27, 'Hometown': 'Boston'}, 'Rebecca': {'Age': 31, 'Hometown': 'Chicago'}}
Dictionary d3: {}
Dictionary d4: {'one': 1, 'two': 2}
现在让我们访问字典中的一个元素。我们可以用与列表相同的方法做到这一点:
# Access the value associated with the key 'John'
print("John's personal data is:")
print(d2["John"])
John's personal data is:
{'Age': 27, 'Hometown': 'Boston'}
接下来,我们还可以修改字典—例如,通过添加新的key:value对:
# Add another name to the dictionary d2
d2["Violet"] = {"Age": 34, "Hometown": "Los Angeles"}
# Print out the modified dictionary
print(d2)
{'John': {'Age': 27, 'Hometown': 'Boston'}, 'Rebecca': {'Age': 31, 'Hometown': 'Chicago'}, 'Violet': {'Age': 34, 'Hometown': 'Los Angeles'}}
我们可以看到,一个新的关键,“紫罗兰”,已被添加。
从字典中删除元素也是可能的,所以通过阅读文档来寻找这样做的方法。此外,你可以阅读关于 Python 字典的更深入的教程(有大量的例子)或者看看 DataQuest 的字典课程。
设置
Python 中的集合可以定义为不可变的唯一元素的可变动态集合。集合中包含的元素必须是不可变的。集合可能看起来非常类似于列表,但实际上,它们是非常不同的。
首先,它们可能只包含唯一的元素,所以不允许重复。因此,集合可以用来从列表中删除重复项。接下来,就像数学中的集合一样,它们有独特的运算可以应用于它们,比如集合并、交集等。最后,它们在检查特定元素是否包含在集合中时非常有效。
因此,器械包的优点是:
- 我们可以对它们执行独特的(但相似的)操作。
- 如果我们想检查某个元素是否包含在一个集合中,它们比列表要快得多。
但是他们的缺点是:
- 集合本质上是无序的。如果我们关心保持插入顺序,它们不是我们的最佳选择。
- 我们不能像处理列表那样通过索引来改变集合元素。
例子
为了创建一个集合,我们可以使用花括号({})或者set()构造函数。不要把集合和字典混淆(字典也使用花括号),因为集合不包含key:value对。但是请注意,与字典键一样,只有不可变的数据结构或类型才允许作为集合元素。这一次,让我们直接创建填充集:
# Create a set using curly brackets
s1 = {1, 2, 3}
# Create a set using the set() constructor
s2 = set([1, 2, 3, 4])
# Print out sets
print(f"Set s1: {s1}")
print(f"Set s2: {s2}")
Set s1: {1, 2, 3}
Set s2: {1, 2, 3, 4}
在第二个例子中,我们使用了一个 iterable (比如一个列表)来创建一个集合。然而,如果我们使用列表作为集合元素,Python 会抛出一个错误。你认为为什么会这样?提示:阅读集合的定义。
为了练习,您可以尝试使用其他数据结构来创建一个集合。
与它们的数学对应物一样,我们可以在集合上执行某些操作。例如,我们可以创建集合的联合,这基本上意味着将两个集合合并在一起。但是,如果两个集合有两个或更多相同的值,则得到的集合将只包含其中一个值。创建并集有两种方法:要么用union()方法,要么用竖线(|)操作符。我们来举个例子:
# Create two new sets
names1 = set(["Glory", "Tony", "Joel", "Dennis"])
names2 = set(["Morgan", "Joel", "Tony", "Emmanuel", "Diego"])
# Create a union of two sets using the union() method
names_union = names1.union(names2)
# Create a union of two sets using the | operator
names_union = names1 | names2
# Print out the resulting union
print(names_union)
{'Glory', 'Dennis', 'Diego', 'Joel', 'Emmanuel', 'Tony', 'Morgan'}
在上面的并集中,我们可以看到Tony和Joel只出现了一次,尽管我们合并了两个集合。
接下来,我们可能还想找出哪些名字同时出现在两个集合中。这可以通过intersection()方法或与(&)运算符来完成。
# Intersection of two sets using the intersection() method
names_intersection = names1.intersection(names2)
# Intersection of two sets using the & operator
names_intersection = names1 & names2
# Print out the resulting intersection
print(names_intersection)
{'Joel', 'Tony'}
Joel和Tony出现在两组中;因此,它们由集合交集返回。
集合运算的最后一个例子是两个集合之间的差。换句话说,该操作将返回第一个集合中的所有元素,而不是第二个集合中的所有元素。我们可以使用difference()方法或减号(-):
# Create a set of all the names present in names1 but absent in names2 with the difference() method
names_difference = names1.difference(names2)
# Create a set of all the names present in names1 but absent in names2 with the - operator
names_difference = names1 - names2
# Print out the resulting difference
print(names_difference)
{'Dennis', 'Glory'}
如果你交换集合的位置会发生什么?试着在尝试之前预测结果。
还有其他操作可以在集合中使用。更多信息,请参考本教程,或 Python 文档。
最后,作为奖励,让我们比较一下使用集合与使用列表相比,在检查集合中元素的存在时有多快。
import time
def find_element(iterable):
"""Find an element in range 0-4999 (included) in an iterable and pass."""
for i in range(5000):
if i in iterable:
pass
# Create a list and a set
s = set(range(10000000))
l = list(range(10000000))
start_time = time.time()
find_element(s) # Find elements in a set
print(f"Finding an element in a set took {time.time() - start_time} seconds.")
start_time = time.time()
find_element(l) # Find elements in a list
print(f"Finding an element in a list took {time.time() - start_time} seconds.")
Finding an element in a set took 0.00016832351684570312 seconds.
Finding an element in a list took 0.04723954200744629 seconds.
显然,使用集合比使用列表要快得多。对于较大的集合和列表,这种差异会增大。
元组
元组几乎与列表相同,因此它们包含元素的有序集合,除了一个属性:它们是不可变的。如果我们需要一个一旦创建就不能再修改的数据结构,我们会使用元组。此外,如果所有元素都是不可变的,元组可以用作字典键。
除此之外,元组具有与列表相同的属性。为了创建一个元组,我们可以使用圆括号(())或者tuple()构造函数。我们可以很容易地将列表转换成元组,反之亦然(回想一下,我们从元组创建了列表l4)。
元组的优点是:
- 它们是不可变的,所以一旦被创建,我们可以确定我们不会错误地改变它们的内容。
- 如果它们的所有元素都是不可变的,那么它们可以用作字典键。
元组的缺点是:
- 当我们必须处理可修改的对象时,我们不能使用它们;我们不得不求助于列表。
- 无法复制元组。
- 它们比列表占用更多的内存。
例子
让我们来看一些例子:
# Create a tuple using round brackets
t1 = (1, 2, 3, 4)
# Create a tuple from a list the tuple() constructor
t2 = tuple([1, 2, 3, 4, 5])
# Create a tuple using the tuple() constructor
t3 = tuple([1, 2, 3, 4, 5, 6])
# Print out tuples
print(f"Tuple t1: {t1}")
print(f"Tuple t2: {t2}")
print(f"Tuple t3: {t3}")
Tuple t1: (1, 2, 3, 4)
Tuple t2: (1, 2, 3, 4, 5)
Tuple t3: (1, 2, 3, 4, 5, 6)
是否有可能从其他数据结构(即集合或字典)创建元组?试着练习一下。
元组是不可变的;因此,一旦它们被创建,我们就不能改变它们的元素。让我们看看如果我们尝试这样做会发生什么:
# Try to change the value at index 0 in tuple t1
t1[0] = 1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
是一个TypeError!元组不支持项赋值,因为它们是不可变的。为了解决这个问题,我们可以将这个元组转换成一个列表。
然而,我们可以通过索引来访问元组中的元素,就像在列表中一样:
# Print out the value at index 1 in the tuple t2
print(f"The value at index 1 in t2 is {t2[1]}.")
The value at index 1 in t2 is 2.
元组也可以用作字典键。例如,我们可以将某些元素及其连续索引存储在一个元组中,并为它们赋值:
# Use tuples as dictionary keys
working_hours = {("Rebecca", 1): 38, ("Thomas", 2): 40}
如果使用元组作为字典键,那么元组必须包含不可变的对象:
# Use tuples containing mutable objects as dictionary keys
working_hours = {(["Rebecca", 1]): 38, (["Thomas", 2]): 40}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [20], in <cell line:="">()
1 # Use tuples containing mutable objects as dictionary keys
----> 2 working_hours = {(["Rebecca", 1]): 38, (["Thomas", 2]): 40}
TypeError: unhashable type: 'list'
如果我们的元组/键包含可变对象(在这种情况下是列表),我们得到一个TypeError。
结论
让我们总结一下从本教程中学到的内容:
- 数据结构是编程中的一个基本概念,是轻松存储和检索数据所必需的。
- Python 有四种主要的数据结构,分为可变(列表、字典和集合)和不可变(元组)类型。
- 列表对于保存相关对象的异构集合非常有用。
- 每当我们需要将一个键链接到一个值并通过一个键快速访问一些数据时,我们就需要字典,就像在现实世界的字典中一样。
- 集合允许我们对它们进行运算,如求交或求差;因此,它们对于比较两组数据很有用。
- 元组类似于列表,但不可变;它们可以用作数据容器,我们不希望被错误地修改。
Python 中的数据类型(简单的初学者指南)
August 8, 2022
Python 实现了内置的数据类型,所以程序员需要知道他们的选项——以及何时使用每种类型
Python 是面向对象的语言,里面的一切都是对象。每个对象都是一个特定的类型,一个类定义了每个类型——这是 Python 中数据类型的定义。当实例化一个属于类的对象时,我们创建了一个新的变量——类就是这个变量的类型。
Python 有多种不同的数据类型。因此,在使用 Python 编程时,了解可用的数据类型和您正在使用的数据类型是非常重要的,因为每种类型的对象都代表不同的事物,并且有自己的方法、属性和功能。
在本文中,我们将介绍 Python 中最常用的内置数据类型,以及它们的一些方法和用例。
数据类型
Python 是一种动态类型语言。这意味着用户在创建变量时不需要指定变量类型,因为 Python 会自己解决这个问题。
这也意味着有可能将一个变量转换成不同于其原始类型的类型,因为,当然,这种转换是可能的(正如我们将在本文后面看到的)。
Python 整数
在处理 Python 数字时,有两种主要选择:整数和浮点数。
顾名思义,integer 类型用于处理整数,比如年龄、年份、计数等等。
>>> age = 37
>>> print(age)
37
>>> print(type(age))
37
<class 'int'>
注意type()函数是如何用来显示数据类型的。此外,该函数的输出明确显示了变量age是int类的一个实例。
Python 浮动
float 类型用于十进制数字,如体重、身高和平均值。
>>> average_age = 25.5
>>> print(average_age)
25.5
>>> print(type(average_age))
<class 'float'>
使用浮点数时,round()函数对于舍入小数非常有用:
>>> average_age = 25.539273
>>> print(round(average_age, ndigits=1))
25.5
n_digits参数设置小数位数。
您可以轻松地将 float 转换为 int,反之亦然,但是我们可以看到它的局限性。例如,如果将浮点数转换为整数,得到的数字将只是整数部分:
>>> print(int(average_age))
25
当转换进行到另一个方向时,变量的值没有变化,只是类型有变化:
>>> print(float(age))
37.0
python 字符串
string 类型通常用于字符串(但更常用于文本)。字符需要放在引号中。在 Python 中,您可以使用单引号或双引号,只要您使用相同的开始和结束序列。此外,在整个代码中保持引号的选择一致也是一个好习惯。
>>> name = 'Matt'
>>> email = '[[email protected]](/cdn-cgi/l/email-protection)'
>>> website = 'www.matt.com'
>>> print(name)
Matt
>>> print(email)
[[email protected]](/cdn-cgi/l/email-protection)
>>> print(website)
www.matt.com
>>> print(type(name))
<class 'str'>
Python 中的str类带有多个内置方法来执行字符串操作。
例如,replace()方法将一个字符串中的任何字符或字符序列替换为另一个:
>>> print(email.replace('dataquest.io', 'gmail.com'))
[[email protected]](/cdn-cgi/l/email-protection)
split()方法将分割给定字符上的字符串:
>>> print(website.split('.'))
['www', 'matt', 'com']
以下是其他一些常用的方法:
| upper() | 将字符串转换为大写 |
| lower() | 将字符串转换为小写 |
| title() | 将每个单词的首字母转换为大写 |
| find() | 在字符串中查找指定的字符或字符序列 |
| startswith() | 检查字符串是否以特定字符或字符序列开头 |
| strip() | 删除指定的前导和尾随字符 |
python 布尔型
布尔数据类型是一个表示两个值之一的变量:true 或 false。在 Python 中,它们由关键字True和False表示。它们有助于跟踪条件或比较值。
比较两个值时,比较的结果总是布尔值:
>>> print(name == email)
False
输出显示存储在name和email变量中的值不相同。但是,如果我们使用一些字符串方法,我们可以改变这个结果:
>>> print(name.lower() == email.split('@')[0])
True
布尔值也可以为代码设置条件。例如,我们可以将上述操作的结果赋给一个变量,并在 if 语句中使用它:
>>> my_boolean = name.lower() == email.split('@')[0]
>>> if my_boolean == True:
... print("My boolean is true")
My boolean is true
>>> print(type(my_boolean))
<class 'bool'>
或者您可以使用较短的版本:
>>> if my_boolean:
... print('My boolean is true.')
My Boolean is true.
布尔也可以作为操作符。Python 中的and和or运算符实际上是布尔运算符。它们接受两个布尔值,并根据给定的值返回一个新的布尔值。
Python 非类型
在 Python 中,None关键字是 NoneType 类的一个对象,代表值的缺失(而且是 Python 的 Null 来自其他编程语言)。它不是零,不是假的——它一点价值都没有。
例如,当一个函数的参数没有返回值,那么它的值就是None。此外,当您将不返回任何内容的函数的结果赋给变量时,该变量中的值也将为 None,如下例所示:
>>> def example(text):
... print(text)
...
>>> variable = example('test')
>>> print(variable)
test
None
如果你检查variable的类型。。。
>>> print(type(variable))
<class 'NoneType'>
尽管我们可以将None赋给一个变量,但是我们不能创建 NoneType 类的新实例。这很好:
>>> a = None
>>> print(a)
None
但这引发了一个错误:
a = NoneType()
NameError: name 'NoneType' is not defined
Python 列表
在 Python 中,列表是存储项目集合的内置对象。它们类似于其他编程语言中的数组,但是它们在存储内容方面没有那么大的限制。列表可以包含任何数据类型的组合,包括其他列表。
例如,列表可以包含整数、浮点数、字符串、布尔值、包含其他数据类型组合的列表等等。
这里有一个例子:
>>> matts_list = ['Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True]
>>> print(matts_list)
['Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com, 37, True]
您可以创建一个如上所示的已填充列表,也可以创建一个空列表并填充它。要向列表中添加值,append()方法很有用。下面的代码与上面的代码产生相同的输出:
>>> matts_list = []
>>> matts_list.append('Matt')
>>> matts_list.append('[[email protected]](/cdn-cgi/l/email-protection)')
>>> matts_list.append('www.matt.com')
>>> matts_list.append(37)
>>> matts_list.append(True)
>>> print(matts_list)
['Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True]
要访问一个元素,你可以使用括号并告知元素的索引。与 Python 中的所有内容一样,第一个元素的索引为零。例如,下面是访问 Matt 电子邮件的代码:
>>> matts_email = matts_list[1]
>>> print(matts_email)
[[email protected]](/cdn-cgi/l/email-protection)
访问多个有序元素叫做切片,语法是my_list[index_of_first_element: index_of_last_element + 1]。因此,要同时访问电子邮件和网站,我们需要做的是:
>>> email_website = matts_list[1:3]
>>> print(email_website)
['[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com']
注意,切片的输出也是一个列表。
以下是其他有用的方法:
pop() |
移除给定索引处的项目 |
|---|---|
lower() |
移除给定元素 |
clear() |
从列表中移除所有元素 |
sort() |
按字母顺序排列列表 |
python 元组
在 Python 中,元组是一种非常类似于列表的数据结构,但有一些重要的区别。元组是不可变的,这意味着我们在创建它们之后不能改变它们,这在您需要存储不应该被修改的数据时会很有用。
元组通常还用于存储相关的信息片段,例如点的坐标或对象的尺寸。与列表不同,元组是通过将值括在括号中创建的。这里有一个例子:
>>> matts_tuple = ('Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True)
>>> print(matts_tuple)
('Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True)
就像列表一样,元组可以存储任何类型的数据,但是因为它们不能被修改,所以只有几个方法:
count():统计给定值的个数index():根据索引查找元素
您可以轻松地将列表存储在元组中,或者将元组存储在列表中:
>>> matts_list = ['Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True, (39.759991, -86.163712)]
>>> print(matts_list)
['Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True, (39.759991, -86.163712)]
Python 词典
字典是一种 Python 数据结构,它以键值对的形式存储数据。这意味着每个元素都与一个键相关联,您可以使用该键来检索相应的值。
像列表一样,字典是可变的,这意味着您可以添加、删除和更新它们的条目。它们通常用于以结构化的方式存储数据。例如,您可以使用字典来存储关于一个人的信息,比如他们的姓名、年龄、地址、电话号码等等。
看看上面的matts_list:你不会马上知道每件事意味着什么。你知道这是关于一个人的信息——你可以看到名字、电子邮件和网站——但很难说出其他条目的意思,你只能通过索引来访问它们。
但是在字典中,您可以将每个变量与一个键配对存储,这个键使您能够知道那个变量是什么,并通过它的名称检索它。这里有一个字典的例子:
>>> matts_dict = {'first_name': 'Matt', 'email':
... '[[email protected]](/cdn-cgi/l/email-protection)','website': 'www.matt.com', 'age': 37,
... 'married': True,'house_coordinates': (39.759991, -86.163712)}
>>> print(matts_dict)
{'first_name': 'Matt', 'email': '[[email protected]](/cdn-cgi/l/email-protection)', 'website': 'www.matt.com', 'age': 37, 'married': True, 'house_coordinates': (39.759991, -86.163712)}
好了,现在你知道 37 实际上是马特的年龄,布尔变量表示马特已婚,元组中的那些数字是他房子的坐标。
如果您想要访问任何数据,您可以通过其键的名称来调用它:
>>> matts_age = matts_dict['age']
>>> print(matts_age)
37
改变变量值的过程是相似的:
>>> matts_dict['first_name'] = 'Matthew'
>>> print(matts_dict['first_name'])
Matthew
还可以添加更多的变量:
>>> matts_dict['nickname'] = 'Matt'
>>> print(matts_dict)
{'first_name': 'Matt', 'email': '[[email protected]](/cdn-cgi/l/email-protection)', 'website': 'www.matt.com', 'age': 37, 'married': True, 'house_coordinates': (39.759991, -86.163712), 'nickname': 'Matt'}
字典有几个内置的方法,比如keys(和values(),它们允许你像这样访问字典中的数据:
>>> print(matts_dict.keys())
dict_keys(['first_name', 'email', 'website', 'age', 'married', 'house_coordinates', 'nickname'])
>>> print(matts_dict.values())
dict_values(['Matthew', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True, (39.759991, -86.163712), 'Matt'])
Python 集合
在 Python 中,集合是一个集合,与列表和元组不同,它是无序和无索引的,这意味着不可能通过索引访问任何项目。我们使用集合来存储唯一值,因为它们不能有重复。
我们可以使用集合来执行数学集合运算,如并、交和差。我们把它们写在大括号里:
>>> matts_set = {'Matt', '[[email protected]](/cdn-cgi/l/email-protection)', 'www.matt.com', 37, True, (39.759991, -86.163712)}
>>> print(matts_set)
{True, 37, 'www.matt.com', '[[email protected]](/cdn-cgi/l/email-protection)', 'Matt', (39.759991, -86.163712)}
请注意,输出中集合的顺序与代码中的顺序不同。这是因为,如前所述,集合根本不存储任何顺序。
我们还使用集合来删除列表中的重复项。一旦您将一个有重复项的列表转换成一个集合,它将丢失重复项,然后您可以将它转换回一个列表,得到一个没有重复项的列表:
>>> duplicates_list = ['Matt', 'Matt', 37]
>>> set_from_list = set(duplicates_list)
>>> new_list = list(set_from_list)
>>> print(new_list)
[37, 'Matt']
当然,它将是无序的。
结论
在本文中,我们介绍了最重要和最常用的 Python 数据类型的主要特征和方法:
IntFloatStrBoolListTupleDictSet
用 ggplot2 实现 R 中的数据可视化:初学者教程
原文:https://www.dataquest.io/blog/data-visualization-in-r-with-ggplot2-a-beginner-tutorial/
September 2, 2020
据说一位著名的将军说过:“一篇好的速写胜过一篇长篇大论。”这些建议可能来自战场,但也适用于许多其他领域,包括数据科学。通过在 R 中使用 ggplot2 可视化来“勾画”我们的数据比简单地描述我们发现的趋势更有影响力。

勾勒出一栋房子的设计比试图用语言描述要清楚得多。对于数据来说也是如此——这就是 ggplot2 数据可视化的用武之地!
这就是为什么我们将数据可视化。我们将数据可视化是因为从我们能看到的东西中学习比阅读更容易。对于使用 R 的数据分析师和数据科学家来说,值得庆幸的是,有一个名为 ggplot2 的 tidyverse 包,让数据可视化变得轻而易举!
在这篇博客文章中,我们将学习如何获取一些数据并使用 R 生成一个可视化。要完成它,最好是你已经了解了 R 编程语法,但是你不需要成为专家或者有任何使用 ggplot2 的经验。
介绍数据
国家健康统计中心从 1900 年开始跟踪美国的死亡率趋势。他们收集了美国公民预期寿命和死亡率的 T2 数据。
我们想知道随着时间的推移,预期寿命是如何变化的。随着医学和技术的进步,我们可以预期寿命会增加,但我们只有看一看才能确定!
如果你想复制我们将在这篇博文中创建的图表,请在此下载数据集并跟随!
(不确定如何在个人电脑上使用 R?查看如何开始使用 RStudio !)
图表中有什么?
在我们开始这篇文章之前,我们需要一些背景知识。有许多类型的可视化,但大多数都可以归结为以下几点:

我们可以将这个图分解成基本的构件:
- 用于创建图的数据:

- 该图的坐标轴:

- 用于可视化数据的几何形状。在这种情况下,一行:

- 有助于读者理解情节的标签或注释:

将剧情分解成层很重要,因为这是 ggplot2包理解和构建剧情的方式。ggplot2包是tidyverse中的一个包,负责可视化。当你继续阅读这篇文章时,请记住这些层次。
导入数据
为了开始可视化,我们需要将数据放入我们的工作空间。我们将引入tidyverse包,并使用read_csv()函数导入数据。我们将数据命名为life_expec.csv,所以您需要根据您对文件的命名来重命名它。
library(tidyverse)
life_expec <- read_csv("life_expec.csv")
让我们看看我们正在处理哪些数据:
colnames(life_expec)
[1] "Year" "Race" “Sex" "Avg_Life_Expec" "Age_Adj_Death_Rate"
我们可以通过 Year 列看到时间是以年为单位编码的。有两栏可以让我们区分不同的种族和性别类别。最后,最后两列对应于预期寿命和死亡率。
让我们快速浏览一下数据,看看某一年的情况如何:
life_expec %>%
filter(Year == 2000)
2000 年有九个数据点:
## # A tibble: 9 x 5
## Year Race Sex Avg_Life_Expec Age_Adj_Death_Rate
##
## 1 2000 All Races Both Sexes 76.8 869
## 2 2000 All Races Female 79.7 731.
## 3 2000 All Races Male 74.3 1054.
## 4 2000 Black Both Sexes 71.8 1121.
## 5 2000 Black Female 75.1 928.
## 6 2000 Black Male 68.2 1404.
## 7 2000 White Both Sexes 77.3 850.
## 8 2000 White Female 79.9 715.
## 9 2000 White Male 74.7 1029.
一年有九个不同的行,每一行对应一个不同的人口统计分区。对于这个可视化,我们将关注美国整体,因此我们需要相应地过滤数据:
life_expec <- life_expec %>%
filter(Race == "All Races", Sex == "Both Sexes")
数据放在一个合适的位置,所以我们可以将它放入一个 ggplot()函数,开始创建一个图表。我们使用 ggplot()函数来表示我们想要创建一个图。
life_expec %>%
ggplot()
这段代码生成了一个空白图(如下所示)。但是它现在“知道”使用life_expec数据,尽管我们还没有看到它的图表。

建造轴线
现在我们已经准备好了数据,我们可以开始构建我们的可视化。我们需要建立的下一层是轴。我们对预期寿命如何随时间变化感兴趣,所以这表示我们的两个轴是什么:Year和Avg_Life_Expec。
为了指定轴,我们需要使用aes()功能。aes是“美学”的缩写,它是我们告诉ggplot我们想要为情节的不同部分使用什么列的地方。我们正试图通过时间来观察预期寿命,所以这意味着Year将走向 x 轴,而Avg_Life_Expec将走向 y 轴。
life_expec %>%
ggplot(aes(x = Year, y = Avg_Life_Expec))
添加了aes()函数后,图表现在知道哪些列属于轴:

但是请注意,图中仍然没有任何内容!我们仍然需要告诉ggplot()使用什么样的形状来可视化Year和Avg_Life_Expec之间的关系。
指定几何图形
通常,当我们想到可视化时,我们通常会想到图形的类型,因为我们看到的形状告诉了我们大多数信息。虽然ggplot2包在选择绘制数据的形状方面给了我们很大的灵活性,但对于我们的问题来说,花一些时间来考虑哪一个是最好的是值得的。
*我们正试图想象预期寿命是如何随着时间的推移而变化的。这意味着应该有一种方法让我们直接比较过去和未来。换句话说,我们需要一个有助于显示连续两年之间关系的形状。对于这一点,线图是很好的。
为了用 ggplot()创建一个线图,我们使用了geom_line()函数。geom是我们希望用来可视化数据的特定形状的名称。所有用于绘制这些形状的函数前面都有geom。geom_line()创建折线图,geom_point()创建散点图,等等。
life_expec %>%
ggplot(aes(x = Year, y = Avg_Life_Expec)) +
geom_line()
注意在使用了ggplot()函数之后,我们开始使用+符号添加更多的层。这一点很重要,因为我们使用%>%来告诉ggplot()哪些数据起作用。在使用ggplot()的之后,我们使用+给剧情添加更多的图层。

这张图表正是我们要找的!看看总的趋势,预期寿命随着时间的推移而增长。
如果我们只是快速查看数据,我们可以在这里停止绘图,但这种情况很少发生。更常见的是,您将为报告或团队中的其他人创建可视化。在这种情况下,情节是不完整的:如果我们把它交给一个没有上下文的队友,他们不会理解这个情节。理想情况下,你所有的情节都应该能够通过注解和标题来解释。
添加标题和轴标签
目前,图形将列名作为两个轴的标签。这对于Year来说已经足够了,但是我们需要改变 y 轴。为了改变绘图的轴标签,我们可以使用labs()函数,并将其作为一个层添加到绘图上。labs()可以改变轴标签和标题,所以我们将在这里合并。
life_expec %>% # data layer
ggplot(aes(x = Year, y = Avg_Life_Expec)) + # axes layer
geom_line() + # geom layer
labs( # annotations layer
title = "United States Life Expectancy: 100 Years of Change",
y = "Average Life Expectancy (Years)"
)
我们最后润色的图表是:

结论:ggplot2 强大!
只用了几行代码,我们就制作出了一个很棒的可视化效果,告诉我们所有我们需要知道的关于美国普通人预期寿命的信息。可视化是所有数据分析师的必备技能,R 让它变得容易掌握。
如果您有兴趣了解更多信息,请查看我们在 R path 的数据分析师!R path 中的数据分析师包括一门关于使用ggplot2在 R 中进行数据可视化的课程,在这里您将学习如何:
- 使用折线图直观显示随时间的变化。
- 使用直方图了解数据分布。
- 使用条形图和箱线图比较图形。
- 使用散点图了解变量之间的关系。
准备好提升你的 R 技能了吗?
我们 R path 的数据分析师涵盖了你找到工作所需的所有技能,包括:
- 使用 ggplot2 进行数据可视化
- 使用 tidyverse 软件包的高级数据清理技能
- R 用户的重要 SQL 技能
- 统计和概率的基础知识
- ...还有多得多的
没有要安装的东西,没有先决条件,也没有时间表。
6 个必须知道的数据可视化技术(2023)
原文:https://www.dataquest.io/blog/data-visualization-techniques/
December 8, 2022
尽管对于任何数据从业者来说,可视化都是一项至关重要的技能,但在许多新人的数据科学学习道路上,可视化往往被视为理所当然。例如,绘制一个简单的图表来显示上个月的收入增加,这似乎是微不足道的。
与其他任务相比,数据可视化似乎过于简单。但是恰当地展示你的数据是一门艺术,可以决定你的项目是被接受还是被拒绝。为了让你的视觉效果脱颖而出,每个小细节都很重要。
在这篇博文中,我们将介绍最常见的数据可视化技术,并给出每种情况下的实际例子。这些技术可以使用各种工具来实现,从 Excel 到特定的数据可视化编程语言和数据可视化软件,如 Power BI 和 Tableau 。
我们将使用 Python 来创建您将在本文中看到的情节,但是不要担心,跟随它不需要任何编码经验。此外,如果你不想马上进入编码,你可以使用市场上最重要的数据可视化工具之一的免费版本 Tableau Public 开始创建你自己的可视化。
如果你想马上进入编码领域,你应该知道有很多选择。为了使事情更简单,这里有一个 Python 中最常用的数据-viz 工具的比较。
我们可视化的数据集
在本文中,我们将使用两个数据集作为示例。让我们快速浏览一下,这样您就可以对我们将要创建的可视化有所了解。
第一个数据集包含特定地方的天气和太阳能电池板发电的每日数据。以下是它包含的变量:
temperature_min:最低温度,单位为摄氏度temperature_max:最高温度,单位为摄氏度humidity_min:最小湿度,单位为%。humidity_max:最大湿度,单位为%。rain_vol:降雨量,单位为毫米。kwh:发电量。
点击此处下载该数据集。
第二个数据集包含一家信用卡公司的客户数据,用于预测客户流失。以下是它包含的变量:
education_level:每个客户的教育程度。credit_limit:客户的信用额度。total_trans_count:成交笔数。total_trans_amount:交易总金额。churn:客户是否有过搅动。
点击此处下载该数据集。
1.表格和热图
桌子
让我们用最简单的可视化数据的方法来热身。表格通常是数据的原始形式,但它们也是可视化汇总数据的一种有价值的技术。然而,我们应该谨慎:表格可能包含太多的信息,这可能会给你的受众带来解释问题。
下表包含一年中每个季度的平均最高温度和发电量:
| 四分之一 | 最高温度 | 千瓦小时 |
| one | Twenty-nine point two seven | Thirty-two point eight eight |
| Two | Twenty-six point four five | Twenty-five point one nine |
| three | Twenty-seven point one one | Twenty-four point three six |
| four | Twenty-six point nine two | Twenty-six point seven seven |
在我们读取数据后,该表仅用一行 Python 代码创建:
df = pd.read_csv('power_and_weather21.csv')
round(df.groupby('quarter')['temperature_max','kwh'].mean(), 2)
如果想在 Excel 中做,只需要插入一个数据透视表,将一年中各个季度的值相加即可。
表格不一定很难阅读,但是要找到你要找的信息可能要花一些时间。这里的主要提示是,为了在演示文稿中使用表格,您应该确保它们不要太长或有很多列。格式化的其他小技巧:移除或增加边框和不必要的网格线的透明度,以突出数据。这样做的目的是增加用于表示数据的墨水(在本例中是像素)相对于整个绘图中墨水(像素)总量的比例。这个比例越高,情节越强调数据。这个概念被称为数据-油墨比。
热图
热图使用颜色使表格更容易阅读。下图包含与我们刚刚看到的表格相同的数据:

色标更容易看出第一季度的温度和发电量最高。
热图是让表格更容易阅读和得出结论的一种很好的方式。
既然我们在讨论使用不同工具的可能性,这里有一些资源可以帮助你使用 Google Sheets 创建相同的热图。
如果您还没有下载发电数据集,并将其上传到 Sheets。然后你只需要创建一个数据透视表和添加条件过滤到你想要创建热图的列上。这个过程是完全可定制的,你可以让你的图表看起来像你想要的样子!
2.折线图
折线图适合绘制时间序列——一个或多个序列如何随时间变化。虽然绘制时间序列不是这种图表的唯一用途,但它是最适合它的。这是因为这条线给读者一种连续性的感觉,如果你要比较两个类别,这看起来并不好,我们将在下面看到。
例如,下图显示了一年中最高温度的变化情况:

我们也可以在单个图表中绘制更多系列。下面是每个月的日最高温度:

然而,如果我们把太多的系列放在一起,即使每个系列都是不同的颜色,也会变得有点乱。试着把注意力集中在你想传达给听众的信息上。这是以另一种方式绘制的同一图表:

请注意,尽管我们仍然将所有的系列绘制在同一个图表上,但我们的观众能够将注意力集中在九月。
当一次绘制多条线时,混乱的图表和良好的图表之间的区别在于使用格式向您的受众传递信息。上面两张图片使用了相同的数据,但是传递了完全不同的信息。
虽然我们可以写一整篇文章来讲述如何让我们的图更漂亮,但主要的想法是让我们的可视化尽可能的清晰,并把重点放在数据上。
这里有一些你可以使用的额外资源:
如果你想学习如何用数据讲故事, Cole Knaflic 的书《用数据讲故事》是最好的资源。同样,在这个话题上,科尔在谷歌上的讲座绝对值得你花时间,如果你想改进你的情节的话。
3.面积图
面积图只是折线图的一种变体,主要区别在于面积图对直线和 x 轴之间的区域应用了阴影。这种图表用于比较多个变量随时间的变化情况。
例如,使用这个客户数据集的修改版本,我们可以绘制每年客户总数的面积图。这个新数据包含了不同年份的数据,增加了无数可能性。

不过,我们需要注意不要不必要地使用面积图。上面的图看起来就像一个普通的折线图,填充区域几乎没有什么不同,除了可能会让读者感到困惑。
然而,当绘制多个变量时,我们可以看到堆积面积图更有意义。下图不仅显示了每年的客户总数,还显示了搅动和未搅动客户的数量:

现在我们可以看到,尽管客户总数在增加,但客户流失率似乎也在以更高的速度增长。
如果 Tableau 是你选择的工具,这里有一个关于使用 Tableau 创建面积图的快速教程。
4.条形图
条形图是最常见、最易读的图表之一。它们最常见的用例是显示不同类别之间的值如何变化。它们是餐桌的很好替代品。
它们很容易理解,你的读者只需快速看一下图表就能理解你的信息。例如,在下面的图表中,我们可以很容易地看到,在这个数据集中,非老客户比老客户多得多:

尽管如此,重要的是要注意,如果我们没有正确使用它们,这种图表是如何具有欺骗性的。下图显示了每组客户的平均收入:

快速浏览一下图表,你可能会得出这样的结论:这两组人之间存在显著差异,喝醉的顾客比没喝醉的顾客赚的钱少得多。然而,事实并非如此。注意 y 轴从 60000 开始,完全改变了剧情的视觉冲击。当 y 轴从零开始时,这个图表看起来是这样的:

尽管被搅动的顾客平均来说赚的钱还是少了,但是差别很小,酒吧的高度看起来几乎一样。使用条形图和修改 y 轴上的单位时,我们需要非常小心。
请注意,我们将值写在了条形上,以使各组之间的差异显而易见。在定制图表时,Python 允许很多可能性。这是这个的源代码:
import pandas as pd
import matplotlib.pyplot as plt
df_churn = pd.read_csv('churn_predict.csv')
fig = plt.figure(figsize=(12,6))
df_income = df_churn.groupby('churn')['estimated_income'].mean().reset_index().sort_values('estimated_income', ascending=False)
plt.bar(df_income['churn'], df_income['estimated_income'])
for _, row in df_income.iterrows():
plt.text(row['churn'], row['estimated_income'] - 10000,
'$'+str(int(row['estimated_income'])), ha='center',
fontsize=14, color='w')
plt.title('Average Income by Churn Status')
plt.tight_layout()
plt.show()
水平条形图
水平条形图是条形图的变体,其效果与其原始形式一样好。这是一个强烈推荐的图表,用于可视化每个类别的值,尤其是当我们有许多名称较长的类别时。
这是因为图表与我们习惯阅读的方向相同——从左到右。例如,看看下面的图表,它代表了受教育程度不同的客户数量:

请注意,我们在图的最左边部分有每个条形的标签,这是我们看它时眼睛首先去的地方,然后我们流入已经知道它的意思的数据。
此外,画一条假想的垂直线比画一条水平线更容易比较每个条形的大小。更容易理解的是,毕业生比其他人更容易流失。
在常规条形图中,我们需要注意 y 轴,而在水平条形图中,我们关注的是 x 轴。重要的是要确保它总是从零开始,或者有一个非常好的理由不这样做。
条形图中的颜色选择也是一个有趣的点,尤其是当我们有几个条形图时。如果每个条形代表一个类别,我们应该用颜色来区分它们。但是如果条形代表一个类别中的变化,那么渐变可能是展示这种关系的好方法。
这里有一篇关于如何为图表选择颜色的完整文章。
堆积条形图
条形图的另一种变体是堆积条形图。这种类型的可视化用于在每个条形内显示另一个变量。这是我们刚刚看到的堆积面积图的条形图版本。
例如,我们可以使用第一个条形图,按照另一个类别(教育水平)对每个条形图进行细分:

这个新的图表不仅显示了被搅动和未被搅动的顾客的数量,还显示了他们是如何被另一个类别划分的。
我们需要小心从这样的图表中得出的见解。举例来说,很容易说没有受过教育的毕业生比受过教育的毕业生多,但考虑到这两个群体的规模,就很难说这是真的了。
因此,一个好的建议是使用百分比而不是名义金额。这被称为规范化数据。这使得条形具有相同的高度,这使得比较更加容易:

请注意,尽管第一个图表中的标称值明显不同,但归一化值基本相同。
为了让你的情节更好,这里有一些设计技巧来帮助你的可视化。
瀑布图
瀑布图是条形图的另一种变体。就像堆积条形图一样,瀑布图的目的是可视化分解成其他变量的条形图的组成。回到我们的第一个数据集,这里有一个瀑布图,显示了今年前六个月以及下半年按月份细分的发电量:

请注意,每个绿色条从上一个结束的高度开始。如果我们把所有的绿色条加在一起,就会得出图表两边的两个蓝色条的差值。
此外,由于每个月都有自己的条形,所以整个图只能显示一个条形的分解情况,在本例中,就是当年的发电量。
瀑布图和堆积条形图之间的另一个区别是,瀑布图可以在主变量的分解中表示负值。想象一下,由于某种奇怪的原因,我们有几个月的负发电量。这是该图的样子:

创建这种图表时要记住的一件重要事情是充分利用颜色。在这种情况下,我们需要三种颜色:一种用于图表左侧和右侧的合并条形,另外两种颜色分别用于正负条形。
红色条代表负值。它们从前一个绿色条的顶部开始,并在该标记下方结束。下一个小节从红色小节的底部开始。
如果你喜欢 Power BI,这里有一个关于如何使用 Power BI 创建瀑布图的完整指南。
5.散点图
散点图用于显示两个变量之间的关系,并检查它们之间是否存在相关性。它们不像以前的可视化那样直观,没有准备的读者可能要花一些时间才能理解它们。
例如,下图显示了交易总数和这些交易的总金额之间存在有趣的相关性:

这很有道理:一个人用信用卡购物的次数越多,他们的总金额就越大。
我们还可以在此图表中添加另一个维度,使用一种颜色来代表客户的分类变量:

我们可以看到,当交易数量或交易总额达到一定程度时,客户变得非常不容易流失。
我们还可以向散点图添加另一个轴来创建三维图表,但通常不建议这样做,因为这会使图表变得混乱,更难阅读。
当查看清楚显示相关性的散点图时,我们在得出结论时必须非常小心。尽管这两个变量可能密切相关,但这并不一定意味着存在因果关系。换句话说,相关性并不意味着因果关系。例如,冰淇淋销售散点图将显示与鲨鱼攻击次数的密切相关。这并不意味着购买冰淇淋会导致鲨鱼攻击,但它确实暗示了一种可能性,即无论是什么在驱动一个也在驱动另一个。在这种情况下,外面的温度导致人们在更热的日子里买冰淇淋或去游泳。
有一系列的统计测试和分析用来确定因果关系。在 Dataquest,你可以通过使用 Python 和 R 来了解更多。
6.饼图
饼图也用于可视化一个分类变量如何被细分成不同的类别。然而,我们在使用这种图表时应该非常小心。那是因为他们通常很难准确地阅读。当两个或多个类别具有相似的值时,人眼几乎不可能区分哪个类别大于另一个类别,因为我们不太擅长估计角度。
下面是客户数据集中的education_level变量类别的饼图:

如你所见,判断Post-Graduate或Doctorate是否代表更大的客户群是一个挑战。但是,如果我们在图表中添加百分比,就更容易区分了:

在这种情况下,条形图可能会使读者更容易比较不同类别的数值。
当饼图只有两三个类别时,效果最好,因此可以进行的比较较少。例如,下面是一个饼状图,显示了不满意客户和不满意客户的数量:

因为我们只有两个类别可以比较,所以确认哪个类别比另一个大要容易得多。
现在我们已经介绍了一些可视化技术,并且您已经有了绘制它们的数据集,如果您想开始使用像 PowerBI 这样的无代码工具,我们没有一个,而是两个视频教程来帮助您。
结论
虽然涵盖所有可能的数据可视化技术已经超出了本文的范围,但是我们在这里介绍的技术可能足以完成大多数基本的可视化工作。
如果你想让你的可视化更加有效和漂亮,这里有一个教程完全集中在如何做到这一点。
然而,如果您有兴趣更深入地研究数据可视化并使用真实数据创建自己的图表,Dataquest 提供了多种课程,将带您从零到英雄,同时在以下方面创建美丽的可视化:
一定要检查他们!
使用 data.world Python 库加速您的数据采集
原文:https://www.dataquest.io/blog/datadotworld-python-tutorial/
March 22, 2017
处理数据时,工作流程的一个关键部分是查找和导入数据集。能够快速定位数据、理解数据并将其与其他来源相结合可能很困难。
一个有助于此的工具是 data.world ,在这里你可以搜索、复制、分析和下载数据集。此外,您可以将您的数据上传到 data.world,并使用它与他人协作。
在本教程中,我们将向您展示如何使用 data.world 的 python 库轻松处理 Python 脚本或 Jupyter 笔记本中的数据。您需要创建一个免费的 data.world 帐户来查看数据集并进行后续操作。
data.world python 库允许您将存储在 data.world 数据集中的数据直接引入您的工作流,而无需首先在本地下载数据并将其转换为您需要的格式。
因为 data.world 中的数据集是以用户最初上传时的格式存储的,所以您经常会发现很棒的数据集以一种不太理想的格式存在,比如 Excel 工作簿的多个工作表,在这种情况下,将它们导入 Python 可能是一件痛苦的事情。data.world Python 库消除了这种麻烦,允许您以自己喜欢的形式轻松处理数据。
安装 data.world 库
您需要做的第一件事是安装库,这可以通过 pip 完成:
pip install git+git://github.com/datadotworld/data.world-py.git
这将安装库及其所有依赖包。这个库的一个便利之处是它的命令行实用程序,它允许您轻松地将 API 令牌存储在本地。这避免了必须把它放在你的脚本或笔记本中,并且在你分享你的作品时必须担心共享你的令牌。
首先,进入 data.world 中的设置>高级并获取您的 API 令牌:

如果您在 virtualenv 或 Conda env 中安装了 python 库,您将需要激活该环境。然后只需运行dw configure,它会提示您输入令牌:
~ (datadotworld) $ dw configure
API token (obtained at: https://data.world/settings/advanced): _
当您输入令牌时,将在您的主目录中创建一个.dw/目录,您的令牌将存储在那里。
我们的数据集
在本教程中,我们将使用电视节目《辛普森一家》的一组数据信息。托德·施奈德为他的文章《辛普森一家》收集了数据,为此他在 GitHub 上提供了刮刀。Kaggle 用户 William Cukierski 使用 scraper 上传数据集,该数据集随后在 data . world上重新托管。
如果您查看 data.world 上的数据集页面,您可以看到数据集中有四个 csv 文件:
- 《辛普森一家》中出现的每个角色。
- 《辛普森一家》的每一集。
- 《辛普森一家》中出现的每个地方。
- 《辛普森一家》每个剧本的每一句台词。
我们将使用 Python 3 和 Jupyter Notebook 处理这些数据。
使用 data.world 的 Python 库来研究数据
首先,让我们导入datadotworld库:
import datadotworld as dw
我们将使用load_dataset()函数来查看数据。当我们第一次使用load_dataset()时,它:
- 从 data.world 下载数据集并缓存在我们的
~/.dw/目录中 - 返回一个代表数据集的
LocalDataset对象
本地缓存数据集是一个非常好的特性——它允许更快的后续加载,允许您离线处理数据,确保您每次运行代码时源数据都是相同的,并且将来将支持数据集版本控制。在第一次为给定的数据集调用load_data_set()之后,它将从缓存的版本中加载数据集。如果您希望从远程版本强制重新加载并覆盖更改,您可以将True传递给可选的force_update参数。
load_dataset()有一个必需的参数dataset_key,您可以从 data.world 上数据集的 URL 中提取这个参数。例如,我们的 simpsons 数据集有一个 URL https://data.world/data-society/the-simpsons-by-the-data,它的 ID 为data-society/the-simpsons-by-the-data。
lds = dw.load_dataset('data-society/the-simpsons-by-the-data')
了解我们的数据
为了更仔细地查看我们的LocalDataset对象,我们可以使用LocalDataset.describe()方法,它返回一个 JSON 对象。
# We use pprint as it makes our output easier to read
pp.pprint(lds.describe())
{
'homepage': 'https://data.world/data-society/the-simpsons-by-the-data',
'name': 'data-society_the-simpsons-by-the-data',
'resources': [ { 'format': 'csv',
'name': 'simpsons_characters',
'path': 'data/simpsons_characters.csv'},
{ 'format': 'csv',
'name': 'simpsons_episodes',
'path': 'data/simpsons_episodes.csv'},
{ 'format': 'csv',
'name': 'simpsons_locations',
'path': 'data/simpsons_locations.csv'},
{ 'format': 'csv',
'name': 'simpsons_script_lines',
'path': 'data/simpsons_script_lines.csv'}]}
我们的 JSON 对象在顶层有三个键/值对:homepage、name和resources。resources是一个包含 data.world 数据集中每个文件信息的列表:它的名称、格式和路径。在上面的例子中,我们可以看到这个数据集中的所有四个资源都是 CSV 文件。
除了LocalDataset.describe()函数,我们的LocalDataset对象还有三个关键属性可以用来访问数据本身:LocalDataset.dataframes、LocalDataset.tables和LocalDataset.raw_data。
这些属性的工作方式相同,但返回的数据格式不同。
for i in [lds.dataframes, lds.tables, lds.raw_data]:
print(i,'n') # pprint does not work on lazy-loaded dicts
{'simpsons_characters': LazyLoadedValue(<pandas.DataFrame>), 'simpsons_episodes': LazyLoadedValue(<pandas.DataFrame>), 'simpsons_locations': LazyLoadedValue(<pandas.DataFrame>), 'simpsons_script_lines': LazyLoadedValue(<pandas.DataFrame>)}
{'simpsons_characters': LazyLoadedValue(<list of rows>), 'simpsons_episodes': LazyLoadedValue(<list of rows>), 'simpsons_locations': LazyLoadedValue(<list of rows>), 'simpsons_script_lines': LazyLoadedValue(<list of rows>)}
{'simpsons_characters': LazyLoadedValue(<bytes>), 'simpsons_episodes': LazyLoadedValue(<bytes>), 'simpsons_locations': LazyLoadedValue(<bytes>), 'simpsons_script_lines': LazyLoadedValue(<bytes>)}
LocalDataset.dataframes返回熊猫 DataFrame 对象的字典,其中 as LocalDataset.tables和LocalDataset.raw_data分别返回 Python 列表和字节格式的字典中的数据。如果我们不想使用 pandas,列表会很有用,如果我们有像图像或数据库文件这样的二进制数据,bytes 会很有用。
由于 pandas 库的强大功能,让我们使用LocalDataset.dataframes来探索和享受我们的数据吧!
simpsons_eps = lds.dataframes['simpsons_episodes']
print(simpsons_eps.info())
simpsons_eps.head()
<class 'pandas.core.frame.dataframe'="">
RangeIndex: 600 entries, 0 to 599
Data columns (total 13 columns):
id 600 non-null int64
title 600 non-null object
original_air_date 600 non-null object
production_code 600 non-null object
season 600 non-null int64
number_in_season 600 non-null int64
number_in_series 600 non-null int64
us_viewers_in_millions 594 non-null float64
views 596 non-null float64
imdb_rating 597 non-null float64
imdb_votes 597 non-null float64
image_url 600 non-null object
video_url 600 non-null object
dtypes: float64(4), int64(4), object(5)
memory usage: 61.0+ KB
None
| 身份证明(identification) | 标题 | 原始航空日期 | 生产代码 | 季节 | 当季数量 | 系列中的数字 | 美国观众(百万) | 视图 | imdb_rating | imdb _ 投票 | 图像 _url | video_url | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Ten | 荷马之夜 | 1990-03-25 | 7G10 | one | Ten | Ten | Thirty point three | Fifty thousand eight hundred and sixteen | Seven point four | One thousand five hundred and eleven | https://static-media.fxx.com/img/FX_Networks_-_… | |
| one | Twelve | 克鲁斯蒂被抓了 | 1990-04-29 | 7G12 | one | Twelve | Twelve | Thirty point four | Sixty-two thousand five hundred and sixty-one | Eight point three | One thousand seven hundred and sixteen | https://static-media.fxx.com/img/FX_Networks_-_… | |
| Two | Fourteen | 巴特得了个“F” | 1990-10-11 | 7F03 | Two | one | Fourteen | Thirty-three point six | Fifty-nine thousand five hundred and seventy-five | Eight point two | One thousand six hundred and thirty-eight | https://static-media.fxx.com/img/FX_Networks_-_… | |
| three | Seventeen | 每个车库有两辆车,晚上有三只眼睛… | 1990-11-01 | 7F01 | Two | four | Seventeen | Twenty-six point one | Sixty-four thousand nine hundred and fifty-nine | Eight point one | One thousand four hundred and fifty-seven | https://static-media.fxx.com/img/FX_Networks_-_… | |
| four | Nineteen | 死亡放置社会 | 1990-11-15 | 7F08 | Two | six | Nineteen | Twenty-five point four | Fifty thousand six hundred and ninety-one | Eight | One thousand three hundred and sixty-six | https://static-media.fxx.com/img/FX_Networks_-_… |
我们可以使用original_air_date栏来查看剧集随时间的变化趋势。首先,让我们从该列中提取年份,然后使用数据透视表来直观显示 IMDB 评级随时间变化的趋势:
simpsons_eps['original_air_date'] = pd.to_datetime(simpsons_eps['original_air_date'])
simpsons_eps['original_air_year'] = simpsons_eps['original_air_date'].dt.year
simpsons_eps.pivot_table(index='original_air_year',values='imdb_rating').plot()
plt.show()

我们在这里可以看到,根据 IMDB 评分者的数据,《辛普森一家》剧集的质量在前 6 年很高,此后一直处于稳步下滑的状态。
使用 SQL/SparQL 查询访问数据
使用 data.world python 库访问数据的第二种方式是使用.query()函数,该函数允许您访问 data.world 的查询工具。
query()函数返回一个QueryResults对象,它有三个属性,类似于LocalDataset对象的属性:QueryResults.dataframe、QueryResults.table和QueryResults.raw_data。
查询工具使用 dwSQL ,data.world 自己风格的 SQL,它接受大多数标准的 SQL 函数和查询类型。如果将可选的querytype='sparql'参数传递给函数,它也将接受 SPARQL 查询。
查询工具允许您将多个数据集中的数据连接在一起,并检索较大数据的子集,以便您可以将处理较大数据的负担从本地系统转移出去。
让我们来看一个例子。包含《辛普森一家》剧集中的 158,000 行。让我们使用 iPython magic command %timeit 对两种不同的绘图方式进行计时,简单分析一下哪些角色拥有最多的脚本行:
- 在处理 pandas 中的数据之前,将数据从一个新的
LocalDataset对象读入 pandas。 - 使用
QueryResults.query()获取 data.world 的查询工具处理数据,然后将结果返回给我们。
def pandas_lines_by_characters():
simpsons_script = lds.dataframes['simpsons_script_lines']
simpsons_script = simpsons_script[simpsons_script['raw_character_text'] != '']
top_10 = simpsons_script['raw_character_text'].value_counts().head(10)
top_10.plot.barh()
plt.show()
1 loop, best of 1: 33.6 s per loop

def query_lines_by_characters():
lds = dw.load_dataset('data-society/the-simpsons-by-the-data',force_update=True)
q ='''
select
raw_character_text,
count(*) as num_lines
from simpsons_script_lines
where raw_character_text != ''
group by raw_character_text
order by num_lines desc;
'''
qr = dw.query('data-society/the-simpsons-by-the-data',q)
top_10 = qr.dataframe.set_index('raw_character_text').head(10)
top_10['num_lines'].plot.barh()
plt.show()
1 loop, best of 1: 2.38 s per loop

使用.query()将我们的运行时间从 36 秒减少到 2 秒——减少了 94%!
我们的查询还可以用于连接单个数据集中多个表的数据,甚至是多个数据集中的数据。让我们修改我们的角色查询来比较前 5 季中我们的主要角色的角色线:
q =
'''
select
ssl.raw_character_text,
se.season, count(*)
as num_lines
from simpsons_script_lines ssl
inner join simpsons_episodes se
on se.id = ssl.episode_id
where ssl.raw_character_text != ''
and se.season < 6
group by
ssl.raw_character_text,
se.season
order by num_lines desc;
'''
qr = dw.query('data-society/the-simpsons-by-the-data',q)
df = qr.dataframe
char_counts = df.pivot_table(index='raw_character_text',
values='num_lines',aggfunc=sum)
top_10_chars = char_counts.sort_values(ascending=False).iloc[:10].index
top_10 = df[df['raw_character_text'].isin(top_10_chars)]
pivot = top_10.pivot_table(index='raw_character_text',
columns='season',values='num_lines')
pivot.plot.bar()
plt.show()

使用 data.world API
除了load_dataset()和query()之外,data.world 库还提供了一个完整的 data.world API 包装器,让您可以访问许多强大的函数,这些函数允许您读取、创建和修改 data.world 上的数据集。
为了演示这一点,让我们将每一集《辛普森一家》开头的黑板插科打诨添加到simpsons_episodes文件中。请注意,您需要成为数据集的贡献者或所有者,才能使用 API 进行更改。
我们将从从网上下载一个黑板游戏列表开始,清理它们以准备加入到主桌上。
# create a list of dataframes from the tables listed on simpsons.wikia.co,
chalkboard_dfs = pd.read_html('https://simpsons.wikia.com/wiki/List_of_chalkboard_gags',match='Gag')
# remove the simpsons movie from the list
chalkboard_dfs = [i for i in chalkboard_dfs if i.shape[0] != 2]
# inspect the format of our dataframes
chalkboard_dfs[0].head()
| Zero | one | Two | three | four | |
|---|---|---|---|---|---|
| Zero | # | 广播日期 | 屏幕上显示程序运行的图片 | 窒息 | 剧集标题 |
| one | one | 一九八九年十二月十七日 | 圆盘烤饼 | 没有插科打诨 | 辛普森一家在火上烤 |
| Two | Two | 1990 年 1 月 14 日 | 圆盘烤饼 | 我不会浪费粉笔 | 天才巴特 |
| three | three | 1990 年 1 月 21 日 | 圆盘烤饼 | 我不会在大厅里玩滑板 | 荷马的奥德赛 |
| four | four | 1990 年 1 月 28 日 | 圆盘烤饼 | 我不会在课堂上打嗝 | 没有比家更丢脸的了 |
# the first row contains the column names, let's create a function to fix this
def cb_cleanup(df):
df.columns = df.iloc[0]
df = df.iloc[1:]
return df
# and then apply the function to the whole list
chalkboard_dfs = [cb_cleanup(i) for i in chalkboard_dfs]
# join the list of dataframes into one big dataframe
chalkboards = pd.concat(chalkboard_dfs,ignore_index=True)
# remove bad row without an id
chalkboards = chalkboards[pd.notnull(chalkboards['#'])]
print(chalkboards.shape)
chalkboards.head()
(605,5)
| # | 广播日期 | 屏幕上显示程序运行的图片 | 窒息 | 剧集标题 | |
|---|---|---|---|---|---|
| Zero | one | 一九八九年十二月十七日 | 圆盘烤饼 | 没有插科打诨 | 辛普森一家在火上烤 |
| one | Two | 1990 年 1 月 14 日 | 圆盘烤饼 | 我不会浪费粉笔 | 天才巴特 |
| Two | three | 1990 年 1 月 21 日 | 圆盘烤饼 | 我不会在大厅里玩滑板 | 荷马的奥德赛 |
| three | four | 1990 年 1 月 28 日 | 圆盘烤饼 | 我不会在课堂上打嗝 | 没有比家更丢脸的了 |
| four | five | 1990 年 2 月 4 日 | 圆盘烤饼 | 没有插科打诨——由于时间原因,开幕式缩短了 | 巴特将军 |
# remove extra columns and normalize column names
chalkboards = chalkboards[['#','Gag']]
chalkboards.columns = ['id','chalkboard_gag']
# convert id column to int
chalkboards['id'] = chalkboards['id'].astype(int)
chalkboards.head()
| 身份证明(identification) | 黑板 _gag | |
|---|---|---|
| Zero | one | 没有插科打诨 |
| one | Two | 我不会浪费粉笔 |
| Two | three | 我不会在大厅里玩滑板 |
| three | four | 我不会在课堂上打嗝 |
| four | five | 没有插科打诨——由于时间原因,开幕式缩短了 |
请注意,我们将带有剧集 id 的列命名为与它在原始表中的名称相同,这将使我们能够轻松地将数据连接在一起。
让我们将黑板引用加入到原始表格中,并将其导出为 CSV 格式。
lds = dw.load_dataset('data-society/the-simpsons-by-the-data')
simpsons_episodes = lds.dataframes['simpsons_episodes']
simpsons_episodes = simpsons_episodes.merge(chalkboards,how='left',on='id')
simpsons_episodes.head()
| 身份证明(identification) | 标题 | 原始航空日期 | 生产代码 | 季节 | 当季数量 | 系列中的数字 | 美国观众(百万) | 视图 | imdb_rating | imdb _ 投票 | 图像 _url | video_url | 黑板 _gag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | Ten | 荷马之夜 | 1990-03-25 | 7G10 | one | Ten | Ten | Thirty point three | Fifty thousand eight hundred and sixteen | Seven point four | One thousand five hundred and eleven | https://static-media.fxx.com/img/FX_Networks_-_… | 我不会叫我的老师“热蛋糕” | |
| one | Twelve | 克鲁斯蒂被抓了 | 1990-04-29 | 7G12 | one | Twelve | Twelve | Thirty point four | Sixty-two thousand five hundred and sixty-one | Eight point three | One thousand seven hundred and sixteen | https://static-media.fxx.com/img/FX_Networks_-_… | 他们在嘲笑我,而不是和我一起 | |
| Two | Fourteen | 巴特得了个“F” | 1990-10-11 | 7F03 | Two | one | Fourteen | Thirty-three point six | Fifty-nine thousand five hundred and seventy-five | Eight point two | One thousand six hundred and thirty-eight | https://static-media.fxx.com/img/FX_Networks_-_… | 我不会鼓励别人飞。(并且在 th… | |
| three | Seventeen | 每个车库有两辆车,晚上有三只眼睛… | 1990-11-01 | 7F01 | Two | four | Seventeen | Twenty-six point one | Sixty-four thousand nine hundred and fifty-nine | Eight point one | One thousand four hundred and fifty-seven | https://static-media.fxx.com/img/FX_Networks_-_… | 我不会复印我的屁股。是土豆,不是锅… | |
| four | Nineteen | 死亡放置社会 | 1990-11-15 | 7F08 | Two | six | Nineteen | Twenty-five point four | Fifty thousand six hundred and ninety-one | Eight | One thousand three hundred and sixty-six | https://static-media.fxx.com/img/FX_Networks_-_… | 我不是一个 32 岁的女人(在那个时候… |
我们几乎准备好上传我们的修改。以下代码:
- 将修改后的数据帧保存到 CSV 文件中
- 启动 data.world API 客户端对象
- 上传我们修改过的 CSV 文件,覆盖原始文件。
simpsons_episodes.to_csv('simpsons_episodes.csv',index=False)
client = dw.api_client()
client.upload_files('data-society/the-simpsons-by-the-data',files='simpsons_episodes.csv')
目前,data.world python 库中的 API 包装器限于 8 个方法,列在库的 README.md 中。你可以通过库的代码中的文档字符串了解更多关于它们如何工作的信息,也可以看看主 API 文档。
您可以使用 data.world Python 库的三种方式— load_dataset()、query()和api_client() —为您提供了一个强大的工具集来简化数据处理。
我很想知道你是如何使用 data.world Python 库的— 让我知道!
感谢 data.world 给我高级权限访问他们的 Python 库来写这篇文章。如果您对如何改进 data.world 库有任何建议,您可以通过项目 GitHub 资源库提交问题和请求
Dataquest 的活动课程:我们如何教授数据科学
原文:https://www.dataquest.io/blog/dataquest-active-curriculum-how-we-teach-data-science/
January 3, 2020
有很多方法可以学习数据科学,包括在线和离线。但在 Dataquest,我们采取了一种独特的方法,这种方法基于我们自己的经验和来自成千上万学生完成数百万个屏幕的多年数据。
在这篇文章中,我们将解释什么是我们的活动课程,以及为什么我们以这种方式教学。
我们正在实施的活动课程。
什么是活动课程?
简而言之,我们的活动课程有三点不同于其他类型的数据科学教育:
- 精心策划的内容
- 实践学习循环
- 数据驱动的优化
我们将更详细地研究这三件事,解释我们为什么要这样做,以及为什么我们认为这种方法反映了教授数据科学技能的最有效方式。
精心策划的内容
我们的活动课程与其他课程的区别之一是,它是由内部专家从头开始精心规划的。
基于真实世界数据工作的内容。
我们的内容团队由前教师和前数据专业人员(包括一些博士)组成。但是,当决定创建什么样的课程内容时,我们首先要深入更广泛的社区。
我们分析了来自世界各地的数百份招聘信息,这样我们就可以教授最受欢迎的内容。我们还与工作数据科学家和该领域的其他专家进行了交谈,以获得有关学生在专业环境中处理数据真正需要的技能的更多信息。
这种对教授现实世界技能的关注也融入了课程本身。随着您学习新的编程和统计概念,您将面临解决现实数据分析和数据科学问题的挑战,这些问题与您在工作场所遇到的问题类似。

在线学习的一个主要挫折是课程之间的差距,这迫使你去别处寻找知识。
无间断的课程顺序。
因为我们的课程几乎都是由内部作者编写的,所以在编写时,我们还会考虑如何将每门课程纳入我们现有的课程目录。
尽管你可以自由选择任何顺序的课程,但是我们的每一条学习路径都是一系列精心设计的课程,允许你作为一个没有编写代码经验的绝对初学者开始。
当你完成每一门课程后,你将能够直接进入下一门课程,而不必浪费时间去寻找先决条件或搜索来填补你的知识空白。因为我们控制和计划课程的每一个方面,我们没有任何这些差距。
这种仔细的课程排序还允许我们使用后面的课程来帮助您复习和练习您在前面的课程中获得的技能。这使我们能够利用间距效应,帮助确保您在我们的学习过程中记住所学内容。
实践学习循环
我们的活动课程的最强原则之一是,为了有效地学习,你需要经常应用你所学的东西。这不仅仅是一个理论,有相当多的科学来支持它。例如,2014 年的一项元研究发现,STEM 课程中不经常应用所学知识的学生失败的可能性是 T2 的 1.5 倍。
学习>应用>反馈循环。
我们的互动平台旨在让您尽快掌握所学内容。在每个屏幕上,你会读到一个新概念,然后立即接受挑战,通过编写代码来应用它,然后由我们的答案检查器检查。以典型的节奏学习,学生不太可能在我们的平台上呆上哪怕五分钟而不写代码。

当学生将 Dataquest 与其他类似的学习平台进行比较时,我们经常听到的一件事是 Dataquest“实际上让你思考”(这里是最近告诉我们这一点的人们的两个 例子)。那是故意的。每一步,我们都想挑战你在专业环境中必须做的事情:编写真正的代码来解决问题。
我们认为,拥有一个真正快速的反馈循环——你学到一点东西,你很快编写代码来应用它,答案检查器会告诉你你是否做对了——会使学习更有吸引力、更有效。这也使得按照你自己的进度学习和在繁忙的时间表中安排学习更加实际。
但我们也知道,现实世界的数据科学工作不会以微小的块发生。这就是为什么我们的每门课程都以一个指导项目结束。这些项目模拟现实的数据科学工作。他们要求你综合并应用到那时为止你所学的一切,同时在你需要的时候提供一些指导,以确保你不会感到沮丧。它们还能帮助你建立一个数据科学项目组合,当你申请下一份工作时,你可以从中受益。
为什么没有视频?
缺少视频是我们的活动课程与大多数其他课程的最大区别之一。我们或许可以写一本书,说明为什么我们不通过视频来教授数据科学,但这里有一些最大的原因:
- 任何学生都会发现他们的注意力水平在整个学习过程中发生了变化。我们的大脑无法长时间保持完全一致的注意力和理解水平,这是很自然的。如果你是通过阅读来学习的,这些小差异并不重要。你会自然而然地调整阅读速度来适应这些变化。但是视频以统一的速度播放,这意味着对于许多学生来说,会有视频感觉太慢的时候,也有视频感觉太快的时候。这会导致无聊和/或错过内容。
- 没有人第一次就能把所有事情都做对。与简单的 Ctrl + F 相比,当你不得不回去回顾一些东西时,搜索视频可能会令人沮丧且耗时。
- 观察人们编码可能很棘手。很容易看到别人做某件事,觉得自己理解了,但后来当你试图自己应用时,才发现自己并没有想象中掌握得那么好。
- 对于非母语人士(即使有字幕)和有网络带宽限制或网速慢的学生来说,视频可能很难播放。
- 视频,除非它们非常短,否则会减缓学习>应用反馈循环。
此外,虽然这些不是视频本身的问题,但许多视频学习平台缺乏代码运行能力,因此用多项选择和填空测验来测试学生。我们不认为这是一种有效的教学方式——如果你不是真的在写代码,你就不是真的在学以致用。

学习写代码最好的方法是写代码,而不是看别人写代码。
真实数据,真实问题,真实代码。
因为我们的重点是教授就业技能,所以我们所有的课程都使用真实世界的数据集,并要求您通过编写真实的代码来解决现实的数据科学问题。这可能是老生常谈,但我们相信一句古老的教练格言:像练习一样打球。
换句话说,如果你的目标是用真实的数据集来解决真实的数据科学问题,你的学习和实践应该是用真实的数据集来解决真实的数据科学问题。这就是为什么即使是以前从未编写过代码的 Dataquest 学生,在开始他们的第一门课程后几分钟内也会使用真实世界的数据集。
专家数据驱动的优化
另一件让我们的活动课程与众不同的事情是,它不是静态的。我们总是在我们的道路上增加新的课程,但我们也在跟踪大量数据,并不断征求反馈,以便我们可以不断改进我们已经拥有的内容。
利用数据更有效地教学。
我们的平台收集了大量关于我们每个课程、任务和屏幕表现的数据。这使得我们的内部课程作者能够快速发现他们的某门课程出现的问题。
例如,如果在特定屏幕上运行的代码异常多,这可能表明该屏幕对于它在课程中的位置来说太靠前了,需要修改或移动。
课程作者经常挖掘这些数据来优化课程,可能包括改变练习、调整解释和改变内容。最终的结果是课程高度优化,并不断改进。
学生反馈。
在 Dataquest,我们热爱数据——这并不奇怪——但我们也会定期征求学生对我们课程的定性反馈。学生的反馈可以帮助我们发现数据中可能不明显的需要改进的地方,它也是帮助我们的课程作者为学生的成功优化他们的课程的另一个有价值的工具。
内部专家。
这种持续的优化是可能的,因为我们几乎所有的课程都是由 Dataquest 的全职员工在内部编写的。
这样可以保证每个课程都有人负责。如果出现问题,课程作者可以立即解决。如果某门课程有改进的方法,课程作者会把它作为他们定期评估课程表现的一部分。
这也意味着我们可以确保我们所有的课程作者都紧跟教育研究和数据科学行业的最新发展。我们定期就新的教学研究进行团队讨论,我们还跟踪行业趋势,以便当新技能、库、包、工作流和流程在数据科学领域变得流行时,我们可以将其应用到我们的课程中。
定期发布新课程。
当然,除了优化我们现有的课程,我们还在不断开发新的课程,为我们现有的课程增加更多的价值,并创造新的课程。例如,在 2019 年,我们推出了十几门新课程和两条完全改进的路径(我们在 R 的数据分析师和数据工程路径)。
我们不打算很快减速!
TL;速度三角形定位法(dead reckoning)
简而言之,Dataquest 的课程有三个特点:
- 我们精心策划的内容
- 我们的快速实践学习循环
- 数据驱动优化,让好课程变得伟大
Dataquest 和 Omdena 推出联合奖学金,打造个性化数据科学教育的未来
December 15, 2021
Dataquest 自豪地宣布,我们已经与 Omdena 合作,Omdena 是一个由全球人工智能工程师组成的平台社区,旨在为社会、环境和医疗保健相关的挑战共同构建现实世界的解决方案。
Dataquest 将为 Omdena 合作者提供 500 份 Dataquest Premium access 奖学金。奖学金将授予接受者获得全套 Dataquest 数据科学课程和途径的权利。
除了奖学金,Dataquest 和 Omdena 还将共同为 Omdena 的合作者构建个性化的学习路径。Dataquest 使命的核心是提供个性化的学习路径,让学习者获得积极、真实的职业成果。这种与使命一致的合作关系将致力于提供个性化和技能驱动的学习途径,包括以下内容:
- 推荐合适的课程
- 通过探索真实世界的数据培养对数据科学的熟练程度
- 确定按需数据技能的优先级
- 监控技能进步并提出改进建议
“数据技能有助于改变生活。建立数据项目和解决现实世界的问题帮助我从在工厂工作到从事在线教育工作。Dataquest 总裁兼创始人 Vik Paruchuri 表示:“通过这种合作关系,我很高兴能够帮助数百名学习者踏上与我相同的旅程。
关于奥姆德纳
Omdena 是世界上最大的合作平台,旨在构建创新和道德的人工智能解决方案。来自 100 多个国家的人工智能工程师通过 Omdena 合作,为联合国、联合国难民署、世界粮食计划署、联合国开发计划署以及 impact startups 等组织解决现实世界中的问题。Omdena 为其社区成员提供发展软硬技能的机会,并建立他们的人工智能/人工智能职业生涯。Omdena 还在 35 个国家拥有 60 多个地方分会,其目标是运行开源人工智能项目,以解决当地社区面临的挑战。
关于 Dataquest
Dataquest 成立于 2015 年,旨在帮助学习者建立现实世界的技能,并推进他们在数据方面的职业生涯。Dataquest 是排名第一的基于浏览器的自主数据科学学习平台。用户直接在浏览器中学习概念、编写代码和构建真实世界的项目。Dataquest 的学习路径是专业设计的,旨在帮助学习者有效地实现他们的数据职业目标,无论他们的经验水平如何。Dataquest 已经帮助成千上万的学习者在亚马逊、SpaceX 和特斯拉等公司开始或推进他们的职业生涯。
Dataquest 和多伦多 Womxn 在#100DaysofCode 挑战赛上成为数据科学领域的合作伙伴
February 14, 2022
Dataquest 自豪地宣布,我们已经与多伦多 womxn 在数据科学领域建立了合作伙伴关系,这是一家社会企业,其愿景是激励和支持 100 万懂数据的 womxn,增加 Womxn 在数据专业的招聘和保留,并鼓励该领域的创新。他们将联合发起#100DaysofCode 挑战,在妇女和女孩中建立数据扫盲实践。挑战从 3 月 1 日持续到 6 月 9 日。
Dataquest 将为所有#100DaysofCode 挑战赛参与者提供三个月免费使用 Dataquest Premium 的机会,获胜者将获得免费一年的奖励。Womxn in Data Science challenge 的参与者将从 Dataquests 的全套数据科学课程和途径中受益。
Dataquest 使命的核心是提供个性化的学习路径,让学习者获得积极、真实的职业成果。这种使命一致的伙伴关系将致力于为 datathon 参与者提供个性化和技能驱动的学习路径,包括以下内容:
- 推荐合适的课程
- 通过探索真实世界的数据培养对数据科学的熟练程度
- 确定按需数据技能的优先级
- 监控技能进步并提出改进建议
“数据技能有助于改变生活。建立数据项目和解决现实世界的问题帮助我从在工厂工作到从事在线教育工作。通过这种合作关系,我很高兴能够帮助这些 datathon 参与者踏上与我相同的旅程。”Dataquest 总裁兼创始人 Vik Paruchuri 说。
关于多伦多数据科学论坛
多伦多数据科学 Womxn 成立于 2018 年,目标是鼓励数据科学和其他数据职业的人才渠道多元化。他们的企业战略是提供在数据中颂扬 womxn 的编程,通过活动、指导和数据产品共同创造来教育那些对该领域感兴趣的人,并与致力于 womxn 能够蓬勃发展的包容性文化的组织合作。
关于 Dataquest
Dataquest 成立于 2015 年,旨在帮助学习者建立现实世界的技能,并推进他们在数据方面的职业生涯。Dataquest 是排名第一的基于浏览器的自主数据科学学习平台。用户直接在浏览器中学习概念、编写代码和构建真实世界的项目。Dataquest 的学习路径是专业设计的,旨在帮助学习者有效地实现他们的数据职业目标,无论他们的经验水平如何。Dataquest 已经帮助成千上万的学习者在亚马逊、SpaceX 和特斯拉等公司开始或推进他们的职业生涯。
“内存不足”——数据技能如何终结 Excel 噩梦
October 6, 2020

简而言之,克里奇洛来到 Dataquest 是有原因的:他正在与一场数据噩梦作斗争。滞后、崩溃、“内存不足”——Excel 无法胜任这项任务。
找到那个问题的解决方案改变了他的生活。
问题:用 Excel 处理牲畜数据
25 岁的柯特利在南美洲圭亚那的家畜发展管理局工作。
“我们的机构负责访问农民,帮助他们成为更好的农民,”他说。为此,他们走访了全国数百个农场,每次访问都提供服务并生成数据。
这是一个重要的程序,但它为 Curtly 带来了大量令人头疼的数据,因为他负责处理所有这些数据。
为了记录数据,该机构使用了一个带有 10 个地区文件夹的 Dropbox 帐户,每个文件夹包含该机构在每个地区提供的 6 项服务的 6 个数据文件。
例如,一个地区的兽医访问将记录在该地区文件夹的兽医文件中,而另一个地区的兽医访问将记录在不同的文件夹和文件中。
以任何有意义的方式处理这些数据意味着尝试将 60 个不同的文件组合成 6 个 Excel 电子表格。而认为意味着手工清理海量数据。
“每个月都要花整整一周的时间来整合和清理数据,”简短地说。由于数据量很大,在这些 Excel 表格中进行任何操作都要花费很长时间。即使是一个简单的复制-粘贴命令也可能需要五分钟来执行,因为 Excel 太慢了。
或者它可能会使 Excel 崩溃。
“在这个时候,我甚至不知道数据科学是一种职业,”唐突地说。“但是我发现 Excel 已经不够用了,所以我在寻找替代解决方案。”
寻找 Excel 的替代品
“我开始阅读[数据科学],”他说。“我意识到,嘿,我其实喜欢数据科学。我不够资格,但我喜欢,怎么学?”他开始在 YouTube 上观看数据科学演示,当他找到一个好的演示时,他联系了它的创作者,询问他如何才能了解更多信息。
创作者建议他去看看 Dataquest。
他学习了一些我们的免费课程,很快发现这与他以前尝试的基于视频讲座的课程非常不同。
起初,他说,“我有点想要视频。”但是他很快就意识到 Dataquest 方法对他很有效。他觉得通过阅读,他学到了更多东西,这给他提供了阅读软件文档的良好实践(很少以视频教程的形式提供)。
他在牲畜发展管理局的老板也很高兴,因为 Dataquest 培训比许多可用的替代方案便宜得多。
不再有 Excel 错误:学习编码!
就编码而言,Curtly 是从绝对零开始的。“我对你们教的所有东西都一无所知,”他说。“当你什么都不知道的时候,你会担心自己会感到困惑。”
但 Dataquest 课程的边做边学结构——以及他可以向老师和同学寻求帮助的事实——使他比他尝试过的其他解决方案更容易取得进展。
(“我对 DataCamp 不太满意,”他说。“Dataquest 要好得多。”)

Dataquest 的学习平台,在这里你编写真实的代码来分析你浏览器中的真实数据。
Curtly 的重点是慢慢地、有意识地完成他的课程:“当我学习时,我试图将我所学的应用到我的日常环境中,以确保我真的学到了概念。”
尽管他说他只完成了网站上数据科学家之路的 22%,但它已经产生了巨大的影响。“我学到了很多,”他说,“有了那 22%的知识,我的生活变得轻松多了。”
从 Excel 噩梦中醒来
他的生活变得更容易的一个例子?他每个月都要努力完成的噩梦般的 Excel 清理和合并任务。
完成我们的熊猫课程后,他又回到那个问题,开始写代码。
起初,它不起作用,但是当他遇到无法解决的问题时,他向我们的学习者社区求助。“最终,”他说,“我让它完美地工作了。”
“把所有 60 个文件组合成 6 个文件花了大约一分钟,这是一种甜蜜的感觉,一种神奇的感觉。”
他的 Python 脚本将一个长达一周的噩梦项目变成了一个完全自动化的、可重复的过程,根本不需要时间。
当然,这一成就并不是 Curtly 旅程的终点。事实上,从长远来看,他有宏伟的计划。
“我的目标是拥有自己的数据科学创业公司,帮助企业和机构提高生产率。”
“遇见 Dataquest 改变了我的生活,”他说。
为什么 Jorge 更喜欢 Dataquest 而不是 DataCamp 学习数据分析
原文:https://www.dataquest.io/blog/dataquest-datacamp-learn-data-analysis/
March 15, 2021
许多数据科学学习者对 DataCamp 和 Dataquest 的问题感兴趣。Jorge Varade 在这两个平台上都呆过,他对哪一个是最好的有强烈的看法。
当 Jorge 完成他的工商管理学位时,他知道他想参与分析。在拉尔夫·劳伦(Ralph Lauren)的销售和营销分析实习教会了他 Excel 的基础知识和一些更高级的技术,如数据透视表,但他渴望更多。“我真的对数据分析很感兴趣,”他说,“但我想做一些与 Python 更相关的事情。”
这就是他如何结束在贝尔格雷夫谷(Belgrave Valley)的经历,这是一家总部位于伦敦的训练营,利用 Dataquest 向学生教授数据科学编程技能。
DataCamp 与 Dataquest
他进入训练营时没有任何真正的编程经验。他说,他曾试着自己四处逛逛,看看视频,尝试了几个不同的平台,包括 DataCamp。但是他没有取得任何进展。“我是个初学者,”他说。
当他到达贝尔格雷夫山谷并开始使用 Dataquest 时,情况很快发生了变化。“我在 Python 和 SQL 方面学到的东西来自贝尔格雷夫谷和 Dataquest,”他说。
对于 Jorge 来说,不同之处在于 Dataquest 如何迫使他思考并应用他在每一步中学到的东西。事实证明,这与他尝试过的其他平台形成了强烈对比:
我想试试数据营看看怎么样。我上过 DataCamp 和 Dataquest 这两个平台的课程,在我看来我认为 Dataquest 要好得多,因为它让你付出努力。在 DataCamp 上,你要写的代码几乎已经给你写好了,你不用学太多。Dataquest 让你开动脑筋,学以致用。我更喜欢[Dataquest]的教学方式,我认为你做得很好。
“项目也非常好,”他说。“我真的很喜欢你的项目类型。”
DQ 队对 DC 队
Jorge 的观点是——Dataquest 通过要求你编写代码来提供更有意义的学习体验——这是我们从 data quest 学习者那里经常听到的观点。但是我们当然不指望你会相信我们的话!
相反,让我们看看这两个网站在第三方评论网站上的排名,看看大多数数据科学学习者是否同意 Jorge 的观点:
|
评论网站
|
数据请求
|
数据营
|
| --- | --- | --- |
| Switchup.org | 4.85 满分 5 分 | 5 分中的 4.62 分 |
| G2 | 5 分中的 4.7 分 | 5 分中的 4.3 分 |
| 课程报告 | 4.94 满分 5 分 | 5 分中的 4.05 分 |
这些数字是截至 2021 年 3 月 16 日的最新数据,其中传达的信息非常明确——第三方审查人员始终将 Dataquest 评为高于 DataCamp。Jorge 并不孤单。
获得数据方面的工作
自从在 bootcamp 项目完成 Dataquest 课程后,Jorge 一直在从事数据分析师的工作——先是在一家银行工作了两周,然后在 Mediacom 全职分析汽车营销数据。在那个职位上干了几个月后,他进入了另一个数据分析师的职位——这一次是在 HelloFresh 。
但是他没有满足于他的荣誉。他说,他已经完成了 Python 路径的数据分析师课程,现在他正转向数据科学家路径,这样他就可以不断增加自己的技能。“我会继续(订阅)Dataquest,”他说,“因为我真的很喜欢你解释课程和内容的方式。”
对于其他想获得数据分析师工作的 Dataquest 学生,Jorge 建议花尽可能多的时间学习,真正让自己沉浸在学习中。“真正关注 Python 如何工作,SQL 如何工作,以及数据分析世界如何工作,”他说。"如果你真的喜欢数据分析,那就花点时间在上面."
想追随乔治的脚步吗? 点击下方开始使用免费帐户——从现在起不到五分钟,您将编写您的第一个代码,并开始成为数据分析师!
Dataquest 帮我在 Noodle.ai 找到了梦想中的工作
原文:https://www.dataquest.io/blog/dataquest-helped-me-get-my-dream-job-at-noodle-ai/
September 24, 2018
Dataquest 的课程是让学员为他们想要的数据工作做好准备。对于许多像 Sunishchal Dev 这样的人来说,这意味着在数据科学领域开始职业生涯。
Sunishchal 拥有技术和创新管理学位,他有商业技能,但他意识到要获得他想要的工作,他的技术技能是缺乏的。
具体来说,他需要学习 Python 。
“我尝试使用 Code Academy 和 DataCamp,但觉得它们的学习模块不够互动,无法让我保持兴趣。我也不喜欢看视频讲座,因为它们并不吝啬。”
Dataquest 与众不同,Sunishchal 解释道:“课程很容易吸收,理论和实践知识达到了恰当的平衡。”
通过他的高级订阅获得职业咨询和社区帮助他建立了前进所需的基础。他相信,说到学习,你会得到你所付出的。他花了很长时间尝试使用免费资源学习编程,他发现他的投入水平与他所付出的相匹配。
“购买 Dataquest 订阅服务这一大胆的举动真的点燃了我的热情。我开始完成课程,并从我的小投资中获得了大量的价值。
Sunishchal 现在为 Noodle.ai 工作,这是一家企业人工智能初创公司,为大型企业建立定制数据管道和机器学习模型。他整天都在为一家喷气发动机制造商做风险建模。
“我真的可以说我找到了我梦想的工作!”
卡洛斯:“Dataquest 向我展示的一切,我都用在了我的新工作中”
原文:https://www.dataquest.io/blog/dataquest-job-success-carlos/
November 8, 2018When Carlos Cutillas de Frutos graduated from the Business Administration program at CUNEF in Madrid, he knew he wanted to add something extra to his business skill set. He quickly settled on data science, because he enjoyed statistics and he knew there was a lot of potential for growth there. But he still had a big problem: he had virtually no experience with programming. After trying a few other options and not finding the success he was looking for. Carlos enrolled in Belgrave Valley. Belgrave, a London-based data science bootcamp program, offers career counseling, networking, and programming training that puts students through our Data Analyst in Python learning path. Starting from the very beginning, Carlos spent his days working through lessons on our site, and slowly getting a handle on how to work effectively as a Python data analyst. He particularly enjoyed our guided projects. “They are the most real thing,” he said, comparing his Dataquest learning experience to his new job working as a Business Intelligence Analyst for Vinterior in London. But it’s not just the guided projects he benefited from. It’s all relevant, he said of his studies: “All the topics Dataquest shows you, you then use.” So how’d he get that new job in data analysis? He built a portfolio of cool projects and then started putting in the work: applying, applying, and more applying. In total, Carlos said he probably applied to around 60 companies, and most of them rejected him. But he got two offers, and the rest is history. These days, Carlos says he spends his working hours using SQL to get data from Postgres, and then crunching the numbers in Python using the skills he learned with Dataquest and Belgrave, including a fair amount linear regression. And told us he’s finding his new job really rewarding. “Things that the company didn’t know, you do something with the data and then you’re able to tell them something new that isn’t obvious,” he said. Want to achieve the same results as Carlos? “Be completely focused,” Carlos says. “You cannot do it here and there, you have to commit.” Feeling inspired? Commit. Dive in and start (or continue) your own data science journey.
Dataquest 八月份产品更新
September 15, 2021
Hi Dataquesters!
我们正在联系你们来更新我们在 8 月份取得的进展,并让你们知道一些即将发生的令人兴奋的事情。本月更新的菜单上:一门新课程,新的评估,几篇新的博客文章,等等!
首先,新内容!
- 我们最近发布了 SQL 技能之路的第五期也是最后一期课程(目前为止)!SQL 子查询课程将帮助您编写更复杂的查询,并使您的 SQL 技能更上一层楼。
- 我们还试发布了 Python 评估版《Python for Data Science:Fundamentals I 》(尚未对所有人开放)。预计在接下来的几个月内会发布更多评估版。

接下来,来自 Dataquest 社区的内容贡献:
- 我们有幸与几位杰出的学习者进行了交流,他们是大卫·拉什顿和维娜·桑吉芙。看一看!
- 我们还发布了一些由 Dataquest 社区撰写的文章,包括 Max Bohomolov 在 web scraping 上发表的精彩文章,以及 Vera Tsien 进入数据科学的 6 个月旅程。
最后,仪表板更新!我们在仪表盘上添加了一些新功能。
- 学习统计——您的仪表板现在还包括一些统计数据,显示您在学习过程中的时间和进度。我们都非常喜欢数据,我们必须包含它🙂。
- 时间估计–您现在可以直接在仪表板上看到完成一节课所需的估计时间。
- 社区亮点–我们知道社区在学习新技能时有多重要,所以我们现在直接在您的仪表板上展示一些亮点,让参与社区变得前所未有的简单!

荣誉奖:
- 工程团队在 Github 中合并了 60 多个 pull 请求,包括 22 个 bug 修复和 9 个小的改进,以解决用户反馈,清理技术债务,并改善用户体验。
- 内容团队合并了 28 个“拉”请求,以解决 47 个内容建议和错误。
接下来:敬请关注 9 月份的更多更新,包括新的评估、更多练习等等!
有什么建议吗?欢迎向我们的反馈板发帖。我亲自审阅每一份提交的材料,非常重视您的意见。提前感谢。
快乐学习!
Dataquest 评论(2020):对 656 名学习者结果的分析
June 24, 2020
每年,Dataquest 都会对我们的大量学习者进行调查,以更好地了解他们如何复习 Dataquest,以及我们教授的技能如何影响他们的生活。
2020 年,我们向超过 5000 名 Dataquest 学习者发送了调查问卷。为了鼓励诚实,我们允许调查受访者保持匿名。截止日期前,我们收到了 656 份调查回复。然后,我们处理这些数字,通读我们的学习者分享的故事。
以下是我们学到的一些东西,以及我们发现的一些故事:
Dataquest Reviews 2022:用学习数据为成功做准备
原文:https://www.dataquest.io/blog/dataquest-reviews-2022-set-yourself-up-for-success-with-learning-data/
April 6, 2022
无论您正在进行数据学习,还是刚刚开始数据学习之旅,来自已实现学习目标的学习者的见解和评价都可以帮助您实现自己的目标。
坦率地说:学习一项新技能并不容易。这需要动力、纪律、耐心,以及更多的组织来平衡你的其他承诺。但这绝对不是不可能完成的任务,正如去年我们 77%的学员所显示的那样,他们实现了自己的目标,推进了自己的职业生涯。
在这篇博文中,我们将分享一些帮助你实现目标的技巧。
学习 Dataquest 可以让你走向成功
获得新技能可以创造许多机会——获得一份新工作、获得晋升或加薪。大多数时候,学习者报告这些好处以及更多。
例如,在去年达到学习目标的 Dataquest 学员中:
- 44%的人开始做更有趣、更令人兴奋的工作
- 38%的人找到了新工作
- 35%的人表示对自己的工作更有信心。
- 33%的人说他们的新技能帮助他们在工作中保持相关性
- 28%的人说,他们的工资增加了,各国的工资中位数增加了 33%
所以要做好准备!达到你的目标会给你带来意想不到的好处,打开你从未想过的大门。
下面是我们的学习者所说的:
“通过使用 Dataquest,我能够在以前的公司横向进入数据分析工作,并使用我的新技能继续学习和成长。我后来转到了一家新公司,现在的工资几乎是原来的两倍!”——泰·洛佩兹——美国。
“给了我数据分析师的工作技能。”—大卫——英国。
“我经历了面试过程,感觉更自信了,技术部分也没什么问题。”—巴西克拉丽莎·山北。
边做边学——行之有效的教学方法
在开始或沿着您的数据学习之旅前进的过程中,当您不知道如何编码时,您可能会感到有点焦虑,或者您可能会有偷工减料的冲动。但是不要担心:
我们的绝大多数学习者(75%)在开始他们的旅程之前都是初学者,所以在开始之前你不需要知道如何编码。我们的大多数学习者称赞我们的动手学习平台是实现您目标的有效途径。
下面是我们的学习者所说的:
“我相信它为没有技能或不了解数据和数据使用的人提供了一个很好的基础。”—加里·罗伯茨——巴哈马群岛。
“这些课程是为了直接教你那些我想要学习和需要的技能而设计的。”——凯尔·罗兰——美国。
“我认为 Dataquest 是一个很好的自学平台,同时还能获得社区的支持。我真的很喜欢这些课程和项目中的实践练习。”—巴西克拉丽莎·山北。
“我想学习数据科学,Dataquest 的方法论帮助了我很多——边做边学。”—丹亚尔·艾哈迈德——巴基斯坦。
“我认为阅读和练习同时进行是最有效的学习方法。”—穆罕默德·巴达维——埃及。
达到目标的秘密
当我们分析成功学习者的学习习惯时,我们发现了一些趋势。大多数达到目标的学员每周至少学习一次,时间超过两个小时,这有助于他们在不到一年的时间内实现目标:
- 89%达到目标的受访者每周至少在 Dataquest 上学习一次。
- 70%达到目标的受访者每周花两个多小时学习。
- 84%达到目标的受访者在不到一年的时间里做到了。
在你的日历和铅笔上选择一个可靠的时间在两个小时内学习。这将有助于确保你的学习之旅不会成为你任务清单上的最后一件事。
通过 Dataquest 阅读 Ashray 如何在几个月内找到新工作的故事。
增加技能和薪水:学生如何复习 Dataquest
原文:https://www.dataquest.io/blog/dataquest-reviews-survey-2019/
April 11, 2019
我们最近调查了长期 Dataquest 学生 (n = 766) ,以获得对我们平台的评论,并了解他们是否获得了他们想要的职业成果。请查看下面的信息图,以直观的形式了解我们在调查中的发现,或者向下滚动以了解更多详细信息。

学生称 Dataquest 改善职业生涯
学生告诉我们,改善他们的职业生涯是学习数据科学的一大动力。70%的受访者表示,他们带着一些职业发展的希望来到 Dataquest,48%的人对职业感兴趣,32%的人希望学习有助于当前工作的技能。
看起来,绝大多数学生离开时都觉得他们得到了他们想要的。高达 96%的学生表示,他们会将 data quest 推荐给希望改善职业机会的人。62.5%的学生表示,他们在目前的工作中运用了在 Dataquest 中学到的技能。
我们的数据还表明,这些技能是有回报的。在这 62.5%的学生(目前正在工作中使用 Dataquest 技能)中,受访者在将他们开始 Dataquest 之前的工资与他们目前的工资进行比较时,发现工资中位数增加了 12,450 美元。
(注意:这个数字不包括全日制学生,因为他们 0 美元的薪水会使结果失真。还要注意,我们在这里使用的是中位数而不是平均值,因为超过 28,000 美元的平均工资增幅更高,这主要是由于一些离群值看到了巨大的工资增长。)
学习数据科学很容易!
嗯,也许不容易—学习数据科学绝对是一项艰苦的工作!但是用 Dataquest 学习并不一定要破坏你的时间表:77.8%的学生说他们每周花在学习上的时间少于 10 小时。这仍然很难——只有 11%的学生每周只学习两个小时或更少——但即使是全日制学生和员工,每周也能抽出 5-10 个小时。
大多数学生表示,他们在短短 2-6 个月内就达到了最初的学习目标,尽管许多人仍然订阅了该平台,以便他们可以不断增加新技能,为面试而学习,并继续使用该平台进行练习。
学生能够进步如此之快的部分原因可能是他们不必去别处寻求帮助或补充学习资源。88%的学生表示,Dataquest 是他们用来学习数据科学的主要或唯一平台。
Dataquest 评论已经出来了
Dataquest 能帮你找工作吗?绝对的。你需要致力于这个项目并投入时间,但它确实有效。Dataquest 可以帮助你,就像它帮助许多其他学生改善他们的职业生涯并朝着数据科学梦想努力一样。
你不必相信我们的话。在在线课程评论网站上查看我们的学生评论,如 Switchup 或课程报告或 G2 人群或任何其他学生评论 Dataquest 的地方,你会发现许多快乐的学习者。
报名参加我们的免费课程并查看我们的免费数据科学职业指南,立即开始您自己的数据科学之旅!
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
申请 Dataquest 和 AI Inclusive 的代表名额不足的 Genders 2021 奖学金!
原文:https://www.dataquest.io/blog/dataquest-scholarship-women-underrepresented-genders/
December 7, 2020
Dataquest 的课程中的部分内容是让每个人都更负担得起、更容易获得数据科学。
我们之前的奖学金项目非常成功,现在我们很高兴地宣布与 AI Inclusive 合作的一系列新奖学金。
第一轮奖学金面向任何认为自己是女性或在数据科学领域代表性不足的任何其他性别的人,现已开放申请。
成功的申请者将在长达六个月的时间里免费使用 Dataquest 的所有课程、项目和其他内容,并可以自由学习他们喜欢的任何内容。
在这里可以找到详细信息、申请指南以及申请表的链接。 请在申请前通读该页面!
申请截止日期为12 月 18 日前。
我们很高兴能与 AI Inclusive 合作,提供这个很棒的机会,这只是许多机会的第一步——在这一轮之后,我们将开启几轮不同资格要求的后续轮次。
如果你没有资格参加这一轮,请留意,因为你可能有资格参加下一轮!注册一个免费的 Dataquest 账户,加入 AI 包容性,在 Twitter 上关注这两个组织,确保你不会错过下一个奖学金公告!
- @dataquestio
- @包括
Dataquest 九月产品更新
原文:https://www.dataquest.io/blog/dataquest-september-product-update/
October 8, 2021
Hi Dataquesters!
我们会联系你们来更新我们在 9 月份取得的进展,并让你们知道一些即将发生的令人兴奋的事情。本月更新的菜单上:一门新课程,新的评估,几篇新的博客文章,等等!
内容更新
- 准备好提高这些 SQL 技能吧!我们发布了几十个新的 SQL 练习。随着额外的 SQL 实践和最后的课程和指导项目,SQL 基础技能路径正式退出测试。
- 新的介绍性 R 练习题现在也可以用了,在接下来的几周里会有更多的练习。
- 我们也有一些新的博客帖子。首先,我们发布了对数据清理最有帮助的 Python 库,其中许多都是在 Dataquest 平台上教授的。数据清理是数据科学过程中最重要、最耗时、最无趣的部分之一。这些库有助于简化数据清理人员的工作。
- 我们最近采访了荷兰 Livit Orthopedie 的软件工程师 Solange Van Der Kolff。看看Solange 的故事,以及她如何利用 Dataquest 解决 Livit 的重要数据库迁移问题。

产品更新
- 开始新的学习之旅可能会让人不知所措。为了帮助新学员轻松体验 Dataquest,我们添加了一个仪表板小部件,概述了这一旅程中的第一步。这些任务将帮助新学员熟悉该平台及其所提供的一切。
- 我们现在支持购买加元、英镑、欧元和澳元 的套餐!这意味着,如果你住在加拿大、英国、澳大利亚或任何欧元区国家,你现在可以用当地货币购买套餐。

随着我们不断改进 Dataquest 学习体验,敬请关注更多更新!有什么建议吗? 欢迎向我们的反馈板 发帖。我亲自审阅每一份提交的材料,非常重视您的意见。提前感谢。
快乐学习!
附注:我们正在寻找主题专家来帮助创作新课程。查看我们的 职业页面 了解更多信息。
Dataquest 如何帮助塔夫茨大学获得数据科学方面的就业机会
原文:https://www.dataquest.io/blog/dataquest-undergrad-job-data-science/
March 12, 2019
Hezekiah Branch 是波士顿塔夫茨大学认知和脑科学专业的本科生,他选修了足够多的专业以外的课程,知道自己喜欢编程和统计。但他不确定这些技能可能与什么样的职业有关,直到简单的谷歌搜索将他引向数据科学领域。
“我真的只是想找一些特别适合这些技能的东西,”他说。不出所料,当他寻找使用编程和统计的工作时,数据科学经常出现。“我开始研究数据科学、数据分析和数据工程之间的区别,”希西家说。“只是大量的谷歌搜索和阅读不同的文章、文件和白皮书。这个过程就是我最终发现 Dataquest 的原因。”
在线学习数据科学
作为目前的本科生,Hezekiah 可以在他的大学里学习编程课程,他说他很喜欢这些课程。尽管他们很优秀,但希西家一直在寻找更专业的东西,他没有从塔夫茨大学更广泛的 CS 课程中获得他需要的数据科学知识。因此,他开始通过 MOOCs 和其他网络资源在线学习数据科学。最终,他看到 Quora 的一个回答中提到了 Dataquest,决定试一试。
一旦注册,Hezekiah 很快就完成了免费的 Python 基础课程,并发现他喜欢这种方法。“我觉得这种严谨和理念非常非常类似于我在塔夫茨大学学到的东西,所以我认为这是一个好迹象,”他说。
“从那以后,我开始尽可能多地参加课程。我开始在 Python track 中做数据分析,然后当 R 中的更新课程发布时,我也开始浏览 R 课程。”
将新技能投入工作
凭借对数据科学基础的扎实掌握,Hezekiah 开始寻找技术实习机会。他没有立即找到一个。他的第一次实习是 2018 年在哈佛大学教育研究生院的一次实习,不是技术性的,但他仍然能够在工作中获得一些与数据相关的技能,同时从事真正重要的事情:公民参与。
然而,他的下一个角色允许他开始利用他新发现的数据科学技能。在波士顿的南端技术中心(SETC),希西家有机会与著名的民权活动家和麻省理工学院教授梅尔·金(Mel King)一起工作,学习 SETC 的经验,通过免费和低成本的技术培训和其他与技术相关的服务来改善波士顿居民的生活。
“这很酷,因为我能够使用 Dataquest 的特定技能,例如处理数据管理和命令行,以及创建可视化和所有这些技能,”他说。“我使用了从[南端技术中心]网站获得的数据,该网站专门与波士顿南端社区的居民合作,并发起了社会运动,为波士顿市带来了变化。”
在 SETC 工作一段时间后,布兰奇在探索暑期职位时,遇到并申请了各种数据科学相关的职位,包括保诚集团的数据分析和业务系统工作。他知道面试过程会很严格,于是又一头扎进了自己的学习中。
他说:“我最后翻遍了我在课堂上记下的所有笔记,翻遍了我从课程中获得的所有资料。”我当时想,“我就看看会怎么样。”"
“结果非常好,”他说。他得到了 Liberty Mutual 和保诚的实习机会,最终选择了保诚的分析职位。“当我收到反馈时,我被告知我的申请脱颖而出,尤其是在数据分析技术面试中。”
布兰奇被安排到保诚最困难的团队之一。此后,他一直专注于磨练自己的数据科学技能和学习工具,如 Hadoop 和 Spark。
给数据科学学生和求职者的建议
Hezekiah 在相对较短的时间内担任过三个与数据科学相关的职位,他还是一名大学生。很明显,他做得很对。他成功的秘诀是什么?他说,一件事是奉献和从容不迫。
“我肯定会建议不要试图尽可能快地完成所有事情,”他说。“即使我上完了 Dataquest 的一课,我还是会回头再看一遍。如果我不看提示就做不到,或者不必多次重复引用某个东西,那么我知道我并没有真正了解它。”
另一个建议:如果你想学习,就去教。希西家说:“这不仅对你学习英语有帮助,还能向其他人展示如何学习英语。”。你是否能“不用统计学、数学术语”来解释事情,这是测试你对正在发生的事情理解程度的一个好方法。“能够用简单的英语把它分解开来,并直截了当地给出结论和结果,这是一项巨大的技能。”
他对找工作的建议?不要期望它是容易的,也不要放弃。希西家估计,他每收到一份实习邀请,就有 50 个地方拒绝了他的申请,或者根本没有回应。如果他没有得到工作机会,他会寻求反馈,并将其应用到下一次申请或下一轮面试中。他还建议对“走出你的舒适区,去一个你可能从未想过要去的地方”持开放态度。
“在这个过程中保持灵活性,给自己一个成长的机会,这和你所学的一样重要,”他说。
如果你有足够的动力,我们有课程可以教你从事数据科学职业所需的技能。查看我们的免费 Python 基础课程和免费编程入门 R 课程开始吧。
图片来源:吕凯(IG: @lei.visuals)
Dataquest vs 跳板:学数据科学哪个最好?
November 20, 2019
Dataquest vs 跳板——学习数据科学哪个选择更好?我们比较了 Springboard 的数据科学训练营和 Dataquest 的数据科学学习平台。
我们不免有点偏颇,但我们会直截了当地告诉你,帮你决定哪一个才是最适合你的选择。让我们从一个高层次的比较开始:
| | 数据请求 | 跳板 |
|---|---|---|
| 成本(无折扣的常规定价) | 49 美元/月 | 1490 美元/月 |
| 在线学习数据科学技能 | ||
| 内部课程 | ||
| 不需要编码经验 | ||
| 构建项目组合 | ||
| 职业服务 | ||
| 一对一指导 | ||
| 工作保障 | (附带条件) | |
| 切换额定值 | 4.9/5 | 4.73/5 |
立即订阅 Dataquest 】,按照您自己的进度开始交互式学习数据技能。
(或者报名免费试用!)
接下来,我们将更深入地了解 Dataquest 和 Springboard 之间的区别,以便您更好地理解两者之间的比较:
费用
或许 Dataquest 和跳板最大的区别就是价格。虽然跳板的月租为 1490 美元,但 Dataquest 的月租仅为 49 美元。
跳板课程为期六个月,所以你的费用上限是 8940 美元。如果你在六个月内完成课程,你只需支付你使用的月份,所以理论上,你只需支付 1490 美元(尽管在这段时间内完成整个课程非常困难)。
相比之下,Dataquest 让你按照自己的节奏学习,所以你的成本不会以同样的方式封顶。在 2019 年对学生成果的调查中,大多数学生表示他们在 2-6 个月内达到了最初的学习目标,所以你可能会在 Dataquest 或跳板上花费大致相同的时间。
即使你工作得更慢,你也可以订阅 data quest 15 年,仍然不会像你在跳板上花那么多钱!
更昂贵的课程的一个好处是,它有助于你的动力——随着数千人的上线,你可能不太可能懈怠,因为你已经在学习上投入了这么多钱。虽然 Dataquest 将为您节省大量资金,但您自己也必须提供额外的动力和奉献精神。
如果您计划加入 Dataquest,您可以考虑我们的年度计划,该计划为您提供超过 40%的折扣,提前支付 12 个月的费用,这有助于克服承诺障碍。
课程
一些在线评论批评了跳板的课程,因为他们的一些课程与更便宜的替代课程合作,并建议学生在其余的课程中使用免费的在线资源。
也就是说,许多跳板课程的学生确实对课程结束时所学的内容表示满意,他们在独立评估平台 Switchup 上的学生评估评分为 4.73/5 就是证明。
相比之下,Dataquest 的课程 100%由我们的内部专家团队构建,因此我们可以提供精心设计的学习体验,并根据我们在学生学习课程过程中收集的数据不断更新和优化。我们在交互式浏览器内编码环境中为数据分析、数据科学和数据工程提供学习途径。
我们在 Switchup 上 4.9/5 的学生评价表明,学生对他们在 Dataquest 上所学的技能非常满意。我们自己的内部数据收集也证实了这一点(在我们的调查中,96%的学生表示他们会推荐 Dataquest。)

先决条件
要进入 Springboard 的数据科学训练营,你需要六个月的活跃编码经验和中级统计知识。如果你没有这些先决条件,跳板课程提供 490 美元的六周课程来学习它们。如果你需要这个课程,它会将跳板项目的总费用提高到 9430 美元(假设你在主项目中度过了整整六个月)。
在 Dataquest,我们教你如何从头开始编码。除了高中水平的数学,我们不要求任何先决知识。
学习时间表
跳板项目的课程设计为期六个月。他们建议大多数学生每周花 15-20 个小时学习。如果你愿意,你可以选择以更快的速度学习,这样可以节省一些学费。然而,这可能需要你每周花 20 多个小时来学习,这对一些学习者来说可能很难安排。
Dataquest 让您按照自己的节奏学习。我们发现,普通学生每周在我们的平台上花费 5-10 个小时,并且可以在大约 6 个月内完成我们的数据科学课程。
指导和支持
Dataquest 和 Springboard 的一个关键区别在于导师。Springboard 给每个学生分配了一个专门的导师,每周与他们进行一对一的视频通话。如果学生需要额外的拜访,可以与其他导师一起安排。
网上评论显示,导师之间的质量可能存在差异,你在跳板的经历实际上取决于你是否被分配到一个高质量的导师。(不幸的是,学生不能选择他们被分配到哪个导师)。
Dataquest 不提供一对一的指导。相反,我们有一个充满活力的在线社区,您可以从您的同学、数据科学家、Dataquest 社区版主和 Dataquest 成功团队那里寻求支持和鼓励。
职业服务
Dataquest 和 Springboard 都提供帮助你找工作的资源,包括简历评论。
此外,Springboard 还为每位学生提供六次一对一的职业指导电话。Dataquest 不提供一对一的职业指导,但是可以通过我们的 Dataquest 社区和以职业为中心的社区版主获得职业支持。我们还有详尽的(完全免费的)数据科学工作申请指南。
工作保障
跳板的一个诱人之处是他们的工作保障。如果你在完成他们的课程后六个月内没有找到工作,他们会退还你全部学费。
虽然这是一个很好的产品,但值得注意的是保证书上的细则。如果你还没有学士学位,你就没有资格,如果你没有在 10 个特定的美国/加拿大大都市地区之一找工作,你也没有资格。也没有保证最低工资。
Dataquest 不提供工作保证。
等级
如上所述,Dataquest 和跳板在 Switchup 的训练营评分中排名很高(尽管 Dataquest 在技术上并不是训练营!).这些评级通常附有书面评论,由学生独立提交,训练营不能删除或编辑。
跳板的评论给了它 4.73/5 的平均评级,而 Dataquest 的评论给了它更高的 4.9/5 评级。
Dataquest vs 跳板:总结
Springboard 比 Dataquest 贵得多——一般学生预计为 Springboard 支付的费用是 Dataquest 的 15 到 25 倍。
对于额外的钱,你可以从导师那里得到定期的一对一帮助和工作保证(尽管有一些附加条件)。
另一方面,Dataquest 提供精心设计并不断优化的课程和学习体验。没有一对一的支持或工作保证,但有资源帮助你的学习和职业生涯。
如果你有学习的动力,Dataquest 可以让你以很低的价格达到目的。

https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
Dataquest vs Udacity:学数据科学哪个最好?
November 22, 2019
data quest vs uda city——学习数据科学哪个选择更好?我们比较了 Udacity 的数据科学纳米学位和 Dataquest 的数据科学家之路。
我们不能不有点偏见,但我们会直截了当地告诉你,以帮助你决定哪个选项是最适合你的选择。让我们从这两个选项的高层次比较开始:
| | 数据请求 | Udacity |
|---|---|---|
| 成本(无折扣的常规定价) | 49 美元/月 | 399 美元/月 |
| 在线学习数据科学技能 | ||
| 在交互式编码环境中 | ||
| 不需要编码经验 | ||
| 构建项目组合 | ||
| 项目评估 | ||
| 职业服务 | ||
| 一对一指导 | ||
| G2 评级 | 4.7/5 | 4.3/5 |
| 切换额定值 | 4.9/5 | 4.45/5 |
立即订阅 Dataquest 】,按照您自己的进度开始交互式学习数据技能。
(或者报名免费试用!)
接下来,让我们更仔细地看看 Dataquest 和 Udacity 之间的区别,这样您就可以更好地理解这两者之间的比较。
价格
按月计算,Udacity 的价格大约是 Dataquest 的八倍。Udacity 每月入住费用为 399 美元,Dataquest 每月仅需 49 美元。
这两门课程都是自定进度的,所以你的最终费用将取决于你浏览材料的速度。Udacity 建议,平均需要四个月来完成他们的纳米学位,所以你可以期待大约 1600 美元。也就是说,nanodegree 并不是从零开始的,所以如果你没有编码背景,你可能最终会为额外的课程付费(下面会有更多)。
在 2019 年对学生成果的调查中,大多数 Dataquest 学生表示他们在 6 个月内达到了最初的学习目标。这使得平均总费用在 300 美元左右,或者说不到 Udacity 一个月的学费。
更昂贵的选择的一个好处是,它有助于你的动力——有超过 1000 美元的风险,你可能不太可能放弃,因为你已经投入了这么多钱。虽然 Dataquest 将为您节省资金,但您必须自己提供额外的动力和奉献精神。
如果您计划加入 Dataquest,您可以考虑我们的年度计划,该计划为您提供超过 40%的折扣,提前支付 12 个月的费用,这有助于克服承诺障碍。
学习环境
Udacity 的教材以视频讲座为中心。中间的视频是测试你的知识的选择题。为了实践你所学的,你需要在你自己的电脑上建立一个编码环境。
Dataquest 不使用任何视频。相反,文本课程与我们的交互式编码环境相结合。您可以在浏览器中完成我们的代码练习,并获得关于您所写内容的即时反馈。
简而言之,Dataquest 平台。
这种动手的方式给学生带来了明显的优势——研究表明动手学习者的表现比通过被动讲座学习的学生平均好 20%。
项目
这两个平台都有项目可以帮助你综合你所学的知识,并建立一个投资组合来帮助你找到工作。
有了 Udacity,你可以在本地自己的电脑上完成项目。相比之下,Dataquest 提供了一个基于网络的交互式环境,因此您可以在没有任何设置要求的情况下完成您的项目。
Udacity 项目根据预先定义的标准进行审查和评估,这可以帮助您获得对您的工作的重要反馈。Dataquest 不提供项目评审。
先决条件
Udacity 的数据科学 nanodegree 需要 SQL、Python 和统计学方面的经验。Udacity 推荐他们将机器学习入门 nanodegree 作为先决条件。这反过来又要求他们把介绍编程 nanodegree 作为先决条件。
综合起来,这些纳米学位为你的学习增加了 8 个月和 3200 美元,尽管你会学到额外的技能。
在 Dataquest,我们教你如何从头开始编码。除了高中水平的数学,我们不要求任何先决知识。
指导和支持
Dataquest 和 Udacity 的另一个关键区别在于导师制度。Udacity 给每个学生分配了一名导师,他们每周都会与导师进行电话联系。这位导师旨在指导你的学习,并帮助你保持正轨。
Dataquest 不提供一对一的指导。相反,我们有一个充满活力的在线社区,您可以从您的同学、数据科学家、Dataquest 社区版主和 Dataquest 成功团队那里寻求支持和鼓励。
职业服务
Dataquest 和 Udacity 都提供帮助你找工作的资源,包括简历评论。
此外,Udacity 还为每位学生提供职业指导电话。Dataquest 不提供一对一的职业指导,但是可以通过我们的 Dataquest 社区和以职业为中心的社区版主获得职业支持。我们还有详尽的(完全免费的)数据科学工作申请指南。
等级
Udacity 和 Dataquest 在 G2 和 Switchup 上的评价都很高。这两个网站都提供真实学生独立撰写的评论,学习网站不能删除或编辑这些评论。
在 G2 上,Udacity 的评论给了它 4.3/5 的平均评级,而 Dataquest 的评论给了它更高的 4.7/5 评级。
同样,在 Switchup Dataquest 的 4.9/5 高于 Udacity 的 4.45/5。Switchup 还连续三年授予 Dataquest 最佳数据科学训练营和连续两年授予最佳在线训练营(尽管我们实际上不是训练营!)
我们自己的内部数据收集也证实了这一点——在我们 2019 年的调查中,96%的学生表示他们会推荐 Dataquest。
Dataquest vs Udacity:摘要
相对于 Dataquest,Udacity 是一个更昂贵的选择。根据你的背景知识,你在 Udacity 上的花费可能比 Dataquest 多 8 到 24 倍。
对于额外的钱,你可以得到个人指导支持和项目评估。
另一方面,Dataquest 提供屡获殊荣的课程和经验证的学习体验。没有一对一的支持,但有社区和其他资源来帮助你的学习和职业生涯。
如果你有学习的动力,Dataquest 可以让你以很低的价格达到目的。
https://www.youtube.com/embed/6a5jbnUNE2E?rel=0
*提升您的数据技能。
查看计划*
熊猫的日期时间:初学者简单指南(2022)
March 22, 2022
我们被不同类型和形式的数据所包围。毫无疑问,时间序列数据是最有趣和最基本的数据类别之一。时间序列数据无处不在,它在各个行业都有很多应用。患者健康指标、股票价格变化、天气记录、经济指标、服务器、网络、传感器和应用程序性能监控都是时间序列数据的例子。
我们可以将时间序列数据定义为在不同时间间隔获得并按时间顺序排列的数据点的集合。
Pandas 库主要用于分析金融时间序列数据,并为处理时间、日期和时间序列数据提供一个全面的框架。
本教程将讨论在熊猫中处理日期和时间的不同方面。完成本教程后,您将了解以下内容:
Timestamp和Period对象的功能- 如何使用时序数据框架
- 如何对时间序列进行切片
DateTimeIndex对象及其方法- 如何对时间序列数据进行重采样
在本教程中,我们假设你知道熊猫系列和数据帧的基础知识。如果你不熟悉熊猫图书馆,你可能想试试我们的熊猫和 NumPy 基础——data quest。
让我们开始吧。
探索熊猫Timestamp和Period物品
pandas 库提供了一个名为 Timestamp 的具有纳秒精度的 DateTime 对象来处理日期和时间值。Timestamp 对象派生自 NumPy 的 datetime64 数据类型,这使得它比 Python 的 datetime 对象更准确,速度也快得多。让我们使用时间戳构造函数创建一些时间戳对象。打开 Jupyter 笔记本或 VS 代码,运行以下代码:
import pandas as pd
import numpy as np
from IPython.display import display
print(pd.Timestamp(year=1982, month=9, day=4, hour=1, minute=35, second=10))
print(pd.Timestamp('1982-09-04 1:35.18'))
print(pd.Timestamp('Sep 04, 1982 1:35.18'))
1982-09-04 01:35:10
1982-09-04 01:35:10
1982-09-04 01:35:10
运行上面的代码会返回输出,这些输出都表示相同的时间或时间戳实例。
如果您将单个整数或浮点值传递给Timestamp构造函数,它将返回一个时间戳,该时间戳相当于 Unix 纪元(1970 年 1 月 1 日)之后的纳秒数:
print(pd.Timestamp(5000))
1970-01-01 00:00:00.000005
对象包含许多方法和属性,帮助我们访问时间戳的不同方面。让我们试试它们:
time_stamp = pd.Timestamp('2022-02-09')
print('{}, {} {}, {}'.format(time_stamp.day_name(), time_stamp.month_name(), time_stamp.day, time_stamp.year))
Wednesday, February 9, 2022
Timestamp类的一个实例代表一个时间点,而Period对象的一个实例代表一段时间,比如一年、一个月等等。
例如,公司监控他们一年的收入。Pandas 库提供了一个名为Period的对象来处理句点,如下所示:
year = pd.Period('2021')
display(year)
Period('2021', 'A-DEC')
您可以在这里看到,它创建了一个表示 2021 年期间的Period对象,'A-DEC'表示该期间是每年的,在 12 月结束。
Period对象提供了许多有用的方法和属性。例如,如果要返回时间段的开始和结束时间,请使用以下属性:
print('Start Time:', year.start_time)
print('End Time:', year.end_time)
Start Time: 2021-01-01 00:00:00
End Time: 2021-12-31 23:59:59.999999999
要创建月期间,您可以将特定月份传递给它,如下所示:
month = pd.Period('2022-01')
display(month)
print('Start Time:', month.start_time)
print('End Time:', month.end_time)
Period('2022-01', 'M')
Start Time: 2022-01-01 00:00:00
End Time: 2022-01-31 23:59:59.999999999
'M'表示周期的频率为每月。您还可以使用freq参数明确指定周期的频率。下面的代码创建了一个表示 2022 年 1 月 1 日期间的 period 对象:
day = pd.Period('2022-01', freq='D')
display(day)
print('Start Time:', day.start_time)
print('End Time:', day.end_time)
Period('2022-01-01', 'D')
Start Time: 2022-01-01 00:00:00
End Time: 2022-01-01 23:59:59.999999999
我们还可以对周期对象执行算术运算。让我们以每小时的频率创建一个新的 period 对象,看看如何进行计算:
hour = pd.Period('2022-02-09 16:00:00', freq='H')
display(hour)
display(hour + 2)
display(hour - 2)
Period('2022-02-09 16:00', 'H')
Period('2022-02-09 18:00', 'H')
Period('2022-02-09 14:00', 'H')
我们可以使用熊猫日期偏移得到相同的结果:
display(hour + pd.offsets.Hour(+2))
display(hour + pd.offsets.Hour(-2))
Period('2022-02-09 18:00', 'H')
Period('2022-02-09 14:00', 'H')
要创建一个日期序列,可以使用 pandas range_dates()方法。让我们在代码片段中尝试一下:
week = pd.date_range('2022-2-7', periods=7)
for day in week:
print('{}-{}\t{}'.format(day.day_of_week, day.day_name(), day.date()))
0-Monday 2022-02-07
1-Tuesday 2022-02-08
2-Wednesday 2022-02-09
3-Thursday 2022-02-10
4-Friday 2022-02-11
5-Saturday 2022-02-12
6-Sunday 2022-02-13
week的数据类型是一个DatetimeIndex对象,week中的每个日期都是Timestamp的一个实例。所以我们可以使用适用于一个Timestamp对象的所有方法和属性。
创建时间序列数据框架
首先,让我们通过从 CSV 文件中读取数据来创建一个数据帧,该文件包含与 50 台服务器相关的关键信息,连续 34 天每小时记录一次:
df = pd.read_csv('https://raw.githubusercontent.com/m-mehdi/pandas_tutorials/main/server_util.csv')
display(df.head())
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 | |
|---|---|---|---|---|---|
| Zero | 2019-03-06 00:00:00 | One hundred | Zero point four | Zero point five four | fifty-two |
| one | 2019-03-06 01:00:00 | One hundred | Zero point four nine | Zero point five one | Fifty-eight |
| Two | 2019-03-06 02:00:00 | One hundred | Zero point four nine | Zero point five four | Fifty-three |
| three | 2019-03-06 03:00:00 | One hundred | Zero point four four | Zero point five six | forty-nine |
| four | 2019-03-06 04:00:00 | One hundred | Zero point four two | Zero point five two | Fifty-four |
让我们看看数据帧的内容。每个数据帧行代表服务器的基本性能指标,包括特定时间戳的 CPU 利用率、空闲内存和会话计数。数据帧分解成一小时的片段。例如,从午夜到凌晨 4 点记录的性能指标位于数据帧的前五行。
现在,让我们详细了解一下数据帧的特征,比如它的大小和每一列的数据类型:
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40800 entries, 0 to 40799
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 40800 non-null object
1 server_id 40800 non-null int64
2 cpu_utilization 40800 non-null float64
3 free_memory 40800 non-null float64
4 session_count 40800 non-null int64
dtypes: float64(2), int64(2), object(1)
memory usage: 1.6+ MB
None
运行上面的语句将返回行数和列数、总内存使用量、每列的数据类型等。
根据上面的信息, datetime 列的数据类型是object,这意味着时间戳被存储为字符串值。要将 datetime 列的数据类型从string对象转换为datetime64对象,我们可以使用 pandas to_datetime()方法,如下所示:
df['datetime'] = pd.to_datetime(df['datetime'])
当我们通过导入 CSV 文件创建 DataFrame 时,日期/时间值被视为字符串对象,而不是日期时间对象。pandas to_datetime()方法将存储在 DataFrame 列中的日期/时间值转换为 DateTime 对象。将日期/时间值作为 DateTime 对象使得操作它们更加容易。运行以下语句并查看更改:
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40800 entries, 0 to 40799
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 40800 non-null datetime64[ns]
1 server_id 40800 non-null int64
2 cpu_utilization 40800 non-null float64
3 free_memory 40800 non-null float64
4 session_count 40800 non-null int64
dtypes: datetime64[ns](1), float64(2), int64(2)
memory usage: 1.6 MB
None
现在,日期时间列的数据类型是一个datetime64[ns]对象。[ns]表示基于纳秒的时间格式,用于指定 DateTime 对象的精度。
此外,我们可以让 pandas read_csv()方法将某些列解析为 DataTime 对象,这比使用to_datetime()方法更简单。让我们来试试:
df = pd.read_csv('https://raw.githubusercontent.com/m-mehdi/pandas_tutorials/main/server_util.csv', parse_dates=['datetime'])
print(df.head())
datetime server_id cpu_utilization free_memory session_count
0 2019-03-06 00:00:00 100 0.40 0.54 52
1 2019-03-06 01:00:00 100 0.49 0.51 58
2 2019-03-06 02:00:00 100 0.49 0.54 53
3 2019-03-06 03:00:00 100 0.44 0.56 49
4 2019-03-06 04:00:00 100 0.42 0.52 54
运行上面的代码会创建一个 DataFrame,其中 datetime 列的数据类型是 datetime 对象。
在进入下一节之前,让我们对datetime列应用一些基本方法。
首先,让我们看看如何在 DataFrame 中返回最早和最晚的日期。为此,我们可以简单地对datetime列应用max()和min()方法,如下所示:
display(df.datetime.min())
display(df.datetime.max())
Timestamp('2019-03-06 00:00:00')
Timestamp('2019-04-08 23:00:00')
要选择两个特定日期之间的 DataFrame 行,我们可以创建一个布尔掩码,并使用.loc方法来过滤特定日期范围内的行:
mask = (df.datetime >= pd.Timestamp('2019-03-06')) & (df.datetime < pd.Timestamp('2019-03-07'))
display(df.loc[mask])
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 | |
|---|---|---|---|---|---|
| Zero | 2019-03-06 00:00:00 | One hundred | Zero point four | Zero point five four | fifty-two |
| one | 2019-03-06 01:00:00 | One hundred | Zero point four nine | Zero point five one | Fifty-eight |
| Two | 2019-03-06 02:00:00 | One hundred | Zero point four nine | Zero point five four | Fifty-three |
| three | 2019-03-06 03:00:00 | One hundred | Zero point four four | Zero point five six | forty-nine |
| four | 2019-03-06 04:00:00 | One hundred | Zero point four two | Zero point five two | Fifty-four |
| … | … | … | … | … | … |
| Forty thousand and three | 2019-03-06 19:00:00 | One hundred and forty-nine | Zero point seven four | Zero point two four | Eighty-one |
| Forty thousand and four | 2019-03-06 20:00:00 | One hundred and forty-nine | Zero point seven three | Zero point two three | Eighty-one |
| Forty thousand and five | 2019-03-06 21:00:00 | One hundred and forty-nine | Zero point seven nine | Zero point two nine | Eighty-three |
| Forty thousand and six | 2019-03-06 22:00:00 | One hundred and forty-nine | Zero point seven three | Zero point two nine | Eighty-two |
| Forty thousand and seven | 2019-03-06 23:00:00 | One hundred and forty-nine | Zero point seven five | Zero point two four | Eighty-four |
1200 行× 5 列
切片时间序列
为了使时间戳切片成为可能,我们需要将datetime列设置为数据帧的索引。要将列设置为数据帧的索引,请使用set_index方法:
df.set_index('datetime', inplace=True)
print(df)
datetime server_id cpu_utilization free_memory session_count
2019-03-06 00:00:00 100 0.40 0.54 52
2019-03-06 01:00:00 100 0.49 0.51 58
2019-03-06 02:00:00 100 0.49 0.54 53
2019-03-06 03:00:00 100 0.44 0.56 49
2019-03-06 04:00:00 100 0.42 0.52 54
... ... ... ... ...
2019-04-08 19:00:00 149 0.73 0.20 81
2019-04-08 20:00:00 149 0.75 0.25 83
2019-04-08 21:00:00 149 0.80 0.26 82
2019-04-08 22:00:00 149 0.75 0.29 82
2019-04-08 23:00:00 149 0.75 0.24 80
[40800 rows x 4 columns]
使用.loc方法选择等于一个索引的所有行:
print(df.loc['2019-03-07 02:00:00'].head(5))
datetime server_id cpu_utilization free_memory session_count
2019-03-07 02:00:00 100 0.44 0.50 56
2019-03-07 02:00:00 101 0.78 0.21 87
2019-03-07 02:00:00 102 0.75 0.27 80
2019-03-07 02:00:00 103 0.76 0.28 85
2019-03-07 02:00:00 104 0.74 0.24 77
您可以在索引列中选择与特定时间戳部分匹配的行。让我们来试试:
print(df.loc['2019-03-07'].head(5))
datetime server_id cpu_utilization free_memory session_count
2019-03-07 00:00:00 100 0.51 0.52 55
2019-03-07 01:00:00 100 0.46 0.50 49
2019-03-07 02:00:00 100 0.44 0.50 56
2019-03-07 03:00:00 100 0.45 0.52 51
2019-03-07 04:00:00 100 0.42 0.50 53
选择字符串可以是任何标准的日期格式,让我们看一些例子:
df.loc['Apr 2019']
df.loc['8th April 2019']
df.loc['April 05, 2019 5pm']
我们还可以使用.loc方法在一个日期范围内对行进行切片。以下语句将返回从 2019 年 4 月 3 日开始到 2019 年 4 月 4 日结束的所有行;开始和结束日期都包括在内:
display(df.loc['03-04-2019':'04-04-2019'])
但是运行它会引发一个令人讨厌的未来警告。为了消除警告,我们可以在对行进行切片之前对索引进行排序:
display(df.sort_index().loc['03-04-2019':'04-04-2019'])
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|---|
| 2019-03-06 00:00:00 | One hundred | Zero point four | Zero point five four | fifty-two |
| 2019-03-06 00:00:00 | One hundred and thirty-five | Zero point five | Zero point five five | Fifty-five |
| 2019-03-06 00:00:00 | One hundred and ten | Zero point five four | Zero point four | Sixty-one |
| 2019-03-06 00:00:00 | One hundred and thirty-six | Zero point five eight | Zero point four | Sixty-four |
| 2019-03-06 00:00:00 | One hundred and nine | Zero point five seven | Zero point four one | Sixty-one |
| … | … | … | … | … |
| 2019-04-04 23:00:00 | One hundred and forty-three | Zero point four three | Zero point five two | Fifty |
| 2019-04-04 23:00:00 | One hundred and eleven | Zero point five three | Zero point five two | Fifty-nine |
| 2019-04-04 23:00:00 | One hundred and forty-nine | Zero point seven five | Zero point two four | eighty-five |
| 2019-04-04 23:00:00 | One hundred and thirty-eight | Zero point four | Zero point five six | Forty-seven |
| 2019-04-04 23:00:00 | One hundred and seven | Zero point six three | Zero point three three | Seventy-three |
36000 行× 4 列
DateTimeIndex方法
一些熊猫数据帧方法仅适用于DateTimeIndex。我们将在本节中研究其中的一些,但是首先,让我们确保我们的数据帧有一个DateTimeIndex:
print(type(df.index))
<class 'pandas.core.indexes.datetimes.DatetimeIndex'>
要返回在特定时间收集的服务器监控数据,而不考虑日期,请使用at_time()方法:
display(df.at_time('09:00'))
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|---|
| 2019-03-06 09:00:00 | One hundred | Zero point four eight | Zero point five one | Fifty-one |
| 2019-03-07 09:00:00 | One hundred | Zero point four five | Zero point four nine | fifty-six |
| 2019-03-08 09:00:00 | One hundred | Zero point four five | Zero point five three | Fifty-three |
| 2019-03-09 09:00:00 | One hundred | Zero point four five | Zero point five one | Fifty-three |
| 2019-03-10 09:00:00 | One hundred | Zero point four nine | Zero point five five | Fifty-five |
| … | … | … | … | … |
| 2019-04-04 09:00:00 | One hundred and forty-nine | Zero point seven five | Zero point two one | Eighty |
| 2019-04-05 09:00:00 | One hundred and forty-nine | Zero point seven one | Zero point two six | Eighty-three |
| 2019-04-06 09:00:00 | One hundred and forty-nine | Zero point seven five | Zero point three | Eighty-three |
| 2019-04-07 09:00:00 | One hundred and forty-nine | Zero point eight one | Zero point two eight | Seventy-seven |
| 2019-04-08 09:00:00 | One hundred and forty-nine | Zero point eight two | Zero point two four | Eighty-six |
1700 行× 4 列
此外,要选择所有日期午夜到凌晨 2 点之间的所有服务器数据,请使用between_time()方法。让我们来试试:
display(df.between_time('00:00','02:00'))
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|---|
| 2019-03-06 00:00:00 | One hundred | Zero point four | Zero point five four | fifty-two |
| 2019-03-06 01:00:00 | One hundred | Zero point four nine | Zero point five one | Fifty-eight |
| 2019-03-06 02:00:00 | One hundred | Zero point four nine | Zero point five four | Fifty-three |
| 2019-03-07 00:00:00 | One hundred | Zero point five one | Zero point five two | Fifty-five |
| 2019-03-07 01:00:00 | One hundred | Zero point four six | Zero point five | forty-nine |
| … | … | … | … | … |
| 2019-04-07 01:00:00 | One hundred and forty-nine | Zero point seven four | Zero point two one | seventy-eight |
| 2019-04-07 02:00:00 | One hundred and forty-nine | Zero point seven six | Zero point two six | Seventy-four |
| 2019-04-08 00:00:00 | One hundred and forty-nine | Zero point seven five | Zero point two eight | Seventy-five |
| 2019-04-08 01:00:00 | One hundred and forty-nine | Zero point six nine | Zero point two seven | Seventy-nine |
| 2019-04-08 02:00:00 | One hundred and forty-nine | Zero point seven eight | Zero point two | eighty-five |
5100 行× 4 列
我们可以使用first()方法根据特定的日期偏移量选择第一个数据帧行。例如,将5B作为日期偏移量传递给该方法将返回前五个工作日内的所有索引行。类似地,将1W传递给last()方法将返回上周内所有带有索引的 DataFrame 行。请注意,数据帧必须按其索引排序,以确保这些方法有效。让我们试试这两个例子:
display(df.sort_index().first('5B'))
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|---|
| 2019-03-06 | One hundred | Zero point four | Zero point five four | fifty-two |
| 2019-03-06 | One hundred and thirty-five | Zero point five | Zero point five five | Fifty-five |
| 2019-03-06 | One hundred and ten | Zero point five four | Zero point four | Sixty-one |
| 2019-03-06 | One hundred and thirty-six | Zero point five eight | Zero point four | Sixty-four |
| 2019-03-06 | One hundred and nine | Zero point five seven | Zero point four one | Sixty-one |
| … | … | … | … | … |
| 2019-03-12 | One hundred and thirty-four | Zero point five three | Zero point four five | Sixty-one |
| 2019-03-12 | One hundred and forty-four | Zero point six eight | Zero point three one | Seventy-three |
| 2019-03-12 | One hundred and thirteen | Zero point seven six | Zero point two four | Eighty-three |
| 2019-03-12 | One hundred and fourteen | Zero point five eight | Zero point four eight | Sixty-seven |
| 2019-03-12 | One hundred and thirty-one | Zero point five eight | Zero point four two | Sixty-seven |
7250 行× 4 列
display(df.sort_index().last('1W'))
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|---|
| 2019-04-08 00:00:00 | One hundred and six | Zero point four four | Zero point six two | forty-nine |
| 2019-04-08 00:00:00 | One hundred and twelve | Zero point seven two | Zero point two nine | Eighty-one |
| 2019-04-08 00:00:00 | One hundred | Zero point four three | Zero point five four | Fifty-one |
| 2019-04-08 00:00:00 | One hundred and thirty-seven | Zero point seven five | Zero point two eight | Eighty-three |
| 2019-04-08 00:00:00 | One hundred and ten | Zero point six one | Zero point four | Sixty-two |
| … | … | … | … | … |
| 2019-04-08 23:00:00 | One hundred and twenty-eight | Zero point six four | Zero point four one | Sixty-four |
| 2019-04-08 23:00:00 | One hundred and twenty-seven | Zero point six seven | Zero point three three | seventy-eight |
| 2019-04-08 23:00:00 | One hundred and twenty-six | Zero point seven one | Zero point three three | Seventy-three |
| 2019-04-08 23:00:00 | One hundred and twenty-three | Zero point seven one | Zero point two two | Eighty-three |
| 2019-04-08 23:00:00 | One hundred and forty-nine | Zero point seven five | Zero point two four | Eighty |
1200 行× 4 列
df.sort_index().last('2W')
| 日期时间 | 服务器 id | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|---|
| 2019-04-01 00:00:00 | One hundred and twenty | Zero point five four | Zero point four eight | Sixty-three |
| 2019-04-01 00:00:00 | One hundred and four | Zero point seven three | Zero point three one | Eighty-three |
| 2019-04-01 00:00:00 | One hundred and three | Zero point seven seven | Zero point two two | Eighty-two |
| 2019-04-01 00:00:00 | One hundred and twenty-four | Zero point three nine | Zero point five five | forty-nine |
| 2019-04-01 00:00:00 | One hundred and twenty-seven | Zero point six eight | Zero point three seven | Seventy-three |
| … | … | … | … | … |
| 2019-04-08 23:00:00 | One hundred and twenty-eight | Zero point six four | Zero point four one | Sixty-four |
| 2019-04-08 23:00:00 | One hundred and twenty-seven | Zero point six seven | Zero point three three | seventy-eight |
| 2019-04-08 23:00:00 | One hundred and twenty-six | Zero point seven one | Zero point three three | Seventy-three |
| 2019-04-08 23:00:00 | One hundred and twenty-three | Zero point seven one | Zero point two two | Eighty-three |
| 2019-04-08 23:00:00 | One hundred and forty-nine | Zero point seven five | Zero point two four | Eighty |
9600 行× 4 列
重采样时间序列数据
resample()方法背后的逻辑类似于groupby()方法。它对任何可能时间段内的数据进行分组。虽然我们可以使用resample()方法进行上采样和下采样,但我们将重点关注如何使用它来执行下采样,这可以降低时间序列数据的频率——例如,将每小时的时间序列数据转换为每天的时间序列数据,或将每天的时间序列数据转换为每月的时间序列数据。
以下示例返回 ID 为 100 的服务器每天的平均 CPU 利用率、可用内存和活动会话数。为此,我们首先需要过滤服务器 ID 为 100 的数据帧的行,然后将每小时的数据重新采样为每天的数据。最后,对结果应用mean()方法,以获得三个指标的日平均值:
df[df.server_id == 100].resample('D')['cpu_utilization', 'free_memory', 'session_count'].mean()
| 日期时间 | cpu _ 利用率 | 空闲内存 | 会话计数 |
|---|---|---|---|
| 2019-03-06 | 0.470417 | 0.535417 | 53.000000 |
| 2019-03-07 | 0.455417 | 0.525417 | 53.666667 |
| 2019-03-08 | 0.478333 | 0.532917 | 54.541667 |
| 2019-03-09 | 0.472917 | 0.523333 | 54.166667 |
| 2019-03-10 | 0.465000 | 0.527500 | 54.041667 |
| 2019-03-11 | 0.469583 | 0.528750 | 53.916667 |
| 2019-03-12 | 0.475000 | 0.533333 | 53.750000 |
| 2019-03-13 | 0.462917 | 0.521667 | 52.541667 |
| 2019-03-14 | 0.472083 | 0.532500 | 54.875000 |
| 2019-03-15 | 0.470417 | 0.530417 | 53.500000 |
| 2019-03-16 | 0.463750 | 0.530833 | 54.416667 |
| 2019-03-17 | 0.472917 | 0.532917 | 52.041667 |
| 2019-03-18 | 0.475417 | 0.535000 | 53.333333 |
| 2019-03-19 | 0.460833 | 0.546667 | 54.791667 |
| 2019-03-20 | 0.467083 | 0.529167 | 54.375000 |
| 2019-03-21 | 0.465833 | 0.543333 | 54.375000 |
| 2019-03-22 | 0.468333 | 0.528333 | 54.083333 |
| 2019-03-23 | 0.462500 | 0.539167 | 53.916667 |
| 2019-03-24 | 0.467917 | 0.537917 | 54.958333 |
| 2019-03-25 | 0.461250 | 0.530000 | 54.000000 |
| 2019-03-26 | 0.456667 | 0.531250 | 54.166667 |
| 2019-03-27 | 0.466667 | 0.530000 | 53.291667 |
| 2019-03-28 | 0.468333 | 0.532083 | 53.291667 |
| 2019-03-29 | 0.472917 | 0.538750 | 53.541667 |
| 2019-03-30 | 0.463750 | 0.526250 | 54.458333 |
| 2019-03-31 | 0.465833 | 0.522500 | 54.833333 |
| 2019-04-01 | 0.468333 | 0.527083 | 53.333333 |
| 2019-04-02 | 0.464583 | 0.515000 | 53.708333 |
| 2019-04-03 | 0.472500 | 0.533333 | 54.583333 |
| 2019-04-04 | 0.472083 | 0.531250 | 53.291667 |
| 2019-04-05 | 0.451250 | 0.540000 | 53.833333 |
| 2019-04-06 | 0.464167 | 0.531250 | 53.750000 |
| 2019-04-07 | 0.472500 | 0.530417 | 54.541667 |
| 2019-04-08 | 0.464583 | 0.534167 | 53.875000 |
我们还可以通过链接groupby()和resample()方法来查看每个服务器 ID 的相同结果。
以下语句返回每个服务器每个月的最大 CPU 利用率和空闲内存。让我们来试试:
df.groupby(df.server_id).resample('M')['cpu_utilization', 'free_memory'].max()
| 服务器 id | 日期时间 | cpu _ 利用率 | 空闲内存 |
|---|---|---|---|
| One hundred | 2019-03-31 | Zero point five six | Zero point six two |
| 2019-04-30 | Zero point five five | Zero point six one | |
| One hundred and one | 2019-03-31 | Zero point nine one | Zero point three two |
| 2019-04-30 | Zero point eight nine | Zero point three | |
| One hundred and two | 2019-03-31 | Zero point eight five | Zero point three six |
| … | … | … | … |
| One hundred and forty-seven | 2019-04-30 | Zero point six one | Zero point five seven |
| One hundred and forty-eight | 2019-03-31 | Zero point eight four | Zero point three five |
| 2019-04-30 | Zero point eight three | Zero point three four | |
| One hundred and forty-nine | 2019-03-31 | Zero point eight five | Zero point three six |
| 2019-04-30 | Zero point eight three | Zero point three four |
100 行× 2 列
在我们结束本教程之前,让我们画出每个月每台服务器的平均 CPU 利用率。这个结果让我们对几个月来每台服务器的平均 CPU 利用率的变化有了足够的了解。
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(24, 8))
df.groupby(df.server_id).resample('M')['cpu_utilization'].mean()\
.plot.bar(color=['green', 'gray'], ax=ax, title='The Average Monthly CPU Utilization Comparison')
<AxesSubplot:title={'center':'The Average Monthly CPU Utilization Comparison'}, xlabel='server_id,datetime'>
结论
Pandas 是一个优秀的分析工具,尤其是在处理时间序列数据时。该库为处理时间索引数据帧提供了丰富的工具。本教程涵盖了在 pandas 中处理日期和时间的基本方面。
如果你想了解更多关于在 pandas 中处理时间序列数据的信息,你可以查看 Dataquest 博客上的Pandas 时间序列分析教程,当然,还有关于时间序列/日期功能的 Pandas 文档。
Python 深度学习简介
原文:https://www.dataquest.io/blog/deep-learning-neural-networks-python/
December 6, 2018Deep learning is a type of machine learning that’s growing at an almost frightening pace. Nearly every projection has the deep learning industry expanding massively over the next decade. This market research report, for example, expects deep learning to grow 71x in the US and more than that globally over the next ten years. There’s never been a better time than now to get started.
为了让你更容易起步,我们刚刚推出了一门新课程:深度学习基础知识。 
本课程旨在向您介绍神经网络和深度学习。您将从这些概念背后的理论开始,并熟悉用图形表示线性和逻辑回归模型。然后,您将开始深入挖掘非线性激活函数等主题,并使用 Python 中的scikit-learn包,通过添加隐藏的神经元层来改进您的模型。最后,您将构建一个深度学习模型,该模型能够查看手写数字的图像,并正确识别/分类它们。
为什么你应该深入学习
增加你的收入
虽然一般数据科学家的工资已经很高了,但作为专家,机器学习和深度学习工程师可以要求更高的工资。例如,根据来自美国的Indeed.com 数据,机器学习工程师的工资平均比数据科学家的工资高 13%左右。在申请数据科学工作时,拥有一些深度学习技能也可以帮助你的简历脱颖而出,即使你尚未达到深度学习专家的水平。
对深度学习的需求正在增长
毫无疑问,机器学习是一个快速发展的领域,在这个领域内,深度学习也在以极快的速度增长。具体的市场预测从公司到公司各不相同,但每个人都同意总的趋势:对深度学习的需求正在飙升。
它节省时间
如果你搞过其他形式的机器学习,你就会知道特征工程——将你的输入参数转换成你的算法可以读取的“特征”——可能是一个相当困难和耗时的过程。但是深度学习中使用的神经网络被设计成自动进行这种转换。因此,举例来说,不需要找出如何从一组图像中提取颜色数据、直方图和其他指标,您只需通过您的神经网络运行原始图像,它就会为您完成工作!当然,这听起来很容易,但事实并非如此;挑战在于让网络达到能够为你做这些工作的程度。但这意味着你将花更多的时间处理算法,花更少的时间摆弄功能。
专业化同时保持灵活性
建立一个专业可以帮助你在任何领域找到工作,但它也可以把你置于一个位置,你注定每天都在做同样的事情,因为你的专业只吸引有限的几家公司,它们都在做同样的事情。令人欣慰的是,深度学习并非如此,它在许多行业都有需求,并被用于解决从图像识别到翻译到机器人的各种问题。
很好玩!
抛开职业优势不谈,我们不要忘记深度学习非常酷。你可以用它让机器做任何事情,从自动给旧照片着色到摧毁世界上最伟大的棋手,而不需要教他们如何做这些事情。准备好潜入深海了吗?新课程的第一课是完全免费的,所以每个人都可以尝试,但你需要高级订阅才能完成课程。
数据可视化的 11 个设计技巧
October 25, 2018
这里有一个很容易忘记的重要事实:我们的数据只有在可以理解的情况下才有帮助。
大多数时候,让数据变得可理解意味着创建某种数据可视化。虽然简单的条形图可能适合内部工作,但使您的数据在视觉上可以理解并具有吸引力可以帮助它获得更多关注,并帮助您脱颖而出,无论您的受众是整个互联网还是只是您公司在每周会议上的首席执行官。
但是平面设计的世界是混乱和主观的,大多数数据科学家可能没有时间去钻研学习设计。幸运的是,你不必!这里有一些简单的规则和技巧,你可以遵循,使你的数据看起来更好。
挑选好颜色,欺骗
颜色选择对于数据可视化很重要,但是当涉及到颜色时,很容易陷入混乱。如果你想走 DIY 路线,我们有一篇关于为你的数据可视化选择颜色的长文。但是你可以走更容易的路:
让网站选择你的颜色:如果你想让一台机器完全选择你的颜色,酷派是一个很好的网站,它会为你做所有的工作。按空格键生成随机匹配的配色方案,直到你找到一个你喜欢的。请注意,您可以“锁定”您喜欢的颜色,然后按空格键以找到更多与之匹配的颜色。
Paletton 是另一个很棒的在线工具,它可以让你选择或输入一种基本颜色,然后根据你选择的其他参数生成各种匹配的颜色。玩三色和四色选项会分别给你一些好的三色和四色方案。别忘了,你可以尝试色调和距离设置,以获得更多的选项(如果你不喜欢默认设置 30,尝试将距离移动到 60 或 90)。
Paletton 还提供了模拟各种色盲的选项,这样即使对于色盲的人来说,你也可以确定你所选择的颜色是彼此不同的。

从照片中窃取你的颜色:生成简单调色板的一个有趣而简单的技巧是选择一张你喜欢的颜色的照片,然后在图像编辑器中打开它,对它进行像素化处理(在 Photoshop 中,你可以通过效果>像素化>马赛克来做到这一点)。反复像素化它(或者只是增加单元大小,取决于你的软件),你会留下几个代表你照片颜色的巨大像素。通常,这些颜色在一起会很好,所以你可以简单地复制它们并在你的数据 viz 设计中使用它们。

从另一个设计中窃取你的颜色:显然,你不应该在任何形式的设计竞赛中这样做,但对于像公司内部演示这样的工作,从其他设计中借用一些或全部颜色是完全可行的选择。如果你的公司有以前的演示文稿,或者有预先定义的调色板的品牌指南,那么你绝对应该利用这些资源,而不是试图重新发明轮子。
保持最小化
这是一个你可以应用到设计的几乎每个方面的建议:不要包含任何超过理解你正在创建的图表所必需的东西。
几个例子:
消除不必要的网格线(通常不需要网格线)

消除任何对获取图表要点不必要的标注或标签

减少线形图和其他图形元素的粗细

如果你可以用一个标注来更简单地传达重要信息,那么就完全去掉 Y 或 X 轴刻度和标签。删除任何多余的数据点(但不要删除太多,以免图表产生误导)。

避免使用小数位,四舍五入到整数即可,除非小数对于表达数据的含义是必不可少的。
使用一种字体、两种粗细和相应的字体大小
匹配字体和排版就像匹配颜色一样复杂,但是你可以通过选择一种主流字体(当有疑问时,从 Google Fonts 中选择一种最流行的字体)并坚持在你的整个设计中只使用这种字体来完全避免这个问题。限制自己使用两种或最多三种具有强烈对比的不同字体粗细。
例如,如果我们选择字体robot to,我们可能会选择只使用“亮”和“黑”字体。这两种字体在同一个设计中会很合适(因为它们是同一个字体的一部分),但是你可以用“黑色”来表示标题和其他关键信息,用“浅色”来表示不太重要的、不太引人注目的细节。
为你的类型选择尺码时,要使它们成比例。例如,您可以使用六的倍数:
- 坐标轴标签:12 磅
- 标注和数据标签:18 磅
- 标题:24 磅

丢掉图标
当将数据放在一起讲述一个故事时,除了数据可视化之外,添加一些更具体的视觉元素总是很有诱惑力的。但是购物车图标真的给我们的销售趋势图添加了任何有意义的信息吗?大概不会。有些情况下,包含图标可能会有所帮助,但十有八九它们只是添加了视觉噪音,会扰乱我们的设计,而不会增加任何意义。

使用值和饱和度来黑你的观众的眼睛
在设计中,颜色的值是其亮度的量度,而饱和度是颜色强度的量度。你可以把它们想象成一个图表的两个轴,纵轴代表从 0 到 100 的值,横轴代表从 0 到 100 的饱和度。

你可以利用这些概念来控制观众看你图表时的眼睛,因为观众的眼睛自然会被吸引到对比度的区域。因此,如果您想要将注意力吸引到可视化的特定区域,请使用其值和饱和度(或两者)与图表其余部分的值和饱和度之间的强烈对比来突出它。例如,在这些图像中,你的眼睛画在哪里?


不要将文本放在正中央
这条建议只适用于那些经常使用标题页制作幻灯片或其他演示文稿的人,但是如果你就是这样的人,这是一条致命的建议:不要把标题放在页面或屏幕的正中央。相反,把它们放在稍微高于那个点的位置。你会发现这通常会让你的设计“感觉”好很多。

(我们已经听到设计师解释说,因为人类每天都在经历重力,我们下意识地给我们正在看的图像添加了一点“重力”,因此完美居中的文本“感觉”有点低,就像要从屏幕上掉下来一样。我们不确定是否有任何实际的科学支持,但不可否认,高于中心的标题通常“感觉”更好。)
动画只有在有意义的时候才会出现
动画图表在数据可视化领域越来越常见,有一些简单的工具可以让制作这种图表变得非常容易。但是值得记住的是,像任何设计工具一样,只有在有充分的理由使用它们时,才应该使用它们。例如,运动可以用来帮助说明一个值随时间的演变,或者引起对图表中特别重要的一点的注意(因为我们的眼睛自然会被运动吸引)。但这也可能是一种无意义的、令人不快的干扰,而且如果你的项目是在网上进行的,它还可能会减慢项目的加载时间。

以上动画都不是必须的。如果你不关心加载时间,右边图表中的向上运动元素可以用来传达增长。然而,左边图表的晃动会分散注意力,不会增加任何价值。
眯着眼看你的设计
眯着眼看是测试设计有效性的一种快速而又肮脏的方式——当你眯着眼看时,设计中最重要的元素应该仍然可见,而不太重要的细节被模糊掉了。你会发现更大和更高对比度的元素在斜视时最容易看到,所以如果你在斜视你的设计时没有获得关键信息,那么调整颜色值和饱和度以增加关键区域的对比度,或者调整关键数据点的大小(在可能的情况下)是使这些元素更加“流行”的好方法。
仔细看看下面的图表,看看你是否能看出哪种设计能更好地快速传达关键信息。

测试您的设计
斜视图是一种快速自测你的设计的方法,但是对于任何重要的项目,你也应该和其他人一起测试你的设计。特别是,你要询问他们的快速收获(看看你的设计首先传达了哪些信息),并询问他们是否看到了数据之间的任何联系。
第二个问题特别重要,因为人们有时会根据诸如接近度之类的东西得出结论——图表 A 紧挨着图表 B,所以人们假设数据是相关的——这可能是你没有预料到的。在一小部分观众面前测试你的设计,并获得他们的反馈,这将有助于你在向你的主要观众展示之前,确保它传达了你想要的东西。
黄金法则:可读性第一
试图让你的数据看起来漂亮很容易,但请记住,好的设计首先是关于交流信息,美学是第二位的。在一个完美的世界里,你的设计将既清晰又漂亮,但是如果你只能选择一个,每次都选清晰。难看但可读的图表仍然传达信息,漂亮但不可读的图表毫无用处。
设计是一门几乎和数据科学一样深入的学科,但是你不必成为一名专业的设计师来创建既有效又有吸引力的数据可视化。以下是为希望提高数据设计技能的数据科学家提供的一些额外设计资源:
- Venngage 有一个 data viz 设计指南,其中包括一些很棒的例子。
- 从第 8 页开始,Hubspot 的 data viz design PDF 提供了一些针对特定图表类型的最佳实践技巧。
- Geckoboard 提供了一张可打印的数据可视化提示海报,你可以挂在办公室里,让一些重要的指导方针在你的脑海中保持新鲜。
- 我们自己的色彩数据指南,即,其中包括许多其他优秀的色彩资源的链接
- Data Viz Project 的大型图表类型图库为每种图表类型提供了真实世界的示例,其中许多非常精彩,令人振奋。
- 加州大学伯克利分校有一个关于数据可视化图形设计的 30 分钟视频,如果你有时间的话,其中有一些很好的信息。
- 关于设计信息图的酷指南,这是向大量观众展示数据科学项目的好方法。
- Visme 博客中关于基于数据的演示的绝佳演示技巧。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
数字海洋和数据科学 Docker
原文:https://www.dataquest.io/blog/digitalocean-docker-data-science/
November 25, 2015
创建基于云的数据科学环境以加快分析速度
有时候,在本地机器上处理数据科学问题不再有用。也许你的电脑太旧了,不能处理更大的数据集。或者,您可能希望能够从任何地方访问您的工作,并与其他人协作。或者你有一个需要很长时间运行的分析,你不想占用你自己的电脑。
在这些情况下,在服务器上运行 Jupyter 很有用,这样就可以通过浏览器访问它。我们可以通过使用 Docker 轻松做到这一点。参见我们之前的帖子,了解如何使用 Docker 设置数据科学环境。这篇文章建立在那篇文章的基础上,并在服务器上设置了 Docker 和 Jupyter。
云托管
第一步是初始化服务器。你可以使用像亚马逊网络服务(T1)或 T2 数字海洋(T3)这样的网站来征用云中的服务器。这两家公司都是云托管提供商——他们有一个服务器池,并按小时出租给想要运行程序的人。
当您租用服务器时,您可以完全访问它,并且可以安装和运行程序,就像在本地计算机上一样。一个很好的理解服务器的方式是把它看作一台物理上位于其他地方的计算机。服务器没有什么特别的,它只是另一台运行操作系统的计算机,你可以通过互联网访问它。为了初始化我们的服务器,我们将使用 DigitalOcean,因为它比 Amazon Web Services 更便宜、更简单。
启动服务器
有了 DigitalOcean,启动服务器又快又简单。第一步,在这里注册一个账号。第二步是创建一个 droplet,这是一个服务器的数字海洋术语。这里有一个关于如何做的很好的教程。
当你浏览教程时,确保你选择了一个至少 2GB 内存的 droplet,选择 Ubuntu 14.04 64 位作为操作系统,并确保你按照本教程添加了一个 ssh 密钥。创建服务器后,请务必记下 IP 地址。创建服务器后,它应该在页面的左上方,看起来像162.243.1.205。此地址是您的服务器在互联网上的位置,您以后将使用它来访问它。
IP 地址应该在左上角
登录服务器
一旦服务器设置好了,你就可以通过 SSH 或者安全 Shell 登录了。SSH 允许您使用一个特殊的密钥远程登录到一台机器进行身份验证(您在前面的教程中生成了这个密钥)。登录后,您将可以访问服务器上的命令行。您可以像在本地计算机上一样执行命令。
见本教程关于如何 SSH 进入你的服务器。如果您得到一个认证错误,您可能需要首先添加正确的 SSH 密钥。您可以在 Linux 和 OSX 上使用ssh-add命令来完成这项工作。键入ssh-add /home/vik/.ssh/id_rsa(用您的密钥的路径替换/home/vik/.ssh/id_rsa)来添加正确的 ssh 密钥,并重试教程步骤以 ssh 到服务器。
创建新的用户帐户
我们目前作为root用户登录到服务器。该用户对系统上的所有内容都有完全访问权限。这对于初次登录来说没问题,但是当我们使用root用户安装软件时,可能会有安全问题。
我们将创建一个新用户,名为ds(数据科学的简称)。按照本教程创建一个新用户。记得使用用户名ds而不是demo,因为它在教程中。当您创建完一个新用户后,通过键入exit退出 SSH 会话。通过键入ssh [[email protected]](/cdn-cgi/l/email-protection)_IP,以新用户ds的身份再次登录服务器(用您的服务器的 IP 地址替换SERVER_IP)。
安装对接器
一旦您以用户ds的身份通过 ssh 连接到服务器,您应该会看到一个命令提示符。这个提示符将允许您执行任何 bash shell 命令,比如用cd来改变目录,用mv来移动文件。
服务器运行的是基于 Linux 的 Ubuntu 14.04。我们要做的第一件事是安装 Docker。按照这里的说明在服务器上安装 Docker。确保在安装 Docker 后运行sudo usermod -aG docker ds,然后使用exit退出 ssh 会话,并使用ssh [[email protected]](/cdn-cgi/l/email-protection)_IP返回 ssh。
创建笔记本目录
第二步是在机器上创建一个目录来保存您的笔记本文件。您应该以ds用户的身份登录,所以只需键入mkdir -p /home/ds/notebooks来创建笔记本目录。
下载适当的 Docker 映像
下一步是下载你想要的 Docker 镜像。以下是我们目前可用的数据科学图片:
dataquestio/python3-starter—这包含一个 python 3 安装、jupyter 笔记本和许多流行的数据科学库,如numpy、pandas、scipy、scikit-learn和nltk。dataquestio/python2-starter—包含 python 2 安装、jupyter 笔记本和许多流行的数据科学库,如numpy、pandas、scrapy、scipy、scikit-learn和nltk。
您可以通过键入以下内容来下载图像
docker pull IMAGE_NAME。
启动容器
一旦下载了映像,您就可以用docker run -d -p 8888:8888 -v /home/ds/notebooks:/home/ds/notebooks dataquestio/python3-starter启动 Docker 容器。用您想要使用的图像名称替换dataquestio/python3-starter。一旦执行完毕,我们将在本地机器上的8888端口运行一个 Jupyter 服务器。
安装 nginx
Nginx 是一个 HTTP 和反向代理服务器。这意味着它可以接收来自互联网的请求,并将它们传递给我们的 Jupyter 服务器。Nginx 可以使面向公众的 web 应用程序的安全性和其他方面变得更加容易。
我们需要做的第一件事是安装 nginx,这可以用sudo apt-get install nginx来完成。现在,您应该能够在浏览器的地址栏中键入您的服务器 IP 地址,并看到一条通用消息,上面写着“欢迎使用 nginx”。
设置证书
我们需要加密浏览器和 Jupyter 笔记本之间的流量。这将防止任何人截取我们来回发送的敏感数据或密码。为此,我们需要生成一个 SSL 证书。此证书使我们的浏览器能够建立到远程服务器的安全链接。
我们必须在我们的服务器上生成并安装证书。您可以按照本指南中的步骤一进行操作。请确保指定您的服务器 IP 地址,而不是域名。确保在第一步之后停止——我们需要做一个不同的 nginx 配置。
创建密码
我们还会为 nginx 生成一个密码,这样只有你才能访问你的 Jupyter 笔记本。为此,我们将运行:
sudo apt-get install apache2-utilssudo htpasswd -c /etc/nginx/.htpasswd ds- 在提示符下输入密码—您的用户名将是
ds,您的密码将被设置为您在此处输入的值。
- 在提示符下输入密码—您的用户名将是
设置 nginx 配置
最后一步是设置 nginx 配置。首先,我们将通过键入sudo rm /etc/nginx/sites-enabled/default删除默认的 nginx 欢迎消息。然后,我们将创建自己的配置文件。类型sudo nano /etc/nginx/sites-enabled/ds。这将打开一个文本编辑器。将以下内容粘贴到文本编辑器中:
server {
listen
80;
return
301 https://$host$request_uri;}
server {
set $custom_host $host;
listen 443 ssl;
ssl_certificate /etc/nginx/ssl/nginx.crt;
ssl_certificate_key /etc/nginx/ssl/nginx.key;
client_max_body_size 10M;
location / {
proxy_set_header Host $custom_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Protocol $scheme;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Origin "";
proxy_pass https://127.0.0.1:8888;
}}
最后,点击关闭并保存文件
Control + X然后Y。然后,输入sudo service nginx重启 nginx。
尝试一下
现在,您可以在浏览器中访问您的服务器 IP 地址。你会被自动重定向到该网站的安全版本。你可能会看到这样一个屏幕(这是来自 Chrome):

这是因为我们使用了自签名 SSL 证书。大多数网站使用由证书颁发机构签署的证书,但这要花钱,我们不想把钱花在很少有人使用的网站上。
绕过这个屏幕保持与网站的连接——使用 Chrome,你可以通过点击Advanced,然后点击底部的Proceed来做到这一点。点按“继续”后,您将看到输入密码的提示。键入ds作为用户名,并输入您在前面步骤中为 nginx 设置的密码。
连接到服务器
您现在已经完成了所有需要的设置!您应该可以连接到 Jupyter 服务器,看起来像这样:
 可以通过 Jupyter 接口上传下载数据文件和笔记本,应该可以开始在云端做数据科学了。
可以通过 Jupyter 接口上传下载数据文件和笔记本,应该可以开始在云端做数据科学了。
接下来的步骤
请阅读我们之前的帖子,了解如何安装新的软件包或修改 Docker 容器。如果你想建立我们在这篇文章中讨论的图片,你可以贡献给我们的 Github 库这里,其中包含 docker 文件。
我们欢迎对我们当前图像的改进,或者添加新的侧重于 Python 之外的工具的图像。如果你对学习数据科学感兴趣,请在 Dataquest 查看我们的交互式数据科学课程。
在 2021 年发现您的数据科学职业
原文:https://www.dataquest.io/blog/discovering-your-data-science-career/
September 30, 2021
数据科学职业是世界上最受欢迎的职业之一,而且这一趋势没有停止的迹象。随着人工智能、物联网设备以及流媒体和实时通信服务的广泛使用,许多人追求数据职业也就不足为奇了。事实上,根据 Glassdoor 的数据,数据科学家是美国第二好的工作。数据科学的这一非凡进步为许多行业创造了对数据专业人员的非凡需求。这对有抱负的数据科学家来说是个好消息,因为这意味着奖励工资和福利。需求的增加加上训练有素的申请人的短缺意味着数十万新的数据科学工作机会。即使您只是刚刚发现数据科学和成为数据专业人员的可能性,也没有比这更好的开始时间了,大量前所未有的机会正等待着您。
数据职业需要什么?
简单地说,数据职业围绕着数据的收集、清理、组织、操作、可视化和解释。即使不同的职业道路专攻不同的领域,并且每条道路都需要一些特定的过程和工具,但许多道路都有一些共同的主题。
从告知政府把税款花在哪里的预算分析师,到帮助像你我这样的用户观看我们最喜欢的电影的数据工程师,数据科学的宇宙是巨大的,并且不断扩大。
因此,在数据世界中有数百个职位,许多职位在所需技能方面有所重叠。这为数据专业人员提供了一个独特而灵活的位置,让他们在发现哪个专业适合自己的同时发展有用的技能。
数据中的一些职位包括:
- 数据分析师
- 金融分析师
- 运营分析师
- 医疗保健分析师
- 营销分析师
- 数据科学家
- 数据工程师
- 数据技术员
- 商业智能分析师
- 数据挖掘工程师
- 研究员
- 数据库管理员
- 数据和分析经理
- 数字营销经理统计学家
- 运输逻辑学家
- 系统分析员
- 定量分析师
- 数据架构师
- 软件开发人员
- 计算机网络架构师
- 数据库管理员
- 信息安全分析师
如果你想知道在哪里获得这些工作,Dataquest 创建了一个关于如何以及在哪里找到数据工作的奇妙资源—链接此处。
如何成为 2021 年及以后的数据专业人士
在过去,获得一份体面的数据工作的唯一途径是获得计算机科学、数学、统计学或其他相关领域的学士学位。但随着对数据专业人员的需求不断增长,而受过培训的申请人供应不足,招聘经理现在更看重技能和相关经验,而不是正规教育。
现在,数据科学领域的新申请人有了前所未有的机会,可以在没有大学学位的情况下获得一份高回报的入门级工作,前提是申请人可以展示出必要技能的资质,以及学习和发展数据职业生涯的愿望。
Glassdoor 的一项研究列出了一些公司,这些公司的许多开放数据科学职位不再要求学位。这些公司包括谷歌、苹果、诺德斯特龙、Publix、星巴克、IBM、美国银行等等。越来越普遍的情况是,企业根据能力而不是学历来招聘员工。
那么,如何开始走上数据科学职业道路?这是我们最好的建议:
- 研究这个领域,发现你的角色。如果数据科学似乎适合你,制定一个学习计划来指导你的职业研究!
- 加入 Kaggle 和 GitHub 等平台上的数据科学社区,寻求想法和支持。如果可以,找个导师!
- 通过在线课程和训练营培养基本的数据科学技能;考虑证书而不是学位。如果你更喜欢通过写代码而不是看视频来学习,我们建议使用 Dataquest 课程来学习。
- 利用这些技能建立一个真实工作的文件夹来展示你的能力。
- 申请实习或你的第一份入门级工作来展示你的能力。
- 永不停止学习;继续接受数据科学方面的进一步教育,磨练您的技能。
数据职业的基本技能、工具和技术
木匠的好坏取决于他的工具。同样,数据专业人员不仅依赖于他们的技能,还依赖于一系列强大的工具和前沿技术。
以下是您作为数据专业人员将使用的资源和技能的概述:
技能
- 分析思维
- 编程能力
- 强大的沟通能力
- 创造性思维
- 解决问题
- 注意细节
- 良好的组织
工具
- Python 库
- (舞台上由人扮的)静态画面
- 火花
- Jupyter 笔记型电脑
- 斯堪的纳维亚航空公司
- 快速采矿机
- 谷歌分析
使用的技术
- 计算机编程语言
- 稀有
- 神谕
- SQLAWS S3 和其他云数据仓库
对于许多数据专业人员来说,这些领域的熟练程度是不容置疑的。幸运的是,已经有令人难以置信的资源可供开始发展从事数据职业的必要技能。数十家公司现在提供在线数据专业训练营、在线课程或认证,可以是通用的,也可以是专业的。例如,Dataquest 提供了具体的职业道路,旨在成为您从初学者到工作就绪所需的唯一资源。
例如,Dataquest 提供了具体的职业道路,旨在成为您从初学者到工作就绪所需的唯一资源。
你也可以选择在我们的技能路径中采用更专业的方法,比如使用 Python 的机器学习入门、使用 Python 的概率和统计、用于数据分析的 R 基础,以及许多其他的。
数据工作的增长和前景
对数据专业人员的需求从未像现在这样高,从各方面来看,他们是一些增长最快的职业机会。世界经济论坛的 2020 年就业报告发现,数据分析师、机器学习专家和大数据专家是美国各行业中增长最快的三个职位。
每年,LinkedIn 都会发布他们的新兴工作报告,根据他们从受欢迎的工作委员会收集的数据,概述最热门的新工作。2020 年,数据科学相关的工作占据了十大新兴工作中的三个:
-
1:人工智能专家角色在过去四年中每年增长 74%。
-
3:数据科学家的角色在过去四年中增长了 37%。
-
8:数据工程师职位在过去四年中增长了 33%。
此外,面试查询博客分析了超过 10,000 份与数据科学相关的面试经历,发现尽管在疫情期间略有放缓,但数据科学职位仍在快速增长:

来源:https://www . interview query . com/blog-data-science-interview-report/
然而,增长率的下降并没有体现在 FAANG 公司身上——与去年相比,他们的面试人数增加了 25%。

来源:https://www . interview query . com/blog-data-science-interview-report/
根据劳工统计局的最新数据,到 2030 年,数据科学就业市场将增长近 33%,是全国平均水平的三倍多。此外,大数据市场规模预计将增长超过 1000 亿美元。
随着这种需求的爆炸式增长,工资也在上涨——即使是入门级的数据专业人员也可以要求可观的数字和福利。Glassdoor 报道称,数据可视化职业的平均工资为 85,000 美元。另一方面,根据 Springboard 的一项研究,在金融、保险、科学或技术服务领域工作的数据分析师可以获得 9 万美元的薪水。根据薪级表,数据科学家的平均年薪为 96,455 美元,而劳工统计局设定的平均年薪略高于 10 万美元。专业、高级或经理数据科学职位的预期薪资可达 20 万美元以上。

你准备好加入数据科学人才崛起的热潮了吗?你可以的!但是获得你需要的技能不会在一夜之间发生。如果你养成健康的学习习惯,并保持频繁的学习日程,在半年到一年内,你就可以开始一个令人难以置信的回报和终身的职业生涯,成为一名数据专家。如果你觉得这听起来不错,Dataquest 的所有人都愿意帮助你开始。
停止等待,立即开始您的数据科学生涯
通过 Dataquest,您可以获得所需的高回报数据科学职位所需的技能和知识。如果你想增加薪水和工作机会,我们有你需要的工具和资源。
多元化和在线教育
原文:https://www.dataquest.io/blog/diversity-online-education/
April 5, 2019
在线教育有机会创造公平的竞争环境,帮助数百万无法接受传统教育的人获得技能并取得成功。但它往往无法缩小差距。在这篇文章中,我将讨论其中的一些原因,并分享我们如何在 Dataquest 上做得更好。
传统的大学教育有许多阻碍平等获得精英证书的障碍。这些障碍分为两类——财务障碍和网络障碍。经济上的障碍使得学生很难 进入大学 ,一旦进入大学 支付学费 。现在大学平均学费接近每年 35,000 美元,而 1997 年大约是 20,000 美元。
网络障碍意味着你出人头地的机会少了。没有强大的关系网,你很难知道有什么机会,或者在你需要的时候得到第二次机会。这意味着传统权力网络之外的人无法出人头地,即使他们证明了自己的价值。
一份 2017 年《纽约时报》的分析 显示,尽管采取了平权行动,但与 1980 年相比,黑人和拉美裔学生在美国顶级大学和学院的代表性甚至更低。这很大程度上是因为资金和网络障碍。
这些障碍也解释了为什么在 1984 年到 2008 年间,计算机科学领域授予女性学士学位的比例从 37%上升到了 18%。尽管计算机科学一直是一个相对多样化的领域,但“成功”程序员的形象模式(内向、孤僻、男性)是在 1984 年确立的。后来,强大的网络强化了这种刻板印象,在这个过程中将许多合格的女性排除在计算机科学之外。
与财务和网络障碍作斗争的人经常不得不应对具有负面长期后果的选择,如 承担学生债务 ,或参加 无法兑现承诺 的营利性研究生项目。
在线教育的前景是,它可以消除这些障碍。在线教育可能相当便宜(相对于面对面的教育),因为它以一种更可扩展的方式提供。从理论上讲,在线教育不应该有网络障碍,因为任何人都可以获得这些材料。
不幸的是,这并不总是发生。许多教育科技公司都是由看起来和想起来都一样的人创建、领导和投资的。这导致产品很快变得排外和难以接近,尽管有相反的说辞。
风险资本投资通常会促使公司优先考虑快速增长,而不是为所有学生提供价值。这方面的例子包括,像 2U 一样,只花 19%的预算在教育项目上,像许多教育科技公司一样,从看起来一样的现有网络中招聘人才。
在 Dataquest,我们想提供一些不同的东西;一些可以打开机会的东西。
我亲身经历过 学习数据科学可以摆脱官僚主义和体力劳动——它可以成为通往自由的门票。这就是为什么 Dataquest 的教训从来都不是尽可能多赚钱。相反,它总是尽可能有效地教学。
因此,Dataquest 非常重视我们的价值观。我们的一些核心教学和公司价值观是:
- 自力更生的企业。这意味着我们的收入来自教学,而不是来自投资者。我们的激励措施始终与学生保持一致。
- 深度课程。教句法而不创造深入的理解是容易的,但这对学生是一种伤害;它不能帮助你将你的技能转化到现实世界中。
- 负担得起的学习。我们努力使我们的价格点(每月 29 美元或每月 49 美元)尽可能为广大受众所承受,我们即将推出的计划将进一步改善这一点。
- 承诺雇佣我们的学生。我们团队的三分之一是以前的 Dataquest 学生,我们喜欢与最了解有抱负的数据科学家的需求的人合作。
- 一家完全偏远的公司。我们在世界各地教书,我们希望我们的团队能反映出这种多样性。
- 多元化的团队。团队的态度通常反映在他们共同开发的产品中,在线教育公司团队的多样性意味着产品随着时间的推移也会变得更加包容和多样化。没有团队多样性,产品很快就会变得独一无二,不再是为了缩小机会差距。
尤其是,在编程这样的专有领域,多样性是一个至关重要的价值。我们在世界各地有成千上万的学生,我们变得越多样化,我们就能更好地为他们服务。我为我们在过去两年里在拥抱多样性和包容性方面取得的进步感到自豪;无论是我们的产品还是我们的团队。
我们努力使我们的招聘流程和领导标准更具包容性。在一个 24 人的团队中,我们中有 11 人是男性,12 人是女性,还有一人是非二元的。我们团队中将近一半的人是有色人种。我们领导团队的一半由女性组成。
我们还采取了其他措施,例如:
- 优先考虑关于多元化和包容性的公开对话,包括定期召开全公司会议,讨论我们如何为学生和团队成员做得更好。
- 调整我们的公司政策,使其更加开放,不再以美国为中心,比如从美国日历转变为提供灵活的 PTO“浮动”假期。
- 开始改善非英语母语者的 Dataquest 体验,他们占我们学生的 60%。我们正在使我们的写作风格更加直接和吸引人,以避免混淆,并试图在我们的教学中使用更适用于广大学生的数据集,而不是使用以美国为中心的例子。
- 从在数据科学领域代表性不足的群体中征集学生故事,并以此为特色。
仍然有进步要做,我们将在未来几年继续改进。在此期间,我们将接触到数百万学生,并与数百名同事合作,重要的是我们要对他们产生正确的影响。
接下来的一年,我们将继续努力:
- 继续为不同背景的人提供机会,让他们成长为 Dataquest 的领导者并加入我们的领导团队。特别是,我们希望在让更多有色人种加入我们的领导团队方面取得进展。
- 继续培养尊重和宽容的文化。
- 围绕我们团队的多元化和包容性,增加指导和辅导机会。
- 增加来自代表性不足的群体的学生参加 Dataquest 课程并取得成功的人数。这涉及到方方面面,从我们在哪里营销我们的课程,到我们针对哪些受众定制我们的内容。
- 让我们的课程对非美国观众更加友好。
对我来说,包容性是在线教育的主要承诺之一,我希望 Dataquest 可以帮助朝着这个方向迈出一步。世界上有数百万人有能力做出惊人的事情,但却面临着难以逾越的障碍。正确的教育是创造公平竞争环境的有力途径。
如果您有任何想法或问题,请通过 【电子邮件保护】 联系我。我希望听到您的意见(尤其是如果您对我们如何做得更好有什么想法的话)。
商业分析师认证:你真的需要它们吗?
原文:https://www.dataquest.io/blog/do-you-need-business-analysis-certifications/
July 18, 2022
业务分析师需要认证,对吗?不一定。技能掌握是游戏的名字。
商业分析是一个有利可图和受欢迎的职业领域。商业分析师的报告是组织决策的核心——他们的薪水反映了他们的价值。
如果你正在考虑成为一名商务人士,或者有转行的想法,你可能想知道你是否需要一个商业分析师证书来说服雇主你是合格的。简短回答:你没有。
在本文中,我们将回顾市场上各种商业分析师认证,包括它们的价值以及如何向雇主展示你的技能。
不同业务分析师认证的列表
有各种各样的机构提供适合不同经验水平的认证。我们来看几个。
认证分析专家
一个突出的认证是认证分析专家(CAP)认证。CAP 认证有强大的课程和积极的评论,但这个认证需要 695 美元,你需要相关领域的硕士或学士学位,以及至少三年的经验。这当然是一条你可以走的路,但是如果你没有相关领域的学位,可能会花更长的时间和更多的钱。
国际商业分析研究所
国际商业分析研究所(IIBA) ,来自加拿大的著名国际组织,是提供特定商业分析师认证的唯一选择。他们提供三种级别的商业分析师认证。入门级认证为经营分析(ECBA) 入门证书。参加并通过 ECBA 考试证明你有基本的商业分析知识,这足以让你进入初级商业分析师的大门。对于 ECBA 认证,你需要参加一个考试,支付申请和考试费用(大约 600 美元),并完成 21 个专业小时的培训课程(亲自或在线)。
国际商业分析资格委员会
国际商业分析资格委员会(IQBBA) 采取了一种更加注重 IT 的商业分析方法。虽然高级课程适用于经验丰富的业务分析师,但基础水平认证是全面发展的业务分析师的基础。这个认证平台向潜在的业务分析师传授该领域的基础知识,包括设计业务解决方案、评估解决方案以及收集和分析数据等技能。创新是该认证的关键部分,它强调了开发创新解决方案以获得市场竞争优势的重要性。
项目管理研究所
与这里列出的其他认证不同,项目管理学院(PMI) 提供的业务分析认证侧重于项目管理。这是因为 PMI 将业务分析视为项目经理的宝贵工具。如果你的目标是项目管理,但你希望业务分析技能在竞争中获得优势, PMI-PBA 是一个可行的选择。PBA 代表“商业分析专业人士”,这个头衔表明了潜在雇主在你的面试开始前需要知道的一切。有了这个认证,你不仅可以设置项目参数,还可以从头到尾管理项目。
认证测试员基础水平
国际软件测试资格委员会 (ISTQB) 不提供特定的业务分析课程。然而,认证测试员基础水平 (CTFL) 教育和认证软件开发相关职位的员工。与软件开发团队密切合作的业务分析师将从 CTFL 中受益。
对于入门级 BAs 来说,认证是多余的
很容易认为积累证书会让你成为更受欢迎的求职者。认证越多越好,对吗?
没那么快。
不要错误地认为工作需要证书。随着对商业分析师需求的增加,这是一个雇员的就业市场。虽然证书在你的简历上肯定会很好看,但你并不需要它。
现实情况是,证书并没有教会你实际工作所需的硬技能,而这正是雇主们想要的。
除了 CTFL,其他的认证都不是很专业,从长远来看对你没有好处。例如,通过编写定制的 SQL 或 Python 脚本来收集和分析数据,会让你在雇主面前看起来像个摇滚明星。背行业行话和流程都比不上。
当你找工作时,想要尽可能多的证书是可以理解的,但是,与项目经理不同,他们通常需要有项目管理专业人员(PMI-PMP)证书,业务分析师不需要证书来获得工作(尽管有些证书会有帮助——见下文)。
所以,如果你想获得认证,就去证明你已经知道的东西。当你已经知道如何做这份工作时,认证只是帮助你的简历脱颖而出。
让你的技能来说话
事实是,雇主正在寻找能做好这项工作的人,他们需要证明这一点。他们花在你身上的时间越少,你就能越快证明自己的价值。
无论您是想成为 IT 业务分析师还是更一般的业务分析师,您都希望显示出对 Microsoft Power BI 和 Excel 等应用程序以及 SQL 等编程语言的熟练程度。
通过完成我们的业务分析师课程,您将学习如何使用这些应用程序,并且您将完成八个项目,这些项目模拟了您作为业务分析师必须完成的真实任务。这给了你一个机会来检验你的技能,并把你的作品收集成作品集展示给雇主。
除了你的作品集,我们相信一个技能认证,即专门展示你的行动能力远比一个普通的商业分析师认证更有价值。通过这种级别的考试将证明你可以与利益相关者合作,为项目设定适当的要求,并将你收集的数据模型化为有效的视觉辅助工具,为决策者的下一步行动提供建议。Dataquest 的业务分析师课程将帮助你准备好通过这样的考试(我们将为你的 PL-300 认证提供 50%的折扣)。
因此,建立您的投资组合并获得 Power BI 认证将帮助您成为一名业务分析师,并确保您能够言出必行。
教程:为数据科学运行 Dockerized Jupyter 服务器
November 22, 2015
在 Dataquest,我们提供了一个易于使用的环境来开始学习数据科学。这个环境预配置了最新版本的 Python、众所周知的数据科学库和一个可运行的代码编辑器。它允许全新的数据科学家和有经验的数据科学家立即开始运行代码。虽然我们在数据集上提供了无缝的学习体验,但当你想切换到自己的数据集时,你必须转移到本地开发环境。
可悲的是,建立自己的本地环境是数据科学家最令人沮丧的经历。处理不一致的包版本、由于错误而失败的冗长安装以及模糊的安装指令甚至使开始编程都变得困难。当在使用不同操作系统的团队中工作时,这些问题被夸大到了更高的程度。对于许多人来说,设置是学习如何编码的最大障碍。
幸运的是,有助于解决这些发展困境的技术已经出现。在这篇文章中,我们将要探索的是一个叫做 Docker 的容器化工具。自 2013 年以来,Docker 使启动支持不同项目基础设施需求的多种数据科学环境变得快速而简单。
在本教程中,我们将向您展示如何使用 Docker 设置您自己的 Jupyter 笔记本服务器。我们将介绍 Docker 和容器化的基础知识,如何安装 Docker,以及如何下载和运行 Docker 化的应用程序。最后,你应该能够运行你自己的本地 Jupyter 服务器,拥有最新的数据科学库。
码头鲸是来帮忙的
码头工人和集装箱化概述
在我们深入了解 Docker 之前,了解一些导致 Docker 等技术兴起的初步软件概念是很重要的。在简介中,我们简要描述了在多个操作系统的团队中工作以及安装第三方库的困难。这些类型的问题从软件开发开始就已经存在了。
一个解决方案是使用虚拟机。虚拟机允许您从本地机器上运行的操作系统模拟替代操作系统。一个常见的例子是在 Linux 虚拟机上运行 Windows 桌面。虚拟机本质上是一个完全隔离的操作系统,其应用程序独立于您自己的系统运行。这在开发团队中非常有用,因为每个成员都可以运行完全相同的系统,而不管他们机器上的操作系统是什么。
然而,虚拟机并不是万能的。它们很难设置,需要大量的系统资源才能运行,并且需要很长时间才能启动。

在 mac 上的虚拟机中使用 Windows 的示例
基于这一虚拟化概念,完全虚拟机隔离的另一种方法称为容器化。容器类似于虚拟机,因为它们也在隔离的环境中运行应用程序。然而,容器化的环境不是运行一个包含所有库的完整操作系统,而是一个运行在容器引擎之上的轻量级进程。
容器引擎运行容器,并为主机操作系统提供向容器共享只读库及其内核的能力。这使得正在运行的容器的大小为几十兆字节,而虚拟机的大小可能为几十千兆字节或更多。Docker 是一种容器引擎。它允许我们下载并运行包含预配置的轻量级操作系统、一组库和应用特定包的映像。当我们运行一个映像时,Docker 引擎产生的进程被称为容器。
如前所述,容器消除了配置问题,确保了跨平台的兼容性,将我们从底层操作系统或硬件的限制中解放出来。与虚拟机类似,基于不同技术(例如 Mac OS X 与微软 Windows)构建的系统可以部署完全相同的容器。与虚拟环境相比,使用容器有多种优势:
- 快速上手的能力。当您只想开始分析时,您不需要等待软件包安装。
- 跨平台一致。Python 包是跨平台的,但是有些包在 Windows 和 Linux 上的行为不同,有些包的依赖项不能安装在 Windows 上。Docker 容器总是运行在 Linux 环境中,所以它们是一致的。
- 检查点和恢复的能力。您可以将软件包安装到 Docker 映像中,然后创建该检查点的新映像。这使您能够快速撤消更改或回滚配置。
在官方 Docker 文档中可以找到对容器化和虚拟机之间的差异的很好的概述。在下一节中,我们将介绍如何在您的系统上设置和运行 Docker。
安装 Docker
有一个用于 Windows 和 Mac 的图形安装程序,使得安装 Docker 很容易。以下是每个操作系统的说明:
在本教程的剩余部分,我们将介绍运行 Docker 的 Linux 和 macOS (Unix)指令。我们提供的示例应该在您的终端应用程序(Unix)或 DOS 提示符(Windows)下运行。虽然我们将突出显示 Unix shell 命令,但是 Windows 命令应该是类似的。如果有任何差异,我们建议检查官方 Docker 文档。要检查 Docker 客户端是否安装正确,这里有几个测试命令:
docker version:返回本地机器上运行的 Docker 版本的信息。docker help:返回 Docker 命令列表。docker run hello-world:运行 hello-world 镜像并验证 Docker 是否正确安装并运行。
从映像运行 Docker 容器
安装 Docker 后,我们现在可以下载和运行图像了。回想一下,映像包含运行应用程序的轻量级操作系统和库,而运行的映像称为容器。你可以把一个图像想象成可执行的文件,这个文件产生的运行进程就是容器。让我们从运行一个基本的 Docker 映像开始。
在 shell 提示符下输入docker run命令(如下)。确保输入完整的命令:docker run ubuntu:16.04如果您的 Docker 安装正确,您应该看到如下输出:
Unable to find image 'ubuntu:16.04' locally
16.04: Pulling from library/ubuntu
297061f60c36: Downloading [============> ] 10.55MB/43.03MB
e9ccef17b516: Download complete
dbc33716854d: Download complete
8fe36b178d25: Download complete 686596545a94: Download complete
我们来分解一下之前的命令。首先,我们开始将run参数传递给docker引擎。这告诉 Docker 下一个参数,ubuntu:16.04是我们想要运行的图像。我们传入的图像参数由图像名称、ubuntu和相应的标签、16.04组成。您可以将标签视为图像版本。此外,如果您将图像标签留空,Docker 将运行最新的图像版本(即docker run ubuntu < - > docker run ubuntu:latest)。
一旦我们发出命令,Docker 通过检查映像是否在您的本地机器上来启动运行过程。如果 Docker 找不到图像,它将检查 Docker hub 并下载图像。Docker hub 是一个图像库,这意味着它托管开源社区构建的图像,可供下载。
最后,下载完图像后,Docker 会将它作为一个容器运行。但是,请注意,当ubuntu容器启动时,它会立即退出。退出的原因是因为我们没有传入额外的参数来为正在运行的容器提供上下文。让我们试着运行另一个带有一些可选参数的图像到run命令。在下面的命令中,我们将提供-i和-t标志,启动一个交互会话和模拟终端(TTY)。
运行以下命令来访问 Docker 容器中运行的 Python 提示符:docker run -i -t python:3.6这相当于:docker run -it python:3.6
运行 Jupyter 笔记本
运行前面的命令后,您应该已经输入了 Python 提示符。在提示符下,您可以像平常一样编写 Python 代码,但是代码将在正在运行的 Docker 容器中执行。当您退出提示符时,您将退出 Python 进程,并离开关闭 Docker 容器的交互式容器模式。到目前为止,我们已经运行了 Ubuntu 和 Python 映像。这些类型的图像非常适合开发,但是它们本身并不令人兴奋。相反,我们将运行一个 Jupyter 映像,它是一个构建在ubuntu映像之上的应用程序特定的映像。
我们将使用的 Jupyter 图片来自 Jupyter 的开发社区。这些图像的蓝图被称为 Dockerfile ,可以在他们的 Github repo 中找到。本教程中我们不会详细讨论 Dockerfiles,所以就把它们看作是创建图像的源代码。图像的 Dockerfile 通常托管在 Github 上,而构建的图像则托管在 Docker Hub 上。首先,让我们在一个 Jupyter 映像上调用 Docker run 命令。
我们将运行只安装了 Python 和 Jupyter 的minimal-notebook。输入下面的命令:docker run jupyter/minimal-notebook使用这个命令,我们将从jupyter Docker hub 帐户中提取minimal-notebook的最新图像。如果您看到以下输出,就知道它已经成功运行了:
[C 06:14:15.384 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
https://localhost:8888/?token=166aead826e247ff182296400d370bd08b1308a5da5f9f87
与运行非 Dockerized Jupyter 笔记本类似,您将拥有一个到 Jupyter 本地主机服务器的链接和一个给定的令牌。但是,如果您尝试导航到提供的链接,您将无法访问服务器。在你的浏览器上,你会看到一个“网站无法访问”的页面。
这是因为 Jupyter 服务器运行在它自己独立的 Docker 容器中。这意味着除非明确指示,否则所有端口、目录或任何其他文件都不会与您的本地计算机共享。为了访问 Docker 容器中的 Jupyter 服务器,我们需要通过传入-p <host_port>:<container_port>标志和参数来打开主机和容器之间的端口。docker run -p 8888:8888 jupyter/minimal-notebook 
如果您看到上面的屏幕,这是您在浏览器中导航到 URL 后应该看到的内容,您正在 Docker 容器中成功地进行开发。概括地说,不需要下载 Python、一些运行时库和 Jupyter 包,只需要安装 Docker、下载官方的 Jupyter 映像并运行容器。接下来,我们将对此进行扩展,并了解如何从您的主机(本地机器)与运行的容器共享笔记本。
在主机和容器之间共享笔记本
首先,我们将在我们的主机上创建一个目录,在那里我们将保存所有的笔记本。在您的主目录中,创建一个名为notebooks的新目录。这里有一个命令可以做到这一点:mkdir ~/notebooks
现在我们有了笔记本的专用目录,我们可以在主机和容器之间共享这个目录。类似于打开端口,我们需要向run命令传递另一个额外的参数。这个参数的标志是-v <host_directory>:<container_directory>,它告诉 Docker 引擎将给定的主机目录挂载到容器目录。在 Jupyter Docker 文档中,它将容器的工作目录指定为/home/jovyan。因此,我们将使用 mount run标志把我们的~/notebooks目录挂载到容器的工作目录。docker run -p 8888:8888 -v ~/notebooks:/home/jovyan jupyter/minimal-notebook安装好目录后,转到 Jupyter 服务器并创建一个新笔记本。将笔记本从“未命名”重命名为“示例笔记本”。 在您的主机上,检查
在您的主机上,检查~/notebooks目录。在那里,您应该会看到一个 iPython 文件:Example Notebook.ipynb!
安装附加软件包
在我们的minimal-notebook Docker 映像中,有预装的 Python 包可供使用。其中一个是我们一直在使用的,Jupyter 笔记本,这是我们在浏览器上访问的笔记本服务器。其他包是隐式安装的,比如requests包,您可以在笔记本中导入它。请注意,这些预安装的包是捆绑在映像中的,不是我们自己安装的。
正如我们已经提到的,使用容器进行开发的主要好处之一就是不必安装包。但是,如果图像缺少您想要使用的数据科学包,比如说用于机器学习的tensorflow,该怎么办?在容器中安装软件包的一种方法是使用 docker exec命令。
exec命令与run命令有相似的参数,但是它不使用参数启动容器,它在已经运行的容器上执行。因此,在从图像创建容器的 insead 中,像 docker run 一样,docker exec需要一个正在运行的容器 ID 或容器名称,它们被称为容器标识符。要定位一个正在运行的容器的标识符,您需要调用 docker ps命令,该命令列出了所有正在运行的容器和一些附加信息。例如,下面是我们的docker ps在minimal-notebook容器运行时的输出。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
874108dfc9d9 jupyter/minimal-notebook "tini -- start-noteb…" Less than a second ago Up 4 seconds 0.0.0.0:8900->8888/tcp thirsty_almeida
现在我们有了容器 ID,我们可以在容器中安装 Python 包了。从 docker exec文档中,我们传入 runnable 命令作为标识符的参数,然后在容器中执行。回想一下,安装 Python 包的命令是pip install <package name>。为了安装tensorflow,我们将在 shell 中运行以下代码。注意:,您的容器 ID 将与提供的示例不同。docker exec 874108dfc9d9 pip install tensorflow
如果成功,您应该会看到 pip 安装输出日志。您将注意到的一件事是,在这个 Docker 容器中安装tensorflow相对较快(假设您有快速的互联网)。如果你以前安装过tensorflow,你会知道这是一个非常繁琐的设置,所以你可能会惊讶于这个过程是多么的轻松。这是一个快速安装过程的原因,因为minimal-notebook映像的编写考虑到了数据科学优化。基于 Jupyter 社区对安装最佳实践的想法,已经预安装了 C 库和其他 Linux 系统级包。这是使用开源社区 developer Docker 图像的最大好处,因为它们通常针对您将要进行的开发工作类型进行了优化。
扩展 Docker 图像
到目前为止,您已经安装了 Docker,运行了您的第一个容器,访问了 Docker 化的 Jupyter 容器,并在一个正在运行的容器上安装了tensorflow。现在,假设您已经使用tensorflow库完成了一天的 Jupyter 容器工作,并且您想要关闭容器以回收处理速度和内存。
要停止容器,您可以运行 docker stop 或 docker rm 命令。第二天,您再次运行容器,并准备开始着手 tensorflow 工作。然而,当你去运行笔记本电池时,你被一个ImportError挡住了。如果你前一天已经安装了tensorflow,怎么会发生这种情况?

问题出在docker exec命令上。回想一下,当您运行exec时,您正在对运行容器的执行给定的命令。容器只是映像的运行进程,其中映像是包含所有预安装库的可执行文件。所以,当你在容器上安装tensorflow时,它只是为那个特定的实例安装的。
因此,关闭容器就是从内存中删除该实例,当您从映像中重新启动一个新容器时,只有映像中包含的库才能再次使用。将tensorflow保存到映像上已安装软件包列表的唯一方法是修改原始 docker 文件并构建一个新映像,或者扩展docker 文件并从这个新 docker 文件构建一个新映像。
不幸的是,这些步骤都需要理解 Dockerfiles,这是一个 Docker 概念,我们在本教程中不会详细介绍。但是,我们使用的是 Jupyter 社区开发的 Docker 映像,所以让我们检查一下是否已经有一个使用tensorflow构建的 Docker 映像。再次查看 Jupyter github 库,可以看到有一个tensorflow笔记本!
不仅仅是tensorflow,还有很多其他的选择。下面的树形图来自他们的文档,描述了 docker 文件和每个使用中的可用图像之间的关系扩展。 因为
因为tensorflow-notebook是从minimal-notebook扩展而来的,我们可以从之前的docker run命令开始,只改变图像的名称。以下是我们如何在您的浏览器上运行预装了tensorflow : docker run -p 8888:8888 -v ~/notebooks:/home/jovyan jupyter/tensorflow-notebook的 Dockerized Jupyter 笔记本服务器,使用前几节描述的相同方法导航到正在运行的服务器。在那里,在一个代码单元中运行import tensorflow,你应该看不到ImportError!
后续步骤
在本教程中,我们讨论了虚拟化和容器化之间的区别,如何安装和运行 Dockerized 应用程序,以及使用开源社区开发人员 Docker 映像的好处。我们使用了一个容器化的 Jupyter 笔记本服务器作为例子,展示了在 Docker 容器中使用 Jupyter 服务器是多么容易。完成本教程后,您应该会对使用 Jupyter 社区图像感到舒适,并能够在日常工作中融入一个文档化的数据科学设置。
虽然我们涵盖了许多 Docker 概念,但这些只是帮助您入门的基础。关于 Docker 以及它的功能有多强大,还有很多东西需要学习。掌握 Docker 不仅有助于您的本地开发时间,而且可以在与数据科学家团队合作时节省时间和金钱。如果喜欢这个例子,这里有一些改进可以帮助你学习更多的 Docker 概念:
- 以分离模式作为后台进程运行 Jupyter 服务器。
- 命名您的运行容器以保持您的进程干净。
- 创建自己的 docker 文件,扩展包含必要数据科学库的
minimal-notebook。 - 从扩展 Dockerfile 文件构建一个映像。
成为一名数据工程师!
现在就学习成为一名数据工程师所需的技能。注册一个免费帐户,访问我们的交互式 Python 数据工程课程内容。
(免费)

https://www.youtube.com/embed/ddM21fz1Tt0?rel=0
如何使用 Python Docstrings 进行有效的代码文档编制
原文:https://www.dataquest.io/blog/documenting-in-python-with-docstrings/
August 15, 2022
对任何数据科学家或软件工程师来说,记录代码都是一项关键技能。了解如何使用 docstrings 来实现这一点。
为什么 Python 中的文档很重要?
Python 的禅告诉我们“可读性很重要”,“显式比隐式好。”这些都是 Python 的必要特征。当我们写代码时,我们是为了最终用户、开发者和我们自己。
请记住,当我们阅读 pandas 文档或 scikit-learn 文档时,我们也是最终用户。这两个软件包都有很好的文档,用户使用它们通常不会有任何问题,因为它们包含了大量的示例和教程。它们还有内置文档,我们可以在您的首选 IDE 中直接访问。
现在想象一下在没有任何参考的情况下使用这些包。我们需要深入研究他们的代码,以了解它做什么,以及我们如何使用它。有一些软件包完全没有文档,通常要花更多的时间来理解它们下面是什么以及我们如何使用它们。如果包很大,函数分布在多个文件中,那么工作量会增加一倍或两倍。
为什么好的文档很重要现在应该更明显了。
接下来,其他开发人员可能想要为我们的项目做出贡献。如果我们的代码有良好的文档记录,他们可以做得更快更有效。如果你不得不花几个小时弄清楚一个项目的不同部分是做什么的,你会愿意在空闲时间为这个项目做贡献吗?我不会。
最后,即使只是我们的私人项目或一个小脚本,我们无论如何都需要文档。我们永远不知道什么时候我们会回到我们的老项目中去修改或改进它。如果它明确地告诉我们它的用途以及它的功能、代码行和模块是做什么的,那么使用它会非常愉快和容易。在编写代码时,我们往往会很快忘记我们在想什么,所以花一些时间解释我们为什么要做一些事情,在返回代码时总是会节省更多的时间(即使它是一天前才编写的)。所以,花些时间在文档上,它会在以后回报你。
Python 文档字符串示例
让我们来看一些 Python 中文档字符串的例子!例如,下面的普通函数采用两个变量,或者返回它们的和(默认情况下),或者返回它们之间的差:
def sum_subtract(a, b, operation="sum"):
if operation == "sum":
return a + b
elif operation == "subtract":
return a - b
else:
print("Incorrect operation.")
print(sum_subtract(1, 2, operation="sum"))
3
这个函数非常简单,但是为了展示 Python docstrings 的强大功能,让我们编写一些文档:
def sum_subtract(a, b, operation="sum"):
"""
Return sum or difference between the numbers 'a' and 'b'.
The type of operation is defined by the 'operation' argument.
If the operation is not supported, print 'Incorrect operation.'
"""
if operation == "sum":
return a + b
elif operation == "subtract":
return a - b
else:
print("Incorrect operation.")
这个函数的 Python docstring 用两边的三个双引号括起来。正如您所看到的,这个字符串解释了这个函数的作用,并指出我们可以如何改变它的功能,以及如果它不支持我们希望它执行的操作会发生什么。这是一个简单的例子,您可能会认为这个函数太明显了,不需要任何解释,但是一旦函数变得复杂并且数量增加,您至少需要一些文档来避免迷失在自己的代码中。
引擎盖下发生了什么?如果我们在sum_subtract()函数上运行help()函数,就会弹出 docstring。所有文档完整的包都有(几乎)所有函数的 docstrings。例如,让我们看看熊猫的数据帧:
import pandas as pd
help(pd.DataFrame)
# Help on class DataFrame in module pandas.core.frame:
# class DataFrame(pandas.core.generic.NDFrame, pandas.core.arraylike.OpsMixin)
# | DataFrame(data=None, index: 'Axes | None' = None, columns: 'Axes | None' = None, dtype: 'Dtype | None' = None, copy: 'bool | None' = None)
# |
# | Two-dimensional, size-mutable, potentially heterogeneous tabular data.
# |
# | Data structure also contains labeled axes (rows and columns).
# | Arithmetic operations align on both row and column labels. Can be
# | thought of as a dict-like container for Series objects. The primary
# | pandas data structure.
# |
# | Parameters
# | ----------
# | data : ndarray (structured or homogeneous), Iterable, dict, or DataFrame
# | Dict can contain Series, arrays, constants, dataclass or list-like objects. If
# | data is a dict, column order follows insertion-order. If a dict contains Series
# | which have an index defined, it is aligned by its index.
# |
# | .. versionchanged:: 0.25.0
# | If data is a list of dicts, column order follows insertion-order.
# |
# | index : Index or array-like
# | Index to use for resulting frame. Will default to RangeIndex if
# | no indexing information part of input data and no index provided.
# | columns : Index or array-like
# | Column labels to use for resulting frame when data does not have them,
# | defaulting to RangeIndex(0, 1, 2, ..., n). If data contains column labels,
# | will perform column selection instead.
# | dtype : dtype, default None
# | Data type to force. Only a single dtype is allowed. If None, infer.
# | copy : bool or None, default None
# | Copy data from inputs.
# | For dict data, the default of None behaves like ``copy=True``. For DataFrame
# | or 2d ndarray input, the default of None behaves like ``copy=False``.
# |
# | .. versionchanged:: 1.3.0
# Docstring continues...
现在,如果我们看一下 pandas源代码,就会发现help向我们展示了DataFrame类的 docstring(搜索class DataFrame(NDFrame, OpsMixin))。
从技术上讲,docstring 被分配给这个对象的一个自动生成的属性,称为__doc__。我们还可以打印出该属性,并看到它与之前完全相同:
print(pd.DataFrame.__doc__[:1570]) # Truncated
Two-dimensional, size-mutable, potentially heterogeneous tabular data.
Data structure also contains labeled axes (rows and columns).
Arithmetic operations align on both row and column labels. Can be
thought of as a dict-like container for Series objects. The primary
pandas data structure.
Parameters
----------
data : ndarray (structured or homogeneous), Iterable, dict, or DataFrame
Dict can contain Series, arrays, constants, dataclass or list-like objects. If
data is a dict, column order follows insertion-order. If a dict contains Series
which have an index defined, it is aligned by its index.
.. versionchanged:: 0.25.0
If data is a list of dicts, column order follows insertion-order.
index : Index or array-like
Index to use for resulting frame. Will default to RangeIndex if
no indexing information part of input data and no index provided.
columns : Index or array-like
Column labels to use for resulting frame when data does not have them,
defaulting to RangeIndex(0, 1, 2, ..., n). If data contains column labels,
will perform column selection instead.
dtype : dtype, default None
Data type to force. Only a single dtype is allowed. If None, infer.
copy : bool or None, default None
Copy data from inputs.
For dict data, the default of None behaves like ``copy=True``. For DataFrame
or 2d ndarray input, the default of None behaves like ``copy=False``.
.. versionchanged:: 1.3.0
文档字符串和代码注释之间的区别
在我们了解了 docstrings 的样子之后,是时候了解它们与常规代码注释的区别了。主要思想是它们(通常)服务于不同的目的。
文档字符串解释了一个函数/类的用途(例如,它的描述、参数和输出——以及任何其他有用的信息),而注释解释了特定代码字符串的作用。换句话说,代码注释是给想要修改代码的人用的,文档字符串是给想要使用代码的人用的。
此外,在计划代码时,代码注释可能是有用的(例如,通过实现伪代码,或者留下你的想法或想法的临时注释,这些想法或想法不是为最终用户准备的)。
文档字符串格式
让我们看看不同类型的文档字符串。首先,浏览 Python 的 PEP 页面是一个极好的主意。我们可以找到 PEP 257 ,里面总结了 Python docstrings。我强烈建议你通读,即使你可能并不完全理解。要点如下:
- 使用三个双引号将文档字符串括起来。
- Docstring 以点结束。
- 它应该描述函数的命令(即函数做什么,所以我们通常以“Return…”开始短语)。
- 如果我们需要添加更多的信息(例如,关于参数),那么我们应该在函数/类的概要和更详细的描述之间留一个空行(关于它的更多信息将在本教程后面给出)。
- 如果能增加可读性,多行文档字符串也不错。
- 应该有参数、输出、异常等的描述。
请注意,这些只是建议,并不是严格的规则。例如,我怀疑我们是否需要向sum_subtract()函数添加更多关于参数或输出的信息,因为摘要已经足够描述了。
有四种主要类型的文档字符串,它们都遵循上述建议:
你可以看看所有的,然后决定你最喜欢哪一个。尽管 reStructuredText 是官方的 Python 文档样式,但 NumPy/SciPy 和 Google docstrings 会更频繁地出现。
让我们来看一个真实世界的数据集,并编写一个函数来应用于它的一个列。
这个数据集包含了 1995-2021 年 Metacritic 上的顶级视频游戏。
from datetime import datetime
import pandas as pd
all_games = pd.read_csv("all_games.csv")
print(all_games.head())
name platform release_date \
0 The Legend of Zelda: Ocarina of Time Nintendo 64 November 23, 1998
1 Tony Hawk's Pro Skater 2 PlayStation September 20, 2000
2 Grand Theft Auto IV PlayStation 3 April 29, 2008
3 SoulCalibur Dreamcast September 8, 1999
4 Grand Theft Auto IV Xbox 360 April 29, 2008
summary meta_score user_review
0 As a young boy, Link is tricked by Ganondorf, ... 99 9.1
1 As most major publishers' development efforts ... 98 7.4
2 [Metacritic's 2008 PS3 Game of the Year; Also ... 98 7.7
3 This is a tale of souls and swords, transcendi... 98 8.4
4 [Metacritic's 2008 Xbox 360 Game of the Year; ... 98 7.9
例如,我们可能对创建一个列感兴趣,该列计算一个游戏在多少天前发布。为此,我们还将使用datetime包(教程一、教程二)。
首先,让我们编写这个函数并测试它:
def days_release(date):
current_date = datetime.now()
release_date_dt = datetime.strptime(date, "%B %d, %Y") # Convert date string into datetime object
return (current_date - release_date_dt).days
print(all_games["release_date"].apply(days_release))
0 8626
1 7959
2 5181
3 8337
4 5181
...
18795 3333
18796 6820
18797 2479
18798 3551
18799 4845
Name: release_date, Length: 18800, dtype: int64
该函数如预期的那样工作,但是最好用 docstrings 来补充它。首先,让我们使用 SciPy/NumPy 格式:
def days_release(date):
"""
Return the difference in days between the current date and game release date.
Parameter
---------
date : str
Release date in string format.
Returns
-------
int64
Integer difference in days.
"""
current_date = datetime.now()
release_date_dt = datetime.strptime(date, "%B %d, %Y") # Convert date string into datetime object
return (current_date - release_date_dt).days
在上面的Returns部分,我没有重复(大部分)已经在总结部分的内容。
接下来,一个 Google docstrings 的例子:
def days_release(date):
"""Return the difference in days between the current date and game release date.
Args:
date (str): Release date in string format.
Returns:
int64: Integer difference in days.
"""
current_date = datetime.now()
release_date_dt = datetime.strptime(date, "%B %d, %Y") # Convert date string into datetime object
return (current_date - release_date_dt).days
一个重组文本的例子:
def days_release(date):
"""Return the difference in days between the current date and game release date.
:param date: Release date in string format.
:type date : str
:returns: Integer difference in days.
:rtype: int64
"""
current_date = datetime.now()
release_date_dt = datetime.strptime(date, "%B %d, %Y") # Convert date string into datetime object
return (current_date - release_date_dt).days
最后,一个 Epytext 的例子:
def days_release(date):
"""Return the difference in days between the current date and the game release date.
@type date: str
@param date: Release date in string format.
@rtype: int64
@returns: Integer difference in days.
"""
current_date = datetime.now()
release_date_dt = datetime.strptime(date, "%B %d, %Y") # Convert date string into datetime object
return (current_date - release_date_dt).days
大多数函数文档字符串至少应该有它们的功能、输入和输出描述的摘要。此外,如果它们更复杂,它们可能包括例子、注释、例外等等。
最后,我没有过多地讨论类,因为它们在数据科学中并不常见,但是除了它们的方法(函数)所包含的内容之外,它们还应该包含以下内容:
- 属性描述
- 方法列表及其功能摘要
- 属性的默认值
编写文档字符串脚本
Python docstrings 还描述了小脚本的功能和使用指南,这些小脚本可能适用于我们一些日常任务的自动化。例如,我经常需要将丹麦克朗转换成欧元。我可以每次在谷歌上输入一个查询,或者我可以下载一个应用程序来帮我完成,但这一切似乎都过于复杂和多余。我知道一欧元大约是 7.45 丹麦克朗,因为我几乎总是在 Linux 终端上工作,所以我决定编写一个小的 CLI 程序,将一种货币转换成另一种货币:
"""
DKK-EUR and EUR-DKK converter.
This script allows the conversion of Danish kroner to euros and euros to Danish kroner with a fixed exchange rate
of 7.45 Danish krone for one euro.
It is required to specify the conversion type: either dkk-eur or eur-dkk as well as the type of the input currency
(EUR or DKK).
This file contains the following functions:
* dkk_converter - converts Danish kroner to euros
* eur_converter - converts euros to Danish kroner
* main - main function of the script
"""
import argparse
# Create the parser
parser = argparse.ArgumentParser(
prog="DKK-EUR converter", description="Converts DKK to EUR and vice versa"
)
# Add arguments
parser.add_argument("--dkk", "-d", help="Danish kroner")
parser.add_argument("--eur", "-e", help="Euros")
parser.add_argument(
"--type",
"-t",
help="Conversion type",
choices=["dkk-eur", "eur-dkk"],
required=True,
)
# Parse the arguments
args = parser.parse_args()
def dkk_converter(amount):
"""Convert Danish kroner to euros."""
amount = float(amount)
print(f"{amount} DKK is {round(amount / 7.45, 2)} EUR.")
def eur_converter(amount):
"""Convert euros to Danish kroner."""
amount = float(amount)
print(f"{amount} EUR is {round(amount * 7.45, 2)} DKK.")
def main():
"""Main function."""
if args.type == "dkk-eur":
dkk_converter(args.dkk)
elif args.type == "eur-dkk":
eur_converter(args.eur)
else:
print("Incorrect conversion type")
main()
该脚本应该有足够的文档记录,以允许用户应用它。在文件的顶部,docstring 应该描述脚本的主要目的、简要指南以及它包含的函数或类。此外,如果使用任何第三方包,应该在 docstrings 中声明,以便用户在使用脚本之前安装它。
如果您使用argparse模块创建 CLI 应用程序,那么它的每个参数都应该在help菜单中描述,以便最终用户可以选择-h选项并确定输入。此外,description参数应该填入ArgumentParser对象中。
最后,如前所述,所有功能都应正确记录。这里,我省略了“参数”和“返回”描述符,因为从我的角度来看,它们是不必要的。
另外,请注意我是如何使用代码注释的,以及它们与 docstrings 有何不同。如果你有一个自己写的脚本,添加一些文档来练习。
关于如何编写 Python 文档字符串和文档的一般建议
为什么文档很重要,为什么文档字符串是 Python 文档的重要组成部分,这应该很清楚了。最后,让我给你一些关于 Python 文档字符串和文档的一般性建议。
- 为人们而不是计算机写文档。它应该是描述性的,但简洁明了。
- 不要过度使用 docstrings。有时它们是不必要的,一个小的代码注释就足够了(甚至根本没有注释)。假设开发人员有一些 Python 的基础知识。
- 文档字符串不应该解释函数如何工作,而是应该解释如何使用它。有时,可能有必要解释一段代码的内部机制,因此使用代码注释。
- 不要用文档字符串代替注释,也不要用注释代替代码。
摘要
以下是我们在本教程中学到的内容:
- 文档是 Python 项目的重要组成部分——它对最终用户、开发人员和您都很重要。
- 文档字符串是给使用代码的的,注释是给修改代码的的。
- PEP 257 总结 Python 文档字符串。
- 有四种主要的 docstring 格式:NumPy/SciPy docstring、Google docstring、 reStructuredText 和 Epytext 。前两种是最常见的。
- 脚本文档字符串应该描述脚本的功能、用法以及其中包含的功能。
我希望你今天学到了一些新东西。请随时在 LinkedIn 或 T2 GitHub 上与我联系。编码快乐!
分享目标对你成功的机会有帮助还是有伤害?
原文:https://www.dataquest.io/blog/does-sharing-goals-help-or-hurt-your-chances-of-success/
October 22, 2018
所以你决定要学习数据科学。你应该在社交媒体上分享你的目标,还是和一个负责任的伙伴分享?还是应该默默工作,直到你学到足够多的知识,可以称自己为数据科学家?
心理学研究表明,分享你的目标可能会对你真正实现目标的机会产生影响。但是要注意:这里没有简单的“分享/不分享”的答案。事实证明,分享的心理要比这复杂得多。
(警告:由于我们在谈论科学研究,本文中的几乎每个链接都是 PDF 链接)。
你应该和一个“负责任的伙伴”分享吗?
传统智慧认为分享是个好主意,因为有人让你负责能帮助你实现目标。研究表明这是真的,但只是在特定条件下。对各种目标跟踪和分享研究的元分析表明问责制的影响会有很大的不同,这取决于谁让你负责,以及我们所说的哪种问责制。
至于谁是谁,你的责任伙伴应该是一个朋友。像这样的研究表明,当你的进步被一个陌生人监控时,它实际上可能是德激励。此外,与朋友分享可能与更高的成功率相关。盖尔·马修斯博士最近开展的这项研究发现,告诉朋友自己对某个目标的承诺的受试者比没有告诉朋友的受试者更有可能实现这个目标。
也不应该是普通朋友。像这样的研究表明,从给予你过程赞扬(基于你的努力和你实际所做的赞扬)的人那里得到反馈,会比向给予你个人赞扬(基于你天生的能力或身份的赞扬)的人报告给你带来更好的结果。
换句话说,你想要一个会说“哇,你真的很努力!”而不是“哇,你真聪明!”事实上,拥有一个给你人称赞的人(“你真聪明!”)可能比完全得不到反馈更糟糕。如果你一直被告知你的成功是由于天生的天赋,当你遇到挑战和失败时,你更有可能把它视为你的先天不足,而不是可以通过更多努力或更好的策略来克服的东西。
你也想找到一个愿意根据你的需求来提供反馈的朋友,因为随着你学习的进展,你的需求可能会改变。研究人员发现,在学习新事物的早期,最好能得到积极的反馈。但是你越有经验,你对负面反馈的回应就越多。
原因是,通常在一个新项目或学习课程的早期阶段,我们的自我评估将集中在我们的承诺程度上。积极的反馈有助于我们肯定和巩固这种承诺。但是随着我们越来越深入,我们倾向于评估实际的进展。在这一点上,获得负面反馈往往会带来更好的结果,因为它会推动我们继续努力。在那个阶段,积极的反馈会让我们把脚从油门上移开。
总之:如果某人是你的朋友,与他人分享可能会有所帮助,如果那个朋友小心翼翼地给你过程上的赞扬,而不是赞扬你的内在品质,并愿意随着你学习的进展从注重积极反馈转向更多的消极反馈,可能会特别有帮助。

你应该分享什么?
所以你已经找到了合适的朋友来做你的责任伙伴。现在,你实际上告诉他们什么?这也很重要。在上面提到的马修斯研究中,与朋友分享目标的受试者比那些不分享的受试者更有可能成功,但是定期给朋友写进度报告的受试者甚至更有可能实现他们的目标。
这可能反映了心理学文献中提出的一个更广泛的观点。对一个过程负责可能比对一个结果负责更好。像这个和这个这样的研究发现,如果你被要求对结果负责,问责制最终会给你带来狭隘的视野,并阻碍批判性的创新思维。
这可能是因为对结果负责会鼓励你在你想要产生的结果的背景下证明你所做的一切,而不是诚实地评估你的行为。这可能会让你继续朝着那个结果努力,即使在调整你的目标变得更加有益之后。
另一方面,对一个过程负责与更好的结果相关,因为它让你致力于工作,但让你自由地批判性地评估,并随着你的进展对你的目标进行合乎逻辑的调整。
换句话说:不要告诉你的朋友你将成为一名数据科学家。告诉他们你每周将花 10 个小时学习和编码(然后每周给他们发送你所做的更新)。
还有一个原因,你不应该告诉朋友你的目标是成为一名数据科学家。对于我们中的许多人来说,成为数据科学家是一个职业目标,但它也是一个身份目标—我们喜欢被他人视为数据科学家的想法。那种想要改变我们身份的愿望可以成为一种激励力量,帮助我们朝着目标前进。但是最近的一项研究表明,公开分享身份目标会破坏他们。当你说你打算成为一名数据科学家时,人们可能会在你真正成为数据科学家之前就开始把你视为一名数据科学家(你也可能开始这样看待自己)。那种成为数据科学家的感觉是你努力工作的回报的一部分,所以如果你在达到目标之前已经得到了一点,你可能就没有坚持到底的内在动力了。
回顾:这里的教训是,如果你要分享,你应该分享关于你承诺要做的工作的过程目标。
社交媒体呢?
当谈到社交媒体分享时,答案明显更加模糊。
上面讨论的更广泛的研究表明,社交媒体分享可能是一个坏主意,因为它是与陌生人而不是朋友分享,并且它给你很少的机会来调节你得到的反馈类型是否有用。此外,像这样的研究表明,听到竞争可能会阻止学生学习,社交媒体充满了其他人学习和成功的故事。
另一方面,这些研究中没有一项是专门针对社交媒体的(其中许多是在社交媒体存在之前进行的)。还有一些研究着眼于社交媒体分享,并发现社交分享和目标实现之间的相关性。例如,这项关于减肥的研究发现,加入 Twitter 社区并在社交媒体上分享进展和技巧与有效减肥有关。
然而,尚不清楚这些结果在多大程度上可能取决于参与的特定社区,以及它们是否可能被暴露于竞争的负面影响所抵消(在数据科学等不断增长的领域中有很多)。说到社交媒体,我们唯一能确定的是是否需要更多的研究。
外卖食品
在我们得意忘形之前,有一些重要的警告:
- 一些科学研究不能证明任何事情,心理学——就像科学研究的所有领域一样——是一个不断发展的领域,随着新信息的出现,主流观点可能会发生变化。
- 每个人都是不同的,对你最有效的方法可能与多年来对大多数参与者最有效的方法不同。
- 我们只是在谈论优化你的机会。决定你成功的最关键因素是你付出了多少努力。在最好的情况下,像这样的提示可以给你一个微小的统计优势。
综上所述,如果你想最大化你实现目标的机会,看起来你应该分享它们,但是在这样做的时候,你应该遵循以下指导方针:
- 与朋友分享,而不是陌生人。如果可能的话,选择那些在给你反馈时愿意满足你的要求的人(见下面的第 4 和第 5 条),否则他们最终可能会带来更多的伤害而不是帮助。
- 分享过程目标,而不是结果或身份。不要告诉你的朋友你计划在四个月后成为一名数据科学家。告诉他们你计划每周花 10 个小时来学习、编码和构建项目。
- 用书面更新经常签到。
- 要求“过程表扬”而不是“个人表扬”或者选择一个自然倾向于称赞你的努力或你在完成任务时采用的策略的朋友,而不是称赞你与生俱来的智力或天赋。
- 先寻求正面反馈,然后在寻求负面反馈。
- 在社交媒体上打自己的电话,但避免关注竞争。特别是在早期,你想的是你在做什么,而不是其他人在做什么。
还不是学生?加入我们,开始免费学习数据科学。
已经是学生了?在 Twitter 上给我们留言,让我们知道什么最适合你——你是与世界分享你的过程还是秘密工作?
董:“Dataquest 帮我找到了一份喜欢的工作”
December 20, 2016
在博士后岗位上工作了 4 年后,董舟开始重新评估学术界。“就薪酬和稳定性而言,这不是一份真正的工作。我决定放弃博士后,尝试在工业界工作。”
董开始探索学习软件开发和数据科学。“我开始试图通过书本学习,但我错过了项目,以及如何将所有东西放在一起。”
“在那之后,我尝试了 Coursera,但我不喜欢视频决定我学习速度的方式。”
在读了 Dataquest 博客上的一篇文章后,董尝试用 Dataquest 学习。
董认为职业咨询是他成功的关键。“我从 Vik 那里得到了很多建议。因为我以前从未在工业界工作过,所以我能够向他了解他的经历。”
在 Dataquest 之前,我学习错误的东西是在浪费时间。Dataquest 给我指出了正确的方向。
“我问了他很多关于找工作的问题。这对我找工作有很大的帮助。有一个资深人士指导你是非常有帮助的。”
董成功地在薛定谔公司找到了一份高级软件开发员的工作。他开发用于制药、生物技术和材料科学研究的化学模拟软件。
“我是一个软件开发团队的成员。我可以把我的科学背景和我的新职业结合起来。”
“我喜欢 Dataquest,因为我可以控制自己解决问题的速度。小规模项目有助于实现从概念到现实的转变。”
“在 Dataquest 之前,我一直在浪费时间学习错误的东西。Dataquest 给我指出了正确的方向。我已经向正在找工作的朋友推荐了 Dataquest。”
“Dataquest 帮助我找到了一份行业工作。我希望我能早点发现它。”
维多利亚如何通过 Dataquest 将工资翻倍
原文:https://www.dataquest.io/blog/double-salary-dataquest-student/
September 19, 2019
维多利亚·古兹克在大学学习接近尾声时发现自己遇到了一个问题。
“我的本科教育实际上是神经科学,”她说,“但我意识到他们不会真的让你用本科学位做神经科学。这是那种需要上升到博士水平的事情。”
她真的想用接下来的五年时间来完成一篇论文吗?她不确定。但是当她反思自己的学习时,她意识到有些事情她是有把握的。“我在本科教育中真正喜欢的一点是统计方法的基础和数据分析的使用,”她说。
她决定继续努力。“我尽可能地接受了最初的几份工作,”她说。“我在一家实验室担任研究助理。我在一家非营利机构做了几年文书工作。”但是她意识到她需要提升自己的数据技能。她就是这样找到 Dataquest 的。
她说:“在内特·西尔弗(Nate Silver)成名的 15 分钟前后,我们突然不再是统计学家了,我们都是数据科学家。”。“因此,我对这个新奇的新术语做了一些研究,Dataquest 推荐我去哪里获得 Python 和 R 方面急需的基础知识,以及本科课程中可能无法获得的更深入的编程知识。”
“这就是 Dataquest 教育的力量。这份工作找到了我
因此,维多利亚开始学习 Dataquest 的数据科学课程。“我真的很喜欢你的平台,”她说。“我研究了其他几个,发现它们太容易拿了,填补了 Dataquest 方法的空白。”
如何一夜之间让工资翻倍
Dataquest 第一次收到维多利亚的来信是因为她想取消订阅。原因?她找到了一份数据分析师的工作。事实上,她甚至没有申请就得到一份数据分析师的工作!
“我完成了 Dataquest 上的项目,完成了课程路径,并在你更新平台的一年多时间里跟上了新内容,因此我是一名订户,”她说。"最终,我在 LinkedIn 上表示,我对招聘人员持开放态度."
就这么简单。
“这就是数据科学教育的力量,也是数据探索教育的力量,”她说。“这份工作找到了我。”
一个招聘人员给她发信息,她跟进了。她很快被安排了一次 Skype 采访,然后是一次面对面的采访。“他们问了我一些编程问题,我的回答让他们很满意。然后他们问我以前的编程工作的一些例子,我给了他们我的 GitHub。她说:“我指出了几个项目,它们特别关注数据分析师优先考虑的事情。
她说他们特别喜欢她完成的一个 Dataquest 引导的项目,该项目对一个电子服务产品的潜在目标市场进行了细分。“他们对此非常热情,”她说。“我绝对可以强调,该项目特别适用于数据分析和数据科学在野外的真实应用。”
事实上,该公司对维多利亚非常热情,以至于在他们第一次就该职位与她联系不到一周后,他们就向她发出了邀请。这是个好主意。
“一夜之间,我的收入翻了一番,”她说。"那份工作一夜之间让我的收入翻了一番."
不用说,她接受了。她现在是 Callisto Media 的数据分析师。
“我每天上班都编码,”她说。“我积极参与我们的研究,积极开发我们的产品。”她说,在平常的一天,她会写 Python 代码来做一些事情,比如为公司产品分析市场。
“我对自己的现状和 Dataquest 让我发展的技能感到非常满意,”她说。
为您的数据科学研究提供实用建议
“数据科学是一个奇妙的领域,超越了任何编程学科,”Victoria 说。“我发现这是最好的机会之一,不仅可以从事引人入胜的技术工作,还可以从事对世界有积极影响的工作。”
如果你想追随维多利亚的脚步,她有三条建议。
首先:“在(你)寻找任何其他来源之前,绝对要先看看 Dataquest,”她说。“我认为,就你发展的技能和你发展这些技能的时间表而言,这是你的时间和金钱的最佳价值。”
"一夜之间,我的收入翻了一番."
第二:“一定要确保不要只是为了做而做项目,而是要确保真正理解它们,并将它们融入到商业环境中,”她说。“回去在笔记本上解释你的代码。不要仅仅把[指导项目]当作家庭作业。你希望在这些项目上投入和你在工作中展示的项目一样多的关心和努力。公司确实对此做出了回应。”
第三:“拥有这些技术技能固然重要,”她说,“但你真的需要深刻理解如何获取数据和分析,并将其转化为对业务的可操作见解。”
她说,这是她推荐 Dataquest 的重要原因。“我真的认为 Dataquest 和他们的项目模型不仅提供了那些硬编程技能,还教会了你如何以有意义的方式应用它们。”
大量调查揭示了最好的万圣节糖果
原文:https://www.dataquest.io/blog/enormous-survey-reveals-the-best-halloween-candies/
October 30, 2021
对于我们这些喜欢糖果的人(也就是所有人)来说,万圣节可以说是最好的节日了。我一直喜欢万圣节,因为不管你多大,你可能都想要某种类型的糖果。但是,离这个季节只有几天了,你可能会想知道两件事:你会穿什么服装,以及(更重要的)你如何确保你得到了不给糖就捣蛋的人想要的糖果?
根据你住的地方,你也许能猜出什么糖果比你所在地区的其他糖果做得更好。但是,思考并不总是足以做出明确的决定。幸运的是,数据和调查让我们有更好的机会做出正确的选择。
特别是在万圣节,有一个数据集很有趣,它揭示了最佳糖果选择的秘密。2017 年, FiveThirtyEight 创建了一个数据集 ,根据超过 26.5 万名参与者的随机匹配,比较了 85 种有趣大小的流行糖果,以一劳永逸地决定真正的万圣节糖果之王。
数据集的第一印象
现在,作为一名热爱糖的数据科学家,为万圣节做准备,我不能错过探索这个数据集的机会,看看我应该在购物清单上添加什么糖果。
最终的万圣节糖果权力排名数据集基于 12 个特征变量比较了 85 种糖果,其中 9 个是描述糖果性质和内容的二元变量,例如它们是否包含巧克力、焦糖或坚果;它们是固体糖果还是棒状的,等等。剩下的 3 个变量描述了糖果的含糖量(或者我认为的甜度),价格,以及基于其他 11 个变量的获奖率。
更深入的探究(了解数据)
我们需要首先看到这些数据,以使用这个数据集来决定这个万圣节最好的糖果——或者只是知道哪个是最好的万圣节糖果。所以,让我们从使用 Python 和熊猫 T3 的简单 数据探索开始。
1。加载数据并浏览基本信息
从 GitHub 克隆数据集后,我们需要将数据集加载到 Pandas 数据框架中,并探索不同的方面,如数据集的大小和其中变量的类型。我们甚至可以将精度设置为 2 个小数点,以便更容易地处理浮点数字数据。
import pandas as pd
span class="token keyword">import matplotlib.pyplot as plt
span class="token operator">%matplotlib inline
andy = pd.read_csv("candy-data.csv")
span class="token comment" spellcheck="true">#Dispaly the size of the dataset
en(candy)
span class="token comment" spellcheck="true">#Examining the shape of the data frame
andy.shape
span class="token comment" spellcheck="true">#Set display precision to 2
d.set_option("display.precision", 2)
span class="token comment" spellcheck="true">#Getting the first 5 rows of the dataframe
andy.head()

我们还可以使用 candy.info()来确定数据集中的变量类型
")
我们可以使用 candy.info()获得基本的统计数据

2。访问和查询数据集
了解变量类型和数据集的构造将允许我们使用简单的查询和分组来探索数据。例如,我们可以只显示含有巧克力和焦糖的糖果,或者显示胜率为 70%或更高的糖果。我们也可以把两个条件放在一起,看看什么巧克力-焦糖糖果的中奖概率会更高。
candy[(candy["chocolate"] == 1) & (candy["caramel"] == 1) & (candy["winpercent"] > 70)]

我们还可以确定任何含有巧克力的糖果相对于同时含有巧克力和焦糖的糖果的平均获胜百分比,以及如果糖果含有巧克力、焦糖和坚果,该百分比将如何变化(将为 60.92%)。
candy.groupby('巧克力')['winpercent']。均值()[1]
3。可视化数据
探索任何新数据集时,我最喜欢的部分是可视化数据。虽然你可以通过查询数据、对一些列和行进行分组,并以书面形式分析数据的内容,但因为我们是视觉动物,所以当信息可视化时,我们会更好地感知信息。此外,有时数据可能包含隐藏的模式或趋势,您只能通过可视化来发现。
假设我们想知道甜度或价格是否会影响糖果的百分比。我们可以用散点图来显示甜度、价格和胜率。如果我们这样做,我们会发现这两个因素之间没有直接的联系。我们可以看到,一些甜度高的糖果,中奖几率很低。价格并不是决定一颗糖果输赢的决定性因素。
ax1 = nba.plot(kind='scatter', x='sugarpercent', y='winpercent', color='r', label ='sweetness leve')
x2 = nba.plot(kind='scatter', x='pricepercent', y='winpercent', color='g', label='price', ax=ax1)
x2.set_xlabel("Sugar/ Price Percentage")
x2.set_ylabel("Win Percentage")
")
所以,这将导致我们想知道哪个因素影响糖果中奖的百分比。然后,我们可以关注 9 个二元变量,看看每个变量如何影响胜率。我们可以从绘制这 9 个变量的平均胜率开始。
cat = ["chocolate","fruity","caramel","peanutyalmondy","nougat","crispedricewafer","hard","bar","pluribus"]
ve_win = [nba.groupby(item)['winpercent'].mean()[1] for item in cat]
lt.figure(figsize=(15,5))
lt.bar(cat, ave_win )
")
从那里,我们可以看到,含有巧克力、坚果(花生或杏仁)和一种酥脆元素(如威化饼)的糖果获胜的几率最高。如果我们根据胜率降序排列数据,然后根据胜率绘制前 10 种糖果,我们会发现这些糖果都含有巧克力和坚果成分。在这个数据集中,前两种糖果是里斯的花生酱杯和它的继任者,迷你里斯的。
从平均值中,我们还可以看到,如果糖果含有水果成分或者是硬糖,他们获胜的机会将比坚果巧克力竞争者少得多。
df = candy.sort_values("winpercent", ascending=False)
f.head(10).plot(x="competitorname" , y="winpercent" , kind="bar")
")
结论
从我们在这个数据集上使用的简单的 数据探索技术 来看,我可以非常自信地告诉你,如果你想在这个万圣节成为热门,就去买含有巧克力、坚果和松脆成分的糖果。这一定会让你的房子成为今年不给糖就捣蛋的人的最爱。
除了赢得万圣节的“不给糖就捣蛋”之战,你还可以使用这个数据集来决定下次聚会要带哪种糖果。你也可以用这个数据集来训练一个机器学习模型,来预测这个数据集中没有的其他糖果的胜率。最后,您可以使用这个数据集和一些聚类算法,根据超过 25 万人的意见创建一个完美糖果的公式。
所以,下次你在选择糖果来满足你的甜食时,要知道这些数据总能帮助你做出更明智的决定。毕竟,没有什么比万圣节前分析糖果更有趣的了。
来自数据科学招聘人员的入门级工作申请提示
原文:https://www.dataquest.io/blog/entry-level-data-science-job-application-tips/
March 5, 2019
毫无疑问,数据科学家的需求量很大。但是缺乏更高层次的数据科学家,加上媒体炒作的“最性感的工作”,吸引了大量新鲜血液进入这个行业。当涉及到入门级职位时,这导致了比你想象的更多的竞争。
那么如何才能获得数据科学的入门级工作呢?我们已经分享了一些来自数据科学家的好建议,但是为了了解更多,我们采访了 Stephanie Leuck。作为数据分析公司 8451 的大学招聘经理,斯蒂芬妮花了大量时间处理入门级数据科学工作申请,她已经见过数千份这样的申请。
我们请她分享了一些关于入门级数据科学申请人如何脱颖而出的见解。以下是她告诉我们的:
通过动手项目展示成功
由于入门级的申请人通常不会有任何工作经验,斯蒂芬妮说她正在寻找下一个最好的东西:做数据科学相关工作的成功证据。
“我在寻找不同技能组合的项目范例,”她说。"你知道,统计项目或面向数据科学的项目,商业分析."具体来说,她喜欢看到展示申请者“具有数据科学家所需的批判性思维和解决问题的能力,以及一些编码经验”的项目
这并不意味着她想在你的简历上看到代码,但她确实想看到编码技能的证据。你展示的项目应该展示你理解数据科学家需要解决的问题,并且应该展示你知道如何使用 SQL、R 或 Python 来解决这些问题。
你展示的项目也应该是独一无二的。斯蒂芬妮说,看到共同的项目不会伤害和她一起的初级申请人,因为所有的实践都是好的实践。但是她知道网上有几十个关于这些项目的教程,所以他们不太可能给她留下深刻印象,因为她知道你可能只是跟着一个教程。
“如果(你的项目)是一个更具原创性的想法或创意,那将增加更多的权重,”她说。
在你的简历上要具体
斯蒂芬妮说,初级申请人可能会让招聘人员的眼睛变得呆滞无神,因为他们对项目的描述含糊不清,不能清楚地表明申请人实际做了什么。像“我使用了统计方法来分析……”或“我将数据科学技术应用于数据……”这样的描述不能给招聘人员任何真实的信息,它们暗示你可能并不真正知道自己在做什么。
相反,斯蒂芬妮说,你应该清楚自己做了什么。这并不意味着你需要包括每一个微小的细节,但是如果你正在描述一个项目,你可能需要包括你在描述中使用的编码语言和具体的统计方法。
所以,举例来说,不要说‘我用统计方法分析了…’,你应该说‘我用 R 做了泊松回归,分析了[我的项目题目]。’这告诉招聘人员你有使用这种特定语言和这种特定统计概念的经验。如果您在数据科学工作中经常使用特定的包或库,您甚至可能希望包括它们的详细信息。
你需要 GitHub
没有工作经验,展示你的项目是至关重要的,至少,你需要有一个 GitHub。斯蒂芬妮说:“我认为 GitHub 是必不可少的。
“GitHub 或网站是很好的资源,因为它很容易访问,”她说。“这是你应该放在简历上的东西,但要确保上面有有价值的信息,是最新的,是活跃的。否则它会伤害你。”
斯蒂芬妮说,在 8451,他们不会在 GitHub 上寻找特定类型的项目,因为该公司处理各种各样的数据科学工作。因此,她说,他们“寻找那些更有激情、终身学习的人。”
“我宁愿看到(申请人)只是涉猎不同的语言,比如 R 或 Python,甚至一些更面向计算机科学的语言,”她说,“只是练习、构建和测试。”
斯蒂芬妮说,无论你包括什么,都要做得好,不要认为 GitHub 是理所当然的。“我认为 GitHub 是一个令人惊叹的工具,它基本上可以让你展示你可以在没有工作的情况下完成这项工作。没有多少行业可以做到这一点。”
求职信:要么做对,要么不做
大多数数据科学应用程序不包括求职信;斯蒂芬妮估计,她看到的应用程序中只有二十分之一配有一个。取决于申请什么时候来,它甚至可能不会被看:“如果我们在秋季,我们在看成千上万的简历,我没有时间也看你的求职信。”
可能有一些很好的理由来提交求职信,特别是如果你正从一个不同的职业进入数据科学,或者在获得一个不相关的学位后进入数据科学。斯蒂芬妮说,如果你能很好地展示你如何为自己在数据科学领域的职业生涯做好准备,求职信可以是解释这一点的好地方。
但这是一个危险的游戏:“我经常看到(求职信)伤害候选人,因为它太模糊了,他们列出了错误的公司,或者它实际上让我质疑:‘你知道你想做什么吗?’"
“如果你提交一封求职信,”她说,“确保它是一封好的。确保它是为公司量身定做的,确保里面有一些有价值的信息。这个想法是,除了简历上的内容之外,求职信还应该为你说话。不要给我重复简历。
证明你知道如何解决问题
斯蒂芬妮说,雇主不指望入门级的申请人完全掌握每一项可能的技术技能,所以如果你对 Python 或 R 和 SQL 有扎实的掌握,你可能拥有获得数据科学工作所需的所有编程技能。
但是除了技术技能之外,你还需要了解你正在使用的统计方法,以及如何应用它们来解决实际问题。如果你知道如何在你的代码中使用线性回归模型,但是你不知道何时或者为什么要应用线性回归模型,那就有问题了。在应用你的技术技能之前,你需要能够批判性地思考,评估问题是什么以及如何解决它。
“我们可以教你如何编码,”斯蒂芬妮说,“但你需要知道如何思考。”
这可能很难在简历中表现出来,但一种方法是展示解决了业务问题的项目,并简要地解释问题是什么以及你的项目如何帮助解决问题。您也可以在 Github 上更深入地了解这类事情。对你的分析解决了什么业务问题、为什么你已经应用了你所做的技术,以及你的结果如何解决了那个问题,这些都有助于证明你不仅仅是编码,你正在使用你的编码和统计技能来识别和解决真正的问题。
(还不具备实现这一目标所需的编码技能或统计知识吗? Dataquest 可以教你从零开始用 Python 或者 R 编码,我们也教你如何并且更重要的是什么时候和为什么应用各种统计和机器学习方法)。
软技能很重要
斯蒂芬妮说:“我们不希望有人只是坐在电脑前写代码。”。"我们需要一个有贡献的团队成员。"
“我们在团队中工作,”她谈到 8451。“我们这里是一个高度协作的工作环境,因此在一个有共同愿景的团队中工作的能力非常重要。其中一部分是对反馈持开放态度,乐于接受反馈,并愿意在需要时提出建设性的批评,比如挑战现状。”
虽然她具体谈到了 8451,但大多数公司都希望在任何职位的入门级求职者身上看到沟通和团队合作技能。对于数据分析师和数据科学家来说尤其如此,因为数据工作通常涉及与其他团队的频繁接触、沟通和协作。即使数据科学团队本身很小,但在一年的时间里,数据科学家与公司的许多其他团队一起收集和分析数据、构建仪表板、进行预测等并不罕见。
那么,你如何在简历中证明你确实拥有这些技能呢?斯蒂芬妮说:“我们喜欢看到人们参与课程之外的事情。”“可以是学生组织、网络组织、社区组织。当然,如果他们是面向数据科学或技术的,会有所帮助。参加案例研究竞赛、黑客马拉松……这些都是可以在简历上展示的好东西,因为这告诉我们你最有可能在一个团队中工作过。”
团队项目是展示这些技能的另一个好方法。斯蒂芬妮说,她很高兴在简历中看到团队项目,因为“这给了我一个跳板,让我可以说‘那么,你在那个团队里是谁?你的角色是什么?你的队友会如何描述你?我可以开始接触一些软技能,以了解你是否是一名团队成员。"
但她也发出了警告:不要成为那种说:‘是的,我团队里的每个人,没有人做工作,我必须领导一切。’
“这让我有点担心,”她说。
结论
如果你希望得到面试的回复,你对任何职位的求职申请都需要脱颖而出。上面所有的建议都应该有所帮助,但是如果你正在寻找一个总结一切的大收获,那就是:对于初级职位,你的工作申请应该显示你能做这份工作。
如果没有工作经验可以评估,招聘人员的第一个任务就是判断你是否具备工作所需的技能。你需要确保你的简历切实证明你拥有这些技能。
- 展示项目,展示你的编程和数据科学技能,并具体描述你做了什么。
- 拥有一个活跃的 Github,表明你正在定期进行数据科学工作,并且你了解你所做工作的背景以及它如何帮助解决业务问题。
- 参加聚会、黑客马拉松和团队项目,展示团队合作和其他软技能。
如果你能处理好应用程序的这些方面,你就能让自己脱颖而出。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
埃里克:“我想要一些实用的东西”
April 25, 2018
Eric Sales De Andrade 通过 Quora 来到 Dataquest。“我读了 Vik 的回复,他似乎知道自己在写什么。”
当时,他从事数据挖掘——“但只是把东西放进数据库。我想要真实的数据。”
他最初尝试了 DataCamp 和 Coursera 上的机器学习课程。但是他想要更实际的东西,使用 Python 和 r 处理真实数据集。
在试用了免费模块后,他认为 Dataquest 是一个很好的选择,因为它提供了有趣的数据集和衡量进展的 KPI。
这是有道理的——投资你的教育,获得一份高薪的工作。
他利用了 Dataquest 内部强大的支持系统,例如面向学生的 Slack channel。“社区是高级订阅的卖点之一。非常有用。”
埃里克获得了几次面试机会,现在是伦敦初创公司 Intelematics 的数据科学家和工程师。他整天致力于可视化和构建仪表板、管道和模型。
他建议同学们不要被吓倒。“一家公司不会指望你在第一周就开发神经网络。打好基础,然后计划在工作中提高自己的技能。”
数据科学的演变:增长与创新
原文:https://www.dataquest.io/blog/evolution-of-data-science-growth-innovation/
October 21, 2021
术语“数据科学”以及实践本身已经发展了多年。近年来,由于世界范围内数据收集、技术和大规模数据生产方面的创新,它的受欢迎程度有了相当大的提高。那些处理数据的人不得不依赖昂贵的程序和大型机的日子已经一去不复返了。像 Python 这样的编程语言以及收集、分析和解释数据的过程的激增为数据科学成为今天的热门领域铺平了道路。
数据科学始于统计学。数据科学发展的一部分是包含了机器学习、人工智能和物联网等概念。随着新信息的涌入和企业寻求增加利润和做出更好决策的新途径,数据科学开始扩展到其他领域,包括医学、工程等。
在本文中,我们将分享数据科学发展的简明摘要-从其作为统计学家梦想的卑微开端到其作为每个可以想象的行业认可的独特科学的当前状态。
在本文中,我们将分享数据科学发展的简明摘要-从其作为统计学家梦想的卑微开端到其作为每个可以想象的行业认可的独特科学的当前状态。
起源、预测、开端
我们可以说,数据科学诞生于应用统计学与计算机科学相结合的想法。由此产生的研究领域将利用现代计算的非凡能力。科学家们意识到,他们不仅可以收集数据和解决统计问题,还可以使用这些数据来解决现实世界的问题,并做出可靠的基于事实的预测。
1962: 美国数学家约翰·w·图基(John W. Tukey)首次阐述了数据科学梦想。在他现在著名的文章《数据分析的未来》中,他预见到在第一台个人电脑出现前近二十年一个新领域的必然出现。虽然图基走在了时代的前面,但他并不是唯一一个早期欣赏后来被称为“数据科学”的人。另一位早期人物是丹麦计算机工程师彼得·诺尔,他的著作《计算机方法简明概览》提供了数据科学的最早定义之一:
一旦建立了数据,处理数据的科学,而数据与其所代表的关系则委托给其他领域和科学
1977: 随着国际统计计算协会(IASC)的成立,Tukey 和 Naur 等“前”数据科学家的理论和预测变得更加具体,该协会的使命是“将传统统计方法、现代计算机技术和领域专家的知识联系起来,以便将数据转化为信息和知识。”
20 世纪 80 年代和 90 年代:随着第一次数据库知识发现(KDD)研讨会的出现和国际船级社联合会(IFCS)的成立,数据科学开始迈出更大的步伐。这两个学会是第一批专注于教育和培训数据科学理论和方法专业人员的学会(尽管该术语尚未被正式采用)。
正是在这一点上,数据科学开始获得希望将大数据和应用统计货币化的领先专业人士的更多关注。
1994: 《商业周刊》发表了一篇关于“ 数据库营销新现象的报道。 “它描述了企业收集和利用大量数据来更多地了解他们的客户、竞争或广告技巧的过程。当时唯一的问题是,这些公司被大量信息淹没,超出了它们的管理能力。海量数据引发了人们对为数据管理建立特定角色的第一波兴趣。企业似乎开始需要一种新的员工来让数据为自己服务。
20 世纪 90 年代和 21 世纪初:我们可以清楚地看到,数据科学已经作为一个公认的专门领域出现。一些数据科学学术期刊开始发行,Jeff Wu 和 William S. Cleveland 等数据科学支持者继续帮助开发和阐述数据科学的必要性和潜力。
2000 年代:通过提供几乎普及的互联网连接、通信和(当然)数据收集,技术取得了巨大的飞跃。
2005: 大数据进场。随着谷歌和脸书等科技巨头发现大量数据,能够处理这些数据的新技术变得必要。Hadoop 迎接了挑战,随后 Spark 和 Cassandra 首次亮相。
2014: 由于数据的重要性日益增加,以及组织对发现模式和做出更好的业务决策的兴趣,世界各地对数据科学家的需求开始大幅增长。

来源:https://www . zarantech . com/blog/why-data-science-jobs-is-in-big-demand/
2015: 机器学习、深度学习、人工智能(AI)正式进入数据科学领域。这些技术在过去十年中推动了创新——从个性化购物和娱乐到自动驾驶汽车,以及所有将这些人工智能的现实应用有效带入我们日常生活的见解。
2018: 该领域的新法规可能是数据科学发展的最大方面之一。
2020 年代:我们看到人工智能、机器学习领域的更多突破,以及对大数据领域合格专业人员不断增长的需求
数据科学的未来
看到我们的世界目前有多少是由数据和数据科学驱动的,我们可以合理地问,我们将何去何从?数据科学的未来会怎样?虽然很难确切知道未来的标志性突破是什么,但所有迹象似乎都表明机器学习的至关重要性。数据科学家正在寻找使用机器学习产生更智能和自主的人工智能的方法。
换句话说,数据科学家正在不知疲倦地致力于深度学习的发展,以使计算机更加智能。这些发展可以带来先进的机器人技术和强大的人工智能。专家预测,在一个前所未有的互联世界中,人工智能将能够理解人类、自动驾驶汽车和自动化公共交通,并与之无缝互动。数据科学将使这个新世界成为可能。
也许,从更令人兴奋的一面来看,我们可能会在不久的将来看到一个大范围自动化劳动的时代。预计这将彻底改变医疗保健、金融、运输和国防工业。
你怎样才能参与进来?
我们仍处于数据科学革命的早期阶段,这是加入的最佳时机。数据科学是一个令人兴奋和不断发展的职业,只会越来越强大,越来越有必要。随之而来的是对合格人才的大量需求。
对数据科学家的高需求和缺乏有才华的专业人士为有志学习者创造了独特的机会。不同行业和组织越来越多地采用数据科学应用将继续推动需求进一步增长。有了 Dataquest,您可以通过参加我们的 数据科学职业道路 来实现您的职业目标,这将使您在不到一年的时间内从初学者到工作就绪。
使用 Python 和 Pandas 的 Excel 教程
December 8, 2017
为什么要用 Python 学习使用 Excel?Excel 是最流行和最广泛使用的数据工具之一;很难找到一个不以某种方式与之合作的组织。从分析师到销售副总裁,再到首席执行官,各种专业人士都使用 Excel 进行快速统计和严肃的数据处理。
随着 Excel 如此普及,数据专业人员必须熟悉它。用 Python 或 R 处理数据比用 Excel 的 UI 更有优势,所以找到一种使用代码处理 Excel 的方法至关重要。令人欣慰的是,已经有一个很好的工具可以将 Excel 与 Python 结合使用,这个工具叫做pandas。
Pandas 拥有从 Excel 文件中读取各种数据的优秀方法。如果您的目标受众喜欢,您也可以将 pandas 中的结果导出回 Excel。Pandas 非常适合其他常规数据分析任务,例如:
- 快速探索性数据分析
- 画出吸引人的情节
- 将数据输入 scikit-learn 等机器学习工具
- 基于您的数据构建机器学习模型
- 将经过清理和处理的数据用于任意数量的数据工具
Pandas 比 Excel 更擅长自动化数据处理任务,包括处理 Excel 文件。
在本教程中,我们将向您展示如何在 pandas 中使用 Excel 文件。我们将涵盖以下概念。
- 用必要的软件安装您的计算机
- 将 Excel 文件中的数据读入 pandas
- 熊猫的数据探索
- 使用 matplotlib 可视化库可视化熊猫中的数据
- 在 pandas 中操作和重塑数据
- 将数据从 pandas 移动到 Excel
请注意,本教程不提供对熊猫的深入研究。要更多地探索熊猫,请查看我们的课程。
系统先决条件
我们将使用 Python 3 和 Jupyter Notebook 来演示本教程中的代码。除了 Python 和 Jupyter Notebook,您还需要以下 Python 模块:
- matplotlib–数据可视化
- NumPy–数字数据功能
- open pyxl–读/写 Excel 2010 xlsx/xlsm 文件
- 熊猫–数据导入、清理、探索和分析
- xlrd–读取 Excel 数据
- xlwt–写入 Excel
- XlsxWriter–写入 Excel (xlsx)文件
有多种方法可以设置所有模块。下面我们介绍三种最常见的场景。
- 如果您通过 Anaconda 包管理器安装了 Python,那么您可以使用命令
conda install安装所需的模块。例如,要安装 pandas,您可以执行命令-conda install pandas。 - 如果您已经在计算机上安装了一个常规的非 Anaconda Python,那么您可以使用
pip来安装所需的模块。打开你的命令行程序,执行命令pip install <module name>安装一个模块。你应该用你要安装的模块的真实名称替换<module name>。例如,要安装 pandas,您可以执行命令-pip install pandas。 - 如果您还没有安装 Python,您应该通过 Anaconda 包管理器来获得它。Anaconda 为 Windows、Mac 和 Linux 计算机提供安装程序。如果您选择完整安装程序,您将在一个包中获得您需要的所有模块,以及 Python 和 pandas。这是最简单快捷的入门方式。
数据集
在本教程中,我们将使用从 Kaggle 的 IMDB 分数数据创建的多表 Excel 文件。你可以在这里下载文件。

我们的 Excel 文件有三张表:“1900 年代”、“2000 年代”和“2010 年代”每一页都有当年的电影数据。
我们将使用该数据集来查找电影的分级分布,可视化具有最高分级和净收益的电影,并计算关于电影的统计信息。我们将使用 Python 和 pandas 来分析和探索这些数据,从而展示 pandas 在 Python 中处理 Excel 数据的能力。
从 Excel 文件中读取数据
我们需要首先将 Excel 文件中的数据导入 pandas。为此,我们从导入 pandas 模块开始。
import pandas as pd
然后,我们使用 pandas 的 read_excel 方法从 excel 文件中读入数据。调用此方法最简单的方法是传递文件名。如果没有指定工作表名称,那么它将读取索引中的第一个工作表(如下所示)。
excel_file = 'movies.xls'
movies = pd.read_excel(excel_file)
这里,read_excel方法将 Excel 文件中的数据读入 pandas DataFrame 对象。Pandas 默认将数据存储在数据帧中。然后,我们将这个数据帧存储到一个名为movies的变量中。
Pandas 有一个内置的DataFrame.head()方法,我们可以使用它轻松地显示数据帧的前几行。如果没有传递参数,它将显示前五行。如果传递了一个数字,它将从顶部开始显示相同数量的行。
movies.head()
| 标题 | 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | … | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 不宽容:爱情的斗争贯穿了整个时代 | One thousand nine hundred and sixteen | 戏剧|历史|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and twenty-three | One point three three | Three hundred and eighty-five thousand nine hundred and seven | 圆盘烤饼 | … | Four hundred and thirty-six | Twenty-two | Nine | Four hundred and eighty-one | Six hundred and ninety-one | one | Ten thousand seven hundred and eighteen | Eighty-eight | Sixty-nine | Eight |
| one | 翻过山去救济院 | One thousand nine hundred and twenty | 犯罪|戏剧 | 圆盘烤饼 | 美利坚合众国 | 圆盘烤饼 | One hundred and ten | One point three three | One hundred thousand | Three million | … | Two | Two | Zero | four | Zero | one | five | one | One | Four point eight |
| Two | 大游行 | One thousand nine hundred and twenty-five | 戏剧|爱情|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and fifty-one | One point three three | Two hundred and forty-five thousand | 圆盘烤饼 | … | Eighty-one | Twelve | Six | One hundred and eight | Two hundred and twenty-six | Zero | Four thousand eight hundred and forty-nine | Forty-five | Forty-eight | Eight point three |
| three | 大都市 | One thousand nine hundred and twenty-seven | 戏剧|科幻 | 德国人 | 德国 | 未评级 | One hundred and forty-five | One point three three | Six million | Twenty-six thousand four hundred and thirty-five | … | One hundred and thirty-six | Twenty-three | Eighteen | Two hundred and three | Twelve thousand | one | One hundred and eleven thousand eight hundred and forty-one | Four hundred and thirteen | Two hundred and sixty | Eight point three |
| four | 潘多拉的盒子 | One thousand nine hundred and twenty-nine | 犯罪|戏剧|爱情 | 德国人 | 德国 | 未评级 | One hundred and ten | One point three three | 圆盘烤饼 | Nine thousand nine hundred and fifty | … | Four hundred and twenty-six | Twenty | Three | Four hundred and fifty-five | Nine hundred and twenty-six | one | Seven thousand four hundred and thirty-one | Eighty-four | Seventy-one | Eight |
5 行× 25 列
Excel 文件通常有多个工作表,读取特定工作表或全部工作表的能力非常重要。为了使这变得简单,pandas read_excel方法采用了一个名为sheetname的参数,它告诉 pandas 从哪个表中读取数据。为此,您可以使用图纸名称或图纸编号。图纸编号从零开始。如果没有给出sheetname参数,则默认为 0,pandas 将导入第一个工作表。
默认情况下,pandas 会自动分配一个从零开始的数字索引或行标签。如果数据中没有包含唯一值的列可以作为更好的索引,您可能希望保留默认索引。如果您认为有一列可以作为更好的索引,您可以通过将index_col属性设置为一列来覆盖默认行为。它采用一个数值来设置一个列作为索引,或者采用一个数值列表来创建一个多索引。
在下面的代码中,我们选择第一列“Title”作为索引(index=0),方法是将 0 传递给参数index_col。
movies_sheet1 = pd.read_excel(excel_file, sheetname=0, index_col=0)
movies_sheet1.head()
| 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | 导演 | … | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 标题 | |||||||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 不宽容:爱情的斗争贯穿了整个时代 | One thousand nine hundred and sixteen | 戏剧|历史|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and twenty-three | One point three three | Three hundred and eighty-five thousand nine hundred and seven | 圆盘烤饼 | 大卫·格里菲斯 | … | Four hundred and thirty-six | Twenty-two | Nine | Four hundred and eighty-one | Six hundred and ninety-one | one | Ten thousand seven hundred and eighteen | Eighty-eight | Sixty-nine | Eight |
| 翻过山去救济院 | One thousand nine hundred and twenty | 犯罪|戏剧 | 圆盘烤饼 | 美利坚合众国 | 圆盘烤饼 | One hundred and ten | One point three three | One hundred thousand | Three million | 哈里·米勒德 | … | Two | Two | Zero | four | Zero | one | five | one | One | Four point eight |
| 大游行 | One thousand nine hundred and twenty-five | 戏剧|爱情|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and fifty-one | One point three three | Two hundred and forty-five thousand | 圆盘烤饼 | 金·维多 | … | Eighty-one | Twelve | Six | One hundred and eight | Two hundred and twenty-six | Zero | Four thousand eight hundred and forty-nine | Forty-five | Forty-eight | Eight point three |
| 大都市 | One thousand nine hundred and twenty-seven | 戏剧|科幻 | 德国人 | 德国 | 未评级 | One hundred and forty-five | One point three three | Six million | Twenty-six thousand four hundred and thirty-five | 弗里茨·兰 | … | One hundred and thirty-six | Twenty-three | Eighteen | Two hundred and three | Twelve thousand | one | One hundred and eleven thousand eight hundred and forty-one | Four hundred and thirteen | Two hundred and sixty | Eight point three |
| 潘多拉的盒子 | One thousand nine hundred and twenty-nine | 犯罪|戏剧|爱情 | 德国人 | 德国 | 未评级 | One hundred and ten | One point three three | 圆盘烤饼 | Nine thousand nine hundred and fifty | 乔治·威廉·帕布斯特 | … | Four hundred and twenty-six | Twenty | Three | Four hundred and fifty-five | Nine hundred and twenty-six | one | Seven thousand four hundred and thirty-one | Eighty-four | Seventy-one | Eight |
5 行× 24 列
正如您在上面注意到的,我们的 Excel 数据文件有三张表。我们已经阅读了上面数据框中的第一页。现在,使用相同的语法,我们也将读入两张表的其余部分。
movies_sheet2 = pd.read_excel(excel_file, sheetname=1, index_col=0)
movies_sheet2.head()
| 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | 导演 | … | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 标题 | |||||||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 102 只斑点狗 | Two thousand | 冒险|喜剧|家庭 | 英语 | 美利坚合众国 | G | One hundred | One point eight five | Eighty-five million | Sixty-six million nine hundred and forty-one thousand five hundred and fifty-nine | 凯文·利玛 | … | Two thousand | Seven hundred and ninety-five | Four hundred and thirty-nine | Four thousand one hundred and eighty-two | Three hundred and seventy-two | one | Twenty-six thousand four hundred and thirteen | Seventy-seven | Eighty-four | Four point eight |
| 28 天 | Two thousand | 喜剧|戏剧 | 英语 | 美利坚合众国 | PG-13 | One hundred and three | one point three seven | Forty-three million | Thirty-seven million thirty-five thousand five hundred and fifteen | 贝蒂·托马斯 | … | Twelve thousand | Ten thousand | Six hundred and sixty-four | Twenty-three thousand eight hundred and sixty-four | Zero | one | Thirty-four thousand five hundred and ninety-seven | One hundred and ninety-four | One hundred and sixteen | Six |
| 三振出局 | Two thousand | 喜剧 | 英语 | 美利坚合众国 | 稀有 | Eighty-two | One point eight five | Six million | Nine million eight hundred and twenty-one thousand three hundred and thirty-five | DJ 维尼 | … | Nine hundred and thirty-nine | Seven hundred and six | Five hundred and eighty-five | Three thousand three hundred and fifty-four | One hundred and eighteen | one | One thousand four hundred and fifteen | Ten | Twenty-two | Four |
| 阿伯丁 | Two thousand | 戏剧 | 英语 | 英国 | 圆盘烤饼 | One hundred and six | One point eight five | Six million five hundred thousand | Sixty-four thousand one hundred and forty-eight | Hans Petter Moland | … | Eight hundred and forty-four | Two | Zero | Eight hundred and forty-six | Two hundred and sixty | Zero | Two thousand six hundred and one | Thirty-five | Twenty-eight | Seven point three |
| 所有漂亮的马 | Two thousand | 戏剧|爱情|西部片 | 英语 | 美利坚合众国 | PG-13 | Two hundred and twenty | Two point three five | Fifty-seven million | Fifteen million five hundred and twenty-seven thousand one hundred and twenty-five | 比利·鲍伯·松顿 | … | Thirteen thousand | Eight hundred and sixty-one | Eight hundred and twenty | Fifteen thousand and six | Six hundred and fifty-two | Two | Eleven thousand three hundred and eighty-eight | One hundred and eighty-three | Eighty-five | Five point eight |
5 行× 24 列
movies_sheet3 = pd.read_excel(excel_file, sheetname=2, index_col=0)
movies_sheet3.head()
| 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | 导演 | … | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 标题 | |||||||||||||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 127 小时 | Two thousand and ten | 冒险|传记|戏剧|惊悚 | 英语 | 美利坚合众国 | 稀有 | Ninety-four | One point eight five | Eighteen million | Eighteen million three hundred and twenty-nine thousand four hundred and sixty-six | 丹尼·鲍伊尔 | … | Eleven thousand | Six hundred and forty-two | Two hundred and twenty-three | Eleven thousand nine hundred and eighty-four | Sixty-three thousand | Zero | Two hundred and seventy-nine thousand one hundred and seventy-nine | Four hundred and forty | Four hundred and fifty | Seven point six |
| 3 个后院 | Two thousand and ten | 戏剧 | 英语 | 美利坚合众国 | 稀有 | Eighty-eight | 圆盘烤饼 | Three hundred thousand | 圆盘烤饼 | 埃里克·门德尔松 | … | Seven hundred and ninety-five | Six hundred and fifty-nine | Three hundred and one | One thousand eight hundred and eighty-four | Ninety-two | Zero | Five hundred and fifty-four | Twenty-three | Twenty | Five point two |
| three | Two thousand and ten | 喜剧|戏剧|爱情 | 德国人 | 德国 | 未征税的 | One hundred and nineteen | Two point three five | 圆盘烤饼 | Fifty-nine thousand seven hundred and seventy-four | 汤姆·提克威 | … | Twenty-four | Twenty | Nine | sixty-nine | Two thousand | Zero | Four thousand two hundred and twelve | Eighteen | Seventy-six | Six point eight |
| 8:摩门教的主张 | Two thousand and ten | 纪录片 | 英语 | 美利坚合众国 | 稀有 | Eighty | One point seven eight | Two million five hundred thousand | Ninety-nine thousand eight hundred and fifty-one | 里德·考恩 | … | One hundred and ninety-one | Twelve | Five | Two hundred and ten | Zero | Zero | One thousand one hundred and thirty-eight | Thirty | Twenty-eight | Seven point one |
| 海龟的故事:萨米的冒险 | Two thousand and ten | 冒险|动画|家庭 | 英语 | 法国 | 宜在家长指导下观看的 | Eighty-eight | Two point three five | 圆盘烤饼 | 圆盘烤饼 | 本·斯塔西 | … | Seven hundred and eighty-three | Seven hundred and forty-nine | Six hundred and two | Three thousand eight hundred and seventy-four | Zero | Two | Five thousand three hundred and eighty-five | Twenty-two | Fifty-six | Six point one |
5 行× 24 列
由于所有三个工作表都有相似的数据,但记录移动不同,我们将从上面创建的所有三个数据帧中创建一个数据帧。为此,我们将使用 pandas concat方法,传入我们刚刚创建的三个数据帧的名称,并将结果分配给一个新的数据帧对象movies。通过保持数据帧名称与之前相同,我们覆盖了之前创建的数据帧。
movies = pd.concat([movies_sheet1, movies_sheet2, movies_sheet3])
我们可以通过检查组合数据帧中的行数来检查这种连接,方法是对其调用方法shape,该方法将给出行数和列数。
movies.shape
(5042, 24)
使用 ExcelFile 类读取多个工作表
我们还可以使用 ExcelFile 类来处理同一个 Excel 文件中的多个工作表。我们首先使用ExcelFile包装 Excel 文件,然后将其传递给read_excel方法。
xlsx = pd.ExcelFile(excel_file)
movies_sheets = []
for sheet in xlsx.sheet_names:
movies_sheets.append(xlsx.parse(sheet))
movies = pd.concat(movies_sheets)
如果您正在读取一个包含许多工作表的 Excel 文件,并且正在创建许多数据帧,那么与read_excel相比,ExcelFile更加方便和高效。使用 ExcelFile,您只需要传递一次 Excel 文件,然后就可以使用它来获取数据帧。使用read_excel时,每次都要传递 Excel 文件,因此每个工作表都要重新加载该文件。如果 Excel 文件有许多包含大量行的工作表,这可能会严重影响性能。
探索数据
现在我们已经从 Excel 文件中读取了电影数据集,我们可以开始使用 pandas 来研究它。pandas DataFrame 以表格格式存储数据,就像 Excel 在工作表中显示数据的方式一样。Pandas 有许多内置方法来探索我们从刚刚读入的 Excel 文件中创建的数据帧。
我们已经在前一节中介绍了方法head,该方法显示数据帧中从顶部开始的几行。让我们看看在探索数据集时更方便的一些方法。
我们可以使用shape方法找出数据帧的行数和列数。
movies.shape
(5042, 25)
这告诉我们,我们的 Excel 文件有 5042 条记录和 25 列或观察值。这对于报告记录和列的数量并将其与源数据集进行比较非常有用。
我们可以使用tail方法来查看底部的行。如果没有传递参数,则只返回底部的五行。
movies.tail()
| 标题 | 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | … | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One thousand five hundred and ninety-nine | 战争与和平 | 圆盘烤饼 | 戏剧|历史|爱情|战争 | 英语 | 英国 | 电视-14 | 圆盘烤饼 | Sixteen | 圆盘烤饼 | 圆盘烤饼 | … | One thousand | Eight hundred and eighty-eight | Five hundred and two | Four thousand five hundred and twenty-eight | Eleven thousand | One | Nine thousand two hundred and seventy-seven | Forty-four | Ten | Eight point two |
| One thousand six hundred | 翅膀 | 圆盘烤饼 | 喜剧|戏剧 | 英语 | 美利坚合众国 | 圆盘烤饼 | Thirty | One point three three | 圆盘烤饼 | 圆盘烤饼 | … | Six hundred and eighty-five | Five hundred and eleven | Four hundred and twenty-four | One thousand eight hundred and eighty-four | One thousand | Five | Seven thousand six hundred and forty-six | Fifty-six | Nineteen | Seven point three |
| One thousand six hundred and one | 沃尔夫克里克 | 圆盘烤饼 | 戏剧|恐怖|惊悚 | 英语 | 澳大利亚 | 圆盘烤饼 | 圆盘烤饼 | Two | 圆盘烤饼 | 圆盘烤饼 | … | Five hundred and eleven | Four hundred and fifty-seven | Two hundred and six | One thousand six hundred and seventeen | Nine hundred and fifty-four | Zero | Seven hundred and twenty-six | Six | Two | Seven point one |
| One thousand six hundred and two | 呼啸山庄 | 圆盘烤饼 | 戏剧|浪漫 | 英语 | 英国 | 圆盘烤饼 | One hundred and forty-two | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | Twenty-seven thousand | Six hundred and ninety-eight | Four hundred and twenty-seven | Twenty-nine thousand one hundred and ninety-six | Zero | Two | Six thousand and fifty-three | Thirty-three | Nine | Seven point seven |
| One thousand six hundred and three | 游戏王。决斗怪物 | 圆盘烤饼 | 动作|冒险|动画|家庭|幻想 | 日本人 | 日本 | 圆盘烤饼 | Twenty-four | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | … | Zero | 圆盘烤饼 | 圆盘烤饼 | Zero | One hundred and twenty-four | Zero | Twelve thousand four hundred and seventeen | Fifty-one | Six | Seven |
5 行× 25 列
在 Excel 中,您可以根据一列或多列中的值对工作表进行排序。在熊猫身上,你可以用sort_values方法做同样的事情。例如,让我们根据总收入列对电影数据帧进行排序。
sorted_by_gross = movies.sort_values(['Gross Earnings'], ascending=False)
因为我们有按列中的值排序的数据,所以我们可以用它做一些有趣的事情。例如,我们可以按总收入显示前 10 部电影。
sorted_by_gross["Gross Earnings"].head(10)
1867 760505847.0
1027 658672302.0
1263 652177271.0
610 623279547.0
611 623279547.0
1774 533316061.0
1281 474544677.0
226 460935665.0
1183 458991599.0
618 448130642.0
Name: Gross Earnings, dtype: float64
我们还可以根据总收入为前 10 名电影创建一个情节。Pandas 通过 matplotlib(一个流行的数据可视化库)可以很容易地用图和图表可视化您的数据。有了几行代码,你就可以开始绘图了。此外,matplotlib 绘图在 Jupyter 笔记本中工作良好,因为您可以在代码下移动绘图。
首先,我们导入 matplotlib 模块,并设置 matplotlib 在 Jupyter 笔记本中显示绘图。
import matplotlib.pyplot as plt%matplotlib inline
我们将绘制一个条形图,其中每个条形代表前 10 部电影中的一部。我们可以通过调用 plot 方法并将参数kind设置为barh来实现这一点。这告诉matplotlib画一个单杠图。
sorted_by_gross['Gross Earnings'].head(10).plot(kind="barh")
plt.show()

让我们创建一个 IMDB 分数直方图,以检查 IMDB 分数在所有电影中的分布。直方图是可视化数据集分布的好方法。我们对来自电影数据帧的 IMDB 分数序列使用plot方法,并向其传递参数。
movies['IMDB Score'].plot(kind="hist")
plt.show()

这种数据可视化表明,大多数 IMDB 得分在 6 到 8 分之间。
获取数据的统计信息
Pandas 有一些非常方便的方法来查看我们数据集的统计数据。例如,我们可以使用describe方法来获得数据集的统计摘要。
movies.describe()
| 年 | 持续时间 | 长宽比 | 预算 | 总收入 | 脸书喜欢——导演 | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数数 | 4935.000000 | 5028.000000 | 4714.000000 | 4.551000e+03 | 4.159000e+03 | 4938.000000 | 5035.000000 | 5029.000000 | 5020.000000 | 5042.000000 | 5042.000000 | 5029.000000 | 5.042000e+03 | 5022.000000 | 4993.000000 | 5042.000000 |
| 意思是 | 2002.470517 | 107.201074 | 2.220403 | 3.975262e+07 | 4.846841e+07 | 686.621709 | 6561.323932 | 1652.080533 | 645.009761 | 9700.959143 | 7527.457160 | 1.371446 | 8.368475e+04 | 272.770808 | 140.194272 | 6.442007 |
| 标准 | 12.474599 | 25.197441 | 1.385113 | 2.061149e+08 | 6.845299e+07 | 2813.602405 | 15021.977635 | 4042.774685 | 1665.041728 | 18165.101925 | 19322.070537 | 2.013683 | 1.384940e+05 | 377.982886 | 121.601675 | 1.125189 |
| 部 | 1916.000000 | 7.000000 | 1.180000 | 2.180000e+02 | 1.620000e+02 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 5.000000e+00 | 1.000000 | 1.000000 | 1.600000 |
| 25% | 1999.000000 | 93.000000 | 1.850000 | 6.000000e+06 | 5.340988e+06 | 7.000000 | 614.500000 | 281.000000 | 133.000000 | 1411.250000 | 0.000000 | 0.000000 | 8.599250e+03 | 65.000000 | 50.000000 | 5.800000 |
| 50% | 2005.000000 | 103.000000 | 2.350000 | 2.000000e+07 | 2.551750e+07 | 49.000000 | 988.000000 | 595.000000 | 371.500000 | 3091.000000 | 166.000000 | 1.000000 | 3.437100e+04 | 156.000000 | 110.000000 | 6.600000 |
| 75% | 2011.000000 | 118.000000 | 2.350000 | 4.500000e+07 | 6.230944e+07 | 194.750000 | 11000.000000 | 918.000000 | 636.000000 | 13758.750000 | 3000.000000 | 2.000000 | 9.634700e+04 | 326.000000 | 195.000000 | 7.200000 |
| 最大 | 2016.000000 | 511.000000 | 16.000000 | 1.221550e+10 | 7.605058e+08 | 23000.000000 | 640000.000000 | 137000.000000 | 23000.000000 | 656730.000000 | 349000.000000 | 43.000000 | 1.689764e+06 | 5060.000000 | 813.000000 | 9.500000 |
describe方法显示每一列的以下信息。
- 值的计数或数量
- 意思是
- 标准偏差
- 最小值、最大值
- 25%、50%和 75%分位数
请注意,此信息仅针对数值进行计算。
我们也可以使用相应的方法一次访问一个信息。例如,要获得特定列的平均值,可以对该列使用mean方法。
movies["Gross Earnings"].mean()
48468407.526809327
就像均值一样,对于我们想要访问的每个统计信息,都有可用的方法。你可以在我们的免费熊猫小抄中读到这些方法。
读取没有标题的文件并跳过记录
在本教程的前面,我们看到了一些读取特定类型的 Excel 文件的方法,这些文件有标题,没有需要跳过的行。有时,Excel 表没有任何标题行。对于这种情况,您可以告诉 pandas 不要将第一行视为标题或列名。如果 Excel 表的前几行包含不应该读入的数据,您可以要求read_excel方法从顶部开始跳过一定数量的行。
例如,看看这个 Excel 文件的前几行。
这个文件显然没有标题,前四行不是实际记录,因此不应该读入。我们可以通过将参数header设置为None来告诉 read_excel 没有标题,并且我们可以通过将参数skiprows设置为 4 来跳过前四行。
movies_skip_rows = pd.read_excel("movies-no-header-skip-rows.xls", header=None, skiprows=4)
movies_skip_rows.head(5)
| Zero | one | Two | three | four | five | six | seven | eight | nine | … | Fifteen | Sixteen | Seventeen | Eighteen | Nineteen | Twenty | Twenty-one | Twenty-two | Twenty-three | Twenty-four | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 大都市 | One thousand nine hundred and twenty-seven | 戏剧|科幻 | 德国人 | 德国 | 未评级 | One hundred and forty-five | One point three three | Six million | Twenty-six thousand four hundred and thirty-five | … | One hundred and thirty-six | Twenty-three | Eighteen | Two hundred and three | Twelve thousand | one | One hundred and eleven thousand eight hundred and forty-one | Four hundred and thirteen | Two hundred and sixty | Eight point three |
| one | 潘多拉的盒子 | One thousand nine hundred and twenty-nine | 犯罪|戏剧|爱情 | 德国人 | 德国 | 未评级 | One hundred and ten | One point three three | 圆盘烤饼 | Nine thousand nine hundred and fifty | … | Four hundred and twenty-six | Twenty | Three | Four hundred and fifty-five | Nine hundred and twenty-six | one | Seven thousand four hundred and thirty-one | Eighty-four | Seventy-one | Eight |
| Two | 百老汇的旋律 | One thousand nine hundred and twenty-nine | 音乐|浪漫 | 英语 | 美利坚合众国 | 通过 | One hundred | one point three seven | Three hundred and seventy-nine thousand | Two million eight hundred and eight thousand | … | Seventy-seven | Twenty-eight | Four | One hundred and nine | One hundred and sixty-seven | eight | Four thousand five hundred and forty-six | Seventy-one | Thirty-six | Six point three |
| three | 地狱天使 | One thousand nine hundred and thirty | 戏剧|战争 | 英语 | 美利坚合众国 | 通过 | Ninety-six | One point two | Three million nine hundred and fifty thousand | 圆盘烤饼 | … | Four hundred and thirty-one | Twelve | Four | Four hundred and fifty-seven | Two hundred and seventy-nine | one | Three thousand seven hundred and fifty-three | Fifty-three | Thirty-five | Seven point eight |
| four | 永别了,武器 | One thousand nine hundred and thirty-two | 戏剧|爱情|战争 | 英语 | 美利坚合众国 | 未征税的 | Seventy-nine | one point three seven | Eight hundred thousand | 圆盘烤饼 | … | Nine hundred and ninety-eight | One hundred and sixty-four | Ninety-nine | One thousand two hundred and eighty-four | Two hundred and thirteen | one | Three thousand five hundred and nineteen | Forty-six | Forty-two | Six point six |
5 行× 25 列
我们跳过了工作表中的四行,没有使用任何一行作为标题。另外,请注意,可以在一个 read 语句中组合不同的选项。要跳过工作表底部的行,您可以使用选项skip_footer,它的工作方式与skiprows类似,唯一的区别是行是从底部向上计数的。
前面数据帧中的列名是数字,由 pandas 默认分配。我们可以通过调用 DataFrame 上的方法columns并将列名作为列表传递来将列名重命名为描述性的名称。
movies_skip_rows.columns = ['Title', 'Year', 'Genres', 'Language', 'Country', 'Content Rating', 'Duration', 'Aspect Ratio', 'Budget', 'Gross Earnings', 'Director', 'Actor 1', 'Actor 2', 'Actor 3', 'Facebook Likes - Director', 'Facebook Likes - Actor 1', 'Facebook Likes - Actor 2', 'Facebook Likes - Actor 3', 'Facebook Likes - cast Total', 'Facebook likes - Movie', 'Facenumber in posters', 'User Votes', 'Reviews by Users', 'Reviews by Crtiics', 'IMDB Score']
movies_skip_rows.head()
| 标题 | 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | … | 脸书喜欢——演员 1 | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 大都市 | One thousand nine hundred and twenty-seven | 戏剧|科幻 | 德国人 | 德国 | 未评级 | One hundred and forty-five | One point three three | Six million | Twenty-six thousand four hundred and thirty-five | … | One hundred and thirty-six | Twenty-three | Eighteen | Two hundred and three | Twelve thousand | one | One hundred and eleven thousand eight hundred and forty-one | Four hundred and thirteen | Two hundred and sixty | Eight point three |
| one | 潘多拉的盒子 | One thousand nine hundred and twenty-nine | 犯罪|戏剧|爱情 | 德国人 | 德国 | 未评级 | One hundred and ten | One point three three | 圆盘烤饼 | Nine thousand nine hundred and fifty | … | Four hundred and twenty-six | Twenty | Three | Four hundred and fifty-five | Nine hundred and twenty-six | one | Seven thousand four hundred and thirty-one | Eighty-four | Seventy-one | Eight |
| Two | 百老汇的旋律 | One thousand nine hundred and twenty-nine | 音乐|浪漫 | 英语 | 美利坚合众国 | 通过 | One hundred | one point three seven | Three hundred and seventy-nine thousand | Two million eight hundred and eight thousand | … | Seventy-seven | Twenty-eight | Four | One hundred and nine | One hundred and sixty-seven | eight | Four thousand five hundred and forty-six | Seventy-one | Thirty-six | Six point three |
| three | 地狱天使 | One thousand nine hundred and thirty | 戏剧|战争 | 英语 | 美利坚合众国 | 通过 | Ninety-six | One point two | Three million nine hundred and fifty thousand | 圆盘烤饼 | … | Four hundred and thirty-one | Twelve | Four | Four hundred and fifty-seven | Two hundred and seventy-nine | one | Three thousand seven hundred and fifty-three | Fifty-three | Thirty-five | Seven point eight |
| four | 永别了,武器 | One thousand nine hundred and thirty-two | 戏剧|爱情|战争 | 英语 | 美利坚合众国 | 未征税的 | Seventy-nine | one point three seven | Eight hundred thousand | 圆盘烤饼 | … | Nine hundred and ninety-eight | One hundred and sixty-four | Ninety-nine | One thousand two hundred and eighty-four | Two hundred and thirteen | one | Three thousand five hundred and nineteen | Forty-six | Forty-two | Six point six |
5 行× 25 列
现在我们已经看到了如何从 Excel 文件中读取行的子集,我们可以学习如何读取列的子集。
读取列的子集
尽管 read_excel 默认读取并导入所有列,但您可以选择仅导入某些列。通过传递 parse_cols=6,我们告诉read_excel方法只读取第一列,直到索引 6 或前 7 列(第一列的索引为零)。
movies_subset_columns = pd.read_excel(excel_file, parse_cols=6)
movies_subset_columns.head()
| 标题 | 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | |
|---|---|---|---|---|---|---|---|
| Zero | 不宽容:爱情的斗争贯穿了整个时代 | One thousand nine hundred and sixteen | 戏剧|历史|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and twenty-three |
| one | 翻过山去救济院 | One thousand nine hundred and twenty | 犯罪|戏剧 | 圆盘烤饼 | 美利坚合众国 | 圆盘烤饼 | One hundred and ten |
| Two | 大游行 | One thousand nine hundred and twenty-five | 戏剧|爱情|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and fifty-one |
| three | 大都市 | One thousand nine hundred and twenty-seven | 戏剧|科幻 | 德国人 | 德国 | 未评级 | One hundred and forty-five |
| four | 潘多拉的盒子 | One thousand nine hundred and twenty-nine | 犯罪|戏剧|爱情 | 德国人 | 德国 | 未评级 | One hundred and ten |
或者,您可以传入一个数字列表,这将允许您在特定索引处导入列。
在列上应用公式
Excel 常用的功能之一是应用公式从现有列值创建新列。在我们的 Excel 文件中,我们有总收入和预算列。我们可以从总收入中减去预算得到净收益。然后,我们可以将 Excel 文件中的公式应用于所有行。我们可以在熊猫身上这样做,如下图所示。
movies["Net Earnings"] = movies["Gross Earnings"] - movies["Budget"]
在上面,我们使用 pandas 创建了一个名为净收入的新列,并用总收入和预算的差额填充它。值得注意的是 Excel 和 pandas 在公式处理上的不同。在 Excel 中,一个公式存在于单元格中,并在数据改变时更新——使用 Python,计算发生,值被存储——如果一部电影的总收入被手动改变,净收入不会被更新。
让我们使用sort_values方法根据我们创建的新列对数据进行排序,并根据净收入可视化排名前 10 位的电影。
sorted_movies = movies[['Net Earnings']].sort_values(['Net Earnings'], ascending=[False])sorted_movies.head(10)['Net Earnings'].plot.barh()
plt.show()

熊猫中的数据透视表
高级 Excel 用户也经常使用数据透视表。数据透视表通过对索引上的数据进行分组并应用排序、求和或平均等操作来汇总另一个表的数据。你也可以在熊猫身上使用这个功能。
我们需要首先确定将用作索引的一列或多列,以及将应用汇总公式的列。让我们从小处着手,选择 Year 作为索引列,选择 Gross Earnings 作为汇总列,并根据这些数据创建一个单独的数据框架。
movies_subset = movies[['Year', 'Gross Earnings']]
movies_subset.head()
| 年 | 总收入 | |
|---|---|---|
| Zero | One thousand nine hundred and sixteen | 圆盘烤饼 |
| one | One thousand nine hundred and twenty | Three million |
| Two | One thousand nine hundred and twenty-five | 圆盘烤饼 |
| three | One thousand nine hundred and twenty-seven | Twenty-six thousand four hundred and thirty-five |
| four | One thousand nine hundred and twenty-nine | Nine thousand nine hundred and fifty |
我们现在对这个数据子集调用pivot_table。方法pivot_table接受一个参数index。如前所述,我们希望使用年份作为索引。
earnings_by_year = movies_subset.pivot_table(index=['Year'])
earnings_by_year.head()
| 总收入 | |
|---|---|
| 年 | |
| --- | --- |
| One thousand nine hundred and sixteen | 圆盘烤饼 |
| One thousand nine hundred and twenty | Three million |
| One thousand nine hundred and twenty-five | 圆盘烤饼 |
| One thousand nine hundred and twenty-seven | Twenty-six thousand four hundred and thirty-five |
| One thousand nine hundred and twenty-nine | One million four hundred and eight thousand nine hundred and seventy-five |
这给了我们一个数据透视表,它按年份分组,按总收入汇总。请注意,我们不需要明确指定总收入列,因为 pandas 会自动确定汇总应该应用的值。
我们可以使用这个数据透视表来创建一些数据可视化。我们可以调用 DataFrame 上的plot方法创建一个线图,并调用show方法在笔记本中显示该图。
earnings_by_year.plot()
plt.show()

我们看到了如何将单个列作为索引进行透视。如果我们可以使用多个列,事情会变得更有趣。让我们创建另一个数据框架子集,但这次我们将选择国家、语言和总收入列。
movies_subset = movies[['Country', 'Language', 'Gross Earnings']]
movies_subset.head()
| 国家 | 语言 | 总收入 | |
|---|---|---|---|
| Zero | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 |
| one | 美利坚合众国 | 圆盘烤饼 | Three million |
| Two | 美利坚合众国 | 圆盘烤饼 | 圆盘烤饼 |
| three | 德国 | 德国人 | Twenty-six thousand four hundred and thirty-five |
| four | 德国 | 德国人 | Nine thousand nine hundred and fifty |
我们将使用国家和语言列作为数据透视表的索引。我们将使用总收入作为汇总表,但是,我们不需要像前面看到的那样明确指定。
earnings_by_co_lang = movies_subset.pivot_table(index=['Country', 'Language'])
earnings_by_co_lang.head()
| 总收入 | ||
|---|---|---|
| 国家 | 语言 | |
| --- | --- | --- |
| 阿富汗 | 达里语 | 1.127331e+06 |
| 阿根廷 | 西班牙语 | 7.230936e+06 |
| 阿鲁巴岛 | 英语 | 1.007614e+07 |
| 澳大利亚 | 土著居民 | 6.165429e+06 |
| 宗卡语 | 5.052950e+05 |
让我们用条形图来可视化这个数据透视表。由于这个数据透视表中还有几百条记录,我们将只画出其中的几条。
earnings_by_co_lang.head(20).plot(kind='bar', figsize=(20,8))
plt.show()

将结果导出到 Excel
如果你要和使用 Excel 的同事一起工作,在 pandas 中保存 Excel 文件是很重要的。您可以使用 pandas to_excel方法将 pandas 数据帧导出或写入 Excel 文件。Pandas 在内部使用xlwt Python 模块写入 Excel 文件。在我们想要导出的数据帧上调用了to_excel方法。我们还需要传递一个文件名,这个数据帧将被写入其中。
movies.to_excel('output.xlsx')
默认情况下,索引也会保存到输出文件中。然而,有时索引并不提供任何有用的信息。例如,movies数据帧有一个数字自动递增索引,它不是原始 Excel 数据的一部分。
movies.head()
| 标题 | 年 | 体裁 | 语言 | 国家 | 内容分级 | 持续时间 | 长宽比 | 预算 | 总收入 | … | 脸书喜欢——演员 2 | 脸书喜欢——演员 3 | 脸书喜欢——演员总数 | 脸书喜欢电影 | 海报中的面号 | 用户投票 | 用户的评论 | 评论家的评论 | IMDB 分数 | 净收益 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 不宽容:爱情的斗争贯穿了整个时代 | One thousand nine hundred and sixteen | 戏剧|历史|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and twenty-three | One point three three | Three hundred and eighty-five thousand nine hundred and seven | 圆盘烤饼 | … | Twenty-two | Nine | Four hundred and eighty-one | Six hundred and ninety-one | One | Ten thousand seven hundred and eighteen | Eighty-eight | Sixty-nine | Eight | 圆盘烤饼 |
| one | 翻过山去救济院 | One thousand nine hundred and twenty | 犯罪|戏剧 | 圆盘烤饼 | 美利坚合众国 | 圆盘烤饼 | One hundred and ten | One point three three | One hundred thousand | Three million | … | Two | Zero | four | Zero | One | five | One | One | Four point eight | Two million nine hundred thousand |
| Two | 大游行 | One thousand nine hundred and twenty-five | 戏剧|爱情|战争 | 圆盘烤饼 | 美利坚合众国 | 未评级 | One hundred and fifty-one | One point three three | Two hundred and forty-five thousand | 圆盘烤饼 | … | Twelve | Six | One hundred and eight | Two hundred and twenty-six | Zero | Four thousand eight hundred and forty-nine | Forty-five | Forty-eight | Eight point three | 圆盘烤饼 |
| three | 大都市 | One thousand nine hundred and twenty-seven | 戏剧|科幻 | 德国人 | 德国 | 未评级 | One hundred and forty-five | One point three three | Six million | Twenty-six thousand four hundred and thirty-five | … | Twenty-three | Eighteen | Two hundred and three | Twelve thousand | One | One hundred and eleven thousand eight hundred and forty-one | Four hundred and thirteen | Two hundred and sixty | Eight point three | -5973565.0 |
| four | 潘多拉的盒子 | One thousand nine hundred and twenty-nine | 犯罪|戏剧|爱情 | 德国人 | 德国 | 未评级 | One hundred and ten | One point three three | 圆盘烤饼 | Nine thousand nine hundred and fifty | … | Twenty | Three | Four hundred and fifty-five | Nine hundred and twenty-six | One | Seven thousand four hundred and thirty-one | Eighty-four | Seventy-one | Eight | 圆盘烤饼 |
5 行× 26 列
您可以通过传递 index-False 来选择跳过索引。
movies.to_excel('output.xlsx', index=False)
在将输出文件发送给同事之前,我们需要能够使输出文件看起来更好。我们可以使用 pandas ExcelWriter类和XlsxWriter Python 模块来应用格式。
我们可以通过创建一个ExcelWriter对象来使用这些高级输出选项,并使用该对象写入 EXcel 文件。
writer = pd.ExcelWriter('output.xlsx', engine='xlsxwriter')
movies.to_excel(writer, index=False, sheet_name='report')
workbook = writer.bookworksheet = writer.sheets['report']
我们可以通过在我们正在写入的工作簿上调用add_format来应用定制。这里我们将标题格式设置为粗体。
header_fmt = workbook.add_format({'bold': True})
worksheet.set_row(0, None, header_fmt)
最后,我们通过调用 writer 对象上的方法save来保存输出文件。
writer.save()
例如,我们保存了列标题设置为粗体的数据。保存的文件如下图所示。

像这样,可以使用XlsxWriter将各种格式应用到输出的 Excel 文件。
结论
熊猫不是 Excel 的替代品。这两种工具在数据分析工作流中都有自己的位置,并且可以成为非常好的配套工具。正如我们所展示的,pandas 可以进行大量复杂的数据分析和操作,这取决于您的需求和专业知识,可以超越您仅使用 Excel 所能实现的。在 Excel 上使用 Python 和 pandas 的主要好处之一是,它通过编写脚本和与自动化数据工作流集成来帮助您自动化 Excel 文件处理。Pandas 也有从 Excel 文件中读取各种数据的优秀方法。如果您的目标受众喜欢,您也可以将 pandas 中的结果导出回 Excel。
另一方面,Excel 是一个如此广泛使用的数据工具,忽视它是不明智的。获得 pandas 和 Excel 的专业知识,并让它们一起工作,可以让你获得帮助你在组织中脱颖而出的技能。
如果你想了解更多关于这个话题的信息,请查看 Dataquest 的交互式 Pandas 和 NumPy Fundamentals 课程,以及我们的Python 数据分析师和Python 数据科学家路径,它们将帮助你在大约 6 个月内做好工作准备。
Excel 与 Python:如何完成常见的数据分析任务
December 3, 2019
在本教程中,我们将通过查看如何跨两种平台执行基本分析任务来比较 Excel 和 Python。
Excel 是世界上最常用的数据分析软件。为什么?一旦你掌握了它,它就很容易掌握并且相当强大。相比之下,Python 的名声是更难使用,尽管一旦你学会了它,你可以做的事情几乎是无限的。
但是这两个数据分析工具实际上是如何比较的呢?他们的名声并不真正反映现实。在本教程中,我们将了解一些常见的数据分析任务,以展示 Python 数据分析的易用性。
本教程假设您对 Excel 有中级水平的了解,包括使用公式和数据透视表。
我们将使用 Python 库 pandas ,它的设计是为了方便 Python 中的数据分析,但是本教程不需要任何 Python 或 pandas 知识。
为什么要用 Python vs Excel?
在我们开始之前,您可能想知道为什么 Python 值得考虑。你为什么不能继续用 Excel 呢?
尽管 Excel 很棒,但在某些领域,像 Python 这样的编程语言更适合某些类型的数据分析。以下是我们的文章中的一些理由【Excel 用户应该考虑学习编程的 9 个理由:
- 您可以阅读和处理几乎任何类型的数据。
- 自动化和重复性的任务更容易。
- 处理大型数据集要快得多,也容易得多。
- 别人更容易复制和审核你的作品。
- 查找和修复错误更加容易。
- Python 是开源的,所以你可以看到你使用的库背后是什么。
- 高级统计和机器学习能力。
- 高级数据可视化功能。
- 跨平台稳定性—您的分析可以在任何计算机上运行。
需要说明的是,我们并不提倡抛弃 Excel 它是一个有很多用途的强大工具!但是作为一个 Excel 用户,能够利用 Python 的强大功能可以节省您数小时的时间,并开启职业发展的机会。
值得记住的是,这两种工具可以很好地协同工作,您可能会发现有些任务最好留在 Excel 中,而其他任务将受益于 Python 提供的强大功能、灵活性和透明性。
导入我们的数据
让我们先熟悉一下我们将在本教程中使用的数据。我们将使用一家有销售人员的公司的虚构数据。下面是我们的数据在 Excel 中的样子:

我们的数据被保存为一个名为sales.csv的 CSV 文件。为了在 pandas 中导入我们的数据,我们需要从导入 pandas 库本身开始。
import pandas as pd
上面的代码导入了熊猫,并将的别名赋予了语法pd。这听起来可能很复杂,但它实际上只是一种昵称——这意味着将来我们可以只使用pd来指代pandas,这样我们就不必每次都打出完整的单词。
为了读取我们的文件,我们使用pd.read_csv():
sales = pd.read_csv('sales.csv')
sales
| 名字 | 部门 | 开始日期 | 结束日期 | 销售一月 | 销售二月 | 销售进行曲 | |
|---|---|---|---|---|---|---|---|
| Zero | 俏皮话 | A | 2017-02-01 | 圆盘烤饼 | Thirty-one thousand | Thirty thousand | Thirty-two thousand |
| one | 安东尼奥 | A | 2018-06-23 | 圆盘烤饼 | Forty-six thousand | Forty-eight thousand | Forty-nine thousand |
| Two | 丽贝卡(女子名ˌ寓意迷人的美) | A | 2019-02-22 | 2019-03-27 | 圆盘烤饼 | Eight thousand | Ten thousand |
| three | 阿里 | B | 2017-05-15 | 圆盘烤饼 | Twenty-eight thousand | Twenty-nine thousand | Twenty-five thousand |
| four | 萨姆(男子名) | B | 2011-02-01 | 圆盘烤饼 | Thirty-eight thousand | Twenty-six thousand | Thirty-one thousand |
| five | 维克内什 | C | 2019-01-25 | 圆盘烤饼 | Two thousand | Twenty-five thousand | Twenty-nine thousand |
| six | 【男性名字】乔恩 | C | 2012-08-14 | 2012-10-16 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| seven | 撒拉 | C | 2018-05-17 | 圆盘烤饼 | Forty-one thousand | Twenty-six thousand | Thirty thousand |
| eight | 锯齿山脊 | C | 2017-03-31 | 圆盘烤饼 | Thirty-three thousand | Thirty-five thousand | Thirty-two thousand |
我们将pd.read_csv()的结果赋给一个名为sales的变量,我们将用它来引用我们的数据。我们还将变量名放在代码的最后一行,它将数据打印在一个格式良好的表中。
很快,我们可以注意到 pandas 表示数据的方式与我们在 Excel 中看到的有一些不同:
- 在 pandas 中,行号从 0 开始,而在 Excel 中是从 1 开始。
- pandas 中的列名取自数据,而 Excel 中的列用字母标记。
- 在原始数据中有缺失值的地方,pandas 用占位符
NaN来表示该值缺失,或者用 null 。 - 销售数据的每个值都添加了一个小数点,因为 pandas 将包含 null (
NaN)值的数值存储为称为 float 的数值类型(这对我们没有任何影响,但我们只想解释为什么会这样)。
在我们学习我们的第一个 pandas 操作之前,我们将快速了解一下我们的数据是如何存储的。
让我们使用type()函数来看看我们的sales变量的类型:
type(sales)
pandas.core.frame.DataFrame
这个输出告诉我们,我们的sales变量是一个数据帧对象,这是 pandas 中的一个特定类型的对象。在 pandas 中,大多数时候当我们想要修改数据帧时,我们会使用一种称为数据帧方法的特殊语法,它允许我们访问与数据帧对象相关的特定功能。当我们完成我们在熊猫中的第一个任务时,我们将看到一个这样的例子!
分类数据
让我们学习如何在 Excel 和 Python 中对数据进行排序。目前,我们的数据还没有分类。在 Excel 中,如果我们想按"Start Date"列对数据进行排序,我们应该:
- 选择我们的数据。
- 点击工具栏上的“排序”按钮。
- 在打开的对话框中选择“开始日期”。

在熊猫身上,我们使用DataFrame.sort_values()方法。我们刚才简要地提到了方法。为了使用它们,我们必须用我们想要应用该方法的数据帧的名称替换DataFrame——在本例中是sales。如果您在 Python 中使用过列表,您将会熟悉来自list.append()方法的这种模式。
我们向该方法提供列名,告诉它根据哪一列进行排序:
sales = sales.sort_values("Start Date")
sales
| 名字 | 部门 | 开始日期 | 结束日期 | 销售一月 | 销售二月 | 销售进行曲 | |
|---|---|---|---|---|---|---|---|
| four | 萨姆(男子名) | B | 2011-02-01 | 圆盘烤饼 | Thirty-eight thousand | Twenty-six thousand | Thirty-one thousand |
| six | 【男性名字】乔恩 | C | 2012-08-14 | 2012-10-16 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| Zero | 俏皮话 | A | 2017-02-01 | 圆盘烤饼 | Thirty-one thousand | Thirty thousand | Thirty-two thousand |
| eight | 锯齿山脊 | C | 2017-03-31 | 圆盘烤饼 | Thirty-three thousand | Thirty-five thousand | Thirty-two thousand |
| three | 阿里 | B | 2017-05-15 | 圆盘烤饼 | Twenty-eight thousand | Twenty-nine thousand | Twenty-five thousand |
| seven | 撒拉 | C | 2018-05-17 | 圆盘烤饼 | Forty-one thousand | Twenty-six thousand | Thirty thousand |
| one | 安东尼奥 | A | 2018-06-23 | 圆盘烤饼 | Forty-six thousand | Forty-eight thousand | Forty-nine thousand |
| five | 维克内什 | C | 2019-01-25 | 圆盘烤饼 | Two thousand | Twenty-five thousand | Twenty-nine thousand |
| Two | 丽贝卡(女子名ˌ寓意迷人的美) | A | 2019-02-22 | 2019-03-27 | 圆盘烤饼 | Eight thousand | Ten thousand |
我们的数据框架中的值已经用一行简单的熊猫代码进行了排序!
合计销售值
我们数据的最后三列包含一年前三个月的销售额,称为第一季度。我们的下一个任务是在 Excel 和 Python 中对这些值求和。
让我们先来看看我们是如何在 Excel 中实现这一点的:
- 在单元格
H1中输入新的列名"Sales Q1"。 - 在像元 H2 中,使用
SUM()公式并使用坐标指定像元的范围。 - 将公式向下拖动到所有行。

在 pandas 中,当我们执行一个操作时,它会立刻自动应用到每一行。我们将通过使用列表中的名称来选择三列:
q1_columns = sales[["Sales January", "Sales February", "Sales March"]]
q1_columns
| 销售一月 | 销售二月 | 销售进行曲 | |
|---|---|---|---|
| four | Thirty-eight thousand | Twenty-six thousand | Thirty-one thousand |
| six | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 |
| Zero | Thirty-one thousand | Thirty thousand | Thirty-two thousand |
| eight | Thirty-three thousand | Thirty-five thousand | Thirty-two thousand |
| three | Twenty-eight thousand | Twenty-nine thousand | Twenty-five thousand |
| seven | Forty-one thousand | Twenty-six thousand | Thirty thousand |
| one | Forty-six thousand | Forty-eight thousand | Forty-nine thousand |
| five | Two thousand | Twenty-five thousand | Twenty-nine thousand |
| Two | 圆盘烤饼 | Eight thousand | Ten thousand |
接下来,我们将使用DataFrame.sum()方法并指定axis=1,这告诉 pandas 我们想要对行求和而不是对列求和。我们将通过在括号内提供新的列名来指定它:
sales["Sales Q1"] = q1_columns.sum(axis=1)
sales
| 名字 | 部门 | 开始日期 | 结束日期 | 销售一月 | 销售二月 | 销售进行曲 | 销售 Q1 | |
|---|---|---|---|---|---|---|---|---|
| four | 萨姆(男子名) | B | 2011-02-01 | 圆盘烤饼 | Thirty-eight thousand | Twenty-six thousand | Thirty-one thousand | Ninety-five thousand |
| six | 【男性名字】乔恩 | C | 2012-08-14 | 2012-10-16 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero |
| Zero | 俏皮话 | A | 2017-02-01 | 圆盘烤饼 | Thirty-one thousand | Thirty thousand | Thirty-two thousand | Ninety-three thousand |
| eight | 锯齿山脊 | C | 2017-03-31 | 圆盘烤饼 | Thirty-three thousand | Thirty-five thousand | Thirty-two thousand | One hundred thousand |
| three | 阿里 | B | 2017-05-15 | 圆盘烤饼 | Twenty-eight thousand | Twenty-nine thousand | Twenty-five thousand | Eighty-two thousand |
| seven | 撒拉 | C | 2018-05-17 | 圆盘烤饼 | Forty-one thousand | Twenty-six thousand | Thirty thousand | Ninety-seven thousand |
| one | 安东尼奥 | A | 2018-06-23 | 圆盘烤饼 | Forty-six thousand | Forty-eight thousand | Forty-nine thousand | One hundred and forty-three thousand |
| five | 维克内什 | C | 2019-01-25 | 圆盘烤饼 | Two thousand | Twenty-five thousand | Twenty-nine thousand | Fifty-six thousand |
| Two | 丽贝卡(女子名ˌ寓意迷人的美) | A | 2019-02-22 | 2019-03-27 | 圆盘烤饼 | Eight thousand | Ten thousand | Eighteen thousand |
在熊猫身上,我们使用的“配方”没有被储存。相反,结果值被直接添加到我们的数据帧中。如果我们想对新列中的值进行调整,我们需要编写新的代码来完成。
加盟经理数据
在我们的电子表格中,我们也有一个小的数据表,关于谁管理每个团队:

让我们看看如何在 Excel 和 Python 中将这些数据连接到一个"Manager"列中。在 Excel 中,我们:
- 首先将列名添加到单元格
I1中。 - 在单元格
I2中使用VLOOKUP()公式,指定:- 从单元格
B2(部门)中查找值 - 在管理器数据的选择中,我们使用坐标来指定
- 我们希望从该数据的第二列中选择值。
- 从单元格
- 单击并向下拖动公式至所有单元格。

要在 pandas 中处理这些数据,首先我们需要从第二个 CSV 导入它,managers.csv:
managers = pd.read_csv('managers.csv')
managers
| 部门 | 经理 | |
|---|---|---|
| Zero | A | 曼纽尔 |
| one | B | elizabeth 的昵称 |
| Two | C | 怜悯 |
为了使用 pandas 将mangers数据连接到sales,我们将使用pandas.merge()函数。我们按顺序提供以下论据:
sales:我们要合并的第一个或左侧数据帧的名称managers:我们要合并的第二个或右侧数据帧的名称how='left':我们想要用来连接数据的方法。left连接指定无论如何,我们都要保留左边(第一个)数据帧中的所有行。on='Department':我们将要连接的两个数据帧中的列名。
sales = pd.merge(sales, managers, how='left', on='Department')
sales
| 名字 | 部门 | 开始日期 | 结束日期 | 销售一月 | 销售二月 | 销售进行曲 | 销售 Q1 | 经理 | |
|---|---|---|---|---|---|---|---|---|---|
| Zero | 萨姆(男子名) | B | 2011-02-01 | 圆盘烤饼 | Thirty-eight thousand | Twenty-six thousand | Thirty-one thousand | Ninety-five thousand | elizabeth 的昵称 |
| one | 【男性名字】乔恩 | C | 2012-08-14 | 2012-10-16 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | 怜悯 |
| Two | 俏皮话 | A | 2017-02-01 | 圆盘烤饼 | Thirty-one thousand | Thirty thousand | Thirty-two thousand | Ninety-three thousand | 曼纽尔 |
| three | 锯齿山脊 | C | 2017-03-31 | 圆盘烤饼 | Thirty-three thousand | Thirty-five thousand | Thirty-two thousand | One hundred thousand | 怜悯 |
| four | 阿里 | B | 2017-05-15 | 圆盘烤饼 | Twenty-eight thousand | Twenty-nine thousand | Twenty-five thousand | Eighty-two thousand | elizabeth 的昵称 |
| five | 撒拉 | C | 2018-05-17 | 圆盘烤饼 | Forty-one thousand | Twenty-six thousand | Thirty thousand | Ninety-seven thousand | 怜悯 |
| six | 安东尼奥 | A | 2018-06-23 | 圆盘烤饼 | Forty-six thousand | Forty-eight thousand | Forty-nine thousand | One hundred and forty-three thousand | 曼纽尔 |
| seven | 维克内什 | C | 2019-01-25 | 圆盘烤饼 | Two thousand | Twenty-five thousand | Twenty-nine thousand | Fifty-six thousand | 怜悯 |
| eight | 丽贝卡(女子名ˌ寓意迷人的美) | A | 2019-02-22 | 2019-03-27 | 圆盘烤饼 | Eight thousand | Ten thousand | Eighteen thousand | 曼纽尔 |
如果一开始这看起来有点混乱,那没关系。Python 中连接数据的模型不同于 Excel 中使用的模型,但它也更强大。请注意,在 Python 中,我们使用清晰的语法和列名来指定如何连接数据。
添加条件列
如果我们看一下"End Date"列,我们可以看到并非所有的员工都还在公司——那些价值缺失的员工仍在工作,但其余的已经离开了。我们的下一个任务是创建一个列,告诉我们每个销售人员是否是当前雇员。我们将在 Excel 和 Python 中执行此操作。
从 Excel 开始,要添加该列,我们:
- 向单元格
J1添加新的列名。 - 使用
IF()公式检查单元格D1(结束日期)是否为空,如果是,用TRUE填充J2,否则用FALSE。 - 将公式拖到下面的单元格中。

在 pandas 中,我们使用pandas.isnull()函数来检查"End Date"列中的空值,并将结果分配给一个新列:
sales["Current Employee"] = pd.isnull(sales['End Date'])
sales
| 名字 | 部门 | 开始日期 | 结束日期 | 销售一月 | 销售二月 | 销售进行曲 | 销售 Q1 | 经理 | 当前员工 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 萨姆(男子名) | B | 2011-02-01 | 圆盘烤饼 | Thirty-eight thousand | Twenty-six thousand | Thirty-one thousand | Ninety-five thousand | elizabeth 的昵称 | 真实的 |
| one | 【男性名字】乔恩 | C | 2012-08-14 | 2012-10-16 | 圆盘烤饼 | 圆盘烤饼 | 圆盘烤饼 | Zero | 怜悯 | 错误的 |
| Two | 俏皮话 | A | 2017-02-01 | 圆盘烤饼 | Thirty-one thousand | Thirty thousand | Thirty-two thousand | Ninety-three thousand | 曼纽尔 | 真实的 |
| three | 锯齿山脊 | C | 2017-03-31 | 圆盘烤饼 | Thirty-three thousand | Thirty-five thousand | Thirty-two thousand | One hundred thousand | 怜悯 | 真实的 |
| four | 阿里 | B | 2017-05-15 | 圆盘烤饼 | Twenty-eight thousand | Twenty-nine thousand | Twenty-five thousand | Eighty-two thousand | elizabeth 的昵称 | 真实的 |
| five | 撒拉 | C | 2018-05-17 | 圆盘烤饼 | Forty-one thousand | Twenty-six thousand | Thirty thousand | Ninety-seven thousand | 怜悯 | 真实的 |
| six | 安东尼奥 | A | 2018-06-23 | 圆盘烤饼 | Forty-six thousand | Forty-eight thousand | Forty-nine thousand | One hundred and forty-three thousand | 曼纽尔 | 真实的 |
| seven | 维克内什 | C | 2019-01-25 | 圆盘烤饼 | Two thousand | Twenty-five thousand | Twenty-nine thousand | Fifty-six thousand | 怜悯 | 真实的 |
| eight | 丽贝卡(女子名ˌ寓意迷人的美) | A | 2019-02-22 | 2019-03-27 | 圆盘烤饼 | Eight thousand | Ten thousand | Eighteen thousand | 曼纽尔 | 错误的 |
数据透视表
Excel 最强大的功能之一是数据透视表,它使用聚合来简化数据分析。我们将看看 Excel 和 Python 中两种不同的数据透视表应用程序。
我们将从 Excel 中的数据透视表开始,它计算每个部门的员工人数:

这个操作——计算一个值在一列中出现的次数——非常常见,以至于在 pandas 中它有自己的语法:Series.value_counts()。
series 类型对本教程来说是新的,但它与我们已经了解过的 DataFrame 非常相似。系列只是单个行或列的熊猫代表。
让我们用熊猫法来计算每个部门的雇员人数:
sales['Department'].value_counts()
C 4
A 3
B 2
Name: Department, dtype: int64
第二个数据透视表示例也按部门进行聚合,但计算的是 Q1 的平均销售额:

为了在熊猫中计算这个,我们将使用DataFrame.pivot_table()方法。我们需要指定一些参数:
index:聚合所依据的列。values:我们要使用其值的列。aggfunc:我们想要使用的聚合函数,在这里是'mean'average。
sales.pivot_table(index='Department', values='Sales Q1', aggfunc='mean')
| 销售 Q1 | |
|---|---|
| 部门 | |
| --- | --- |
| A | 84666.666667 |
| B | 88500.000000 |
| C | 63250.000000 |
Excel vs Python:总结
在本教程中,我们学习了以下 Excel 功能的 Python 等价物:
- 分类数据
SUM()VLOOKUP()IF()- 数据透视表
对于我们看到的每个例子,pandas 语法的复杂性与您在 Excel 中使用的公式或菜单选项相似。但是 Python 提供了一些优势,比如更快地处理大型数据集,更多的定制和复杂性,以及更透明的错误检查和审计(因为您所做的一切都清楚地显示在代码中,而不是隐藏在单元格中)。
精通 Excel 的人完全有能力跨越到使用 Python。从长远来看,将 Python 技能添加到您的技能集将使您成为更快、更强大的分析师,并且您将发现新的工作流,这些工作流利用 Excel 和 Python 进行比单独使用 Excel 更高效、更强大的数据分析。
如果你想学习如何用 Python 分析数据,我们的 Python path 中的 Data Analyst 旨在教你你需要知道的一切,即使你以前从未编写过代码。在开始学习我们在本教程中使用的 pandas 库之前,您将从两门教授 Python 基础知识的课程开始。
探索女子陆军辅助部队数据
原文:https://www.dataquest.io/blog/exploring-womens-army-auxiliary-corps-data/
March 28, 2018
今天我想去参观一下作为数据的目录。英国国家档案馆的发现目录是这项活动的一个极好的资源,因为 a)它有许多记录,在目录中有“项目”或“件”级别的文件描述,包含可以量化和可视化的非常结构化的信息(如日期、地点、职业);b)更重要的是,它具有导出功能,允许您下载多达 10,000 条 CSV 格式的记录。(它还为那些具有一些编程技能的人提供了完整的 API,但 10,000 条记录会让你走得很远,而且你经常可以将较大的集合分成块,例如使用日期过滤器)。
您需要非常小心地使用 Discovery 高级搜索来获得正确的搜索结果集(它可以指定特定的记录、日期、目录级别等)—这里有一些有用的提示。然后你很可能需要使用像 OpenRefine 这样的工具将信息分离到单独的数据字段中,并清理/规范化日期等(查看本教程)。
我在 TNA 的在线指南上闲逛,寻找一些我一无所知的关于女性的记录,而女子陆军辅助军团 1917-20 ( WO 398 引起了我的注意:
【1917 年至 1920 年间加入女子陆军辅助队(WAAC)的 7,000 多名妇女的服役记录 QMAAC 于 1918 年 4 月成为 QMAAC,并于 1921 年 9 月解散
在 7000 张唱片中,这听起来像是一个很好的大小,完全在下载限制之内。看一看目录条目显示,除了女性的名字之外,它还有一些不错的信息(不像一个类似的更大的系列,WO399,它只有转录的名字)。给我几个小时的时间提取和清理数据,我能学到什么?
| 为...记录 | 艾伦,莎拉·安·尼·菲利普斯 |
| 出生地: | 北威尔士高街·塞夫恩·莫尔 |
| 出生日期: | 1894 年 8 月 22 日 |
首先,就可用数据而言,这实际上提供了什么?出生日期是一个显而易见的日期:仔细观察会发现它的格式是一致的,有完整的日期(大多数);几乎每种情况下都至少提供一年,这可以很容易地提取到标准的出生年份字段中。出生地也有潜力,但是更多样,需要更多的清理,所以我还没用那个做什么;但这可能会成为一个有趣的绘图练习。或许不太明显的是,“ nee Phillips ”暗示着——如果你能有把握地假设女性总是给出这些信息的话!–还可以推断出一个女人是否结过婚。给定出生日期和名字,您还可以做的另一件好事是寻找婴儿命名的模式(尽管这可能真的需要更大的数据集)。
两个警告,一个主要的和一个次要的:
- 在线指南清楚地表明,这 7000 条记录只是原始收藏(57000 条记录)的一小部分,因为许多记录在二战的一次空袭中被毁。所以可能不能代表被招募的女性。
- 数据中的错误——即使是质量最好的材料,你也必须时刻注意。在这种情况下,有几个明显的出生日期转录错误。我们可以 100%确定 1822 年、1917-18 年和 1988 年的出生年份只是错了。但实际上更成问题的是看起来不太可能但并非完全不可能的异常值:1844 年?1903?幸运的是,它们只占极少数的记录。还有 278 个数字被记录为 18880 或 18930:我得出结论,这些实际上是年份日期,不知何故被添加了一个额外的零,并相应地进行了更正。
可视化通常对突出显示数据中的错误和问题特别有用。但是,研究人员必须决定如何处理这种异常(以及它们是否严重到足以使整个数据集不可靠而不值得使用)。
我最初希望记录日期将代表女性参军的具体日期,但结果是整个系列只有一个覆盖日期。因为它只涵盖了 4 年,这不是一个真正的问题;相反,我只是计算出了他们在 1918 年的年龄(假设战争结束后不会再有新兵招募),并过滤掉了六个可能出生于 1860 年之前或 1903 年之后的人。
所以我今天学到的是,天哪,他们太年轻了。

作为可视化,表格可能不如图表引人注目,但它们具有在相对较小的空间内呈现大量精确信息的优点;这篇文章底部的表格显示,在 1918 年,超过 60%的女性年龄在 25 岁或以下,大约 90%在 30 岁以下。他们中很少有人年龄足够大,能够利用战争结束时妇女投票权的有限扩大。
一点背景阅读证实了这一点——根据露西·诺克斯在英国和爱尔兰妇女战争动员上的说法,“WAAC 的大部分新兵是年轻的工人阶级妇女”。如果我们可以合理地假设关于婚前姓氏的信息是一个完整的记录,或者接近完整的记录,那么绝大多数女性也是未婚的——总体而言接近 95%。我怀疑很少有已婚女性会自愿参加这种类型的服务(这可能会把她们带到海外并接近战斗),因此可以预计大多数人会很年轻——平均而言,很可能比男性士兵年轻。你还可以看到,25 岁以上的女性中,已婚/曾经结过婚的比例要高得多——但与你可能在总人口中预期的比例相比,这一比例看起来仍然非常低(我想知道其中是否有相当多的人是寡妇)。

当我从诺克斯那里得知他们的年轻(毫无疑问,是阶级)导致了一些负面看法时,我并不感到惊讶:
然而,在公众心目中,她们有时被视为寻求刺激的人,被冒险和浪漫的欲望所吸引,招募入伍时担心女性会找到与士兵发生性关系的机会。政府对这些谣言如此担忧,以至于成立了一个调查委员会,其中包括显示 WAAC 未婚成员怀孕数量低于未婚平民的数字……

Queen Mary’s Army Auxiliary Corps (Art.IWM PST 13167): “The GIRL behind the man behind the gun” (!) © IWM

编者按:这最初是发布在早期现代笔记上,作为我们关注女性历史月的一部分,已经被 perlesson 转载。作者莎伦·霍华德在谢菲尔德大学担任数字历史项目的项目经理。
教程:过滤熊猫数据帧
原文:https://www.dataquest.io/blog/filtering-pandas-dataframes/
February 24, 2022
Pandas 库是一个快速、强大且易于使用的数据处理工具。它通过提供改变游戏规则的功能,帮助我们清理、探索、分析和可视化数据。将数据作为 Pandas DataFrame 允许我们以各种方式分割数据,并毫不费力地过滤数据帧的行。本教程将介绍使用不同的过滤技术从数据帧中获取数据的主要方法。
什么是数据帧?
在讨论不同的数据帧过滤技术之前,让我们先回顾一下数据帧。从技术上讲,DataFrame 建立在 Pandas 系列对象的基础上,系列是索引数据的一维数组。直观上,数据框架在许多方面类似于电子表格;它可以有多个包含不同数据类型的列和标有行索引的行。
创建数据帧
首先,让我们使用下面的代码片段创建一个包含公司员工个人详细信息的虚拟数据帧:
import pandas as pd
import numpy as np
from IPython.display import display
data = pd.DataFrame({'EmployeeName': ['Callen Dunkley', 'Sarah Rayner', 'Jeanette Sloan','Kaycee Acosta', 'Henri Conroy', 'Emma Peralta','Martin Butt', 'Alex Jensen', 'Kim Howarth', 'Jane Burnett'],
'Department': ['Accounting', 'Engineering', 'Engineering', 'HR', 'HR','HR','Data Science','Data Science', 'Accounting', 'Data Science'],
'HireDate': [2010, 2018, 2012, 2014, 2014, 2018, 2020, 2018, 2020, 2012],
'Gender': ['M','F','F','F','M','F','M','M','M','F'],
'DoB':['04/09/1982', '14/04/1981','06/05/1997','08/01/1986','10/10/1988','12/11/1992', '10/04/1991','16/07/1995','08/10/1992','11/10/1979'],
'Weight':[78,80,66,67,90,57,115,87,95,57],
'Height':[176,160,169,157,185,164,195,180,174,165]
})
display(data)
| 员工姓名 | 部门 | 你在说什么 | 性别 | 告发 | 重量 | 高度 | |
|---|---|---|---|---|---|---|---|
| Zero | 卡伦·邓克利 | 会计 | Two thousand and ten | M | 04/09/1982 | seventy-eight | One hundred and seventy-six |
| one | 莎拉·雷纳 | 工程 | Two thousand and eighteen | F | 14/04/1981 | Eighty | One hundred and sixty |
| Two | 珍妮特·斯隆 | 工程 | Two thousand and twelve | F | 06/05/1997 | Sixty-six | One hundred and sixty-nine |
| three | 凯茜·阿科斯塔 | 人力资源(部) | Two thousand and fourteen | F | 08/01/1986 | Sixty-seven | One hundred and fifty-seven |
| four | 亨利康罗伊 | 人力资源(部) | Two thousand and fourteen | M | 10/10/1988 | Ninety | One hundred and eighty-five |
| five | 艾玛·佩拉尔塔 | 人力资源(部) | Two thousand and eighteen | F | 12/11/1992 | Fifty-seven | One hundred and sixty-four |
| six | 马丁·巴特 | 数据科学 | Two thousand and twenty | M | 10/04/1991 | One hundred and fifteen | One hundred and ninety-five |
| seven | 艾利克斯詹森 | 数据科学 | Two thousand and eighteen | M | 16/07/1995 | Eighty-seven | one hundred and eighty |
| eight | 金·豪沃思 | 会计 | Two thousand and twenty | M | 08/10/1992 | Ninety-five | One hundred and seventy-four |
| nine | 简·伯内特 | 数据科学 | Two thousand and twelve | F | 11/10/1979 | Fifty-seven | One hundred and sixty-five |
运行上面的代码。它用上述数据创建一个数据帧。
让我们通过运行以下语句来看看列的数据类型:
print(data.dtypes)
EmployeeName object
Department object
HireDate int64
Gender object
DoB object
Weight int64
Height int64
dtype: object
Pandas 字符串值的数据类型是对象,这就是为什么像 EmployeeName 或 Department 这样包含字符串的列的数据类型是对象。数据帧的每一列都有特定的数据类型;换句话说,数据帧的列不共享相同的数据类型。
另一个有用的 DataFrame 属性是.values,它返回一个列表数组,每个列表代表 DataFrame 的一行。
print(data.values)
[['Callen Dunkley' 'Accounting' 2010 'M' '04/09/1982' 78 176]
['Sarah Rayner' 'Engineering' 2018 'F' '14/04/1981' 80 160]
['Jeanette Sloan' 'Engineering' 2012 'F' '06/05/1997' 66 169]
['Kaycee Acosta' 'HR' 2014 'F' '08/01/1986' 67 157]
['Henri Conroy' 'HR' 2014 'M' '10/10/1988' 90 185]
['Emma Peralta' 'HR' 2018 'F' '12/11/1992' 57 164]
['Martin Butt' 'Data Science' 2020 'M' '10/04/1991' 115 195]
['Alex Jensen' 'Data Science' 2018 'M' '16/07/1995' 87 180]
['Kim Howarth' 'Accounting' 2020 'M' '08/10/1992' 95 174]
['Jane Burnett' 'Data Science' 2012 'F' '11/10/1979' 57 165]]
如果您想知道数据帧的行数和列数,您可以如下使用.shape属性:
print(data.shape)
(10, 7)
上面的元组分别表示行数和列数。
从每个可能的角度切割数据帧
到目前为止,我们已经创建并检查了一个数据帧。如前所述,过滤数据帧有不同的方法。在这一节中,我们将讨论最流行和最有效的方法。但是,最好先看看我们如何选择特定的列。
要获取特定列的全部内容,我们可以使用以下语法:
DataFrame.ColumnName # if the column name does not contain any spaces
OR
DataFrame["ColumnName"]
例如,让我们抓住数据帧的部门列。
display(data.Department)
0 Accounting
1 Engineering
2 Engineering
3 HR
4 HR
5 HR
6 Data Science
7 Data Science
8 Accounting
9 Data Science
Name: Department, dtype: object
运行上面的语句将返回包含部门列数据的序列。
此外,我们可以通过传递列名列表来选择多个列,如下所示:
display(data[['EmployeeName','Department','Gender']])
| 员工姓名 | 部门 | 性别 | |
|---|---|---|---|
| Zero | 卡伦·邓克利 | 会计 | M |
| one | 莎拉·雷纳 | 工程 | F |
| Two | 珍妮特·斯隆 | 工程 | F |
| three | 凯茜·阿科斯塔 | 人力资源(部) | F |
| four | 亨利康罗伊 | 人力资源(部) | M |
| five | 艾玛·佩拉尔塔 | 人力资源(部) | F |
| six | 马丁·巴特 | 数据科学 | M |
| seven | 艾利克斯詹森 | 数据科学 | M |
| eight | 金·豪沃思 | 会计 | M |
| nine | 简·伯内特 | 数据科学 | F |
运行上面的语句给我们一个数据帧,它是原始数据帧的子集。
.loc和.iloc方法
我们可以使用切片技术从数据帧中提取特定的行。分割数据帧并选择特定列的最佳方式是使用.loc和.iloc方法。这两种方法分别使用基于标签或基于整数的索引创建数据帧的子集。
DataFrame.loc[row_indexer,column_indexer]
DataFrame.iloc[row_indexer,column_indexer]
两种方法中的第一个位置指定行索引器,第二个位置指定列索引器,用逗号分隔。
在我们想练习使用.loc和.iloc方法之前,让我们将 EmployeeName 列设置为 DataFrame 的索引。这样做不是必需的,但有助于我们讨论这些方法的所有功能。为此,使用set_index()方法使 EmployeeName 列成为 DataFrame 的索引:
data = data.set_index('EmployeeName')
display(data)
| 部门 | 你在说什么 | 性别 | 告发 | 重量 | 高度 | |
|---|---|---|---|---|---|---|
| 员工姓名 | ||||||
| --- | --- | --- | --- | --- | --- | --- |
| 卡伦·邓克利 | 会计 | Two thousand and ten | M | 04/09/1982 | seventy-eight | One hundred and seventy-six |
| 莎拉·雷纳 | 工程 | Two thousand and eighteen | F | 14/04/1981 | Eighty | One hundred and sixty |
| 珍妮特·斯隆 | 工程 | Two thousand and twelve | F | 06/05/1997 | Sixty-six | One hundred and sixty-nine |
| 凯茜·阿科斯塔 | 人力资源(部) | Two thousand and fourteen | F | 08/01/1986 | Sixty-seven | One hundred and fifty-seven |
| 亨利康罗伊 | 人力资源(部) | Two thousand and fourteen | M | 10/10/1988 | Ninety | One hundred and eighty-five |
| 艾玛·佩拉尔塔 | 人力资源(部) | Two thousand and eighteen | F | 12/11/1992 | Fifty-seven | One hundred and sixty-four |
| 马丁·巴特 | 数据科学 | Two thousand and twenty | M | 10/04/1991 | One hundred and fifteen | One hundred and ninety-five |
| 艾利克斯詹森 | 数据科学 | Two thousand and eighteen | M | 16/07/1995 | Eighty-seven | one hundred and eighty |
| 金·豪沃思 | 会计 | Two thousand and twenty | M | 08/10/1992 | Ninety-five | One hundred and seventy-four |
| 简·伯内特 | 数据科学 | Two thousand and twelve | F | 11/10/1979 | Fifty-seven | One hundred and sixty-five |
现在,我们有了基于标签的索引,而不是基于整数的索引,这使得尝试用于切片和切割数据帧的.loc和.iloc方法的所有功能更加容易。
注
.loc方法是基于标签的,所以您必须根据它们的标签来指定行和列。另一方面,iloc方法是基于整数索引的,所以您必须根据它们的整数索引来选择行和列。
以下语句实际上返回相同的结果:
display(data.loc[['Henri Conroy', 'Kim Howarth']])
display(data.iloc[[4,8]])
| 部门 | 你在说什么 | 性别 | 告发 | 重量 | 高度 | |
|---|---|---|---|---|---|---|
| 员工姓名 | ||||||
| --- | --- | --- | --- | --- | --- | --- |
| 亨利康罗伊 | 人力资源(部) | Two thousand and fourteen | M | 10/10/1988 | Ninety | One hundred and eighty-five |
| 金·豪沃思 | 会计 | Two thousand and twenty | M | 08/10/1992 | Ninety-five | One hundred and seventy-four |
| 部门 | 你在说什么 | 性别 | 告发 | 重量 | 高度 | |
|---|---|---|---|---|---|---|
| 员工姓名 | ||||||
| --- | --- | --- | --- | --- | --- | --- |
| 亨利康罗伊 | 人力资源(部) | Two thousand and fourteen | M | 10/10/1988 | Ninety | One hundred and eighty-five |
| 金·豪沃思 | 会计 | Two thousand and twenty | M | 08/10/1992 | Ninety-five | One hundred and seventy-four |
在上面的代码中,.loc方法获得一个雇员姓名列表作为行标签,并返回一个包含与这两个雇员相关的行的 DataFrame。
.iloc方法做同样的事情,但是它不是获取带标签的索引,而是获取行的整数索引。
现在,让我们使用.loc和.iloc方法提取一个包含前三名雇员的姓名、部门和性别值的子数据帧:
display(data.iloc[:3,[0,2]])
display(data.loc['Callen Dunkley':'Jeanette Sloan',['Department','Gender']])
| 部门 | 性别 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 卡伦·邓克利 | 会计 | M |
| 莎拉·雷纳 | 工程 | F |
| 珍妮特·斯隆 | 工程 | F |
| 部门 | 性别 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 卡伦·邓克利 | 会计 | M |
| 莎拉·雷纳 | 工程 | F |
| 珍妮特·斯隆 | 工程 | F |
运行上述语句会返回相同的结果,如下所示:
EmployeeName Department Gender
Callen Dunkley Accounting M
Sarah Rayner Engineering F
Jeanette Sloan Engineering F
.loc和.iloc方法非常相似;唯一的区别是如何引用数据帧中的列和行。
以下语句返回数据帧的所有行:
display(data.iloc[:,[0,2]])
display(data.loc[:,['Department','Gender']])
| 部门 | 性别 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 卡伦·邓克利 | 会计 | M |
| 莎拉·雷纳 | 工程 | F |
| 珍妮特·斯隆 | 工程 | F |
| 凯茜·阿科斯塔 | 人力资源(部) | F |
| 亨利康罗伊 | 人力资源(部) | M |
| 艾玛·佩拉尔塔 | 人力资源(部) | F |
| 马丁·巴特 | 数据科学 | M |
| 艾利克斯詹森 | 数据科学 | M |
| 金·豪沃思 | 会计 | M |
| 简·伯内特 | 数据科学 | F |
| 部门 | 性别 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 卡伦·邓克利 | 会计 | M |
| 莎拉·雷纳 | 工程 | F |
| 珍妮特·斯隆 | 工程 | F |
| 凯茜·阿科斯塔 | 人力资源(部) | F |
| 亨利康罗伊 | 人力资源(部) | M |
| 艾玛·佩拉尔塔 | 人力资源(部) | F |
| 马丁·巴特 | 数据科学 | M |
| 艾利克斯詹森 | 数据科学 | M |
| 金·豪沃思 | 会计 | M |
| 简·伯内特 | 数据科学 | F |
我们也可以对列进行切片。下面的语句返回数据帧中每隔一行的Weight和Height列:
display(data.loc[::2,'Weight':'Height'])
display(data.iloc[::2,4:6])
| 重量 | 高度 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 卡伦·邓克利 | seventy-eight | One hundred and seventy-six |
| 珍妮特·斯隆 | Sixty-six | One hundred and sixty-nine |
| 亨利康罗伊 | Ninety | One hundred and eighty-five |
| 马丁·巴特 | One hundred and fifteen | One hundred and ninety-five |
| 金·豪沃思 | Ninety-five | One hundred and seventy-four |
| 重量 | 高度 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 卡伦·邓克利 | seventy-eight | One hundred and seventy-six |
| 珍妮特·斯隆 | Sixty-six | One hundred and sixty-nine |
| 亨利康罗伊 | Ninety | One hundred and eighty-five |
| 马丁·巴特 | One hundred and fifteen | One hundred and ninety-five |
| 金·豪沃思 | Ninety-five | One hundred and seventy-four |
我们在上面的代码中对数据帧的行和列执行切片。语法类似于 Python 中的列表切片。我们需要指定开始索引、停止索引和步长。
EmployeeName Weight Height
Callen Dunkley 78 176
Jeanette Sloan 66 169
Henri Conroy 90 185
Martin Butt 115 195
Kim Howarth 95 174
注意,在使用.loc方法的带标签切片中,开始和停止标签都包括在内。然而,在使用.iloc方法的切片中,停止索引被排除。
在 Pandas 中过滤数据帧
到目前为止,我们已经学会了如何分割数据帧,但是我们如何获取符合特定标准的数据呢?在 Pandas 中,使用布尔掩码是过滤数据帧的常用方法。首先让我们看看什么是布尔掩码:
print(data.HireDate > 2015)
EmployeeName
Callen Dunkley False
Sarah Rayner True
Jeanette Sloan False
Kaycee Acosta False
Henri Conroy False
Emma Peralta True
Martin Butt True
Alex Jensen True
Kim Howarth True
Jane Burnett False
Name: HireDate, dtype: bool
通过运行上面的代码,我们可以看到HireDate列中的哪些条目大于 2015。布尔值表示是否满足条件。
现在,我们可以使用布尔掩码来获取包含 2015 年后雇佣的
员工的数据帧子集:
display(data[data.HireDate > 2015])
| 部门 | 你在说什么 | 性别 | 告发 | 重量 | 高度 | |
|---|---|---|---|---|---|---|
| 员工姓名 | ||||||
| --- | --- | --- | --- | --- | --- | --- |
| 莎拉·雷纳 | 工程 | Two thousand and eighteen | F | 14/04/1981 | Eighty | One hundred and sixty |
| 艾玛·佩拉尔塔 | 人力资源(部) | Two thousand and eighteen | F | 12/11/1992 | Fifty-seven | One hundred and sixty-four |
| 马丁·巴特 | 数据科学 | Two thousand and twenty | M | 10/04/1991 | One hundred and fifteen | One hundred and ninety-five |
| 艾利克斯詹森 | 数据科学 | Two thousand and eighteen | M | 16/07/1995 | Eighty-seven | one hundred and eighty |
| 金·豪沃思 | 会计 | Two thousand and twenty | M | 08/10/1992 | Ninety-five | One hundred and seventy-four |
我们还可以使用.loc方法过滤行并返回某些列,如下所示:
display(data.loc[data.HireDate > 2015, ['Department', 'HireDate']])
| 部门 | 你在说什么 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 莎拉·雷纳 | 工程 | Two thousand and eighteen |
| 艾玛·佩拉尔塔 | 人力资源(部) | Two thousand and eighteen |
| 马丁·巴特 | 数据科学 | Two thousand and twenty |
| 艾利克斯詹森 | 数据科学 | Two thousand and eighteen |
| 金·豪沃思 | 会计 | Two thousand and twenty |
我们能够使用逻辑运算符将两个或多个标准结合起来。让我们列出那些在数据科学团队工作的男性员工:
display(data.loc[(data.Gender == "M") & (data.Department=='Data Science'),
['Department', 'Gender', 'HireDate']]
)
| 部门 | 性别 | 你在说什么 | |
|---|---|---|---|
| 员工姓名 | |||
| --- | --- | --- | --- |
| 马丁·巴特 | 数据科学 | M | Two thousand and twenty |
| 艾利克斯詹森 | 数据科学 | M | Two thousand and eighteen |
如果我们想让所有员工身高在 170 cm 到 190 cm 之间怎么办?
display(data.loc[data.Height.between(170,190),
['Department', 'Gender', 'Height']]
)
| 部门 | 性别 | 高度 | |
|---|---|---|---|
| 员工姓名 | |||
| --- | --- | --- | --- |
| 卡伦·邓克利 | 会计 | M | One hundred and seventy-six |
| 亨利康罗伊 | 人力资源(部) | M | One hundred and eighty-five |
| 艾利克斯詹森 | 数据科学 | M | one hundred and eighty |
| 金·豪沃思 | 会计 | M | One hundred and seventy-four |
在between()方法中,范围的两端都包括在内。
另一个有用的方法是isin(),它为包含在指定值列表中的值创建一个布尔掩码。让我们尝试一下检索在人力资源或会计部门工作的雇员的方法:
display(data.loc[data.Department.isin(['HR', 'Accounting']),['Department', 'Gender', 'HireDate']])
| 部门 | 性别 | 你在说什么 | |
|---|---|---|---|
| 员工姓名 | |||
| --- | --- | --- | --- |
| 卡伦·邓克利 | 会计 | M | Two thousand and ten |
| 凯茜·阿科斯塔 | 人力资源(部) | F | Two thousand and fourteen |
| 亨利康罗伊 | 人力资源(部) | M | Two thousand and fourteen |
| 艾玛·佩拉尔塔 | 人力资源(部) | F | Two thousand and eighteen |
| 金·豪沃思 | 会计 | M | Two thousand and twenty |
为了过滤数据帧,我们可以使用正则表达式来搜索模式,而不是精确的内容。以下示例显示了如何使用正则表达式来获取那些姓氏以“tt”或“th”结尾的雇员:
display(data.loc[data.index.str.contains(r'tt$|th$'),
['Department', 'Gender']])
| 部门 | 性别 | |
|---|---|---|
| 员工姓名 | ||
| --- | --- | --- |
| 马丁·巴特 | 数据科学 | M |
| 金·豪沃思 | 会计 | M |
| 简·伯内特 | 数据科学 | F |
结论
在本教程中,我们讨论了对数据帧进行切片和切块以及使用特定标准过滤行的不同方式。我们讨论了如何通过选择列、对行进行切片以及基于条件、方法或正则表达式进行过滤来获取数据子集。
历史学家学习 R 的五个理由
原文:https://www.dataquest.io/blog/five-reasons-for-historians-to-learn-r/
April 17, 2018In which I do some cheerleading for the R Project for Statistical Computing.
1.你几乎肯定会发现努力是值得的
通常,在无休止的“学者是否应该学习编码”的争论中,对于新来者来说,一旦你投入了大量的时间去学习它,你并不清楚你实际上可以用这些代码做什么。复制粘贴在线教程不会让事情变得更清楚。你是如何从“你好世界!”你研究的实际应用?但是 R 都是关于分析和展示数据的,没有多少历史学家迟早会不处理某种数据。如果您已经使用
电子表格、SPSS 或某种数据库,如果你曾经在论文中展示过表格或图表,你几乎肯定会从学习中有所收获,即使是少量的 R(并且可能会有 R 包,使其易于与你当前的工具一起使用)。r 是灵活的:它可以用于传统的表格统计数据,也可以用于语言语料库和其他文本数据集。你可以用它来处理重量级的数字、文本挖掘、项目开始时的探索性可视化,以及演示和出版中的壮观场景——各种各样的人文数据都使用。(我真的真的真的很想在这篇博文中找到美丽 viz 的应用。)
2.你不必在命令行上做这些
我知道有些人喜欢命令行工具。但是一个好的图形用户界面对于新手和我们这些实际上并不期待启动终端的人来说是非常重要的。安装 R 本身后,
RStudio 是接下来要下载的东西(免费)。这是一个合适的工作平台,包括代码编辑器、控制台、R 包管理器、可视化工具、预览器等等。如果你已经在使用 Markdown(也许即使你还没有),你会爱上 RMarkdown 和 R 笔记本。(关于另一个与 GUI 相关的主题,请参见: GitHub 桌面。不客气)
3.潮汐
我的一个定期咆哮是,历史学家在担心编程代码之前,需要理解数据和数据建模(即使他们不认为他们与“数据”打交道)。有了 R,你可以同时了解两者。这
Tidyverse 被描述为“为数据科学设计的 R 包的固执己见的集合”,它们“共享一个底层哲学”;创建和使用整齐数据的工具。
4.历史学家的在线学习资源
这
编程历史学家有几个 R 教程,从非常基础的到更高级的技术。目前我认为有四个:
- r 表格数据基础
- R 中的数据争论和管理
- R 中的基本文本处理
- 历史研究与 R 的对应分析
除了这些简短的教程,Lincoln Mullen 还开发了一个免费的在线教材,
计算历史方法,“如何识别来源和框架历史问题,然后通过计算方法回答它们”,使用 r。另请参见 Scott Weingart 的资源列表,用于教自己为 DH 编写代码。
5.共享、开放和可复制的研究
我已经写完了最后两篇
会议 论文完全在 r 中。这意味着一切都是纯文本,我可以轻松地在网上发布我使用的所有数据、代码和可视化。我把它们放在 Github 上,但也有其他选择,比如 RPubs (来自 RStudio 的开发者,从 RStudio 直接发送东西到 RPubs 真的很容易)。编者按:这最初是发布在早期现代笔记上,现在已经用 perlesson 重新发布了。作者莎伦·霍华德在谢菲尔德大学担任数字历史项目的项目经理。 想学 R?我们的基础课程将让你在不知不觉中挖掘数据。
修正教育:动机与自由
February 8, 2018
公共教育,至少在美国,只让你接触一种学习方式——自上而下的等级制度和作业。虽然有些人在这种环境中茁壮成长,但我不是其中之一。大学毕业后,我带着 2.1 的 GPA,没有真本事,不知道下一步该怎么做,被扔进了这个世界。我并不孤单。
由于这个系统对我不起作用,我认为我不喜欢学习,像数学和物理这样“更难”的科目不适合我。我从一个职业跳到另一个职业——UPS 卸货员、百事可乐仓库经理、美国外交官——才意识到我可以按照自己的方式学习我想学的东西。

我已经详细描述了如何 其他地方,但对我来说,故事最有趣的部分不是我如何学习,甚至不是结果——而是我如何从枯燥的学习变成快乐的学习。关键部分是探索的自由,以及能够解决有趣的问题(例如预测股票市场)。
在这篇文章中,我分享了我认为我们需要的教育变革。我在这里的观点并不适用于每个人,因为教育不是放之四海而皆准的,但我确实相信它们对许多人来说是正确的。让我们开始吧。
鼓励动力和探索
如何激励学生并给予他们探索的自由,这个核心问题在教育界还没有得到很好的解决(尽管这正在慢慢地改变 T2)。即使在线教育可以进行更多的尝试,但仍然或多或少地局限于内容交付模式,创新围绕着内容交付模式(视频、交互式代码等)。).
为了鼓励动机,你必须允许学生选择他们学什么,以及他们如何学。真正想学习的人可以解决最枯燥的数学课本,并理解其中的概念。然而,一个没有动机的学生可能会因为一开始被迫阅读这本书、这本书的大小或任何其他负面因素而感到厌烦。
当我两年前开始 Dataquest 时,我们几乎完全是关于内容交付的——我们有交互式数据科学教程,要求学生编写代码来解决问题。随着时间的推移,我们已经发展到通过在浏览器中构建更多的开放式项目来帮助学生应用他们的知识,然后让他们进行评审。随着学生能力的提升,学习变得越来越不基于内容,而更多的是基于项目。

这种学习方式让你变得更加独立。当您编写第一个 Javascript 应用程序时,您可能需要先学习编程概念和其他基础知识,这需要大量的介绍性内容。然而,一旦你写了 20 个应用程序,并且你正在写另一个使用服务工作者的应用程序,一个你还没有听说过的概念,你可能需要文档和一些来自同行的反馈。随着你获得技能,不仅你需要多少帮助会改变,你需要的帮助类型也会改变。
转向基于项目的学习
在“真实世界”的工作中,你基本上只是创建一系列的项目。每个项目都有一定的时间范围,并最终根据其质量进行评判。当您构建项目时,您会查阅许多资源来了解您需要的所有概念。因为这就是真实世界的工作,所以学习使用项目也是有意义的。你的学习方式和现实世界中的做事方式之间的差距越大,转变就越困难。
创建项目也很有动力。想想我之前关于预测股票市场的例子——我就是这样学习统计学的。我发现了一些我感兴趣的东西,并逆向学习完成这个项目所需要的东西。
我相信理想的在线学习环境是相似的——你能够学习一些基础知识,选择你感兴趣的项目,并且只获得你需要的帮助来完成这些项目。这种帮助可以是来自导师的反馈、文档链接、内容或其他任何东西。这种学习永远不会结束——你可以继续处理不同的兴趣领域来获得技能。
不幸的是,建立这种学习方式有几个挑战。其中最重要的是教育没有灵丹妙药。例如,如果你从事乘车共享,你可以制作一个连接乘客和司机的应用程序,筹集大量资金,并向 hypergrowth 问好。
然而,在教育领域,学生有如此多不同的目标和偏好的学习方法,以至于开发一个新产品要花很多时间。你必须编写和修改内容,设计一个支持这些内容的平台,了解你的学生和他们是如何学习的,然后在我前面描述的所有其他帮助方法上再加一层。最重要的是,你必须能够有效地向以结果为导向的学生推销你所做的事情。很明显,大多数最大的教育科技公司(Pluralsight、Lynda、Coursera、Udemy)的教学方式基本相同,这与面授课程的教学方式非常相似——结构化的课程,由讲师向你讲述。
构建基于项目的学习的其他挑战包括:
- 如何帮助学生探索他们感兴趣的东西
- 如何判断学生在什么时候需要什么帮助
- 设计吸引人且有效的项目
- 弄清楚如何将学生与项目匹配到合适的技能水平
诚然,解决这个问题令人生畏,但影响将是巨大的。
今后
真正的终身学习可以确保没有人拥有错误的技能,或者陷入自己不喜欢的职业。能够激励传统体制不兼容的学生也可以帮助世界上数百万在毕业后没有太多机会的人。这是一个关键问题,尤其是当学费上涨只会加剧教育机会不平等的问题时。
尽管存在挑战,但我相信在未来几年里,我们有很好的机会来建立更吸引人的在线学习体验。在线教育仍然很新(MOOC 的年份是 2013 年),非传统证书正变得越来越被接受(尤其是在科技领域),互联网接入正在迅速增加。
迟早,在线教育将提供比面对面教育更好的体验——问题只是什么时候。
如果你对这篇文章有任何想法,或者你对教育有强烈的意见,我很乐意和你聊天(尤其是如果你不同意的话)。在 【邮件保护】 给我发邮件!
如何在 R 中使用 For 循环(有 18 个代码示例)
June 13, 2022
for 循环是 R 编程语言中主要的控制流结构之一。那是什么意思,你如何使用它?
在本教程中,我们将讨论 R 中的 for 循环是什么,它有什么语法,什么时候可以应用,如何在不同的数据结构上使用它,如何嵌套几个 for 循环,以及如何调节 for 循环的执行。
什么是 R 中的 For 循环?
for 循环是 R 编程语言的主要控制流结构之一。它用于迭代对象集合,如向量、列表、矩阵或数据帧,并对给定数据结构的每一项应用相同的操作集。我们使用 for 循环来保持代码的整洁,避免代码块不必要的重复。
R 中 for 循环的基本语法如下:
for (variable in sequence) {
expression
}
这里,序列是 for 循环迭代的对象(例如向量)的集合,变量是该集合在每次迭代中的一项,循环体中的表达式是为每一项计算的一组运算。
从上面的语法来看,关键字for和in是强制的,括号也是。其他元素,如花括号、缩进、将表达式和结束花括号放在新行上、for 循环头和循环体之间的空白,不是强制的,但强烈建议使用。推荐使用它们的目的是为了突出 for 循环的主要部分,从而提高代码的可读性并便于调试(如果需要的话)。
除非使用了break语句,否则 for 循环会在对象集合的最后一项之后停止(我们将在本教程的后面考虑该语句)。
如何在 R 中使用 For 循环
让我们看看 R 中的 for 循环如何用于遍历各种类型的对象集合。特别地,让我们考虑一个向量、一个列表和一个矩阵。
对向量使用 For 循环
从一个非常简单的例子开始,让我们打印从 1 到 5 的所有数字。为此,我们将采用由:操作符(1:5)创建的相应向量,并使用print()函数作为表达式:
for (x in 1:5) {
print(x)
}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
在现实世界中,我们可能希望使用更有意义的变量名,而不是x(例如price、month等)。).
如果我们需要将每个值打印为一个字符,给出更多的上下文,我们可以将paste()函数添加到表达式中:
for (month in 1:5) {
print(paste('Month:', month))
}
[1] "Month: 1"
[1] "Month: 2"
[1] "Month: 3"
[1] "Month: 4"
[1] "Month: 5"
通常,我们需要评估 for 循环体中的条件表达式,并基于此输出相应的结果:
for (month in 1:5) {
if (month < 3) {
print(paste('Winter, month', month))
} else {
print(paste('Spring, month', month))
}
}
[1] "Winter, month 1"
[1] "Winter, month 2"
[1] "Spring, month 3"
[1] "Spring, month 4"
[1] "Spring, month 5"
使用易于理解且一致的语法,注意缩进,并将循环体的每个部分放在新的一行上,我们清楚地看到,对于第 1 个月和第 2 个月(即小于 3 个月),for 循环打印“Winter”和该月的数字。对于其他月份,For 循环输出“Spring”和月份号。通过下面这段代码,我们有效地获得了相同的结果:
for(month in 1:5) if(month < 3)print(paste('Winter, month', month))else print(paste('Spring, month', month))
[1] "Winter, month 1"
[1] "Winter, month 2"
[1] "Spring, month 3"
[1] "Spring, month 4"
[1] "Spring, month 5"
在第二种情况下,代码看起来更难掌握。这证实了使用正确的语法,包括非强制元素,对于提高代码可读性是非常重要的。
我们可以通过将每次迭代的结果附加到一个最初为空的向量,将 for 循环的输出存储在一个新的向量中,如下例所示:
vect_1 <- c(2, 7, 4, 9, 8)
vect_2 <- numeric()
for(num in vect_1) {
vect_2 <- c(vect_2, num * 10)
}
vect_2
- Twenty
- Seventy
- Forty
- Ninety
- Eighty
上面,我们将数值向量vect_1的每一项乘以 10,并将每次迭代的值加到vect_2。
for 循环也适用于字符向量:
animals <- c('koala', 'cat', 'dog', 'panda')
for (animal in animals) {
print(animal)
}
[1] "koala"
[1] "cat"
[1] "dog"
[1] "panda"
在列表中使用 For 循环
让我们尝试在列表上应用 for 循环。
首先,让我们创建一个混合数据类型和结构的列表:
my_list <- list(c(5, 8, 2, 9), 'cat', 'dog', c('koala', 'panda', 'rabbit'), TRUE, 3.14)
my_list
- “猫”
* “狗”
- 真实的
* Three point one four
我们可以打印列表中每个项目的值:
for (item in my_list) {
print(item)
}
[1] 5 8 2 9
[1] "cat"
[1] "dog"
[1] "koala" "panda" "rabbit"
[1] TRUE
[1] 3.14
我们还可以打印列表中每个项目的长度:
for (item in my_list) {
print(length(item))
}
[1] 4
[1] 1
[1] 1
[1] 3
[1] 1
[1] 1
现在,让我们基于my_list创建一个新列表,初始列表的每一项都复制两次:
my_list_2 <- list()
for(i in 1:length(my_list)) {
my_list_2[[i]] <- rep(my_list[[i]], 2)
}
my_list_2
正如我们在向量部分所做的那样,我们可以在上面的 for 循环体中添加一个条件评估。让我们创建一个新的列表`my_list_3`,同样基于`my_list`,初始列表的每个条目复制两次,*,但是只针对长度大于 1* 的条目。否则会加一个人物`'Too short item'`:
my_list_3 <- list()
for(i in 1:length(my_list)) {
if (length(my_list[[i]]) > 1) {
my_list_3[[i]] <- rep(my_list[[i]], 2)
} else {
my_list_3[[i]] <- 'Too short item'
}
}
my_list_3
2. '太短的项目'
- '太短的项目'
'太短的项目'
- '太短的项目'
在矩阵上使用 For 循环
由于 R 中的矩阵是具有行和列的二维数据结构,为了循环通过矩阵,我们必须使用**嵌套 for 循环**,即一个 for 循环在另一个 for 循环内:
my_matrix <- matrix(1:9, nrow=3, ncol=3)
for (row in 1:nrow(my_matrix)) {
for (col in 1:ncol(my_matrix)) {
print(paste('Row', row, 'col', col, 'value', my_matrix[row, col]))
}
}
[1] "Row 1 col 1 value 1"
[1] "Row 1 col 2 value 4"
[1] "Row 1 col 3 value 7"
[1] "Row 2 col 1 value 2"
[1] "Row 2 col 2 value 5"
[1] "Row 2 col 3 value 8"
[1] "Row 3 col 1 value 3"
[1] "Row 3 col 2 value 6"
[1] "Row 3 col 3 value 9"
在上面这段代码中,我们创建了一个 3×3 的矩阵,用 1 到 9 的整数填充它,并使用 2 个嵌套的 for 循环来遍历行和列,并打印矩阵中每个单元格的值。
通过嵌套的 for 循环,我们可以修改矩阵的值。例如,让我们重置矩阵的所有值,使每个值都等于相应单元格的索引之和。为此,我们将使用一个内置的 R 函数`dim()`来返回矩阵的维数:
for(i in 1:dim(my_matrix)[1]) {
for(j in 1:dim(my_matrix)[2]) {
my_matrix[i, j] = i + j
}
}
my_matrix
Two |
three |
four |
three |
four |
five |
four |
five |
six |
R 中的嵌套 for 循环不仅适用于操作矩阵。下面是一个简单的例子,说明如何创建两个向量值的各种组合并打印这些组合:
qualities <- c('funny', 'cute', 'friendly')
animals <- c('koala', 'cat', 'dog', 'panda')
for (x in qualities) {
for (y in animals) {
print(paste(x, y))
}
}
[1] "funny koala"
[1] "funny cat"
[1] "funny dog"
[1] "funny panda"
[1] "cute koala"
[1] "cute cat"
[1] "cute dog"
[1] "cute panda"
[1] "friendly koala"
[1] "friendly cat"
[1] "friendly dog"
[1] "friendly panda"
在数据帧上使用 For 循环
就像我们对上述矩阵所做的一样,我们可以循环遍历 dataframe,它也是一个二维数据结构:
super_sleepers <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10))
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
for (row in 1:nrow(super_sleepers)) {
for (col in 1:ncol(super_sleepers)) {
print(paste('Row', row, 'col', col, 'value', super_sleepers[row, col]))
}
}
[1] "Row 1 col 1 value 1"
[1] "Row 1 col 2 value koala"
[1] "Row 1 col 3 value Australia"
[1] "Row 1 col 4 value 21"
[1] "Row 2 col 1 value 2"
[1] "Row 2 col 2 value hedgehog"
[1] "Row 2 col 3 value Italy"
[1] "Row 2 col 4 value 18"
[1] "Row 3 col 1 value 3"
[1] "Row 3 col 2 value sloth"
[1] "Row 3 col 3 value Peru"
[1] "Row 3 col 4 value 17"
[1] "Row 4 col 1 value 4"
[1] "Row 4 col 2 value panda"
[1] "Row 4 col 3 value China"
[1] "Row 4 col 4 value 10"
在 For 循环中使用`Break`语句
在 for 循环的逻辑条件中使用了`break`语句,以便在遍历完所有项之前退出循环。在嵌套循环的情况下,该语句只中断最内层的循环。
让我们遍历前一个例子中的动物的字符向量,一旦遇到少于 4 个字符的项,就停止 for 循环:
animals <- c('koala', 'cat', 'dog', 'panda')
for (animal in animals) {
if (nchar(animal) < 4) {
break
}
print(animal)
}
[1] "koala"
我们看到,即使在“koala”之后的某个地方,我们的向量`animals`中有另一个至少有 4 个字符的项目(“panda”),for 循环也没有达到那个值,并在第一次出现一个少于 4 个字符的项目(“cat”)时停止执行。
在 For 循环中使用`Next`语句
与`break`语句不同,这个语句用于根据某些预定义的条件跳过迭代,而不是退出整个循环。
为了理解这条语句是如何工作的,让我们运行与上面相同的代码,用`next`替换`break`:
animals <- c('koala', 'cat', 'dog', 'panda')
for (animal in animals) {
if (nchar(animal) < 4) {
next
}
print(animal)
}
[1] "koala"
[1] "panda"
这一次,少于 4 个字符的两个项目(“猫”和“狗”)都被丢弃,而另外两个项目(“考拉”和“熊猫”)被打印。
结论
在本教程中,我们探讨了 r 中 for 循环的用法。现在我们知道了以下内容:
* 如何在 R 中定义 for 循环
* for 循环的语法——以及哪些语法元素是必需的
* R 中 for 循环的目的
* 如何在向量、列表和矩阵上使用 for 循环
* 如何以及为什么嵌套多个 for 循环
* 哪些语句有助于控制 for 循环的行为,以及如何使用它们
四年后,仍然每天使用来自 Dataquest 的数据科学技能
January 15, 2020
更新了!我们在 2016 年首次介绍了弗朗西斯科·索萨,但我们在 2020 年再次与他联系,以了解他对自己的数据科学技能的感受。
像许多 Dataquest 的学生一样,弗朗西斯科·索萨是从 Excel 进入数据科学的。
他是一名人力资源分析师,使用 Excel 分析数据和解决问题。他正在产生影响,但他可以看出 Excel 在拖他的后腿。他决定尝试学习编程。
他尝试了 Codecademy、Udacity 和 DataCamp,但觉得它们都太基础了:“它们牵着你的手,”弗朗西斯科说。“你不用想了。说明书确切地告诉你该做什么。你以为你在学习,但你没有。”
弗朗西斯科发现 Dataquest 的方法令人耳目一新。他需要学习的指导就在那里,但平台提供了更多的挑战。“在困难的时候,你学得更好,你需要努力找到解决办法,”他当时说。Dataquest 在太容易和太难以至于你气馁之间找到了平衡
四年后,他仍然有这种感觉。他现在是 Healthcare.com 的一名数据科学家,他说:“我肯定还在使用我在 Dataquest 学到的技能。我每天都在使用这些技能。”
工作数据科学家的生活
当然,数据科学家的生活中没有典型的一天,但 Francisco 说,大多数时候,他都在使用 Python 处理与数据科学或数据工程相关的任务。“我做的大部分工作是将机器学习模型投入生产,”他说,但数据团队的成员应该能够构建端到端的产品,所以他的工作也需要一些数据工程。
它还包括许多熊猫,弗朗西斯科说这是数据团队大多数数据清理和探索任务的首选工具。这是他从 Dataquest 得到的一些东西,他提醒我们:“我认为 Dataquest 中的熊猫课程可能是我做过的最好的课程。那是我推荐给大家的。”
在他的职业生涯发生重大转变的四年后,很明显,弗朗西斯科正在他想要的地方:作为一家快速发展的公司的专门团队的一部分,每天做数据科学。
如何像弗朗西斯科一样
早在 2016 年,当弗朗西斯科·索萨第一次开始寻找数据工作时,他面临着一个真正的挑战:没有多少可以找到。
“因为危地马拉不是最先进的国家,”他告诉我们,“我开始关注那些可能拥有大量数据的公司。我找到了一些有趣的公司,但他们的网站上没有列出任何职位。”
但是弗朗西斯科并没有气馁。相反,他申请了他能找到的任何工作,并试图在对话中加入数据。“我会得到一份营销工作的面试机会,然后在面试中我会谈论我可以用数据做些什么来帮助公司。”
而且成功了!2016 年,弗朗西斯科被外包公司 Allied Global 聘为数据科学家,他加入了一个新成立的数据科学家团队,致力于优化该公司呼叫中心的运营方式。
“我肯定还在使用我在 Dataquest 中学到的技能。我每天都在使用这些技能。”
在跳槽之前,他在那里工作了大约一年,并继续以数据科学家的身份从事自由职业咨询工作,最终担任了另一份全职工作:他目前在 healthcare.com 的工作。
他建议像他一样对职业转换感兴趣的 Dataquest 学生在完成平台上的指导项目后,通过构建自己的项目来实践他们在 Dataquest 课程中所学的内容。他说:“我认为处理真实数据和真实问题会暴露你技能上的弱点,这是你学到最多的地方。”。
“申请工作的时候,”他说,“看着招聘启事和上面列出的所有技能真的很吓人。但是不要害怕,也不要认为你需要 100%掌握所有的技能,或者甚至拥有他们列出的所有技能。申请就行。”
“数据科学领域的招聘人员通常并不确切知道他们在寻找什么。他们只是上网看看其他一些招聘信息,然后复制数据科学家可能拥有的所有技能。所以你应该申请。”
40 个免费数据集,打造不可抗拒的投资组合(2023)
原文:https://www.dataquest.io/blog/free-datasets-for-projects/
December 21, 2022
在本帖中,我们将向您展示在哪里可以找到以下领域各种项目的数据集:
- 擅长
- 计算机编程语言
- 稀有
- 数据科学
- 数据可视化
- 数据清理
- 机器学习
- 概率与统计
无论您是想通过展示您可以很好地可视化数据来加强您的投资组合,还是您有几个小时的空闲时间并想练习您的机器学习技能,本文都有您需要的一切。
寻找数据集来构建项目?我们已经为你准备好了
如果你想找到免费的数据集,这样你就可以通过构建项目来学习,我们为你提供了很多选择。
在 Dataquest,我们的大多数课程都包含项目,供您使用真实的高质量数据集完成。这些项目旨在帮助你展示你的技能,并给你一些东西添加到你的投资组合中。
如果你有兴趣,可以看看下面我们提供的一些项目。注册完全免费,数据集可以下载。
擅长
- 确定可能流失的客户: 使用 Excel 数据集为电信提供商进行探索性数据分析(EDA),以确定有流失风险的客户。
- 分析零售: 处理零售数据,探索趋势和关系。建立基本模型来确认你的见解的统计意义。
我们的数据分析与 Excel 路径包含 2 个其他项目。在这里免费注册。
数据清理(Python)
- 分析星战调查: 利用调查数据更好地了解星战粉丝。
- 探索易贝汽车销售数据: 使用易贝二手车清单的定制报废数据集来练习数据清理和数据探索。
- 查找 I-94 上的繁忙交通指标: 使用关于州际公路上交通的数据集,并执行探索性数据可视化。
- 探索黑客新闻帖子: 使用来自黑客新闻提交的数据集练习使用 Python 中的循环、清理字符串和日期。
我们的 Python 路径数据清理包含 4 个其他项目。在这里免费注册。
数据分析和可视化(Python)
- 创建欧元汇率数据可视化: 使用欧洲中央银行的数据集,使用 Matplotlib 创建可视化。
- 确定哪些移动应用吸引更多用户: 使用两个独立的数据集分析 Android 和 iOS 应用,确定有可能吸引用户的应用类型。
我们的 Python path 数据分析和可视化包含 3 个其他项目。在这里免费注册。
数据分析
- 调查新冠肺炎趋势: 使用 Kaggle 数据集和 RStudio 分析重要的新冠肺炎趋势。
- 分析书店的销售数据: 使用数据集应用控制流循环和函数,创建可重用的数据工作流。
我们的 R 基础数据分析路径包含 2 个其他项目。在这里免费注册。
机器学习(Python)
- 预测房屋销售价格: 利用美国某城市的房屋数据建立并改进线性回归模型。
- 预测股市: 利用 S & P 500 指数的历史数据对未来价格进行预测。
- 预测自行车租赁: 使用自行车租赁数据集,并应用决策树和随机森林来预测未来自行车租赁的数量。
我们的 Python 路径机器学习介绍包含 15 个其他项目。在这里免费报名。
概率和统计(Python)
- 调查 Fandango 电影评分: 使用我们团队制作的自定义数据集,进行实际分析,确定 Fandango 电影评分系统是否存在偏差。
- 寻找广告投放的最佳市场: 使用 freeCodeCamp 的调查数据,为一个电子学习平台确定最有效的广告市场。
- 构建垃圾邮件过滤器: 使用垃圾短信收集数据集,使用条件概率和朴素贝叶斯构建垃圾邮件过滤器。
我们的概率和统计与 Python 路径包含 9 个其他项目。在这里免费报名。
数据可视化项目的公共数据集
一个典型的数据可视化项目可能是类似于“我想制作一个关于美国各州收入差异的信息图”的东西。在为数据可视化项目寻找好的数据集时,有一些注意事项需要记住:
- 它不应该是杂乱的,因为你不想花很多时间清理数据。
- 它应该细致入微,足够有趣,可以制作图表。
- 理想情况下,每一列都应该得到很好的解释,这样可视化才会准确。
- 数据集不应该有太多的行或列,所以很容易处理。
为数据可视化项目寻找好数据集的好地方是公开发布数据的新闻网站。他们通常会为您清理数据,并且已经有了您可以复制或改进的图表。
1.五三八

FiveThirtyEight 是一个非常受欢迎的互动新闻和体育网站,由内特·西尔弗创办。他们写了一些有趣的数据驱动的文章,比如“不要把制造业缺乏招聘归咎于技能差距”和“2016 年 NFL 预测”
FiveThirtyEight 将其文章中使用的数据集发布在 GitHub 上。
以下是一些例子:
研究药物 —美国服用 Adderall 的数据。
2.BuzzFeed

BuzzFeed 最初是一家低质量文章的供应商,但后来有所发展,现在写一些调查性的文章,如《统治世界的法庭》和《迪昂特窖藏的短暂人生
BuzzFeed 将其文章中使用的数据集发布在 Github 上。
以下是一些例子:
3。美国宇航局
美国宇航局是一个公共资助的政府组织,因此它的所有数据都是公开的。它维护着网站,任何人都可以下载它的与地球科学相关的数据集和与太空相关的数据集。例如,您甚至可以在地球科学网站上按格式排序来查找所有可用的 CSV 数据集。
数据处理项目的公共数据集
有时您只想处理大型数据集。最终结果没有读入和分析数据的过程重要。您可能会使用像 Spark 或 Hadoop 这样的工具将处理分布在多个节点上。寻找好的数据处理数据集时要记住的事情:
- 数据越干净越好-清理大型数据集可能非常耗时。
- 数据集应该是有趣的。
- 应该有一个有趣的问题可以用数据来回答。
寻找大型公共数据集的好地方是云托管提供商,如亚马逊和 T2 的谷歌。他们有托管数据集的动机,因为他们让你使用他们的基础设施来分析数据集(并付钱让他们使用)。
4.AWS 公共数据集

亚马逊在其亚马逊网络服务平台上提供大型数据集。你可以下载数据并在自己的电脑上使用,或者通过 EMR 使用 EC2 和 Hadoop 分析云中的数据。你可以在这里阅读更多关于这个项目如何运作的信息。
亚马逊有一个页面列出了所有的数据集供你浏览。你需要一个 AWS 账户,尽管亚马逊为新账户提供了一个免费的访问层,让你可以免费浏览数据。
以下是一些例子:
5.谷歌公共数据集

与亚马逊非常相似,谷歌也有云托管服务,名为谷歌云平台。有了 GCP,你可以使用一个叫做的工具来探索大型数据集。
谷歌在一个页面上列出了所有的数据集。你需要注册一个 GCP 账户,但是你的前 1TB 查询是免费的。
以下是一些例子:
历史天气—1929 年至 2016 年 9000 个 NOAA 气象站的数据。
6.维基百科(一个基于 wiki 技术的多语言的百科全书协作计划ˌ也是一部用不同语言写成的网络百科全书ˌ 其目标及宗旨是为全人类提供自由的百科全书)ˌ开放性的百科全书

维基百科是一个免费的在线社区编辑的百科全书。维基百科包含了惊人的知识广度,包含了从奥斯曼-哈布斯堡战争到伦纳德·尼莫伊的所有页面。作为维基百科推进知识的承诺的一部分,他们免费提供内容,并定期生成网站上所有文章的转储。此外,维基百科提供编辑历史和活动,因此你可以跟踪一个主题的页面如何随着时间的推移而演变,以及谁对此做出了贡献。
你可以在维基百科网站上找到各种下载数据的方法。您还会发现以各种方式重新格式化数据的脚本。
以下是一些例子:
- 来自维基百科的所有图片和其他媒体 —维基百科上的所有图片和其他媒体文件。
- 维基百科上各种格式的内容的全站点转储。
机器学习项目的公共数据集
当您在处理机器学习项目时,您希望能够从数据集中的其他列预测某一列。为了能够做到这一点,我们需要确保:
- 数据集不是太乱——如果是,我们将花费所有的时间来清理数据。
- 有一个有趣的目标列可以进行预测。
- 其他变量对目标列有一定的解释力。
有一些专门用于机器学习的在线数据集存储库。这些数据集通常被预先清理,并允许非常快速地测试算法。
7.卡格尔

Kaggle 是一个主办机器学习竞赛的数据科学社区。网站上有各种外部贡献的、有趣的数据集。Kaggle 既有现场比赛,也有历史比赛。你可以下载其中任何一个的数据,但你必须注册 Kaggle 并接受比赛的服务条款。
你可以通过进入一个竞赛从 Kaggle 下载数据。每个比赛都有自己的相关数据集。在新的 Kaggle 数据集中也有用户贡献的数据集。
以下是一些例子:
选择题 —选择题及其对应正确答案的数据集。目标是预测任何给定问题的答案。
8.UCI 机器学习知识库

UCI 机器学习库是网络上最古老的数据集来源之一。虽然数据集是用户贡献的,因此具有不同级别的文档和清洁度,但绝大多数都是干净的,可以应用机器学习。当寻找有趣的数据集时,UCI 是一个很好的第一站。
你可以直接从 UCI 机器学习知识库下载数据,无需注册。这些数据集往往相当小,没有太多细微差别,但有利于机器学习。
以下是一些例子:
太阳耀斑 —太阳耀斑的属性,用于预测耀斑的特征。
9.Quandl

Quandl 是一个经济和金融数据仓库。有些信息是免费的,但许多数据集需要购买。Quandl 对于构建模型来预测经济指标或股票价格非常有用。由于有大量的可用数据集,因此可以构建一个复杂的模型,使用许多数据集来预测另一个数据集的值。
以下是一些例子:
- 按种族和其他因素划分的企业家活动 —包含考夫曼基金会关于美国企业家的数据。
- 美国美联储数据 —美国经济指标,来自美联储。
数据清理项目的公共数据集
为数据清理项目寻找好的数据集时,您需要:
- 分布在多个文件中。
- 有很多细微差别,有很多可能的角度。
- 需要大量的研究才能理解。
- 尽可能“真实”。
这些类型的数据集通常可以在数据集的聚合器上找到。这些聚合器倾向于拥有来自多个来源的数据集,没有太多的管理。过多的监管给了我们过于整洁的数据集,很难对其进行大范围的清理。
10.数据世界

data.world 称自己是“数据人的社交网络”,但更准确的说法是“数据 GitHub”这是一个可以搜索、复制、分析和下载数据集的地方。此外,您可以将您的数据上传到 data.world,并使用它与他人协作。
在相对较短的时间内,它已经成为获取数据的“首选”地点之一,拥有大量用户贡献的数据集以及通过 data.world 与各种组织建立的合作伙伴关系,包括来自美国联邦政府的大量数据。
data.world 的一个关键区别在于,他们构建了一些工具来简化数据处理——您可以在他们的界面中编写 SQL 查询来浏览数据和连接多个数据集。他们还为 R 和 Python 提供了 SDK,使得在您选择的工具中获取和处理数据变得更加容易(您可能有兴趣阅读我们关于 data.world Python SDK 的教程)。)
11.Data.gov

Data.gov 是一个相对较新的网站,是美国开放政府努力的一部分。Data.gov 使得从多个美国政府机构下载数据成为可能。数据范围从政府预算到学校成绩。许多数据需要额外的研究,有时很难确定哪个数据集是“正确的”版本。任何人都可以下载数据,尽管有些数据集需要通过额外的关卡,比如同意许可协议。
你可以直接在 Data.gov 上浏览数据集,无需注册。您可以按主题区域浏览或搜索特定数据集。
以下是一些例子:
- 食品环境图册——包含当地食物选择如何影响美国饮食的数据。
- 学校系统财务 —对美国学校系统财务的调查。
慢性病数据 —美国各地区慢性病指标数据。
12.世界银行
世界银行是一个全球性的发展组织,向发展中国家提供贷款和建议。世界银行定期资助发展中国家的项目,然后收集数据来监测这些项目的成功。
您可以直接浏览世界银行的数据集,无需注册。数据集有许多缺失值,有时需要点击几次才能找到数据。
以下是一些例子:
世界银行项目成本 —世界银行项目及其相应成本的数据。
13./r/数据集

广受欢迎的社区讨论网站 Reddit 有一个专门分享有趣数据集的板块。它被称为数据集子编辑,或/r/datasets。这些数据集的范围变化很大,因为它们都是用户提交的,但它们往往非常有趣和微妙。
你可以在这里浏览子编辑。你也可以在这里看到投票率最高的数据集。
以下是一些例子:
- 所有 reddit 子债券 —包含 2015 年的 Reddit 子债券。
- 危险问题 —游戏中的问题和分值显示危险。
纽约市财产税数据 —关于纽约市房产和评估价值的数据。
14.学术洪流

学术种子是一个新网站,致力于分享科学论文的数据集。这是一个较新的网站,所以很难说最常见的数据集类型会是什么样子。目前,它有大量缺乏背景的有趣数据集。
您可以在网站上直接浏览数据集。因为这是一个 torrent 网站,所有的数据集都可以立即下载,但是你需要一个 Bittorrent 客户端。大洪是一个不错的免费选择。
以下是一些例子:
奖励:流式数据
在构建数据科学项目时,下载数据集并对其进行处理是非常常见的。然而,随着在线服务生成越来越多的数据,越来越多的数据是实时生成的,而不是以数据集形式提供的。这方面的一些例子包括来自 Twitter 的推文数据,以及股票价格数据。获取这类数据的好来源并不多,但我们会列出一些,以防您想尝试流数据项目。
15.推特

Twitter 有一个很好的流媒体 API,可以相对简单地过滤和传输推文。这里可以开始。这里有大量的选项——你可以找出哪个州最幸福,或者哪个国家使用最复杂的语言。我们最近还写了一篇文章,让你开始使用 Twitter API 这里。
16.开源代码库

GitHub 有一个 API,允许你访问存储库活动和代码。你可以在这里开始使用 API 。选择是无穷无尽的——你可以构建一个系统来自动评估代码质量,或者指出在大型项目中代码是如何随时间演变的。
17.地下世界

Wunderground 有一个天气预报 API,每天可以释放多达 500 个 API 调用。您可以使用这些呼叫建立一组历史天气数据,并预测明天的天气。
18.全球健康观察站

世界卫生组织(世卫组织)在全球卫生观察站(GHO) 维持着一个庞大的全球卫生数据集。该数据集包括新冠肺炎全球疫情上的所有世卫组织数据。GHO 提供了关于抗生素耐药性、痴呆症、空气污染和免疫等主题的各种数据。
您可以在 GHO 找到几乎任何健康相关主题的数据,这使得它成为健康领域数据科学家的一个非常有价值的免费数据集资源。
查看世卫组织的数据集。
19.皮尤研究中心

皮尤研究中心因政治和社会科学研究而闻名。为了促进研究和公共讨论,他们在一段时间后,公开下载他们所有的数据集进行二次分析。
你可以从美国政治、新闻和媒体、互联网和技术、科学和社会、宗教和公共生活以及其他主题的数据集中进行选择。
20.国家气候数据中心

气候变化是目前的热门话题,请原谅我的双关语。想要处理天气和气候数据的数据科学家可以从国家环境信息中心(NCEI)获取大量美国数据集。
奖金:个人资料
互联网上充满了你可以使用的很酷的数据集。但是对于真正独特的东西,如何分析你自己的个人数据呢?
这里有一些受欢迎的网站,可以下载和使用您生成的数据。
21.亚马孙
亚马逊允许你下载你的个人消费数据、订单历史等等。要访问它,单击此链接(您需要登录才能使用)或导航到右上角的帐户和列表按钮。
在下一页上,找到订购和购物首选项部分,然后单击标题下的链接“下载订单报告”这是一个简单的数据项目教程,你可以用你自己的亚马逊数据来分析你的消费习惯。
22.脸谱网
脸书还允许你下载你的个人活动数据。要访问它,单击此链接(您需要登录才能使用)并选择您想要下载的数据类型。这里有一个的例子,一个简单的数据项目,你可以使用你自己的个人脸书数据来构建。
23.网飞
网飞允许你请求下载自己的数据,尽管这会让你经历一些麻烦,并会警告你整理数据的过程可能需要 30 天。截至我们上次检查时,他们允许您下载的数据是相当有限的,但它仍然可以适用于某些类型的项目和分析。
额外奖励:强大的数据集搜索工具
24。谷歌数据集搜索
好的,所以这不是一个严格意义上的数据集——而是一个寻找相关数据集的搜索工具。正如你已经知道的,谷歌是一个数据发电站,所以它的搜索工具击败了其他寻找特定数据集的方法是有道理的。
您需要做的就是直接进入谷歌数据集搜索并在搜索栏中键入与您要查找的数据集相关的关键词或短语。结果将列出谷歌为该特定搜索词索引的所有数据集。数据集通常来自高质量的来源,其中一些是免费的,另一些是收费或订阅的。
后续步骤
在这篇文章中,我们介绍了为任何类型的数据科学项目寻找数据集的好地方。我们希望你能找到一些有趣的东西,让你可以尽情享受!
在 Dataquest ,我们的互动指导项目旨在帮助您开始构建数据科学组合,向雇主展示您的技能,并获得一份数据方面的工作。如果你感兴趣,你可以注册并免费学习我们的第一个模块。
如果你喜欢这篇文章,你可能会喜欢阅读我们“构建数据科学组合”系列中的其他文章:
如何在 Github 上展示你的数据科学作品集。
免费 Python 测验-测试您的技能(2023)
November 21, 2022
Dataquest 的数据专家为您带来了这个 Python 测验,它将帮助您确定您在数据科学学习之旅中的位置。
这个 Python 测验包括 23 个基础和中级问题,将帮助您确定自己在 Python 中的优势和劣势。在本文的最后,我们将提供 Dataquest 课程和博客的有用链接,您可以使用它们来提高您的 Python 技能。
完成 Python 测试的预计时间大约为 10-15 分钟。我们还提供了每个问题的正确答案和简短解释。
六个月从牧师到数据工程师:Dataquest 如何帮助 Eddie
原文:https://www.dataquest.io/blog/from-priest-to-data-engineer-in-six-months-how-dataquest-helped-eddie/
February 28, 2022
https://www.youtube.com/embed/ddM21fz1Tt0?feature=oembed
*埃迪·柯克兰准备改变他的生活。
他的学位是管理和神学。他的简历包括非营利工作,相当一段时间是一名在职音乐家,最近是在一所教堂担任了六年的首席牧师。
“我在大学时喜欢统计学,所以我开始寻找职业,自从我离开后,这个庞大的数据科学世界已经开放了。”
“我开始探索它,并想‘我想我有足够的基础来理解这些概念。’我知道我需要很多技能。(但是)尽管我的学位是管理学,我的研究生学位是神学,但我认为,通过一些在线学习,我可能真的能够在这里开创一条真正酷的道路。"
一头扎进数据科学
当他开始寻找最好的数据科学 MOOCs 和在线课程时,“data quest 是最热门的结果之一。”但是由于没有编程经验,他仍然不确定自己对繁重的编程课程会有什么感觉。
“我基本上是这样想的,好吧,我要试试这个,我只是去看看,”他说。“这听起来很有趣,但可能很糟糕,所以让我试试,看看一个月后我是否还喜欢它。”
因为 Dataquest 提供了很多免费内容,所以尝试起来很容易。“我喜欢有几个免费模块可以帮助我熟悉环境,”Eddie 说。
弄湿脚后没多久,埃迪就一头扎了进去。“在第一个半月内,我购买了完整版本,我一直工作到凌晨 2 点,编写 Python 代码,非常喜欢。喜欢绝对喜欢。没人逼我这么做。这都是我自己的时间,我真的真的很喜欢它。"
“我真正喜欢的是,它让[Dataquest]与众不同,”他说,“它是基于文本的,而不是基于视频的。阅读文本,查看示例,然后自己动手编写代码,这真的非常非常有帮助。”
他还喜欢 Dataquest 的路径结构为他安排了一系列合乎逻辑的课程,并迫使他在前进的每一步都应用和重新应用他所学的知识。“这就是我认为 Dataquest 真的很有帮助的地方,”他说。“它给了我一条非常清晰的实践学习之路。
当然,这并非一帆风顺。学习编程可能会令人沮丧,尤其是在开始时,Dataquest 挑战学习者在学习旅程的早期开始构建真正的项目。有一次,埃迪笑着说,“我想把我的电脑扔过一面墙。”另一次是在一个引导项目中,他说,“我花了一整天,就像在星巴克呆了八个小时,试图通过一个无法运行的细胞。”
不过,从长远来看,这种努力是值得的:“(参与这些项目)帮助我获得了自信,知道了:‘好吧,我真的可以做这些事情。’
由于有如此多的空闲时间投入到学习中,埃迪以令人难以置信的速度完成了我们的课程。他在两个月内完成了我们整个Python 路径的数据分析师,一个月后到达了数据科学家路径的终点。
然后就该开始找工作了。
找一份全职工作
“我的第一个想法是,‘好吧,我在这个行业的第一份工作可能是分析师,而不是全面的数据科学家,’”埃迪说。
但他知道他需要做的第一件事是伸出手,建立一些联系,同时建立一些与他所在地区的公司相关的投资组合项目。他联系了小企业的朋友,告诉他们他一直在学习数据科学,并询问他们是否有他可以免费帮助他们分析的数据。
“他们的眼睛变得非常大,”他说。“他们说,‘哦,天哪,我们不知道我们在用数据做什么,所以在这里。’"
“由于[Dataquest]指导的项目,我有了一个基本的工作流程,”当一个朋友给他一个数据集时,Eddie 说。我知道如何接近它和攻击它,而不是不得不回去通过视频学习课程,只是不断地搜索 StackOverflow 的东西。我有一个已经完成的框架,这让我有信心说‘好吧,我试试看’。"
他说:“我认为 Dataquest 非常有帮助,不是因为我可以把它放在简历上,而是因为它给了我信心,让我走进一个房间,说:‘我不是什么都知道,但我确实知道一些事情,而且我知道的足够多,可以伸出手来开始帮助。”"
尽管如此,当一系列的关系导致一个潜在的数据工程师的角色时,埃迪犹豫了。“一开始我想,‘不可能,这不可能。我做不了这个。”(Dataquest 确实提供了一条数据工程的道路,但 Eddie 没有经历过)。
他还是参加了会议。“我进去和他们谈了谈,然后他们给了我一个实践评估,”他说。“我立刻明白了:这就是我学到的 SQL 知识。这里有很多我必须做的数据清理工作,并且是关于连接和 Python 的。这是我从数据分析师课程中学到的所有东西。”
埃迪不确定他是否能胜任数据工程师的工作,但他还是参加了会议。
他说,当他完成评估时,他意识到:“我想我至少可以开始做这件事。我知道的没有做这件事的人多,但我什么都不知道。我从这个[Dataquest]课程中学到了一些东西,这对我帮助很大。”
他的新雇主同意了,埃迪现在是一名全职数据工程师。
“我每天都在大量使用 Python,”他谈到自己的新工作时说。“我使用 Spark 处理数据块,所以我经常使用 Python。我大量使用 SQL。如果有什么不同的话,我希望我在课程的 SQL 部分集中了更多的注意力,因为它非常有帮助。”
他还表示,他很欣赏 Dataquest 的课程有多少是专注于数据清理的,这现在是他工作的一大部分。
作为一名新的数据工程师,Eddie 不能只依赖他已经知道的东西。他也在学习新的技能和工具。“它的到来比我想象的要快得多,我认为这是因为我通过[Dataquest]计划接触了太多的实践编码和学习。”
最重要的是,埃迪很开心。“这是一个很大的变化,”他谈到自己的新职业时说,“但我真的很喜欢它[……]用你能给他们的信息帮助人们做出明智的决定——我真的真的很喜欢它。”
对 Dataquest 学习者的建议
当我们问 Eddie 他会给其他 Dataquest 学习者什么建议时,他首先想到的是给予鼓励。“你真的可以做到这一点,”他说,“你只需要坚持下去,而且必须勤奋。”
“大约一个半月前,我记得坐在我的客厅里。我在打电话,打开 Dataquest 网站,阅读已经找到工作的人的推荐。这让我想到:'不要气馁。这需要时间,但这是可能的,也是可能发生的。’”
除了坚持这个项目并保持积极的态度,埃迪还建议你找工作时要围绕真正的人际关系。他说:“在你的世界里,结识新朋友,保持联系。”。“在我看来,最好的策略是不要说‘我需要一份工作’,而是说‘嘿,我对数据科学非常感兴趣。我们能聚一聚吗?我想知道你是做什么的。"
“我有过很多这样的对话,”他说。“我说‘告诉我你是做什么的,你喜欢你的工作什么,你讨厌你的工作什么?’这种自然的对话带来了非常棒的机会。"
“这不是招聘启事。不是所有其他的东西。与已经在该领域工作的人进行一对一的交谈。
埃迪还推荐了《设计你的生活 》这本书。“这基本上是采用产品设计思维和方法,并将其应用于生活变化,并说,我如何才能像制造产品一样对待我的职业生涯,在那里你将构建和迭代测试。”埃迪说,书中有一章是关于重复职业对话的,还有“如何进行对话的脚本,‘嘿,像我这样的人有什么步骤可以加入这样的组织吗?’而不是说“我真的需要一份工作。”"
最后,埃迪说,如果你发现你的学习非常具有挑战性,不要气馁,尤其是在开始的时候,不要被面前的复杂性吓倒。“对我来说,整个过程中最难的部分是开始时的数据清理。我想部分原因是因为 Python 对我来说太新了,一般来说编码也太新了,但那是超级难的部分。”
“一旦我完成了机器学习的东西,与早期的东西相比,它实际上是相当容易的,”他说,“这真的很酷,因为我已经看到它在地平线上有一段时间了,它就像'哦,伙计,我永远不会通过它。你知道,你会看到人工智能和它是如何工作的,你会认为不可能。那会花去我几个月的时间。"
“但是一旦你到了那里,”他说,你理解了语法,你理解了这些对象应该如何工作,然后就像按下 run 然后放手一样,这真的很有趣。我第一次在电脑上运行一个模型时,我跳了一小段舞,心想,“这太酷了!”这很有趣,是值得期待的事情,而不是令人恐惧的事情。"*
数据故事:父亲在美国公开赛父亲节表现更好
原文:https://www.dataquest.io/blog/golf-us-open-fathers-day-data-analysis/
June 14, 2019
对于高尔夫球迷来说,美国公开赛是最令人兴奋的赛事之一。多年来,比赛一直安排在六月中旬,所以比赛的最后一天正好是父亲节。这个节日是锦标赛中一些最激动人心的时刻的来源,包括去年当新爸爸汤米·弗利特伍德度过了一个绝对壮观的日子,并且只差一杆就赢得了锦标赛。
那场表演让我不禁想:当爸爸的高尔夫球手在父亲节会打得更好吗?
这个问题并不像看起来那么荒谬。高尔夫球是一项非常需要脑力的运动。球员必须在高压力的情况下集中注意力,即使是一点点额外的积极性也可能会有所不同。
那么,在父亲节做父亲会带来某种小优势吗?没有办法确切知道因果关系,但数据表明,无论原因是什么,父亲们在父亲节往往比其他人表现得更好。
为了弄清楚这一点,我从 USGA 的美国公开赛网站上搜集了过去十年来每一位高尔夫球手在父亲节的表现数据。然后,我从的 PGA 巡回赛网站获取数据,其中包括每个球员的传记资料,包括他们孩子的生日(如果他们有孩子的话)。这让我能够计算出在过去十年的每个父亲节,每个球员是否是父亲,并相应地分析他们的表现。
由于美国网球公开赛每年在不同的球场举行,所以没有办法比较每年的表现,所以下面的图表显示了从 2009 年开始,在锦标赛的每一年中,是父亲的球员与不是父亲的球员的表现。

箱形图,极端异常值以点的形式绘制。
上图每个方框中的黑线代表非父亲(蓝色)和父亲(绿色)的中值分数。如你所见,在过去的十年中,有六年的父亲节,父亲的得分低于非父亲的得分(回想一下,在高尔夫球比赛中,得分最低的获胜)。
在另外两年中,父亲和非父亲的得分中值持平。在过去的十个父亲节里,没有父亲的美国公开赛平均成绩只赢过父亲两次。
诚然,这可能并不意味着父亲有任何特殊的父亲节权力。美国公开赛确实包括业余高尔夫球手,他们的分数往往高于职业球手。这些业余爱好者的平均年龄也可能比专业人士小,因此不太可能成为父母,这可能是父亲的一个优势。
还值得指出的是,这里的边距很小——在大多数情况下,差别只有一两个笔画。
尽管如此,数字不会说谎:不管是什么原因,在过去十年的美国公开赛上,父亲们在父亲节的表现比其他高尔夫球手都要好。
也许泰格·伍兹、达斯汀·约翰逊和本周末锦标赛中的其他父亲们可以希望得到一点鼓励,因为他们试图阻止年轻的布鲁克斯·科普卡(Brooks Koepka)获得美国公开赛的三连冠,布鲁克斯不是父亲。
成为数据分析师!
立即学习成为数据分析师所需的技能。注册一个免费帐户,获得免费的交互式 Python、R 和 SQL 课程内容。
(不需要信用卡!)
做一个好的倾听者可以帮助你得到一份数据科学的工作
原文:https://www.dataquest.io/blog/good-listener-help-data-science-job/
March 20, 2019
获得一份数据科学的工作(或者其他任何工作)感觉就像一场马拉松。在所有的申请、招聘人员筛选电话、问题集和几轮视频或面对面面试之间,从申请到录用的跑道令人疲惫不堪。能够在提供“正确答案”的同时有效地与不同的人交流是很重要的,但一项软技能可能对于获取和做数据科学工作来说都是一样的:倾听。
这听起来很简单,但却很重要——听和听是有区别的,尤其是在求职面试中。
《数据挖掘食谱》 作者和 OliviaGroup 首席执行官奥利维亚·帕尔-鲁德说,“做一个好的倾听者”在求职面试中真的很有帮助,她在招聘数据科学家时多次坐在面试桌的另一边。
她也知道在数据科学中倾听的重要性在你得到工作后,与思科、富国银行、IBM 和 Nationwide 等客户合作过。
她说:“事实上,倾听,然后甚至可能重复对那个人说,‘好的,我只是想确保我明白你在寻找什么’,然后可能再深入一点,让他们感觉被听到了,这是非常重要的。”。“然后他们知道你明白了,他们知道你的想法超出了他们的想象。他们会对你的领导感到满意,并信任你所做的工作。”
“让我感到惊讶的是,有多少人感觉不到被倾听,而仅仅是倾听的行为就能真正地将你联系起来,”她说。
“对我来说,这会给正在面试的人带来巨大的优势,即使是在无意识的层面上。问‘你最大的痛点是什么,你有数据解决方案吗?我想探索一些我可能采取的方法。"
帕尔-鲁德说,这种问题将有助于你与面试官建立真正的联系,并传达出你不只是在努力推销自己,你正在积极参与解决公司的问题(正如面试官所看到的),并希望解决这些问题。
回声效应的心理学
有一些硬科学支持帕尔-鲁德的建议,即受访者重述面试问题。根据最近的几项研究,这种倾听然后重复面试官所说的话的行为可以给面试官(或任何与你交谈的人)留下更积极的印象。研究人员称之为回声效应,并且有大量的证据证明这一点。
例如,一项研究 (PDF 链接)发现,如果研究人员假扮成产品的销售人员,向测试对象重复他们的观点以示确认,测试对象更有可能对产品产生积极的印象。所以像这样的交换:
主题:“我倾向于主要喝可乐和雪碧。”研究员:“所以你主要喝可乐和雪碧。”
…比这样的交流更能给人留下积极的印象:
主题:“我倾向于主要喝可乐和雪碧。”研究员:“好的,我知道你对此的看法了。”
其他研究表明了同样的事情。在第一次中,研究人员发现,当女服务员逐字重复餐厅的订单时(而不是简单地写下来或说“好的!”之类的话),她们会得到更多的小费或者“明白了!”).
在另一个中,研究人员发现,当销售人员在回答顾客问题之前重复这些问题时,他们会完成更多的销售,并且那些问题被重复的顾客会对销售人员和商店留下更好的印象。
最近的一项研究发现,在货币交易中,如果收银员重复他们说过的话,无论是一字不差还是意译,人们会更频繁地捐款,给更多的钱。
虽然没有任何研究专门针对数据科学领域的招聘,但有充分的理由怀疑这种影响也在发挥作用。求职面试至少在某种程度上是对自己的推销,因此,如果“回声效应”在其他销售环境中留下了积极的印象,它可能也适用于求职面试。
也就是说,最好用帕尔-鲁德的术语来思考这个问题。专注于重复面试官的问题,因为你在真诚地倾听和理解他们。简单地一字不差地重复每一个问题可能会引发危险信号,特别是如果你不能用一个答案来证明你真的在听的话。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
数据分组:Pandas 中分组的分步指南
原文:https://www.dataquest.io/blog/grouping-data-a-step-by-step-tutorial-to-groupby-in-pandas/
February 2, 2022
在本教程中,我们将探索如何在 Python 的 pandas 库中创建一个 GroupBy 对象,以及这个对象是如何工作的。我们将详细了解分组过程的每一步,哪些方法可以应用于 GroupBy 对象,以及我们可以从中提取哪些信息。
Groupby 流程的 3 个步骤
任何 groupby 流程都涉及以下 3 个步骤的某种组合:
- 根据定义的标准将原始对象分成组。
- 对每组应用一个函数。
- 结合结果。
让我们用一个来自 Kaggle 诺贝尔奖数据集的例子来一步一步地探索这个分离-应用-组合链:
import pandas as pd
import numpy as np
pd.set_option('max_columns', None)
df = pd.read_csv('complete.csv')
df = df[['awardYear', 'category', 'prizeAmount', 'prizeAmountAdjusted', 'name', 'gender', 'birth_continent']]
df.head()
| 获奖年份 | 种类 | 奖金数额 | prizeAmountAdjusted | 名字 | 性别 | 出生地 _ 大陆 | |
|---|---|---|---|---|---|---|---|
| Zero | Two thousand and one | 经济科学 | Ten million | Twelve million two hundred and ninety-five thousand and eighty-two | A·迈克尔·斯宾思 | 男性的 | 北美洲 |
| one | One thousand nine hundred and seventy-five | 物理学 | Six hundred and thirty thousand | Three million four hundred and four thousand one hundred and seventy-nine | Aage N. Bohr | 男性的 | 欧洲 |
| Two | Two thousand and four | 化学 | Ten million | Eleven million seven hundred and sixty-two thousand eight hundred and sixty-one | Aaron Ciechanover | 男性的 | 亚洲 |
| three | One thousand nine hundred and eighty-two | 化学 | One million one hundred and fifty thousand | Three million one hundred and two thousand five hundred and eighteen | 阿伦·克卢格 | 男性的 | 欧洲 |
| four | One thousand nine hundred and seventy-nine | 物理学 | Eight hundred thousand | Two million nine hundred and eighty-eight thousand and forty-eight | Abdus Salam | 男性的 | 亚洲 |
将原始对象拆分成组
在这个阶段,我们调用熊猫DataFrame.groupby()函数。我们使用它根据预定义的标准将数据分组,按照行(默认情况下,axis=0)或列(axis=1)。换句话说,这个函数将标签映射到组名。
例如,在我们的例子中,我们可以按奖项类别对诺贝尔奖的数据进行分组:
grouped = df.groupby('category')
也可以使用多个列来执行数据分组,传递列的列表。让我们先按奖项类别对数据进行分组,然后,在每个已创建的组中,我们将根据获奖年份应用附加分组:
grouped_category_year = df.groupby(['category', 'awardYear'])
现在,如果我们尝试打印我们创建的两个 GroupBy 对象中的一个,我们实际上将看不到任何组:
print(grouped)
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000026083789DF0>
需要注意的是,创建 GroupBy 对象只检查我们是否传递了正确的映射;它不会真正执行拆分-应用-组合链的任何操作,直到我们显式地对这个对象使用某种方法或提取它的某些属性。
为了简单地检查产生的 GroupBy 对象,并检查组是如何被精确地分割的,我们可以从中提取出groups或indices属性。它们都返回一个字典,其中键是创建的组,值是原始数据帧中每个组的实例的轴标签(对于groups属性)或索引(对于indices属性)的列表:
grouped.indices
{'Chemistry': array([ 2, 3, 7, 9, 10, 11, 13, 14, 15, 17, 19, 39, 62,
64, 66, 71, 75, 80, 81, 86, 92, 104, 107, 112, 129, 135,
153, 169, 175, 178, 181, 188, 197, 199, 203, 210, 215, 223, 227,
239, 247, 249, 258, 264, 265, 268, 272, 274, 280, 282, 284, 289,
296, 298, 310, 311, 317, 318, 337, 341, 343, 348, 352, 357, 362,
365, 366, 372, 374, 384, 394, 395, 396, 415, 416, 419, 434, 440,
442, 444, 446, 448, 450, 455, 456, 459, 461, 463, 465, 469, 475,
504, 505, 508, 518, 522, 523, 524, 539, 549, 558, 559, 563, 567,
571, 572, 585, 591, 596, 599, 627, 630, 632, 641, 643, 644, 648,
659, 661, 666, 667, 668, 671, 673, 679, 681, 686, 713, 715, 717,
719, 720, 722, 723, 725, 726, 729, 732, 738, 742, 744, 746, 751,
756, 759, 763, 766, 773, 776, 798, 810, 813, 814, 817, 827, 828,
829, 832, 839, 848, 853, 855, 862, 866, 880, 885, 886, 888, 889,
892, 894, 897, 902, 904, 914, 915, 920, 921, 922, 940, 941, 943,
946, 947], dtype=int64),
'Economic Sciences': array([ 0, 5, 45, 46, 58, 90, 96, 139, 140, 145, 152, 156, 157,
180, 187, 193, 207, 219, 231, 232, 246, 250, 269, 279, 283, 295,
305, 324, 346, 369, 418, 422, 425, 426, 430, 432, 438, 458, 467,
476, 485, 510, 525, 527, 537, 538, 546, 580, 594, 595, 605, 611,
636, 637, 657, 669, 670, 678, 700, 708, 716, 724, 734, 737, 739,
745, 747, 749, 750, 753, 758, 767, 800, 805, 854, 856, 860, 864,
871, 882, 896, 912, 916, 924], dtype=int64),
'Literature': array([ 21, 31, 40, 49, 52, 98, 100, 101, 102, 111, 115, 142, 149,
159, 170, 177, 201, 202, 220, 221, 233, 235, 237, 253, 257, 259,
275, 277, 278, 286, 312, 315, 316, 321, 326, 333, 345, 347, 350,
355, 359, 364, 370, 373, 385, 397, 400, 403, 406, 411, 435, 439,
441, 454, 468, 479, 480, 482, 483, 492, 501, 506, 511, 516, 556,
569, 581, 602, 604, 606, 613, 614, 618, 631, 633, 635, 640, 652,
653, 655, 656, 665, 675, 683, 699, 761, 765, 771, 774, 777, 779,
780, 784, 786, 788, 796, 799, 803, 836, 840, 842, 850, 861, 867,
868, 878, 881, 883, 910, 917, 919, 927, 928, 929, 930, 936],
dtype=int64),
'Peace': array([ 6, 12, 16, 25, 26, 27, 34, 36, 44, 47, 48, 54, 61,
65, 72, 78, 79, 82, 95, 99, 116, 119, 120, 126, 137, 146,
151, 166, 167, 171, 200, 204, 205, 206, 209, 213, 225, 236, 240,
244, 255, 260, 266, 267, 270, 287, 303, 320, 329, 356, 360, 361,
377, 386, 387, 388, 389, 390, 391, 392, 393, 433, 447, 449, 471,
477, 481, 489, 491, 500, 512, 514, 517, 528, 529, 530, 533, 534,
540, 542, 544, 545, 547, 553, 555, 560, 562, 574, 578, 590, 593,
603, 607, 608, 609, 612, 615, 616, 617, 619, 620, 628, 634, 639,
642, 664, 677, 688, 697, 703, 705, 710, 727, 736, 787, 793, 795,
806, 823, 846, 847, 852, 865, 875, 876, 877, 895, 926, 934, 935,
937, 944, 948, 949], dtype=int64),
'Physics': array([ 1, 4, 8, 20, 23, 24, 30, 32, 38, 51, 59, 60, 67,
68, 69, 70, 74, 84, 89, 97, 103, 105, 108, 109, 114, 117,
118, 122, 125, 127, 128, 130, 133, 141, 143, 144, 155, 162, 163,
164, 165, 168, 173, 174, 176, 179, 183, 195, 212, 214, 216, 222,
224, 228, 230, 234, 238, 241, 243, 251, 256, 263, 271, 276, 291,
292, 297, 301, 306, 307, 308, 323, 327, 328, 330, 335, 336, 338,
349, 351, 353, 354, 363, 367, 375, 376, 378, 381, 382, 398, 399,
402, 404, 405, 408, 410, 412, 413, 420, 421, 424, 428, 429, 436,
445, 451, 453, 457, 460, 462, 470, 472, 487, 495, 498, 499, 509,
513, 515, 521, 526, 532, 535, 536, 541, 548, 550, 552, 557, 561,
564, 565, 566, 573, 576, 577, 579, 583, 586, 588, 592, 601, 610,
621, 622, 623, 629, 647, 650, 651, 654, 658, 674, 676, 682, 684,
690, 691, 693, 694, 695, 696, 698, 702, 707, 711, 714, 721, 730,
731, 735, 743, 752, 755, 770, 772, 775, 781, 785, 790, 792, 797,
801, 802, 808, 822, 833, 834, 835, 844, 851, 870, 872, 879, 884,
887, 890, 893, 900, 901, 903, 905, 907, 908, 909, 913, 925, 931,
932, 933, 938, 942, 945], dtype=int64),
'Physiology or Medicine': array([ 18, 22, 28, 29, 33, 35, 37, 41, 42, 43, 50, 53, 55,
56, 57, 63, 73, 76, 77, 83, 85, 87, 88, 91, 93, 94,
106, 110, 113, 121, 123, 124, 131, 132, 134, 136, 138, 147, 148,
150, 154, 158, 160, 161, 172, 182, 184, 185, 186, 189, 190, 191,
192, 194, 196, 198, 208, 211, 217, 218, 226, 229, 242, 245, 248,
252, 254, 261, 262, 273, 281, 285, 288, 290, 293, 294, 299, 300,
302, 304, 309, 313, 314, 319, 322, 325, 331, 332, 334, 339, 340,
342, 344, 358, 368, 371, 379, 380, 383, 401, 407, 409, 414, 417,
423, 427, 431, 437, 443, 452, 464, 466, 473, 474, 478, 484, 486,
488, 490, 493, 494, 496, 497, 502, 503, 507, 519, 520, 531, 543,
551, 554, 568, 570, 575, 582, 584, 587, 589, 597, 598, 600, 624,
625, 626, 638, 645, 646, 649, 660, 662, 663, 672, 680, 685, 687,
689, 692, 701, 704, 706, 709, 712, 718, 728, 733, 740, 741, 748,
754, 757, 760, 762, 764, 768, 769, 778, 782, 783, 789, 791, 794,
804, 807, 809, 811, 812, 815, 816, 818, 819, 820, 821, 824, 825,
826, 830, 831, 837, 838, 841, 843, 845, 849, 857, 858, 859, 863,
869, 873, 874, 891, 898, 899, 906, 911, 918, 923, 939], dtype=int64)}
为了找到 GroupBy 对象中的组数,我们可以从中提取出ngroups属性或者调用 Python 标准库的len函数:
print(grouped.ngroups)
print(len(grouped))
6
6
如果我们需要可视化每个组的所有或部分条目,我们可以迭代 GroupBy 对象:
for name, entries in grouped:
print(f'First 2 entries for the "{name}" category:')
print(30*'-')
print(entries.head(2), '\n\n')
First 2 entries for the "Chemistry" category:
------------------------------
awardYear category prizeAmount prizeAmountAdjusted name \
2 2004 Chemistry 10000000 11762861 Aaron Ciechanover
3 1982 Chemistry 1150000 3102518 Aaron Klug
gender birth_continent
2 male Asia
3 male Europe
First 2 entries for the "Economic Sciences" category:
------------------------------
awardYear category prizeAmount prizeAmountAdjusted \
0 2001 Economic Sciences 10000000 12295082
5 2019 Economic Sciences 9000000 9000000
name gender birth_continent
0 A. Michael Spence male North America
5 Abhijit Banerjee male Asia
First 2 entries for the "Literature" category:
------------------------------
awardYear category prizeAmount prizeAmountAdjusted \
21 1957 Literature 208629 2697789
31 1970 Literature 400000 3177966
name gender birth_continent
21 Albert Camus male Africa
31 Alexandr Solzhenitsyn male Europe
First 2 entries for the "Peace" category:
------------------------------
awardYear category prizeAmount prizeAmountAdjusted \
6 2019 Peace 9000000 9000000
12 1980 Peace 880000 2889667
name gender birth_continent
6 Abiy Ahmed Ali male Africa
12 Adolfo Pérez Esquivel male South America
First 2 entries for the "Physics" category:
------------------------------
awardYear category prizeAmount prizeAmountAdjusted name gender \
1 1975 Physics 630000 3404179 Aage N. Bohr male
4 1979 Physics 800000 2988048 Abdus Salam male
birth_continent
1 Europe
4 Asia
First 2 entries for the "Physiology or Medicine" category:
------------------------------
awardYear category prizeAmount prizeAmountAdjusted \
18 1963 Physiology or Medicine 265000 2839286
22 1974 Physiology or Medicine 550000 3263449
name gender birth_continent
18 Alan Hodgkin male Europe
22 Albert Claude male Europe
相反,如果我们想以 DataFrame 的形式选择一个组,我们应该对 GroupBy 对象使用方法get_group():
grouped.get_group('Economic Sciences')
| 获奖年份 | 种类 | 奖金数额 | prizeAmountAdjusted | 名字 | 性别 | 出生地 _ 大陆 | |
|---|---|---|---|---|---|---|---|
| Zero | Two thousand and one | 经济科学 | Ten million | Twelve million two hundred and ninety-five thousand and eighty-two | A·迈克尔·斯宾思 | 男性的 | 北美洲 |
| five | Two thousand and nineteen | 经济科学 | Nine million | Nine million | 阿比吉特·班纳吉 | 男性的 | 亚洲 |
| Forty-five | Two thousand and twelve | 经济科学 | Eight million | Eight million three hundred and sixty-one thousand two hundred and four | 埃尔文·E·罗斯 | 男性的 | 北美洲 |
| Forty-six | One thousand nine hundred and ninety-eight | 经济科学 | Seven million six hundred thousand | Nine million seven hundred and thirteen thousand seven hundred and one | 阿马蒂亚·森 | 男性的 | 亚洲 |
| Fifty-eight | Two thousand and fifteen | 经济科学 | Eight million | Eight million three hundred and eighty-four thousand five hundred and seventy-two | 安格斯·迪顿 | 男性的 | 欧洲 |
| … | … | … | … | … | … | … | … |
| Eight hundred and eighty-two | Two thousand and two | 经济科学 | Ten million | Twelve million thirty-four thousand six hundred and sixty | 弗农·L·史密斯 | 男性的 | 北美洲 |
| Eight hundred and ninety-six | One thousand nine hundred and seventy-three | 经济科学 | Five hundred and ten thousand | Three million three hundred and thirty-one thousand eight hundred and eighty-two | 瓦西里·列昂季耶夫 | 男性的 | 欧洲 |
| Nine hundred and twelve | Two thousand and eighteen | 经济科学 | Nine million | Nine million | 威廉·诺德豪斯 | 男性的 | 北美洲 |
| Nine hundred and sixteen | One thousand nine hundred and ninety | 经济科学 | Four million | Six million three hundred and twenty-nine thousand one hundred and fourteen | 威廉·夏普 | 男性的 | 北美洲 |
| Nine hundred and twenty-four | One thousand nine hundred and ninety-six | 经济科学 | Seven million four hundred thousand | Nine million four hundred and ninety thousand four hundred and twenty-four | 威廉·维克瑞 | 男性的 | 北美洲 |
84 行× 7 列
按组应用函数
在分割原始数据并(可选地)检查结果组之后,我们可以对每个组执行以下操作之一或它们的组合(不一定按照给定的顺序):
- 聚合:计算每个组的汇总统计数据(例如,组大小、平均值、中间值或总和),并输出多个数据点的单一数字。
- 转换:按组进行一些操作,比如计算每组的 z 值。
- 过滤:根据预定义的条件,如组大小、平均值、中间值或总和,拒绝一些组。这也可以包括从每个组中过滤出特定的行。
聚合
要聚合 GroupBy 对象的数据(即,按组计算汇总统计数据),我们可以在对象上使用agg()方法:
# Showing only 1 decimal for all float numbers
pd.options.display.float_format = '{:.1f}'.format
grouped.agg(np.mean)
| 获奖年份 | 奖金数额 | prizeAmountAdjusted | |
|---|---|---|---|
| 种类 | |||
| --- | --- | --- | --- |
| 化学 | One thousand nine hundred and seventy-two point three | Three million six hundred and twenty-nine thousand two hundred and seventy-nine point four | Six million two hundred and fifty-seven thousand eight hundred and sixty-eight point one |
| 经济科学 | One thousand nine hundred and ninety-six point one | Six million one hundred and five thousand eight hundred and forty-five point two | Seven million eight hundred and thirty-seven thousand seven hundred and seventy-nine point two |
| 文学 | One thousand nine hundred and sixty point nine | Two million four hundred and ninety-three thousand eight hundred and eleven point two | Five million five hundred and ninety-eight thousand two hundred and fifty-six point three |
| 和平 | One thousand nine hundred and sixty-four point five | Three million one hundred and twenty-four thousand eight hundred and seventy-nine point two | Six million one hundred and sixty-three thousand nine hundred and six point nine |
| 物理学 | One thousand nine hundred and seventy-one point one | Three million four hundred and seven thousand nine hundred and thirty-eight point six | Six million eighty-six thousand nine hundred and seventy-eight point two |
| 生理学或医学 | One thousand nine hundred and seventy point four | Three million seventy-two thousand nine hundred and seventy-two point nine | Five million seven hundred and thirty-eight thousand three hundred point seven |
上面的代码生成一个 DataFrame,将组名作为它的新索引,并按组显示每个数值列的平均值。
我们可以不使用agg()方法,而是直接在 GroupBy 对象上应用相应的 pandas 方法。最常用的方法有mean()、median()、mode()、sum()、size()、count()、min()、max()、std()、var()(计算每组的方差)、describe()(按组输出描述性统计量)、nunique()(给出每组唯一值的个数)。
grouped.sum()
| 获奖年份 | 奖金数额 | prizeAmountAdjusted | |
|---|---|---|---|
| 种类 | |||
| --- | --- | --- | --- |
| 化学 | Three hundred and sixty-two thousand nine hundred and twelve | Six hundred and sixty-seven million seven hundred and eighty-seven thousand four hundred and eighteen | One billion one hundred and fifty-one million four hundred and forty-seven thousand seven hundred and twenty-six |
| 经济科学 | One hundred and sixty-seven thousand six hundred and seventy-four | Five hundred and twelve million eight hundred and ninety-one thousand | Six hundred and fifty-eight million three hundred and seventy-three thousand four hundred and forty-nine |
| 文学 | Two hundred and twenty-seven thousand four hundred and sixty-eight | Two hundred and eighty-nine million two hundred and eighty-two thousand one hundred and two | Six hundred and forty-nine million three hundred and ninety-seven thousand seven hundred and thirty-one |
| 和平 | Two hundred and sixty-three thousand two hundred and forty-eight | Four hundred and eighteen million seven hundred and thirty-three thousand eight hundred and seven | Eight hundred and twenty-five million nine hundred and sixty-three thousand five hundred and twenty-one |
| 物理学 | Four hundred and nineteen thousand eight hundred and thirty-seven | Seven hundred and twenty-five million eight hundred and ninety thousand nine hundred and twenty-eight | One billion two hundred and ninety-six million five hundred and twenty-six thousand three hundred and fifty-two |
| 生理学或医学 | Four hundred and thirty-one thousand five hundred and eight | Six hundred and seventy-two million nine hundred and eighty-one thousand and sixty-six | One billion two hundred and fifty-six million six hundred and eighty-seven thousand eight hundred and fifty-seven |
通常,我们只对某些特定列的统计数据感兴趣,所以我们需要指定它(或它们)。在上面的例子中,我们肯定不想对所有年份求和。相反,我们可能希望按奖项类别对奖项值求和。为此,我们可以选择 GroupBy 对象的prizeAmountAdjusted列,就像我们选择 DataFrame 的一列一样,并对其应用sum()函数:
grouped['prizeAmountAdjusted'].sum()
category
Chemistry 1151447726
Economic Sciences 658373449
Literature 649397731
Peace 825963521
Physics 1296526352
Physiology or Medicine 1256687857
Name: prizeAmountAdjusted, dtype: int64
对于上面的这段代码(以及下面的一些例子),我们可以使用一个等价的语法,在选择必要的列之前对 GroupBy 对象应用函数:grouped.sum()['prizeAmountAdjusted']。但是,前面的语法更可取,因为它的性能更好,尤其是在大型数据集上。
如果我们需要合计两列或更多列的数据,我们使用双方括号:
grouped[['prizeAmount', 'prizeAmountAdjusted']].sum()
| 奖金数额 | prizeAmountAdjusted | |
|---|---|---|
| 种类 | ||
| --- | --- | --- |
| 化学 | Six hundred and sixty-seven million seven hundred and eighty-seven thousand four hundred and eighteen | One billion one hundred and fifty-one million four hundred and forty-seven thousand seven hundred and twenty-six |
| 经济科学 | Five hundred and twelve million eight hundred and ninety-one thousand | Six hundred and fifty-eight million three hundred and seventy-three thousand four hundred and forty-nine |
| 文学 | Two hundred and eighty-nine million two hundred and eighty-two thousand one hundred and two | Six hundred and forty-nine million three hundred and ninety-seven thousand seven hundred and thirty-one |
| 和平 | Four hundred and eighteen million seven hundred and thirty-three thousand eight hundred and seven | Eight hundred and twenty-five million nine hundred and sixty-three thousand five hundred and twenty-one |
| 物理学 | Seven hundred and twenty-five million eight hundred and ninety thousand nine hundred and twenty-eight | One billion two hundred and ninety-six million five hundred and twenty-six thousand three hundred and fifty-two |
| 生理学或医学 | Six hundred and seventy-two million nine hundred and eighty-one thousand and sixty-six | One billion two hundred and fifty-six million six hundred and eighty-seven thousand eight hundred and fifty-seven |
可以对 GroupBy 对象的一列或多列同时应用多个函数。为此,我们再次需要agg()方法和感兴趣的函数列表:
grouped[['prizeAmount', 'prizeAmountAdjusted']].agg([np.sum, np.mean, np.std])
| 奖金数额 | prizeAmountAdjusted | |
|---|---|---|
| 总和 | 意思是 | |
| --- | --- | --- |
| 种类 | ||
| --- | --- | --- |
| 化学 | Six hundred and sixty-seven million seven hundred and eighty-seven thousand four hundred and eighteen | Three million six hundred and twenty-nine thousand two hundred and seventy-nine point four |
| 经济科学 | Five hundred and twelve million eight hundred and ninety-one thousand | Six million one hundred and five thousand eight hundred and forty-five point two |
| 文学 | Two hundred and eighty-nine million two hundred and eighty-two thousand one hundred and two | Two million four hundred and ninety-three thousand eight hundred and eleven point two |
| 和平 | Four hundred and eighteen million seven hundred and thirty-three thousand eight hundred and seven | Three million one hundred and twenty-four thousand eight hundred and seventy-nine point two |
| 物理学 | Seven hundred and twenty-five million eight hundred and ninety thousand nine hundred and twenty-eight | Three million four hundred and seven thousand nine hundred and thirty-eight point six |
| 生理学或医学 | Six hundred and seventy-two million nine hundred and eighty-one thousand and sixty-six | Three million seventy-two thousand nine hundred and seventy-two point nine |
此外,我们可以考虑通过传递一个字典,对 GroupBy 对象的不同列应用不同的聚合函数:
grouped.agg({'prizeAmount': [np.sum, np.size], 'prizeAmountAdjusted': np.mean})
| 奖金数额 | prizeAmountAdjusted | |
|---|---|---|
| 总和 | 大小 | |
| --- | --- | --- |
| 种类 | ||
| --- | --- | --- |
| 化学 | Six hundred and sixty-seven million seven hundred and eighty-seven thousand four hundred and eighteen | One hundred and eighty-four |
| 经济科学 | Five hundred and twelve million eight hundred and ninety-one thousand | Eighty-four |
| 文学 | Two hundred and eighty-nine million two hundred and eighty-two thousand one hundred and two | One hundred and sixteen |
| 和平 | Four hundred and eighteen million seven hundred and thirty-three thousand eight hundred and seven | One hundred and thirty-four |
| 物理学 | Seven hundred and twenty-five million eight hundred and ninety thousand nine hundred and twenty-eight | Two hundred and thirteen |
| 生理学或医学 | Six hundred and seventy-two million nine hundred and eighty-one thousand and sixty-six | Two hundred and nineteen |
转换
与聚合方法不同(也与过滤方法不同,我们将很快看到),转换方法返回一个新的数据帧,该数据帧具有与原始数据帧相同的形状和索引,但具有转换后的单个值。这里需要注意的是,转换不能修改原始数据帧中的任何值,这意味着此类操作不能就地执行。
转换 GroupBy 对象的数据的最常见的 pandas 方法是transform()。例如,它有助于计算每个组的 z 分数:
grouped[['prizeAmount', 'prizeAmountAdjusted']].transform(lambda x: (x - x.mean()) / x.std())
| 奖金数额 | prizeAmountAdjusted | |
|---|---|---|
| Zero | One | One point three |
| one | -0.7 | -0.8 |
| Two | one point six | One point seven |
| three | -0.6 | -1.0 |
| four | -0.6 | -0.9 |
| … | … | … |
| Nine hundred and forty-five | -0.7 | -0.8 |
| Nine hundred and forty-six | -0.8 | -1.1 |
| Nine hundred and forty-seven | -0.9 | Zero point three |
| Nine hundred and forty-eight | -0.5 | -1.0 |
| Nine hundred and forty-nine | -0.7 | -1.0 |
950 行× 2 列
通过变换方法,我们还可以用组均值、中值、众数或任何其他值替换缺失数据:
grouped['gender'].transform(lambda x: x.fillna(x.mode()[0]))
0 male
1 male
2 male
3 male
4 male
...
945 male
946 male
947 female
948 male
949 male
Name: gender, Length: 950, dtype: object
我们还可以使用其他一些 pandas 方法来按对象转换 GroupBy 数据:bfill()、ffill()、diff()、pct_change()、rank()、shift()、quantile()等。
过滤
过滤方法基于预定义的条件丢弃组或每个组中的特定行,并返回原始数据的子集。例如,我们可能希望只保留所有组中某一列的值,其中该列的组平均值大于预定义的值。在我们的数据框架中,让我们过滤掉所有组,使prizeAmountAdjusted列的组平均值小于 7,000,000,并且在输出中只保留这一列:
grouped['prizeAmountAdjusted'].filter(lambda x: x.mean() > 7000000)
0 12295082
5 9000000
45 8361204
46 9713701
58 8384572
...
882 12034660
896 3331882
912 9000000
916 6329114
924 9490424
Name: prizeAmountAdjusted, Length: 84, dtype: int64
另一个例子是过滤掉具有超过一定数量的元素的组:
grouped['prizeAmountAdjusted'].filter(lambda x: len(x) < 100)
0 12295082
5 9000000
45 8361204
46 9713701
58 8384572
...
882 12034660
896 3331882
912 9000000
916 6329114
924 9490424
Name: prizeAmountAdjusted, Length: 84, dtype: int64
在上面的两个操作中,我们使用了将 lambda 函数作为参数传递的filter()方法。这种应用于整个组的函数根据该组与预定义统计条件的比较结果返回True或False。换句话说,filter()方法中的函数决定在新的数据帧中保留哪些组。
除了过滤掉整个组,还可以从每个组中丢弃某些行。这里有一些有用的方法是first()、last()和nth()。将其中一个应用于 GroupBy 对象会相应地返回每个组的第一个/最后一个/第 n 个条目:
grouped.last()
| 获奖年份 | 奖金数额 | prizeAmountAdjusted | 名字 | 性别 | 出生地 _ 大陆 | |
|---|---|---|---|---|---|---|
| 种类 | ||||||
| --- | --- | --- | --- | --- | --- | --- |
| 化学 | One thousand nine hundred and eleven | One hundred and forty thousand six hundred and ninety-five | Seven million three hundred and twenty-seven thousand eight hundred and sixty-five | 玛丽·居里 | 女性的 | 欧洲 |
| 经济科学 | One thousand nine hundred and ninety-six | Seven million four hundred thousand | Nine million four hundred and ninety thousand four hundred and twenty-four | 威廉·维克瑞 | 男性的 | 北美洲 |
| 文学 | One thousand nine hundred and sixty-eight | Three hundred and fifty thousand | Three million fifty-two thousand three hundred and twenty-six | 川端康成 | 男性的 | 亚洲 |
| 和平 | One thousand nine hundred and sixty-three | Two hundred and sixty-five thousand | Two million eight hundred and thirty-nine thousand two hundred and eighty-six | 红十字国际委员会 | 男性的 | 亚洲 |
| 物理学 | One thousand nine hundred and seventy-two | Four hundred and eighty thousand | Three million three hundred and forty-five thousand seven hundred and twenty-five | 约翰巴丁 | 男性的 | 北美洲 |
| 生理学或医学 | Two thousand and sixteen | Eight million | Eight million three hundred and one thousand and fifty-one | 大隅良典 | 男性的 | 亚洲 |
对于nth()方法,我们必须传递一个整数,该整数代表我们想要为每个组返回的条目的索引:
grouped.nth(1)
| 获奖年份 | 奖金数额 | prizeAmountAdjusted | 名字 | 性别 | 出生地 _ 大陆 | |
|---|---|---|---|---|---|---|
| 种类 | ||||||
| --- | --- | --- | --- | --- | --- | --- |
| 化学 | One thousand nine hundred and eighty-two | One million one hundred and fifty thousand | Three million one hundred and two thousand five hundred and eighteen | 阿伦·克卢格 | 男性的 | 欧洲 |
| 经济科学 | Two thousand and nineteen | Nine million | Nine million | 阿比吉特·班纳吉 | 男性的 | 亚洲 |
| 文学 | One thousand nine hundred and seventy | Four hundred thousand | Three million one hundred and seventy-seven thousand nine hundred and sixty-six | 亚历山大·巴甫洛夫·索尔仁尼琴 | 男性的 | 欧洲 |
| 和平 | One thousand nine hundred and eighty | Eight hundred and eighty thousand | Two million eight hundred and eighty-nine thousand six hundred and sixty-seven | 阿道夫·佩雷斯·埃斯基维尔 | 男性的 | 南美。参见 AMERICA |
| 物理学 | One thousand nine hundred and seventy-nine | Eight hundred thousand | Two million nine hundred and eighty-eight thousand and forty-eight | Abdus Salam | 男性的 | 亚洲 |
| 生理学或医学 | One thousand nine hundred and seventy-four | Five hundred and fifty thousand | Three million two hundred and sixty-three thousand four hundred and forty-nine | 阿尔伯特克劳德 | 男性的 | 欧洲 |
上面这段代码收集了所有组的第二个条目,记住 Python 中的 0 索引。
过滤出每组中的行的另外两种方法是head()和tail(),对应返回每组的第一个/最后一个 n 行(默认为 5 行):
grouped.head(3)
| 获奖年份 | 种类 | 奖金数额 | prizeAmountAdjusted | 名字 | 性别 | 出生地 _ 大陆 | |
|---|---|---|---|---|---|---|---|
| Zero | Two thousand and one | 经济科学 | Ten million | Twelve million two hundred and ninety-five thousand and eighty-two | A·迈克尔·斯宾思 | 男性的 | 北美洲 |
| one | One thousand nine hundred and seventy-five | 物理学 | Six hundred and thirty thousand | Three million four hundred and four thousand one hundred and seventy-nine | Aage N. Bohr | 男性的 | 欧洲 |
| Two | Two thousand and four | 化学 | Ten million | Eleven million seven hundred and sixty-two thousand eight hundred and sixty-one | Aaron Ciechanover | 男性的 | 亚洲 |
| three | One thousand nine hundred and eighty-two | 化学 | One million one hundred and fifty thousand | Three million one hundred and two thousand five hundred and eighteen | 阿伦·克卢格 | 男性的 | 欧洲 |
| four | One thousand nine hundred and seventy-nine | 物理学 | Eight hundred thousand | Two million nine hundred and eighty-eight thousand and forty-eight | Abdus Salam | 男性的 | 亚洲 |
| five | Two thousand and nineteen | 经济科学 | Nine million | Nine million | 阿比吉特·班纳吉 | 男性的 | 亚洲 |
| six | Two thousand and nineteen | 和平 | Nine million | Nine million | 阿比·艾哈迈德·阿里 | 男性的 | 非洲 |
| seven | Two thousand and nine | 化学 | Ten million | Ten million nine hundred and fifty-eight thousand five hundred and four | 艾达·约纳什 | 女性的 | 亚洲 |
| eight | Two thousand and eleven | 物理学 | Ten million | Ten million five hundred and forty-five thousand five hundred and fifty-seven | 亚当·g·里斯 | 男性的 | 北美洲 |
| Twelve | One thousand nine hundred and eighty | 和平 | Eight hundred and eighty thousand | Two million eight hundred and eighty-nine thousand six hundred and sixty-seven | 阿道夫·佩雷斯·埃斯基维尔 | 男性的 | 南美。参见 AMERICA |
| Sixteen | Two thousand and seven | 和平 | Ten million | Eleven million three hundred and one thousand nine hundred and eighty-nine | 阿尔戈尔 | 男性的 | 北美洲 |
| Eighteen | One thousand nine hundred and sixty-three | 生理学或医学 | Two hundred and sixty-five thousand | Two million eight hundred and thirty-nine thousand two hundred and eighty-six | 艾伦·霍奇金 | 男性的 | 欧洲 |
| Twenty-one | One thousand nine hundred and fifty-seven | 文学 | Two hundred and eight thousand six hundred and twenty-nine | Two million six hundred and ninety-seven thousand seven hundred and eighty-nine | 阿尔伯特·加缪 | 男性的 | 非洲 |
| Twenty-two | One thousand nine hundred and seventy-four | 生理学或医学 | Five hundred and fifty thousand | Three million two hundred and sixty-three thousand four hundred and forty-nine | 阿尔伯特克劳德 | 男性的 | 欧洲 |
| Twenty-eight | One thousand nine hundred and thirty-seven | 生理学或医学 | One hundred and fifty-eight thousand four hundred and sixty-three | Four million seven hundred and sixteen thousand one hundred and sixty-one | 阿尔伯特·圣奎奇 | 男性的 | 欧洲 |
| Thirty-one | One thousand nine hundred and seventy | 文学 | Four hundred thousand | Three million one hundred and seventy-seven thousand nine hundred and sixty-six | 亚历山大·巴甫洛夫·索尔仁尼琴 | 男性的 | 欧洲 |
| Forty | Two thousand and thirteen | 文学 | Eight million | Eight million three hundred and sixty-five thousand eight hundred and sixty-seven | 爱丽丝·门罗 | 女性的 | 北美洲 |
| Forty-five | Two thousand and twelve | 经济科学 | Eight million | Eight million three hundred and sixty-one thousand two hundred and four | 埃尔文·E·罗斯 | 男性的 | 北美洲 |
合并结果
拆分-应用-合并链的最后一步——合并结果——是由熊猫在幕后完成的。它包括获取在 GroupBy 对象上执行的所有操作的输出,并将它们重新组合在一起,产生一个新的数据结构,如序列或数据帧。将这个数据结构赋给一个变量,我们可以用它来解决其他任务。
结论
在本教程中,我们介绍了使用 pandas groupby 函数和处理结果对象的许多方面。特别是,我们了解到以下情况:
- 分组过程包括的步骤
- 分割-应用-合并链如何一步一步地工作
- 如何创建 GroupBy 对象
- 如何简要检查 GroupBy 对象
- GroupBy 对象的属性
- 可应用于 GroupBy 对象的操作
- 如何按组计算汇总统计数据,有哪些方法可用于此目的
- 如何对 GroupBy 对象的一列或多列同时应用多个函数
- 如何对 GroupBy 对象的不同列应用不同的聚合函数
- 如何以及为什么转换原始数据帧中的值
- 如何筛选 GroupBy 对象的组或每个组的特定行
- 熊猫如何组合一个分组过程的结果
- 分组过程产生的数据结构
有了这些信息,你就可以开始在熊猫小组中运用你的技能了。
生日快乐,巨蟒!
February 14, 2022
根据统计数据,Python 拥有 29.69%的全球份额,远远超过第二大流行的编程语言。这种多才多艺的语言占据榜首有很多原因。今年,Python 已经 31 岁了,我们想看看是什么让它如此伟大!
是什么激发了 Python 的创作?
Python 在 20 世纪 80 年代末首次成为一个概念。开发人员吉多·范·罗苏姆在荷兰的 Centrum Wiskunde & Informatica 工作时设计了这个系统。他想创造一种 ABC 编程语言的继任者,能够处理异常并与 Amoeba 操作系统接口。Van Rossum 于 1989 年开始实施,他将一直是该项目的唯一首席开发人员,直到 2018 年他从“终身仁慈的独裁者”(Python 社区授予他的头衔)的职责中退休。一个新的五人小组作为“指导委员会”接管了这个项目。
Python 是什么?
从技术上讲,Python 是一种多范式编程语言,支持面向对象和结构化编程。Python 是一个开源项目,它依赖于动态类型和引用计数,以及用于内存管理的循环检测垃圾收集器。
更一般地说,Python 是一种简单、整洁的语言,允许开发人员决定他们自己的编码方法。Python 有很多应用,包括 web 开发、科学计算、人工智能、信息安全、数据科学(我们最喜欢的)等等。这种应用范围是 Python 如此受欢迎的重要原因。
你知道吗?
Python 支持来自世界各地的开发人员丰富而繁荣的文化。依赖 Python 的组织包括谷歌、维基百科、雅虎!、美国宇航局、脸书、亚马逊、Spotify 和 Reddit。它的名字来源于巨蟒剧团的飞行马戏团,范·罗森是该马戏团的粉丝。在代码和 Python 文化中有许多对 Monty Python 的引用。有一个名为 PyCon 的关于 Python 的定期学术会议,以及许多 Python 指导小组,如 Pyladies。
数据科学家对 Python 有一种特殊的崇敬,它仍然是该领域的一个重要研究课题。加入我们——以及 Python 社区的其他人——祝这种令人惊叹的语言 31 岁生日快乐!让我们都去为它写点东西吧。
Harry:“data quest 帮助我开始了我的数据职业生涯”
July 11, 2017
作为一名石油服务公司的地球物理学家,Harry Robinson 发现自己对数据感兴趣。
“我的工作涉及大量数据,但它总是保持一定距离。我们在应用算法,但我从未见过它们。
“我想知道发生了什么,为什么,这样我就可以解释结果。”
他决定尝试学习一些数据技能来帮助他的地球物理学工作。
“我在网上做了大量的搜索和阅读。有时候你花 45 分钟看完一个教程,发现它并不是很好。如果没有正确的指导,你会浪费很多时间。
“接下来,我尝试使用 Codecademy。我喜欢这种风格,但它太简单了。它填鸭式地给我灌输信息,而我没有学习。
寻找 Dataquest 是一个令人耳目一新的变化。“他们找到了平衡。每个概念都解释得很清楚,不会移动得太慢以至于你感到厌烦。”
他发现真实世界的数据集和场景有助于他在工作中应用所学。"我能够使用 Python 和 matplotlib 来构建油井数据的可视化."
Dataquest 不仅教你基本原理,还教你如何保持学习…所以你永远不会卡住。
随着不断学习,Harry 渴望更多地使用数据。“我对 Dataquest 了解得越多,就越觉得工作受到限制,越想更深入地研究数据。”
起初,他发现找工作很难。“因为我是一名地球物理学家,公司发现很难理解我的技能是如何转移的。”
“我发现,当我传达了我是如何应用我学到的技能时,我开始在面试中取得成功。”
Harry 使用了一系列数据科学项目来展示他的技能。“当我参加面试时,我向他们展示了我的投资组合,这让我脱颖而出。他们告诉我,我的投资组合很强大,这帮助我得到了这份工作。”
Harry 现在是营销机构 Share Creative 的数据策略师。
“没有在 Dataquest 学到的技能,我无法完成我的工作。我经常使用 Python 和 pandas 来进行分析、自动生成报告和构建模型。”
“Dataquest 不仅教你基本面,还教你如何保持学习。他们向您展示如何使用文档和堆栈溢出,这样您就不会陷入困境。”
哈利最喜欢的 Dataquest 部分是社区。“这是我经历的一部分。我以前也加入过其他平台,但是那里没有社区,可能会很烦人。我从未觉得这是一项数据任务——每个人都乐于投资于这个问题,这是一种草根氛围。”
当被问及对崭露头角的科学家有什么建议时,哈利建议慢慢来。“不要急于学习。从我的经验来看,花时间去真正了解一些事情,比什么都知道一点更有价值。”
“不断学习很重要。我对数据的热情没有枯竭,我每周都使用 Dataquest,这样我的技能就新鲜了。”
人工智能将如何改变医疗保健
原文:https://www.dataquest.io/blog/how-ai-will-change-healthcare/
October 15, 2018
编者按:这篇文章是与 MAA 中心合作撰写的,这是一个为那些接触过石棉和希望了解更多石棉的人提供的在线资源。劳伦·伊顿是 MAA 大学的交流专家。我们希望这篇文章能让你了解数据是如何成为每个领域的一部分的。
从我们口袋里的智能手机到医疗保健行业的进步,技术对我们生活的影响是不可否认的。技术的潜在用途似乎是无穷无尽的,尤其是对医疗保健专业人员而言。展示这些不断增长的可能性的一个领域是人工智能(AI)。人工智能有可能彻底改变医疗保健行业,从简化管理任务到更复杂的医疗用途,如改善早期诊断。
数据处理和优化管理
无论是一般信息还是专门的测试结果,医疗保健提供商每天都需要处理和组织大量信息。根据威斯康星大学和美国医学协会的研究人员 2017 年的一项研究,“初级保健医生在门诊时间和下班后花了超过一半的工作日,近 6 个小时,与 EHR(电子健康记录)互动。”
人工智能有可能通过提高 EHR 和其他文档及流程的效率来大幅缩短这一时间。例如,人工智能可以取代过时的办公设备,如传真机,以及其他耗时的技术,提供商认为这些技术是管理流程的组成部分。同样,人工智能“虚拟助理”也可以用来处理日常请求或优先考虑医生的待办事项。
理想情况下,这些变化将改善工作流程,提高信息可访问性,并为提供商节省时间。但是,这些技术变革和“虚拟助手”如何在考场上帮助医疗专业人员呢?病人如何从这种新的帮助中受益?
从图像分析到辅助诊断
人工智能有能力影响提供商和患者与医疗保健的互动方式。以前,人工智能已经有效地为放射学等专业进行了图像分析,但最近,使用人工智能来辅助临床判断和诊断的好处已经开始显现。
爱荷华州的一家医疗保健组织甚至依靠“第一个自主人工智能诊断系统”来检测糖尿病视网膜病变,这是一种影响眼睛的罕见糖尿病并发症。虽然人工智能辅助诊断的应用仍然很少,但这种特定的用途可以加快病人护理,并增加医疗专业人员与病人在一起的时间。
人工智能对早期诊断意味着什么
虽然人工智能不太可能完全取代人类医生,但人工智能有可能影响病人的存活率,因为这项技术可能会影响诊断过程。研究人员已经提出,人工智能可能会对患者的预后产生重大影响,特别是对偶尔被误诊的个体,如心脏病和某些形式的癌症。
例如,早期癌症诊断可能是非常宝贵的,因为早期检测可能会极大地影响对被诊断患有罕见癌症的患者的护理。对于潜伏期较长的癌症来说尤其如此,如间皮瘤。间皮瘤患者通常在首次接触石棉等致癌物质 10 至 50 年后开始出现症状。这尤其危险,因为早期症状经常被误认为是更常见的疾病,如流感、肺炎或肺癌。
那么,人工智能对医疗保健意味着什么?
尽管自动化和优化很有用,但人工智能是独一无二的,因为它是为了模仿人脑而设计的,而不是依赖于预制的算法。这是人工智能可能对医疗保健行业产生巨大影响的主要原因之一。它让机器“学习”的能力可能会使技术以与医疗保健行业以往截然不同的方式做出贡献。
虽然人工智能可以使某些管理任务变得更容易,但它在辅助临床诊断方面可能扮演的角色有可能为提供商和患者带来有价值的见解。无论是更早还是更准确的诊断,人工智能都有助于确保患者得到更有效和高效的治疗。
学习数据新闻:避免我的三大错误
原文:https://www.dataquest.io/blog/how-become-data-journalist/
September 1, 2022
在我成为一名数据记者的旅程中,我犯了很多错误,浪费了很多时间。
你可能想知道为什么我要和全世界分享我的灾难故事。我当然不会为自己的失误感到骄傲。但如果我能帮助其他人避免我在试图掌握数据新闻时遇到的麻烦,那么也许我的经历就值得了。
让我们来看看我在学习数据新闻时犯的三个大错误。然后,我们将讨论如何避免犯同样的错误,从而加快你成为数据记者的步伐。
是什么阻止了大多数记者在数据新闻业取得成功
学习数据技能对任何从事记者工作的人都有明显的用处。即使是最基本的数据分析也能帮助发现新的故事和补充传统的报道。但是对于许多记者来说,成为一名数据记者有一个很大的障碍:学习编码。
那正是阻止我的障碍。
在加入 Dataquest 之前,我从事新闻工作近十年。近十年来,我反复尝试学习数据新闻编程。但我从未走远。
大多数“如何成为数据记者”项目的问题
我对学习编码的追求让我找到了一些不同的在线资源。令我沮丧的是,它们充满了令人困惑的解释,令人痛苦地感到毫不相关。我记得我艰难地读完了这本书,艰难地学习 Python,,构建了一个文本冒险游戏,并对自己说,这对我从事数据新闻工作到底有什么帮助呢?
当然,答案是根本不会帮助我。我失去了动力,在项目进行到一半的时候退出了。
具有讽刺意味的是,直到我离开新闻业,我才发现有一种更简单的方法来学习数据新闻所需的技术技能。虽然我仍然不是数据专家,但我已经达到了可以做数据新闻的地步——我可以收集独特和原始的数据集,我可以清理数据,我可以分析它,并可视化它以获得有趣的模式。
我花了比你想象的少得多的时间达到这一点。
一路走来,我发现在我过去学习编程的尝试中,我犯了三个大错误。对我来说,学习这三课是成功和失败的区别。现在,我想与你分享我的见解。

第 1 课:数据新闻基本上是数据科学
在我努力成为一名数据记者的过程中,我犯的一个最大的错误是,我本质上是在试图“学习编程”。
不需要学编程(至少不是一般意义上的)
编程是数据新闻的必备技能。但是,当你试图学习一般意义上的“编程”时,你最终会学到很多无关紧要的东西。这就是我如何发现自己试图建立一个文本冒险游戏。这也是许多有抱负的数据记者发现自己在做的事情,比如尝试开发移动应用程序。
这些通用的“学习编程”课程的问题在于:它们试图一次教会你所有的东西。这种方法效率不高,而且做不相关的事情会削弱你的动力。
专注于你真正需要的技能!
幸运的是,成为一名有效的数据记者所需的技能与数据分析师所需的技能直接重叠。这意味着你可以学习数据新闻所需的技能,而不必在不相关的课程上浪费太多时间。有很多平台可以帮助你掌握数据科学方面的必要技能。
例如,Dataquest 是学习数据新闻工作所需数据技能的绝佳资源。以下是一些很酷的功能:
- 您将在几分钟内编写真正的代码
- 没有无聊的视频——你通过做来学习
- 几乎每门课程都包含一个可以帮助你建立作品集的项目
- 注册是免费的
这是我用过的,我相信它也会帮助你。我推荐数据分析师道路,因为你将学到的技能对数据新闻业帮助最大。

第二课:动机很重要
这让我们犯了第二个错误:试图通过做我不感兴趣的事情来学习我感兴趣的东西(数据新闻)(构建像文本冒险游戏这样不相关的项目)。
虽然这种学习方法是可行的,但并不理想。大多数记者都是全职专业人士,他们试图在紧张的截止日期和旅行日程中偷偷参加学习会议。
当你已经压力很大,时间又很紧的时候,努力编写一些感觉与你的目标无关的东西会让你不知所措。它会令人窒息,以至于你想放弃。我几乎做到了。
激励的关键?相关性!
不过,好消息是。我发现当你有动力时,学习会容易得多!保持动力的关键是专注于感觉相关的事情。
这是我们在 Dataquest 平台上使用的方法的很大一部分。我们让学生立即处理真实世界的数据,以减少“这有什么意义?”尝试学习编程语法时经常会有这种感觉。
可以自学数据新闻学吗?
你可以试着自己复制这种体验。但是你需要找到并下载一个有趣的数据集,在 Jupyter 笔记本上做好准备,并开始尝试一些东西。
你觉得你还没准备好吗?这直接引出了我学到的最后一课。。。

第三课:没准备好?无论如何都要做!
当我尝试学习数据新闻但失败时,我经常发现自己陷入困境。我永远也不能越过课本上规定的练习题和项目。我甚至从未试图建立一个真正的数据新闻项目。为什么?因为我觉得我还没准备好。
我当时不知道的是,根本没有“准备好”这回事。即使是最高级的程序员和数据科学家也会花大量的时间搜索问题,检查 StackOverflow,浏览文档,试图让事情运转起来。
不断失败?那你一定做对了
我希望我那时就知道失败、搜索、寻求帮助和直接复制粘贴 StackOverflow 的代码片段都是学习过程的一部分。
当我开始的时候,我的第一个真正的数据新闻项目对我来说就像是一个荒谬的白日梦。那是因为它是。我几乎没有任何所需的技能。但是我也有一个想法,它让我非常感兴趣,所以我决定尝试一下。
这个项目需要从大约 700 个网页上搜集数据,我不知道如何去做。然后,我需要将冗长的文本字符串转换成具有不同数据类型的数据集中的列,以便我可以实际分析它们。我也不能做那些事。我当然对视觉化一无所知。
然而,几个星期后,我完成了一个有工作代码的项目。不是因为我特别聪明或者天生就是程序员——我两者都不是——而是因为我一步一步地遵循了我在早期的 Dataquest 指导项目中学到的经验。
你可能已经“准备好”学习数据科学
我的建议?不要浪费时间准备学习如何成为一名数据记者。我希望我没有。相反,开始做你真正感兴趣的项目。这会给你一种动力去学习你从课本习题集里学不到的东西。
从我的经验来看,你学习做数据项目的方法主要是一头扎进去,在这个过程中学习你需要什么。每个数据集都是不同的,所以你不可能对你可能遇到的一切都“准备好”。
那么先决条件是什么呢?
需要一定的技能才能入门吗?如果你想从 Dataquest 的数据分析师路径开始,那么你可以从零经验开始。如果没有,那么第一步就是先学习基本语法。一旦解决了这个问题,你就可以开始投入你感兴趣的项目了。
从那里开始,你将能够解决大部分问题。不要被愚弄:这有时会很有挑战性。这就是为什么当你需要的时候,有一个朋友或社区可以提供一些帮助会产生奇迹!Dataquest 社区是一个无价的资源。在这里,你可以为一个问题寻求帮助,与你的同行分享你的工作,获得与你同路的其他人的支持。

数据新闻入门
准备好投身数据新闻业了吗?我强烈建议你避免我的三个错误,并在你成为一名数据记者的道路上牢记这些教训:
- 不要浪费时间去学习不相关的技能或者数据相关性不大的通用编程技能。
- 寻找能让你保持兴趣和动力的学习资源和项目。
- 在你认为自己已经“准备好”之前,尽快开始真正的项目
有了 Dataquest ,你可以马上开始学习从事数据新闻工作所必需的技能。注册是免费的,你还在等什么?今天就打开你作为数据记者的职业大门吧!
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
完美数据科学简历的 8 步指南(2022)
原文:https://www.dataquest.io/blog/how-data-science-resume-cv/
September 28, 2022
如果你想要一份数据科学方面的工作,你必须通过“看门人”,也就是广为人知的招聘人员或招聘经理。这意味着要写一份出色的简历。
这是一个严酷的事实:无论你在数据科学方面拥有多少技术技能,如果没有一份令人印象深刻的简历,你的职业生涯根本不会起步。
这份文件可能会阻碍你和你梦想的职业生涯,这可能不公平,但这是绝对的事实!
幸运的是,有一些有效写简历的技巧和诀窍。这些可以帮助你在其他数据科学申请者中脱颖而出。
想知道它们是什么吗?继续读!
在本帖中,我们将揭示一些鲜为人知的关于如何撰写一份优秀的数据科学简历的秘密。你将获得业内真正的招聘经理的专家推荐,以及一些让你的简历脱颖而出的专业建议。在这个过程中,我们会指出一些需要避免的关键错误——那些被招聘人员视为危险信号的错误!
需要相关的技能和知识放在你的简历上吗?立即免费查看我们全面的数据科学课程!
第一步:保持数据科学简历不超过一页!
挑战在于既要彻底又要简洁。一份好的简历应该只有一页长(除非你有十年的相关工作经验)。
即便如此,仍有招聘人员会投出任何超过一页的简历。疯狂?也许吧。但这是有原因的。
招聘经理每天都会收到很多简历。所以,他们只有大约 30 秒的时间浏览每份简历并做出决定。
“老实说,”数据分析咨询公司 Willow Data Strategy 的总裁兼首席顾问斯蒂芬·余(Stephen Yu)说。“在我见某人之前,我花在(每份简历上的)时间不到 30 秒。如果那份简历不符合我的要求(这种情况只发生在十分之一的简历中),我甚至不会给应聘者打电话。”
简历危险信号:冗长的简历
这里的外卖?你需要分清主次。将你的经历浓缩到最重要、最相关的点上,以便于浏览。
超过一页的冗长简历是招聘人员的禁忌!
第二步:定制,定制,定制!
想想吧。如果你是一名招聘经理,你会对一份普通的简历还是一份符合你特定公司文化和工作要求的简历印象更深刻?没错。
是的,它比复制粘贴方法需要更多的前期工作。但是根据具体的工作在这里或那里添加一些小的细节肯定会给你加分。
这是不是意味着你每次申请工作都需要进行大规模的重写和重新设计?不会。但是,至少,要寻找招聘启事中提到的重要关键词和技能,并确保将它们包含在你的简历中。
提示:输入你的写作风格和语调
如果你在申请你梦想的工作,你真的想给人留下深刻印象,你可以更进一步。方法如下:看看该公司的网站,了解他们喜欢的风格和语气。然后,相应调整简历的写法和审美。
“你必须找到一种方式来构建自己,这样当雇主看着你的简历时,他们会说,‘这个人是为了我的特殊职位而从天堂下来的,’”sharpes minds 联合创始人爱德华·哈里斯说。
第三步:明智地选择你的模板
你选择的简历模板类型应该与你申请的公司类型一致。
例如,如果你申请的是更传统的公司(如戴尔、惠普和 IBM ),试着写一份更经典、低调的简历。

另一方面,如果你的目标是一家更具创业文化或创意氛围的公司(比如谷歌、Meta、Pinterest 等)。),你可以选择一个模板或创建一份更有才华的简历。

您选择的模板也可以是一个组织工具。例如,专栏式简历可以帮助你在页面上容纳更多的信息。
提示:使用在线简历模板
你能从头开始创建自己的简历吗?当然可以。但是从免费网站的创意简历模板开始可能更容易,比如 Creddle 、 VisualCV 、 CVMKR 或 Enhancv 。你甚至可以使用谷歌文档简历模板。
第四步:整理你的联系信息
一旦你选择了简历模板,花点时间仔细检查联系信息部分。你的名字、标题和联系信息应该总是出现在页面顶部的。
*为什么?你不希望招聘人员或招聘经理不得不翻遍整份简历来找到与你联系的方法,对吗?让他们轻松点!
关于数据科学简历中的联系信息,以下是一些需要记住的关键事项:
- 简化你的地址,只写城市和州。
- 列出一个好的工作电话号码和一个看起来很专业的电子邮件地址。
- 包括你的个性化 LinkedIn 网址。
- 将 GitHub 链接或个人资料链接添加到您的联系信息中,并使其可点击。
确保你的标题(通常在你的名字下面)反映了你想要得到的工作,而不是你现在的工作。例如,如果你想成为一名数据科学家,你的标题应该是“数据科学家”,即使你目前是一名厨师。

步骤#5:包括数据科学项目和出版物
在任何一份好的数据科学简历中,你想突出的主要内容是你创造了什么。包括一个单独的部分,专门用于您的数据科学项目和出版物。将这些信息紧接在您的姓名、标题和联系信息之后。
招聘公司想看看你能用你列出的技能做些什么。这可能包括数据分析项目、机器学习项目,甚至发表的科学文章或编码教程。
大多数数据科学雇主会想看看你的项目组合,看看你做了多少常规工作,你在做什么类型的项目。
“我们面试的大多数人都在简历上列出了他们的 GitHub 页面,”CiBo Technologies 人才招聘经理贾米森·瓦斯奎兹说。“我认为这很重要。”
展示相关项目
当选择在简历上突出哪些项目时,记住一个重要因素:相关性。只选择那些与你申请的工作相关的项目。Pramp 首席执行官 Refael "Rafi" Zikavashvili 解释了原因:
“数据科学家只有一个目标,那就是解决业务问题。这不是关于挑战在技术上有多难,也不是关于解决方案有多酷,或者你正在使用的工具。这是关于你是否能够解决商业问题。
你应该列出多少项目/出版物?您可以在一页参数中容纳尽可能多的内容。
危险信号:数据科学恢复,没有项目或出版物
没有任何项目或出版物的简历肯定会给招聘经理亮起红灯。这种空白不会被忽视。相反,这会凸显出你缺乏经验,让招聘人员怀疑你为什么还要费心去申请!
需要帮助为你的简历和作品集整理项目吗?我们有一系列博客文章来指导你构建伟大的数据科学项目。另外,本指南的下一章将讨论你应该在求职申请中展示哪些项目以及如何展示。
突出你的技能
尽可能具体地描述你在每个项目中使用的技能、工具和技术。指定编码语言、使用的库等。谈谈你是如何创建这个项目的,如果是团队项目,指出你个人的贡献。
亲提示:冗余是可以的!
感觉你在项目部分重复了你计划在技能部分列出的相同技能?别担心。事实上,你在简历中添加那些关键工具、技术和技能的次数越多越好。
为什么?招聘人员和人事经理经常使用简单的关键词搜索来浏览简历。所以,你想在尽可能多的地方突出你的相关技能!
强调沟通技巧
数据科学招聘人员正在寻找拥有他们需要的技术技能的人,当然。但他们也希望员工是有效的沟通者,并且了解大局。他们想要能有效用数据讲故事的数据科学家。
展示这些特质的一个方法是突出合作项目。这证明你可以和团队一起工作和交流。
另一种方法是在业务指标的背景下框定你的成就。这表明你理解你的分析如何应用于你试图解决的更大的商业问题。
将这些想法写在你的项目和工作经历部分。
让你的项目脱颖而出
可能会有很多人申请你想要的工作。如何为您应用程序提供所需的竞争优势?这里还有两个策略可以考虑。
提及非结构化数据
也就是说,您处理过的任何数据都需要您自己构建电子表格/数据表。
这方面的例子包括处理视频、帖子、博客、客户评论和音频。处理非结构化数据的经验令人印象深刻。这表明你有能力处理杂乱的数据,而不仅仅是处理原始数据集中的数字。
确定可衡量的结果
“如果你想让你的简历变得更好,确保列出可衡量的成就,”Zety.com 招聘人员埃娃·扎克泽斯卡说。
例如,如果您创建了一个机器学习模型,作为您的一个项目,它可以将销售目标提高 15%,请这么说!
“‘这就是我一直在努力做的事情,这就是我所做的,这些就是结果。’G2 Crowd 的数据科学和分析经理迈克尔·胡普说:“像这样安排项目确实能创造一份强有力的简历。
以下是简历中这一部分的示例:

第六步:详述你的相关工作经历
接下来是你的工作经历。你最近的工作经历应该列在最上面,然后是之前的工作,依此类推。
你应该追溯到多远?那得看情况。五年通常是上限,但是如果你有比这更早的相关工作经验,你可能会想把它包括在内。
简历危险信号:工作经历中的空白
记住,对于招聘人员和招聘经理来说,你的工作经历中超过六个月的空白是一个主要的危险信号。如果你有这样的差距,你肯定想在简历上说明。
例如,如果你在 2015 年至 2017 年间休了两年假来抚养孩子,你仍然希望在简历中添加这些日期。简单地说明你在那段时间是全职妈妈。
写入作业条目
编写本节时,每个条目应包括以下内容:
- 你的职位名称
- 公司
- 你担任该职位的时间
- 你在该职位上的成就
如果你有与你申请的工作相关的工作经验,确保你的描述主要包括 T2 的成就而不是职责。雇主希望看到你实际做了什么,而不仅仅是你应该做什么。
如果你的工作经验与你申请的工作不相关,那么你还是会想把它列出来。但是,你只需要包括公司名称,你的职位和工作日期。你不需要用一份不相关的工作的所有细节来占据空间。
以下是一份相关工作中你应该包括的内容:

第七步:列出你的学历
很多简历模板都是先列出学历。但如果你有工作经验和/或相关项目要展示,你会想先展示这些,把学历放在更靠后的位置。
仅列出个大专学位(即社区学院、大学和研究生学位)。如果你上过大学,但没有获得学位,最好不要列出那所学校。
如果你的学位与你申请的工作不相关怎么办?你还是应该列出来。有些职位只需要任何领域的学位,所以你要确保你在这些职位的竞争中。
提示:不要忘记你的数据科学证书!
最后,在这里列出相关的“微学位”、在线培训认证和其他专业培训。
像通过 Dataquest 提供的数据科学证书是很好的补充。这是因为他们可以向招聘人员展示有针对性的技能。另外,每门 Dataquest 课程都包括一个创造技能型项目的机会,你也可以把它写进你的简历!
简历危险信号:较老的学位和高中文凭
如果你的学位毕业日期是 15 年前,你可以自行决定是否要加上日期。不幸的是,一些公司认为以 19XX 开始的毕业日期是一个危险信号。如果你没有学位,就不要担心。把教育部分完全从你的简历中去掉。你不想做的是列出你的高中信息。对于招聘人员和招聘经理来说,这是另一个危险信号。

第八步:添加技能和临时演员
除了列出你的数据科学项目和出版物之外,还有一些方法可以展示你的技能:
- 在“技能”部分包括你学到的相关技能。
- 添加一个包含相关活动和培训的“附加内容”部分。
技能部分不是可选的!
招聘人员和人事经理很可能会在查看你的简历时首先进行关键词搜索。你要确保像、【Python】、或、【机器学习】、这样的关键词被突出显示。
招聘人员假设你首先列出的技能是你最强的技能,你最后列出的技能是你最弱的。因此,首先列出你最强和最相关的技能。把你不太适应的技能或者不太可能与职位相关的技能留在清单的后面。
简历红旗:你无法解释的技能
你要小心不要在这里走极端。
“我认为一个巨大的危险信号是在[简历]上放了太多的技术,然后却不能支持它们,特别是在一个电话里,”圣裘德儿童研究医院的生物信息学软件开发经理 Clay McLeod 说。
Stephanie Leuck 是 84.51 T1 的大学招聘人员,她每年会看到数千份入门级数据科学简历。她附和了这一观点。“确保[你在简历中列出的技能]是你实际上可以交流的技能。如果你曾经读过一本关于 R 的书,但是你实际上不会用 R 编码,你也从来没有用 R 编码过,不要把 R 列为你的技能之一。只把你能说的技能放在上面。”
亲提示:不要列举软技能
这里应该包括软技能吗?大概不会。招聘人员倾向于浏览这一部分,寻找他们需要的特定技能。声称你擅长“沟通”或“团队合作”不会让你的简历脱颖而出。
最好在项目和工作经验部分说明自己具备这些技能。在这里,你可以强调你的“软”和“硬”技能是如何一起产生有意义的结果的。
何时添加附加部分
如果你有空间,考虑包括一个“额外”部分。例如,此部分可以标记为“奖励”、“认证”或“培训”。
在数据科学领域,对于这一部分,您有几个选项。例如,你可能想列出你参加过的任何好的 Kaggle 比赛结果或你参加过的相关聚会/活动。任何其他表明你积极参与学习和做数据科学的事情也是公平的游戏。
像 Machinehack 和 Hackerearth 这样的数据科学和机器学习黑客马拉松是你简历上的一大亮点。这表明你有健康的竞争精神。此外,它让招聘人员知道你可以在创建实际内容和项目的同时提高自己的技能和知识。
以下是技能和附加部分的示例:

润色润色
一旦你将所有相关内容添加到简历中,最后要做的主要事情是拼写和语法检查。对招聘人员和招聘经理来说,简历中的语法或拼写错误是一个巨大的危险信号。
简历红旗:错误和错别字
记住,招聘人员经常会收到成百上千份入门级工作的申请。他们经常寻找任何可能的借口来淘汰候选人!
虽然这看起来很小,但一个简单的打字错误暗示了对细节的忽视。信不信由你,这足以让一些招聘人员扔掉你的简历,不管你有什么技能和经验。
所以要确保文章没有错误,所有的措辞都简单明了。让编辑朋友检查你的简历总是一个好主意,但是像海明威和语法这样的应用程序也可以帮助你清理和简化你的写作。
专业提示:使用人工编辑器
注意不要太相信自动语法检查软件。即使是最好的应用程序也会出错。
一份完整的数据科学简历可能如下所示:

当然,如果你不能证明你已经掌握了简历中列出的技能,简历就没有意义了。在下一章,我们将深入了解你应该做什么样的项目,以及你应该如何在你的投资组合中突出它们。
本文是我们深入的数据科学职业指南的一部分。
- 简介和目录
- 申请前:考虑你的选择
- 如何以及在哪里找到数据科学工作
- 如何写一份数据科学简历—你在这里。
- 如何创建数据科学项目组合
- 如何填写申请表,何时申请,以及其他注意事项
- 准备数据科学领域的工作面试
- 评估和协商工作机会
成为数据分析师!
立即学习成为数据分析师所需的技能。注册一个免费帐户,获得免费的交互式 Python、R 和 SQL 课程内容。
(不需要信用卡!)*
Dataquest 如何让 Stacey 的数据工作与众不同
原文:https://www.dataquest.io/blog/how-dataquest-made-a-difference-for-stacey-data-skills/
December 18, 2019
如今,Stacey Ustian 是一名数据工程师。但是带领她来到这里的道路并不总是一帆风顺,一路上有一些坎坷和曲折。
她的数据科学之旅始于一个相当不寻常的地方:法律图书馆。
在获得图书馆和信息科学硕士学位后,Stacey 在一家律师事务所的图书馆工作。但她发现自己更喜欢这份工作中与信息打交道的部分,而不是把书放在书架上。几年后,她转行到另一家公司担任研究分析师。
我偶然发现了 Dataquest 并检查了一下。老实说,那对我来说是个转折点。
“那份工作 50%是定性研究,”她说,“但另一半是使用 Excel 进行定量数据分析。”
“我对那些[Excel 数据]项目感到非常兴奋。我发现这是我真正喜欢做的事情,”她说。
早期斗争
她的丈夫是一名数据科学家,他建议她开始学习 SQL 以拓展技能。经过一番搜索,Stacey 找到了一个学习平台— 而不是 Dataquest —,并开始学习 SQL 和 Python。
但是有一个问题。
“我记下了基本的语法,但我发现当我开始自己的数据项目时,我遇到了很多麻烦,”她说。“我真的不知道如何开始,做什么,等等。这非常令人沮丧。”
另一个问题是:在她作为研究分析师的工作中,她无法应用她从 T1 学到的任何 Python 或 SQL 技能。那份工作除了 Excel 之外不需要任何东西。Stacey 想做大。
所以她决定大胆一试。
“经过一番自我反省,”她说,“我决定离开那个职位,然后全身心投入到学习所有这些获得数据分析师工作所需的技能上。”
在 Dataquest 全押学习数据技能
“那时,”她说,“我知道另一个(学习)平台不是我想要的。”因此,她开始寻找替代方案。最终,她找到了 Dataquest。
“老实说,那对我来说是一个转折点,”她说。
“我回去开始在 Dataquest 上重新学习 Python 和 SQL。除了教我语法,[Dataquest]还教了我输入内容背后的理论和思想,这让我对事物有了更深入的理解。”
简而言之,Dataquest 平台。
她说,Dataquest 将它的课程建立在数据分析师、数据科学家和数据工程师实际工作的背景下,这也很有帮助。
“[Dataquest 教授]你如何在数据分析的世界中使用它,”她说。“那是我当时真正需要的。这正是我想要了解的信息类型,对我来说再合适不过了。”
所以她全押了。“我刚刚在全职完成了的数据分析师之路,我不知道,大概两个半月,”她说。“我一天做八个小时。”
而且成功了。“我完成了这条路,”她说,“当我在接下来的几个月里独自做数据项目时,我发现我知道从哪里开始,知道要考虑的事情和解决不同问题的方法。这就是我在 Dataquest 中学到的所有东西。”
从分析师到工程师
Stacey 打算找一份数据分析师的工作。因此,在她整合了一系列项目之后,包括 Dataquest 的一个 SQL 指导项目,她开始寻找数据分析师的工作。
令她惊讶的是,一名外部招聘人员在 LinkedIn 上联系她,询问数据工程师的职位。“我经历了那个面试过程,”她说,“结果发现他们真的只是在寻找一个了解 Python 和 SQL,并且愿意学习他们在这个数据工程职位上需要学习的东西的人。”
他们给她这份工作时,她接受了。“太完美了,”她说,“因为我知道 Dataquest 刚刚启动了数据工程之路。”
“我想,‘好吧,我知道我的下一个任务是什么:开始那个,学习数据工程,’”她笑着说。
经验教训
她说,从史黛西的故事中得到的一个教训是,你不应该目光短浅,只关注有特定职称的工作。“如果可能的话,”她说,“在工作描述中搜索更多的关键词。我申请并面试了许多不同的工作,这些工作都不是‘数据分析师’,但它们都是数据分析工作。”
要知道,你的数据技能可以打开许多扇门,包括一些意想不到的门。“老实说,了解复杂的 SQL 查询可以让你得到很多东西,”她说。“你永远不会真正知道。”
她说,另一个原因是了解你自己的学习风格。“我不通过视频学习,”Stacey 说,所以她知道要选择一个不通过视频教学的平台。
“我建议花点时间去真正了解不同的平台,以及哪一个是最好的,”她说。“我当然认为 Dataquest 是最好的,”她补充道。但是没有一个平台适合所有人,所以知道什么适合你是一个好的开始。

坚持有规律的学习是 Stacey 成功的关键之一。
她还说,坚持学习是关键。“我有一个工作时间表,”她说。"我早上工作,午休,然后下午工作。"
虽然不是每个人都能像 Stacey 一样每天投入那么多时间,但她说 Dataquest 也非常适合那些日程比较忙的人。“Dataquest 被分解成更小的块,因此非常有利于实现这一点。你只有一个小时,好吧,嗯,只要做一两个部分就可以了。你只需要尽可能挤出时间。”
最后,她说,找工作时要知道“你将不得不面对拒绝,这很正常,每个人都会经历。不要让它使你气馁,继续前进。我想,在找到工作之前,我申请了 115 个不同的地方。”
对于 Stacey 来说,目的地是值得的。她现在在纽约市的一家企业营销技术初创公司担任数据工程师。
当然,她正在学习更多的数据工程技能!在撰写本文时,她最后一次登录 Dataquest 是在昨天。
我如何在 6 个月内学会数据科学
原文:https://www.dataquest.io/blog/how-i-learned-data-science-6-months/
August 16, 2021
每个人成为数据科学家的旅程都是不同的,学习曲线会因许多因素而异,包括时间可用性、先验知识、您使用的工具等。一名学员分享了她如何在 Dataquest 的 6 个月内成为一名数据科学家的故事。她的旅程是这样开始的:
正如标题所示,这是我 Dataquest 旅程中的一个分析项目,它让我在不到 6 个月的时间里学会了数据科学。我真的很兴奋能在新年前完成这个项目。有什么比彻底的回顾更好的方式来送走这一年呢?
我看到来自世界各地的人们每天都在努力学习和进步。所以我做这个项目的动机不仅仅是重温我的旅程,而是通过给初学者一个窥视前方道路的机会来鼓励他们。但是请记住,完成这条道路的时间和努力与个人情况高度相关。我将在本文后面解释我的观点。
这个项目也是受这个社区的人启发,特别是@otavios.s 的惊人项目希望这不是问题,但是我刮了社区。由于他的项目,我被介绍给了 Selenium 和 ChromeDriver 。是的,我还浏览了 DQ 网站以获取完整的数据科学家课程,希望没问题…
在详细讲述我如何在 6 个月内从零编码技能成为数据科学家之前,我想先分享一下我的发现。
在这个项目中得到答案的问题是:
- 我花了多少天走完这条路?(时间跨度,包括我没有花在学习上的时间间隔)
- 175 天。从 6 月 19 日到 12 月 11 日。
- 我最好的学习成绩和一般的学习成绩是多少?
- 我最好的学习成绩是 20 天,平均 6.6875 天。从我个人的经验来看,进入最佳状态并坚持下去很重要。10 月份休息了一周,又过了一周才恢复到和以前一样的学习效率。
- 总共花了多少时间?
- 跑完全程总共花费了 306.4 小时。这意味着如果我全天候学习,这条路可以在大约 13 天内走完。相反,我花了 175 天。我敢肯定机器人在嘲笑我们人类。
- 在我学习的几周里,我平均花了多少小时?
- 假设我平均每周学习 5 天,在我学习的 24 周,我将学习 120 天。这意味着我平均每天花 3 个小时学习 Dataquest。这听起来差不多,但请注意,这是一个粗略的估计。另外,我确实花了相当多的时间在社区和阅读课程材料,这些都不算在这个项目中。
- 完成一节课的平均时间是多少?
- 111.43 分钟,换句话说接近 2 小时。看起来要花很长时间才能完成一课。但这也包括花在指导项目上的时间,这比仅仅学习课程要耗费更多的时间。花几天时间在一个指导项目上并不罕见。我希望我有更多关于每节课所花时间的详细数据,这样我就可以看到项目和非项目任务所花的平均时间,但是我不知道这些数据是否存在。
- 课程中有哪些减速带?
- 第 2、4、5、6 步比其他步骤花了更多的时间来完成。其中, Step 2 和 6 的任务数量最多, Step 2 的引导项目数量也最多。这使得第 4 步和第 5 步成为最耗时的步骤。两者之间,第四步比第五步更耗时。这很好地反映了我的记忆。第 4 步,耗时的部分是 SQL ,第 5 步,是关于概率的课程。
现在,简单介绍一下我个人的学习情况:
- 6 月 19 日开始 Python 中的数据科学家路径,12 月 11 日结束。虽然最后两周我花的时间不多,但是大部分都花在完成最后两个指导项目(算两节课)和课外项目上了。这可能就是为什么我在 11 月的最后一个月之后没有收到任何学习进度邮件的原因。
- 我以前是数字营销客户经理,编码技能几乎为零。在我决定转向 Dataquest 之前,我从 Udemy 上的数据科学课程中学习了几个星期的 Python 基础知识。
- 在开始这条道路的几周前,我完成了吴恩达在 Coursera 上的机器学习课程。在那门课程中,我学习了基本八度音阶。
- 我目前失业,所以我有很多业余时间学习。
对项目的近距离观察
a)数据收集(电子邮件解析和网页抓取)
我在这个项目中使用的数据是从两个来源收集的:
- 这个项目的进展数据来自每周一我从 Dataquest 收到的每周成就邮件,如果我在上周取得了足够的进展。它包括:
- 日期:电子邮件的接收日期—通常是星期一
- 任务 _ 已完成:已完成的课程数量
- missions_increase_pct:与上周相比,已完成课程数量的增加/减少百分比
- minutes _ spent:花在学习上的分钟数
- minutes_increase_pct:与上周相比,花费的分钟数增加/减少的百分比
- learning_streak(days):连续学习的天数
- 最佳连胜:最佳学习连胜
- 为了获得每周邮件,我首先在我的 Gmail 中创建了一个标签,将我想要的邮件分组,然后去谷歌外卖下载它们。在这个过程中你可以选择文件格式——我下载的是一个. mbox 文件。Python 有一个用于解析这类文件的库,叫做邮箱。你会在文章末尾的 GitHub 链接中找到这个项目中使用的代码。
(下面是每周修养邮件截图)
*** 本项目中的课程数据来自 Data quest dashboard for The Data Scientist path。它由 8 个步骤、32 门课程和 165 节课组成,包括 22 个按等级顺序排列的指导项目。正如帖子开头提到的,我第一次使用 Selenium 和 ChromeDriver。课程信息所在的仪表板页面包含步骤网格以及课程和任务的可折叠列表;有自动登录和大量的点击。稍后我可能会写另一篇关于抓取这一页的文章。**
**
b)数据插补
这个项目中的每周电子邮件数据集非常小,只有 16 行包含 16 周的数据。但是我的学习时间实际上是 26 周。有几个星期我根本没有学习,但是,对于这样一个小数据集,我真的不能承受丢失 10 个星期的数据。
幸运的是,在个人资料页面上,Dataquest 提供了整个路径的学习曲线。因此,我想出了一个插补策略:尽可能地填补空白,绘制现有数据,然后与 Dataquest 生成的学习曲线进行比较,并结合我的个人经历(例如,度假和休闲的照片和记忆)🙂)来估算缺失的已完成课程数数据。然后根据一节课的平均时间计算花费的时间。在项目中更详细。
虽然我认为插补相当成功(满足了该项目的需求),但我希望我们能从 Dataquest 中获得更多关于我们学习之旅的数据。
c)本项目中的可视化:
我使用 Plotly 来绘制这个项目中所有的可视化。我很满意下面的花费时间与完成任务的对比图。它帮助我做了一些有趣的观察,并回答了本文开头的课程相关问题。同样,你可以在文章末尾的 GitHub 链接中阅读详细内容。
为了分享像这样的帖子中的情节,我还尝试了图表工作室。下面的图来自 chart studio cloud,并使用 chart studio 生成的 html 嵌入。
- 我的学习曲线

- 每周花费的小时数和完成的相应课时数以及它们所属的步骤

- 每个学习步骤中的课程和指导项目的数量

- Dataquest 上 Python path 中数据科学家的完整课程表

除了回答这个项目开始时的所有问题。我还想给这门课的初学者补充一点,我在这个项目中所做的是更多的数据收集、数据清理和插补,这些你将在前四个步骤中学到。这意味着,在数据科学家之路的中途,您将具备完成所有这些工作的能力!
附注:如果任何人对这个项目或 DQ 数据科学家之路有更多问题,请随时在评论中问我或通过 【电子邮件保护】 联系我。我会尽力回答你的问题。
点击此处查看完整项目。
你下一步应该做什么?
- 报名参加我们的Python 职业道路中的数据科学家,获得在数据领域找到工作所需的所有技能!
这篇文章是由钱薇拉写的。你可以在 Github 上找到她。**
我是如何在三个步骤中收集到超过 25,000 个论坛帖子的
原文:https://www.dataquest.io/blog/how-i-scraped-over-25000-forum-posts-in-3-steps/
August 18, 2021
动机
Dataquest 社区正在发展。在过去的几个月里,我一直在关注活跃用户、新话题和讨论领域的增长。在过去的六个月中,该平台为开发各种标签做出了巨大贡献,以促进相关信息的过滤和搜索。
但是让我们尝试直接从我们的帖子和消息中创建一个标签列表。也许他们会比 Dataquest 团队提供给我们的更好,也许不会。但我认为这肯定会很有趣
我计划在这项研究的过程中写几篇文章。这是他们中的第一个。它关注的是我们最终应该得到什么,我们可以使用什么数据,以及从哪里获得这些数据背后的推理。以及数据收集本身。
计划
我们需要做的是:
- 数据
- 建模方法
- 啤酒(那我们真的还需要别的吗?)
- 利润

但是让我们更详细地检查一下我们复杂的计划。
1.数据
基于什么数据我们可以建立我们的标签?
- 主题标题
- 主题的文本
- 主题中帖子的文本
- 项目 1-3 的组合
主题标题-这应该给我们最干净的结果。因为,随着社区的发展,人们开始创造更干净的标题。理解这是我们首先看到的,所以我们有越多的标题来识别问题,我们就越有可能解决问题。
主题的文本——这给读者提供了更多的信息,但也增加了噪音。英语与俄语不同,它的结构更严格,句法修改更少。尽管如此,我们许多人的母语不是英语,有个人的写作风格,使用罕见的词汇。但主要问题是,文本通常包含代码。这可能是有用的(例如,我们可以根据我们看到“import lib”短语的频率为库创建一个标签)——这也可能是绝对无用的:想想变量、基本函数、库等等。
主题中的文章——有时候主题中的文章比主题本身更有用。他们给出了一个问题的解决方案或另一种观点(也许你对这篇文章的另一种观点是“他到底在说什么?”或者“哇,我怎么也看不够!”).但是许多帖子是无用的,因为它们可能是鼓励的话语。它们可能是离题很远的推理或澄清。这些对我们人类来说很重要,但对标签来说有必要吗?
所以,我计划用三种数据做我所有的实验。
- 仅标题
- 标题+主题文本
- 标题+主题文本,主题中的帖子。
在第 3 阶段,我们将主题数据合并到一个文档中,但是我们将帖子视为独立的文档。
但是我们从哪里得到数据呢?
我想如果我接触了 Dataquest 团队,我就可以从他们那里得到一部分数据库来做我的研究。但是真正的英雄总是反其道而行之,所以作为一名网络抓取专家(你们中的许多人都知道我是一个不需要硒来完成这项任务的人),我将为 Dataquest 编写一个爬虫。显然是时候展示我的技能了!
2.建模方法
我们有数据。那我们怎么把标签弄出来呢?我相信这是一个叫做主题建模的自然语言处理问题。但是这是一个特例,我们需要将讨论类型减少到它们的关键词。这很好,但是我们应该使用哪种主题建模方法呢?LSA,LDA,深度学习?
我们试试我能找到的一切(你可以在这里阅读),然后比较最后的结果,怎么样?或者你也可以参加这项研究,它会走上一条与我现在想象的完全不同的道路。嗯,我想尝试一切,听起来很棒,听起来很有野心。
3.利润
我们应该得到什么样的结果?有趣是好的,但你不能用它来买啤酒。所以我们要去找有形的东西。
我们将使用一个更简单的例子来处理建模主题的不同方法。我们将会看到哪种方法更有效。如果我们发现我们可以用它来制作一个好的工具,我们将会用一个应用程序和一个部署来结束这个系列。
那么,我们想要多少个标签呢?假设是 100 个,但是他们必须很棒!或者不是。让我们开始吧。
收集数据
扫描策略
在对这个网站做了一些研究之后,https://community.dataquest.io/提出了以下计划。
为了收集数据,我们实际上需要三个步骤:
- 从头到尾滚动浏览https://community.dataquest.io/latest,直到我们收集到这些主题的链接。
- 转到每个主题获取文章的正文。
- 在每个主题中,滚动浏览所有帖子以收集每个帖子,因为我们有像https://community . data quest . io/t/welcome-to-our-community/236/这样的怪物,有超过 900 个帖子。
也许有人已经在想,如果不使用 selenium,我将如何呈现 js——或者我可能已经决定,在这种情况下,Selenium 有意义吗?
没有(惊喜,惊喜!).这个任务不需要使用硒。
这就是我们如何获得数据:
- 浏览我们使用的主题目录-https://community.dataquest.io/latest.json?ascending=false&no _ definitions = true&page = 0如您所见,将页面参数更改为“翻页”就足够了。我们将通过检查当前页面上是否有 more_topics_url 参数来实现。如果没有这样的参数,那么我们已经到达最后一页。
- 比那要复杂一点。我们有一个模板 python f " https://community . data quest . io/t/{ post _ id }/posts . JSON 的链接?{ posts _ ids } & include _ suggested = true ",它返回主题正文和其中的帖子。在最后一步中,我们能够获得主题 post_id 的 id。但是我们在哪里可以获得包含消息 id 的 posts _ ids 列表呢?要做到这一点,我们必须直接进入主题的 HTML 页面,并获取链接到它的所有帖子的 id。
你不惊讶它们只是存储在主题的页面体中吗?哦,是的,话语是一个非常冗余的系统,它传输的数据比必要的多得多。但这是 21 世纪的现实。开发者的时间比你的资源更有价值。一旦我们有了这些数据,我们就可以自由地访问任何消息。
技术选择
那么我们该怎么做呢?
单线程听起来和硒一样可悲。
多线程?我很擅长这个,然后我们要么需要提前知道我们要处理的所有链接,要么使用队列和同步。老实说,这种方法没有什么困难。如果你的网络不好,你需要大约 5 分钟来计算出总共有 261 页列出了所有的线程。
鉴于此,您可以将 261 页分成多个线程,获得所有必要的链接,然后将这 7800 多篇文章分成多个线程。之后,您可以收集所有消息,或者在队列中传递数据。
但是你也可以阅读 100,500 篇关于它的文章。那就用 asyncio 吧。用于输入和输出操作的异步 Python 是最近几年的趋势。即使我们不是在构建一个 web 应用程序,它对我们来说也是有用的。
底线是我们的 web 请求库将会是 aiohttp。还有其他用于 web 请求的库,但我认为你必须很好地控制你的 web 流,aiohttp 有一个非常完善的代码库,所以这对我们有好处。此外,我们需要记住,Python 中几乎所有的 web 请求库都试图支持请求中的 API 结构。
我打算用 MongoDB 来存储数据。首先,因为它在社区中被不应有的忽视了。其次,说实话,存储数据比用 SQL 数据库更省时。
好吧,我们终于找到密码了。
用于处理数据库的简单类:
class MongoManage:
client = client
def __init__(self):
connect =self.client[MONGODB_SETTINGS.get('db', 'dataquest')]
self.topic_collection = connect.topic_collection
self.posts_collection = connect.posts_collection
async def get_data(self, collection, filter_query, filter_fields):
current_filter_fields = {"_id": 0}
current_filter_fields |= filter_fields
cursor = collection.find(filter_query, current_filter_fields)
return (doc async for doc in cursor)
async def write_data(self, collection, data):
if isinstance(data, list):
collection.insert_many(data)
else:
collection.insert_one(data)
async def get_topics(self, *args):
return await self.get_data(self.topic_collection, *args)
async def write_topics(self, *args):
await self.write_data(self.topic_collection, *args)
async def get_posts(self, *args):
return await self.get_data(self.posts_collection, *args)
async def write_posts(self, *args):
await self.write_data(self.posts_collection, *args)
async def close(self):
self.client.close()
因为我只有 2 个数据集合,所以我想出了一个简单的方法和函数来处理这些集合。事实上,在您将在下面看到的所有代码中,我只需要调用 get 和 write 函数。如果我发现我比其他人更频繁地进行某些查询,我也可以将它们包含在这个类中。我觉得这样就够方便了。
您会注意到这里使用了 async / await。
因为我将创建一个异步方法来收集数据,所以我不希望我的代码在处理数据库时被阻塞。是的,你在使用 asyncio 时的主要问题是你必须了解哪些操作会阻塞你的代码。除此之外,您还需要找到异步库和驱动程序。对于 MongoDB,这是马达。
编码
关于网页抓取中的异步,你不想知道什么

如果您正在解析来自 asyncio 的数据,您应该遵循的最重要的规则是请求控制。
Asyncio 实际上会产生处理您的请求的套接字。这意味着,如果您对一个站点创建 500 个请求,而没有对请求函数使用 await,那么您将打开 500 个套接字来访问一个站点。您将创建 500 个请求。你听说过 DDoS 攻击吗?恭喜你,你已经开始了那个方向的旅程。
示例:
for _ in range(500):
asyncio.create_task(asyncio_requests()) # There is no await, you have just created 500 requests for the site
你也可以这样做
for _ in range(500):
await asyncio.create_task(asyncio_requests()) # There is await here you make 1 request. And you wait for it to finish
你刚刚使你的代码同步。那为什么还要使用 asyncio 呢?
这当然是一个玩笑,但也是一个 100%的工作方法。您可以用这种方式解析来自多个站点的数据,同时对一个特定的站点创建不超过一个请求。这一切都发生在一个线程中。魔法。
在 asyncio 中,很容易创建一种生成级联查询的情况。
一页主题有 30 个主题。我们总共收到 31 个请求:30 个主题+下一页的主题。该网站可能没有时间来回应所有的请求,你将最终创建另一个 31。因此,您将在服务器站点上产生不断增长的负载。
我们需要记住,所有的资源都是有限的。一个站点可能处理不超过 100 个并行请求,另一个站点可以处理 1000 个。但是您应该明白,您创建的负载会干扰其他用户,或者使服务器扩展,而这需要成本。这就是为什么有些人把防刮擦保护到位。除了使用代理之外,我不会提及这些保护的任何其他解决方法。
所以,我已经概述了这个问题。在 Dataquest 的情况下,您会收到一个通知,提示您创建了太多的请求。
在 asyncio 中如何解决这个问题?使用旗语。
我创建了一个类,它不允许创建超过特定限制的并发查询,并且还将数据缓存到磁盘。
class Downloader:
cache_path = CACHE_PATH
attemps = 20
def __init__(self):
self.locker = asyncio.Semaphore(REQUESTS_LIMIT) # Creates a semaphore object
if not self.cache_path.exists():
self.cache_path.mkdir(parents=True)
async def start(self):
self.session = ClientSession(headers=HEADERS)
async def stop(self):
await self.session.close()
async def request(self, method, url, *args, **kwargs):
async with self.locker: # Here we use a semaphore. Not allowing to create queries greater than REQUESTS_LIMIT
for _ in range(self.attemps):
async with self.session.request(method, url, *args, **kwargs) as resp:
if resp.status == 200:
return await resp.read()
else:
await asyncio.sleep(2)
async def get(self, *args, **kwargs):
return await self.cache("GET", *args, **kwargs)
async def post(self, *args, **kwargs):
return await self.cache("POST", *args, **kwargs)
async def cache(self, method, url, *args, **kwargs):
url_hash = md5(url.encode()).hexdigest()
file_name = f"{url_hash}.cache"
file_path = Path(self.cache_path, file_name)
if file_path.exists():
async with aopen(file_path, 'rb') as f:
response_data = await f.read()
logger.info(f"Url {url} read from {file_name} cache")
else:
response_data = await self.request(method, url, *args, **kwargs)
if not response_data or b"Too Many Requests" in response_data:
raise Exception("Not Data")
async with aopen(file_path, 'wb') as f:
await f.write(response_data)
logger.info(f"Url {url} cached in {file_name} cache")
return response_data
缓存——由 Web 解析器提供
为什么要把数据缓存到磁盘上呢?
假设你访问了一个页面并得到了结果。然后您注意到您忘记在结果中包含一个或多个字段。然后,您需要重新启动脚本。这需要时间,给网站造成负担。
如果你缓存数据,而不是在网站上重新运行你的脚本,你只是从你的磁盘读取数据。这意味着数据可以随时访问,您可以更改数据库中的结果字段并快速更新数据,所有这些都不会给网站带来额外的负担。
当然,如果您需要定期更新数据,您必须为缓存创建一个生命周期机制。例如,如果数据必须每天更新,那么您必须删除前一天的所有缓存文件。
优化和发布
在我的脚本中,我限制并发查询不超过 3 个。考虑到我仍然需要将数据保存到数据库中,即使没有代理,它也能提供相当高的性能。
每个解析器函数要么将结果保存在数据库中,要么将数据传递给下一个函数。我不必担心额外的数据同步,并且我获得了很高的有竞争力的执行值,这产生了很低的内存和 CPU 负载。
async def category_loading(self, page):
logger.info(f"Loading category page {page}")
url = CATEGORY_URL.format(page=page)
response_content = await self.downloader.get(url)
json_data = json.loads(response_content)
topics, more_topic = self.category_parser(json_data)
if more_topic:
next_page = int(page) + 1
asyncio.create_task(self.category_loading(next_page)) # I call the same function with the new parameter
for topic in topics:
asyncio.create_task(self.topic_loader(topic)) # I create tasks for parsing all the found topics. That's up to 30 new requests
很有意思值得注意的一点是 stop 方法。
async def stop(self):
while len(asyncio.all_tasks()) > 1: # The script will close when one task remains. The current function
logger.warning(f"Current tasks pool {len(asyncio.all_tasks())}")
await asyncio.sleep(10)
logger.warning(f"Current tasks pool {len(asyncio.all_tasks())}")
await self.downloader.stop()
因为我在任何地方都使用 create_task,所以我不会等待任务完成。如果我不检查事件循环中的任务是否完成,我的脚本几乎会立即结束。而这并不是我想要达到的行为。
当只剩下一个任务时,脚本就完成了,因为该任务是实际的完成任务。如果我让我的脚本在 0 终止,那么我的脚本将永远不会停止
结果,开始扫描的功能具有非常简单的外观:
async def start_scan():
try:
mongo = MongoManage()
crowler = Crowler(db_manager=mongo)
await crowler.start(start_page=0)
await crowler.stop()
except Exception as e:
logger.exception(e)
finally:
await mongo.close()
结果
所以我们有 7809 个主题和 25666 个帖子。这样,我们就创建了一个高性能的 web 解析器。这个语句很简单,但是你必须遵循所有 3 个步骤来创建扫描仪。
- 扫描策略
- 技术选择
- 奥丁
千万不要从第三点开始。你会让自己和网站所有者的日子不好过。
你可以在 GitHub 库上阅读完整版本的代码—https://github.com/Mantisus/dataquests_tag_modelling

学习 Python 真的需要多长时间?(2022 版)
原文:https://www.dataquest.io/blog/how-long-does-it-take-to-learn-python/
August 4, 2022
对这个问题令人沮丧的陈词滥调的回答是。。。看情况。
每个人都有不同的目标,每个人都在不同的场景中工作,所以每个人的真实答案可能会大不相同。请考虑以下情况:
你学 Python 是为了什么?是为了大学课程、市场营销职位,还是为了追求全新的数据科学职业?
你的起点在哪里?你懂 Python 基础还是零编程经验?
你能投入多少时间来练习?每天一小时?每周 40 小时?
如果你在寻找一个通用的答案,这里就是:
如果你只是想学习 Python 基础,可能只需要几个星期。然而,如果你从一开始就从事数据科学职业,你可能需要 4 到 12 个月的时间来学习足够高级的 Python,以便为工作做好准备。
上面的估计来自我们参加了我们的 Python 基础课程的学生,以及那些完成了我们的 Python 职业道路的学生,这些课程让零编程经验的人使用真实世界的代码尽快做好工作准备。
本文将回答初学者在学习 Python 时最常见的一些问题,如下所示:
- Python 难学吗?
- 可以自学 Python 吗?
- 应该学 Python 2 还是 3?
- 为什么要学习 Python?
- 怎样可以更快的学习 Python?
还有很多很多
2022 年学 Python 值得吗?
是的。从职业前景、财务回报和多功能性的角度来看,学习 Python 当然是值得的。
高需求
各行各业都需要 Python 开发人员。
然而,Python 在数据科学行业尤其热门,Python 被用于从基本数据分析和可视化到创建高级机器学习算法的一切。
Indeed.com 的 HiringLab 调查了 2020 年的技术技能趋势,发现数据科学领域对 Python 技能的需求在过去五年中增长了 128%,在 2019 年期间增长了 12%!
丰厚的薪水
在美国,需要 Python 技能的职业年薪可以超过 10 万美元。
以下是需要 Python 编程知识的工作清单——以及这些工作在 2022 年 8 月的美国薪资:
- 数据分析师:$ 96323(在这里成为一个)
- 数据工程师:$ 117917(在这里成为一个)
- 数据科学家:$ 120610(在这里成为一个)
- Python 开发者:$ 113938
- 机器学习工程师::124545 美元
- 软件工程师:11.7996 万美元
难以置信的多功能性
Python 社区有一个内部笑话,Python 是所有语言中第二好的语言。当然,什么是最好的是主观的,但是 Python 具有难以置信的灵活性。它是数据科学中最常用的语言(R 紧随其后),在许多其他行业中也经常使用。
它广泛流行的一个原因是它是处理数据时最容易学习和使用的语言之一。幸运的是,对于雇主和数据科学家来说,不需要多年的学习就能掌握。
学习 Python 真的需要多长时间?
正如我们之前提到的,这个问题的答案取决于你的目标。Python 不仅仅是一种编程语言——它还是一种工具,你可以学习如何在你试图解决的问题中使用它。
以下是一些场景。。。
想要一点优势的营销人员
例如,如果你是一名想要更严格地分析谷歌分析数据的营销人员,你可以在几周内学会基本的 Python 语法和所需的 pandas 技术。这不会让你成为合格的 Python 开发人员或数据分析师,但足以解决你的问题。
寻找新的数据科学职业
如果你是从零开始学习,并且正在寻找使用 Python 的全职工作,你可以期望至少花几个月的时间来兼职学习。几个月取决于你要找的工作。例如,通过我们的 Python 课程路径中的数据分析师,你将为申请数据分析师的工作做好准备。大多数学习者至少需要三个月来完成这条道路。
不过,需要明确的是,你可以花一生的时间来学习 Python。有数百个库,其中许多库定期改进和发展,语言本身也随着时间的推移而变化。
用 Python 解决问题并不需要太长时间,但是掌握 Python 意味着在职业生涯中不断学习和成长。
可以自学 Python 吗?
是的,自学 Python 是很有可能的。网上有很多学习资源可以帮助你学习 Python,从 web 开发到人工智能。
在 Dataquest,我们已经帮助成千上万的学生学习 Python 和在数据科学领域找到工作,所有这些都按照他们自己的时间表,在他们自己舒适的家中完成。
不过,自学 Python 确实需要时间。您还必须确保您正在编写代码,并在现实世界的场景中应用您所学的内容,而不仅仅是观看讲座视频和回答选择题。
当你通过自学学习时,采用正确的方法学习 Python 也是成败的关键。
学 Python 难吗?
不会,Python 对大多数人来说并不难学。事实上,Python 被认为是最容易学习的编程语言之一。虽然任何人都可以学习 Python 编程——即使你以前从未写过一行 Python 代码——但你应该预料到这需要时间,而且你应该预料到挫折的时刻。
学 Python 需要数学好吗?
不,学 Python 不需要数学很好。虽然传统观点一直认为拥有数学天赋会让学习编程更容易,但最近的一项研究表明事实并非如此。
事实上,如果你学过一门外语,你可能会发现学习 Python 比“数学人”更容易。
我们已经看到来自各种背景的学习者通过我们的课程取得了成功,所以不要让你自己的背景阻止你尝试 Python!
我应该学 Python 2 还是 Python 3?
你应该学 Python 3 而不是 Python 2。虽然一些过时的学习资源仍然教授 Python 2,但该版本的语言不再受支持,安全漏洞也不会被修补。
你应该学习 Python 的最新版本,也就是 Python 3。
为什么你应该学习 Python
这里有三个你应该开始学习 Python 的理由,为了你的工作生活,个人生活,或者两者兼而有之。。。
1.您可以自动执行任务
Python 是一种通用的编程语言,这意味着每个人都有适合自己的东西。一旦你学会了 Python,你就能做到以下几点:
- 轻松处理海量数据集。
- 从网络上抓取数据并访问 API
- 使用它来增强您在 Excel 中的工作
- 自动化各种任务。
因为你的时间是宝贵的,所以学会自动完成任务是非常强大的。让机器人给你发邮件,从互联网上获取数据。如果你感觉特别有野心,你甚至可以创建下一个咖啡递送应用程序,这样你就可以每天早上轻松获得咖啡因。
(不过,这可能需要更多的工作。)
更有可能的是,你将能够开始为你工作的人和公司找到创造性的解决方案。当你学习 Python 时,你实际上是在学习一种建立在识别和预测模式基础上的新语言。当你发现模式时,你将能够以一种对你的行业和世界产生重大影响的方式交流这些发现。
2.你可以打动你的老板
学习 Python 也是在工作中给人留下深刻印象(或者获得你一直在争取的晋升)的好方法。
对于那些不会编程的人来说,编程的能力有时就像是一种超能力。编程让你有能力利用你的知识,增加你的产出。有了它,你可以在同样的时间内完成十倍的工作。
正如我们上面提到的,当你学习 Python 时,你将能够快速收集数据并将数据“翻译”成现实世界的解决方案。
例如,在一个商业环境中,你可以通过做一些事情来增加价值,比如抓取网页、自动发送电子邮件,甚至分析供应链生产来发现错过的成本节约或质量控制的机会。
如果你的老板提到了解数据科学可以帮助你实现职业目标,那么帮助你在线学习 Python 的自定进度 Python 课程可能是平衡数据职业和个人发展的最佳方式。
3.它创造了令人兴奋的新的职业机会
如果你正在寻找一个全新的职业,或者对目前的工作不满意,那么你来对地方了。
对 Python 开发人员的需求,尤其是在数据科学领域,从未如此之高。数据科学是有回报的,报酬非常高。
这些机会有时是远程提供的,所以你可以在任何地方为一家美国公司工作,而不必受限于美国的位置。数据科学是一个相对较新的领域,随之而来的是现代招聘实践。对理解你的技能和能够推动结果的强调,正慢慢开始压倒对四年制学位和走廊尽头办公室的需求。
我们已经看到许多校友在完成数据科学课程后找到了有价值的职业(无论是在办公室还是远程)。事实上,我们已经组织了我们的课程来帮助你在找工作时有所帮助。你将拥有处理真实世界数据的经验,并拥有一个完整的数据科学项目组合。
对于评估你简历的人力资源部门来说,这可能比你的学位更重要。
怎样才能更快的学习 Python?
如果你正在自学 Python,创造性的时间管理习惯将非常有帮助——尤其是如果你想尽早学习 Python 的话。虽然五个小时对于你已经很忙的周计划来说似乎太多了,但对于一个全职工作的人来说——或者有一个满满的学校承诺的日历,这是非常可以实现的。
这里有几种方法可以帮你找到空闲时间。。。
1.把你的闹钟提前 30 分钟
每天早上是你学习 Python 的最佳时间。
从生物学上讲,你最好、最有效率的时间是每天的前两个小时。你不想牺牲任何睡眠,但你可能想早点上床睡觉,这样你可以在工作前练习一下。
毫无疑问,这是一种承诺。但是,如果你在前一天晚上把衣服放在一边,准备好咖啡,并且已经知道你将在 Python 的哪些方面工作,这就容易一些。告诉自己,不花 30 分钟学习 Python,就不能看手机或邮件,并养成习惯!
它节省的时间和你职业生涯中的进步将值得你付出额外的努力。一个额外的好处是,当你在一天中有一个富有成效的开端时,你会感到格外健康。
2.注销你晚上网飞的习惯
如果你每天早上 5 点就起床去上班,那么早起可能不是你的最佳选择。
在这种情况下,你可以在每天下班回家的前两个小时学习 Python。如果你被在上下班、健身房、晚餐时间和休息时间之间找出两个小时的想法所淹没,花一周时间真正地审视一下你是如何度过你的夜晚的。
准确地写下你这周每天都做了什么:
- 你在网飞花了多少时间?
- 你在社交媒体上浪费了几个小时吗?
- 您在亚马逊上滚动时迷路了吗?
- 你能在周日做饭以减少工作日晚上做饭的时间吗?
把堡垒之夜的战斗巴士放在一边一个晚上,记住那些你想开始学习 Python 的原因。
或者,您可以用数据科学来结束您的一天。在把早晨的时间留给最重要的项目后,你可以在睡觉前回顾你的工作或参加论坛来帮助你掌握。
3.利用安静的周六早晨
我们已经看到,每天练习是尽快掌握 Python 的最好方法。
保持一致很重要,但有时生活会碍事。这就是周末的意义。如果你每天从早上 5 点到下午 6 点都被排满了,你可以通过在周末加班来让自己保持正常。
另外,这是在专门学习 Python 的空间中寻找不间断时间的好方法。
有一点要记住:每天学习两个小时远比周末一天学习十个小时好。如果你在一周中有其他的任务,与一周只看一次 Python 材料相比,即使每天早上十分钟也会有所不同。
4.加入 Python 程序员社区
加入 Python 开发者社区将有助于你朝着学习 Python 的目标前进。
Python meetups 在 Meetup.com 相当常见,你会从这些群组的其他成员那里获得推荐。此外,Dataquest 的学生使用我们的成员社区来交流和讨论 Python 问题、故障排除和数据科学组合项目。
如果你每天抽出几分钟来建立人际关系网,当你进入就业市场时,你会带着一项新技能和一个新的人际网络完成你的课程。
5.在 Kaggle 上竞争
Kaggle 举办数据科学竞赛。注册是免费的,成员提交 Python 脚本来为给定的数据集找到最佳模型。在您的 Dataquest 产品组合中,您会发现许多目标与指导项目相似的竞赛。
如果你是我们上面提到的堡垒之夜迷之一,在 Kaggle 比赛中与其他 Dataquest 学生合作可以帮助取代你的一些游戏时间,帮助你学习 Python,而不会失去竞争优势!
6.阅读 Python 书籍
有许多针对 Python 一般和特殊应用的指南,我们已经强调了几个,只要你不介意浏览数字副本,你就可以免费阅读。
您可以使用这些书籍来补充您的 Dataquest 课程,在那里您将了解这些信息以及更多专门针对数据分析和数据科学的信息。这非常适合那些希望在真实世界中学习我们的数据科学课程的学生。
准备好按照自己的进度学习 Python 了吗?
所有的数据科学家都有帮助他们的技巧和诀窍。有些人可能会夸口说他们只花了一个月就学会了 Python,而另一些人则花了好几年才达到他们所期望的精通程度。
对自己温和一点,给自己留出时间,以最适合自己的速度学习 Python。多花一点时间总比没有在基本面上打好坚实的基础就匆匆忙忙的做完所有事情要好!
掌握 Python 基础知识将有助于你实现生活和工作的自动化,在当前的工作中脱颖而出,甚至可以让你开始新的工作。 Dataquest 的互动课程提供即时的实践学习,以及一个能在您的旅程中为您提供帮助的同学社区。
如果你的目标不仅是学习 Python 数据科学,而且是真正掌握它,Dataquest 就是你的理想之选。
当你完成我们的免费课程时,你已经开始学习 Python 了。今天就开始我们完全免费的数据科学家之路,你将在几分钟内完成你的第一行代码!
学习 SQL 需要多长时间?
March 10, 2021
学习 SQL 真的需要多长时间?
对于几乎所有使用数据或数据库的人来说,SQL 是一项关键技能。虽然学习一门新的编程语言绝不是在公园散步,但我们有一些好消息——通常不需要太长时间就能掌握 SQL 的基础知识。但是真正学会 SQL 需要多久呢?
答案真的取决于你,你的目标,和你的背景。因此,我们没有试图给你一个放之四海而皆准的答案,而是设计了许多不同的场景。让我们深入细节。
什么是 SQL?
要了解学习 SQL 需要什么,了解 SQL 实际上是什么很重要。在上一节中,我称之为一种编程语言,但更准确地说,SQL 是一种查询语言。
查询语言是一种编程语言,它只为一件事而构建:与数据库交互。当你学会了 SQL,你会用它来做一些事情,例如:
- 从数据库中获取您想要的特定数据
- 将数据库中不同数据表的元素连接在一起
- 执行计算、分析和过滤数据以回答问题
如果你有存储在基于 SQL 的数据库中的数据——你可能会这样做,大多数公司使用某种形式的基于 SQL 的数据库管理系统 —SQL 是帮助你快速选择和处理你需要的特定数据的工具。
这意味着 SQL 不像 Python 那样是一种完全的编程语言。SQL 不会成为你用来编写视频游戏或开发移动应用程序的语言。它实际上只对涉及处理数据库中的数据的任务有用。
但这是好事!因为 SQL 特别专注于处理数据,所以您需要学习的内容很少,并且您遇到的大多数 SQL 教育材料都将专注于使用 SQL 执行常见的数据任务。
为什么要学 SQL?
我们写了一整篇关于为什么你应该学习 SQL 的文章,提供了 2021 年以来的最新工作信息。整篇文章绝对值得一读,但如果你不想点击进入,这里有几个简单的理由:
- 几乎每个公司都使用某种基于 SQL 的数据库来存储数据。 MySQL , Oracle ,微软 SQL Server 等。—所有这些都是基于 SQL 的数据库管理系统,这意味着几乎任何公司都需要 SQL 技能来高效地处理数据库。
- SQL 让你的工作比 Excel 更加高效透明。SQL 使您能够快速处理大型数据集,因为它是一种书面语言,所以您所做的一切都是透明的,并且易于理解、适应和重复。没有隐藏的单元格公式去寻找,也没有更多的复杂的 VLOOKUP 噩梦!
- SQL 技能抢手。在数据科学领域尤其如此,但即使是市场营销等不相关领域的工作也越来越需要 SQL 技能,因为分析和处理数据成为许多工作中越来越重要的一部分。

https://www.youtube.com/embed/JFlukJudHrk?feature=oembed
*## 学习 SQL 真的要花多少时间?
这个问题的答案取决于你的背景和你学习 SQL 的目标。
因此,与其给你一个放之四海而皆准的答案,不如让我们把它分解成几个不同的场景。每个场景都假设您从零开始使用 SQL,并且希望学习到指定的技能水平。
请随意选择最能描述您的副标题:
- 没有编程经验,想通过学习基础 SQL
- 没有编程经验,想通过学习中级 SQL
- 没有编程经验,想通过学习高级 SQL
- 之前有编程经验,想通过学习基础 SQL
- 之前有编程经验,想通过 学习中级 SQL
- 之前有编程经验,想通过 学习高级 SQL
(注意:这里所有的时间估计都假设你已经有一份全职工作,并且像大多数成年人一样,每周只限于几个小时的学习时间。如果你能每周花更多的时间学习,你会进步得更快。
没有编程经验,想学习到基础 SQL
也许你的工作不是技术性的,但是你有兴趣从你公司的数据中学习更多的东西,或者定期运行一些特定的查询来了解更多关于你正在做的工作的影响。如果您以前从未编写过代码,但是您想学习足够的 SQL 来运行快速查询以不时地回答问题,这一节是为您准备的。
SQL 的基础真的不会花很长时间去学习。例如,我们的第一门 SQL 课程,大多数人需要大约一个小时才能完成。
因为你以前没有编程语言的经验,你可能会想留出一点额外的时间来考虑所有的事情。你肯定会想留出一些额外的时间来练习。
尽管如此,您应该期望能够学习 SQL 的基础知识——如何从数据库中查询特定的数据表,如何从这些表中选择特定的列,如何使用 SQL 进行基本的数学运算,以及如何限制查询返回的输出——只需要几个小时,或者最多一个周末。
没有编程经验,想通过学习中级 SQL
如果您以前没有编码经验,但您希望经常使用 SQL,并承担一些更复杂的任务,如将不同的表连接在一起以创建新的表进行分析,本节将介绍您。
这需要多少时间因人而异,但你应该预计它需要一个周末到几周的时间(我们假设你已经有一份全职工作,只能在空闲时间偶尔学习)。
如果您正在学习 Dataquest,这一部分将映射到我们的前两到三门 SQL 课程,这取决于您需要为您的特定用例学习多少。你大概可以在五六个小时内完成所有三门课程(不包括指导项目),但你绝对应该留出额外的时间进行练习,并通过项目来巩固你的学习。
没有编程经验,想通过学习高级 SQL
如果你没有编码经验,但你正在寻找一份非常依赖 SQL 技能的工作,比如数据分析师的工作,或者甚至是数据工程的工作,这一部分就是为你准备的。
您将希望通过高级查询从基础开始学习一切,但是您可能还希望学习像使用 PostgreSQL 创建数据库这样的技能。
取决于你需要深入到什么程度,这可能需要一个月到几个月的时间,因为你将学习高级查询,但你也需要涵盖像构建和优化数据库、数据库安全等主题。
注意,如果你在找一份像数据工程师这样的工作,SQL 技能并不是你唯一需要学习的东西,所以你做好工作准备的时间会比学习 SQL 的时间长很多。一些数据分析师工作还会有额外的技术要求,比如一些 Python 编程的知识,尽管有些分析师工作只需要 SQL。
有编程经验,想学习从到的基本 SQL
如果您已经有了一些编程语言的经验,并且您只是想学习足够的知识来查询您公司的数据库以找到正确的表——也许您正计划将这些数据放入 Python 或 R 中进行分析——这一节是为您准备的。
SQL 的基础可能只需要一两个小时就能学会。与其他编程语言相比,您可能会发现它非常简单,因为 SQL 可读性很强。
有编程经验,想学习从到的中级 SQL
如果您已经有了一些编码经验,但是您希望经常使用 SQL 来做一些事情,比如连接不同列上的数据表和过滤您需要的特定数据,这一节是为您准备的。
确切地说,需要多长时间将取决于您希望 SQL 进行到什么程度,但是您可能能够在一周内轻松地完成我们前两到三门 SQL 课程的内容。完成指导项目可能会将时间延长一点,但你可能会在开始学习的几个小时内开始查询公司的数据库,并以有意义的方式使用你的新 SQL 技能。
有编程经验,想学习从到的高级 SQL
如果你已经有了一些编码经验,但是你正打算进入一个需要大量 SQL 工作的全职角色,这一节是为你准备的。
您将希望学习上一节中的所有查询技巧,但是您可能还需要学习更多关于创建数据库、优化数据库以及确保数据库安全的知识。这意味着你需要花额外的时间学习类似于 PostgreSQL 的东西,并从数据工程师的角度思考你需要的 SQL 技能。
这可能会花去你一两个月的时间,尽管值得注意的是,这些类型的角色通常还需要其他技术技能,如果你还不知道这些技能,那就需要额外的时间来学习。
准备好开始了吗?
SQL 可以开启一个全新的数据世界,让您的所有工作更高效、更有影响力。注册一个免费的 Dataquest 帐户,你就可以尝试我们的 SQL 基础课程,看看你能多快在学习 SQL 方面取得真正的进步!
用正确的方法学习 SQL!
- 编写真正的查询
- 使用真实数据
- 就在你的浏览器里!
当你可以 边做边学 的时候,为什么要被动的看视频讲座?
你在亚马逊上花了多少钱?分析亚马逊数据
原文:https://www.dataquest.io/blog/how-much-spent-amazon-data-analysis/
September 10, 2019
我在亚马逊上花了多少钱?这个问题会让这家电子商务巨头的长期客户感兴趣,也可能让他们感到害怕。但是如果你想要答案,它是可用。你可以发现你在亚马逊上花了多少钱,甚至更多。
让我们来看看。
我们将使用一点 Python 编程来分析我们的亚马逊数据。但是如果你以前从来没有编码过任何东西,不要担心!我们会一起走过这一切。到本文结束时,您已经编写了不到三十行代码,并且已经完成了一些很酷的事情,比如:
- 算出你在亚马逊上总共花了多少钱。
- 找到您最贵和最便宜的订单,以及您的平均和中值订单总数。
- 计算出你付了多少税,以及你在亚马逊上的有效销售税率。
- 将你每天的消费习惯可视化在一个条形图中。
- 定制条形图的一些元素,如大小和颜色。
如果你曾经想过学习一点代码,或者如果你曾经想知道你在亚马逊上花了多少钱,那就和我们一起来吧!你会对你能做的事情感到惊讶(尽管你可能会对你花了多少钱感到震惊)。
为分析做准备
1.下载和安装工具
为了进行这种分析,我们将进行一点 Python 编程。但是不要慌!即使你一生中从未写过一行代码,你也可以这样做!我们将一步一步地完成这个过程。
第一步是在您的计算机上安装一个名为 Anaconda 的工具。这将允许我们使用一种叫做 Jupyter 笔记本的东西来编程。Jupyter Notebooks 是做这种数据分析项目的一个很好的工具,一旦你掌握了它,你可能会发现自己经常使用它。
如果你想深入了解,我们有一个关于 Jupyter 笔记本的深入教程,但是今天我们要做的事情非常简单,我们将在这一页上一一介绍。
首先,我们需要前往 Anaconda 网站的页面,稍微向下滚动,然后选择我们的操作系统——Windows、Mac 或 Linux。一旦我们选择了您正在使用的正确操作系统,我们将点击 Python 3.7 版本下的绿色“下载”按钮来下载 Anaconda。

下载完成后,我们可以像安装任何其他应用程序或程序一样安装它:只需双击下载的文件,就会弹出一个安装向导来指导我们完成安装过程。
对于我们这里的目的,默认安装设置就可以了。不过,我们需要记下安装它的文件夹。虽然我们可以在 Jupyter 笔记本电脑的任何地方保存和访问文件,但今天我们将数据集和 Jupyter 笔记本文件保存在同一个文件夹中,以便于访问。
一旦 Anaconda 安装完毕,我们就可以进行下一步了:
下载亚马逊订单历史数据
亚马逊允许你下载大量的订单报告,尽管可用的数据只能追溯到 2006 年。不过,如果你是亚马逊的普通用户,十多年的数据很可能包含一些有趣的见解!
要获取数据,登录后点击此链接会直接将我们带到订单报告下载页面。但是如果这不起作用,我们也可以直接导航到那个页面:去 Amazon.com,点击右上角的账户和列表按钮。在下一页上,找到订购和购物首选项部分,然后单击标题下的“下载订单报告”链接。
如果你想完成本教程,但不想使用你自己的数据,你可以下载我们在本教程中使用的相同的匿名数据集。

Amazon 提供四种不同的报告类型。现在,我们将下载一个订单和发货报告,因此从下拉菜单中选择该选项。然后,我们可以为想要查看的数据选择开始日期和结束日期。要查看亚马逊的所有存储数据,我们需要将开始日期设置为 2006 年 1 月 1 日。然后,我们可以点击结束日期旁边的小“使用今天”按钮来自动填写今天的日期。
(如果我们不想查看所有订单历史记录,页面右侧还有“快速设置选项”,可以用来快速输入我们可能想要查看的常见时间段,如去年或最近一个月。但是如果我们想知道我们在亚马逊上总共花了多少钱,那么我们需要下载从 2006 年到今天的所有东西。)
我们还可以选择为报告添加一个名称—这不是必需的,保留为空也没关系,但是如果您计划下载大量不同的报告,并希望能够轻松区分它们,那么这样做可能是值得的。

一旦一切准备就绪,点击“请求报告”,亚马逊将开始为您构建报告。你要求的数据越多,你下的订单越多,这个过程就需要越长的时间!但是在一两分钟内,我们应该会弹出一个下载. csv 文件的消息。这是报告,请点击“保存”下载。
(如果您没有看到弹出提示,您也可以通过单击“您的报告”表的“操作”部分中的“下载”来下载,该表位于同一页面上“请求订单历史记录报告”表单的正下方。)
重命名和移动亚马逊订单数据
我们几乎已经准备好开始编程和分析了。但是首先,让我们通过重命名和移动我们刚刚下载的文件来使事情变得简单一些。默认情况下,这可能会被称为类似于01_Jan_2006_to_10_Sept_2019.csv的东西,但让我们将其重命名为更简单的东西:amazon-orders.csv。
接下来,我们将把amazon-orders.csv文件移动到我们安装 Anaconda 的同一个文件夹中,这样我们就可以很容易地从 Jupyter 笔记本中访问它。如果您在安装过程中没有更改默认文件夹,在 Windows 上这将是C:/Users/YourUsername/。
Open a Jupyter Notebook
现在我们终于开始有趣的部分了!打开 Anaconda Navigator 应用。你可以通过在电脑上搜索“Anaconda Navigator”来找到它。在 Windows 上,你也可以在开始菜单中找到它,在 Mac 上,它应该在你的应用程序文件夹中。打开后,您会看到一个类似这样的屏幕:

点击 Jupyter 笔记本下的“启动”按钮。这将在您的浏览器中打开一个新的屏幕。在该屏幕的右上角,单击“新建”,然后在下拉菜单中的“笔记本”下,单击“Python 3”。

瞧啊。你已经打开了一个空白的 Jupyter 笔记本,我们准备开始我们的分析!
我在亚马逊上花了多少钱?
Jupyter 笔记本允许我们在单元格中编写和运行小代码片段。在屏幕上,在菜单和按钮的下方,你会看到一个小方块,上面写着In [ ]:,并有一个闪烁的光标。这是第一个单元格,我们可以在这里写代码。
对于这个分析,我们将使用 Python,这是一种非常通用的编程语言,在数据分析中很流行。我们还将使用名为 pandas 和 matplotlib 的 Python 包。您可以将包想象成某种类似浏览器插件的东西——它们是帮助扩展常规 Python 功能的工具。Pandas 和 matplotlib 已经安装了 Anaconda,所以我们不需要自己下载或安装。
将数据输入熊猫体内
我们的第一步将是编写代码来打开并查看我们的 Amazon 数据,这样我们就可以看到我们正在处理什么。在我们的大部分分析中,我们将使用 pandas,所以我们的第一步将是导入 pandas 包,并给它一个昵称pd,这样我们就可以在代码中更容易地引用它。
接下来,我们将创建一个名为df的新变量,DataFrame 的缩写,然后告诉 pandas 将我们的 Amazon 数据存储在该变量中。数据帧基本上只是一个表格的熊猫名称。我们在这里真正做的是以表格格式存储我们的数据。
为此,我们需要告诉 pandas 将.csv.文件作为数据帧读取。为此,我们将使用pd.read_csv('file_name.csv')。让我们一点一点地分解它:
- 告诉 Python 使用熊猫来完成这个操作
- 告诉熊猫读取一个 csv 文件,并将其存储为数据帧
- 括号内的
'file_name.csv'部分告诉 pandas 读取一个具有该文件名的 csv 文件,该文件位于安装 Anaconda 的同一个文件夹中。
(如果我们想从不同的文件夹中获得一个 CSV 文件,我们必须输入完整的文件路径,比如C:/Users/Username/file_name.csv。因为我们将amazon-orders.csv文件存储在安装 Anaconda 的同一个文件夹中,所以我们只需要在这里包含文件名。)
最后,我们将使用一个名为.head()的 pandas 函数来查看我们的数据的前五行,这将让我们了解我们正在处理什么,以及亚马逊的订单历史包括哪些类型的数据。为此,我们使用语法DataFrame.head(),因此由于我们的数据帧存储在变量df中,我们将使用df.head()。
我们将在本教程中大量使用.head()——这是一个很好的快速方法来复查我们的代码是否已经做出了我们认为已经做出的更改,至少当我们做出的更改从视觉上看表格时是明显的。
这是它看起来的样子。让我们将这个代码输入到我们的第一个 Jupyter 笔记本单元格中,然后点击“运行”按钮,或者使用键盘上的 Shift+Enter(Mac 上的 Cmd + Enter)来运行所选的单元格。
import pandas as pd
df = pd.read_csv('amazon-orders.csv')
df.head()
| 订单日期 | 订单 ID | 支付工具类型 | 网站(全球资讯网的主机站) | 采购订单编号 | 订购客户电子邮件 | 装运日期 | 送货地址名称 | 送货地址街道 1 | 送货地址街道 2 | … | 订单状态 | 承运人名称和跟踪号码 | 小计 | 运送费 | 促销前纳税 | 晋升总数 | 已征税 | 收费总额 | 买家姓名 | 组名 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 04/01/19 | 112-0000000-0000001 | 签证-0001 | Amazon.com | 圆盘烤饼 | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | 圆盘烤饼 | … | 装船 | 美国邮政总局(0001) | $35.00 | $0.00 | $1.93 | $0.00 | $1.93 | $36.93 | 你的名字 | 圆盘烤饼 | |||
| one | 04/01/19 | 112-0000000-0000002 | 签证-0001 | Amazon.com | 圆盘烤饼 | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | 圆盘烤饼 | … | 装船 | 美国邮政总局(0001) | $16.99 | $0.00 | $0.00 | $0.00 | $0.00 | $16.99 | 你的名字 | 圆盘烤饼 | |||
| Two | 04/01/19 | 112-0000000-0000003 | 签证-0001 | Amazon.com | 圆盘烤饼 | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | 圆盘烤饼 | … | 装船 | 美国邮政总局(0001) | $9.99 | $0.00 | $0.00 | $0.00 | $0.00 | $9.99 | 你的名字 | 圆盘烤饼 | |||
| three | 04/04/19 | 112-0000000-0000004 | 签证-0001 | Amazon.com | 圆盘烤饼 | 【电子邮件保护】 | 04/05/19 | 你的名字 | 1 你的街道 | 圆盘烤饼 | … | 装船 | 不间断电源(0002) | $147.98 | $0.00 | $8.14 | $0.00 | $8.14 | $156.12 | 你的名字 | 圆盘烤饼 | |||
| four | 04/05/19 | 112-0000000-0000005 | 签证-0001 | Amazon.com | 圆盘烤饼 | 【电子邮件保护】 | 04/07/19 | 你的名字 | 1 你的街道 | 圆盘烤饼 | … | 装船 | 美国邮政总局(0001) | $14.99 | $0.00 | $0.00 | $0.00 | $0.00 | $14.99 | 你的名字 | 圆盘烤饼 |
 爽!只用了三行代码,我们就导入了所有的数据,现在我们能够以方便的表格格式预览这些数据。
爽!只用了三行代码,我们就导入了所有的数据,现在我们能够以方便的表格格式预览这些数据。
如果我们想得到数据集的完整尺寸,我们可以使用df.shape。这给了我们数据框架的尺寸。
df.shape
(59, 23)
现在我们知道我们的数据帧有 59 行 23 列。(在本教程中,我们使用了一个非常小的数据集;你的数据框架可能会大很多!)
看着上面的表格,你首先注意到的可能是它是假数据。我们在本教程中使用的数据集是我自己的一些亚马逊购买历史的编辑版本。为了保护我的隐私,我已经更改了姓名、地址、卡号和购买价格,但这些数据的格式与你将从亚马逊下载的真实数据完全相同,我们对这些匿名数据使用的代码也将适用于你的真实数据——无论你有多少数据。
默认情况下,Amazon 数据附带的列名非常具有描述性,很明显,这个数据集中有一些有趣的东西值得关注。我们的第一个目标是算出我们总共花了多少钱,并计算出每份订单的平均价格。这意味着Total Charged栏中的数据对我们来说肯定很重要。
看着上面的内容,我们可能还会注意到一些列有值NaN。这是一个空值;NaN是熊猫代表数据的缺席的方式。当我们进行分析时,我们必须意识到数据集中这些缺失的值。
清理数据
清理数据是大多数数据分析项目的重要部分,在我们进行分析并找出我们在 Amazon 上花费的总金额之前,我们需要在这里做一点数据清理。
让我们从处理那些NaN值开始。我们需要用我们的数据做一些数学运算,但是1 + NaN是一个很难解决的数学问题。NaN毕竟不是一个数字!因为NaN代表没有信息,所以让我们使用 pandas 方便的df.fillna()函数来填充所有的NaN值。这允许我们自动地用其他值替换每一个NaN值。在这种情况下,让我们用数字零替换NaN。
不过,我们需要小心一点。我们不只是想暂时取代那些价值观!我们希望替换它们,然后将数据帧的版本存储为我们的新数据帧。我们将使用df = df.fillna(0)来替换这些值,并重新定义我们的df变量以指向新的数据帧。
然后,我们将再次使用.head()函数来确保我们的更改生效。
df = df.fillna(0)
df.head()
| 订单日期 | 订单 ID | 支付工具类型 | 网站(全球资讯网的主机站) | 采购订单编号 | 订购客户电子邮件 | 装运日期 | 送货地址名称 | 送货地址街道 1 | 送货地址街道 2 | … | 订单状态 | 承运人名称和跟踪号码 | 小计 | 运送费 | 促销前纳税 | 晋升总数 | 已征税 | 收费总额 | 买家姓名 | 组名 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 04/01/19 | 112-0000000-0000001 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $35.00 | $0.00 | $1.93 | $0.00 | $1.93 | $36.93 | 你的名字 | Zero | |||
| one | 04/01/19 | 112-0000000-0000002 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $16.99 | $0.00 | $0.00 | $0.00 | $0.00 | $16.99 | 你的名字 | Zero | |||
| Two | 04/01/19 | 112-0000000-0000003 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $9.99 | $0.00 | $0.00 | $0.00 | $0.00 | $9.99 | 你的名字 | Zero | |||
| three | 04/04/19 | 112-0000000-0000004 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/05/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 不间断电源(0002) | $147.98 | $0.00 | $8.14 | $0.00 | $8.14 | $156.12 | 你的名字 | Zero | |||
| four | 04/05/19 | 112-0000000-0000005 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/07/19 | 你的名字 | 1 您所在的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $14.99 | $0.00 | $0.00 | $0.00 | $0.00 | $14.99 | 你的名字 | Zero |
太好了!正如我们所看到的,我们的空值已经被替换为零,这将使计算变得更容易。
不过,我们仍然有一个小小的数据清理问题。这个数据集中的价格被存储为字符串,这意味着计算机将它们视为一系列字符,而不是可以相加的数字。它们还包括字符$,它不是一个数字。
在我们可以用这些值执行计算之前,我们需要删除那些美元符号,然后我们需要将字符串值转换成floats——一种 Python 可以轻松执行计算的数字数据类型。幸运的是,这些操作只需要几行代码。
具体来说,有两个熊猫函数我们可以使用。首先,Series.str.replace()允许我们在数据帧的任何列(在 pandas 中称为一个系列)中用另一个字符或一组字符替换一个字符或一组字符。对于我们的目的来说,这是很有帮助的,因为我们可以使用语法df["Total Charged"].str.replace('$','')来告诉 Python 用第二个集合中的内容(什么都没有)替换第一个集合中的内容(在“总费用”列中)。
换句话说,我们告诉熊猫在那一列中用空字符替换字符$。那样的话,剩下的就只有数字了。一旦我们在列中有了数字,我们就可以使用函数.astype(float)将列中的每个条目转换成 float 类型,这样我们就可以进行计算了。
同样,我们不想临时进行这些更改,我们想修改我们的数据帧,然后将我们的df变量指向数据帧的新版本。然而,由于这一次我们只修改数据的一列,我们将使用df["Total Charged"]来指定我们只希望在那一列中进行这些更改。
现在,让我们把它们放在一起,然后再次使用head()来检查我们在下一行的工作。
df["Total Charged"] = df["Total Charged"].str.replace('$','').astype(float)
df.head()
| 订单日期 | 订单 ID | 支付工具类型 | 网站(全球资讯网的主机站) | 采购订单编号 | 订购客户电子邮件 | 装运日期 | 送货地址名称 | 送货地址街道 1 | 送货地址街道 2 | … | 订单状态 | 承运人名称和跟踪号码 | 小计 | 运送费 | 促销前纳税 | 晋升总数 | 已征税 | 收费总额 | 买家姓名 | 组名 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 04/01/19 | 112-0000000-0000001 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $35.00 | $0.00 | $1.93 | $0.00 | $1.93 | Thirty-six point nine three | 你的名字 | Zero | ||
| one | 04/01/19 | 112-0000000-0000002 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $16.99 | $0.00 | $0.00 | $0.00 | $0.00 | Sixteen point nine nine | 你的名字 | Zero | ||
| Two | 04/01/19 | 112-0000000-0000003 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $9.99 | $0.00 | $0.00 | $0.00 | $0.00 | Nine point nine nine | 你的名字 | Zero | ||
| three | 04/04/19 | 112-0000000-0000004 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/05/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 不间断电源(0002) | $147.98 | $0.00 | $8.14 | $0.00 | $8.14 | One hundred and fifty-six point one two | 你的名字 | Zero | ||
| four | 04/05/19 | 112-0000000-0000005 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/07/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $14.99 | $0.00 | $0.00 | $0.00 | $0.00 | Fourteen point nine nine | 你的名字 | Zero |
在这个表格中向右滚动,你可以看到我们已经做到了:美元符号都消失了。现在是有趣的部分,或者可能是可怕的部分:找出这些年来我们在亚马逊上实际花了多少钱!
计算花在亚马逊上的钱的总数
Pandas 包括一些我们可以在本专栏中使用的基本数学函数。让我们从.sum()开始,它将给出该列中每个数字的总数——换句话说,我们在亚马逊上花费的总数。
df["Total Charged"].sum()
1777.7300000000002
找到了:1777.73 美元。这是我在亚马逊上花的钱,至少在这个有限的和编辑过的数据集范围内。
我不想分享我在分析亚马逊 13 年的订单历史时发现的真实总数,但它……更大。你的总分让你吃惊吗?
计算其他东西:在亚马逊上的平均花费,最大购买量,等等。
找到总数并不是我们唯一能做的事情,因为我们已经清理了那一列数据!熊猫让我们能够非常快速地进行一些其他的计算。例如,平均购买价格是多少?我们可以使用.mean()来找出:
df["Total Charged"].mean()
30.131016949152542
显然,我每笔订单的平均支出约为 30 美元。
因为查看平均值有时会隐藏异常值,所以查看中间值也很好。我们可以使用.median()来做到这一点。
df["Total Charged"].median()
15.95
真有意思!我的平均花费比我的平均花费低很多。看起来我做了一些昂贵的订单。让我们通过使用max()来看看价格最高的订单是什么:
df["Total Charged"].max()
210.99
好吧,我最贵的订单是 211 美元。我的最低价订单怎么办?我们可以使用.min()来找到那个:
df["Total Charged"].min()
1.04
我在亚马逊上到底买了什么才花了 1 美元?我不记得了!(我可以在另一份亚马逊报告中找到这个问题,即 Items 报告,但这有点复杂,因此是另一个话题。)
我支付了多少营业税?
这是对我为每份订单支付的总价格的许多有趣的分析,但是如果我想查看不同的列呢?例如,如果我想知道我已经支付了多少销售税,该怎么办?
该数据存储在Tax Charged列中。这个列还没有被清理,所以它和我们开始时的Total Charged列有同样的问题。
但是编程的美妙之处在于:我们已经编写了可以修复 T4 的代码。我们需要做的就是从上面复制粘贴我们的列清理代码,并用"Tax Charged"替换"Total Charged",告诉 Python 对"Tax Charged"列执行相同的操作。
df["Tax Charged"] = df["Tax Charged"].str.replace('$','').astype(float)
df.head()
| 订单日期 | 订单 ID | 支付工具类型 | 网站(全球资讯网的主机站) | 采购订单编号 | 订购客户电子邮件 | 装运日期 | 送货地址名称 | 送货地址街道 1 | 送货地址街道 2 | … | 订单状态 | 承运人名称和跟踪号码 | 小计 | 运送费 | 促销前纳税 | 晋升总数 | 已征税 | 收费总额 | 买家姓名 | 组名 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 04/01/19 | 112-0000000-0000001 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $35.00 | $0.00 | $1.93 | $0.00 | One point nine three | Thirty-six point nine three | 你的名字 | Zero | ||
| one | 04/01/19 | 112-0000000-0000002 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $16.99 | $0.00 | $0.00 | $0.00 | Zero | Sixteen point nine nine | 你的名字 | Zero | ||
| Two | 04/01/19 | 112-0000000-0000003 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $9.99 | $0.00 | $0.00 | $0.00 | Zero | Nine point nine nine | 你的名字 | Zero | ||
| three | 04/04/19 | 112-0000000-0000004 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/05/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 不间断电源(0002) | $147.98 | $0.00 | $8.14 | $0.00 | Eight point one four | One hundred and fifty-six point one two | 你的名字 | Zero | ||
| four | 04/05/19 | 112-0000000-0000005 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/07/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $14.99 | $0.00 | $0.00 | $0.00 | Zero | Fourteen point nine nine | 你的名字 | Zero |
很快,色谱柱就可以进行我们想要的任何分析了。例如,根据这个数据集,我们缴纳的税款总额是多少?我们将再次使用.sum()来找出:
df["Tax Charged"].sum()
52.60999999999999
显然,我在亚马逊上花掉的钱中有 52.61 美元用于缴税。不同商品的税率不同——我们可以在上面的数据框架预览中看到,有些商品根本不征税。但是如果我们想的话,我们可以通过简单地将我们的"Total Charged"总和除以我们的"Tax Charged"总和来计算出总税率,就像这样:
df["Tax Charged"].sum() / df["Total Charged"].sum()
0.02959392033660904
在此期间,我支付的总体有效销售税率约为 2.9%。
到目前为止,我们在这里做的分析非常酷,我们已经了解了一些关于我们亚马逊消费习惯的事情。如果你以前从未编写过任何代码,并且想学习更多这类东西,我建议你就此打住,报名参加我们的Python for Data Science Fundamentals 课程。这是免费的,它会给你一个很好的基础,所以很快,你就会对自己承担这样的项目,甚至更复杂的项目感到舒适。
如果你现在想要更多的挑战,我们可以用这个数据集做更多的事情。让我们通过对这些日期栏进行分析,来了解我们的消费习惯是如何随着时间的推移而改变的。
随着时间的推移分析亚马逊支出
在 Python 中处理日期之前,我们需要将它们转换成datetime数据类型,这样计算机就可以将它们识别为日期。幸运的是,对于熊猫来说,这很简单!我们可以使用.pd.to_datetime()并在括号中指定我们想要修改的列,告诉 pandas 将该列作为日期读取。
和以前一样,我们希望确保将这一更改存储在我们的df数据帧中,因此我们将指定我们正在修改df['Order Date']列,然后将它分配给我们的df变量中的“订单日期”列,以便旧的"Order Date"列被我们更改后的版本所替换。
我们真的只需要看到一行就可以确定我们的日期已经更改,所以让我们为我们的老朋友df.head()提供一个自定义参数。我们可以自定义它显示的行数。如果我们将数字1放在括号内,它将显示数据集的一行。
df['Order Date'] = pd.to_datetime(df['Order Date'])
df.head()
| 订单日期 | 订单 ID | 支付工具类型 | 网站(全球资讯网的主机站) | 采购订单编号 | 订购客户电子邮件 | 装运日期 | 送货地址名称 | 送货地址街道 1 | 送货地址街道 2 | … | 订单状态 | 承运人名称和跟踪号码 | 小计 | 运送费 | 促销前纳税 | 晋升总数 | 已征税 | 收费总额 | 买家姓名 | 组名 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | 2019-04-01 | 112-0000000-0000001 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $35.00 | $0.00 | $1.93 | $0.00 | One point nine three | Thirty-six point nine three | 你的名字 | Zero | ||
| one | 2019-04-01 | 112-0000000-0000002 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $16.99 | $0.00 | $0.00 | $0.00 | Zero | Sixteen point nine nine | 你的名字 | Zero | ||
| Two | 2019-04-01 | 112-0000000-0000003 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/01/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $9.99 | $0.00 | $0.00 | $0.00 | Zero | Nine point nine nine | 你的名字 | Zero | ||
| three | 2019-04-04 | 112-0000000-0000004 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/05/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 不间断电源(0002) | $147.98 | $0.00 | $8.14 | $0.00 | Eight point one four | One hundred and fifty-six point one two | 你的名字 | Zero | ||
| four | 2019-04-05 | 112-0000000-0000005 | 签证-0001 | Amazon.com | Zero | 【电子邮件保护】 | 04/07/19 | 你的名字 | 1 你的街道 | Zero | … | 装船 | 美国邮政总局(0001) | $14.99 | $0.00 | $0.00 | $0.00 | Zero | Fourteen point nine nine | 你的名字 | Zero |
从这一行中,我们可以看到日期格式从2019/04/01变成了2019-04-01。这是一个好的迹象,表明我们对datetime的改变已经奏效,我们可以进行下一步的分析了。
一件有趣的事情是,在这个数据集中,每天花了多少钱。这是一个最容易直观看到的分析,也许是以条形图的形式。幸运的是,pandas 和 matplotlib 包使我们能够在 Jupyter 笔记本中构建和查看各种图表类型!
我们将从一个小的 Jupyter 笔记本魔术开始,它将允许我们在我们的 noteboot 中显示图表。(注意:当您运行这个代码单元格时,没有什么明显的变化,但是它将使 matplotlib 能够在您的笔记本中显示图表。)
太好了!我们可以使用df.plot.bar()以非常简单的方式制作一个基本的条形图。我们可以将所需的 X 轴和 Y 轴列作为参数传递给该函数,并且我们还可以添加其他参数来执行旋转 X 轴标签之类的操作。但是看看当我们按原样绘制数据框架时会发生什么:
df.plot.bar(x='Order Date', y='Total Charged', rot=90)
<matplotlib.axes._subplots.AxesSubplot at 0x1c30f9c4e10>

这个图表有点小,很难看出我们是否真的得到了我们想要的。让我们把它变大,这样我们可以更容易地读取数据。
我们可以通过在绘图代码中添加一个名为figsize的参数来做到这一点。这允许我们通过宽度和高度来定义图形的大小(fig 是 figure 的简称)。它使用的单位不是特别直观,但是对于大多数图表来说,(20, 10)是一个很好的默认值,如果需要,我们可以进一步调整。
我们所需要做的就是将figsize=(20,10)添加到我们代码中已经有的参数中。请注意,每个单独的参数都用逗号分隔。
df.plot.bar(x='Order Date', y='Total Charged', rot=90, figsize=(20,10))
<matplotlib.axes._subplots.AxesSubplot at 0x1c3129870b8>

那更好读!但是如果我们仔细观察上面的图表,我们可以发现一个问题:当在同一天下了多个订单时,每个订单在条形图中都有一个单独的条。例如,看看图表上的前三个柱线——这三个柱线都是 4 月 1 日的,代表当天下了三个单独的订单。
这并不是我们真正想要想象的。我们想知道每天花了多少钱。每个条形应该代表一天,而不是一个订单,所以如果当天有一个以上的订单,这些订单的总费用应该加在一起。
我们可以使用另一个内置的熊猫函数:df.groupby()。
这里的语法有点复杂,但是我们可以把我们想要做的分成两部分:1 .我们希望按'Order Date'对数据进行分组,这样,所有共享相同日期的订单都被计算在一行中(即,我们希望 4 月 1 日占一行,而不是三行)。2.我们希望获得每个日期在'Total Charged'列中支付的价格的总和,并将其作为相关日期行中'Total Charged'的值(即,我们希望 4 月 1 日行中'Total Charged'的值是当天三个订单的总和)。
因为我们是按订单日期分组的,所以我们将从df.groupby('Order Date')开始。下一步我们需要做的是对该组中的'Total Charged'列求和,并将 make 设置为新的'Total Charged'列,因此我们将在第一部分之后添加.sum()["Total Charged"]。
我们想把熊猫系列的结果赋给一个新的变量。姑且称之为daily_orders。
以下是它的整体外观:
daily_orders = df.groupby('Order Date').sum()["Total Charged"]
daily_orders.head()
Order Date
2019-04-01 63.91
2019-04-04 156.12
2019-04-05 27.64
2019-04-07 40.63
2019-04-08 44.99
Name: Total Charged, dtype: float64
正如我们所见,.head()的结果在这里看起来有点不同。这是因为这是一个系列,而不是一个数据框架。它看起来有两列,但实际上只有一列:'Order Date'列条目实际上是我们求和的索引标签。
准确理解这是如何工作的对于本教程来说并不重要,但是如果你向上滚动到你之前的一个df.head()打印输出,你可能会注意到在表格的最左边是降序的数字:0,1,2,3,4…这些数字是索引标签。
令人欣慰的是,pandas 能够很好地用日期作为索引标签来绘制一系列数据,所以我们不必对我们的数据做任何其他事情。如果我们检查前面数据框中的数字,我们可以看到这里的总数是正确的。2019 年 4 月 1 日有三个单独的订单,“36.93 美元”、“16.99 美元”和“9.99 美元”。这三者之和为$63.91,这是daily_orders中 4 月 1 日的值。完美!
是时候把它做成条形图了。我们可以用Series.plot.bar()做到这一点,因为我们的系列只有一列和一组索引标签,我们甚至不需要定义 x 和 y 轴。熊猫会自动这么做。
daily_orders.plot.bar(figsize=(20,10))
<matplotlib.axes._subplots.AxesSubplot at 0x1c3110bbf60>

现在我们已经得到了我们想要的图表,但是我们还可以做另一个快速的改进。
这张图表中的不同颜色有点误导。每个条形实际上代表了同样东西的价值(亚马逊当天向我们收取的订单总额)。但是因为每一条都是不同的颜色,一些人在看这个图表时可能会认为这些颜色有一定的含义,每一条代表不同的东西。
我们可以用另一个类似figsize的论点来改变这一点。这个叫color。例如,将参数color="blue"添加到我们的绘图代码中会使图表中的每一条都变成蓝色。
该参数可以接受基本颜色,如“蓝色”,但也可以接受其他格式的颜色信息,包括您可能在 web 上看到过的十六进制代码。让我们用更有趣的颜色代替蓝色:Dataquest green!我们绿色的十六进制代码是#61D199,所以我们将使用color='#61D199'。
让我们把它放到我们的代码中,看看它看起来怎么样!
daily_orders.plot.bar(figsize=(20, 10), color='#61D199')
<matplotlib.axes._subplots.AxesSubplot at 0x1c311dcd5c0>

厉害!这张图表向我们展示了我们之前的分析没有展示的东西:尽管最大的单笔订单刚刚超过 200 美元,但在 7 月的某一天,几笔订单的总额远远超过了 400 美元。
很明显,在这张图表上,我们还有很多可以改进的地方。我们可以删除底部的时间代码,添加一个 Y 标签和一个图表标题,插入没有订单的日期,以便更一致地显示订单的时间,等等。
但我们在这里的目标不是创建一个完美的图表。那就是使用一些快速编程从大量数据中挖掘出一些洞察力。而且我们学到了很多!我们了解到:
- 这期间我在亚马逊上花了多少钱。
- 我的最高、最低和平均订单总数是多少。
- 我付了多少税,以及我支付的有效销售税率。
- 我的支出如何随时间波动
- 哪一天我花的钱最多
我们只用了不到 30 行代码就完成了所有这些!
如何进一步推进这个项目
想更深入吗?根据您的兴趣,以下是您可以尝试进一步扩展该项目的一些方法:
- 查看添加到情节代码中的其他参数,以进一步美化图形。
- 将
'Tax Charged'添加到每一天。 - 按月或年,而不是按天来划分你的开销。
- 在亚马逊上下载你的商品订单报告,并对你购买最多或花费最多的商品类别进行分析。(这将需要修改一些现有的代码,因为 Items 报告有更多的列)。
- 想办法把每一天(甚至是没有订单的日子)都放入你的数据集中,这样你就可以更容易地想象你一段时间的花费。
- 你还在哪些网站上购物?看看他们是否允许你访问你的数据。
如果你发现自己喜欢本教程,或者如果你认为这些技能对你的生活或职业有价值,你可能总是想考虑在我们的数据科学途径中学习数据技能。前两门课程完全免费,将涵盖 Python 编程的所有基础知识。
注册一个免费账户 ,你还会每周收到一封电子邮件,里面有学习数据技能和推进职业发展的酷资源。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。


在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
我不能用 Excel 做这个吗?
当然,我们在本教程中所做的很多事情也可以用 Excel 或 Google Sheets 这样的产品来完成。有时,使用电子表格程序是最快最容易的选择。然而,有几个重要的原因可以解释为什么对于像这样的项目来说,能够做一点编程通常比 Excel 要好。
1.编码更强大
你可能知道如何做一些我们在本教程中做过的事情,比如在 Excel 中求一列的和。但是使用代码就可以完成更复杂的分析。
在 spreadhseet 软件中,类似于条件化(ifthis happen,then do that)的事情是可能的,但它很快变得复杂混乱,而在代码中却相对简单。更高级的分析类型,如许多类型的机器学习,在电子表格软件中是完全不可能的。
2.编码对大数据可能更好
在本教程中,我们使用了一个非常小的数据集,这种数据集很容易作为电子表格使用。但是你真正的亚马逊订单历史,或者你的 Fitbit 数据,或者你公司的销售记录,或者你想要处理的任何其他数据都可能会更大。一辆比一辆大很多。
在电子表格软件中,大数据集可能变得难以处理,甚至导致速度变慢和崩溃。毕竟,该软件必须可视化地表示每一个数据点,并跟踪你正在做的所有其他事情。
另一方面,代码一次执行一个操作,并且只显示您特别可视化请求的输出。这使得它能够以更快的速度和更高的稳定性处理大型数据集。
3.编码可以更好地处理多个文件
想象一下,每个月您都必须在 Excel 中获取大量不同的报告,并将它们合并成一个报告进行分析。这是一个 Dataquest 的学生遇到的真正问题,他将每个月试图将几十个不同的 Excel 表格合并成一份分析报告的过程描述为一场痛苦的噩梦。
使用代码来组合和清理多个数据集既简单又快速。通过编程,您可以编写一些代码来自动访问和组合所有文件,而不是打开几十个窗口并将数据一个接一个地复制粘贴到一个主表中。例如,上面提到的 Dataquest 学生将 Excel 中过去需要一周的数据合成和分析任务变成了 Python 中只需几分钟的任务。
只要他还在做那份工作,他在编写代码上的时间投资就会有回报,因为…
4.编码更具可重复性
一旦您编写了从特定数据源导入、清理和分析数据的代码,它将适用于以相同格式输入的任何数据。
例如,如果您想每月对您的 Amazon 数据执行本教程中的分析,您需要做的就是每月下载当月的数据,在第一个代码片段中更改read_csv()正在读取的文件名,然后运行所有的代码单元格,我们刚刚对该数据集进行的所有分析都会自动在您的新数据集上执行。
5.编码更加透明
虽然您可以在电子表格软件中进行复杂的计算,但这些计算通常隐藏在单元格中。如果你得到的是别人的 Excel 文件,这个文件正在做一些复杂的分析,你可能要花很长时间才能弄清楚到底发生了什么。在电子表格中,你可以看到所有的数据,但是对其执行的操作和计算是你通常必须逐个单元格搜索的东西。
代码恰恰相反:大部分数据本身是不可见的,但是对其执行的所有操作和计算都是显而易见的,它们的执行顺序也是如此。当然,你确实需要学习基本的语法来阅读代码,但是一旦你记下了,就很容易一目了然地看到分析中到底发生了什么。
这也使得捕捉错误变得更加容易,比如在某个地方使用了+而不是-,在这种情况下,隐藏在大型电子表格的单个单元格中的错误可能很长时间都不会被注意到。
6.使用代码访问数据更容易
您想要分析的数据并不总是以电子表格的形式出现。许多应用程序和服务只能让你通过 API 访问数据,你需要编码技能才能访问。
或者,您可能希望通过从网站抓取数据来收集自己的数据集,同样,这是您无法使用电子表格软件完成的事情(并且将数据点一个一个地复制粘贴到 Excel 中是非常累人的)。
7.编码更有趣
也许你以前从未想过自己是一名程序员,但是如果你读完了本教程,你已经比大多数人编写和运行了更多的代码。感觉很好,不是吗?
编写代码有时肯定会令人沮丧。但是当你让一切都按计划运行时,这是一种真正令人满意的感觉。通过自动化重复的分析项目,你可以为自己节省的时间是惊人的。
如果你想了解更多,我们的其他 Python 教程是一个很好的资源,我们的交互式数据科学课程可以带你在各种数据和编程技能领域从零到工作就绪。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
初学者如何用 Python 分析调查数据
原文:https://www.dataquest.io/blog/how-to-analyze-survey-data-python-beginner/
October 10, 2019
开展调查和投票是收集数据和深入了解诸如为什么客户会离开我们的网站等问题的最佳方式之一。或为什么选民会被这位候选人吸引?但是分析调查数据可能是一项真正的挑战!
在本教程中,我们将介绍如何使用 Python 分析调查数据。但是不要担心——即使你以前从来没有写过代码,你也能处理好这件事!我们将一步一步来,在本教程结束时,您将看到如何通过几行代码来释放一些令人印象深刻的分析能力!
出于本文的目的,我们将分析 StackOverflow 的 2019 年开发者调查数据,因为这是一个大型的最新调查数据集,并且是公开的和适当匿名的。但是这些技术几乎适用于任何种类的调查数据。
大多数调查数据的格式与我们在这里使用的类似:一个电子表格,其中每行包含一个人的答案,每列包含一个特定问题的所有答案。这是我们数据集的一个片段;你的可能看起来很相似。

现在,让我们开始分析这些数据吧!我们将从几个快速步骤开始,为分析做好准备。
步骤 1:获取 CSV 文件
形式的调查回复
为了使用代码分析我们的调查数据,我们需要以.csv文件的形式获取它。如果你想使用我们正在使用的相同数据集来完成本教程,你可以在这里获取 2019 年 StackOverflow 开发者调查结果数据,它已经准备好了一个 CSV 文件(在.zip文件内)。
如果您想开始处理自己的数据,以下是获取 CSV 格式数据的方法:
- 如果您进行了在线调查,您可以直接从您使用的调查服务下载 CSV。Typeform 和许多其他在线调查工具将允许您下载包含您所有调查回答的 CSV 文件,这使事情变得简单而美好。
- 如果您在调查中使用了谷歌表单,您的数据将以谷歌表单的形式在线提供。在 Google Sheets 界面中,点击
File > Download然后选择Comma-separated values (.csv, current sheet)以 CSV 格式下载您的数据。 - 如果你已经通过其他方式收集了数据,但是你是以电子表格格式保存的,你可以从 Excel 或者其他电子表格程序中保存电子表格为 CSV 文件。在 Excel 中,您需要导航到
File > Save As。在Save as type:字段中,选择CSV (Comma delimited) (*.csv),然后点击保存。在其他电子表格软件中,过程应该非常相似。
在继续之前,您可能希望用电子表格软件打开您的 CSV 文件并查看其格式。如果分析看起来像我们前面看到的代码片段,那么分析将是最简单的:问题在电子表格的第一行,应答者的答案在后面的每一行。例如,如果您的数据在顶部有一些额外的行,最好在继续之前删除这些行,这样数据集中的第一行就是您的调查问题,随后的每一行都是一个受访者的答案。
步骤 2:设置你的编码环境
(如果你已经安装了 Anaconda,并且熟悉 Jupyter 笔记本,可以跳过这一步。)
下一步是建立一个叫做 Jupyter 笔记本的工具。Jupyter 笔记本是一种流行的数据分析工具,因为它们安装快速,使用非常方便。我们已经写了一个深入的 Jupyter 笔记本教程,里面有很多细节,但是我们将在这里讨论你需要设置和运行的内容。
首先,前往蟒蛇网站。稍微向下滚动,选择你电脑的操作系统,然后点击Download进入 Python 3.7 版本。
文件下载完成后,打开它并按照提示将其安装到您的计算机上您选择的位置。如果你不确定你需要什么,默认选项就可以了。
安装完成后,打开 Anaconda Navigator 应用程序。您将能够在您刚刚安装 Anaconda 的任何目录中找到它,或者只需在您的计算机上搜索“Anaconda”。当应用程序打开时,您可能会看到几个屏幕闪烁,然后您会看到:
点击中间选项“Jupyter 笔记本”下“启动”。这将在您的网络浏览器中打开一个新标签。从那里,点击右上角的“新建”,然后在下拉菜单中的“笔记本”下,点击“Python 3”。
转眼间。您已经打开了一个新的 Jupyter 笔记本,我们准备开始编写一些代码!
步骤 3:将我们的调查数据导入 Python
我们编写的前两行代码将允许我们将数据集导入 Python 和我们的 Jupyter 笔记本,这样我们就可以开始使用它了。
我们将首先导入一个名为pandas的 Python 库,并给它起名叫pd,这样我们就可以在代码中轻松地引用它。为此,我们将使用语法import pandas as pd。这段代码告诉 Python 导入熊猫库,然后告诉它当我们使用字母pd时,我们希望它引用那个熊猫库。
Python 库有点像浏览器插件;它们增加了额外的特性和功能,因此我们可以用 Python 做更多的事情。Pandas 是一个非常受欢迎的数据分析库,它将使我们的分析工作更加容易。
使用“昵称”pd并不是强制性的,但这是 pandas 用户中常见的一种习惯,所以习惯使用它将使阅读其他人的代码更容易。
一旦我们导入了熊猫,我们需要读取我们的 CSV 来创建所谓的熊猫数据框架。一个数据框架只是一个数据表,我们可以用熊猫来操作它。一会儿我们将看到数据帧是什么样子,但是要将我们的数据放入 Python 和 pandas,我们需要做两件事:
- 阅读我们下载的 CSV 文件,我们可以使用一个名为
.read_csv()的熊猫函数来完成 - 将 CSV 数据赋给一个变量,以便我们可以轻松地引用它
函数是对输入执行操作的代码。在这种情况下,我们将输入 CSV 文件的文件名,然后.read_csv()函数会自动将该文件解析为 pandas 数据帧。
你可以把 Python 中的变量想象成一本书的标题。书名让查阅书籍变得容易——我们只需说杀死一只知更鸟,人们就会知道我们在谈论什么,所以我们不必背诵整本书。变量的工作方式类似。它们就像一个简短的标题,我们可以用它来引用 Python 到更大的信息(比如我们试图分析的调查数据),而不必重述所有的信息。
但是,我们第一次使用变量时,必须告诉 Python 我们在讨论什么。我们将使用变量名df(data frame 的缩写)来表示我们的调查数据。
因此,我们将用来读取数据集的代码如下所示:df = pd.read_csv('survey_results_public.csv')。下面是这段代码从左到右告诉 Python 的内容:
-
df =告诉 Python 我们正在创建一个名为df的新变量,当你看到df时,请参考以下信息: -
告诉 Python 查看我们之前导入的 pandas 库。
-
.read_csv('survey_results_public.csv')告诉 Python 使用函数.read_csv()读取文件survey_results_public.csv。
请注意,如果您的 CSV 文件与您正在使用的 Jupyter 笔记本不在同一个文件夹中,您需要为数据集指定文件路径。这将根据您保存它的时间而变化,但它可能看起来像这样:df = pd.read_csv('C://Users/Username/Documents/Filename.csv')。
序言说得够多了。让我们运行我们的代码,在 Jupyter 笔记本的第一个单元格中输入这个,然后点击 Run 按钮:
import pandas as pd
df = pd.read_csv('survey_results_public.csv')
但是等等,什么都没发生!那是因为我们实际上没有告诉 Python 给我们任何类型的响应。我们的代码真的有效吗?
为了验证,让我们使用另一个名为.head()的 pandas 方法。这个将向我们展示一个数据帧的前几行。我们可以通过在那些括号之间放一个数字来指定我们想要看到多少行,或者我们可以简单地让它保持原样,它将显示前五行。
不过,我们确实需要告诉.head()要查看什么数据帧,所以我们将使用语法df.head()。df告诉 Python 我们想要查看我们刚刚用 CSV 数据制作的数据帧,.告诉 Python 我们要对该数据帧做些什么,然后head()告诉 Python 我们想要做什么:显示前五行。
df.head()
| 被告 | 枝 | 业余爱好者 | 开放源码 | 开源 | 雇用 | 国家 | 学生 | EdLevel | 大学校长 | … | 欢迎改变 | SONewContent | 年龄 | 性别 | 反式 | 性别 | 种族划分 | 受赡养者 | 测量长度 | 检验简易 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | one | 我是一名正在学习编码的学生 | 是 | 从不 | 开放源码软件和封闭源码软件的质量… | 没有工作,也没有在找工作 | 联合王国 | 不 | 小学/小学 | 圆盘烤饼 | … | 就像我去年一样受欢迎 | 其他开发人员撰写的技术文章;工业… | Fourteen | 男人 | 不 | 异性恋/异性恋 | 圆盘烤饼 | 不 | 长度合适 | 既不容易也不困难 |
| one | Two | 我是一名正在学习编码的学生 | 不 | 每年不到一次 | 开放源码软件和封闭源码软件的质量… | 未就业,正在找工作 | 波斯尼亚和黑塞哥维那 | 是的,全职 | 中学(如美国高中,G… | 圆盘烤饼 | … | 就像我去年一样受欢迎 | 其他开发人员撰写的技术文章;工业… | Nineteen | 男人 | 不 | 异性恋/异性恋 | 圆盘烤饼 | 不 | 长度合适 | 既不容易也不困难 |
| Two | three | 我主要不是一个开发人员,但我写公司… | 是 | 从不 | 开放源码软件和封闭源码软件的质量… | 全职受雇 | 泰国 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 网页开发或网页设计 | … | 就像我去年一样受欢迎 | 你所在地区的技术会议或活动;关于…的课程 | Twenty-eight | 男人 | 不 | 异性恋/异性恋 | 圆盘烤饼 | 是 | 长度合适 | 既不容易也不困难 |
| three | four | 我的职业是开发人员 | 不 | 从不 | 开放源码软件和封闭源码软件的质量… | 全职受雇 | 美国 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 计算机科学、计算机工程或软件工程 | … | 就像我去年一样受欢迎 | 其他开发人员撰写的技术文章;工业… | Twenty-two | 男人 | 不 | 异性恋/异性恋 | 白人或欧洲后裔 | 不 | 长度合适 | 容易的 |
| four | five | 我的职业是开发人员 | 是 | 每月一次或更频繁 | 一般来说,开放源码软件比专业软件质量更高 | 全职受雇 | 乌克兰 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 计算机科学、计算机工程或软件工程 | … | 就像我去年一样受欢迎 | 你所在地区的技术会议或活动;关于…的课程 | Thirty | 男人 | 不 | 异性恋/异性恋 | 白人或欧洲后裔;多民族的 | 不 | 长度合适 | 容易的 |
5 行× 85 列
这是我们的数据框!看起来很像电子表格,对吧?我们可以看到一些答案看起来被截断了,但是不要担心,数据没有丢失,只是没有直观地显示出来。
我们可能还会注意到该数据中其他一些奇怪的事情,比如在一些行中出现了NaN。我们稍后将处理这个问题,但是首先,让我们使用另一个名为.shape的 pandas 特性来更仔细地查看我们的数据集,以给出我们数据集的大小。
df.shape
(88883, 85)
这告诉我们,我们的数据集中有 88,883 行和 85 列。这些数字应该与调查中回答者(行)和问题(列)的数量完全一致。如果是这样,这意味着我们所有的调查数据现在都存储在该数据框架中,并准备好进行分析。
第四步:分析选择题
从这里开始,你如何继续你的分析真的取决于你,有 85 个问题,有吨我们可以用这些数据做不同的事情。但是让我们从简单的问题开始:一个是或否的问题。
(注意:可能很难弄清楚 StackOverflow 数据中某些列名的含义,但是数据集下载附带了一个模式文件,其中包含每个问题的完整文本,因此您可能需要不时地参考该文件,以便将列名与受访者实际看到的问题进行匹配。)
调查中一个比较独特的是或否问题是这样的:“你认为今天出生的人会比他们的父母过得更好吗?”
看看 StackOverflow 的社区对未来有多乐观可能会很有趣!我们可以通过一个叫做value_counts()的便捷的熊猫函数来实现。
value_counts()函数一次查看一列数据,并计算该列包含的每个唯一条目的实例数。(在 pandas 行话中,一个单独的列被称为一个系列,因此您可能会看到这个函数被称为Series.value_counts()。)
要使用它,我们需要做的就是告诉 Python 我们想要查看的特定系列(也称为列),然后告诉它执行.value_counts()。我们可以通过写 dataframe 的名称来指定一个特定的列,后面跟着括号中的列名,就像这样:df['BetterLife']。
(就像我们的列表一样,因为'BetterLife'是一个字符串,而不是一个数字或变量名,我们需要把它放在撇号或引号内,以防止 Python 混淆)。
让我们运行代码,看看我们得到了什么!
df['BetterLife'].value_counts()
Yes 54938
No 31331
Name: BetterLife, dtype: int64
不错!现在我们知道,在我们的数据集中的 88,883 名受访者中,有 54,938 人认为未来是光明的。
不过,如果将它表示为总响应数的百分比,可能会更有帮助。幸运的是,我们可以通过简单地在value_counts()括号内添加一个输入来实现。函数输入在编程中被称为参数,可以用来向函数传递影响其输出内容的信息。
在这种情况下,我们要传递一个类似这样的论点:normalize=True。 pandas 文档对此有一些细节,但长话短说:如果我们不在函数中放入任何东西,value_counts 将假设我们希望normalize是False,因此它将返回每个值的原始计数。
然而,如果我们将normalize设置为True,它将通过将计数表示为我们指定的 pandas 系列中总行数的百分比来“规范化”计数。
df['BetterLife'].value_counts(normalize=True)
Yes 0.636822
No 0.363178
Name: BetterLife, dtype: float64
现在我们可以看到,大约 64%的开发者认为今天出生的孩子生活变得更好,大约 36%的人认为今天的孩子生活质量相似或更差。
让我们在另一个有趣的是/否问题上尝试同样的事情:“你认为你需要成为一名经理来赚更多的钱吗?”许多硅谷公司声称管理并不是获得财务成功的唯一途径,但开发商们买账吗?
df['MgrMoney'].value_counts(normalize=True)
No 0.512550
Yes 0.291528
Not sure 0.195922
Name: MgrMoney, dtype: float64
显然,大多数开发商并不买账。事实上,不到 30%的人认为他们不进入管理层也能赚更多的钱!
我们还可以看到,尽管这是一个是/否问题,StackOverflow 包含了第三个响应选项(“不确定”),我们的代码仍然以同样的方式工作。对任何选择题都有效。
第五步:绘制选择题答案
看数字可能会有启发,但人类是视觉动物。幸运的是,对我们来说,直观地绘制这些问题的答案非常简单!
既然我们是在 Jupyter 笔记本上写代码,我们就从一行 Jupyter 魔术开始:
%matplotlib inline
这段代码不是我们分析的一部分,它只是一个指令,告诉我们的 Jupyter 笔记本在我们正在工作的笔记本中内联显示我们的图表。
一旦我们运行了,我们需要做的就是在代码的末尾添加一小段代码:.plot(kind='bar')。这告诉 Python 获取我们刚刚给它的任何东西,并在条形图中绘制结果。(如果我们愿意,我们可以用'pie'代替'bar',得到一个饼状图)。
让我们尝试一下关于开发者偏好的社交媒体网站的选择题:
df['SocialMedia'].value_counts().plot(kind="bar")
<matplotlib.axes._subplots.AxesSubplot at 0x2142658a9b0>

这已经很酷了,但是我们可以通过向那个.plot()函数添加几个参数来让它看起来更好。具体来说,我们再补充两个:
- 名为
figsize的参数以英寸为单位的宽度和高度的形式定义了图表的大小(即(15,7) - 名为
color的参数定义了条形的颜色。
让我们使用#61D199,Dataquest 的绿色:
df['SocialMedia'].value_counts().plot(kind="bar", figsize=(15,7), color="#61d199")
<matplotlib.axes._subplots.AxesSubplot at 0x214268d4048>

对于这个图表,我们还可以做更多的事情,但是对于我们的目的来说,这已经足够了——我们只是在快速可视化!
步骤 6:分析调查数据子集
当然,我们经常想做得更深入,而不仅仅是打印出我们结果的简单计数!我们可以使用 Python 和 pandas,根据我们设定的几乎任何条件,轻松地选择和分析非常精细的数据子集。
例如,我们之前看到,StackOverflow 用户中有一小部分,但也是相当大的一小部分,根据他们对我们分析的'BetterLife'问题的回答,认为世界会变得更糟。举例来说,这部分用户可能比更乐观的开发者年龄更大还是更小?
我们可以使用所谓的布尔值来对我们的数据进行排序,并只显示对该问题回答“是”或“否”的人的回答。
我们将通过指定我们想要查看的数据帧和系列(即列)来创建我们的布尔值,然后通过使用条件运算符只过滤该系列中满足特定标准的响应。
这一次,让我们先运行代码,然后我们将仔细看看它在做什么:
said_no = df[df['BetterLife'] == 'No']
said_no.head(3)
| 被告 | 枝 | 业余爱好者 | 开放源码 | 开源 | 雇用 | 国家 | 学生 | EdLevel | 大学校长 | … | 欢迎改变 | SONewContent | 年龄 | 性别 | 反式 | 性别 | 种族划分 | 受赡养者 | 测量长度 | 检验简易 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| five | six | 我主要不是一个开发人员,但我写公司… | 是 | 从不 | 开放源码软件和封闭源码软件的质量… | 全职受雇 | 加拿大 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 数学或统计 | … | 就像我去年一样受欢迎 | 其他开发人员撰写的技术文章;工业… | Twenty-eight | 男人 | 不 | 异性恋/异性恋 | 东亚人 | 不 | 太长 | 既不容易也不困难 |
| six | seven | 我的职业是开发人员 | 不 | 从不 | 开放源码软件和封闭源码软件的质量… | 独立承包人,自由职业者,或自… | 乌克兰 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 另一个工程学科(例如土木、电气… | … | 现在比去年更受欢迎 | 圆盘烤饼 | Forty-two | 男人 | 不 | 异性恋/异性恋 | 白人或欧洲后裔 | 是 | 长度合适 | 既不容易也不困难 |
| eight | nine | 我的职业是开发人员 | 是 | 每月一次或更频繁 | 开放源码软件和封闭源码软件的质量… | 全职受雇 | 新西兰 | 不 | 有些学院/大学学习不挣钱… | 计算机科学、计算机工程或软件工程 | … | 就像我去年一样受欢迎 | 圆盘烤饼 | Twenty-three | 男人 | 不 | 两性的 | 白人或欧洲后裔 | 不 | 长度合适 | 既不容易也不困难 |
3 行× 85 列
为了证实这一点,我们可以用.shape检查这个数据集的大小,并使用我们的老朋友.value_counts()比较said_no中的行数和回答“否”的人数。
said_no.shape
(31331, 85)
df['BetterLife'].value_counts()
Yes 54938
No 31331
Name: BetterLife, dtype: int64
我们可以看到我们的新数据框架有 31,331 行,与回答“生活更美好”的人数相同。我们可以通过对这个新数据帧运行一个快速的value_counts()来进一步确认过滤器已经工作:
said_no['BetterLife'].value_counts()
No 31331
Name: BetterLife, dtype: int64
完美。好了,让我们回溯一下,更深入地看看这段代码:
said_no = df[df['BetterLife'] == 'No']
这里发生了什么事?从左至右:
- 告诉 Python 创建一个名为 said_no 的新变量,并使它等于等号右边的值。
df正在告诉 Python 让said_no等价于df数据帧(我们的原始数据集),但是之后…[df['BetterLife'] == 'No']告诉 Python只有包含来自df的行,其中'BetterLife'列中的答案等于'No'。
注意这里的双等号。在 Python 中,当我们想要赋值时,我们使用一个等号,即a = 1。我们使用一个双等号来检查等价性,Python 实际返回的不是True就是False。在这种情况下,我们告诉 Python 只返回那些df['BetterLife'] == 'No'返回True的行。
现在我们有了这个只包含“否”答案的数据框架,让我们为“是”的人做一个等价的数据框架,然后进行一些比较。
said_yes = df[df['BetterLife'] == 'Yes']
现在,让我们看看通过比较这些组和人们如何回答关于他们年龄的问题,我们能确定什么。这个问题的答案是整数,所以我们可以对它们进行数学运算。我们可以做的一个快速检查是,看看在美好生活问题上回答“是”和“不是”的人的平均年龄或中位年龄是否有显著差异。
我们将在这段代码中使用一些新技巧:.mean()和.median()函数,它们将分别自动计算一列数字数据的平均值和中值。我们还将把我们的计算放在一个print()命令中,这样所有的四个数字将被一次打印出来。
print(said_no['Age'].mean(),
said_yes['Age'].mean(),
said_no['Age'].median(),
said_yes['Age'].median()
)
31.85781027611728 29.439848681016347 30.0 28.0
正如我们在这里看到的,悲观主义者倾向于稍微老一点,但不是很明显。观察特定年龄组如何回答这个问题以及答案是否不同可能会很有趣。例如,如果悲观主义者的年龄稍大,我们会看到 50 岁以上和 25 岁以下的开发者的答案有显著差异吗?
我们可以使用我们一直在使用的相同的布尔技巧来找出答案,但是我们将使用>=和<=而不是使用==来检查我们的条件,因为我们想要过滤'Age'为 50 及以上或 25 及以下的回答者。
over50 = df[df['Age'] >= 50]
under25 = df[df['Age'] < = 25]
print(over50['BetterLife'].value_counts(normalize=True))
print(under25['BetterLife'].value_counts(normalize=True))
No 0.514675
Yes 0.485325
Name: BetterLife, dtype: float64
Yes 0.704308
No 0.295692
Name: BetterLife, dtype: float64
有意思!看起来年龄最大的发展中国家真的很悲观,略多于一半的人说今天出生的孩子不会比他们的父母过得更好。另一方面,年轻的开发者似乎比一般人更乐观。
然而,检查我们在这里处理的样本实际上有多大是值得的。我们可以使用len()函数快速完成这项工作,它将计算一个列表中的项目数或一个数据帧中的行数。
print(len(over50))
print(len(under25))
3406
26294
与总数据相比,这两个组都不算大,但都足够大,这可能代表了真正的分裂。
步骤 7:过滤更具体的子集
到目前为止,我们一直在使用布尔一次一个地过滤我们的数据,以查看以特定方式回答特定问题的人。但是我们实际上可以把布尔链在一起,非常快速地过滤到一个非常精细的级别。
为此,我们将使用几个熊猫布尔运算符、&和&~。
正如我们所料,&允许我们将两个布尔值串在一起,并且仅当两个条件都为真时才返回True。因此,在我们的上下文中,如果我们通过过滤原始数据帧中的行来创建新的数据帧,在两个布尔之间使用&将允许我们只添加满足和两个条件的行。
我们可以认为&~的意思是“而不是”如果我们在两个布尔值之间使用&~,那么只有当第一个布尔值为True而第二个为False时,它才会返回一行。
就语法而言,使用单个布尔值的唯一变化是,当我们将多个布尔值串在一起时,我们需要将每个布尔值括在括号中,因此基本格式如下:df[(Boolean 1) & (Boolean 2)]
让我们通过筛选生活在印度、对“更美好的生活”问题回答“是”的人来尝试一下:
filtered_1 = df[(df['BetterLife'] == 'Yes') & (df['Country'] == 'India')]
通过快速检查我们筛选出的答案的值计数,我们可以确认这正如预期的那样起作用:
print(filtered_1['BetterLife'].value_counts())
print(filtered_1['Country'].value_counts())
Yes 6136
Name: BetterLife, dtype: int64
India 6136
Name: Country, dtype: int64
如我们所见,我们的新数据框架filtered_1,只包含对未来给出乐观答案的印度人。
刚才我们合并了两个布尔。但是我们可以串在一起的数量是没有限制的,所以让我们尝试一个更复杂的深入研究。我们将只筛选符合以下条件的人:
- 对“更好的生活”这个问题回答“是”
- 超过 50 岁
- 住在印度
- 不要把编程当成一种爱好
- 至少偶尔为开源项目做点贡献
我们开始吧:
filtered = df[(df['BetterLife'] == 'Yes') & (df['Age'] >= 50) & (df['Country'] == 'India') &~ (df['Hobbyist'] == "Yes") &~ (df['OpenSourcer'] == "Never")]
filtered
| 被告 | 枝 | 业余爱好者 | 开放源码 | 开源 | 雇用 | 国家 | 学生 | EdLevel | 大学校长 | … | 欢迎改变 | SONewContent | 年龄 | 性别 | 反式 | 性别 | 种族划分 | 受赡养者 | 测量长度 | 检验简易 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two thousand two hundred and one | Two thousand two hundred and nine | 我主要不是一个开发人员,但我写公司… | 不 | 每月少于一次,但每…超过一次 | 开放源码软件和封闭源码软件的质量… | 独立承包人,自由职业者,或自… | 印度 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 另一个工程学科(例如土木、电气… | … | 现在比去年更受欢迎 | 圆盘烤饼 | Fifty-five | 男人 | 不 | 异性恋/异性恋 | 黑人或非洲后裔;东亚;西班牙语… | 是 | 太长 | 既不容易也不困难 |
| Eighteen thousand four hundred and one | Eighteen thousand five hundred and four | 我主要不是一个开发人员,但我写公司… | 不 | 每年不到一次 | 开放源码软件和封闭源码软件的质量… | 独立承包人,自由职业者,或自… | 印度 | 不 | 其他博士学位(哲学博士、教育学博士等。) | 商业纪律(例如会计、金融… | … | 就像我去年一样受欢迎 | 其他开发人员撰写的技术文章;工业… | Fifty-five | 男人 | 不 | 异性恋/异性恋 | 南亚人 | 是 | 太长 | 容易的 |
| Fifty-two thousand three hundred and fifty-nine | Fifty-two thousand six hundred and ninety-five | 我的职业是开发人员 | 不 | 每年不到一次 | 开放源码软件和封闭源码软件的质量… | 全职受雇 | 印度 | 不 | 学士学位(文学学士、理学学士、工程学士等)) | 商业纪律(例如会计、金融… | … | 现在比去年更受欢迎 | 其他开发人员撰写的技术文章 | Fifty-three | 男人 | 不 | 异性恋/异性恋 | 圆盘烤饼 | 是 | 长度合适 | 既不容易也不困难 |
| Sixty-four thousand four hundred and sixty-four | Sixty-four thousand eight hundred and seventy-seven | 我以前的职业是开发人员,但是没有… | 不 | 每月一次或更频繁 | 一般来说,开放源码软件比专业软件质量更高 | 未就业,正在找工作 | 印度 | 是的,全职 | 硕士学位(硕士、硕士、工程硕士、工商管理硕士等)) | 计算机科学、计算机工程或软件工程 | … | 就像我去年一样受欢迎 | 你感兴趣的技术课程 | Ninety-five | 男人 | 不 | 异性恋/异性恋 | 圆盘烤饼 | 不 | 太长 | 既不容易也不困难 |
| Seventy-five thousand three hundred and eighty-two | Seventy-five thousand eight hundred and fifty-six | 我的职业是开发人员 | 不 | 每年不到一次 | 一般来说,开放源码软件的质量低于正版… | 全职受雇 | 印度 | 是的,全职 | 学士学位(文学学士、理学学士、工程学士等)) | 计算机科学、计算机工程或软件工程 | … | 现在比去年不受欢迎多了 | 其他开发人员撰写的技术文章;工业… | Ninety-eight | 男人 | 不 | 两性的 | 南亚人 | 是 | 长度合适 | 既不容易也不困难 |
5 行× 85 列
现在我们已经开始看到使用编程来分析调查数据的真正力量了!从超过 88,000 个回复的初始数据集中,我们找到了一个仅由五个人组成的非常特定的受众!
使用电子表格软件试图快速筛选出这样一个特定的受众是相当具有挑战性的,但是在这里我们用一行代码构建并运行了过滤器。
步骤 8:分析多答案调查问题
在分析调查数据的背景下,我们可能需要做的另一件事是处理多答案问题。例如,在这项调查中,被调查者被问及他们使用什么编程语言,并被要求尽可能多地选择合适的答案。
不同的调查可能会以不同的方式处理这些问题的答案。有时,每个答案可能在一个单独的列中,或者一个回答者的所有答案可以存储在一个单独的列中,每个答案之间有某种分隔符。因此,我们的第一项任务是查看相关的栏目,看看在这个特定的调查中是如何记录答案的。
df["LanguageWorkedWith"].head()
0 HTML/CSS;Java;JavaScript;Python
1 C++;HTML/CSS;Python
2 HTML/CSS
3 C;C++;C#;Python;SQL
4 C++;HTML/CSS;Java;JavaScript;Python;SQL;VBA
Name: LanguageWorkedWith, dtype: object
在本次调查中,我们可以看到受访者的答案存储在一个单独的列中,使用;作为分隔符。
因为我们在本教程中使用 Python,所以让我们开始分析这个调查数据,看看有多少开发人员在使用 Python。
一种方法是查看该列中有多少行包含字符串Python。Pandas 有一个内置的方法来做这件事,这个系列叫做Series.str.contains。这将查看序列中的每一行(在本例中是我们的LanguageWorkedWith列),并确定它是否包含我们作为参数给它的任何字符串。如果该行包含该字符串参数,它将返回True,否则将返回False。
知道了这一点,我们可以很快计算出有多少回答者在他们的回答中使用了 Python 语言。我们将告诉 Python 我们想要查看的系列(df["LanguageWorkedWith"]),然后使用带有参数Python的str.contains()。这将给我们一个布尔序列,从那里我们所要做的就是使用value_counts()计算“真”响应的数量。
同样,我们可以使用参数normalize=True以百分比的形式查看结果,而不是查看原始计数。
python_bool = df["LanguageWorkedWith"].str.contains('Python')
python_bool.value_counts(normalize=True)
False 0.583837
True 0.416163
Name: LanguageWorkedWith, dtype: float64
这是得到我们答案的一种快速而肮脏的方式(几乎 42%的所有开发者使用 Python!).但通常,我们可能希望能够分解本专栏中的答案,以便进行更深入的分析。
比方说,我们想知道每种语言被提及的频率。要使用上面的代码做到这一点,我们需要知道每一个可能的响应,然后我们需要对每一个潜在的答案运行类似上面的代码。
在某些情况下,这可能是可行的,但如果有大量的潜在答案(例如,如果允许回答者选择“其他”选项并填写他们自己的选择),这种方法可能不可行。相反,我们需要使用之前找到的分隔符来分隔每个单独的答案。
正如我们使用Series.str.contains来查看 pandas 系列中的字符串是否包含子串一样,我们可以使用Series.string.split根据作为参数传递给该函数的分隔符来拆分系列中的每一行。在这种情况下,我们知道分隔符是;,所以我们可以使用.str.split(';')。
我们还将向str.split()添加一个额外的参数expand=True。这将从我们的系列中创建一个新的数据框架,使每种语言成为自己的列(每行仍然代表一个应答者)。你可以在这里阅读更多关于这是如何运作的。
让我们运行'LanguageWorkedWith'列上的代码,并将结果存储为名为lang_lists的新熊猫系列。
lang_lists = df["LanguageWorkedWith"].str.split(';', expand=True)
lang_lists.head()
| Zero | one | Two | three | four | five | six | seven | eight | nine | … | Eighteen | Nineteen | Twenty | Twenty-one | Twenty-two | Twenty-three | Twenty-four | Twenty-five | Twenty-six | Twenty-seven | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero | HTML/CSS | Java 语言(一种计算机语言,尤用于创建网站) | Java Script 语言 | 计算机编程语言 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | … | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 |
| one | C++ | HTML/CSS | 计算机编程语言 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | … | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 |
| Two | HTML/CSS | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | … | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 |
| three | C | C++ | C# | 计算机编程语言 | 结构化查询语言 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | … | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 |
| four | C++ | HTML/CSS | Java 语言(一种计算机语言,尤用于创建网站) | Java Script 语言 | 计算机编程语言 | 结构化查询语言 | VBA | 没有人 | 没有人 | 没有人 | … | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 | 没有人 |
5 行× 28 列
正如我们所看到的,我们的字符串分裂成功了。现在,我们系列中的每一行都是新数据框中的一行,每种语言都从其他语言中分离出来,成为唯一的列。
但是我们想知道每种语言被提及的次数,我们还没有完成。在这里帮不了我们——我们只能在熊猫系列上使用它,而不能在数据帧上使用。
为了能够看到每种语言被提及的总次数,我们需要做更多的工作。有很多方法可以解决这个问题,但这里有一个:
-
使用
df.stack()来堆叠该数据帧,将每一列切片,然后将它们堆叠在彼此之上,以便数据帧中的每个数据点出现在单个熊猫系列中。 -
在这个新的“堆叠”系列中使用
value_counts()来获得每种语言被提及的总次数。
这有点复杂,所以让我们先用一个简单的例子来试一下,这样我们可以直观地观察发生了什么。我们将从一个非常类似于lang_lists的数据帧开始,只是短了很多,以便更容易理解。
这是我们的数据框架(因为这不是我们真实数据集的一部分,你可能不想尝试用这一点来编码,只需阅读本页上的代码,并尝试跟踪正在发生的事情):
new_df
| Zero | one | Two | three | |
|---|---|---|---|---|
| Zero | 计算机编程语言 | java 描述语言 | 结构化查询语言 | 圆盘烤饼 |
| one | HTML/CSS | java 描述语言 | Java 语言(一种计算机语言,尤用于创建网站) | C# |
| Two | 稀有 | 计算机编程语言 | 圆盘烤饼 | 圆盘烤饼 |
首先,我们将使用.stack()来分割这个数据帧,并将各列堆叠在一起。请注意,当这种情况发生时,插入到上述数据帧中的空值将被自动删除。
new_df.stack()
0 0 Python
1 Javascript
2 SQL
1 0 HTML/CSS
1 Javascript
2 Java
3 C#
2 0 R
1 Python
dtype: object
这是这里发生的事情的动画视图:

既然我们已经将每个答案都堆叠到一个序列中,我们可以使用value_counts()来计算总数:
new_df.stack().value_counts()
Javascript 2
Python 2
Java 1
C# 1
SQL 1
HTML/CSS 1
R 1
dtype: int64
这就是我们需要的原始数据!注意,这里我们不能使用normalize=True来获得基于百分比的读数,因为计算是基于序列的长度,这个序列有九个行,而我们的原始数据集只有三个响应。
现在我们知道如何做到这一点,不过,让我们使用我们已经创建的lang_lists系列在我们的真实数据集上尝试同样的事情。
lang_lists.stack().value_counts()
JavaScript 59219
HTML/CSS 55466
SQL 47544
Python 36443
Java 35917
Bash/Shell/PowerShell 31991
C# 27097
PHP 23030
C++ 20524
TypeScript 18523
C 18017
Other(s): 7920
Ruby 7331
Go 7201
Assembly 5833
Swift 5744
Kotlin 5620
R 5048
VBA 4781
Objective-C 4191
Scala 3309
Rust 2794
Dart 1683
Elixir 1260
Clojure 1254
WebAssembly 1015
F# 973
Erlang 777
dtype: int64
这正是我们要找的信息!现在,让我们对我们的分析项目做一个最后的润色,通过可视化地绘制这些信息,使用我们之前使用的相同的绘图方法。
lang_df.stack().value_counts().plot(kind='bar', figsize=(15,7), color="#61d199")
<matplotlib.axes._subplots.AxesSubplot at 0x2144192ea20>

厉害!
分析调查数据:后续步骤
在本教程中,我们介绍了使用 Python 分析测量数据的一些基本方法。虽然这是一个很长的阅读,如果你回头看,你会发现我们实际上只使用了几行代码。一旦你掌握了它,做这种分析实际上是非常快的!
当然,我们只是触及了表面。您可以做的事情还有很多很多,尤其是对于这么大的数据集。如果你在寻找挑战,这里有一些你可以尝试回答的问题。
- 如果你根据我们的统计除以总调查受访者(88,883)算出百分比,你会注意到它们与 StackOverflow 报告的数字并不完全相同。这是因为有一小部分受访者没有回答语言问题。你如何找到并计算这些回答者,以找到列出每种语言的回答者的确切百分比?
- 上面的结果给了我们所有被调查的开发人员中最流行的语言,但是这个调查中的一个不同的问题确定了不同类型的角色,包括数据科学家、数据分析师等。您能创建一个图表来显示数据专业人员中最流行的语言吗?
想更深入地了解这类事情吗?在我们的互动数据科学课程中开始学习 Python 和 pandas。
这个教程有帮助吗?
选择你的道路,不断学习有价值的数据技能。
在我们的免费教程中练习 Python 编程技能。
通过我们的交互式浏览器数据科学课程,投入到 Python、R、SQL 等语言的学习中。
如何成为一名伟大的数据科学家
原文:https://www.dataquest.io/blog/how-to-be-a-great-data-scientist/
June 20, 2019
你花了时间学习技能,你用正确的方法申请工作,现在你找到了一份数据科学方面的工作。太好了!但是现在你已经得到了那份工作,你如何保持它并且做得更好呢?你如何证明自己作为一名伟大的数据科学家的价值?
这个问题并不总是像听起来那么简单。拥有技能是关键,但一名成功的数据科学家还需要知道如何应用这些技能来产生有意义的商业影响——证明数据科学家获得的高薪是合理的。
你的分析必须是好的。但更重要的是,它必须支撑你公司的底线。
在较大的公司,做到这一点通常非常简单。大公司可能有既定的数据科学流程和适合你的团队,有明确定义的目标,管理层知道这些目标将为他们的数据科学投资带来回报。
但在较小的公司,这可能要困难得多。你可能是公司的第一个数据科学雇员,对于你的角色将如何帮助公司取得成功可能没有清晰的愿景。你的任务可能是“寻找机会”,然后任其自生自灭。
这种自由可能是一种祝福,但如果你不确定你能在哪里产生影响,它也可能是一种诅咒。当它与进入新公司的新角色时经常出现的“冒名顶替综合症”结合在一起时,真的很难处理。
但是不要绝望,你可以做到的!作为一名伟大的数据科学家,有许多的方法来证明你对公司的价值。以下是其中的一些。
让自己融入商业团队
如果你是公司里唯一的“数据人”,不要成为孤岛!你的第一步应该是花些时间与核心业务团队(销售、营销、产品等)密切合作。)来了解他们最优先考虑的是什么,哪些数据对他们最重要,以及您能够提供哪些信息来帮助他们。
在这个早期阶段,保持开放和灵活非常重要。“我建议的第一件事是放弃任务驱动的思维模式,”丹尼尔·贾德扎克说,他是 Netguru 的高级开发人员。“这是一个充满发现的过程,在早期阶段,行业并不真正知道如何从机器学习中受益。这意味着你必须准备好提出解决方案,快速重复想法,并保持灵活性。”当你融入团队时,尝试一下吧!
很有可能仅仅是嵌入一个商业团队就能给你带来一些机会。它也可能会产生一些来自团队成员的请求。记下所有的事情,但是记住要分清轻重缓急。在小公司,数据科学工作会有大量的机会,所以关键是找到那些可以产生最大影响的机会,并首先关注这些机会。
哪些项目可能影响最大?这取决于你在调查你的公司如何决策时发现了什么。
注意决策
当你与不同的团队合作时,你也应该密切关注公司的重要决策是如何、何时以及由谁做出的。首席执行官确定营销战略吗?战略是来自营销总监吗?策略每个月都有评估吗?每个季度?
您还需要考虑哪些类型的数据会影响这些决策,哪些其他数据可能是相关的,以及如何衡量成功和失败。
知道这些问题的答案将使你更容易影响公司,因为你可以将精力集中在为关键决策提供信息的数据项目上。例如,建立一个营销仪表板来帮助团队执行他们当前的战略,可能不如使用预测分析来展示不同的战略如何产生更好的结果有影响力。
找到你可以收集的有价值的数据
这可能有点老生常谈,但这也是事实:你的分析只和你的数据一样好。
“如果一家公司无法获得良好的大型数据集,那么无论他们应用的机器学习算法有多复杂,他们的模型和从这些模型中得出的有趣研究都只会和他们的数据集一样好,”数据科学家 Indra Ikauniece 说。
“数据科学中的许多创新来自于将现有方法应用于新类型的数据,而不是发明新的机器学习模型。”
如果你在一家小公司从事数据方面的工作,那么很有可能会有机会——很有可能是大量的机会——来收集数据,而没有人利用这些机会。在公司层面上,其他团队成员可能缺乏收集和正确存储数据以供分析所需的技能或时间,并且可能还有您的公司没有注意到的有价值的行业数据。
你在业务团队中的嵌入应该能让你很好地了解公司已经拥有哪些数据,以及这些数据是如何被使用的,所以下一步是问这样的问题:
- 我们没有收集哪些客户数据?
- 我们没有收集哪些公司数据?
- 我们没有收集哪些行业数据?
- 我们正在收集但没有使用哪些数据?
同样,在一家小公司,你是一个小型数据团队的一员,或者可能是工资单上唯一的数据分析师或数据科学家,这些问题可能有许多答案,所以你的挑战是确定优先顺序。
这就是为什么嵌入业务团队如此有用,为什么这是一个很好的第一步——一旦你做到了这一点,你应该对最重要的优先事项有一个很好的想法,这应该有助于你决定首先关注哪种数据。
了解客户行为
几乎任何一家公司都值得你花时间进行数据收集和分析的一个特定领域是客户行为。
很可能你的公司正在收集一些关于客户做什么以及他们如何与你的公司和产品互动的数据。在小公司,这些数据也很有可能未被充分利用,并且可能包含有价值的见解。
探索和实验是这里的关键,因为在这些数据中可能有公司里没有人想到去寻找的洞见。你的目标应该只是挖掘数据,试图了解更多关于客户如何与你的公司及其产品互动。
在你查看数据之前,不要太相信关于客户做什么或为什么做的假设。在公司被认为是“常识”的东西仍然可能是错误的,而且它比你想象的更容易出错。
分析竞争对手
特别是在小公司,可能没有人花太多时间考虑竞争。当有很多工作要做,而很少人去做的时候,人们倾向于关注内部执行。他们可能根本没有考虑竞争对手。
这是一个潜在的“盲点”,作为一名数据科学家,您应该留意这一点。您不太可能从任何竞争对手那里获得内部指标,但可能会有公共数据、行业数据、社交媒体数据等。你仍然可以得到。从这些数据中,你也许能够识别出适合你自己公司复制的策略,你公司可以利用的竞争对手的弱点,或者其他机会。
即使你没有发现任何东西,深入挖掘外部行业和竞争对手的数据也会让你更全面地了解你的公司在其业务领域的背景,从长远来看,这可能会让你成为一名更有效的数据科学家。
注意问题
当您与公司的业务团队密切合作时,您可能会听到每个团队面临的问题。数据科学家增加价值的一个关键方法是识别问题的原因,以便解决问题。
当您探索数据时,也很有可能会发现没有人意识到的问题,或者您的模型会预测团队没有预见到的未来问题。这些也是增加价值的好方法,假设你有说服管理层解决问题的沟通技巧。
鼓励数据驱动的文化
如果你在一个小型的数据团队中,你的角色之一很可能是你公司中其他人的事实上的数据教育者。您可以通过向他们展示如何利用数据做出决策来帮助他们的团队来增加价值。您还可以帮助他们建立定期的数据报告和分析系统,这样他们就可以自己使用数据,而不必依赖您。
你能做的一件特别重要的事情是帮助将公司目标转化为可以用数据可靠测量的指标。你可能比公司里的任何人都更了解哪些数据是实际可用的,以及如何对这些数据进行有意义的分析,所以你通常是最有资格接受广泛的指导,将它们转化为可衡量的指标,然后衡量它们并预测未来绩效的人。
继续发展你的技能
最后,不要固步自封!数据科学是一个快速变化的领域。如果你想让你的公司保持在最前沿(并在时机到来时为下一份工作做好准备),你需要保持你的技能敏锐。您需要与数据科学社区保持联系,了解可能有助于您工作表现的新研究和新工具。
在 Dataquest,我们有一个庞大且快速增长的交互式在线数据科学课程目录,可以帮助你通过(例如)学习 Python 之外的一些 R,或在简历中添加一些数据工程专业知识来增加你的技能。
我们还有一份每周简讯,让您了解数据科学的最新动态。注册一个免费账户获得一份。
您还应该通过参与社交媒体讨论、参加会议和聚会等方式与更广泛的数据科学社区保持联系。当然,当您发现自己感兴趣的项目或希望获得更多实践的技能时,您应该在业余时间一直从事并分享数据科学项目。
(注意:如果管理层对你的需求没有太多的指导,本文旨在帮助你作为一名数据科学家找到有价值的工作。你可能还会遇到沟通和办公室政治方面的问题,我们在另一篇文章中为这些问题提供了解决方案。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何通过 5 个步骤成为商业分析师(2022 年)
原文:https://www.dataquest.io/blog/how-to-become-a-business-analyst-in-5-steps-in-2022/
July 1, 2022
对商业分析师的需求正在稳步增长。这是你开始在这个领域工作所需要知道的。
商业分析师是目前世界上最受欢迎的专家之一,对他们的需求只会越来越多。在本文发表前的一年里,LinkedIn 上随时都有大约 20 万个商业分析师职位空缺。
那么为什么数据科学这个专业这么热门呢?如今,每个企业都积累了大量的数据,他们需要人们帮助他们分析这些数据,并提取有意义的见解。我们拥有的数据越多,对业务分析师的需求就越高。。。而且我们有大量的数据!
现在是开始商业分析职业生涯的最佳时机。如果你想知道如何成为一名商业分析师,那么你来对地方了。我们已经列出了五个最重要的步骤,不管你的技能水平如何,这些步骤将带你从一个完全的新手成为一个专业的商业分析师。
他们来了。。。
第一步:确定商业分析是否是你的正确选择
就像进入任何其他新领域一样,第一个合乎逻辑的步骤是收集足够的信息,看看这个角色是否适合你——以及你是否真的喜欢它。
你可以从问自己以下问题开始:
- 什么是业务分析师,他们做什么?
- 业务分析师和数据分析师的区别是什么?
- 这个角色会给我带来什么样的职业机会?
- 要成为一名业务分析师,我应该发展哪些技术和软技能?
- 我能期望多少薪水?
- 成为一名商业分析师需要多长时间?
用一点谷歌和 YouTube 搜索,你会发现大量有用的资源,形成对商业分析新职业的初步看法。
这里有一些提示:
- 从在国际商业分析研究所网站上阅读商业分析开始。这将有助于你从国际公认的专业机构获取信息。
- 在 YouTube 上搜索关键词,如“商业分析的利弊”或“商业分析师的一天”。这将为你提供那些经历过成为商业分析师过程的人的观点。
- 阅读博客或观看视频,了解业务分析师、数据分析师和数据科学家之间的差异,这将有助于你识别这些角色之间的相似之处和不同之处,并有助于你的决策。
然而,不要花几个月的时间去挖掘所有的细节。在这个阶段,你的目标只是了解这个角色需要什么,它与其他角色有什么不同,以及利弊,你将如何度过你的一天,以及你是否喜欢这份工作。
你决定了商业分析师的工作是否吸引你吗?如果是,那么我们就进入下一步。
第二步:确定你有什么技能,你需要什么技能
开始业务分析师职业生涯的第二步是确定该职位所需的技能——有些是必不可少的,有些可以在工作中学习。业务分析师角色的核心目标是识别业务需求和问题,分析您的发现,并提供建议。如果您是 IT 业务分析师、管理顾问、需求分析师或流程分析师,您将处理的问题类型会有所不同,但您的核心职能是相同的。
如果你没有下面列出的所有技能,也不要担心;雇主们知道,初级专家会随着他们的进步而学习。然而,你知道的越多,你得到你想要的特定职位的机会就越大。
商业分析师软技能:
- 积极的倾听技巧
- 时间管理和组织技能
- 人际关系技巧
- 解决问题
- 分析和批判性思维
- 通讯技能
- 谈判技巧
- 小组管理
商业分析师硬技能:
- 识别问题和机会的研究技能
- 项目管理
- 数据分析技能
- 使用 SQL 处理数据库
- 用 Excel 管理数据
- 使用 Power BI 传达见解
第三步:开始一个能让你获得正确技能的学习计划
此时,您已经决定成为一名业务分析师,并且您已经确定了您应该掌握(或温习)的技能。现在,是时候选择一个好的学习计划了。
你可以在网上找到很多关于商业分析的课程,但选择正确的课程并不容易。如果你真的想在没有任何知识或经验的情况下进入这个行业,你需要关注的首要技能是分析硬数据,以便找到有助于组织改善业务的数据模式。
以下是我们建议你在学习计划中寻找的内容:
- 涵盖基本业务分析师技能和工具的综合课程
- 一个可以让你从零经验到工作就绪的计划
- 练习新技能的实践练习和项目
- 一个由学习者和专业人士组成的支持社区
就我个人而言,我选择了在 Dataquest 的商业分析师职业道路,以及其他道路,因为它不仅符合上述所有条件,而且价格实惠。我发现这条道路非常全面、全面、实用,而且设计完美,可以让我在商业分析领域从“零到英雄”。课程完全在线,自定进度,涵盖了我们之前讨论过的所有技术技能,并提供了大量基于真实数据的练习和项目组合。
第四步:建立一个文件夹,向雇主展示你的技能
向雇主展示你技能的最好方式是创建一个项目组合。一个完成的项目向雇主展示你实际上可以解决真正的问题。
如果你想在某个特定的行业工作,我建议你创建与该领域相关的项目。然而,如果你不确定你想在哪个部门工作,创建解决不同商业问题的项目——这将显示出你的适应能力。此外,我强烈建议您演示不同分析工具的使用,如 Excel、SQL、Microsoft Power BI 或 Tableau。在项目中使用数据可视化很重要,因为这是你向同事展示的方式。
你的作品集也是展示你软技能的好方法。投资组合不仅展示了你解决业务问题的能力,还展示了你对业务数据的好奇心、独立工作或团队工作的准备程度以及你的分析思维。
加分提示: 不要只在简历上声称自己有良好的沟通能力。相反,通过有效地陈述目标并解释你在投资组合项目中的发现,将这种超能力付诸实践。使用清晰的语言,避免技术术语。而且要简洁!
第五步:获得认证,制作简历,开始申请
让我们假设你完成了学习计划并建立了一个文件夹。下一步是什么?获得特定工具的认证是个好主意,比如微软 Power BI 的 PL-300 认证。这突出了你的技能,也表明你愿意付出额外的努力来得到这份工作。在 Dataquest,如果您完成了业务分析师课程,我们将为您的 PL-300 认证提供 50%的折扣。
现在是时候写一份令人印象深刻的简历,并开始申请商业分析师的职位空缺了。
首先,制作一份长长的多页简历,其中包括你所有的技术和软技能、项目、课程、工作经验(如果看起来与商业分析无关也可以)、教育、成就、实习、出版物、证书、志愿活动等。
无论何时你申请一份新的商业分析师的工作,只要复制你简历的大版本,然后为这个特殊的职位量身定做。特别注意职位描述中使用的关键词,把简历合并到只有一页。
不要因为不可避免的拒绝而气馁,这只不过是求职过程中很自然的一部分。保持乐观,不断申请工作——这是最可靠的成功之道!
开始你的学习之旅
总之,我们讨论了一个有抱负的业务分析师的职业路线图的五个步骤。现在你知道了以下内容:
- 在决定这个领域是否适合你之前,你应该问自己(和谷歌)什么问题
- 如何学习商业分析,
- 发展什么样的技能以及如何向潜在雇主展示这些技能
- 如何获得商业分析师的第一份工作?
如果你觉得你已经为这个激动人心的旅程做好了准备,今天就开始学习吧!
2022 年如何成为数据分析师(循序渐进)
原文:https://www.dataquest.io/blog/how-to-become-a-data-analyst/
November 14, 2022
由于数据是商业智能的一个重要方面,数据分析师非常受欢迎,而且这一趋势还在不断增长!这份工作对许多类型的项目都很关键,比如分析市场趋势或为政治投票收集数据。
如果你想学习成为一名数据分析师,你来对地方了。我们为你制定了 5 个步骤来开始你的旅程。
第一步:知道什么适合你
数据行业分为几个学科。例如,无论是数据科学还是数据分析,每一项都有自己的特点,但它们有时会重叠。此外,有时同一领域的专业人员会使用不同的编程语言。
虽然这听起来令人困惑,但我们在这里为你分解它。毕竟,我们希望你知道自己最适合哪个领域,这样你就不会浪费时间或精力。
确保数据分析适合您
如果你已经开始研究数据,你会知道理解数据分析师角色和其他数据相关工作之间的区别可能会有点混乱。我们有一些资源绝对可以帮助澄清事情:
- 文章:数据工程师、数据分析师、数据科学家——有什么区别?
- 文章:商业分析师 vs .数据分析师:哪个适合你?(2022)
- 圆桌视频:了解不同的数据角色
- 视频:如何开始你的数据职业生涯:找到你的角色,学习技能,建立投资组合
最后,如果你对数据科学家职业更感兴趣,这里有一些帮助你成为数据科学家的提示。或者,如果数据分析师职业似乎对你更有意义,请继续阅读——我们已经涵盖了你。
选择正确的编程语言:Python 与 R
在选择想要学习的编程语言之前,先熟悉一下数据分析师的关键技能:
Python 和 R 是数据分析师使用的两种编程语言,它们产生相同的最终结果,尽管方式不同。R 的功能性更强,Python 的面向对象性更强。最后,两个程序对每项任务的工作量要求差不多,所以学习一个程序比学习另一个程序节省不了多少时间。下面的参考资料可以帮助您更好地理解 Python 和 r。
第二步:学习基础知识
作为一名数据分析师,你将成为发现数字背后隐藏意义的关键人物。例如,您将调查为什么客户更喜欢一种产品。你甚至可以发现哪些类型的消费者购买了某些产品,将看似随机的数据点联系起来,以创建一个清晰的购买行为模式。
从哪里开始
这里有几个你可以学习成为数据分析师的地方:
- Dataquest — Dataquest 的产生是因为学习 Python 没有简单的方法。除了提供成为数据分析师所需的所有课程之外,Dataquest 还提供涵盖基础知识的基本 Python 课程。
- Humble Bundle —如果你不熟悉 Humble Bundle,它是一个在线视频游戏店面,出售视频游戏、书籍和软件。该网站总是提供至少一个 Python 或以数据为中心的包。现在,由麻省理工学院出版社出版的基本知识计算机和技术包包括 24 本关于数据科学、深度学习、人工智能机器学习等的书籍。
- YouTube——专注于数据的 YouTube 用户数量惊人,他们在数据行业工作,为新人提供有见地的知识。无论你是想更多地了解某个领域,还是想通过创建自己的视频课程来自学,YouTube 都不缺乏选择。
步骤 3:构建项目
在我大学的政治学数据课程中,理论课是典型的场景,材料非常技术性,很多都超出了我的理解范围。然而,在实践课上,我们使用数据库,它保存了从一个人的年龄到他们的政治倾向到他们的收入的所有信息——这更有趣也更有效。
通过实践练习和项目运用你在整个课程中学到的技能是让他们坚持下去的最好方法。实践是一种久经考验的方法,可以学习如何解决复杂的任务,并确保你在工作中能够处理它们。
你可以在 Dataquest 上开始两个数据分析师路径中的一个,这将挑战你 20 多个项目,例如为彩票成瘾构建一个移动应用程序,用朴素贝叶斯构建一个垃圾邮件过滤器,甚至是在 Jeopardy 中获胜的策略。
寻找你感兴趣的项目
当你在学习成为一名数据分析师时,你可以在业余时间做其他你感兴趣的项目。我发现为自己做点什么来满足我的好奇心是一个巨大的激励工具。
项目表明你有主动性,这是雇主非常看重的一种美德。此外,它将帮助你确定你有多喜欢这个领域。如果你发现自己为了“乐趣”而从事个人数据项目,那么你来对地方了。
当涉及到个人项目时,你可以做任何你感兴趣的事情。只要你有数据,你的想象力就是唯一的限制。
从别处寻找灵感
你也可以从书籍或其他媒体中找到项目的灵感。例如,梁锦松的,就是一个利用数据做有趣事情的很好的例子。这本书关注超级英雄漫画,它由解释关于超级英雄的随机数据点的信息图表组成。
**书中的一个甘特图分解了不同的超级英雄在(奇迹般地)复活之前保持死亡的时间。另一张横坐标图显示了超人和闪电侠谁是世界上跑得最快的人——剧透:是闪电侠。超级图像星球大战是一样的,除了关于遥远星系中发生的事情的图表。
在 2022 年早些时候,似乎每个人都在玩 Wordle,这是一个给你 6 次机会来解决 5 个字母单词的游戏。如果你玩这个游戏,你可能有一个专有的方法来解决这个问题,其他人也一样。但是来自 The Why Axis 的一名数据报告员制作了一个基于数据的图表,找到了 Wordle 中最常用的五个字母:E、R、A、O 和 t。这个有趣而聪明的图表消除了玩游戏的一些神秘感,但它确实帮助了许多人的日常 Wordle 游戏。
- 超级图形 和 超级图形星球大战——这两本书以任何人都可以享受的有趣方式使用数据(不仅仅是数据分析师)。
** 每个人都应该阅读的 Dataviz 书籍 —如果你想学习如何制作引人注目的信息图,你应该阅读的书籍的综合列表。* 【2022 年 12 个最佳信息图表工具(全面对比指南) —简化信息图表制作的工具。* 对 Wordle 中字母使用频率的简单、不剧透的分析——了解更多关于记者如何了解 Wordle 中字母使用频率的信息。* 通用回形针(Universal Paper Clips)——这个简单的游戏与现代标准相比几乎算不上一个游戏,但它需要一个善于分析的头脑来击败它。作为回形针制造商,您必须考虑每个回形针的价格、公众需求、材料成本和营销。很难放下。*
*## 步骤 4:创建强大的投资组合
与其想象你的工作会是什么样子,你作为一名数据分析师会面临什么,一个基于项目的课程可以在你涉足未来的工作场所之前就给你这种洞察力。你的投资组合将向未来的雇主展示,而不仅仅是告诉他们你有能力做什么。投资组合对于初级数据分析师尤其重要,因为你可能没有工作经验。
这里有一些资源可以帮助你建立自己的投资组合:
当与其他数据分析师竞争同一份工作时,一份强大的投资组合可能是一封带录用函的电子邮件和一封不带录用函的电子邮件之间的差异。没有人比 Miguel Couto 更了解这一点,他是一家大型在线流媒体公司的数据分析师,在走上数据分析师道路后找到了一份工作。
“Dataquest 上的项目让我开始建立 GitHub 组合,”Miguel 说。" Dataquest 实际上让你思考并运用你的技能."虽然不是课程中的每一个项目都会纳入你的文件夹,但你会有工具在课程之外制作你自己的项目。
这些个人项目对任何投资组合来说都是很棒的,表明你有主动性和支持它的经验。对于 Miguel 来说,GitHub 是展示他的工作的完美地方,因为他可以展示他的项目以及每个项目背后的文档和代码。
第五步:走出去
将你的作品集放在一个网站上是一个很好的开始,但这可能缺乏个性。虽然雇主和同事会看到你的工作,但他们可能会错过你的与众不同之处。例如,你可以写一篇关于数据分析的博客。
写作并不是你专业表达自己的唯一媒介。虽然社交媒体平台似乎是最不可能讨论数据分析的地方,但你会对你的发现感到惊讶。一名抖音用户开始在这个平台上创建微软 Excel 内容,她通过教人们如何使用电子表格软件将这变成了一份职业。
Reddit 是另一个很好的例子。有数据科学和数据分析社区,以及其他以数据为中心的领域。这是一个发布成就、提出问题或认识其他同舟共济的人的好地方。Discord 是一个类似于 Slack 的消息平台,是另一个你可以与人见面并谈论一切数据分析的地方。
在利基社区中互动的好处是,你很有可能会遇到对你的职业有帮助的人。你可能会找到一份工作,或者遇到能把你介绍给他们雇主的人。但就个人而言,这是一种很好的交友方式。
- Reddit—r/数据分析
- 不和谐— 数据分析
- Slack — 15 个数据科学 Slack 社区将加入
迈出成为数据分析师的第一步
我们往往会因为认为某件事太难、太贵或者只是太费时间而让自己紧张。但是你已经迈出了第一步。既然你已经有了如何成为一名数据分析师的基本轮廓,事实证明它既不太难,也不太贵,也不太耗时。而且你甚至不需要认证。。。
- 数据分析认证:2022 年你真的需要一个吗?
一名前 Dataquest 学员现在为 Fractal 工作,他对 Data Analyst path 教授数学等复杂学科的方式印象深刻。“只教授了最重要的概念,而且它们被分解得非常好,我认为任何有基本算术技能的人都可以开始学习数据分析和统计。”
Dataquest 数据分析师道路是负担得起的,具有挑战性和灵活性。无论你是在做一份全职工作,还是在想下一步该怎么走,这条路都是你自己走的。你可以在短短五个月内完成,每周 10 小时,或者你可以把它分散在一年内完成。最后,它正在完成路径(不是花了多长时间!)这是最重要的。
如何在 2023 年成为数据科学家(可操作指南)
原文:https://www.dataquest.io/blog/how-to-become-a-data-scientist/
December 28, 2022
如果你想知道如何成为一名数据科学家,那么你来对地方了。我也经历过你的处境,现在我想帮你。
十年前,我只是一个拥有历史学位的大学毕业生。然后我成为了一名机器学习工程师、数据科学顾问,现在是 Dataquest 的首席执行官。
如果一切可以重来,我会按照我在这篇文章中与你分享的步骤去做。它会加速我的职业生涯,为我节省数千小时,并防止一些白发。
错误与正确的方式
当我学习时,我试图遵循各种在线数据科学指南,但我最终感到无聊,并且没有任何实际的数据科学技能来展示我的时间。
这些导游就像学校里的一个老师,递给我一堆书,告诉我要全部读完——这种学习方法从来没有吸引过我。这是令人沮丧和弄巧成拙的。
随着时间的推移,我意识到当我在研究我感兴趣的问题时,我学习的效率最高。
然后一拍即合。
我没有学习数据科学技能的清单,而是决定专注于围绕真实数据构建项目。这种学习方法不仅激励了我,也反映了我在实际的数据科学家角色中所做的工作。
这种方法加速了我的学习,我一直都很开心。
我创建了这个指南来帮助和我处于相同位置的有抱负的数据科学家。事实上,这也是我创建 Dataquest 的原因。我们的数据科学课程将在几个月内使用实际代码带你从初学者到工作就绪。
然而,一系列的课程是不够的。如果你想成为一名数据科学家,你需要知道如何有效地思考、学习、计划和执行。这份可行的指南包含了你需要知道的一切。
如何成为一名数据科学家:
- 质疑一切
- 第二步:学习基础知识
- 步骤 3:构建项目
- 第四步:分享你的作品
- 第五步:向他人学习
- 第六步:拓展你的界限
现在,让我们一个一个地检查一下。
质疑一切
数据科学领域很有吸引力,因为你可以用实际数据和代码回答有趣的问题。这些问题的范围可以从 我能预测航班是否会准时吗? 到 美国每个学生的教育支出是多少?
要回答这些问题,你需要培养一种分析思维。
培养这种心态的最好方法是从分析新闻文章开始。首先,找一篇讨论数据的新闻文章。这里有两个很棒的例子:跑步能让你变得更聪明吗?或糖真的对你有害吗?。
然后,思考以下问题:
- 根据他们讨论的数据,他们是如何得出结论的
- 你如何设计一项研究来进一步调查
- 如果您有权访问底层数据,您可能会问什么问题
一些文章,如这篇关于美国枪支死亡的文章和这篇关于支持唐纳德·川普的在线社区的文章实际上有可供下载的基础数据。这可以让你探索得更深。您可以执行以下操作:
- 下载数据,并在 Excel 或等效工具中打开它
- 通过目测,看看你能在数据中找到什么样的模式
- 你认为数据支持文章的结论吗?为什么或为什么不?
- 你认为你可以用这些数据回答哪些额外的问题?
以下是一些查找数据驱动文章的好地方:
显示
在你阅读文章几周后,反思你是否喜欢提出问题并回答它们。成为一名数据科学家是一条漫长的道路,你需要对这个领域充满热情,才能一路走下去。
数据科学家不断提出问题,并使用数学模型和数据分析工具来回答这些问题。
所以,如果你不喜欢对数据进行推理和提出问题的过程,你应该考虑尝试找到数据和你确实喜欢的事情之间的重叠。
如果你缺乏兴趣,分析你喜欢的事情
也许你不喜欢抽象地提出问题的过程,但也许你喜欢分析健康或教育数据。找到你的激情所在,然后开始用分析的心态看待这种激情。
我个人对股市数据非常感兴趣,这促使我建立一个模型来预测市场。
如果你想花几个月的时间努力学习数据科学,从事你热爱的事情将有助于你在面临挫折时保持动力。
第二步:学习基础知识
一旦你想出了如何问正确的问题,你就准备好开始学习回答这些问题所需的技巧。我推荐通过学习 Python 的编程基础来学习数据科学。
Python 是一种具有一致语法的编程语言,经常被推荐给初学者。对于极其复杂的数据科学和机器学习相关的工作,例如深度学习或使用大数据的人工智能,它也足够通用。
许多人担心选择哪种编程语言,但以下是需要记住的要点:
- 数据科学是关于回答问题和推动商业价值,而不是工具
- 学习概念比学习语法更重要
- 构建项目并共享它们是您在实际的数据科学角色中要做的事情,通过这种方式学习将给您一个良好的开端
超级重要提示:目标不是学会一切;这是为了学习刚刚够开始建设项目。
你应该在哪里学习
这里有几个学习的好地方:
- Dataquest —我创建 Dataquest 是为了让学习数据科学的 Python 变得更容易、更快、更有趣。我们提供基础 Python 基础课程,一直到一体化路径,包含成为数据科学家所需的所有课程。
- 艰难地学习 Python——这本书教授从基础到更深入程序的 Python 概念。
- Python 教程—Python 主站点提供的免费教程。
关键是学习基础知识,并开始回答你在过去几周浏览文章时提出的一些问题。
步骤 3:构建项目
当您学习编码的基础知识时,您应该开始构建能够回答有趣问题的项目,以展示您的数据科学技能。
您构建的项目不必很复杂。例如,您可以分析超级碗冠军来寻找模式。
关键是找到有趣的数据集,提出关于数据的问题,然后用代码回答这些问题。如果你需要寻找数据集的帮助,看看这篇文章中的可以找到一个很好的地方列表。
在构建项目时,请记住:
- 大多数数据科学工作都是数据清理。
- 最常见的机器学习技术是线性回归。
- 每个人都有起点。即使你觉得你正在做的事情并不令人印象深刻,它仍然值得继续努力。
哪里可以找到项目创意
构建项目不仅有助于您练习技能和理解真正的数据科学工作,还能帮助您构建投资组合,向潜在雇主展示。
以下是一些关于自己构建项目的更详细的指南:
此外,Dataquest 的大多数课程都包含互动项目,您可以在学习过程中完成这些项目。以下是几个例子:
- 越狱 —找点乐子,用 Python 和 Jupyter Notebook 分析一个直升机越狱的数据集。
- 探索黑客新闻帖子——使用热门技术网站 Hacker News 的提交数据集。
- 探索易贝汽车销售数据——使用 Python 处理从德国易贝网站分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
- 《星球大战》调查 —使用 Jupyter Notebook 分析《星球大战》电影的数据。
- 分析纽约高中数据 —使用散点图和地图发现不同人口统计的 SAT 成绩。
增加项目复杂性
一旦你完成了一些较小的项目,最好找到一个感兴趣的领域,并持续深入下去。
对我来说,这是试图预测股票市场。随着你技能的提高,你可以通过添加细微差别,如每分钟的价格和更准确的预测,使问题变得更加复杂。查看这篇关于 Python 项目的文章,获取更多灵感。
第四步:分享你的作品
一旦你完成了一些项目,就在 GitHub 上与他人分享吧!
原因如下:
- 它让你思考如何最好地展示你的项目,这是你在数据科学岗位上应该做的。
- 他们允许您的同事查看您的项目并提供反馈。
- 他们允许雇主查看你的项目。
有用的资源:
创建一个简单的博客
除了将你的作品上传到 GitHub,你还应该考虑发布一个博客。当我学习数据科学时,写博客帮助我做到了以下几点:
- 引起招聘人员的兴趣
- 更彻底地学习概念(教学的过程真正帮助你学习)
- 与同行联系
以下是博客帖子的一些好主题:
- 解释数据科学和编程概念
- 讨论你的项目和浏览你的发现
- 讨论您如何学习数据科学
这里有一个我多年前在我的博客上制作的可视化例子,展示了辛普森一家中的每个角色有多喜欢其他角色:

第五步:向他人学习
在你开始建立在线形象之后,开始与其他数据科学家接触是一个好主意。你可以亲自去做,也可以在网上社区做。以下是一些不错的在线社区:
在 Dataquest,我们有一个在线社区,学习者可以用它来接收项目反馈,讨论棘手的数据相关问题,并与数据专业人员建立关系。
我个人在学习的时候在 Quora 和 Kaggle 上很活跃,对我帮助很大。加入在线社区是实现以下目标的好方法:
- 找其他人一起学习
- 提升您的个人资料并寻找机会
- 通过向他人学习来强化你的知识
您还可以通过 Meetups 与人面对面交流。亲自参与可以帮助您结识您所在领域更有经验的数据科学家,并向他们学习。
第六步:拓展你的界限
公司希望雇佣那些发现关键见解的数据科学家,这些见解可以为他们省钱或让他们的客户更开心。你必须将同样的过程应用于学习——不断寻找新问题来回答,并不断回答更难、更复杂的问题。
如果你回顾一两个月前的项目,你看不到改进的空间,你可能没有充分拓展你的界限。你应该每个月都有很大的进步,你的工作应该反映这一点。
以下是一些拓展您的界限和更快学习数据科学的方法:
- 尝试使用更大的数据集
- 开始一个需要你不具备的知识的项目
- 尝试让您的项目运行得更快
- 把你在项目中所做的教给其他人
你能行的!
学习成为一名数据科学家并不容易,但关键是保持动力并享受你正在做的事情。如果你一直在构建项目并分享它们,你将积累你的专业知识并得到你想要的数据科学家的工作。
我没有给你一个学习数据科学的确切路线图,但是如果你遵循这个过程,你会比你想象的走得更远。如果你有足够的动力,任何人都可以成为数据科学家。
在对传统网站教授数据科学的方式感到沮丧多年后,我创建了 Dataquest ,这是一种在线学习数据科学的更好方式。 Dataquest 解决了 MOOCs 的问题,在 MOOCs 中,你永远不知道接下来要上什么课,你也永远不会被你正在学习的东西所激励。
Dataquest 利用了我从帮助成千上万的人学习数据科学中学到的经验,它专注于使学习体验变得有趣。在 Dataquest,你将建立几十个项目,你将学到成为一名成功的数据科学家所需的所有技能。Dataquest 的学生已经被埃森哲和 T2 太空探索技术公司雇佣。
祝你成为一名数据科学家!
成为数据科学家—常见问题
数据科学家资格是什么?
数据科学家需要掌握相关的技术技能,包括用 Python 或 R 编程,用 SQL 编写查询,构建和优化机器学习模型,以及一些“工作流”技能,如 Git 和命令行。
数据科学家还需要很强的解决问题、数据可视化和沟通技巧。数据分析师通常会被要求回答一个问题,而数据科学家则需要探索数据,找到其他人可能错过的相关问题和商业机会。
虽然以前没有经验的数据科学家也有可能找到工作,但对于没有相关专业经验的有抱负的数据科学家来说,在过渡到数据科学家角色之前先做数据分析师是更常见的途径。
数据科学家的教育要求是什么?
大多数数据科学家职位至少需要学士学位。拥有计算机科学和统计学等技术领域的学位,以及博士和硕士等更高的学位可能会更好。然而,高学历通常不是严格要求的(即使招聘广告上写着有)。
雇主最关心的是你的技能。拥有不太高级或不太相关的技术学位的申请人可以通过展示他们从事相关数据科学工作的高级技能和经验的优秀项目组合来抵消这一劣势。
成为一名数据科学家需要哪些技能?
不同工作的具体要求可能会有很大不同,随着行业的成熟,更多的专业角色将会出现。不过,一般来说,以下技能对于几乎任何数据科学职位都是必要的:
- 用 Python 或 R 编程
- 结构化查询语言
- 概率与统计
- 构建和优化机器学习模型
- 数据可视化
- 沟通
- 大数据
- 数据挖掘技术
- 数据分析
每个数据科学家都需要了解基础知识,但一个角色可能需要对自然语言处理(NLP)有更深入的了解,而另一个角色可能需要您构建生产就绪的预测算法。
成为一名数据科学家很难吗?
是的,在成为数据科学家的过程中,你应该会面临挑战。这个角色需要相当高的编程技能和统计知识,以及很强的沟通技巧。
任何人都可以学习这些技能,但你需要动力来推动自己度过艰难时刻。
选择正确的学习平台和方法也有助于简化学习过程。
成为一名数据科学家需要多久?
成为数据科学家需要的时间长短因人而异。在 Dataquest,我们的大多数学生报告说在一年或更短的时间内达到了他们的学习目标。学习过程需要多长时间取决于你能投入多少时间。
同样,求职过程的时间长短也可能因你做过的项目、你的其他资格、你的专业背景等等而异。
数据科学是个好的职业选择吗?
是的,数据科学职业是一个很棒的选择。对数据科学家的需求很高,世界每天都在产生大量(并且不断增加)的数据。
我们并不声称拥有水晶球或知道未来会发生什么,但数据科学是一个快速增长的领域,需求高,薪水丰厚。
数据科学家的职业道路是什么?
典型的数据科学家职业道路通常始于其他数据职业,如数据分析师,然后通过内部晋升或工作变动进入其他数据科学角色。
从那里,更有经验的数据科学家可以寻找高级数据科学家的角色。
具有管理技能的经验丰富的数据科学家可以晋升为数据科学总监以及类似的总监和高管级别的角色。
数据科学家的薪水是多少?
根据地点和申请人的经验水平,工资差别很大。然而,平均而言,数据科学家的薪水非常丰厚。2022 年,美国数据科学家的平均年薪超过 12 万美元。
其他数据科学职位也要求高薪:
- 数据分析师:$ 96707
- 数据架构师::135,096 美元
- 商业分析师:$ 97224
数据科学哪个认证最好?
许多人认为数据科学认证或完成数据科学训练营是招聘经理在合格候选人身上寻找的东西,但这不是真的。
招聘经理正在寻找工作所需技能的证明。不幸的是,数据科学证书并不能最好地展示你的技能。
原因很简单。
有许多训练营和数据科学认证项目。许多地方都提供这种服务——从初创公司到大学,再到学习平台。因为太多了,用人单位无从得知哪些是最严谨的。
虽然雇主可能会将证书视为渴望继续学习的一个例子,但他们不会将其视为技能或能力的展示。展示你技能的最好方式是项目和强大的投资组合。
如何建立黑仔数据科学投资组合
原文:https://www.dataquest.io/blog/how-to-build-a-killer-data-science-portfolio/
December 1, 2021
即使缺乏合格的申请人,数据科学就业市场的竞争也可能相当激烈。对于那些试图获得第一份数据科学工作的人来说,比其他人更引人注目很重要。
有一点被认为是数据科学求职的关键,那就是强大的数据科学组合。但是,如何构建脱颖而出的数据科学产品组合呢?首先,了解你需要展示给雇主留下深刻印象的技能才是真正重要的。
你的数据科学简历和投资组合是建立可信度和信任的两件事。这将有助于潜在雇主评估你胜任你申请的职位的能力,以及你可能为他们公司带来的价值。
创建一个能为你打开大门的投资组合不是一件容易或快速的任务。处理数据需要时间、耐心和大量时间。在本帖中,我们将为您提供一些关于如何创建一个杀手级数据科学投资组合的提示,它将在其他投资组合中占据主导地位。
使用 Github 获得优势
在 Github 上有一个活跃的个人资料,并确保你有一个到你简历的链接是必须的。你不仅可以主持你的项目的远程版本,而且它也打开了巨大的合作机会,以改善他们。
但是你在 Github 上有多活跃呢?Github 记录每天的贡献。而这些贡献别人也能看到。你希望潜在雇主看到你对数据科学的承诺有多坚定。因此,请确保定期更新您的 Github 个人资料。
此外,你应该定制你的 Github 个人资料页面,使其更好地与你申请的工作职位相匹配。例如,如果你申请 IT 或网络安全行业的工作,参加 GitHub 安全计划并获得徽章肯定会帮助你脱颖而出。
让你的投资组合具有相关性
即使一个潜在的雇主正在寻找一个入门级的候选人,列出你参与过的与他们的业务相关的项目肯定会给他们留下印象。如果你申请的主要是医疗保健行业的工作,一定要把重点放在这个特定行业的项目上。
例如,如果你申请的公司遵循基于订阅的模式,你会想要突出显示你处理过的与这些类型的业务相关的数据集。多走一步,深入了解你申请的公司。感受一下他们可能面临的挑战,看看你是否已经在你的项目中解决了类似的挑战。如果你发现你有,一定要把它们放在最前面让他们看到。
如果你没有任何相关的东西,并且你真的想建立一个投资组合,有效地证明你适合数据科学的角色,我们建议你找到相关的项目来工作。它们可以是一个或两个小项目,但这将在入围某个角色时产生巨大的影响。
组织是关键
你必须确保你的投资组合整洁有序。在这里,你可以轻松地带领你的潜在雇主快速浏览你参与过的、与他们的特定行业或商业模式相关的项目。
如果你的项目是一堆乱七八糟的文件和文件夹,这将表明你缺乏对细节和组织的关注,这将大大降低有人会花时间浏览你的文件夹的可能性。
给你的文件起一个合适的名字,并以一种简单易懂的方式排列它们。清理你的代码,并提供详细的执行说明,让招聘经理能够轻松愉快地查看你的投资组合。始终包含一个自述文件,以帮助查看者轻松浏览、理解您的项目而不必太费力,并了解数据中的任何异常。
总是想象
数据可视化本身就是一项重要的技能。在数据科学领域,能够从数据集中得出一个令人信服的故事是一种非常有价值的才能。通过对所有数据项目使用健壮的数据可视化,您将从整体上提升项目的影响力。
它还会增强你讲故事的能力,强化你的结论,展示你创作优秀作品的愿望和能力。请务必添加您认为必要的评论和解释。这将有助于你的读者跟上每一步。
正确执行数据可视化将展示你识别相关值的创造力和诀窍,以及你从原始数据中构思一个迷人故事的能力。记住,人们喜欢图片,尤其是当他们对数据驱动的行为比对数据本身更感兴趣的时候。
参加比赛
竞赛帮助你磨砺和增长技能。但是你在这些数据科学竞赛中的表现也可以作为成就,为你的工作增加可信度。你可以这样想:如果你参加了一个比赛,没有获胜,但进入了数百名参与者的候选名单,这肯定会给你未来的雇主留下印象。
此外,你可以选择关注你感兴趣的品牌举办的比赛。这将有助于你熟悉品牌本身和他们面临的一些挑战。同时,这将向你的潜在雇主展示你对为他们公司工作的兴趣程度。
在你的作品集里展示你参加过的比赛和你在比赛中的表现,肯定会增加你上升到巅峰的机会。
展示你的社区服务
您是否参与了任何数据科学社区?你经常帮助回答数据科学家或分析师的问题吗?一定要把这些列出来。但更重要的是,更进一步,链接到与你申请的公司/工作职位相关的答案。
你的数据科学投资组合的目标应该是脱颖而出,独一无二或独一无二,而不是众多中的一个。这将有助于你说服潜在的雇主,你是独一无二的适合一个职位的人。最终的结果将是一个展示你的数据科学熟练程度的投资组合,这是招聘经理和潜在雇主无法忽视的。
nlp 项目第 2 部分:如何清理和修复用于分析的数据
原文:https://www.dataquest.io/blog/how-to-clean-and-prepare-your-data-for-analysis/
January 24, 2022
这是描述我的自然语言处理项目的系列文章的第二篇。要真正从这篇 NLP 文章中受益,您应该阅读的第一篇文章,了解如何使用 pandas 处理文本数据,并了解列表理解和 lambda 函数。我们还将编写一些函数,并导入许多包和工具。在继续之前,有必要熟悉一下这些概念。
这篇文章的主要目的是分析学员在 Dataquest 社区上收到的回复。Dataquest 鼓励学习者在他们的论坛上发布他们的指导项目。发布项目后,其他学习者或工作人员可以分享他们对项目的看法。我们对这些观点的内容感兴趣。
在第一帖中,我们学习了如何使用美汤进行网页抓取。我们从 Dataquest 的论坛页面收集数据,并将其组织在一个熊猫数据框架中:
- 我们提取了每个帖子的标题、链接、回复数和浏览量
- 我们还抓取了帖子的网站——具体来说,我们锁定了帖子的第一个回复
这是我们继续工作的地方。在这篇文章中,我们将清理和分析文本数据。我们将从小处着手:清理和组织标题数据,然后我们将对每个标题的数字信息(浏览、回复)进行一些数据分析。我们主要是展示潜力,然后快速前进。
接下来,我们将处理和分析反馈帖子。我们将使用各种 NLP 技术来分析反馈的内容:
- 标记化
- N-grams
- 词性标注
- 组块
- 词汇化
我们将使用上面提到的所有技术。我们的主要目标是了解提供了什么样的反馈。我们特别感兴趣的是关于我们项目的技术建议。比起情感分析,我们更感兴趣的是什么样的技术评论是最常见的。
你可以在我的 Github 上找到这个项目的文件夹。所有文件都已经在那个文件夹中了,所以如果你想在不抓取数据的情况下处理数据,你可以下载数据集。笔记本也有。如果你有任何问题,请随时伸出手问我任何事情: Dataquest , LinkedIn 。
第 1 部分:标题问题——每个人都想要一个不同的标题
我们都有罪:我们想发布我们的项目并获得关注。获得一定关注的最简单方法是什么?想一个有趣又原创的标题!所以现在当有人想把所有的文章按标题分组时。我们得到 1102 个结果,因为有 1102 个不同的标题。我们知道不同项目的数量接近 20 或 30 个。所以让我们试着根据内容对这些帖子进行分类。
小写、标点和停用词
在我们开始打扫卫生之前,让我们先了解一个简单的事实:
'ebay' == 'Ebay'
输出
False
如上所述,Python 是一种区分大小写的语言——“e”与“e”不同。这就是为什么清理字符串数据的第一步是将所有单词转换为小写:
df['title'] = df['title'].str.lower()
现在让我们继续删除标点符号;我们将创建一个简单的函数,并将其应用于每个“标题”单元格:
import string
# create function for punctuation removal:
def remove_punctuations(text):
for char in string.punctuation:
text = text.replace(char, '')
return text
# apply the function:
df['title'] = df['title'].apply(remove_punctuations)
请注意我们是如何从“string”包中导入标点符号列表的,而不是创建一个列表并手动填充所有这些符号。我们将更频繁地使用这种方法,因为它更快更容易。
上面的方法是一个易于理解的函数,但不是最有效的方法。如果您的数据集非常大,您应该检查堆栈溢出以获得更好的解决方案。
停止言语
最后但同样重要的是,我们将删除停用词。什么是停用词?如果我们只是问一个搜索引擎,我们应该会收到一个字典的答案:
停用词 —从计算机生成的索引或索引中自动省略的词。
来自牛津语言的定义
有很多“the”、“in”、“I”和其他单词使我们的标题语法正确,但往往没有任何其他用途。
让我们检查其中一个标题的删除示例:
# import list of stopwords:
from nltk.corpus import stopwords
stop = stopwords.words('english')
# remove stopwords from the below example:
example1 = 'guided project visualizing the gender gap in college degrees'
' '.join([word for word in example1.split() if word not in stop])
输出
'guided project visualizing gender gap college degrees'
我们已经删除了停用词,但内容仍然很容易理解。值得一提的是有时候删除停用词并不是最好的主意。
我们可以将上面的方法应用于所有的“标题”单元格,但在此之前,我们想在列表中添加一些我们选择的单词。我们知道许多标题包含“项目”、“反馈”等词。他们没有给我们任何关于帖子内容的信息,所以我们应该删除它们:
# add more words to stopwords list:
guided_list = ['guided', 'project', 'feedback']
stop_extended = stop + guided_list
# create a column without the stopwords:
df['title_nostop'] = df['title'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop_extended]))
让我们在最初的几个步骤之后检查一下我们有多少独特的标题:
len(df['title_nostop'].unique())
输出
927
与预期的 20-30 本相比,这仍然是一个非常大的数字。我们必须要有创意!
使用标签号
df['content'][1]
输出
<tr class="topic-list-item category-share-guided-project tag-python tag-pandas tag-469 tag-data-analysis-business tag-469-11 has-excerpt ember-view" data-topic-id="558226" id="ember77">\n<td class="main-link clearfix" colspan="">\n<div class="topic-details">\n<div class="topic-title">\n<span class="link-top-line">\n<a class="title raw-link raw-topic-link" data-topic-id="558226" href="https://community.dataquest.io/t/re-upload-project-feedback-popular-data-science-questions/558226/2" level="2" role="heading"><span dir="ltr">[Re-upload]Project Feedback - Popular Data Science Questions</span></a>\n<span class="topic-post-badges"></span>\n</span>\n</div>\n<div class="discourse-tags"><a class="discourse-tag bullet" data-tag-name="python" href="https://community.dataquest.io/tag/python">python</a> <a class="discourse-tag bullet" data-tag-name="pandas" href="https://community.dataquest.io/tag/pandas">pandas</a> <a class="discourse-tag bullet" data-tag-name="469" href="https://community.dataquest.io/tag/469">469</a> <a class="discourse-tag bullet" data-tag-name="data-analysis-business" href="https://community.dataquest.io/tag/data-analysis-business">data-analysis-business</a> <a class="discourse-tag bullet" data-tag-name="469-11" href="https://community.dataquest.io/tag/469-11">469-11</a> </div>\n<div class="actions-and-meta-data">\n</div>\n</div></td>\n<td class="posters">\n<a class="" data-user-card="kevindarley2024" href="https://community.dataquest.io/u/kevindarley2024"><img alt="" aria-label="kevindarley2024 - Original Poster" class="avatar" height="25" src="./Latest Share_Guided Project topics - Dataquest Community_files/50(1).png" title="kevindarley2024 - Original Poster" width="25"/></a>\n<a class="latest" data-user-card="jesmaxavier" href="https://community.dataquest.io/u/jesmaxavier"><img alt="" aria-label="jesmaxavier - Most Recent Poster" class="avatar latest" height="25" src="./Latest Share_Guided Project topics - Dataquest Community_files/50(2).png" title="jesmaxavier - Most Recent Poster" width="25"/></a>\n</td>\n<td class="num posts-map posts" title="This topic has 3 replies">\n<button class="btn-link posts-map badge-posts">\n<span aria-label="This topic has 3 replies" class="number">3</span>\n</button>\n</td>\n<td class="num likes">\n</td>\n<td class="num views"><span class="number" title="this topic has been viewed 47 times">47</span></td>\n<td class="num age activity" title="First post: Nov 14, 2021 2:57 am\nPosted: Nov 18, 2021 6:38 pm">\n<a class="post-activity" href="https://community.dataquest.io/t/re-upload-project-feedback-popular-data-science-questions/558226/4"><span class="relative-date" data-format="tiny" data-time="1637221085326">3d</span></a>\n</td>\n</tr>
指导项目的每一课都有唯一的编号。大多数发布的项目都标有这些数字。利用这些知识,我们可以尽可能地提取标签号:
df['tag'] = df['content'].str.extract('data-tag-name="(\d+)" href')
现在,让我们检查一下有多少帖子标有课程编号:
df['tag'].value_counts().sum()
输出
700
1102 个帖子中有 700 个贴上了课程编号;现在我们必须填写缺失的部分。我们将这样解决这个问题:
- 检查每个课程编号标题中最常见的单词
- 如果该词出现不止一次,或者与项目内容无关,则将其从所有标题中删除
- 循环遍历顶部的 25 个(可以调整为不同的数量)标签,对于每个标签,执行以下操作:
- 检查该标签最常用的单词
- 选择标题包含最常用单词且“标签”值为空的行
- 将当前标签分配给这些行
第一步。检查每个标签最常用的单词
from collections import Counter
for a_tag in df['tag'].value_counts()[:25].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(1)[0][0]
print(a_tag,top_word)
输出
294 ebay
356 黑客
350 app
257 cia
146 学院
348 出口
149 性别
201 战争
217 nyc
191 sql
524 交通
469 数据
155 汽车
310 极品
288 fandango
529 交流
64
第二步:删除重复出现的单词
上述大多数关键词都指向我们都必须忍受的教训。但是“最佳”或“数据”并不能真正给我们任何关于这个项目的信息。最重要的是,两个不同的标签有相同的单词(“预测”)作为最常见的单词。让我们去掉这些词:
more_stop = ['predicting','best','analyzing','data','exploring']
df['title_nostop'] = df['title_nostop'].apply(lambda x: ' '.join([word for word in x.split() if word not in (more_stop)]))
for a_tag in df['tag'].value_counts()[:25].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(1)[0][0]
print(a_tag,top_word)
步骤 3:遍历标签号
for a_tag in df['tag'].value_counts()[:25].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(1)[0][0]
df.loc[(df['title_nostop'].str.contains(top_word)) & df['tag'].isnull(), 'tag'] = a_tag
df[df['tag'].isnull()].shape
“汽车”问题
你可能注意到了,tag 155 最常见的词是 car 不幸的是,这个词在易贝项目中非常常见。以下是将不正确的标签编号分配给不正确的项目的问题的快速解决方法:
df.loc[(df['title_nostop'].str.contains('german')) & (df['tag']=='155'),'tag'] = '294'
df[df['tag'].isnull()].shape
输出
(59, 8)
我们可以删除 59 行以获得一致的数据集;当我们这样做时,让我们删除原来的“标题”列:
df = df[~(df['tag'].isnull())].copy()
df = df.drop(columns='title')
好的,我们有一个数据集,其中每一行都有一个指定的课程编号,但是为了执行进一步的分析,我们不想过于依赖这些编号。毕竟,“294”并没有告诉我们太多,但“易趣”已经给了我们一个项目的线索。但一个单词有时是不够的,所以让我们为每个课号检查最常见的两个单词,并为它们创建一个列。有时这种组合不会按照预期的顺序,但它会清楚地指向项目的主题。
有一个问题:我们只能用前 29 课的数字来做;其余的只出现一次,所以如果标题在数据集中只出现一次,我们就无法检查最常见的单词。
# create empty dictionary and a column filled with '0's
pop_tags = {}
df['short_title'] = None
# loop trough first 29 tags and extract 2 most common words, merge them into 1 string and store it in a dictionary:
for a_tag in df['tag'].value_counts()[:29].index:
top_word = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(2)[0][0]
top_word2 = Counter(" ".join(df[df['tag']==a_tag]['title_nostop']).split()).most_common(2)[1][0]
pop_tags[a_tag] = top_word+' '+top_word2
现在,我们已经有了一个字典,其中包含了每个课程编号最常用的两个单词,让我们将它们分配给每一行:
for a_tag in df['tag'].value_counts()[:29].index:
df.loc[df['tag']==a_tag, 'short_title'] = pop_tags[a_tag]
让我们来看看 10 个最受欢迎的短篇:
df['short_title'].value_counts()[:10]
输出
| 新闻黑客 | One hundred and sixty-three |
| 易趣汽车 | One hundred and fifty-five |
| app 盈利 | One hundred and thirty-eight |
| 大学可视化 | Eighty-seven |
| 中情局实况报道 | Eighty-one |
| 离职员工 | sixty-eight |
| 星球大战 | Forty-eight |
| 性别差距 | Forty-three |
| 纽约高中 | forty-two |
| sql 使用 | Thirty-eight |
| 名称:短标题 | dtype: int64 |
第 2 部分:EDA 潜力
“星球大战”对于一部太空歌剧来说并不是一个朗朗上口的名字,但我们可以认出一个熟悉的话题。现在,我们可以将每个独特的标题归类到一个特定的项目,我们可以开始分析数据集。哪个项目的职位数量最多?
import matplotlib.pyplot as plt
# group the dataset by project title:
plot_index = df.groupby('short_title')['views'].sum().sort_values()[-15:].index
plot_counts = df.groupby('short_title')['views'].count().sort_values()[-15:].values
# create a plot:
fig, ax = plt.subplots(figsize=(16,12))
plt.barh(plot_index,plot_counts, label='number of posts')
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.set_xlabel('Number of posts')
plt.title('Number of posts for each project',fontsize=22,pad=24)
plt.show()
这只是我们可以使用当前数据集生成的许多可能图中的一个;以下是更多情节的一些想法:
- 每个项目的平均查看次数
- 每个项目的平均回复数
- 观点比例/帖子数量
我们还可以继续从我们收集的原始 HTML 块中提取数据——我们仍然可以提取日期并跟踪主题随时间的流行程度。
另一个潜在的方法是将项目分为不同的技能级别,并根据项目的难度跟踪所有的度量标准。
在我们做以上任何事情之前,我们应该组织标题,并确保单词的顺序是合乎逻辑的,这样我们就不会再有“星球大战”的案例了。
我们可以做到所有这些,甚至更多,但现在不是这样做的时间和地点。这篇文章是关于自然语言处理技术的,我们还没有完全覆盖它们。这就是为什么我们将跳过数值数据的探索性数据分析,转到第 3 部分。
第 3 部分:使用 NLP 技术的反馈分析
清理文本数据
df['feedback'][0]
输出
\nprocessing data inside a function saves memory (the variables you create stay inside the function and are not stored in memory, when you’re done with the function) it’s important when you’re working with larger datasets - if you’re interested with experimenting:\nhttps://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page\nTry cleaning 1 month of this dataset on kaggle notebook (and look at your RAM usage) outside the function and inside the function, compare the RAM usage in both examples\n
让我们从删除不必要的 HTML 代码和小写字母开始。下一步,我们将展开所有的缩写(将“不”展开为“不”等。)—我们将为此使用一个方便的收缩包。之后,我们将删除标点并将结果存储在一个新列中。为什么?去掉标点符号会阻止我们识别句子,我们会想要分析单个的句子。这就是为什么我们要保留两个选项:带标点和不带标点的字符串。接下来,我们将删除停用词和 10 个最常出现的词。
import contractions
# remove '\n' and punctuation, lowercase all letters
df['feedback'] = df['feedback'].str.replace('\n',' ').str.lower()
# expand contractions
df['feedback'] = df['feedback'].apply(lambda x: contractions.fix(x))
# remove punctuations
df['feedback_clean'] = df['feedback'].apply(remove_punctuations)
# remove stopwords
df['feedback_clean'] = df['feedback_clean'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
# check 10 most common words:
freq10 = pd.Series(' '.join(df['feedback_clean']).split()).value_counts()[:10]
# remove 10 most common words:
df['feedback_clean2'] = df['feedback_clean'].apply(lambda x: ' '.join([word for word in x.split() if word not in (freq10)]))
最流行的词
我们已经清理了数据。我们根据清理文本的强度将它存储在几列中。现在我们可以开始一些分析了。让我们从一件非常简单的事情开始:检查最流行的词。
请记住,我们还没有从“反馈”栏中删除停用词。我们不会检查它—该专栏中最流行的单词将是停用词。知道“the”、“to”或“you”在文本中出现了多少次,不会给我们任何关于内容的概念。相反,我们将检查“反馈 _ 清理”和“反馈 _ 清理 2”:
from collections import Counter
# function for checking popular words:
def popular_words(series):
df['temp_list'] = series.apply(lambda x:str(x).split())
top = Counter([item for sublist in df['temp_list'] for item in sublist])
temp = pd.DataFrame(top.most_common(10))
temp.columns = ['Common_words','count']
return temp
popular_words(df['feedback_clean'])
输出
| | 常用词 | 数数 |
| Zero | 项目 | Two thousand two hundred and thirty-nine |
| one | 密码 | One thousand one hundred and forty |
| Two | 好的 | Seven hundred and twenty-one |
| three | 喜欢 | Five hundred and fifty-one |
| four | 将 | Five hundred and forty-four |
| five | 共享 | Five hundred and twenty-five |
| six | 你好 | Five hundred and twenty-two |
| seven | 也 | Five hundred and twenty-one |
| eight | 良好的 | Four hundred and ninety-four |
| nine | 工作 | Four hundred and thirty-five |
popular_words(df['feedback_clean2'])
输出
| | 常用词 | 数数 |
| Zero | 数据 | Four hundred and thirty-four |
| one | 谢谢 | Four hundred and twenty-one |
| Two | 伟大的 | Three hundred and ninety-four |
| three | 使用 | Three hundred and eighty-nine |
| four | 较好的 | Three hundred and eighty-five |
| five | 细胞 | Three hundred and sixty-eight |
| six | 幸福的 | Three hundred and sixty-one |
| seven | 社区 | Three hundred and fifty-three |
| eight | 评论 | Three hundred and forty-seven |
| nine | 结论 | Three hundred and forty-three |
我们可以继续剔除那些不能给我们任何重要信息的单词(“谢谢”、“太好了”、“开心”),或者尝试不同的方法。但在此之前,我们先来学习如何标记文本。
标记化
许多 NLP 技术需要输入标记化的字符串。什么是标记化?本质上,它是将一个字符串分割成更小的单元(记号)。最常见的方法是单词标记化。这里有一个简单的例子:
from nltk.tokenize import word_tokenize
word_tokenize('The most common method is word tokenizing.')
输出
['The', 'most', 'common', 'method', 'is', 'word', 'tokenizing', '.']
在对句子进行标记后,我们得到了句子中所有单词(和符号)的列表。另一种常见的方法是句子标记化,它将文本分成一系列句子:
from nltk.tokenize import sent_tokenize
sent_tokenize("You can also come across sentence tokenizing. This is a simple example.")
输出
['You can also come across sentence tokenizing.', 'This is a simple example.']
您应该至少知道这两种类型的标记化;有许多方法可以达到预期的输出。在本文中,我们不会关注它们,但是如果您感兴趣,这里有一些可以探索:更多关于标记化的阅读
旁注:nltk
到目前为止,您可能已经注意到我们已经从 nltk 库中导入了一些包。当处理文本数据时,您应该熟悉他们的网站和 nltk 工具的潜力。我们将使用许多从他们的库中导入的包和函数。
N-grams
那么,我们为什么要把这些文本分成列表呢?正如我们提到的,许多 NLP 技术需要输入标记化的文本。让我们从 n-grams 开始。n-gram 是 N 个单词的序列:
- Unigram:“计算机”
- Bigram:“快速计算机”
- 三元模型:“非常快的计算机”
等等。
在积累了超过 1000 个反馈帖子后,我们希望看到一些 n-grams 更频繁地出现,这应该表明我们在共享项目中的常见错误。
from nltk.util import ngrams
import collections
trigrams = ngrams(word_tokenize(df['feedback_clean2'].sum()), 3)
trigrams_freq = collections.Counter(trigrams)
trigrams_freq.most_common(10)
您是否注意到我们必须将标记化的文本传递给 n 元语法函数?
输出
[(('otherwise', 'everything', 'look'), 47),
(('cell', 'order', 'start'), 30),
(('order', 'start', '1'), 30),
(('upload', 'ipynb', 'file'), 29),
(('upcoming', 'project', 'happy'), 28),
(('best', 'upcoming', 'project'), 27),
(('everything', 'look', 'nice'), 25),
(('project', '’', 's'), 25),
(('guide', 'community', 'helpful'), 25),
(('community', 'helpful', 'difficulty'), 25)]
不幸的是,许多 n-grams 是祝贺和赞美的一些积极变化;这很好,但是它没有给我们任何与反馈内容相关的信息。如果我们能只过滤掉某些 n-gram,我们会得到一个更好的图片。我们假设以“考虑”、“制作”或“使用”这样的词开头的 n 元语法应该会让我们非常感兴趣。另一方面,如果一个 n-gram 包含像“快乐”、“祝贺”或“社区”这样的词,它对我们就没有任何意义。这应该不难,因为我们可以通过收集。计数器输出到熊猫数据帧:
f4grams = ngrams(word_tokenize(df['feedback_clean2'].sum()), 4)
f4grams_freq = collections.Counter(f4grams)
df_4grams = pd.DataFrame(f4grams_freq.most_common())
df_4grams.head()
输出
| | Zero | one |
| Zero | (单元格,顺序,开始,1) | Thirty |
| one | (最佳、即将推出、项目、快乐) | Twenty-six |
| Two | (指南、社区、帮助、困难) | Twenty-five |
| three | (社区、帮助、困难、获得) | Twenty-five |
| four | (有帮助、困难、得到、帮助) | Twenty-five |
以下是我们将要遵循的步骤:
- 创建一个我们想要避免的单词列表——我们将排除包含这些单词的 n 元语法
- 创建一个我们最感兴趣的单词列表——我们将过滤掉第一个单词中不包含这些单词的行
# lists of words to exclude and include:
exclude = ['best','help', 'happy', 'congratulation', 'learning', 'community', 'feedback', 'project', 'guided','guide', 'job', 'great', 'example',
'sharing', 'suggestion', 'share', 'download', 'topic', 'everything', 'nice', 'well', 'done', 'look', 'file', 'might']
include = ['use', 'consider', 'should', 'make', 'get', 'give', 'should', 'better', "would", 'code', 'markdown','cell']
# change the name of the columns:
df_4grams.columns = ['n_gram','count']
# filter out the n-grams:
df_4grams = df_4grams[(~df_4grams['n_gram'].str[0].isin(exclude))&(~df_4grams['n_gram'].str[1].isin(exclude))&(~df_4grams['n_gram'].str[2].isin(exclude))&(~df_4grams['n_gram'].str[3].isin(exclude))]
df_4grams = df_4grams[df_4grams['n_gram'].str[0].isin(include)]
df_4grams[:10]
输出
| | n_gram | 数数 |
| forty-two | (考虑、重新运行、顺序、排序) | Four hundred and thirty-four |
| Eighty | (制造、适当、文件、开始) | Four hundred and twenty-one |
| eighty-nine | (使用、技术、文字、文档) | Three hundred and ninety-four |
| One hundred and twenty-five | (用途、制服、风格、报价) | Three hundred and eighty-nine |
| One hundred and twenty-nine | (品牌、项目、专业、社交) | Three hundred and eighty-five |
| Two hundred and twenty-five | (使用,“,我们,”) | Three hundred and sixty-eight |
| Two hundred and forty-eight | (制作、始终、考虑、重新运行) | Three hundred and sixty-one |
| Two hundred and seventy-eight | (用途、类型、成功、数据) | Three hundred and fifty-three |
| Two hundred and ninety | (更好,使用,统一,引用) | Three hundred and forty-seven |
| Two hundred and ninety-one | (使用、统一、引用、标记) | Three hundred and forty-three |
瞧啊。我们可以在上面的 n-grams 中清楚地看到一些适当的建议。看起来我们的大多数 n-grams 都包含一个动词作为第一个单词。如果我们能以某种方式只过滤掉开头带动词的 n 元语法,那就太好了。仔细想想,一个动词后跟一个名词或形容词会很完美。要是有办法就好了。。。
词性标注
在语料库语言学中,词性标注,也称为“语法标注”,是根据词的定义和上下文将文本中的词标记为对应于特定词性的过程。
来源:维基百科
如果你更喜欢实践而不是理论,这里有一个 POS 的例子:
from nltk import pos_tag
pos_tag(word_tokenize('The most common method is word tokenizing.'))
输出
[('The', 'DT'),
('most', 'RBS'),
('common', 'JJ'),
('method', 'NN'),
('is', 'VBZ'),
('word', 'NN'),
('tokenizing', 'NN'),
('.', '.')]
我们得到了一些分析!我们可以快速解读大多数标签(名词,JJ,形容词等等)。).但是要获得完整的列表,只需使用这一行:
nltk.help.upenn_tagset()
…或者查看这篇文章
组块
我们可以标记每个单词,所以让我们试着寻找特定的模式(也就是组块!).我们在找什么?许多反馈帖子中反复出现的主题之一是建议添加或更改某些内容。我们如何从语法上构建这个句子?让我们检查一下!
pos_tag(word_tokenize('You should add more color.'))
输出
[('You', 'PRP'),
('should', 'MD'),
('add', 'VB'),
('more', 'JJR'),
('color', 'NN'),
('.', '.')]
我们只对“添加更多颜色”部分感兴趣,它被标记为 VB、JJR 和 NN。(动词、比较级形容词和名词)。我们如何只针对文本的特定部分?这是作战计划:
- 我们将把一小段保存到变量中;这一段将包括我们想要的组块语法(类似于“添加更多的颜色”)
- 我们将标记变量,然后我们将标记词性
新的部分来了:
-
命名我们正在寻找的块(例如,“target_phrase”),并使用 POS 标签来指定我们正在寻找的内容。
-
解析段落,并打印结果。
from nltk import RegexpParser
1.我们的段落:
paragraph = '我认为你可以改进内容。你应该补充更多的信息。我就是这样做的,我永远是对的'
2.对段落进行标记,然后使用词性标注:
paragraph_tokenized = word_tokenize(paragraph)
3.命名并组织我们正在寻找的语法:
grammar = "target_phrase:{<vb><jjr><nn>}"
CP = nltk.RegexpParser(grammar)
4.解析带标签的段落:
result = CP.parse(paragraph_taged)
print(result)
输出
(S
I/PRP
think/VBP
you/PRP
can/MD
improve/VB
content/NN
./.
You/PRP
should/MD
(target_phrase add/VB more/JJR information/NN)
./.
I/PRP
do/VBP
it/PRP
that/DT
way/NN
and/CC
I/PRP
am/VBP
always/RB
right/RB)
如果我们只对我们要找的那块感兴趣呢?我们不想显示整个文本!我们的反馈帖子中会有很多文字!
target_chunks = []
for subtree in result.subtrees(filter=lambda t: t.label() == 'target_phrase'):
target_chunks.append(tuple(subtree))
print(target_chunks)
Output
[(('add', 'VB'), ('more', 'JJR'), ('information', 'NN'))]
好了,问题解决了。现在我们要做的最后一件事是计算我们的块在文本中出现的次数:
from collections import Counter
# create a Counter:
chunk_counter = Counter()
# loop through the list of target_chunks
for chunk in target_chunks:
chunk_counter[chunk] += 1
print(chunk_counter)
输出
Counter({(('add', 'VB'), ('more', 'JJR'), ('information', 'NN')): 1})
在完成了小段落的词性标注和组块之后,让我们来看一个更大的集合:所有的反馈帖子。我们将遵循类似的路径来分析反馈帖子。为了更容易地分析不同的文本和 POS 模式,我们将创建三个独立的函数,以便我们可以随时交换输入的文本数据或 POS regex 模式。
第一个功能将为 NLP 工作准备文本数据:它将标记句子和单词,然后标记词性。它将返回一个带有词性标签的单词列表。
def prep_text(text):
# tokenize sentences:
sent_tokenized = sent_tokenize(text)
# tokenize words:
word_tokens = []
for sent in sent_tokenized:
word_tokens.append(word_tokenize(sent))
# POS tagging:
pos_tagged = []
for sent in word_tokens:
pos_tagged.append(pos_tag(sent))
return pos_tagged
我们将使用第一个函数来准备所有反馈帖子的文本数据:
all_feedback = df['feedback'].sum()
all_feedback_tagged = prep_text(all_feedback)
第二个函数将解析所有标记文本数据,并寻找我们将提供的特定块语法;如果单词的标签与提供的模式匹配,它会用一个标签标记这个块。
def parser(regex_pattern, pos_tagged):
np_chunk_grammar = regex_pattern
np_chunk_parser = RegexpParser(np_chunk_grammar)
np_chunked_text = []
for pos_tagged_sentence in pos_tagged:
np_chunked_text.append(np_chunk_parser.parse(pos_tagged_sentence))
return np_chunked_text
chunked_text = parser("bingo: {<VB|NN|NNP><JJR><NN|NNS>}",all_feedback_tagged)
最后一个函数将只过滤出我们要查找的块,并计算它们出现的次数,它还将显示前 10 个:
def chunk_counter(chunked_sentences):
chunks = []
# loop through each chunked sentence to extract phrase chunks of our desired sequence:
for chunked_sentence in chunked_sentences:
for subtree in chunked_sentence.subtrees(filter=lambda t: t.label() == 'bingo'):
chunks.append(tuple(subtree))
# create a Counter object and loop through the list of chunks
chunk_counter = Counter()
for chunk in chunks:
chunk_counter[chunk] += 1
# return 10 most frequent chunks
return chunk_counter.most_common(10)
chunk_counter(chunked_text)
输出
[((('add', 'VB'), ('more', 'JJR'), ('information', 'NN')), 3),
((('add', 'VB'), ('more', 'JJR'), ('weight', 'NN')), 3),
((('see', 'VB'), ('more', 'JJR'), ('projects', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('explanations', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('comments', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('info', 'NNS')), 2),
((('add', 'VB'), ('more', 'JJR'), ('readability', 'NN')), 2),
((('find', 'VB'), ('more', 'JJR'), ('tips', 'NNS')), 1),
((('add', 'VB'), ('more', 'JJR'), ('detail', 'NN')), 1),
((('attract', 'NN'), ('more', 'JJR'), ('users', 'NNS')), 1)]
因为我们的文本已经被标记,如果我们想要寻找不同的模式,我们只需要交换最后两个函数的输入:
chunked_text = parser("bingo: {<VB|NN><RB|VBG>?<JJ><NN|NNS><NN|NNS>?}",all_feedback_tagged)
np_chunk_counter(chunked_text)
[((('make', 'VB'), ('proper', 'JJ'), ('documentation', 'NN')), 9),
((('have', 'VB'), ('sequential', 'JJ'), ('ordering', 'NN')), 6),
((('combine', 'VB'), ('adjacent', 'JJ'), ('code', 'NN'), ('cells', 'NNS')),
4),
((('vs', 'NN'), ('shallow', 'JJ'), ('copy', 'NN'), ('vs', 'NN')), 4),
((('avoid', 'VB'),
('too', 'RB'),
('obvious', 'JJ'),
('code', 'NN'),
('comments', 'NNS')),
3),
((('combine', 'VB'), ('subsequent', 'JJ'), ('code', 'NN'), ('cells', 'NNS')),
3),
((('rotate', 'VB'), ('x-tick', 'JJ'), ('labels', 'NNS')), 3),
((('remove', 'VB'), ('unnecessary', 'JJ'), ('spines', 'NNS')), 3),
((('remove', 'VB'), ('empty', 'JJ'), ('lines', 'NNS')), 2),
((('show', 'NN'), ('original', 'JJ'), ('hi', 'NN')), 2)]
chunked_text = parser("bingo: {<VB><DT><NN|NNS>}",all_feedback_tagged)
chunk_counter(chunked_text)
输出
[((('have', 'VB'), ('a', 'DT'), ('look', 'NN')), 19),
((('take', 'VB'), ('a', 'DT'), ('look', 'NN')), 14),
((('improve', 'VB'), ('the', 'DT'), ('readability', 'NN')), 13),
((('view', 'VB'), ('the', 'DT'), ('jupyter', 'NN')), 12),
((('re-run', 'VB'), ('the', 'DT'), ('project', 'NN')), 12),
((('add', 'VB'), ('a', 'DT'), ('title', 'NN')), 11),
((('create', 'VB'), ('a', 'DT'), ('function', 'NN')), 11),
((('add', 'VB'), ('a', 'DT'), ('conclusion', 'NN')), 11),
((('follow', 'VB'), ('the', 'DT'), ('guideline', 'NN')), 9),
((('add', 'VB'), ('some', 'DT'), ('information', 'NN')), 9)]
chunked_text = parser("bingo: {<JJR><NN|NNS>}",all_feedback_tagged)
np_chunk_counter(chunked_text)
输出
[((('better', 'JJR'), ('readability', 'NN')), 15),
((('more', 'JJR'), ('information', 'NN')), 12),
((('more', 'JJR'), ('comments', 'NNS')), 11),
((('better', 'JJR'), ('understanding', 'NN')), 10),
((('more', 'JJR'), ('projects', 'NNS')), 7),
((('more', 'JJR'), ('explanations', 'NNS')), 6),
((('more', 'JJR'), ('clarification', 'NN')), 5),
((('more', 'JJR'), ('details', 'NNS')), 5),
((('more', 'JJR'), ('detail', 'NN')), 4),
((('more', 'JJR'), ('users', 'NNS')), 4)]
注意一些组合几乎是相同的:“更多细节”和“更多细节”这给了我们一个引入引理化的好机会
词汇化
我们可以把词汇化描述为把单词剥离到它的词根形式。如果我们的文本充满了同一个单词的单数或复数形式,或者同一个动词的不同时态,这可能是有用的。下面举个简单的例子:看函数下面的文字;看完课文后,我们将分析这个函数。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def lemmatize_it(sent):
empty = []
for word, tag in pos_tag(word_tokenize(sent)):
wntag = tag[0].lower()
wntag = wntag if wntag in ['a', 'r', 'n', 'v'] else None
if not wntag:
lemma = word
empty.append(lemma)
else:
lemma = lemmatizer.lemmatize(word, wntag)
empty.append(lemma)
return ' '.join(empty)
string1 = 'Adam wrote this great article, spending many hours on his computer. He is truly amazing.'
lemmatize_it(string1)
输出
Adam write this great article , spend many hour on his computer . He be truly amazing
我们可以看到所有的动词都简化成了它们的词根形式。此外,“小时”,是唯一的复数名词,减少到单数形式。如果我们看一下上面的函数,我们可以看到词汇化首先需要词性标注。如果我们忽略了词性标注,分类器将只处理名词的单数形式。大多数动词会保持原样。
让我们看看,当我们在词条化的文本上使用我们的 POS 管道时,会发生什么:
lemmatized = lemmatize_it(df['feedback'].sum())
feedback_lemmed_tagged = prep_text(lemmatized)
chunked_text = parser("bingo: {<VB|NN><RB|VBG>?<JJ><NN|NNS><NN|NNS>?}",feedback_lemmed_tagged)
chunk_counter(chunked_text)
输出
[((('render', 'VB'), ('good', 'JJ'), ('output', 'NN')), 11),
((('make', 'VB'), ('proper', 'JJ'), ('documentation', 'NN')), 9),
((('be', 'VB'), ('not', 'RB'), ('skip', 'JJ'), ('sql', 'NN')), 7),
((('have', 'VB'), ('sequential', 'JJ'), ('ordering', 'NN')), 6),
((('combine', 'VB'), ('adjacent', 'JJ'), ('code', 'NN'), ('cell', 'NN')), 4),
((('v', 'NN'), ('shallow', 'JJ'), ('copy', 'NN'), ('v', 'NN')), 4),
((('add', 'VB'), ('empty', 'JJ'), ('line', 'NN')), 3),
((('combine', 'VB'), ('subsequent', 'JJ'), ('code', 'NN'), ('cell', 'NN')),
3),
((('rotate', 'VB'), ('x-tick', 'JJ'), ('label', 'NN')), 3),
((('remove', 'VB'), ('unnecessary', 'JJ'), ('spine', 'NN')), 3)]
查看 POS 标记的结果,我们可以看到,第一名被一个甚至没有进入前 10 名的组合占据。它为我们提供了最常见组合的更好表示,但另一方面,单词的词条化使这些结构更难理解。另一个重要的因素是计算能力和引理满足所需的时间。生成上述输出所需的时间增加了一倍。
我们还没有介绍词汇化的一个兄弟:词干。这在计算上要便宜得多,但是结果并不理想。如果你对它们之间的区别感兴趣,请阅读这篇关于堆栈溢出的文章:词干化与词汇化。
一锤定音
如果你觉得这很难理解,以下是我们采取的主要步骤的总结:
- 正确清理文本数据:
- 应用小写
- 删除停用词
- 删除标点符号
- 保留原始文本和清理后的版本
- 将文本数据标记化
- 使用词干或词汇化(记住正确的词汇化需要词性标注)
- 根据数据集大小/目标/内存可用性,您可以检查以下内容:
- 最流行的词
- 常见 n 元语法
- 寻找特定的语法块
进一步的工作
如果你想要更多的编码经验,这里有一些想法可以考虑:
- 将项目分成 2-3 个难度级别,这样我们就可以分析最常见的 n-gram、POS 等。在初级和高级项目中,看看它们有什么不同。
- 引理化后重做 n-gram 分析。
- 考虑每种方法需要多少时间和计算能力——在你考虑之后,进行实际的计算。
有什么问题吗?
随时伸出手问我任何事情: Dataquest , LinkedIn , GitHub
Python 中有效数据可视化的 1 个技巧
原文:https://www.dataquest.io/blog/how-to-communicate-with-data/
February 9, 2017Yes, you read correctly — this post will only give you 1 tip. I know most posts like this have 5 or more tips. I once saw a post with 15 tips, but I may have been daydreaming at the time. You’re probably wondering what makes this 1 tip so special. “Vik”, you may ask, “I’ve been reading posts that have 7 tips all day. Why should I spend the time and effort to read a whole post for only 1 tip?” I can only answer that data visualization is about quality, not quantity. Like me, you probably spent hours learning about all the various charts that are out there — pie charts, line charts, bar charts, horizontal bar charts, and millions of others. Like me, you thought you understood data visualization. But we were wrong. Because data visualization isn’t about making different types of fancy charts. It’s about understanding your audience and helping them achieve their goals. Oh, this is embarrassing — I just gave away the tip. Well, if you keep reading, I promise that you’ll learn all about making effective data visualization, and why this one tip is useful. By the end, you’ll be able to make useful plots like this: 
先说一些日常生活中可能会让你惊讶的数据可视化。你知道吗,每当你在电视上看到天气图,查看挂钟上的时间,或者在红绿灯前停下来,你看到的都是数字数据的可视化表示。不相信我?让我们更深入地了解一下挂钟是如何显示时间的。当时机成熟时
你看不到时钟上的实际时间。而是你看到一只小“手”指向5,一只大“手”指向1,像这样:
我们被训练将数据的视觉表现转化为时间,
5:05。不幸的是,挂钟是数据可视化的一个例子,这使得理解底层数据变得更加困难。解析挂钟的时间比解析数字钟的时间要花费更多的脑力。在数字显示器上显示时间成为可能之前,挂钟就已经出现了,所以唯一的解决方案就是通过两个“指针”来显示时间。让我们来看一个更容易理解底层数据的可视化工具,即天气图。让我们以这张地图为例:
看着上面的地图,你可以立刻看出安得拉邦和泰米尔纳德邦的海岸是印度最热的地方。阿鲁纳恰尔邦和查谟和克什米尔是最冷的地区。我们可以看到较高平均温度过渡到较低平均温度的“线”。该地图非常适合查看地理温度趋势,尽管地图存在显示问题-一些标注溢出了它们的框,或者太亮。如果我们将它表示为一个表,我们将会“丢失”大量的数据。例如,从地图上,我们可以很快看出海德拉巴比安得拉邦的海岸更冷。为了传达地图中的所有信息,我们需要一个充满印度每个地方温度数据的表格,如下所示,但要长一些:
| 城市 | 年平均温度 | |
|---|---|---|
| Zero | 海得拉巴 | Twenty-seven |
| one | 金奈 | Twenty-nine point five |
| Two | 赖布尔 | Twenty-six |
| three | 新德里 | Twenty-three |
这张桌子很难从地理角度来考虑。表中相邻的两个城市可能在地理上相邻,也可能相距甚远。当你一次查看一个城市时,很难弄清楚地理趋势,所以这个表对于查看高层次的地理温度变化没有用。然而,这个表格对于查找你所在城市的平均温度非常有用——比地图有用得多。你可以立刻看出海德拉巴的年平均温度是
27.0摄氏度。理解哪些数据表示在哪些上下文中是有用的,对于创建有效的数据可视化是至关重要的。
到目前为止我们所了解到的
- 在表示数据方面,可视化并不总是比数字更好。
- 即使是看起来不怎么样的可视化,如果和受众的目标相匹配,也是有效果的。
- 有效的可视化可以让观众发现他们用数字表示永远找不到的模式。
在本帖中,我们将学习如何通过可视化我们投资组合的表现来进行有效的可视化。我们将用几种不同的方法来表示数据,并讨论每种方法的优缺点。太多教程都是从制作图表开始,却从来不讨论
为什么制作这些图表?在这篇文章的最后,你会对什么样的图表在什么情况下有用有更多的了解,并且能够更有效地使用数据进行交流。如果你想更深入地了解,你应该试试我们关于探索性数据可视化和通过数据可视化讲故事的课程。我们将使用 Python 3.5 和 Jupyter notebook 以防你想跟进。
数据的表格表示
假设我们持有一些股票,我们想跟踪它们的表现:
AAPL— 500 股GOOG— 450 股BA— 250 股CMG— 200 股NVDA— 100 股RHT— 500 股
我们在 2016 年 11 月 7 日购买了所有股票,我们希望跟踪他们迄今为止的表现。我们首先需要下载每日股价数据,这可以通过
雅虎财经套餐。我们可以使用pip install yahoo-finance来安装包。在下面的代码中,我们:
- 导入
yahoo-finance包。 - 设置要下载的符号列表。
- 遍历每个符号
- 下载从
2016-11-07到前一天的数据。 - 提取每天的收盘价。
- 下载从
- 创建一个包含所有价格数据的数据框架。
- 显示数据帧。
from yahoo_finance import Share
import pandas as pd
from datetime import date, timedelta
symbols = ["AAPL", "GOOG", "BA", "CMG", "NVDA", "RHT"]
data = {}
days = []
for symbol in symbols:
share = Share(symbol)
yesterday = (date.today() - timedelta(days=1)).strftime("%Y-%m-%d")
prices = share.get_historical('2016-11-7', yesterday)
close = [float(p["Close"]) for p in prices]
days = [p["Date"] for p in prices]
data[symbol] = close
stocks = pd.DataFrame(data, index=days)
stocks.head()
| AAPL | 钡 | 圣迈克尔与圣乔治三等爵士 | 谷歌 | NVDA | RHT | |
|---|---|---|---|---|---|---|
| 2017-02-08 | 132.039993 | 163.809998 | 402.940002 | 808.380005 | 118.610001 | 78.660004 |
| 2017-02-07 | 131.529999 | 166.500000 | 398.640015 | 806.969971 | 119.129997 | 78.860001 |
| 2017-02-06 | 130.289993 | 163.979996 | 395.589996 | 801.340027 | 117.309998 | 78.220001 |
| 2017-02-03 | 129.080002 | 162.399994 | 404.079987 | 801.489990 | 114.379997 | 78.129997 |
| 2017-02-02 | 128.529999 | 162.259995 | 423.299988 | 798.530029 | 115.389999 | 77.709999 |
正如您在上面看到的,这给了我们一个表格,其中每一列是一个股票代码,每一行是一个日期,每个单元格是该股票代码在该日期的价格。整个数据帧有
62成排。如果我们想在特定的一天查找特定股票的价格,这是非常好的。例如,我可以很快知道 2017 年 2 月 1 日收盘时AAPL股票的价格是128.75。然而,我们可能只关心我们是否从每个股票代码中赚钱或赔钱。我们可以找到每股买入时的价格和当前价格之间的差额。在下面的代码中,我们从当前股票价格中减去买入时的价格。
change = stocks.loc["2017-02-06"] - stocks.loc["2016-11-07"]
change
AAPL 19.879989
BA 20.949997
CMG 13.100006
GOOG 18.820007
NVDA 46.040001
RHT 1.550003
dtype: float64
太好了!看起来我们每笔投资都赚了钱。然而,我们无法知道我们的投资增加了多少。我们可以用一个稍微复杂一点的公式来实现:
pct_change = (stocks.loc["2017-02-06"] - stocks.loc["2016-11-07"]) / stocks.loc["2016-11-07"]
pct_change
AAPL 0.180056
BA 0.146473
CMG 0.034249
GOOG 0.024051
NVDA 0.645994
RHT 0.020217
dtype: float64
看起来我们的投资在百分比上表现得非常好。但是很难说我们总共赚了多少钱。让我们将价格变化乘以我们的股份数,看看我们赚了多少:
import numpy as np
share_counts = np.array([500, 250, 200, 450, 100, 500])
portfolio_change = change * share_counts
portfolio_change
AAPL 9939.99450
BA 5237.49925
CMG 2620.00120
GOOG 8469.00315
NVDA 4604.00010
RHT 775.00150
dtype: float64
最后,我们可以合计一下我们总共赚了多少:
sum(portfolio_change)
31645.49969999996
看看我们的购买价格,看看我们赚了多少百分比:
sum(stocks.loc["2016-11-07"] * share_counts)
565056.50745000003
我们在数字数据表示方面已经走得很远了。我们能够计算出我们的投资组合价值增加了多少。在许多情况下,数据可视化是不必要的,一些数字可以表达你想分享的一切。在本节中,我们了解到:
- 数据的数字表示足以讲述一个故事。
- 在转向可视化之前,尽可能简化表格数据是一个好办法。
- 理解受众的目标对于有效地展示数据非常重要。
当您想要在数据中找到模式或趋势时,数字表示就不再适用了。假设我们想弄清楚 12 月份是否有股票波动更大,或者是否有股票下跌然后回升。我们可以尝试使用一些措施,比如
标准偏差,但他们不会告诉我们全部情况:
stocks.std()
AAPL 6.135476
BA 6.228163
CMG 15.352962
GOOG 21.431396
NVDA 11.686528
RHT 3.225995
dtype: float64
以上告诉我们
在我们的时间段内,AAPL的68%收盘股价在均价的5.54范围内。不过,很难说这表明波动性是低还是高。也不好说AAPL最近有没有涨价。在下一节中,我们将弄清楚如何可视化我们的数据,以确定这些难以量化的趋势。
绘制我们所有的股票符号
我们可以做的第一件事是对每个股票系列做一个绘图。我们可以通过使用
熊猫。DataFrame.plot 方法。这将为每个股票代码创建一个每日收盘价线图。我们需要首先对数据帧进行逆序排序,因为目前它是按日期的降序排序的,我们希望它按升序排序:
stocks = stocks.iloc[::-1]
stocks.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1105cd048>

上面的情节是一个好的开始,我们已经在很短的时间内走了很远。不幸的是,图表有点混乱,很难说出一些低价符号的总体趋势。让我们将图表标准化,将每天的收盘价显示为起始价的一部分:
normalized_stocks = stocks / stocks.loc["2016-11-07"]
normalized_stocks.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x10f81b8d0>

该图更适合于查看每只股票价格的相对趋势。每条线都向我们展示了股票的价值相对于其购买价格是如何变化的。这向我们展示了哪些股票在百分比的基础上增加了,哪些没有。我们可以看到
我们买下它后,股票价格迅速上涨,并持续增值。RHT12 月底似乎损失了不少价值,但价格一直在稳步回升。不幸的是,这个情节有一些视觉问题,使情节难以阅读。这些标签挤在一起,很难看出GOOG、CMG、RHT、BA和AAPL发生了什么,因为这些线捆在一起了。我们将使用figsize关键字参数增加绘图的大小,并增加线条的宽度来解决这些问题。我们还将增加轴标签和轴字体大小,使它们更容易阅读。
import matplotlib.pyplot as plt
normalized_stocks.plot(figsize=(15,8), linewidth=3, fontsize=14)
plt.legend(fontsize=14)
<matplotlib.legend.Legend at 0x10eaba160>

在上面的图中,从视觉上分离线条要容易得多,因为我们有更多的空间,而且线条更粗。标签也更容易阅读,因为它们更大。比方说,我们想知道随着时间的推移,每只股票占我们总投资组合价值的百分比是多少。我们需要首先用我们持有的股票数量乘以每个股票价格系列,然后除以总投资组合价值,然后绘制面积图。这将让我们看到一些股票的涨幅是否足以构成我们整个投资组合中更大的份额。在下面的代码中,我们:
- 将每只股票的价格乘以我们持有的股份数量,得到我们拥有的每种符号的股份总价值。
- 将每行除以当日投资组合的总价值,计算出每只股票占投资组合价值的百分比。
- 在面积图中绘制数值,其中 y 轴从
0到1。 - 隐藏 y 轴标签。
portfolio = stocks * share_counts
portfolio_percentages = portfolio.apply(lambda x: x/sum(x), axis=1)
portfolio_percentages.plot(kind="area", ylim=(0,1), figsize=(15,8), fontsize=14)
plt.yticks([])
plt.legend(fontsize=14)
<matplotlib.legend.Legend at 0x10ea8cda0>

正如你在上面看到的,我们投资组合的大部分价值在
GOOG股票。自从我们购买股票以来,每个股票代码的美元总分配没有太大变化。从另一个角度来看之前的数据,我们知道NVDA的价格在过去几个月里增长很快,但是从这个角度来看,我们可以看到它的总价值在我们的投资组合中并不算多。这意味着,尽管NVDA的股价大幅上涨,但它并没有对我们的整体投资组合价值产生巨大影响。请注意,上面的图表很难解析,也很难看出。这是一个图表的例子,通常最好是一系列数字,显示每只股票占投资组合价值的平均百分比。思考这个问题的一个好方法是“这个图表比其他图表能更好地回答什么问题?”如果答案是“没有问题”,那么你可能会更喜欢别的东西。为了更好地把握我们的整体投资组合价值,我们可以绘制出:
portfolio.sum(axis=1).plot(figsize=(15,8), fontsize=14, linewidth=3)
<matplotlib.axes._subplots.AxesSubplot at 0x110dede48>

当看上面的图时,我们可以看到我们的投资组合在 11 月初、12 月底和 1 月底损失了很多钱。当我们查看以前的一些地块时,我们会发现这主要是由于价格的下降
这是我们投资组合的大部分价值。能够从不同角度可视化数据有助于我们理清整个投资组合的故事,并更明智地回答问题。例如,制作这些图表帮助我们发现:
- 整体投资组合价值趋势。
- 哪些股票占我们投资组合价值的百分比。
- 个股的走势。
如果不理解这三点,我们就无法理解为什么我们的投资组合的价格会变化。让我们回到开始这篇文章时的技巧,理解你的读者和他们会问的问题会帮助你设计出符合他们目标的可视化效果。有效可视化的关键是确保它能帮助您的受众更容易地理解复杂的表格数据。
后续步骤
在这篇文章中,你学到了:
- 如何简化数字数据?
- 哪些问题可以用数字数据来回答,哪些问题需要可视化。
- 如何设计视觉效果来回答问题?
- 为什么我们首先要进行可视化?
- 为什么有些图表对我们的观众没那么有用。
如果您想更深入地了解如何探索数据并使用数据讲述故事,您应该查看我们在
如何通过开展大型调查来收集自己的数据
原文:https://www.dataquest.io/blog/how-to-conduct-a-survey-and-collect-data-for-a-data-science-project/
November 27, 2018In this post, we’ll learn to create an online survey and how to prevent some common mistakes made in surveys. We’ll cover all steps of the survey process, including:
- 选择人口
- 取样方法
- 制定数据分析计划
- 写好问题
- 分发选项
数据科学家知道,如果基于的数据不可靠,那么即使是最巧妙的代码、最好的数据分析和最漂亮的可视化效果也是毫无价值的。那么,我们如何确保我们的调查数据是准确和有意义的呢?这是一个过程,但是让我们从一个快速测试开始。你能从这些真实的调查问题中发现问题吗?
你认为大多数政客都不诚实还是像其他人一样?【来源】
❍是❍否
你上一次升级电脑和打印机是什么时候?【来源】
❍年前 ❍月前 ❍几周前 ❍几天前
这些调查问题很难解释,也很难回答。如果读者不认为政客不诚实或者不喜欢其他人呢?而如果读者前几天升级了电脑,却没有打印机呢?我们将设计一个调查来避免犯这样的错误。
在线调查和调查过程
数据科学家对了解人们的想法和行为感兴趣,调查是收集这类数据的最直接的方式之一。管理调查的传统方法包括电话采访、邮件调查和个人采访。但是今天,在线调查是收集人们信息的最受欢迎的方式之一,因为它有几个优点:
- 轻松创建和管理:有许多工具可以让您轻松设计和分发调查。
- 接触大量人群:没有印刷成本、发行时间等限制。
- 广泛的地理覆盖范围:我们可以将我们的调查发送给世界各地可以访问互联网的人。
- 高响应速度:受访者很容易完成——不需要打印调查表、填写并通过邮件返回。
- 直接数据输入:这减少了导入数据的时间和数据错误,这是数据科学家的一大优势。
当然,没有什么是完美的,在线调查也有缺点:
- 低回复率:只有一小部分参与在线调查的人可能会点击并填写全部内容(尽管这可以通过良好的调查设计和有趣的问题得到一定程度的缓解)。
- 样本并不总是代表人口:在线调查只接触到能上网的人。
这篇文章主要关注在线调查这种方法,但是确保在线调查是实现你的研究目标的最佳方法是很重要的。如果你工作的人群少,面对面的面试可能会更好。在人口非常多的情况下,寻找能够最好地绘制概率样本的方法,因为这允许最多的数据分析选项。包括在线调查在内的所有调查类型都遵循相同的步骤:
1。确定你的目标。
2。选择受访者。
3。创建数据分析计划。
4。开展调查。
5。预测试调查。
6。分发并开展调查。
7。分析数据。
8。报告结果。
让我们一步一步地完成调查过程。
第一步:确定你的目标
每个调查都以一个目的或主题开始,这个目的或主题需要分解成目标。我们的目标应该明确定义,因为它们为我们的问题和数据分析提供了信息。确保目标是具体的,可衡量的,并告知行动(如定价策略或营销活动)。让我们看一个例子:
调查的目的:评估员工对允许狗进入办公室的看法。
目标 1:评估人们对在办公室养狗的看法。
目标 2:了解员工是否对狗过敏。
–目标 3:评估关于每月花费大约 100 美元购买狗粮的意见。
目标 4:确定人们是否养狗以及数量。
为了定义明确的目标,我们可以研究文献,征求他人的意见,并进行定性研究。定性研究,如面对面的采访,有助于我们更多地了解我们正在研究的问题及其背景。向他人征求意见和研究文献可能有助于我们快速发现问题,为进一步研究锁定主题,或发现可能为我们的分析提供信息的现有数据集。
第二步:人口和抽样
定义人口
我们试图通过调查来研究的一群人被称为人口。在我们的办公室里的狗的例子中,人口是公司的所有雇员。因此,我们将从生成所有群体成员的列表开始,我们称之为采样框架。在我们的狗的例子中,我们可以从人力资源部门获得员工姓名和电子邮件地址的列表。像 SurveyMonkey 和 Google Surveys 这样的调查公司也可以帮助你找到受访者。
受访者或参与者是实际参与我们研究项目的人。如果我们向所有员工(全体员工)发出参与调查的邀请,我们就是在进行人口普查。但是,通常不可能收集整个人口的数据——例如,当研究是关于美国青少年的消费习惯时。
为了解决这个问题,我们可以选择一个小组:样本。这并不理想,但如果我们抽取一个与我们的总体非常相似的样本(即,在统计上代表总体),我们就可以根据我们调查的样本得出关于总体的结论。让我们假设我们例子中的公司非常大。我们可能需要抽取一个样本,因为调查整个公司太困难了。这意味着我们需要确保样本没有偏见(例如,我们不想只选择喜欢猫的人),所以让我们在下一节看看如何绘制一个好的样本。
在线调查的抽样方法
讨论所有的抽样方法超出了本文的范围,所以我们将集中讨论在线调查的抽样方法的选择,正如 Sue 和 Ritter 在他们关于在线调查的优秀著作中所推荐的。数据科学家通常使用概率样本。要绘制一个概率样本,我们需要一个明确定义的抽样框架,比如一个员工姓名列表。概率样本取决于随机选择,这意味着群体中的每个个体都有相同的机会被选中。使用随机选择允许您根据统计数据得出关于总体的结论。一些概率抽样方法包括:
- 简单随机抽样和系统随机抽样,群体中每个人被选中的机会相同。
- 分层抽样和整群抽样,允许我们从不同的亚群体中选择人,如年龄组或性别。
(讨论如何抽取概率样本超出了本文的范围,但是这门课可以帮助你了解更多关于那个话题的知识。)有一些非概率抽样技术常用于在线调查,但它们并不理想,因为它们不能用来概括整个人口。例如,方便抽样是一种对谁可以参与研究没有限制的方法。
使用这种方法的一种常见方式是在网站上发布一个调查链接来寻找参与者。这可能会导致大量的响应,但是如果没有控制谁响应的方法,我们将很难从这些数据中得出有意义的结论。另一种技术是拦截抽样,通过弹出窗口邀请网站访问者参与调查,例如,提供关于他们体验的反馈。同样,这种方法并不理想:我们无法使用这种方法对人口进行概括,而且它极大地限制了我们在分析数据时可以使用的统计方法。
误差来源和样本量
我们希望我们的样本与总体相似。然而,我们从总体和样本中收集的数据之间总是存在差异,我们称之为采样误差。当样本看起来非常像我们正在调查的人口时,抽样误差很低。误差幅度和置信度反映了样本代表总体的程度。误差幅度越大,人们就越不应该相信调查结果能很好地代表人口。研究人员通常决定置信度,反映样本与从实际人群中收集的结果有多大差异。
减少误差的一个方法是增加样本量。同样的 Dataquest 课程可以帮助您衡量您的样本是否能很好地代表您的总体,以及您应该使用多大的样本量。请记住,非概率样本比概率样本需要不同的样本大小准则。当我们选择一个样本时,并不一定意味着我们知道所有将参与我们调查的人。
未回答错误是一个术语,描述了有多少被选中的人实际填写了调查。测量无应答是重要的,因为它影响样本是否能很好地代表总体。也有一些人开始填写调查,但没有完成或跳过问题,我们称之为辍学者。稍后,当我们测试我们的调查时,分析退出和跳过的问题将非常重要,因为它们可以表明我们的问题存在问题,如内容、长度、问题措辞或软件错误,这些问题将影响我们的结果。
第三步:创建数据分析计划
在设计我们的调查之前,我们需要一个分析计划。这将确保我们考虑我们想要分析的一切,以及我们如何才能获得统计上有代表性的结果,让我们进行分析。创建分析计划最简单的方法是写出我们的调查目标以及我们计划如何分析每个目标。例如:目标 4:确定人们是否养狗以及有多少只
- 调查问题:你家有几只狗?
- 答案选项:0,1,2,3,4,5,6+。
- 计量水平:区间数据。
- 分析计划:计算最小值、最大值、平均值。
在我们撰写调查问题时,我们希望继续参考我们的分析计划,以确保我们为所需的分析收集了正确的数据。让我们花点时间来看看衡量的水平,它决定了我们正在收集的信息的性质。我们可以收集四种类型的数据:名义、序数、比率和区间。
这些级别是分层的,间隔是我们可以收集的最高级别的数据。名义数据是与数值无关的信息,不以任何方式排序。
例如,询问性别、喜欢的狗的种类或某人的种族:
你是什么种族?
□亚裔/太平洋岛民 □非裔美国人 □白人 □拉美裔 □美洲土著/阿拉斯加土著 □其他
序数数据是可以排序的数据。然而,等级之间没有相等的距离。例如:教育水平或购买产品的经历:
您对在我们网站上购买产品的体验满意吗?
❍很不满意❍有点不满意 ❍中立 ❍有点满意 ❍很满意
比率数据是数值,带有可解释的距离和绝对零度。一个例子是年龄:我们知道 50 岁的人比 10 岁的人大 5 倍。
你的年龄是多少?
…..岁。
区间数据与比率相同,但没有绝对零点。例如,用摄氏度测量的温度,其中零点是任意的,实际上并不意味着没有任何东西。
第四步:设计调查
至此,我们已经确定了您的目标、人口、抽样策略、调查方法和分析计划。这些都将有助于下一步:写问题和设计我们的调查。大多数调查收集三种类型的信息:
- 被调查者的人口统计数据,包括年龄、性别、收入、受教育程度,可以用来描述被调查者和比较被调查者的群体。
- 可量化信息我们可以统计分析。
- 允许回答者添加定性数据的开放式问题。
问题可以开放式和封闭式两种形式提出。开放式问题允许用户输入自己的答案,但不提供预定义的回答选项。开放式问题会产生难以分析的回答,对受访者来说可能是一个障碍,会增加辍学率。出于这些原因,专家们说应该少用它们,主要是为了探索一个主题和获得可引用的材料。下面是一个开放式问题的例子:
你最喜欢你工作的哪一点?
封闭式问题提供不同类型的回答选项,受访者可以从中选择一个选项。与开放式问题相比,封闭式问题易于回答,并允许我们对结果进行统计分析。封闭式问题的形式包括:
- 选择题。
- 二分问题:提供两个(或三个)选项,如“是”和“否”。它们还可以包含第三个选项,如“不知道”。
- 排名(Rankings):允许你对你认为某件事相对于其他选项的重要性进行排名。
- 评定等级:允许你表明你对某事的认同程度或对某事的评价。
让我们看一些例子:
选择题:
你在我们公司的就业状况如何?
□全职 □兼职 □包工头 □其他
二分问题:
你喜欢狗吗?
❍是❍否
排名问题:
请按重要性从 1 到 4 排列以下各项,其中 1 最重要。
干净的办公室☐ 热闹的办公室☐ 安静的办公室心无旁骛的☐ 好玩的办公室☐
评定量表问题:
表明你在多大程度上同意这种说法:有狗在身边能提高我的幸福感。
❍强烈不同意 ❍不同意 ❍既不同意也不反对 ❍同意 ❍强烈同意
对于所有类型的问题,我们的答案选项必须详尽,这一点很重要。由于这个原因,调查问题通常包括答案选项“其他”和“我不知道”。我们认为应该包括这些选项,但要谨慎使用,尽量包括所有的答案选项,这样回答者就不会用它们来回避问题。
答案还需要是互斥的,这意味着它们不会彼此重叠。大多数调查还使用偶然性问题,即一个接一个的问题,并允许受访者跳过问题。在线调查有助于自动跳过与之前的答案不相关的问题。
例如:
应急问题 : 你养狗吗?
❍是❍否
你愿意偶尔带你的狗去上班吗?
❍是❍否
在精心设计的在线调查中,对第一个问题回答“否”的用户不会被要求回答第二个问题。不要忘记,我们的问题应该由我们的目标和分析计划提供信息。
写好问题
写出好的调查问题需要付出努力,这些问题要容易理解,对受访者有意义。难以理解的问题会导致烦恼和辍学,而不感兴趣或不相关的问题会导致“无态度”,参与者不断地使用猜测或“不知道”选项。这篇文章的引言展示了糟糕的调查问题的例子:难以解释和回答的问题。这是我们简介中最糟糕的调查问题之一:
你认为大多数政客都不诚实还是像其他人一样? ❍有 ❍没有这个问题是:
- 双管齐下:它确实由两个问题组成(“你认为政客诚实吗?”以及“你认为政治家和其他人一样吗?”),很难完整回答。
- 这意味着“其他人”通常是诚实的,这表明如果我们认为政客不像其他人,那么我们也必须相信他们不诚实。
- 暧昧:有待解读。
总的来说,这个问题回答起来很烦,烦的问题会造成掉线和不回应。我们不想那样。这是引言中第二个“糟糕”的调查问题:
你上次升级电脑和打印机是什么时候?
❍年前 ❍月前 ❍几周前 ❍几天前
这个问题很难回答,因为它假设我们同时拥有一台计算机和一台打印机,并且我们在相似的时间升级它们。如果我们不拥有其中一个,或者我们拥有它们,但只升级了一个,不清楚我们应该选择哪个答案。好的调查问题包括:
- 不言自明:它们应该容易理解和回答。
- 明确的:应该只有一种方式来解释或理解问题。
- 对我们的受访者有意义。
- 穷尽。
- 互斥。
- 短。
- 没有行话。
- 视觉吸引力。
- 没有绝对:我们应该提供多种答案选项,避免在我们的问题中使用“总是”或“曾经”这样的词。
- 匹配受访者的语言:我们应该使用受访者能够理解的语言,并解释任何需要的技术术语。
让我们改写引言中的两个“糟糕”的调查问题:
糟糕的调查问题:
你认为大多数政客都不诚实还是像其他人一样?
❍是❍否
好的调查问题:
表明你在多大程度上同意这种说法:“我认为美国目前在职的政客不诚实”。
❍强烈不同意 ❍不同意 ❍既不同意也不反对 ❍同意 ❍强烈同意
糟糕的调查问题:
你上一次升级电脑和打印机是什么时候?
❍年前 ❍月前 ❍几周前 ❍几天前
好的调查问题(分成两个问题):
你上次升级电脑是什么时候?
❍从未 ❍年前 ❍月前 ❍几周前 ❍几天前 ❍我没有自己的电脑
您上次升级打印机是什么时候?
❍从未 ❍年前 ❍月前 ❍几周前 ❍几天前 ❍我没有自己的打印机
提出有效的问题
我们希望我们的调查问题能够衡量它们应该衡量的东西。如果我们试图衡量人们是否升级了他们的电脑,人们用“几年前”来回答“不好”的调查问题,因为他们没有打印机,也从来没有升级过他们的电脑,我们实际上没有衡量任何东西。
此外,我们需要确保我们正在收集准确的信息。回答者回答问题不准确有几个原因。正如 Schaeffer 和 Presser 所指出的,人们可能并不总是对与你的调查相关的事件有准确的记忆。为了最大限度地减少这种影响,我们应该尝试要求受访者只回忆最近发生的事件,我们应该尝试询问具体的事件(而不是一系列事件)。参与者也可以根据他们认为对他们的期望,或者根据社会规范来回答问题。我们称之为社会期望偏见。
但是这里有一个好消息:根据克罗伊特等人的说法。艾尔。与其他调查方法相比,在线调查实际上增加了敏感信息的报告。因此,这种偏见不会像电话调查那样强烈地影响我们的调查。即便如此,所有的调查类型都有社会期望偏差的风险。
我们可以通过强调匿名性和保密性来减少这种偏见,并在可能有社会理由撒谎时,以一种使答案看起来可以接受的方式来措辞问题。
比如:不好的调查问题:
你曾经违章超速吗?
更好的调查问题:
在过去的一周内,你是否超速驾驶过?(提醒:本次调查的回答是匿名的)
参与者可能无法准确回答我们的调查问题的其他原因是他们不知道如何回答,或者回答他们实际上没有意见的问题。在测试您的调查问题时寻找这一点并相应地调整它们是很重要的。询问受访者他们是如何理解某个问题的,或者询问他们为什么选择某个选项。他们的回答可能会揭示这类问题。
格式化调查
在线调查工具使设计调查变得容易,并使其具有吸引力。但是,有几点需要注意。正如 Mick P. Couper 在他的书 设计有效的网络调查 中指出的,在线调查的设计非常重要,因为没有面试官来补偿糟糕的设计并解释其含义。
如果我们决定在调查中使用起始页,我们需要确保以有趣的方式介绍调查。我们还应该提到完成需要多长时间,并感谢参与者花时间填写。强调匿名和保密。简介要简短。问题的顺序应该基于我们的回答者(不仅仅是我们)感兴趣的内容,因为我们希望他们填写整个调查。
你有没有做过一个让你觉得自己在回答无穷无尽的人口统计学问题的调查?这是一个众所周知的烦恼。保持调查简短,以人口统计学问题结束调查,而不是以人口统计学问题开始调查。我们可以使用任何数量的不同格式和风格,但是无论我们选择什么都需要是常规的和可读的(在颜色、字体和大小方面)。它还需要包括明确的指示。如果我们使用评级和尺度,它们也应该是清晰和常规的。以下是一些众所周知的响应格式:
- 小圆圈(单选按钮):这些通常表示你可以在选择题中选择一个选项。
- 复选框:这通常意味着你可以选择所有适用的选项。
- 下拉菜单:这些菜单通常会显示“选择一个”的文字,这样回答者就知道他们可以向下滚动选择。请注意,下拉菜单对用户不太友好,因为用户需要单击/点击并滚动才能看到所有可能的答案。只有当我们必须包含一长串答案时(例如,询问居住国家),才最好使用下拉列表。
- 文本框:用于回答开放式问题。
- 排名选项:这些选项允许回答者添加 1、2、3、4、5 等。对偏好进行排序。
重要的是,我们的调查可以被我们样本中的每个人访问,包括残障人士、慢速互联网连接和不同类型的设备。这对我们的影响程度将取决于我们的样本。不同的语言选项和声音选项是我们可能要考虑添加的常见功能。
第五步:预测试
仅仅因为我们已经写好了调查问题,并不意味着调查已经准备好了!下一步是测试,以确保我们将获得我们所期待的响应质量。预测试可以揭示许多问题,比如措辞不当的问题和遗漏的回答类别。首先,我们可以自己做一些测试:
- 检查不同的电脑、平板电脑、手机和浏览器,确保一切正常。比如:评分量表在手机上能用吗?
- 检查是否有任何应急问题自动跳过。
- 确保图像,图形,声音,链接和图表的工作和加载。
- 寻找风格问题。你能向下滚动吗?字体好读吗?
其次,我们将召集一小群以前没有看过调查的人。然后,我们将让他们参加调查,如果他们有问题,不提供任何帮助或澄清。之后,我们可以和他们谈谈,看看他们的回答,看看我们的调查中是否有需要纠正的问题。
最后,在更大的人群中测试调查,并跟踪他们是如何做的。我们希望测量完成问题和整个调查所需的时间,我们将关注人们在哪些地方“辍学”,以及他们跳过了哪些问题。有一些分析工具可以帮助解决这个问题。所有这些测试阶段都应该提供有用的见解,我们可以使用这些见解来提高我们调查的质量。做出更改后,我们将继续测试循环,直到测试发现的所有问题都得到解决。那么终于到了…
第六步:进行调查
分发调查有不同的方式:
- 通过电子邮件发送。
- 使用链接在网站或应用程序上嵌入或做广告。
- 在网站或应用程序上使用弹出窗口。
- 在社交媒体上发帖。
这些方法中的每一种都与不同的采样策略相关,并且每一种都会影响我们在获得结果后所拥有的数据分析选项。我们可以用来帮助设计和分发调查的在线工具包括 SurveyMonkey 、谷歌调查和 Typeform 。这些工具可以帮助调查过程中的大多数步骤,包括抽样框架、设计调查、调查广告和简单的数据分析。我们可以通过多种方式提高调查的回复率:
- 使用吸引人的调查邀请(或广告)。
- 保持调查简短。
- 向回答者提供一些东西,作为他们填写调查的交换条件,比如某个产品的折扣(但请注意,这会影响抽样误差)。
- 后续邀请提醒人们填写您的调查。
第七步:数据分析
大多数调查工具包括基本的统计和简单的数据分析选项。但这是 Dataquest,我们是数据科学家!我们肯定希望下载数据并进行我们自己的分析,因为这为我们提供了更多的可能性。我们在处理数据时不要忘记的一件事是:我们还应该分析受访者接受调查的方式。
我们应该跟踪人们从哪里退出,他们花了多长时间完成调查,等等。,并使用这些见解来增强我们的数据分析。我们还应该分析数据丢失的原因(如果有丢失的话),并查看异常值以了解这些异常值如何影响结果。具体的方法超出了本文的范围,但是 Dataquest 课程可以帮助你掌握这些技能。
第八步:报告结果
最后一步是报告调查结果。根据我们调查的目的,我们可能会做以下事情:
- 写一份报告。
- 在会议上介绍结果。
- 将结果作为更大研究项目的一部分。
如果我们要写一份报告,我们需要事先确定它的读者群,并把他们考虑在内。例如,如果听众是一个忙碌的主管,他们可能想要一个最相关和可操作的信息的快速鸟瞰总结;其他受众可能想要更深入的逐问题分析。在任何类型的报告中,我们都要记住,对于某些人来说,数字似乎很抽象,很难理解。我们应该使用视觉辅助工具(如图表)来描述我们的结果。
结论
在线调查是为数据科学项目收集数据的有效方式。然而,需要对调查过程中的每一步给予认真关注,以确保调查将产生有用、有效、有代表性的答复数据。下面快速回顾一下这些步骤,以供参考:
1。确定你的目标。
2。选择受访者。
3。创建数据分析计划。
4。开展调查。
5。预测试调查。
6。分发并开展调查。
7。分析数据。
8。报告结果。
资源
偏导数:克里斯·阿尔邦、黄邦贤·摩根和维迪亚·斯潘达纳(2017 年)、
“你的调查糟透了”。Mick P. Couper (2008),设计有效的网络调查,剑桥大学出版社。斯坦利·普莱塞、米克·p·库帕、朱迪思·t·莱斯勒、伊丽莎白·马丁、让·马丹、詹妮弗·m·罗斯格布&埃莉诺·辛格(2004)、
《调查问题的测试与评估方法》《民意季刊》。Kreuter,f .,Presser,s .,和 Tourangeau,R. (2008 年),
“CATI、IVR 和网络调查中的社会期望偏差:模式和问题敏感性的影响”,《公共舆论季刊》。Bradburn,s . sud man 和 b . Wansink(2004 年),
“提问:问卷设计的权威指南——用于市场研究、政治民意调查以及社会和健康问卷(社会科学的研究方法)”,Wiley and sons。谢弗,北卡罗来纳州,和普雷斯,S. (2003 年),
《提问的科学》《社会学年刊》。瓦莱丽·m·苏&洛伊斯·a·里特(2007)、
开展在线调查,Sage Publications。
如何用 30 个代码示例在 R 中创建一个数据框架
原文:https://www.dataquest.io/blog/how-to-create-a-dataframe-in-r/
May 31, 2022
数据帧是 R 编程语言中的基本数据结构。在本教程中,我们将讨论如何在 r 中创建数据帧。
R 中的数据帧是表格(即二维矩形)数据结构,用于存储任何数据类型的值。它是一个基数 R 的数据结构,这意味着我们不需要安装任何特定的包来创建数据帧并使用它。
与任何其他表一样,每个数据帧都由列(表示变量或属性)和行(表示数据条目)组成。就 R 而言,数据帧是一个长度相等的向量列表,同时也是一个二维数据结构,它类似于一个 R 矩阵,不同之处在于:一个矩阵必须只包含一种数据类型,而一个数据帧则更加通用,因为它可以有多种数据类型。然而,虽然数据帧的不同列可以有不同的数据类型,但是每一列都应该是相同的数据类型。
从向量创建 R 中的数据帧
为了从一个或多个相同长度的向量创建 R 中的数据帧,我们使用了 data.frame() 函数。其最基本的语法如下:
df <- data.frame(vector_1, vector_2)
我们可以传递任意多的向量给这个函数。每个向量将代表一个数据帧列,并且任何向量的长度将对应于新数据帧中的行数。也可以只传递一个向量给data.frame()函数,在这种情况下,将创建一个只有一列的 DataFrame。
从向量创建 R 数据帧的一种方法是首先创建每个向量,然后按照必要的顺序将它们传递给data.frame()函数:
rating <- 1:4
animal <- c('koala', 'hedgehog', 'sloth', 'panda')
country <- c('Australia', 'Italy', 'Peru', 'China')
avg_sleep_hours <- c(21, 18, 17, 10)
super_sleepers <- data.frame(rating, animal, country, avg_sleep_hours)
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
(边注:更准确的说,刺猬和树懒的地理范围更广一点,但是我们不要那么挑剔!)
或者,我们可以在下面的函数中直接提供所有的向量:
super_sleepers <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10))
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
我们得到了与前面代码中相同的数据帧。请注意以下特征:
- 可使用
c()函数(如c('koala', 'hedgehog', 'sloth', 'panda'))或范围(如1:4)创建数据帧的向量。 - 在第一种情况下,我们使用赋值操作符
<-来创建向量。在第二个例子中,我们使用了参数赋值操作符=。 - 在这两种情况下,向量的名称变成了结果数据帧的列名。
- 在第二个例子中,我们可以在引号中包含每个向量名(例如
'rating'=1:4),但这并不是真正必要的——结果是一样的。
让我们确认我们得到的数据结构确实是一个数据帧:
print(class(super_sleepers))
[1] "data.frame"
现在,让我们探索它的结构:
print(str(super_sleepers))
'data.frame': 4 obs. of 4 variables:
$ rating : int 1 2 3 4
$ animal : Factor w/ 4 levels "hedgehog","koala",..: 2 1 4 3
$ country : Factor w/ 4 levels "Australia","China",..: 1 3 4 2
$ avg_sleep_hours: num 21 18 17 10
NULL
我们看到,尽管animal和country向量最初是字符向量,但是对应的列具有 factor 数据类型。这种转换是data.frame()函数的默认行为。为了抑制它,我们需要添加一个可选参数stringsAsFactors,并将其设置为FALSE:
super_sleepers <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10),
stringsAsFactors=FALSE)
print(str(super_sleepers))
'data.frame': 4 obs. of 4 variables:
$ rating : int 1 2 3 4
$ animal : chr "koala" "hedgehog" "sloth" "panda"
$ country : chr "Australia" "Italy" "Peru" "China"
$ avg_sleep_hours: num 21 18 17 10
NULL
现在我们看到从字符向量创建的列也是字符数据类型。
还可以添加数据帧中各行的名称(默认情况下,这些行是从 1 开始的连续整数)。为此,我们使用可选参数row.names,如下所示:
super_sleepers <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10),
row.names=c('row_1', 'row_2', 'row_3', 'row_4'))
print(super_sleepers)
rating animal country avg_sleep_hours
row_1 1 koala Australia 21
row_2 2 hedgehog Italy 18
row_3 3 sloth Peru 17
row_4 4 panda China 10
注意,在 R 数据帧中,列名和行名(如果存在的话)必须是唯一的。如果我们错误地为两列提供了相同的名称,R 会自动为其中的第二列添加一个后缀:
# Adding by mistake 2 columns called 'animal'
super_sleepers <- data.frame(animal=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10))
print(super_sleepers)
animal animal.1 country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
相反,如果我们在行名上犯了类似的错误,程序将抛出一个错误:
# Naming by mistake 2 rows 'row_1'
super_sleepers <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10),
row.names=c('row_1', 'row_1', 'row_3', 'row_4'))
print(super_sleepers)
Error in data.frame(rating = 1:4, animal = c("koala", "hedgehog", "sloth", : duplicate row.names: row_1
Traceback:
1\. data.frame(rating = 1:4, animal = c("koala", "hedgehog", "sloth",
. "panda"), country = c("Australia", "Italy", "Peru", "China"),
. avg_sleep_hours = c(21, 18, 17, 10), row.names = c("row_1",
. "row_1", "row_3", "row_4"))
2\. stop(gettextf("duplicate row.names: %s", paste(unique(row.names[duplicated(row.names)]),
. collapse = ", ")), domain = NA)
如有必要,我们可以在创建后使用names()函数重命名数据帧的列:
names(super_sleepers) <- c('col_1', 'col_2', 'col_3', 'col_4')
print(super_sleepers)
col_1 col_2 col_3 col_4
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
从矩阵创建 R 中的数据帧
从矩阵中创建 R 数据帧是可能的。然而,在这种情况下,一个新数据帧的所有值将是相同的数据类型。
假设我们有以下矩阵:
my_matrix <- matrix(c(1, 2, 3, 4, 5, 6), nrow=2)
print(my_matrix)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
我们可以使用相同的data.frame()函数从它创建一个数据帧:
df_from_matrix <- data.frame(my_matrix)
print(df_from_matrix)
X1 X2 X3
1 1 3 5
2 2 4 6
不幸的是,在这种情况下,无法使用一些可选参数直接在函数内部更改列名(然而,具有讽刺意味的是,我们仍然可以使用row.names参数重命名行)。由于默认的列名不是描述性的(或者至少是有意义的),我们必须在创建 DataFrame 之后通过应用names()函数来修复它:
names(df_from_matrix) <- c('col_1', 'col_2', 'col_3')
print(df_from_matrix)
col_1 col_2 col_3
1 1 3 5
2 2 4 6
从向量列表中创建 R 中的数据帧
在 R 中创建数据帧的另一种方法是向data.frame()函数提供一个向量列表。事实上,我们可以把 R 数据帧看作是所有向量长度相同的向量列表的一个特例。
假设我们有下面的向量列表:
my_list <- list(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10))
print(my_list)
$rating
[1] 1 2 3 4
$animal
[1] "koala" "hedgehog" "sloth" "panda"
$country
[1] "Australia" "Italy" "Peru" "China"
$avg_sleep_hours
[1] 21 18 17 10
现在,我们想从它创建一个数据帧:
super_sleepers <- data.frame(my_list)
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
需要再次强调的是,为了能够从向量列表中创建数据帧,所提供的列表中的每个向量必须具有相同数量的条目;否则,程序会抛出一个错误。例如,如果我们试图在创建my_list时删除“考拉”,我们仍然可以创建向量列表。然而,当我们试图使用该列表创建数据帧时,我们会得到一个错误。
这里需要注意的另一点是,列表的项应该是名为的(直接在创建向量列表时,就像我们做的那样,或者稍后,在列表上应用names()函数)。如果我们不这样做,并将一个包含“无名”向量的列表传递给data.frame()函数,我们将得到一个包含毫无意义的列名的数据帧:
my_list <- list(1:4,
c('koala', 'hedgehog', 'sloth', 'panda'),
c('Australia', 'Italy', 'Peru', 'China'),
c(21, 18, 17, 10))
super_sleepers <- data.frame(my_list)
print(super_sleepers)
X1.4 c..koala....hedgehog....sloth....panda..
1 1 koala
2 2 hedgehog
3 3 sloth
4 4 panda
c..Australia....Italy....Peru....China.. c.21..18..17..10.
1 Australia 21
2 Italy 18
3 Peru 17
4 China 10
从其他数据帧创建 R 中的数据帧
我们可以通过组合两个或多个其他数据帧来创建 R 中的一个数据帧。我们可以水平或垂直地做这件事。
为了水平组合数据帧(即将一个数据帧的列添加到另一个数据帧的列中),我们使用了cbind()函数,在这里我们传递必要的数据帧。
*假设我们有一个只包含super_sleepers表的前两列的数据帧:
super_sleepers_1 <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'))
print(super_sleepers_1)
rating animal
1 1 koala
2 2 hedgehog
3 3 sloth
4 4 panda
super_sleepers的后两列保存在另一个数据帧中:
super_sleepers_2 <- data.frame(country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10))
print(super_sleepers_2)
country avg_sleep_hours
1 Australia 21
2 Italy 18
3 Peru 17
4 China 10
现在,我们将应用cbind()函数来连接两个数据帧,并获得初始的super_sleepers数据帧:
super_sleepers <- cbind(super_sleepers_1, super_sleepers_2)
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
注意,为了成功执行上述操作,数据帧必须具有相同的行数;否则,我们会得到一个错误。
类似地,为了垂直组合数据帧(即,将一个数据帧的行添加到另一个数据帧的行),我们使用rbind()函数,在这里我们传递必要的数据帧。
*假设我们有一个只包含前两行super_sleepers的数据帧:
super_sleepers_1 <- data.frame(rating=1:2,
animal=c('koala', 'hedgehog'),
country=c('Australia', 'Italy'),
avg_sleep_hours=c(21, 18))
print(super_sleepers_1)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
另一个数据帧包含最后两行super_sleepers:
super_sleepers_2 <- data.frame(rating=3:4,
animal=c('sloth', 'panda'),
country=c('Peru', 'China'),
avg_sleep_hours=c(17, 10))
print(super_sleepers_2)
rating animal country avg_sleep_hours
1 3 sloth Peru 17
2 4 panda China 10
让我们使用rbind()函数将它们垂直组合起来,得到我们的初始数据帧:
super_sleepers <- rbind(super_sleepers_1, super_sleepers_2)
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
注意,为了成功执行该操作,数据帧必须具有相同数量的列和相同顺序的相同列名。否则,我们会得到一个错误。
在 R 中创建一个空的数据帧
在某些情况下,我们可能需要创建一个空的 R 数据帧,只有列名和列数据类型,没有行——然后使用 for 循环填充。为此,我们再次应用data.frame()函数,如下所示:
super_sleepers_empty <- data.frame(rating=numeric(),
animal=character(),
country=character(),
avg_sleep_hours=numeric())
print(super_sleepers_empty)
[1] rating animal country avg_sleep_hours
<0 rows> (or 0-length row.names)
让我们检查新的空数据帧的列的数据类型:
print(str(super_sleepers_empty))
'data.frame': 0 obs. of 4 variables:
$ rating : num
$ animal : Factor w/ 0 levels:
$ country : Factor w/ 0 levels:
$ avg_sleep_hours: num
NULL
正如我们前面看到的,由于由data.frame()函数进行的默认转换,我们希望成为字符数据类型的列实际上是因子数据类型。如前所述,我们可以通过引入一个可选参数stringsAsFactors=FALSE来修复它:
super_sleepers_empty <- data.frame(rating=numeric(),
animal=character(),
country=character(),
avg_sleep_hours=numeric(),
stringsAsFactors=FALSE)
print(str(super_sleepers_empty))
'data.frame': 0 obs. of 4 variables:
$ rating : num
$ animal : chr
$ country : chr
$ avg_sleep_hours: num
NULL
注意:当应用
data.frame()函数时,添加stringsAsFactors=FALSE参数总是一个好的实践。我们在本教程中并没有太多使用它,只是为了避免代码过载,把重点放在主要细节上。但是,对于实际任务,您应该始终考虑添加此参数,以防止包含字符数据类型的数据帧出现不良行为。
在 R 中创建空数据帧的另一种方法是创建另一个数据帧的空“副本”(实际上意味着我们只复制列名和它们的数据类型)。
让我们重新创建原始的super_sleepers(这次,使用stringsAsFactors=FALSE参数):
super_sleepers <- data.frame(rating=1:4,
animal=c('koala', 'hedgehog', 'sloth', 'panda'),
country=c('Australia', 'Italy', 'Peru', 'China'),
avg_sleep_hours=c(21, 18, 17, 10),
stringsAsFactors=FALSE)
print(super_sleepers)
rating animal country avg_sleep_hours
1 1 koala Australia 21
2 2 hedgehog Italy 18
3 3 sloth Peru 17
4 4 panda China 10
现在,使用以下语法创建一个空模板作为新的数据帧:
super_sleepers_empty <- super_sleepers[FALSE, ]
print(super_sleepers_empty)
[1] rating animal country avg_sleep_hours
<0 rows> (or 0-length row.names)
让我们仔细检查原始数据帧的列的数据类型是否保留在新的空数据帧中:
print(str(super_sleepers_empty))
'data.frame': 0 obs. of 4 variables:
$ rating : int
$ animal : chr
$ country : chr
$ avg_sleep_hours: num
NULL
最后,我们可以从一个没有行和必要列数的矩阵中创建一个空的数据帧,然后给它分配相应的列名:
columns= c('rating', 'animal', 'country', 'avg_sleep_hours')
super_sleepers_empty = data.frame(matrix(nrow=0, ncol=length(columns)))
names(super_sleepers_empty) = columns
print(super_sleepers_empty)
[1] rating animal country avg_sleep_hours
<0 rows> (or 0-length row.names)
最后一种方法的一个潜在缺点是没有从一开始就设置列的数据类型:
print(str(super_sleepers_empty))
'data.frame': 0 obs. of 4 variables:
$ rating : logi
$ animal : logi
$ country : logi
$ avg_sleep_hours: logi
NULL
从文件中读取 R 中的数据帧
除了在 R 中从头开始创建数据帧之外,我们还可以以表格形式导入一个已经存在的数据集,并将其保存为数据帧。事实上,这是为现实任务创建 R 数据框架的最常见方式。
为了了解它是如何工作的,让我们在本地机器上下载一个 Kaggle 数据集橙子对葡萄柚,将其保存在与笔记本相同的文件夹中,将其作为新的数据帧citrus读取,并可视化数据帧的前六行。由于原始数据集以 csv 文件的形式存在,我们将使用read.csv()函数来读取它:
citrus <- read.csv('citrus.csv')
print(head(citrus))
name diameter weight red green blue
1 orange 2.96 86.76 172 85 2
2 orange 3.91 88.05 166 78 3
3 orange 4.42 95.17 156 81 2
4 orange 4.47 95.60 163 81 4
5 orange 4.48 95.76 161 72 9
6 orange 4.59 95.86 142 100 2
注意:不强制将下载的文件保存在工作笔记本的同一文件夹中。如果文件保存在另一个地方,我们只需要提供文件的完整路径,而不仅仅是文件名(例如,
'C:/Users/User/Downloads/citrus.csv')。然而,将数据集文件保存在与工作笔记本相同的文件中是一个好的做法。
上面的代码将数据集'citrus.csv'读入名为citrus的数据帧。
也可以阅读其他类型的文件,而不是 csv 。在其他情况下,我们可以找到有用的函数 read.table() (用于读取任何类型的表格数据)、 read.delim() (用于制表符分隔的文本文件),以及 read.fwf() (用于固定宽度的格式化文件)。
结论
在本教程中,我们探索了在 R 中创建数据帧的不同方法:从一个或多个向量、从一个矩阵、从向量列表、水平或垂直组合其他数据帧、读取可用的表格数据集并将其分配给新的数据帧。此外,我们考虑了在 R 中创建空数据帧的三种不同方法,以及这些方法何时适用。我们特别关注代码的语法及其变体、技术上的细微差别、好的和坏的实践、可能的陷阱以及修复或避免它们的变通方法。**
如何让你的数据科学工作申请脱颖而出
原文:https://www.dataquest.io/blog/how-to-data-science-job-application-stand-out/
January 31, 2019
申请数据科学工作可能会令人生畏,尤其是如果这是你的第一份工作,而且你之前没有任何经验。虽然有大量的工作适合数据科学家,但现代就业市场的性质仍然是,你可能会与数十名其他候选人竞争,甚至可能有数百甚至数千人竞争高知名度的工作。招聘经理可能在看了你的申请 30 秒后就做出决定。怎么做才能脱颖而出?
为了找到答案,我们采访了 Refael“Rafi”Zikavashvili,他是提供免费数据科学面试实践的在线求职面试实践网站 Pramp 的首席执行官和联合创始人。这本身就是一个很好的资源,但 Rafi 的工作性质决定了他花了大量时间思考和实际进行数据科学招聘。对于想要脱颖而出的数据科学求职者,他有一个很大的建议:删掉求职信,用更好的东西代替。
比求职信更好
“求职信已经过时了,”拉菲说。“至少在技术领域,你不会经常看到它们,坦率地说,我不会建议任何人这么做。”
“但在我看来,有一种类似求职信的东西要好得多,”他说。
具体来说,拉菲建议你给潜在雇主发一封电子邮件,指出他们的企业可能面临的挑战,以及你将如何解决它。“那会给我留下非常深刻的印象,”他说。“仅仅根据公开信息就能发现问题的人,会更进一步,提出解决问题的方法?那会让我大吃一惊。”
“基本上,那个人可以从我这里得到即时采访。不问任何问题。在这一点上,我甚至会跳过简历。”
事实上,拉菲说,这甚至不一定需要与正式的工作申请一起发送。拉菲说:“这可能是一个真正喜欢这家公司的候选人,他只是决定看看是否有适合他们的职位,或者是对一个空缺职位的回应。”。“没关系。真正重要的是他们采取什么行动。积极主动地帮助公司,这一直让我印象深刻。”
当然,如果你地毯式轰炸市场,申请你遇到的每一份工作,这并不是你能为你申请的每一份工作都做到的。因为这需要大量的时间投入,所以这种技巧最好留给你真正感兴趣的招聘信息或公司。
拉菲建议:“找一家你真正喜欢的、你充满激情的公司。”“分析一下那家公司。找一个你认为你能帮助解决的挑战。想出解决办法。这是我能给别人的最好的建议。这是一种脱颖而出的方式。”
换句话说:通过展示你确实关心这家有问题的公司,对它的商业问题感兴趣并参与其中,从而脱颖而出。
高风险:将数据分析作为工作应用
首先,你需要仔细选择你感兴趣的公司和/或工作。这是一个耗时的过程,所以你应该只对你非常感兴趣的职位进行面试。要明白这是一个高风险的游戏,所以要确保潜在的回报——这份工作——对你来说是值得的。
其次,你需要确定你有联系招聘经理、首席执行官或其他决策者的方法。很可能是工作申请过程混淆了这些信息,但是如果你要大费周章地做一个自定义分析,你要确保有人真的看到它,所以把它发送到一个人的电子邮件地址更好。好消息是,如果你知道这个人的名字,找到他应该不会太难;如果你知道对方的名字和公司网址,像 Hunter.io 和 VoilaNorbert 这样的服务可以帮助你非常确定地找到商务邮件。
一旦你知道这份工作是值得的,并且你已经有了一个可靠的方法来联系一个真实的人(招聘经理、首席执行官、数据科学负责人等)。)在公司,是时候开始你的研究了。如果你稍微挖掘一下,你可能会惊讶于公开市场甚至公司数据的数量。
您所做的将在很大程度上取决于您正在寻找的公司的具体情况,但您应该像考虑任何以业务为中心的数据科学项目一样考虑这一点,遵循以下步骤:
- 识别公司已经存在或可能存在的业务问题
- 确定哪些类型的数据可能有助于提出这些问题的解决方案
- 收集、清理和组织数据
- 做一些探索性的数据分析和可视化
- 深入最有成效的领域进行进一步分析
- 可视化和/或写下你的分析
如果你在这类项目的任何技术方面需要帮助,我们有易于理解、动手操作的在线课程会教你你需要知道的一切。
但是假设你已经掌握了所有的技术技能,这里最重要的是最后一步:在商业环境中清晰地传达你的分析。换句话说:有什么问题?这个问题的解决方案是什么,为什么?这是你需要传达的最重要的信息。不要向招聘人员扔一堆高等数学或代码,即使你认为他们会理解。
做这些努力的目的是为了证明:
- 你对这家公司感兴趣,并且已经开始深入思考它的业务问题。
- 你拥有在这家公司分析商业问题所需的技术技能
- 你积极主动,主动进取
毫无疑问,这并不总是行得通的。数小时的工作可能以一封电子邮件结束,而你得到的只是礼貌的“不,谢谢”,或者根本没有回复。但是,如果有一家公司你真的很喜欢,并且你很想在众多应聘者中脱颖而出,这种打破常规的策略可能是你需要的,可以让你在招聘经理的名单中名列前茅。
低风险:在传统的申请和面试中使用这个建议
这背后的基本想法是,公司希望看到你在思考和解决他们的业务问题。如果你不想全力以赴一个公司特定的数据分析项目,仍然有一些方法可以帮助你脱颖而出,通过证明你是在一个更传统的应用程序流程的背景下做这件事的。
例如,如果你申请同一领域的几家不同的公司,你可以做一个与该行业相关的数据科学项目,然后将其包括在你的申请中。这不会像做一个公司特定的项目那样有突出的影响,但它确实表明你已经对你将在你申请的公司的行业中做的工作做了一些思考。
一旦你进入了面试阶段,你将有另一个机会展示你对这家公司及其业务问题的思考程度。向你未来的新雇主提出正确的问题真的能帮你脱颖而出。Rafi 说,作为一名优秀的数据科学申请人,“我期待一些非常深入的问题,涉及我们拥有的一些流程,我们拥有的一些假设,对我们至关重要的 KPI。”
“如果我没有看到数据科学家问这些问题,那对我来说是一个危险信号,”他说。
如何找到一份数据科学的工作(来自 NASA 数据专家的建议)
原文:https://www.dataquest.io/blog/how-to-find-an-entry-level-job-in-data-science/
August 30, 2022
要在该领域取得成功,你不必成为数据科学领域的资深人士。问问美国国家航空航天局的数据员艾丽莎·哥伦布就知道了。
虽然 Alyssa 今年早些时候从大学毕业,但她已经在太平洋人寿担任全职数据科学家。她还自诩有一长串演讲约会,并成立了一个名为“T2”的当地女性团体。
哦,我们有没有提到她是国家航空航天局的数据员?
我们问艾丽莎如何打入这个行业。她说的话可能会让你吃惊。
以下是她对基本技能、实习、投资组合以及成功求职的六步秘诀的建议:
建立正确的基础
许多人都在寻找一根魔杖,能让他们立即成为一名成功的数据科学家。尽管 Alyssa 看似一夜成名,但她向我们保证没有灵丹妙药。当然,没有什么可以替代数据中的扎实技能。
“从 Coursera、EdX 和麻省理工学院开放式课程平台上获取一些免费的在线课程,”Alyssa 说。具体来说,她推荐了麻省理工和哈佛的计算机科学导论课程、麻省理工的机器学习和统计学课程和斯坦福的机器学习课程。
她还推荐了 Dataquest (我们发誓,我们没有要求她):
“我参加了一些 Dataquest 课程,发现它们非常有用,”她说。“我带了命令行和 Git 和版本控制;我也建议这样做。”
获得一些现场经验
一旦你有了基本的基础,下一步就很清楚了:通过一些在职培训来巩固它。艾丽莎说你不能害怕实习。
她说:“如果你工作非常努力并表现出主动性,实习和研究职位最终可能会变成全职工作。”。
“在今年夏天太平洋人寿的实习中,我非常努力地工作,以超出预期,这就是我如何获得全职数据科学家角色的原因。我也有以前的实习经历;我在数据分析部门实习过两三次。这无疑帮助我获得了更多的经验、技能和专业知识。”
让自己在线可见
根据 Alyssa 的说法,光有技能永远不会让你找到工作。潜在雇主必须能够亲眼看到你的能力。让他们看到这一点的最好方式是在网上。
“如果你真的想脱颖而出,”Alyssa 说,“以网站、作品集、GitHub、博客、Kaggle 个人资料(或所有这些)的形式展示你对数据科学的兴趣、热情和熟练程度。”
在线展示的优势
“你强大的在线形象不仅会帮助你申请工作,”艾丽莎说,“雇主和其他人也可能会向你提供自由职业项目、面试和演讲。”
事实上,你现在正在读的这篇文章就是一个很好的例子。Dataquest 采访了 Alyssa,因为我们看到她作为 R 女士推特账户的轮值馆长发布了一些很酷的东西。把自己放在网上可能会让人害怕,但也可能带来意想不到的机会。
在线分享什么
你到底应该发布什么来引起招聘人员的注意?Alyssa 说你至少需要一个作品集和一个网站:
“如果你还没有网站,就给自己弄一个。对于一个数据科学家来说,拥有一个网站和一个 GitHub 是必不可少的,”她说。" GitHub Pages 可以免费托管您的网站。你甚至可以用 R 语言写你的网站,我推荐 Blogdown 这样做。”
然后,是至关重要的投资组合。
好的数据科学产品组合是由什么组成的?
每个人都知道建立一个好的投资组合对于寻找数据科学工作很重要。但是你作品集的内容真的取决于你未来想做的工作。Alyssa 建议先研究一下你想找的角色类型。然后,计划展示与这些角色相关的技能的项目组合项目。
专业建议:包括 4 个展示你深度和广度的项目
Alyssa 在开发一个成功的投资组合时不需要猜测:“当你开始建立你的投资组合时,想想你已经完成或可能很快完成的四个项目,这些项目显示了专业知识的深度和范围。”
您肯定希望包含突出您在数据科学职位招聘中要求的顶级语言之一的编码技能的项目(即,按顺序为 Python、R 和 SQL)。艾丽莎建议,确保代码看起来专业。
拥有清晰可读的代码,使用版本控制,将你的项目分成多个文件。评论,再评论一些。”
她还推荐可视化或讲故事:
"除了交流,讲故事也是一项重要的技能."
你的故事可以采用数据可视化的形式,或者只是一篇写得很好的文章。最终目标是以一种既有吸引力又易于理解的格式呈现您的数据。Alyssa 建议,即使项目不是以讲故事为重点,也要写一篇评论。
“在 Github 上发布代码很好,但最好能有一个文字记录,无论是自述文件、博客帖子还是其他东西,”她说。
她还建议加入一个展示你部署能力的项目,“无论是你训练的机器学习模型的 RESTful API,还是漂亮的 R Shiny 或 Tableau 仪表板。”
“如果你想更多地了解数据科学,我推荐 R Shiny,”她说。“如果你希望更多地进入商业智能或数据分析师的角色,那么我建议从 Tableau 开始,特别是如果你还不习惯编码的话。”
选择投资组合时要有选择性
要明白,招聘人员在评估你的投资组合时,也会从字里行间去揣摩。
“投资组合也是关于你没有包括的东西,”艾丽莎说。你的作品集应该展示你最好的作品,所以不要把每一份家庭作业都扔进去。它也需要反映你的技能,所以只有当你对小组项目有重大贡献时,才应该包括在内。
此外,您不应该过于关注简单的数据清理或探索性数据分析。这些元素可以作为其他项目的一部分,但它们可能不应该成为你的文件夹中展示的项目的焦点。
最后,你的作品集应该展示你真正感兴趣的独特项目。在面试中,你会被问到这些项目:
“你的兴奋肯定会让面试官更乐意雇用你,”艾丽莎说。"我是凭经验说的,但这也是常识。"
专业提示:data quest 的大多数数据科学课程都包含一个全面的交互式项目,您可以将其添加到您的项目组合中。例如,如果你完成了我们整个数据科学家之路,你将总共完成 26 个项目。注册是免费的。
如何找到入门级的工作(提示:你可能做错了)
一旦你获得了技能和投资组合,是时候去技术类职位栏,开始寻找很酷的工作了,对吗?不对。
求职公告板不是答案(至少最初不是)
根据 Alyssa 的说法,求职公告板应该是你最后一个要找的地方。
“当你找工作时,在公司网站上寻找工作或查看特定的工作公告板可能很有诱惑力,但根据包括我在内的数据科学行业从业人员的说法,这些是最没有帮助的找工作方式之一,”Alyssa 说。
这是为什么呢?
“如果你的简历在任何方面都不突出,很多这些都会变成黑洞,”艾丽莎说。在基于网络的求职网站上申请工作又快又容易,所以你的简历将会被淹没在堆积如山的其他申请人中。
那么,寻找工作机会的正确方法是什么呢?
获得数据科学工作的步骤
Alyssa 提供了获得第一份数据工作的具体方法:
“按顺序,我会通过招聘人员,然后是朋友/家人/同事,然后是招聘会或招聘活动,然后是 LinkedIn 这样的普通求职板,然后是公司网站,然后是技术求职板,”她说。
总而言之,下面是艾丽莎建议你继续找工作的方法:
- 招聘人员
- 朋友/家人/同事
- 招聘会
- 一般职位公告板(如 LinkedIn)
- 公司网站
- 技术工作板
给所有新手的提示
但是,如果你是一个完全的新手,在这个行业中没有招聘联系人或关系网,该怎么办呢?首先,你应该通过参加聚会和会议以及利用其他社交机会来解决这个问题。但是 Alyssa 说直接联系你不认识的招聘人员也是可以的:
“我会在 LinkedIn 上寻求帮助。我会在 LinkedIn 上搜索“数据科学家招聘人员”或类似的内容,在要求联系之前给他们发消息,或者在要求联系时给他们发消息。”
关键是要记住求职是双向的。
“不要只是发信息给他们‘你有工作给我吗?’”艾丽莎说相反,想想如何让他们的工作更容易,寻找你知道他们需要的候选人。研究他们的公司,看看他们最大的挑战在哪里,并解释你如何帮助解决这些问题。她说,这是获得面试机会的最快途径。
“表达你对帮助他们发展业务的兴趣比立即给他们发信息要求面试要重要得多。”艾丽莎说。“你付出什么就会得到什么,所以尽你所能展示你如何能做出贡献,希望接下来会有面试。”
五大要点
以下是艾丽莎分享的五条重要的智慧。在你递交下一份工作申请之前,请记住以下几点:
- 不要看不起实习。工作经验就是工作经验,它们可以直接通向全职员工的职位。
- 把你自己放到网上和现实生活中去。你永远不知道什么样的工作或其他机会会找上你,但是如果你不在网上出现,不积极参与社区,什么也不会找上你。
- 根据你想要的工作和你的激情来定制你的作品集。在面试中你必须谈论很多东西,所以做一些你会兴奋地谈论的事情。
- 远离求职网站。通过与招聘者建立关系,利用你的人脉,你会得到更好的结果。
- 记住关系是双向的。不要只向人要工作;想想你能如何帮助他们(即使只是给他们买咖啡)。
Dataquest 感谢 Alyssa Columbus 抽出时间与我们交谈。你可以在 她的网站*上了解她的工作,在 Twitter 上关注她 。*
*还有别忘了看看艾丽莎推荐的 Dataquest 课程 !
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何获得数据科学工作
原文:https://www.dataquest.io/blog/how-to-get-a-data-science-job/
December 14, 2016You’ve done it. You just spent months learning how to analyze data and make predictions. You’re now able to go from raw data to well structured insights in a matter of hours. After all that effort, you feel like it’s time to take the next step, and get your first data science job. Unfortunately for you, this is where the process starts to get much harder. There’s no clear path to go from having data science skills to getting a data science job. You’ll need to put in a lot of hard work to forge your own. But don’t give up hope! Getting a data science job after learning on your own is very possible. In this post, we’ll discuss the things you should be doing to put yourself in position to start getting data science interviews. In a subsequent post, we’ll cover the interview process itself, and how to prepare. Afterwards, you might get a snazzy new company laptop! If you feel like your data science skills aren’t yet well developed enough to start looking for a job, you might want to check out our post on how to learn data science, or go to Dataquest and start one of our data science learning paths.
1.通过构建项目不断学习
这可能看起来违反直觉,因为你每天只有这么多时间,你可能想把所有的时间都花在找工作上。但是,请这样想一想,每个数据科学家的主要职责是学习。新的工具不断涌现,什么技能被定义为“数据科学技能”也在不断变化。通过学习,你掌握了这些技能,并提高了你在雇主眼中的吸引力。我强烈建议你把大部分时间花在学习上。为了给自己找工作做好准备,你会想通过做项目来学习。项目是您在数据科学工作中将要创建的东西,自己构建项目是一种很好的实践方式。项目还能帮助你完善你的投资组合,增加你获得面试机会的几率。创建一个项目可以遵循这个粗略的过程:
- 找到一个有趣的数据集。你可以参考这份寻找数据集的地点列表。
- 列出几个你想用数据集回答的问题。拉入您想要使用的任何补充数据集。
- 确保这些问题中至少有一两个拓展了你的知识范围,或者迫使你学习新的工具。
- 使用 Jupyter Notebook 或等效工具探索和分析数据。
- 将您的笔记本存储在 Github 上。
如果你需要更多的指导,请看这篇文章和这篇文章以获得制定和创建这些项目的帮助。
Jupyter 笔记本让数据分析变得简单。在您学习的过程中,请务必特别注意以下主题,这些主题在大多数数据科学教材中往往没有得到充分强调:
- 数据清理——能够清理数据是一项关键技能,也是你工作的大部分。你可以参加data quest 数据清理课程来帮助你。
- 统计学—作为一名数据科学家,严谨是一个很好的方面,这涉及到统计学。你可以参加data quest 统计课程来帮助你。
- 端到端—从原始数据集到严格的分析是一项非常重要的技能。
2.展示你的作品
当你学习数据科学时,你有希望建立一个项目组合。理想情况下,这些项目将在 Jupyter 笔记本或等效工具中进行创作。项目是锻炼你技能的好方法,但是只有当你展示它们的时候,它们才会在你找工作的时候变得非常有价值。通过公开发布你的作品集,你提升了你的形象,并让其他人看到你的作品和技能。
Github
分享你的作品的最快方法是创建一个 Github 帐户,并开始将你的笔记本上传到他们自己的存储库中。以下是一些示例项目存储库:
如您所见,两个项目都有一个README文件,清楚地解释了它们做什么,以及如何使用它们。如果你上传一个 Jupyter 笔记本到 Github,就像这个例子一样,它会自动渲染在界面中,让上传笔记本成为炫耀自己作品的绝佳方式。当你开始找工作时,你应该在 Github 上有 5-10 个项目。
Github 上的一个项目。
创建博客
展示你的工作的一个较慢但更有回报的方法是写一篇关于它的博客。一篇博文通常会描述你是如何创建这个项目的,以及你为什么要采取某些步骤。以下是一些不错的项目演练博客帖子:
为了创建类似上面的帖子,你需要创建自己的博客。你可以在这里阅读一篇关于创建你自己的数据科学博客的很好的教程。当你开始找工作时,你的目标应该是拥有 5 篇左右的博客文章。
3.分享你的作品
随着你在数据科学领域的知名度提高,你会发现获得新机会变得更加容易。提升你形象的一个方法是在相关的背景下与他人分享你的工作。有相当多的数据科学和编程社区欣赏教程或项目演练博客帖子:
- /r/machinelearning —通用机器学习相关文章和教程。
- /r/datascience —通用数据科学相关文章和教程。
- /r/python —广泛介绍 python 的文章/
- /r/learnpython —关于学习 python 的文章或教程。
- /r/learnprogramming —关于学习编程的文章或教程。
- 数据科学社区
在你提交你的文章到任何一个社区之前,确保你参与了这个社区,并且了解他们对什么类型的内容反应良好。这通常包括阅读几周社区中的文章,并发表相关评论。通过分享您的作品,您的博客将获得流量,这可以带来:
- 改进工作的建议。
- 来自招聘人员的直接线索。
- 来自公司和社区成员的直接机会。
- 对数据科学市场的了解,以及谁在招聘。
4.网络
人际关系网是引起公司兴趣的好方法,也是发现你技能上的漏洞的好方法。你应该主要通过在线社区、聚会和咖啡会议来建立关系网。
在线社区
作为分享工作的一部分,你应该加入在线社区。请务必阅读这些社区中的文章,了解什么是数据科学趋势。此外,确保定期发表评论,这样你就可以分享你的观点并结识其他人。创建帖子向他人寻求建议也很常见。以下是一些来自数据科学社区的有用帖子示例:
随着您与社区的接触越来越多,您将会对数据科学世界有更多的了解,并且在找工作时处于更有利的位置。
聚会
聚会是一个很好的方式,可以同时见到很多数据科学家,并听到有趣的谈话。你可以在这里浏览你所在城市的聚会。搜索与你感兴趣的内容相关的关键词,比如“数据科学”、“数据可视化”、“Python”或“R”,会很有帮助。一些聚会是由雇佣数据科学家的公司赞助的,因此是寻找机会的好方法。注意不要只是在聚会上听演讲——和你周围的人互动,和他们交谈。你会惊讶于这些活动中偶然的互动所带来的机会。但是,一定不要把这些随意的互动视为纯粹的社交机会。如果你能帮助别人,你就能建立一个更真实的双向关系。
咖啡会议
试着每周和你所在地区的 1-2 个人进行咖啡会议。通过搜索你所在城市的数据科学家,你可以在 LinkedIn 或 T2 AngelList 上找到人。你也可以在推特上,或者通过流行的数据科学博客找到数据科学家。不要太担心只与经理或负责招聘的人建立关系网。通常,最好的推荐来自你的同事,所以要注重与其他数据科学家建立联系。在联系之前,通过评论他们的博客,在 Twitter 上与他们聊天,或者评论他们的回答来与他们建立关系也是一个好主意。一旦你准备好发电子邮件,联系人们的一个很好的方式就是说一些类似这样的话:
嗨!一直在学数据科学,现在正在找工作。如果你有时间去喝咖啡,我想听听你的建议。我一直在网上关注你,我喜欢你的[在此插入他们的一些作品]。
我对[在此插入问题]特别感兴趣。我很乐意去你的办公室。[在此插入时间]为我工作,但是如果这些对你不工作,我很高兴适应你的时间表。
一些好的问题包括:
- 任何与你联系的人的背景,以及他们是如何开始的。
- 关于这个人现在正在做的工作,以及他们的日常生活的问题。
- 关于特定行业数据科学应用的问题。示例:“教育中最有趣的数据科学应用有哪些?”
- 关于你要见的人的雇主的空缺职位的问题,以及他们是否正在招聘。
- “我能帮你什么吗?”—信不信由你,你可能拥有和你会面的人不具备的技能和经验。如果你能帮助他们一些事情,你会建立一个更强大,更真实的关系。
一些不好问的问题是:
- “我怎么才能找到工作?”—问题越集中越好。这个问题的一个更好的版本应该是“我已经创建了涵盖随机森林、数据清理和可视化的项目。你的雇主在新员工中寻找什么其他技能?接下来我应该在哪些技能上下功夫?”
- "你能看看我的作品集吗?"—审查投资组合并给出良好的反馈可能会花费很多时间,而你只有在建立了良好的关系后才想问这个问题。
- “我怎么在 R 里做这个东西?”—关注高水平的职业建议,最大限度地利用您的时间。
你可能会得到这样一种4回应:
- 沉默。如果得到这个回应,可以再跟进一次,但是如果还是没有得到回应,最好还是继续前进。不是每个人都有时间参加这些会议,或者接受这些会议。
- 抱歉,我现在没时间。这是常见的反应,没关系。感谢他们的时间,继续前进。
- “我没有时间亲自见面,但我愿意打电话和/或通过电子邮件回答更多问题”。这是一个很好的回应,你应该尽快跟进。
- “我很想亲自见见”——太棒了!你刚刚赢得了一次宝贵的面对面交流机会。小心地问一些有针对性的问题,最大限度地利用你的时间。

有太多设备的咖啡会议。
5.建立在线形象
为了获得潜在客户,你需要建立一个在线形象。至少,你应该出现在以下网站上:
确保你的个人资料是最新的,有你项目的链接,并且有你所有的相关经验。您可能还想考虑在以下网站上开展业务:
6.选择性消息公司
到目前为止,我们所有的注意力都放在获得潜在客户和机会上。你还需要有选择地寻找出国机会。LinkedIn 和 AngelList 可以很容易地表明对数百家公司的兴趣,但你会想避免这种策略。这导致了大量时间和精力的浪费,这实际上增加了找工作的难度。相反,你应该非常有选择性:
- 弄清楚你对什么样的公司感兴趣。希望通过你的人际关系网,你应该对不同行业不同类型的公司的数据科学工作有一个很好的了解。如果你真的对医疗保健充满热情,并且喜欢在小公司工作,你应该只考虑较小的健康公司。
- 找到你感兴趣的行业中感兴趣的公司。你可以在 AngelList 上搜索这个。列出 20-30 家你认为感兴趣的公司。
- 针对您选择的行业优化您的在线形象和投资组合。例如,如果你关心医疗保健,你应该写医疗保健相关的博客帖子,像这个。
- 与你感兴趣的公司的数据科学家建立联系。看看你是否能和你感兴趣的公司的数据科学家一起喝咖啡。
- 申请你感兴趣的公司的工作。确保给招聘经理写一封电子邮件(如果你能找到的话),描述你对这个职位的具体热情,以及为什么你会是一个很好的人选。如果你人际关系网很好,你也能得到推荐。
如果在浏览了20–30家公司后,你没有得到任何面试机会,你可能想得到一些具体的建议,改变你的方法。咖啡会议是获得这种建议的好方法。如果你有选择地给公司发信息,但没有得到面试机会,一些最常见的原因是:
- 你的简历和求职信不太适合这家公司。
- 你没有从公司的人那里得到任何推荐。
- 这些工作需要比你现在更多的经验和技能。
底线
没有保证,但如果你遵循这些步骤,你将处于一个很好的位置去得到一份数据科学的工作。我个人在过渡到数据科学的过程中经历了多年的旅程,你可以在这里阅读。关键是保持耐心。只要你在学习并展示你的技能,你就会被雇佣。
接下来的步骤
如果您还没有学习关键的数据科学技能,您可能想在 Dataquest 查看我们的交互式数据场景课程。我们围绕这篇文章中概述的理念建立了我们的课程,我们可以带你从零开始,到你可以开始竞争入门级数据工作的点。如果你感兴趣,你可以注册并免费学习我们的第一个模块。
您可能还想阅读以下其他资源:
- 我是如何在数据科学领域找到第一份工作的?
- 数据科学入门
- 我如何找到一份数据科学家的工作?
如何获得真实世界的数据科学经验
原文:https://www.dataquest.io/blog/how-to-get-real-world-data-science-experience/
October 28, 2021
对于许多崭露头角的数据专业人士来说,获得第一份“真正的”数据科学工作有点像“第 22 条军规”没有一定的专业数据科学经验是不能被录用的,但是没有被录用就没有经验。
虽然雇主期望你立即拥有大量经验似乎不合理,但与其他一些领域相比,数据科学是独一无二的。至关重要的是,你实际上拥有你声称的技能,并且在你被录用之前,你已经在专业能力上证明了这些技能。
如果您对获得专业数据体验这一看似艰巨的任务感到困惑或害怕,我们可以随时提供帮助。这里有九种方法可以让你开始获得真实世界的数据科学经验,这将发展你的职业技能并强化你的简历:
- 建立一个个人项目组合
- 在开源数据项目上合作
- 从事数据科学自由职业
- 数据科学工作志愿者
- 参加黑客马拉松和数据科学竞赛
- 解决实践问题并进行案例研究
- 通过教学成长
建立一个个人项目组合
在数据科学领域获得关注的关键是强大而有吸引力的产品组合。建立能吸引招聘经理眼球的投资组合需要努力,但对于任何试图在数据领域开始职业生涯的人来说,这是必须的。
如果你刚刚开始投资组合,从小处着手很重要。完成大量较小的工作,并取得可衡量的结果,远比第一次尝试就承担一个大项目更有成效。
从简单的事情开始,比如收集和清理杂乱的数据集,探索数据集,并使用您的发现进行预测或发现问题。假设你着手解决一个数据问题(这是数据专业人员工作中必不可少的一部分),尝试创建自己的机器学习模型来为你解决问题。记录你的工作,提供你所使用的代码,并且创建有意义的可视化来展示你的能力。
像 Kaggle 这样的平台为你提供了很多机会来做这些类型的练习,但你不想只局限于这些。虽然 Kaggle 练习很有帮助,但如果你想给任何潜在雇主留下深刻印象,你无疑会想在你的投资组合中展示你自己的数据项目。
其他平台如 Omdena 为世界各地的人工智能工程师和数据科学家提供了在协作环境中解决现实世界问题的机会。作为 Omdena 的合作者,您有机会与世界知名的组织(如联合国信息和通信技术办公室、联合国难民署、世界资源研究所、世界能源理事会、世界粮食计划署、联合国开发计划署)以及来自超过 35 个国家的 impact startups 一起构建人工智能解决方案。
建立一个强大的投资组合将迫使你探索新的可能性,发展你的技能,并增强你的信心。利用 GitHub 作为你的个人数据科学广告牌来展示你的投资组合。此外,确保保持一份最新的简历和履历,详细说明你参与的任何实时项目。在 LinkedIn 上保持活跃也是一个好主意。分享您的数据科学之旅,并更新您完成的任何成就、证书或成功项目。
通过多做这一步,你可以向招聘经理展示你对这个领域充满热情,有很强的学习动力,并且有能力完成工作。
在开源数据项目上合作
除了从事自己的项目之外,您还可以通过加入其他数据专业人员的开源数据项目来积累经验。通过帮助一个合作项目,你将在许多方面受益。
首先,您将有难以置信的机会将您的技能付诸实践,并获得各种不同数据问题和解决方案的经验。其次,你将有机会与许多其他数据专业人士建立关系网。这些领域的专家可以向你展示这一行业的诀窍和技巧。第三,通过与数据专家网络合作,你将发展团队合作和沟通的强大技能。有些人倾向于关注技术能力,但软技能在数据科学中是非常宝贵的,它们可以帮助你与招聘经理建立融洽的关系。
通过加入开源项目,无论您的经验水平如何,您都打开了进入数据科学社区的大门。你会遇到许多其他有相似兴趣和目标的专业人士,发现解决老问题的新方法,并为比自己更伟大的事情做出贡献。如果你对开源项目的合作感兴趣,这里有一些你可以考虑的:
从事数据科学自由职业
正在进行的疫情迫使许多企业转向在线空间,并削减开支以节省资金;这导致了零工经济的爆发。因此,你可以开始获得现实世界的付费体验的一种方式是开始自由职业你的数据科学服务。
如果你有一些营销知识,你可以创建自己的品牌,并通过网站或品牌社交媒体账户营销你的服务。但如果你不是天生的推销员,还是有希望的!有几个平台可供任何想在 gig 基础上提供服务的人使用:
自由职业的好处很多。首先,你可以承担尽可能少或尽可能多的工作,这可以让你练习你的多任务处理技能。由于工作的性质,你还将获得与不同数据集和数据团队打交道的令人难以置信的丰富经验。如果你有兴趣解决某个特定类型的数据问题,你很有可能会找到一个短期的自由职业项目,让你获得更多的经验。一旦你完成了几场演出,你就能向招聘经理证明你的成功。你将能够展示丰富多样的现实工作经验、出色的证明以及帮助企业克服挑战的热情。
数据科学工作志愿者
许多数据专业人士忽略了他们可以通过志愿帮助非营利组织满足数据科学需求而获得的机会。虽然这份工作没有报酬,但自由职业者也有很多相同的好处。通过志愿帮助一项更伟大的事业,你将获得数据科学方面的实践和各种各样的经验,同时建立作为一名热衷于解决数据问题的专业人士的声誉。
这一宝贵的经历将使你能够收集专业参考资料,并强化你简历上的技能。不仅如此,这些花在志愿服务上的时间也会在求职面试中提供很好的讨论话题!另外,你永远不知道志愿者工作什么时候会变成有报酬的工作。
志愿服务的另一个好处是:有足够的机会。这里有几个平台,你可以用来志愿提供你的数据技能:
参加黑客马拉松和数据科学竞赛
很少有什么能像健康和富有成效的竞争一样推动人们提高技能。 黑客马拉松和数据科学竞赛提供了一个独特的机会,通过测试你的技能来展示你的工作准备情况。他们也给你极好的机会去建立关系网,从别人的成功和失败中学习。
如果你没有太多的专业数据科学经验,这些比赛可以证明你有一些有价值的技能。这些活动的整体目标是创造一个高压和高压力的环境,参与者必须解决复杂的问题并将假设转化为行动。通过这样做,这些事件密切反映了数据科学中的工作现实。解决问题、创造性的即兴创作和赶在最后期限之前完成都是一揽子计划的一部分。列出一个或多个数据科学竞赛中的良好表现将会给你的简历增加不少内容,你甚至可能在此过程中获得一些现金奖励。
如果这听起来像是你想要的,这里有几个选择:
解决实践问题并进行案例研究
许多数据专业人士都有一些 MOOC 认证,但它们通常不足以让雇主相信你已经准备好工作了。如果你想让你的技能更上一层楼,你可以从练习题和案例分析开始。
夯实基础永远不会有坏处,尤其是考虑到数据科学中某些工具和硬技能的不可或缺的重要性。考虑到这一点,花额外的时间解决尽可能多的数据问题是值得的,直到基础知识成为第二天性;如果你没有多做一点,你会表现得更好。
Dataquest 就是以这种额外的练习为中心的。事实上,这是我们整个教学方法的基础。在整个 我们的课程 中,您将完成练习题和指导项目,这将帮助您发展、完善和保留您的数据科学职业技能。花些时间提高您的熟练程度,并拓宽您对不同数据集和挑战的体验:
通过教学成长
向他人传授数据科学概念将极大地有助于您缩小任何潜在的知识差距。与世界分享你的知识不仅能获得实践经验,还能让你在招聘经理面前脱颖而出。
无论是通过博客还是视频,你都可以通过解释你已经完成或解决的项目来传播你的专业知识。获得经验不仅仅是能够执行技术任务。展示你是一个有效的沟通者和热心的学习者将 减少申请数据科学工作时被拒绝的机会。
记住所有这些事情,重要的是观察“专业工作经验”不太可能落入你的大腿;这是你必须走出去寻找的东西。你可能不得不尝试几种不同的路线,并进行一些尝试和错误,但在一天结束时,这一切都是为了获得经验。这正是招聘经理所寻求的:通过实际的、真实世界的数据科学经验来展示技能,他们并不特别关心你从哪里得到的,或者你的工作报酬是多少。
如何获得数据科学家的第一份工作?
原文:https://www.dataquest.io/blog/how-to-get-your-first-data-science-job/
August 15, 2017
许多有抱负的数据科学家专注于进行 Kaggle 竞赛,以此作为建立投资组合的一种方式。Kaggle 是一种很好的实践方式,但它应该只是你在数据科学项目中使用的众多方法之一。这是因为 Kaggle 竞赛只关注数据科学工作的一小部分。更具体地说:
- Kaggle 主要处理机器学习,这只是数据科学的一个方面。
- 当你在 Kaggle 上工作时,你主要是在处理预先清理过的数据,所以你没有足够的经验清理杂乱的数据,这是(通俗地说)数据科学家所做的 80%。
- 因为有大量的人参加 Kaggle 比赛,进入前百分之几或赢得比赛不仅需要技巧,还需要大量的时间和一些运气。
为了更全面地培养你的技能,做自己的项目是个好主意。在 Github 上分享这些代码以引起潜在雇主的兴趣是很常见的,但在发布什么代码和如何发布代码时要非常有目的性,这一点很重要。
虽然在 Github 上抛出一些代码并希望有人看到它很快,但从长远来看,将时间和精力投入到如何构建和展示您的投资组合上会更有效。
在 Dataquest ,我们提倡建立一个项目组合来帮助我们的学生获得他们的第一份数据科学工作,许多人已经成功地做到了这一点。
我将根据我的经验分享一些策略,用于建立一个数据科学投资组合,即使你没有该行业的经验,也会引起你的注意并帮助你找到工作。
让我们首先检查为什么投资组合是有效的。

为什么要制作作品集
数据科学投资组合有用的原因是,它表明你可以做雇主想让你做的事情。这实际上是你缺乏的工作经验的替代品。
从雇主的角度考虑一下——他们希望最大化雇佣优秀候选人的机会,最小化雇佣弱势候选人的机会。作为一名候选人,你的“工作”就是向他们展示你拥有他们所需要的技能和素质。
一个强大的数据科学组合由几个中等规模的数据科学项目组成,这些项目向雇主证明你拥有他们所需要的关键技能。
确保你的投资组合专注于正确的事情
虽然大多数数据科学学习都侧重于机器学习,但你的第一个数据科学角色不太可能涉及大量机器学习工作。
这是你在这个行业的第一份工作,所以你应该做好准备,你会被考虑担任初级职位,然后你可以从那里开始逐步提升。
这些角色甚至可能不叫“数据科学家”,而叫“数据分析师”或“业务分析师”。谦虚一点,愿意尽一切努力进入这个行业。
出于这个原因,用机器学习项目填充你的投资组合是错误的努力方向(尽管我确实建议至少有一个)。当您考虑要包含什么类型的项目时,请考虑这一点。
项目类型
不同的项目可以展示不同的东西。以下是您可以构建的几种不同类型的项目:
- 数据清理项目——展示了你可以取多个杂乱的数据集,清理它们,组合它们,并使用它们进行分析。( 例子 )
- 数据讲故事项目——表明你可以从数据中提取见解,交流这些见解,并用数据进行推理。( 例子 )
- 数据可视化项目–展示您可以使用适当的图表直观地交流数据。
- 机器学习项目——表明你可以有效地建立一个用数据做出准确预测的模型( 例子 )
- 端到端项目–展示您可以构建一个独立的系统,该系统可以接收数据、处理数据并以特定的形式生成输出。( 例子 )
- 解释性帖子–表明你可以通过解释统计概念或机器学习算法等概念来很好地交流和解释数据
在选择将什么项目添加到你的投资组合中时,你应该考虑你想要什么样的工作。如上所述,它们不应该都是机器学习项目。
例如,如果您对数据可视化特别感兴趣,您可能会制作几个数据可视化项目,并添加一些交互式可视化来展示您在该领域的技能。
你应该熟悉你要去找的工作的广告——看看他们要求的技能,并以此作为如何为你的投资组合选择项目的指示。
如果你需要帮助为你的项目寻找数据集,我会看看这个伟大的资源: 18 个地方寻找数据科学项目的数据集。
好好展示你的项目
一个有效的项目不是简单的做一些分析然后上传。你需要花时间和精力让你的项目易于理解和消化。
这意味着给你的项目一个介绍或自述文件。你需要“推销”你的项目,记住你的自述文件很可能是一些人唯一会看的东西。让你的项目感觉像是被雇佣来做这个项目的——解释目的是什么,你采取了什么方法,你使用的数据和结果。
您还应该确保您的自述文件中有安装或运行项目的说明,这样任何想要复制您的作品的人都可以轻松完成。
因此,您需要确保包含所有相关的文件和数据集,并提供运行项目所需的库列表(例如 Python 项目的 requirements.txt 文件)
如果您的项目由独立的脚本组成,您应该确保它们易于阅读,并且在代码中使用注释来解释您正在做什么以及为什么。
如果你的项目使用笔记本,在你的项目中添加 markdown 来解释你在做什么,并在你做的过程中解释你的结果。
如果你想要更多关于展示你的作品的信息,这篇文章是一个很好的资源。
迎合不同类型的人会看到你的投资组合
请注意,在招聘过程中,不同类型的人会看你的投资组合,他们会有不同的技能和理解水平。
在招聘过程早期查看你的投资组合的招聘经理可能对技术了解有限。你应该确保对这种类型的人有很多解释,甚至可以考虑将你的项目放在博客和 GitHub 上,这样你就可以写更多关于你的项目的细节,并解释它如何为技术背景较浅的人工作。
在这个过程的后期,你的作品集可能会被公司经理看到,他们会对你如何为公司创造价值以及如何与公司沟通感兴趣。你应该确保你所有的解释都是清楚的,并且你的项目实现了它的目标。
最后,你应该期待某个技术人员会评估你的投资组合。你应该确保你的代码是干净的,可重构的,高效的。
对于不同的公司,招聘流程会有所不同,有些公司可能只让其中几个人来检查你的投资组合。你应该仔细考虑并为每一个做好准备。
让雇主了解你的投资组合
一个常见的错误是将一些项目放在 GitHub 上,然后简单地将您的 GitHub 个人资料 URL 添加到您的简历顶部。记住,招聘过程是艰难的,所以你需要让那些看你申请的人容易找到并评估你的投资组合。
不要只是“添加网址”并希望有人能找到它,在求职信中明确提及你的投资组合和具体项目。如果你接到某人的电话,提及你的投资组合,以及它如何展示你如何为企业提供价值。抓住一切机会推销你的投资组合。
另一个有效的方法是在你的简历上列出你的投资组合项目,就好像它们是短期合同一样(尽管注意不要有欺骗性)。对目标和它所展示的技能做一个简短的总结,并提供一个易于理解的链接。
记住这一点也很有帮助,一般来说,在招聘过程的早期,你会遇到较少的技术人员,而随后会遇到较多的技术人员。因此,你最初的申请可能会更突出地列出你的作品集“博客”。
TL;博士;医生
在寻找第一份数据科学工作时,投资组合是替代经验的一种极其有效的方式。然而,为了使你的作品集有效,你需要在如何构建和展示你的作品上花些心思和精力。
你应该建立几个实质性的项目,展示与你想得到的工作相关的特定技能。你应该花时间好好展示这些,并注意在招聘过程中会看到你的简历的不同类型的人。
最后,你应该努力确保你的作品集是你申请的重要部分,并考虑像短期合同一样展示你的作品集项目。
Dataquest 是学习成为数据科学家的最佳在线平台。除了教授您需要的概念,我们还支持基于项目的学习方法,并有许多指导项目,可以构成您数据科学组合的开端。
您可以在data quest . io注册并免费完成我们的第一门课程
本帖基于本 Quora 答案
如何在您的计算机上安装 Anaconda 发行版
原文:https://www.dataquest.io/blog/how-to-install-the-anaconda-distribution-on-your-computer/
February 4, 2022
在进入数据科学之前,您需要设置所需的软件和工具,并学习如何使用它们。本教程将教您如何安装和使用 Anaconda 平台来构建数据科学生态系统。您还将学习如何使用命令行界面管理包和环境。让我们开始吧。
什么是 Anaconda 发行版?
Anaconda 是一个受信任的套件,它捆绑了 Python 和 R 发行版。Anaconda 是一个包管理器和虚拟环境管理器,它包括一组预安装的软件包。Anaconda 开源生态系统主要用于数据科学、机器学习和大规模数据分析。Anaconda 之所以受欢迎,是因为它安装简单,并且它提供了对数据专业人员所需的几乎所有工具和包的访问,包括:
- Python 解释器
- 大量的包裹
- Conda,一个软件包和虚拟环境管理系统
- Jupyter Notebook,一个基于 web 的交互式集成开发环境(IDE ),它在同一个文档中结合了代码、文本和可视化
- Anaconda Navigator 是一个桌面应用程序,它使启动 Anaconda 发行版附带的软件包变得容易,并且无需使用命令行命令就可以管理软件包和虚拟环境
如何安装 Anaconda
Anaconda 是一个跨平台的 Python 发行版,可以安装在 Windows、macOS 或不同的 Linux 发行版上。
注意如果已经安装了 Python,就不需要卸载了。您仍然可以继续安装 Anaconda,并使用 Anaconda 发行版附带的 Python 版本。
- 从https://www.anaconda.com/downloads下载适用于您的操作系统的 Anaconda 安装程序。

- 下载完成后,双击这个包开始安装 Anaconda。安装程序将引导您完成向导以完成安装;默认设置在大多数情况下都能正常工作。

- 点击简介、自述和许可屏幕上的
Continue。出现以下提示后,点击Agree继续安装。

- 在目的地选择屏幕上,选择“仅为我安装”建议在默认路径下安装 Anaconda 为此,点击
Install。如果你想在不同的位置安装 Anaconda,点击Change Install Location…并改变安装路径。

- 在 PyCharm IDE 屏幕上,点击
Continue安装 Anaconda,不安装 PyCharm IDE。 - 安装完成后,点击摘要屏幕上的
Close关闭安装向导。

- 有两种方法可以验证您的 Anaconda 安装:在您计算机上已安装的应用程序中找到 Anaconda Navigator,然后双击它的图标。

如果 Anaconda 安装正确,Anaconda 导航器将会运行。

通过命令行界面运行conda info命令。如果 Anaconda 安装正确,它将显示所有当前 conda 安装信息。
康达怎么用
在本节中,我们将学习如何使用 Conda 来创建、激活和停用虚拟环境。此外,我们将讨论在环境中安装软件包和管理通道。
如果你想了解更多关于 Python 虚拟环境的知识,你可以阅读 Dataquest 博客上的Python 虚拟环境的完整指南。
首先,让我们检查一下我们电脑上安装的conda版本。为此,在 macOS/Linux 上打开一个终端窗口,或者在 Windows 上打开一个 Anaconda 提示符,然后运行以下命令:
(base) ~ % conda --version
conda 4.11.0
Anaconda 中的默认环境是在安装 Anaconda 时创建的基础环境。因此,每次打开终端窗口时,环境的名称都会出现在终端提示符开头的括号中。基础环境包含conda以及 400 多个预安装的包。现在,让我们讨论如何使用 conda 命令管理环境。
创造康达环境
要创建 Conda 环境,使用conda create命令:
(base) ~ % conda create -n my_env
上面的命令创建了一个新的 Conda 环境,其中my_env是环境的名称。你需要输入y然后按Enter,或者出现以下提示时只需按Enter。
Proceed ([y]/n)?
默认情况下,所有环境都将被创建到anaconda3文件夹的envs文件夹中,没有任何包。下面的命令创建了一个新的 Conda 环境,其中包含最新版本的 Python:
(base) ~ % conda create -n my_env python
或者,如果您希望创建一个具有特定 Python 版本的环境,请运行以下命令:
(base) ~ % conda create -n my_env python=3.6
它显示了将在环境中安装的所有软件包。看到提示后,按Enter:
Proceed ([y]/n)?
所有软件包都将安装在环境中。
激活 Conda 环境
要激活环境,运行conda activate命令:
(base) ~ % conda activate my_env
运行上面的命令会激活 my_env环境,它会在命令提示符开始处的括号中显示活动环境的名称。以下命令显示活动环境的详细信息:
(my_env) ~ % conda info
在环境中安装软件包
要将软件包安装到当前环境中,使用conda install <package-name>命令。例如,下面的命令在环境中安装最新版本的熊猫包。
(my_env) ~ % conda install pandas
要安装软件包的特定版本,如 pandas ,您可以使用以下命令:
conda install pandas=1.2.4
您也可以使用单个conda install命令安装一组软件包,如下所示:
(my_env) ~ % conda install seaborn scikit-learn jupyter
如果您想查看当前环境中已安装的软件包,请运行以下命令:
(my_env) ~ % conda list
要签出环境列表,请使用以下命令列出您计算机上的环境,并用星号突出显示活动环境:
(my_env) ~ % conda env list
注
如果您想要更新环境中的所有软件包,请运行conda update命令。
再现康达环境
在您的计算机或其他计算机上复制环境是一项常见的任务。Conda 允许我们创建一个 YAML 文件,包含环境中所有已安装的包以及版本。让我们看看如何通过将活动环境导出到 YAML 文件来创建文件:
(my_env) ~ % conda env export > environment.yml
运行上面的命令会创建environment.yml文件,该文件可用于创建另一个包含相同包的环境。如果您想确保您的环境文件在各种平台上工作,请使用conda env export命令末尾的--from history选项,如下所示:
(my_env) ~ % conda env export --from history > environment.yml
新的environment.yml文件更加跨平台兼容,因为它只包含我们显式安装的包,而不像以前的文件包含环境中所有已安装的包。现在,您可以使用环境文件在任何机器上重现 Anaconda 环境。
(my_env) ~ % conda env create -n new_env --file environment.yml
上面的命令创建了一个新环境new_env,并安装了environment.yml文件中列出的所有包。
管理 Conda 渠道
通道是存放在远程服务器上的 Conda 包存储库。每当您想要安装一个软件包时,Conda 都会搜索这些包含 Conda 软件包的存储库。然后软件包将自动从频道下载并安装。该命令返回当前 Conda 通道:
(base) ~ % conda config --show channels
channels:
- defaults
要显示默认频道文件夹的 URL,请运行以下命令:
(base) ~ % conda config —show default_channels
default_channels:
- https://repo.anaconda.com/pkgs/main
- https://repo.anaconda.com/pkgs/r
有时,当我们想安装一个软件包时,Conda 会发出PackagesNotFoundError 消息,这意味着该软件包在当前渠道中不可用。让我们来看看:
(my_env) ~ % conda install click-default-group
运行上面的命令表明click-default-group包在当前频道中不可用。有两种方法可以解决这个问题:
- 第一种解决方案是使用以下命令指定软件包在其存储库中存在的通道:
(my_env) ~ % conda install -c conda-forge click-default-group
- 第二种解决方案是将包含该软件包的新频道添加到频道列表的顶部,然后安装该软件包:
(my_env) ~ % conda config --add channels conda-forge
(my_env) ~ % conda install click-default-group
停用 Conda 环境
要停用 Conda 环境,运行 conda deactivate命令。停用环境将使您返回到基本环境。
移除 Conda 环境
要删除环境,首先停用它,然后在终端窗口中运行命令:
(base) ~ %conda remove -n my_env
注
如果您不喜欢通过在命令行 shell 中键入 Conda 命令来管理环境和包,您可以使用 Anaconda Navigator。Navigator 提供了一个图形用户界面(GUI)来管理环境和软件包,而无需使用 Conda 命令。
结论
在本教程中,您学习了如何安装 Anaconda 并使用 conda 来管理环境和安装包。Anaconda 发行版的核心是 Jupyter 笔记本;数据科学家喜欢 Jupyter Notebook,因为它简化了交互式开发和演示他们的项目。如果你有兴趣了解更多关于 Jupyter Notebook 的信息,Dataquest 博客上有一个很好的教程,在如何在 2020 年使用 Jupyter Notebook:初学者教程。
如何快速学习:学习新技能的 7 个科学支持的学习技巧
原文:https://www.dataquest.io/blog/how-to-learn-fast-science-based-study-tips/
October 8, 2020
学习新技能对职业发展至关重要。但是如果你是全职工作,找到时间学习会是一个巨大的挑战。你学得越快,你需要在时间表中找到的时间就越少。那么如何才能学得更快呢?
谢天谢地,科学家们已经花了数年时间研究人脑。虽然没有神奇的捷径可以帮助你在一夜之间学会像数据分析这样的新技能,但是你可以做一些事情来提高你的学习效率。
想要保留更多您所学的内容并更快地达到您的学习目标?我们有 7 个科学支持的小贴士来加速你的学习。
1.做笔记(但不要抄写)
如果你读到把记笔记作为学习技巧,你会经常看到 2014 年的这项研究被引用作为你应该用手记笔记的证据。但是他们实际发现的要比这复杂一些。
我们已经在这里写了更多关于做笔记背后的科学细节,但是这里有一个简短的总结:
研究发现,在概念性问题上,手写笔记的学生比笔记本笔记的学生表现更好。然而,这可能是因为笔记本电脑用户做了更多的逐字记录。在一项后续研究中,指导笔记本电脑记录员用自己的话做笔记提高了他们的分数。
手写笔记的表现仍然更好,但这还不是全部。现有的科学表明,经常回顾你的笔记对记忆很重要。由于打字笔记可以保存到云平台上,并可以在任何地方查看,如果他们的笔记是打字而不是手写的,许多学习者可能会更容易遵循这个建议。
同样值得注意的是,2014 年的研究样本量非常小。从中得出任何铁一般的结论可能不是一个好主意。
在进一步的研究证明并非如此之前,在你喜欢的任何平台上做笔记可能都是好的,只要你能定期回顾它们。只要确保无论你如何记笔记,你都是用自己的话来记,而不是抄录或复制粘贴。
2.学以致用
这一点似乎很明显,但是很多在线学习平台实际上并不需要它。观看别人做某事的视频可以帮助你更好地理解这项技能,但要真正掌握它,你可能需要亲自动手,亲自动手。
几十年来,实践学习相对于死记硬背的价值已经在科学文献中得到充分证实。20 世纪 80 年代的一项元研究回顾了 57 项其他研究,发现动手学习者比死记硬背的学习者表现好 20%。
这些结果一直保持着。2014 年的一项元研究查看了数百项其他研究,发现从讲座中被动学习的学生失败的可能性是其他学生的 1.5 倍。
3.远离你的手机
听说过手机邻近效应吗?如果你没有,我们刚刚链接的那篇文章值得一读,虽然有点吓人!
不过,总结一下这些研究的结果:身边有一部手机可能会影响你的认知能力——即使它已经关机,甚至看不见了。此外,您可能没有意识到它正在影响您。即使你很自信你的手机不会分散你的注意力,它也有可能是。
谢天谢地,解决办法很简单:当你学习的时候,尽可能远离它。理想情况下,这意味着关掉它,把它放在一个不同的房间里,关上门。
(如果情况不允许,把它放在看不见的地方,比如包里,比放在看得见的地方要好,尽管它可能仍然会影响你的表现)。

不要这样用手机学习!
4.制定详细的计划
像这样的研究表明,制定详细计划的人比不制定计划的人更有可能坚持到底。
“细节”部分是这里的关键——每周选择一个你要学习新技能的时间和地点。选择一个“备份”计划来弥补失去的时间,以防你不得不错过或跳过某个环节。
有了这个详细的计划,你就更有可能坚持到底,不太可能翘课。反过来,这将帮助你更快地进步,更快地达到你的目标。
5.获得正确的反馈
与负责任的伙伴分享你的进步有时会有所帮助。但是如果你要分享,你应该给他们一点科学上的提示:如果你在学习的早期收到积极的反馈,稍后收到消极的反馈,那是最好的。
原因很简单——新的学习者需要鼓励才能坚持下去。当你在这条路上走得更远时,负面反馈可以帮助你避免自满,推动你不断成长。
研究还表明,你应该向你的朋友寻求“过程表扬”,而不是“个人表扬”换句话说,你想要一个会说“哇,你真的很努力!”而不是说“哇,你真聪明!”
6.在学习期间休息一下
尤其是当你很忙的时候,当你找到空闲时间的时候,试着把尽可能多的学习挤进去是很有诱惑力的。但是这种临时抱佛脚的方式效率不高。
2018 年的一项研究发现,考试期间短暂休息有助于对抗持续脑力劳动带来的表现下降和学习下降。在一些测试问题之间短暂休息的学习者比那些没有休息的学习者表现得更好。
就像肌肉一样,长时间的持续努力,你的大脑会变得疲劳,功能也会变差。也像肌肉一样,给大脑一些休息时间有助于它恢复。(这当然只是比喻。大脑不是肌肉!)
这并不意味着你不能进行马拉松式的四小时学习。但是比起连续学习四个小时,你可能会取得更大的进步,如果你建立一些短暂的休息,让你的大脑有时间恢复。

这只猫想出了下一个窍门。
7.多睡会儿
说起来容易做起来难,对吧?睡个好觉可能是个挑战。但说到学习,它真的有回报。睡眠在很多方面对你的大脑有好处,但其中之一是它似乎有助于记忆。
更多的睡眠与更好的学习成绩、更好的记忆力和更多的快乐联系在一起。虽然在忙碌的日子里睡足八小时的好觉可能很困难,但是利用时间好好睡会让你一天中做的每件事都变得更好——包括加快学习新技能。
学习任何新技能都需要时间。这些建议将帮助你更快、更有效地学习,但不要搞错——你仍然需要付出努力。应用这些技巧并选择一个设计良好的学习平台会有所帮助。但最终,学习一项新技能掌握在你手中!
(不过,不要让这吓倒你。你能行的!)
如何通过 5 个步骤学习数据科学 Python
原文:https://www.dataquest.io/blog/how-to-learn-python-for-data-science-in-5-steps/
July 12, 2022
为什么学 Python 是为了数据科学?
Python 是数据科学家选择的编程语言。虽然它不是第一种主要的编程语言,但它的受欢迎程度已经增长了很多年。
- 2016 年,它在数据科学竞赛的首要平台 Kaggle 上超过了 R。
- 2017 年,在 KDNuggets 的数据科学家最常用工具年度调查中,它超过了 R。
- 2018 年,66%的数据科学家报告使用 Python daily 的,使其成为分析专业人士的头号语言。
- 2021 年,它在 TIOBE 指数上超过了 Java,现在是最受欢迎的编程语言。
此外,数据科学专家预计这一趋势将持续下去。
对于数据科学家来说,当前的劳动力市场是什么样的?
根据 Glassdoor 的数据,2022 年数据科学家的平均工资为 119,118 美元。
随着对数据科学家的需求增加,这一数字预计只会上升。2020 年,数据科学家的空缺职位是前一年的三倍。
数据科学和 Python 的未来似乎非常光明。幸运的是,学习 Python 现在比以往任何时候都容易。我们将用五个简单的步骤向您展示如何做到这一点。
数据科学如何学习 Python
步骤 1:学习 Python 基础知识
每个人都有起点。第一步是学习 Python 编程基础。(如果你还不熟悉数据科学,你还需要一个介绍。)
你可以通过在线课程(【Dataquest 提供的)、数据科学训练营、自学或大学课程来实现这一点。学习 Python 基础知识没有对错之分。关键是选择一条道路,并保持一致。
寻找在线社区
为了帮助保持动力,加入一个在线社区。大多数社区允许你通过你或其他人问小组的问题来学习。
您还可以联系其他社区成员,并与行业专业人士建立关系。这也增加了你的就业机会,因为员工推荐占所有雇员的 30% 。
许多学生也发现创建一个 Kaggle 账户并加入当地的 Meetup 群组很有帮助。
如果你是 Dataquest 的订阅者,你可以访问 Dataquest 的学习者社区,在那里你可以找到来自在校学生和校友的支持。
第二步:实践动手学习
加快你的教育的最好方法之一是通过实践学习。
Python 项目实践
当您构建小型 Python 项目时,您理解的速度之快可能会让您吃惊。幸运的是,几乎每门 Dataquest 课程都包含一个项目来增强你的学习。以下是其中的几个例子:
- 越狱 —找点乐子,用 Python 和 Jupyter Notebook 分析一个直升机越狱的数据集。
- App Store 和 Google Play 市场的盈利应用简介 —在这个指导性项目中,你将在一家开发移动应用的公司担任数据分析师。您将使用 Python 通过实际的数据分析来提供价值。
- 探索黑客新闻帖子——使用热门技术网站 Hacker News 的提交数据集。
- 探索易贝汽车销售数据——使用 Python 处理从德国易贝网站分类广告栏目易贝·克莱纳泽根收集的二手车数据集。
本文也为初学者提供了大量其他 Python 项目的想法:
实践和学习的替代方法
为了完善你的课程并找到你所遇到的 Python 编程问题的答案,阅读指南、博客文章、 Python 教程,或者其他人的开源代码来寻找新的想法。
如果您还想了解更多,请查看这篇关于学习 Python 数据科学的不同方法的文章。
步骤 3:学习 Python 数据科学库
四个最重要的 Python 库是 NumPy、Pandas、Matplotlib 和 Scikit-learn。
- NumPy —一个让各种数学和统计操作变得更简单的库;这也是熊猫图书馆许多特色的基础。
- pandas —一个专门为数据处理而创建的 Python 库。这是大量 Python 数据科学工作的基础。
- Matplotlib —一个可视化库,可以快速轻松地从数据中生成图表。
- sci kit-learn—Python 中最流行的机器学习工作库。
NumPy 和 Pandas 非常适合探索和处理数据。Matplotlib 是一个数据可视化库,可以像在 Excel 或 Google 工作表中一样制作图表。
下面是对数据科学最重要的 15 个 Python 库的有用指南。
步骤 4:在学习 Python 的同时构建数据科学组合
对于有抱负的数据科学家来说,投资组合是必需的 —这是招聘经理在合格候选人身上寻找的最重要的东西之一。
这些项目应该包括使用几个不同的数据集,每个项目都应该分享你发现的有趣的见解。以下是一些需要考虑的项目类型:
- 数据清理项目 —任何涉及你清理和分析的肮脏或“非结构化”数据的项目都会给潜在雇主留下深刻印象,因为大多数真实世界的数据都需要清理。
- 数据可视化项目(Data Visualization Project)——制作有吸引力的、易读的可视化是一项编程和设计挑战,但如果你能做好,你的分析将会非常有用。在项目中拥有漂亮的图表会让你的投资组合脱颖而出。
- 机器学习项目 —如果你渴望成为一名数据科学家,你肯定会需要一个展示你的 ML 技能的项目。你可能想要几个不同的机器学习项目,每个项目都专注于一个不同的算法。
有效地展示你的作品集
你的分析应该清晰易读——最好是像 Jupyter 笔记本那样的格式,这样技术观众就可以阅读你的代码。(非技术读者可以跟随你的图表和书面解释。)
你的作品集需要主题吗?
你的作品集不一定需要一个特定的主题。找到你感兴趣的数据集,然后开发一种连接它们的方法。如果你想在特定的公司或特定的行业工作,展示与该行业相关的项目是个好主意。
展示这样的项目向未来的雇主表明,你已经花时间学习 Python 和其他重要的编程技能。
步骤 5:应用先进的数据科学技术
最后,提高自己的技能。您的数据科学之旅将充满不断的学习,但您可以完成高级 Python 课程,以确保您已经覆盖了所有基础。
学会熟悉回归、分类和 k-means 聚类模型。你也可以通过学习自举模型和使用 Scikit-learn 创建神经网络来进入机器学习。
对初学者有帮助的 Python 学习技巧
提问
你不知道你不知道什么!
Python 有一个丰富的专家社区,他们愿意在您使用 Python 学习数据科学时为您提供帮助。像 Quora、Stack Overflow 和 Dataquest 的学习者社区这样的资源充满了乐于分享他们的知识并帮助你学习 Python 编程的人们。我们还为每节课提供了一个常见问题解答,帮助您解决在 Dataquest 编程课程中遇到的问题。
使用 Git 进行版本控制
Git 是一个流行的工具,可以帮助你跟踪代码的变化。这使得纠正错误、实验和与他人合作变得更加容易。
学习初级和中级统计
在学习 Python 数据科学的过程中,您会希望在统计学方面打下坚实的基础。理解统计数据会给你一种心态,你需要这种心态来有效地集中注意力,找到有价值的见解(和真正的解决方案)。
开始学习木星笔记本
Jupyter 笔记本是一个非常重要的工具,你应该马上开始学习。它预先打包了 Python 库,这很有帮助。
Python 用于数据科学常见问题解答
学习 Python 需要多长时间?
虽然每个人都是不同的,但我们发现学习 Python 数据科学需要三个月到一年的持续实践。
我们看到人们在我们的课程中以闪电般的速度前进,我们也看到其他人以较慢的速度前进。这完全取决于你能花多少时间学习 Python 编程,以及你能多快获得新信息。
幸运的是,我们已经为您设计了 Dataquest 的课程,让您按照自己的速度学习。
每条道路都充满了课程、实践学习和提问机会,以便您能够掌握数据科学的基础知识。我们的实践学习方法使用真实的数据集,这不仅能帮助你更快地学习,还能帮助你了解如何应用你的知识。
免费开始。跟随我们的数据科学家之路学习 Python,从今天开始掌握一项新技能!
哪里可以学习数据科学的 Python?
因为 Python 被用于各种其他编程学科,从游戏开发到移动应用,一般的“学习 Python”资源试图教授所有的东西,但这意味着你将学习与数据科学无关的东西。
当你的主要目标是学习 Python 进行数据分析,而不是努力学习一门教你构建游戏的课程时,很容易变得沮丧并想放弃。
有很多免费的 Python 数据科学教程。如果你不想付费学习 Python,这些可以是一个不错的选择。这个链接提供了几十个按难度和关注领域分类的教程。
如果您想最大限度地提高学习效果,最好是找到一个平台,提供为数据科学教育开发的课程。Dataquest 就是这样一个平台。我们的课程可以带你从初学者到工作就绪,成为 Python 中的数据分析师、数据科学家或数据工程师。
Python 在数据科学领域有必要吗?
使用 Python 或 r 都可以作为数据科学家工作。每种语言都有其优点和缺点。两者都在行业中广泛使用。Python 总体上更受欢迎,但 R 在某些行业占主导地位(特别是在学术界和研究领域)。
对于数据科学,你肯定需要学习这两种语言中的至少一种。(无论您选择哪种语言,您还必须学习一些 SQL。)
Python 比 R 更适合数据科学吗?
这是数据科学中一个永恒的讨论话题,但真正的答案是,这取决于你在寻找什么和你喜欢什么。
r 是专门为统计和数学而构建的,但是有一些令人惊奇的包使得它非常容易用于数据科学。此外,它有一个非常支持的在线社区。
Python 是一种更好的全能编程语言。您的 Python 技能可以转移到许多其他学科。也稍微受欢迎一点。一些人会争辩说它更容易学,尽管很多 R 的人不同意。
与其阅读观点,不如看看这篇关于Python 和 R 如何处理类似的数据科学任务的文章,看看哪个看起来更吸引你。
如何在 Python 中让你的情节吸引人
原文:https://www.dataquest.io/blog/how-to-make-your-plots-appealing-in-python/
January 19, 2022
数据可视化可以说是数据科学项目中最重要的一步,因为这是你向观众传达你的发现的方式。你这样做可能有多种原因:说服投资者为你的项目提供资金,强调公司变革的重要性,或者只是在年度报告中展示结果,强调最有价值的成就。
无论你的最终目标是什么,清晰地呈现数据是至关重要的。在这篇文章中,我将谈论在 Python 中改进 T2 数据可视化的技术方面。然而,取决于你的听众,这些方面中的一些可能比另一些更相关,所以在决定展示什么时要明智地选择。
我们将使用包含网飞电影和电视节目(https://www.kaggle.com/shivamb/netflix-shows)数据的数据集。
我们开始吧!
基本情节
首先,我们来看数据集。
# Imports
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
netflix_movies = pd.read_csv("./data/netflix_titles.csv") # From
netflix_movies.head()
我们有大量的列,我们可以很容易地可视化。我们的一个问题可能是网飞有多少部电影和电视剧?
netflix_movies["type"].value_counts()
我们的电影大约是电视剧的 2.5 倍。然而,简单地用数字来表示你的结果并不是一个好主意(除非是“我们今年增长了 30%!”,那么这个号可以很有效)。普通的数字比可视化更抽象。
好了,开始出图吧。表示分类数据的一个好方法是使用简单的条形图。
netflix_movies["type"].value_counts().plot.bar()
这是我们用熊猫可以做出的最基本的剧情。我们现在可以很容易地看到电影和电视节目数量的差异。
首次改进
我已经看到了第一个问题:我们仍然有纯数字。我认为显示这些数据中有趣的东西的最好方法是显示相对百分比。
netflix_movies["type"].value_counts(normalize=True).mul(100).plot.bar()

这样好多了。但是如果我们想确定电影和节目的确切比例呢?我们可以从每个条形到 y 轴来回猜测,但这不是一件容易的事情。我们应该把数字直接标在条形的上方!
# Label bars with percentages
ax = netflix_movies["type"].value_counts(normalize=True).mul(100).plot.bar()
for p in ax.patches:
y = p.get_height()
x = p.get_x() + p.get_width() / 2
# Label of bar height
label = "{:.1f}%".format(y)
# Annotate plot
ax.annotate(
label,
xy=(x, y),
xytext=(0, 5),
textcoords="offset points",
ha="center",
fontsize=14,
)
# Remove y axis
ax.get_yaxis().set_visible(False)
上面的代码相当高级,所以花些时间在文档中理解它是如何工作的。可以从这一页开始。

现在看起来干净多了:我们通过去除无用的杂波提高了信噪比。
下一步是使用 figsize 参数增加绘图的大小。让我们也把脊骨去掉。
# Increase the size of the plot
ax = netflix_movies["type"].value_counts(normalize=True).mul(100).plot.bar(figsize=(12, 7))
# Remove spines
sns.despine()
# Label bars with percentages
for p in ax.patches:
y = p.get_height()
x = p.get_x() + p.get_width() / 2
# Label of bar height
label = "{:.1f}%".format(y)
# Annotate plot
ax.annotate(
label,
xy=(x, y),
xytext=(0, 5),
textcoords="offset points",
ha="center",
fontsize=14,
)
# Remove y axis
ax.get_yaxis().set_visible(False)

剧情开始好看了。然而,我们几乎看不到 x 记号标签(“电影”和“电视节目”)。此外,我们还需要将它们旋转 90 度以提高可读性。
我还认为我们需要增加 x 记号标签的透明度,因为这些标签不应该成为关注的焦点。也就是说,观众首先要看到两个杠的高度差异,然后才关注周围的信息。
但是,我将百分比的透明度保持在 100%,因为这是我们想要传达的信息(两个条形之间有很大的差异)。
将以下代码行添加到前面的代码中:
# Increase x ticks label size, rotate them by 90 degrees, and remove tick lines
plt.tick_params(axis="x", labelsize=18, rotation=0, length=0)
# Increase x ticks transparency
plt.xticks(alpha=0.75)
 停一下,回头看看原来的剧情。注意不同之处。现在想想你做过的所有决定。在计划的每一步,你都应该考虑你在做什么,否则最终的计划会变得不可理解和不准确。
停一下,回头看看原来的剧情。注意不同之处。现在想想你做过的所有决定。在计划的每一步,你都应该考虑你在做什么,否则最终的计划会变得不可理解和不准确。
添加标题和副标题
现在我们继续。我们遗漏了两条关键信息:标题和副标题。标题应该告诉我们正在看什么,而副标题应该把观众的注意力引向我们认为重要的东西。
天生的本能就是只用plt.title()。然而,居中对齐的文本使我们的情节看起来笨拙,因为我们的眼睛喜欢直线。因此,我们将把标题和副标题靠左对齐,使其与第一栏完全成直线。
我还决定移除底部和左侧的脊骨(通过使用sns.despine()中的参数left=True和bottom=True),因为它们不会与其他元素对齐。你可以看到我正在迭代地做决定,所以如果你第一次接近数据集时不能创建一个完美的图,不要气馁。实验!
像前面一样,将以下代码行添加到前面的代码中:
# Font for title
title_font = {
"size": 22,
"alpha": 0.75
}
# Font for subtitle
subtitle_font = {
"size": 16,
"alpha": 0.80
}
# Title
plt.text(
x=-0.25,
y=80,
s="Proportions of Movies and TV Shows on Netflix",
ha="left",
fontdict=title_font,
)
# Subtitle
plt.text(
x=-0.25,
y=75,
s="Movies are more than two times more frequent on Netflix",
ha="left",
fontdict=subtitle_font,
)
![]() 颜色
颜色
 颜色
颜色颜色呢?首先,默认的蓝色看起来很好看!然而,我们可以选择其他颜色来补充我们的品牌或传达一种情感。不要使用非常强烈的默认颜色(“红色”、“绿色”等)。).这些不是我们在自然界中常见的颜色。而是在谷歌上看一些大自然的照片,挑一个你最喜欢的颜色。我正在使用 ColorZilla 扩展来挑选颜色的十六进制代码。在这种情况下,我会选择另一种蓝色
## Complete code to generate the plot below. Note that the only difference is the color parameter in the first line
# Increase the size of the plot
ax = netflix_movies["type"].value_counts(normalize=True).mul(100).plot.bar(figsize=(12, 7), color="#3B97B6")
# Remove spines
sns.despine(left=True, bottom=True)
# Label bars with percentages
for p in ax.patches:
y = p.get_height()
x = p.get_x() + p.get_width() / 2
# Label of bar height
label = "{:.1f}%".format(y)
# Annotate plot
ax.annotate(
label,
xy=(x, y),
xytext=(0, 5),
textcoords="offset points",
ha="center",
fontsize=14,
)
# Remove y axis
ax.get_yaxis().set_visible(False)
# Increase x ticks label size, rotate them by 90 degrees, and remove tick lines
plt.tick_params(axis="x", labelsize=18, rotation=0, length=0)
# Increase x ticks transparency
plt.xticks(alpha=0.75)
# Font for title
title_font = {
"size": 22,
"alpha": 0.75
}
# Font for subtitle
subtitle_font = {
"size": 16,
"alpha": 0.80
}
# Title
plt.text(
x=-0.25,
y=80,
s="Proportions of Movies and TV Shows on Netflix",
ha="left",
fontdict=title_font,
)
# Subtitle
plt.text(
x=-0.25,
y=75,
s="Movies are more than two times more frequent on Netflix",
ha="left",
fontdict=subtitle_font,
)

现在剧情看起来真好看!但是我们能改善它吗?当然可以。
横条图!
我们可以创建一个水平条形图,并对齐所有文本数据!让我们看一看。
# Increase the size of the plot
ax = netflix_movies["type"].value_counts(normalize=True).mul(100).plot.barh(figsize=(12, 7), color="#0C476E")
# Remove spines
sns.despine(left=True)
# Label bars with percentages
ax.bar_label(
ax.containers[0],
labels=["69.6%", "30.4%"],
label_type="edge",
size=13,
padding=-50,
color="white",
weight="bold"
)
# Increase y ticks label size, rotate them by 90 degrees, and remove tick lines
plt.tick_params(axis="y", labelsize=18, rotation=0, length=0)
# Increase x ticks transparency
plt.yticks(alpha=0.75)
# Remove x axis
ax.get_xaxis().set_visible(False)
# Font for titles
title_font = {
"size": 22,
"alpha": 0.75
}
# Font for subtitles
subtitle_font = {
"size": 16,
"alpha": 0.80
}
# Title
plt.text(
x=-9,
y=1.55,
s="Proportions of Movies and TV Shows on Netflix",
ha="left",
fontdict=title_font,
)
# Subtitle
plt.text(
x=-9,
y=1.4,
s="Movies are more than two times more frequent on Netflix",
ha="left",
fontdict=subtitle_font,
)
# Extend bottom spine to align it with titles and labels
ax.spines.bottom.set_bounds((-9, 69.6))
# Add total
plt.text(
x=63,
y=-0.6,
s="Total",
fontdict={"alpha": 0.75},
)
# Add 100%
plt.text(
x=67,
y=-0.6,
s="100%",
fontdict={"alpha": 0.75},
)
 与之前的图相比,除了将标题和副标题与标签对齐之外,我还在条形内直接添加了刻度标签以减少混乱,更改了颜色以提高对比度,并恢复了与图的其余部分对齐的底部脊线。您还可以看到,我添加了“总计 100%”来表示百分比的总和为 100。
与之前的图相比,除了将标题和副标题与标签对齐之外,我还在条形内直接添加了刻度标签以减少混乱,更改了颜色以提高对比度,并恢复了与图的其余部分对齐的底部脊线。您还可以看到,我添加了“总计 100%”来表示百分比的总和为 100。
看这个图,我们立刻注意到条形图的不同,我们的目光自然地从左到右、从上到下移动;因此,我们将所有需要的信息放在战略位置,以便与受众进行清晰的交流。
结论
完成绘图后,我注意到我可以增加百分比的字体大小,使它们更加明显,我还可以反转 y 轴,将“电影”栏移动到“电视节目”栏上方,因为较高的值自然应该在顶部。
但我觉得就是不值得努力。在某些时候,你应该停止改进一个情节,而只是说它“足够好了”当你在学习的时候,尽你所能制作最好的情节,浏览文档,学习新技术!然而,当您必须交付数据可视化时,只需在某个点停止—当绘图质量可以接受时。
概括来说,我们介绍了以下内容:
- 增加地块的大小
- 取消情节
- 放大轴的标签
- 包括标题和副标题
- 让二手信息更加透明
- 对齐绘图的所有元素
- 使用自然的颜色
通过应用这七条规则,你会让你的情节对你的观众更有吸引力和信息量。
欢迎在 LinkedIn 或 T2 GitHub 上问我任何问题。快乐编码,快乐绘图!
如何让你的数据科学薪水最大化
原文:https://www.dataquest.io/blog/how-to-maximize-your-data-science-salary/
December 1, 2021
谈判薪资是许多人不愿意面对的事情,但正如数据显示的那样,克服这种不舒服会带来难以置信的回报。如果你在阅读这篇文章时,正试图在数据科学领域找到自己的第一份工作,或者在现有的数据科学岗位上增加收入,那么我们为你写了这篇文章。
O'Reilly 数据科学工资指南报告发现,高达 18%的数据科学家从未要求过更高的工资。此外,同一份报告发现,将谈判技巧评为“优秀”的数据科学家比那些将谈判技巧评为“非常差”的数据科学家每年多获得高达 5 万美元的收入。
对于许多员工来说,谈判薪水可能会感觉尴尬甚至令人生畏,但克服这一挑战每年可以让你的口袋里多出几千美元。我们会为你提供最好的建议,让你在薪资谈判中获得最佳结果。无论你是在接受你的第一个数据科学职位之前直接与招聘经理谈判,还是与现有雇主谈论你的年收入,这些技巧都将为你成功的薪资谈判做好准备!
了解你的市场价值
在试图协商更高的薪水之前,你要做的第一件事是确定你的真实市场价值。如果你的目标是让雇主相信你应该得到更高的薪水,你需要明白你能带来什么。
你可以通过研究你工作的行业和你申请的职位来开始这个过程,使用一些普通的资源,比如和玻璃门。你也可以和你的同事或你职业关系网中的人谈谈,因为他们可能会有你需要的答案。
但最终,你并不是因为其他人的工资多少而要求加薪。你要求加薪是因为你应该得到多少报酬。
你可以使用前面提到的资源作为基准来确定你的市场价值,但你最终必须用批判的眼光来审视你自己的技能、经验和过去的工作表现,才能更接近目标。考虑你多年的经验,你的教育,你的技能,以及你给这份工作带来的任何独特的附加因素。
记下任何你熟悉的数据科学工具、你发展的新技能或能让你成为团队中有价值成员的专长。你需要为自己提出一个令人信服的理由,表明你为雇主提供了足够的发展和盈利机会,因此更高的薪水是显而易见的。
运行数字
一旦你对自己的市场价值有了一个概念,你就必须做好准备去参加谈判。你要做的第一件事是设定你的期望。你知道你的价值和你给公司带来的价值,所以不要害怕要求你应得的。
参加会议时,你需要在头脑中有两个数字。第一个数字应该是基于你的市场价值,你想挣多少工资。这个数字应该是现实的,但要确保你仍然志存高远,为妥协留出空间。第二个值是你的离开数字,这意味着当你离开谈判桌时,低于这个数字的任何数量都会产生一个礼貌的谈判结论。
只有您能够准确地决定这两个数字,但是在决定将您的估计放在哪里时,有几件事情需要记住。当要估算你的工资的更高价值时,一定不要根据你想要的或别人拥有的来判断,而要根据你的市场价值来判断什么是合理的。关于更低的数字,请记住,如果你是第一次改变职业道路并进入数据科学或者刚刚开始进入该领域,那么一开始期望更低的工资并不是不合理的。
最后但同样重要的是,不要拒绝低于你期望的薪水,直到你看到整个薪酬方案的全貌,所有这些都可以通过谈判来弥补实际工资收入的不足。
练习这个过程
尽管听起来或感觉可能很傻,但让你的朋友、同事或爱人为你进行一次模拟薪资谈判会有很大帮助,尤其是在解决问题和巩固你的演讲基础的时候。就像其他事情一样,熟能生巧,你在谈判过程中越自如,你就越有可能做好陈述。
还有其他资源可以帮助你更熟悉这个过程。如果你需要帮助准备你的主要谈话要点、提议和还价,以及完善你的执行,你可以和招聘人员谈谈。
招聘人员专门帮助应聘者找到工作并获得更高的薪水。因此,在准备你的谈判陈述时,它们会是很有价值的资源。如果你真的想了解谈判的艺术,看看杰克·查普曼的《谈判你的薪水:如何一分钟赚 1000 美元》。
进入积极的心态
我们需要消除对薪资谈判的一些误解。首先,如果你已经在招聘过程中走到这一步,公司希望你为他们工作。可以说,他们已经在想象你在他们的团队中,让他们更有利可图。
提出加薪的证据不太可能让他们收回最初的提议,让你一无所有。事实上,一个鲜为人知的秘密是谈判不仅是可以接受的,而且在许多情况下,这是意料之中的。
其次,要求更多的钱不是一种侮辱,也没有什么好尴尬的。这种不舒服只是因为你内心深处的恐惧,让你觉得你会冒犯你的雇主,你不应该得到更多的钱,或者你无法履行高薪职位的职责。
这就是为什么你已经做了尽职调查,确定了你的市场价值,以确保你要求的薪水对你的数据科学职位来说是合理的。记住,帮助你,而不是伤害你,对你的雇主最有利。记住这一点,你就能拥有自信和积极的心态,这种心态会让你在整个谈判中取得成功。
定调子
一旦你坐在将要和你谈判薪水的人对面,重要的是你要用正确的语气。你的态度不仅决定了你的谈判将如何进行,而且也是影响你与雇主未来关系的一个因素。
了解你的市场价值,理解你带来了什么,并认识到坐在你对面的人不是来抓你的,这将使你能够自信地发言。如果你参加了这次会议,那是因为与你谈判的人希望你和你宝贵的数据科学技能成为团队的一部分。记住这一点,遵守我们的关键建议,以获得更高的初始报价,即让他们提出第一笔金额。
如果他们问你期望的报酬,你可以这样说,“我正在考虑任何有竞争力的提议”,或者试着说,“我更关心整体的报酬,而不是只看薪水。”不要用自己的估计来限制自己。相反,让他们提出报价,然后在此基础上进行谈判。你可能会惊讶于别人赋予你的价值!
其次,避免表现得急切或绝望。同样,这次谈判有可能为长期业务关系定下基调。把个人原因排除在你的谈判策略之外。你不想根据你的开支或你的生活方式的要求来谈判,而是根据你给公司带来的价值。
最后,不要让你的自信表现为苛求或唠叨的行为。一副自以为是的样子会比其他任何事情更快地破坏谈判,所以确保你不要越过自信和傲慢之间的界限。
提出你的理由
这是整个过程中最重要的一步,因为这是你向你的招聘经理或雇主证明你带来了独特价值的地方。在薪资谈判过程中,唯一真正重要的事情是,你要证明你会让团队或公司整体受益匪浅。
但是不能随便说!如果你想加薪,你必须证明这一点。因此,当向雇主展示你的价值时,关注你的成功,比如你的工作如何影响了你现在工作的地方或过去公司的底线。详细解释你的工作如何通过为你所做的事情提供真正的价值来节省或创造额外的收入。
展示你的工作所产生的影响的有力证据是你能提供的最有影响力的证据。这就是强大的数据科学产品组合派上用场的地方。详细介绍项目、成就和其他资质是证明你的才华、技能和影响力的最可靠的方式之一。
接下来,利用你宝贵的技能、经验和杰出的资质,让你独一无二地适合这个特殊的角色。这与谈论其他人在类似职位上的收入或你在其他职位上的收入是不同的。这个想法是,这个数据科学的角色,你目前正在谈判的薪水是你最适合的。
谈论自己并不总是容易的,尤其是如果你想提升自己,谈论你擅长的事情。许多人低估了自己的价值,这在谈判薪水时没有帮助。如果你在这方面有困难,咨询招聘人员或参加谈判课程,这将有助于你为自己的价值或你给这份工作带来的价值展开有力的辩论。
评估报价
一旦你向公司展示了自己是一笔有价值的资产,他们就该给你一份工作了。这里有一些谈判过程中的经验法则。
首先,永远不要当场接受提议。这些谈判可能会让人感到紧张和不舒服,当你做重大决定时,这绝不是一个好的环境。无论提议是好是坏,永远不要在谈判的时候回答提议。相反,花些时间考虑一下。
其次,从大的方面来看薪资待遇。想想在你的职业生涯中什么对你真正重要,并考虑薪水带来的其他好处。想想其他的东西会如何补充你的价值观。
从假期和医疗保险,到公司电话和汽油报销,一切都加起来。看 offer 的时候,不要只看丰厚的薪水。如果薪酬方案的其余部分提供了你高度重视的替代福利,你可能会接受较低的薪水。
总是协商
在花时间从大局的角度考虑报价后,是你谈判的时候了。第一条规则是总是协商。即使最初的提议很好,问问你自己,如果每年多几千美元或增加一些 PTO,你真的会不开心吗?此外,这次谈判的结果将是你未来所有谈判的基准,所以你最好尽力而为。
现在是时候给你的雇主一个具体的数字了,如果你还没有这么做的话。记住你的离开次数。如果你的雇主不能以工资的形式给你你应得的东西,但你仍然想接受这份工作,发挥创造力,通过增加其他方面的价值,比如福利,来缩小工资差距。
一切都有待协商
如果你的潜在或当前雇主不能灵活对待你的工资,是时候发挥创造力,尝试协商你重视的其他领域,如定期奖金、更多 PTO、假期、额外报销或任何你能想到的东西。如果它是你重视的能让你生活更好的东西,你可以把它扔进谈判中来抵消较少的薪水。
一个简单的例子是,你可以通过简单地谈判购买一部公司电话,每年轻松地将 1000 美元额外收入囊中。这样,你就可以一次性更换你的私人电话并消除你每月的电话费。
重拾你的热情,保持你的价值
在谈判的这一阶段,重要的是你要重新燃起对你正在寻找的公司或职位的热情,并重申你将会或已经给公司带来的价值。你希望你的信息是这样的,“我很乐意成为其中的一员,我知道我会给你的团队带来难以置信的价值,正如我已经证明的那样,但我所寻找的更接近于……”从这里开始,在空白处填入你所寻找的。
此外,在这一点上,提及其他公司给你的竞争性报价可能是有价值的。这不仅是一个诚实和透明的信号,而且也可能成为推进有利谈判的额外动力。
接受提议或者走开
一旦你开始了谈判过程,你需要准备好要么接受提议,要么离开谈判桌。没有什么比从雇主那里获得有利的谈判,并且仍然对你对他们公司的承诺持观望态度更快破釜沉舟了。
在这一点上,他们给了你一个提议,你已经评估了这个提议。你还提出了一个重新协商的提议,他们要么接受,要么拒绝,要么再次重新协商。这种来回的过程应该被最小化,因为这对双方来说都是乏味的。
在开始谈判之前,你需要提前计划,知道你想要什么,并根据你可以纳入薪酬方案的其他好处,记住你的离职人数。
如果你再次得到另一份工作,不要当场或一时冲动接受它。评估它是否会补偿你的价值,不仅仅是根据数字,还要评估它是否会让你足够开心,为这个角色牺牲掉你醒着的许多时间。
如果你已经尽了最大努力进行谈判,并且结果是有利的,那么恭喜你!你成功地克服了员工可能面临的最棘手的任务之一,不仅如此,你还脱颖而出。
如果谈判失败,你对结果不满意,简单地感谢他们的考虑,然后走开。如果你对自己的市场价值有信心,并且相信自己的期望不是不合理的,那就去别处寻找机会。
毕竟,数据科学市场竞争异常激烈,非常需要有技能的数据科学家。如果一家公司不欣赏你的贡献,另一家会的!
结论
对大多数人来说,谈判薪水不是一件有趣或容易的事情。但是你准备得越充分,练习得越多,你就越有可能展现出你最好的一面,为增加你的收入创造最佳的机会。
管理期望是谈判过程的一个重要部分。你有你自己的期望,你的雇主也有他们的期望,但是为了产生最佳的谈判能力,这些期望需要非常明确。
你需要知道你的价值,你能提供什么,你愿意接受什么。公司需要了解作为员工他们对你的期望,以及作为雇主你对他们的期望。
记住:永远谈判!
如何永远克服冒名顶替综合症
原文:https://www.dataquest.io/blog/how-to-overcome-imposter-syndrome-for-good/
May 30, 2018
当我开始怀疑自己是否有点欺诈的时候,我正在做一份我热爱的工作。数字战略和客户服务是我的强项。但是,当我被赋予额外的职责,突然让我主持与顶级全球营销人员的会议时(尽管我在这一领域的经验很少),我开始感到力不从心。有时,我确信我会被发现。当业绩考核来临时,我想知道我是否最终会听到,“你不会被淘汰。”
然而,我收到的每一条反馈都是积极的。我的啊哈!我偶然发现了一篇关于冒名顶替综合症的文章——我发誓我是在读关于我自己的文章。意识到其他成功人士也经历过同样的感受是一种极大的解脱。
从那以后,我已经无数次发现其他人患有冒名顶替综合症。就在几天前,我在指导一位同事时,她开始表现出许多相同的症状:缺乏自信和自我怀疑,尽管得到了积极的评价。当我告诉她关于冒名顶替综合症的事情时,她也如释重负。
那么什么是冒名顶替综合症呢?
简而言之,这是许多成功人士共有的一种心理现象,他们认为自己不够好,他们的成就仅仅是运气。这种现象尤其影响千禧一代。研究发现,今天 20 多岁的年轻人中有三分之一在工作场所严重缺乏自信。当人们已经和他们的同事不一样时,他们也更有可能感到被欺骗。根据美国心理协会(APA)的说法,女性、有色人种和 LGBTQ 工作者可能是更危险的人群。知道这种经历有多常见应该会给我们带来安慰,但我们也需要一些策略来处理它,并将我们对成功的渴望转化为一种优势。以下是我学到的一些应对冒名顶替综合症的技巧:
1。认识到正在发生的事情。能够识别我正在经历的是一件大事,它让我的感觉变得清晰。问问你自己,“为什么我在怀疑自己?”试着找出为什么你会有不充分的感觉。即使只是认识到你的行为也有助于将它们最小化,这样你就可以自信地重新设定和重新聚焦。你是一个完美主义者吗?你很少寻求帮助吗?根据美国心理学会的说法,这些都是综合症的症状。将自己与他人——他们的工作、性格或环境——进行比较也是通常会泄露秘密的迹象。尽管这些特征可能很不幸,但它们可以帮助你更好地识别你是否有欺诈现象(并在以后寻求改变它)。
2。记住:你并不孤单。当我感到怀疑时,我会向雪莉·桑德伯格和朱迪·福斯特这样有影响力的女性求助,她们也承认自己有欺骗的感觉。“我认为这是一个很大的侥幸,”谈到 1988 年因《被告》获得奥斯卡奖时说。“我以为每个人都会发现,然后他们会拿回奥斯卡。”记住不可否认的成功人士都有同样的挣扎可以提供很好的视角。
3。看数据。获得视角的另一个好方法是数据。审视我们自己成就的事实可以让我们的感觉更加踏实,让我们对我们在工作中产生的客观影响放心。密切关注团队跟踪的关键绩效指标。收集你钦佩和信任的人的意见。用事实来提醒自己,如果表现不佳,你就不会在这里。
4。假装直到你成功。表现出自信会让别人对你有信心。所以当你的自我感觉脆弱的时候,就暂时假装一下。自信地交流,练习眼神交流,对周围的人微笑。渐渐地,你意识到在某种情况下你实际上比你想象的更有能力。
5。明白前方有一段旅程。仅仅认识到你正在与冒名顶替综合症作斗争并不意味着它会在一夜之间消失。克服这些感觉需要时间。没关系。重要的是建立应对能力,并继续带着“我以前克服过这种情况,我会再做一次”的心态应对挑战
6。让他人了解他们的成就。使用这些策略不仅对我们自己很重要,对帮助其他遭受痛苦的人也很重要。当有人表现出自我怀疑的迹象时,问:“你认为你为什么在这里与自信作斗争?有证据表明你表现不好吗?”帮助那个人获得和你一样的视角。
让我们重新定义冒名顶替综合症——不是一种使人衰弱的状况,而是一种优势。它与伟大的事情相关,比如渴望成长和高成就。体验欺骗的感觉实际上让你置身于一个非常酷的俱乐部。如果你学会认识到它是什么,它可以让你保持自我,让你的眼睛坚定地盯着前方的目标。
莎拉·约翰逊是加速合伙人的客户服务部副总裁。Sarah 在 AP 的领导团队工作了五年多,负责 60 人客户服务团队的成功和我们客户的幸福。 编者按:这是最初发布在 Glassdoor 上的,已经用 perlesson 转贴了。
如何克服面试中尴尬的沉默
原文:https://www.dataquest.io/blog/how-to-overcome-that-awkward-silence-in-interviews/
August 8, 2018
吉利安·克雷默
我们都经历过这种情况:当我们与招聘经理沉默地坐在一起时,我们认为是一次出色的面试很快就降级了——留下的只是想知道我们做错了什么,以鼓励我们的同事完全停止说话。(说说尴尬!)所以,我们明白了:“面试中的沉默是艰难的,”求职和职业专家 J. T .安东内尔说,这不仅仅是因为我们认为招聘经理负责面试和谈话流程。“如果有一个沉默,我们不想接管的情况下,并试图填补它,”同情安东内尔。“有时招聘经理会做笔记。无论是哪种情况,我们都需要耐心,深呼吸,等待他们重新参与进来。”
但当情况并非如此时——当招聘经理没有带头填补这个奇怪的空缺时——你可以站出来。这里有六种方法可以克服尴尬的面试沉默。
1.不要打破沉默。
笑着忍受那个尴尬的时刻是很难的,但是安东内尔鼓励你走向沉默。“试着对招聘经理微笑,并在座位上保持不动,”她鼓励道。“你越烦躁,就越容易分心。展现你保持冷静和沉着的能力。”为了打破沉默——并保持沉默——安东内尔说,你应该“把你的思想集中在你认为是你最好的品质上”,这将有助于“你的心态保持积极,你自然的面部表情会传达这种积极。你不说话并不意味着你不能在沉默中说话,在你的肢体语言和面部表情中表现出一个自信、快乐的人。”
你可能会想,我为什么要在面试中保持沉默?但事实是:“一些沉默[总是]是自然对话的一部分,”职业教练哈利·克劳福德说。面试中时不时的停顿不仅是可以的,而且是意料之中的。克劳福德说:“停顿是谈话正常节奏的一部分。她建议,“在这种情况下,通过坐直、微笑和眼神交流来表明你仍在参与对话。”
2.慢慢来。
你可能没有意识到,但是你的行为可能会创造出那些超级尴尬的沉默时刻。克劳福德指出:“如果你紧张,回答得太快,可能会有一段尴尬的沉默期。”。但幸运的是,克劳福德说,有一个简单的方法:“深呼吸,用正常的语速说话,试着平静你的神经和想法,”克劳福德说。“在回复之前,花几秒钟处理一个问题也是有帮助的。如果短暂停顿后,你不确定该如何回答,那么你可以在回答之前先问问招聘经理。
3.求澄清。
想象一下:你给出了一个很棒的答案,但是你仍然会遇到蟋蟀。高管教练、《找到你的甜蜜点》一书的作者卡伦·埃利扎加说,你应该“抓住这个机会,积极主动。”Aske,“你想让我澄清我刚才提到的吗?”伊利莎加建议,或者说,“根据我刚才的解释,你认为这在这里会如何运作?”这让经理有责任做出回应。
4.找出令人尴尬的沉默的原因。
“你的招聘经理会花很长时间看你的简历或你的投资组合吗?”克劳福德问道。如果是这样,现在是时候大声说出来,问问你是否能解决任何潜在的问题。“试试类似这样的问题,‘你对我能提出的资格有任何疑虑吗?’克劳福德建议道。或者,如果他们在你分享了一个明星故事后花了很长时间,试着这样问,“我举的例子中有没有你想让我澄清的地方?”这为你提供了一个机会,让谈话继续下去,解决经理的任何问题。"
5.开始一个相关的思考。
当尴尬的沉默变得让人无法忍受时,“抓住机会详述你刚刚给出的答案,或者用一种不同的方式回答面试官的问题,这样可以让你展示你的肌肉,分享你丰富的经验,”伊丽莎白建议道。比如说,“再考虑一下……”她开始说道,“然后分享一个与你正在思考的问题相关的见解。"
6.问自己的问题。
如果你坐在令人不舒服的沉默中,是时候问自己一些问题来填补这种沉默了。克劳福德指出,毕竟,沉默可能是经理“给你提供一个提问或评论的机会”的方式。所以,“利用这个机会来解决你对这个职位、工作环境或面试中可能出现的其他问题的任何担忧。你也可以利用这种意外的沉默,让经理知道你对这个职位和为公司工作的可能性感到兴奋。
吉利安·克莱默是一位获奖的自由撰稿人,住在纽约。她写关于食物和饮料,旅游,妇女问题——思考:堕胎权利和性别平等——金钱,以及在线和印刷出版物的职业策略。
编者按:这篇文章最初发表在 Glassdoor 上,并被 perlesson 转载。
如何在 Matplotlib 中绘制条形图:简单的方法
原文:https://www.dataquest.io/blog/how-to-plot-a-bar-graph-matplotlib/
July 30, 2021

条形图是最常见的可视化类型之一,在 Matplotlib 中非常容易创建。我们需要做的就是编写一小段 Python 代码。
然而,如果我们想要创建一个信息丰富、易读的条形图,有效地揭示数据背后的故事,我们必须记住几个重要的事情。这就是我们要在本文中讨论的内容。
这些建议中的一些仅针对条形图;其他的适用于任何类型的数据可视化。
为了练习我们的条形图,我们将使用 Kaggle 的一个与酒吧密切相关的数据集— 世界各地的酒精消费量

 。该表是 2010 年的,所以让我们回到过去。我们将使用 Matplotlib 和 Python 来进行数据探索和数据可视化。
。该表是 2010 年的,所以让我们回到过去。我们将使用 Matplotlib 和 Python 来进行数据探索和数据可视化。
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('drinks.csv')
print('Number of all the countries:', len(df), '\n')
# Removing the countries with 0 alcohol consumption
df = df[df['total_litres_of_pure_alcohol'] > 0]\
.reset_index(drop=True)
print(df.head(3), '\n')
print('Number of all the drinking countries:', len(df))
输出:
Number of all the countries: 193
country beer_servings spirit_servings wine_servings \
0 Albania 89 132 54
1 Algeria 25 0 14
2 Andorra 245 138 312
total_litres_of_pure_alcohol
0 4.9
1 0.7
2 12.4
Number of all the drinking countries: 180
去杂乱
一般来说,我们应该最大化图表的数据-墨水比率,因此,排除所有不能通过数据为我们讲述故事提供任何额外信息的东西。
移除冗余特征
首先,我们应该避免情节上任何可能转移读者注意力的特征:
- 不必要的刺和扁虱
- 网格,如果它是多余的
- 尽可能用十进制数,尤其是那些有很多小数点的数字
- 将精确的数字(十进制或非十进制)放在每个条的顶部:如果我们真的需要它们,我们可以用相应的表格来补充我们的图表。或者,我们可以只在条形顶部使用这些直接标签,并删除数字轴,以避免重复相同的信息。
标签和尺寸
创建条形图时,讲故事的一个看似明显但有时被忽视或误用的方面与标签和尺寸有关:
- 图形足够的宽度和高度
- 图表标题、轴标签、记号和注释(如果有)的易读字体大小
- 标题尽可能简洁,同时尽可能详尽地描述,不超过 2-3 行(如果很长的话)
- 清除坐标轴标签
- 旋转刻度标签(如有必要)
- 包含在轴标签中或直接包含在标题中的测量值的单位(%、分数或任何绝对值)
- 如果分类轴的值是不言自明的,我们可以省略这个轴标签
永远要避免的事情
创建条形图时,请始终避免以下功能:
- 3D 条形图:它们严重扭曲了现实,造成了一种视觉错觉,使识别每个条形的真实高度(长度)变得更加困难。此外,前面的条形可以完全覆盖后面的条形,使读者看不到它们。
- 交互性(极少数情况除外)。
- 装饰品或色彩效果。
让我们比较下面的两个条形图,它们在数据方面是相同的,但在风格上是不同的。此外,我们还将找出 2010 年哪些国家消费了最多的酒:
top5_alcohol = df.sort_values('total_litres_of_pure_alcohol',
ascending=False)[:5]\\
.reset_index(drop=True)
ss="token punctuation">, ax = plt.subplots(figsize=(16,7))
ss="token punctuation">.tight_layout(pad=2)
ss="token punctuation">.subplot(1,2,1)
ss="token punctuation">.set_style('whitegrid')
ss="token operator">= sns.barplot(x='country', y='total_litres_of_pure_alcohol',
data=top5_alcohol)
"token keyword">for p in ax.patches:
class="token punctuation">.annotate(format(p.get_height(), '.1f'),
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
xytext=(0, 7), textcoords='offset points')
ss="token punctuation">.title('TOP5 countries by pure alcohol consumption')
ss="token punctuation">.xlabel('Countries')
ss="token punctuation">.ylabel('Litres per person')
s="token punctuation">.grid(True)
ss="token punctuation">.subplot(1,2,2)
ss="token punctuation">.set_style('ticks')
ss="token operator">= sns.barplot(x='country', y='total_litres_of_pure_alcohol',
data=top5_alcohol)
ss="token punctuation">.title('TOP5 countries by pure alcohol consumption', fontsize=30)
ss="token punctuation">.xlabel(None)
ss="token punctuation">.xticks(fontsize=22, rotation=30)
ss="token punctuation">.ylabel('Litres per person', fontsize=25)
ss="token punctuation">.yticks(fontsize=22)
ss="token punctuation">.despine(bottom=True)
s="token punctuation">.grid(False)
s="token punctuation">.tick_params(bottom=False, left=True)
"token keyword">for _,s in ax.spines.items():
lass="token punctuation">.set_color('black')
ss="token punctuation">.show()

第二个条形图,即使仍然不理想,也肯定比第一个干净得多,可读性更好。我们删除了不必要的脊线、分类轴上的刻度、网格、条形值指示、增加的字体大小、旋转的 x 刻度标签,并省略了分类轴标签。
是的,我们清楚地看到哪些国家在 2010 年喝了更多的酒。不过,最有可能的是,他们喝的是不同种类的饮料。我们很快会调查这个问题。
着色
我们已经提到,使用额外的颜色效果,如背景或字体颜色,不是一个好的做法。为条形图选择颜色时,还有一些其他的事情需要考虑。
突出显示一些条形
当应用不同的颜色不能传达任何关于数据的信息时,我们应该避免。默认情况下,seaborn 条形图中的每个条形都有不同的颜色,正如我们前面看到的那样。我们可以通过引入颜色参数并给所有的条分配相同的颜色来覆盖它。然而,我们仍然可以特别强调一些条形,并用灰色显示其他条形。例如,在我们上面的前 5 个国家中,让我们突出饮用特定烈酒的领导者。除了颜色强调,我们还将添加相应的注释:
spirit_top = top5_alcohol['spirit_servings']
colors = ['grey' if (s < max(spirit_top)) else 'red' for s in spirit_top]
fig, ax = plt.subplots(figsize=(10,5))
sns.set_style('white')
ax=sns.barplot(x='country', y='total_litres_of_pure_alcohol',
data=top5_alcohol, palette=colors)
plt.title('TOP5 countries by pure alcohol consumption', fontsize=25)
plt.xlabel(None)
plt.xticks(fontsize=16)
plt.ylabel('Litres per person', fontsize=20)
plt.yticks(fontsize=15)
ax.text(x=2.5, y=12.3, s='the highest \\nspirit servings',
color='red', size=17, weight='bold')
sns.despine(bottom=True)
ax.grid(False)
ax.tick_params(bottom=False, left=True)
plt.show()

加勒比海的一个小岛国,格林纳达,在纯酒精消费中排名第四,在排名前五的国家中,它是烈酒消费量最高的国家。
使用色盲调色板
为了让我们的条形图获得更广泛的受众,我们应该考虑使用色盲友好的颜色。有各种在线工具(如斯塔克或科尔布林德)可以测试不同类型色盲的图像。然而,它最常见的形式涉及区分红色和绿色,所以一个好的方法是避免调色板上有这两种颜色。另一种方法是使用色盲 10 调色盘的画面。缺点是它提供的颜色选择相当有限。
避免违反直觉的颜色
对于大多数人来说,一些颜色与某些类别的现象或品质有很强的联系。
例如,紫红色被广泛认为是女性的颜色。交通灯调色板通常用于区分危险区、中立区和安全区。而红蓝调色板与温度等有关。即使你是一个坚定的不墨守成规者,总是反对任何刻板印象,在创建分组条形图时遵循这些不成文的约定也是一个好主意,以避免误导读者。
如果我们的小组没有特定的惯例,一个好的做法是尝试提出(如果可能的话)一些上下文相关但易于理解的决策。比方说,我们将创建一个过去 10 年全球考拉和狐狸数量的分组条形图。在这种情况下,我们可以考虑用橙色代表狐狸,灰色代表考拉,而不是相反。
让我们回到纯酒精消费排名前五的国家,并检查每个国家饮用啤酒和葡萄酒的比例。当然,有些类型的啤酒是深红色的(例如樱桃色的),有些葡萄酒是金黄色的(白葡萄酒或梅子酒)。尽管如此,这些饮料最直观的颜色联想是葡萄酒的深红色和啤酒的金黄色:
fig, ax = plt.subplots(figsize=(10,5))
x = np.arrange(len(top5_alcohol))
width = 0.4
plt.bar(x-0.2, top5_alcohol['wine_servings'],
width, color='tab:red', label='wine')
plt.bar(x+0.2, top5_alcohol['beer_servings'],
width, color='gold', label='beer')
plt.title('TOP5 countries by pure alcohol consumption', fontsize=25)
plt.xlabel(None)
plt.xticks(top5_alcohol.index, top5_alcohol['country'], fontsize=17)
plt.ylabel('Servings per person', fontsize=20)
plt.yticks(fontsize=17)
sns.despine(bottom=True)
ax.grid(False)
ax.tick_params(bottom=False, left=True)
plt.legend(frameon=False, fontsize=15)
plt.show()

现在我们很容易发现,在法国,人们喝的葡萄酒比啤酒多得多,而在立陶宛和格林纳达,情况正好相反。在安道尔,这两种饮料都相当受欢迎,葡萄酒略占主导地位。
配置
垂直与水平条形图
尽管垂直条形图通常是默认的,但有时水平条形图更受欢迎:
- 用于标称变量绘图
- 当 x 刻度标签太长时,旋转它们有助于避免重叠,但会降低可读性
- 当我们有大量的类别(条)时
在最后一种情况下,水平条形图特别有利于在狭窄的手机屏幕上查看图形。
垂直条形图更适合绘制顺序变量或时间序列。例如,我们可以用它来按地质时期绘制地球上的总生物量,或按月份绘制 UFO 目击数量,等等。
由于 country 列代表一个名义变量,并且一些国家的名称相当长,所以让我们选择许多类别(人均啤酒消费量排名前 20 位的国家),并查看水平条形图:
top20_beer = df.sort_values('beer_servings', ascending=False)[:20]
fig, ax = plt.subplots(figsize=(40,18))
fig.tight_layout(pad=5)
# Creating a case-specific function to avoid code repetition
def plot_hor_vs_vert(subplot, x, y, xlabel, ylabel, rotation,
tick_bottom, tick_left):
ax=plt.subplot(1,2,subplot)
sns.barplot(x, y, data=top20_beer, color='slateblue')
plt.title('TOP20 countries \\nby beer consumption', fontsize=85)
plt.xlabel(xlabel, fontsize=60)
plt.xticks(fontsize=45, rotation=rotation)
plt.ylabel(ylabel, fontsize=60)
plt.yticks(fontsize=45)
sns.despine(bottom=False, left=True)
ax.grid(False)
ax.tick_params(bottom=tick_bottom, left=tick_left)
return None
plot_hor_vs_vert(1, x='country', y='beer_servings',
xlabel=None, ylabel='Servings per person',
rotation=90, tick_bottom=False, tick_left=True)
plot_hor_vs_vert(2, x='beer_servings', y='country',
xlabel='Servings per person', ylabel=None,
rotation=None, tick_bottom=True, tick_left=False)
plt.show()

水平翻转所有单词(包括测量值轴的标签)会使第二个图表更具可读性。
纳米比亚开放这个列表,随后是捷克共和国。除了立陶宛,我们再也看不到酒精消费量最高的国家了,立陶宛已经下降到第五位。似乎他们在之前评级中的高位置是用喝烈酒和葡萄酒而不是啤酒来解释的。
排序
如果我们提取人们饮酒超过平均水平的所有国家,然后将这些数据可视化为条形图,得到的条形图将按字母顺序按基本类别(国家)排序。不过,最有可能的是,在这种情况下,我们更感兴趣的是看到按人均葡萄酒数量排序的数据。让我们比较一下这两种方法:
wine_more_than_mean = (df[df['wine_servings'] > df['wine_servings']\\
.mean()])
sort_wine_more_than_mean = wine_more_than_mean\\
.sort_values('wine_servings',
ascending=False)
fig, ax = plt.subplots(figsize=(30,30))
fig.tight_layout(pad=5)
# Creating a case-specific function to avoid code repetition
def plot_hor_bar(subplot, data):
plt.subplot(1,2,subplot)
ax = sns.barplot(y='country', x='wine_servings', data=data,
color='slateblue')
plt.title('Countries drinking wine \\nmore than average',
fontsize=70)
plt.xlabel('Servings per person', fontsize=50)
plt.xticks(fontsize=40)
plt.ylabel(None)
plt.yticks(fontsize=40)
sns.despine(left=True)
ax.grid(False)
ax.tick_params(bottom=True, left=False)
return None
plot_hor_bar(1, wine_more_than_mean)
plot_hor_bar(2, sort_wine_more_than_mean)
plt.show()

在第一个情节中,我们可以通过人均葡萄酒饮用量(仅指人们饮酒量超过平均水平的国家)来区分排名第一和最后三个国家,然后事情变得过于复杂。在第二个情节中,我们可以很容易地追溯整个国家的评级。为了更真实的描述,我们应该考虑到每个国家的人口(当然,将俄罗斯联邦与库克群岛和圣卢西亚进行比较并不完全正确),并且可能排除弃权者。然而,这里的要点是,如果我们想从可视化中获得最大限度的信息,我们应该始终考虑在绘制数据之前对数据进行排序。这不一定是按值排序:相反,我们可以决定按类别本身对数据进行排序(如果它们是有序的,如年龄范围),或者如果必要的话,它背后可能有任何其他逻辑。
从 0 开始
虽然其他类型的图不必从零开始,但条形图总是从零开始。原因是条形图应该显示每个数据点的大小和所有数据点之间的比例,而不是像线形图那样只显示变量的变化。
如果我们从 0 以外的值开始截断 y 轴(或 x 轴,如果是水平条形图),我们还会截断每个条形的长度,因此我们的图表无法正确显示——无论是每个类别的单个值还是它们之间的比率:
usa = df[df['country']=='USA'].transpose()[1:4].reset_index()
usa.columns = ['drinks', 'servings']
fig = plt.figure(figsize=(16,6))
fig.tight_layout(pad=5)
# Creating a case-specific function to avoid code repetition
def plot_vert_bar(subplot, y_min):
plt.subplot(1,2,subplot)
ax = sns.barplot(x='drinks', y='servings',
data=usa, color='slateblue')
plt.title('Drink consumption in the USA', fontsize=30)
plt.xlabel(None)
plt.xticks(usa.index, ['Beer', 'Spirit', 'Wine'], fontsize=25)
plt.ylabel('Servings per person', fontsize=25)
plt.yticks(fontsize=17)
plt.ylim(y_min, None)
sns.despine(bottom=True)
ax.grid(False)
ax.tick_params(bottom=False, left=True)
return None
plot_vert_bar(1, y_min=80)
plot_vert_bar(2, y_min=None)
plt.show()

左边的图给了我们一个误导的印象,即在美国,葡萄酒的消费量比烈酒的消费量低 15 倍左右,而烈酒的消费量还不到啤酒的一半。在右边的图上,我们看到完全不同的比例,这是正确的比例。
分组和堆叠
视觉明显的分组
创建成组条形图时,注意条形之间的距离很重要,当每个组内条形之间的间距小于(最大为 0)相邻组条形之间的间距时,我们认为分组正确。
回到纯酒精消费量排名前五的国家,现在让我们来看看每个国家饮用烈酒和葡萄酒的比例:
top5_alcohol_rev = top5_alcohol\\
.sort_values('total_litres_of_pure_alcohol')\\
.reset_index(drop=True)
fig, ax = plt.subplots(figsize=(20,9))
fig.tight_layout(pad=5)
# Creating a case-specific function to avoid code repetition
def plot_grouped_bar(subplot, width, gap):
plt.subplot(1,2,subplot)
x = np.arange(len(top5_alcohol_rev['wine_servings']))
plt.barh(x, top5_alcohol_rev['wine_servings'],
width, color='tab:red', label='wine')
plt.barh(x+width+gap, top5_alcohol_rev['spirit_servings'],
width, color='aqua', label='spirit')
plt.yticks(x+width/2, top5_alcohol_rev['country'], fontsize=28)
plt.title('TOP5 countries \\nby pure alcohol consumption',
fontsize=40)
plt.xlabel('Servings per person', fontsize=30)
plt.xticks(fontsize=22)
sns.despine(left=True)
plt.tick_params(bottom=True, left=False)
ax.grid(False)
plt.legend(loc='right', frameon=False, fontsize=23)
return None
plot_grouped_bar(1, width=0.4, gap=0.1)
plot_grouped_bar(2, width=0.3, gap=0)
plt.show()

在左侧的图表中,很难立即区分相邻组之间的边界,因为每个组内部和组之间的条形之间的距离是相等的。然而,右边的图表清楚地显示了每个条形与哪个国家相关。我们现在看到,格林纳达、白俄罗斯和立陶宛的人更喜欢烈酒,而不是葡萄酒,而法国和安道尔的情况正好相反。
堆积条形图与分组条形图
在堆积条形图和分组条形图之间进行选择时,我们应该考虑可视化的主要信息:
- 如果我们最感兴趣的是几个类别的总体值,并且作为次要目标,我们希望估计哪个组件在最大或最小的总体值中贡献最大,那么最佳选择是堆积条形图。然而,这里的问题是,除了第一个元素(即,垂直堆积条形图中的最底部或水平条形图中的最左侧),很难找出其单个元素的趋势。这在我们有很多小节的情况下尤其重要,有时,我们甚至会得到一个欺骗性的印象,并得出一个不正确的结论。
- 如果我们想跟踪各个类别中每个单独组件的趋势,我们最好使用分组条形图。显然,在这种情况下,我们不能说按类别的总价值。
让我们将堆积和分组条形图应用于波罗的海国家,以确定他们的饮酒偏好:
baltics = df[(df['country']=='Latvia')|(df['country']=='Lithuania')\\
|(df['country']=='Estonia')].iloc[:,:4]
baltics.columns = ['country', 'beer', 'spirit', 'wine']
baltics.reset_index(drop=True, inplace=True)
labels = baltics['country'].tolist()
beer = np.array(baltics['beer'])
spirit = np.array(baltics['spirit'])
wine = np.array(baltics['wine'])
fig, ax = plt.subplots(figsize=(16,7))
fig.tight_layout(pad=5)
# Creating a case-specific function to avoid code repetition
def plot_stacked_grouped(subplot, shift, width, bot1, bot2):
x = np.arrange(len(baltics))
plt.subplot(1,2,subplot)
plt.bar(x-shift, beer, width,
label='beer', color='gold')
plt.bar(x, spirit, width, bottom=bot1,
label='spirit', color='aqua')
plt.bar(x+shift, wine, width, bottom=bot2,
label='wine', color='tab:red')
plt.title('Drink consumption \\nin Baltic countries',
fontsize=35)
plt.xlabel(None)
plt.xticks(baltics.index, labels, fontsize=25)
plt.ylabel('Servings per person', fontsize=27)
plt.yticks(fontsize=20)
sns.despine(bottom=True)
plt.tick_params(bottom=False, left=True)
plt.legend(frameon=False, fontsize=17)
return None
plot_stacked_grouped(1, shift=0, width=0.35,
bot1=beer, bot2=beer+spirit)
plot_stacked_grouped(2, shift=0.2, width=0.2,
bot1=0, bot2=0)
plt.show()

在上面的堆叠图中,我们看到,在所有三个波罗的海国家中,立陶宛的酒精消费量最高,而爱沙尼亚的最低。两种情况下的主要贡献都来自啤酒。关于这些国家烈酒和葡萄酒的消费,从这个情节中我们说不出什么精确的东西。事实上,数量似乎相等。
分组图清楚地表明,立陶宛也领先于饮酒,而爱沙尼亚再次显示最低水平。不过,这种饮料的区别并不像啤酒那样明显。至于葡萄酒,差异就更不明显了,但似乎拉脱维亚的葡萄酒消费量最高,而立陶宛的消费量最低。然而,从这个图表中,猜测这些国家的总体酒精消费量已经变得更加困难。我们必须做一些心算,如果有三个以上的酒吧团体,这个任务就变得不切实际了。
结论
在创建有意义的可视化并从中获得正确的见解之前,我们必须考虑以下细节:
- 我们的目标
- 我们的目标受众
- 从我们的图表中获得的重要信息,以及如何在显示更多有用信息的同时强调这些信息
- 如何排除对我们讲故事没用的特征
感谢阅读,和 za zdorovie!

想了解更多关于改进条形图可视化的信息吗?
如何轻松地从 Python 列表中移除重复项(2022)
原文:https://www.dataquest.io/blog/how-to-remove-duplicates-from-a-python-list/
September 12, 2022
Python 列表是有序的、零索引的、可变的对象集合。我们通过将相似或不同数据类型的对象放在用逗号分隔的方括号中来创建它。关于 Python 列表如何工作的复习,请参考这个 DataQuest 教程。
从列表中删除重复项是一个重要的数据预处理步骤,例如,确定上个月从礼品店购买促销产品的唯一客户。有几个顾客可能在过去的一个月里不止一次从这家店买过礼物,他们的名字会随着他们光顾这家店的次数而出现。
在本教程中,我们将学习从 Python 列表中移除重复项的不同方法。
1.使用del关键字
我们使用del关键字从列表中删除对象及其索引位置。当列表很小并且没有很多重复元素时,我们使用这种方法。例如,一个由六名学生组成的班级被问及他们最喜欢的编程语言,他们的回答被保存在students列表中。几个学生喜欢相同的编程语言,所以我们在students列表中有重复的,我们将使用del关键字删除。
students = ['Python', 'R', 'C#', 'Python', 'R', 'Java']
# Remove the `Python` duplicate with its index number: 3
del students[3]
print(students)
['Python', 'R', 'C#', 'R', 'Java']
# Remove the `R` duplicate with its index number: 3
del students[3]
print(students)
['Python', 'R', 'C#', 'Java']
我们成功地从列表中删除了重复项。但是为什么我们两次使用索引 3 呢?原students列表的len为 6。Python 列表是零索引的。列表中的第一个元素的索引为 0,最后一个元素的索引为 5。副本'Python'的索引为 3。删除'Python'副本后,students列表的len减 1。副本'Python'之后的元素现在呈现其索引位置。这就是为什么重复的'R'索引从 4 变为 3。使用这种方法的缺点是,我们必须跟踪不断变化的副本索引。这对于一个非常大的列表来说是很困难的。
接下来,我们将使用for-loop更有效地从列表中删除重复项。
2.使用for-loop
我们使用for-loop来迭代一个 iterable:例如,一个 Python 列表。关于for-loop的工作原理,请参考 DataQuest 博客上的 for-loop 教程。
要使用for-loop删除重复项,首先创建一个新的空列表。然后,迭代包含重复项的列表中的元素,并在新列表中只追加每个元素的第一个匹配项。下面的代码展示了如何使用for-loop从students列表中删除重复项。
# Using for-loop
students = ['Python', 'R', 'C#', 'Python', 'R', 'Java']
new_list = []
for one_student_choice in students:
if one_student_choice not in new_list:
new_list.append(one_student_choice)
print(new_list)
['Python', 'R', 'C#', 'Java']
瞧!我们成功地删除了重复项,而无需跟踪元素的索引。这种方法可以帮助我们删除大型列表中的重复项。然而,这需要大量的代码。应该有更简单的方法。有什么猜测吗?
列表理解!在下一个例子中,我们将使用列表理解来简化上面的代码:
# Using list comprehension
new_list = []
[new_list.append(item) for item in students if item not in new_list]
print(new_list)
['Python', 'R', 'C#', 'Java']
我们用更少的代码行完成了工作。我们可以将for-loop与enumerate和zip函数结合起来,编写奇异的代码来消除重复。这些代码的工作原理与上面的例子是一样的。
接下来,我们将看到如何在不使用set迭代的情况下从列表中删除重复项。
3.使用set
Python 中的集合是唯一元素的无序集合。就其本质而言,重复是不允许的。因此,将列表转换为集合会删除重复项。将集合更改为列表会生成一个没有重复项的新列表。
以下示例显示了如何使用set从students列表中删除重复项。
# Removing duplicates by first changing to a set and then back to a list
new_list = list(set(students))
print(new_list)
['R', 'Python', 'Java', 'C#']
请注意,列表中元素的顺序与我们之前的示例不同。这是因为set不能维持秩序。接下来,我们将看到如何使用字典从列表中删除重复项。
4.使用dict
Python 字典是键值对的集合,要求键必须是唯一的。因此,如果我们能使列表的元素成为字典的键,我们将删除 Python 列表中的重复项。我们不能将简单的students列表转换成字典,因为字典是用键值对创建的。如果我们试图将students列表转换成一个字典,我们会得到以下错误:
# We get ValueError when we try to convert a simple list into a dictionary
print(dict(students))
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-6-43bfe4b3db83> in <module>
1 # We get ValueError when we try to convert a simple list into a dictionary
2
----> 3 dict(students)
ValueError: dictionary update sequence element #0 has length 6; 2 is required
然而,我们可以从元组列表中创建一个字典——之后,我们将获得字典的唯一键,并将它们转换成一个列表。从students列表中获取元组列表的矢量化方法是使用 map 函数:
# Convert `students` list into a list of tuples
list_of_tuples = list(map(lambda x: (x, None), students))
print(list_of_tuples, end='\n\n')
[('Python', None), ('R', None), ('C#', None), ('Python', None), ('R', None), ('Java', None)]
在上面的代码块中,students列表中的每个元素都通过lambda函数来创建一个元组(element, None)。当元组列表变成字典时,元组中的第一个元素是键,第二个元素是值。使用keys()方法从字典中提取唯一键,并将其转换为一个列表:
# Convert list of tuples into a dictionary
dict_students = dict(list_of_tuples)
print('The resulting dictionary from the list of tuples:')
print(dict_students, end='\n\n')
The resulting dictionary from the list of tuples:
{'Python': None, 'R': None, 'C#': None, 'Java': None}
# Get the unique keys from the dictionary and convert into a list
new_list = list(dict_students.keys())
print('The new list without duplicates:')
print(new_list, end='\n\n')
The new list without duplicates:
['Python', 'R', 'C#', 'Java']
dict.fromkeys()方法将一个列表转换成一个元组列表,并将元组列表转换成一个字典。然后,我们可以获得唯一的字典键,并将它们转换成一个列表。然而,在转换成列表之前,我们使用了dict.keys()方法从字典中获取惟一键。这真的没有必要。默认情况下,字典上的操作(如迭代和转换为列表)使用字典键。
# Using dict.fromkeys() methods to get a dictionary from a list
new_dict_students = dict.fromkeys(students)
print('The resulting dictionary from the dict.fromkeys():')
print(new_dict_students, end='\n\n')
print('The new list without duplicates using dict.fromkeys():')
print(list(new_dict_students), end='\n\n')
The resulting dictionary from the dict.fromkeys():
{'Python': None, 'R': None, 'C#': None, 'Java': None}
The new list without duplicates using dict.fromkeys():
['Python', 'R', 'C#', 'Java']
4.使用Counter和FreqDist
我们可以使用字典子类如 Counter 和 FreqDist 从 Python 列表中删除重复项。Counter和FreqDist的工作方式相同。它们是集合,其中唯一的元素是字典键,它们出现的次数是值。如同在字典中一样,没有重复项的列表来自字典键。
# Using the dict subclass FreqDist
from nltk.probability import FreqDist
freq_dict = FreqDist(students)
print('The tabulate key-value pairs from FreqDist:')
freq_dict.tabulate()
print('\nThe new list without duplicates:')
print(list(freq_dict), end='\n\n')
The tabulate key-value pairs from FreqDist:
Python R C# Java
2 2 1 1
The new list without duplicates:
['Python', 'R', 'C#', 'Java']
# Using the dict subclass Counter
from collections import Counter
counter_dict = Counter(students)
print(counter_dict, end='\n\n')
print('The new list without duplicates:')
print(list(counter_dict), end='\n\n')
Counter({'Python': 2, 'R': 2, 'C#': 1, 'Java': 1})
The new list without duplicates:
['Python', 'R', 'C#', 'Java']
5.使用pd.unique和np.unique
pd.unique和np.unique都接受一个有副本的列表,并返回列表中元素的唯一数组。产生的数组被转换成列表。当np.unique按升序对唯一元素排序时,pd.unique保持列表中元素的顺序。
import numpy as np
import pandas as pd
print('The new list without duplicates using np.unique():')
print(list(np.unique(students)), end='\n\n')
print('\nThe new list without duplicates using pd.unique():')
print(list(pd.unique(students)), end='\n\n')
The new list without duplicates using np.unique():
['C#', 'Java', 'Python', 'R']
The new list without duplicates using pd.unique():
['Python', 'R', 'C#', 'Java']
应用:礼品店重游
在这一节中,我们将重温我们的礼品店插图。礼品店在 50 人的附近。平均每天有 10 个人从店里进货,店铺一个月开 10 天。您收到了一个包含上个月在该商店购物的客户姓名的列表,您的任务是获取促销优惠的唯一客户的姓名。
# Install the `names` package
!pip install names
# Get package to generate names
import names
import random
random.seed(43)
# Generate names for 50 people in the neighbourhood
names_neighbourhood = [names.get_full_name() for _ in range(50)]
# Import package that randomly select names
from random import choices
# Customers do not have equal probabilities of purchasing from the shop
weights = [random.randint(-20, 20) for _ in range(50)]
# Randomly generate 20 customers that purchased from the store for 10 days
customers_month = [choices(names_neighbourhood, weights=weights, k=10) for _ in range(10)]
在上面的代码块中,我们随机生成了在过去一个月中从商店购买商品的客户列表。我们希望获得每月从商店购买商品的唯一客户,因此我们将为此任务创建get_customer_names函数。
我们已经包括了可选的输入和输出数据类型。Python 是一种动态类型的编程语言,在运行时隐式处理这种情况。然而,显示复杂数据结构的输入和输出数据类型是很有用的。或者,我们可以用一个docstring描述函数的输入和输出。customers_purchases: List[List[str]]告诉我们customers_purchases参数是一个包含带字符串的列表的列表,-> List[Tuple[str, int]]告诉我们函数返回一个包含带字符串和整数的元组的列表。
from typing import List, Tuple
def get_customer_names(customers_purchases: List[List[str]]) -> List[Tuple[str, int]]:
# Get a single list of all the customers' names from the list of lists
full_list_month = []
for a_day_purchase in customers_purchases:
full_list_month.extend(a_day_purchase)
return Counter(full_list_month).most_common()
customers_list_tuples = get_customer_names(customers_month)
customers_list_tuples
[('Nicole Moore', 14),
('Diane Paredes', 13),
('Mathew Jacobs', 11),
('Katherine Piazza', 10),
('Alvin Cloud', 8),
('Robert Mcadams', 8),
('Roger Lee', 8),
('Becky Hubert', 7),
('Paul Frisch', 7),
('Danielle Mccormick', 5),
('Donna Salvato', 3),
('Sally Thompson', 2),
('Franklin Copeland', 2),
('Linda Sample', 2)]
客户的名字是随机生成的——如果您不使用相同的seed值,您的名字可能会不同。customers_list_tuples中唯一客户的名称来自于首先将元组列表转换为字典,然后将字典键转换为列表:
# Unique customers for the previous month
list(dict(customers_list_tuples))
['Nicole Moore',
'Diane Paredes',
'Mathew Jacobs',
'Katherine Piazza',
'Alvin Cloud',
'Robert Mcadams',
'Roger Lee',
'Becky Hubert',
'Paul Frisch',
'Danielle Mccormick',
'Donna Salvato',
'Sally Thompson',
'Franklin Copeland',
'Linda Sample']
结论
在本教程中,我们学习了如何从 Python 列表中删除重复项。我们学习了如何用关键字del删除小列表中的重复项。对于更大的列表,我们看到使用for-loop和列表理解方法比使用del关键字更有效。此外,我们了解到set的值和字典的键是惟一的,这使得它们适合从列表中删除重复项。最后,我们了解到 dictionary 子类从列表中删除重复项的方式与 dictionary 非常相似,我们还看到了从列表中获取唯一元素的 NumPy 和 pandas 方法。
如何在 2022 年设置 Visual Studio 代码(最简单的方法)
原文:https://www.dataquest.io/blog/how-to-set-up-visual-studio-code/
April 1, 2022
Visual Studio 代码是一个强大的、可扩展的轻量级代码编辑器,已经成为 Python 社区中首选的代码编辑器之一。
在本教程中,我们将学习如何安装 Visual Studio 代码并为 Python 开发进行设置,以及如何更高效地使用 VS 代码。
让我们开始吧!
安装 Visual Studio 代码
这一节将逐步介绍如何在 macOS 上安装 VS 代码。让我们开始吧。
注
由于 Windows 和 macOS 之间的本质区别,Windows 用户需要做一些小的修改来安装 VS 代码。然而,在 Windows 上安装 VS 代码很简单,类似于安装其他 Windows 应用程序。
- 首先从其官网下载 macOS 或 Windows 的 Visual Studio 代码。下载页面会自动检测您的操作系统,并显示一个大按钮,用于在您的计算机上下载最新版本的 Python 安装程序。如果没有,请单击向下箭头按钮,并选择与您计算机上安装的操作系统相匹配的稳定 VS 代码版本:

- 双击下载的文件,提取存档内容:
![Double click the download file]()
- 将 Visual Studio 代码应用程序移动到 application 文件夹,使其在 macOS launchpad 中可用:
![Move the Visual Studio Code application to the Application folder]()
- 启动 Visual Studio 代码,然后打开 Python 脚本所在的文件夹或创建一个新文件夹。例如,在你的桌面上创建一个新文件夹,并将其命名为
py_scripts,然后尝试在 VS 代码上打开该文件夹。
通常情况下,VS 代码需要你的权限才能访问你桌面文件夹中的文件;点击确定:
![Grant the proper permission for VS Code]()
另外,您可能需要声明您信任存储在您桌面文件夹中的文件的作者:
![Declare that you trust the authors of the files]()
- 创建一个扩展名为
.py的新文件。例如,创建一个新文件,并将其命名为prog_01.py。VS 代码检测到.py扩展,想安装一个 Python 扩展:
![Create a new file in VS Code with .py extension]()
要在 VS 代码内部使用 Python,我们需要使用 Python 扩展,它带来了很多有用的特性,比如带智能感知的代码完成、调试、单元测试支持等:
![Why it's important to use VS Code extensions]()
点击安装:
![Click the install button]()
我们也可以通过浏览扩展来安装 Python 扩展。单击 VS 代码左侧的扩展图标:








这将显示 VS 代码市场上最流行的 VS 代码扩展列表。现在,我们可以选择 Python 扩展并安装它:

- 一旦安装了扩展,您必须选择一个 Python 解释器。点击选择 Python 解释器:
![Select the Python Interpreter button]()
然后在列表中选择推荐的 Python 解释器:
![Select the recommended Python interpreter]()
如果您的 Mac 上安装了多个 Python 版本,请选择最新版本:
![Select the latest Python version]()
您也可以使用命令面板中的Python:Select Interpreter命令选择一个 Python 解释器。为此,按下CMD+SHIFT+P,键入 Python,并选择选择解释器。



用 VS 代码创建和运行 Python 文件
非常好。我们拥有在 VS 代码中编写和运行 Python 代码所需的一切。让我们用 VS 代码写下面的代码,然后运行它。
def palindrome(a):
a = a.upper()
return a == a[::-1]
name = input("Enter a name: ")
if palindrome(name):
print("It's a palindrome name.")
else:
print("It's not a palindrome name.")
通过点击 VS 代码右上角的▶️按钮来运行代码。首先,它在集成终端中询问名称;输入一个名称,然后按回车键。如果输入的名字是回文,它输出It's a palindrome name.,否则输出It's not a palindrome name.。
回文单词是一个字母序列,向后读和向前读是一样的,例如 Hannah、Anna 和 Bob。

如您所见,所有输出都出现在集成终端中。让我们再多谈谈这个奇妙的特性。
由于执行终端命令几乎是编写代码不可或缺的一部分,VS 代码通过将这一优秀特性嵌入到 IDE 中为开发人员带来了极大的便利。要查看终端,可以在 macOS 或 Windows 机器上键入Ctrl + ```py,或者使用查看>终端菜单命令。另外,如果你想关闭一个集成终端,点击终端窗口右上角的 bin 图标。从技术上讲,集成终端使用计算机上安装的 Shell,例如,Windows 上的 PowerShell 或命令提示符,macOS 和 Linux 上的 bash 或 zsh。
Visual Studio 代码允许我们使用终端设置自定义终端的外观。为此,打开终端设置页面,点击终端窗口右上角的向下箭头按钮,选择配置终端设置选项;您可以轻松定制字体、间距和光标样式:

VS 代码的另一个很好的特性是,您可以轻松地在多个 shell 之间切换,甚至可以更改集成终端中使用的默认 shell。为此,单击终端窗口右上角的向下箭头按钮,并选择选择默认配置文件选项:

将出现一个预先填充的可用 shell 列表,您可以选择其中一个作为默认终端 shell。让我们选择 bash shell:

一旦您通过单击终端窗口右上角的加号图标创建了一个新的终端,它将使用 bash shell,如下所示:

使用 REPL
VS 代码中另一个有用的特性是运行单行或多行代码,只需选择它们并从上下文菜单中选择运行选择 Python 终端中的行选项。让我们试一试。
在同一个 Python 文件中,编写以下语句:
print("Hello, world!")
```py
然后选择语句,右键选择**在 Python 终端**中运行选择/行选项,如下:

输出出现在集成终端中但是以一种不同的形式出现,叫做 REPL。让我们了解一下 REPL 和它的优点。
REPL 代表阅读,评估,打印,循环。这是一种使用 Python 解释器并直接在终端中运行命令的交互方式。在 REPL,三个右箭头符号表示输入行。
另一种在 VS 代码中启动 REPL 的方法如下:
打开命令调板,搜索 REPL,点击 **Python:启动 REPL** :

会出现交互式 Python shell,我们可以在`>>>`提示符下输入我们的命令,然后只需按下`Enter`或`return`键就可以执行它们,如下:

REPL 的一个很大的特点就是可以即时看到运行命令的结果。所以,如果你想尝试一些代码或者 API,REPL 是一个很好的方法。
## 格式化 Python 代码
一旦开始编写程序,你就应该养成以适当的格式编写代码的习惯。Python 有一个著名的 Python 代码风格指南,叫做 PEP 8,它让你的代码易于阅读和理解。你可以在 Python 官方网站上找到风格指南,网址是[PEP 8——Python 代码风格指南| Python.org](https://www.python.org/dev/peps/pep-0008/)。
在这一节中,我们将学习如何使用 Autopep8 包将格式自动应用到我们的代码中。这个包可以使用`pip`命令安装,它自动格式化 Python 代码以符合 PEP 8 风格指南。好消息是 VS 代码支持使用 Autopep8 包自动格式化代码。
让我们看看如何在 VS 代码中安装包并启用它。
首先,在集成终端中执行以下命令来安装 Autopep8 软件包:
pip3 install autopep8
安装完成后,关闭终端。现在打开 VS 代码的设置,搜索 *Python 格式化*,**Autopep8 Path**和 **Provider** 字段都需要用 auto pep 8 填充,如下:

最后一步是在保存时启用自动格式化。为此,在保存时搜索*格式,并检查保存**格式**选项:

启用此特性将在我们保存文件时应用 Python 源文件上的所有 PEP 8 规则。*
PEP 8 风格指南提供了一些注意事项。我们真的鼓励你学习 PEP 8 规则,并通过 Autopep8 格式化包将它们自动应用到你的源代码中。
## 重构 Python 代码
在讨论在 VS 代码中重构 Python 代码之前,我们先定义一下:
> 代码重构是在不改变其外部行为的情况下,重新构造现有计算机代码的过程——改变因子分解——以使其更易于阅读和维护——[维基百科](https://en.wikipedia.org/wiki/Code_refactoring)。
> Python 扩展提供了基本的重构功能,如重命名符号、提取方法、提取变量等。
> 例如,要将`palindrome()`方法名改为`check_palindrome()`,右击方法名,选择**重命名符号**选项:

在文本框中输入新名称,*check _ 回文*,然后按回车键重命名:

现在,你可以看到所有的`palindrome`事件都被更改为`check_palindrome` :

在关闭本节之前,让我们尝试一下提取方法功能。创建一个新的 Python 文件,并将以下代码粘贴到其中。
height = 5
width = 4
area = height * width
print("Room's area =", area, "square meters")
选择第三行,点击右键,从上下文菜单中选择重构选项:

然后点击**提取方法**按钮,在出现的文本框中输入新名称 *calc_area* ,然后回车重命名:

## Python 交互式窗口
好消息是 Visual Studio 代码支持使用 Jupyter 笔记本。要在交互窗口中运行当前文件,在资源管理器窗格中右击文件名,从上下文菜单中选择**在交互窗口中运行当前文件**选项,如下:

如果 Jupyter 包还没有安装,会显示一个对话框,要求您安装:

安装完成后,会出现一个交互窗口,在这种情况下, 你需要输入一个名字来检查是否是回文:

最后,你可以在交互窗口看到结果,如下:

另外,要在 VS 代码中创建新的 Jupyter 笔记本,打开命令面板,选择 **Jupyter:新建 Jupyter 笔记本**,如下:

会新建一个 Jupyter 笔记本,你可以简单的创建 markdown 和 Code 单元格
## 结论
本教程讨论了 VS 代码的有用特性。然而,不可能在一个教程中涵盖 Visual Studio 代码功能,从而以更少的工作量更高效地进行编码。如果您想了解更多关于使用 VS 代码进行 Python 开发的信息,您可以查看 Visual Studio 官方代码网站上的[入门教程,了解 Visual Studio 中的 Python 代码](https://code.visualstudio.com/docs/python/python-tutorial)。
# 为你的投资组合建立一个数据科学博客
> 原文:<https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/>
June 14, 2016Data science blogs can be a fantastic way to demonstrate your skills, learn topics in more depth, and build an audience. There are quite a few examples of [data science](https://github.com/rushter/data-science-blogs) and [programming](https://www.quora.com/What-are-the-best-programming-blogs) blogs that have helped their authors land jobs or make important connections. Writing a data science blog is thus one of the most important things that any aspiring programmer or data scientist should be doing on a regular basis. *(This is the second in a series of posts on how to build a Data Science Portfolio. You can find links to the other posts in this series at the bottom of the post.)* Unfortunately, one very arbitrary barrier to blogging can be knowing how to set up a blog in the first place. In this post, we’ll cover how to create a blog using Python, how to create posts using Jupyter notebook, and how to deploy the blog live using GitHub Pages. After reading this post, you’ll be able to create your own data science blog, and author posts in a familiar and simple interface.
## 静态站点
从根本上说,静态站点只是一个装满 HTML 文件的文件夹。我们可以运行一个允许其他人连接到这个文件夹并检索文件的服务器。这样做的好处是,它不需要数据库或任何其他移动部件,并且很容易在 GitHub 这样的网站上托管。让您的数据科学博客成为一个静态网站是一个很好的主意,因为这使得维护它变得非常简单。创建静态站点的一种方法是手动编辑 HTML,然后将装满 HTML 的文件夹上传到服务器。在这种情况下,您至少需要一个
`index.html`文件。如果你的网址是`thebestblog.com`,访问者访问了`https://www.thebestblog.com`,他们就会看到`index.html`的内容。下面是一个 HTML 文件夹如何寻找`thebestblog.com`:
```py
thebestblog.com
│ index.html
│ first-post.html
│ how-to-use-python.html
│ how-to-do-machine-learning.html
│ styles.css
在上述网站上,访问
https://www.thebestblog.com/first-post.html会显示first-post.html中的内容,以此类推。first-post.html可能是这样的:
<html>
<head>
<title>The best blog!</title>
<meta name="description" content="The best blog!"/>
<link rel="stylesheet" href="styles.css" />
</head>
<body>
<h1>First post!</h1>
<p>This is the first post in what will soon become (if it already isn't) the best blog.</p>
<p>Future posts will teach you about data science.</p>
<div class="footer">
<p>Thanks for visiting!</p>
</div>
</body>
</html>
您可能会立即注意到手动编辑 HTML 时的一些问题:
- 手动编辑 HTML 非常痛苦。
- 如果你想写多篇文章,你必须复制样式和其他元素,比如标题和页脚。
- 如果你想集成评论或其他插件,你必须写 JavaScript。
一般来说,当你写博客的时候,你想把注意力集中在内容上,而不是花时间和 HTML 较劲。幸运的是,您可以创建一个数据科学博客,而无需使用静态站点生成器工具手工编辑 HTML。
静态现场发电机
静态站点生成器允许你以简单的格式写博客文章,通常是 markdown,然后定义一些设置。然后生成器会自动将你的帖子转换成 HTML。使用静态站点生成器,我们可以大大简化
first-post.html变成first-post.md:
# First post!
This is the first post in what will soon become (if it already isn't) the best blog.
Future posts will teach you about data science.
这比 HTML 文件更容易管理!常见的元素,如标题和页脚,可以放在模板中,因此可以很容易地更改它们。有几种不同的静态站点生成器。最流行的叫做
杰基尔,而且是用红宝石写的。由于我们将创建一个数据科学博客,我们需要一个静态的站点生成器来处理 Jupyter 笔记本。 Pelican 是一个用 Python 编写的静态站点生成器,它可以接收 Jupyter 笔记本文件并将它们转换成 HTML 博客文章。Pelican 还使得将我们的博客部署到 GitHub 页面变得容易,其他人可以在那里阅读我们的博客。
安装鹈鹕
在我们开始之前,
这是一个回购协议,这是我们最终会达成的一个例子。如果您没有安装 Python,那么在我们开始之前,您需要做一些初步的设置。这里的是 Python 的设置说明。我们推荐使用Python 3.5。安装 Python 后:
- 创建一个文件夹—我们会将我们的博客内容和风格放在该文件夹中。在本教程中,我们将它称为
jupyter-blog,但是您可以随意称呼它。 cd变成jupyter-blog。- 创建一个名为
.gitignore的文件,并将来自的内容添加到这个文件中。我们最终需要将我们的回购提交给 git,当我们这样做时,这将排除一些文件。 - 创建并激活一个虚拟环境。
- 在
jupyter-blog中创建一个名为requirements.txt的文件,内容如下:
Markdown==2.6.6
pelican==3.6.3
jupyter>=1.0
ipython>=4.0
nbconvert>=4.0
beautifulsoup4
ghp-import==0.4.1
matplotlib==1.5.1
- 运行
jupyter-blog中的pip install -r requirements.txt,安装requirements.txt中的所有软件包。
创建您的数据科学博客
一旦你完成了初步的设置,你就可以创建你的博客了!奔跑
在jupyter-blog中的pelican-quickstart,为您的博客启动一个交互式设置序列。你会得到一系列的问题来帮助你正确地建立你的博客。对于大多数问题,只要点击Enter并接受默认值就可以了。您应该填写的只是网站的标题、网站的作者、URL 前缀的n和时区。这里有一个例子:
(jupyter-blog)➜ jupyter-blog ✗ pelican-quickstart
Welcome to pelican-quickstart v3.6.3.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files
needed by Pelican.
> Where do you want to create your new web site? [.]
> What will be the title of this web site? Vik's Blog
> Who will be the author of this web site? Vik Paruchuri
> What will be the default language of this web site? [en]
> Do you want to specify a URL prefix? e.g., https://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n)
> How many articles per page do you want? [10]
> What is your time zone? [Europe/Paris] America/Los_Angeles
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n)
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n)
> Do you want to upload your website using FTP? (y/N)
> Do you want to upload your website using SSH? (y/N)
> Do you want to upload your website using Dropbox? (y/N)
> Do you want to upload your website using S3? (y/N)
> Do you want to upload your website using Rackspace Cloud Files? (y/N)
> Do you want to upload your website using GitHub Pages? (y/N)
跑步后
pelican-quickstart,你应该有两个新文件夹在jupyter-blog、content、output,还有几个文件,比如pelicanconf.py、publishconf.py。以下是文件夹中应包含内容的示例:
jupyter-blog
│ output
│ content
│ .gitignore
│ develop_server.sh
│ fabfile.py
│ Makefile
│ requirements.txt
│ pelicanconf.py
│ publishconf.py
安装 Jupyter 插件
默认情况下,Pelican 不支持使用 Jupyter 写博客——我们需要安装一个
支持此行为的插件。我们将把这个插件作为 git 子模块来安装,以便于管理。如果你没有安装 git,你可以在这里找到说明。一旦安装了 git:
- 运行
git init将当前文件夹初始化为 git 存储库。 - 创建文件夹
plugins。 - 运行
git submodule add git://github.com/danielfrg/pelican-ipynb.git plugins/ipynb添加插件。
您现在应该有一个
.gitmodules文件和一个plugins文件夹:
jupyter-blog
│ output
│ content
│ plugins
│ .gitignore
│ .gitmodules
│ develop_server.sh
│ fabfile.py
│ Makefile
│ requirements.txt
│ pelicanconf.py
│ publishconf.py
为了激活插件,我们需要修改
在底部加上这几行:
MARKUP = ('md', 'ipynb')
PLUGIN_PATH = './plugins'
PLUGINS = ['ipynb.markup']
这些行告诉 Pelican 在生成 HTML 时激活插件。
写你的第一篇文章
一旦插件安装完毕,我们就可以创建第一篇文章了:
- 用一些基本的内容创建一个 Jupyter 笔记本。这里有一个例子,你可以下载。
- 将笔记本文件复制到
content文件夹中。 - 创建一个与您的笔记本同名的文件,但扩展名为
.ipynb-meta。这里有一个的例子。 - 将以下内容添加到
ipynb-meta文件中,但更改字段以匹配您自己的帖子:
Title: First Post
Slug: first-post
Date: 2016-06-08 20:00
Category: posts
Tags: python firsts
author: Vik Paruchuri
Summary: My first post, read it to find out.
以下是对这些字段的解释:
Title—帖子的标题。Slug—在服务器上访问帖子的路径。如果 slug 是first-post,而你的服务器是jupyter-blog.com,你将在访问帖子。
*Date—帖子发布的日期。*Category—文章的类别(可以是任何内容)。*Tags—用于帖子的标签的空格分隔列表。这些可以是任何东西。*Author—帖子作者的姓名。*Summary—帖子的简短摘要。
`您需要复制一个笔记本文件,并创建一个
每当你想在博客上发表新文章时,就提交文件。一旦创建了笔记本和元文件,就可以生成博客 HTML 文件了。下面是一个示例,展示了jupyter-blog文件夹现在应该是什么样子:
jupyter-blog
│ output
│ content
│ first-post.ipynb
│ first-post.ipynb-meta
│ plugins
│ .gitignore
│ .gitmodules
│ develop_server.sh
│ fabfile.py
│ Makefile
│ requirements.txt
│ pelicanconf.py
│ publishconf.py
生成 HTML
为了从我们的帖子生成 HTML,我们需要运行 Pelican 将笔记本转换为 HTML,然后运行本地服务器来查看它们:
- 切换到
jupyter-blog文件夹。 - 运行
pelican content来生成 HTML。 - 切换到
output目录。 - 运行
python -m pelican.server。 - 在浏览器中访问
localhost:8000来预览博客。
您应该能够浏览数据科学博客中所有帖子的列表,以及您创建的特定帖子。
创建 GitHub 页面
GitHub Pages 是 GitHub 的一个特性,允许你快速部署一个静态站点,并允许任何人使用唯一的 URL 访问它。为了进行设置,您需要:
- 如果你还没有注册 GitHub,请注册。
- 创建一个名为
username.github.io的存储库,其中username是您的 GitHub 用户名。这里有一个关于如何做的更详细的指南。 - 切换到
jupyter-blog文件夹。 - 通过运行
git remote add origin [[email protected]](/cdn-cgi/l/email-protection):username/username.github.io.git将存储库添加为本地 git 存储库的远程存储库——用您的 GitHub 用户名替换对username的两个引用。
GitHub 页面将显示推送到
位于 URL username.github.io的仓库username.github.io的master分支(仓库名称和 URL 相同)。首先,我们需要修改 Pelican,使 URL 指向正确的位置:
- 编辑
publishconf.py中的SITEURL,使其设置为https://username.github.io,其中username是你的 GitHub 用户名。 - 运行
pelican content -s publishconf.py。当你想在本地预览你的博客时,运行pelican content。在你部署之前,运行pelican content -s publishconf.py。这将使用正确的设置文件进行部署。
提交您的文件
如果您想将实际的笔记本和其他文件存储在与 GitHub 页面相同的 Git repo 中,可以使用 Git 分支。
- 运行
git checkout -b dev创建并切换到一个名为dev的分支。我们不能使用master来存储我们的笔记本,因为那是 GitHub Pages 使用的分支。 - 像平常一样创建一个提交并推送到 GitHub(使用
git add、git commit和git push)。
部署到 GitHub 页面
我们需要将博客的内容添加到
master branch for GitHub 页面正常工作。目前,HTML 内容在文件夹output中,但是我们需要它在存储库的根目录中,而不是在子文件夹中。为此,我们可以使用 ghp-import 工具:
- 运行
ghp-import output -b master将output文件夹中的所有内容导入到master分支。 - 使用
git push origin master将您的内容推送到 GitHub。 - 尝试访问
username.github.io—您应该会看到您的页面!
每当您对数据科学博客进行更改时,只需重新运行
上面的pelican content -s publishconf.py、ghp-import和git push命令,你的 GitHub 页面就会更新。
添加注释
评论是与客人互动的一种方式。Disqus 是一个很好的工具,它与 Pelican 无缝集成。请遵循以下步骤:
- 前往 Disqus 网站进行注册。
- 点击“开始”,然后选择“我想在我的网站上安装 Disqus”。
- 输入您的网站名称。通过将 Disqus 传递到
publishconf.py文件中,这将作为链接 Disqus 到您的博客的唯一键。(在以后的步骤中会详细介绍这一点。) - 选择 Disqus 订阅计划——基本计划最适合个人博客。
- 当 Disqus 询问你的站点在哪个平台上时,向下滚动并选择“我没有看到我的平台被列出,用通用代码手动安装”。
- 在通用代码页面上,再次向下滚动并单击“配置”。
- 在“配置”页面上,用您的实际网站地址(
https://username.github.io)填写“网站 URL”部分。您还可以添加关于您的评论策略的信息(如果您没有评论策略,Disqus 会给出建议),并为您的站点输入描述。点击“完成设置”。 - 现在,您将能够配置您站点的社区设置。点击进入这一部分,环顾四周。在其他事情中,你可以控制客人是否可以评论,并激活广告。
- 在左边的工具栏中,点击“高级”并将您的网站作为
username.github.io添加到可信域中。 - 最后,更新
publishconf.py。确保指定DISQUS_SITENAME = "website-name",其中“网站名称”来自步骤 3。
现在重新运行
pelican content -s publishconf.py、ghp-import output -b master和git push origin master命令来更新你的 GitHub 页面。刷新你的网站,你会看到每个帖子下面都有 Disqus。
选择一个主题
鹈鹕社区提供了各种各样的主题
pelicanthemes.com。您可以选择您喜欢的任何主题,但这里有一些快速提示:
- 保持简单。设计不应该偏离实际内容。
- 记住“三色法则”。根据多伦多大学的研究,大多数人更喜欢两到三种颜色的组合。这样颜色就不会争抢注意力。
- 注意你的页面的宽度——它应该足以包含你可能想要发布的信息图和代码。
一旦你选择了一个主题,去你想存放你的主题的文件夹并创建一个仓库:
git clone --recursive https://github.com/getpelican/pelican-themes pelican-themes。在您的pelicanconf.py文件中创建一个THEME变量,并将其值设置为主题的位置:THEME = 'E:\\Pelican\\pelican-themes\\flex这里,我们使用了一个由 Alexandre Vincenzi 设计的 flex 主题。运行常用的修整命令— pelican content、ghp-import和git push —享受全新的外观!
接下来的步骤
我们已经走了很长的路了!您现在应该能够创作博客文章并将其推送到 GitHub 页面。任何人都应该能够访问您的数据科学博客
username.github.io(用你的 GitHub 用户名替换username)。这为您展示您的数据科学产品组合提供了一个绝佳的方式。随着你写的文章越来越多并赢得了读者,你可能会想深入几个领域:
- 你自己的自定义网址。
- 使用
username.github.io很好,但是有时你想要一个更加定制的域。这里是关于使用 GitHub 页面自定义域名的指南。
- 使用
- 插件
- 点击查看插件列表。插件可以帮助你设置分析、评论等等。
- 促进
在
Dataquest ,我们的互动指导项目旨在帮助您开始构建数据科学组合,向雇主展示您的技能,并获得一份数据方面的工作。如果你感兴趣,你可以注册并免费学习我们的第一个模块。
如果你喜欢这篇文章,你可能会喜欢阅读我们“构建数据科学组合”系列中的其他文章:
- 用数据讲故事。
- 打造机器学习项目。
- 建立数据科学投资组合的关键是让你找到工作。
- 寻找数据科学项目数据集的 17 个地方
- 如何在 GitHub 上展示您的数据科学作品集`
如何在 GitHub 上展示您的数据科学产品组合
原文:https://www.dataquest.io/blog/how-to-share-data-science-portfolio/
January 14, 2017This is the fifth and final post in a series of posts on how to build a Data Science Portfolio. In the previous posts in our portfolio series, we talked about how to build a storytelling project, how to create a data science blog, how to create a machine learning project, and how to construct a portfolio. In this post, we’ll discuss how to present and share your portfolio. You’ll learn how to showcase your work on GitHub, a popular site that hosts code repositories, data, and interactive explorations. In the first part of the post, we’ll cover how to upload your work to GitHub. In the second part of the post, we’ll cover how to present your work on GitHub, and how to impress hiring managers. Before diving into this post, you should have a couple of projects that you want to showcase. If you need some inspiration, you can consult our previous posts via the links above.
第一部分— git 和 GitHub 教程
GitHub 是围绕一项名为
git ,分布式版本控制系统。这听起来可能有点吓人,但它的意思是,它允许您在不同的时间点创建代码的检查点,然后在这些检查点之间随意切换。例如,假设我有以下 Python 脚本,摘自 scikit-learn examples :
lr = linear_model.LinearRegression()
boston = datasets.load_boston()
y = boston.target
predicted = cross_val_predict(lr, boston.data, y, cv=10)
我现在使用 git 创建一个检查点,并在代码中添加一些行。在下面的代码中,我们:
- 更改数据集
- 更改 CV 折叠的数量
- 展示一个情节
lr = linear_model.LinearRegression()
diabetes = datasets.load_diabetes()
y = diabetes.target
predicted = cross_val_predict(lr, diabetes.data, y, cv=20)
fig, ax = plt.subplots()
ax.scatter(y, predicted)
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
plt.show()
如果我们用 git 创建另一个检查点,我们将能够随时回到第一个检查点,并在两个检查点之间自由切换。检查点通常被称为提交,我们将继续使用这个术语。我们可以将提交上传到 GitHub,这样其他人就可以看到我们的代码。git 比提交系统强大得多,您应该这样做
如果您想了解更多,请尝试我们的 git 课程。然而,为了上传你的作品集,可以这样想。
设置 git 和 Github
为了用 git 创建一个 commit 并上传到 GitHub,首先需要安装和配置 git。完整的说明如下
此处,但我们将在此处总结步骤:
- 使用这个链接安装 git
- 打开电脑上的终端应用程序
- 通过输入
git config --global user.email YOUR_EMAIL设置你的 git 邮箱。用电子邮件帐户替换YOUR_EMAIL。 - 通过键入
git config --global user.name YOUR_NAME设置您的 git 名称。用你的全名代替YOUR_NAME,比如John Smith。
一旦你完成了这些,git 就被设置和配置好了。接下来,我们需要在 GitHub 上创建一个帐户,然后配置 git 来使用 GitHub:
- 创建一个 GitHub 账户。理想情况下,您应该使用之前配置 git 时使用的电子邮件。
- 创建一个 SSH 密钥
- 将密钥添加到您的 GitHub 帐户
上述设置将让您
向 Github 推送提交,从 GitHub 拉取提交。
创建存储库
git 中的提交发生在存储库内部。存储库类似于您的项目所在的文件夹。对于教程的这一部分,我们将使用具有如下文件结构的文件夹:
loans
│ README.md
│ main.py
│
└───data
│ test.csv
│ train.csv
你可以自己下载文件夹的 zip 文件
这里的在接下来的步骤中使用。你可以用任何解压文件的程序来解压它。上图中的 git 存储库是项目文件夹,或loans。为了创建提交,我们首先需要将文件夹初始化为 git 存储库。我们可以通过导航到该文件夹,然后键入git init来做到这一点:
$ cd loans
$ git init
Initialized empty Git repository in /loans/.git/
这将创建一个名为
.git在loans文件夹里面。您将得到输出,表明存储库已正确初始化。git 使用.git文件夹来存储关于提交的信息:
loans
│ README.md
│ main.py
└───.git
│
└───data
│ test.csv
│ train.csv
的内容
在本教程中,没有必要探究文件夹,但是您可能希望浏览一下,看看是否能够弄清楚提交数据是如何存储的。初始化存储库之后,我们需要将文件添加到潜在的提交中。这会将文件添加到临时区域。当我们对暂存区中的文件满意时,我们可以生成一个提交。我们可以使用git add来做到这一点:
$ git add README.md
上面的命令将添加
README.md文件到暂存区。这不会改变磁盘上的文件,但是会告诉 git 我们想要将文件的当前状态添加到下一次提交中。我们可以通过git status检查中转区的状态:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.md
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
main.py
您会看到我们已经添加了
文件到暂存区,但仍有一些未跟踪的文件没有添加。我们可以添加所有带git add .的文件。在我们将所有文件添加到暂存区域之后,我们可以使用git commit创建一个提交:
$ git commit -m "Initial version"
[master (root-commit) 907e793] Initial version
4 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 README.md
create mode 100644 data/test.csv
create mode 100644 data/train.csv
create mode 100644 main.py
这
-m选项指定提交消息。您可以稍后回顾提交消息,查看提交中包含哪些文件和更改。commit 从临时区域中获取所有文件,并将临时区域留空。
对存储库进行更改
当我们对存储库进行进一步的更改时,我们可以将更改后的文件添加到暂存区,并进行第二次提交。这允许我们随着时间的推移保持存储库的历史。我们可以像以前一样向提交添加更改。假设我们改变了
README.md文件。我们首先运行git status来看看发生了什么变化:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
然后,我们可以确切地看到发生了什么变化
git diff。如果更改是我们所期望的,我们可以将这些更改添加到新的提交中:
$ git add .
然后我们可以再次承诺:
$ git commit -m "Update README.md"
[master 5bec608] Update README.md
1 file changed, 1 insertion(+)
你可能已经注意到这个世界
master在许多这些命令执行后出现。master是我们当前所在的分支的名称。分支允许多个人同时处理一个存储库,或者一个人同时处理多个特性。分支是极其强大的,但我们不会在这里深入研究它们。如果你有兴趣了解更多,我们的 Dataquest 交互式 git 教程详细介绍了如何使用多个分支。现在,知道存储库中的主要分支叫做master就足够了。到目前为止,我们已经对master分支做了所有的修改。我们将把master推送到 GitHub,这是其他人会看到的。
推送到 GitHub
一旦创建了 commit,就可以将存储库推送到 GitHub 了。为此,您首先需要
在 GitHub 接口中创建一个公共存储库。您可以通过以下方式做到这一点:
- 点击 GitHub 界面右上角的“+”图标,然后点击“新建资源库”。

创建 GitHub 存储库。
- 输入存储库的名称,并根据需要输入描述。然后,决定是公开还是保密。如果是公开的,任何人都可以立即看到。您可以随时将存储库从公共存储库更改为私有存储库,反之亦然。建议在存储库准备好共享之前保持其私有性。请注意,创建私有存储库需要一个付费计划。准备就绪后,单击“创建存储库”完成。

完成存储库创建。
创建回购后,您将看到如下屏幕:

使用存储库的选项。
查看“…或从命令行推送现有的存储库”部分,并将这两行复制到那里。然后在命令行中运行它们:
$ cd loans
$ git remote add origin [[email protected]](/cdn-cgi/l/email-protection):YOUR_GITHUB_USERNAME/YOUR_GIT_REPO_NAME.git
$ git push -u origin master
Counting objects: 7, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 608 bytes | 0 bytes/s, done.
Total 7 (delta 0), reused 0 (delta 0)
To [[email protected]](/cdn-cgi/l/email-protection):YOUR_GITHUB_USERNAME/YOUR_GIT_REPO_NAME.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
如果您在 GitHub 上重新加载与您的回购对应的页面(
,您现在应该可以看到您添加的文件。默认情况下,README.md将在资源库: 中呈现
中呈现
查看项目文件和自述文件。
恭喜你!现在,您已经将一个存储库推送到 GitHub。如果你想公开,你可以跟着
这些指令。
第二部分——展示你的作品集
现在您已经知道了如何创建和上传一个存储库,我们将讨论如何展示它。在我们开始本节之前,看一些示例项目可能会有所帮助:
要求
确保任何人都可以安装和运行您的作品是非常重要的。即使你的作品是 Jupyter 笔记本,也可能有其他人需要安装的包。您可以列出项目使用的所有包
如果你使用虚拟环境。您将得到如下输出:
$ pip freeze
Django==1.10.5
MechanicalSoup==0.6.0
Pillow==4.0.0
输出是库名,然后是版本号。上面的输出告诉我们
例如Django版本1.10.5安装。您需要将这些需求复制到项目中名为requirements.txt的文件夹中。该文件应该如下所示:
Django==1.10.5
MechanicalSoup==0.6.0
Pillow==4.0.0
现在,任何人都可以使用
pip install -r requirements.txt。这将安装我们机器上的库的精确版本。如果您想安装每个库的最新版本,您可以忽略requirements.txt中的版本号:
Django
MechanicalSoup
Pillow
如果你想做一个
requirements.txt文件,但没有为您的项目使用 virtualenv,您将需要手动浏览您在项目中导入的库,并将它们添加到requirements.txt中,但不添加版本号,例如:
pandas
numpy
Pillow
路径
当您在本地工作时,硬编码数据文件的绝对路径是很常见的,比如
/Users/vik/Documents/data.csv。其他想要运行您的项目的人在他们的计算机上不会有那些相同的路径,所以他们将不能运行您的项目。您可以很容易地用相对路径来替换它们,这允许与您的项目在同一个文件夹中拥有数据但没有相同绝对路径的人使用您的代码。假设我们有这样的代码:
with open("/Users/vik/Documents/data.csv") as f:
data = f.read()
假设我们的项目代码在
/Users/vik/Documents/Project.ipynb。我们可以用相对路径替换代码,比如:
with open("data.csv") as f:
data = f.read()
通常,最好将数据放在与项目相同的文件夹中,或者放在子文件夹中,以使相对路径和加载数据更容易。
附加文件
默认情况下,运行
git add .和git commit -m "Message""会将文件夹中的所有文件添加到 git 提交中。然而,有许多您不想添加的工件文件。下面是一个文件夹示例:
loans
│ __pycache__
│ main.py
│ main.pyc
│ temp.json
│
└───data
│ test.csv
│ train.csv
注意文件,如
__pycache__、main.pyc和temp.json。项目主要代码在main.py,数据在data/test.csv,和data/train.csv。对于运行项目的人来说,这些是他们唯一需要的文件。像__pycache__和main.pyc这样的文件夹是在我们运行代码或者安装包的时候由 Python 自动生成的。这些使得 Python 脚本和包的安装更加快速和可靠。但是,这些文件不是您项目的一部分,因此不应该分发给其他人。我们可以用一个.gitignore文件忽略这样的文件。我们可以添加一个.gitignore文件到我们的文件夹:
loans
│ .gitignore
│ __pycache__
│ main.py
│ main.pyc
│ temp.json
│
└───data
│ test.csv
│ train.csv
的内容
.gitignore file 是要忽略的文件列表。我们可以创建一个.gitignore文件,然后添加*.pyc和__pycache__来忽略我们文件夹中生成的文件:
*.pyc
__pycache__
这仍然留下了
temp.json文件。我们可以添加另一行来忽略这个文件:
*.pyc
__pycache__
temp.json
这将确保这些文件不会被 git 跟踪,并在您运行时添加到新的 git 提交中
git add .。然而,如果您之前已经将文件添加到 git 提交中,那么您需要首先使用git rm temp.json --cached删除它们。建议尽快创建一个.gitignore文件,并快速添加临时文件的条目。你可以在这里找到一个很好的入门 gitignore 文件。通常建议使用这个文件作为您的.gitignore文件,然后根据需要添加新条目。最好忽略任何动态的、生成的或临时的文件。您应该只提交您的源代码、文档和数据(取决于您的数据有多大——我们将在另一节中讨论这一点)。
密钥或文件
许多项目使用密钥来访问资源。api 键就是一个很好的例子,比如
AWS_ACCESS_KEY="3434ffdsfd"。您绝对不希望与他人共享您的密钥——这会让他们访问您的资源,并可能让您损失金钱。下面是一些使用密钥的示例代码:
import forecastio
forecast = forecastio.load_forecast("34343434fdfddf", 37.77493, -122.41942)
在上面的代码中,
是一个密钥,我们将它传递到一个图书馆以获取天气预报。如果我们提交代码,任何浏览 Github 的人都可以看到我们的秘密数据。幸运的是,有一个简单的方法可以解决这个问题,并允许任何使用该项目的人提供他们自己的密钥,这样他们仍然可以运行代码。首先,我们创建一个名为settings.py的文件,包含以下几行:
API_KEY = ""
try:
from .private import *
except Exception:
pass
上述代码定义了一个名为
API_KEY。它还会尝试从名为private.py的文件导入,如果该文件不存在,它就不会执行任何操作。我们接下来需要添加一个private.py,内容如下:
API_KEY = "34343434fdfddf"
然后,我们需要添加
private.py到.gitignore这样它就不会被提交:
private.py
然后,我们修改我们的原始代码:
import settings
forecast = forecastio.load_forecast(settings.API_KEY, 37.77493, -122.41942)
我们在上面所做的所有更改会产生以下结果:
- 代码导入设置文件
- 设置文件导入
private.py文件- 这会用私有文件中定义的
API_KEY覆盖设置文件中的API_KEY变量
- 这会用私有文件中定义的
- 代码使用设置文件中的
API_KEY,它等于"34343434fdfddf"
下次提交 git 时,
private.py将被忽略。然而,如果其他人查看您的存储库,他们会发现他们需要用自己的设置填写settings.py,以使事情正常工作。所以一切都会对你起作用,你不会和别人分享你的秘钥,事情也会对别人起作用。
大型或受限数据文件
下载数据文件时,查看用户协议很重要。有些文件是不允许重新分发的。有些文件也太大,无法下载。其他文件更新很快,分发它们没有意义—您希望用户下载一个新的副本。在这种情况下,将数据文件添加到
.gitignore文件。这确保了数据文件不会包含在存储库中。不过,了解如何在README.md中下载数据是很重要的。我们将在下一节讨论这个问题。
自述文件
自述文件对您的项目非常重要。自述文件通常命名为
README.md,为降价格式。GitHub 会自动解析 Markdown 格式并呈现出来。您的自述文件应描述:
- 项目的目标
- 您创建项目的思路和方法
- 如何安装您的项目
- 如何运行您的项目
您希望一个普通的技术熟练的陌生人能够阅读您的自述文件,然后自己运行项目。这确保了更多的技术招聘经理可以复制你的工作并检查你的代码。您可以找到很好的自述示例
这里和这里。在新文件夹或新电脑上亲自完成安装步骤很重要,以确保一切正常。README 也是第一个,也可能是唯一一个有人会看的东西,因为 GitHub 把它呈现在存储库文件视图下面。重要的是“推销”这个项目是什么,你为什么要做它,它有什么有趣的地方。这里有一个例子:
# Loan Price Prediction
In this project, I analyzed data on loans issued through the [LendingClub](https://www.lendingclub.com/) platform. On the LendingClub platform, potential lenders see some information about potential borrowers, along with an interest rate they'll be paid. The potential lenders then decide if the interest on the loan is worth the risk of a default (the loan not being repaid), and decide whether to lend to the borrower. LendingClub publishes anonymous data about its loans and their repayment rates.
Using the data, I analyzed factors that correlated with loans being repaid on time, and did some exploratory visualization and analysis. I then created a model that predicts the chance that a loan will be repaid given the data surfaced on the LendingClub site. This model could be useful for potential lenders trying to decide if they should fund a loan. You can see the exploratory data analysis in the `Exploration.ipynb` notebook above. You can see the model code and explanations in the `algo` folder.
您的自述文件应该比上面的例子更广泛、更深入,但这是一个很好的起点。理想情况下,您还需要:
- 一些你在探索中发现的有趣观察的要点
- 你制作的任何有趣的图表
- 关于模型的信息,例如算法
- 误差率和关于预测的其他信息
- 关于该模型的实际应用有什么注意事项吗
这里的总结是,自述文件是推销您的项目的最佳方式,您不应该忽视它。不要花太多精力做一个好项目,然后让人们跳过看它,因为他们不觉得它有趣!
内嵌解释
如果您正在编写 Python 脚本文件,您会希望包含大量行内注释,以使您的逻辑更容易理解。你不会想分享这样的东西:
def count_performance_rows():
counts = {}
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
for i, line in enumerate(f):
if i == 0:
continue
loan_id, date = line.split("|")
loan_id = int(loan_id)
if loan_id not in counts:
counts[loan_id] = {
"foreclosure_status": False,
"performance_count": 0
}
counts[loan_id]["performance_count"] += 1
if len(date.strip()) > 0:
counts[loan_id]["foreclosure_status"] = True
return counts
更好的选择是:
def count_performance_rows():
"""
A function to count the number of rows that deal with performance for each loan.
Each row in the source text file is a loan_id and date.
If there's a date, it means the loan was foreclosed on.
We'll return a dictionary that indicates if each loan was foreclosed on, along with the number of performance events per loan.
"""
counts = {}
# Read the data file.
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
for i, line in enumerate(f):
if i == 0:
# Skip the header row
continue
# Each row is a loan id and a date, separated by a |
loan_id, date = line.split("|")
# Convert to integer
loan_id = int(loan_id)
# Add the loan to the counts dictionary, so we can count the number of performance events.
if loan_id not in counts:
counts[loan_id] = {
"foreclosure_status": False,
"performance_count": 0
}
# Increment the counter.
counts[loan_id]["performance_count"] += 1
# If there's a date, it indicates that the loan was foreclosed on
if len(date.strip()) > 0:
counts[loan_id]["foreclosure_status"] = True
return counts
在上面的例子中,这个函数在做什么,以及为什么做,就清楚多了。尽可能减少遵循你的逻辑的脑力劳动是很重要的。阅读代码很费时间,并不是每个浏览你的项目的人都会投资。评论使事情更顺利,并确保更多的人阅读你的项目。
朱庇特笔记本
Jupyter 笔记本,
像这个,都是 GitHub 自动渲染的,所以人们可以在浏览器中查看。请务必验证您上传的每台笔记本的几项内容:
- 确保它在界面中呈现时看起来不错
- 确保经常解释,并且清楚每一步发生了什么
- 一个好的比率是每个降价单元不超过 2 个码单元
- 确保笔记本中的所有解释清晰易懂。你可以在我们之前的博客文章中了解更多。
- 确保自述文件链接到笔记本,并简要说明您在笔记本中做了什么
第二步也是最后一步尤其重要。你希望人们能够很容易地发现你的分析在笔记本上,以及你做了什么分析。只有代码单元的笔记本很难理解,也不能展示你的数据科学技能。雇主在寻找会编程的人
和有效沟通。
公开你的作品
完成上述所有步骤后,您需要对您的项目进行最终评审,然后将其公开!您可以通过“存储库设置”按钮来完成此操作:

“存储库设置”按钮位于右侧。
接下来的步骤
您现在知道如何将项目放到 GitHub 上,并且希望有一些项目可以上传。下一步是将你的项目添加到你的简历和作品集页面。一些需要考虑的事项:
- 如果你有一个博客,把每个项目写成一篇独立的文章,深入讲述你是如何建立它的,以及你发现了什么
- 将您的项目添加到您的 LinkedIn 个人资料中
- 将您的项目添加到您的 AngelList 个人资料中
- 在简历中列出你的项目
- 如果你有一个个人网站,制作一个作品集页面,列出你的项目
如果您有几十个项目,并且不想在简历中添加每个资源库的链接,一个策略是制作一个名为 portfolio 的 Github 资源库。在这个存储库的自述文件中,列出您的所有项目,以及每个项目的简短说明和链接。这将使您能够共享单个链接,但仍然让人们看到您的所有项目。一定要提供好的解释,这样人们才会愿意点击进入!你现在应该知道足够多,可以把你的作品集放到 Github 上,给招聘经理留下深刻印象。如果你对这篇文章有任何意见或反馈,我们很乐意
如果你喜欢这篇文章,你可能会喜欢阅读我们“构建数据科学组合”系列中的其他文章:
如何开始数据科学聚会
原文:https://www.dataquest.io/blog/how-to-start-a-data-science-meetup/
November 16, 2017
聚会是很好的工具,你可以结识业内人士,了解行业新闻,学习如何“侃侃而谈”在我开始参加聚会之前,我并不知道有多少东西我不知道,还需要学习,更不用说我在如何编写代码和进行分析方面缺少了什么。在我的职业生涯中,参加聚会对我的帮助超出了我的预期——无论是我学到了什么,还是提供了建立关系网的机会。
当我想了解更多关于数据科学的知识时,我寻找当地的聚会。在我的城市澳大利亚布里斯班没有。我环顾四周,发现有一些活动是为 R、Python、Tableau、机器学习和人工智能、统计学、商业智能等等组织的。数据科学的所有独立的原子元素,但与数据科学本身无关。然而,通过 meetup.com 表达了大量的兴趣(该网站显示了没有相应群体的搜索的流行程度)。因为没有其他人在做这件事,所以我决定自己动手做一个。
这是一项艰苦的工作,但也是一次极好的学习经历。我学到了很多关于数据科学的知识,我所在领域的工作人员,学到了比我个人学习更多的行业概念和想法。
在这篇文章中,我将回顾我是如何组织一次聚会的,我所面临的挑战,我所犯的错误,以及给任何想这样做的人的建议。
在继续之前,我们先来看一下 Meetup 网站。Meetup 允许人们按主题和名称搜索群组,并查看他们的同事可能参加了哪些群组。
对于组织者来说,它允许创建 meetup 组、发布活动细节、给成员发消息以及其他类似的功能。组织一次聚会大约需要 15 美元,但我建议你自己调查一下价格,因为价格可能会因地区而异。

如何组织一次聚会——泛泛而谈
我认为聚会至少需要三样东西:
- 一次
- 一个地方
- 演示文稿
时间和地点是密不可分的,但我将分别讨论它们,因为它们有自己的考虑。它们也是最容易设置的部分。然而,安排一致的演示可能是一个持续的挑战。稍后会详细介绍。
为你的聚会选择一个时间
通过meetup.com,meetup 的初始设置是一个相当简单的过程。我在那里创建了我的群/页面,输入了我的信用卡信息,并选择了活动的重复日期。对于我的数据科学会议,我选择了每个月的第二个星期四,让与会者容易记住。布里斯班的大多数开发者聚会都使用这种规则,并且对他们很有效。
在 Meetup 网站上这样做是相当容易的,因为它允许你很容易地设置重复的事件。我建议您只需设置重复事件,并根据需要进行修改。您可能需要更改特定事件的日期或时间。在我的情况下,有几个第二个星期四是不可用的。最近,由于超额预定,我不得不提前一个多月更改日期。Meetup 的伟大之处在于,您可以向群组中的所有成员发送消息,提醒他们任何变化。您还可以在事件描述中发布更改。
时间安排好了,让我们看看在哪里举行聚会。
选择聚会的地点
找到一个固定的地点和安排一个固定的活动遵循相同的逻辑:人们知道时间和地点。
我去了以前参加聚会的各种场所。这包括当地的德勤和微软办公室,各种共享的工作场所,以及几家提供展示空间的当地咖啡馆。我通过他们公司的网站联系了大多数场馆,或者给他们的行政办公室发了电子邮件。我走进咖啡馆,问我是否可以和他们的经理或者任何适合活动询问的人谈谈。
第一个回答我的问题的是 Fishburners,一个本地的共享工作场所。他们非常希望使用他们的活动空间,并且很乐意让你免费使用,只要求你在活动信息中包含一个提供的段落。他们还非常友好地赞助了这次活动,为最初的几次聚会提供了啤酒和比萨饼。我们将在稍后的文章中更详细地介绍赞助。
取决于你住在哪里,可能有不同的选择来考虑场地。布里斯班有 200 多万居民,一个繁忙的中央商业区,以及各种其他卫星城镇/郊区。我们也看到了共享工作空间的出现,这使得我的搜索变得更加容易。
在试图寻找一个地点时,我会按以下顺序推荐:
- 共享工作区
- 分析公司的当地办事处
- 科技公司的本地办事处
- 有展示空间的咖啡馆(最好靠近城镇的商业区)
- 社区会堂和类似场所
我之所以把它们按照特定的顺序排列,是因为我个人对聚会的经验,以及聚会可能会有适合演讲的视听设备。例如,如果你在社区会堂举办活动,你可能需要自带投影仪和其他设备。不管你把它放在哪里,我都建议你带上一台安装了 PowerPoint 的笔记本电脑,这样任何演示都可以又好又快地开始运行。当你第一次参观这个空间的时候,你可以根据他们所提供的东西来解决这个问题。
在不同的地方询问,告诉他们你将举办活动的时间和频率,并随时更新你的活动页面。你可能不得不根据地点改变你的日期和/或时间,但是如果你一开始就这么做,人们会理解你还在做准备。一旦你开始了,试着保持日期和时间的一致。
如前所述,我在场地和预定日期/时间方面遇到了一些问题。最严重的一次是当他们的空间被超额预定,无法容纳更多的人和我的聚会。谢天谢地,这是一个多月前的警告,我把日期改到了同一周的星期二。我通过 meetup.com 给我所有的与会者发消息让他们知道,并在我的活动描述中提到了这一点。只要记得对你的主人慷慨大方,并确保你写的东西读起来是一个诚实的错误。
你如何减少计划失误的可能性?尽可能提前预订。我现在确保我总是在我的场地预定了未来 12 个月。你可能会也可能不会这样做,这取决于你的场地,但这是值得一问的事情。
现在您有了地点、日期和时间,但是您仍然需要会议内容。
为 meetup 查找演示文稿
这是事情变得棘手的地方,也是 meetup 最可能的持续努力来源:将会发生什么?我们要做什么?
我决定直接接触潜在的演讲者,让他们在会议上发言。几个月前,在一次分会会议上,我有幸看到了澳大利亚分析专家协会(IAPA)成员的精彩演讲。我还认识几个在数据科学或数据科学相关领域工作的人。
我建议你也这样做,并通过网络寻找主持人。你会惊讶地发现,有多少人乐于抽出一点时间来帮助社区。寻找演讲者的其他方法包括:
- 在你的活动描述中发出演讲者的号召
- 询问与会者是否愿意发言,并征求主题建议
- 参加其他会议
- 通过 LinkedIn 和其他社交网络联系
关于演讲,我想给你一个建议:找到一个贯穿所有或大部分活动的主题,让你的潜在演讲者知道。考虑一下你所在地区的其他活动和聚会可能遗漏了什么,并填补这个空白。这将使你的活动与众不同,一旦口碑传开,你就会脱颖而出。
当我在布里斯班看不同的数据科学相关会议时,我注意到真的没有人专注于实际交流数据科学。其他会议集中在使用的工具,算法和分析方法,以及一般如何做,但现在如何与其他人谈论。没有人关注你如何把你的发现呈现给决策者。没有关于如何讲故事,将你的结果,坚持在别人的脑海中,并帮助形成决定。所以我选择围绕交流的主题来组织我的聚会。
其他考虑
尝试在行业中找到一两个赞助商,他们有兴趣支付食物和饮料的费用,以换取在你的 Meetup 页面上出现他们的标志和公司描述,以及在活动开始时大声呼喊。对他们来说,好处是公司的形象可以廉价传播给他们感兴趣雇佣的人。为了你自己?你会接触到一些合适的人,制造一些噪音。更多人会知道你的 Meetup,你可以随时让他们在 LinkedIn 或类似网站上与你联系。这是一个双赢的局面。
寻找赞助商可能很棘手,但最终还是要接近他们并提出要求。IAPA 地方分会的组织者恰好是一家商业情报公司的首席执行官,该公司名为 Catapult BI 。我通过 LinkedIn 问他是否有兴趣赞助这项活动。在我等待回复的时候,我给其他几家分析和数据科学公司打了电话,询问我需要与谁讨论此次活动的潜在赞助事宜。我接触了大约九家不同的公司,并向它们发出了询问。
最终,我得到了两个赞助商:弹射器 BI 和 AARNet 。他们每月轮流赞助,我通过电子邮件与他们联系,组织披萨和饮料。我在当地一家披萨店订了一份定期订单,在活动前一天确认订单,并提供在 Catapult BI 或 AARNet 组织付款的人的电子邮件地址。物流可能会有所不同,取决于你可能会找到的其他赞助商,但这已被证明是为我们工作至今。
请记住,赞助商将需要你的活动提前通知。不要以为告诉他们“在每个月的第二个星期四”,他们就会准备好在短时间内提供赞助。我犯了这个错误,参加了一个没有披萨的活动。事情没有我想象的那么糟糕,我的与会者都很理解,但现在我知道至少要提前两周联系赞助商,问他们是否愿意赞助下一次聚会。如果你幸运地找到了不止一个,确保你和他们都谈过,并安排合适的轮流赞助。
我的第一次聚会很顺利,接下来呢?
继续走。找到更多的演讲者,建立一个社区(建立一个 Slack 组或类似的),继续参加相关的聚会(机器学习,统计学,python,R,可视化等),并与其他组织者联系。努力工作的同时,这些步骤会让你建立关系网,学习,并让你的名字出现在那里。你甚至可以要求其他组织者赞助你的聚会(准备好回报)。
除了参加相关的聚会,我建议找一个更大的软件开发聚会(我个人参加。布里斯班网一)。作为一名数据科学家,能够与开发人员一起工作会让你在市场上占有优势。
进一步的考虑
重申以上几点,并补充一些新的,排名不分先后:
- 问一下你的与会者和演讲者,他们是否知道有谁有兴趣参加演讲。
- 去别的 meetups 看看场景是什么样的,一个里面还涉及到什么。
- 开始时,向组织者或其他聚会者寻求建议。他们可能会给你一些你所在地区的具体建议。
- 尽量提前预订演讲者/演示。不要只是一个月一个月的做。三个月的缓冲期应该是好的,大多数人会知道他们在下个季度做什么。
- 在 LinkedIn 上找找你所在地区可能有兴趣展示的 sata 古人类。
- 就会议事宜与任何赞助商或潜在赞助商保持联系。
- 保持事件页面与任何更改保持同步。
- 尽可能提前预定未来的活动场地,以避免使用你不喜欢的日期。
- 和你的与会者谈谈他们可能想从会议中得到什么。他们可能会有一些想法,可以在以后实施。
- 如果一开始没有太多人参加,也不用担心。像这样的事情需要一段时间来加速。
我想强调最后一点:有些人可能会成为常客,参加所有或大部分活动。有些人只会去他们感兴趣的地方。根据你所在的地方和人口情况,这也可能会影响到出勤率。
有关组织活动和使用 meetup 网站的指导,请访问布里斯班数据科学 Meetup 查看我的 Meetup。
布里斯班的其他数据科学会议都失败了,这让我想知道我是不是很幸运,或者我做了什么让我的会议成功了。组织者告诉我,有两件事是持续成功的关键:
- 我还是要去。其他聚会/组织者很早就放弃了,不一定对举办活动表现出很高的热情。
- 我有一个我努力坚持的主题。
最终,您可能会考虑使用您的 meetup 来举办其他类型的活动:
- 讨论小组:选择一个主题,让一些专家参与进来,允许观众提问。
- 辅导会议:选择一种你的成员可能有兴趣了解更多或者可能吸引更多成员的技术或方法。
目前,我正在考虑建立一个数据科学黑客马拉松。这将是一个挑战,但是我通过我的关系网可以赞助这样的活动。我把这个想法告诉了我的 meetup 会员,并收到了很多积极的回应——从建议到有兴趣帮助组织它。把你的想法带给团队总是有帮助的。
最终想法
开始我的 meetup 让我学会了参与现场讨论所必需的数据科学术语。这才是举办聚会的真正魅力所在——随着聚会的发展,你也会随之成长。
如何使用 Dataquest 实现您的学习目标
原文:https://www.dataquest.io/blog/how-to-use-dataquest-to-achieve-your-learning-goals/
November 18, 2021
在新冠肺炎疫情之前,每天产生和收集的数据量都在加速增长。这导致全球对数据科学家的需求增加。随着需求的增加,出现了对专业课程的需求,这些课程可以教授合适的技能来填补所有这些新职位。
那么,掌握数据科学基础知识并最大限度发挥学习潜力的最佳方式是什么呢?从让您在不到一年的时间内做好工作准备的高质量内容到始终愿意提供帮助的充满活力的社区,Dataquest 拥有您在数据科学领域起步所需的一切。
从路径开始
Dataquest 是这样工作的:我们将学习材料分成我们称之为“路径”的部分。我们设计了每条路径,要么让你为数据科学中的特定职业做好准备(就像我们在 Python 职业路径 中的 数据分析师),要么帮助你发展特定技能(就像我们的 机器学习入门技能路径 )。
我们的道路分为几个部分,依次又分为不同的课程。每门课程都包括大量的课程,最后,每门课程都是一系列独立屏幕的集合。
这是一个直观的表示:

使用 Dataquest 的一个好处是,您可以按照自己的步调,想做多少就做多少。你可以选择一条完整的道路,也可以选择一门课程——这完全取决于你。我们努力让学习数据科学技能变得快速、简单和有效。
在 Dataquest,我们的教学理念专注于结合自我导向学习和结构化学习的优点。我们的创始人之所以这样设计 Dataquest,正是因为他相信你不必非选其一。
我们的课程提供了让你保持责任感和积极性的结构,帮助你克服障碍的支持,以及帮助你快速学习的实用指导。你可以按照自己的进度自由学习,想上多少课就上多少课。无论你想在我们的学习道路上行走、跑步或冲刺,我们都将帮助你实现你的目标。
如果你想学习 Dataquest,可以今天 注册 开始学习。我们有许多免费和有价值的资源,但如果你真的想在数据科学领域发展事业,我们强烈建议你注册高级订阅。你可以无限制地使用我们提供的一切,让你在一年之内做好工作准备。它又快又简单,而且您的帐户永不过期。
随着您对 Dataquest 的了解,您将在仪表板上花费大量时间。在这里,您可以鸟瞰您的学习路径,并管理您的学习体验。我们写了一篇 整篇文章 致力于帮助您最大限度地利用您所拥有的工具,包括有用的键盘快捷键、仪表板定制以及其他将节省您时间和精力的提示和技巧!
设定一致且可实现的学习目标
发展新技能的最大障碍是无法坚持不懈。如果你要用 Dataquest 完成一门课程或整个技能路线,你必须设定一致且可实现的学习目标。人们永远达不到目标的一些最大原因是未能充分计划和缺乏一致性。罗马不是一天建成的,你也不可能在一天之内成为数据科学家。你必须对自己有耐心,并以可持续的速度学习。
使用 Dataquest,您可以自己决定速度。不管你是每周花两个小时还是每天花两个小时学习,坚持才是最重要的。只要你在前进,即使你迈着小步也没关系。我们已经注意到,在开始时,你很容易被兴奋冲昏头脑,贪多嚼不烂。如果发生这种情况,不用担心!简单地重新调整你的学习计划,然后坚持下去。
学习、成长、实践、建设
学习。成长。练习。建造。这些简单的步骤是获得数据科学职位的秘诀!随着您在学习道路上的进步,您将从我们的实践和互动教学方法中获益。您将通过使用真实的代码解决真实的问题来学习新的概念和技术。您将使用真实世界的数据来发展相关的和受欢迎的数据科学技能。
但是仅仅获得这些知识是不够的。你也要保留它,提炼它。这就是 Dataquest 提供练习题和指导性项目的原因,这些练习题和项目将结合你所学到的一切。我们坚信边做边学。使用 Dataquest,您将立即看到课程的实际效果。
这种教学方法的另一个好处是,您将建立一个强大的数据科学组合来展示您在该领域的技能和熟练程度。如果你想接到招聘经理的电话,一份强大的投资组合是你首先需要的也是最重要的东西之一。在我们几乎所有课程结束时,您将完成一个数据科学项目,您可以将其添加到您的文件夹中。这将为你下一次工作面试提供谈话要点。
学习、成长、实践、建设。这就是你如何从完全的初学者到工作就绪。
加入社区
Dataquest 学习方法的另一个重要组成部分是,你永远不会独自学习。我们知道,拉平数据科学学习曲线的最快方法之一是与数据科学学习者和专业人士建立联系。更好的是,向别人寻求建议。数据科学社区提供了一个从他人的经验中学习的绝佳机会,好好利用吧!
在 Dataquest,我们很高兴为您提供一个由数据学习者和专业人士 组成的繁荣和支持的 社区来帮助您学习。我们活跃的论坛提供了几种获得支持的方法。你可以与其他数据专业的学生建立联系,分享知识和经验,如果遇到困难,可以提出问题。
你还应该考虑活跃在 GitHub 和 Kaggle 上,这两者对于有抱负的数据科学专业人士来说都是无价的资源。当你这样做的时候,尝试一下 Dataquest 30 天挑战 ,并承诺每天都要学习一些东西。
学习的道路并不总是一帆风顺的,有时你可能会与动力作斗争。在这些时刻,Dataquest 可以帮助您回到正轨。通过加入一个志同道合的数据专业人员团队,您将找到完成目标所需的综合经验、支持和动力。
结论
恭喜你!现在,您已经具备了使用 Dataquest 成功学习所需的一切。准备好加入使用我们职业发展平台的学习者了吗?没有比用 Dataquest 学习更好的方法了!
通过免费注册开始您今天的学习之路。然后,当你发现 Dataquest 如此伟大的原因时,升级到 高级 ,简化你的学习过程。它会让你做得更多,更快。
我们期待帮助您实现目标。 今天加入我们的 !
如何使用 Dataquest
March 1, 2019
Dataquest 的学习平台非常用户友好,如果你愿意,你可以直接进入其中。但是如果你是那种喜欢先浏览用户手册的人,这篇文章就是为你准备的!
在本课程中,我们将介绍 Dataquest 平台的基本功能,并传递一些有用的提示和技巧,让您在学习过程中更加高效!
Dataquest 基础:路径、课程和教训
Dataquest 的学习内容分为(按从大到小的顺序)路径、步骤、课程、课程和指导项目以及屏幕。

路径是围绕特定职位和编码语言组织的特定课程序列,如 Python 中的数据科学家或 R 中的数据分析师。
您可以随时在路径之间切换,并且不必先完成前面的课程,然后再开始后面的课程。不过,我们还是建议您尝试按顺序完成这些路径。
路径被分成个步骤,这些步骤是专注于特定技能的更小的课程序列。例如,Python 路径中的数据科学家路径的第一步包括两门课程,涵盖了用 Python 进行数据科学编程的基础知识,以及几个引导性项目,挑战您应用和扩展这些技能。
一旦你完成了一个步骤,你就可以进入下一步的课程,下一步的课程将着重于帮助你建立一套不同的技能,这样到最后,你已经完成了多个步骤,每个步骤都帮助你在先前所学的基础上发展重要的新技能。
步骤被分成个课程,通常每个步骤会有 2-5 个课程。每门课程都专注于一个较小的特定主题。例如,在数据科学家道路的第二步中,第一门课程重点讲述如何使用 pandas 和 numpy 库来完成数据科学任务。
每门课程都有几节课,更小的学习单元集中在课程主题的副主题上。例如,在前面提到的关于熊猫和 numpy 的课程中,有一节课介绍了熊猫,一节课介绍了用熊猫探索数据,一节课介绍了 numpy,等等。课程把课程分成容易理解的部分。对许多学生来说,在一次学习中完成一节课应该是可能的。
指导性项目通常在每门课程结束时进行,它们的目的是让你在学习课程的过程中应用学到的新技能。指导性项目在长度和复杂程度上各不相同,并且相对开放,以鼓励你应用你的技能和创造力。
最后,屏幕是 Dataquest 上最小的学习单元,每个课程或指导项目被分解成一系列屏幕。通常,一个屏幕在屏幕的左侧呈现一个新概念,然后通过在屏幕的右侧编写代码来挑战你应用他们刚刚学到的东西。然后将这些代码与正确的答案进行核对,这样您就可以立即得到关于您是否已经掌握了这个概念的反馈。

你总能在目录的中找到 Dataquest 的所有课程,点击任何路径或课程都会带你到一个页面,上面有它包含的详细内容。
仪表板:您的学习中心
仪表板是您在 Dataquest 上的大本营,是跟踪和衡量您的 Dataquest 进度的最佳位置。当您登录 Dataquest 时,这将是您看到的第一个屏幕,但是只要您已经登录,您也可以在www.dataquest.io/dashboard访问它。
您将在仪表板中看到的第一件事是提示您从上次停止学习的地方开始。下面是一个进度跟踪器,显示您所选择的路径已完成的百分比(所选路径上方的绿色条)。这一部分还显示了你在过去的一个月里在这个网站上花了多少时间,以及你完成了多少课程和项目。
注意:由于我们一直在添加新课程,您可能会偶尔看到您的完成率略有下降,因为我们在您的道路上添加了一门新课程。

您可以随时通过点按“当前路径”旁边的铅笔图标来更改您所在的路径无论您选择哪条路径,您的进度都将被保存,因此可以随意来回切换!
在这一部分下面,您将看到您的学习时间表,以及基于您的计划时间表和路径进度的每周日程。这是用来为你设定每周学习目标的。你可以通过点击铅笔图标随时改变你计划学习的小时数,你的日程会相应地自动调整。

在这下面,你会看到一个更详细的可视化的你的每一步的进展情况。例如,在下图中,您可以看到该学生已经完成了该路径的步骤 1,目前正在学习步骤 2 中的第二门课程探索性数据可视化课程。

学习界面
当你进入任何 Dataquest 课程时,你可能会看到一个介绍性的文本屏幕,但你会很快从那里转到一个双窗口屏幕,如下图所示。
该屏幕布局是 Dataquest 学习体验的基础,它允许您在左侧窗口中阅读新概念,然后在右侧窗口中立即试验和应用您所学的内容。

这个屏幕包含了很多功能,让我们仔细看看。
学习界面:顶部栏

沿着屏幕的顶部,你会看到一个灰色的菜单栏。从左到右,这包含:
- 返回仪表板的仪表板按钮
- 您当前正在学习的第课的标题
- 指示虚拟代码运行器状态的页面图标。如果这是一个绿色的勾号,你就可以运行代码了!您可以单击此图标了解有关您的连接和虚拟机状态的更多详细信息。
- 答?按钮,帮助您解决问题,并与我们的支持团队联系
- 一个钟形图标,将显示您从平台收到的任何通知
- 帐户图标。点击此按钮将打开一个菜单,链接到重要页面,如您的仪表板、您的帐户页面、您当前的 Dataquest 计划、您的 Dataquest 个人资料等。
学习界面:左侧窗口

在左侧窗口的顶部,您会注意到两个标签:学习和课程参考。
默认情况下,该窗口将显示 Learn 选项卡,在这里您将看到新的概念。在学习选项卡中,您将通读一个新概念的简单解释,通常包括代码示例和图表。当你到达这个解释的末尾时,你将滚动到标签的一个叫做指令的部分,它将解释你需要在右边的编码窗口中做什么来完成屏幕。

如果您遇到问题,您可以进一步向下滚动并单击“获取帮助”按钮来查看自定义提示、正确答案或联系支持人员。
课程参考选项卡打开一个搜索栏,允许您从已经完成的课程和屏幕中快速搜索信息。如果您忘记了以前学过的内容,需要快速复习,您可以在“课程参考”标签中找到相关内容并快速轻松地复习。
学习界面:右侧窗口

屏幕右侧是您编写代码以完成屏幕左侧概述的指令的地方。
这里通常有两个选项卡。默认选项卡是一个脚本选项卡,通常称为 script.py 或 script.r,这是您编写代码的地方。但是通常还有第二个选项卡,它将以您正在处理的数据集命名。单击此选项卡会以表格形式显示标题行和数据集的前五个条目,因此您可以轻松地参考数据的外观。
在 scripting 选项卡中,当您打开每个新屏幕时,您通常会看到为您编写的一些代码。您在之前的屏幕中编写的代码将被保存,以便您在回顾该屏幕时可以看到您所做的事情。虽然这不是必需的,但是在编写代码的时候给代码添加注释是一个好主意,这样当你回头看的时候,你就可以阅读你自己对代码所做事情的解释。
当您编写代码时,您会注意到您的文本会根据您所编写的内容改变颜色。这被称为语法突出显示,它帮助你区分代码中不同的语法元素。您还会注意到,该窗口会根据您所写的内容自动缩进代码,并且会提示您自动完成诸如变量名之类的内容,而不是必须键入它们。这些节省时间的特性使得编写代码更加高效。
另请注意,一旦您在一个屏幕中定义了一个变量,该变量将在本课程的其余部分中存储,因此您不必在每次来到新屏幕时都重新定义它。例如,如果您在第一个屏幕中创建一个名为 my_dataset 的列表变量列表,您将能够在第二个屏幕中编写一个 for 循环来遍历 my_dataset,而不必在第二个屏幕中重新生成所有 my_dataset 代码。
在右侧窗口的底部,您会看到四个按钮。从左到右依次是:运行代码、提交答案、重置代码、打开控制台。
运行代码按钮做的正是你所期望的:运行你的代码。在准备提交答案之前,您可以使用此按钮运行代码片段并进行实验。
提交答案按钮运行您的代码,并将其作为您的答案提交给我们的答案检查系统进行检查。单击此按钮有三种可能的结果:
- 你的代码是正确的。在这种情况下,您将听到一声欢快的“乒”声,并看到一个提示,提示您进入下一个屏幕。
- 您的代码工作正常,但不正确。在这种情况下,您已经编写了工作代码,但是它没有产生我们期望的答案,并且您将得到一个错误显示,显示哪些变量或元素与答案检查器期望的不同。
- 你的代码不起作用。您可能有语法错误,或者您编写代码的方式有其他问题,您将会看到基于您使用的编码语言的错误消息。
重置代码按钮会将该屏幕上的代码重置为默认状态——无论您第一次打开该屏幕时显示的是什么。
打开控制台按钮会打开一个小的子窗口,您可以在其中键入并运行小的代码片段,而不会影响您正在上面编写的脚本。这对实验很有用。
学习界面:底部栏

沿着屏幕底部,您会看到另一个灰色条。在左手边,你会看到你正在操作的当前屏幕的名称,以及一个三明治菜单按钮,如果你点击它,它会打开一个带有链接和当前课程中每个屏幕名称的菜单。
在该栏的右侧,您会看到一个计数器,指示您当前的屏幕编号和该课程的屏幕总数(即,1/10 表示您在该课程的 10 个屏幕中的第 1 个屏幕上)。在这个计数器的两边是后退和下一步按钮,如果点击的话,将分别带你到上一个屏幕或下一个屏幕。
快捷键
我们已经介绍了我们学习平台的所有视觉功能,但如果你想以最高效率工作,你不需要使用按钮。您还可以使用键盘快捷键快速浏览平台。将鼠标停留在每个按钮上可以查看快捷方式:

下面是所有可用键盘快捷键的表格,便于参考。您也可以在我们的知识库中访问这些信息。
| Windows/Linux | 苹果个人计算机 |
|---|---|
| 运行您的代码 | alt +空格 |
| 提交答案 | alt + Enter |
| 上一个屏幕 | alt + b |
| 下一个屏幕 | alt + n |
| 恢复到初始代码 | alt + r |
| 将代码转换为注释 | ctrl + / |
下面是代码转换快捷方式在实践中的样子。如果您用光标在一行中输入快捷方式,该行将被注释掉。如果用光标高亮显示多行,当您输入快捷方式时,所有的行将被注释掉。

您还可以使用此快捷方式将注释快速转换回代码。
定制学习界面
如果您想在 Dataquest 上定制您的体验,您可以做几件事情。首先,可以拖动左右窗口之间的中间栏来调整这些窗口的大小,根据您的喜好,为您提供更多的阅读空间或代码空间。
您还可以在默认的“亮模式”和“暗模式”之间切换,用于界面的左窗口和右窗口。此设置可在您的帐户页面的“设置”区域访问,分别位于左侧和右侧窗口的“文本主题”和“编辑器主题”下。(默认情况下,文本主题设置为浅色,编辑器主题设置为深色)。

学习界面:其他情况
虽然我们的大部分课程都使用了上面描述的界面,但也有一些课程略有不同。例如,命令行课程利用屏幕右侧的虚拟命令行环境(而不是 Python 或 R 编码环境)。一些课程和项目将使用嵌入式版本的 Jupyter 笔记本。
当你遇到这些替代界面时,课程说明会解释如何使用它们。但是特别是 Jupyter 笔记本,有一些你需要注意的复杂情况。
首先是一些 ISP 阻止或过滤用于连接 Juptyer 笔记本的连接类型,所以如果你遇到问题,请参考我们关于 jup tyer不加载或频繁断开的支持文章。
第二,如果你使用我们网站上嵌入的 Jupyter 笔记本,你的代码不会自动永久保存。如果你想长期保存它,你应该点击顶栏上的“下载”按钮来下载你的笔记本。也就是说,我们建议您安装 Anaconda,以便您可以习惯在本地使用 Jupyter 笔记本,这将使您更容易在 Dataquest 网站之外承担项目。

还要注意,如果您需要帮助或者只是希望保存它以供将来参考,单击顶部栏中的按键按钮将允许您访问和下载解决方案文件。
外卖食品
虽然每节课中的大多数屏幕都使用上述学习界面,但每节课的最后一个屏幕将为您提供一个可下载的 PDF,我们称之为外卖。每一课都总结了你在本课中学到的重要概念,并提供了它们的用法和语法的例子。

这些要点旨在成为快速简单的参考。您可以在编写代码的任何时候(在 Dataquest 或其他地方)参考它们,重温您所学到的知识。它们也是有用的快速学习指南或复习工具。例如,如果您将它们加载到您的移动设备上,您可以翻阅它们,并从任何地方获得一点数据科学研究。
提示和技巧
Dataquest 平台非常简单,但这里有一些关键的提示和技巧,可以帮助您更有效地使用 Dataquest:
- 不要忘记提示、答案和常见问题 。如果你真的需要支持,它会帮助你,但很多时候你可以利用这些资源解决自己的问题。
- 键盘快捷键很好玩 。只需几秒钟就能学会它们,它们将加快您浏览 Dataquest 的速度。
- 注释你的代码。虽然这不是大多数课程的必修课,但这是一个很好的练习,将来会对你有所帮助。因为您为每个屏幕编写的代码都保存在那个屏幕上,所以如果您对它进行了注释,您可以回过头来查看您自己对代码所做工作的解释。
- 下载外卖。它们非常有助于快速查阅,你可以将它们加载到移动设备上,像便笺一样翻阅它们,以便在旅途中进行学习。
如何在 2022 年使用 Python 计数器(带有 23 个代码示例)
原文:https://www.dataquest.io/blog/how-to-use-python-counters/
November 7, 2022
作为 Python 开发人员,我们可能需要开发一段代码来同时计算几个重复的对象。有不同的方法来执行这项任务。然而,Python 的collections模块中的Counter类提供了最有效和直接的解决方案来计算 iterable 对象中的单个项目。
在本教程中,我们将学习Counter类以及在 Python 中使用它的基础知识。
完成本教程后,您将会对以下内容有很好的理解
- 什么是
Counter类。 - 如何创建一个
Counter对象? - 如何更新现有的
Counter对象。 - 如何确定 iterable 对象中最频繁出现的项?
- 如何组合或减去
Counter对象。 - 如何对两个
Counter对象进行并集和交集运算?
我们假设您了解 Python 的基础知识,包括基本的数据结构和函数。如果你不熟悉这些或者渴望提高你的 Python 技能,你可能想试试我们的用于数据分析的 Python 基础——Data quest。
Python 的Counter类是什么
Python 的Counter是 dictionary 数据类型的一个子类,用于通过创建一个字典来对可散列对象进行计数,其中 iterable 的元素存储为键,它们的计数存储为值。
换句话说,Counter的构造函数接受一个 iterable 对象,并返回一个字典,其中包含 iterable 对象中每一项的频率,只要这些对象是可散列的。
好消息是一些算术运算适用于Counter对象。
在下一节中,我们将讨论使用Counter来确定列表、字符串和其他可迭代对象中可哈希对象的频率。
使用计数器对象
如前所述,Counter对象提供了一种快速计算 iterable 对象中项的简单方法。
为了演示Counter对象如何工作并显示其结果,让我们从从collections模块导入Counter类开始,然后将它应用于一个字符串,如下所示:
from collections import Counter
a_str = 'barbara'
counter_obj = Counter(a_str)
print(counter_obj)
Counter({'a': 3, 'b': 2, 'r': 2})
如图所示,上面的代码计算单词中的字母。让我们通过在前面的代码中添加以下几行来使输出更有吸引力。
for item in counter_obj.items():
print("Item: ", item[0]," Frequency: ", item[1])
Item: b Frequency: 2
Item: a Frequency: 3
Item: r Frequency: 2
Counter类实现了有用的方法,比如update()和most_common([n])。update()方法获取一个 iterable 对象,并将其添加到现有的 counter 对象中。
让我们试试吧:
counter_obj.update("wallace")
print(counter_obj)
Counter({'a': 5, 'b': 2, 'r': 2, 'l': 2, 'w': 1, 'c': 1, 'e': 1})
most_common([n])方法返回一个有序的元组列表,其中包含n个最常见的
项及其计数。
print(counter_obj.most_common(1))
[('a', 5)]
上面的代码返回了a_str对象中最频繁出现的项目。
为了更好地理解Counter对象的用法,让我们来确定下列句子中出现最频繁的项目:
“恐惧导致愤怒;愤怒导致仇恨;仇恨导致冲突;冲突导致痛苦。”下面是我们的做法:
quote_1 = "Fear leads to anger; anger leads to hatred; hatred leads to conflict; conflict leads to suffering."
words_1 = quote_1.replace(';','').replace('.','').split()
word_counts = Counter(words_1)
the_most_frequent = word_counts.most_common(1)
print(the_most_frequent)
[('leads', 4)]
在上面的代码中,Counter对象生成一个字典,将输入序列中的可散列项映射到出现的次数,如下所示:
{
'Fear': 1,
'leads': 4,
'to': 4,
'anger': 2,
'hatred': 2,
'conflict': 2,
'suffering': 1
}
正如本教程第一部分所提到的,Counter对象的一个有价值的特性是它们可以用数学运算来组合。例如:
from pprint import pprint
quote_2 = "Fear, anger, and hatred essentially come from a lack of perspective as to what life is all about."
words_2 = quote_2.replace(',','').replace('.','').split()
dict_1 = Counter(words_1)
dict_2 = Counter(words_2)
pprint(dict_1)
print()
pprint(dict_2)
Counter({'leads': 4,
'to': 4,
'anger': 2,
'hatred': 2,
'conflict': 2,
'Fear': 1,
'suffering': 1})
Counter({'Fear': 1,
'anger': 1,
'and': 1,
'hatred': 1,
'essentially': 1,
'come': 1,
'from': 1,
'a': 1,
'lack': 1,
'of': 1,
'perspective': 1,
'as': 1,
'to': 1,
'what': 1,
'life': 1,
'is': 1,
'all': 1,
'about': 1})
现在,我们能够合并或减去这两个计数器实例。让我们试试它们:
pprint(dict_1 + dict_2)
Counter({'to': 5,
'leads': 4,
'anger': 3,
'hatred': 3,
'Fear': 2,
'conflict': 2,
'suffering': 1,
'and': 1,
'essentially': 1,
'come': 1,
'from': 1,
'a': 1,
'lack': 1,
'of': 1,
'perspective': 1,
'as': 1,
'what': 1,
'life': 1,
'is': 1,
'all': 1,
'about': 1})
pprint(dict_1 - dict_2)
Counter({'leads': 4,
'to': 3,
'conflict': 2,
'anger': 1,
'hatred': 1,
'suffering': 1})
到目前为止,我们已经尝试了带有字符串值的Counter对象。同样,我们可以将 list、tuple 或 dictionary 对象给Counter,并计算它们出现的频率。让我们在接下来的部分中探索它们。
Python 的Counter包含列表、元组和字典对象
为了探索如何将赋予 Python 的Counter的 list、tuple 和 dictionary 对象转换为键值对形式的可散列对象,让我们考虑一家销售三种颜色(绿色、白色和红色)t 恤的精品店。
以下 iterable 对象显示了连续两天的 t 恤销售额,如下所示:
sales_day_1 = ['red','green','white','red','red','green', 'white','green','red','red','red', 'white', 'white']
sales_day_2 = ('red','red','green','white','green','white','red','red','green', 'white','green','red','green','red','red')
price = {'red':74.99, 'green':83.99, 'white':51.99}
sales_day_1_counter = Counter(sales_day_1)
sales_day_2_counter = Counter(sales_day_2)
price_counter = Counter(price)
total_sales = sales_day_1_counter + sales_day_2_counter
sales_increment = sales_day_2_counter - sales_day_1_counter
minimum_sales = sales_day_1_counter & sales_day_2_counter
maximum_sales = sales_day_1_counter | sales_day_2_counter
print("Total Sales:", total_sales)
print("Sales Increment over Two Days:", sales_increment)
print("Minimun Sales:", minimum_sales)
print("Maximum Sales:", maximum_sales)
Total Sales: Counter({'red': 13, 'green': 8, 'white': 7})
Sales Increment over Two Days: Counter({'green': 2, 'red': 1})
Minimun Sales: Counter({'red': 6, 'green': 3, 'white': 3})
Maximum Sales: Counter({'red': 7, 'green': 5, 'white': 4})
在上面的例子中,sales_increment计数器不包含白衬衫,因为计数器对象不显示负值。这就是为什么柜台里只有绿色和红色的衬衫。白衬衫的数量减少到-1 并被忽略。
我们在上面的代码中使用了&和|操作符来返回每件 t 恤颜色的最小和最大销售额。这里就来讨论一下这两个算子。交集运算符(&)返回两个计数器中计数最小的对象,而并集运算符(|)返回两个计数器中计数最大的对象。
要计算每种颜色的总销售额,我们可以使用下面的代码片段:
for color,quantity in total_sales.items():
print(f"Total sales of '{color}' T-shirts: ${quantity*price_counter[color]:.2f}")
Total sales of 'red' T-shirts: $974.87
Total sales of 'green' T-shirts: $671.92
Total sales of 'white' T-shirts: $363.93
为了检索用于创建Counter的原始数据,我们可以使用elements()方法,如下所示:
for item in sales_day_1_counter.elements():
print(item)
red
red
red
red
red
red
green
green
green
white
white
white
white
上面的输出显示,计数器的元素以与sales_day_1_counter对象相同的顺序返回。
结论
本教程讨论了 Python 的Counter,它提供了一种有效的方法来计算 iterable 对象中的项数,而无需处理循环和不同的数据结构。我们还了解了Counter的方法和操作符,这些方法和操作符帮助我们从存储在集合中的数据中获取最大的洞察力。
我希望你今天学到了一些新东西。请随时在 LinkedIn 或 Twitter 上与我联系。
如何在 2022 年使用 Python 数据类(初学者指南)
原文:https://www.dataquest.io/blog/how-to-use-python-data-classes/
November 1, 2022
在 Python 中,数据类是被设计成只保存数据值的类。它们和普通的类没有什么不同,但是它们通常没有其他的方法。它们通常用于存储将在程序或系统的不同部分之间传递的信息。
然而,当创建仅作为数据容器的类时,重复编写__init__方法会产生大量的工作和潜在的错误。
dataclasses 模块是 Python 3.7 中引入的一个特性,它提供了一种以更简单的方式创建数据类的方法,无需编写方法。
在本文中,我们将看到如何利用这个模块来快速创建新的类,这些类不仅包含了__init__,还包含了其他一些已经实现的方法,因此我们不需要手动实现它们。此外,我们只用几行代码就可以做到这一点。
我们希望您有一些中级 python 经验,包括对如何创建类和一般面向对象编程的理解。
使用dataclasses模块
作为一个开始的例子,假设我们正在实现一个类来存储关于某一组人的数据。对于每个人,我们将有诸如姓名、年龄、身高和电子邮件地址等属性。这是一个普通班级的样子:
class Person():
def __init__(self, name, age, height, email):
self.name = name
self.age = age
self.height = height
self.email = email
然而,如果我们使用dataclasses模块,我们需要导入dataclass来在我们创建的类中使用它作为装饰器。当我们这样做时,我们不再需要编写 init 函数,只需要指定类的属性和它们的类型。下面是同样的Person类,以这种方式实现:
from dataclasses import dataclass
@dataclass
class Person():
name: str
age: int
height: float
email: str
我们还可以为类属性设置默认值:
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str = '[[email protected]](/cdn-cgi/l/email-protection)'
print(Person())
Person(name='Joe', age=30, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)')
提醒一下,Python 不接受类和函数中 default 之后的非默认属性,所以这会抛出一个错误:
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_5540/741473360.py in <module>
1 @dataclass
----> 2 class Person():
3 name: str = 'Joe'
4 age: int = 30
5 height: float = 1.85
~\anaconda3\lib\dataclasses.py in dataclass(cls, init, repr, eq, order, unsafe_hash, frozen)
1019
1020 # We're called as @dataclass without parens.
-> 1021 return wrap(cls)
1022
1023
~\anaconda3\lib\dataclasses.py in wrap(cls)
1011
1012 def wrap(cls):
-> 1013 return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
1014
1015 # See if we're being called as @dataclass or @dataclass().
~\anaconda3\lib\dataclasses.py in _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
925 if f._field_type in (_FIELD, _FIELD_INITVAR)]
926 _set_new_attribute(cls, '__init__',
--> 927 _init_fn(flds,
928 frozen,
929 has_post_init,
~\anaconda3\lib\dataclasses.py in _init_fn(fields, frozen, has_post_init, self_name, globals)
502 seen_default = True
503 elif seen_default:
--> 504 raise TypeError(f'non-default argument {f.name!r} '
505 'follows default argument')
506
TypeError: non-default argument 'email' follows default argument
一旦定义了类,就很容易实例化一个新对象并访问其属性,就像使用标准类一样:
person = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
print(person.name)
Joe
到目前为止,我们已经使用了常规的数据类型,如 string、integer 和 float 我们还可以将dataclass与typing模块结合起来,在类中创建任何类型的属性。例如,让我们给Person添加一个house_coordinates属性:
from typing import Tuple
@dataclass
class Person():
name: str
age: int
height: float
email: str
house_coordinates: Tuple
print(Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)', (40.748441, -73.985664)))
Person(name='Joe', age=25, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)', house_coordinates=(40.748441, -73.985664))
按照同样的逻辑,我们可以创建一个数据类来保存Person类的多个实例:
from typing import List
@dataclass
class People():
people: List[Person]
注意,People类中的people属性被定义为Person类的实例列表。例如,我们可以像这样实例化一个People对象:
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)', (40.748441, -73.985664))
mary = Person('Mary', 43, 1.67, '[[email protected]](/cdn-cgi/l/email-protection)', (-73.985664, 40.748441))
print(People([joe, mary]))
People(people=[Person(name='Joe', age=25, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)', house_coordinates=(40.748441, -73.985664)), Person(name='Mary', age=43, height=1.67, email='[[email protected]](/cdn-cgi/l/email-protection)', house_coordinates=(-73.985664, 40.748441))])
这允许我们将属性定义为我们想要的任何类型,也可以是数据类型的组合。
表示和比较
正如我们前面提到的,dataclass不仅实现了__init__方法,还实现了其他几个方法,包括__repr__方法。在一个常规的类中,我们使用这个方法来显示类中一个对象的表示。
例如,当我们调用对象时,我们将定义如下例所示的方法:
class Person():
def __init__(self, name, age, height, email):
self.name = name
self.age = age
self.height = height
self.email = email
def __repr__(self):
return (f'{self.__class__.__name__}(name={self.name}, age={self.age}, height={self.height}, email={self.email})')
person = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
print(person)
Person(name=Joe, age=25, height=1.85, [[email protected]](/cdn-cgi/l/email-protection))
然而,当使用dataclass时,没有必要写这些:
@dataclass
class Person():
name: str
age: int
height: float
email: str
person = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
print(person)
Person(name='Joe', age=25, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)')
注意,如果没有这些代码,输出就相当于标准 Python 类的输出。
如果我们想要定制我们类的表示,我们总是可以覆盖它:
@dataclass
class Person():
name: str
age: int
height: float
email: str
def __repr__(self):
return (f'''This is a {self.__class__.__name__} called {self.name}.''')
person = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
print(person)
This is a Person called Joe.
请注意,表示的输出是定制的。
说到比较,dataclasses模块让我们的生活更轻松。例如,我们可以像这样直接比较一个类的两个实例:
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str = '[[email protected]](/cdn-cgi/l/email-protection)'
print(Person() == Person())
True
请注意,我们使用了默认属性来缩短示例。
在这种情况下,比较是有效的,因为dataclass在幕后创建了一个执行比较的__eq__方法。没有装饰器,我们必须自己创建这个方法。
如果使用标准 Python 类,即使这些类实际上彼此相等,相同的比较也会产生不同的结果:
class Person():
def __init__(self, name='Joe', age=30, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)'):
self.name = name
self.age = age
self.height = height
self.email = email
print(Person() == Person())
False
如果不使用dataclass装饰器,该类不会测试两个实例是否相等。因此,默认情况下,Python 将使用对象的id进行比较,正如我们在下面看到的,它们是不同的:
print(id(Person()))
print(id(Person()))
1734438049008
1734438050976
所有这些意味着我们必须编写一个__eq__方法来进行比较:
class Person():
def __init__(self, name='Joe', age=30, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)'):
self.name = name
self.age = age
self.height = height
self.email = email
def __eq__(self, other):
if isinstance(other, Person):
return (self.name, self.age,
self.height, self.email) == (other.name, other.age,
other.height, other.email)
return NotImplemented
print(Person() == Person())
True
现在我们看到这两个对象是相等的,但是我们不得不写更多的代码来得到这个结果。
@dataclass参数
正如我们在上面看到的,当使用dataclass装饰器时,__init__、__repr__和__eq__方法为我们实现。所有这些方法的创建由dataclass的init、repr和eq参数设置。这三个参数默认为True。如果其中一个是在类内部创建的,那么该参数将被忽略。
然而,在继续之前,我们还需要了解dataclass的其他参数:
order:启用类的排序,我们将在下一节看到。默认为False。frozen:当True时,类的实例内的值在创建后不能修改。默认是False。
您可以在文档中查看其他一些方法。
整理
在处理数据时,我们经常需要对值进行排序。在我们的场景中,我们可能希望根据一些属性对不同的人进行排序。为此,我们将使用上面提到的dataclass装饰器的order参数,它支持类中的排序:
@dataclass(order=True)
class Person():
name: str
age: int
height: float
email: str
当order参数设置为True时,自动生成用于排序的__lt__(小于)、__le__(小于等于)、__gt__(大于)、__ge__(大于等于)方法。
让我们实例化我们的joe和mary对象,看看一个是否比另一个大:
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
mary = Person('Mary', 43, 1.67, '[[email protected]](/cdn-cgi/l/email-protection)')
print(joe > mary)
False
Python 告诉我们joe不大于mary,但是基于什么标准呢?该类将对象作为包含其属性的元组进行比较,如下所示:
print(('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)') > ('Mary', 43, 1.67, '[[email protected]](/cdn-cgi/l/email-protection)'))
False
由于字母“J”在“M”之前,所以它表示joe < mary。如果名称相同,它将移动到每个元组中的下一个元素。实际上,它是按字母顺序比较对象。尽管根据我们正在处理的问题,这可能有一定的意义,但我们希望能够控制对象的排序方式。
为了实现这一点,我们将利用dataclasses模块的另外两个特性。
首先是field函数。此函数用于单独定制数据类的一个属性,这允许我们定义依赖于另一个属性的新属性,并且仅在对象被实例化后创建。
在我们的排序问题中,我们将使用field在类中创建一个sort_index属性。该属性只能在对象实例化后创建,并且是dataclasses用于排序的属性:
from dataclasses import dataclass, field
@dataclass(order=True)
class Person():
sort_index: int = field(init=False, repr=False)
name: str
age: int
height: float
email: str
我们作为False传递的两个参数声明这个属性不在__init__中,并且当我们调用__repr__时它不应该被显示。在field功能中还有其他参数,您可以在文档中查看。
在我们引用了这个新属性之后,我们将使用第二个新工具:__post_int__方法。顾名思义,这个方法紧接在__init__方法之后执行。我们将使用__post_int__来定义sort_index,就在对象创建之后。举个例子,假设我们想根据人们的年龄来比较他们。方法如下:
@dataclass(order=True)
class Person():
sort_index: int = field(init=False, repr=False)
name: str
age: int
height: float
email: str
def __post_init__(self):
self.sort_index = self.age
如果我们做同样的比较,我们知道乔比玛丽年轻:
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
mary = Person('Mary', 43, 1.67, '[[email protected]](/cdn-cgi/l/email-protection)')
print(joe > mary)
False
如果我们想按身高对人进行排序,我们可以使用以下代码:
@dataclass(order=True)
class Person():
sort_index: float = field(init=False, repr=False)
name: str
age: int
height: float
email: str
def __post_init__(self):
self.sort_index = self.height
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
mary = Person('Mary', 43, 1.67, '[[email protected]](/cdn-cgi/l/email-protection)')
print(joe > mary)
True
乔比玛丽高。注意,我们将sort_index设置为float。
我们能够在数据类中实现排序,而不需要编写多个方法。
使用不可变数据类
我们上面提到的@dataclass的另一个参数是frozen。当设置为True时,frozen不允许我们在对象创建后修改其属性。
有了frozen=False,我们可以很容易地进行这样的修改:
@dataclass()
class Person():
name: str
age: int
height: float
email: str
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
joe.age = 35
print(joe)
Person(name='Joe', age=35, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)')
我们创建了一个Person对象,然后修改了age属性,没有任何问题。
但是,当设置为True时,任何修改对象的尝试都会引发错误:
@dataclass(frozen=True)
class Person():
name: str
age: int
height: float
email: str
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
joe.age = 35
print(joe)
---------------------------------------------------------------------------
FrozenInstanceError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_5540/2036839054.py in <module>
8 joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
9
---> 10 joe.age = 35
11 print(joe)
<string> in __setattr__(self, name, value)
FrozenInstanceError: cannot assign to field 'age'
请注意,错误消息显示的是FrozenInstanceError。
有一个技巧可以修改不可变数据类的值。如果我们的类包含一个可变属性,即使类被冻结了,这个属性也会改变。这看起来似乎没有意义,但是让我们看一个例子。
让我们回忆一下我们在本文前面创建的People类,但是现在让我们把它变成不可变的:
@dataclass(frozen=True)
class People():
people: List[Person]
@dataclass(frozen=True)
class Person():
name: str
age: int
height: float
email: str
然后我们创建了两个Person类的实例,并使用它们创建了一个People的实例,我们将其命名为two_people:
joe = Person('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
mary = Person('Mary', 43, 1.67, '[[email protected]](/cdn-cgi/l/email-protection)')
two_people = People([joe, mary])
print(two_people)
People(people=[Person(name='Joe', age=25, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)'), Person(name='Mary', age=43, height=1.67, email='[[email protected]](/cdn-cgi/l/email-protection)')])
People类中的people属性是一个列表。我们可以很容易地在two_people对象中访问这个列表中的值:
print(two_people.people[0])
Person(name='Joe', age=25, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)')
因此,尽管Person和People类都是不可变的,但列表不是,这意味着我们可以改变列表中的值:
two_people.people[0] = Person('Joe', 35, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)')
print(two_people.people[0])
Person(name='Joe', age=35, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)')
请注意,年龄现在是 35 岁。
我们没有改变不可变类的任何对象的属性,但是我们用不同的元素替换了列表的第一个元素,并且列表是可变的。
记住,为了安全地使用不可变的数据类,类的所有属性也应该是不可变的。
用dataclasses继承
dataclasses模块也支持继承,这意味着我们可以创建一个使用另一个数据类属性的数据类。仍然使用我们的Person类,我们将创建一个新的Employee类,它继承了Person的所有属性。
于是我们有了Person:
@dataclass(order=True)
class Person():
name: str
age: int
height: float
email: str
还有新的Employee类:
@dataclass(order=True)
class Employee(Person):
salary: int
departament: str
现在我们可以使用Person类的所有属性创建一个Employee类的对象:
print(Employee('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)', 100000, 'Marketing'))
Employee(name='Joe', age=25, height=1.85, email='[[email protected]](/cdn-cgi/l/email-protection)', salary=100000, departament='Marketing')
从现在开始,我们也可以在Employee类中使用本文中看到的所有内容。
请注意默认属性。假设我们在Person中有默认属性,但在Employee中没有。如下面的代码所示,这种情况会引发一个错误:
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str = '[[email protected]](/cdn-cgi/l/email-protection)'
@dataclass(order=True)
class Employee(Person):
salary: int
departament: str
print(Employee('Joe', 25, 1.85, '[[email protected]](/cdn-cgi/l/email-protection)', 100000, 'Marketing'))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_5540/1937366284.py in <module>
9
10 @dataclass(order=True)
---> 11 class Employee(Person):
12 salary: int
13 departament: str
~\anaconda3\lib\dataclasses.py in wrap(cls)
1011
1012 def wrap(cls):
-> 1013 return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
1014
1015 # See if we're being called as @dataclass or @dataclass().
~\anaconda3\lib\dataclasses.py in _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
925 if f._field_type in (_FIELD, _FIELD_INITVAR)]
926 _set_new_attribute(cls, '__init__',
--> 927 _init_fn(flds,
928 frozen,
929 has_post_init,
~\anaconda3\lib\dataclasses.py in _init_fn(fields, frozen, has_post_init, self_name, globals)
502 seen_default = True
503 elif seen_default:
--> 504 raise TypeError(f'non-default argument {f.name!r} '
505 'follows default argument')
506
TypeError: non-default argument 'salary' follows default argument
如果基类有默认属性,那么从它派生的类中的所有属性也必须有默认值。
结论
在本文中,我们看到了dataclasses模块是一个非常强大的工具,可以快速、直观地创建数据类。虽然我们在本文中已经看到了很多,但是该模块包含了更多的工具,并且总是有更多的东西需要学习。
到目前为止,我们已经学会了如何:
-
使用
dataclasses定义一个类 -
使用默认属性及其规则
-
创建一种表示方法
-
比较数据类
-
排序数据类
-
对数据类使用继承
-
使用不可变数据类
利用我们新的高级函数 Python 课程编写更好的代码
原文:https://www.dataquest.io/blog/how-to-write-better-code-python-course/
September 26, 2019
当谈到学习数据科学时,写更好的代码并不总是首先想到的——我们通常更关心的是让代码工作,并确保分析是正确的。
但是,作为一个有效的数据科学团队的一部分,您必须能够编写可读、可维护、可测试和可调试的代码,而不仅仅是功能性的代码。
这就是为什么我们很高兴地宣布,我们刚刚在 Python 数据科学家路径中推出了一门新课程,名为函数:高级。
这是一门深入的 Python 函数课程,旨在向您展示如何使用函数编程编写更好的代码。如果您正在从事数据工作,或者渴望从事数据工作,本课程涵盖了使您的代码更易于阅读、维护、测试和调试的关键技能。
点击下面的按钮,开始学习。
本课程需要高级订阅(限时半价)。
为什么要学习写更好的代码?
编写好的、干净的代码不仅仅对于软件工程师来说很重要!
是的,如果你是唯一一个曾经看过你的代码的人,那么它是如何写的可能并不太重要。但是在专业数据科学工作的背景下,很少会出现这种情况。
通常,您将作为团队的一员工作,团队中的其他数据科学家、分析师和工程师可能会阅读和审查您的代码。并且您可能正在构建可重复的过程和/或数据产品,这些过程和/或数据产品需要维护数月或数年。
成为数据科学团队中富有成效的成员意味着能够编写团队成员容易阅读的代码,以及任何人都可以维护和调试的代码。
这让你的同事生活更轻松,但也让你的生活更轻松——如果其他人可以轻松地使用你的代码,这意味着你可以休假,而不会被一些紧急问题打扰。这意味着你可以转移到另一个你感兴趣的项目,让别人接手你的分析,而不必浪费时间向接替你的人解释你的代码。这意味着,如果你决定在未来的某个时候接受一份不同的工作,你可以让你目前的公司处于一个很好的位置,以你的工作为基础,而不是让他们陷入困境。
通常,编写更好的代码意味着专注于函数式编程,因为纯函数是无状态的——它们只需要给定的输入来产生输出。这使得它们相对容易阅读。当您查看一个纯函数时,您可以确切地看到输入了什么,对该输入执行了什么,以及返回了什么。这使得您的代码更容易阅读、理解和调试。
不确定您是否掌握了在数据科学编程环境中使用函数的最佳实践?这就是 Python 中的高级函数课程的用武之地。
这门课程包括什么?
函数:高级从在团队环境中编写函数的最佳实践开始。您将了解文档字符串以及如何包含它们。我们将介绍编写优秀代码的一些基本原则:做一件事,不要重复,你将学会为函数设置默认参数。
然后,我们将深入 Python 中函数式编程的世界,以涵盖上下文管理器:为运行代码建立上下文、运行代码、然后移除该上下文的函数。您将学习何时使用它们,何时不使用它们,并且您将学习使用装饰器编写自己的程序。
课程的最后两节课都是关于 Python decorators 的,你可以用它来包装其他函数并修改它们的行为。当你对装饰者有了直觉,并开始掌握嵌套函数、作用域和闭包等概念时,你会学到基础知识。
之后,您将更深入地研究 decorator,学习识别公共模式并编写可以接受多个参数的 decorator。您还能够确保您的修饰函数不会丢失任何元数据。
通过这一切,您将在我们的交互式浏览器内编码环境中工作,并且您将通过编写和运行实际代码的每一步来应用您所学的知识。当你学完这门课程时,你会真正体会到如何写出更好、更简洁的代码。

简而言之,Dataquest 平台。
准备好开始了吗?查看课程或浏览我们的完整数据科学家路径,看看你接下来想学什么!
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
一位人文学科教师如何通过 Dataquest 学习数据科学
原文:https://www.dataquest.io/blog/humanities-learn-data-science/
February 4, 2019
Greg Iannarella 生动地证明了学习数据科学不需要数学、科学或编程背景。
“我的整个学术背景都是非常严格的人文学科,”他说。“没有数学或科学或类似的东西。我一直对这些东西很感兴趣。但你知道学校是如何运作的:如果你在某方面没有完全的天赋,有时你会被劝退。”
因此,格雷格在大学时专注于人文学科,然后在研究生院再次。但是当他在那里的时候,他遇到了一位教授,他正在做有趣的语言学工作:统计特定的单词在文本中出现的频率,“并就这似乎如何告知我们对文学如何工作的更大文化理解进行辩论。”
这位教授没有进行任何数据科学编程——事实上,格雷格说,他正在用手计算单词——但分析数字数据以更好地理解文献的想法很有趣。在格雷格看来,分析方法可以与他读到的一个更广泛的趋势相结合:数字人文,使用数字工具和分析来解决人文问题。
*尽管如此,仅凭这一点还不足以让 Greg 投身于数据科学。是什么最终把他推到了悬崖边?打赌。
他的哥哥是一名计算机科学家,在一次旅行中,两人就哪门课程更难展开了辩论:格雷格的英语硕士和他哥哥的计算机科学硕士。他们决定用一个赌注来解决这场争论:格雷格将学习计算机科学,他的兄弟将学习英国文学。
使用 Dataquest 学习
尽管 Greg 认为学习数据科学编程很有意义,但他不确定具体从哪里开始。“我只是在寻找我可以开始使用的免费工具,”他说。
“在我找到[Dataquest]之前,我已经浏览了 Codecademy 的所有免费内容,”他说。“我找到了 Dataquest,轻松地通过了免费部分和免费课程,[我]尝试了许多其他竞争对手。”
“将我带回 Dataquest 的是您的 shell,在您的 shell 中工作并拥有并排视图。感觉很舒服。”

学以致用,在 Dataquest 平台上并肩前行。
他还喜欢 Dataquest 平台解释了为什么以及如何。“我认为这是你们应该关注的一件事,”格雷格说,“这就是我们为什么要这么做,这就是我们下一步该怎么做。这很有帮助。这对我帮助很大。”
“不是每个服务都这样做,”他补充道。“有时候他们真的会把你扔进深水区。那就是你了。游来游去。”
Greg 从我们的数据科学途径的 Python 开始。但他并没有就此止步。他还在其他网站上学习课程,在 EdX 上了一堂生物信息学课后,他也开始用 Dataquest 钻研学习 R。
面向所有人的数据科学
在学习的同时,Greg 还在思考如何将新的数据科学知识应用到工作中:在 Seton Hall 大学为新生教授英语和文学。
“我认识到的一件事是,有时候……这是关于改变你对提问的想法,”他说。"然后我如何把它应用到教人们如何写文章上?"
他想出的是一个将更多“数字人文”融入西顿霍尔大学新生英语课程的计划。
当然,他没有要求大一的英语学生学习编程,但他给了他们一个数据分析工具,让他们可以绘制和查看数据,如给定位置的公民医疗支出或教育水平。使用这个工具,学生们可以自己进行数据分析,然后写文章反思他们的发现。
格雷格说,这个项目“非常成功”,数字人文学科正在流行起来。他将在今年春天展示他的成果,试图鼓励更多类似的工作。他还发现了一群对数据研究感兴趣的其他人文学者。“是英语系、宗教系和历史系的人,我们都在学习 R,讨论如何使用 R 来参与我们的学习。这很酷,”他说。“我把很多人推向 Dataquest,作为一种尝试的方式。”
这种编程、科学、数学和人文学科的综合对 Greg 来说很自然。“我总觉得这种奇怪的感觉,人文和科学一开始就被分开了。它们看起来像是相互补充、相互补充的东西。沃森和克里克关于双螺旋的论文和著作都充满了难以置信的诗意。还有英国的浪漫派和维多利亚派,他们都在探索科学。”
他还认为拥抱数据和技术是人文学科研究的下一个明显进步。“我认为很多不用技术就能完成的人文学科的工作已经完成了,”他说。“我认为,未来将着眼于我们使用技术的方式。”
寻找成功
学习数据科学并不总是一帆风顺。Greg 面临的最大挑战之一是在本地进行设置,这样他就可以在自己的计算机上编写代码。“我可以在 Dataquest 的外壳上做一些事情,但我无法让我的电脑做这些事情。在那个时候,我准备把我的电脑扔出窗外,完全放弃它。但是你必须深呼吸,认识到答案就在某个地方。你只需要愿意研究并有耐心。”
你还需要认识到这将是一个漫长的旅程。“我什么时候和我哥哥一起去旅行的?那一定是两年前了。这会花你很长时间。”
“你只需要保持一致,不要气馁,”他说。
如果你想快速进步,格雷格建议你要专注于接触,让自己沉浸在所学的东西中。“有一件事很有帮助,当我不能在电脑前时,我会在手机上下载免费的 PDF 书籍,”格雷格说。"试着流利地使用这种语言,并继续让自己接触它."
至于计算机科学和英语孰优孰劣?
格雷格说:“(我哥哥)仍然阅读有趣和优秀的文学作品,但我肯定不是计算机科学或数据科学的硕士。”。“但我一直朝着它努力。”
“所以是啊。我想我们大概扯平了。”
无论你的学术背景如何,你也可以学习数据科学。点击这里免费上手 Python 或RT5。*
统计学新课程:R 中的假设检验
November 5, 2019
能够确定统计显著性是数据科学中最重要的技能之一。例如,如果您观察到数据中的趋势,它在统计上有意义吗,或者只是数据中的一些随机噪声?能够构建一个有用的假设并通过假设检验对其进行评估是至关重要的。
这就是为什么我们很兴奋地宣布我们的 R 数据分析师途径的最新成员:R 中的假设检验
准备好开始学习了吗?单击下面的按钮深入研究 R 中的假设检验,或者向下滚动以了解关于这门新课程的更多信息。
R 中的假设检验是什么?
本课程旨在帮助您对重要的统计学概念(如显著性检验)有一个实用的理解,并带您实践 A/B 检验、卡方检验等。
很像我们的 Python 假设检验课程,R 中的假设检验要求你写代码,分析真实世界的数据(包括来自游戏节目 Jeopardy 的数据! )当你学会如何科学地检验假设。
它从关注统计显著性开始,当您开始使用编码技能挖掘数据时,您将学习像 p 值和表示分布这样的重要概念。然后,课程进入卡方检验,这使我们能够科学地量化观察到的和预期的分类值之间的差异。
您将了解多类别卡方测试,然后深入研究一个新的指导性项目,该项目将挑战您应用您所获得的编程技能和统计知识来提出一个获胜的 Jeopardy!策略。
您将分析长期电视智力竞赛节目中的问题来寻找模式。然后,您将应用假设检验技巧和卡方检验的新知识来确定哪些模式是有意义的。
本课程结束时,您将对假设检验有一个深刻的理解,并且将有在真实数据科学场景中应用显著性和卡方检验等检验的经验。
为什么学这个?
假设检验对于在分析数据时能够区分信号和噪声至关重要。确定一个结果是否具有统计显著性有助于您知道何时可以从您找到的模式中得出结论。
对于任何打算从事数据分析或数据科学工作的人来说,让您的分析具有这种程度的统计严谨性尤为重要。公司渴望成为数据驱动型企业,并将向他们的数据团队寻求指导。如果你不明白你的哪些结果是真正重要的,你可能最终会把你的公司引向错误的方向。
假设检验为数据分析提供了坚实的科学和统计基础。没有这个基础,你通常不可能评估你是否在数据中发现了一个有意义的模式。
立即开始学习 R 中的假设检验:
我勉强从大学毕业,这没什么
原文:https://www.dataquest.io/blog/i-barely-graduated-college/
November 11, 2016
我高中成绩不太好。我的平均绩点大约是 2.5 分(满分 4 分)。我在一些我感兴趣的科目上表现很好,比如数学、计算机科学和历史,但是其他的都很差。
一堂课要求我做的作业越少,我的成绩就越好。在大多数课堂上,我都是看着挂钟慢慢地指向我们可以离开的时间。
我对学校没有热情,我也不是那种看起来总是能够适应家庭作业、社交生活、体育和 10 个俱乐部的被驱使的高中生。
由于我自己的不感兴趣,系统把我一笔勾销了。在申请暑期实习时,一位老师为我写了一封反推荐信,警告他们不要选择我。我的父母对我上哪所大学有很高的期望——哈佛、麻省理工或巴斯特。
说这不现实是一种低估。我的指导顾问告诉我,上大学是一件难事。

我的高中被拆了。
我申请了大约 15 所大学,并进入了其中的两所——马里兰大学,我的州立学校和加州大学欧文分校。我最终作为 2008 届的一员去了马里兰。
我来自一个非常看重学习成绩的印度裔美国家庭,所以这是多年来的耻辱。我会告诉人们“我被列入了麻省理工学院的候选名单”,或者“因为学费低,我实际上选择了马里兰”。现在回想起来,这是一种愚蠢的态度,但我当时年轻,我非常看重外表。
在马里兰,我不确定我想主修什么。我父母希望我成为一名医生。我对它不太感兴趣,但我还是上了一些医学预科课程。我选择了通学作为专业(不知道自己想学什么专业的人的专业),并开始满足我的基本要求。
大学真的是无组织的,我陷入了一种模式,我根本不去上课,也不做作业。大多数课程都很无聊,我根本无法在课堂上学习。当我去上课的时候,我又一次盯着一个钟或我的手表,直到该离开的时候。我发现学习只是我不擅长的事情。
我喜欢一些课程,比如微生物学,我们在培养皿中培养细菌,还有历史和数学课。在我不再去听课之后,我才发现我喜欢多变量微积分——前三分之一的时间我每天都去上课,但考试不及格。考试前,我转而呆在家里看书,并开始得到 A。

至少 UMD 有一个非常漂亮的校园!
我在大学里从来没有真正找到自己的激情,大学也没有提供帮助我找到激情的工具。这意味着我在普通研究中漂泊了一年,然后当我的成绩显然不会让我进入任何医学院时,我将我的专业转向了美国历史。
当你习惯性地认为糟糕的成绩反映了你糟糕的性格时,真的很容易认为你有问题。如果没有一个真正的内部和外部支持结构,这将不可避免地导致萧条和恶性循环。
大学几年后,我决定我需要追求自己的人生目标。其中一部分是支付大学和我自己的生活费用。
没有多少工作适合绩点低的大学生,但体力劳动总是招人。我去了 UPS 当装卸工。我的起薪大约是每小时 8 美元。当人们问我做什么时,我会告诉他们,“我把箱子扔进卡车里”。箱子很快从传送带上下来,我们把它们从传送带上拿下来,扫描它们,然后把它们堆在半挂车里,这些半挂车会被送到其他 UPS“中心”。

这是一面“墙”,以及您如何在 UPS 装载卡车。这是一个很好的-大多数看起来很糟糕。
我最终被提升为“兼职主管”,这意味着我负责管理一个装货区,并管理大约 10 个人。我一周工作 30 个小时左右,其余时间都精疲力尽。我开始不像往常那样去上课了。从好的方面来说,UPS 用他们的报销计划支付了我一半的学费,我有足够的钱支付我的生活费用,甚至还能存一点。
我想既然我的平均绩点接近 2.0,我就应该在大学毕业后继续在 UPS 工作。接下来的两年也是如此。我很喜欢我的一些历史课,特别是我的顶点课程,在那里我学习了二战后日本的重建。2008 年毕业时,我的平均绩点是 2.1。有几次,我差点被留校察看,但通过提前逃课、转到更容易的课程或者更加努力,我成功地摆脱了它。
毕业后,我的选择相当黯淡。ups 的高层希望我留下来,但他们认为我有一个态度问题,我需要先解决这个问题,然后他们才愿意提拔我(UPS 的大多数政策都是落后和空洞的,导致我所监管的人受到伤害,所以我非常沮丧)。
体力劳动的悲剧在于,你的收入潜力在 20 多岁时达到顶峰。我在 UPS 工作了 10 多年的同事都有背部和膝盖问题。我受过几次伤,我的膝盖也不是很好,所以留在 UPS 可能是个糟糕的选择。我在那里学到了很多东西——关于努力工作、激励和管理他人——但这并不是一份长期的工作。
多亏了一个朋友,我最终在百事可乐找到了一份运营经理的工作。大约在我开始在百事可乐工作的时候,我也一时兴起申请了美国外交部。没有多少工作会接受大学平均成绩低和没有“硬”技能的人,但进入外交部门需要通过考试,所以看起来很适合。另外,我对它感兴趣是因为我研究了日本的重建。
我最终进入了外交部门,尽管我最终发现这也不是一个好的长期选择。我开始学习编码是在我在外交部门工作的末期(如果你感兴趣,你可以在这里阅读更多关于这段经历的内容)。

我被派往圭亚那乔治敦从事外交工作。
编程是我的激情所在,但我只是在经历了多年的换工作和怀疑是否能找到有趣的事情后才真正发现了它。
回想起来,有迹象表明。我在中学的时候每天都坐公交车上学,学习给我的 TI-83 计算器编程,然后做一个简单的游戏,让一个怪物在屏幕上追逐你。我在做暑期实习的时候做了脚本来自动化某些任务。我曾经玩过一个网游,黑了一些简单的脚本帮我管理东西。但是我没有意识到脚本可以比一种使“真正的工作”更快更简单的方法更有价值。
我父亲也转行做编程,但他在大型咨询公司工作,做的工作他和我都不觉得特别有趣。我认为这才是“真正的编程”,我所做的所有有趣的脚本都是次要的。即使当我离开外交部,回到美国,继续学习编码,我也没有一个清晰的最终目标。我只是知道我在做一件让我深深感兴趣的事情,所以我一直在做。
我想预测股市,但不知道如何预测。我花时间阅读 C#和 Ruby,并与股票价格引擎进行交互。我最终制定了一个可怕的“算法”,其中包含硬编码的规则(如果股票上周上涨,今天就卖出)。我记得当我发现我可以编写网络代码让一些机器成为“工作人员”并控制一台机器时的兴奋。

我试图预测股票市场。
我写的算法从来没有任何价值,但我对股票价格预测的兴趣让我选择了机器学习,这让我找到了 Kaggle 。Kaggle 是一个机器学习的竞赛平台。你可以制作算法,与世界上其他人制作的算法竞争。这是一个很好的替代认证方法——你可以说“我没有麻省理工的学位,但是我在一次 Kaggle 竞赛中打败了几个博士”。
当时卡格尔对我来说是个完美的地方。我每天都在学习、编写算法和比赛。我最终在一次股票交易比赛中获得了 100 名左右的第五名,然后我在债券交易和自动化论文评分方面赢得了一些比赛。我仍然记得我在第一次比赛中表现出色时的感觉,当我情绪低落时回想起来——那种我确实擅长某事的得意洋洋。
卡格尔的伟大之处在于,我突然在这个领域获得了一些认可。我能够利用我制作的自动论文评分算法,帮助我在 edX 找到一份机器学习工程师的工作,这是哈佛/麻省理工学院/伯克利合作的在线学习项目。

我工作的 edX 办公室。
在 edX 的时候,我能够观察到他们如何试图使用技术来提供传统教育系统的替代方案。虽然他们做了很多正确的事情,但我不禁认为有些事情可以用不同的方式来做。
我对改善教育系统产生了浓厚的兴趣,这促使我在 2015 年开始建立 Dataquest 。在 Dataquest,我们帮助任何人在浏览器中学习数据科学。我们的学习经验基于我在自己的旅程中学到的许多经验,以及我们对成功的数据科学家如何学习的观察。
在线教育让竞争变得公平——你可以廉价而有效地学到在学校或训练营需要花费数万元才能学到的技能。不幸的是,大多数在线教育没有解决动机的问题。我很幸运,因为我发现了一个问题——预测股市——这个问题深深地激励着我,推动着我前进。许多人没有这么幸运。
我们经常认为激发学生的学习动机是学生的责任,教授课程内容也是学生的责任。如果你没有从一门课程中学到东西,那是你的错,不是课程的错。不幸的是,正是这种心态导致了我对大学的失望。大学的态度是,学习是你的责任,如果你不学,那就是你的错。没有把重点放在让学习变得有趣或向你展示你正在做的事情的实际应用上。
有效的在线教育既能提供信息,又能激励人。如果你有足够的动力,你可以学习并取得任何成就。在 Dataquest,我们通过关注以下几个关键要素,致力于建立一种激励性和参与性的学习体验:
- 有趣的课程。你将通过预测航空事故来学习机器学习,通过寻找 NBA 最好的球员来学习统计学。
- 具有挑战性的项目。项目是有意义的,并且帮助你综合和应用你所学的东西。
- 探索的自由。您可以自由探索课程中的数据,以及课程之外的不同主题和项目。
- 社区互动。向同龄人学习是非常强大和激励人心的。
开始 18 个月后,我们已经帮助数千人改善了他们的职业生涯。你可以在这里阅读他们的一些故事。我们认为应该根据你拥有的技能来评判你,而不是你上过的大学,我们真的很高兴能在改变这个体系方面发挥一点作用。
我们的 Dataquest 浏览器界面。
我开始做我从未想象过的事情,这都是因为我没有让系统决定我应该做什么。发现或追求你感兴趣的东西永远不会太晚。你可以随时改变自己的道路。
如果你和我一样,需要找人聊天,请随时联系,或者给我发电子邮件。我知道这有多难,我也知道和有不同观点的人交谈有多有价值。
如果您对学习数据科学感兴趣,您可以从今天开始免费学习 Dataquest。
获取免费的数据科学资源
免费注册获取我们的每周时事通讯,包括数据科学、 Python 、 R 和 SQL 资源链接。此外,您还可以访问我们免费的交互式在线课程内容!
如何在 Ubuntu 上安装和配置 Docker Swarm
原文:https://www.dataquest.io/blog/install-and-configure-docker-swarm-on-ubuntu/
February 15, 2018Docker Swarm is a clustering tool that turns a group of Docker hosts into a single virtual server. Docker Swarm ensures availability and high performance for your application by distributing it over the number of Docker hosts inside a cluster. Docker Swarm also allows you to increase the number of container instance for the same application. Clustering is an important feature of container technology for redundancy and high availability. You can manage and control clusters through a swarm manager. The swarm manager allows you to create a primary manager instance and multiple replica instances in case the primary instance fails. Docker Swarm exposes standard Docker API, meaning that any tool that you used to communicate with Docker (Docker CLI, Docker Compose, Krane, and Dokku) can work equally well with Docker Swarm. Features of Swarm Mode:
- 提供 Docker 引擎 CLI 来创建一群 Docker 引擎,您可以在其中部署应用程序服务。你不需要任何额外的软件工具来创建或管理一个群体。
- 群管理器为群中的每个服务分配一个唯一的 DNS 名称。因此,您可以通过 DNS 名称轻松查询 swarm 中运行的每个容器。
- 群中的每个节点强制执行 TLS 相互认证和加密,以确保自身和所有其他节点之间的通信安全。您也可以使用自签名根证书或来自自定义根 CA 的证书。
- 允许您以增量方式将服务更新应用到节点。
- 允许您为服务指定覆盖网络,以及如何在节点之间分发服务容器。
在本帖中,我们将介绍如何在 Ubuntu 16.04 服务器上安装和配置 Docker Swarm 模式。我们将:
- 安装一个服务发现工具,并在所有节点上运行 swarm 容器。
- 安装 Docker 并配置 swarm manager。
- 将所有节点添加到 Manager 节点(下一节将详细介绍节点)。
为了充分利用这篇文章,你应该:
- Ubuntu 和 Docker 的基础知识。
- 安装了 ubuntu 16.04 的两个节点。
- 在两个节点上都设置了具有 sudo 权限的非 root 用户。
- 在管理节点和工作节点上配置的静态 IP 地址。这里,我们将对管理器节点使用 IP 192.168.0.103,对工作者节点使用 IP 192.168.0.104。
我们先来看节点。
管理者节点和工作者节点
Docker Swarm 由两个主要组件组成:
- 管理器节点
- 工作节点
管理器节点管理器节点用于处理集群管理任务,例如维护集群状态、调度服务和服务群模式 HTTP API 端点。群体模式下 Docker 最重要的特性之一就是管理者定额。manager quorum 存储有关集群的信息,信息的一致性通过 Raft 共识算法达成共识。如果任何一个管理节点意外死亡,另一个管理节点可以接管任务并将服务恢复到稳定状态。Raft 最多允许(N-1)/2 次失败,并且需要(N/2)+1 个成员的多数或法定人数来同意向集群提议的值。这意味着在运行 Raft 的 5 个管理器的集群中,如果 3 个节点不可用,系统将无法处理更多的请求来调度额外的任务。现有任务继续运行,但如果管理器集不健康,调度程序无法重新平衡任务来应对故障。工人节点工人节点用于执行容器。工作节点不参与 Raft 分布式状态,不做调度决策。您可以创建一个由一个管理器节点组成的群组,但是您不能拥有一个没有至少一个管理器节点的工作器节点。当管理器节点脱机进行维护时,也可以将工作节点升级为管理器。正如引言中提到的,我们在本文中使用了两个节点——一个作为管理者节点,另一个作为工作者节点。
入门指南
在开始之前,您应该用最新版本更新您的系统存储库。您可以使用以下命令更新它:
更新存储库后,重启系统以应用所有更新。
安装 Docker
您还需要在两个节点上安装 Docker 引擎。默认情况下,Docker 在 Ubuntu 16.04 资源库中不可用。因此,您需要首先建立一个 Docker 存储库。您可以使用以下命令安装所需的软件包:
sudo apt-get install apt-transport-https software-properties-common ca-certificates -y接下来,为 Docker 添加 GPG 键:wget https://download.docker.com/linux/ubuntu/gpg && sudo apt-key add gpg然后,添加 Docker 存储库并更新包缓存:sudo echo "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" >> /etc/apt/sources.list sudo apt-get update -y最后,使用以下命令安装 Docker 引擎:sudo apt-get install docker-ce -y一旦安装了 Docker,启动 Docker 服务并使其在引导时启动:sudo systemctl start docker && sudo systemctl enable docker默认情况下,Docker 守护进程总是以 root 用户身份运行,其他用户只能使用 sudo 访问它。如果想在不使用 sudo 的情况下运行docker命令,那么创建一个名为 docker 的 Unix 组,并向其中添加用户。您可以通过运行下面的命令来做到这一点:sudo groupadd docker && sudo usermod -aG docker dockeruser接下来,注销并使用 dockeruser 重新登录到您的系统,以便重新评估您的组成员资格。注意:记住在两个节点上运行上述命令。
配置防火墙
您需要为一个群集群配置防火墙规则,以便在两个节点上正常工作。使用 UFW 防火墙和以下命令允许端口 7946、4789、2376、2376、2377 和 80:
sudo ufw allow 2376/tcp && sudo ufw allow 7946/udp && sudo ufw allow 7946/tcp && sudo ufw allow 80/tcp && sudo ufw allow 2377/tcp && sudo ufw allow 4789/udp接下来,重新加载 UFW 防火墙并使其在引导时启动:sudo ufw reload && sudo ufw enable重新启动 Docker 服务以影响 Docker 规则:sudo systemctl restart docker
创建 Docker 群集群
首先,您需要用 IP 地址初始化集群,以便您的节点充当管理节点。在 Manager 节点上,运行以下命令来通告 IP 地址:
您应该会看到以下输出:
Swarm initialized: current node (iwjtf6u951g7rpx6ugkty3ksa) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5p5f6p6tv1cmjzq9ntx3zmck9kpgt355qq0uaqoj2ple629dl4-5880qso8jio78djpx5mzbqcfu 192.168.0.103:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
上面输出中显示的令牌将用于在下一步中向集群添加工作节点。Docker 引擎根据您提供给docker swarm join命令的 join-token 加入集群。节点仅在加入时使用令牌。如果您随后轮换令牌,它不会影响现有的群节点。现在,使用以下命令检查 Manager 节点的状态:docker node ls如果一切正常,您应该会看到以下输出:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
iwjtf6u951g7rpx6ugkty3ksa * Manager-Node Ready Active Leader
你也可以检查 Docker Swarm 集群的状态:code>docker info
您应该会看到以下输出:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 0
Server Version: 17.09.0-ce
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: active
NodeID: iwjtf6u951g7rpx6ugkty3ksa
Is Manager: true
ClusterID: fo24c1dvp7ent771rhrjhplnu
Managers: 1
Nodes: 1
Orchestration:
Task History Retention Limit: 5
Raft:
Snapshot Interval: 10000
Number of Old Snapshots to Retain: 0
Heartbeat Tick: 1
Election Tick: 3
Dispatcher:
Heartbeat Period: 5 seconds
CA Configuration:
Expiry Duration: 3 months
Force Rotate: 0
Autolock Managers: false
Root Rotation In Progress: false
Node Address: 192.168.0.103
Manager Addresses:
192.168.0.103:2377
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 06b9cb35161009dcb7123345749fef02f7cea8e0
runc version: 3f2f8b84a77f73d38244dd690525642a72156c64
init version: 949e6fa
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 4.4.0-45-generic
Operating System: Ubuntu 16.04.1 LTS
OSType: linux
Architecture: x86_64
CPUs: 1
Total Memory: 992.5MiB
Name: Manager-Node
ID: R5H4:JL3F:OXVI:NLNY:76MV:5FJU:XMVM:SCJG:VIL5:ISG4:YSDZ:KUV4
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
将工作节点添加到群集群
管理器节点现在已经正确配置,是时候将工作者节点添加到群集群中了。首先,复制上一步中“swarm init”命令的输出,然后将该输出粘贴到 Worker 节点上以加入 swarm 集群:
docker swarm join --token SWMTKN-1-5p5f6p6tv1cmjzq9ntx3zmck9kpgt355qq0uaqoj2ple629dl4-5880qso8jio78djpx5mzbqcfu 192.168.0.103:2377
您应该会看到以下输出:
This node joined a swarm as a worker.
现在,在 Manager 节点上,运行以下命令来列出 Worker 节点:docker node ls
您应该在以下输出中看到 Worker 节点:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
iwjtf6u951g7rpx6ugkty3ksa * Manager-Node Ready Active Leader
snrfyhi8pcleagnbs08g6nnmp Worker-Node Ready Active
在 Docker Swarm 中启动 web 服务
Docker Swarm 集群现在已经启动并运行,是时候在 Docker Swarm 模式中启动 web 服务了。在 Manager 节点上,运行以下命令来部署 web 服务器服务:docker service create --name webserver -p 80:80 httpd
上面的命令将创建一个 Apache web 服务器容器,并将其映射到端口 80,这样您就可以从远程系统访问 Apache web 服务器。现在,您可以使用下面的命令检查正在运行的服务:docker service ls您应该会看到下面的输出:
ID NAME
MODE REPLICAS IMAGE PORTS
nnt7i1lipo0h webserver replicated 0/1 apache:latest *:80->80/tcp
接下来,使用下面的命令跨两个容器扩展 web 服务器服务:docker service scale webserver=2
然后,使用以下命令检查 web 服务器服务的状态:docker service ps webserver您应该会看到以下输出:
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
7roily9zpjvq webserver.1 httpd:latest Worker-Node Running Preparing about a minute ago
r7nzo325cu73 webserver.2 httpd:latest Manager-Node Running Preparing 58 seconds ago
测试码头工人群
Apache web 服务器现在运行在管理器节点上。现在,您可以通过将 web 浏览器指向管理器节点 IP 来访问 web 服务器
或者工作者节点 IP 如下所示: Apache web 服务器服务现在分布在两个节点上。Docker Swarm 还为您的服务提供高可用性。如果 web 服务器在 Worker 节点上关闭,那么新的容器将在 Manager 节点上启动。要测试高可用性,只需停止 Worker 节点上的 Docker 服务:
Apache web 服务器服务现在分布在两个节点上。Docker Swarm 还为您的服务提供高可用性。如果 web 服务器在 Worker 节点上关闭,那么新的容器将在 Manager 节点上启动。要测试高可用性,只需停止 Worker 节点上的 Docker 服务:sudo systemctl stop docker在 Manager 节点上,使用以下命令运行 web 服务器服务 status:docker service ps webserver您应该看到 Manager 节点上启动了一个新的容器:
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
ia2qc8a5f5n4 webserver.1 httpd:latest Manager-Node Ready Ready 1 second ago
7roily9zpjvq \_ webserver.1 httpd:latest Worker-Node Shutdown Running 15 seconds ago r7nzo325cu73 webserver.2 httpd:latest Manager-Node Running Running 23 minutes ago
结论
恭喜你!您已经在 Ubuntu 16.04 上成功安装并配置了 Docker Swarm 集群。现在,您可以轻松地将应用程序扩展到一千个节点和五万个容器,而不会降低性能。现在你已经有了一个基本的集群设置,去看看 Docker Swarm 文档了解更多关于 Swarm 的信息。您可能希望根据组织的高可用性要求,为您的集群配置一个以上的管理器节点。
如何在 Windows 上安装 MySQL:简单指南(2022)
June 30, 2022
MySQL 是目前最流行的数据库管理系统(DBMS)之一。它是轻量级的、开源的、易于安装和使用,这使它成为那些开始学习和使用关系数据库的人的一个好选择。
尽管对于初学者来说这是一个很好的选择,但 MySQL 也足够健壮,可以支持更大的生产应用程序,支持多用户和多线程。
在本文中,我们将介绍在本地 Windows 机器上安装 MySQL 的过程,从下载到创建和使用第一个数据库。完成后,您将拥有一个功能完整的 MySQL 服务器,并且可以在本地使用。
安装过程
让我们开门见山吧。在 Windows 上安装 MySQL 是一个非常简单但漫长的过程。在本文中,我们将一步一步地介绍如何使用 MySQL 安装程序,这是数据库文档推荐的方法。
首先,你需要下载安装程序。点击此处,选择与您的操作系统兼容的版本(32 位或 64 位),点击 Download 。请注意,您也可以选择 web 安装程序或脱机安装程序。最后一个要重得多,而第一个下载起来会更快。
当您尝试开始下载时,网站会要求您登录或创建帐户,但您不必这样做。注意 No thanks, just start my download 按钮。
当您打开安装程序时,它将首先配置安装,然后询问用户是否允许继续:
当这一切结束时,我们将最终看到安装界面。如下图所示,该过程由四个步骤组成:
- 选择安装类型
- 下载文件
- 安装软件
- 完成安装

在第一步中有五种类型的安装可用,您可以检查侧边的框来查看每种类型将安装什么。但是,我们强烈建议您选择默认选项,尤其是如果您刚刚开始使用 SQL 的话。
此安装程序将安装的最重要的功能包括:
- MySQL 服务器:数据库服务器本身
- MySQL Workbench:管理服务器的应用程序
- MySQL for Visual Studio:这个特性使用户能够从 Visual Studio 中使用 MySQL
- 文档和教程
也可以选择完全安装,因为这将安装所有可用的 MySQL 资源。
选择设置选项后,点击 Next 。
要求
此时,可能会要求您安装一些必需的软件,最常见的是可视代码。安装程序可以自动解决一些需求问题,但是,这里的情况并非如此:

如果遇到这种情况,可以在这里找到所需版本的可视化代码。不过,这个问题不会阻止安装的进行。
下载和安装
您现在已经到达下载部分。该部分的名称是不言自明的:您将下载您选择的安装选项中的所有组件。

点击 Execute ,下载开始。这可能需要几分钟才能完成。
完成后,您应该会在每个项目上看到勾号。然后你可以继续。
您将看到的下一个屏幕与上一个几乎相同,但现在它将安装您刚刚下载的所有组件。这一步将比前一步花费更长的时间。
结束后,您会再次看到所有的刻度线:

配置
下一步是配置服务器。您将看到以下屏幕。点击 Next 。

首先,安装程序会要求您配置网络:

在配置类型字段中保留开发计算机很重要,因为你可能会将它安装在你的个人计算机上,而不是专用机器上。您可以选择端口,但是默认端口也可以。点击 Next 。
对于身份验证方法,让我们坚持使用推荐的选项,并单击 Next :

现在该创建根账户了。您将被要求设置密码。记得用结实的。
在同一个屏幕上,您可以创建其他用户并设置他们的密码和权限。你只需点击 Add User 并填空即可。然后,点击 Next 。

现在你可以选择 Windows 服务的详细信息,比如服务名、账号类型,以及开机时是否要启动 MySQL。同样,默认选项在大多数情况下都有效:

下一个屏幕应用配置。执行它。这一步也需要一段时间才能完成。

结束后,就完成这个过程。

最后的步骤
我们快到了!下一步是连接到服务器。键入 root 帐户的密码,然后点击检查。您将看到连接成功状态:

该屏幕之后是另一个要求应用配置的屏幕。执行后点击 Finish 即可。
我们终于到达了最后一个屏幕。

在这里,您可以选择是否启动工作台和 Shell,并查看文档或其他示例。
使用 MySQL Workbench 创建第一个数据库
如果您选择在完成安装后启动工作台,您将看到以下屏幕:

选择与您创建的服务器的连接并登录。
这是你的工作空间:

注意在 SCHEMAS 窗口中,您已经有了几个可以使用的样本数据库。在 Information 窗口中,可以看到您选择的数据库。当然,您拥有编写 SQL 代码的主窗口。
使用此窗口运行以下命令创建您的第一个数据库:
CREATE DATABASE my_first_database

使用闪电图标运行命令,然后点击 SCHEMAS 窗口中的 Refresh 按钮。新的数据库应该在那里。
注意在 Output 窗口中有一条消息显示该命令被成功执行。
现在,您将拥有一个功能齐全的数据库。您可以开始创建表格、插入数据和构建自己的应用程序。
摘要
MySQL 不仅对于学习关系数据库和 SQL 的人来说是一个非常有用的工具,对于创建真实世界的生产级应用程序来说也是如此。
在本文中,我们讨论了以下主题。
- 下载 MySQL Windows 安装程序
- 安装和配置 MySQL 服务器和工具
- 使用 MySQL Workbench 创建第一个数据库
在 R 中安装软件包的简单方法(有 8 个代码示例)
April 13, 2022
r 是一种强大的编程语言,有许多数据科学应用。但是在我们把它的软件包投入使用之前,我们需要安装它们。以下是方法。
r 是一种用于统计计算的编程语言,对于执行数据科学任务尤其有效。这种流行是因为 R 提供了令人印象深刻的面向数据科学的包的选择,这些包是实现 basic R 中没有的特定功能的方法的集合。
从 CRAN 库安装 R 包
全面的 R Archive Network ( CRAN )存储库存储了数千个稳定的 R 包,这些包是为各种数据相关的任务而设计的。大多数情况下,您将使用这个库来安装各种 R 包。
要从 CRAN 安装 R 包,我们可以使用install.packages()功能:
install.packages('readr')
这里,我们安装了用于从不同类型的文件中读取数据的 readr R 包:逗号分隔值(CSV)、制表符分隔值(TSV)、固定宽度文件等。确保包的名称在引号中。
我们可以用同一个函数一次安装几个 R 包。在这种情况下,我们需要首先应用c()函数来创建一个包含所有需要的包作为其项目的字符向量:
install.packages(c('readr', 'ggplot2', 'tidyr'))
上面,我们已经安装了三个 R 包:已经熟悉的 readr 、 ggplot2 (用于数据可视化),以及 tidyr (用于数据清理)。
如果我们不确定某个数据科学任务使用哪个 R 模块,我们可以访问 CRAN Task Views 页面。在这里,我们找到了一个方便的任务类别(主题)列表和每个类别的简要描述。选择必要的主题,我们将打开与该类别相关的所有 R 包的页面,以及对每个包的用法的详尽描述。
在上面的两个例子中,我们只向install.packages()函数传递了一个参数,它实际上是pkgs参数的值。对于大多数情况来说,这通常就足够了。然而,这个函数有许多可选参数,在某些情况下可能有用(我们很快就会看到一些例子)。有关install.packages()功能用法的完整信息,包括其所有可能的参数及其详细描述,请查看 R 文档页面。
从 CRAN 库安装 R 包:替代方法
如果我们在 IDE 中使用 R,我们可以使用菜单而不是install.packages()函数从 CRAN 库中安装必要的模块。例如,在 R 最流行的 IDE R studio 中,我们需要完成以下步骤:
- 点击
Tools→Install Packages - 在
Install from:槽中选择Repository (CRAN) - 键入包名(或多个包名,用空格或逗号分隔)
- 默认勾选
Install dependencies - 点击
Install
在使用 R 的其他 ide 中,按钮和命令的调用会有所不同,但是它们背后的逻辑是相同的,所有的步骤通常都很直观。
从其他来源安装 R 包
从 GitHub 安装 R 包
有时,我们可能想要安装一个特定的包而不是来自 CRAN 的,而是来自另一个库。最常见的例子是当我们需要使用只在 GitHub 上可用的 R 模块时。在这种情况下,我们应该执行以下步骤:
-
如果 RTools 还没有安装,安装它(否则,跳过这一步
- 打开https://cran.r-project.org/
- 选择下载安装程序所需的操作系统(如
Download R for Windows) - 选择
RTools - 选择最新版本的 RTools
- 等待下载完成
- 默认使用所有选项运行安装程序(这里我们可能需要在第一个弹出窗口上单击
Run anyway) - 对于 R (v4.0.0)的新版本,将
PATH='${RTOOLS40_HOME}\usr\bin;${PATH}'添加到.Renviron文件中
-
从 CRAN 安装 devtools 包:
install.packages('devtools')
运筹学
install.packages('devtools', lib='~/R/lib')
-
Call the
install_github()function from the devtools package (no need to download the whole package) using the following syntax:devtools::install_github(username/repo_name[/subdir])例如:
devtools::install_github('rstudio/shiny')
上述方法仅适用于公共 GitHub 库。要从私有存储库中安装 R 包,我们需要用从https://github.com/settings/tokens获得的令牌来设置install_github()函数的auth_token可选参数。有关install_github()功能用法的更多信息,请查阅 R 文档
从其他外部存储库安装 R 包
如果我们需要安装一个既没有存储在 CRAN 上也没有存储在 GitHub 上,而是存储在另一个外部存储库中的包,我们必须再次使用install.packages()函数,这一次有两个可选参数:repos表示必要存储库的 URL,dependencies设置为TRUE或FALSE,这取决于我们是否也想安装它们。例如:
install.packages('furrr', repos='http://cran.us.r-project.org', dependencies=TRUE)
注意:上面的代码使用了一个 CRAN 包作为例子,但是我们可以使用任何其他的 URL 来存储必要的模块。
当使用 Jupyter Notebook 中的 R 来安装 essentials 中没有的包时,也会用到repos和dependencies参数。
从 Zip 文件安装 R 包
如果你有一个 R 包以. zip 或 tar.gz 文件的形式下载到你的本地机器上,你可以使用install.packages()函数来安装它,该函数传递 zip 文件的保存路径(这实际上是pkgs参数),将repos设置为NULL,将type设置为source。例如:
install.packages('C:/Users/User/Downloads/abc_2.1.zip', repos=NULL, type='source')
当 zip 文件不在我们的本地计算机上,而是直接在 CRAN 这样的存储库上时,这种方法也能很好地工作。在这种情况下,我们只需要提供相应的 URL,而不是本地路径。
或者,如果我们在 IDE 中使用 R,我们可以使用菜单而不是install.packages()函数从保存在本地机器上的. zip 或 tar.gz 文件中安装必要的包,就像我们之前从 CRAN 存储库中安装包一样。例如,在 RStudio 中,我们需要完成以下步骤:
- 点击
Tools→Install Packages - 在
Install from:槽中选择Package Archive File (.zip, .tar.gz) - 在本地机器上找到相应的文件,点击
Open - 点击
Install
在其他使用 R 的 ide 中,过程是相似的。
正在加载 R 包
一旦在我们的计算机上安装了必要的包,下一步就是加载每个包来开始使用它们。虽然我们只需要安装每个包一次(例如,第一次在特定的计算机上使用 R ),但是我们必须为每个新的 R 会话加载每个包。为此,我们使用library()函数并传入包名,如下所示:
library(readr)
注意,在这种情况下,我们不需要在引号中包含包名。
结论
在本教程中,我们讨论了在本地机器上安装各种来源的 R 包的方法,例如官方的 CRAN 资源库、公共或私有的 GitHub repos、任何其他外部资源库以及. zip 或 tar.gz 文件。此外,我们还讲述了如何为特定的数据科学问题选择必要的包,以及如何在安装后加载包以开始使用它。
如何在 Windows 上安装 PIP:带截图的简单指南(2022)
June 9, 2022
在本教程中,我们将识别 Python 的 PIP,何时使用,如何安装,如何检查其版本,如何在 Windows 上配置,以及如何升级(或降级)。
Python 的 PIP 是什么?
PIP 代表“PIP Installs Packages”,这是一个递归的首字母缩略词(指的是它自己),由它的创建者创造。从更实际的角度来说,PIP 是一个广泛使用的包管理系统,旨在在我们的本地机器上安装 Python 编程语言的标准发行版中没有包含的库,然后从命令行管理它们。
默认情况下,PIP 从 Python 包索引(PyPI)中获取这样的库,Python 包索引是一个中央在线存储库,包含各种应用程序的大量第三方包。如果需要,PIP 还可以连接到另一个本地或在线存储库,只要它符合 PEP 503 。
如何在 Windows 上安装 PIP
在继续在 Windows 上安装 PIP 之前,我们需要确保 Python 已经安装,并且 PIP 是而不是安装的。
检查 Python 是否可用
为了验证 Python 在我们的本地机器上可用,我们需要打开命令行(在 Windows search 中,键入cmd并按Enter打开命令提示符,或者右键单击Start按钮并选择Windows PowerShell,键入python,并按Enter。
如果 Python 安装正确,我们将会看到如下所示的通知:
Python 3.10.2 (tags/v3.10.2:a58ebcc, Jan 17 2022, 14:12:15) [MSC v.1929 64 bit (AMD64)] on win32 Type "help," "copyright," "credits," or "license" for more information.
在相反的情况下,我们会看到以下通知:
'python' is not recognized as an internal or external command, operable program or batch file.
这意味着 Python 要么没有安装在我们的本地机器上,要么安装不正确,需要设置系统变量。如果您需要关于如何在 Windows 上正确安装 Python 的进一步指导,可以使用 Dataquest 博客中的这篇文章:教程:在 Windows 上安装 Python。
检查 PIP 是否已经安装
既然我们已经验证了 Python 已经安装在 Windows 上(或者,如果没有,已经安装了它),让我们检查一下 PIP 是否已经安装在我们的系统上。
最新发布的 Python 3.4+和 Python 2.7.9+,以及虚拟环境virtualenv和pyvenv,都自动附带 PIP(我们可以通过在命令行运行python --version或python -V来检查我们的 Python 版本)。然而,Python 的旧版本在默认情况下没有这个优势。如果我们使用较旧的 Python 版本,但由于某种原因无法升级(例如,当我们必须使用与较新版本不兼容的旧版本 Python 中的项目时),我们可能需要手动下载并在 Windows 上安装 PIP。
要检查 PIP 是否已经安装在 Windows 上,我们应该再次打开命令行,键入pip,然后按下Enter。
如果安装了 PIP,我们会收到一个很长的通知,解释程序的用法,所有可用的命令和选项。否则,如果没有安装 PIP,输出将是:
'pip' is not recognized as an internal or external command, operable program or batch file.
当我们必须在 Windows 上手动安装 PIP 时,情况正是如此。
下载 PIP
在安装 PIP 之前,我们必须下载get-pip.py文件。我们可以通过两种方式做到这一点:
- 转到 https://bootstrap.pypa.io/get-pip.py的,在 Python 所在的同一个文件夹下将该文件另存为
get-pip.py。
默认情况下,Python 安装存储在文件夹AppData中。整个路径可能如下所示:
C:\Users\User\AppData\Local\Programs\Python\Python310
文件夹User可以在特定的机器上以不同的方式调用,而且上面路径中的最终文件夹取决于 Python 的版本。在我们的例子中——Python 3.10:

- 打开命令行,使用
cd命令导航到存储 Python 的文件夹(如果您不确定 Python 的位置,请参见上一点)。
现在,运行下面的 curl 命令:
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py

在 Windows 上安装 PIP
现在我们已经下载了get-pip.py文件,我们需要完成以下步骤。
- 打开命令行
- 使用
cd命令导航到存储 Python 和get-pip.py文件的文件夹 - 通过运行以下命令启动安装程序:
python get-pip.py

在快速安装过程之后,会出现一条包含所有安装详细信息的消息,最后一行如下所示:
Successfully installed pip-22.0.1 wheel-0.37.1
PIP 现已成功安装在 Windows 上。
验证 PIP 安装过程并检查 PIP 版本
要再次检查 PIP 是否已正确安装并检查其版本,我们需要在命令行中运行以下命令之一:
pip --version
或者
pip -V
如果 PIP 安装正确,我们将看到一条消息,指示 PIP 的版本及其在本地系统上的位置,如下所示:
pip 22.0.2 from C:\Users\Utente\AppData\Local\Programs\Python\Python310\lib\site-packages\pip (python 3.10)。
相反,如果抛出错误,则需要重复安装过程。
将 PIP 添加到 Windows 环境变量中
为了能够从命令行中的任何文件夹运行 PIP 而不出现问题(而不是像前面那样每次都导航到存储 PIP 安装程序的文件夹),我们必须将带有get-pip.py文件的文件夹的路径添加到 Windows 环境变量中。这在极少数情况下尤其重要,因为我们已经安装了几个版本的 Python,包括旧版本。在这种情况下,为了避免为每个旧版本的 Python 单独安装 PIP,我们应该只为其中一个版本安装 PIP,然后执行以下步骤:
- 打开
Control Panel(在 Windows 搜索中输入),选择System and Security,然后选择System。 - 转到打开窗口的末尾,选择
Advanced system settings:

- 点击
Environment Variables:

- 在
System variables部分,找到并双击变量Path:

- 点击
New并将路径添加到存储 PIP 安装程序的文件夹中:


- 点击
OK确认修改。
在 Windows 上升级 PIP
有时,我们可能需要将 Windows 上的 PIP 更新到最新版本,以保持其最新并完美地工作。为此,我们可以在命令行中运行以下命令:
python -m pip install --upgrade pip
因此,旧版本的 PIP 将被卸载,而最新版本将被安装。
在 Windows 上降级画中画
我们还可以将 PIP 降级到特定的旧版本。在某些情况下,此操作可能是必要的,例如,如果新版本存在一些兼容性问题。要在 Windows 上降级 PIP,我们需要打开命令行并运行具有以下语法的命令:
python -m pip install pip==<version>
比方说,我们想将其降级到 v20.3。那么确切的命令将是:
python -m pip install pip==20.3
在降级 PIP 之后,我们可以通过运行python -V来验证我们现在拥有了它的必要版本。
结论
在本教程中,我们讨论了关于在 Windows 上安装 PIP 的各种主题:
- PIP 如何工作
- 如何检查 Python 和 PIP 是否已经安装
- 当可能需要在 Windows 上手动安装 PIP 时
- 如何在 Windows 上下载和安装 PIP
- 如何验证 PIP 是否已成功安装并检查其版本
- 如何在 Windows 上配置 PIP 以及何时需要配置
- 何时以及如何升级或降级 Windows 上的 PIP
现在我们已经在 Windows 上正确安装了 PIP,我们可以开始使用它来管理 Python 库。让我们从在命令行运行pip help开始,探索这个程序可用的命令和选项。
教程:在 Mac 上安装 Python
January 12, 2022
Python 是最强大的编程语言之一,主要用于数据科学、机器学习和大数据分析。所以,安装 Python 对所有程序员来说都是必不可少的。作为一名程序员新手,你可能想知道如何在 Mac 上正确安装或更新 Python。在这里,我们将介绍在 macOS 上安装和更新 Python 的不同方法。
然后,为了在集成开发环境(IDE)中编写和运行我们的 Python 代码,我们将学习如何在 Mac 上安装和配置 Visual Studio 代码。在 Mac 上安装和更新 Python 有不同的方法,但让我们坚持 Python 的禅的第三个原则,即:“简单比复杂好。“因此,我们会尝试简单的方法,而不是复杂的方法。在我们开始学习如何在 Mac 上安装或更新 Python 之前,让我们先回顾一下我们将在本教程中讨论的内容:
在 Mac 上安装和更新 Python
我有两条消息要告诉你:一个好,一个坏。好消息是为了兼容遗留系统,你的 Mac 上预装了 Python 2.7,坏消息是 Python 2.7 已经退役了。因此,不建议新的开发使用它。所以,如果你想利用新 Python 版本的许多特性和改进,你需要安装最新的 Python 和 macOS 上预装的版本。在开始安装最新版本的 Python 之前,我们先来看看为什么同一个编程语言会有不同的版本。随着时间的推移,所有的编程语言都通过添加新的特性来发展。编程语言开发人员通过增加版本号来宣布这些变化和改进。
将 Python 3 作为命令行开发工具的一部分进行安装
要检查已经安装的 Python 的当前版本,请通过键入 command + space 打开终端应用程序,然后拼出 Terminal 并按 return 键。现在,键入以下命令,然后按 return 键查看您已经在 Mac 上预装了 Python 2.7:
% python --version
现在,尝试以下命令来检查您的 Mac 上是否安装了 Python 3:
~ % python3 --version
终端窗口上可能会出现以下消息,
xcode-select: note: no developer tools were found at '/Applications/Xcode.app', requesting install. Choose an option in the dialog to download the command line developer tools.
在终端窗口旁边,会自动出现一个对话框,提示该命令需要命令行开发工具。首先,让我们确定命令行开发工具。简而言之,命令行开发人员工具包是一套主要用于开发过程的工具。它们帮助运行特定的命令,如 make、git、python3 等。所以,虽然不安装命令行开发者工具也有其他方法在 Mac 上安装 Python 3.x,但是我还是推荐你安装,因为它提供了一串在 Mac 上开发的工具。要安装该软件包,请单击 install 按钮,并按照步骤完成安装过程。安装过程完成后,重新运行前面的命令。是的,Python 3.x 安装在您的 Mac 上。
~ % python3 --version
用官方安装程序安装 Python 3
从 Python 官方网站(python.org)下载最新的 Python 版本是在 Mac 上安装 Python 最常见的(也是推荐的)方法。让我们试一试。
1.首先,从 Python 网站下载一个安装包。为此,请在您的 Mac 上访问https://www.python.org/downloads/;它会自动检测您的操作系统,并显示一个大按钮,用于在 Mac 上下载最新版本的 Python 安装程序。如果没有,请单击 macOS 链接并选择最新的 Python 版本。
2.下载完成后,双击包开始安装 Python。安装程序将引导您完成安装,在大多数情况下,默认设置很好,所以像 macOS 上的其他应用程序一样安装它。您可能还需要输入您的 Mac 密码,让它知道您同意安装 Python。

注意如果你用的是苹果 M1 Mac,你需要安装 Rosetta。Rosetta 使基于英特尔的特性能够在苹果硅 MAC 上运行。
3.安装完成后,将打开 Python 文件夹。

4.让我们验证一下 Python 和 IDLE 的最新版本是否安装正确。为此,双击 IDLE,这是 Python 附带的集成开发环境。如果一切正常,IDLE 显示 Python shell 如下:

5.让我们编写一个简单的 Python 代码,并在空闲时运行它。键入以下语句,然后按回车键。
print(“Hello, World!”)

或者我们用 Python 做一个基本计算如下:

注意这种安装方法令人兴奋的优点是,您可以通过下载最新的 Python 安装程序来轻松更新过时的 Python 安装。安装完成后,新版本的 Python 就可以在 Mac 上使用了。
在 Mac 上安装 Visual Studio 代码
虽然我们可以使用 IDLE 或终端应用程序来编写 Python 脚本,但我们更喜欢使用功能强大、可扩展的轻量级代码编辑器,而不是僵化的编码环境。在教程的这一部分,我们将在 macOS 上安装用于 Python 开发的 Visual Studio 代码。
1.首先,你需要在 https://code.visualstudio.com/的官方网站下载 macOS 的 Visual Studio 代码。

2。双击下载的文件以提取存档的内容。

3。将 Visual Studio 代码应用程序移动到 application 文件夹,使其在 macOS launchpad 中可用。

4。启动 Visual Studio 代码,然后打开 Python 脚本所在的文件夹(或创建一个新文件夹)。例如,在你的桌面上创建一个新文件夹,并将其命名为py_scripts,然后尝试在 VS 代码上打开该文件夹。通常,VS 代码需要你的权限才能访问你桌面文件夹中的文件;单击确定。
此外,您可能需要声明您信任存储在桌面文件夹中的文件的作者。

5。创建一个扩展名为.py的新文件。例如,创建一个新文件,并将其命名为prog_01.py. VS 代码检测到了.py扩展名,并希望安装一个 Python 扩展。

要在 VS 代码内部使用 Python,我们需要使用 Python 扩展,它包含了很多有用的特性,比如带智能感知的代码完成、调试、单元测试支持等。
点击安装按钮进行安装。

我们也可以通过浏览扩展来安装 Python 扩展。单击 VS 代码左侧的扩展图标。

这将显示 VS 代码市场上最流行的 VS 代码扩展列表。现在,我们可以选择 Python 扩展并安装它。

6.一旦安装了扩展,您必须选择一个 Python 解释器。点击选择 Python 解释器按钮:

然后在列表中选择推荐的 Python 解释器。

如果你的 Mac 上安装了多个 Python 版本,最好选择最新版本。

您也可以使用命令面板中的 Python: Select Interpreter 命令来选择 Python 解释器。为此,请按 CMD + SHIFT + P,键入 Python,然后选择选择解释器。
在 Mac 上运行我们的第一个 Python 脚本
太好了,我们拥有了在 VS 代码中编写和运行 Python 代码所需的一切。让我们用 VS 代码写下面的代码,然后运行它。
print("Hello, World!)
name = input("What's your name? ")
print("Hello {}!\nWelcome to Dataquest!".format(name))
通过点击 VS 代码右上角的▶️按钮来运行代码。首先,它显示你好,世界!在综合终端,然后它问你的名字;输入你的名字,然后按回车键。它输出Hello <your name,>,并在下一行写入Welcome to Dataquest!。

结论
在本教程中,我们学习了如何在 Mac 上安装最新版本的 Python,以及更新过时的 Python 版本。此外,我们还学习了如何将 Visual Studio 代码安装为代码编辑器,并对其进行配置以运行 Python 脚本。最后,我们用 VS 代码编写了一个小的 Python 脚本,并成功运行。在下一个教程中,我们将学习 Python 虚拟环境以及如何创建和使用它们。恭喜你!从现在开始,前途无量,你可以成为伟大的皮托尼斯塔!
如果你想了解这个话题的更多信息,请查看 Dataquest 的 Python 课程的互动介绍,以及我们的 Python 的数据分析师和 Python 的数据科学家,它们将帮助你在大约 6 个月内做好工作准备。
教程:在 Windows 上安装 Python
原文:https://www.dataquest.io/blog/installing-python-on-windows/
January 13, 2022
Python 是一种流行的开源高级编程语言。它很直观,并且提供了许多有用的工具和库——Python 是您工具包中的强大数据科学资产。要开始使用 Python,我们首先需要下载它并将其安装在我们的操作系统上(在本例中是 Windows)。
如何在 Windows 上安装 Python
在 Windows 上安装 Python 主要有两种方式:从官方 Python 网站安装或者从 Anaconda 安装,这是 Python 和 R 编程语言的一个方便分发版本。如果您是一名出于各种目的使用 Python 的程序员,请选择第一个选项:创建网站、网络编程、开发软件应用程序。相反,如果你的工作专注于数据科学和机器学习,那么 Anaconda 是你的最佳选择。本质上,Anaconda 是一个强大的数据科学平台,提供了 1500 多个内置的 Python 和 R 数据科学包,以及最流行的 Python IDEs。使用 Anaconda,您可以选择使用图形用户界面(GUI)而不是命令行。此外,它还适用于处理大量数据,轻松处理不同的环境和应用程序,以及管理软件包版本。
检查 Python 是否已经安装
在开始安装过程之前,我们希望检查 Python 是否已经安装在您的计算机上(例如,由以前的用户安装),如果是,Python 的版本是什么。为此,打开命令行应用程序命令提示符(在 Windows 搜索中,键入cmd并按下Enter)或 Windows PowerShell(右键单击Start按钮并选择Windows PowerShell)并在那里键入python -V。如果您发现 Python 已经安装在您的计算机上,并且想要检查安装路径,请在命令行应用程序中运行where.exe python。
从 Python 官方网站在 Windows 上安装 Python
如果看到 Python 没有安装,可以使用 Python 官方网站安装。
第一步。打开 Python Releases for Windows 页面,选择 Python 版本,下载 Python 可执行安装程序

在这里,您可以选择是下载 Python 2 还是 Python 3(或者两者都下载)。稍后,我们将更详细地讨论下载和安装 Python 2 和 Python 3 的技术步骤,但首先,让我们确定您真正需要哪一个(或两个)。
Python 3 是 2008 年发布的 Python 的更新版本,旨在修复 Python 2 中的问题。与 Python 2 相比,Python 3 具有更简单和更直观的语法,它提供了大量有用的库(尤其是对于数据科学),并且有一个庞大的 Python 开发人员社区来维护它。相比之下,Python 2 是不再支持。因此,如果您不确定使用哪个版本,下载最新的 Python 3 版本通常是最佳选择。如果您要处理新项目,您很可能只需要 Python 3。
但是,在某些情况下,您可能还需要 Python 2。例如,如果您公司的一些项目是用 Python 2 编写的,而 Python 2 与 Python 3 不兼容,那么您可能必须运行旧的脚本。此外,有时,您可能希望使用 Python 3 中尚未更新的 Python 包。在这种情况下,您将需要 Python 2。
如果您选择下载最新的 Python 2 版本,请选择Windows x86-64 MSI installer,它将自动识别您的 Windows 版本(32 位或 64 位):

要下载最新的 Python 3 版本,您必须手动选择适合您的 Windows 版本的安装程序:

第二步。运行安装程序
让我们分别为 Python 2 和 Python 3 一步步地遵循这个过程。请记住,根据您的需要,您可以安装其中一个或两个。这不会导致任何问题,并且您可以随时选择使用哪个 Python 版本。
Python 2。
运行下载的 Python 2 可执行文件,该文件将在您的Downloads文件夹中找到。在每个步骤中选择以下选项:


之后,只需在每个弹出窗口确认一切,就完成了安装。
现在您已经成功安装了最新的 Python 2 版本。
Python 3。
下载 Python 3 的安装程序,并在Downloads文件夹中找到它。在第一个弹出窗口中,选中底部的两个复选框,以便在 Windows 中自动将 Python 添加到路径中。然后选择Install Now:

安装过程可能需要几分钟时间。然后,在下一个窗口中,选择Disable path length limit以避免将来长路径名的潜在问题:

您的计算机上已经安装了最新的 Python 3 版本。
第三步。验证 Python 是否成功安装在 Windows 上
如果您只安装了 Python 的一个版本,打开命令行并运行python -V。如果您同时安装了 Python 2 和 Python 3,您必须做一个小的调整,我们将在下面的(可选)步骤中讨论。
步骤 4(仅当您同时安装了 Python 2 和 Python 3 时)。重新分配系统变量
为了能够从命令行轻松访问这两个 Python 版本,这一步是必要的。
如果您现在在命令行中运行python,您将只看到 Python 2 的版本(在我们的例子中,是 Python 2.7.18)。发生这种情况是因为,即使您为两个 Python 版本启用了系统路径,安装程序还是被保存为不同路径级别的变量集:系统级别(Python 2)和用户级别(Python 3)。在这种情况下,优先考虑系统路径,因此优先考虑 Python 2。你可以通过探索 Windows 的环境变量来验证:在 Windows 搜索中,键入advanced system settings,选择View advanced system settings,打开Advanced标签,点击Environment Variables按钮。在弹出窗口中,您将看到 Python 3 与用户变量相关,而 Python 2 与系统变量相关:

要解决这个问题,您可以为 Python 3: python3分配不同的访问权限,而不仅仅是python:
- 在 Windows 搜索中打开
File Explorerapp,找到安装 Python 3 的文件夹。默认情况下,路径应该如下:C:\ Users `username`\ AppData \ Local \ Programs \ Python \ Python 310 - 制作
python.exe文件的副本,并将该副本重命名为python3.exe:

- 重新打开命令行。
- 现在,您可以返回到步骤 3,验证 Python 2 和 Python 3 的 Python 版本:
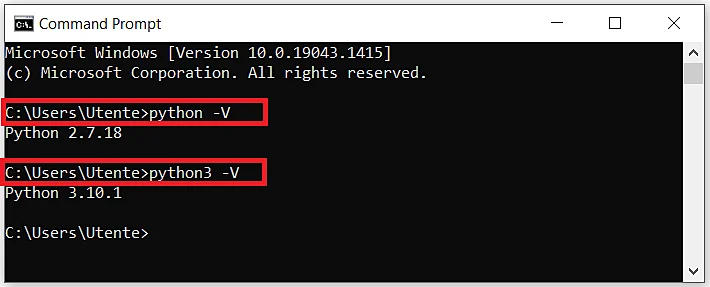
从 Anaconda Navigator 在 Windows 上安装 Python
您可以使用开源的 Anaconda Navigator,这是一个流行的 Python 和 R 发行版,用于数据科学和机器学习任务,而不是来自官方 Python 网站的完整安装程序。
第一步。打开蟒蛇官方网站,在产品菜单中选择个人版
第二步。下载安装程序
系统会自动建议最适合您的操作系统(Windows)的软件包:

第三步。运行安装程序
在您的Downloads文件夹中找到下载的 Anaconda 安装程序,并运行它:

在安装过程中,保留所有屏幕上的所有默认选项。不过,在其中一个窗口中,您可以决定更改安装位置,但通常最好保持原样:

安装过程可能需要几分钟时间。
现在 Anaconda 已经成功安装在您的计算机上。
如何在 Windows 上运行您的第一个 Python 代码
现在您已经安装了 Python,无论是从官方 Python 网站还是使用 Anaconda Navigator,您都已经准备好运行您的第一个 Python 代码了。
如果你从 Python 官方网站安装了 Python
在 Windows 搜索中输入idle,选择需要的 IDLE 版本(如果你安装了不同的 Python 版本,会有相应的 IDLE 版本):

现在您可以开始编码了,甚至可以在不同的 Python 版本中并行编码:

如果您从 Anaconda 个人版安装了 Python
- 在 Windows 搜索中输入
anaconda,打开Anaconda Navigator:

- 从众多应用程序中选择最适合您的应用程序。例如,您可以选择 Jupyter Notebook,这是一个流行的数据科学应用程序,用于创建和共享结合了代码、图表和故事的文档:

- 导航到要保存代码的文件夹,并创建一个新的 Python 笔记本:

- 开始编码:

如何在 Windows 上将 Python 更新到最新版本
如果你从 Python 官方网站安装了 Python
就像最初安装 Python 时一样,打开 Python Releases for Windows 页面,选择最新的 Python 版本,下载并运行合适的安装程序。
如果最新版本只是与当前版本(例如,3.9.8 和 3.9.9)具有相同主要版本的新 Python 补丁,您将在弹出窗口中看到以下选项:

在这种情况下,最新的 Python 版本将安装在您的计算机上,而之前的版本将被移除。之后你需要重启你的机器。
如果最新版本是 Python 相对于当前版本的新主要版本(例如 3.9 和 3.10),您将看到与初始安装相同的选项:

在这种情况下,最新的 Python 版本将安装在您的计算机上,但之前的版本也将保留。如有必要,您可以使用控制面板手动卸载它。
如果您从 Anaconda 个人版安装了 Python
在 Windows 搜索中键入anaconda,打开Anaconda Prompt.将基础(根)环境的 Python 版本更新到最新的 Python 版本 available for the current Anaconda release,运行conda update python。
(附注:您可能需要首先通过运行 conda update conda将 Anaconda 本身更新到最新版本。)
在下面的快照中,您可以看到在将 Anaconda 上的 Python 版本更新到最新版本之后,实际上什么都没有改变:版本仍然是 3.9.7,而不是更新到最新的(当前的)Python 版本 3.10.1:

这是因为 Python 3.9.7 是当前 Anaconda 版本中最新的 Python 版本。
您可以等待下一个 Anaconda 版本,或者考虑在 Anaconda 上创建一个新的虚拟环境:
conda create-n python 10 python = 3.10

上面,您创建了一个名为python10的虚拟 Anaconda 环境(可以随意给它取其他名字),使用的是官方最新版本 Python 3.10。
现在,为了能够在这个环境中工作,您必须激活它,运行conda activate python10:

注意活动环境的名称是如何从base变成python10的。另外,请注意,如果您检查 Python 版本,您会看到它已经更新到 Python 3.10.0。
不幸的是,在创建新的虚拟环境时,不可能指定最新版本的确切补丁(这意味着您只能写python=3.10而不能写python=3.10.1)。
您可以从命令行在创建的虚拟环境中继续使用 Python 3.10.0 编码。或者,因为 Anaconda 首先是一个方便的 GUI 界面,所以您可以再次进入 Anaconda Navigator,选择新的环境,安装您需要的任何应用程序(如果它们适用于该环境),并在那里开始工作。

您还可以直接从 Anaconda Navigator 使用必要的 Python 版本轻松创建新的虚拟环境:
- 打开 Anaconda Navigator 的
Environments标签。 - 按下屏幕底部的
Create按钮。 - 为新环境命名,并选择 Python 的版本。

一个名为python10_new的新环境已经创建:

- 转到 Home 选项卡,在这里已经自动选择了新环境。
- 安装您需要的任何可用应用程序,并开始编码。
结论
在本教程中,您已经学习了如何从官方网站和 Anaconda 正确下载和安装 Python,必要时将其更新到最新版本,以及在 Windows 上运行 Python 脚本。现在,您已经拥有了开始使用 Python 的所有必要工具和设置。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号